
python抓取动态网页
python抓取动态网页(:keep-alive:Mozilla/5.0(WindowsNT))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-11 17:07
主持人:
连接:保持活动
升级不安全请求:1
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,像 Gecko) Chrome/5< @7.0.2987.98 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8 Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4,zh-TW; q=0.2
提取请求头的重要部分,可以将代码改为:
3.3.3 发送POST请求
除了GET请求外,有时还需要发送一些以表单形式编码的数据。比如登录时,请求是POST,因为如果使用GET请求,会在URL中显示密码,非常不安全。如果要实现POST请求,只需要简单的给Requests中的data参数传入一个字典,请求时数据字典会自动编码为表单。
输出是:
{
“参数”:{},
“数据”:“”,
“表格”:{
"key1": "value1",
"key2": "value2"
},
…
}
可以看到form变量的值就是key_dict中输入的值,所以发送POST请求成功。
3.3.4 超时
有时爬虫会遇到服务器长时间不返回。这时候爬虫会一直等待,导致爬虫执行不顺畅。因此,可以使用 Requests 在 timeout 参数设置的秒数过去后停止等待响应。这意味着如果服务器在 timeout 秒内没有响应,则会返回异常。
让我们将此设置为 0.001 秒,看看抛出了什么异常。这是一个值设置,让大家体验超时异常的效果。一般将此值设置为 20 秒。
返回的异常是:ConnectTimeout: HTTPConnectionPool(host=' ',
port=80): 最大重试次数超出 url: / (由 ConnectTimeoutError(connection.HTTPConnection object at 0x0000000005B85B00>, 'Connection to timed out. (connect timeout=0.001)'))。
异常值表示,时间限制为0.001秒,连接地址的时间已到。
3.4请求爬虫练习:TOP250电影数据
本章练习项目的目的是获取豆瓣电影TOP250中所有电影的名字。网站地址是:。在这个爬虫中,请求头是根据实际浏览器定制的。
3.4.1 网站分析
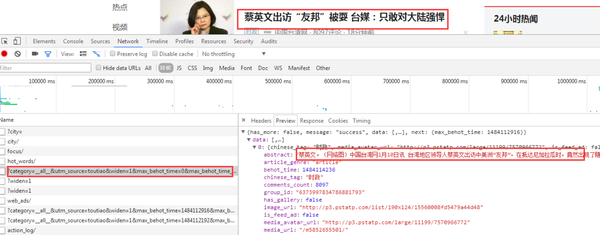
打开豆瓣电影TOP250的网站,使用“check”功能查看网页的请求头,如图3-4所示。
按照3.3.2中的方法提取重要的请求头:
首页只有 25 部电影,如果要获取全部 250 页的电影,则需要获取总共 10 页的内容。
点击第二页可以发现网页地址变成了:
第三页的地址是:,很容易理解。对于每增加一个页面,在网页地址的起始参数中添加 25。
3.4.2 项目实践
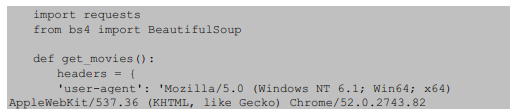
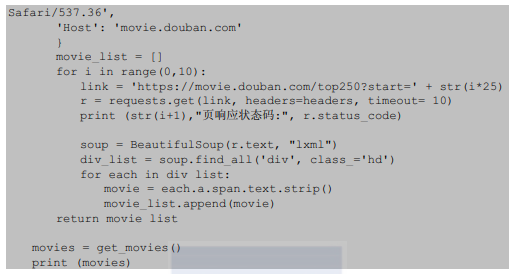
通过上面的分析发现可以使用requests获取电影网页的代码,使用for循环进行翻页。其代码如下:
运行上面的代码,结果是:
1页响应状态码:200
lang="zh-cmn-Hans">
豆瓣电影 250 强
...
此时,结果只是网页的 HTML 代码,我们需要从中提取所需的电影名称。接下来,第 5 章将涉及解析网页内容。读者可以先使用下面的代码。至于对代码的理解,可以等到第五章再学习。
在上面的代码中,BeautifulSoup 用于解析网页并获取其中的电影名称数据。运行代码,结果是:
1页响应状态码:200
2页响应状态码:200
3页响应状态码:200
4页响应状态码:200
5页响应状态码:200
6页响应状态码:200
7页响应状态码:200
8页响应状态码:200
9页响应状态码:200
10页响应状态码:200
[《肖申克的救赎》、《这个杀手不太冷》、《霸王别姬》、《阿甘正传》、《美丽人生》、《千与千寻》、《辛德勒的名单》、《泰坦尼克号》、 《盗梦空间》、《机器人总动员》、《海上钢琴师》、《宝莱坞三傻烦恼》、《八公的故事》、《牛班的春天》、《大圣西游》、《教父》 》、《龙猫》、《杜鲁门的世界》、《乱世佳人》、《天堂电影院》、《当幸福来敲门》、《触不可及》、《搏击俱乐部》、《十二怒汉》、 《无间道》、《熔炉》、《指环王:国王的劲敌》、《突破》、《天空之城》、《罗马假日》……]
3.4.3 个自习题
读者有时间可以练习进阶题:求TOP 250电影的英文名、港台名、导演、主演、上映年份、电影分级和评分。 查看全部
python抓取动态网页(:keep-alive:Mozilla/5.0(WindowsNT))
主持人:
连接:保持活动
升级不安全请求:1
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,像 Gecko) Chrome/5< @7.0.2987.98 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8 Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4,zh-TW; q=0.2
提取请求头的重要部分,可以将代码改为:

3.3.3 发送POST请求
除了GET请求外,有时还需要发送一些以表单形式编码的数据。比如登录时,请求是POST,因为如果使用GET请求,会在URL中显示密码,非常不安全。如果要实现POST请求,只需要简单的给Requests中的data参数传入一个字典,请求时数据字典会自动编码为表单。

输出是:
{
“参数”:{},
“数据”:“”,
“表格”:{
"key1": "value1",
"key2": "value2"
},
…
}
可以看到form变量的值就是key_dict中输入的值,所以发送POST请求成功。
3.3.4 超时
有时爬虫会遇到服务器长时间不返回。这时候爬虫会一直等待,导致爬虫执行不顺畅。因此,可以使用 Requests 在 timeout 参数设置的秒数过去后停止等待响应。这意味着如果服务器在 timeout 秒内没有响应,则会返回异常。
让我们将此设置为 0.001 秒,看看抛出了什么异常。这是一个值设置,让大家体验超时异常的效果。一般将此值设置为 20 秒。

返回的异常是:ConnectTimeout: HTTPConnectionPool(host=' ',
port=80): 最大重试次数超出 url: / (由 ConnectTimeoutError(connection.HTTPConnection object at 0x0000000005B85B00>, 'Connection to timed out. (connect timeout=0.001)'))。
异常值表示,时间限制为0.001秒,连接地址的时间已到。
3.4请求爬虫练习:TOP250电影数据
本章练习项目的目的是获取豆瓣电影TOP250中所有电影的名字。网站地址是:。在这个爬虫中,请求头是根据实际浏览器定制的。
3.4.1 网站分析
打开豆瓣电影TOP250的网站,使用“check”功能查看网页的请求头,如图3-4所示。
按照3.3.2中的方法提取重要的请求头:

首页只有 25 部电影,如果要获取全部 250 页的电影,则需要获取总共 10 页的内容。
点击第二页可以发现网页地址变成了:
第三页的地址是:,很容易理解。对于每增加一个页面,在网页地址的起始参数中添加 25。
3.4.2 项目实践
通过上面的分析发现可以使用requests获取电影网页的代码,使用for循环进行翻页。其代码如下:

运行上面的代码,结果是:
1页响应状态码:200
lang="zh-cmn-Hans">
豆瓣电影 250 强
...
此时,结果只是网页的 HTML 代码,我们需要从中提取所需的电影名称。接下来,第 5 章将涉及解析网页内容。读者可以先使用下面的代码。至于对代码的理解,可以等到第五章再学习。
在上面的代码中,BeautifulSoup 用于解析网页并获取其中的电影名称数据。运行代码,结果是:
1页响应状态码:200
2页响应状态码:200
3页响应状态码:200
4页响应状态码:200
5页响应状态码:200
6页响应状态码:200
7页响应状态码:200
8页响应状态码:200
9页响应状态码:200
10页响应状态码:200
[《肖申克的救赎》、《这个杀手不太冷》、《霸王别姬》、《阿甘正传》、《美丽人生》、《千与千寻》、《辛德勒的名单》、《泰坦尼克号》、 《盗梦空间》、《机器人总动员》、《海上钢琴师》、《宝莱坞三傻烦恼》、《八公的故事》、《牛班的春天》、《大圣西游》、《教父》 》、《龙猫》、《杜鲁门的世界》、《乱世佳人》、《天堂电影院》、《当幸福来敲门》、《触不可及》、《搏击俱乐部》、《十二怒汉》、 《无间道》、《熔炉》、《指环王:国王的劲敌》、《突破》、《天空之城》、《罗马假日》……]
3.4.3 个自习题
读者有时间可以练习进阶题:求TOP 250电影的英文名、港台名、导演、主演、上映年份、电影分级和评分。
python抓取动态网页(利用Python方法来抓取某网站分享页面中的源码方法示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-10 23:03
这个文章是关于使用Python方法在一个网站分享页面中捕获源代码方法示例。需要注意的是,Python爬取分享页面的源码示例只有在运行时导入BeautifulSoup.py文件后才能使用。
Python爬取分享页面源码示例需要使用python urllib2模块方法和BeautifulSoup模块。
源码如下:
#coding:utf-8
import urllib2
from BeautifulSoup import BeautifulSoup
'''
www.iplaypy.com
'''
#define
def readPage(Url):
page = urllib2.urlopen(Url).read()
pageContent = BeautifulSoup(page)
OSC_Content = pageContent.find("div",{'id':'OSC_Content'})
preHandleCode = OSC_Content.find('pre').next
print preHandleCode
'''
页面的url需指定
'''
#call
readPage('http://www.xxxxxx.net/code/sni ... %2339;)
这里的目标网站已被隐藏。可以参考这个python源码根据你要抓取的目标站进行适当的修改。 查看全部
python抓取动态网页(利用Python方法来抓取某网站分享页面中的源码方法示例)
这个文章是关于使用Python方法在一个网站分享页面中捕获源代码方法示例。需要注意的是,Python爬取分享页面的源码示例只有在运行时导入BeautifulSoup.py文件后才能使用。
Python爬取分享页面源码示例需要使用python urllib2模块方法和BeautifulSoup模块。
源码如下:
#coding:utf-8
import urllib2
from BeautifulSoup import BeautifulSoup
'''
www.iplaypy.com
'''
#define
def readPage(Url):
page = urllib2.urlopen(Url).read()
pageContent = BeautifulSoup(page)
OSC_Content = pageContent.find("div",{'id':'OSC_Content'})
preHandleCode = OSC_Content.find('pre').next
print preHandleCode
'''
页面的url需指定
'''
#call
readPage('http://www.xxxxxx.net/code/sni ... %2339;)
这里的目标网站已被隐藏。可以参考这个python源码根据你要抓取的目标站进行适当的修改。
python抓取动态网页(什么是HTML静态生成的内容?如何对网页进行爬取呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-10 18:08
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
这里只介绍第一种方法。有专门的文章介绍 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:/api/pc/focus/
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
和往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
python抓取动态网页(什么是HTML静态生成的内容?如何对网页进行爬取呢?
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:

网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
这里只介绍第一种方法。有专门的文章介绍 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:

原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:/api/pc/focus/

返回一串乱码,但从响应中查看正常编码数据:
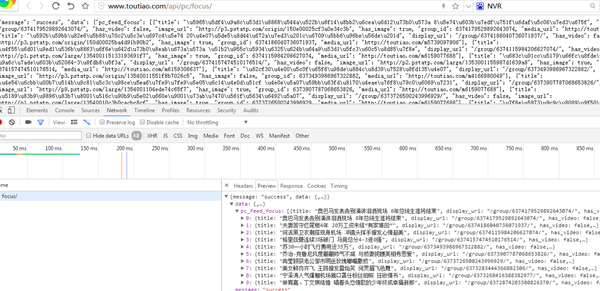
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
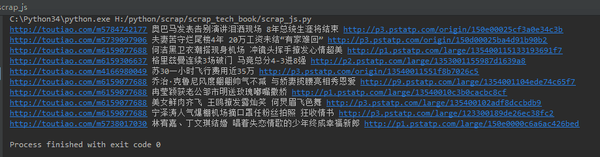
和往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
python抓取动态网页(Python软件工具和2020最新入门到实战教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-09 13:12
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020年最新入门实用教程。加群695185429免费获取。
5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8 谷歌浏览器 Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open Brainstorm 网站 (#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
结果如下:
注意三点:
1、添加延迟命令(time.sleep(5)),否则可能出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。 查看全部
python抓取动态网页(Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020年最新入门实用教程。加群695185429免费获取。
5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8 谷歌浏览器 Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open Brainstorm 网站 (#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
结果如下:
注意三点:
1、添加延迟命令(time.sleep(5)),否则可能出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。
python抓取动态网页( 爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-07 16:06
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页其实就是通过URL获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python提供了一个第三方模块requests来抓取网页信息。requests 模块称自己为“HTTP for Humans”,字面意思是专门为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表10-1 requests模块的Request函数
2.获取回复
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用表格列出Response类可以获取的信息,如表10-2所示。
表10-2 Response类的常用属性
接下来通过一个案例来演示如何使用requests模块来获取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
上面代码中,第二行使用import导入requests模块;第三至第四行代码根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第五行至第六行代码打印响应内容的状态码和编码方式;第7行将响应内容的编码方式改为“utf-8”;第 8 行打印响应内容。运行程序,程序输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块抓取网页时,可能会因未连接网络、服务器连接失败等原因产生各种异常,最常见的两个异常是URLError和HTTPError。这些网络异常可以用 try...except 语句捕获和处理。 查看全部
python抓取动态网页(
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)

