
python抓取动态网页
python抓取动态网页(爬虫了解爬虫的基本原理及过程Requests+Xpath实现通用爬虫套路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-22 11:21
)
使用爬虫,我们可以获得大量有价值的数据,从而获得感性知识无法获得的信息,例如:
1.为市场研究和业务分析抓取数据。
抓取知乎优质答案,为你筛选出每个主题下的最佳内容。捕捉房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析。爬取招聘网站各类职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据。
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
抓取知乎钓鱼帖图片网站获取福利图片。
原本我们可以手动完成这些事情,但是如果我们只是简单地复制粘贴,那是非常耗时的。比如要获取100万行数据,大约需要两年左右的重复工作。爬虫可以在一天内为你完成,完全不需要任何干预。
对于小白来说,爬虫可能是一件很复杂的事情,技术门槛很高。比如有人认为学习爬虫一定要精通Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来;有的人觉得必须先掌握网页的知识,于是就入手了HTML CSS,结果进了前端的坑,累死了……
但是掌握正确的方法,能够在短时间内爬取主流的网站数据,其实是很容易实现的。但建议你从一开始就有一个明确的目标,你要爬取哪些网站的数据,以及多大的量级。
以目标为驱动,您的学习将更加准确和高效。所有你认为必要的必备知识,都可以在完成目标的过程中学习。这是一个流畅的、从零开始的快速入门学习路径。
1.了解爬虫的基本原理和流程
2.Requests+Xpath 实现通用爬虫例程
3.了解非结构化数据的存储
4.学习scrapy并构建一个工程爬虫
5.学习数据库知识,处理大规模数据存储和提取
6.掌握各种技巧应对特殊网站防爬措施
7.分布式爬虫,实现大规模并发采集,提高效率
1.了解爬虫的基本原理和流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单了解HTTP协议和网页的基础知识,如POSTGET、HTML、CSS、JS等,无需系统学习即可简单了解。
2.学习Python包,实现基本爬取流程
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路都差不多。一般的静态网站完全没有问题,小猪、豆瓣、尴尬百科、腾讯新闻等基本都能上手。
我们来看一个抓取豆瓣短评的例子:
选择第一个短注释,右键-“勾选”,可以查看源码
复制短评论信息的XPath信息
通过定位,我们得到了第一条短评论的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p
但是通常我们会想要抓取很多简短的评论,然后我们会想要得到很多这样的 XPath 信息:
//*[@id="comments"]/ul/li[1]/div[2]/p//*[@id="comments"]/ul/li[2]/div[2]/p//*[@id="comments"]/ul/li[3]/div[2]/p………………………………
观察1、2、2条短评论的XPath信息,你会发现模式,只有
后面的序号不一样,只对应短评的序号。那么如果我们想爬取这个页面上所有的短评信息,那么没有这个序列号就可以了。
通过 XPath 信息,我们可以用简单的代码进行爬取:
import requestsfrom lxml import etree#我们邀抓取的页面链接url='https://book.douban.com/subjec ... 3B%23用requests库的get方法下载网页r=requests.get(url).text#解析网页并且定位短评s=etree.HTML(r)file=s.xpath('//*[@id="comments"]/ul/li/div[2]/p/text()')#打印抓取的信息print(file)
爬取的页面所有短评信息
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样一来,动态知乎、、TripAdvisor网站基本没问题。
在此过程中,您还需要了解一些 Python 基础知识:
文件读写操作:用于读取参数并保存爬下的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for...while):用于循环遍历爬虫步骤
3.了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为文本、csv等文件。或者继续上面的例子:
存储是用 Python 的基础语言实现的:
with open('pinglun.text','w',encoding='utf-8') as f: for i in file: print(i) f.write(i)
以 pandas 语言存储:
#import pandas as pd#df = pd.DataFrame(file)#df.to_excel('pinglun.xlsx')
两段代码都可以存储已经爬下来的短评论信息,将爬取代码后面的代码粘贴进去。
存储此页面的简短评论数据
当然你可能会发现爬回来的数据不干净,可能有缺失、错误等,你还需要对数据进行清洗,可以学习pandas包的基本用法做数据预处理,得到更干净的数据. 具备以下知识点为好:
4.掌握各种技巧应对特殊网站防爬措施
爬取一个页面的数据是没有问题的,但是我们通常要爬取多个页面。
这时候我们需要看看翻页时url是如何变化的,或者以短评的页面为例,我们看看多个页面的url是如何不同的:
https://book.douban.com/subjec ... p%3D4……………………
通过前四页,我们可以找到规律。不同的页面只在末尾标有页面的序列号。我们以爬取5个页面为例,写一个循环更新页面地址即可。
for a in range(5): url="http://book.douban.com/subject ... Fp%3D{}".format(a)
当然,在爬取过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析页面加载信息,经常会得到意想不到的结果。
使用开发人员工具分析加载的信息
比如很多情况下,如果我们通过代码发现网页无法访问,可以尝试添加userAgent信息。
浏览器中的 userAgent 信息
在代码中添加 userAgent 信息
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
5.学习爬虫框架,搭建工程爬虫
掌握之前技术一般水平的数据和代码基本没有问题,但是在非常复杂的情况下,你可能还是做不到你想要的。这时候,强大的scrapy框架就非常有用了。
scrapy 是一个非常强大的爬虫框架。它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,让你可以设计爬虫,模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
6.学习数据库基础,处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
7.分布式爬虫实现大规模并发采集
爬取基础数据不再是问题,你的瓶颈将集中在爬取海量数据的效率上。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy + MongoDB + Redis这三个工具。
之前我们说过,Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取网页的队列,即任务队列。
所以不要被看起来很深的东西吓倒。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
你看,经过这条学习路径,你已经可以成为一名老司机了,非常顺利。所以一开始尽量不要系统地啃一些东西,找一个实用的项目(可以从豆瓣小猪这种简单的东西入手),直接入手。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,并且可以保证每次学习都是最需要的部分。
当然,唯一的困难是,当你一开始没有经验的时候,你在寻找资源和解决问题的方法时总会遇到一些困难,因为我们通常很难在一开始就将具体的问题描述清楚。如果有大神帮忙指点学习路径,答疑解惑,效率会高很多。
查看全部
python抓取动态网页(爬虫了解爬虫的基本原理及过程Requests+Xpath实现通用爬虫套路
)
使用爬虫,我们可以获得大量有价值的数据,从而获得感性知识无法获得的信息,例如:
1.为市场研究和业务分析抓取数据。
抓取知乎优质答案,为你筛选出每个主题下的最佳内容。捕捉房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析。爬取招聘网站各类职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据。
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
抓取知乎钓鱼帖图片网站获取福利图片。
原本我们可以手动完成这些事情,但是如果我们只是简单地复制粘贴,那是非常耗时的。比如要获取100万行数据,大约需要两年左右的重复工作。爬虫可以在一天内为你完成,完全不需要任何干预。
对于小白来说,爬虫可能是一件很复杂的事情,技术门槛很高。比如有人认为学习爬虫一定要精通Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来;有的人觉得必须先掌握网页的知识,于是就入手了HTML CSS,结果进了前端的坑,累死了……
但是掌握正确的方法,能够在短时间内爬取主流的网站数据,其实是很容易实现的。但建议你从一开始就有一个明确的目标,你要爬取哪些网站的数据,以及多大的量级。
以目标为驱动,您的学习将更加准确和高效。所有你认为必要的必备知识,都可以在完成目标的过程中学习。这是一个流畅的、从零开始的快速入门学习路径。
1.了解爬虫的基本原理和流程
2.Requests+Xpath 实现通用爬虫例程
3.了解非结构化数据的存储
4.学习scrapy并构建一个工程爬虫
5.学习数据库知识,处理大规模数据存储和提取
6.掌握各种技巧应对特殊网站防爬措施
7.分布式爬虫,实现大规模并发采集,提高效率
1.了解爬虫的基本原理和流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单了解HTTP协议和网页的基础知识,如POSTGET、HTML、CSS、JS等,无需系统学习即可简单了解。
2.学习Python包,实现基本爬取流程
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路都差不多。一般的静态网站完全没有问题,小猪、豆瓣、尴尬百科、腾讯新闻等基本都能上手。
我们来看一个抓取豆瓣短评的例子:
选择第一个短注释,右键-“勾选”,可以查看源码

复制短评论信息的XPath信息
通过定位,我们得到了第一条短评论的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p
但是通常我们会想要抓取很多简短的评论,然后我们会想要得到很多这样的 XPath 信息:
//*[@id="comments"]/ul/li[1]/div[2]/p//*[@id="comments"]/ul/li[2]/div[2]/p//*[@id="comments"]/ul/li[3]/div[2]/p………………………………
观察1、2、2条短评论的XPath信息,你会发现模式,只有
后面的序号不一样,只对应短评的序号。那么如果我们想爬取这个页面上所有的短评信息,那么没有这个序列号就可以了。
通过 XPath 信息,我们可以用简单的代码进行爬取:
import requestsfrom lxml import etree#我们邀抓取的页面链接url='https://book.douban.com/subjec ... 3B%23用requests库的get方法下载网页r=requests.get(url).text#解析网页并且定位短评s=etree.HTML(r)file=s.xpath('//*[@id="comments"]/ul/li/div[2]/p/text()')#打印抓取的信息print(file)

爬取的页面所有短评信息
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样一来,动态知乎、、TripAdvisor网站基本没问题。
在此过程中,您还需要了解一些 Python 基础知识:
文件读写操作:用于读取参数并保存爬下的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for...while):用于循环遍历爬虫步骤
3.了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为文本、csv等文件。或者继续上面的例子:
存储是用 Python 的基础语言实现的:
with open('pinglun.text','w',encoding='utf-8') as f: for i in file: print(i) f.write(i)
以 pandas 语言存储:
#import pandas as pd#df = pd.DataFrame(file)#df.to_excel('pinglun.xlsx')
两段代码都可以存储已经爬下来的短评论信息,将爬取代码后面的代码粘贴进去。

存储此页面的简短评论数据
当然你可能会发现爬回来的数据不干净,可能有缺失、错误等,你还需要对数据进行清洗,可以学习pandas包的基本用法做数据预处理,得到更干净的数据. 具备以下知识点为好:
4.掌握各种技巧应对特殊网站防爬措施
爬取一个页面的数据是没有问题的,但是我们通常要爬取多个页面。
这时候我们需要看看翻页时url是如何变化的,或者以短评的页面为例,我们看看多个页面的url是如何不同的:
https://book.douban.com/subjec ... p%3D4……………………
通过前四页,我们可以找到规律。不同的页面只在末尾标有页面的序列号。我们以爬取5个页面为例,写一个循环更新页面地址即可。
for a in range(5): url="http://book.douban.com/subject ... Fp%3D{}".format(a)
当然,在爬取过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析页面加载信息,经常会得到意想不到的结果。
使用开发人员工具分析加载的信息
比如很多情况下,如果我们通过代码发现网页无法访问,可以尝试添加userAgent信息。

浏览器中的 userAgent 信息

在代码中添加 userAgent 信息
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
5.学习爬虫框架,搭建工程爬虫
掌握之前技术一般水平的数据和代码基本没有问题,但是在非常复杂的情况下,你可能还是做不到你想要的。这时候,强大的scrapy框架就非常有用了。
scrapy 是一个非常强大的爬虫框架。它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,让你可以设计爬虫,模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
6.学习数据库基础,处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
7.分布式爬虫实现大规模并发采集
爬取基础数据不再是问题,你的瓶颈将集中在爬取海量数据的效率上。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy + MongoDB + Redis这三个工具。
之前我们说过,Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取网页的队列,即任务队列。
所以不要被看起来很深的东西吓倒。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
你看,经过这条学习路径,你已经可以成为一名老司机了,非常顺利。所以一开始尽量不要系统地啃一些东西,找一个实用的项目(可以从豆瓣小猪这种简单的东西入手),直接入手。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,并且可以保证每次学习都是最需要的部分。
当然,唯一的困难是,当你一开始没有经验的时候,你在寻找资源和解决问题的方法时总会遇到一些困难,因为我们通常很难在一开始就将具体的问题描述清楚。如果有大神帮忙指点学习路径,答疑解惑,效率会高很多。

python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-20 15:11
Selenium 是一个用于测试 WebUI 的自动化测试框架。它通过调用Chrome和Firefox来完成动态页面(包括Javascript)的加载,因此也可以用来完成动态网页抓取。
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、启动 selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受一个url字符串,然后在自己的进程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端。
3、安装硒
sudo apt-get install python-selenium
这个包是selenium客户端的python包,当然也可以通过pypi或者pip手动安装。
文档可以在这里找到。
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、在非 X11 环境中使用
可以通过xvfb来完成,这是一个模拟xserver的程序,可以在没有xserver的机器上运行,为xserver服务。
sudo apt-get install xvfb
运行
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与Scrapy结合
请参考我之前写的文章《Python爬虫框架Scrapy快速入门教程》,并不复杂。 查看全部
python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
Selenium 是一个用于测试 WebUI 的自动化测试框架。它通过调用Chrome和Firefox来完成动态页面(包括Javascript)的加载,因此也可以用来完成动态网页抓取。
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、启动 selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受一个url字符串,然后在自己的进程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端。
3、安装硒
sudo apt-get install python-selenium
这个包是selenium客户端的python包,当然也可以通过pypi或者pip手动安装。
文档可以在这里找到。
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、在非 X11 环境中使用
可以通过xvfb来完成,这是一个模拟xserver的程序,可以在没有xserver的机器上运行,为xserver服务。
sudo apt-get install xvfb
运行
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与Scrapy结合
请参考我之前写的文章《Python爬虫框架Scrapy快速入门教程》,并不复杂。
python抓取动态网页( Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-19 13:20
Python网络爬虫内容提取器)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源代码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行如下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到,网页中的手机名称和价格已经被正确抓取了
4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
转载于: 查看全部
python抓取动态网页(
Python网络爬虫内容提取器)

1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源代码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:

Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。

第二步:执行如下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到,网页中的手机名称和价格已经被正确抓取了

4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
转载于:
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-18 03:09
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如 Javascript 脚本执行产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 respOnse=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索以前的文章或继续浏览下方的相关文章,希望大家以后多多支持!
推荐内容:免费高清PNG素材下载 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如 Javascript 脚本执行产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 respOnse=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索以前的文章或继续浏览下方的相关文章,希望大家以后多多支持!
推荐内容:免费高清PNG素材下载
python抓取动态网页(网页正文抽取的方法,你知道吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-16 06:24
我们前面实现的爬虫,运行后可以快速爬取大量网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
提取网页正文的方法
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
标题区
元数据区(发布时间等)
地图区域(如果您也想提取地图)
文本区
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
上海用“智慧”激活城市交通脉搏,让道路更安全、更有序、更顺畅-新华网
“沪港高校联盟”今日在复旦大学成立_教育_新民网
三亚老人踢司机致公交车失控撞墙被判3年监禁_手机网易网
外交部:中美外交与安全对话9日在美国举行
中国国际进口博览会:中国作为举世瞩目,中国作为世界赞誉
资本市场迎来重大变革,科创板的成立有何意义?- 新华网
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 释放时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是基于老猿多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' 查看全部
python抓取动态网页(网页正文抽取的方法,你知道吗?(图))
我们前面实现的爬虫,运行后可以快速爬取大量网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
提取网页正文的方法
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
标题区
元数据区(发布时间等)
地图区域(如果您也想提取地图)
文本区
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
上海用“智慧”激活城市交通脉搏,让道路更安全、更有序、更顺畅-新华网
“沪港高校联盟”今日在复旦大学成立_教育_新民网
三亚老人踢司机致公交车失控撞墙被判3年监禁_手机网易网
外交部:中美外交与安全对话9日在美国举行
中国国际进口博览会:中国作为举世瞩目,中国作为世界赞誉
资本市场迎来重大变革,科创板的成立有何意义?- 新华网
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 释放时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是基于老猿多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r'
python抓取动态网页(网页爬虫的运行流程及存储方式(关键词))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-15 04:01
关键词:
知识的领域是无限的,我们的学习也是如此。本文章主要介绍Python爬虫的基础知识,希望对大家有所帮助。
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request response = urllib.request.urlopen(‘http://www.baidu.com‘)buff = response.read()html = buff.decode("utf8")print(html) |
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request request = urllib.request.Request(‘http://www.baidu.com‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
携带参数
新建一个baidu2.py,内容如下:
import urllib.requestimport urllib.parse url = ‘http://www.baidu.com‘values = {‘name‘: ‘voidking‘,‘language‘: ‘Python‘}data = urllib.parse.urlencode(values).encode(encoding=‘utf-8‘,errors=‘ignore‘)headers = { ‘User-Agent‘ : ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0‘ }request = urllib.request.Request(url=url, data=data,headers=headers,method=‘GET‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.requestimport http.cookiejar # 创建cookie容器cj = http.cookiejar.CookieJar()# 创建openeropener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))# 给urllib.request安装openerurllib.request.install_opener(opener) # 请求request = urllib.request.Request(‘http://www.baidu.com/‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html)print(cj) |
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4print(bs4) |
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4from bs4 import BeautifulSoup # 根据html网页字符串创建BeautifulSoup对象html_doc = """The Dormouse‘s story<p class="title">The Dormouse‘s story
Once upon a time there were three little sisters; and their names wereElsie,Lacie andTillie;and they lived at the bottom of a well.
..."""soup = BeautifulSoup(html_doc)print(soup.prettify()) </p>
2、访问节点
print(soup.title)print(soup.title.name)print(soup.title.string)print(soup.title.parent.name) print(soup.p)print(soup.p[‘class‘])
3、指定标签、类或id
print(soup.find_all(‘a‘))print(soup.find(‘a‘))print(soup.find(class_=‘title‘))print(soup.find(id="link3"))print(soup.find(‘p‘,class_=‘title‘))
4、从文档中找到所有 `` 标签的链接
for link in soup.find_all(‘a‘): print(link.get(‘href‘))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,‘html.parser‘)
5、从文档中获取所有文本内容
print(soup.get_text()
6、常规赛
soup.find(‘a‘,href=re.compile(r"til"))print(link_node) |
?``` |
# 后记
python爬虫基础知识,至此足够,接下来,在实战中学习更高级的知识。
至此,这篇关于Python爬虫基础的文章就讲完了。如果您的问题无法解决,请参考以下文章: 查看全部
python抓取动态网页(网页爬虫的运行流程及存储方式(关键词))
关键词:
知识的领域是无限的,我们的学习也是如此。本文章主要介绍Python爬虫的基础知识,希望对大家有所帮助。
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。

