
python抓取动态网页
python抓取动态网页( 百度:request爬虫001我想通过自动抓取百度贴吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-25 03:16
百度:request爬虫001我想通过自动抓取百度贴吧)
蟒蛇爬虫
001
我想通过自动爬取百度贴吧“python爬虫吧”中的帖子数据,找到那些付费写爬虫的帖子,赚点零花钱!为了尝试新技术,我使用了python中的request模块,因为这个模块简化了http请求的编写。而具体的html内容分析我还是使用xpath技术。
百度:索取手册
百度:xpath
002
分析百度贴吧的url地址:“%E7%88%AC%E8%99%AB&fr=search”,其中中间的kw字段就是本次爬取的贴吧的名字区域“python 爬虫栏”。
首先,使用 request.get 方法获取 贴吧 主页上的帖子列表。我们希望捕捉到所有的帖子标题,通过标题来判断用户是否有付费的需求或想法。
[代码]
导入请求
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以把params参数传给print(r.text)
[代码]
request.get 可以通过数组传入get的参数!此代码获取 贴吧 的主页。这里的page变量是保留变量,用于以后获取其他分页的内容!
003
关于 xpath 没什么好说的。接下来重点分析首页html的结构。我们打开chorme【开发者工具】,找到帖子标题对应的css代码。然后使用 xpath 方法获取这些帖子。看下面两张图来理解这个过程:
AB5A9754-6CE7-44EF-9199-D29956832FFA.png
5934D6B4-9E8B-4799-AB2A-CE82A6946778.png
[代码]
导入请求
从 lxml 导入 etree
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以通过# print(r.text)root = etree.HTML(r.text)中的params参数
result = root.xpath("//ul[@class='threadlist_bright j_threadlist_bright']/li") #查找列表 print(len(result))for i in range(len(result)):
title = (result[i].xpath(".//div[@class='threadlist_title pull_left j_th_tit ']/a/text()")) #查找标题
打印(标题)
[代码]
请注意,最重要的是从列表+帖子标题中提取的两个xpath。这需要针对 chorme 进行调试才能将其写出。初步成功,爬取标题列表如下:
48[]
['新手帮助解决异步库问题']
['python2.7环境爬图,初学者请多多指教']
【‘江湖告急,来个大佬,怎么用python监控手机推送通知,py交易就可以了’】
['中国裁判网站爬取有问题,求大神指点']
['分享源码,爬取甜美图妞,怕你硬盘不够大']
['问为什么这个头条网址获取不到完整代码']
['Python爬虫应该如何学习?学习步骤是什么?Python爬虫应该如何学习']
['免费写爬虫,留下你的需求,我来写']
['爬取图片保存后只有一张图片是怎么回事']
【‘慕课七月老师分享Python3入门+进阶课程视频’】
['如何开始使用Python爬虫?']
['scrapy 创建错误 10060']
['大神指点这个错误是什么意思,我爬了网站里的所有图,我就是一个']
['Python基本问答']
【‘云计算和大数据路过,Python不知道但有人感兴趣吗?']
['Python各种安装包,你需要的任何安装包都可以在下方留言']
['有靠谱的python微信学习交流群']
【‘七秋新公司最新工商登记数据来源’】
['scrapy 框架使用默认文件管道下载视频时出现问题'] 查看全部
python抓取动态网页(
百度:request爬虫001我想通过自动抓取百度贴吧)
蟒蛇爬虫
001
我想通过自动爬取百度贴吧“python爬虫吧”中的帖子数据,找到那些付费写爬虫的帖子,赚点零花钱!为了尝试新技术,我使用了python中的request模块,因为这个模块简化了http请求的编写。而具体的html内容分析我还是使用xpath技术。
百度:索取手册
百度:xpath
002
分析百度贴吧的url地址:“%E7%88%AC%E8%99%AB&fr=search”,其中中间的kw字段就是本次爬取的贴吧的名字区域“python 爬虫栏”。
首先,使用 request.get 方法获取 贴吧 主页上的帖子列表。我们希望捕捉到所有的帖子标题,通过标题来判断用户是否有付费的需求或想法。
[代码]
导入请求
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以把params参数传给print(r.text)
[代码]
request.get 可以通过数组传入get的参数!此代码获取 贴吧 的主页。这里的page变量是保留变量,用于以后获取其他分页的内容!
003
关于 xpath 没什么好说的。接下来重点分析首页html的结构。我们打开chorme【开发者工具】,找到帖子标题对应的css代码。然后使用 xpath 方法获取这些帖子。看下面两张图来理解这个过程:
AB5A9754-6CE7-44EF-9199-D29956832FFA.png
5934D6B4-9E8B-4799-AB2A-CE82A6946778.png
[代码]
导入请求
从 lxml 导入 etree
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以通过# print(r.text)root = etree.HTML(r.text)中的params参数
result = root.xpath("//ul[@class='threadlist_bright j_threadlist_bright']/li") #查找列表 print(len(result))for i in range(len(result)):
title = (result[i].xpath(".//div[@class='threadlist_title pull_left j_th_tit ']/a/text()")) #查找标题
打印(标题)
[代码]
请注意,最重要的是从列表+帖子标题中提取的两个xpath。这需要针对 chorme 进行调试才能将其写出。初步成功,爬取标题列表如下:
48[]
['新手帮助解决异步库问题']
['python2.7环境爬图,初学者请多多指教']
【‘江湖告急,来个大佬,怎么用python监控手机推送通知,py交易就可以了’】
['中国裁判网站爬取有问题,求大神指点']
['分享源码,爬取甜美图妞,怕你硬盘不够大']
['问为什么这个头条网址获取不到完整代码']
['Python爬虫应该如何学习?学习步骤是什么?Python爬虫应该如何学习']
['免费写爬虫,留下你的需求,我来写']
['爬取图片保存后只有一张图片是怎么回事']
【‘慕课七月老师分享Python3入门+进阶课程视频’】
['如何开始使用Python爬虫?']
['scrapy 创建错误 10060']
['大神指点这个错误是什么意思,我爬了网站里的所有图,我就是一个']
['Python基本问答']
【‘云计算和大数据路过,Python不知道但有人感兴趣吗?']
['Python各种安装包,你需要的任何安装包都可以在下方留言']
['有靠谱的python微信学习交流群']
【‘七秋新公司最新工商登记数据来源’】
['scrapy 框架使用默认文件管道下载视频时出现问题']
python抓取动态网页(一下Python爬虫可以做什么?可以获取网页的源代码吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-24 23:13
Python爬虫这个词在生活中出现的频率越来越高,那么你知道Python爬虫能做什么吗?那么今天,老师就给大家展示一下Python爬虫能做什么。
Python爬虫是一个网络爬虫。通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。我们可以使用爬虫爬取图片、爬取视频等我们想要爬取的数据,只要能够通过爬虫获取到可以通过浏览器访问的数据即可。
Python爬虫可以获取网页的源代码,源代码中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。事实上,获取网页——分析网页源代码——提取信息是爬虫的基本过程。
Python爬虫的一个重要作用就是提取信息,它可以把杂乱的数据整理好,方便我们以后对数据进行处理和分析。Python爬虫的一种常用方法是使用正则表达式。网页的结构有一定的规则,有一些库根据网页节点属性、CSS选择器或XPath来提取网页信息。使用这些库,可以高效、快速地提取网页信息。
Python爬虫有什么优势?
1、简单:Python是一种代表简单思想的语言。
2. 易用性:Python 简单易学,文档通俗易懂。
3、速度快:运行速度快,因为Python中的标准库和第三方库都是用C编写的,所以速度很快。
4. 免费和开源:Python 是 FLOSS(免费/源代码软件)之一,用户可以自由分发该软件的副本,阅读其源代码,对其进行更改,在软件中免费使用其中的一部分.
5. 面向对象:Python 支持过程和面向对象的编程。在“面向过程”的语言中,程序是由只是可重用代码的过程或函数构建的。在“面向对象”语言中,程序是由结合了数据和功能的对象构建的。
Python爬虫的出现给我们的采集信息带来了便利。越来越多的人开始学习 Python 爬虫。你知道 Python 爬虫能做什么吗? 查看全部
python抓取动态网页(一下Python爬虫可以做什么?可以获取网页的源代码吗?)
Python爬虫这个词在生活中出现的频率越来越高,那么你知道Python爬虫能做什么吗?那么今天,老师就给大家展示一下Python爬虫能做什么。