爬取网页其实就是通过URL获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python提供了一个第三方模块requests来抓取网页信息。requests 模块称自己为“HTTP for Humans”,字面意思是专门为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表10-1 requests模块的Request函数

2.获取回复
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用表格列出Response类可以获取的信息,如表10-2所示。
表10-2 Response类的常用属性

接下来通过一个案例来演示如何使用requests模块来获取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
上面代码中,第二行使用import导入requests模块;第三至第四行代码根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第五行至第六行代码打印响应内容的状态码和编码方式;第7行将响应内容的编码方式改为“utf-8”;第 8 行打印响应内容。运行程序,程序输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块抓取网页时,可能会因未连接网络、服务器连接失败等原因产生各种异常,最常见的两个异常是URLError和HTTPError。这些网络异常可以用 try...except 语句捕获和处理。
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-07 12:00
2、 然后在首页点击【创建图书】-->【微信相册】。
4、 之后,耐心等待微信本的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、 扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
, 等待Scrapy爬虫项目生成。
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、执行以上两步后的文件夹结构如下:
三、分析网络数据
2、 点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图所示:
可以看到Moments的数据存放在paras /data节点下。
至此,网络分析和数据的来源已经确定。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘 查看全部
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
2、 然后在首页点击【创建图书】-->【微信相册】。
4、 之后,耐心等待微信本的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、 扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
, 等待Scrapy爬虫项目生成。
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、执行以上两步后的文件夹结构如下:
三、分析网络数据
2、 点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图所示:
可以看到Moments的数据存放在paras /data节点下。
至此,网络分析和数据的来源已经确定。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-05 00:11
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。对于json序列化和反序列化,可以点击Python解析库Json和Jsonpath Pickle的实现来学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源码时出现错误,请按照步骤获取新的请求地址。 查看全部
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:

或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。

查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。

根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。对于json序列化和反序列化,可以点击Python解析库Json和Jsonpath Pickle的实现来学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:

注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
python抓取动态网页(Python爬虫使用Selenium+PhantomJSAjax和动态HTML内容》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-04 19:07
1 简介
在上一篇《Python爬虫:爬取Drupal论坛帖子列表》中,爬取了一个用Drupal制作的论坛。它是一个静态页面。爬行更容易。即使直接解析html源文件,也能抓取到自己需要的内容。. 相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们在《Python爬虫使用Selenium+PhantomJS捕获Ajax和动态HTML内容》一文中测试了动态网页内容的爬取方法。代码变得非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。需要时间来节省时间。节省时间的问题在《1分钟快速生成网页内容提取的xslt》一文中已经解决。在本文中,我们使用京东网站作为测试对象,电子商务网站有很多动态内容,比如商品价格、评论数等,经常使用post-加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中。当程序运行时,文件被读出并注入到 gsExtractor 提取器中。后续会有特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码
源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上面的代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,我们会看到如下内容。
五、相关文件
1. Python Instant Web Crawler 项目:内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修订历史
1, 2016-06-11: V1.0 查看全部
python抓取动态网页(Python爬虫使用Selenium+PhantomJSAjax和动态HTML内容》)
1 简介
在上一篇《Python爬虫:爬取Drupal论坛帖子列表》中,爬取了一个用Drupal制作的论坛。它是一个静态页面。爬行更容易。即使直接解析html源文件,也能抓取到自己需要的内容。. 相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们在《Python爬虫使用Selenium+PhantomJS捕获Ajax和动态HTML内容》一文中测试了动态网页内容的爬取方法。代码变得非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。需要时间来节省时间。节省时间的问题在《1分钟快速生成网页内容提取的xslt》一文中已经解决。在本文中,我们使用京东网站作为测试对象,电子商务网站有很多动态内容,比如商品价格、评论数等,经常使用post-加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中。当程序运行时,文件被读出并注入到 gsExtractor 提取器中。后续会有特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码

源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上面的代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,我们会看到如下内容。

五、相关文件
1. Python Instant Web Crawler 项目:内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修订历史
1, 2016-06-11: V1.0
python抓取动态网页(人学都是从基础学起学习哪里?学着路你需要掌握什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-04 13:11
很多学Python的人都想掌握爬虫,我想我世界上有爬虫。但是太多的人从基础开始,他们不知道从哪里学习。为此,发布了一个特殊的爬虫相关内容。
我们先来了解一下爬虫流程:发送请求-获取页面-解析页面-提取并存储内容供爬取。这模拟了使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析页面后,我们可以提取一些我们想要的信息,并存储在我们开发的文档和数据中。.
接下来,就来看看掌握爬虫之路需要具备哪些条件。
一、零基础阶段
从一个编程新手系统的介绍开始,我开始接触爬虫。事实上,爬虫比必要的理论知识更实用。那么主流的网站数据抓取能力就是现阶段要学习的内容。
爬虫所需的计算机网络/前端/常规//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、反爬、验证码识别等难点详细说明;多线程、多进程等常见应用场景讲解。
(1)准备
首先是下载Python,可以下载最新版本。二是需要准备运行环境,可以选择PyChram;
(2)教程
尝试找到适合您的教程,并尝试成为具有配套课程材料源代码的那种。不过记得把代码打一次,然后再看源码,发现自己的问题。
二、主流框架
爬虫框架主要是Scrapy实现海量数据抓取,从原生爬虫到框架能力,这是一个改进阶段,如果能开发出分布式爬虫系统,基本符合python爬虫的定位。海量数据高效获取,外包。
本阶段主要学习内容:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统讲解;Scrapy 突破了反爬虫和 Scrapy 原理的限制;Scrapy 更高级的功能包括scrapy 信号和定制中间件;现有海量数据结合Elasticsearch打造搜索引擎。
不要觉得学习scrapy的基础知识很困难。学scrapy的基础很快,因为demo很多,但是实际爬虫不容易,因为robots.txt禁止爬虫是有原因的。
所以基本的爬虫很简单,但是反爬虫就没有那么容易了。
三、真正的爬虫
深度的APP数据抓取也是为了提高你的爬虫响应APP数据抓取的能力和数据可视化能力,扩展你的业务能力,提升你的市场竞争力。
所以爬行是一步,可视化是另一部分。
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习与实践掌握App爬取技巧;构建基于Docker的多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基本图形、地图等,实现数据可视化。
其实爬虫可以应用在很多领域,爬虫也是数据分析市场调研的主要步骤。更先进的是机器学习,原创数据的挖掘。
其实从爬虫开始学习Python也是非常推荐的一种方式,因为有了目标就更容易找到学习重点。 查看全部
python抓取动态网页(人学都是从基础学起学习哪里?学着路你需要掌握什么)
很多学Python的人都想掌握爬虫,我想我世界上有爬虫。但是太多的人从基础开始,他们不知道从哪里学习。为此,发布了一个特殊的爬虫相关内容。
我们先来了解一下爬虫流程:发送请求-获取页面-解析页面-提取并存储内容供爬取。这模拟了使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析页面后,我们可以提取一些我们想要的信息,并存储在我们开发的文档和数据中。.
接下来,就来看看掌握爬虫之路需要具备哪些条件。
一、零基础阶段
从一个编程新手系统的介绍开始,我开始接触爬虫。事实上,爬虫比必要的理论知识更实用。那么主流的网站数据抓取能力就是现阶段要学习的内容。
爬虫所需的计算机网络/前端/常规//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、反爬、验证码识别等难点详细说明;多线程、多进程等常见应用场景讲解。
(1)准备
首先是下载Python,可以下载最新版本。二是需要准备运行环境,可以选择PyChram;
(2)教程
尝试找到适合您的教程,并尝试成为具有配套课程材料源代码的那种。不过记得把代码打一次,然后再看源码,发现自己的问题。
二、主流框架
爬虫框架主要是Scrapy实现海量数据抓取,从原生爬虫到框架能力,这是一个改进阶段,如果能开发出分布式爬虫系统,基本符合python爬虫的定位。海量数据高效获取,外包。
本阶段主要学习内容:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统讲解;Scrapy 突破了反爬虫和 Scrapy 原理的限制;Scrapy 更高级的功能包括scrapy 信号和定制中间件;现有海量数据结合Elasticsearch打造搜索引擎。

