
无规则采集器列表算法
采集器的工作流程列表页采集到内容页的地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-12 06:19
我们知道采集器的工作流程是从列表页采集到内容页的地址,然后就可以按照规则采集content页中对应的内容进行操作。
比如我们采集“幽默笑话”分类中文章的地址就是我们列表页的地址
我们在起始 URL 中添加列表页面的地址:那里
然后在多级URL中获取:设置在那里,采集到类别下的内容页地址
这是我们编写采集规则的一般步骤,也称为一级URL获取。整个过程来自分类页地址采集内容页地址。
如果遇到大类页地址采集小类页地址(或者类可以多级),然后采集到内容页地址,我们的思路是从大类开始,采集去小类,然后在采集小类采集content页面地址,上图说明
我们从采集下的“经典网文”、“诙谐笑话”、“冷笑话”等子类大类下手
我们以经典网页文本为起始地址,然后从多级网站获取,设置规则,采集到小类的地址如下:
选择自己比较熟练的方式获取子类地址
让我们测试 URL采集Result:
看到我们已经到了小类采集的地址,现在需要采集小类下的文章地址
我们在多级URL获取部分再次添加文章address采集设置,选择你比较熟悉的获取方式。我用的是第一个:
保存后如下图:
测试结果如下:
点击打开一个小分类地址。以下是该分类下的文章地址
起始页为0级URL,采集到达的子类地址为1级URL,地址文章为2级地址,以此类推。从而实现无限列表网址采集。我们这里只设置了3个级别,其实你可以这样设置无限极点,添加的方法是
同理,希望大家能有所推论。
还有一点,如果你要采集的地址不是列表页的地址,直接作为内容页采集比如我要直接采集这个地址
将此地址添加到起始页地址中,多级留空如下图:
我们测试过
采集器 不会是采集 以下的地址。只需将此地址用作内容页采集。它也通常被称为 0 级 采集。
网站采集相关服务,请联系我们:
QQ全年24小时在线:389311875 网址:“采集超市” 查看全部
采集器的工作流程列表页采集到内容页的地址
我们知道采集器的工作流程是从列表页采集到内容页的地址,然后就可以按照规则采集content页中对应的内容进行操作。
比如我们采集“幽默笑话”分类中文章的地址就是我们列表页的地址

我们在起始 URL 中添加列表页面的地址:那里
然后在多级URL中获取:设置在那里,采集到类别下的内容页地址
这是我们编写采集规则的一般步骤,也称为一级URL获取。整个过程来自分类页地址采集内容页地址。
如果遇到大类页地址采集小类页地址(或者类可以多级),然后采集到内容页地址,我们的思路是从大类开始,采集去小类,然后在采集小类采集content页面地址,上图说明

我们从采集下的“经典网文”、“诙谐笑话”、“冷笑话”等子类大类下手
我们以经典网页文本为起始地址,然后从多级网站获取,设置规则,采集到小类的地址如下:

选择自己比较熟练的方式获取子类地址

让我们测试 URL采集Result:

看到我们已经到了小类采集的地址,现在需要采集小类下的文章地址

我们在多级URL获取部分再次添加文章address采集设置,选择你比较熟悉的获取方式。我用的是第一个:

保存后如下图:

测试结果如下:

点击打开一个小分类地址。以下是该分类下的文章地址
起始页为0级URL,采集到达的子类地址为1级URL,地址文章为2级地址,以此类推。从而实现无限列表网址采集。我们这里只设置了3个级别,其实你可以这样设置无限极点,添加的方法是
同理,希望大家能有所推论。
还有一点,如果你要采集的地址不是列表页的地址,直接作为内容页采集比如我要直接采集这个地址
将此地址添加到起始页地址中,多级留空如下图:

我们测试过

采集器 不会是采集 以下的地址。只需将此地址用作内容页采集。它也通常被称为 0 级 采集。
网站采集相关服务,请联系我们:
QQ全年24小时在线:389311875 网址:“采集超市”
3.推荐算法产品框架基于算法和最小可行性(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-08-04 21:36
本文从定义和框架入手,结合实际案例,简单而深刻地阐述了基于内容的推荐算法及其产品设计。
一、前言&定义
对于需要内容推荐的产品,可能很多像作者一样不是数据或算法类的产品同学无法下手。各种算法的基本原理和公式虽然网上都能搜到,但可能太专业了,或者直接呈现最终的逻辑,但是怎么做还是不知所措。我抛开理论和复杂的公式,直接从产品出发,设计一套从0到1的可行性最小的推荐算法能力。
什么是基于内容的推荐算法?
基于内容的推荐:核心思想是根据推荐项目或内容的元数据发现项目或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的项目。
简单的理解就是:根据用户过去喜欢的内容,为用户推荐与他过去喜欢的内容相似的内容。
二、算法整体架构描述1.明确算法目的
我们在开始推荐算法的时候,一定要明确初始阶段的目的:在保证内容质量的前提下,尽可能根据用户行为推荐满足用户期望的丰富内容。
这句话虽然很短,但收录了三个非常重要的关键词:内容的质量、内容的丰富性(多样性)、符合预期。
2.推荐算法整体逻辑
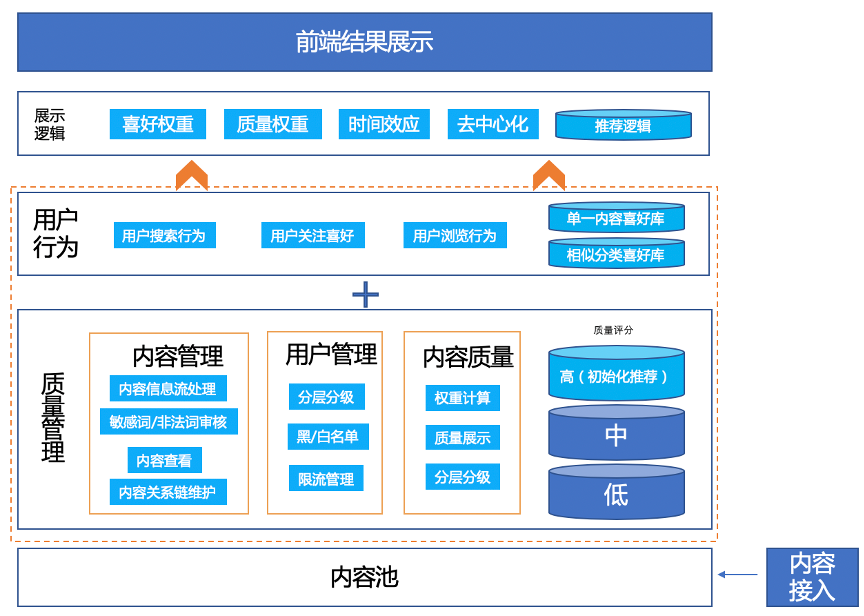
基于计算出的场景,我们可以很容易地找到推荐逻辑:当用户进行在线操作时,系统向后台发起用户数据召回请求,然后根据需要形成最终用户看到的内容排序模型,最终通过用户的请求完成并记录用户行为,用于后续的内容匹配。常见的计算如下:
虽然图片看起来有点复杂,但其实是三个核心:一套内容管理后端+多种加权算法+显示逻辑。
3.推荐算法产品框架
根据算法逻辑和最小可行性目的,我们可以梳理出一个简单的产品框架,如下图:
显然,算法推荐公式可以不用立即建立复杂的算法模型。只要有基本的用户管理和内容管理能力,结合内容质量权重和用户偏好权重,兼顾去中心化和时间效应,就可以做到根据用户推荐尽可能满足用户期望的丰富内容保证内容质量前提下的行为。
三、特定算法权重设计1.质量管理评分公式
质量总分Score是通过对三大模块的分数进行加权计算得出的,计算公式如下:
(系数可根据业务情况调整,从100)开始
其中A、B、C分别是三个模块的分数。分数是三个模块的分数乘以各自的系数。
每个模块的分数是通过对其多个评分指标和相应系数进行加权计算得出的。这是模块 A 的示例:
哪里
是模块A对应的各个指标的得分,
为各指标得分对应的权重系数。
A-内容流模块评分
内容流量反映了内容吸引流量的能力,以及初始产品推荐的核心人气权重:停留时间(退出率)>评论>喜欢>采集>PV/UV>转发。下表是一个案例:
B 内容质量模块评级
判断主要是根据后台内容的状态。在机器审核能力完全建立之前,这个模块会受到很大的人为影响。
附件:评分公式
目前推荐内容推荐评分算法采用贝叶斯平均评分方法。公式如下:
其中,n为当前内容的评分数,M为总内容的平均分,S为单个内容的总分,C为动态系数。
单项内容评分=(总内容平均分*C因素)+单品评分总和)/(当前内容评分数+C因素)
C系数是每个内容被评分的平均次数,即C=所有内容被评论的总次数/所有内容的次数。例如:一共1000条文章被评论了50000次,那么C就等于50000/1000=50。
小案例:
(贝叶斯平均法评价示例)
结论:基于贝叶斯平均的排名更能反映真实情况。分数越高分数越高的产品越先进,分数越多分数越低的产品越近。这个结果比仅仅根据每个产品的平均分来排序更有意义。
C 用户质量模块评级
用户质量由两个维度组成,基于后台人工识别用户属性和发帖质量。
2.用户偏好评分公式
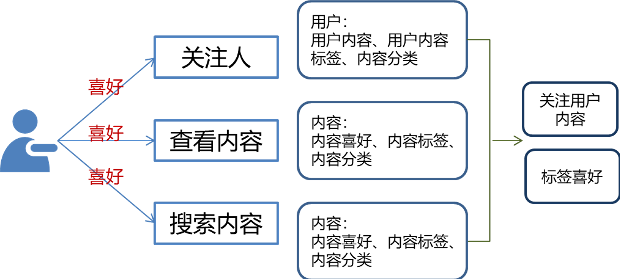
用户行为记录是获取用户相关推荐的主要依据。初始阶段基于用户关注度、浏览偏好和用户搜索关键词。计算用户偏好。基本逻辑如下:
偏好分数=浏览偏好类别*0.6+关注内容*0.4 +搜索内容类别*0.0
(系数可根据业务情况调整,从100)开始
插图:
(1)通过用户浏览历史获取用户最喜欢的标签
然后根据公式为同类别下的内容增加偏好值。
(2)获取用户关注用户,获取采集标签
然后根据以下用户内容的公式增加偏好值。
(3)如果内容1属于类别A,由用户D创建,则该内容为用户添加两个权重值=查看内容类别*0.6+关注人内容*0.4
四、前端显示重量设计
通过质量分数和用户偏好分数,我们可以获得内容导向。根据不同用户的内容质量和偏好分数,可以得到一个简单的推荐逻辑(推荐列表):根据用户的偏好分数推荐质量分数较高的内容,如果分数相同则推荐以与内容创建时间相反的顺序。
但在实际推荐中,除了保证用户偏好外,还需要尝试去中心化的内容展示方式,所以最终展示的推荐内容应该来自三个模块:
A.用户偏好列表:通过用户偏好评分,为用户推荐优质内容。这是主要推荐的内容。
推荐逻辑:先根据用户偏好值从高到低对内容进行排序,然后在高于阈值的内容中随机推荐健康值高于阈值B、阈值C、阈值D的内容偏好值A,低于阈值D不推荐。
B.优质非采集列表:用户偏好值低于一定阈值但内容流量得分较高的内容。
C.初始流量推荐列表:通过用户偏好评分,推荐内容质量经过审核但流量较低的内容。
旧用户算法为:Score=A*0.7+B*0.2 +C*0.1(系数可根据业务情况调整)
0.7、0.2、0.1 数字A、B、C为三个模块的初始系数,受时间影响。
新用户的冷启动算法为:ScoreL= B*0.9 +C*0.1
B 模块直接调用流量池的健康评分。
注意:当偏好分数和健康值相同时,加载量是随机选择的,需要在同一轮加载中去除相同的信息。
1.时间效果计算方法
为了进一步去中心化和推荐精度,根据热冷却公式:
本期系数 = 上期系数 x exp(-(冷却系数) x 间隔小时数)。 T是初始热量,
这里默认是0.7,
前一段时间的温度,
是冷却系数,即间隔的小时数。
五、关于 A/B 测试
A/B 测试更需要计算推荐,因为我们无法知道初始化过程中具体的权重设置是否合理,但可以保证不会有垃圾推荐的流出,所以 A/ B 测试结果 对于优化权重尤其重要。用户被转移到相应的解决方案。在保证每组用户特征一致的前提下,基于用户真实的数据反馈,帮助产品决策。当然,随着测试样本数量的增加,对技术架构的挑战也越大。
六、尾声
如开头所说,本文算法是基于内容推荐算法理论公式的设计,是基于实际产品设计的。其核心是在保证内容质量的同时,根据用户行为,尽可能推荐满足用户期望的丰富内容。相当有限,适用于没有完整算法团队并进行最小可行实验的产品。希望文章能给像我这样没有算法基础的同学带来帮助和启发。耶鲁兹的产品令人伤心。欢迎大家交流。
本文由@jingtianz 原创发表,人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏 查看全部
3.推荐算法产品框架基于算法和最小可行性(组图)
本文从定义和框架入手,结合实际案例,简单而深刻地阐述了基于内容的推荐算法及其产品设计。

一、前言&定义
对于需要内容推荐的产品,可能很多像作者一样不是数据或算法类的产品同学无法下手。各种算法的基本原理和公式虽然网上都能搜到,但可能太专业了,或者直接呈现最终的逻辑,但是怎么做还是不知所措。我抛开理论和复杂的公式,直接从产品出发,设计一套从0到1的可行性最小的推荐算法能力。
什么是基于内容的推荐算法?
基于内容的推荐:核心思想是根据推荐项目或内容的元数据发现项目或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的项目。

简单的理解就是:根据用户过去喜欢的内容,为用户推荐与他过去喜欢的内容相似的内容。
二、算法整体架构描述1.明确算法目的
我们在开始推荐算法的时候,一定要明确初始阶段的目的:在保证内容质量的前提下,尽可能根据用户行为推荐满足用户期望的丰富内容。
这句话虽然很短,但收录了三个非常重要的关键词:内容的质量、内容的丰富性(多样性)、符合预期。
2.推荐算法整体逻辑
基于计算出的场景,我们可以很容易地找到推荐逻辑:当用户进行在线操作时,系统向后台发起用户数据召回请求,然后根据需要形成最终用户看到的内容排序模型,最终通过用户的请求完成并记录用户行为,用于后续的内容匹配。常见的计算如下:

虽然图片看起来有点复杂,但其实是三个核心:一套内容管理后端+多种加权算法+显示逻辑。
3.推荐算法产品框架
根据算法逻辑和最小可行性目的,我们可以梳理出一个简单的产品框架,如下图:
显然,算法推荐公式可以不用立即建立复杂的算法模型。只要有基本的用户管理和内容管理能力,结合内容质量权重和用户偏好权重,兼顾去中心化和时间效应,就可以做到根据用户推荐尽可能满足用户期望的丰富内容保证内容质量前提下的行为。
三、特定算法权重设计1.质量管理评分公式
质量总分Score是通过对三大模块的分数进行加权计算得出的,计算公式如下:
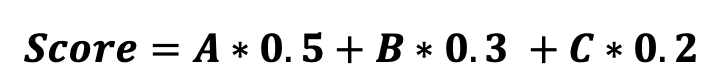
(系数可根据业务情况调整,从100)开始
其中A、B、C分别是三个模块的分数。分数是三个模块的分数乘以各自的系数。
每个模块的分数是通过对其多个评分指标和相应系数进行加权计算得出的。这是模块 A 的示例:

哪里
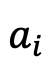
是模块A对应的各个指标的得分,

为各指标得分对应的权重系数。
A-内容流模块评分
内容流量反映了内容吸引流量的能力,以及初始产品推荐的核心人气权重:停留时间(退出率)>评论>喜欢>采集>PV/UV>转发。下表是一个案例:

B 内容质量模块评级
判断主要是根据后台内容的状态。在机器审核能力完全建立之前,这个模块会受到很大的人为影响。

附件:评分公式
目前推荐内容推荐评分算法采用贝叶斯平均评分方法。公式如下:

其中,n为当前内容的评分数,M为总内容的平均分,S为单个内容的总分,C为动态系数。
单项内容评分=(总内容平均分*C因素)+单品评分总和)/(当前内容评分数+C因素)
C系数是每个内容被评分的平均次数,即C=所有内容被评论的总次数/所有内容的次数。例如:一共1000条文章被评论了50000次,那么C就等于50000/1000=50。
小案例:

(贝叶斯平均法评价示例)
结论:基于贝叶斯平均的排名更能反映真实情况。分数越高分数越高的产品越先进,分数越多分数越低的产品越近。这个结果比仅仅根据每个产品的平均分来排序更有意义。
C 用户质量模块评级
用户质量由两个维度组成,基于后台人工识别用户属性和发帖质量。

2.用户偏好评分公式
用户行为记录是获取用户相关推荐的主要依据。初始阶段基于用户关注度、浏览偏好和用户搜索关键词。计算用户偏好。基本逻辑如下:
偏好分数=浏览偏好类别*0.6+关注内容*0.4 +搜索内容类别*0.0
(系数可根据业务情况调整,从100)开始

插图:
(1)通过用户浏览历史获取用户最喜欢的标签
然后根据公式为同类别下的内容增加偏好值。
(2)获取用户关注用户,获取采集标签

然后根据以下用户内容的公式增加偏好值。
(3)如果内容1属于类别A,由用户D创建,则该内容为用户添加两个权重值=查看内容类别*0.6+关注人内容*0.4
四、前端显示重量设计
通过质量分数和用户偏好分数,我们可以获得内容导向。根据不同用户的内容质量和偏好分数,可以得到一个简单的推荐逻辑(推荐列表):根据用户的偏好分数推荐质量分数较高的内容,如果分数相同则推荐以与内容创建时间相反的顺序。
但在实际推荐中,除了保证用户偏好外,还需要尝试去中心化的内容展示方式,所以最终展示的推荐内容应该来自三个模块:
A.用户偏好列表:通过用户偏好评分,为用户推荐优质内容。这是主要推荐的内容。
推荐逻辑:先根据用户偏好值从高到低对内容进行排序,然后在高于阈值的内容中随机推荐健康值高于阈值B、阈值C、阈值D的内容偏好值A,低于阈值D不推荐。
B.优质非采集列表:用户偏好值低于一定阈值但内容流量得分较高的内容。
C.初始流量推荐列表:通过用户偏好评分,推荐内容质量经过审核但流量较低的内容。

旧用户算法为:Score=A*0.7+B*0.2 +C*0.1(系数可根据业务情况调整)
0.7、0.2、0.1 数字A、B、C为三个模块的初始系数,受时间影响。
新用户的冷启动算法为:ScoreL= B*0.9 +C*0.1
B 模块直接调用流量池的健康评分。
注意:当偏好分数和健康值相同时,加载量是随机选择的,需要在同一轮加载中去除相同的信息。
1.时间效果计算方法
为了进一步去中心化和推荐精度,根据热冷却公式:

本期系数 = 上期系数 x exp(-(冷却系数) x 间隔小时数)。 T是初始热量,
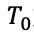
这里默认是0.7,
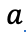
前一段时间的温度,
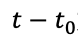
是冷却系数,即间隔的小时数。
五、关于 A/B 测试
A/B 测试更需要计算推荐,因为我们无法知道初始化过程中具体的权重设置是否合理,但可以保证不会有垃圾推荐的流出,所以 A/ B 测试结果 对于优化权重尤其重要。用户被转移到相应的解决方案。在保证每组用户特征一致的前提下,基于用户真实的数据反馈,帮助产品决策。当然,随着测试样本数量的增加,对技术架构的挑战也越大。
六、尾声
如开头所说,本文算法是基于内容推荐算法理论公式的设计,是基于实际产品设计的。其核心是在保证内容质量的同时,根据用户行为,尽可能推荐满足用户期望的丰富内容。相当有限,适用于没有完整算法团队并进行最小可行实验的产品。希望文章能给像我这样没有算法基础的同学带来帮助和启发。耶鲁兹的产品令人伤心。欢迎大家交流。
本文由@jingtianz 原创发表,人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
基于内容视频数据进行的人物匹配问题示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-04 21:36
头像| CSDN视觉中国下载
简介
人员重新识别 (re-ID) 在现实世界中是一项非常具有挑战性的任务。它旨在通过视觉算法模型,从不同的角度匹配不同摄像机下的同一个人。无处不在的遮挡、复杂的背景、光线的变化等都让这个问题变得困难。目前大部分开源数据集,如Market1501、DukeMTMC等,都是采集监控视频下的行人数据。这些数据集中的人物大多是直立和固定的姿势。目前主流的算法模型都是针对这些数据集进行了很好的性能优化和提升。然而,基于内容视频数据的字符重识别研究工作很少。不同于传统的监控视频,内容视频中存在大量的手动剪辑和镜头切换,以及大量的多角度、多机位镜头拍摄。这些都使得内容视频中的人物出现了不同程度的遮挡和人体区域的丢失。角度、姿势和大小的变化。我们可以通过图1所示的一个具体例子来看一看。图1(a)中,A和B用于描述同一场景的不同角度和摄像机位置。镜头A和镜头B中的人物匹配问题可以看成是全身和半身的匹配问题。在图 1(b) 中,镜头 A 中的人有一个可识别的正面。这时候,如果我们能在镜头B中匹配到同一个人,那么我们就可以最终识别出那些只出现在某些镜头中的人了。只有背面或侧面的字符信息。这有助于我们提高视频内容分析指标的准确性和有效性。
(a) (b) 图 1 内容视频中的字符匹配。综上所述,我们可以看出内容视频中re-ID算法要解决的主要问题之一是部分字符图像的遮挡或匹配。学术界通常将其称为部分 re-ID 或 occluded re-ID。目前业界对此类问题的主要解决方案是通过将局部区域特征重构为全局特征来实现隐式对齐操作,另一种是利用人体空间的划分来实现相同的显式特征。区域。对齐操作。然而,这些现有方法的问题在于,一方面训练数据集的数据与内容视频的数据差异较大,另一方面,粗粒度的空间区域划分不能适应复杂的人内容视频中的姿势。因此,我们从数据集和算法模型两个方面考虑优化内容视频中的re-ID算法。
数据集构建
图2是开源数据集和电视剧视频数据的对比。从图中我们发现,剧中人物的姿态变化更大,分辨率更高,并伴随着大量人体部位的遮挡或丢失。 ,而开源数据集中人物的姿势相对固定,而且大多是直立全身的图像。因此,很难将在当前开源数据集上训练的算法模型直接应用于内容视频。基于此,我们直接构建了一个戏剧场景中的大规模re-ID数据集。
图 2 数据集对比
整个数据集的构建过程主要分为以下几个步骤:1.Screening the episodes:根据时间和流行度选择大约500集,每集选择10-20集。 2.Sampling 帧检测:对于每一集视频帧检测,使用人体检测模型获取人体的帧图片。 3.数据分组:将检测到的人框图片按show分组,减少标注工作量。 4.Data annotation:用person ID对分组的数据集进行注释,每个ID大约30张图片。最后,我们获得了戏剧场景中的 Drama-ReID 数据集。整个数据集大约有 1W 个 ID 号,包括大约 38W 个图片。是业内最大的戏剧场景的re-ID数据集。
算法模型
我们的整体算法模型框架如图3所示,基础网络部分使用了预训练的resnet50。为了获得更大的特征图,我们将backbone最后一个卷积层的stride设置为1。backbone后面主要有3个模块:人体语义分割、信息熵测量模块、语义对齐与匹配。整个网络结构是端到端的训练。
图 3 网络结构
1. 人体语义分割不同于现有的将人体区域划分为空间区域的算法。我们使用人体语义分割来划分人体语义区域,如图4所示:
图 4 人体语义分割
一方面,我们可以利用人体语义区域的划分来实现语义级别的特征对齐。另一方面,我们可以去除背景区域特征,以防止部分复杂背景图像影响字符匹配。同时,我们没有像现有的一些算法那样使用单独的语义分割模型来提取人体语义区域,而是使用了多任务学习人体语义分割。它的好处之一是可以降低模型的复杂度和复杂度。计算量,另一个是通过增加语义分割的监督损失,可以有效提高基本特征的空间表示能力2.信息熵测量模块多任务人类语义分割可以帮助我们提取人类语义区域,但是同时我们还需要考虑语义分割错误的情况。错误的语义分割会导致错误的特征对齐,导致错误的字符匹配。考虑到某个区域的分割概率越高,这个区域被正确分割的概率就越大,我们通过计算分割概率的信息熵来衡量这个分割的不确定性。计算公式如下:
如果它更小,则意味着模型更确定这部分区域被正确分割。这样我们就可以计算出特征图上每个点的信息熵,然后通过设置合适的信息熵阈值,将整个人体区域划分为高熵和低熵区域。
整个信息熵测量模块如图5所示:
图5 信息熵测量的高熵区域是语义分割中不确定性高的部分。它们可能无法正确划分为某个语义区域。我们直接提取它们的全局特征。并且往往同一个角色的高熵部分具有一定的独特性(比如某个角色的特殊帽子)。这种独特而稀有的元素很难正确分割,但它是我们字符匹配的重要组成部分。基础和我们高熵区域的全局特征是这种特征的独特元素。低熵区域是语义分割中不确定性较低的部分。它们往往是很容易被正确分割的部位,它们往往与人体的区域结构密切相关。我们使用熵注意图来增强语义分割中具有高确定性的表示,同时抑制语义分割中低确定性的表示。一方面增强了稳定语义成分的表达,另一方面降低了错位的可能性。同时,在模型训练过程中,整体信息熵会随着分割损失的减小而减小。在训练初期,模型不能很好地进行语义分割,导致信息熵高,大部分区域会被划分为高熵区域。这时字符比较的特征主要是全局特征。随着训练的进行,模型的语义分割能力会增加,信息熵会减少,大部分区域会被划分为低熵区域。此时,字符比较的特征主要是语义特征。这就像特征选择中模型的自对抗学习,在训练过程中动态选择高熵全局特征和低熵局部特征。 3.语义对齐匹配在得到高熵全局特征和低熵语义特征后,我们首先会根据以下公式计算它们各自的重要性得分。对于高熵区域,如果收录人体的区域特征越多,其重要性得分就越高。对于低熵区域,如果人体语义区域不可见、被遮挡或无关紧要,则其重要性得分较低。语义对齐匹配如下图所示:
图 6 语义对齐匹配
根据各自的重要性得分和对应的特征比较距离,可以计算出最终字符匹配的总距离。
此时我们已经实现了人体区域的动态对齐匹配。
结果分析
我们对比了我们模型的一些SOTA模型在开源数据集上的效果,结果如下:
图 7 整体数据集对比
图 8 Partial 数据集对比 图 7 是全身数据集的对比结果,图 8 是 Partial 数据集的对比结果。同时,我们也在自己构建的Drama-ReID数据集上进行了测试对比,结果如下:
图 9 戏剧数据集对比
体检单申请案例
通过加入Partial re-ID特性,我们可以获得更多的准完整视频字符数据。这些数据目前主要用于电影体检中各种指标的计算,比如人物的外貌、人物的互动、故事情节等。同时,我们可以将视频内容根据以上指标进行量化编辑优化或内容评价。以下是“冰糖炖雪梨”的一些案例应用。
图 10 人物出现率
图 11 故事线分布
图 12 角色的社交网络关系
<p class="js_darkmode__74" data-darkmode-bgcolor-15971410476758="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15971410476758="rgb(255, 255, 255)" data-darkmode-color-15971410476758="rgb(157, 157, 157)" data-darkmode-original-color-15971410476758="rgb(73, 73, 73)" data-style="margin: 15px 8px; color: rgb(73, 73, 73); white-space: normal; font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; letter-spacing: 0.544px; font-size: 11pt; line-height: 1.75em;" data-darkmode-bgcolor-15973128395730="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15973128395730="rgb(255, 255, 255)" data-darkmode-color-15973128395730="rgb(157, 157, 157)" data-darkmode-original-color-15973128395730="rgb(73, 73, 73)" style="margin: 15px 8px;color: rgb(73, 73, 73);white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;font-size: 11pt;line-height: 1.75em;">更多精彩推荐</p>
☞去世这天是她的生日,全球首位女性图灵奖得主 Frances Allen 的传奇人生☞华为云 GaussDB 数据库,会是新的国产之光吗?☞小米十年,雷军的一往无前☞用Bi-GRU语义解析,实现中文人物关系分析☞CPU:别再拿我当搬砖工!☞DeFi升空助推器:收益耕作者「Yield Farming」点分享点点赞点在看 查看全部
基于内容视频数据进行的人物匹配问题示例
头像| CSDN视觉中国下载
简介
人员重新识别 (re-ID) 在现实世界中是一项非常具有挑战性的任务。它旨在通过视觉算法模型,从不同的角度匹配不同摄像机下的同一个人。无处不在的遮挡、复杂的背景、光线的变化等都让这个问题变得困难。目前大部分开源数据集,如Market1501、DukeMTMC等,都是采集监控视频下的行人数据。这些数据集中的人物大多是直立和固定的姿势。目前主流的算法模型都是针对这些数据集进行了很好的性能优化和提升。然而,基于内容视频数据的字符重识别研究工作很少。不同于传统的监控视频,内容视频中存在大量的手动剪辑和镜头切换,以及大量的多角度、多机位镜头拍摄。这些都使得内容视频中的人物出现了不同程度的遮挡和人体区域的丢失。角度、姿势和大小的变化。我们可以通过图1所示的一个具体例子来看一看。图1(a)中,A和B用于描述同一场景的不同角度和摄像机位置。镜头A和镜头B中的人物匹配问题可以看成是全身和半身的匹配问题。在图 1(b) 中,镜头 A 中的人有一个可识别的正面。这时候,如果我们能在镜头B中匹配到同一个人,那么我们就可以最终识别出那些只出现在某些镜头中的人了。只有背面或侧面的字符信息。这有助于我们提高视频内容分析指标的准确性和有效性。
(a) (b) 图 1 内容视频中的字符匹配。综上所述,我们可以看出内容视频中re-ID算法要解决的主要问题之一是部分字符图像的遮挡或匹配。学术界通常将其称为部分 re-ID 或 occluded re-ID。目前业界对此类问题的主要解决方案是通过将局部区域特征重构为全局特征来实现隐式对齐操作,另一种是利用人体空间的划分来实现相同的显式特征。区域。对齐操作。然而,这些现有方法的问题在于,一方面训练数据集的数据与内容视频的数据差异较大,另一方面,粗粒度的空间区域划分不能适应复杂的人内容视频中的姿势。因此,我们从数据集和算法模型两个方面考虑优化内容视频中的re-ID算法。
数据集构建
图2是开源数据集和电视剧视频数据的对比。从图中我们发现,剧中人物的姿态变化更大,分辨率更高,并伴随着大量人体部位的遮挡或丢失。 ,而开源数据集中人物的姿势相对固定,而且大多是直立全身的图像。因此,很难将在当前开源数据集上训练的算法模型直接应用于内容视频。基于此,我们直接构建了一个戏剧场景中的大规模re-ID数据集。
图 2 数据集对比
整个数据集的构建过程主要分为以下几个步骤:1.Screening the episodes:根据时间和流行度选择大约500集,每集选择10-20集。 2.Sampling 帧检测:对于每一集视频帧检测,使用人体检测模型获取人体的帧图片。 3.数据分组:将检测到的人框图片按show分组,减少标注工作量。 4.Data annotation:用person ID对分组的数据集进行注释,每个ID大约30张图片。最后,我们获得了戏剧场景中的 Drama-ReID 数据集。整个数据集大约有 1W 个 ID 号,包括大约 38W 个图片。是业内最大的戏剧场景的re-ID数据集。
算法模型
我们的整体算法模型框架如图3所示,基础网络部分使用了预训练的resnet50。为了获得更大的特征图,我们将backbone最后一个卷积层的stride设置为1。backbone后面主要有3个模块:人体语义分割、信息熵测量模块、语义对齐与匹配。整个网络结构是端到端的训练。
图 3 网络结构
1. 人体语义分割不同于现有的将人体区域划分为空间区域的算法。我们使用人体语义分割来划分人体语义区域,如图4所示:
图 4 人体语义分割
一方面,我们可以利用人体语义区域的划分来实现语义级别的特征对齐。另一方面,我们可以去除背景区域特征,以防止部分复杂背景图像影响字符匹配。同时,我们没有像现有的一些算法那样使用单独的语义分割模型来提取人体语义区域,而是使用了多任务学习人体语义分割。它的好处之一是可以降低模型的复杂度和复杂度。计算量,另一个是通过增加语义分割的监督损失,可以有效提高基本特征的空间表示能力2.信息熵测量模块多任务人类语义分割可以帮助我们提取人类语义区域,但是同时我们还需要考虑语义分割错误的情况。错误的语义分割会导致错误的特征对齐,导致错误的字符匹配。考虑到某个区域的分割概率越高,这个区域被正确分割的概率就越大,我们通过计算分割概率的信息熵来衡量这个分割的不确定性。计算公式如下:
如果它更小,则意味着模型更确定这部分区域被正确分割。这样我们就可以计算出特征图上每个点的信息熵,然后通过设置合适的信息熵阈值,将整个人体区域划分为高熵和低熵区域。
整个信息熵测量模块如图5所示:
图5 信息熵测量的高熵区域是语义分割中不确定性高的部分。它们可能无法正确划分为某个语义区域。我们直接提取它们的全局特征。并且往往同一个角色的高熵部分具有一定的独特性(比如某个角色的特殊帽子)。这种独特而稀有的元素很难正确分割,但它是我们字符匹配的重要组成部分。基础和我们高熵区域的全局特征是这种特征的独特元素。低熵区域是语义分割中不确定性较低的部分。它们往往是很容易被正确分割的部位,它们往往与人体的区域结构密切相关。我们使用熵注意图来增强语义分割中具有高确定性的表示,同时抑制语义分割中低确定性的表示。一方面增强了稳定语义成分的表达,另一方面降低了错位的可能性。同时,在模型训练过程中,整体信息熵会随着分割损失的减小而减小。在训练初期,模型不能很好地进行语义分割,导致信息熵高,大部分区域会被划分为高熵区域。这时字符比较的特征主要是全局特征。随着训练的进行,模型的语义分割能力会增加,信息熵会减少,大部分区域会被划分为低熵区域。此时,字符比较的特征主要是语义特征。这就像特征选择中模型的自对抗学习,在训练过程中动态选择高熵全局特征和低熵局部特征。 3.语义对齐匹配在得到高熵全局特征和低熵语义特征后,我们首先会根据以下公式计算它们各自的重要性得分。对于高熵区域,如果收录人体的区域特征越多,其重要性得分就越高。对于低熵区域,如果人体语义区域不可见、被遮挡或无关紧要,则其重要性得分较低。语义对齐匹配如下图所示:
图 6 语义对齐匹配
根据各自的重要性得分和对应的特征比较距离,可以计算出最终字符匹配的总距离。
此时我们已经实现了人体区域的动态对齐匹配。
结果分析
我们对比了我们模型的一些SOTA模型在开源数据集上的效果,结果如下:
图 7 整体数据集对比
图 8 Partial 数据集对比 图 7 是全身数据集的对比结果,图 8 是 Partial 数据集的对比结果。同时,我们也在自己构建的Drama-ReID数据集上进行了测试对比,结果如下:
图 9 戏剧数据集对比
体检单申请案例
通过加入Partial re-ID特性,我们可以获得更多的准完整视频字符数据。这些数据目前主要用于电影体检中各种指标的计算,比如人物的外貌、人物的互动、故事情节等。同时,我们可以将视频内容根据以上指标进行量化编辑优化或内容评价。以下是“冰糖炖雪梨”的一些案例应用。
图 10 人物出现率
图 11 故事线分布
图 12 角色的社交网络关系
<p class="js_darkmode__74" data-darkmode-bgcolor-15971410476758="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15971410476758="rgb(255, 255, 255)" data-darkmode-color-15971410476758="rgb(157, 157, 157)" data-darkmode-original-color-15971410476758="rgb(73, 73, 73)" data-style="margin: 15px 8px; color: rgb(73, 73, 73); white-space: normal; font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; letter-spacing: 0.544px; font-size: 11pt; line-height: 1.75em;" data-darkmode-bgcolor-15973128395730="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15973128395730="rgb(255, 255, 255)" data-darkmode-color-15973128395730="rgb(157, 157, 157)" data-darkmode-original-color-15973128395730="rgb(73, 73, 73)" style="margin: 15px 8px;color: rgb(73, 73, 73);white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;font-size: 11pt;line-height: 1.75em;">更多精彩推荐</p>
☞去世这天是她的生日,全球首位女性图灵奖得主 Frances Allen 的传奇人生☞华为云 GaussDB 数据库,会是新的国产之光吗?☞小米十年,雷军的一往无前☞用Bi-GRU语义解析,实现中文人物关系分析☞CPU:别再拿我当搬砖工!☞DeFi升空助推器:收益耕作者「Yield Farming」
对比国内外十大主流采集软件,帮助你选择最适合的爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 528 次浏览 • 2021-08-01 18:33
对比国内外十大主流采集软件,帮助你选择最适合的爬虫
正文|优采云大数据
大数据技术经过多年的演进,从一个看起来很酷的新技术,变成了企业在生产经营中实际部署的服务。其中,data采集产品迎来了广阔的市场前景。无论在国内还是国外,市场上都有很多技术上不同的采集软件。
今天,我们将对比国内外十大主流采集软件的优缺点,助您选择最合适的爬虫,体验数据狩猎的乐趣。
国内文章
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网络上分散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据。其用户定位主要面向有一定代码基础的人,适合编程老手。
采集功能齐全,不限于网页和内容,任意文件格式均可下载
智能多重识别系统,可选验证方式,保障安全
支持PHP和C#插件扩展,方便数据的修改和处理
同义词、同义词替换、参数替换、伪原创必备技能
采集难,没有编程基础的用户难
结论:优采云适合编程高手,规则更复杂,软件定位更专业精准。
2.优采云
可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现采集数据自动化,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,云采集可以更精准、更高效、更大规模。
可视化操作,无需写代码,生产规则采集,适合零编程基础的用户
即将推出的7.0 版本是智能的,内置智能算法和建立采集 规则。用户可通过设置相应参数实现网站,APP自动采集。
云采集是其主要功能,支持关闭采集,实现采集自动定时
支持多IP动态分配和验证码破解,避免IP阻塞
采集数据表格化,支持多种导出方式和import网站
结论:优采云是一款适合小白用户试用的采集软件。它具有强大的云功能。当然,老爬虫也可以开发它的高级功能。
3.集搜客
一款简单易用的网络信息抓取软件,可以抓取网页文本、图表、超链接等网络元素。 采集也可以通过一个简单的可视化过程来服务任何有采集数据需求的人。
可视化的流程操作,不同于优采云,采集客户的流程侧重于定义抓取的数据和抓取路径。 优采云的规则流程非常清晰,软件操作的每一步都由用户决定
支持抓取指数图表上浮动显示的数据,也可以抓取手机网站的数据
会员可以互相帮助爬取,提高采集效率,还有模板资源可以申请
结论:收客的操作比较简单,适合初学者。功能方面功能不多,后续支付需求较多。
4.优采云云攀虫
新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网络数据。
直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示,本地化隐私保护,云端采集,可隐藏用户IP
结论:优采云类似于一个爬虫系统框架,具体来说采集要求用户自己编写爬虫,并且需要一个代码库。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
支持批量替换和过滤文章内容中的文字和链接
可以批量发帖到网站或论坛多个版块
带有采集或发帖任务完成后自动关机功能
结论:专注于对论坛和博客文本内容的抓取。全网数据的采集通用性不高。
国外文章
1.Import.io
Import.io 是一个基于网页的网页数据采集平台,用户无需编写代码和点击即可生成提取器。与国内大部分采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户也可以一键输入采集数据的URL。
提供云服务,自动分配云节点,提供SaaS平台存储数据
提供API导出接口,可导出Google Sheets、Excel、Tableau等格式
根据采集条目的数量,收费方式提供三个版本:基础版、专业版、企业版
结论:Import.io智能开发,采集简单,但在处理一些复杂的网页结构上相对较弱。
2.Octoparse
Octoparse 是一款功能齐全的互联网采集 工具,内置了许多高效工具。用户无需编写代码即可从复杂的网页结构中采集结构化数据。 采集页面设计简洁友好,操作完全可视化,适合新手用户。
提供cloud采集服务,可以达到4-10倍的速度cloud采集
广告拦截功能通过减少加载时间提高采集efficiency
提供Xpath设置,准确定位网页数据元素
支持导出CSV、Excel、XML等多种数据格式
多版本选择,分为免费版和付费版,所有付费版均提供云服务
结论:Octoparse 功能齐全,价格合理。它可以应用于复杂的网络结构。如果你想不翻墙使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
3.Visual Web Ripper
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。
可提取多种数据格式(列表页)
提供IP代理,避免IP阻塞
支持多种数据导出格式,通过编程自定义输出格式
内置调试器,帮助用户自定义采集进程和输出格式
结论:Visual Web Ripper功能强大,自定义采集能力强,适合编程经验丰富的用户使用。不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber 是最强大的网页抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
内置调试器,帮助用户调试代码
对接一些软件开发平台,供用户编辑爬虫脚本
提供API导出接口,支持自定义编程接口
结论:Content Grabber 网页适用性强,功能强大。它没有完全为用户提供基本功能,适合具有高级编程技能的人。
5.Mozenda
Mozenda是一款基于云服务的data采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
能够提取各种数据格式,但难以处理不规则的数据结构(如列表、表格)
内置正则表达式工具,用户需要自己编写
支持多种数据导出格式但不提供自定义接口
结论:Mozenda提供数据云存储,但难以处理复杂的网页结构,软件操作界面跳转,用户体验不够友好,适合有基本爬虫经验的人使用。
<p>以上爬虫软件已经能够满足国内外用户采集的需求。其中一些工具,例如优采云、优采云、Octoparse、Content Grabber,提供了许多高级功能来帮助用户使用内置的正则表达式、XPath 工具和代理服务器从复杂的网页中抓取准确的数据。 查看全部
对比国内外十大主流采集软件,帮助你选择最适合的爬虫

正文|优采云大数据
大数据技术经过多年的演进,从一个看起来很酷的新技术,变成了企业在生产经营中实际部署的服务。其中,data采集产品迎来了广阔的市场前景。无论在国内还是国外,市场上都有很多技术上不同的采集软件。
今天,我们将对比国内外十大主流采集软件的优缺点,助您选择最合适的爬虫,体验数据狩猎的乐趣。
国内文章
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网络上分散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据。其用户定位主要面向有一定代码基础的人,适合编程老手。

采集功能齐全,不限于网页和内容,任意文件格式均可下载
智能多重识别系统,可选验证方式,保障安全
支持PHP和C#插件扩展,方便数据的修改和处理
同义词、同义词替换、参数替换、伪原创必备技能
采集难,没有编程基础的用户难
结论:优采云适合编程高手,规则更复杂,软件定位更专业精准。
2.优采云
可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现采集数据自动化,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,云采集可以更精准、更高效、更大规模。
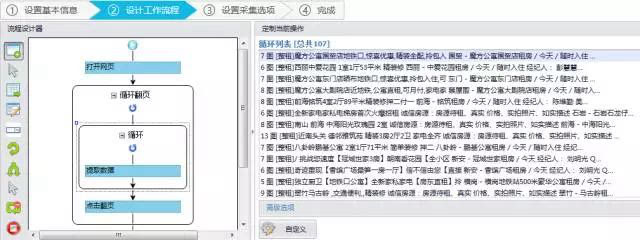
可视化操作,无需写代码,生产规则采集,适合零编程基础的用户
即将推出的7.0 版本是智能的,内置智能算法和建立采集 规则。用户可通过设置相应参数实现网站,APP自动采集。
云采集是其主要功能,支持关闭采集,实现采集自动定时
支持多IP动态分配和验证码破解,避免IP阻塞
采集数据表格化,支持多种导出方式和import网站
结论:优采云是一款适合小白用户试用的采集软件。它具有强大的云功能。当然,老爬虫也可以开发它的高级功能。
3.集搜客
一款简单易用的网络信息抓取软件,可以抓取网页文本、图表、超链接等网络元素。 采集也可以通过一个简单的可视化过程来服务任何有采集数据需求的人。

可视化的流程操作,不同于优采云,采集客户的流程侧重于定义抓取的数据和抓取路径。 优采云的规则流程非常清晰,软件操作的每一步都由用户决定
支持抓取指数图表上浮动显示的数据,也可以抓取手机网站的数据
会员可以互相帮助爬取,提高采集效率,还有模板资源可以申请
结论:收客的操作比较简单,适合初学者。功能方面功能不多,后续支付需求较多。
4.优采云云攀虫
新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网络数据。

直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示,本地化隐私保护,云端采集,可隐藏用户IP
结论:优采云类似于一个爬虫系统框架,具体来说采集要求用户自己编写爬虫,并且需要一个代码库。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
支持批量替换和过滤文章内容中的文字和链接
可以批量发帖到网站或论坛多个版块
带有采集或发帖任务完成后自动关机功能
结论:专注于对论坛和博客文本内容的抓取。全网数据的采集通用性不高。
国外文章
1.Import.io
Import.io 是一个基于网页的网页数据采集平台,用户无需编写代码和点击即可生成提取器。与国内大部分采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户也可以一键输入采集数据的URL。
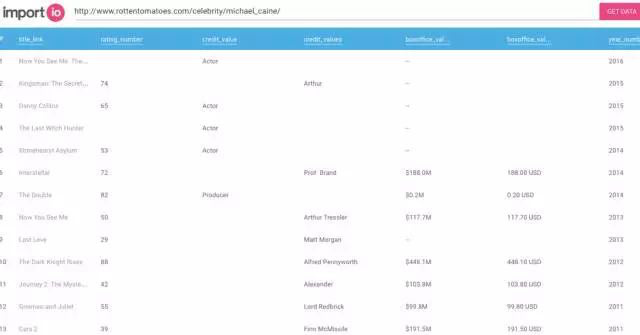
提供云服务,自动分配云节点,提供SaaS平台存储数据
提供API导出接口,可导出Google Sheets、Excel、Tableau等格式
根据采集条目的数量,收费方式提供三个版本:基础版、专业版、企业版
结论:Import.io智能开发,采集简单,但在处理一些复杂的网页结构上相对较弱。
2.Octoparse
Octoparse 是一款功能齐全的互联网采集 工具,内置了许多高效工具。用户无需编写代码即可从复杂的网页结构中采集结构化数据。 采集页面设计简洁友好,操作完全可视化,适合新手用户。
提供cloud采集服务,可以达到4-10倍的速度cloud采集
广告拦截功能通过减少加载时间提高采集efficiency
提供Xpath设置,准确定位网页数据元素
支持导出CSV、Excel、XML等多种数据格式
多版本选择,分为免费版和付费版,所有付费版均提供云服务
结论:Octoparse 功能齐全,价格合理。它可以应用于复杂的网络结构。如果你想不翻墙使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
3.Visual Web Ripper
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。