Python爬虫是一个网络爬虫。通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。我们可以使用爬虫爬取图片、爬取视频等我们想要爬取的数据,只要能够通过爬虫获取到可以通过浏览器访问的数据即可。
Python爬虫可以获取网页的源代码,源代码中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。事实上,获取网页——分析网页源代码——提取信息是爬虫的基本过程。
Python爬虫的一个重要作用就是提取信息,它可以把杂乱的数据整理好,方便我们以后对数据进行处理和分析。Python爬虫的一种常用方法是使用正则表达式。网页的结构有一定的规则,有一些库根据网页节点属性、CSS选择器或XPath来提取网页信息。使用这些库,可以高效、快速地提取网页信息。
Python爬虫有什么优势?
1、简单:Python是一种代表简单思想的语言。
2. 易用性:Python 简单易学,文档通俗易懂。
3、速度快:运行速度快,因为Python中的标准库和第三方库都是用C编写的,所以速度很快。
4. 免费和开源:Python 是 FLOSS(免费/源代码软件)之一,用户可以自由分发该软件的副本,阅读其源代码,对其进行更改,在软件中免费使用其中的一部分.
5. 面向对象:Python 支持过程和面向对象的编程。在“面向过程”的语言中,程序是由只是可重用代码的过程或函数构建的。在“面向对象”语言中,程序是由结合了数据和功能的对象构建的。
Python爬虫的出现给我们的采集信息带来了便利。越来越多的人开始学习 Python 爬虫。你知道 Python 爬虫能做什么吗?
python抓取动态网页(作为爬虫程序,如何获取网页API接口?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-24 23:12
)
在之前的文章文章中,我们学习的是静态数据的爬取,即获取的数据是网页上一直存在的数据,不会改变。这些数据的获取相对简单。.
但是,在爬虫的实际应用场景中,很多数据并不是静态存在的,大部分都是以动态的形式存在的,即随时取用,不需要取用。它只会在查看此数据的内容时出现,所有其他时间都在数据库中。
这种方式减少了网页的臃肿感,但需要更高层次的数据库应用和网页编写。
作为爬虫,如何获取动态数据?
这就是 文章 的意义所在。
前面的文献中提到,很多网页的数据是动态生成的,也就是说在浏览器窗口中查看网页源代码时,在HTML代码中是找不到这些内容的。获取静态数据的方式不起作用。
在这种情况下,如果要获取数据,则需要找到网络API接口来获取这些数据。
那么,什么是 API 接口?
API,即Application Programming Interface,应用程序接口。
API 的功能是为应用程序和开发人员提供访问基于一个软件或硬件的一组例程的能力,而无需访问原创代码。
用人类的话来说,网页制作者只需要将API接口与他们制作的网页连接起来,不需要网页制作者自己建立数据库。即网页前端与数据后端的连接通道。
按照上面的题目,如何获取网页的API接口呢?
下面是一个网站“百度图片”的例子。打开网页后,按F12键显示网页源代码,如图:
当然,在这个接口中是找不到API接口的。在这个界面找到NETWORK选项,点击查看API界面。
只要找到API接口,就可以进行下一步了。
硒
对于初学者,可以使用自动化测试工具 Selenium,它提供了浏览器自动化的 API 接口,从而可以通过操作浏览器来获取动态内容。
当然,如果你想使用它,你必须先安装它。像往常一样,我们打开CMD,输入pip3 install selenium,回车,让系统自行下载安装。
接下来,我们使用 Selenium 来练习。
我们开通了中国最大的同性恋交友网站网站——BiBiLiLi 。
打开哔哩哔哩直播,使用Selenium获取各个直播间的封面图。代码显示如下:
从 bs4 导入 BeautifulSoup
从硒导入网络驱动程序
从 mon.keys 导入密钥
定义主():
驱动程序 = webdriver.Chrome()
driver.get('#39;)
汤 = BeautifulSoup(driver.page_source, 'lxml')
对于 soup.body.select('img[src]') 中的 img_tag:
打印(img_tag.attrs['src'])
如果 __name__ == '__main__':
主要的()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果我们要控制其他浏览器,可以创建相应的浏览器对象,比如Firefox、IE等。
Selenium 更具体的功能可以去其官方网站了解。
如果想了解更多技术知识,可以点击关注。
如果对文章的内容有什么疑惑,可以在评论区提出自己的问题,学会和大家交流,解决各种问题,共同进步。
青年研究陪伴所有年轻人
查看全部
python抓取动态网页(作为爬虫程序,如何获取网页API接口?(组图)
)
在之前的文章文章中,我们学习的是静态数据的爬取,即获取的数据是网页上一直存在的数据,不会改变。这些数据的获取相对简单。.
但是,在爬虫的实际应用场景中,很多数据并不是静态存在的,大部分都是以动态的形式存在的,即随时取用,不需要取用。它只会在查看此数据的内容时出现,所有其他时间都在数据库中。
这种方式减少了网页的臃肿感,但需要更高层次的数据库应用和网页编写。
作为爬虫,如何获取动态数据?
这就是 文章 的意义所在。
前面的文献中提到,很多网页的数据是动态生成的,也就是说在浏览器窗口中查看网页源代码时,在HTML代码中是找不到这些内容的。获取静态数据的方式不起作用。
在这种情况下,如果要获取数据,则需要找到网络API接口来获取这些数据。
那么,什么是 API 接口?
API,即Application Programming Interface,应用程序接口。
API 的功能是为应用程序和开发人员提供访问基于一个软件或硬件的一组例程的能力,而无需访问原创代码。
用人类的话来说,网页制作者只需要将API接口与他们制作的网页连接起来,不需要网页制作者自己建立数据库。即网页前端与数据后端的连接通道。
按照上面的题目,如何获取网页的API接口呢?
下面是一个网站“百度图片”的例子。打开网页后,按F12键显示网页源代码,如图:
当然,在这个接口中是找不到API接口的。在这个界面找到NETWORK选项,点击查看API界面。
只要找到API接口,就可以进行下一步了。
硒
对于初学者,可以使用自动化测试工具 Selenium,它提供了浏览器自动化的 API 接口,从而可以通过操作浏览器来获取动态内容。
当然,如果你想使用它,你必须先安装它。像往常一样,我们打开CMD,输入pip3 install selenium,回车,让系统自行下载安装。
接下来,我们使用 Selenium 来练习。
我们开通了中国最大的同性恋交友网站网站——BiBiLiLi 。
打开哔哩哔哩直播,使用Selenium获取各个直播间的封面图。代码显示如下:
从 bs4 导入 BeautifulSoup
从硒导入网络驱动程序
从 mon.keys 导入密钥
定义主():
驱动程序 = webdriver.Chrome()
driver.get('#39;)
汤 = BeautifulSoup(driver.page_source, 'lxml')
对于 soup.body.select('img[src]') 中的 img_tag:
打印(img_tag.attrs['src'])
如果 __name__ == '__main__':
主要的()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果我们要控制其他浏览器,可以创建相应的浏览器对象,比如Firefox、IE等。
Selenium 更具体的功能可以去其官方网站了解。
如果想了解更多技术知识,可以点击关注。
如果对文章的内容有什么疑惑,可以在评论区提出自己的问题,学会和大家交流,解决各种问题,共同进步。
青年研究陪伴所有年轻人
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-24 19:27
Python专题教程:爬取网站,模拟登录,爬取动态网页版本:v1.0Crifan Li 拿网站,模拟登录,抓取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27 下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/python_topic_web_scrape /release/html/python_topic_web_scrape.html 如果您有任何意见、建议、提交bug等,欢迎在讨论组发帖:/bbs/categories/python_topic_web_scrape/ 修订历史修订1.02013-02 -06crl 1. 整理之前教程的地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /文件/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt 6 /files/doc/docbook/python_topic_web_s crape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/释放/html/python_topic_web_scrape.html.7z 9 /files/ doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape。 chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/rtf/python_topic_web_scrape .rtf.7z 14/files/doc/docbook/python_topic_web_scrape /release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:爬取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 Copyright © 2013 Crifan,此文章合规性:署名-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 前言iv 1.本文目的iv 2.前提iv 1.如何在Python中实现< @网站爬取、模拟登录、爬取动态网页1 2. Python 2 中的网络处理3. Python 3 中的HTMl 解析参考书目4iii 前言1. 这篇文章的目的这篇文章目的是,在了解了爬取网站、模拟登录、爬取动态网页的逻辑之后,如何用Python语言来实现现在这部分的逻辑。
2. 前提讨论如何使用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解不清楚的可以参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站抓取、模拟登录、抓取动态网页相关老帖【教程】Python版本1抓取网页并提取所需信息从网页【教程】模拟登录网站的Python版本(包括两个版本的完整可运行代码)2 其实对于urllib等库,已经做得很好了,尤其是在易用性,使用起来已经很方便了。比如直接通过下面的代码,可以从网页中获取地址,得到网页的源代码 TODO: add code 但是因为事实,和网页抓取,网页模拟登录等。 , 需要用到 cookie 等头部参数,要想得到一个强大易用的网络爬取功能,需要付出很多额外的努力。后来,我在折腾web爬取,前后。 ,通过实际使用积累了很多这方面的经验,最后写了一个相关的功能,功能更强大,使用更方便。
主要是2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:再添加一个相关函数的解释,包括downloadFile等。其实函数主要分为两个方面:一方面是抓取网站的内容,涉及到网络处理相关的模块。另一方面,如何解析抓取到的内容,也就是HTML解析下面会讲解这两个方面的相关逻辑,以及如何使用Python来实现这部分的相应功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章Python中的网络处理主要涉及到一些网络处理相关的模块,urllib,urllib2等相关老帖 【整理】Python用来解析Http包。 Module/Library 1 [已解决] Python中使用cookielib的FileCookieJar来save(),结果报错:2NotImplementedError [Organization] Python中的cookie处理:自动处理cookie,保存为cookie文件,从文件中加载3Cookie TODO:组织对应是的,请在 urllib 和 urllib2 上发帖。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第三章 Python中HTMl解析相关的旧帖 BeautifulSoup模块介绍1【教程】Python解析HTML的第三方库:BeautifulSoup 2【总结】第一部分Python之三方库BeautifulSoup使用心得3【整理】Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】json时出错。在Python中加载->注意要解码的Json字符的编码:第1行第1列(char 1) [已解决] Python中使用json.loads解码字符串时出错:ValueError:无法解码JSON对象Python并解析抓取到的网站内容,即解析HTML、JSON等,相关模块有,BeautifulSoup,json等 1/files/ DOC / DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautifulsoup_in_python 4/5 some_notation_about_python_beautifulsoup_parse_parse_backs 6 ash_style_html_json_string / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9/1个python_json_loads_valueerror_no_json_object_could_be_decoded3参考文献[1]和[教程]爬行网页提取Python版本1所需的信息/ crawl_website_html_and_extract_info_using_python/4 查看全部
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
Python专题教程:爬取网站,模拟登录,爬取动态网页版本:v1.0Crifan Li 拿网站,模拟登录,抓取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27 下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/python_topic_web_scrape /release/html/python_topic_web_scrape.html 如果您有任何意见、建议、提交bug等,欢迎在讨论组发帖:/bbs/categories/python_topic_web_scrape/ 修订历史修订1.02013-02 -06crl 1. 整理之前教程的地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /文件/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt 6 /files/doc/docbook/python_topic_web_s crape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/释放/html/python_topic_web_scrape.html.7z 9 /files/ doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape。 chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/rtf/python_topic_web_scrape .rtf.7z 14/files/doc/docbook/python_topic_web_scrape /release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:爬取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 Copyright © 2013 Crifan,此文章合规性:署名-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 前言iv 1.本文目的iv 2.前提iv 1.如何在Python中实现< @网站爬取、模拟登录、爬取动态网页1 2. Python 2 中的网络处理3. Python 3 中的HTMl 解析参考书目4iii 前言1. 这篇文章的目的这篇文章目的是,在了解了爬取网站、模拟登录、爬取动态网页的逻辑之后,如何用Python语言来实现现在这部分的逻辑。
2. 前提讨论如何使用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解不清楚的可以参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站抓取、模拟登录、抓取动态网页相关老帖【教程】Python版本1抓取网页并提取所需信息从网页【教程】模拟登录网站的Python版本(包括两个版本的完整可运行代码)2 其实对于urllib等库,已经做得很好了,尤其是在易用性,使用起来已经很方便了。比如直接通过下面的代码,可以从网页中获取地址,得到网页的源代码 TODO: add code 但是因为事实,和网页抓取,网页模拟登录等。 , 需要用到 cookie 等头部参数,要想得到一个强大易用的网络爬取功能,需要付出很多额外的努力。后来,我在折腾web爬取,前后。 ,通过实际使用积累了很多这方面的经验,最后写了一个相关的功能,功能更强大,使用更方便。
主要是2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:再添加一个相关函数的解释,包括downloadFile等。其实函数主要分为两个方面:一方面是抓取网站的内容,涉及到网络处理相关的模块。另一方面,如何解析抓取到的内容,也就是HTML解析下面会讲解这两个方面的相关逻辑,以及如何使用Python来实现这部分的相应功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章Python中的网络处理主要涉及到一些网络处理相关的模块,urllib,urllib2等相关老帖 【整理】Python用来解析Http包。 Module/Library 1 [已解决] Python中使用cookielib的FileCookieJar来save(),结果报错:2NotImplementedError [Organization] Python中的cookie处理:自动处理cookie,保存为cookie文件,从文件中加载3Cookie TODO:组织对应是的,请在 urllib 和 urllib2 上发帖。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第三章 Python中HTMl解析相关的旧帖 BeautifulSoup模块介绍1【教程】Python解析HTML的第三方库:BeautifulSoup 2【总结】第一部分Python之三方库BeautifulSoup使用心得3【整理】Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】json时出错。在Python中加载->注意要解码的Json字符的编码:第1行第1列(char 1) [已解决] Python中使用json.loads解码字符串时出错:ValueError:无法解码JSON对象Python并解析抓取到的网站内容,即解析HTML、JSON等,相关模块有,BeautifulSoup,json等 1/files/ DOC / DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautifulsoup_in_python 4/5 some_notation_about_python_beautifulsoup_parse_parse_backs 6 ash_style_html_json_string / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9/1个python_json_loads_valueerror_no_json_object_could_be_decoded3参考文献[1]和[教程]爬行网页提取Python版本1所需的信息/ crawl_website_html_and_extract_info_using_python/4
python抓取动态网页(python抓取动态网页源码的三种方法:爬虫源码内网传输)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 13:03
python抓取动态网页源码的三种方法:爬虫源码内网传输php抓取html源码网页最好不要全页截图,会增加抓取的难度。打开爬虫网页源码看看,是不是所有的链接都是已经存在的,所以有一个问题是找不到已经存在的网页信息,这就是所谓的动态网页。动态网页存在一个很严重的问题,加载的时间过长,且源码本身就存在字符重复,这个时候抓取难度就更大了。
如果把所有的动态页面过滤了,能避免抓取这个动态网页。但是加载的过长,会导致手动抓取数据慢,这个时候就需要用python抓取了。在数据抓取前需要将动态页面解析成一个json字符串(blob)格式,解析得到一个json数组,然后再抓取,这样抓取数据速度快,在本例中json文件格式为[{},{},{}].主要步骤有:1.先加载字符串内容到内存2.在解析json数组从json文件中取出动态内容3.读取结果,放入标准库4.再次合并json数组5.最后保存到数据库获取动态网页源码步骤1:写入字符串,如下代码例子2:在解析json数组的时候,需要注意很多接口的限制:动态内容,是个自定义名称,例如我们需要从phpurl-1.io提取动态网页sessionid,那么这个接口返回的json解析文件名为phpsessimportjson_generator.json("phpsessimportjson_generator.json")如下代码例子3:读取json格式的数据时,需要注意格式严格一些,例如上面代码代码中phpsessimportjson_generator.json("phpsessimportjson_generator.json")因为php文件格式规定动态文件的格式为json格式,那么利用json格式中的特殊字符json.dump("phpsessimportjson_generator.json")抓取动态内容得到如下代码例子5:最后把json转换成一个array格式的字典importjsonarr=json.loads(json_generator.json("phpsessimportjson_generator.json"))s=[{"id":123456,"user":"zhangsan","password":"123456"}]这个时候可以把动态内容返回。 查看全部
python抓取动态网页(python抓取动态网页源码的三种方法:爬虫源码内网传输)
python抓取动态网页源码的三种方法:爬虫源码内网传输php抓取html源码网页最好不要全页截图,会增加抓取的难度。打开爬虫网页源码看看,是不是所有的链接都是已经存在的,所以有一个问题是找不到已经存在的网页信息,这就是所谓的动态网页。动态网页存在一个很严重的问题,加载的时间过长,且源码本身就存在字符重复,这个时候抓取难度就更大了。
如果把所有的动态页面过滤了,能避免抓取这个动态网页。但是加载的过长,会导致手动抓取数据慢,这个时候就需要用python抓取了。在数据抓取前需要将动态页面解析成一个json字符串(blob)格式,解析得到一个json数组,然后再抓取,这样抓取数据速度快,在本例中json文件格式为[{},{},{}].主要步骤有:1.先加载字符串内容到内存2.在解析json数组从json文件中取出动态内容3.读取结果,放入标准库4.再次合并json数组5.最后保存到数据库获取动态网页源码步骤1:写入字符串,如下代码例子2:在解析json数组的时候,需要注意很多接口的限制:动态内容,是个自定义名称,例如我们需要从phpurl-1.io提取动态网页sessionid,那么这个接口返回的json解析文件名为phpsessimportjson_generator.json("phpsessimportjson_generator.json")如下代码例子3:读取json格式的数据时,需要注意格式严格一些,例如上面代码代码中phpsessimportjson_generator.json("phpsessimportjson_generator.json")因为php文件格式规定动态文件的格式为json格式,那么利用json格式中的特殊字符json.dump("phpsessimportjson_generator.json")抓取动态内容得到如下代码例子5:最后把json转换成一个array格式的字典importjsonarr=json.loads(json_generator.json("phpsessimportjson_generator.json"))s=[{"id":123456,"user":"zhangsan","password":"123456"}]这个时候可以把动态内容返回。
python抓取动态网页(pyquery库就是jQuery的Python实现库官方文档文档介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-22 09:07
)
照片/文字:着迷
我们是python爬虫,需要正则匹配通过requests抓取内容,或者其他解析库解析内容。可能很多人和我一样用jquery,还是很爽的。 pyquery库是jQuery的Python实现,可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
Beautiful Soup 中虽然可以使用 CSS 选择器,但似乎他的 CSS 选择器并没有想象中的那么强大,PyQuery 更好。因此,我们来说说Python爬虫神器:PyQuery。
PyQuery 库官方文档
官方文档:
PyPI:
Github:
1、PyQuery初始化内容
PyQuery 初始化采用三种形式:
1.1、直接初始化requests返回的html内容
from pyquery import PyQuery as pq
#初始化为PyQuery对象
doc = pq(html)
print(type(doc))
print(doc)
1.2、直接读取文件的形式
1.3、读取URL的形式
doc = pq(url = 'https://www.toutiao.com')
print(type(doc))
print(doc)
2、常用 CSS 选择器:
pyquery 的强大之处在于它使用与 jquery 相同的选项来解析网页节点。
html = """
Python
大法
好
"""
获取id为object-1的标签
print(doc('#object-1'))
#返回:
好
#还可以:
print(doc('#container #object-1'))
获取类为object-1的标签
print(doc('.object-1'))
#返回:
Python 查看全部
python抓取动态网页(pyquery库就是jQuery的Python实现库官方文档文档介绍
)
照片/文字:着迷
我们是python爬虫,需要正则匹配通过requests抓取内容,或者其他解析库解析内容。可能很多人和我一样用jquery,还是很爽的。 pyquery库是jQuery的Python实现,可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
Beautiful Soup 中虽然可以使用 CSS 选择器,但似乎他的 CSS 选择器并没有想象中的那么强大,PyQuery 更好。因此,我们来说说Python爬虫神器:PyQuery。
PyQuery 库官方文档
官方文档:
PyPI:
Github:
1、PyQuery初始化内容
PyQuery 初始化采用三种形式:
1.1、直接初始化requests返回的html内容
from pyquery import PyQuery as pq
#初始化为PyQuery对象
doc = pq(html)
print(type(doc))
print(doc)
1.2、直接读取文件的形式
1.3、读取URL的形式
doc = pq(url = 'https://www.toutiao.com')
print(type(doc))
print(doc)
2、常用 CSS 选择器:
pyquery 的强大之处在于它使用与 jquery 相同的选项来解析网页节点。
html = """
Python
大法
好
"""
获取id为object-1的标签
print(doc('#object-1'))
#返回:
好
#还可以:
print(doc('#container #object-1'))
获取类为object-1的标签
print(doc('.object-1'))
#返回:
Python
python抓取动态网页(用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-22 09:06
作为数据科学家,我的第一项任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何抓取一个网站——比如从Fast Track 中获取2018 年前100 家公司的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
如果觉得篇幅太长不想看,可以关注转发。私聊小编“01”领取全部代码。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
以 Tech Track Top 100 Enterprises (%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例,右键点击表格,选择“检查”。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。然而,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数,或者遍历所有页面,才能爬取完整的数据。
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需要一个循环,就可以读取所有的表格数据并保存到一个文件中。
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(如 Insomnia)发出请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。
接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:
接下来,我们可以使用 urllib 连接到这个 URL,将内容保存在 page 变量中,然后使用 BeautifulSoup 对页面进行处理,并将处理结果存储在 soup 变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
现在所有的内容都在表(tag)中,我们可以在soup对象中搜索我们需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。
看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面上是一致的(但在其他网站上可能就没有这么简单了!),所以我们可以再次使用find_all方法,通过搜索元素,逐行提取数据并将其存储在一个变量,方便以后写入csv或者json文件。
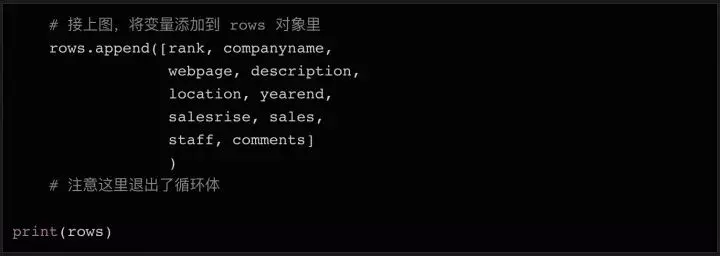
循环遍历所有元素并存储在变量中
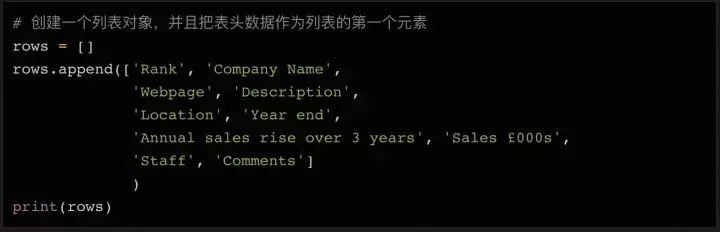
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填入初始表头(方便以后在CSV文件中使用),然后数据只需要调用列表对象的append方法即可。
这将打印我们刚刚添加到列表对象行的第一行标题。
你可能注意到我输入的表头比网页上的表多了几个列名,比如Webpage(网页)和Description(描述),请仔细看上面打印的soup变量数据——第一个第二行第二列的数据不仅收录公司名称,还收录公司网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为头部使用了标签和没有标签,所以我们简单的查询标签中的数据,丢弃空值。
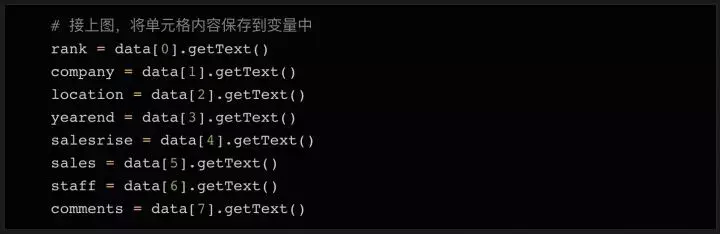
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。
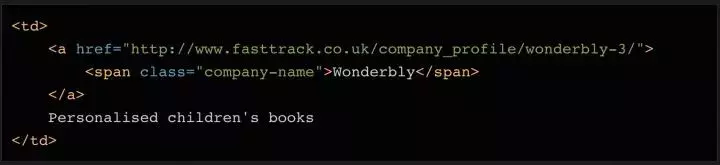
我们要将公司变量的内容拆分为公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
为了删除 sales 变量中的多余字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
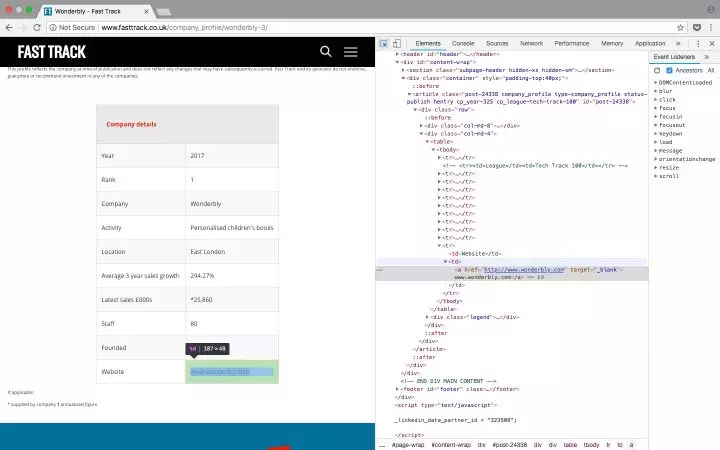
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
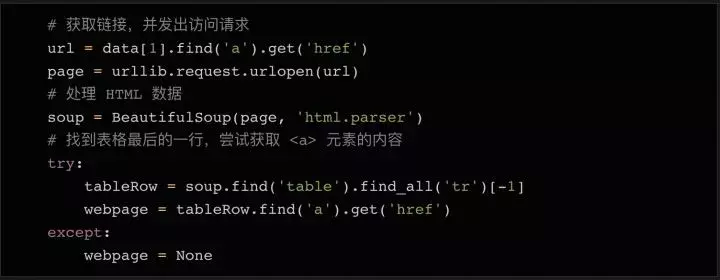
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
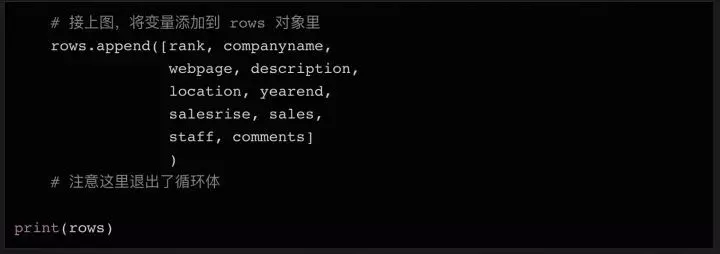
同样,最后一行可能没有链接。因此,我们添加了 try...except 语句,如果未找到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。
最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不明白的,请在下方留言,我会尽力为您解答!
最后,如果有想要学习Python的朋友,可以关注、转发、后台私信小编“01”,免费获取Python学习资料。 查看全部
python抓取动态网页(用脚本将获取信息上获取2018年100强企业的信息)
作为数据科学家,我的第一项任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何抓取一个网站——比如从Fast Track 中获取2018 年前100 家公司的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
如果觉得篇幅太长不想看,可以关注转发。私聊小编“01”领取全部代码。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:

安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
以 Tech Track Top 100 Enterprises (%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例,右键点击表格,选择“检查”。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
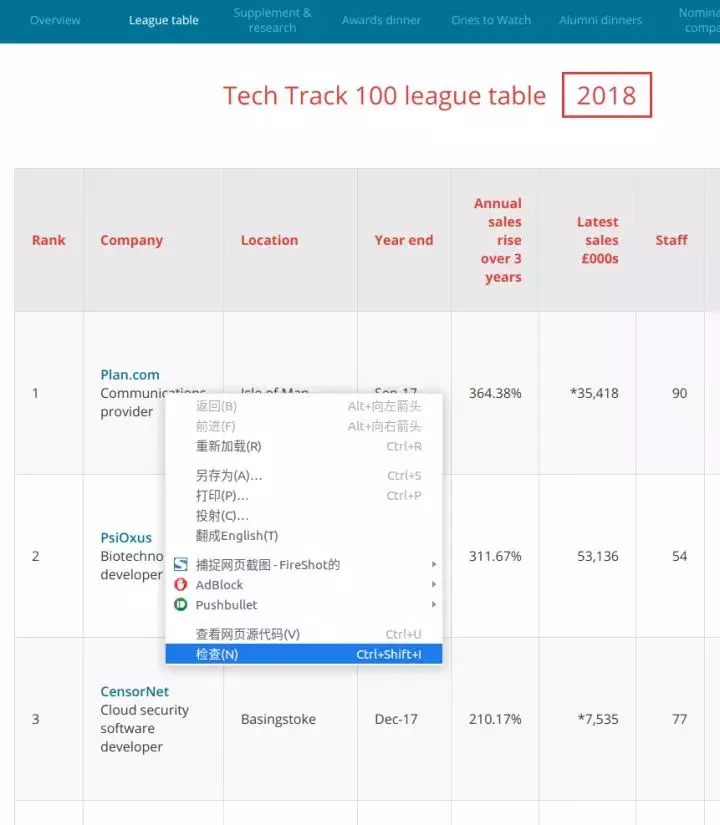
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。然而,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数,或者遍历所有页面,才能爬取完整的数据。
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:

每一行都在一个标签中,也就是我们不需要太复杂的代码,只需要一个循环,就可以读取所有的表格数据并保存到一个文件中。
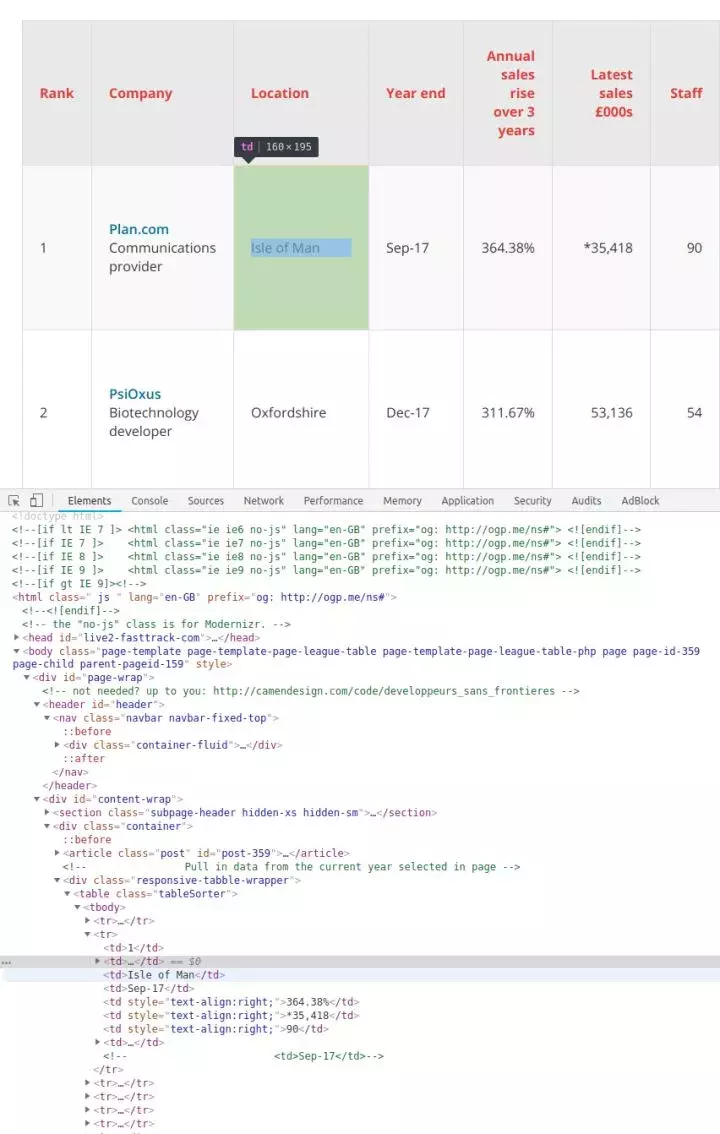
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(如 Insomnia)发出请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。

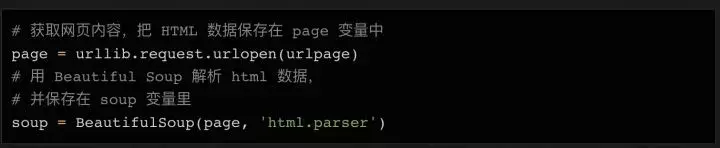
接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:

接下来,我们可以使用 urllib 连接到这个 URL,将内容保存在 page 变量中,然后使用 BeautifulSoup 对页面进行处理,并将处理结果存储在 soup 变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:

如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
现在所有的内容都在表(tag)中,我们可以在soup对象中搜索我们需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。

看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面上是一致的(但在其他网站上可能就没有这么简单了!),所以我们可以再次使用find_all方法,通过搜索元素,逐行提取数据并将其存储在一个变量,方便以后写入csv或者json文件。
循环遍历所有元素并存储在变量中
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填入初始表头(方便以后在CSV文件中使用),然后数据只需要调用列表对象的append方法即可。
这将打印我们刚刚添加到列表对象行的第一行标题。
你可能注意到我输入的表头比网页上的表多了几个列名,比如Webpage(网页)和Description(描述),请仔细看上面打印的soup变量数据——第一个第二行第二列的数据不仅收录公司名称,还收录公司网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为头部使用了标签和没有标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。

我们要将公司变量的内容拆分为公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
为了删除 sales 变量中的多余字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,最后一行可能没有链接。因此,我们添加了 try...except 语句,如果未找到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。
最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不明白的,请在下方留言,我会尽力为您解答!
最后,如果有想要学习Python的朋友,可以关注、转发、后台私信小编“01”,免费获取Python学习资料。
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-20 19:15
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area"
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&"
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict["stock"]["jdPrice"]["op"]}")
print(f"定价为: {goods_dict["stock"]["jdPrice"]["m"]}")
print(f"会员价为: {goods_dict["stock"]["jdPrice"]["tpp"]}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现抓取网页中动态加载的数据的文章文章就介绍到这里了。更多关于Python抓取网页动态数据的内容,请搜索云海天教程之前的文章或继续浏览以下相关文章希望大家以后多多支持云海天教程!
原文链接: 查看全部
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。

1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:

或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。

在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。

查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。

根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area"
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&"
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict["stock"]["jdPrice"]["op"]}")
print(f"定价为: {goods_dict["stock"]["jdPrice"]["m"]}")
print(f"会员价为: {goods_dict["stock"]["jdPrice"]["tpp"]}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:

注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现抓取网页中动态加载的数据的文章文章就介绍到这里了。更多关于Python抓取网页动态数据的内容,请搜索云海天教程之前的文章或继续浏览以下相关文章希望大家以后多多支持云海天教程!
原文链接:
python抓取动态网页(开发环境操作系统:windows10Python版本:3.6爬取网页模块:requests分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-18 16:16
开发环境
操作系统:Windows 10
Python 版本:3.6
抓取网页模块:请求
分析网页模块:json
模块安装
pip3 install requests
网页分析
我们使用豆瓣电影页面开始分析
https://movie.douban.com/explo ... t%3D0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容
当我们点击加载更多时,可以通过开发者工具的Network选项中的XHR获取动态加载的js
打开获取的连接
https://movie.douban.com/j/sea ... %3D20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式的
这里我们构造一个链接,从第一部电影开始,显示 100
https://movie.douban.com/j/sea ... t%3D0
对于JSON的解析,我们可以先用一个在线的网站查看
https://jsonformatter.curiousconcept.com/
这里可以看到收录以下信息
代码介绍
这里逐行介绍代码
1.导入相关模块
import requests
import json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)
content=r.content
3.使用json.load将json格式转成python字典格式
这时候就可以使用字典的相关方法来处理网页了
result=json.loads(content)
tvs=result['subjects']
4. 获取相关信息并存入字典
执行结果
我们可以选择将获取的数据放入数据库中
来源地点 查看全部
python抓取动态网页(开发环境操作系统:windows10Python版本:3.6爬取网页模块:requests分析)
开发环境
操作系统:Windows 10
Python 版本:3.6
抓取网页模块:请求
分析网页模块:json
模块安装
pip3 install requests
网页分析
我们使用豆瓣电影页面开始分析
https://movie.douban.com/explo ... t%3D0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容
当我们点击加载更多时,可以通过开发者工具的Network选项中的XHR获取动态加载的js
打开获取的连接
https://movie.douban.com/j/sea ... %3D20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式的
这里我们构造一个链接,从第一部电影开始,显示 100
https://movie.douban.com/j/sea ... t%3D0
对于JSON的解析,我们可以先用一个在线的网站查看
https://jsonformatter.curiousconcept.com/
这里可以看到收录以下信息
代码介绍
这里逐行介绍代码
1.导入相关模块
import requests
import json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)
content=r.content
3.使用json.load将json格式转成python字典格式
这时候就可以使用字典的相关方法来处理网页了
result=json.loads(content)
tvs=result['subjects']
4. 获取相关信息并存入字典
执行结果
我们可以选择将获取的数据放入数据库中
来源地点
python抓取动态网页(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-17 15:17
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。 查看全部
python抓取动态网页(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-17 00:18
前言
在爬取常规静态网页时,我们直接请求对应的url就可以得到完整的HTML页面,但是对于动态页面,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候我们获取页面的HTML,我们无法获取我们想要使用的内容。这时候我们就可以使用 selenium 库来获取我们需要的内容了。
待安装的三方库示例代码
示例描述:获取德邦官网已开设分店的城市区域名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/")
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
遇到的小问题 使用“pip install selenium”安装 selenium 库时失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时出现的问题,我在网上看到的文章使用的是火狐浏览器,他们可以直接使用webdriver.Firefox(),而我用的是谷歌浏览器,我以为用的是谷歌浏览器与使用 Firefox 相同,但在运行时出错。后来,我在网上找到了。就是从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数时,需要传递executable_path参数,这个参数的值就是Chrome Driver.exe文件下载到的路径selenium 官网位于。在示例中,我把chromedriver.exe放在根目录下,所以我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox浏览器插件:Katalon Recorder,Katalon Recorder是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以将记录导出为各种代码,其中收录 Python 2 的代码。有时借用它,我们可以很容易地得到我们需要的数据,而无需分析 HTML 的结构,这对于 HTML 结构杂乱的网页非常有帮助。 查看全部
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
前言
在爬取常规静态网页时,我们直接请求对应的url就可以得到完整的HTML页面,但是对于动态页面,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候我们获取页面的HTML,我们无法获取我们想要使用的内容。这时候我们就可以使用 selenium 库来获取我们需要的内容了。
待安装的三方库示例代码
示例描述:获取德邦官网已开设分店的城市区域名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/";)
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
遇到的小问题 使用“pip install selenium”安装 selenium 库时失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时出现的问题,我在网上看到的文章使用的是火狐浏览器,他们可以直接使用webdriver.Firefox(),而我用的是谷歌浏览器,我以为用的是谷歌浏览器与使用 Firefox 相同,但在运行时出错。后来,我在网上找到了。就是从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数时,需要传递executable_path参数,这个参数的值就是Chrome Driver.exe文件下载到的路径selenium 官网位于。在示例中,我把chromedriver.exe放在根目录下,所以我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox浏览器插件:Katalon Recorder,Katalon Recorder是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以将记录导出为各种代码,其中收录 Python 2 的代码。有时借用它,我们可以很容易地得到我们需要的数据,而无需分析 HTML 的结构,这对于 HTML 结构杂乱的网页非常有帮助。
python抓取动态网页(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-16 01:08
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(解释来源:百度百科-《动态网页》,如果链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求变化的内容,比如某宝的商品价格和评论,比如某阀门的热门影评,某条新闻的视频等,通过先加载网页整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单翻译成页面起点的意思,再看上面的“page_limit”,大概就是页面限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们需要得到下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码
注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一个非常通用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF攻击的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。管理员权限下运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:
注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能很长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。 查看全部
python抓取动态网页(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(解释来源:百度百科-《动态网页》,如果链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求变化的内容,比如某宝的商品价格和评论,比如某阀门的热门影评,某条新闻的视频等,通过先加载网页整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单翻译成页面起点的意思,再看上面的“page_limit”,大概就是页面限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们需要得到下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码

注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一个非常通用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF攻击的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。管理员权限下运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:

注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能很长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。
python抓取动态网页(:utf-8importurllib2fromBeautifulSoupimportBeautifulSoup;BeautifulSoup)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-14 08:14
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--
博客 Markdown 编辑器上线了! Wrox精品红皮电脑书PMBOK第五版,那些年我们一直在关注的,是火星敏捷开发1001题的视频教程
Python实现网络爬虫爬取静态网页[代码]
类别:蟒蛇
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--------- -------------------------------------------------- -------------------def main():#ץuserMainUrl = "?id=38b94c4ed8add8bcccabd7d31b22&fr=userbar"; #修改抓取的链接地址 req = urllib2.@ >Request(userMainUrl);resp = urllib2.@>urlopen(req);respHtml = resp.read();print "respHtml=",respHtml; #在这里输出所有捕获的HTML源代码#ȡsongtasteHtmlEncoding = "GBK";#修改编码字符集的格式soup = BeautifulSoup(respHtml, fromEncoding=songtasteHtmlEncoding);foundClassH1user = soup.find(attrs={"target":"_blank "});#修改抓取的内容 print "foundClassH1user=%s ",foundClassH1user;if(foundClassH1user):h1userStr = foundClassH1user.string;print "h1userStr=",h1userStr;############ ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# #if __name__=="__main__":main() ;
获取 1 类标签
#eg:siteUrls=soup.findAll('a')
获取 2 个类标签
#eg:foundClassH1user = soup.find(attrs={"target":"_blank"});
获取 2 个类标签
#foundClassH1user = soup.find(attrs={"class":"h1user"});
上一篇文章在notepad++下搭建python编译器
喜欢 1 不喜欢 0
主题推荐猜你在找什么 查看全部
python抓取动态网页(:utf-8importurllib2fromBeautifulSoupimportBeautifulSoup;BeautifulSoup)
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--
博客 Markdown 编辑器上线了! Wrox精品红皮电脑书PMBOK第五版,那些年我们一直在关注的,是火星敏捷开发1001题的视频教程
Python实现网络爬虫爬取静态网页[代码]
类别:蟒蛇
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--------- -------------------------------------------------- -------------------def main():#ץuserMainUrl = "?id=38b94c4ed8add8bcccabd7d31b22&fr=userbar"; #修改抓取的链接地址 req = urllib2.@ >Request(userMainUrl);resp = urllib2.@>urlopen(req);respHtml = resp.read();print "respHtml=",respHtml; #在这里输出所有捕获的HTML源代码#ȡsongtasteHtmlEncoding = "GBK";#修改编码字符集的格式soup = BeautifulSoup(respHtml, fromEncoding=songtasteHtmlEncoding);foundClassH1user = soup.find(attrs={"target":"_blank "});#修改抓取的内容 print "foundClassH1user=%s ",foundClassH1user;if(foundClassH1user):h1userStr = foundClassH1user.string;print "h1userStr=",h1userStr;############ ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# #if __name__=="__main__":main() ;
获取 1 类标签
#eg:siteUrls=soup.findAll('a')
获取 2 个类标签
#eg:foundClassH1user = soup.find(attrs={"target":"_blank"});
获取 2 个类标签
#foundClassH1user = soup.find(attrs={"class":"h1user"});
上一篇文章在notepad++下搭建python编译器
喜欢 1 不喜欢 0
主题推荐猜你在找什么
python抓取动态网页(我该怎么办抓取动态加载的网站() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-13 23:05
)
这是我第一次获取动态加载的网站,我一直在尝试获取该网站的团队名称和赔率
我在这个 文章
中用 PyQt5 试过这个
从 PyQt4 到 PyQt5 -> mainFrame() 已弃用,需要修复才能加载网页
class Page(QWebEnginePage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebEnginePage.__init__(self)
self.html = ''
self.loadFinished.connect(self._on_load_finished)
self.load(QUrl(url))
self.app.exec_()
def _on_load_finished(self):
self.html = self.toHtml(self.Callable)
print('Load finished')
def Callable(self, html_str):
self.html = html_str
self.app.quit()
def main():
page = Page('https://www.cashpoint.com/de/fussball/deutschland/bundesliga')
soup = bs.BeautifulSoup(page.html, 'html.parser')
js_test = soup.find('div', class_='game__team game__team__football')
print(js_test.text)
if __name__ == '__main__': main()
但这不适用于我试图抓取的 网站。我得到一个 AttributeError: 'NoneType' object has no attribute 'text' 错误。虽然在上面的文章中有一个为动态加载的网站写的方法,但是我并没有通过这个方法得到网站的内容。正如我所读到的,处理动态加载的 网站 的第一种方法是确定如何在页面上呈现数据。我该怎么办?为什么 PyQt5 不能在那个 网站 上工作? Selenium 方式对我来说不是一个选择,因为它太慢而无法获得实时赔率。当我检查 网站 使用的 HTML 内容,然后使用 Beautifulsoup 或 Scrapy 的常规方法时,是否可以获得该 网站 的 HTML 内容?提前谢谢你。
解决方案
提供的代码失败,因为即使页面已完成加载,新创建的元素(例如 div)也是异步创建的,例如你想得到 "game__team" 和 "game__team__football",所以当 loadFinished 发出信号时,即使没有创建这些元素也是一样的。
一种可能的解决方案是直接使用javascript通过runJavaScript()方法获取文本列表,如果列表为空,则在时间T重试,直到列表不为空。
import sys
from PyQt5 import QtCore, QtWidgets, QtWebEngineWidgets
class Scrapper(QtCore.QObject):
def __init__(self, interval=500, parent=None):
super().__init__(parent)
self._result = []
self._interval = interval
self.page = QtWebEngineWidgets.QWebEnginePage(self)
self.page.loadFinished.connect(self.on_load_finished)
self.page.load(
QtCore.QUrl("https://www.cashpoint.com/de/f ... 6quot;)
)
@property
def result(self):
return self._result
@property
def interval(self):
return self._interval
@interval.setter
def interval(self, interval):
self._interval = interval
@QtCore.pyqtSlot(bool)
def on_load_finished(self, ok):
if ok:
self.execute_javascript()
else:
QtCore.QCoreApplication.exit(-1)
def execute_javascript(self):
self.page.runJavaScript(
"""
function text_by_classname(classname){
var texts = [];
var elements = document.getElementsByClassName(classname);
for (const e of elements) {
texts.push(e.textContent);
}
return texts;
}
[].concat(text_by_classname("game__team"), text_by_classname("game__team__football"));
""",
self.javascript_callback,
)
def javascript_callback(self, result):
if result:
self._result = result
QtCore.QCoreApplication.quit()
else:
QtCore.QTimer.singleShot(self.interval, self.execute_javascript)
def main():
app = QtWidgets.QApplication(sys.argv)
scrapper = Scrapper(interval=1000)
app.exec_()
result = scrapper.result
del scrapper, app
print(result)
if __name__ == "__main__":
main()
输出:
[' 1899 Hoffenheim ', ' FC Augsburg ', ' Bayern München ', ' Werder Bremen ', ' Hertha BSC ', ' SC Freiburg ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' 1. FC Köln ', ' Bayer 04 Leverkusen ', ' SC Paderborn ', ' FC Union Berlin ', ' Fortuna Düsseldorf ', ' RB Leipzig ', ' VFL Wolfsburg ', ' Borussia Mönchengladbach ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' Werder Bremen ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' RB Leipzig ', ' FC Augsburg ', ' Fortuna Düsseldorf ', ' FC Union Berlin ', ' 1899 Hoffenheim ', ' Bayer 04 Leverkusen ', ' Hertha BSC ', ' Borussia Mönchengladbach ', ' SC Paderborn ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' 1. FC Köln ', ' SC Freiburg ', ' Bayern München ', ' 1899 Hoffenheim ', ' Borussia Dortmund ', ' Bayern München ', ' VFL Wolfsburg ', ' 1899 Hoffenheim ', ' Bayern München ', ' Hertha BSC ', ' 1. Fsv Mainz 05 ', ' 1. FC Köln ', ' SC Paderborn ', ' Fortuna Düsseldorf ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Werder Bremen ', ' Borussia Dortmund ', ' FC Augsburg ', ' FC Union Berlin ', ' Bayer 04 Leverkusen ', ' Borussia Mönchengladbach ', ' VFL Wolfsburg ', ' Eintracht Frankfurt ', ' SC Freiburg ', ' 1899 Hoffenheim ', ' Bayern München '] 查看全部
python抓取动态网页(我该怎么办抓取动态加载的网站()
)
这是我第一次获取动态加载的网站,我一直在尝试获取该网站的团队名称和赔率
我在这个 文章
中用 PyQt5 试过这个
从 PyQt4 到 PyQt5 -> mainFrame() 已弃用,需要修复才能加载网页
class Page(QWebEnginePage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebEnginePage.__init__(self)
self.html = ''
self.loadFinished.connect(self._on_load_finished)
self.load(QUrl(url))
self.app.exec_()
def _on_load_finished(self):
self.html = self.toHtml(self.Callable)
print('Load finished')
def Callable(self, html_str):
self.html = html_str
self.app.quit()
def main():
page = Page('https://www.cashpoint.com/de/fussball/deutschland/bundesliga')
soup = bs.BeautifulSoup(page.html, 'html.parser')
js_test = soup.find('div', class_='game__team game__team__football')
print(js_test.text)
if __name__ == '__main__': main()
但这不适用于我试图抓取的 网站。我得到一个 AttributeError: 'NoneType' object has no attribute 'text' 错误。虽然在上面的文章中有一个为动态加载的网站写的方法,但是我并没有通过这个方法得到网站的内容。正如我所读到的,处理动态加载的 网站 的第一种方法是确定如何在页面上呈现数据。我该怎么办?为什么 PyQt5 不能在那个 网站 上工作? Selenium 方式对我来说不是一个选择,因为它太慢而无法获得实时赔率。当我检查 网站 使用的 HTML 内容,然后使用 Beautifulsoup 或 Scrapy 的常规方法时,是否可以获得该 网站 的 HTML 内容?提前谢谢你。
解决方案
提供的代码失败,因为即使页面已完成加载,新创建的元素(例如 div)也是异步创建的,例如你想得到 "game__team" 和 "game__team__football",所以当 loadFinished 发出信号时,即使没有创建这些元素也是一样的。
一种可能的解决方案是直接使用javascript通过runJavaScript()方法获取文本列表,如果列表为空,则在时间T重试,直到列表不为空。
import sys
from PyQt5 import QtCore, QtWidgets, QtWebEngineWidgets
class Scrapper(QtCore.QObject):
def __init__(self, interval=500, parent=None):
super().__init__(parent)
self._result = []
self._interval = interval
self.page = QtWebEngineWidgets.QWebEnginePage(self)
self.page.loadFinished.connect(self.on_load_finished)
self.page.load(
QtCore.QUrl("https://www.cashpoint.com/de/f ... 6quot;)
)
@property
def result(self):
return self._result
@property
def interval(self):
return self._interval
@interval.setter
def interval(self, interval):
self._interval = interval
@QtCore.pyqtSlot(bool)
def on_load_finished(self, ok):
if ok:
self.execute_javascript()
else:
QtCore.QCoreApplication.exit(-1)
def execute_javascript(self):
self.page.runJavaScript(
"""
function text_by_classname(classname){
var texts = [];
var elements = document.getElementsByClassName(classname);
for (const e of elements) {
texts.push(e.textContent);
}
return texts;
}
[].concat(text_by_classname("game__team"), text_by_classname("game__team__football"));
""",
self.javascript_callback,
)
def javascript_callback(self, result):
if result:
self._result = result
QtCore.QCoreApplication.quit()
else:
QtCore.QTimer.singleShot(self.interval, self.execute_javascript)
def main():
app = QtWidgets.QApplication(sys.argv)
scrapper = Scrapper(interval=1000)
app.exec_()
result = scrapper.result
del scrapper, app
print(result)
if __name__ == "__main__":
main()
输出:
[' 1899 Hoffenheim ', ' FC Augsburg ', ' Bayern München ', ' Werder Bremen ', ' Hertha BSC ', ' SC Freiburg ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' 1. FC Köln ', ' Bayer 04 Leverkusen ', ' SC Paderborn ', ' FC Union Berlin ', ' Fortuna Düsseldorf ', ' RB Leipzig ', ' VFL Wolfsburg ', ' Borussia Mönchengladbach ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' Werder Bremen ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' RB Leipzig ', ' FC Augsburg ', ' Fortuna Düsseldorf ', ' FC Union Berlin ', ' 1899 Hoffenheim ', ' Bayer 04 Leverkusen ', ' Hertha BSC ', ' Borussia Mönchengladbach ', ' SC Paderborn ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' 1. FC Köln ', ' SC Freiburg ', ' Bayern München ', ' 1899 Hoffenheim ', ' Borussia Dortmund ', ' Bayern München ', ' VFL Wolfsburg ', ' 1899 Hoffenheim ', ' Bayern München ', ' Hertha BSC ', ' 1. Fsv Mainz 05 ', ' 1. FC Köln ', ' SC Paderborn ', ' Fortuna Düsseldorf ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Werder Bremen ', ' Borussia Dortmund ', ' FC Augsburg ', ' FC Union Berlin ', ' Bayer 04 Leverkusen ', ' Borussia Mönchengladbach ', ' VFL Wolfsburg ', ' Eintracht Frankfurt ', ' SC Freiburg ', ' 1899 Hoffenheim ', ' Bayern München ']
python抓取动态网页(动态网页爬虫什么是动态(爬虫)(AJAX技术))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 11:07
动态网页爬虫 什么是动态网页爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的本地数据,无需重新加载。例如,在拉狗网的招聘页面,在页面变化的过程中,url没有变化,但是招聘数据是动态变化的。AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓的AJAX,其实,数据交互基本上是使用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。动态网络爬虫的解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用 Selenium+chromedriver 模拟浏览器行为获取数据。selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:通过 id 查找元素。find_element_by_class_name:按类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:按标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据 css 选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
Selenium 表单操作:webelement.send_keys:将输入框填入内容。webelement.click:点击。操作select标签:需要先用from selenium.webdriver.support.ui import Select包裹选中的对象,然后才能进行选择:selenium行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类mon.action_chains.ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):在不释放鼠标的情况下单击。
context_click(element):右键单击。
double_click(element):双击。
下面是B站的登录和拖动验证滑块。
以下是键盘操作
设置浏览器的参数就是在定义驱动时设置chrome_options参数,是Options类实例化的对象。
参数是设置浏览器是否可视化以及请求头等信息。
浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。
Selenium 提供了一些延迟功能
无形等待是在设定的时间段内检测网页是否加载完毕,即浏览器标签栏的小圆圈不再旋转,才执行下一步。
显式等待可以根据判断条件灵活等待。程序每隔一定时间检测一次,如果结果和检测条件成立,则执行下一步。显式等待的使用涉及几个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait的参数说明如下: driver:浏览器对象驱动;timeout:超时时间;poll_frequency:检测时间间隔;
忽略的异常:忽略的异常。until:条件判断,参数必须是expected_conditions对象。
更多方法请参考:
为什么需要行为链?
因为有些网站可能会在浏览器端做一些验证,看行为是否符合人类行为做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,比如双击、右键等,在自动化测试中非常有用。
操作 cookie:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})
隐式等待和显式等待: 隐式等待:指定将保持等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定在一定时间内,如果满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是从 selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:在selenium中打开新窗口没有特殊的方法,通过window.execute_script()以执行js脚本的形式打开新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开一个新窗口后,驱动的当前页面还是和以前一样。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
通过ChromeOptions设置代理,示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999")
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip")
补充:get_property:获取html标签中官方写的属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求会失败,所以你可以保存当前页面的截图以供以后分析。 查看全部
python抓取动态网页(动态网页爬虫什么是动态(爬虫)(AJAX技术))
动态网页爬虫 什么是动态网页爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的本地数据,无需重新加载。例如,在拉狗网的招聘页面,在页面变化的过程中,url没有变化,但是招聘数据是动态变化的。AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓的AJAX,其实,数据交互基本上是使用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。动态网络爬虫的解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用 Selenium+chromedriver 模拟浏览器行为获取数据。selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:通过 id 查找元素。find_element_by_class_name:按类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:按标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据 css 选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
Selenium 表单操作:webelement.send_keys:将输入框填入内容。webelement.click:点击。操作select标签:需要先用from selenium.webdriver.support.ui import Select包裹选中的对象,然后才能进行选择:selenium行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类mon.action_chains.ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):在不释放鼠标的情况下单击。
context_click(element):右键单击。
double_click(element):双击。
下面是B站的登录和拖动验证滑块。

以下是键盘操作

设置浏览器的参数就是在定义驱动时设置chrome_options参数,是Options类实例化的对象。
参数是设置浏览器是否可视化以及请求头等信息。

浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。
Selenium 提供了一些延迟功能
无形等待是在设定的时间段内检测网页是否加载完毕,即浏览器标签栏的小圆圈不再旋转,才执行下一步。
显式等待可以根据判断条件灵活等待。程序每隔一定时间检测一次,如果结果和检测条件成立,则执行下一步。显式等待的使用涉及几个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait的参数说明如下: driver:浏览器对象驱动;timeout:超时时间;poll_frequency:检测时间间隔;
忽略的异常:忽略的异常。until:条件判断,参数必须是expected_conditions对象。

更多方法请参考:
为什么需要行为链?
因为有些网站可能会在浏览器端做一些验证,看行为是否符合人类行为做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,比如双击、右键等,在自动化测试中非常有用。
操作 cookie:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})

隐式等待和显式等待: 隐式等待:指定将保持等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定在一定时间内,如果满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是从 selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:在selenium中打开新窗口没有特殊的方法,通过window.execute_script()以执行js脚本的形式打开新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开一个新窗口后,驱动的当前页面还是和以前一样。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
通过ChromeOptions设置代理,示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999";)
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip";)
补充:get_property:获取html标签中官方写的属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求会失败,所以你可以保存当前页面的截图以供以后分析。
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-13 00:02
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path=”geckodriver”; 并且 2.x 是 executable_path=”wires”
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请在从事码网前搜索高代马文章或继续浏览以下相关文章希望大家来高代$ma #com搞$*码网,以后支持高代马搞码网! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path=”geckodriver”; 并且 2.x 是 executable_path=”wires”
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请在从事码网前搜索高代马文章或继续浏览以下相关文章希望大家来高代$ma #com搞$*码网,以后支持高代马搞码网!
python抓取动态网页(python模拟浏览器行为更新网页获取更新后的数据怎么抓)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-13 00:00
使用python爬取网站数据非常方便高效,但是常用的组合是使用BeautifSoup和requests爬取静态页面(即网页上显示的数据可以在html源码中找到)代码,不是网站通过js或者ajax异步加载的),这种类型的网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码来更新的,传统的方法不太适用。在这种情况下有几种方法:
清除网页上的网络信息,更新页面,观察网页发出的请求。有的网站可以通过这种方式构造参数,从而简化爬虫。但适用范围不够广泛。
使用 selenium 模拟浏览器行为来更新网页以获取更新的数据。本文将在以下部分重点介绍此方法。
一、准备
模拟浏览器需要两个工具:
1.selenium 可以通过 pip install selenium 直接安装。
2.PhantomJS,这是一个无接口,可脚本化的WebKit浏览器引擎,百度搜索,在其官网下载,下载后无需安装,放到指定路径,只需要使用指定路径文件所在的位置。
二、使用selenium模拟浏览器
本文爬取网站的例子为::8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要爬太多页面,只需通过过程了解如何爬取即可。
打开网站后,可以看到要爬取的数据是一个正则表,但是页面很多。
在这个网站中,点击下一页的url是没有变化的,通过执行一段js代码来更新页面。因此,本文的思路是利用selenium模拟浏览器点击,点击“下一页”更新页面数据,获取更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346','yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个网页中,这个标签没有唯一可识别的id,也没有class。如果是通过xpath定位,则首页和其他页面的xpath路径不完全相同,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击。
硒的功能非常强大。可以解决很多普通爬虫在爬虫中使用时无法解决的问题。可以模拟点击、鼠标移动、提交表单(登录邮箱、登录wifi等应用,网上有很多例子,我暂时还没试过),当你遇到一些标新立异的网站数据爬取很困难,不妨试试selenium+phantomjs。 查看全部
python抓取动态网页(python模拟浏览器行为更新网页获取更新后的数据怎么抓)
使用python爬取网站数据非常方便高效,但是常用的组合是使用BeautifSoup和requests爬取静态页面(即网页上显示的数据可以在html源码中找到)代码,不是网站通过js或者ajax异步加载的),这种类型的网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码来更新的,传统的方法不太适用。在这种情况下有几种方法:
清除网页上的网络信息,更新页面,观察网页发出的请求。有的网站可以通过这种方式构造参数,从而简化爬虫。但适用范围不够广泛。
使用 selenium 模拟浏览器行为来更新网页以获取更新的数据。本文将在以下部分重点介绍此方法。
一、准备
模拟浏览器需要两个工具:
1.selenium 可以通过 pip install selenium 直接安装。
2.PhantomJS,这是一个无接口,可脚本化的WebKit浏览器引擎,百度搜索,在其官网下载,下载后无需安装,放到指定路径,只需要使用指定路径文件所在的位置。
二、使用selenium模拟浏览器
本文爬取网站的例子为::8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要爬太多页面,只需通过过程了解如何爬取即可。
打开网站后,可以看到要爬取的数据是一个正则表,但是页面很多。

