
python抓取动态网页
python抓取动态网页( 学习使用Python爬取动态网页内容时需要先学习动态网页的基本概念)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-28 21:15
学习使用Python爬取动态网页内容时需要先学习动态网页的基本概念)
Python爬虫学习动态网页爬虫的3个基础
由于静态网页和动态网页在原理上的差异,在学习使用Python抓取动态网页内容时,需要了解动态网页的基本概念,了解动态网页与静态网页的区别。
动态网页技术AJAX技术的基本原理
即异步 JavaScript 和 XML,通过后台和服务器之间的少量数据交换,可以异步更新网页。AJAX 技术可以在不重新加载整个网页的情况下部分更新网页。
AJAX技术节省了网页重复内容的下载,节省了流量,因此得到了广泛的应用。
↓AJAX技术的应用
使用 AJAX 技术动态识别的内容(如网页评论等)在 HTML 文件中由一段 JavaScript 代码表示。
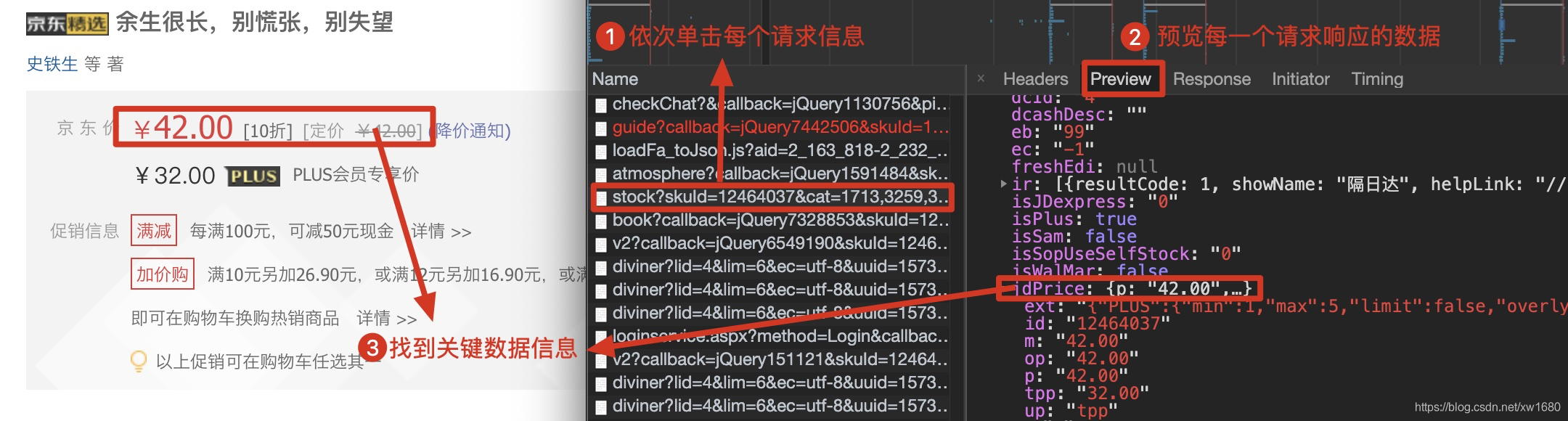
· 抓取 AJAX 加载的动态网页
①浏览器评论元素解析地址
②使用Selenium模拟浏览器爬行
浏览器检查元素使用浏览器检查元素解析真实地址
①在指定网页下打开浏览器“检查元素”功能的窗口视图
②选择网络子标签,刷新网页——此时网络标签会显示从网络服务器获取的所有文件(此过程为“抓包”,可以过滤掉所有文件中的目标文件获得的数据)
③通常这些数据都是以json文件格式获取的,选择网络中的XHR子标签,继续过滤获取目标文件数据的URL
④ 定义link为目标URL,使用新创建的请求对象抓取目标内容
⑤ 使用json库解析数据,进一步提取目标数据
——使用json.loads()将数据转换为json格式(注意r.text不能直接转换为json.load,需要中间转换过程)
——使用json数据结构提取列表comment_list,使用for循环提取文本并输出需要打印的信息到控制台
①浏览器解析真实地址,使用requests抓取信息并输出r.text
import requests
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print (r.text)
②解析真实地址,使用json转换数据进行初步分析,循环输出评论内容:
import requests
import json
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
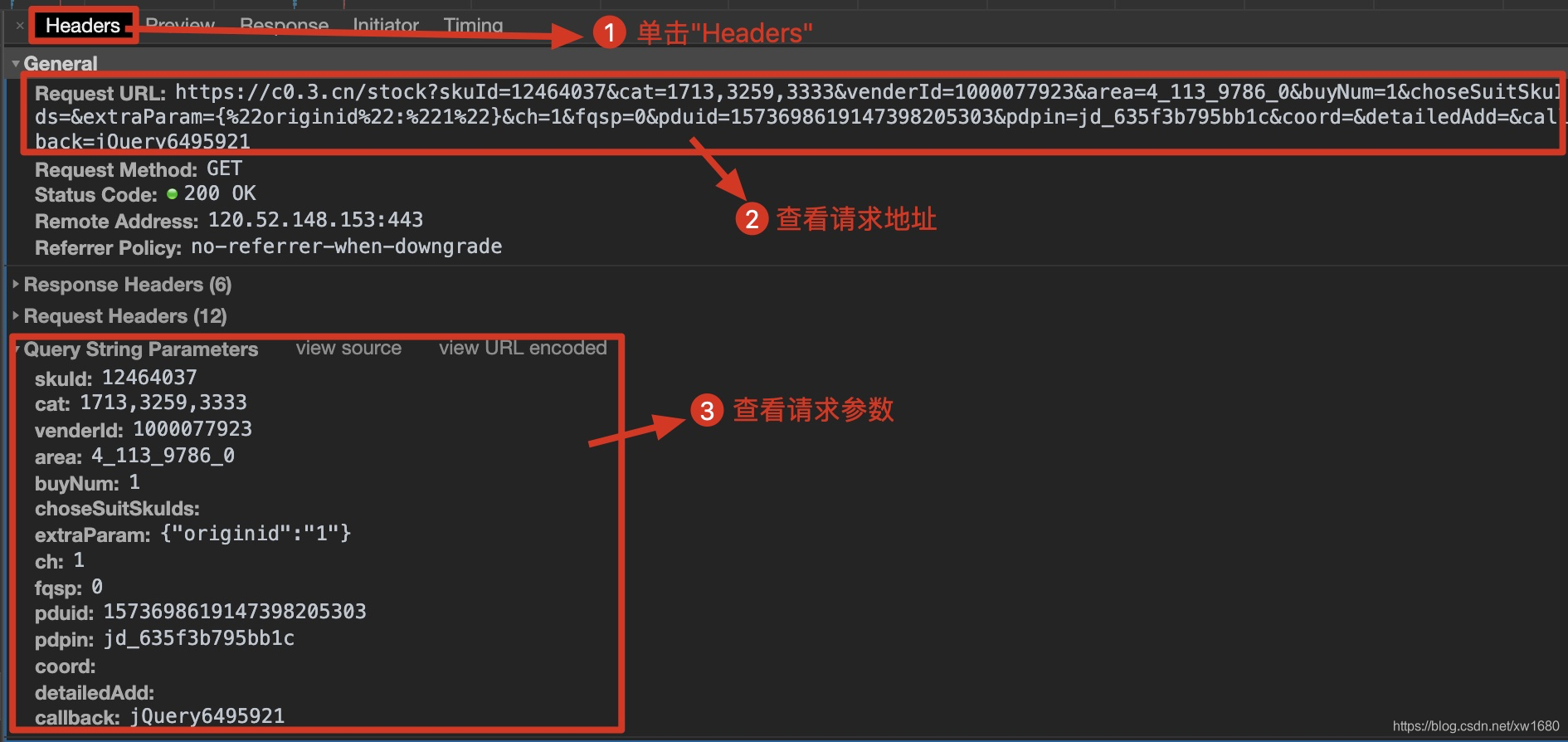
URL 中的重要变量
通过解析真实地址,可以发现URL中有一些重要的变量类型:
①limit:每个网页目标内容的最大值 查看全部
python抓取动态网页(
学习使用Python爬取动态网页内容时需要先学习动态网页的基本概念)
Python爬虫学习动态网页爬虫的3个基础
由于静态网页和动态网页在原理上的差异,在学习使用Python抓取动态网页内容时,需要了解动态网页的基本概念,了解动态网页与静态网页的区别。
动态网页技术AJAX技术的基本原理
即异步 JavaScript 和 XML,通过后台和服务器之间的少量数据交换,可以异步更新网页。AJAX 技术可以在不重新加载整个网页的情况下部分更新网页。
AJAX技术节省了网页重复内容的下载,节省了流量,因此得到了广泛的应用。
↓AJAX技术的应用
使用 AJAX 技术动态识别的内容(如网页评论等)在 HTML 文件中由一段 JavaScript 代码表示。
· 抓取 AJAX 加载的动态网页
①浏览器评论元素解析地址
②使用Selenium模拟浏览器爬行
浏览器检查元素使用浏览器检查元素解析真实地址
①在指定网页下打开浏览器“检查元素”功能的窗口视图
②选择网络子标签,刷新网页——此时网络标签会显示从网络服务器获取的所有文件(此过程为“抓包”,可以过滤掉所有文件中的目标文件获得的数据)
③通常这些数据都是以json文件格式获取的,选择网络中的XHR子标签,继续过滤获取目标文件数据的URL
④ 定义link为目标URL,使用新创建的请求对象抓取目标内容
⑤ 使用json库解析数据,进一步提取目标数据
——使用json.loads()将数据转换为json格式(注意r.text不能直接转换为json.load,需要中间转换过程)
——使用json数据结构提取列表comment_list,使用for循环提取文本并输出需要打印的信息到控制台
①浏览器解析真实地址,使用requests抓取信息并输出r.text
import requests
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print (r.text)
②解析真实地址,使用json转换数据进行初步分析,循环输出评论内容:
import requests
import json
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
URL 中的重要变量
通过解析真实地址,可以发现URL中有一些重要的变量类型:
①limit:每个网页目标内容的最大值
python抓取动态网页(Python一个抓取网页内容的一个库-0x00库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-28 19:21
Requests是Python用来获取web内容的库
下面是对它的详细描述
0x00、请求
以下是捕获web内容的示例:
import requests #引入requests库
a = requests.get("https://www.mmuaa.com/link") #使用get方法抓取url
这样,就成功捕获了“”
我们可以使用以下代码查看抓取结果
a.status_code #抓取的HTTP状态码
a.text #抓取到的内容
上面是使用get方法来请求数据。同样,我们可以使用post、head、options和put
比如说
a = requests.put("http://httpbin.org/put")
a = requests.delete("http://httpbin.org/delete")
a = requests.head("http://httpbin.org/get")
a = requests.options("http://httpbin.org/get")
等等
0x01、参数
例如:
import requests
g = {"type" : "1"} #用字典的方式存储我们要请求的数据
a = requests.get("http://api.mmuaa.com/link", g) #发送带参数的get请求
a.url #查看发送的url
如您所见,请求库自动为我们处理URL参数并将其发送出去
同样,我们也可以使用post
得到了正确的结果
0x02、响应头
使用headers函数查看响应头,返回类型为dictionary
0x03、Cookies
将Cookie发送到服务器:
url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
r.text
这将发送cookie\将具有工作值的cookie发送到服务器
接收服务器返回的cookie:
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
r.cookies['example_cookie_name']
这将返回服务器返回的名为“exa,ple_cookie_name”的cookie的值 查看全部
python抓取动态网页(Python一个抓取网页内容的一个库-0x00库)
Requests是Python用来获取web内容的库
下面是对它的详细描述
0x00、请求
以下是捕获web内容的示例:
import requests #引入requests库
a = requests.get("https://www.mmuaa.com/link";) #使用get方法抓取url
这样,就成功捕获了“”
我们可以使用以下代码查看抓取结果
a.status_code #抓取的HTTP状态码
a.text #抓取到的内容

上面是使用get方法来请求数据。同样,我们可以使用post、head、options和put
比如说
a = requests.put("http://httpbin.org/put";)
a = requests.delete("http://httpbin.org/delete";)
a = requests.head("http://httpbin.org/get";)
a = requests.options("http://httpbin.org/get";)
等等
0x01、参数
例如:
import requests
g = {"type" : "1"} #用字典的方式存储我们要请求的数据
a = requests.get("http://api.mmuaa.com/link", g) #发送带参数的get请求
a.url #查看发送的url

