
python抓取动态网页
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-03-21 05:13
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多python如何爬取动态网站请搜索德牛网之前的文章或继续浏览以下相关文章希望大家以后多多支持牛网! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多python如何爬取动态网站请搜索德牛网之前的文章或继续浏览以下相关文章希望大家以后多多支持牛网!
python抓取动态网页(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 05:10
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这种类型的 网站 大体相似。本文以凤凰网的新闻视频网站为例,采用反向推送的方式介绍如何通过流量分析获取视频下载的url,然后进行批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出网页的规律变化。首先是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。
4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。
5、每个网页收录24个视频,如下图所示。
/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
3、你找到规律了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中查找第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。
2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。
4、它的 url 如下所示。
5、 仔细寻找规则,我们发现唯一需要改变的是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。
4、利用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。
5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图。
/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。该方法简单易行,效果显着,欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。如果觉得还不错,记得给个star。 查看全部
python抓取动态网页(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这种类型的 网站 大体相似。本文以凤凰网的新闻视频网站为例,采用反向推送的方式介绍如何通过流量分析获取视频下载的url,然后进行批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出网页的规律变化。首先是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。
4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。
5、每个网页收录24个视频,如下图所示。
/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
3、你找到规律了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中查找第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。
2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。
4、它的 url 如下所示。
5、 仔细寻找规则,我们发现唯一需要改变的是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。
4、利用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。
5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图。
/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。该方法简单易行,效果显着,欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。如果觉得还不错,记得给个star。
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-21 01:18
)
如上所述,我们可以通过分析 Ajax 访问服务器的方式来获取 Ajax 数据。Ajax 也是一种动态呈现的页面。因此,动态页面也可以被爬取。
文章目录
硒
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。总之,Selenium 可以模拟用户操作浏览器,因此它也可以提取动态页面。
安装硒
在cmd中输入:
pip install selenium
同时下载对应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的脚本中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后,我们就可以使用调用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用 get() 方法来请求一个网页,只需传入 URL。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这个方法比上面的方法更灵活,需要传入两个参数,搜索方法By和值:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的是它可以与浏览器交互。常用的有:输入文本的send_key()方法;用于清除文本的 clear() 方法;用于单击按钮的 click() 方法。一个例子如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size) 查看全部
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用
)
如上所述,我们可以通过分析 Ajax 访问服务器的方式来获取 Ajax 数据。Ajax 也是一种动态呈现的页面。因此,动态页面也可以被爬取。
文章目录
硒
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。总之,Selenium 可以模拟用户操作浏览器,因此它也可以提取动态页面。
安装硒
在cmd中输入:
pip install selenium
同时下载对应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的脚本中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后,我们就可以使用调用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用 get() 方法来请求一个网页,只需传入 URL。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这个方法比上面的方法更灵活,需要传入两个参数,搜索方法By和值:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的是它可以与浏览器交互。常用的有:输入文本的send_key()方法;用于清除文本的 clear() 方法;用于单击按钮的 click() 方法。一个例子如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
python抓取动态网页(Python下的爬虫库,基于urllib,但是更方便易用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2022-03-20 14:11
Python下的爬虫库一般分为3类python大网站。
爬虫类
urllib(Python3),这是Python自带的一个库,可以模拟浏览器请求,获取Response进行解析,提供了丰富的请求方法,支持Cookiespython大规模网站,Headers,等类参数,很多爬虫库基本都是基于它构建的,建议学习一下,因为一些少见的问题需要底层方法解决。
requestspython large 网站,基于urllib,但使用更方便。强烈建议精通。
解析类
re: 官方正则表达式库python大网站,不仅是为了学习爬虫使用,在其他字符串处理或者自然语言处理的过程中,这是一个绕不开的库,强烈推荐掌握。
BeautifulSoup:好用的python大网站,好用,推荐掌握。通过选择器选择页面元素并获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,终极推荐。XPath 对网页解析的支持非常强大且易于使用。它最初是为 XML 元素选择而设计的,但它也支持 HTML。
pyquery:另一个强大的解析库,有兴趣的可以学习一下。
各种各样的
Selenium:所见即所得的爬虫,集爬取和解析两种功能于一体,提供一站式解决方案。很多动态网页都不容易通过requests和scrapy直接爬取。例如,一些 url 后面有加密的随机数。这些算法不容易破解。页面源代码,直接从网页元素中解析内容,在这种情况下,Selenium 是最好的选择。但是 Selenium 最初是为测试而设计的。强烈推荐。
scrapy:又一个爬虫神器,适用于爬取大量页面,甚至对分布式爬虫提供了很好的支持。强烈推荐。
这些是我个人经常使用的库,但还有许多其他工具值得学习。比如Splash还支持动态网页的爬取;Appium可以帮助我们抓取App的内容;Charles可以帮我们抓取数据包,无论是移动端还是PC网页,都有很好的支持;pyspider 也是一个综合框架;MySQL(pymysql)、MongoDB(pymongo),数据抓取的时候一定要存储,不能绕过数据库。
掌握了以上,基本上大部分爬虫任务对你来说都不难了!
也可以关注我的头条号,或者我的个人博客,会有一些爬虫分享。计数孔:/
公司一般用什么语言做网站后端,什么数据库?
谁让你开发网站后台使用java,PHP、.net、python、C++等都可以。后端开发使用的语言完全取决于需求、团队的技术栈、现有系统的架构……如果是个人网站,应该简单粗暴保存钱,linux+apache+php+mysql的lamp架构就够了。如果是企业内部系统,运行windows系统,最好使用.net+sql server。后端是基于python的。电子政务,大网站喜欢用Java。java做网站backend不是因为java生来就是做网站backend,相反java并不是特别“适合”开发web,学着用数据库开发一个简单的程序,php要快很多. Java的优势在于框架和生态,很容易找到一堆Java技术不错、价格低廉的程序员。通常很难找到这么多廉价而熟练的其他语言程序员。其实现在大中网站经常在后台混用多种语言。
如何使用 Python 抓取静态 网站 及其内部资源?
这个很简单,requests+BeautifulSoup的组合很容易实现。下面我简单介绍一下。有兴趣的朋友可以自己试一试。下面是爬虫百科网站数据的例子(静态网站):
1.首先,安装requets 模块。只需在cmd窗口中输入命令“pip install requests”即可,如下:
2. 然后安装 bs4 模块,其中包括 BeautifulSoup。如果安装了,直接像requests一样输入安装命令“pip install bs4”即可,如下:
3.最后是requests+BeautifulSoup的组合爬虫百科,requests用来请求页面,BeautifulSoup用来解析页面提取数据。主要步骤及截图如下:
这里假设爬取的数据收录以下字段,包括用户昵称、内容、搞笑数和评论:
然后打开对应网页的源码,可以直接看到字段信息,内容如下,嵌套在各个标签中,然后解析这些标签提取数据: 基于以上网页内容,测试代码如下,很简单,直接找到对应的标签,提取文本内容即可:
程序运行截图如下,成功抓取网站的数据:
至此,我们已经完成了使用python爬取到静态网站。总的来说,整个过程非常简单,也是最基本的爬虫内容。只要有一定的python基础,熟悉上面的例子,就能很快掌握。当然,你也可以使用 urllib 来匹配正则表达式。等等,没关系,网上也有相关的教程和资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容能对你有所帮助,欢迎评论并留言补充。 查看全部
python抓取动态网页(Python下的爬虫库,基于urllib,但是更方便易用)
Python下的爬虫库一般分为3类python大网站。
爬虫类
urllib(Python3),这是Python自带的一个库,可以模拟浏览器请求,获取Response进行解析,提供了丰富的请求方法,支持Cookiespython大规模网站,Headers,等类参数,很多爬虫库基本都是基于它构建的,建议学习一下,因为一些少见的问题需要底层方法解决。
requestspython large 网站,基于urllib,但使用更方便。强烈建议精通。
解析类
re: 官方正则表达式库python大网站,不仅是为了学习爬虫使用,在其他字符串处理或者自然语言处理的过程中,这是一个绕不开的库,强烈推荐掌握。
BeautifulSoup:好用的python大网站,好用,推荐掌握。通过选择器选择页面元素并获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,终极推荐。XPath 对网页解析的支持非常强大且易于使用。它最初是为 XML 元素选择而设计的,但它也支持 HTML。
pyquery:另一个强大的解析库,有兴趣的可以学习一下。
各种各样的
Selenium:所见即所得的爬虫,集爬取和解析两种功能于一体,提供一站式解决方案。很多动态网页都不容易通过requests和scrapy直接爬取。例如,一些 url 后面有加密的随机数。这些算法不容易破解。页面源代码,直接从网页元素中解析内容,在这种情况下,Selenium 是最好的选择。但是 Selenium 最初是为测试而设计的。强烈推荐。
scrapy:又一个爬虫神器,适用于爬取大量页面,甚至对分布式爬虫提供了很好的支持。强烈推荐。
这些是我个人经常使用的库,但还有许多其他工具值得学习。比如Splash还支持动态网页的爬取;Appium可以帮助我们抓取App的内容;Charles可以帮我们抓取数据包,无论是移动端还是PC网页,都有很好的支持;pyspider 也是一个综合框架;MySQL(pymysql)、MongoDB(pymongo),数据抓取的时候一定要存储,不能绕过数据库。
掌握了以上,基本上大部分爬虫任务对你来说都不难了!
也可以关注我的头条号,或者我的个人博客,会有一些爬虫分享。计数孔:/
公司一般用什么语言做网站后端,什么数据库?
谁让你开发网站后台使用java,PHP、.net、python、C++等都可以。后端开发使用的语言完全取决于需求、团队的技术栈、现有系统的架构……如果是个人网站,应该简单粗暴保存钱,linux+apache+php+mysql的lamp架构就够了。如果是企业内部系统,运行windows系统,最好使用.net+sql server。后端是基于python的。电子政务,大网站喜欢用Java。java做网站backend不是因为java生来就是做网站backend,相反java并不是特别“适合”开发web,学着用数据库开发一个简单的程序,php要快很多. Java的优势在于框架和生态,很容易找到一堆Java技术不错、价格低廉的程序员。通常很难找到这么多廉价而熟练的其他语言程序员。其实现在大中网站经常在后台混用多种语言。
如何使用 Python 抓取静态 网站 及其内部资源?
这个很简单,requests+BeautifulSoup的组合很容易实现。下面我简单介绍一下。有兴趣的朋友可以自己试一试。下面是爬虫百科网站数据的例子(静态网站):
1.首先,安装requets 模块。只需在cmd窗口中输入命令“pip install requests”即可,如下:
2. 然后安装 bs4 模块,其中包括 BeautifulSoup。如果安装了,直接像requests一样输入安装命令“pip install bs4”即可,如下:
3.最后是requests+BeautifulSoup的组合爬虫百科,requests用来请求页面,BeautifulSoup用来解析页面提取数据。主要步骤及截图如下:
这里假设爬取的数据收录以下字段,包括用户昵称、内容、搞笑数和评论:
然后打开对应网页的源码,可以直接看到字段信息,内容如下,嵌套在各个标签中,然后解析这些标签提取数据: 基于以上网页内容,测试代码如下,很简单,直接找到对应的标签,提取文本内容即可:
程序运行截图如下,成功抓取网站的数据:
至此,我们已经完成了使用python爬取到静态网站。总的来说,整个过程非常简单,也是最基本的爬虫内容。只要有一定的python基础,熟悉上面的例子,就能很快掌握。当然,你也可以使用 urllib 来匹配正则表达式。等等,没关系,网上也有相关的教程和资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容能对你有所帮助,欢迎评论并留言补充。
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程实例说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-20 02:14
Python爬虫4.2——ajax【动态网页数据】使用教程示例说明其他博文链接
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,特别是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“做一个长得好看的程序员是什么感觉”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程实例说明)
Python爬虫4.2——ajax【动态网页数据】使用教程示例说明其他博文链接
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,特别是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“做一个长得好看的程序员是什么感觉”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
python抓取动态网页(PHP、java、javascript、python,其中python可以说是操作起来最方便,缺点最少的语言了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-18 17:03
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便,缺点最少的语言。
前几天想写一个爬虫,但是和朋友商量后,决定过几天一起写。爬虫的一个重要部分就是爬取页面中的链接,这里我就简单实现一下。
首先我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后,使用命令python setup.py install本地安装。
我也在慢慢翻译这个模块的文档,翻译完会上传给大家(英文版先在附件中发)。正如它的描述所说,为人类建造,为人类设计。使用起来很方便,自己看文档。最简单的,requests.get() 发送一个 get 请求。
代码如下:
代码如下:
#编码:utf-8
重新导入
导入请求
# 获取网页内容
r = requests.get('')
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(? 查看全部
python抓取动态网页(PHP、java、javascript、python,其中python可以说是操作起来最方便,缺点最少的语言了)
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便,缺点最少的语言。
前几天想写一个爬虫,但是和朋友商量后,决定过几天一起写。爬虫的一个重要部分就是爬取页面中的链接,这里我就简单实现一下。
首先我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后,使用命令python setup.py install本地安装。
我也在慢慢翻译这个模块的文档,翻译完会上传给大家(英文版先在附件中发)。正如它的描述所说,为人类建造,为人类设计。使用起来很方便,自己看文档。最简单的,requests.get() 发送一个 get 请求。
代码如下:
代码如下:
#编码:utf-8
重新导入
导入请求
# 获取网页内容
r = requests.get('')
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(?
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 16:22
2、然后点击首页的【创建图书】-->【微信图书】。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
,等待生成Scrapy爬虫项目。
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网络数据
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,并放入JSON在线解析器中,如下图所示:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你有收获吗?请转发并分享给更多人
Python爬虫和数据挖掘 查看全部
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
2、然后点击首页的【创建图书】-->【微信图书】。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
,等待生成Scrapy爬虫项目。
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网络数据
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,并放入JSON在线解析器中,如下图所示:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你有收获吗?请转发并分享给更多人
Python爬虫和数据挖掘
python抓取动态网页(Python网络爬虫从入门到实践(第2版)作者博客的HelloWorld文章为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-17 23:07
内容
1 动态爬取技术介绍
AJAX(Asynchronous Javascript And XML)的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面节省了流量,因此AJAX得到了广泛的应用。
有两种动态网页抓取方法可以从使用 AJAX 加载的动态网页中抓取动态加载的内容:
2 解析真实地址抓取
以《Python网络爬虫从入门到实践(第2版)》作者博客的Hello World文章为例,目标是抓取文章下的所有评论。文章网址是:
步骤 01 打开“检查”功能。在 Chrome 浏览器中打开 Hello World文章。右键单击页面任意位置,在弹出的弹出菜单中单击“检查”命令。
Step 02 找到真正的数据地址。单击页面中的网络选项并刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。一般这个过程就变成了“抓包”。
从文件中快速找到评论数据所在文件的方法: 搜索评论内容可以快速定位到具体评论所在的文件。
Step 03 爬取真实评论数据地址。既然找到了真实地址,就可以直接使用requests请求这个地址来获取数据了。
步骤 04 从 json 数据中提取注释。您可以使用 json 库来解析数据并从中提取所需的数据。
import requests
import json
link = "https://api-zero.livere.com/v1 ... ot%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
接下来可以使用for循环爬取多页评论数据。可以对比不同页面的真实地址,找出参数的差异,改变discount参数的值来切换页面。
import requests
import json
def single_page_comment(link):
headers = {
'User-Agent': 'https://api-zero.livere.com/v1/comments/list?callback=jQuery112407919796508302595_1646571637355&limit=10&offset=2&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
max_comments = 50 # 设置要爬取的最大评论数
for page in range(1,max_comments // 10 + 1):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361"
page_str = str(page)
link = link1 + page_str + link2
print(link)
single_page_comment(link)
3 通过 Selenium 模拟浏览器抓取
有些网站非常复杂,使用“inspect”功能很难找到调用页面的URL。另外,有些数据的真实地址的URL也很复杂,有些网站为了避免这些爬取,会对地址进行加密,造成一些变量的混淆。因此,这里有另一个介绍。一种方法是使用浏览器渲染引擎。使用浏览器直接显示网页时解析 HTML、应用 CSS 样式和执行 JavaScript 的语句。通俗的讲,就是通过浏览器渲染的方式,把爬取的动态页面变成爬取的静态页面。
在这里,抓取是使用 Python 的 Selenium 库来模拟浏览器完成的。Selenium 是用于 Web 应用程序测试的工具。
3.1 Selenium 基本介绍
浏览器驱动下载地址:
铬合金:
Edge:Microsoft Edge 驱动程序 - Microsoft Edge 开发人员
Firefox:发布 · mozilla/geckodriver · GitHub
Safari:Safari 10 中的 WebDriver 支持 网络套件
使用Selenium打开浏览器和网页,代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.2 Selenium 实践案例
步骤 01 找到评论的 HTML 代码标签。使用Chrome打开文章页面,右键该页面,在弹出的快捷菜单中点击“检查”命令。
Step 02 尝试获取评论数据。对原打开页面的代码数据使用如下代码,获取第一条评论数据。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
# 转化iframe
driver.switch_to.frame(driver.find_element(by='css selector', value='iframe[title="livere-comment"]'))
# 获取css标签为div.reply-content
comment = driver.find_element(by='css selector', value='div.reply-content')
content = comment.find_element(by='tag name', value='p')
print(content.text)
3.3 Selenium 获取 文章 的所有评论
如果要获取所有评论,需要一个可以自动点击“+10查看更多”的脚本,这样所有评论才能显示出来。所以我们需要找到“+10 查看更多”的元素地址,然后让 Selenium 模拟点击并加载评论。具体代码如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
# 下滑到页面底部(左下角)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
print("wait for 3 seconds")
time.sleep(3)
for i in range(1, 19):
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
# load_more = driver.find_element(by="css selector", value="button[data-page=\'%d\']'%i")
if i > 11:
x_path = './/div[@class="more-wrapper"]/button[' + str(i - 9) + ']'
else:
x_path = './/div[@class="more-wrapper"]/button[' + str(i) + ']'
load_more = driver.find_element(by="xpath", value=x_path)
load_more.send_keys("Enter") # 点击前先按下Enter,可以解决因跳转点击时出现失去焦点而导致的click单击无效的情况
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
print("Click and waiting loading --- please waiting for 5s")
time.sleep(5)
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
comments = driver.find_elements(by="css selector", value="div.reply-content")
for each_comment in comments:
content = each_comment.find_element(by="tag name", value="p")
print(content.text)
driver.switch_to.default_content()
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(2)
Selenium 中常用的元素操作方法如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/")
time.sleep(5)
user = driver.find_element(by="name", value="username")
user.send_keys("123456")
pwd = driver.find_element(by="password") # 找到密码输入框
pwd.clear() # 清除密码输入框内容
pwd.send_keys("******") # 在框中输入密码
driver.find_element(by="id", value="loginBtn").click() # 单击登录
除了简单的鼠标操作,Selenium 还可以实现复杂的双击、拖放操作。此外,Selenium 还可以获取网页中每个元素的大小,甚至可以模拟键盘的操作。
3.4 Selenium 的高级操作
常用的加快Selenium爬取速度的方法有:
3.4.1 控制 CSS
在爬取过程中,只爬取页面的内容。CSS 样式文件用于控制页面的外观和元素的放置,对内容没有影响。因此,我们可以限制网页上 CSS 的加载,以减少爬取时间。其代码如下:
# 控制CSS
from selenium import webdriver
# 使用fp控制CSS的加载
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.stylesheet", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.2 限制图片加载
如果不需要抓取网页上的图片,最好禁止图片加载。限制图片加载可以帮助我们大大提高网络爬虫的效率。
# 限制图片的加载
from selenium import webdriver
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.image", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.3 控制 JavaScript 的执行
如果要爬取的内容不是通过 JavaScript 动态加载的,我们可以通过禁止 JavaScript 的执行来提高爬取的效率。因为大多数网页使用 JavaScript 异步加载大量内容,我们不仅不需要这些内容,而且加载它们会浪费时间。
# 限制JavaScript的执行
from selenium import webdriver
fp=webdriver.FirefoxOptions()
fp.set_preference("javascript.enabled",False)
driver=webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
参考
[1] 唐松.2019.Python网络爬虫从入门到实践(第2版)[M]. 北京:机械工业出版社 查看全部
python抓取动态网页(Python网络爬虫从入门到实践(第2版)作者博客的HelloWorld文章为例)
内容
1 动态爬取技术介绍
AJAX(Asynchronous Javascript And XML)的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面节省了流量,因此AJAX得到了广泛的应用。
有两种动态网页抓取方法可以从使用 AJAX 加载的动态网页中抓取动态加载的内容:
2 解析真实地址抓取
以《Python网络爬虫从入门到实践(第2版)》作者博客的Hello World文章为例,目标是抓取文章下的所有评论。文章网址是:
步骤 01 打开“检查”功能。在 Chrome 浏览器中打开 Hello World文章。右键单击页面任意位置,在弹出的弹出菜单中单击“检查”命令。
Step 02 找到真正的数据地址。单击页面中的网络选项并刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。一般这个过程就变成了“抓包”。
从文件中快速找到评论数据所在文件的方法: 搜索评论内容可以快速定位到具体评论所在的文件。
Step 03 爬取真实评论数据地址。既然找到了真实地址,就可以直接使用requests请求这个地址来获取数据了。
步骤 04 从 json 数据中提取注释。您可以使用 json 库来解析数据并从中提取所需的数据。
import requests
import json
link = "https://api-zero.livere.com/v1 ... ot%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
接下来可以使用for循环爬取多页评论数据。可以对比不同页面的真实地址,找出参数的差异,改变discount参数的值来切换页面。
import requests
import json
def single_page_comment(link):
headers = {
'User-Agent': 'https://api-zero.livere.com/v1/comments/list?callback=jQuery112407919796508302595_1646571637355&limit=10&offset=2&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
max_comments = 50 # 设置要爬取的最大评论数
for page in range(1,max_comments // 10 + 1):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361"
page_str = str(page)
link = link1 + page_str + link2
print(link)
single_page_comment(link)
3 通过 Selenium 模拟浏览器抓取
有些网站非常复杂,使用“inspect”功能很难找到调用页面的URL。另外,有些数据的真实地址的URL也很复杂,有些网站为了避免这些爬取,会对地址进行加密,造成一些变量的混淆。因此,这里有另一个介绍。一种方法是使用浏览器渲染引擎。使用浏览器直接显示网页时解析 HTML、应用 CSS 样式和执行 JavaScript 的语句。通俗的讲,就是通过浏览器渲染的方式,把爬取的动态页面变成爬取的静态页面。
在这里,抓取是使用 Python 的 Selenium 库来模拟浏览器完成的。Selenium 是用于 Web 应用程序测试的工具。
3.1 Selenium 基本介绍
浏览器驱动下载地址:
铬合金:
Edge:Microsoft Edge 驱动程序 - Microsoft Edge 开发人员
Firefox:发布 · mozilla/geckodriver · GitHub
Safari:Safari 10 中的 WebDriver 支持 网络套件
使用Selenium打开浏览器和网页,代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.2 Selenium 实践案例
步骤 01 找到评论的 HTML 代码标签。使用Chrome打开文章页面,右键该页面,在弹出的快捷菜单中点击“检查”命令。
Step 02 尝试获取评论数据。对原打开页面的代码数据使用如下代码,获取第一条评论数据。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
# 转化iframe
driver.switch_to.frame(driver.find_element(by='css selector', value='iframe[title="livere-comment"]'))
# 获取css标签为div.reply-content
comment = driver.find_element(by='css selector', value='div.reply-content')
content = comment.find_element(by='tag name', value='p')
print(content.text)
3.3 Selenium 获取 文章 的所有评论
如果要获取所有评论,需要一个可以自动点击“+10查看更多”的脚本,这样所有评论才能显示出来。所以我们需要找到“+10 查看更多”的元素地址,然后让 Selenium 模拟点击并加载评论。具体代码如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
# 下滑到页面底部(左下角)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
print("wait for 3 seconds")
time.sleep(3)
for i in range(1, 19):
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
# load_more = driver.find_element(by="css selector", value="button[data-page=\'%d\']'%i")
if i > 11:
x_path = './/div[@class="more-wrapper"]/button[' + str(i - 9) + ']'
else:
x_path = './/div[@class="more-wrapper"]/button[' + str(i) + ']'
load_more = driver.find_element(by="xpath", value=x_path)
load_more.send_keys("Enter") # 点击前先按下Enter,可以解决因跳转点击时出现失去焦点而导致的click单击无效的情况
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
print("Click and waiting loading --- please waiting for 5s")
time.sleep(5)
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
comments = driver.find_elements(by="css selector", value="div.reply-content")
for each_comment in comments:
content = each_comment.find_element(by="tag name", value="p")
print(content.text)
driver.switch_to.default_content()
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(2)
Selenium 中常用的元素操作方法如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/";)
time.sleep(5)
user = driver.find_element(by="name", value="username")
user.send_keys("123456")
pwd = driver.find_element(by="password") # 找到密码输入框
pwd.clear() # 清除密码输入框内容
pwd.send_keys("******") # 在框中输入密码
driver.find_element(by="id", value="loginBtn").click() # 单击登录
除了简单的鼠标操作,Selenium 还可以实现复杂的双击、拖放操作。此外,Selenium 还可以获取网页中每个元素的大小,甚至可以模拟键盘的操作。
3.4 Selenium 的高级操作
常用的加快Selenium爬取速度的方法有:
3.4.1 控制 CSS
在爬取过程中,只爬取页面的内容。CSS 样式文件用于控制页面的外观和元素的放置,对内容没有影响。因此,我们可以限制网页上 CSS 的加载,以减少爬取时间。其代码如下:
# 控制CSS
from selenium import webdriver
# 使用fp控制CSS的加载
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.stylesheet", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.2 限制图片加载
如果不需要抓取网页上的图片,最好禁止图片加载。限制图片加载可以帮助我们大大提高网络爬虫的效率。
# 限制图片的加载
from selenium import webdriver
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.image", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.3 控制 JavaScript 的执行
如果要爬取的内容不是通过 JavaScript 动态加载的,我们可以通过禁止 JavaScript 的执行来提高爬取的效率。因为大多数网页使用 JavaScript 异步加载大量内容,我们不仅不需要这些内容,而且加载它们会浪费时间。
# 限制JavaScript的执行
from selenium import webdriver
fp=webdriver.FirefoxOptions()
fp.set_preference("javascript.enabled",False)
driver=webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
参考
[1] 唐松.2019.Python网络爬虫从入门到实践(第2版)[M]. 北京:机械工业出版社
python抓取动态网页(Python爬虫入门②Selenium动态网页抓取初步解析(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-17 02:25
)
Python爬虫介绍② Selenium动态网页抓取初步分析
详细介绍:
Selenium是一个web应用的自动化框架,通过它我们可以编写一些自动化程序,可以直接在浏览器上运行,支持所有主流浏览器,包括一些非接口浏览器,可以接收指令,让浏览器自动加载页面,获取html、css、js和一些图片数据,甚至获取页面截图(类似于百度截图)。
PhantomJS:基于 Webkit 的“无头浏览器”,将网页加载到内存中并在页面上执行 JavaScript
Chromedriver:可以用selenium驱动的浏览器,与PhantomJS不同,因为它有接口
Selenium 3.0 版本的自动化框架:
①:Selenium 客户端库
②:浏览器驱动:
③:浏览器
演示:通过python+selenium完成自动打开百度、搜索、网页截图功能
import selenium
from selenium import webdriver
import time
if __name__=="__main__" :
#1.创建浏览器对象
driver=webdriver.Firefox(executable_path='/home/wang/桌面/geckodriver')#添加可执行路径
#2.请求页面
driver.get('https://www.baidu.com')
#3.页面的基本操作(点击,输入)
driver.find_element_by_id('kw').send_keys('Python')
driver.find_element_by_id('su').click()
time.sleep(5)#延迟
driver.save_screenshot('baidu1.png')
#获取渲染之后的数据
print(driver.page_source)
#获取当前的cookie值
print(driver.get_cookies())
#获取当前的url路径
print(driver.current_url)
#关闭页面
driver.close()
#关闭浏览器
driver.quit()
Selenium 如何获取元素:
方法名角色
find_element_by_id()
根据 id 属性的值获取元素列表
find_element_by_class_name
按类名获取元素列表
find_element_by_xpath
通过 xpath 选择返回元素列表
find_element_by_link_text
根据链接地址获取元素列表,精准定位
find_element_by_name
按元素名称选择
find_element_by_tag_name
按标签名称获取元素列表
find_element_by_css_selector
按元素类选择
Demo:豆瓣文章通过Selenium获取元素文章:
from selenium import webdriver
if __name__=="__main__":
driver = webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get('https://www.douban.com/gallery ... %2339;)
#1.通过id获取属性
r1 = driver.find_element_by_id('content')
#2通过标签的id值获取多个标签----得到的是列表:
r2 = driver.find_elements_by_id('dale_explore_home_middle_right')
#3.通过标签的class属性获取标签
r3 = driver.find_element_by_class_name('topic-abstract')
#通过xpath获取左上教豆瓣图片的<a>标签
r4 = driver.find_element_by_xpath('/html/body/div[2]/div/div/div[1]/a')
#通过标签包裹的文本'话题广场'获取元素列表(精确定位)
r5 = driver.find_element_by_link_text('话题广场')
#通过标签包裹文本'画出你的'获取元素的列表(模糊定位)
r6 = driver.find_element_by_partial_link_text('话题')
#通过标签名获取元素列表
r7 = driver.find_element_by_tag_name('div')
#通过标签包裹的文本内容
r8=driver.find_element_by_tag_name('h1')
driver.quit()
其他硒方法:
名称角色
清除
清除元素的内容
发送键
模拟按键输入
点击
点击元素
提交
提交表格
向前
向前翻页
背部
返回页面
switch_to.window
页面转换
案例:实现豆瓣自动登录
通过selenium,我们分析了一系列通往豆瓣的xss路径。根据这些路径和selenium方法,我们可以使用如下代码自动登录:
from selenium import webdriver
if __name__ =="__main__":
driver =webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get("https://www.douban.com/")
#进入嵌套页面
driver.switch_to_frame(0)
driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]').click()
#账户和密码根据不同选择执行,这里是我瞎写的^_^
driver.find_element_by_xpath('//*[@id="username"]').send_keys('3385452176')
driver.find_element_by_xpath('//*[@id="password"]').send_keys('kexingbeiguxiang')
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
Selenium 高级操作
由于 Selenium 直到整个页面加载完毕后才开始爬取内容,因此往往会很慢,因此我们使用一些控件来加快爬取内容的速度。
①:限制CSS的加载:
在爬取的过程中,我们只爬取页面的内容,所以css样式文件对内容没有影响。通过限制 Css,我们可以减少加载时间。代码内容如下:
②:限制图片加载:
如果我们不需要从网络上抓取图片,那么我们最好禁用图片的加载
from selenium import webdriver
fp=webdriver.FirfoxProfile()
fp.set_preference("permissions.default.stylesheet",2)#控制css加载
fp.set_preference("permissions.deault.image",2)#控制图片加载
fp.set_preference("javascript.enabled",False)#控制Javascript加载
driver=webdriver.Firfox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
driver.get("https:"//www.bilibli.com)
项目实战:爬取Airbnb南京房源
项目分析:
如果要爬取南京的房源,需要找到出租房屋、房型、价格、简介对应的标签。通过检查,我们可以得到响应的元素关系如下
数据元素类
房子的所有数据
div
_14csrlku
房屋类型数据
div
呜呜呜
房价数据
跨度
_j1kt73
房屋评估数据
跨度
_69pvqtq
房屋档案资料
div
_dadnbjj
所以写
from selenium import webdriver
import time
fp=webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)#限制图片的加载,提高爬取速度
fp.set_preference("permissions.dafault.stylesheet",2)#限制Css加载,提高爬取速度
driver =webdriver.Firefox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
link1="https://www.airbnb.cn/s/%25E5% ... ot%3B
#找到页面内的所有租房
rent_list = driver.find_elements_by_css_selector('div._14csrlku')
for eachhouse in rent_list:
#爬取房屋类型
Housenm=eachhouse.find_element_by_css_selector('div._wuffzwa')
Housenm=Housenm.text
#爬取房屋价格:
Housepc=eachhouse.find_element_by_css_selector('span._j1kt73')
Housepc=Housepc.text.replace("每晚","").replace("价格","").replace("\n","")
#爬取房屋简介:
Housety=eachhouse.find_element_by_css_selector('div._dadnbjj')
Housety=Housety.text
#爬取评价人数:
try:
Mennnum=eachhouse.find_element_by_css_selector('span._69pvqtq')
Mennnum=Mennnum.text
Mennnum=str(Mennnum)
except:
Mennnum=str(0)
with open ("南京短租房","a+")as fl:
fl.write("户型:"+Housenm+" ")
fl.write("价格:"+Housepc+" ")
fl.write("评价人数:"+Mennnum+" ")
fl.write("简介:"+Housety+" ")
fl.write("\n")
driver.quit() 查看全部
python抓取动态网页(Python爬虫入门②Selenium动态网页抓取初步解析(图)
)
Python爬虫介绍② Selenium动态网页抓取初步分析
详细介绍:
Selenium是一个web应用的自动化框架,通过它我们可以编写一些自动化程序,可以直接在浏览器上运行,支持所有主流浏览器,包括一些非接口浏览器,可以接收指令,让浏览器自动加载页面,获取html、css、js和一些图片数据,甚至获取页面截图(类似于百度截图)。
PhantomJS:基于 Webkit 的“无头浏览器”,将网页加载到内存中并在页面上执行 JavaScript
Chromedriver:可以用selenium驱动的浏览器,与PhantomJS不同,因为它有接口
Selenium 3.0 版本的自动化框架:
①:Selenium 客户端库
②:浏览器驱动:
③:浏览器
演示:通过python+selenium完成自动打开百度、搜索、网页截图功能
import selenium
from selenium import webdriver
import time
if __name__=="__main__" :
#1.创建浏览器对象
driver=webdriver.Firefox(executable_path='/home/wang/桌面/geckodriver')#添加可执行路径
#2.请求页面
driver.get('https://www.baidu.com')
#3.页面的基本操作(点击,输入)
driver.find_element_by_id('kw').send_keys('Python')
driver.find_element_by_id('su').click()
time.sleep(5)#延迟
driver.save_screenshot('baidu1.png')
#获取渲染之后的数据
print(driver.page_source)
#获取当前的cookie值
print(driver.get_cookies())
#获取当前的url路径
print(driver.current_url)
#关闭页面
driver.close()
#关闭浏览器
driver.quit()
Selenium 如何获取元素:
方法名角色
find_element_by_id()
根据 id 属性的值获取元素列表
find_element_by_class_name
按类名获取元素列表
find_element_by_xpath
通过 xpath 选择返回元素列表
find_element_by_link_text
根据链接地址获取元素列表,精准定位
find_element_by_name
按元素名称选择
find_element_by_tag_name
按标签名称获取元素列表
find_element_by_css_selector
按元素类选择
Demo:豆瓣文章通过Selenium获取元素文章:
from selenium import webdriver
if __name__=="__main__":
driver = webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get('https://www.douban.com/gallery ... %2339;)
#1.通过id获取属性
r1 = driver.find_element_by_id('content')
#2通过标签的id值获取多个标签----得到的是列表:
r2 = driver.find_elements_by_id('dale_explore_home_middle_right')
#3.通过标签的class属性获取标签
r3 = driver.find_element_by_class_name('topic-abstract')
#通过xpath获取左上教豆瓣图片的<a>标签
r4 = driver.find_element_by_xpath('/html/body/div[2]/div/div/div[1]/a')
#通过标签包裹的文本'话题广场'获取元素列表(精确定位)
r5 = driver.find_element_by_link_text('话题广场')
#通过标签包裹文本'画出你的'获取元素的列表(模糊定位)
r6 = driver.find_element_by_partial_link_text('话题')
#通过标签名获取元素列表
r7 = driver.find_element_by_tag_name('div')
#通过标签包裹的文本内容
r8=driver.find_element_by_tag_name('h1')
driver.quit()
其他硒方法:
名称角色
清除
清除元素的内容
发送键
模拟按键输入
点击
点击元素
提交
提交表格
向前
向前翻页
背部
返回页面
switch_to.window
页面转换
案例:实现豆瓣自动登录
通过selenium,我们分析了一系列通往豆瓣的xss路径。根据这些路径和selenium方法,我们可以使用如下代码自动登录:
from selenium import webdriver
if __name__ =="__main__":
driver =webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get("https://www.douban.com/";)
#进入嵌套页面
driver.switch_to_frame(0)
driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]').click()
#账户和密码根据不同选择执行,这里是我瞎写的^_^
driver.find_element_by_xpath('//*[@id="username"]').send_keys('3385452176')
driver.find_element_by_xpath('//*[@id="password"]').send_keys('kexingbeiguxiang')
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
Selenium 高级操作
由于 Selenium 直到整个页面加载完毕后才开始爬取内容,因此往往会很慢,因此我们使用一些控件来加快爬取内容的速度。
①:限制CSS的加载:
在爬取的过程中,我们只爬取页面的内容,所以css样式文件对内容没有影响。通过限制 Css,我们可以减少加载时间。代码内容如下:
②:限制图片加载:
如果我们不需要从网络上抓取图片,那么我们最好禁用图片的加载
from selenium import webdriver
fp=webdriver.FirfoxProfile()
fp.set_preference("permissions.default.stylesheet",2)#控制css加载
fp.set_preference("permissions.deault.image",2)#控制图片加载
fp.set_preference("javascript.enabled",False)#控制Javascript加载
driver=webdriver.Firfox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
driver.get("https:"//www.bilibli.com)
项目实战:爬取Airbnb南京房源
项目分析:
如果要爬取南京的房源,需要找到出租房屋、房型、价格、简介对应的标签。通过检查,我们可以得到响应的元素关系如下
数据元素类
房子的所有数据
div
_14csrlku
房屋类型数据
div
呜呜呜
房价数据
跨度
_j1kt73
房屋评估数据
跨度
_69pvqtq
房屋档案资料
div
_dadnbjj
所以写
from selenium import webdriver
import time
fp=webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)#限制图片的加载,提高爬取速度
fp.set_preference("permissions.dafault.stylesheet",2)#限制Css加载,提高爬取速度
driver =webdriver.Firefox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
link1="https://www.airbnb.cn/s/%25E5% ... ot%3B
#找到页面内的所有租房
rent_list = driver.find_elements_by_css_selector('div._14csrlku')
for eachhouse in rent_list:
#爬取房屋类型
Housenm=eachhouse.find_element_by_css_selector('div._wuffzwa')
Housenm=Housenm.text
#爬取房屋价格:
Housepc=eachhouse.find_element_by_css_selector('span._j1kt73')
Housepc=Housepc.text.replace("每晚","").replace("价格","").replace("\n","")
#爬取房屋简介:
Housety=eachhouse.find_element_by_css_selector('div._dadnbjj')
Housety=Housety.text
#爬取评价人数:
try:
Mennnum=eachhouse.find_element_by_css_selector('span._69pvqtq')
Mennnum=Mennnum.text
Mennnum=str(Mennnum)
except:
Mennnum=str(0)
with open ("南京短租房","a+")as fl:
fl.write("户型:"+Housenm+" ")
fl.write("价格:"+Housepc+" ")
fl.write("评价人数:"+Mennnum+" ")
fl.write("简介:"+Housety+" ")
fl.write("\n")
driver.quit()
python抓取动态网页(1.Python爬取动态生成的网页(框架)需要具备哪些知识或者使用哪些库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-16 23:02
1.Python爬取动态生成的网页(框架)需要哪些知识或库
1、爬取网页、模拟登录等背后的一般逻辑和原理;
2、以从songtaste网页中提取标题为例,详细讲解如何爬取网站并提取网页内容;
3、以百度的模拟登录为例讲解如何模拟登录网站;
4、以抓取网易博文中的最新读者信息为例,详细讲解如何抓取动态网页中的内容;
5、详细介绍了如何使用相应的网页分析工具,如IE9的F12、Chrome的Ctrl+Shift+J、Firefox的Firebug,在模拟登录和爬取动态网页的过程中分析相应的逻辑;
6、对于爬取网站、模拟登录、爬取动态网页,给出了多语言的所有完整可用的示例代码:Python、C#、Java、Go等。
2.Python如何获取js动态加载的数据
使用WebBrowser控件获取js动态加载的数据:
首先,我需要在 DocumentCompleted 事件中获取内容,因为在加载文档后会触发控件。其次,这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe,也会触发这个事件,所以我们要做出判断:
if (wb.ReadyState == WebBrowserReadyState.Complete && e.Url.ToString() == wb.Url.ToString())
wb.Document.Body.InnerHtml;//这样就得到了数据
3.nodejs目前有什么框架?哪一个是最好的?
restify 是一个基于nodejs 的REST 应用框架,支持服务端和客户端。Restify比express更专注于rest服务,去掉express中的template、render等功能,同时加强了rest协议的使用,版本支持,标签加标签进行扩展,而不是写JS生成, dojo 的 API 模仿 Java 类库的组织方式。
用dojo写Web OS非常方便。Dojo 现在是 4.0。dojo的强大之处在于对接口和特效的封装,让开发者可以快速构建一些兼容标准的接口。
优点:库比较齐全,开发时间比较长,功能强大。据说可以使用dojo的io.bind()来实现彗星。它功能强大且非同寻常,得到了 IBM 和 SUN 的支持。缺点:文件比较大,200多KB,初次下载比较慢,另外使用dojo的类库不是那么好用,js语法增强不如prototype。Prototype(JS OO库):是一个非常优雅的JS库,定义了JS、DOM操作API、事件等的面向对象扩展,以原型为核心,形成外围各种JS扩展库,是一个非常有前途的JS底层框架,值得推荐。感觉是现实中使用最广泛的库类(RoR集成AJAX JS库)。在它之上,Scriptaculous 实现了一些 JS 组件功能和效果。
优点:基础底层,易学易用,甚至是其他一些js特效开发包的底层,体积最小。劣势:如果是劣势,那可能是功能是他的弱点。Scriptaculous(基于prototype的JS UI组件):Scriptaculous是一个基于prototype.js框架的JS效果。
收录6个js文件,不同的文件对应不同的js效果,所以如果底层使用prototype的话,js效果用Scriptaculous比较合适,连大名鼎鼎的digg都在用,所以不正常优点:基于prototype是最大的优势。由于prototype的大量使用,无疑是为用户书籍锦上添花,而《ajax in action》中用Scriptaculous来描述js效果。缺点:刚刚兴起,需要时间去磨练 界面效果媲美backbase,使用纯javascript代码开发。真正的可编辑表单Edit Grid支持XML和Json数据类型,
许多组件实现了对数据源的支持,例如动态布局、可编辑表格控件、动态加载的树控件、动态拖放效果等。1.0 beta版开始与Jquery合作,推出了基于jQuery的Ext 1.0,提供了更多有趣的功能。
优点:结构化,类似java的结构,清晰明了,底层使用了jquery的一些功能,这样就有了集成使用的选项,最重要的一点就是界面太震撼了。缺点:过于复杂,整个界面的结构过于复杂。
jquery:jQuery是一个类似prototype的优秀js开发库类,特别是对css和XPath的支持,让我们写js更加方便!如果你不是 js 专家,想写出优秀的 js 效果,jQuery 可以帮助你实现目标!而引入的语法和高效率一直是jQuery所追求的目标。优点:注重介绍和效率,js效果有yui-ext的选择,因为yui-ext复用了jQuery的很多功能。缺点:据说太嫩,历史悠久。Mochikit:MochiKit 自称是一个轻量级的 js 框架。
MochiKit 的主要灵感来自 Python 和 Python 标准库提供的许多便利,此外还减少了浏览器版本之间的不一致。其中,MochiKit.DOM 尤其好用,可以比原生 JavaScript 更友好地处理 DOM 对象。
大多数 MochiKit.DOM 是为 XHTML 文档定制的,当与 MochiKit 和 Ajax 结合使用时,使用 XHTML 包装的微格式特别方便。Mochikit可以直接格式化输出字符串或者数字,比较实用方便。
它还有自己的js代码解释器优点:MochiKit.DOM这部分很实用,介绍也很突出缺点:轻量级缺点mootools:MooTools是一个简洁、模块化、面向对象的JavaScript框架。它可以帮助您更快、更轻松地编写可扩展且兼容的 JavaScript 代码。
Mootools 类似于prototypejs,语法几乎相同。但是它提供了比prototypejs更多的功能,更强大。
例如,添加了动画效果、拖放操作等。优点:可以自定义自己需要的功能,可以说是prototypejs的增强版。
缺点:不会太小,不会太小,具体应用具体分析moo.fx:moo.fx是一个超轻量级的javascript特效库(7k),可以配合prototype.js或者mootools框架使用。它非常快速、易于使用、跨浏览器、符合标准,并提供对任何 HTML 元素(包括颜色)的 CSS 属性的控制和修改。
它有一个内置的检查器,可以防止用户通过多次或疯狂的点击破坏效果。moo.fx 整体采用模块化设计,您可以在此基础上开发任何您需要的特效。
优点:体积小,能力大缺点:这么小,已经不错了。
5.如何使用htmlunit获取JS加载的网页信息
有两种方式可供选择。我推荐第一个。一种是读取相关网页中的js和网页请求后的header,通过hander知道获取这些信息的接口。单元框架提供的方法:
JavascriptExecutor jsExecutor = (JavascriptExecutor) 驱动程序;
jsExecutor.executeScript("LoginSubmit();", ""); 这里的LoginSubmit就是页面中js方法的名称(页面中肯定有这个js方法,当然你也可以自己写一些js)。然后通过dom操作得到你想要的信息。
转载请注明出处 JS代码网 » 哪些框架可以抓取js加载的数据(Python爬取动态生成的网页(框架)需要哪些知识或库) 查看全部
python抓取动态网页(1.Python爬取动态生成的网页(框架)需要具备哪些知识或者使用哪些库)
1.Python爬取动态生成的网页(框架)需要哪些知识或库
1、爬取网页、模拟登录等背后的一般逻辑和原理;
2、以从songtaste网页中提取标题为例,详细讲解如何爬取网站并提取网页内容;
3、以百度的模拟登录为例讲解如何模拟登录网站;
4、以抓取网易博文中的最新读者信息为例,详细讲解如何抓取动态网页中的内容;
5、详细介绍了如何使用相应的网页分析工具,如IE9的F12、Chrome的Ctrl+Shift+J、Firefox的Firebug,在模拟登录和爬取动态网页的过程中分析相应的逻辑;
6、对于爬取网站、模拟登录、爬取动态网页,给出了多语言的所有完整可用的示例代码:Python、C#、Java、Go等。
2.Python如何获取js动态加载的数据
使用WebBrowser控件获取js动态加载的数据:
首先,我需要在 DocumentCompleted 事件中获取内容,因为在加载文档后会触发控件。其次,这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe,也会触发这个事件,所以我们要做出判断:
if (wb.ReadyState == WebBrowserReadyState.Complete && e.Url.ToString() == wb.Url.ToString())
wb.Document.Body.InnerHtml;//这样就得到了数据
3.nodejs目前有什么框架?哪一个是最好的?
restify 是一个基于nodejs 的REST 应用框架,支持服务端和客户端。Restify比express更专注于rest服务,去掉express中的template、render等功能,同时加强了rest协议的使用,版本支持,标签加标签进行扩展,而不是写JS生成, dojo 的 API 模仿 Java 类库的组织方式。
用dojo写Web OS非常方便。Dojo 现在是 4.0。dojo的强大之处在于对接口和特效的封装,让开发者可以快速构建一些兼容标准的接口。
优点:库比较齐全,开发时间比较长,功能强大。据说可以使用dojo的io.bind()来实现彗星。它功能强大且非同寻常,得到了 IBM 和 SUN 的支持。缺点:文件比较大,200多KB,初次下载比较慢,另外使用dojo的类库不是那么好用,js语法增强不如prototype。Prototype(JS OO库):是一个非常优雅的JS库,定义了JS、DOM操作API、事件等的面向对象扩展,以原型为核心,形成外围各种JS扩展库,是一个非常有前途的JS底层框架,值得推荐。感觉是现实中使用最广泛的库类(RoR集成AJAX JS库)。在它之上,Scriptaculous 实现了一些 JS 组件功能和效果。
优点:基础底层,易学易用,甚至是其他一些js特效开发包的底层,体积最小。劣势:如果是劣势,那可能是功能是他的弱点。Scriptaculous(基于prototype的JS UI组件):Scriptaculous是一个基于prototype.js框架的JS效果。
收录6个js文件,不同的文件对应不同的js效果,所以如果底层使用prototype的话,js效果用Scriptaculous比较合适,连大名鼎鼎的digg都在用,所以不正常优点:基于prototype是最大的优势。由于prototype的大量使用,无疑是为用户书籍锦上添花,而《ajax in action》中用Scriptaculous来描述js效果。缺点:刚刚兴起,需要时间去磨练 界面效果媲美backbase,使用纯javascript代码开发。真正的可编辑表单Edit Grid支持XML和Json数据类型,
许多组件实现了对数据源的支持,例如动态布局、可编辑表格控件、动态加载的树控件、动态拖放效果等。1.0 beta版开始与Jquery合作,推出了基于jQuery的Ext 1.0,提供了更多有趣的功能。
优点:结构化,类似java的结构,清晰明了,底层使用了jquery的一些功能,这样就有了集成使用的选项,最重要的一点就是界面太震撼了。缺点:过于复杂,整个界面的结构过于复杂。
jquery:jQuery是一个类似prototype的优秀js开发库类,特别是对css和XPath的支持,让我们写js更加方便!如果你不是 js 专家,想写出优秀的 js 效果,jQuery 可以帮助你实现目标!而引入的语法和高效率一直是jQuery所追求的目标。优点:注重介绍和效率,js效果有yui-ext的选择,因为yui-ext复用了jQuery的很多功能。缺点:据说太嫩,历史悠久。Mochikit:MochiKit 自称是一个轻量级的 js 框架。
MochiKit 的主要灵感来自 Python 和 Python 标准库提供的许多便利,此外还减少了浏览器版本之间的不一致。其中,MochiKit.DOM 尤其好用,可以比原生 JavaScript 更友好地处理 DOM 对象。
大多数 MochiKit.DOM 是为 XHTML 文档定制的,当与 MochiKit 和 Ajax 结合使用时,使用 XHTML 包装的微格式特别方便。Mochikit可以直接格式化输出字符串或者数字,比较实用方便。
它还有自己的js代码解释器优点:MochiKit.DOM这部分很实用,介绍也很突出缺点:轻量级缺点mootools:MooTools是一个简洁、模块化、面向对象的JavaScript框架。它可以帮助您更快、更轻松地编写可扩展且兼容的 JavaScript 代码。
Mootools 类似于prototypejs,语法几乎相同。但是它提供了比prototypejs更多的功能,更强大。
例如,添加了动画效果、拖放操作等。优点:可以自定义自己需要的功能,可以说是prototypejs的增强版。
缺点:不会太小,不会太小,具体应用具体分析moo.fx:moo.fx是一个超轻量级的javascript特效库(7k),可以配合prototype.js或者mootools框架使用。它非常快速、易于使用、跨浏览器、符合标准,并提供对任何 HTML 元素(包括颜色)的 CSS 属性的控制和修改。
它有一个内置的检查器,可以防止用户通过多次或疯狂的点击破坏效果。moo.fx 整体采用模块化设计,您可以在此基础上开发任何您需要的特效。
优点:体积小,能力大缺点:这么小,已经不错了。
5.如何使用htmlunit获取JS加载的网页信息
有两种方式可供选择。我推荐第一个。一种是读取相关网页中的js和网页请求后的header,通过hander知道获取这些信息的接口。单元框架提供的方法:
JavascriptExecutor jsExecutor = (JavascriptExecutor) 驱动程序;
jsExecutor.executeScript("LoginSubmit();", ""); 这里的LoginSubmit就是页面中js方法的名称(页面中肯定有这个js方法,当然你也可以自己写一些js)。然后通过dom操作得到你想要的信息。
转载请注明出处 JS代码网 » 哪些框架可以抓取js加载的数据(Python爬取动态生成的网页(框架)需要哪些知识或库)
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-16 13:08
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网上的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。
1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素。在这里,我们只简要介绍一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本要素。在使用爬虫的过程中,我们需要随时随地分析网页的构成要素。分析很有帮助。 查看全部
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网上的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。
1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素。在这里,我们只简要介绍一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本要素。在使用爬虫的过程中,我们需要随时随地分析网页的构成要素。分析很有帮助。
python抓取动态网页(网页爬取的效果图:什么是selenium?介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-16 10:02
python抓取动态网页:qq群搜索进行网页爬取,然后放到excel进行分析。效果图:技术选型1.selenium介绍:什么是selenium?selenium(superexamplelibrary)是开发的基于浏览器的自动化测试框架,selenium为google浏览器及各种浏览器提供高效、简单、可靠的api。
软件工程师用户可用selenium来开发用户界面(例如:在网页上操作,抓取数据,等等)2.python工具库介绍python自己有一套自己的的工具,实现对http,https,爬虫,异步等其他网络请求和调用的支持。3.实现思路接下来我们接着看上面一步的。我们分别爬取,豆瓣图书的评分,小黄鸭的图片信息我们可以看到,图片评分和图片名称都是我们想要抓取的评分图片评分爬取爬取网页内容content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\redispicker.jpg')content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\bizpicker.jpg')plt.font('simhei')plt.render("",'html_sprites')分析内容的思路我们可以看到,用到了爬虫模块里面的pyquery获取数据并保存plt.font('simhei')plt.render("",'html_sprites')1.登录豆瓣2.创建div3.创建div,和二级域名。
4.创建image相关类和小黄鸭类,这里不多说了plt.image('/\/images/redispicker.jpg',div={'src':'{}','imageurl':'{}'})plt.image('\/images/bizpicker.jpg',div={'src':'{}','imageurl':'{}'})我们再看下什么叫爬虫我们首先创建这样一个爬虫div,里面的imgurl就是我们想要爬取的imageurl相关代码如下pygameimportdivclassbizpicker:def__init__(self,content,screen):self.content=contentself.screen=screendefget(self,data):self.content=data.replace("","'")returnself.content.replace("\n","")defget_image(self,data):url=''#获取imageurlimgurl=url+str(self.content)#获取二级域名path=self.content.get_path('')#获取imageurlpath=self.content.get_path('/')#获取爬虫内容的包名request=urllib.urlencode(p。 查看全部
python抓取动态网页(网页爬取的效果图:什么是selenium?介绍)
python抓取动态网页:qq群搜索进行网页爬取,然后放到excel进行分析。效果图:技术选型1.selenium介绍:什么是selenium?selenium(superexamplelibrary)是开发的基于浏览器的自动化测试框架,selenium为google浏览器及各种浏览器提供高效、简单、可靠的api。
软件工程师用户可用selenium来开发用户界面(例如:在网页上操作,抓取数据,等等)2.python工具库介绍python自己有一套自己的的工具,实现对http,https,爬虫,异步等其他网络请求和调用的支持。3.实现思路接下来我们接着看上面一步的。我们分别爬取,豆瓣图书的评分,小黄鸭的图片信息我们可以看到,图片评分和图片名称都是我们想要抓取的评分图片评分爬取爬取网页内容content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\redispicker.jpg')content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\bizpicker.jpg')plt.font('simhei')plt.render("",'html_sprites')分析内容的思路我们可以看到,用到了爬虫模块里面的pyquery获取数据并保存plt.font('simhei')plt.render("",'html_sprites')1.登录豆瓣2.创建div3.创建div,和二级域名。
4.创建image相关类和小黄鸭类,这里不多说了plt.image('/\/images/redispicker.jpg',div={'src':'{}','imageurl':'{}'})plt.image('\/images/bizpicker.jpg',div={'src':'{}','imageurl':'{}'})我们再看下什么叫爬虫我们首先创建这样一个爬虫div,里面的imgurl就是我们想要爬取的imageurl相关代码如下pygameimportdivclassbizpicker:def__init__(self,content,screen):self.content=contentself.screen=screendefget(self,data):self.content=data.replace("","'")returnself.content.replace("\n","")defget_image(self,data):url=''#获取imageurlimgurl=url+str(self.content)#获取二级域名path=self.content.get_path('')#获取imageurlpath=self.content.get_path('/')#获取爬虫内容的包名request=urllib.urlencode(p。
python抓取动态网页( 本节讲解PythonSelenium爬虫爬虫实战案例(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-16 03:19
本节讲解PythonSelenium爬虫爬虫实战案例(一)(图))
Python Selenium爬虫的实际应用
本节讲解Python Selenium爬虫的实际案例。通过实际案例的讲解,可以进一步了解 Selenium 框架。
实战案例的目标:抓取京东商城()的商品名称、商品价格、评论数、店铺名称。例如,如果您输入搜索“Python 书籍”,则会捕获以下数据:
{'name': 'Python编程 从入门到实践 第2版 人民邮电出版社', 'price': '¥52.50', 'count': '200+条评价', 'shop': '智囊图书专营店'}
{'name': 'Python编程 从入门到实践 第2版(图灵出品)', 'price': '¥62.10', 'count': '20万+条评价', 'shop': '人民邮电出版社'}
…
Selenium 框架的学习重点是定位元素节点。我们介绍了 8 种定位方法,其中 Xpath 表达式适用性强,方便快捷。因此,建议您熟悉 Xpath 表达式的相关语法规则。本节的大部分案例都是使用Xpath表达式来定位元素,希望能帮助你更新知识。
本节案例涉及几个技术难点:一是如何下拉滚动条下载产品;二、如何翻页,即抓取下一页的内容;第三,如何判断数据是否被抓取,即结束页面。下面我们一步一步解释。
实现自动搜索
是实现自动输出和自动搜索的最基本步骤。先定位输入框的节点,再定位搜索按钮节点。这与实现百度自动搜索的思路是一致的。最重要的是正确定位元素节点。
通过开发者调试工具查看对应位置,可以得到如下Xpath表达式:
输入框表达式://*[@id="key"]
搜索按钮表达式://*[@class='form']/button
代码如下所示:
from selenium import webdriver
broswer=webdriver.Chrome()
broswer.get('https://www.jd.com/')
broswer.find_element_by_xpath('//*[@id="key"]').send_keys("python书籍")
broswer.find_element_by_xpath("//*[@class='form']/button").click()
滚动条
实现自动搜索后,接下来就是爬取页面中的商品信息,你会发现只有当滑块滚动到底部时,商品才会满载。滚轮操作的代码如下:
# scrollTo(xpos,ypos)
# execute_script()执行js语句,拉动进度条件
#scrollHeight属性,表示可滚动内容的高度
self.browser.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'#拉动进度条至底部
)
之后,通过Xpath表达式匹配所有产品,放入一个大列表中,通过循环列表取出每个产品,最后提取出想要的信息。
li_list=self.browser.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li')
for li in li_list:
item={}
# 提取商品名
item['name']=li.find_element_by_xpath('.//div[@class="p-name"]/a/em').text.strip()
# 提取价格
item['price']=li.find_element_by_xpath('.//div[@class="p-price"]').text.strip()
# 提取评论数量
item['count']=li.find_element_by_xpath('.//div[@class="p-commit"]/strong').text.strip()
# 提取商家店铺
item['shop']=li.find_element_by_xpath('.//div[@class="p-shopnum"]').text.strip()
实现翻页
如何实现翻页取数据,判断数据已经取到?这其实不难想到,我们可以跳转到最后一页(即最后一页)。此时最后一页的“下一页”不可用,其元素节点如下: 查看全部
python抓取动态网页(
本节讲解PythonSelenium爬虫爬虫实战案例(一)(图))
Python Selenium爬虫的实际应用
本节讲解Python Selenium爬虫的实际案例。通过实际案例的讲解,可以进一步了解 Selenium 框架。
实战案例的目标:抓取京东商城()的商品名称、商品价格、评论数、店铺名称。例如,如果您输入搜索“Python 书籍”,则会捕获以下数据:
{'name': 'Python编程 从入门到实践 第2版 人民邮电出版社', 'price': '¥52.50', 'count': '200+条评价', 'shop': '智囊图书专营店'}
{'name': 'Python编程 从入门到实践 第2版(图灵出品)', 'price': '¥62.10', 'count': '20万+条评价', 'shop': '人民邮电出版社'}
…
Selenium 框架的学习重点是定位元素节点。我们介绍了 8 种定位方法,其中 Xpath 表达式适用性强,方便快捷。因此,建议您熟悉 Xpath 表达式的相关语法规则。本节的大部分案例都是使用Xpath表达式来定位元素,希望能帮助你更新知识。
本节案例涉及几个技术难点:一是如何下拉滚动条下载产品;二、如何翻页,即抓取下一页的内容;第三,如何判断数据是否被抓取,即结束页面。下面我们一步一步解释。
实现自动搜索
是实现自动输出和自动搜索的最基本步骤。先定位输入框的节点,再定位搜索按钮节点。这与实现百度自动搜索的思路是一致的。最重要的是正确定位元素节点。
通过开发者调试工具查看对应位置,可以得到如下Xpath表达式:
输入框表达式://*[@id="key"]
搜索按钮表达式://*[@class='form']/button
代码如下所示:
from selenium import webdriver
broswer=webdriver.Chrome()
broswer.get('https://www.jd.com/')
broswer.find_element_by_xpath('//*[@id="key"]').send_keys("python书籍")
broswer.find_element_by_xpath("//*[@class='form']/button").click()
滚动条
实现自动搜索后,接下来就是爬取页面中的商品信息,你会发现只有当滑块滚动到底部时,商品才会满载。滚轮操作的代码如下:
# scrollTo(xpos,ypos)
# execute_script()执行js语句,拉动进度条件
#scrollHeight属性,表示可滚动内容的高度
self.browser.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'#拉动进度条至底部
)
之后,通过Xpath表达式匹配所有产品,放入一个大列表中,通过循环列表取出每个产品,最后提取出想要的信息。
li_list=self.browser.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li')
for li in li_list:
item={}
# 提取商品名
item['name']=li.find_element_by_xpath('.//div[@class="p-name"]/a/em').text.strip()
# 提取价格
item['price']=li.find_element_by_xpath('.//div[@class="p-price"]').text.strip()
# 提取评论数量
item['count']=li.find_element_by_xpath('.//div[@class="p-commit"]/strong').text.strip()
# 提取商家店铺
item['shop']=li.find_element_by_xpath('.//div[@class="p-shopnum"]').text.strip()
实现翻页
如何实现翻页取数据,判断数据已经取到?这其实不难想到,我们可以跳转到最后一页(即最后一页)。此时最后一页的“下一页”不可用,其元素节点如下:
python抓取动态网页(【图说】你有get和post方法,用什么都行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2022-03-15 16:02
python抓取动态网页获取字段信息可以用eggplot2,eggplot2包含gif、png、svg格式的网页生成图。不同于python原生spider,eggplot2提供图形化接口,方便抓取图片。
多看看github~
ifallofyouwanttobuildarepo,welcometostackoverflowwheregithubistheonlylocalrepototeachyouhowtobuildyourusefulreports。welcometostackoverflow。here'smyupdate:github-rubygems/stackoverflow:rubyuser'swikioftherubyreference。
theseupdatescanbeomittedifyou'regoingtobuildreports,andwhatisupinmywriting。ifyougiveatweet,youcanlistyourtweetsin:github-earthchef/cheat-sheet:cheatsheetwritteninstackoverflowthankyou。
如果你是要注册类目的,可以用spyder。spyder是python的pandas模块。
你有get和post方法,不用担心吧,用什么都行。
gif格式怎么搞?具体写法可以看这里有什么好用的python生成gif图的库?
不是,请问你在网页上编写的抓取任务是什么,你以什么格式展示你的抓取结果(大小、格式、速度)。 查看全部
python抓取动态网页(【图说】你有get和post方法,用什么都行)
python抓取动态网页获取字段信息可以用eggplot2,eggplot2包含gif、png、svg格式的网页生成图。不同于python原生spider,eggplot2提供图形化接口,方便抓取图片。
多看看github~
ifallofyouwanttobuildarepo,welcometostackoverflowwheregithubistheonlylocalrepototeachyouhowtobuildyourusefulreports。welcometostackoverflow。here'smyupdate:github-rubygems/stackoverflow:rubyuser'swikioftherubyreference。
theseupdatescanbeomittedifyou'regoingtobuildreports,andwhatisupinmywriting。ifyougiveatweet,youcanlistyourtweetsin:github-earthchef/cheat-sheet:cheatsheetwritteninstackoverflowthankyou。
如果你是要注册类目的,可以用spyder。spyder是python的pandas模块。
你有get和post方法,不用担心吧,用什么都行。
gif格式怎么搞?具体写法可以看这里有什么好用的python生成gif图的库?