在这个网站中,点击下一页的url是没有变化的,通过执行一段js代码来更新页面。因此,本文的思路是利用selenium模拟浏览器点击,点击“下一页”更新页面数据,获取更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346','yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个网页中,这个标签没有唯一可识别的id,也没有class。如果是通过xpath定位,则首页和其他页面的xpath路径不完全相同,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击。
硒的功能非常强大。可以解决很多普通爬虫在爬虫中使用时无法解决的问题。可以模拟点击、鼠标移动、提交表单(登录邮箱、登录wifi等应用,网上有很多例子,我暂时还没试过),当你遇到一些标新立异的网站数据爬取很困难,不妨试试selenium+phantomjs。
python抓取动态网页(常见的反爬机制及处理方式-苏州安嘉网络)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-12 23:33
常见的反爬机制及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决方法:通过F12获取headers,传给requests.get()方法
2、IP限制:网站根据IP地址访问频率进行反爬,短时间内进行IP访问
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent限制:类似于IP限制
解决方案:构建自己的User-A[emailprotected]#code network gent pool,每次访问随机选择
5、查询参数或表单数据的认证(salt、sign)
解决方法:找到js文件,分析js处理方式,用python同理处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中headers和formdata的常规处理
1、pycharm输入法:Ctrl+r,选择Regex
2、 处理标题和表单数据
(.*): (.*)
“1”:“1”:“2”,
3、点击全部替换
民政部网站数据采集
目标:掌握最新的中华人民共和国县级以上行政区划代码
网址:--民政资料--行政区划代码
实施步骤
1、从民政数据中提取最新的行政区划代码链接网站
最新的是上面,命名格式:中华人民共和国县级以上行政区划代码X,2019
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/ ... 39%3B headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('.[email protected]/* */')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('.[email protected]/* */')[0] print(two_link) break
2、从二级页面链接中提取真实链接(反爬-JS嵌入响应网页内容,指向新的网页链接)
向二级页面链接发送请求,获取响应内容,并查看嵌入的JS代码
定期提取真正的二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中检查该链接是否已经被爬取,构建增量爬虫
在数据库中创建版本表来存储爬取的链接
每次程序执行时检查版本表中的记录,看是否被爬取
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/ ... 39%3B self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载的数据抓取 - Ajax
特征
右键->查看网页源代码中没有具体数据
滚动鼠标滚轮或其他操作时加载
抓
F12打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过 XHR–>Header–>Query String Parameters(查询参数)
豆瓣电影数据采集案例
目标
地址:豆瓣电影-排名-剧情
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:爬取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、查询字符串参数
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL + 查询参数
';
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/cha ... 39%3B self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/cha ... pe%3D{}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据采集(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页的源码可知,需要的数据是通过Ajax动态加载的
通过F12抓取网络数据包进行分析
一级页面抓取数据:职位名称
二级页面抓取数据:岗位职责、岗位要求
一级页面json地址(pageIndex在变化,timestamp没查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面中获取)
{}&language=zh-CN
用户代理.py 文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/te ... ex%3D{}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/te ... Id%3D{}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。 查看全部
python抓取动态网页(常见的反爬机制及处理方式-苏州安嘉网络)
常见的反爬机制及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决方法:通过F12获取headers,传给requests.get()方法
2、IP限制:网站根据IP地址访问频率进行反爬,短时间内进行IP访问
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent限制:类似于IP限制
解决方案:构建自己的User-A[emailprotected]#code network gent pool,每次访问随机选择
5、查询参数或表单数据的认证(salt、sign)
解决方法:找到js文件,分析js处理方式,用python同理处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中headers和formdata的常规处理
1、pycharm输入法:Ctrl+r,选择Regex
2、 处理标题和表单数据
(.*): (.*)
“1”:“1”:“2”,
3、点击全部替换
民政部网站数据采集
目标:掌握最新的中华人民共和国县级以上行政区划代码
网址:--民政资料--行政区划代码
实施步骤
1、从民政数据中提取最新的行政区划代码链接网站
最新的是上面,命名格式:中华人民共和国县级以上行政区划代码X,2019
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/ ... 39%3B headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('.[email protected]/* */')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('.[email protected]/* */')[0] print(two_link) break
2、从二级页面链接中提取真实链接(反爬-JS嵌入响应网页内容,指向新的网页链接)
向二级页面链接发送请求,获取响应内容,并查看嵌入的JS代码
定期提取真正的二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中检查该链接是否已经被爬取,构建增量爬虫
在数据库中创建版本表来存储爬取的链接
每次程序执行时检查版本表中的记录,看是否被爬取
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/ ... 39%3B self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载的数据抓取 - Ajax
特征
右键->查看网页源代码中没有具体数据
滚动鼠标滚轮或其他操作时加载
抓
F12打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过 XHR–>Header–>Query String Parameters(查询参数)
豆瓣电影数据采集案例
目标
地址:豆瓣电影-排名-剧情
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:爬取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、查询字符串参数
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL + 查询参数
';
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/cha ... 39%3B self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/cha ... pe%3D{}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据采集(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页的源码可知,需要的数据是通过Ajax动态加载的
通过F12抓取网络数据包进行分析
一级页面抓取数据:职位名称
二级页面抓取数据:岗位职责、岗位要求
一级页面json地址(pageIndex在变化,timestamp没查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面中获取)
{}&language=zh-CN
用户代理.py 文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/te ... ex%3D{}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/te ... Id%3D{}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。
python抓取动态网页(Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-12 11:23
想知道Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗?Kenneth Reitz 将为大家讲解 Python 使用 lxml 和 Requests 抓取 HTML 的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python、lxml、Requests、HTML一起学习
网页抓取
使用 HTML 描述网站。这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以 csv 或 json 等易于处理的格式提供数据。
这就是网页抓取的用武之地。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使标签非常混乱。我们将使用 Requests(#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块
让我们从以下导入开始:
from lxml import html
import requests
接下来,我们将使用 requests.get 通过使用 html 模块解析它并将结果保存到树中来从网页中获取我们的数据
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector 如果您使用的是 Chrome,您可以右键单击该元素并选择“检查元素”以再次突出显示此代码右键单击并选择“复制 XPath”
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个类为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功地通过 lxml 和 Request 从网页中抓取了我们想要的所有数据 我们将它们作为列表保存在内存中 现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,也可以将它保存为归档并与世界分享
我们可以想一些更酷的想法:修改脚本以遍历这个示例数据集中的剩余页面或使用多线程重写应用程序以加快速度
相关文章 查看全部
python抓取动态网页(Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗)
想知道Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗?Kenneth Reitz 将为大家讲解 Python 使用 lxml 和 Requests 抓取 HTML 的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python、lxml、Requests、HTML一起学习
网页抓取
使用 HTML 描述网站。这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以 csv 或 json 等易于处理的格式提供数据。
这就是网页抓取的用武之地。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使标签非常混乱。我们将使用 Requests(#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块
让我们从以下导入开始:
from lxml import html
import requests
接下来,我们将使用 requests.get 通过使用 html 模块解析它并将结果保存到树中来从网页中获取我们的数据
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector 如果您使用的是 Chrome,您可以右键单击该元素并选择“检查元素”以再次突出显示此代码右键单击并选择“复制 XPath”
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个类为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功地通过 lxml 和 Request 从网页中抓取了我们想要的所有数据 我们将它们作为列表保存在内存中 现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,也可以将它保存为归档并与世界分享
我们可以想一些更酷的想法:修改脚本以遍历这个示例数据集中的剩余页面或使用多线程重写应用程序以加快速度
相关文章
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-11 17:12
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本 查看全部
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本
python抓取动态网页( 百度:request爬虫001我想通过自动抓取百度贴吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-25 03:16
百度:request爬虫001我想通过自动抓取百度贴吧)
蟒蛇爬虫
001
我想通过自动爬取百度贴吧“python爬虫吧”中的帖子数据,找到那些付费写爬虫的帖子,赚点零花钱!为了尝试新技术,我使用了python中的request模块,因为这个模块简化了http请求的编写。而具体的html内容分析我还是使用xpath技术。
百度:索取手册
百度:xpath
002
分析百度贴吧的url地址:“%E7%88%AC%E8%99%AB&fr=search”,其中中间的kw字段就是本次爬取的贴吧的名字区域“python 爬虫栏”。
首先,使用 request.get 方法获取 贴吧 主页上的帖子列表。我们希望捕捉到所有的帖子标题,通过标题来判断用户是否有付费的需求或想法。
[代码]
导入请求
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以把params参数传给print(r.text)
[代码]
request.get 可以通过数组传入get的参数!此代码获取 贴吧 的主页。这里的page变量是保留变量,用于以后获取其他分页的内容!
003
关于 xpath 没什么好说的。接下来重点分析首页html的结构。我们打开chorme【开发者工具】,找到帖子标题对应的css代码。然后使用 xpath 方法获取这些帖子。看下面两张图来理解这个过程:
AB5A9754-6CE7-44EF-9199-D29956832FFA.png
5934D6B4-9E8B-4799-AB2A-CE82A6946778.png
[代码]
导入请求
从 lxml 导入 etree
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以通过# print(r.text)root = etree.HTML(r.text)中的params参数
result = root.xpath("//ul[@class='threadlist_bright j_threadlist_bright']/li") #查找列表 print(len(result))for i in range(len(result)):
title = (result[i].xpath(".//div[@class='threadlist_title pull_left j_th_tit ']/a/text()")) #查找标题
打印(标题)
[代码]
请注意,最重要的是从列表+帖子标题中提取的两个xpath。这需要针对 chorme 进行调试才能将其写出。初步成功,爬取标题列表如下:
48[]
['新手帮助解决异步库问题']
['python2.7环境爬图,初学者请多多指教']
【‘江湖告急,来个大佬,怎么用python监控手机推送通知,py交易就可以了’】
['中国裁判网站爬取有问题,求大神指点']
['分享源码,爬取甜美图妞,怕你硬盘不够大']
['问为什么这个头条网址获取不到完整代码']
['Python爬虫应该如何学习?学习步骤是什么?Python爬虫应该如何学习']
['免费写爬虫,留下你的需求,我来写']
['爬取图片保存后只有一张图片是怎么回事']
【‘慕课七月老师分享Python3入门+进阶课程视频’】
['如何开始使用Python爬虫?']
['scrapy 创建错误 10060']
['大神指点这个错误是什么意思,我爬了网站里的所有图,我就是一个']
['Python基本问答']
【‘云计算和大数据路过,Python不知道但有人感兴趣吗?']
['Python各种安装包,你需要的任何安装包都可以在下方留言']
['有靠谱的python微信学习交流群']
【‘七秋新公司最新工商登记数据来源’】
['scrapy 框架使用默认文件管道下载视频时出现问题'] 查看全部
python抓取动态网页(
百度:request爬虫001我想通过自动抓取百度贴吧)
蟒蛇爬虫
001
我想通过自动爬取百度贴吧“python爬虫吧”中的帖子数据,找到那些付费写爬虫的帖子,赚点零花钱!为了尝试新技术,我使用了python中的request模块,因为这个模块简化了http请求的编写。而具体的html内容分析我还是使用xpath技术。
百度:索取手册
百度:xpath
002
分析百度贴吧的url地址:“%E7%88%AC%E8%99%AB&fr=search”,其中中间的kw字段就是本次爬取的贴吧的名字区域“python 爬虫栏”。
首先,使用 request.get 方法获取 贴吧 主页上的帖子列表。我们希望捕捉到所有的帖子标题,通过标题来判断用户是否有付费的需求或想法。
[代码]
导入请求
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以把params参数传给print(r.text)
[代码]
request.get 可以通过数组传入get的参数!此代码获取 贴吧 的主页。这里的page变量是保留变量,用于以后获取其他分页的内容!
003
关于 xpath 没什么好说的。接下来重点分析首页html的结构。我们打开chorme【开发者工具】,找到帖子标题对应的css代码。然后使用 xpath 方法获取这些帖子。看下面两张图来理解这个过程:
AB5A9754-6CE7-44EF-9199-D29956832FFA.png
5934D6B4-9E8B-4799-AB2A-CE82A6946778.png
[代码]
导入请求
从 lxml 导入 etree
page=1 #首页数据= {"id":"utf-8", "kw":"python爬虫", "pn":page}
r = requests.get('', params=data) #你见过吗,get可以通过# print(r.text)root = etree.HTML(r.text)中的params参数
result = root.xpath("//ul[@class='threadlist_bright j_threadlist_bright']/li") #查找列表 print(len(result))for i in range(len(result)):
title = (result[i].xpath(".//div[@class='threadlist_title pull_left j_th_tit ']/a/text()")) #查找标题
打印(标题)
[代码]
请注意,最重要的是从列表+帖子标题中提取的两个xpath。这需要针对 chorme 进行调试才能将其写出。初步成功,爬取标题列表如下:
48[]
['新手帮助解决异步库问题']
['python2.7环境爬图,初学者请多多指教']
【‘江湖告急,来个大佬,怎么用python监控手机推送通知,py交易就可以了’】
['中国裁判网站爬取有问题,求大神指点']
['分享源码,爬取甜美图妞,怕你硬盘不够大']
['问为什么这个头条网址获取不到完整代码']
['Python爬虫应该如何学习?学习步骤是什么?Python爬虫应该如何学习']
['免费写爬虫,留下你的需求,我来写']
['爬取图片保存后只有一张图片是怎么回事']
【‘慕课七月老师分享Python3入门+进阶课程视频’】
['如何开始使用Python爬虫?']
['scrapy 创建错误 10060']
['大神指点这个错误是什么意思,我爬了网站里的所有图,我就是一个']
['Python基本问答']
【‘云计算和大数据路过,Python不知道但有人感兴趣吗?']
['Python各种安装包,你需要的任何安装包都可以在下方留言']
['有靠谱的python微信学习交流群']
【‘七秋新公司最新工商登记数据来源’】
['scrapy 框架使用默认文件管道下载视频时出现问题']
python抓取动态网页(一下Python爬虫可以做什么?可以获取网页的源代码吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-24 23:13
Python爬虫这个词在生活中出现的频率越来越高,那么你知道Python爬虫能做什么吗?那么今天,老师就给大家展示一下Python爬虫能做什么。
Python爬虫是一个网络爬虫。通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。我们可以使用爬虫爬取图片、爬取视频等我们想要爬取的数据,只要能够通过爬虫获取到可以通过浏览器访问的数据即可。
Python爬虫可以获取网页的源代码,源代码中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。事实上,获取网页——分析网页源代码——提取信息是爬虫的基本过程。
Python爬虫的一个重要作用就是提取信息,它可以把杂乱的数据整理好,方便我们以后对数据进行处理和分析。Python爬虫的一种常用方法是使用正则表达式。网页的结构有一定的规则,有一些库根据网页节点属性、CSS选择器或XPath来提取网页信息。使用这些库,可以高效、快速地提取网页信息。
Python爬虫有什么优势?
1、简单:Python是一种代表简单思想的语言。
2. 易用性:Python 简单易学,文档通俗易懂。
3、速度快:运行速度快,因为Python中的标准库和第三方库都是用C编写的,所以速度很快。
4. 免费和开源:Python 是 FLOSS(免费/源代码软件)之一,用户可以自由分发该软件的副本,阅读其源代码,对其进行更改,在软件中免费使用其中的一部分.
5. 面向对象:Python 支持过程和面向对象的编程。在“面向过程”的语言中,程序是由只是可重用代码的过程或函数构建的。在“面向对象”语言中,程序是由结合了数据和功能的对象构建的。
Python爬虫的出现给我们的采集信息带来了便利。越来越多的人开始学习 Python 爬虫。你知道 Python 爬虫能做什么吗? 查看全部
python抓取动态网页(一下Python爬虫可以做什么?可以获取网页的源代码吗?)
Python爬虫这个词在生活中出现的频率越来越高,那么你知道Python爬虫能做什么吗?那么今天,老师就给大家展示一下Python爬虫能做什么。
Python爬虫是一个网络爬虫。通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。我们可以使用爬虫爬取图片、爬取视频等我们想要爬取的数据,只要能够通过爬虫获取到可以通过浏览器访问的数据即可。
Python爬虫可以获取网页的源代码,源代码中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。事实上,获取网页——分析网页源代码——提取信息是爬虫的基本过程。
Python爬虫的一个重要作用就是提取信息,它可以把杂乱的数据整理好,方便我们以后对数据进行处理和分析。Python爬虫的一种常用方法是使用正则表达式。网页的结构有一定的规则,有一些库根据网页节点属性、CSS选择器或XPath来提取网页信息。使用这些库,可以高效、快速地提取网页信息。
Python爬虫有什么优势?
1、简单:Python是一种代表简单思想的语言。
2. 易用性:Python 简单易学,文档通俗易懂。
3、速度快:运行速度快,因为Python中的标准库和第三方库都是用C编写的,所以速度很快。
4. 免费和开源:Python 是 FLOSS(免费/源代码软件)之一,用户可以自由分发该软件的副本,阅读其源代码,对其进行更改,在软件中免费使用其中的一部分.
5. 面向对象:Python 支持过程和面向对象的编程。在“面向过程”的语言中,程序是由只是可重用代码的过程或函数构建的。在“面向对象”语言中,程序是由结合了数据和功能的对象构建的。
Python爬虫的出现给我们的采集信息带来了便利。越来越多的人开始学习 Python 爬虫。你知道 Python 爬虫能做什么吗?
python抓取动态网页(作为爬虫程序,如何获取网页API接口?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-24 23:12
)
在之前的文章文章中,我们学习的是静态数据的爬取,即获取的数据是网页上一直存在的数据,不会改变。这些数据的获取相对简单。.
但是,在爬虫的实际应用场景中,很多数据并不是静态存在的,大部分都是以动态的形式存在的,即随时取用,不需要取用。它只会在查看此数据的内容时出现,所有其他时间都在数据库中。
这种方式减少了网页的臃肿感,但需要更高层次的数据库应用和网页编写。
作为爬虫,如何获取动态数据?
这就是 文章 的意义所在。
前面的文献中提到,很多网页的数据是动态生成的,也就是说在浏览器窗口中查看网页源代码时,在HTML代码中是找不到这些内容的。获取静态数据的方式不起作用。
在这种情况下,如果要获取数据,则需要找到网络API接口来获取这些数据。
那么,什么是 API 接口?
API,即Application Programming Interface,应用程序接口。
API 的功能是为应用程序和开发人员提供访问基于一个软件或硬件的一组例程的能力,而无需访问原创代码。
用人类的话来说,网页制作者只需要将API接口与他们制作的网页连接起来,不需要网页制作者自己建立数据库。即网页前端与数据后端的连接通道。
按照上面的题目,如何获取网页的API接口呢?
下面是一个网站“百度图片”的例子。打开网页后,按F12键显示网页源代码,如图:
当然,在这个接口中是找不到API接口的。在这个界面找到NETWORK选项,点击查看API界面。
只要找到API接口,就可以进行下一步了。
硒
对于初学者,可以使用自动化测试工具 Selenium,它提供了浏览器自动化的 API 接口,从而可以通过操作浏览器来获取动态内容。
当然,如果你想使用它,你必须先安装它。像往常一样,我们打开CMD,输入pip3 install selenium,回车,让系统自行下载安装。
接下来,我们使用 Selenium 来练习。
我们开通了中国最大的同性恋交友网站网站——BiBiLiLi 。
打开哔哩哔哩直播,使用Selenium获取各个直播间的封面图。代码显示如下:
从 bs4 导入 BeautifulSoup
从硒导入网络驱动程序
从 mon.keys 导入密钥
定义主():
驱动程序 = webdriver.Chrome()
driver.get('#39;)
汤 = BeautifulSoup(driver.page_source, 'lxml')
对于 soup.body.select('img[src]') 中的 img_tag:
打印(img_tag.attrs['src'])
如果 __name__ == '__main__':
主要的()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果我们要控制其他浏览器,可以创建相应的浏览器对象,比如Firefox、IE等。
Selenium 更具体的功能可以去其官方网站了解。
如果想了解更多技术知识,可以点击关注。
如果对文章的内容有什么疑惑,可以在评论区提出自己的问题,学会和大家交流,解决各种问题,共同进步。
青年研究陪伴所有年轻人
查看全部
python抓取动态网页(作为爬虫程序,如何获取网页API接口?(组图)
)
在之前的文章文章中,我们学习的是静态数据的爬取,即获取的数据是网页上一直存在的数据,不会改变。这些数据的获取相对简单。.
但是,在爬虫的实际应用场景中,很多数据并不是静态存在的,大部分都是以动态的形式存在的,即随时取用,不需要取用。它只会在查看此数据的内容时出现,所有其他时间都在数据库中。
这种方式减少了网页的臃肿感,但需要更高层次的数据库应用和网页编写。
作为爬虫,如何获取动态数据?
这就是 文章 的意义所在。
前面的文献中提到,很多网页的数据是动态生成的,也就是说在浏览器窗口中查看网页源代码时,在HTML代码中是找不到这些内容的。获取静态数据的方式不起作用。
在这种情况下,如果要获取数据,则需要找到网络API接口来获取这些数据。
那么,什么是 API 接口?
API,即Application Programming Interface,应用程序接口。
API 的功能是为应用程序和开发人员提供访问基于一个软件或硬件的一组例程的能力,而无需访问原创代码。
用人类的话来说,网页制作者只需要将API接口与他们制作的网页连接起来,不需要网页制作者自己建立数据库。即网页前端与数据后端的连接通道。
按照上面的题目,如何获取网页的API接口呢?
下面是一个网站“百度图片”的例子。打开网页后,按F12键显示网页源代码,如图:
当然,在这个接口中是找不到API接口的。在这个界面找到NETWORK选项,点击查看API界面。
只要找到API接口,就可以进行下一步了。
硒
对于初学者,可以使用自动化测试工具 Selenium,它提供了浏览器自动化的 API 接口,从而可以通过操作浏览器来获取动态内容。
当然,如果你想使用它,你必须先安装它。像往常一样,我们打开CMD,输入pip3 install selenium,回车,让系统自行下载安装。
接下来,我们使用 Selenium 来练习。
我们开通了中国最大的同性恋交友网站网站——BiBiLiLi 。
打开哔哩哔哩直播,使用Selenium获取各个直播间的封面图。代码显示如下:
从 bs4 导入 BeautifulSoup
从硒导入网络驱动程序
从 mon.keys 导入密钥
定义主():
驱动程序 = webdriver.Chrome()
driver.get('#39;)
汤 = BeautifulSoup(driver.page_source, 'lxml')
对于 soup.body.select('img[src]') 中的 img_tag:
打印(img_tag.attrs['src'])
如果 __name__ == '__main__':
主要的()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果我们要控制其他浏览器,可以创建相应的浏览器对象,比如Firefox、IE等。
Selenium 更具体的功能可以去其官方网站了解。
如果想了解更多技术知识,可以点击关注。
如果对文章的内容有什么疑惑,可以在评论区提出自己的问题,学会和大家交流,解决各种问题,共同进步。
青年研究陪伴所有年轻人
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-24 19:27
Python专题教程:爬取网站,模拟登录,爬取动态网页版本:v1.0Crifan Li 拿网站,模拟登录,抓取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27 下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/python_topic_web_scrape /release/html/python_topic_web_scrape.html 如果您有任何意见、建议、提交bug等,欢迎在讨论组发帖:/bbs/categories/python_topic_web_scrape/ 修订历史修订1.02013-02 -06crl 1. 整理之前教程的地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /文件/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt 6 /files/doc/docbook/python_topic_web_s crape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/释放/html/python_topic_web_scrape.html.7z 9 /files/ doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape。 chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/rtf/python_topic_web_scrape .rtf.7z 14/files/doc/docbook/python_topic_web_scrape /release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:爬取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 Copyright © 2013 Crifan,此文章合规性:署名-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 前言iv 1.本文目的iv 2.前提iv 1.如何在Python中实现< @网站爬取、模拟登录、爬取动态网页1 2. Python 2 中的网络处理3. Python 3 中的HTMl 解析参考书目4iii 前言1. 这篇文章的目的这篇文章目的是,在了解了爬取网站、模拟登录、爬取动态网页的逻辑之后,如何用Python语言来实现现在这部分的逻辑。
2. 前提讨论如何使用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解不清楚的可以参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站抓取、模拟登录、抓取动态网页相关老帖【教程】Python版本1抓取网页并提取所需信息从网页【教程】模拟登录网站的Python版本(包括两个版本的完整可运行代码)2 其实对于urllib等库,已经做得很好了,尤其是在易用性,使用起来已经很方便了。比如直接通过下面的代码,可以从网页中获取地址,得到网页的源代码 TODO: add code 但是因为事实,和网页抓取,网页模拟登录等。 , 需要用到 cookie 等头部参数,要想得到一个强大易用的网络爬取功能,需要付出很多额外的努力。后来,我在折腾web爬取,前后。 ,通过实际使用积累了很多这方面的经验,最后写了一个相关的功能,功能更强大,使用更方便。
主要是2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:再添加一个相关函数的解释,包括downloadFile等。其实函数主要分为两个方面:一方面是抓取网站的内容,涉及到网络处理相关的模块。另一方面,如何解析抓取到的内容,也就是HTML解析下面会讲解这两个方面的相关逻辑,以及如何使用Python来实现这部分的相应功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章Python中的网络处理主要涉及到一些网络处理相关的模块,urllib,urllib2等相关老帖 【整理】Python用来解析Http包。 Module/Library 1 [已解决] Python中使用cookielib的FileCookieJar来save(),结果报错:2NotImplementedError [Organization] Python中的cookie处理:自动处理cookie,保存为cookie文件,从文件中加载3Cookie TODO:组织对应是的,请在 urllib 和 urllib2 上发帖。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第三章 Python中HTMl解析相关的旧帖 BeautifulSoup模块介绍1【教程】Python解析HTML的第三方库:BeautifulSoup 2【总结】第一部分Python之三方库BeautifulSoup使用心得3【整理】Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】json时出错。在Python中加载->注意要解码的Json字符的编码:第1行第1列(char 1) [已解决] Python中使用json.loads解码字符串时出错:ValueError:无法解码JSON对象Python并解析抓取到的网站内容,即解析HTML、JSON等,相关模块有,BeautifulSoup,json等 1/files/ DOC / DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautifulsoup_in_python 4/5 some_notation_about_python_beautifulsoup_parse_parse_backs 6 ash_style_html_json_string / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9/1个python_json_loads_valueerror_no_json_object_could_be_decoded3参考文献[1]和[教程]爬行网页提取Python版本1所需的信息/ crawl_website_html_and_extract_info_using_python/4 查看全部
python抓取动态网页(Python专题教程:抓取网站,模拟登陆,抓取动态网页)
Python专题教程:爬取网站,模拟登录,爬取动态网页版本:v1.0Crifan Li 拿网站,模拟登录,抓取动态网页。主要涉及网络处理相关的模块(urllib、urllib2等)和HTML解析相关的模块(BeautifulSoup、json等)。本文提供多种格式: HTML 1 HTMLsPDF 3 CHM 4TXT 5RTF 6 WEBHELP27 下载(7zip压缩包) HTML 8 HTMLsPDF 10 CHM 11 TXT 12 RTF 13 WEBHELP914 HTML版在线地址为:/files/doc/docbook/python_topic_web_scrape /release/html/python_topic_web_scrape.html 如果您有任何意见、建议、提交bug等,欢迎在讨论组发帖:/bbs/categories/python_topic_web_scrape/ 修订历史修订1.02013-02 -06crl 1. 整理之前教程的地址 1 /files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html 2 /files/doc/docbook/python_topic_web_scrape/release/htmls/index.html 3 /文件/doc/docbook/python_topic_web_scrape /release/pdf/python_topic_web_scrape.pdf 4 /files/doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape.chm 5 /files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt 6 /files/doc/docbook/python_topic_web_s crape/release/rtf/python_topic_web_scrape.rtf 7 /files/doc/docbook/python_topic_web_scrape/release/webhelp/index.html 8 /files/doc/docbook/python_topic_web_scrape/释放/html/python_topic_web_scrape.html.7z 9 /files/ doc/docbook/python_topic_web_scrape/release/htmls/index.html.7z 10/files/doc/docbook/python_topic_web_scrape/release/pdf/python_topic_web_scrape.pdf.7z 11/files /doc/docbook/python_topic_web_scrape/release/chm/python_topic_web_scrape。 chm.7z 12/files/doc/docbook/python_topic_web_scrape/release/txt/python_topic_web_scrape.txt.7z 13/files/doc/docbook/python_topic_web_scrape/release/rtf/python_topic_web_scrape .rtf.7z 14/files/doc/docbook/python_topic_web_scrape /release/webhelp/ python_topic_web_scrape.webhelp.7z Python主题教程:爬取网站,模拟登录,抓取动态网页:Crifan Li 版本:v1.0 发布日期2013-02-06 Copyright © 2013 Crifan,此文章合规性:署名-非商业用途2.5 中国大陆(CC BY-NC 2.5)15 15/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cc_by_nc 前言iv 1.本文目的iv 2.前提iv 1.如何在Python中实现< @网站爬取、模拟登录、爬取动态网页1 2. Python 2 中的网络处理3. Python 3 中的HTMl 解析参考书目4iii 前言1. 这篇文章的目的这篇文章目的是,在了解了爬取网站、模拟登录、爬取动态网页的逻辑之后,如何用Python语言来实现现在这部分的逻辑。
2. 前提讨论如何使用Python实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解不清楚的可以参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解1 1 /files/doc/docbook/ web_scrape_emulate_login/release/html/ web_scrape_emulate_login.htmliv 第1章如何使用Python实现网站抓取、模拟登录、抓取动态网页相关老帖【教程】Python版本1抓取网页并提取所需信息从网页【教程】模拟登录网站的Python版本(包括两个版本的完整可运行代码)2 其实对于urllib等库,已经做得很好了,尤其是在易用性,使用起来已经很方便了。比如直接通过下面的代码,可以从网页中获取地址,得到网页的源代码 TODO: add code 但是因为事实,和网页抓取,网页模拟登录等。 , 需要用到 cookie 等头部参数,要想得到一个强大易用的网络爬取功能,需要付出很多额外的努力。后来,我在折腾web爬取,前后。 ,通过实际使用积累了很多这方面的经验,最后写了一个相关的功能,功能更强大,使用更方便。
主要是2个函数:getUrlResponse和getUrlRespHtml TODO:从crifanLib的解释中添加两个函数 TODO:添加这两个函数的几个用法 TODO:再添加一个相关函数的解释,包括downloadFile等。其实函数主要分为两个方面:一方面是抓取网站的内容,涉及到网络处理相关的模块。另一方面,如何解析抓取到的内容,也就是HTML解析下面会讲解这两个方面的相关逻辑,以及如何使用Python来实现这部分的相应功能。 1 /crawl_website_html_and_extract_info_using_python/ 2 /emulate_login_website_using_python/1 第2章Python中的网络处理主要涉及到一些网络处理相关的模块,urllib,urllib2等相关老帖 【整理】Python用来解析Http包。 Module/Library 1 [已解决] Python中使用cookielib的FileCookieJar来save(),结果报错:2NotImplementedError [Organization] Python中的cookie处理:自动处理cookie,保存为cookie文件,从文件中加载3Cookie TODO:组织对应是的,请在 urllib 和 urllib2 上发帖。
1 /python_http_package_parser_lib_module 2 /python_cookiejar_filecookiejar_save_error_notimplementederror 3 /python_auto_handle_cookie_and_save_to_from_cookie_file2 第三章 Python中HTMl解析相关的旧帖 BeautifulSoup模块介绍1【教程】Python解析HTML的第三方库:BeautifulSoup 2【总结】第一部分Python之三方库BeautifulSoup使用心得3【整理】Python 4中使用html处理库函数BeautifulSoup的注意事项【已解决】使用BeautifulSoup解析Html格式的Json字符串5【经验记录】json时出错。在Python中加载->注意要解码的Json字符的编码:第1行第1列(char 1) [已解决] Python中使用json.loads解码字符串时出错:ValueError:无法解码JSON对象Python并解析抓取到的网站内容,即解析HTML、JSON等,相关模块有,BeautifulSoup,json等 1/files/ DOC / DocBook的/ python_summary /释放/ HTML / python_summary.html#python_lib_beautifulsoup 2 / python_third_party_lib_html_parser_beautifulsoup 3 / summary_usage_of_beautifulsoup_in_python 4/5 some_notation_about_python_beautifulsoup_parse_parse_backs 6 ash_style_html_json_string / notation_about_use_python_json_loads 7/8 use_python_json_loads_parse_string_contain_newline_will_fail_error / python_json_loads_valueerror_expecting_property_name_line_1_column_1_char_1 9/1个python_json_loads_valueerror_no_json_object_could_be_decoded3参考文献[1]和[教程]爬行网页提取Python版本1所需的信息/ crawl_website_html_and_extract_info_using_python/4
python抓取动态网页(python抓取动态网页源码的三种方法:爬虫源码内网传输)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 13:03
python抓取动态网页源码的三种方法:爬虫源码内网传输php抓取html源码网页最好不要全页截图,会增加抓取的难度。打开爬虫网页源码看看,是不是所有的链接都是已经存在的,所以有一个问题是找不到已经存在的网页信息,这就是所谓的动态网页。动态网页存在一个很严重的问题,加载的时间过长,且源码本身就存在字符重复,这个时候抓取难度就更大了。
如果把所有的动态页面过滤了,能避免抓取这个动态网页。但是加载的过长,会导致手动抓取数据慢,这个时候就需要用python抓取了。在数据抓取前需要将动态页面解析成一个json字符串(blob)格式,解析得到一个json数组,然后再抓取,这样抓取数据速度快,在本例中json文件格式为[{},{},{}].主要步骤有:1.先加载字符串内容到内存2.在解析json数组从json文件中取出动态内容3.读取结果,放入标准库4.再次合并json数组5.最后保存到数据库获取动态网页源码步骤1:写入字符串,如下代码例子2:在解析json数组的时候,需要注意很多接口的限制:动态内容,是个自定义名称,例如我们需要从phpurl-1.io提取动态网页sessionid,那么这个接口返回的json解析文件名为phpsessimportjson_generator.json("phpsessimportjson_generator.json")如下代码例子3:读取json格式的数据时,需要注意格式严格一些,例如上面代码代码中phpsessimportjson_generator.json("phpsessimportjson_generator.json")因为php文件格式规定动态文件的格式为json格式,那么利用json格式中的特殊字符json.dump("phpsessimportjson_generator.json")抓取动态内容得到如下代码例子5:最后把json转换成一个array格式的字典importjsonarr=json.loads(json_generator.json("phpsessimportjson_generator.json"))s=[{"id":123456,"user":"zhangsan","password":"123456"}]这个时候可以把动态内容返回。 查看全部
python抓取动态网页(python抓取动态网页源码的三种方法:爬虫源码内网传输)
python抓取动态网页源码的三种方法:爬虫源码内网传输php抓取html源码网页最好不要全页截图,会增加抓取的难度。打开爬虫网页源码看看,是不是所有的链接都是已经存在的,所以有一个问题是找不到已经存在的网页信息,这就是所谓的动态网页。动态网页存在一个很严重的问题,加载的时间过长,且源码本身就存在字符重复,这个时候抓取难度就更大了。
如果把所有的动态页面过滤了,能避免抓取这个动态网页。但是加载的过长,会导致手动抓取数据慢,这个时候就需要用python抓取了。在数据抓取前需要将动态页面解析成一个json字符串(blob)格式,解析得到一个json数组,然后再抓取,这样抓取数据速度快,在本例中json文件格式为[{},{},{}].主要步骤有:1.先加载字符串内容到内存2.在解析json数组从json文件中取出动态内容3.读取结果,放入标准库4.再次合并json数组5.最后保存到数据库获取动态网页源码步骤1:写入字符串,如下代码例子2:在解析json数组的时候,需要注意很多接口的限制:动态内容,是个自定义名称,例如我们需要从phpurl-1.io提取动态网页sessionid,那么这个接口返回的json解析文件名为phpsessimportjson_generator.json("phpsessimportjson_generator.json")如下代码例子3:读取json格式的数据时,需要注意格式严格一些,例如上面代码代码中phpsessimportjson_generator.json("phpsessimportjson_generator.json")因为php文件格式规定动态文件的格式为json格式,那么利用json格式中的特殊字符json.dump("phpsessimportjson_generator.json")抓取动态内容得到如下代码例子5:最后把json转换成一个array格式的字典importjsonarr=json.loads(json_generator.json("phpsessimportjson_generator.json"))s=[{"id":123456,"user":"zhangsan","password":"123456"}]这个时候可以把动态内容返回。
python抓取动态网页(pyquery库就是jQuery的Python实现库官方文档文档介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-22 09:07
)
照片/文字:着迷
我们是python爬虫,需要正则匹配通过requests抓取内容,或者其他解析库解析内容。可能很多人和我一样用jquery,还是很爽的。 pyquery库是jQuery的Python实现,可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
Beautiful Soup 中虽然可以使用 CSS 选择器,但似乎他的 CSS 选择器并没有想象中的那么强大,PyQuery 更好。因此,我们来说说Python爬虫神器:PyQuery。
PyQuery 库官方文档
官方文档:
PyPI:
Github:
1、PyQuery初始化内容
PyQuery 初始化采用三种形式:
1.1、直接初始化requests返回的html内容
from pyquery import PyQuery as pq
#初始化为PyQuery对象
doc = pq(html)
print(type(doc))
print(doc)
1.2、直接读取文件的形式
1.3、读取URL的形式
doc = pq(url = 'https://www.toutiao.com')
print(type(doc))
print(doc)
2、常用 CSS 选择器:
pyquery 的强大之处在于它使用与 jquery 相同的选项来解析网页节点。
html = """
Python
大法
好
"""
获取id为object-1的标签
print(doc('#object-1'))
#返回:
好
#还可以:
print(doc('#container #object-1'))
获取类为object-1的标签
print(doc('.object-1'))
#返回:
Python 查看全部
python抓取动态网页(pyquery库就是jQuery的Python实现库官方文档文档介绍
)
照片/文字:着迷
我们是python爬虫,需要正则匹配通过requests抓取内容,或者其他解析库解析内容。可能很多人和我一样用jquery,还是很爽的。 pyquery库是jQuery的Python实现,可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
Beautiful Soup 中虽然可以使用 CSS 选择器,但似乎他的 CSS 选择器并没有想象中的那么强大,PyQuery 更好。因此,我们来说说Python爬虫神器:PyQuery。
PyQuery 库官方文档
官方文档:
PyPI:
Github:
1、PyQuery初始化内容
PyQuery 初始化采用三种形式:
1.1、直接初始化requests返回的html内容
from pyquery import PyQuery as pq
#初始化为PyQuery对象
doc = pq(html)
print(type(doc))
print(doc)
1.2、直接读取文件的形式
1.3、读取URL的形式
doc = pq(url = 'https://www.toutiao.com')
print(type(doc))
print(doc)
2、常用 CSS 选择器:
pyquery 的强大之处在于它使用与 jquery 相同的选项来解析网页节点。
html = """
Python
大法
好
"""
获取id为object-1的标签
print(doc('#object-1'))
#返回:
好
#还可以:
print(doc('#container #object-1'))
获取类为object-1的标签
print(doc('.object-1'))
#返回:
Python
python抓取动态网页(用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-22 09:06
作为数据科学家,我的第一项任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何抓取一个网站——比如从Fast Track 中获取2018 年前100 家公司的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
如果觉得篇幅太长不想看,可以关注转发。私聊小编“01”领取全部代码。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
以 Tech Track Top 100 Enterprises (%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例,右键点击表格,选择“检查”。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。然而,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数,或者遍历所有页面,才能爬取完整的数据。
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需要一个循环,就可以读取所有的表格数据并保存到一个文件中。
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(如 Insomnia)发出请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。
接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:
接下来,我们可以使用 urllib 连接到这个 URL,将内容保存在 page 变量中,然后使用 BeautifulSoup 对页面进行处理,并将处理结果存储在 soup 变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
现在所有的内容都在表(tag)中,我们可以在soup对象中搜索我们需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。
看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面上是一致的(但在其他网站上可能就没有这么简单了!),所以我们可以再次使用find_all方法,通过搜索元素,逐行提取数据并将其存储在一个变量,方便以后写入csv或者json文件。
循环遍历所有元素并存储在变量中
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填入初始表头(方便以后在CSV文件中使用),然后数据只需要调用列表对象的append方法即可。
这将打印我们刚刚添加到列表对象行的第一行标题。
你可能注意到我输入的表头比网页上的表多了几个列名,比如Webpage(网页)和Description(描述),请仔细看上面打印的soup变量数据——第一个第二行第二列的数据不仅收录公司名称,还收录公司网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为头部使用了标签和没有标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。
我们要将公司变量的内容拆分为公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
为了删除 sales 变量中的多余字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,最后一行可能没有链接。因此,我们添加了 try...except 语句,如果未找到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。
最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不明白的,请在下方留言,我会尽力为您解答!
最后,如果有想要学习Python的朋友,可以关注、转发、后台私信小编“01”,免费获取Python学习资料。 查看全部
python抓取动态网页(用脚本将获取信息上获取2018年100强企业的信息)
作为数据科学家,我的第一项任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何抓取一个网站——比如从Fast Track 中获取2018 年前100 家公司的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
如果觉得篇幅太长不想看,可以关注转发。私聊小编“01”领取全部代码。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
以 Tech Track Top 100 Enterprises (%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例,右键点击表格,选择“检查”。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。然而,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数,或者遍历所有页面,才能爬取完整的数据。
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需要一个循环,就可以读取所有的表格数据并保存到一个文件中。
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(如 Insomnia)发出请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。
接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:
接下来,我们可以使用 urllib 连接到这个 URL,将内容保存在 page 变量中,然后使用 BeautifulSoup 对页面进行处理,并将处理结果存储在 soup 变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
现在所有的内容都在表(tag)中,我们可以在soup对象中搜索我们需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。
看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面上是一致的(但在其他网站上可能就没有这么简单了!),所以我们可以再次使用find_all方法,通过搜索元素,逐行提取数据并将其存储在一个变量,方便以后写入csv或者json文件。
循环遍历所有元素并存储在变量中
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填入初始表头(方便以后在CSV文件中使用),然后数据只需要调用列表对象的append方法即可。
这将打印我们刚刚添加到列表对象行的第一行标题。
你可能注意到我输入的表头比网页上的表多了几个列名,比如Webpage(网页)和Description(描述),请仔细看上面打印的soup变量数据——第一个第二行第二列的数据不仅收录公司名称,还收录公司网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为头部使用了标签和没有标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。
我们要将公司变量的内容拆分为公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
为了删除 sales 变量中的多余字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,最后一行可能没有链接。因此,我们添加了 try...except 语句,如果未找到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。
最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不明白的,请在下方留言,我会尽力为您解答!
最后,如果有想要学习Python的朋友,可以关注、转发、后台私信小编“01”,免费获取Python学习资料。
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-20 19:15
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area"
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&"
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict["stock"]["jdPrice"]["op"]}")
print(f"定价为: {goods_dict["stock"]["jdPrice"]["m"]}")
print(f"会员价为: {goods_dict["stock"]["jdPrice"]["tpp"]}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现抓取网页中动态加载的数据的文章文章就介绍到这里了。更多关于Python抓取网页动态数据的内容,请搜索云海天教程之前的文章或继续浏览以下相关文章希望大家以后多多支持云海天教程!
原文链接: 查看全部
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area"
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&"
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict["stock"]["jdPrice"]["op"]}")
print(f"定价为: {goods_dict["stock"]["jdPrice"]["m"]}")
print(f"会员价为: {goods_dict["stock"]["jdPrice"]["tpp"]}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现抓取网页中动态加载的数据的文章文章就介绍到这里了。更多关于Python抓取网页动态数据的内容,请搜索云海天教程之前的文章或继续浏览以下相关文章希望大家以后多多支持云海天教程!
原文链接:
python抓取动态网页(开发环境操作系统:windows10Python版本:3.6爬取网页模块:requests分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-18 16:16
开发环境
操作系统:Windows 10
Python 版本:3.6
抓取网页模块:请求
分析网页模块:json
模块安装
pip3 install requests
网页分析
我们使用豆瓣电影页面开始分析
https://movie.douban.com/explo ... t%3D0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容
当我们点击加载更多时,可以通过开发者工具的Network选项中的XHR获取动态加载的js
打开获取的连接
https://movie.douban.com/j/sea ... %3D20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式的
这里我们构造一个链接,从第一部电影开始,显示 100
https://movie.douban.com/j/sea ... t%3D0
对于JSON的解析,我们可以先用一个在线的网站查看
https://jsonformatter.curiousconcept.com/
这里可以看到收录以下信息
代码介绍
这里逐行介绍代码
1.导入相关模块
import requests
import json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)
content=r.content
3.使用json.load将json格式转成python字典格式
这时候就可以使用字典的相关方法来处理网页了
result=json.loads(content)
tvs=result['subjects']
4. 获取相关信息并存入字典
执行结果
我们可以选择将获取的数据放入数据库中
来源地点 查看全部
python抓取动态网页(开发环境操作系统:windows10Python版本:3.6爬取网页模块:requests分析)
开发环境
操作系统:Windows 10
Python 版本:3.6
抓取网页模块:请求
分析网页模块:json
模块安装
pip3 install requests
网页分析
我们使用豆瓣电影页面开始分析
https://movie.douban.com/explo ... t%3D0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容
当我们点击加载更多时,可以通过开发者工具的Network选项中的XHR获取动态加载的js
打开获取的连接
https://movie.douban.com/j/sea ... %3D20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式的
这里我们构造一个链接,从第一部电影开始,显示 100
https://movie.douban.com/j/sea ... t%3D0
对于JSON的解析,我们可以先用一个在线的网站查看
https://jsonformatter.curiousconcept.com/
这里可以看到收录以下信息
代码介绍
这里逐行介绍代码
1.导入相关模块
import requests
import json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)
content=r.content
3.使用json.load将json格式转成python字典格式
这时候就可以使用字典的相关方法来处理网页了
result=json.loads(content)
tvs=result['subjects']
4. 获取相关信息并存入字典
执行结果
我们可以选择将获取的数据放入数据库中
来源地点
python抓取动态网页(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-17 15:17
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。 查看全部
python抓取动态网页(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... 39%3B
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-17 00:18
前言
在爬取常规静态网页时,我们直接请求对应的url就可以得到完整的HTML页面,但是对于动态页面,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候我们获取页面的HTML,我们无法获取我们想要使用的内容。这时候我们就可以使用 selenium 库来获取我们需要的内容了。
待安装的三方库示例代码
示例描述:获取德邦官网已开设分店的城市区域名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/")
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
遇到的小问题 使用“pip install selenium”安装 selenium 库时失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时出现的问题,我在网上看到的文章使用的是火狐浏览器,他们可以直接使用webdriver.Firefox(),而我用的是谷歌浏览器,我以为用的是谷歌浏览器与使用 Firefox 相同,但在运行时出错。后来,我在网上找到了。就是从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数时,需要传递executable_path参数,这个参数的值就是Chrome Driver.exe文件下载到的路径selenium 官网位于。在示例中,我把chromedriver.exe放在根目录下,所以我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox浏览器插件:Katalon Recorder,Katalon Recorder是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以将记录导出为各种代码,其中收录 Python 2 的代码。有时借用它,我们可以很容易地得到我们需要的数据,而无需分析 HTML 的结构,这对于 HTML 结构杂乱的网页非常有帮助。 查看全部
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
前言
在爬取常规静态网页时,我们直接请求对应的url就可以得到完整的HTML页面,但是对于动态页面,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候我们获取页面的HTML,我们无法获取我们想要使用的内容。这时候我们就可以使用 selenium 库来获取我们需要的内容了。
待安装的三方库示例代码
示例描述:获取德邦官网已开设分店的城市区域名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/";)
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
遇到的小问题 使用“pip install selenium”安装 selenium 库时失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时出现的问题,我在网上看到的文章使用的是火狐浏览器,他们可以直接使用webdriver.Firefox(),而我用的是谷歌浏览器,我以为用的是谷歌浏览器与使用 Firefox 相同,但在运行时出错。后来,我在网上找到了。就是从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数时,需要传递executable_path参数,这个参数的值就是Chrome Driver.exe文件下载到的路径selenium 官网位于。在示例中,我把chromedriver.exe放在根目录下,所以我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox浏览器插件:Katalon Recorder,Katalon Recorder是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以将记录导出为各种代码,其中收录 Python 2 的代码。有时借用它,我们可以很容易地得到我们需要的数据,而无需分析 HTML 的结构,这对于 HTML 结构杂乱的网页非常有帮助。
python抓取动态网页(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-16 01:08
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(解释来源:百度百科-《动态网页》,如果链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求变化的内容,比如某宝的商品价格和评论,比如某阀门的热门影评,某条新闻的视频等,通过先加载网页整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单翻译成页面起点的意思,再看上面的“page_limit”,大概就是页面限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们需要得到下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码
注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一个非常通用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF攻击的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。管理员权限下运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:
注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能很长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。 查看全部
python抓取动态网页(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(解释来源:百度百科-《动态网页》,如果链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求变化的内容,比如某宝的商品价格和评论,比如某阀门的热门影评,某条新闻的视频等,通过先加载网页整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单翻译成页面起点的意思,再看上面的“page_limit”,大概就是页面限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们需要得到下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码
注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一个非常通用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF攻击的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。管理员权限下运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:
注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能很长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。
python抓取动态网页(:utf-8importurllib2fromBeautifulSoupimportBeautifulSoup;BeautifulSoup)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-14 08:14
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--
博客 Markdown 编辑器上线了! Wrox精品红皮电脑书PMBOK第五版,那些年我们一直在关注的,是火星敏捷开发1001题的视频教程
Python实现网络爬虫爬取静态网页[代码]
类别:蟒蛇
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--------- -------------------------------------------------- -------------------def main():#ץuserMainUrl = "?id=38b94c4ed8add8bcccabd7d31b22&fr=userbar"; #修改抓取的链接地址 req = urllib2.@ >Request(userMainUrl);resp = urllib2.@>urlopen(req);respHtml = resp.read();print "respHtml=",respHtml; #在这里输出所有捕获的HTML源代码#ȡsongtasteHtmlEncoding = "GBK";#修改编码字符集的格式soup = BeautifulSoup(respHtml, fromEncoding=songtasteHtmlEncoding);foundClassH1user = soup.find(attrs={"target":"_blank "});#修改抓取的内容 print "foundClassH1user=%s ",foundClassH1user;if(foundClassH1user):h1userStr = foundClassH1user.string;print "h1userStr=",h1userStr;############ ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# #if __name__=="__main__":main() ;
获取 1 类标签
#eg:siteUrls=soup.findAll('a')
获取 2 个类标签
#eg:foundClassH1user = soup.find(attrs={"target":"_blank"});
获取 2 个类标签
#foundClassH1user = soup.find(attrs={"class":"h1user"});
上一篇文章在notepad++下搭建python编译器
喜欢 1 不喜欢 0
主题推荐猜你在找什么 查看全部
python抓取动态网页(:utf-8importurllib2fromBeautifulSoupimportBeautifulSoup;BeautifulSoup)
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--
博客 Markdown 编辑器上线了! Wrox精品红皮电脑书PMBOK第五版,那些年我们一直在关注的,是火星敏捷开发1001题的视频教程
Python实现网络爬虫爬取静态网页[代码]
类别:蟒蛇
#---------------------导入------------ ---------------#coding:utf-8import urllib2;from BeautifulSoup import BeautifulSoup;#--------- -------------------------------------------------- -------------------def main():#ץuserMainUrl = "?id=38b94c4ed8add8bcccabd7d31b22&fr=userbar"; #修改抓取的链接地址 req = urllib2.@ >Request(userMainUrl);resp = urllib2.@>urlopen(req);respHtml = resp.read();print "respHtml=",respHtml; #在这里输出所有捕获的HTML源代码#ȡsongtasteHtmlEncoding = "GBK";#修改编码字符集的格式soup = BeautifulSoup(respHtml, fromEncoding=songtasteHtmlEncoding);foundClassH1user = soup.find(attrs={"target":"_blank "});#修改抓取的内容 print "foundClassH1user=%s ",foundClassH1user;if(foundClassH1user):h1userStr = foundClassH1user.string;print "h1userStr=",h1userStr;############ ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# ################################################# #if __name__=="__main__":main() ;
获取 1 类标签
#eg:siteUrls=soup.findAll('a')
获取 2 个类标签
#eg:foundClassH1user = soup.find(attrs={"target":"_blank"});
获取 2 个类标签
#foundClassH1user = soup.find(attrs={"class":"h1user"});
上一篇文章在notepad++下搭建python编译器
喜欢 1 不喜欢 0
主题推荐猜你在找什么
python抓取动态网页(我该怎么办抓取动态加载的网站() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-13 23:05
)
这是我第一次获取动态加载的网站,我一直在尝试获取该网站的团队名称和赔率
我在这个 文章
中用 PyQt5 试过这个
从 PyQt4 到 PyQt5 -> mainFrame() 已弃用,需要修复才能加载网页
class Page(QWebEnginePage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebEnginePage.__init__(self)
self.html = ''
self.loadFinished.connect(self._on_load_finished)
self.load(QUrl(url))
self.app.exec_()
def _on_load_finished(self):
self.html = self.toHtml(self.Callable)
print('Load finished')
def Callable(self, html_str):
self.html = html_str
self.app.quit()
def main():
page = Page('https://www.cashpoint.com/de/fussball/deutschland/bundesliga')
soup = bs.BeautifulSoup(page.html, 'html.parser')
js_test = soup.find('div', class_='game__team game__team__football')
print(js_test.text)
if __name__ == '__main__': main()
但这不适用于我试图抓取的 网站。我得到一个 AttributeError: 'NoneType' object has no attribute 'text' 错误。虽然在上面的文章中有一个为动态加载的网站写的方法,但是我并没有通过这个方法得到网站的内容。正如我所读到的,处理动态加载的 网站 的第一种方法是确定如何在页面上呈现数据。我该怎么办?为什么 PyQt5 不能在那个 网站 上工作? Selenium 方式对我来说不是一个选择,因为它太慢而无法获得实时赔率。当我检查 网站 使用的 HTML 内容,然后使用 Beautifulsoup 或 Scrapy 的常规方法时,是否可以获得该 网站 的 HTML 内容?提前谢谢你。
解决方案
提供的代码失败,因为即使页面已完成加载,新创建的元素(例如 div)也是异步创建的,例如你想得到 "game__team" 和 "game__team__football",所以当 loadFinished 发出信号时,即使没有创建这些元素也是一样的。
一种可能的解决方案是直接使用javascript通过runJavaScript()方法获取文本列表,如果列表为空,则在时间T重试,直到列表不为空。
import sys
from PyQt5 import QtCore, QtWidgets, QtWebEngineWidgets
class Scrapper(QtCore.QObject):
def __init__(self, interval=500, parent=None):
super().__init__(parent)
self._result = []
self._interval = interval
self.page = QtWebEngineWidgets.QWebEnginePage(self)
self.page.loadFinished.connect(self.on_load_finished)
self.page.load(
QtCore.QUrl("https://www.cashpoint.com/de/f ... 6quot;)
)
@property
def result(self):
return self._result
@property
def interval(self):
return self._interval
@interval.setter
def interval(self, interval):
self._interval = interval
@QtCore.pyqtSlot(bool)
def on_load_finished(self, ok):
if ok:
self.execute_javascript()
else:
QtCore.QCoreApplication.exit(-1)
def execute_javascript(self):
self.page.runJavaScript(
"""
function text_by_classname(classname){
var texts = [];
var elements = document.getElementsByClassName(classname);
for (const e of elements) {
texts.push(e.textContent);
}
return texts;
}
[].concat(text_by_classname("game__team"), text_by_classname("game__team__football"));
""",
self.javascript_callback,
)
def javascript_callback(self, result):
if result:
self._result = result
QtCore.QCoreApplication.quit()
else:
QtCore.QTimer.singleShot(self.interval, self.execute_javascript)
def main():
app = QtWidgets.QApplication(sys.argv)
scrapper = Scrapper(interval=1000)
app.exec_()
result = scrapper.result
del scrapper, app
print(result)
if __name__ == "__main__":
main()
输出:
[' 1899 Hoffenheim ', ' FC Augsburg ', ' Bayern München ', ' Werder Bremen ', ' Hertha BSC ', ' SC Freiburg ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' 1. FC Köln ', ' Bayer 04 Leverkusen ', ' SC Paderborn ', ' FC Union Berlin ', ' Fortuna Düsseldorf ', ' RB Leipzig ', ' VFL Wolfsburg ', ' Borussia Mönchengladbach ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' Werder Bremen ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' RB Leipzig ', ' FC Augsburg ', ' Fortuna Düsseldorf ', ' FC Union Berlin ', ' 1899 Hoffenheim ', ' Bayer 04 Leverkusen ', ' Hertha BSC ', ' Borussia Mönchengladbach ', ' SC Paderborn ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' 1. FC Köln ', ' SC Freiburg ', ' Bayern München ', ' 1899 Hoffenheim ', ' Borussia Dortmund ', ' Bayern München ', ' VFL Wolfsburg ', ' 1899 Hoffenheim ', ' Bayern München ', ' Hertha BSC ', ' 1. Fsv Mainz 05 ', ' 1. FC Köln ', ' SC Paderborn ', ' Fortuna Düsseldorf ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Werder Bremen ', ' Borussia Dortmund ', ' FC Augsburg ', ' FC Union Berlin ', ' Bayer 04 Leverkusen ', ' Borussia Mönchengladbach ', ' VFL Wolfsburg ', ' Eintracht Frankfurt ', ' SC Freiburg ', ' 1899 Hoffenheim ', ' Bayern München '] 查看全部
python抓取动态网页(我该怎么办抓取动态加载的网站()
)
这是我第一次获取动态加载的网站,我一直在尝试获取该网站的团队名称和赔率
我在这个 文章
中用 PyQt5 试过这个
从 PyQt4 到 PyQt5 -> mainFrame() 已弃用,需要修复才能加载网页
class Page(QWebEnginePage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebEnginePage.__init__(self)
self.html = ''
self.loadFinished.connect(self._on_load_finished)
self.load(QUrl(url))
self.app.exec_()
def _on_load_finished(self):
self.html = self.toHtml(self.Callable)
print('Load finished')
def Callable(self, html_str):
self.html = html_str
self.app.quit()
def main():
page = Page('https://www.cashpoint.com/de/fussball/deutschland/bundesliga')
soup = bs.BeautifulSoup(page.html, 'html.parser')
js_test = soup.find('div', class_='game__team game__team__football')
print(js_test.text)
if __name__ == '__main__': main()
但这不适用于我试图抓取的 网站。我得到一个 AttributeError: 'NoneType' object has no attribute 'text' 错误。虽然在上面的文章中有一个为动态加载的网站写的方法,但是我并没有通过这个方法得到网站的内容。正如我所读到的,处理动态加载的 网站 的第一种方法是确定如何在页面上呈现数据。我该怎么办?为什么 PyQt5 不能在那个 网站 上工作? Selenium 方式对我来说不是一个选择,因为它太慢而无法获得实时赔率。当我检查 网站 使用的 HTML 内容,然后使用 Beautifulsoup 或 Scrapy 的常规方法时,是否可以获得该 网站 的 HTML 内容?提前谢谢你。
解决方案
提供的代码失败,因为即使页面已完成加载,新创建的元素(例如 div)也是异步创建的,例如你想得到 "game__team" 和 "game__team__football",所以当 loadFinished 发出信号时,即使没有创建这些元素也是一样的。
一种可能的解决方案是直接使用javascript通过runJavaScript()方法获取文本列表,如果列表为空,则在时间T重试,直到列表不为空。
import sys
from PyQt5 import QtCore, QtWidgets, QtWebEngineWidgets
class Scrapper(QtCore.QObject):
def __init__(self, interval=500, parent=None):
super().__init__(parent)
self._result = []
self._interval = interval
self.page = QtWebEngineWidgets.QWebEnginePage(self)
self.page.loadFinished.connect(self.on_load_finished)
self.page.load(
QtCore.QUrl("https://www.cashpoint.com/de/f ... 6quot;)
)
@property
def result(self):
return self._result
@property
def interval(self):
return self._interval
@interval.setter
def interval(self, interval):
self._interval = interval
@QtCore.pyqtSlot(bool)
def on_load_finished(self, ok):
if ok:
self.execute_javascript()
else:
QtCore.QCoreApplication.exit(-1)
def execute_javascript(self):
self.page.runJavaScript(
"""
function text_by_classname(classname){
var texts = [];
var elements = document.getElementsByClassName(classname);
for (const e of elements) {
texts.push(e.textContent);
}
return texts;
}
[].concat(text_by_classname("game__team"), text_by_classname("game__team__football"));
""",
self.javascript_callback,
)
def javascript_callback(self, result):
if result:
self._result = result
QtCore.QCoreApplication.quit()
else:
QtCore.QTimer.singleShot(self.interval, self.execute_javascript)
def main():
app = QtWidgets.QApplication(sys.argv)
scrapper = Scrapper(interval=1000)
app.exec_()
result = scrapper.result
del scrapper, app
print(result)
if __name__ == "__main__":
main()
输出:
[' 1899 Hoffenheim ', ' FC Augsburg ', ' Bayern München ', ' Werder Bremen ', ' Hertha BSC ', ' SC Freiburg ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' 1. FC Köln ', ' Bayer 04 Leverkusen ', ' SC Paderborn ', ' FC Union Berlin ', ' Fortuna Düsseldorf ', ' RB Leipzig ', ' VFL Wolfsburg ', ' Borussia Mönchengladbach ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' Werder Bremen ', ' 1. Fsv Mainz 05 ', ' Borussia Dortmund ', ' RB Leipzig ', ' FC Augsburg ', ' Fortuna Düsseldorf ', ' FC Union Berlin ', ' 1899 Hoffenheim ', ' Bayer 04 Leverkusen ', ' Hertha BSC ', ' Borussia Mönchengladbach ', ' SC Paderborn ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Eintracht Frankfurt ', ' 1. FC Köln ', ' SC Freiburg ', ' Bayern München ', ' 1899 Hoffenheim ', ' Borussia Dortmund ', ' Bayern München ', ' VFL Wolfsburg ', ' 1899 Hoffenheim ', ' Bayern München ', ' Hertha BSC ', ' 1. Fsv Mainz 05 ', ' 1. FC Köln ', ' SC Paderborn ', ' Fortuna Düsseldorf ', ' VFL Wolfsburg ', ' FC Schalke 04 ', ' Werder Bremen ', ' Borussia Dortmund ', ' FC Augsburg ', ' FC Union Berlin ', ' Bayer 04 Leverkusen ', ' Borussia Mönchengladbach ', ' VFL Wolfsburg ', ' Eintracht Frankfurt ', ' SC Freiburg ', ' 1899 Hoffenheim ', ' Bayern München ']