不要觉得学习scrapy的基础知识很困难。学scrapy的基础很快,因为demo很多,但是实际爬虫不容易,因为robots.txt禁止爬虫是有原因的。
所以基本的爬虫很简单,但是反爬虫就没有那么容易了。
三、真正的爬虫
深度的APP数据抓取也是为了提高你的爬虫响应APP数据抓取的能力和数据可视化能力,扩展你的业务能力,提升你的市场竞争力。
所以爬行是一步,可视化是另一部分。
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习与实践掌握App爬取技巧;构建基于Docker的多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基本图形、地图等,实现数据可视化。
其实爬虫可以应用在很多领域,爬虫也是数据分析市场调研的主要步骤。更先进的是机器学习,原创数据的挖掘。
其实从爬虫开始学习Python也是非常推荐的一种方式,因为有了目标就更容易找到学习重点。
python抓取动态网页(2.利用selenium+phantomJS模拟浏览器来抓取动态(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 01:10
网页分为静态网页和动态网页。静态网页就是我们平时爬取的网页,但也有一些网页来自动态网页。比如今日头条的网站就是动态的。遵循静态网页的方法。爬行是不可能的。所以我们要学习如何从动态网页中提取信息。
网页抓取主要有两种方式:
1.找到动态网页的请求地址
2.使用selenium+phantomJS模拟浏览器抓取动态网页
今天讲第一种方法,后面会写一篇文章文章讲解第二种方法。
(提示:这里有个福利:关注转发后可以私聊获取python基础、python web开发、python爬虫、机器学习、数据挖掘、深度学习等信息)
今天的内容主要包括几个方面:
如何区分静态网页和动态网页-如何获取动态网页的真实请求地址-一个简单的动态网页抓取示例
下面解释:
1.如何区分静态网页和动态网页
有两个主要区别:
首先看网页是否有语法;
其次看网页中的内容是否与网页框架中的内容相匹配。
如何打开网页的语言代码?
方法:(1)按[win+F12]会弹出一个页面(2)在弹出的页面中找到[元素],点击查看网页语法代码。< /@1) p>
静态网页识别示例说明(以知乎网站为例):
第一:静态网页上一般没有的语法,如下图:
第二:网页的语法代码对应网页上的内容,如下图:
动态网页识别示例说明(以今日头条网站为例):
第一:动态网页的语法必须如下图所示:
动态网页的语法
第二:网页的语法代码与网页内容不对应(找不到任何文字对应),如下图:
找不到文字对应
至此,读者已经掌握了静态和动态网站的区别。判断一个网页的动态和静态是基于上面解释的两种方法。
2.如何获取动态网页的真实请求地址(以今日头条为例):
方法步骤如下:
(1)按【win+F12】,找到【网络】,点击
(2)找到【XHR】,点击【win+F5】刷新
(3)左下角[name]对应的focus/等就是网页内容的存储位置,比如我们点击focus/项,点击[预览]在【名称】的右边,然后点击中间的【数据】,会弹出如下网页的文字,发现文字内容对应新闻、社会、娱乐、体育、军事、名人内容在电脑端标题顶部图标。
(4)对于动态内容的抓取,找到动态网页的请求地址很重要。方法:在[名称]右侧找到[headers],点击,可以看到[Request] below URL],这个URL就是请求的URL,如下图:
3.一个简单的动态网络爬虫示例(爬取热门搜索的标题和链接):
今天教大家如何爬取动态网页的内容,并用少量代码告诉大家一个简单的例子,帮助初学者或没学过的朋友快速理解和掌握。
抓取以下 [pc_hot_search] 搜索最多的内容:
(1)示例代码如下:
(2)运行结果截图:
注意:作者代码中[Test Only]的输出非常重要。我们可以根据输出结果状态分析下一段代码是如何编写或布局的。记住作者教你的不是代码示例项目,而是教你如何分析问题,让你有潜在的编程思维。
有时候你会发现自己想做一个项目,不看教程文档就无法开始。是什么原因?
这是因为你没有这种分析和思考如何写代码。
今天的内容到此结束。喜欢的朋友关注转发一波。更多精彩内容等着你。希望今天的内容对读者有所帮助。 查看全部
python抓取动态网页(2.利用selenium+phantomJS模拟浏览器来抓取动态(图))
网页分为静态网页和动态网页。静态网页就是我们平时爬取的网页,但也有一些网页来自动态网页。比如今日头条的网站就是动态的。遵循静态网页的方法。爬行是不可能的。所以我们要学习如何从动态网页中提取信息。
网页抓取主要有两种方式:
1.找到动态网页的请求地址
2.使用selenium+phantomJS模拟浏览器抓取动态网页
今天讲第一种方法,后面会写一篇文章文章讲解第二种方法。
(提示:这里有个福利:关注转发后可以私聊获取python基础、python web开发、python爬虫、机器学习、数据挖掘、深度学习等信息)
今天的内容主要包括几个方面:
如何区分静态网页和动态网页-如何获取动态网页的真实请求地址-一个简单的动态网页抓取示例
下面解释:
1.如何区分静态网页和动态网页
有两个主要区别:
首先看网页是否有语法;
其次看网页中的内容是否与网页框架中的内容相匹配。
如何打开网页的语言代码?
方法:(1)按[win+F12]会弹出一个页面(2)在弹出的页面中找到[元素],点击查看网页语法代码。< /@1) p>
静态网页识别示例说明(以知乎网站为例):
第一:静态网页上一般没有的语法,如下图:
第二:网页的语法代码对应网页上的内容,如下图:
动态网页识别示例说明(以今日头条网站为例):
第一:动态网页的语法必须如下图所示:
动态网页的语法
第二:网页的语法代码与网页内容不对应(找不到任何文字对应),如下图:
找不到文字对应
至此,读者已经掌握了静态和动态网站的区别。判断一个网页的动态和静态是基于上面解释的两种方法。
2.如何获取动态网页的真实请求地址(以今日头条为例):
方法步骤如下:
(1)按【win+F12】,找到【网络】,点击
(2)找到【XHR】,点击【win+F5】刷新
(3)左下角[name]对应的focus/等就是网页内容的存储位置,比如我们点击focus/项,点击[预览]在【名称】的右边,然后点击中间的【数据】,会弹出如下网页的文字,发现文字内容对应新闻、社会、娱乐、体育、军事、名人内容在电脑端标题顶部图标。
(4)对于动态内容的抓取,找到动态网页的请求地址很重要。方法:在[名称]右侧找到[headers],点击,可以看到[Request] below URL],这个URL就是请求的URL,如下图:
3.一个简单的动态网络爬虫示例(爬取热门搜索的标题和链接):
今天教大家如何爬取动态网页的内容,并用少量代码告诉大家一个简单的例子,帮助初学者或没学过的朋友快速理解和掌握。
抓取以下 [pc_hot_search] 搜索最多的内容:
(1)示例代码如下:
(2)运行结果截图:
注意:作者代码中[Test Only]的输出非常重要。我们可以根据输出结果状态分析下一段代码是如何编写或布局的。记住作者教你的不是代码示例项目,而是教你如何分析问题,让你有潜在的编程思维。
有时候你会发现自己想做一个项目,不看教程文档就无法开始。是什么原因?
这是因为你没有这种分析和思考如何写代码。
今天的内容到此结束。喜欢的朋友关注转发一波。更多精彩内容等着你。希望今天的内容对读者有所帮助。
python抓取动态网页( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-31 22:04
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/")
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是对于所有爬虫来说,不能在/?开头的路径无法访问匹配/pop/*.html的路径。
以下四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫爬取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL,直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实是需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。 BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup('',"html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> 'meta'
# attributes属性
tag.attrs
>>> {'content': 'all', 'name': 'robots'}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> '[document]'
# 字符串的提取
markup='房产'
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> '房产'
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find('table',width='780')
# 解析
for i in lptable.find_all("td",width="680"):
title = i.b.strong.a.text
href = "http://www.cwestc.com"+i.find('a')['href']
# href = i.find('a')['href']
date = href.split("/")[4]
print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。 XPath 可用于遍历 XML 文档中的元素和属性。 XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two
crossgate
pinggu
"""
#这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容
selector=etree.HTML(html)
content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
for i in content:
print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */
con=selector.xpath([email protected]/* */')
for i in con:
print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的
con=selector.xpath([email protected]/* */')
print (len(con))
print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常有.htm、.html、.shtml、.xml等后缀。静态网页一般是最简单的HTML网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?”在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
动态网页应具备以下特点:
总结一下:网页内容变了,网址也会跟着变化。基本上,它是一个静态网页,反之,它是一个动态网页。
四、动态网页和静态网页的爬取
1.静态网页
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=1"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests
from bs4 import BeautifulSoup
url = "http://news.cqcoal.com/blank/nl.jsp?tid=238"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text
在抓取网页时,您看不到任何证明是动态网页的信息。正确的爬取方法如下。
import urllib
import urllib.request
import requests
url = "http://news.cqcoal.com/manage/ ... ot%3B
post_param = {'pageNum':'1',\
'pageSize':'20',\
'jsonStr':'{"typeid":"238"}'}
return_data = requests.post(url,data =post_param)
content=return_data.text
content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多相关Python爬取数据内容,请搜索之前的文章或继续浏览下方相关文章,希望大家以后多多支持! 查看全部
python抓取动态网页(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/";)
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是对于所有爬虫来说,不能在/?开头的路径无法访问匹配/pop/*.html的路径。
以下四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫爬取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL,直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实是需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。 BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup('',"html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> 'meta'
# attributes属性
tag.attrs
>>> {'content': 'all', 'name': 'robots'}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> '[document]'
# 字符串的提取
markup='房产'
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> '房产'
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find('table',width='780')
# 解析
for i in lptable.find_all("td",width="680"):
title = i.b.strong.a.text
href = "http://www.cwestc.com"+i.find('a')['href']
# href = i.find('a')['href']
date = href.split("/")[4]
print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。 XPath 可用于遍历 XML 文档中的元素和属性。 XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two
crossgate
pinggu
"""
#这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容
selector=etree.HTML(html)
content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
for i in content:
print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */
con=selector.xpath([email protected]/* */')
for i in con:
print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的
con=selector.xpath([email protected]/* */')
print (len(con))
print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常有.htm、.html、.shtml、.xml等后缀。静态网页一般是最简单的HTML网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?”在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
动态网页应具备以下特点:
总结一下:网页内容变了,网址也会跟着变化。基本上,它是一个静态网页,反之,它是一个动态网页。
四、动态网页和静态网页的爬取
1.静态网页
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=1"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests
from bs4 import BeautifulSoup
url = "http://news.cqcoal.com/blank/nl.jsp?tid=238"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text
在抓取网页时,您看不到任何证明是动态网页的信息。正确的爬取方法如下。
import urllib
import urllib.request
import requests
url = "http://news.cqcoal.com/manage/ ... ot%3B
post_param = {'pageNum':'1',\
'pageSize':'20',\
'jsonStr':'{"typeid":"238"}'}
return_data = requests.post(url,data =post_param)
content=return_data.text
content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多相关Python爬取数据内容,请搜索之前的文章或继续浏览下方相关文章,希望大家以后多多支持!
python抓取动态网页(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-30 18:05
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登陆网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">[整理]关于抓取网页,分析网页内容,模拟登录网站的逻辑/流程和注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度首页)内部逻辑流程
"target="_top">【教程】如何使用IE9的F12分析网站登录过程的复杂(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">【整理】关于使用正则表达式处理html代码的建议 查看全部
python抓取动态网页(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登陆网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">[整理]关于抓取网页,分析网页内容,模拟登录网站的逻辑/流程和注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度首页)内部逻辑流程
"target="_top">【教程】如何使用IE9的F12分析网站登录过程的复杂(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">【整理】关于使用正则表达式处理html代码的建议
python抓取动态网页(代码最大的瓶颈并不在于你想多进程来爬?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-30 18:03
然后就可以设置上面的模板了。
完整模板列表(python):
def main(start_url,data_selector,next_page_selector):
current_url = start_url
while True:
# 下载页面
page = ......getdata(current_url)
# 根据我们定义的selector选择感兴趣的页面元素列表
data_list = page.selector(data_selector)
# 如果这个页面选择不到元素了,说明我们已经读取完了
# 也可以计算页面元素数量的最大值,比如你第一页爬到了10个元素
# 当你到了第N页,你只爬到了2个,说明这就是最后一页了
if len(data_list) == 0:
break
# 对每一个元素,我们把它放进另一个函数中读取
for data in data_list:
claw_data_from_detail_page(data.getattr("href"))
# 当这一页完成的时候,我们就更新一下当前页面的url地址,
# 回到while loop最开始的地方开始下一页
current_url = page.selector(next_page_selector).getattr("href")
def claw_data_from_detail_page(url):
# 详细页面就具体问题,具体分析了。。。。。。。。
跟进:
有人会问,我觉得这个单线程太慢怎么办?我想在多个进程中爬行?
其实上面代码最大的瓶颈不是main,而是你每次发布详细任务的claw_data_from_detail_page(url)。因此,你可以在这个子功能中做文章,比如:
我们不直接在这个子函数中下载内容,而是将其放入队列或数据库中。如果可能的话,我们可以搞N台机器去下载具体的内容。所以你有一个主/从结构。master是运行MAIN函数的机器,slave从你的master机器的数据库中获取url,然后抓取机器的详细数据。
注意:不要在main函数中下载data的内容,这里只需要获取你感兴趣的元素列表即可。因为这类爬虫最大的瓶颈就是下载每个详情页的时间。main函数本身也不会太慢,因为每次运行一个循环,都会发布N个claw_data_from_detail_page任务。所以主函数不需要多线程,只要子函数取数据的功能做好就可以了。您可以获得快速高效的抓取页面。
此外:
安利,我写的chrome插件,可以帮你自动找到上面的data_selector和next_page_selector。这个插件目前是alpha,功能有点不完善,但是对于百度贴吧这种结构非常统一的来说已经足够了。
直接从github下载:
GitHub-huangwc94/scraping-helper-chrome-extension: Scraping Helper 将帮助您找到某些元素的最佳 html/css 选择器
谷歌插件库下载:
/webstore/detail/%E6%95%B0%E6%8D%AE%E6%8A%93%E5%8F%96%E5%88%86%E6%9E%90%E5%B7%A5%E5% 85%B7/kmghfpaenbmakjffjhjncacmhagadgbg 查看全部
python抓取动态网页(代码最大的瓶颈并不在于你想多进程来爬?)
然后就可以设置上面的模板了。
完整模板列表(python):
def main(start_url,data_selector,next_page_selector):
current_url = start_url
while True:
# 下载页面
page = ......getdata(current_url)
# 根据我们定义的selector选择感兴趣的页面元素列表
data_list = page.selector(data_selector)
# 如果这个页面选择不到元素了,说明我们已经读取完了
# 也可以计算页面元素数量的最大值,比如你第一页爬到了10个元素
# 当你到了第N页,你只爬到了2个,说明这就是最后一页了
if len(data_list) == 0:
break
# 对每一个元素,我们把它放进另一个函数中读取
for data in data_list:
claw_data_from_detail_page(data.getattr("href"))
# 当这一页完成的时候,我们就更新一下当前页面的url地址,
# 回到while loop最开始的地方开始下一页
current_url = page.selector(next_page_selector).getattr("href")
def claw_data_from_detail_page(url):
# 详细页面就具体问题,具体分析了。。。。。。。。
跟进:
有人会问,我觉得这个单线程太慢怎么办?我想在多个进程中爬行?
其实上面代码最大的瓶颈不是main,而是你每次发布详细任务的claw_data_from_detail_page(url)。因此,你可以在这个子功能中做文章,比如:
我们不直接在这个子函数中下载内容,而是将其放入队列或数据库中。如果可能的话,我们可以搞N台机器去下载具体的内容。所以你有一个主/从结构。master是运行MAIN函数的机器,slave从你的master机器的数据库中获取url,然后抓取机器的详细数据。
注意:不要在main函数中下载data的内容,这里只需要获取你感兴趣的元素列表即可。因为这类爬虫最大的瓶颈就是下载每个详情页的时间。main函数本身也不会太慢,因为每次运行一个循环,都会发布N个claw_data_from_detail_page任务。所以主函数不需要多线程,只要子函数取数据的功能做好就可以了。您可以获得快速高效的抓取页面。
此外:
安利,我写的chrome插件,可以帮你自动找到上面的data_selector和next_page_selector。这个插件目前是alpha,功能有点不完善,但是对于百度贴吧这种结构非常统一的来说已经足够了。
直接从github下载:
GitHub-huangwc94/scraping-helper-chrome-extension: Scraping Helper 将帮助您找到某些元素的最佳 html/css 选择器
谷歌插件库下载:
/webstore/detail/%E6%95%B0%E6%8D%AE%E6%8A%93%E5%8F%96%E5%88%86%E6%9E%90%E5%B7%A5%E5% 85%B7/kmghfpaenbmakjffjhjncacmhagadgbg
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-30 11:17
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录
js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
value = content.text
这篇关于python如何抓取动态网站的文章到此结束。更多相关python如何抓取动态网站内容,请搜索noodle教程之前的文章或继续浏览下方相关文章。希望大家以后多多支持面条。教程! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录
js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
value = content.text
这篇关于python如何抓取动态网站的文章到此结束。更多相关python如何抓取动态网站内容,请搜索noodle教程之前的文章或继续浏览下方相关文章。希望大家以后多多支持面条。教程!
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-29 20:10
Python专题教程:爬取网站、模拟登录、爬取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发人员,介绍如何使用Python语言实现爬取网站和模拟登录。抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,请到讨论组发帖讨论:阅读 HTML 在线下载 (7zip)压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revision1.
前提是讨论如何用Python实现,网站爬取,模拟登录,动态网页爬取。前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬网、模拟登录、爬取动态网页的原理及实现详解(Python、C#等) 网站爬取、模拟登录、爬取动态网页相关的老帖子【教程】抓取网页,提取网页中需要的信息。其实对于urllib这样的库,已经做得很好了,尤其是在易用性方面。使用起来非常方便。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。然而,事实上,网页抓取和网页模拟登录需要cookies。, 以及其他header参数,所以如果想要获得强大易用的网页抓取功能,还是需要花费大量的额外工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要有两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个函数解释自crifanLib TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数其实主要分为两个方面:一方面是抓取网站的内容,和网络处理模块有关。另一方面,就是如何解析抓取到的内容,也就是HTML解析相关的模块等等,下面解释一下。两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理对应关系是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python相关的HTMl解析旧帖BeautifulSoup模块介绍【已解决】Python中json.loads解析收录
\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析爬取的网站内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc 查看全部
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
Python专题教程:爬取网站、模拟登录、爬取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发人员,介绍如何使用Python语言实现爬取网站和模拟登录。抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,请到讨论组发帖讨论:阅读 HTML 在线下载 (7zip)压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revision1.
前提是讨论如何用Python实现,网站爬取,模拟登录,动态网页爬取。前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬网、模拟登录、爬取动态网页的原理及实现详解(Python、C#等) 网站爬取、模拟登录、爬取动态网页相关的老帖子【教程】抓取网页,提取网页中需要的信息。其实对于urllib这样的库,已经做得很好了,尤其是在易用性方面。使用起来非常方便。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。然而,事实上,网页抓取和网页模拟登录需要cookies。, 以及其他header参数,所以如果想要获得强大易用的网页抓取功能,还是需要花费大量的额外工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要有两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个函数解释自crifanLib TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数其实主要分为两个方面:一方面是抓取网站的内容,和网络处理模块有关。另一方面,就是如何解析抓取到的内容,也就是HTML解析相关的模块等等,下面解释一下。两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理对应关系是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python相关的HTMl解析旧帖BeautifulSoup模块介绍【已解决】Python中json.loads解析收录
\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析爬取的网站内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-29 20:07
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是通过js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我调用的动态网页生成的图片,所以当你打开一个漫画页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
这里ConnectionKeep-Alive,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们需要在请求头中添加上面的信息,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱情漫画网站中某部漫画的所有章节url,根据章节url获取该章节的总页数,获取该页面的每个url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以从爱漫画网站抓取漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是通过js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我调用的动态网页生成的图片,所以当你打开一个漫画页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
这里ConnectionKeep-Alive,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们需要在请求头中添加上面的信息,经过测试,只需要添加Referer