爬虫架构的组成

URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程

URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request response = urllib.request.urlopen(‘http://www.baidu.com‘)buff = response.read()html = buff.decode("utf8")print(html) |
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request request = urllib.request.Request(‘http://www.baidu.com‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
携带参数
新建一个baidu2.py,内容如下:
import urllib.requestimport urllib.parse url = ‘http://www.baidu.com‘values = {‘name‘: ‘voidking‘,‘language‘: ‘Python‘}data = urllib.parse.urlencode(values).encode(encoding=‘utf-8‘,errors=‘ignore‘)headers = { ‘User-Agent‘ : ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0‘ }request = urllib.request.Request(url=url, data=data,headers=headers,method=‘GET‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。

虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。

查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。

然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器

import urllib.requestimport http.cookiejar # 创建cookie容器cj = http.cookiejar.CookieJar()# 创建openeropener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))# 给urllib.request安装openerurllib.request.install_opener(opener) # 请求request = urllib.request.Request(‘http://www.baidu.com/‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html)print(cj) |
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4print(bs4) |
使用说明


基本用法
1、创建 BeautifulSoup 对象
import bs4from bs4 import BeautifulSoup # 根据html网页字符串创建BeautifulSoup对象html_doc = """The Dormouse‘s story<p class="title">The Dormouse‘s story
Once upon a time there were three little sisters; and their names wereElsie,Lacie andTillie;and they lived at the bottom of a well.
..."""soup = BeautifulSoup(html_doc)print(soup.prettify()) </p>
2、访问节点
print(soup.title)print(soup.title.name)print(soup.title.string)print(soup.title.parent.name) print(soup.p)print(soup.p[‘class‘])
3、指定标签、类或id
print(soup.find_all(‘a‘))print(soup.find(‘a‘))print(soup.find(class_=‘title‘))print(soup.find(id="link3"))print(soup.find(‘p‘,class_=‘title‘))
4、从文档中找到所有 `` 标签的链接
for link in soup.find_all(‘a‘): print(link.get(‘href‘))

出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,‘html.parser‘)
5、从文档中获取所有文本内容
print(soup.get_text()
6、常规赛
soup.find(‘a‘,href=re.compile(r"til"))print(link_node) |
?``` |
# 后记
python爬虫基础知识,至此足够,接下来,在实战中学习更高级的知识。
至此,这篇关于Python爬虫基础的文章就讲完了。如果您的问题无法解决,请参考以下文章:
python抓取动态网页(华为中国发文《小白看过来,让Python爬虫成为你的好帮手》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-15 03:36
据华为中国官方消息,近日,华为中国发文《小白过来,让Python爬虫做你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。
以下为《小白过来,让Python爬虫做你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词不再陌生。但是什么是爬虫以及如何使用爬虫为自己服务,这些对于ICT技术新手来说听起来有点高。别着急,下面的文章带你走近爬虫的世界,让即使你是ICT技术的新手,也能快速了解如何使用Python爬虫高效抓图。
什么是专用爬虫?
网络爬虫是一种从 Internet 上抓取数据和信息的自动化程序。如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫是沿着网络抓取猎物(数据)的小蜘蛛(程序)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取的持续高效运行。分为通用爬虫和专用爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为某一类人提供服务,爬取的目标网页定位在主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
爬行动物如何工作
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫首先要做的是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。实际上,获取网页——分析网页源代码——提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页的结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Requests、pyquery、lxml等。使用这些库,网页信息可以高效快速地提取,例如属性、文本值等。节点的数量可以简单地保存为 TXT 文本或 JSON 文本。这些信息可以保存到数据库,如 MySQL 和 MongoDB,或远程服务器,如使用 SFTP 操作。提取信息对于爬虫来说是一个非常重要的角色,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
使用爬虫如此简单
你想让爬虫做你的助手吗?帮助您通过关键字从网页中提取您需要的信息?针对对Python编程或网络爬虫感兴趣的大众、高校师生,华为开发了“使用Python爬虫抓图”微认证。学生学习Python网络爬虫的理论知识,结合华为云服务完成爬虫操作和数据。存储实践,可以了解网络爬虫背后的HTML和HTTP原理,通过实践掌握爬虫的编程和操作方法,帮助你快速高效的根据关键词抓取图片,高效获取信息。
开始学习华为云微认证《使用Python爬虫抓图》,你会发现抓图信息就是这么简单快捷。
创新互联网提供动态拨号vps服务器等。创新互联网不仅有全国20多个省160多个城市的动态ip拨号VPS,还有海外香港、日本的动态拨号VPS 、美国、台湾、韩国、菲律宾等国家和地区。非常适合排名、网站优化、网络营销、爬虫、数据抓取、数据分析、刷单、投票等领域;如有需要,请联系创新互联网客服! 查看全部
python抓取动态网页(华为中国发文《小白看过来,让Python爬虫成为你的好帮手》)
据华为中国官方消息,近日,华为中国发文《小白过来,让Python爬虫做你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。

以下为《小白过来,让Python爬虫做你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词不再陌生。但是什么是爬虫以及如何使用爬虫为自己服务,这些对于ICT技术新手来说听起来有点高。别着急,下面的文章带你走近爬虫的世界,让即使你是ICT技术的新手,也能快速了解如何使用Python爬虫高效抓图。
什么是专用爬虫?
网络爬虫是一种从 Internet 上抓取数据和信息的自动化程序。如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫是沿着网络抓取猎物(数据)的小蜘蛛(程序)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取的持续高效运行。分为通用爬虫和专用爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为某一类人提供服务,爬取的目标网页定位在主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
爬行动物如何工作
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫首先要做的是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。实际上,获取网页——分析网页源代码——提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页的结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Requests、pyquery、lxml等。使用这些库,网页信息可以高效快速地提取,例如属性、文本值等。节点的数量可以简单地保存为 TXT 文本或 JSON 文本。这些信息可以保存到数据库,如 MySQL 和 MongoDB,或远程服务器,如使用 SFTP 操作。提取信息对于爬虫来说是一个非常重要的角色,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
使用爬虫如此简单
你想让爬虫做你的助手吗?帮助您通过关键字从网页中提取您需要的信息?针对对Python编程或网络爬虫感兴趣的大众、高校师生,华为开发了“使用Python爬虫抓图”微认证。学生学习Python网络爬虫的理论知识,结合华为云服务完成爬虫操作和数据。存储实践,可以了解网络爬虫背后的HTML和HTTP原理,通过实践掌握爬虫的编程和操作方法,帮助你快速高效的根据关键词抓取图片,高效获取信息。
开始学习华为云微认证《使用Python爬虫抓图》,你会发现抓图信息就是这么简单快捷。
创新互联网提供动态拨号vps服务器等。创新互联网不仅有全国20多个省160多个城市的动态ip拨号VPS,还有海外香港、日本的动态拨号VPS 、美国、台湾、韩国、菲律宾等国家和地区。非常适合排名、网站优化、网络营销、爬虫、数据抓取、数据分析、刷单、投票等领域;如有需要,请联系创新互联网客服!
python抓取动态网页(爬取浏览器click事件也执行click事件执行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-14 00:20
最近突然想到爬百度的学术参考。大家可以看看我之前的博客: 但是如果用这种方法,太痛苦了,需要手动复制粘贴,所以这里介绍一下使用selenium来实现这个。函数,粘贴代码:
#-*- coding:utf-8 -*-
from selenium import webdriver
import time
from bs4 import BeautifulSoup
#拼接url
titlename='Application of biosorption for the removal of organic pollutants: a review'
url_name=titlename.split(' ')
url='http://xueshu.baidu.com/s?wd='+'+'.join(url_name)
#打开Firefox
diver=webdriver.Firefox()
diver.get(url)
#防止引用太多,不断click,直到参考文献下不存在‘加载更多’
try:
for i in range(0,50):
# 等待网站加载完成
time.sleep(0.2)
diver.find_elements_by_class_name('request_situ')[1].click()
except:
print '********************************************************'
#等到加载完成获取网页源码
time.sleep(10)
#使用BeautifulSoup获取参考文献
soup=BeautifulSoup(diver.page_source,'lxml')
items=soup.find('div',{'class':'con_reference'}).find_all('li')
for i in items:
print i.find('a').get_text()
#关闭网页
diver.close()
注意:
代码标记为红色。因为这个错误,我花了很长时间。
我遇到了一个问题。每次第一次抓取,click事件都没有响应。我可以用断点检查,发现是OK的,然后就OK了。我不知道为什么会这样。
Chrome 浏览器点击事件不执行
如果不想看到浏览器出现,可以使用 diver=webdriver.PhantomJS() 代替 diver=webdriver.Firefox()
以上的基础是安装PhantomJS、geckodriver.exe 查看全部
python抓取动态网页(爬取浏览器click事件也执行click事件执行)
最近突然想到爬百度的学术参考。大家可以看看我之前的博客: 但是如果用这种方法,太痛苦了,需要手动复制粘贴,所以这里介绍一下使用selenium来实现这个。函数,粘贴代码:
#-*- coding:utf-8 -*-
from selenium import webdriver
import time
from bs4 import BeautifulSoup
#拼接url
titlename='Application of biosorption for the removal of organic pollutants: a review'
url_name=titlename.split(' ')
url='http://xueshu.baidu.com/s?wd='+'+'.join(url_name)
#打开Firefox
diver=webdriver.Firefox()
diver.get(url)
#防止引用太多,不断click,直到参考文献下不存在‘加载更多’
try:
for i in range(0,50):
# 等待网站加载完成
time.sleep(0.2)
diver.find_elements_by_class_name('request_situ')[1].click()
except:
print '********************************************************'
#等到加载完成获取网页源码
time.sleep(10)
#使用BeautifulSoup获取参考文献
soup=BeautifulSoup(diver.page_source,'lxml')
items=soup.find('div',{'class':'con_reference'}).find_all('li')
for i in items:
print i.find('a').get_text()
#关闭网页
diver.close()
注意:
代码标记为红色。因为这个错误,我花了很长时间。
我遇到了一个问题。每次第一次抓取,click事件都没有响应。我可以用断点检查,发现是OK的,然后就OK了。我不知道为什么会这样。
Chrome 浏览器点击事件不执行
如果不想看到浏览器出现,可以使用 diver=webdriver.PhantomJS() 代替 diver=webdriver.Firefox()
以上的基础是安装PhantomJS、geckodriver.exe
python抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-02-14 00:18
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。
ajax数据获取方式:
1、直接分析ajax调用的接口。然后通过代码请求这个接口。
2、使用 Selenium+chromedriver 模拟浏览器行为获取数据。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以模拟人类在浏览器上的一些行为,自动处理浏览器上的一些行为,比如点击、填充数据、删除cookies等。chromedriver是驱动Chrome浏览器的驱动,可以用来驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、铬:
2、火狐:
3、边缘:
4、Safari:
安装 Selenium 和 chromedriver:
安装 Selenium:Selenium 支持多种语言,包括 java、ruby、python 等,我们可以下载 python 版本。
点安装硒
安装chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。
快速开始:
下面我们以一个简单的获取百度主页的例子来谈谈如何快速上手 Selenium 和 chromedriver:
selenium的常用操作:
关闭页面:
1、driver.close():关闭当前页面。
2、driver.quit():退出整个浏览器。
定位要素:
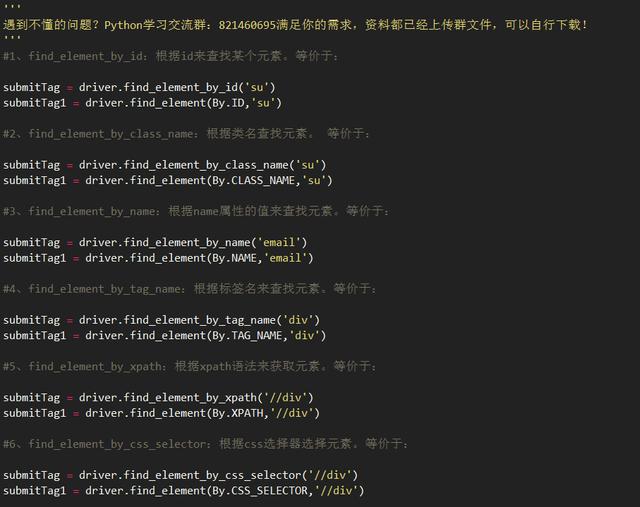
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
作为表单元素:
1、操作输入框:分两步。第一步:找到元素。第 2 步:使用 send_keys(value) 填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear()
2、操作复选框:因为需要选中复选框标签,所以在网页中用鼠标点击。所以如果要选中checkbox标签,先选中标签,然后执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:
4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
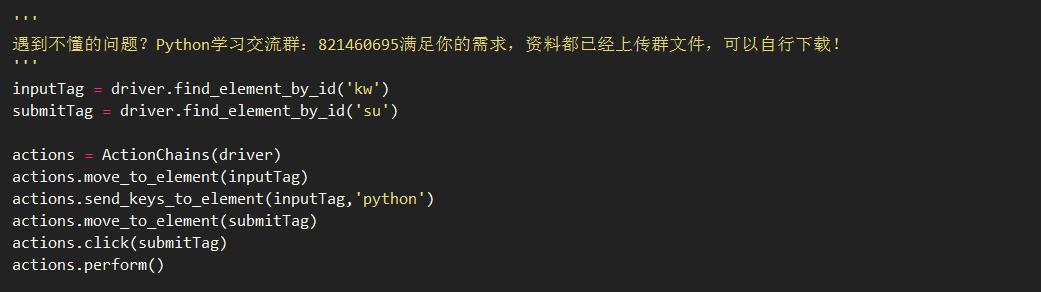
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:
显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:
其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。 查看全部
python抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。

ajax数据获取方式:
1、直接分析ajax调用的接口。然后通过代码请求这个接口。
2、使用 Selenium+chromedriver 模拟浏览器行为获取数据。

Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以模拟人类在浏览器上的一些行为,自动处理浏览器上的一些行为,比如点击、填充数据、删除cookies等。chromedriver是驱动Chrome浏览器的驱动,可以用来驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、铬:
2、火狐:
3、边缘:
4、Safari:
安装 Selenium 和 chromedriver:
安装 Selenium:Selenium 支持多种语言,包括 java、ruby、python 等,我们可以下载 python 版本。
点安装硒
安装chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。
快速开始:
下面我们以一个简单的获取百度主页的例子来谈谈如何快速上手 Selenium 和 chromedriver:

selenium的常用操作:
关闭页面:
1、driver.close():关闭当前页面。
2、driver.quit():退出整个浏览器。
定位要素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
作为表单元素:
1、操作输入框:分两步。第一步:找到元素。第 2 步:使用 send_keys(value) 填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear()
2、操作复选框:因为需要选中复选框标签,所以在网页中用鼠标点击。所以如果要选中checkbox标签,先选中标签,然后执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:

4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:

显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:

其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。
python抓取动态网页(动态加载网页一什么是动态网页(附详细源码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-11 21:12
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。
项目背景
事情是这样的,前几天,我的公众号写了一篇关于爬虫文章的介绍的文章,叫做《实战|教你如何使用Python爬虫(附详细源码)》。寄出后不到一天,一位从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住慌了。
简单交流了一下,原来他是在自学爬虫,但是发现翻页的时候,url还是一样的。其实他爬的是比较难的网页,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会给他指点方向,在最短的时间内从青铜到白银。
网页的AJAX动态加载
一
什么是动态网页
J哥一直注重理论与实践的结合,一定要知道自己为什么会这样,才能应对一切变化而不作改变。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量减少、内容更新快、可以完成的功能多等特点。
二
什么是 AJAX
随着人们对动态网页加载速度的要求越来越高,AJAX技术应运而生,成为众多网站的首选。AJAX 是一种用于创建快速和动态网页的技术,它通过在后台与服务器交换少量数据来实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何爬取 AJAX 动态加载的网页
1. 解析接口
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它悄悄加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站难以解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但已经被广泛的用户爬取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。特点:代码比较简单,爬取速度慢,ip容易被封.
项目实践
说了这么多理论,说实话,J哥不想这么啰嗦。不过这些东西经常被问到,干脆写下来,下次有人问,直接把这个文章发给他,一劳永逸!
好,我们回到王律师的部分。作为一名资深律师,王律师深知,研究法院历年发布的法院信息和执行信息对于提升业务能力具有重要作用。于是,他兴高采烈地打开了法庭信息公示页面。
它看起来像这样:
然后,他按照J哥之前写的爬虫文章的介绍爬取了数据,成功提取了第一页,激动万分。
紧接着,他加了一个for循环,想花几分钟把网站2164页的32457条法庭公告的数据提取到excel中。
那么,就没有了。看完前面的理论部分,你也应该知道这是一个AJAX动态加载的网页。无论您如何点击下一页,网址都不会改变。不信,点进去给你看,左上角的url像山一样耸立在那里:
一
解析接口
在这种情况下,让我们启动爬虫的正确姿势,首先使用解析接口的方法来编写爬虫。
首先,找到真正的请求。右键查看,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。是的,就是这么简单,真正的请求隐藏在里面。
让我们仔细看看这个jsp,简直是宝藏。有一个真实的请求url,一个请求方法post,Headers,和Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我把我的饼干做了马赛克,机智的朋友可能已经注意到我顺便给自己做了一个广告。
让我们仔细看看这些参数。pagesnum参数不代表页数!王律师顿悟了。原来,他在这里全心全意地翻开了这一页!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有pagesnum参数会改变。
既然已经找到了,就赶紧抓起来吧。J哥以闪电般的速度打开PyCharm,导入爬虫所需的库。
from urllib.parse import urlencode
import csv
import random
import requests
import traceback
from time import sleep
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真实的请求并添加Headers。J哥这里没有贴出自己的User-Agent和Cookie,主要是一向胆小的J哥怕了。
base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B #这里要换成对应Ajax请求中的链接
headers = {
'Connection': 'keep-alive',
'Accept': '*/*',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': '你的User-Agent',
'Origin': 'http://www.hshfy.sh.cn',
'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B,
'Accept-Language': 'zh-CN,zh;q=0.9',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': '你的Cookie'
}
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,使用post方法请求网页数据。这里注意对返回的数据进行解码,编码为'gbk',否则返回的数据会乱码!此外,我还添加了异常处理优化,以防止意外发生。
def get_page(page):
n = 3
while True:
try:
sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
data = {
'yzm': 'yxAH',
'ft':'',
'ktrqks': '2020-05-22',
'ktrqjs': '2020-06-22',
'spc':'',
'yg':'',
'bg':'',
'ah':'',
'pagesnum': page
}
url = base_url + urlencode(data)
print(url)
try:
response = requests.request("POST",url, headers = headers)
#print(response)
if response.status_code == 200:
re = response.content.decode('gbk')
# print(re)
return re # 解析内容
except requests.ConnectionError as e:
print('Error', e.args) # 输出异常信息
except (TimeoutError, Exception):
n -= 1
if n == 0:
print('请求3次均失败,放弃此url请求,检查请求条件')
return
else:
print('请求失败,重新请求')
continue
构建parse_page函数,解析返回的网页数据,用Xpath提取所有字段内容,保存为csv格式。有人会问为什么J哥这么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我不能做一个普通的大法来安装x。J弟兄,我做不到。
def parse_page(html):
try:
parse = etree.HTML(html) # 解析网页
items = parse.xpath('//*[@id="report"]/tbody/tr')
for item in items[1:]:
item = {
'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
'c': ''.join(item.xpath('./td[3]/text()')).strip(),
'd': ''.join(item.xpath('./td[4]/text()')).strip(),
'e': ''.join(item.xpath('./td[5]/text()')).strip(),
'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
'h': ''.join(item.xpath('./td[8]/text()')).strip(),
'i': ''.join(item.xpath('./td[9]/text()')).strip()
}
#print(item)
try:
with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
writer = csv.DictWriter(fp,fieldnames)
writer.writerow(item)
except Exception:
print(traceback.print_exc()) #代替print e 来输出详细的异常信息
except Exception:
print(traceback.print_exc())
最后,遍历页数,调用函数。OK完成!
for page in range(1,5): #这里设置想要爬取的页数
html = get_page(page)
#print(html)
print("第" + str(page) + "页提取完成")
让我们看看最终的结果:
二
硒
有心学习的朋友可能还想看看Selenium如何爬取AJAX动态加载的网页。J哥自然会满足你的好奇心。于是我赶紧新建了一个py文件,准备趁势利用Selenium爬下这个网站。
首先,导入相关库。
from lxml import etree
import time
from selenium import webdriver
from selenium. webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
然后,使用 chromedriver 驱动程序打开这个 网站。
def main():
# 爬取首页url
url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
# 定义谷歌webdriver
driver = webdriver.Chrome('./chromedriver')
driver.maximize_window() # 将浏览器最大化
driver.get(url)
所以,我惊讶地发现这是错误的。有了六级英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器的版本不匹配,只支持79版本的浏览器。
J哥很郁闷,因为我之前从来没有遇到过Selenium for爬虫的这种问题。J哥不甘心,打开谷歌浏览器看了看版本号。
我失去了它!全部更新到81版!遇到这种情况,请好奇的朋友等J哥设置浏览器自动更新重新下载最新驱动,下次再来听Selenium爬虫,记得关注这个公众号,不要'错过了~
结语
综上所述,对于AJAX动态加载的网络爬虫,一般有两种方式:解析接口;硒。J哥推荐解析接口的方式。如果解析的是json数据,爬起来会更好。真的没有办法使用 Selenium。
参考链接:
阿贾克斯:;
ajax_json:;
例子: 查看全部
python抓取动态网页(动态加载网页一什么是动态网页(附详细源码))
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。
项目背景
事情是这样的,前几天,我的公众号写了一篇关于爬虫文章的介绍的文章,叫做《实战|教你如何使用Python爬虫(附详细源码)》。寄出后不到一天,一位从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住慌了。
简单交流了一下,原来他是在自学爬虫,但是发现翻页的时候,url还是一样的。其实他爬的是比较难的网页,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会给他指点方向,在最短的时间内从青铜到白银。
网页的AJAX动态加载
一
什么是动态网页
J哥一直注重理论与实践的结合,一定要知道自己为什么会这样,才能应对一切变化而不作改变。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量减少、内容更新快、可以完成的功能多等特点。
二
什么是 AJAX
随着人们对动态网页加载速度的要求越来越高,AJAX技术应运而生,成为众多网站的首选。AJAX 是一种用于创建快速和动态网页的技术,它通过在后台与服务器交换少量数据来实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何爬取 AJAX 动态加载的网页
1. 解析接口
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它悄悄加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站难以解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但已经被广泛的用户爬取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。特点:代码比较简单,爬取速度慢,ip容易被封.
项目实践
说了这么多理论,说实话,J哥不想这么啰嗦。不过这些东西经常被问到,干脆写下来,下次有人问,直接把这个文章发给他,一劳永逸!
好,我们回到王律师的部分。作为一名资深律师,王律师深知,研究法院历年发布的法院信息和执行信息对于提升业务能力具有重要作用。于是,他兴高采烈地打开了法庭信息公示页面。
它看起来像这样:
然后,他按照J哥之前写的爬虫文章的介绍爬取了数据,成功提取了第一页,激动万分。
紧接着,他加了一个for循环,想花几分钟把网站2164页的32457条法庭公告的数据提取到excel中。
那么,就没有了。看完前面的理论部分,你也应该知道这是一个AJAX动态加载的网页。无论您如何点击下一页,网址都不会改变。不信,点进去给你看,左上角的url像山一样耸立在那里:
一
解析接口
在这种情况下,让我们启动爬虫的正确姿势,首先使用解析接口的方法来编写爬虫。
首先,找到真正的请求。右键查看,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。是的,就是这么简单,真正的请求隐藏在里面。
让我们仔细看看这个jsp,简直是宝藏。有一个真实的请求url,一个请求方法post,Headers,和Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我把我的饼干做了马赛克,机智的朋友可能已经注意到我顺便给自己做了一个广告。
让我们仔细看看这些参数。pagesnum参数不代表页数!王律师顿悟了。原来,他在这里全心全意地翻开了这一页!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有pagesnum参数会改变。
既然已经找到了,就赶紧抓起来吧。J哥以闪电般的速度打开PyCharm,导入爬虫所需的库。
from urllib.parse import urlencode
import csv
import random
import requests
import traceback
from time import sleep
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真实的请求并添加Headers。J哥这里没有贴出自己的User-Agent和Cookie,主要是一向胆小的J哥怕了。
base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B #这里要换成对应Ajax请求中的链接
headers = {
'Connection': 'keep-alive',
'Accept': '*/*',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': '你的User-Agent',
'Origin': 'http://www.hshfy.sh.cn',
'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B,
'Accept-Language': 'zh-CN,zh;q=0.9',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': '你的Cookie'
}
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,使用post方法请求网页数据。这里注意对返回的数据进行解码,编码为'gbk',否则返回的数据会乱码!此外,我还添加了异常处理优化,以防止意外发生。
def get_page(page):
n = 3
while True:
try:
sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
data = {
'yzm': 'yxAH',
'ft':'',
'ktrqks': '2020-05-22',
'ktrqjs': '2020-06-22',
'spc':'',
'yg':'',
'bg':'',
'ah':'',
'pagesnum': page
}
url = base_url + urlencode(data)
print(url)
try:
response = requests.request("POST",url, headers = headers)
#print(response)
if response.status_code == 200:
re = response.content.decode('gbk')
# print(re)
return re # 解析内容
except requests.ConnectionError as e:
print('Error', e.args) # 输出异常信息
except (TimeoutError, Exception):
n -= 1
if n == 0:
print('请求3次均失败,放弃此url请求,检查请求条件')
return
else:
print('请求失败,重新请求')
continue
构建parse_page函数,解析返回的网页数据,用Xpath提取所有字段内容,保存为csv格式。有人会问为什么J哥这么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我不能做一个普通的大法来安装x。J弟兄,我做不到。
def parse_page(html):
try:
parse = etree.HTML(html) # 解析网页
items = parse.xpath('//*[@id="report"]/tbody/tr')
for item in items[1:]:
item = {
'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
'c': ''.join(item.xpath('./td[3]/text()')).strip(),
'd': ''.join(item.xpath('./td[4]/text()')).strip(),
'e': ''.join(item.xpath('./td[5]/text()')).strip(),
'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
'h': ''.join(item.xpath('./td[8]/text()')).strip(),
'i': ''.join(item.xpath('./td[9]/text()')).strip()
}
#print(item)
try:
with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
writer = csv.DictWriter(fp,fieldnames)
writer.writerow(item)
except Exception:
print(traceback.print_exc()) #代替print e 来输出详细的异常信息
except Exception:
print(traceback.print_exc())
最后,遍历页数,调用函数。OK完成!
for page in range(1,5): #这里设置想要爬取的页数
html = get_page(page)
#print(html)
print("第" + str(page) + "页提取完成")
让我们看看最终的结果:
二
硒
有心学习的朋友可能还想看看Selenium如何爬取AJAX动态加载的网页。J哥自然会满足你的好奇心。于是我赶紧新建了一个py文件,准备趁势利用Selenium爬下这个网站。
首先,导入相关库。
from lxml import etree
import time
from selenium import webdriver
from selenium. webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
然后,使用 chromedriver 驱动程序打开这个 网站。
def main():
# 爬取首页url
url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
# 定义谷歌webdriver
driver = webdriver.Chrome('./chromedriver')
driver.maximize_window() # 将浏览器最大化
driver.get(url)
所以,我惊讶地发现这是错误的。有了六级英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器的版本不匹配,只支持79版本的浏览器。
J哥很郁闷,因为我之前从来没有遇到过Selenium for爬虫的这种问题。J哥不甘心,打开谷歌浏览器看了看版本号。
我失去了它!全部更新到81版!遇到这种情况,请好奇的朋友等J哥设置浏览器自动更新重新下载最新驱动,下次再来听Selenium爬虫,记得关注这个公众号,不要'错过了~
结语
综上所述,对于AJAX动态加载的网络爬虫,一般有两种方式:解析接口;硒。J哥推荐解析接口的方式。如果解析的是json数据,爬起来会更好。真的没有办法使用 Selenium。
参考链接:
阿贾克斯:;
ajax_json:;
例子:
python抓取动态网页(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-09 07:08
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜科谋数个单元直观的标注功能,可以非常快速的自动生成调试好的抓取规则。其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
Step 3:如下图所示,网页中的手机名称和价格被正确抓取
4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29: V2.1,增加Chapter 5: Source code download source,并替换github源码的URL 查看全部
python抓取动态网页(Python网络爬虫内容提取器)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:

Step 1:利用吉搜科谋数个单元直观的标注功能,可以非常快速的自动生成调试好的抓取规则。其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。

第二步:执行以下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
Step 3:如下图所示,网页中的手机名称和价格被正确抓取

4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29: V2.1,增加Chapter 5: Source code download source,并替换github源码的URL
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-09 01:21
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i 查看全部
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i
python抓取动态网页(比如说我们要爬取上交所的浦发银行这支股票背后的公司信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-05 22:07
我们都知道,爬虫可以抓取很多数据。如果我们爬取一个简单的页面,就可以轻松实现。如果我们要爬取动态页面,我们应该怎么做?
比如我们要爬取东方财富网站的股票信息:
但是当我们查看源代码时,我们看不到任何关于股票信息的数据。可以看出这些股票数据是异步加载的。果断F12打开chrome开发者工具,在Network选项中勾选。如果没有,您可以使用 F5 刷新页面。出来。
QQ图片244.png
然后点击异步api,会打开一个新页面,出现如下数据:
var C1Cache={quotation:["0000011,上证指数,3166.98,170854125568,13.89,0.44%,876|201|246|142,1380|270|360|204","3990012,深证成指,10130.12,215605108736,74.55,0.74%,876|201|246|142,1380|270|360|204"]}
我以为是json数据,但是服务器发过来一个js变量,值和json数据差不多,这应该是为了开发方便,但是我们要json数据,所以需要过滤一下,split(" = ") 然后取右边的字符串,但是要注意这个右边不是json数据,注意json的key需要有双引号(在java和python中),可能在js中也可以,所以我们需要在java中进行替换,这是一个json字符串,然后转换成json对象,可以使用jackson的objectmapper,反正方法很多。然后我们可以将这些数据持久化到数据库中,这样我们就可以爬取一些动态页面。
但这里需要注意的是,有些网站不允许你跨域访问,即使你有对策通过伪装服务器来阻止你直接调用api,那么此时你需要使用另一种方法, webmagic selenium ,这个原理是先运行一个浏览器内核来加载页面,等到整个页面加载完毕,然后获取html代码,再进行处理。
比如我们要爬取浦发银行股票背后的公司信息,
当我们查看异步加载的api时,发现不允许你直接访问这个api,所以只能使用第二种方法。
以下是项目的依赖项:
compile 'us.codecraft:webmagic-core:0.5.3'
compile('us.codecraft:webmagic-extension:0.5.3')
compile 'org.seleniumhq.selenium:selenium-java:2.8.0'
compile group: 'us.codecraft', name: 'webmagic-selenium', version: '0.5.2'
源代码如下:
public class CompanyProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000)
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36");
public void process(Page page) {
WebDriver driver = new ChromeDriver();
driver.get("http://www.sse.com.cn/assortme ... 6quot;);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement webElement = driver.findElement(By.id("tableData_stockListCompany"));
// WebElement webElement = driver.findElement(By.xpath("//div[@class='table-responsive sse_table_T05']"));
String str = webElement.getAttribute("outerHTML");
System.out.println(str);
Html html = new Html(str);
System.out.println(html.xpath("//tbody/tr").all());
String companyCode = html.xpath("//tbody/tr[1]/td/text()").get();
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
String dateString = html.xpath("//tbody/tr[3]/td/text()").get().split("/")[0];
String stockCode = html.xpath("//tbody/tr[2]/td/text()").get().split("/")[0];
String name = html.xpath("//tbody/tr[5]/td/text()").get().split("/")[0];
String department = html.xpath("//tbody/tr[14]/td/text()").get().split("/")[0];
System.out.println(companyCode);
System.out.println(stockCode);
System.out.println(name);
System.out.println(department);
driver.close();
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CompanyProcessor())
.addUrl("http://www.sse.com.cn/assortme ... 6quot;)
.thread(5)
.run();
}
}
这里有一些webmagic的知识。不熟悉的可以看中文文档。因为这个爬虫框架是中国人写的,所以中文文档很详细。
注意这里的这行代码:
WebDriver driver = new ChromeDriver();
如果你想让代码成功运行,你需要下载一个chromedriver。如果你是windows,你可以去这个网站。虽然是 32 位,但也可以使用 64 位。如果不是或者你是其他操作系统,你可以去官方网站。
为什么不直接推荐去官网下载最新的呢?因为之前用过,所以我两台电脑上最新的windows系统都有问题。现在解压到C:\Windows\System32目录下,或者设置一个环境变量。
然后就可以运行了,然后就是提取一些数据或者url,就像处理静态页面一样。 查看全部
python抓取动态网页(比如说我们要爬取上交所的浦发银行这支股票背后的公司信息)
我们都知道,爬虫可以抓取很多数据。如果我们爬取一个简单的页面,就可以轻松实现。如果我们要爬取动态页面,我们应该怎么做?
比如我们要爬取东方财富网站的股票信息:
但是当我们查看源代码时,我们看不到任何关于股票信息的数据。可以看出这些股票数据是异步加载的。果断F12打开chrome开发者工具,在Network选项中勾选。如果没有,您可以使用 F5 刷新页面。出来。