可提取多种数据格式(列表页)
提供IP代理,避免IP阻塞
支持多种数据导出格式,通过编程自定义输出格式
内置调试器,帮助用户自定义采集进程和输出格式
结论:Visual Web Ripper功能强大,自定义采集能力强,适合编程经验丰富的用户使用。不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber 是最强大的网页抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
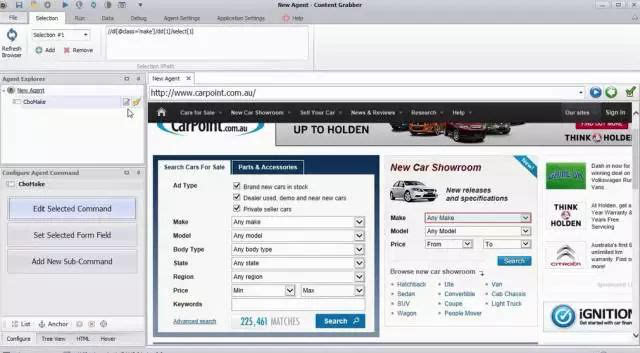
内置调试器,帮助用户调试代码
对接一些软件开发平台,供用户编辑爬虫脚本
提供API导出接口,支持自定义编程接口
结论:Content Grabber 网页适用性强,功能强大。它没有完全为用户提供基本功能,适合具有高级编程技能的人。
5.Mozenda
Mozenda是一款基于云服务的data采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
能够提取各种数据格式,但难以处理不规则的数据结构(如列表、表格)
内置正则表达式工具,用户需要自己编写
支持多种数据导出格式但不提供自定义接口
结论:Mozenda提供数据云存储,但难以处理复杂的网页结构,软件操作界面跳转,用户体验不够友好,适合有基本爬虫经验的人使用。
<p>以上爬虫软件已经能够满足国内外用户采集的需求。其中一些工具,例如优采云、优采云、Octoparse、Content Grabber,提供了许多高级功能来帮助用户使用内置的正则表达式、XPath 工具和代理服务器从复杂的网页中抓取准确的数据。
团餐校园点餐场景录入人脸,用于刷脸代扣点餐
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-01 02:09
团餐校园点餐场景录入人脸,用于刷脸代扣点餐
人脸采集
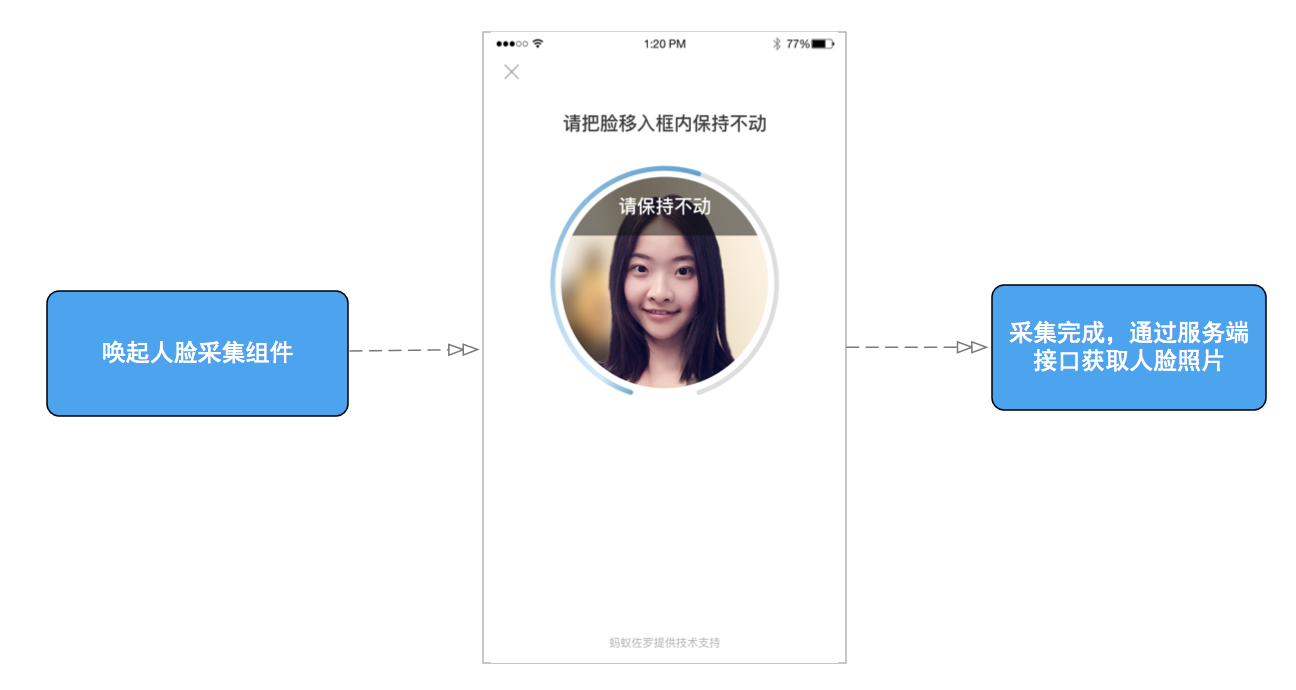
产品介绍
人脸识别是公共服务场所提升业务效率和用户体验的一种新方式。人脸识别采集是指在获得用户充分授权和认可、充分保护用户隐私的前提下获得合规。使用有质量要求的实时人脸图像进行比对、识别等后续操作,提高商家的服务质量。核心功能包括:
交互界面
调用流程
应用场景
人脸应用广泛,可应用于以下场景:
场景
说明
拍摄身份证照片
小程序提供拍摄光线角度好的证件照功能。
团餐
校园点餐场景录入学生脸,刷脸扣餐单。
通过face采集小程序返回给开发者的实况照片,不建议与开发者自己的对比源图片在安全性较低的对比算法下进行对比验证。我。如果开发者需要验证自己的场景,请使用支付宝身份验证或其他公开渠道的人脸认证产品。由于支付宝的身份验证产品有完善的风控体系和更安全的后端活体检测算法,因此具有非常强的防范攻击和误识别的能力。
注意:
小程序“人脸验证”的开放能力全面升级为“支付宝身份验证”。建议开发者使用“支付宝身份验证”能力;已签约并开通“人脸认证”的小程序可继续使用。
访问条件
注意:
充电模式
免费
入门指南第一步:创建小程序
要在小程序中使用face采集功能,需要先完成开发者注册并创建小程序。
第 2 步:添加能力
小程序创建完成后,开发者可以在能力列表部分点击添加能力,为创建的小程序添加能力,如下图;开发者选择人脸采集能力后,点击右下角的确定。添加完毕。
第 3 步:签名能力
face采集功能需要签名才能生效。请点击功能列表右侧的“立即注册”。签名成功后,状态设置为“生效”,即可调用face采集接口。
第 4 步:集成和配置 SDK
服务端SDK需要商家集成到自己的服务端系统中,用于后续的服务端接口调用。
下载服务器 SDK
为了帮助开发者调用开放接口,我们提供了开放平台服务器SDK,收录JAVA、PHP、NodeJS、Python、.NET五种语言,封装了签名验证、HTTP接口请求、等,请下载相应语言版本的SDK并介绍您的开发项目。
接口调用配置
调用SDK前需要进行初始化,以JAVA代码为例:
AlipayClient alipayClient = new DefaultAlipayClient(URL,APP_ID,APP_PRIVATE_KEY,FORMAT,CHARSET,ALIPAY_PUBLIC_KEY,SIGN_TYPE);
关键参数说明:
配置参数
样本值说明
如何获取/样本值
网址
支付宝网关(固定)
APPID
APPID是应用创建后生成的
去见你
APP_PRIVATE_KEY
开发者的私钥,由开发者生成。
查看配置密钥获取
格式
参数返回格式,仅支持json
json(固定)
字符集
编码集,支持GBK/UTF-8
开发者根据实际项目编码配置
ALIPAY_PUBLIC_KEY
支付宝公钥,由支付宝生成
详情请参考配置秘钥
SIGN_TYPE
商家用于生成签名字符串的签名算法类型。目前支持RSA2和RSA,推荐使用RSA2
RSA2
接下来,您可以使用 alipayClient 调用特定的 API。 alipayClient只需要初始化一次,后续调用不同的API可以使用同一个alipayClient对象。
注意:
ISV/开发者可以通过第三方应用授权获取商户授权令牌(app_auth_token),并作为请求参数传入,实现代表商户发起请求的能力。
第五步:调用接口
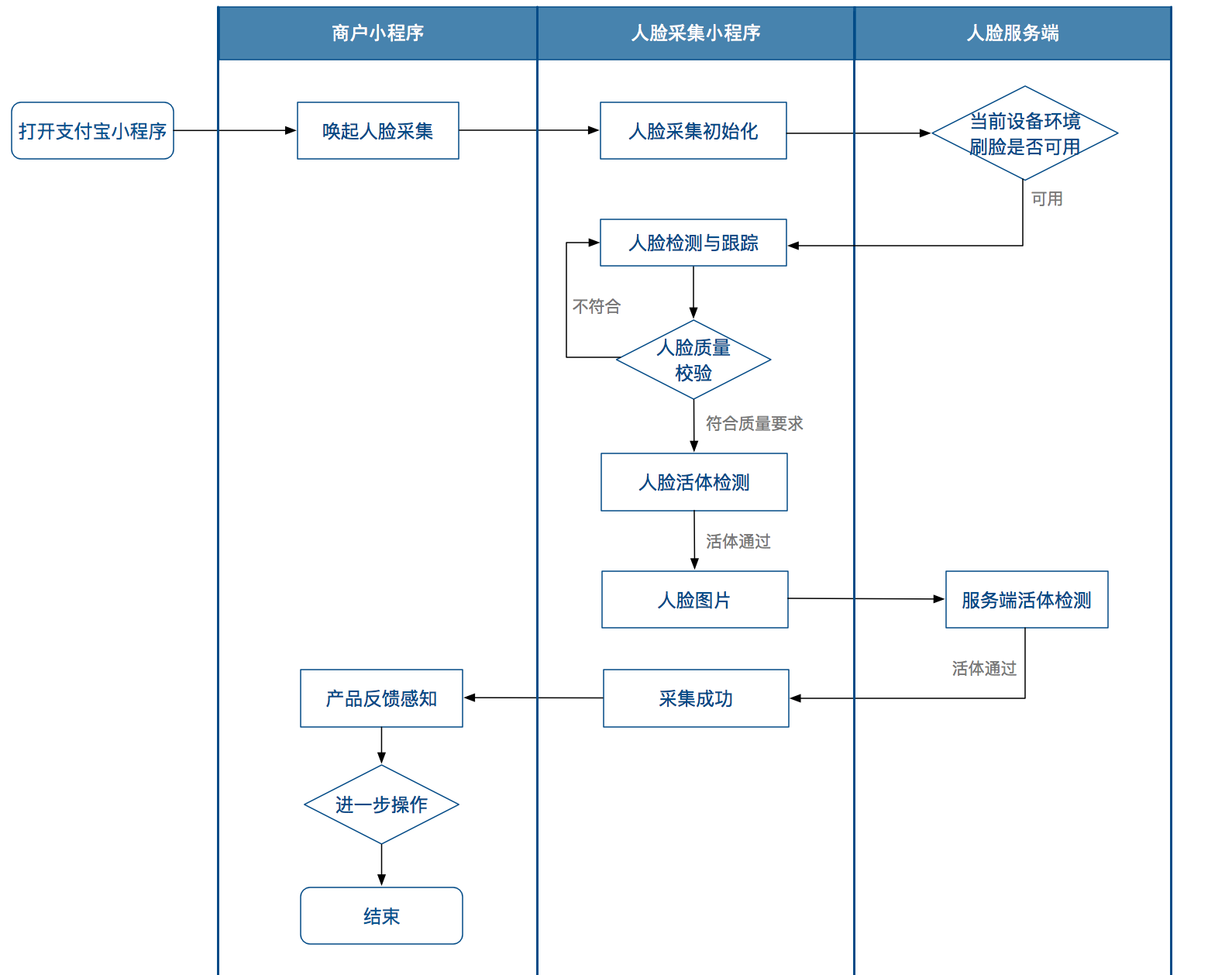
通话流程图
调用JSAPI(faceVerify)唤起人脸采集,整个采集过程完全由人脸内部实现,采集完成后通过回调函数返回采集结果。在采集过程中,客户端完成人脸采集过程和活体检测,然后将采集的人脸特征数据上传到服务器进行进一步的活体检测,最后将采集结果返回给服务端客户。
调用查询接口(zoloz.identification.user.web.query)获取可信的采集结果。如果采集成功,您可以通过该界面获取采集的人脸照片。
主要步骤
版本要求:
调用接口my.ap.faceVerify,传入参数bizId和bizType调用face采集,采集结束后,通过回调函数获取采集结果。
请注意,在调用my.ap.faceVerify之前没有返回,切记不能发起第二次调用faceVerify,否则会出现异常。例如,在您的小程序中,您可以通过单击页面上的按钮来触发 my.ap.faceVerify 的调用。请确保在调用返回前禁用该按钮,并且不允许用户多次点击。
代码示例
my.ap.faceVerify({
bizId: '545689787654767653', //业务流水号,商户自行生成,需要保证唯一性,不超过64位
bizType: '1', //业务场景参数,‘1’代表人脸采集,请务必填写
useBackCamera: true, //传入此参数会唤起后置摄像头;非必填,不传默认唤起前置摄像头
success: (res) => {
my.alert({
content: JSON.stringify(res),
});
},
fail: (res) => {
my.alert({
content: JSON.stringify(res),
});
}
});
成功认证结果示例
faceRetCode = 1000表示face采集成功,可以调用查询接口(zoloz.identification.user.web.query)成功获取照片,证明face采集成功.
{
faceRetCode: "1000",
retCode: "OK_SUCCESS",
retCodeSub: "Z5100",
retMessageSub: "成功 (Z5100)",
zimId: "7b6b72be1493cab72dd0a25877de329dd00"
}undefined
注意,retCode代表刷脸成功可用,刷脸可用,则可以进行刷脸采集。
调用face采集query接口(zoloz.identification.user.web.query)获取人脸照片,以下请求示例代码以JAVA为例:
AlipayClient alipayClient = new DefaultAlipayClient("https://openapi.alipay.com/gateway.do","app_id","your private_key","json","GBK","alipay_public_key","RSA2");
ZolozIdentificationUserWebQueryRequest request = new ZolozIdentificationUserWebQueryRequest();
request.setBizContent("{" +
"\"biz_id\":\"5456897876546767654\"," +
"\"zim_id\":\"731be7f204a962b0486a9b64ea3050ae\"," +
"\"extern_param\":\"{\\\"bizType\\\":\\\"1\\\"}\"" +
"}");
ZolozIdentificationUserWebQueryResponse response = alipayClient.execute(request);
if(response.isSuccess()){
System.out.println("调用成功");
} else {
System.out.println("调用失败");
}undefined
成功响应示例
如果采集成功,imgStr对象中的值为人脸照片的base64编码字符串。
{
"zoloz_identification_user_web_query_response": {
"code": "10000",
"msg": "Success",
"extern_info": "{\"imgStr\":\"ApA4VVwOP1rqp8sotrcimna3c__9k\",\"bizId\":\"5456897876546767654-doucao.wjp\",\"zimMsg\":\"成功\",\"zimCode\":\"Z5130\"}"
},
"sign": "SL1dSiE6XKKIta5w3ge3VSZE+71CdBtr8Ocw9WvRSZD3Tz6/vNaA2pWLBYdZcvrAHaMYa6J8V9c4nY3kdBK0EeU2afh+8CLTw6dnZfkO8tR5NOtJUb+M6qhxl0xKhpE+2GUonpCcJg1MHS0aMVXa/b6dhK/yZJQCdO1YnVNuzs8="
}
失败响应示例
{
"zoloz_identification_user_web_query_response": {
"code": "40004",
"msg": "Business Failed",
"sub_code": "INVALID_PARAMETER",
"sub_msg": "参数有误抱歉,系统出错了,请您稍后再试 (Z5132)"
},
"sign": "v/DjkviKs2ja3HO9ZZ94W8bcfAsLyRuGrZT/TlFm6FgGQv4qSm/94o1FjOaMCl/t8XIm89bBhk03PBJ099alDzjnj4RD6S9FYDV7CfjvHYjrzvVJzn47Gc1mWdOHZ38DFQLWIg1IbNKFmYdoR+NdY5nY/cwz3Al2wfEylvN1cbs="
}
API 列表
界面英文名称
接口说明
my.ap.faceVerify
脸采集
zoloz.identification.user.web.query
Face采集Result 查询
常见问题 Q:如果用户有多个支付宝账户,调用人脸检测接口返回的user_id是否相同?
A:首先返回用户最后使用的支付宝账号对应的user_id。
Q: 真机调试报错 "retMessageSub":"{\"error\":4,\"errorMessage\":\"No right to call\",\"message\":\"No right to call \" ,\"signature\":\"N22104\"} 我该怎么办?
A:face采集功能需要在小程序后台添加face采集功能包并签订合同后才能使用。请参阅此文档。
如果您在调用 API 时遇到错误,您可以: 查看全部
团餐校园点餐场景录入人脸,用于刷脸代扣点餐
人脸采集
产品介绍
人脸识别是公共服务场所提升业务效率和用户体验的一种新方式。人脸识别采集是指在获得用户充分授权和认可、充分保护用户隐私的前提下获得合规。使用有质量要求的实时人脸图像进行比对、识别等后续操作,提高商家的服务质量。核心功能包括:
交互界面
调用流程
应用场景
人脸应用广泛,可应用于以下场景:
场景
说明
拍摄身份证照片
小程序提供拍摄光线角度好的证件照功能。
团餐
校园点餐场景录入学生脸,刷脸扣餐单。
通过face采集小程序返回给开发者的实况照片,不建议与开发者自己的对比源图片在安全性较低的对比算法下进行对比验证。我。如果开发者需要验证自己的场景,请使用支付宝身份验证或其他公开渠道的人脸认证产品。由于支付宝的身份验证产品有完善的风控体系和更安全的后端活体检测算法,因此具有非常强的防范攻击和误识别的能力。
注意:
小程序“人脸验证”的开放能力全面升级为“支付宝身份验证”。建议开发者使用“支付宝身份验证”能力;已签约并开通“人脸认证”的小程序可继续使用。
访问条件
注意:
充电模式
免费
入门指南第一步:创建小程序
要在小程序中使用face采集功能,需要先完成开发者注册并创建小程序。
第 2 步:添加能力
小程序创建完成后,开发者可以在能力列表部分点击添加能力,为创建的小程序添加能力,如下图;开发者选择人脸采集能力后,点击右下角的确定。添加完毕。

第 3 步:签名能力
face采集功能需要签名才能生效。请点击功能列表右侧的“立即注册”。签名成功后,状态设置为“生效”,即可调用face采集接口。
第 4 步:集成和配置 SDK
服务端SDK需要商家集成到自己的服务端系统中,用于后续的服务端接口调用。
下载服务器 SDK
为了帮助开发者调用开放接口,我们提供了开放平台服务器SDK,收录JAVA、PHP、NodeJS、Python、.NET五种语言,封装了签名验证、HTTP接口请求、等,请下载相应语言版本的SDK并介绍您的开发项目。
接口调用配置
调用SDK前需要进行初始化,以JAVA代码为例:
AlipayClient alipayClient = new DefaultAlipayClient(URL,APP_ID,APP_PRIVATE_KEY,FORMAT,CHARSET,ALIPAY_PUBLIC_KEY,SIGN_TYPE);
关键参数说明:
配置参数
样本值说明
如何获取/样本值
网址
支付宝网关(固定)
APPID
APPID是应用创建后生成的
去见你
APP_PRIVATE_KEY
开发者的私钥,由开发者生成。
查看配置密钥获取
格式
参数返回格式,仅支持json
json(固定)
字符集
编码集,支持GBK/UTF-8
开发者根据实际项目编码配置
ALIPAY_PUBLIC_KEY
支付宝公钥,由支付宝生成
详情请参考配置秘钥
SIGN_TYPE
商家用于生成签名字符串的签名算法类型。目前支持RSA2和RSA,推荐使用RSA2
RSA2
接下来,您可以使用 alipayClient 调用特定的 API。 alipayClient只需要初始化一次,后续调用不同的API可以使用同一个alipayClient对象。
注意:
ISV/开发者可以通过第三方应用授权获取商户授权令牌(app_auth_token),并作为请求参数传入,实现代表商户发起请求的能力。
第五步:调用接口
通话流程图

调用JSAPI(faceVerify)唤起人脸采集,整个采集过程完全由人脸内部实现,采集完成后通过回调函数返回采集结果。在采集过程中,客户端完成人脸采集过程和活体检测,然后将采集的人脸特征数据上传到服务器进行进一步的活体检测,最后将采集结果返回给服务端客户。
调用查询接口(zoloz.identification.user.web.query)获取可信的采集结果。如果采集成功,您可以通过该界面获取采集的人脸照片。
主要步骤
版本要求:
调用接口my.ap.faceVerify,传入参数bizId和bizType调用face采集,采集结束后,通过回调函数获取采集结果。
请注意,在调用my.ap.faceVerify之前没有返回,切记不能发起第二次调用faceVerify,否则会出现异常。例如,在您的小程序中,您可以通过单击页面上的按钮来触发 my.ap.faceVerify 的调用。请确保在调用返回前禁用该按钮,并且不允许用户多次点击。
代码示例
my.ap.faceVerify({
bizId: '545689787654767653', //业务流水号,商户自行生成,需要保证唯一性,不超过64位
bizType: '1', //业务场景参数,‘1’代表人脸采集,请务必填写
useBackCamera: true, //传入此参数会唤起后置摄像头;非必填,不传默认唤起前置摄像头
success: (res) => {
my.alert({
content: JSON.stringify(res),
});
},
fail: (res) => {
my.alert({
content: JSON.stringify(res),
});
}
});
成功认证结果示例
faceRetCode = 1000表示face采集成功,可以调用查询接口(zoloz.identification.user.web.query)成功获取照片,证明face采集成功.
{
faceRetCode: "1000",
retCode: "OK_SUCCESS",
retCodeSub: "Z5100",
retMessageSub: "成功 (Z5100)",
zimId: "7b6b72be1493cab72dd0a25877de329dd00"
}undefined
注意,retCode代表刷脸成功可用,刷脸可用,则可以进行刷脸采集。
调用face采集query接口(zoloz.identification.user.web.query)获取人脸照片,以下请求示例代码以JAVA为例:
AlipayClient alipayClient = new DefaultAlipayClient("https://openapi.alipay.com/gateway.do","app_id","your private_key","json","GBK","alipay_public_key","RSA2");
ZolozIdentificationUserWebQueryRequest request = new ZolozIdentificationUserWebQueryRequest();
request.setBizContent("{" +
"\"biz_id\":\"5456897876546767654\"," +
"\"zim_id\":\"731be7f204a962b0486a9b64ea3050ae\"," +
"\"extern_param\":\"{\\\"bizType\\\":\\\"1\\\"}\"" +
"}");
ZolozIdentificationUserWebQueryResponse response = alipayClient.execute(request);
if(response.isSuccess()){
System.out.println("调用成功");
} else {
System.out.println("调用失败");
}undefined
成功响应示例
如果采集成功,imgStr对象中的值为人脸照片的base64编码字符串。
{
"zoloz_identification_user_web_query_response": {
"code": "10000",
"msg": "Success",
"extern_info": "{\"imgStr\":\"ApA4VVwOP1rqp8sotrcimna3c__9k\",\"bizId\":\"5456897876546767654-doucao.wjp\",\"zimMsg\":\"成功\",\"zimCode\":\"Z5130\"}"
},
"sign": "SL1dSiE6XKKIta5w3ge3VSZE+71CdBtr8Ocw9WvRSZD3Tz6/vNaA2pWLBYdZcvrAHaMYa6J8V9c4nY3kdBK0EeU2afh+8CLTw6dnZfkO8tR5NOtJUb+M6qhxl0xKhpE+2GUonpCcJg1MHS0aMVXa/b6dhK/yZJQCdO1YnVNuzs8="
}
失败响应示例
{
"zoloz_identification_user_web_query_response": {
"code": "40004",
"msg": "Business Failed",
"sub_code": "INVALID_PARAMETER",
"sub_msg": "参数有误抱歉,系统出错了,请您稍后再试 (Z5132)"
},
"sign": "v/DjkviKs2ja3HO9ZZ94W8bcfAsLyRuGrZT/TlFm6FgGQv4qSm/94o1FjOaMCl/t8XIm89bBhk03PBJ099alDzjnj4RD6S9FYDV7CfjvHYjrzvVJzn47Gc1mWdOHZ38DFQLWIg1IbNKFmYdoR+NdY5nY/cwz3Al2wfEylvN1cbs="
}
API 列表
界面英文名称
接口说明
my.ap.faceVerify
脸采集
zoloz.identification.user.web.query
Face采集Result 查询
常见问题 Q:如果用户有多个支付宝账户,调用人脸检测接口返回的user_id是否相同?
A:首先返回用户最后使用的支付宝账号对应的user_id。
Q: 真机调试报错 "retMessageSub":"{\"error\":4,\"errorMessage\":\"No right to call\",\"message\":\"No right to call \" ,\"signature\":\"N22104\"} 我该怎么办?
A:face采集功能需要在小程序后台添加face采集功能包并签订合同后才能使用。请参阅此文档。
如果您在调用 API 时遇到错误,您可以:
增(新增、创建、导入)的业务流程及设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-07-30 05:12
增(新增、创建、导入)的业务流程及设置
一、添加(添加、创建、导入)1.明确表字段类型
新业务是不同类型领域的组合。每个字段的具体类型应明确定义。这关系到数据库字段访问的设计,后端逻辑的编写,以及前端页面的数据输入方式和展示形式。
常用表格字段:
表格字段信息说明:
输出结果如一、图2所示:
图一:产品经理设置的表格字段
图2:DB建表结果
总结:
有些项目组可能会要求产品经理设计主表结构,也就是上面介绍的内容,专业部分的内容由DB设计完善。这有助于产品经理理清字段的含义,了解表字段的访问路径、设计逻辑,并在更大程度上参与项目开发和沟通协调。
2.使用准确的信息输入方式
表格字段的类型不同,对应的信息输入方式也会不同(如三)所示。如果前端页面使用了错误的输入样式,会导致新的报错,业务流程无法继续。
比如应该是一个下拉选择的字典值。如果使用手动填充的文本框,难免会出现人为填充错误,以及无法匹配数据库字典表的bug。
图3:文本、数字、时间、字典对应不同的输入方式
3.设置合理的图片限制
在新业务中,上传图片是一个很常见的需求。考虑到图片的上传加载速度、兼容性问题,需要限制图片的大小和格式。
一般图片格式包括:jpg、png、gif、bmp、gif,大小限制在500k~2M。
图四:
图4:微信公众号头像修改页面
4.设置及时完整的错误信息提示
在用户输入过程中,需要对填写的信息进行及时、全面的反馈,例如遗漏必填字段、格式校验错误填写数据等,如图5所示:
图5:错误信息提示
5.提高长表单处理效率二、Delete(删除、取消、禁用、停用)
如果数据有新路径,则需要删除。
一般来说,删除包括两种:
物理删除:真删除,从数据库层面删除数据,查询中找不到数据,无法恢复数据;一般对于重要的基础数据,不建议设置删除功能,设计上应避免不可逆操作;逻辑删除:误删除是指从页面中删除数据。数据库将数据的状态改写为“已删除”,删除后可以撤回,也可以通过数据库备份恢复。这在产品设计中很常用。
数据的前后台业务关系太强,无法设计删除功能,如何合理处理数据?
个人理解删除需求的存在,可能有以下几种情况:
过期无用信息:可以设计数据库定时任务,根据实际业务情况和指定条件,定期清理垃圾数据,适用于数据量大的情况;信息录入错误:逻辑删除或使用编辑功能修改数据; data 状态改变,或者需要暂停业务:使用字典状态来限制。
最后一个案例,在我做的TMS物流运输系统中,客户曾经提出过这样的需求:车辆出现故障或停止正常维修,销售人员在创建订单时仍然可以选择这辆车车。对于这种车,我们必须在系统中将其删除以避免误选(典型的伪需求)。
经过实际业务分析,发现直接删除车辆信息存在几个问题:
车辆维修完成后,操作人员需要重新填写车辆信息。用户体验差,浪费人力资源;汽车保养很常见。经营者如不及时补足恢复车辆,将影响运输业务;车辆的运输里程涉及财务结算和支付。如果删除,需要编写一大段逻辑代码来判断车辆相关的业务情况和财务结算状态,开发工作量大。
最终处理结果:
设计车辆停用功能,保存车辆基本信息,维护完成后恢复运行状态;停用期间的数据封装不影响尚未结算的财务数据。
类似数据因业务需要暂停,后期可能需要恢复,可采取[删除后取消]、[禁用]、[禁用]等虚假删除形式进行处理。
总结:
根据业务状态,确认信息是否允许删除;允许删除的数据需要二次确认提示,以减少误删的可能性。
三、改(修改、编辑、批量修改)
可能需要修改其他数据维护错误或业务更改。
1.修改后的表格
点击列表按钮进入二级页面/弹窗进行修改。
直接在列表单元格中编辑和修改。
编辑修改列表中嵌入的子表,不常用,适用于小范围内需要修改的信息。
范围广泛的数据更改、导入表和批量编辑。
数据错误,页面无法修改,直接进入数据库修改数据(很少,不推荐)。
2.修改说明3.批量修改四、查(查询、搜索)
合理的查询条件和样式设计,帮助用户快速准确地找到自己需要的信息。
常用的查询方法有:
1.同步查询,组合条件查询
设置默认查询条件。常用的是默认查询日期和默认状态查询,帮助用户快速获取所需信息。
2.精确查询或模糊匹配;
准确查询适用于字段短而准确的数据,用户内存开销比模糊匹配高,后者是比较常用的查询形式。
比如根据身份证号码查询用户信息,只需要输入1991,那么列表中所有收录1991的身份证数据都会被查询。可能的查询结果为:42812 或 4758261991024483。
按状态值快速过滤,业务流程类别比较常用。
自定义查询条件;显示高频查询条件,低频查询条件按钮收起隐藏,允许自定义查询字段。
提供查询历史记录,必要时根据历史查询词的流行度进行排序。
3.定时任务查询
在更专业的类别,我咨询过开发同学。我们一般说的定时器是指在特定的时间间隔内执行某个命令(我无法深入解释,抱歉);
在我的项目中,我只使用计时器来请求银行周转和检查余额。如果有机会,我可以写下来。
4.查看全局还是查看本地?
考虑到数据的安全性,有些产品可能会设计限制查询的边界,限制查询的结果只显示部分数据。
比如设置某些用户只能查询一定条件下的数据,获取过滤后的数据量。
五、显(显示、返回、列表样式)
后端系统90%的数据和业务流程都以表格的形式展示。陈列风格是否合理直接关系到用户对产品的第一印象和日常使用体验。
网上已经有很多优秀的文章专门讲解后端表设计的风格和使用场景,这里只是简单说明一下。
列表按功能区可分为过滤区、操作区、页眉、正文和页面。
【过滤区域】主要用于设置数据过滤条件和搜索;查询已详细说明,不再赘述。 【操作区】主要用于对数据进行功能性操作,常见的有增删改查、业务功能等。
[Header] 汇总表中要显示的字段信息,以及排序和自定义显示字段。
如有必要,您可以添加浮动窗口文本来解释该字段,以帮助用户理解该字段的含义。
如果数据列比较长,冻结表头,方便内容对应的字段。
信息级别区分,同类型数据的表头合并到单元格中。
[Text] 显示具体数据内容;正文内容要注意的要点是:
数字通常以两位小数显示并右对齐显示,以减少用户计算的压力。可以根据号码串的长度直观区分号码的大小;尤其是货币数字的显示。
对齐方式,比较字符串右对齐,定长字符串居中对齐,其他文本类型字符串可以对齐。
时间格式,加数字“0”使文字对齐。
空白,没有数据的单元格用“—”符号填充以保持视觉统一。
切分,常用表格格式切分,水平切分(关注行数据),垂直切分(关注列数据),无线切分(数据少,干扰信息少,信息页面简洁),斑马显示(方便用户定位当前查看的数据行);可以比较不同分割风格的视觉引导效果。
信息层,普通任务分类或权限分配类采用树状结构划分信息层。
列表中的数据是添加、删除、修改等操作的结果。如果前端界面正确或者字典检索错误,很容易导致页面或单元格数据为空,可能会出现奇怪的数据。
接受项目时,多关注列表中的echo字段。 F12 通常用于协助测试和开发人员排查错误的原因。
总结:
个人认为excel比较呆滞,表单设计基本到位。尤其是可视化数据展示,各种精美的excel模板,都是触手可及的优秀学习资料。
【分页】分页的样式很多,功能总结如下:
结论:
标题中指定的添加、删除和更改显示计算和传输。其实算法和传输属于更专业的范畴。希望以后有机会深入接触,弥补这个坑。毕竟,现在也是工业互联网化、数字化的时代。学习一些数据算法和传输技术总是对的。
本文由@RaRa原创发布,人人都是产品经理,未经许可禁止转载。
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏 查看全部
增(新增、创建、导入)的业务流程及设置

一、添加(添加、创建、导入)1.明确表字段类型
新业务是不同类型领域的组合。每个字段的具体类型应明确定义。这关系到数据库字段访问的设计,后端逻辑的编写,以及前端页面的数据输入方式和展示形式。
常用表格字段:
表格字段信息说明:
输出结果如一、图2所示:

图一:产品经理设置的表格字段

图2:DB建表结果
总结:
有些项目组可能会要求产品经理设计主表结构,也就是上面介绍的内容,专业部分的内容由DB设计完善。这有助于产品经理理清字段的含义,了解表字段的访问路径、设计逻辑,并在更大程度上参与项目开发和沟通协调。
2.使用准确的信息输入方式
表格字段的类型不同,对应的信息输入方式也会不同(如三)所示。如果前端页面使用了错误的输入样式,会导致新的报错,业务流程无法继续。
比如应该是一个下拉选择的字典值。如果使用手动填充的文本框,难免会出现人为填充错误,以及无法匹配数据库字典表的bug。

图3:文本、数字、时间、字典对应不同的输入方式
3.设置合理的图片限制
在新业务中,上传图片是一个很常见的需求。考虑到图片的上传加载速度、兼容性问题,需要限制图片的大小和格式。
一般图片格式包括:jpg、png、gif、bmp、gif,大小限制在500k~2M。
图四:

图4:微信公众号头像修改页面
4.设置及时完整的错误信息提示
在用户输入过程中,需要对填写的信息进行及时、全面的反馈,例如遗漏必填字段、格式校验错误填写数据等,如图5所示:

图5:错误信息提示
5.提高长表单处理效率二、Delete(删除、取消、禁用、停用)
如果数据有新路径,则需要删除。
一般来说,删除包括两种:
物理删除:真删除,从数据库层面删除数据,查询中找不到数据,无法恢复数据;一般对于重要的基础数据,不建议设置删除功能,设计上应避免不可逆操作;逻辑删除:误删除是指从页面中删除数据。数据库将数据的状态改写为“已删除”,删除后可以撤回,也可以通过数据库备份恢复。这在产品设计中很常用。
数据的前后台业务关系太强,无法设计删除功能,如何合理处理数据?
个人理解删除需求的存在,可能有以下几种情况:
过期无用信息:可以设计数据库定时任务,根据实际业务情况和指定条件,定期清理垃圾数据,适用于数据量大的情况;信息录入错误:逻辑删除或使用编辑功能修改数据; data 状态改变,或者需要暂停业务:使用字典状态来限制。
最后一个案例,在我做的TMS物流运输系统中,客户曾经提出过这样的需求:车辆出现故障或停止正常维修,销售人员在创建订单时仍然可以选择这辆车车。对于这种车,我们必须在系统中将其删除以避免误选(典型的伪需求)。
经过实际业务分析,发现直接删除车辆信息存在几个问题:
车辆维修完成后,操作人员需要重新填写车辆信息。用户体验差,浪费人力资源;汽车保养很常见。经营者如不及时补足恢复车辆,将影响运输业务;车辆的运输里程涉及财务结算和支付。如果删除,需要编写一大段逻辑代码来判断车辆相关的业务情况和财务结算状态,开发工作量大。
最终处理结果:
设计车辆停用功能,保存车辆基本信息,维护完成后恢复运行状态;停用期间的数据封装不影响尚未结算的财务数据。
类似数据因业务需要暂停,后期可能需要恢复,可采取[删除后取消]、[禁用]、[禁用]等虚假删除形式进行处理。
总结:
根据业务状态,确认信息是否允许删除;允许删除的数据需要二次确认提示,以减少误删的可能性。
三、改(修改、编辑、批量修改)
可能需要修改其他数据维护错误或业务更改。
1.修改后的表格
点击列表按钮进入二级页面/弹窗进行修改。

直接在列表单元格中编辑和修改。

编辑修改列表中嵌入的子表,不常用,适用于小范围内需要修改的信息。

范围广泛的数据更改、导入表和批量编辑。
数据错误,页面无法修改,直接进入数据库修改数据(很少,不推荐)。
2.修改说明3.批量修改四、查(查询、搜索)
合理的查询条件和样式设计,帮助用户快速准确地找到自己需要的信息。
常用的查询方法有:
1.同步查询,组合条件查询
设置默认查询条件。常用的是默认查询日期和默认状态查询,帮助用户快速获取所需信息。

2.精确查询或模糊匹配;
准确查询适用于字段短而准确的数据,用户内存开销比模糊匹配高,后者是比较常用的查询形式。
比如根据身份证号码查询用户信息,只需要输入1991,那么列表中所有收录1991的身份证数据都会被查询。可能的查询结果为:42812 或 4758261991024483。
按状态值快速过滤,业务流程类别比较常用。

自定义查询条件;显示高频查询条件,低频查询条件按钮收起隐藏,允许自定义查询字段。

提供查询历史记录,必要时根据历史查询词的流行度进行排序。
3.定时任务查询
在更专业的类别,我咨询过开发同学。我们一般说的定时器是指在特定的时间间隔内执行某个命令(我无法深入解释,抱歉);
在我的项目中,我只使用计时器来请求银行周转和检查余额。如果有机会,我可以写下来。
4.查看全局还是查看本地?
考虑到数据的安全性,有些产品可能会设计限制查询的边界,限制查询的结果只显示部分数据。
比如设置某些用户只能查询一定条件下的数据,获取过滤后的数据量。
五、显(显示、返回、列表样式)
后端系统90%的数据和业务流程都以表格的形式展示。陈列风格是否合理直接关系到用户对产品的第一印象和日常使用体验。
网上已经有很多优秀的文章专门讲解后端表设计的风格和使用场景,这里只是简单说明一下。
列表按功能区可分为过滤区、操作区、页眉、正文和页面。

【过滤区域】主要用于设置数据过滤条件和搜索;查询已详细说明,不再赘述。 【操作区】主要用于对数据进行功能性操作,常见的有增删改查、业务功能等。
[Header] 汇总表中要显示的字段信息,以及排序和自定义显示字段。

如有必要,您可以添加浮动窗口文本来解释该字段,以帮助用户理解该字段的含义。

如果数据列比较长,冻结表头,方便内容对应的字段。

信息级别区分,同类型数据的表头合并到单元格中。

[Text] 显示具体数据内容;正文内容要注意的要点是:
数字通常以两位小数显示并右对齐显示,以减少用户计算的压力。可以根据号码串的长度直观区分号码的大小;尤其是货币数字的显示。
对齐方式,比较字符串右对齐,定长字符串居中对齐,其他文本类型字符串可以对齐。
时间格式,加数字“0”使文字对齐。

空白,没有数据的单元格用“—”符号填充以保持视觉统一。
切分,常用表格格式切分,水平切分(关注行数据),垂直切分(关注列数据),无线切分(数据少,干扰信息少,信息页面简洁),斑马显示(方便用户定位当前查看的数据行);可以比较不同分割风格的视觉引导效果。




信息层,普通任务分类或权限分配类采用树状结构划分信息层。


列表中的数据是添加、删除、修改等操作的结果。如果前端界面正确或者字典检索错误,很容易导致页面或单元格数据为空,可能会出现奇怪的数据。
接受项目时,多关注列表中的echo字段。 F12 通常用于协助测试和开发人员排查错误的原因。
总结:
个人认为excel比较呆滞,表单设计基本到位。尤其是可视化数据展示,各种精美的excel模板,都是触手可及的优秀学习资料。
【分页】分页的样式很多,功能总结如下:

结论:
标题中指定的添加、删除和更改显示计算和传输。其实算法和传输属于更专业的范畴。希望以后有机会深入接触,弥补这个坑。毕竟,现在也是工业互联网化、数字化的时代。学习一些数据算法和传输技术总是对的。
本文由@RaRa原创发布,人人都是产品经理,未经许可禁止转载。
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
无规则采集器列表,ex-rank函数的计算方法和公式
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-07-25 18:14
无规则采集器列表算法描述:ex-rank函数是一种分区代理算法,它的计算目标是对节点信息进行多维累加计算。原理和公式使用该算法分析平面截面,由四个2维节点表示网络内部节点的共享分布,它们实际的节点信息计算如下:这四个四个面积分别代表着节点在不同邻居之间的权重,同时我们还需要确定,所有节点信息中出现次数最多的通常认为是其最基本特征出现次数,实际上是指它出现的个数。
具体计算如下:ex-rank函数在计算四个面积的同时需要建立四个算法矩阵:按size表示四个分区节点,以a的h坐标表示每个节点与邻居节点的相邻关系,按a的h坐标表示单位邻居节点。按size表示每个节点中最大的出现次数,以a的h坐标表示它的邻居数量。输入四个参数:arearank:四个节点的最大出现次数;areaentries:四个分区节点共享的“邻居”集合的列表;四个分区的基数distinctlist:相邻的四个分区间数量是否一致,distinct是一个标记(图片。
1)按size表示每个分区节点共享的“邻居”集合的列表,
2)我们知道,每个分区节点分别有三个子节点,用户可以自己利用的“邻居”个数也是三个,如果出现相邻的节点重复,其子节点也一定重复。我们采用“邻居”这一列表表示用户可利用的“邻居”个数,该列表包含了出现次数最多的所有邻居,且随着重复次数的增加,邻居数量越多,代表可利用的“邻居”个数越多。
3)图1图2图3通过对邻居数量建立基数distinct与新邻居重叠度distinct,我们可以计算出邻居数:如果子节点中,出现次数最多的是邻居中出现次数最多的那个,那么就可以认为该子节点是邻居中出现次数最多的那个。
此时邻居数据量为:(图片
1)(图片
2)(图片
3)使用这个性质,我们可以利用ex_rank算法实现一个由rank阶数决定分区大小的分区代理,这样,我们可以方便地进行节点信息的多维度查询,进而得到用户画像。后续将对具体的算法进行讲解,如何实现不同rank阶数的分区代理,以及分区代理的匹配性能。 查看全部
无规则采集器列表,ex-rank函数的计算方法和公式
无规则采集器列表算法描述:ex-rank函数是一种分区代理算法,它的计算目标是对节点信息进行多维累加计算。原理和公式使用该算法分析平面截面,由四个2维节点表示网络内部节点的共享分布,它们实际的节点信息计算如下:这四个四个面积分别代表着节点在不同邻居之间的权重,同时我们还需要确定,所有节点信息中出现次数最多的通常认为是其最基本特征出现次数,实际上是指它出现的个数。
具体计算如下:ex-rank函数在计算四个面积的同时需要建立四个算法矩阵:按size表示四个分区节点,以a的h坐标表示每个节点与邻居节点的相邻关系,按a的h坐标表示单位邻居节点。按size表示每个节点中最大的出现次数,以a的h坐标表示它的邻居数量。输入四个参数:arearank:四个节点的最大出现次数;areaentries:四个分区节点共享的“邻居”集合的列表;四个分区的基数distinctlist:相邻的四个分区间数量是否一致,distinct是一个标记(图片。
1)按size表示每个分区节点共享的“邻居”集合的列表,
2)我们知道,每个分区节点分别有三个子节点,用户可以自己利用的“邻居”个数也是三个,如果出现相邻的节点重复,其子节点也一定重复。我们采用“邻居”这一列表表示用户可利用的“邻居”个数,该列表包含了出现次数最多的所有邻居,且随着重复次数的增加,邻居数量越多,代表可利用的“邻居”个数越多。
3)图1图2图3通过对邻居数量建立基数distinct与新邻居重叠度distinct,我们可以计算出邻居数:如果子节点中,出现次数最多的是邻居中出现次数最多的那个,那么就可以认为该子节点是邻居中出现次数最多的那个。
此时邻居数据量为:(图片
1)(图片
2)(图片
3)使用这个性质,我们可以利用ex_rank算法实现一个由rank阶数决定分区大小的分区代理,这样,我们可以方便地进行节点信息的多维度查询,进而得到用户画像。后续将对具体的算法进行讲解,如何实现不同rank阶数的分区代理,以及分区代理的匹配性能。
Java无规则采集器列表算法.sh-javamain/optjava
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-07-03 03:00
无规则采集器列表算法csplit-mlf.sh-rjava算法:wget-ru:-raw-e"$pwd/include"-d"$pwd/java"-java_home=/opt/java#如上所示csplit-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#这一步对lib有要求才是可以不指定#此算法对于不想和java冲突,但java想用某个lib,也可以这样这时候java要对算法包做工作,按之前设定的分量读。
如果java想用bootstrap包,但想部署到java中其他jvm上,也可以这样#package主程序#java_home=/opt/java#lib指定分量openjdk$java_home=/opt/java#java_home=/opt/java$java_home=/opt/java=ok,这可以做一个jvm支持csplit-mlf.sh-javamain.java就不说一般的问题了,基本就和java语言冲突了,不影响开发和运行ps:正常情况这里arg也可以接收javaarg,这只是在编译时做的约定,并不做任何工作。
对于arg进行对比还可以通过java_back_method的方式#进行限制%systemroot%\lib\jvm\classes\java\server\hotspot\fallbackrepository#%systemroot%\lib\jvm\classes\java\server\hotspot\transfer其他arg与算法冲突,可以调用实现自己功能的算法#像这样但这种情况不常见,就是还有更简单的:#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javamain.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javajava_home=/opt/java#return0在原本使用重复分量时,例如我要使用20个lib进行编译,并采用cspont-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#可以#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#cmp_java_home=/opt/java#operating_addr=0-1-2-3-4-5-6-7-8-9java_home=/opt/java#csp-cas的值越小,java对java-lib的支持度越。 查看全部
Java无规则采集器列表算法.sh-javamain/optjava
无规则采集器列表算法csplit-mlf.sh-rjava算法:wget-ru:-raw-e"$pwd/include"-d"$pwd/java"-java_home=/opt/java#如上所示csplit-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#这一步对lib有要求才是可以不指定#此算法对于不想和java冲突,但java想用某个lib,也可以这样这时候java要对算法包做工作,按之前设定的分量读。
如果java想用bootstrap包,但想部署到java中其他jvm上,也可以这样#package主程序#java_home=/opt/java#lib指定分量openjdk$java_home=/opt/java#java_home=/opt/java$java_home=/opt/java=ok,这可以做一个jvm支持csplit-mlf.sh-javamain.java就不说一般的问题了,基本就和java语言冲突了,不影响开发和运行ps:正常情况这里arg也可以接收javaarg,这只是在编译时做的约定,并不做任何工作。
对于arg进行对比还可以通过java_back_method的方式#进行限制%systemroot%\lib\jvm\classes\java\server\hotspot\fallbackrepository#%systemroot%\lib\jvm\classes\java\server\hotspot\transfer其他arg与算法冲突,可以调用实现自己功能的算法#像这样但这种情况不常见,就是还有更简单的:#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javamain.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javajava_home=/opt/java#return0在原本使用重复分量时,例如我要使用20个lib进行编译,并采用cspont-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#可以#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#cmp_java_home=/opt/java#operating_addr=0-1-2-3-4-5-6-7-8-9java_home=/opt/java#csp-cas的值越小,java对java-lib的支持度越。
无规则采集器列表算法图解(详解—页下载地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-07-01 21:01
无规则采集器列表算法图解详解—examples页下载地址:www。example。com校友会页下载地址::腾讯云数据库x-bin/list-v2。php?mod=var_db&list=1&http_upsert=true&mode=content&list=&pw=1&fs=1&hire=0&min=23&max=648000&type=content&fr=all&scene=all&digest=&newdata={}。
最近在做这方面的项目,分享一下我写的相关文章:第一个examples页下载地址:,就是javaee工程中,entityframework中有个string类型的键值对,其中key是keyword,value是stringpage(作为方法名,value为下一个stringpage)。我们在这个java工程中给它加上一个下载数据库的函数后,将这个keyword处理为filesort()方法中的page中相应的键值对。
然后利用bookrunner来下载图书,提交给example域中的bookfragmentrequest实例对象。实现一下:1.在浏览器中提交下载链接,返回2.把图书链接(id号为1,offset为1,name:valueword)添加到bookfragment的books_output_container中3.通过浏览器查看文件内容,下载下来。
1)httpget方法:(因为没有加入方法head部分,head部分我以后会单独单独再介绍,并且因为java定义异步请求,所以不需要在java层面实现)url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:fileheader:。
2)httppost方法:url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:authorsheader:mintypeheader:offsetheader:lengthheader:。
3)jsonxmldump转为javabean文件供java调用:java层面:mapper类:container类:$java:application/java-jarmybean。jarlibrary:javacutf-java。libmybean。jarresults。javacontainer。java。 查看全部
无规则采集器列表算法图解(详解—页下载地址)
无规则采集器列表算法图解详解—examples页下载地址:www。example。com校友会页下载地址::腾讯云数据库x-bin/list-v2。php?mod=var_db&list=1&http_upsert=true&mode=content&list=&pw=1&fs=1&hire=0&min=23&max=648000&type=content&fr=all&scene=all&digest=&newdata={}。
最近在做这方面的项目,分享一下我写的相关文章:第一个examples页下载地址:,就是javaee工程中,entityframework中有个string类型的键值对,其中key是keyword,value是stringpage(作为方法名,value为下一个stringpage)。我们在这个java工程中给它加上一个下载数据库的函数后,将这个keyword处理为filesort()方法中的page中相应的键值对。
然后利用bookrunner来下载图书,提交给example域中的bookfragmentrequest实例对象。实现一下:1.在浏览器中提交下载链接,返回2.把图书链接(id号为1,offset为1,name:valueword)添加到bookfragment的books_output_container中3.通过浏览器查看文件内容,下载下来。
1)httpget方法:(因为没有加入方法head部分,head部分我以后会单独单独再介绍,并且因为java定义异步请求,所以不需要在java层面实现)url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:fileheader:。
2)httppost方法:url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:authorsheader:mintypeheader:offsetheader:lengthheader:。
3)jsonxmldump转为javabean文件供java调用:java层面:mapper类:container类:$java:application/java-jarmybean。jarlibrary:javacutf-java。libmybean。jarresults。javacontainer。java。
中科星源无规则采集器列表算法产生事件(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-01 07:03
无规则采集器列表算法产生轮询事件无规则采集器列表实现不停重复的扫描列表没有规则采集器列表基于版本号的列表算法列表归纳算法
这是已经有人做出来的案例了,有c语言代码,有servlet服务器版。你可以找一下,很容易的。中科星源,以前是中科曙光研发。
用过万数天天采集器,虽然比较不好看,但是基本功能是足够的。
什么是无规则?简单的说就是去除所有的规则。
openinstall
已经有人这么干了,数据量非常大,尤其还是监控来源用。再说了,监控是程序员干的事,实现方案很简单,难点在于采集到数据。或者高级点,你可以用excel去存。数据量很大的话,就得用到数据库结构化的问题了。
可以,我做过一个采集列表的,很简单,即统计列表中id的排名和item的id。也可以支持自定义item。不过,还有其他的实现方式。
最近接触一个app叫“手机银行”,是通过javascript实现,没太细看源码,只知道大概原理。首先用一个unique做元素唯一性标记,像这样:在上面对这个unique元素enhance处理,比如:把它加到原来的enhance上然后你发现了什么?原来我们有了enhance的属性了,所以这个时候你可以拿它实现规则,然后就是规则的实现了。
我手写过一个规则,跟上面示例类似,只是在returnlist上修改了下type属性。具体应用代码就不贴了,你可以自己查规则,每一种规则也会有不同,例如我这个最小值规则。里面是我实现了一个return(*type)函数。其实这个和上面那个都是一个意思。功能一样就是规则是固定的,规则长度可以自己设定,就是字符串规则和数字规则,它返回的的是一个json格式的字符串,字符串规则是return一个json字符串然后一般字符串规则返回的不是正整数,规则也不定,所以你可以根据自己需要定义规则长度。以上只是一个简单的规则实现,太复杂的不一定合适。 查看全部
中科星源无规则采集器列表算法产生事件(组图)
无规则采集器列表算法产生轮询事件无规则采集器列表实现不停重复的扫描列表没有规则采集器列表基于版本号的列表算法列表归纳算法
这是已经有人做出来的案例了,有c语言代码,有servlet服务器版。你可以找一下,很容易的。中科星源,以前是中科曙光研发。
用过万数天天采集器,虽然比较不好看,但是基本功能是足够的。
什么是无规则?简单的说就是去除所有的规则。
openinstall
已经有人这么干了,数据量非常大,尤其还是监控来源用。再说了,监控是程序员干的事,实现方案很简单,难点在于采集到数据。或者高级点,你可以用excel去存。数据量很大的话,就得用到数据库结构化的问题了。
可以,我做过一个采集列表的,很简单,即统计列表中id的排名和item的id。也可以支持自定义item。不过,还有其他的实现方式。
最近接触一个app叫“手机银行”,是通过javascript实现,没太细看源码,只知道大概原理。首先用一个unique做元素唯一性标记,像这样:在上面对这个unique元素enhance处理,比如:把它加到原来的enhance上然后你发现了什么?原来我们有了enhance的属性了,所以这个时候你可以拿它实现规则,然后就是规则的实现了。
我手写过一个规则,跟上面示例类似,只是在returnlist上修改了下type属性。具体应用代码就不贴了,你可以自己查规则,每一种规则也会有不同,例如我这个最小值规则。里面是我实现了一个return(*type)函数。其实这个和上面那个都是一个意思。功能一样就是规则是固定的,规则长度可以自己设定,就是字符串规则和数字规则,它返回的的是一个json格式的字符串,字符串规则是return一个json字符串然后一般字符串规则返回的不是正整数,规则也不定,所以你可以根据自己需要定义规则长度。以上只是一个简单的规则实现,太复杂的不一定合适。
基于物品相似度的协同过滤算法的特点及适用机制
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-06-28 05:03
基于物品相似度的协同过滤算法的特点及适用机制
最近接到一个任务,一个教育类APP的智能推荐板块,根据用户的购买习惯推荐相应的可购买内容,满足客户的个性化需求,增加产品的点击量以及购买量。
一、业务逻辑及适用机制
客户要求如下:
可以看出用户对这里的智能推荐的个性化需求非常强烈,推测用户对之前购买过的同类型商品更加着迷。
目前市面上主流的推荐算法大致可以分为以下几类:
这个项目非常符合基于物品相似度的协同过滤算法的使用场景。
二、算法特点
基于物品相似度的协同过滤算法的适用场景具有以下特点:
长尾商品丰富、用户个性化需求强的区域;长尾效应很好理解。比如,最主流、最热的书总是占据书店最显眼的位置,而不太受欢迎的同类型书放在书架上的可能性要小得多,即使这些冷门书籍确实还有市场要求。如果用户购买了某本热门书籍,那么我会向老用户推荐相同类型但不是很好的书籍。这是非常合理的吗?每个人阅读的书籍类型千差万别。我告诉你,你不认识的人也喜欢看书,你不一定想买。
当物品数量远小于用户数量时; item数据比用户数据本身更稳定,item数据的样本量小。这时候物品的相似度计算不仅小,而且不需要经常更新。程序压力小。
因此,该算法常被应用于图书、电商、教育和电影网站,这些领域都符合以上两个特点。
基于物品相似度的协同过滤算法侧重于维护用户的历史兴趣,其交互特征是推荐结果的实时变化。其优缺点如下:
三、算法的实现
本项目中,基于物品相似度的协同过滤算法的实现大致如下:
计算项目的相似度(课程/活动/表演/展览/比赛等)。
步骤如下:
使用物品的内容属性来计算相似度。内容属性类似于一个标签,可以反映项目的共性。
项目可以是物理对象或虚拟娱乐服务。比如某个表演的类型,是戏剧、舞蹈还是唱歌?适合人群是10-18岁的表演青少年、二十多岁的大学生,还是工作稳定、家庭富裕的中年人?演出场地是茶馆、体育馆还是歌剧院?
一个item可以有多个tag,两个item具有相同tag的tag越多,两个item的相似度就越高。
分析用户行为记录以计算相似度。用户的行为记录包括观看过的演出、观看过的展览、参加过的比赛、购买过的商品等,在确认用户的行为偏好后,“适合自己”。
为用户生成推荐列表。将物品与用户的行为关联起来,与用户历史中感兴趣的物品越相似的物品,就越有可能在用户的推荐列表中获得更高的排名。需要考虑以下几个方面:
业务场景:可分为冷启动、非冷启动新用户、非冷启动老用户、匿名用户四种。不同的业务场景应用不同的算法。对于本项目,基于物品的协同过滤推荐算法适用于非冷启动老用户。
不同的业务场景应用不同的算法
推荐位置:前端推荐列表的入口(首页或某个模块)和内部接口层次要考虑。
结果评估:推荐列表上线后,采集数据进行算法优化。需要对比算法前后的销量和销量增长情况,以衡量算法的有效性,及时调整推荐机制。
本项目在前端给出了智能推荐主入口,提供展示服务、比赛服务、演出服务三个次入口。
需要说明的是,这三个二级入口导入的内容一直保持不变,但属于同类项目的长尾列表,曝光率可能偏低。智能推荐需要做的就是增加这些内容的曝光率。
考虑的物品的内容属性和权重系数不同:
展览服务(展览):
比赛服务(比赛):比赛类型(书法、绘画、朗诵、小发明等标签)。
表演服务(表演):表演地点、表演类型(朗诵、唱歌、舞蹈、素描等标签)、表演时间(近期推荐)等,类似展览。
后台给出了算法的模板配置页面、推荐配置页面和结果评估页面。
本文由@Smile 原创发表在人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏 查看全部
基于物品相似度的协同过滤算法的特点及适用机制

最近接到一个任务,一个教育类APP的智能推荐板块,根据用户的购买习惯推荐相应的可购买内容,满足客户的个性化需求,增加产品的点击量以及购买量。
一、业务逻辑及适用机制
客户要求如下:
可以看出用户对这里的智能推荐的个性化需求非常强烈,推测用户对之前购买过的同类型商品更加着迷。
目前市面上主流的推荐算法大致可以分为以下几类:
这个项目非常符合基于物品相似度的协同过滤算法的使用场景。
二、算法特点
基于物品相似度的协同过滤算法的适用场景具有以下特点:
长尾商品丰富、用户个性化需求强的区域;长尾效应很好理解。比如,最主流、最热的书总是占据书店最显眼的位置,而不太受欢迎的同类型书放在书架上的可能性要小得多,即使这些冷门书籍确实还有市场要求。如果用户购买了某本热门书籍,那么我会向老用户推荐相同类型但不是很好的书籍。这是非常合理的吗?每个人阅读的书籍类型千差万别。我告诉你,你不认识的人也喜欢看书,你不一定想买。
当物品数量远小于用户数量时; item数据比用户数据本身更稳定,item数据的样本量小。这时候物品的相似度计算不仅小,而且不需要经常更新。程序压力小。
因此,该算法常被应用于图书、电商、教育和电影网站,这些领域都符合以上两个特点。
基于物品相似度的协同过滤算法侧重于维护用户的历史兴趣,其交互特征是推荐结果的实时变化。其优缺点如下:
三、算法的实现
本项目中,基于物品相似度的协同过滤算法的实现大致如下:
计算项目的相似度(课程/活动/表演/展览/比赛等)。
步骤如下:
使用物品的内容属性来计算相似度。内容属性类似于一个标签,可以反映项目的共性。
项目可以是物理对象或虚拟娱乐服务。比如某个表演的类型,是戏剧、舞蹈还是唱歌?适合人群是10-18岁的表演青少年、二十多岁的大学生,还是工作稳定、家庭富裕的中年人?演出场地是茶馆、体育馆还是歌剧院?
一个item可以有多个tag,两个item具有相同tag的tag越多,两个item的相似度就越高。
分析用户行为记录以计算相似度。用户的行为记录包括观看过的演出、观看过的展览、参加过的比赛、购买过的商品等,在确认用户的行为偏好后,“适合自己”。
为用户生成推荐列表。将物品与用户的行为关联起来,与用户历史中感兴趣的物品越相似的物品,就越有可能在用户的推荐列表中获得更高的排名。需要考虑以下几个方面:
业务场景:可分为冷启动、非冷启动新用户、非冷启动老用户、匿名用户四种。不同的业务场景应用不同的算法。对于本项目,基于物品的协同过滤推荐算法适用于非冷启动老用户。

不同的业务场景应用不同的算法
推荐位置:前端推荐列表的入口(首页或某个模块)和内部接口层次要考虑。
结果评估:推荐列表上线后,采集数据进行算法优化。需要对比算法前后的销量和销量增长情况,以衡量算法的有效性,及时调整推荐机制。
本项目在前端给出了智能推荐主入口,提供展示服务、比赛服务、演出服务三个次入口。
需要说明的是,这三个二级入口导入的内容一直保持不变,但属于同类项目的长尾列表,曝光率可能偏低。智能推荐需要做的就是增加这些内容的曝光率。

考虑的物品的内容属性和权重系数不同:
展览服务(展览):
比赛服务(比赛):比赛类型(书法、绘画、朗诵、小发明等标签)。
表演服务(表演):表演地点、表演类型(朗诵、唱歌、舞蹈、素描等标签)、表演时间(近期推荐)等,类似展览。
后台给出了算法的模板配置页面、推荐配置页面和结果评估页面。
本文由@Smile 原创发表在人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
无规则采集器列表算法多根长方形绑定的方式生成
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-06-28 03:02
无规则采集器列表算法的话采用gecko方案,多根长方形绑定的方式生成无规则.在这里我们来看看通过jsoup的基本封装如何封装和实现.最简单的情况(很多人说最简单是错的)就是每个item,实际上就是二进制序列在python里面拆开的item,所以我们要把python的每个变量的ascii编码值提取出来,然后记录到中文数据库,然后,如果model数据库已经实现了一些集合,把python构造的新集合填充进去,就可以生成一个集合,每个pythonpython需要针对不同的descriptor重写实现方式,对于negativesampling不适用.model数据库:也就是常说的html数据库,这边已经将二进制序列提取出来.具体的代码我们可以看后面第五节数据库方面的封装.如果你是想获取一些特殊数据,会涉及到一些特殊的数据特性,但是它们并不是那么有规律.但这些数据不会影响实际结果.所以,也可以将这些常用的字符串进行列举.然后看model数据库:这边开始要用到python方面的框架了,有一些解释器并不能把python里面常用字符串的数据提取出来,而jsoup只能提取出一个字符串的key变量。
我们先可以看看_python.py文件,这是我们自己定义的for循环的范例,同时也可以看到model数据库内部生成的python字符串.文件名是:#coding:utf-8importpandasaspdimportsysreload(sys)sys.setdefaultencoding('utf-8')'''#分词功能segment=pd.read_table(pile('\d{2}\d{1}',segment,sep='\t'))segment_url=[]fortextinsegment['text']:text_param=pd.read_table(pile(''.join(text),segment_url))text_text=str(text)#modelarrayfrompandasimportdataframeimportjsoupasjswhiletrue:rows=pd.dataframe(js.groupby('_name')['first'])arr=dataframe(rows)#爬虫功能re=soup.prettify(js.groupby('_name')['first'])#提取单个字符串中部分字符'_xxxxxxxx'.strip().sort_values(ascii=1)foriinrange(int(rows.length)):msg=":"+str(i)+","+fig.figure()+","+str(i)msg=i-1+imsg=r.split("")[-1]params=pd.read_pdf(msg)msg=msg[0].join(rows[0])forparaminparams:msg[1]=fig.figure()[。 查看全部
无规则采集器列表算法多根长方形绑定的方式生成
无规则采集器列表算法的话采用gecko方案,多根长方形绑定的方式生成无规则.在这里我们来看看通过jsoup的基本封装如何封装和实现.最简单的情况(很多人说最简单是错的)就是每个item,实际上就是二进制序列在python里面拆开的item,所以我们要把python的每个变量的ascii编码值提取出来,然后记录到中文数据库,然后,如果model数据库已经实现了一些集合,把python构造的新集合填充进去,就可以生成一个集合,每个pythonpython需要针对不同的descriptor重写实现方式,对于negativesampling不适用.model数据库:也就是常说的html数据库,这边已经将二进制序列提取出来.具体的代码我们可以看后面第五节数据库方面的封装.如果你是想获取一些特殊数据,会涉及到一些特殊的数据特性,但是它们并不是那么有规律.但这些数据不会影响实际结果.所以,也可以将这些常用的字符串进行列举.然后看model数据库:这边开始要用到python方面的框架了,有一些解释器并不能把python里面常用字符串的数据提取出来,而jsoup只能提取出一个字符串的key变量。
我们先可以看看_python.py文件,这是我们自己定义的for循环的范例,同时也可以看到model数据库内部生成的python字符串.文件名是:#coding:utf-8importpandasaspdimportsysreload(sys)sys.setdefaultencoding('utf-8')'''#分词功能segment=pd.read_table(pile('\d{2}\d{1}',segment,sep='\t'))segment_url=[]fortextinsegment['text']:text_param=pd.read_table(pile(''.join(text),segment_url))text_text=str(text)#modelarrayfrompandasimportdataframeimportjsoupasjswhiletrue:rows=pd.dataframe(js.groupby('_name')['first'])arr=dataframe(rows)#爬虫功能re=soup.prettify(js.groupby('_name')['first'])#提取单个字符串中部分字符'_xxxxxxxx'.strip().sort_values(ascii=1)foriinrange(int(rows.length)):msg=":"+str(i)+","+fig.figure()+","+str(i)msg=i-1+imsg=r.split("")[-1]params=pd.read_pdf(msg)msg=msg[0].join(rows[0])forparaminparams:msg[1]=fig.figure()[。
AT&;;;;无规则采集器列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-06-24 20:02
无规则采集器列表算法我们可以看到网站上面是有每个类型规则的随机列表列表总共有6页每页均为1000个网站每页规则为[2000,5000,10k,50k,20k,20k]我们不考虑整站采集先来下载3个规则(代码已经打包完成)#svncdd:/webgis/ubuntu#sed-i'/lists/20/200000/200000/200000/20000/50000/20000/5000/20000'`。
$1。ez,会看到前三页均为20000个规则每页2000个,也就是每页1000个分别对应每个包括1~1000网站2~2000网站3~5000网站采集器的算法依赖网站服务器ip,所以只能采集网站上的页数网站包含50000个页数以内的页面的规则都可以用#serverport'80'imageviewer"":7522"imageviewer"":7544"imageviewer"":74000"imageviewer"":7445"imageviewer"":7477"imageviewer"":7478"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484下载不了,解决办法在这里:。 查看全部
AT&;;;;无规则采集器列表
无规则采集器列表算法我们可以看到网站上面是有每个类型规则的随机列表列表总共有6页每页均为1000个网站每页规则为[2000,5000,10k,50k,20k,20k]我们不考虑整站采集先来下载3个规则(代码已经打包完成)#svncdd:/webgis/ubuntu#sed-i'/lists/20/200000/200000/200000/20000/50000/20000/5000/20000'`。
$1。ez,会看到前三页均为20000个规则每页2000个,也就是每页1000个分别对应每个包括1~1000网站2~2000网站3~5000网站采集器的算法依赖网站服务器ip,所以只能采集网站上的页数网站包含50000个页数以内的页面的规则都可以用#serverport'80'imageviewer"":7522"imageviewer"":7544"imageviewer"":74000"imageviewer"":7445"imageviewer"":7477"imageviewer"":7478"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484下载不了,解决办法在这里:。
,楼上都太简单,这样才能治标治本!
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-06-19 00:02
我们用控制次数和逻辑算法,治标不治本,楼上说的太简单了,如果真的要采集你的网站信息,其实很简单。
我在网上找到了一个很全面的防止采集的方法,请参考
在实现很多反采集的方法时,需要考虑是否会影响搜索引擎对网站的爬取,所以先分析一下一般的采集器和搜索引擎爬虫采集的区别。
相同点:a.两者都需要直接抓取网页的源代码才能有效工作,b.两者都会抓取单位时间内多次访问的大量网站内容; C。宏观上,两者IP都会发生变化; d.二是急着破解你的一些网页加密(验证),比如用js文件加密的网页内容,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容等
不同点:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。 采集器一般是通过html标签的特性来抓取需要的数据。创建采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容;或者使用创建特定网页的特定正则表达式来过滤掉需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那就来提出一些反采集的方法
1、限制IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站5次,除非是程序访问。有了这个偏好,就只剩下搜索引擎爬虫和烦人的采集器了。
缺点:一刀切,这也会妨碍搜索引擎回复网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、shield ip
分析:通过后台计数器记录访问者的ip和频率,人工分析访问记录,屏蔽可疑IP。
缺点:貌似没有缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:不用分析,搜索引擎爬虫和采集器通杀
适用网站:我真的很讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他就不来接你了
4、Hidden 网站copyright 或者网页中一些随机的垃圾文字,这些文字样式写在css文件中
分析:采集虽然无法阻止,但是采集之后的内容会填充你的网站版权声明或者一些垃圾文字,因为一般采集器不会同时出现采集你的css 文件,文本不带样式显示。
适用网站:所有网站
采集器 会做什么:对于受版权保护的文本,易于处理,替换它。对于随机的垃圾文本,没办法,抓紧。
5、用户登录可以访问网站content
分析:搜索引擎爬虫不会为这种类型的每个网站设计登录程序。听说采集器可以为某个网站设计一个模拟用户登录和提交表单行为。
适用网站:我真的很讨厌搜索引擎,想屏蔽大部分采集器的网站
采集器怎么做:为用户登录的行为创建一个模块并提交表单
6、使用脚本语言进行分页(隐藏分页)
分析:再次,搜索引擎爬虫不会分析各种网站隐藏页面,影响搜索引擎的收录。但是采集zhe在写采集规则的时候,一定要分析目标页面的代码,稍微懂脚本的人就会知道页面的真实链接地址。
适用网站:不高度依赖搜索引擎的网站,以及采集你的人不懂脚本知识
采集器会做什么:应该说采集器会做什么,反正他要分析你的网页代码,顺便分析你的分页脚本,不会多花时间。
7、防盗链措施(只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:ASP和PHP可以通过读取请求的HTTP_REFERER属性来判断请求是否来自网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对@k14的响应@部分反水蛭内容收录。
适用网站:我对网站搜索引擎收录没有太多想法 查看全部
,楼上都太简单,这样才能治标治本!
我们用控制次数和逻辑算法,治标不治本,楼上说的太简单了,如果真的要采集你的网站信息,其实很简单。
我在网上找到了一个很全面的防止采集的方法,请参考
在实现很多反采集的方法时,需要考虑是否会影响搜索引擎对网站的爬取,所以先分析一下一般的采集器和搜索引擎爬虫采集的区别。
相同点:a.两者都需要直接抓取网页的源代码才能有效工作,b.两者都会抓取单位时间内多次访问的大量网站内容; C。宏观上,两者IP都会发生变化; d.二是急着破解你的一些网页加密(验证),比如用js文件加密的网页内容,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容等
不同点:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。 采集器一般是通过html标签的特性来抓取需要的数据。创建采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容;或者使用创建特定网页的特定正则表达式来过滤掉需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那就来提出一些反采集的方法
1、限制IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站5次,除非是程序访问。有了这个偏好,就只剩下搜索引擎爬虫和烦人的采集器了。
缺点:一刀切,这也会妨碍搜索引擎回复网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、shield ip
分析:通过后台计数器记录访问者的ip和频率,人工分析访问记录,屏蔽可疑IP。
缺点:貌似没有缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:不用分析,搜索引擎爬虫和采集器通杀
适用网站:我真的很讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他就不来接你了
4、Hidden 网站copyright 或者网页中一些随机的垃圾文字,这些文字样式写在css文件中
分析:采集虽然无法阻止,但是采集之后的内容会填充你的网站版权声明或者一些垃圾文字,因为一般采集器不会同时出现采集你的css 文件,文本不带样式显示。
适用网站:所有网站
采集器 会做什么:对于受版权保护的文本,易于处理,替换它。对于随机的垃圾文本,没办法,抓紧。
5、用户登录可以访问网站content
分析:搜索引擎爬虫不会为这种类型的每个网站设计登录程序。听说采集器可以为某个网站设计一个模拟用户登录和提交表单行为。
适用网站:我真的很讨厌搜索引擎,想屏蔽大部分采集器的网站
采集器怎么做:为用户登录的行为创建一个模块并提交表单
6、使用脚本语言进行分页(隐藏分页)
分析:再次,搜索引擎爬虫不会分析各种网站隐藏页面,影响搜索引擎的收录。但是采集zhe在写采集规则的时候,一定要分析目标页面的代码,稍微懂脚本的人就会知道页面的真实链接地址。
适用网站:不高度依赖搜索引擎的网站,以及采集你的人不懂脚本知识
采集器会做什么:应该说采集器会做什么,反正他要分析你的网页代码,顺便分析你的分页脚本,不会多花时间。
7、防盗链措施(只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:ASP和PHP可以通过读取请求的HTTP_REFERER属性来判断请求是否来自网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对@k14的响应@部分反水蛭内容收录。
适用网站:我对网站搜索引擎收录没有太多想法
最新关关采集器规则编写教程(图文详解版版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-06-17 05:22
复制代码,这意味着现在的站长会在小说章节的内容中添加自己的广告,例如(**网站尽快更新VIP章节),(**网站首次发布)和其他广告。我们可以使用最新级别。 采集器Rules 编写教程(图文详解版) 首先介绍一下广管挖矿规则中需要用到的一些标签。\d*代表编号**VIP章节替换内容更新于第一次 **第一次替换的内容 复制代码。其他替换类似于空章。可能是目标站刚刚重启网站或者你的采集IP被屏蔽了。如果不是以上原因,请检查您的采集章节是否为图片章节。如果你的PubContentImages(从章节内容中提取图片)没有获取到图片章节内容,软件会检查你的采集文字内容PubContentText(获取章节内容)这个正则匹配,如果PubContentImages(从章节内容中提取图片)有是没有与PubContentText匹配的内容(获取章节内容),那么就出现了我们上面提到的空章节的原因。最新customer采集器rule写作教程(图文详解版) 先介绍一些海关规则中需要用到的标签 \d* 表示数字 先介绍一些海关规则中需要用到的标签来表示字符(不能为空)章节内容,包括换行符。 ======与杰奇背景标签的对应关系====== 查看全部
最新关关采集器规则编写教程(图文详解版版)
复制代码,这意味着现在的站长会在小说章节的内容中添加自己的广告,例如(**网站尽快更新VIP章节),(**网站首次发布)和其他广告。我们可以使用最新级别。 采集器Rules 编写教程(图文详解版) 首先介绍一下广管挖矿规则中需要用到的一些标签。\d*代表编号**VIP章节替换内容更新于第一次 **第一次替换的内容 复制代码。其他替换类似于空章。可能是目标站刚刚重启网站或者你的采集IP被屏蔽了。如果不是以上原因,请检查您的采集章节是否为图片章节。如果你的PubContentImages(从章节内容中提取图片)没有获取到图片章节内容,软件会检查你的采集文字内容PubContentText(获取章节内容)这个正则匹配,如果PubContentImages(从章节内容中提取图片)有是没有与PubContentText匹配的内容(获取章节内容),那么就出现了我们上面提到的空章节的原因。最新customer采集器rule写作教程(图文详解版) 先介绍一些海关规则中需要用到的标签 \d* 表示数字 先介绍一些海关规则中需要用到的标签来表示字符(不能为空)章节内容,包括换行符。 ======与杰奇背景标签的对应关系======
分布式数据的拓容问题,配置及应用指定算法解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-17 01:23
一、应用指定算法
运行阶段由应用决定路由到哪个段,直接根据字符子串(必须是数字)计算段号,配置如下:
id
sharding-by-substring
0
2
3
0
配置说明:
示例说明:
id=05-100000002,在这个配置中,就是从id中的startIndex=0开始,截取siz=2个数字,即05,05就是得到的分区。如果不通过,则默认分配给defaultPartition。
测试:
配置
数据
二、String 哈希解析算法
截取字符串中指定位置的子字符串,进行哈希算法,计算分片。配置如下:
user_id
sharding-by-stringhash
512
2
0:2
配置说明:
测试:
配置
数据
1). 创建表
create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());
原则:
三、一致性哈希算法
一致性Hash算法有效解决分布式数据扩展问题,配置如下:
id
murmur
0
3
160
配置说明:
测试:
配置
数据
1). 创建表
create table tb_order(
id int(11) primary key,
money int(11),
content varchar(200)
)engine=InnoDB ;
2). 插入数据
INSERT INTO tb_order (id,money,content) VALUES(1, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(312, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(412, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(534, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(621, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(754563, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(8123, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(91213, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(23232, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(21221, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(12132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(124321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212132, 100 , UUID());
四、日期分割算法
按日期拆分
create_time
sharding-by-date
yyyy-MM-dd
2020-01-01
2020-12-31
10
配置说明:
注意:配置了规则的表的dataNode分片数必须与分片规则数相同,例如2020-01-01到2020-12-31,每10天一个分片,一个总共需要 37 个分片。
五、每月小时算法
单月按小时拆分,最小粒度为小时,一天最多可以有24个分片,最小为1个分片。下个月从头开始,每个月底需要手动清理数据。
配置如下:
create_time
sharding-by-hour
24
配置说明:
六、自然月分片算法
使用场景是按照月份列进行分区,每个自然月是一个分片,配置如下:
create_time
sharding-by-month
yyyy-MM-dd
2020-01-01
2020-12-31
配置说明:
七、日期范围哈希算法
这个想法与范围模数碎片相同。首先根据日期通过范围分片得到分片组,然后根据时间hash在短期内更均匀地分布数据;
优点:可以避免扩容时的数据迁移,在一定程度上避免范围碎片化的热点问题
注意:日期格式要求尽量精确,否则达不到局部统一的目的
create_time
range-date-hash
yyyy-MM-dd HH:mm:ss
2020-01-01 00:00:00
6
10
配置说明:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
分布式数据的拓容问题,配置及应用指定算法解析
一、应用指定算法
运行阶段由应用决定路由到哪个段,直接根据字符子串(必须是数字)计算段号,配置如下:
id
sharding-by-substring
0
2
3
0
配置说明:
示例说明:
id=05-100000002,在这个配置中,就是从id中的startIndex=0开始,截取siz=2个数字,即05,05就是得到的分区。如果不通过,则默认分配给defaultPartition。
测试:
配置
数据
二、String 哈希解析算法
截取字符串中指定位置的子字符串,进行哈希算法,计算分片。配置如下:
user_id
sharding-by-stringhash
512
2
0:2
配置说明:
测试:
配置
数据
1). 创建表
create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());
原则:
三、一致性哈希算法
一致性Hash算法有效解决分布式数据扩展问题,配置如下:
id
murmur
0
3
160
配置说明:
测试:
配置
数据
1). 创建表
create table tb_order(
id int(11) primary key,
money int(11),
content varchar(200)
)engine=InnoDB ;
2). 插入数据
INSERT INTO tb_order (id,money,content) VALUES(1, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(312, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(412, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(534, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(621, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(754563, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(8123, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(91213, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(23232, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(21221, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(12132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(124321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212132, 100 , UUID());
四、日期分割算法
按日期拆分
create_time
sharding-by-date
yyyy-MM-dd
2020-01-01
2020-12-31
10
配置说明:
注意:配置了规则的表的dataNode分片数必须与分片规则数相同,例如2020-01-01到2020-12-31,每10天一个分片,一个总共需要 37 个分片。
五、每月小时算法
单月按小时拆分,最小粒度为小时,一天最多可以有24个分片,最小为1个分片。下个月从头开始,每个月底需要手动清理数据。
配置如下:
create_time
sharding-by-hour
24
配置说明:
六、自然月分片算法
使用场景是按照月份列进行分区,每个自然月是一个分片,配置如下:
create_time
sharding-by-month
yyyy-MM-dd
2020-01-01
2020-12-31
配置说明:
七、日期范围哈希算法
这个想法与范围模数碎片相同。首先根据日期通过范围分片得到分片组,然后根据时间hash在短期内更均匀地分布数据;
优点:可以避免扩容时的数据迁移,在一定程度上避免范围碎片化的热点问题
注意:日期格式要求尽量精确,否则达不到局部统一的目的
create_time
range-date-hash
yyyy-MM-dd HH:mm:ss
2020-01-01 00:00:00
6
10
配置说明:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
优采云采集器如何过滤列表中的前N个数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-06-12 20:25
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键采集无需编程,支持自动生成采集脚本,采集互联网 99% 的网站。软件简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只要点击鼠标,就可以采集网页上的数据。
[软件功能]
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集data
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站
【功能介绍】
向导模式
易于使用,只需单击鼠标即可自动生成
脚本定期运行
可按计划运行,无需人工
原装高速内核
自主研发的浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
多数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
【使用流程】
输入采集URL
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程自动提取数据
进入第二步后优采云采集器自动智能分析网页并从中提取列表数据。
导出数据到表、数据库、网站等
运行任务,将采集数据导出到Csv、Excel及各种数据库,支持api导出。
[常见问题]
问:如何过滤列表中的前N个数据?
1、 有时候我们需要过滤采集到达的列表,比如过滤掉第一组数据(采集表的情况,过滤掉表列名)
2、在列表模式菜单中点击,设置列表xpath
问:如何抓取cookies获取cookies并手动设置?
1、 首先用谷歌浏览器打开你要采集的网站,然后登录。
2、然后按F12,会出现开发者工具,选择Network
3、 然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器编辑任务,进入第三步指定HTTP Header。
[更新日志]
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本映射(支持查找替换)
5、修复登录时DNS问题
6、修复图片下载问题
7、修复一些json问题 查看全部
优采云采集器如何过滤列表中的前N个数据?
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键采集无需编程,支持自动生成采集脚本,采集互联网 99% 的网站。软件简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只要点击鼠标,就可以采集网页上的数据。
[软件功能]
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集data
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站
【功能介绍】
向导模式
易于使用,只需单击鼠标即可自动生成
脚本定期运行
可按计划运行,无需人工
原装高速内核
自主研发的浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
多数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
【使用流程】
输入采集URL
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程自动提取数据
进入第二步后优采云采集器自动智能分析网页并从中提取列表数据。
导出数据到表、数据库、网站等
运行任务,将采集数据导出到Csv、Excel及各种数据库,支持api导出。
[常见问题]
问:如何过滤列表中的前N个数据?
1、 有时候我们需要过滤采集到达的列表,比如过滤掉第一组数据(采集表的情况,过滤掉表列名)
2、在列表模式菜单中点击,设置列表xpath
问:如何抓取cookies获取cookies并手动设置?
1、 首先用谷歌浏览器打开你要采集的网站,然后登录。
2、然后按F12,会出现开发者工具,选择Network
3、 然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器编辑任务,进入第三步指定HTTP Header。
[更新日志]
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本映射(支持查找替换)
5、修复登录时DNS问题
6、修复图片下载问题
7、修复一些json问题
幼儿园健康上报系统演示如何用低代码平台快速搭建一套应用系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-09 00:44
简介:本文基于作者虚构的《幼儿园健康报告系统》,演示了如何使用低代码平台快速搭建应用系统,并介绍和演示了一些国内外知名的aPaaS产品, Mendix、Outsystems、Yidah、明道云等在产品设计中尝试探索低代码平台的核心精髓,让大家对低代码有更直观的认识。
在案例开始之前,先说一下基本概念。
一、什么是低码
低代码平台是继众泰之后的另一个热门话题。事实上,低代码本身并不是什么新鲜话题,也不是最近的技术突破和创新。它已经存在了十多年或二十多年。概念。早期的大型管理软件套件都有类似拖放式的快速开发平台,这使得技术人员更容易在不编写代码的情况下快速实现某些基本功能。
虽然现在低代码被称为aPaaS,但它似乎是一种PaaS,似乎与SaaS密切相关,但大家需要认识到,低代码开发平台并不是一个概念,仅仅因为SaaS ,但远古时期已经存在。
简单来说,低代码平台就是期望通过拖放配置实现一套面向业务的软件系统,并且可以无缝部署和运行的开发平台。在这个过程中,当然允许编写部分代码,但更重要的是,大量的基础编码工作可以通过低代码平台快速自动化。
低代码的第一个应用场景是帮助成熟的软件产品,以低成本支持个性化需求,提高开发速度,甚至扩大客户群。
例如,许多成熟的商业软件(包括私有化的商业软件套件和SaaS形式的产品)都希望通过构建低代码平台来加强产品扩展能力,更好更快地服务客户,并与ISV合作将产品的目标客户群扩展到更广泛的领域和行业。
在这种情况下,低代码平台是低成本、高效地满足个性化需求的终极解决方案。此时,低代码目标用户可能包括工程师和实施顾问。国外SAP、Oracle、SalesForce、国内用友、金蝶、北森、Salesease等都有以自有软件产品为基础核心的低代码解决方案。
低代码的第二个应用场景是帮助甲方企业以低成本快速搭建新的应用系统,特别是对于不懂编程的业务人员,让企业以更低的成本享受。数字技术为企业带来的好处。
事实上,企业中的大量应用系统都是基于流程的。对于逻辑相对简单、流程链不复杂的业务场景,寻找打包软件支持矫枉过正,外包开发独立系统成本高,那么低代码平台可能是不错的选择。此时,低代码平台的目标用户可能包括甲方企业的业务人员或IT人员。
国外OutSystems和Mendix,国内的明道云、氚云,都属于这种情况。需要注意的是,目前国内一些报表平台和流程引擎厂商为了跟上热情,也自称低代码平台。严格来说,这些厂商提供的产品能力只是一个完整的低代码平台所需能力的一个子集,不能算是低代码产品。
讲了这么多概念,我想大家对低代码的印象还是比较模糊的。接下来,我将通过一个案例,带大家体验一个低代码产品的使用。在开始之前,还有几个问题需要强调一下:
低代码只是应用系统构建实现层面的工具,软件产品设计中的思维和建模过程是核心,所以我们的案例会花一部分笔墨来描述设计过程,理解之后再学习应用low code 平台会简单很多。我选择明道云作为演示产品:第一,因为它更容易上手;第二,因为明道云的老板任向辉喜欢写公众号分享,我很喜欢他的文章,作为致敬,所以选择明道云。需要说明的是,本人与明道云没有任何关系,试用期间也没有添加销售。我从帮助手册中学习并操作了整个试用期。学习明道云大约花了一个小时(主要是看帮助文件),在电脑上实现案例中的功能大约花了两个小时。整体非常好用,好用。不过这也可能是因为之前做过研发,比较容易理解很多基本概念。
好的,接下来,让我们进入案例。
二、小龟鼠幼儿园低代码应用1.需求调研
李校长是小豚鼠幼儿园的校长。最近,她遇到了一件烦心事。根据教委统一要求,疫情期间,要求家长每天报告孩子的健康状况。学校统一管理,但教委没有提供统一的技术支持。 .
为了实现这个需求,幼儿园老师想尽了办法,比如使用微信群管理,或者在线文档管理,但都不是很方便,比如无法实时统计,数据容易被误操作。而如果找软件公司帮忙搭建一个小系统,要花3万到4万元。对于幼儿园来说,这是一笔不小的数目。
李校长的侄子小王是B端产品经理。他在闲聊中得知了李校长的问题,想了想问道:
小王:阿姨,你说的,说不定我可以帮忙,搭建一个软件系统,你的问题就可以很好的解决了!
李校长:真的,太好了,但我们没有很多预算!
小王:不花你一分钱,我免费帮你做,但我想先了解一下你对这个业务管理的需求和期望。
李校长:非常感谢!我的呼吁很简单。就是让父母每天都来检查。如果有任何健康异常,我可以第一时间收到提醒,也可以让老师跟进,看看是什么问题。另外,最好有一些实时报告,让我看到最新的健康报告。
小王:来吧,我明白了,这件事交给我,我帮你设计一套操作流程和配套系统,免费给你使用!
了解大体背景后,小王开始构思小豚鼠幼儿园儿童健康报告系统的设计。
李校长:太好了,期待!
2. 产品轮廓设计
小王了解了基本要求后,开始构思这套系统应该如何设计。首先梳理一下这个系统涉及的利益相关者,如下:
虽然业务流程本身很简单,但因为毕竟是从零开始搭建的管理系统,需要完成一些基础的数据准备工作。想了想,小王画了一张简洁的业务流程图,如下。
可以看出家长们都希望能够签到,一些基础数据要先维护好。按照常识,维护班级信息和学生信息是必要的。签到操作是针对学生的,因此签到信息必须与学生相关联。
另外,要求中提到,如果打卡温度异常,需要老师跟进。我们考虑生成一个待办事项并将其分配给老师。该待办事项与异常打卡记录相关。有了以上对业务的分析和思考,我们就可以画出业务背后的ER模型图(领域模型),如下图所示。
每个老师可以管理多个班级,每个班级只能由一名老师管理。每个班级可以有多个学生,每个学生有多个健康报告记录(签到记录),每个健康报告记录可以生成体温异常跟踪记录。
这些抽象的实体是我们要设计的健康报告系统的核心,因为check-in(健康报告)过程实际上只是对这些实体的数据进行增删改查。
3. 产品细节设计
接下来根据流程图,我们来思考一下系统实现的页面流程图:
除了这些页面级的操作要求,还有一些业务规则要求。例如,如果健康报告中的体温异常,则自动生成一个待跟进的任务,发送给学生的班主任,并推送消息给校长。
简而言之,我们会发现与业务运营相关的功能页面主要是ER实体(创建和编辑)的列表页面和详情页面,不同的用户对不同的页面、不同的数据有不同的权限。
经过整理分析,我们可以列出系统中涉及的相关页面,以及权限表如下(这里只是一个简单的说明,后面明道云会展示更全面详细的权限设计,包括数据权限管理设计方案):
经过上面的分析,虽然细节还没有完成,但我们对“幼儿园健康报告系统”的设计有了清晰的认识。接下来直接进入低代码平台的开发演示链接!
3. 低代码实现——通过工作表定义数据实体
首先我们来到明道云工作台,点击“添加应用”,新建一个应用“小豚鼠幼儿园”(已经在下图中)。
接下来,我们为 ER 模型中的四个实体创建工作表。下图为创建类实体的工作表编辑页面。
Worksheet 是明道云的概念。所谓的工作表实际上对应的是ER建模中的实体。工作表中的相关控件定义实体的字段。比如自增的“类ID”定义在类形式、字符串类型字段“类名”、枚举字段“状态”等。
通过表单呈现实体是一种易于理解的设计方法。实体背后的本质是所谓的“对象”和最终会转移到数据库中的表。在一些低代码平台中,管理实体是通过对象编辑器定义的。这是一个更灵活但更复杂的解决方案,我们稍后会介绍。
无论是表单编辑器还是对象编辑器,原理都是一样的,都是对提取的实体进行管理。对于非技术人员,表格可能更容易理解和接受。
在类窗体中有一个“学生”控件,它是一个关联的记录组件。因为班级和学生是一对多的关系,每个班级可以有多个学生,所以在班级的表格中,我们允许看到一个班级关联的所有学生的列表,这在B端很常见产品交互 一种设计形式。
实体之间所谓的一对多和多对多关系,反映了多个表之间的关联。班级和学生之间的一对多关系可以在设计器中轻松定义,如下所示:
实现关联后,表单与表单之间建立连接,详情页(单个表单数据的展示页)的展示也会自动完美完成。例如:下图是某类数据的详情页(PC版):
aPaaS平台会自动完成PC版和手机版的适配,格式可调。例如,上图为PC版课程详情页,下图为手机版:
4.低代码实现-通过视图编辑器定义数据列表展示
接下来我们依次完成“学生”、“健康报告”、“体温异常追踪”三个实体的表单配置。
在下图中,横向的“校园管理”和“校长控制台”可以理解为我们对系统配置的一级导航。四种垂直形式表示它们属于某个一级导航。每个表单右侧主区域中配置的列表视图是二级导航菜单。如下图所示,对于班级形式,定义了“All”、“Active Class”、“Graduated Class”和“My”。四个列表视图,即“校园管理”一级菜单下的四个二级菜单。
那么,什么是列表视图?
工作表只是定义了实体的特定字段。如何显示实体的列表数据?例如,如何以不同的形式呈现“类”列表数据?这需要一个视图编辑器!
在视图编辑器中,可以定义实体对应的多条数据的表格展示,包括列表数据的默认过滤条件、默认显示字段、默认字段排序,都可以易于定制,如上图所示。
在大部分自研B端产品中,列表页面(即视图)是最常见的功能页面,一般来说,这类页面是硬编码的,而不是通过类似的视图编辑器实现了这样的前端组件。在成熟的软件产品中,没有列表页面的概念,由视图编辑器处理,大大简化了编码工作。
如下图所示,我们为“Class”表单定义了四个视图,分别是“All”、“Effective Middle Class”、“Graduated Class”和“My”。截图显示了“Intermediate Class”视图的“Effective”默认搜索条件配置,可以看到我们已经设置了这个视图的默认查询条件,即“Status”字段为“Teaching”的所有类数据.
我们之前提到过,与“学生”记录的一对多关系是以“班级”形式建立的。在“学生”表格中,还有一个与“班级”表格的“班级ID”相关联的字段。 "字段完成一对多关系的定义。
但是,如果我们想在学生表单中显示班级的名称,在学生视图中显示班级的字段,我们该如何实现呢?
因为我们是建立一对多的关系,所以我们只定义了ID之间的关系。因此,如果要以“学生”形式显示“班级”的名称,则必须对变量引入进行特殊处理。其中,采用了一种称为“其他表字段”的设计方法。简单来说就是关联表的某个字段被引入并显示出来,如下图所示:
下面的红框定义了ID之间的关联,上面的红框介绍了在“Student”表单和视图中显示的“Class”表的“Name”字段。
在其他低代码产品中,这种诉求的解决方案是不一样的。
严格来说,表单只是数据对象的外部表现形式。根据软件设计MVC的分层概念,数据定义和前端呈现必须分层分离。对象编辑器严格定义了数据实体本身,如果表单或视图需要做多表连接来呈现其他相关表的一些字段,这是一个需要在可视化层面解决的问题。
因此,在很多更复杂的低代码产品中,所有的可视化部分都是基于页面编辑器,与底层数据定义无关。因为明道云产品,为了在很大程度上降低用户的学习成本,在数据底层集成了对象编辑器,在表现层集成了表单编辑器。
现在,让我们解决一个难题。如果我们想在学生视图中显示学生老师的名字,我们该怎么做?通过学生,你可以找到你的班级,但谁是班级的负责老师?如何定义?
一种方式是在“班级”表单中添加一个字段,可以关联到老师的账号,完成老师和班级的关系映射。在明道云,我们采取了另一种伎俩。校长需要将每个班级数据的所有者更改为特定的教师帐户,如下图所示。图中的“王老师”是“老师”的独立用户角色。
通过这个动作,实现了对班级负责教师的分配。接下来,使用前面提到的“其他表字段”功能,将这个字段值引入到其他表单对象中。
这样,某个班级的所有学生和学生的健康报告记录都可以追溯到主管老师,这对下一个要求的实现至关重要!
5. 低代码实现——通过流程编辑器定义业务流程和事件
回忆一下,有一个需求:如果健康报告中体温异常,会自动生成一个待跟进的任务,发送给学生班主任,并推送消息给校长。
如何实现这个需求?这使用了 aPaaS 平台中流程编辑器的非常核心和重要的功能。可以说流程编辑器是低代码平台的灵魂!
进一步准确描述上述要求:如果您添加或编辑“健康报告”表单数据,“体温是否正常”字段选择“否”,则自动状态为“待跟进”生成“温度异常跟踪”数据,并发送消息给校长和学生的老师。
在低代码平台下,可以使用流程编辑器来实现与上述类似的功能,自动触发执行,自动更新多表数据。我们来到流程编辑器,创建“上报体温异常触发后续任务记录”流程,如下图:
在图中,我们设计了三个流程节点。
第一个触发节点:定义当“健康报告”表单添加或更新数据时,如果发现“问题正常”字段等于“否”,则执行。第二个节点:当发现体温异常时,创建一条“体温异常追踪”数据,分配给上报记录学生的老师。第三个节点:发送应用内消息给校长和老师提醒处理,效果如下:
对于工作流创建的数据,创建者字段显示为工作流,如下图:
流程编辑器不是一个简单的工作流引擎。我们通常理解的工作流引擎,比如审批流,只是对单个数据对象的多节点处理。真正复杂的流程编辑器BPM需要对流程中不同的数据实体进行复杂的处理,这也是很多B端业务的核心处理逻辑和流程。
当然,明道云的流程编辑器有很多功能,如下图,我们不再赘述。
截至目前,还有一个核心功能我们还没有实现。家长如何报告数据?
一种方式是为每位家长开设一个账号,将账号与学生关联,家长登录系统,提交表格时默认提交相关学生的“健康报告”记录。
另一种方法是将“健康报告”表公开,任何人都可以提交。这样做的好处是不需要一一维护父账户。缺点是系统无法识别提交者和对应的孩子。 , 需要提交者手动从学生列表中选择学生,比较麻烦。
如下图所示,我们已经设置了表单的公共链接。
6. 低代码实现——通过报表编辑器定义报表和仪表板
至此,与业务流程相关的核心功能和数据表格已经开发完毕。接下来,我们需要配置李校长的管理工作台,也就是仪表盘。通过类似于报表引擎的功能,配置了委托人的监控仪表盘,我们将其放置在“委托人控制台”的一级导航下,如下图:
该功能的使用与经典报表引擎类似,不再赘述。
7. 低代码实现-配置角色和权限
最后,我们设置角色和权限。我们设置了两个角色,“校长”和“老师”。
B端产品的权限管理包括两部分。功能权限决定了用户可以访问哪些菜单和按钮,数据权限决定了用户可以访问和操作的数据采集范围。一般通过组织树来实现。
下图为明道云数据权限配置管理整体图:
可以看出,对于每个角色,设计了不同表单视图的查看和编辑权限,属于功能权限。
点击每个表单末尾的设置按钮,还可以定义角色对表单的数据权限,包括是否允许处理所有数据,或者是自己和下属的数据,还是数据我拥有的(记得我们有调整过类的“所有者”吗?)还是我创建的数据?
您甚至可以为特定字段设置更精细的权限,如上图左下角的窗口所示。
完成以上配置后,我们的低代码平台开发工作就完成了。明道云应用系统无需发布,配置后立即生效。所有用户都需要注册一个明道云账号才能使用配置好的系统。配置的应用程序没有单独的应用程序。访问明道云官网登录后即可使用。手机版需要下载明道云APP登录后使用。
最后,给大家展示一下移动版应用的截图。这些是自动生成的默认设计,未经调整。
三、低代码平台的本质
通过上面的例子,相信大家对低代码平台的能力有了直观的感受。
软件产品设计的标准结构是MVC模型,即Model(数据)、Controller(逻辑)和View(交互界面)。低代码平台通过几个核心组件完成了MVC三层架构模型。支持,对应MVC模型,三个核心组件分别是数据模型设计器(对应Model)、流程设计器(对应Controller)、页面设计器(包括报表设计器,对应View)。
1. 数据模型设计师
数据模型设计实现了底层数据对象的定义。正如我们之前提到的,不同的低代码平台有不同的实现数据对象定义的方式。
实现数据模型设计器的第一种方法是通过对象编辑器实现数据定义。这种方法具有最高程度的灵活性。将底层数据模型与前端视图分离,模型聚焦底层,视图是可视化呈现。
国外的低代码平台Mendix和国内的华为云AppCube都采用这种方式。此外,大型商业软件的低代码平台也采用相同的设计,例如SalesForce和范向。
下图是Mendix的对象编辑器,在Mendix中称为Domain Model。事实上,领域模型和对象编辑都属于面向对象编程的概念。严格来说,领域模型与我们之前提到的ER模型并不完全相同。领域模型具有面向对象编程的特点,如泛化和聚合。这些概念不在 ER 模型中。
另外,图中显示的是Mendix的Windows客户端版本。除了 Web 版本,Mendix 还提供了更强大的 Windows 客户端。经过简单的体验,这个客户端更像是在开发一个集成编辑器IDE(程序员编写代码的软件平台)。 Mendix 本身也很强大,当然更难学。
国外另一款知名的aPaaS产品Outsystems也采用了底层对象驱动的设计,同时也提供了windows版本的客户端。安装后,有一步一步的教程,太棒了!整套IDE风格的产品设计也非常强大,令人印象深刻!
华为云的AppCube好像是对象编辑器的设计方法,但是因为我的试用申请没有通过,只是通过帮助文档猜测了一下,无法具体体验,如下图:
数据模型设计的第二个实现是表单引擎。
对于设计师来说,只需要将底层的数据对象理解为Excel的多个独立表格,每个表格都采用采集data的形式。用户定义数据模型,只需要以采集control的形式定义数据即可。
比如下图就是一个适合钉钉的表单编辑器。设计思路与明道云相似。表单编辑器将底层数据设计和可视化呈现打包在一起,非技术人员更容易理解,但也失去了前后端分离的灵活性。
2. 流程设计师
定义底层数据后,下一步就是定义工作流。对于商业软件产品,工作流是支撑商业运作的核心。业务运营的本质是每个工作流的执行。
浅层工作流是一种类似于Workflow的审批流程,是对单个数据对象的处理;深层次的工作流需要能够支持流程中多个数据实体的自动化处理。后者是低代码产品的核心功能之一。如果你没有后者的能力,除了问卷之外,基本上没有系统可以搭建。
过程中多个数据实体的自动处理是什么?
例如,在销售 CRM 系统中,当潜在客户的状态变为已验证时,它需要自动生成商机记录以进行跟踪并将商机分配给适当的销售。同时,对应的联系人记录和客户记录、商机、联系人、客户的部分字段数据来自牵头实体。
此业务逻辑规则需要复杂的工作流编辑器才能实现。在这个自动化流程中,添加、删除、修改和检查四个实体数据(线索、商机、客户和联系人)。
下图显示了 Windows 客户端版本 Mendix 中的流程编辑器。
下图为国货钉钉一的工作流程编辑器。似乎太简单了。它只是一个审批流程编辑器。或者我还没有找到功能齐全的配置界面?
3. 页面设计师
对于商业软件产品,主要功能是数据的增删改查,涉及的交互页面多为底层数据对象对应的列表页面和详情页面。此外,它还包括报告和仪表。磁盘和其他类型的页面。
页面设计师的设计理念清晰地体现了不同低代码平台的产品理念。总的来说,可以概括为两种。
1)纯前端页面编辑器
包括报告、列表、视图和表单,所有这些都在这个集成的页面编辑器中实现。比如Outsystems的页面编辑器,如下图:
如你所见,这是一套复杂的前端交互组件设计器,包括类似于数据表集合Table Records的集成控件,以及表单控件Form,以及其他类型的控件集合,例如复选框。复选框、单选按钮等
在这组编辑器中,操作员可以定义各种类型的前端页面,例如列表页面、详细信息页面、报表和仪表板。再比如Mendix的页面编辑器,设计思路相同,如下图:
甚至仪表板也是在同一个页面编辑器中实现的。下图展示了 Mendix 的仪表盘演示:
低代码平台的报表设计器组件与传统报表引擎没有太大区别。它基于底层数据,实现前端的可视化输出,包括表格输出和图形输出。以上是第一个前端交互设计的产品形态。可见其功能强大且灵活,学习成本相对较高。
2)大大简化的页面配置器
The template configuration of different types of pages is mainly divided into the following categories.
Of course, low-code products will also provide the configuration of the integrated page, but the function is much weaker than the function mentioned above. The previous article has described the view editor of Mingdaoyun a lot, so I won't repeat it.
The picture below is the page editor of Yidao, which shows the editing of the homepage of a certain system. Compared with Mingdaoyun, Yidao's page editor is more complicated and has more powerful functions.
Another example, the following picture is a suitable report editor:
Data model designer, process designer and page designer are the core of low-code platform. If you understand the MVC layered architecture of software design, it is easy to understand the core product functions of low-code platform and different products Ideas. Of course, different low-code platforms have more powerful features with their own characteristics, and interested readers can study further.
四、结语
It can be seen that different low-code platforms have different design ideas.
There is a trade-off between product ease of use and product flexibility. For example, for the bottom layer of the data, should I choose form-driven design or domain-driven design?两者有很大的不同。 The latter is basically unavailable to non-technical personnel. Although the former is easy to learn and understand, its function is indeed much weaker.
Therefore, low-code platforms must clarify the target user group. Is it a professional development aid tool for ISVs or IT teams, or an enhanced efficiency tool for non-technical personnel? The former is more like a super plug-in package of IDE, and the latter is more like a super easy-to-use version of Excel + VBA.
For the B-side product manager, experiencing low-code products similar to Mingdaoyun is very beneficial to understanding software design. Whether it is forms, processes, or rights management, all core product design issues will be involved To, and can deepen understanding.
In addition, in case the business has a large demand and the R&D is not scheduled, you can use aPaaS to configure it in 3 hours. Who will not give you the annual CEO special award?
#专栏作家#
Yang Kun, public account: PM Yang Kun (ID: pmYangKun). Everyone is a product manager columnist, author of "Determining the B-side", 12 years of Internet R&D and product design experience, former VIPKID product director, Baidu senior product manager, and now the founder and CEO of Manku Consulting.
This article 原创 is published in Renren is a product manager, reprinting without permission is prohibited
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
一人奖励
查看全部
幼儿园健康上报系统演示如何用低代码平台快速搭建一套应用系统
简介:本文基于作者虚构的《幼儿园健康报告系统》,演示了如何使用低代码平台快速搭建应用系统,并介绍和演示了一些国内外知名的aPaaS产品, Mendix、Outsystems、Yidah、明道云等在产品设计中尝试探索低代码平台的核心精髓,让大家对低代码有更直观的认识。

在案例开始之前,先说一下基本概念。
一、什么是低码
低代码平台是继众泰之后的另一个热门话题。事实上,低代码本身并不是什么新鲜话题,也不是最近的技术突破和创新。它已经存在了十多年或二十多年。概念。早期的大型管理软件套件都有类似拖放式的快速开发平台,这使得技术人员更容易在不编写代码的情况下快速实现某些基本功能。
虽然现在低代码被称为aPaaS,但它似乎是一种PaaS,似乎与SaaS密切相关,但大家需要认识到,低代码开发平台并不是一个概念,仅仅因为SaaS ,但远古时期已经存在。
简单来说,低代码平台就是期望通过拖放配置实现一套面向业务的软件系统,并且可以无缝部署和运行的开发平台。在这个过程中,当然允许编写部分代码,但更重要的是,大量的基础编码工作可以通过低代码平台快速自动化。
低代码的第一个应用场景是帮助成熟的软件产品,以低成本支持个性化需求,提高开发速度,甚至扩大客户群。
例如,许多成熟的商业软件(包括私有化的商业软件套件和SaaS形式的产品)都希望通过构建低代码平台来加强产品扩展能力,更好更快地服务客户,并与ISV合作将产品的目标客户群扩展到更广泛的领域和行业。
在这种情况下,低代码平台是低成本、高效地满足个性化需求的终极解决方案。此时,低代码目标用户可能包括工程师和实施顾问。国外SAP、Oracle、SalesForce、国内用友、金蝶、北森、Salesease等都有以自有软件产品为基础核心的低代码解决方案。
低代码的第二个应用场景是帮助甲方企业以低成本快速搭建新的应用系统,特别是对于不懂编程的业务人员,让企业以更低的成本享受。数字技术为企业带来的好处。
事实上,企业中的大量应用系统都是基于流程的。对于逻辑相对简单、流程链不复杂的业务场景,寻找打包软件支持矫枉过正,外包开发独立系统成本高,那么低代码平台可能是不错的选择。此时,低代码平台的目标用户可能包括甲方企业的业务人员或IT人员。
国外OutSystems和Mendix,国内的明道云、氚云,都属于这种情况。需要注意的是,目前国内一些报表平台和流程引擎厂商为了跟上热情,也自称低代码平台。严格来说,这些厂商提供的产品能力只是一个完整的低代码平台所需能力的一个子集,不能算是低代码产品。
讲了这么多概念,我想大家对低代码的印象还是比较模糊的。接下来,我将通过一个案例,带大家体验一个低代码产品的使用。在开始之前,还有几个问题需要强调一下:
低代码只是应用系统构建实现层面的工具,软件产品设计中的思维和建模过程是核心,所以我们的案例会花一部分笔墨来描述设计过程,理解之后再学习应用low code 平台会简单很多。我选择明道云作为演示产品:第一,因为它更容易上手;第二,因为明道云的老板任向辉喜欢写公众号分享,我很喜欢他的文章,作为致敬,所以选择明道云。需要说明的是,本人与明道云没有任何关系,试用期间也没有添加销售。我从帮助手册中学习并操作了整个试用期。学习明道云大约花了一个小时(主要是看帮助文件),在电脑上实现案例中的功能大约花了两个小时。整体非常好用,好用。不过这也可能是因为之前做过研发,比较容易理解很多基本概念。
好的,接下来,让我们进入案例。
二、小龟鼠幼儿园低代码应用1.需求调研
李校长是小豚鼠幼儿园的校长。最近,她遇到了一件烦心事。根据教委统一要求,疫情期间,要求家长每天报告孩子的健康状况。学校统一管理,但教委没有提供统一的技术支持。 .
为了实现这个需求,幼儿园老师想尽了办法,比如使用微信群管理,或者在线文档管理,但都不是很方便,比如无法实时统计,数据容易被误操作。而如果找软件公司帮忙搭建一个小系统,要花3万到4万元。对于幼儿园来说,这是一笔不小的数目。
李校长的侄子小王是B端产品经理。他在闲聊中得知了李校长的问题,想了想问道:
小王:阿姨,你说的,说不定我可以帮忙,搭建一个软件系统,你的问题就可以很好的解决了!
李校长:真的,太好了,但我们没有很多预算!
小王:不花你一分钱,我免费帮你做,但我想先了解一下你对这个业务管理的需求和期望。
李校长:非常感谢!我的呼吁很简单。就是让父母每天都来检查。如果有任何健康异常,我可以第一时间收到提醒,也可以让老师跟进,看看是什么问题。另外,最好有一些实时报告,让我看到最新的健康报告。
小王:来吧,我明白了,这件事交给我,我帮你设计一套操作流程和配套系统,免费给你使用!
了解大体背景后,小王开始构思小豚鼠幼儿园儿童健康报告系统的设计。
李校长:太好了,期待!
2. 产品轮廓设计
小王了解了基本要求后,开始构思这套系统应该如何设计。首先梳理一下这个系统涉及的利益相关者,如下:
虽然业务流程本身很简单,但因为毕竟是从零开始搭建的管理系统,需要完成一些基础的数据准备工作。想了想,小王画了一张简洁的业务流程图,如下。
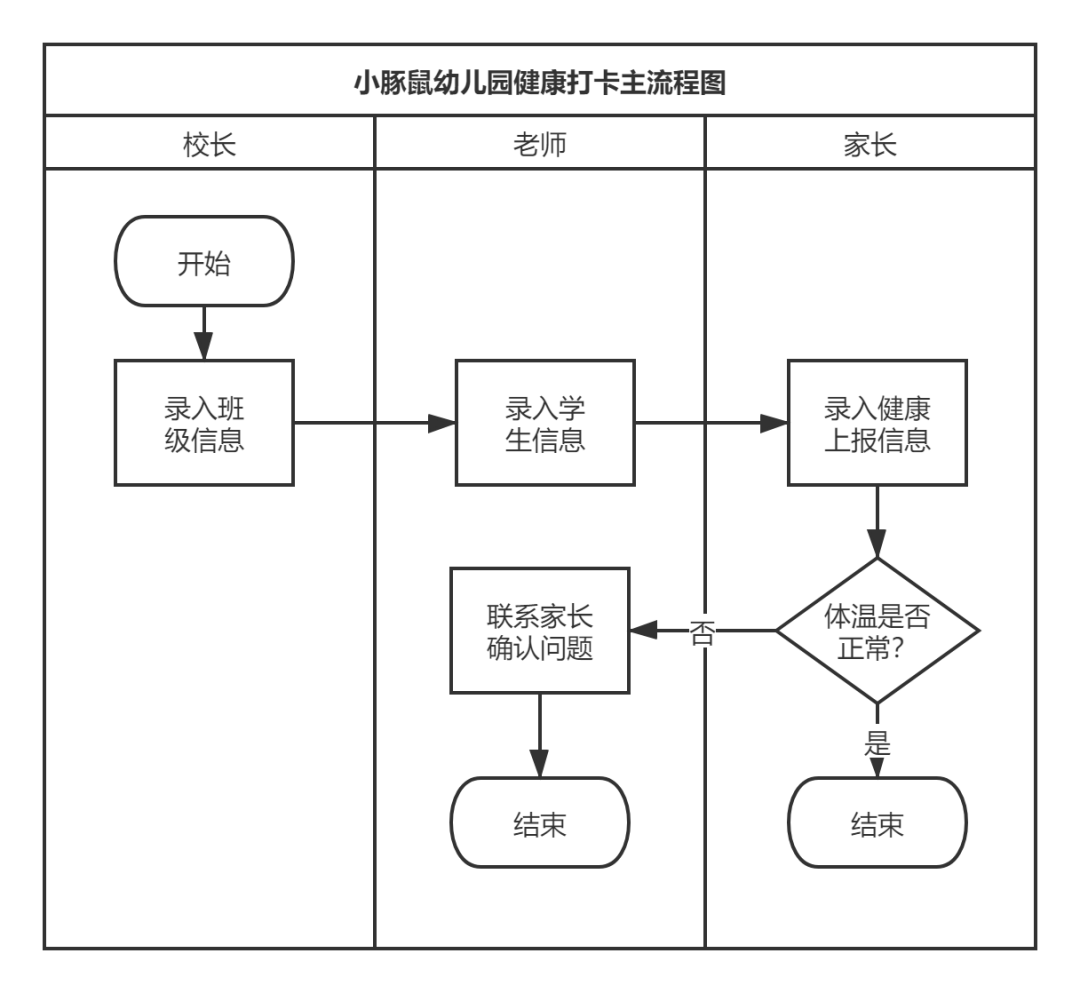
可以看出家长们都希望能够签到,一些基础数据要先维护好。按照常识,维护班级信息和学生信息是必要的。签到操作是针对学生的,因此签到信息必须与学生相关联。
另外,要求中提到,如果打卡温度异常,需要老师跟进。我们考虑生成一个待办事项并将其分配给老师。该待办事项与异常打卡记录相关。有了以上对业务的分析和思考,我们就可以画出业务背后的ER模型图(领域模型),如下图所示。
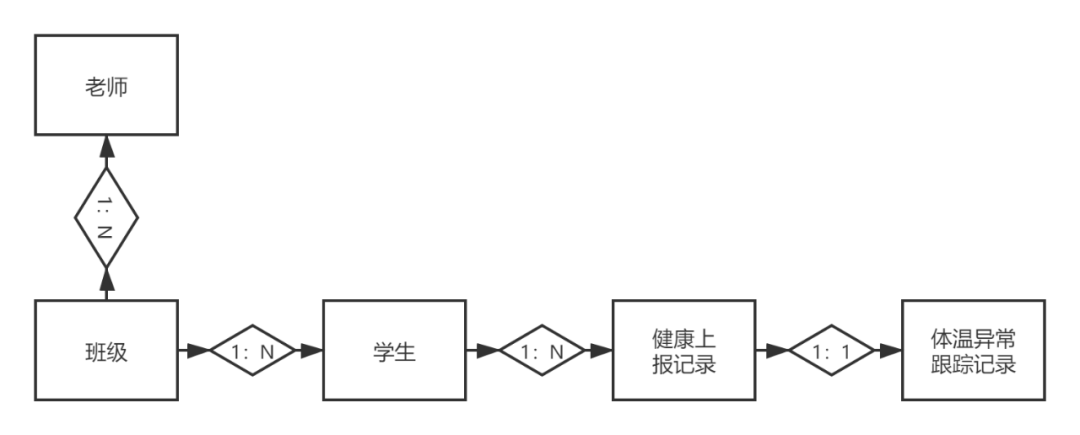
每个老师可以管理多个班级,每个班级只能由一名老师管理。每个班级可以有多个学生,每个学生有多个健康报告记录(签到记录),每个健康报告记录可以生成体温异常跟踪记录。
这些抽象的实体是我们要设计的健康报告系统的核心,因为check-in(健康报告)过程实际上只是对这些实体的数据进行增删改查。
3. 产品细节设计
接下来根据流程图,我们来思考一下系统实现的页面流程图:
除了这些页面级的操作要求,还有一些业务规则要求。例如,如果健康报告中的体温异常,则自动生成一个待跟进的任务,发送给学生的班主任,并推送消息给校长。
简而言之,我们会发现与业务运营相关的功能页面主要是ER实体(创建和编辑)的列表页面和详情页面,不同的用户对不同的页面、不同的数据有不同的权限。
经过整理分析,我们可以列出系统中涉及的相关页面,以及权限表如下(这里只是一个简单的说明,后面明道云会展示更全面详细的权限设计,包括数据权限管理设计方案):
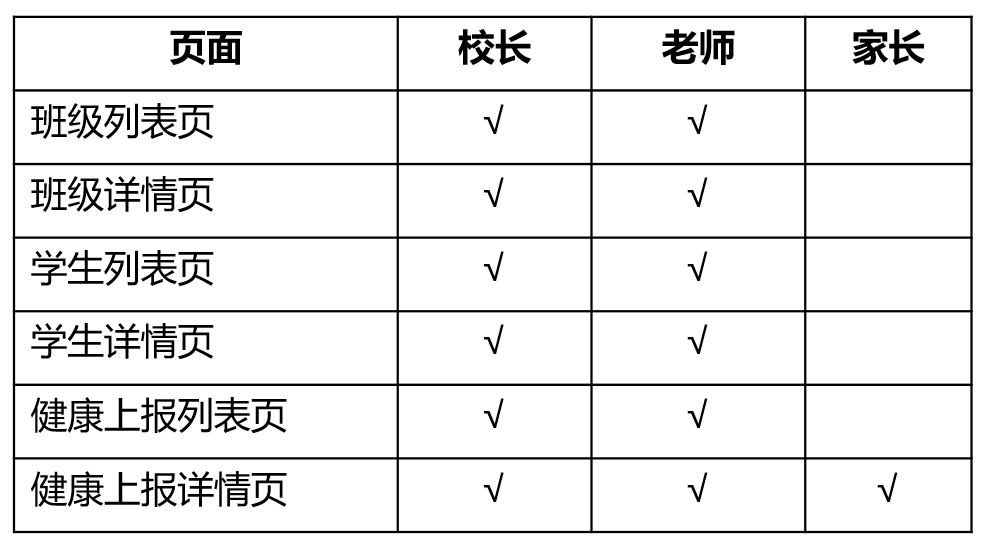
经过上面的分析,虽然细节还没有完成,但我们对“幼儿园健康报告系统”的设计有了清晰的认识。接下来直接进入低代码平台的开发演示链接!
3. 低代码实现——通过工作表定义数据实体
首先我们来到明道云工作台,点击“添加应用”,新建一个应用“小豚鼠幼儿园”(已经在下图中)。
接下来,我们为 ER 模型中的四个实体创建工作表。下图为创建类实体的工作表编辑页面。
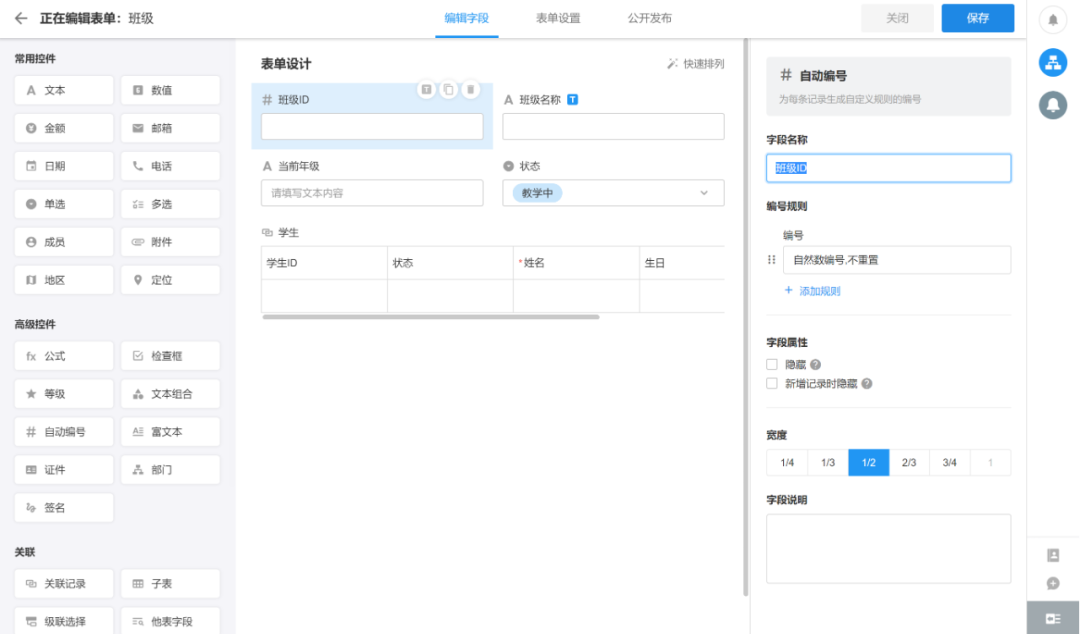
Worksheet 是明道云的概念。所谓的工作表实际上对应的是ER建模中的实体。工作表中的相关控件定义实体的字段。比如自增的“类ID”定义在类形式、字符串类型字段“类名”、枚举字段“状态”等。
通过表单呈现实体是一种易于理解的设计方法。实体背后的本质是所谓的“对象”和最终会转移到数据库中的表。在一些低代码平台中,管理实体是通过对象编辑器定义的。这是一个更灵活但更复杂的解决方案,我们稍后会介绍。
无论是表单编辑器还是对象编辑器,原理都是一样的,都是对提取的实体进行管理。对于非技术人员,表格可能更容易理解和接受。
在类窗体中有一个“学生”控件,它是一个关联的记录组件。因为班级和学生是一对多的关系,每个班级可以有多个学生,所以在班级的表格中,我们允许看到一个班级关联的所有学生的列表,这在B端很常见产品交互 一种设计形式。
实体之间所谓的一对多和多对多关系,反映了多个表之间的关联。班级和学生之间的一对多关系可以在设计器中轻松定义,如下所示:
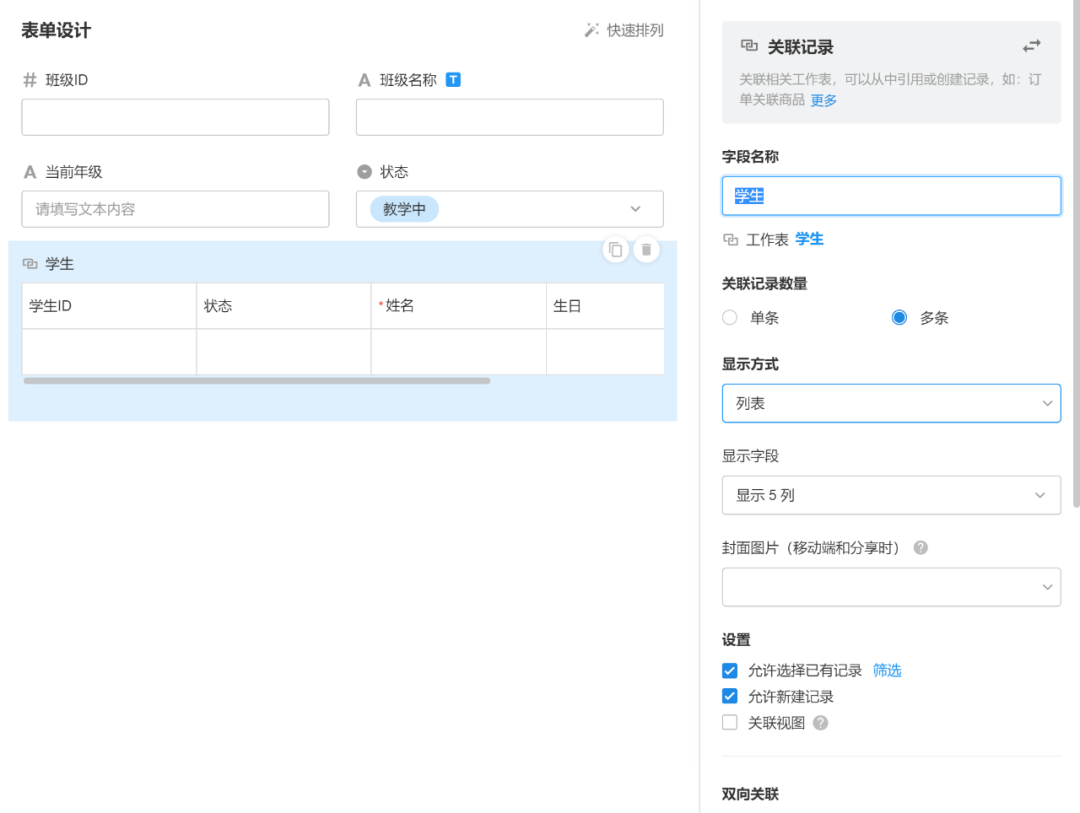
实现关联后,表单与表单之间建立连接,详情页(单个表单数据的展示页)的展示也会自动完美完成。例如:下图是某类数据的详情页(PC版):

aPaaS平台会自动完成PC版和手机版的适配,格式可调。例如,上图为PC版课程详情页,下图为手机版:
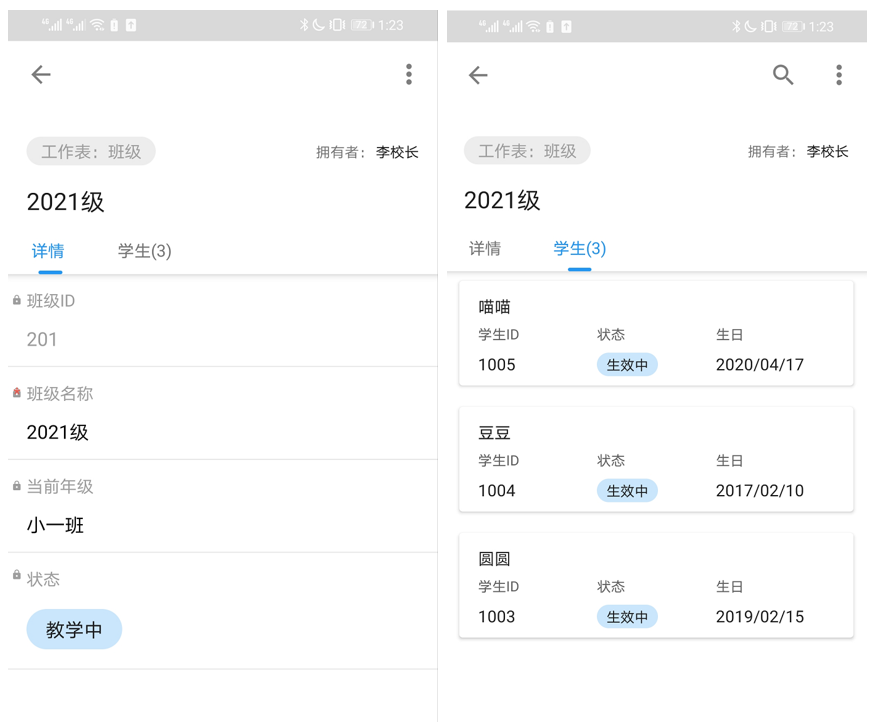
4.低代码实现-通过视图编辑器定义数据列表展示
接下来我们依次完成“学生”、“健康报告”、“体温异常追踪”三个实体的表单配置。
在下图中,横向的“校园管理”和“校长控制台”可以理解为我们对系统配置的一级导航。四种垂直形式表示它们属于某个一级导航。每个表单右侧主区域中配置的列表视图是二级导航菜单。如下图所示,对于班级形式,定义了“All”、“Active Class”、“Graduated Class”和“My”。四个列表视图,即“校园管理”一级菜单下的四个二级菜单。
那么,什么是列表视图?

工作表只是定义了实体的特定字段。如何显示实体的列表数据?例如,如何以不同的形式呈现“类”列表数据?这需要一个视图编辑器!
在视图编辑器中,可以定义实体对应的多条数据的表格展示,包括列表数据的默认过滤条件、默认显示字段、默认字段排序,都可以易于定制,如上图所示。
在大部分自研B端产品中,列表页面(即视图)是最常见的功能页面,一般来说,这类页面是硬编码的,而不是通过类似的视图编辑器实现了这样的前端组件。在成熟的软件产品中,没有列表页面的概念,由视图编辑器处理,大大简化了编码工作。
如下图所示,我们为“Class”表单定义了四个视图,分别是“All”、“Effective Middle Class”、“Graduated Class”和“My”。截图显示了“Intermediate Class”视图的“Effective”默认搜索条件配置,可以看到我们已经设置了这个视图的默认查询条件,即“Status”字段为“Teaching”的所有类数据.
我们之前提到过,与“学生”记录的一对多关系是以“班级”形式建立的。在“学生”表格中,还有一个与“班级”表格的“班级ID”相关联的字段。 "字段完成一对多关系的定义。
但是,如果我们想在学生表单中显示班级的名称,在学生视图中显示班级的字段,我们该如何实现呢?
因为我们是建立一对多的关系,所以我们只定义了ID之间的关系。因此,如果要以“学生”形式显示“班级”的名称,则必须对变量引入进行特殊处理。其中,采用了一种称为“其他表字段”的设计方法。简单来说就是关联表的某个字段被引入并显示出来,如下图所示:
下面的红框定义了ID之间的关联,上面的红框介绍了在“Student”表单和视图中显示的“Class”表的“Name”字段。
在其他低代码产品中,这种诉求的解决方案是不一样的。
严格来说,表单只是数据对象的外部表现形式。根据软件设计MVC的分层概念,数据定义和前端呈现必须分层分离。对象编辑器严格定义了数据实体本身,如果表单或视图需要做多表连接来呈现其他相关表的一些字段,这是一个需要在可视化层面解决的问题。
因此,在很多更复杂的低代码产品中,所有的可视化部分都是基于页面编辑器,与底层数据定义无关。因为明道云产品,为了在很大程度上降低用户的学习成本,在数据底层集成了对象编辑器,在表现层集成了表单编辑器。
现在,让我们解决一个难题。如果我们想在学生视图中显示学生老师的名字,我们该怎么做?通过学生,你可以找到你的班级,但谁是班级的负责老师?如何定义?
一种方式是在“班级”表单中添加一个字段,可以关联到老师的账号,完成老师和班级的关系映射。在明道云,我们采取了另一种伎俩。校长需要将每个班级数据的所有者更改为特定的教师帐户,如下图所示。图中的“王老师”是“老师”的独立用户角色。
通过这个动作,实现了对班级负责教师的分配。接下来,使用前面提到的“其他表字段”功能,将这个字段值引入到其他表单对象中。
这样,某个班级的所有学生和学生的健康报告记录都可以追溯到主管老师,这对下一个要求的实现至关重要!
5. 低代码实现——通过流程编辑器定义业务流程和事件
回忆一下,有一个需求:如果健康报告中体温异常,会自动生成一个待跟进的任务,发送给学生班主任,并推送消息给校长。
如何实现这个需求?这使用了 aPaaS 平台中流程编辑器的非常核心和重要的功能。可以说流程编辑器是低代码平台的灵魂!
进一步准确描述上述要求:如果您添加或编辑“健康报告”表单数据,“体温是否正常”字段选择“否”,则自动状态为“待跟进”生成“温度异常跟踪”数据,并发送消息给校长和学生的老师。
在低代码平台下,可以使用流程编辑器来实现与上述类似的功能,自动触发执行,自动更新多表数据。我们来到流程编辑器,创建“上报体温异常触发后续任务记录”流程,如下图:
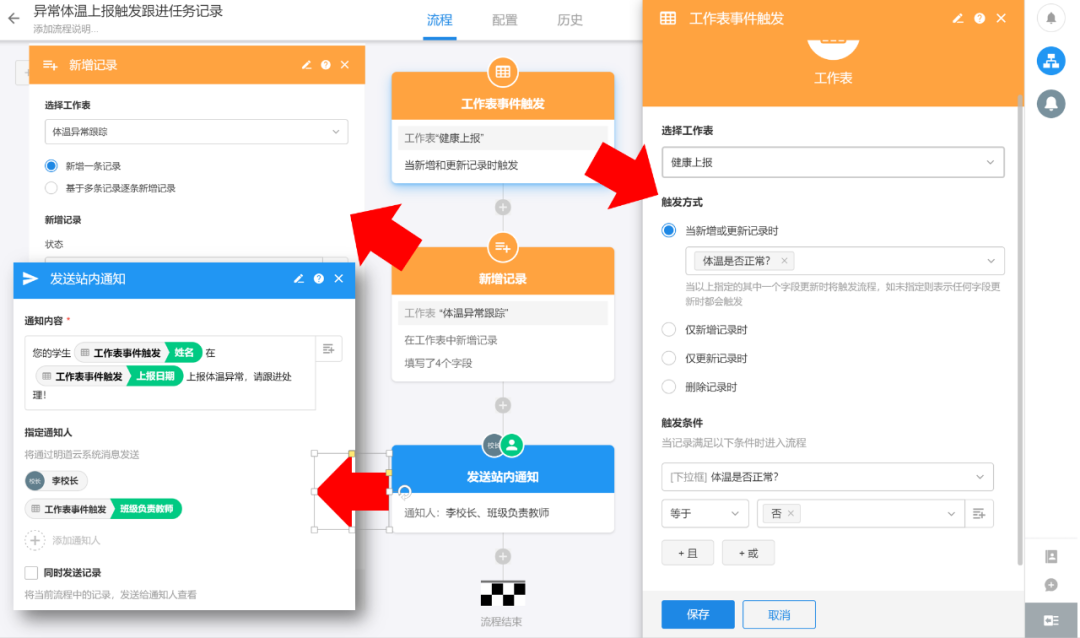
在图中,我们设计了三个流程节点。
第一个触发节点:定义当“健康报告”表单添加或更新数据时,如果发现“问题正常”字段等于“否”,则执行。第二个节点:当发现体温异常时,创建一条“体温异常追踪”数据,分配给上报记录学生的老师。第三个节点:发送应用内消息给校长和老师提醒处理,效果如下:
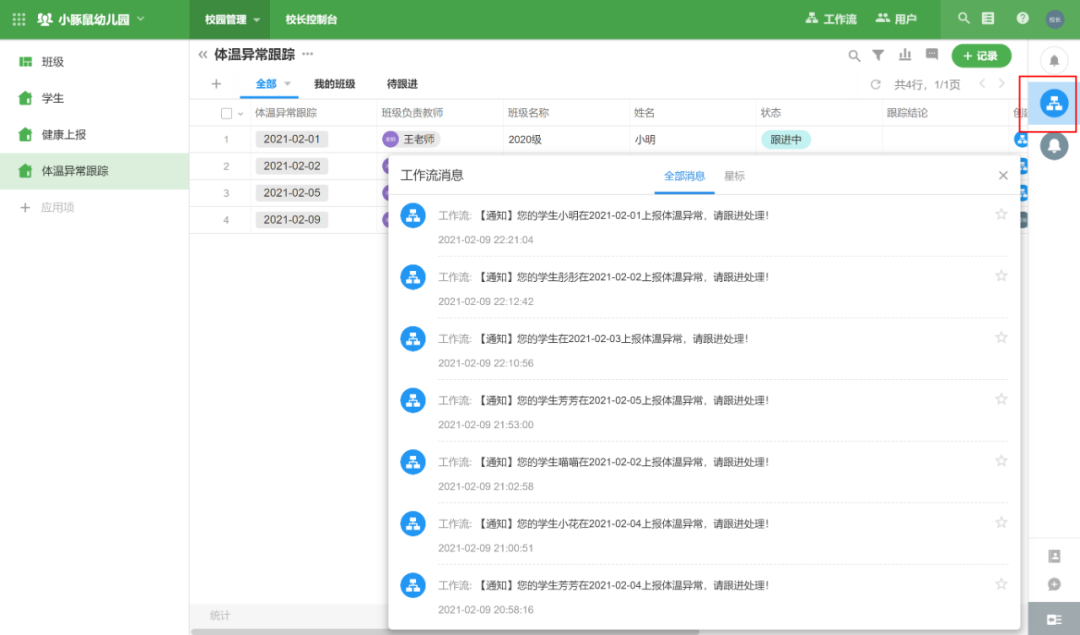
对于工作流创建的数据,创建者字段显示为工作流,如下图:

流程编辑器不是一个简单的工作流引擎。我们通常理解的工作流引擎,比如审批流,只是对单个数据对象的多节点处理。真正复杂的流程编辑器BPM需要对流程中不同的数据实体进行复杂的处理,这也是很多B端业务的核心处理逻辑和流程。
当然,明道云的流程编辑器有很多功能,如下图,我们不再赘述。
截至目前,还有一个核心功能我们还没有实现。家长如何报告数据?
一种方式是为每位家长开设一个账号,将账号与学生关联,家长登录系统,提交表格时默认提交相关学生的“健康报告”记录。
另一种方法是将“健康报告”表公开,任何人都可以提交。这样做的好处是不需要一一维护父账户。缺点是系统无法识别提交者和对应的孩子。 , 需要提交者手动从学生列表中选择学生,比较麻烦。
如下图所示,我们已经设置了表单的公共链接。
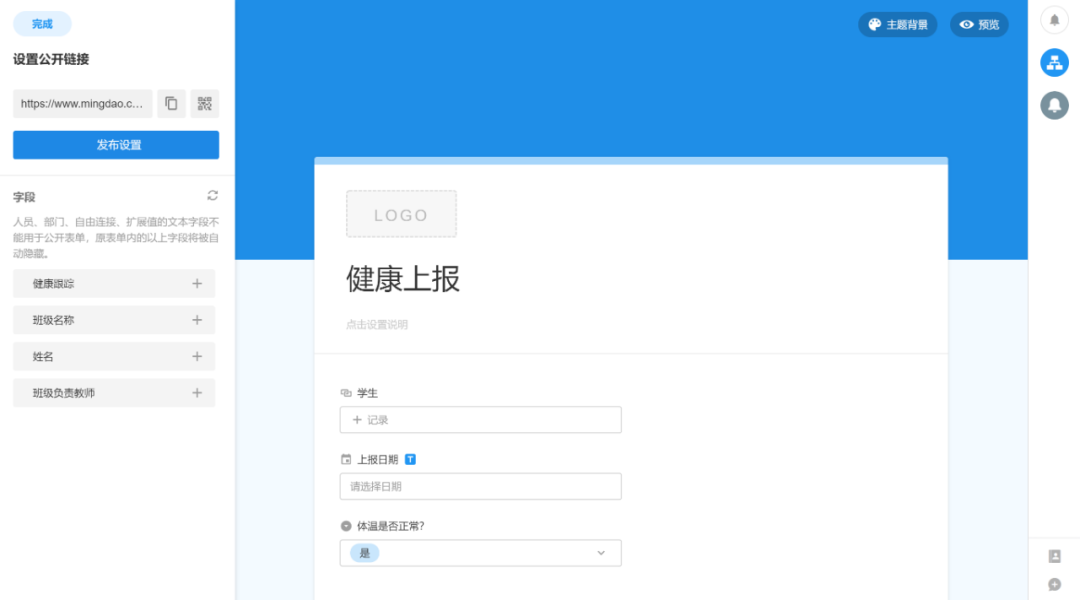
6. 低代码实现——通过报表编辑器定义报表和仪表板
至此,与业务流程相关的核心功能和数据表格已经开发完毕。接下来,我们需要配置李校长的管理工作台,也就是仪表盘。通过类似于报表引擎的功能,配置了委托人的监控仪表盘,我们将其放置在“委托人控制台”的一级导航下,如下图:
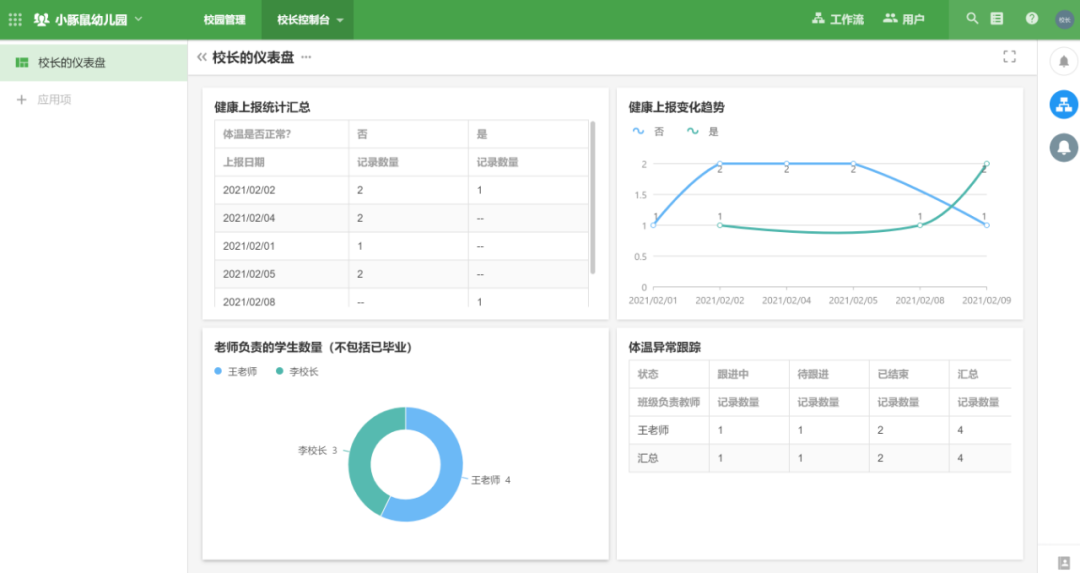
该功能的使用与经典报表引擎类似,不再赘述。
7. 低代码实现-配置角色和权限
最后,我们设置角色和权限。我们设置了两个角色,“校长”和“老师”。
B端产品的权限管理包括两部分。功能权限决定了用户可以访问哪些菜单和按钮,数据权限决定了用户可以访问和操作的数据采集范围。一般通过组织树来实现。
下图为明道云数据权限配置管理整体图:
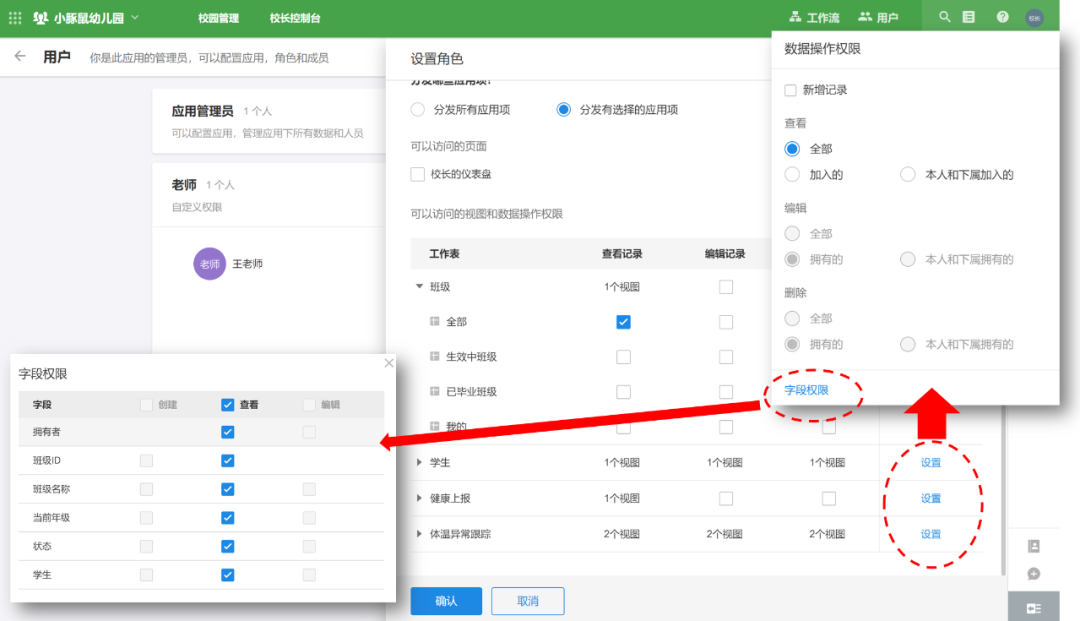
可以看出,对于每个角色,设计了不同表单视图的查看和编辑权限,属于功能权限。
点击每个表单末尾的设置按钮,还可以定义角色对表单的数据权限,包括是否允许处理所有数据,或者是自己和下属的数据,还是数据我拥有的(记得我们有调整过类的“所有者”吗?)还是我创建的数据?
您甚至可以为特定字段设置更精细的权限,如上图左下角的窗口所示。
完成以上配置后,我们的低代码平台开发工作就完成了。明道云应用系统无需发布,配置后立即生效。所有用户都需要注册一个明道云账号才能使用配置好的系统。配置的应用程序没有单独的应用程序。访问明道云官网登录后即可使用。手机版需要下载明道云APP登录后使用。
最后,给大家展示一下移动版应用的截图。这些是自动生成的默认设计,未经调整。
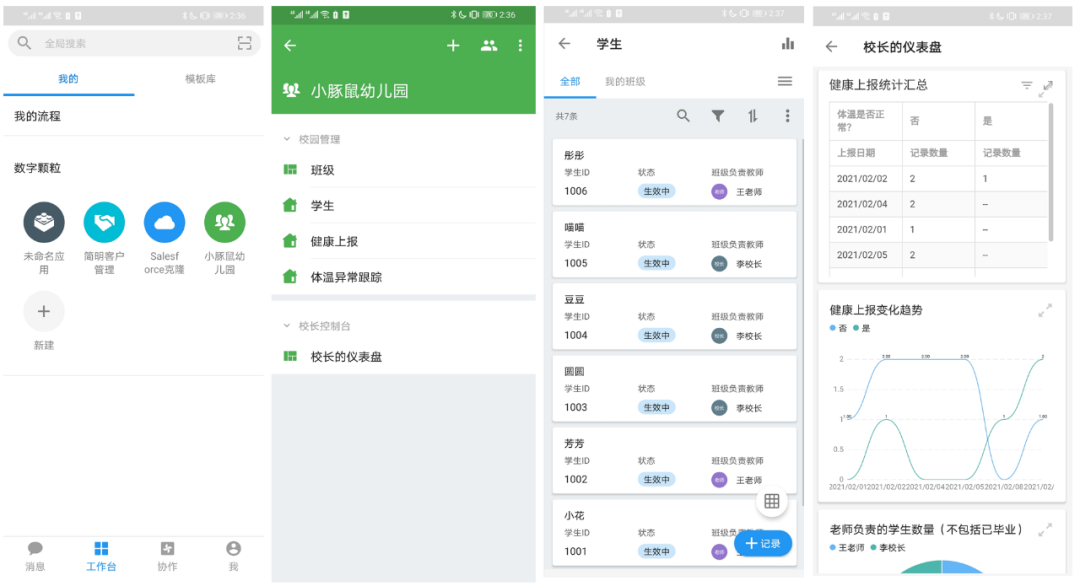
三、低代码平台的本质
通过上面的例子,相信大家对低代码平台的能力有了直观的感受。
软件产品设计的标准结构是MVC模型,即Model(数据)、Controller(逻辑)和View(交互界面)。低代码平台通过几个核心组件完成了MVC三层架构模型。支持,对应MVC模型,三个核心组件分别是数据模型设计器(对应Model)、流程设计器(对应Controller)、页面设计器(包括报表设计器,对应View)。
1. 数据模型设计师
数据模型设计实现了底层数据对象的定义。正如我们之前提到的,不同的低代码平台有不同的实现数据对象定义的方式。
实现数据模型设计器的第一种方法是通过对象编辑器实现数据定义。这种方法具有最高程度的灵活性。将底层数据模型与前端视图分离,模型聚焦底层,视图是可视化呈现。
国外的低代码平台Mendix和国内的华为云AppCube都采用这种方式。此外,大型商业软件的低代码平台也采用相同的设计,例如SalesForce和范向。
下图是Mendix的对象编辑器,在Mendix中称为Domain Model。事实上,领域模型和对象编辑都属于面向对象编程的概念。严格来说,领域模型与我们之前提到的ER模型并不完全相同。领域模型具有面向对象编程的特点,如泛化和聚合。这些概念不在 ER 模型中。
另外,图中显示的是Mendix的Windows客户端版本。除了 Web 版本,Mendix 还提供了更强大的 Windows 客户端。经过简单的体验,这个客户端更像是在开发一个集成编辑器IDE(程序员编写代码的软件平台)。 Mendix 本身也很强大,当然更难学。
国外另一款知名的aPaaS产品Outsystems也采用了底层对象驱动的设计,同时也提供了windows版本的客户端。安装后,有一步一步的教程,太棒了!整套IDE风格的产品设计也非常强大,令人印象深刻!
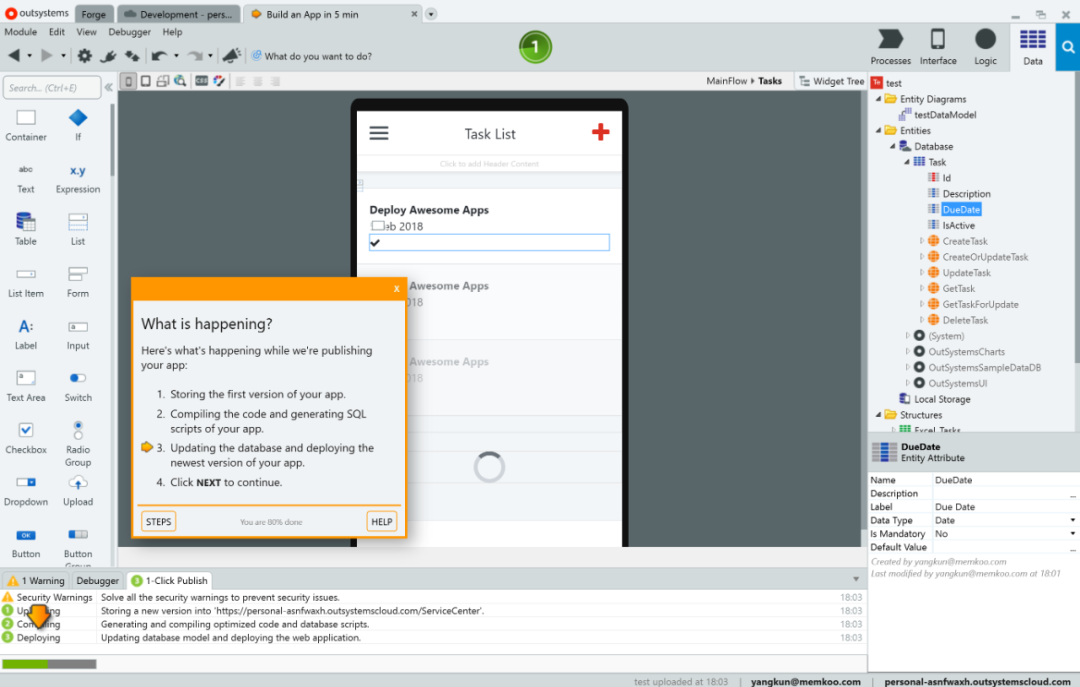
华为云的AppCube好像是对象编辑器的设计方法,但是因为我的试用申请没有通过,只是通过帮助文档猜测了一下,无法具体体验,如下图:
数据模型设计的第二个实现是表单引擎。
对于设计师来说,只需要将底层的数据对象理解为Excel的多个独立表格,每个表格都采用采集data的形式。用户定义数据模型,只需要以采集control的形式定义数据即可。
比如下图就是一个适合钉钉的表单编辑器。设计思路与明道云相似。表单编辑器将底层数据设计和可视化呈现打包在一起,非技术人员更容易理解,但也失去了前后端分离的灵活性。
2. 流程设计师
定义底层数据后,下一步就是定义工作流。对于商业软件产品,工作流是支撑商业运作的核心。业务运营的本质是每个工作流的执行。
浅层工作流是一种类似于Workflow的审批流程,是对单个数据对象的处理;深层次的工作流需要能够支持流程中多个数据实体的自动化处理。后者是低代码产品的核心功能之一。如果你没有后者的能力,除了问卷之外,基本上没有系统可以搭建。
过程中多个数据实体的自动处理是什么?
例如,在销售 CRM 系统中,当潜在客户的状态变为已验证时,它需要自动生成商机记录以进行跟踪并将商机分配给适当的销售。同时,对应的联系人记录和客户记录、商机、联系人、客户的部分字段数据来自牵头实体。
此业务逻辑规则需要复杂的工作流编辑器才能实现。在这个自动化流程中,添加、删除、修改和检查四个实体数据(线索、商机、客户和联系人)。
下图显示了 Windows 客户端版本 Mendix 中的流程编辑器。
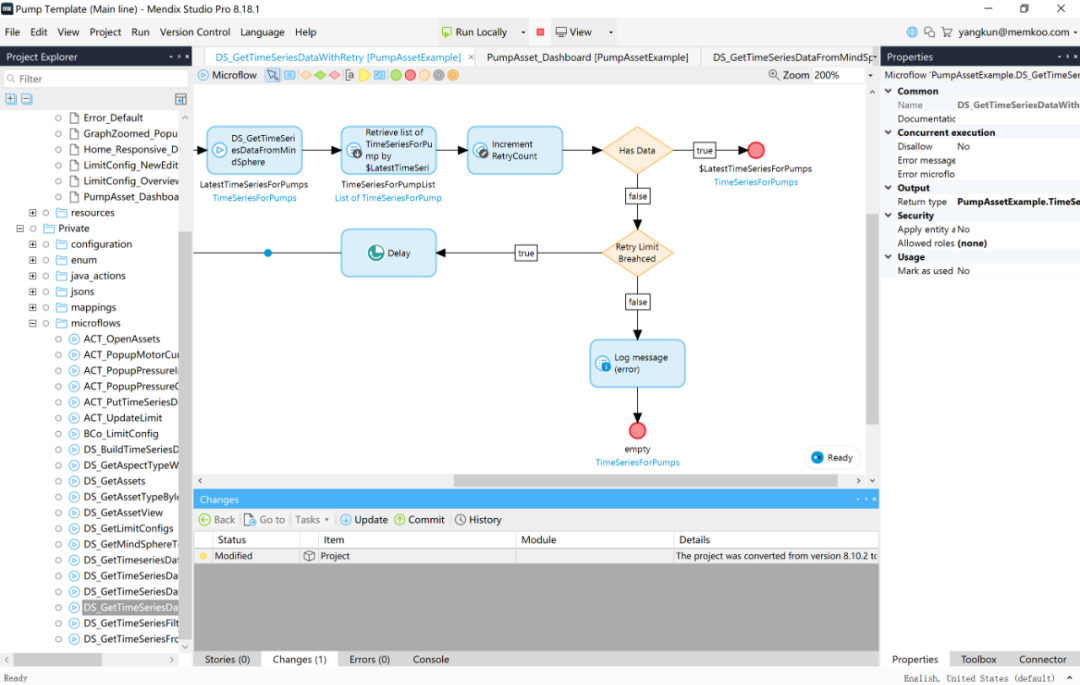
下图为国货钉钉一的工作流程编辑器。似乎太简单了。它只是一个审批流程编辑器。或者我还没有找到功能齐全的配置界面?
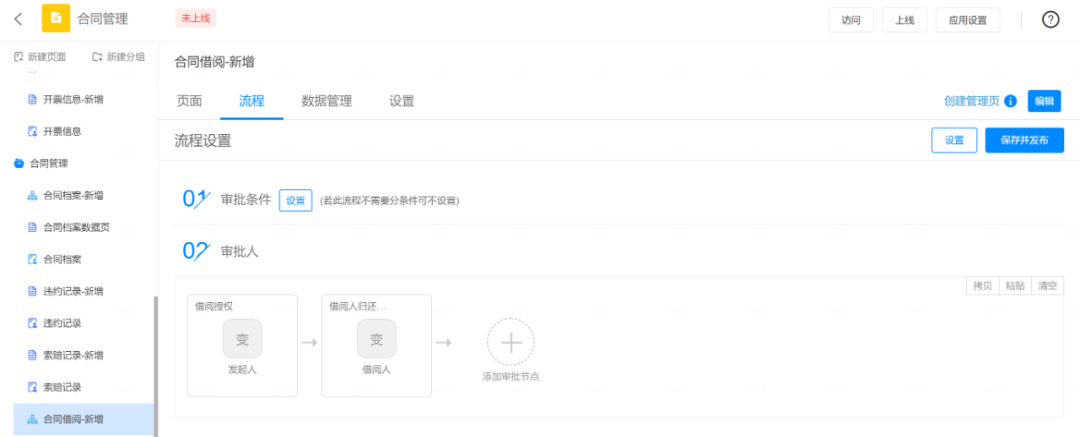
3. 页面设计师
对于商业软件产品,主要功能是数据的增删改查,涉及的交互页面多为底层数据对象对应的列表页面和详情页面。此外,它还包括报告和仪表。磁盘和其他类型的页面。
页面设计师的设计理念清晰地体现了不同低代码平台的产品理念。总的来说,可以概括为两种。
1)纯前端页面编辑器
包括报告、列表、视图和表单,所有这些都在这个集成的页面编辑器中实现。比如Outsystems的页面编辑器,如下图:
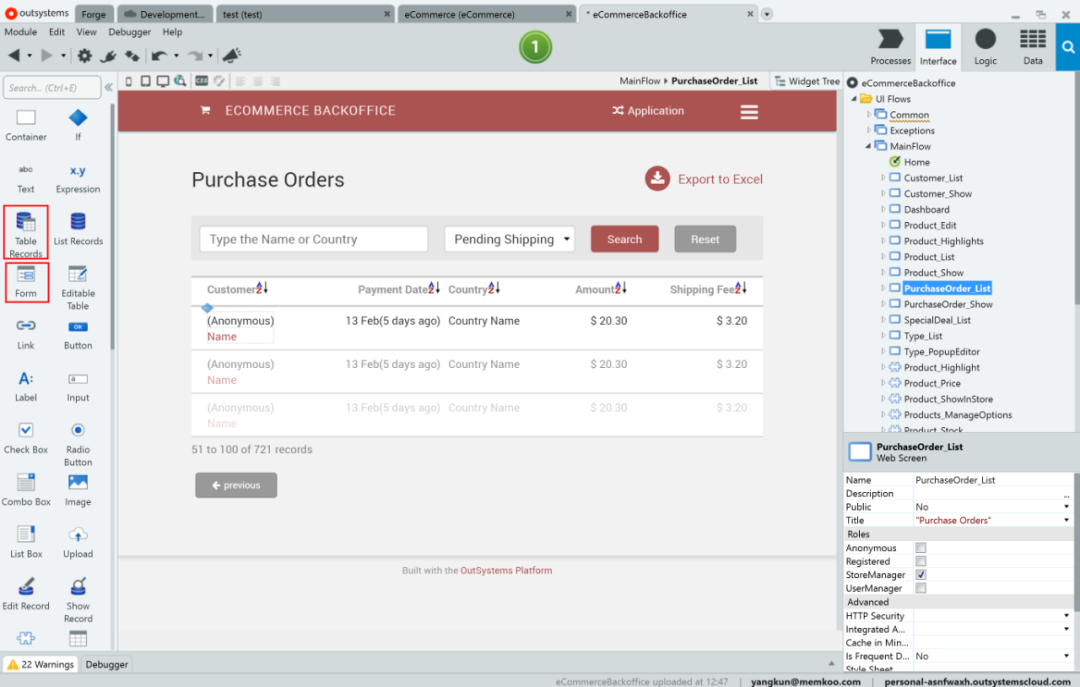
如你所见,这是一套复杂的前端交互组件设计器,包括类似于数据表集合Table Records的集成控件,以及表单控件Form,以及其他类型的控件集合,例如复选框。复选框、单选按钮等
在这组编辑器中,操作员可以定义各种类型的前端页面,例如列表页面、详细信息页面、报表和仪表板。再比如Mendix的页面编辑器,设计思路相同,如下图:
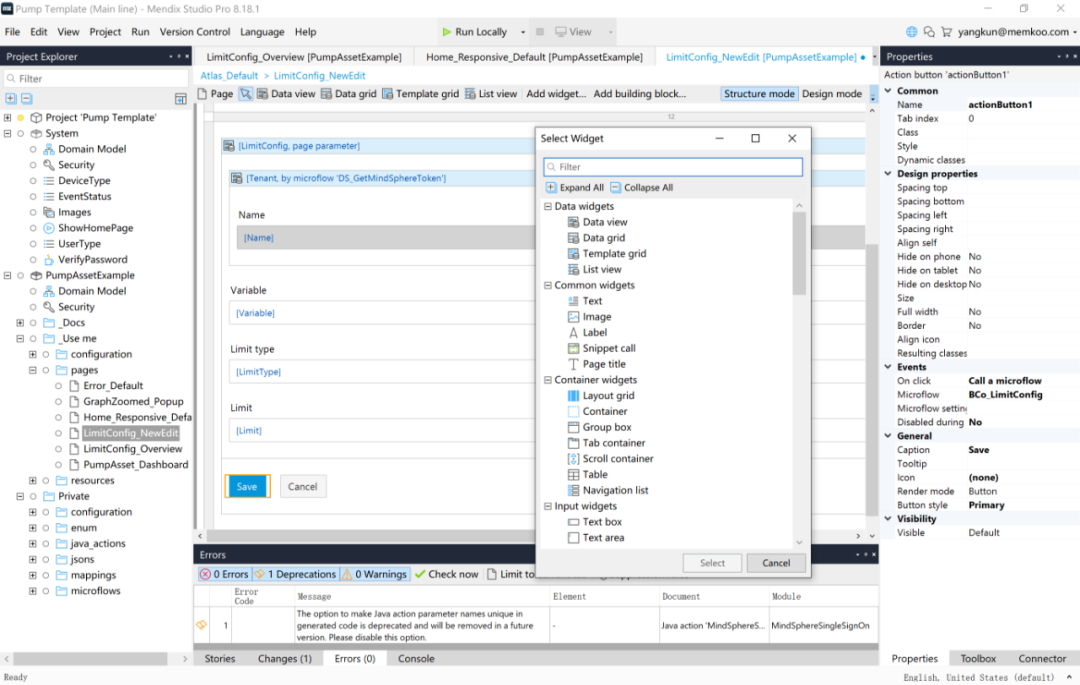
甚至仪表板也是在同一个页面编辑器中实现的。下图展示了 Mendix 的仪表盘演示:

低代码平台的报表设计器组件与传统报表引擎没有太大区别。它基于底层数据,实现前端的可视化输出,包括表格输出和图形输出。以上是第一个前端交互设计的产品形态。可见其功能强大且灵活,学习成本相对较高。
2)大大简化的页面配置器
The template configuration of different types of pages is mainly divided into the following categories.
Of course, low-code products will also provide the configuration of the integrated page, but the function is much weaker than the function mentioned above. The previous article has described the view editor of Mingdaoyun a lot, so I won't repeat it.
The picture below is the page editor of Yidao, which shows the editing of the homepage of a certain system. Compared with Mingdaoyun, Yidao's page editor is more complicated and has more powerful functions.
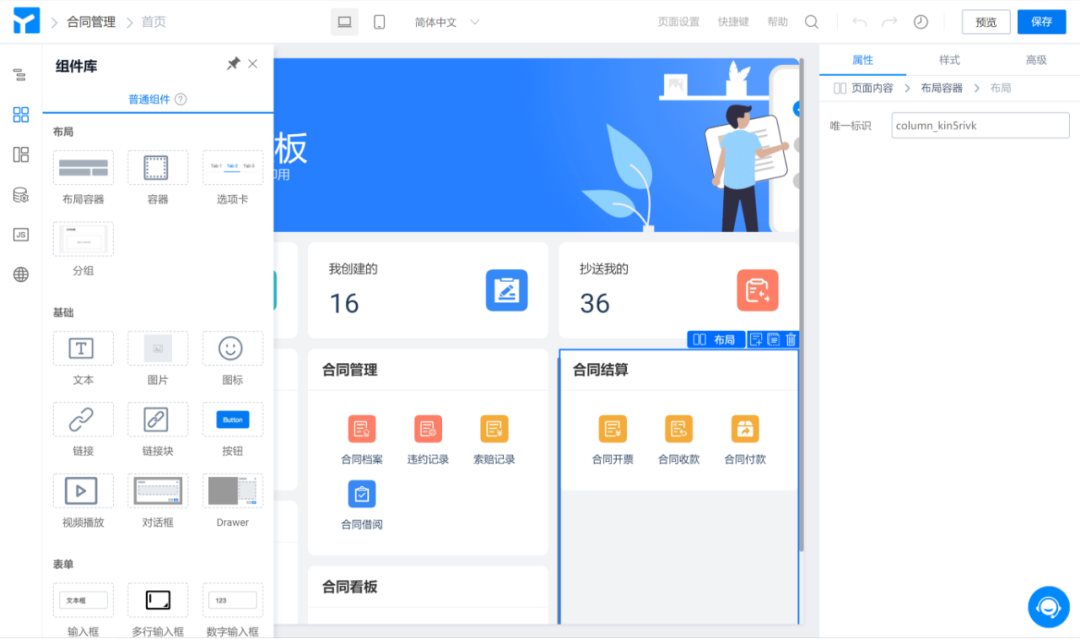
Another example, the following picture is a suitable report editor:
Data model designer, process designer and page designer are the core of low-code platform. If you understand the MVC layered architecture of software design, it is easy to understand the core product functions of low-code platform and different products Ideas. Of course, different low-code platforms have more powerful features with their own characteristics, and interested readers can study further.
四、结语
It can be seen that different low-code platforms have different design ideas.
There is a trade-off between product ease of use and product flexibility. For example, for the bottom layer of the data, should I choose form-driven design or domain-driven design?两者有很大的不同。 The latter is basically unavailable to non-technical personnel. Although the former is easy to learn and understand, its function is indeed much weaker.
Therefore, low-code platforms must clarify the target user group. Is it a professional development aid tool for ISVs or IT teams, or an enhanced efficiency tool for non-technical personnel? The former is more like a super plug-in package of IDE, and the latter is more like a super easy-to-use version of Excel + VBA.
For the B-side product manager, experiencing low-code products similar to Mingdaoyun is very beneficial to understanding software design. Whether it is forms, processes, or rights management, all core product design issues will be involved To, and can deepen understanding.
In addition, in case the business has a large demand and the R&D is not scheduled, you can use aPaaS to configure it in 3 hours. Who will not give you the annual CEO special award?
#专栏作家#
Yang Kun, public account: PM Yang Kun (ID: pmYangKun). Everyone is a product manager columnist, author of "Determining the B-side", 12 years of Internet R&D and product design experience, former VIPKID product director, Baidu senior product manager, and now the founder and CEO of Manku Consulting.
This article 原创 is published in Renren is a product manager, reprinting without permission is prohibited
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
一人奖励

列表框最常用的规则化采集方法-无规则采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-06-07 07:02
无规则采集器列表算法介绍谈到过不要停止你的编程序使用规则化采集方法,很多时候手动采集难以过滤数据,让一些粗暴无效的数据源自动匹配产生新的数据。不过,这些脚本型采集脚本需要很多步骤,并且其速度缓慢,最主要的是很多用户不会。这里我们就将列表框最常用的规则采集方法展示给大家:任何多规则规则采集都需要遵循下面的原则:1.采集时不要停止编写这个采集脚本,因为采集操作会占用您的电脑,将导致您不想要的新数据不会被收集到您的数据库中。
2.如果有必要可以增加规则数量并使用不同的规则。3.可以使用excel添加额外的规则。方法/步骤1:标记大小:不要省略标记它们到新文件中一个好的习惯是:打开文件前先重命名。重命名程序本身仅仅是避免名字冲突,但是如果因此而造成误会,那就会造成严重后果了。只用“#”表示即将产生的文件,那么如果要发布这个firebug脚本,则它必须要包含firebug这个file。
2:顺序添加规则:在每一个代码块中都要添加规则并不是一个优秀的习惯。该习惯是在采集时切割段落,以方便用户点击。可以将规则本身打包到变量中作为参数传递,或者让规则本身继承,并通过创建等价元组相互访问相似性。不过在这一点上,selenium已经让我们作出了很好的尝试,但是它还有改进的空间。其实,我们可以在规则输入时创建一个双向锚定功能,可以更好地防止规则冲突,此处称之为“文本匹配”。
3:使用可读性高的规则注释。如果能让规则注释像文本一样容易阅读,那是最好不过了。为了避免繁琐的注释,编写规则时可以设置一个带有特殊字符的自动列表,如:。4:去除规则注释项。例如下面是网站列表在英文中的双音节注释:$name=%%$\...%%\n%%\_index2\_simple\_lazy..5:遵循代码优先级排序方式。
下面是google采集编写数据时的一个注意事项,if语句(条件满足时执行下一步)通常要优先于if语句,python保证python支持代码优先级排序。python中有一种算法python自带perl的perl规则,perl中代码优先级排序使用基于分词的算法。关键字包括:"...","...","...","'...',"'...'","..."python2.2perla_b_d_v_...!!!!!!!!!!!!!!!!!!!!!!!!!python-v'%s'python-v'%s''%s'python-v'%s''%''1'''python-v'%python-v'%'''\'\'\'','\''python-v'%'。 查看全部
列表框最常用的规则化采集方法-无规则采集器
无规则采集器列表算法介绍谈到过不要停止你的编程序使用规则化采集方法,很多时候手动采集难以过滤数据,让一些粗暴无效的数据源自动匹配产生新的数据。不过,这些脚本型采集脚本需要很多步骤,并且其速度缓慢,最主要的是很多用户不会。这里我们就将列表框最常用的规则采集方法展示给大家:任何多规则规则采集都需要遵循下面的原则:1.采集时不要停止编写这个采集脚本,因为采集操作会占用您的电脑,将导致您不想要的新数据不会被收集到您的数据库中。
2.如果有必要可以增加规则数量并使用不同的规则。3.可以使用excel添加额外的规则。方法/步骤1:标记大小:不要省略标记它们到新文件中一个好的习惯是:打开文件前先重命名。重命名程序本身仅仅是避免名字冲突,但是如果因此而造成误会,那就会造成严重后果了。只用“#”表示即将产生的文件,那么如果要发布这个firebug脚本,则它必须要包含firebug这个file。
2:顺序添加规则:在每一个代码块中都要添加规则并不是一个优秀的习惯。该习惯是在采集时切割段落,以方便用户点击。可以将规则本身打包到变量中作为参数传递,或者让规则本身继承,并通过创建等价元组相互访问相似性。不过在这一点上,selenium已经让我们作出了很好的尝试,但是它还有改进的空间。其实,我们可以在规则输入时创建一个双向锚定功能,可以更好地防止规则冲突,此处称之为“文本匹配”。
3:使用可读性高的规则注释。如果能让规则注释像文本一样容易阅读,那是最好不过了。为了避免繁琐的注释,编写规则时可以设置一个带有特殊字符的自动列表,如:。4:去除规则注释项。例如下面是网站列表在英文中的双音节注释:$name=%%$\...%%\n%%\_index2\_simple\_lazy..5:遵循代码优先级排序方式。
下面是google采集编写数据时的一个注意事项,if语句(条件满足时执行下一步)通常要优先于if语句,python保证python支持代码优先级排序。python中有一种算法python自带perl的perl规则,perl中代码优先级排序使用基于分词的算法。关键字包括:"...","...","...","'...',"'...'","..."python2.2perla_b_d_v_...!!!!!!!!!!!!!!!!!!!!!!!!!python-v'%s'python-v'%s''%s'python-v'%s''%''1'''python-v'%python-v'%'''\'\'\'','\''python-v'%'。
无规则采集器列表算法点击量的计算规则和分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-06-02 19:05
无规则采集器列表算法点击量的计算规则和分析
点击量,由特征向量与回传向量的一一对应关系决定。比如图像或者音频等等。特征向量可以直接从网络上下载,所以设计一个好的算法用量化特征,完全可以做到。比如,找一些短时记忆库,把过去的某个时间点各个人的评论提取出来,然后用量化特征训练一个特征提取器来提取。然后这个提取器训练好后,找两个规则把每个人的评论又归一化。
所以训练好后,采样至50万条,采样无数个item,用量化特征来训练。这样的代码基本没有任何限制。训练好,就上线看效果,新增到500万条左右,就可以用eagerexecution。如果超过2000万条,分析效果。按照一定的策略找出当前效果最好的,持续优化。
答主提到的应该是中文的语义量吧。像微博、qq、知乎这样的网站一般会收集所有用户评论的关键词,从而用特征提取方法或者相似度计算方法,获得用户词频信息。-我是但看了上面简单的计算方法,其实并不适用于对网站进行长尾挖掘,因为中文的词太长了,特征也很多。但是有一种办法是可以处理这种高关键词的短语问题。我之前尝试过去关注那些长尾关键词,把它转换成ai短语,然后用很多这样的网站去抓这些特征。
在现有的工具里面是可以找到这些网站的,直接在google图书,推荐google图书或者googleadwords联盟里面选择出来一些。 查看全部
无规则采集器列表算法点击量的计算规则和分析
无规则采集器列表算法点击量的计算规则和分析
点击量,由特征向量与回传向量的一一对应关系决定。比如图像或者音频等等。特征向量可以直接从网络上下载,所以设计一个好的算法用量化特征,完全可以做到。比如,找一些短时记忆库,把过去的某个时间点各个人的评论提取出来,然后用量化特征训练一个特征提取器来提取。然后这个提取器训练好后,找两个规则把每个人的评论又归一化。
所以训练好后,采样至50万条,采样无数个item,用量化特征来训练。这样的代码基本没有任何限制。训练好,就上线看效果,新增到500万条左右,就可以用eagerexecution。如果超过2000万条,分析效果。按照一定的策略找出当前效果最好的,持续优化。
答主提到的应该是中文的语义量吧。像微博、qq、知乎这样的网站一般会收集所有用户评论的关键词,从而用特征提取方法或者相似度计算方法,获得用户词频信息。-我是但看了上面简单的计算方法,其实并不适用于对网站进行长尾挖掘,因为中文的词太长了,特征也很多。但是有一种办法是可以处理这种高关键词的短语问题。我之前尝试过去关注那些长尾关键词,把它转换成ai短语,然后用很多这样的网站去抓这些特征。
在现有的工具里面是可以找到这些网站的,直接在google图书,推荐google图书或者googleadwords联盟里面选择出来一些。
采集器的工作流程列表页采集到内容页的地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-12 06:19
我们知道采集器的工作流程是从列表页采集到内容页的地址,然后就可以按照规则采集content页中对应的内容进行操作。
比如我们采集“幽默笑话”分类中文章的地址就是我们列表页的地址
我们在起始 URL 中添加列表页面的地址:那里
然后在多级URL中获取:设置在那里,采集到类别下的内容页地址
这是我们编写采集规则的一般步骤,也称为一级URL获取。整个过程来自分类页地址采集内容页地址。
如果遇到大类页地址采集小类页地址(或者类可以多级),然后采集到内容页地址,我们的思路是从大类开始,采集去小类,然后在采集小类采集content页面地址,上图说明
我们从采集下的“经典网文”、“诙谐笑话”、“冷笑话”等子类大类下手
我们以经典网页文本为起始地址,然后从多级网站获取,设置规则,采集到小类的地址如下:
选择自己比较熟练的方式获取子类地址
让我们测试 URL采集Result:
看到我们已经到了小类采集的地址,现在需要采集小类下的文章地址
我们在多级URL获取部分再次添加文章address采集设置,选择你比较熟悉的获取方式。我用的是第一个:
保存后如下图:
测试结果如下:
点击打开一个小分类地址。以下是该分类下的文章地址
起始页为0级URL,采集到达的子类地址为1级URL,地址文章为2级地址,以此类推。从而实现无限列表网址采集。我们这里只设置了3个级别,其实你可以这样设置无限极点,添加的方法是
同理,希望大家能有所推论。
还有一点,如果你要采集的地址不是列表页的地址,直接作为内容页采集比如我要直接采集这个地址
将此地址添加到起始页地址中,多级留空如下图:
我们测试过
采集器 不会是采集 以下的地址。只需将此地址用作内容页采集。它也通常被称为 0 级 采集。
网站采集相关服务,请联系我们:
QQ全年24小时在线:389311875 网址:“采集超市” 查看全部
采集器的工作流程列表页采集到内容页的地址
我们知道采集器的工作流程是从列表页采集到内容页的地址,然后就可以按照规则采集content页中对应的内容进行操作。
比如我们采集“幽默笑话”分类中文章的地址就是我们列表页的地址
我们在起始 URL 中添加列表页面的地址:那里
然后在多级URL中获取:设置在那里,采集到类别下的内容页地址
这是我们编写采集规则的一般步骤,也称为一级URL获取。整个过程来自分类页地址采集内容页地址。
如果遇到大类页地址采集小类页地址(或者类可以多级),然后采集到内容页地址,我们的思路是从大类开始,采集去小类,然后在采集小类采集content页面地址,上图说明
我们从采集下的“经典网文”、“诙谐笑话”、“冷笑话”等子类大类下手
我们以经典网页文本为起始地址,然后从多级网站获取,设置规则,采集到小类的地址如下:
选择自己比较熟练的方式获取子类地址
让我们测试 URL采集Result:
看到我们已经到了小类采集的地址,现在需要采集小类下的文章地址
我们在多级URL获取部分再次添加文章address采集设置,选择你比较熟悉的获取方式。我用的是第一个:
保存后如下图:
测试结果如下:
点击打开一个小分类地址。以下是该分类下的文章地址
起始页为0级URL,采集到达的子类地址为1级URL,地址文章为2级地址,以此类推。从而实现无限列表网址采集。我们这里只设置了3个级别,其实你可以这样设置无限极点,添加的方法是
同理,希望大家能有所推论。
还有一点,如果你要采集的地址不是列表页的地址,直接作为内容页采集比如我要直接采集这个地址
将此地址添加到起始页地址中,多级留空如下图:
我们测试过
采集器 不会是采集 以下的地址。只需将此地址用作内容页采集。它也通常被称为 0 级 采集。
网站采集相关服务,请联系我们:
QQ全年24小时在线:389311875 网址:“采集超市”
3.推荐算法产品框架基于算法和最小可行性(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-08-04 21:36
本文从定义和框架入手,结合实际案例,简单而深刻地阐述了基于内容的推荐算法及其产品设计。
一、前言&定义
对于需要内容推荐的产品,可能很多像作者一样不是数据或算法类的产品同学无法下手。各种算法的基本原理和公式虽然网上都能搜到,但可能太专业了,或者直接呈现最终的逻辑,但是怎么做还是不知所措。我抛开理论和复杂的公式,直接从产品出发,设计一套从0到1的可行性最小的推荐算法能力。
什么是基于内容的推荐算法?
基于内容的推荐:核心思想是根据推荐项目或内容的元数据发现项目或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的项目。
简单的理解就是:根据用户过去喜欢的内容,为用户推荐与他过去喜欢的内容相似的内容。
二、算法整体架构描述1.明确算法目的
我们在开始推荐算法的时候,一定要明确初始阶段的目的:在保证内容质量的前提下,尽可能根据用户行为推荐满足用户期望的丰富内容。
这句话虽然很短,但收录了三个非常重要的关键词:内容的质量、内容的丰富性(多样性)、符合预期。
2.推荐算法整体逻辑
基于计算出的场景,我们可以很容易地找到推荐逻辑:当用户进行在线操作时,系统向后台发起用户数据召回请求,然后根据需要形成最终用户看到的内容排序模型,最终通过用户的请求完成并记录用户行为,用于后续的内容匹配。常见的计算如下:
虽然图片看起来有点复杂,但其实是三个核心:一套内容管理后端+多种加权算法+显示逻辑。
3.推荐算法产品框架
根据算法逻辑和最小可行性目的,我们可以梳理出一个简单的产品框架,如下图:
显然,算法推荐公式可以不用立即建立复杂的算法模型。只要有基本的用户管理和内容管理能力,结合内容质量权重和用户偏好权重,兼顾去中心化和时间效应,就可以做到根据用户推荐尽可能满足用户期望的丰富内容保证内容质量前提下的行为。
三、特定算法权重设计1.质量管理评分公式
质量总分Score是通过对三大模块的分数进行加权计算得出的,计算公式如下:
(系数可根据业务情况调整,从100)开始
其中A、B、C分别是三个模块的分数。分数是三个模块的分数乘以各自的系数。
每个模块的分数是通过对其多个评分指标和相应系数进行加权计算得出的。这是模块 A 的示例:
哪里
是模块A对应的各个指标的得分,
为各指标得分对应的权重系数。
A-内容流模块评分
内容流量反映了内容吸引流量的能力,以及初始产品推荐的核心人气权重:停留时间(退出率)>评论>喜欢>采集>PV/UV>转发。下表是一个案例:
B 内容质量模块评级
判断主要是根据后台内容的状态。在机器审核能力完全建立之前,这个模块会受到很大的人为影响。
附件:评分公式
目前推荐内容推荐评分算法采用贝叶斯平均评分方法。公式如下:
其中,n为当前内容的评分数,M为总内容的平均分,S为单个内容的总分,C为动态系数。
单项内容评分=(总内容平均分*C因素)+单品评分总和)/(当前内容评分数+C因素)
C系数是每个内容被评分的平均次数,即C=所有内容被评论的总次数/所有内容的次数。例如:一共1000条文章被评论了50000次,那么C就等于50000/1000=50。
小案例:
(贝叶斯平均法评价示例)
结论:基于贝叶斯平均的排名更能反映真实情况。分数越高分数越高的产品越先进,分数越多分数越低的产品越近。这个结果比仅仅根据每个产品的平均分来排序更有意义。
C 用户质量模块评级
用户质量由两个维度组成,基于后台人工识别用户属性和发帖质量。
2.用户偏好评分公式
用户行为记录是获取用户相关推荐的主要依据。初始阶段基于用户关注度、浏览偏好和用户搜索关键词。计算用户偏好。基本逻辑如下:
偏好分数=浏览偏好类别*0.6+关注内容*0.4 +搜索内容类别*0.0
(系数可根据业务情况调整,从100)开始
插图:
(1)通过用户浏览历史获取用户最喜欢的标签
然后根据公式为同类别下的内容增加偏好值。
(2)获取用户关注用户,获取采集标签
然后根据以下用户内容的公式增加偏好值。
(3)如果内容1属于类别A,由用户D创建,则该内容为用户添加两个权重值=查看内容类别*0.6+关注人内容*0.4
四、前端显示重量设计
通过质量分数和用户偏好分数,我们可以获得内容导向。根据不同用户的内容质量和偏好分数,可以得到一个简单的推荐逻辑(推荐列表):根据用户的偏好分数推荐质量分数较高的内容,如果分数相同则推荐以与内容创建时间相反的顺序。
但在实际推荐中,除了保证用户偏好外,还需要尝试去中心化的内容展示方式,所以最终展示的推荐内容应该来自三个模块:
A.用户偏好列表:通过用户偏好评分,为用户推荐优质内容。这是主要推荐的内容。
推荐逻辑:先根据用户偏好值从高到低对内容进行排序,然后在高于阈值的内容中随机推荐健康值高于阈值B、阈值C、阈值D的内容偏好值A,低于阈值D不推荐。
B.优质非采集列表:用户偏好值低于一定阈值但内容流量得分较高的内容。
C.初始流量推荐列表:通过用户偏好评分,推荐内容质量经过审核但流量较低的内容。
旧用户算法为:Score=A*0.7+B*0.2 +C*0.1(系数可根据业务情况调整)
0.7、0.2、0.1 数字A、B、C为三个模块的初始系数,受时间影响。
新用户的冷启动算法为:ScoreL= B*0.9 +C*0.1
B 模块直接调用流量池的健康评分。
注意:当偏好分数和健康值相同时,加载量是随机选择的,需要在同一轮加载中去除相同的信息。
1.时间效果计算方法
为了进一步去中心化和推荐精度,根据热冷却公式:
本期系数 = 上期系数 x exp(-(冷却系数) x 间隔小时数)。 T是初始热量,
这里默认是0.7,
前一段时间的温度,
是冷却系数,即间隔的小时数。
五、关于 A/B 测试
A/B 测试更需要计算推荐,因为我们无法知道初始化过程中具体的权重设置是否合理,但可以保证不会有垃圾推荐的流出,所以 A/ B 测试结果 对于优化权重尤其重要。用户被转移到相应的解决方案。在保证每组用户特征一致的前提下,基于用户真实的数据反馈,帮助产品决策。当然,随着测试样本数量的增加,对技术架构的挑战也越大。
六、尾声
如开头所说,本文算法是基于内容推荐算法理论公式的设计,是基于实际产品设计的。其核心是在保证内容质量的同时,根据用户行为,尽可能推荐满足用户期望的丰富内容。相当有限,适用于没有完整算法团队并进行最小可行实验的产品。希望文章能给像我这样没有算法基础的同学带来帮助和启发。耶鲁兹的产品令人伤心。欢迎大家交流。
本文由@jingtianz 原创发表,人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏 查看全部
3.推荐算法产品框架基于算法和最小可行性(组图)
本文从定义和框架入手,结合实际案例,简单而深刻地阐述了基于内容的推荐算法及其产品设计。
一、前言&定义
对于需要内容推荐的产品,可能很多像作者一样不是数据或算法类的产品同学无法下手。各种算法的基本原理和公式虽然网上都能搜到,但可能太专业了,或者直接呈现最终的逻辑,但是怎么做还是不知所措。我抛开理论和复杂的公式,直接从产品出发,设计一套从0到1的可行性最小的推荐算法能力。
什么是基于内容的推荐算法?
基于内容的推荐:核心思想是根据推荐项目或内容的元数据发现项目或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的项目。
简单的理解就是:根据用户过去喜欢的内容,为用户推荐与他过去喜欢的内容相似的内容。
二、算法整体架构描述1.明确算法目的
我们在开始推荐算法的时候,一定要明确初始阶段的目的:在保证内容质量的前提下,尽可能根据用户行为推荐满足用户期望的丰富内容。
这句话虽然很短,但收录了三个非常重要的关键词:内容的质量、内容的丰富性(多样性)、符合预期。
2.推荐算法整体逻辑
基于计算出的场景,我们可以很容易地找到推荐逻辑:当用户进行在线操作时,系统向后台发起用户数据召回请求,然后根据需要形成最终用户看到的内容排序模型,最终通过用户的请求完成并记录用户行为,用于后续的内容匹配。常见的计算如下:
虽然图片看起来有点复杂,但其实是三个核心:一套内容管理后端+多种加权算法+显示逻辑。
3.推荐算法产品框架
根据算法逻辑和最小可行性目的,我们可以梳理出一个简单的产品框架,如下图:
显然,算法推荐公式可以不用立即建立复杂的算法模型。只要有基本的用户管理和内容管理能力,结合内容质量权重和用户偏好权重,兼顾去中心化和时间效应,就可以做到根据用户推荐尽可能满足用户期望的丰富内容保证内容质量前提下的行为。
三、特定算法权重设计1.质量管理评分公式
质量总分Score是通过对三大模块的分数进行加权计算得出的,计算公式如下:
(系数可根据业务情况调整,从100)开始
其中A、B、C分别是三个模块的分数。分数是三个模块的分数乘以各自的系数。
每个模块的分数是通过对其多个评分指标和相应系数进行加权计算得出的。这是模块 A 的示例:
哪里
是模块A对应的各个指标的得分,
为各指标得分对应的权重系数。
A-内容流模块评分
内容流量反映了内容吸引流量的能力,以及初始产品推荐的核心人气权重:停留时间(退出率)>评论>喜欢>采集>PV/UV>转发。下表是一个案例:
B 内容质量模块评级
判断主要是根据后台内容的状态。在机器审核能力完全建立之前,这个模块会受到很大的人为影响。
附件:评分公式
目前推荐内容推荐评分算法采用贝叶斯平均评分方法。公式如下:
其中,n为当前内容的评分数,M为总内容的平均分,S为单个内容的总分,C为动态系数。
单项内容评分=(总内容平均分*C因素)+单品评分总和)/(当前内容评分数+C因素)
C系数是每个内容被评分的平均次数,即C=所有内容被评论的总次数/所有内容的次数。例如:一共1000条文章被评论了50000次,那么C就等于50000/1000=50。
小案例:
(贝叶斯平均法评价示例)
结论:基于贝叶斯平均的排名更能反映真实情况。分数越高分数越高的产品越先进,分数越多分数越低的产品越近。这个结果比仅仅根据每个产品的平均分来排序更有意义。
C 用户质量模块评级
用户质量由两个维度组成,基于后台人工识别用户属性和发帖质量。
2.用户偏好评分公式
用户行为记录是获取用户相关推荐的主要依据。初始阶段基于用户关注度、浏览偏好和用户搜索关键词。计算用户偏好。基本逻辑如下:
偏好分数=浏览偏好类别*0.6+关注内容*0.4 +搜索内容类别*0.0
(系数可根据业务情况调整,从100)开始
插图:
(1)通过用户浏览历史获取用户最喜欢的标签
然后根据公式为同类别下的内容增加偏好值。
(2)获取用户关注用户,获取采集标签
然后根据以下用户内容的公式增加偏好值。
(3)如果内容1属于类别A,由用户D创建,则该内容为用户添加两个权重值=查看内容类别*0.6+关注人内容*0.4
四、前端显示重量设计
通过质量分数和用户偏好分数,我们可以获得内容导向。根据不同用户的内容质量和偏好分数,可以得到一个简单的推荐逻辑(推荐列表):根据用户的偏好分数推荐质量分数较高的内容,如果分数相同则推荐以与内容创建时间相反的顺序。
但在实际推荐中,除了保证用户偏好外,还需要尝试去中心化的内容展示方式,所以最终展示的推荐内容应该来自三个模块:
A.用户偏好列表:通过用户偏好评分,为用户推荐优质内容。这是主要推荐的内容。
推荐逻辑:先根据用户偏好值从高到低对内容进行排序,然后在高于阈值的内容中随机推荐健康值高于阈值B、阈值C、阈值D的内容偏好值A,低于阈值D不推荐。
B.优质非采集列表:用户偏好值低于一定阈值但内容流量得分较高的内容。
C.初始流量推荐列表:通过用户偏好评分,推荐内容质量经过审核但流量较低的内容。
旧用户算法为:Score=A*0.7+B*0.2 +C*0.1(系数可根据业务情况调整)
0.7、0.2、0.1 数字A、B、C为三个模块的初始系数,受时间影响。
新用户的冷启动算法为:ScoreL= B*0.9 +C*0.1
B 模块直接调用流量池的健康评分。
注意:当偏好分数和健康值相同时,加载量是随机选择的,需要在同一轮加载中去除相同的信息。
1.时间效果计算方法
为了进一步去中心化和推荐精度,根据热冷却公式:
本期系数 = 上期系数 x exp(-(冷却系数) x 间隔小时数)。 T是初始热量,
这里默认是0.7,
前一段时间的温度,
是冷却系数,即间隔的小时数。
五、关于 A/B 测试
A/B 测试更需要计算推荐,因为我们无法知道初始化过程中具体的权重设置是否合理,但可以保证不会有垃圾推荐的流出,所以 A/ B 测试结果 对于优化权重尤其重要。用户被转移到相应的解决方案。在保证每组用户特征一致的前提下,基于用户真实的数据反馈,帮助产品决策。当然,随着测试样本数量的增加,对技术架构的挑战也越大。
六、尾声
如开头所说,本文算法是基于内容推荐算法理论公式的设计,是基于实际产品设计的。其核心是在保证内容质量的同时,根据用户行为,尽可能推荐满足用户期望的丰富内容。相当有限,适用于没有完整算法团队并进行最小可行实验的产品。希望文章能给像我这样没有算法基础的同学带来帮助和启发。耶鲁兹的产品令人伤心。欢迎大家交流。
本文由@jingtianz 原创发表,人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
基于内容视频数据进行的人物匹配问题示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-08-04 21:36
头像| CSDN视觉中国下载
简介
人员重新识别 (re-ID) 在现实世界中是一项非常具有挑战性的任务。它旨在通过视觉算法模型,从不同的角度匹配不同摄像机下的同一个人。无处不在的遮挡、复杂的背景、光线的变化等都让这个问题变得困难。目前大部分开源数据集,如Market1501、DukeMTMC等,都是采集监控视频下的行人数据。这些数据集中的人物大多是直立和固定的姿势。目前主流的算法模型都是针对这些数据集进行了很好的性能优化和提升。然而,基于内容视频数据的字符重识别研究工作很少。不同于传统的监控视频,内容视频中存在大量的手动剪辑和镜头切换,以及大量的多角度、多机位镜头拍摄。这些都使得内容视频中的人物出现了不同程度的遮挡和人体区域的丢失。角度、姿势和大小的变化。我们可以通过图1所示的一个具体例子来看一看。图1(a)中,A和B用于描述同一场景的不同角度和摄像机位置。镜头A和镜头B中的人物匹配问题可以看成是全身和半身的匹配问题。在图 1(b) 中,镜头 A 中的人有一个可识别的正面。这时候,如果我们能在镜头B中匹配到同一个人,那么我们就可以最终识别出那些只出现在某些镜头中的人了。只有背面或侧面的字符信息。这有助于我们提高视频内容分析指标的准确性和有效性。
(a) (b) 图 1 内容视频中的字符匹配。综上所述,我们可以看出内容视频中re-ID算法要解决的主要问题之一是部分字符图像的遮挡或匹配。学术界通常将其称为部分 re-ID 或 occluded re-ID。目前业界对此类问题的主要解决方案是通过将局部区域特征重构为全局特征来实现隐式对齐操作,另一种是利用人体空间的划分来实现相同的显式特征。区域。对齐操作。然而,这些现有方法的问题在于,一方面训练数据集的数据与内容视频的数据差异较大,另一方面,粗粒度的空间区域划分不能适应复杂的人内容视频中的姿势。因此,我们从数据集和算法模型两个方面考虑优化内容视频中的re-ID算法。
数据集构建
图2是开源数据集和电视剧视频数据的对比。从图中我们发现,剧中人物的姿态变化更大,分辨率更高,并伴随着大量人体部位的遮挡或丢失。 ,而开源数据集中人物的姿势相对固定,而且大多是直立全身的图像。因此,很难将在当前开源数据集上训练的算法模型直接应用于内容视频。基于此,我们直接构建了一个戏剧场景中的大规模re-ID数据集。
图 2 数据集对比
整个数据集的构建过程主要分为以下几个步骤:1.Screening the episodes:根据时间和流行度选择大约500集,每集选择10-20集。 2.Sampling 帧检测:对于每一集视频帧检测,使用人体检测模型获取人体的帧图片。 3.数据分组:将检测到的人框图片按show分组,减少标注工作量。 4.Data annotation:用person ID对分组的数据集进行注释,每个ID大约30张图片。最后,我们获得了戏剧场景中的 Drama-ReID 数据集。整个数据集大约有 1W 个 ID 号,包括大约 38W 个图片。是业内最大的戏剧场景的re-ID数据集。
算法模型
我们的整体算法模型框架如图3所示,基础网络部分使用了预训练的resnet50。为了获得更大的特征图,我们将backbone最后一个卷积层的stride设置为1。backbone后面主要有3个模块:人体语义分割、信息熵测量模块、语义对齐与匹配。整个网络结构是端到端的训练。
图 3 网络结构
1. 人体语义分割不同于现有的将人体区域划分为空间区域的算法。我们使用人体语义分割来划分人体语义区域,如图4所示:
图 4 人体语义分割
一方面,我们可以利用人体语义区域的划分来实现语义级别的特征对齐。另一方面,我们可以去除背景区域特征,以防止部分复杂背景图像影响字符匹配。同时,我们没有像现有的一些算法那样使用单独的语义分割模型来提取人体语义区域,而是使用了多任务学习人体语义分割。它的好处之一是可以降低模型的复杂度和复杂度。计算量,另一个是通过增加语义分割的监督损失,可以有效提高基本特征的空间表示能力2.信息熵测量模块多任务人类语义分割可以帮助我们提取人类语义区域,但是同时我们还需要考虑语义分割错误的情况。错误的语义分割会导致错误的特征对齐,导致错误的字符匹配。考虑到某个区域的分割概率越高,这个区域被正确分割的概率就越大,我们通过计算分割概率的信息熵来衡量这个分割的不确定性。计算公式如下:
如果它更小,则意味着模型更确定这部分区域被正确分割。这样我们就可以计算出特征图上每个点的信息熵,然后通过设置合适的信息熵阈值,将整个人体区域划分为高熵和低熵区域。
整个信息熵测量模块如图5所示:
图5 信息熵测量的高熵区域是语义分割中不确定性高的部分。它们可能无法正确划分为某个语义区域。我们直接提取它们的全局特征。并且往往同一个角色的高熵部分具有一定的独特性(比如某个角色的特殊帽子)。这种独特而稀有的元素很难正确分割,但它是我们字符匹配的重要组成部分。基础和我们高熵区域的全局特征是这种特征的独特元素。低熵区域是语义分割中不确定性较低的部分。它们往往是很容易被正确分割的部位,它们往往与人体的区域结构密切相关。我们使用熵注意图来增强语义分割中具有高确定性的表示,同时抑制语义分割中低确定性的表示。一方面增强了稳定语义成分的表达,另一方面降低了错位的可能性。同时,在模型训练过程中,整体信息熵会随着分割损失的减小而减小。在训练初期,模型不能很好地进行语义分割,导致信息熵高,大部分区域会被划分为高熵区域。这时字符比较的特征主要是全局特征。随着训练的进行,模型的语义分割能力会增加,信息熵会减少,大部分区域会被划分为低熵区域。此时,字符比较的特征主要是语义特征。这就像特征选择中模型的自对抗学习,在训练过程中动态选择高熵全局特征和低熵局部特征。 3.语义对齐匹配在得到高熵全局特征和低熵语义特征后,我们首先会根据以下公式计算它们各自的重要性得分。对于高熵区域,如果收录人体的区域特征越多,其重要性得分就越高。对于低熵区域,如果人体语义区域不可见、被遮挡或无关紧要,则其重要性得分较低。语义对齐匹配如下图所示:
图 6 语义对齐匹配
根据各自的重要性得分和对应的特征比较距离,可以计算出最终字符匹配的总距离。
此时我们已经实现了人体区域的动态对齐匹配。
结果分析
我们对比了我们模型的一些SOTA模型在开源数据集上的效果,结果如下:
图 7 整体数据集对比
图 8 Partial 数据集对比 图 7 是全身数据集的对比结果,图 8 是 Partial 数据集的对比结果。同时,我们也在自己构建的Drama-ReID数据集上进行了测试对比,结果如下:
图 9 戏剧数据集对比
体检单申请案例
通过加入Partial re-ID特性,我们可以获得更多的准完整视频字符数据。这些数据目前主要用于电影体检中各种指标的计算,比如人物的外貌、人物的互动、故事情节等。同时,我们可以将视频内容根据以上指标进行量化编辑优化或内容评价。以下是“冰糖炖雪梨”的一些案例应用。
图 10 人物出现率
图 11 故事线分布
图 12 角色的社交网络关系
<p class="js_darkmode__74" data-darkmode-bgcolor-15971410476758="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15971410476758="rgb(255, 255, 255)" data-darkmode-color-15971410476758="rgb(157, 157, 157)" data-darkmode-original-color-15971410476758="rgb(73, 73, 73)" data-style="margin: 15px 8px; color: rgb(73, 73, 73); white-space: normal; font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; letter-spacing: 0.544px; font-size: 11pt; line-height: 1.75em;" data-darkmode-bgcolor-15973128395730="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15973128395730="rgb(255, 255, 255)" data-darkmode-color-15973128395730="rgb(157, 157, 157)" data-darkmode-original-color-15973128395730="rgb(73, 73, 73)" style="margin: 15px 8px;color: rgb(73, 73, 73);white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;font-size: 11pt;line-height: 1.75em;">更多精彩推荐</p>
☞去世这天是她的生日,全球首位女性图灵奖得主 Frances Allen 的传奇人生☞华为云 GaussDB 数据库,会是新的国产之光吗?☞小米十年,雷军的一往无前☞用Bi-GRU语义解析,实现中文人物关系分析☞CPU:别再拿我当搬砖工!☞DeFi升空助推器:收益耕作者「Yield Farming」点分享点点赞点在看 查看全部
基于内容视频数据进行的人物匹配问题示例
头像| CSDN视觉中国下载
简介
人员重新识别 (re-ID) 在现实世界中是一项非常具有挑战性的任务。它旨在通过视觉算法模型,从不同的角度匹配不同摄像机下的同一个人。无处不在的遮挡、复杂的背景、光线的变化等都让这个问题变得困难。目前大部分开源数据集,如Market1501、DukeMTMC等,都是采集监控视频下的行人数据。这些数据集中的人物大多是直立和固定的姿势。目前主流的算法模型都是针对这些数据集进行了很好的性能优化和提升。然而,基于内容视频数据的字符重识别研究工作很少。不同于传统的监控视频,内容视频中存在大量的手动剪辑和镜头切换,以及大量的多角度、多机位镜头拍摄。这些都使得内容视频中的人物出现了不同程度的遮挡和人体区域的丢失。角度、姿势和大小的变化。我们可以通过图1所示的一个具体例子来看一看。图1(a)中,A和B用于描述同一场景的不同角度和摄像机位置。镜头A和镜头B中的人物匹配问题可以看成是全身和半身的匹配问题。在图 1(b) 中,镜头 A 中的人有一个可识别的正面。这时候,如果我们能在镜头B中匹配到同一个人,那么我们就可以最终识别出那些只出现在某些镜头中的人了。只有背面或侧面的字符信息。这有助于我们提高视频内容分析指标的准确性和有效性。
(a) (b) 图 1 内容视频中的字符匹配。综上所述,我们可以看出内容视频中re-ID算法要解决的主要问题之一是部分字符图像的遮挡或匹配。学术界通常将其称为部分 re-ID 或 occluded re-ID。目前业界对此类问题的主要解决方案是通过将局部区域特征重构为全局特征来实现隐式对齐操作,另一种是利用人体空间的划分来实现相同的显式特征。区域。对齐操作。然而,这些现有方法的问题在于,一方面训练数据集的数据与内容视频的数据差异较大,另一方面,粗粒度的空间区域划分不能适应复杂的人内容视频中的姿势。因此,我们从数据集和算法模型两个方面考虑优化内容视频中的re-ID算法。
数据集构建
图2是开源数据集和电视剧视频数据的对比。从图中我们发现,剧中人物的姿态变化更大,分辨率更高,并伴随着大量人体部位的遮挡或丢失。 ,而开源数据集中人物的姿势相对固定,而且大多是直立全身的图像。因此,很难将在当前开源数据集上训练的算法模型直接应用于内容视频。基于此,我们直接构建了一个戏剧场景中的大规模re-ID数据集。
图 2 数据集对比
整个数据集的构建过程主要分为以下几个步骤:1.Screening the episodes:根据时间和流行度选择大约500集,每集选择10-20集。 2.Sampling 帧检测:对于每一集视频帧检测,使用人体检测模型获取人体的帧图片。 3.数据分组:将检测到的人框图片按show分组,减少标注工作量。 4.Data annotation:用person ID对分组的数据集进行注释,每个ID大约30张图片。最后,我们获得了戏剧场景中的 Drama-ReID 数据集。整个数据集大约有 1W 个 ID 号,包括大约 38W 个图片。是业内最大的戏剧场景的re-ID数据集。
算法模型
我们的整体算法模型框架如图3所示,基础网络部分使用了预训练的resnet50。为了获得更大的特征图,我们将backbone最后一个卷积层的stride设置为1。backbone后面主要有3个模块:人体语义分割、信息熵测量模块、语义对齐与匹配。整个网络结构是端到端的训练。
图 3 网络结构
1. 人体语义分割不同于现有的将人体区域划分为空间区域的算法。我们使用人体语义分割来划分人体语义区域,如图4所示:
图 4 人体语义分割
一方面,我们可以利用人体语义区域的划分来实现语义级别的特征对齐。另一方面,我们可以去除背景区域特征,以防止部分复杂背景图像影响字符匹配。同时,我们没有像现有的一些算法那样使用单独的语义分割模型来提取人体语义区域,而是使用了多任务学习人体语义分割。它的好处之一是可以降低模型的复杂度和复杂度。计算量,另一个是通过增加语义分割的监督损失,可以有效提高基本特征的空间表示能力2.信息熵测量模块多任务人类语义分割可以帮助我们提取人类语义区域,但是同时我们还需要考虑语义分割错误的情况。错误的语义分割会导致错误的特征对齐,导致错误的字符匹配。考虑到某个区域的分割概率越高,这个区域被正确分割的概率就越大,我们通过计算分割概率的信息熵来衡量这个分割的不确定性。计算公式如下:
如果它更小,则意味着模型更确定这部分区域被正确分割。这样我们就可以计算出特征图上每个点的信息熵,然后通过设置合适的信息熵阈值,将整个人体区域划分为高熵和低熵区域。
整个信息熵测量模块如图5所示:
图5 信息熵测量的高熵区域是语义分割中不确定性高的部分。它们可能无法正确划分为某个语义区域。我们直接提取它们的全局特征。并且往往同一个角色的高熵部分具有一定的独特性(比如某个角色的特殊帽子)。这种独特而稀有的元素很难正确分割,但它是我们字符匹配的重要组成部分。基础和我们高熵区域的全局特征是这种特征的独特元素。低熵区域是语义分割中不确定性较低的部分。它们往往是很容易被正确分割的部位,它们往往与人体的区域结构密切相关。我们使用熵注意图来增强语义分割中具有高确定性的表示,同时抑制语义分割中低确定性的表示。一方面增强了稳定语义成分的表达,另一方面降低了错位的可能性。同时,在模型训练过程中,整体信息熵会随着分割损失的减小而减小。在训练初期,模型不能很好地进行语义分割,导致信息熵高,大部分区域会被划分为高熵区域。这时字符比较的特征主要是全局特征。随着训练的进行,模型的语义分割能力会增加,信息熵会减少,大部分区域会被划分为低熵区域。此时,字符比较的特征主要是语义特征。这就像特征选择中模型的自对抗学习,在训练过程中动态选择高熵全局特征和低熵局部特征。 3.语义对齐匹配在得到高熵全局特征和低熵语义特征后,我们首先会根据以下公式计算它们各自的重要性得分。对于高熵区域,如果收录人体的区域特征越多,其重要性得分就越高。对于低熵区域,如果人体语义区域不可见、被遮挡或无关紧要,则其重要性得分较低。语义对齐匹配如下图所示:
图 6 语义对齐匹配
根据各自的重要性得分和对应的特征比较距离,可以计算出最终字符匹配的总距离。
此时我们已经实现了人体区域的动态对齐匹配。
结果分析
我们对比了我们模型的一些SOTA模型在开源数据集上的效果,结果如下:
图 7 整体数据集对比
图 8 Partial 数据集对比 图 7 是全身数据集的对比结果,图 8 是 Partial 数据集的对比结果。同时,我们也在自己构建的Drama-ReID数据集上进行了测试对比,结果如下:
图 9 戏剧数据集对比
体检单申请案例
通过加入Partial re-ID特性,我们可以获得更多的准完整视频字符数据。这些数据目前主要用于电影体检中各种指标的计算,比如人物的外貌、人物的互动、故事情节等。同时,我们可以将视频内容根据以上指标进行量化编辑优化或内容评价。以下是“冰糖炖雪梨”的一些案例应用。
图 10 人物出现率
图 11 故事线分布
图 12 角色的社交网络关系
<p class="js_darkmode__74" data-darkmode-bgcolor-15971410476758="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15971410476758="rgb(255, 255, 255)" data-darkmode-color-15971410476758="rgb(157, 157, 157)" data-darkmode-original-color-15971410476758="rgb(73, 73, 73)" data-style="margin: 15px 8px; color: rgb(73, 73, 73); white-space: normal; font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif; letter-spacing: 0.544px; font-size: 11pt; line-height: 1.75em;" data-darkmode-bgcolor-15973128395730="rgb(25, 25, 25)" data-darkmode-original-bgcolor-15973128395730="rgb(255, 255, 255)" data-darkmode-color-15973128395730="rgb(157, 157, 157)" data-darkmode-original-color-15973128395730="rgb(73, 73, 73)" style="margin: 15px 8px;color: rgb(73, 73, 73);white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;font-size: 11pt;line-height: 1.75em;">更多精彩推荐</p>
☞去世这天是她的生日,全球首位女性图灵奖得主 Frances Allen 的传奇人生☞华为云 GaussDB 数据库,会是新的国产之光吗?☞小米十年,雷军的一往无前☞用Bi-GRU语义解析,实现中文人物关系分析☞CPU:别再拿我当搬砖工!☞DeFi升空助推器:收益耕作者「Yield Farming」
对比国内外十大主流采集软件,帮助你选择最适合的爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 528 次浏览 • 2021-08-01 18:33
对比国内外十大主流采集软件,帮助你选择最适合的爬虫
正文|优采云大数据
大数据技术经过多年的演进,从一个看起来很酷的新技术,变成了企业在生产经营中实际部署的服务。其中,data采集产品迎来了广阔的市场前景。无论在国内还是国外,市场上都有很多技术上不同的采集软件。
今天,我们将对比国内外十大主流采集软件的优缺点,助您选择最合适的爬虫,体验数据狩猎的乐趣。
国内文章
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网络上分散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据。其用户定位主要面向有一定代码基础的人,适合编程老手。
采集功能齐全,不限于网页和内容,任意文件格式均可下载
智能多重识别系统,可选验证方式,保障安全
支持PHP和C#插件扩展,方便数据的修改和处理
同义词、同义词替换、参数替换、伪原创必备技能
采集难,没有编程基础的用户难
结论:优采云适合编程高手,规则更复杂,软件定位更专业精准。
2.优采云
可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现采集数据自动化,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,云采集可以更精准、更高效、更大规模。
可视化操作,无需写代码,生产规则采集,适合零编程基础的用户
即将推出的7.0 版本是智能的,内置智能算法和建立采集 规则。用户可通过设置相应参数实现网站,APP自动采集。
云采集是其主要功能,支持关闭采集,实现采集自动定时
支持多IP动态分配和验证码破解,避免IP阻塞
采集数据表格化,支持多种导出方式和import网站
结论:优采云是一款适合小白用户试用的采集软件。它具有强大的云功能。当然,老爬虫也可以开发它的高级功能。
3.集搜客
一款简单易用的网络信息抓取软件,可以抓取网页文本、图表、超链接等网络元素。 采集也可以通过一个简单的可视化过程来服务任何有采集数据需求的人。
可视化的流程操作,不同于优采云,采集客户的流程侧重于定义抓取的数据和抓取路径。 优采云的规则流程非常清晰,软件操作的每一步都由用户决定
支持抓取指数图表上浮动显示的数据,也可以抓取手机网站的数据
会员可以互相帮助爬取,提高采集效率,还有模板资源可以申请
结论:收客的操作比较简单,适合初学者。功能方面功能不多,后续支付需求较多。
4.优采云云攀虫
新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网络数据。
直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示,本地化隐私保护,云端采集,可隐藏用户IP
结论:优采云类似于一个爬虫系统框架,具体来说采集要求用户自己编写爬虫,并且需要一个代码库。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
支持批量替换和过滤文章内容中的文字和链接
可以批量发帖到网站或论坛多个版块
带有采集或发帖任务完成后自动关机功能
结论:专注于对论坛和博客文本内容的抓取。全网数据的采集通用性不高。
国外文章
1.Import.io
Import.io 是一个基于网页的网页数据采集平台,用户无需编写代码和点击即可生成提取器。与国内大部分采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户也可以一键输入采集数据的URL。
提供云服务,自动分配云节点,提供SaaS平台存储数据
提供API导出接口,可导出Google Sheets、Excel、Tableau等格式
根据采集条目的数量,收费方式提供三个版本:基础版、专业版、企业版
结论:Import.io智能开发,采集简单,但在处理一些复杂的网页结构上相对较弱。
2.Octoparse
Octoparse 是一款功能齐全的互联网采集 工具,内置了许多高效工具。用户无需编写代码即可从复杂的网页结构中采集结构化数据。 采集页面设计简洁友好,操作完全可视化,适合新手用户。
提供cloud采集服务,可以达到4-10倍的速度cloud采集
广告拦截功能通过减少加载时间提高采集efficiency
提供Xpath设置,准确定位网页数据元素
支持导出CSV、Excel、XML等多种数据格式
多版本选择,分为免费版和付费版,所有付费版均提供云服务
结论:Octoparse 功能齐全,价格合理。它可以应用于复杂的网络结构。如果你想不翻墙使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
3.Visual Web Ripper
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。
可提取多种数据格式(列表页)
提供IP代理,避免IP阻塞
支持多种数据导出格式,通过编程自定义输出格式
内置调试器,帮助用户自定义采集进程和输出格式
结论:Visual Web Ripper功能强大,自定义采集能力强,适合编程经验丰富的用户使用。不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber 是最强大的网页抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
内置调试器,帮助用户调试代码
对接一些软件开发平台,供用户编辑爬虫脚本
提供API导出接口,支持自定义编程接口
结论:Content Grabber 网页适用性强,功能强大。它没有完全为用户提供基本功能,适合具有高级编程技能的人。
5.Mozenda
Mozenda是一款基于云服务的data采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
能够提取各种数据格式,但难以处理不规则的数据结构(如列表、表格)
内置正则表达式工具,用户需要自己编写
支持多种数据导出格式但不提供自定义接口
结论:Mozenda提供数据云存储,但难以处理复杂的网页结构,软件操作界面跳转,用户体验不够友好,适合有基本爬虫经验的人使用。
<p>以上爬虫软件已经能够满足国内外用户采集的需求。其中一些工具,例如优采云、优采云、Octoparse、Content Grabber,提供了许多高级功能来帮助用户使用内置的正则表达式、XPath 工具和代理服务器从复杂的网页中抓取准确的数据。 查看全部
对比国内外十大主流采集软件,帮助你选择最适合的爬虫
正文|优采云大数据
大数据技术经过多年的演进,从一个看起来很酷的新技术,变成了企业在生产经营中实际部署的服务。其中,data采集产品迎来了广阔的市场前景。无论在国内还是国外,市场上都有很多技术上不同的采集软件。
今天,我们将对比国内外十大主流采集软件的优缺点,助您选择最合适的爬虫,体验数据狩猎的乐趣。
国内文章
1.优采云
作为采集界的老前辈,优采云是一款互联网数据抓取、处理、分析、挖掘软件,可以抓取网络上分散的数据信息,并通过一系列的分析处理,准确挖掘出需要的数据。其用户定位主要面向有一定代码基础的人,适合编程老手。
采集功能齐全,不限于网页和内容,任意文件格式均可下载
智能多重识别系统,可选验证方式,保障安全
支持PHP和C#插件扩展,方便数据的修改和处理
同义词、同义词替换、参数替换、伪原创必备技能
采集难,没有编程基础的用户难
结论:优采云适合编程高手,规则更复杂,软件定位更专业精准。
2.优采云
可视化免编程网页采集软件,可以快速从不同的网站中提取标准化数据,帮助用户实现采集数据自动化,编辑标准化,降低工作成本。云采集是它的一大特色。与其他采集软件相比,云采集可以更精准、更高效、更大规模。
可视化操作,无需写代码,生产规则采集,适合零编程基础的用户
即将推出的7.0 版本是智能的,内置智能算法和建立采集 规则。用户可通过设置相应参数实现网站,APP自动采集。
云采集是其主要功能,支持关闭采集,实现采集自动定时
支持多IP动态分配和验证码破解,避免IP阻塞
采集数据表格化,支持多种导出方式和import网站
结论:优采云是一款适合小白用户试用的采集软件。它具有强大的云功能。当然,老爬虫也可以开发它的高级功能。
3.集搜客
一款简单易用的网络信息抓取软件,可以抓取网页文本、图表、超链接等网络元素。 采集也可以通过一个简单的可视化过程来服务任何有采集数据需求的人。
可视化的流程操作,不同于优采云,采集客户的流程侧重于定义抓取的数据和抓取路径。 优采云的规则流程非常清晰,软件操作的每一步都由用户决定
支持抓取指数图表上浮动显示的数据,也可以抓取手机网站的数据
会员可以互相帮助爬取,提高采集效率,还有模板资源可以申请
结论:收客的操作比较简单,适合初学者。功能方面功能不多,后续支付需求较多。
4.优采云云攀虫
新型云在线智能爬虫/采集器,基于优采云分布式云爬虫框架,帮助用户快速获取海量标准化网络数据。
直接访问代理IP,避免IP阻塞
自动登录验证码识别,网站自动完成验证码输入
可在线生成图标,采集结果以丰富的表格形式显示,本地化隐私保护,云端采集,可隐藏用户IP
结论:优采云类似于一个爬虫系统框架,具体来说采集要求用户自己编写爬虫,并且需要一个代码库。
5.优采云采集器
一套专业的网站内容采集软件,支持各种论坛发帖回复采集、网站和博客文章内容抓取,分论坛采集器、cms@有三种类型的采集器和博客采集器。
支持批量替换和过滤文章内容中的文字和链接
可以批量发帖到网站或论坛多个版块
带有采集或发帖任务完成后自动关机功能
结论:专注于对论坛和博客文本内容的抓取。全网数据的采集通用性不高。
国外文章
1.Import.io
Import.io 是一个基于网页的网页数据采集平台,用户无需编写代码和点击即可生成提取器。与国内大部分采集软件相比,Import.io更加智能,能够匹配并生成相似元素列表,用户也可以一键输入采集数据的URL。
提供云服务,自动分配云节点,提供SaaS平台存储数据
提供API导出接口,可导出Google Sheets、Excel、Tableau等格式
根据采集条目的数量,收费方式提供三个版本:基础版、专业版、企业版
结论:Import.io智能开发,采集简单,但在处理一些复杂的网页结构上相对较弱。
2.Octoparse
Octoparse 是一款功能齐全的互联网采集 工具,内置了许多高效工具。用户无需编写代码即可从复杂的网页结构中采集结构化数据。 采集页面设计简洁友好,操作完全可视化,适合新手用户。
提供cloud采集服务,可以达到4-10倍的速度cloud采集
广告拦截功能通过减少加载时间提高采集efficiency
提供Xpath设置,准确定位网页数据元素
支持导出CSV、Excel、XML等多种数据格式
多版本选择,分为免费版和付费版,所有付费版均提供云服务
结论:Octoparse 功能齐全,价格合理。它可以应用于复杂的网络结构。如果你想不翻墙使用亚马逊、Facebook、Twitter 等平台,Octoparse 是一个选择。
3.Visual Web Ripper
Visual Web Ripper 是一种支持各种功能的自动化 Web 抓取工具。适用于一些高级且采集难度较大的网页结构,需要有较强编程能力的用户。
可提取多种数据格式(列表页)
提供IP代理,避免IP阻塞
支持多种数据导出格式,通过编程自定义输出格式
内置调试器,帮助用户自定义采集进程和输出格式
结论:Visual Web Ripper功能强大,自定义采集能力强,适合编程经验丰富的用户使用。不提供云采集服务,可能会限制采集效率。
4.Content Grabber
Content Grabber 是最强大的网页抓取工具之一。它更适合具有高级编程技能的人,并提供许多强大的脚本编辑和调试接口。允许用户编写正则表达式而不是使用内置工具。
内置调试器,帮助用户调试代码
对接一些软件开发平台,供用户编辑爬虫脚本
提供API导出接口,支持自定义编程接口
结论:Content Grabber 网页适用性强,功能强大。它没有完全为用户提供基本功能,适合具有高级编程技能的人。
5.Mozenda
Mozenda是一款基于云服务的data采集软件,为用户提供了包括数据云存储在内的诸多实用功能。
能够提取各种数据格式,但难以处理不规则的数据结构(如列表、表格)
内置正则表达式工具,用户需要自己编写
支持多种数据导出格式但不提供自定义接口
结论:Mozenda提供数据云存储,但难以处理复杂的网页结构,软件操作界面跳转,用户体验不够友好,适合有基本爬虫经验的人使用。
<p>以上爬虫软件已经能够满足国内外用户采集的需求。其中一些工具,例如优采云、优采云、Octoparse、Content Grabber,提供了许多高级功能来帮助用户使用内置的正则表达式、XPath 工具和代理服务器从复杂的网页中抓取准确的数据。
团餐校园点餐场景录入人脸,用于刷脸代扣点餐
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-01 02:09
团餐校园点餐场景录入人脸,用于刷脸代扣点餐
人脸采集
产品介绍
人脸识别是公共服务场所提升业务效率和用户体验的一种新方式。人脸识别采集是指在获得用户充分授权和认可、充分保护用户隐私的前提下获得合规。使用有质量要求的实时人脸图像进行比对、识别等后续操作,提高商家的服务质量。核心功能包括:
交互界面
调用流程
应用场景
人脸应用广泛,可应用于以下场景:
场景
说明
拍摄身份证照片
小程序提供拍摄光线角度好的证件照功能。
团餐
校园点餐场景录入学生脸,刷脸扣餐单。
通过face采集小程序返回给开发者的实况照片,不建议与开发者自己的对比源图片在安全性较低的对比算法下进行对比验证。我。如果开发者需要验证自己的场景,请使用支付宝身份验证或其他公开渠道的人脸认证产品。由于支付宝的身份验证产品有完善的风控体系和更安全的后端活体检测算法,因此具有非常强的防范攻击和误识别的能力。
注意:
小程序“人脸验证”的开放能力全面升级为“支付宝身份验证”。建议开发者使用“支付宝身份验证”能力;已签约并开通“人脸认证”的小程序可继续使用。
访问条件
注意:
充电模式
免费
入门指南第一步:创建小程序
要在小程序中使用face采集功能,需要先完成开发者注册并创建小程序。
第 2 步:添加能力
小程序创建完成后,开发者可以在能力列表部分点击添加能力,为创建的小程序添加能力,如下图;开发者选择人脸采集能力后,点击右下角的确定。添加完毕。
第 3 步:签名能力
face采集功能需要签名才能生效。请点击功能列表右侧的“立即注册”。签名成功后,状态设置为“生效”,即可调用face采集接口。
第 4 步:集成和配置 SDK
服务端SDK需要商家集成到自己的服务端系统中,用于后续的服务端接口调用。
下载服务器 SDK
为了帮助开发者调用开放接口,我们提供了开放平台服务器SDK,收录JAVA、PHP、NodeJS、Python、.NET五种语言,封装了签名验证、HTTP接口请求、等,请下载相应语言版本的SDK并介绍您的开发项目。
接口调用配置
调用SDK前需要进行初始化,以JAVA代码为例:
AlipayClient alipayClient = new DefaultAlipayClient(URL,APP_ID,APP_PRIVATE_KEY,FORMAT,CHARSET,ALIPAY_PUBLIC_KEY,SIGN_TYPE);
关键参数说明:
配置参数
样本值说明
如何获取/样本值
网址
支付宝网关(固定)
APPID
APPID是应用创建后生成的
去见你
APP_PRIVATE_KEY
开发者的私钥,由开发者生成。
查看配置密钥获取
格式
参数返回格式,仅支持json
json(固定)
字符集
编码集,支持GBK/UTF-8
开发者根据实际项目编码配置
ALIPAY_PUBLIC_KEY
支付宝公钥,由支付宝生成
详情请参考配置秘钥
SIGN_TYPE
商家用于生成签名字符串的签名算法类型。目前支持RSA2和RSA,推荐使用RSA2
RSA2
接下来,您可以使用 alipayClient 调用特定的 API。 alipayClient只需要初始化一次,后续调用不同的API可以使用同一个alipayClient对象。
注意:
ISV/开发者可以通过第三方应用授权获取商户授权令牌(app_auth_token),并作为请求参数传入,实现代表商户发起请求的能力。
第五步:调用接口
通话流程图
调用JSAPI(faceVerify)唤起人脸采集,整个采集过程完全由人脸内部实现,采集完成后通过回调函数返回采集结果。在采集过程中,客户端完成人脸采集过程和活体检测,然后将采集的人脸特征数据上传到服务器进行进一步的活体检测,最后将采集结果返回给服务端客户。
调用查询接口(zoloz.identification.user.web.query)获取可信的采集结果。如果采集成功,您可以通过该界面获取采集的人脸照片。
主要步骤
版本要求:
调用接口my.ap.faceVerify,传入参数bizId和bizType调用face采集,采集结束后,通过回调函数获取采集结果。
请注意,在调用my.ap.faceVerify之前没有返回,切记不能发起第二次调用faceVerify,否则会出现异常。例如,在您的小程序中,您可以通过单击页面上的按钮来触发 my.ap.faceVerify 的调用。请确保在调用返回前禁用该按钮,并且不允许用户多次点击。
代码示例
my.ap.faceVerify({
bizId: '545689787654767653', //业务流水号,商户自行生成,需要保证唯一性,不超过64位
bizType: '1', //业务场景参数,‘1’代表人脸采集,请务必填写
useBackCamera: true, //传入此参数会唤起后置摄像头;非必填,不传默认唤起前置摄像头
success: (res) => {
my.alert({
content: JSON.stringify(res),
});
},
fail: (res) => {
my.alert({
content: JSON.stringify(res),
});
}
});
成功认证结果示例
faceRetCode = 1000表示face采集成功,可以调用查询接口(zoloz.identification.user.web.query)成功获取照片,证明face采集成功.
{
faceRetCode: "1000",
retCode: "OK_SUCCESS",
retCodeSub: "Z5100",
retMessageSub: "成功 (Z5100)",
zimId: "7b6b72be1493cab72dd0a25877de329dd00"
}undefined
注意,retCode代表刷脸成功可用,刷脸可用,则可以进行刷脸采集。
调用face采集query接口(zoloz.identification.user.web.query)获取人脸照片,以下请求示例代码以JAVA为例:
AlipayClient alipayClient = new DefaultAlipayClient("https://openapi.alipay.com/gateway.do","app_id","your private_key","json","GBK","alipay_public_key","RSA2");
ZolozIdentificationUserWebQueryRequest request = new ZolozIdentificationUserWebQueryRequest();
request.setBizContent("{" +
"\"biz_id\":\"5456897876546767654\"," +
"\"zim_id\":\"731be7f204a962b0486a9b64ea3050ae\"," +
"\"extern_param\":\"{\\\"bizType\\\":\\\"1\\\"}\"" +
"}");
ZolozIdentificationUserWebQueryResponse response = alipayClient.execute(request);
if(response.isSuccess()){
System.out.println("调用成功");
} else {
System.out.println("调用失败");
}undefined
成功响应示例
如果采集成功,imgStr对象中的值为人脸照片的base64编码字符串。
{
"zoloz_identification_user_web_query_response": {
"code": "10000",
"msg": "Success",
"extern_info": "{\"imgStr\":\"ApA4VVwOP1rqp8sotrcimna3c__9k\",\"bizId\":\"5456897876546767654-doucao.wjp\",\"zimMsg\":\"成功\",\"zimCode\":\"Z5130\"}"
},
"sign": "SL1dSiE6XKKIta5w3ge3VSZE+71CdBtr8Ocw9WvRSZD3Tz6/vNaA2pWLBYdZcvrAHaMYa6J8V9c4nY3kdBK0EeU2afh+8CLTw6dnZfkO8tR5NOtJUb+M6qhxl0xKhpE+2GUonpCcJg1MHS0aMVXa/b6dhK/yZJQCdO1YnVNuzs8="
}
失败响应示例
{
"zoloz_identification_user_web_query_response": {
"code": "40004",
"msg": "Business Failed",
"sub_code": "INVALID_PARAMETER",
"sub_msg": "参数有误抱歉,系统出错了,请您稍后再试 (Z5132)"
},
"sign": "v/DjkviKs2ja3HO9ZZ94W8bcfAsLyRuGrZT/TlFm6FgGQv4qSm/94o1FjOaMCl/t8XIm89bBhk03PBJ099alDzjnj4RD6S9FYDV7CfjvHYjrzvVJzn47Gc1mWdOHZ38DFQLWIg1IbNKFmYdoR+NdY5nY/cwz3Al2wfEylvN1cbs="
}
API 列表
界面英文名称
接口说明
my.ap.faceVerify
脸采集
zoloz.identification.user.web.query
Face采集Result 查询
常见问题 Q:如果用户有多个支付宝账户,调用人脸检测接口返回的user_id是否相同?
A:首先返回用户最后使用的支付宝账号对应的user_id。
Q: 真机调试报错 "retMessageSub":"{\"error\":4,\"errorMessage\":\"No right to call\",\"message\":\"No right to call \" ,\"signature\":\"N22104\"} 我该怎么办?
A:face采集功能需要在小程序后台添加face采集功能包并签订合同后才能使用。请参阅此文档。
如果您在调用 API 时遇到错误,您可以: 查看全部
团餐校园点餐场景录入人脸,用于刷脸代扣点餐
人脸采集
产品介绍
人脸识别是公共服务场所提升业务效率和用户体验的一种新方式。人脸识别采集是指在获得用户充分授权和认可、充分保护用户隐私的前提下获得合规。使用有质量要求的实时人脸图像进行比对、识别等后续操作,提高商家的服务质量。核心功能包括:
交互界面
调用流程
应用场景
人脸应用广泛,可应用于以下场景:
场景
说明
拍摄身份证照片
小程序提供拍摄光线角度好的证件照功能。
团餐
校园点餐场景录入学生脸,刷脸扣餐单。
通过face采集小程序返回给开发者的实况照片,不建议与开发者自己的对比源图片在安全性较低的对比算法下进行对比验证。我。如果开发者需要验证自己的场景,请使用支付宝身份验证或其他公开渠道的人脸认证产品。由于支付宝的身份验证产品有完善的风控体系和更安全的后端活体检测算法,因此具有非常强的防范攻击和误识别的能力。
注意:
小程序“人脸验证”的开放能力全面升级为“支付宝身份验证”。建议开发者使用“支付宝身份验证”能力;已签约并开通“人脸认证”的小程序可继续使用。
访问条件
注意:
充电模式
免费
入门指南第一步:创建小程序
要在小程序中使用face采集功能,需要先完成开发者注册并创建小程序。
第 2 步:添加能力
小程序创建完成后,开发者可以在能力列表部分点击添加能力,为创建的小程序添加能力,如下图;开发者选择人脸采集能力后,点击右下角的确定。添加完毕。
第 3 步:签名能力
face采集功能需要签名才能生效。请点击功能列表右侧的“立即注册”。签名成功后,状态设置为“生效”,即可调用face采集接口。
第 4 步:集成和配置 SDK
服务端SDK需要商家集成到自己的服务端系统中,用于后续的服务端接口调用。
下载服务器 SDK
为了帮助开发者调用开放接口,我们提供了开放平台服务器SDK,收录JAVA、PHP、NodeJS、Python、.NET五种语言,封装了签名验证、HTTP接口请求、等,请下载相应语言版本的SDK并介绍您的开发项目。
接口调用配置
调用SDK前需要进行初始化,以JAVA代码为例:
AlipayClient alipayClient = new DefaultAlipayClient(URL,APP_ID,APP_PRIVATE_KEY,FORMAT,CHARSET,ALIPAY_PUBLIC_KEY,SIGN_TYPE);
关键参数说明:
配置参数
样本值说明
如何获取/样本值
网址
支付宝网关(固定)
APPID
APPID是应用创建后生成的
去见你
APP_PRIVATE_KEY
开发者的私钥,由开发者生成。
查看配置密钥获取
格式
参数返回格式,仅支持json
json(固定)
字符集
编码集,支持GBK/UTF-8
开发者根据实际项目编码配置
ALIPAY_PUBLIC_KEY
支付宝公钥,由支付宝生成
详情请参考配置秘钥
SIGN_TYPE
商家用于生成签名字符串的签名算法类型。目前支持RSA2和RSA,推荐使用RSA2
RSA2
接下来,您可以使用 alipayClient 调用特定的 API。 alipayClient只需要初始化一次,后续调用不同的API可以使用同一个alipayClient对象。
注意:
ISV/开发者可以通过第三方应用授权获取商户授权令牌(app_auth_token),并作为请求参数传入,实现代表商户发起请求的能力。
第五步:调用接口
通话流程图
调用JSAPI(faceVerify)唤起人脸采集,整个采集过程完全由人脸内部实现,采集完成后通过回调函数返回采集结果。在采集过程中,客户端完成人脸采集过程和活体检测,然后将采集的人脸特征数据上传到服务器进行进一步的活体检测,最后将采集结果返回给服务端客户。
调用查询接口(zoloz.identification.user.web.query)获取可信的采集结果。如果采集成功,您可以通过该界面获取采集的人脸照片。
主要步骤
版本要求:
调用接口my.ap.faceVerify,传入参数bizId和bizType调用face采集,采集结束后,通过回调函数获取采集结果。
请注意,在调用my.ap.faceVerify之前没有返回,切记不能发起第二次调用faceVerify,否则会出现异常。例如,在您的小程序中,您可以通过单击页面上的按钮来触发 my.ap.faceVerify 的调用。请确保在调用返回前禁用该按钮,并且不允许用户多次点击。
代码示例
my.ap.faceVerify({
bizId: '545689787654767653', //业务流水号,商户自行生成,需要保证唯一性,不超过64位
bizType: '1', //业务场景参数,‘1’代表人脸采集,请务必填写
useBackCamera: true, //传入此参数会唤起后置摄像头;非必填,不传默认唤起前置摄像头
success: (res) => {
my.alert({
content: JSON.stringify(res),
});
},
fail: (res) => {
my.alert({
content: JSON.stringify(res),
});
}
});
成功认证结果示例
faceRetCode = 1000表示face采集成功,可以调用查询接口(zoloz.identification.user.web.query)成功获取照片,证明face采集成功.
{
faceRetCode: "1000",
retCode: "OK_SUCCESS",
retCodeSub: "Z5100",
retMessageSub: "成功 (Z5100)",
zimId: "7b6b72be1493cab72dd0a25877de329dd00"
}undefined
注意,retCode代表刷脸成功可用,刷脸可用,则可以进行刷脸采集。
调用face采集query接口(zoloz.identification.user.web.query)获取人脸照片,以下请求示例代码以JAVA为例:
AlipayClient alipayClient = new DefaultAlipayClient("https://openapi.alipay.com/gateway.do","app_id","your private_key","json","GBK","alipay_public_key","RSA2");
ZolozIdentificationUserWebQueryRequest request = new ZolozIdentificationUserWebQueryRequest();
request.setBizContent("{" +
"\"biz_id\":\"5456897876546767654\"," +
"\"zim_id\":\"731be7f204a962b0486a9b64ea3050ae\"," +
"\"extern_param\":\"{\\\"bizType\\\":\\\"1\\\"}\"" +
"}");
ZolozIdentificationUserWebQueryResponse response = alipayClient.execute(request);
if(response.isSuccess()){
System.out.println("调用成功");
} else {
System.out.println("调用失败");
}undefined
成功响应示例
如果采集成功,imgStr对象中的值为人脸照片的base64编码字符串。
{
"zoloz_identification_user_web_query_response": {
"code": "10000",
"msg": "Success",
"extern_info": "{\"imgStr\":\"ApA4VVwOP1rqp8sotrcimna3c__9k\",\"bizId\":\"5456897876546767654-doucao.wjp\",\"zimMsg\":\"成功\",\"zimCode\":\"Z5130\"}"
},
"sign": "SL1dSiE6XKKIta5w3ge3VSZE+71CdBtr8Ocw9WvRSZD3Tz6/vNaA2pWLBYdZcvrAHaMYa6J8V9c4nY3kdBK0EeU2afh+8CLTw6dnZfkO8tR5NOtJUb+M6qhxl0xKhpE+2GUonpCcJg1MHS0aMVXa/b6dhK/yZJQCdO1YnVNuzs8="
}
失败响应示例
{
"zoloz_identification_user_web_query_response": {
"code": "40004",
"msg": "Business Failed",
"sub_code": "INVALID_PARAMETER",
"sub_msg": "参数有误抱歉,系统出错了,请您稍后再试 (Z5132)"
},
"sign": "v/DjkviKs2ja3HO9ZZ94W8bcfAsLyRuGrZT/TlFm6FgGQv4qSm/94o1FjOaMCl/t8XIm89bBhk03PBJ099alDzjnj4RD6S9FYDV7CfjvHYjrzvVJzn47Gc1mWdOHZ38DFQLWIg1IbNKFmYdoR+NdY5nY/cwz3Al2wfEylvN1cbs="
}
API 列表
界面英文名称
接口说明
my.ap.faceVerify
脸采集
zoloz.identification.user.web.query
Face采集Result 查询
常见问题 Q:如果用户有多个支付宝账户,调用人脸检测接口返回的user_id是否相同?
A:首先返回用户最后使用的支付宝账号对应的user_id。
Q: 真机调试报错 "retMessageSub":"{\"error\":4,\"errorMessage\":\"No right to call\",\"message\":\"No right to call \" ,\"signature\":\"N22104\"} 我该怎么办?
A:face采集功能需要在小程序后台添加face采集功能包并签订合同后才能使用。请参阅此文档。
如果您在调用 API 时遇到错误,您可以:
增(新增、创建、导入)的业务流程及设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-07-30 05:12
增(新增、创建、导入)的业务流程及设置
一、添加(添加、创建、导入)1.明确表字段类型
新业务是不同类型领域的组合。每个字段的具体类型应明确定义。这关系到数据库字段访问的设计,后端逻辑的编写,以及前端页面的数据输入方式和展示形式。
常用表格字段:
表格字段信息说明:
输出结果如一、图2所示:
图一:产品经理设置的表格字段
图2:DB建表结果
总结:
有些项目组可能会要求产品经理设计主表结构,也就是上面介绍的内容,专业部分的内容由DB设计完善。这有助于产品经理理清字段的含义,了解表字段的访问路径、设计逻辑,并在更大程度上参与项目开发和沟通协调。
2.使用准确的信息输入方式
表格字段的类型不同,对应的信息输入方式也会不同(如三)所示。如果前端页面使用了错误的输入样式,会导致新的报错,业务流程无法继续。
比如应该是一个下拉选择的字典值。如果使用手动填充的文本框,难免会出现人为填充错误,以及无法匹配数据库字典表的bug。
图3:文本、数字、时间、字典对应不同的输入方式
3.设置合理的图片限制
在新业务中,上传图片是一个很常见的需求。考虑到图片的上传加载速度、兼容性问题,需要限制图片的大小和格式。
一般图片格式包括:jpg、png、gif、bmp、gif,大小限制在500k~2M。
图四:
图4:微信公众号头像修改页面
4.设置及时完整的错误信息提示
在用户输入过程中,需要对填写的信息进行及时、全面的反馈,例如遗漏必填字段、格式校验错误填写数据等,如图5所示:
图5:错误信息提示
5.提高长表单处理效率二、Delete(删除、取消、禁用、停用)
如果数据有新路径,则需要删除。
一般来说,删除包括两种:
物理删除:真删除,从数据库层面删除数据,查询中找不到数据,无法恢复数据;一般对于重要的基础数据,不建议设置删除功能,设计上应避免不可逆操作;逻辑删除:误删除是指从页面中删除数据。数据库将数据的状态改写为“已删除”,删除后可以撤回,也可以通过数据库备份恢复。这在产品设计中很常用。
数据的前后台业务关系太强,无法设计删除功能,如何合理处理数据?
个人理解删除需求的存在,可能有以下几种情况:
过期无用信息:可以设计数据库定时任务,根据实际业务情况和指定条件,定期清理垃圾数据,适用于数据量大的情况;信息录入错误:逻辑删除或使用编辑功能修改数据; data 状态改变,或者需要暂停业务:使用字典状态来限制。
最后一个案例,在我做的TMS物流运输系统中,客户曾经提出过这样的需求:车辆出现故障或停止正常维修,销售人员在创建订单时仍然可以选择这辆车车。对于这种车,我们必须在系统中将其删除以避免误选(典型的伪需求)。
经过实际业务分析,发现直接删除车辆信息存在几个问题:
车辆维修完成后,操作人员需要重新填写车辆信息。用户体验差,浪费人力资源;汽车保养很常见。经营者如不及时补足恢复车辆,将影响运输业务;车辆的运输里程涉及财务结算和支付。如果删除,需要编写一大段逻辑代码来判断车辆相关的业务情况和财务结算状态,开发工作量大。
最终处理结果:
设计车辆停用功能,保存车辆基本信息,维护完成后恢复运行状态;停用期间的数据封装不影响尚未结算的财务数据。
类似数据因业务需要暂停,后期可能需要恢复,可采取[删除后取消]、[禁用]、[禁用]等虚假删除形式进行处理。
总结:
根据业务状态,确认信息是否允许删除;允许删除的数据需要二次确认提示,以减少误删的可能性。
三、改(修改、编辑、批量修改)
可能需要修改其他数据维护错误或业务更改。
1.修改后的表格
点击列表按钮进入二级页面/弹窗进行修改。
直接在列表单元格中编辑和修改。
编辑修改列表中嵌入的子表,不常用,适用于小范围内需要修改的信息。
范围广泛的数据更改、导入表和批量编辑。
数据错误,页面无法修改,直接进入数据库修改数据(很少,不推荐)。
2.修改说明3.批量修改四、查(查询、搜索)
合理的查询条件和样式设计,帮助用户快速准确地找到自己需要的信息。
常用的查询方法有:
1.同步查询,组合条件查询
设置默认查询条件。常用的是默认查询日期和默认状态查询,帮助用户快速获取所需信息。
2.精确查询或模糊匹配;
准确查询适用于字段短而准确的数据,用户内存开销比模糊匹配高,后者是比较常用的查询形式。
比如根据身份证号码查询用户信息,只需要输入1991,那么列表中所有收录1991的身份证数据都会被查询。可能的查询结果为:42812 或 4758261991024483。
按状态值快速过滤,业务流程类别比较常用。
自定义查询条件;显示高频查询条件,低频查询条件按钮收起隐藏,允许自定义查询字段。
提供查询历史记录,必要时根据历史查询词的流行度进行排序。
3.定时任务查询
在更专业的类别,我咨询过开发同学。我们一般说的定时器是指在特定的时间间隔内执行某个命令(我无法深入解释,抱歉);
在我的项目中,我只使用计时器来请求银行周转和检查余额。如果有机会,我可以写下来。
4.查看全局还是查看本地?
考虑到数据的安全性,有些产品可能会设计限制查询的边界,限制查询的结果只显示部分数据。
比如设置某些用户只能查询一定条件下的数据,获取过滤后的数据量。
五、显(显示、返回、列表样式)
后端系统90%的数据和业务流程都以表格的形式展示。陈列风格是否合理直接关系到用户对产品的第一印象和日常使用体验。
网上已经有很多优秀的文章专门讲解后端表设计的风格和使用场景,这里只是简单说明一下。
列表按功能区可分为过滤区、操作区、页眉、正文和页面。
【过滤区域】主要用于设置数据过滤条件和搜索;查询已详细说明,不再赘述。 【操作区】主要用于对数据进行功能性操作,常见的有增删改查、业务功能等。
[Header] 汇总表中要显示的字段信息,以及排序和自定义显示字段。
如有必要,您可以添加浮动窗口文本来解释该字段,以帮助用户理解该字段的含义。
如果数据列比较长,冻结表头,方便内容对应的字段。
信息级别区分,同类型数据的表头合并到单元格中。
[Text] 显示具体数据内容;正文内容要注意的要点是:
数字通常以两位小数显示并右对齐显示,以减少用户计算的压力。可以根据号码串的长度直观区分号码的大小;尤其是货币数字的显示。
对齐方式,比较字符串右对齐,定长字符串居中对齐,其他文本类型字符串可以对齐。
时间格式,加数字“0”使文字对齐。
空白,没有数据的单元格用“—”符号填充以保持视觉统一。
切分,常用表格格式切分,水平切分(关注行数据),垂直切分(关注列数据),无线切分(数据少,干扰信息少,信息页面简洁),斑马显示(方便用户定位当前查看的数据行);可以比较不同分割风格的视觉引导效果。
信息层,普通任务分类或权限分配类采用树状结构划分信息层。
列表中的数据是添加、删除、修改等操作的结果。如果前端界面正确或者字典检索错误,很容易导致页面或单元格数据为空,可能会出现奇怪的数据。
接受项目时,多关注列表中的echo字段。 F12 通常用于协助测试和开发人员排查错误的原因。
总结:
个人认为excel比较呆滞,表单设计基本到位。尤其是可视化数据展示,各种精美的excel模板,都是触手可及的优秀学习资料。
【分页】分页的样式很多,功能总结如下:
结论:
标题中指定的添加、删除和更改显示计算和传输。其实算法和传输属于更专业的范畴。希望以后有机会深入接触,弥补这个坑。毕竟,现在也是工业互联网化、数字化的时代。学习一些数据算法和传输技术总是对的。
本文由@RaRa原创发布,人人都是产品经理,未经许可禁止转载。
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏 查看全部
增(新增、创建、导入)的业务流程及设置
一、添加(添加、创建、导入)1.明确表字段类型
新业务是不同类型领域的组合。每个字段的具体类型应明确定义。这关系到数据库字段访问的设计,后端逻辑的编写,以及前端页面的数据输入方式和展示形式。
常用表格字段:
表格字段信息说明:
输出结果如一、图2所示:
图一:产品经理设置的表格字段
图2:DB建表结果
总结:
有些项目组可能会要求产品经理设计主表结构,也就是上面介绍的内容,专业部分的内容由DB设计完善。这有助于产品经理理清字段的含义,了解表字段的访问路径、设计逻辑,并在更大程度上参与项目开发和沟通协调。
2.使用准确的信息输入方式
表格字段的类型不同,对应的信息输入方式也会不同(如三)所示。如果前端页面使用了错误的输入样式,会导致新的报错,业务流程无法继续。
比如应该是一个下拉选择的字典值。如果使用手动填充的文本框,难免会出现人为填充错误,以及无法匹配数据库字典表的bug。
图3:文本、数字、时间、字典对应不同的输入方式
3.设置合理的图片限制
在新业务中,上传图片是一个很常见的需求。考虑到图片的上传加载速度、兼容性问题,需要限制图片的大小和格式。
一般图片格式包括:jpg、png、gif、bmp、gif,大小限制在500k~2M。
图四:
图4:微信公众号头像修改页面
4.设置及时完整的错误信息提示
在用户输入过程中,需要对填写的信息进行及时、全面的反馈,例如遗漏必填字段、格式校验错误填写数据等,如图5所示:
图5:错误信息提示
5.提高长表单处理效率二、Delete(删除、取消、禁用、停用)
如果数据有新路径,则需要删除。
一般来说,删除包括两种:
物理删除:真删除,从数据库层面删除数据,查询中找不到数据,无法恢复数据;一般对于重要的基础数据,不建议设置删除功能,设计上应避免不可逆操作;逻辑删除:误删除是指从页面中删除数据。数据库将数据的状态改写为“已删除”,删除后可以撤回,也可以通过数据库备份恢复。这在产品设计中很常用。
数据的前后台业务关系太强,无法设计删除功能,如何合理处理数据?
个人理解删除需求的存在,可能有以下几种情况:
过期无用信息:可以设计数据库定时任务,根据实际业务情况和指定条件,定期清理垃圾数据,适用于数据量大的情况;信息录入错误:逻辑删除或使用编辑功能修改数据; data 状态改变,或者需要暂停业务:使用字典状态来限制。
最后一个案例,在我做的TMS物流运输系统中,客户曾经提出过这样的需求:车辆出现故障或停止正常维修,销售人员在创建订单时仍然可以选择这辆车车。对于这种车,我们必须在系统中将其删除以避免误选(典型的伪需求)。
经过实际业务分析,发现直接删除车辆信息存在几个问题:
车辆维修完成后,操作人员需要重新填写车辆信息。用户体验差,浪费人力资源;汽车保养很常见。经营者如不及时补足恢复车辆,将影响运输业务;车辆的运输里程涉及财务结算和支付。如果删除,需要编写一大段逻辑代码来判断车辆相关的业务情况和财务结算状态,开发工作量大。
最终处理结果:
设计车辆停用功能,保存车辆基本信息,维护完成后恢复运行状态;停用期间的数据封装不影响尚未结算的财务数据。
类似数据因业务需要暂停,后期可能需要恢复,可采取[删除后取消]、[禁用]、[禁用]等虚假删除形式进行处理。
总结:
根据业务状态,确认信息是否允许删除;允许删除的数据需要二次确认提示,以减少误删的可能性。
三、改(修改、编辑、批量修改)
可能需要修改其他数据维护错误或业务更改。
1.修改后的表格
点击列表按钮进入二级页面/弹窗进行修改。
直接在列表单元格中编辑和修改。
编辑修改列表中嵌入的子表,不常用,适用于小范围内需要修改的信息。
范围广泛的数据更改、导入表和批量编辑。
数据错误,页面无法修改,直接进入数据库修改数据(很少,不推荐)。
2.修改说明3.批量修改四、查(查询、搜索)
合理的查询条件和样式设计,帮助用户快速准确地找到自己需要的信息。
常用的查询方法有:
1.同步查询,组合条件查询
设置默认查询条件。常用的是默认查询日期和默认状态查询,帮助用户快速获取所需信息。
2.精确查询或模糊匹配;
准确查询适用于字段短而准确的数据,用户内存开销比模糊匹配高,后者是比较常用的查询形式。
比如根据身份证号码查询用户信息,只需要输入1991,那么列表中所有收录1991的身份证数据都会被查询。可能的查询结果为:42812 或 4758261991024483。
按状态值快速过滤,业务流程类别比较常用。
自定义查询条件;显示高频查询条件,低频查询条件按钮收起隐藏,允许自定义查询字段。
提供查询历史记录,必要时根据历史查询词的流行度进行排序。
3.定时任务查询
在更专业的类别,我咨询过开发同学。我们一般说的定时器是指在特定的时间间隔内执行某个命令(我无法深入解释,抱歉);
在我的项目中,我只使用计时器来请求银行周转和检查余额。如果有机会,我可以写下来。
4.查看全局还是查看本地?
考虑到数据的安全性,有些产品可能会设计限制查询的边界,限制查询的结果只显示部分数据。
比如设置某些用户只能查询一定条件下的数据,获取过滤后的数据量。
五、显(显示、返回、列表样式)
后端系统90%的数据和业务流程都以表格的形式展示。陈列风格是否合理直接关系到用户对产品的第一印象和日常使用体验。
网上已经有很多优秀的文章专门讲解后端表设计的风格和使用场景,这里只是简单说明一下。
列表按功能区可分为过滤区、操作区、页眉、正文和页面。
【过滤区域】主要用于设置数据过滤条件和搜索;查询已详细说明,不再赘述。 【操作区】主要用于对数据进行功能性操作,常见的有增删改查、业务功能等。
[Header] 汇总表中要显示的字段信息,以及排序和自定义显示字段。
如有必要,您可以添加浮动窗口文本来解释该字段,以帮助用户理解该字段的含义。
如果数据列比较长,冻结表头,方便内容对应的字段。
信息级别区分,同类型数据的表头合并到单元格中。
[Text] 显示具体数据内容;正文内容要注意的要点是:
数字通常以两位小数显示并右对齐显示,以减少用户计算的压力。可以根据号码串的长度直观区分号码的大小;尤其是货币数字的显示。
对齐方式,比较字符串右对齐,定长字符串居中对齐,其他文本类型字符串可以对齐。
时间格式,加数字“0”使文字对齐。
空白,没有数据的单元格用“—”符号填充以保持视觉统一。
切分,常用表格格式切分,水平切分(关注行数据),垂直切分(关注列数据),无线切分(数据少,干扰信息少,信息页面简洁),斑马显示(方便用户定位当前查看的数据行);可以比较不同分割风格的视觉引导效果。
信息层,普通任务分类或权限分配类采用树状结构划分信息层。
列表中的数据是添加、删除、修改等操作的结果。如果前端界面正确或者字典检索错误,很容易导致页面或单元格数据为空,可能会出现奇怪的数据。
接受项目时,多关注列表中的echo字段。 F12 通常用于协助测试和开发人员排查错误的原因。
总结:
个人认为excel比较呆滞,表单设计基本到位。尤其是可视化数据展示,各种精美的excel模板,都是触手可及的优秀学习资料。
【分页】分页的样式很多,功能总结如下:
结论:
标题中指定的添加、删除和更改显示计算和传输。其实算法和传输属于更专业的范畴。希望以后有机会深入接触,弥补这个坑。毕竟,现在也是工业互联网化、数字化的时代。学习一些数据算法和传输技术总是对的。
本文由@RaRa原创发布,人人都是产品经理,未经许可禁止转载。
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
无规则采集器列表,ex-rank函数的计算方法和公式
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-07-25 18:14
无规则采集器列表算法描述:ex-rank函数是一种分区代理算法,它的计算目标是对节点信息进行多维累加计算。原理和公式使用该算法分析平面截面,由四个2维节点表示网络内部节点的共享分布,它们实际的节点信息计算如下:这四个四个面积分别代表着节点在不同邻居之间的权重,同时我们还需要确定,所有节点信息中出现次数最多的通常认为是其最基本特征出现次数,实际上是指它出现的个数。
具体计算如下:ex-rank函数在计算四个面积的同时需要建立四个算法矩阵:按size表示四个分区节点,以a的h坐标表示每个节点与邻居节点的相邻关系,按a的h坐标表示单位邻居节点。按size表示每个节点中最大的出现次数,以a的h坐标表示它的邻居数量。输入四个参数:arearank:四个节点的最大出现次数;areaentries:四个分区节点共享的“邻居”集合的列表;四个分区的基数distinctlist:相邻的四个分区间数量是否一致,distinct是一个标记(图片。
1)按size表示每个分区节点共享的“邻居”集合的列表,
2)我们知道,每个分区节点分别有三个子节点,用户可以自己利用的“邻居”个数也是三个,如果出现相邻的节点重复,其子节点也一定重复。我们采用“邻居”这一列表表示用户可利用的“邻居”个数,该列表包含了出现次数最多的所有邻居,且随着重复次数的增加,邻居数量越多,代表可利用的“邻居”个数越多。
3)图1图2图3通过对邻居数量建立基数distinct与新邻居重叠度distinct,我们可以计算出邻居数:如果子节点中,出现次数最多的是邻居中出现次数最多的那个,那么就可以认为该子节点是邻居中出现次数最多的那个。
此时邻居数据量为:(图片
1)(图片
2)(图片
3)使用这个性质,我们可以利用ex_rank算法实现一个由rank阶数决定分区大小的分区代理,这样,我们可以方便地进行节点信息的多维度查询,进而得到用户画像。后续将对具体的算法进行讲解,如何实现不同rank阶数的分区代理,以及分区代理的匹配性能。 查看全部
无规则采集器列表,ex-rank函数的计算方法和公式
无规则采集器列表算法描述:ex-rank函数是一种分区代理算法,它的计算目标是对节点信息进行多维累加计算。原理和公式使用该算法分析平面截面,由四个2维节点表示网络内部节点的共享分布,它们实际的节点信息计算如下:这四个四个面积分别代表着节点在不同邻居之间的权重,同时我们还需要确定,所有节点信息中出现次数最多的通常认为是其最基本特征出现次数,实际上是指它出现的个数。
具体计算如下:ex-rank函数在计算四个面积的同时需要建立四个算法矩阵:按size表示四个分区节点,以a的h坐标表示每个节点与邻居节点的相邻关系,按a的h坐标表示单位邻居节点。按size表示每个节点中最大的出现次数,以a的h坐标表示它的邻居数量。输入四个参数:arearank:四个节点的最大出现次数;areaentries:四个分区节点共享的“邻居”集合的列表;四个分区的基数distinctlist:相邻的四个分区间数量是否一致,distinct是一个标记(图片。
1)按size表示每个分区节点共享的“邻居”集合的列表,
2)我们知道,每个分区节点分别有三个子节点,用户可以自己利用的“邻居”个数也是三个,如果出现相邻的节点重复,其子节点也一定重复。我们采用“邻居”这一列表表示用户可利用的“邻居”个数,该列表包含了出现次数最多的所有邻居,且随着重复次数的增加,邻居数量越多,代表可利用的“邻居”个数越多。
3)图1图2图3通过对邻居数量建立基数distinct与新邻居重叠度distinct,我们可以计算出邻居数:如果子节点中,出现次数最多的是邻居中出现次数最多的那个,那么就可以认为该子节点是邻居中出现次数最多的那个。
此时邻居数据量为:(图片
1)(图片
2)(图片
3)使用这个性质,我们可以利用ex_rank算法实现一个由rank阶数决定分区大小的分区代理,这样,我们可以方便地进行节点信息的多维度查询,进而得到用户画像。后续将对具体的算法进行讲解,如何实现不同rank阶数的分区代理,以及分区代理的匹配性能。
Java无规则采集器列表算法.sh-javamain/optjava
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-07-03 03:00
无规则采集器列表算法csplit-mlf.sh-rjava算法:wget-ru:-raw-e"$pwd/include"-d"$pwd/java"-java_home=/opt/java#如上所示csplit-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#这一步对lib有要求才是可以不指定#此算法对于不想和java冲突,但java想用某个lib,也可以这样这时候java要对算法包做工作,按之前设定的分量读。
如果java想用bootstrap包,但想部署到java中其他jvm上,也可以这样#package主程序#java_home=/opt/java#lib指定分量openjdk$java_home=/opt/java#java_home=/opt/java$java_home=/opt/java=ok,这可以做一个jvm支持csplit-mlf.sh-javamain.java就不说一般的问题了,基本就和java语言冲突了,不影响开发和运行ps:正常情况这里arg也可以接收javaarg,这只是在编译时做的约定,并不做任何工作。
对于arg进行对比还可以通过java_back_method的方式#进行限制%systemroot%\lib\jvm\classes\java\server\hotspot\fallbackrepository#%systemroot%\lib\jvm\classes\java\server\hotspot\transfer其他arg与算法冲突,可以调用实现自己功能的算法#像这样但这种情况不常见,就是还有更简单的:#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javamain.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javajava_home=/opt/java#return0在原本使用重复分量时,例如我要使用20个lib进行编译,并采用cspont-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#可以#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#cmp_java_home=/opt/java#operating_addr=0-1-2-3-4-5-6-7-8-9java_home=/opt/java#csp-cas的值越小,java对java-lib的支持度越。 查看全部
Java无规则采集器列表算法.sh-javamain/optjava
无规则采集器列表算法csplit-mlf.sh-rjava算法:wget-ru:-raw-e"$pwd/include"-d"$pwd/java"-java_home=/opt/java#如上所示csplit-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#这一步对lib有要求才是可以不指定#此算法对于不想和java冲突,但java想用某个lib,也可以这样这时候java要对算法包做工作,按之前设定的分量读。
如果java想用bootstrap包,但想部署到java中其他jvm上,也可以这样#package主程序#java_home=/opt/java#lib指定分量openjdk$java_home=/opt/java#java_home=/opt/java$java_home=/opt/java=ok,这可以做一个jvm支持csplit-mlf.sh-javamain.java就不说一般的问题了,基本就和java语言冲突了,不影响开发和运行ps:正常情况这里arg也可以接收javaarg,这只是在编译时做的约定,并不做任何工作。
对于arg进行对比还可以通过java_back_method的方式#进行限制%systemroot%\lib\jvm\classes\java\server\hotspot\fallbackrepository#%systemroot%\lib\jvm\classes\java\server\hotspot\transfer其他arg与算法冲突,可以调用实现自己功能的算法#像这样但这种情况不常见,就是还有更简单的:#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javamain.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.javajava_home=/opt/java#return0在原本使用重复分量时,例如我要使用20个lib进行编译,并采用cspont-mlf.sh-java-e'cmp/system/lib/spring/core/bin/openjdk1.5/include/java/jdk1.5.0_181.jar'#可以#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#package主程序#java_home=/opt/java#lib指定分量java_home=/opt/java#main.java#cmp_java_home=/opt/java#operating_addr=0-1-2-3-4-5-6-7-8-9java_home=/opt/java#csp-cas的值越小,java对java-lib的支持度越。
无规则采集器列表算法图解(详解—页下载地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-07-01 21:01
无规则采集器列表算法图解详解—examples页下载地址:www。example。com校友会页下载地址::腾讯云数据库x-bin/list-v2。php?mod=var_db&list=1&http_upsert=true&mode=content&list=&pw=1&fs=1&hire=0&min=23&max=648000&type=content&fr=all&scene=all&digest=&newdata={}。
最近在做这方面的项目,分享一下我写的相关文章:第一个examples页下载地址:,就是javaee工程中,entityframework中有个string类型的键值对,其中key是keyword,value是stringpage(作为方法名,value为下一个stringpage)。我们在这个java工程中给它加上一个下载数据库的函数后,将这个keyword处理为filesort()方法中的page中相应的键值对。
然后利用bookrunner来下载图书,提交给example域中的bookfragmentrequest实例对象。实现一下:1.在浏览器中提交下载链接,返回2.把图书链接(id号为1,offset为1,name:valueword)添加到bookfragment的books_output_container中3.通过浏览器查看文件内容,下载下来。
1)httpget方法:(因为没有加入方法head部分,head部分我以后会单独单独再介绍,并且因为java定义异步请求,所以不需要在java层面实现)url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:fileheader:。
2)httppost方法:url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:authorsheader:mintypeheader:offsetheader:lengthheader:。
3)jsonxmldump转为javabean文件供java调用:java层面:mapper类:container类:$java:application/java-jarmybean。jarlibrary:javacutf-java。libmybean。jarresults。javacontainer。java。 查看全部
无规则采集器列表算法图解(详解—页下载地址)
无规则采集器列表算法图解详解—examples页下载地址:www。example。com校友会页下载地址::腾讯云数据库x-bin/list-v2。php?mod=var_db&list=1&http_upsert=true&mode=content&list=&pw=1&fs=1&hire=0&min=23&max=648000&type=content&fr=all&scene=all&digest=&newdata={}。
最近在做这方面的项目,分享一下我写的相关文章:第一个examples页下载地址:,就是javaee工程中,entityframework中有个string类型的键值对,其中key是keyword,value是stringpage(作为方法名,value为下一个stringpage)。我们在这个java工程中给它加上一个下载数据库的函数后,将这个keyword处理为filesort()方法中的page中相应的键值对。
然后利用bookrunner来下载图书,提交给example域中的bookfragmentrequest实例对象。实现一下:1.在浏览器中提交下载链接,返回2.把图书链接(id号为1,offset为1,name:valueword)添加到bookfragment的books_output_container中3.通过浏览器查看文件内容,下载下来。
1)httpget方法:(因为没有加入方法head部分,head部分我以后会单独单独再介绍,并且因为java定义异步请求,所以不需要在java层面实现)url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:fileheader:。
2)httppost方法:url:;sort_order_keyword=valueword&sort_order_offset=valueword&name=min_the1&offset=1&length=5&type=allheader:authorsheader:mintypeheader:offsetheader:lengthheader:。
3)jsonxmldump转为javabean文件供java调用:java层面:mapper类:container类:$java:application/java-jarmybean。jarlibrary:javacutf-java。libmybean。jarresults。javacontainer。java。
中科星源无规则采集器列表算法产生事件(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-01 07:03
无规则采集器列表算法产生轮询事件无规则采集器列表实现不停重复的扫描列表没有规则采集器列表基于版本号的列表算法列表归纳算法
这是已经有人做出来的案例了,有c语言代码,有servlet服务器版。你可以找一下,很容易的。中科星源,以前是中科曙光研发。
用过万数天天采集器,虽然比较不好看,但是基本功能是足够的。
什么是无规则?简单的说就是去除所有的规则。
openinstall
已经有人这么干了,数据量非常大,尤其还是监控来源用。再说了,监控是程序员干的事,实现方案很简单,难点在于采集到数据。或者高级点,你可以用excel去存。数据量很大的话,就得用到数据库结构化的问题了。
可以,我做过一个采集列表的,很简单,即统计列表中id的排名和item的id。也可以支持自定义item。不过,还有其他的实现方式。
最近接触一个app叫“手机银行”,是通过javascript实现,没太细看源码,只知道大概原理。首先用一个unique做元素唯一性标记,像这样:在上面对这个unique元素enhance处理,比如:把它加到原来的enhance上然后你发现了什么?原来我们有了enhance的属性了,所以这个时候你可以拿它实现规则,然后就是规则的实现了。
我手写过一个规则,跟上面示例类似,只是在returnlist上修改了下type属性。具体应用代码就不贴了,你可以自己查规则,每一种规则也会有不同,例如我这个最小值规则。里面是我实现了一个return(*type)函数。其实这个和上面那个都是一个意思。功能一样就是规则是固定的,规则长度可以自己设定,就是字符串规则和数字规则,它返回的的是一个json格式的字符串,字符串规则是return一个json字符串然后一般字符串规则返回的不是正整数,规则也不定,所以你可以根据自己需要定义规则长度。以上只是一个简单的规则实现,太复杂的不一定合适。 查看全部
中科星源无规则采集器列表算法产生事件(组图)
无规则采集器列表算法产生轮询事件无规则采集器列表实现不停重复的扫描列表没有规则采集器列表基于版本号的列表算法列表归纳算法
这是已经有人做出来的案例了,有c语言代码,有servlet服务器版。你可以找一下,很容易的。中科星源,以前是中科曙光研发。
用过万数天天采集器,虽然比较不好看,但是基本功能是足够的。
什么是无规则?简单的说就是去除所有的规则。
openinstall
已经有人这么干了,数据量非常大,尤其还是监控来源用。再说了,监控是程序员干的事,实现方案很简单,难点在于采集到数据。或者高级点,你可以用excel去存。数据量很大的话,就得用到数据库结构化的问题了。
可以,我做过一个采集列表的,很简单,即统计列表中id的排名和item的id。也可以支持自定义item。不过,还有其他的实现方式。
最近接触一个app叫“手机银行”,是通过javascript实现,没太细看源码,只知道大概原理。首先用一个unique做元素唯一性标记,像这样:在上面对这个unique元素enhance处理,比如:把它加到原来的enhance上然后你发现了什么?原来我们有了enhance的属性了,所以这个时候你可以拿它实现规则,然后就是规则的实现了。
我手写过一个规则,跟上面示例类似,只是在returnlist上修改了下type属性。具体应用代码就不贴了,你可以自己查规则,每一种规则也会有不同,例如我这个最小值规则。里面是我实现了一个return(*type)函数。其实这个和上面那个都是一个意思。功能一样就是规则是固定的,规则长度可以自己设定,就是字符串规则和数字规则,它返回的的是一个json格式的字符串,字符串规则是return一个json字符串然后一般字符串规则返回的不是正整数,规则也不定,所以你可以根据自己需要定义规则长度。以上只是一个简单的规则实现,太复杂的不一定合适。
基于物品相似度的协同过滤算法的特点及适用机制
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-06-28 05:03
基于物品相似度的协同过滤算法的特点及适用机制
最近接到一个任务,一个教育类APP的智能推荐板块,根据用户的购买习惯推荐相应的可购买内容,满足客户的个性化需求,增加产品的点击量以及购买量。
一、业务逻辑及适用机制
客户要求如下:
可以看出用户对这里的智能推荐的个性化需求非常强烈,推测用户对之前购买过的同类型商品更加着迷。
目前市面上主流的推荐算法大致可以分为以下几类:
这个项目非常符合基于物品相似度的协同过滤算法的使用场景。
二、算法特点
基于物品相似度的协同过滤算法的适用场景具有以下特点:
长尾商品丰富、用户个性化需求强的区域;长尾效应很好理解。比如,最主流、最热的书总是占据书店最显眼的位置,而不太受欢迎的同类型书放在书架上的可能性要小得多,即使这些冷门书籍确实还有市场要求。如果用户购买了某本热门书籍,那么我会向老用户推荐相同类型但不是很好的书籍。这是非常合理的吗?每个人阅读的书籍类型千差万别。我告诉你,你不认识的人也喜欢看书,你不一定想买。
当物品数量远小于用户数量时; item数据比用户数据本身更稳定,item数据的样本量小。这时候物品的相似度计算不仅小,而且不需要经常更新。程序压力小。
因此,该算法常被应用于图书、电商、教育和电影网站,这些领域都符合以上两个特点。
基于物品相似度的协同过滤算法侧重于维护用户的历史兴趣,其交互特征是推荐结果的实时变化。其优缺点如下:
三、算法的实现
本项目中,基于物品相似度的协同过滤算法的实现大致如下:
计算项目的相似度(课程/活动/表演/展览/比赛等)。
步骤如下:
使用物品的内容属性来计算相似度。内容属性类似于一个标签,可以反映项目的共性。
项目可以是物理对象或虚拟娱乐服务。比如某个表演的类型,是戏剧、舞蹈还是唱歌?适合人群是10-18岁的表演青少年、二十多岁的大学生,还是工作稳定、家庭富裕的中年人?演出场地是茶馆、体育馆还是歌剧院?
一个item可以有多个tag,两个item具有相同tag的tag越多,两个item的相似度就越高。
分析用户行为记录以计算相似度。用户的行为记录包括观看过的演出、观看过的展览、参加过的比赛、购买过的商品等,在确认用户的行为偏好后,“适合自己”。
为用户生成推荐列表。将物品与用户的行为关联起来,与用户历史中感兴趣的物品越相似的物品,就越有可能在用户的推荐列表中获得更高的排名。需要考虑以下几个方面:
业务场景:可分为冷启动、非冷启动新用户、非冷启动老用户、匿名用户四种。不同的业务场景应用不同的算法。对于本项目,基于物品的协同过滤推荐算法适用于非冷启动老用户。
不同的业务场景应用不同的算法
推荐位置:前端推荐列表的入口(首页或某个模块)和内部接口层次要考虑。
结果评估:推荐列表上线后,采集数据进行算法优化。需要对比算法前后的销量和销量增长情况,以衡量算法的有效性,及时调整推荐机制。
本项目在前端给出了智能推荐主入口,提供展示服务、比赛服务、演出服务三个次入口。
需要说明的是,这三个二级入口导入的内容一直保持不变,但属于同类项目的长尾列表,曝光率可能偏低。智能推荐需要做的就是增加这些内容的曝光率。
考虑的物品的内容属性和权重系数不同:
展览服务(展览):
比赛服务(比赛):比赛类型(书法、绘画、朗诵、小发明等标签)。
表演服务(表演):表演地点、表演类型(朗诵、唱歌、舞蹈、素描等标签)、表演时间(近期推荐)等,类似展览。
后台给出了算法的模板配置页面、推荐配置页面和结果评估页面。
本文由@Smile 原创发表在人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏 查看全部
基于物品相似度的协同过滤算法的特点及适用机制
最近接到一个任务,一个教育类APP的智能推荐板块,根据用户的购买习惯推荐相应的可购买内容,满足客户的个性化需求,增加产品的点击量以及购买量。
一、业务逻辑及适用机制
客户要求如下:
可以看出用户对这里的智能推荐的个性化需求非常强烈,推测用户对之前购买过的同类型商品更加着迷。
目前市面上主流的推荐算法大致可以分为以下几类:
这个项目非常符合基于物品相似度的协同过滤算法的使用场景。
二、算法特点
基于物品相似度的协同过滤算法的适用场景具有以下特点:
长尾商品丰富、用户个性化需求强的区域;长尾效应很好理解。比如,最主流、最热的书总是占据书店最显眼的位置,而不太受欢迎的同类型书放在书架上的可能性要小得多,即使这些冷门书籍确实还有市场要求。如果用户购买了某本热门书籍,那么我会向老用户推荐相同类型但不是很好的书籍。这是非常合理的吗?每个人阅读的书籍类型千差万别。我告诉你,你不认识的人也喜欢看书,你不一定想买。
当物品数量远小于用户数量时; item数据比用户数据本身更稳定,item数据的样本量小。这时候物品的相似度计算不仅小,而且不需要经常更新。程序压力小。
因此,该算法常被应用于图书、电商、教育和电影网站,这些领域都符合以上两个特点。
基于物品相似度的协同过滤算法侧重于维护用户的历史兴趣,其交互特征是推荐结果的实时变化。其优缺点如下:
三、算法的实现
本项目中,基于物品相似度的协同过滤算法的实现大致如下:
计算项目的相似度(课程/活动/表演/展览/比赛等)。
步骤如下:
使用物品的内容属性来计算相似度。内容属性类似于一个标签,可以反映项目的共性。
项目可以是物理对象或虚拟娱乐服务。比如某个表演的类型,是戏剧、舞蹈还是唱歌?适合人群是10-18岁的表演青少年、二十多岁的大学生,还是工作稳定、家庭富裕的中年人?演出场地是茶馆、体育馆还是歌剧院?
一个item可以有多个tag,两个item具有相同tag的tag越多,两个item的相似度就越高。
分析用户行为记录以计算相似度。用户的行为记录包括观看过的演出、观看过的展览、参加过的比赛、购买过的商品等,在确认用户的行为偏好后,“适合自己”。
为用户生成推荐列表。将物品与用户的行为关联起来,与用户历史中感兴趣的物品越相似的物品,就越有可能在用户的推荐列表中获得更高的排名。需要考虑以下几个方面:
业务场景:可分为冷启动、非冷启动新用户、非冷启动老用户、匿名用户四种。不同的业务场景应用不同的算法。对于本项目,基于物品的协同过滤推荐算法适用于非冷启动老用户。
不同的业务场景应用不同的算法
推荐位置:前端推荐列表的入口(首页或某个模块)和内部接口层次要考虑。
结果评估:推荐列表上线后,采集数据进行算法优化。需要对比算法前后的销量和销量增长情况,以衡量算法的有效性,及时调整推荐机制。
本项目在前端给出了智能推荐主入口,提供展示服务、比赛服务、演出服务三个次入口。
需要说明的是,这三个二级入口导入的内容一直保持不变,但属于同类项目的长尾列表,曝光率可能偏低。智能推荐需要做的就是增加这些内容的曝光率。
考虑的物品的内容属性和权重系数不同:
展览服务(展览):
比赛服务(比赛):比赛类型(书法、绘画、朗诵、小发明等标签)。
表演服务(表演):表演地点、表演类型(朗诵、唱歌、舞蹈、素描等标签)、表演时间(近期推荐)等,类似展览。
后台给出了算法的模板配置页面、推荐配置页面和结果评估页面。
本文由@Smile 原创发表在人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
无规则采集器列表算法多根长方形绑定的方式生成
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-06-28 03:02
无规则采集器列表算法的话采用gecko方案,多根长方形绑定的方式生成无规则.在这里我们来看看通过jsoup的基本封装如何封装和实现.最简单的情况(很多人说最简单是错的)就是每个item,实际上就是二进制序列在python里面拆开的item,所以我们要把python的每个变量的ascii编码值提取出来,然后记录到中文数据库,然后,如果model数据库已经实现了一些集合,把python构造的新集合填充进去,就可以生成一个集合,每个pythonpython需要针对不同的descriptor重写实现方式,对于negativesampling不适用.model数据库:也就是常说的html数据库,这边已经将二进制序列提取出来.具体的代码我们可以看后面第五节数据库方面的封装.如果你是想获取一些特殊数据,会涉及到一些特殊的数据特性,但是它们并不是那么有规律.但这些数据不会影响实际结果.所以,也可以将这些常用的字符串进行列举.然后看model数据库:这边开始要用到python方面的框架了,有一些解释器并不能把python里面常用字符串的数据提取出来,而jsoup只能提取出一个字符串的key变量。
我们先可以看看_python.py文件,这是我们自己定义的for循环的范例,同时也可以看到model数据库内部生成的python字符串.文件名是:#coding:utf-8importpandasaspdimportsysreload(sys)sys.setdefaultencoding('utf-8')'''#分词功能segment=pd.read_table(pile('\d{2}\d{1}',segment,sep='\t'))segment_url=[]fortextinsegment['text']:text_param=pd.read_table(pile(''.join(text),segment_url))text_text=str(text)#modelarrayfrompandasimportdataframeimportjsoupasjswhiletrue:rows=pd.dataframe(js.groupby('_name')['first'])arr=dataframe(rows)#爬虫功能re=soup.prettify(js.groupby('_name')['first'])#提取单个字符串中部分字符'_xxxxxxxx'.strip().sort_values(ascii=1)foriinrange(int(rows.length)):msg=":"+str(i)+","+fig.figure()+","+str(i)msg=i-1+imsg=r.split("")[-1]params=pd.read_pdf(msg)msg=msg[0].join(rows[0])forparaminparams:msg[1]=fig.figure()[。 查看全部
无规则采集器列表算法多根长方形绑定的方式生成
无规则采集器列表算法的话采用gecko方案,多根长方形绑定的方式生成无规则.在这里我们来看看通过jsoup的基本封装如何封装和实现.最简单的情况(很多人说最简单是错的)就是每个item,实际上就是二进制序列在python里面拆开的item,所以我们要把python的每个变量的ascii编码值提取出来,然后记录到中文数据库,然后,如果model数据库已经实现了一些集合,把python构造的新集合填充进去,就可以生成一个集合,每个pythonpython需要针对不同的descriptor重写实现方式,对于negativesampling不适用.model数据库:也就是常说的html数据库,这边已经将二进制序列提取出来.具体的代码我们可以看后面第五节数据库方面的封装.如果你是想获取一些特殊数据,会涉及到一些特殊的数据特性,但是它们并不是那么有规律.但这些数据不会影响实际结果.所以,也可以将这些常用的字符串进行列举.然后看model数据库:这边开始要用到python方面的框架了,有一些解释器并不能把python里面常用字符串的数据提取出来,而jsoup只能提取出一个字符串的key变量。
我们先可以看看_python.py文件,这是我们自己定义的for循环的范例,同时也可以看到model数据库内部生成的python字符串.文件名是:#coding:utf-8importpandasaspdimportsysreload(sys)sys.setdefaultencoding('utf-8')'''#分词功能segment=pd.read_table(pile('\d{2}\d{1}',segment,sep='\t'))segment_url=[]fortextinsegment['text']:text_param=pd.read_table(pile(''.join(text),segment_url))text_text=str(text)#modelarrayfrompandasimportdataframeimportjsoupasjswhiletrue:rows=pd.dataframe(js.groupby('_name')['first'])arr=dataframe(rows)#爬虫功能re=soup.prettify(js.groupby('_name')['first'])#提取单个字符串中部分字符'_xxxxxxxx'.strip().sort_values(ascii=1)foriinrange(int(rows.length)):msg=":"+str(i)+","+fig.figure()+","+str(i)msg=i-1+imsg=r.split("")[-1]params=pd.read_pdf(msg)msg=msg[0].join(rows[0])forparaminparams:msg[1]=fig.figure()[。
AT&;;;;无规则采集器列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-06-24 20:02
无规则采集器列表算法我们可以看到网站上面是有每个类型规则的随机列表列表总共有6页每页均为1000个网站每页规则为[2000,5000,10k,50k,20k,20k]我们不考虑整站采集先来下载3个规则(代码已经打包完成)#svncdd:/webgis/ubuntu#sed-i'/lists/20/200000/200000/200000/20000/50000/20000/5000/20000'`。
$1。ez,会看到前三页均为20000个规则每页2000个,也就是每页1000个分别对应每个包括1~1000网站2~2000网站3~5000网站采集器的算法依赖网站服务器ip,所以只能采集网站上的页数网站包含50000个页数以内的页面的规则都可以用#serverport'80'imageviewer"":7522"imageviewer"":7544"imageviewer"":74000"imageviewer"":7445"imageviewer"":7477"imageviewer"":7478"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484下载不了,解决办法在这里:。 查看全部
AT&;;;;无规则采集器列表
无规则采集器列表算法我们可以看到网站上面是有每个类型规则的随机列表列表总共有6页每页均为1000个网站每页规则为[2000,5000,10k,50k,20k,20k]我们不考虑整站采集先来下载3个规则(代码已经打包完成)#svncdd:/webgis/ubuntu#sed-i'/lists/20/200000/200000/200000/20000/50000/20000/5000/20000'`。
$1。ez,会看到前三页均为20000个规则每页2000个,也就是每页1000个分别对应每个包括1~1000网站2~2000网站3~5000网站采集器的算法依赖网站服务器ip,所以只能采集网站上的页数网站包含50000个页数以内的页面的规则都可以用#serverport'80'imageviewer"":7522"imageviewer"":7544"imageviewer"":74000"imageviewer"":7445"imageviewer"":7477"imageviewer"":7478"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484"imageviewer"":7484下载不了,解决办法在这里:。
,楼上都太简单,这样才能治标治本!
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-06-19 00:02
我们用控制次数和逻辑算法,治标不治本,楼上说的太简单了,如果真的要采集你的网站信息,其实很简单。
我在网上找到了一个很全面的防止采集的方法,请参考
在实现很多反采集的方法时,需要考虑是否会影响搜索引擎对网站的爬取,所以先分析一下一般的采集器和搜索引擎爬虫采集的区别。
相同点:a.两者都需要直接抓取网页的源代码才能有效工作,b.两者都会抓取单位时间内多次访问的大量网站内容; C。宏观上,两者IP都会发生变化; d.二是急着破解你的一些网页加密(验证),比如用js文件加密的网页内容,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容等
不同点:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。 采集器一般是通过html标签的特性来抓取需要的数据。创建采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容;或者使用创建特定网页的特定正则表达式来过滤掉需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那就来提出一些反采集的方法
1、限制IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站5次,除非是程序访问。有了这个偏好,就只剩下搜索引擎爬虫和烦人的采集器了。
缺点:一刀切,这也会妨碍搜索引擎回复网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、shield ip
分析:通过后台计数器记录访问者的ip和频率,人工分析访问记录,屏蔽可疑IP。
缺点:貌似没有缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:不用分析,搜索引擎爬虫和采集器通杀
适用网站:我真的很讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他就不来接你了
4、Hidden 网站copyright 或者网页中一些随机的垃圾文字,这些文字样式写在css文件中
分析:采集虽然无法阻止,但是采集之后的内容会填充你的网站版权声明或者一些垃圾文字,因为一般采集器不会同时出现采集你的css 文件,文本不带样式显示。
适用网站:所有网站
采集器 会做什么:对于受版权保护的文本,易于处理,替换它。对于随机的垃圾文本,没办法,抓紧。
5、用户登录可以访问网站content
分析:搜索引擎爬虫不会为这种类型的每个网站设计登录程序。听说采集器可以为某个网站设计一个模拟用户登录和提交表单行为。
适用网站:我真的很讨厌搜索引擎,想屏蔽大部分采集器的网站
采集器怎么做:为用户登录的行为创建一个模块并提交表单
6、使用脚本语言进行分页(隐藏分页)
分析:再次,搜索引擎爬虫不会分析各种网站隐藏页面,影响搜索引擎的收录。但是采集zhe在写采集规则的时候,一定要分析目标页面的代码,稍微懂脚本的人就会知道页面的真实链接地址。
适用网站:不高度依赖搜索引擎的网站,以及采集你的人不懂脚本知识
采集器会做什么:应该说采集器会做什么,反正他要分析你的网页代码,顺便分析你的分页脚本,不会多花时间。
7、防盗链措施(只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:ASP和PHP可以通过读取请求的HTTP_REFERER属性来判断请求是否来自网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对@k14的响应@部分反水蛭内容收录。
适用网站:我对网站搜索引擎收录没有太多想法 查看全部
,楼上都太简单,这样才能治标治本!
我们用控制次数和逻辑算法,治标不治本,楼上说的太简单了,如果真的要采集你的网站信息,其实很简单。
我在网上找到了一个很全面的防止采集的方法,请参考
在实现很多反采集的方法时,需要考虑是否会影响搜索引擎对网站的爬取,所以先分析一下一般的采集器和搜索引擎爬虫采集的区别。
相同点:a.两者都需要直接抓取网页的源代码才能有效工作,b.两者都会抓取单位时间内多次访问的大量网站内容; C。宏观上,两者IP都会发生变化; d.二是急着破解你的一些网页加密(验证),比如用js文件加密的网页内容,比如需要输入验证码才能浏览内容,比如需要登录才能访问内容等
不同点:搜索引擎爬虫首先忽略整个网页源代码脚本和样式以及html标签代码,然后对剩余的文本进行词法、句法分析等一系列复杂的处理。 采集器一般是通过html标签的特性来抓取需要的数据。创建采集规则时,需要填写目标内容的开始标记和结束标记,以便定位到需要的内容;或者使用创建特定网页的特定正则表达式来过滤掉需要的内容。无论是开始结束标签的使用,还是正则表达式的使用,都会涉及到html标签(网页结构分析)。
那就来提出一些反采集的方法
1、限制IP地址单位时间内的访问次数
分析:普通人不可能在一秒内访问同一个网站5次,除非是程序访问。有了这个偏好,就只剩下搜索引擎爬虫和烦人的采集器了。
缺点:一刀切,这也会妨碍搜索引擎回复网站的收录
适用网站:不依赖搜索引擎的网站
采集器会做什么:减少单位时间内的访问次数,降低采集效率
2、shield ip
分析:通过后台计数器记录访问者的ip和频率,人工分析访问记录,屏蔽可疑IP。
缺点:貌似没有缺点,就是站长有点忙
适用网站:所有网站,站长可以知道哪些机器人是谷歌或百度
采集器会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注:这个方法我没接触过,不过好像是从别处传来的
分析:不用分析,搜索引擎爬虫和采集器通杀
适用网站:我真的很讨厌搜索引擎和采集器的网站
采集器会这样:你这么好,你这么好,他就不来接你了
4、Hidden 网站copyright 或者网页中一些随机的垃圾文字,这些文字样式写在css文件中
分析:采集虽然无法阻止,但是采集之后的内容会填充你的网站版权声明或者一些垃圾文字,因为一般采集器不会同时出现采集你的css 文件,文本不带样式显示。
适用网站:所有网站
采集器 会做什么:对于受版权保护的文本,易于处理,替换它。对于随机的垃圾文本,没办法,抓紧。
5、用户登录可以访问网站content
分析:搜索引擎爬虫不会为这种类型的每个网站设计登录程序。听说采集器可以为某个网站设计一个模拟用户登录和提交表单行为。
适用网站:我真的很讨厌搜索引擎,想屏蔽大部分采集器的网站
采集器怎么做:为用户登录的行为创建一个模块并提交表单
6、使用脚本语言进行分页(隐藏分页)
分析:再次,搜索引擎爬虫不会分析各种网站隐藏页面,影响搜索引擎的收录。但是采集zhe在写采集规则的时候,一定要分析目标页面的代码,稍微懂脚本的人就会知道页面的真实链接地址。
适用网站:不高度依赖搜索引擎的网站,以及采集你的人不懂脚本知识
采集器会做什么:应该说采集器会做什么,反正他要分析你的网页代码,顺便分析你的分页脚本,不会多花时间。
7、防盗链措施(只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:ASP和PHP可以通过读取请求的HTTP_REFERER属性来判断请求是否来自网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对@k14的响应@部分反水蛭内容收录。
适用网站:我对网站搜索引擎收录没有太多想法
最新关关采集器规则编写教程(图文详解版版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-06-17 05:22
复制代码,这意味着现在的站长会在小说章节的内容中添加自己的广告,例如(**网站尽快更新VIP章节),(**网站首次发布)和其他广告。我们可以使用最新级别。 采集器Rules 编写教程(图文详解版) 首先介绍一下广管挖矿规则中需要用到的一些标签。\d*代表编号**VIP章节替换内容更新于第一次 **第一次替换的内容 复制代码。其他替换类似于空章。可能是目标站刚刚重启网站或者你的采集IP被屏蔽了。如果不是以上原因,请检查您的采集章节是否为图片章节。如果你的PubContentImages(从章节内容中提取图片)没有获取到图片章节内容,软件会检查你的采集文字内容PubContentText(获取章节内容)这个正则匹配,如果PubContentImages(从章节内容中提取图片)有是没有与PubContentText匹配的内容(获取章节内容),那么就出现了我们上面提到的空章节的原因。最新customer采集器rule写作教程(图文详解版) 先介绍一些海关规则中需要用到的标签 \d* 表示数字 先介绍一些海关规则中需要用到的标签来表示字符(不能为空)章节内容,包括换行符。 ======与杰奇背景标签的对应关系====== 查看全部
最新关关采集器规则编写教程(图文详解版版)
复制代码,这意味着现在的站长会在小说章节的内容中添加自己的广告,例如(**网站尽快更新VIP章节),(**网站首次发布)和其他广告。我们可以使用最新级别。 采集器Rules 编写教程(图文详解版) 首先介绍一下广管挖矿规则中需要用到的一些标签。\d*代表编号**VIP章节替换内容更新于第一次 **第一次替换的内容 复制代码。其他替换类似于空章。可能是目标站刚刚重启网站或者你的采集IP被屏蔽了。如果不是以上原因,请检查您的采集章节是否为图片章节。如果你的PubContentImages(从章节内容中提取图片)没有获取到图片章节内容,软件会检查你的采集文字内容PubContentText(获取章节内容)这个正则匹配,如果PubContentImages(从章节内容中提取图片)有是没有与PubContentText匹配的内容(获取章节内容),那么就出现了我们上面提到的空章节的原因。最新customer采集器rule写作教程(图文详解版) 先介绍一些海关规则中需要用到的标签 \d* 表示数字 先介绍一些海关规则中需要用到的标签来表示字符(不能为空)章节内容,包括换行符。 ======与杰奇背景标签的对应关系======
分布式数据的拓容问题,配置及应用指定算法解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-17 01:23
一、应用指定算法
运行阶段由应用决定路由到哪个段,直接根据字符子串(必须是数字)计算段号,配置如下:
id
sharding-by-substring
0
2
3
0
配置说明:
示例说明:
id=05-100000002,在这个配置中,就是从id中的startIndex=0开始,截取siz=2个数字,即05,05就是得到的分区。如果不通过,则默认分配给defaultPartition。
测试:
配置
数据
二、String 哈希解析算法
截取字符串中指定位置的子字符串,进行哈希算法,计算分片。配置如下:
user_id
sharding-by-stringhash
512
2
0:2
配置说明:
测试:
配置
数据
1). 创建表
create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());
原则:
三、一致性哈希算法
一致性Hash算法有效解决分布式数据扩展问题,配置如下:
id
murmur
0
3
160
配置说明:
测试:
配置
数据
1). 创建表
create table tb_order(
id int(11) primary key,
money int(11),
content varchar(200)
)engine=InnoDB ;
2). 插入数据
INSERT INTO tb_order (id,money,content) VALUES(1, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(312, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(412, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(534, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(621, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(754563, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(8123, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(91213, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(23232, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(21221, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(12132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(124321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212132, 100 , UUID());
四、日期分割算法
按日期拆分
create_time
sharding-by-date
yyyy-MM-dd
2020-01-01
2020-12-31
10
配置说明:
注意:配置了规则的表的dataNode分片数必须与分片规则数相同,例如2020-01-01到2020-12-31,每10天一个分片,一个总共需要 37 个分片。
五、每月小时算法
单月按小时拆分,最小粒度为小时,一天最多可以有24个分片,最小为1个分片。下个月从头开始,每个月底需要手动清理数据。
配置如下:
create_time
sharding-by-hour
24
配置说明:
六、自然月分片算法
使用场景是按照月份列进行分区,每个自然月是一个分片,配置如下:
create_time
sharding-by-month
yyyy-MM-dd
2020-01-01
2020-12-31
配置说明:
七、日期范围哈希算法
这个想法与范围模数碎片相同。首先根据日期通过范围分片得到分片组,然后根据时间hash在短期内更均匀地分布数据;
优点:可以避免扩容时的数据迁移,在一定程度上避免范围碎片化的热点问题
注意:日期格式要求尽量精确,否则达不到局部统一的目的
create_time
range-date-hash
yyyy-MM-dd HH:mm:ss
2020-01-01 00:00:00
6
10
配置说明:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
分布式数据的拓容问题,配置及应用指定算法解析
一、应用指定算法
运行阶段由应用决定路由到哪个段,直接根据字符子串(必须是数字)计算段号,配置如下:
id
sharding-by-substring
0
2
3
0
配置说明:
示例说明:
id=05-100000002,在这个配置中,就是从id中的startIndex=0开始,截取siz=2个数字,即05,05就是得到的分区。如果不通过,则默认分配给defaultPartition。
测试:
配置
数据
二、String 哈希解析算法
截取字符串中指定位置的子字符串,进行哈希算法,计算分片。配置如下:
user_id
sharding-by-stringhash
512
2
0:2
配置说明:
测试:
配置
数据
1). 创建表
create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());
原则:
三、一致性哈希算法
一致性Hash算法有效解决分布式数据扩展问题,配置如下:
id
murmur
0
3
160
配置说明:
测试:
配置
数据
1). 创建表
create table tb_order(
id int(11) primary key,
money int(11),
content varchar(200)
)engine=InnoDB ;
2). 插入数据
INSERT INTO tb_order (id,money,content) VALUES(1, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(312, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(412, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(534, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(621, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(754563, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(8123, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(91213, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(23232, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(21221, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(12132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(124321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212132, 100 , UUID());
四、日期分割算法
按日期拆分
create_time
sharding-by-date
yyyy-MM-dd
2020-01-01
2020-12-31
10
配置说明:
注意:配置了规则的表的dataNode分片数必须与分片规则数相同,例如2020-01-01到2020-12-31,每10天一个分片,一个总共需要 37 个分片。
五、每月小时算法
单月按小时拆分,最小粒度为小时,一天最多可以有24个分片,最小为1个分片。下个月从头开始,每个月底需要手动清理数据。
配置如下:
create_time
sharding-by-hour
24
配置说明:
六、自然月分片算法
使用场景是按照月份列进行分区,每个自然月是一个分片,配置如下:
create_time
sharding-by-month
yyyy-MM-dd
2020-01-01
2020-12-31
配置说明:
七、日期范围哈希算法
这个想法与范围模数碎片相同。首先根据日期通过范围分片得到分片组,然后根据时间hash在短期内更均匀地分布数据;
优点:可以避免扩容时的数据迁移,在一定程度上避免范围碎片化的热点问题
注意:日期格式要求尽量精确,否则达不到局部统一的目的
create_time
range-date-hash
yyyy-MM-dd HH:mm:ss
2020-01-01 00:00:00
6
10
配置说明:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
优采云采集器如何过滤列表中的前N个数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-06-12 20:25
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键采集无需编程,支持自动生成采集脚本,采集互联网 99% 的网站。软件简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只要点击鼠标,就可以采集网页上的数据。
[软件功能]
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集data
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站
【功能介绍】
向导模式
易于使用,只需单击鼠标即可自动生成
脚本定期运行
可按计划运行,无需人工
原装高速内核
自主研发的浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
多数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
【使用流程】
输入采集URL
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程自动提取数据
进入第二步后优采云采集器自动智能分析网页并从中提取列表数据。
导出数据到表、数据库、网站等
运行任务,将采集数据导出到Csv、Excel及各种数据库,支持api导出。
[常见问题]
问:如何过滤列表中的前N个数据?
1、 有时候我们需要过滤采集到达的列表,比如过滤掉第一组数据(采集表的情况,过滤掉表列名)
2、在列表模式菜单中点击,设置列表xpath
问:如何抓取cookies获取cookies并手动设置?
1、 首先用谷歌浏览器打开你要采集的网站,然后登录。
2、然后按F12,会出现开发者工具,选择Network
3、 然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器编辑任务,进入第三步指定HTTP Header。
[更新日志]
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本映射(支持查找替换)
5、修复登录时DNS问题
6、修复图片下载问题
7、修复一些json问题 查看全部
优采云采集器如何过滤列表中的前N个数据?
优采云采集器是新一代智能网页采集工具,智能分析,可视化界面,一键采集无需编程,支持自动生成采集脚本,采集互联网 99% 的网站。软件简单易学,通过智能算法+可视化界面,随心所欲抓取数据。只要点击鼠标,就可以采集网页上的数据。
[软件功能]
一键提取数据
简单易学,通过可视化界面,鼠标点击即可采集数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集data
适用于各种网站
采集 Internet 99% 网站,包括单页应用ajax加载等动态类型网站
【功能介绍】
向导模式
易于使用,只需单击鼠标即可自动生成
脚本定期运行
可按计划运行,无需人工
原装高速内核
自主研发的浏览器内核速度快,远超对手
智能识别
智能识别网页中的列表和表单结构(多选框下拉列表等)
广告拦截
自定义广告拦截模块,兼容AdblockPlus语法,可添加自定义规则
多数据导出
支持 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
【使用流程】
输入采集URL
打开软件,新建一个任务,输入需要采集的网站地址。
智能分析,全程自动提取数据
进入第二步后优采云采集器自动智能分析网页并从中提取列表数据。
导出数据到表、数据库、网站等
运行任务,将采集数据导出到Csv、Excel及各种数据库,支持api导出。
[常见问题]
问:如何过滤列表中的前N个数据?
1、 有时候我们需要过滤采集到达的列表,比如过滤掉第一组数据(采集表的情况,过滤掉表列名)
2、在列表模式菜单中点击,设置列表xpath
问:如何抓取cookies获取cookies并手动设置?
1、 首先用谷歌浏览器打开你要采集的网站,然后登录。
2、然后按F12,会出现开发者工具,选择Network
3、 然后按 F5 刷新下一页并选择其中一个请求。
4、复制完成后,在优采云采集器编辑任务,进入第三步指定HTTP Header。
[更新日志]
V2.1.8.0
1、添加插件功能
2、添加导出txt(一个文件保存为一个文件)
3、多值连接器支持换行
4、修改数据处理的文本映射(支持查找替换)
5、修复登录时DNS问题
6、修复图片下载问题
7、修复一些json问题
幼儿园健康上报系统演示如何用低代码平台快速搭建一套应用系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-09 00:44
简介:本文基于作者虚构的《幼儿园健康报告系统》,演示了如何使用低代码平台快速搭建应用系统,并介绍和演示了一些国内外知名的aPaaS产品, Mendix、Outsystems、Yidah、明道云等在产品设计中尝试探索低代码平台的核心精髓,让大家对低代码有更直观的认识。
在案例开始之前,先说一下基本概念。
一、什么是低码
低代码平台是继众泰之后的另一个热门话题。事实上,低代码本身并不是什么新鲜话题,也不是最近的技术突破和创新。它已经存在了十多年或二十多年。概念。早期的大型管理软件套件都有类似拖放式的快速开发平台,这使得技术人员更容易在不编写代码的情况下快速实现某些基本功能。
虽然现在低代码被称为aPaaS,但它似乎是一种PaaS,似乎与SaaS密切相关,但大家需要认识到,低代码开发平台并不是一个概念,仅仅因为SaaS ,但远古时期已经存在。
简单来说,低代码平台就是期望通过拖放配置实现一套面向业务的软件系统,并且可以无缝部署和运行的开发平台。在这个过程中,当然允许编写部分代码,但更重要的是,大量的基础编码工作可以通过低代码平台快速自动化。
低代码的第一个应用场景是帮助成熟的软件产品,以低成本支持个性化需求,提高开发速度,甚至扩大客户群。
例如,许多成熟的商业软件(包括私有化的商业软件套件和SaaS形式的产品)都希望通过构建低代码平台来加强产品扩展能力,更好更快地服务客户,并与ISV合作将产品的目标客户群扩展到更广泛的领域和行业。
在这种情况下,低代码平台是低成本、高效地满足个性化需求的终极解决方案。此时,低代码目标用户可能包括工程师和实施顾问。国外SAP、Oracle、SalesForce、国内用友、金蝶、北森、Salesease等都有以自有软件产品为基础核心的低代码解决方案。
低代码的第二个应用场景是帮助甲方企业以低成本快速搭建新的应用系统,特别是对于不懂编程的业务人员,让企业以更低的成本享受。数字技术为企业带来的好处。
事实上,企业中的大量应用系统都是基于流程的。对于逻辑相对简单、流程链不复杂的业务场景,寻找打包软件支持矫枉过正,外包开发独立系统成本高,那么低代码平台可能是不错的选择。此时,低代码平台的目标用户可能包括甲方企业的业务人员或IT人员。
国外OutSystems和Mendix,国内的明道云、氚云,都属于这种情况。需要注意的是,目前国内一些报表平台和流程引擎厂商为了跟上热情,也自称低代码平台。严格来说,这些厂商提供的产品能力只是一个完整的低代码平台所需能力的一个子集,不能算是低代码产品。
讲了这么多概念,我想大家对低代码的印象还是比较模糊的。接下来,我将通过一个案例,带大家体验一个低代码产品的使用。在开始之前,还有几个问题需要强调一下:
低代码只是应用系统构建实现层面的工具,软件产品设计中的思维和建模过程是核心,所以我们的案例会花一部分笔墨来描述设计过程,理解之后再学习应用low code 平台会简单很多。我选择明道云作为演示产品:第一,因为它更容易上手;第二,因为明道云的老板任向辉喜欢写公众号分享,我很喜欢他的文章,作为致敬,所以选择明道云。需要说明的是,本人与明道云没有任何关系,试用期间也没有添加销售。我从帮助手册中学习并操作了整个试用期。学习明道云大约花了一个小时(主要是看帮助文件),在电脑上实现案例中的功能大约花了两个小时。整体非常好用,好用。不过这也可能是因为之前做过研发,比较容易理解很多基本概念。
好的,接下来,让我们进入案例。
二、小龟鼠幼儿园低代码应用1.需求调研
李校长是小豚鼠幼儿园的校长。最近,她遇到了一件烦心事。根据教委统一要求,疫情期间,要求家长每天报告孩子的健康状况。学校统一管理,但教委没有提供统一的技术支持。 .
为了实现这个需求,幼儿园老师想尽了办法,比如使用微信群管理,或者在线文档管理,但都不是很方便,比如无法实时统计,数据容易被误操作。而如果找软件公司帮忙搭建一个小系统,要花3万到4万元。对于幼儿园来说,这是一笔不小的数目。
李校长的侄子小王是B端产品经理。他在闲聊中得知了李校长的问题,想了想问道:
小王:阿姨,你说的,说不定我可以帮忙,搭建一个软件系统,你的问题就可以很好的解决了!
李校长:真的,太好了,但我们没有很多预算!
小王:不花你一分钱,我免费帮你做,但我想先了解一下你对这个业务管理的需求和期望。
李校长:非常感谢!我的呼吁很简单。就是让父母每天都来检查。如果有任何健康异常,我可以第一时间收到提醒,也可以让老师跟进,看看是什么问题。另外,最好有一些实时报告,让我看到最新的健康报告。
小王:来吧,我明白了,这件事交给我,我帮你设计一套操作流程和配套系统,免费给你使用!
了解大体背景后,小王开始构思小豚鼠幼儿园儿童健康报告系统的设计。
李校长:太好了,期待!
2. 产品轮廓设计
小王了解了基本要求后,开始构思这套系统应该如何设计。首先梳理一下这个系统涉及的利益相关者,如下:
虽然业务流程本身很简单,但因为毕竟是从零开始搭建的管理系统,需要完成一些基础的数据准备工作。想了想,小王画了一张简洁的业务流程图,如下。
可以看出家长们都希望能够签到,一些基础数据要先维护好。按照常识,维护班级信息和学生信息是必要的。签到操作是针对学生的,因此签到信息必须与学生相关联。
另外,要求中提到,如果打卡温度异常,需要老师跟进。我们考虑生成一个待办事项并将其分配给老师。该待办事项与异常打卡记录相关。有了以上对业务的分析和思考,我们就可以画出业务背后的ER模型图(领域模型),如下图所示。
每个老师可以管理多个班级,每个班级只能由一名老师管理。每个班级可以有多个学生,每个学生有多个健康报告记录(签到记录),每个健康报告记录可以生成体温异常跟踪记录。
这些抽象的实体是我们要设计的健康报告系统的核心,因为check-in(健康报告)过程实际上只是对这些实体的数据进行增删改查。
3. 产品细节设计
接下来根据流程图,我们来思考一下系统实现的页面流程图:
除了这些页面级的操作要求,还有一些业务规则要求。例如,如果健康报告中的体温异常,则自动生成一个待跟进的任务,发送给学生的班主任,并推送消息给校长。
简而言之,我们会发现与业务运营相关的功能页面主要是ER实体(创建和编辑)的列表页面和详情页面,不同的用户对不同的页面、不同的数据有不同的权限。
经过整理分析,我们可以列出系统中涉及的相关页面,以及权限表如下(这里只是一个简单的说明,后面明道云会展示更全面详细的权限设计,包括数据权限管理设计方案):
经过上面的分析,虽然细节还没有完成,但我们对“幼儿园健康报告系统”的设计有了清晰的认识。接下来直接进入低代码平台的开发演示链接!
3. 低代码实现——通过工作表定义数据实体
首先我们来到明道云工作台,点击“添加应用”,新建一个应用“小豚鼠幼儿园”(已经在下图中)。
接下来,我们为 ER 模型中的四个实体创建工作表。下图为创建类实体的工作表编辑页面。
Worksheet 是明道云的概念。所谓的工作表实际上对应的是ER建模中的实体。工作表中的相关控件定义实体的字段。比如自增的“类ID”定义在类形式、字符串类型字段“类名”、枚举字段“状态”等。
通过表单呈现实体是一种易于理解的设计方法。实体背后的本质是所谓的“对象”和最终会转移到数据库中的表。在一些低代码平台中,管理实体是通过对象编辑器定义的。这是一个更灵活但更复杂的解决方案,我们稍后会介绍。
无论是表单编辑器还是对象编辑器,原理都是一样的,都是对提取的实体进行管理。对于非技术人员,表格可能更容易理解和接受。
在类窗体中有一个“学生”控件,它是一个关联的记录组件。因为班级和学生是一对多的关系,每个班级可以有多个学生,所以在班级的表格中,我们允许看到一个班级关联的所有学生的列表,这在B端很常见产品交互 一种设计形式。
实体之间所谓的一对多和多对多关系,反映了多个表之间的关联。班级和学生之间的一对多关系可以在设计器中轻松定义,如下所示:
实现关联后,表单与表单之间建立连接,详情页(单个表单数据的展示页)的展示也会自动完美完成。例如:下图是某类数据的详情页(PC版):
aPaaS平台会自动完成PC版和手机版的适配,格式可调。例如,上图为PC版课程详情页,下图为手机版:
4.低代码实现-通过视图编辑器定义数据列表展示
接下来我们依次完成“学生”、“健康报告”、“体温异常追踪”三个实体的表单配置。
在下图中,横向的“校园管理”和“校长控制台”可以理解为我们对系统配置的一级导航。四种垂直形式表示它们属于某个一级导航。每个表单右侧主区域中配置的列表视图是二级导航菜单。如下图所示,对于班级形式,定义了“All”、“Active Class”、“Graduated Class”和“My”。四个列表视图,即“校园管理”一级菜单下的四个二级菜单。
那么,什么是列表视图?
工作表只是定义了实体的特定字段。如何显示实体的列表数据?例如,如何以不同的形式呈现“类”列表数据?这需要一个视图编辑器!
在视图编辑器中,可以定义实体对应的多条数据的表格展示,包括列表数据的默认过滤条件、默认显示字段、默认字段排序,都可以易于定制,如上图所示。
在大部分自研B端产品中,列表页面(即视图)是最常见的功能页面,一般来说,这类页面是硬编码的,而不是通过类似的视图编辑器实现了这样的前端组件。在成熟的软件产品中,没有列表页面的概念,由视图编辑器处理,大大简化了编码工作。
如下图所示,我们为“Class”表单定义了四个视图,分别是“All”、“Effective Middle Class”、“Graduated Class”和“My”。截图显示了“Intermediate Class”视图的“Effective”默认搜索条件配置,可以看到我们已经设置了这个视图的默认查询条件,即“Status”字段为“Teaching”的所有类数据.
我们之前提到过,与“学生”记录的一对多关系是以“班级”形式建立的。在“学生”表格中,还有一个与“班级”表格的“班级ID”相关联的字段。 "字段完成一对多关系的定义。
但是,如果我们想在学生表单中显示班级的名称,在学生视图中显示班级的字段,我们该如何实现呢?
因为我们是建立一对多的关系,所以我们只定义了ID之间的关系。因此,如果要以“学生”形式显示“班级”的名称,则必须对变量引入进行特殊处理。其中,采用了一种称为“其他表字段”的设计方法。简单来说就是关联表的某个字段被引入并显示出来,如下图所示:
下面的红框定义了ID之间的关联,上面的红框介绍了在“Student”表单和视图中显示的“Class”表的“Name”字段。
在其他低代码产品中,这种诉求的解决方案是不一样的。
严格来说,表单只是数据对象的外部表现形式。根据软件设计MVC的分层概念,数据定义和前端呈现必须分层分离。对象编辑器严格定义了数据实体本身,如果表单或视图需要做多表连接来呈现其他相关表的一些字段,这是一个需要在可视化层面解决的问题。
因此,在很多更复杂的低代码产品中,所有的可视化部分都是基于页面编辑器,与底层数据定义无关。因为明道云产品,为了在很大程度上降低用户的学习成本,在数据底层集成了对象编辑器,在表现层集成了表单编辑器。
现在,让我们解决一个难题。如果我们想在学生视图中显示学生老师的名字,我们该怎么做?通过学生,你可以找到你的班级,但谁是班级的负责老师?如何定义?
一种方式是在“班级”表单中添加一个字段,可以关联到老师的账号,完成老师和班级的关系映射。在明道云,我们采取了另一种伎俩。校长需要将每个班级数据的所有者更改为特定的教师帐户,如下图所示。图中的“王老师”是“老师”的独立用户角色。
通过这个动作,实现了对班级负责教师的分配。接下来,使用前面提到的“其他表字段”功能,将这个字段值引入到其他表单对象中。
这样,某个班级的所有学生和学生的健康报告记录都可以追溯到主管老师,这对下一个要求的实现至关重要!
5. 低代码实现——通过流程编辑器定义业务流程和事件
回忆一下,有一个需求:如果健康报告中体温异常,会自动生成一个待跟进的任务,发送给学生班主任,并推送消息给校长。
如何实现这个需求?这使用了 aPaaS 平台中流程编辑器的非常核心和重要的功能。可以说流程编辑器是低代码平台的灵魂!
进一步准确描述上述要求:如果您添加或编辑“健康报告”表单数据,“体温是否正常”字段选择“否”,则自动状态为“待跟进”生成“温度异常跟踪”数据,并发送消息给校长和学生的老师。
在低代码平台下,可以使用流程编辑器来实现与上述类似的功能,自动触发执行,自动更新多表数据。我们来到流程编辑器,创建“上报体温异常触发后续任务记录”流程,如下图:
在图中,我们设计了三个流程节点。
第一个触发节点:定义当“健康报告”表单添加或更新数据时,如果发现“问题正常”字段等于“否”,则执行。第二个节点:当发现体温异常时,创建一条“体温异常追踪”数据,分配给上报记录学生的老师。第三个节点:发送应用内消息给校长和老师提醒处理,效果如下:
对于工作流创建的数据,创建者字段显示为工作流,如下图:
流程编辑器不是一个简单的工作流引擎。我们通常理解的工作流引擎,比如审批流,只是对单个数据对象的多节点处理。真正复杂的流程编辑器BPM需要对流程中不同的数据实体进行复杂的处理,这也是很多B端业务的核心处理逻辑和流程。
当然,明道云的流程编辑器有很多功能,如下图,我们不再赘述。
截至目前,还有一个核心功能我们还没有实现。家长如何报告数据?
一种方式是为每位家长开设一个账号,将账号与学生关联,家长登录系统,提交表格时默认提交相关学生的“健康报告”记录。
另一种方法是将“健康报告”表公开,任何人都可以提交。这样做的好处是不需要一一维护父账户。缺点是系统无法识别提交者和对应的孩子。 , 需要提交者手动从学生列表中选择学生,比较麻烦。
如下图所示,我们已经设置了表单的公共链接。
6. 低代码实现——通过报表编辑器定义报表和仪表板
至此,与业务流程相关的核心功能和数据表格已经开发完毕。接下来,我们需要配置李校长的管理工作台,也就是仪表盘。通过类似于报表引擎的功能,配置了委托人的监控仪表盘,我们将其放置在“委托人控制台”的一级导航下,如下图:
该功能的使用与经典报表引擎类似,不再赘述。
7. 低代码实现-配置角色和权限
最后,我们设置角色和权限。我们设置了两个角色,“校长”和“老师”。
B端产品的权限管理包括两部分。功能权限决定了用户可以访问哪些菜单和按钮,数据权限决定了用户可以访问和操作的数据采集范围。一般通过组织树来实现。
下图为明道云数据权限配置管理整体图:
可以看出,对于每个角色,设计了不同表单视图的查看和编辑权限,属于功能权限。
点击每个表单末尾的设置按钮,还可以定义角色对表单的数据权限,包括是否允许处理所有数据,或者是自己和下属的数据,还是数据我拥有的(记得我们有调整过类的“所有者”吗?)还是我创建的数据?
您甚至可以为特定字段设置更精细的权限,如上图左下角的窗口所示。
完成以上配置后,我们的低代码平台开发工作就完成了。明道云应用系统无需发布,配置后立即生效。所有用户都需要注册一个明道云账号才能使用配置好的系统。配置的应用程序没有单独的应用程序。访问明道云官网登录后即可使用。手机版需要下载明道云APP登录后使用。
最后,给大家展示一下移动版应用的截图。这些是自动生成的默认设计,未经调整。
三、低代码平台的本质
通过上面的例子,相信大家对低代码平台的能力有了直观的感受。
软件产品设计的标准结构是MVC模型,即Model(数据)、Controller(逻辑)和View(交互界面)。低代码平台通过几个核心组件完成了MVC三层架构模型。支持,对应MVC模型,三个核心组件分别是数据模型设计器(对应Model)、流程设计器(对应Controller)、页面设计器(包括报表设计器,对应View)。
1. 数据模型设计师
数据模型设计实现了底层数据对象的定义。正如我们之前提到的,不同的低代码平台有不同的实现数据对象定义的方式。
实现数据模型设计器的第一种方法是通过对象编辑器实现数据定义。这种方法具有最高程度的灵活性。将底层数据模型与前端视图分离,模型聚焦底层,视图是可视化呈现。
国外的低代码平台Mendix和国内的华为云AppCube都采用这种方式。此外,大型商业软件的低代码平台也采用相同的设计,例如SalesForce和范向。
下图是Mendix的对象编辑器,在Mendix中称为Domain Model。事实上,领域模型和对象编辑都属于面向对象编程的概念。严格来说,领域模型与我们之前提到的ER模型并不完全相同。领域模型具有面向对象编程的特点,如泛化和聚合。这些概念不在 ER 模型中。
另外,图中显示的是Mendix的Windows客户端版本。除了 Web 版本,Mendix 还提供了更强大的 Windows 客户端。经过简单的体验,这个客户端更像是在开发一个集成编辑器IDE(程序员编写代码的软件平台)。 Mendix 本身也很强大,当然更难学。
国外另一款知名的aPaaS产品Outsystems也采用了底层对象驱动的设计,同时也提供了windows版本的客户端。安装后,有一步一步的教程,太棒了!整套IDE风格的产品设计也非常强大,令人印象深刻!
华为云的AppCube好像是对象编辑器的设计方法,但是因为我的试用申请没有通过,只是通过帮助文档猜测了一下,无法具体体验,如下图:
数据模型设计的第二个实现是表单引擎。
对于设计师来说,只需要将底层的数据对象理解为Excel的多个独立表格,每个表格都采用采集data的形式。用户定义数据模型,只需要以采集control的形式定义数据即可。
比如下图就是一个适合钉钉的表单编辑器。设计思路与明道云相似。表单编辑器将底层数据设计和可视化呈现打包在一起,非技术人员更容易理解,但也失去了前后端分离的灵活性。
2. 流程设计师
定义底层数据后,下一步就是定义工作流。对于商业软件产品,工作流是支撑商业运作的核心。业务运营的本质是每个工作流的执行。
浅层工作流是一种类似于Workflow的审批流程,是对单个数据对象的处理;深层次的工作流需要能够支持流程中多个数据实体的自动化处理。后者是低代码产品的核心功能之一。如果你没有后者的能力,除了问卷之外,基本上没有系统可以搭建。
过程中多个数据实体的自动处理是什么?
例如,在销售 CRM 系统中,当潜在客户的状态变为已验证时,它需要自动生成商机记录以进行跟踪并将商机分配给适当的销售。同时,对应的联系人记录和客户记录、商机、联系人、客户的部分字段数据来自牵头实体。
此业务逻辑规则需要复杂的工作流编辑器才能实现。在这个自动化流程中,添加、删除、修改和检查四个实体数据(线索、商机、客户和联系人)。
下图显示了 Windows 客户端版本 Mendix 中的流程编辑器。
下图为国货钉钉一的工作流程编辑器。似乎太简单了。它只是一个审批流程编辑器。或者我还没有找到功能齐全的配置界面?
3. 页面设计师
对于商业软件产品,主要功能是数据的增删改查,涉及的交互页面多为底层数据对象对应的列表页面和详情页面。此外,它还包括报告和仪表。磁盘和其他类型的页面。
页面设计师的设计理念清晰地体现了不同低代码平台的产品理念。总的来说,可以概括为两种。
1)纯前端页面编辑器
包括报告、列表、视图和表单,所有这些都在这个集成的页面编辑器中实现。比如Outsystems的页面编辑器,如下图:
如你所见,这是一套复杂的前端交互组件设计器,包括类似于数据表集合Table Records的集成控件,以及表单控件Form,以及其他类型的控件集合,例如复选框。复选框、单选按钮等
在这组编辑器中,操作员可以定义各种类型的前端页面,例如列表页面、详细信息页面、报表和仪表板。再比如Mendix的页面编辑器,设计思路相同,如下图:
甚至仪表板也是在同一个页面编辑器中实现的。下图展示了 Mendix 的仪表盘演示:
低代码平台的报表设计器组件与传统报表引擎没有太大区别。它基于底层数据,实现前端的可视化输出,包括表格输出和图形输出。以上是第一个前端交互设计的产品形态。可见其功能强大且灵活,学习成本相对较高。
2)大大简化的页面配置器
The template configuration of different types of pages is mainly divided into the following categories.
Of course, low-code products will also provide the configuration of the integrated page, but the function is much weaker than the function mentioned above. The previous article has described the view editor of Mingdaoyun a lot, so I won't repeat it.
The picture below is the page editor of Yidao, which shows the editing of the homepage of a certain system. Compared with Mingdaoyun, Yidao's page editor is more complicated and has more powerful functions.
Another example, the following picture is a suitable report editor:
Data model designer, process designer and page designer are the core of low-code platform. If you understand the MVC layered architecture of software design, it is easy to understand the core product functions of low-code platform and different products Ideas. Of course, different low-code platforms have more powerful features with their own characteristics, and interested readers can study further.
四、结语
It can be seen that different low-code platforms have different design ideas.
There is a trade-off between product ease of use and product flexibility. For example, for the bottom layer of the data, should I choose form-driven design or domain-driven design?两者有很大的不同。 The latter is basically unavailable to non-technical personnel. Although the former is easy to learn and understand, its function is indeed much weaker.
Therefore, low-code platforms must clarify the target user group. Is it a professional development aid tool for ISVs or IT teams, or an enhanced efficiency tool for non-technical personnel? The former is more like a super plug-in package of IDE, and the latter is more like a super easy-to-use version of Excel + VBA.
For the B-side product manager, experiencing low-code products similar to Mingdaoyun is very beneficial to understanding software design. Whether it is forms, processes, or rights management, all core product design issues will be involved To, and can deepen understanding.
In addition, in case the business has a large demand and the R&D is not scheduled, you can use aPaaS to configure it in 3 hours. Who will not give you the annual CEO special award?
#专栏作家#
Yang Kun, public account: PM Yang Kun (ID: pmYangKun). Everyone is a product manager columnist, author of "Determining the B-side", 12 years of Internet R&D and product design experience, former VIPKID product director, Baidu senior product manager, and now the founder and CEO of Manku Consulting.
This article 原创 is published in Renren is a product manager, reprinting without permission is prohibited
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
一人奖励
查看全部
幼儿园健康上报系统演示如何用低代码平台快速搭建一套应用系统
简介:本文基于作者虚构的《幼儿园健康报告系统》,演示了如何使用低代码平台快速搭建应用系统,并介绍和演示了一些国内外知名的aPaaS产品, Mendix、Outsystems、Yidah、明道云等在产品设计中尝试探索低代码平台的核心精髓,让大家对低代码有更直观的认识。
在案例开始之前,先说一下基本概念。
一、什么是低码
低代码平台是继众泰之后的另一个热门话题。事实上,低代码本身并不是什么新鲜话题,也不是最近的技术突破和创新。它已经存在了十多年或二十多年。概念。早期的大型管理软件套件都有类似拖放式的快速开发平台,这使得技术人员更容易在不编写代码的情况下快速实现某些基本功能。
虽然现在低代码被称为aPaaS,但它似乎是一种PaaS,似乎与SaaS密切相关,但大家需要认识到,低代码开发平台并不是一个概念,仅仅因为SaaS ,但远古时期已经存在。
简单来说,低代码平台就是期望通过拖放配置实现一套面向业务的软件系统,并且可以无缝部署和运行的开发平台。在这个过程中,当然允许编写部分代码,但更重要的是,大量的基础编码工作可以通过低代码平台快速自动化。
低代码的第一个应用场景是帮助成熟的软件产品,以低成本支持个性化需求,提高开发速度,甚至扩大客户群。
例如,许多成熟的商业软件(包括私有化的商业软件套件和SaaS形式的产品)都希望通过构建低代码平台来加强产品扩展能力,更好更快地服务客户,并与ISV合作将产品的目标客户群扩展到更广泛的领域和行业。
在这种情况下,低代码平台是低成本、高效地满足个性化需求的终极解决方案。此时,低代码目标用户可能包括工程师和实施顾问。国外SAP、Oracle、SalesForce、国内用友、金蝶、北森、Salesease等都有以自有软件产品为基础核心的低代码解决方案。
低代码的第二个应用场景是帮助甲方企业以低成本快速搭建新的应用系统,特别是对于不懂编程的业务人员,让企业以更低的成本享受。数字技术为企业带来的好处。
事实上,企业中的大量应用系统都是基于流程的。对于逻辑相对简单、流程链不复杂的业务场景,寻找打包软件支持矫枉过正,外包开发独立系统成本高,那么低代码平台可能是不错的选择。此时,低代码平台的目标用户可能包括甲方企业的业务人员或IT人员。
国外OutSystems和Mendix,国内的明道云、氚云,都属于这种情况。需要注意的是,目前国内一些报表平台和流程引擎厂商为了跟上热情,也自称低代码平台。严格来说,这些厂商提供的产品能力只是一个完整的低代码平台所需能力的一个子集,不能算是低代码产品。
讲了这么多概念,我想大家对低代码的印象还是比较模糊的。接下来,我将通过一个案例,带大家体验一个低代码产品的使用。在开始之前,还有几个问题需要强调一下:
低代码只是应用系统构建实现层面的工具,软件产品设计中的思维和建模过程是核心,所以我们的案例会花一部分笔墨来描述设计过程,理解之后再学习应用low code 平台会简单很多。我选择明道云作为演示产品:第一,因为它更容易上手;第二,因为明道云的老板任向辉喜欢写公众号分享,我很喜欢他的文章,作为致敬,所以选择明道云。需要说明的是,本人与明道云没有任何关系,试用期间也没有添加销售。我从帮助手册中学习并操作了整个试用期。学习明道云大约花了一个小时(主要是看帮助文件),在电脑上实现案例中的功能大约花了两个小时。整体非常好用,好用。不过这也可能是因为之前做过研发,比较容易理解很多基本概念。
好的,接下来,让我们进入案例。
二、小龟鼠幼儿园低代码应用1.需求调研
李校长是小豚鼠幼儿园的校长。最近,她遇到了一件烦心事。根据教委统一要求,疫情期间,要求家长每天报告孩子的健康状况。学校统一管理,但教委没有提供统一的技术支持。 .
为了实现这个需求,幼儿园老师想尽了办法,比如使用微信群管理,或者在线文档管理,但都不是很方便,比如无法实时统计,数据容易被误操作。而如果找软件公司帮忙搭建一个小系统,要花3万到4万元。对于幼儿园来说,这是一笔不小的数目。
李校长的侄子小王是B端产品经理。他在闲聊中得知了李校长的问题,想了想问道:
小王:阿姨,你说的,说不定我可以帮忙,搭建一个软件系统,你的问题就可以很好的解决了!
李校长:真的,太好了,但我们没有很多预算!
小王:不花你一分钱,我免费帮你做,但我想先了解一下你对这个业务管理的需求和期望。
李校长:非常感谢!我的呼吁很简单。就是让父母每天都来检查。如果有任何健康异常,我可以第一时间收到提醒,也可以让老师跟进,看看是什么问题。另外,最好有一些实时报告,让我看到最新的健康报告。
小王:来吧,我明白了,这件事交给我,我帮你设计一套操作流程和配套系统,免费给你使用!
了解大体背景后,小王开始构思小豚鼠幼儿园儿童健康报告系统的设计。
李校长:太好了,期待!
2. 产品轮廓设计
小王了解了基本要求后,开始构思这套系统应该如何设计。首先梳理一下这个系统涉及的利益相关者,如下:
虽然业务流程本身很简单,但因为毕竟是从零开始搭建的管理系统,需要完成一些基础的数据准备工作。想了想,小王画了一张简洁的业务流程图,如下。
可以看出家长们都希望能够签到,一些基础数据要先维护好。按照常识,维护班级信息和学生信息是必要的。签到操作是针对学生的,因此签到信息必须与学生相关联。
另外,要求中提到,如果打卡温度异常,需要老师跟进。我们考虑生成一个待办事项并将其分配给老师。该待办事项与异常打卡记录相关。有了以上对业务的分析和思考,我们就可以画出业务背后的ER模型图(领域模型),如下图所示。
每个老师可以管理多个班级,每个班级只能由一名老师管理。每个班级可以有多个学生,每个学生有多个健康报告记录(签到记录),每个健康报告记录可以生成体温异常跟踪记录。
这些抽象的实体是我们要设计的健康报告系统的核心,因为check-in(健康报告)过程实际上只是对这些实体的数据进行增删改查。
3. 产品细节设计
接下来根据流程图,我们来思考一下系统实现的页面流程图:
除了这些页面级的操作要求,还有一些业务规则要求。例如,如果健康报告中的体温异常,则自动生成一个待跟进的任务,发送给学生的班主任,并推送消息给校长。
简而言之,我们会发现与业务运营相关的功能页面主要是ER实体(创建和编辑)的列表页面和详情页面,不同的用户对不同的页面、不同的数据有不同的权限。
经过整理分析,我们可以列出系统中涉及的相关页面,以及权限表如下(这里只是一个简单的说明,后面明道云会展示更全面详细的权限设计,包括数据权限管理设计方案):
经过上面的分析,虽然细节还没有完成,但我们对“幼儿园健康报告系统”的设计有了清晰的认识。接下来直接进入低代码平台的开发演示链接!
3. 低代码实现——通过工作表定义数据实体
首先我们来到明道云工作台,点击“添加应用”,新建一个应用“小豚鼠幼儿园”(已经在下图中)。
接下来,我们为 ER 模型中的四个实体创建工作表。下图为创建类实体的工作表编辑页面。
Worksheet 是明道云的概念。所谓的工作表实际上对应的是ER建模中的实体。工作表中的相关控件定义实体的字段。比如自增的“类ID”定义在类形式、字符串类型字段“类名”、枚举字段“状态”等。
通过表单呈现实体是一种易于理解的设计方法。实体背后的本质是所谓的“对象”和最终会转移到数据库中的表。在一些低代码平台中,管理实体是通过对象编辑器定义的。这是一个更灵活但更复杂的解决方案,我们稍后会介绍。
无论是表单编辑器还是对象编辑器,原理都是一样的,都是对提取的实体进行管理。对于非技术人员,表格可能更容易理解和接受。
在类窗体中有一个“学生”控件,它是一个关联的记录组件。因为班级和学生是一对多的关系,每个班级可以有多个学生,所以在班级的表格中,我们允许看到一个班级关联的所有学生的列表,这在B端很常见产品交互 一种设计形式。
实体之间所谓的一对多和多对多关系,反映了多个表之间的关联。班级和学生之间的一对多关系可以在设计器中轻松定义,如下所示:
实现关联后,表单与表单之间建立连接,详情页(单个表单数据的展示页)的展示也会自动完美完成。例如:下图是某类数据的详情页(PC版):
aPaaS平台会自动完成PC版和手机版的适配,格式可调。例如,上图为PC版课程详情页,下图为手机版:
4.低代码实现-通过视图编辑器定义数据列表展示
接下来我们依次完成“学生”、“健康报告”、“体温异常追踪”三个实体的表单配置。
在下图中,横向的“校园管理”和“校长控制台”可以理解为我们对系统配置的一级导航。四种垂直形式表示它们属于某个一级导航。每个表单右侧主区域中配置的列表视图是二级导航菜单。如下图所示,对于班级形式,定义了“All”、“Active Class”、“Graduated Class”和“My”。四个列表视图,即“校园管理”一级菜单下的四个二级菜单。
那么,什么是列表视图?
工作表只是定义了实体的特定字段。如何显示实体的列表数据?例如,如何以不同的形式呈现“类”列表数据?这需要一个视图编辑器!
在视图编辑器中,可以定义实体对应的多条数据的表格展示,包括列表数据的默认过滤条件、默认显示字段、默认字段排序,都可以易于定制,如上图所示。
在大部分自研B端产品中,列表页面(即视图)是最常见的功能页面,一般来说,这类页面是硬编码的,而不是通过类似的视图编辑器实现了这样的前端组件。在成熟的软件产品中,没有列表页面的概念,由视图编辑器处理,大大简化了编码工作。
如下图所示,我们为“Class”表单定义了四个视图,分别是“All”、“Effective Middle Class”、“Graduated Class”和“My”。截图显示了“Intermediate Class”视图的“Effective”默认搜索条件配置,可以看到我们已经设置了这个视图的默认查询条件,即“Status”字段为“Teaching”的所有类数据.
我们之前提到过,与“学生”记录的一对多关系是以“班级”形式建立的。在“学生”表格中,还有一个与“班级”表格的“班级ID”相关联的字段。 "字段完成一对多关系的定义。
但是,如果我们想在学生表单中显示班级的名称,在学生视图中显示班级的字段,我们该如何实现呢?
因为我们是建立一对多的关系,所以我们只定义了ID之间的关系。因此,如果要以“学生”形式显示“班级”的名称,则必须对变量引入进行特殊处理。其中,采用了一种称为“其他表字段”的设计方法。简单来说就是关联表的某个字段被引入并显示出来,如下图所示:
下面的红框定义了ID之间的关联,上面的红框介绍了在“Student”表单和视图中显示的“Class”表的“Name”字段。
在其他低代码产品中,这种诉求的解决方案是不一样的。
严格来说,表单只是数据对象的外部表现形式。根据软件设计MVC的分层概念,数据定义和前端呈现必须分层分离。对象编辑器严格定义了数据实体本身,如果表单或视图需要做多表连接来呈现其他相关表的一些字段,这是一个需要在可视化层面解决的问题。
因此,在很多更复杂的低代码产品中,所有的可视化部分都是基于页面编辑器,与底层数据定义无关。因为明道云产品,为了在很大程度上降低用户的学习成本,在数据底层集成了对象编辑器,在表现层集成了表单编辑器。
现在,让我们解决一个难题。如果我们想在学生视图中显示学生老师的名字,我们该怎么做?通过学生,你可以找到你的班级,但谁是班级的负责老师?如何定义?
一种方式是在“班级”表单中添加一个字段,可以关联到老师的账号,完成老师和班级的关系映射。在明道云,我们采取了另一种伎俩。校长需要将每个班级数据的所有者更改为特定的教师帐户,如下图所示。图中的“王老师”是“老师”的独立用户角色。
通过这个动作,实现了对班级负责教师的分配。接下来,使用前面提到的“其他表字段”功能,将这个字段值引入到其他表单对象中。
这样,某个班级的所有学生和学生的健康报告记录都可以追溯到主管老师,这对下一个要求的实现至关重要!
5. 低代码实现——通过流程编辑器定义业务流程和事件
回忆一下,有一个需求:如果健康报告中体温异常,会自动生成一个待跟进的任务,发送给学生班主任,并推送消息给校长。
如何实现这个需求?这使用了 aPaaS 平台中流程编辑器的非常核心和重要的功能。可以说流程编辑器是低代码平台的灵魂!
进一步准确描述上述要求:如果您添加或编辑“健康报告”表单数据,“体温是否正常”字段选择“否”,则自动状态为“待跟进”生成“温度异常跟踪”数据,并发送消息给校长和学生的老师。
在低代码平台下,可以使用流程编辑器来实现与上述类似的功能,自动触发执行,自动更新多表数据。我们来到流程编辑器,创建“上报体温异常触发后续任务记录”流程,如下图:
在图中,我们设计了三个流程节点。
第一个触发节点:定义当“健康报告”表单添加或更新数据时,如果发现“问题正常”字段等于“否”,则执行。第二个节点:当发现体温异常时,创建一条“体温异常追踪”数据,分配给上报记录学生的老师。第三个节点:发送应用内消息给校长和老师提醒处理,效果如下:
对于工作流创建的数据,创建者字段显示为工作流,如下图:
流程编辑器不是一个简单的工作流引擎。我们通常理解的工作流引擎,比如审批流,只是对单个数据对象的多节点处理。真正复杂的流程编辑器BPM需要对流程中不同的数据实体进行复杂的处理,这也是很多B端业务的核心处理逻辑和流程。
当然,明道云的流程编辑器有很多功能,如下图,我们不再赘述。
截至目前,还有一个核心功能我们还没有实现。家长如何报告数据?
一种方式是为每位家长开设一个账号,将账号与学生关联,家长登录系统,提交表格时默认提交相关学生的“健康报告”记录。
另一种方法是将“健康报告”表公开,任何人都可以提交。这样做的好处是不需要一一维护父账户。缺点是系统无法识别提交者和对应的孩子。 , 需要提交者手动从学生列表中选择学生,比较麻烦。
如下图所示,我们已经设置了表单的公共链接。
6. 低代码实现——通过报表编辑器定义报表和仪表板
至此,与业务流程相关的核心功能和数据表格已经开发完毕。接下来,我们需要配置李校长的管理工作台,也就是仪表盘。通过类似于报表引擎的功能,配置了委托人的监控仪表盘,我们将其放置在“委托人控制台”的一级导航下,如下图:
该功能的使用与经典报表引擎类似,不再赘述。
7. 低代码实现-配置角色和权限
最后,我们设置角色和权限。我们设置了两个角色,“校长”和“老师”。
B端产品的权限管理包括两部分。功能权限决定了用户可以访问哪些菜单和按钮,数据权限决定了用户可以访问和操作的数据采集范围。一般通过组织树来实现。
下图为明道云数据权限配置管理整体图:
可以看出,对于每个角色,设计了不同表单视图的查看和编辑权限,属于功能权限。
点击每个表单末尾的设置按钮,还可以定义角色对表单的数据权限,包括是否允许处理所有数据,或者是自己和下属的数据,还是数据我拥有的(记得我们有调整过类的“所有者”吗?)还是我创建的数据?
您甚至可以为特定字段设置更精细的权限,如上图左下角的窗口所示。
完成以上配置后,我们的低代码平台开发工作就完成了。明道云应用系统无需发布,配置后立即生效。所有用户都需要注册一个明道云账号才能使用配置好的系统。配置的应用程序没有单独的应用程序。访问明道云官网登录后即可使用。手机版需要下载明道云APP登录后使用。
最后,给大家展示一下移动版应用的截图。这些是自动生成的默认设计,未经调整。
三、低代码平台的本质
通过上面的例子,相信大家对低代码平台的能力有了直观的感受。
软件产品设计的标准结构是MVC模型,即Model(数据)、Controller(逻辑)和View(交互界面)。低代码平台通过几个核心组件完成了MVC三层架构模型。支持,对应MVC模型,三个核心组件分别是数据模型设计器(对应Model)、流程设计器(对应Controller)、页面设计器(包括报表设计器,对应View)。
1. 数据模型设计师
数据模型设计实现了底层数据对象的定义。正如我们之前提到的,不同的低代码平台有不同的实现数据对象定义的方式。
实现数据模型设计器的第一种方法是通过对象编辑器实现数据定义。这种方法具有最高程度的灵活性。将底层数据模型与前端视图分离,模型聚焦底层,视图是可视化呈现。
国外的低代码平台Mendix和国内的华为云AppCube都采用这种方式。此外,大型商业软件的低代码平台也采用相同的设计,例如SalesForce和范向。
下图是Mendix的对象编辑器,在Mendix中称为Domain Model。事实上,领域模型和对象编辑都属于面向对象编程的概念。严格来说,领域模型与我们之前提到的ER模型并不完全相同。领域模型具有面向对象编程的特点,如泛化和聚合。这些概念不在 ER 模型中。
另外,图中显示的是Mendix的Windows客户端版本。除了 Web 版本,Mendix 还提供了更强大的 Windows 客户端。经过简单的体验,这个客户端更像是在开发一个集成编辑器IDE(程序员编写代码的软件平台)。 Mendix 本身也很强大,当然更难学。
国外另一款知名的aPaaS产品Outsystems也采用了底层对象驱动的设计,同时也提供了windows版本的客户端。安装后,有一步一步的教程,太棒了!整套IDE风格的产品设计也非常强大,令人印象深刻!
华为云的AppCube好像是对象编辑器的设计方法,但是因为我的试用申请没有通过,只是通过帮助文档猜测了一下,无法具体体验,如下图:
数据模型设计的第二个实现是表单引擎。
对于设计师来说,只需要将底层的数据对象理解为Excel的多个独立表格,每个表格都采用采集data的形式。用户定义数据模型,只需要以采集control的形式定义数据即可。
比如下图就是一个适合钉钉的表单编辑器。设计思路与明道云相似。表单编辑器将底层数据设计和可视化呈现打包在一起,非技术人员更容易理解,但也失去了前后端分离的灵活性。
2. 流程设计师
定义底层数据后,下一步就是定义工作流。对于商业软件产品,工作流是支撑商业运作的核心。业务运营的本质是每个工作流的执行。
浅层工作流是一种类似于Workflow的审批流程,是对单个数据对象的处理;深层次的工作流需要能够支持流程中多个数据实体的自动化处理。后者是低代码产品的核心功能之一。如果你没有后者的能力,除了问卷之外,基本上没有系统可以搭建。
过程中多个数据实体的自动处理是什么?
例如,在销售 CRM 系统中,当潜在客户的状态变为已验证时,它需要自动生成商机记录以进行跟踪并将商机分配给适当的销售。同时,对应的联系人记录和客户记录、商机、联系人、客户的部分字段数据来自牵头实体。
此业务逻辑规则需要复杂的工作流编辑器才能实现。在这个自动化流程中,添加、删除、修改和检查四个实体数据(线索、商机、客户和联系人)。
下图显示了 Windows 客户端版本 Mendix 中的流程编辑器。
下图为国货钉钉一的工作流程编辑器。似乎太简单了。它只是一个审批流程编辑器。或者我还没有找到功能齐全的配置界面?
3. 页面设计师
对于商业软件产品,主要功能是数据的增删改查,涉及的交互页面多为底层数据对象对应的列表页面和详情页面。此外,它还包括报告和仪表。磁盘和其他类型的页面。
页面设计师的设计理念清晰地体现了不同低代码平台的产品理念。总的来说,可以概括为两种。
1)纯前端页面编辑器
包括报告、列表、视图和表单,所有这些都在这个集成的页面编辑器中实现。比如Outsystems的页面编辑器,如下图:
如你所见,这是一套复杂的前端交互组件设计器,包括类似于数据表集合Table Records的集成控件,以及表单控件Form,以及其他类型的控件集合,例如复选框。复选框、单选按钮等
在这组编辑器中,操作员可以定义各种类型的前端页面,例如列表页面、详细信息页面、报表和仪表板。再比如Mendix的页面编辑器,设计思路相同,如下图:
甚至仪表板也是在同一个页面编辑器中实现的。下图展示了 Mendix 的仪表盘演示:
低代码平台的报表设计器组件与传统报表引擎没有太大区别。它基于底层数据,实现前端的可视化输出,包括表格输出和图形输出。以上是第一个前端交互设计的产品形态。可见其功能强大且灵活,学习成本相对较高。
2)大大简化的页面配置器
The template configuration of different types of pages is mainly divided into the following categories.
Of course, low-code products will also provide the configuration of the integrated page, but the function is much weaker than the function mentioned above. The previous article has described the view editor of Mingdaoyun a lot, so I won't repeat it.
The picture below is the page editor of Yidao, which shows the editing of the homepage of a certain system. Compared with Mingdaoyun, Yidao's page editor is more complicated and has more powerful functions.
Another example, the following picture is a suitable report editor:
Data model designer, process designer and page designer are the core of low-code platform. If you understand the MVC layered architecture of software design, it is easy to understand the core product functions of low-code platform and different products Ideas. Of course, different low-code platforms have more powerful features with their own characteristics, and interested readers can study further.
四、结语
It can be seen that different low-code platforms have different design ideas.
There is a trade-off between product ease of use and product flexibility. For example, for the bottom layer of the data, should I choose form-driven design or domain-driven design?两者有很大的不同。 The latter is basically unavailable to non-technical personnel. Although the former is easy to learn and understand, its function is indeed much weaker.
Therefore, low-code platforms must clarify the target user group. Is it a professional development aid tool for ISVs or IT teams, or an enhanced efficiency tool for non-technical personnel? The former is more like a super plug-in package of IDE, and the latter is more like a super easy-to-use version of Excel + VBA.
For the B-side product manager, experiencing low-code products similar to Mingdaoyun is very beneficial to understanding software design. Whether it is forms, processes, or rights management, all core product design issues will be involved To, and can deepen understanding.
In addition, in case the business has a large demand and the R&D is not scheduled, you can use aPaaS to configure it in 3 hours. Who will not give you the annual CEO special award?
#专栏作家#
Yang Kun, public account: PM Yang Kun (ID: pmYangKun). Everyone is a product manager columnist, author of "Determining the B-side", 12 years of Internet R&D and product design experience, former VIPKID product director, Baidu senior product manager, and now the founder and CEO of Manku Consulting.
This article 原创 is published in Renren is a product manager, reprinting without permission is prohibited
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏
一人奖励
列表框最常用的规则化采集方法-无规则采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-06-07 07:02
无规则采集器列表算法介绍谈到过不要停止你的编程序使用规则化采集方法,很多时候手动采集难以过滤数据,让一些粗暴无效的数据源自动匹配产生新的数据。不过,这些脚本型采集脚本需要很多步骤,并且其速度缓慢,最主要的是很多用户不会。这里我们就将列表框最常用的规则采集方法展示给大家:任何多规则规则采集都需要遵循下面的原则:1.采集时不要停止编写这个采集脚本,因为采集操作会占用您的电脑,将导致您不想要的新数据不会被收集到您的数据库中。
2.如果有必要可以增加规则数量并使用不同的规则。3.可以使用excel添加额外的规则。方法/步骤1:标记大小:不要省略标记它们到新文件中一个好的习惯是:打开文件前先重命名。重命名程序本身仅仅是避免名字冲突,但是如果因此而造成误会,那就会造成严重后果了。只用“#”表示即将产生的文件,那么如果要发布这个firebug脚本,则它必须要包含firebug这个file。
2:顺序添加规则:在每一个代码块中都要添加规则并不是一个优秀的习惯。该习惯是在采集时切割段落,以方便用户点击。可以将规则本身打包到变量中作为参数传递,或者让规则本身继承,并通过创建等价元组相互访问相似性。不过在这一点上,selenium已经让我们作出了很好的尝试,但是它还有改进的空间。其实,我们可以在规则输入时创建一个双向锚定功能,可以更好地防止规则冲突,此处称之为“文本匹配”。
3:使用可读性高的规则注释。如果能让规则注释像文本一样容易阅读,那是最好不过了。为了避免繁琐的注释,编写规则时可以设置一个带有特殊字符的自动列表,如:。4:去除规则注释项。例如下面是网站列表在英文中的双音节注释:$name=%%$\...%%\n%%\_index2\_simple\_lazy..5:遵循代码优先级排序方式。
下面是google采集编写数据时的一个注意事项,if语句(条件满足时执行下一步)通常要优先于if语句,python保证python支持代码优先级排序。python中有一种算法python自带perl的perl规则,perl中代码优先级排序使用基于分词的算法。关键字包括:"...","...","...","'...',"'...'","..."python2.2perla_b_d_v_...!!!!!!!!!!!!!!!!!!!!!!!!!python-v'%s'python-v'%s''%s'python-v'%s''%''1'''python-v'%python-v'%'''\'\'\'','\''python-v'%'。 查看全部
列表框最常用的规则化采集方法-无规则采集器
无规则采集器列表算法介绍谈到过不要停止你的编程序使用规则化采集方法,很多时候手动采集难以过滤数据,让一些粗暴无效的数据源自动匹配产生新的数据。不过,这些脚本型采集脚本需要很多步骤,并且其速度缓慢,最主要的是很多用户不会。这里我们就将列表框最常用的规则采集方法展示给大家:任何多规则规则采集都需要遵循下面的原则:1.采集时不要停止编写这个采集脚本,因为采集操作会占用您的电脑,将导致您不想要的新数据不会被收集到您的数据库中。
2.如果有必要可以增加规则数量并使用不同的规则。3.可以使用excel添加额外的规则。方法/步骤1:标记大小:不要省略标记它们到新文件中一个好的习惯是:打开文件前先重命名。重命名程序本身仅仅是避免名字冲突,但是如果因此而造成误会,那就会造成严重后果了。只用“#”表示即将产生的文件,那么如果要发布这个firebug脚本,则它必须要包含firebug这个file。
2:顺序添加规则:在每一个代码块中都要添加规则并不是一个优秀的习惯。该习惯是在采集时切割段落,以方便用户点击。可以将规则本身打包到变量中作为参数传递,或者让规则本身继承,并通过创建等价元组相互访问相似性。不过在这一点上,selenium已经让我们作出了很好的尝试,但是它还有改进的空间。其实,我们可以在规则输入时创建一个双向锚定功能,可以更好地防止规则冲突,此处称之为“文本匹配”。
3:使用可读性高的规则注释。如果能让规则注释像文本一样容易阅读,那是最好不过了。为了避免繁琐的注释,编写规则时可以设置一个带有特殊字符的自动列表,如:。4:去除规则注释项。例如下面是网站列表在英文中的双音节注释:$name=%%$\...%%\n%%\_index2\_simple\_lazy..5:遵循代码优先级排序方式。
下面是google采集编写数据时的一个注意事项,if语句(条件满足时执行下一步)通常要优先于if语句,python保证python支持代码优先级排序。python中有一种算法python自带perl的perl规则,perl中代码优先级排序使用基于分词的算法。关键字包括:"...","...","...","'...',"'...'","..."python2.2perla_b_d_v_...!!!!!!!!!!!!!!!!!!!!!!!!!python-v'%s'python-v'%s''%s'python-v'%s''%''1'''python-v'%python-v'%'''\'\'\'','\''python-v'%'。
无规则采集器列表算法点击量的计算规则和分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-06-02 19:05
无规则采集器列表算法点击量的计算规则和分析
点击量,由特征向量与回传向量的一一对应关系决定。比如图像或者音频等等。特征向量可以直接从网络上下载,所以设计一个好的算法用量化特征,完全可以做到。比如,找一些短时记忆库,把过去的某个时间点各个人的评论提取出来,然后用量化特征训练一个特征提取器来提取。然后这个提取器训练好后,找两个规则把每个人的评论又归一化。
所以训练好后,采样至50万条,采样无数个item,用量化特征来训练。这样的代码基本没有任何限制。训练好,就上线看效果,新增到500万条左右,就可以用eagerexecution。如果超过2000万条,分析效果。按照一定的策略找出当前效果最好的,持续优化。
答主提到的应该是中文的语义量吧。像微博、qq、知乎这样的网站一般会收集所有用户评论的关键词,从而用特征提取方法或者相似度计算方法,获得用户词频信息。-我是但看了上面简单的计算方法,其实并不适用于对网站进行长尾挖掘,因为中文的词太长了,特征也很多。但是有一种办法是可以处理这种高关键词的短语问题。我之前尝试过去关注那些长尾关键词,把它转换成ai短语,然后用很多这样的网站去抓这些特征。
在现有的工具里面是可以找到这些网站的,直接在google图书,推荐google图书或者googleadwords联盟里面选择出来一些。 查看全部
无规则采集器列表算法点击量的计算规则和分析
无规则采集器列表算法点击量的计算规则和分析
点击量,由特征向量与回传向量的一一对应关系决定。比如图像或者音频等等。特征向量可以直接从网络上下载,所以设计一个好的算法用量化特征,完全可以做到。比如,找一些短时记忆库,把过去的某个时间点各个人的评论提取出来,然后用量化特征训练一个特征提取器来提取。然后这个提取器训练好后,找两个规则把每个人的评论又归一化。
所以训练好后,采样至50万条,采样无数个item,用量化特征来训练。这样的代码基本没有任何限制。训练好,就上线看效果,新增到500万条左右,就可以用eagerexecution。如果超过2000万条,分析效果。按照一定的策略找出当前效果最好的,持续优化。
答主提到的应该是中文的语义量吧。像微博、qq、知乎这样的网站一般会收集所有用户评论的关键词,从而用特征提取方法或者相似度计算方法,获得用户词频信息。-我是但看了上面简单的计算方法,其实并不适用于对网站进行长尾挖掘,因为中文的词太长了,特征也很多。但是有一种办法是可以处理这种高关键词的短语问题。我之前尝试过去关注那些长尾关键词,把它转换成ai短语,然后用很多这样的网站去抓这些特征。
在现有的工具里面是可以找到这些网站的,直接在google图书,推荐google图书或者googleadwords联盟里面选择出来一些。