如您所见,请求库自动为我们处理URL参数并将其发送出去
同样,我们也可以使用post

得到了正确的结果
0x02、响应头
使用headers函数查看响应头,返回类型为dictionary
0x03、Cookies
将Cookie发送到服务器:
url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
r.text
这将发送cookie\将具有工作值的cookie发送到服务器
接收服务器返回的cookie:
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
r.cookies['example_cookie_name']
这将返回服务器返回的名为“exa,ple_cookie_name”的cookie的值
python抓取动态网页(python爬取js执行后输出的解决方案(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-09-23 18:11
Python有许多库让我们轻松编写网络爬行动物,爬上某些页面,得到宝贵的信息!但在许多情况下,要采取爬行动物页面只是一个静态页面,该页面的源代码,如浏览器中的“查看页面源”。一些动态的东西,例如在JavaScript脚本之后生成的信息,这里可以用于提供这样的程序,可用于Python爬行JS执行输出的信息。
1.两个基本解决方案
1. 1带有dryscrape库动态抓取页
js脚本由浏览器执行并返回信息,因此抓住了JS执行后的页面,以及最直接的方式是使用Python模拟浏览器的行为。 WebKit是一个开源浏览器引擎,Python提供了许多文库来调用此引擎,Dryscrape是其中之一,它调用WebKit引擎来处理收录JS的网页!
1 importdryscrape2#使用dryscrape数据库动态捕获页面
3 defget_url_dynamic(URL):4 session_req = dryscrape.session()5 session_req.visit(url)#请求页
6 response = session_req.body()#网网文
7 #print(响应)
8 return response9 get_text_line(get_url_dynamic(url))#将输出文本
这也适用于收录JS的剩余网页!虽然它可以满足动态页面的要求,但缺点仍然非常明显:慢!太慢,实际上思考它合理地,python调用webkit请求页面,而其他页面被加载,加载js文件,让js执行,返回执行页面,慢慢慢!有许多图书馆可以调用webkit:pythonwebkit,pygebkitgit,pygt(你可以编写浏览器),睡衣等,我听说他们也可以实现相同的功能!
1. 2硒网测试框架
Selenium是一个Web测试框架,允许呼叫呼叫本地浏览器引擎发送Web请求,因此它也可以达到捕获页面的要求。
#使用selenium webdriver,但实时打开浏览器窗口
1 defget_url_dynamic2(URL):2驱动程序= webdriver.firefox()#coll uncoup firefox浏览器,甚至可以
3 driver.get(url)#请求页面,打开浏览器窗口
4 html_text = driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url))#out文本
这不是临时解决方案!还有一个与硒类似的硒的风车,这稍微复杂,然后再去!
2. selenium安装和使用
2. 1硒安装
在Ubuntu上安装可以直接使用pip安装selenium。由于以下原因:
1. selenium 3. x start,webdriver / firefox / webdriver.py __init__,secututable_path =“geckodriver”; 2. x是可执行文件_path =“线”
2. firefox 47或以上,您需要下载第三方驱动程序,哪个geckodriver
需要一些特殊操作:
1.下载geckodriverckod地址:mozilla / geckodriver
2.装装置go o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o up下载/ geckodriver / usr / local / bin /
2. 2 selenium的使用
1.运行错误:
驱动程序= webdriver.chrome()
typeerror:'模块'对象不是可调用的
解决方案:浏览器的名称需要大写Chrome和Firefox,即
2.通过
1 content = driver.find_element_by_class_name('content')
当元素定位时,该方法返回FirefoxWebElement,并且当您想要获取收录的值时,可以通过
1值= content.text 查看全部
python抓取动态网页(python爬取js执行后输出的解决方案(一))
Python有许多库让我们轻松编写网络爬行动物,爬上某些页面,得到宝贵的信息!但在许多情况下,要采取爬行动物页面只是一个静态页面,该页面的源代码,如浏览器中的“查看页面源”。一些动态的东西,例如在JavaScript脚本之后生成的信息,这里可以用于提供这样的程序,可用于Python爬行JS执行输出的信息。
1.两个基本解决方案
1. 1带有dryscrape库动态抓取页
js脚本由浏览器执行并返回信息,因此抓住了JS执行后的页面,以及最直接的方式是使用Python模拟浏览器的行为。 WebKit是一个开源浏览器引擎,Python提供了许多文库来调用此引擎,Dryscrape是其中之一,它调用WebKit引擎来处理收录JS的网页!
1 importdryscrape2#使用dryscrape数据库动态捕获页面
3 defget_url_dynamic(URL):4 session_req = dryscrape.session()5 session_req.visit(url)#请求页
6 response = session_req.body()#网网文
7 #print(响应)
8 return response9 get_text_line(get_url_dynamic(url))#将输出文本
这也适用于收录JS的剩余网页!虽然它可以满足动态页面的要求,但缺点仍然非常明显:慢!太慢,实际上思考它合理地,python调用webkit请求页面,而其他页面被加载,加载js文件,让js执行,返回执行页面,慢慢慢!有许多图书馆可以调用webkit:pythonwebkit,pygebkitgit,pygt(你可以编写浏览器),睡衣等,我听说他们也可以实现相同的功能!
1. 2硒网测试框架
Selenium是一个Web测试框架,允许呼叫呼叫本地浏览器引擎发送Web请求,因此它也可以达到捕获页面的要求。
#使用selenium webdriver,但实时打开浏览器窗口
1 defget_url_dynamic2(URL):2驱动程序= webdriver.firefox()#coll uncoup firefox浏览器,甚至可以
3 driver.get(url)#请求页面,打开浏览器窗口
4 html_text = driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url))#out文本
这不是临时解决方案!还有一个与硒类似的硒的风车,这稍微复杂,然后再去!
2. selenium安装和使用
2. 1硒安装
在Ubuntu上安装可以直接使用pip安装selenium。由于以下原因:
1. selenium 3. x start,webdriver / firefox / webdriver.py __init__,secututable_path =“geckodriver”; 2. x是可执行文件_path =“线”
2. firefox 47或以上,您需要下载第三方驱动程序,哪个geckodriver
需要一些特殊操作:
1.下载geckodriverckod地址:mozilla / geckodriver
2.装装置go o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o up下载/ geckodriver / usr / local / bin /
2. 2 selenium的使用
1.运行错误:
驱动程序= webdriver.chrome()
typeerror:'模块'对象不是可调用的
解决方案:浏览器的名称需要大写Chrome和Firefox,即
2.通过
1 content = driver.find_element_by_class_name('content')
当元素定位时,该方法返回FirefoxWebElement,并且当您想要获取收录的值时,可以通过
1值= content.text
python抓取动态网页(爬取《Python网络爬虫》动态网页抓取的两种技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-23 18:09
由于主流网站,使用JavaScript显示web内容,静态网页的前面简单是不同的。当使用JavaScript,许多内容将不会出现在HTML源代码,但在HTML源位置的JavaScript代码的最后一节,最后给出的数据是由JavaScript提取服务器返回的数据进行渲染。因此,抓取静态网页的技术可能无法正常使用。因此,我们需要由动态网页捕获两种技术:
1.通过浏览器审查元件解析所述实际网页地址;
2.使用硒,模拟浏览器。
我们首先先介绍第一种方法。
以“Python的网络爬虫:从入门到实践”一书的作者的个人博客作为一个例子。网址:1) “队长”:找到真正的数据地址
右键单击“检查”,单击“网络”,选择“JS”。刷新页面,选择当页面刷新列出的数据,并选择此JS文件。检查右边的头。如该图所示:
,其中请求URL是一个真正的数据地址。
滚动鼠标滚轮在该状态下,找到用户代理。
2)相关的代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代Ĵj_string.find()API分辨率:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码JSON_STRING.FIND( '{')返回 “{” 在json_string串的索引位置。
2)如果添加代码打印在你的代码json_string,输出的结果是(因为过多的输出内容,只有起点和终点,在关键位置是在红色标记):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上述输出的输出已知的,我们加入JSON_STRING = JSON_STRING [JSON_STRING.FIND( '{'): - 2]。在您的代码
如果json_string.find(“{”)不添加,结果是不合法的JSON格式,不能顺利形成JSON文件;如果它不拦截第二比特,结果含有过量);它也无法合法JSON格式。
3)对于在中间[“内容”]代码comment_list = json_data [“结果”] [“父母”]和消息中的字符串型标签在中间支架,可以是2)关键部件查找,即,由“结果”和“父母”拦截合法JSON文件使用了两个中间支架一步一步的位置,因为我们爬的评论,其内容是在这个JSON文件中的“内容“标签,使用[” 内容“]来的位置。
据观察,OFFSET在真实数据地址的页面的数量。 查看全部
python抓取动态网页(爬取《Python网络爬虫》动态网页抓取的两种技术)
由于主流网站,使用JavaScript显示web内容,静态网页的前面简单是不同的。当使用JavaScript,许多内容将不会出现在HTML源代码,但在HTML源位置的JavaScript代码的最后一节,最后给出的数据是由JavaScript提取服务器返回的数据进行渲染。因此,抓取静态网页的技术可能无法正常使用。因此,我们需要由动态网页捕获两种技术:
1.通过浏览器审查元件解析所述实际网页地址;
2.使用硒,模拟浏览器。
我们首先先介绍第一种方法。
以“Python的网络爬虫:从入门到实践”一书的作者的个人博客作为一个例子。网址:1) “队长”:找到真正的数据地址
右键单击“检查”,单击“网络”,选择“JS”。刷新页面,选择当页面刷新列出的数据,并选择此JS文件。检查右边的头。如该图所示:
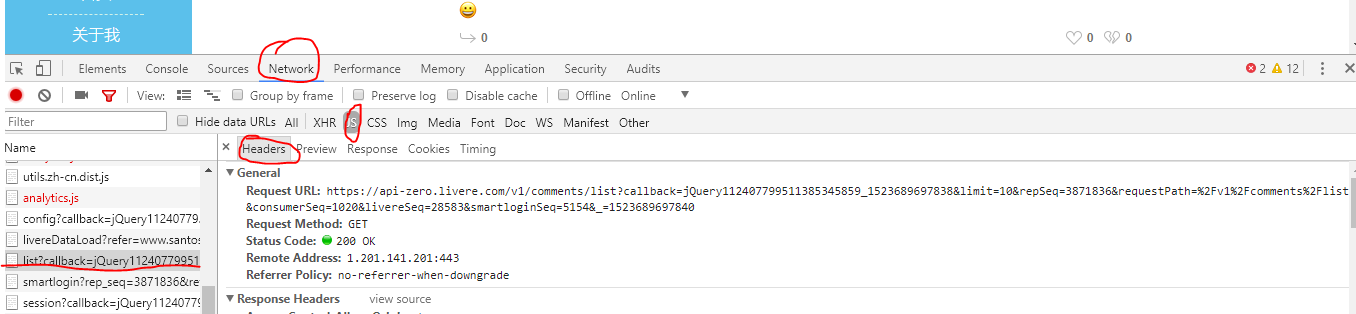
,其中请求URL是一个真正的数据地址。
滚动鼠标滚轮在该状态下,找到用户代理。
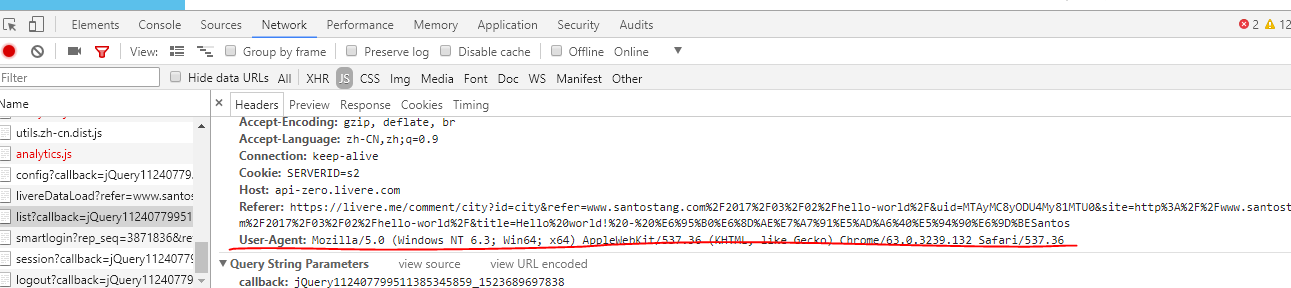
2)相关的代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代Ĵj_string.find()API分辨率:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码JSON_STRING.FIND( '{')返回 “{” 在json_string串的索引位置。
2)如果添加代码打印在你的代码json_string,输出的结果是(因为过多的输出内容,只有起点和终点,在关键位置是在红色标记):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上述输出的输出已知的,我们加入JSON_STRING = JSON_STRING [JSON_STRING.FIND( '{'): - 2]。在您的代码
如果json_string.find(“{”)不添加,结果是不合法的JSON格式,不能顺利形成JSON文件;如果它不拦截第二比特,结果含有过量);它也无法合法JSON格式。
3)对于在中间[“内容”]代码comment_list = json_data [“结果”] [“父母”]和消息中的字符串型标签在中间支架,可以是2)关键部件查找,即,由“结果”和“父母”拦截合法JSON文件使用了两个中间支架一步一步的位置,因为我们爬的评论,其内容是在这个JSON文件中的“内容“标签,使用[” 内容“]来的位置。
据观察,OFFSET在真实数据地址的页面的数量。
python抓取动态网页(博主不蛋疼时也会更新博客的哈~~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-22 22:03
我还没来得及写一点我前段时间写的东西。如果今天我的眼睛痛,我会写下来~~(结果是博客作者在没有鸡蛋痛的时候会更新他们的博客~)
Python爬行网页基金会
Python本身有许多与网络应用程序相关的模块,例如用于FTP相关操作的ftplib、用于发送和接收电子邮件的SMTP lib和poplib等。完全可以使用这些模块编写FTP软件或电子邮件客户端软件。我只是尝试发送和接收电子邮件,并完全使用Python脚本操作自己的FTP服务器。当然,这些都不是今天的主角。我们今天将使用的模块有:urlib、urlib2、cookielib和beautiful soup。我们先简单介绍一下。Urllib和Urllib 2自然地处理与URL相关的操作。Urllib可以从指定的URL下载文件,或者对某些字符串进行编码和解码,使其成为特定的URL字符串。Urllib 2比Urllib多一点。哦,不,它更棒一点。它有多种处理程序和处理器,可以处理更复杂的问题,如网络身份验证、使用代理服务器、使用cookie等等。第三个cookie IB,顾名思义,处理与cookie相关的操作,我没有深入讨论其他操作。最后一个包Beauty soup是一个第三方包,专门用于解析HTML和XML文件。使用它是非常傻瓜式。我们依靠它来解析网页源代码,可以从下载。当然,你也可以使用easy_uuu安装它,这里是它的中文使用文档。很多例子都很好
让我们看一看最简单的网页捕获。事实上,网页捕获就是下载所需的网页源代码文件,然后对其进行分析,为我们自己提取有用的信息。最简单的抓取只需一句话:
1
2
import urllib
html_src = urllib.urlopen('http://www.baidu.com').read()
这将打印出百度主页的HTML源代码,这仍然很容易。Urllib的urlopen函数将返回一个“class file”对象,因此您可以直接调用read()来获取内容。然而,印刷内容混乱,布局不美观,编码问题没有得到解决,所以你看不到汉字。这需要我们漂亮的汤包装。我们可以使用上面获得的源代码字符串HTML来初始化beautifulsoup对象:
1
2
from BeautifulSoup import BeautifulSoup
parser = BeautifulSoup(html_src)
这样,HTML源代码的后续处理就留给解析器变量了。我们可以简单地调用解析器的prettify函数来相对美观地显示源代码,这样我们就可以看到中文字符,因为beautiful soup可以自动处理字符问题,并将返回的结果转换为Unicode编码格式。此外,beautiful soup可以快速找到满足条件的指定标记,稍后我们将使用这些标记~
关注人人网的消息
我们讨论了最简单的爬行情况,但通常我们需要面对更复杂的情况。例如,人人网需要登录到自己的帐户才能显示新内容,因此我们只能使用urlib2模块。想象一下,我们需要一个开场白来打开你的人人网主页。为了进入,我们首先需要身份验证,而此登录身份验证需要cookie支持,因此我们需要在此开场白上构建cookie处理程序:
1
2
3
4
import urllib,urllib2,cookielib
from BeautifulSoup import BeautifulSoup
myCookie = urllib2.HTTPCookieProcessor(cookielib.CookieJar());
opener = urllib2.build_opener(myCookie)
首先导入我们需要的所有模块,然后使用urlib2模块的HTTP cookie处理器构建cookie处理程序,并将cookie IB模块的cookie jar函数作为参数传入。此函数用于处理HTTP cookies。简而言之,它从HTTP请求中提取cookie并将它们返回给HTTP响应。然后使用urlib2_uuOpener的构建来创建我们需要的Opener。此开启器已满足我们处理cookies的要求
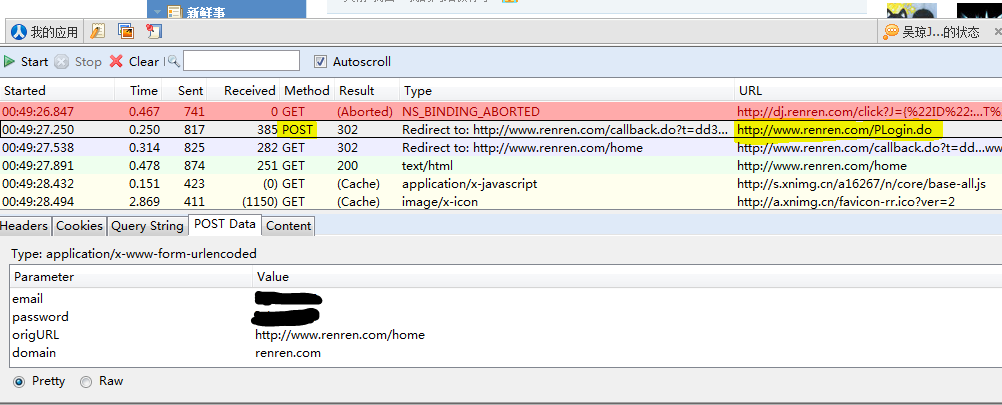
那么这个处理器是如何工作的呢?如前所述,它需要捕获HTTP请求。也就是说,我们需要知道登录时发送了哪些数据包。令人敬畏的人可以使用各种命令行数据包捕获工具,如tcpdump。让我们等待晓敏的到来。在这里,我们借助Firefox的httpfox实现它。你可以在这里添加这个很棒的插件。安装插件后,我们使用Firefox登录人人网,然后输入帐户和密码。然后,不要担心,不要按登录按钮,从状态栏打开httpfox插件,单击开始按钮开始捕获数据包,然后单击人人网的登录。登录过程完成后,单击httpfox停止捕获数据包,如果一切正常,您应该看到以下信息
我们可以看到,在登录人人网的过程中,浏览器向人人网的服务器发送post请求数据。共有四项,其中两项是您的帐户和密码。让我们使用代码模拟来提出相同的请求
1
2
3
4
5
6
7
8
9
post_data = {
'email':'xxxxx',
'password':'xxxxx',
'origURL':'http://www.renren.com/Home.do',
'domain':'renren.com'
}
req = urllib2.Request('http://www.renren.com/PLogin.do', urllib.urlencode(post_data))
html_src = openner.open(req).read()
parser = BeautifulSoup(html_src)
首先,构造一个字典来存储我们刚刚捕获的post数据,然后通过urllib 2的请求类自己构造一个“request”对象。请求的提交URL是上面捕获的post请求的URL部分,后面是我们的post数据。注意,我们需要使用urllib的URLEncode方法在这里重新编码,使其成为合法的URL字符串。下面的过程与上面提到的简单爬网过程相同,只是这里打开的不是简单的web地址,而是封装web地址和post数据后的请求。类似地,我们将源代码分配给beautifulsoup以供以后处理
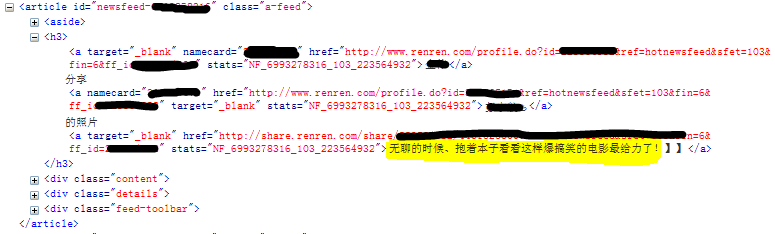
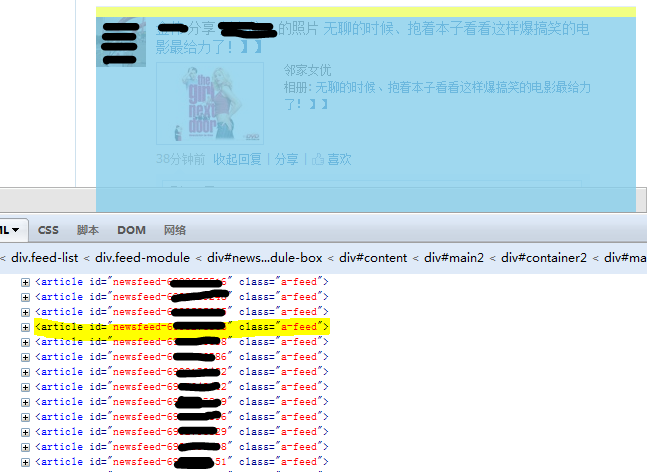
现在,我们在解析器中存储的是收录来自朋友的新闻的网页源代码。我们如何提取有用的信息?分析网页的粗略工作应该交给Firefox的firebug(在这里下载)。登录人人网,任意右键点击新闻中某人的状态,选择“查看元素”,弹出如下窗口,显示您点击的部分对应的源代码:
我们可以看到,每个新事件都对应于article标记。让我们仔细看看文章标签的细节:
里面的H3标签收录朋友的姓名和状态。当然,肥猪流也有一些表达地址。那些接触过HTML的人应该对此很熟悉。这就是我们要抓到的H3
Beautifulsoup抓取标签内容
下面是我们的解析器展示它的时候了。Beautifulsoup提供了许多定位标记的方法。简而言之,它主要包括find函数和findall函数。常用参数是name和attrs。一个是标记的名称,另一个是标记的属性,名称是字符串,attrs是字典,例如find('img'),{'SRC':'abc.JPG'})将返回如下标签:
find和findall之间的区别在于find只返回满足要求的第一个标记,而findall返回满足要求的所有标记的列表。在获得标签后,有许多方便的方法来获得子标签。例如,标签。A可以通过点运算符获取由tag表示的标记下的子标记A,然后tag.contents可以获取其所有子标记。对于更多应用程序,您可以查看其文档。让我们以这个例子来了解如何捕获我们想要的内容
1
2
3
4
5
6
7
8
9
10
11
article_list = parser.find('div','feed-list').findAll('article')
for my_article in article_list:
state = []
for my_tag in my_article.h3.contents:
factor = my_tag.string
if factor != None:
factor = factor.replace(u'\xa0','')
factor = factor.strip(u'\r\n')
factor = factor.strip(u'\n')
state.append(factor)
print ' '.join(state)
这里,我们使用find('div','feedlist')。Findall('article')获取其类属性为提要列表的div标记。当第二个参数直接是字符串时,它表示CSS的class属性,然后获取所有文章的列表。与上图相比,这句话实际上得到了所有新事物的列表。然后我们遍历这个列表,为每个文章标记获取其H3标记,并提取内部信息。如果标签直接收录文本,则可以通过string属性获取。最后,我们删除了一些控制字符,例如换行符。最后,我们打印结果。当然,这只能获得一小部分,“更多新事物”的功能是无法实现的。如果你感兴趣,继续学习。我认为通过httpfox实现并不困难
团购信息聚合小工具
有了同样的知识,我们还可以做一些有趣的应用,比如流行的团购信息聚合。其实这个想法还是很简单的,就是分析网站源代码,提取团购标题、图片和价格。在这里,我们发布了源代码文件,有兴趣的人可以研究它!pyqt制作的界面中的按钮功能尚未实现,因此我们只能将其提取为“美团”、“”和“团购”网站,可通过下拉列表框选择显示。图片将保存在本地目录中。让我们拍一张截图~
未实现交叉按钮功能。这是文件下载,一个PYW主表单文件,另外两个py文件,一个是UI,另一个是resource
软件包下载 查看全部
python抓取动态网页(博主不蛋疼时也会更新博客的哈~~)
我还没来得及写一点我前段时间写的东西。如果今天我的眼睛痛,我会写下来~~(结果是博客作者在没有鸡蛋痛的时候会更新他们的博客~)
Python爬行网页基金会
Python本身有许多与网络应用程序相关的模块,例如用于FTP相关操作的ftplib、用于发送和接收电子邮件的SMTP lib和poplib等。完全可以使用这些模块编写FTP软件或电子邮件客户端软件。我只是尝试发送和接收电子邮件,并完全使用Python脚本操作自己的FTP服务器。当然,这些都不是今天的主角。我们今天将使用的模块有:urlib、urlib2、cookielib和beautiful soup。我们先简单介绍一下。Urllib和Urllib 2自然地处理与URL相关的操作。Urllib可以从指定的URL下载文件,或者对某些字符串进行编码和解码,使其成为特定的URL字符串。Urllib 2比Urllib多一点。哦,不,它更棒一点。它有多种处理程序和处理器,可以处理更复杂的问题,如网络身份验证、使用代理服务器、使用cookie等等。第三个cookie IB,顾名思义,处理与cookie相关的操作,我没有深入讨论其他操作。最后一个包Beauty soup是一个第三方包,专门用于解析HTML和XML文件。使用它是非常傻瓜式。我们依靠它来解析网页源代码,可以从下载。当然,你也可以使用easy_uuu安装它,这里是它的中文使用文档。很多例子都很好
让我们看一看最简单的网页捕获。事实上,网页捕获就是下载所需的网页源代码文件,然后对其进行分析,为我们自己提取有用的信息。最简单的抓取只需一句话:
1
2
import urllib
html_src = urllib.urlopen('http://www.baidu.com').read()
这将打印出百度主页的HTML源代码,这仍然很容易。Urllib的urlopen函数将返回一个“class file”对象,因此您可以直接调用read()来获取内容。然而,印刷内容混乱,布局不美观,编码问题没有得到解决,所以你看不到汉字。这需要我们漂亮的汤包装。我们可以使用上面获得的源代码字符串HTML来初始化beautifulsoup对象:
1
2
from BeautifulSoup import BeautifulSoup
parser = BeautifulSoup(html_src)
这样,HTML源代码的后续处理就留给解析器变量了。我们可以简单地调用解析器的prettify函数来相对美观地显示源代码,这样我们就可以看到中文字符,因为beautiful soup可以自动处理字符问题,并将返回的结果转换为Unicode编码格式。此外,beautiful soup可以快速找到满足条件的指定标记,稍后我们将使用这些标记~
关注人人网的消息
我们讨论了最简单的爬行情况,但通常我们需要面对更复杂的情况。例如,人人网需要登录到自己的帐户才能显示新内容,因此我们只能使用urlib2模块。想象一下,我们需要一个开场白来打开你的人人网主页。为了进入,我们首先需要身份验证,而此登录身份验证需要cookie支持,因此我们需要在此开场白上构建cookie处理程序:
1
2
3
4
import urllib,urllib2,cookielib
from BeautifulSoup import BeautifulSoup
myCookie = urllib2.HTTPCookieProcessor(cookielib.CookieJar());
opener = urllib2.build_opener(myCookie)
首先导入我们需要的所有模块,然后使用urlib2模块的HTTP cookie处理器构建cookie处理程序,并将cookie IB模块的cookie jar函数作为参数传入。此函数用于处理HTTP cookies。简而言之,它从HTTP请求中提取cookie并将它们返回给HTTP响应。然后使用urlib2_uuOpener的构建来创建我们需要的Opener。此开启器已满足我们处理cookies的要求
那么这个处理器是如何工作的呢?如前所述,它需要捕获HTTP请求。也就是说,我们需要知道登录时发送了哪些数据包。令人敬畏的人可以使用各种命令行数据包捕获工具,如tcpdump。让我们等待晓敏的到来。在这里,我们借助Firefox的httpfox实现它。你可以在这里添加这个很棒的插件。安装插件后,我们使用Firefox登录人人网,然后输入帐户和密码。然后,不要担心,不要按登录按钮,从状态栏打开httpfox插件,单击开始按钮开始捕获数据包,然后单击人人网的登录。登录过程完成后,单击httpfox停止捕获数据包,如果一切正常,您应该看到以下信息
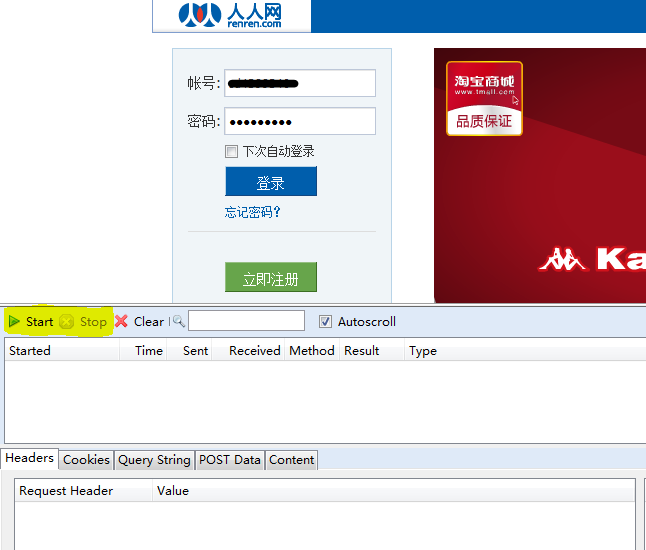
我们可以看到,在登录人人网的过程中,浏览器向人人网的服务器发送post请求数据。共有四项,其中两项是您的帐户和密码。让我们使用代码模拟来提出相同的请求
1
2
3
4
5
6
7
8
9
post_data = {
'email':'xxxxx',
'password':'xxxxx',
'origURL':'http://www.renren.com/Home.do',
'domain':'renren.com'
}
req = urllib2.Request('http://www.renren.com/PLogin.do', urllib.urlencode(post_data))
html_src = openner.open(req).read()
parser = BeautifulSoup(html_src)
首先,构造一个字典来存储我们刚刚捕获的post数据,然后通过urllib 2的请求类自己构造一个“request”对象。请求的提交URL是上面捕获的post请求的URL部分,后面是我们的post数据。注意,我们需要使用urllib的URLEncode方法在这里重新编码,使其成为合法的URL字符串。下面的过程与上面提到的简单爬网过程相同,只是这里打开的不是简单的web地址,而是封装web地址和post数据后的请求。类似地,我们将源代码分配给beautifulsoup以供以后处理
现在,我们在解析器中存储的是收录来自朋友的新闻的网页源代码。我们如何提取有用的信息?分析网页的粗略工作应该交给Firefox的firebug(在这里下载)。登录人人网,任意右键点击新闻中某人的状态,选择“查看元素”,弹出如下窗口,显示您点击的部分对应的源代码:
我们可以看到,每个新事件都对应于article标记。让我们仔细看看文章标签的细节:
里面的H3标签收录朋友的姓名和状态。当然,肥猪流也有一些表达地址。那些接触过HTML的人应该对此很熟悉。这就是我们要抓到的H3
Beautifulsoup抓取标签内容
下面是我们的解析器展示它的时候了。Beautifulsoup提供了许多定位标记的方法。简而言之,它主要包括find函数和findall函数。常用参数是name和attrs。一个是标记的名称,另一个是标记的属性,名称是字符串,attrs是字典,例如find('img'),{'SRC':'abc.JPG'})将返回如下标签:

find和findall之间的区别在于find只返回满足要求的第一个标记,而findall返回满足要求的所有标记的列表。在获得标签后,有许多方便的方法来获得子标签。例如,标签。A可以通过点运算符获取由tag表示的标记下的子标记A,然后tag.contents可以获取其所有子标记。对于更多应用程序,您可以查看其文档。让我们以这个例子来了解如何捕获我们想要的内容
1
2
3
4
5
6
7
8
9
10
11
article_list = parser.find('div','feed-list').findAll('article')
for my_article in article_list:
state = []
for my_tag in my_article.h3.contents:
factor = my_tag.string
if factor != None:
factor = factor.replace(u'\xa0','')
factor = factor.strip(u'\r\n')
factor = factor.strip(u'\n')
state.append(factor)
print ' '.join(state)
这里,我们使用find('div','feedlist')。Findall('article')获取其类属性为提要列表的div标记。当第二个参数直接是字符串时,它表示CSS的class属性,然后获取所有文章的列表。与上图相比,这句话实际上得到了所有新事物的列表。然后我们遍历这个列表,为每个文章标记获取其H3标记,并提取内部信息。如果标签直接收录文本,则可以通过string属性获取。最后,我们删除了一些控制字符,例如换行符。最后,我们打印结果。当然,这只能获得一小部分,“更多新事物”的功能是无法实现的。如果你感兴趣,继续学习。我认为通过httpfox实现并不困难
团购信息聚合小工具
有了同样的知识,我们还可以做一些有趣的应用,比如流行的团购信息聚合。其实这个想法还是很简单的,就是分析网站源代码,提取团购标题、图片和价格。在这里,我们发布了源代码文件,有兴趣的人可以研究它!pyqt制作的界面中的按钮功能尚未实现,因此我们只能将其提取为“美团”、“”和“团购”网站,可通过下拉列表框选择显示。图片将保存在本地目录中。让我们拍一张截图~

未实现交叉按钮功能。这是文件下载,一个PYW主表单文件,另外两个py文件,一个是UI,另一个是resource
软件包下载
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-21 12:11
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
python抓取动态网页(zerocapture、httpyjs框架内部ajax交互方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-19 00:06
python抓取动态网页数据,在诸多方法中,如gzip压缩和flask框架内部ajax交互,一直存在着问题。一来url前缀单一,“-static”路径提取时无法从原网页采集数据,二来有可能抓取到不安全数据。而利用xpath,三者已经是标配。zerocapture、httpyjs的主要应用,同时也是百度搜索引擎的抓取方案。
在多次尝试中,zerocapture的各种方法由于运行速度慢而逐渐被弃用。最终,爬取这个页面的项目方案,可以直接套用xpath。python解析url:'//useragent.#1\s/testing\album\reto\o29_o29_o29\b29\testing\album\reto\o29_o29\b29\testing\album\reto\o29_o29\testing\album\reto\o29_o29\fauto_o29\reto\sd',url('')'我们已经知道了网页的各个参数,以及具体参数对应的类型。
那么,python是否就可以从网页的整个页面抓取数据呢?答案是可以的。首先,我们先确定url本身具有从页面的一个或多个页面获取某些信息的能力。通常表现为:返回json或其他形式的字符串或xml,数据包含moreparts等标签。注意:该url是对单页进行抓取时,返回值为整页的返回。可以看出,我们已经抓取了「四个侧栏」。
接下来,我们一个个页面进行抓取。这里我们需要注意的是,在抓取每个侧栏时,需要把当前页面上所有我们想抓取的信息列表所在的内容(包括标签),包括返回值列表所在的内容都抓取。这一步非常关键,因为列表所在的内容抓取后就永远不会被下一页抓取。虽然这样比较麻烦,但作为新手,这一步还是值得弄懂的。然后,就是利用gzip压缩保存数据了。
下面我们可以通过一个简单的xpath函数完成这个操作。xpath生成能从单个页面获取某些信息的解析xpath调用链接#[a-za-z0-9]{2,5,5}xpath{2,5,5}第一步生成url,a-za-z0-9代表a~za中文开头与结尾的最后一个字符串,a代表第二个汉字,b~c代表u+1~v-7,用来将中文前缀部分和中文后缀部分用aa表示。
网页源码中需要包含json格式的字符串。对于url而言,参数gzip=json.loads(dirname('flasy.url')),json=json.dumps(url)#正则匹配[x,y]#分页从flasy.url中获取内容p=gzip.json('flasy.url')#json.dump(xpath,url)#json.dump(json,gzip)->(['b','b','d','b','c','d','a','a','b','b','c','。 查看全部
python抓取动态网页(zerocapture、httpyjs框架内部ajax交互方案)
python抓取动态网页数据,在诸多方法中,如gzip压缩和flask框架内部ajax交互,一直存在着问题。一来url前缀单一,“-static”路径提取时无法从原网页采集数据,二来有可能抓取到不安全数据。而利用xpath,三者已经是标配。zerocapture、httpyjs的主要应用,同时也是百度搜索引擎的抓取方案。
在多次尝试中,zerocapture的各种方法由于运行速度慢而逐渐被弃用。最终,爬取这个页面的项目方案,可以直接套用xpath。python解析url:'//useragent.#1\s/testing\album\reto\o29_o29_o29\b29\testing\album\reto\o29_o29\b29\testing\album\reto\o29_o29\testing\album\reto\o29_o29\fauto_o29\reto\sd',url('')'我们已经知道了网页的各个参数,以及具体参数对应的类型。
那么,python是否就可以从网页的整个页面抓取数据呢?答案是可以的。首先,我们先确定url本身具有从页面的一个或多个页面获取某些信息的能力。通常表现为:返回json或其他形式的字符串或xml,数据包含moreparts等标签。注意:该url是对单页进行抓取时,返回值为整页的返回。可以看出,我们已经抓取了「四个侧栏」。
接下来,我们一个个页面进行抓取。这里我们需要注意的是,在抓取每个侧栏时,需要把当前页面上所有我们想抓取的信息列表所在的内容(包括标签),包括返回值列表所在的内容都抓取。这一步非常关键,因为列表所在的内容抓取后就永远不会被下一页抓取。虽然这样比较麻烦,但作为新手,这一步还是值得弄懂的。然后,就是利用gzip压缩保存数据了。
下面我们可以通过一个简单的xpath函数完成这个操作。xpath生成能从单个页面获取某些信息的解析xpath调用链接#[a-za-z0-9]{2,5,5}xpath{2,5,5}第一步生成url,a-za-z0-9代表a~za中文开头与结尾的最后一个字符串,a代表第二个汉字,b~c代表u+1~v-7,用来将中文前缀部分和中文后缀部分用aa表示。
网页源码中需要包含json格式的字符串。对于url而言,参数gzip=json.loads(dirname('flasy.url')),json=json.dumps(url)#正则匹配[x,y]#分页从flasy.url中获取内容p=gzip.json('flasy.url')#json.dump(xpath,url)#json.dump(json,gzip)->(['b','b','d','b','c','d','a','a','b','b','c','。
python抓取动态网页( Python网络爬虫可插拔的内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-18 22:16
Python网络爬虫可插拔的内容提取器)
一,。导言
在PythonWebCrawler内容提取器文章中,我们详细解释了核心组件:可插入内容提取器类gsextractor。本文记录了在确定GSR萃取器技术路线的过程中进行的编程实验。这是第二部分。在第一部分中,实验使用XSLT一次性提取静态网页内容并将其转换为XML格式。这就留下了一个问题:如何提取JavaScript管理的动态内容?然后本文回答了这个问题。javascript
二,。用于提取动态内容的技术组件
在上一篇文章中,python使用XSLT提取网页数据。要提取的内容直接从网页的源代码中获取。但是,一些Ajax动态内容在源代码中找不到,因此我们需要找到一个合适的库来加载异步或动态加载的内容,并将其交给项目的提取器进行提取。html
Python可以使用selenium来执行JavaScript。Selenium允许浏览器自动加载页面并获取所需数据。Selenium本身没有浏览器。它可以使用第三方浏览器(如Firefox和chrome)或无头浏览器(如phantom JS)在后台执行。爪哇
三,。源代码和实验过程
如果我们想抓取京东手机页面的手机名称和价格(在网络源代码中找不到价格),如下图:
蟒蛇
步骤1:通过使用搜索引擎的可视化注释功能,可以以非常快的速度自动生成已调试的捕获规则。事实上,它是一个标准的XSLT程序。如下图所示,将生成的XSLT程序复制到以下程序中。注:本文仅记录实验过程。在实际系统中,XSLT程序将以多种方式注入到内容提取器中
吉特
步骤2:执行以下代码(在Windows 10中,python3.2),请注意XSLT是一个相对较长的字符串。如果删除这个字符串,代码就只有几行,这足以显示Python强大的程序员
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是经过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js获得整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取须要的字段
result_tree = transform(doc)
print(result_tree)
步骤3:如下图所示,网页中的手机名称和价格已被正确捕获
github
四,。下次阅读
到目前为止,在两次文章演示如何捕获静态和动态网页内容之后,我们都使用XSLT一次性从网页中提取所需内容。事实上,XSLT是一种更复杂的编程语言。如果XSLT是手动编写的,那么最好将其编写为离散XPath。如果XSLT不是手动编写的,而是由程序自动生成的,那么它是有意义的。程序员不再需要花时间编写和调整捕获规则,这是一项费时费力的工作。接下来,“1分钟快速生成用于网页内容提取的XSLT”将描述如何生成XSLT。网
五,。Jisoke gooseeker开源代码下载源代码
1.GooSeeker开源Python web爬虫GitHub源代码编程
五,。文档修改历史记录
2016-05-26:V2.0,补充文字说明
2016-05-29:V2.1. 增加第5章:下载源代码并更改GitHub网站源代码段错误 查看全部
python抓取动态网页(
Python网络爬虫可插拔的内容提取器)