QQ图片244.png
然后点击异步api,会打开一个新页面,出现如下数据:
var C1Cache={quotation:["0000011,上证指数,3166.98,170854125568,13.89,0.44%,876|201|246|142,1380|270|360|204","3990012,深证成指,10130.12,215605108736,74.55,0.74%,876|201|246|142,1380|270|360|204"]}
我以为是json数据,但是服务器发过来一个js变量,值和json数据差不多,这应该是为了开发方便,但是我们要json数据,所以需要过滤一下,split(" = ") 然后取右边的字符串,但是要注意这个右边不是json数据,注意json的key需要有双引号(在java和python中),可能在js中也可以,所以我们需要在java中进行替换,这是一个json字符串,然后转换成json对象,可以使用jackson的objectmapper,反正方法很多。然后我们可以将这些数据持久化到数据库中,这样我们就可以爬取一些动态页面。
但这里需要注意的是,有些网站不允许你跨域访问,即使你有对策通过伪装服务器来阻止你直接调用api,那么此时你需要使用另一种方法, webmagic selenium ,这个原理是先运行一个浏览器内核来加载页面,等到整个页面加载完毕,然后获取html代码,再进行处理。
比如我们要爬取浦发银行股票背后的公司信息,
当我们查看异步加载的api时,发现不允许你直接访问这个api,所以只能使用第二种方法。
以下是项目的依赖项:
compile 'us.codecraft:webmagic-core:0.5.3'
compile('us.codecraft:webmagic-extension:0.5.3')
compile 'org.seleniumhq.selenium:selenium-java:2.8.0'
compile group: 'us.codecraft', name: 'webmagic-selenium', version: '0.5.2'
源代码如下:
public class CompanyProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000)
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36");
public void process(Page page) {
WebDriver driver = new ChromeDriver();
driver.get("http://www.sse.com.cn/assortme ... 6quot;);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement webElement = driver.findElement(By.id("tableData_stockListCompany"));
// WebElement webElement = driver.findElement(By.xpath("//div[@class='table-responsive sse_table_T05']"));
String str = webElement.getAttribute("outerHTML");
System.out.println(str);
Html html = new Html(str);
System.out.println(html.xpath("//tbody/tr").all());
String companyCode = html.xpath("//tbody/tr[1]/td/text()").get();
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
String dateString = html.xpath("//tbody/tr[3]/td/text()").get().split("/")[0];
String stockCode = html.xpath("//tbody/tr[2]/td/text()").get().split("/")[0];
String name = html.xpath("//tbody/tr[5]/td/text()").get().split("/")[0];
String department = html.xpath("//tbody/tr[14]/td/text()").get().split("/")[0];
System.out.println(companyCode);
System.out.println(stockCode);
System.out.println(name);
System.out.println(department);
driver.close();
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CompanyProcessor())
.addUrl("http://www.sse.com.cn/assortme ... 6quot;)
.thread(5)
.run();
}
}
这里有一些webmagic的知识。不熟悉的可以看中文文档。因为这个爬虫框架是中国人写的,所以中文文档很详细。
注意这里的这行代码:
WebDriver driver = new ChromeDriver();
如果你想让代码成功运行,你需要下载一个chromedriver。如果你是windows,你可以去这个网站。虽然是 32 位,但也可以使用 64 位。如果不是或者你是其他操作系统,你可以去官方网站。
为什么不直接推荐去官网下载最新的呢?因为之前用过,所以我两台电脑上最新的windows系统都有问题。现在解压到C:\Windows\System32目录下,或者设置一个环境变量。
然后就可以运行了,然后就是提取一些数据或者url,就像处理静态页面一样。
python抓取动态网页(python自动化工具之pywinauto实例详解(一)数据提取及拆分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-03 07:01
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
所以我用 Python3 语法写了一个简单的 catch
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
于是写了一个使用Python3语法爬取网页图片的简单例子,希望对大家有所帮助,也希望大家批评指正。
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持染美科技。
上一篇:python自动化工具pywinauto实例详解 下一篇:python数据提取与拆分的实现代码 查看全部
python抓取动态网页(python自动化工具之pywinauto实例详解(一)数据提取及拆分)
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
所以我用 Python3 语法写了一个简单的 catch
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
于是写了一个使用Python3语法爬取网页图片的简单例子,希望对大家有所帮助,也希望大家批评指正。
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持染美科技。
上一篇:python自动化工具pywinauto实例详解 下一篇:python数据提取与拆分的实现代码
python抓取动态网页(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 04:14
缺点:
仅检索页面的静态内容
不能用于解析 HTML
无法处理用纯 JavaScript 制作的 网站
2.lxml
lxml 是一个高性能、快速、高生产力的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算抓取大型数据集时,它工作得很好。
在网页抓取中,lxml 经常与 Requests 结合使用,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python库的优缺点是什么?
优势:
比大多数解析器更快
轻的
使用元素树
Pythonic API
缺点:
不适用于设计不佳的 HTML
官方文档不太适合初学者
3.美汤
BeautifulSoup 可能是用于网络抓取的最广泛使用的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。还自动将传入文档转换为 Unicode,将传出文档自动转换为 UTF-8。
将“BeautifulSoup”与“Requests”相结合在业内非常普遍。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,Beautiful Soup 也可以与 lxml 等其他解析器结合使用。
但相应地,这种易用性也带来了很大的运行成本——它比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面了解一下 BeautifulSoup 库的优缺点。
优势:
需要几行代码
质量文件
易于初学者学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您不能轻易地从动态填充的 网站 中抓取数据。
有时发生这种情况的原因是页面上的数据是通过 JavaScript 加载的。简短的总结是,如果页面不是静态的,前面提到的 Python 库很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。
Selenium 最初是一个用于自动测试 Web 应用程序的 Python 库,一个用于呈现网页的 Web 驱动程序,这就是为什么 Selenium 可以在其他库无法运行 JavaScript 的地方工作:单击页面、填写表单、滚动页面等等.
这种在网页中运行 JavaScript 的能力使 Selenium 能够抓取动态填充的网页。但是这里有一个“缺陷”,它为每个页面加载和运行 JavaScript,使其速度较慢,不适合大型项目。
如果你不在乎时间和速度,那么 Selenium 绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动网页浏览器
可以在网页上执行任何操作,类似于人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. 爬虫
又到了介绍Python网页抓取库的BOSS——Scrapy!
Scrapy 不仅仅是一个库,它是由 Scrapinghub 联合创始人 Pablo Hoffman 和 Shane Evans 创建的一个完整的 Web 抓取框架,这是一个可以完成所有繁重工作的成熟的 Web 抓取解决方案。
Scrapy 提供的爬虫机器人可以抓取多个 网站 并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或作为 API。在几分钟内创建功能齐全的蜘蛛网,当然还可以使用 Scrapy 创建管道。
Scrapy 最好的地方在于它是异步的,这意味着可以同时发出多个 HTTP 请求,为我们节省了大量时间并提高了效率(这不就是我们为之奋斗的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。虽然 Scrapy 不能像 selenium 那样处理 JavaScript,但它可以与一个名为 Splash(一种轻量级 Web 浏览器)的库配对。借助 Splash,Scrapy 可以从动态 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他你用得好的库,欢迎留言~
原文链接:
分类:
技术要点:
相关文章: 查看全部
python抓取动态网页(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
缺点:
仅检索页面的静态内容
不能用于解析 HTML
无法处理用纯 JavaScript 制作的 网站
2.lxml
lxml 是一个高性能、快速、高生产力的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算抓取大型数据集时,它工作得很好。
在网页抓取中,lxml 经常与 Requests 结合使用,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python库的优缺点是什么?
优势:
比大多数解析器更快
轻的
使用元素树
Pythonic API
缺点:
不适用于设计不佳的 HTML
官方文档不太适合初学者
3.美汤
BeautifulSoup 可能是用于网络抓取的最广泛使用的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。还自动将传入文档转换为 Unicode,将传出文档自动转换为 UTF-8。
将“BeautifulSoup”与“Requests”相结合在业内非常普遍。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,Beautiful Soup 也可以与 lxml 等其他解析器结合使用。
但相应地,这种易用性也带来了很大的运行成本——它比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面了解一下 BeautifulSoup 库的优缺点。
优势:
需要几行代码
质量文件
易于初学者学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您不能轻易地从动态填充的 网站 中抓取数据。
有时发生这种情况的原因是页面上的数据是通过 JavaScript 加载的。简短的总结是,如果页面不是静态的,前面提到的 Python 库很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。
Selenium 最初是一个用于自动测试 Web 应用程序的 Python 库,一个用于呈现网页的 Web 驱动程序,这就是为什么 Selenium 可以在其他库无法运行 JavaScript 的地方工作:单击页面、填写表单、滚动页面等等.
这种在网页中运行 JavaScript 的能力使 Selenium 能够抓取动态填充的网页。但是这里有一个“缺陷”,它为每个页面加载和运行 JavaScript,使其速度较慢,不适合大型项目。
如果你不在乎时间和速度,那么 Selenium 绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动网页浏览器
可以在网页上执行任何操作,类似于人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. 爬虫
又到了介绍Python网页抓取库的BOSS——Scrapy!
Scrapy 不仅仅是一个库,它是由 Scrapinghub 联合创始人 Pablo Hoffman 和 Shane Evans 创建的一个完整的 Web 抓取框架,这是一个可以完成所有繁重工作的成熟的 Web 抓取解决方案。
Scrapy 提供的爬虫机器人可以抓取多个 网站 并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或作为 API。在几分钟内创建功能齐全的蜘蛛网,当然还可以使用 Scrapy 创建管道。
Scrapy 最好的地方在于它是异步的,这意味着可以同时发出多个 HTTP 请求,为我们节省了大量时间并提高了效率(这不就是我们为之奋斗的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。虽然 Scrapy 不能像 selenium 那样处理 JavaScript,但它可以与一个名为 Splash(一种轻量级 Web 浏览器)的库配对。借助 Splash,Scrapy 可以从动态 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他你用得好的库,欢迎留言~
原文链接:
分类:
技术要点:
相关文章:
python抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-01 14:13
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
<br />pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
<br />from selenium import webdriver<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
<br />from selenium import webdriver<br />from selenium.webdriver.common.keys import Keys<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com')<br />assert '百度' in browser.title<br />elem = browser.find_element_by_name('p') # Find the search box<br />elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键<br />browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
<br />import unittest<br />class BaiduTestCase(unittest.TestCase):<br /> def setUp(self):<br /> self.browser = webdriver.Firefox()<br /> self.addCleanup(self.browser.quit)<br /> def testPageTitle(self):<br /> self.browser.get('http://www.baidu.com')<br /> self.assertIn('百度', self.browser.title)<br />if __name__ == '__main__':<br /> unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
你可能感兴趣文章:python+jinja2实现接口数据批量生成工具Python的Flask框架自带模板引擎Jinja2 Python的Tornado框架教程配置Jinja2模板引擎的使用方法Python的Flask Jinja2模板引擎学习教程框架中python使用pyh生成html文档方法示例python解析html提取数据,生成word文档实例解析python使用HTMLTestRunner.py生成测试报告使用CasperJS在python中获取js渲染生成的html内容教程python使用jinja2模板生成html代码示例 查看全部
python抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
<br />pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
<br />from selenium import webdriver<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
<br />from selenium import webdriver<br />from selenium.webdriver.common.keys import Keys<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com')<br />assert '百度' in browser.title<br />elem = browser.find_element_by_name('p') # Find the search box<br />elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键<br />browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
<br />import unittest<br />class BaiduTestCase(unittest.TestCase):<br /> def setUp(self):<br /> self.browser = webdriver.Firefox()<br /> self.addCleanup(self.browser.quit)<br /> def testPageTitle(self):<br /> self.browser.get('http://www.baidu.com')<br /> self.assertIn('百度', self.browser.title)<br />if __name__ == '__main__':<br /> unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
你可能感兴趣文章:python+jinja2实现接口数据批量生成工具Python的Flask框架自带模板引擎Jinja2 Python的Tornado框架教程配置Jinja2模板引擎的使用方法Python的Flask Jinja2模板引擎学习教程框架中python使用pyh生成html文档方法示例python解析html提取数据,生成word文档实例解析python使用HTMLTestRunner.py生成测试报告使用CasperJS在python中获取js渲染生成的html内容教程python使用jinja2模板生成html代码示例
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-31 16:26
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i 查看全部
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i
python抓取动态网页(如何爬取动态网页动态加载出来的我们可以直接使用一些开发者工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-28 07:27
好久没有更新Python相关的内容了。本专题主要讲Python在爬虫中的应用,包括爬取和处理。
第二节,我们介绍如何爬取动态网页
动态网页是指通过js动态加载的网页内容
我们可以直接使用一些开发者工具来查看
这里我使用谷歌浏览器的开发者工具
开发环境
操作系统:windows 10
Python 版本:3.6
爬网模块:请求
解析网页模块:json
模块安装
pip3 安装请求
网页分析
我们使用豆瓣电影页面开始分析
#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容。
当我们点击加载更多时,我们可以通过开发者工具的Network选项中的XHR来获取动态加载的js
打开获取的连接
%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式
这里我们构建一个连接,从第一部电影开始并显示 100
%E7%83%AD%E9%97%A8&sort=推荐&page_limit=100&page_start=0
对于JSON解析,我们可以先用一个网上的网站来查看
在这里可以看到收录以下信息
评分 电影名称 电影豆瓣链接 封面地址 代码介绍
这是一行一行的代码
1. 导入相关模块
导入请求导入 json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)content=r.content
3. 使用 json.load 将 json 格式转换为 python 字典格式
这时候就可以使用字典的相关方法来处理网页了。
结果=json.loads(content)tvs=result['subjects']
4. 获取相关信息并存入字典
结果
我们可以选择将获取的数据放入数据库
源位置 查看全部
python抓取动态网页(如何爬取动态网页动态加载出来的我们可以直接使用一些开发者工具)
好久没有更新Python相关的内容了。本专题主要讲Python在爬虫中的应用,包括爬取和处理。
第二节,我们介绍如何爬取动态网页
动态网页是指通过js动态加载的网页内容
我们可以直接使用一些开发者工具来查看
这里我使用谷歌浏览器的开发者工具
开发环境
操作系统:windows 10
Python 版本:3.6
爬网模块:请求
解析网页模块:json
模块安装
pip3 安装请求
网页分析
我们使用豆瓣电影页面开始分析
#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容。
当我们点击加载更多时,我们可以通过开发者工具的Network选项中的XHR来获取动态加载的js
打开获取的连接
%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式
这里我们构建一个连接,从第一部电影开始并显示 100
%E7%83%AD%E9%97%A8&sort=推荐&page_limit=100&page_start=0
对于JSON解析,我们可以先用一个网上的网站来查看
在这里可以看到收录以下信息
评分 电影名称 电影豆瓣链接 封面地址 代码介绍
这是一行一行的代码
1. 导入相关模块
导入请求导入 json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)content=r.content
3. 使用 json.load 将 json 格式转换为 python 字典格式
这时候就可以使用字典的相关方法来处理网页了。
结果=json.loads(content)tvs=result['subjects']
4. 获取相关信息并存入字典
结果
我们可以选择将获取的数据放入数据库
源位置
python抓取动态网页(Python爬虫[动态网页数据]用法教程综述(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-28 05:10
Python爬虫4.2——ajax【动态网页数据】使用教程
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,尤其是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“长得好看的程序员是怎样一种体验”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
python抓取动态网页(Python爬虫[动态网页数据]用法教程综述(2))
Python爬虫4.2——ajax【动态网页数据】使用教程
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,尤其是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“长得好看的程序员是怎样一种体验”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
python抓取动态网页(终于我还是要自己动手从网页爬取数据了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-27 18:22
最后我还是得自己从网上抓取数据。
R的rvest包是初学者,python基本不是。代码仅供参考,爬取数据时不要问我,我应该无法回答。
rvest包抓取静态网页数据
使用的基本步骤:首先使用read_html()函数读取一个html页面,然后通过CSS或Xpath获取需要的节点并使用html_nodes()函数读取节点内容,最后使用html_text()函数在节点中获取所需的文本。
获取xpath的步骤如图1所示。
<p># install packages
install.packages("tidyverse")
install.packages("rvest")
library(tidyverse)
library(rvest)
# 以在NCBI PubMed搜索非小细胞肺癌相关文献为例
# 1、读取一个html页面
> nsclc = read_html("https://pubmed.ncbi.nlm.nih.gov/?term=NSCLC")
> nsclc
{html_document}
[1] article = nsclc %>% html_nodes(xpath = "//*[@id='search-results']/section/div[1]/div/article[1]/div[2]/div[1]/a")
> article
{xml_nodeset (1)}
[1] 查看全部
python抓取动态网页(终于我还是要自己动手从网页爬取数据了(组图))
最后我还是得自己从网上抓取数据。
R的rvest包是初学者,python基本不是。代码仅供参考,爬取数据时不要问我,我应该无法回答。
rvest包抓取静态网页数据
使用的基本步骤:首先使用read_html()函数读取一个html页面,然后通过CSS或Xpath获取需要的节点并使用html_nodes()函数读取节点内容,最后使用html_text()函数在节点中获取所需的文本。
获取xpath的步骤如图1所示。
<p># install packages
install.packages("tidyverse")
install.packages("rvest")
library(tidyverse)
library(rvest)
# 以在NCBI PubMed搜索非小细胞肺癌相关文献为例
# 1、读取一个html页面
> nsclc = read_html("https://pubmed.ncbi.nlm.nih.gov/?term=NSCLC";)
> nsclc
{html_document}
[1] article = nsclc %>% html_nodes(xpath = "//*[@id='search-results']/section/div[1]/div/article[1]/div[2]/div[1]/a")
> article
{xml_nodeset (1)}
[1]
python抓取动态网页(爬虫了解爬虫的基本原理及过程Requests+Xpath实现通用爬虫套路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-22 11:21