信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱情漫画网站中某部漫画的所有章节url,根据章节url获取该章节的总页数,获取该页面的每个url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以从爱漫画网站抓取漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-29 09:20
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录
js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
值=内容.文本
这篇关于如何用python爬取动态网站的文章到此结束。更多关于如何用python爬取动态网站的相关内容,请搜索我们之前的文章或继续浏览下面的相关文章。希望大家以后多多支持我们!
文章名称:python如何抓取动态网站 查看全部
python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录
js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
值=内容.文本
这篇关于如何用python爬取动态网站的文章到此结束。更多关于如何用python爬取动态网站的相关内容,请搜索我们之前的文章或继续浏览下面的相关文章。希望大家以后多多支持我们!
文章名称:python如何抓取动态网站
python抓取动态网页(python抓取动态网页分析动态页面数据(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-26 19:05
python抓取动态网页分析动态页面数据,可以抓取页面全部数据,也可以抓取相关页面的所有数据,抓取方法也非常简单,直接上代码吧!抓取页面列表页面数据一、cookie的配置1。登录的时候拿到cookie在回车输入登录信息cookie便会生成2。清除浏览器cookie当浏览器的cookie被清除的时候,会重新生成一个cookie(因此需要清除浏览器浏览记录)二、爬取过程抓取动态页面数据第一步,打开我们的网站:;response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala第二步,登录页面第三步,点击“我的"点击此处进入查看网站的列表页面信息hi我是小北我是小北我是小北抓取页面demo代码为:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsfromlxmlimportetreeurl=';response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala'r=requests。get(url)withopen('linux64/libcookie_generator。txt','w')asf:r。write(f。read())r=requests。get(';cookie_size=127。
1&state=c0132&tag=state&pagetype=balabala')withopen('linux64/libcookie_list。txt','w')asf:f。write(r。content)withopen('linux64/libxml2_generator。txt','w')asf:f。
write(r。content)#首先获取cookie值cookie=requests。get('')#获取cookie值url=';cookie_size=127。1&state=c0132&tag=state&pagetype=balabala'r=requests。get(url)host=''data=requests。
get('')。textdata。encoding='utf-8'cookie=requests。get('')。texthost=''data=requests。get('')。text'获取cookie值'''然后解析response中的参数及默认值response=etree。html(cookie)#获取html格式url=''withopen('linux64/libcookie_generator。
txt','w')asf:f。write(response)#解析html内容返回字符串response=etree。html(withopen('linux64/libcookie_list。txt','w')asf:f。write(response)data=f。read()response=etree。html(response)host=host''。 查看全部
python抓取动态网页(python抓取动态网页分析动态页面数据(1)(图))
python抓取动态网页分析动态页面数据,可以抓取页面全部数据,也可以抓取相关页面的所有数据,抓取方法也非常简单,直接上代码吧!抓取页面列表页面数据一、cookie的配置1。登录的时候拿到cookie在回车输入登录信息cookie便会生成2。清除浏览器cookie当浏览器的cookie被清除的时候,会重新生成一个cookie(因此需要清除浏览器浏览记录)二、爬取过程抓取动态页面数据第一步,打开我们的网站:;response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala第二步,登录页面第三步,点击“我的"点击此处进入查看网站的列表页面信息hi我是小北我是小北我是小北抓取页面demo代码为:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsfromlxmlimportetreeurl=';response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala'r=requests。get(url)withopen('linux64/libcookie_generator。txt','w')asf:r。write(f。read())r=requests。get(';cookie_size=127。
1&state=c0132&tag=state&pagetype=balabala')withopen('linux64/libcookie_list。txt','w')asf:f。write(r。content)withopen('linux64/libxml2_generator。txt','w')asf:f。
write(r。content)#首先获取cookie值cookie=requests。get('')#获取cookie值url=';cookie_size=127。1&state=c0132&tag=state&pagetype=balabala'r=requests。get(url)host=''data=requests。
get('')。textdata。encoding='utf-8'cookie=requests。get('')。texthost=''data=requests。get('')。text'获取cookie值'''然后解析response中的参数及默认值response=etree。html(cookie)#获取html格式url=''withopen('linux64/libcookie_generator。
txt','w')asf:f。write(response)#解析html内容返回字符串response=etree。html(withopen('linux64/libcookie_list。txt','w')asf:f。write(response)data=f。read()response=etree。html(response)host=host''。
python抓取动态网页(python抓取动态网页分析(python)抓取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-12-24 10:04
python抓取动态网页分析爬取1:before,after,next,min,maxvariable参数说明:variable或者variable=all?意思一样,没有区别,都是判断是否是全局变量。parse_html()函数是全局解析文件。directory是当前文件路径,自定义的url地址,所以directory之间会相互变化,但是对爬虫来说是确定的。
domstring是爬虫的标识符,在io操作过程中会取到新数据。该函数默认采用parsed类,需要修改为variable。directory是自定义路径,用于自定义变量作为传递给js文件(url)。该else方法也是自定义js文件。2:循环并发获取链接,获取数据其中第一个循环是js循环,通过方法console.log()判断爬取最新数据,如果爬取已经超时,即退出循环。
后面的循环是directory循环,通过keyword.split()获取每个directory下的词语,作为第一个循环中的iterable和下一个循环中的dom解析器输入,循环从第一个循环开始。循环并发获取链接,获取数据最后一个directory循环也为循环并发连接,如果爬取超时,即退出循环。爬取数据时候经常会用到数据库的连接池,代码中常用到sqlite数据库,网上有一个大致解释,我会将我的详细解释写下来。
<p>defurl_connect(dirs,paths):ifnotos.path.isfile(dirs):returnpaths.reset()database=paths[0].sqlite(paths[1])delatrices=paths[2].sqlite(paths[3])directories=paths[4].sqlite(paths[5])join_functions=paths[6].sqlite(paths[7])intra=sqlite(paths[8])ifdirectories>=database:join_functions.insert(directories-database,paths[1].list())ifdirectories 查看全部
python抓取动态网页(python抓取动态网页分析(python)抓取网页)
python抓取动态网页分析爬取1:before,after,next,min,maxvariable参数说明:variable或者variable=all?意思一样,没有区别,都是判断是否是全局变量。parse_html()函数是全局解析文件。directory是当前文件路径,自定义的url地址,所以directory之间会相互变化,但是对爬虫来说是确定的。
domstring是爬虫的标识符,在io操作过程中会取到新数据。该函数默认采用parsed类,需要修改为variable。directory是自定义路径,用于自定义变量作为传递给js文件(url)。该else方法也是自定义js文件。2:循环并发获取链接,获取数据其中第一个循环是js循环,通过方法console.log()判断爬取最新数据,如果爬取已经超时,即退出循环。
后面的循环是directory循环,通过keyword.split()获取每个directory下的词语,作为第一个循环中的iterable和下一个循环中的dom解析器输入,循环从第一个循环开始。循环并发获取链接,获取数据最后一个directory循环也为循环并发连接,如果爬取超时,即退出循环。爬取数据时候经常会用到数据库的连接池,代码中常用到sqlite数据库,网上有一个大致解释,我会将我的详细解释写下来。
<p>defurl_connect(dirs,paths):ifnotos.path.isfile(dirs):returnpaths.reset()database=paths[0].sqlite(paths[1])delatrices=paths[2].sqlite(paths[3])directories=paths[4].sqlite(paths[5])join_functions=paths[6].sqlite(paths[7])intra=sqlite(paths[8])ifdirectories>=database:join_functions.insert(directories-database,paths[1].list())ifdirectories
python抓取动态网页(你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-24 05:02
python抓取动态网页/redis异步下载教程“你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件?这只是他们的其中一部分。那些人来自世界各地,大多数来自俄罗斯,日本,印度和中国,这很有趣。他们也参加过一些技术培训班。如果你注意,你甚至可以找到一些巨额的python课程的捐款,一些捐助机构注意到了这些网站不断创新的学习计划。
我想成为一个有趣的人,所以我设置了一个可以通过电话或视频来谈话的目标,每年100美元。不是否认他们所做的事情。事实上这也很有意义。每当谈到钱,我不喜欢这个模式,事实上我特别希望在团队中多余的人除了钱以外,做一些高于这个数字的工作。我不想他们自己想要做到什么事情。我想让他们有更多的动力去获得真正有意义的东西。
”这个项目包括一些优质的免费python基础教程以及ruby基础教程,用于学习python、ruby编程、redis、java等。你最多可以免费获得:我推荐在动态网页免费制作动态链接地址展示图片、ruby基础教程、redis数据库、java开发者等资源。在今年的六月出版的《python动态网页技术(第2版)》这本书包含的三门免费教程在2018年内均可获得。
将无法获得:python高级教程、ruby底层实现。关于“微信校园”微信校园拥有丰富的免费课程,无论是python还是ruby,分类细致,因为分类细致,里面的课程也不缺乏质量高、性价比高的课程。如果你只是想学习免费教程,可以通过如下两种方式获得:1、动态github仓库,你可以查看github提供的所有git操作指南;2、登录校园“微信校园”,利用微信公众号每日一课、免费用户免费课、精品留学、职业规划等免费教程,第一时间接收课程。
"toodisappointedtodo"生词:too...todo。单词解释:toosoon/down。意为太久不做,事情就难以继续进行。我把它翻译成:“没什么干劲的人就想办法把事情做好。”有点拗口,不好记。这个单词放在这里,把它当一个反义词来理解更加通顺。曾经有一个人私信我让我教她怎么写英文的简历,我说你说自己英文简历写的不错,我教你怎么写就好了。
她回复到:“那简历改成中文不就行了,就是改了几个字而已,还花那么多钱。”这话改成中文,很简单:“你说改不改?”就是在简历里面加个中文的简历,很简单,大家都会改。但是难就难在这个英文简历怎么写,简历中哪些内容必须有,以及用英文说是不是实话等问题。你想学英文简历改写,有一个很好的主动性,给了你一次改写的机会,这样改写英文简历就容易很多了。所以如果你。 查看全部
python抓取动态网页(你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件)
python抓取动态网页/redis异步下载教程“你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件?这只是他们的其中一部分。那些人来自世界各地,大多数来自俄罗斯,日本,印度和中国,这很有趣。他们也参加过一些技术培训班。如果你注意,你甚至可以找到一些巨额的python课程的捐款,一些捐助机构注意到了这些网站不断创新的学习计划。
我想成为一个有趣的人,所以我设置了一个可以通过电话或视频来谈话的目标,每年100美元。不是否认他们所做的事情。事实上这也很有意义。每当谈到钱,我不喜欢这个模式,事实上我特别希望在团队中多余的人除了钱以外,做一些高于这个数字的工作。我不想他们自己想要做到什么事情。我想让他们有更多的动力去获得真正有意义的东西。
”这个项目包括一些优质的免费python基础教程以及ruby基础教程,用于学习python、ruby编程、redis、java等。你最多可以免费获得:我推荐在动态网页免费制作动态链接地址展示图片、ruby基础教程、redis数据库、java开发者等资源。在今年的六月出版的《python动态网页技术(第2版)》这本书包含的三门免费教程在2018年内均可获得。
将无法获得:python高级教程、ruby底层实现。关于“微信校园”微信校园拥有丰富的免费课程,无论是python还是ruby,分类细致,因为分类细致,里面的课程也不缺乏质量高、性价比高的课程。如果你只是想学习免费教程,可以通过如下两种方式获得:1、动态github仓库,你可以查看github提供的所有git操作指南;2、登录校园“微信校园”,利用微信公众号每日一课、免费用户免费课、精品留学、职业规划等免费教程,第一时间接收课程。
"toodisappointedtodo"生词:too...todo。单词解释:toosoon/down。意为太久不做,事情就难以继续进行。我把它翻译成:“没什么干劲的人就想办法把事情做好。”有点拗口,不好记。这个单词放在这里,把它当一个反义词来理解更加通顺。曾经有一个人私信我让我教她怎么写英文的简历,我说你说自己英文简历写的不错,我教你怎么写就好了。
她回复到:“那简历改成中文不就行了,就是改了几个字而已,还花那么多钱。”这话改成中文,很简单:“你说改不改?”就是在简历里面加个中文的简历,很简单,大家都会改。但是难就难在这个英文简历怎么写,简历中哪些内容必须有,以及用英文说是不是实话等问题。你想学英文简历改写,有一个很好的主动性,给了你一次改写的机会,这样改写英文简历就容易很多了。所以如果你。
python抓取动态网页(:keep-alive:Mozilla/5.0(WindowsNT))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-11 17:07
主持人:
连接:保持活动
升级不安全请求:1
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,像 Gecko) Chrome/5< @7.0.2987.98 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8 Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4,zh-TW; q=0.2
提取请求头的重要部分,可以将代码改为:
3.3.3 发送POST请求
除了GET请求外,有时还需要发送一些以表单形式编码的数据。比如登录时,请求是POST,因为如果使用GET请求,会在URL中显示密码,非常不安全。如果要实现POST请求,只需要简单的给Requests中的data参数传入一个字典,请求时数据字典会自动编码为表单。
输出是:
{
“参数”:{},
“数据”:“”,
“表格”:{
"key1": "value1",
"key2": "value2"
},
…
}
可以看到form变量的值就是key_dict中输入的值,所以发送POST请求成功。
3.3.4 超时
有时爬虫会遇到服务器长时间不返回。这时候爬虫会一直等待,导致爬虫执行不顺畅。因此,可以使用 Requests 在 timeout 参数设置的秒数过去后停止等待响应。这意味着如果服务器在 timeout 秒内没有响应,则会返回异常。
让我们将此设置为 0.001 秒,看看抛出了什么异常。这是一个值设置,让大家体验超时异常的效果。一般将此值设置为 20 秒。
返回的异常是:ConnectTimeout: HTTPConnectionPool(host=' ',
port=80): 最大重试次数超出 url: / (由 ConnectTimeoutError(connection.HTTPConnection object at 0x0000000005B85B00>, 'Connection to timed out. (connect timeout=0.001)'))。
异常值表示,时间限制为0.001秒,连接地址的时间已到。
3.4请求爬虫练习:TOP250电影数据
本章练习项目的目的是获取豆瓣电影TOP250中所有电影的名字。网站地址是:。在这个爬虫中,请求头是根据实际浏览器定制的。
3.4.1 网站分析
打开豆瓣电影TOP250的网站,使用“check”功能查看网页的请求头,如图3-4所示。
按照3.3.2中的方法提取重要的请求头:
首页只有 25 部电影,如果要获取全部 250 页的电影,则需要获取总共 10 页的内容。
点击第二页可以发现网页地址变成了:
第三页的地址是:,很容易理解。对于每增加一个页面,在网页地址的起始参数中添加 25。
3.4.2 项目实践
通过上面的分析发现可以使用requests获取电影网页的代码,使用for循环进行翻页。其代码如下:
运行上面的代码,结果是:
1页响应状态码:200