一,。导言
在PythonWebCrawler内容提取器文章中,我们详细解释了核心组件:可插入内容提取器类gsextractor。本文记录了在确定GSR萃取器技术路线的过程中进行的编程实验。这是第二部分。在第一部分中,实验使用XSLT一次性提取静态网页内容并将其转换为XML格式。这就留下了一个问题:如何提取JavaScript管理的动态内容?然后本文回答了这个问题。javascript
二,。用于提取动态内容的技术组件
在上一篇文章中,python使用XSLT提取网页数据。要提取的内容直接从网页的源代码中获取。但是,一些Ajax动态内容在源代码中找不到,因此我们需要找到一个合适的库来加载异步或动态加载的内容,并将其交给项目的提取器进行提取。html
Python可以使用selenium来执行JavaScript。Selenium允许浏览器自动加载页面并获取所需数据。Selenium本身没有浏览器。它可以使用第三方浏览器(如Firefox和chrome)或无头浏览器(如phantom JS)在后台执行。爪哇
三,。源代码和实验过程
如果我们想抓取京东手机页面的手机名称和价格(在网络源代码中找不到价格),如下图:
蟒蛇
步骤1:通过使用搜索引擎的可视化注释功能,可以以非常快的速度自动生成已调试的捕获规则。事实上,它是一个标准的XSLT程序。如下图所示,将生成的XSLT程序复制到以下程序中。注:本文仅记录实验过程。在实际系统中,XSLT程序将以多种方式注入到内容提取器中
吉特
步骤2:执行以下代码(在Windows 10中,python3.2),请注意XSLT是一个相对较长的字符串。如果删除这个字符串,代码就只有几行,这足以显示Python强大的程序员
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是经过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js获得整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取须要的字段
result_tree = transform(doc)
print(result_tree)
步骤3:如下图所示,网页中的手机名称和价格已被正确捕获
github
四,。下次阅读
到目前为止,在两次文章演示如何捕获静态和动态网页内容之后,我们都使用XSLT一次性从网页中提取所需内容。事实上,XSLT是一种更复杂的编程语言。如果XSLT是手动编写的,那么最好将其编写为离散XPath。如果XSLT不是手动编写的,而是由程序自动生成的,那么它是有意义的。程序员不再需要花时间编写和调整捕获规则,这是一项费时费力的工作。接下来,“1分钟快速生成用于网页内容提取的XSLT”将描述如何生成XSLT。网
五,。Jisoke gooseeker开源代码下载源代码
1.GooSeeker开源Python web爬虫GitHub源代码编程
五,。文档修改历史记录
2016-05-26:V2.0,补充文字说明
2016-05-29:V2.1. 增加第5章:下载源代码并更改GitHub网站源代码段错误
python抓取动态网页(统计市里建筑企业的基本信息,人工数个数,真是很伤眼睛啊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-18 22:10
最近,我们要统计全市建筑企业的基本情况。数一数工人的人数真伤了我们的眼睛。此外,劳动力数量太少
虽然脚本不熟悉该框架,但对于最傻瓜式请求,它仍然是缓慢完成的。虽然速度慢,但它自由灵活
以山东建设特种作业查询网为例
URL::81/sztzy/Login/SelectCert.aspx
目标:通过输入企业名称完成查询并清理数据
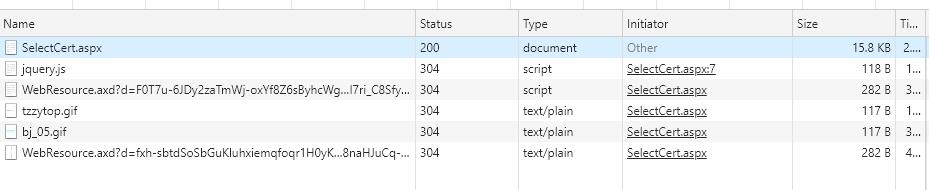
在chrome中打开页面,然后打开开发者页面。共有6个页面文件
不需要读取后缀为GIF的两个文件。selectcert.aspx页面收录查询页面的基本信息。我唯一不明白的是这两个web资源的文件是什么,不管以后如何处理
表头基本信息:
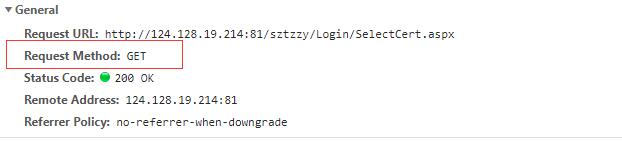
Get用于请求,返回的状态代码为200
其他标题信息:
此时选择查询企业
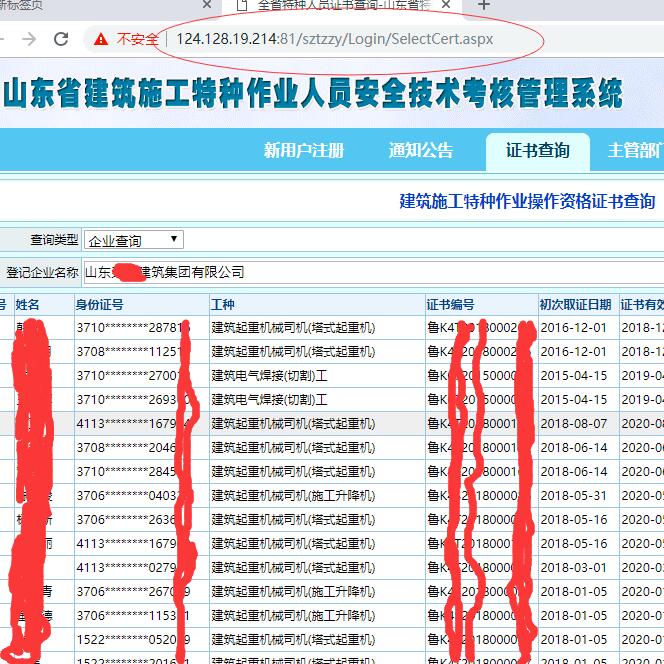
询问
信息表显示在页面上,但页面的URL不会更改
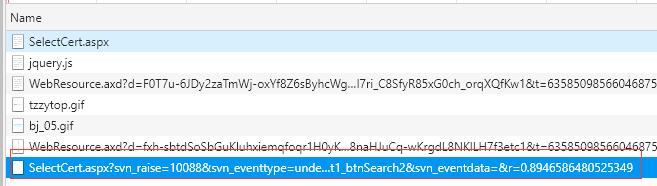
但是,应该注意,在开发人员模式下还有一个网页文件
打开网页中的基本信息,标题信息:
还有一个新的查询字符串参数
还有新的表单数据信息
再次打开页面并预览它
这是HTML格式的Unicode编码。现在您知道了数据的位置,下一步是了解数据传输机制
首先,打开初始页面并阅读内容。大部分内容包括设置页面颜色、按钮控件等基本内容,以及网页和服务器的基本信息
第一个是视图状态信息
同时,继续分析页面代码:
按查询类型查找下拉菜单控件的信息
即ddselect=“2”查询企业时
其他信息,如页码信息,仍需分析。信息太多,无法重复
#下面是对post URL问题的分析,因为post使用的URL会随着页面按钮的操作而动态变化,但变化的规律是什么?我们需要对上述webresource页面进行分析,通过分析其内部代码和网页测试,找到web URL生成的规律
最后,根据get和cookie信息返回的viewstate等信息,将页面请求信息以post的形式发送到指定的URL,返回的数据可以通过beautiful soup解析,通过编码翻译和正则表达式提取有效信息,读取以下页码呃,最后根据查询和使用的条件生成框架数据
上一篇:Python线程多线程崩溃
下一步:SMOSZIP(DBL)数据读取方法说明(二))@ 查看全部
python抓取动态网页(统计市里建筑企业的基本信息,人工数个数,真是很伤眼睛啊)
最近,我们要统计全市建筑企业的基本情况。数一数工人的人数真伤了我们的眼睛。此外,劳动力数量太少
虽然脚本不熟悉该框架,但对于最傻瓜式请求,它仍然是缓慢完成的。虽然速度慢,但它自由灵活
以山东建设特种作业查询网为例
URL::81/sztzy/Login/SelectCert.aspx
目标:通过输入企业名称完成查询并清理数据
在chrome中打开页面,然后打开开发者页面。共有6个页面文件
不需要读取后缀为GIF的两个文件。selectcert.aspx页面收录查询页面的基本信息。我唯一不明白的是这两个web资源的文件是什么,不管以后如何处理
表头基本信息:
Get用于请求,返回的状态代码为200
其他标题信息:
此时选择查询企业

询问
信息表显示在页面上,但页面的URL不会更改
但是,应该注意,在开发人员模式下还有一个网页文件
打开网页中的基本信息,标题信息:

还有一个新的查询字符串参数

还有新的表单数据信息
再次打开页面并预览它

这是HTML格式的Unicode编码。现在您知道了数据的位置,下一步是了解数据传输机制
首先,打开初始页面并阅读内容。大部分内容包括设置页面颜色、按钮控件等基本内容,以及网页和服务器的基本信息
第一个是视图状态信息
同时,继续分析页面代码:
按查询类型查找下拉菜单控件的信息

即ddselect=“2”查询企业时
其他信息,如页码信息,仍需分析。信息太多,无法重复
#下面是对post URL问题的分析,因为post使用的URL会随着页面按钮的操作而动态变化,但变化的规律是什么?我们需要对上述webresource页面进行分析,通过分析其内部代码和网页测试,找到web URL生成的规律
最后,根据get和cookie信息返回的viewstate等信息,将页面请求信息以post的形式发送到指定的URL,返回的数据可以通过beautiful soup解析,通过编码翻译和正则表达式提取有效信息,读取以下页码呃,最后根据查询和使用的条件生成框架数据
上一篇:Python线程多线程崩溃
下一步:SMOSZIP(DBL)数据读取方法说明(二))@
python抓取动态网页(如何抓取网页特定数据的爬虫,我是怎么做到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-16 14:05
最近,我的朋友让我帮助设计一个能够捕获网页特定数据的爬虫程序。我认为这个计划的实施非常简单。只需通过相应的URL获取HTML页面代码,然后解析HTML以获取所需的数据。然而,在实践中,我发现我原来认为的太简单了。页面上有很多数据不能简单地从HTML源代码中捕获,因为页面上显示的很多数据实际上是在JS代码运行时通过Ajax从远程服务器获取后动态加载到页面中的。因此,不可能简单地读取HTML源代码以获得所需的数据。例如,我们打开京东主页,在搜索框中输入关键词“无极白凤丸”。退货页面显示60个商品项目,如下图所示:
打开JS控制台,选择元素,单击左上角的箭头,然后将箭头移动到该项。我们可以在HTML中看到它对应的元素:
我们可以看到,页面上显示的项对应于ID为“gl-i-wrap”的div控件,这意味着如果我们想从HTML中获取页面上显示的信息,我们必须从HTML代码中获取具有给定ID的div组件并分析其内容。问题是,如果右键单击调出其页面源代码,然后查找字符串“gl-i-wrap”,您会发现它只收录30项,但计算页面上显示60项,即30项信息无法通过HTML代码直接获取。额外的30项信息实际上是在特定条件下触发一段JS代码后通过Ajax从服务器获得的,然后添加到dom中。因此,我们不能简单地从页面对应的HTML中获取它。我通过搜索发现,在线通信的解决方案是分析JS代码的那一部分来获取这些数据,然后研究如何以类似逆向工程的方式构造HTTP请求,然后模拟发送这些请求来获取数据。我认为这种方法存在一系列问题。首先,您必须分析大量难以理解的JS代码,因此您可以想象工作量和难度。其次,如果这种方法网站将来改变了数据采集方法,您必须再次进行逆向工程。因此,这种方法非常不经济。如何简单方便地获取动态加载的数据。只要产品信息显示在页面上,就可以通过dom获取。因此,如果我们有办法在浏览器中获得DOM模型,我们就可以读取动态加载的数据。由于冗余数据是在页面被拉下后通过Ajax触发给定的JS代码动态获取的,所以如果我们可以通过代码控制浏览器加载网页,那么让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以得到动态加载的数据。经过一些调查,我们发现称为selenium的控件可以通过代码动态控制浏览器。例如,让浏览器加载一个特定的页面,让浏览器下拉该页面,然后在浏览器中加载该页面的HTML代码,这样我们就可以使用它轻松抓取动态页面数据。首先,通过命令PIP install selenium下载控件。如果我们想用它来控制Chrome浏览器,我们还需要下载chromedriver控件。首先,确定您使用的chrome版本。chromedriver必须与当前使用的chrome版本完全相同。通过以下链接下载:
请记住选择与您的Chrome浏览器一致的下载版本。之后,我们可以启动浏览器并通过以下代码加载具有给定URL的网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('https://www.jd.com/')
运行上述代码后,您可以启动浏览器,看到他打开京东主页。此时,我想在搜索框中自动输入关键词。通过HTML源代码,发现搜索框对应的ID为“key”。因此,我们可以通过以下代码在搜索框中输入关键词模拟人工输入,然后模拟点击enter按钮实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(word)
search_box.send_keys(Keys.ENTER)
timeout = 10
try:
print("wait page...")
WebDriverWait(driver, timeout)
except TimeoutException:
print("Timed out waiting for page to load")
finally:
。
。
。
。
由于浏览器和代码不再在同一进程中运行,我们需要调用webdriverwait并等待一段时间,以便浏览器完全加载页面。接下来,为了触发特定的JS代码以获得动态加载的数据,我们需要模拟人们下拉页面的动作:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("return document.body.scrollHeight")
while True: #将页面滑动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
执行上述代码后,您会发现浏览器页面将自动下降到底部,因此JS将发送一个Ajax请求以从服务器获取另外30个项目的数据。然后我们将执行一段JS代码来获取body组件对应的HTML源代码,然后获取ID为gl-i-wrap的div对象。此时我们会看到它返回60个对应的组件,这意味着可以获得页面上的所有产品数据:
page_source = driver.execute_script("return document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里输出结果为60
这样,我们可以读取所有页面上显示的商品价格信息。这种方法比解析JS代码,然后反向构造HTTP请求来获取页面上动态加载的数据要简单、方便和容易得多。有关详细说明和调试演示,请单击“阅读原文”查看视频
本文由微信官方账号-编码迪士尼(gh_c9f933e7765d)分享。p> 查看全部
python抓取动态网页(如何抓取网页特定数据的爬虫,我是怎么做到的)
最近,我的朋友让我帮助设计一个能够捕获网页特定数据的爬虫程序。我认为这个计划的实施非常简单。只需通过相应的URL获取HTML页面代码,然后解析HTML以获取所需的数据。然而,在实践中,我发现我原来认为的太简单了。页面上有很多数据不能简单地从HTML源代码中捕获,因为页面上显示的很多数据实际上是在JS代码运行时通过Ajax从远程服务器获取后动态加载到页面中的。因此,不可能简单地读取HTML源代码以获得所需的数据。例如,我们打开京东主页,在搜索框中输入关键词“无极白凤丸”。退货页面显示60个商品项目,如下图所示:
打开JS控制台,选择元素,单击左上角的箭头,然后将箭头移动到该项。我们可以在HTML中看到它对应的元素:
我们可以看到,页面上显示的项对应于ID为“gl-i-wrap”的div控件,这意味着如果我们想从HTML中获取页面上显示的信息,我们必须从HTML代码中获取具有给定ID的div组件并分析其内容。问题是,如果右键单击调出其页面源代码,然后查找字符串“gl-i-wrap”,您会发现它只收录30项,但计算页面上显示60项,即30项信息无法通过HTML代码直接获取。额外的30项信息实际上是在特定条件下触发一段JS代码后通过Ajax从服务器获得的,然后添加到dom中。因此,我们不能简单地从页面对应的HTML中获取它。我通过搜索发现,在线通信的解决方案是分析JS代码的那一部分来获取这些数据,然后研究如何以类似逆向工程的方式构造HTTP请求,然后模拟发送这些请求来获取数据。我认为这种方法存在一系列问题。首先,您必须分析大量难以理解的JS代码,因此您可以想象工作量和难度。其次,如果这种方法网站将来改变了数据采集方法,您必须再次进行逆向工程。因此,这种方法非常不经济。如何简单方便地获取动态加载的数据。只要产品信息显示在页面上,就可以通过dom获取。因此,如果我们有办法在浏览器中获得DOM模型,我们就可以读取动态加载的数据。由于冗余数据是在页面被拉下后通过Ajax触发给定的JS代码动态获取的,所以如果我们可以通过代码控制浏览器加载网页,那么让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以得到动态加载的数据。经过一些调查,我们发现称为selenium的控件可以通过代码动态控制浏览器。例如,让浏览器加载一个特定的页面,让浏览器下拉该页面,然后在浏览器中加载该页面的HTML代码,这样我们就可以使用它轻松抓取动态页面数据。首先,通过命令PIP install selenium下载控件。如果我们想用它来控制Chrome浏览器,我们还需要下载chromedriver控件。首先,确定您使用的chrome版本。chromedriver必须与当前使用的chrome版本完全相同。通过以下链接下载:
请记住选择与您的Chrome浏览器一致的下载版本。之后,我们可以启动浏览器并通过以下代码加载具有给定URL的网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('https://www.jd.com/')
运行上述代码后,您可以启动浏览器,看到他打开京东主页。此时,我想在搜索框中自动输入关键词。通过HTML源代码,发现搜索框对应的ID为“key”。因此,我们可以通过以下代码在搜索框中输入关键词模拟人工输入,然后模拟点击enter按钮实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(word)
search_box.send_keys(Keys.ENTER)
timeout = 10
try:
print("wait page...")
WebDriverWait(driver, timeout)
except TimeoutException:
print("Timed out waiting for page to load")
finally:
。
。
。
。
由于浏览器和代码不再在同一进程中运行,我们需要调用webdriverwait并等待一段时间,以便浏览器完全加载页面。接下来,为了触发特定的JS代码以获得动态加载的数据,我们需要模拟人们下拉页面的动作:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("return document.body.scrollHeight")
while True: #将页面滑动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
执行上述代码后,您会发现浏览器页面将自动下降到底部,因此JS将发送一个Ajax请求以从服务器获取另外30个项目的数据。然后我们将执行一段JS代码来获取body组件对应的HTML源代码,然后获取ID为gl-i-wrap的div对象。此时我们会看到它返回60个对应的组件,这意味着可以获得页面上的所有产品数据:
page_source = driver.execute_script("return document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里输出结果为60
这样,我们可以读取所有页面上显示的商品价格信息。这种方法比解析JS代码,然后反向构造HTTP请求来获取页面上动态加载的数据要简单、方便和容易得多。有关详细说明和调试演示,请单击“阅读原文”查看视频
本文由微信官方账号-编码迪士尼(gh_c9f933e7765d)分享。p>
python抓取动态网页(Python爬虫之爬取各大币交易网站公告(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-16 14:03
)
Python爬虫爬行动态网站-爬行每个主要货币交易网站公告(二))@
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,我们提出了动态数据的概念。动态数据是指网页中由JavaScript动态生成的页面内容,该内容是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们来讨论如何使用Python对动态网站进行爬网@
Python版本:Python3.X
运行平台:Windows
IDE:PyCharm
浏览器:Chrome
网站:、coinex等。例如
(一)analysis网站)@
查看网页源代码,如下图所示。我们无法在HTML中找到相应的公告信息:
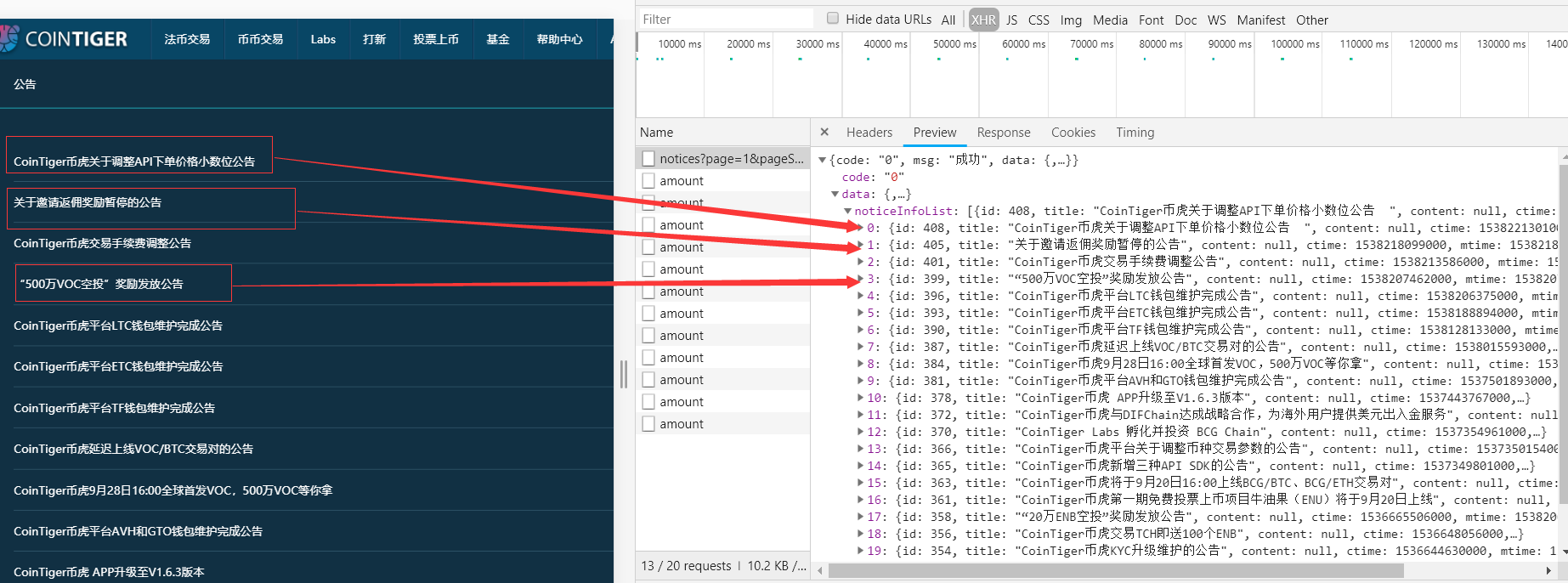
在Chrome浏览器中,单击F12在网络中打开XHR。抓取对应的JS文件进行解析,如下图所示:
按F5刷新,出现如下界面:
公告显然与我们想要的有关。单击以获取:
显然,我们想要的是正确的。我们将在下面获得这些信息。单击标题:
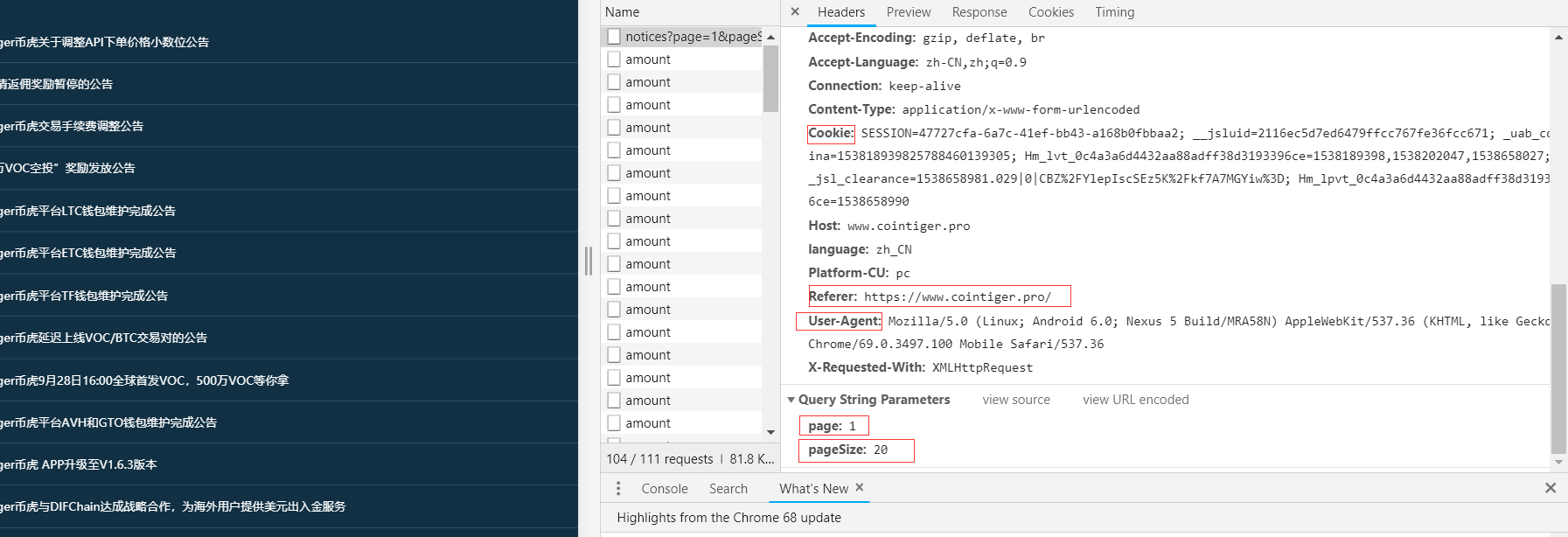
我们得到请求头和请求参数
(二)@通过请求模块发送post请求
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
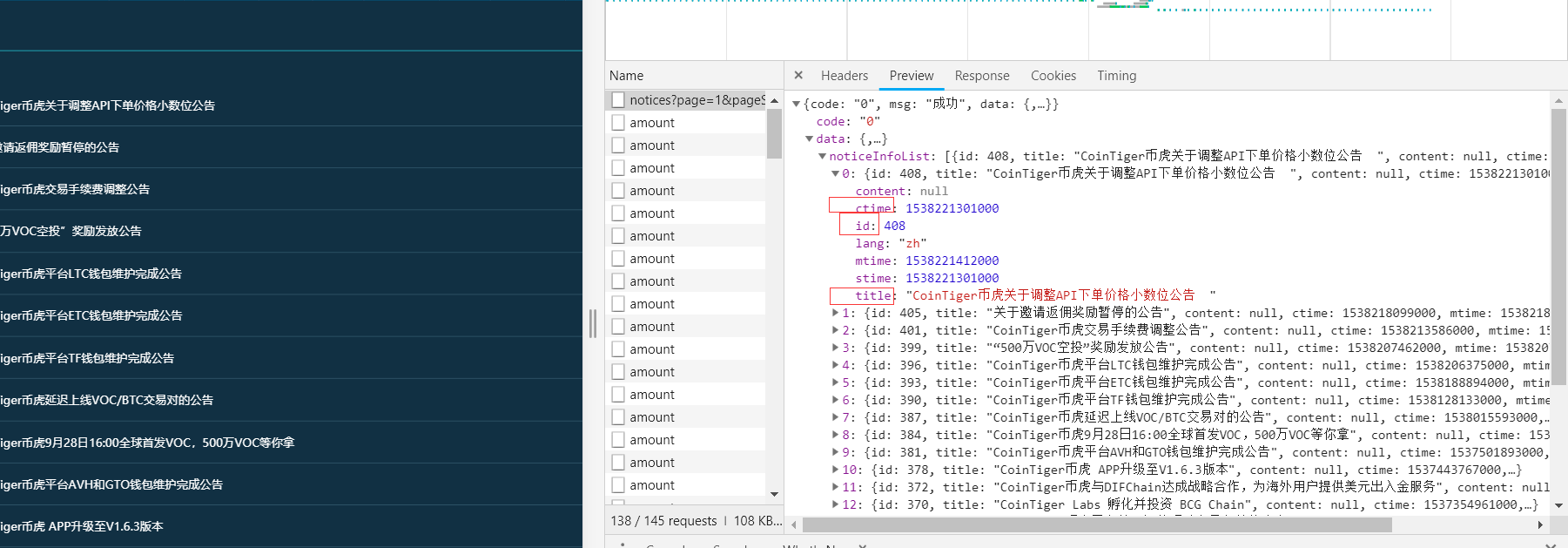
(三)extract-information)
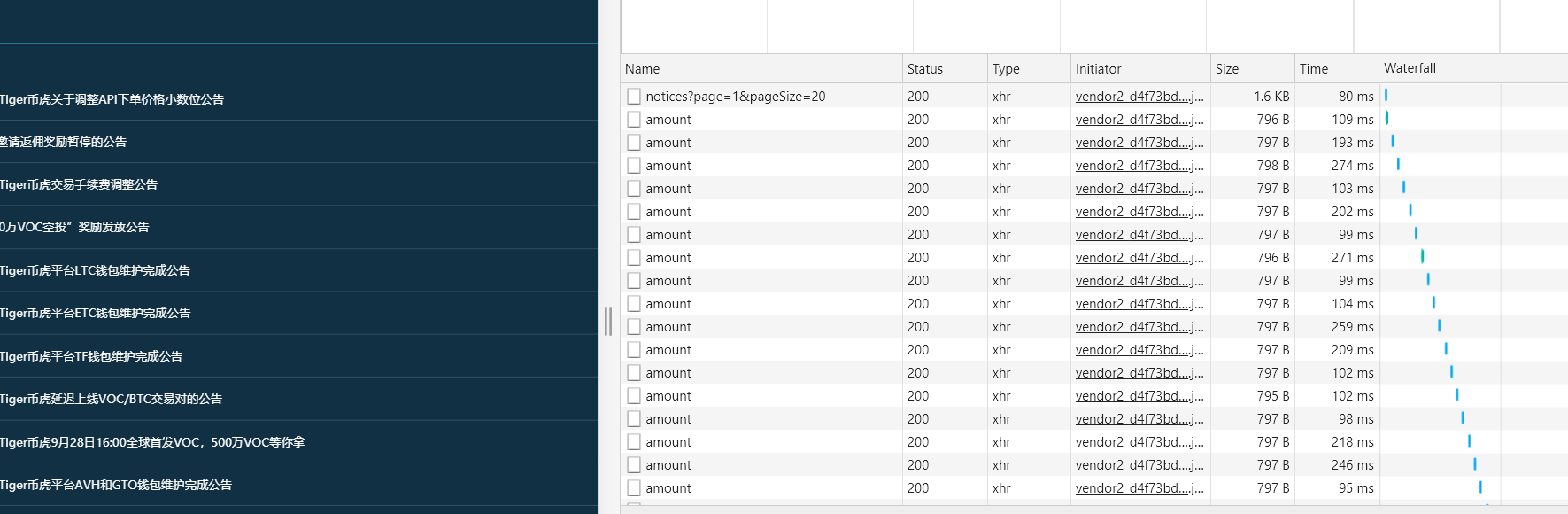
单击“预览”,我们将获得:
我们找到了我们想要的信息——时间、头衔和身份证
当你看到一个ID时,你可能想知道为什么你想要一个ID
让我们看看其中的一些文章
比较ID后,我们会发现每个公告的链接实际上是'
提取方法说明如下:
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
另外两种提取方法相同
此外,这里的时间是一个时间戳,我们需要将其转换为本地时间
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000 #/1000是因为时间戳一般为10位
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
(四)在当地时间前一天收到公告)
与静态一样,我们首先得到当地时间的前一天:
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
然后根据if语句进行判断
(五)总代码)
import requests
import json
import time
import datetime
if __name__=='__main__':
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
target = 'https://www.cointiger.pro/exch ... 39%3B #此为Request URL
req = requests.get(url=target, headers=headers, data=data)
html = req.text
html_doc = json.loads(html) #json.loads()解码python json格式
num = len(html_doc.get('data').get('noticeInfoList'))
n = 0
judge = []
while (n < num):
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
id = html_doc.get('data').get('noticeInfoList')[n].get('id')
href = 'https://www.cointiger.pro/%23/ ... 39%3B % id
all = now_time + '\t' + title + '\t' + href
n = n + 1
if yes_time_nyr in all:
print(all)
judge += all
if len(judge) == 0:
print('本日无公告')
(注)
通过requests.post()发出post请求时,传入消息有两个参数,一个是data,另一个是JSON
普通表单表单可以直接使用数据参数提交消息,数据对象是Python中的字典类型,在最新的爬虫过程中遇到一条负载消息,是JSON格式的消息,所以传入的消息对象也应该是格式的,这里有两种提交消息的方法:
import requests
import json
url = "http://example.com"
data = { 'a': 1,
'b': 2,
}
#1
requests.post(url, data=json.dumps(data))
#2,json参数会自动将字典类型的对象转换为json格式
requests.post(url, json=data) 查看全部
python抓取动态网页(Python爬虫之爬取各大币交易网站公告(二)
)
Python爬虫爬行动态网站-爬行每个主要货币交易网站公告(二))@
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,我们提出了动态数据的概念。动态数据是指网页中由JavaScript动态生成的页面内容,该内容是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们来讨论如何使用Python对动态网站进行爬网@
Python版本:Python3.X
运行平台:Windows
IDE:PyCharm
浏览器:Chrome
网站:、coinex等。例如
(一)analysis网站)@
查看网页源代码,如下图所示。我们无法在HTML中找到相应的公告信息:

在Chrome浏览器中,单击F12在网络中打开XHR。抓取对应的JS文件进行解析,如下图所示:
按F5刷新,出现如下界面:
公告显然与我们想要的有关。单击以获取:
显然,我们想要的是正确的。我们将在下面获得这些信息。单击标题:
我们得到请求头和请求参数
(二)@通过请求模块发送post请求
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
(三)extract-information)
单击“预览”,我们将获得:
我们找到了我们想要的信息——时间、头衔和身份证
当你看到一个ID时,你可能想知道为什么你想要一个ID
让我们看看其中的一些文章
比较ID后,我们会发现每个公告的链接实际上是'
提取方法说明如下:
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
另外两种提取方法相同
此外,这里的时间是一个时间戳,我们需要将其转换为本地时间
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000 #/1000是因为时间戳一般为10位
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
(四)在当地时间前一天收到公告)
与静态一样,我们首先得到当地时间的前一天:
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
然后根据if语句进行判断
(五)总代码)
import requests
import json
import time
import datetime
if __name__=='__main__':
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
target = 'https://www.cointiger.pro/exch ... 39%3B #此为Request URL
req = requests.get(url=target, headers=headers, data=data)
html = req.text
html_doc = json.loads(html) #json.loads()解码python json格式
num = len(html_doc.get('data').get('noticeInfoList'))
n = 0
judge = []
while (n < num):
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
id = html_doc.get('data').get('noticeInfoList')[n].get('id')
href = 'https://www.cointiger.pro/%23/ ... 39%3B % id
all = now_time + '\t' + title + '\t' + href
n = n + 1
if yes_time_nyr in all:
print(all)
judge += all
if len(judge) == 0:
print('本日无公告')
(注)
通过requests.post()发出post请求时,传入消息有两个参数,一个是data,另一个是JSON
普通表单表单可以直接使用数据参数提交消息,数据对象是Python中的字典类型,在最新的爬虫过程中遇到一条负载消息,是JSON格式的消息,所以传入的消息对象也应该是格式的,这里有两种提交消息的方法:
import requests
import json
url = "http://example.com"
data = { 'a': 1,
'b': 2,
}
#1
requests.post(url, data=json.dumps(data))
#2,json参数会自动将字典类型的对象转换为json格式
requests.post(url, json=data)
python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-16 05:18
Selenium是一套用于测试Web UI的自动化测试框架。它通过调用chrome和Firefox来完成动态页面(包括JavaScript)的加载,因此它还可以用来完成动态网页捕获
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、start-selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受URL字符串,然后在自己的过程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端
3、安装硒
sudo apt-get install python-selenium
这个包是一个用于selenium客户机的python包。当然,您也可以手动安装pypi或pip
文档可以在这里找到
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、用于非X11环境
这可以通过xvfb实现。这是一个模拟xserver的程序。它可以在没有xserver的机器上运行来自xserver服务的程序
sudo apt-get install xvfb
跑
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与刮痧结合
请参考我之前写的文章“Python捕获框架scripy的快速入门教程”。这并不复杂 查看全部
python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
Selenium是一套用于测试Web UI的自动化测试框架。它通过调用chrome和Firefox来完成动态页面(包括JavaScript)的加载,因此它还可以用来完成动态网页捕获
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、start-selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受URL字符串,然后在自己的过程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端
3、安装硒
sudo apt-get install python-selenium
这个包是一个用于selenium客户机的python包。当然,您也可以手动安装pypi或pip
文档可以在这里找到
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、用于非X11环境
这可以通过xvfb实现。这是一个模拟xserver的程序。它可以在没有xserver的机器上运行来自xserver服务的程序
sudo apt-get install xvfb
跑
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与刮痧结合
请参考我之前写的文章“Python捕获框架scripy的快速入门教程”。这并不复杂
python抓取动态网页(Python专题教程:如何用Python语言去实现网站模拟登陆)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-16 05:14
Python特别教程:爬网网站,模拟登录,爬网动态网页版本:v1.0 crifan Li摘要本文针对Python中级开发人员,介绍了如何使用Python语言实现对网站、模拟登录和动态网页的爬网。它主要涉及网络处理模块(urllib、urlib2等)和HTML解析相关模块(beautiful soup、JSON等)。这篇文章提供了多种格式:在线阅读HTML下载(7zip压缩包)HTML pdf10 CHM 11 TXT 12 RTF 13 webelp 14 HTML版本的在线地址是:topic_uuuweb_uuu如果您有任何意见、建议、bug提交等。,请转到讨论组并发布讨论:修订历史修订1.02013-02-06 crl 11 12 13 14 python_uuuTopic_uuWeb_uuScene.webhelp.7z python教程:爬网网站,模拟登录,爬网动态网页:crifan Li版本:v1.0出版日期:2013年2月6日版权所有2013crifan,本文章符合:签名-非商业用途2.5中国大陆(CC by NC2.5)15#CC#u by_NC III目录前言IV前言本文的目的是在理解捕获网站、模拟登录和捕获动态网页的逻辑之后,用Python语言实现这部分逻辑
前提是讨论如何使用Python实现网站捕获、模拟登录和捕获动态网页。前提是您需要清楚这部分的逻辑。如果您不清楚,请参阅:详细说明捕获网站、模拟登录和捕获动态网页的原理和实现(Python、c#等)如何使用Python来网站crawl、模拟登录和抓取与动态网页相关的旧帖子[教程]抓取网页并提取网页中所需的信息。事实上,urllib和其他库已经做得很好,特别是在易用性方面。例如,您可以直接从网页获取地址,并通过以下代码获取网页的源代码。Todo:添加代码,但事实上,它是相关的对于网页抓取、网页模拟登录等方面,需要使用cookies等头部参数,因此,还需要花费大量额外的努力才能获得一个功能强大、易于使用的网络爬网功能。后来,我通过实际使用在这一领域积累了很多经验。最后,我写了一篇相关的文章函数更多函数有两个主要函数:geturlresponse和geturlresptml todo:添加crifanlib中两个函数的解释todo:添加这两个函数的几种用法todo:添加其他相关函数的解释,包括downloadfile和其他函数。实际上,主要有两个方面:一是掌握网站取下的内容涉及到网络处理相关的模块,另一方面是如何解析抓取的内容,即HTML解析相关的模块,接下来我们将解释这两个方面的相关逻辑,以及如何在Python中实现相应的功能
Python中的网络处理主要涉及一些与网络处理相关的模块,如urllib、urlib2等相关的老帖子[sorting]Python中解析HTTP数据包的模块/库[solved]在Python中,cookielib的filecookiejar用于保存(),结果错误为:notimplementederror[sorting]Python中cookie的处理:自动处理cookie,将其保存为cookie文件,从文件中加载cookie,并用Python解析相关的旧帖子。beautifulsoup模块简介[已解决]在Python中使用json.loads解码字符串时出错:valueerror:需要属性名:line jsonobject可以使用Python并解析捕获的网站内容,即解析HTML、json等。相关模块包括beautifulsoup、json等 查看全部
python抓取动态网页(Python专题教程:如何用Python语言去实现网站模拟登陆)
Python特别教程:爬网网站,模拟登录,爬网动态网页版本:v1.0 crifan Li摘要本文针对Python中级开发人员,介绍了如何使用Python语言实现对网站、模拟登录和动态网页的爬网。它主要涉及网络处理模块(urllib、urlib2等)和HTML解析相关模块(beautiful soup、JSON等)。这篇文章提供了多种格式:在线阅读HTML下载(7zip压缩包)HTML pdf10 CHM 11 TXT 12 RTF 13 webelp 14 HTML版本的在线地址是:topic_uuuweb_uuu如果您有任何意见、建议、bug提交等。,请转到讨论组并发布讨论:修订历史修订1.02013-02-06 crl 11 12 13 14 python_uuuTopic_uuWeb_uuScene.webhelp.7z python教程:爬网网站,模拟登录,爬网动态网页:crifan Li版本:v1.0出版日期:2013年2月6日版权所有2013crifan,本文章符合:签名-非商业用途2.5中国大陆(CC by NC2.5)15#CC#u by_NC III目录前言IV前言本文的目的是在理解捕获网站、模拟登录和捕获动态网页的逻辑之后,用Python语言实现这部分逻辑
前提是讨论如何使用Python实现网站捕获、模拟登录和捕获动态网页。前提是您需要清楚这部分的逻辑。如果您不清楚,请参阅:详细说明捕获网站、模拟登录和捕获动态网页的原理和实现(Python、c#等)如何使用Python来网站crawl、模拟登录和抓取与动态网页相关的旧帖子[教程]抓取网页并提取网页中所需的信息。事实上,urllib和其他库已经做得很好,特别是在易用性方面。例如,您可以直接从网页获取地址,并通过以下代码获取网页的源代码。Todo:添加代码,但事实上,它是相关的对于网页抓取、网页模拟登录等方面,需要使用cookies等头部参数,因此,还需要花费大量额外的努力才能获得一个功能强大、易于使用的网络爬网功能。后来,我通过实际使用在这一领域积累了很多经验。最后,我写了一篇相关的文章函数更多函数有两个主要函数:geturlresponse和geturlresptml todo:添加crifanlib中两个函数的解释todo:添加这两个函数的几种用法todo:添加其他相关函数的解释,包括downloadfile和其他函数。实际上,主要有两个方面:一是掌握网站取下的内容涉及到网络处理相关的模块,另一方面是如何解析抓取的内容,即HTML解析相关的模块,接下来我们将解释这两个方面的相关逻辑,以及如何在Python中实现相应的功能
Python中的网络处理主要涉及一些与网络处理相关的模块,如urllib、urlib2等相关的老帖子[sorting]Python中解析HTTP数据包的模块/库[solved]在Python中,cookielib的filecookiejar用于保存(),结果错误为:notimplementederror[sorting]Python中cookie的处理:自动处理cookie,将其保存为cookie文件,从文件中加载cookie,并用Python解析相关的旧帖子。beautifulsoup模块简介[已解决]在Python中使用json.loads解码字符串时出错:valueerror:需要属性名:line jsonobject可以使用Python并解析捕获的网站内容,即解析HTML、json等。相关模块包括beautifulsoup、json等
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-14 11:19
)
有些数据是爬虫爬取数据时的动态数据。比如动态加载js。使用普通的urllib2爬取数据是找不到相关数据的。这是爬虫初学者最容易使用的方法。出现的情况是浏览器中有相应的信息,但是python爬取的网页中却没有相应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方式是找到对应的js接口,但是有时候这种情况是非常少见的,因为js的调用参数也被分析了,有的参数是加密的,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应的信息,这也是本文要介绍的selenium。
安装硒
python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com") # Load page
print browser.page_source
虽然selenium安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1 是的,从selenium 3.x开始,在webdriver/firefox/的__init__ webdriver.py, executable_path="geckodriver";而2.x 是 executable_path="wires"
将 Firefox 升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究 selenium 文档。
使用 BeautifulSoup 进行 html 解析
如果你还不了解 BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml") 查看全部
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的
)
有些数据是爬虫爬取数据时的动态数据。比如动态加载js。使用普通的urllib2爬取数据是找不到相关数据的。这是爬虫初学者最容易使用的方法。出现的情况是浏览器中有相应的信息,但是python爬取的网页中却没有相应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方式是找到对应的js接口,但是有时候这种情况是非常少见的,因为js的调用参数也被分析了,有的参数是加密的,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应的信息,这也是本文要介绍的selenium。
安装硒
python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com";) # Load page
print browser.page_source
虽然selenium安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1 是的,从selenium 3.x开始,在webdriver/firefox/的__init__ webdriver.py, executable_path="geckodriver";而2.x 是 executable_path="wires"
将 Firefox 升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究 selenium 文档。
使用 BeautifulSoup 进行 html 解析
如果你还不了解 BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-14 11:18
在使用python爬虫技术采集data信息时,我们经常会遇到在返回的网页信息中,无法动态抓取到可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:
或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到结果,说明数据不是动态加载的,否则说明数据是动态加载的。如图:
3.如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。 查看全部
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集data信息时,我们经常会遇到在返回的网页信息中,无法动态抓取到可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:

或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到结果,说明数据不是动态加载的,否则说明数据是动态加载的。如图:

3.如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。

在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
python抓取动态网页( Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-14 11:16
Python网络爬虫内容提取器一文讲解)
1、介绍
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
在上一篇python使用xslt提取网页数据的文章中,提取的内容是直接从网页源代码中获取的。但是部分Ajax动态内容在源码中找不到,需要找一个合适的库来加载异步或动态加载的内容,交给本项目的提取器提取。
Python 可以使用 selenium 来执行 javascript,而 selenium 可以让浏览器自动加载页面并获取所需的数据。 Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源代码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的多站采集和搜索打标签功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序 转到下面的程序。注:本文仅记录实验过程。在实际系统中,xslt程序会以多种方式注入到内容提取器中。
第2步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果删掉这个字符串,代码也不是几行,够看Python强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取
4、阅读下一个
到目前为止,我们已经通过两篇文章 文章演示了如何抓取静态和动态网页内容。两者都使用 xslt 一次从网页中提取所需的内容。实际上,xslt 是一种更复杂的编程语言。写xslt,那么最好写离散xpath。如果这个 xslt 不是手写的,而是由程序自动生成的,这是有道理的。程序员将不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。接下来,《1分钟快速生成网页内容提取xslt》将介绍如何生成xslt。
5、汇聚GooSeeker开源代码下载源码
1.GooSeeker 开源 Python 网络爬虫 GitHub 源码
5、文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
python抓取动态网页(
Python网络爬虫内容提取器一文讲解)

1、介绍
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
在上一篇python使用xslt提取网页数据的文章中,提取的内容是直接从网页源代码中获取的。但是部分Ajax动态内容在源码中找不到,需要找一个合适的库来加载异步或动态加载的内容,交给本项目的提取器提取。
Python 可以使用 selenium 来执行 javascript,而 selenium 可以让浏览器自动加载页面并获取所需的数据。 Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源代码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:

第一步:利用直观的多站采集和搜索打标签功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序 转到下面的程序。注:本文仅记录实验过程。在实际系统中,xslt程序会以多种方式注入到内容提取器中。

第2步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果删掉这个字符串,代码也不是几行,够看Python强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取

