
python抓取动态网页
python抓取动态网页(如何判断一个链接下的文章是不是优质需要一个很复杂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-15 08:30
我一直想做一个平台,可以帮我过滤掉高质量的文章和博客。我把它命名为Moven。. 其实施过程分为三个阶段:
1. Downloader:下载指定的url,将获取到的内容传递给Analyser——这是最简单的启动方式
2. 分析器:使用正则表达式或者XPath或者BeautifulSoup/lxml对接收到的内容进行过滤和简化——这部分不是太难
3.智能爬虫:爬取高质量的文章链接——这部分是最难的:
基于Scrapy Framework可以快速搭建爬虫
但是判断一个链接下的文章是否优质需要一个非常复杂的算法
最近开始做Downloader和Analyser:我最近搭建了一个l2z的故事,还有一个Z Life和Z Life@Sina以及她的博客作为Downloader和Analyser的练习。我写这个东西是为了监控上面的。四个站点并将它们的内容同步到此站点:
应用程序的特点
除了顶部的黑色导航栏和右侧的关于本站部分外,本站所有其他内容均自动从其他站点获取
原则上,你可以在这个东西上添加任何博客或网站地址。. . 当然因为这是L2Z Story..所以里面只有收录四个站点
特点是:只要站主不停止更新,这东西就会一直存在——这就是优采云的力量
值得一提的是,Content菜单是在客户端使用JavaScript自动生成的——这样可以节省服务器上的资源消耗
这里我们使用html全页抓取,所以对于那些feed没有全文输出的网站,这个app可以抓取它想要隐藏的文字
因为程序会自动跳转到一个没有全文输出的页面去抓取文章的所有列表、作者信息、更新时间以及文章的全文,所以加载时间会比较长。. 所以打开的时候请耐心等待。. . 数据存储部分将在下一步中添加,因此会很快。.
技术准备
前端:
1. CSS 信奉简单原则。Twitter 的 bootstrap.css 满足了我的大部分需求。我真的很喜欢它的网格系统。
2. 在 Javascript 上,我当然选择了 jQuery。自从我在我的第一个小项目中开始使用 jQuery 以来,我就爱上了它。动态目录系统由jQuery快速生成。
为了配合bootstrap.css,还用到了bootstrap-dropdown.js
服务器:
此应用程序有两个版本:
一个运行在我的Apache上,但是因为我的网络是ADSL,所以ip会一直变化。基本上,它只用于我所谓的局域网中的自检。. 这个版本是纯Django的
另一个运行在Google App Engine上的地址是当我将Django配置为GAE时,我花了很多精力来设置框架。
有关详细信息,请参阅:将 Django 与 Google App Engine GAE 结合使用:l2Z 故事设置-步骤 1
后台:
主要语言是Python--不解释,认识Python后就没离开过
使用的主要模块有
1. BeautifulSoup.py 用于html解析--不解释
2. feedparser.py 是用来解析feed xml的——网上很多人说GAE不支持feedparser..给你答案了。. 能。. 我在这里花了很长时间才弄清楚发生了什么。. 简而言之,就是:能用!但是feedparser.py这个文件必须和app.yaml放在同一个目录下,不然网上有人会说feedparser无法导入。
数据库:
Google Datastore:下一步,这个程序会每30分钟唤醒一次,检查每个站点是否已经更新,并抓取更新后的文章并存储在Google的Datastore中
应用配置
按照谷歌的规则,配置文件app.yaml如下:
这里主要是定义一些静态目录——css和javascript的位置
复制代码代码如下:
应用程序:l2zstory
版本:1
运行时:python
api_version: 1
处理程序:
-网址:/图像
static_dir: l2zstory/templates/template2/images
-网址:/css
static_dir: l2zstory/templates/template2/css
-网址:/js
静态目录:l2zstory/templates/template2/js
-网址:/js
静态目录:l2zstory/templates/template2/js
-url: /.*
脚本:main.py
以上就是使用Django和GAE Python在后台爬取多个网站页面全文的详细内容。更多详情请关注html中文网站其他相关文章! 查看全部
python抓取动态网页(如何判断一个链接下的文章是不是优质需要一个很复杂)
我一直想做一个平台,可以帮我过滤掉高质量的文章和博客。我把它命名为Moven。. 其实施过程分为三个阶段:
1. Downloader:下载指定的url,将获取到的内容传递给Analyser——这是最简单的启动方式
2. 分析器:使用正则表达式或者XPath或者BeautifulSoup/lxml对接收到的内容进行过滤和简化——这部分不是太难
3.智能爬虫:爬取高质量的文章链接——这部分是最难的:
基于Scrapy Framework可以快速搭建爬虫
但是判断一个链接下的文章是否优质需要一个非常复杂的算法
最近开始做Downloader和Analyser:我最近搭建了一个l2z的故事,还有一个Z Life和Z Life@Sina以及她的博客作为Downloader和Analyser的练习。我写这个东西是为了监控上面的。四个站点并将它们的内容同步到此站点:

应用程序的特点
除了顶部的黑色导航栏和右侧的关于本站部分外,本站所有其他内容均自动从其他站点获取
原则上,你可以在这个东西上添加任何博客或网站地址。. . 当然因为这是L2Z Story..所以里面只有收录四个站点
特点是:只要站主不停止更新,这东西就会一直存在——这就是优采云的力量
值得一提的是,Content菜单是在客户端使用JavaScript自动生成的——这样可以节省服务器上的资源消耗

这里我们使用html全页抓取,所以对于那些feed没有全文输出的网站,这个app可以抓取它想要隐藏的文字
因为程序会自动跳转到一个没有全文输出的页面去抓取文章的所有列表、作者信息、更新时间以及文章的全文,所以加载时间会比较长。. 所以打开的时候请耐心等待。. . 数据存储部分将在下一步中添加,因此会很快。.
技术准备
前端:
1. CSS 信奉简单原则。Twitter 的 bootstrap.css 满足了我的大部分需求。我真的很喜欢它的网格系统。
2. 在 Javascript 上,我当然选择了 jQuery。自从我在我的第一个小项目中开始使用 jQuery 以来,我就爱上了它。动态目录系统由jQuery快速生成。
为了配合bootstrap.css,还用到了bootstrap-dropdown.js
服务器:
此应用程序有两个版本:
一个运行在我的Apache上,但是因为我的网络是ADSL,所以ip会一直变化。基本上,它只用于我所谓的局域网中的自检。. 这个版本是纯Django的
另一个运行在Google App Engine上的地址是当我将Django配置为GAE时,我花了很多精力来设置框架。
有关详细信息,请参阅:将 Django 与 Google App Engine GAE 结合使用:l2Z 故事设置-步骤 1
后台:
主要语言是Python--不解释,认识Python后就没离开过
使用的主要模块有
1. BeautifulSoup.py 用于html解析--不解释
2. feedparser.py 是用来解析feed xml的——网上很多人说GAE不支持feedparser..给你答案了。. 能。. 我在这里花了很长时间才弄清楚发生了什么。. 简而言之,就是:能用!但是feedparser.py这个文件必须和app.yaml放在同一个目录下,不然网上有人会说feedparser无法导入。
数据库:
Google Datastore:下一步,这个程序会每30分钟唤醒一次,检查每个站点是否已经更新,并抓取更新后的文章并存储在Google的Datastore中
应用配置
按照谷歌的规则,配置文件app.yaml如下:
这里主要是定义一些静态目录——css和javascript的位置
复制代码代码如下:
应用程序:l2zstory
版本:1
运行时:python
api_version: 1
处理程序:
-网址:/图像
static_dir: l2zstory/templates/template2/images
-网址:/css
static_dir: l2zstory/templates/template2/css
-网址:/js
静态目录:l2zstory/templates/template2/js
-网址:/js
静态目录:l2zstory/templates/template2/js
-url: /.*
脚本:main.py
以上就是使用Django和GAE Python在后台爬取多个网站页面全文的详细内容。更多详情请关注html中文网站其他相关文章!
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-15 05:31
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是linux。比较理想的方式是无接口爬取,所以用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。 查看全部
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是linux。比较理想的方式是无接口爬取,所以用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-15 05:28
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python实现抓取< @网站,模拟登录,抓取动态网页。其中主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,欢迎您在讨论组发帖讨论:阅读 HTML 在线下载( 7zip 压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revisions1.
前提是讨论如何使用Python来实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解如何使用Python实现网站@ > 爬取,模拟登录,如何使用Python爬取动态网页网站 爬取,模拟登录,爬取动态网页相关的老帖子【教程】爬取网页,从网页中提取需要的信息。其实对于urllib这样的库,我们已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。例如,可以直接从以下代码中获取网页地址,网页源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要是两个函数:getUrlResponse 和 getUrlRespHtml TODO:添加两个函数从 crifanLib 解释 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括 downloadFile 等函数其实主要分为两个方面:关于一只手,就是抓取网站的内容,涉及到网络处理相关的模块。另一方面就是如何解析抓取到的内容,也就是在HTML解析等相关的模块下,我们来讲解一下这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能.
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理和对应是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python中的HTMl解析相关老帖子BeautifulSoup模块介绍【已解决】Python中json.loads解析收录\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析 网站 的捕获内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc 查看全部
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python实现抓取< @网站,模拟登录,抓取动态网页。其中主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,欢迎您在讨论组发帖讨论:阅读 HTML 在线下载( 7zip 压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revisions1.
前提是讨论如何使用Python来实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解如何使用Python实现网站@ > 爬取,模拟登录,如何使用Python爬取动态网页网站 爬取,模拟登录,爬取动态网页相关的老帖子【教程】爬取网页,从网页中提取需要的信息。其实对于urllib这样的库,我们已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。例如,可以直接从以下代码中获取网页地址,网页源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要是两个函数:getUrlResponse 和 getUrlRespHtml TODO:添加两个函数从 crifanLib 解释 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括 downloadFile 等函数其实主要分为两个方面:关于一只手,就是抓取网站的内容,涉及到网络处理相关的模块。另一方面就是如何解析抓取到的内容,也就是在HTML解析等相关的模块下,我们来讲解一下这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能.
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理和对应是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python中的HTMl解析相关老帖子BeautifulSoup模块介绍【已解决】Python中json.loads解析收录\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析 网站 的捕获内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc
python抓取动态网页(python怎样爬取动态网站的相关内容吗,爱喝马黛茶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-15 03:16
想知道python是如何抓取动态网站内容的吗?爱喝马黛茶的Anthony,为大家详细讲解python如何爬取动态网站相关知识和一些代码示例。欢迎阅读并指正,先画重点:python,动态网站,一起学习。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
相关文章 查看全部
python抓取动态网页(python怎样爬取动态网站的相关内容吗,爱喝马黛茶)
想知道python是如何抓取动态网站内容的吗?爱喝马黛茶的Anthony,为大家详细讲解python如何爬取动态网站相关知识和一些代码示例。欢迎阅读并指正,先画重点:python,动态网站,一起学习。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
相关文章
python抓取动态网页(python爬虫遇到ajax动态页面怎么办?直接指向当前目录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-15 03:14
一般情况下,python爬虫遇到ajax动态页面时,通常会直接分析模拟ajax请求获取数据。但是今天遇到了一个网站,因为某些原因没有公开网址。点击搜索按钮后,先跳到a页,然后从a页跳到b页,再从b页跳回a页。这两个跳转完成后,ajax提交给a页面的请求就会返回结果。
我也怀疑是cookie或者refenen的问题,结果证明不是这个原因。即使你伪造请求头后访问页面a,返回的也不是真正的结果页面,而是一段跳转到页面b的js代码。
既然你不知道网站在跳跃过程中做了什么,那我们就直接上大杀器吧。
phantomjs 可以简单理解为一个js解释器,不用说selenium,用pip安装就行了。
从(当然也可以自己下载源码)下载编译好的包,解压后的bin目录就是我们需要的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
if __name__ == "__main__":
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.resourceTimeout"] = 5
dcap["phantomjs.page.settings.loadImages"] = False
# 伪造ua信息
dcap["phantomjs.page.settings.userAgent"] = ("myua")
# 添加头文件
# dcap["phantomjs.page.customHeaders.Referer"] = (
# "https://www.google.com/"
#)
# 代理
service_args = [
'--proxy=127.0.0.1:8080',
#'--proxy-type=http',
#'--proxy-type=socks5',
#'--proxy-auth=username:password'
]
driver = webdriver.PhantomJS(
executable_path='./phantomjs',
service_args=service_args,
desired_capabilities=dcap
)
driver.get("http://www.xxx.cn/")
driver.find_element_by_id('kw').send_keys("xxx") #模仿填写搜索内容
driver.find_element_by_id("btn_ci").click() #模仿点击搜索按钮
time.sleep(7)#等待页面加载
page = driver.page_source
open("res.html","w").write(page)
driver.quit()
其中,我的源代码直接放在bin目录下,所以executable_path直接指向当前目录。 Find_element_by_id 查看目标网站源码即可看到,睡眠时间也应根据实际情况进行修改。 Driver.implicitly_wait(30)这里也可以用,但是这个网站的data id是随机生成的,所以我直接用sleep。
参考网站: 查看全部
python抓取动态网页(python爬虫遇到ajax动态页面怎么办?直接指向当前目录?)
一般情况下,python爬虫遇到ajax动态页面时,通常会直接分析模拟ajax请求获取数据。但是今天遇到了一个网站,因为某些原因没有公开网址。点击搜索按钮后,先跳到a页,然后从a页跳到b页,再从b页跳回a页。这两个跳转完成后,ajax提交给a页面的请求就会返回结果。
我也怀疑是cookie或者refenen的问题,结果证明不是这个原因。即使你伪造请求头后访问页面a,返回的也不是真正的结果页面,而是一段跳转到页面b的js代码。
既然你不知道网站在跳跃过程中做了什么,那我们就直接上大杀器吧。
phantomjs 可以简单理解为一个js解释器,不用说selenium,用pip安装就行了。
从(当然也可以自己下载源码)下载编译好的包,解压后的bin目录就是我们需要的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
if __name__ == "__main__":
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.resourceTimeout"] = 5
dcap["phantomjs.page.settings.loadImages"] = False
# 伪造ua信息
dcap["phantomjs.page.settings.userAgent"] = ("myua")
# 添加头文件
# dcap["phantomjs.page.customHeaders.Referer"] = (
# "https://www.google.com/"
#)
# 代理
service_args = [
'--proxy=127.0.0.1:8080',
#'--proxy-type=http',
#'--proxy-type=socks5',
#'--proxy-auth=username:password'
]
driver = webdriver.PhantomJS(
executable_path='./phantomjs',
service_args=service_args,
desired_capabilities=dcap
)
driver.get("http://www.xxx.cn/";)
driver.find_element_by_id('kw').send_keys("xxx") #模仿填写搜索内容
driver.find_element_by_id("btn_ci").click() #模仿点击搜索按钮
time.sleep(7)#等待页面加载
page = driver.page_source
open("res.html","w").write(page)
driver.quit()
其中,我的源代码直接放在bin目录下,所以executable_path直接指向当前目录。 Find_element_by_id 查看目标网站源码即可看到,睡眠时间也应根据实际情况进行修改。 Driver.implicitly_wait(30)这里也可以用,但是这个网站的data id是随机生成的,所以我直接用sleep。
参考网站:
python抓取动态网页(Python中有之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-14 22:36
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
最简单的想法之一可以动态分析页面信息。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块就安装好了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com")
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。 查看全部
python抓取动态网页(Python中有之前)
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
最简单的想法之一可以动态分析页面信息。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块就安装好了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com";)
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。
python抓取动态网页( 安东尼在本篇内容里小编的相关知识点内容(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-14 20:33
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章的文章就介绍到这里了,更多相关python如何爬取动态网站请搜索脚本之家@之前的文章@k7 >或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
python抓取动态网页(
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章的文章就介绍到这里了,更多相关python如何爬取动态网站请搜索脚本之家@之前的文章@k7 >或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
python抓取动态网页(:正则抓取动态网页,抓取网页最基本的知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-14 17:02
python抓取动态网页,抓取动态网页最基本的知识是获取当前页面的源代码,首先要获取的是动态网页的html代码,然后用正则表达式模拟抓取网页。一、html文件的获取。1.获取div{position:absolute;//不发生改变的属性}2.获取top1{position:absolute;//不发生改变的属性}3.获取top2{position:absolute;//不发生改变的属性}4.获取top3{position:absolute;//不发生改变的属性}5.获取top4{position:absolute;//不发生改变的属性}6.获取img{position:absolute;//不发生改变的属性}7.获取input{position:absolute;//不发生改变的属性}8.获取文字内容{position:absolute;//不发生改变的属性}9.获取text{position:absolute;//不发生改变的属性}10.获取目录{position:absolute;//不发生改变的属性}二、正则表达式的使用。
1.mysql查询中正则表达式的应用。2.正则表达式的使用:使用mysql查询中正则表达式的应用。3.正则表达式相关参数例题如下。1.关键字匹配任意网页中定义的一个或多个关键字,也可以匹配可选字符。html中的任意定义的任一关键字称为keyword(关键字)。常用的关键字有:标签keyword:class,id等p标签keyword:href,para,div等2.范围匹配任意网页定义的一个或多个选择表达式在正则表达式中嵌入选择表达式实际上是定义这样一个有限选择表达式(只有1-n个选择,且是给定正则表达式的子集):标准的google查询:googlesearchhttp://[网站]3.分组匹配选择一组关键字,也可以是选择多组关键字。
常用的有:[网站]class,id,div,p标签中可以匹配多个选择表达式,每组均有一个选择表达式。网站查询为[class]:class,id,div4.对比匹配对比匹配一组关键字,通常都匹配多个关键字。id和id定义的不同关键字匹配到同一网页定义的相同字符。常用的有:p,h1,text,relu中id和id定义的不同关键字匹配到同一网页(三个连续的相同字符串)。
常用的有:string,name,lastlength,total,register,regex5.字符串匹配出classkeyword:标签名,idid:identitylefttext:内容,短网址,http/1.1内容复制为带空格的python字符串:class,id,idx,div,form,text5.shell切片shell切片就是在正则表达式中找值,从1~n数字填充全部的选择表达式中剩余空间shell切片一般是以1作为切分,也可以用%s来切分所有的选择表。 查看全部
python抓取动态网页(:正则抓取动态网页,抓取网页最基本的知识)
python抓取动态网页,抓取动态网页最基本的知识是获取当前页面的源代码,首先要获取的是动态网页的html代码,然后用正则表达式模拟抓取网页。一、html文件的获取。1.获取div{position:absolute;//不发生改变的属性}2.获取top1{position:absolute;//不发生改变的属性}3.获取top2{position:absolute;//不发生改变的属性}4.获取top3{position:absolute;//不发生改变的属性}5.获取top4{position:absolute;//不发生改变的属性}6.获取img{position:absolute;//不发生改变的属性}7.获取input{position:absolute;//不发生改变的属性}8.获取文字内容{position:absolute;//不发生改变的属性}9.获取text{position:absolute;//不发生改变的属性}10.获取目录{position:absolute;//不发生改变的属性}二、正则表达式的使用。
1.mysql查询中正则表达式的应用。2.正则表达式的使用:使用mysql查询中正则表达式的应用。3.正则表达式相关参数例题如下。1.关键字匹配任意网页中定义的一个或多个关键字,也可以匹配可选字符。html中的任意定义的任一关键字称为keyword(关键字)。常用的关键字有:标签keyword:class,id等p标签keyword:href,para,div等2.范围匹配任意网页定义的一个或多个选择表达式在正则表达式中嵌入选择表达式实际上是定义这样一个有限选择表达式(只有1-n个选择,且是给定正则表达式的子集):标准的google查询:googlesearchhttp://[网站]3.分组匹配选择一组关键字,也可以是选择多组关键字。
常用的有:[网站]class,id,div,p标签中可以匹配多个选择表达式,每组均有一个选择表达式。网站查询为[class]:class,id,div4.对比匹配对比匹配一组关键字,通常都匹配多个关键字。id和id定义的不同关键字匹配到同一网页定义的相同字符。常用的有:p,h1,text,relu中id和id定义的不同关键字匹配到同一网页(三个连续的相同字符串)。
常用的有:string,name,lastlength,total,register,regex5.字符串匹配出classkeyword:标签名,idid:identitylefttext:内容,短网址,http/1.1内容复制为带空格的python字符串:class,id,idx,div,form,text5.shell切片shell切片就是在正则表达式中找值,从1~n数字填充全部的选择表达式中剩余空间shell切片一般是以1作为切分,也可以用%s来切分所有的选择表。
python抓取动态网页(1.模拟用户向指定网站发送请求需要下载(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-13 16:15
)
1.模拟用户向指定的网站发送请求
需要下载requests模块,模拟用户向网站发送请求,在终端输入如下命令:
pip install requests
1> 了解网页的结构
学习网页基础知识(通常由HTML(基本网页骨架)、CSS(页面样式)、JS(与用户动态交互)三部分组成)
2> 了解爬虫
网络爬虫(也称为网络蜘蛛)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗的讲就是通过程序获取网页上你想要的数据,也就是自动抓取数据
3>了解防爬
搜索引擎可以使用爬虫来抓取网页信息,进行数据分析等,但是网站中的一些网页信息是不想被抓取的。涉及到反爬虫技术。
反爬虫技术如下:
1. 通过user-Agent控制访问(user-agent使服务器能够识别用户的操作系统和版本,cpu类型,浏览器类型和版本,有的网站会设置user-agent列表范围,范围内可以正常访问),2.受IP限制,3.设置请求间隔,4.自动化测试工具,5.参数通过加密,6.@ > 使用robots.txt 限制爬虫等。
2.分析网页数据
requests库已经可以抓取网页的源代码了,接下来我们需要从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库功能更强大,速度更快,所以我个人建议安装 lxml 库。
pip install bs4
pip install lxml
3.代码部分
1> 抓取图片网站的具体代码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
urllist = []
for i in data:
urllist.append(i.get("data-src"))
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
sp = spider("https://wallhaven.cc/search%3F ... 6quot;)
sp.get()
2> 详细代码
封装了代码,方便批量抓取。首先,导入两个包:requests 和 BeautifulSoup。Requests 是模拟用户向浏览器发送请求,而 BeautifulSoup 是抓取网页中的数据。
url 是目标 URL:
设置请求头:
在请求标头中找到用户代理并复制和粘贴
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
发送请求获取响应数据:(这里html为HTML文本数据)
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
通过BeautifulSoup解析数据:(BeautifulSoup的第一个参数是要解析的数据,第二个参数是解析的方式)
# 解析数据
info = BeautifulSoup(html, "lxml")
使用select选择器定位数据(我们需要图片的url来抓取图片,所以我们需要定位到url)
复制选择器所在的位置:
复制选择器得到:
#thumbs > section > ul > li:nth-child(1) > figure > img
但这只是一张图片,我们要的是当前页面的所有图片,所以这里需要改一下(删除li::后的第n个子(1)):
#thumbs > section > ul > li > figure > img
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
数据输出的结构如下:
得到图片地址后:新建一个列表,把所有的URL都加入列表中
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("data-src"))
名单如下:
再次发送请求,通过解析后的url获取图片。图片名称是通过将url地址字符串分割成片的方式分配给名称,最后以二进制方式写入指定目录。
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
查看结果:
批量抓取另一张网站图片的源码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#main > div.slist > ul > li > a > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("src"))
print(urllist)
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
# name = pictureurl.split("/")[-1]
response = requests.get(url="https://pic.netbian.com"+pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
global number
with open("D:\spiderPicture\pic\%d.jpg" % number, "wb") as f:
f.write(response.content)
number += 1
i = 3
number = 1
while 1:
url = "https://pic.netbian.com/4kmein ... B%25i
sp = spider(url)
sp.get()
i += 1 查看全部
python抓取动态网页(1.模拟用户向指定网站发送请求需要下载(图)
)
1.模拟用户向指定的网站发送请求
需要下载requests模块,模拟用户向网站发送请求,在终端输入如下命令:
pip install requests
1> 了解网页的结构
学习网页基础知识(通常由HTML(基本网页骨架)、CSS(页面样式)、JS(与用户动态交互)三部分组成)
2> 了解爬虫
网络爬虫(也称为网络蜘蛛)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗的讲就是通过程序获取网页上你想要的数据,也就是自动抓取数据
3>了解防爬
搜索引擎可以使用爬虫来抓取网页信息,进行数据分析等,但是网站中的一些网页信息是不想被抓取的。涉及到反爬虫技术。
反爬虫技术如下:
1. 通过user-Agent控制访问(user-agent使服务器能够识别用户的操作系统和版本,cpu类型,浏览器类型和版本,有的网站会设置user-agent列表范围,范围内可以正常访问),2.受IP限制,3.设置请求间隔,4.自动化测试工具,5.参数通过加密,6.@ > 使用robots.txt 限制爬虫等。
2.分析网页数据
requests库已经可以抓取网页的源代码了,接下来我们需要从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库功能更强大,速度更快,所以我个人建议安装 lxml 库。
pip install bs4
pip install lxml
3.代码部分
1> 抓取图片网站的具体代码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
urllist = []
for i in data:
urllist.append(i.get("data-src"))
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
sp = spider("https://wallhaven.cc/search%3F ... 6quot;)
sp.get()
2> 详细代码
封装了代码,方便批量抓取。首先,导入两个包:requests 和 BeautifulSoup。Requests 是模拟用户向浏览器发送请求,而 BeautifulSoup 是抓取网页中的数据。
url 是目标 URL:

设置请求头:
在请求标头中找到用户代理并复制和粘贴
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
发送请求获取响应数据:(这里html为HTML文本数据)
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
通过BeautifulSoup解析数据:(BeautifulSoup的第一个参数是要解析的数据,第二个参数是解析的方式)
# 解析数据
info = BeautifulSoup(html, "lxml")
使用select选择器定位数据(我们需要图片的url来抓取图片,所以我们需要定位到url)

复制选择器所在的位置:
复制选择器得到:
#thumbs > section > ul > li:nth-child(1) > figure > img
但这只是一张图片,我们要的是当前页面的所有图片,所以这里需要改一下(删除li::后的第n个子(1)):
#thumbs > section > ul > li > figure > img
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
数据输出的结构如下:

得到图片地址后:新建一个列表,把所有的URL都加入列表中
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("data-src"))
名单如下:

再次发送请求,通过解析后的url获取图片。图片名称是通过将url地址字符串分割成片的方式分配给名称,最后以二进制方式写入指定目录。
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
查看结果:

批量抓取另一张网站图片的源码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#main > div.slist > ul > li > a > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("src"))
print(urllist)
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
# name = pictureurl.split("/")[-1]
response = requests.get(url="https://pic.netbian.com"+pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
global number
with open("D:\spiderPicture\pic\%d.jpg" % number, "wb") as f:
f.write(response.content)
number += 1
i = 3
number = 1
while 1:
url = "https://pic.netbian.com/4kmein ... B%25i
sp = spider(url)
sp.get()
i += 1
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-10 23:47
前言
在抓取一个普通的静态网页时,我们可以直接请求相应的URL来获取完整的HTML页面,但是对于动态页面来说,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/")
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。 查看全部
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
前言
在抓取一个普通的静态网页时,我们可以直接请求相应的URL来获取完整的HTML页面,但是对于动态页面来说,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/";)
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。
python抓取动态网页(switch环境配置lxml抓取静态网页的难点及难点分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-10 11:14
背景说明
有使用switch游戏文件的需要,于是找了一个网站,网站有很多游戏资源,但是这种网站很容易失败,所以我打算用爬虫把资源下载下来,但是在实际爬取的过程中,为了获取实际的网盘地址,需要点击特定的按钮打开,所以结合selenium和html,抓包比较流行网站中的游戏实现
主要收录四个部分
Selenium 环境配置
lxml 获取静态网页[√]
硒得到饼干
selenium 获取下载链接
掌握了以上部分后,就可以算是对爬虫的介绍了
获取游戏的具体页面
爬虫环境在上一章已经配置好了。有兴趣的可以在专栏中找到。本章将抓取网站中各个游戏的具体链接
网站 有按流行度排序的功能,可以按下载量对所有游戏进行排序。大约有四十页的数据。
这个界面的网址很简单。第一个页面的格式是/games/page/1?order=hot 第二个页面的格式是/games/page/2?order=hot
所以首先可以创建一个需要爬取的web_list 网站 准备爬取
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
然后以第一页为例,分析在获取整体页面的情况下如何获取游戏名称和具体的网站。
我们把鼠标右键放在游戏画面上,点击右键选择check
可以解析出网站的实际元素组成
可以看到实际需要的游戏网站和游戏名称都在div层,其中网站在a节点的href元素中,游戏名称在alt元素中a节点的子节点img
所以我们可以写出下面的代码来得到
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
首先将父节点为div的节点a存储在game_list中,然后game_url获取节点a的href元素,game_name获取节点a的子节点img的alt元素,最后保存在write_dir中作为字典保存后续使用
上面的完整代码如下
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
网站 命名避免版权冲突,我们做了编码处理,有需要的朋友可以私信
下一节将处理具体游戏的第二关网站。下一章也是过程中的主要难点,重点分析 查看全部
python抓取动态网页(switch环境配置lxml抓取静态网页的难点及难点分析方法)
背景说明
有使用switch游戏文件的需要,于是找了一个网站,网站有很多游戏资源,但是这种网站很容易失败,所以我打算用爬虫把资源下载下来,但是在实际爬取的过程中,为了获取实际的网盘地址,需要点击特定的按钮打开,所以结合selenium和html,抓包比较流行网站中的游戏实现
主要收录四个部分
Selenium 环境配置
lxml 获取静态网页[√]
硒得到饼干
selenium 获取下载链接
掌握了以上部分后,就可以算是对爬虫的介绍了
获取游戏的具体页面
爬虫环境在上一章已经配置好了。有兴趣的可以在专栏中找到。本章将抓取网站中各个游戏的具体链接
网站 有按流行度排序的功能,可以按下载量对所有游戏进行排序。大约有四十页的数据。
这个界面的网址很简单。第一个页面的格式是/games/page/1?order=hot 第二个页面的格式是/games/page/2?order=hot
所以首先可以创建一个需要爬取的web_list 网站 准备爬取
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
然后以第一页为例,分析在获取整体页面的情况下如何获取游戏名称和具体的网站。
我们把鼠标右键放在游戏画面上,点击右键选择check
可以解析出网站的实际元素组成
可以看到实际需要的游戏网站和游戏名称都在div层,其中网站在a节点的href元素中,游戏名称在alt元素中a节点的子节点img
所以我们可以写出下面的代码来得到
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
首先将父节点为div的节点a存储在game_list中,然后game_url获取节点a的href元素,game_name获取节点a的子节点img的alt元素,最后保存在write_dir中作为字典保存后续使用

上面的完整代码如下
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
网站 命名避免版权冲突,我们做了编码处理,有需要的朋友可以私信
下一节将处理具体游戏的第二关网站。下一章也是过程中的主要难点,重点分析
python抓取动态网页( Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-09 15:04
Python网络爬虫内容提取器一文讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(在windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,那几行代码也不多,够看Python了强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
python抓取动态网页(
Python网络爬虫内容提取器一文讲解)

1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。

第二步:执行如下代码(在windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,那几行代码也不多,够看Python了强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取

4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
python抓取动态网页(工具分析登录页面打开登录过程从分析可以看到哪些信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-10-09 15:03
最近的项目在做一些数据集成,各种系统对应的接口就更陌生了。数据整合的过程可以用八个字来概括:山上有路,水中有桥。
这两天碰巧出了问题。我们要集成的WEB系统没有提供专门的数据集成接口,没有API可以调整,数据库是不允许访问的。无奈中,想知道能不能用python自动爬取。页。网页有SSO,应该使用开源的CAS框架,后面的页面都是动态JS和AJAX异步加载的。显然,这不像是直接使用Scrapy上传的普通静态页面。它必须是完美的。要模拟登陆动作,抓取后续动态内容,对页面结构和抓取内容的分析必不可少。
工具分析登陆页面
打开登录页面,按F12打开Chrome自带的分析工具。在网络选项卡上,可以看到当前浏览器显示页面的详细信息和提交的登录信息,如下图
网站 登录页面
从截图中可以看到,当我们访问app/this url的日志时,由于我们还没有登录,SSO会自动重定向到登录页面,所以http状态是302重定向。
接下来,我们在页面输入账号密码,点击登录按钮,通过页面跟踪分析和模拟整个登录过程。这个过程一定要特别小心,因为很多CAS在登录页面都埋了很多隐藏的标记,一处是模仿不来的。它将无法登录,然后被重定向到开头。
分析登录过程
从分析中可以看出,在提交登录按钮时,会使用POST方式提交表单,并且表单中除了账号密码等显眼的字段外,还有一个lt。经验告诉我们,这个字段应该隐藏在之前的登录页面上。它用于验证登录页面的合法性,因此我们需要从登录页面中查找并提取此信息。同时注意http的消息头。最好根据浏览器抓到的消息头来构造,因为网站也会验证里面的信息。
以下是登录的主要代码。我们基于python3和requests包处理https访问请求,模拟浏览器的行为,构造认证所需的信息发送给网站。
import requestsimport urllib3from lxml import etreefrom ows_scrapy.ows_spider.write_csv import write_list_to_csv
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
s = requests.session()
s.trust_env = False # fastercookie = Noneusername = 'username'password = 'pwd'def login():
header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Cookie': 'JSESSIONID=73E10849812940333A4AD2A2ABAEFB7D8CFF3E76A45340FFB687FD587D2EB97A49FC5F156D09DB1E17F129465AB8D8EBACEC', 'Host': '', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
form_data = { 'username': username, 'password': password, '_eventId': 'submit', 'pwdfirst': password[0:2], 'pwdsecond': password[2:5], 'pwdthird': password[5:]
}
login_url = 'https://.com/app/'
print('login...')
res = s.get(login_url, headers=header, verify=False) global cookie
cookie = res.cookies # 注意要保存cookie
print("get response from ows {0}, http status {1}".format(login_url, res.status_code))
login_url = res.url
header['Referer'] = login_url
header['Cookie'] = 'JSESSIONID=' + cookie['JSESSIONID']
form_data['lt'] = str(etree.HTML(res.content).xpath('//input[@name="lt"]/@value')[0]) #用xpath从页面上提取lt
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
cookie = res.cookies
print("post login params to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie))
res = s.send(res.next, allow_redirects=False, verify=False)
cookie = res.cookies
print("redirect to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie)) if res.status_code == 200 or res.status_code == 302: if cookie is not None and cookie.get(name='JSESSIONID', path='/app') is not None :
print('Successful login.') else:
print('WRONG w3id/password!')
sys.exit(0)
这里要特别注意,因为http是无状态的,需要cookies来保存网页的登录状态。页面成功后,页面的响应将收录一个带有有效标记的cookie。登录的最终目的是获取并保存这个有效的cookie,这样后续的访问就不会被重定向到登录页面。
在 requests 方法中,只需将 cookie 添加到请求中即可。
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
分析动态内容页面
在动态页面中,页面显示的内容往往是通过js或者AJAX异步获取的,这明显不同于静态html页面的分析过程。使用 Chrome 的分析工具也可以轻松获取此信息。
分析动态页面
动态页面加载完成后,我们从所有请求中过滤出XHR类型,找到我们想要的请求,然后在请求的Preview中就可以看到完整的对应信息了,请求的URL也可以从Obtained中查看在标题选项卡中。
接下来要做的和上面类似,构造一个消息来模拟浏览器向网站发送请求:
def get_content(order_id):
form_data = { 'roarand': 'BW09el5W3mW2sfbGbtWe7mWlwBsWqXg6znppnqkW3woJ5fcz5DnhfWXGonqkLsd0', 'start': '0', 'limit': '20', 'orderid': order_id, 'serviceId': 'test_gscsocsecurityincidentmanage_log_getList2'
}
header = { 'Accept': 'text/plain, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8', 'Host': '.com', 'Origin': 'https://.com', 'Referer': 'https://.com/app/104h/spl/test/ID_480_1511441539904_workflowdetail.spl?orderid=SOC-20180220-00000003', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'
}
print('Start to scan order id ' + order_id)
url = 'https://.com/app/pageservices/service.do?forAccessLog={serviceName:test_gscsocsecurityincidentmanage_log_getList2,userId:571bdd42-10ca-4ce1-b41c-8a3f6632141f,tenantId:104h}&trackId=fec68f8e-f30a-4fa1-a8b1-41d3dd11fa4c'
res = s.post(url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False) #要加载上面登录成功的cookie
print(res.content) return res
重点其实就是从XHR中找到请求的URI,构造请求头并提交表单,最后一定要添加成功登录cookie,否则会被重定向到登录页面。
有很多方法可以抓取动态页面。这种方式依赖的包相对较少,代码也比较灵活。爬取复杂登录页面时效果更好,但在分析页面登录机制时一定要特别小心。 查看全部
python抓取动态网页(工具分析登录页面打开登录过程从分析可以看到哪些信息)
最近的项目在做一些数据集成,各种系统对应的接口就更陌生了。数据整合的过程可以用八个字来概括:山上有路,水中有桥。
这两天碰巧出了问题。我们要集成的WEB系统没有提供专门的数据集成接口,没有API可以调整,数据库是不允许访问的。无奈中,想知道能不能用python自动爬取。页。网页有SSO,应该使用开源的CAS框架,后面的页面都是动态JS和AJAX异步加载的。显然,这不像是直接使用Scrapy上传的普通静态页面。它必须是完美的。要模拟登陆动作,抓取后续动态内容,对页面结构和抓取内容的分析必不可少。
工具分析登陆页面
打开登录页面,按F12打开Chrome自带的分析工具。在网络选项卡上,可以看到当前浏览器显示页面的详细信息和提交的登录信息,如下图

