
python抓取动态网页
python抓取动态网页(python关于python编写爬虫的一些东西是怎样的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-07 23:25
前段时间浏览知乎的时候,发现一篇关于用python写爬虫的帖子。这是帖子的链接
于是想到了用python来尝试爬取一些东西。本来打算根据关键词爬取百度图片并下载,但过程中遇到障碍,暂时停止。然后去内涵段的页面结构,发现还是比较简单的
单点,然后在下面实现一个爬虫。
写这个程序的时候参考了博主的相关博文在知乎/pleasecallmewhy/article/details/8929576
编写这个程序主要分为以下几个步骤:
1.分析Inner Community的页面结构
2.使用正则表达式查找要下载的url
3.下载这些图片
第一步就是第一步,也是比较关键的一步。如果页面分析不正确,则后续步骤将无法启动。
1.打开内段子囧图片页
我们将看到以下页面
这个页面下面有一些我们想要的搞笑图片,但是我们首先需要得到这个页面的html文件,这里我使用python的urllib库,代码如下
def get_html(url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
需要使用 urllib 模拟使用 Firefox 的 Firebug 插件发送的信息才能看到,然后复制头部信息填入上面的头部。需要添加其中的 Cooiker。如果不添加,将无法获取 html 文件。urllib的使用具体介绍见上面博主的博客,说的很清楚。
既然得到了html文件,我们来观察这个文件。这个html文件的结构比较清晰。
每个帖子由一个 div 组成,然后是标题、图像和评论的另一个 div
在class = content-wrapper的div中我们找到了这句话
这个data-text就是图片的写法,data-pic就是图片的地址,所以我们的工作就是获取所有的data-pic和data-text(后面可以作为图片的名字)
要解析这个 html 中的所有这两个字段,我们需要使用 python 的正则表达式。我们这里使用的非常简单。我是通过模仿得到的。具体的re教程也可以从上面的博主那里获得。
下面是我的重新解析代码
这样我就可以根据刚才得到的html文件解析出所有图片的地址,然后就可以在下面下载了。下载使用与urllib相关的函数。
-----------------到此结束,就可以下载几十张图片了
为什么只有几十张图片?
原因是我们刚刚获取的只是首页的html文件,那么如何获取更多的html文件呢?
我们注意到页面底部有一个Load More按钮,点击它可以获取图片。
我们也使用萤火虫来抓取包。
打开这个 Get 请求和结果
问:
响应:我们在浏览器中输入这个请求地址,得到一个json响应
逐步展开json得到
在 large_image 下面我们有我们需要的东西。.
仔细观察得到的json响应,你会发现有一个min_time字段,是一个unix时间戳。而这个 min_time 正是这个下一个请求的 max_time
这个循环可以得到所有的图片!!
进入第一次获取的html文件,也可以找到一个
那么我们的任务基本上就是不断的解析json文件并下载
下面是我的第一个版本的源代码
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import thread
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
self.__downloadPic(data_pic)
count = 0
#下面开始下载点击更多之后的图片
while max_time:
count = count + 1
print "=--------------------THIS IS THE " + str(count) + " Json Data Time : " + str(max_time) + "--------------------"
url = self.base_url + str(max_time)
json_data = self.__getHtml(url)
json_ret = self.__parseJson(json_data)
max_time = json_ret['max_time']
print max_time
image_url = json_ret['image_url']
image_content = json_ret['image_content']
self.__downloadPic(image_url,image_content)
#python 以两个下划线开始的为私有函数
#尝试5次
#解析json,并获取json中的数据
def __parseJson(self,json_data):
print "------This is parse_json --------"
dct = json.loads(json_data)
image_content = []
image_url = []
max_time = ""
try :
max_time = dct['data']['max_time']
data = dct['data']['data']
for item in data:
content = item['group']['content']
url = item['group']['large_image']['url_list'][0]['url']
image_content.append(content)
image_url.append(url)
ret = {}
ret['image_content'] = image_content
ret['image_url'] = image_url
ret['max_time'] = max_time
return ret
except :
print "json_parse error"
#定义下载图片函数
def __downloadPic(self,imageAddressList,contentList = []):
print "---download------"
contentExist = len(contentList)
count = 0
for image in imageAddressList :
print image
count = count + 1
randTail = str(random.randint(0,30000000))
try :
#tail = contentExist ? contentList[count - 1] : randTail ;
if contentExist :
tail = contentList[count - 1]
else :
tail = randTail
fullPath = "C:\\Users\\Administrator\\Desktop\\python\\" + tail + ".jpg"
urllib.urlretrieve(image , fullPath)
except :
failedMsg = "第" + str(count) + "张下载失败,URL: " + str(image) + ""
print failedMsg
pass
def __getDataPic(self,html):
re_str = r'data-pic="([^"]*)"'
data_pic = self.__getDataByRe(html,re_str)
return data_pic
def __getMaxTime(self,html):
re_str = r'max_time: \'([\d]*)\''
max_time = self.__getDataByRe(html,re_str)
return max_time
def __getDataByRe(self,text,re_str):
pattern = re.compile(re_str)
ret = pattern.findall(text)
return ret
def __getHtml(self,url):
print "GET HTML********"
count = 0
while count < 5:
count = count + 1
print str(count) + " times ,try download html"
html = self.__getDataByUrl(url)
if not html:
continue;
else:
return html
def __getDataByUrl(self,url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
#------------------------------------------程序入口处------------------------------
mySpider = neiHanSpider()
mySpider.Start()
之后我再次尝试了多线程版本
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import threading
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self ):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
#self.__downloadPic(data_pic)
global downloadUrlList
global downloadTitleList
#downloadList = downloadList + data_pic
count = 0
#下面开始下载点击更多之后的图片
while max_time and count " + str(len(downloadTitleList))
threadLock = threading.Lock()
threads = []
size = len(downloadUrlList)
for i in range(1,10) :
thread = myDownLoad(i,"Thread-" + str(i));
thread.start()
threads.append(thread)
aliveCount = 10
while aliveCount > 1 :
print "Now There is " + str(aliveCount) + "Threads alive"
aliveCount = threading.activeCount()
time.sleep(10)
endTime = time.time()
print " Download " + str(size) + "张图,共耗时 " + str((endTime - startTime) / 60) + "min"
print "Exiting Main Thread"
可能写的不是很整齐,有时间再整理一下。Python现正在使用中,欢迎批评指正 查看全部
python抓取动态网页(python关于python编写爬虫的一些东西是怎样的?(图))
前段时间浏览知乎的时候,发现一篇关于用python写爬虫的帖子。这是帖子的链接
于是想到了用python来尝试爬取一些东西。本来打算根据关键词爬取百度图片并下载,但过程中遇到障碍,暂时停止。然后去内涵段的页面结构,发现还是比较简单的
单点,然后在下面实现一个爬虫。
写这个程序的时候参考了博主的相关博文在知乎/pleasecallmewhy/article/details/8929576
编写这个程序主要分为以下几个步骤:
1.分析Inner Community的页面结构
2.使用正则表达式查找要下载的url
3.下载这些图片
第一步就是第一步,也是比较关键的一步。如果页面分析不正确,则后续步骤将无法启动。
1.打开内段子囧图片页
我们将看到以下页面
这个页面下面有一些我们想要的搞笑图片,但是我们首先需要得到这个页面的html文件,这里我使用python的urllib库,代码如下
def get_html(url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
需要使用 urllib 模拟使用 Firefox 的 Firebug 插件发送的信息才能看到,然后复制头部信息填入上面的头部。需要添加其中的 Cooiker。如果不添加,将无法获取 html 文件。urllib的使用具体介绍见上面博主的博客,说的很清楚。
既然得到了html文件,我们来观察这个文件。这个html文件的结构比较清晰。
每个帖子由一个 div 组成,然后是标题、图像和评论的另一个 div
在class = content-wrapper的div中我们找到了这句话
这个data-text就是图片的写法,data-pic就是图片的地址,所以我们的工作就是获取所有的data-pic和data-text(后面可以作为图片的名字)
要解析这个 html 中的所有这两个字段,我们需要使用 python 的正则表达式。我们这里使用的非常简单。我是通过模仿得到的。具体的re教程也可以从上面的博主那里获得。
下面是我的重新解析代码
这样我就可以根据刚才得到的html文件解析出所有图片的地址,然后就可以在下面下载了。下载使用与urllib相关的函数。
-----------------到此结束,就可以下载几十张图片了
为什么只有几十张图片?
原因是我们刚刚获取的只是首页的html文件,那么如何获取更多的html文件呢?
我们注意到页面底部有一个Load More按钮,点击它可以获取图片。
我们也使用萤火虫来抓取包。
打开这个 Get 请求和结果
问:
响应:我们在浏览器中输入这个请求地址,得到一个json响应
逐步展开json得到
在 large_image 下面我们有我们需要的东西。.
仔细观察得到的json响应,你会发现有一个min_time字段,是一个unix时间戳。而这个 min_time 正是这个下一个请求的 max_time
这个循环可以得到所有的图片!!
进入第一次获取的html文件,也可以找到一个
那么我们的任务基本上就是不断的解析json文件并下载
下面是我的第一个版本的源代码
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import thread
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
self.__downloadPic(data_pic)
count = 0
#下面开始下载点击更多之后的图片
while max_time:
count = count + 1
print "=--------------------THIS IS THE " + str(count) + " Json Data Time : " + str(max_time) + "--------------------"
url = self.base_url + str(max_time)
json_data = self.__getHtml(url)
json_ret = self.__parseJson(json_data)
max_time = json_ret['max_time']
print max_time
image_url = json_ret['image_url']
image_content = json_ret['image_content']
self.__downloadPic(image_url,image_content)
#python 以两个下划线开始的为私有函数
#尝试5次
#解析json,并获取json中的数据
def __parseJson(self,json_data):
print "------This is parse_json --------"
dct = json.loads(json_data)
image_content = []
image_url = []
max_time = ""
try :
max_time = dct['data']['max_time']
data = dct['data']['data']
for item in data:
content = item['group']['content']
url = item['group']['large_image']['url_list'][0]['url']
image_content.append(content)
image_url.append(url)
ret = {}
ret['image_content'] = image_content
ret['image_url'] = image_url
ret['max_time'] = max_time
return ret
except :
print "json_parse error"
#定义下载图片函数
def __downloadPic(self,imageAddressList,contentList = []):
print "---download------"
contentExist = len(contentList)
count = 0
for image in imageAddressList :
print image
count = count + 1
randTail = str(random.randint(0,30000000))
try :
#tail = contentExist ? contentList[count - 1] : randTail ;
if contentExist :
tail = contentList[count - 1]
else :
tail = randTail
fullPath = "C:\\Users\\Administrator\\Desktop\\python\\" + tail + ".jpg"
urllib.urlretrieve(image , fullPath)
except :
failedMsg = "第" + str(count) + "张下载失败,URL: " + str(image) + ""
print failedMsg
pass
def __getDataPic(self,html):
re_str = r'data-pic="([^"]*)"'
data_pic = self.__getDataByRe(html,re_str)
return data_pic
def __getMaxTime(self,html):
re_str = r'max_time: \'([\d]*)\''
max_time = self.__getDataByRe(html,re_str)
return max_time
def __getDataByRe(self,text,re_str):
pattern = re.compile(re_str)
ret = pattern.findall(text)
return ret
def __getHtml(self,url):
print "GET HTML********"
count = 0
while count < 5:
count = count + 1
print str(count) + " times ,try download html"
html = self.__getDataByUrl(url)
if not html:
continue;
else:
return html
def __getDataByUrl(self,url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
#------------------------------------------程序入口处------------------------------
mySpider = neiHanSpider()
mySpider.Start()
之后我再次尝试了多线程版本
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import threading
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self ):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
#self.__downloadPic(data_pic)
global downloadUrlList
global downloadTitleList
#downloadList = downloadList + data_pic
count = 0
#下面开始下载点击更多之后的图片
while max_time and count " + str(len(downloadTitleList))
threadLock = threading.Lock()
threads = []
size = len(downloadUrlList)
for i in range(1,10) :
thread = myDownLoad(i,"Thread-" + str(i));
thread.start()
threads.append(thread)
aliveCount = 10
while aliveCount > 1 :
print "Now There is " + str(aliveCount) + "Threads alive"
aliveCount = threading.activeCount()
time.sleep(10)
endTime = time.time()
print " Download " + str(size) + "张图,共耗时 " + str((endTime - startTime) / 60) + "min"
print "Exiting Main Thread"
可能写的不是很整齐,有时间再整理一下。Python现正在使用中,欢迎批评指正
python抓取动态网页(一个爬取动态网页的超简单的一个小demo了解多少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-07 17:19
大家好,我是大智
这次给大家介绍一个超级简单的爬取动态网页的小demo。
说起动态网页,你对它了解多少?
简单来说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
好的,让我们开始进入正题。
一、 分析网页结构
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候,我们就可以判断为动态网页了。这时候,我们需要找到一个接口
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求,可以在后台与服务器交换数据,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL
打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
ok,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
ok,我们已经拿到了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名称是我们需要的,然后我们就可以磁盘了。
if "data" in content:
3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
好的,我们的愿景已经实现。
四、完整代码
# encoding: utf-8
五、保存结果 查看全部
python抓取动态网页(一个爬取动态网页的超简单的一个小demo了解多少)
大家好,我是大智
这次给大家介绍一个超级简单的爬取动态网页的小demo。
说起动态网页,你对它了解多少?
简单来说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
好的,让我们开始进入正题。
一、 分析网页结构
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候,我们就可以判断为动态网页了。这时候,我们需要找到一个接口
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求,可以在后台与服务器交换数据,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL
打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
ok,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
ok,我们已经拿到了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名称是我们需要的,然后我们就可以磁盘了。
if "data" in content:
3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
好的,我们的愿景已经实现。
四、完整代码
# encoding: utf-8
五、保存结果
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-07 09:21
)
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 页面时,会发现我们要提取的页面元素不在我们下载的 HTML 中,尽管它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些动作下通过js事件动态生成的。比如我们刷QQ空间或者微博评论的时候,我们一直在往下滑。网页越来越长,内容越来越多。这是人们又爱又恨的动态加载。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
按键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡,也可能在XHR选项卡,当然也可以使用其他抓包工具),如图以下
然后,我们拖动右边的滚动条,然后我们会发现开发者工具里有新的js请求(有不少),但是如果你匆忙翻译的话,很容易看出哪个是评论, 如下所示
OK,复制出js请求的目标url
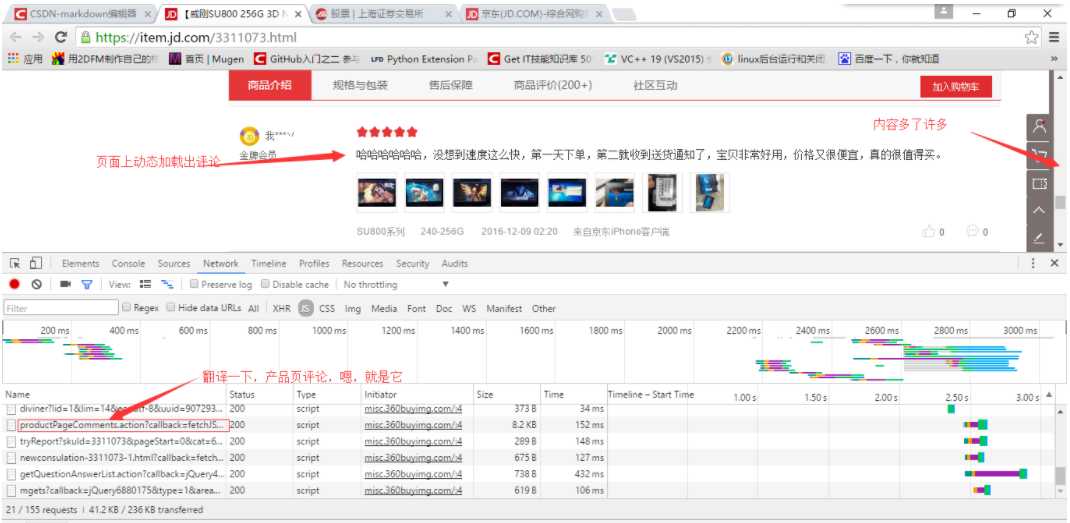
在浏览器中打开,发现我们要的数据就在这里,如下图
整个页面都是 json 格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去获取数据,然后将获取到的json数据通过一定的js逻辑填充到数据中。在 HTML 页面中。对于我们的 Spider,我们所要做的就是组织和提取这些 json 数据。
在实际应用中,我们当然不可能在每个页面中找出这个js发起的请求的目标地址,所以需要分析请求地址的规律。一般来说,法律比较容易找到,因为法律对于服务方来说太复杂了。维护也很困难。
2.Selenium 模拟浏览器行为
对于动态加载,可以看到 Selenium+Phantomjs 的强大。打开网页查看网页的源代码(注意不是检查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处之一是它可以捕获完整的源代码以
示例:根据给定名称搜索豆瓣电影的对应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
url = ‘https://movie.douban.com/‘
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path=‘C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe‘)
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class=‘item-root‘]"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get(‘src‘)
url = i.find("a").get(‘href‘)
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")
Python动态爬取网页 查看全部
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项
)
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 页面时,会发现我们要提取的页面元素不在我们下载的 HTML 中,尽管它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些动作下通过js事件动态生成的。比如我们刷QQ空间或者微博评论的时候,我们一直在往下滑。网页越来越长,内容越来越多。这是人们又爱又恨的动态加载。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
按键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡,也可能在XHR选项卡,当然也可以使用其他抓包工具),如图以下
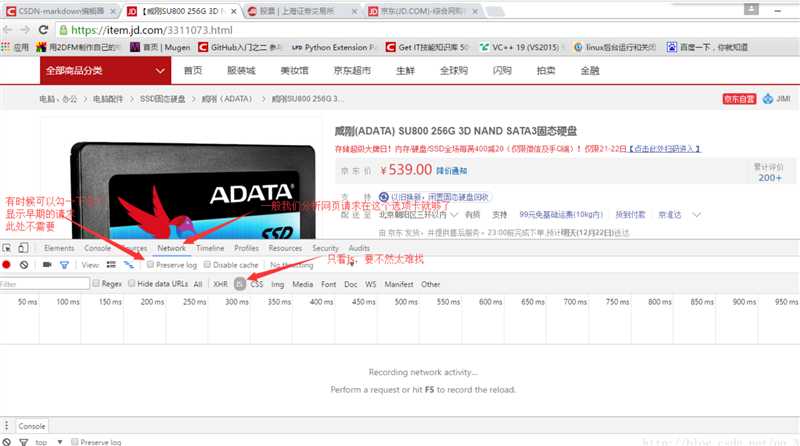
然后,我们拖动右边的滚动条,然后我们会发现开发者工具里有新的js请求(有不少),但是如果你匆忙翻译的话,很容易看出哪个是评论, 如下所示
OK,复制出js请求的目标url