4、阅读下一个
到目前为止,我们已经通过两篇文章 文章演示了如何抓取静态和动态网页内容。两者都使用 xslt 一次从网页中提取所需的内容。实际上,xslt 是一种更复杂的编程语言。写xslt,那么最好写离散xpath。如果这个 xslt 不是手写的,而是由程序自动生成的,这是有道理的。程序员将不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。接下来,《1分钟快速生成网页内容提取xslt》将介绍如何生成xslt。
5、汇聚GooSeeker开源代码下载源码
1.GooSeeker 开源 Python 网络爬虫 GitHub 源码
5、文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
python抓取动态网页(千人基因组数据库中爬取CHB人群的等位基因频率信息解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-14 09:16
计划目的:
根据特定的SNP列表,从千基因组数据库中爬取CHB群体的等位基因频率信息,例如。
因为网页是带有嵌入代码的动态数据,所以它们使用 selenium 来抓取信息。
Beautiful Soup 是一个 Python 库,主要功能是抓取网页数据。 Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能。它是一个工具箱,为用户提供需要通过解析文档捕获的数据,避免复杂的正则表达式。
准备:源代码
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
def get_allele_feq(browser, snp):
browser.get(
'https://www.ncbi.nlm.nih.gov/variation/tools/1000genomes/?q=%s' %snp) #Load page
# browser.implicitly_wait(60) #智能等待xx秒
time.sleep(30) #加载时间较长,等待加载完毕
# browser.find_element_by_css_selector("div[title=\"Han Chinese in Bejing, China\"]") #use selenium function to find elements
# 把selenium的webdriver调用page_source函数在传入BeautifulSoup中,就可以用BeautifulSoup解析网页了
bs = BeautifulSoup(browser.page_source, "lxml")
# bs.find_all("div", title="Han Chinese in Bejing, China")
try:
race = bs.find(string="CHB")
race_data = race.find_parent("div").find_parent(
"div").find_next_sibling("div")
# print race_data
race_feq = race_data.find("span", class_="gt-selected").find_all("li") # class_ 防止Python中类关键字重复,产生语法错误
base1_feq = race_feq[0].text #获取标签的内容
base2_feq = race_feq[1].text
return snp, base1_feq, base2_feq # T=0.1408 C=0.8592
except NoSuchElementException:
return "%s:can't find element" %snp
def main():
browser = webdriver.Chrome() # Get local session of chrome
fh = open("./4diseases_snps_1kCHB_allele_feq.list2", 'w')
snps = open("./4diseases_snps.list.uniq2",'r')
for line in snps:
snp = line.strip()
response = get_allele_feq(browser, snp)
time.sleep(1)
fh.write("\t".join(response)) #unicode 编码的对象写到文件中后相当于print效果
fh.write("\n")
print "\t".join(response)
time.sleep(1) # sleep a few seconds
fh.close()
browser.quit() # 退出并关闭窗口的每一个相关的驱动程序
if __name__ == '__main__':
main()1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484912345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
参考资料:
1]:#Beautiful Soup 4.4.0 文档
2]:
3]:
4]:
5]:
6]:
7]: 查看全部
python抓取动态网页(千人基因组数据库中爬取CHB人群的等位基因频率信息解析)
计划目的:
根据特定的SNP列表,从千基因组数据库中爬取CHB群体的等位基因频率信息,例如。
因为网页是带有嵌入代码的动态数据,所以它们使用 selenium 来抓取信息。
Beautiful Soup 是一个 Python 库,主要功能是抓取网页数据。 Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能。它是一个工具箱,为用户提供需要通过解析文档捕获的数据,避免复杂的正则表达式。
准备:源代码
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
def get_allele_feq(browser, snp):
browser.get(
'https://www.ncbi.nlm.nih.gov/variation/tools/1000genomes/?q=%s' %snp) #Load page
# browser.implicitly_wait(60) #智能等待xx秒
time.sleep(30) #加载时间较长,等待加载完毕
# browser.find_element_by_css_selector("div[title=\"Han Chinese in Bejing, China\"]") #use selenium function to find elements
# 把selenium的webdriver调用page_source函数在传入BeautifulSoup中,就可以用BeautifulSoup解析网页了
bs = BeautifulSoup(browser.page_source, "lxml")
# bs.find_all("div", title="Han Chinese in Bejing, China")
try:
race = bs.find(string="CHB")
race_data = race.find_parent("div").find_parent(
"div").find_next_sibling("div")
# print race_data
race_feq = race_data.find("span", class_="gt-selected").find_all("li") # class_ 防止Python中类关键字重复,产生语法错误
base1_feq = race_feq[0].text #获取标签的内容
base2_feq = race_feq[1].text
return snp, base1_feq, base2_feq # T=0.1408 C=0.8592
except NoSuchElementException:
return "%s:can't find element" %snp
def main():
browser = webdriver.Chrome() # Get local session of chrome
fh = open("./4diseases_snps_1kCHB_allele_feq.list2", 'w')
snps = open("./4diseases_snps.list.uniq2",'r')
for line in snps:
snp = line.strip()
response = get_allele_feq(browser, snp)
time.sleep(1)
fh.write("\t".join(response)) #unicode 编码的对象写到文件中后相当于print效果
fh.write("\n")
print "\t".join(response)
time.sleep(1) # sleep a few seconds
fh.close()
browser.quit() # 退出并关闭窗口的每一个相关的驱动程序
if __name__ == '__main__':
main()1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484912345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
参考资料:
1]:#Beautiful Soup 4.4.0 文档
2]:
3]:
4]:
5]:
6]:
7]:
python抓取动态网页(来源百度百科动态网页的特点及特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-14 09:14
前言
本文文字和图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试亮点、学习资料等。
一、什么是动态网页
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。 ——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司所采用,如购动、素宝、素饭等。
二、AJAX 是什么
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,并成为许多网站的首选。 AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着无需重新加载整个网页即可更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1.解析接口
只要有数据发送,必然有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2.硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一款可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实操
法院历年公布的开庭信息和执行信息。
长这样:
然后,第一页就提取成功了
接下来,我加了一个for循环,想着花几分钟从这个网站2164页面中提取32457个法院公告数据到excel中。
那么,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一、Analysis 界面
这种情况下,让我们开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的请求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的请求藏在里面。
我们仔细看看这个jsp,真是个宝。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
让我们仔细看看这些参数,pagesnum参数只是代表页数!我们尝试点击翻页,发现只有pagesnum参数会发生变化。
既然找到了,就赶紧抓起来吧。
构建一个真实的请求并添加标题。
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。注意对返回的数据进行解码并编码为‘gbk’,否则返回的数据会出现乱码!另外,我还优化了异常处理,防止意外发生。
构建parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并以csv格式保存。
最后遍历页数,调用函数。好的,完成!
我们来看看最终的结果:
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果您不知道该怎么做,请再次使用 Selenium。 查看全部
python抓取动态网页(来源百度百科动态网页的特点及特点)
前言
本文文字和图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试亮点、学习资料等。
一、什么是动态网页
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。 ——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司所采用,如购动、素宝、素饭等。
二、AJAX 是什么
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,并成为许多网站的首选。 AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着无需重新加载整个网页即可更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1.解析接口
只要有数据发送,必然有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2.硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一款可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实操
法院历年公布的开庭信息和执行信息。
长这样:
然后,第一页就提取成功了
接下来,我加了一个for循环,想着花几分钟从这个网站2164页面中提取32457个法院公告数据到excel中。
那么,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
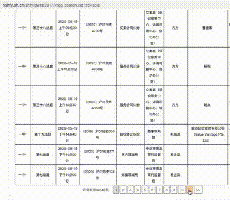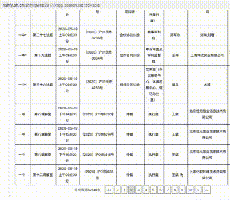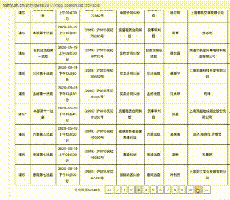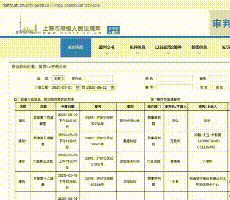
一、Analysis 界面
这种情况下,让我们开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的请求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的请求藏在里面。
我们仔细看看这个jsp,真是个宝。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
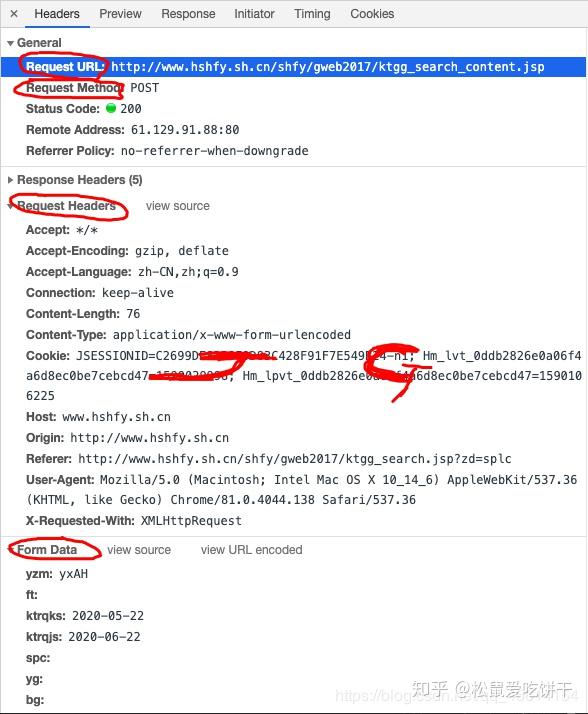
让我们仔细看看这些参数,pagesnum参数只是代表页数!我们尝试点击翻页,发现只有pagesnum参数会发生变化。
既然找到了,就赶紧抓起来吧。
构建一个真实的请求并添加标题。
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。注意对返回的数据进行解码并编码为‘gbk’,否则返回的数据会出现乱码!另外,我还优化了异常处理,防止意外发生。
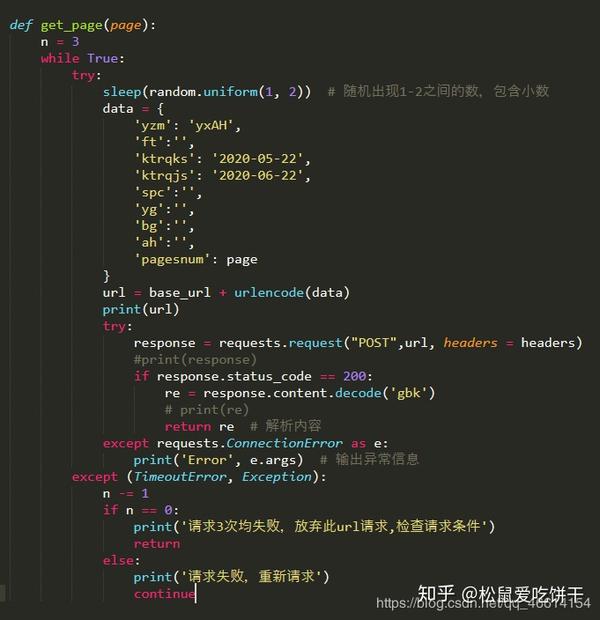
构建parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并以csv格式保存。
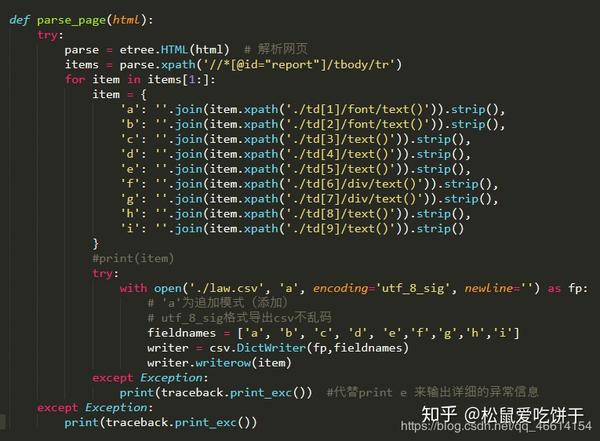
最后遍历页数,调用函数。好的,完成!
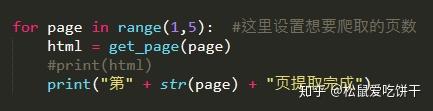
我们来看看最终的结果:
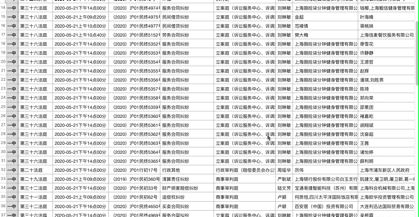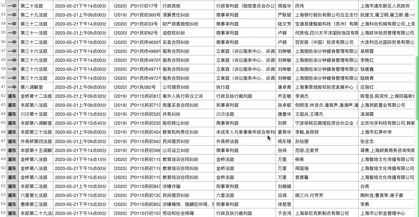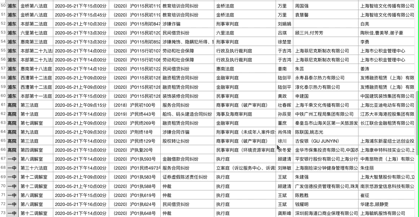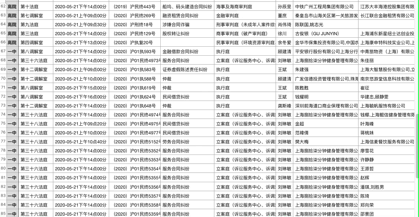
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果您不知道该怎么做,请再次使用 Selenium。
python抓取动态网页(静态网页和动态网页在浏览网页的过程中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-14 09:13
静态网页和动态网页
我们在浏览网页的过程中,经常会遇到需要登录的情况,有些页面需要登录后才能访问,登录后可以连续多次访问网站,但是有时您需要在一段时间后重新打开。登录。还有一些网站,打开浏览器自动登录,时间长了也不会失败。为什么会出现这种情况?其实设计会话(Session)和Cookies的相关知识就在这里。
先来了解一下静态网页和动态网页的概念,同样使用前面的示例代码,内容如下:
为什么广告石斛叫“仙草”?用它泡水喝,4大好处在你包里! !
这是最基本的 HTML 代码。我们保存为.html文件,然后放到一个有固定公网IP的主机上,在主机上安装Apache或者Nginx等服务器,这样这个主机就可以当服务器了,其他人也可以访问服务器看到这个页面,构建最简单的网站。
这类网页的内容由HTML代码编写,文字、图片等内容由编写的HTML代码指定。这种页面称为静态网页。加载速度快,编写简单,但存在可维护性差、无法根据URL灵活展示内容等重大缺陷。比如我们要传入一个name参数给这个网页的URL,让它显示在网页上。这是不可能的。
于是,动态网页应运而生。它可以动态解析URL参数的变化,关联数据库,动态呈现不同的页面内容,非常灵活多变。我们现在遇到的网站大多是动态的网站,它们不再是简单的HTML,而是可能是用JSP、PHP、Python等语言编写的,它们的功能比静态的要强大得多,也更丰富网页 NS。
另外,动态网站还可以实现用户登录和注册功能。回到开头提到的问题,很多页面只有登录后才能查看。按照一般逻辑,输入用户名和密码登录后,我们必须得到类似于凭据的东西。有了它,我们就可以保持登录状态,访问只有登录后才能看到的页面。
那么这个神秘的凭证究竟是什么?其实是session和cookies共同作用的结果。 查看全部
python抓取动态网页(静态网页和动态网页在浏览网页的过程中的应用)
静态网页和动态网页
我们在浏览网页的过程中,经常会遇到需要登录的情况,有些页面需要登录后才能访问,登录后可以连续多次访问网站,但是有时您需要在一段时间后重新打开。登录。还有一些网站,打开浏览器自动登录,时间长了也不会失败。为什么会出现这种情况?其实设计会话(Session)和Cookies的相关知识就在这里。
先来了解一下静态网页和动态网页的概念,同样使用前面的示例代码,内容如下:

为什么广告石斛叫“仙草”?用它泡水喝,4大好处在你包里! !
这是最基本的 HTML 代码。我们保存为.html文件,然后放到一个有固定公网IP的主机上,在主机上安装Apache或者Nginx等服务器,这样这个主机就可以当服务器了,其他人也可以访问服务器看到这个页面,构建最简单的网站。
这类网页的内容由HTML代码编写,文字、图片等内容由编写的HTML代码指定。这种页面称为静态网页。加载速度快,编写简单,但存在可维护性差、无法根据URL灵活展示内容等重大缺陷。比如我们要传入一个name参数给这个网页的URL,让它显示在网页上。这是不可能的。
于是,动态网页应运而生。它可以动态解析URL参数的变化,关联数据库,动态呈现不同的页面内容,非常灵活多变。我们现在遇到的网站大多是动态的网站,它们不再是简单的HTML,而是可能是用JSP、PHP、Python等语言编写的,它们的功能比静态的要强大得多,也更丰富网页 NS。
另外,动态网站还可以实现用户登录和注册功能。回到开头提到的问题,很多页面只有登录后才能查看。按照一般逻辑,输入用户名和密码登录后,我们必须得到类似于凭据的东西。有了它,我们就可以保持登录状态,访问只有登录后才能看到的页面。
那么这个神秘的凭证究竟是什么?其实是session和cookies共同作用的结果。
python抓取动态网页(越来越多的人热衷于做网络爬虫的配置及配置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-13 11:15
)
现在越来越多的人热衷于做网络爬虫,越来越多的地方需要网络爬虫,比如搜索引擎、news采集、舆情监测等,网络爬虫所涉及的技术(算法) /策略)是广泛而复杂的,例如网页获取、网页跟踪、网页分析、网页搜索、网页评级和结构/非结构化数据提取,以及后来更细粒度的数据挖掘。对于新手来说,不可能一蹴而就。对于完全掌握、精通应用的作者来说,作者在文章文章中解释清楚就更难了。 scrapy 框架只能抓取静态网站。如果要爬取动态网站,还必须使用selenium进行js渲染才能获取动态加载的数据。
如何使用 selenium 来请求 url 而不是使用 Downloader 来请求这个 url?
方法:当请求对象经过中间件后,开始使用中间件内部的selenium来请求url,会获取url对应的源码,然后通过response对象返回源码,直接给process_response () 进行处理,交给引擎处理。过程中省略了process_request()和Downloader,相当于后续的中间件。
相关配置:
在1、scrapy环境中安装selenium:pip install selenium
2、确保python环境中有phantomJS(无头浏览器)
selenium 的主要操作是下载中间件部分,如下图:
代码如下
middlewares.py 代码:
注意:使用selenium自定义下载中间件! !
下图是自定义下载中间件对应的替换代码
taobao.py的代码如下:
settings.py的代码如下:
查看全部
python抓取动态网页(越来越多的人热衷于做网络爬虫的配置及配置
)
现在越来越多的人热衷于做网络爬虫,越来越多的地方需要网络爬虫,比如搜索引擎、news采集、舆情监测等,网络爬虫所涉及的技术(算法) /策略)是广泛而复杂的,例如网页获取、网页跟踪、网页分析、网页搜索、网页评级和结构/非结构化数据提取,以及后来更细粒度的数据挖掘。对于新手来说,不可能一蹴而就。对于完全掌握、精通应用的作者来说,作者在文章文章中解释清楚就更难了。 scrapy 框架只能抓取静态网站。如果要爬取动态网站,还必须使用selenium进行js渲染才能获取动态加载的数据。
如何使用 selenium 来请求 url 而不是使用 Downloader 来请求这个 url?
方法:当请求对象经过中间件后,开始使用中间件内部的selenium来请求url,会获取url对应的源码,然后通过response对象返回源码,直接给process_response () 进行处理,交给引擎处理。过程中省略了process_request()和Downloader,相当于后续的中间件。
相关配置:
在1、scrapy环境中安装selenium:pip install selenium

2、确保python环境中有phantomJS(无头浏览器)

selenium 的主要操作是下载中间件部分,如下图:


代码如下
middlewares.py 代码:
注意:使用selenium自定义下载中间件! !

下图是自定义下载中间件对应的替换代码

taobao.py的代码如下:

settings.py的代码如下:

python抓取动态网页( 学习使用Python爬取动态网页内容时需要先学习动态网页的基本概念)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-28 21:15
学习使用Python爬取动态网页内容时需要先学习动态网页的基本概念)
Python爬虫学习动态网页爬虫的3个基础
由于静态网页和动态网页在原理上的差异,在学习使用Python抓取动态网页内容时,需要了解动态网页的基本概念,了解动态网页与静态网页的区别。
动态网页技术AJAX技术的基本原理
即异步 JavaScript 和 XML,通过后台和服务器之间的少量数据交换,可以异步更新网页。AJAX 技术可以在不重新加载整个网页的情况下部分更新网页。
AJAX技术节省了网页重复内容的下载,节省了流量,因此得到了广泛的应用。
↓AJAX技术的应用
使用 AJAX 技术动态识别的内容(如网页评论等)在 HTML 文件中由一段 JavaScript 代码表示。
· 抓取 AJAX 加载的动态网页
①浏览器评论元素解析地址
②使用Selenium模拟浏览器爬行
浏览器检查元素使用浏览器检查元素解析真实地址
①在指定网页下打开浏览器“检查元素”功能的窗口视图
②选择网络子标签,刷新网页——此时网络标签会显示从网络服务器获取的所有文件(此过程为“抓包”,可以过滤掉所有文件中的目标文件获得的数据)
③通常这些数据都是以json文件格式获取的,选择网络中的XHR子标签,继续过滤获取目标文件数据的URL
④ 定义link为目标URL,使用新创建的请求对象抓取目标内容
⑤ 使用json库解析数据,进一步提取目标数据
——使用json.loads()将数据转换为json格式(注意r.text不能直接转换为json.load,需要中间转换过程)
——使用json数据结构提取列表comment_list,使用for循环提取文本并输出需要打印的信息到控制台
①浏览器解析真实地址,使用requests抓取信息并输出r.text
import requests
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print (r.text)
②解析真实地址,使用json转换数据进行初步分析,循环输出评论内容:
import requests
import json
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
URL 中的重要变量
通过解析真实地址,可以发现URL中有一些重要的变量类型:
①limit:每个网页目标内容的最大值 查看全部
python抓取动态网页(
学习使用Python爬取动态网页内容时需要先学习动态网页的基本概念)
Python爬虫学习动态网页爬虫的3个基础
由于静态网页和动态网页在原理上的差异,在学习使用Python抓取动态网页内容时,需要了解动态网页的基本概念,了解动态网页与静态网页的区别。
动态网页技术AJAX技术的基本原理
即异步 JavaScript 和 XML,通过后台和服务器之间的少量数据交换,可以异步更新网页。AJAX 技术可以在不重新加载整个网页的情况下部分更新网页。
AJAX技术节省了网页重复内容的下载,节省了流量,因此得到了广泛的应用。
↓AJAX技术的应用
使用 AJAX 技术动态识别的内容(如网页评论等)在 HTML 文件中由一段 JavaScript 代码表示。
· 抓取 AJAX 加载的动态网页
①浏览器评论元素解析地址
②使用Selenium模拟浏览器爬行
浏览器检查元素使用浏览器检查元素解析真实地址
①在指定网页下打开浏览器“检查元素”功能的窗口视图
②选择网络子标签,刷新网页——此时网络标签会显示从网络服务器获取的所有文件(此过程为“抓包”,可以过滤掉所有文件中的目标文件获得的数据)
③通常这些数据都是以json文件格式获取的,选择网络中的XHR子标签,继续过滤获取目标文件数据的URL
④ 定义link为目标URL,使用新创建的请求对象抓取目标内容
⑤ 使用json库解析数据,进一步提取目标数据
——使用json.loads()将数据转换为json格式(注意r.text不能直接转换为json.load,需要中间转换过程)
——使用json数据结构提取列表comment_list,使用for循环提取文本并输出需要打印的信息到控制台
①浏览器解析真实地址,使用requests抓取信息并输出r.text
import requests
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print (r.text)
②解析真实地址,使用json转换数据进行初步分析,循环输出评论内容:
import requests
import json
link = """https://api-zero.livere.com/v1 ... ot%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
URL 中的重要变量
通过解析真实地址,可以发现URL中有一些重要的变量类型:
①limit:每个网页目标内容的最大值
python抓取动态网页(Python一个抓取网页内容的一个库-0x00库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-28 19:21
Requests是Python用来获取web内容的库
下面是对它的详细描述
0x00、请求
以下是捕获web内容的示例:
import requests #引入requests库
a = requests.get("https://www.mmuaa.com/link") #使用get方法抓取url
这样,就成功捕获了“”
我们可以使用以下代码查看抓取结果
a.status_code #抓取的HTTP状态码
a.text #抓取到的内容
上面是使用get方法来请求数据。同样,我们可以使用post、head、options和put
比如说
a = requests.put("http://httpbin.org/put")
a = requests.delete("http://httpbin.org/delete")
a = requests.head("http://httpbin.org/get")
a = requests.options("http://httpbin.org/get")
等等
0x01、参数
例如:
import requests
g = {"type" : "1"} #用字典的方式存储我们要请求的数据
a = requests.get("http://api.mmuaa.com/link", g) #发送带参数的get请求
a.url #查看发送的url
如您所见,请求库自动为我们处理URL参数并将其发送出去
同样,我们也可以使用post
得到了正确的结果
0x02、响应头
使用headers函数查看响应头,返回类型为dictionary
0x03、Cookies
将Cookie发送到服务器:
url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
r.text
这将发送cookie\将具有工作值的cookie发送到服务器
接收服务器返回的cookie:
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
r.cookies['example_cookie_name']
这将返回服务器返回的名为“exa,ple_cookie_name”的cookie的值 查看全部
python抓取动态网页(Python一个抓取网页内容的一个库-0x00库)
Requests是Python用来获取web内容的库
下面是对它的详细描述
0x00、请求
以下是捕获web内容的示例:
import requests #引入requests库
a = requests.get("https://www.mmuaa.com/link";) #使用get方法抓取url
这样,就成功捕获了“”
我们可以使用以下代码查看抓取结果
a.status_code #抓取的HTTP状态码
a.text #抓取到的内容
上面是使用get方法来请求数据。同样,我们可以使用post、head、options和put
比如说
a = requests.put("http://httpbin.org/put";)
a = requests.delete("http://httpbin.org/delete";)
a = requests.head("http://httpbin.org/get";)
a = requests.options("http://httpbin.org/get";)
等等
0x01、参数
例如:
import requests
g = {"type" : "1"} #用字典的方式存储我们要请求的数据
a = requests.get("http://api.mmuaa.com/link", g) #发送带参数的get请求
a.url #查看发送的url
如您所见,请求库自动为我们处理URL参数并将其发送出去
同样,我们也可以使用post
得到了正确的结果
0x02、响应头
使用headers函数查看响应头,返回类型为dictionary
0x03、Cookies
将Cookie发送到服务器:
url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
r.text
这将发送cookie\将具有工作值的cookie发送到服务器
接收服务器返回的cookie:
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
r.cookies['example_cookie_name']
这将返回服务器返回的名为“exa,ple_cookie_name”的cookie的值
python抓取动态网页(python爬取js执行后输出的解决方案(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-09-23 18:11
Python有许多库让我们轻松编写网络爬行动物,爬上某些页面,得到宝贵的信息!但在许多情况下,要采取爬行动物页面只是一个静态页面,该页面的源代码,如浏览器中的“查看页面源”。一些动态的东西,例如在JavaScript脚本之后生成的信息,这里可以用于提供这样的程序,可用于Python爬行JS执行输出的信息。
1.两个基本解决方案
1. 1带有dryscrape库动态抓取页
js脚本由浏览器执行并返回信息,因此抓住了JS执行后的页面,以及最直接的方式是使用Python模拟浏览器的行为。 WebKit是一个开源浏览器引擎,Python提供了许多文库来调用此引擎,Dryscrape是其中之一,它调用WebKit引擎来处理收录JS的网页!
1 importdryscrape2#使用dryscrape数据库动态捕获页面
3 defget_url_dynamic(URL):4 session_req = dryscrape.session()5 session_req.visit(url)#请求页
6 response = session_req.body()#网网文
7 #print(响应)
8 return response9 get_text_line(get_url_dynamic(url))#将输出文本
这也适用于收录JS的剩余网页!虽然它可以满足动态页面的要求,但缺点仍然非常明显:慢!太慢,实际上思考它合理地,python调用webkit请求页面,而其他页面被加载,加载js文件,让js执行,返回执行页面,慢慢慢!有许多图书馆可以调用webkit:pythonwebkit,pygebkitgit,pygt(你可以编写浏览器),睡衣等,我听说他们也可以实现相同的功能!
1. 2硒网测试框架
Selenium是一个Web测试框架,允许呼叫呼叫本地浏览器引擎发送Web请求,因此它也可以达到捕获页面的要求。
#使用selenium webdriver,但实时打开浏览器窗口
1 defget_url_dynamic2(URL):2驱动程序= webdriver.firefox()#coll uncoup firefox浏览器,甚至可以
3 driver.get(url)#请求页面,打开浏览器窗口
4 html_text = driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url))#out文本
这不是临时解决方案!还有一个与硒类似的硒的风车,这稍微复杂,然后再去!
2. selenium安装和使用
2. 1硒安装
在Ubuntu上安装可以直接使用pip安装selenium。由于以下原因:
1. selenium 3. x start,webdriver / firefox / webdriver.py __init__,secututable_path =“geckodriver”; 2. x是可执行文件_path =“线”
2. firefox 47或以上,您需要下载第三方驱动程序,哪个geckodriver
需要一些特殊操作:
1.下载geckodriverckod地址:mozilla / geckodriver
2.装装置go o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o up下载/ geckodriver / usr / local / bin /
2. 2 selenium的使用
1.运行错误:
驱动程序= webdriver.chrome()
typeerror:'模块'对象不是可调用的
解决方案:浏览器的名称需要大写Chrome和Firefox,即
2.通过
1 content = driver.find_element_by_class_name('content')
当元素定位时,该方法返回FirefoxWebElement,并且当您想要获取收录的值时,可以通过
1值= content.text 查看全部
python抓取动态网页(python爬取js执行后输出的解决方案(一))
Python有许多库让我们轻松编写网络爬行动物,爬上某些页面,得到宝贵的信息!但在许多情况下,要采取爬行动物页面只是一个静态页面,该页面的源代码,如浏览器中的“查看页面源”。一些动态的东西,例如在JavaScript脚本之后生成的信息,这里可以用于提供这样的程序,可用于Python爬行JS执行输出的信息。
1.两个基本解决方案
1. 1带有dryscrape库动态抓取页
js脚本由浏览器执行并返回信息,因此抓住了JS执行后的页面,以及最直接的方式是使用Python模拟浏览器的行为。 WebKit是一个开源浏览器引擎,Python提供了许多文库来调用此引擎,Dryscrape是其中之一,它调用WebKit引擎来处理收录JS的网页!
1 importdryscrape2#使用dryscrape数据库动态捕获页面
3 defget_url_dynamic(URL):4 session_req = dryscrape.session()5 session_req.visit(url)#请求页
6 response = session_req.body()#网网文
7 #print(响应)
8 return response9 get_text_line(get_url_dynamic(url))#将输出文本
这也适用于收录JS的剩余网页!虽然它可以满足动态页面的要求,但缺点仍然非常明显:慢!太慢,实际上思考它合理地,python调用webkit请求页面,而其他页面被加载,加载js文件,让js执行,返回执行页面,慢慢慢!有许多图书馆可以调用webkit:pythonwebkit,pygebkitgit,pygt(你可以编写浏览器),睡衣等,我听说他们也可以实现相同的功能!
1. 2硒网测试框架
Selenium是一个Web测试框架,允许呼叫呼叫本地浏览器引擎发送Web请求,因此它也可以达到捕获页面的要求。
#使用selenium webdriver,但实时打开浏览器窗口
1 defget_url_dynamic2(URL):2驱动程序= webdriver.firefox()#coll uncoup firefox浏览器,甚至可以
3 driver.get(url)#请求页面,打开浏览器窗口
4 html_text = driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url))#out文本
这不是临时解决方案!还有一个与硒类似的硒的风车,这稍微复杂,然后再去!
2. selenium安装和使用
2. 1硒安装
在Ubuntu上安装可以直接使用pip安装selenium。由于以下原因:
1. selenium 3. x start,webdriver / firefox / webdriver.py __init__,secututable_path =“geckodriver”; 2. x是可执行文件_path =“线”
2. firefox 47或以上,您需要下载第三方驱动程序,哪个geckodriver
需要一些特殊操作:
1.下载geckodriverckod地址:mozilla / geckodriver
2.装装置go o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o up下载/ geckodriver / usr / local / bin /
2. 2 selenium的使用
1.运行错误:
驱动程序= webdriver.chrome()
typeerror:'模块'对象不是可调用的
解决方案:浏览器的名称需要大写Chrome和Firefox,即
2.通过
1 content = driver.find_element_by_class_name('content')
当元素定位时,该方法返回FirefoxWebElement,并且当您想要获取收录的值时,可以通过
1值= content.text
python抓取动态网页(爬取《Python网络爬虫》动态网页抓取的两种技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-23 18:09
由于主流网站,使用JavaScript显示web内容,静态网页的前面简单是不同的。当使用JavaScript,许多内容将不会出现在HTML源代码,但在HTML源位置的JavaScript代码的最后一节,最后给出的数据是由JavaScript提取服务器返回的数据进行渲染。因此,抓取静态网页的技术可能无法正常使用。因此,我们需要由动态网页捕获两种技术:
1.通过浏览器审查元件解析所述实际网页地址;
2.使用硒,模拟浏览器。
我们首先先介绍第一种方法。
以“Python的网络爬虫:从入门到实践”一书的作者的个人博客作为一个例子。网址:1) “队长”:找到真正的数据地址
右键单击“检查”,单击“网络”,选择“JS”。刷新页面,选择当页面刷新列出的数据,并选择此JS文件。检查右边的头。如该图所示:
,其中请求URL是一个真正的数据地址。
滚动鼠标滚轮在该状态下,找到用户代理。
2)相关的代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代Ĵj_string.find()API分辨率:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码JSON_STRING.FIND( '{')返回 “{” 在json_string串的索引位置。
2)如果添加代码打印在你的代码json_string,输出的结果是(因为过多的输出内容,只有起点和终点,在关键位置是在红色标记):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上述输出的输出已知的,我们加入JSON_STRING = JSON_STRING [JSON_STRING.FIND( '{'): - 2]。在您的代码
如果json_string.find(“{”)不添加,结果是不合法的JSON格式,不能顺利形成JSON文件;如果它不拦截第二比特,结果含有过量);它也无法合法JSON格式。
3)对于在中间[“内容”]代码comment_list = json_data [“结果”] [“父母”]和消息中的字符串型标签在中间支架,可以是2)关键部件查找,即,由“结果”和“父母”拦截合法JSON文件使用了两个中间支架一步一步的位置,因为我们爬的评论,其内容是在这个JSON文件中的“内容“标签,使用[” 内容“]来的位置。
据观察,OFFSET在真实数据地址的页面的数量。 查看全部
python抓取动态网页(爬取《Python网络爬虫》动态网页抓取的两种技术)
由于主流网站,使用JavaScript显示web内容,静态网页的前面简单是不同的。当使用JavaScript,许多内容将不会出现在HTML源代码,但在HTML源位置的JavaScript代码的最后一节,最后给出的数据是由JavaScript提取服务器返回的数据进行渲染。因此,抓取静态网页的技术可能无法正常使用。因此,我们需要由动态网页捕获两种技术:
1.通过浏览器审查元件解析所述实际网页地址;
2.使用硒,模拟浏览器。
我们首先先介绍第一种方法。
以“Python的网络爬虫:从入门到实践”一书的作者的个人博客作为一个例子。网址:1) “队长”:找到真正的数据地址
右键单击“检查”,单击“网络”,选择“JS”。刷新页面,选择当页面刷新列出的数据,并选择此JS文件。检查右边的头。如该图所示:
,其中请求URL是一个真正的数据地址。
滚动鼠标滚轮在该状态下,找到用户代理。
2)相关的代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代Ĵj_string.find()API分辨率:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码JSON_STRING.FIND( '{')返回 “{” 在json_string串的索引位置。
2)如果添加代码打印在你的代码json_string,输出的结果是(因为过多的输出内容,只有起点和终点,在关键位置是在红色标记):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上述输出的输出已知的,我们加入JSON_STRING = JSON_STRING [JSON_STRING.FIND( '{'): - 2]。在您的代码
如果json_string.find(“{”)不添加,结果是不合法的JSON格式,不能顺利形成JSON文件;如果它不拦截第二比特,结果含有过量);它也无法合法JSON格式。
3)对于在中间[“内容”]代码comment_list = json_data [“结果”] [“父母”]和消息中的字符串型标签在中间支架,可以是2)关键部件查找,即,由“结果”和“父母”拦截合法JSON文件使用了两个中间支架一步一步的位置,因为我们爬的评论,其内容是在这个JSON文件中的“内容“标签,使用[” 内容“]来的位置。
据观察,OFFSET在真实数据地址的页面的数量。
python抓取动态网页(博主不蛋疼时也会更新博客的哈~~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-22 22:03
我还没来得及写一点我前段时间写的东西。如果今天我的眼睛痛,我会写下来~~(结果是博客作者在没有鸡蛋痛的时候会更新他们的博客~)
Python爬行网页基金会
Python本身有许多与网络应用程序相关的模块,例如用于FTP相关操作的ftplib、用于发送和接收电子邮件的SMTP lib和poplib等。完全可以使用这些模块编写FTP软件或电子邮件客户端软件。我只是尝试发送和接收电子邮件,并完全使用Python脚本操作自己的FTP服务器。当然,这些都不是今天的主角。我们今天将使用的模块有:urlib、urlib2、cookielib和beautiful soup。我们先简单介绍一下。Urllib和Urllib 2自然地处理与URL相关的操作。Urllib可以从指定的URL下载文件,或者对某些字符串进行编码和解码,使其成为特定的URL字符串。Urllib 2比Urllib多一点。哦,不,它更棒一点。它有多种处理程序和处理器,可以处理更复杂的问题,如网络身份验证、使用代理服务器、使用cookie等等。第三个cookie IB,顾名思义,处理与cookie相关的操作,我没有深入讨论其他操作。最后一个包Beauty soup是一个第三方包,专门用于解析HTML和XML文件。使用它是非常傻瓜式。我们依靠它来解析网页源代码,可以从下载。当然,你也可以使用easy_uuu安装它,这里是它的中文使用文档。很多例子都很好
让我们看一看最简单的网页捕获。事实上,网页捕获就是下载所需的网页源代码文件,然后对其进行分析,为我们自己提取有用的信息。最简单的抓取只需一句话:
1
2
import urllib
html_src = urllib.urlopen('http://www.baidu.com').read()
这将打印出百度主页的HTML源代码,这仍然很容易。Urllib的urlopen函数将返回一个“class file”对象,因此您可以直接调用read()来获取内容。然而,印刷内容混乱,布局不美观,编码问题没有得到解决,所以你看不到汉字。这需要我们漂亮的汤包装。我们可以使用上面获得的源代码字符串HTML来初始化beautifulsoup对象:
1
2
from BeautifulSoup import BeautifulSoup
parser = BeautifulSoup(html_src)
这样,HTML源代码的后续处理就留给解析器变量了。我们可以简单地调用解析器的prettify函数来相对美观地显示源代码,这样我们就可以看到中文字符,因为beautiful soup可以自动处理字符问题,并将返回的结果转换为Unicode编码格式。此外,beautiful soup可以快速找到满足条件的指定标记,稍后我们将使用这些标记~
关注人人网的消息
我们讨论了最简单的爬行情况,但通常我们需要面对更复杂的情况。例如,人人网需要登录到自己的帐户才能显示新内容,因此我们只能使用urlib2模块。想象一下,我们需要一个开场白来打开你的人人网主页。为了进入,我们首先需要身份验证,而此登录身份验证需要cookie支持,因此我们需要在此开场白上构建cookie处理程序:
1
2
3
4
import urllib,urllib2,cookielib
from BeautifulSoup import BeautifulSoup
myCookie = urllib2.HTTPCookieProcessor(cookielib.CookieJar());
opener = urllib2.build_opener(myCookie)
首先导入我们需要的所有模块,然后使用urlib2模块的HTTP cookie处理器构建cookie处理程序,并将cookie IB模块的cookie jar函数作为参数传入。此函数用于处理HTTP cookies。简而言之,它从HTTP请求中提取cookie并将它们返回给HTTP响应。然后使用urlib2_uuOpener的构建来创建我们需要的Opener。此开启器已满足我们处理cookies的要求
那么这个处理器是如何工作的呢?如前所述,它需要捕获HTTP请求。也就是说,我们需要知道登录时发送了哪些数据包。令人敬畏的人可以使用各种命令行数据包捕获工具,如tcpdump。让我们等待晓敏的到来。在这里,我们借助Firefox的httpfox实现它。你可以在这里添加这个很棒的插件。安装插件后,我们使用Firefox登录人人网,然后输入帐户和密码。然后,不要担心,不要按登录按钮,从状态栏打开httpfox插件,单击开始按钮开始捕获数据包,然后单击人人网的登录。登录过程完成后,单击httpfox停止捕获数据包,如果一切正常,您应该看到以下信息
我们可以看到,在登录人人网的过程中,浏览器向人人网的服务器发送post请求数据。共有四项,其中两项是您的帐户和密码。让我们使用代码模拟来提出相同的请求
1
2
3
4
5
6
7
8
9
post_data = {
'email':'xxxxx',
'password':'xxxxx',
'origURL':'http://www.renren.com/Home.do',
'domain':'renren.com'
}
req = urllib2.Request('http://www.renren.com/PLogin.do', urllib.urlencode(post_data))
html_src = openner.open(req).read()
parser = BeautifulSoup(html_src)
首先,构造一个字典来存储我们刚刚捕获的post数据,然后通过urllib 2的请求类自己构造一个“request”对象。请求的提交URL是上面捕获的post请求的URL部分,后面是我们的post数据。注意,我们需要使用urllib的URLEncode方法在这里重新编码,使其成为合法的URL字符串。下面的过程与上面提到的简单爬网过程相同,只是这里打开的不是简单的web地址,而是封装web地址和post数据后的请求。类似地,我们将源代码分配给beautifulsoup以供以后处理
现在,我们在解析器中存储的是收录来自朋友的新闻的网页源代码。我们如何提取有用的信息?分析网页的粗略工作应该交给Firefox的firebug(在这里下载)。登录人人网,任意右键点击新闻中某人的状态,选择“查看元素”,弹出如下窗口,显示您点击的部分对应的源代码:
我们可以看到,每个新事件都对应于article标记。让我们仔细看看文章标签的细节:
里面的H3标签收录朋友的姓名和状态。当然,肥猪流也有一些表达地址。那些接触过HTML的人应该对此很熟悉。这就是我们要抓到的H3
Beautifulsoup抓取标签内容
下面是我们的解析器展示它的时候了。Beautifulsoup提供了许多定位标记的方法。简而言之,它主要包括find函数和findall函数。常用参数是name和attrs。一个是标记的名称,另一个是标记的属性,名称是字符串,attrs是字典,例如find('img'),{'SRC':'abc.JPG'})将返回如下标签:
find和findall之间的区别在于find只返回满足要求的第一个标记,而findall返回满足要求的所有标记的列表。在获得标签后,有许多方便的方法来获得子标签。例如,标签。A可以通过点运算符获取由tag表示的标记下的子标记A,然后tag.contents可以获取其所有子标记。对于更多应用程序,您可以查看其文档。让我们以这个例子来了解如何捕获我们想要的内容
1
2
3
4
5
6
7
8
9
10
11
article_list = parser.find('div','feed-list').findAll('article')
for my_article in article_list:
state = []
for my_tag in my_article.h3.contents:
factor = my_tag.string
if factor != None:
factor = factor.replace(u'\xa0','')
factor = factor.strip(u'\r\n')
factor = factor.strip(u'\n')
state.append(factor)
print ' '.join(state)
这里,我们使用find('div','feedlist')。Findall('article')获取其类属性为提要列表的div标记。当第二个参数直接是字符串时,它表示CSS的class属性,然后获取所有文章的列表。与上图相比,这句话实际上得到了所有新事物的列表。然后我们遍历这个列表,为每个文章标记获取其H3标记,并提取内部信息。如果标签直接收录文本,则可以通过string属性获取。最后,我们删除了一些控制字符,例如换行符。最后,我们打印结果。当然,这只能获得一小部分,“更多新事物”的功能是无法实现的。如果你感兴趣,继续学习。我认为通过httpfox实现并不困难
团购信息聚合小工具
有了同样的知识,我们还可以做一些有趣的应用,比如流行的团购信息聚合。其实这个想法还是很简单的,就是分析网站源代码,提取团购标题、图片和价格。在这里,我们发布了源代码文件,有兴趣的人可以研究它!pyqt制作的界面中的按钮功能尚未实现,因此我们只能将其提取为“美团”、“”和“团购”网站,可通过下拉列表框选择显示。图片将保存在本地目录中。让我们拍一张截图~
未实现交叉按钮功能。这是文件下载,一个PYW主表单文件,另外两个py文件,一个是UI,另一个是resource
软件包下载 查看全部
python抓取动态网页(博主不蛋疼时也会更新博客的哈~~)
我还没来得及写一点我前段时间写的东西。如果今天我的眼睛痛,我会写下来~~(结果是博客作者在没有鸡蛋痛的时候会更新他们的博客~)
Python爬行网页基金会
Python本身有许多与网络应用程序相关的模块,例如用于FTP相关操作的ftplib、用于发送和接收电子邮件的SMTP lib和poplib等。完全可以使用这些模块编写FTP软件或电子邮件客户端软件。我只是尝试发送和接收电子邮件,并完全使用Python脚本操作自己的FTP服务器。当然,这些都不是今天的主角。我们今天将使用的模块有:urlib、urlib2、cookielib和beautiful soup。我们先简单介绍一下。Urllib和Urllib 2自然地处理与URL相关的操作。Urllib可以从指定的URL下载文件,或者对某些字符串进行编码和解码,使其成为特定的URL字符串。Urllib 2比Urllib多一点。哦,不,它更棒一点。它有多种处理程序和处理器,可以处理更复杂的问题,如网络身份验证、使用代理服务器、使用cookie等等。第三个cookie IB,顾名思义,处理与cookie相关的操作,我没有深入讨论其他操作。最后一个包Beauty soup是一个第三方包,专门用于解析HTML和XML文件。使用它是非常傻瓜式。我们依靠它来解析网页源代码,可以从下载。当然,你也可以使用easy_uuu安装它,这里是它的中文使用文档。很多例子都很好
让我们看一看最简单的网页捕获。事实上,网页捕获就是下载所需的网页源代码文件,然后对其进行分析,为我们自己提取有用的信息。最简单的抓取只需一句话:
1
2
import urllib
html_src = urllib.urlopen('http://www.baidu.com').read()
这将打印出百度主页的HTML源代码,这仍然很容易。Urllib的urlopen函数将返回一个“class file”对象,因此您可以直接调用read()来获取内容。然而,印刷内容混乱,布局不美观,编码问题没有得到解决,所以你看不到汉字。这需要我们漂亮的汤包装。我们可以使用上面获得的源代码字符串HTML来初始化beautifulsoup对象:
1
2
from BeautifulSoup import BeautifulSoup
parser = BeautifulSoup(html_src)
这样,HTML源代码的后续处理就留给解析器变量了。我们可以简单地调用解析器的prettify函数来相对美观地显示源代码,这样我们就可以看到中文字符,因为beautiful soup可以自动处理字符问题,并将返回的结果转换为Unicode编码格式。此外,beautiful soup可以快速找到满足条件的指定标记,稍后我们将使用这些标记~
关注人人网的消息
我们讨论了最简单的爬行情况,但通常我们需要面对更复杂的情况。例如,人人网需要登录到自己的帐户才能显示新内容,因此我们只能使用urlib2模块。想象一下,我们需要一个开场白来打开你的人人网主页。为了进入,我们首先需要身份验证,而此登录身份验证需要cookie支持,因此我们需要在此开场白上构建cookie处理程序:
1
2
3
4
import urllib,urllib2,cookielib
from BeautifulSoup import BeautifulSoup
myCookie = urllib2.HTTPCookieProcessor(cookielib.CookieJar());
opener = urllib2.build_opener(myCookie)
首先导入我们需要的所有模块,然后使用urlib2模块的HTTP cookie处理器构建cookie处理程序,并将cookie IB模块的cookie jar函数作为参数传入。此函数用于处理HTTP cookies。简而言之,它从HTTP请求中提取cookie并将它们返回给HTTP响应。然后使用urlib2_uuOpener的构建来创建我们需要的Opener。此开启器已满足我们处理cookies的要求
那么这个处理器是如何工作的呢?如前所述,它需要捕获HTTP请求。也就是说,我们需要知道登录时发送了哪些数据包。令人敬畏的人可以使用各种命令行数据包捕获工具,如tcpdump。让我们等待晓敏的到来。在这里,我们借助Firefox的httpfox实现它。你可以在这里添加这个很棒的插件。安装插件后,我们使用Firefox登录人人网,然后输入帐户和密码。然后,不要担心,不要按登录按钮,从状态栏打开httpfox插件,单击开始按钮开始捕获数据包,然后单击人人网的登录。登录过程完成后,单击httpfox停止捕获数据包,如果一切正常,您应该看到以下信息
我们可以看到,在登录人人网的过程中,浏览器向人人网的服务器发送post请求数据。共有四项,其中两项是您的帐户和密码。让我们使用代码模拟来提出相同的请求
1
2
3
4
5
6
7
8
9
post_data = {
'email':'xxxxx',
'password':'xxxxx',
'origURL':'http://www.renren.com/Home.do',
'domain':'renren.com'
}
req = urllib2.Request('http://www.renren.com/PLogin.do', urllib.urlencode(post_data))
html_src = openner.open(req).read()
parser = BeautifulSoup(html_src)
首先,构造一个字典来存储我们刚刚捕获的post数据,然后通过urllib 2的请求类自己构造一个“request”对象。请求的提交URL是上面捕获的post请求的URL部分,后面是我们的post数据。注意,我们需要使用urllib的URLEncode方法在这里重新编码,使其成为合法的URL字符串。下面的过程与上面提到的简单爬网过程相同,只是这里打开的不是简单的web地址,而是封装web地址和post数据后的请求。类似地,我们将源代码分配给beautifulsoup以供以后处理
现在,我们在解析器中存储的是收录来自朋友的新闻的网页源代码。我们如何提取有用的信息?分析网页的粗略工作应该交给Firefox的firebug(在这里下载)。登录人人网,任意右键点击新闻中某人的状态,选择“查看元素”,弹出如下窗口,显示您点击的部分对应的源代码:
我们可以看到,每个新事件都对应于article标记。让我们仔细看看文章标签的细节:
里面的H3标签收录朋友的姓名和状态。当然,肥猪流也有一些表达地址。那些接触过HTML的人应该对此很熟悉。这就是我们要抓到的H3
Beautifulsoup抓取标签内容
下面是我们的解析器展示它的时候了。Beautifulsoup提供了许多定位标记的方法。简而言之,它主要包括find函数和findall函数。常用参数是name和attrs。一个是标记的名称,另一个是标记的属性,名称是字符串,attrs是字典,例如find('img'),{'SRC':'abc.JPG'})将返回如下标签:
find和findall之间的区别在于find只返回满足要求的第一个标记,而findall返回满足要求的所有标记的列表。在获得标签后,有许多方便的方法来获得子标签。例如,标签。A可以通过点运算符获取由tag表示的标记下的子标记A,然后tag.contents可以获取其所有子标记。对于更多应用程序,您可以查看其文档。让我们以这个例子来了解如何捕获我们想要的内容
1
2
3
4
5
6
7
8
9
10
11
article_list = parser.find('div','feed-list').findAll('article')
for my_article in article_list:
state = []
for my_tag in my_article.h3.contents:
factor = my_tag.string
if factor != None:
factor = factor.replace(u'\xa0','')
factor = factor.strip(u'\r\n')
factor = factor.strip(u'\n')
state.append(factor)
print ' '.join(state)
这里,我们使用find('div','feedlist')。Findall('article')获取其类属性为提要列表的div标记。当第二个参数直接是字符串时,它表示CSS的class属性,然后获取所有文章的列表。与上图相比,这句话实际上得到了所有新事物的列表。然后我们遍历这个列表,为每个文章标记获取其H3标记,并提取内部信息。如果标签直接收录文本,则可以通过string属性获取。最后,我们删除了一些控制字符,例如换行符。最后,我们打印结果。当然,这只能获得一小部分,“更多新事物”的功能是无法实现的。如果你感兴趣,继续学习。我认为通过httpfox实现并不困难
团购信息聚合小工具
有了同样的知识,我们还可以做一些有趣的应用,比如流行的团购信息聚合。其实这个想法还是很简单的,就是分析网站源代码,提取团购标题、图片和价格。在这里,我们发布了源代码文件,有兴趣的人可以研究它!pyqt制作的界面中的按钮功能尚未实现,因此我们只能将其提取为“美团”、“”和“团购”网站,可通过下拉列表框选择显示。图片将保存在本地目录中。让我们拍一张截图~
未实现交叉按钮功能。这是文件下载,一个PYW主表单文件,另外两个py文件,一个是UI,另一个是resource
软件包下载
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-21 12:11
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
python抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
python抓取动态网页(zerocapture、httpyjs框架内部ajax交互方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-19 00:06