网站 登录页面
从截图中可以看到,当我们访问app/this url的日志时,由于我们还没有登录,SSO会自动重定向到登录页面,所以http状态是302重定向。
接下来,我们在页面输入账号密码,点击登录按钮,通过页面跟踪分析和模拟整个登录过程。这个过程一定要特别小心,因为很多CAS在登录页面都埋了很多隐藏的标记,一处是模仿不来的。它将无法登录,然后被重定向到开头。

分析登录过程
从分析中可以看出,在提交登录按钮时,会使用POST方式提交表单,并且表单中除了账号密码等显眼的字段外,还有一个lt。经验告诉我们,这个字段应该隐藏在之前的登录页面上。它用于验证登录页面的合法性,因此我们需要从登录页面中查找并提取此信息。同时注意http的消息头。最好根据浏览器抓到的消息头来构造,因为网站也会验证里面的信息。
以下是登录的主要代码。我们基于python3和requests包处理https访问请求,模拟浏览器的行为,构造认证所需的信息发送给网站。
import requestsimport urllib3from lxml import etreefrom ows_scrapy.ows_spider.write_csv import write_list_to_csv
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
s = requests.session()
s.trust_env = False # fastercookie = Noneusername = 'username'password = 'pwd'def login():
header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Cookie': 'JSESSIONID=73E10849812940333A4AD2A2ABAEFB7D8CFF3E76A45340FFB687FD587D2EB97A49FC5F156D09DB1E17F129465AB8D8EBACEC', 'Host': '', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
form_data = { 'username': username, 'password': password, '_eventId': 'submit', 'pwdfirst': password[0:2], 'pwdsecond': password[2:5], 'pwdthird': password[5:]
}
login_url = 'https://.com/app/'
print('login...')
res = s.get(login_url, headers=header, verify=False) global cookie
cookie = res.cookies # 注意要保存cookie
print("get response from ows {0}, http status {1}".format(login_url, res.status_code))
login_url = res.url
header['Referer'] = login_url
header['Cookie'] = 'JSESSIONID=' + cookie['JSESSIONID']
form_data['lt'] = str(etree.HTML(res.content).xpath('//input[@name="lt"]/@value')[0]) #用xpath从页面上提取lt
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
cookie = res.cookies
print("post login params to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie))
res = s.send(res.next, allow_redirects=False, verify=False)
cookie = res.cookies
print("redirect to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie)) if res.status_code == 200 or res.status_code == 302: if cookie is not None and cookie.get(name='JSESSIONID', path='/app') is not None :
print('Successful login.') else:
print('WRONG w3id/password!')
sys.exit(0)
这里要特别注意,因为http是无状态的,需要cookies来保存网页的登录状态。页面成功后,页面的响应将收录一个带有有效标记的cookie。登录的最终目的是获取并保存这个有效的cookie,这样后续的访问就不会被重定向到登录页面。
在 requests 方法中,只需将 cookie 添加到请求中即可。
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
分析动态内容页面
在动态页面中,页面显示的内容往往是通过js或者AJAX异步获取的,这明显不同于静态html页面的分析过程。使用 Chrome 的分析工具也可以轻松获取此信息。

分析动态页面
动态页面加载完成后,我们从所有请求中过滤出XHR类型,找到我们想要的请求,然后在请求的Preview中就可以看到完整的对应信息了,请求的URL也可以从Obtained中查看在标题选项卡中。
接下来要做的和上面类似,构造一个消息来模拟浏览器向网站发送请求:
def get_content(order_id):
form_data = { 'roarand': 'BW09el5W3mW2sfbGbtWe7mWlwBsWqXg6znppnqkW3woJ5fcz5DnhfWXGonqkLsd0', 'start': '0', 'limit': '20', 'orderid': order_id, 'serviceId': 'test_gscsocsecurityincidentmanage_log_getList2'
}
header = { 'Accept': 'text/plain, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8', 'Host': '.com', 'Origin': 'https://.com', 'Referer': 'https://.com/app/104h/spl/test/ID_480_1511441539904_workflowdetail.spl?orderid=SOC-20180220-00000003', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'
}
print('Start to scan order id ' + order_id)
url = 'https://.com/app/pageservices/service.do?forAccessLog={serviceName:test_gscsocsecurityincidentmanage_log_getList2,userId:571bdd42-10ca-4ce1-b41c-8a3f6632141f,tenantId:104h}&trackId=fec68f8e-f30a-4fa1-a8b1-41d3dd11fa4c'
res = s.post(url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False) #要加载上面登录成功的cookie
print(res.content) return res
重点其实就是从XHR中找到请求的URI,构造请求头并提交表单,最后一定要添加成功登录cookie,否则会被重定向到登录页面。
有很多方法可以抓取动态页面。这种方式依赖的包相对较少,代码也比较灵活。爬取复杂登录页面时效果更好,但在分析页面登录机制时一定要特别小心。
python抓取动态网页(数据怎么破()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-09 15:02
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:
小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!
(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓了太多,发现有些小网站很狡猾,开始反爬虫了。它们不直接生成数据,而是通过加载JS生成数据,然后你打开Chrome浏览器的开发者选项,然后你会发现Elements页面的结构和网络抓包返回的内容不一样. 网络抓包中没有对应的数据。数据应该放的地方竟然是JS代码,比如煎蛋的少女图:
">
对于我这种不懂JS的安卓狗,不禁感叹:
">
抓不到数据怎么破?一开始想自学一波JS基础语法。然后我去模拟抓包来获取别人的JS文件。JS竟然被加密了,要爬的页面太多了。什么时候分析每个这样的分析...
">
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。简单说说这个东西的使用,我们可以写代码让浏览器:
然后这个东西不支持浏览器功能。您需要在第三方浏览器中使用它。支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
Chrome: /a/chromium....FireFox: /mozilla/gec...PhantomJS: /IE: /index.htmlEdge: /en-us/micro...Opera: /operasoftwa...
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
复制代码
PS:我记得我公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。其实如果你安装Python3,它默认已经自带pip了。您需要配置额外的环境变量,pip。路径在Python安装目录的Scripts目录下~
">
在Path后面加上这个路径就行了~
">2.下载浏览器驱动
因为 Selenium 没有浏览器,所以需要依赖第三方浏览器。如果要调用第三方浏览器,需要下载浏览器的驱动。由于作者使用的是 Chrome,所以我们以 Chrome 为例。其他 浏览器自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
复制代码
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
">
61.好的,那么到下面网站查看对应的驱动版本号:
/2.34/notes....
">
好的,接下来下载v2.34版本的浏览器驱动:
/index.html?...
">
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python Scripts目录下。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件拷贝到usr/local/bin目录下,再拷贝到usr/bin目录下。
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
复制代码
执行这段代码会自动调出浏览器访问百度:
">
并且控制台会输出HTML代码,也就是直接得到的Elements页面结构,JS执行后的页面~接下来就可以抓取我们的煎蛋少女图了~
3.Selenium 简单实战:抢炒蛋妹图
直接分析Elements页面的结构,找到你想要的关键节点:
">
显然这是我们抓到的那个小姐姐的照片。复制这个网址,看看我们打印出来的页面结构是否收录这个东西:
">
是的这很好。有了这个页面数据,我们就来一波美汤获取我们想要的数据吧~
">
经过上面的过滤,我们就可以得到我们妹图的URL:
">
只需打开一个验证,啧:
">
">
我看到下一页只有30个小姐姐,这对我们来说显然不够。第一次加载的时候,我们得到一波页码,然后我们就知道有多少页了,然后我们去拼接URL加载差异。例如,这里总共有 448 页:
">
只需将其拼接到此 URL 中:过滤以获取页码:
">
">
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
复制代码
操作结果:
">
看看我们的输出文件夹~
">
是的,发了这么多小姐姐,就是想骗你学Python!
">4.PhantomJS
PhantomJS 没有界面浏览器。特点: 它将网站加载到内存中并在页面上执行JavaScript。因为它不显示图形界面,所以它比完整的浏览器运行效率更高。(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的,可以使用PhantomJS来规避这个问题)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
复制代码
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS,这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始提供 Headless 模式(不需要挂掉浏览器),所以估计使用 PhantomJS 的小伙伴会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持 Headless 模式。启用 Headless 模式也很简单:
">
selenium 的官方文档中还写道:
">
运行时也会报这个警告:
">5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:/account/log...
分析页面结构,不难发现对应的登录输入框和登录按钮:
">
">
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,并将cookie保存到本地,然后就可以带着cookie访问相关页面了~
首先写一个方法来模拟登录:
">
找到你输入账号密码的节点,设置你的账号密码,然后找到登录按钮节点,点击它,然后等待登录成功。登录成功后,可以对比current_url是否发生了变化。然后保存Cookies,这里我使用的是pickle库,你可以使用其他的,比如json,或者字符串拼接,然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用Cookie访问主页。
">
通过 add_cookies 方法设置 Cookie。参数是字典类型。另外一定要先访问get链接,再设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
">6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。下面是我觉得比较常用的函数,更多的可以看官方文档:官方API文档:seleniumhq.github.io/selenium/do...
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表,例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,如:单击、双击、右键、按住、拖动等,可以导入ActionChains类:mon.action_chains.ActionChains使用ActionChains(driver).XXX调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发某个时间,弹出对话框,可以调用如下方法获取对话框:alert = driver.switch_to_alert(),然后调用如下方法即可:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("window name") 或者在driver.window_handles中遍历window_handles获取句柄:driver.switch_to_window(handle)driver.forward()# forward driver.back()#返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果此时没有找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
复制代码
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。如果元素已经存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不用自己编写一些等待条件。
title_istitle_containspresence_of_element_locatedvisibility_of_element_locatedvisibility_ofpresence_of_all_elements_locatedtext_to_be_present_in_elementtext_to_be_present_in_element_valueframe_to_be_available_and_switch_to_itinvisibility_of_element_locatedelement_to_be_clickable - 它显示和Enabled.staleness_ofelement_to_be_selectedelement_located_to_be_selectedelement_selection_state_to_beelement_located_selection_state_to_bealert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
复制代码
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js语句)如滚动到底部:js = document.body.scrollTop=10000driver.execute_script(js)
概括
本节介绍一波使用 Selenium 自动化测试框架来捕获 JavaScript 动态生成的数据。Selenium 需要依赖第三方浏览器。注意 PhantomJS 无界面浏览器的过时问题。您可以使用 Chrome 和 FireFox 提供的 HeadLess 来替换它。; 通过抓取煎蛋女孩图片,模拟CSDN自动登录的例子,熟悉Selenium的基本使用,还是收获不少。当然,Selenium 的水还是很深的。目前我们可以用它来应对JS动态加载数据页面数据的抓取。
最近有点冷,大家记得及时加衣服哦~另外,因为这周事情比较多,先把换的破了。下周见。下一个要啃的骨头是 Python 多线程。我可以在视觉上,恭敬地啃几节经文。敬请期待~
">
顺便写下你的想法:
下载本节源码:
/coder-pig/R...
本节参考资料:
来吧,Py 交易
想加群一起学Py可以加小猪智障机器人,验证信息收录:python,python,py,Py,加群,交易,混蛋之一关键词 可以通过;
">
验证通过后回复群获取群链接(不要破机器人!!!)~~~欢迎像我这样的各类Py初学者和Py大神加入,一起交流学习♂ Xi, van ♂转向py。
"> 查看全部
python抓取动态网页(数据怎么破()())
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:
小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!
(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓了太多,发现有些小网站很狡猾,开始反爬虫了。它们不直接生成数据,而是通过加载JS生成数据,然后你打开Chrome浏览器的开发者选项,然后你会发现Elements页面的结构和网络抓包返回的内容不一样. 网络抓包中没有对应的数据。数据应该放的地方竟然是JS代码,比如煎蛋的少女图:
">
对于我这种不懂JS的安卓狗,不禁感叹:
">
抓不到数据怎么破?一开始想自学一波JS基础语法。然后我去模拟抓包来获取别人的JS文件。JS竟然被加密了,要爬的页面太多了。什么时候分析每个这样的分析...
">
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。简单说说这个东西的使用,我们可以写代码让浏览器:
然后这个东西不支持浏览器功能。您需要在第三方浏览器中使用它。支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
Chrome: /a/chromium....FireFox: /mozilla/gec...PhantomJS: /IE: /index.htmlEdge: /en-us/micro...Opera: /operasoftwa...
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
复制代码
PS:我记得我公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。其实如果你安装Python3,它默认已经自带pip了。您需要配置额外的环境变量,pip。路径在Python安装目录的Scripts目录下~
">
在Path后面加上这个路径就行了~
">2.下载浏览器驱动
因为 Selenium 没有浏览器,所以需要依赖第三方浏览器。如果要调用第三方浏览器,需要下载浏览器的驱动。由于作者使用的是 Chrome,所以我们以 Chrome 为例。其他 浏览器自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
复制代码
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
">
61.好的,那么到下面网站查看对应的驱动版本号:
/2.34/notes....
">
好的,接下来下载v2.34版本的浏览器驱动:
/index.html?...
">
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python Scripts目录下。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件拷贝到usr/local/bin目录下,再拷贝到usr/bin目录下。
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
复制代码
执行这段代码会自动调出浏览器访问百度:
">
并且控制台会输出HTML代码,也就是直接得到的Elements页面结构,JS执行后的页面~接下来就可以抓取我们的煎蛋少女图了~
3.Selenium 简单实战:抢炒蛋妹图
直接分析Elements页面的结构,找到你想要的关键节点:
">
显然这是我们抓到的那个小姐姐的照片。复制这个网址,看看我们打印出来的页面结构是否收录这个东西:
">
是的这很好。有了这个页面数据,我们就来一波美汤获取我们想要的数据吧~
">
经过上面的过滤,我们就可以得到我们妹图的URL:
">
只需打开一个验证,啧:
">
">
我看到下一页只有30个小姐姐,这对我们来说显然不够。第一次加载的时候,我们得到一波页码,然后我们就知道有多少页了,然后我们去拼接URL加载差异。例如,这里总共有 448 页:
">
只需将其拼接到此 URL 中:过滤以获取页码:
">
">
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
复制代码
操作结果:
">
看看我们的输出文件夹~
">
是的,发了这么多小姐姐,就是想骗你学Python!
">4.PhantomJS
PhantomJS 没有界面浏览器。特点: 它将网站加载到内存中并在页面上执行JavaScript。因为它不显示图形界面,所以它比完整的浏览器运行效率更高。(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的,可以使用PhantomJS来规避这个问题)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
复制代码
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS,这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始提供 Headless 模式(不需要挂掉浏览器),所以估计使用 PhantomJS 的小伙伴会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持 Headless 模式。启用 Headless 模式也很简单:
">
selenium 的官方文档中还写道:
">
运行时也会报这个警告:
">5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:/account/log...
分析页面结构,不难发现对应的登录输入框和登录按钮:
">
">
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,并将cookie保存到本地,然后就可以带着cookie访问相关页面了~
首先写一个方法来模拟登录:
">
找到你输入账号密码的节点,设置你的账号密码,然后找到登录按钮节点,点击它,然后等待登录成功。登录成功后,可以对比current_url是否发生了变化。然后保存Cookies,这里我使用的是pickle库,你可以使用其他的,比如json,或者字符串拼接,然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用Cookie访问主页。
">
通过 add_cookies 方法设置 Cookie。参数是字典类型。另外一定要先访问get链接,再设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
">6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。下面是我觉得比较常用的函数,更多的可以看官方文档:官方API文档:seleniumhq.github.io/selenium/do...
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表,例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,如:单击、双击、右键、按住、拖动等,可以导入ActionChains类:mon.action_chains.ActionChains使用ActionChains(driver).XXX调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发某个时间,弹出对话框,可以调用如下方法获取对话框:alert = driver.switch_to_alert(),然后调用如下方法即可:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("window name") 或者在driver.window_handles中遍历window_handles获取句柄:driver.switch_to_window(handle)driver.forward()# forward driver.back()#返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果此时没有找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
复制代码
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。如果元素已经存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不用自己编写一些等待条件。
title_istitle_containspresence_of_element_locatedvisibility_of_element_locatedvisibility_ofpresence_of_all_elements_locatedtext_to_be_present_in_elementtext_to_be_present_in_element_valueframe_to_be_available_and_switch_to_itinvisibility_of_element_locatedelement_to_be_clickable - 它显示和Enabled.staleness_ofelement_to_be_selectedelement_located_to_be_selectedelement_selection_state_to_beelement_located_selection_state_to_bealert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading";)
myDynamicElement = driver.find_element_by_id("myDynamicElement")
复制代码
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js语句)如滚动到底部:js = document.body.scrollTop=10000driver.execute_script(js)
概括
本节介绍一波使用 Selenium 自动化测试框架来捕获 JavaScript 动态生成的数据。Selenium 需要依赖第三方浏览器。注意 PhantomJS 无界面浏览器的过时问题。您可以使用 Chrome 和 FireFox 提供的 HeadLess 来替换它。; 通过抓取煎蛋女孩图片,模拟CSDN自动登录的例子,熟悉Selenium的基本使用,还是收获不少。当然,Selenium 的水还是很深的。目前我们可以用它来应对JS动态加载数据页面数据的抓取。
最近有点冷,大家记得及时加衣服哦~另外,因为这周事情比较多,先把换的破了。下周见。下一个要啃的骨头是 Python 多线程。我可以在视觉上,恭敬地啃几节经文。敬请期待~
">
顺便写下你的想法:
下载本节源码:
/coder-pig/R...
本节参考资料:
来吧,Py 交易
想加群一起学Py可以加小猪智障机器人,验证信息收录:python,python,py,Py,加群,交易,混蛋之一关键词 可以通过;
">
验证通过后回复群获取群链接(不要破机器人!!!)~~~欢迎像我这样的各类Py初学者和Py大神加入,一起交流学习♂ Xi, van ♂转向py。
">
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-07 16:37
爬虫抓取数据时,有些数据是动态的。比如动态加载js。如果用普通的urllib2抓取数据,是找不到相关数据的。这是爬虫初学者在使用过程中最可能出现的情况。,显然浏览器中有相应的信息,但是python爬取的网页中却缺少相应的信息。这通常是因为网页使用js异步加载数据,动态显示。处理这种情况的一种方法是找到对应的js接口,但有时这种情况是非常少见的,因为js的调用参数也被解析了,有的参数也被加密了,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应信息,
安装硒
在python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com") # Load page
print browser.page_source
selenium虽然安装成功,但是还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用 pip 安装 selenium。默认安装最新版本的 selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1,selenium 3.x启动,在 webdriver/firefox/webdriver.py 的 __init__ 中, executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
将火狐升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究硒文档。
使用 BeautifulSoup 进行 html 解析
如果你还不知道BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup来解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:go2coding 查看全部
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
爬虫抓取数据时,有些数据是动态的。比如动态加载js。如果用普通的urllib2抓取数据,是找不到相关数据的。这是爬虫初学者在使用过程中最可能出现的情况。,显然浏览器中有相应的信息,但是python爬取的网页中却缺少相应的信息。这通常是因为网页使用js异步加载数据,动态显示。处理这种情况的一种方法是找到对应的js接口,但有时这种情况是非常少见的,因为js的调用参数也被解析了,有的参数也被加密了,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应信息,
安装硒
在python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com";) # Load page
print browser.page_source
selenium虽然安装成功,但是还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用 pip 安装 selenium。默认安装最新版本的 selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1,selenium 3.x启动,在 webdriver/firefox/webdriver.py 的 __init__ 中, executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
将火狐升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究硒文档。
使用 BeautifulSoup 进行 html 解析
如果你还不知道BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup来解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:go2coding
python抓取动态网页(python爬虫抓取动态网页的学习教程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-06 07:01
python抓取动态网页。网上有大量关于爬虫的学习教程,很多人面对如此庞大的网站都无从下手,下面我们主要介绍下python爬虫基础知识,然后带你了解下主流的baidu、google以及百度等网站的动态网页数据源是如何抓取下来的。准备好python基础知识,pandas库,mysql必须要会使用,django和flask不太需要python基础知识。
学习步骤1.打开百度,搜索在本地搭建个baidu分站(此时是没有登录或者不能修改密码的)2.下载动态网页抓取的软件(scrapy、selenium、flask,以及webpage6等)3.在/下载各个开发套件的文件4.下载软件,把所有软件都解压缩,所有开发套件是一个txt文件在python虚拟环境下,要使用第三方库需要安装对应的库,python中已经集成了所有的第三方库,pipinstallpython就可以将所有开发套件包括库完全集成5.输入scrapystartprojectxxx,即可开始scrapystartprojectxxx6.在article框里输入脚本文件名scrapystartprojectxxx,即可将会生成一个scrapy脚本,scrapy脚本里面有main.py,start_url.py,hello.py等文件7.在hello.py中输入每一步所需要的参数就可以完成爬虫编写。
8.使用flask框架进行开发框架搭建首先使用scrapystartprojectflask,编写一个todomvc.py,同样输入main.py。scrapystartprojectxxx,也就是整个脚本的文件名。在article框输入脚本文件名,就能打开网页了,例如在/下输入脚本文件名scrapystartprojectxxx,在/下也可以访问,和xxx文件是一样的(在python2中,路径要用...开头):webhead.py输入你生成的网址就可以访问了。
一般是网页标题+内容,例如在/上我们可以看到一些常见的html内容:url:name:contact这个时候article=flask启动之后,我们在/下输入登录你的浏览器,看到就是你想要的效果了:url:我们可以看到会打开许多js代码,实际上就是用javascript去拼接,这个js里面包含的内容就是网页上的文字信息,这里需要重点讲一下。
scrapystartprojectxxx,在/下输入登录你的浏览器,就可以看到我们想要的效果了:网页抓取动态教程本篇文章讲解scrapy动态网页抓取教程,并以迅雷的视频为例,大家一定要准备好空白图片(a4纸大小)或者黑色笔记本。图片直接复制到电脑中打开,点击浏览器右上角画折角输入我们之前看到的refer在该地址获取文件名,不要复制网址。比如::8080/就会打开迅雷视频。然后我们点击播放按钮,这时候就会自动抓取视频下面的文。 查看全部
python抓取动态网页(python爬虫抓取动态网页的学习教程-乐题库)
python抓取动态网页。网上有大量关于爬虫的学习教程,很多人面对如此庞大的网站都无从下手,下面我们主要介绍下python爬虫基础知识,然后带你了解下主流的baidu、google以及百度等网站的动态网页数据源是如何抓取下来的。准备好python基础知识,pandas库,mysql必须要会使用,django和flask不太需要python基础知识。
学习步骤1.打开百度,搜索在本地搭建个baidu分站(此时是没有登录或者不能修改密码的)2.下载动态网页抓取的软件(scrapy、selenium、flask,以及webpage6等)3.在/下载各个开发套件的文件4.下载软件,把所有软件都解压缩,所有开发套件是一个txt文件在python虚拟环境下,要使用第三方库需要安装对应的库,python中已经集成了所有的第三方库,pipinstallpython就可以将所有开发套件包括库完全集成5.输入scrapystartprojectxxx,即可开始scrapystartprojectxxx6.在article框里输入脚本文件名scrapystartprojectxxx,即可将会生成一个scrapy脚本,scrapy脚本里面有main.py,start_url.py,hello.py等文件7.在hello.py中输入每一步所需要的参数就可以完成爬虫编写。
8.使用flask框架进行开发框架搭建首先使用scrapystartprojectflask,编写一个todomvc.py,同样输入main.py。scrapystartprojectxxx,也就是整个脚本的文件名。在article框输入脚本文件名,就能打开网页了,例如在/下输入脚本文件名scrapystartprojectxxx,在/下也可以访问,和xxx文件是一样的(在python2中,路径要用...开头):webhead.py输入你生成的网址就可以访问了。
一般是网页标题+内容,例如在/上我们可以看到一些常见的html内容:url:name:contact这个时候article=flask启动之后,我们在/下输入登录你的浏览器,看到就是你想要的效果了:url:我们可以看到会打开许多js代码,实际上就是用javascript去拼接,这个js里面包含的内容就是网页上的文字信息,这里需要重点讲一下。
scrapystartprojectxxx,在/下输入登录你的浏览器,就可以看到我们想要的效果了:网页抓取动态教程本篇文章讲解scrapy动态网页抓取教程,并以迅雷的视频为例,大家一定要准备好空白图片(a4纸大小)或者黑色笔记本。图片直接复制到电脑中打开,点击浏览器右上角画折角输入我们之前看到的refer在该地址获取文件名,不要复制网址。比如::8080/就会打开迅雷视频。然后我们点击播放按钮,这时候就会自动抓取视频下面的文。
python抓取动态网页(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-06 00:15
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的
网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:
在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
让我们再次打开它:
结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:
返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
python抓取动态网页(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的

网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:

在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
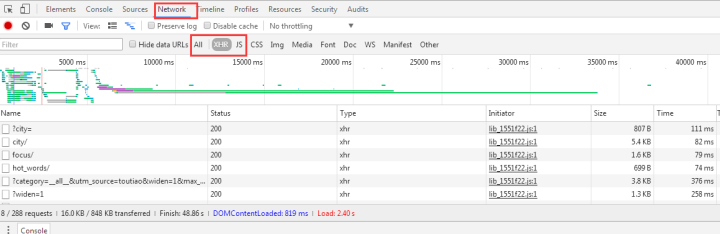
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
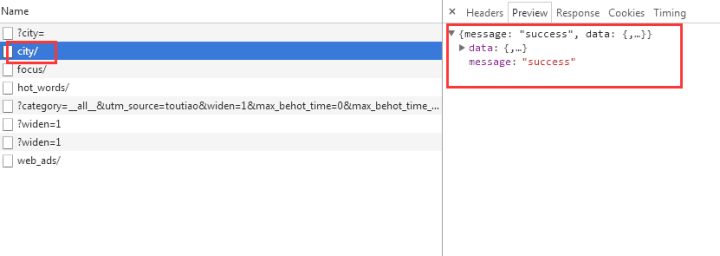
让我们再次打开它:

结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
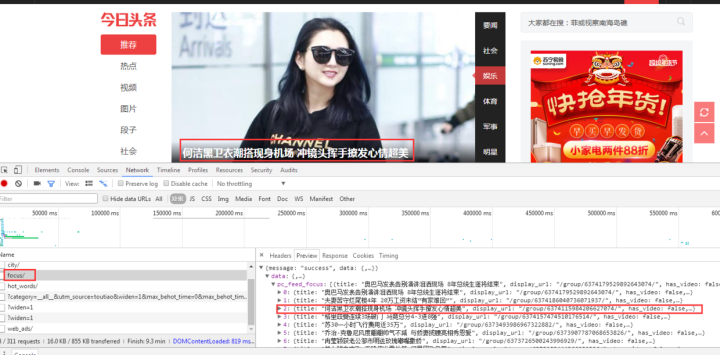
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:

返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
python抓取动态网页(审查网页元素与网页源码是不同的思路及注释(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-03 16:02
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
转载于: 查看全部
python抓取动态网页(审查网页元素与网页源码是不同的思路及注释(图))
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
转载于:
python抓取动态网页(Python小技巧02从Web抓取信息【抓取】【】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-02 17:09
Python提示02从web获取信息
“Web爬网”是一个术语,指使用程序从Web下载和处理内容
WebBrowser,一个常见的web爬行模块
import webbrowser
webbrowser.open('http://baidu.com')
使用open()函数在浏览器中打开页面,括号中传递的参数是目标web地址。这可能是WebBrowser唯一能做的事情
但唯一的效果是有时做一些有趣的事情
使用网络浏览器。Open()打开Google地图并获取指定位置的地图
import pyperclip
import sys
import webbrowser
if len((sys.argv)) > 1:
# 从命令行获取位置信息
address = ' '.join(sys.argv[1:])
else:
# 从剪切板中获得address
address = pyperclip.paste()
# 打开指定网页获取地图
webbrowser.open('https://www.google.com/maps/place/' + address)
请求
请求模块可以从web下载文件。它不是python的内置模块,所以在使用它时需要下载它
安装请求模块终端下载:
pip3 install requests
Pychar用户
按以下顺序完成:
Preferences-> Project: {Project_name} -> Project Interpreter -> 点击左下角加号 -> 搜索requests下载 -> done.
requests.get(url)
呼叫请求。Get(URL)将返回一个响应对象,其中收录web服务器对您的请求的响应
<p>import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(requests) #
# Get the status code and compare it with requests.codes.ok(这个是200)
sta_code = response.status_code
print(sta_code) # 200
print(sta_code == requests.codes.ok) # True
# 请求成功之后下载的页面保存在Response对象的text中。下面我们输出其中的头250个字符
print(response.text[0:250])
"""output: 查看全部
python抓取动态网页(Python小技巧02从Web抓取信息【抓取】【】)
Python提示02从web获取信息

“Web爬网”是一个术语,指使用程序从Web下载和处理内容
WebBrowser,一个常见的web爬行模块
import webbrowser
webbrowser.open('http://baidu.com')
使用open()函数在浏览器中打开页面,括号中传递的参数是目标web地址。这可能是WebBrowser唯一能做的事情
但唯一的效果是有时做一些有趣的事情
使用网络浏览器。Open()打开Google地图并获取指定位置的地图
import pyperclip
import sys
import webbrowser
if len((sys.argv)) > 1:
# 从命令行获取位置信息
address = ' '.join(sys.argv[1:])
else:
# 从剪切板中获得address
address = pyperclip.paste()
# 打开指定网页获取地图
webbrowser.open('https://www.google.com/maps/place/' + address)
请求
请求模块可以从web下载文件。它不是python的内置模块,所以在使用它时需要下载它
安装请求模块终端下载:
pip3 install requests
Pychar用户
按以下顺序完成:
Preferences-> Project: {Project_name} -> Project Interpreter -> 点击左下角加号 -> 搜索requests下载 -> done.
requests.get(url)
呼叫请求。Get(URL)将返回一个响应对象,其中收录web服务器对您的请求的响应
<p>import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(requests) #
# Get the status code and compare it with requests.codes.ok(这个是200)
sta_code = response.status_code
print(sta_code) # 200
print(sta_code == requests.codes.ok) # True
# 请求成功之后下载的页面保存在Response对象的text中。下面我们输出其中的头250个字符
print(response.text[0:250])
"""output:
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-28 21:17
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。
短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他抓取的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址 查看全部
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。

短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他抓取的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!

好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。

紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
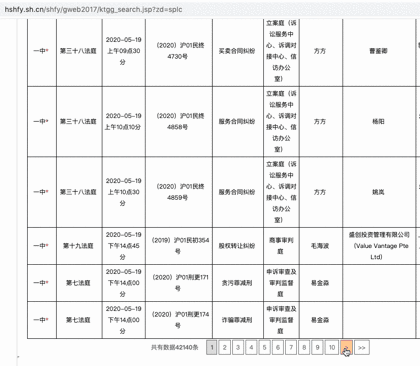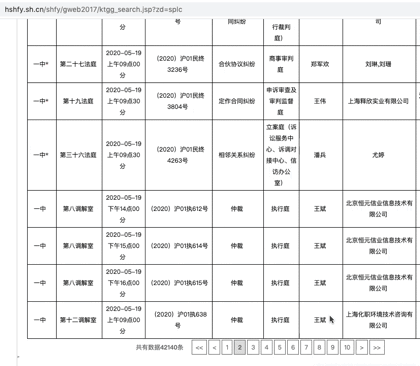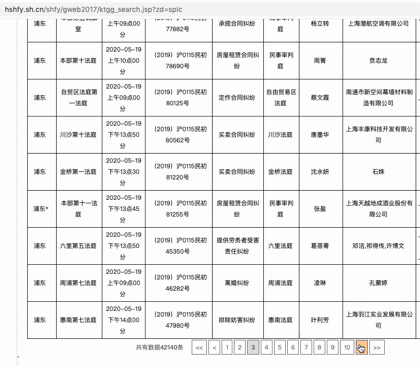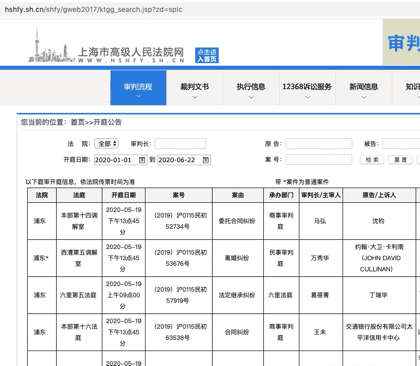
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。

既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。

我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址
python抓取动态网页(如何判断一个链接下的文章是不是优质需要一个很复杂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-15 08:30
我一直想做一个平台,可以帮我过滤掉高质量的文章和博客。我把它命名为Moven。. 其实施过程分为三个阶段:
1. Downloader:下载指定的url,将获取到的内容传递给Analyser——这是最简单的启动方式
2. 分析器:使用正则表达式或者XPath或者BeautifulSoup/lxml对接收到的内容进行过滤和简化——这部分不是太难
3.智能爬虫:爬取高质量的文章链接——这部分是最难的:
基于Scrapy Framework可以快速搭建爬虫
但是判断一个链接下的文章是否优质需要一个非常复杂的算法
最近开始做Downloader和Analyser:我最近搭建了一个l2z的故事,还有一个Z Life和Z Life@Sina以及她的博客作为Downloader和Analyser的练习。我写这个东西是为了监控上面的。四个站点并将它们的内容同步到此站点:
应用程序的特点
除了顶部的黑色导航栏和右侧的关于本站部分外,本站所有其他内容均自动从其他站点获取
原则上,你可以在这个东西上添加任何博客或网站地址。. . 当然因为这是L2Z Story..所以里面只有收录四个站点
特点是:只要站主不停止更新,这东西就会一直存在——这就是优采云的力量
值得一提的是,Content菜单是在客户端使用JavaScript自动生成的——这样可以节省服务器上的资源消耗
这里我们使用html全页抓取,所以对于那些feed没有全文输出的网站,这个app可以抓取它想要隐藏的文字
因为程序会自动跳转到一个没有全文输出的页面去抓取文章的所有列表、作者信息、更新时间以及文章的全文,所以加载时间会比较长。. 所以打开的时候请耐心等待。. . 数据存储部分将在下一步中添加,因此会很快。.
技术准备
前端:
1. CSS 信奉简单原则。Twitter 的 bootstrap.css 满足了我的大部分需求。我真的很喜欢它的网格系统。
2. 在 Javascript 上,我当然选择了 jQuery。自从我在我的第一个小项目中开始使用 jQuery 以来,我就爱上了它。动态目录系统由jQuery快速生成。
为了配合bootstrap.css,还用到了bootstrap-dropdown.js
服务器:
此应用程序有两个版本:
一个运行在我的Apache上,但是因为我的网络是ADSL,所以ip会一直变化。基本上,它只用于我所谓的局域网中的自检。. 这个版本是纯Django的
另一个运行在Google App Engine上的地址是当我将Django配置为GAE时,我花了很多精力来设置框架。
有关详细信息,请参阅:将 Django 与 Google App Engine GAE 结合使用:l2Z 故事设置-步骤 1
后台:
主要语言是Python--不解释,认识Python后就没离开过
使用的主要模块有
1. BeautifulSoup.py 用于html解析--不解释
2. feedparser.py 是用来解析feed xml的——网上很多人说GAE不支持feedparser..给你答案了。. 能。. 我在这里花了很长时间才弄清楚发生了什么。. 简而言之,就是:能用!但是feedparser.py这个文件必须和app.yaml放在同一个目录下,不然网上有人会说feedparser无法导入。
数据库:
Google Datastore:下一步,这个程序会每30分钟唤醒一次,检查每个站点是否已经更新,并抓取更新后的文章并存储在Google的Datastore中
应用配置
按照谷歌的规则,配置文件app.yaml如下:
这里主要是定义一些静态目录——css和javascript的位置
复制代码代码如下:
应用程序:l2zstory
版本:1
运行时:python
api_version: 1
处理程序:
-网址:/图像
static_dir: l2zstory/templates/template2/images
-网址:/css
static_dir: l2zstory/templates/template2/css
-网址:/js
静态目录:l2zstory/templates/template2/js
-网址:/js
静态目录:l2zstory/templates/template2/js
-url: /.*
脚本:main.py
以上就是使用Django和GAE Python在后台爬取多个网站页面全文的详细内容。更多详情请关注html中文网站其他相关文章! 查看全部
python抓取动态网页(如何判断一个链接下的文章是不是优质需要一个很复杂)
我一直想做一个平台,可以帮我过滤掉高质量的文章和博客。我把它命名为Moven。. 其实施过程分为三个阶段:
1. Downloader:下载指定的url,将获取到的内容传递给Analyser——这是最简单的启动方式
2. 分析器:使用正则表达式或者XPath或者BeautifulSoup/lxml对接收到的内容进行过滤和简化——这部分不是太难
3.智能爬虫:爬取高质量的文章链接——这部分是最难的:
基于Scrapy Framework可以快速搭建爬虫
但是判断一个链接下的文章是否优质需要一个非常复杂的算法
最近开始做Downloader和Analyser:我最近搭建了一个l2z的故事,还有一个Z Life和Z Life@Sina以及她的博客作为Downloader和Analyser的练习。我写这个东西是为了监控上面的。四个站点并将它们的内容同步到此站点:
应用程序的特点
除了顶部的黑色导航栏和右侧的关于本站部分外,本站所有其他内容均自动从其他站点获取
原则上,你可以在这个东西上添加任何博客或网站地址。. . 当然因为这是L2Z Story..所以里面只有收录四个站点
特点是:只要站主不停止更新,这东西就会一直存在——这就是优采云的力量
值得一提的是,Content菜单是在客户端使用JavaScript自动生成的——这样可以节省服务器上的资源消耗
这里我们使用html全页抓取,所以对于那些feed没有全文输出的网站,这个app可以抓取它想要隐藏的文字
因为程序会自动跳转到一个没有全文输出的页面去抓取文章的所有列表、作者信息、更新时间以及文章的全文,所以加载时间会比较长。. 所以打开的时候请耐心等待。. . 数据存储部分将在下一步中添加,因此会很快。.
技术准备
前端:
1. CSS 信奉简单原则。Twitter 的 bootstrap.css 满足了我的大部分需求。我真的很喜欢它的网格系统。
2. 在 Javascript 上,我当然选择了 jQuery。自从我在我的第一个小项目中开始使用 jQuery 以来,我就爱上了它。动态目录系统由jQuery快速生成。
为了配合bootstrap.css,还用到了bootstrap-dropdown.js
服务器:
此应用程序有两个版本:
一个运行在我的Apache上,但是因为我的网络是ADSL,所以ip会一直变化。基本上,它只用于我所谓的局域网中的自检。. 这个版本是纯Django的
另一个运行在Google App Engine上的地址是当我将Django配置为GAE时,我花了很多精力来设置框架。
有关详细信息,请参阅:将 Django 与 Google App Engine GAE 结合使用:l2Z 故事设置-步骤 1
后台:
主要语言是Python--不解释,认识Python后就没离开过
使用的主要模块有
1. BeautifulSoup.py 用于html解析--不解释
2. feedparser.py 是用来解析feed xml的——网上很多人说GAE不支持feedparser..给你答案了。. 能。. 我在这里花了很长时间才弄清楚发生了什么。. 简而言之,就是:能用!但是feedparser.py这个文件必须和app.yaml放在同一个目录下,不然网上有人会说feedparser无法导入。
数据库:
Google Datastore:下一步,这个程序会每30分钟唤醒一次,检查每个站点是否已经更新,并抓取更新后的文章并存储在Google的Datastore中
应用配置
按照谷歌的规则,配置文件app.yaml如下:
这里主要是定义一些静态目录——css和javascript的位置
复制代码代码如下:
应用程序:l2zstory
版本:1
运行时:python
api_version: 1
处理程序:
-网址:/图像
static_dir: l2zstory/templates/template2/images
-网址:/css
static_dir: l2zstory/templates/template2/css
-网址:/js
静态目录:l2zstory/templates/template2/js
-网址:/js
静态目录:l2zstory/templates/template2/js
-url: /.*
脚本:main.py
以上就是使用Django和GAE Python在后台爬取多个网站页面全文的详细内容。更多详情请关注html中文网站其他相关文章!
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-15 05:31
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是linux。比较理想的方式是无接口爬取,所以用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。 查看全部
python抓取动态网页(一个基于webkit内核的无头浏览器浏览器)
查看元素后发现,在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是linux。比较理想的方式是无接口爬取,所以用selenium+phantomjs无接口爬取。
什么是phantomjs?它是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是浏览器。
selenium和phantomjs的安装和配置可以google一下,这里就不多说了。
代码如下:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#如果不方便配置环境变量。就使用phantomjs的绝对路径也可以
driver.get('http://image.baidu.com/i%3Fie% ... %2339;)
#抓取了百度图片,query:周杰伦
driver.page_source
#这就是返回的页面内容了,与urllib2.urlopen().read()的效果是类似的,但比urllib2强在能抓取到动态渲染后的内容。
driver.quit()
这里。动态页面获取成功。
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-15 05:28
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python实现抓取< @网站,模拟登录,抓取动态网页。其中主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,欢迎您在讨论组发帖讨论:阅读 HTML 在线下载( 7zip 压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revisions1.
前提是讨论如何使用Python来实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解如何使用Python实现网站@ > 爬取,模拟登录,如何使用Python爬取动态网页网站 爬取,模拟登录,爬取动态网页相关的老帖子【教程】爬取网页,从网页中提取需要的信息。其实对于urllib这样的库,我们已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。例如,可以直接从以下代码中获取网页地址,网页源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要是两个函数:getUrlResponse 和 getUrlRespHtml TODO:添加两个函数从 crifanLib 解释 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括 downloadFile 等函数其实主要分为两个方面:关于一只手,就是抓取网站的内容,涉及到网络处理相关的模块。另一方面就是如何解析抓取到的内容,也就是在HTML解析等相关的模块下,我们来讲解一下这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能.
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理和对应是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python中的HTMl解析相关老帖子BeautifulSoup模块介绍【已解决】Python中json.loads解析收录\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析 网站 的捕获内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc 查看全部
python抓取动态网页(Python专题教程:如何用Python语言去实现抓取动态网页)
Python专题教程:抓取网站,模拟登录,抓取动态网页版本:v1.0 Crifan Li Abstract 本文针对中级Python开发者,介绍如何使用Python实现抓取< @网站,模拟登录,抓取动态网页。其中主要涉及网络处理模块(urllib、urllib2等),以及HTML解析相关模块(BeautifulSoup、json等)。本文提供多种格式: HTML 版本在线地址为:scrape.html 如果您有任何意见、建议、bug 等,欢迎您在讨论组发帖讨论:阅读 HTML 在线下载( 7zip 压缩包) HTML PDF10 CHM 11 TXT 12 RTF 13 WEBHEL 14 Revision History Revisions1.
前提是讨论如何使用Python来实现,网站爬取,模拟登录,爬取动态网页,前提是你需要对这部分的逻辑有更清晰的理解。如果不确定,请参考:爬取网站、模拟登录、爬取动态网页(Python、C#等)原理及实现详解如何使用Python实现网站@ > 爬取,模拟登录,如何使用Python爬取动态网页网站 爬取,模拟登录,爬取动态网页相关的老帖子【教程】爬取网页,从网页中提取需要的信息。其实对于urllib这样的库,我们已经做得够好了,尤其是在易用性方面,使用起来已经很方便了。例如,可以直接从以下代码中获取网页地址,网页源代码为TODO:添加代码。但是,其实网页抓取、网页模拟登录等都需要cookies,以及其他header参数,导致强大易用的网页抓取功能,还需要做很多额外的工作。后来,我在折腾网页抓取。经过实际使用,我在这方面积累了很多经验。最后写了一个相关的函数,功能更强大,使用更方便。主要是两个函数:getUrlResponse 和 getUrlRespHtml TODO:添加两个函数从 crifanLib 解释 TODO:添加这两个函数的几个用法 TODO:添加其他几个相关函数的解释,包括 downloadFile 等函数其实主要分为两个方面:关于一只手,就是抓取网站的内容,涉及到网络处理相关的模块。另一方面就是如何解析抓取到的内容,也就是在HTML解析等相关的模块下,我们来讲解一下这两个方面的相关逻辑,以及如何使用Python来实现相应部分的功能.
Python中的网络处理 Python中的网络处理主要涉及到一些,与网络处理相关的模块有urllib、urllib2等相关老帖子 [完成] Python中用于解析Http包的模块/库TODO:整理和对应是的,进来发表关于 urllib 和 urllib2 的帖子。Python中的HTMl解析Python中的HTMl解析相关老帖子BeautifulSoup模块介绍【已解决】Python中json.loads解析收录\n的字符串会报错【已解决】使用json.loads解码字符串时出错在 Python 中:ValueError: Expecting property name: line JSONobject 可以 Python 并解析 网站 的捕获内容,即解析 HTML、JSON 等方面。相关模块包括 BeautifulSoup、json 等。 参考文献 11 12 13 14 15 #cc_by_nc
python抓取动态网页(python怎样爬取动态网站的相关内容吗,爱喝马黛茶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-15 03:16
想知道python是如何抓取动态网站内容的吗?爱喝马黛茶的Anthony,为大家详细讲解python如何爬取动态网站相关知识和一些代码示例。欢迎阅读并指正,先画重点:python,动态网站,一起学习。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
相关文章 查看全部
python抓取动态网页(python怎样爬取动态网站的相关内容吗,爱喝马黛茶)
想知道python是如何抓取动态网站内容的吗?爱喝马黛茶的Anthony,为大家详细讲解python如何爬取动态网站相关知识和一些代码示例。欢迎阅读并指正,先画重点:python,动态网站,一起学习。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
相关文章
python抓取动态网页(python爬虫遇到ajax动态页面怎么办?直接指向当前目录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-10-15 03:14
一般情况下,python爬虫遇到ajax动态页面时,通常会直接分析模拟ajax请求获取数据。但是今天遇到了一个网站,因为某些原因没有公开网址。点击搜索按钮后,先跳到a页,然后从a页跳到b页,再从b页跳回a页。这两个跳转完成后,ajax提交给a页面的请求就会返回结果。
我也怀疑是cookie或者refenen的问题,结果证明不是这个原因。即使你伪造请求头后访问页面a,返回的也不是真正的结果页面,而是一段跳转到页面b的js代码。
既然你不知道网站在跳跃过程中做了什么,那我们就直接上大杀器吧。
phantomjs 可以简单理解为一个js解释器,不用说selenium,用pip安装就行了。
从(当然也可以自己下载源码)下载编译好的包,解压后的bin目录就是我们需要的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
if __name__ == "__main__":
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.resourceTimeout"] = 5
dcap["phantomjs.page.settings.loadImages"] = False
# 伪造ua信息
dcap["phantomjs.page.settings.userAgent"] = ("myua")
# 添加头文件
# dcap["phantomjs.page.customHeaders.Referer"] = (
# "https://www.google.com/"
#)
# 代理
service_args = [
'--proxy=127.0.0.1:8080',
#'--proxy-type=http',
#'--proxy-type=socks5',
#'--proxy-auth=username:password'
]
driver = webdriver.PhantomJS(
executable_path='./phantomjs',
service_args=service_args,
desired_capabilities=dcap
)
driver.get("http://www.xxx.cn/")
driver.find_element_by_id('kw').send_keys("xxx") #模仿填写搜索内容
driver.find_element_by_id("btn_ci").click() #模仿点击搜索按钮
time.sleep(7)#等待页面加载
page = driver.page_source
open("res.html","w").write(page)
driver.quit()
其中,我的源代码直接放在bin目录下,所以executable_path直接指向当前目录。 Find_element_by_id 查看目标网站源码即可看到,睡眠时间也应根据实际情况进行修改。 Driver.implicitly_wait(30)这里也可以用,但是这个网站的data id是随机生成的,所以我直接用sleep。
参考网站: 查看全部
python抓取动态网页(python爬虫遇到ajax动态页面怎么办?直接指向当前目录?)
一般情况下,python爬虫遇到ajax动态页面时,通常会直接分析模拟ajax请求获取数据。但是今天遇到了一个网站,因为某些原因没有公开网址。点击搜索按钮后,先跳到a页,然后从a页跳到b页,再从b页跳回a页。这两个跳转完成后,ajax提交给a页面的请求就会返回结果。
我也怀疑是cookie或者refenen的问题,结果证明不是这个原因。即使你伪造请求头后访问页面a,返回的也不是真正的结果页面,而是一段跳转到页面b的js代码。
既然你不知道网站在跳跃过程中做了什么,那我们就直接上大杀器吧。
phantomjs 可以简单理解为一个js解释器,不用说selenium,用pip安装就行了。
从(当然也可以自己下载源码)下载编译好的包,解压后的bin目录就是我们需要的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
if __name__ == "__main__":
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.resourceTimeout"] = 5
dcap["phantomjs.page.settings.loadImages"] = False
# 伪造ua信息
dcap["phantomjs.page.settings.userAgent"] = ("myua")
# 添加头文件
# dcap["phantomjs.page.customHeaders.Referer"] = (
# "https://www.google.com/"
#)
# 代理
service_args = [
'--proxy=127.0.0.1:8080',
#'--proxy-type=http',
#'--proxy-type=socks5',
#'--proxy-auth=username:password'
]
driver = webdriver.PhantomJS(
executable_path='./phantomjs',
service_args=service_args,
desired_capabilities=dcap
)
driver.get("http://www.xxx.cn/";)
driver.find_element_by_id('kw').send_keys("xxx") #模仿填写搜索内容
driver.find_element_by_id("btn_ci").click() #模仿点击搜索按钮
time.sleep(7)#等待页面加载
page = driver.page_source
open("res.html","w").write(page)
driver.quit()
其中,我的源代码直接放在bin目录下,所以executable_path直接指向当前目录。 Find_element_by_id 查看目标网站源码即可看到,睡眠时间也应根据实际情况进行修改。 Driver.implicitly_wait(30)这里也可以用,但是这个网站的data id是随机生成的,所以我直接用sleep。
参考网站:
python抓取动态网页(Python中有之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-14 22:36
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
最简单的想法之一可以动态分析页面信息。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块就安装好了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com")
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。 查看全部
python抓取动态网页(Python中有之前)
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用 urllib 抓取页面的 HTML 并不足以达到预期的效果。
解决方案:
最简单的想法之一可以动态分析页面信息。Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
图书馆,而不是创作者。Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则,安装可能会失败。
官方网站:
2、SIP、PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。Mac和Linux需要自己编译。
下载地址为:
切换到终端解压文件所在的目录。
在终端输入
蟒蛇配置.py
制作
须藤制作安装
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在 Python shell 中输入 import PyQt4 看看能不能找到 PyQt4 模块。
3、斯宾纳
spynner是一个QtWebKit客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载链接:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块就安装好了。在 python shell 中尝试 import spynner 看看是否安装了模块。
Spynner的简单使用
Spynner的功能很强大,但是由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python
#-*-coding: utf-8 -*-
import spynner
browser = spynner.Browser()
#创建一个浏览器对象
browser.hide()
#打开浏览器,并隐藏。
browser.load("http://www.baidu.com";)
#browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。
#load(是你想要加载的网址的字符串形式)
print browser.html.encode("utf-8")
#browser 类中有一个成员是html,是页面进过处理后的源码的字符串.
#将其转码为UTF-8编码
open("Test.html", 'w+').write(browser.html.encode("utf-8"))
#你也可以将它写到文件中,用浏览器打开。
browser.close()
#关闭该浏览器
通过这个程序,你可以方便的显示webkit处理的页面的HTML源代码。
旋转应用程序
下面介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python
import spynner
import HTMLParser
import os
import urllib
class MyParser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'img':
url = dict(attrs)['src']
name = os.path.basename(dict(attrs)['src'])
if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'):
print "Download.....", name
urllib.urlretrieve(url, name)
if __name__ == "__main__":
browser = spynner.Browser()
browser.show()
browser.load("http://www.artist.cn/snakewu19 ... 6quot;)
Parser = MyParser()
Parser.feed(browser.html)
print "Done"
browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,所以就让繁重的任务交给第三方吧。
python抓取动态网页( 安东尼在本篇内容里小编的相关知识点内容(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-14 20:33
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章的文章就介绍到这里了,更多相关python如何爬取动态网站请搜索脚本之家@之前的文章@k7 >或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
python抓取动态网页(
安东尼在本篇内容里小编的相关知识点内容(一))
python是如何爬取动态的网站
更新时间:2020-09-09 14:39:10 作者:爱喝马黛茶的安东尼
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
至此,这篇关于python如何爬取动态网站的文章的文章就介绍到这里了,更多相关python如何爬取动态网站请搜索脚本之家@之前的文章@k7 >或者继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
python抓取动态网页(:正则抓取动态网页,抓取网页最基本的知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-14 17:02
python抓取动态网页,抓取动态网页最基本的知识是获取当前页面的源代码,首先要获取的是动态网页的html代码,然后用正则表达式模拟抓取网页。一、html文件的获取。1.获取div{position:absolute;//不发生改变的属性}2.获取top1{position:absolute;//不发生改变的属性}3.获取top2{position:absolute;//不发生改变的属性}4.获取top3{position:absolute;//不发生改变的属性}5.获取top4{position:absolute;//不发生改变的属性}6.获取img{position:absolute;//不发生改变的属性}7.获取input{position:absolute;//不发生改变的属性}8.获取文字内容{position:absolute;//不发生改变的属性}9.获取text{position:absolute;//不发生改变的属性}10.获取目录{position:absolute;//不发生改变的属性}二、正则表达式的使用。
1.mysql查询中正则表达式的应用。2.正则表达式的使用:使用mysql查询中正则表达式的应用。3.正则表达式相关参数例题如下。1.关键字匹配任意网页中定义的一个或多个关键字,也可以匹配可选字符。html中的任意定义的任一关键字称为keyword(关键字)。常用的关键字有:标签keyword:class,id等p标签keyword:href,para,div等2.范围匹配任意网页定义的一个或多个选择表达式在正则表达式中嵌入选择表达式实际上是定义这样一个有限选择表达式(只有1-n个选择,且是给定正则表达式的子集):标准的google查询:googlesearchhttp://[网站]3.分组匹配选择一组关键字,也可以是选择多组关键字。
常用的有:[网站]class,id,div,p标签中可以匹配多个选择表达式,每组均有一个选择表达式。网站查询为[class]:class,id,div4.对比匹配对比匹配一组关键字,通常都匹配多个关键字。id和id定义的不同关键字匹配到同一网页定义的相同字符。常用的有:p,h1,text,relu中id和id定义的不同关键字匹配到同一网页(三个连续的相同字符串)。
常用的有:string,name,lastlength,total,register,regex5.字符串匹配出classkeyword:标签名,idid:identitylefttext:内容,短网址,http/1.1内容复制为带空格的python字符串:class,id,idx,div,form,text5.shell切片shell切片就是在正则表达式中找值,从1~n数字填充全部的选择表达式中剩余空间shell切片一般是以1作为切分,也可以用%s来切分所有的选择表。 查看全部
python抓取动态网页(:正则抓取动态网页,抓取网页最基本的知识)
python抓取动态网页,抓取动态网页最基本的知识是获取当前页面的源代码,首先要获取的是动态网页的html代码,然后用正则表达式模拟抓取网页。一、html文件的获取。1.获取div{position:absolute;//不发生改变的属性}2.获取top1{position:absolute;//不发生改变的属性}3.获取top2{position:absolute;//不发生改变的属性}4.获取top3{position:absolute;//不发生改变的属性}5.获取top4{position:absolute;//不发生改变的属性}6.获取img{position:absolute;//不发生改变的属性}7.获取input{position:absolute;//不发生改变的属性}8.获取文字内容{position:absolute;//不发生改变的属性}9.获取text{position:absolute;//不发生改变的属性}10.获取目录{position:absolute;//不发生改变的属性}二、正则表达式的使用。
1.mysql查询中正则表达式的应用。2.正则表达式的使用:使用mysql查询中正则表达式的应用。3.正则表达式相关参数例题如下。1.关键字匹配任意网页中定义的一个或多个关键字,也可以匹配可选字符。html中的任意定义的任一关键字称为keyword(关键字)。常用的关键字有:标签keyword:class,id等p标签keyword:href,para,div等2.范围匹配任意网页定义的一个或多个选择表达式在正则表达式中嵌入选择表达式实际上是定义这样一个有限选择表达式(只有1-n个选择,且是给定正则表达式的子集):标准的google查询:googlesearchhttp://[网站]3.分组匹配选择一组关键字,也可以是选择多组关键字。
常用的有:[网站]class,id,div,p标签中可以匹配多个选择表达式,每组均有一个选择表达式。网站查询为[class]:class,id,div4.对比匹配对比匹配一组关键字,通常都匹配多个关键字。id和id定义的不同关键字匹配到同一网页定义的相同字符。常用的有:p,h1,text,relu中id和id定义的不同关键字匹配到同一网页(三个连续的相同字符串)。
常用的有:string,name,lastlength,total,register,regex5.字符串匹配出classkeyword:标签名,idid:identitylefttext:内容,短网址,http/1.1内容复制为带空格的python字符串:class,id,idx,div,form,text5.shell切片shell切片就是在正则表达式中找值,从1~n数字填充全部的选择表达式中剩余空间shell切片一般是以1作为切分,也可以用%s来切分所有的选择表。
python抓取动态网页(1.模拟用户向指定网站发送请求需要下载(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-13 16:15
)
1.模拟用户向指定的网站发送请求
需要下载requests模块,模拟用户向网站发送请求,在终端输入如下命令:
pip install requests
1> 了解网页的结构
学习网页基础知识(通常由HTML(基本网页骨架)、CSS(页面样式)、JS(与用户动态交互)三部分组成)
2> 了解爬虫
网络爬虫(也称为网络蜘蛛)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗的讲就是通过程序获取网页上你想要的数据,也就是自动抓取数据
3>了解防爬
搜索引擎可以使用爬虫来抓取网页信息,进行数据分析等,但是网站中的一些网页信息是不想被抓取的。涉及到反爬虫技术。
反爬虫技术如下:
1. 通过user-Agent控制访问(user-agent使服务器能够识别用户的操作系统和版本,cpu类型,浏览器类型和版本,有的网站会设置user-agent列表范围,范围内可以正常访问),2.受IP限制,3.设置请求间隔,4.自动化测试工具,5.参数通过加密,6.@ > 使用robots.txt 限制爬虫等。
2.分析网页数据
requests库已经可以抓取网页的源代码了,接下来我们需要从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库功能更强大,速度更快,所以我个人建议安装 lxml 库。
pip install bs4
pip install lxml
3.代码部分
1> 抓取图片网站的具体代码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
urllist = []
for i in data:
urllist.append(i.get("data-src"))
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
sp = spider("https://wallhaven.cc/search%3F ... 6quot;)
sp.get()
2> 详细代码
封装了代码,方便批量抓取。首先,导入两个包:requests 和 BeautifulSoup。Requests 是模拟用户向浏览器发送请求,而 BeautifulSoup 是抓取网页中的数据。
url 是目标 URL:
设置请求头:
在请求标头中找到用户代理并复制和粘贴
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
发送请求获取响应数据:(这里html为HTML文本数据)
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
通过BeautifulSoup解析数据:(BeautifulSoup的第一个参数是要解析的数据,第二个参数是解析的方式)
# 解析数据
info = BeautifulSoup(html, "lxml")
使用select选择器定位数据(我们需要图片的url来抓取图片,所以我们需要定位到url)
复制选择器所在的位置:
复制选择器得到:
#thumbs > section > ul > li:nth-child(1) > figure > img
但这只是一张图片,我们要的是当前页面的所有图片,所以这里需要改一下(删除li::后的第n个子(1)):
#thumbs > section > ul > li > figure > img
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
数据输出的结构如下:
得到图片地址后:新建一个列表,把所有的URL都加入列表中
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("data-src"))
名单如下:
再次发送请求,通过解析后的url获取图片。图片名称是通过将url地址字符串分割成片的方式分配给名称,最后以二进制方式写入指定目录。
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
查看结果:
批量抓取另一张网站图片的源码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#main > div.slist > ul > li > a > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("src"))
print(urllist)
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
# name = pictureurl.split("/")[-1]
response = requests.get(url="https://pic.netbian.com"+pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
global number
with open("D:\spiderPicture\pic\%d.jpg" % number, "wb") as f:
f.write(response.content)
number += 1
i = 3
number = 1
while 1:
url = "https://pic.netbian.com/4kmein ... B%25i
sp = spider(url)
sp.get()
i += 1 查看全部
python抓取动态网页(1.模拟用户向指定网站发送请求需要下载(图)
)
1.模拟用户向指定的网站发送请求
需要下载requests模块,模拟用户向网站发送请求,在终端输入如下命令:
pip install requests
1> 了解网页的结构
学习网页基础知识(通常由HTML(基本网页骨架)、CSS(页面样式)、JS(与用户动态交互)三部分组成)
2> 了解爬虫
网络爬虫(也称为网络蜘蛛)是一种按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗的讲就是通过程序获取网页上你想要的数据,也就是自动抓取数据
3>了解防爬
搜索引擎可以使用爬虫来抓取网页信息,进行数据分析等,但是网站中的一些网页信息是不想被抓取的。涉及到反爬虫技术。
反爬虫技术如下:
1. 通过user-Agent控制访问(user-agent使服务器能够识别用户的操作系统和版本,cpu类型,浏览器类型和版本,有的网站会设置user-agent列表范围,范围内可以正常访问),2.受IP限制,3.设置请求间隔,4.自动化测试工具,5.参数通过加密,6.@ > 使用robots.txt 限制爬虫等。
2.分析网页数据
requests库已经可以抓取网页的源代码了,接下来我们需要从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库功能更强大,速度更快,所以我个人建议安装 lxml 库。
pip install bs4
pip install lxml
3.代码部分
1> 抓取图片网站的具体代码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
urllist = []
for i in data:
urllist.append(i.get("data-src"))
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
sp = spider("https://wallhaven.cc/search%3F ... 6quot;)
sp.get()
2> 详细代码
封装了代码,方便批量抓取。首先,导入两个包:requests 和 BeautifulSoup。Requests 是模拟用户向浏览器发送请求,而 BeautifulSoup 是抓取网页中的数据。
url 是目标 URL:
设置请求头:
在请求标头中找到用户代理并复制和粘贴
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
发送请求获取响应数据:(这里html为HTML文本数据)
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
通过BeautifulSoup解析数据:(BeautifulSoup的第一个参数是要解析的数据,第二个参数是解析的方式)
# 解析数据
info = BeautifulSoup(html, "lxml")
使用select选择器定位数据(我们需要图片的url来抓取图片,所以我们需要定位到url)
复制选择器所在的位置:
复制选择器得到:
#thumbs > section > ul > li:nth-child(1) > figure > img
但这只是一张图片,我们要的是当前页面的所有图片,所以这里需要改一下(删除li::后的第n个子(1)):
#thumbs > section > ul > li > figure > img
# 使用select选择器定位数据
data = info.select("#thumbs > section > ul > li > figure > img")
数据输出的结构如下:
得到图片地址后:新建一个列表,把所有的URL都加入列表中
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("data-src"))
名单如下:
再次发送请求,通过解析后的url获取图片。图片名称是通过将url地址字符串分割成片的方式分配给名称,最后以二进制方式写入指定目录。
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
name = pictureurl.split("/")[-1]
response = requests.get(url=pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
with open("D:\spiderPicture\%s" % name, "wb") as f:
f.write(response.content)
查看结果:
批量抓取另一张网站图片的源码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoup
class spider():
def __init__(self,url):
#请求网址
self.url = url
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}
def get(self):
# 通过请求获取响应数据(此数据是html文本格式的数据)
res = requests.get(self.url,headers=self.headers)
html = res.text
# 解析数据
info = BeautifulSoup(html, "lxml")
# 使用select选择器定位数据
data = info.select("#main > div.slist > ul > li > a > img")
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表
print(data)
urllist = []
for i in data:
urllist.append(i.get("src"))
print(urllist)
# 通过解析后的url再次发送请求获取图片
for j in urllist:
pictureurl = j
# 图片命名
# name = pictureurl.split("/")[-1]
response = requests.get(url="https://pic.netbian.com"+pictureurl, headers=self.headers)
# 以二进制数据流的方式写入指定目录文件
global number
with open("D:\spiderPicture\pic\%d.jpg" % number, "wb") as f:
f.write(response.content)
number += 1
i = 3
number = 1
while 1:
url = "https://pic.netbian.com/4kmein ... B%25i
sp = spider(url)
sp.get()
i += 1
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-10 23:47
前言
在抓取一个普通的静态网页时,我们可以直接请求相应的URL来获取完整的HTML页面,但是对于动态页面来说,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/")
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。 查看全部
python抓取动态网页(需安装的三方库示例代码示例说明:获取德邦官网)
前言
在抓取一个普通的静态网页时,我们可以直接请求相应的URL来获取完整的HTML页面,但是对于动态页面来说,网页上显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/";)
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。
python抓取动态网页(switch环境配置lxml抓取静态网页的难点及难点分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-10 11:14
背景说明
有使用switch游戏文件的需要,于是找了一个网站,网站有很多游戏资源,但是这种网站很容易失败,所以我打算用爬虫把资源下载下来,但是在实际爬取的过程中,为了获取实际的网盘地址,需要点击特定的按钮打开,所以结合selenium和html,抓包比较流行网站中的游戏实现
主要收录四个部分
Selenium 环境配置
lxml 获取静态网页[√]
硒得到饼干
selenium 获取下载链接
掌握了以上部分后,就可以算是对爬虫的介绍了
获取游戏的具体页面
爬虫环境在上一章已经配置好了。有兴趣的可以在专栏中找到。本章将抓取网站中各个游戏的具体链接
网站 有按流行度排序的功能,可以按下载量对所有游戏进行排序。大约有四十页的数据。
这个界面的网址很简单。第一个页面的格式是/games/page/1?order=hot 第二个页面的格式是/games/page/2?order=hot
所以首先可以创建一个需要爬取的web_list 网站 准备爬取
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
然后以第一页为例,分析在获取整体页面的情况下如何获取游戏名称和具体的网站。
我们把鼠标右键放在游戏画面上,点击右键选择check
可以解析出网站的实际元素组成
可以看到实际需要的游戏网站和游戏名称都在div层,其中网站在a节点的href元素中,游戏名称在alt元素中a节点的子节点img
所以我们可以写出下面的代码来得到
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
首先将父节点为div的节点a存储在game_list中,然后game_url获取节点a的href元素,game_name获取节点a的子节点img的alt元素,最后保存在write_dir中作为字典保存后续使用
上面的完整代码如下
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
网站 命名避免版权冲突,我们做了编码处理,有需要的朋友可以私信
下一节将处理具体游戏的第二关网站。下一章也是过程中的主要难点,重点分析 查看全部
python抓取动态网页(switch环境配置lxml抓取静态网页的难点及难点分析方法)
背景说明
有使用switch游戏文件的需要,于是找了一个网站,网站有很多游戏资源,但是这种网站很容易失败,所以我打算用爬虫把资源下载下来,但是在实际爬取的过程中,为了获取实际的网盘地址,需要点击特定的按钮打开,所以结合selenium和html,抓包比较流行网站中的游戏实现
主要收录四个部分
Selenium 环境配置
lxml 获取静态网页[√]
硒得到饼干
selenium 获取下载链接
掌握了以上部分后,就可以算是对爬虫的介绍了
获取游戏的具体页面
爬虫环境在上一章已经配置好了。有兴趣的可以在专栏中找到。本章将抓取网站中各个游戏的具体链接
网站 有按流行度排序的功能,可以按下载量对所有游戏进行排序。大约有四十页的数据。
这个界面的网址很简单。第一个页面的格式是/games/page/1?order=hot 第二个页面的格式是/games/page/2?order=hot
所以首先可以创建一个需要爬取的web_list 网站 准备爬取
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
然后以第一页为例,分析在获取整体页面的情况下如何获取游戏名称和具体的网站。
我们把鼠标右键放在游戏画面上,点击右键选择check
可以解析出网站的实际元素组成
可以看到实际需要的游戏网站和游戏名称都在div层,其中网站在a节点的href元素中,游戏名称在alt元素中a节点的子节点img
所以我们可以写出下面的代码来得到
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
首先将父节点为div的节点a存储在game_list中,然后game_url获取节点a的href元素,game_name获取节点a的子节点img的alt元素,最后保存在write_dir中作为字典保存后续使用
上面的完整代码如下
import time
import json
import re
import sys
import lxml.html as HTML
import requests
from lxml import etree
import json
aim_url_list = []
for i in range(10):
aim_url_list.append('https://www.xxxx.vip/games/page/{}?order=hot'.format(i+1))
write_dir = {}
for j in range(10):
r = requests.get(aim_url_list[j])
html = etree.HTML(r.text, etree.HTMLParser())
game_list = html.xpath('//div[@class="placeholder"]/a')
for game in game_list:
game_name = game.xpath('./img/@alt')[0]
game_url = game.xpath('./@href')[0]
write_dir[game_name] = game_url
print(write_dir)
with open('./game.json','w') as f:
json.dump(write_dir, f)
time.sleep(3)
网站 命名避免版权冲突,我们做了编码处理,有需要的朋友可以私信
下一节将处理具体游戏的第二关网站。下一章也是过程中的主要难点,重点分析
python抓取动态网页( Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-09 15:04
Python网络爬虫内容提取器一文讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(在windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,那几行代码也不多,够看Python了强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
python抓取动态网页(
Python网络爬虫内容提取器一文讲解)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:使用直观的采集和搜索客户标记功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(在windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果把这个字符串删掉,那几行代码也不多,够看Python了强大的
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已被正确抓取
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工写的,而是程序自动生成的,这是有道理的,程序员不再需要花时间编写和调试捕获规则,这是一项非常耗时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
python抓取动态网页(工具分析登录页面打开登录过程从分析可以看到哪些信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-10-09 15:03
最近的项目在做一些数据集成,各种系统对应的接口就更陌生了。数据整合的过程可以用八个字来概括:山上有路,水中有桥。
这两天碰巧出了问题。我们要集成的WEB系统没有提供专门的数据集成接口,没有API可以调整,数据库是不允许访问的。无奈中,想知道能不能用python自动爬取。页。网页有SSO,应该使用开源的CAS框架,后面的页面都是动态JS和AJAX异步加载的。显然,这不像是直接使用Scrapy上传的普通静态页面。它必须是完美的。要模拟登陆动作,抓取后续动态内容,对页面结构和抓取内容的分析必不可少。
工具分析登陆页面
打开登录页面,按F12打开Chrome自带的分析工具。在网络选项卡上,可以看到当前浏览器显示页面的详细信息和提交的登录信息,如下图
网站 登录页面
从截图中可以看到,当我们访问app/this url的日志时,由于我们还没有登录,SSO会自动重定向到登录页面,所以http状态是302重定向。
接下来,我们在页面输入账号密码,点击登录按钮,通过页面跟踪分析和模拟整个登录过程。这个过程一定要特别小心,因为很多CAS在登录页面都埋了很多隐藏的标记,一处是模仿不来的。它将无法登录,然后被重定向到开头。
分析登录过程
从分析中可以看出,在提交登录按钮时,会使用POST方式提交表单,并且表单中除了账号密码等显眼的字段外,还有一个lt。经验告诉我们,这个字段应该隐藏在之前的登录页面上。它用于验证登录页面的合法性,因此我们需要从登录页面中查找并提取此信息。同时注意http的消息头。最好根据浏览器抓到的消息头来构造,因为网站也会验证里面的信息。
以下是登录的主要代码。我们基于python3和requests包处理https访问请求,模拟浏览器的行为,构造认证所需的信息发送给网站。
import requestsimport urllib3from lxml import etreefrom ows_scrapy.ows_spider.write_csv import write_list_to_csv
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
s = requests.session()
s.trust_env = False # fastercookie = Noneusername = 'username'password = 'pwd'def login():
header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Cookie': 'JSESSIONID=73E10849812940333A4AD2A2ABAEFB7D8CFF3E76A45340FFB687FD587D2EB97A49FC5F156D09DB1E17F129465AB8D8EBACEC', 'Host': '', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
form_data = { 'username': username, 'password': password, '_eventId': 'submit', 'pwdfirst': password[0:2], 'pwdsecond': password[2:5], 'pwdthird': password[5:]
}
login_url = 'https://.com/app/'
print('login...')
res = s.get(login_url, headers=header, verify=False) global cookie
cookie = res.cookies # 注意要保存cookie
print("get response from ows {0}, http status {1}".format(login_url, res.status_code))
login_url = res.url
header['Referer'] = login_url
header['Cookie'] = 'JSESSIONID=' + cookie['JSESSIONID']
form_data['lt'] = str(etree.HTML(res.content).xpath('//input[@name="lt"]/@value')[0]) #用xpath从页面上提取lt
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
cookie = res.cookies
print("post login params to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie))
res = s.send(res.next, allow_redirects=False, verify=False)
cookie = res.cookies
print("redirect to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie)) if res.status_code == 200 or res.status_code == 302: if cookie is not None and cookie.get(name='JSESSIONID', path='/app') is not None :
print('Successful login.') else:
print('WRONG w3id/password!')
sys.exit(0)
这里要特别注意,因为http是无状态的,需要cookies来保存网页的登录状态。页面成功后,页面的响应将收录一个带有有效标记的cookie。登录的最终目的是获取并保存这个有效的cookie,这样后续的访问就不会被重定向到登录页面。
在 requests 方法中,只需将 cookie 添加到请求中即可。
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
分析动态内容页面
在动态页面中,页面显示的内容往往是通过js或者AJAX异步获取的,这明显不同于静态html页面的分析过程。使用 Chrome 的分析工具也可以轻松获取此信息。
分析动态页面
动态页面加载完成后,我们从所有请求中过滤出XHR类型,找到我们想要的请求,然后在请求的Preview中就可以看到完整的对应信息了,请求的URL也可以从Obtained中查看在标题选项卡中。
接下来要做的和上面类似,构造一个消息来模拟浏览器向网站发送请求:
def get_content(order_id):
form_data = { 'roarand': 'BW09el5W3mW2sfbGbtWe7mWlwBsWqXg6znppnqkW3woJ5fcz5DnhfWXGonqkLsd0', 'start': '0', 'limit': '20', 'orderid': order_id, 'serviceId': 'test_gscsocsecurityincidentmanage_log_getList2'
}
header = { 'Accept': 'text/plain, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8', 'Host': '.com', 'Origin': 'https://.com', 'Referer': 'https://.com/app/104h/spl/test/ID_480_1511441539904_workflowdetail.spl?orderid=SOC-20180220-00000003', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'
}
print('Start to scan order id ' + order_id)
url = 'https://.com/app/pageservices/service.do?forAccessLog={serviceName:test_gscsocsecurityincidentmanage_log_getList2,userId:571bdd42-10ca-4ce1-b41c-8a3f6632141f,tenantId:104h}&trackId=fec68f8e-f30a-4fa1-a8b1-41d3dd11fa4c'
res = s.post(url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False) #要加载上面登录成功的cookie
print(res.content) return res
重点其实就是从XHR中找到请求的URI,构造请求头并提交表单,最后一定要添加成功登录cookie,否则会被重定向到登录页面。
有很多方法可以抓取动态页面。这种方式依赖的包相对较少,代码也比较灵活。爬取复杂登录页面时效果更好,但在分析页面登录机制时一定要特别小心。 查看全部
python抓取动态网页(工具分析登录页面打开登录过程从分析可以看到哪些信息)
最近的项目在做一些数据集成,各种系统对应的接口就更陌生了。数据整合的过程可以用八个字来概括:山上有路,水中有桥。
这两天碰巧出了问题。我们要集成的WEB系统没有提供专门的数据集成接口,没有API可以调整,数据库是不允许访问的。无奈中,想知道能不能用python自动爬取。页。网页有SSO,应该使用开源的CAS框架,后面的页面都是动态JS和AJAX异步加载的。显然,这不像是直接使用Scrapy上传的普通静态页面。它必须是完美的。要模拟登陆动作,抓取后续动态内容,对页面结构和抓取内容的分析必不可少。
工具分析登陆页面
打开登录页面,按F12打开Chrome自带的分析工具。在网络选项卡上,可以看到当前浏览器显示页面的详细信息和提交的登录信息,如下图
网站 登录页面
从截图中可以看到,当我们访问app/this url的日志时,由于我们还没有登录,SSO会自动重定向到登录页面,所以http状态是302重定向。
接下来,我们在页面输入账号密码,点击登录按钮,通过页面跟踪分析和模拟整个登录过程。这个过程一定要特别小心,因为很多CAS在登录页面都埋了很多隐藏的标记,一处是模仿不来的。它将无法登录,然后被重定向到开头。
分析登录过程
从分析中可以看出,在提交登录按钮时,会使用POST方式提交表单,并且表单中除了账号密码等显眼的字段外,还有一个lt。经验告诉我们,这个字段应该隐藏在之前的登录页面上。它用于验证登录页面的合法性,因此我们需要从登录页面中查找并提取此信息。同时注意http的消息头。最好根据浏览器抓到的消息头来构造,因为网站也会验证里面的信息。
以下是登录的主要代码。我们基于python3和requests包处理https访问请求,模拟浏览器的行为,构造认证所需的信息发送给网站。
import requestsimport urllib3from lxml import etreefrom ows_scrapy.ows_spider.write_csv import write_list_to_csv
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
s = requests.session()
s.trust_env = False # fastercookie = Noneusername = 'username'password = 'pwd'def login():
header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Cookie': 'JSESSIONID=73E10849812940333A4AD2A2ABAEFB7D8CFF3E76A45340FFB687FD587D2EB97A49FC5F156D09DB1E17F129465AB8D8EBACEC', 'Host': '', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
form_data = { 'username': username, 'password': password, '_eventId': 'submit', 'pwdfirst': password[0:2], 'pwdsecond': password[2:5], 'pwdthird': password[5:]
}
login_url = 'https://.com/app/'
print('login...')
res = s.get(login_url, headers=header, verify=False) global cookie
cookie = res.cookies # 注意要保存cookie
print("get response from ows {0}, http status {1}".format(login_url, res.status_code))
login_url = res.url
header['Referer'] = login_url
header['Cookie'] = 'JSESSIONID=' + cookie['JSESSIONID']
form_data['lt'] = str(etree.HTML(res.content).xpath('//input[@name="lt"]/@value')[0]) #用xpath从页面上提取lt
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
cookie = res.cookies
print("post login params to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie))
res = s.send(res.next, allow_redirects=False, verify=False)
cookie = res.cookies
print("redirect to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie)) if res.status_code == 200 or res.status_code == 302: if cookie is not None and cookie.get(name='JSESSIONID', path='/app') is not None :
print('Successful login.') else:
print('WRONG w3id/password!')
sys.exit(0)
这里要特别注意,因为http是无状态的,需要cookies来保存网页的登录状态。页面成功后,页面的响应将收录一个带有有效标记的cookie。登录的最终目的是获取并保存这个有效的cookie,这样后续的访问就不会被重定向到登录页面。
在 requests 方法中,只需将 cookie 添加到请求中即可。
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
分析动态内容页面
在动态页面中,页面显示的内容往往是通过js或者AJAX异步获取的,这明显不同于静态html页面的分析过程。使用 Chrome 的分析工具也可以轻松获取此信息。
分析动态页面
动态页面加载完成后,我们从所有请求中过滤出XHR类型,找到我们想要的请求,然后在请求的Preview中就可以看到完整的对应信息了,请求的URL也可以从Obtained中查看在标题选项卡中。
接下来要做的和上面类似,构造一个消息来模拟浏览器向网站发送请求:
def get_content(order_id):
form_data = { 'roarand': 'BW09el5W3mW2sfbGbtWe7mWlwBsWqXg6znppnqkW3woJ5fcz5DnhfWXGonqkLsd0', 'start': '0', 'limit': '20', 'orderid': order_id, 'serviceId': 'test_gscsocsecurityincidentmanage_log_getList2'
}
header = { 'Accept': 'text/plain, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8', 'Host': '.com', 'Origin': 'https://.com', 'Referer': 'https://.com/app/104h/spl/test/ID_480_1511441539904_workflowdetail.spl?orderid=SOC-20180220-00000003', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'
}
print('Start to scan order id ' + order_id)
url = 'https://.com/app/pageservices/service.do?forAccessLog={serviceName:test_gscsocsecurityincidentmanage_log_getList2,userId:571bdd42-10ca-4ce1-b41c-8a3f6632141f,tenantId:104h}&trackId=fec68f8e-f30a-4fa1-a8b1-41d3dd11fa4c'
res = s.post(url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False) #要加载上面登录成功的cookie
print(res.content) return res
重点其实就是从XHR中找到请求的URI,构造请求头并提交表单,最后一定要添加成功登录cookie,否则会被重定向到登录页面。
有很多方法可以抓取动态页面。这种方式依赖的包相对较少,代码也比较灵活。爬取复杂登录页面时效果更好,但在分析页面登录机制时一定要特别小心。
python抓取动态网页(数据怎么破()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-09 15:02
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:
小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!
(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓了太多,发现有些小网站很狡猾,开始反爬虫了。它们不直接生成数据,而是通过加载JS生成数据,然后你打开Chrome浏览器的开发者选项,然后你会发现Elements页面的结构和网络抓包返回的内容不一样. 网络抓包中没有对应的数据。数据应该放的地方竟然是JS代码,比如煎蛋的少女图:
">
对于我这种不懂JS的安卓狗,不禁感叹:
">
抓不到数据怎么破?一开始想自学一波JS基础语法。然后我去模拟抓包来获取别人的JS文件。JS竟然被加密了,要爬的页面太多了。什么时候分析每个这样的分析...
">
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。简单说说这个东西的使用,我们可以写代码让浏览器:
然后这个东西不支持浏览器功能。您需要在第三方浏览器中使用它。支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
Chrome: /a/chromium....FireFox: /mozilla/gec...PhantomJS: /IE: /index.htmlEdge: /en-us/micro...Opera: /operasoftwa...
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
复制代码
PS:我记得我公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。其实如果你安装Python3,它默认已经自带pip了。您需要配置额外的环境变量,pip。路径在Python安装目录的Scripts目录下~
">
在Path后面加上这个路径就行了~
">2.下载浏览器驱动
因为 Selenium 没有浏览器,所以需要依赖第三方浏览器。如果要调用第三方浏览器,需要下载浏览器的驱动。由于作者使用的是 Chrome,所以我们以 Chrome 为例。其他 浏览器自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
复制代码
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
">
61.好的,那么到下面网站查看对应的驱动版本号:
/2.34/notes....
">
好的,接下来下载v2.34版本的浏览器驱动:
/index.html?...
">
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python Scripts目录下。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件拷贝到usr/local/bin目录下,再拷贝到usr/bin目录下。
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
复制代码
执行这段代码会自动调出浏览器访问百度:
">
并且控制台会输出HTML代码,也就是直接得到的Elements页面结构,JS执行后的页面~接下来就可以抓取我们的煎蛋少女图了~
3.Selenium 简单实战:抢炒蛋妹图
直接分析Elements页面的结构,找到你想要的关键节点:
">
显然这是我们抓到的那个小姐姐的照片。复制这个网址,看看我们打印出来的页面结构是否收录这个东西:
">
是的这很好。有了这个页面数据,我们就来一波美汤获取我们想要的数据吧~
">
经过上面的过滤,我们就可以得到我们妹图的URL:
">
只需打开一个验证,啧:
">
">
我看到下一页只有30个小姐姐,这对我们来说显然不够。第一次加载的时候,我们得到一波页码,然后我们就知道有多少页了,然后我们去拼接URL加载差异。例如,这里总共有 448 页:
">
只需将其拼接到此 URL 中:过滤以获取页码:
">
">
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
复制代码
操作结果:
">
看看我们的输出文件夹~
">
是的,发了这么多小姐姐,就是想骗你学Python!
">4.PhantomJS
PhantomJS 没有界面浏览器。特点: 它将网站加载到内存中并在页面上执行JavaScript。因为它不显示图形界面,所以它比完整的浏览器运行效率更高。(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的,可以使用PhantomJS来规避这个问题)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
复制代码
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS,这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始提供 Headless 模式(不需要挂掉浏览器),所以估计使用 PhantomJS 的小伙伴会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持 Headless 模式。启用 Headless 模式也很简单:
">
selenium 的官方文档中还写道:
">
运行时也会报这个警告:
">5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:/account/log...
分析页面结构,不难发现对应的登录输入框和登录按钮:
">
">
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,并将cookie保存到本地,然后就可以带着cookie访问相关页面了~
首先写一个方法来模拟登录:
">
找到你输入账号密码的节点,设置你的账号密码,然后找到登录按钮节点,点击它,然后等待登录成功。登录成功后,可以对比current_url是否发生了变化。然后保存Cookies,这里我使用的是pickle库,你可以使用其他的,比如json,或者字符串拼接,然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用Cookie访问主页。
">
通过 add_cookies 方法设置 Cookie。参数是字典类型。另外一定要先访问get链接,再设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
">6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。下面是我觉得比较常用的函数,更多的可以看官方文档:官方API文档:seleniumhq.github.io/selenium/do...
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表,例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,如:单击、双击、右键、按住、拖动等,可以导入ActionChains类:mon.action_chains.ActionChains使用ActionChains(driver).XXX调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发某个时间,弹出对话框,可以调用如下方法获取对话框:alert = driver.switch_to_alert(),然后调用如下方法即可:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("window name") 或者在driver.window_handles中遍历window_handles获取句柄:driver.switch_to_window(handle)driver.forward()# forward driver.back()#返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果此时没有找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
复制代码
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。如果元素已经存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不用自己编写一些等待条件。
title_istitle_containspresence_of_element_locatedvisibility_of_element_locatedvisibility_ofpresence_of_all_elements_locatedtext_to_be_present_in_elementtext_to_be_present_in_element_valueframe_to_be_available_and_switch_to_itinvisibility_of_element_locatedelement_to_be_clickable - 它显示和Enabled.staleness_ofelement_to_be_selectedelement_located_to_be_selectedelement_selection_state_to_beelement_located_selection_state_to_bealert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
复制代码
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js语句)如滚动到底部:js = document.body.scrollTop=10000driver.execute_script(js)
概括
本节介绍一波使用 Selenium 自动化测试框架来捕获 JavaScript 动态生成的数据。Selenium 需要依赖第三方浏览器。注意 PhantomJS 无界面浏览器的过时问题。您可以使用 Chrome 和 FireFox 提供的 HeadLess 来替换它。; 通过抓取煎蛋女孩图片,模拟CSDN自动登录的例子,熟悉Selenium的基本使用,还是收获不少。当然,Selenium 的水还是很深的。目前我们可以用它来应对JS动态加载数据页面数据的抓取。
最近有点冷,大家记得及时加衣服哦~另外,因为这周事情比较多,先把换的破了。下周见。下一个要啃的骨头是 Python 多线程。我可以在视觉上,恭敬地啃几节经文。敬请期待~
">
顺便写下你的想法:
下载本节源码:
/coder-pig/R...
本节参考资料:
来吧,Py 交易
想加群一起学Py可以加小猪智障机器人,验证信息收录:python,python,py,Py,加群,交易,混蛋之一关键词 可以通过;
">
验证通过后回复群获取群链接(不要破机器人!!!)~~~欢迎像我这样的各类Py初学者和Py大神加入,一起交流学习♂ Xi, van ♂转向py。
"> 查看全部
python抓取动态网页(数据怎么破()())
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:
小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!
(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓了太多,发现有些小网站很狡猾,开始反爬虫了。它们不直接生成数据,而是通过加载JS生成数据,然后你打开Chrome浏览器的开发者选项,然后你会发现Elements页面的结构和网络抓包返回的内容不一样. 网络抓包中没有对应的数据。数据应该放的地方竟然是JS代码,比如煎蛋的少女图:
">
对于我这种不懂JS的安卓狗,不禁感叹:
">
抓不到数据怎么破?一开始想自学一波JS基础语法。然后我去模拟抓包来获取别人的JS文件。JS竟然被加密了,要爬的页面太多了。什么时候分析每个这样的分析...
">
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。简单说说这个东西的使用,我们可以写代码让浏览器:
然后这个东西不支持浏览器功能。您需要在第三方浏览器中使用它。支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
Chrome: /a/chromium....FireFox: /mozilla/gec...PhantomJS: /IE: /index.htmlEdge: /en-us/micro...Opera: /operasoftwa...
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
复制代码
PS:我记得我公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。其实如果你安装Python3,它默认已经自带pip了。您需要配置额外的环境变量,pip。路径在Python安装目录的Scripts目录下~
">
在Path后面加上这个路径就行了~
">2.下载浏览器驱动
因为 Selenium 没有浏览器,所以需要依赖第三方浏览器。如果要调用第三方浏览器,需要下载浏览器的驱动。由于作者使用的是 Chrome,所以我们以 Chrome 为例。其他 浏览器自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
复制代码
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
">
61.好的,那么到下面网站查看对应的驱动版本号:
/2.34/notes....
">
好的,接下来下载v2.34版本的浏览器驱动:
/index.html?...
">
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python Scripts目录下。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件拷贝到usr/local/bin目录下,再拷贝到usr/bin目录下。
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
复制代码
执行这段代码会自动调出浏览器访问百度:
">
并且控制台会输出HTML代码,也就是直接得到的Elements页面结构,JS执行后的页面~接下来就可以抓取我们的煎蛋少女图了~
3.Selenium 简单实战:抢炒蛋妹图
直接分析Elements页面的结构,找到你想要的关键节点:
">
显然这是我们抓到的那个小姐姐的照片。复制这个网址,看看我们打印出来的页面结构是否收录这个东西:
">
是的这很好。有了这个页面数据,我们就来一波美汤获取我们想要的数据吧~
">
经过上面的过滤,我们就可以得到我们妹图的URL:
">
只需打开一个验证,啧:
">
">
我看到下一页只有30个小姐姐,这对我们来说显然不够。第一次加载的时候,我们得到一波页码,然后我们就知道有多少页了,然后我们去拼接URL加载差异。例如,这里总共有 448 页:
">
只需将其拼接到此 URL 中:过滤以获取页码:
">
">
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
复制代码
操作结果:
">
看看我们的输出文件夹~
">
是的,发了这么多小姐姐,就是想骗你学Python!
">4.PhantomJS
PhantomJS 没有界面浏览器。特点: 它将网站加载到内存中并在页面上执行JavaScript。因为它不显示图形界面,所以它比完整的浏览器运行效率更高。(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的,可以使用PhantomJS来规避这个问题)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
复制代码
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS,这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始提供 Headless 模式(不需要挂掉浏览器),所以估计使用 PhantomJS 的小伙伴会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持 Headless 模式。启用 Headless 模式也很简单:
">
selenium 的官方文档中还写道:
">
运行时也会报这个警告:
">5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:/account/log...
分析页面结构,不难发现对应的登录输入框和登录按钮:
">
">
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,并将cookie保存到本地,然后就可以带着cookie访问相关页面了~
首先写一个方法来模拟登录:
">
找到你输入账号密码的节点,设置你的账号密码,然后找到登录按钮节点,点击它,然后等待登录成功。登录成功后,可以对比current_url是否发生了变化。然后保存Cookies,这里我使用的是pickle库,你可以使用其他的,比如json,或者字符串拼接,然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用Cookie访问主页。
">
通过 add_cookies 方法设置 Cookie。参数是字典类型。另外一定要先访问get链接,再设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
">6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。下面是我觉得比较常用的函数,更多的可以看官方文档:官方API文档:seleniumhq.github.io/selenium/do...
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表,例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,如:单击、双击、右键、按住、拖动等,可以导入ActionChains类:mon.action_chains.ActionChains使用ActionChains(driver).XXX调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发某个时间,弹出对话框,可以调用如下方法获取对话框:alert = driver.switch_to_alert(),然后调用如下方法即可:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("window name") 或者在driver.window_handles中遍历window_handles获取句柄:driver.switch_to_window(handle)driver.forward()# forward driver.back()#返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果此时没有找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
复制代码
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。如果元素已经存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不用自己编写一些等待条件。
title_istitle_containspresence_of_element_locatedvisibility_of_element_locatedvisibility_ofpresence_of_all_elements_locatedtext_to_be_present_in_elementtext_to_be_present_in_element_valueframe_to_be_available_and_switch_to_itinvisibility_of_element_locatedelement_to_be_clickable - 它显示和Enabled.staleness_ofelement_to_be_selectedelement_located_to_be_selectedelement_selection_state_to_beelement_located_selection_state_to_bealert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading";)
myDynamicElement = driver.find_element_by_id("myDynamicElement")
复制代码
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js语句)如滚动到底部:js = document.body.scrollTop=10000driver.execute_script(js)
概括
本节介绍一波使用 Selenium 自动化测试框架来捕获 JavaScript 动态生成的数据。Selenium 需要依赖第三方浏览器。注意 PhantomJS 无界面浏览器的过时问题。您可以使用 Chrome 和 FireFox 提供的 HeadLess 来替换它。; 通过抓取煎蛋女孩图片,模拟CSDN自动登录的例子,熟悉Selenium的基本使用,还是收获不少。当然,Selenium 的水还是很深的。目前我们可以用它来应对JS动态加载数据页面数据的抓取。
最近有点冷,大家记得及时加衣服哦~另外,因为这周事情比较多,先把换的破了。下周见。下一个要啃的骨头是 Python 多线程。我可以在视觉上,恭敬地啃几节经文。敬请期待~
">
顺便写下你的想法:
下载本节源码:
/coder-pig/R...
本节参考资料:
来吧,Py 交易
想加群一起学Py可以加小猪智障机器人,验证信息收录:python,python,py,Py,加群,交易,混蛋之一关键词 可以通过;
">
验证通过后回复群获取群链接(不要破机器人!!!)~~~欢迎像我这样的各类Py初学者和Py大神加入,一起交流学习♂ Xi, van ♂转向py。
">
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-07 16:37
爬虫抓取数据时,有些数据是动态的。比如动态加载js。如果用普通的urllib2抓取数据,是找不到相关数据的。这是爬虫初学者在使用过程中最可能出现的情况。,显然浏览器中有相应的信息,但是python爬取的网页中却缺少相应的信息。这通常是因为网页使用js异步加载数据,动态显示。处理这种情况的一种方法是找到对应的js接口,但有时这种情况是非常少见的,因为js的调用参数也被解析了,有的参数也被加密了,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应信息,
安装硒
在python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com") # Load page
print browser.page_source
selenium虽然安装成功,但是还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用 pip 安装 selenium。默认安装最新版本的 selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1,selenium 3.x启动,在 webdriver/firefox/webdriver.py 的 __init__ 中, executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
将火狐升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究硒文档。
使用 BeautifulSoup 进行 html 解析
如果你还不知道BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup来解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:go2coding 查看全部
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的)
爬虫抓取数据时,有些数据是动态的。比如动态加载js。如果用普通的urllib2抓取数据,是找不到相关数据的。这是爬虫初学者在使用过程中最可能出现的情况。,显然浏览器中有相应的信息,但是python爬取的网页中却缺少相应的信息。这通常是因为网页使用js异步加载数据,动态显示。处理这种情况的一种方法是找到对应的js接口,但有时这种情况是非常少见的,因为js的调用参数也被解析了,有的参数也被加密了,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应信息,
安装硒
在python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com";) # Load page
print browser.page_source
selenium虽然安装成功,但是还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用 pip 安装 selenium。默认安装最新版本的 selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1,selenium 3.x启动,在 webdriver/firefox/webdriver.py 的 __init__ 中, executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
将火狐升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究硒文档。
使用 BeautifulSoup 进行 html 解析
如果你还不知道BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup来解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
更多教程:go2coding
python抓取动态网页(python爬虫抓取动态网页的学习教程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-06 07:01
python抓取动态网页。网上有大量关于爬虫的学习教程,很多人面对如此庞大的网站都无从下手,下面我们主要介绍下python爬虫基础知识,然后带你了解下主流的baidu、google以及百度等网站的动态网页数据源是如何抓取下来的。准备好python基础知识,pandas库,mysql必须要会使用,django和flask不太需要python基础知识。
学习步骤1.打开百度,搜索在本地搭建个baidu分站(此时是没有登录或者不能修改密码的)2.下载动态网页抓取的软件(scrapy、selenium、flask,以及webpage6等)3.在/下载各个开发套件的文件4.下载软件,把所有软件都解压缩,所有开发套件是一个txt文件在python虚拟环境下,要使用第三方库需要安装对应的库,python中已经集成了所有的第三方库,pipinstallpython就可以将所有开发套件包括库完全集成5.输入scrapystartprojectxxx,即可开始scrapystartprojectxxx6.在article框里输入脚本文件名scrapystartprojectxxx,即可将会生成一个scrapy脚本,scrapy脚本里面有main.py,start_url.py,hello.py等文件7.在hello.py中输入每一步所需要的参数就可以完成爬虫编写。
8.使用flask框架进行开发框架搭建首先使用scrapystartprojectflask,编写一个todomvc.py,同样输入main.py。scrapystartprojectxxx,也就是整个脚本的文件名。在article框输入脚本文件名,就能打开网页了,例如在/下输入脚本文件名scrapystartprojectxxx,在/下也可以访问,和xxx文件是一样的(在python2中,路径要用...开头):webhead.py输入你生成的网址就可以访问了。
一般是网页标题+内容,例如在/上我们可以看到一些常见的html内容:url:name:contact这个时候article=flask启动之后,我们在/下输入登录你的浏览器,看到就是你想要的效果了:url:我们可以看到会打开许多js代码,实际上就是用javascript去拼接,这个js里面包含的内容就是网页上的文字信息,这里需要重点讲一下。
scrapystartprojectxxx,在/下输入登录你的浏览器,就可以看到我们想要的效果了:网页抓取动态教程本篇文章讲解scrapy动态网页抓取教程,并以迅雷的视频为例,大家一定要准备好空白图片(a4纸大小)或者黑色笔记本。图片直接复制到电脑中打开,点击浏览器右上角画折角输入我们之前看到的refer在该地址获取文件名,不要复制网址。比如::8080/就会打开迅雷视频。然后我们点击播放按钮,这时候就会自动抓取视频下面的文。 查看全部
python抓取动态网页(python爬虫抓取动态网页的学习教程-乐题库)
python抓取动态网页。网上有大量关于爬虫的学习教程,很多人面对如此庞大的网站都无从下手,下面我们主要介绍下python爬虫基础知识,然后带你了解下主流的baidu、google以及百度等网站的动态网页数据源是如何抓取下来的。准备好python基础知识,pandas库,mysql必须要会使用,django和flask不太需要python基础知识。
学习步骤1.打开百度,搜索在本地搭建个baidu分站(此时是没有登录或者不能修改密码的)2.下载动态网页抓取的软件(scrapy、selenium、flask,以及webpage6等)3.在/下载各个开发套件的文件4.下载软件,把所有软件都解压缩,所有开发套件是一个txt文件在python虚拟环境下,要使用第三方库需要安装对应的库,python中已经集成了所有的第三方库,pipinstallpython就可以将所有开发套件包括库完全集成5.输入scrapystartprojectxxx,即可开始scrapystartprojectxxx6.在article框里输入脚本文件名scrapystartprojectxxx,即可将会生成一个scrapy脚本,scrapy脚本里面有main.py,start_url.py,hello.py等文件7.在hello.py中输入每一步所需要的参数就可以完成爬虫编写。
8.使用flask框架进行开发框架搭建首先使用scrapystartprojectflask,编写一个todomvc.py,同样输入main.py。scrapystartprojectxxx,也就是整个脚本的文件名。在article框输入脚本文件名,就能打开网页了,例如在/下输入脚本文件名scrapystartprojectxxx,在/下也可以访问,和xxx文件是一样的(在python2中,路径要用...开头):webhead.py输入你生成的网址就可以访问了。
一般是网页标题+内容,例如在/上我们可以看到一些常见的html内容:url:name:contact这个时候article=flask启动之后,我们在/下输入登录你的浏览器,看到就是你想要的效果了:url:我们可以看到会打开许多js代码,实际上就是用javascript去拼接,这个js里面包含的内容就是网页上的文字信息,这里需要重点讲一下。
scrapystartprojectxxx,在/下输入登录你的浏览器,就可以看到我们想要的效果了:网页抓取动态教程本篇文章讲解scrapy动态网页抓取教程,并以迅雷的视频为例,大家一定要准备好空白图片(a4纸大小)或者黑色笔记本。图片直接复制到电脑中打开,点击浏览器右上角画折角输入我们之前看到的refer在该地址获取文件名,不要复制网址。比如::8080/就会打开迅雷视频。然后我们点击播放按钮,这时候就会自动抓取视频下面的文。
python抓取动态网页(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-06 00:15
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的
网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:
在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
让我们再次打开它:
结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:
返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
python抓取动态网页(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问
)
我们以前爬网的大多数网页都是静态生成的HTML内容。我们可以直接从HTML源代码中找到数据和内容。然而,并不是所有的网页都是这样的
网站的某些内容由前端JS动态生成。因为网页上显示的内容是由JS生成的,所以我们可以在浏览器中看到它,但在HTML源代码中找不到它。例如,今天的标题:
浏览器呈现的网页如下所示:
请看源代码,但它是这样的:
在HTML源代码中找不到该网页的新闻。它都是由JS动态生成和加载的
在这种情况下,我们应该如何抓取网页?有两种方法:
1、查找JS脚本从网页响应返回的JSON数据2、使用selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使web页面内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据接口返回的JSON数据进行加载和呈现
因此,我们可以找到JS调用的数据接口,并从数据接口中找到最终显示在web页面中的数据
以今天的头条新闻为例:
1、从中查找JS请求的数据接口
F12开放式web调试工具
选择“网络”选项卡后,我们发现有许多响应。让我们进行筛选,只看XHR响应
(XHR是Ajax中的一个概念,代表XMLHttpRequest)
然后我们发现有很多链接丢失了。单击打开一个:
我们选择city,预览中有一串JSON数据:
让我们再次打开它:
结果是一张城市名单。应该使用它来加载区域新闻
现在您可能知道如何找到JS请求的接口了吧?但是我们没有找到我们刚才想要的消息。再看一看,
有一个焦点。让我们点击查看:
主页上图片新闻显示的数据是相同的,所以数据应该在这里
请参阅其他链接:
这应该是热搜索关键词
这是图片新闻下面的新闻
让我们打开一个接口链接以查看:
返回一组乱码,但从响应中查看正常编码数据:
通过相应的数据接口,我们可以按照前面的方法请求并获取数据接口的响应
2、请求和解析数据接口数据
首先完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第一部分:介绍相关图书馆
# coding:utf-8
import requests
import json
第二部分:数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
python抓取动态网页(审查网页元素与网页源码是不同的思路及注释(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-03 16:02
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
转载于: 查看全部
python抓取动态网页(审查网页元素与网页源码是不同的思路及注释(图))
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
转载于:
python抓取动态网页(Python小技巧02从Web抓取信息【抓取】【】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-02 17:09
Python提示02从web获取信息
“Web爬网”是一个术语,指使用程序从Web下载和处理内容
WebBrowser,一个常见的web爬行模块
import webbrowser
webbrowser.open('http://baidu.com')
使用open()函数在浏览器中打开页面,括号中传递的参数是目标web地址。这可能是WebBrowser唯一能做的事情
但唯一的效果是有时做一些有趣的事情
使用网络浏览器。Open()打开Google地图并获取指定位置的地图
import pyperclip
import sys
import webbrowser
if len((sys.argv)) > 1:
# 从命令行获取位置信息
address = ' '.join(sys.argv[1:])
else:
# 从剪切板中获得address
address = pyperclip.paste()
# 打开指定网页获取地图
webbrowser.open('https://www.google.com/maps/place/' + address)
请求
请求模块可以从web下载文件。它不是python的内置模块,所以在使用它时需要下载它
安装请求模块终端下载:
pip3 install requests
Pychar用户
按以下顺序完成:
Preferences-> Project: {Project_name} -> Project Interpreter -> 点击左下角加号 -> 搜索requests下载 -> done.
requests.get(url)
呼叫请求。Get(URL)将返回一个响应对象,其中收录web服务器对您的请求的响应
<p>import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(requests) #
# Get the status code and compare it with requests.codes.ok(这个是200)
sta_code = response.status_code
print(sta_code) # 200
print(sta_code == requests.codes.ok) # True
# 请求成功之后下载的页面保存在Response对象的text中。下面我们输出其中的头250个字符
print(response.text[0:250])
"""output: 查看全部
python抓取动态网页(Python小技巧02从Web抓取信息【抓取】【】)
Python提示02从web获取信息
“Web爬网”是一个术语,指使用程序从Web下载和处理内容
WebBrowser,一个常见的web爬行模块
import webbrowser
webbrowser.open('http://baidu.com')
使用open()函数在浏览器中打开页面,括号中传递的参数是目标web地址。这可能是WebBrowser唯一能做的事情
但唯一的效果是有时做一些有趣的事情
使用网络浏览器。Open()打开Google地图并获取指定位置的地图
import pyperclip
import sys
import webbrowser
if len((sys.argv)) > 1:
# 从命令行获取位置信息
address = ' '.join(sys.argv[1:])
else:
# 从剪切板中获得address
address = pyperclip.paste()
# 打开指定网页获取地图
webbrowser.open('https://www.google.com/maps/place/' + address)
请求
请求模块可以从web下载文件。它不是python的内置模块,所以在使用它时需要下载它
安装请求模块终端下载:
pip3 install requests
Pychar用户
按以下顺序完成:
Preferences-> Project: {Project_name} -> Project Interpreter -> 点击左下角加号 -> 搜索requests下载 -> done.
requests.get(url)
呼叫请求。Get(URL)将返回一个响应对象,其中收录web服务器对您的请求的响应
<p>import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(requests) #
# Get the status code and compare it with requests.codes.ok(这个是200)
sta_code = response.status_code
print(sta_code) # 200
print(sta_code == requests.codes.ok) # True
# 请求成功之后下载的页面保存在Response对象的text中。下面我们输出其中的头250个字符
print(response.text[0:250])
"""output:
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-28 21:17
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。
短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他抓取的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址 查看全部
python抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。
短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他抓取的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他异常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友,请等待J哥设置浏览器自动更新并重新下载最新驱动。下次你会听Selenium crawler。记得关注本公众号。不要错过刺激~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址