lang="zh-cmn-Hans">
豆瓣电影 250 强
...
此时,结果只是网页的 HTML 代码,我们需要从中提取所需的电影名称。接下来,第 5 章将涉及解析网页内容。读者可以先使用下面的代码。至于对代码的理解,可以等到第五章再学习。
在上面的代码中,BeautifulSoup 用于解析网页并获取其中的电影名称数据。运行代码,结果是:
1页响应状态码:200
2页响应状态码:200
3页响应状态码:200
4页响应状态码:200
5页响应状态码:200
6页响应状态码:200
7页响应状态码:200
8页响应状态码:200
9页响应状态码:200
10页响应状态码:200
[《肖申克的救赎》、《这个杀手不太冷》、《霸王别姬》、《阿甘正传》、《美丽人生》、《千与千寻》、《辛德勒的名单》、《泰坦尼克号》、 《盗梦空间》、《机器人总动员》、《海上钢琴师》、《宝莱坞三傻烦恼》、《八公的故事》、《牛班的春天》、《大圣西游》、《教父》 》、《龙猫》、《杜鲁门的世界》、《乱世佳人》、《天堂电影院》、《当幸福来敲门》、《触不可及》、《搏击俱乐部》、《十二怒汉》、 《无间道》、《熔炉》、《指环王:国王的劲敌》、《突破》、《天空之城》、《罗马假日》……]
3.4.3 个自习题
读者有时间可以练习进阶题:求TOP 250电影的英文名、港台名、导演、主演、上映年份、电影分级和评分。 查看全部
python抓取动态网页(:keep-alive:Mozilla/5.0(WindowsNT))
主持人:
连接:保持活动
升级不安全请求:1
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,像 Gecko) Chrome/5< @7.0.2987.98 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8 Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4,zh-TW; q=0.2
提取请求头的重要部分,可以将代码改为:
3.3.3 发送POST请求
除了GET请求外,有时还需要发送一些以表单形式编码的数据。比如登录时,请求是POST,因为如果使用GET请求,会在URL中显示密码,非常不安全。如果要实现POST请求,只需要简单的给Requests中的data参数传入一个字典,请求时数据字典会自动编码为表单。
输出是:
{
“参数”:{},
“数据”:“”,
“表格”:{
"key1": "value1",
"key2": "value2"
},
…
}
可以看到form变量的值就是key_dict中输入的值,所以发送POST请求成功。
3.3.4 超时
有时爬虫会遇到服务器长时间不返回。这时候爬虫会一直等待,导致爬虫执行不顺畅。因此,可以使用 Requests 在 timeout 参数设置的秒数过去后停止等待响应。这意味着如果服务器在 timeout 秒内没有响应,则会返回异常。
让我们将此设置为 0.001 秒,看看抛出了什么异常。这是一个值设置,让大家体验超时异常的效果。一般将此值设置为 20 秒。
返回的异常是:ConnectTimeout: HTTPConnectionPool(host=' ',
port=80): 最大重试次数超出 url: / (由 ConnectTimeoutError(connection.HTTPConnection object at 0x0000000005B85B00>, 'Connection to timed out. (connect timeout=0.001)'))。
异常值表示,时间限制为0.001秒,连接地址的时间已到。
3.4请求爬虫练习:TOP250电影数据
本章练习项目的目的是获取豆瓣电影TOP250中所有电影的名字。网站地址是:。在这个爬虫中,请求头是根据实际浏览器定制的。
3.4.1 网站分析
打开豆瓣电影TOP250的网站,使用“check”功能查看网页的请求头,如图3-4所示。
按照3.3.2中的方法提取重要的请求头:
首页只有 25 部电影,如果要获取全部 250 页的电影,则需要获取总共 10 页的内容。
点击第二页可以发现网页地址变成了:
第三页的地址是:,很容易理解。对于每增加一个页面,在网页地址的起始参数中添加 25。
3.4.2 项目实践
通过上面的分析发现可以使用requests获取电影网页的代码,使用for循环进行翻页。其代码如下:
运行上面的代码,结果是:
1页响应状态码:200
lang="zh-cmn-Hans">
豆瓣电影 250 强
...
此时,结果只是网页的 HTML 代码,我们需要从中提取所需的电影名称。接下来,第 5 章将涉及解析网页内容。读者可以先使用下面的代码。至于对代码的理解,可以等到第五章再学习。
在上面的代码中,BeautifulSoup 用于解析网页并获取其中的电影名称数据。运行代码,结果是:
1页响应状态码:200
2页响应状态码:200
3页响应状态码:200
4页响应状态码:200
5页响应状态码:200
6页响应状态码:200
7页响应状态码:200
8页响应状态码:200
9页响应状态码:200
10页响应状态码:200
[《肖申克的救赎》、《这个杀手不太冷》、《霸王别姬》、《阿甘正传》、《美丽人生》、《千与千寻》、《辛德勒的名单》、《泰坦尼克号》、 《盗梦空间》、《机器人总动员》、《海上钢琴师》、《宝莱坞三傻烦恼》、《八公的故事》、《牛班的春天》、《大圣西游》、《教父》 》、《龙猫》、《杜鲁门的世界》、《乱世佳人》、《天堂电影院》、《当幸福来敲门》、《触不可及》、《搏击俱乐部》、《十二怒汉》、 《无间道》、《熔炉》、《指环王:国王的劲敌》、《突破》、《天空之城》、《罗马假日》……]
3.4.3 个自习题
读者有时间可以练习进阶题:求TOP 250电影的英文名、港台名、导演、主演、上映年份、电影分级和评分。
python抓取动态网页(利用Python方法来抓取某网站分享页面中的源码方法示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-10 23:03
这个文章是关于使用Python方法在一个网站分享页面中捕获源代码方法示例。需要注意的是,Python爬取分享页面的源码示例只有在运行时导入BeautifulSoup.py文件后才能使用。
Python爬取分享页面源码示例需要使用python urllib2模块方法和BeautifulSoup模块。
源码如下:
#coding:utf-8
import urllib2
from BeautifulSoup import BeautifulSoup
'''
www.iplaypy.com
'''
#define
def readPage(Url):
page = urllib2.urlopen(Url).read()
pageContent = BeautifulSoup(page)
OSC_Content = pageContent.find("div",{'id':'OSC_Content'})
preHandleCode = OSC_Content.find('pre').next
print preHandleCode
'''
页面的url需指定
'''
#call
readPage('http://www.xxxxxx.net/code/sni ... %2339;)
这里的目标网站已被隐藏。可以参考这个python源码根据你要抓取的目标站进行适当的修改。 查看全部
python抓取动态网页(利用Python方法来抓取某网站分享页面中的源码方法示例)
这个文章是关于使用Python方法在一个网站分享页面中捕获源代码方法示例。需要注意的是,Python爬取分享页面的源码示例只有在运行时导入BeautifulSoup.py文件后才能使用。
Python爬取分享页面源码示例需要使用python urllib2模块方法和BeautifulSoup模块。
源码如下:
#coding:utf-8
import urllib2
from BeautifulSoup import BeautifulSoup
'''
www.iplaypy.com
'''
#define
def readPage(Url):
page = urllib2.urlopen(Url).read()
pageContent = BeautifulSoup(page)
OSC_Content = pageContent.find("div",{'id':'OSC_Content'})
preHandleCode = OSC_Content.find('pre').next
print preHandleCode
'''
页面的url需指定
'''
#call
readPage('http://www.xxxxxx.net/code/sni ... %2339;)
这里的目标网站已被隐藏。可以参考这个python源码根据你要抓取的目标站进行适当的修改。
python抓取动态网页(什么是HTML静态生成的内容?如何对网页进行爬取呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-10 18:08
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
这里只介绍第一种方法。有专门的文章介绍 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:/api/pc/focus/
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
和往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
python抓取动态网页(什么是HTML静态生成的内容?如何对网页进行爬取呢?
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
这里只介绍第一种方法。有专门的文章介绍 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:/api/pc/focus/
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
和往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
python抓取动态网页(Python软件工具和2020最新入门到实战教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-09 13:12
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020年最新入门实用教程。加群695185429免费获取。
5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8 谷歌浏览器 Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open Brainstorm 网站 (#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
结果如下:
注意三点:
1、添加延迟命令(time.sleep(5)),否则可能出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。 查看全部
python抓取动态网页(Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020年最新入门实用教程。加群695185429免费获取。
5月1日假期学习了Python爬取动态网页信息相关的操作,结合封面上的参考书和在线教程,编写了能满足自己需求的代码。由于最初是python的介入,所以过程中有很多曲折。为了避免以后出现问题,我找不到相关资料来创建这篇文章。
准备工具:
Python 3.8 谷歌浏览器 Googledriver
测试网站:
1.想法 (#cb)
考试前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json分析的方式;另一种是硒的方式。requests方法速度快,但是有些元素的链接信息抓不到;selenium 方法通过模拟打开浏览器来捕获数据。由于需要打开浏览器,所以速度比较慢,但是能抓取到的信息比较全面。
主要抓取内容如下:(网站中部分可转债数据)
获取网站信息的请求方法:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入 pip install requests 命令,安装成功后会有提示。如果一次安装不成功,多安装几次。
(前提是相关端口没有关闭)。如果 pip 版本不是最新的,它会提醒你更新 pip 版本,pip 环境变量也要设置。设置方法参考python设置方法。
请求抓取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的网址:chrome open Brainstorm 网站 (#cb)。点击F12键,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5键刷新。在名称栏中一一点击,找到所需的 XHR。通过预览我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
JSON转换请求的数据格式,方便数据搜索。转换成json格式后,requests的数据格式和preview的数据格式一样。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考请求安装)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。把它放在安装chrome的文件夹中,并设置环境变量。
selenium 抓取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
结果如下:
注意三点:
1、添加延迟命令(time.sleep(5)),否则可能出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在网页开发者中右键copy xpath来确认元素的路径。
3、发送ID时,将字符转换为数值,注意去掉空字符
捕获的数据也可以通过python保存到excel中。
python抓取动态网页( 爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-07 16:06
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页其实就是通过URL获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python提供了一个第三方模块requests来抓取网页信息。requests 模块称自己为“HTTP for Humans”,字面意思是专门为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表10-1 requests模块的Request函数
2.获取回复
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用表格列出Response类可以获取的信息,如表10-2所示。
表10-2 Response类的常用属性
接下来通过一个案例来演示如何使用requests模块来获取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
上面代码中,第二行使用import导入requests模块;第三至第四行代码根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第五行至第六行代码打印响应内容的状态码和编码方式;第7行将响应内容的编码方式改为“utf-8”;第 8 行打印响应内容。运行程序,程序输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块抓取网页时,可能会因未连接网络、服务器连接失败等原因产生各种异常,最常见的两个异常是URLError和HTTPError。这些网络异常可以用 try...except 语句捕获和处理。 查看全部
python抓取动态网页(
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页其实就是通过URL获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python提供了一个第三方模块requests来抓取网页信息。requests 模块称自己为“HTTP for Humans”,字面意思是专门为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表10-1 requests模块的Request函数
2.获取回复
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用表格列出Response类可以获取的信息,如表10-2所示。
表10-2 Response类的常用属性
接下来通过一个案例来演示如何使用requests模块来获取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
上面代码中,第二行使用import导入requests模块;第三至第四行代码根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第五行至第六行代码打印响应内容的状态码和编码方式;第7行将响应内容的编码方式改为“utf-8”;第 8 行打印响应内容。运行程序,程序输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块抓取网页时,可能会因未连接网络、服务器连接失败等原因产生各种异常,最常见的两个异常是URLError和HTTPError。这些网络异常可以用 try...except 语句捕获和处理。
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-07 12:00
2、 然后在首页点击【创建图书】-->【微信相册】。
4、 之后,耐心等待微信本的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、 扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
, 等待Scrapy爬虫项目生成。
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、执行以上两步后的文件夹结构如下:
三、分析网络数据
2、 点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图所示:
可以看到Moments的数据存放在paras /data节点下。
至此,网络分析和数据的来源已经确定。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘 查看全部
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
2、 然后在首页点击【创建图书】-->【微信相册】。
4、 之后,耐心等待微信本的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、 扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
, 等待Scrapy爬虫项目生成。
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、执行以上两步后的文件夹结构如下:
三、分析网络数据
2、 点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图所示:
可以看到Moments的数据存放在paras /data节点下。
至此,网络分析和数据的来源已经确定。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-05 00:11
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。对于json序列化和反序列化,可以点击Python解析库Json和Jsonpath Pickle的实现来学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源码时出现错误,请按照步骤获取新的请求地址。 查看全部
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。对于json序列化和反序列化,可以点击Python解析库Json和Jsonpath Pickle的实现来学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
python抓取动态网页(Python爬虫使用Selenium+PhantomJSAjax和动态HTML内容》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-04 19:07
1 简介
在上一篇《Python爬虫:爬取Drupal论坛帖子列表》中,爬取了一个用Drupal制作的论坛。它是一个静态页面。爬行更容易。即使直接解析html源文件,也能抓取到自己需要的内容。. 相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们在《Python爬虫使用Selenium+PhantomJS捕获Ajax和动态HTML内容》一文中测试了动态网页内容的爬取方法。代码变得非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。需要时间来节省时间。节省时间的问题在《1分钟快速生成网页内容提取的xslt》一文中已经解决。在本文中,我们使用京东网站作为测试对象,电子商务网站有很多动态内容,比如商品价格、评论数等,经常使用post-加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中。当程序运行时,文件被读出并注入到 gsExtractor 提取器中。后续会有特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码
源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上面的代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,我们会看到如下内容。
五、相关文件
1. Python Instant Web Crawler 项目:内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修订历史
1, 2016-06-11: V1.0 查看全部
python抓取动态网页(Python爬虫使用Selenium+PhantomJSAjax和动态HTML内容》)
1 简介
在上一篇《Python爬虫:爬取Drupal论坛帖子列表》中,爬取了一个用Drupal制作的论坛。它是一个静态页面。爬行更容易。即使直接解析html源文件,也能抓取到自己需要的内容。. 相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们在《Python爬虫使用Selenium+PhantomJS捕获Ajax和动态HTML内容》一文中测试了动态网页内容的爬取方法。代码变得非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。需要时间来节省时间。节省时间的问题在《1分钟快速生成网页内容提取的xslt》一文中已经解决。在本文中,我们使用京东网站作为测试对象,电子商务网站有很多动态内容,比如商品价格、评论数等,经常使用post-加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中。当程序运行时,文件被读出并注入到 gsExtractor 提取器中。后续会有特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码
源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上面的代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,我们会看到如下内容。
五、相关文件
1. Python Instant Web Crawler 项目:内容提取器的定义
6、采集GooSeeker开源代码下载
1. GooSeeker开源Python网络爬虫GitHub源码
7. 文档修订历史
1, 2016-06-11: V1.0
python抓取动态网页(人学都是从基础学起学习哪里?学着路你需要掌握什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-04 13:11
很多学Python的人都想掌握爬虫,我想我世界上有爬虫。但是太多的人从基础开始,他们不知道从哪里学习。为此,发布了一个特殊的爬虫相关内容。
我们先来了解一下爬虫流程:发送请求-获取页面-解析页面-提取并存储内容供爬取。这模拟了使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析页面后,我们可以提取一些我们想要的信息,并存储在我们开发的文档和数据中。.
接下来,就来看看掌握爬虫之路需要具备哪些条件。
一、零基础阶段
从一个编程新手系统的介绍开始,我开始接触爬虫。事实上,爬虫比必要的理论知识更实用。那么主流的网站数据抓取能力就是现阶段要学习的内容。
爬虫所需的计算机网络/前端/常规//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、反爬、验证码识别等难点详细说明;多线程、多进程等常见应用场景讲解。
(1)准备
首先是下载Python,可以下载最新版本。二是需要准备运行环境,可以选择PyChram;
(2)教程
尝试找到适合您的教程,并尝试成为具有配套课程材料源代码的那种。不过记得把代码打一次,然后再看源码,发现自己的问题。
二、主流框架
爬虫框架主要是Scrapy实现海量数据抓取,从原生爬虫到框架能力,这是一个改进阶段,如果能开发出分布式爬虫系统,基本符合python爬虫的定位。海量数据高效获取,外包。
本阶段主要学习内容:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统讲解;Scrapy 突破了反爬虫和 Scrapy 原理的限制;Scrapy 更高级的功能包括scrapy 信号和定制中间件;现有海量数据结合Elasticsearch打造搜索引擎。
不要觉得学习scrapy的基础知识很困难。学scrapy的基础很快,因为demo很多,但是实际爬虫不容易,因为robots.txt禁止爬虫是有原因的。
所以基本的爬虫很简单,但是反爬虫就没有那么容易了。
三、真正的爬虫
深度的APP数据抓取也是为了提高你的爬虫响应APP数据抓取的能力和数据可视化能力,扩展你的业务能力,提升你的市场竞争力。
所以爬行是一步,可视化是另一部分。
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习与实践掌握App爬取技巧;构建基于Docker的多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基本图形、地图等,实现数据可视化。
其实爬虫可以应用在很多领域,爬虫也是数据分析市场调研的主要步骤。更先进的是机器学习,原创数据的挖掘。
其实从爬虫开始学习Python也是非常推荐的一种方式,因为有了目标就更容易找到学习重点。 查看全部
python抓取动态网页(人学都是从基础学起学习哪里?学着路你需要掌握什么)
很多学Python的人都想掌握爬虫,我想我世界上有爬虫。但是太多的人从基础开始,他们不知道从哪里学习。为此,发布了一个特殊的爬虫相关内容。
我们先来了解一下爬虫流程:发送请求-获取页面-解析页面-提取并存储内容供爬取。这模拟了使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析页面后,我们可以提取一些我们想要的信息,并存储在我们开发的文档和数据中。.
接下来,就来看看掌握爬虫之路需要具备哪些条件。
一、零基础阶段
从一个编程新手系统的介绍开始,我开始接触爬虫。事实上,爬虫比必要的理论知识更实用。那么主流的网站数据抓取能力就是现阶段要学习的内容。
爬虫所需的计算机网络/前端/常规//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、反爬、验证码识别等难点详细说明;多线程、多进程等常见应用场景讲解。
(1)准备
首先是下载Python,可以下载最新版本。二是需要准备运行环境,可以选择PyChram;
(2)教程
尝试找到适合您的教程,并尝试成为具有配套课程材料源代码的那种。不过记得把代码打一次,然后再看源码,发现自己的问题。
二、主流框架
爬虫框架主要是Scrapy实现海量数据抓取,从原生爬虫到框架能力,这是一个改进阶段,如果能开发出分布式爬虫系统,基本符合python爬虫的定位。海量数据高效获取,外包。
本阶段主要学习内容:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统讲解;Scrapy 突破了反爬虫和 Scrapy 原理的限制;Scrapy 更高级的功能包括scrapy 信号和定制中间件;现有海量数据结合Elasticsearch打造搜索引擎。
不要觉得学习scrapy的基础知识很困难。学scrapy的基础很快,因为demo很多,但是实际爬虫不容易,因为robots.txt禁止爬虫是有原因的。
所以基本的爬虫很简单,但是反爬虫就没有那么容易了。
三、真正的爬虫
深度的APP数据抓取也是为了提高你的爬虫响应APP数据抓取的能力和数据可视化能力,扩展你的业务能力,提升你的市场竞争力。
所以爬行是一步,可视化是另一部分。
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习与实践掌握App爬取技巧;构建基于Docker的多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基本图形、地图等,实现数据可视化。
其实爬虫可以应用在很多领域,爬虫也是数据分析市场调研的主要步骤。更先进的是机器学习,原创数据的挖掘。
其实从爬虫开始学习Python也是非常推荐的一种方式,因为有了目标就更容易找到学习重点。
python抓取动态网页(2.利用selenium+phantomJS模拟浏览器来抓取动态(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 01:10
网页分为静态网页和动态网页。静态网页就是我们平时爬取的网页,但也有一些网页来自动态网页。比如今日头条的网站就是动态的。遵循静态网页的方法。爬行是不可能的。所以我们要学习如何从动态网页中提取信息。
网页抓取主要有两种方式:
1.找到动态网页的请求地址
2.使用selenium+phantomJS模拟浏览器抓取动态网页
今天讲第一种方法,后面会写一篇文章文章讲解第二种方法。
(提示:这里有个福利:关注转发后可以私聊获取python基础、python web开发、python爬虫、机器学习、数据挖掘、深度学习等信息)
今天的内容主要包括几个方面:
如何区分静态网页和动态网页-如何获取动态网页的真实请求地址-一个简单的动态网页抓取示例
下面解释:
1.如何区分静态网页和动态网页
有两个主要区别:
首先看网页是否有语法;
其次看网页中的内容是否与网页框架中的内容相匹配。
如何打开网页的语言代码?
方法:(1)按[win+F12]会弹出一个页面(2)在弹出的页面中找到[元素],点击查看网页语法代码。< /@1) p>
静态网页识别示例说明(以知乎网站为例):
第一:静态网页上一般没有的语法,如下图:
第二:网页的语法代码对应网页上的内容,如下图:
动态网页识别示例说明(以今日头条网站为例):
第一:动态网页的语法必须如下图所示:
动态网页的语法
第二:网页的语法代码与网页内容不对应(找不到任何文字对应),如下图:
找不到文字对应
至此,读者已经掌握了静态和动态网站的区别。判断一个网页的动态和静态是基于上面解释的两种方法。
2.如何获取动态网页的真实请求地址(以今日头条为例):
方法步骤如下:
(1)按【win+F12】,找到【网络】,点击
(2)找到【XHR】,点击【win+F5】刷新
(3)左下角[name]对应的focus/等就是网页内容的存储位置,比如我们点击focus/项,点击[预览]在【名称】的右边,然后点击中间的【数据】,会弹出如下网页的文字,发现文字内容对应新闻、社会、娱乐、体育、军事、名人内容在电脑端标题顶部图标。
(4)对于动态内容的抓取,找到动态网页的请求地址很重要。方法:在[名称]右侧找到[headers],点击,可以看到[Request] below URL],这个URL就是请求的URL,如下图:
3.一个简单的动态网络爬虫示例(爬取热门搜索的标题和链接):
今天教大家如何爬取动态网页的内容,并用少量代码告诉大家一个简单的例子,帮助初学者或没学过的朋友快速理解和掌握。
抓取以下 [pc_hot_search] 搜索最多的内容:
(1)示例代码如下:
(2)运行结果截图:
注意:作者代码中[Test Only]的输出非常重要。我们可以根据输出结果状态分析下一段代码是如何编写或布局的。记住作者教你的不是代码示例项目,而是教你如何分析问题,让你有潜在的编程思维。
有时候你会发现自己想做一个项目,不看教程文档就无法开始。是什么原因?
这是因为你没有这种分析和思考如何写代码。
今天的内容到此结束。喜欢的朋友关注转发一波。更多精彩内容等着你。希望今天的内容对读者有所帮助。 查看全部
python抓取动态网页(2.利用selenium+phantomJS模拟浏览器来抓取动态(图))
网页分为静态网页和动态网页。静态网页就是我们平时爬取的网页,但也有一些网页来自动态网页。比如今日头条的网站就是动态的。遵循静态网页的方法。爬行是不可能的。所以我们要学习如何从动态网页中提取信息。
网页抓取主要有两种方式:
1.找到动态网页的请求地址
2.使用selenium+phantomJS模拟浏览器抓取动态网页
今天讲第一种方法,后面会写一篇文章文章讲解第二种方法。
(提示:这里有个福利:关注转发后可以私聊获取python基础、python web开发、python爬虫、机器学习、数据挖掘、深度学习等信息)
今天的内容主要包括几个方面:
如何区分静态网页和动态网页-如何获取动态网页的真实请求地址-一个简单的动态网页抓取示例
下面解释:
1.如何区分静态网页和动态网页
有两个主要区别:
首先看网页是否有语法;
其次看网页中的内容是否与网页框架中的内容相匹配。
如何打开网页的语言代码?
方法:(1)按[win+F12]会弹出一个页面(2)在弹出的页面中找到[元素],点击查看网页语法代码。< /@1) p>
静态网页识别示例说明(以知乎网站为例):
第一:静态网页上一般没有的语法,如下图:
第二:网页的语法代码对应网页上的内容,如下图:
动态网页识别示例说明(以今日头条网站为例):
第一:动态网页的语法必须如下图所示:
动态网页的语法
第二:网页的语法代码与网页内容不对应(找不到任何文字对应),如下图:
找不到文字对应
至此,读者已经掌握了静态和动态网站的区别。判断一个网页的动态和静态是基于上面解释的两种方法。
2.如何获取动态网页的真实请求地址(以今日头条为例):
方法步骤如下:
(1)按【win+F12】,找到【网络】,点击
(2)找到【XHR】,点击【win+F5】刷新
(3)左下角[name]对应的focus/等就是网页内容的存储位置,比如我们点击focus/项,点击[预览]在【名称】的右边,然后点击中间的【数据】,会弹出如下网页的文字,发现文字内容对应新闻、社会、娱乐、体育、军事、名人内容在电脑端标题顶部图标。
(4)对于动态内容的抓取,找到动态网页的请求地址很重要。方法:在[名称]右侧找到[headers],点击,可以看到[Request] below URL],这个URL就是请求的URL,如下图:
3.一个简单的动态网络爬虫示例(爬取热门搜索的标题和链接):
今天教大家如何爬取动态网页的内容,并用少量代码告诉大家一个简单的例子,帮助初学者或没学过的朋友快速理解和掌握。
抓取以下 [pc_hot_search] 搜索最多的内容:
(1)示例代码如下:
(2)运行结果截图:
注意:作者代码中[Test Only]的输出非常重要。我们可以根据输出结果状态分析下一段代码是如何编写或布局的。记住作者教你的不是代码示例项目,而是教你如何分析问题,让你有潜在的编程思维。
有时候你会发现自己想做一个项目,不看教程文档就无法开始。是什么原因?
这是因为你没有这种分析和思考如何写代码。
今天的内容到此结束。喜欢的朋友关注转发一波。更多精彩内容等着你。希望今天的内容对读者有所帮助。
python抓取动态网页( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-31 22:04
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/")
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是对于所有爬虫来说,不能在/?开头的路径无法访问匹配/pop/*.html的路径。
以下四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫爬取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL,直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实是需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。 BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup('',"html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> 'meta'
# attributes属性
tag.attrs
>>> {'content': 'all', 'name': 'robots'}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> '[document]'
# 字符串的提取
markup='房产'
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> '房产'
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find('table',width='780')
# 解析
for i in lptable.find_all("td",width="680"):
title = i.b.strong.a.text
href = "http://www.cwestc.com"+i.find('a')['href']
# href = i.find('a')['href']
date = href.split("/")[4]
print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。 XPath 可用于遍历 XML 文档中的元素和属性。 XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two
crossgate
pinggu
"""
#这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容
selector=etree.HTML(html)
content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
for i in content:
print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */
con=selector.xpath([email protected]/* */')
for i in con:
print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的
con=selector.xpath([email protected]/* */')
print (len(con))
print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常有.htm、.html、.shtml、.xml等后缀。静态网页一般是最简单的HTML网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?”在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
动态网页应具备以下特点:
总结一下:网页内容变了,网址也会跟着变化。基本上,它是一个静态网页,反之,它是一个动态网页。
四、动态网页和静态网页的爬取
1.静态网页
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=1"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests
from bs4 import BeautifulSoup