python抓取动态网页数据,在诸多方法中,如gzip压缩和flask框架内部ajax交互,一直存在着问题。一来url前缀单一,“-static”路径提取时无法从原网页采集数据,二来有可能抓取到不安全数据。而利用xpath,三者已经是标配。zerocapture、httpyjs的主要应用,同时也是百度搜索引擎的抓取方案。
在多次尝试中,zerocapture的各种方法由于运行速度慢而逐渐被弃用。最终,爬取这个页面的项目方案,可以直接套用xpath。python解析url:'//useragent.#1\s/testing\album\reto\o29_o29_o29\b29\testing\album\reto\o29_o29\b29\testing\album\reto\o29_o29\testing\album\reto\o29_o29\fauto_o29\reto\sd',url('')'我们已经知道了网页的各个参数,以及具体参数对应的类型。
那么,python是否就可以从网页的整个页面抓取数据呢?答案是可以的。首先,我们先确定url本身具有从页面的一个或多个页面获取某些信息的能力。通常表现为:返回json或其他形式的字符串或xml,数据包含moreparts等标签。注意:该url是对单页进行抓取时,返回值为整页的返回。可以看出,我们已经抓取了「四个侧栏」。
接下来,我们一个个页面进行抓取。这里我们需要注意的是,在抓取每个侧栏时,需要把当前页面上所有我们想抓取的信息列表所在的内容(包括标签),包括返回值列表所在的内容都抓取。这一步非常关键,因为列表所在的内容抓取后就永远不会被下一页抓取。虽然这样比较麻烦,但作为新手,这一步还是值得弄懂的。然后,就是利用gzip压缩保存数据了。
下面我们可以通过一个简单的xpath函数完成这个操作。xpath生成能从单个页面获取某些信息的解析xpath调用链接#[a-za-z0-9]{2,5,5}xpath{2,5,5}第一步生成url,a-za-z0-9代表a~za中文开头与结尾的最后一个字符串,a代表第二个汉字,b~c代表u+1~v-7,用来将中文前缀部分和中文后缀部分用aa表示。
网页源码中需要包含json格式的字符串。对于url而言,参数gzip=json.loads(dirname('flasy.url')),json=json.dumps(url)#正则匹配[x,y]#分页从flasy.url中获取内容p=gzip.json('flasy.url')#json.dump(xpath,url)#json.dump(json,gzip)->(['b','b','d','b','c','d','a','a','b','b','c','。 查看全部
python抓取动态网页(zerocapture、httpyjs框架内部ajax交互方案)
python抓取动态网页数据,在诸多方法中,如gzip压缩和flask框架内部ajax交互,一直存在着问题。一来url前缀单一,“-static”路径提取时无法从原网页采集数据,二来有可能抓取到不安全数据。而利用xpath,三者已经是标配。zerocapture、httpyjs的主要应用,同时也是百度搜索引擎的抓取方案。
在多次尝试中,zerocapture的各种方法由于运行速度慢而逐渐被弃用。最终,爬取这个页面的项目方案,可以直接套用xpath。python解析url:'//useragent.#1\s/testing\album\reto\o29_o29_o29\b29\testing\album\reto\o29_o29\b29\testing\album\reto\o29_o29\testing\album\reto\o29_o29\fauto_o29\reto\sd',url('')'我们已经知道了网页的各个参数,以及具体参数对应的类型。
那么,python是否就可以从网页的整个页面抓取数据呢?答案是可以的。首先,我们先确定url本身具有从页面的一个或多个页面获取某些信息的能力。通常表现为:返回json或其他形式的字符串或xml,数据包含moreparts等标签。注意:该url是对单页进行抓取时,返回值为整页的返回。可以看出,我们已经抓取了「四个侧栏」。
接下来,我们一个个页面进行抓取。这里我们需要注意的是,在抓取每个侧栏时,需要把当前页面上所有我们想抓取的信息列表所在的内容(包括标签),包括返回值列表所在的内容都抓取。这一步非常关键,因为列表所在的内容抓取后就永远不会被下一页抓取。虽然这样比较麻烦,但作为新手,这一步还是值得弄懂的。然后,就是利用gzip压缩保存数据了。
下面我们可以通过一个简单的xpath函数完成这个操作。xpath生成能从单个页面获取某些信息的解析xpath调用链接#[a-za-z0-9]{2,5,5}xpath{2,5,5}第一步生成url,a-za-z0-9代表a~za中文开头与结尾的最后一个字符串,a代表第二个汉字,b~c代表u+1~v-7,用来将中文前缀部分和中文后缀部分用aa表示。
网页源码中需要包含json格式的字符串。对于url而言,参数gzip=json.loads(dirname('flasy.url')),json=json.dumps(url)#正则匹配[x,y]#分页从flasy.url中获取内容p=gzip.json('flasy.url')#json.dump(xpath,url)#json.dump(json,gzip)->(['b','b','d','b','c','d','a','a','b','b','c','。
python抓取动态网页( Python网络爬虫可插拔的内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-18 22:16
Python网络爬虫可插拔的内容提取器)
一,。导言
在PythonWebCrawler内容提取器文章中,我们详细解释了核心组件:可插入内容提取器类gsextractor。本文记录了在确定GSR萃取器技术路线的过程中进行的编程实验。这是第二部分。在第一部分中,实验使用XSLT一次性提取静态网页内容并将其转换为XML格式。这就留下了一个问题:如何提取JavaScript管理的动态内容?然后本文回答了这个问题。javascript
二,。用于提取动态内容的技术组件
在上一篇文章中,python使用XSLT提取网页数据。要提取的内容直接从网页的源代码中获取。但是,一些Ajax动态内容在源代码中找不到,因此我们需要找到一个合适的库来加载异步或动态加载的内容,并将其交给项目的提取器进行提取。html
Python可以使用selenium来执行JavaScript。Selenium允许浏览器自动加载页面并获取所需数据。Selenium本身没有浏览器。它可以使用第三方浏览器(如Firefox和chrome)或无头浏览器(如phantom JS)在后台执行。爪哇
三,。源代码和实验过程
如果我们想抓取京东手机页面的手机名称和价格(在网络源代码中找不到价格),如下图:
蟒蛇
步骤1:通过使用搜索引擎的可视化注释功能,可以以非常快的速度自动生成已调试的捕获规则。事实上,它是一个标准的XSLT程序。如下图所示,将生成的XSLT程序复制到以下程序中。注:本文仅记录实验过程。在实际系统中,XSLT程序将以多种方式注入到内容提取器中
吉特
步骤2:执行以下代码(在Windows 10中,python3.2),请注意XSLT是一个相对较长的字符串。如果删除这个字符串,代码就只有几行,这足以显示Python强大的程序员
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是经过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js获得整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取须要的字段
result_tree = transform(doc)
print(result_tree)
步骤3:如下图所示,网页中的手机名称和价格已被正确捕获
github
四,。下次阅读
到目前为止,在两次文章演示如何捕获静态和动态网页内容之后,我们都使用XSLT一次性从网页中提取所需内容。事实上,XSLT是一种更复杂的编程语言。如果XSLT是手动编写的,那么最好将其编写为离散XPath。如果XSLT不是手动编写的,而是由程序自动生成的,那么它是有意义的。程序员不再需要花时间编写和调整捕获规则,这是一项费时费力的工作。接下来,“1分钟快速生成用于网页内容提取的XSLT”将描述如何生成XSLT。网
五,。Jisoke gooseeker开源代码下载源代码
1.GooSeeker开源Python web爬虫GitHub源代码编程
五,。文档修改历史记录
2016-05-26:V2.0,补充文字说明
2016-05-29:V2.1. 增加第5章:下载源代码并更改GitHub网站源代码段错误 查看全部
python抓取动态网页(
Python网络爬虫可插拔的内容提取器)
一,。导言
在PythonWebCrawler内容提取器文章中,我们详细解释了核心组件:可插入内容提取器类gsextractor。本文记录了在确定GSR萃取器技术路线的过程中进行的编程实验。这是第二部分。在第一部分中,实验使用XSLT一次性提取静态网页内容并将其转换为XML格式。这就留下了一个问题:如何提取JavaScript管理的动态内容?然后本文回答了这个问题。javascript
二,。用于提取动态内容的技术组件
在上一篇文章中,python使用XSLT提取网页数据。要提取的内容直接从网页的源代码中获取。但是,一些Ajax动态内容在源代码中找不到,因此我们需要找到一个合适的库来加载异步或动态加载的内容,并将其交给项目的提取器进行提取。html
Python可以使用selenium来执行JavaScript。Selenium允许浏览器自动加载页面并获取所需数据。Selenium本身没有浏览器。它可以使用第三方浏览器(如Firefox和chrome)或无头浏览器(如phantom JS)在后台执行。爪哇
三,。源代码和实验过程
如果我们想抓取京东手机页面的手机名称和价格(在网络源代码中找不到价格),如下图:
蟒蛇
步骤1:通过使用搜索引擎的可视化注释功能,可以以非常快的速度自动生成已调试的捕获规则。事实上,它是一个标准的XSLT程序。如下图所示,将生成的XSLT程序复制到以下程序中。注:本文仅记录实验过程。在实际系统中,XSLT程序将以多种方式注入到内容提取器中
吉特
步骤2:执行以下代码(在Windows 10中,python3.2),请注意XSLT是一个相对较长的字符串。如果删除这个字符串,代码就只有几行,这足以显示Python强大的程序员
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是经过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js获得整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取须要的字段
result_tree = transform(doc)
print(result_tree)
步骤3:如下图所示,网页中的手机名称和价格已被正确捕获
github
四,。下次阅读
到目前为止,在两次文章演示如何捕获静态和动态网页内容之后,我们都使用XSLT一次性从网页中提取所需内容。事实上,XSLT是一种更复杂的编程语言。如果XSLT是手动编写的,那么最好将其编写为离散XPath。如果XSLT不是手动编写的,而是由程序自动生成的,那么它是有意义的。程序员不再需要花时间编写和调整捕获规则,这是一项费时费力的工作。接下来,“1分钟快速生成用于网页内容提取的XSLT”将描述如何生成XSLT。网
五,。Jisoke gooseeker开源代码下载源代码
1.GooSeeker开源Python web爬虫GitHub源代码编程
五,。文档修改历史记录
2016-05-26:V2.0,补充文字说明
2016-05-29:V2.1. 增加第5章:下载源代码并更改GitHub网站源代码段错误
python抓取动态网页(统计市里建筑企业的基本信息,人工数个数,真是很伤眼睛啊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-18 22:10
最近,我们要统计全市建筑企业的基本情况。数一数工人的人数真伤了我们的眼睛。此外,劳动力数量太少
虽然脚本不熟悉该框架,但对于最傻瓜式请求,它仍然是缓慢完成的。虽然速度慢,但它自由灵活
以山东建设特种作业查询网为例
URL::81/sztzy/Login/SelectCert.aspx
目标:通过输入企业名称完成查询并清理数据
在chrome中打开页面,然后打开开发者页面。共有6个页面文件
不需要读取后缀为GIF的两个文件。selectcert.aspx页面收录查询页面的基本信息。我唯一不明白的是这两个web资源的文件是什么,不管以后如何处理
表头基本信息:
Get用于请求,返回的状态代码为200
其他标题信息:
此时选择查询企业
询问
信息表显示在页面上,但页面的URL不会更改
但是,应该注意,在开发人员模式下还有一个网页文件
打开网页中的基本信息,标题信息:
还有一个新的查询字符串参数
还有新的表单数据信息
再次打开页面并预览它
这是HTML格式的Unicode编码。现在您知道了数据的位置,下一步是了解数据传输机制
首先,打开初始页面并阅读内容。大部分内容包括设置页面颜色、按钮控件等基本内容,以及网页和服务器的基本信息
第一个是视图状态信息
同时,继续分析页面代码:
按查询类型查找下拉菜单控件的信息
即ddselect=“2”查询企业时
其他信息,如页码信息,仍需分析。信息太多,无法重复
#下面是对post URL问题的分析,因为post使用的URL会随着页面按钮的操作而动态变化,但变化的规律是什么?我们需要对上述webresource页面进行分析,通过分析其内部代码和网页测试,找到web URL生成的规律
最后,根据get和cookie信息返回的viewstate等信息,将页面请求信息以post的形式发送到指定的URL,返回的数据可以通过beautiful soup解析,通过编码翻译和正则表达式提取有效信息,读取以下页码呃,最后根据查询和使用的条件生成框架数据
上一篇:Python线程多线程崩溃
下一步:SMOSZIP(DBL)数据读取方法说明(二))@ 查看全部
python抓取动态网页(统计市里建筑企业的基本信息,人工数个数,真是很伤眼睛啊)
最近,我们要统计全市建筑企业的基本情况。数一数工人的人数真伤了我们的眼睛。此外,劳动力数量太少
虽然脚本不熟悉该框架,但对于最傻瓜式请求,它仍然是缓慢完成的。虽然速度慢,但它自由灵活
以山东建设特种作业查询网为例
URL::81/sztzy/Login/SelectCert.aspx
目标:通过输入企业名称完成查询并清理数据
在chrome中打开页面,然后打开开发者页面。共有6个页面文件
不需要读取后缀为GIF的两个文件。selectcert.aspx页面收录查询页面的基本信息。我唯一不明白的是这两个web资源的文件是什么,不管以后如何处理
表头基本信息:
Get用于请求,返回的状态代码为200
其他标题信息:
此时选择查询企业
询问
信息表显示在页面上,但页面的URL不会更改
但是,应该注意,在开发人员模式下还有一个网页文件
打开网页中的基本信息,标题信息:
还有一个新的查询字符串参数
还有新的表单数据信息
再次打开页面并预览它
这是HTML格式的Unicode编码。现在您知道了数据的位置,下一步是了解数据传输机制
首先,打开初始页面并阅读内容。大部分内容包括设置页面颜色、按钮控件等基本内容,以及网页和服务器的基本信息
第一个是视图状态信息
同时,继续分析页面代码:
按查询类型查找下拉菜单控件的信息
即ddselect=“2”查询企业时
其他信息,如页码信息,仍需分析。信息太多,无法重复
#下面是对post URL问题的分析,因为post使用的URL会随着页面按钮的操作而动态变化,但变化的规律是什么?我们需要对上述webresource页面进行分析,通过分析其内部代码和网页测试,找到web URL生成的规律
最后,根据get和cookie信息返回的viewstate等信息,将页面请求信息以post的形式发送到指定的URL,返回的数据可以通过beautiful soup解析,通过编码翻译和正则表达式提取有效信息,读取以下页码呃,最后根据查询和使用的条件生成框架数据
上一篇:Python线程多线程崩溃
下一步:SMOSZIP(DBL)数据读取方法说明(二))@
python抓取动态网页(如何抓取网页特定数据的爬虫,我是怎么做到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-16 14:05
最近,我的朋友让我帮助设计一个能够捕获网页特定数据的爬虫程序。我认为这个计划的实施非常简单。只需通过相应的URL获取HTML页面代码,然后解析HTML以获取所需的数据。然而,在实践中,我发现我原来认为的太简单了。页面上有很多数据不能简单地从HTML源代码中捕获,因为页面上显示的很多数据实际上是在JS代码运行时通过Ajax从远程服务器获取后动态加载到页面中的。因此,不可能简单地读取HTML源代码以获得所需的数据。例如,我们打开京东主页,在搜索框中输入关键词“无极白凤丸”。退货页面显示60个商品项目,如下图所示:
打开JS控制台,选择元素,单击左上角的箭头,然后将箭头移动到该项。我们可以在HTML中看到它对应的元素:
我们可以看到,页面上显示的项对应于ID为“gl-i-wrap”的div控件,这意味着如果我们想从HTML中获取页面上显示的信息,我们必须从HTML代码中获取具有给定ID的div组件并分析其内容。问题是,如果右键单击调出其页面源代码,然后查找字符串“gl-i-wrap”,您会发现它只收录30项,但计算页面上显示60项,即30项信息无法通过HTML代码直接获取。额外的30项信息实际上是在特定条件下触发一段JS代码后通过Ajax从服务器获得的,然后添加到dom中。因此,我们不能简单地从页面对应的HTML中获取它。我通过搜索发现,在线通信的解决方案是分析JS代码的那一部分来获取这些数据,然后研究如何以类似逆向工程的方式构造HTTP请求,然后模拟发送这些请求来获取数据。我认为这种方法存在一系列问题。首先,您必须分析大量难以理解的JS代码,因此您可以想象工作量和难度。其次,如果这种方法网站将来改变了数据采集方法,您必须再次进行逆向工程。因此,这种方法非常不经济。如何简单方便地获取动态加载的数据。只要产品信息显示在页面上,就可以通过dom获取。因此,如果我们有办法在浏览器中获得DOM模型,我们就可以读取动态加载的数据。由于冗余数据是在页面被拉下后通过Ajax触发给定的JS代码动态获取的,所以如果我们可以通过代码控制浏览器加载网页,那么让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以得到动态加载的数据。经过一些调查,我们发现称为selenium的控件可以通过代码动态控制浏览器。例如,让浏览器加载一个特定的页面,让浏览器下拉该页面,然后在浏览器中加载该页面的HTML代码,这样我们就可以使用它轻松抓取动态页面数据。首先,通过命令PIP install selenium下载控件。如果我们想用它来控制Chrome浏览器,我们还需要下载chromedriver控件。首先,确定您使用的chrome版本。chromedriver必须与当前使用的chrome版本完全相同。通过以下链接下载:
请记住选择与您的Chrome浏览器一致的下载版本。之后,我们可以启动浏览器并通过以下代码加载具有给定URL的网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('https://www.jd.com/')
运行上述代码后,您可以启动浏览器,看到他打开京东主页。此时,我想在搜索框中自动输入关键词。通过HTML源代码,发现搜索框对应的ID为“key”。因此,我们可以通过以下代码在搜索框中输入关键词模拟人工输入,然后模拟点击enter按钮实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(word)
search_box.send_keys(Keys.ENTER)
timeout = 10
try:
print("wait page...")
WebDriverWait(driver, timeout)
except TimeoutException:
print("Timed out waiting for page to load")
finally:
。
。
。
。
由于浏览器和代码不再在同一进程中运行,我们需要调用webdriverwait并等待一段时间,以便浏览器完全加载页面。接下来,为了触发特定的JS代码以获得动态加载的数据,我们需要模拟人们下拉页面的动作:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("return document.body.scrollHeight")
while True: #将页面滑动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
执行上述代码后,您会发现浏览器页面将自动下降到底部,因此JS将发送一个Ajax请求以从服务器获取另外30个项目的数据。然后我们将执行一段JS代码来获取body组件对应的HTML源代码,然后获取ID为gl-i-wrap的div对象。此时我们会看到它返回60个对应的组件,这意味着可以获得页面上的所有产品数据:
page_source = driver.execute_script("return document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里输出结果为60
这样,我们可以读取所有页面上显示的商品价格信息。这种方法比解析JS代码,然后反向构造HTTP请求来获取页面上动态加载的数据要简单、方便和容易得多。有关详细说明和调试演示,请单击“阅读原文”查看视频
本文由微信官方账号-编码迪士尼(gh_c9f933e7765d)分享。p> 查看全部
python抓取动态网页(如何抓取网页特定数据的爬虫,我是怎么做到的)
最近,我的朋友让我帮助设计一个能够捕获网页特定数据的爬虫程序。我认为这个计划的实施非常简单。只需通过相应的URL获取HTML页面代码,然后解析HTML以获取所需的数据。然而,在实践中,我发现我原来认为的太简单了。页面上有很多数据不能简单地从HTML源代码中捕获,因为页面上显示的很多数据实际上是在JS代码运行时通过Ajax从远程服务器获取后动态加载到页面中的。因此,不可能简单地读取HTML源代码以获得所需的数据。例如,我们打开京东主页,在搜索框中输入关键词“无极白凤丸”。退货页面显示60个商品项目,如下图所示:
打开JS控制台,选择元素,单击左上角的箭头,然后将箭头移动到该项。我们可以在HTML中看到它对应的元素:
我们可以看到,页面上显示的项对应于ID为“gl-i-wrap”的div控件,这意味着如果我们想从HTML中获取页面上显示的信息,我们必须从HTML代码中获取具有给定ID的div组件并分析其内容。问题是,如果右键单击调出其页面源代码,然后查找字符串“gl-i-wrap”,您会发现它只收录30项,但计算页面上显示60项,即30项信息无法通过HTML代码直接获取。额外的30项信息实际上是在特定条件下触发一段JS代码后通过Ajax从服务器获得的,然后添加到dom中。因此,我们不能简单地从页面对应的HTML中获取它。我通过搜索发现,在线通信的解决方案是分析JS代码的那一部分来获取这些数据,然后研究如何以类似逆向工程的方式构造HTTP请求,然后模拟发送这些请求来获取数据。我认为这种方法存在一系列问题。首先,您必须分析大量难以理解的JS代码,因此您可以想象工作量和难度。其次,如果这种方法网站将来改变了数据采集方法,您必须再次进行逆向工程。因此,这种方法非常不经济。如何简单方便地获取动态加载的数据。只要产品信息显示在页面上,就可以通过dom获取。因此,如果我们有办法在浏览器中获得DOM模型,我们就可以读取动态加载的数据。由于冗余数据是在页面被拉下后通过Ajax触发给定的JS代码动态获取的,所以如果我们可以通过代码控制浏览器加载网页,那么让浏览器拉下页面,然后读取浏览器页面对应的DOM,就可以得到动态加载的数据。经过一些调查,我们发现称为selenium的控件可以通过代码动态控制浏览器。例如,让浏览器加载一个特定的页面,让浏览器下拉该页面,然后在浏览器中加载该页面的HTML代码,这样我们就可以使用它轻松抓取动态页面数据。首先,通过命令PIP install selenium下载控件。如果我们想用它来控制Chrome浏览器,我们还需要下载chromedriver控件。首先,确定您使用的chrome版本。chromedriver必须与当前使用的chrome版本完全相同。通过以下链接下载:
请记住选择与您的Chrome浏览器一致的下载版本。之后,我们可以启动浏览器并通过以下代码加载具有给定URL的网页:
op = webdriver.ChromeOptions()
webdriver.Chrome('/Users/apple/Documents/chromedriver/chromedriver', chrome_options = op)
driver.get('https://www.jd.com/')
运行上述代码后,您可以启动浏览器,看到他打开京东主页。此时,我想在搜索框中自动输入关键词。通过HTML源代码,发现搜索框对应的ID为“key”。因此,我们可以通过以下代码在搜索框中输入关键词模拟人工输入,然后模拟点击enter按钮实现搜索请求:
search_box = driver.find_element_by_id('key')
search_box.send_keys(word)
search_box.send_keys(Keys.ENTER)
timeout = 10
try:
print("wait page...")
WebDriverWait(driver, timeout)
except TimeoutException:
print("Timed out waiting for page to load")
finally:
。
。
。
。
由于浏览器和代码不再在同一进程中运行,我们需要调用webdriverwait并等待一段时间,以便浏览器完全加载页面。接下来,为了触发特定的JS代码以获得动态加载的数据,我们需要模拟人们下拉页面的动作:
SCROLL_PAUSE_TIME = 0.5
last_height = driver.execute_script("return document.body.scrollHeight")
while True: #将页面滑动到底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
执行上述代码后,您会发现浏览器页面将自动下降到底部,因此JS将发送一个Ajax请求以从服务器获取另外30个项目的数据。然后我们将执行一段JS代码来获取body组件对应的HTML源代码,然后获取ID为gl-i-wrap的div对象。此时我们会看到它返回60个对应的组件,这意味着可以获得页面上的所有产品数据:
page_source = driver.execute_script("return document.body.innerHTML;")
bs = BeautifulSoup(page_source, 'html.parser')
info_divs = bs.find_all("div", {"class" : "gl-i-wrap"})
print(len(info_divs)) #这里输出结果为60
这样,我们可以读取所有页面上显示的商品价格信息。这种方法比解析JS代码,然后反向构造HTTP请求来获取页面上动态加载的数据要简单、方便和容易得多。有关详细说明和调试演示,请单击“阅读原文”查看视频
本文由微信官方账号-编码迪士尼(gh_c9f933e7765d)分享。p>
python抓取动态网页(Python爬虫之爬取各大币交易网站公告(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-16 14:03
)
Python爬虫爬行动态网站-爬行每个主要货币交易网站公告(二))@
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,我们提出了动态数据的概念。动态数据是指网页中由JavaScript动态生成的页面内容,该内容是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们来讨论如何使用Python对动态网站进行爬网@
Python版本:Python3.X
运行平台:Windows
IDE:PyCharm
浏览器:Chrome
网站:、coinex等。例如
(一)analysis网站)@
查看网页源代码,如下图所示。我们无法在HTML中找到相应的公告信息:
在Chrome浏览器中,单击F12在网络中打开XHR。抓取对应的JS文件进行解析,如下图所示:
按F5刷新,出现如下界面:
公告显然与我们想要的有关。单击以获取:
显然,我们想要的是正确的。我们将在下面获得这些信息。单击标题:
我们得到请求头和请求参数
(二)@通过请求模块发送post请求
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
(三)extract-information)
单击“预览”,我们将获得:
我们找到了我们想要的信息——时间、头衔和身份证
当你看到一个ID时,你可能想知道为什么你想要一个ID
让我们看看其中的一些文章
比较ID后,我们会发现每个公告的链接实际上是'
提取方法说明如下:
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
另外两种提取方法相同
此外,这里的时间是一个时间戳,我们需要将其转换为本地时间
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000 #/1000是因为时间戳一般为10位
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
(四)在当地时间前一天收到公告)
与静态一样,我们首先得到当地时间的前一天:
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
然后根据if语句进行判断
(五)总代码)
import requests
import json
import time
import datetime
if __name__=='__main__':
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
target = 'https://www.cointiger.pro/exch ... 39%3B #此为Request URL
req = requests.get(url=target, headers=headers, data=data)
html = req.text
html_doc = json.loads(html) #json.loads()解码python json格式
num = len(html_doc.get('data').get('noticeInfoList'))
n = 0
judge = []
while (n < num):
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
id = html_doc.get('data').get('noticeInfoList')[n].get('id')
href = 'https://www.cointiger.pro/%23/ ... 39%3B % id
all = now_time + '\t' + title + '\t' + href
n = n + 1
if yes_time_nyr in all:
print(all)
judge += all
if len(judge) == 0:
print('本日无公告')
(注)
通过requests.post()发出post请求时,传入消息有两个参数,一个是data,另一个是JSON
普通表单表单可以直接使用数据参数提交消息,数据对象是Python中的字典类型,在最新的爬虫过程中遇到一条负载消息,是JSON格式的消息,所以传入的消息对象也应该是格式的,这里有两种提交消息的方法:
import requests
import json
url = "http://example.com"
data = { 'a': 1,
'b': 2,
}
#1
requests.post(url, data=json.dumps(data))
#2,json参数会自动将字典类型的对象转换为json格式
requests.post(url, json=data) 查看全部
python抓取动态网页(Python爬虫之爬取各大币交易网站公告(二)
)
Python爬虫爬行动态网站-爬行每个主要货币交易网站公告(二))@
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,我们提出了动态数据的概念。动态数据是指网页中由JavaScript动态生成的页面内容,该内容是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们来讨论如何使用Python对动态网站进行爬网@
Python版本:Python3.X
运行平台:Windows
IDE:PyCharm
浏览器:Chrome
网站:、coinex等。例如
(一)analysis网站)@
查看网页源代码,如下图所示。我们无法在HTML中找到相应的公告信息:
在Chrome浏览器中,单击F12在网络中打开XHR。抓取对应的JS文件进行解析,如下图所示:
按F5刷新,出现如下界面:
公告显然与我们想要的有关。单击以获取:
显然,我们想要的是正确的。我们将在下面获得这些信息。单击标题:
我们得到请求头和请求参数
(二)@通过请求模块发送post请求
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
(三)extract-information)
单击“预览”,我们将获得:
我们找到了我们想要的信息——时间、头衔和身份证
当你看到一个ID时,你可能想知道为什么你想要一个ID
让我们看看其中的一些文章
比较ID后,我们会发现每个公告的链接实际上是'
提取方法说明如下:
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
另外两种提取方法相同
此外,这里的时间是一个时间戳,我们需要将其转换为本地时间
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000 #/1000是因为时间戳一般为10位
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
(四)在当地时间前一天收到公告)
与静态一样,我们首先得到当地时间的前一天:
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
然后根据if语句进行判断
(五)总代码)
import requests
import json
import time
import datetime
if __name__=='__main__':
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
headers = {
'User - Agent': 'Mozilla / 5.0(Linux;Android6.0;Nexus5Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 67.0.3396.62MobileSafari / 537.36',
'Cookie': 'SESSION= 6b464d53 - 0609 - 4165 - 936a - a05755e6aa50;__jsluid = 2116ec5d7ed6479ffcc767fe36fcc671;Hm_lvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189398;_uab_collina = 153818939825788460139305;__jsl_clearance = 1538189703.864 | 0 | UEnHiXDEq4kQ805BL4iBLIKbm % 2Fc % 3D;Hm_lpvt_0c4a3a6d4432aa88adff38d3193396ce = 1538189712',
'Referer': 'https: // www.cointiger.pro /'
}
data = {
'page': '1',
'pageSize': '20'
}
target = 'https://www.cointiger.pro/exch ... 39%3B #此为Request URL
req = requests.get(url=target, headers=headers, data=data)
html = req.text
html_doc = json.loads(html) #json.loads()解码python json格式
num = len(html_doc.get('data').get('noticeInfoList'))
n = 0
judge = []
while (n < num):
title = html_doc.get('data').get('noticeInfoList')[n].get('title')
timestamp = html_doc.get('data').get('noticeInfoList')[n].get('ctime') / 1000
timeArray = time.localtime(timestamp)
now_time = time.strftime("%Y-%m-%d-%H:%M:%S", timeArray)
id = html_doc.get('data').get('noticeInfoList')[n].get('id')
href = 'https://www.cointiger.pro/%23/ ... 39%3B % id
all = now_time + '\t' + title + '\t' + href
n = n + 1
if yes_time_nyr in all:
print(all)
judge += all
if len(judge) == 0:
print('本日无公告')
(注)
通过requests.post()发出post请求时,传入消息有两个参数,一个是data,另一个是JSON
普通表单表单可以直接使用数据参数提交消息,数据对象是Python中的字典类型,在最新的爬虫过程中遇到一条负载消息,是JSON格式的消息,所以传入的消息对象也应该是格式的,这里有两种提交消息的方法:
import requests
import json
url = "http://example.com"
data = { 'a': 1,
'b': 2,
}
#1
requests.post(url, data=json.dumps(data))
#2,json参数会自动将字典类型的对象转换为json格式
requests.post(url, json=data)
python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-16 05:18
Selenium是一套用于测试Web UI的自动化测试框架。它通过调用chrome和Firefox来完成动态页面(包括JavaScript)的加载,因此它还可以用来完成动态网页捕获
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、start-selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受URL字符串,然后在自己的过程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端
3、安装硒
sudo apt-get install python-selenium
这个包是一个用于selenium客户机的python包。当然,您也可以手动安装pypi或pip
文档可以在这里找到
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、用于非X11环境
这可以通过xvfb实现。这是一个模拟xserver的程序。它可以在没有xserver的机器上运行来自xserver服务的程序
sudo apt-get install xvfb
跑
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与刮痧结合
请参考我之前写的文章“Python捕获框架scripy的快速入门教程”。这并不复杂 查看全部
python抓取动态网页(Python抓取框架Scrapy快速入门教程》的运行流程及运行)
Selenium是一套用于测试Web UI的自动化测试框架。它通过调用chrome和Firefox来完成动态页面(包括JavaScript)的加载,因此它还可以用来完成动态网页捕获
1、下载硒
wget http://selenium-release.storag ... 0.jar
2、start-selenium-standalone
java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
上面启动的是一个web服务器,它可以接受URL字符串,然后在自己的过程中启动浏览器,解析并与客户端交互,并根据需要将解析结果返回给客户端
3、安装硒
sudo apt-get install python-selenium
这个包是一个用于selenium客户机的python包。当然,您也可以手动安装pypi或pip
文档可以在这里找到
4、代码
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
# Init selenium replace the ip port with your own selenium-standalone
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',