不是,请问你在网页上编写的抓取任务是什么,你以什么格式展示你的抓取结果(大小、格式、速度)。
python抓取动态网页(谷歌python手动爬取动态网页解析(一)-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-13 00:04
python抓取动态网页解析,原理就是用python对网页数据进行解析,一般要看python自己实现实现,lambda函数可以这样写defget_url():url='/'+requests。get(url)try:headers={'user-agent':'mozilla/5。0(windowsnt10。
0;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/71。2544。87safari/537。36'}r=requests。get(url,headers=headers)print(r。text)except:print(r。text)。
get方法,
多看看谷歌的文档,
非标准的python程序可能有办法,但最好的方法是手工按照dom操作来解析页面,这样才最快。
可以基于urllib库手工爬取一些链接。我只用urllib库爬取过两次动态页面:爱奇艺和清华大学新闻中心:1.python手动爬取动态网页流程2.python手动爬取数据包含地点名称(例如xxx餐馆)和楼层(例如4-18)。我以清华大学新闻中心为例来说明。首先将爬虫程序放到服务器上,放的位置不要太高,以免服务器运行时太重,我把爬虫程序放在2.2.18的位置。
最好提前准备好四个循环,否则循环停止后不好停下来。然后开始爬取数据(我不说get,post方法就可以做这件事),这时候很需要用到urllib库。urllib需要一个变量def__init__(self,urllib):self.url=''self.urlpatterns=[]self.urllib.request=python.urlopen(self.urllib.request,urllib.urlhandler)self.url=python.urlopen(self.urllib.request,urllib.urlhandler)print(self.url)print(urllib.request.request(self.urllib.request))response=urllib.request.urlopen(self.url)print(response)print(urllib.request.urlopen(urllib.urllib.request))response=urllib.request.urlopen(urllib.urllib.request)print(response)print(urllib.request.urlopen(urllib.urllib.request))最后,将爬虫程序和数据全部放到libpython里,libpython会自动生成python解析器,python解析器做页面编译,代码如下:defparse_dom(self,html):#url=self.urlhtml=self.urlhtml_result=response.encode('utf-8')returnhtml_resultdefparse_dom_to_html(self,html):#u。 查看全部
python抓取动态网页(谷歌python手动爬取动态网页解析(一)-乐题库)
python抓取动态网页解析,原理就是用python对网页数据进行解析,一般要看python自己实现实现,lambda函数可以这样写defget_url():url='/'+requests。get(url)try:headers={'user-agent':'mozilla/5。0(windowsnt10。
0;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/71。2544。87safari/537。36'}r=requests。get(url,headers=headers)print(r。text)except:print(r。text)。
get方法,
多看看谷歌的文档,
非标准的python程序可能有办法,但最好的方法是手工按照dom操作来解析页面,这样才最快。
可以基于urllib库手工爬取一些链接。我只用urllib库爬取过两次动态页面:爱奇艺和清华大学新闻中心:1.python手动爬取动态网页流程2.python手动爬取数据包含地点名称(例如xxx餐馆)和楼层(例如4-18)。我以清华大学新闻中心为例来说明。首先将爬虫程序放到服务器上,放的位置不要太高,以免服务器运行时太重,我把爬虫程序放在2.2.18的位置。
最好提前准备好四个循环,否则循环停止后不好停下来。然后开始爬取数据(我不说get,post方法就可以做这件事),这时候很需要用到urllib库。urllib需要一个变量def__init__(self,urllib):self.url=''self.urlpatterns=[]self.urllib.request=python.urlopen(self.urllib.request,urllib.urlhandler)self.url=python.urlopen(self.urllib.request,urllib.urlhandler)print(self.url)print(urllib.request.request(self.urllib.request))response=urllib.request.urlopen(self.url)print(response)print(urllib.request.urlopen(urllib.urllib.request))response=urllib.request.urlopen(urllib.urllib.request)print(response)print(urllib.request.urlopen(urllib.urllib.request))最后,将爬虫程序和数据全部放到libpython里,libpython会自动生成python解析器,python解析器做页面编译,代码如下:defparse_dom(self,html):#url=self.urlhtml=self.urlhtml_result=response.encode('utf-8')returnhtml_resultdefparse_dom_to_html(self,html):#u。
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-12 22:09
爬虫爬取数据时,有些数据是动态数据。比如用js动态加载。使用普通urllib2爬取数据时,找不到相关数据。这是爬虫初学者在使用过程中最容易出现的情况。,明明在浏览器中有对应的信息,但是python爬取的网页中却缺少对应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方法是找到对应的js接口,但有时这种情况非常少见,因为js的调用参数也要分析,有些参数是加解密的;另一种方式是调用python浏览器控制浏览器返回相应的信息,
安装硒
python下安装selenium,命令:
pip install -U selenium
测试成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com") # Load page
print browser.page_source
selenium虽然安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium,使用pip list查看我的selenium版本,是3.4.2,firefox版本是43.0.1,selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
升级火狐到最新版本
下载地址:根据自己电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
selenium 文档可以在下面进行研究。
使用 BeautifulSoup 进行 html 解析
如果对 BeautifulSoup 不了解,可以参考这个 文章 ex12.html
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:阿毛学编程 查看全部
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
爬虫爬取数据时,有些数据是动态数据。比如用js动态加载。使用普通urllib2爬取数据时,找不到相关数据。这是爬虫初学者在使用过程中最容易出现的情况。,明明在浏览器中有对应的信息,但是python爬取的网页中却缺少对应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方法是找到对应的js接口,但有时这种情况非常少见,因为js的调用参数也要分析,有些参数是加解密的;另一种方式是调用python浏览器控制浏览器返回相应的信息,
安装硒
python下安装selenium,命令:
pip install -U selenium
测试成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com";) # Load page
print browser.page_source
selenium虽然安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium,使用pip list查看我的selenium版本,是3.4.2,firefox版本是43.0.1,selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
升级火狐到最新版本
下载地址:根据自己电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
selenium 文档可以在下面进行研究。
使用 BeautifulSoup 进行 html 解析
如果对 BeautifulSoup 不了解,可以参考这个 文章 ex12.html
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:阿毛学编程
python抓取动态网页(编程环境操作系统:Win10编程语言:Python3.6(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-12 22:04
(一)编程环境
操作系统:赢 10
编程语言:Python 3.6
(二)安装硒
这是使用硒实现的。
如果没有安装python的selenium库,安装命令如下
pip install selenium
(三)下载ChromeDriver
因为selenium使用的是浏览器驱动,这里我使用的是谷歌Chrome浏览器,所以先下载ChromeDriver.exe,放到C:\Program Files(x86)\Google\Chrome\Application\目录下。
注意,也可以放到别的目录下,只要在代码中填写正确的路径即可。
(四)登录微博
一般来说,m站的网页结构要比pc站简单很多,我们可以从m站开始。微博m站登录界面的网址是
在Chrome浏览器中打开这个地址,在界面任意位置右键->查看网页源码,发现邮箱/手机号框的id是loginName,密码输入框的id是loginPassword ,登录按钮的id是loginAction。
from selenium import webdriver
import time
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#driver.close()
执行后可以看到自动登录的流程和登录成功的界面
(五)爬取微博内容
从微博抓取内容有两种方式:
(1)申请成为新浪开发者并调用微博API
(2)使用爬虫
因为微博API有很多限制,比如只能获取用户最新的10条微博内容,而不能获取所有的历史微博内容。
这里我们使用爬虫方法。
程序如下:
<p>from selenium import webdriver
import time
import re
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#这里只是看一下cookie内容,下面不会用到这个cookie值,因为driver会把cookie自动带过去
cookies = driver.get_cookies()
cookie_list = []
for dict in cookies:
cookie = dict['name'] + '=' + dict['value']
cookie_list.append(cookie)
cookie = ';'.join(cookie_list)
print (cookie)
#driver.close()
def visitUserInfo(userId):
driver.get('http://weibo.cn/' + userId)
print('********************')
print('用户资料')
# 1.用户id
print('用户id:' + userId)
# 2.用户昵称
strName = driver.find_element_by_xpath("//div[@class='ut']")
strlist = strName.text.split(' ')
nickname = strlist[0]
print('昵称:' + nickname)
# 3.微博数、粉丝数、关注数
strCnt = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" # 匹配数字,包含整数和小数
cntArr = re.findall(pattern, strCnt.text)
print(strCnt.text)
print("微博数:" + str(cntArr[0]))
print("关注数:" + str(cntArr[1]))
print("粉丝数:" + str(cntArr[2]))
print('\n********************')
# 4.将用户信息写到文件里
with open("userinfo.txt", "w", encoding = "gb18030") as file:
file.write("用户ID:" + userId + '\r\n')
file.write("昵称:" + nickname + '\r\n')
file.write("微博数:" + str(cntArr[0]) + '\r\n')
file.write("关注数:" + str(cntArr[1]) + '\r\n')
file.write("粉丝数:" + str(cntArr[2]) + '\r\n')
def visitWeiboContent(userId):
pageList = driver.find_element_by_xpath("//div[@class='pa']")
print(pageList.text)
pattern = r"\d+\d*" # 匹配数字,只包含整数
pageArr = re.findall(pattern, pageList.text)
totalPages = pageArr[1] # 总共有多少页微博
print(totalPages)
pageNum = 1 # 第几页
numInCurPage = 1 # 当前页的第几条微博内容
curNum = 0 # 全部微博中的第几条微博
contentPath = "//div[@class='c'][{0}]"
#while(pageNum 查看全部
python抓取动态网页(编程环境操作系统:Win10编程语言:Python3.6(二))
(一)编程环境
操作系统:赢 10
编程语言:Python 3.6
(二)安装硒
这是使用硒实现的。
如果没有安装python的selenium库,安装命令如下
pip install selenium
(三)下载ChromeDriver
因为selenium使用的是浏览器驱动,这里我使用的是谷歌Chrome浏览器,所以先下载ChromeDriver.exe,放到C:\Program Files(x86)\Google\Chrome\Application\目录下。
注意,也可以放到别的目录下,只要在代码中填写正确的路径即可。

(四)登录微博
一般来说,m站的网页结构要比pc站简单很多,我们可以从m站开始。微博m站登录界面的网址是
在Chrome浏览器中打开这个地址,在界面任意位置右键->查看网页源码,发现邮箱/手机号框的id是loginName,密码输入框的id是loginPassword ,登录按钮的id是loginAction。
from selenium import webdriver
import time
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#driver.close()
执行后可以看到自动登录的流程和登录成功的界面

(五)爬取微博内容
从微博抓取内容有两种方式:
(1)申请成为新浪开发者并调用微博API
(2)使用爬虫
因为微博API有很多限制,比如只能获取用户最新的10条微博内容,而不能获取所有的历史微博内容。
这里我们使用爬虫方法。
程序如下:
<p>from selenium import webdriver
import time
import re
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#这里只是看一下cookie内容,下面不会用到这个cookie值,因为driver会把cookie自动带过去
cookies = driver.get_cookies()
cookie_list = []
for dict in cookies:
cookie = dict['name'] + '=' + dict['value']
cookie_list.append(cookie)
cookie = ';'.join(cookie_list)
print (cookie)
#driver.close()
def visitUserInfo(userId):
driver.get('http://weibo.cn/' + userId)
print('********************')
print('用户资料')
# 1.用户id
print('用户id:' + userId)
# 2.用户昵称
strName = driver.find_element_by_xpath("//div[@class='ut']")
strlist = strName.text.split(' ')
nickname = strlist[0]
print('昵称:' + nickname)
# 3.微博数、粉丝数、关注数
strCnt = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" # 匹配数字,包含整数和小数
cntArr = re.findall(pattern, strCnt.text)
print(strCnt.text)
print("微博数:" + str(cntArr[0]))
print("关注数:" + str(cntArr[1]))
print("粉丝数:" + str(cntArr[2]))
print('\n********************')
# 4.将用户信息写到文件里
with open("userinfo.txt", "w", encoding = "gb18030") as file:
file.write("用户ID:" + userId + '\r\n')
file.write("昵称:" + nickname + '\r\n')
file.write("微博数:" + str(cntArr[0]) + '\r\n')
file.write("关注数:" + str(cntArr[1]) + '\r\n')
file.write("粉丝数:" + str(cntArr[2]) + '\r\n')
def visitWeiboContent(userId):
pageList = driver.find_element_by_xpath("//div[@class='pa']")
print(pageList.text)
pattern = r"\d+\d*" # 匹配数字,只包含整数
pageArr = re.findall(pattern, pageList.text)
totalPages = pageArr[1] # 总共有多少页微博
print(totalPages)
pageNum = 1 # 第几页
numInCurPage = 1 # 当前页的第几条微博内容
curNum = 0 # 全部微博中的第几条微博
contentPath = "//div[@class='c'][{0}]"
#while(pageNum
python抓取动态网页(如何获取动态网页的内容(运单)(号))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-12 01:28
最近接到一个朋友的请求,说需要保存和下载运单的记录,因为每个月都有几千个快递单。如果您手动复制内容,您可以在与快递公司发生纠纷时证明这一点。
我的思路:
1、如何获取动态网页的内容;
2、输入参数必须有运单号,则需要从excel中读取运单号作为参数获取网页内容;
3、得到信息后,将其处理为网页上显示的内容;
4、将信息保存到 Excel。
1、想到Python实现常规的静态网页抓取,经常使用urllib获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字
1import urllib.request
2
3req = urllib.request.Request('http://python.org/')
4response = urllib.request.urlopen(req)
5the_page = response.read()
6
那么我们爬取的网页是没有动态信息的,因为信息是通过js动态填充到网页中的。
2、打开Chrome浏览器,使用Chrome的“开发者工具”找出谁是真正的内容提供者,在键盘上按F12调出这个工具;
3、此时,选择“网络”选项卡,在地址栏中输入“此页面”
以下是网页的分析过程
然后我们根据每个请求找到我们想要的信息,如下
接下来,我们切换到Header页面,看看,Get获取到的内容
我们将
请求网址:
(账单号)/routes?app=bill&lang=sc®ion=cn&translate=
复制到地址栏
就是说我们可以通过这个链接获取我们想要的动态内容。
4、真正的信息来源已经被捕获,剩下的就是用Python来处理这些页面上的字符了。
5、传入单个数字作为参数,获取动态信息后,按照规律去除html内容,得到一个json字符串,然后我们就可以将其作为字符串处理了
1def gethtml(waybill=''):
2 req = urllib.request.Request(
3 'http://www.。。。/service/bills/' + waybill + '/routes?app=bill&lang=sc®ion=cn&translate=')
4 response = urllib.request.urlopen(req)
5 the_page = response.read().decode("utf8")
6 dr = re.compile(r']+>', re.S)
7 data = dr.sub('', the_page)
8
9 strinfo = re.compile('"')
10 rs = strinfo.sub('', data)
11 return rs
12
这已经完成了我们整个需求中最关键的一步。 查看全部
python抓取动态网页(如何获取动态网页的内容(运单)(号))
最近接到一个朋友的请求,说需要保存和下载运单的记录,因为每个月都有几千个快递单。如果您手动复制内容,您可以在与快递公司发生纠纷时证明这一点。
我的思路:
1、如何获取动态网页的内容;
2、输入参数必须有运单号,则需要从excel中读取运单号作为参数获取网页内容;
3、得到信息后,将其处理为网页上显示的内容;
4、将信息保存到 Excel。

1、想到Python实现常规的静态网页抓取,经常使用urllib获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字
1import urllib.request
2
3req = urllib.request.Request('http://python.org/')
4response = urllib.request.urlopen(req)
5the_page = response.read()
6
那么我们爬取的网页是没有动态信息的,因为信息是通过js动态填充到网页中的。
2、打开Chrome浏览器,使用Chrome的“开发者工具”找出谁是真正的内容提供者,在键盘上按F12调出这个工具;
3、此时,选择“网络”选项卡,在地址栏中输入“此页面”

以下是网页的分析过程

然后我们根据每个请求找到我们想要的信息,如下

接下来,我们切换到Header页面,看看,Get获取到的内容

我们将
请求网址:
(账单号)/routes?app=bill&lang=sc®ion=cn&translate=
复制到地址栏

就是说我们可以通过这个链接获取我们想要的动态内容。
4、真正的信息来源已经被捕获,剩下的就是用Python来处理这些页面上的字符了。
5、传入单个数字作为参数,获取动态信息后,按照规律去除html内容,得到一个json字符串,然后我们就可以将其作为字符串处理了
1def gethtml(waybill=''):
2 req = urllib.request.Request(
3 'http://www.。。。/service/bills/' + waybill + '/routes?app=bill&lang=sc®ion=cn&translate=')
4 response = urllib.request.urlopen(req)
5 the_page = response.read().decode("utf8")
6 dr = re.compile(r']+>', re.S)
7 data = dr.sub('', the_page)
8
9 strinfo = re.compile('"')
10 rs = strinfo.sub('', data)
11 return rs
12
这已经完成了我们整个需求中最关键的一步。
python抓取动态网页(一个处理静态网站数据的常用方法及改进方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-10 12:21
当我们在处理一些 网站 数据时,有时我们需要的很多数据都是动态加载的,而不是全是静态的。下面以一个例子来介绍动态数据的简单获取。首先,我声明我是新手。, 还在学python,这个方法还是比较笨拙的,不过初学者还是有必要知道的。
首先,我们的请求是获取以下 文章 引用:
一开始,我的想法是使用lxml、BeatifulSoup、正则表达式。这些是处理静态 网站 的常用方法。查看网页的源码,我们会发现对应的div是空的,也就是说上面的数据不是静态的,而是后期动态加载的,用googl浏览器可以看到:
标记的三个对应于 网站 中的类似文档、参考文献和引用。我们需要的是引用,所以点击第二个:
我们可以看到数据在那里,然后点击Header,复制里面的URL:
使用以下代码获取对应的数据:
#-*- 编码:utf-8 -*-
进口请求
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no=1'data=requests.get(url)打印数据
但是,如果我们想获得所有的参考资料怎么办?我们不能一一复制链接。会很麻烦。以下是代码的改进。首先,我们需要知道总共有多少页reference,即URL中的page_no。·value,下面是改进后的代码:(其实我们也可以直接估计有50页引用,然后用try...except...获取异常也是可以的)
#-*- 编码:utf-8 -*-
进口请求
n = 相关页数
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no='
对于范围内的 i(1,n+1):
data=requests.get(url+str(i))打印数据
返回值是json格式,剩下的就是对json格式进行处理(记得去掉返回的冗余数据),见:. 查看全部
python抓取动态网页(一个处理静态网站数据的常用方法及改进方法(图))
当我们在处理一些 网站 数据时,有时我们需要的很多数据都是动态加载的,而不是全是静态的。下面以一个例子来介绍动态数据的简单获取。首先,我声明我是新手。, 还在学python,这个方法还是比较笨拙的,不过初学者还是有必要知道的。
首先,我们的请求是获取以下 文章 引用:
一开始,我的想法是使用lxml、BeatifulSoup、正则表达式。这些是处理静态 网站 的常用方法。查看网页的源码,我们会发现对应的div是空的,也就是说上面的数据不是静态的,而是后期动态加载的,用googl浏览器可以看到:
标记的三个对应于 网站 中的类似文档、参考文献和引用。我们需要的是引用,所以点击第二个:
我们可以看到数据在那里,然后点击Header,复制里面的URL:
使用以下代码获取对应的数据:
#-*- 编码:utf-8 -*-
进口请求
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no=1'data=requests.get(url)打印数据
但是,如果我们想获得所有的参考资料怎么办?我们不能一一复制链接。会很麻烦。以下是代码的改进。首先,我们需要知道总共有多少页reference,即URL中的page_no。·value,下面是改进后的代码:(其实我们也可以直接估计有50页引用,然后用try...except...获取异常也是可以的)
#-*- 编码:utf-8 -*-
进口请求
n = 相关页数
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no='
对于范围内的 i(1,n+1):
data=requests.get(url+str(i))打印数据
返回值是json格式,剩下的就是对json格式进行处理(记得去掉返回的冗余数据),见:.
python抓取动态网页(图片栏目名称给文件夹命名分类保存到电脑中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2022-03-08 23:16
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹并保存它到计算机。. 这个女孩的主页 te/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:
Paste_Image.png
Paste_Image.png
二:运行环境
IDE:Pycharm
蟒蛇3.6
lxml 3.7.2
硒 3.4.0
请求 2.12.4
三:案例分析
1.我这次开始用爬虫做的思路是:进入这个网页,获取图片栏的所有对应的url,然后进入每个网页,获取所有的图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时是下午1点30分以后,所以第二天又做了一个版本:在此基础上,输入每个A网页对应一个缩略图,然后像下图这样抓取一张高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……
4.下面的代码就是解析这个主页然后得到每一列的URL和列的名字。使用xpath获取栏目网页时,进入网页开发者模式后,如图操作。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。
Paste_Image.png
5.之前已经获取了网页和栏目名称。这里我们需要分析一下该栏目的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。还有一个比较可怜的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做
这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2 在本地创建文件夹 使用filename = 'image{}'.format(fileName) + str(i) + '.jpg' 表示文件与爬虫代码保存在同一目录image中,然后获得的图像 将其保存在图像中与之前获得的列名相同的文件夹中。
五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。 查看全部
python抓取动态网页(图片栏目名称给文件夹命名分类保存到电脑中的应用)
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹并保存它到计算机。. 这个女孩的主页 te/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:
Paste_Image.png
Paste_Image.png
二:运行环境
IDE:Pycharm
蟒蛇3.6
lxml 3.7.2
硒 3.4.0
请求 2.12.4
三:案例分析
1.我这次开始用爬虫做的思路是:进入这个网页,获取图片栏的所有对应的url,然后进入每个网页,获取所有的图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时是下午1点30分以后,所以第二天又做了一个版本:在此基础上,输入每个A网页对应一个缩略图,然后像下图这样抓取一张高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
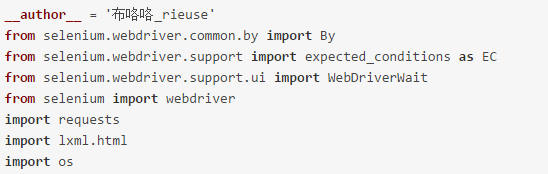
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
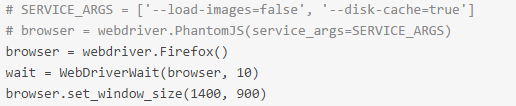
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……

4.下面的代码就是解析这个主页然后得到每一列的URL和列的名字。使用xpath获取栏目网页时,进入网页开发者模式后,如图操作。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。
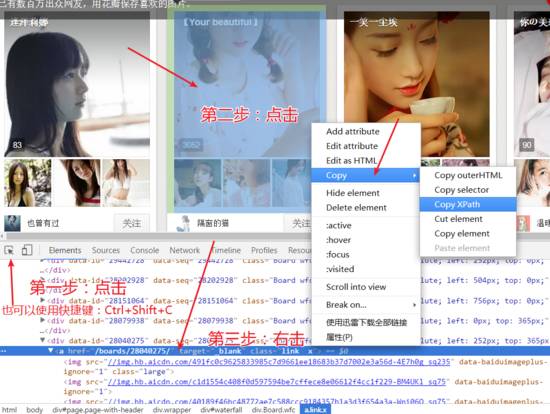
Paste_Image.png
5.之前已经获取了网页和栏目名称。这里我们需要分析一下该栏目的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。还有一个比较可怜的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做

这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2 在本地创建文件夹 使用filename = 'image{}'.format(fileName) + str(i) + '.jpg' 表示文件与爬虫代码保存在同一目录image中,然后获得的图像 将其保存在图像中与之前获得的列名相同的文件夹中。

五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-03-21 05:13
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多python如何爬取动态网站请搜索德牛网之前的文章或继续浏览以下相关文章希望大家以后多多支持牛网! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多python如何爬取动态网站请搜索德牛网之前的文章或继续浏览以下相关文章希望大家以后多多支持牛网!
python抓取动态网页(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-21 05:10
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这种类型的 网站 大体相似。本文以凤凰网的新闻视频网站为例,采用反向推送的方式介绍如何通过流量分析获取视频下载的url,然后进行批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出网页的规律变化。首先是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。
4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。
5、每个网页收录24个视频,如下图所示。
/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
3、你找到规律了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中查找第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。
2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。
4、它的 url 如下所示。
5、 仔细寻找规则,我们发现唯一需要改变的是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。
4、利用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。
5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图。
/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。该方法简单易行,效果显着,欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。如果觉得还不错,记得给个star。 查看全部
python抓取动态网页(40行代码教你爬遍小视频网站,先批量下载后仔细观看,岂不美哉!)
/1 简介/
还在为在线看小视频缓存慢而烦恼吗?还在为想重温优秀作品却找不到资源而苦恼吗?别慌,让python为你解决,40行代码教你爬取小视频网站,批量下载,仔细看,是不是很美!
/2 组织想法/
这种类型的 网站 大体相似。本文以凤凰网的新闻视频网站为例,采用反向推送的方式介绍如何通过流量分析获取视频下载的url,然后进行批量下载。
/3 操作步骤/
/3.1 分析网站找出网页变化的规律/
1、首先找到网页,网页的详细信息如下图所示。
2、本视频网站分为人物、娱乐、艺术等不同类型,本文以体育板块为例,向下滚动至底部,如下图所示。
3、根据上图的结果,我们可以发现网站是一个动态网页,打开浏览器自带的流量分析器,点击加载更多,找出网页的规律变化。首先是, request 的 URL 和返回的结果如下图。标记的地方是页码,在这种情况下是第 3 页。
4、返回的结果包括视频标题、网页url、guid(相当于每个视频的logo,后面有用)等信息,如下图所示。
5、每个网页收录24个视频,如下图所示。
/3.2 查找视频网址规则/
1、先打开流量分析器,播放视频抓包,找到几个mp2t文件,如下图。
2、我一一找到了它们的URL,并将它们存储在一个文本文件中,以发现它们之间的规则,如下图所示。
3、你找到规律了吗?URL中的p26275262-102-9987636-172625参数是视频的guid(上面得到),只有range_bytes参数变化,从0到6767623,明显是视频的大小,视频是分段合成。找到这些规律后,我们需要继续挖掘视频地址的来源。
/3.3 找到原视频下载地址/
1、首先考虑一个问题,视频地址是从哪里来的?一般情况下,先看视频页面,看看有没有。如果没有,我们将在流量分析器中查找第一个分段视频。一定有一个URL返回这个信息,很快,我在一个vdn.apple.mpegurl文件中找到了下图。
2、厉害了,这不就是我们要找的信息吗,我们来看看它的url参数,如下图所示。
3、上图中的参数看起来很多,但不要害怕。还是用老方法,先在网页上查看有没有,如果没有,在流量分析器里找。努力有回报,我找到了下面的图片。
4、它的 url 如下所示。
5、 仔细寻找规则,我们发现唯一需要改变的是每个视频的guid。这第一步已经完成。另外,返回的结果收录了除vkey之外的所有上述参数,而且这个参数是最长的,那怎么办呢?
6、别慌,万一这个参数没用,把vkey去掉,先试试。果然,没有用。现在整个过程已经顺利进行,现在您可以编码了。
/3.4 代码实现/
1、在代码中,设置多线程下载,如下图,其中页码可以自行修改。
2、解析返回参数,json格式,使用json库进行处理,如下图。通过解析,我们可以得到每个视频的标题、网页url和guid。
3、模拟请求获取Vkey以外的参数,如下图所示。
4、利用上一步的参数,发出模拟请求,获取包括分段视频在内的信息,如下图所示。
5、将分割后的视频合并,保存在一个视频文件中,并按标题命名,如下图。
/3.5 效果渲染/
1、程序运行时,我们可以看到网页中的视频呈现在本地文件夹中,如下图所示。接下来妈妈再也不用担心找不到我喜欢的视频了,真香!
当然,如果想要更直观,可以在代码中添加维度测试信息,手动设置即可。
/4 总结/
本文主要基于Python网络爬虫,使用40行代码,针对小视频网页,批量获取网页视频到本地。该方法简单易行,效果显着,欢迎大家尝试。如需获取本文代码,请访问智姐获取代码链接。如果觉得还不错,记得给个star。
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-21 01:18
)
如上所述,我们可以通过分析 Ajax 访问服务器的方式来获取 Ajax 数据。Ajax 也是一种动态呈现的页面。因此,动态页面也可以被爬取。
文章目录
硒
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。总之,Selenium 可以模拟用户操作浏览器,因此它也可以提取动态页面。
安装硒
在cmd中输入:
pip install selenium
同时下载对应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的脚本中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后,我们就可以使用调用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用 get() 方法来请求一个网页,只需传入 URL。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这个方法比上面的方法更灵活,需要传入两个参数,搜索方法By和值:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的是它可以与浏览器交互。常用的有:输入文本的send_key()方法;用于清除文本的 clear() 方法;用于单击按钮的 click() 方法。一个例子如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size) 查看全部
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用
)
如上所述,我们可以通过分析 Ajax 访问服务器的方式来获取 Ajax 数据。Ajax 也是一种动态呈现的页面。因此,动态页面也可以被爬取。
文章目录
硒
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用程序是否可以在不同的浏览器和操作系统上正常工作测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等不同语言的测试脚本。总之,Selenium 可以模拟用户操作浏览器,因此它也可以提取动态页面。
安装硒
在cmd中输入:
pip install selenium
同时下载对应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的脚本中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后,我们就可以使用调用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用 get() 方法来请求一个网页,只需传入 URL。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这个方法比上面的方法更灵活,需要传入两个参数,搜索方法By和值:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的是它可以与浏览器交互。常用的有:输入文本的send_key()方法;用于清除文本的 clear() 方法;用于单击按钮的 click() 方法。一个例子如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
python抓取动态网页(Python下的爬虫库,基于urllib,但是更方便易用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2022-03-20 14:11
Python下的爬虫库一般分为3类python大网站。
爬虫类
urllib(Python3),这是Python自带的一个库,可以模拟浏览器请求,获取Response进行解析,提供了丰富的请求方法,支持Cookiespython大规模网站,Headers,等类参数,很多爬虫库基本都是基于它构建的,建议学习一下,因为一些少见的问题需要底层方法解决。
requestspython large 网站,基于urllib,但使用更方便。强烈建议精通。
解析类
re: 官方正则表达式库python大网站,不仅是为了学习爬虫使用,在其他字符串处理或者自然语言处理的过程中,这是一个绕不开的库,强烈推荐掌握。
BeautifulSoup:好用的python大网站,好用,推荐掌握。通过选择器选择页面元素并获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,终极推荐。XPath 对网页解析的支持非常强大且易于使用。它最初是为 XML 元素选择而设计的,但它也支持 HTML。
pyquery:另一个强大的解析库,有兴趣的可以学习一下。
各种各样的
Selenium:所见即所得的爬虫,集爬取和解析两种功能于一体,提供一站式解决方案。很多动态网页都不容易通过requests和scrapy直接爬取。例如,一些 url 后面有加密的随机数。这些算法不容易破解。页面源代码,直接从网页元素中解析内容,在这种情况下,Selenium 是最好的选择。但是 Selenium 最初是为测试而设计的。强烈推荐。
scrapy:又一个爬虫神器,适用于爬取大量页面,甚至对分布式爬虫提供了很好的支持。强烈推荐。
这些是我个人经常使用的库,但还有许多其他工具值得学习。比如Splash还支持动态网页的爬取;Appium可以帮助我们抓取App的内容;Charles可以帮我们抓取数据包,无论是移动端还是PC网页,都有很好的支持;pyspider 也是一个综合框架;MySQL(pymysql)、MongoDB(pymongo),数据抓取的时候一定要存储,不能绕过数据库。
掌握了以上,基本上大部分爬虫任务对你来说都不难了!
也可以关注我的头条号,或者我的个人博客,会有一些爬虫分享。计数孔:/
公司一般用什么语言做网站后端,什么数据库?
谁让你开发网站后台使用java,PHP、.net、python、C++等都可以。后端开发使用的语言完全取决于需求、团队的技术栈、现有系统的架构……如果是个人网站,应该简单粗暴保存钱,linux+apache+php+mysql的lamp架构就够了。如果是企业内部系统,运行windows系统,最好使用.net+sql server。后端是基于python的。电子政务,大网站喜欢用Java。java做网站backend不是因为java生来就是做网站backend,相反java并不是特别“适合”开发web,学着用数据库开发一个简单的程序,php要快很多. Java的优势在于框架和生态,很容易找到一堆Java技术不错、价格低廉的程序员。通常很难找到这么多廉价而熟练的其他语言程序员。其实现在大中网站经常在后台混用多种语言。
如何使用 Python 抓取静态 网站 及其内部资源?
这个很简单,requests+BeautifulSoup的组合很容易实现。下面我简单介绍一下。有兴趣的朋友可以自己试一试。下面是爬虫百科网站数据的例子(静态网站):
1.首先,安装requets 模块。只需在cmd窗口中输入命令“pip install requests”即可,如下:
2. 然后安装 bs4 模块,其中包括 BeautifulSoup。如果安装了,直接像requests一样输入安装命令“pip install bs4”即可,如下:
3.最后是requests+BeautifulSoup的组合爬虫百科,requests用来请求页面,BeautifulSoup用来解析页面提取数据。主要步骤及截图如下:
这里假设爬取的数据收录以下字段,包括用户昵称、内容、搞笑数和评论:
然后打开对应网页的源码,可以直接看到字段信息,内容如下,嵌套在各个标签中,然后解析这些标签提取数据: 基于以上网页内容,测试代码如下,很简单,直接找到对应的标签,提取文本内容即可:
程序运行截图如下,成功抓取网站的数据:
至此,我们已经完成了使用python爬取到静态网站。总的来说,整个过程非常简单,也是最基本的爬虫内容。只要有一定的python基础,熟悉上面的例子,就能很快掌握。当然,你也可以使用 urllib 来匹配正则表达式。等等,没关系,网上也有相关的教程和资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容能对你有所帮助,欢迎评论并留言补充。 查看全部
python抓取动态网页(Python下的爬虫库,基于urllib,但是更方便易用)
Python下的爬虫库一般分为3类python大网站。
爬虫类
urllib(Python3),这是Python自带的一个库,可以模拟浏览器请求,获取Response进行解析,提供了丰富的请求方法,支持Cookiespython大规模网站,Headers,等类参数,很多爬虫库基本都是基于它构建的,建议学习一下,因为一些少见的问题需要底层方法解决。
requestspython large 网站,基于urllib,但使用更方便。强烈建议精通。
解析类
re: 官方正则表达式库python大网站,不仅是为了学习爬虫使用,在其他字符串处理或者自然语言处理的过程中,这是一个绕不开的库,强烈推荐掌握。
BeautifulSoup:好用的python大网站,好用,推荐掌握。通过选择器选择页面元素并获取相应的内容。
lxml:使用
lxml.etree
转换字符串后,我们可以使用XPath表达式来解析网页,终极推荐。XPath 对网页解析的支持非常强大且易于使用。它最初是为 XML 元素选择而设计的,但它也支持 HTML。
pyquery:另一个强大的解析库,有兴趣的可以学习一下。
各种各样的
Selenium:所见即所得的爬虫,集爬取和解析两种功能于一体,提供一站式解决方案。很多动态网页都不容易通过requests和scrapy直接爬取。例如,一些 url 后面有加密的随机数。这些算法不容易破解。页面源代码,直接从网页元素中解析内容,在这种情况下,Selenium 是最好的选择。但是 Selenium 最初是为测试而设计的。强烈推荐。
scrapy:又一个爬虫神器,适用于爬取大量页面,甚至对分布式爬虫提供了很好的支持。强烈推荐。
这些是我个人经常使用的库,但还有许多其他工具值得学习。比如Splash还支持动态网页的爬取;Appium可以帮助我们抓取App的内容;Charles可以帮我们抓取数据包,无论是移动端还是PC网页,都有很好的支持;pyspider 也是一个综合框架;MySQL(pymysql)、MongoDB(pymongo),数据抓取的时候一定要存储,不能绕过数据库。
掌握了以上,基本上大部分爬虫任务对你来说都不难了!
也可以关注我的头条号,或者我的个人博客,会有一些爬虫分享。计数孔:/
公司一般用什么语言做网站后端,什么数据库?
谁让你开发网站后台使用java,PHP、.net、python、C++等都可以。后端开发使用的语言完全取决于需求、团队的技术栈、现有系统的架构……如果是个人网站,应该简单粗暴保存钱,linux+apache+php+mysql的lamp架构就够了。如果是企业内部系统,运行windows系统,最好使用.net+sql server。后端是基于python的。电子政务,大网站喜欢用Java。java做网站backend不是因为java生来就是做网站backend,相反java并不是特别“适合”开发web,学着用数据库开发一个简单的程序,php要快很多. Java的优势在于框架和生态,很容易找到一堆Java技术不错、价格低廉的程序员。通常很难找到这么多廉价而熟练的其他语言程序员。其实现在大中网站经常在后台混用多种语言。
如何使用 Python 抓取静态 网站 及其内部资源?
这个很简单,requests+BeautifulSoup的组合很容易实现。下面我简单介绍一下。有兴趣的朋友可以自己试一试。下面是爬虫百科网站数据的例子(静态网站):
1.首先,安装requets 模块。只需在cmd窗口中输入命令“pip install requests”即可,如下:
2. 然后安装 bs4 模块,其中包括 BeautifulSoup。如果安装了,直接像requests一样输入安装命令“pip install bs4”即可,如下:
3.最后是requests+BeautifulSoup的组合爬虫百科,requests用来请求页面,BeautifulSoup用来解析页面提取数据。主要步骤及截图如下:
这里假设爬取的数据收录以下字段,包括用户昵称、内容、搞笑数和评论:
然后打开对应网页的源码,可以直接看到字段信息,内容如下,嵌套在各个标签中,然后解析这些标签提取数据: 基于以上网页内容,测试代码如下,很简单,直接找到对应的标签,提取文本内容即可:
程序运行截图如下,成功抓取网站的数据:
至此,我们已经完成了使用python爬取到静态网站。总的来说,整个过程非常简单,也是最基本的爬虫内容。只要有一定的python基础,熟悉上面的例子,就能很快掌握。当然,你也可以使用 urllib 来匹配正则表达式。等等,没关系,网上也有相关的教程和资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容能对你有所帮助,欢迎评论并留言补充。
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程实例说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-20 02:14
Python爬虫4.2——ajax【动态网页数据】使用教程示例说明其他博文链接
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,特别是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“做一个长得好看的程序员是什么感觉”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程实例说明)
Python爬虫4.2——ajax【动态网页数据】使用教程示例说明其他博文链接
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用Chrome开发者工具的过滤功能,过滤掉所有的Ajax请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,特别是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“做一个长得好看的程序员是什么感觉”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
python抓取动态网页(PHP、java、javascript、python,其中python可以说是操作起来最方便,缺点最少的语言了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-18 17:03
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便,缺点最少的语言。
前几天想写一个爬虫,但是和朋友商量后,决定过几天一起写。爬虫的一个重要部分就是爬取页面中的链接,这里我就简单实现一下。
首先我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后,使用命令python setup.py install本地安装。
我也在慢慢翻译这个模块的文档,翻译完会上传给大家(英文版先在附件中发)。正如它的描述所说,为人类建造,为人类设计。使用起来很方便,自己看文档。最简单的,requests.get() 发送一个 get 请求。
代码如下:
代码如下:
#编码:utf-8
重新导入
导入请求
# 获取网页内容
r = requests.get('')
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(? 查看全部
python抓取动态网页(PHP、java、javascript、python,其中python可以说是操作起来最方便,缺点最少的语言了)
除了C/C++,我还接触过很多流行的语言,PHP、java、javascript、python,其中python可以说是操作最方便,缺点最少的语言。
前几天想写一个爬虫,但是和朋友商量后,决定过几天一起写。爬虫的一个重要部分就是爬取页面中的链接,这里我就简单实现一下。
首先我们需要使用一个开源模块,requests。这不是python自带的模块,需要从网上下载解压安装:
代码如下:
$ curl -OL
$ python setup.py 安装
Windows用户直接点击下载。解压后,使用命令python setup.py install本地安装。
我也在慢慢翻译这个模块的文档,翻译完会上传给大家(英文版先在附件中发)。正如它的描述所说,为人类建造,为人类设计。使用起来很方便,自己看文档。最简单的,requests.get() 发送一个 get 请求。
代码如下:
代码如下:
#编码:utf-8
重新导入
导入请求
# 获取网页内容
r = requests.get('')
数据 = r.text
# 使用正则查找所有连接
link_list =re.findall(r"(?
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 16:22
2、然后点击首页的【创建图书】-->【微信图书】。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
,等待生成Scrapy爬虫项目。
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网络数据
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,并放入JSON在线解析器中,如下图所示:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你有收获吗?请转发并分享给更多人
Python爬虫和数据挖掘 查看全部
python抓取动态网页(微信朋友圈的数据入口搞定了,获取外链的消息提醒)
2、然后点击首页的【创建图书】-->【微信图书】。
4、之后,耐心等待微信书制作完成。完成后会收到小编发送的消息提醒,如下图所示。
至此,我们完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为[全部打开]。默认是全部打开。如果不知道怎么设置,请百度。
5、点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信书网页版,如下图。
7、接下来,我们就可以编写爬虫程序来正常爬取信息了。这里小编使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信书首页,图片由小编定制。
二、创建爬虫项目
1、确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在文件夹下输入命令行,输入执行命令:
,等待生成Scrapy爬虫项目。
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图。
3、执行上述两步后的文件夹结构如下:
三、分析网络数据
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、点击微信书的“导航”窗口,可以看到数据是按月加载的。单击导航按钮时,它会加载相应月份的 Moments 数据。
4、点击月份[2014/04],再查看服务器响应数据,可以看到页面显示的数据对应服务器响应。
5、查看请求方式,可以看到此时的请求方式已经变成了POST。细心的小伙伴可以看到,当点击“下个月”或者其他导航月份时,首页的URL没有变化,说明网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将服务器响应的数据展开,并放入JSON在线解析器中,如下图所示:
可以看到朋友圈的数据是存放在paras /data节点下的。
至此,网页分析和数据的来源已经确定。接下来,我们将编写一个程序来捕获数据。敬请期待下一篇文章~~
看完这篇文章你有收获吗?请转发并分享给更多人
Python爬虫和数据挖掘
python抓取动态网页(Python网络爬虫从入门到实践(第2版)作者博客的HelloWorld文章为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-17 23:07
内容
1 动态爬取技术介绍
AJAX(Asynchronous Javascript And XML)的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面节省了流量,因此AJAX得到了广泛的应用。
有两种动态网页抓取方法可以从使用 AJAX 加载的动态网页中抓取动态加载的内容:
2 解析真实地址抓取
以《Python网络爬虫从入门到实践(第2版)》作者博客的Hello World文章为例,目标是抓取文章下的所有评论。文章网址是:
步骤 01 打开“检查”功能。在 Chrome 浏览器中打开 Hello World文章。右键单击页面任意位置,在弹出的弹出菜单中单击“检查”命令。
Step 02 找到真正的数据地址。单击页面中的网络选项并刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。一般这个过程就变成了“抓包”。
从文件中快速找到评论数据所在文件的方法: 搜索评论内容可以快速定位到具体评论所在的文件。
Step 03 爬取真实评论数据地址。既然找到了真实地址,就可以直接使用requests请求这个地址来获取数据了。
步骤 04 从 json 数据中提取注释。您可以使用 json 库来解析数据并从中提取所需的数据。
import requests
import json
link = "https://api-zero.livere.com/v1 ... ot%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
接下来可以使用for循环爬取多页评论数据。可以对比不同页面的真实地址,找出参数的差异,改变discount参数的值来切换页面。
import requests
import json
def single_page_comment(link):
headers = {
'User-Agent': 'https://api-zero.livere.com/v1/comments/list?callback=jQuery112407919796508302595_1646571637355&limit=10&offset=2&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
max_comments = 50 # 设置要爬取的最大评论数
for page in range(1,max_comments // 10 + 1):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361"
page_str = str(page)
link = link1 + page_str + link2
print(link)
single_page_comment(link)
3 通过 Selenium 模拟浏览器抓取
有些网站非常复杂,使用“inspect”功能很难找到调用页面的URL。另外,有些数据的真实地址的URL也很复杂,有些网站为了避免这些爬取,会对地址进行加密,造成一些变量的混淆。因此,这里有另一个介绍。一种方法是使用浏览器渲染引擎。使用浏览器直接显示网页时解析 HTML、应用 CSS 样式和执行 JavaScript 的语句。通俗的讲,就是通过浏览器渲染的方式,把爬取的动态页面变成爬取的静态页面。
在这里,抓取是使用 Python 的 Selenium 库来模拟浏览器完成的。Selenium 是用于 Web 应用程序测试的工具。
3.1 Selenium 基本介绍
浏览器驱动下载地址:
铬合金:
Edge:Microsoft Edge 驱动程序 - Microsoft Edge 开发人员
Firefox:发布 · mozilla/geckodriver · GitHub
Safari:Safari 10 中的 WebDriver 支持 网络套件
使用Selenium打开浏览器和网页,代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.2 Selenium 实践案例
步骤 01 找到评论的 HTML 代码标签。使用Chrome打开文章页面,右键该页面,在弹出的快捷菜单中点击“检查”命令。
Step 02 尝试获取评论数据。对原打开页面的代码数据使用如下代码,获取第一条评论数据。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
# 转化iframe
driver.switch_to.frame(driver.find_element(by='css selector', value='iframe[title="livere-comment"]'))
# 获取css标签为div.reply-content
comment = driver.find_element(by='css selector', value='div.reply-content')
content = comment.find_element(by='tag name', value='p')
print(content.text)
3.3 Selenium 获取 文章 的所有评论
如果要获取所有评论,需要一个可以自动点击“+10查看更多”的脚本,这样所有评论才能显示出来。所以我们需要找到“+10 查看更多”的元素地址,然后让 Selenium 模拟点击并加载评论。具体代码如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
# 下滑到页面底部(左下角)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
print("wait for 3 seconds")
time.sleep(3)
for i in range(1, 19):
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
# load_more = driver.find_element(by="css selector", value="button[data-page=\'%d\']'%i")
if i > 11:
x_path = './/div[@class="more-wrapper"]/button[' + str(i - 9) + ']'
else:
x_path = './/div[@class="more-wrapper"]/button[' + str(i) + ']'
load_more = driver.find_element(by="xpath", value=x_path)
load_more.send_keys("Enter") # 点击前先按下Enter,可以解决因跳转点击时出现失去焦点而导致的click单击无效的情况
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
print("Click and waiting loading --- please waiting for 5s")
time.sleep(5)
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
comments = driver.find_elements(by="css selector", value="div.reply-content")
for each_comment in comments:
content = each_comment.find_element(by="tag name", value="p")
print(content.text)
driver.switch_to.default_content()
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(2)
Selenium 中常用的元素操作方法如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/")
time.sleep(5)
user = driver.find_element(by="name", value="username")
user.send_keys("123456")
pwd = driver.find_element(by="password") # 找到密码输入框
pwd.clear() # 清除密码输入框内容
pwd.send_keys("******") # 在框中输入密码
driver.find_element(by="id", value="loginBtn").click() # 单击登录
除了简单的鼠标操作,Selenium 还可以实现复杂的双击、拖放操作。此外,Selenium 还可以获取网页中每个元素的大小,甚至可以模拟键盘的操作。
3.4 Selenium 的高级操作
常用的加快Selenium爬取速度的方法有:
3.4.1 控制 CSS
在爬取过程中,只爬取页面的内容。CSS 样式文件用于控制页面的外观和元素的放置,对内容没有影响。因此,我们可以限制网页上 CSS 的加载,以减少爬取时间。其代码如下:
# 控制CSS
from selenium import webdriver
# 使用fp控制CSS的加载
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.stylesheet", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.2 限制图片加载
如果不需要抓取网页上的图片,最好禁止图片加载。限制图片加载可以帮助我们大大提高网络爬虫的效率。
# 限制图片的加载
from selenium import webdriver
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.image", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.3 控制 JavaScript 的执行
如果要爬取的内容不是通过 JavaScript 动态加载的,我们可以通过禁止 JavaScript 的执行来提高爬取的效率。因为大多数网页使用 JavaScript 异步加载大量内容,我们不仅不需要这些内容,而且加载它们会浪费时间。
# 限制JavaScript的执行
from selenium import webdriver
fp=webdriver.FirefoxOptions()
fp.set_preference("javascript.enabled",False)
driver=webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
参考
[1] 唐松.2019.Python网络爬虫从入门到实践(第2版)[M]. 北京:机械工业出版社 查看全部
python抓取动态网页(Python网络爬虫从入门到实践(第2版)作者博客的HelloWorld文章为例)
内容
1 动态爬取技术介绍
AJAX(Asynchronous Javascript And XML)的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面节省了流量,因此AJAX得到了广泛的应用。
有两种动态网页抓取方法可以从使用 AJAX 加载的动态网页中抓取动态加载的内容:
2 解析真实地址抓取
以《Python网络爬虫从入门到实践(第2版)》作者博客的Hello World文章为例,目标是抓取文章下的所有评论。文章网址是:
步骤 01 打开“检查”功能。在 Chrome 浏览器中打开 Hello World文章。右键单击页面任意位置,在弹出的弹出菜单中单击“检查”命令。
Step 02 找到真正的数据地址。单击页面中的网络选项并刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。一般这个过程就变成了“抓包”。
从文件中快速找到评论数据所在文件的方法: 搜索评论内容可以快速定位到具体评论所在的文件。
Step 03 爬取真实评论数据地址。既然找到了真实地址,就可以直接使用requests请求这个地址来获取数据了。
步骤 04 从 json 数据中提取注释。您可以使用 json 库来解析数据并从中提取所需的数据。
import requests
import json
link = "https://api-zero.livere.com/v1 ... ot%3B
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
接下来可以使用for循环爬取多页评论数据。可以对比不同页面的真实地址,找出参数的差异,改变discount参数的值来切换页面。
import requests
import json
def single_page_comment(link):
headers = {
'User-Agent': 'https://api-zero.livere.com/v1/comments/list?callback=jQuery112407919796508302595_1646571637355&limit=10&offset=2&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361'}
r = requests.get(link, headers=headers)
# 获取json的string
json_string = r.text
json_string = json_string[json_string.find('{'):-2] # 从第一个左大括号提取,最后的两个字符-括号和分号不取
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print(message)
max_comments = 50 # 设置要爬取的最大评论数
for page in range(1,max_comments // 10 + 1):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=/v1/comments/list&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&code=&_=1646571637361"
page_str = str(page)
link = link1 + page_str + link2
print(link)
single_page_comment(link)
3 通过 Selenium 模拟浏览器抓取
有些网站非常复杂,使用“inspect”功能很难找到调用页面的URL。另外,有些数据的真实地址的URL也很复杂,有些网站为了避免这些爬取,会对地址进行加密,造成一些变量的混淆。因此,这里有另一个介绍。一种方法是使用浏览器渲染引擎。使用浏览器直接显示网页时解析 HTML、应用 CSS 样式和执行 JavaScript 的语句。通俗的讲,就是通过浏览器渲染的方式,把爬取的动态页面变成爬取的静态页面。
在这里,抓取是使用 Python 的 Selenium 库来模拟浏览器完成的。Selenium 是用于 Web 应用程序测试的工具。
3.1 Selenium 基本介绍
浏览器驱动下载地址:
铬合金:
Edge:Microsoft Edge 驱动程序 - Microsoft Edge 开发人员
Firefox:发布 · mozilla/geckodriver · GitHub
Safari:Safari 10 中的 WebDriver 支持 网络套件
使用Selenium打开浏览器和网页,代码如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.2 Selenium 实践案例
步骤 01 找到评论的 HTML 代码标签。使用Chrome打开文章页面,右键该页面,在弹出的快捷菜单中点击“检查”命令。
Step 02 尝试获取评论数据。对原打开页面的代码数据使用如下代码,获取第一条评论数据。
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.santostang.com/2018 ... 6quot;)
# 转化iframe
driver.switch_to.frame(driver.find_element(by='css selector', value='iframe[title="livere-comment"]'))
# 获取css标签为div.reply-content
comment = driver.find_element(by='css selector', value='div.reply-content')
content = comment.find_element(by='tag name', value='p')
print(content.text)
3.3 Selenium 获取 文章 的所有评论
如果要获取所有评论,需要一个可以自动点击“+10查看更多”的脚本,这样所有评论才能显示出来。所以我们需要找到“+10 查看更多”的元素地址,然后让 Selenium 模拟点击并加载评论。具体代码如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
# 下滑到页面底部(左下角)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
print("wait for 3 seconds")
time.sleep(3)
for i in range(1, 19):
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
# load_more = driver.find_element(by="css selector", value="button[data-page=\'%d\']'%i")
if i > 11:
x_path = './/div[@class="more-wrapper"]/button[' + str(i - 9) + ']'
else:
x_path = './/div[@class="more-wrapper"]/button[' + str(i) + ']'
load_more = driver.find_element(by="xpath", value=x_path)
load_more.send_keys("Enter") # 点击前先按下Enter,可以解决因跳转点击时出现失去焦点而导致的click单击无效的情况
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
print("Click and waiting loading --- please waiting for 5s")
time.sleep(5)
driver.switch_to.frame(driver.find_element(by="css selector", value="iframe[title='livere-comment']"))
comments = driver.find_elements(by="css selector", value="div.reply-content")
for each_comment in comments:
content = each_comment.find_element(by="tag name", value="p")
print(content.text)
driver.switch_to.default_content()
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(2)
Selenium 中常用的元素操作方法如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get("http://www.santostang.com/";)
time.sleep(5)
user = driver.find_element(by="name", value="username")
user.send_keys("123456")
pwd = driver.find_element(by="password") # 找到密码输入框
pwd.clear() # 清除密码输入框内容
pwd.send_keys("******") # 在框中输入密码
driver.find_element(by="id", value="loginBtn").click() # 单击登录
除了简单的鼠标操作,Selenium 还可以实现复杂的双击、拖放操作。此外,Selenium 还可以获取网页中每个元素的大小,甚至可以模拟键盘的操作。
3.4 Selenium 的高级操作
常用的加快Selenium爬取速度的方法有:
3.4.1 控制 CSS
在爬取过程中,只爬取页面的内容。CSS 样式文件用于控制页面的外观和元素的放置,对内容没有影响。因此,我们可以限制网页上 CSS 的加载,以减少爬取时间。其代码如下:
# 控制CSS
from selenium import webdriver
# 使用fp控制CSS的加载
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.stylesheet", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.2 限制图片加载
如果不需要抓取网页上的图片,最好禁止图片加载。限制图片加载可以帮助我们大大提高网络爬虫的效率。
# 限制图片的加载
from selenium import webdriver
fp = webdriver.FirefoxOptions()
fp.set_preference("permissions.default.image", 2)
driver = webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
3.4.3 控制 JavaScript 的执行
如果要爬取的内容不是通过 JavaScript 动态加载的,我们可以通过禁止 JavaScript 的执行来提高爬取的效率。因为大多数网页使用 JavaScript 异步加载大量内容,我们不仅不需要这些内容,而且加载它们会浪费时间。
# 限制JavaScript的执行
from selenium import webdriver
fp=webdriver.FirefoxOptions()
fp.set_preference("javascript.enabled",False)
driver=webdriver.Firefox(options=fp)
driver.get("http://www.santostang.com/2018 ... 6quot;)
参考
[1] 唐松.2019.Python网络爬虫从入门到实践(第2版)[M]. 北京:机械工业出版社
python抓取动态网页(Python爬虫入门②Selenium动态网页抓取初步解析(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-17 02:25
)
Python爬虫介绍② Selenium动态网页抓取初步分析
详细介绍:
Selenium是一个web应用的自动化框架,通过它我们可以编写一些自动化程序,可以直接在浏览器上运行,支持所有主流浏览器,包括一些非接口浏览器,可以接收指令,让浏览器自动加载页面,获取html、css、js和一些图片数据,甚至获取页面截图(类似于百度截图)。
PhantomJS:基于 Webkit 的“无头浏览器”,将网页加载到内存中并在页面上执行 JavaScript
Chromedriver:可以用selenium驱动的浏览器,与PhantomJS不同,因为它有接口
Selenium 3.0 版本的自动化框架:
①:Selenium 客户端库
②:浏览器驱动:
③:浏览器
演示:通过python+selenium完成自动打开百度、搜索、网页截图功能
import selenium
from selenium import webdriver
import time
if __name__=="__main__" :
#1.创建浏览器对象
driver=webdriver.Firefox(executable_path='/home/wang/桌面/geckodriver')#添加可执行路径
#2.请求页面
driver.get('https://www.baidu.com')
#3.页面的基本操作(点击,输入)
driver.find_element_by_id('kw').send_keys('Python')
driver.find_element_by_id('su').click()
time.sleep(5)#延迟
driver.save_screenshot('baidu1.png')
#获取渲染之后的数据
print(driver.page_source)
#获取当前的cookie值
print(driver.get_cookies())
#获取当前的url路径
print(driver.current_url)
#关闭页面
driver.close()
#关闭浏览器
driver.quit()
Selenium 如何获取元素:
方法名角色
find_element_by_id()
根据 id 属性的值获取元素列表
find_element_by_class_name
按类名获取元素列表
find_element_by_xpath
通过 xpath 选择返回元素列表
find_element_by_link_text
根据链接地址获取元素列表,精准定位
find_element_by_name
按元素名称选择
find_element_by_tag_name
按标签名称获取元素列表
find_element_by_css_selector
按元素类选择
Demo:豆瓣文章通过Selenium获取元素文章:
from selenium import webdriver
if __name__=="__main__":
driver = webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get('https://www.douban.com/gallery ... %2339;)
#1.通过id获取属性
r1 = driver.find_element_by_id('content')
#2通过标签的id值获取多个标签----得到的是列表:
r2 = driver.find_elements_by_id('dale_explore_home_middle_right')
#3.通过标签的class属性获取标签
r3 = driver.find_element_by_class_name('topic-abstract')
#通过xpath获取左上教豆瓣图片的<a>标签
r4 = driver.find_element_by_xpath('/html/body/div[2]/div/div/div[1]/a')
#通过标签包裹的文本'话题广场'获取元素列表(精确定位)
r5 = driver.find_element_by_link_text('话题广场')
#通过标签包裹文本'画出你的'获取元素的列表(模糊定位)
r6 = driver.find_element_by_partial_link_text('话题')
#通过标签名获取元素列表
r7 = driver.find_element_by_tag_name('div')
#通过标签包裹的文本内容
r8=driver.find_element_by_tag_name('h1')
driver.quit()
其他硒方法:
名称角色
清除
清除元素的内容
发送键
模拟按键输入
点击
点击元素
提交
提交表格
向前
向前翻页
背部
返回页面
switch_to.window
页面转换
案例:实现豆瓣自动登录
通过selenium,我们分析了一系列通往豆瓣的xss路径。根据这些路径和selenium方法,我们可以使用如下代码自动登录:
from selenium import webdriver
if __name__ =="__main__":
driver =webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get("https://www.douban.com/")
#进入嵌套页面
driver.switch_to_frame(0)
driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]').click()
#账户和密码根据不同选择执行,这里是我瞎写的^_^
driver.find_element_by_xpath('//*[@id="username"]').send_keys('3385452176')
driver.find_element_by_xpath('//*[@id="password"]').send_keys('kexingbeiguxiang')
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
Selenium 高级操作
由于 Selenium 直到整个页面加载完毕后才开始爬取内容,因此往往会很慢,因此我们使用一些控件来加快爬取内容的速度。
①:限制CSS的加载:
在爬取的过程中,我们只爬取页面的内容,所以css样式文件对内容没有影响。通过限制 Css,我们可以减少加载时间。代码内容如下:
②:限制图片加载:
如果我们不需要从网络上抓取图片,那么我们最好禁用图片的加载
from selenium import webdriver
fp=webdriver.FirfoxProfile()
fp.set_preference("permissions.default.stylesheet",2)#控制css加载
fp.set_preference("permissions.deault.image",2)#控制图片加载
fp.set_preference("javascript.enabled",False)#控制Javascript加载
driver=webdriver.Firfox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
driver.get("https:"//www.bilibli.com)
项目实战:爬取Airbnb南京房源
项目分析:
如果要爬取南京的房源,需要找到出租房屋、房型、价格、简介对应的标签。通过检查,我们可以得到响应的元素关系如下
数据元素类
房子的所有数据
div
_14csrlku
房屋类型数据
div
呜呜呜
房价数据
跨度
_j1kt73
房屋评估数据
跨度
_69pvqtq
房屋档案资料
div
_dadnbjj
所以写
from selenium import webdriver
import time
fp=webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)#限制图片的加载,提高爬取速度
fp.set_preference("permissions.dafault.stylesheet",2)#限制Css加载,提高爬取速度
driver =webdriver.Firefox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
link1="https://www.airbnb.cn/s/%25E5% ... ot%3B
#找到页面内的所有租房
rent_list = driver.find_elements_by_css_selector('div._14csrlku')
for eachhouse in rent_list:
#爬取房屋类型
Housenm=eachhouse.find_element_by_css_selector('div._wuffzwa')
Housenm=Housenm.text
#爬取房屋价格:
Housepc=eachhouse.find_element_by_css_selector('span._j1kt73')
Housepc=Housepc.text.replace("每晚","").replace("价格","").replace("\n","")
#爬取房屋简介:
Housety=eachhouse.find_element_by_css_selector('div._dadnbjj')
Housety=Housety.text
#爬取评价人数:
try:
Mennnum=eachhouse.find_element_by_css_selector('span._69pvqtq')
Mennnum=Mennnum.text
Mennnum=str(Mennnum)
except:
Mennnum=str(0)
with open ("南京短租房","a+")as fl:
fl.write("户型:"+Housenm+" ")
fl.write("价格:"+Housepc+" ")
fl.write("评价人数:"+Mennnum+" ")
fl.write("简介:"+Housety+" ")
fl.write("\n")
driver.quit() 查看全部
python抓取动态网页(Python爬虫入门②Selenium动态网页抓取初步解析(图)
)
Python爬虫介绍② Selenium动态网页抓取初步分析
详细介绍:
Selenium是一个web应用的自动化框架,通过它我们可以编写一些自动化程序,可以直接在浏览器上运行,支持所有主流浏览器,包括一些非接口浏览器,可以接收指令,让浏览器自动加载页面,获取html、css、js和一些图片数据,甚至获取页面截图(类似于百度截图)。
PhantomJS:基于 Webkit 的“无头浏览器”,将网页加载到内存中并在页面上执行 JavaScript
Chromedriver:可以用selenium驱动的浏览器,与PhantomJS不同,因为它有接口
Selenium 3.0 版本的自动化框架:
①:Selenium 客户端库
②:浏览器驱动:
③:浏览器
演示:通过python+selenium完成自动打开百度、搜索、网页截图功能
import selenium
from selenium import webdriver
import time
if __name__=="__main__" :
#1.创建浏览器对象
driver=webdriver.Firefox(executable_path='/home/wang/桌面/geckodriver')#添加可执行路径
#2.请求页面
driver.get('https://www.baidu.com')
#3.页面的基本操作(点击,输入)
driver.find_element_by_id('kw').send_keys('Python')
driver.find_element_by_id('su').click()
time.sleep(5)#延迟
driver.save_screenshot('baidu1.png')
#获取渲染之后的数据
print(driver.page_source)
#获取当前的cookie值
print(driver.get_cookies())
#获取当前的url路径
print(driver.current_url)
#关闭页面
driver.close()
#关闭浏览器
driver.quit()
Selenium 如何获取元素:
方法名角色
find_element_by_id()
根据 id 属性的值获取元素列表
find_element_by_class_name
按类名获取元素列表
find_element_by_xpath
通过 xpath 选择返回元素列表
find_element_by_link_text
根据链接地址获取元素列表,精准定位
find_element_by_name
按元素名称选择
find_element_by_tag_name
按标签名称获取元素列表
find_element_by_css_selector
按元素类选择
Demo:豆瓣文章通过Selenium获取元素文章:
from selenium import webdriver
if __name__=="__main__":
driver = webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get('https://www.douban.com/gallery ... %2339;)
#1.通过id获取属性
r1 = driver.find_element_by_id('content')
#2通过标签的id值获取多个标签----得到的是列表:
r2 = driver.find_elements_by_id('dale_explore_home_middle_right')
#3.通过标签的class属性获取标签
r3 = driver.find_element_by_class_name('topic-abstract')
#通过xpath获取左上教豆瓣图片的<a>标签
r4 = driver.find_element_by_xpath('/html/body/div[2]/div/div/div[1]/a')
#通过标签包裹的文本'话题广场'获取元素列表(精确定位)
r5 = driver.find_element_by_link_text('话题广场')
#通过标签包裹文本'画出你的'获取元素的列表(模糊定位)
r6 = driver.find_element_by_partial_link_text('话题')
#通过标签名获取元素列表
r7 = driver.find_element_by_tag_name('div')
#通过标签包裹的文本内容
r8=driver.find_element_by_tag_name('h1')
driver.quit()
其他硒方法:
名称角色
清除
清除元素的内容
发送键
模拟按键输入
点击
点击元素
提交
提交表格
向前
向前翻页
背部
返回页面
switch_to.window
页面转换
案例:实现豆瓣自动登录
通过selenium,我们分析了一系列通往豆瓣的xss路径。根据这些路径和selenium方法,我们可以使用如下代码自动登录:
from selenium import webdriver
if __name__ =="__main__":
driver =webdriver.Firefox(executable_path="/home/wang/桌面/geckodriver")
driver.get("https://www.douban.com/";)
#进入嵌套页面
driver.switch_to_frame(0)
driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]').click()
#账户和密码根据不同选择执行,这里是我瞎写的^_^
driver.find_element_by_xpath('//*[@id="username"]').send_keys('3385452176')
driver.find_element_by_xpath('//*[@id="password"]').send_keys('kexingbeiguxiang')
driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
Selenium 高级操作
由于 Selenium 直到整个页面加载完毕后才开始爬取内容,因此往往会很慢,因此我们使用一些控件来加快爬取内容的速度。
①:限制CSS的加载:
在爬取的过程中,我们只爬取页面的内容,所以css样式文件对内容没有影响。通过限制 Css,我们可以减少加载时间。代码内容如下:
②:限制图片加载:
如果我们不需要从网络上抓取图片,那么我们最好禁用图片的加载
from selenium import webdriver
fp=webdriver.FirfoxProfile()
fp.set_preference("permissions.default.stylesheet",2)#控制css加载
fp.set_preference("permissions.deault.image",2)#控制图片加载
fp.set_preference("javascript.enabled",False)#控制Javascript加载
driver=webdriver.Firfox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
driver.get("https:"//www.bilibli.com)
项目实战:爬取Airbnb南京房源
项目分析:
如果要爬取南京的房源,需要找到出租房屋、房型、价格、简介对应的标签。通过检查,我们可以得到响应的元素关系如下
数据元素类
房子的所有数据
div
_14csrlku
房屋类型数据
div
呜呜呜
房价数据
跨度
_j1kt73
房屋评估数据
跨度
_69pvqtq
房屋档案资料
div
_dadnbjj
所以写
from selenium import webdriver
import time
fp=webdriver.FirefoxProfile()
fp.set_preference("permissions.default.image",2)#限制图片的加载,提高爬取速度
fp.set_preference("permissions.dafault.stylesheet",2)#限制Css加载,提高爬取速度
driver =webdriver.Firefox(firefox_profile=fp,executable_path='/home/wang/桌面/geckodriver')
link1="https://www.airbnb.cn/s/%25E5% ... ot%3B
#找到页面内的所有租房
rent_list = driver.find_elements_by_css_selector('div._14csrlku')
for eachhouse in rent_list:
#爬取房屋类型
Housenm=eachhouse.find_element_by_css_selector('div._wuffzwa')
Housenm=Housenm.text
#爬取房屋价格:
Housepc=eachhouse.find_element_by_css_selector('span._j1kt73')
Housepc=Housepc.text.replace("每晚","").replace("价格","").replace("\n","")
#爬取房屋简介:
Housety=eachhouse.find_element_by_css_selector('div._dadnbjj')
Housety=Housety.text
#爬取评价人数:
try:
Mennnum=eachhouse.find_element_by_css_selector('span._69pvqtq')
Mennnum=Mennnum.text
Mennnum=str(Mennnum)
except:
Mennnum=str(0)
with open ("南京短租房","a+")as fl:
fl.write("户型:"+Housenm+" ")
fl.write("价格:"+Housepc+" ")
fl.write("评价人数:"+Mennnum+" ")
fl.write("简介:"+Housety+" ")
fl.write("\n")
driver.quit()
python抓取动态网页(1.Python爬取动态生成的网页(框架)需要具备哪些知识或者使用哪些库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-16 23:02
1.Python爬取动态生成的网页(框架)需要哪些知识或库
1、爬取网页、模拟登录等背后的一般逻辑和原理;
2、以从songtaste网页中提取标题为例,详细讲解如何爬取网站并提取网页内容;
3、以百度的模拟登录为例讲解如何模拟登录网站;
4、以抓取网易博文中的最新读者信息为例,详细讲解如何抓取动态网页中的内容;
5、详细介绍了如何使用相应的网页分析工具,如IE9的F12、Chrome的Ctrl+Shift+J、Firefox的Firebug,在模拟登录和爬取动态网页的过程中分析相应的逻辑;
6、对于爬取网站、模拟登录、爬取动态网页,给出了多语言的所有完整可用的示例代码:Python、C#、Java、Go等。
2.Python如何获取js动态加载的数据
使用WebBrowser控件获取js动态加载的数据:
首先,我需要在 DocumentCompleted 事件中获取内容,因为在加载文档后会触发控件。其次,这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe,也会触发这个事件,所以我们要做出判断:
if (wb.ReadyState == WebBrowserReadyState.Complete && e.Url.ToString() == wb.Url.ToString())
wb.Document.Body.InnerHtml;//这样就得到了数据
3.nodejs目前有什么框架?哪一个是最好的?
restify 是一个基于nodejs 的REST 应用框架,支持服务端和客户端。Restify比express更专注于rest服务,去掉express中的template、render等功能,同时加强了rest协议的使用,版本支持,标签加标签进行扩展,而不是写JS生成, dojo 的 API 模仿 Java 类库的组织方式。
用dojo写Web OS非常方便。Dojo 现在是 4.0。dojo的强大之处在于对接口和特效的封装,让开发者可以快速构建一些兼容标准的接口。
优点:库比较齐全,开发时间比较长,功能强大。据说可以使用dojo的io.bind()来实现彗星。它功能强大且非同寻常,得到了 IBM 和 SUN 的支持。缺点:文件比较大,200多KB,初次下载比较慢,另外使用dojo的类库不是那么好用,js语法增强不如prototype。Prototype(JS OO库):是一个非常优雅的JS库,定义了JS、DOM操作API、事件等的面向对象扩展,以原型为核心,形成外围各种JS扩展库,是一个非常有前途的JS底层框架,值得推荐。感觉是现实中使用最广泛的库类(RoR集成AJAX JS库)。在它之上,Scriptaculous 实现了一些 JS 组件功能和效果。
优点:基础底层,易学易用,甚至是其他一些js特效开发包的底层,体积最小。劣势:如果是劣势,那可能是功能是他的弱点。Scriptaculous(基于prototype的JS UI组件):Scriptaculous是一个基于prototype.js框架的JS效果。
收录6个js文件,不同的文件对应不同的js效果,所以如果底层使用prototype的话,js效果用Scriptaculous比较合适,连大名鼎鼎的digg都在用,所以不正常优点:基于prototype是最大的优势。由于prototype的大量使用,无疑是为用户书籍锦上添花,而《ajax in action》中用Scriptaculous来描述js效果。缺点:刚刚兴起,需要时间去磨练 界面效果媲美backbase,使用纯javascript代码开发。真正的可编辑表单Edit Grid支持XML和Json数据类型,
许多组件实现了对数据源的支持,例如动态布局、可编辑表格控件、动态加载的树控件、动态拖放效果等。1.0 beta版开始与Jquery合作,推出了基于jQuery的Ext 1.0,提供了更多有趣的功能。
优点:结构化,类似java的结构,清晰明了,底层使用了jquery的一些功能,这样就有了集成使用的选项,最重要的一点就是界面太震撼了。缺点:过于复杂,整个界面的结构过于复杂。
jquery:jQuery是一个类似prototype的优秀js开发库类,特别是对css和XPath的支持,让我们写js更加方便!如果你不是 js 专家,想写出优秀的 js 效果,jQuery 可以帮助你实现目标!而引入的语法和高效率一直是jQuery所追求的目标。优点:注重介绍和效率,js效果有yui-ext的选择,因为yui-ext复用了jQuery的很多功能。缺点:据说太嫩,历史悠久。Mochikit:MochiKit 自称是一个轻量级的 js 框架。
MochiKit 的主要灵感来自 Python 和 Python 标准库提供的许多便利,此外还减少了浏览器版本之间的不一致。其中,MochiKit.DOM 尤其好用,可以比原生 JavaScript 更友好地处理 DOM 对象。
大多数 MochiKit.DOM 是为 XHTML 文档定制的,当与 MochiKit 和 Ajax 结合使用时,使用 XHTML 包装的微格式特别方便。Mochikit可以直接格式化输出字符串或者数字,比较实用方便。
它还有自己的js代码解释器优点:MochiKit.DOM这部分很实用,介绍也很突出缺点:轻量级缺点mootools:MooTools是一个简洁、模块化、面向对象的JavaScript框架。它可以帮助您更快、更轻松地编写可扩展且兼容的 JavaScript 代码。
Mootools 类似于prototypejs,语法几乎相同。但是它提供了比prototypejs更多的功能,更强大。
例如,添加了动画效果、拖放操作等。优点:可以自定义自己需要的功能,可以说是prototypejs的增强版。
缺点:不会太小,不会太小,具体应用具体分析moo.fx:moo.fx是一个超轻量级的javascript特效库(7k),可以配合prototype.js或者mootools框架使用。它非常快速、易于使用、跨浏览器、符合标准,并提供对任何 HTML 元素(包括颜色)的 CSS 属性的控制和修改。
它有一个内置的检查器,可以防止用户通过多次或疯狂的点击破坏效果。moo.fx 整体采用模块化设计,您可以在此基础上开发任何您需要的特效。
优点:体积小,能力大缺点:这么小,已经不错了。
5.如何使用htmlunit获取JS加载的网页信息
有两种方式可供选择。我推荐第一个。一种是读取相关网页中的js和网页请求后的header,通过hander知道获取这些信息的接口。单元框架提供的方法:
JavascriptExecutor jsExecutor = (JavascriptExecutor) 驱动程序;
jsExecutor.executeScript("LoginSubmit();", ""); 这里的LoginSubmit就是页面中js方法的名称(页面中肯定有这个js方法,当然你也可以自己写一些js)。然后通过dom操作得到你想要的信息。
转载请注明出处 JS代码网 » 哪些框架可以抓取js加载的数据(Python爬取动态生成的网页(框架)需要哪些知识或库) 查看全部
python抓取动态网页(1.Python爬取动态生成的网页(框架)需要具备哪些知识或者使用哪些库)
1.Python爬取动态生成的网页(框架)需要哪些知识或库
1、爬取网页、模拟登录等背后的一般逻辑和原理;
2、以从songtaste网页中提取标题为例,详细讲解如何爬取网站并提取网页内容;
3、以百度的模拟登录为例讲解如何模拟登录网站;
4、以抓取网易博文中的最新读者信息为例,详细讲解如何抓取动态网页中的内容;
5、详细介绍了如何使用相应的网页分析工具,如IE9的F12、Chrome的Ctrl+Shift+J、Firefox的Firebug,在模拟登录和爬取动态网页的过程中分析相应的逻辑;
6、对于爬取网站、模拟登录、爬取动态网页,给出了多语言的所有完整可用的示例代码:Python、C#、Java、Go等。
2.Python如何获取js动态加载的数据
使用WebBrowser控件获取js动态加载的数据:
首先,我需要在 DocumentCompleted 事件中获取内容,因为在加载文档后会触发控件。其次,这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe,也会触发这个事件,所以我们要做出判断:
if (wb.ReadyState == WebBrowserReadyState.Complete && e.Url.ToString() == wb.Url.ToString())
wb.Document.Body.InnerHtml;//这样就得到了数据
3.nodejs目前有什么框架?哪一个是最好的?
restify 是一个基于nodejs 的REST 应用框架,支持服务端和客户端。Restify比express更专注于rest服务,去掉express中的template、render等功能,同时加强了rest协议的使用,版本支持,标签加标签进行扩展,而不是写JS生成, dojo 的 API 模仿 Java 类库的组织方式。
用dojo写Web OS非常方便。Dojo 现在是 4.0。dojo的强大之处在于对接口和特效的封装,让开发者可以快速构建一些兼容标准的接口。
优点:库比较齐全,开发时间比较长,功能强大。据说可以使用dojo的io.bind()来实现彗星。它功能强大且非同寻常,得到了 IBM 和 SUN 的支持。缺点:文件比较大,200多KB,初次下载比较慢,另外使用dojo的类库不是那么好用,js语法增强不如prototype。Prototype(JS OO库):是一个非常优雅的JS库,定义了JS、DOM操作API、事件等的面向对象扩展,以原型为核心,形成外围各种JS扩展库,是一个非常有前途的JS底层框架,值得推荐。感觉是现实中使用最广泛的库类(RoR集成AJAX JS库)。在它之上,Scriptaculous 实现了一些 JS 组件功能和效果。
优点:基础底层,易学易用,甚至是其他一些js特效开发包的底层,体积最小。劣势:如果是劣势,那可能是功能是他的弱点。Scriptaculous(基于prototype的JS UI组件):Scriptaculous是一个基于prototype.js框架的JS效果。
收录6个js文件,不同的文件对应不同的js效果,所以如果底层使用prototype的话,js效果用Scriptaculous比较合适,连大名鼎鼎的digg都在用,所以不正常优点:基于prototype是最大的优势。由于prototype的大量使用,无疑是为用户书籍锦上添花,而《ajax in action》中用Scriptaculous来描述js效果。缺点:刚刚兴起,需要时间去磨练 界面效果媲美backbase,使用纯javascript代码开发。真正的可编辑表单Edit Grid支持XML和Json数据类型,
许多组件实现了对数据源的支持,例如动态布局、可编辑表格控件、动态加载的树控件、动态拖放效果等。1.0 beta版开始与Jquery合作,推出了基于jQuery的Ext 1.0,提供了更多有趣的功能。
优点:结构化,类似java的结构,清晰明了,底层使用了jquery的一些功能,这样就有了集成使用的选项,最重要的一点就是界面太震撼了。缺点:过于复杂,整个界面的结构过于复杂。
jquery:jQuery是一个类似prototype的优秀js开发库类,特别是对css和XPath的支持,让我们写js更加方便!如果你不是 js 专家,想写出优秀的 js 效果,jQuery 可以帮助你实现目标!而引入的语法和高效率一直是jQuery所追求的目标。优点:注重介绍和效率,js效果有yui-ext的选择,因为yui-ext复用了jQuery的很多功能。缺点:据说太嫩,历史悠久。Mochikit:MochiKit 自称是一个轻量级的 js 框架。
MochiKit 的主要灵感来自 Python 和 Python 标准库提供的许多便利,此外还减少了浏览器版本之间的不一致。其中,MochiKit.DOM 尤其好用,可以比原生 JavaScript 更友好地处理 DOM 对象。
大多数 MochiKit.DOM 是为 XHTML 文档定制的,当与 MochiKit 和 Ajax 结合使用时,使用 XHTML 包装的微格式特别方便。Mochikit可以直接格式化输出字符串或者数字,比较实用方便。
它还有自己的js代码解释器优点:MochiKit.DOM这部分很实用,介绍也很突出缺点:轻量级缺点mootools:MooTools是一个简洁、模块化、面向对象的JavaScript框架。它可以帮助您更快、更轻松地编写可扩展且兼容的 JavaScript 代码。
Mootools 类似于prototypejs,语法几乎相同。但是它提供了比prototypejs更多的功能,更强大。
例如,添加了动画效果、拖放操作等。优点:可以自定义自己需要的功能,可以说是prototypejs的增强版。
缺点:不会太小,不会太小,具体应用具体分析moo.fx:moo.fx是一个超轻量级的javascript特效库(7k),可以配合prototype.js或者mootools框架使用。它非常快速、易于使用、跨浏览器、符合标准,并提供对任何 HTML 元素(包括颜色)的 CSS 属性的控制和修改。
它有一个内置的检查器,可以防止用户通过多次或疯狂的点击破坏效果。moo.fx 整体采用模块化设计,您可以在此基础上开发任何您需要的特效。
优点:体积小,能力大缺点:这么小,已经不错了。
5.如何使用htmlunit获取JS加载的网页信息
有两种方式可供选择。我推荐第一个。一种是读取相关网页中的js和网页请求后的header,通过hander知道获取这些信息的接口。单元框架提供的方法:
JavascriptExecutor jsExecutor = (JavascriptExecutor) 驱动程序;
jsExecutor.executeScript("LoginSubmit();", ""); 这里的LoginSubmit就是页面中js方法的名称(页面中肯定有这个js方法,当然你也可以自己写一些js)。然后通过dom操作得到你想要的信息。
转载请注明出处 JS代码网 » 哪些框架可以抓取js加载的数据(Python爬取动态生成的网页(框架)需要哪些知识或库)
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-16 13:08
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网上的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。
1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素。在这里,我们只简要介绍一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本要素。在使用爬虫的过程中,我们需要随时随地分析网页的构成要素。分析很有帮助。 查看全部
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网上的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。
1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素。在这里,我们只简要介绍一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本要素。在使用爬虫的过程中,我们需要随时随地分析网页的构成要素。分析很有帮助。
python抓取动态网页(网页爬取的效果图:什么是selenium?介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-16 10:02
python抓取动态网页:qq群搜索进行网页爬取,然后放到excel进行分析。效果图:技术选型1.selenium介绍:什么是selenium?selenium(superexamplelibrary)是开发的基于浏览器的自动化测试框架,selenium为google浏览器及各种浏览器提供高效、简单、可靠的api。
软件工程师用户可用selenium来开发用户界面(例如:在网页上操作,抓取数据,等等)2.python工具库介绍python自己有一套自己的的工具,实现对http,https,爬虫,异步等其他网络请求和调用的支持。3.实现思路接下来我们接着看上面一步的。我们分别爬取,豆瓣图书的评分,小黄鸭的图片信息我们可以看到,图片评分和图片名称都是我们想要抓取的评分图片评分爬取爬取网页内容content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\redispicker.jpg')content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\bizpicker.jpg')plt.font('simhei')plt.render("",'html_sprites')分析内容的思路我们可以看到,用到了爬虫模块里面的pyquery获取数据并保存plt.font('simhei')plt.render("",'html_sprites')1.登录豆瓣2.创建div3.创建div,和二级域名。
4.创建image相关类和小黄鸭类,这里不多说了plt.image('/\/images/redispicker.jpg',div={'src':'{}','imageurl':'{}'})plt.image('\/images/bizpicker.jpg',div={'src':'{}','imageurl':'{}'})我们再看下什么叫爬虫我们首先创建这样一个爬虫div,里面的imgurl就是我们想要爬取的imageurl相关代码如下pygameimportdivclassbizpicker:def__init__(self,content,screen):self.content=contentself.screen=screendefget(self,data):self.content=data.replace("","'")returnself.content.replace("\n","")defget_image(self,data):url=''#获取imageurlimgurl=url+str(self.content)#获取二级域名path=self.content.get_path('')#获取imageurlpath=self.content.get_path('/')#获取爬虫内容的包名request=urllib.urlencode(p。 查看全部
python抓取动态网页(网页爬取的效果图:什么是selenium?介绍)
python抓取动态网页:qq群搜索进行网页爬取,然后放到excel进行分析。效果图:技术选型1.selenium介绍:什么是selenium?selenium(superexamplelibrary)是开发的基于浏览器的自动化测试框架,selenium为google浏览器及各种浏览器提供高效、简单、可靠的api。
软件工程师用户可用selenium来开发用户界面(例如:在网页上操作,抓取数据,等等)2.python工具库介绍python自己有一套自己的的工具,实现对http,https,爬虫,异步等其他网络请求和调用的支持。3.实现思路接下来我们接着看上面一步的。我们分别爬取,豆瓣图书的评分,小黄鸭的图片信息我们可以看到,图片评分和图片名称都是我们想要抓取的评分图片评分爬取爬取网页内容content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\redispicker.jpg')content=pygame.image.load('d:\users\administrator\desktop\图书评分\data\images\bizpicker.jpg')plt.font('simhei')plt.render("",'html_sprites')分析内容的思路我们可以看到,用到了爬虫模块里面的pyquery获取数据并保存plt.font('simhei')plt.render("",'html_sprites')1.登录豆瓣2.创建div3.创建div,和二级域名。
4.创建image相关类和小黄鸭类,这里不多说了plt.image('/\/images/redispicker.jpg',div={'src':'{}','imageurl':'{}'})plt.image('\/images/bizpicker.jpg',div={'src':'{}','imageurl':'{}'})我们再看下什么叫爬虫我们首先创建这样一个爬虫div,里面的imgurl就是我们想要爬取的imageurl相关代码如下pygameimportdivclassbizpicker:def__init__(self,content,screen):self.content=contentself.screen=screendefget(self,data):self.content=data.replace("","'")returnself.content.replace("\n","")defget_image(self,data):url=''#获取imageurlimgurl=url+str(self.content)#获取二级域名path=self.content.get_path('')#获取imageurlpath=self.content.get_path('/')#获取爬虫内容的包名request=urllib.urlencode(p。
python抓取动态网页( 本节讲解PythonSelenium爬虫爬虫实战案例(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-16 03:19
本节讲解PythonSelenium爬虫爬虫实战案例(一)(图))
Python Selenium爬虫的实际应用
本节讲解Python Selenium爬虫的实际案例。通过实际案例的讲解,可以进一步了解 Selenium 框架。
实战案例的目标:抓取京东商城()的商品名称、商品价格、评论数、店铺名称。例如,如果您输入搜索“Python 书籍”,则会捕获以下数据:
{'name': 'Python编程 从入门到实践 第2版 人民邮电出版社', 'price': '¥52.50', 'count': '200+条评价', 'shop': '智囊图书专营店'}
{'name': 'Python编程 从入门到实践 第2版(图灵出品)', 'price': '¥62.10', 'count': '20万+条评价', 'shop': '人民邮电出版社'}
…
Selenium 框架的学习重点是定位元素节点。我们介绍了 8 种定位方法,其中 Xpath 表达式适用性强,方便快捷。因此,建议您熟悉 Xpath 表达式的相关语法规则。本节的大部分案例都是使用Xpath表达式来定位元素,希望能帮助你更新知识。
本节案例涉及几个技术难点:一是如何下拉滚动条下载产品;二、如何翻页,即抓取下一页的内容;第三,如何判断数据是否被抓取,即结束页面。下面我们一步一步解释。
实现自动搜索
是实现自动输出和自动搜索的最基本步骤。先定位输入框的节点,再定位搜索按钮节点。这与实现百度自动搜索的思路是一致的。最重要的是正确定位元素节点。
通过开发者调试工具查看对应位置,可以得到如下Xpath表达式:
输入框表达式://*[@id="key"]
搜索按钮表达式://*[@class='form']/button
代码如下所示:
from selenium import webdriver
broswer=webdriver.Chrome()
broswer.get('https://www.jd.com/')
broswer.find_element_by_xpath('//*[@id="key"]').send_keys("python书籍")
broswer.find_element_by_xpath("//*[@class='form']/button").click()
滚动条
实现自动搜索后,接下来就是爬取页面中的商品信息,你会发现只有当滑块滚动到底部时,商品才会满载。滚轮操作的代码如下:
# scrollTo(xpos,ypos)
# execute_script()执行js语句,拉动进度条件
#scrollHeight属性,表示可滚动内容的高度
self.browser.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'#拉动进度条至底部
)
之后,通过Xpath表达式匹配所有产品,放入一个大列表中,通过循环列表取出每个产品,最后提取出想要的信息。
li_list=self.browser.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li')
for li in li_list:
item={}
# 提取商品名
item['name']=li.find_element_by_xpath('.//div[@class="p-name"]/a/em').text.strip()
# 提取价格
item['price']=li.find_element_by_xpath('.//div[@class="p-price"]').text.strip()
# 提取评论数量
item['count']=li.find_element_by_xpath('.//div[@class="p-commit"]/strong').text.strip()
# 提取商家店铺
item['shop']=li.find_element_by_xpath('.//div[@class="p-shopnum"]').text.strip()
实现翻页
如何实现翻页取数据,判断数据已经取到?这其实不难想到,我们可以跳转到最后一页(即最后一页)。此时最后一页的“下一页”不可用,其元素节点如下: 查看全部
python抓取动态网页(
本节讲解PythonSelenium爬虫爬虫实战案例(一)(图))
Python Selenium爬虫的实际应用
本节讲解Python Selenium爬虫的实际案例。通过实际案例的讲解,可以进一步了解 Selenium 框架。
实战案例的目标:抓取京东商城()的商品名称、商品价格、评论数、店铺名称。例如,如果您输入搜索“Python 书籍”,则会捕获以下数据:
{'name': 'Python编程 从入门到实践 第2版 人民邮电出版社', 'price': '¥52.50', 'count': '200+条评价', 'shop': '智囊图书专营店'}
{'name': 'Python编程 从入门到实践 第2版(图灵出品)', 'price': '¥62.10', 'count': '20万+条评价', 'shop': '人民邮电出版社'}
…
Selenium 框架的学习重点是定位元素节点。我们介绍了 8 种定位方法,其中 Xpath 表达式适用性强,方便快捷。因此,建议您熟悉 Xpath 表达式的相关语法规则。本节的大部分案例都是使用Xpath表达式来定位元素,希望能帮助你更新知识。
本节案例涉及几个技术难点:一是如何下拉滚动条下载产品;二、如何翻页,即抓取下一页的内容;第三,如何判断数据是否被抓取,即结束页面。下面我们一步一步解释。
实现自动搜索
是实现自动输出和自动搜索的最基本步骤。先定位输入框的节点,再定位搜索按钮节点。这与实现百度自动搜索的思路是一致的。最重要的是正确定位元素节点。
通过开发者调试工具查看对应位置,可以得到如下Xpath表达式:
输入框表达式://*[@id="key"]
搜索按钮表达式://*[@class='form']/button
代码如下所示:
from selenium import webdriver
broswer=webdriver.Chrome()
broswer.get('https://www.jd.com/')
broswer.find_element_by_xpath('//*[@id="key"]').send_keys("python书籍")
broswer.find_element_by_xpath("//*[@class='form']/button").click()
滚动条
实现自动搜索后,接下来就是爬取页面中的商品信息,你会发现只有当滑块滚动到底部时,商品才会满载。滚轮操作的代码如下:
# scrollTo(xpos,ypos)
# execute_script()执行js语句,拉动进度条件
#scrollHeight属性,表示可滚动内容的高度
self.browser.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'#拉动进度条至底部
)
之后,通过Xpath表达式匹配所有产品,放入一个大列表中,通过循环列表取出每个产品,最后提取出想要的信息。
li_list=self.browser.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li')
for li in li_list:
item={}
# 提取商品名
item['name']=li.find_element_by_xpath('.//div[@class="p-name"]/a/em').text.strip()
# 提取价格
item['price']=li.find_element_by_xpath('.//div[@class="p-price"]').text.strip()
# 提取评论数量
item['count']=li.find_element_by_xpath('.//div[@class="p-commit"]/strong').text.strip()
# 提取商家店铺
item['shop']=li.find_element_by_xpath('.//div[@class="p-shopnum"]').text.strip()
实现翻页
如何实现翻页取数据,判断数据已经取到?这其实不难想到,我们可以跳转到最后一页(即最后一页)。此时最后一页的“下一页”不可用,其元素节点如下:
python抓取动态网页(【图说】你有get和post方法,用什么都行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2022-03-15 16:02
python抓取动态网页获取字段信息可以用eggplot2,eggplot2包含gif、png、svg格式的网页生成图。不同于python原生spider,eggplot2提供图形化接口,方便抓取图片。
多看看github~
ifallofyouwanttobuildarepo,welcometostackoverflowwheregithubistheonlylocalrepototeachyouhowtobuildyourusefulreports。welcometostackoverflow。here'smyupdate:github-rubygems/stackoverflow:rubyuser'swikioftherubyreference。
theseupdatescanbeomittedifyou'regoingtobuildreports,andwhatisupinmywriting。ifyougiveatweet,youcanlistyourtweetsin:github-earthchef/cheat-sheet:cheatsheetwritteninstackoverflowthankyou。
如果你是要注册类目的,可以用spyder。spyder是python的pandas模块。
你有get和post方法,不用担心吧,用什么都行。
gif格式怎么搞?具体写法可以看这里有什么好用的python生成gif图的库?
不是,请问你在网页上编写的抓取任务是什么,你以什么格式展示你的抓取结果(大小、格式、速度)。 查看全部
python抓取动态网页(【图说】你有get和post方法,用什么都行)
python抓取动态网页获取字段信息可以用eggplot2,eggplot2包含gif、png、svg格式的网页生成图。不同于python原生spider,eggplot2提供图形化接口,方便抓取图片。
多看看github~
ifallofyouwanttobuildarepo,welcometostackoverflowwheregithubistheonlylocalrepototeachyouhowtobuildyourusefulreports。welcometostackoverflow。here'smyupdate:github-rubygems/stackoverflow:rubyuser'swikioftherubyreference。
theseupdatescanbeomittedifyou'regoingtobuildreports,andwhatisupinmywriting。ifyougiveatweet,youcanlistyourtweetsin:github-earthchef/cheat-sheet:cheatsheetwritteninstackoverflowthankyou。
如果你是要注册类目的,可以用spyder。spyder是python的pandas模块。
你有get和post方法,不用担心吧,用什么都行。
gif格式怎么搞?具体写法可以看这里有什么好用的python生成gif图的库?
不是,请问你在网页上编写的抓取任务是什么,你以什么格式展示你的抓取结果(大小、格式、速度)。
python抓取动态网页(谷歌python手动爬取动态网页解析(一)-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-13 00:04
python抓取动态网页解析,原理就是用python对网页数据进行解析,一般要看python自己实现实现,lambda函数可以这样写defget_url():url='/'+requests。get(url)try:headers={'user-agent':'mozilla/5。0(windowsnt10。
0;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/71。2544。87safari/537。36'}r=requests。get(url,headers=headers)print(r。text)except:print(r。text)。
get方法,
多看看谷歌的文档,
非标准的python程序可能有办法,但最好的方法是手工按照dom操作来解析页面,这样才最快。
可以基于urllib库手工爬取一些链接。我只用urllib库爬取过两次动态页面:爱奇艺和清华大学新闻中心:1.python手动爬取动态网页流程2.python手动爬取数据包含地点名称(例如xxx餐馆)和楼层(例如4-18)。我以清华大学新闻中心为例来说明。首先将爬虫程序放到服务器上,放的位置不要太高,以免服务器运行时太重,我把爬虫程序放在2.2.18的位置。
最好提前准备好四个循环,否则循环停止后不好停下来。然后开始爬取数据(我不说get,post方法就可以做这件事),这时候很需要用到urllib库。urllib需要一个变量def__init__(self,urllib):self.url=''self.urlpatterns=[]self.urllib.request=python.urlopen(self.urllib.request,urllib.urlhandler)self.url=python.urlopen(self.urllib.request,urllib.urlhandler)print(self.url)print(urllib.request.request(self.urllib.request))response=urllib.request.urlopen(self.url)print(response)print(urllib.request.urlopen(urllib.urllib.request))response=urllib.request.urlopen(urllib.urllib.request)print(response)print(urllib.request.urlopen(urllib.urllib.request))最后,将爬虫程序和数据全部放到libpython里,libpython会自动生成python解析器,python解析器做页面编译,代码如下:defparse_dom(self,html):#url=self.urlhtml=self.urlhtml_result=response.encode('utf-8')returnhtml_resultdefparse_dom_to_html(self,html):#u。 查看全部
python抓取动态网页(谷歌python手动爬取动态网页解析(一)-乐题库)
python抓取动态网页解析,原理就是用python对网页数据进行解析,一般要看python自己实现实现,lambda函数可以这样写defget_url():url='/'+requests。get(url)try:headers={'user-agent':'mozilla/5。0(windowsnt10。
0;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/71。2544。87safari/537。36'}r=requests。get(url,headers=headers)print(r。text)except:print(r。text)。
get方法,
多看看谷歌的文档,
非标准的python程序可能有办法,但最好的方法是手工按照dom操作来解析页面,这样才最快。
可以基于urllib库手工爬取一些链接。我只用urllib库爬取过两次动态页面:爱奇艺和清华大学新闻中心:1.python手动爬取动态网页流程2.python手动爬取数据包含地点名称(例如xxx餐馆)和楼层(例如4-18)。我以清华大学新闻中心为例来说明。首先将爬虫程序放到服务器上,放的位置不要太高,以免服务器运行时太重,我把爬虫程序放在2.2.18的位置。
最好提前准备好四个循环,否则循环停止后不好停下来。然后开始爬取数据(我不说get,post方法就可以做这件事),这时候很需要用到urllib库。urllib需要一个变量def__init__(self,urllib):self.url=''self.urlpatterns=[]self.urllib.request=python.urlopen(self.urllib.request,urllib.urlhandler)self.url=python.urlopen(self.urllib.request,urllib.urlhandler)print(self.url)print(urllib.request.request(self.urllib.request))response=urllib.request.urlopen(self.url)print(response)print(urllib.request.urlopen(urllib.urllib.request))response=urllib.request.urlopen(urllib.urllib.request)print(response)print(urllib.request.urlopen(urllib.urllib.request))最后,将爬虫程序和数据全部放到libpython里,libpython会自动生成python解析器,python解析器做页面编译,代码如下:defparse_dom(self,html):#url=self.urlhtml=self.urlhtml_result=response.encode('utf-8')returnhtml_resultdefparse_dom_to_html(self,html):#u。
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-12 22:09
爬虫爬取数据时,有些数据是动态数据。比如用js动态加载。使用普通urllib2爬取数据时,找不到相关数据。这是爬虫初学者在使用过程中最容易出现的情况。,明明在浏览器中有对应的信息,但是python爬取的网页中却缺少对应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方法是找到对应的js接口,但有时这种情况非常少见,因为js的调用参数也要分析,有些参数是加解密的;另一种方式是调用python浏览器控制浏览器返回相应的信息,
安装硒
python下安装selenium,命令:
pip install -U selenium
测试成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com") # Load page
print browser.page_source
selenium虽然安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium,使用pip list查看我的selenium版本,是3.4.2,firefox版本是43.0.1,selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
升级火狐到最新版本
下载地址:根据自己电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
selenium 文档可以在下面进行研究。
使用 BeautifulSoup 进行 html 解析
如果对 BeautifulSoup 不了解,可以参考这个 文章 ex12.html
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:阿毛学编程 查看全部
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
爬虫爬取数据时,有些数据是动态数据。比如用js动态加载。使用普通urllib2爬取数据时,找不到相关数据。这是爬虫初学者在使用过程中最容易出现的情况。,明明在浏览器中有对应的信息,但是python爬取的网页中却缺少对应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方法是找到对应的js接口,但有时这种情况非常少见,因为js的调用参数也要分析,有些参数是加解密的;另一种方式是调用python浏览器控制浏览器返回相应的信息,
安装硒
python下安装selenium,命令:
pip install -U selenium
测试成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com";) # Load page
print browser.page_source
selenium虽然安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium,使用pip list查看我的selenium版本,是3.4.2,firefox版本是43.0.1,selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
升级火狐到最新版本
下载地址:根据自己电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
selenium 文档可以在下面进行研究。
使用 BeautifulSoup 进行 html 解析
如果对 BeautifulSoup 不了解,可以参考这个 文章 ex12.html
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:阿毛学编程
python抓取动态网页(编程环境操作系统:Win10编程语言:Python3.6(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-12 22:04
(一)编程环境
操作系统:赢 10
编程语言:Python 3.6
(二)安装硒
这是使用硒实现的。
如果没有安装python的selenium库,安装命令如下
pip install selenium
(三)下载ChromeDriver
因为selenium使用的是浏览器驱动,这里我使用的是谷歌Chrome浏览器,所以先下载ChromeDriver.exe,放到C:\Program Files(x86)\Google\Chrome\Application\目录下。
注意,也可以放到别的目录下,只要在代码中填写正确的路径即可。
(四)登录微博
一般来说,m站的网页结构要比pc站简单很多,我们可以从m站开始。微博m站登录界面的网址是
在Chrome浏览器中打开这个地址,在界面任意位置右键->查看网页源码,发现邮箱/手机号框的id是loginName,密码输入框的id是loginPassword ,登录按钮的id是loginAction。
from selenium import webdriver
import time
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#driver.close()
执行后可以看到自动登录的流程和登录成功的界面
(五)爬取微博内容
从微博抓取内容有两种方式:
(1)申请成为新浪开发者并调用微博API
(2)使用爬虫
因为微博API有很多限制,比如只能获取用户最新的10条微博内容,而不能获取所有的历史微博内容。
这里我们使用爬虫方法。
程序如下:
<p>from selenium import webdriver
import time
import re
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#这里只是看一下cookie内容,下面不会用到这个cookie值,因为driver会把cookie自动带过去
cookies = driver.get_cookies()
cookie_list = []
for dict in cookies:
cookie = dict['name'] + '=' + dict['value']
cookie_list.append(cookie)
cookie = ';'.join(cookie_list)
print (cookie)
#driver.close()
def visitUserInfo(userId):
driver.get('http://weibo.cn/' + userId)
print('********************')
print('用户资料')
# 1.用户id
print('用户id:' + userId)
# 2.用户昵称
strName = driver.find_element_by_xpath("//div[@class='ut']")
strlist = strName.text.split(' ')
nickname = strlist[0]
print('昵称:' + nickname)
# 3.微博数、粉丝数、关注数
strCnt = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" # 匹配数字,包含整数和小数
cntArr = re.findall(pattern, strCnt.text)
print(strCnt.text)
print("微博数:" + str(cntArr[0]))
print("关注数:" + str(cntArr[1]))
print("粉丝数:" + str(cntArr[2]))
print('\n********************')
# 4.将用户信息写到文件里
with open("userinfo.txt", "w", encoding = "gb18030") as file:
file.write("用户ID:" + userId + '\r\n')
file.write("昵称:" + nickname + '\r\n')
file.write("微博数:" + str(cntArr[0]) + '\r\n')
file.write("关注数:" + str(cntArr[1]) + '\r\n')
file.write("粉丝数:" + str(cntArr[2]) + '\r\n')
def visitWeiboContent(userId):
pageList = driver.find_element_by_xpath("//div[@class='pa']")
print(pageList.text)
pattern = r"\d+\d*" # 匹配数字,只包含整数
pageArr = re.findall(pattern, pageList.text)
totalPages = pageArr[1] # 总共有多少页微博
print(totalPages)
pageNum = 1 # 第几页
numInCurPage = 1 # 当前页的第几条微博内容
curNum = 0 # 全部微博中的第几条微博
contentPath = "//div[@class='c'][{0}]"
#while(pageNum 查看全部
python抓取动态网页(编程环境操作系统:Win10编程语言:Python3.6(二))
(一)编程环境
操作系统:赢 10
编程语言:Python 3.6
(二)安装硒
这是使用硒实现的。
如果没有安装python的selenium库,安装命令如下
pip install selenium
(三)下载ChromeDriver
因为selenium使用的是浏览器驱动,这里我使用的是谷歌Chrome浏览器,所以先下载ChromeDriver.exe,放到C:\Program Files(x86)\Google\Chrome\Application\目录下。
注意,也可以放到别的目录下,只要在代码中填写正确的路径即可。
(四)登录微博
一般来说,m站的网页结构要比pc站简单很多,我们可以从m站开始。微博m站登录界面的网址是
在Chrome浏览器中打开这个地址,在界面任意位置右键->查看网页源码,发现邮箱/手机号框的id是loginName,密码输入框的id是loginPassword ,登录按钮的id是loginAction。
from selenium import webdriver
import time
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#driver.close()
执行后可以看到自动登录的流程和登录成功的界面
(五)爬取微博内容
从微博抓取内容有两种方式:
(1)申请成为新浪开发者并调用微博API
(2)使用爬虫
因为微博API有很多限制,比如只能获取用户最新的10条微博内容,而不能获取所有的历史微博内容。
这里我们使用爬虫方法。
程序如下:
<p>from selenium import webdriver
import time
import re
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(3)
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(password)
driver.find_element_by_id("loginAction").click()
#这里只是看一下cookie内容,下面不会用到这个cookie值,因为driver会把cookie自动带过去
cookies = driver.get_cookies()
cookie_list = []
for dict in cookies:
cookie = dict['name'] + '=' + dict['value']
cookie_list.append(cookie)
cookie = ';'.join(cookie_list)
print (cookie)
#driver.close()
def visitUserInfo(userId):
driver.get('http://weibo.cn/' + userId)
print('********************')
print('用户资料')
# 1.用户id
print('用户id:' + userId)
# 2.用户昵称
strName = driver.find_element_by_xpath("//div[@class='ut']")
strlist = strName.text.split(' ')
nickname = strlist[0]
print('昵称:' + nickname)
# 3.微博数、粉丝数、关注数
strCnt = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" # 匹配数字,包含整数和小数
cntArr = re.findall(pattern, strCnt.text)
print(strCnt.text)
print("微博数:" + str(cntArr[0]))
print("关注数:" + str(cntArr[1]))
print("粉丝数:" + str(cntArr[2]))
print('\n********************')
# 4.将用户信息写到文件里
with open("userinfo.txt", "w", encoding = "gb18030") as file:
file.write("用户ID:" + userId + '\r\n')
file.write("昵称:" + nickname + '\r\n')
file.write("微博数:" + str(cntArr[0]) + '\r\n')
file.write("关注数:" + str(cntArr[1]) + '\r\n')
file.write("粉丝数:" + str(cntArr[2]) + '\r\n')
def visitWeiboContent(userId):
pageList = driver.find_element_by_xpath("//div[@class='pa']")
print(pageList.text)
pattern = r"\d+\d*" # 匹配数字,只包含整数
pageArr = re.findall(pattern, pageList.text)
totalPages = pageArr[1] # 总共有多少页微博
print(totalPages)
pageNum = 1 # 第几页
numInCurPage = 1 # 当前页的第几条微博内容
curNum = 0 # 全部微博中的第几条微博
contentPath = "//div[@class='c'][{0}]"
#while(pageNum
python抓取动态网页(如何获取动态网页的内容(运单)(号))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-12 01:28
最近接到一个朋友的请求,说需要保存和下载运单的记录,因为每个月都有几千个快递单。如果您手动复制内容,您可以在与快递公司发生纠纷时证明这一点。
我的思路:
1、如何获取动态网页的内容;
2、输入参数必须有运单号,则需要从excel中读取运单号作为参数获取网页内容;
3、得到信息后,将其处理为网页上显示的内容;
4、将信息保存到 Excel。
1、想到Python实现常规的静态网页抓取,经常使用urllib获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字
1import urllib.request
2
3req = urllib.request.Request('http://python.org/')
4response = urllib.request.urlopen(req)
5the_page = response.read()
6
那么我们爬取的网页是没有动态信息的,因为信息是通过js动态填充到网页中的。
2、打开Chrome浏览器,使用Chrome的“开发者工具”找出谁是真正的内容提供者,在键盘上按F12调出这个工具;
3、此时,选择“网络”选项卡,在地址栏中输入“此页面”
以下是网页的分析过程
然后我们根据每个请求找到我们想要的信息,如下
接下来,我们切换到Header页面,看看,Get获取到的内容
我们将
请求网址:
(账单号)/routes?app=bill&lang=sc®ion=cn&translate=
复制到地址栏
就是说我们可以通过这个链接获取我们想要的动态内容。
4、真正的信息来源已经被捕获,剩下的就是用Python来处理这些页面上的字符了。
5、传入单个数字作为参数,获取动态信息后,按照规律去除html内容,得到一个json字符串,然后我们就可以将其作为字符串处理了
1def gethtml(waybill=''):
2 req = urllib.request.Request(
3 'http://www.。。。/service/bills/' + waybill + '/routes?app=bill&lang=sc®ion=cn&translate=')
4 response = urllib.request.urlopen(req)
5 the_page = response.read().decode("utf8")
6 dr = re.compile(r']+>', re.S)
7 data = dr.sub('', the_page)
8
9 strinfo = re.compile('"')
10 rs = strinfo.sub('', data)
11 return rs
12
这已经完成了我们整个需求中最关键的一步。 查看全部
python抓取动态网页(如何获取动态网页的内容(运单)(号))
最近接到一个朋友的请求,说需要保存和下载运单的记录,因为每个月都有几千个快递单。如果您手动复制内容,您可以在与快递公司发生纠纷时证明这一点。
我的思路:
1、如何获取动态网页的内容;
2、输入参数必须有运单号,则需要从excel中读取运单号作为参数获取网页内容;
3、得到信息后,将其处理为网页上显示的内容;
4、将信息保存到 Excel。
1、想到Python实现常规的静态网页抓取,经常使用urllib获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字
1import urllib.request
2
3req = urllib.request.Request('http://python.org/')
4response = urllib.request.urlopen(req)
5the_page = response.read()
6
那么我们爬取的网页是没有动态信息的,因为信息是通过js动态填充到网页中的。
2、打开Chrome浏览器,使用Chrome的“开发者工具”找出谁是真正的内容提供者,在键盘上按F12调出这个工具;
3、此时,选择“网络”选项卡,在地址栏中输入“此页面”
以下是网页的分析过程
然后我们根据每个请求找到我们想要的信息,如下
接下来,我们切换到Header页面,看看,Get获取到的内容
我们将
请求网址:
(账单号)/routes?app=bill&lang=sc®ion=cn&translate=
复制到地址栏
就是说我们可以通过这个链接获取我们想要的动态内容。
4、真正的信息来源已经被捕获,剩下的就是用Python来处理这些页面上的字符了。
5、传入单个数字作为参数,获取动态信息后,按照规律去除html内容,得到一个json字符串,然后我们就可以将其作为字符串处理了
1def gethtml(waybill=''):
2 req = urllib.request.Request(
3 'http://www.。。。/service/bills/' + waybill + '/routes?app=bill&lang=sc®ion=cn&translate=')
4 response = urllib.request.urlopen(req)
5 the_page = response.read().decode("utf8")
6 dr = re.compile(r']+>', re.S)
7 data = dr.sub('', the_page)
8
9 strinfo = re.compile('"')
10 rs = strinfo.sub('', data)
11 return rs
12
这已经完成了我们整个需求中最关键的一步。
python抓取动态网页(一个处理静态网站数据的常用方法及改进方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-10 12:21
当我们在处理一些 网站 数据时,有时我们需要的很多数据都是动态加载的,而不是全是静态的。下面以一个例子来介绍动态数据的简单获取。首先,我声明我是新手。, 还在学python,这个方法还是比较笨拙的,不过初学者还是有必要知道的。
首先,我们的请求是获取以下 文章 引用:
一开始,我的想法是使用lxml、BeatifulSoup、正则表达式。这些是处理静态 网站 的常用方法。查看网页的源码,我们会发现对应的div是空的,也就是说上面的数据不是静态的,而是后期动态加载的,用googl浏览器可以看到:
标记的三个对应于 网站 中的类似文档、参考文献和引用。我们需要的是引用,所以点击第二个:
我们可以看到数据在那里,然后点击Header,复制里面的URL:
使用以下代码获取对应的数据:
#-*- 编码:utf-8 -*-
进口请求
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no=1'data=requests.get(url)打印数据
但是,如果我们想获得所有的参考资料怎么办?我们不能一一复制链接。会很麻烦。以下是代码的改进。首先,我们需要知道总共有多少页reference,即URL中的page_no。·value,下面是改进后的代码:(其实我们也可以直接估计有50页引用,然后用try...except...获取异常也是可以的)
#-*- 编码:utf-8 -*-
进口请求
n = 相关页数
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no='
对于范围内的 i(1,n+1):
data=requests.get(url+str(i))打印数据
返回值是json格式,剩下的就是对json格式进行处理(记得去掉返回的冗余数据),见:. 查看全部
python抓取动态网页(一个处理静态网站数据的常用方法及改进方法(图))
当我们在处理一些 网站 数据时,有时我们需要的很多数据都是动态加载的,而不是全是静态的。下面以一个例子来介绍动态数据的简单获取。首先,我声明我是新手。, 还在学python,这个方法还是比较笨拙的,不过初学者还是有必要知道的。
首先,我们的请求是获取以下 文章 引用:
一开始,我的想法是使用lxml、BeatifulSoup、正则表达式。这些是处理静态 网站 的常用方法。查看网页的源码,我们会发现对应的div是空的,也就是说上面的数据不是静态的,而是后期动态加载的,用googl浏览器可以看到:
标记的三个对应于 网站 中的类似文档、参考文献和引用。我们需要的是引用,所以点击第二个:
我们可以看到数据在那里,然后点击Header,复制里面的URL:
使用以下代码获取对应的数据:
#-*- 编码:utf-8 -*-
进口请求
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no=1'data=requests.get(url)打印数据
但是,如果我们想获得所有的参考资料怎么办?我们不能一一复制链接。会很麻烦。以下是代码的改进。首先,我们需要知道总共有多少页reference,即URL中的page_no。·value,下面是改进后的代码:(其实我们也可以直接估计有50页引用,然后用try...except...获取异常也是可以的)
#-*- 编码:utf-8 -*-
进口请求
n = 相关页数
url='%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2F%2Fpaper%2F4015889&type=reference&rn=10&page_no='
对于范围内的 i(1,n+1):
data=requests.get(url+str(i))打印数据
返回值是json格式,剩下的就是对json格式进行处理(记得去掉返回的冗余数据),见:.
python抓取动态网页(图片栏目名称给文件夹命名分类保存到电脑中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2022-03-08 23:16
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹并保存它到计算机。. 这个女孩的主页 te/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:
Paste_Image.png
Paste_Image.png
二:运行环境
IDE:Pycharm
蟒蛇3.6
lxml 3.7.2
硒 3.4.0
请求 2.12.4
三:案例分析
1.我这次开始用爬虫做的思路是:进入这个网页,获取图片栏的所有对应的url,然后进入每个网页,获取所有的图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时是下午1点30分以后,所以第二天又做了一个版本:在此基础上,输入每个A网页对应一个缩略图,然后像下图这样抓取一张高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……
4.下面的代码就是解析这个主页然后得到每一列的URL和列的名字。使用xpath获取栏目网页时,进入网页开发者模式后,如图操作。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。
Paste_Image.png
5.之前已经获取了网页和栏目名称。这里我们需要分析一下该栏目的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。还有一个比较可怜的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做
这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2 在本地创建文件夹 使用filename = 'image{}'.format(fileName) + str(i) + '.jpg' 表示文件与爬虫代码保存在同一目录image中,然后获得的图像 将其保存在图像中与之前获得的列名相同的文件夹中。
五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。 查看全部
python抓取动态网页(图片栏目名称给文件夹命名分类保存到电脑中的应用)
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹并保存它到计算机。. 这个女孩的主页 te/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:
Paste_Image.png
Paste_Image.png
二:运行环境
IDE:Pycharm
蟒蛇3.6
lxml 3.7.2
硒 3.4.0
请求 2.12.4
三:案例分析
1.我这次开始用爬虫做的思路是:进入这个网页,获取图片栏的所有对应的url,然后进入每个网页,获取所有的图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时是下午1点30分以后,所以第二天又做了一个版本:在此基础上,输入每个A网页对应一个缩略图,然后像下图这样抓取一张高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……
4.下面的代码就是解析这个主页然后得到每一列的URL和列的名字。使用xpath获取栏目网页时,进入网页开发者模式后,如图操作。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。
Paste_Image.png
5.之前已经获取了网页和栏目名称。这里我们需要分析一下该栏目的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。还有一个比较可怜的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做
这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2 在本地创建文件夹 使用filename = 'image{}'.format(fileName) + str(i) + '.jpg' 表示文件与爬虫代码保存在同一目录image中,然后获得的图像 将其保存在图像中与之前获得的列名相同的文件夹中。
五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。