python抓取动态网页(动态网页爬虫什么是动态(爬虫)(AJAX技术))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 11:07
动态网页爬虫 什么是动态网页爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的本地数据,无需重新加载。例如,在拉狗网的招聘页面,在页面变化的过程中,url没有变化,但是招聘数据是动态变化的。AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓的AJAX,其实,数据交互基本上是使用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。动态网络爬虫的解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用 Selenium+chromedriver 模拟浏览器行为获取数据。selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:通过 id 查找元素。find_element_by_class_name:按类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:按标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据 css 选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
Selenium 表单操作:webelement.send_keys:将输入框填入内容。webelement.click:点击。操作select标签:需要先用from selenium.webdriver.support.ui import Select包裹选中的对象,然后才能进行选择:selenium行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类mon.action_chains.ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):在不释放鼠标的情况下单击。
context_click(element):右键单击。
double_click(element):双击。
下面是B站的登录和拖动验证滑块。
以下是键盘操作
设置浏览器的参数就是在定义驱动时设置chrome_options参数,是Options类实例化的对象。
参数是设置浏览器是否可视化以及请求头等信息。
浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。
Selenium 提供了一些延迟功能
无形等待是在设定的时间段内检测网页是否加载完毕,即浏览器标签栏的小圆圈不再旋转,才执行下一步。
显式等待可以根据判断条件灵活等待。程序每隔一定时间检测一次,如果结果和检测条件成立,则执行下一步。显式等待的使用涉及几个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait的参数说明如下: driver:浏览器对象驱动;timeout:超时时间;poll_frequency:检测时间间隔;
忽略的异常:忽略的异常。until:条件判断,参数必须是expected_conditions对象。
更多方法请参考:
为什么需要行为链?
因为有些网站可能会在浏览器端做一些验证,看行为是否符合人类行为做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,比如双击、右键等,在自动化测试中非常有用。
操作 cookie:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})
隐式等待和显式等待: 隐式等待:指定将保持等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定在一定时间内,如果满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是从 selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:在selenium中打开新窗口没有特殊的方法,通过window.execute_script()以执行js脚本的形式打开新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开一个新窗口后,驱动的当前页面还是和以前一样。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
通过ChromeOptions设置代理,示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999")
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip")
补充:get_property:获取html标签中官方写的属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求会失败,所以你可以保存当前页面的截图以供以后分析。 查看全部
python抓取动态网页(动态网页爬虫什么是动态(爬虫)(AJAX技术))
动态网页爬虫 什么是动态网页爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的本地数据,无需重新加载。例如,在拉狗网的招聘页面,在页面变化的过程中,url没有变化,但是招聘数据是动态变化的。AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓的AJAX,其实,数据交互基本上是使用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。动态网络爬虫的解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用 Selenium+chromedriver 模拟浏览器行为获取数据。selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:通过 id 查找元素。find_element_by_class_name:按类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:按标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据 css 选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
Selenium 表单操作:webelement.send_keys:将输入框填入内容。webelement.click:点击。操作select标签:需要先用from selenium.webdriver.support.ui import Select包裹选中的对象,然后才能进行选择:selenium行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类mon.action_chains.ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):在不释放鼠标的情况下单击。
context_click(element):右键单击。
double_click(element):双击。
下面是B站的登录和拖动验证滑块。
以下是键盘操作
设置浏览器的参数就是在定义驱动时设置chrome_options参数,是Options类实例化的对象。
参数是设置浏览器是否可视化以及请求头等信息。
浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。
Selenium 提供了一些延迟功能
无形等待是在设定的时间段内检测网页是否加载完毕,即浏览器标签栏的小圆圈不再旋转,才执行下一步。
显式等待可以根据判断条件灵活等待。程序每隔一定时间检测一次,如果结果和检测条件成立,则执行下一步。显式等待的使用涉及几个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait的参数说明如下: driver:浏览器对象驱动;timeout:超时时间;poll_frequency:检测时间间隔;
忽略的异常:忽略的异常。until:条件判断,参数必须是expected_conditions对象。
更多方法请参考:
为什么需要行为链?
因为有些网站可能会在浏览器端做一些验证,看行为是否符合人类行为做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,比如双击、右键等,在自动化测试中非常有用。
操作 cookie:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})
隐式等待和显式等待: 隐式等待:指定将保持等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定在一定时间内,如果满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是从 selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:在selenium中打开新窗口没有特殊的方法,通过window.execute_script()以执行js脚本的形式打开新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开一个新窗口后,驱动的当前页面还是和以前一样。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
通过ChromeOptions设置代理,示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999";)
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip";)
补充:get_property:获取html标签中官方写的属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求会失败,所以你可以保存当前页面的截图以供以后分析。
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-13 00:02
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path=”geckodriver”; 并且 2.x 是 executable_path=”wires”
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请在从事码网前搜索高代马文章或继续浏览以下相关文章希望大家来高代$ma #com搞$*码网,以后支持高代马搞码网! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path=”geckodriver”; 并且 2.x 是 executable_path=”wires”
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请在从事码网前搜索高代马文章或继续浏览以下相关文章希望大家来高代$ma #com搞$*码网,以后支持高代马搞码网!
python抓取动态网页(python模拟浏览器行为更新网页获取更新后的数据怎么抓)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-13 00:00
使用python爬取网站数据非常方便高效,但是常用的组合是使用BeautifSoup和requests爬取静态页面(即网页上显示的数据可以在html源码中找到)代码,不是网站通过js或者ajax异步加载的),这种类型的网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码来更新的,传统的方法不太适用。在这种情况下有几种方法:
清除网页上的网络信息,更新页面,观察网页发出的请求。有的网站可以通过这种方式构造参数,从而简化爬虫。但适用范围不够广泛。
使用 selenium 模拟浏览器行为来更新网页以获取更新的数据。本文将在以下部分重点介绍此方法。
一、准备
模拟浏览器需要两个工具:
1.selenium 可以通过 pip install selenium 直接安装。
2.PhantomJS,这是一个无接口,可脚本化的WebKit浏览器引擎,百度搜索,在其官网下载,下载后无需安装,放到指定路径,只需要使用指定路径文件所在的位置。
二、使用selenium模拟浏览器
本文爬取网站的例子为::8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要爬太多页面,只需通过过程了解如何爬取即可。
打开网站后,可以看到要爬取的数据是一个正则表,但是页面很多。
在这个网站中,点击下一页的url是没有变化的,通过执行一段js代码来更新页面。因此,本文的思路是利用selenium模拟浏览器点击,点击“下一页”更新页面数据,获取更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346','yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个网页中,这个标签没有唯一可识别的id,也没有class。如果是通过xpath定位,则首页和其他页面的xpath路径不完全相同,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击。
硒的功能非常强大。可以解决很多普通爬虫在爬虫中使用时无法解决的问题。可以模拟点击、鼠标移动、提交表单(登录邮箱、登录wifi等应用,网上有很多例子,我暂时还没试过),当你遇到一些标新立异的网站数据爬取很困难,不妨试试selenium+phantomjs。 查看全部
python抓取动态网页(python模拟浏览器行为更新网页获取更新后的数据怎么抓)
使用python爬取网站数据非常方便高效,但是常用的组合是使用BeautifSoup和requests爬取静态页面(即网页上显示的数据可以在html源码中找到)代码,不是网站通过js或者ajax异步加载的),这种类型的网站数据比较容易爬取。但是网站上的一些数据是通过执行js代码来更新的,传统的方法不太适用。在这种情况下有几种方法:
清除网页上的网络信息,更新页面,观察网页发出的请求。有的网站可以通过这种方式构造参数,从而简化爬虫。但适用范围不够广泛。
使用 selenium 模拟浏览器行为来更新网页以获取更新的数据。本文将在以下部分重点介绍此方法。
一、准备
模拟浏览器需要两个工具:
1.selenium 可以通过 pip install selenium 直接安装。
2.PhantomJS,这是一个无接口,可脚本化的WebKit浏览器引擎,百度搜索,在其官网下载,下载后无需安装,放到指定路径,只需要使用指定路径文件所在的位置。
二、使用selenium模拟浏览器
本文爬取网站的例子为::8099/ths-report/report!list.action?xmlname=46(最新测试发现网站打不开,2021年5月25日)
学习示例时请不要爬太多页面,只需通过过程了解如何爬取即可。
打开网站后,可以看到要爬取的数据是一个正则表,但是页面很多。
在这个网站中,点击下一页的url是没有变化的,通过执行一段js代码来更新页面。因此,本文的思路是利用selenium模拟浏览器点击,点击“下一页”更新页面数据,获取更新后的页面数据。这是完整的代码:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
import time
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
curpath=sys.path[0]
print curpath
def getData(url):
# 使用下载好的phantomjs,网上也有人用firefox,chrome,但是我没有成功,用这个也挺方便
driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe")
driver.set_page_load_timeout(30)
time.sleep(3)
html=driver.get(url[0]) # 使用get方法请求url,因为是模拟浏览器,所以不需要headers信息
for page in range(3):
html=driver.page_source # 获取网页的html数据
soup=BeautifulSoup(html,'lxml') # 对html进行解析,如果提示lxml未安装,直接pip install lxml即可
table=soup.find('table',class_="report-table")
name=[]
for th in table.find_all('tr')[0].find_all('th'):
name.append(th.get_text()) # 获取表格的字段名称作为字典的键
flag=0 # 标记,当爬取字段数据是为0,否则为1
for tr in table.find_all('tr'):
# 第一行为表格字段数据,因此跳过第一行
if flag==1:
dic={}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])#保存数据
flag=1
# 利用find_element_by_link_text方法得到下一页所在的位置并点击,点击后页面会自动更新,只需要重新获取driver.page_source即可
driver.find_element_by_link_text(u"下一页").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346','yzc'] # yzc为文件名,此处输入中文会报错,前面加u也不行,只好保存后手动改文件名……
getData(url) # 调用函数
本文通过driver.find_element_by_link_text方法获取下一页的位置。这是因为在这个网页中,这个标签没有唯一可识别的id,也没有class。如果是通过xpath定位,则首页和其他页面的xpath路径不完全相同,需要加一个if来判断。所以直接通过链接的text参数定位。click() 函数模拟浏览器中的点击。
硒的功能非常强大。可以解决很多普通爬虫在爬虫中使用时无法解决的问题。可以模拟点击、鼠标移动、提交表单(登录邮箱、登录wifi等应用,网上有很多例子,我暂时还没试过),当你遇到一些标新立异的网站数据爬取很困难,不妨试试selenium+phantomjs。
python抓取动态网页(常见的反爬机制及处理方式-苏州安嘉网络)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-12 23:33
常见的反爬机制及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决方法:通过F12获取headers,传给requests.get()方法
2、IP限制:网站根据IP地址访问频率进行反爬,短时间内进行IP访问
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent限制:类似于IP限制
解决方案:构建自己的User-A[emailprotected]#code network gent pool,每次访问随机选择
5、查询参数或表单数据的认证(salt、sign)
解决方法:找到js文件,分析js处理方式,用python同理处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中headers和formdata的常规处理
1、pycharm输入法:Ctrl+r,选择Regex
2、 处理标题和表单数据
(.*): (.*)
“1”:“1”:“2”,
3、点击全部替换
民政部网站数据采集
目标:掌握最新的中华人民共和国县级以上行政区划代码
网址:--民政资料--行政区划代码
实施步骤
1、从民政数据中提取最新的行政区划代码链接网站
最新的是上面,命名格式:中华人民共和国县级以上行政区划代码X,2019
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/ ... 39%3B headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('.[email protected]/* */')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('.[email protected]/* */')[0] print(two_link) break
2、从二级页面链接中提取真实链接(反爬-JS嵌入响应网页内容,指向新的网页链接)
向二级页面链接发送请求,获取响应内容,并查看嵌入的JS代码
定期提取真正的二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中检查该链接是否已经被爬取,构建增量爬虫
在数据库中创建版本表来存储爬取的链接
每次程序执行时检查版本表中的记录,看是否被爬取
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/ ... 39%3B self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载的数据抓取 - Ajax
特征
右键->查看网页源代码中没有具体数据
滚动鼠标滚轮或其他操作时加载
抓
F12打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过 XHR–>Header–>Query String Parameters(查询参数)
豆瓣电影数据采集案例
目标
地址:豆瓣电影-排名-剧情
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:爬取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、查询字符串参数
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL + 查询参数
';
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/cha ... 39%3B self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/cha ... pe%3D{}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据采集(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页的源码可知,需要的数据是通过Ajax动态加载的
通过F12抓取网络数据包进行分析
一级页面抓取数据:职位名称
二级页面抓取数据:岗位职责、岗位要求
一级页面json地址(pageIndex在变化,timestamp没查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面中获取)
{}&language=zh-CN
用户代理.py 文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/te ... ex%3D{}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/te ... Id%3D{}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。 查看全部
python抓取动态网页(常见的反爬机制及处理方式-苏州安嘉网络)
常见的反爬机制及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决方法:通过F12获取headers,传给requests.get()方法
2、IP限制:网站根据IP地址访问频率进行反爬,短时间内进行IP访问
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent限制:类似于IP限制
解决方案:构建自己的User-A[emailprotected]#code network gent pool,每次访问随机选择
5、查询参数或表单数据的认证(salt、sign)
解决方法:找到js文件,分析js处理方式,用python同理处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中headers和formdata的常规处理
1、pycharm输入法:Ctrl+r,选择Regex
2、 处理标题和表单数据
(.*): (.*)
“1”:“1”:“2”,
3、点击全部替换
民政部网站数据采集
目标:掌握最新的中华人民共和国县级以上行政区划代码
网址:--民政资料--行政区划代码
实施步骤
1、从民政数据中提取最新的行政区划代码链接网站
最新的是上面,命名格式:中华人民共和国县级以上行政区划代码X,2019
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/ ... 39%3B headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('.[email protected]/* */')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('.[email protected]/* */')[0] print(two_link) break
2、从二级页面链接中提取真实链接(反爬-JS嵌入响应网页内容,指向新的网页链接)
向二级页面链接发送请求,获取响应内容,并查看嵌入的JS代码
定期提取真正的二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中检查该链接是否已经被爬取,构建增量爬虫
在数据库中创建版本表来存储爬取的链接
每次程序执行时检查版本表中的记录,看是否被爬取
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/ ... 39%3B self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载的数据抓取 - Ajax
特征
右键->查看网页源代码中没有具体数据
滚动鼠标滚轮或其他操作时加载
抓
F12打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过 XHR–>Header–>Query String Parameters(查询参数)
豆瓣电影数据采集案例
目标
地址:豆瓣电影-排名-剧情
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:爬取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、查询字符串参数
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL + 查询参数
';
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/cha ... 39%3B self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/cha ... pe%3D{}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据采集(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页的源码可知,需要的数据是通过Ajax动态加载的
通过F12抓取网络数据包进行分析
一级页面抓取数据:职位名称
二级页面抓取数据:岗位职责、岗位要求
一级页面json地址(pageIndex在变化,timestamp没查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面中获取)
{}&language=zh-CN
用户代理.py 文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/te ... ex%3D{}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/te ... Id%3D{}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持高代马搞码网。
python抓取动态网页(Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-12 11:23
想知道Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗?Kenneth Reitz 将为大家讲解 Python 使用 lxml 和 Requests 抓取 HTML 的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python、lxml、Requests、HTML一起学习
网页抓取
使用 HTML 描述网站。这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以 csv 或 json 等易于处理的格式提供数据。
这就是网页抓取的用武之地。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使标签非常混乱。我们将使用 Requests(#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块
让我们从以下导入开始:
from lxml import html
import requests
接下来,我们将使用 requests.get 通过使用 html 模块解析它并将结果保存到树中来从网页中获取我们的数据
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector 如果您使用的是 Chrome,您可以右键单击该元素并选择“检查元素”以再次突出显示此代码右键单击并选择“复制 XPath”
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个类为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功地通过 lxml 和 Request 从网页中抓取了我们想要的所有数据 我们将它们作为列表保存在内存中 现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,也可以将它保存为归档并与世界分享
我们可以想一些更酷的想法:修改脚本以遍历这个示例数据集中的剩余页面或使用多线程重写应用程序以加快速度
相关文章 查看全部
python抓取动态网页(Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗)
想知道Python使用lxml模块和Requests模块抓取HTML页面的教程的相关内容吗?Kenneth Reitz 将为大家讲解 Python 使用 lxml 和 Requests 抓取 HTML 的相关知识以及一些代码示例。欢迎阅读和指正。我们先来关注一下:Python、lxml、Requests、HTML一起学习
网页抓取
使用 HTML 描述网站。这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以 csv 或 json 等易于处理的格式提供数据。
这就是网页抓取的用武之地。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使标签非常混乱。我们将使用 Requests(#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块
让我们从以下导入开始:
from lxml import html
import requests
接下来,我们将使用 requests.get 通过使用 html 模块解析它并将结果保存到树中来从网页中获取我们的数据
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector 如果您使用的是 Chrome,您可以右键单击该元素并选择“检查元素”以再次突出显示此代码右键单击并选择“复制 XPath”
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个类为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功地通过 lxml 和 Request 从网页中抓取了我们想要的所有数据 我们将它们作为列表保存在内存中 现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,也可以将它保存为归档并与世界分享
我们可以想一些更酷的想法:修改脚本以遍历这个示例数据集中的剩余页面或使用多线程重写应用程序以加快速度
相关文章
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-11 17:12
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本 查看全部
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1. 两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url):4 session_req=dryscrape.Session()5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页的文本
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) # 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也可以
3 driver.get(url) #请求一个页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2. selenium 的安装和使用
2.1 硒安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后geckodriverckod存放在/usr/local/bin/: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序= webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
1 内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = 内容.文本