desired_capabilities=DesiredCapabilities.FIREFOX
)
# Remote get dynamic page on selenium-standalone
try:
driver.set_page_load_timeout(5)
driver.get(response.url)
except:
pass
# Parse
for tag in driver.find_elements_by_xpath(xpath):
# ...process
pass
# Cleanup selenium
driver.close()
5、用于非X11环境
这可以通过xvfb实现。这是一个模拟xserver的程序。它可以在没有xserver的机器上运行来自xserver服务的程序
sudo apt-get install xvfb
跑
xvfb-run java -jar ./selenium-server-standalone-2.44.0.jar -singleWindow
6、关于与刮痧结合
请参考我之前写的文章“Python捕获框架scripy的快速入门教程”。这并不复杂
python抓取动态网页(Python专题教程:如何用Python语言去实现网站模拟登陆)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-16 05:14
Python特别教程:爬网网站,模拟登录,爬网动态网页版本:v1.0 crifan Li摘要本文针对Python中级开发人员,介绍了如何使用Python语言实现对网站、模拟登录和动态网页的爬网。它主要涉及网络处理模块(urllib、urlib2等)和HTML解析相关模块(beautiful soup、JSON等)。这篇文章提供了多种格式:在线阅读HTML下载(7zip压缩包)HTML pdf10 CHM 11 TXT 12 RTF 13 webelp 14 HTML版本的在线地址是:topic_uuuweb_uuu如果您有任何意见、建议、bug提交等。,请转到讨论组并发布讨论:修订历史修订1.02013-02-06 crl 11 12 13 14 python_uuuTopic_uuWeb_uuScene.webhelp.7z python教程:爬网网站,模拟登录,爬网动态网页:crifan Li版本:v1.0出版日期:2013年2月6日版权所有2013crifan,本文章符合:签名-非商业用途2.5中国大陆(CC by NC2.5)15#CC#u by_NC III目录前言IV前言本文的目的是在理解捕获网站、模拟登录和捕获动态网页的逻辑之后,用Python语言实现这部分逻辑
前提是讨论如何使用Python实现网站捕获、模拟登录和捕获动态网页。前提是您需要清楚这部分的逻辑。如果您不清楚,请参阅:详细说明捕获网站、模拟登录和捕获动态网页的原理和实现(Python、c#等)如何使用Python来网站crawl、模拟登录和抓取与动态网页相关的旧帖子[教程]抓取网页并提取网页中所需的信息。事实上,urllib和其他库已经做得很好,特别是在易用性方面。例如,您可以直接从网页获取地址,并通过以下代码获取网页的源代码。Todo:添加代码,但事实上,它是相关的对于网页抓取、网页模拟登录等方面,需要使用cookies等头部参数,因此,还需要花费大量额外的努力才能获得一个功能强大、易于使用的网络爬网功能。后来,我通过实际使用在这一领域积累了很多经验。最后,我写了一篇相关的文章函数更多函数有两个主要函数:geturlresponse和geturlresptml todo:添加crifanlib中两个函数的解释todo:添加这两个函数的几种用法todo:添加其他相关函数的解释,包括downloadfile和其他函数。实际上,主要有两个方面:一是掌握网站取下的内容涉及到网络处理相关的模块,另一方面是如何解析抓取的内容,即HTML解析相关的模块,接下来我们将解释这两个方面的相关逻辑,以及如何在Python中实现相应的功能
Python中的网络处理主要涉及一些与网络处理相关的模块,如urllib、urlib2等相关的老帖子[sorting]Python中解析HTTP数据包的模块/库[solved]在Python中,cookielib的filecookiejar用于保存(),结果错误为:notimplementederror[sorting]Python中cookie的处理:自动处理cookie,将其保存为cookie文件,从文件中加载cookie,并用Python解析相关的旧帖子。beautifulsoup模块简介[已解决]在Python中使用json.loads解码字符串时出错:valueerror:需要属性名:line jsonobject可以使用Python并解析捕获的网站内容,即解析HTML、json等。相关模块包括beautifulsoup、json等 查看全部
python抓取动态网页(Python专题教程:如何用Python语言去实现网站模拟登陆)
Python特别教程:爬网网站,模拟登录,爬网动态网页版本:v1.0 crifan Li摘要本文针对Python中级开发人员,介绍了如何使用Python语言实现对网站、模拟登录和动态网页的爬网。它主要涉及网络处理模块(urllib、urlib2等)和HTML解析相关模块(beautiful soup、JSON等)。这篇文章提供了多种格式:在线阅读HTML下载(7zip压缩包)HTML pdf10 CHM 11 TXT 12 RTF 13 webelp 14 HTML版本的在线地址是:topic_uuuweb_uuu如果您有任何意见、建议、bug提交等。,请转到讨论组并发布讨论:修订历史修订1.02013-02-06 crl 11 12 13 14 python_uuuTopic_uuWeb_uuScene.webhelp.7z python教程:爬网网站,模拟登录,爬网动态网页:crifan Li版本:v1.0出版日期:2013年2月6日版权所有2013crifan,本文章符合:签名-非商业用途2.5中国大陆(CC by NC2.5)15#CC#u by_NC III目录前言IV前言本文的目的是在理解捕获网站、模拟登录和捕获动态网页的逻辑之后,用Python语言实现这部分逻辑
前提是讨论如何使用Python实现网站捕获、模拟登录和捕获动态网页。前提是您需要清楚这部分的逻辑。如果您不清楚,请参阅:详细说明捕获网站、模拟登录和捕获动态网页的原理和实现(Python、c#等)如何使用Python来网站crawl、模拟登录和抓取与动态网页相关的旧帖子[教程]抓取网页并提取网页中所需的信息。事实上,urllib和其他库已经做得很好,特别是在易用性方面。例如,您可以直接从网页获取地址,并通过以下代码获取网页的源代码。Todo:添加代码,但事实上,它是相关的对于网页抓取、网页模拟登录等方面,需要使用cookies等头部参数,因此,还需要花费大量额外的努力才能获得一个功能强大、易于使用的网络爬网功能。后来,我通过实际使用在这一领域积累了很多经验。最后,我写了一篇相关的文章函数更多函数有两个主要函数:geturlresponse和geturlresptml todo:添加crifanlib中两个函数的解释todo:添加这两个函数的几种用法todo:添加其他相关函数的解释,包括downloadfile和其他函数。实际上,主要有两个方面:一是掌握网站取下的内容涉及到网络处理相关的模块,另一方面是如何解析抓取的内容,即HTML解析相关的模块,接下来我们将解释这两个方面的相关逻辑,以及如何在Python中实现相应的功能
Python中的网络处理主要涉及一些与网络处理相关的模块,如urllib、urlib2等相关的老帖子[sorting]Python中解析HTTP数据包的模块/库[solved]在Python中,cookielib的filecookiejar用于保存(),结果错误为:notimplementederror[sorting]Python中cookie的处理:自动处理cookie,将其保存为cookie文件,从文件中加载cookie,并用Python解析相关的旧帖子。beautifulsoup模块简介[已解决]在Python中使用json.loads解码字符串时出错:valueerror:需要属性名:line jsonobject可以使用Python并解析捕获的网站内容,即解析HTML、json等。相关模块包括beautifulsoup、json等
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-14 11:19
)
有些数据是爬虫爬取数据时的动态数据。比如动态加载js。使用普通的urllib2爬取数据是找不到相关数据的。这是爬虫初学者最容易使用的方法。出现的情况是浏览器中有相应的信息,但是python爬取的网页中却没有相应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方式是找到对应的js接口,但是有时候这种情况是非常少见的,因为js的调用参数也被分析了,有的参数是加密的,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应的信息,这也是本文要介绍的selenium。
安装硒
python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com") # Load page
print browser.page_source
虽然selenium安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1 是的,从selenium 3.x开始,在webdriver/firefox/的__init__ webdriver.py, executable_path="geckodriver";而2.x 是 executable_path="wires"
将 Firefox 升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究 selenium 文档。
使用 BeautifulSoup 进行 html 解析
如果你还不了解 BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml") 查看全部
python抓取动态网页(爬虫抓取数据时有些数据是动态数据,js动态加载的
)
有些数据是爬虫爬取数据时的动态数据。比如动态加载js。使用普通的urllib2爬取数据是找不到相关数据的。这是爬虫初学者最容易使用的方法。出现的情况是浏览器中有相应的信息,但是python爬取的网页中却没有相应的信息。这通常是因为网页使用js异步加载数据并动态显示。一种处理方式是找到对应的js接口,但是有时候这种情况是非常少见的,因为js的调用参数也被分析了,有的参数是加密的,还进行了解密;另一种方式是调用python Browser,控制浏览器返回相应的信息,这也是本文要介绍的selenium。
安装硒
python下安装selenium,命令:
pip install -U selenium
测试是否成功:
#!/usr/bin/python
#coding=utf-8
"""
start python 项目
"""
from selenium import webdriver
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://www.baidu.com";) # Load page
print browser.page_source
虽然selenium安装成功,但还是报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
这是因为:
使用pip安装selenium,默认安装最新版本的selenium。用pip list查看我的selenium版本是3.4.2,firefox版本是43.0.1 是的,从selenium 3.x开始,在webdriver/firefox/的__init__ webdriver.py, executable_path="geckodriver";而2.x 是 executable_path="wires"
将 Firefox 升级到最新版本
下载地址:根据自己的电脑,下载win64位;
在firefox安装目录下,解压geckodriver,然后将path添加到path环境变量中。
可以相应地研究 selenium 文档。
使用 BeautifulSoup 进行 html 解析
如果你还不了解 BeautifulSoup,可以参考这个文章
找到html后,可以使用BeautifulSoup进行解析。
from bs4 import BeautifulSoup
bs = BeautifulSoup(browser.page_source, "lxml")
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-14 11:18
在使用python爬虫技术采集data信息时,我们经常会遇到在返回的网页信息中,无法动态抓取到可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:
或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到结果,说明数据不是动态加载的,否则说明数据是动态加载的。如图:
3.如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。 查看全部
python抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集data信息时,我们经常会遇到在返回的网页信息中,无法动态抓取到可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据?
通过requests模块爬取的数据每次都看不到。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。 (猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据,如果找到搜索结果,数据不是动态加载的,否则表示数据是动态加载的。如图:
或者在要爬取的页面上点击鼠标右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到结果,说明数据不是动态加载的,否则说明数据是动态加载的。如图:
3.如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监视器中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,并得到对应的请求地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和需要的参数,如下图。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法提取数据。如果在运行源码时出现错误,请按照步骤获取新的请求地址。
python抓取动态网页( Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-14 11:16
Python网络爬虫内容提取器一文讲解)
1、介绍
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
在上一篇python使用xslt提取网页数据的文章中,提取的内容是直接从网页源代码中获取的。但是部分Ajax动态内容在源码中找不到,需要找一个合适的库来加载异步或动态加载的内容,交给本项目的提取器提取。
Python 可以使用 selenium 来执行 javascript,而 selenium 可以让浏览器自动加载页面并获取所需的数据。 Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源代码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的多站采集和搜索打标签功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序 转到下面的程序。注:本文仅记录实验过程。在实际系统中,xslt程序会以多种方式注入到内容提取器中。
第2步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果删掉这个字符串,代码也不是几行,够看Python强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取
4、阅读下一个
到目前为止,我们已经通过两篇文章 文章演示了如何抓取静态和动态网页内容。两者都使用 xslt 一次从网页中提取所需的内容。实际上,xslt 是一种更复杂的编程语言。写xslt,那么最好写离散xpath。如果这个 xslt 不是手写的,而是由程序自动生成的,这是有道理的。程序员将不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。接下来,《1分钟快速生成网页内容提取xslt》将介绍如何生成xslt。
5、汇聚GooSeeker开源代码下载源码
1.GooSeeker 开源 Python 网络爬虫 GitHub 源码
5、文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址 查看全部
python抓取动态网页(
Python网络爬虫内容提取器一文讲解)
1、介绍
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。这就留下了一个问题:如何提取javascript管理的动态内容?那么这篇文章就回答了这个问题。
2.提取动态内容的技术成分
在上一篇python使用xslt提取网页数据的文章中,提取的内容是直接从网页源代码中获取的。但是部分Ajax动态内容在源码中找不到,需要找一个合适的库来加载异步或动态加载的内容,交给本项目的提取器提取。
Python 可以使用 selenium 来执行 javascript,而 selenium 可以让浏览器自动加载页面并获取所需的数据。 Selenium本身没有浏览器,可以使用Firefox、Chrome等第三方浏览器,也可以使用PhantomJS等无头浏览器在后台执行。
3、源代码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中没有找到价格),如下图:
第一步:利用直观的多站采集和搜索打标签功能,可以很快自动生成调试好的抓包规则,其实就是一个标准的xslt程序,如下图,复制生成的xslt程序 转到下面的程序。注:本文仅记录实验过程。在实际系统中,xslt程序会以多种方式注入到内容提取器中。
第2步:执行如下代码(windows10下测试,python3.2),请注意:xslt是一个比较长的字符串,如果删掉这个字符串,代码也不是几行,够看Python强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页上手机的名称和价格已经被正确抓取
4、阅读下一个
到目前为止,我们已经通过两篇文章 文章演示了如何抓取静态和动态网页内容。两者都使用 xslt 一次从网页中提取所需的内容。实际上,xslt 是一种更复杂的编程语言。写xslt,那么最好写离散xpath。如果这个 xslt 不是手写的,而是由程序自动生成的,这是有道理的。程序员将不再花时间编写和调试捕获规则,这是一项非常耗时费力的工作。接下来,《1分钟快速生成网页内容提取xslt》将介绍如何生成xslt。
5、汇聚GooSeeker开源代码下载源码
1.GooSeeker 开源 Python 网络爬虫 GitHub 源码
5、文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第五章:源码下载源码,修改github源码地址
python抓取动态网页(千人基因组数据库中爬取CHB人群的等位基因频率信息解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-14 09:16
计划目的:
根据特定的SNP列表,从千基因组数据库中爬取CHB群体的等位基因频率信息,例如。
因为网页是带有嵌入代码的动态数据,所以它们使用 selenium 来抓取信息。
Beautiful Soup 是一个 Python 库,主要功能是抓取网页数据。 Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能。它是一个工具箱,为用户提供需要通过解析文档捕获的数据,避免复杂的正则表达式。
准备:源代码
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
def get_allele_feq(browser, snp):
browser.get(
'https://www.ncbi.nlm.nih.gov/variation/tools/1000genomes/?q=%s' %snp) #Load page
# browser.implicitly_wait(60) #智能等待xx秒
time.sleep(30) #加载时间较长,等待加载完毕
# browser.find_element_by_css_selector("div[title=\"Han Chinese in Bejing, China\"]") #use selenium function to find elements
# 把selenium的webdriver调用page_source函数在传入BeautifulSoup中,就可以用BeautifulSoup解析网页了
bs = BeautifulSoup(browser.page_source, "lxml")
# bs.find_all("div", title="Han Chinese in Bejing, China")
try:
race = bs.find(string="CHB")
race_data = race.find_parent("div").find_parent(
"div").find_next_sibling("div")
# print race_data
race_feq = race_data.find("span", class_="gt-selected").find_all("li") # class_ 防止Python中类关键字重复,产生语法错误
base1_feq = race_feq[0].text #获取标签的内容
base2_feq = race_feq[1].text
return snp, base1_feq, base2_feq # T=0.1408 C=0.8592
except NoSuchElementException:
return "%s:can't find element" %snp
def main():
browser = webdriver.Chrome() # Get local session of chrome
fh = open("./4diseases_snps_1kCHB_allele_feq.list2", 'w')
snps = open("./4diseases_snps.list.uniq2",'r')
for line in snps:
snp = line.strip()
response = get_allele_feq(browser, snp)
time.sleep(1)
fh.write("\t".join(response)) #unicode 编码的对象写到文件中后相当于print效果
fh.write("\n")
print "\t".join(response)
time.sleep(1) # sleep a few seconds
fh.close()
browser.quit() # 退出并关闭窗口的每一个相关的驱动程序
if __name__ == '__main__':
main()1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484912345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
参考资料:
1]:#Beautiful Soup 4.4.0 文档
2]:
3]:
4]:
5]:
6]:
7]: 查看全部
python抓取动态网页(千人基因组数据库中爬取CHB人群的等位基因频率信息解析)
计划目的:
根据特定的SNP列表,从千基因组数据库中爬取CHB群体的等位基因频率信息,例如。
因为网页是带有嵌入代码的动态数据,所以它们使用 selenium 来抓取信息。
Beautiful Soup 是一个 Python 库,主要功能是抓取网页数据。 Beautiful Soup 提供了一些简单的、python 风格的函数来处理导航、搜索、修改分析树和其他功能。它是一个工具箱,为用户提供需要通过解析文档捕获的数据,避免复杂的正则表达式。
准备:源代码
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
def get_allele_feq(browser, snp):
browser.get(
'https://www.ncbi.nlm.nih.gov/variation/tools/1000genomes/?q=%s' %snp) #Load page
# browser.implicitly_wait(60) #智能等待xx秒
time.sleep(30) #加载时间较长,等待加载完毕
# browser.find_element_by_css_selector("div[title=\"Han Chinese in Bejing, China\"]") #use selenium function to find elements
# 把selenium的webdriver调用page_source函数在传入BeautifulSoup中,就可以用BeautifulSoup解析网页了
bs = BeautifulSoup(browser.page_source, "lxml")
# bs.find_all("div", title="Han Chinese in Bejing, China")
try:
race = bs.find(string="CHB")
race_data = race.find_parent("div").find_parent(
"div").find_next_sibling("div")
# print race_data
race_feq = race_data.find("span", class_="gt-selected").find_all("li") # class_ 防止Python中类关键字重复,产生语法错误
base1_feq = race_feq[0].text #获取标签的内容
base2_feq = race_feq[1].text
return snp, base1_feq, base2_feq # T=0.1408 C=0.8592
except NoSuchElementException:
return "%s:can't find element" %snp
def main():
browser = webdriver.Chrome() # Get local session of chrome
fh = open("./4diseases_snps_1kCHB_allele_feq.list2", 'w')
snps = open("./4diseases_snps.list.uniq2",'r')
for line in snps:
snp = line.strip()
response = get_allele_feq(browser, snp)
time.sleep(1)
fh.write("\t".join(response)) #unicode 编码的对象写到文件中后相当于print效果
fh.write("\n")
print "\t".join(response)
time.sleep(1) # sleep a few seconds
fh.close()
browser.quit() # 退出并关闭窗口的每一个相关的驱动程序
if __name__ == '__main__':
main()1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484912345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
参考资料:
1]:#Beautiful Soup 4.4.0 文档
2]:
3]:
4]:
5]:
6]:
7]:
python抓取动态网页(来源百度百科动态网页的特点及特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-14 09:14
前言
本文文字和图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试亮点、学习资料等。
一、什么是动态网页
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。 ——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司所采用,如购动、素宝、素饭等。
二、AJAX 是什么
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,并成为许多网站的首选。 AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着无需重新加载整个网页即可更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1.解析接口
只要有数据发送,必然有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2.硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一款可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实操
法院历年公布的开庭信息和执行信息。
长这样:
然后,第一页就提取成功了
接下来,我加了一个for循环,想着花几分钟从这个网站2164页面中提取32457个法院公告数据到excel中。
那么,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一、Analysis 界面
这种情况下,让我们开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的请求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的请求藏在里面。
我们仔细看看这个jsp,真是个宝。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
让我们仔细看看这些参数,pagesnum参数只是代表页数!我们尝试点击翻页,发现只有pagesnum参数会发生变化。
既然找到了,就赶紧抓起来吧。
构建一个真实的请求并添加标题。
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。注意对返回的数据进行解码并编码为‘gbk’,否则返回的数据会出现乱码!另外,我还优化了异常处理,防止意外发生。
构建parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并以csv格式保存。
最后遍历页数,调用函数。好的,完成!
我们来看看最终的结果:
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果您不知道该怎么做,请再次使用 Selenium。 查看全部
python抓取动态网页(来源百度百科动态网页的特点及特点)
前言
本文文字和图片来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
欢迎关注小编。除了分享技术文章,还有很多好处。您可以收到私人学习资料,包括但不限于Python实践练习、PDF电子文档、面试亮点、学习资料等。
一、什么是动态网页
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。 ——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司所采用,如购动、素宝、素饭等。
二、AJAX 是什么
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,并成为许多网站的首选。 AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着无需重新加载整个网页即可更新网页的某些部分。
三、如何抓取AJAX动态加载网页
1.解析接口
只要有数据发送,必然有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2.硒
什么是硒?它最初是一个自动化测试工具,但被广泛的用户抓取。是一款可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实操
法院历年公布的开庭信息和执行信息。
长这样:
然后,第一页就提取成功了
接下来,我加了一个for循环,想着花几分钟从这个网站2164页面中提取32457个法院公告数据到excel中。
那么,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一、Analysis 界面
这种情况下,让我们开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的请求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的请求藏在里面。
我们仔细看看这个jsp,真是个宝。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!
让我们仔细看看这些参数,pagesnum参数只是代表页数!我们尝试点击翻页,发现只有pagesnum参数会发生变化。
既然找到了,就赶紧抓起来吧。
构建一个真实的请求并添加标题。
构建get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。注意对返回的数据进行解码并编码为‘gbk’,否则返回的数据会出现乱码!另外,我还优化了异常处理,防止意外发生。
构建parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并以csv格式保存。
最后遍历页数,调用函数。好的,完成!
我们来看看最终的结果:
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。建议解析接口。如果是解析json数据,最好是爬取。如果您不知道该怎么做,请再次使用 Selenium。
python抓取动态网页(静态网页和动态网页在浏览网页的过程中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-14 09:13
静态网页和动态网页
我们在浏览网页的过程中,经常会遇到需要登录的情况,有些页面需要登录后才能访问,登录后可以连续多次访问网站,但是有时您需要在一段时间后重新打开。登录。还有一些网站,打开浏览器自动登录,时间长了也不会失败。为什么会出现这种情况?其实设计会话(Session)和Cookies的相关知识就在这里。
先来了解一下静态网页和动态网页的概念,同样使用前面的示例代码,内容如下:
为什么广告石斛叫“仙草”?用它泡水喝,4大好处在你包里! !
这是最基本的 HTML 代码。我们保存为.html文件,然后放到一个有固定公网IP的主机上,在主机上安装Apache或者Nginx等服务器,这样这个主机就可以当服务器了,其他人也可以访问服务器看到这个页面,构建最简单的网站。
这类网页的内容由HTML代码编写,文字、图片等内容由编写的HTML代码指定。这种页面称为静态网页。加载速度快,编写简单,但存在可维护性差、无法根据URL灵活展示内容等重大缺陷。比如我们要传入一个name参数给这个网页的URL,让它显示在网页上。这是不可能的。
于是,动态网页应运而生。它可以动态解析URL参数的变化,关联数据库,动态呈现不同的页面内容,非常灵活多变。我们现在遇到的网站大多是动态的网站,它们不再是简单的HTML,而是可能是用JSP、PHP、Python等语言编写的,它们的功能比静态的要强大得多,也更丰富网页 NS。
另外,动态网站还可以实现用户登录和注册功能。回到开头提到的问题,很多页面只有登录后才能查看。按照一般逻辑,输入用户名和密码登录后,我们必须得到类似于凭据的东西。有了它,我们就可以保持登录状态,访问只有登录后才能看到的页面。
那么这个神秘的凭证究竟是什么?其实是session和cookies共同作用的结果。 查看全部
python抓取动态网页(静态网页和动态网页在浏览网页的过程中的应用)
静态网页和动态网页
我们在浏览网页的过程中,经常会遇到需要登录的情况,有些页面需要登录后才能访问,登录后可以连续多次访问网站,但是有时您需要在一段时间后重新打开。登录。还有一些网站,打开浏览器自动登录,时间长了也不会失败。为什么会出现这种情况?其实设计会话(Session)和Cookies的相关知识就在这里。
先来了解一下静态网页和动态网页的概念,同样使用前面的示例代码,内容如下:
为什么广告石斛叫“仙草”?用它泡水喝,4大好处在你包里! !
这是最基本的 HTML 代码。我们保存为.html文件,然后放到一个有固定公网IP的主机上,在主机上安装Apache或者Nginx等服务器,这样这个主机就可以当服务器了,其他人也可以访问服务器看到这个页面,构建最简单的网站。
这类网页的内容由HTML代码编写,文字、图片等内容由编写的HTML代码指定。这种页面称为静态网页。加载速度快,编写简单,但存在可维护性差、无法根据URL灵活展示内容等重大缺陷。比如我们要传入一个name参数给这个网页的URL,让它显示在网页上。这是不可能的。
于是,动态网页应运而生。它可以动态解析URL参数的变化,关联数据库,动态呈现不同的页面内容,非常灵活多变。我们现在遇到的网站大多是动态的网站,它们不再是简单的HTML,而是可能是用JSP、PHP、Python等语言编写的,它们的功能比静态的要强大得多,也更丰富网页 NS。
另外,动态网站还可以实现用户登录和注册功能。回到开头提到的问题,很多页面只有登录后才能查看。按照一般逻辑,输入用户名和密码登录后,我们必须得到类似于凭据的东西。有了它,我们就可以保持登录状态,访问只有登录后才能看到的页面。
那么这个神秘的凭证究竟是什么?其实是session和cookies共同作用的结果。
python抓取动态网页(越来越多的人热衷于做网络爬虫的配置及配置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-13 11:15
)
现在越来越多的人热衷于做网络爬虫,越来越多的地方需要网络爬虫,比如搜索引擎、news采集、舆情监测等,网络爬虫所涉及的技术(算法) /策略)是广泛而复杂的,例如网页获取、网页跟踪、网页分析、网页搜索、网页评级和结构/非结构化数据提取,以及后来更细粒度的数据挖掘。对于新手来说,不可能一蹴而就。对于完全掌握、精通应用的作者来说,作者在文章文章中解释清楚就更难了。 scrapy 框架只能抓取静态网站。如果要爬取动态网站,还必须使用selenium进行js渲染才能获取动态加载的数据。
如何使用 selenium 来请求 url 而不是使用 Downloader 来请求这个 url?
方法:当请求对象经过中间件后,开始使用中间件内部的selenium来请求url,会获取url对应的源码,然后通过response对象返回源码,直接给process_response () 进行处理,交给引擎处理。过程中省略了process_request()和Downloader,相当于后续的中间件。
相关配置:
在1、scrapy环境中安装selenium:pip install selenium
2、确保python环境中有phantomJS(无头浏览器)
selenium 的主要操作是下载中间件部分,如下图:
代码如下
middlewares.py 代码:
注意:使用selenium自定义下载中间件! !
下图是自定义下载中间件对应的替换代码
taobao.py的代码如下:
settings.py的代码如下:
查看全部
python抓取动态网页(越来越多的人热衷于做网络爬虫的配置及配置
)
现在越来越多的人热衷于做网络爬虫,越来越多的地方需要网络爬虫,比如搜索引擎、news采集、舆情监测等,网络爬虫所涉及的技术(算法) /策略)是广泛而复杂的,例如网页获取、网页跟踪、网页分析、网页搜索、网页评级和结构/非结构化数据提取,以及后来更细粒度的数据挖掘。对于新手来说,不可能一蹴而就。对于完全掌握、精通应用的作者来说,作者在文章文章中解释清楚就更难了。 scrapy 框架只能抓取静态网站。如果要爬取动态网站,还必须使用selenium进行js渲染才能获取动态加载的数据。
如何使用 selenium 来请求 url 而不是使用 Downloader 来请求这个 url?
方法:当请求对象经过中间件后,开始使用中间件内部的selenium来请求url,会获取url对应的源码,然后通过response对象返回源码,直接给process_response () 进行处理,交给引擎处理。过程中省略了process_request()和Downloader,相当于后续的中间件。
相关配置:
在1、scrapy环境中安装selenium:pip install selenium
2、确保python环境中有phantomJS(无头浏览器)
selenium 的主要操作是下载中间件部分,如下图:
代码如下
middlewares.py 代码:
注意:使用selenium自定义下载中间件! !
下图是自定义下载中间件对应的替换代码
taobao.py的代码如下:
settings.py的代码如下:

