python抓取动态网页(工具分析登录页面打开登录过程从分析可以看到哪些信息)
优采云 发布时间: 2021-10-09 15:03python抓取动态网页(工具分析登录页面打开登录过程从分析可以看到哪些信息)
最近的项目在做一些数据集成,各种系统对应的接口就更陌生了。数据整合的过程可以用八个字来概括:山上有路,水中有桥。
这两天碰巧出了问题。我们要集成的WEB系统没有提供专门的数据集成接口,没有API可以调整,数据库是不允许访问的。无奈中,想知道能不能用python自动爬取。页。网页有SSO,应该使用开源的CAS框架,后面的页面都是动态JS和AJAX异步加载的。显然,这不像是直接使用Scrapy上传的普通静态页面。它必须是完美的。要模拟登陆动作,抓取后续动态内容,对页面结构和抓取内容的分析必不可少。
工具分析登陆页面
打开登录页面,按F12打开Chrome自带的分析工具。在网络选项卡上,可以看到当前浏览器显示页面的详细信息和提交的登录信息,如下图
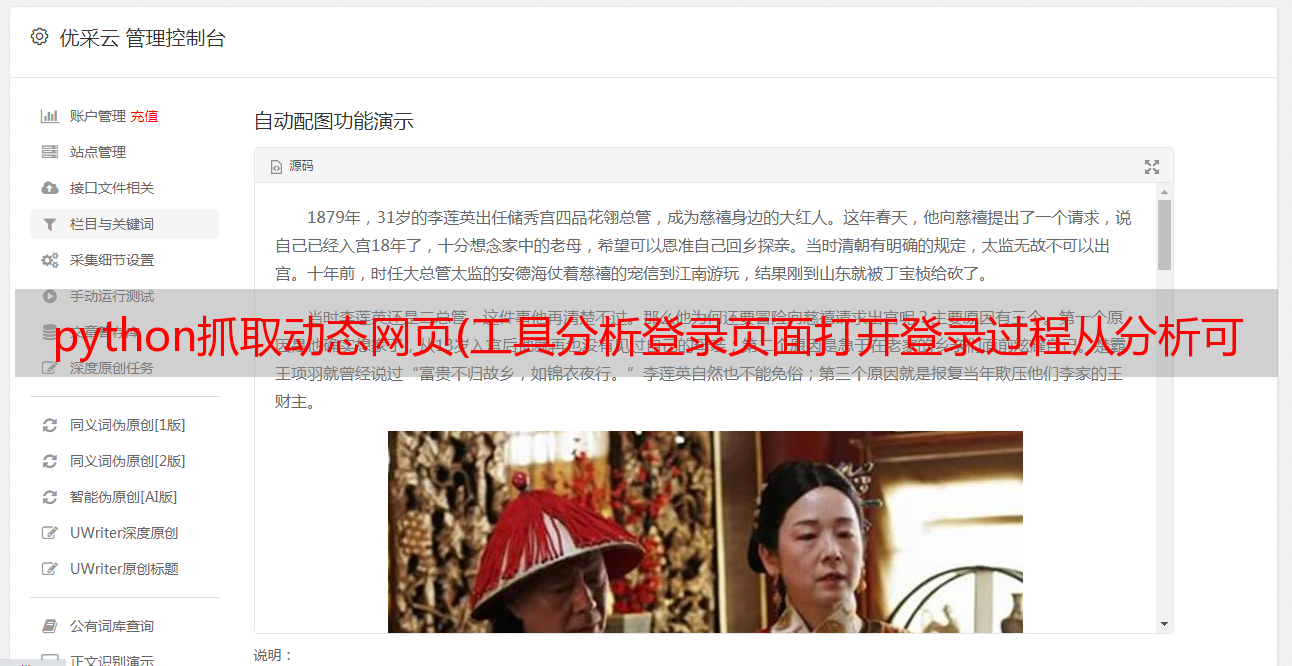
网站 登录页面
从截图中可以看到,当我们访问app/this url的日志时,由于我们还没有登录,SSO会自动重定向到登录页面,所以http状态是302重定向。
接下来,我们在页面输入账号密码,点击登录按钮,通过页面跟踪分析和模拟整个登录过程。这个过程一定要特别小心,因为很多CAS在登录页面都埋了很多隐藏的标记,一处是模仿不来的。它将无法登录,然后被重定向到开头。
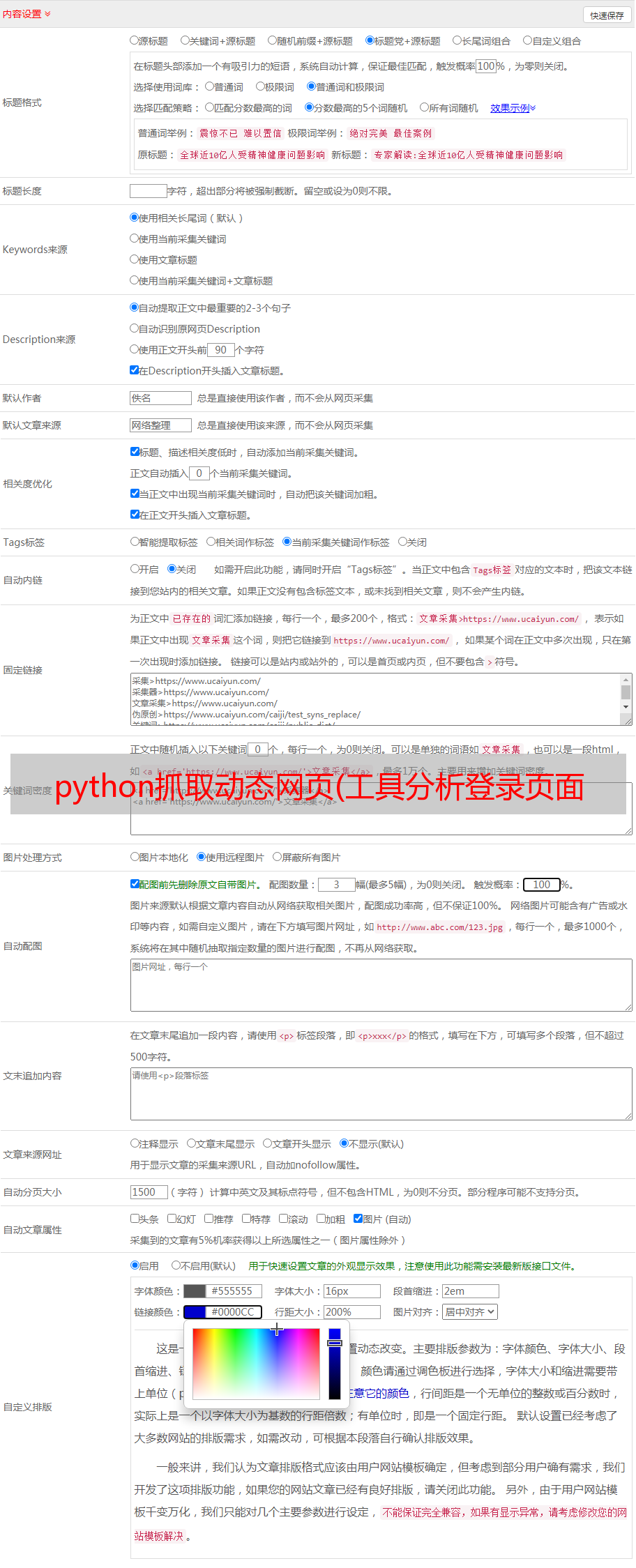
分析登录过程
从分析中可以看出,在提交登录按钮时,会使用POST方式提交表单,并且表单中除了账号密码等显眼的字段外,还有一个lt。经验告诉我们,这个字段应该隐藏在之前的登录页面上。它用于验证登录页面的合法性,因此我们需要从登录页面中查找并提取此信息。同时注意http的消息头。最好根据浏览器抓到的消息头来构造,因为网站也会验证里面的信息。
以下是登录的主要代码。我们基于python3和requests包处理https访问请求,模拟浏览器的行为,构造认证所需的信息发送给网站。
import requestsimport urllib3from lxml import etreefrom ows_scrapy.ows_spider.write_csv import write_list_to_csv
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
s = requests.session()
s.trust_env = False # fastercookie = Noneusername = 'username'password = 'pwd'def login():
