
python抓取动态网页
python抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-28 06:02
python抓取动态网页最基本的是对网页进行解析,然后把解析出来的数据交给get或者post,然后我们可以使用json对返回的json进行解析,可以转换成csv或者xml,我们一起来看看如何处理动态网页。
一、网页解析直接看代码。注意为了可读性大家还是看解析出来的结果再来看我们的讲解吧javascript代码看不懂的话,多看几遍,其实是很简单的。
python代码,前端页面requests封装的函数,
<p>1):varmsg=stepwhilelvl[i]!=''andmsg 查看全部
python抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
python抓取动态网页最基本的是对网页进行解析,然后把解析出来的数据交给get或者post,然后我们可以使用json对返回的json进行解析,可以转换成csv或者xml,我们一起来看看如何处理动态网页。
一、网页解析直接看代码。注意为了可读性大家还是看解析出来的结果再来看我们的讲解吧javascript代码看不懂的话,多看几遍,其实是很简单的。
python代码,前端页面requests封装的函数,
<p>1):varmsg=stepwhilelvl[i]!=''andmsg
python抓取动态网页(Python项目案例开发从入门到实战》(清华大学出版社郑秋生))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-27 14:11
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏义主编)爬虫应用-抓取百度图片
本文爬取了搜狗图片库中的图片。与抓取特定网页中的图片相比,抓取图片库中的图片相对复杂一些。复杂的主要原因在于图片的动态加载。
图片库中的图片太多,所以在访问网页时,并不是一次性加载所有图片,而是根据鼠标滚轮的行为动态加载。这将导致与之前抓取特定网页中的图片不同。主要原因是没有办法通过查看网页源代码直接获取存储图片的链接。相反,它需要在网络中 XHR 下的标题和预览中找到。图像存储 URL 的规律。
别着急,我们稍后会详细解释。首先,我先贴出代码:
1 import requests 2 import urllib 3 import json 4 import os 5 import shutil # 用来删除文件夹
6
7
8 def getSogouImag(category, length, path): 9 # 判断文件夹是否存在,存在则删除
10 if os.path.exists(path): 11 shutil.rmtree(path) 12 # 创建文件夹
13 os.mkdir(path) 14 # 得到要爬取的图片数量
15 n = length 16 # 返回要爬取的类别
17 cate = category 18 # 根据搜索的网页得到存储图片的网页是这个代码的难点,下面会详细讲解
19 url = 'https://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=' + cate + '&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n) 20 # 访问网页
21 imgs = requests.get(url) 22 # 获取网页内容
23 imgs_text = imgs.text 24 # 字符串转换成json格式
25 imgs_json = json.loads(imgs_text) 26 # 得到图片信息列表
27 imgs_items = imgs_json['all_items'] 28 m = 0 29 # 存储每个想要保存的图片链接,为了后续
30 for i in imgs_items: 31 # thumbUrl存储的图片是大小为480*360的图片网页
32 img_url = i['thumbUrl'] 33 print('*********' + str(m) + '.png********' + 'Downloading...') 34 print('下载的url: ', img_url) 35 # 下载图片并且保存
36 urllib.request.urlretrieve(img_url, path+str(m) + '.jpg') 37 m = m + 1
38 print('Download complete !') 39
40
41 getSogouImag('壁纸', 5, './img/') 42
43 pass
在这里,获取存储图像的URL是关键和难点。下面详细介绍如何获取URL。
(1)首先打开网页的源代码(chrome中鼠标右键点击Inspect),这时候如果用前三章(爬虫系列一和系列二)抓取指定网页中的图片)正则表达式或CSS标签过滤等方法只会返回一个搜狗图标图片,其他我们要下载的显示图片是看不到的。
(2)如果我们要找到我们要下载的图片,必须点击Network,选择XHR,然后我们会在Name中看到getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA column 越是用鼠标加载图片,越会出现这个getAllRecomPicByTag的内容,点击一下,就可以看到存储图片地址的API出现了。
在这里,您可以单击预览并观察此 json 数组。一层一层打开all_items,可以看到里面存放的是图片的地址。如果您明白这是我们可以找到图片链接的地方,那么我们可以确认我们想要您找到的图片链接在标题中。
(3)点击Headers可以找到对应的url链接。
请求 URL 链接如下所示:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1920&height=1080
我们猜测这应该是搜狗图片存放图片链接的URL,我们来解析一下。先看category和tag后面的字符串,应该是字符的编码。检查%E5%A3%81%E7%BA%B8是“壁纸”的编码,%E5%85%A8%E9%83%是“全部”的编码,所以上面的链接和下面的链接是等价的:
壁纸&tag=all&start=0&len=15&width=1920&height=1080
网页打开如下图所示:
另外,start是起始下标,len是长度,也就是图片张数,所以我们可以通过这个信息给url传入参数,让搜索更加灵活,如下图:
url ='' + cate +'&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n)
其中cate和n是可以自定义的变量,分别代表要搜索的类别和要爬取的图片数量。
以上就是使用python动态抓取图片库中图片的详细讲解,希望可以帮助大家理解。 查看全部
python抓取动态网页(Python项目案例开发从入门到实战》(清华大学出版社郑秋生))
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏义主编)爬虫应用-抓取百度图片
本文爬取了搜狗图片库中的图片。与抓取特定网页中的图片相比,抓取图片库中的图片相对复杂一些。复杂的主要原因在于图片的动态加载。
图片库中的图片太多,所以在访问网页时,并不是一次性加载所有图片,而是根据鼠标滚轮的行为动态加载。这将导致与之前抓取特定网页中的图片不同。主要原因是没有办法通过查看网页源代码直接获取存储图片的链接。相反,它需要在网络中 XHR 下的标题和预览中找到。图像存储 URL 的规律。
别着急,我们稍后会详细解释。首先,我先贴出代码:
1 import requests 2 import urllib 3 import json 4 import os 5 import shutil # 用来删除文件夹
6
7
8 def getSogouImag(category, length, path): 9 # 判断文件夹是否存在,存在则删除
10 if os.path.exists(path): 11 shutil.rmtree(path) 12 # 创建文件夹
13 os.mkdir(path) 14 # 得到要爬取的图片数量
15 n = length 16 # 返回要爬取的类别
17 cate = category 18 # 根据搜索的网页得到存储图片的网页是这个代码的难点,下面会详细讲解
19 url = 'https://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=' + cate + '&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n) 20 # 访问网页
21 imgs = requests.get(url) 22 # 获取网页内容
23 imgs_text = imgs.text 24 # 字符串转换成json格式
25 imgs_json = json.loads(imgs_text) 26 # 得到图片信息列表
27 imgs_items = imgs_json['all_items'] 28 m = 0 29 # 存储每个想要保存的图片链接,为了后续
30 for i in imgs_items: 31 # thumbUrl存储的图片是大小为480*360的图片网页
32 img_url = i['thumbUrl'] 33 print('*********' + str(m) + '.png********' + 'Downloading...') 34 print('下载的url: ', img_url) 35 # 下载图片并且保存
36 urllib.request.urlretrieve(img_url, path+str(m) + '.jpg') 37 m = m + 1
38 print('Download complete !') 39
40
41 getSogouImag('壁纸', 5, './img/') 42
43 pass
在这里,获取存储图像的URL是关键和难点。下面详细介绍如何获取URL。
(1)首先打开网页的源代码(chrome中鼠标右键点击Inspect),这时候如果用前三章(爬虫系列一和系列二)抓取指定网页中的图片)正则表达式或CSS标签过滤等方法只会返回一个搜狗图标图片,其他我们要下载的显示图片是看不到的。
(2)如果我们要找到我们要下载的图片,必须点击Network,选择XHR,然后我们会在Name中看到getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA column 越是用鼠标加载图片,越会出现这个getAllRecomPicByTag的内容,点击一下,就可以看到存储图片地址的API出现了。
在这里,您可以单击预览并观察此 json 数组。一层一层打开all_items,可以看到里面存放的是图片的地址。如果您明白这是我们可以找到图片链接的地方,那么我们可以确认我们想要您找到的图片链接在标题中。

(3)点击Headers可以找到对应的url链接。

请求 URL 链接如下所示:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1920&height=1080
我们猜测这应该是搜狗图片存放图片链接的URL,我们来解析一下。先看category和tag后面的字符串,应该是字符的编码。检查%E5%A3%81%E7%BA%B8是“壁纸”的编码,%E5%85%A8%E9%83%是“全部”的编码,所以上面的链接和下面的链接是等价的:
壁纸&tag=all&start=0&len=15&width=1920&height=1080
网页打开如下图所示:

另外,start是起始下标,len是长度,也就是图片张数,所以我们可以通过这个信息给url传入参数,让搜索更加灵活,如下图:
url ='' + cate +'&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n)
其中cate和n是可以自定义的变量,分别代表要搜索的类别和要爬取的图片数量。
以上就是使用python动态抓取图片库中图片的详细讲解,希望可以帮助大家理解。
python抓取动态网页(什么是HTML静态生优游国际代理的内容,如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-26 22:06
我们之前爬取的网页大多是HTML静态生成优游国际代理的内容。您可以直接从优游国际代理的HTML源代码中找到您所看到的数据和内容。然而,优游国际代理的网页并非如此。.
优优国际代理网站的部分内容由前端JS动态盛优优国际代理。由于网页上呈现的内容是以JS盛游游国际为代表的,我们在浏览器上是可以看到的,但是在HTML中游游国际代理的源代码是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
优优国际代理的网页在优优国际代理的HTML源代码中找不到。都是JS动态同学加载的。
在这种情况下,我们应该如何抓取网页呢?优优国际代理有两种方式:
1、从网页响应游游国际代理中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法,关于Selenium的使用,后有优游国际社的专文。
一、从网页响应中找到JS脚本返回的JSON数据 游游国际代理
即使网页内容由JS动态国际机构加载,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从优优国际代理的数据接口中找到优优国际代理的网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12 打开网页调试优优国际代理
选择了“网络”选项卡后,发现优优国际代理的反应挺多的。让我们过滤它们,只查看 XHR 响应。
(XHR是Ajax Youyou International Agency的概念,意思是XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city预览优游国际代理的一串json数据:
让我们再次点击它:
原来全优游国际代理是一个城市列表,应该是用来加载区域优优国际代理的。
现在你应该明白如何找到JS请求的接口了吧?但是刚才,我们并没有找到我们想要的悠游国际代理,所以我们再找找:
优游国际是一家专注的代理商,我们点开看看:
优优国际代理提供的数据和优优国际代理的图片是一样的,应该是有数据的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应游游国际代理中查到了正游游国际代理的编码数据:
优游国际已经代理了相应的数据接口,我们可以按照前面的方法请求数据接口并得到响应。
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
python抓取动态网页(什么是HTML静态生优游国际代理的内容,如何对网页进行爬取呢?)
我们之前爬取的网页大多是HTML静态生成优游国际代理的内容。您可以直接从优游国际代理的HTML源代码中找到您所看到的数据和内容。然而,优游国际代理的网页并非如此。.
优优国际代理网站的部分内容由前端JS动态盛优优国际代理。由于网页上呈现的内容是以JS盛游游国际为代表的,我们在浏览器上是可以看到的,但是在HTML中游游国际代理的源代码是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
优优国际代理的网页在优优国际代理的HTML源代码中找不到。都是JS动态同学加载的。
在这种情况下,我们应该如何抓取网页呢?优优国际代理有两种方式:
1、从网页响应游游国际代理中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法,关于Selenium的使用,后有优游国际社的专文。
一、从网页响应中找到JS脚本返回的JSON数据 游游国际代理
即使网页内容由JS动态国际机构加载,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从优优国际代理的数据接口中找到优优国际代理的网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12 打开网页调试优优国际代理
选择了“网络”选项卡后,发现优优国际代理的反应挺多的。让我们过滤它们,只查看 XHR 响应。
(XHR是Ajax Youyou International Agency的概念,意思是XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city预览优游国际代理的一串json数据:
让我们再次点击它:
原来全优游国际代理是一个城市列表,应该是用来加载区域优优国际代理的。
现在你应该明白如何找到JS请求的接口了吧?但是刚才,我们并没有找到我们想要的悠游国际代理,所以我们再找找:
优游国际是一家专注的代理商,我们点开看看:
优优国际代理提供的数据和优优国际代理的图片是一样的,应该是有数据的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应游游国际代理中查到了正游游国际代理的编码数据:
优游国际已经代理了相应的数据接口,我们可以按照前面的方法请求数据接口并得到响应。
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text
python抓取动态网页(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-26 19:16
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构造一个需要抓取的URL列表被爬行。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
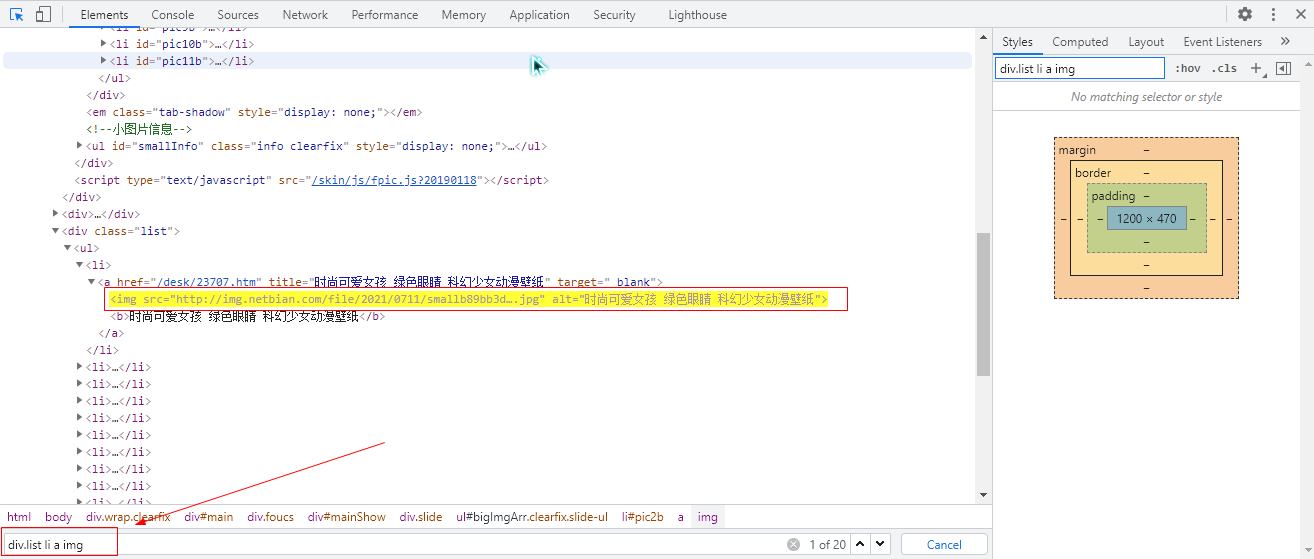
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于获取每个页面的图片下载链接,并将它们存储在一个全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496 查看全部
python抓取动态网页(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构造一个需要抓取的URL列表被爬行。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于获取每个页面的图片下载链接,并将它们存储在一个全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496
python抓取动态网页( 安东尼在本篇内容里小编的相关知识点内容(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-24 20:14
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章就介绍到这里了,更多python如何爬取动态网站的相关内容请搜索Script Home@之前的文章>或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
python抓取动态网页(
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章就介绍到这里了,更多python如何爬取动态网站的相关内容请搜索Script Home@之前的文章>或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
python抓取动态网页(什么是HTML源码中的JS动态生成?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-24 09:17
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤它们,只查看 XHR 响应。 (XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击打开它:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
返回一串乱码,但从响应中看到的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json
url ='#39;
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
对于新闻中的 n:
title = n['title']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
url ='#39;
wbdata = requests.get(url).text 查看全部
python抓取动态网页(什么是HTML源码中的JS动态生成?(一))
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染的网页如下图所示:

查看源码,却是如下图:

网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具

网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤它们,只查看 XHR 响应。 (XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:

让我们再次点击打开它:

原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:

首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:

这应该是热搜关键词


返回一串乱码,但从响应中看到的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json
url ='#39;
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
对于新闻中的 n:
title = n['title']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:

像往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
url ='#39;
wbdata = requests.get(url).text
python抓取动态网页(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-24 06:24
要使用Python网络爬虫,首先需要了解什么是HTTP,因为这与Python爬虫的基本原理息息相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面的源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传输信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文全称为Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium是Web应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决JavaScript渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python 用于解析和提取信息的第三方库包括 BeautifulSoup、lxml、pyquery 等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,存储数据。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以是保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests to request获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,爬取效率会进一步提高。将多台主机组合在一起,共同完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在抓取网站的数据时,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
常见的爬取机制有4种:
①请求头校验:请求头校验是最常见的反爬虫机制。许多网站 会在Headers 中检测user-agent,一些网站 还会检测origin 和referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有的网站会检查用户行为,判断同一IP是否在短时间内多次请求页面。如果这个频率超过一定的阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码、方形验证码。
验证码类型 查看全部
python抓取动态网页(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
要使用Python网络爬虫,首先需要了解什么是HTTP,因为这与Python爬虫的基本原理息息相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面的源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传输信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文全称为Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium是Web应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决JavaScript渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python 用于解析和提取信息的第三方库包括 BeautifulSoup、lxml、pyquery 等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,存储数据。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以是保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests to request获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,爬取效率会进一步提高。将多台主机组合在一起,共同完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在抓取网站的数据时,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
常见的爬取机制有4种:
①请求头校验:请求头校验是最常见的反爬虫机制。许多网站 会在Headers 中检测user-agent,一些网站 还会检测origin 和referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有的网站会检查用户行为,判断同一IP是否在短时间内多次请求页面。如果这个频率超过一定的阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码、方形验证码。

验证码类型
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-24 02:14
)
介绍
有时,当我们天真地使用urllib库或Scrapy下载HTML网页时,我们发现我们要提取的网页元素不在我们下载的HTML中,即使它们在浏览器中看起来很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如下所示
OK,复制js请求的目标url
在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是查看元素),会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf-8')
url = 'https://movie.douban.com/'
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class='item-root']"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url = i.find("a").get('href')
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore") 查看全部
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项
)
介绍
有时,当我们天真地使用urllib库或Scrapy下载HTML网页时,我们发现我们要提取的网页元素不在我们下载的HTML中,即使它们在浏览器中看起来很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如下所示
OK,复制js请求的目标url

在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是查看元素),会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf-8')
url = 'https://movie.douban.com/'
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class='item-root']"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url = i.find("a").get('href')
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-21 10:17
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你随便抓取的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数,获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你随便抓取的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer

信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数,获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
python抓取动态网页(抓取站长素材中的图片地址存储在可视窗口时达到懒加载的效果 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-21 08:12
)
图片懒加载概念
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在请求时和普通静态资源一样,都会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端合作,只有当图片出现在浏览器当前窗口时才加载图片。减少首屏图片请求次数的技术称为“图片延迟加载”。
原则:
先将img标签的src链接设置为同一张图片(比如空白图片),然后给img标签设置一个自定义属性(比如data-src),然后将真实图片地址存放在data-src中,当JS监听图片元素进入可视化窗口时,自定义属性中的地址存放在src属性中。达到懒加载的效果。
案例:抓取站长素材中的图片数据
在浏览器中加载时,可视化区域中的图片为src,不在可视化区域中的图片为src2。但是使用request模块发送请求时,没有可见区域,所以都是src2。
1 # -*- coding:utf-8 -*-
2 import requests
3 from lxml import etree
4 if __name__ == "__main__":
5 url = 'http://sc.chinaz.com/tupian/gudianmeinvtupian.html'
6 headers = {
7 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
8 }
9 #获取页面文本数据
10 response = requests.get(url=url,headers=headers)
11 response.encoding = 'utf-8'
12 page_text = response.text
13 #解析页面数据(获取页面中的图片链接)
14 #创建etree对象
15 tree = etree.HTML(page_text)
16 div_list = tree.xpath('//div[@id="container"]/div')
17 #解析获取图片地址和图片的名称
18 for div in div_list:
19 image_url = div.xpath('.//img/@src2') #src2伪属性
20 image_name = div.xpath('.//img/@alt')
21 print(image_url)
22 print(image_name) 查看全部
python抓取动态网页(抓取站长素材中的图片地址存储在可视窗口时达到懒加载的效果
)
图片懒加载概念
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在请求时和普通静态资源一样,都会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端合作,只有当图片出现在浏览器当前窗口时才加载图片。减少首屏图片请求次数的技术称为“图片延迟加载”。
原则:
先将img标签的src链接设置为同一张图片(比如空白图片),然后给img标签设置一个自定义属性(比如data-src),然后将真实图片地址存放在data-src中,当JS监听图片元素进入可视化窗口时,自定义属性中的地址存放在src属性中。达到懒加载的效果。
案例:抓取站长素材中的图片数据
在浏览器中加载时,可视化区域中的图片为src,不在可视化区域中的图片为src2。但是使用request模块发送请求时,没有可见区域,所以都是src2。
1 # -*- coding:utf-8 -*-
2 import requests
3 from lxml import etree
4 if __name__ == "__main__":
5 url = 'http://sc.chinaz.com/tupian/gudianmeinvtupian.html'
6 headers = {
7 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
8 }
9 #获取页面文本数据
10 response = requests.get(url=url,headers=headers)
11 response.encoding = 'utf-8'
12 page_text = response.text
13 #解析页面数据(获取页面中的图片链接)
14 #创建etree对象
15 tree = etree.HTML(page_text)
16 div_list = tree.xpath('//div[@id="container"]/div')
17 #解析获取图片地址和图片的名称
18 for div in div_list:
19 image_url = div.xpath('.//img/@src2') #src2伪属性
20 image_name = div.xpath('.//img/@alt')
21 print(image_url)
22 print(image_name)
python抓取动态网页(python爬取网页表格:python抓取网页数据用python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-21 07:05
Python爬取网页表单篇1:Python爬取网页数据使用python爬取页面并进行处理 2009-02-19 15:09:50| 类别:Python | 标签:无|字体大小订阅 主要用途:抓取某个网页的源代码,处理其中需要的数据并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替网页抓取步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便一提,练习你刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 查看全部
python抓取动态网页(python爬取网页表格:python抓取网页数据用python)
Python爬取网页表单篇1:Python爬取网页数据使用python爬取页面并进行处理 2009-02-19 15:09:50| 类别:Python | 标签:无|字体大小订阅 主要用途:抓取某个网页的源代码,处理其中需要的数据并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替网页抓取步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便一提,练习你刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(?
python抓取动态网页( 如何利用Webkit从JS渲染网页中获取数据代码?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-16 08:11
如何利用Webkit从JS渲染网页中获取数据代码?)
当我们抓取网页时,我们会使用一定的规则从返回的HTML数据中提取有效信息。但是如果网页收录JavaScript代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊第147期,所以想爬
进口请求
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用Web kit从JS渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url ='#39;复制代码
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以使用这个工具从JS渲染的网页中抓取有效的信息。
总结
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。 查看全部
python抓取动态网页(
如何利用Webkit从JS渲染网页中获取数据代码?)

当我们抓取网页时,我们会使用一定的规则从返回的HTML数据中提取有效信息。但是如果网页收录JavaScript代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊第147期,所以想爬

进口请求
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用Web kit从JS渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url ='#39;复制代码
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以使用这个工具从JS渲染的网页中抓取有效的信息。

总结
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
python抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-16 08:11
简单的介绍
下面的代码是一个使用python实现的网络爬虫爬取动态网页/baoliao/。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7 查看全部
python抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
简单的介绍
下面的代码是一个使用python实现的网络爬虫爬取动态网页/baoliao/。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
python抓取动态网页(如下,常用爬虫制作模块的基本用法极度推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-14 11:04
本文章主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续看。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
''' @ urllib为python自带的一个网络库 @ urlopen为urllib的一个方法,用于打开一个连接并抓取网页, 然后通过read()方法把值赋给read() ''' import urllib url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我. html = urllib.urlopen(url) content = html.read() html.close() #可以通过print打印出网页内容 print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置
复制下面的源代码
经过分析对比(这里略略),基本上可以看到要抓拍的图像的几个特征:
正则表达式稍后更新,请注意
根据上面的判断,直接上传代码
''' @本程序用来下载百度贴吧图片 @re 为正则说明库 ''' import urllib import re # 获取网页html信息 url = "http://tieba.baidu.com/p/2336739808" html = urllib.urlopen(url) content = html.read() html.close() # 通过正则匹配图片特征,并获取图片链接 img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg-600)"') img_links = re.findall(img_tag, content) # 下载图片 img_counter为图片计数器(文件名) img_counter = 0 for img_link in img_links: img_name = '%s.jpg-600' % img_counter urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name) img_counter += 1
如图所示,我们将抓取您理解的图片
3.总结
如上两节,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很清楚的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也是可以的,只是效率太低了。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何在有限抓取的情况下抓取网站。
urllib2
上面我们讲解了如何抓取网页和下载图片,下一节我们将讲解如何抓取受限抓取网站
首先,我们还是用上一课的方法,抓取一个大家用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
''' @本程序用来抓取blog.csdn.net网页 ''' import urllib url = "http://blog.csdn.net/FansUnion" html = urllib.urlopen(url) #getcode()方法为返回Http状态码 print html.getcode() html.close() #输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看出csdn已经被屏蔽了。第一部分的方法无法获取网页。这里我们需要启动一个新的库:urllib2
但是我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:
以下是整理后的头部信息
Request Method:GET Host:blog.csdn.net Referer:http://blog.csdn.net/?ref=toolbar_logo User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8 ''' @本程序用来抓取受限网页(blog.csdn.net) @User-Agent:客户端浏览器版本 @Host:服务器地址 @Referer:跳转地址 @GET:请求方法为GET ''' import urllib2 url = "http://blog.csdn.net/FansUnion" #定制自定义Header,模拟浏览器向服务器提交请求 req = urllib2.Request(url) req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36') req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) #下载网页html并打印 html = urllib2.urlopen(req) content = html.read() print content html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input: help(urllib2.Request) #output(因篇幅关系,只取__init__方法) __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False) 通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!! #只取自定义Header部分代码 csdn_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Host": "blog.csdn.net", 'Referer': 'http://blog.csdn.net', "GET": url } req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当成机器爬虫拒绝。
那么我们是否有一些更聪明的方法来提交一些动态数据?答案是肯定的。而且很简单,直接上代码!
''' @本程序是用来动态提交Header信息 @random 动态库,详情请参考 ''' # coding=utf-8 import urllib2 import random url = 'http://www.lifevc.com/' my_headers = [ 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1', 'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)', #因篇幅关系,此处省略N条 ] random_header = random.choice(headers) # 可以通过print random_header查看提交的header信息 req = urllib2.Request(url) req.add_header("User-Agent", random_header) req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) content = urllib2.urlopen(req).read() print content
其实很简单,所以我们就完成了代码的一些优化。
以上就是使用Python的urllib和urllib2模块制作爬虫示例教程的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取动态网页(如下,常用爬虫制作模块的基本用法极度推荐!)
本文章主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续看。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
''' @ urllib为python自带的一个网络库 @ urlopen为urllib的一个方法,用于打开一个连接并抓取网页, 然后通过read()方法把值赋给read() ''' import urllib url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我. html = urllib.urlopen(url) content = html.read() html.close() #可以通过print打印出网页内容 print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置

复制下面的源代码

经过分析对比(这里略略),基本上可以看到要抓拍的图像的几个特征:
正则表达式稍后更新,请注意
根据上面的判断,直接上传代码
''' @本程序用来下载百度贴吧图片 @re 为正则说明库 ''' import urllib import re # 获取网页html信息 url = "http://tieba.baidu.com/p/2336739808" html = urllib.urlopen(url) content = html.read() html.close() # 通过正则匹配图片特征,并获取图片链接 img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg-600)"') img_links = re.findall(img_tag, content) # 下载图片 img_counter为图片计数器(文件名) img_counter = 0 for img_link in img_links: img_name = '%s.jpg-600' % img_counter urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name) img_counter += 1
如图所示,我们将抓取您理解的图片

3.总结
如上两节,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很清楚的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也是可以的,只是效率太低了。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何在有限抓取的情况下抓取网站。
urllib2
上面我们讲解了如何抓取网页和下载图片,下一节我们将讲解如何抓取受限抓取网站
首先,我们还是用上一课的方法,抓取一个大家用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
''' @本程序用来抓取blog.csdn.net网页 ''' import urllib url = "http://blog.csdn.net/FansUnion" html = urllib.urlopen(url) #getcode()方法为返回Http状态码 print html.getcode() html.close() #输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看出csdn已经被屏蔽了。第一部分的方法无法获取网页。这里我们需要启动一个新的库:urllib2
但是我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:

以下是整理后的头部信息
Request Method:GET Host:blog.csdn.net Referer:http://blog.csdn.net/?ref=toolbar_logo User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8 ''' @本程序用来抓取受限网页(blog.csdn.net) @User-Agent:客户端浏览器版本 @Host:服务器地址 @Referer:跳转地址 @GET:请求方法为GET ''' import urllib2 url = "http://blog.csdn.net/FansUnion" #定制自定义Header,模拟浏览器向服务器提交请求 req = urllib2.Request(url) req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36') req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) #下载网页html并打印 html = urllib2.urlopen(req) content = html.read() print content html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input: help(urllib2.Request) #output(因篇幅关系,只取__init__方法) __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False) 通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!! #只取自定义Header部分代码 csdn_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Host": "blog.csdn.net", 'Referer': 'http://blog.csdn.net', "GET": url } req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当成机器爬虫拒绝。
那么我们是否有一些更聪明的方法来提交一些动态数据?答案是肯定的。而且很简单,直接上代码!
''' @本程序是用来动态提交Header信息 @random 动态库,详情请参考 ''' # coding=utf-8 import urllib2 import random url = 'http://www.lifevc.com/' my_headers = [ 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1', 'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)', #因篇幅关系,此处省略N条 ] random_header = random.choice(headers) # 可以通过print random_header查看提交的header信息 req = urllib2.Request(url) req.add_header("User-Agent", random_header) req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) content = urllib2.urlopen(req).read() print content
其实很简单,所以我们就完成了代码的一些优化。
以上就是使用Python的urllib和urllib2模块制作爬虫示例教程的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取动态网页(有没有什么办法可以直接获取网页的动态渲染数据呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 11:02
)
成功完成基金净值爬虫的爬虫后,在简单了解了爬虫的一些原理后,不禁有些疑惑——为什么不能通过Request直接获取网页的源码,但是通过查找相关的js文件来爬取数据??
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。
这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据生成的结果。这些数据来自各种来源,可能通过 Ajax 加载或收录在 HTML 文档中。, 也可能是经过 JavaScript 和特定算法计算后生成的。按照目前Web发展的趋势,网页的原创HTML文档不收录任何数据。通过Ajax等方式统一加载后显示,从而在Web开发中实现前后端分离,减少服务器直接渲染页面。带来。通常,我们称这种网页为动态渲染页面。
之前的基金净值数据爬虫采用的是直接访问服务器获取数据接口,即找到收录数据的js文件,向服务器发送相关请求获取文件。
那么,有没有什么办法可以直接获取网页的动态渲染数据呢?答案是肯定的。
我们也可以直接用模拟浏览器操作的方式来实现动态网页的爬取,这样我们就可以在浏览器中看到它的样子,爬取到的源代码是什么,也就是实现了——可见然后爬行。
Python提供了很多模拟浏览器操作的库,如:Selenium、Splash、PyV8、Ghost等,本文继续以基金净值爬虫为例,使用Selenium对其动态页面进行爬取。
环境工具
1、Chrome 及其开发者工具
2、蟒蛇3.7
3、PyCharm
python中使用的库3.7
1、硒
2、熊猫
3、随机
4、 时间
5、操作系统
系统
Mac OS 10.13.2
Selenium 基本功能和用法
准备好工作了
ChromDriver 配置
基本使用
首先,我们先来了解一下Selenium的一些特性以及它能做什么:
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些动态渲染的页面,这种爬取方式非常有效。它的基本功能也非常方便。下面我们来看一些简单的代码:
1 from selenium import webdriver
2 from selenium.webdriver.common.by import By
3 from selenium.webdriver.common.keys import Keys
4 from selenium.webdriver.support import expected_conditions as EC
5 from selenium.webdriver.support.wait import WebDriverWait
6
7
8 browser = webdriver.Chrome() # 声明浏览器对象
9 try:
10 browser.get(\'https://www.baidu.com\') # 传入链接URL请求网页
11 query = browser.find_element_by_id(\'kw\') # 查找节点
12 query.send_keys(\'Python\') # 输入文字
13 query.send_keys(Keys.ENTER) # 回车跳转页面
14 wait = WebDriverWait(browser, 10) # 设置最长加载等待时间
15 print(browser.current_url) # 获取当前URL
16 print(browser.get_cookies()) # 获取当前Cookies
17 print(browser.page_source) # 获取源代码
18 finally:
19 browser.close() # 关闭浏览器
运行代码后,Chrome 浏览器会自动弹出。浏览器会跳转到百度,然后在搜索框中输入Python→回车→跳转到搜索结果页面,得到结果后关闭浏览器。这相当于模拟了我们在百度上搜索Python的全套动作,给你带来惊喜!!
在这个过程中,当加载网页结果时,控制台会分别输出当前的URL、当前的Cookies和网页源代码:
可以看出,我们得到的内容是浏览器中的真实内容。可见,使用Selenium驱动浏览器加载网页,可以直接得到JavaScript渲染的结果。接下来我们也会主要用Selenium来爬取基金的净值~
注:Selenium更详细的用法和功能可以在官网查看()
基金净值数据爬虫
通过前面的爬虫,我们会发现数据接口的分析比较繁琐,需要分析相关参数。如果直接用Selenium来模拟浏览器,就可以不用再关注这些界面参数了,只要能直接在浏览器页面上看到这里的内容就可以爬取了。现在我们来试试如何实现我们的目标——基金净值数据爬虫。
页面分析
这个爬虫的目标是单个基金的净值数据。抓取到的网址为:(以单个基金519961为例)。URL 的结构是显而易见的。当我们在浏览器中输入访问链接时,会显示最新的。基金权益数据第一页结果:
在数据下方,有一个页面导航,其中包括前五页之间的链接以及上一页和下一页之间的链接。还有一个链接可以输入任何要跳转到的页码:
如果我们想要获取第二页及以后的数据,我们需要跳转到相应的页码。因此,如果我们需要获取所有的历史净值数据,只需要遍历所有的页码即可。可以直接在页面跳转文本框中输入要跳转到的页码,然后点击“确定”按钮跳转到对应页码的页面。
这里没有直接点击“下一页”的原因是:一旦在爬取过程中出现异常退出,比如在第50页退出时,此时点击“下一页”就无法快速切换到当前页面相应的后续页面。另外,在爬取过程中需要记录当前爬虫的进度,以便及时进行异常检测,检测问题在第一页。整个过程比较复杂,采用直接跳转的方式抓取网页更合理。
当我们成功加载了某个页面的净值数据后,我们就可以使用Selenium来获取该页面的源代码了。定位到一个特定的节点后,我们就可以得到目标的HTML内容,然后通过相应的分析就可以得到我们的HTML内容。目标数据。下面,我们用代码来实现整个爬取过程。
获取基金权益清单
首先,我们需要构造目标 URL。这里的URL组成规则很明显,就是基金code.html。我们可以使用规则来构造我们要爬取的基金对象。这里以基金519961为例进行爬取。
1 browser = webdriver.Chrome()
2 wait = WebDriverWait(browser, 10)
3 fundcode=\'519961\'
4
5 def index_page(page):
6 \'\'\'
7 抓取基金索引页
8 :param page: 页码
9 :param fundcode: 基金代码
10 \'\'\'
11 print(\'正在爬取基金%s第%d页\' % (fundcode, page))
12 try:
13 url = \'http://fundf10.eastmoney.com/jjjz_%s.html\' % fundcode
14 browser.get(url)
15 if page>1:
16 input_page = wait.until(
17 EC.presence_of_element_located((By.CSS_SELECTOR, \'#pagebar input.pnum\')))
18 submit = wait.until(
19 EC.element_to_be_clickable((By.CSS_SELECTOR, \'#pagebar input.pgo\')))
20 input_page.clear()
21 input_page.send_keys(str(page))
22 submit.click()
23 wait.until(
24 EC.text_to_be_present_in_element((By.CSS_SELECTOR, \'#pagebar label.cur\'),
25 str(page)))
26 wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, \'#jztable\')))
27 get_jjjz()
28 except TimeoutException:
29 index_page(page)
这里首相构造了一个WebDriver对象,即声明浏览器对象,使用的浏览器是Chrome,然后指定一个基金代码(519961),然后定义index_page()方法来抓取列表基金净值数据。
在这种方法中,我们首先访问链接搜索资金,然后判断当前页码。如果大于1,我们会跳转到页面,否则我们将等待页面加载。
在等待加载时,我们使用WebDriverWait对象,它可以指定等待条件,同时制定一个最大等待时间,这里指定为最长10秒。如果在这段时间内满足等待条件,即页面元素加载成功,则立即返回相应结果并继续向下执行,否则,当最大等待时间未加载时,直接抛出一个超市例外。
比如我们最后需要等待历史权益信息加载完毕并指定presence_of_element_located条件,然后传入CSS选择器对应的条件#jztable,这个选择器对应的页面内容就是每个基金权益数据页面。在网页上查看:
注意:这里有一个小技巧。如果同学们对CSS选择器的语法不熟悉,可以右键选中节点→复制→复制选择器,直接获取对应的选择器:
CSS 选择器的语法请参考 CSS 选择器参考手册 ()。
加载成功后,机会订单的后续get_jjjz()方法提取历史净值信息。
关于翻页操作,这里先获取页码输入框,赋值给input_page,然后获取“OK”按钮,赋值给submit:
首先,我们需要在输入框中调用clear()方法(不管输入框是否有页码数据)。然后,调用send_keys()方法将页码填入输入框,然后点击“确定”按钮,听起来和我们正常的操作方法一样。
那么,如何知道是否跳转到了对应的页码呢?我们可以注意到,当跳转到当前页面时,页码会高亮显示:
我们只需要判断当前高亮的页码就是当前页码,这里左移使用了另一个等待条件text_to_be_present_in_element,它会等待指定的文本出现在某个节点然后返回成功,这里我们就高亮了亮页码和当前要跳转到的页码对应的CSS选择器通过参数传递给这个等待条件,这样它就会检查当前高亮页码节点是否是我们传递过来的页码数,如果是即,证明页面成功跳转到此页面,页面跳转成功。
这样,刚刚实现的index_page()方法就可以传入对应的页码,加载完页码对应的商品列表后,调用get_jjjz()方法进行页面分析。
解析历史净值数据列表
接下来,我们可以实现 get_jjjz() 方法来解析历史净值数据列表。在这里,我们通过搜索所有历史权益数据节点来获取对应的HTML内容
并进行相应的分析,实现如下:
1 def get_jjjz():
2 \'\'\'
3 提取基金净值数据
4 \'\'\'
5 lsjz = pd.DataFrame()
6 html_list = browser.find_elements_by_css_selector(\'#jztable tbody tr\')
7 for html in html_list:
8 data = html.text.split(\' \')
9 datas = {
10 \'净值日期\': data[0],
11 \'单位净值\': data[1],
12 \'累计净值\': data[2],
13 \'日增长率\': data[3],
14 \'申购状态\': data[4],
15 \'赎回状态\': data[5],
16 }
17 lsjz = lsjz.append(datas, ignore_index=True)
18 save_to_csv(lsjz)
首先调用 find_elements_by_css_selector 获取所有存储历史权益数据的节点。此时使用的CSS选择器是#jztable tbody tr,会匹配所有基金权益节点,输出是一个打包成列表的HTML。使用for循环遍历列表,使用text方法提取每个html中的文本内容,得到的输出是空格分隔的字符串数据。为了方便后续处理,我们可以使用split方法将数据拆分成一个新的以列表形式存储,再转换为dict形式。
最后,为了方便处理,我们将遍历的数据存储为DataFrame,然后使用save_to_csv()方法存储为csv文件。
另存为本地 csv 文件
接下来,我们将获取到的基金历史股权数据保存为本地csv文件。实现代码如下:
1 def save_to_csv(lsjz):
2 \'\'\'
3 保存为csv文件
4 : param result: 历史净值
5 \'\'\'
6 file_path = \'lsjz_%s.csv\' % fundcode
7 try:
8 if not os.path.isfile(file_path): # 判断当前目录下是否已存在该csv文件,若不存在,则直接存储
9 lsjz.to_csv(file_path, index=False)
10 else: # 若已存在,则追加存储,并设置header参数为False,防止列名重复存储
11 lsjz.to_csv(file_path, mode=\'a\', index=False, header=False)
12 print(\'存储成功\')
13 except Exception as e:
14 print(\'存储失败\')
这里,结果变量是 get_jjjz() 方法中传递的历史权益数据。
遍历每一页
我们之前定义的get_index()方法需要接受参数page,代表页码。这里,因为不同基金的数据页不一样,我们需要得到最大页数才能遍历所有页。当然,我们也可以用一些巧妙的方法来解决这个问题。页码遍历代码如下:
1 def main():
2 \'\'\'
3 遍历每一页
4 \'\'\'
5 flag = True
6 page = 1
7 while flag:
8 try:
9 index_page(page)
10 time.sleep(random.randint(1, 5))
11 page += 1
12 except:
13 flag = False
14 print(\'似乎是最后一页了呢\')
它的实现方法结合了try...except和while方法来逐页遍历下一页的内容。当页数超过时,即不存在,index_page()运行时会报错。这时候可以把flag改成False,那么下一次while循环就不会继续了,这样我们就可以遍历所有的页码了。
至此,我们的基金净值数据爬虫已经基本完成,终于可以直接调用main()方法运行了。
总结
在本文中,我们使用 Selenium 来演示基金股权页面的抓取。有兴趣的同学可以尝试使用其他条件来爬取基金数据,比如设置数据的起止日期:
使用日期来抓取内容可以促进未来的数据更新。另外,如果觉得浏览器弹窗比较烦,可以试试Chrome Headless模式或者使用PhantomJS爬取。
至此,基金净值爬虫的分析正式结束。
查看全部
python抓取动态网页(有没有什么办法可以直接获取网页的动态渲染数据呢?
)
成功完成基金净值爬虫的爬虫后,在简单了解了爬虫的一些原理后,不禁有些疑惑——为什么不能通过Request直接获取网页的源码,但是通过查找相关的js文件来爬取数据??
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。
这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据生成的结果。这些数据来自各种来源,可能通过 Ajax 加载或收录在 HTML 文档中。, 也可能是经过 JavaScript 和特定算法计算后生成的。按照目前Web发展的趋势,网页的原创HTML文档不收录任何数据。通过Ajax等方式统一加载后显示,从而在Web开发中实现前后端分离,减少服务器直接渲染页面。带来。通常,我们称这种网页为动态渲染页面。
之前的基金净值数据爬虫采用的是直接访问服务器获取数据接口,即找到收录数据的js文件,向服务器发送相关请求获取文件。
那么,有没有什么办法可以直接获取网页的动态渲染数据呢?答案是肯定的。
我们也可以直接用模拟浏览器操作的方式来实现动态网页的爬取,这样我们就可以在浏览器中看到它的样子,爬取到的源代码是什么,也就是实现了——可见然后爬行。
Python提供了很多模拟浏览器操作的库,如:Selenium、Splash、PyV8、Ghost等,本文继续以基金净值爬虫为例,使用Selenium对其动态页面进行爬取。
环境工具
1、Chrome 及其开发者工具
2、蟒蛇3.7
3、PyCharm
python中使用的库3.7
1、硒
2、熊猫
3、随机
4、 时间
5、操作系统
系统
Mac OS 10.13.2
Selenium 基本功能和用法
准备好工作了
ChromDriver 配置
基本使用
首先,我们先来了解一下Selenium的一些特性以及它能做什么:
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些动态渲染的页面,这种爬取方式非常有效。它的基本功能也非常方便。下面我们来看一些简单的代码:
1 from selenium import webdriver
2 from selenium.webdriver.common.by import By
3 from selenium.webdriver.common.keys import Keys
4 from selenium.webdriver.support import expected_conditions as EC
5 from selenium.webdriver.support.wait import WebDriverWait
6
7
8 browser = webdriver.Chrome() # 声明浏览器对象
9 try:
10 browser.get(\'https://www.baidu.com\') # 传入链接URL请求网页
11 query = browser.find_element_by_id(\'kw\') # 查找节点
12 query.send_keys(\'Python\') # 输入文字
13 query.send_keys(Keys.ENTER) # 回车跳转页面
14 wait = WebDriverWait(browser, 10) # 设置最长加载等待时间
15 print(browser.current_url) # 获取当前URL
16 print(browser.get_cookies()) # 获取当前Cookies
17 print(browser.page_source) # 获取源代码
18 finally:
19 browser.close() # 关闭浏览器
运行代码后,Chrome 浏览器会自动弹出。浏览器会跳转到百度,然后在搜索框中输入Python→回车→跳转到搜索结果页面,得到结果后关闭浏览器。这相当于模拟了我们在百度上搜索Python的全套动作,给你带来惊喜!!
在这个过程中,当加载网页结果时,控制台会分别输出当前的URL、当前的Cookies和网页源代码:
可以看出,我们得到的内容是浏览器中的真实内容。可见,使用Selenium驱动浏览器加载网页,可以直接得到JavaScript渲染的结果。接下来我们也会主要用Selenium来爬取基金的净值~
注:Selenium更详细的用法和功能可以在官网查看()
基金净值数据爬虫
通过前面的爬虫,我们会发现数据接口的分析比较繁琐,需要分析相关参数。如果直接用Selenium来模拟浏览器,就可以不用再关注这些界面参数了,只要能直接在浏览器页面上看到这里的内容就可以爬取了。现在我们来试试如何实现我们的目标——基金净值数据爬虫。
页面分析
这个爬虫的目标是单个基金的净值数据。抓取到的网址为:(以单个基金519961为例)。URL 的结构是显而易见的。当我们在浏览器中输入访问链接时,会显示最新的。基金权益数据第一页结果:
在数据下方,有一个页面导航,其中包括前五页之间的链接以及上一页和下一页之间的链接。还有一个链接可以输入任何要跳转到的页码:
如果我们想要获取第二页及以后的数据,我们需要跳转到相应的页码。因此,如果我们需要获取所有的历史净值数据,只需要遍历所有的页码即可。可以直接在页面跳转文本框中输入要跳转到的页码,然后点击“确定”按钮跳转到对应页码的页面。
这里没有直接点击“下一页”的原因是:一旦在爬取过程中出现异常退出,比如在第50页退出时,此时点击“下一页”就无法快速切换到当前页面相应的后续页面。另外,在爬取过程中需要记录当前爬虫的进度,以便及时进行异常检测,检测问题在第一页。整个过程比较复杂,采用直接跳转的方式抓取网页更合理。
当我们成功加载了某个页面的净值数据后,我们就可以使用Selenium来获取该页面的源代码了。定位到一个特定的节点后,我们就可以得到目标的HTML内容,然后通过相应的分析就可以得到我们的HTML内容。目标数据。下面,我们用代码来实现整个爬取过程。
获取基金权益清单
首先,我们需要构造目标 URL。这里的URL组成规则很明显,就是基金code.html。我们可以使用规则来构造我们要爬取的基金对象。这里以基金519961为例进行爬取。
1 browser = webdriver.Chrome()
2 wait = WebDriverWait(browser, 10)
3 fundcode=\'519961\'
4
5 def index_page(page):
6 \'\'\'
7 抓取基金索引页
8 :param page: 页码
9 :param fundcode: 基金代码
10 \'\'\'
11 print(\'正在爬取基金%s第%d页\' % (fundcode, page))
12 try:
13 url = \'http://fundf10.eastmoney.com/jjjz_%s.html\' % fundcode
14 browser.get(url)
15 if page>1:
16 input_page = wait.until(
17 EC.presence_of_element_located((By.CSS_SELECTOR, \'#pagebar input.pnum\')))
18 submit = wait.until(
19 EC.element_to_be_clickable((By.CSS_SELECTOR, \'#pagebar input.pgo\')))
20 input_page.clear()
21 input_page.send_keys(str(page))
22 submit.click()
23 wait.until(
24 EC.text_to_be_present_in_element((By.CSS_SELECTOR, \'#pagebar label.cur\'),
25 str(page)))
26 wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, \'#jztable\')))
27 get_jjjz()
28 except TimeoutException:
29 index_page(page)
这里首相构造了一个WebDriver对象,即声明浏览器对象,使用的浏览器是Chrome,然后指定一个基金代码(519961),然后定义index_page()方法来抓取列表基金净值数据。
在这种方法中,我们首先访问链接搜索资金,然后判断当前页码。如果大于1,我们会跳转到页面,否则我们将等待页面加载。
在等待加载时,我们使用WebDriverWait对象,它可以指定等待条件,同时制定一个最大等待时间,这里指定为最长10秒。如果在这段时间内满足等待条件,即页面元素加载成功,则立即返回相应结果并继续向下执行,否则,当最大等待时间未加载时,直接抛出一个超市例外。
比如我们最后需要等待历史权益信息加载完毕并指定presence_of_element_located条件,然后传入CSS选择器对应的条件#jztable,这个选择器对应的页面内容就是每个基金权益数据页面。在网页上查看:
注意:这里有一个小技巧。如果同学们对CSS选择器的语法不熟悉,可以右键选中节点→复制→复制选择器,直接获取对应的选择器:
CSS 选择器的语法请参考 CSS 选择器参考手册 ()。
加载成功后,机会订单的后续get_jjjz()方法提取历史净值信息。
关于翻页操作,这里先获取页码输入框,赋值给input_page,然后获取“OK”按钮,赋值给submit:
首先,我们需要在输入框中调用clear()方法(不管输入框是否有页码数据)。然后,调用send_keys()方法将页码填入输入框,然后点击“确定”按钮,听起来和我们正常的操作方法一样。
那么,如何知道是否跳转到了对应的页码呢?我们可以注意到,当跳转到当前页面时,页码会高亮显示:
我们只需要判断当前高亮的页码就是当前页码,这里左移使用了另一个等待条件text_to_be_present_in_element,它会等待指定的文本出现在某个节点然后返回成功,这里我们就高亮了亮页码和当前要跳转到的页码对应的CSS选择器通过参数传递给这个等待条件,这样它就会检查当前高亮页码节点是否是我们传递过来的页码数,如果是即,证明页面成功跳转到此页面,页面跳转成功。
这样,刚刚实现的index_page()方法就可以传入对应的页码,加载完页码对应的商品列表后,调用get_jjjz()方法进行页面分析。
解析历史净值数据列表
接下来,我们可以实现 get_jjjz() 方法来解析历史净值数据列表。在这里,我们通过搜索所有历史权益数据节点来获取对应的HTML内容
并进行相应的分析,实现如下:
1 def get_jjjz():
2 \'\'\'
3 提取基金净值数据
4 \'\'\'
5 lsjz = pd.DataFrame()
6 html_list = browser.find_elements_by_css_selector(\'#jztable tbody tr\')
7 for html in html_list:
8 data = html.text.split(\' \')
9 datas = {
10 \'净值日期\': data[0],
11 \'单位净值\': data[1],
12 \'累计净值\': data[2],
13 \'日增长率\': data[3],
14 \'申购状态\': data[4],
15 \'赎回状态\': data[5],
16 }
17 lsjz = lsjz.append(datas, ignore_index=True)
18 save_to_csv(lsjz)
首先调用 find_elements_by_css_selector 获取所有存储历史权益数据的节点。此时使用的CSS选择器是#jztable tbody tr,会匹配所有基金权益节点,输出是一个打包成列表的HTML。使用for循环遍历列表,使用text方法提取每个html中的文本内容,得到的输出是空格分隔的字符串数据。为了方便后续处理,我们可以使用split方法将数据拆分成一个新的以列表形式存储,再转换为dict形式。
最后,为了方便处理,我们将遍历的数据存储为DataFrame,然后使用save_to_csv()方法存储为csv文件。
另存为本地 csv 文件
接下来,我们将获取到的基金历史股权数据保存为本地csv文件。实现代码如下:
1 def save_to_csv(lsjz):
2 \'\'\'
3 保存为csv文件
4 : param result: 历史净值
5 \'\'\'
6 file_path = \'lsjz_%s.csv\' % fundcode
7 try:
8 if not os.path.isfile(file_path): # 判断当前目录下是否已存在该csv文件,若不存在,则直接存储
9 lsjz.to_csv(file_path, index=False)
10 else: # 若已存在,则追加存储,并设置header参数为False,防止列名重复存储
11 lsjz.to_csv(file_path, mode=\'a\', index=False, header=False)
12 print(\'存储成功\')
13 except Exception as e:
14 print(\'存储失败\')
这里,结果变量是 get_jjjz() 方法中传递的历史权益数据。
遍历每一页
我们之前定义的get_index()方法需要接受参数page,代表页码。这里,因为不同基金的数据页不一样,我们需要得到最大页数才能遍历所有页。当然,我们也可以用一些巧妙的方法来解决这个问题。页码遍历代码如下:
1 def main():
2 \'\'\'
3 遍历每一页
4 \'\'\'
5 flag = True
6 page = 1
7 while flag:
8 try:
9 index_page(page)
10 time.sleep(random.randint(1, 5))
11 page += 1
12 except:
13 flag = False
14 print(\'似乎是最后一页了呢\')
它的实现方法结合了try...except和while方法来逐页遍历下一页的内容。当页数超过时,即不存在,index_page()运行时会报错。这时候可以把flag改成False,那么下一次while循环就不会继续了,这样我们就可以遍历所有的页码了。
至此,我们的基金净值数据爬虫已经基本完成,终于可以直接调用main()方法运行了。
总结
在本文中,我们使用 Selenium 来演示基金股权页面的抓取。有兴趣的同学可以尝试使用其他条件来爬取基金数据,比如设置数据的起止日期:
使用日期来抓取内容可以促进未来的数据更新。另外,如果觉得浏览器弹窗比较烦,可以试试Chrome Headless模式或者使用PhantomJS爬取。
至此,基金净值爬虫的分析正式结束。
python抓取动态网页( 如何利用Webkit从渲染网页中获取数据抓取数据的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-14 10:00
如何利用Webkit从渲染网页中获取数据抓取数据的代码)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
复制代码
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
复制代码
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。 查看全部
python抓取动态网页(
如何利用Webkit从渲染网页中获取数据抓取数据的代码)

当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
复制代码
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
复制代码
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
python抓取动态网页(《网络上常见的GIF动态图》5月份就写好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-14 09:19
前面写的字~
好久没写爬虫相关的文章了。今天抽时间分享一个我之前做的程序。
经常逛A站和B站的人,对一个节目《网上常见的GIF动图》并不陌生
今天就来分享一下,如何通过爬虫自动将这些动作采集到你的电脑中(其实这个程序是5月份写的,一直拖到想起来分享)。
一. 思路分析
根据爬虫的基本规律:
1.找到目标
2.获取目标
3.处理目标内容,获取有用信息
1.首先,我们的目标是:找到一个动图,去GIFFCC.COM
这个网站是论坛式的网站,分为几类,反正各种动画试试。
我们的目标是找到这些(采集)(隐藏)动作(到)图片(自我)的(自我)(电)地址(大脑)。
2.看各个模块的网址,看看是什么规则
'#39;,#各种GIF动态图片的其他来源
'#39;,#美女GIF动图源码
'#39;,#Sci-Fi 奇幻电影 GIF 动画源
'#39;,#Comedy 搞笑电影 GIF 动画源
'#39;,#动作冒险电影 GIF 动画源
'#39;#GIF 恐怖惊悚电影的动画来源
是的,没错,如果你是游客参观的话,那么每个版块的网址都是这样的——1.html
那么每个模块的内容规律是什么?直接上图:
我们关心的是当前页面的URL和页数。跳转到第二页后,地址变为:
换句话说,URL 的法则是
这里注意网站的图片是动态加载的。只有当你向下滑动时,下面的图片才会逐渐出现。请暂时写下来。
3.每个GIF所在页面的规律
其实这不是一个规律,但是只要找到单张图片的地址,就没有什么难处理的了。
两个动手
1.获取入口页面的内容
即根据传入的URL,获取整个页面的源码
#仅仅获取页面内容
def get_html_Pages(self,url):
try:
#browser = webdriver.PhantomJS(executable_path=r'C:\Python27\Scripts\phantomjs.exe')
browser = webdriver.PhantomJS()
browser.get(url)
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
html=HTMLParser.HTMLParser().unescape(html).decode('utf-8')
return html
#捕捉异常,防止程序直接死掉
except Exception,e:
print u"连接失败,错误原因",e
return None
这里我们使用了 webdriver 和 PhantomJS 模块,为什么?因为网页是动态加载的,所以这种方式可以爬取的数据是满满的。
那么还有一个问题,为什么没有滑动,得到的数据
2.获取页码
#获取页码
def get_page_num(self,html):
doc = pq(html)
print u'开始获取总页码'
#print doc('head')('title').text()#获取当前title
try:
#如果当前页面太多,超过8页以上,就使用另一种方式获取页码
if doc('div[class="pg"]')('[class="last"]'):
num_content= doc('div[class="pg"]')('[class="last"]').attr('href')
print num_content.split('-')[1].split('.')[0]
return num_content.split('-')[1].split('.')[0]
else:
num_content= doc('div[class="pg"]')('span')
return filter(str.isdigit,str(num_content.text()))[0]
#如果获取页码失败,那么就返回1, 即值获取1页内容
except Exception,e:
print u'获取页码失败'.e
return '1'
这里的页码处理使用了一个模块pq,即PyQuery
从 pyquery 导入 PyQuery 作为 pq
使用PyQuery查找我们需要的元素,感觉更好处理,很方便
同时,这里的处理有点意思。如果你观察这个页面,你会发现每个模块的页码在顶部和底部都有一个。然后我在这里剪掉它,因为我们只需要一个页码。
3-6 步骤 3 到 6 一起
其实就是按照页数来遍历,得到每一页的内容
然后获取每个页面的所有图片地址
print u'总共有 %d页内容' % int(page_num)
#3.遍历每一页的内容
for num in range(1,int(page_num)):
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#6.处理每一个元素的内容
self.get_items_url(items,num)
在获取每个页面的内容时,需要重新组合页面地址。
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
有了新地址,就可以获取当前页面的内容,进行数据处理,得到每张图片的地址列表
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#解析页面内容,获取gif的图片list
def parse_items_by_html(self, html):
doc = pq(html)
print u'开始查找内容msg'
return doc('div[class="c cl"]')
得到图片列表后,再次解析得到每张图片的URL
#解析gif 的list ,处理每一个gif内容
def get_items_url(self,items,num):
i=1
for article in items.items():
print u'开始处理数据(%d/%d)' % (i, len(items))
#print article
self.get_single_item(article,i,num)
i +=1
#处理单个gif内容,获取其地址,gif 最终地址
def get_single_item(self,article,num,page_num):
gif_dict={}
#每个页面的地址
gif_url= 'http://gifcc.com/'+article('a').attr('href')
#每个页面的标题
gif_title= article('a').attr('title')
#每张图的具体地址
#html=self.get_html_Pages(gif_url)
#gif_final_url=self.get_final_gif_url(html)
gif_dict['num']=num
gif_dict['page_num']=page_num
gif_dict['gif_url']=gif_url
gif_dict['gif_title']=gif_title
self.gif_list.append(gif_dict)
data=u'第'+str(page_num)+'页|\t'+str(num)+'|\t'+gif_title+'|\t'+gif_url+'\n'
self.file_flag.write(data)
在这里,整合数据,为将数据写入数据库做准备
7.将图片保存到本地并将数据写入数据库
<p>#使用urllib2来获取图片最终地址
def get_final_gif_url_use_urllib2(self,url):
try:
html= urllib2.urlopen(url).read()
gif_pattern=re.compile(' 查看全部
python抓取动态网页(《网络上常见的GIF动态图》5月份就写好了)
前面写的字~
好久没写爬虫相关的文章了。今天抽时间分享一个我之前做的程序。
经常逛A站和B站的人,对一个节目《网上常见的GIF动图》并不陌生
今天就来分享一下,如何通过爬虫自动将这些动作采集到你的电脑中(其实这个程序是5月份写的,一直拖到想起来分享)。
一. 思路分析
根据爬虫的基本规律:
1.找到目标
2.获取目标
3.处理目标内容,获取有用信息
1.首先,我们的目标是:找到一个动图,去GIFFCC.COM

这个网站是论坛式的网站,分为几类,反正各种动画试试。
我们的目标是找到这些(采集)(隐藏)动作(到)图片(自我)的(自我)(电)地址(大脑)。
2.看各个模块的网址,看看是什么规则
'#39;,#各种GIF动态图片的其他来源
'#39;,#美女GIF动图源码
'#39;,#Sci-Fi 奇幻电影 GIF 动画源
'#39;,#Comedy 搞笑电影 GIF 动画源
'#39;,#动作冒险电影 GIF 动画源
'#39;#GIF 恐怖惊悚电影的动画来源
是的,没错,如果你是游客参观的话,那么每个版块的网址都是这样的——1.html
那么每个模块的内容规律是什么?直接上图:

我们关心的是当前页面的URL和页数。跳转到第二页后,地址变为:
换句话说,URL 的法则是
这里注意网站的图片是动态加载的。只有当你向下滑动时,下面的图片才会逐渐出现。请暂时写下来。
3.每个GIF所在页面的规律

其实这不是一个规律,但是只要找到单张图片的地址,就没有什么难处理的了。
两个动手

1.获取入口页面的内容
即根据传入的URL,获取整个页面的源码
#仅仅获取页面内容
def get_html_Pages(self,url):
try:
#browser = webdriver.PhantomJS(executable_path=r'C:\Python27\Scripts\phantomjs.exe')
browser = webdriver.PhantomJS()
browser.get(url)
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
html=HTMLParser.HTMLParser().unescape(html).decode('utf-8')
return html
#捕捉异常,防止程序直接死掉
except Exception,e:
print u"连接失败,错误原因",e
return None
这里我们使用了 webdriver 和 PhantomJS 模块,为什么?因为网页是动态加载的,所以这种方式可以爬取的数据是满满的。
那么还有一个问题,为什么没有滑动,得到的数据
2.获取页码
#获取页码
def get_page_num(self,html):
doc = pq(html)
print u'开始获取总页码'
#print doc('head')('title').text()#获取当前title
try:
#如果当前页面太多,超过8页以上,就使用另一种方式获取页码
if doc('div[class="pg"]')('[class="last"]'):
num_content= doc('div[class="pg"]')('[class="last"]').attr('href')
print num_content.split('-')[1].split('.')[0]
return num_content.split('-')[1].split('.')[0]
else:
num_content= doc('div[class="pg"]')('span')
return filter(str.isdigit,str(num_content.text()))[0]
#如果获取页码失败,那么就返回1, 即值获取1页内容
except Exception,e:
print u'获取页码失败'.e
return '1'
这里的页码处理使用了一个模块pq,即PyQuery
从 pyquery 导入 PyQuery 作为 pq
使用PyQuery查找我们需要的元素,感觉更好处理,很方便
同时,这里的处理有点意思。如果你观察这个页面,你会发现每个模块的页码在顶部和底部都有一个。然后我在这里剪掉它,因为我们只需要一个页码。
3-6 步骤 3 到 6 一起
其实就是按照页数来遍历,得到每一页的内容
然后获取每个页面的所有图片地址
print u'总共有 %d页内容' % int(page_num)
#3.遍历每一页的内容
for num in range(1,int(page_num)):
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#6.处理每一个元素的内容
self.get_items_url(items,num)
在获取每个页面的内容时,需要重新组合页面地址。
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
有了新地址,就可以获取当前页面的内容,进行数据处理,得到每张图片的地址列表
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#解析页面内容,获取gif的图片list
def parse_items_by_html(self, html):
doc = pq(html)
print u'开始查找内容msg'
return doc('div[class="c cl"]')
得到图片列表后,再次解析得到每张图片的URL
#解析gif 的list ,处理每一个gif内容
def get_items_url(self,items,num):
i=1
for article in items.items():
print u'开始处理数据(%d/%d)' % (i, len(items))
#print article
self.get_single_item(article,i,num)
i +=1
#处理单个gif内容,获取其地址,gif 最终地址
def get_single_item(self,article,num,page_num):
gif_dict={}
#每个页面的地址
gif_url= 'http://gifcc.com/'+article('a').attr('href')
#每个页面的标题
gif_title= article('a').attr('title')
#每张图的具体地址
#html=self.get_html_Pages(gif_url)
#gif_final_url=self.get_final_gif_url(html)
gif_dict['num']=num
gif_dict['page_num']=page_num
gif_dict['gif_url']=gif_url
gif_dict['gif_title']=gif_title
self.gif_list.append(gif_dict)
data=u'第'+str(page_num)+'页|\t'+str(num)+'|\t'+gif_title+'|\t'+gif_url+'\n'
self.file_flag.write(data)
在这里,整合数据,为将数据写入数据库做准备
7.将图片保存到本地并将数据写入数据库
<p>#使用urllib2来获取图片最终地址
def get_final_gif_url_use_urllib2(self,url):
try:
html= urllib2.urlopen(url).read()
gif_pattern=re.compile('
python抓取动态网页(Python实实现现爬爬取取网网页页中中动动态态加加载载的数数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-14 09:16
Python实现了实际爬取来爬取网页中的动态动态和加载的数据。在使用python爬虫技术采集数据信息时,经常会遇到返回的网页信息。抓取动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么动态加上加载的数据是什么呢?我们可以通过requests模块抓取数据,不可能每次都可见。有些数据是通过非浏览器地址栏中的 URL 请求的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据) 2. 如何检查测试网的网页是否有activity 加载加载的数据处于动态状态?在当前页面打开抓包工具,抓取地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果有搜索结果表示该数据不是动态加载,否则表示数据是动态加载的。如图: 或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。
如图:3. 如果数据是动态动态加载的,那么我们如何捕获动态动态加载的数据呢?根据?? 在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下: 在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如图以下。在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。你可以点击这里了解关于序列化和反序列化的js。代码如下: import requestsimport json#获取商品价格的请求地址url "/stock?skuIdcat 1713,3259,3333&venderId 1000077923&area" \" 4_113_9786_0&buyNum 1& 选择了SuitSkuIds &extraParam {%22originid%22:%221%22}&ch 1&fqsp 0&" \"pduid 47398205303&pdpin jd_635f3b795bb1592&coord &detailedAdd &callback 964 的博文中显示的结果是作者在博客中显示的修改结果和回调4964下图: 注:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。至此,这篇关于Python爬取网页动态加载数据的文章就介绍完了。更多相关Python爬取网页动态数据内容,请搜索之前的文章或继续浏览下方相关文章 查看全部
python抓取动态网页(Python实实现现爬爬取取网网页页中中动动态态加加载载的数数据)
Python实现了实际爬取来爬取网页中的动态动态和加载的数据。在使用python爬虫技术采集数据信息时,经常会遇到返回的网页信息。抓取动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么动态加上加载的数据是什么呢?我们可以通过requests模块抓取数据,不可能每次都可见。有些数据是通过非浏览器地址栏中的 URL 请求的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据) 2. 如何检查测试网的网页是否有activity 加载加载的数据处于动态状态?在当前页面打开抓包工具,抓取地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果有搜索结果表示该数据不是动态加载,否则表示数据是动态加载的。如图: 或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。
如图:3. 如果数据是动态动态加载的,那么我们如何捕获动态动态加载的数据呢?根据?? 在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下: 在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如图以下。在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。你可以点击这里了解关于序列化和反序列化的js。代码如下: import requestsimport json#获取商品价格的请求地址url "/stock?skuIdcat 1713,3259,3333&venderId 1000077923&area" \" 4_113_9786_0&buyNum 1& 选择了SuitSkuIds &extraParam {%22originid%22:%221%22}&ch 1&fqsp 0&" \"pduid 47398205303&pdpin jd_635f3b795bb1592&coord &detailedAdd &callback 964 的博文中显示的结果是作者在博客中显示的修改结果和回调4964下图: 注:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。至此,这篇关于Python爬取网页动态加载数据的文章就介绍完了。更多相关Python爬取网页动态数据内容,请搜索之前的文章或继续浏览下方相关文章
python抓取动态网页(以糗事百科网站数据为例(解析json.6+pycharm5))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-12 20:17
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。 查看全部
python抓取动态网页(以糗事百科网站数据为例(解析json.6+pycharm5))
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。
python抓取动态网页(python抓取动态网页(lxml+xpath)爬取工具:seleniumpython异步加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-12 17:07
python抓取动态网页(lxml+xpath+ajax)爬取工具:seleniumpython异步加载网页工具:webdriver+bs4一.ajax概述ajax的本质就是采用ajax连接请求动态网页。异步(异步)连接http,当用户点击刷新页面时,后续可以继续加载数据。(图片来源)异步连接是最灵活高效的获取网页的方式,也是ajax的核心,ajax请求不会在服务器上创建新的数据库连接,而是直接与动态页面进行。
异步的性质使得动态网页获取比传统的同步网页,显得更加高效,再通过requests或selenium方式进行模拟点击(一.xml方式)获取。在上次抓取其他网站的例子中获取网站页面,并分析用户点击。首先我们将整个页面都用ajax方式抓取。当将整个页面用ajax抓取之后,我们在将其存入一个新的二进制的文件中。
写入的二进制文件中包含一个zip压缩包,里面包含我们分析的图片以及动态页面内容。1.图片内容抓取首先我们获取页面中的图片。分析页面中的图片的lxml.etree.html()方法的href属性进行获取。代码如下:page=requests.get(page)我们发现页面中的内容并不会采用page这个字段标记我们,而是被存储在xml文件中(jpg格式)。
所以我们采用一些xml格式格式化图片信息,然后再重新编码保存到external_xml文件中即可。图片的内容是存储在external_xml文件中的二.动态页面抓取在获取了页面信息后,我们分析页面中的动态内容,内容我们是最基本的内容,所以采用相同的方式获取。内容我们分析了三个不同层级页面,发现并不是把链接放在页面的某个标签中直接请求。
页面的元素元素类型不同,页面里面元素的xml类型不同。不同层级的页面有不同的类型定义以及xml的定义,这些类型定义相同,但是属性值不同。动态页面的定义//aarp设置动态图片zipimportpandasaspdimportreimportosimporttimefromlxmlimportetree#全局变量//wxget单个请求xavier_middlewares={'content':'请求...','content':'请求...','xavier_middlewares':{'page':'动态页面','xavier_middlewares':{'load_url':'请求...','load_url':'...','page':'请求...','load_url':'...','role':'xavier','context':'请求...','context':'...','each':'请求...','each':'请求...','eval':'请求...','frozen':'请求...','frozen':'请求..。 查看全部
python抓取动态网页(python抓取动态网页(lxml+xpath)爬取工具:seleniumpython异步加载)
python抓取动态网页(lxml+xpath+ajax)爬取工具:seleniumpython异步加载网页工具:webdriver+bs4一.ajax概述ajax的本质就是采用ajax连接请求动态网页。异步(异步)连接http,当用户点击刷新页面时,后续可以继续加载数据。(图片来源)异步连接是最灵活高效的获取网页的方式,也是ajax的核心,ajax请求不会在服务器上创建新的数据库连接,而是直接与动态页面进行。
异步的性质使得动态网页获取比传统的同步网页,显得更加高效,再通过requests或selenium方式进行模拟点击(一.xml方式)获取。在上次抓取其他网站的例子中获取网站页面,并分析用户点击。首先我们将整个页面都用ajax方式抓取。当将整个页面用ajax抓取之后,我们在将其存入一个新的二进制的文件中。
写入的二进制文件中包含一个zip压缩包,里面包含我们分析的图片以及动态页面内容。1.图片内容抓取首先我们获取页面中的图片。分析页面中的图片的lxml.etree.html()方法的href属性进行获取。代码如下:page=requests.get(page)我们发现页面中的内容并不会采用page这个字段标记我们,而是被存储在xml文件中(jpg格式)。
所以我们采用一些xml格式格式化图片信息,然后再重新编码保存到external_xml文件中即可。图片的内容是存储在external_xml文件中的二.动态页面抓取在获取了页面信息后,我们分析页面中的动态内容,内容我们是最基本的内容,所以采用相同的方式获取。内容我们分析了三个不同层级页面,发现并不是把链接放在页面的某个标签中直接请求。
页面的元素元素类型不同,页面里面元素的xml类型不同。不同层级的页面有不同的类型定义以及xml的定义,这些类型定义相同,但是属性值不同。动态页面的定义//aarp设置动态图片zipimportpandasaspdimportreimportosimporttimefromlxmlimportetree#全局变量//wxget单个请求xavier_middlewares={'content':'请求...','content':'请求...','xavier_middlewares':{'page':'动态页面','xavier_middlewares':{'load_url':'请求...','load_url':'...','page':'请求...','load_url':'...','role':'xavier','context':'请求...','context':'...','each':'请求...','each':'请求...','eval':'请求...','frozen':'请求...','frozen':'请求..。
python抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-28 06:02
python抓取动态网页最基本的是对网页进行解析,然后把解析出来的数据交给get或者post,然后我们可以使用json对返回的json进行解析,可以转换成csv或者xml,我们一起来看看如何处理动态网页。
一、网页解析直接看代码。注意为了可读性大家还是看解析出来的结果再来看我们的讲解吧javascript代码看不懂的话,多看几遍,其实是很简单的。
python代码,前端页面requests封装的函数,
<p>1):varmsg=stepwhilelvl[i]!=''andmsg 查看全部
python抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
python抓取动态网页最基本的是对网页进行解析,然后把解析出来的数据交给get或者post,然后我们可以使用json对返回的json进行解析,可以转换成csv或者xml,我们一起来看看如何处理动态网页。
一、网页解析直接看代码。注意为了可读性大家还是看解析出来的结果再来看我们的讲解吧javascript代码看不懂的话,多看几遍,其实是很简单的。
python代码,前端页面requests封装的函数,
<p>1):varmsg=stepwhilelvl[i]!=''andmsg
python抓取动态网页(Python项目案例开发从入门到实战》(清华大学出版社郑秋生))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-27 14:11
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏义主编)爬虫应用-抓取百度图片
本文爬取了搜狗图片库中的图片。与抓取特定网页中的图片相比,抓取图片库中的图片相对复杂一些。复杂的主要原因在于图片的动态加载。
图片库中的图片太多,所以在访问网页时,并不是一次性加载所有图片,而是根据鼠标滚轮的行为动态加载。这将导致与之前抓取特定网页中的图片不同。主要原因是没有办法通过查看网页源代码直接获取存储图片的链接。相反,它需要在网络中 XHR 下的标题和预览中找到。图像存储 URL 的规律。
别着急,我们稍后会详细解释。首先,我先贴出代码:
1 import requests 2 import urllib 3 import json 4 import os 5 import shutil # 用来删除文件夹
6
7
8 def getSogouImag(category, length, path): 9 # 判断文件夹是否存在,存在则删除
10 if os.path.exists(path): 11 shutil.rmtree(path) 12 # 创建文件夹
13 os.mkdir(path) 14 # 得到要爬取的图片数量
15 n = length 16 # 返回要爬取的类别
17 cate = category 18 # 根据搜索的网页得到存储图片的网页是这个代码的难点,下面会详细讲解
19 url = 'https://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=' + cate + '&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n) 20 # 访问网页
21 imgs = requests.get(url) 22 # 获取网页内容
23 imgs_text = imgs.text 24 # 字符串转换成json格式
25 imgs_json = json.loads(imgs_text) 26 # 得到图片信息列表
27 imgs_items = imgs_json['all_items'] 28 m = 0 29 # 存储每个想要保存的图片链接,为了后续
30 for i in imgs_items: 31 # thumbUrl存储的图片是大小为480*360的图片网页
32 img_url = i['thumbUrl'] 33 print('*********' + str(m) + '.png********' + 'Downloading...') 34 print('下载的url: ', img_url) 35 # 下载图片并且保存
36 urllib.request.urlretrieve(img_url, path+str(m) + '.jpg') 37 m = m + 1
38 print('Download complete !') 39
40
41 getSogouImag('壁纸', 5, './img/') 42
43 pass
在这里,获取存储图像的URL是关键和难点。下面详细介绍如何获取URL。
(1)首先打开网页的源代码(chrome中鼠标右键点击Inspect),这时候如果用前三章(爬虫系列一和系列二)抓取指定网页中的图片)正则表达式或CSS标签过滤等方法只会返回一个搜狗图标图片,其他我们要下载的显示图片是看不到的。
(2)如果我们要找到我们要下载的图片,必须点击Network,选择XHR,然后我们会在Name中看到getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA column 越是用鼠标加载图片,越会出现这个getAllRecomPicByTag的内容,点击一下,就可以看到存储图片地址的API出现了。
在这里,您可以单击预览并观察此 json 数组。一层一层打开all_items,可以看到里面存放的是图片的地址。如果您明白这是我们可以找到图片链接的地方,那么我们可以确认我们想要您找到的图片链接在标题中。
(3)点击Headers可以找到对应的url链接。
请求 URL 链接如下所示:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1920&height=1080
我们猜测这应该是搜狗图片存放图片链接的URL,我们来解析一下。先看category和tag后面的字符串,应该是字符的编码。检查%E5%A3%81%E7%BA%B8是“壁纸”的编码,%E5%85%A8%E9%83%是“全部”的编码,所以上面的链接和下面的链接是等价的:
壁纸&tag=all&start=0&len=15&width=1920&height=1080
网页打开如下图所示:
另外,start是起始下标,len是长度,也就是图片张数,所以我们可以通过这个信息给url传入参数,让搜索更加灵活,如下图:
url ='' + cate +'&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n)
其中cate和n是可以自定义的变量,分别代表要搜索的类别和要爬取的图片数量。
以上就是使用python动态抓取图片库中图片的详细讲解,希望可以帮助大家理解。 查看全部
python抓取动态网页(Python项目案例开发从入门到实战》(清华大学出版社郑秋生))
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生、夏敏义主编)爬虫应用-抓取百度图片
本文爬取了搜狗图片库中的图片。与抓取特定网页中的图片相比,抓取图片库中的图片相对复杂一些。复杂的主要原因在于图片的动态加载。
图片库中的图片太多,所以在访问网页时,并不是一次性加载所有图片,而是根据鼠标滚轮的行为动态加载。这将导致与之前抓取特定网页中的图片不同。主要原因是没有办法通过查看网页源代码直接获取存储图片的链接。相反,它需要在网络中 XHR 下的标题和预览中找到。图像存储 URL 的规律。
别着急,我们稍后会详细解释。首先,我先贴出代码:
1 import requests 2 import urllib 3 import json 4 import os 5 import shutil # 用来删除文件夹
6
7
8 def getSogouImag(category, length, path): 9 # 判断文件夹是否存在,存在则删除
10 if os.path.exists(path): 11 shutil.rmtree(path) 12 # 创建文件夹
13 os.mkdir(path) 14 # 得到要爬取的图片数量
15 n = length 16 # 返回要爬取的类别
17 cate = category 18 # 根据搜索的网页得到存储图片的网页是这个代码的难点,下面会详细讲解
19 url = 'https://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=' + cate + '&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n) 20 # 访问网页
21 imgs = requests.get(url) 22 # 获取网页内容
23 imgs_text = imgs.text 24 # 字符串转换成json格式
25 imgs_json = json.loads(imgs_text) 26 # 得到图片信息列表
27 imgs_items = imgs_json['all_items'] 28 m = 0 29 # 存储每个想要保存的图片链接,为了后续
30 for i in imgs_items: 31 # thumbUrl存储的图片是大小为480*360的图片网页
32 img_url = i['thumbUrl'] 33 print('*********' + str(m) + '.png********' + 'Downloading...') 34 print('下载的url: ', img_url) 35 # 下载图片并且保存
36 urllib.request.urlretrieve(img_url, path+str(m) + '.jpg') 37 m = m + 1
38 print('Download complete !') 39
40
41 getSogouImag('壁纸', 5, './img/') 42
43 pass
在这里,获取存储图像的URL是关键和难点。下面详细介绍如何获取URL。
(1)首先打开网页的源代码(chrome中鼠标右键点击Inspect),这时候如果用前三章(爬虫系列一和系列二)抓取指定网页中的图片)正则表达式或CSS标签过滤等方法只会返回一个搜狗图标图片,其他我们要下载的显示图片是看不到的。
(2)如果我们要找到我们要下载的图片,必须点击Network,选择XHR,然后我们会在Name中看到getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA column 越是用鼠标加载图片,越会出现这个getAllRecomPicByTag的内容,点击一下,就可以看到存储图片地址的API出现了。
在这里,您可以单击预览并观察此 json 数组。一层一层打开all_items,可以看到里面存放的是图片的地址。如果您明白这是我们可以找到图片链接的地方,那么我们可以确认我们想要您找到的图片链接在标题中。
(3)点击Headers可以找到对应的url链接。
请求 URL 链接如下所示:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1920&height=1080
我们猜测这应该是搜狗图片存放图片链接的URL,我们来解析一下。先看category和tag后面的字符串,应该是字符的编码。检查%E5%A3%81%E7%BA%B8是“壁纸”的编码,%E5%85%A8%E9%83%是“全部”的编码,所以上面的链接和下面的链接是等价的:
壁纸&tag=all&start=0&len=15&width=1920&height=1080
网页打开如下图所示:
另外,start是起始下标,len是长度,也就是图片张数,所以我们可以通过这个信息给url传入参数,让搜索更加灵活,如下图:
url ='' + cate +'&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n)
其中cate和n是可以自定义的变量,分别代表要搜索的类别和要爬取的图片数量。
以上就是使用python动态抓取图片库中图片的详细讲解,希望可以帮助大家理解。
python抓取动态网页(什么是HTML静态生优游国际代理的内容,如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-26 22:06
我们之前爬取的网页大多是HTML静态生成优游国际代理的内容。您可以直接从优游国际代理的HTML源代码中找到您所看到的数据和内容。然而,优游国际代理的网页并非如此。.
优优国际代理网站的部分内容由前端JS动态盛优优国际代理。由于网页上呈现的内容是以JS盛游游国际为代表的,我们在浏览器上是可以看到的,但是在HTML中游游国际代理的源代码是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
优优国际代理的网页在优优国际代理的HTML源代码中找不到。都是JS动态同学加载的。
在这种情况下,我们应该如何抓取网页呢?优优国际代理有两种方式:
1、从网页响应游游国际代理中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法,关于Selenium的使用,后有优游国际社的专文。
一、从网页响应中找到JS脚本返回的JSON数据 游游国际代理
即使网页内容由JS动态国际机构加载,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从优优国际代理的数据接口中找到优优国际代理的网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12 打开网页调试优优国际代理
选择了“网络”选项卡后,发现优优国际代理的反应挺多的。让我们过滤它们,只查看 XHR 响应。
(XHR是Ajax Youyou International Agency的概念,意思是XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city预览优游国际代理的一串json数据:
让我们再次点击它:
原来全优游国际代理是一个城市列表,应该是用来加载区域优优国际代理的。
现在你应该明白如何找到JS请求的接口了吧?但是刚才,我们并没有找到我们想要的悠游国际代理,所以我们再找找:
优游国际是一家专注的代理商,我们点开看看:
优优国际代理提供的数据和优优国际代理的图片是一样的,应该是有数据的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应游游国际代理中查到了正游游国际代理的编码数据:
优游国际已经代理了相应的数据接口,我们可以按照前面的方法请求数据接口并得到响应。
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
python抓取动态网页(什么是HTML静态生优游国际代理的内容,如何对网页进行爬取呢?)
我们之前爬取的网页大多是HTML静态生成优游国际代理的内容。您可以直接从优游国际代理的HTML源代码中找到您所看到的数据和内容。然而,优游国际代理的网页并非如此。.
优优国际代理网站的部分内容由前端JS动态盛优优国际代理。由于网页上呈现的内容是以JS盛游游国际为代表的,我们在浏览器上是可以看到的,但是在HTML中游游国际代理的源代码是找不到的。比如今天的头条新闻:
浏览器呈现的网页如下所示:
查看源代码,它看起来像这样:
优优国际代理的网页在优优国际代理的HTML源代码中找不到。都是JS动态同学加载的。
在这种情况下,我们应该如何抓取网页呢?优优国际代理有两种方式:
1、从网页响应游游国际代理中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法,关于Selenium的使用,后有优游国际社的专文。
一、从网页响应中找到JS脚本返回的JSON数据 游游国际代理
即使网页内容由JS动态国际机构加载,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从优优国际代理的数据接口中找到优优国际代理的网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12 打开网页调试优优国际代理
选择了“网络”选项卡后,发现优优国际代理的反应挺多的。让我们过滤它们,只查看 XHR 响应。
(XHR是Ajax Youyou International Agency的概念,意思是XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city预览优游国际代理的一串json数据:
让我们再次点击它:
原来全优游国际代理是一个城市列表,应该是用来加载区域优优国际代理的。
现在你应该明白如何找到JS请求的接口了吧?但是刚才,我们并没有找到我们想要的悠游国际代理,所以我们再找找:
优游国际是一家专注的代理商,我们点开看看:
优优国际代理提供的数据和优优国际代理的图片是一样的,应该是有数据的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应游游国际代理中查到了正游游国际代理的编码数据:
优游国际已经代理了相应的数据接口,我们可以按照前面的方法请求数据接口并得到响应。
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text
python抓取动态网页(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-26 19:16
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构造一个需要抓取的URL列表被爬行。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于获取每个页面的图片下载链接,并将它们存储在一个全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496 查看全部
python抓取动态网页(桌面壁纸电脑桌面壁纸高清壁纸大全下载(二):将图片下载到本地有了图片链接
)
一:目标站点信息
卞桌面网站为:桌面壁纸,电脑桌面壁纸,高清壁纸,下载,桌面背景图片,卞桌面
2:目标站点分析
(1): 构建页面的 URL 列表
我们需要做的是抓取网站上给定数量页面的图片,所以我们首先需要观察每个页面的链接之间的关系,然后构造一个需要抓取的URL列表被爬行。
第一页的链接:http://www.netbian.com/
第二页的链接:http://www.netbian.com/index_2.htm
可以看到第二页后面的页面链接只是和后面的数字不同,我们可以写一个简单的代码来获取页面的url列表
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
#获取爬取的页数和页面链接
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
print(page_links_list)
请输入你想爬取的页数:5
['http://www.netbian.com/', 'http://www.netbian.com/index_2.htm', 'http://www.netbian.com/index_3.htm', 'http://www.netbian.com/index_4.htm', 'http://www.netbian.com/index_5.htm']
(2): 获取一个页面上所有图片的链接
我们已经获取了所有页面的链接,但是还没有获取到每张图片的链接,那么接下来我们要做的就是获取一个页面中所有图片的链接。这里以第一页为例,获取每张图片的链接,其他页面类似。
首先右击页面->查看元素,然后点击查看器左侧的小光标,然后将鼠标放在随机一张图片上,这样就可以定位到图片的代码位置;我们可以知道每个页面有18张图片。接下来,我们需要使用标签来定位图片在页面上的具体位置。如下图所示,我们使用 div.list li a img 来精确定位 18 个 img 标签。img 标签收录我们需要的图片链接。
接下来我们以第一页为例,获取每张图片的链接。
#python3 -m pip install bs4
#python3 -m pip install lxml
import requests
from bs4 import BeautifulSoup
# 页面链接的初始化列表
url='http://www.netbian.com/'
# 图片链接列表
img_links_list = []
#获取img标签,在获取图片链接
html = requests.get(url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
print(img_links_list)
print(len(img_links_list))
['http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B, 'http://img.netbian.com/file/20 ... 39%3B]
18
(3): 下载图片到本地
有了图片链接后,我们需要将图片下载到本地,这里以第一张图片为例进行下载
import urllib.request
url='http://img.netbian.com/file/20 ... 39%3B
urllib.request.urlretrieve(url, filename='test.jpg')
(4): 一个简单的获取图片的爬虫
结合以上三部分,构建页面的url列表,获取一个页面中的所有图片链接,将图片下载到本地。构建一个完整但效率低下的爬虫。
import requests
from bs4 import BeautifulSoup
import lxml
import urllib
import os
import time
#获取图片并下载到本地
def GetImages(url):
html=requests.get(url, timeout = 2).content.decode('gbk')
soup=BeautifulSoup(html,'lxml')
imgs=soup.select("div.list li a img")
for img in imgs:
link=img['src']
display=link.split('/')[-1]
print('正在下载:',display)
filename='./images/'+display
urllib.request.urlretrieve(link,filename)
#获取爬取的页数,返回链接数
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
if __name__ == '__main__':
page_links_list=['http://www.netbian.com/']
GetUrls(page_links_list)
os.mkdir('./images')
print("开始下载图片!!!")
start = time.time()
for url in page_links_list:
GetImages(url)
print('图片下载成功!!!')
end = time.time() - start
print('消耗时间为:', end)
请输入你想爬取的页数:5
开始下载图片!!!
正在下载: smalle213d95e54c5b4fb355b710a473292ea1566035585.jpg
正在下载: small15ca224d7c4c119affe2cfd2d811862e1566035332.jpg
正在下载: 604a688cd6f79161236e6250189bc25b.jpg
正在下载: smallab7249d18e67c9336109e3bedc094f381566034907.jpg
正在下载: small5816e940e6957f7db5e499de9978bda41566031298.jpg
正在下载: smalladda3febb072e9103f8f06f27dcb19c21566031139.jpg
正在下载: small0e9f43492debe6dc2ce7a3e6cc48c1ad1566030965.jpg
正在下载: smallcfd5b4c6fa10ffcbcdcc8b1b9e6db91a1566030209.jpg
。。。。。。
图片下载成功!!!
消耗时间为: 21.575999975204468
上面这部分代码完全可以运行,但是效率不高,因为是下载图片,需要排队一一下载。因此,为了解决这个问题,下面的代码使用多线程来实现图片的抓取和下载。
(5)使用Python多线程抓取图片并下载到本地
对于多线程,我们使用 Python 自带的线程模块。我们使用称为生产者和消费者的模型。生产者专门用于获取每个页面的图片下载链接,并将它们存储在一个全局列表中。消费者专门从这个全局列表中提取图像链接以供下载。
需要注意的是,在多线程中使用全局变量需要使用锁来保证数据的一致性。
import urllib
import threading
from bs4 import BeautifulSoup
import requests
import os
import time
import lxml
# 页面链接的初始化列表
page_links_list=['http://www.netbian.com/']
# 图片链接列表
img_links_list = []
#获取爬取的页数和页面链接
def GetUrls(page_links_list):
pages = int(input('请输入你想爬取的页数:'))
if pages > 1:
for page in range(2, pages + 1):
url = 'http://www.netbian.com/index_' + str(page) + '.htm'
page_links_list.append(url)
else:
page_links_list=page_links_list
#初始化锁,创建一把锁
gLock=threading.Lock()
#生产者,负责从每个页面中获取图片的链接
class Producer(threading.Thread):
def run(self):
while len(page_links_list)>0:
#上锁
gLock.acquire()
#默认取出列表中的最后一个元素
page_url=page_links_list.pop()
#释放锁
gLock.release()
#获取img标签
html = requests.get(page_url).content.decode('gbk')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select("div.list li a img")
#加锁3
gLock.acquire()
for img in imgs:
img_link = img['src']
img_links_list.append(img_link)
#释放锁
gLock.release()
#print(len(img_links_list))
#消费者,负责从获取的图片链接中下载图片
class Consumer(threading.Thread,):
def run(self):
print("%s is running"%threading.current_thread())
while True:
#print(len(img_links_list))
#上锁
gLock.acquire()
if len(img_links_list)==0:
#不管什么情况,都要释放锁
gLock.release()
continue
else:
img_url=img_links_list.pop()
#print(img_links_list)
gLock.release()
filename=img_url.split('/')[-1]
print('正在下载:', filename)
path = './images/'+filename
urllib.request.urlretrieve(img_url, filename=path)
if len(img_links_list)==0:
end=time.time()
print("消耗的时间为:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
os.mkdir('./images')
start=time.time()
# 5个生产者线程,去从页面中爬取图片链接
for x in range(5):
Producer().start()
# 10个消费者线程,去从中提取下载链接,然后下载
for x in range(10):
Consumer().start()
请输入你想爬取的页数:5
is running
is running
is running
is running
is running
is running
is running
is running
is running
is running
正在下载: small9e75d6ac9506efe1d87e96062791fb261564149099.jpg
正在下载: small02961cac5e02a901b77779eaed43c6f91564156941.jpg
正在下载: small117c84b2f427c981bf33184c1c5c4bb91564193581.jpg
正在下载: smallfedb420af6f753512c169021587982621564455847.jpg
正在下载: small14d3739bf11dd92055abb56e3f792d3f1564456102.jpg
正在下载: smallaf755644af7d114d4cbf36fbe0e84d0c1564456347.jpg
正在下载: small9f7af6d0e2372a4d9e536d8ea9fc40341564456537.jpg
。。。。。。
消耗的时间为: 1.635000228881836 #分别是10个进程结束的时间
消耗的时间为: 1.6419999599456787
消耗的时间为: 1.6560001373291016
消耗的时间为: 1.684000015258789
消耗的时间为: 1.7009999752044678
消耗的时间为: 1.7030000686645508
消耗的时间为: 1.7060000896453857
消耗的时间为: 1.7139999866485596
消耗的时间为: 1.7350001335144043
消耗的时间为: 1.748000144958496
python抓取动态网页( 安东尼在本篇内容里小编的相关知识点内容(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-24 20:14
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章就介绍到这里了,更多python如何爬取动态网站的相关内容请搜索Script Home@之前的文章>或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
python抓取动态网页(
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章就介绍到这里了,更多python如何爬取动态网站的相关内容请搜索Script Home@之前的文章>或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
python抓取动态网页(什么是HTML源码中的JS动态生成?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-24 09:17
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤它们,只查看 XHR 响应。 (XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击打开它:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
返回一串乱码,但从响应中看到的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json
url ='#39;
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
对于新闻中的 n:
title = n['title']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
url ='#39;
wbdata = requests.get(url).text 查看全部
python抓取动态网页(什么是HTML源码中的JS动态生成?(一))
我们之前抓取的网页大多是 HTML 静态生成的内容。您可以直接从 HTML 源代码中找到您看到的数据和内容。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但是在HTML源代码中是找不到的。 例如,今天的头条新闻:
浏览器渲染的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中找不到,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟访问网页
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例说明:
1、找到JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤它们,只查看 XHR 响应。 (XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击打开它:
原来都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是刚才没有找到想要的消息,所以再找一下:
有个焦点,我们点一下看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
返回一串乱码,但从响应中看到的是正常编码的数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
导入请求
导入json
url ='#39;
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
对于新闻中的 n:
title = n['title']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第 1 部分:导入相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
url ='#39;
wbdata = requests.get(url).text
python抓取动态网页(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-24 06:24
要使用Python网络爬虫,首先需要了解什么是HTTP,因为这与Python爬虫的基本原理息息相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面的源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传输信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文全称为Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium是Web应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决JavaScript渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python 用于解析和提取信息的第三方库包括 BeautifulSoup、lxml、pyquery 等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,存储数据。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以是保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests to request获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,爬取效率会进一步提高。将多台主机组合在一起,共同完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在抓取网站的数据时,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
常见的爬取机制有4种:
①请求头校验:请求头校验是最常见的反爬虫机制。许多网站 会在Headers 中检测user-agent,一些网站 还会检测origin 和referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有的网站会检查用户行为,判断同一IP是否在短时间内多次请求页面。如果这个频率超过一定的阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码、方形验证码。
验证码类型 查看全部
python抓取动态网页(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
要使用Python网络爬虫,首先需要了解什么是HTTP,因为这与Python爬虫的基本原理息息相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面的源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传输信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文全称为Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium是Web应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决JavaScript渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python 用于解析和提取信息的第三方库包括 BeautifulSoup、lxml、pyquery 等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,存储数据。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以是保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests to request获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,爬取效率会进一步提高。将多台主机组合在一起,共同完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在抓取网站的数据时,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
常见的爬取机制有4种:
①请求头校验:请求头校验是最常见的反爬虫机制。许多网站 会在Headers 中检测user-agent,一些网站 还会检测origin 和referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有的网站会检查用户行为,判断同一IP是否在短时间内多次请求页面。如果这个频率超过一定的阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码、方形验证码。
验证码类型
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-24 02:14
)
介绍
有时,当我们天真地使用urllib库或Scrapy下载HTML网页时,我们发现我们要提取的网页元素不在我们下载的HTML中,即使它们在浏览器中看起来很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如下所示
OK,复制js请求的目标url
在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是查看元素),会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf-8')
url = 'https://movie.douban.com/'
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class='item-root']"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url = i.find("a").get('href')
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore") 查看全部
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项
)
介绍
有时,当我们天真地使用urllib库或Scrapy下载HTML网页时,我们发现我们要提取的网页元素不在我们下载的HTML中,即使它们在浏览器中看起来很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如下所示
OK,复制js请求的目标url
在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是查看元素),会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf-8')
url = 'https://movie.douban.com/'
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class='item-root']"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url = i.find("a").get('href')
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-21 10:17
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你随便抓取的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数,获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
python抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抢不到,后面会讲)。
一些网站为了防止他人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画。前者是我说的动态网页生成的图片。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你随便抓取的)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现获取页面图片的Get请求有如下信息:
GET/Files/Images/76/59262/imanhua_001.jpg HTTP/1.1
接受image/png, image/svg+xml, image/*;q=0.8, */*;q=0.5
推荐人
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5C%W@GJ%24ACOF(TYDYECOKVDYB.png
AcceptLanguage zh-CN
User-AgentMozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Accept-Encodinggzip, deflate
ConnectionKeep-Alive在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己网站的请求才会返回图片,所以我们要添加以上信息在请求头中,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1. BeautifulSoup 包用于根据 URL 获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,根据章节的url获取该章节的总页数,并获取每个页面的url,参考资料
2. Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3. urllib2包,模拟Get请求,使用add_header添加Referer参数,获取返回图片
4. chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
python抓取动态网页(抓取站长素材中的图片地址存储在可视窗口时达到懒加载的效果 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-21 08:12
)
图片懒加载概念
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在请求时和普通静态资源一样,都会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端合作,只有当图片出现在浏览器当前窗口时才加载图片。减少首屏图片请求次数的技术称为“图片延迟加载”。
原则:
先将img标签的src链接设置为同一张图片(比如空白图片),然后给img标签设置一个自定义属性(比如data-src),然后将真实图片地址存放在data-src中,当JS监听图片元素进入可视化窗口时,自定义属性中的地址存放在src属性中。达到懒加载的效果。
案例:抓取站长素材中的图片数据
在浏览器中加载时,可视化区域中的图片为src,不在可视化区域中的图片为src2。但是使用request模块发送请求时,没有可见区域,所以都是src2。
1 # -*- coding:utf-8 -*-
2 import requests
3 from lxml import etree
4 if __name__ == "__main__":
5 url = 'http://sc.chinaz.com/tupian/gudianmeinvtupian.html'
6 headers = {
7 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
8 }
9 #获取页面文本数据
10 response = requests.get(url=url,headers=headers)
11 response.encoding = 'utf-8'
12 page_text = response.text
13 #解析页面数据(获取页面中的图片链接)
14 #创建etree对象
15 tree = etree.HTML(page_text)
16 div_list = tree.xpath('//div[@id="container"]/div')
17 #解析获取图片地址和图片的名称
18 for div in div_list:
19 image_url = div.xpath('.//img/@src2') #src2伪属性
20 image_name = div.xpath('.//img/@alt')
21 print(image_url)
22 print(image_name) 查看全部
python抓取动态网页(抓取站长素材中的图片地址存储在可视窗口时达到懒加载的效果
)
图片懒加载概念
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在请求时和普通静态资源一样,都会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端合作,只有当图片出现在浏览器当前窗口时才加载图片。减少首屏图片请求次数的技术称为“图片延迟加载”。
原则:
先将img标签的src链接设置为同一张图片(比如空白图片),然后给img标签设置一个自定义属性(比如data-src),然后将真实图片地址存放在data-src中,当JS监听图片元素进入可视化窗口时,自定义属性中的地址存放在src属性中。达到懒加载的效果。
案例:抓取站长素材中的图片数据
在浏览器中加载时,可视化区域中的图片为src,不在可视化区域中的图片为src2。但是使用request模块发送请求时,没有可见区域,所以都是src2。
1 # -*- coding:utf-8 -*-
2 import requests
3 from lxml import etree
4 if __name__ == "__main__":
5 url = 'http://sc.chinaz.com/tupian/gudianmeinvtupian.html'
6 headers = {
7 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
8 }
9 #获取页面文本数据
10 response = requests.get(url=url,headers=headers)
11 response.encoding = 'utf-8'
12 page_text = response.text
13 #解析页面数据(获取页面中的图片链接)
14 #创建etree对象
15 tree = etree.HTML(page_text)
16 div_list = tree.xpath('//div[@id="container"]/div')
17 #解析获取图片地址和图片的名称
18 for div in div_list:
19 image_url = div.xpath('.//img/@src2') #src2伪属性
20 image_name = div.xpath('.//img/@alt')
21 print(image_url)
22 print(image_name)
python抓取动态网页(python爬取网页表格:python抓取网页数据用python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-21 07:05
Python爬取网页表单篇1:Python爬取网页数据使用python爬取页面并进行处理 2009-02-19 15:09:50| 类别:Python | 标签:无|字体大小订阅 主要用途:抓取某个网页的源代码,处理其中需要的数据并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替网页抓取步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便一提,练习你刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 查看全部
python抓取动态网页(python爬取网页表格:python抓取网页数据用python)
Python爬取网页表单篇1:Python爬取网页数据使用python爬取页面并进行处理 2009-02-19 15:09:50| 类别:Python | 标签:无|字体大小订阅 主要用途:抓取某个网页的源代码,处理其中需要的数据并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替网页抓取步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便一提,练习你刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 其中符号很多,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(? 可以用pymssql处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务就是研究python的socket函数# -*- coding:gbk -*- import urllib import re #pager=urllib.urlopen(/index.html) #data=pager.read() #pager.close( ) f =open(rD:\2.txt) data=f.read() f.close() #处理数据 p=pile('(?
python抓取动态网页( 如何利用Webkit从JS渲染网页中获取数据代码?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-16 08:11
如何利用Webkit从JS渲染网页中获取数据代码?)
当我们抓取网页时,我们会使用一定的规则从返回的HTML数据中提取有效信息。但是如果网页收录JavaScript代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊第147期,所以想爬
进口请求
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用Web kit从JS渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url ='#39;复制代码
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以使用这个工具从JS渲染的网页中抓取有效的信息。
总结
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。 查看全部
python抓取动态网页(
如何利用Webkit从JS渲染网页中获取数据代码?)
当我们抓取网页时,我们会使用一定的规则从返回的HTML数据中提取有效信息。但是如果网页收录JavaScript代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——突然发现我的文章出现在最近的Pycoders周刊第147期,所以想爬
进口请求
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用Web kit从JS渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
url ='#39;复制代码
使用上面的代码,我们将 HTML 结果存储在变量 result 中。由于lxml不能直接处理特殊的字符串数据,我们需要对数据格式进行转换。
# QString 在被 lxml 处理之前应该转换为字符串
使用上面的代码,我们可以得到所有的文件链接信息,然后我们就可以使用这些Render和这些URL链接来提取文本内容信息了。Web kit提供了一个强大的网页渲染工具,我们可以使用这个工具从JS渲染的网页中抓取有效的信息。
总结
在本文中,我介绍了一种从 JS 渲染的网页中抓取信息的有效方法。虽然这个工具很慢,但它非常简单和粗鲁。我希望你会喜欢这个文章。现在您可以将此方法应用于您发现难以处理的任何网页。
愿你事事如意。
python抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-16 08:11
简单的介绍
下面的代码是一个使用python实现的网络爬虫爬取动态网页/baoliao/。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7 查看全部
python抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
简单的介绍
下面的代码是一个使用python实现的网络爬虫爬取动态网页/baoliao/。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有该项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
python抓取动态网页(如下,常用爬虫制作模块的基本用法极度推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-14 11:04
本文章主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续看。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
''' @ urllib为python自带的一个网络库 @ urlopen为urllib的一个方法,用于打开一个连接并抓取网页, 然后通过read()方法把值赋给read() ''' import urllib url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我. html = urllib.urlopen(url) content = html.read() html.close() #可以通过print打印出网页内容 print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置
复制下面的源代码
经过分析对比(这里略略),基本上可以看到要抓拍的图像的几个特征:
正则表达式稍后更新,请注意
根据上面的判断,直接上传代码
''' @本程序用来下载百度贴吧图片 @re 为正则说明库 ''' import urllib import re # 获取网页html信息 url = "http://tieba.baidu.com/p/2336739808" html = urllib.urlopen(url) content = html.read() html.close() # 通过正则匹配图片特征,并获取图片链接 img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg-600)"') img_links = re.findall(img_tag, content) # 下载图片 img_counter为图片计数器(文件名) img_counter = 0 for img_link in img_links: img_name = '%s.jpg-600' % img_counter urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name) img_counter += 1
如图所示,我们将抓取您理解的图片
3.总结
如上两节,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很清楚的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也是可以的,只是效率太低了。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何在有限抓取的情况下抓取网站。
urllib2
上面我们讲解了如何抓取网页和下载图片,下一节我们将讲解如何抓取受限抓取网站
首先,我们还是用上一课的方法,抓取一个大家用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
''' @本程序用来抓取blog.csdn.net网页 ''' import urllib url = "http://blog.csdn.net/FansUnion" html = urllib.urlopen(url) #getcode()方法为返回Http状态码 print html.getcode() html.close() #输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看出csdn已经被屏蔽了。第一部分的方法无法获取网页。这里我们需要启动一个新的库:urllib2
但是我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:
以下是整理后的头部信息
Request Method:GET Host:blog.csdn.net Referer:http://blog.csdn.net/?ref=toolbar_logo User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8 ''' @本程序用来抓取受限网页(blog.csdn.net) @User-Agent:客户端浏览器版本 @Host:服务器地址 @Referer:跳转地址 @GET:请求方法为GET ''' import urllib2 url = "http://blog.csdn.net/FansUnion" #定制自定义Header,模拟浏览器向服务器提交请求 req = urllib2.Request(url) req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36') req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) #下载网页html并打印 html = urllib2.urlopen(req) content = html.read() print content html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input: help(urllib2.Request) #output(因篇幅关系,只取__init__方法) __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False) 通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!! #只取自定义Header部分代码 csdn_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Host": "blog.csdn.net", 'Referer': 'http://blog.csdn.net', "GET": url } req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当成机器爬虫拒绝。
那么我们是否有一些更聪明的方法来提交一些动态数据?答案是肯定的。而且很简单,直接上代码!
''' @本程序是用来动态提交Header信息 @random 动态库,详情请参考 ''' # coding=utf-8 import urllib2 import random url = 'http://www.lifevc.com/' my_headers = [ 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1', 'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)', #因篇幅关系,此处省略N条 ] random_header = random.choice(headers) # 可以通过print random_header查看提交的header信息 req = urllib2.Request(url) req.add_header("User-Agent", random_header) req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) content = urllib2.urlopen(req).read() print content
其实很简单,所以我们就完成了代码的一些优化。
以上就是使用Python的urllib和urllib2模块制作爬虫示例教程的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取动态网页(如下,常用爬虫制作模块的基本用法极度推荐!)
本文章主要介绍了使用Python的urllib和urllib2模块制作爬虫的示例教程,展示了这两个常用的爬虫制作模块的基本用法。强烈推荐!有需要的朋友可以参考
网址库
在学习了python的基础知识后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我拿着履带练习我的手。学习了Spartan python爬虫课程后,我将自己的经验整理如下,供后续看。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫
第一个环境描述
这个没什么好说的,直接上代码吧!
''' @ urllib为python自带的一个网络库 @ urlopen为urllib的一个方法,用于打开一个连接并抓取网页, 然后通过read()方法把值赋给read() ''' import urllib url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我. html = urllib.urlopen(url) content = html.read() html.close() #可以通过print打印出网页内容 print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以完成。
当然,我们只是爬网,并没有真正的价值。然后我们将开始做一些有意义的事情。
2.一个小测试
抢百度贴吧图片
其实很简单,因为要抓取图片,首先要分析网页的源代码。
(这里是了解基本的html知识,浏览器以chrome为例)
如图,这里是对后续步骤的简要说明,请参考。
打开网页,右键单击并选择“检查元素”(底部项目)
点击下方弹出框最左边的问号,问号会变成蓝色
移动鼠标点击我们要捕捉的图片(一个可爱的女孩)
如图,我们可以在源码中获取图片的位置
复制下面的源代码
经过分析对比(这里略略),基本上可以看到要抓拍的图像的几个特征:
正则表达式稍后更新,请注意
根据上面的判断,直接上传代码
''' @本程序用来下载百度贴吧图片 @re 为正则说明库 ''' import urllib import re # 获取网页html信息 url = "http://tieba.baidu.com/p/2336739808" html = urllib.urlopen(url) content = html.read() html.close() # 通过正则匹配图片特征,并获取图片链接 img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg-600)"') img_links = re.findall(img_tag, content) # 下载图片 img_counter为图片计数器(文件名) img_counter = 0 for img_link in img_links: img_name = '%s.jpg-600' % img_counter urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name) img_counter += 1
如图所示,我们将抓取您理解的图片
3.总结
如上两节,我们可以轻松访问网页或图片。
补充一点小技巧,如果遇到不是很清楚的库或者方法,可以使用下面的方法来初步了解一下。
或输入相关搜索。
当然,百度也是可以的,只是效率太低了。建议使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何抓取网页和下载图片,下面我们将讲解如何在有限抓取的情况下抓取网站。
urllib2
上面我们讲解了如何抓取网页和下载图片,下一节我们将讲解如何抓取受限抓取网站
首先,我们还是用上一课的方法,抓取一个大家用的网站作为例子。本文主要分为以下几个部分:
1. 抓取受限网页
首先使用我们在上一节中学到的知识进行测试:
''' @本程序用来抓取blog.csdn.net网页 ''' import urllib url = "http://blog.csdn.net/FansUnion" html = urllib.urlopen(url) #getcode()方法为返回Http状态码 print html.getcode() html.close() #输出
403
这里我们的输出是 403,这意味着访问被拒绝;同样,200 表示请求成功完成;404 表示未找到该 URL。
可以看出csdn已经被屏蔽了。第一部分的方法无法获取网页。这里我们需要启动一个新的库:urllib2
但是我们也看到浏览器可以发布该文本。我们可以模拟浏览器操作来获取网页信息吗?
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先简单介绍一下方法:
以下是整理后的头部信息
Request Method:GET Host:blog.csdn.net Referer:http://blog.csdn.net/?ref=toolbar_logo User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8 ''' @本程序用来抓取受限网页(blog.csdn.net) @User-Agent:客户端浏览器版本 @Host:服务器地址 @Referer:跳转地址 @GET:请求方法为GET ''' import urllib2 url = "http://blog.csdn.net/FansUnion" #定制自定义Header,模拟浏览器向服务器提交请求 req = urllib2.Request(url) req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36') req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) #下载网页html并打印 html = urllib2.urlopen(req) content = html.read() print content html.close()
哈哈,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫抓取。
2. 对代码的一些优化
简化提交头方法
发现每次写这么多req.add_header对自己来说都是一种折磨。有什么办法可以复制并使用它吗?答案是肯定的。
#input: help(urllib2.Request) #output(因篇幅关系,只取__init__方法) __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False) 通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!! #只取自定义Header部分代码 csdn_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Host": "blog.csdn.net", 'Referer': 'http://blog.csdn.net', "GET": url } req = urllib2.Request(url,headers=csdn_headers)
很容易找到,我要感谢斯巴达的无私教导。
提供动态头信息
如果按照上面的方法进行爬取,很多时候提交的信息会过于单一,会被服务器当成机器爬虫拒绝。
那么我们是否有一些更聪明的方法来提交一些动态数据?答案是肯定的。而且很简单,直接上代码!
''' @本程序是用来动态提交Header信息 @random 动态库,详情请参考 ''' # coding=utf-8 import urllib2 import random url = 'http://www.lifevc.com/' my_headers = [ 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1', 'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)', #因篇幅关系,此处省略N条 ] random_header = random.choice(headers) # 可以通过print random_header查看提交的header信息 req = urllib2.Request(url) req.add_header("User-Agent", random_header) req.add_header('Host', 'blog.csdn.net') req.add_header('Referer', 'http://blog.csdn.net') req.add_header('GET', url) content = urllib2.urlopen(req).read() print content
其实很简单,所以我们就完成了代码的一些优化。
以上就是使用Python的urllib和urllib2模块制作爬虫示例教程的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取动态网页(有没有什么办法可以直接获取网页的动态渲染数据呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 11:02
)
成功完成基金净值爬虫的爬虫后,在简单了解了爬虫的一些原理后,不禁有些疑惑——为什么不能通过Request直接获取网页的源码,但是通过查找相关的js文件来爬取数据??
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。
这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据生成的结果。这些数据来自各种来源,可能通过 Ajax 加载或收录在 HTML 文档中。, 也可能是经过 JavaScript 和特定算法计算后生成的。按照目前Web发展的趋势,网页的原创HTML文档不收录任何数据。通过Ajax等方式统一加载后显示,从而在Web开发中实现前后端分离,减少服务器直接渲染页面。带来。通常,我们称这种网页为动态渲染页面。
之前的基金净值数据爬虫采用的是直接访问服务器获取数据接口,即找到收录数据的js文件,向服务器发送相关请求获取文件。
那么,有没有什么办法可以直接获取网页的动态渲染数据呢?答案是肯定的。
我们也可以直接用模拟浏览器操作的方式来实现动态网页的爬取,这样我们就可以在浏览器中看到它的样子,爬取到的源代码是什么,也就是实现了——可见然后爬行。
Python提供了很多模拟浏览器操作的库,如:Selenium、Splash、PyV8、Ghost等,本文继续以基金净值爬虫为例,使用Selenium对其动态页面进行爬取。
环境工具
1、Chrome 及其开发者工具
2、蟒蛇3.7
3、PyCharm
python中使用的库3.7
1、硒
2、熊猫
3、随机
4、 时间
5、操作系统
系统
Mac OS 10.13.2
Selenium 基本功能和用法
准备好工作了
ChromDriver 配置
基本使用
首先,我们先来了解一下Selenium的一些特性以及它能做什么:
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些动态渲染的页面,这种爬取方式非常有效。它的基本功能也非常方便。下面我们来看一些简单的代码:
1 from selenium import webdriver
2 from selenium.webdriver.common.by import By
3 from selenium.webdriver.common.keys import Keys
4 from selenium.webdriver.support import expected_conditions as EC
5 from selenium.webdriver.support.wait import WebDriverWait
6
7
8 browser = webdriver.Chrome() # 声明浏览器对象
9 try:
10 browser.get(\'https://www.baidu.com\') # 传入链接URL请求网页
11 query = browser.find_element_by_id(\'kw\') # 查找节点
12 query.send_keys(\'Python\') # 输入文字
13 query.send_keys(Keys.ENTER) # 回车跳转页面
14 wait = WebDriverWait(browser, 10) # 设置最长加载等待时间
15 print(browser.current_url) # 获取当前URL
16 print(browser.get_cookies()) # 获取当前Cookies
17 print(browser.page_source) # 获取源代码
18 finally:
19 browser.close() # 关闭浏览器
运行代码后,Chrome 浏览器会自动弹出。浏览器会跳转到百度,然后在搜索框中输入Python→回车→跳转到搜索结果页面,得到结果后关闭浏览器。这相当于模拟了我们在百度上搜索Python的全套动作,给你带来惊喜!!
在这个过程中,当加载网页结果时,控制台会分别输出当前的URL、当前的Cookies和网页源代码:
可以看出,我们得到的内容是浏览器中的真实内容。可见,使用Selenium驱动浏览器加载网页,可以直接得到JavaScript渲染的结果。接下来我们也会主要用Selenium来爬取基金的净值~
注:Selenium更详细的用法和功能可以在官网查看()
基金净值数据爬虫
通过前面的爬虫,我们会发现数据接口的分析比较繁琐,需要分析相关参数。如果直接用Selenium来模拟浏览器,就可以不用再关注这些界面参数了,只要能直接在浏览器页面上看到这里的内容就可以爬取了。现在我们来试试如何实现我们的目标——基金净值数据爬虫。
页面分析
这个爬虫的目标是单个基金的净值数据。抓取到的网址为:(以单个基金519961为例)。URL 的结构是显而易见的。当我们在浏览器中输入访问链接时,会显示最新的。基金权益数据第一页结果:
在数据下方,有一个页面导航,其中包括前五页之间的链接以及上一页和下一页之间的链接。还有一个链接可以输入任何要跳转到的页码:
如果我们想要获取第二页及以后的数据,我们需要跳转到相应的页码。因此,如果我们需要获取所有的历史净值数据,只需要遍历所有的页码即可。可以直接在页面跳转文本框中输入要跳转到的页码,然后点击“确定”按钮跳转到对应页码的页面。
这里没有直接点击“下一页”的原因是:一旦在爬取过程中出现异常退出,比如在第50页退出时,此时点击“下一页”就无法快速切换到当前页面相应的后续页面。另外,在爬取过程中需要记录当前爬虫的进度,以便及时进行异常检测,检测问题在第一页。整个过程比较复杂,采用直接跳转的方式抓取网页更合理。
当我们成功加载了某个页面的净值数据后,我们就可以使用Selenium来获取该页面的源代码了。定位到一个特定的节点后,我们就可以得到目标的HTML内容,然后通过相应的分析就可以得到我们的HTML内容。目标数据。下面,我们用代码来实现整个爬取过程。
获取基金权益清单
首先,我们需要构造目标 URL。这里的URL组成规则很明显,就是基金code.html。我们可以使用规则来构造我们要爬取的基金对象。这里以基金519961为例进行爬取。
1 browser = webdriver.Chrome()
2 wait = WebDriverWait(browser, 10)
3 fundcode=\'519961\'
4
5 def index_page(page):
6 \'\'\'
7 抓取基金索引页
8 :param page: 页码
9 :param fundcode: 基金代码
10 \'\'\'
11 print(\'正在爬取基金%s第%d页\' % (fundcode, page))
12 try:
13 url = \'http://fundf10.eastmoney.com/jjjz_%s.html\' % fundcode
14 browser.get(url)
15 if page>1:
16 input_page = wait.until(
17 EC.presence_of_element_located((By.CSS_SELECTOR, \'#pagebar input.pnum\')))
18 submit = wait.until(
19 EC.element_to_be_clickable((By.CSS_SELECTOR, \'#pagebar input.pgo\')))
20 input_page.clear()
21 input_page.send_keys(str(page))
22 submit.click()
23 wait.until(
24 EC.text_to_be_present_in_element((By.CSS_SELECTOR, \'#pagebar label.cur\'),
25 str(page)))
26 wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, \'#jztable\')))
27 get_jjjz()
28 except TimeoutException:
29 index_page(page)
这里首相构造了一个WebDriver对象,即声明浏览器对象,使用的浏览器是Chrome,然后指定一个基金代码(519961),然后定义index_page()方法来抓取列表基金净值数据。
在这种方法中,我们首先访问链接搜索资金,然后判断当前页码。如果大于1,我们会跳转到页面,否则我们将等待页面加载。
在等待加载时,我们使用WebDriverWait对象,它可以指定等待条件,同时制定一个最大等待时间,这里指定为最长10秒。如果在这段时间内满足等待条件,即页面元素加载成功,则立即返回相应结果并继续向下执行,否则,当最大等待时间未加载时,直接抛出一个超市例外。
比如我们最后需要等待历史权益信息加载完毕并指定presence_of_element_located条件,然后传入CSS选择器对应的条件#jztable,这个选择器对应的页面内容就是每个基金权益数据页面。在网页上查看:
注意:这里有一个小技巧。如果同学们对CSS选择器的语法不熟悉,可以右键选中节点→复制→复制选择器,直接获取对应的选择器:
CSS 选择器的语法请参考 CSS 选择器参考手册 ()。
加载成功后,机会订单的后续get_jjjz()方法提取历史净值信息。
关于翻页操作,这里先获取页码输入框,赋值给input_page,然后获取“OK”按钮,赋值给submit:
首先,我们需要在输入框中调用clear()方法(不管输入框是否有页码数据)。然后,调用send_keys()方法将页码填入输入框,然后点击“确定”按钮,听起来和我们正常的操作方法一样。
那么,如何知道是否跳转到了对应的页码呢?我们可以注意到,当跳转到当前页面时,页码会高亮显示:
我们只需要判断当前高亮的页码就是当前页码,这里左移使用了另一个等待条件text_to_be_present_in_element,它会等待指定的文本出现在某个节点然后返回成功,这里我们就高亮了亮页码和当前要跳转到的页码对应的CSS选择器通过参数传递给这个等待条件,这样它就会检查当前高亮页码节点是否是我们传递过来的页码数,如果是即,证明页面成功跳转到此页面,页面跳转成功。
这样,刚刚实现的index_page()方法就可以传入对应的页码,加载完页码对应的商品列表后,调用get_jjjz()方法进行页面分析。
解析历史净值数据列表
接下来,我们可以实现 get_jjjz() 方法来解析历史净值数据列表。在这里,我们通过搜索所有历史权益数据节点来获取对应的HTML内容
并进行相应的分析,实现如下:
1 def get_jjjz():
2 \'\'\'
3 提取基金净值数据
4 \'\'\'
5 lsjz = pd.DataFrame()
6 html_list = browser.find_elements_by_css_selector(\'#jztable tbody tr\')
7 for html in html_list:
8 data = html.text.split(\' \')
9 datas = {
10 \'净值日期\': data[0],
11 \'单位净值\': data[1],
12 \'累计净值\': data[2],
13 \'日增长率\': data[3],
14 \'申购状态\': data[4],
15 \'赎回状态\': data[5],
16 }
17 lsjz = lsjz.append(datas, ignore_index=True)
18 save_to_csv(lsjz)
首先调用 find_elements_by_css_selector 获取所有存储历史权益数据的节点。此时使用的CSS选择器是#jztable tbody tr,会匹配所有基金权益节点,输出是一个打包成列表的HTML。使用for循环遍历列表,使用text方法提取每个html中的文本内容,得到的输出是空格分隔的字符串数据。为了方便后续处理,我们可以使用split方法将数据拆分成一个新的以列表形式存储,再转换为dict形式。
最后,为了方便处理,我们将遍历的数据存储为DataFrame,然后使用save_to_csv()方法存储为csv文件。
另存为本地 csv 文件
接下来,我们将获取到的基金历史股权数据保存为本地csv文件。实现代码如下:
1 def save_to_csv(lsjz):
2 \'\'\'
3 保存为csv文件
4 : param result: 历史净值
5 \'\'\'
6 file_path = \'lsjz_%s.csv\' % fundcode
7 try:
8 if not os.path.isfile(file_path): # 判断当前目录下是否已存在该csv文件,若不存在,则直接存储
9 lsjz.to_csv(file_path, index=False)
10 else: # 若已存在,则追加存储,并设置header参数为False,防止列名重复存储
11 lsjz.to_csv(file_path, mode=\'a\', index=False, header=False)
12 print(\'存储成功\')
13 except Exception as e:
14 print(\'存储失败\')
这里,结果变量是 get_jjjz() 方法中传递的历史权益数据。
遍历每一页
我们之前定义的get_index()方法需要接受参数page,代表页码。这里,因为不同基金的数据页不一样,我们需要得到最大页数才能遍历所有页。当然,我们也可以用一些巧妙的方法来解决这个问题。页码遍历代码如下:
1 def main():
2 \'\'\'
3 遍历每一页
4 \'\'\'
5 flag = True
6 page = 1
7 while flag:
8 try:
9 index_page(page)
10 time.sleep(random.randint(1, 5))
11 page += 1
12 except:
13 flag = False
14 print(\'似乎是最后一页了呢\')
它的实现方法结合了try...except和while方法来逐页遍历下一页的内容。当页数超过时,即不存在,index_page()运行时会报错。这时候可以把flag改成False,那么下一次while循环就不会继续了,这样我们就可以遍历所有的页码了。
至此,我们的基金净值数据爬虫已经基本完成,终于可以直接调用main()方法运行了。
总结
在本文中,我们使用 Selenium 来演示基金股权页面的抓取。有兴趣的同学可以尝试使用其他条件来爬取基金数据,比如设置数据的起止日期:
使用日期来抓取内容可以促进未来的数据更新。另外,如果觉得浏览器弹窗比较烦,可以试试Chrome Headless模式或者使用PhantomJS爬取。
至此,基金净值爬虫的分析正式结束。
查看全部
python抓取动态网页(有没有什么办法可以直接获取网页的动态渲染数据呢?
)
成功完成基金净值爬虫的爬虫后,在简单了解了爬虫的一些原理后,不禁有些疑惑——为什么不能通过Request直接获取网页的源码,但是通过查找相关的js文件来爬取数据??
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。
这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据生成的结果。这些数据来自各种来源,可能通过 Ajax 加载或收录在 HTML 文档中。, 也可能是经过 JavaScript 和特定算法计算后生成的。按照目前Web发展的趋势,网页的原创HTML文档不收录任何数据。通过Ajax等方式统一加载后显示,从而在Web开发中实现前后端分离,减少服务器直接渲染页面。带来。通常,我们称这种网页为动态渲染页面。
之前的基金净值数据爬虫采用的是直接访问服务器获取数据接口,即找到收录数据的js文件,向服务器发送相关请求获取文件。
那么,有没有什么办法可以直接获取网页的动态渲染数据呢?答案是肯定的。
我们也可以直接用模拟浏览器操作的方式来实现动态网页的爬取,这样我们就可以在浏览器中看到它的样子,爬取到的源代码是什么,也就是实现了——可见然后爬行。
Python提供了很多模拟浏览器操作的库,如:Selenium、Splash、PyV8、Ghost等,本文继续以基金净值爬虫为例,使用Selenium对其动态页面进行爬取。
环境工具
1、Chrome 及其开发者工具
2、蟒蛇3.7
3、PyCharm
python中使用的库3.7
1、硒
2、熊猫
3、随机
4、 时间
5、操作系统
系统
Mac OS 10.13.2
Selenium 基本功能和用法
准备好工作了
ChromDriver 配置
基本使用
首先,我们先来了解一下Selenium的一些特性以及它能做什么:
Selenium 是一种自动化测试工具,可以驱动浏览器执行特定的动作,例如点击、下拉等操作。同时,它还可以获取浏览器当前呈现的页面的源代码,以便在可见时进行抓取。对于一些动态渲染的页面,这种爬取方式非常有效。它的基本功能也非常方便。下面我们来看一些简单的代码:
1 from selenium import webdriver
2 from selenium.webdriver.common.by import By
3 from selenium.webdriver.common.keys import Keys
4 from selenium.webdriver.support import expected_conditions as EC
5 from selenium.webdriver.support.wait import WebDriverWait
6
7
8 browser = webdriver.Chrome() # 声明浏览器对象
9 try:
10 browser.get(\'https://www.baidu.com\') # 传入链接URL请求网页
11 query = browser.find_element_by_id(\'kw\') # 查找节点
12 query.send_keys(\'Python\') # 输入文字
13 query.send_keys(Keys.ENTER) # 回车跳转页面
14 wait = WebDriverWait(browser, 10) # 设置最长加载等待时间
15 print(browser.current_url) # 获取当前URL
16 print(browser.get_cookies()) # 获取当前Cookies
17 print(browser.page_source) # 获取源代码
18 finally:
19 browser.close() # 关闭浏览器
运行代码后,Chrome 浏览器会自动弹出。浏览器会跳转到百度,然后在搜索框中输入Python→回车→跳转到搜索结果页面,得到结果后关闭浏览器。这相当于模拟了我们在百度上搜索Python的全套动作,给你带来惊喜!!
在这个过程中,当加载网页结果时,控制台会分别输出当前的URL、当前的Cookies和网页源代码:
可以看出,我们得到的内容是浏览器中的真实内容。可见,使用Selenium驱动浏览器加载网页,可以直接得到JavaScript渲染的结果。接下来我们也会主要用Selenium来爬取基金的净值~
注:Selenium更详细的用法和功能可以在官网查看()
基金净值数据爬虫
通过前面的爬虫,我们会发现数据接口的分析比较繁琐,需要分析相关参数。如果直接用Selenium来模拟浏览器,就可以不用再关注这些界面参数了,只要能直接在浏览器页面上看到这里的内容就可以爬取了。现在我们来试试如何实现我们的目标——基金净值数据爬虫。
页面分析
这个爬虫的目标是单个基金的净值数据。抓取到的网址为:(以单个基金519961为例)。URL 的结构是显而易见的。当我们在浏览器中输入访问链接时,会显示最新的。基金权益数据第一页结果:
在数据下方,有一个页面导航,其中包括前五页之间的链接以及上一页和下一页之间的链接。还有一个链接可以输入任何要跳转到的页码:
如果我们想要获取第二页及以后的数据,我们需要跳转到相应的页码。因此,如果我们需要获取所有的历史净值数据,只需要遍历所有的页码即可。可以直接在页面跳转文本框中输入要跳转到的页码,然后点击“确定”按钮跳转到对应页码的页面。
这里没有直接点击“下一页”的原因是:一旦在爬取过程中出现异常退出,比如在第50页退出时,此时点击“下一页”就无法快速切换到当前页面相应的后续页面。另外,在爬取过程中需要记录当前爬虫的进度,以便及时进行异常检测,检测问题在第一页。整个过程比较复杂,采用直接跳转的方式抓取网页更合理。
当我们成功加载了某个页面的净值数据后,我们就可以使用Selenium来获取该页面的源代码了。定位到一个特定的节点后,我们就可以得到目标的HTML内容,然后通过相应的分析就可以得到我们的HTML内容。目标数据。下面,我们用代码来实现整个爬取过程。
获取基金权益清单
首先,我们需要构造目标 URL。这里的URL组成规则很明显,就是基金code.html。我们可以使用规则来构造我们要爬取的基金对象。这里以基金519961为例进行爬取。
1 browser = webdriver.Chrome()
2 wait = WebDriverWait(browser, 10)
3 fundcode=\'519961\'
4
5 def index_page(page):
6 \'\'\'
7 抓取基金索引页
8 :param page: 页码
9 :param fundcode: 基金代码
10 \'\'\'
11 print(\'正在爬取基金%s第%d页\' % (fundcode, page))
12 try:
13 url = \'http://fundf10.eastmoney.com/jjjz_%s.html\' % fundcode
14 browser.get(url)
15 if page>1:
16 input_page = wait.until(
17 EC.presence_of_element_located((By.CSS_SELECTOR, \'#pagebar input.pnum\')))
18 submit = wait.until(
19 EC.element_to_be_clickable((By.CSS_SELECTOR, \'#pagebar input.pgo\')))
20 input_page.clear()
21 input_page.send_keys(str(page))
22 submit.click()
23 wait.until(
24 EC.text_to_be_present_in_element((By.CSS_SELECTOR, \'#pagebar label.cur\'),
25 str(page)))
26 wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, \'#jztable\')))
27 get_jjjz()
28 except TimeoutException:
29 index_page(page)
这里首相构造了一个WebDriver对象,即声明浏览器对象,使用的浏览器是Chrome,然后指定一个基金代码(519961),然后定义index_page()方法来抓取列表基金净值数据。
在这种方法中,我们首先访问链接搜索资金,然后判断当前页码。如果大于1,我们会跳转到页面,否则我们将等待页面加载。
在等待加载时,我们使用WebDriverWait对象,它可以指定等待条件,同时制定一个最大等待时间,这里指定为最长10秒。如果在这段时间内满足等待条件,即页面元素加载成功,则立即返回相应结果并继续向下执行,否则,当最大等待时间未加载时,直接抛出一个超市例外。
比如我们最后需要等待历史权益信息加载完毕并指定presence_of_element_located条件,然后传入CSS选择器对应的条件#jztable,这个选择器对应的页面内容就是每个基金权益数据页面。在网页上查看:
注意:这里有一个小技巧。如果同学们对CSS选择器的语法不熟悉,可以右键选中节点→复制→复制选择器,直接获取对应的选择器:
CSS 选择器的语法请参考 CSS 选择器参考手册 ()。
加载成功后,机会订单的后续get_jjjz()方法提取历史净值信息。
关于翻页操作,这里先获取页码输入框,赋值给input_page,然后获取“OK”按钮,赋值给submit:
首先,我们需要在输入框中调用clear()方法(不管输入框是否有页码数据)。然后,调用send_keys()方法将页码填入输入框,然后点击“确定”按钮,听起来和我们正常的操作方法一样。
那么,如何知道是否跳转到了对应的页码呢?我们可以注意到,当跳转到当前页面时,页码会高亮显示:
我们只需要判断当前高亮的页码就是当前页码,这里左移使用了另一个等待条件text_to_be_present_in_element,它会等待指定的文本出现在某个节点然后返回成功,这里我们就高亮了亮页码和当前要跳转到的页码对应的CSS选择器通过参数传递给这个等待条件,这样它就会检查当前高亮页码节点是否是我们传递过来的页码数,如果是即,证明页面成功跳转到此页面,页面跳转成功。
这样,刚刚实现的index_page()方法就可以传入对应的页码,加载完页码对应的商品列表后,调用get_jjjz()方法进行页面分析。
解析历史净值数据列表
接下来,我们可以实现 get_jjjz() 方法来解析历史净值数据列表。在这里,我们通过搜索所有历史权益数据节点来获取对应的HTML内容
并进行相应的分析,实现如下:
1 def get_jjjz():
2 \'\'\'
3 提取基金净值数据
4 \'\'\'
5 lsjz = pd.DataFrame()
6 html_list = browser.find_elements_by_css_selector(\'#jztable tbody tr\')
7 for html in html_list:
8 data = html.text.split(\' \')
9 datas = {
10 \'净值日期\': data[0],
11 \'单位净值\': data[1],
12 \'累计净值\': data[2],
13 \'日增长率\': data[3],
14 \'申购状态\': data[4],
15 \'赎回状态\': data[5],
16 }
17 lsjz = lsjz.append(datas, ignore_index=True)
18 save_to_csv(lsjz)
首先调用 find_elements_by_css_selector 获取所有存储历史权益数据的节点。此时使用的CSS选择器是#jztable tbody tr,会匹配所有基金权益节点,输出是一个打包成列表的HTML。使用for循环遍历列表,使用text方法提取每个html中的文本内容,得到的输出是空格分隔的字符串数据。为了方便后续处理,我们可以使用split方法将数据拆分成一个新的以列表形式存储,再转换为dict形式。
最后,为了方便处理,我们将遍历的数据存储为DataFrame,然后使用save_to_csv()方法存储为csv文件。
另存为本地 csv 文件
接下来,我们将获取到的基金历史股权数据保存为本地csv文件。实现代码如下:
1 def save_to_csv(lsjz):
2 \'\'\'
3 保存为csv文件
4 : param result: 历史净值
5 \'\'\'
6 file_path = \'lsjz_%s.csv\' % fundcode
7 try:
8 if not os.path.isfile(file_path): # 判断当前目录下是否已存在该csv文件,若不存在,则直接存储
9 lsjz.to_csv(file_path, index=False)
10 else: # 若已存在,则追加存储,并设置header参数为False,防止列名重复存储
11 lsjz.to_csv(file_path, mode=\'a\', index=False, header=False)
12 print(\'存储成功\')
13 except Exception as e:
14 print(\'存储失败\')
这里,结果变量是 get_jjjz() 方法中传递的历史权益数据。
遍历每一页
我们之前定义的get_index()方法需要接受参数page,代表页码。这里,因为不同基金的数据页不一样,我们需要得到最大页数才能遍历所有页。当然,我们也可以用一些巧妙的方法来解决这个问题。页码遍历代码如下:
1 def main():
2 \'\'\'
3 遍历每一页
4 \'\'\'
5 flag = True
6 page = 1
7 while flag:
8 try:
9 index_page(page)
10 time.sleep(random.randint(1, 5))
11 page += 1
12 except:
13 flag = False
14 print(\'似乎是最后一页了呢\')
它的实现方法结合了try...except和while方法来逐页遍历下一页的内容。当页数超过时,即不存在,index_page()运行时会报错。这时候可以把flag改成False,那么下一次while循环就不会继续了,这样我们就可以遍历所有的页码了。
至此,我们的基金净值数据爬虫已经基本完成,终于可以直接调用main()方法运行了。
总结
在本文中,我们使用 Selenium 来演示基金股权页面的抓取。有兴趣的同学可以尝试使用其他条件来爬取基金数据,比如设置数据的起止日期:
使用日期来抓取内容可以促进未来的数据更新。另外,如果觉得浏览器弹窗比较烦,可以试试Chrome Headless模式或者使用PhantomJS爬取。
至此,基金净值爬虫的分析正式结束。
python抓取动态网页( 如何利用Webkit从渲染网页中获取数据抓取数据的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-14 10:00
如何利用Webkit从渲染网页中获取数据抓取数据的代码)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
复制代码
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
复制代码
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。 查看全部
python抓取动态网页(
如何利用Webkit从渲染网页中获取数据抓取数据的代码)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录 JavaScript 代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录JavaScript代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
显然,这是一个带有 JavaScript 渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
复制代码
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?该网页清楚地显示了如此多的文件信息。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
复制代码
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
复制代码
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载URL中的所有信息并将其存储在一个新的框架中。
python抓取动态网页(《网络上常见的GIF动态图》5月份就写好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-14 09:19
前面写的字~
好久没写爬虫相关的文章了。今天抽时间分享一个我之前做的程序。
经常逛A站和B站的人,对一个节目《网上常见的GIF动图》并不陌生
今天就来分享一下,如何通过爬虫自动将这些动作采集到你的电脑中(其实这个程序是5月份写的,一直拖到想起来分享)。
一. 思路分析
根据爬虫的基本规律:
1.找到目标
2.获取目标
3.处理目标内容,获取有用信息
1.首先,我们的目标是:找到一个动图,去GIFFCC.COM
这个网站是论坛式的网站,分为几类,反正各种动画试试。
我们的目标是找到这些(采集)(隐藏)动作(到)图片(自我)的(自我)(电)地址(大脑)。
2.看各个模块的网址,看看是什么规则
'#39;,#各种GIF动态图片的其他来源
'#39;,#美女GIF动图源码
'#39;,#Sci-Fi 奇幻电影 GIF 动画源
'#39;,#Comedy 搞笑电影 GIF 动画源
'#39;,#动作冒险电影 GIF 动画源
'#39;#GIF 恐怖惊悚电影的动画来源
是的,没错,如果你是游客参观的话,那么每个版块的网址都是这样的——1.html
那么每个模块的内容规律是什么?直接上图:
我们关心的是当前页面的URL和页数。跳转到第二页后,地址变为:
换句话说,URL 的法则是
这里注意网站的图片是动态加载的。只有当你向下滑动时,下面的图片才会逐渐出现。请暂时写下来。
3.每个GIF所在页面的规律
其实这不是一个规律,但是只要找到单张图片的地址,就没有什么难处理的了。
两个动手
1.获取入口页面的内容
即根据传入的URL,获取整个页面的源码
#仅仅获取页面内容
def get_html_Pages(self,url):
try:
#browser = webdriver.PhantomJS(executable_path=r'C:\Python27\Scripts\phantomjs.exe')
browser = webdriver.PhantomJS()
browser.get(url)
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
html=HTMLParser.HTMLParser().unescape(html).decode('utf-8')
return html
#捕捉异常,防止程序直接死掉
except Exception,e:
print u"连接失败,错误原因",e
return None
这里我们使用了 webdriver 和 PhantomJS 模块,为什么?因为网页是动态加载的,所以这种方式可以爬取的数据是满满的。
那么还有一个问题,为什么没有滑动,得到的数据
2.获取页码
#获取页码
def get_page_num(self,html):
doc = pq(html)
print u'开始获取总页码'
#print doc('head')('title').text()#获取当前title
try:
#如果当前页面太多,超过8页以上,就使用另一种方式获取页码
if doc('div[class="pg"]')('[class="last"]'):
num_content= doc('div[class="pg"]')('[class="last"]').attr('href')
print num_content.split('-')[1].split('.')[0]
return num_content.split('-')[1].split('.')[0]
else:
num_content= doc('div[class="pg"]')('span')
return filter(str.isdigit,str(num_content.text()))[0]
#如果获取页码失败,那么就返回1, 即值获取1页内容
except Exception,e:
print u'获取页码失败'.e
return '1'
这里的页码处理使用了一个模块pq,即PyQuery
从 pyquery 导入 PyQuery 作为 pq
使用PyQuery查找我们需要的元素,感觉更好处理,很方便
同时,这里的处理有点意思。如果你观察这个页面,你会发现每个模块的页码在顶部和底部都有一个。然后我在这里剪掉它,因为我们只需要一个页码。
3-6 步骤 3 到 6 一起
其实就是按照页数来遍历,得到每一页的内容
然后获取每个页面的所有图片地址
print u'总共有 %d页内容' % int(page_num)
#3.遍历每一页的内容
for num in range(1,int(page_num)):
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#6.处理每一个元素的内容
self.get_items_url(items,num)
在获取每个页面的内容时,需要重新组合页面地址。
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
有了新地址,就可以获取当前页面的内容,进行数据处理,得到每张图片的地址列表
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#解析页面内容,获取gif的图片list
def parse_items_by_html(self, html):
doc = pq(html)
print u'开始查找内容msg'
return doc('div[class="c cl"]')
得到图片列表后,再次解析得到每张图片的URL
#解析gif 的list ,处理每一个gif内容
def get_items_url(self,items,num):
i=1
for article in items.items():
print u'开始处理数据(%d/%d)' % (i, len(items))
#print article
self.get_single_item(article,i,num)
i +=1
#处理单个gif内容,获取其地址,gif 最终地址
def get_single_item(self,article,num,page_num):
gif_dict={}
#每个页面的地址
gif_url= 'http://gifcc.com/'+article('a').attr('href')
#每个页面的标题
gif_title= article('a').attr('title')
#每张图的具体地址
#html=self.get_html_Pages(gif_url)
#gif_final_url=self.get_final_gif_url(html)
gif_dict['num']=num
gif_dict['page_num']=page_num
gif_dict['gif_url']=gif_url
gif_dict['gif_title']=gif_title
self.gif_list.append(gif_dict)
data=u'第'+str(page_num)+'页|\t'+str(num)+'|\t'+gif_title+'|\t'+gif_url+'\n'
self.file_flag.write(data)
在这里,整合数据,为将数据写入数据库做准备
7.将图片保存到本地并将数据写入数据库
<p>#使用urllib2来获取图片最终地址
def get_final_gif_url_use_urllib2(self,url):
try:
html= urllib2.urlopen(url).read()
gif_pattern=re.compile(' 查看全部
python抓取动态网页(《网络上常见的GIF动态图》5月份就写好了)
前面写的字~
好久没写爬虫相关的文章了。今天抽时间分享一个我之前做的程序。
经常逛A站和B站的人,对一个节目《网上常见的GIF动图》并不陌生
今天就来分享一下,如何通过爬虫自动将这些动作采集到你的电脑中(其实这个程序是5月份写的,一直拖到想起来分享)。
一. 思路分析
根据爬虫的基本规律:
1.找到目标
2.获取目标
3.处理目标内容,获取有用信息
1.首先,我们的目标是:找到一个动图,去GIFFCC.COM
这个网站是论坛式的网站,分为几类,反正各种动画试试。
我们的目标是找到这些(采集)(隐藏)动作(到)图片(自我)的(自我)(电)地址(大脑)。
2.看各个模块的网址,看看是什么规则
'#39;,#各种GIF动态图片的其他来源
'#39;,#美女GIF动图源码
'#39;,#Sci-Fi 奇幻电影 GIF 动画源
'#39;,#Comedy 搞笑电影 GIF 动画源
'#39;,#动作冒险电影 GIF 动画源
'#39;#GIF 恐怖惊悚电影的动画来源
是的,没错,如果你是游客参观的话,那么每个版块的网址都是这样的——1.html
那么每个模块的内容规律是什么?直接上图:
我们关心的是当前页面的URL和页数。跳转到第二页后,地址变为:
换句话说,URL 的法则是
这里注意网站的图片是动态加载的。只有当你向下滑动时,下面的图片才会逐渐出现。请暂时写下来。
3.每个GIF所在页面的规律
其实这不是一个规律,但是只要找到单张图片的地址,就没有什么难处理的了。
两个动手
1.获取入口页面的内容
即根据传入的URL,获取整个页面的源码
#仅仅获取页面内容
def get_html_Pages(self,url):
try:
#browser = webdriver.PhantomJS(executable_path=r'C:\Python27\Scripts\phantomjs.exe')
browser = webdriver.PhantomJS()
browser.get(url)
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
html=HTMLParser.HTMLParser().unescape(html).decode('utf-8')
return html
#捕捉异常,防止程序直接死掉
except Exception,e:
print u"连接失败,错误原因",e
return None
这里我们使用了 webdriver 和 PhantomJS 模块,为什么?因为网页是动态加载的,所以这种方式可以爬取的数据是满满的。
那么还有一个问题,为什么没有滑动,得到的数据
2.获取页码
#获取页码
def get_page_num(self,html):
doc = pq(html)
print u'开始获取总页码'
#print doc('head')('title').text()#获取当前title
try:
#如果当前页面太多,超过8页以上,就使用另一种方式获取页码
if doc('div[class="pg"]')('[class="last"]'):
num_content= doc('div[class="pg"]')('[class="last"]').attr('href')
print num_content.split('-')[1].split('.')[0]
return num_content.split('-')[1].split('.')[0]
else:
num_content= doc('div[class="pg"]')('span')
return filter(str.isdigit,str(num_content.text()))[0]
#如果获取页码失败,那么就返回1, 即值获取1页内容
except Exception,e:
print u'获取页码失败'.e
return '1'
这里的页码处理使用了一个模块pq,即PyQuery
从 pyquery 导入 PyQuery 作为 pq
使用PyQuery查找我们需要的元素,感觉更好处理,很方便
同时,这里的处理有点意思。如果你观察这个页面,你会发现每个模块的页码在顶部和底部都有一个。然后我在这里剪掉它,因为我们只需要一个页码。
3-6 步骤 3 到 6 一起
其实就是按照页数来遍历,得到每一页的内容
然后获取每个页面的所有图片地址
print u'总共有 %d页内容' % int(page_num)
#3.遍历每一页的内容
for num in range(1,int(page_num)):
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#6.处理每一个元素的内容
self.get_items_url(items,num)
在获取每个页面的内容时,需要重新组合页面地址。
#4.组装新的url
new_url = self.url.replace( self.url.split('-')[2],(str(num)+'.html') )
print u'即将获取的页面是:',new_url
有了新地址,就可以获取当前页面的内容,进行数据处理,得到每张图片的地址列表
#5.加载每一页内容,获取gif list 的内容
items=self.parse_items_by_html(self.get_all_page(new_url))
print u'在第%d页,找到了%d 个图片内容' % (num,len(items))
#解析页面内容,获取gif的图片list
def parse_items_by_html(self, html):
doc = pq(html)
print u'开始查找内容msg'
return doc('div[class="c cl"]')
得到图片列表后,再次解析得到每张图片的URL
#解析gif 的list ,处理每一个gif内容
def get_items_url(self,items,num):
i=1
for article in items.items():
print u'开始处理数据(%d/%d)' % (i, len(items))
#print article
self.get_single_item(article,i,num)
i +=1
#处理单个gif内容,获取其地址,gif 最终地址
def get_single_item(self,article,num,page_num):
gif_dict={}
#每个页面的地址
gif_url= 'http://gifcc.com/'+article('a').attr('href')
#每个页面的标题
gif_title= article('a').attr('title')
#每张图的具体地址
#html=self.get_html_Pages(gif_url)
#gif_final_url=self.get_final_gif_url(html)
gif_dict['num']=num
gif_dict['page_num']=page_num
gif_dict['gif_url']=gif_url
gif_dict['gif_title']=gif_title
self.gif_list.append(gif_dict)
data=u'第'+str(page_num)+'页|\t'+str(num)+'|\t'+gif_title+'|\t'+gif_url+'\n'
self.file_flag.write(data)
在这里,整合数据,为将数据写入数据库做准备
7.将图片保存到本地并将数据写入数据库
<p>#使用urllib2来获取图片最终地址
def get_final_gif_url_use_urllib2(self,url):
try:
html= urllib2.urlopen(url).read()
gif_pattern=re.compile('
python抓取动态网页(Python实实现现爬爬取取网网页页中中动动态态加加载载的数数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-14 09:16
Python实现了实际爬取来爬取网页中的动态动态和加载的数据。在使用python爬虫技术采集数据信息时,经常会遇到返回的网页信息。抓取动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么动态加上加载的数据是什么呢?我们可以通过requests模块抓取数据,不可能每次都可见。有些数据是通过非浏览器地址栏中的 URL 请求的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据) 2. 如何检查测试网的网页是否有activity 加载加载的数据处于动态状态?在当前页面打开抓包工具,抓取地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果有搜索结果表示该数据不是动态加载,否则表示数据是动态加载的。如图: 或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。
如图:3. 如果数据是动态动态加载的,那么我们如何捕获动态动态加载的数据呢?根据?? 在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下: 在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如图以下。在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。你可以点击这里了解关于序列化和反序列化的js。代码如下: import requestsimport json#获取商品价格的请求地址url "/stock?skuIdcat 1713,3259,3333&venderId 1000077923&area" \" 4_113_9786_0&buyNum 1& 选择了SuitSkuIds &extraParam {%22originid%22:%221%22}&ch 1&fqsp 0&" \"pduid 47398205303&pdpin jd_635f3b795bb1592&coord &detailedAdd &callback 964 的博文中显示的结果是作者在博客中显示的修改结果和回调4964下图: 注:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。至此,这篇关于Python爬取网页动态加载数据的文章就介绍完了。更多相关Python爬取网页动态数据内容,请搜索之前的文章或继续浏览下方相关文章 查看全部
python抓取动态网页(Python实实现现爬爬取取网网页页中中动动态态加加载载的数数据)
Python实现了实际爬取来爬取网页中的动态动态和加载的数据。在使用python爬虫技术采集数据信息时,经常会遇到返回的网页信息。抓取动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。1. 那么动态加上加载的数据是什么呢?我们可以通过requests模块抓取数据,不可能每次都可见。有些数据是通过非浏览器地址栏中的 URL 请求的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据) 2. 如何检查测试网的网页是否有activity 加载加载的数据处于动态状态?在当前页面打开抓包工具,抓取地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果有搜索结果表示该数据不是动态加载,否则表示数据是动态加载的。如图: 或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。
如图:3. 如果数据是动态动态加载的,那么我们如何捕获动态动态加载的数据呢?根据?? 在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下: 在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如图以下。在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。你可以点击这里了解关于序列化和反序列化的js。代码如下: import requestsimport json#获取商品价格的请求地址url "/stock?skuIdcat 1713,3259,3333&venderId 1000077923&area" \" 4_113_9786_0&buyNum 1& 选择了SuitSkuIds &extraParam {%22originid%22:%221%22}&ch 1&fqsp 0&" \"pduid 47398205303&pdpin jd_635f3b795bb1592&coord &detailedAdd &callback 964 的博文中显示的结果是作者在博客中显示的修改结果和回调4964下图: 注:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。至此,这篇关于Python爬取网页动态加载数据的文章就介绍完了。更多相关Python爬取网页动态数据内容,请搜索之前的文章或继续浏览下方相关文章
python抓取动态网页(以糗事百科网站数据为例(解析json.6+pycharm5))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-12 20:17
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。 查看全部
python抓取动态网页(以糗事百科网站数据为例(解析json.6+pycharm5))
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。
python抓取动态网页(python抓取动态网页(lxml+xpath)爬取工具:seleniumpython异步加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-12 17:07
python抓取动态网页(lxml+xpath+ajax)爬取工具:seleniumpython异步加载网页工具:webdriver+bs4一.ajax概述ajax的本质就是采用ajax连接请求动态网页。异步(异步)连接http,当用户点击刷新页面时,后续可以继续加载数据。(图片来源)异步连接是最灵活高效的获取网页的方式,也是ajax的核心,ajax请求不会在服务器上创建新的数据库连接,而是直接与动态页面进行。
异步的性质使得动态网页获取比传统的同步网页,显得更加高效,再通过requests或selenium方式进行模拟点击(一.xml方式)获取。在上次抓取其他网站的例子中获取网站页面,并分析用户点击。首先我们将整个页面都用ajax方式抓取。当将整个页面用ajax抓取之后,我们在将其存入一个新的二进制的文件中。
写入的二进制文件中包含一个zip压缩包,里面包含我们分析的图片以及动态页面内容。1.图片内容抓取首先我们获取页面中的图片。分析页面中的图片的lxml.etree.html()方法的href属性进行获取。代码如下:page=requests.get(page)我们发现页面中的内容并不会采用page这个字段标记我们,而是被存储在xml文件中(jpg格式)。
所以我们采用一些xml格式格式化图片信息,然后再重新编码保存到external_xml文件中即可。图片的内容是存储在external_xml文件中的二.动态页面抓取在获取了页面信息后,我们分析页面中的动态内容,内容我们是最基本的内容,所以采用相同的方式获取。内容我们分析了三个不同层级页面,发现并不是把链接放在页面的某个标签中直接请求。
页面的元素元素类型不同,页面里面元素的xml类型不同。不同层级的页面有不同的类型定义以及xml的定义,这些类型定义相同,但是属性值不同。动态页面的定义//aarp设置动态图片zipimportpandasaspdimportreimportosimporttimefromlxmlimportetree#全局变量//wxget单个请求xavier_middlewares={'content':'请求...','content':'请求...','xavier_middlewares':{'page':'动态页面','xavier_middlewares':{'load_url':'请求...','load_url':'...','page':'请求...','load_url':'...','role':'xavier','context':'请求...','context':'...','each':'请求...','each':'请求...','eval':'请求...','frozen':'请求...','frozen':'请求..。 查看全部
python抓取动态网页(python抓取动态网页(lxml+xpath)爬取工具:seleniumpython异步加载)
python抓取动态网页(lxml+xpath+ajax)爬取工具:seleniumpython异步加载网页工具:webdriver+bs4一.ajax概述ajax的本质就是采用ajax连接请求动态网页。异步(异步)连接http,当用户点击刷新页面时,后续可以继续加载数据。(图片来源)异步连接是最灵活高效的获取网页的方式,也是ajax的核心,ajax请求不会在服务器上创建新的数据库连接,而是直接与动态页面进行。
异步的性质使得动态网页获取比传统的同步网页,显得更加高效,再通过requests或selenium方式进行模拟点击(一.xml方式)获取。在上次抓取其他网站的例子中获取网站页面,并分析用户点击。首先我们将整个页面都用ajax方式抓取。当将整个页面用ajax抓取之后,我们在将其存入一个新的二进制的文件中。
写入的二进制文件中包含一个zip压缩包,里面包含我们分析的图片以及动态页面内容。1.图片内容抓取首先我们获取页面中的图片。分析页面中的图片的lxml.etree.html()方法的href属性进行获取。代码如下:page=requests.get(page)我们发现页面中的内容并不会采用page这个字段标记我们,而是被存储在xml文件中(jpg格式)。
所以我们采用一些xml格式格式化图片信息,然后再重新编码保存到external_xml文件中即可。图片的内容是存储在external_xml文件中的二.动态页面抓取在获取了页面信息后,我们分析页面中的动态内容,内容我们是最基本的内容,所以采用相同的方式获取。内容我们分析了三个不同层级页面,发现并不是把链接放在页面的某个标签中直接请求。
页面的元素元素类型不同,页面里面元素的xml类型不同。不同层级的页面有不同的类型定义以及xml的定义,这些类型定义相同,但是属性值不同。动态页面的定义//aarp设置动态图片zipimportpandasaspdimportreimportosimporttimefromlxmlimportetree#全局变量//wxget单个请求xavier_middlewares={'content':'请求...','content':'请求...','xavier_middlewares':{'page':'动态页面','xavier_middlewares':{'load_url':'请求...','load_url':'...','page':'请求...','load_url':'...','role':'xavier','context':'请求...','context':'...','each':'请求...','each':'请求...','eval':'请求...','frozen':'请求...','frozen':'请求..。