url = "http://news.cqcoal.com/blank/nl.jsp?tid=238"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text
在抓取网页时,您看不到任何证明是动态网页的信息。正确的爬取方法如下。
import urllib
import urllib.request
import requests
url = "http://news.cqcoal.com/manage/ ... ot%3B
post_param = {'pageNum':'1',\
'pageSize':'20',\
'jsonStr':'{"typeid":"238"}'}
return_data = requests.post(url,data =post_param)
content=return_data.text
content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多相关Python爬取数据内容,请搜索之前的文章或继续浏览下方相关文章,希望大家以后多多支持! 查看全部
python抓取动态网页(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/";)
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是对于所有爬虫来说,不能在/?开头的路径无法访问匹配/pop/*.html的路径。
以下四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫爬取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL,直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实是需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。 BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup('',"html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> 'meta'
# attributes属性
tag.attrs
>>> {'content': 'all', 'name': 'robots'}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> '[document]'
# 字符串的提取
markup='房产'
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> '房产'
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find('table',width='780')
# 解析
for i in lptable.find_all("td",width="680"):
title = i.b.strong.a.text
href = "http://www.cwestc.com"+i.find('a')['href']
# href = i.find('a')['href']
date = href.split("/")[4]
print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。 XPath 可用于遍历 XML 文档中的元素和属性。 XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two
crossgate
pinggu
"""
#这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容
selector=etree.HTML(html)
content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
for i in content:
print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */
con=selector.xpath([email protected]/* */')
for i in con:
print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的
con=selector.xpath([email protected]/* */')
print (len(con))
print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常有.htm、.html、.shtml、.xml等后缀。静态网页一般是最简单的HTML网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。 .
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?”在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现。在同一个网站上面,动态网页内容和静态网页内容同时存在也是很常见的。
动态网页应具备以下特点:
总结一下:网页内容变了,网址也会跟着变化。基本上,它是一个静态网页,反之,它是一个动态网页。
四、动态网页和静态网页的爬取
1.静态网页
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=1"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests
from bs4 import BeautifulSoup
url = "http://news.cqcoal.com/blank/nl.jsp?tid=238"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
soup.text
在抓取网页时,您看不到任何证明是动态网页的信息。正确的爬取方法如下。
import urllib
import urllib.request
import requests
url = "http://news.cqcoal.com/manage/ ... ot%3B
post_param = {'pageNum':'1',\
'pageSize':'20',\
'jsonStr':'{"typeid":"238"}'}
return_data = requests.post(url,data =post_param)
content=return_data.text
content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多相关Python爬取数据内容,请搜索之前的文章或继续浏览下方相关文章,希望大家以后多多支持!
python抓取动态网页(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-30 18:05
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登陆网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">[整理]关于抓取网页,分析网页内容,模拟登录网站的逻辑/流程和注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度首页)内部逻辑流程
"target="_top">【教程】如何使用IE9的F12分析网站登录过程的复杂(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">【整理】关于使用正则表达式处理html代码的建议 查看全部
python抓取动态网页(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登陆网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">[整理]关于抓取网页,分析网页内容,模拟登录网站的逻辑/流程和注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录网站(百度首页)内部逻辑流程
"target="_top">【教程】如何使用IE9的F12分析网站登录过程的复杂(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">【整理】关于使用正则表达式处理html代码的建议
python抓取动态网页(代码最大的瓶颈并不在于你想多进程来爬?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-30 18:03
然后就可以设置上面的模板了。
完整模板列表(python):
def main(start_url,data_selector,next_page_selector):
current_url = start_url
while True:
# 下载页面
page = ......getdata(current_url)
# 根据我们定义的selector选择感兴趣的页面元素列表
data_list = page.selector(data_selector)
# 如果这个页面选择不到元素了,说明我们已经读取完了
# 也可以计算页面元素数量的最大值,比如你第一页爬到了10个元素
# 当你到了第N页,你只爬到了2个,说明这就是最后一页了
if len(data_list) == 0:
break
# 对每一个元素,我们把它放进另一个函数中读取
for data in data_list:
claw_data_from_detail_page(data.getattr("href"))
# 当这一页完成的时候,我们就更新一下当前页面的url地址,
# 回到while loop最开始的地方开始下一页
current_url = page.selector(next_page_selector).getattr("href")
def claw_data_from_detail_page(url):
# 详细页面就具体问题,具体分析了。。。。。。。。
跟进:
有人会问,我觉得这个单线程太慢怎么办?我想在多个进程中爬行?
其实上面代码最大的瓶颈不是main,而是你每次发布详细任务的claw_data_from_detail_page(url)。因此,你可以在这个子功能中做文章,比如:
我们不直接在这个子函数中下载内容,而是将其放入队列或数据库中。如果可能的话,我们可以搞N台机器去下载具体的内容。所以你有一个主/从结构。master是运行MAIN函数的机器,slave从你的master机器的数据库中获取url,然后抓取机器的详细数据。
注意:不要在main函数中下载data的内容,这里只需要获取你感兴趣的元素列表即可。因为这类爬虫最大的瓶颈就是下载每个详情页的时间。main函数本身也不会太慢,因为每次运行一个循环,都会发布N个claw_data_from_detail_page任务。所以主函数不需要多线程,只要子函数取数据的功能做好就可以了。您可以获得快速高效的抓取页面。
此外:
安利,我写的chrome插件,可以帮你自动找到上面的data_selector和next_page_selector。这个插件目前是alpha,功能有点不完善,但是对于百度贴吧这种结构非常统一的来说已经足够了。
直接从github下载:
GitHub-huangwc94/scraping-helper-chrome-extension: Scraping Helper 将帮助您找到某些元素的最佳 html/css 选择器
谷歌插件库下载:
/webstore/detail/%E6%95%B0%E6%8D%AE%E6%8A%93%E5%8F%96%E5%88%86%E6%9E%90%E5%B7%A5%E5% 85%B7/kmghfpaenbmakjffjhjncacmhagadgbg 查看全部
python抓取动态网页(代码最大的瓶颈并不在于你想多进程来爬?)
然后就可以设置上面的模板了。
完整模板列表(python):
def main(start_url,data_selector,next_page_selector):
current_url = start_url
while True:
# 下载页面
page = ......getdata(current_url)
# 根据我们定义的selector选择感兴趣的页面元素列表
data_list = page.selector(data_selector)
# 如果这个页面选择不到元素了,说明我们已经读取完了
# 也可以计算页面元素数量的最大值,比如你第一页爬到了10个元素
# 当你到了第N页,你只爬到了2个,说明这就是最后一页了
if len(data_list) == 0:
break
# 对每一个元素,我们把它放进另一个函数中读取
for data in data_list:
claw_data_from_detail_page(data.getattr("href"))
# 当这一页完成的时候,我们就更新一下当前页面的url地址,
# 回到while loop最开始的地方开始下一页
current_url = page.selector(next_page_selector).getattr("href")
def claw_data_from_detail_page(url):
# 详细页面就具体问题,具体分析了。。。。。。。。
跟进:
有人会问,我觉得这个单线程太慢怎么办?我想在多个进程中爬行?
其实上面代码最大的瓶颈不是main,而是你每次发布详细任务的claw_data_from_detail_page(url)。因此,你可以在这个子功能中做文章,比如:
我们不直接在这个子函数中下载内容,而是将其放入队列或数据库中。如果可能的话,我们可以搞N台机器去下载具体的内容。所以你有一个主/从结构。master是运行MAIN函数的机器,slave从你的master机器的数据库中获取url,然后抓取机器的详细数据。
注意:不要在main函数中下载data的内容,这里只需要获取你感兴趣的元素列表即可。因为这类爬虫最大的瓶颈就是下载每个详情页的时间。main函数本身也不会太慢,因为每次运行一个循环,都会发布N个claw_data_from_detail_page任务。所以主函数不需要多线程,只要子函数取数据的功能做好就可以了。您可以获得快速高效的抓取页面。
此外:
安利,我写的chrome插件,可以帮你自动找到上面的data_selector和next_page_selector。这个插件目前是alpha,功能有点不完善,但是对于百度贴吧这种结构非常统一的来说已经足够了。
直接从github下载:
GitHub-huangwc94/scraping-helper-chrome-extension: Scraping Helper 将帮助您找到某些元素的最佳 html/css 选择器
谷歌插件库下载:
/webstore/detail/%E6%95%B0%E6%8D%AE%E6%8A%93%E5%8F%96%E5%88%86%E6%9E%90%E5%B7%A5%E5% 85%B7/kmghfpaenbmakjffjhjncacmhagadgbg
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-30 11:17
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录
js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
value = content.text
这篇关于python如何抓取动态网站的文章到此结束。更多相关python如何抓取动态网站内容,请搜索noodle教程之前的文章或继续浏览下方相关文章。希望大家以后多多支持面条。教程! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录
js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
value = content.text
这篇关于python如何抓取动态网站的文章到此结束。更多相关python如何抓取动态网站内容,请搜索noodle教程之前的文章或继续浏览下方相关文章。希望大家以后多多支持面条。教程!
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-29 20:10
Python专题教程:爬取网站、模拟登录、爬取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发人员,介绍如何使用Python语言实现爬取网站和模拟登录。抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,请到讨论组发帖讨论:阅读 HTML 在线下载 (7zip)压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revision1.
前提是讨论如何用Python实现,网站爬取,模拟登录,动态网页爬取。前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬网、模拟登录、爬取动态网页的原理及实现详解(Python、C#等) 网站爬取、模拟登录、爬取动态网页相关的老帖子【教程】抓取网页,提取网页中需要的信息。其实对于urllib这样的库,已经做得很好了,尤其是在易用性方面。使用起来非常方便。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。然而,事实上,网页抓取和网页模拟登录需要cookies。, 以及其他header参数,所以如果想要获得强大易用的网页抓取功能,还是需要花费大量的额外工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要有两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个函数解释自crifanLib TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数其实主要分为两个方面:一方面是抓取网站的内容,和网络处理模块有关。另一方面,就是如何解析抓取到的内容,也就是HTML解析相关的模块等等,下面解释一下。两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理对应关系是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python相关的HTMl解析旧帖BeautifulSoup模块介绍【已解决】Python中json.loads解析收录
\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析爬取的网站内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc 查看全部
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
Python专题教程:爬取网站、模拟登录、爬取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发人员,介绍如何使用Python语言实现爬取网站和模拟登录。抓取动态网页。其中,主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,请到讨论组发帖讨论:阅读 HTML 在线下载 (7zip)压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revision1.
前提是讨论如何用Python实现,网站爬取,模拟登录,动态网页爬取。前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬网、模拟登录、爬取动态网页的原理及实现详解(Python、C#等) 网站爬取、模拟登录、爬取动态网页相关的老帖子【教程】抓取网页,提取网页中需要的信息。其实对于urllib这样的库,已经做得很好了,尤其是在易用性方面。使用起来非常方便。比如可以直接从下面的代码中获取网页的地址,网页的源代码为TODO:添加代码。然而,事实上,网页抓取和网页模拟登录需要cookies。, 以及其他header参数,所以如果想要获得强大易用的网页抓取功能,还是需要花费大量的额外工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要有两个函数:getUrlResponse和getUrlRespHtml TODO:添加两个函数解释自crifanLib TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括downloadFile等函数其实主要分为两个方面:一方面是抓取网站的内容,和网络处理模块有关。另一方面,就是如何解析抓取到的内容,也就是HTML解析相关的模块等等,下面解释一下。两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能。
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理对应关系是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python相关的HTMl解析旧帖BeautifulSoup模块介绍【已解决】Python中json.loads解析收录
\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析爬取的网站内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-29 20:07
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是通过js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我调用的动态网页生成的图片,所以当你打开一个漫画页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
这里ConnectionKeep-Alive,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们需要在请求头中添加上面的信息,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱情漫画网站中某部漫画的所有章节url,根据章节url获取该章节的总页数,获取该页面的每个url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以从爱漫画网站抓取漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是通过js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我调用的动态网页生成的图片,所以当你打开一个漫画页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
这里ConnectionKeep-Alive,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们需要在请求头中添加上面的信息,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱情漫画网站中某部漫画的所有章节url,根据章节url获取该章节的总页数,获取该页面的每个url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以从爱漫画网站抓取漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-29 09:20
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录
js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
值=内容.文本
这篇关于如何用python爬取动态网站的文章到此结束。更多关于如何用python爬取动态网站的相关内容,请搜索我们之前的文章或继续浏览下面的相关文章。希望大家以后多多支持我们!
文章名称:python如何抓取动态网站 查看全部
python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但是很多时候,爬虫抓取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录
js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录
js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录
的值时,你可以通过
值=内容.文本
这篇关于如何用python爬取动态网站的文章到此结束。更多关于如何用python爬取动态网站的相关内容,请搜索我们之前的文章或继续浏览下面的相关文章。希望大家以后多多支持我们!
文章名称:python如何抓取动态网站
python抓取动态网页(python抓取动态网页分析动态页面数据(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-26 19:05
python抓取动态网页分析动态页面数据,可以抓取页面全部数据,也可以抓取相关页面的所有数据,抓取方法也非常简单,直接上代码吧!抓取页面列表页面数据一、cookie的配置1。登录的时候拿到cookie在回车输入登录信息cookie便会生成2。清除浏览器cookie当浏览器的cookie被清除的时候,会重新生成一个cookie(因此需要清除浏览器浏览记录)二、爬取过程抓取动态页面数据第一步,打开我们的网站:;response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala第二步,登录页面第三步,点击“我的"点击此处进入查看网站的列表页面信息hi我是小北我是小北我是小北抓取页面demo代码为:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsfromlxmlimportetreeurl=';response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala'r=requests。get(url)withopen('linux64/libcookie_generator。txt','w')asf:r。write(f。read())r=requests。get(';cookie_size=127。
1&state=c0132&tag=state&pagetype=balabala')withopen('linux64/libcookie_list。txt','w')asf:f。write(r。content)withopen('linux64/libxml2_generator。txt','w')asf:f。
write(r。content)#首先获取cookie值cookie=requests。get('')#获取cookie值url=';cookie_size=127。1&state=c0132&tag=state&pagetype=balabala'r=requests。get(url)host=''data=requests。
get('')。textdata。encoding='utf-8'cookie=requests。get('')。texthost=''data=requests。get('')。text'获取cookie值'''然后解析response中的参数及默认值response=etree。html(cookie)#获取html格式url=''withopen('linux64/libcookie_generator。
txt','w')asf:f。write(response)#解析html内容返回字符串response=etree。html(withopen('linux64/libcookie_list。txt','w')asf:f。write(response)data=f。read()response=etree。html(response)host=host''。 查看全部
python抓取动态网页(python抓取动态网页分析动态页面数据(1)(图))
python抓取动态网页分析动态页面数据,可以抓取页面全部数据,也可以抓取相关页面的所有数据,抓取方法也非常简单,直接上代码吧!抓取页面列表页面数据一、cookie的配置1。登录的时候拿到cookie在回车输入登录信息cookie便会生成2。清除浏览器cookie当浏览器的cookie被清除的时候,会重新生成一个cookie(因此需要清除浏览器浏览记录)二、爬取过程抓取动态页面数据第一步,打开我们的网站:;response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala第二步,登录页面第三步,点击“我的"点击此处进入查看网站的列表页面信息hi我是小北我是小北我是小北抓取页面demo代码为:#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsfromlxmlimportetreeurl=';response_type=action&scope=status&state=content&root=127。
1&state=e0132&tag=state&pagetype=balabala'r=requests。get(url)withopen('linux64/libcookie_generator。txt','w')asf:r。write(f。read())r=requests。get(';cookie_size=127。
1&state=c0132&tag=state&pagetype=balabala')withopen('linux64/libcookie_list。txt','w')asf:f。write(r。content)withopen('linux64/libxml2_generator。txt','w')asf:f。
write(r。content)#首先获取cookie值cookie=requests。get('')#获取cookie值url=';cookie_size=127。1&state=c0132&tag=state&pagetype=balabala'r=requests。get(url)host=''data=requests。
get('')。textdata。encoding='utf-8'cookie=requests。get('')。texthost=''data=requests。get('')。text'获取cookie值'''然后解析response中的参数及默认值response=etree。html(cookie)#获取html格式url=''withopen('linux64/libcookie_generator。
txt','w')asf:f。write(response)#解析html内容返回字符串response=etree。html(withopen('linux64/libcookie_list。txt','w')asf:f。write(response)data=f。read()response=etree。html(response)host=host''。
python抓取动态网页(python抓取动态网页分析(python)抓取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-12-24 10:04
python抓取动态网页分析爬取1:before,after,next,min,maxvariable参数说明:variable或者variable=all?意思一样,没有区别,都是判断是否是全局变量。parse_html()函数是全局解析文件。directory是当前文件路径,自定义的url地址,所以directory之间会相互变化,但是对爬虫来说是确定的。
domstring是爬虫的标识符,在io操作过程中会取到新数据。该函数默认采用parsed类,需要修改为variable。directory是自定义路径,用于自定义变量作为传递给js文件(url)。该else方法也是自定义js文件。2:循环并发获取链接,获取数据其中第一个循环是js循环,通过方法console.log()判断爬取最新数据,如果爬取已经超时,即退出循环。
后面的循环是directory循环,通过keyword.split()获取每个directory下的词语,作为第一个循环中的iterable和下一个循环中的dom解析器输入,循环从第一个循环开始。循环并发获取链接,获取数据最后一个directory循环也为循环并发连接,如果爬取超时,即退出循环。爬取数据时候经常会用到数据库的连接池,代码中常用到sqlite数据库,网上有一个大致解释,我会将我的详细解释写下来。
<p>defurl_connect(dirs,paths):ifnotos.path.isfile(dirs):returnpaths.reset()database=paths[0].sqlite(paths[1])delatrices=paths[2].sqlite(paths[3])directories=paths[4].sqlite(paths[5])join_functions=paths[6].sqlite(paths[7])intra=sqlite(paths[8])ifdirectories>=database:join_functions.insert(directories-database,paths[1].list())ifdirectories 查看全部
python抓取动态网页(python抓取动态网页分析(python)抓取网页)
python抓取动态网页分析爬取1:before,after,next,min,maxvariable参数说明:variable或者variable=all?意思一样,没有区别,都是判断是否是全局变量。parse_html()函数是全局解析文件。directory是当前文件路径,自定义的url地址,所以directory之间会相互变化,但是对爬虫来说是确定的。
domstring是爬虫的标识符,在io操作过程中会取到新数据。该函数默认采用parsed类,需要修改为variable。directory是自定义路径,用于自定义变量作为传递给js文件(url)。该else方法也是自定义js文件。2:循环并发获取链接,获取数据其中第一个循环是js循环,通过方法console.log()判断爬取最新数据,如果爬取已经超时,即退出循环。
后面的循环是directory循环,通过keyword.split()获取每个directory下的词语,作为第一个循环中的iterable和下一个循环中的dom解析器输入,循环从第一个循环开始。循环并发获取链接,获取数据最后一个directory循环也为循环并发连接,如果爬取超时,即退出循环。爬取数据时候经常会用到数据库的连接池,代码中常用到sqlite数据库,网上有一个大致解释,我会将我的详细解释写下来。
<p>defurl_connect(dirs,paths):ifnotos.path.isfile(dirs):returnpaths.reset()database=paths[0].sqlite(paths[1])delatrices=paths[2].sqlite(paths[3])directories=paths[4].sqlite(paths[5])join_functions=paths[6].sqlite(paths[7])intra=sqlite(paths[8])ifdirectories>=database:join_functions.insert(directories-database,paths[1].list())ifdirectories
python抓取动态网页(你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-24 05:02
python抓取动态网页/redis异步下载教程“你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件?这只是他们的其中一部分。那些人来自世界各地,大多数来自俄罗斯,日本,印度和中国,这很有趣。他们也参加过一些技术培训班。如果你注意,你甚至可以找到一些巨额的python课程的捐款,一些捐助机构注意到了这些网站不断创新的学习计划。
我想成为一个有趣的人,所以我设置了一个可以通过电话或视频来谈话的目标,每年100美元。不是否认他们所做的事情。事实上这也很有意义。每当谈到钱,我不喜欢这个模式,事实上我特别希望在团队中多余的人除了钱以外,做一些高于这个数字的工作。我不想他们自己想要做到什么事情。我想让他们有更多的动力去获得真正有意义的东西。
”这个项目包括一些优质的免费python基础教程以及ruby基础教程,用于学习python、ruby编程、redis、java等。你最多可以免费获得:我推荐在动态网页免费制作动态链接地址展示图片、ruby基础教程、redis数据库、java开发者等资源。在今年的六月出版的《python动态网页技术(第2版)》这本书包含的三门免费教程在2018年内均可获得。
将无法获得:python高级教程、ruby底层实现。关于“微信校园”微信校园拥有丰富的免费课程,无论是python还是ruby,分类细致,因为分类细致,里面的课程也不缺乏质量高、性价比高的课程。如果你只是想学习免费教程,可以通过如下两种方式获得:1、动态github仓库,你可以查看github提供的所有git操作指南;2、登录校园“微信校园”,利用微信公众号每日一课、免费用户免费课、精品留学、职业规划等免费教程,第一时间接收课程。
"toodisappointedtodo"生词:too...todo。单词解释:toosoon/down。意为太久不做,事情就难以继续进行。我把它翻译成:“没什么干劲的人就想办法把事情做好。”有点拗口,不好记。这个单词放在这里,把它当一个反义词来理解更加通顺。曾经有一个人私信我让我教她怎么写英文的简历,我说你说自己英文简历写的不错,我教你怎么写就好了。
她回复到:“那简历改成中文不就行了,就是改了几个字而已,还花那么多钱。”这话改成中文,很简单:“你说改不改?”就是在简历里面加个中文的简历,很简单,大家都会改。但是难就难在这个英文简历怎么写,简历中哪些内容必须有,以及用英文说是不是实话等问题。你想学英文简历改写,有一个很好的主动性,给了你一次改写的机会,这样改写英文简历就容易很多了。所以如果你。 查看全部
python抓取动态网页(你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件)
python抓取动态网页/redis异步下载教程“你知道那些成功的python和ruby初学者吗?有几个人给我发来了附加了密码的邮件?这只是他们的其中一部分。那些人来自世界各地,大多数来自俄罗斯,日本,印度和中国,这很有趣。他们也参加过一些技术培训班。如果你注意,你甚至可以找到一些巨额的python课程的捐款,一些捐助机构注意到了这些网站不断创新的学习计划。
我想成为一个有趣的人,所以我设置了一个可以通过电话或视频来谈话的目标,每年100美元。不是否认他们所做的事情。事实上这也很有意义。每当谈到钱,我不喜欢这个模式,事实上我特别希望在团队中多余的人除了钱以外,做一些高于这个数字的工作。我不想他们自己想要做到什么事情。我想让他们有更多的动力去获得真正有意义的东西。
”这个项目包括一些优质的免费python基础教程以及ruby基础教程,用于学习python、ruby编程、redis、java等。你最多可以免费获得:我推荐在动态网页免费制作动态链接地址展示图片、ruby基础教程、redis数据库、java开发者等资源。在今年的六月出版的《python动态网页技术(第2版)》这本书包含的三门免费教程在2018年内均可获得。
将无法获得:python高级教程、ruby底层实现。关于“微信校园”微信校园拥有丰富的免费课程,无论是python还是ruby,分类细致,因为分类细致,里面的课程也不缺乏质量高、性价比高的课程。如果你只是想学习免费教程,可以通过如下两种方式获得:1、动态github仓库,你可以查看github提供的所有git操作指南;2、登录校园“微信校园”,利用微信公众号每日一课、免费用户免费课、精品留学、职业规划等免费教程,第一时间接收课程。
"toodisappointedtodo"生词:too...todo。单词解释:toosoon/down。意为太久不做,事情就难以继续进行。我把它翻译成:“没什么干劲的人就想办法把事情做好。”有点拗口,不好记。这个单词放在这里,把它当一个反义词来理解更加通顺。曾经有一个人私信我让我教她怎么写英文的简历,我说你说自己英文简历写的不错,我教你怎么写就好了。
她回复到:“那简历改成中文不就行了,就是改了几个字而已,还花那么多钱。”这话改成中文,很简单:“你说改不改?”就是在简历里面加个中文的简历,很简单,大家都会改。但是难就难在这个英文简历怎么写,简历中哪些内容必须有,以及用英文说是不是实话等问题。你想学英文简历改写,有一个很好的主动性,给了你一次改写的机会,这样改写英文简历就容易很多了。所以如果你。