header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Cookie': 'JSESSIONID=73E10849812940333A4AD2A2ABAEFB7D8CFF3E76A45340FFB687FD587D2EB97A49FC5F156D09DB1E17F129465AB8D8EBACEC', 'Host': '', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
form_data = { 'username': username, 'password': password, '_eventId': 'submit', 'pwdfirst': password[0:2], 'pwdsecond': password[2:5], 'pwdthird': password[5:]
}
login_url = 'https://.com/app/'
print('login...')
res = s.get(login_url, headers=header, verify=False) global cookie
cookie = res.cookies # 注意要保存cookie
print("get response from ows {0}, http status {1}".format(login_url, res.status_code))
login_url = res.url
header['Referer'] = login_url
header['Cookie'] = 'JSESSIONID=' + cookie['JSESSIONID']
form_data['lt'] = str(etree.HTML(res.content).xpath('//input[@name="lt"]/@value')[0]) #用xpath从页面上提取lt
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
cookie = res.cookies
print("post login params to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie))
res = s.send(res.next, allow_redirects=False, verify=False)
cookie = res.cookies
print("redirect to {0}, http status {1}, cookie : {2}".format(login_url, res.status_code, cookie)) if res.status_code == 200 or res.status_code == 302: if cookie is not None and cookie.get(name='JSESSIONID', path='/app') is not None :
print('Successful login.') else:
print('WRONG w3id/password!')
sys.exit(0)
这里要特别注意,因为http是无状态的,需要cookies来保存网页的登录状态。页面成功后,页面的响应将收录一个带有有效标记的cookie。登录的最终目的是获取并保存这个有效的cookie,这样后续的访问就不会被重定向到登录页面。
在 requests 方法中,只需将 cookie 添加到请求中即可。
res = s.post(login_url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False)
分析动态内容页面
在动态页面中,页面显示的内容往往是通过js或者AJAX异步获取的,这明显不同于静态html页面的分析过程。使用 Chrome 的分析工具也可以轻松获取此信息。
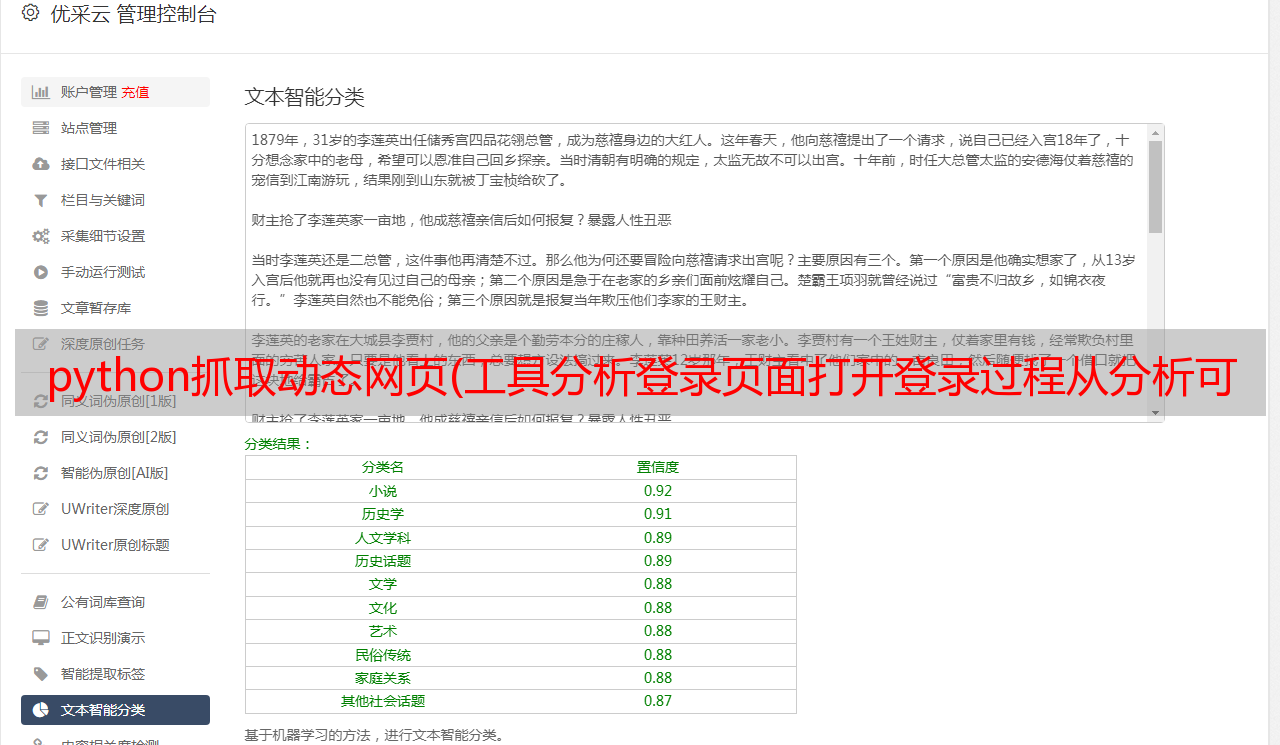
分析动态页面
动态页面加载完成后,我们从所有请求中过滤出XHR类型,找到我们想要的请求,然后在请求的Preview中就可以看到完整的对应信息了,请求的URL也可以从Obtained中查看在标题选项卡中。
接下来要做的和上面类似,构造一个消息来模拟浏览器向网站发送请求:
def get_content(order_id):
form_data = { 'roarand': 'BW09el5W3mW2sfbGbtWe7mWlwBsWqXg6znppnqkW3woJ5fcz5DnhfWXGonqk*敏*感*词*0', 'start': '0', 'limit': '20', 'orderid': order_id, 'serviceId': 'test_gscsocsecurityincidentmanage_log_getList2'
}
header = { 'Accept': 'text/plain, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8', 'Host': '.com', 'Origin': 'https://.com', 'Referer': 'https://.com/app/104h/spl/test/ID_480_1511441539904_workflowdetail.spl?orderid=SOC-20180220-00000003', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'
}
print('Start to scan order id ' + order_id)
url = 'https://.com/app/pageservices/service.do?forAccessLog={serviceName:test_gscsocsecurityincidentmanage_log_getList2,userId:571bdd42-10ca-4ce1-b41c-8a3f6632141f,tenantId:104h}&trackId=fec68f8e-f30a-4fa1-a8b1-41d3dd11fa4c'
res = s.post(url, headers=header, params=form_data, cookies=cookie, allow_redirects=False, verify=False) #要加载上面登录成功的cookie
print(res.content) return res
重点其实就是从XHR中找到请求的URI,构造请求头并提交表单,最后一定要添加成功登录cookie,否则会被重定向到登录页面。
有很多方法可以抓取动态页面。这种方式依赖的包相对较少,代码也比较灵活。爬取复杂登录页面时效果更好,但在分析页面登录机制时一定要特别小心。