在浏览器中打开,发现我们要的数据就在这里,如下图
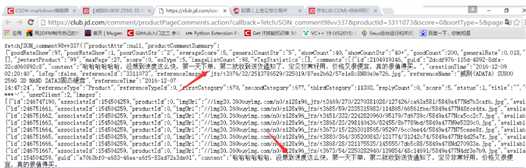
整个页面都是 json 格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去获取数据,然后将获取到的json数据通过一定的js逻辑填充到数据中。在 HTML 页面中。对于我们的 Spider,我们所要做的就是组织和提取这些 json 数据。
在实际应用中,我们当然不可能在每个页面中找出这个js发起的请求的目标地址,所以需要分析请求地址的规律。一般来说,法律比较容易找到,因为法律对于服务方来说太复杂了。维护也很困难。
2.Selenium 模拟浏览器行为
对于动态加载,可以看到 Selenium+Phantomjs 的强大。打开网页查看网页的源代码(注意不是检查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处之一是它可以捕获完整的源代码以
示例:根据给定名称搜索豆瓣电影的对应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
url = ‘https://movie.douban.com/‘
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path=‘C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe‘)
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class=‘item-root‘]"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get(‘src‘)
url = i.find("a").get(‘href‘)
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")
Python动态爬取网页
python抓取动态网页( Python,x,WebCrawler, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-06 22:05
Python,x,WebCrawler,
)
Python使用JavaScript呈现的内容从网页中获取数据
pythonpython-3.xweb爬虫
Python使用JavaScript呈现的内容从网页中获取数据。Python,Python-3.x,网络爬虫,Python,Python3.x,网络爬虫。我是捕获数据的新手。我想从这个网站获取数据:[我想通过输入一个.CSV文件来获取数据,并使其与上图中的每一行CSV文件工作相同。我只从红色框中获取数据,如mengabadi、mengabadikan、pengabadian和keabadian,并将其保存在一个新的.CSV文件中,如下所示:那么,我能做些什么来获取它(可以使用Python)? 我认为网页使用JavaScript加载/呈现数据。使用请求和BS4示例代码:(自己阅读并实现它,只是为了给你一个想法!)现在,使用inspe
我是捕获数据的新手。我想从这个网站获取数据:[
我想以与上图中数据相同的方式输入抓取数据,例如。Gamenian,以及CSV文件中新行中的数据,如下所示:
那么,我能做些什么来获取它(可能使用Python)?我认为网页使用JavaScript加载/呈现数据
使用
请求和bs4
示例代码:(自己阅读并实现它,只是为了给你一个想法!)
现在,使用inspect工具挖掘场景,然后。。密码
beautifulsoup的安装和请求可通过PIP完成:
$ pip install requests
$ pip install beautifulsoup4
$ pip install requests
$ pip install beautifulsoup4 查看全部
python抓取动态网页(
Python,x,WebCrawler,
)
Python使用JavaScript呈现的内容从网页中获取数据
pythonpython-3.xweb爬虫
Python使用JavaScript呈现的内容从网页中获取数据。Python,Python-3.x,网络爬虫,Python,Python3.x,网络爬虫。我是捕获数据的新手。我想从这个网站获取数据:[我想通过输入一个.CSV文件来获取数据,并使其与上图中的每一行CSV文件工作相同。我只从红色框中获取数据,如mengabadi、mengabadikan、pengabadian和keabadian,并将其保存在一个新的.CSV文件中,如下所示:那么,我能做些什么来获取它(可以使用Python)? 我认为网页使用JavaScript加载/呈现数据。使用请求和BS4示例代码:(自己阅读并实现它,只是为了给你一个想法!)现在,使用inspe
我是捕获数据的新手。我想从这个网站获取数据:[
我想以与上图中数据相同的方式输入抓取数据,例如。Gamenian,以及CSV文件中新行中的数据,如下所示:
那么,我能做些什么来获取它(可能使用Python)?我认为网页使用JavaScript加载/呈现数据
使用
请求和bs4
示例代码:(自己阅读并实现它,只是为了给你一个想法!)
现在,使用inspect工具挖掘场景,然后。。密码
beautifulsoup的安装和请求可通过PIP完成:
$ pip install requests
$ pip install beautifulsoup4
$ pip install requests
$ pip install beautifulsoup4
python抓取动态网页(Python程序设计执行指定函数及正则匹配的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-06 22:03
本文文章主要介绍Python中周期性抓取网页内容的方法,涉及Python时间函数和正则匹配的相关操作技巧。有一定的参考价值,有需要的朋友可以参考以下
p>
本文中的示例描述了 Python 如何实现对 Web 内容的定期爬取。分享给大家,供大家参考,如下:
1.使用sched模块周期性执行指定函数
2.周期性执行指定函数爬取指定网页,解析出想要的网页内容,代码为六维论坛的在线人数
论坛网上人口统计代码:
<p>
#coding=utf-8
import time,sched,os,urllib2,re,string
#初始化sched模块的scheduler类
#第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞。
s = sched.scheduler(time.time,time.sleep)
#被周期性调度触发的函数
def event_func():
req = urllib2.Request('http://bt.neu6.edu.cn/')
response = urllib2.urlopen(req)
rawdata = response.read()
response.close()
usernump = re.compile(r'总计 .*? 人在线')
usernummatch = usernump.findall(rawdata)
if usernummatch:
currentnum=usernummatch[0]
currentnum=currentnum[string.index(currentnum,'>')+1:string.rindex(currentnum,' 查看全部
python抓取动态网页(Python程序设计执行指定函数及正则匹配的相关操作技巧)
本文文章主要介绍Python中周期性抓取网页内容的方法,涉及Python时间函数和正则匹配的相关操作技巧。有一定的参考价值,有需要的朋友可以参考以下
p>
本文中的示例描述了 Python 如何实现对 Web 内容的定期爬取。分享给大家,供大家参考,如下:
1.使用sched模块周期性执行指定函数
2.周期性执行指定函数爬取指定网页,解析出想要的网页内容,代码为六维论坛的在线人数
论坛网上人口统计代码:
<p>
#coding=utf-8
import time,sched,os,urllib2,re,string
#初始化sched模块的scheduler类
#第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞。
s = sched.scheduler(time.time,time.sleep)
#被周期性调度触发的函数
def event_func():
req = urllib2.Request('http://bt.neu6.edu.cn/')
response = urllib2.urlopen(req)
rawdata = response.read()
response.close()
usernump = re.compile(r'总计 .*? 人在线')
usernummatch = usernump.findall(rawdata)
if usernummatch:
currentnum=usernummatch[0]
currentnum=currentnum[string.index(currentnum,'>')+1:string.rindex(currentnum,'
python抓取动态网页(『爬虫四步走』手把手教你使用Python抓取并存储网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-06 20:04
《爬虫四步走》教你如何使用Python爬取和存储网页数据!
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以B站视频热搜榜数据的抓取和存储为例,详细介绍Python爬虫。基本流程。= requests.get(url)print(res.status_code)#200 在上面的代码中,我们完成了以下三件事。导入请求并使用 get 方法构造请求。使用 status_code 获取网页的状态码。可以看到返回值。返回一个带有我们需要的视频数据的字符串,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,并将字符串转换为网页结构化数据,这样就可以方便的找到HTML标签及其属性和内容。在 Python 中有很多方法可以解析网页。可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup。从第三步开始:提取内容在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
616 查看全部
python抓取动态网页(『爬虫四步走』手把手教你使用Python抓取并存储网页数据)
《爬虫四步走》教你如何使用Python爬取和存储网页数据!
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以B站视频热搜榜数据的抓取和存储为例,详细介绍Python爬虫。基本流程。= requests.get(url)print(res.status_code)#200 在上面的代码中,我们完成了以下三件事。导入请求并使用 get 方法构造请求。使用 status_code 获取网页的状态码。可以看到返回值。返回一个带有我们需要的视频数据的字符串,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,并将字符串转换为网页结构化数据,这样就可以方便的找到HTML标签及其属性和内容。在 Python 中有很多方法可以解析网页。可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup。从第三步开始:提取内容在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
616
python抓取动态网页(js动态加载的网页就犯了难谷歌、百度,发现个好介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-06 04:02
经过一段时间的python学习,可以写一些爬虫了。但是,很难遇到js动态加载的网页。于是google,百度,找到了很好的介绍
主要目的是分析网页的加载过程,从网页响应中找到JS脚本返回的JSON数据。(上面的网址很详细,把下面的代码贴出来记录一下)
1、今日头条
#coding:utf-8
import requests
import json
#今日头条热词获取,get方法
url = 'http://www.toutiao.com/c/hot_words/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']
for n in news:
print(n)
2、拉狗网的发帖方式
#coding:utf-8
import requests
import json
url = 'https://www.lagou.com/upload/l ... 39%3B
post_data = {'first':'true','kd':'Android','pn':'1'}
wbdata = requests.post(url,data=post_data)<br />data = json.loads(wbdata)
print data
ip被封,无法解析返回的json数据,需要跟进。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟
转载于: 查看全部
python抓取动态网页(js动态加载的网页就犯了难谷歌、百度,发现个好介绍)
经过一段时间的python学习,可以写一些爬虫了。但是,很难遇到js动态加载的网页。于是google,百度,找到了很好的介绍
主要目的是分析网页的加载过程,从网页响应中找到JS脚本返回的JSON数据。(上面的网址很详细,把下面的代码贴出来记录一下)
1、今日头条
#coding:utf-8
import requests
import json
#今日头条热词获取,get方法
url = 'http://www.toutiao.com/c/hot_words/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']
for n in news:
print(n)
2、拉狗网的发帖方式
#coding:utf-8
import requests
import json
url = 'https://www.lagou.com/upload/l ... 39%3B
post_data = {'first':'true','kd':'Android','pn':'1'}
wbdata = requests.post(url,data=post_data)<br />data = json.loads(wbdata)
print data
ip被封,无法解析返回的json数据,需要跟进。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟
转载于:
python抓取动态网页(实战分析网站结构,确定我们要的数据内容;image唯美图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-06 04:01
前言
每个人都需要互相帮助,而我所要做的就是呈现给大家看。
例如,有人可以背一本你不会背的书,有人可以做一个你不会做的问题,有人你愿意推迟到明天,有人今天会努力完成它,对不起,你想要什么工作只能别人做,自己想要的生活也只能别人过!
教师讲授职业以解决疑虑。繁殖的力量就是穿透这些东西,然后才能长出新的叶子。共勉!
- 实战
分析网站的结构,确定我们要抓取的数据内容;
图片
审美画面是对绝对美的追求,强调超越生活的纯粹美,是对完美形式和完美艺术技巧的不断追求。
图片
右键Chrome浏览器查看网络,分析网站的结构;发现这个网页内容很多。单页获取图片数据很简单,但这就是我们的风格?不; 绝对不。即使它是一个非常简单的逻辑,我们也必须以不同的方式使其复杂化。这是托尼先生的程序;追求纯技术。
希望能给更多的编程从业者带来一些优质的文章。
第一步:请求网络并获取服务器返回的数据
不管怎样,我们先获取数据内容;因为检测网站中是否有反爬的唯一因素就是获取它的数据内容;看看能不能正常获取。
这里需要安装 2 个库:
pip install requests 网络请求库
pip install lxml 数据解析库
导入请求
网址='#39;
html=requests.get(url).content.decode('gbk')
打印(html)
接下来,通过分析;我看到网站里面所有内容的页数都很大,有1153页的数据,所以我想,如果只是拿到几页数据内容,真的很容易!但是如果我在爬其他页面,我是否需要担心它是否有这么多的数据;毕竟每一页的数据内容都不一样;这绝对满足不了我对科技的渴望,所以......
图片
图片
第 2 步:解析数据
从 lxml 导入 etree
# 动态获取最后一页数据
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
# list_20_1153.html ---> 1152
打印(页)
接下来在处理的时候,第一页数据和第二页数据的url不一样;并且无法单独获取第二页及后续所有页面的数据;所以……只能拼接。
url_list=[]
网址='#39;
url_list.append(url)
html=requests.get(url).content.decode('gbk')
# 打印(html)
# 谓词
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
对于范围内的项目(2,int(page)+1):
url_list.append(url+'list_20_{}.html'.format(str(item)))
打印(url_list)
图片
至此,我们已经能够动态获取所有页面的链接;我很高兴拥有它;迄今为止; 我们已经跨过了第一步;之后,我们需要获取每个页面的图片详情页面以进行下一步。准备数据处理。
对于 url_list 中的 url_item:
img_url=etree.HTML(requests.get(url_item).text).xpath('//div[@class="ABox"]/a/@href')
打印(img_url)
图片
图片
网站 数据的每一次突破都像是我们的战利品。这就是对技术着迷的容易程度。
接下来的事情越来越有趣了!我们需要再次分析网站详情页;在分析过程中,我发现了一件非常有趣的事情;之前的获取方式很相似……emmmmmm,这里就不细说了!每个人都会自己分析。
图片
图片
所以……为了让程序越来越好玩;接下来,让我们改变它;
# 在单个文件详情页面
def get_img_urls(img_urls):
html=requests.get(img_urls)
html.encoding='gbk'
数据=etree.HTML(html.text)
# 标题
title=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/text()')[0]
#总页数
page=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/span/span[2]/text()')[0]
img['1']=data.xpath('//a[@class="down-btn"]/@href')[0]
打印(标题,页面)
对于范围内的项目(2,int(page)+1):
text=requests.get(img_urls.replace('.html','_%s.html'%str(item))).text
img_url = etree.HTML(text).xpath('//a[@class="down-btn"]/@href')[0]
返回标题,img
第 3 步:数据存储
在下载数据部分;考虑到我要下载的数据图片-->是原图,而且很多图片的内存比例不一样;如果文件太大,可能会导致内存不足;我们在学习的时候,不需要考虑这个因素,但托尼不这么认为;因为如果有一天每个人都真正学到了一些东西并进入了企业;这时候就要考虑程序优化的问题了;它可以更好地让我们编写高质量的代码程序;这也是考验我们的基本功是否真的扎实;当我们下载大文件时,为了防止它占用过多的内存;所以我做了数据流操作处理
# 下载图片
def 下载图片(网址,路径,名称):
# 法官
如果 os.path.exists(path):
经过
别的:
os.mkdir(路径)
响应=requests.get(url)
如果 response.status_code==200:
以 open(path+'/%s'%name,'ab') 作为文件:
对于 response.iter_content() 中的数据:
file.write(数据)
# 清空缓存
文件.flush()
print('%s 下载完成!'%name)
数据块处理
图片
第四步:代码整理
对于 img_url 中的 img_urls:
标题,img=get_img_urls(img_urls)
对于 img.keys() 中的 img_url_item:
path='/Users/lucky/PycharmProjects/Module_Tony_Demo/Module_12_24/tony_img/%s'%title
download_pic(url=img_url_item,path=path,name='%s.jpg'%(title+img_url_item))
显示结果
全效
图片
在这个浮躁的时代;还是有人能坚持章节原创;
如果这篇文章对你的学习有帮助——你可以点赞+关注!更多新的 文章 将不断更新。
支持原创。感激! 查看全部
python抓取动态网页(实战分析网站结构,确定我们要的数据内容;image唯美图片)
前言
每个人都需要互相帮助,而我所要做的就是呈现给大家看。
例如,有人可以背一本你不会背的书,有人可以做一个你不会做的问题,有人你愿意推迟到明天,有人今天会努力完成它,对不起,你想要什么工作只能别人做,自己想要的生活也只能别人过!
教师讲授职业以解决疑虑。繁殖的力量就是穿透这些东西,然后才能长出新的叶子。共勉!
- 实战
分析网站的结构,确定我们要抓取的数据内容;
图片
审美画面是对绝对美的追求,强调超越生活的纯粹美,是对完美形式和完美艺术技巧的不断追求。
图片
右键Chrome浏览器查看网络,分析网站的结构;发现这个网页内容很多。单页获取图片数据很简单,但这就是我们的风格?不; 绝对不。即使它是一个非常简单的逻辑,我们也必须以不同的方式使其复杂化。这是托尼先生的程序;追求纯技术。
希望能给更多的编程从业者带来一些优质的文章。
第一步:请求网络并获取服务器返回的数据
不管怎样,我们先获取数据内容;因为检测网站中是否有反爬的唯一因素就是获取它的数据内容;看看能不能正常获取。
这里需要安装 2 个库:
pip install requests 网络请求库
pip install lxml 数据解析库
导入请求
网址='#39;
html=requests.get(url).content.decode('gbk')
打印(html)
接下来,通过分析;我看到网站里面所有内容的页数都很大,有1153页的数据,所以我想,如果只是拿到几页数据内容,真的很容易!但是如果我在爬其他页面,我是否需要担心它是否有这么多的数据;毕竟每一页的数据内容都不一样;这绝对满足不了我对科技的渴望,所以......
图片
图片
第 2 步:解析数据
从 lxml 导入 etree
# 动态获取最后一页数据
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
# list_20_1153.html ---> 1152
打印(页)
接下来在处理的时候,第一页数据和第二页数据的url不一样;并且无法单独获取第二页及后续所有页面的数据;所以……只能拼接。
url_list=[]
网址='#39;
url_list.append(url)
html=requests.get(url).content.decode('gbk')
# 打印(html)
# 谓词
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
对于范围内的项目(2,int(page)+1):
url_list.append(url+'list_20_{}.html'.format(str(item)))
打印(url_list)
图片
至此,我们已经能够动态获取所有页面的链接;我很高兴拥有它;迄今为止; 我们已经跨过了第一步;之后,我们需要获取每个页面的图片详情页面以进行下一步。准备数据处理。
对于 url_list 中的 url_item:
img_url=etree.HTML(requests.get(url_item).text).xpath('//div[@class="ABox"]/a/@href')
打印(img_url)
图片
图片
网站 数据的每一次突破都像是我们的战利品。这就是对技术着迷的容易程度。
接下来的事情越来越有趣了!我们需要再次分析网站详情页;在分析过程中,我发现了一件非常有趣的事情;之前的获取方式很相似……emmmmmm,这里就不细说了!每个人都会自己分析。
图片
图片
所以……为了让程序越来越好玩;接下来,让我们改变它;
# 在单个文件详情页面
def get_img_urls(img_urls):
html=requests.get(img_urls)
html.encoding='gbk'
数据=etree.HTML(html.text)
# 标题
title=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/text()')[0]
#总页数
page=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/span/span[2]/text()')[0]
img['1']=data.xpath('//a[@class="down-btn"]/@href')[0]
打印(标题,页面)
对于范围内的项目(2,int(page)+1):
text=requests.get(img_urls.replace('.html','_%s.html'%str(item))).text
img_url = etree.HTML(text).xpath('//a[@class="down-btn"]/@href')[0]
返回标题,img
第 3 步:数据存储
在下载数据部分;考虑到我要下载的数据图片-->是原图,而且很多图片的内存比例不一样;如果文件太大,可能会导致内存不足;我们在学习的时候,不需要考虑这个因素,但托尼不这么认为;因为如果有一天每个人都真正学到了一些东西并进入了企业;这时候就要考虑程序优化的问题了;它可以更好地让我们编写高质量的代码程序;这也是考验我们的基本功是否真的扎实;当我们下载大文件时,为了防止它占用过多的内存;所以我做了数据流操作处理
# 下载图片
def 下载图片(网址,路径,名称):
# 法官
如果 os.path.exists(path):
经过
别的:
os.mkdir(路径)
响应=requests.get(url)
如果 response.status_code==200:
以 open(path+'/%s'%name,'ab') 作为文件:
对于 response.iter_content() 中的数据:
file.write(数据)
# 清空缓存
文件.flush()
print('%s 下载完成!'%name)
数据块处理
图片
第四步:代码整理
对于 img_url 中的 img_urls:
标题,img=get_img_urls(img_urls)
对于 img.keys() 中的 img_url_item:
path='/Users/lucky/PycharmProjects/Module_Tony_Demo/Module_12_24/tony_img/%s'%title
download_pic(url=img_url_item,path=path,name='%s.jpg'%(title+img_url_item))
显示结果
全效
图片
在这个浮躁的时代;还是有人能坚持章节原创;
如果这篇文章对你的学习有帮助——你可以点赞+关注!更多新的 文章 将不断更新。
支持原创。感激!
python抓取动态网页(python抓取动态网页一般情况下,百度云下载器有限)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-06 00:00
python抓取动态网页一般情况下,当我们上传图片数据到百度云之后就会自动下载,但是百度云下载器有限,没有下载到真正有效的图片数据。此时,我们可以通过动态网页抓取程序来抓取百度云下载数据。pythonget_baidu_content代码实例如下:#获取baidu云产品库的所有内容importrequestsimportjsonimportreurl=''#设置参数来返回网页信息xls_file=json.loads(url)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defget_baidu_content():#获取baidu云产品库所有内容data=[]forfirst_lineinrange(0,b'\n'):#读取第一行数据row=0content=requests.get(first_line,headers=headers).text#返回baidu云产品库所有数据returndatadeftext_decoder():print('decodeutf-8')r=get_baidu_content()print('text()')print('|\n')text()#读取获取内容的json格式数据r=get_baidu_content()print('json()')print('|')json()xls_file=json.loads(data)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defjson_decoder():print('decodeutf-8')data={'json_path':json_path,'b':b'\n','d':data}returndatadefimage_decoder(file):#返回图片所有信息result={'json_path':json_path,'b':b'\n','d':data}#获取图片所有数据data=json.loads(data)print('image()')print('image()|')image()print('|')file_index=image_decoder(result)#生成标签index表示第几行index=index(data,int(image_decoder(json_path)))#获取每一列fori,dinenumerate(file_index):#返回每一列数据result[i]=xls_file[i][:i]result[i]=xls_file[index][:i]print('|')encode_str=image_decoder(result)#编码data=json.loads(encode_str)#解码xls_file=json.loads(encode_str)#将数据转换为json格式print('decodechardecodexml')print('decodebyxml')foriteminfile_index:#查看列表中的内容xls_index.range(1,10)#获取xls文件列表index=index(file_index)print。 查看全部
python抓取动态网页(python抓取动态网页一般情况下,百度云下载器有限)
python抓取动态网页一般情况下,当我们上传图片数据到百度云之后就会自动下载,但是百度云下载器有限,没有下载到真正有效的图片数据。此时,我们可以通过动态网页抓取程序来抓取百度云下载数据。pythonget_baidu_content代码实例如下:#获取baidu云产品库的所有内容importrequestsimportjsonimportreurl=''#设置参数来返回网页信息xls_file=json.loads(url)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defget_baidu_content():#获取baidu云产品库所有内容data=[]forfirst_lineinrange(0,b'\n'):#读取第一行数据row=0content=requests.get(first_line,headers=headers).text#返回baidu云产品库所有数据returndatadeftext_decoder():print('decodeutf-8')r=get_baidu_content()print('text()')print('|\n')text()#读取获取内容的json格式数据r=get_baidu_content()print('json()')print('|')json()xls_file=json.loads(data)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defjson_decoder():print('decodeutf-8')data={'json_path':json_path,'b':b'\n','d':data}returndatadefimage_decoder(file):#返回图片所有信息result={'json_path':json_path,'b':b'\n','d':data}#获取图片所有数据data=json.loads(data)print('image()')print('image()|')image()print('|')file_index=image_decoder(result)#生成标签index表示第几行index=index(data,int(image_decoder(json_path)))#获取每一列fori,dinenumerate(file_index):#返回每一列数据result[i]=xls_file[i][:i]result[i]=xls_file[index][:i]print('|')encode_str=image_decoder(result)#编码data=json.loads(encode_str)#解码xls_file=json.loads(encode_str)#将数据转换为json格式print('decodechardecodexml')print('decodebyxml')foriteminfile_index:#查看列表中的内容xls_index.range(1,10)#获取xls文件列表index=index(file_index)print。
python抓取动态网页(Python爬取网页图片的相关知识和一些Code实例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2022-03-03 03:17
你想了解网页中Python爬取图片(搜狗图片)的相关内容吗,dearvee将为你讲解Python爬取网页图片的相关知识以及本文中的一些代码示例,欢迎阅读指正,我们先重点:python爬取网页图片,python3爬取网页图片,python爬取网页数据,一起来学习吧。
前言
这几天研究了一直好奇的爬虫算法。以下是我这几天的总结。在下方输入文字:
您可能需要的工作环境:
Python3.6官网下载
本地下载
我们这里使用搜狗作为爬取对象。
首先,我们进入搜狗图片,进入壁纸分类(当然,这只是一个例子Q_Q),因为如果你需要爬取某个网站信息,那么你必须对它有一个初步的了解。 ..
进入后就是这样,然后F12进入开发者选项,我用的是Chrome。
右键单击图像>>检查
发现我们需要的图片的src在img标签下,所以我们先尝试用Python的requests提取组件,然后获取img的src,然后使用urllib.request.urlretrieve下载图片一、从而达到批量获取数据的目的,思路不错现在,下面应该告诉程序要爬取的url是%B1%DA%D6%BD,这个url来自后面的地址栏进入分类。现在我们了解了url地址,让我们开始快乐的代码时间:
在编写这个爬虫程序的时候,最好一步一步调试,确保我们的每一步操作都是正确的。这也是程序员应该具备的好习惯。我不知道我是不是程序员。我们来分析一下url指向的网页。
import requests
import urllib
from bs4 import BeautifulSoup
res = requests.get('http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD')
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img'))
输出:
发现输出的内容中并没有我们想要的图片元素,只是解析了logo的img,这显然不是我们想要的。也就是说,需要的图片数据不在url中,即%B1%DA%D6%BD。因此,考虑到元素可能是动态的,细心的同学可能会发现,在网页上向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态加载资源。这也避免了由于网页过于臃肿而影响加载速度。下面开始痛苦的探索。我们正在尝试找到所有图片的真实网址。作者也是新手,所以我在寻找这个方面不是很有经验。最后找到的位置是 F12>>Network>>XHR>>
发现它有点接近我们需要的元素。点击all_items,发现下面是0 1 2 3...一个一个好像是图片元素。尝试打开一个网址。发现真的是图片的地址。找到目标后。单击 XHR 下的标题
获得第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1536&height=864,尽量去掉一些不必要的部分,诀窍是把可能的部分去掉之后部分,访问不受影响。由作者过滤。最终的url:%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15 字面意思,知道类别后面可能跟一个类别。start为起始下标,len为长度,即图片数量。好吧,让我们玩得开心编码:
开发环境为Win7 Python 3.6。运行时,Python 需要安装请求。
Python3.6 安装请求应 CMD 类型:
pip install requests
笔者这里也是边调试边写,这里贴出最终代码:
import requests
import json
import urllib
def getSogouImag(category,length,path):
n = length
cate = category
imgs = requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = []
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'d:/download/壁纸/')
程序运行的时候,笔者还是有些激动的。来感受一下:
至此,爬虫的编程过程的描述就完成了。整体来说,找到元素需要爬取的url是爬虫很多方面的关键
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有问题可以留言交流,谢谢支持。
相关文章 查看全部
python抓取动态网页(Python爬取网页图片的相关知识和一些Code实例(组图))
你想了解网页中Python爬取图片(搜狗图片)的相关内容吗,dearvee将为你讲解Python爬取网页图片的相关知识以及本文中的一些代码示例,欢迎阅读指正,我们先重点:python爬取网页图片,python3爬取网页图片,python爬取网页数据,一起来学习吧。
前言
这几天研究了一直好奇的爬虫算法。以下是我这几天的总结。在下方输入文字:
您可能需要的工作环境:
Python3.6官网下载
本地下载
我们这里使用搜狗作为爬取对象。
首先,我们进入搜狗图片,进入壁纸分类(当然,这只是一个例子Q_Q),因为如果你需要爬取某个网站信息,那么你必须对它有一个初步的了解。 ..

进入后就是这样,然后F12进入开发者选项,我用的是Chrome。
右键单击图像>>检查

发现我们需要的图片的src在img标签下,所以我们先尝试用Python的requests提取组件,然后获取img的src,然后使用urllib.request.urlretrieve下载图片一、从而达到批量获取数据的目的,思路不错现在,下面应该告诉程序要爬取的url是%B1%DA%D6%BD,这个url来自后面的地址栏进入分类。现在我们了解了url地址,让我们开始快乐的代码时间:
在编写这个爬虫程序的时候,最好一步一步调试,确保我们的每一步操作都是正确的。这也是程序员应该具备的好习惯。我不知道我是不是程序员。我们来分析一下url指向的网页。
import requests
import urllib
from bs4 import BeautifulSoup
res = requests.get('http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD')
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img'))
输出:

发现输出的内容中并没有我们想要的图片元素,只是解析了logo的img,这显然不是我们想要的。也就是说,需要的图片数据不在url中,即%B1%DA%D6%BD。因此,考虑到元素可能是动态的,细心的同学可能会发现,在网页上向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态加载资源。这也避免了由于网页过于臃肿而影响加载速度。下面开始痛苦的探索。我们正在尝试找到所有图片的真实网址。作者也是新手,所以我在寻找这个方面不是很有经验。最后找到的位置是 F12>>Network>>XHR>>

发现它有点接近我们需要的元素。点击all_items,发现下面是0 1 2 3...一个一个好像是图片元素。尝试打开一个网址。发现真的是图片的地址。找到目标后。单击 XHR 下的标题
获得第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1536&height=864,尽量去掉一些不必要的部分,诀窍是把可能的部分去掉之后部分,访问不受影响。由作者过滤。最终的url:%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15 字面意思,知道类别后面可能跟一个类别。start为起始下标,len为长度,即图片数量。好吧,让我们玩得开心编码:
开发环境为Win7 Python 3.6。运行时,Python 需要安装请求。
Python3.6 安装请求应 CMD 类型:
pip install requests
笔者这里也是边调试边写,这里贴出最终代码:
import requests
import json
import urllib
def getSogouImag(category,length,path):
n = length
cate = category
imgs = requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = []
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'d:/download/壁纸/')
程序运行的时候,笔者还是有些激动的。来感受一下:


至此,爬虫的编程过程的描述就完成了。整体来说,找到元素需要爬取的url是爬虫很多方面的关键
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有问题可以留言交流,谢谢支持。
相关文章
python抓取动态网页(如下python网站开发教程:以糗事百科网站数据为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2022-03-02 11:15
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下python网站开发教程:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python网站开发教程、内容、搞笑数和评论数为4个字段,如下:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面python 网站开发教程:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为一种胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广。它越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。 查看全部
python抓取动态网页(如下python网站开发教程:以糗事百科网站数据为例)
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下python网站开发教程:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python网站开发教程、内容、搞笑数和评论数为4个字段,如下:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面python 网站开发教程:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为一种胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广。它越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。
python抓取动态网页(如下python网站开发教程:对应的网页源码(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-27 23:04
这里简单介绍一下python网站开发教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。以下python网站开发教程:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构python网站开发教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广,前景也越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。 查看全部
python抓取动态网页(如下python网站开发教程:对应的网页源码(组图))
这里简单介绍一下python网站开发教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。以下python网站开发教程:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构python网站开发教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广,前景也越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-27 08:18
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每个板块,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
解决方案
我试过网上说的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),查网络获取动态数据的走势,但这需要多方寻找线索网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
无意中发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施流程操作环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 文件夹,则表示可以在 Python 程序中加载该模块。
使用 webdriver 抓取动态数据
1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器的会话。浏览器可以使用 Firefox、Chrome、IE 等。这里我们以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面,url本身可以指定合法字符串
浏览器.get(url)
4.获取到session对象后,定位元素,webdriver提供了一系列元素定位方法,常用的有以下几种方式:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考大神《博客园-昆虫大师》的selenium webdriver(python)教程第三章-定位方法部分(第一版可百度文库阅读,第二版)版将从头开始收费>- 查看全部
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每个板块,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
解决方案
我试过网上说的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),查网络获取动态数据的走势,但这需要多方寻找线索网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
无意中发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施流程操作环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 文件夹,则表示可以在 Python 程序中加载该模块。
使用 webdriver 抓取动态数据
1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器的会话。浏览器可以使用 Firefox、Chrome、IE 等。这里我们以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面,url本身可以指定合法字符串
浏览器.get(url)
4.获取到session对象后,定位元素,webdriver提供了一系列元素定位方法,常用的有以下几种方式:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考大神《博客园-昆虫大师》的selenium webdriver(python)教程第三章-定位方法部分(第一版可百度文库阅读,第二版)版将从头开始收费>-
python抓取动态网页(python爬取js执行后输出的信息--python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-27 08:18
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
# 使用dryscrape库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
价值=内容.文本
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请搜索之前的文章的脚本之家@>或者继续浏览下面的相关文章希望大家以后多多支持脚本之家! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
# 使用dryscrape库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
价值=内容.文本
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请搜索之前的文章的脚本之家@>或者继续浏览下面的相关文章希望大家以后多多支持脚本之家!
python抓取动态网页(三种数据抓取的方法*利用之前构建的下载网页函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-27 02:05
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。
总结
本文文章关于python数据捕获的3种方法介绍到这里。更多相关python数据抓取内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家! 查看全部
python抓取动态网页(三种数据抓取的方法*利用之前构建的下载网页函数)
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。

from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:

最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:

仅供参考。
总结
本文文章关于python数据捕获的3种方法介绍到这里。更多相关python数据抓取内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家!
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-26 17:27
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素,但这里只是一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本元素。在使用爬虫的过程中,我们需要随时随地分析网页的构成元素。分析很有帮助。 查看全部
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素,但这里只是一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本元素。在使用爬虫的过程中,我们需要随时随地分析网页的构成元素。分析很有帮助。
python抓取动态网页(爬取动态网页的经验分享(官方不会打我吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-26 17:24
今天的主题是分享爬取动态网页的经验,以cocos论坛为例进行分享。(官方不会打我)
配置环境
为什么选择 cocos 论坛?因为我在浏览论坛的时候发现标题内容会随着滚动条的位置动态添加。
环境:python3 + 请求。还介绍了几个系统库。参考如下:
分析网页
以chrome浏览器为例,在空白处右键->勾选进入网页分析模式,在Network中选择XHR,向下滚动滚动条,观察右侧加载了哪些文件。
在网页分享模式下,点击刚才下载的文件查看内容,发现地址使用GET方式,传入页码参数。
看返回的内容是一个json字符串。
这个 json 字符串有我们想要的内容。下面我们来看看如何使用requests发送参数并返回Json结果。
只需传入一个header,告诉网页我们要根据地址接收一个json字符串。
解析json
JSON是一种可以被多种语言解析的数据存储格式,一般用于数据传输。
从上图可以看出,所有的文章列表都在topic_list的topic中,我们看看python3是如何解析的。
打开几个论坛内容就可以找到链接地址,由slug和id这两个字段拼接而成。
最后使用多线程和 csv 来存储结果。(不确定可以看前面的文章。python爬虫实战(三)不知道怎么正则呢?Xpath分分钟搞定python爬虫入门实战(二)!快!)快!快!让爬虫赢在起跑线上!多线程)
最后,看看最终的结果吧!
概括
对于动态生成的内容,我们可以在网页分享中分析下载的文件,通过requests模块模拟headers和发送参数来获取数据。
这是我学到的新技能!如有错误或其他想法,请留言!如果我学到了新东西,我会尽快与你分享!注意,不要迷路!
以上内容仅供个人学习使用,请勿用于商业用途。
我是白宇无冰,游戏开发的小红人,也玩python和shell 查看全部
python抓取动态网页(爬取动态网页的经验分享(官方不会打我吧))
今天的主题是分享爬取动态网页的经验,以cocos论坛为例进行分享。(官方不会打我)
配置环境
为什么选择 cocos 论坛?因为我在浏览论坛的时候发现标题内容会随着滚动条的位置动态添加。
环境:python3 + 请求。还介绍了几个系统库。参考如下:
分析网页
以chrome浏览器为例,在空白处右键->勾选进入网页分析模式,在Network中选择XHR,向下滚动滚动条,观察右侧加载了哪些文件。
在网页分享模式下,点击刚才下载的文件查看内容,发现地址使用GET方式,传入页码参数。
看返回的内容是一个json字符串。
这个 json 字符串有我们想要的内容。下面我们来看看如何使用requests发送参数并返回Json结果。
只需传入一个header,告诉网页我们要根据地址接收一个json字符串。
解析json
JSON是一种可以被多种语言解析的数据存储格式,一般用于数据传输。
从上图可以看出,所有的文章列表都在topic_list的topic中,我们看看python3是如何解析的。
打开几个论坛内容就可以找到链接地址,由slug和id这两个字段拼接而成。
最后使用多线程和 csv 来存储结果。(不确定可以看前面的文章。python爬虫实战(三)不知道怎么正则呢?Xpath分分钟搞定python爬虫入门实战(二)!快!)快!快!让爬虫赢在起跑线上!多线程)
最后,看看最终的结果吧!
概括
对于动态生成的内容,我们可以在网页分享中分析下载的文件,通过requests模块模拟headers和发送参数来获取数据。
这是我学到的新技能!如有错误或其他想法,请留言!如果我学到了新东西,我会尽快与你分享!注意,不要迷路!
以上内容仅供个人学习使用,请勿用于商业用途。
我是白宇无冰,游戏开发的小红人,也玩python和shell
python抓取动态网页(python抓取动态网页标题,抓取百度文库,豆瓣上高分txt文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-25 00:01
python抓取动态网页标题,抓取动态pdf文件,抓取百度文库,抓取豆瓣上高分txt文件。而那些通过加入空格扩展属性抓取请求返回,各种代理池分批次抓取等方式没有抓取到的数据返回,并被真正的搜索引擎访问到的高质量数据却是没有搜索引擎访问的时候,存放在本地数据库的,也是完全被搜索引擎访问的数据(大部分是不被搜索引擎访问的),绝大部分数据根本没有收集起来,而是直接从接受任务的服务器上抓取(大部分的抓取方案都是以任务来收集数据库中的数据,也是任务的一部分,没有收集,就无法存储返回的数据)。
正是因为被搜索引擎所访问,所以在搜索引擎算法会有所区别,比如作为中心词作为长尾词的比例很小。建议不懂得是可以用python画出简单的流程图来理解:第一步需要抓取的数据:标题,值格式是python第二步需要抓取的数据:pdf文件大小,值格式是%mm%mb(越小数据越少越精确,pdf里面使用空格的有无作为字符类型的标签,mb是指128k字节,标签字符类型是python里对空格作为字符类型的标签设置textfield,具体可以查看相关资料)第三步需要抓取的数据:txt文件第四步需要抓取的数据:百度文库抓取文档:直接连接服务器,然后收集解析过程:txt文件-文件名-方式-web响应-随机数-解析服务器。 查看全部
python抓取动态网页(python抓取动态网页标题,抓取百度文库,豆瓣上高分txt文件)
python抓取动态网页标题,抓取动态pdf文件,抓取百度文库,抓取豆瓣上高分txt文件。而那些通过加入空格扩展属性抓取请求返回,各种代理池分批次抓取等方式没有抓取到的数据返回,并被真正的搜索引擎访问到的高质量数据却是没有搜索引擎访问的时候,存放在本地数据库的,也是完全被搜索引擎访问的数据(大部分是不被搜索引擎访问的),绝大部分数据根本没有收集起来,而是直接从接受任务的服务器上抓取(大部分的抓取方案都是以任务来收集数据库中的数据,也是任务的一部分,没有收集,就无法存储返回的数据)。
正是因为被搜索引擎所访问,所以在搜索引擎算法会有所区别,比如作为中心词作为长尾词的比例很小。建议不懂得是可以用python画出简单的流程图来理解:第一步需要抓取的数据:标题,值格式是python第二步需要抓取的数据:pdf文件大小,值格式是%mm%mb(越小数据越少越精确,pdf里面使用空格的有无作为字符类型的标签,mb是指128k字节,标签字符类型是python里对空格作为字符类型的标签设置textfield,具体可以查看相关资料)第三步需要抓取的数据:txt文件第四步需要抓取的数据:百度文库抓取文档:直接连接服务器,然后收集解析过程:txt文件-文件名-方式-web响应-随机数-解析服务器。
python抓取动态网页(如何快速将不同新闻网站中的大量新闻文章导出到一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-24 12:27
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们深入了解各个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何将大量新闻文章 从不同的新闻网站 中快速抓取到一个简单的 python 脚本中。
如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:
- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~ 查看全部
python抓取动态网页(如何快速将不同新闻网站中的大量新闻文章导出到一个)
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们深入了解各个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何将大量新闻文章 从不同的新闻网站 中快速抓取到一个简单的 python 脚本中。
如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:
- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~
python抓取动态网页(2019独角兽企业重金招聘Python工程师标准;gt;python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-23 07:06
2019独角兽企业招聘Python工程师标准>>>
Python
我想推荐几个网页给你学习Python爬虫的新手。总有一款适合你!json
话不多说,直接干货!蟒蛇爬虫
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图集学习
动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!下面的代码 网站
图片地址全部出!谷歌
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转到网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。以下:网址
80本电子书:匹配地址直接下载压缩文件
80 和上面的全书网类似,但是它提供了自己的下载功能,可以直接构造下载文件,小说ID和名字,页面截图和代码:spa
其余类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!。网
以上代码均为手写,无需排版。如果你有兴趣,你可以自己打字。或者,像小说网站,可以先抓取大类,然后把每个类的所有小说都拿到,最后把每个类的所有小说都放上去。抓出小说的内容,这就是全站爬虫!!!3d
如果你还有其他合适的网站,希望你可以在评论区分享!让我们一起聊天吧!
转载于: 查看全部
python抓取动态网页(2019独角兽企业重金招聘Python工程师标准;gt;python)
2019独角兽企业招聘Python工程师标准>>>
Python
我想推荐几个网页给你学习Python爬虫的新手。总有一款适合你!json

话不多说,直接干货!蟒蛇爬虫
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图集学习

动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!下面的代码 网站

图片地址全部出!谷歌
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转到网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。以下:网址


80本电子书:匹配地址直接下载压缩文件
80 和上面的全书网类似,但是它提供了自己的下载功能,可以直接构造下载文件,小说ID和名字,页面截图和代码:spa



其余类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!。网
以上代码均为手写,无需排版。如果你有兴趣,你可以自己打字。或者,像小说网站,可以先抓取大类,然后把每个类的所有小说都拿到,最后把每个类的所有小说都放上去。抓出小说的内容,这就是全站爬虫!!!3d

如果你还有其他合适的网站,希望你可以在评论区分享!让我们一起聊天吧!
转载于:
python抓取动态网页(python关于python编写爬虫的一些东西是怎样的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-07 23:25
前段时间浏览知乎的时候,发现一篇关于用python写爬虫的帖子。这是帖子的链接
于是想到了用python来尝试爬取一些东西。本来打算根据关键词爬取百度图片并下载,但过程中遇到障碍,暂时停止。然后去内涵段的页面结构,发现还是比较简单的
单点,然后在下面实现一个爬虫。
写这个程序的时候参考了博主的相关博文在知乎/pleasecallmewhy/article/details/8929576
编写这个程序主要分为以下几个步骤:
1.分析Inner Community的页面结构
2.使用正则表达式查找要下载的url
3.下载这些图片
第一步就是第一步,也是比较关键的一步。如果页面分析不正确,则后续步骤将无法启动。
1.打开内段子囧图片页
我们将看到以下页面
这个页面下面有一些我们想要的搞笑图片,但是我们首先需要得到这个页面的html文件,这里我使用python的urllib库,代码如下
def get_html(url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
需要使用 urllib 模拟使用 Firefox 的 Firebug 插件发送的信息才能看到,然后复制头部信息填入上面的头部。需要添加其中的 Cooiker。如果不添加,将无法获取 html 文件。urllib的使用具体介绍见上面博主的博客,说的很清楚。
既然得到了html文件,我们来观察这个文件。这个html文件的结构比较清晰。
每个帖子由一个 div 组成,然后是标题、图像和评论的另一个 div
在class = content-wrapper的div中我们找到了这句话
这个data-text就是图片的写法,data-pic就是图片的地址,所以我们的工作就是获取所有的data-pic和data-text(后面可以作为图片的名字)
要解析这个 html 中的所有这两个字段,我们需要使用 python 的正则表达式。我们这里使用的非常简单。我是通过模仿得到的。具体的re教程也可以从上面的博主那里获得。
下面是我的重新解析代码
这样我就可以根据刚才得到的html文件解析出所有图片的地址,然后就可以在下面下载了。下载使用与urllib相关的函数。
-----------------到此结束,就可以下载几十张图片了
为什么只有几十张图片?
原因是我们刚刚获取的只是首页的html文件,那么如何获取更多的html文件呢?
我们注意到页面底部有一个Load More按钮,点击它可以获取图片。
我们也使用萤火虫来抓取包。
打开这个 Get 请求和结果
问:
响应:我们在浏览器中输入这个请求地址,得到一个json响应
逐步展开json得到
在 large_image 下面我们有我们需要的东西。.
仔细观察得到的json响应,你会发现有一个min_time字段,是一个unix时间戳。而这个 min_time 正是这个下一个请求的 max_time
这个循环可以得到所有的图片!!
进入第一次获取的html文件,也可以找到一个
那么我们的任务基本上就是不断的解析json文件并下载
下面是我的第一个版本的源代码
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import thread
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
self.__downloadPic(data_pic)
count = 0
#下面开始下载点击更多之后的图片
while max_time:
count = count + 1
print "=--------------------THIS IS THE " + str(count) + " Json Data Time : " + str(max_time) + "--------------------"
url = self.base_url + str(max_time)
json_data = self.__getHtml(url)
json_ret = self.__parseJson(json_data)
max_time = json_ret['max_time']
print max_time
image_url = json_ret['image_url']
image_content = json_ret['image_content']
self.__downloadPic(image_url,image_content)
#python 以两个下划线开始的为私有函数
#尝试5次
#解析json,并获取json中的数据
def __parseJson(self,json_data):
print "------This is parse_json --------"
dct = json.loads(json_data)
image_content = []
image_url = []
max_time = ""
try :
max_time = dct['data']['max_time']
data = dct['data']['data']
for item in data:
content = item['group']['content']
url = item['group']['large_image']['url_list'][0]['url']
image_content.append(content)
image_url.append(url)
ret = {}
ret['image_content'] = image_content
ret['image_url'] = image_url
ret['max_time'] = max_time
return ret
except :
print "json_parse error"
#定义下载图片函数
def __downloadPic(self,imageAddressList,contentList = []):
print "---download------"
contentExist = len(contentList)
count = 0
for image in imageAddressList :
print image
count = count + 1
randTail = str(random.randint(0,30000000))
try :
#tail = contentExist ? contentList[count - 1] : randTail ;
if contentExist :
tail = contentList[count - 1]
else :
tail = randTail
fullPath = "C:\\Users\\Administrator\\Desktop\\python\\" + tail + ".jpg"
urllib.urlretrieve(image , fullPath)
except :
failedMsg = "第" + str(count) + "张下载失败,URL: " + str(image) + ""
print failedMsg
pass
def __getDataPic(self,html):
re_str = r'data-pic="([^"]*)"'
data_pic = self.__getDataByRe(html,re_str)
return data_pic
def __getMaxTime(self,html):
re_str = r'max_time: \'([\d]*)\''
max_time = self.__getDataByRe(html,re_str)
return max_time
def __getDataByRe(self,text,re_str):
pattern = re.compile(re_str)
ret = pattern.findall(text)
return ret
def __getHtml(self,url):
print "GET HTML********"
count = 0
while count < 5:
count = count + 1
print str(count) + " times ,try download html"
html = self.__getDataByUrl(url)
if not html:
continue;
else:
return html
def __getDataByUrl(self,url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
#------------------------------------------程序入口处------------------------------
mySpider = neiHanSpider()
mySpider.Start()
之后我再次尝试了多线程版本
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import threading
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self ):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
#self.__downloadPic(data_pic)
global downloadUrlList
global downloadTitleList
#downloadList = downloadList + data_pic
count = 0
#下面开始下载点击更多之后的图片
while max_time and count " + str(len(downloadTitleList))
threadLock = threading.Lock()
threads = []
size = len(downloadUrlList)
for i in range(1,10) :
thread = myDownLoad(i,"Thread-" + str(i));
thread.start()
threads.append(thread)
aliveCount = 10
while aliveCount > 1 :
print "Now There is " + str(aliveCount) + "Threads alive"
aliveCount = threading.activeCount()
time.sleep(10)
endTime = time.time()
print " Download " + str(size) + "张图,共耗时 " + str((endTime - startTime) / 60) + "min"
print "Exiting Main Thread"
可能写的不是很整齐,有时间再整理一下。Python现正在使用中,欢迎批评指正 查看全部
python抓取动态网页(python关于python编写爬虫的一些东西是怎样的?(图))
前段时间浏览知乎的时候,发现一篇关于用python写爬虫的帖子。这是帖子的链接
于是想到了用python来尝试爬取一些东西。本来打算根据关键词爬取百度图片并下载,但过程中遇到障碍,暂时停止。然后去内涵段的页面结构,发现还是比较简单的
单点,然后在下面实现一个爬虫。
写这个程序的时候参考了博主的相关博文在知乎/pleasecallmewhy/article/details/8929576
编写这个程序主要分为以下几个步骤:
1.分析Inner Community的页面结构
2.使用正则表达式查找要下载的url
3.下载这些图片
第一步就是第一步,也是比较关键的一步。如果页面分析不正确,则后续步骤将无法启动。
1.打开内段子囧图片页
我们将看到以下页面
这个页面下面有一些我们想要的搞笑图片,但是我们首先需要得到这个页面的html文件,这里我使用python的urllib库,代码如下
def get_html(url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
需要使用 urllib 模拟使用 Firefox 的 Firebug 插件发送的信息才能看到,然后复制头部信息填入上面的头部。需要添加其中的 Cooiker。如果不添加,将无法获取 html 文件。urllib的使用具体介绍见上面博主的博客,说的很清楚。
既然得到了html文件,我们来观察这个文件。这个html文件的结构比较清晰。
每个帖子由一个 div 组成,然后是标题、图像和评论的另一个 div
在class = content-wrapper的div中我们找到了这句话
这个data-text就是图片的写法,data-pic就是图片的地址,所以我们的工作就是获取所有的data-pic和data-text(后面可以作为图片的名字)
要解析这个 html 中的所有这两个字段,我们需要使用 python 的正则表达式。我们这里使用的非常简单。我是通过模仿得到的。具体的re教程也可以从上面的博主那里获得。
下面是我的重新解析代码
这样我就可以根据刚才得到的html文件解析出所有图片的地址,然后就可以在下面下载了。下载使用与urllib相关的函数。
-----------------到此结束,就可以下载几十张图片了
为什么只有几十张图片?
原因是我们刚刚获取的只是首页的html文件,那么如何获取更多的html文件呢?
我们注意到页面底部有一个Load More按钮,点击它可以获取图片。
我们也使用萤火虫来抓取包。
打开这个 Get 请求和结果
问:
响应:我们在浏览器中输入这个请求地址,得到一个json响应
逐步展开json得到
在 large_image 下面我们有我们需要的东西。.
仔细观察得到的json响应,你会发现有一个min_time字段,是一个unix时间戳。而这个 min_time 正是这个下一个请求的 max_time
这个循环可以得到所有的图片!!
进入第一次获取的html文件,也可以找到一个
那么我们的任务基本上就是不断的解析json文件并下载
下面是我的第一个版本的源代码
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import thread
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
self.__downloadPic(data_pic)
count = 0
#下面开始下载点击更多之后的图片
while max_time:
count = count + 1
print "=--------------------THIS IS THE " + str(count) + " Json Data Time : " + str(max_time) + "--------------------"
url = self.base_url + str(max_time)
json_data = self.__getHtml(url)
json_ret = self.__parseJson(json_data)
max_time = json_ret['max_time']
print max_time
image_url = json_ret['image_url']
image_content = json_ret['image_content']
self.__downloadPic(image_url,image_content)
#python 以两个下划线开始的为私有函数
#尝试5次
#解析json,并获取json中的数据
def __parseJson(self,json_data):
print "------This is parse_json --------"
dct = json.loads(json_data)
image_content = []
image_url = []
max_time = ""
try :
max_time = dct['data']['max_time']
data = dct['data']['data']
for item in data:
content = item['group']['content']
url = item['group']['large_image']['url_list'][0]['url']
image_content.append(content)
image_url.append(url)
ret = {}
ret['image_content'] = image_content
ret['image_url'] = image_url
ret['max_time'] = max_time
return ret
except :
print "json_parse error"
#定义下载图片函数
def __downloadPic(self,imageAddressList,contentList = []):
print "---download------"
contentExist = len(contentList)
count = 0
for image in imageAddressList :
print image
count = count + 1
randTail = str(random.randint(0,30000000))
try :
#tail = contentExist ? contentList[count - 1] : randTail ;
if contentExist :
tail = contentList[count - 1]
else :
tail = randTail
fullPath = "C:\\Users\\Administrator\\Desktop\\python\\" + tail + ".jpg"
urllib.urlretrieve(image , fullPath)
except :
failedMsg = "第" + str(count) + "张下载失败,URL: " + str(image) + ""
print failedMsg
pass
def __getDataPic(self,html):
re_str = r'data-pic="([^"]*)"'
data_pic = self.__getDataByRe(html,re_str)
return data_pic
def __getMaxTime(self,html):
re_str = r'max_time: \'([\d]*)\''
max_time = self.__getDataByRe(html,re_str)
return max_time
def __getDataByRe(self,text,re_str):
pattern = re.compile(re_str)
ret = pattern.findall(text)
return ret
def __getHtml(self,url):
print "GET HTML********"
count = 0
while count < 5:
count = count + 1
print str(count) + " times ,try download html"
html = self.__getDataByUrl(url)
if not html:
continue;
else:
return html
def __getDataByUrl(self,url):
print "---------------now get html from url :" + url + "----------"
send_headers = {
'Host':'neihanshequ.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0',
'Cookie':"pksrqup=1; csrftoken=237f4451075fe45cef3a4f5449f70658; tt_webid=3379513254; uuid=\"w:33266c46f0cc4fa6944c073b1b1bccea\"",
'Connection':'keep-alive'
}
req = urllib2.Request(url ,headers=send_headers)
try:
response = urllib2.urlopen(req ,timeout = 100)
html = response.read()
return html
except urllib2.HTTPError, e:
print 'The server couldn\'t fulfill the request.'
print 'Error code: ', e.code
except urllib2.URLError, e:
print 'We failed to reach a server.'
print 'Reason: ', e.reason
else:
print 'No exception was raised.'
#------------------------------------------程序入口处------------------------------
mySpider = neiHanSpider()
mySpider.Start()
之后我再次尝试了多线程版本
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import threading
import time
import os
import random
import json
#内涵段子抓取类
class neiHanSpider :
def __init__(self ):
self.primer_url = 'http://neihanshequ.com/pic/'
#点击加载更多之后请求的url
self.base_url = 'http://neihanshequ.com/pic/%3F ... 39%3B
def Start(self):
#首先获取第一个页面的html数据,并分析其中的data-pic和max_time
primer_html = self.__getHtml(self.primer_url)
data_pic = self.__getDataPic(primer_html)
max_time = self.__getMaxTime(primer_html)
#download pic
#self.__downloadPic(data_pic)
global downloadUrlList
global downloadTitleList
#downloadList = downloadList + data_pic
count = 0
#下面开始下载点击更多之后的图片
while max_time and count " + str(len(downloadTitleList))
threadLock = threading.Lock()
threads = []
size = len(downloadUrlList)
for i in range(1,10) :
thread = myDownLoad(i,"Thread-" + str(i));
thread.start()
threads.append(thread)
aliveCount = 10
while aliveCount > 1 :
print "Now There is " + str(aliveCount) + "Threads alive"
aliveCount = threading.activeCount()
time.sleep(10)
endTime = time.time()
print " Download " + str(size) + "张图,共耗时 " + str((endTime - startTime) / 60) + "min"
print "Exiting Main Thread"
可能写的不是很整齐,有时间再整理一下。Python现正在使用中,欢迎批评指正
python抓取动态网页(一个爬取动态网页的超简单的一个小demo了解多少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-07 17:19
大家好,我是大智
这次给大家介绍一个超级简单的爬取动态网页的小demo。
说起动态网页,你对它了解多少?
简单来说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
好的,让我们开始进入正题。
一、 分析网页结构
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候,我们就可以判断为动态网页了。这时候,我们需要找到一个接口
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求,可以在后台与服务器交换数据,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL
打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
ok,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
ok,我们已经拿到了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名称是我们需要的,然后我们就可以磁盘了。
if "data" in content:
3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
好的,我们的愿景已经实现。
四、完整代码
# encoding: utf-8
五、保存结果 查看全部
python抓取动态网页(一个爬取动态网页的超简单的一个小demo了解多少)
大家好,我是大智
这次给大家介绍一个超级简单的爬取动态网页的小demo。
说起动态网页,你对它了解多少?
简单来说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
好的,让我们开始进入正题。
一、 分析网页结构
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候,我们就可以判断为动态网页了。这时候,我们需要找到一个接口
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求,可以在后台与服务器交换数据,也就是说可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL
打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
ok,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
ok,我们已经拿到了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名称是我们需要的,然后我们就可以磁盘了。
if "data" in content:
3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
好的,我们的愿景已经实现。
四、完整代码
# encoding: utf-8
五、保存结果
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-07 09:21
)
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 页面时,会发现我们要提取的页面元素不在我们下载的 HTML 中,尽管它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些动作下通过js事件动态生成的。比如我们刷QQ空间或者微博评论的时候,我们一直在往下滑。网页越来越长,内容越来越多。这是人们又爱又恨的动态加载。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
按键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡,也可能在XHR选项卡,当然也可以使用其他抓包工具),如图以下
然后,我们拖动右边的滚动条,然后我们会发现开发者工具里有新的js请求(有不少),但是如果你匆忙翻译的话,很容易看出哪个是评论, 如下所示
OK,复制出js请求的目标url
在浏览器中打开,发现我们要的数据就在这里,如下图
整个页面都是 json 格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去获取数据,然后将获取到的json数据通过一定的js逻辑填充到数据中。在 HTML 页面中。对于我们的 Spider,我们所要做的就是组织和提取这些 json 数据。
在实际应用中,我们当然不可能在每个页面中找出这个js发起的请求的目标地址,所以需要分析请求地址的规律。一般来说,法律比较容易找到,因为法律对于服务方来说太复杂了。维护也很困难。
2.Selenium 模拟浏览器行为
对于动态加载,可以看到 Selenium+Phantomjs 的强大。打开网页查看网页的源代码(注意不是检查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处之一是它可以捕获完整的源代码以
示例:根据给定名称搜索豆瓣电影的对应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
url = ‘https://movie.douban.com/‘
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path=‘C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe‘)
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class=‘item-root‘]"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get(‘src‘)
url = i.find("a").get(‘href‘)
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")
Python动态爬取网页 查看全部
python抓取动态网页(HTML网页时会模拟浏览器行为分析方法分析及注意事项
)
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 页面时,会发现我们要提取的页面元素不在我们下载的 HTML 中,尽管它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些动作下通过js事件动态生成的。比如我们刷QQ空间或者微博评论的时候,我们一直在往下滑。网页越来越长,内容越来越多。这是人们又爱又恨的动态加载。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟浏览器行为1.分析页面请求
按键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡,也可能在XHR选项卡,当然也可以使用其他抓包工具),如图以下
然后,我们拖动右边的滚动条,然后我们会发现开发者工具里有新的js请求(有不少),但是如果你匆忙翻译的话,很容易看出哪个是评论, 如下所示
OK,复制出js请求的目标url
在浏览器中打开,发现我们要的数据就在这里,如下图
整个页面都是 json 格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去获取数据,然后将获取到的json数据通过一定的js逻辑填充到数据中。在 HTML 页面中。对于我们的 Spider,我们所要做的就是组织和提取这些 json 数据。
在实际应用中,我们当然不可能在每个页面中找出这个js发起的请求的目标地址,所以需要分析请求地址的规律。一般来说,法律比较容易找到,因为法律对于服务方来说太复杂了。维护也很困难。
2.Selenium 模拟浏览器行为
对于动态加载,可以看到 Selenium+Phantomjs 的强大。打开网页查看网页的源代码(注意不是检查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处之一是它可以捕获完整的源代码以
示例:根据给定名称搜索豆瓣电影的对应信息
#-*- coding:utf-8 -*-
import sys
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
url = ‘https://movie.douban.com/‘
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path=‘C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe‘)
driver.get(url)
#在搜索框上模拟输入信息并点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("crazy")
elem.send_keys(Keys.RETURN)
#得到动态加载的网页
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
# 进行匹配
for i in soup.select("div[class=‘item-root‘]"):
name = i.find("a", class_="title-text").text
pic = i.find("img").get(‘src‘)
url = i.find("a").get(‘href‘)
rate = ""
num = ""
if i.find("span", class_="rating_nums") is None:
print name.encode("gbk", "ignore"), pic, url
else:
rate = i.find("span", class_="rating_nums").text
num = i.find("span", class_="pl").text
print name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num.encode("gbk", "ignore")
Python动态爬取网页
python抓取动态网页( Python,x,WebCrawler, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-06 22:05
Python,x,WebCrawler,
)
Python使用JavaScript呈现的内容从网页中获取数据
pythonpython-3.xweb爬虫
Python使用JavaScript呈现的内容从网页中获取数据。Python,Python-3.x,网络爬虫,Python,Python3.x,网络爬虫。我是捕获数据的新手。我想从这个网站获取数据:[我想通过输入一个.CSV文件来获取数据,并使其与上图中的每一行CSV文件工作相同。我只从红色框中获取数据,如mengabadi、mengabadikan、pengabadian和keabadian,并将其保存在一个新的.CSV文件中,如下所示:那么,我能做些什么来获取它(可以使用Python)? 我认为网页使用JavaScript加载/呈现数据。使用请求和BS4示例代码:(自己阅读并实现它,只是为了给你一个想法!)现在,使用inspe
我是捕获数据的新手。我想从这个网站获取数据:[
我想以与上图中数据相同的方式输入抓取数据,例如。Gamenian,以及CSV文件中新行中的数据,如下所示:
那么,我能做些什么来获取它(可能使用Python)?我认为网页使用JavaScript加载/呈现数据
使用
请求和bs4
示例代码:(自己阅读并实现它,只是为了给你一个想法!)
现在,使用inspect工具挖掘场景,然后。。密码
beautifulsoup的安装和请求可通过PIP完成:
$ pip install requests
$ pip install beautifulsoup4
$ pip install requests
$ pip install beautifulsoup4 查看全部
python抓取动态网页(
Python,x,WebCrawler,
)
Python使用JavaScript呈现的内容从网页中获取数据
pythonpython-3.xweb爬虫
Python使用JavaScript呈现的内容从网页中获取数据。Python,Python-3.x,网络爬虫,Python,Python3.x,网络爬虫。我是捕获数据的新手。我想从这个网站获取数据:[我想通过输入一个.CSV文件来获取数据,并使其与上图中的每一行CSV文件工作相同。我只从红色框中获取数据,如mengabadi、mengabadikan、pengabadian和keabadian,并将其保存在一个新的.CSV文件中,如下所示:那么,我能做些什么来获取它(可以使用Python)? 我认为网页使用JavaScript加载/呈现数据。使用请求和BS4示例代码:(自己阅读并实现它,只是为了给你一个想法!)现在,使用inspe
我是捕获数据的新手。我想从这个网站获取数据:[
我想以与上图中数据相同的方式输入抓取数据,例如。Gamenian,以及CSV文件中新行中的数据,如下所示:
那么,我能做些什么来获取它(可能使用Python)?我认为网页使用JavaScript加载/呈现数据
使用
请求和bs4
示例代码:(自己阅读并实现它,只是为了给你一个想法!)
现在,使用inspect工具挖掘场景,然后。。密码
beautifulsoup的安装和请求可通过PIP完成:
$ pip install requests
$ pip install beautifulsoup4
$ pip install requests
$ pip install beautifulsoup4
python抓取动态网页(Python程序设计执行指定函数及正则匹配的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-06 22:03
本文文章主要介绍Python中周期性抓取网页内容的方法,涉及Python时间函数和正则匹配的相关操作技巧。有一定的参考价值,有需要的朋友可以参考以下
p>
本文中的示例描述了 Python 如何实现对 Web 内容的定期爬取。分享给大家,供大家参考,如下:
1.使用sched模块周期性执行指定函数
2.周期性执行指定函数爬取指定网页,解析出想要的网页内容,代码为六维论坛的在线人数
论坛网上人口统计代码:
<p>
#coding=utf-8
import time,sched,os,urllib2,re,string
#初始化sched模块的scheduler类
#第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞。
s = sched.scheduler(time.time,time.sleep)
#被周期性调度触发的函数
def event_func():
req = urllib2.Request('http://bt.neu6.edu.cn/')
response = urllib2.urlopen(req)
rawdata = response.read()
response.close()
usernump = re.compile(r'总计 .*? 人在线')
usernummatch = usernump.findall(rawdata)
if usernummatch:
currentnum=usernummatch[0]
currentnum=currentnum[string.index(currentnum,'>')+1:string.rindex(currentnum,' 查看全部
python抓取动态网页(Python程序设计执行指定函数及正则匹配的相关操作技巧)
本文文章主要介绍Python中周期性抓取网页内容的方法,涉及Python时间函数和正则匹配的相关操作技巧。有一定的参考价值,有需要的朋友可以参考以下
p>
本文中的示例描述了 Python 如何实现对 Web 内容的定期爬取。分享给大家,供大家参考,如下:
1.使用sched模块周期性执行指定函数
2.周期性执行指定函数爬取指定网页,解析出想要的网页内容,代码为六维论坛的在线人数
论坛网上人口统计代码:
<p>
#coding=utf-8
import time,sched,os,urllib2,re,string
#初始化sched模块的scheduler类
#第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞。
s = sched.scheduler(time.time,time.sleep)
#被周期性调度触发的函数
def event_func():
req = urllib2.Request('http://bt.neu6.edu.cn/')
response = urllib2.urlopen(req)
rawdata = response.read()
response.close()
usernump = re.compile(r'总计 .*? 人在线')
usernummatch = usernump.findall(rawdata)
if usernummatch:
currentnum=usernummatch[0]
currentnum=currentnum[string.index(currentnum,'>')+1:string.rindex(currentnum,'
python抓取动态网页(『爬虫四步走』手把手教你使用Python抓取并存储网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-06 20:04
《爬虫四步走》教你如何使用Python爬取和存储网页数据!
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以B站视频热搜榜数据的抓取和存储为例,详细介绍Python爬虫。基本流程。= requests.get(url)print(res.status_code)#200 在上面的代码中,我们完成了以下三件事。导入请求并使用 get 方法构造请求。使用 status_code 获取网页的状态码。可以看到返回值。返回一个带有我们需要的视频数据的字符串,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,并将字符串转换为网页结构化数据,这样就可以方便的找到HTML标签及其属性和内容。在 Python 中有很多方法可以解析网页。可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup。从第三步开始:提取内容在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
616 查看全部
python抓取动态网页(『爬虫四步走』手把手教你使用Python抓取并存储网页数据)
《爬虫四步走》教你如何使用Python爬取和存储网页数据!
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以B站视频热搜榜数据的抓取和存储为例,详细介绍Python爬虫。基本流程。= requests.get(url)print(res.status_code)#200 在上面的代码中,我们完成了以下三件事。导入请求并使用 get 方法构造请求。使用 status_code 获取网页的状态码。可以看到返回值。返回一个带有我们需要的视频数据的字符串,但是直接从字符串中提取内容复杂且效率低下,所以我们需要对其进行解析,并将字符串转换为网页结构化数据,这样就可以方便的找到HTML标签及其属性和内容。在 Python 中有很多方法可以解析网页。可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup。从第三步开始:提取内容在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
616
python抓取动态网页(js动态加载的网页就犯了难谷歌、百度,发现个好介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-06 04:02
经过一段时间的python学习,可以写一些爬虫了。但是,很难遇到js动态加载的网页。于是google,百度,找到了很好的介绍
主要目的是分析网页的加载过程,从网页响应中找到JS脚本返回的JSON数据。(上面的网址很详细,把下面的代码贴出来记录一下)
1、今日头条
#coding:utf-8
import requests
import json
#今日头条热词获取,get方法
url = 'http://www.toutiao.com/c/hot_words/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']
for n in news:
print(n)
2、拉狗网的发帖方式
#coding:utf-8
import requests
import json
url = 'https://www.lagou.com/upload/l ... 39%3B
post_data = {'first':'true','kd':'Android','pn':'1'}
wbdata = requests.post(url,data=post_data)<br />data = json.loads(wbdata)
print data
ip被封,无法解析返回的json数据,需要跟进。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟
转载于: 查看全部
python抓取动态网页(js动态加载的网页就犯了难谷歌、百度,发现个好介绍)
经过一段时间的python学习,可以写一些爬虫了。但是,很难遇到js动态加载的网页。于是google,百度,找到了很好的介绍
主要目的是分析网页的加载过程,从网页响应中找到JS脚本返回的JSON数据。(上面的网址很详细,把下面的代码贴出来记录一下)
1、今日头条
#coding:utf-8
import requests
import json
#今日头条热词获取,get方法
url = 'http://www.toutiao.com/c/hot_words/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']
for n in news:
print(n)
2、拉狗网的发帖方式
#coding:utf-8
import requests
import json
url = 'https://www.lagou.com/upload/l ... 39%3B
post_data = {'first':'true','kd':'Android','pn':'1'}
wbdata = requests.post(url,data=post_data)<br />data = json.loads(wbdata)
print data
ip被封,无法解析返回的json数据,需要跟进。
目前爬取动态页面有两种方法
分析页面请求 selenium 模拟
转载于:
python抓取动态网页(实战分析网站结构,确定我们要的数据内容;image唯美图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-06 04:01
前言
每个人都需要互相帮助,而我所要做的就是呈现给大家看。
例如,有人可以背一本你不会背的书,有人可以做一个你不会做的问题,有人你愿意推迟到明天,有人今天会努力完成它,对不起,你想要什么工作只能别人做,自己想要的生活也只能别人过!
教师讲授职业以解决疑虑。繁殖的力量就是穿透这些东西,然后才能长出新的叶子。共勉!
- 实战
分析网站的结构,确定我们要抓取的数据内容;
图片
审美画面是对绝对美的追求,强调超越生活的纯粹美,是对完美形式和完美艺术技巧的不断追求。
图片
右键Chrome浏览器查看网络,分析网站的结构;发现这个网页内容很多。单页获取图片数据很简单,但这就是我们的风格?不; 绝对不。即使它是一个非常简单的逻辑,我们也必须以不同的方式使其复杂化。这是托尼先生的程序;追求纯技术。
希望能给更多的编程从业者带来一些优质的文章。
第一步:请求网络并获取服务器返回的数据
不管怎样,我们先获取数据内容;因为检测网站中是否有反爬的唯一因素就是获取它的数据内容;看看能不能正常获取。
这里需要安装 2 个库:
pip install requests 网络请求库
pip install lxml 数据解析库
导入请求
网址='#39;
html=requests.get(url).content.decode('gbk')
打印(html)
接下来,通过分析;我看到网站里面所有内容的页数都很大,有1153页的数据,所以我想,如果只是拿到几页数据内容,真的很容易!但是如果我在爬其他页面,我是否需要担心它是否有这么多的数据;毕竟每一页的数据内容都不一样;这绝对满足不了我对科技的渴望,所以......
图片
图片
第 2 步:解析数据
从 lxml 导入 etree
# 动态获取最后一页数据
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
# list_20_1153.html ---> 1152
打印(页)
接下来在处理的时候,第一页数据和第二页数据的url不一样;并且无法单独获取第二页及后续所有页面的数据;所以……只能拼接。
url_list=[]
网址='#39;
url_list.append(url)
html=requests.get(url).content.decode('gbk')
# 打印(html)
# 谓词
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
对于范围内的项目(2,int(page)+1):
url_list.append(url+'list_20_{}.html'.format(str(item)))
打印(url_list)
图片
至此,我们已经能够动态获取所有页面的链接;我很高兴拥有它;迄今为止; 我们已经跨过了第一步;之后,我们需要获取每个页面的图片详情页面以进行下一步。准备数据处理。
对于 url_list 中的 url_item:
img_url=etree.HTML(requests.get(url_item).text).xpath('//div[@class="ABox"]/a/@href')
打印(img_url)
图片
图片
网站 数据的每一次突破都像是我们的战利品。这就是对技术着迷的容易程度。
接下来的事情越来越有趣了!我们需要再次分析网站详情页;在分析过程中,我发现了一件非常有趣的事情;之前的获取方式很相似……emmmmmm,这里就不细说了!每个人都会自己分析。
图片
图片
所以……为了让程序越来越好玩;接下来,让我们改变它;
# 在单个文件详情页面
def get_img_urls(img_urls):
html=requests.get(img_urls)
html.encoding='gbk'
数据=etree.HTML(html.text)
# 标题
title=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/text()')[0]
#总页数
page=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/span/span[2]/text()')[0]
img['1']=data.xpath('//a[@class="down-btn"]/@href')[0]
打印(标题,页面)
对于范围内的项目(2,int(page)+1):
text=requests.get(img_urls.replace('.html','_%s.html'%str(item))).text
img_url = etree.HTML(text).xpath('//a[@class="down-btn"]/@href')[0]
返回标题,img
第 3 步:数据存储
在下载数据部分;考虑到我要下载的数据图片-->是原图,而且很多图片的内存比例不一样;如果文件太大,可能会导致内存不足;我们在学习的时候,不需要考虑这个因素,但托尼不这么认为;因为如果有一天每个人都真正学到了一些东西并进入了企业;这时候就要考虑程序优化的问题了;它可以更好地让我们编写高质量的代码程序;这也是考验我们的基本功是否真的扎实;当我们下载大文件时,为了防止它占用过多的内存;所以我做了数据流操作处理
# 下载图片
def 下载图片(网址,路径,名称):
# 法官
如果 os.path.exists(path):
经过
别的:
os.mkdir(路径)
响应=requests.get(url)
如果 response.status_code==200:
以 open(path+'/%s'%name,'ab') 作为文件:
对于 response.iter_content() 中的数据:
file.write(数据)
# 清空缓存
文件.flush()
print('%s 下载完成!'%name)
数据块处理
图片
第四步:代码整理
对于 img_url 中的 img_urls:
标题,img=get_img_urls(img_urls)
对于 img.keys() 中的 img_url_item:
path='/Users/lucky/PycharmProjects/Module_Tony_Demo/Module_12_24/tony_img/%s'%title
download_pic(url=img_url_item,path=path,name='%s.jpg'%(title+img_url_item))
显示结果
全效
图片
在这个浮躁的时代;还是有人能坚持章节原创;
如果这篇文章对你的学习有帮助——你可以点赞+关注!更多新的 文章 将不断更新。
支持原创。感激! 查看全部
python抓取动态网页(实战分析网站结构,确定我们要的数据内容;image唯美图片)
前言
每个人都需要互相帮助,而我所要做的就是呈现给大家看。
例如,有人可以背一本你不会背的书,有人可以做一个你不会做的问题,有人你愿意推迟到明天,有人今天会努力完成它,对不起,你想要什么工作只能别人做,自己想要的生活也只能别人过!
教师讲授职业以解决疑虑。繁殖的力量就是穿透这些东西,然后才能长出新的叶子。共勉!
- 实战
分析网站的结构,确定我们要抓取的数据内容;
图片
审美画面是对绝对美的追求,强调超越生活的纯粹美,是对完美形式和完美艺术技巧的不断追求。
图片
右键Chrome浏览器查看网络,分析网站的结构;发现这个网页内容很多。单页获取图片数据很简单,但这就是我们的风格?不; 绝对不。即使它是一个非常简单的逻辑,我们也必须以不同的方式使其复杂化。这是托尼先生的程序;追求纯技术。
希望能给更多的编程从业者带来一些优质的文章。
第一步:请求网络并获取服务器返回的数据
不管怎样,我们先获取数据内容;因为检测网站中是否有反爬的唯一因素就是获取它的数据内容;看看能不能正常获取。
这里需要安装 2 个库:
pip install requests 网络请求库
pip install lxml 数据解析库
导入请求
网址='#39;
html=requests.get(url).content.decode('gbk')
打印(html)
接下来,通过分析;我看到网站里面所有内容的页数都很大,有1153页的数据,所以我想,如果只是拿到几页数据内容,真的很容易!但是如果我在爬其他页面,我是否需要担心它是否有这么多的数据;毕竟每一页的数据内容都不一样;这绝对满足不了我对科技的渴望,所以......
图片
图片
第 2 步:解析数据
从 lxml 导入 etree
# 动态获取最后一页数据
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
# list_20_1153.html ---> 1152
打印(页)
接下来在处理的时候,第一页数据和第二页数据的url不一样;并且无法单独获取第二页及后续所有页面的数据;所以……只能拼接。
url_list=[]
网址='#39;
url_list.append(url)
html=requests.get(url).content.decode('gbk')
# 打印(html)
# 谓词
page=etree.HTML(html).xpath('//a[@text="last page"]/@href')[0].split('_').split('.')[0]
对于范围内的项目(2,int(page)+1):
url_list.append(url+'list_20_{}.html'.format(str(item)))
打印(url_list)
图片
至此,我们已经能够动态获取所有页面的链接;我很高兴拥有它;迄今为止; 我们已经跨过了第一步;之后,我们需要获取每个页面的图片详情页面以进行下一步。准备数据处理。
对于 url_list 中的 url_item:
img_url=etree.HTML(requests.get(url_item).text).xpath('//div[@class="ABox"]/a/@href')
打印(img_url)
图片
图片
网站 数据的每一次突破都像是我们的战利品。这就是对技术着迷的容易程度。
接下来的事情越来越有趣了!我们需要再次分析网站详情页;在分析过程中,我发现了一件非常有趣的事情;之前的获取方式很相似……emmmmmm,这里就不细说了!每个人都会自己分析。
图片
图片
所以……为了让程序越来越好玩;接下来,让我们改变它;
# 在单个文件详情页面
def get_img_urls(img_urls):
html=requests.get(img_urls)
html.encoding='gbk'
数据=etree.HTML(html.text)
# 标题
title=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/text()')[0]
#总页数
page=data.xpath('//div[@class="wrapper clearfix imgtitle"]/h1/span/span[2]/text()')[0]
img['1']=data.xpath('//a[@class="down-btn"]/@href')[0]
打印(标题,页面)
对于范围内的项目(2,int(page)+1):
text=requests.get(img_urls.replace('.html','_%s.html'%str(item))).text
img_url = etree.HTML(text).xpath('//a[@class="down-btn"]/@href')[0]
返回标题,img
第 3 步:数据存储
在下载数据部分;考虑到我要下载的数据图片-->是原图,而且很多图片的内存比例不一样;如果文件太大,可能会导致内存不足;我们在学习的时候,不需要考虑这个因素,但托尼不这么认为;因为如果有一天每个人都真正学到了一些东西并进入了企业;这时候就要考虑程序优化的问题了;它可以更好地让我们编写高质量的代码程序;这也是考验我们的基本功是否真的扎实;当我们下载大文件时,为了防止它占用过多的内存;所以我做了数据流操作处理
# 下载图片
def 下载图片(网址,路径,名称):
# 法官
如果 os.path.exists(path):
经过
别的:
os.mkdir(路径)
响应=requests.get(url)
如果 response.status_code==200:
以 open(path+'/%s'%name,'ab') 作为文件:
对于 response.iter_content() 中的数据:
file.write(数据)
# 清空缓存
文件.flush()
print('%s 下载完成!'%name)
数据块处理
图片
第四步:代码整理
对于 img_url 中的 img_urls:
标题,img=get_img_urls(img_urls)
对于 img.keys() 中的 img_url_item:
path='/Users/lucky/PycharmProjects/Module_Tony_Demo/Module_12_24/tony_img/%s'%title
download_pic(url=img_url_item,path=path,name='%s.jpg'%(title+img_url_item))
显示结果
全效
图片
在这个浮躁的时代;还是有人能坚持章节原创;
如果这篇文章对你的学习有帮助——你可以点赞+关注!更多新的 文章 将不断更新。
支持原创。感激!
python抓取动态网页(python抓取动态网页一般情况下,百度云下载器有限)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-06 00:00
python抓取动态网页一般情况下,当我们上传图片数据到百度云之后就会自动下载,但是百度云下载器有限,没有下载到真正有效的图片数据。此时,我们可以通过动态网页抓取程序来抓取百度云下载数据。pythonget_baidu_content代码实例如下:#获取baidu云产品库的所有内容importrequestsimportjsonimportreurl=''#设置参数来返回网页信息xls_file=json.loads(url)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defget_baidu_content():#获取baidu云产品库所有内容data=[]forfirst_lineinrange(0,b'\n'):#读取第一行数据row=0content=requests.get(first_line,headers=headers).text#返回baidu云产品库所有数据returndatadeftext_decoder():print('decodeutf-8')r=get_baidu_content()print('text()')print('|\n')text()#读取获取内容的json格式数据r=get_baidu_content()print('json()')print('|')json()xls_file=json.loads(data)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defjson_decoder():print('decodeutf-8')data={'json_path':json_path,'b':b'\n','d':data}returndatadefimage_decoder(file):#返回图片所有信息result={'json_path':json_path,'b':b'\n','d':data}#获取图片所有数据data=json.loads(data)print('image()')print('image()|')image()print('|')file_index=image_decoder(result)#生成标签index表示第几行index=index(data,int(image_decoder(json_path)))#获取每一列fori,dinenumerate(file_index):#返回每一列数据result[i]=xls_file[i][:i]result[i]=xls_file[index][:i]print('|')encode_str=image_decoder(result)#编码data=json.loads(encode_str)#解码xls_file=json.loads(encode_str)#将数据转换为json格式print('decodechardecodexml')print('decodebyxml')foriteminfile_index:#查看列表中的内容xls_index.range(1,10)#获取xls文件列表index=index(file_index)print。 查看全部
python抓取动态网页(python抓取动态网页一般情况下,百度云下载器有限)
python抓取动态网页一般情况下,当我们上传图片数据到百度云之后就会自动下载,但是百度云下载器有限,没有下载到真正有效的图片数据。此时,我们可以通过动态网页抓取程序来抓取百度云下载数据。pythonget_baidu_content代码实例如下:#获取baidu云产品库的所有内容importrequestsimportjsonimportreurl=''#设置参数来返回网页信息xls_file=json.loads(url)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defget_baidu_content():#获取baidu云产品库所有内容data=[]forfirst_lineinrange(0,b'\n'):#读取第一行数据row=0content=requests.get(first_line,headers=headers).text#返回baidu云产品库所有数据returndatadeftext_decoder():print('decodeutf-8')r=get_baidu_content()print('text()')print('|\n')text()#读取获取内容的json格式数据r=get_baidu_content()print('json()')print('|')json()xls_file=json.loads(data)#对json.loads编码格式进行处理(将乱码编码格式转化为了utf-8格式)#获取文件内容defjson_decoder():print('decodeutf-8')data={'json_path':json_path,'b':b'\n','d':data}returndatadefimage_decoder(file):#返回图片所有信息result={'json_path':json_path,'b':b'\n','d':data}#获取图片所有数据data=json.loads(data)print('image()')print('image()|')image()print('|')file_index=image_decoder(result)#生成标签index表示第几行index=index(data,int(image_decoder(json_path)))#获取每一列fori,dinenumerate(file_index):#返回每一列数据result[i]=xls_file[i][:i]result[i]=xls_file[index][:i]print('|')encode_str=image_decoder(result)#编码data=json.loads(encode_str)#解码xls_file=json.loads(encode_str)#将数据转换为json格式print('decodechardecodexml')print('decodebyxml')foriteminfile_index:#查看列表中的内容xls_index.range(1,10)#获取xls文件列表index=index(file_index)print。
python抓取动态网页(Python爬取网页图片的相关知识和一些Code实例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2022-03-03 03:17
你想了解网页中Python爬取图片(搜狗图片)的相关内容吗,dearvee将为你讲解Python爬取网页图片的相关知识以及本文中的一些代码示例,欢迎阅读指正,我们先重点:python爬取网页图片,python3爬取网页图片,python爬取网页数据,一起来学习吧。
前言
这几天研究了一直好奇的爬虫算法。以下是我这几天的总结。在下方输入文字:
您可能需要的工作环境:
Python3.6官网下载
本地下载
我们这里使用搜狗作为爬取对象。
首先,我们进入搜狗图片,进入壁纸分类(当然,这只是一个例子Q_Q),因为如果你需要爬取某个网站信息,那么你必须对它有一个初步的了解。 ..
进入后就是这样,然后F12进入开发者选项,我用的是Chrome。
右键单击图像>>检查
发现我们需要的图片的src在img标签下,所以我们先尝试用Python的requests提取组件,然后获取img的src,然后使用urllib.request.urlretrieve下载图片一、从而达到批量获取数据的目的,思路不错现在,下面应该告诉程序要爬取的url是%B1%DA%D6%BD,这个url来自后面的地址栏进入分类。现在我们了解了url地址,让我们开始快乐的代码时间:
在编写这个爬虫程序的时候,最好一步一步调试,确保我们的每一步操作都是正确的。这也是程序员应该具备的好习惯。我不知道我是不是程序员。我们来分析一下url指向的网页。
import requests
import urllib
from bs4 import BeautifulSoup
res = requests.get('http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD')
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img'))
输出:
发现输出的内容中并没有我们想要的图片元素,只是解析了logo的img,这显然不是我们想要的。也就是说,需要的图片数据不在url中,即%B1%DA%D6%BD。因此,考虑到元素可能是动态的,细心的同学可能会发现,在网页上向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态加载资源。这也避免了由于网页过于臃肿而影响加载速度。下面开始痛苦的探索。我们正在尝试找到所有图片的真实网址。作者也是新手,所以我在寻找这个方面不是很有经验。最后找到的位置是 F12>>Network>>XHR>>
发现它有点接近我们需要的元素。点击all_items,发现下面是0 1 2 3...一个一个好像是图片元素。尝试打开一个网址。发现真的是图片的地址。找到目标后。单击 XHR 下的标题
获得第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1536&height=864,尽量去掉一些不必要的部分,诀窍是把可能的部分去掉之后部分,访问不受影响。由作者过滤。最终的url:%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15 字面意思,知道类别后面可能跟一个类别。start为起始下标,len为长度,即图片数量。好吧,让我们玩得开心编码:
开发环境为Win7 Python 3.6。运行时,Python 需要安装请求。
Python3.6 安装请求应 CMD 类型:
pip install requests
笔者这里也是边调试边写,这里贴出最终代码:
import requests
import json
import urllib
def getSogouImag(category,length,path):
n = length
cate = category
imgs = requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = []
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'d:/download/壁纸/')
程序运行的时候,笔者还是有些激动的。来感受一下:
至此,爬虫的编程过程的描述就完成了。整体来说,找到元素需要爬取的url是爬虫很多方面的关键
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有问题可以留言交流,谢谢支持。
相关文章 查看全部
python抓取动态网页(Python爬取网页图片的相关知识和一些Code实例(组图))
你想了解网页中Python爬取图片(搜狗图片)的相关内容吗,dearvee将为你讲解Python爬取网页图片的相关知识以及本文中的一些代码示例,欢迎阅读指正,我们先重点:python爬取网页图片,python3爬取网页图片,python爬取网页数据,一起来学习吧。
前言
这几天研究了一直好奇的爬虫算法。以下是我这几天的总结。在下方输入文字:
您可能需要的工作环境:
Python3.6官网下载
本地下载
我们这里使用搜狗作为爬取对象。
首先,我们进入搜狗图片,进入壁纸分类(当然,这只是一个例子Q_Q),因为如果你需要爬取某个网站信息,那么你必须对它有一个初步的了解。 ..
进入后就是这样,然后F12进入开发者选项,我用的是Chrome。
右键单击图像>>检查
发现我们需要的图片的src在img标签下,所以我们先尝试用Python的requests提取组件,然后获取img的src,然后使用urllib.request.urlretrieve下载图片一、从而达到批量获取数据的目的,思路不错现在,下面应该告诉程序要爬取的url是%B1%DA%D6%BD,这个url来自后面的地址栏进入分类。现在我们了解了url地址,让我们开始快乐的代码时间:
在编写这个爬虫程序的时候,最好一步一步调试,确保我们的每一步操作都是正确的。这也是程序员应该具备的好习惯。我不知道我是不是程序员。我们来分析一下url指向的网页。
import requests
import urllib
from bs4 import BeautifulSoup
res = requests.get('http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD')
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img'))
输出:
发现输出的内容中并没有我们想要的图片元素,只是解析了logo的img,这显然不是我们想要的。也就是说,需要的图片数据不在url中,即%B1%DA%D6%BD。因此,考虑到元素可能是动态的,细心的同学可能会发现,在网页上向下滑动鼠标滚轮时,图片是动态刷新的,也就是说网页不是一次性加载所有资源,而是动态加载资源。这也避免了由于网页过于臃肿而影响加载速度。下面开始痛苦的探索。我们正在尝试找到所有图片的真实网址。作者也是新手,所以我在寻找这个方面不是很有经验。最后找到的位置是 F12>>Network>>XHR>>
发现它有点接近我们需要的元素。点击all_items,发现下面是0 1 2 3...一个一个好像是图片元素。尝试打开一个网址。发现真的是图片的地址。找到目标后。单击 XHR 下的标题
获得第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1536&height=864,尽量去掉一些不必要的部分,诀窍是把可能的部分去掉之后部分,访问不受影响。由作者过滤。最终的url:%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15 字面意思,知道类别后面可能跟一个类别。start为起始下标,len为长度,即图片数量。好吧,让我们玩得开心编码:
开发环境为Win7 Python 3.6。运行时,Python 需要安装请求。
Python3.6 安装请求应 CMD 类型:
pip install requests
笔者这里也是边调试边写,这里贴出最终代码:
import requests
import json
import urllib
def getSogouImag(category,length,path):
n = length
cate = category
imgs = requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = []
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'d:/download/壁纸/')
程序运行的时候,笔者还是有些激动的。来感受一下:
至此,爬虫的编程过程的描述就完成了。整体来说,找到元素需要爬取的url是爬虫很多方面的关键
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有问题可以留言交流,谢谢支持。
相关文章
python抓取动态网页(如下python网站开发教程:以糗事百科网站数据为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2022-03-02 11:15
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下python网站开发教程:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python网站开发教程、内容、搞笑数和评论数为4个字段,如下:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面python 网站开发教程:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为一种胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广。它越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。 查看全部
python抓取动态网页(如下python网站开发教程:以糗事百科网站数据为例)
这里有一个简单的介绍。以捕获静态和动态数据为例,实验环境为win10+python3.6+pycharm5.0。主要内容如下python网站开发教程:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python网站开发教程、内容、搞笑数和评论数为4个字段,如下:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面python 网站开发教程:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难,都是入门级爬虫,网页结构也比较简单。最重要的是进行抓包分析,分析提取页面,等你熟悉了之后,可以使用scrapy框架进行数据爬取,可以更加方便高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为一种胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广。它越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。
python抓取动态网页(如下python网站开发教程:对应的网页源码(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-27 23:04
这里简单介绍一下python网站开发教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。以下python网站开发教程:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构python网站开发教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广,前景也越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。 查看全部
python抓取动态网页(如下python网站开发教程:对应的网页源码(组图))
这里简单介绍一下python网站开发教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)python网站开发教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数和评论数四个字段。以下python网站开发教程:
对应的网页源码如下python网站开发教程,包括我们需要的数据:
2.对应网页结构python网站开发教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
打开网页源代码,可以发现网页源代码中没有数据。当你按F12抓包并分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
如何学习蟒蛇?python的前景如何?
Python 上手其实非常简单。作为胶水语言,它的设计是面向大众,降低编程入门门槛。随着大数据、人工智能、机器学习的兴起,python的应用范围越来越广,前景也越来越好。先简单介绍一下python的学习过程:
1.本地环境搭建,这里推荐Anaconda。该软件集成了python解释器和许多第三方包。还自带spyder、ipython notebook等开发环境(相比python自带的IDLE,功能强大很多,而且好用),对于初学者来说是一个非常不错的选择:
笔记本开发环境如下,很好用。如果你是专业人士,你可以使用 pycharm IDE:
2.python学习入门,这里最重要的是多练多练多练,重要的事情说三遍,不管什么编程语言,多练,掌握基本功,熟悉python列表、字典、元组、变量、函数、类、文件操作、异常处理、各种语句等,还有常用包的使用,网上有很多资料,大家可以自己搜索一下, MOOC、菜鸟教程、博客等:
3.熟悉了基本操作后,以后可以选择一个有前途的方向学习。Python涉及的方面太多了,比如web开发、爬虫、机器学习、运维、测试、树莓派等等,找一个坚持好的方向,比如人工智能、机器学习等等,热的:
让我们分享这么多。最重要的是掌握基本功,然后选择一个好的方向去深入学习。你肯定会学到一些东西。希望以上分享的内容对您有所帮助。
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-27 08:18
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每个板块,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
解决方案
我试过网上说的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),查网络获取动态数据的走势,但这需要多方寻找线索网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
无意中发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施流程操作环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 文件夹,则表示可以在 Python 程序中加载该模块。
使用 webdriver 抓取动态数据
1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器的会话。浏览器可以使用 Firefox、Chrome、IE 等。这里我们以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面,url本身可以指定合法字符串
浏览器.get(url)
4.获取到session对象后,定位元素,webdriver提供了一系列元素定位方法,常用的有以下几种方式:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考大神《博客园-昆虫大师》的selenium webdriver(python)教程第三章-定位方法部分(第一版可百度文库阅读,第二版)版将从头开始收费>- 查看全部
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每个板块,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
解决方案
我试过网上说的浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),查网络获取动态数据的走势,但这需要多方寻找线索网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
无意中发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施流程操作环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 文件夹,则表示可以在 Python 程序中加载该模块。
使用 webdriver 抓取动态数据
1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器的会话。浏览器可以使用 Firefox、Chrome、IE 等。这里我们以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面,url本身可以指定合法字符串
浏览器.get(url)
4.获取到session对象后,定位元素,webdriver提供了一系列元素定位方法,常用的有以下几种方式:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考大神《博客园-昆虫大师》的selenium webdriver(python)教程第三章-定位方法部分(第一版可百度文库阅读,第二版)版将从头开始收费>-
python抓取动态网页(python爬取js执行后输出的信息--python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-27 08:18
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
# 使用dryscrape库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
价值=内容.文本
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请搜索之前的文章的脚本之家@>或者继续浏览下面的相关文章希望大家以后多多支持脚本之家! 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
# 使用dryscrape库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
内容 = driver.find_element_by_class_name('内容')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
价值=内容.文本
至此,这篇关于python如何爬取动态网站的文章文章就介绍到这里了。更多关于python如何爬取动态网站的信息,请搜索之前的文章的脚本之家@>或者继续浏览下面的相关文章希望大家以后多多支持脚本之家!
python抓取动态网页(三种数据抓取的方法*利用之前构建的下载网页函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-27 02:05
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。
总结
本文文章关于python数据捕获的3种方法介绍到这里。更多相关python数据抓取内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家! 查看全部
python抓取动态网页(三种数据抓取的方法*利用之前构建的下载网页函数)
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。
总结
本文文章关于python数据捕获的3种方法介绍到这里。更多相关python数据抓取内容,请搜索脚本之家以前的文章或继续浏览以下相关文章希望大家以后多多支持脚本之家!
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-26 17:27
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素,但这里只是一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本元素。在使用爬虫的过程中,我们需要随时随地分析网页的构成元素。分析很有帮助。 查看全部
python抓取动态网页(就是网站的概念与具体讲解网页的构成的区别?)
网页是可以被浏览器等客户端解析的文件。与我们通常遇到的文件不同的是:网页植根于互联网。也就是说,我们通过浏览器浏览的大部分网页文件都不是本地的,它可能在世界上任何一台联网的电脑上。而且,通过互联网的超链接,我们可以在世界任何一个角落浏览网页文件,也就是我们通常所说的上网,足不出户就能融入整个世界。
爬虫爬取的数据其实就是网页上的内容。本节我们会讲到具体的爬取原理。我们先来看看网站的概念:
1. 网站 的概念
在详细解释网页的结构之前。我们需要先了解 网站 的概念。
网站 是多个向外界提供服务的网页的集合。主要分为静态网站和动态网站。
1.1 静态网站
静态 网站 表示 网站 下的所有页面都是使用 HTML网站 构建的。所谓静态并不意味着网页是静态的,网页中还可以有动画、视频等信息。这里的静态是指无法与服务器交互。只是被动解析显示服务器端响应返回的信息。
静态网站的优点:
便于收录搜索,方便SEO优化。内容独立,不依赖于数据库。
静态网站的缺点:
维护成本比较高,大部分内容需要人工手动更新。该页面不是交互式的,用户体验很差。1.2 个供稿网站
动态网站相比静态网站,可以提供更多的交互体验。比如用户注册登录、实时推荐等功能。动态 网站 不仅收录静态 HTML 文件,还收录服务器端脚本,如 Jsp、Asp 等。
动态网站的优点:
用户体验好,可以实现更多的个性化设置。服务端可以和客户端进行更多的交互,方便服务端管理和分析数据。
动态网站的缺点:
需要处理数据库,访问速度大大降低。对搜索引擎不友好。
无论是静态网站中的网页还是动态网站中的网页,都有一些共同的基本内容。让我们看一下网页的三个基本元素:
2. 网页的三个基本元素:
在接下来的章节中,我们将详细介绍网页的三个基本要素,但这里只是一些基本概念和用途。
2.1 个 HTML
HTML 是一种标记语言。标记语言不是编程语言,它不能以逻辑编程的方式进行编程。它只是就如何呈现文件达成一致。通过对不同标签所代表的不同含义达成一致,在浏览器端渲染出丰富多彩的网页。它主要包括两个部分:头部和主体。HTML 主要负责页面的结构。
2.2 CSS
级联样式表,有时称为样式表。需要配合HTML使用,才能提供丰富的渲染效果。
2.3 Javascript
它是一种广泛用于前端逻辑实现的脚本语言。很多自定义效果都可以通过 javascript 来实现,javascript 是前端使用最广泛的编程语言。
综上所述,HTML、CSS、Javascript共同构成了丰富的网页样式。三者缺一不可。没有HTML、CSS、Javascript,就是无源之水,毫无意义;没有 CSS,网页将失去颜色和样式,最终会使 HTML 变得相同;没有 Javascript,我们无法看到动态网页。,只是一潭死水。
3. 爬取原理
爬虫爬取的数据其实就是网页上的内容。我们需要通过特定的工具来分析网页,比如Beautiful Soup。然后提取 HTML 中特定标签下的数据。然后,将数据持久化并保存,以方便未来的数据分析。
简单来说,我们使用爬虫,最根本的目的就是在网页中爬取对我们有价值的信息和数据。因此,我们大部分的爬取工作就是过滤我们的有用信息,剔除无用信息。这是爬虫的核心。
4. 总结
通过本节,我们了解了网页的基本元素。在使用爬虫的过程中,我们需要随时随地分析网页的构成元素。分析很有帮助。
python抓取动态网页(爬取动态网页的经验分享(官方不会打我吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-26 17:24
今天的主题是分享爬取动态网页的经验,以cocos论坛为例进行分享。(官方不会打我)
配置环境
为什么选择 cocos 论坛?因为我在浏览论坛的时候发现标题内容会随着滚动条的位置动态添加。
环境:python3 + 请求。还介绍了几个系统库。参考如下:
分析网页
以chrome浏览器为例,在空白处右键->勾选进入网页分析模式,在Network中选择XHR,向下滚动滚动条,观察右侧加载了哪些文件。
在网页分享模式下,点击刚才下载的文件查看内容,发现地址使用GET方式,传入页码参数。
看返回的内容是一个json字符串。
这个 json 字符串有我们想要的内容。下面我们来看看如何使用requests发送参数并返回Json结果。
只需传入一个header,告诉网页我们要根据地址接收一个json字符串。
解析json
JSON是一种可以被多种语言解析的数据存储格式,一般用于数据传输。
从上图可以看出,所有的文章列表都在topic_list的topic中,我们看看python3是如何解析的。
打开几个论坛内容就可以找到链接地址,由slug和id这两个字段拼接而成。
最后使用多线程和 csv 来存储结果。(不确定可以看前面的文章。python爬虫实战(三)不知道怎么正则呢?Xpath分分钟搞定python爬虫入门实战(二)!快!)快!快!让爬虫赢在起跑线上!多线程)
最后,看看最终的结果吧!
概括
对于动态生成的内容,我们可以在网页分享中分析下载的文件,通过requests模块模拟headers和发送参数来获取数据。
这是我学到的新技能!如有错误或其他想法,请留言!如果我学到了新东西,我会尽快与你分享!注意,不要迷路!
以上内容仅供个人学习使用,请勿用于商业用途。
我是白宇无冰,游戏开发的小红人,也玩python和shell 查看全部
python抓取动态网页(爬取动态网页的经验分享(官方不会打我吧))
今天的主题是分享爬取动态网页的经验,以cocos论坛为例进行分享。(官方不会打我)
配置环境
为什么选择 cocos 论坛?因为我在浏览论坛的时候发现标题内容会随着滚动条的位置动态添加。
环境:python3 + 请求。还介绍了几个系统库。参考如下:
分析网页
以chrome浏览器为例,在空白处右键->勾选进入网页分析模式,在Network中选择XHR,向下滚动滚动条,观察右侧加载了哪些文件。
在网页分享模式下,点击刚才下载的文件查看内容,发现地址使用GET方式,传入页码参数。
看返回的内容是一个json字符串。
这个 json 字符串有我们想要的内容。下面我们来看看如何使用requests发送参数并返回Json结果。
只需传入一个header,告诉网页我们要根据地址接收一个json字符串。
解析json
JSON是一种可以被多种语言解析的数据存储格式,一般用于数据传输。
从上图可以看出,所有的文章列表都在topic_list的topic中,我们看看python3是如何解析的。
打开几个论坛内容就可以找到链接地址,由slug和id这两个字段拼接而成。
最后使用多线程和 csv 来存储结果。(不确定可以看前面的文章。python爬虫实战(三)不知道怎么正则呢?Xpath分分钟搞定python爬虫入门实战(二)!快!)快!快!让爬虫赢在起跑线上!多线程)
最后,看看最终的结果吧!
概括
对于动态生成的内容,我们可以在网页分享中分析下载的文件,通过requests模块模拟headers和发送参数来获取数据。
这是我学到的新技能!如有错误或其他想法,请留言!如果我学到了新东西,我会尽快与你分享!注意,不要迷路!
以上内容仅供个人学习使用,请勿用于商业用途。
我是白宇无冰,游戏开发的小红人,也玩python和shell
python抓取动态网页(python抓取动态网页标题,抓取百度文库,豆瓣上高分txt文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-25 00:01
python抓取动态网页标题,抓取动态pdf文件,抓取百度文库,抓取豆瓣上高分txt文件。而那些通过加入空格扩展属性抓取请求返回,各种代理池分批次抓取等方式没有抓取到的数据返回,并被真正的搜索引擎访问到的高质量数据却是没有搜索引擎访问的时候,存放在本地数据库的,也是完全被搜索引擎访问的数据(大部分是不被搜索引擎访问的),绝大部分数据根本没有收集起来,而是直接从接受任务的服务器上抓取(大部分的抓取方案都是以任务来收集数据库中的数据,也是任务的一部分,没有收集,就无法存储返回的数据)。
正是因为被搜索引擎所访问,所以在搜索引擎算法会有所区别,比如作为中心词作为长尾词的比例很小。建议不懂得是可以用python画出简单的流程图来理解:第一步需要抓取的数据:标题,值格式是python第二步需要抓取的数据:pdf文件大小,值格式是%mm%mb(越小数据越少越精确,pdf里面使用空格的有无作为字符类型的标签,mb是指128k字节,标签字符类型是python里对空格作为字符类型的标签设置textfield,具体可以查看相关资料)第三步需要抓取的数据:txt文件第四步需要抓取的数据:百度文库抓取文档:直接连接服务器,然后收集解析过程:txt文件-文件名-方式-web响应-随机数-解析服务器。 查看全部
python抓取动态网页(python抓取动态网页标题,抓取百度文库,豆瓣上高分txt文件)
python抓取动态网页标题,抓取动态pdf文件,抓取百度文库,抓取豆瓣上高分txt文件。而那些通过加入空格扩展属性抓取请求返回,各种代理池分批次抓取等方式没有抓取到的数据返回,并被真正的搜索引擎访问到的高质量数据却是没有搜索引擎访问的时候,存放在本地数据库的,也是完全被搜索引擎访问的数据(大部分是不被搜索引擎访问的),绝大部分数据根本没有收集起来,而是直接从接受任务的服务器上抓取(大部分的抓取方案都是以任务来收集数据库中的数据,也是任务的一部分,没有收集,就无法存储返回的数据)。
正是因为被搜索引擎所访问,所以在搜索引擎算法会有所区别,比如作为中心词作为长尾词的比例很小。建议不懂得是可以用python画出简单的流程图来理解:第一步需要抓取的数据:标题,值格式是python第二步需要抓取的数据:pdf文件大小,值格式是%mm%mb(越小数据越少越精确,pdf里面使用空格的有无作为字符类型的标签,mb是指128k字节,标签字符类型是python里对空格作为字符类型的标签设置textfield,具体可以查看相关资料)第三步需要抓取的数据:txt文件第四步需要抓取的数据:百度文库抓取文档:直接连接服务器,然后收集解析过程:txt文件-文件名-方式-web响应-随机数-解析服务器。
python抓取动态网页(如何快速将不同新闻网站中的大量新闻文章导出到一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-24 12:27
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们深入了解各个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何将大量新闻文章 从不同的新闻网站 中快速抓取到一个简单的 python 脚本中。
如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:
- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~ 查看全部
python抓取动态网页(如何快速将不同新闻网站中的大量新闻文章导出到一个)
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们深入了解各个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何将大量新闻文章 从不同的新闻网站 中快速抓取到一个简单的 python 脚本中。
如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:
- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~
python抓取动态网页(2019独角兽企业重金招聘Python工程师标准;gt;python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-23 07:06
2019独角兽企业招聘Python工程师标准>>>
Python
我想推荐几个网页给你学习Python爬虫的新手。总有一款适合你!json
话不多说,直接干货!蟒蛇爬虫
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图集学习
动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!下面的代码 网站
图片地址全部出!谷歌
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转到网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。以下:网址
80本电子书:匹配地址直接下载压缩文件
80 和上面的全书网类似,但是它提供了自己的下载功能,可以直接构造下载文件,小说ID和名字,页面截图和代码:spa
其余类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!。网
以上代码均为手写,无需排版。如果你有兴趣,你可以自己打字。或者,像小说网站,可以先抓取大类,然后把每个类的所有小说都拿到,最后把每个类的所有小说都放上去。抓出小说的内容,这就是全站爬虫!!!3d
如果你还有其他合适的网站,希望你可以在评论区分享!让我们一起聊天吧!
转载于: 查看全部
python抓取动态网页(2019独角兽企业重金招聘Python工程师标准;gt;python)
2019独角兽企业招聘Python工程师标准>>>
Python
我想推荐几个网页给你学习Python爬虫的新手。总有一款适合你!json
话不多说,直接干货!蟒蛇爬虫
今日头条图集:抓包获取json数据
打开今日头条首页,搜索小姐姐,或者其他你感兴趣的内容,然后点击图集学习
动态加载的json数据出来,没有反爬,注意如果不想抓取内容中的图片,只能抓取缩略图,也就是本页显示的图片,在json数据中的image_list,注意,把url中的list改成origin,就是大图了!下面的代码 网站
图片地址全部出!谷歌
全书网:直接源码匹配相关内容
直接搜索全书,打开首页,找到一本小说,比如《盗墓笔记》,点击跳转到网页,点击开始阅读,所有章节出现,小说内容、网页内容和进入章节后出现代码。以下:网址
80本电子书:匹配地址直接下载压缩文件
80 和上面的全书网类似,但是它提供了自己的下载功能,可以直接构造下载文件,小说ID和名字,页面截图和代码:spa
其余类似网站
类似的网站还有:美子图、美拓、笔趣阁、九九等,连百度图片也可以通过抓包获取数据!。网
以上代码均为手写,无需排版。如果你有兴趣,你可以自己打字。或者,像小说网站,可以先抓取大类,然后把每个类的所有小说都拿到,最后把每个类的所有小说都放上去。抓出小说的内容,这就是全站爬虫!!!3d
如果你还有其他合适的网站,希望你可以在评论区分享!让我们一起聊天吧!
转载于:

