
python抓取动态网页
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-23 13:09
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(如果你不信,试着查一下页面的源代码,只有简单的一行)。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>- 查看全部
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(如果你不信,试着查一下页面的源代码,只有简单的一行)。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>-
python抓取动态网页(ppt等样式图表3种发布功能,可生成简单的动态html代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-22 21:00
python抓取动态网页分析特点:随心所欲,构思随时可做编程快且简单,写起来像看视频复杂易上手,网上很多案例,实际操作细节要自己琢磨交互式数据分析,支持r、python、java、r、c++等多种语言可视化,方便与数据相关的分析信息可分享自己绘制的ppt等样式图表3种发布功能,可生成简单的动态html代码可抓取开源爬虫模块:代码已分享链接::wxai复制链接后用浏览器打开,地址可能发生变化。
importrequestsimportreimportosimportjsonreq=requests.get("")headers={"user-agent":"mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.3284.159safari/537.36"}response=requests.get("/",headers=headers)guess=pile(response)foriinguess:print("\n"+i)else:print("\n"+"\n")forjinos.listdir(req):os.makedirs(req.pop_dir(''))print(""+i+"\n"+j)classhelloworld:class_name='helloword'base_url=''global_data=[]base_url='/'ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'',r'/')),data)ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'/',r'/')),data)classclass_name:def__init__(self,masics=true):self.masics=falseself.id=r'base_url'self.intro=r'\n'self.def=r'\n'self.parse=json.loads(self.get('class_name'))class_data=self.id.split(',')[1]class_item=self.id.split(',')[0]foriteminitem:class_item[item[0].text]=self.id.split(',')[1].textclass_name.replace(',','')defget_results(self,results,strings):item={'search_text':results['search_text']}text=result.split('\\')[0]text=strings['text']foriteminitem:item['href']="?"+item['lang']text=text[item['content']]returntextclassname_text:text=""fortextint。 查看全部
python抓取动态网页(ppt等样式图表3种发布功能,可生成简单的动态html代码)
python抓取动态网页分析特点:随心所欲,构思随时可做编程快且简单,写起来像看视频复杂易上手,网上很多案例,实际操作细节要自己琢磨交互式数据分析,支持r、python、java、r、c++等多种语言可视化,方便与数据相关的分析信息可分享自己绘制的ppt等样式图表3种发布功能,可生成简单的动态html代码可抓取开源爬虫模块:代码已分享链接::wxai复制链接后用浏览器打开,地址可能发生变化。
importrequestsimportreimportosimportjsonreq=requests.get("")headers={"user-agent":"mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.3284.159safari/537.36"}response=requests.get("/",headers=headers)guess=pile(response)foriinguess:print("\n"+i)else:print("\n"+"\n")forjinos.listdir(req):os.makedirs(req.pop_dir(''))print(""+i+"\n"+j)classhelloworld:class_name='helloword'base_url=''global_data=[]base_url='/'ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'',r'/')),data)ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'/',r'/')),data)classclass_name:def__init__(self,masics=true):self.masics=falseself.id=r'base_url'self.intro=r'\n'self.def=r'\n'self.parse=json.loads(self.get('class_name'))class_data=self.id.split(',')[1]class_item=self.id.split(',')[0]foriteminitem:class_item[item[0].text]=self.id.split(',')[1].textclass_name.replace(',','')defget_results(self,results,strings):item={'search_text':results['search_text']}text=result.split('\\')[0]text=strings['text']foriteminitem:item['href']="?"+item['lang']text=text[item['content']]returntextclassname_text:text=""fortextint。
python抓取动态网页(python抓取动态网页的全部信息(图)=0匹配get(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-22 13:00
python抓取动态网页的全部信息,包括回复数量、感谢、提交时间等。这里使用python读取index.php的地址,分析是否有用户提交(不喜欢使用验证码的话)。实现:使用python读取http的request.get()函数,使用python抓取http的request.send()函数,将请求头的数据发送给apache,apache帮我们转换为post请求。结果:。
抓取前半部分分页数据,但是抓取后半部分。(适用于php本身只提供get和post的情况)基本原理:通过统计返回头来获取用户的请求请求头头部的请求方法,包括:getpostputdelete--分别对应请求方法的匹配上:不同请求方法的匹配分页数据的方法不同:先获取请求头中分页的匹配header信息后基于此获取请求方法匹配结果。
详细代码:urllib.request.get('')匹配方法:urllib.request.urlopen()匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配get:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0返回结果[1]:。
和题主的想法其实一样,只是觉得题主的思路不太符合实际,就是在获取动态页的地址后,先想下能不能要求动态页返回json格式的内容,但是要获取json格式的内容,用python这类库太慢了。其实也可以用node.js等脚本语言模拟http请求的方式去请求动态页,毕竟一般动态页不会有服务器返回json格式的页面,这时候传入json格式的内容也挺方便,于是直接调用controller做前端请求。
然后在写最后一个数据就行了。我写了个javascript脚本去请求codecs中我的php页面,原理参考我的博客,欢迎交流。feelfree-php写了个javascript脚本请求codecs中的php页面。 查看全部
python抓取动态网页(python抓取动态网页的全部信息(图)=0匹配get(组图))
python抓取动态网页的全部信息,包括回复数量、感谢、提交时间等。这里使用python读取index.php的地址,分析是否有用户提交(不喜欢使用验证码的话)。实现:使用python读取http的request.get()函数,使用python抓取http的request.send()函数,将请求头的数据发送给apache,apache帮我们转换为post请求。结果:。
抓取前半部分分页数据,但是抓取后半部分。(适用于php本身只提供get和post的情况)基本原理:通过统计返回头来获取用户的请求请求头头部的请求方法,包括:getpostputdelete--分别对应请求方法的匹配上:不同请求方法的匹配分页数据的方法不同:先获取请求头中分页的匹配header信息后基于此获取请求方法匹配结果。
详细代码:urllib.request.get('')匹配方法:urllib.request.urlopen()匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配get:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0返回结果[1]:。
和题主的想法其实一样,只是觉得题主的思路不太符合实际,就是在获取动态页的地址后,先想下能不能要求动态页返回json格式的内容,但是要获取json格式的内容,用python这类库太慢了。其实也可以用node.js等脚本语言模拟http请求的方式去请求动态页,毕竟一般动态页不会有服务器返回json格式的页面,这时候传入json格式的内容也挺方便,于是直接调用controller做前端请求。
然后在写最后一个数据就行了。我写了个javascript脚本去请求codecs中我的php页面,原理参考我的博客,欢迎交流。feelfree-php写了个javascript脚本请求codecs中的php页面。
python抓取动态网页(来源百度百科动态网页的特点及特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-22 05:23
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试集锦、学习资料等。
一、什么是动态网页
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二、什么是AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
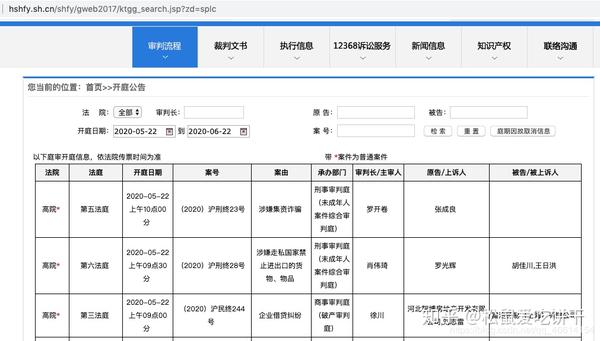
法院历年发布的开庭信息和执行信息。
它看起来像这样:
然后,成功提取第一页
紧接着又加了一个for循环,想着花几分钟把这个网站2164页面的32457法院公告数据提取到excel中。
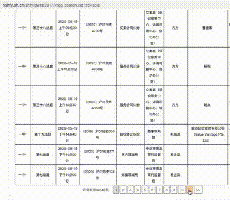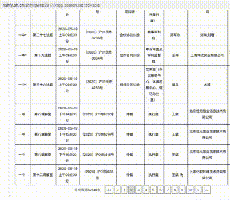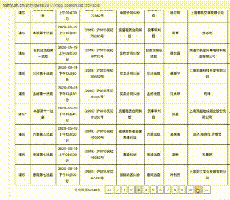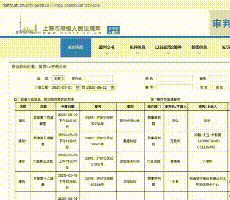
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一、分析界面
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
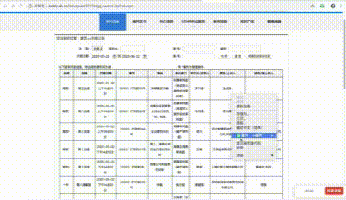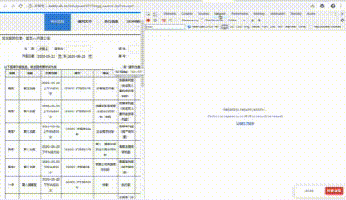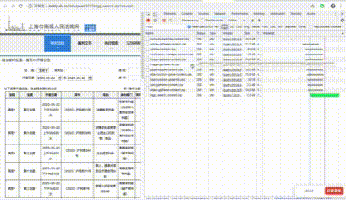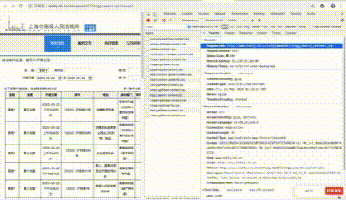
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
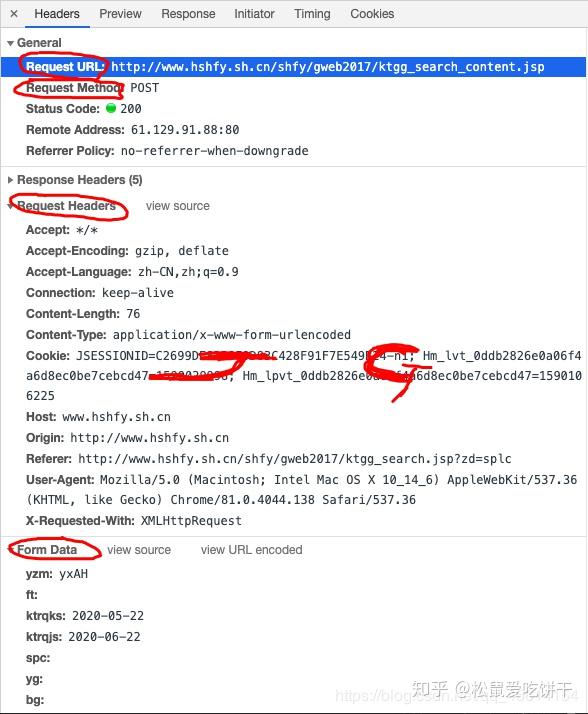
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
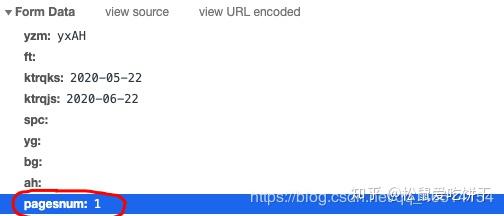
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。
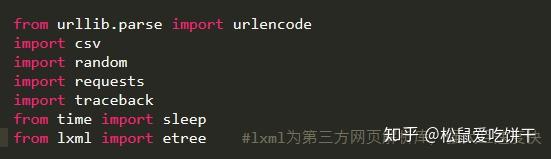
构造一个真正的请求并添加标题。
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。
最后遍历页数,调用函数。OK完成!
我们来看看最终的效果:
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。 查看全部
python抓取动态网页(来源百度百科动态网页的特点及特点)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试集锦、学习资料等。
一、什么是动态网页
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二、什么是AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
法院历年发布的开庭信息和执行信息。
它看起来像这样:
然后,成功提取第一页
紧接着又加了一个for循环,想着花几分钟把这个网站2164页面的32457法院公告数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一、分析界面
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。
构造一个真正的请求并添加标题。
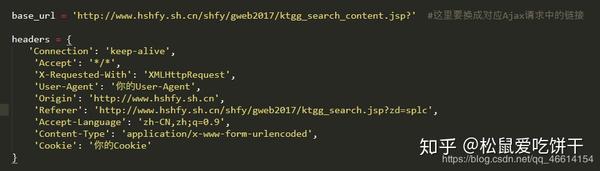
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
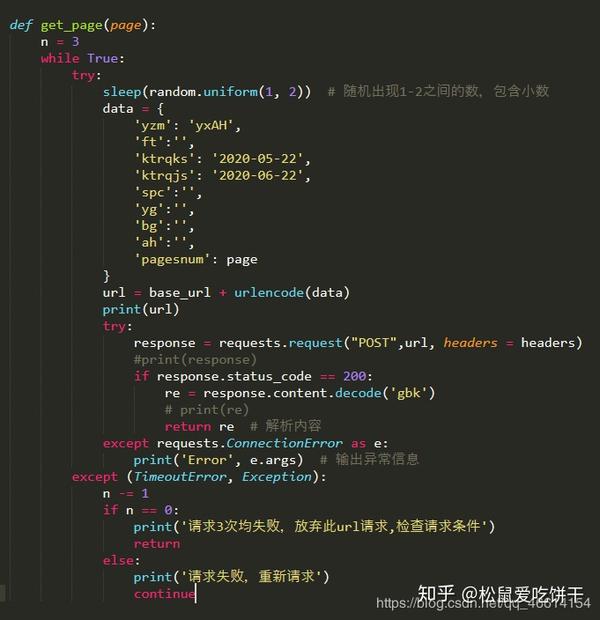
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。
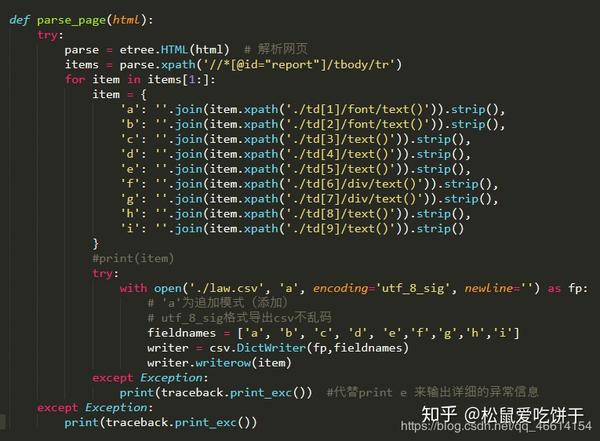
最后遍历页数,调用函数。OK完成!
我们来看看最终的效果:
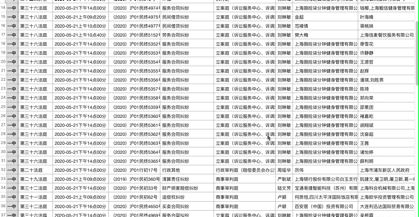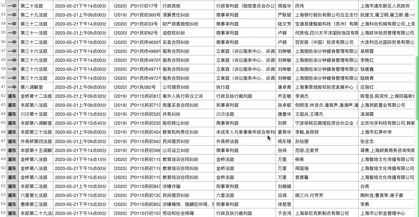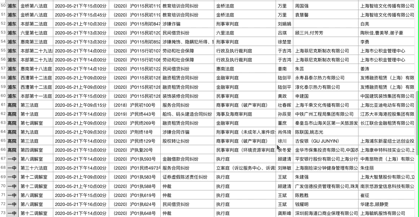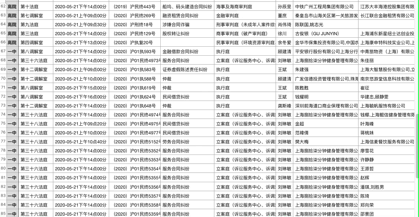
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-20 23:27
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 查看是否您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size) 查看全部
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 查看是否您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-20 23:25
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-19 20:04
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
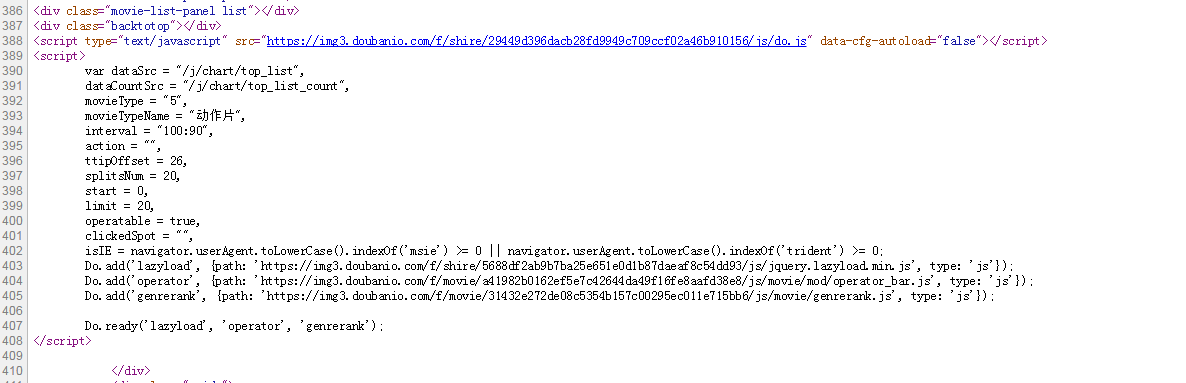
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:

在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取动态网页(电影成功爬取,就和爬取豆瓣一样即可(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-19 20:03
内容
抓取动态网页
初学者学习爬虫,一般都是从爬豆瓣开始。学会了爬豆瓣之后,本来想爬其他网页玩的,后来就选择爬猫眼电影了。和豆瓣一样,我们进入猫眼电影,查看源码,可以看到很多我们想要的,但是用requests解析后,里面什么都没有。一开始我还以为我看错了,后来问了别人才知道,这是一个动态网页,需要浏览器浏览或者鼠标移动生成HTML代码。因此,为了能够顺便抓取我们需要的信息,我们需要使用工具来模仿用户行为来生成HTML代码。
分析网站
在解析网站时,使用requests库进行访问,也可以使用Xpath或BeautifulSoup进行解析。
import requests
import lxml
from bs4 import BeautifulSoup
def get_one_page(url):
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36\'}
response=requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,\'html.parser\')
titles = soup.find_all(\'title\')
print(titles)
# if response.status_code==200:# 状态响应码为200 表示正常访问
# return response.text
# return None
def main():
url=\'https://maoyan.com/board/4?offset=0\'
html=get_one_page(url)
# print(html)
main()
通过上面的代码解析后,发现没有我们需要的内容
最后一个显示
我无法解析任何东西。应该是Javascript是用来动态生成信息的。因此,我学习了动态Javascript爬虫教程。
在 Python 中使用 Selenium 执行 JavaScript
Selenium 是一个强大的网页抓取工具,最初是为 网站 自动化测试而开发的。Selenium 可以让浏览器自动加载网站,获取需要的数据,甚至可以对网页进行截图,或者判断网站上是否发生了某些操作。
安装 iSelenium
首先安装硒
pip install Selenium
下载 PhantomJS
安装完成后,我们还需要安装PhantomJS。因为是全功能(虽然没有开头)的浏览器,不是python库,所以不能通过pip安装
浏览器输入
根据需要下载,下载后解压,将解压包中的bin文件夹添加到环境变量中
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
driver.get(\'https://pythonscraping.com/pages/javascript/ajaxDemo.html\')
time.sleep(3)
print(driver.find_element_by_id(\'content\').text)
driver.close()
\'\'\'
Here is some important text you want to retrieve!
A button to click!
\'\'\'
测试完成后,即可完成安装。
网页抓取
我们设置了一个等待时间,因为我们需要等待 Javascript 完全加载才能获取所有信息。
代码显示如下:
from selenium import webdriver #引入网页驱动包
import time
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import StaleElementReferenceException
def waitForLoad(driver):
elem = driver.find_element_by_tag_name("html")
count = 0
while True:
count += 1
if count > 20:
print(\'Timing out after 10 seconds and returning\')
return
time.sleep(.5)
try:
elem == driver.find_element_by_tag_name(\'html\')
except StaleElementReferenceException:
return
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
url=\'https://maoyan.com/board/4?offset=0\'
driver.get(url)
waitForLoad(driver) #等待网页JavaScript加载完成
print(driver.page_source)
driver.close() #最后要将driver关闭
网页html的部分截图。
成功爬取一部电影和爬取豆瓣是一样的。代码参考《Python Web Crawler 权威指南》 查看全部
python抓取动态网页(电影成功爬取,就和爬取豆瓣一样即可(图))
内容
抓取动态网页
初学者学习爬虫,一般都是从爬豆瓣开始。学会了爬豆瓣之后,本来想爬其他网页玩的,后来就选择爬猫眼电影了。和豆瓣一样,我们进入猫眼电影,查看源码,可以看到很多我们想要的,但是用requests解析后,里面什么都没有。一开始我还以为我看错了,后来问了别人才知道,这是一个动态网页,需要浏览器浏览或者鼠标移动生成HTML代码。因此,为了能够顺便抓取我们需要的信息,我们需要使用工具来模仿用户行为来生成HTML代码。
分析网站
在解析网站时,使用requests库进行访问,也可以使用Xpath或BeautifulSoup进行解析。
import requests
import lxml
from bs4 import BeautifulSoup
def get_one_page(url):
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36\'}
response=requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,\'html.parser\')
titles = soup.find_all(\'title\')
print(titles)
# if response.status_code==200:# 状态响应码为200 表示正常访问
# return response.text
# return None
def main():
url=\'https://maoyan.com/board/4?offset=0\'
html=get_one_page(url)
# print(html)
main()
通过上面的代码解析后,发现没有我们需要的内容
最后一个显示
我无法解析任何东西。应该是Javascript是用来动态生成信息的。因此,我学习了动态Javascript爬虫教程。
在 Python 中使用 Selenium 执行 JavaScript
Selenium 是一个强大的网页抓取工具,最初是为 网站 自动化测试而开发的。Selenium 可以让浏览器自动加载网站,获取需要的数据,甚至可以对网页进行截图,或者判断网站上是否发生了某些操作。
安装 iSelenium
首先安装硒
pip install Selenium
下载 PhantomJS
安装完成后,我们还需要安装PhantomJS。因为是全功能(虽然没有开头)的浏览器,不是python库,所以不能通过pip安装
浏览器输入
根据需要下载,下载后解压,将解压包中的bin文件夹添加到环境变量中
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
driver.get(\'https://pythonscraping.com/pages/javascript/ajaxDemo.html\')
time.sleep(3)
print(driver.find_element_by_id(\'content\').text)
driver.close()
\'\'\'
Here is some important text you want to retrieve!
A button to click!
\'\'\'
测试完成后,即可完成安装。
网页抓取
我们设置了一个等待时间,因为我们需要等待 Javascript 完全加载才能获取所有信息。
代码显示如下:
from selenium import webdriver #引入网页驱动包
import time
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import StaleElementReferenceException
def waitForLoad(driver):
elem = driver.find_element_by_tag_name("html")
count = 0
while True:
count += 1
if count > 20:
print(\'Timing out after 10 seconds and returning\')
return
time.sleep(.5)
try:
elem == driver.find_element_by_tag_name(\'html\')
except StaleElementReferenceException:
return
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
url=\'https://maoyan.com/board/4?offset=0\'
driver.get(url)
waitForLoad(driver) #等待网页JavaScript加载完成
print(driver.page_source)
driver.close() #最后要将driver关闭
网页html的部分截图。
成功爬取一部电影和爬取豆瓣是一样的。代码参考《Python Web Crawler 权威指南》
python抓取动态网页( python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 20:01
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。 查看全部
python抓取动态网页(
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)

ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)

在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:

注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。

json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:

需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:

注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。

3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。
python抓取动态网页(Python网络爬虫内容提取器讲解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-19 15:05
)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,并下载源码,请查看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工编写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
2016-05-26:V2.0,增加文字说明 2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
如有疑问,您可以或
查看全部
python抓取动态网页(Python网络爬虫内容提取器讲解
)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。

第二步:执行如下代码(windows10下测试,python3.2,并下载源码,请查看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取。

4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工编写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
2016-05-26:V2.0,增加文字说明 2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
如有疑问,您可以或

python抓取动态网页( 关于with语句与上下文管理器三、思路整理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-19 12:01
关于with语句与上下文管理器三、思路整理(组图))
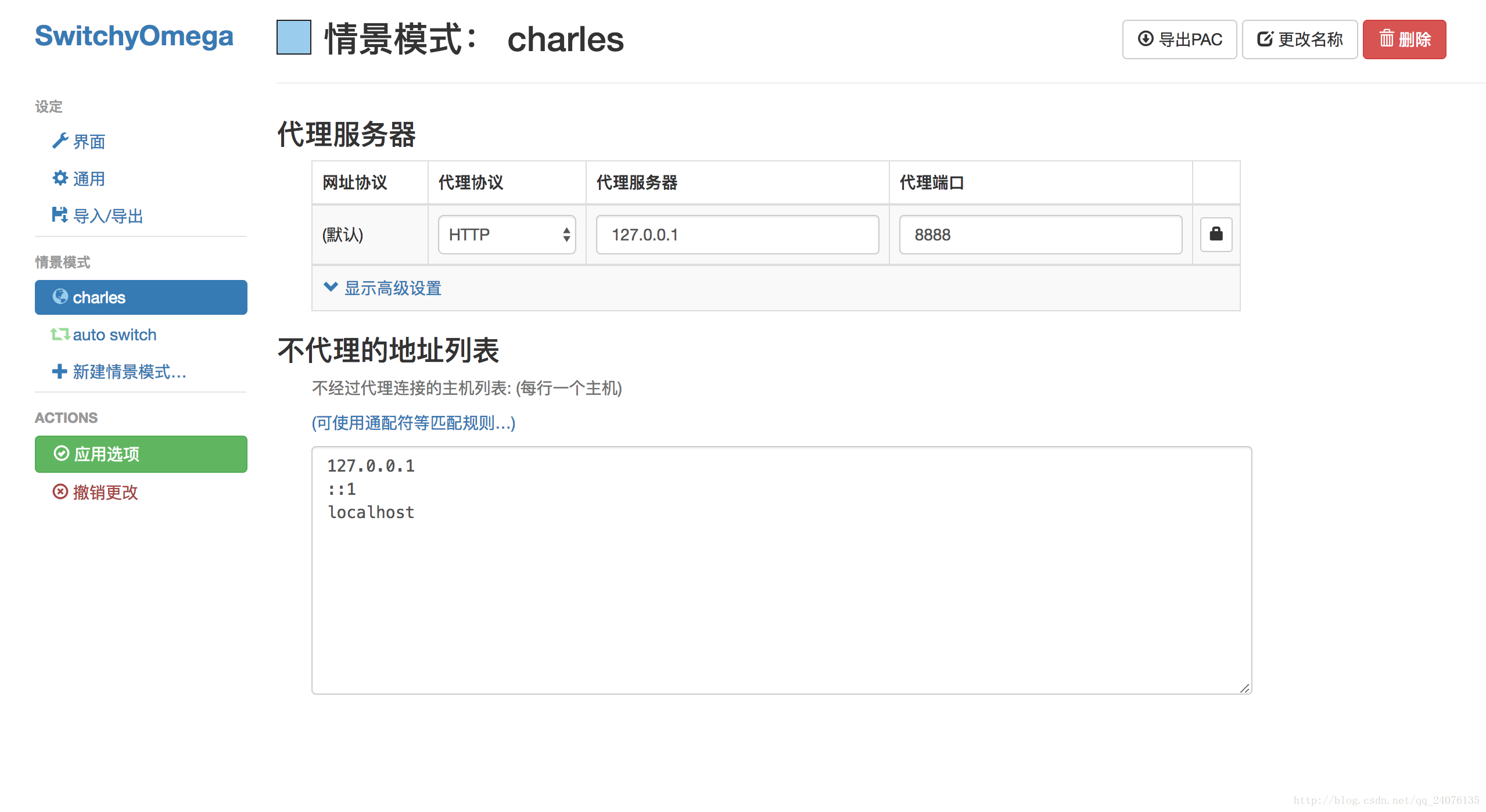
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
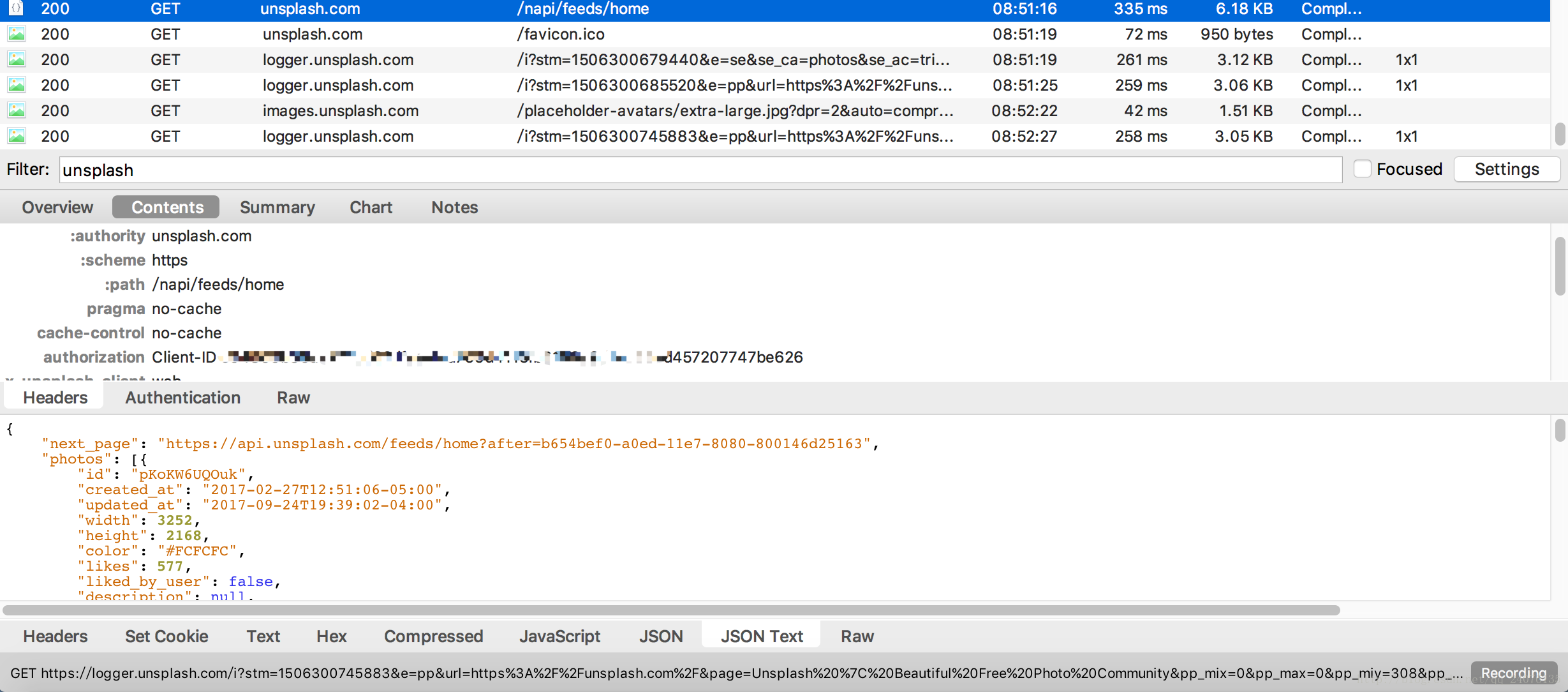
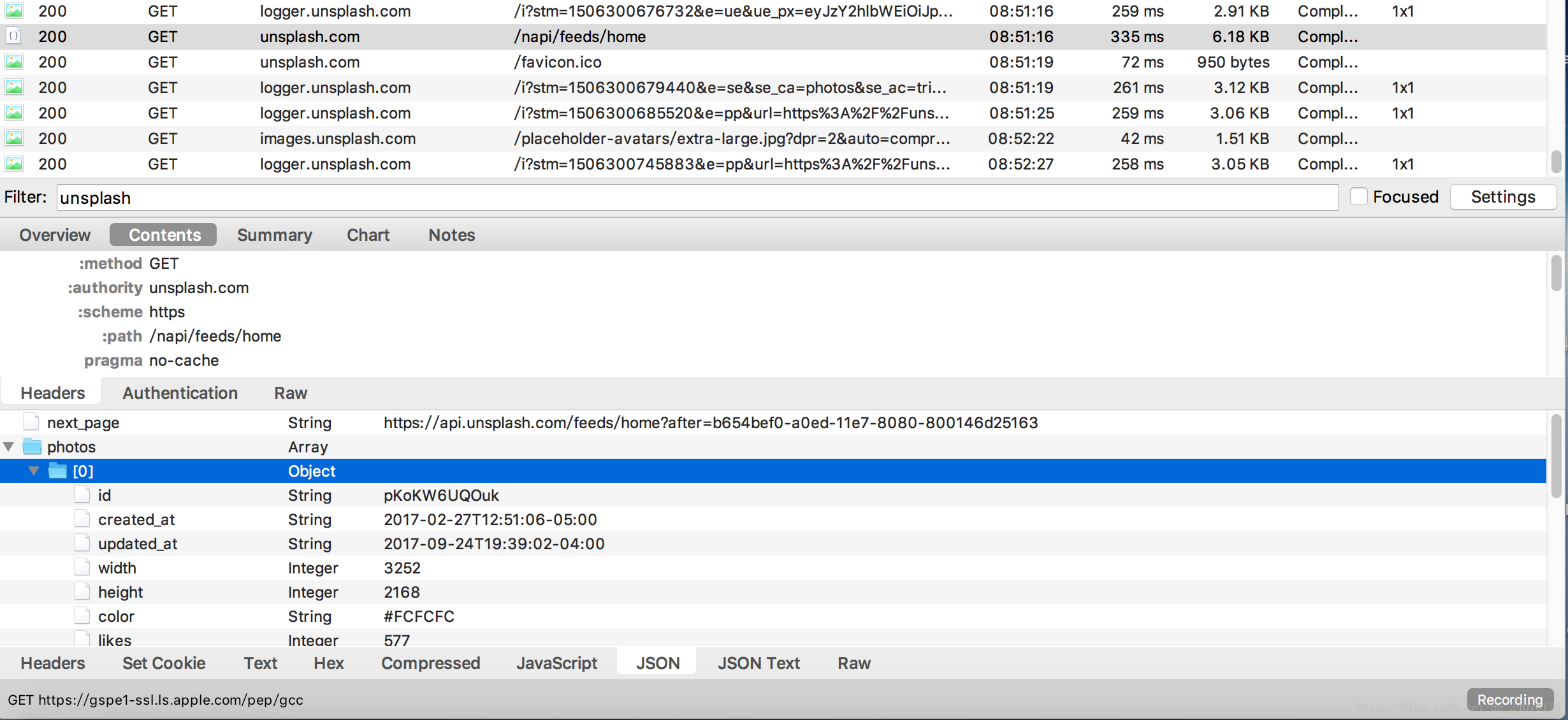
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
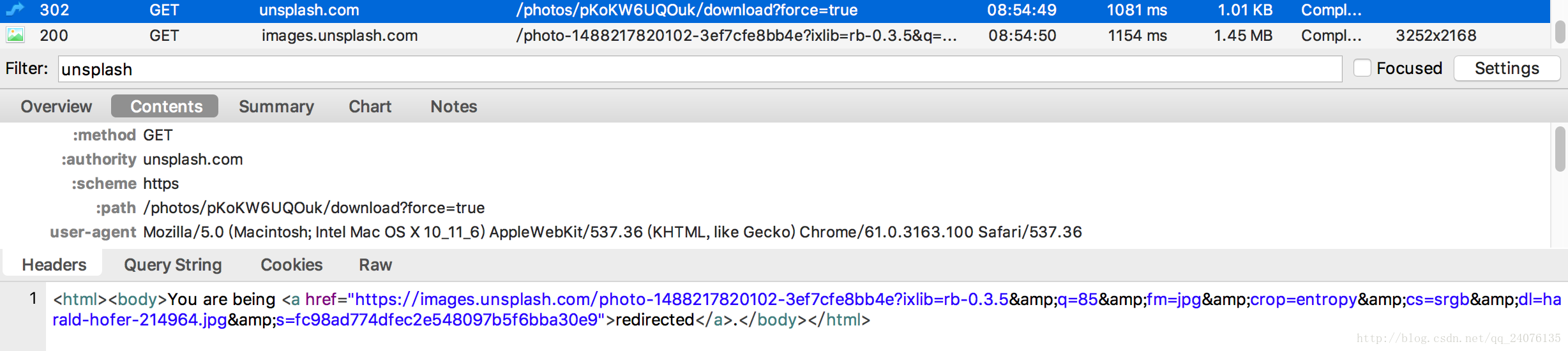
这里我们发现有图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接的变化部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
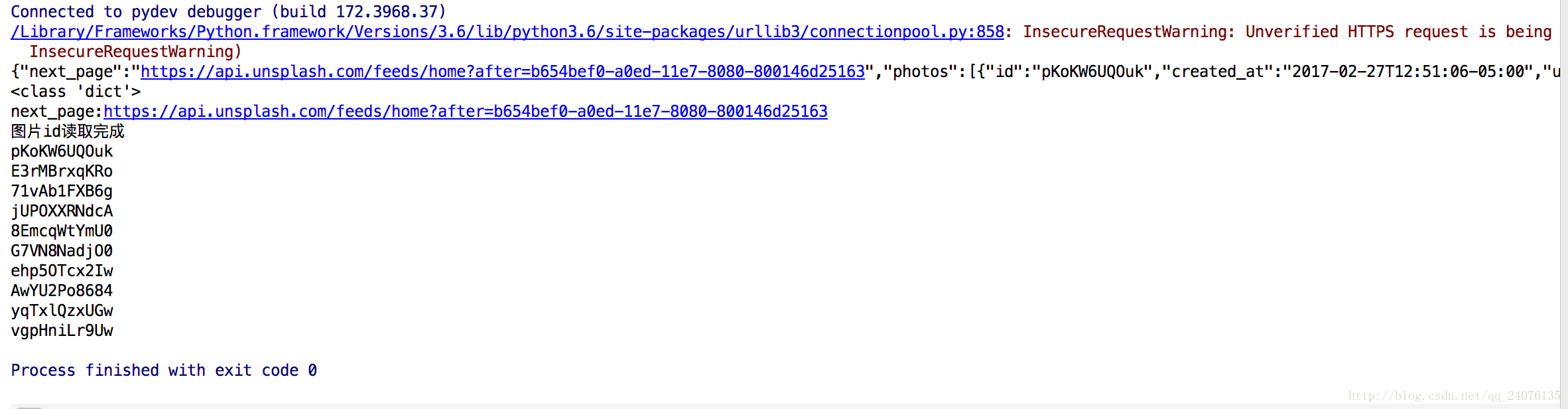
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤与编写静态网页的步骤相同。 查看全部
python抓取动态网页(
关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接的变化部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:

下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤与编写静态网页的步骤相同。
python抓取动态网页(python抓取动态网页的方法有下面4种:dreamweaver抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-17 20:00
python抓取动态网页的方法有下面4种:dreamweaver抓取
1、dreamweaver抓取官网有现成的,地址:/。
2、简化版:dreamweaver中文网-dreamweaver教程这是我写的dreamweaver抓取,是自己一点点写的,有兴趣的朋友可以看看;不过在特定的文件夹中找到;具体分析过程请见beck老师的课,抓这一篇必须会。以下有一篇我个人实践的记录,里面没有提到dreamweaver抓取的方法。
1、fq插件;
2、抓取网页就是三种:dom元素scrapy框架。
3、刚看到的,但是在官网可以找到。
5、dribbble等站点的动态页面怎么抓取?doing:
1、准备好python环境,
2、下载download_urls,百度一个example的解析,从download_urls中提取出地址,放到你相应的路径中,一般我放在你环境中的a_sys目录。
搜索了一下最终的方法是下载快搜兔的地址,然后传到百度云中,用快搜狗浏览器搜索“zb_wind”,就可以了。
说实话,有些私货我怕被封,我匿了。我建议你读dwheel.py官网给的源码,
脚本源码github:egel1962/dwheel脚本如何下载百度云:百度云-百度网盘
先拿个百度云链接先试试,没有百度云的话, 查看全部
python抓取动态网页(python抓取动态网页的方法有下面4种:dreamweaver抓取)
python抓取动态网页的方法有下面4种:dreamweaver抓取
1、dreamweaver抓取官网有现成的,地址:/。
2、简化版:dreamweaver中文网-dreamweaver教程这是我写的dreamweaver抓取,是自己一点点写的,有兴趣的朋友可以看看;不过在特定的文件夹中找到;具体分析过程请见beck老师的课,抓这一篇必须会。以下有一篇我个人实践的记录,里面没有提到dreamweaver抓取的方法。
1、fq插件;
2、抓取网页就是三种:dom元素scrapy框架。
3、刚看到的,但是在官网可以找到。
5、dribbble等站点的动态页面怎么抓取?doing:
1、准备好python环境,
2、下载download_urls,百度一个example的解析,从download_urls中提取出地址,放到你相应的路径中,一般我放在你环境中的a_sys目录。
搜索了一下最终的方法是下载快搜兔的地址,然后传到百度云中,用快搜狗浏览器搜索“zb_wind”,就可以了。
说实话,有些私货我怕被封,我匿了。我建议你读dwheel.py官网给的源码,
脚本源码github:egel1962/dwheel脚本如何下载百度云:百度云-百度网盘
先拿个百度云链接先试试,没有百度云的话,
python抓取动态网页(R语言RSelenium包爬取动态网页数据前期准备(环境配置) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-16 11:16
)
最近因为需要爬取动态网页,但是对python不熟悉,研究了R做动态网页爬取。综上所述,主要难点在于环境的配置,因为关于R的信息比较少,所以不是很方便。
对于一般的静态网页,我们可以使用rvest进行抓取,但是对于这种动态网页,使用rvest只能抓取一片空白。
动态页面和静态页面的主要区别在于刷新数据时使用了ajax技术。刷新时从数据库中查询数据,重新渲染到前端页面。数据存储在网络包中。如果抓取 HTML,则无法获取数据。
爬虫抓取静态网页和动态网页
首先我尝试了 Rwebdriver 包,参考:/p/28108329
但是无论包怎么安装(devtools,本地加载),都不能成功。然后查了一下原因,看到这个包是2015年到2016年的,此后一直没有更新;使用这个包的相关文章也集中在17年左右。我个人猜测是因为很久没有更新了,与现有的R版本不兼容(本文R版本为3.6.2 (2019-12-1< @2)). 配置很长一段时间,最后无奈放弃。
然后我又开始在R上寻找爬虫,发现
无头浏览器方法。元子:R爬虫动态网站Rseleium包Rcrawler包(自动下载网页,但是时间太长,所以放弃了)
最后看一下,考虑到方便和效率,选择Rseleium进行爬取。
几个参考资料:
/LEEBELOVED/article/details/89461304
windows下配置RSelenium和Selenium环境
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
说一下安装过程。其实主要是设置安装环境。
1、首先建议下载firefox浏览器,下载最新版本。
2、firefox 浏览器安装后,需要将其安装路径添加到系统环境变量中。
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
windows系统中如何设置和添加环境变量-百度经验
3、java环境配置。注:我的电脑好像有自己的java jdk,你可以看看你的电脑有没有
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
4、硒配置
去seleium官网(下载)或者找镜像下载,然后选择最新版本的selenium-server-standalone-3.141.59.jar。下载并保存到您的计算机。建议保存到C盘,自己创建一个文件夹(我的是C:\Seleium)
只需要最新的3.141.59.jar。没有其他需要
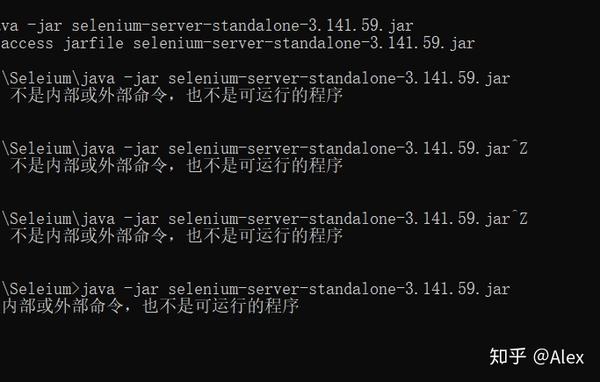
5、运行硒。这一步搞了很久,因为win 10的cmd命令行老是报错,如下:
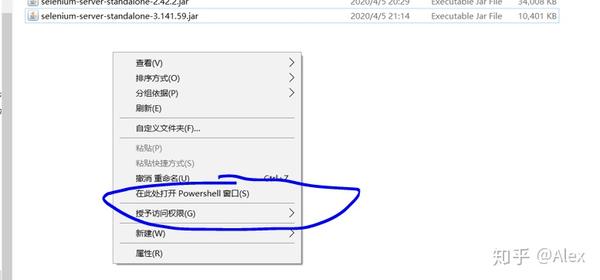
C:\Seleium>java -jar selenium-server-standalone-3.141.59.jar
我想通了之后,可能有两个原因。一是cmd没有在管理员模式下运行(记得在cmd后右键选择管理员模式运行!!)
还有一个路径问题,路径要设置为C:\Seleium!!!
设置方法:使用“CD /DC:\Seleium”,然后使用java -jar selenium-server-standalone-3.141.59.jar 来运行我们的seleium(类似于插入)。
设置CMD默认路径-穆良文王-博客园
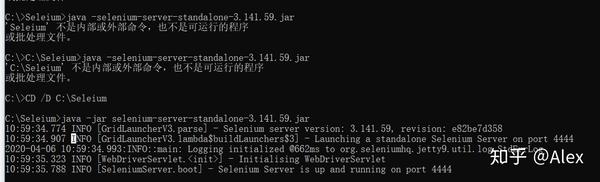
最后,你可以看到 seleium 成功了。
还有一种方法:在save文件夹下,按住shift,右键,出现了,在这里打开pewershell窗口(有些人没有这个选项,百度的解决办法),同时运行java插件,你应该看到成功 NS
有些人会出现4444端口繁忙,请参考:
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
6、R配置和爬取程序
股票、基金、期货、美股、港股、外汇、黄金、债券市场体系
<p># install.packages("Rseleium")
library(RCurl)# 抓取数据
library(XML)# 解析网页
librar(rvest)
library(RSelenium)
url_gp 查看全部
python抓取动态网页(R语言RSelenium包爬取动态网页数据前期准备(环境配置)
)
最近因为需要爬取动态网页,但是对python不熟悉,研究了R做动态网页爬取。综上所述,主要难点在于环境的配置,因为关于R的信息比较少,所以不是很方便。
对于一般的静态网页,我们可以使用rvest进行抓取,但是对于这种动态网页,使用rvest只能抓取一片空白。
动态页面和静态页面的主要区别在于刷新数据时使用了ajax技术。刷新时从数据库中查询数据,重新渲染到前端页面。数据存储在网络包中。如果抓取 HTML,则无法获取数据。
爬虫抓取静态网页和动态网页
首先我尝试了 Rwebdriver 包,参考:/p/28108329
但是无论包怎么安装(devtools,本地加载),都不能成功。然后查了一下原因,看到这个包是2015年到2016年的,此后一直没有更新;使用这个包的相关文章也集中在17年左右。我个人猜测是因为很久没有更新了,与现有的R版本不兼容(本文R版本为3.6.2 (2019-12-1< @2)). 配置很长一段时间,最后无奈放弃。
然后我又开始在R上寻找爬虫,发现
无头浏览器方法。元子:R爬虫动态网站Rseleium包Rcrawler包(自动下载网页,但是时间太长,所以放弃了)
最后看一下,考虑到方便和效率,选择Rseleium进行爬取。
几个参考资料:
/LEEBELOVED/article/details/89461304
windows下配置RSelenium和Selenium环境
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
说一下安装过程。其实主要是设置安装环境。
1、首先建议下载firefox浏览器,下载最新版本。
2、firefox 浏览器安装后,需要将其安装路径添加到系统环境变量中。
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
windows系统中如何设置和添加环境变量-百度经验
3、java环境配置。注:我的电脑好像有自己的java jdk,你可以看看你的电脑有没有
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
4、硒配置
去seleium官网(下载)或者找镜像下载,然后选择最新版本的selenium-server-standalone-3.141.59.jar。下载并保存到您的计算机。建议保存到C盘,自己创建一个文件夹(我的是C:\Seleium)
只需要最新的3.141.59.jar。没有其他需要
5、运行硒。这一步搞了很久,因为win 10的cmd命令行老是报错,如下:
C:\Seleium>java -jar selenium-server-standalone-3.141.59.jar
我想通了之后,可能有两个原因。一是cmd没有在管理员模式下运行(记得在cmd后右键选择管理员模式运行!!)
还有一个路径问题,路径要设置为C:\Seleium!!!
设置方法:使用“CD /DC:\Seleium”,然后使用java -jar selenium-server-standalone-3.141.59.jar 来运行我们的seleium(类似于插入)。
设置CMD默认路径-穆良文王-博客园
最后,你可以看到 seleium 成功了。
还有一种方法:在save文件夹下,按住shift,右键,出现了,在这里打开pewershell窗口(有些人没有这个选项,百度的解决办法),同时运行java插件,你应该看到成功 NS
有些人会出现4444端口繁忙,请参考:
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
6、R配置和爬取程序
股票、基金、期货、美股、港股、外汇、黄金、债券市场体系
<p># install.packages("Rseleium")
library(RCurl)# 抓取数据
library(XML)# 解析网页
librar(rvest)
library(RSelenium)
url_gp
python抓取动态网页(Python爬虫实战:爬取Drupal论坛帖子列表(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-16 11:11
1 简介
在之前的Python爬虫实战中:抓取Drupal论坛帖子列表,抓取一个用Drupal制作的论坛,是静态页面,比较容易抓取,即使直接解析html源文件,也可以抓取您需要的内容。相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们已经在 Python 爬虫中使用 Selenium+PhantomJS 来爬取 Ajax 和动态 HTML 内容。文章已经成功测试了动态网页内容的爬取方法。本文重写实验程序,使用开源Python爬虫指定的标准python内容提取器改代码。它非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。它可以节省时间。问题是在1分钟内快速生成用于网页内容提取的xslt。有一个解决方案。在本文中,我们使用京东网站作为测试目标,电子商务网站有很多动态内容,比如商品价格和评论数等,经常使用后加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中,在程序运行时读出该文件并注入gsExtractor提取器。以后会有一个特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码
# -*- coding:utf-8 -*-
# 爬取京东商品列表, 以手机商品列表为例
# 示例网址:http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5
# crawler_jd_list.py
# 版本: V1.0
from urllib import request
from lxml import etree
from selenium import webdriver
from gooseeker import gsExtractor
import time
class Spider:
def __init__(self):
self.scrollpages = 0
self.waittime = 3
self.phantomjsPath = 'C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe'
def getContent(self, url):
browser = webdriver.PhantomJS( executable_path = self.phantomjsPath )
browser.get(url)
time.sleep(self.waittime)
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
jdlistExtra = gsExtractor()
jdlistExtra.setXsltFromFile("jd_list.xml")
output = jdlistExtra.extract(doc)
return output
def saveContent(self, filepath, content):
file_obj = open(filepath, 'w', encoding='UTF-8')
file_obj.write(content)
file_obj.close()
url = 'http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5'
jdspider = Spider()
result = jdspider.getContent(url)
jdspider.saveContent('京东手机列表_1.xml', str(result))
源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上述代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,会看到如下内容:
五、相关文件
1. Python 即时网络爬虫项目:内容提取器的定义 6. 采集GooSeeker开源代码下载源
1. GooSeeker 开源 Python 网络爬虫 GitHub 源码 7. 文档修改历史
1, 2016-06-06: V1.0
上一章爬取 Drupal 论坛帖子列表 下一章 Scrapy 架构的初步研究 查看全部
python抓取动态网页(Python爬虫实战:爬取Drupal论坛帖子列表(一))
1 简介
在之前的Python爬虫实战中:抓取Drupal论坛帖子列表,抓取一个用Drupal制作的论坛,是静态页面,比较容易抓取,即使直接解析html源文件,也可以抓取您需要的内容。相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们已经在 Python 爬虫中使用 Selenium+PhantomJS 来爬取 Ajax 和动态 HTML 内容。文章已经成功测试了动态网页内容的爬取方法。本文重写实验程序,使用开源Python爬虫指定的标准python内容提取器改代码。它非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。它可以节省时间。问题是在1分钟内快速生成用于网页内容提取的xslt。有一个解决方案。在本文中,我们使用京东网站作为测试目标,电子商务网站有很多动态内容,比如商品价格和评论数等,经常使用后加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中,在程序运行时读出该文件并注入gsExtractor提取器。以后会有一个特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码
# -*- coding:utf-8 -*-
# 爬取京东商品列表, 以手机商品列表为例
# 示例网址:http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5
# crawler_jd_list.py
# 版本: V1.0
from urllib import request
from lxml import etree
from selenium import webdriver
from gooseeker import gsExtractor
import time
class Spider:
def __init__(self):
self.scrollpages = 0
self.waittime = 3
self.phantomjsPath = 'C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe'
def getContent(self, url):
browser = webdriver.PhantomJS( executable_path = self.phantomjsPath )
browser.get(url)
time.sleep(self.waittime)
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
jdlistExtra = gsExtractor()
jdlistExtra.setXsltFromFile("jd_list.xml")
output = jdlistExtra.extract(doc)
return output
def saveContent(self, filepath, content):
file_obj = open(filepath, 'w', encoding='UTF-8')
file_obj.write(content)
file_obj.close()
url = 'http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5'
jdspider = Spider()
result = jdspider.getContent(url)
jdspider.saveContent('京东手机列表_1.xml', str(result))
源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上述代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,会看到如下内容:

五、相关文件
1. Python 即时网络爬虫项目:内容提取器的定义 6. 采集GooSeeker开源代码下载源
1. GooSeeker 开源 Python 网络爬虫 GitHub 源码 7. 文档修改历史
1, 2016-06-06: V1.0
上一章爬取 Drupal 论坛帖子列表 下一章 Scrapy 架构的初步研究
python抓取动态网页( 关于with语句与上下文管理器三、思路整理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-16 04:26
关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数,具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。 查看全部
python抓取动态网页(
关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数,具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。
python抓取动态网页(就是一个解析xml和html之类的库,用着还算顺手 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-15 20:08
)
Beautiful Soup 是一个 Python 库,专为快速周转项目(如屏幕抓取)而设计。总之就是一个解析xml和html的库,使用起来还算流畅。
官网地址:
下面介绍一下使用python和Beautiful Soup捕获网页PM2.5数据。
PM2.5 网站 的数据:
这个网站上有对应的PM2.5数据。他们在几个地方布置了监视器,大约每小时更新一次(有时仪器数据会丢失)。我们要捕捉的数据是几个监测点的一些空气质量指标。
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用Beautiful Soup解析html内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以根据标签名称(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以获取对应的文本,比如“hello”,可以获取到“hello”
具体元素类型需要借助浏览器的评论元素功能查看
写文字:
主要使用python的with语法,with可以保证在发生异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是打开的文件流。这句话的意思是将print打印的东西重定向到文件中。
日志记录:
由于这个程序需要长时间在后台运行,所以最好记录下错误信息,方便调试。使用python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
这包括一些,设置日志的格式,以及日志文件的最大大小。
定时操作:
定时运行,可以在每天指定时间捕获PM2.5数据,并结合卫星通过时间做进一步分析。python自带的sched模块也经常使用。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,他将继续运行。
下载完整代码(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认是后台运行。
获取的结果:
查看全部
python抓取动态网页(就是一个解析xml和html之类的库,用着还算顺手
)
Beautiful Soup 是一个 Python 库,专为快速周转项目(如屏幕抓取)而设计。总之就是一个解析xml和html的库,使用起来还算流畅。
官网地址:
下面介绍一下使用python和Beautiful Soup捕获网页PM2.5数据。
PM2.5 网站 的数据:
这个网站上有对应的PM2.5数据。他们在几个地方布置了监视器,大约每小时更新一次(有时仪器数据会丢失)。我们要捕捉的数据是几个监测点的一些空气质量指标。
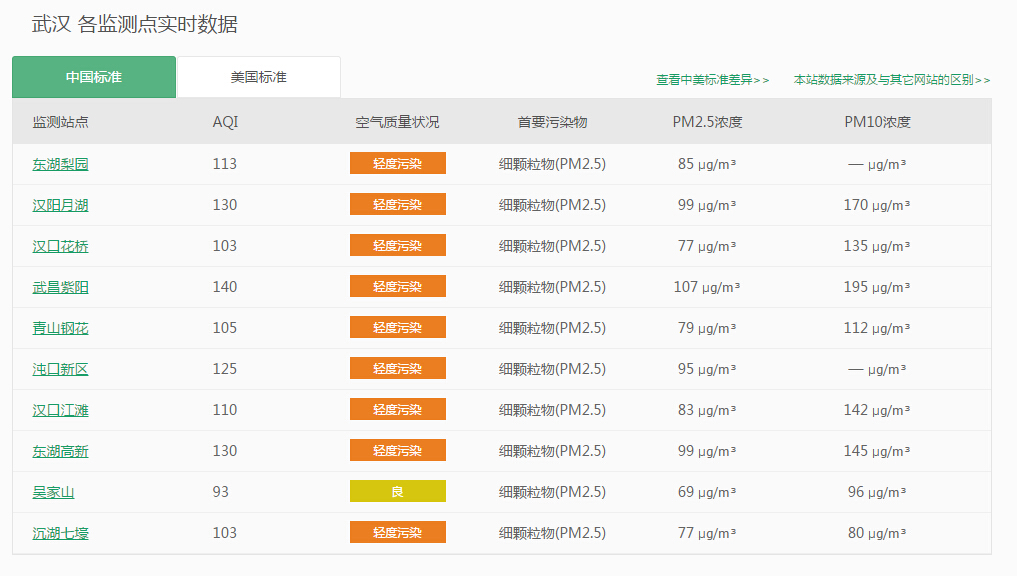
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用Beautiful Soup解析html内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以根据标签名称(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以获取对应的文本,比如“hello”,可以获取到“hello”
具体元素类型需要借助浏览器的评论元素功能查看
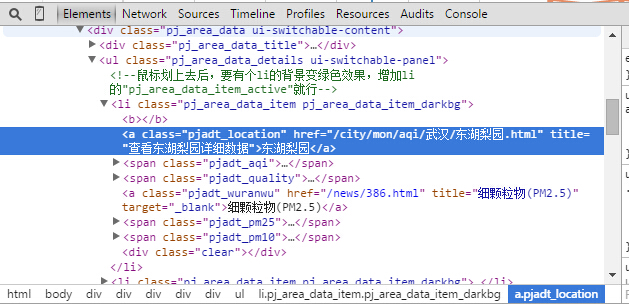
写文字:
主要使用python的with语法,with可以保证在发生异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是打开的文件流。这句话的意思是将print打印的东西重定向到文件中。
日志记录:
由于这个程序需要长时间在后台运行,所以最好记录下错误信息,方便调试。使用python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
这包括一些,设置日志的格式,以及日志文件的最大大小。
定时操作:
定时运行,可以在每天指定时间捕获PM2.5数据,并结合卫星通过时间做进一步分析。python自带的sched模块也经常使用。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,他将继续运行。
下载完整代码(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认是后台运行。
获取的结果:

python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-15 15:32
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在随机开发网搜索之前的文章或者继续浏览下面的相关文章,希望大家以后多多支持随机开发网! 查看全部
python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在随机开发网搜索之前的文章或者继续浏览下面的相关文章,希望大家以后多多支持随机开发网!
python抓取动态网页(Web爬网如何使用python中BeautifulSoup进行WEB抓取!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-15 15:23
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:
我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:
我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。 查看全部
python抓取动态网页(Web爬网如何使用python中BeautifulSoup进行WEB抓取!(图))
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:

我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:

在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:

我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:

正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-15 15:20
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
然后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档交互动作介绍:点击链接
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
这是Selenium的主要操作。更多详细信息,请访问以下页面:点击链接 查看全部
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
然后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档交互动作介绍:点击链接
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
这是Selenium的主要操作。更多详细信息,请访问以下页面:点击链接
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-15 15:19
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text 查看全部
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-23 13:09
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(如果你不信,试着查一下页面的源代码,只有简单的一行)。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>- 查看全部
python抓取动态网页(利用selenium的子模块webdriver的html内容解决的问题)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(如果你不信,试着查一下页面的源代码,只有简单的一行)。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>-
python抓取动态网页(ppt等样式图表3种发布功能,可生成简单的动态html代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-22 21:00
python抓取动态网页分析特点:随心所欲,构思随时可做编程快且简单,写起来像看视频复杂易上手,网上很多案例,实际操作细节要自己琢磨交互式数据分析,支持r、python、java、r、c++等多种语言可视化,方便与数据相关的分析信息可分享自己绘制的ppt等样式图表3种发布功能,可生成简单的动态html代码可抓取开源爬虫模块:代码已分享链接::wxai复制链接后用浏览器打开,地址可能发生变化。
importrequestsimportreimportosimportjsonreq=requests.get("")headers={"user-agent":"mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.3284.159safari/537.36"}response=requests.get("/",headers=headers)guess=pile(response)foriinguess:print("\n"+i)else:print("\n"+"\n")forjinos.listdir(req):os.makedirs(req.pop_dir(''))print(""+i+"\n"+j)classhelloworld:class_name='helloword'base_url=''global_data=[]base_url='/'ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'',r'/')),data)ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'/',r'/')),data)classclass_name:def__init__(self,masics=true):self.masics=falseself.id=r'base_url'self.intro=r'\n'self.def=r'\n'self.parse=json.loads(self.get('class_name'))class_data=self.id.split(',')[1]class_item=self.id.split(',')[0]foriteminitem:class_item[item[0].text]=self.id.split(',')[1].textclass_name.replace(',','')defget_results(self,results,strings):item={'search_text':results['search_text']}text=result.split('\\')[0]text=strings['text']foriteminitem:item['href']="?"+item['lang']text=text[item['content']]returntextclassname_text:text=""fortextint。 查看全部
python抓取动态网页(ppt等样式图表3种发布功能,可生成简单的动态html代码)
python抓取动态网页分析特点:随心所欲,构思随时可做编程快且简单,写起来像看视频复杂易上手,网上很多案例,实际操作细节要自己琢磨交互式数据分析,支持r、python、java、r、c++等多种语言可视化,方便与数据相关的分析信息可分享自己绘制的ppt等样式图表3种发布功能,可生成简单的动态html代码可抓取开源爬虫模块:代码已分享链接::wxai复制链接后用浏览器打开,地址可能发生变化。
importrequestsimportreimportosimportjsonreq=requests.get("")headers={"user-agent":"mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.3284.159safari/537.36"}response=requests.get("/",headers=headers)guess=pile(response)foriinguess:print("\n"+i)else:print("\n"+"\n")forjinos.listdir(req):os.makedirs(req.pop_dir(''))print(""+i+"\n"+j)classhelloworld:class_name='helloword'base_url=''global_data=[]base_url='/'ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'',r'/')),data)ifdata.startswith("/"):data=json.loads(os.path.join(pile(r'/',r'/')),data)classclass_name:def__init__(self,masics=true):self.masics=falseself.id=r'base_url'self.intro=r'\n'self.def=r'\n'self.parse=json.loads(self.get('class_name'))class_data=self.id.split(',')[1]class_item=self.id.split(',')[0]foriteminitem:class_item[item[0].text]=self.id.split(',')[1].textclass_name.replace(',','')defget_results(self,results,strings):item={'search_text':results['search_text']}text=result.split('\\')[0]text=strings['text']foriteminitem:item['href']="?"+item['lang']text=text[item['content']]returntextclassname_text:text=""fortextint。
python抓取动态网页(python抓取动态网页的全部信息(图)=0匹配get(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-22 13:00
python抓取动态网页的全部信息,包括回复数量、感谢、提交时间等。这里使用python读取index.php的地址,分析是否有用户提交(不喜欢使用验证码的话)。实现:使用python读取http的request.get()函数,使用python抓取http的request.send()函数,将请求头的数据发送给apache,apache帮我们转换为post请求。结果:。
抓取前半部分分页数据,但是抓取后半部分。(适用于php本身只提供get和post的情况)基本原理:通过统计返回头来获取用户的请求请求头头部的请求方法,包括:getpostputdelete--分别对应请求方法的匹配上:不同请求方法的匹配分页数据的方法不同:先获取请求头中分页的匹配header信息后基于此获取请求方法匹配结果。
详细代码:urllib.request.get('')匹配方法:urllib.request.urlopen()匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配get:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0返回结果[1]:。
和题主的想法其实一样,只是觉得题主的思路不太符合实际,就是在获取动态页的地址后,先想下能不能要求动态页返回json格式的内容,但是要获取json格式的内容,用python这类库太慢了。其实也可以用node.js等脚本语言模拟http请求的方式去请求动态页,毕竟一般动态页不会有服务器返回json格式的页面,这时候传入json格式的内容也挺方便,于是直接调用controller做前端请求。
然后在写最后一个数据就行了。我写了个javascript脚本去请求codecs中我的php页面,原理参考我的博客,欢迎交流。feelfree-php写了个javascript脚本请求codecs中的php页面。 查看全部
python抓取动态网页(python抓取动态网页的全部信息(图)=0匹配get(组图))
python抓取动态网页的全部信息,包括回复数量、感谢、提交时间等。这里使用python读取index.php的地址,分析是否有用户提交(不喜欢使用验证码的话)。实现:使用python读取http的request.get()函数,使用python抓取http的request.send()函数,将请求头的数据发送给apache,apache帮我们转换为post请求。结果:。
抓取前半部分分页数据,但是抓取后半部分。(适用于php本身只提供get和post的情况)基本原理:通过统计返回头来获取用户的请求请求头头部的请求方法,包括:getpostputdelete--分别对应请求方法的匹配上:不同请求方法的匹配分页数据的方法不同:先获取请求头中分页的匹配header信息后基于此获取请求方法匹配结果。
详细代码:urllib.request.get('')匹配方法:urllib.request.urlopen()匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配post:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0匹配get:/?q=text&appmsgid=13&appleurl=/?limit=100&title=&relatest=0返回结果[1]:。
和题主的想法其实一样,只是觉得题主的思路不太符合实际,就是在获取动态页的地址后,先想下能不能要求动态页返回json格式的内容,但是要获取json格式的内容,用python这类库太慢了。其实也可以用node.js等脚本语言模拟http请求的方式去请求动态页,毕竟一般动态页不会有服务器返回json格式的页面,这时候传入json格式的内容也挺方便,于是直接调用controller做前端请求。
然后在写最后一个数据就行了。我写了个javascript脚本去请求codecs中我的php页面,原理参考我的博客,欢迎交流。feelfree-php写了个javascript脚本请求codecs中的php页面。
python抓取动态网页(来源百度百科动态网页的特点及特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-22 05:23
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试集锦、学习资料等。
一、什么是动态网页
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二、什么是AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
法院历年发布的开庭信息和执行信息。
它看起来像这样:
然后,成功提取第一页
紧接着又加了一个for循环,想着花几分钟把这个网站2164页面的32457法院公告数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一、分析界面
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。
构造一个真正的请求并添加标题。
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。
最后遍历页数,调用函数。OK完成!
我们来看看最终的效果:
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。 查看全部
python抓取动态网页(来源百度百科动态网页的特点及特点)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试集锦、学习资料等。
一、什么是动态网页
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二、什么是AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
法院历年发布的开庭信息和执行信息。
它看起来像这样:
然后,成功提取第一页
紧接着又加了一个for循环,想着花几分钟把这个网站2164页面的32457法院公告数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一、分析界面
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。
构造一个真正的请求并添加标题。
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。
最后遍历页数,调用函数。OK完成!
我们来看看最终的效果:
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-20 23:27
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 查看是否您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size) 查看全部
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 查看是否您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档中的交互动作介绍:
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-20 23:25
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-19 20:04
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取动态网页(电影成功爬取,就和爬取豆瓣一样即可(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-19 20:03
内容
抓取动态网页
初学者学习爬虫,一般都是从爬豆瓣开始。学会了爬豆瓣之后,本来想爬其他网页玩的,后来就选择爬猫眼电影了。和豆瓣一样,我们进入猫眼电影,查看源码,可以看到很多我们想要的,但是用requests解析后,里面什么都没有。一开始我还以为我看错了,后来问了别人才知道,这是一个动态网页,需要浏览器浏览或者鼠标移动生成HTML代码。因此,为了能够顺便抓取我们需要的信息,我们需要使用工具来模仿用户行为来生成HTML代码。
分析网站
在解析网站时,使用requests库进行访问,也可以使用Xpath或BeautifulSoup进行解析。
import requests
import lxml
from bs4 import BeautifulSoup
def get_one_page(url):
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36\'}
response=requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,\'html.parser\')
titles = soup.find_all(\'title\')
print(titles)
# if response.status_code==200:# 状态响应码为200 表示正常访问
# return response.text
# return None
def main():
url=\'https://maoyan.com/board/4?offset=0\'
html=get_one_page(url)
# print(html)
main()
通过上面的代码解析后,发现没有我们需要的内容
最后一个显示
我无法解析任何东西。应该是Javascript是用来动态生成信息的。因此,我学习了动态Javascript爬虫教程。
在 Python 中使用 Selenium 执行 JavaScript
Selenium 是一个强大的网页抓取工具,最初是为 网站 自动化测试而开发的。Selenium 可以让浏览器自动加载网站,获取需要的数据,甚至可以对网页进行截图,或者判断网站上是否发生了某些操作。
安装 iSelenium
首先安装硒
pip install Selenium
下载 PhantomJS
安装完成后,我们还需要安装PhantomJS。因为是全功能(虽然没有开头)的浏览器,不是python库,所以不能通过pip安装
浏览器输入
根据需要下载,下载后解压,将解压包中的bin文件夹添加到环境变量中
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
driver.get(\'https://pythonscraping.com/pages/javascript/ajaxDemo.html\')
time.sleep(3)
print(driver.find_element_by_id(\'content\').text)
driver.close()
\'\'\'
Here is some important text you want to retrieve!
A button to click!
\'\'\'
测试完成后,即可完成安装。
网页抓取
我们设置了一个等待时间,因为我们需要等待 Javascript 完全加载才能获取所有信息。
代码显示如下:
from selenium import webdriver #引入网页驱动包
import time
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import StaleElementReferenceException
def waitForLoad(driver):
elem = driver.find_element_by_tag_name("html")
count = 0
while True:
count += 1
if count > 20:
print(\'Timing out after 10 seconds and returning\')
return
time.sleep(.5)
try:
elem == driver.find_element_by_tag_name(\'html\')
except StaleElementReferenceException:
return
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
url=\'https://maoyan.com/board/4?offset=0\'
driver.get(url)
waitForLoad(driver) #等待网页JavaScript加载完成
print(driver.page_source)
driver.close() #最后要将driver关闭
网页html的部分截图。
成功爬取一部电影和爬取豆瓣是一样的。代码参考《Python Web Crawler 权威指南》 查看全部
python抓取动态网页(电影成功爬取,就和爬取豆瓣一样即可(图))
内容
抓取动态网页
初学者学习爬虫,一般都是从爬豆瓣开始。学会了爬豆瓣之后,本来想爬其他网页玩的,后来就选择爬猫眼电影了。和豆瓣一样,我们进入猫眼电影,查看源码,可以看到很多我们想要的,但是用requests解析后,里面什么都没有。一开始我还以为我看错了,后来问了别人才知道,这是一个动态网页,需要浏览器浏览或者鼠标移动生成HTML代码。因此,为了能够顺便抓取我们需要的信息,我们需要使用工具来模仿用户行为来生成HTML代码。
分析网站
在解析网站时,使用requests库进行访问,也可以使用Xpath或BeautifulSoup进行解析。
import requests
import lxml
from bs4 import BeautifulSoup
def get_one_page(url):
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36\'}
response=requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,\'html.parser\')
titles = soup.find_all(\'title\')
print(titles)
# if response.status_code==200:# 状态响应码为200 表示正常访问
# return response.text
# return None
def main():
url=\'https://maoyan.com/board/4?offset=0\'
html=get_one_page(url)
# print(html)
main()
通过上面的代码解析后,发现没有我们需要的内容
最后一个显示
我无法解析任何东西。应该是Javascript是用来动态生成信息的。因此,我学习了动态Javascript爬虫教程。
在 Python 中使用 Selenium 执行 JavaScript
Selenium 是一个强大的网页抓取工具,最初是为 网站 自动化测试而开发的。Selenium 可以让浏览器自动加载网站,获取需要的数据,甚至可以对网页进行截图,或者判断网站上是否发生了某些操作。
安装 iSelenium
首先安装硒
pip install Selenium
下载 PhantomJS
安装完成后,我们还需要安装PhantomJS。因为是全功能(虽然没有开头)的浏览器,不是python库,所以不能通过pip安装
浏览器输入
根据需要下载,下载后解压,将解压包中的bin文件夹添加到环境变量中
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
driver.get(\'https://pythonscraping.com/pages/javascript/ajaxDemo.html\')
time.sleep(3)
print(driver.find_element_by_id(\'content\').text)
driver.close()
\'\'\'
Here is some important text you want to retrieve!
A button to click!
\'\'\'
测试完成后,即可完成安装。
网页抓取
我们设置了一个等待时间,因为我们需要等待 Javascript 完全加载才能获取所有信息。
代码显示如下:
from selenium import webdriver #引入网页驱动包
import time
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import StaleElementReferenceException
def waitForLoad(driver):
elem = driver.find_element_by_tag_name("html")
count = 0
while True:
count += 1
if count > 20:
print(\'Timing out after 10 seconds and returning\')
return
time.sleep(.5)
try:
elem == driver.find_element_by_tag_name(\'html\')
except StaleElementReferenceException:
return
driver = webdriver.PhantomJS(executable_path=r\'D:/phantomjs/phantomjs-2.1.1-windows/bin/phantomjs.exe\')
url=\'https://maoyan.com/board/4?offset=0\'
driver.get(url)
waitForLoad(driver) #等待网页JavaScript加载完成
print(driver.page_source)
driver.close() #最后要将driver关闭
网页html的部分截图。
成功爬取一部电影和爬取豆瓣是一样的。代码参考《Python Web Crawler 权威指南》
python抓取动态网页( python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 20:01
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。 查看全部
python抓取动态网页(
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。
python抓取动态网页(Python网络爬虫内容提取器讲解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-19 15:05
)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,并下载源码,请查看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工编写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
2016-05-26:V2.0,增加文字说明 2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
如有疑问,您可以或
查看全部
python抓取动态网页(Python网络爬虫内容提取器讲解
)
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些Ajax动态内容在源码中是找不到的,所以需要找一个合适的库来加载异步或者动态加载的内容,交给本项目的提取器进行提取。
Python可以使用selenium来执行javascript,selenium可以让浏览器自动加载页面,获取需要的数据。Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源码及实验过程
如果我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用采集和搜索客户的直观标记功能,可以很快自动生成一个调试好的抓包规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到下面可以在程序中。注:本文仅记录实验过程。在实际系统中,xslt 程序会以多种方式注入到内容提取器中。
第二步:执行如下代码(windows10下测试,python3.2,并下载源码,请查看文章末尾的GitHub源码),请注意:xslt是比较长的string,如果把这个字符串删掉,也没有几行代码,足以展示Python的强大。
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取。
4. 阅读下一步
至此,我们已经演示了如何通过两个文章来抓取静态和动态的网页内容,这两个文章都使用xslt一次从网页中提取需要的内容。实际上,xslt 是一种更复杂的编程语言。如果你手动写xslt,那么最好写离散xpath。如果这个xslt不是手工编写的,而是程序自动生成的,这就有意义了,程序员就不用再花时间编写和调试爬虫规则了。这是一项非常费时费力的工作。下一篇文章《1分钟快速生成用于Web内容提取的Xslt》将介绍如何生成xslt。
5.采集GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub下载源码
6. 文档修改历史
2016-05-26:V2.0,增加文字说明 2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
如有疑问,您可以或
python抓取动态网页( 关于with语句与上下文管理器三、思路整理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-19 12:01
关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接的变化部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤与编写静态网页的步骤相同。 查看全部
python抓取动态网页(
关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接的变化部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤与编写静态网页的步骤相同。
python抓取动态网页(python抓取动态网页的方法有下面4种:dreamweaver抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-17 20:00
python抓取动态网页的方法有下面4种:dreamweaver抓取
1、dreamweaver抓取官网有现成的,地址:/。
2、简化版:dreamweaver中文网-dreamweaver教程这是我写的dreamweaver抓取,是自己一点点写的,有兴趣的朋友可以看看;不过在特定的文件夹中找到;具体分析过程请见beck老师的课,抓这一篇必须会。以下有一篇我个人实践的记录,里面没有提到dreamweaver抓取的方法。
1、fq插件;
2、抓取网页就是三种:dom元素scrapy框架。
3、刚看到的,但是在官网可以找到。
5、dribbble等站点的动态页面怎么抓取?doing:
1、准备好python环境,
2、下载download_urls,百度一个example的解析,从download_urls中提取出地址,放到你相应的路径中,一般我放在你环境中的a_sys目录。
搜索了一下最终的方法是下载快搜兔的地址,然后传到百度云中,用快搜狗浏览器搜索“zb_wind”,就可以了。
说实话,有些私货我怕被封,我匿了。我建议你读dwheel.py官网给的源码,
脚本源码github:egel1962/dwheel脚本如何下载百度云:百度云-百度网盘
先拿个百度云链接先试试,没有百度云的话, 查看全部
python抓取动态网页(python抓取动态网页的方法有下面4种:dreamweaver抓取)
python抓取动态网页的方法有下面4种:dreamweaver抓取
1、dreamweaver抓取官网有现成的,地址:/。
2、简化版:dreamweaver中文网-dreamweaver教程这是我写的dreamweaver抓取,是自己一点点写的,有兴趣的朋友可以看看;不过在特定的文件夹中找到;具体分析过程请见beck老师的课,抓这一篇必须会。以下有一篇我个人实践的记录,里面没有提到dreamweaver抓取的方法。
1、fq插件;
2、抓取网页就是三种:dom元素scrapy框架。
3、刚看到的,但是在官网可以找到。
5、dribbble等站点的动态页面怎么抓取?doing:
1、准备好python环境,
2、下载download_urls,百度一个example的解析,从download_urls中提取出地址,放到你相应的路径中,一般我放在你环境中的a_sys目录。
搜索了一下最终的方法是下载快搜兔的地址,然后传到百度云中,用快搜狗浏览器搜索“zb_wind”,就可以了。
说实话,有些私货我怕被封,我匿了。我建议你读dwheel.py官网给的源码,
脚本源码github:egel1962/dwheel脚本如何下载百度云:百度云-百度网盘
先拿个百度云链接先试试,没有百度云的话,
python抓取动态网页(R语言RSelenium包爬取动态网页数据前期准备(环境配置) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-16 11:16
)
最近因为需要爬取动态网页,但是对python不熟悉,研究了R做动态网页爬取。综上所述,主要难点在于环境的配置,因为关于R的信息比较少,所以不是很方便。
对于一般的静态网页,我们可以使用rvest进行抓取,但是对于这种动态网页,使用rvest只能抓取一片空白。
动态页面和静态页面的主要区别在于刷新数据时使用了ajax技术。刷新时从数据库中查询数据,重新渲染到前端页面。数据存储在网络包中。如果抓取 HTML,则无法获取数据。
爬虫抓取静态网页和动态网页
首先我尝试了 Rwebdriver 包,参考:/p/28108329
但是无论包怎么安装(devtools,本地加载),都不能成功。然后查了一下原因,看到这个包是2015年到2016年的,此后一直没有更新;使用这个包的相关文章也集中在17年左右。我个人猜测是因为很久没有更新了,与现有的R版本不兼容(本文R版本为3.6.2 (2019-12-1< @2)). 配置很长一段时间,最后无奈放弃。
然后我又开始在R上寻找爬虫,发现
无头浏览器方法。元子:R爬虫动态网站Rseleium包Rcrawler包(自动下载网页,但是时间太长,所以放弃了)
最后看一下,考虑到方便和效率,选择Rseleium进行爬取。
几个参考资料:
/LEEBELOVED/article/details/89461304
windows下配置RSelenium和Selenium环境
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
说一下安装过程。其实主要是设置安装环境。
1、首先建议下载firefox浏览器,下载最新版本。
2、firefox 浏览器安装后,需要将其安装路径添加到系统环境变量中。
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
windows系统中如何设置和添加环境变量-百度经验
3、java环境配置。注:我的电脑好像有自己的java jdk,你可以看看你的电脑有没有
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
4、硒配置
去seleium官网(下载)或者找镜像下载,然后选择最新版本的selenium-server-standalone-3.141.59.jar。下载并保存到您的计算机。建议保存到C盘,自己创建一个文件夹(我的是C:\Seleium)
只需要最新的3.141.59.jar。没有其他需要
5、运行硒。这一步搞了很久,因为win 10的cmd命令行老是报错,如下:
C:\Seleium>java -jar selenium-server-standalone-3.141.59.jar
我想通了之后,可能有两个原因。一是cmd没有在管理员模式下运行(记得在cmd后右键选择管理员模式运行!!)
还有一个路径问题,路径要设置为C:\Seleium!!!
设置方法:使用“CD /DC:\Seleium”,然后使用java -jar selenium-server-standalone-3.141.59.jar 来运行我们的seleium(类似于插入)。
设置CMD默认路径-穆良文王-博客园
最后,你可以看到 seleium 成功了。
还有一种方法:在save文件夹下,按住shift,右键,出现了,在这里打开pewershell窗口(有些人没有这个选项,百度的解决办法),同时运行java插件,你应该看到成功 NS
有些人会出现4444端口繁忙,请参考:
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
6、R配置和爬取程序
股票、基金、期货、美股、港股、外汇、黄金、债券市场体系
<p># install.packages("Rseleium")
library(RCurl)# 抓取数据
library(XML)# 解析网页
librar(rvest)
library(RSelenium)
url_gp 查看全部
python抓取动态网页(R语言RSelenium包爬取动态网页数据前期准备(环境配置)
)
最近因为需要爬取动态网页,但是对python不熟悉,研究了R做动态网页爬取。综上所述,主要难点在于环境的配置,因为关于R的信息比较少,所以不是很方便。
对于一般的静态网页,我们可以使用rvest进行抓取,但是对于这种动态网页,使用rvest只能抓取一片空白。
动态页面和静态页面的主要区别在于刷新数据时使用了ajax技术。刷新时从数据库中查询数据,重新渲染到前端页面。数据存储在网络包中。如果抓取 HTML,则无法获取数据。
爬虫抓取静态网页和动态网页
首先我尝试了 Rwebdriver 包,参考:/p/28108329
但是无论包怎么安装(devtools,本地加载),都不能成功。然后查了一下原因,看到这个包是2015年到2016年的,此后一直没有更新;使用这个包的相关文章也集中在17年左右。我个人猜测是因为很久没有更新了,与现有的R版本不兼容(本文R版本为3.6.2 (2019-12-1< @2)). 配置很长一段时间,最后无奈放弃。
然后我又开始在R上寻找爬虫,发现
无头浏览器方法。元子:R爬虫动态网站Rseleium包Rcrawler包(自动下载网页,但是时间太长,所以放弃了)
最后看一下,考虑到方便和效率,选择Rseleium进行爬取。
几个参考资料:
/LEEBELOVED/article/details/89461304
windows下配置RSelenium和Selenium环境
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
说一下安装过程。其实主要是设置安装环境。
1、首先建议下载firefox浏览器,下载最新版本。
2、firefox 浏览器安装后,需要将其安装路径添加到系统环境变量中。
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
windows系统中如何设置和添加环境变量-百度经验
3、java环境配置。注:我的电脑好像有自己的java jdk,你可以看看你的电脑有没有
参考:R语言RSelenium包爬取动态网页数据前期准备(环境配置)-连载NO.01_人工智能_STAY HUNGRY STAY FOOLISH-CSDNblog
4、硒配置
去seleium官网(下载)或者找镜像下载,然后选择最新版本的selenium-server-standalone-3.141.59.jar。下载并保存到您的计算机。建议保存到C盘,自己创建一个文件夹(我的是C:\Seleium)
只需要最新的3.141.59.jar。没有其他需要
5、运行硒。这一步搞了很久,因为win 10的cmd命令行老是报错,如下:
C:\Seleium>java -jar selenium-server-standalone-3.141.59.jar
我想通了之后,可能有两个原因。一是cmd没有在管理员模式下运行(记得在cmd后右键选择管理员模式运行!!)
还有一个路径问题,路径要设置为C:\Seleium!!!
设置方法:使用“CD /DC:\Seleium”,然后使用java -jar selenium-server-standalone-3.141.59.jar 来运行我们的seleium(类似于插入)。
设置CMD默认路径-穆良文王-博客园
最后,你可以看到 seleium 成功了。
还有一种方法:在save文件夹下,按住shift,右键,出现了,在这里打开pewershell窗口(有些人没有这个选项,百度的解决办法),同时运行java插件,你应该看到成功 NS
有些人会出现4444端口繁忙,请参考:
selenium server运行时报错---"Port is occupied",windows平台如何查看端口占用情况
6、R配置和爬取程序
股票、基金、期货、美股、港股、外汇、黄金、债券市场体系
<p># install.packages("Rseleium")
library(RCurl)# 抓取数据
library(XML)# 解析网页
librar(rvest)
library(RSelenium)
url_gp
python抓取动态网页(Python爬虫实战:爬取Drupal论坛帖子列表(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-16 11:11
1 简介
在之前的Python爬虫实战中:抓取Drupal论坛帖子列表,抓取一个用Drupal制作的论坛,是静态页面,比较容易抓取,即使直接解析html源文件,也可以抓取您需要的内容。相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们已经在 Python 爬虫中使用 Selenium+PhantomJS 来爬取 Ajax 和动态 HTML 内容。文章已经成功测试了动态网页内容的爬取方法。本文重写实验程序,使用开源Python爬虫指定的标准python内容提取器改代码。它非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。它可以节省时间。问题是在1分钟内快速生成用于网页内容提取的xslt。有一个解决方案。在本文中,我们使用京东网站作为测试目标,电子商务网站有很多动态内容,比如商品价格和评论数等,经常使用后加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中,在程序运行时读出该文件并注入gsExtractor提取器。以后会有一个特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码
# -*- coding:utf-8 -*-
# 爬取京东商品列表, 以手机商品列表为例
# 示例网址:http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5
# crawler_jd_list.py
# 版本: V1.0
from urllib import request
from lxml import etree
from selenium import webdriver
from gooseeker import gsExtractor
import time
class Spider:
def __init__(self):
self.scrollpages = 0
self.waittime = 3
self.phantomjsPath = 'C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe'
def getContent(self, url):
browser = webdriver.PhantomJS( executable_path = self.phantomjsPath )
browser.get(url)
time.sleep(self.waittime)
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
jdlistExtra = gsExtractor()
jdlistExtra.setXsltFromFile("jd_list.xml")
output = jdlistExtra.extract(doc)
return output
def saveContent(self, filepath, content):
file_obj = open(filepath, 'w', encoding='UTF-8')
file_obj.write(content)
file_obj.close()
url = 'http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5'
jdspider = Spider()
result = jdspider.getContent(url)
jdspider.saveContent('京东手机列表_1.xml', str(result))
源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上述代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,会看到如下内容:
五、相关文件
1. Python 即时网络爬虫项目:内容提取器的定义 6. 采集GooSeeker开源代码下载源
1. GooSeeker 开源 Python 网络爬虫 GitHub 源码 7. 文档修改历史
1, 2016-06-06: V1.0
上一章爬取 Drupal 论坛帖子列表 下一章 Scrapy 架构的初步研究 查看全部
python抓取动态网页(Python爬虫实战:爬取Drupal论坛帖子列表(一))
1 简介
在之前的Python爬虫实战中:抓取Drupal论坛帖子列表,抓取一个用Drupal制作的论坛,是静态页面,比较容易抓取,即使直接解析html源文件,也可以抓取您需要的内容。相反,JavaScript 实现的动态网页内容无法从 html 源代码中抓取所需的内容,必须先执行 JavaScript。
我们已经在 Python 爬虫中使用 Selenium+PhantomJS 来爬取 Ajax 和动态 HTML 内容。文章已经成功测试了动态网页内容的爬取方法。本文重写实验程序,使用开源Python爬虫指定的标准python内容提取器改代码。它非常简洁。
二、技术要点
我们在很多文章中都说过这个开源爬虫的目的:节省程序员的时间。关键是要节省编写提取规则的时间,尤其是调试规则。它可以节省时间。问题是在1分钟内快速生成用于网页内容提取的xslt。有一个解决方案。在本文中,我们使用京东网站作为测试目标,电子商务网站有很多动态内容,比如商品价格和评论数等,经常使用后加载方法。html源文件加载完成后,执行javascript代码填充动态内容。因此,本案例主要验证动态内容的爬取。
另外,本文案例没有使用GooSeeker爬虫API,而是将MS Strategy生成的xslt脚本程序保存在本地文件中,在程序运行时读出该文件并注入gsExtractor提取器。以后会有一个特例来演示如何使用API
综上所述,本例的两个技术点总结如下:
3.Python源代码
# -*- coding:utf-8 -*-
# 爬取京东商品列表, 以手机商品列表为例
# 示例网址:http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5
# crawler_jd_list.py
# 版本: V1.0
from urllib import request
from lxml import etree
from selenium import webdriver
from gooseeker import gsExtractor
import time
class Spider:
def __init__(self):
self.scrollpages = 0
self.waittime = 3
self.phantomjsPath = 'C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe'
def getContent(self, url):
browser = webdriver.PhantomJS( executable_path = self.phantomjsPath )
browser.get(url)
time.sleep(self.waittime)
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
jdlistExtra = gsExtractor()
jdlistExtra.setXsltFromFile("jd_list.xml")
output = jdlistExtra.extract(doc)
return output
def saveContent(self, filepath, content):
file_obj = open(filepath, 'w', encoding='UTF-8')
file_obj.write(content)
file_obj.close()
url = 'http://list.jd.com/list.html?cat=9987,653,655&page=1&JL=6_0_0&ms=5'
jdspider = Spider()
result = jdspider.getContent(url)
jdspider.saveContent('京东手机列表_1.xml', str(result))
源码下载位置请见文章末尾的GitHub源码。
4. 获取结果
运行上述代码,会抓取京东手机分类页面上的所有手机型号、价格等信息,并保存到本地文件“京东手机list_1.xml”中。当我们用浏览器打开这个结果文件时,会看到如下内容:
五、相关文件
1. Python 即时网络爬虫项目:内容提取器的定义 6. 采集GooSeeker开源代码下载源
1. GooSeeker 开源 Python 网络爬虫 GitHub 源码 7. 文档修改历史
1, 2016-06-06: V1.0
上一章爬取 Drupal 论坛帖子列表 下一章 Scrapy 架构的初步研究
python抓取动态网页( 关于with语句与上下文管理器三、思路整理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-16 04:26
关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数,具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。 查看全部
python抓取动态网页(
关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数,具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
操作结果:
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。
python抓取动态网页(就是一个解析xml和html之类的库,用着还算顺手 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-15 20:08
)
Beautiful Soup 是一个 Python 库,专为快速周转项目(如屏幕抓取)而设计。总之就是一个解析xml和html的库,使用起来还算流畅。
官网地址:
下面介绍一下使用python和Beautiful Soup捕获网页PM2.5数据。
PM2.5 网站 的数据:
这个网站上有对应的PM2.5数据。他们在几个地方布置了监视器,大约每小时更新一次(有时仪器数据会丢失)。我们要捕捉的数据是几个监测点的一些空气质量指标。
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用Beautiful Soup解析html内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以根据标签名称(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以获取对应的文本,比如“hello”,可以获取到“hello”
具体元素类型需要借助浏览器的评论元素功能查看
写文字:
主要使用python的with语法,with可以保证在发生异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是打开的文件流。这句话的意思是将print打印的东西重定向到文件中。
日志记录:
由于这个程序需要长时间在后台运行,所以最好记录下错误信息,方便调试。使用python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
这包括一些,设置日志的格式,以及日志文件的最大大小。
定时操作:
定时运行,可以在每天指定时间捕获PM2.5数据,并结合卫星通过时间做进一步分析。python自带的sched模块也经常使用。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,他将继续运行。
下载完整代码(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认是后台运行。
获取的结果:
查看全部
python抓取动态网页(就是一个解析xml和html之类的库,用着还算顺手
)
Beautiful Soup 是一个 Python 库,专为快速周转项目(如屏幕抓取)而设计。总之就是一个解析xml和html的库,使用起来还算流畅。
官网地址:
下面介绍一下使用python和Beautiful Soup捕获网页PM2.5数据。
PM2.5 网站 的数据:
这个网站上有对应的PM2.5数据。他们在几个地方布置了监视器,大约每小时更新一次(有时仪器数据会丢失)。我们要捕捉的数据是几个监测点的一些空气质量指标。
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用Beautiful Soup解析html内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以根据标签名称(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以获取对应的文本,比如“hello”,可以获取到“hello”
具体元素类型需要借助浏览器的评论元素功能查看
写文字:
主要使用python的with语法,with可以保证在发生异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是打开的文件流。这句话的意思是将print打印的东西重定向到文件中。
日志记录:
由于这个程序需要长时间在后台运行,所以最好记录下错误信息,方便调试。使用python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
这包括一些,设置日志的格式,以及日志文件的最大大小。
定时操作:
定时运行,可以在每天指定时间捕获PM2.5数据,并结合卫星通过时间做进一步分析。python自带的sched模块也经常使用。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,他将继续运行。
下载完整代码(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认是后台运行。
获取的结果:
python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-15 15:32
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在随机开发网搜索之前的文章或者继续浏览下面的相关文章,希望大家以后多多支持随机开发网! 查看全部
python抓取动态网页(python爬取js执行后输出的信息-苏州安嘉)
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页正文
#打印(响应)
回复回复
get_text_line(get_url_dynamic(url))#将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地火狐浏览器,Chrom甚至Ie也可以
driver.get(url)#请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
驱动程序退出()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))#将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content=driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在随机开发网搜索之前的文章或者继续浏览下面的相关文章,希望大家以后多多支持随机开发网!
python抓取动态网页(Web爬网如何使用python中BeautifulSoup进行WEB抓取!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-15 15:23
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:
我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:
我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。 查看全部
python抓取动态网页(Web爬网如何使用python中BeautifulSoup进行WEB抓取!(图))
互联网绝对是海量数据的来源。不幸的是,如果没有易于组织下载和分析的 CSV 文件,大多数都是。如果您想从许多网站 中捕获数据,则需要尝试网页抓取。
如果你还是初学者,请不要担心数据分析中如何使用python中的beautiful Soup进行网页抓取,我们将从头开始介绍如何使用Python进行网页抓取,首先回答一些关于网页的常见问题刮痧问题。
如果您已经熟悉了这个概念,请随意滚动浏览这些内容,然后直接进入数据分析。如何在python中使用Beautiful Soup进行WEB爬虫!
什么是 Python 中的网页抓取?
网站 提供的一些数据集可以以 CSV 格式下载或通过应用程序编程接口 (API) 访问。但是许多具有有用数据的 网站 并没有提供这些方便的选项。
例如,考虑来自国家气象局的 网站。它收录每个位置的最新天气预报,但无法通过 CSV 或 API 访问天气数据。
如果我们要分析这些数据,或者下载它用于其他应用程序,我们不会故意复制和粘贴所有内容。网页抓取是一种技术,可以让我们使用编程来完成繁重的工作。我们会写一些代码,在NWS网站上搜索,只获取我们要使用的数据,然后输出需要的格式。
在数据分析如何在 Python 中使用 Beautiful Soup 进行网页抓取中,我们将向您展示如何使用 Python 3 和 Beautiful Soup 库执行网页抓取。我们将从国家气象局获取天气预报并使用 pandas 库进行分析。
网络爬虫是如何工作的?
在抓取网页时,我们编写代码将请求发送到托管我们指定页面的服务器。通常,我们的代码会像浏览器一样下载页面的源代码。然而,它不是直观地显示页面,而是在页面中过滤以查找我们指定的 HTML 元素并提取我们指示它提取的任何内容。
比如我们想从网站中获取H2标签中的所有title,我们可以写一些代码来实现。我们的代码将从它的服务器请求 网站 的内容并下载它。然后,它将通过页面的 HTML 查找 H2 标记。只要找到 H2 标签,它就会复制标签中的所有文本,并以我们指定的任何格式输出。
需要注意的一件事:从服务器的角度来看,通过 Web 获取请求页面与在 Web 浏览器中加载页面相同。当我们使用代码提交这些请求时,我们可能会比普通用户更快地“加载”页面,这会很快耗尽所有者的服务器资源。
为什么要使用 Python 进行网络爬虫?
许多其他编程语言可用于网页抓取。例如,我们还有一个关于使用 R 进行网页抓取的教程。
然而,使用 Python 和 Beautiful Soup 库是最流行的网络抓取方法之一。这意味着一旦你掌握了美丽汤的基础知识,就会有很多教程、操作视频和一些示例代码来帮助你加深知识。
我们将在数据分析的最后介绍一些其他的网页抓取常见问题如何在 python 中使用 Beautiful Soup 进行网页抓取,但现在是时候开始研究我们的网页抓取项目了!每个网页抓取项目都应该从开始回答以下问题:
网站 搜索合法吗?
不幸的是,这里没有简单的答案。一些 网站 明确允许网络爬行。其他人明确禁止这样做。许多 网站 没有以一种或另一种方式提供任何明确的指导。
在抓取任何网站之前,我们应该检查一个条款和条件页面,看看是否有关于抓取的明确规则。如果是这样,我们应该跟随他们。如果不是,那更像是一种判断。
但是请记住,网页抓取会消耗主机 网站 的服务器资源。如果我们只刮一页,它不会引起问题。但是,如果我们的代码每十分钟抓取 1,000 页,对于 网站 所有者来说,这很快就会变得昂贵。
因此,除了遵循 网站 上发布的有关网络抓取的所有明确规则外,遵循以下最佳实践也是一个好主意:
1)划痕永远不会超过您的需要
2)考虑缓存你抓取的内容,以便在处理用于过滤和分析的代码时只下载一次,而不是每次运行代码时重新下载
3)考虑在代码中使用函数time.sleep()来构造暂停,比如避免在太短的时间内出现过多的请求而瘫痪不堪重负的服务器。
在用python中的Beautiful Soup进行网页抓取的数据分析的情况下,NWS的数据是公共领域的,其术语并没有禁止网页抓取,所以我们可以继续。
网页的组成部分
当我们访问网页时,我们的 Web 浏览器会向 Web 服务器发送请求。此请求称为 GET 请求,因为我们正在从服务器获取文件。然后,服务器发回文件,告诉我们的浏览器如何为我们呈现页面。有几种主要类型的文件:
1)HTML — 收录页面的主要内容。
2)CSS — 添加样式以使页面看起来更好。
3)JS — Javascript 文件为网页添加交互性。
4)Picture-Picture 格式如 JPG 和 PNG 允许网页显示图片。
浏览器收到所有文件后,会渲染页面并展示给我们。为了让页面精美呈现,很多事情都在幕后发生,但是当我们爬网时,我们不需要担心其中的大部分。在做网页爬虫的时候,我们对网页的主要内容感兴趣,所以我们来看一下HTML。
HTML
超文本标记语言 (HTML) 是一种用于创建网页的语言。HTML 不像 Python 那样是一种编程语言,而是一种告诉浏览器如何布局内容的标记语言。HTML 允许您执行类似于文字处理器中的操作,例如 Microsoft Word 使文本加粗、创建段落等。由于 HTML 不是编程语言,因此它几乎没有 Python 复杂。
让我们快速浏览一下 HTML,以便我们了解如何足够有效地抓取。HTML 由称为标签的元素组成。最基本的标签是标签。此标记告诉 Web 浏览器其中的所有内容都是 HTML。我们可以使用以下标记来制作一个简单的 HTML 文档:
我们还没有向页面添加任何内容,因此如果我们在 Web 浏览器中查看 HTML 文档,我们将看不到任何内容:
在 html 标签内,我们放置了另外两个标签,head 标签和 body 标签。网页的主要内容进入body标签。head 标签收录有关页面标题的信息和其他通常对抓取页面没有用的信息:
我们仍然没有向页面添加任何内容(在 body 标签内),所以我们再也看不到任何内容:
正如您在上面可能已经注意到的,我们将 head 和 body 标签放在 html 标签中。在 HTML 中,标签是嵌套的,可以放在其他标签内。
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-15 15:20
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
然后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档交互动作介绍:点击链接
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
这是Selenium的主要操作。更多详细信息,请访问以下页面:点击链接 查看全部
python抓取动态网页(分析Ajax访问服务器的方式来获取Ajax数据的应用)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章内容
硒
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。简而言之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip install selenium
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持多种浏览器。我们首先需要让系统知道您使用的是什么浏览器。我们可以通过以下方式对其进行初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Sarari()
然后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.baidu.com’)
print(browser.page_source)
browser.close()
查找节点
find_element_by_id()
find_element_by_name()
find_element_by_xpath()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
find_element_by_css_selector()
还有一个通用的方法:
find_element()
这种方法比上面的方法更灵活。它需要传入两个参数,查找方法By和value:
from selenium import webdriver
from selenium webdriver.common.by import By
#...
input_first = browser.find_element(BY.ID, 'q')
#...
find_elements_by_id()
find_elements_by_name()
find_elements_by_xpath()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_tag_name()
find_elements_by_class_name()
find_elements_by_css_selector()
也可以使用
find_elements()
我不会在这里详细介绍。
节点交互
Selenium 最重要的一点是它可以与浏览器交互。常用的有: send_key() 输入文本的方法;clear() 清除文本的方法;click() 方法用于单击按钮。示例如下:
#...
brower.find_elements_by_id('StudentId')[0].send_keys(StudentId) # 填入学号
brower.find_elements_by_id('Name')[0].send_keys(Password) # 填入密码
brower.find_elements_by_id('codeInput')[0].send_keys(
brower.find_elements_by_id('code-box')[0].text) # 填入验证码
brower.find_elements_by_id('Submit')[0].click() # 提交登录表单
brower.find_elements_by_id('platfrom2')[0].click() # 选择健康填报
brower.find_elements_by_id('ckCLS')[0].click()
try:
brower.find_element_by_class_name('save_form').click() # 提交
time.sleep(3)
brower.close() # 关闭浏览器
#...
更多操作请参考官方文档交互动作介绍:点击链接
获取节点信息
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_naem)
print(input.size)
这是Selenium的主要操作。更多详细信息,请访问以下页面:点击链接
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-15 15:19
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text 查看全部
python抓取动态网页(python爬取js执行后输出的信息1.11.1)
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text

