3.推荐算法产品框架基于算法和最小可行性(组图)
优采云 发布时间: 2021-08-04 21:363.推荐算法产品框架基于算法和最小可行性(组图)
本文从定义和框架入手,结合实际案例,简单而深刻地阐述了基于内容的推荐算法及其产品设计。
一、前言&定义
对于需要内容推荐的产品,可能很多像作者一样不是数据或算法类的产品同学无法下手。各种算法的基本原理和公式虽然网上都能搜到,但可能太专业了,或者直接呈现最终的逻辑,但是怎么做还是不知所措。我抛开理论和复杂的公式,直接从产品出发,设计一套从0到1的可行性最小的推荐算法能力。
什么是基于内容的推荐算法?
基于内容的推荐:核心思想是根据推荐项目或内容的元数据发现项目或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的项目。
简单的理解就是:根据用户过去喜欢的内容,为用户推荐与他过去喜欢的内容相似的内容。
二、算法整体架构描述1.明确算法目的
我们在开始推荐算法的时候,一定要明确初始阶段的目的:在保证内容质量的前提下,尽可能根据用户行为推荐满足用户期望的丰富内容。
这句话虽然很短,但收录了三个非常重要的关键词:内容的质量、内容的丰富性(多样性)、符合预期。
2.推荐算法整体逻辑
基于计算出的场景,我们可以很容易地找到推荐逻辑:当用户进行在线操作时,系统向后台发起用户数据召回请求,然后根据需要形成最终用户看到的内容排序模型,最终通过用户的请求完成并记录用户行为,用于后续的内容匹配。常见的计算如下:
虽然图片看起来有点复杂,但其实是三个核心:一套内容管理后端+多种加权算法+显示逻辑。
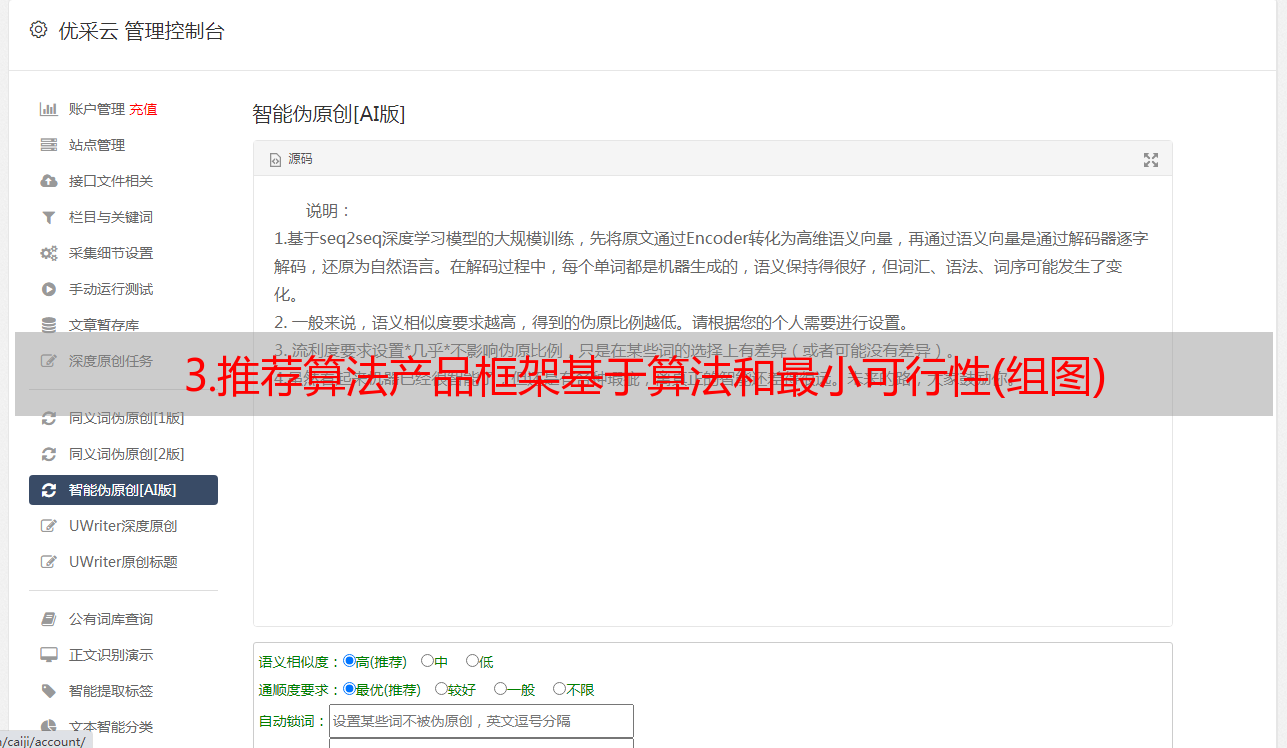
3.推荐算法产品框架
根据算法逻辑和最小可行性目的,我们可以梳理出一个简单的产品框架,如下图:
显然,算法推荐公式可以不用立即建立复杂的算法模型。只要有基本的用户管理和内容管理能力,结合内容质量权重和用户偏好权重,兼顾去中心化和时间效应,就可以做到根据用户推荐尽可能满足用户期望的丰富内容保证内容质量前提下的行为。
三、特定算法权重设计1.质量管理评分公式
质量总分Score是通过对三大模块的分数进行加权计算得出的,计算公式如下:
(系数可根据业务情况调整,从100)开始
其中A、B、C分别是三个模块的分数。分数是三个模块的分数乘以各自的系数。
每个模块的分数是通过对其多个评分指标和相应系数进行加权计算得出的。这是模块 A 的示例:
哪里
是模块A对应的各个指标的得分,
为各指标得分对应的权重系数。
A-内容流模块评分
内容流量反映了内容吸引流量的能力,以及初始产品推荐的核心人气权重:停留时间(退出率)>评论>喜欢>采集>PV/UV>转发。下表是一个案例:
B 内容质量模块评级
判断主要是根据后台内容的状态。在机器审核能力完全建立之前,这个模块会受到很大的人为影响。
附件:评分公式
目前推荐内容推荐评分算法采用贝叶斯平均评分方法。公式如下:
其中,n为当前内容的评分数,M为总内容的平均分,S为单个内容的总分,C为动态系数。
单项内容评分=(总内容平均分*C因素)+单品评分总和)/(当前内容评分数+C因素)
C系数是每个内容被评分的平均次数,即C=所有内容被评论的总次数/所有内容的次数。例如:一共1000条文章被评论了50000次,那么C就等于50000/1000=50。
小案例:
(贝叶斯平均法评价示例)
结论:基于贝叶斯平均的排名更能反映真实情况。分数越高分数越高的产品越先进,分数越多分数越低的产品越近。这个结果比仅仅根据每个产品的平均分来排序更有意义。
C 用户质量模块评级
用户质量由两个维度组成,基于后台人工识别用户属性和发帖质量。
2.用户偏好评分公式
用户行为记录是获取用户相关推荐的主要依据。初始阶段基于用户关注度、浏览偏好和用户搜索关键词。计算用户偏好。基本逻辑如下:
偏好分数=浏览偏好类别*0.6+关注内容*0.4 +搜索内容类别*0.0
(系数可根据业务情况调整,从100)开始
插图:
(1)通过用户浏览历史获取用户最喜欢的标签
然后根据公式为同类别下的内容增加偏好值。
(2)获取用户关注用户,获取采集标签
然后根据以下用户内容的公式增加偏好值。
(3)如果内容1属于类别A,由用户D创建,则该内容为用户添加两个权重值=查看内容类别*0.6+关注人内容*0.4
四、前端显示重量设计
通过质量分数和用户偏好分数,我们可以获得内容导向。根据不同用户的内容质量和偏好分数,可以得到一个简单的推荐逻辑(推荐列表):根据用户的偏好分数推荐质量分数较高的内容,如果分数相同则推荐以与内容创建时间相反的顺序。
但在实际推荐中,除了保证用户偏好外,还需要尝试去中心化的内容展示方式,所以最终展示的推荐内容应该来自三个模块:
A.用户偏好列表:通过用户偏好评分,为用户推荐优质内容。这是主要推荐的内容。
推荐逻辑:先根据用户偏好值从高到低对内容进行排序,然后在高于阈值的内容中随机推荐健康值高于阈值B、阈值C、阈值D的内容偏好值A,低于阈值D不推荐。
B.优质非采集列表:用户偏好值低于一定阈值但内容流量得分较高的内容。
C.初始流量推荐列表:通过用户偏好评分,推荐内容质量经过审核但流量较低的内容。
旧用户算法为:Score=A*0.7+B*0.2 +C*0.1(系数可根据业务情况调整)
0.7、0.2、0.1 数字A、B、C为三个模块的初始系数,受时间影响。
新用户的冷启动算法为:ScoreL= B*0.9 +C*0.1
B 模块直接调用流量池的健康评分。
注意:当偏好分数和健康值相同时,加载量是随机选择的,需要在同一轮加载中去除相同的信息。
1.时间效果计算方法
为了进一步去中心化和推荐精度,根据热冷却公式:
本期系数 = 上期系数 x exp(-(冷却系数) x 间隔小时数)。 T是初始热量,
这里默认是0.7,
前一段时间的温度,
是冷却系数,即间隔的小时数。
五、关于 A/B 测试
A/B 测试更需要计算推荐,因为我们无法知道初始化过程中具体的权重设置是否合理,但可以保证不会有垃圾推荐的流出,所以 A/ B 测试结果 对于优化权重尤其重要。用户被转移到相应的解决方案。在保证每组用户特征一致的前提下,基于用户真实的数据反馈,帮助产品决策。当然,随着测试样本数量的增加,对技术架构的挑战也越大。
六、尾声
如开头所说,本文算法是基于内容推荐算法理论公式的设计,是基于实际产品设计的。其核心是在保证内容质量的同时,根据用户行为,尽可能推荐满足用户期望的丰富内容。相当有限,适用于没有完整算法团队并进行最小可行实验的产品。希望文章能给像我这样没有算法基础的同学带来帮助和启发。耶鲁兹的产品令人伤心。欢迎大家交流。
本文由@jingtianz 原创发表,人人网是产品经理。未经许可禁止转载
标题图片来自Unsplash,基于CC0协议
奖励作者,鼓励他努力!
欣赏