)
使用爬虫,我们可以获得大量有价值的数据,从而获得感性知识无法获得的信息,例如:
1.为市场研究和业务分析抓取数据。
抓取知乎优质答案,为你筛选出每个主题下的最佳内容。捕捉房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析。爬取招聘网站各类职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据。
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
抓取知乎钓鱼帖图片网站获取福利图片。
原本我们可以手动完成这些事情,但是如果我们只是简单地复制粘贴,那是非常耗时的。比如要获取100万行数据,大约需要两年左右的重复工作。爬虫可以在一天内为你完成,完全不需要任何干预。
对于小白来说,爬虫可能是一件很复杂的事情,技术门槛很高。比如有人认为学习爬虫一定要精通Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来;有的人觉得必须先掌握网页的知识,于是就入手了HTML CSS,结果进了前端的坑,累死了……
但是掌握正确的方法,能够在短时间内爬取主流的网站数据,其实是很容易实现的。但建议你从一开始就有一个明确的目标,你要爬取哪些网站的数据,以及多大的量级。
以目标为驱动,您的学习将更加准确和高效。所有你认为必要的必备知识,都可以在完成目标的过程中学习。这是一个流畅的、从零开始的快速入门学习路径。
1.了解爬虫的基本原理和流程
2.Requests+Xpath 实现通用爬虫例程
3.了解非结构化数据的存储
4.学习scrapy并构建一个工程爬虫
5.学习数据库知识,处理大规模数据存储和提取
6.掌握各种技巧应对特殊网站防爬措施
7.分布式爬虫,实现大规模并发采集,提高效率
1.了解爬虫的基本原理和流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单了解HTTP协议和网页的基础知识,如POSTGET、HTML、CSS、JS等,无需系统学习即可简单了解。
2.学习Python包,实现基本爬取流程
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路都差不多。一般的静态网站完全没有问题,小猪、豆瓣、尴尬百科、腾讯新闻等基本都能上手。
我们来看一个抓取豆瓣短评的例子:
选择第一个短注释,右键-“勾选”,可以查看源码
复制短评论信息的XPath信息
通过定位,我们得到了第一条短评论的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p
但是通常我们会想要抓取很多简短的评论,然后我们会想要得到很多这样的 XPath 信息:
//*[@id="comments"]/ul/li[1]/div[2]/p//*[@id="comments"]/ul/li[2]/div[2]/p//*[@id="comments"]/ul/li[3]/div[2]/p………………………………
观察1、2、2条短评论的XPath信息,你会发现模式,只有
后面的序号不一样,只对应短评的序号。那么如果我们想爬取这个页面上所有的短评信息,那么没有这个序列号就可以了。
通过 XPath 信息,我们可以用简单的代码进行爬取:
import requestsfrom lxml import etree#我们邀抓取的页面链接url='https://book.douban.com/subjec ... 3B%23用requests库的get方法下载网页r=requests.get(url).text#解析网页并且定位短评s=etree.HTML(r)file=s.xpath('//*[@id="comments"]/ul/li/div[2]/p/text()')#打印抓取的信息print(file)
爬取的页面所有短评信息
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样一来,动态知乎、、TripAdvisor网站基本没问题。
在此过程中,您还需要了解一些 Python 基础知识:
文件读写操作:用于读取参数并保存爬下的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for...while):用于循环遍历爬虫步骤
3.了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为文本、csv等文件。或者继续上面的例子:
存储是用 Python 的基础语言实现的:
with open('pinglun.text','w',encoding='utf-8') as f: for i in file: print(i) f.write(i)
以 pandas 语言存储:
#import pandas as pd#df = pd.DataFrame(file)#df.to_excel('pinglun.xlsx')
两段代码都可以存储已经爬下来的短评论信息,将爬取代码后面的代码粘贴进去。
存储此页面的简短评论数据
当然你可能会发现爬回来的数据不干净,可能有缺失、错误等,你还需要对数据进行清洗,可以学习pandas包的基本用法做数据预处理,得到更干净的数据. 具备以下知识点为好:
4.掌握各种技巧应对特殊网站防爬措施
爬取一个页面的数据是没有问题的,但是我们通常要爬取多个页面。
这时候我们需要看看翻页时url是如何变化的,或者以短评的页面为例,我们看看多个页面的url是如何不同的:
https://book.douban.com/subjec ... p%3D4……………………
通过前四页,我们可以找到规律。不同的页面只在末尾标有页面的序列号。我们以爬取5个页面为例,写一个循环更新页面地址即可。
for a in range(5): url="http://book.douban.com/subject ... Fp%3D{}".format(a)
当然,在爬取过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析页面加载信息,经常会得到意想不到的结果。
使用开发人员工具分析加载的信息
比如很多情况下,如果我们通过代码发现网页无法访问,可以尝试添加userAgent信息。
浏览器中的 userAgent 信息
在代码中添加 userAgent 信息
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
5.学习爬虫框架,搭建工程爬虫
掌握之前技术一般水平的数据和代码基本没有问题,但是在非常复杂的情况下,你可能还是做不到你想要的。这时候,强大的scrapy框架就非常有用了。
scrapy 是一个非常强大的爬虫框架。它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,让你可以设计爬虫,模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
6.学习数据库基础,处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
7.分布式爬虫实现大规模并发采集
爬取基础数据不再是问题,你的瓶颈将集中在爬取海量数据的效率上。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy + MongoDB + Redis这三个工具。
之前我们说过,Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取网页的队列,即任务队列。
所以不要被看起来很深的东西吓倒。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
你看,经过这条学习路径,你已经可以成为一名老司机了,非常顺利。所以一开始尽量不要系统地啃一些东西,找一个实用的项目(可以从豆瓣小猪这种简单的东西入手),直接入手。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,并且可以保证每次学习都是最需要的部分。
当然,唯一的困难是,当你一开始没有经验的时候,你在寻找资源和解决问题的方法时总会遇到一些困难,因为我们通常很难在一开始就将具体的问题描述清楚。如果有大神帮忙指点学习路径,答疑解惑,效率会高很多。
查看全部
python抓取动态网页(爬虫了解爬虫的基本原理及过程Requests+Xpath实现通用爬虫套路
)
使用爬虫,我们可以获得大量有价值的数据,从而获得感性知识无法获得的信息,例如:
1.为市场研究和业务分析抓取数据。
抓取知乎优质答案,为你筛选出每个主题下的最佳内容。捕捉房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析。爬取招聘网站各类职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据。
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
抓取知乎钓鱼帖图片网站获取福利图片。
原本我们可以手动完成这些事情,但是如果我们只是简单地复制粘贴,那是非常耗时的。比如要获取100万行数据,大约需要两年左右的重复工作。爬虫可以在一天内为你完成,完全不需要任何干预。
对于小白来说,爬虫可能是一件很复杂的事情,技术门槛很高。比如有人认为学习爬虫一定要精通Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来;有的人觉得必须先掌握网页的知识,于是就入手了HTML CSS,结果进了前端的坑,累死了……
但是掌握正确的方法,能够在短时间内爬取主流的网站数据,其实是很容易实现的。但建议你从一开始就有一个明确的目标,你要爬取哪些网站的数据,以及多大的量级。
以目标为驱动,您的学习将更加准确和高效。所有你认为必要的必备知识,都可以在完成目标的过程中学习。这是一个流畅的、从零开始的快速入门学习路径。
1.了解爬虫的基本原理和流程
2.Requests+Xpath 实现通用爬虫例程
3.了解非结构化数据的存储
4.学习scrapy并构建一个工程爬虫
5.学习数据库知识,处理大规模数据存储和提取
6.掌握各种技巧应对特殊网站防爬措施
7.分布式爬虫,实现大规模并发采集,提高效率
1.了解爬虫的基本原理和流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单了解HTTP协议和网页的基础知识,如POSTGET、HTML、CSS、JS等,无需系统学习即可简单了解。
2.学习Python包,实现基本爬取流程
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路都差不多。一般的静态网站完全没有问题,小猪、豆瓣、尴尬百科、腾讯新闻等基本都能上手。
我们来看一个抓取豆瓣短评的例子:
选择第一个短注释,右键-“勾选”,可以查看源码
复制短评论信息的XPath信息
通过定位,我们得到了第一条短评论的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p
但是通常我们会想要抓取很多简短的评论,然后我们会想要得到很多这样的 XPath 信息:
//*[@id="comments"]/ul/li[1]/div[2]/p//*[@id="comments"]/ul/li[2]/div[2]/p//*[@id="comments"]/ul/li[3]/div[2]/p………………………………
观察1、2、2条短评论的XPath信息,你会发现模式,只有
后面的序号不一样,只对应短评的序号。那么如果我们想爬取这个页面上所有的短评信息,那么没有这个序列号就可以了。
通过 XPath 信息,我们可以用简单的代码进行爬取:
import requestsfrom lxml import etree#我们邀抓取的页面链接url='https://book.douban.com/subjec ... 3B%23用requests库的get方法下载网页r=requests.get(url).text#解析网页并且定位短评s=etree.HTML(r)file=s.xpath('//*[@id="comments"]/ul/li/div[2]/p/text()')#打印抓取的信息print(file)
爬取的页面所有短评信息
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样一来,动态知乎、、TripAdvisor网站基本没问题。
在此过程中,您还需要了解一些 Python 基础知识:
文件读写操作:用于读取参数并保存爬下的内容
list(列表)、dict(字典):用于对爬取的数据进行序列化
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for...while):用于循环遍历爬虫步骤
3.了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为文本、csv等文件。或者继续上面的例子:
存储是用 Python 的基础语言实现的:
with open('pinglun.text','w',encoding='utf-8') as f: for i in file: print(i) f.write(i)
以 pandas 语言存储:
#import pandas as pd#df = pd.DataFrame(file)#df.to_excel('pinglun.xlsx')
两段代码都可以存储已经爬下来的短评论信息,将爬取代码后面的代码粘贴进去。
存储此页面的简短评论数据
当然你可能会发现爬回来的数据不干净,可能有缺失、错误等,你还需要对数据进行清洗,可以学习pandas包的基本用法做数据预处理,得到更干净的数据. 具备以下知识点为好:
4.掌握各种技巧应对特殊网站防爬措施
爬取一个页面的数据是没有问题的,但是我们通常要爬取多个页面。
这时候我们需要看看翻页时url是如何变化的,或者以短评的页面为例,我们看看多个页面的url是如何不同的:
https://book.douban.com/subjec ... p%3D4……………………
通过前四页,我们可以找到规律。不同的页面只在末尾标有页面的序列号。我们以爬取5个页面为例,写一个循环更新页面地址即可。
for a in range(5): url="http://book.douban.com/subject ... Fp%3D{}".format(a)
当然,在爬取过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析页面加载信息,经常会得到意想不到的结果。
使用开发人员工具分析加载的信息
比如很多情况下,如果我们通过代码发现网页无法访问,可以尝试添加userAgent信息。
浏览器中的 userAgent 信息
在代码中添加 userAgent 信息
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
5.学习爬虫框架,搭建工程爬虫
掌握之前技术一般水平的数据和代码基本没有问题,但是在非常复杂的情况下,你可能还是做不到你想要的。这时候,强大的scrapy框架就非常有用了。
scrapy 是一个非常强大的爬虫框架。它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。不过,最让人惊喜的是它的超高性能,让你可以设计爬虫,模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
6.学习数据库基础,处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
7.分布式爬虫实现大规模并发采集
爬取基础数据不再是问题,你的瓶颈将集中在爬取海量数据的效率上。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理,让多个爬虫同时工作。你需要掌握Scrapy + MongoDB + Redis这三个工具。
之前我们说过,Scrapy用于基本的页面爬取,MongoDB用于存储爬取的数据,Redis用于存储待爬取网页的队列,即任务队列。
所以不要被看起来很深的东西吓倒。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
你看,经过这条学习路径,你已经可以成为一名老司机了,非常顺利。所以一开始尽量不要系统地啃一些东西,找一个实用的项目(可以从豆瓣小猪这种简单的东西入手),直接入手。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,并且可以保证每次学习都是最需要的部分。
当然,唯一的困难是,当你一开始没有经验的时候,你在寻找资源和解决问题的方法时总会遇到一些困难,因为我们通常很难在一开始就将具体的问题描述清楚。如果有大神帮忙指点学习路径,答疑解惑,效率会高很多。
python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-20 15:11
Selenium 是一个用于测试 WebUI 的自动化测试框架。它通过调用Chrome和Firefox来完成动态页面(包括Javascript)的加载,因此也可以用来完成动态网页抓取。
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、启动 selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受一个url字符串,然后在自己的进程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端。
3、安装硒
sudo apt-get install python-selenium
这个包是selenium客户端的python包,当然也可以通过pypi或者pip手动安装。
文档可以在这里找到。
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、在非 X11 环境中使用
可以通过xvfb来完成,这是一个模拟xserver的程序,可以在没有xserver的机器上运行,为xserver服务。
sudo apt-get install xvfb
运行
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与Scrapy结合
请参考我之前写的文章《Python爬虫框架Scrapy快速入门教程》,并不复杂。 查看全部
python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
Selenium 是一个用于测试 WebUI 的自动化测试框架。它通过调用Chrome和Firefox来完成动态页面(包括Javascript)的加载,因此也可以用来完成动态网页抓取。
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、启动 selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受一个url字符串,然后在自己的进程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端。
3、安装硒
sudo apt-get install python-selenium
这个包是selenium客户端的python包,当然也可以通过pypi或者pip手动安装。
文档可以在这里找到。
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、在非 X11 环境中使用
可以通过xvfb来完成,这是一个模拟xserver的程序,可以在没有xserver的机器上运行,为xserver服务。
sudo apt-get install xvfb
运行
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与Scrapy结合
请参考我之前写的文章《Python爬虫框架Scrapy快速入门教程》,并不复杂。
python抓取动态网页( Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-19 13:20
Python网络爬虫内容提取器)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源代码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行如下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到,网页中的手机名称和价格已经被正确抓取了
4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
转载于: 查看全部
python抓取动态网页(
Python网络爬虫内容提取器)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源代码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行如下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url="http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser=webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:可以看到,网页中的手机名称和价格已经被正确抓取了
4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
转载于:
python抓取动态网页(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-18 03:09
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如 Javascript 脚本执行产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 respOnse=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索以前的文章或继续浏览下方的相关文章,希望大家以后多多支持!
推荐内容:免费高清PNG素材下载 查看全部
python抓取动态网页(python爬取js执行后输出的信息--python库)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多时候,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如 Javascript 脚本执行产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 respOnse=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 硒的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content = driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索以前的文章或继续浏览下方的相关文章,希望大家以后多多支持!
推荐内容:免费高清PNG素材下载
python抓取动态网页(网页正文抽取的方法,你知道吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-16 06:24
我们前面实现的爬虫,运行后可以快速爬取大量网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
提取网页正文的方法
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
标题区
元数据区(发布时间等)
地图区域(如果您也想提取地图)
文本区
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
上海用“智慧”激活城市交通脉搏,让道路更安全、更有序、更顺畅-新华网
“沪港高校联盟”今日在复旦大学成立_教育_新民网
三亚老人踢司机致公交车失控撞墙被判3年监禁_手机网易网
外交部:中美外交与安全对话9日在美国举行
中国国际进口博览会:中国作为举世瞩目,中国作为世界赞誉
资本市场迎来重大变革,科创板的成立有何意义?- 新华网
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 释放时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是基于老猿多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' 查看全部
python抓取动态网页(网页正文抽取的方法,你知道吗?(图))
我们前面实现的爬虫,运行后可以快速爬取大量网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
提取网页正文的方法
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
标题区
元数据区(发布时间等)
地图区域(如果您也想提取地图)
文本区
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
上海用“智慧”激活城市交通脉搏,让道路更安全、更有序、更顺畅-新华网
“沪港高校联盟”今日在复旦大学成立_教育_新民网
三亚老人踢司机致公交车失控撞墙被判3年监禁_手机网易网
外交部:中美外交与安全对话9日在美国举行
中国国际进口博览会:中国作为举世瞩目,中国作为世界赞誉
资本市场迎来重大变革,科创板的成立有何意义?- 新华网
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 释放时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是基于老猿多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r'
python抓取动态网页(网页爬虫的运行流程及存储方式(关键词))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-15 04:01
关键词:
知识的领域是无限的,我们的学习也是如此。本文章主要介绍Python爬虫的基础知识,希望对大家有所帮助。
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request response = urllib.request.urlopen(‘http://www.baidu.com‘)buff = response.read()html = buff.decode("utf8")print(html) |
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request request = urllib.request.Request(‘http://www.baidu.com‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
携带参数
新建一个baidu2.py,内容如下:
import urllib.requestimport urllib.parse url = ‘http://www.baidu.com‘values = {‘name‘: ‘voidking‘,‘language‘: ‘Python‘}data = urllib.parse.urlencode(values).encode(encoding=‘utf-8‘,errors=‘ignore‘)headers = { ‘User-Agent‘ : ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0‘ }request = urllib.request.Request(url=url, data=data,headers=headers,method=‘GET‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.requestimport http.cookiejar # 创建cookie容器cj = http.cookiejar.CookieJar()# 创建openeropener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))# 给urllib.request安装openerurllib.request.install_opener(opener) # 请求request = urllib.request.Request(‘http://www.baidu.com/‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html)print(cj) |
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4print(bs4) |
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4from bs4 import BeautifulSoup # 根据html网页字符串创建BeautifulSoup对象html_doc = """The Dormouse‘s story<p class="title">The Dormouse‘s story
Once upon a time there were three little sisters; and their names wereElsie,Lacie andTillie;and they lived at the bottom of a well.
..."""soup = BeautifulSoup(html_doc)print(soup.prettify()) </p>
2、访问节点
print(soup.title)print(soup.title.name)print(soup.title.string)print(soup.title.parent.name) print(soup.p)print(soup.p[‘class‘])
3、指定标签、类或id
print(soup.find_all(‘a‘))print(soup.find(‘a‘))print(soup.find(class_=‘title‘))print(soup.find(id="link3"))print(soup.find(‘p‘,class_=‘title‘))
4、从文档中找到所有 `` 标签的链接
for link in soup.find_all(‘a‘): print(link.get(‘href‘))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,‘html.parser‘)
5、从文档中获取所有文本内容
print(soup.get_text()
6、常规赛
soup.find(‘a‘,href=re.compile(r"til"))print(link_node) |
?``` |
# 后记
python爬虫基础知识,至此足够,接下来,在实战中学习更高级的知识。
至此,这篇关于Python爬虫基础的文章就讲完了。如果您的问题无法解决,请参考以下文章: 查看全部
python抓取动态网页(网页爬虫的运行流程及存储方式(关键词))
关键词:
知识的领域是无限的,我们的学习也是如此。本文章主要介绍Python爬虫的基础知识,希望对大家有所帮助。
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request response = urllib.request.urlopen(‘http://www.baidu.com‘)buff = response.read()html = buff.decode("utf8")print(html) |
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request request = urllib.request.Request(‘http://www.baidu.com‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
携带参数
新建一个baidu2.py,内容如下:
import urllib.requestimport urllib.parse url = ‘http://www.baidu.com‘values = {‘name‘: ‘voidking‘,‘language‘: ‘Python‘}data = urllib.parse.urlencode(values).encode(encoding=‘utf-8‘,errors=‘ignore‘)headers = { ‘User-Agent‘ : ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0‘ }request = urllib.request.Request(url=url, data=data,headers=headers,method=‘GET‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html) |
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.requestimport http.cookiejar # 创建cookie容器cj = http.cookiejar.CookieJar()# 创建openeropener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))# 给urllib.request安装openerurllib.request.install_opener(opener) # 请求request = urllib.request.Request(‘http://www.baidu.com/‘)response = urllib.request.urlopen(request)buff = response.read()html = buff.decode("utf8")print(html)print(cj) |
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4print(bs4) |
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4from bs4 import BeautifulSoup # 根据html网页字符串创建BeautifulSoup对象html_doc = """The Dormouse‘s story<p class="title">The Dormouse‘s story
Once upon a time there were three little sisters; and their names wereElsie,Lacie andTillie;and they lived at the bottom of a well.
..."""soup = BeautifulSoup(html_doc)print(soup.prettify()) </p>
2、访问节点
print(soup.title)print(soup.title.name)print(soup.title.string)print(soup.title.parent.name) print(soup.p)print(soup.p[‘class‘])
3、指定标签、类或id
print(soup.find_all(‘a‘))print(soup.find(‘a‘))print(soup.find(class_=‘title‘))print(soup.find(id="link3"))print(soup.find(‘p‘,class_=‘title‘))
4、从文档中找到所有 `` 标签的链接
for link in soup.find_all(‘a‘): print(link.get(‘href‘))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,‘html.parser‘)
5、从文档中获取所有文本内容
print(soup.get_text()
6、常规赛
soup.find(‘a‘,href=re.compile(r"til"))print(link_node) |
?``` |
# 后记
python爬虫基础知识,至此足够,接下来,在实战中学习更高级的知识。
至此,这篇关于Python爬虫基础的文章就讲完了。如果您的问题无法解决,请参考以下文章:
python抓取动态网页(华为中国发文《小白看过来,让Python爬虫成为你的好帮手》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-15 03:36
据华为中国官方消息,近日,华为中国发文《小白过来,让Python爬虫做你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。
以下为《小白过来,让Python爬虫做你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词不再陌生。但是什么是爬虫以及如何使用爬虫为自己服务,这些对于ICT技术新手来说听起来有点高。别着急,下面的文章带你走近爬虫的世界,让即使你是ICT技术的新手,也能快速了解如何使用Python爬虫高效抓图。
什么是专用爬虫?
网络爬虫是一种从 Internet 上抓取数据和信息的自动化程序。如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫是沿着网络抓取猎物(数据)的小蜘蛛(程序)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取的持续高效运行。分为通用爬虫和专用爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为某一类人提供服务,爬取的目标网页定位在主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
爬行动物如何工作
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫首先要做的是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。实际上,获取网页——分析网页源代码——提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页的结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Requests、pyquery、lxml等。使用这些库,网页信息可以高效快速地提取,例如属性、文本值等。节点的数量可以简单地保存为 TXT 文本或 JSON 文本。这些信息可以保存到数据库,如 MySQL 和 MongoDB,或远程服务器,如使用 SFTP 操作。提取信息对于爬虫来说是一个非常重要的角色,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
使用爬虫如此简单
你想让爬虫做你的助手吗?帮助您通过关键字从网页中提取您需要的信息?针对对Python编程或网络爬虫感兴趣的大众、高校师生,华为开发了“使用Python爬虫抓图”微认证。学生学习Python网络爬虫的理论知识,结合华为云服务完成爬虫操作和数据。存储实践,可以了解网络爬虫背后的HTML和HTTP原理,通过实践掌握爬虫的编程和操作方法,帮助你快速高效的根据关键词抓取图片,高效获取信息。
开始学习华为云微认证《使用Python爬虫抓图》,你会发现抓图信息就是这么简单快捷。
创新互联网提供动态拨号vps服务器等。创新互联网不仅有全国20多个省160多个城市的动态ip拨号VPS,还有海外香港、日本的动态拨号VPS 、美国、台湾、韩国、菲律宾等国家和地区。非常适合排名、网站优化、网络营销、爬虫、数据抓取、数据分析、刷单、投票等领域;如有需要,请联系创新互联网客服! 查看全部
python抓取动态网页(华为中国发文《小白看过来,让Python爬虫成为你的好帮手》)
据华为中国官方消息,近日,华为中国发文《小白过来,让Python爬虫做你的好帮手》,文章详细介绍了Python爬虫的工作原理,一起来看看吧。
以下为《小白过来,让Python爬虫做你的好帮手》全文:
随着信息社会的到来,人们对网络爬虫这个词不再陌生。但是什么是爬虫以及如何使用爬虫为自己服务,这些对于ICT技术新手来说听起来有点高。别着急,下面的文章带你走近爬虫的世界,让即使你是ICT技术的新手,也能快速了解如何使用Python爬虫高效抓图。
什么是专用爬虫?
网络爬虫是一种从 Internet 上抓取数据和信息的自动化程序。如果我们把互联网比作一个大蜘蛛网,数据存储在蜘蛛网的每个节点中,而爬虫是沿着网络抓取猎物(数据)的小蜘蛛(程序)。
爬虫可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取的持续高效运行。分为通用爬虫和专用爬虫。通用爬虫是搜索引擎爬虫系统的重要组成部分。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份;专用爬虫主要为某一类人提供服务,爬取的目标网页定位在主题相关的页面中,节省了大量的服务器资源和带宽资源。比如想要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
爬行动物如何工作
爬虫可以根据我们提供的信息从网页中获取大量图片。它是如何工作的?
爬虫首先要做的是获取网页的源代码,其中收录了网页的一些有用信息;然后爬虫构造一个请求并发送给服务器,服务器接收响应并解析。实际上,获取网页——分析网页源代码——提取信息是爬虫工作的三部曲。如何提取信息?最常用的方法是使用正则表达式。网页的结构有一定的规则,有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Requests、pyquery、lxml等。使用这些库,网页信息可以高效快速地提取,例如属性、文本值等。节点的数量可以简单地保存为 TXT 文本或 JSON 文本。这些信息可以保存到数据库,如 MySQL 和 MongoDB,或远程服务器,如使用 SFTP 操作。提取信息对于爬虫来说是一个非常重要的角色,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
使用爬虫如此简单
你想让爬虫做你的助手吗?帮助您通过关键字从网页中提取您需要的信息?针对对Python编程或网络爬虫感兴趣的大众、高校师生,华为开发了“使用Python爬虫抓图”微认证。学生学习Python网络爬虫的理论知识,结合华为云服务完成爬虫操作和数据。存储实践,可以了解网络爬虫背后的HTML和HTTP原理,通过实践掌握爬虫的编程和操作方法,帮助你快速高效的根据关键词抓取图片,高效获取信息。
开始学习华为云微认证《使用Python爬虫抓图》,你会发现抓图信息就是这么简单快捷。
创新互联网提供动态拨号vps服务器等。创新互联网不仅有全国20多个省160多个城市的动态ip拨号VPS,还有海外香港、日本的动态拨号VPS 、美国、台湾、韩国、菲律宾等国家和地区。非常适合排名、网站优化、网络营销、爬虫、数据抓取、数据分析、刷单、投票等领域;如有需要,请联系创新互联网客服!
python抓取动态网页(爬取浏览器click事件也执行click事件执行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-14 00:20
最近突然想到爬百度的学术参考。大家可以看看我之前的博客: 但是如果用这种方法,太痛苦了,需要手动复制粘贴,所以这里介绍一下使用selenium来实现这个。函数,粘贴代码:
#-*- coding:utf-8 -*-
from selenium import webdriver
import time
from bs4 import BeautifulSoup
#拼接url
titlename='Application of biosorption for the removal of organic pollutants: a review'
url_name=titlename.split(' ')
url='http://xueshu.baidu.com/s?wd='+'+'.join(url_name)
#打开Firefox
diver=webdriver.Firefox()
diver.get(url)
#防止引用太多,不断click,直到参考文献下不存在‘加载更多’
try:
for i in range(0,50):
# 等待网站加载完成
time.sleep(0.2)
diver.find_elements_by_class_name('request_situ')[1].click()
except:
print '********************************************************'
#等到加载完成获取网页源码
time.sleep(10)
#使用BeautifulSoup获取参考文献
soup=BeautifulSoup(diver.page_source,'lxml')
items=soup.find('div',{'class':'con_reference'}).find_all('li')
for i in items:
print i.find('a').get_text()
#关闭网页
diver.close()
注意:
代码标记为红色。因为这个错误,我花了很长时间。
我遇到了一个问题。每次第一次抓取,click事件都没有响应。我可以用断点检查,发现是OK的,然后就OK了。我不知道为什么会这样。
Chrome 浏览器点击事件不执行
如果不想看到浏览器出现,可以使用 diver=webdriver.PhantomJS() 代替 diver=webdriver.Firefox()
以上的基础是安装PhantomJS、geckodriver.exe 查看全部
python抓取动态网页(爬取浏览器click事件也执行click事件执行)
最近突然想到爬百度的学术参考。大家可以看看我之前的博客: 但是如果用这种方法,太痛苦了,需要手动复制粘贴,所以这里介绍一下使用selenium来实现这个。函数,粘贴代码:
#-*- coding:utf-8 -*-
from selenium import webdriver
import time
from bs4 import BeautifulSoup
#拼接url
titlename='Application of biosorption for the removal of organic pollutants: a review'
url_name=titlename.split(' ')
url='http://xueshu.baidu.com/s?wd='+'+'.join(url_name)
#打开Firefox
diver=webdriver.Firefox()
diver.get(url)
#防止引用太多,不断click,直到参考文献下不存在‘加载更多’
try:
for i in range(0,50):
# 等待网站加载完成
time.sleep(0.2)
diver.find_elements_by_class_name('request_situ')[1].click()
except:
print '********************************************************'
#等到加载完成获取网页源码
time.sleep(10)
#使用BeautifulSoup获取参考文献
soup=BeautifulSoup(diver.page_source,'lxml')
items=soup.find('div',{'class':'con_reference'}).find_all('li')
for i in items:
print i.find('a').get_text()
#关闭网页
diver.close()
注意:
代码标记为红色。因为这个错误,我花了很长时间。
我遇到了一个问题。每次第一次抓取,click事件都没有响应。我可以用断点检查,发现是OK的,然后就OK了。我不知道为什么会这样。
Chrome 浏览器点击事件不执行
如果不想看到浏览器出现,可以使用 diver=webdriver.PhantomJS() 代替 diver=webdriver.Firefox()
以上的基础是安装PhantomJS、geckodriver.exe
python抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-02-14 00:18
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。
ajax数据获取方式:
1、直接分析ajax调用的接口。然后通过代码请求这个接口。
2、使用 Selenium+chromedriver 模拟浏览器行为获取数据。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以模拟人类在浏览器上的一些行为,自动处理浏览器上的一些行为,比如点击、填充数据、删除cookies等。chromedriver是驱动Chrome浏览器的驱动,可以用来驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、铬:
2、火狐:
3、边缘:
4、Safari:
安装 Selenium 和 chromedriver:
安装 Selenium:Selenium 支持多种语言,包括 java、ruby、python 等,我们可以下载 python 版本。
点安装硒
安装chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。
快速开始:
下面我们以一个简单的获取百度主页的例子来谈谈如何快速上手 Selenium 和 chromedriver:
selenium的常用操作:
关闭页面:
1、driver.close():关闭当前页面。
2、driver.quit():退出整个浏览器。
定位要素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
作为表单元素:
1、操作输入框:分两步。第一步:找到元素。第 2 步:使用 send_keys(value) 填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear()
2、操作复选框:因为需要选中复选框标签,所以在网页中用鼠标点击。所以如果要选中checkbox标签,先选中标签,然后执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:
4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:
显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:
其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。 查看全部
python抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
什么是阿贾克斯:
Ajax (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。
ajax数据获取方式:
1、直接分析ajax调用的接口。然后通过代码请求这个接口。
2、使用 Selenium+chromedriver 模拟浏览器行为获取数据。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以模拟人类在浏览器上的一些行为,自动处理浏览器上的一些行为,比如点击、填充数据、删除cookies等。chromedriver是驱动Chrome浏览器的驱动,可以用来驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、铬:
2、火狐:
3、边缘:
4、Safari:
安装 Selenium 和 chromedriver:
安装 Selenium:Selenium 支持多种语言,包括 java、ruby、python 等,我们可以下载 python 版本。
点安装硒
安装chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。
快速开始:
下面我们以一个简单的获取百度主页的例子来谈谈如何快速上手 Selenium 和 chromedriver:
selenium的常用操作:
关闭页面:
1、driver.close():关闭当前页面。
2、driver.quit():退出整个浏览器。
定位要素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
作为表单元素:
1、操作输入框:分两步。第一步:找到元素。第 2 步:使用 send_keys(value) 填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear()
2、操作复选框:因为需要选中复选框标签,所以在网页中用鼠标点击。所以如果要选中checkbox标签,先选中标签,然后执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:
4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:
显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:
其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。
python抓取动态网页(动态加载网页一什么是动态网页(附详细源码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-11 21:12
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。
项目背景
事情是这样的,前几天,我的公众号写了一篇关于爬虫文章的介绍的文章,叫做《实战|教你如何使用Python爬虫(附详细源码)》。寄出后不到一天,一位从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住慌了。
简单交流了一下,原来他是在自学爬虫,但是发现翻页的时候,url还是一样的。其实他爬的是比较难的网页,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会给他指点方向,在最短的时间内从青铜到白银。
网页的AJAX动态加载
一
什么是动态网页
J哥一直注重理论与实践的结合,一定要知道自己为什么会这样,才能应对一切变化而不作改变。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量减少、内容更新快、可以完成的功能多等特点。
二
什么是 AJAX
随着人们对动态网页加载速度的要求越来越高,AJAX技术应运而生,成为众多网站的首选。AJAX 是一种用于创建快速和动态网页的技术,它通过在后台与服务器交换少量数据来实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何爬取 AJAX 动态加载的网页
1. 解析接口
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它悄悄加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站难以解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但已经被广泛的用户爬取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。特点:代码比较简单,爬取速度慢,ip容易被封.
项目实践
说了这么多理论,说实话,J哥不想这么啰嗦。不过这些东西经常被问到,干脆写下来,下次有人问,直接把这个文章发给他,一劳永逸!
好,我们回到王律师的部分。作为一名资深律师,王律师深知,研究法院历年发布的法院信息和执行信息对于提升业务能力具有重要作用。于是,他兴高采烈地打开了法庭信息公示页面。
它看起来像这样:
然后,他按照J哥之前写的爬虫文章的介绍爬取了数据,成功提取了第一页,激动万分。
紧接着,他加了一个for循环,想花几分钟把网站2164页的32457条法庭公告的数据提取到excel中。
那么,就没有了。看完前面的理论部分,你也应该知道这是一个AJAX动态加载的网页。无论您如何点击下一页,网址都不会改变。不信,点进去给你看,左上角的url像山一样耸立在那里:
一
解析接口
在这种情况下,让我们启动爬虫的正确姿势,首先使用解析接口的方法来编写爬虫。
首先,找到真正的请求。右键查看,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。是的,就是这么简单,真正的请求隐藏在里面。
让我们仔细看看这个jsp,简直是宝藏。有一个真实的请求url,一个请求方法post,Headers,和Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我把我的饼干做了马赛克,机智的朋友可能已经注意到我顺便给自己做了一个广告。
让我们仔细看看这些参数。pagesnum参数不代表页数!王律师顿悟了。原来,他在这里全心全意地翻开了这一页!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有pagesnum参数会改变。
既然已经找到了,就赶紧抓起来吧。J哥以闪电般的速度打开PyCharm,导入爬虫所需的库。
from urllib.parse import urlencode
import csv
import random
import requests
import traceback
from time import sleep
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真实的请求并添加Headers。J哥这里没有贴出自己的User-Agent和Cookie,主要是一向胆小的J哥怕了。
base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B #这里要换成对应Ajax请求中的链接
headers = {
'Connection': 'keep-alive',
'Accept': '*/*',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': '你的User-Agent',
'Origin': 'http://www.hshfy.sh.cn',
'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B,
'Accept-Language': 'zh-CN,zh;q=0.9',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': '你的Cookie'
}
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,使用post方法请求网页数据。这里注意对返回的数据进行解码,编码为'gbk',否则返回的数据会乱码!此外,我还添加了异常处理优化,以防止意外发生。
def get_page(page):
n = 3
while True:
try:
sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
data = {
'yzm': 'yxAH',
'ft':'',
'ktrqks': '2020-05-22',
'ktrqjs': '2020-06-22',
'spc':'',
'yg':'',
'bg':'',
'ah':'',
'pagesnum': page
}
url = base_url + urlencode(data)
print(url)
try:
response = requests.request("POST",url, headers = headers)
#print(response)
if response.status_code == 200:
re = response.content.decode('gbk')
# print(re)
return re # 解析内容
except requests.ConnectionError as e:
print('Error', e.args) # 输出异常信息
except (TimeoutError, Exception):
n -= 1
if n == 0:
print('请求3次均失败,放弃此url请求,检查请求条件')
return
else:
print('请求失败,重新请求')
continue
构建parse_page函数,解析返回的网页数据,用Xpath提取所有字段内容,保存为csv格式。有人会问为什么J哥这么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我不能做一个普通的大法来安装x。J弟兄,我做不到。
def parse_page(html):
try:
parse = etree.HTML(html) # 解析网页
items = parse.xpath('//*[@id="report"]/tbody/tr')
for item in items[1:]:
item = {
'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
'c': ''.join(item.xpath('./td[3]/text()')).strip(),
'd': ''.join(item.xpath('./td[4]/text()')).strip(),
'e': ''.join(item.xpath('./td[5]/text()')).strip(),
'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
'h': ''.join(item.xpath('./td[8]/text()')).strip(),
'i': ''.join(item.xpath('./td[9]/text()')).strip()
}
#print(item)
try:
with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
writer = csv.DictWriter(fp,fieldnames)
writer.writerow(item)
except Exception:
print(traceback.print_exc()) #代替print e 来输出详细的异常信息
except Exception:
print(traceback.print_exc())
最后,遍历页数,调用函数。OK完成!
for page in range(1,5): #这里设置想要爬取的页数
html = get_page(page)
#print(html)
print("第" + str(page) + "页提取完成")
让我们看看最终的结果:
二
硒
有心学习的朋友可能还想看看Selenium如何爬取AJAX动态加载的网页。J哥自然会满足你的好奇心。于是我赶紧新建了一个py文件,准备趁势利用Selenium爬下这个网站。
首先,导入相关库。
from lxml import etree
import time
from selenium import webdriver
from selenium. webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
然后,使用 chromedriver 驱动程序打开这个 网站。
def main():
# 爬取首页url
url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
# 定义谷歌webdriver
driver = webdriver.Chrome('./chromedriver')
driver.maximize_window() # 将浏览器最大化
driver.get(url)
所以,我惊讶地发现这是错误的。有了六级英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器的版本不匹配,只支持79版本的浏览器。
J哥很郁闷,因为我之前从来没有遇到过Selenium for爬虫的这种问题。J哥不甘心,打开谷歌浏览器看了看版本号。
我失去了它!全部更新到81版!遇到这种情况,请好奇的朋友等J哥设置浏览器自动更新重新下载最新驱动,下次再来听Selenium爬虫,记得关注这个公众号,不要'错过了~
结语
综上所述,对于AJAX动态加载的网络爬虫,一般有两种方式:解析接口;硒。J哥推荐解析接口的方式。如果解析的是json数据,爬起来会更好。真的没有办法使用 Selenium。
参考链接:
阿贾克斯:;
ajax_json:;
例子: 查看全部
python抓取动态网页(动态加载网页一什么是动态网页(附详细源码))
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。
项目背景
事情是这样的,前几天,我的公众号写了一篇关于爬虫文章的介绍的文章,叫做《实战|教你如何使用Python爬虫(附详细源码)》。寄出后不到一天,一位从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住慌了。
简单交流了一下,原来他是在自学爬虫,但是发现翻页的时候,url还是一样的。其实他爬的是比较难的网页,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会给他指点方向,在最短的时间内从青铜到白银。
网页的AJAX动态加载
一
什么是动态网页
J哥一直注重理论与实践的结合,一定要知道自己为什么会这样,才能应对一切变化而不作改变。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量减少、内容更新快、可以完成的功能多等特点。
二
什么是 AJAX
随着人们对动态网页加载速度的要求越来越高,AJAX技术应运而生,成为众多网站的首选。AJAX 是一种用于创建快速和动态网页的技术,它通过在后台与服务器交换少量数据来实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何爬取 AJAX 动态加载的网页
1. 解析接口
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它悄悄加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站难以解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但已经被广泛的用户爬取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。特点:代码比较简单,爬取速度慢,ip容易被封.
项目实践
说了这么多理论,说实话,J哥不想这么啰嗦。不过这些东西经常被问到,干脆写下来,下次有人问,直接把这个文章发给他,一劳永逸!
好,我们回到王律师的部分。作为一名资深律师,王律师深知,研究法院历年发布的法院信息和执行信息对于提升业务能力具有重要作用。于是,他兴高采烈地打开了法庭信息公示页面。
它看起来像这样:
然后,他按照J哥之前写的爬虫文章的介绍爬取了数据,成功提取了第一页,激动万分。
紧接着,他加了一个for循环,想花几分钟把网站2164页的32457条法庭公告的数据提取到excel中。
那么,就没有了。看完前面的理论部分,你也应该知道这是一个AJAX动态加载的网页。无论您如何点击下一页,网址都不会改变。不信,点进去给你看,左上角的url像山一样耸立在那里:
一
解析接口
在这种情况下,让我们启动爬虫的正确姿势,首先使用解析接口的方法来编写爬虫。
首先,找到真正的请求。右键查看,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。是的,就是这么简单,真正的请求隐藏在里面。
让我们仔细看看这个jsp,简直是宝藏。有一个真实的请求url,一个请求方法post,Headers,和Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我把我的饼干做了马赛克,机智的朋友可能已经注意到我顺便给自己做了一个广告。
让我们仔细看看这些参数。pagesnum参数不代表页数!王律师顿悟了。原来,他在这里全心全意地翻开了这一页!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有pagesnum参数会改变。
既然已经找到了,就赶紧抓起来吧。J哥以闪电般的速度打开PyCharm,导入爬虫所需的库。
from urllib.parse import urlencode
import csv
import random
import requests
import traceback
from time import sleep
from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真实的请求并添加Headers。J哥这里没有贴出自己的User-Agent和Cookie,主要是一向胆小的J哥怕了。
base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B #这里要换成对应Ajax请求中的链接
headers = {
'Connection': 'keep-alive',
'Accept': '*/*',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': '你的User-Agent',
'Origin': 'http://www.hshfy.sh.cn',
'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 27%3B,
'Accept-Language': 'zh-CN,zh;q=0.9',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': '你的Cookie'
}
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,使用post方法请求网页数据。这里注意对返回的数据进行解码,编码为'gbk',否则返回的数据会乱码!此外,我还添加了异常处理优化,以防止意外发生。
def get_page(page):
n = 3
while True:
try:
sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
data = {
'yzm': 'yxAH',
'ft':'',
'ktrqks': '2020-05-22',
'ktrqjs': '2020-06-22',
'spc':'',
'yg':'',
'bg':'',
'ah':'',
'pagesnum': page
}
url = base_url + urlencode(data)
print(url)
try:
response = requests.request("POST",url, headers = headers)
#print(response)
if response.status_code == 200:
re = response.content.decode('gbk')
# print(re)
return re # 解析内容
except requests.ConnectionError as e:
print('Error', e.args) # 输出异常信息
except (TimeoutError, Exception):
n -= 1
if n == 0:
print('请求3次均失败,放弃此url请求,检查请求条件')
return
else:
print('请求失败,重新请求')
continue
构建parse_page函数,解析返回的网页数据,用Xpath提取所有字段内容,保存为csv格式。有人会问为什么J哥这么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我不能做一个普通的大法来安装x。J弟兄,我做不到。
def parse_page(html):
try:
parse = etree.HTML(html) # 解析网页
items = parse.xpath('//*[@id="report"]/tbody/tr')
for item in items[1:]:
item = {
'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
'c': ''.join(item.xpath('./td[3]/text()')).strip(),
'd': ''.join(item.xpath('./td[4]/text()')).strip(),
'e': ''.join(item.xpath('./td[5]/text()')).strip(),
'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
'h': ''.join(item.xpath('./td[8]/text()')).strip(),
'i': ''.join(item.xpath('./td[9]/text()')).strip()
}
#print(item)
try:
with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'为追加模式(添加)
# utf_8_sig格式导出csv不乱码
fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
writer = csv.DictWriter(fp,fieldnames)
writer.writerow(item)
except Exception:
print(traceback.print_exc()) #代替print e 来输出详细的异常信息
except Exception:
print(traceback.print_exc())
最后,遍历页数,调用函数。OK完成!
for page in range(1,5): #这里设置想要爬取的页数
html = get_page(page)
#print(html)
print("第" + str(page) + "页提取完成")
让我们看看最终的结果:
二
硒
有心学习的朋友可能还想看看Selenium如何爬取AJAX动态加载的网页。J哥自然会满足你的好奇心。于是我赶紧新建了一个py文件,准备趁势利用Selenium爬下这个网站。
首先,导入相关库。
from lxml import etree
import time
from selenium import webdriver
from selenium. webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
然后,使用 chromedriver 驱动程序打开这个 网站。
def main():
# 爬取首页url
url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
# 定义谷歌webdriver
driver = webdriver.Chrome('./chromedriver')
driver.maximize_window() # 将浏览器最大化
driver.get(url)
所以,我惊讶地发现这是错误的。有了六级英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器的版本不匹配,只支持79版本的浏览器。
J哥很郁闷,因为我之前从来没有遇到过Selenium for爬虫的这种问题。J哥不甘心,打开谷歌浏览器看了看版本号。
我失去了它!全部更新到81版!遇到这种情况,请好奇的朋友等J哥设置浏览器自动更新重新下载最新驱动,下次再来听Selenium爬虫,记得关注这个公众号,不要'错过了~
结语
综上所述,对于AJAX动态加载的网络爬虫,一般有两种方式:解析接口;硒。J哥推荐解析接口的方式。如果解析的是json数据,爬起来会更好。真的没有办法使用 Selenium。
参考链接:
阿贾克斯:;
ajax_json:;
例子:
python抓取动态网页(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-09 07:08
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜科谋数个单元直观的标注功能,可以非常快速的自动生成调试好的抓取规则。其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
Step 3:如下图所示,网页中的手机名称和价格被正确抓取
4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29: V2.1,增加Chapter 5: Source code download source,并替换github源码的URL 查看全部
python抓取动态网页(Python网络爬虫内容提取器)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜科谋数个单元直观的标注功能,可以非常快速的自动生成调试好的抓取规则。其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2,源码下载地址请参考文章末尾的GitHub),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码,足以看出Python的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
Step 3:如下图所示,网页中的手机名称和价格被正确抓取
4. 继续阅读
至此,我们通过两篇文章文章演示了如何爬取静态和动态网页内容,均使用xslt一次性从网页中提取需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。下一篇《1分钟快速生成网页内容提取的xslt》将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29: V2.1,增加Chapter 5: Source code download source,并替换github源码的URL
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-09 01:21
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i 查看全部
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i
python抓取动态网页(比如说我们要爬取上交所的浦发银行这支股票背后的公司信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-05 22:07
我们都知道,爬虫可以抓取很多数据。如果我们爬取一个简单的页面,就可以轻松实现。如果我们要爬取动态页面,我们应该怎么做?
比如我们要爬取东方财富网站的股票信息:
但是当我们查看源代码时,我们看不到任何关于股票信息的数据。可以看出这些股票数据是异步加载的。果断F12打开chrome开发者工具,在Network选项中勾选。如果没有,您可以使用 F5 刷新页面。出来。
QQ图片244.png
然后点击异步api,会打开一个新页面,出现如下数据:
var C1Cache={quotation:["0000011,上证指数,3166.98,170854125568,13.89,0.44%,876|201|246|142,1380|270|360|204","3990012,深证成指,10130.12,215605108736,74.55,0.74%,876|201|246|142,1380|270|360|204"]}
我以为是json数据,但是服务器发过来一个js变量,值和json数据差不多,这应该是为了开发方便,但是我们要json数据,所以需要过滤一下,split(" = ") 然后取右边的字符串,但是要注意这个右边不是json数据,注意json的key需要有双引号(在java和python中),可能在js中也可以,所以我们需要在java中进行替换,这是一个json字符串,然后转换成json对象,可以使用jackson的objectmapper,反正方法很多。然后我们可以将这些数据持久化到数据库中,这样我们就可以爬取一些动态页面。
但这里需要注意的是,有些网站不允许你跨域访问,即使你有对策通过伪装服务器来阻止你直接调用api,那么此时你需要使用另一种方法, webmagic selenium ,这个原理是先运行一个浏览器内核来加载页面,等到整个页面加载完毕,然后获取html代码,再进行处理。
比如我们要爬取浦发银行股票背后的公司信息,
当我们查看异步加载的api时,发现不允许你直接访问这个api,所以只能使用第二种方法。
以下是项目的依赖项:
compile 'us.codecraft:webmagic-core:0.5.3'
compile('us.codecraft:webmagic-extension:0.5.3')
compile 'org.seleniumhq.selenium:selenium-java:2.8.0'
compile group: 'us.codecraft', name: 'webmagic-selenium', version: '0.5.2'
源代码如下:
public class CompanyProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000)
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36");
public void process(Page page) {
WebDriver driver = new ChromeDriver();
driver.get("http://www.sse.com.cn/assortme ... 6quot;);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement webElement = driver.findElement(By.id("tableData_stockListCompany"));
// WebElement webElement = driver.findElement(By.xpath("//div[@class='table-responsive sse_table_T05']"));
String str = webElement.getAttribute("outerHTML");
System.out.println(str);
Html html = new Html(str);
System.out.println(html.xpath("//tbody/tr").all());
String companyCode = html.xpath("//tbody/tr[1]/td/text()").get();
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
String dateString = html.xpath("//tbody/tr[3]/td/text()").get().split("/")[0];
String stockCode = html.xpath("//tbody/tr[2]/td/text()").get().split("/")[0];
String name = html.xpath("//tbody/tr[5]/td/text()").get().split("/")[0];
String department = html.xpath("//tbody/tr[14]/td/text()").get().split("/")[0];
System.out.println(companyCode);
System.out.println(stockCode);
System.out.println(name);
System.out.println(department);
driver.close();
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CompanyProcessor())
.addUrl("http://www.sse.com.cn/assortme ... 6quot;)
.thread(5)
.run();
}
}
这里有一些webmagic的知识。不熟悉的可以看中文文档。因为这个爬虫框架是中国人写的,所以中文文档很详细。
注意这里的这行代码:
WebDriver driver = new ChromeDriver();
如果你想让代码成功运行,你需要下载一个chromedriver。如果你是windows,你可以去这个网站。虽然是 32 位,但也可以使用 64 位。如果不是或者你是其他操作系统,你可以去官方网站。
为什么不直接推荐去官网下载最新的呢?因为之前用过,所以我两台电脑上最新的windows系统都有问题。现在解压到C:\Windows\System32目录下,或者设置一个环境变量。
然后就可以运行了,然后就是提取一些数据或者url,就像处理静态页面一样。 查看全部
python抓取动态网页(比如说我们要爬取上交所的浦发银行这支股票背后的公司信息)
我们都知道,爬虫可以抓取很多数据。如果我们爬取一个简单的页面,就可以轻松实现。如果我们要爬取动态页面,我们应该怎么做?
比如我们要爬取东方财富网站的股票信息:
但是当我们查看源代码时,我们看不到任何关于股票信息的数据。可以看出这些股票数据是异步加载的。果断F12打开chrome开发者工具,在Network选项中勾选。如果没有,您可以使用 F5 刷新页面。出来。
QQ图片244.png
然后点击异步api,会打开一个新页面,出现如下数据:
var C1Cache={quotation:["0000011,上证指数,3166.98,170854125568,13.89,0.44%,876|201|246|142,1380|270|360|204","3990012,深证成指,10130.12,215605108736,74.55,0.74%,876|201|246|142,1380|270|360|204"]}
我以为是json数据,但是服务器发过来一个js变量,值和json数据差不多,这应该是为了开发方便,但是我们要json数据,所以需要过滤一下,split(" = ") 然后取右边的字符串,但是要注意这个右边不是json数据,注意json的key需要有双引号(在java和python中),可能在js中也可以,所以我们需要在java中进行替换,这是一个json字符串,然后转换成json对象,可以使用jackson的objectmapper,反正方法很多。然后我们可以将这些数据持久化到数据库中,这样我们就可以爬取一些动态页面。
但这里需要注意的是,有些网站不允许你跨域访问,即使你有对策通过伪装服务器来阻止你直接调用api,那么此时你需要使用另一种方法, webmagic selenium ,这个原理是先运行一个浏览器内核来加载页面,等到整个页面加载完毕,然后获取html代码,再进行处理。
比如我们要爬取浦发银行股票背后的公司信息,
当我们查看异步加载的api时,发现不允许你直接访问这个api,所以只能使用第二种方法。
以下是项目的依赖项:
compile 'us.codecraft:webmagic-core:0.5.3'
compile('us.codecraft:webmagic-extension:0.5.3')
compile 'org.seleniumhq.selenium:selenium-java:2.8.0'
compile group: 'us.codecraft', name: 'webmagic-selenium', version: '0.5.2'
源代码如下:
public class CompanyProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000)
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36");
public void process(Page page) {
WebDriver driver = new ChromeDriver();
driver.get("http://www.sse.com.cn/assortme ... 6quot;);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement webElement = driver.findElement(By.id("tableData_stockListCompany"));
// WebElement webElement = driver.findElement(By.xpath("//div[@class='table-responsive sse_table_T05']"));
String str = webElement.getAttribute("outerHTML");
System.out.println(str);
Html html = new Html(str);
System.out.println(html.xpath("//tbody/tr").all());
String companyCode = html.xpath("//tbody/tr[1]/td/text()").get();
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
String dateString = html.xpath("//tbody/tr[3]/td/text()").get().split("/")[0];
String stockCode = html.xpath("//tbody/tr[2]/td/text()").get().split("/")[0];
String name = html.xpath("//tbody/tr[5]/td/text()").get().split("/")[0];
String department = html.xpath("//tbody/tr[14]/td/text()").get().split("/")[0];
System.out.println(companyCode);
System.out.println(stockCode);
System.out.println(name);
System.out.println(department);
driver.close();
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CompanyProcessor())
.addUrl("http://www.sse.com.cn/assortme ... 6quot;)
.thread(5)
.run();
}
}
这里有一些webmagic的知识。不熟悉的可以看中文文档。因为这个爬虫框架是中国人写的,所以中文文档很详细。
注意这里的这行代码:
WebDriver driver = new ChromeDriver();
如果你想让代码成功运行,你需要下载一个chromedriver。如果你是windows,你可以去这个网站。虽然是 32 位,但也可以使用 64 位。如果不是或者你是其他操作系统,你可以去官方网站。
为什么不直接推荐去官网下载最新的呢?因为之前用过,所以我两台电脑上最新的windows系统都有问题。现在解压到C:\Windows\System32目录下,或者设置一个环境变量。
然后就可以运行了,然后就是提取一些数据或者url,就像处理静态页面一样。
python抓取动态网页(python自动化工具之pywinauto实例详解(一)数据提取及拆分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-03 07:01
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
所以我用 Python3 语法写了一个简单的 catch
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
于是写了一个使用Python3语法爬取网页图片的简单例子,希望对大家有所帮助,也希望大家批评指正。
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持染美科技。
上一篇:python自动化工具pywinauto实例详解 下一篇:python数据提取与拆分的实现代码 查看全部
python抓取动态网页(python自动化工具之pywinauto实例详解(一)数据提取及拆分)
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
所以我用 Python3 语法写了一个简单的 catch
现在网上有很多用python2写的爬虫抓取网页图片的例子,但是不适合新手(新手都用python3环境,不兼容python2),
于是写了一个使用Python3语法爬取网页图片的简单例子,希望对大家有所帮助,也希望大家批评指正。
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持染美科技。
上一篇:python自动化工具pywinauto实例详解 下一篇:python数据提取与拆分的实现代码
python抓取动态网页(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 04:14
缺点:
仅检索页面的静态内容
不能用于解析 HTML
无法处理用纯 JavaScript 制作的 网站
2.lxml
lxml 是一个高性能、快速、高生产力的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算抓取大型数据集时,它工作得很好。
在网页抓取中,lxml 经常与 Requests 结合使用,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python库的优缺点是什么?
优势:
比大多数解析器更快
轻的
使用元素树
Pythonic API
缺点:
不适用于设计不佳的 HTML
官方文档不太适合初学者
3.美汤
BeautifulSoup 可能是用于网络抓取的最广泛使用的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。还自动将传入文档转换为 Unicode,将传出文档自动转换为 UTF-8。
将“BeautifulSoup”与“Requests”相结合在业内非常普遍。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,Beautiful Soup 也可以与 lxml 等其他解析器结合使用。
但相应地,这种易用性也带来了很大的运行成本——它比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面了解一下 BeautifulSoup 库的优缺点。
优势:
需要几行代码
质量文件
易于初学者学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您不能轻易地从动态填充的 网站 中抓取数据。
有时发生这种情况的原因是页面上的数据是通过 JavaScript 加载的。简短的总结是,如果页面不是静态的,前面提到的 Python 库很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。
Selenium 最初是一个用于自动测试 Web 应用程序的 Python 库,一个用于呈现网页的 Web 驱动程序,这就是为什么 Selenium 可以在其他库无法运行 JavaScript 的地方工作:单击页面、填写表单、滚动页面等等.
这种在网页中运行 JavaScript 的能力使 Selenium 能够抓取动态填充的网页。但是这里有一个“缺陷”,它为每个页面加载和运行 JavaScript,使其速度较慢,不适合大型项目。
如果你不在乎时间和速度,那么 Selenium 绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动网页浏览器
可以在网页上执行任何操作,类似于人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. 爬虫
又到了介绍Python网页抓取库的BOSS——Scrapy!
Scrapy 不仅仅是一个库,它是由 Scrapinghub 联合创始人 Pablo Hoffman 和 Shane Evans 创建的一个完整的 Web 抓取框架,这是一个可以完成所有繁重工作的成熟的 Web 抓取解决方案。
Scrapy 提供的爬虫机器人可以抓取多个 网站 并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或作为 API。在几分钟内创建功能齐全的蜘蛛网,当然还可以使用 Scrapy 创建管道。
Scrapy 最好的地方在于它是异步的,这意味着可以同时发出多个 HTTP 请求,为我们节省了大量时间并提高了效率(这不就是我们为之奋斗的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。虽然 Scrapy 不能像 selenium 那样处理 JavaScript,但它可以与一个名为 Splash(一种轻量级 Web 浏览器)的库配对。借助 Splash,Scrapy 可以从动态 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他你用得好的库,欢迎留言~
原文链接:
分类:
技术要点:
相关文章: 查看全部
python抓取动态网页(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
缺点:
仅检索页面的静态内容
不能用于解析 HTML
无法处理用纯 JavaScript 制作的 网站
2.lxml
lxml 是一个高性能、快速、高生产力的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算抓取大型数据集时,它工作得很好。
在网页抓取中,lxml 经常与 Requests 结合使用,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python库的优缺点是什么?
优势:
比大多数解析器更快
轻的
使用元素树
Pythonic API
缺点:
不适用于设计不佳的 HTML
官方文档不太适合初学者
3.美汤
BeautifulSoup 可能是用于网络抓取的最广泛使用的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。还自动将传入文档转换为 Unicode,将传出文档自动转换为 UTF-8。
将“BeautifulSoup”与“Requests”相结合在业内非常普遍。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,Beautiful Soup 也可以与 lxml 等其他解析器结合使用。
但相应地,这种易用性也带来了很大的运行成本——它比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面了解一下 BeautifulSoup 库的优缺点。
优势:
需要几行代码
质量文件
易于初学者学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您不能轻易地从动态填充的 网站 中抓取数据。
有时发生这种情况的原因是页面上的数据是通过 JavaScript 加载的。简短的总结是,如果页面不是静态的,前面提到的 Python 库很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。
Selenium 最初是一个用于自动测试 Web 应用程序的 Python 库,一个用于呈现网页的 Web 驱动程序,这就是为什么 Selenium 可以在其他库无法运行 JavaScript 的地方工作:单击页面、填写表单、滚动页面等等.
这种在网页中运行 JavaScript 的能力使 Selenium 能够抓取动态填充的网页。但是这里有一个“缺陷”,它为每个页面加载和运行 JavaScript,使其速度较慢,不适合大型项目。
如果你不在乎时间和速度,那么 Selenium 绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动网页浏览器
可以在网页上执行任何操作,类似于人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. 爬虫
又到了介绍Python网页抓取库的BOSS——Scrapy!
Scrapy 不仅仅是一个库,它是由 Scrapinghub 联合创始人 Pablo Hoffman 和 Shane Evans 创建的一个完整的 Web 抓取框架,这是一个可以完成所有繁重工作的成熟的 Web 抓取解决方案。
Scrapy 提供的爬虫机器人可以抓取多个 网站 并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或作为 API。在几分钟内创建功能齐全的蜘蛛网,当然还可以使用 Scrapy 创建管道。
Scrapy 最好的地方在于它是异步的,这意味着可以同时发出多个 HTTP 请求,为我们节省了大量时间并提高了效率(这不就是我们为之奋斗的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。虽然 Scrapy 不能像 selenium 那样处理 JavaScript,但它可以与一个名为 Splash(一种轻量级 Web 浏览器)的库配对。借助 Splash,Scrapy 可以从动态 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他你用得好的库,欢迎留言~
原文链接:
分类:
技术要点:
相关文章:
python抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-01 14:13
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
<br />pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
<br />from selenium import webdriver<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
<br />from selenium import webdriver<br />from selenium.webdriver.common.keys import Keys<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com')<br />assert '百度' in browser.title<br />elem = browser.find_element_by_name('p') # Find the search box<br />elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键<br />browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
<br />import unittest<br />class BaiduTestCase(unittest.TestCase):<br /> def setUp(self):<br /> self.browser = webdriver.Firefox()<br /> self.addCleanup(self.browser.quit)<br /> def testPageTitle(self):<br /> self.browser.get('http://www.baidu.com')<br /> self.assertIn('百度', self.browser.title)<br />if __name__ == '__main__':<br /> unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
你可能感兴趣文章:python+jinja2实现接口数据批量生成工具Python的Flask框架自带模板引擎Jinja2 Python的Tornado框架教程配置Jinja2模板引擎的使用方法Python的Flask Jinja2模板引擎学习教程框架中python使用pyh生成html文档方法示例python解析html提取数据,生成word文档实例解析python使用HTMLTestRunner.py生成测试报告使用CasperJS在python中获取js渲染生成的html内容教程python使用jinja2模板生成html代码示例 查看全部
python抓取动态网页(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
<br />pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
<br />from selenium import webdriver<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
<br />from selenium import webdriver<br />from selenium.webdriver.common.keys import Keys<br />browser = webdriver.Firefox()<br />browser.get('http://www.baidu.com')<br />assert '百度' in browser.title<br />elem = browser.find_element_by_name('p') # Find the search box<br />elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键<br />browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
<br />import unittest<br />class BaiduTestCase(unittest.TestCase):<br /> def setUp(self):<br /> self.browser = webdriver.Firefox()<br /> self.addCleanup(self.browser.quit)<br /> def testPageTitle(self):<br /> self.browser.get('http://www.baidu.com')<br /> self.assertIn('百度', self.browser.title)<br />if __name__ == '__main__':<br /> unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
你可能感兴趣文章:python+jinja2实现接口数据批量生成工具Python的Flask框架自带模板引擎Jinja2 Python的Tornado框架教程配置Jinja2模板引擎的使用方法Python的Flask Jinja2模板引擎学习教程框架中python使用pyh生成html文档方法示例python解析html提取数据,生成word文档实例解析python使用HTMLTestRunner.py生成测试报告使用CasperJS在python中获取js渲染生成的html内容教程python使用jinja2模板生成html代码示例
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-31 16:26
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i 查看全部
python抓取动态网页(利用Selenium+Phantomjs动态获取网站数据信息信息的例子
)
刚开始学习爬虫,从网上找资料,写了一个使用Selenium+Phantomjs动态获取网站数据信息的例子。当然要先安装Selenium+Phantomjs,详情见
硒下载:
phantomjs使用参考:及官网:
源码如下:
<p># coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
import os
class Crawler:
def __init__(self, firstUrl = "https://list.jd.com/list.html?cat=9987,653,655",
nextUrl = "https://list.jd.com/list.html?cat=9987,653,655&page=%d&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main"):
self.firstUrl = firstUrl
self.nextUrl = nextUrl
def getDetails(self,pageIndex,id = "plist"):
'''
获取详细信息
:param pageIndex: 页索引
:param id: 标签对应的id
:return:
'''
element = self.driver.find_element_by_id(id)
txt = element.text.encode('utf8')
items = txt.split('¥')
for item in items:
if len(item) > 0:
details = item.split('\n')
print '¥' + item
# print '单价:¥'+ details[0]
# print '品牌:' + details[1]
# print '参与评价:' + details[2]
# print '店铺:' + details[3]
print ' '
print '第 ' + str(pageIndex) + '页'
def CatchData(self,id = "plist",totalpageCountLable = "//span[@class='p-skip']/em/b"):
'''
抓取数据
:param id:获取数据的标签id
:param totalpageCountLable:获取总页数标记
:return:
'''
start = time.clock()
self.driver = webdriver.PhantomJS()
wait = ui.WebDriverWait(self.driver, 10)
self.driver.get(self.firstUrl)
#在等待页面元素加载全部完成后才进行下一步操作
wait.until(lambda driver: self.driver.find_element_by_xpath(totalpageCountLable))
# 获取总页数
pcount = self.driver.find_element_by_xpath(totalpageCountLable)
txt = pcount.text.encode('utf8')
print '总页数:' + txt
print '第1页'
print ' '
pageNum = int(txt)
pageNum = 3 # 只执行三次
i = 2
while (i
python抓取动态网页(如何爬取动态网页动态加载出来的我们可以直接使用一些开发者工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-28 07:27
好久没有更新Python相关的内容了。本专题主要讲Python在爬虫中的应用,包括爬取和处理。
第二节,我们介绍如何爬取动态网页
动态网页是指通过js动态加载的网页内容
我们可以直接使用一些开发者工具来查看
这里我使用谷歌浏览器的开发者工具
开发环境
操作系统:windows 10
Python 版本:3.6
爬网模块:请求
解析网页模块:json
模块安装
pip3 安装请求
网页分析
我们使用豆瓣电影页面开始分析
#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容。
当我们点击加载更多时,我们可以通过开发者工具的Network选项中的XHR来获取动态加载的js
打开获取的连接
%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式
这里我们构建一个连接,从第一部电影开始并显示 100
%E7%83%AD%E9%97%A8&sort=推荐&page_limit=100&page_start=0
对于JSON解析,我们可以先用一个网上的网站来查看
在这里可以看到收录以下信息
评分 电影名称 电影豆瓣链接 封面地址 代码介绍
这是一行一行的代码
1. 导入相关模块
导入请求导入 json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)content=r.content
3. 使用 json.load 将 json 格式转换为 python 字典格式
这时候就可以使用字典的相关方法来处理网页了。
结果=json.loads(content)tvs=result['subjects']
4. 获取相关信息并存入字典
结果
我们可以选择将获取的数据放入数据库
源位置 查看全部
python抓取动态网页(如何爬取动态网页动态加载出来的我们可以直接使用一些开发者工具)
好久没有更新Python相关的内容了。本专题主要讲Python在爬虫中的应用,包括爬取和处理。
第二节,我们介绍如何爬取动态网页
动态网页是指通过js动态加载的网页内容
我们可以直接使用一些开发者工具来查看
这里我使用谷歌浏览器的开发者工具
开发环境
操作系统:windows 10
Python 版本:3.6
爬网模块:请求
解析网页模块:json
模块安装
pip3 安装请求
网页分析
我们使用豆瓣电影页面开始分析
#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
因为是动态加载的,所以我们无法通过get方法直接获取网页的内容。
当我们点击加载更多时,我们可以通过开发者工具的Network选项中的XHR来获取动态加载的js
打开获取的连接
%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20
我们可以找到连接规律,即page_limit和page_start
可以看到打开的内容是json格式
这里我们构建一个连接,从第一部电影开始并显示 100
%E7%83%AD%E9%97%A8&sort=推荐&page_limit=100&page_start=0
对于JSON解析,我们可以先用一个网上的网站来查看
在这里可以看到收录以下信息
评分 电影名称 电影豆瓣链接 封面地址 代码介绍
这是一行一行的代码
1. 导入相关模块
导入请求导入 json
2. 使用请求模块打开并获取网页内容
r = requests.get(url,verify=False)content=r.content
3. 使用 json.load 将 json 格式转换为 python 字典格式
这时候就可以使用字典的相关方法来处理网页了。
结果=json.loads(content)tvs=result['subjects']
4. 获取相关信息并存入字典
结果
我们可以选择将获取的数据放入数据库
源位置
python抓取动态网页(Python爬虫[动态网页数据]用法教程综述(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-28 05:10
Python爬虫4.2——ajax【动态网页数据】使用教程
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,尤其是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“长得好看的程序员是怎样一种体验”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
python抓取动态网页(Python爬虫[动态网页数据]用法教程综述(2))
Python爬虫4.2——ajax【动态网页数据】使用教程
概述
本系列文档用于提供Python爬虫技术学习的简单教程。在巩固你的技术知识的同时,如果你不小心对你有用,那就更好了。
Python 版本是 3.7.4
有时当我们抓取带有请求的页面时,我们得到的结果可能与我们在浏览器中看到的不同。正常显示的页面数据在浏览器中是可以看到的,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
因此,在本文中,我们主要了解Ajax是什么以及如何分析和爬取Ajax请求。
AJAX简介什么是AJAX
AJAX(异步 JavaScript 和 XML)异步 JavaScript 和 XML。通过在后台交换与服务器协商的数据,Ajax 实现了网页的异步更新,这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。传统网页(不使用Ajax)如果内容需要更新,必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。其实数据交互的限制基本上就是用JSON,Ajax加载的数据,即使用JS渲染数据到浏览器,查看网页源码的时候还是看不到加载的数据通过 Ajax,您只能看到 Ajax 加载的数据。由 url 加载的 HTML 代码。
示例说明
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如微博、今日头条等,有的是根据鼠标下拉自动加载的。这些其实就是Ajax加载的过程。我们可以看到页面并没有完全刷新,也就是说页面的链接没有变化,但是网页中有新的内容,也就是通过Ajax获取新数据并渲染的过程。
请求分析
使用 Chrome 开发者工具的过滤功能过滤掉所有的 Ajax 请求,这里不再详述。
也可以使用 Fiddler 数据包捕获工具进行数据包捕获分析。Fiddler工具的使用方法这里不做说明。您可以在线搜索和查看。
Ajax 响应结果一般为 json 数据格式。
获取方式直接分析Ajax使用的接口,然后通过代码请求该接口获取数据(下面的例子就是这样一个通用的)。使用 Selenium + Chromedriver 模拟浏览器行为获取数据(继续关注文章)。该方法的优点和缺点
分析界面
可以直接请求数据,不需要做一些解析工作,代码量小,性能高。
解析接口比较复杂,尤其是一些被js搞糊涂的接口,必须对js有一定的了解,很容易被爬虫发现。
硒
直接模拟浏览器的行为,浏览器能请求的也可以用selenium来请求,爬虫更稳定。
大量代码和低性能。
示例说明
让我们举个例子,爬取“长得好看的程序员是怎样一种体验”这个问题的所有答案。在问题 知乎 下。示例代码如下:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
python抓取动态网页(终于我还是要自己动手从网页爬取数据了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-27 18:22
最后我还是得自己从网上抓取数据。
R的rvest包是初学者,python基本不是。代码仅供参考,爬取数据时不要问我,我应该无法回答。
rvest包抓取静态网页数据
使用的基本步骤:首先使用read_html()函数读取一个html页面,然后通过CSS或Xpath获取需要的节点并使用html_nodes()函数读取节点内容,最后使用html_text()函数在节点中获取所需的文本。
获取xpath的步骤如图1所示。
<p># install packages
install.packages("tidyverse")
install.packages("rvest")
library(tidyverse)
library(rvest)
# 以在NCBI PubMed搜索非小细胞肺癌相关文献为例
# 1、读取一个html页面
> nsclc = read_html("https://pubmed.ncbi.nlm.nih.gov/?term=NSCLC")
> nsclc
{html_document}
[1] article = nsclc %>% html_nodes(xpath = "//*[@id='search-results']/section/div[1]/div/article[1]/div[2]/div[1]/a")
> article
{xml_nodeset (1)}
[1] 查看全部
python抓取动态网页(终于我还是要自己动手从网页爬取数据了(组图))
最后我还是得自己从网上抓取数据。
R的rvest包是初学者,python基本不是。代码仅供参考,爬取数据时不要问我,我应该无法回答。
rvest包抓取静态网页数据
使用的基本步骤:首先使用read_html()函数读取一个html页面,然后通过CSS或Xpath获取需要的节点并使用html_nodes()函数读取节点内容,最后使用html_text()函数在节点中获取所需的文本。
获取xpath的步骤如图1所示。
<p># install packages
install.packages("tidyverse")
install.packages("rvest")
library(tidyverse)
library(rvest)
# 以在NCBI PubMed搜索非小细胞肺癌相关文献为例
# 1、读取一个html页面
> nsclc = read_html("https://pubmed.ncbi.nlm.nih.gov/?term=NSCLC";)
> nsclc
{html_document}
[1] article = nsclc %>% html_nodes(xpath = "//*[@id='search-results']/section/div[1]/div/article[1]/div[2]/div[1]/a")
> article
{xml_nodeset (1)}
[1]

