
nodejs抓取动态网页
nodejs抓取动态网页(1.防范sql注入注入简单些说一些违法用户拼接一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-25 04:08
1.防止sql注入
简单来说,sql注入是指一些非法用户拼接一个特殊的用户名或密码,因为我们要将用户名和密码插入到数据库中,肯定会根据用户名和密码拼接一条sql语句。而这个非法用户的特殊用户名声明可能会删除我们数据库中的所有数据。
因为用的是mysql数据库。Nodejs 模块也是 npm 上使用最多的 Mysql 模块。这个模块本身已经提供了访问mysql集群的能力和防止注入的能力。
具体方法请参考官方文档
2.防止接口攻击
我们这里需要做的就是写一个循环,在一些非法用户获取我们的界面时,频繁访问我们的界面。为了防止一些非法用户,他们只是在请求中添加令牌。它是向服务器发出请求时返回给前端的一个令牌,而这个令牌是在前端向后端请求时带上来的。如果令牌在后端被验证,令牌将被销毁。另一个例子是验证请求的源 IP。这里需要注意的是,我们在验证IP的时候,要获取HTTP协议头域中x-forwarded-for属性的值。(两种方法可以一起使用)
不过后来我从后台RD了解到,公司有专门的服务可以用来防作弊,策略也比较全面。目前正在研究以准备访问。
内网机器访问外网
关于跨机房访问、同机房访问、内网访问外网,这些基本都涉及到运维的话题。百度内部有现成的服务接入文档。每个公司可能以不同的方式提供能力。这里不多介绍。
这里有一些小细节。看看下面的图片:
一句话总结:当一个请求到达接入层时,它并不知道自己要访问的是内网环境中机房的服务器。相反,如果内网的机器上有请求外网的链接,例如: . 您需要通过代理访问外网服务器。
要访问界面,我使用请求模块。通过 promise npm 上的 request-promise,我们可以通过名称知道每个方法或调用结果返回什么。该模块已经默认提供了代理参数的相关配置。详情请参考文档
这里涉及到很多知识,比如代理隧道,https请求的代理。阅读官方配置文档的时候,搜索一些关键词,学习一些其他相关知识。
如果有相关需求,可以参考我的配置。如果我的配置不能解决你的问题,请仔细阅读官方文档。,
let options = {
'url': params.url,
'encoding': 'binary',
'rejectUnauthorized': false // 取消https证书的校验
};
// 解决代理https请求的行为 测试机需要配置环境变量 PANSHI_HTTPS_PROXY
if (process.env.PANSHI_DEBUG !== 'true' || PANSHI_HTTPS_PROXY) {
options.tunnel = false;
options.proxy = 'http://xxxx.proxy.com:8080';
}
发送电子邮件
关于开发的介绍到这里就完成了。以下是针对运营和产品要求的一些功能开发。每天将注册用户发送给相应的负责人。
如果你想满足这个功能,你需要有一个邮件服务器。这在公司是公开的,很容易找到。另一种是配置服务的crontab定时执行脚本查询数据库发送邮件。
这里主要使用nodejs模块nodemailer。具体的相关配置和发送邮件的方法请参考官方文档配置,直接点击即可。
网络优化
上面的列表是几个典型的点。例如,将 CSS 放在 head 标签的头部,将 script 标签放在 body 标签的底部。这些应该属于前端工程师的常识。
静态文件部署CDN就不多介绍了,每个公司都会有自己的一套方法。这里主要介绍合并静态文件和缓存静态文件。
1.合并静态文件
默认情况下,FIS3 具有支持合并静态文件的插件。因为我这次开发了很多页面(一共11个主站点页面),并且因为使用块开发来加载模块和静态文件。如果不合并,一个页面加载后需要有10-20个静态文件请求。它会影响页面的加载速度。
准备用FIS3插件合并静态文件的时候,发现配置静态文件一页一页打包合并还是有点麻烦。最后请其他部门的同事使用我们接入层服务器提供的comb功能,服务器会帮我们合并静态文件(其实就是Nginx的concat模块提供的功能)。此处不做过多介绍,直接搜索文章即可了解。
2.缓存静态文件
先看下一张图
上图中红框是http协议中与静态文件缓存相关的字段。如果这些字段的概念比较模糊,可以阅读这篇文章加深印象“HTTP Cache”直接点击
无论使用 express 还是 koa(koa 可以使用 koa-static-cache 中间件),对应的服务静态文件的中间件都提供了配置这些字段的能力。Express可以通过以下方式进行配置(具体可以阅读express文档)
const express = require('express')
// 配置与静态文件相关的参数
express.static('xxxxx')
报酬
最后说说这次开发的收获 查看全部
nodejs抓取动态网页(1.防范sql注入注入简单些说一些违法用户拼接一个)
1.防止sql注入
简单来说,sql注入是指一些非法用户拼接一个特殊的用户名或密码,因为我们要将用户名和密码插入到数据库中,肯定会根据用户名和密码拼接一条sql语句。而这个非法用户的特殊用户名声明可能会删除我们数据库中的所有数据。
因为用的是mysql数据库。Nodejs 模块也是 npm 上使用最多的 Mysql 模块。这个模块本身已经提供了访问mysql集群的能力和防止注入的能力。
具体方法请参考官方文档
2.防止接口攻击
我们这里需要做的就是写一个循环,在一些非法用户获取我们的界面时,频繁访问我们的界面。为了防止一些非法用户,他们只是在请求中添加令牌。它是向服务器发出请求时返回给前端的一个令牌,而这个令牌是在前端向后端请求时带上来的。如果令牌在后端被验证,令牌将被销毁。另一个例子是验证请求的源 IP。这里需要注意的是,我们在验证IP的时候,要获取HTTP协议头域中x-forwarded-for属性的值。(两种方法可以一起使用)
不过后来我从后台RD了解到,公司有专门的服务可以用来防作弊,策略也比较全面。目前正在研究以准备访问。
内网机器访问外网
关于跨机房访问、同机房访问、内网访问外网,这些基本都涉及到运维的话题。百度内部有现成的服务接入文档。每个公司可能以不同的方式提供能力。这里不多介绍。
这里有一些小细节。看看下面的图片:

一句话总结:当一个请求到达接入层时,它并不知道自己要访问的是内网环境中机房的服务器。相反,如果内网的机器上有请求外网的链接,例如: . 您需要通过代理访问外网服务器。
要访问界面,我使用请求模块。通过 promise npm 上的 request-promise,我们可以通过名称知道每个方法或调用结果返回什么。该模块已经默认提供了代理参数的相关配置。详情请参考文档
这里涉及到很多知识,比如代理隧道,https请求的代理。阅读官方配置文档的时候,搜索一些关键词,学习一些其他相关知识。
如果有相关需求,可以参考我的配置。如果我的配置不能解决你的问题,请仔细阅读官方文档。,
let options = {
'url': params.url,
'encoding': 'binary',
'rejectUnauthorized': false // 取消https证书的校验
};
// 解决代理https请求的行为 测试机需要配置环境变量 PANSHI_HTTPS_PROXY
if (process.env.PANSHI_DEBUG !== 'true' || PANSHI_HTTPS_PROXY) {
options.tunnel = false;
options.proxy = 'http://xxxx.proxy.com:8080';
}
发送电子邮件
关于开发的介绍到这里就完成了。以下是针对运营和产品要求的一些功能开发。每天将注册用户发送给相应的负责人。
如果你想满足这个功能,你需要有一个邮件服务器。这在公司是公开的,很容易找到。另一种是配置服务的crontab定时执行脚本查询数据库发送邮件。
这里主要使用nodejs模块nodemailer。具体的相关配置和发送邮件的方法请参考官方文档配置,直接点击即可。
网络优化
上面的列表是几个典型的点。例如,将 CSS 放在 head 标签的头部,将 script 标签放在 body 标签的底部。这些应该属于前端工程师的常识。
静态文件部署CDN就不多介绍了,每个公司都会有自己的一套方法。这里主要介绍合并静态文件和缓存静态文件。
1.合并静态文件
默认情况下,FIS3 具有支持合并静态文件的插件。因为我这次开发了很多页面(一共11个主站点页面),并且因为使用块开发来加载模块和静态文件。如果不合并,一个页面加载后需要有10-20个静态文件请求。它会影响页面的加载速度。
准备用FIS3插件合并静态文件的时候,发现配置静态文件一页一页打包合并还是有点麻烦。最后请其他部门的同事使用我们接入层服务器提供的comb功能,服务器会帮我们合并静态文件(其实就是Nginx的concat模块提供的功能)。此处不做过多介绍,直接搜索文章即可了解。
2.缓存静态文件
先看下一张图

上图中红框是http协议中与静态文件缓存相关的字段。如果这些字段的概念比较模糊,可以阅读这篇文章加深印象“HTTP Cache”直接点击
无论使用 express 还是 koa(koa 可以使用 koa-static-cache 中间件),对应的服务静态文件的中间件都提供了配置这些字段的能力。Express可以通过以下方式进行配置(具体可以阅读express文档)
const express = require('express')
// 配置与静态文件相关的参数
express.static('xxxxx')
报酬
最后说说这次开发的收获
nodejs抓取动态网页(抓取动态网页可以用/boostrap-tab插件/首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-23 08:07
nodejs抓取动态网页可以用github-faircracker/crawler:crawleranddecoderfornodejsbygoogleandyahoo.推荐使用firebug。
chrome控制台中的resources-a-html页面-tab/id538156076?mt=8
百度搜:分页抓取
楼上搞定我百度一下,
bootstraptabing教程感谢大神一步步手把手实现
github-ludwins/boostrap-tab:bootstrap插件boostraptabesreferenceruntime/
首页-{{你的昵称}}·nodejs博客-csdn博客bootstrapqueryselector/boostrap-tabreferenceatmaster·boostrap-tab/boostrap-tab
百度cdn已经提供了丰富的浏览器渲染内容解决方案~chrome浏览器-【携程旅游】
"/(欢迎爬虫客户端)""(持续更新...)todo:爬虫公司先退出股票:8080/path/to/"
boostrapbootstrapgithub-test-happylihood/test-happy:bootstrap实现的爬虫应用,不论是bootstrap2,3还是最新的trap,
完美解决原生实现的爬虫方案-ci-爱开发-博客园 查看全部
nodejs抓取动态网页(抓取动态网页可以用/boostrap-tab插件/首页)
nodejs抓取动态网页可以用github-faircracker/crawler:crawleranddecoderfornodejsbygoogleandyahoo.推荐使用firebug。
chrome控制台中的resources-a-html页面-tab/id538156076?mt=8
百度搜:分页抓取
楼上搞定我百度一下,
bootstraptabing教程感谢大神一步步手把手实现
github-ludwins/boostrap-tab:bootstrap插件boostraptabesreferenceruntime/
首页-{{你的昵称}}·nodejs博客-csdn博客bootstrapqueryselector/boostrap-tabreferenceatmaster·boostrap-tab/boostrap-tab
百度cdn已经提供了丰富的浏览器渲染内容解决方案~chrome浏览器-【携程旅游】
"/(欢迎爬虫客户端)""(持续更新...)todo:爬虫公司先退出股票:8080/path/to/"
boostrapbootstrapgithub-test-happylihood/test-happy:bootstrap实现的爬虫应用,不论是bootstrap2,3还是最新的trap,
完美解决原生实现的爬虫方案-ci-爱开发-博客园
nodejs抓取动态网页(如何使用PhantomJS来抓取动态网页,至于PhantomJS是啥啊 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-21 17:17
)
今天我们将学习如何使用 PhantomJS 抓取动态网页。至于 PhantomJS 是什么,这里不讨论 PhantomJS 的基础知识。下面的话题就是今天,我们来抢网易新闻1.我们先准备一下,打开浏览器,输入网址,然后分析我们来抢下图所示的部分
2.编写获取网页的代码,需要使用网页模块API创建页面如下
var page=require('webpage').create();
看完上面的API,我们先获取网页并返回,即使用
var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.body);//输出网页
} else {
console.log("网页加载失败");
}
phantom.exit(0);//退出系统
});
输出如下:
可以看到网页的全文已经输出了(现在延迟比较严重,有几秒的延迟,当然我们这里不重点讲这个,之前想跑也不好你已经学会走路了),我们来吧。分析如何获取我们需要的内容,这里我们使用DOM来解析,也可以使用cheerio来解析,看下图
分析表明我们现在正在解析的DOM语句可以是这样的
var pattern = 'ul li.newsdata_item div.ndi_main div a';
现在我们要使用 DOM 语句,这里是另一个网页 API
page.open('http://m.bing.com',function(status){
vartitle=page.evaluate(function(s){
returndocument.querySelector(s).innerText;
},'title');
console.log(title);
phantom.exit();
});
#####本例中page.evaluate()接受两个参数,第一个为必填项,表示需要在页面上下文中运行的函数fn;第二个是可选的,表示需要传递给fn参数param。fn 允许一个返回值返回,这个返回值最终被用作 page.evaluate() 的返回值。以下是刚刚命名的参数和返回的一些附加说明和注意事项。对于整个幻象进程,page.evaluate()运行在沙箱中,fn无法访问幻象域中的所有变量;同样,在 page.evaluate() 方法之外不应尝试访问页面上下文中的内容。那么如果两个scope需要交换一些数据,就只能依靠param和return了。但是限制非常大,param 和 return 必须能够转换成 JSON 字符串,也就是说只能是基本的数据类型或者简单的对象,比如 DOM 节点,$objects,函数,闭包等都无能为力。这种方法是同步的。如果要执行的内容不是后续操作的前端,可以尝试异步方法来提高性能:page.evaluateAsync()。
了解API后,我们继续工作,修改如下
<p>var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.evaluate(function(){
var d = '';
//匹配 DOM 查询语句
var pattern = 'ul li.newsdata_item div.ndi_main div a img';
var c = document.querySelectorAll(pattern);//查询
var l = c.length;
//遍历输出
for(var i =0;i 查看全部
nodejs抓取动态网页(如何使用PhantomJS来抓取动态网页,至于PhantomJS是啥啊
)
今天我们将学习如何使用 PhantomJS 抓取动态网页。至于 PhantomJS 是什么,这里不讨论 PhantomJS 的基础知识。下面的话题就是今天,我们来抢网易新闻1.我们先准备一下,打开浏览器,输入网址,然后分析我们来抢下图所示的部分

2.编写获取网页的代码,需要使用网页模块API创建页面如下
var page=require('webpage').create();
看完上面的API,我们先获取网页并返回,即使用
var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.body);//输出网页
} else {
console.log("网页加载失败");
}
phantom.exit(0);//退出系统
});
输出如下:

可以看到网页的全文已经输出了(现在延迟比较严重,有几秒的延迟,当然我们这里不重点讲这个,之前想跑也不好你已经学会走路了),我们来吧。分析如何获取我们需要的内容,这里我们使用DOM来解析,也可以使用cheerio来解析,看下图

分析表明我们现在正在解析的DOM语句可以是这样的
var pattern = 'ul li.newsdata_item div.ndi_main div a';
现在我们要使用 DOM 语句,这里是另一个网页 API
page.open('http://m.bing.com',function(status){
vartitle=page.evaluate(function(s){
returndocument.querySelector(s).innerText;
},'title');
console.log(title);
phantom.exit();
});
#####本例中page.evaluate()接受两个参数,第一个为必填项,表示需要在页面上下文中运行的函数fn;第二个是可选的,表示需要传递给fn参数param。fn 允许一个返回值返回,这个返回值最终被用作 page.evaluate() 的返回值。以下是刚刚命名的参数和返回的一些附加说明和注意事项。对于整个幻象进程,page.evaluate()运行在沙箱中,fn无法访问幻象域中的所有变量;同样,在 page.evaluate() 方法之外不应尝试访问页面上下文中的内容。那么如果两个scope需要交换一些数据,就只能依靠param和return了。但是限制非常大,param 和 return 必须能够转换成 JSON 字符串,也就是说只能是基本的数据类型或者简单的对象,比如 DOM 节点,$objects,函数,闭包等都无能为力。这种方法是同步的。如果要执行的内容不是后续操作的前端,可以尝试异步方法来提高性能:page.evaluateAsync()。
了解API后,我们继续工作,修改如下
<p>var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.evaluate(function(){
var d = '';
//匹配 DOM 查询语句
var pattern = 'ul li.newsdata_item div.ndi_main div a img';
var c = document.querySelectorAll(pattern);//查询
var l = c.length;
//遍历输出
for(var i =0;i
nodejs抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2022-01-21 17:15
现在大部分网页都是动态网页。如果单纯的爬取网页的HTML文件,就无法爬取商品价格或后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了。对于小型爬虫来说,分析那些复杂的脚本是不值得的,更何况网站会与时俱进。破解难度大,更新一次就得从头开始,大大增加了小爬虫的难度。
不过好在Node.js中有这样一个神器,不用担心网站的登录限制和反爬虫措施,它可以在不改变的情况下响应所有的变化,而且大部分可以被简单的模拟用户破解手术。限制,是Puppeteer,谷歌出品的爬取动态网页神器。
1.木偶师的优缺点
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按键精灵。一个网页很难区分是人类用户还是爬虫,所以无处可谈限制。
它的美妙之处在于它很简单,非常简单,可能是所有可以爬取动态网页的库中最简单的。
但缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以它的运行效率远不如其他库,不适合大数据的爬取。但对于小爬行动物来说已经绰绰有余了。
接下来,以我写的爬取jd产品页面的小爬虫为例,看看这有多简单。我写这个爬虫是为了买苹果的魔控板。看了一圈,发现京东金银岛的价格很诱人。这应该是金银岛上唯一值得一抢的商品了,只是数量稀少,拖了很久。一个会出现。
于是想到了监控产品页面,一旦发现新的Magic Trackpad,就会弹出提醒。甚至可以实现自动竞价,不过我没写,毕竟我不想买除了触摸板以外的东西,所以无法测试是否能成功拍卖。
好的,让我们开始吧!
2.第一步是安装Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
复制代码
3.第二步,链接网页
链接网页也很简单,只需要几行代码:
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
复制代码
这样,链接就成功了!Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为true,如果为false,会显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦找到符合条件的产品,就可以将headless改为false。
4.爬取商品信息
链接网页后,下一步就是爬取商品信息,然后进行分析。
网址:魔术触控板
4.1 获取对应的元素标签
从页面可以看到,一旦旁边的同类宝藏中出现了类似的商品,我们只需要抓取那里的信息即可。有两种方法:
一个是$eval,相当于js中的document.querySelector,只爬取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与document.querySelector 相同。让我们看一下代码:
//我们拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
复制代码
4.2.分析产品信息
既然已经获得了同类寻宝中所有产品的标签信息,我就开始分析这些信息。获取其中所有产品的名称,然后检查关键字是否存在。如果存在,将headless改为false,弹出窗口提醒。如果不存在,半小时后重新链接。
Puppeteer 提供了等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据元素的加载进度等待。
5.优化代码
对于这个小爬虫来说,效率损失不大,也不需要优化,但作为一个强迫症,还是希望尽量去掉。
5.1截取图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了提高一点运行效率,截取了所有图片:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
复制代码
5.2调整窗口大小
当浏览器弹出时,你会发现打开的窗口的显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是需要调整一下:
await page.setViewport({
width: 1920,
height: 1080,
})
复制代码
至此,所有代码都已经完成,我们来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i < el.length; i++) {
let n = el[i].querySelector('div.p-name').textContent
if(n.includes('妙控板')){
return true
} else {
return false
}
}
} catch (error) {
return false
}
})
if(!bool){
return console.log('网页已打开,不再监控')
}
await goods.then(async (b)=>{
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
复制代码
也可以通过Github获取完整代码:/Card007/Nod...如果对你有帮助,请关注我,我会继续输出更多好的文章! 查看全部
nodejs抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处)
现在大部分网页都是动态网页。如果单纯的爬取网页的HTML文件,就无法爬取商品价格或后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了。对于小型爬虫来说,分析那些复杂的脚本是不值得的,更何况网站会与时俱进。破解难度大,更新一次就得从头开始,大大增加了小爬虫的难度。
不过好在Node.js中有这样一个神器,不用担心网站的登录限制和反爬虫措施,它可以在不改变的情况下响应所有的变化,而且大部分可以被简单的模拟用户破解手术。限制,是Puppeteer,谷歌出品的爬取动态网页神器。
1.木偶师的优缺点
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按键精灵。一个网页很难区分是人类用户还是爬虫,所以无处可谈限制。
它的美妙之处在于它很简单,非常简单,可能是所有可以爬取动态网页的库中最简单的。
但缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以它的运行效率远不如其他库,不适合大数据的爬取。但对于小爬行动物来说已经绰绰有余了。
接下来,以我写的爬取jd产品页面的小爬虫为例,看看这有多简单。我写这个爬虫是为了买苹果的魔控板。看了一圈,发现京东金银岛的价格很诱人。这应该是金银岛上唯一值得一抢的商品了,只是数量稀少,拖了很久。一个会出现。
于是想到了监控产品页面,一旦发现新的Magic Trackpad,就会弹出提醒。甚至可以实现自动竞价,不过我没写,毕竟我不想买除了触摸板以外的东西,所以无法测试是否能成功拍卖。
好的,让我们开始吧!
2.第一步是安装Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
复制代码
3.第二步,链接网页
链接网页也很简单,只需要几行代码:
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
复制代码
这样,链接就成功了!Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为true,如果为false,会显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦找到符合条件的产品,就可以将headless改为false。
4.爬取商品信息
链接网页后,下一步就是爬取商品信息,然后进行分析。
网址:魔术触控板
4.1 获取对应的元素标签
从页面可以看到,一旦旁边的同类宝藏中出现了类似的商品,我们只需要抓取那里的信息即可。有两种方法:
一个是$eval,相当于js中的document.querySelector,只爬取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与document.querySelector 相同。让我们看一下代码:
//我们拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
复制代码
4.2.分析产品信息
既然已经获得了同类寻宝中所有产品的标签信息,我就开始分析这些信息。获取其中所有产品的名称,然后检查关键字是否存在。如果存在,将headless改为false,弹出窗口提醒。如果不存在,半小时后重新链接。
Puppeteer 提供了等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据元素的加载进度等待。
5.优化代码
对于这个小爬虫来说,效率损失不大,也不需要优化,但作为一个强迫症,还是希望尽量去掉。
5.1截取图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了提高一点运行效率,截取了所有图片:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
复制代码
5.2调整窗口大小
当浏览器弹出时,你会发现打开的窗口的显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是需要调整一下:
await page.setViewport({
width: 1920,
height: 1080,
})
复制代码
至此,所有代码都已经完成,我们来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i < el.length; i++) {
let n = el[i].querySelector('div.p-name').textContent
if(n.includes('妙控板')){
return true
} else {
return false
}
}
} catch (error) {
return false
}
})
if(!bool){
return console.log('网页已打开,不再监控')
}
await goods.then(async (b)=>{
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
复制代码
也可以通过Github获取完整代码:/Card007/Nod...如果对你有帮助,请关注我,我会继续输出更多好的文章!
nodejs抓取动态网页(GoogleScripttoreaddataaprojectto)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-20 17:15
问题描述
我想使用 Google 脚本从其他 网站 读取项目的一些数据。问题中的页面是动态的;它们收录在初始页面加载后由服务器通过 JavaScript 调用加载的内容。通常,对于静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,所以不知道如何通过 JavaScript(例如通过 AJAX)异步加载内容。
我想为使用 Google Script 的项目从其他网站读取一些数据。有问题的页面是动态的;它们收录在初始页面加载后通过对服务器的 JavaScript 调用加载的内容。通常,对于一些静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,因此如果通过 JavaScript(例如通过 AJAX)异步加载内容,我不知道如何获取内容。
可以在此处找到一个示例,该示例显示了广播电台上播放的最后一首曲目。但是,曲目是使用 JavaScript 加载的,而不是带有我得到的字符串的表格
可以在此处找到一个示例,该示例显示了广播电台最后播放的曲目。但是,这些曲目是使用 JavaScript 加载的,而不是收录我得到的字符串的表
当我使用时:
UrlFetchApp.fetch(url).getContentText();
如果我将 HTML 保存在浏览器中,则存在正确的数据字符串:
如果我将 HTML 保存在浏览器中,那么正确的数据字符串就在那里:
15:12 Will Smith - Men In Black
^^^^^^^ ^^^^^ ^^^^^^^^^^ ^^^^^^^^^^^^
有没有办法使用 Google Apps 脚本来做到这一点?
有没有办法使用 Google Apps 脚本来做到这一点?
推荐答案
一般不会,不会。如果您可以对它的功能进行逆向工程,您可能可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则不太可能。理论上,它可以在 Running a JavaScript browser implementation in Google Apps Script (like env-js) 中完成,这可以做到,但在实践中,我认为即使不是不可能,也很难让它工作。
一般不会,不会。如果您可以对它正在做的事情进行逆向工程,您也许可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则可能性不大。理论上,可以在 Google Apps Script(如 env-js)中运行 JavaScript 浏览器实现,这样可以做到这一点,但在实践中,我认为即使不是不可能,也是非常困难的。 查看全部
nodejs抓取动态网页(GoogleScripttoreaddataaprojectto)
问题描述
我想使用 Google 脚本从其他 网站 读取项目的一些数据。问题中的页面是动态的;它们收录在初始页面加载后由服务器通过 JavaScript 调用加载的内容。通常,对于静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,所以不知道如何通过 JavaScript(例如通过 AJAX)异步加载内容。
我想为使用 Google Script 的项目从其他网站读取一些数据。有问题的页面是动态的;它们收录在初始页面加载后通过对服务器的 JavaScript 调用加载的内容。通常,对于一些静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,因此如果通过 JavaScript(例如通过 AJAX)异步加载内容,我不知道如何获取内容。
可以在此处找到一个示例,该示例显示了广播电台上播放的最后一首曲目。但是,曲目是使用 JavaScript 加载的,而不是带有我得到的字符串的表格
可以在此处找到一个示例,该示例显示了广播电台最后播放的曲目。但是,这些曲目是使用 JavaScript 加载的,而不是收录我得到的字符串的表
当我使用时:
UrlFetchApp.fetch(url).getContentText();
如果我将 HTML 保存在浏览器中,则存在正确的数据字符串:
如果我将 HTML 保存在浏览器中,那么正确的数据字符串就在那里:
15:12 Will Smith - Men In Black
^^^^^^^ ^^^^^ ^^^^^^^^^^ ^^^^^^^^^^^^
有没有办法使用 Google Apps 脚本来做到这一点?
有没有办法使用 Google Apps 脚本来做到这一点?
推荐答案
一般不会,不会。如果您可以对它的功能进行逆向工程,您可能可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则不太可能。理论上,它可以在 Running a JavaScript browser implementation in Google Apps Script (like env-js) 中完成,这可以做到,但在实践中,我认为即使不是不可能,也很难让它工作。
一般不会,不会。如果您可以对它正在做的事情进行逆向工程,您也许可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则可能性不大。理论上,可以在 Google Apps Script(如 env-js)中运行 JavaScript 浏览器实现,这样可以做到这一点,但在实践中,我认为即使不是不可能,也是非常困难的。
nodejs抓取动态网页(NodeJS.js改文件使用脚本生成文件解决思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-20 17:14
)
使用NodeJS为项目动态添加参数需求
显示页面中代码的构建(打包)时间
解决方案
首先定义一个文件build_time.js
文件可以是空文件,然后创建一个js文件generateBuildTime.js,然后在文件中写代码动态添加参数,然后将要生成的代码内容添加到文件中
const fs = require("fs");
let text = `export default ${new Date().valueOf()}`;
fs.writeFile("./src/utils/buildTime.js", text, () => {});
然后在需要使用的地方直接导入buildTime.js文件,并使用默认暴露的时间戳
然后你需要调用 generateBuildTime 脚本来生成文件。有两种方式:
在 package.json 中配置 npm 脚本
"scripts": {
"serve": "node src/utils/genarateBuildTime.js && vue-cli-service serve",
"build": "node src/utils/genarateBuildTime.js && vue-cli-service build"
},
在项目配置文件中直接引入脚本,编译或打包时会执行该脚本
以vue-cli项目为例:
直接在vue.config.js中引入并执行脚本
// 每次编译打包之前设置打包时间
require("./src/utils/genarateBuildTime"); 查看全部
nodejs抓取动态网页(NodeJS.js改文件使用脚本生成文件解决思路
)
使用NodeJS为项目动态添加参数需求
显示页面中代码的构建(打包)时间
解决方案
首先定义一个文件build_time.js
文件可以是空文件,然后创建一个js文件generateBuildTime.js,然后在文件中写代码动态添加参数,然后将要生成的代码内容添加到文件中
const fs = require("fs");
let text = `export default ${new Date().valueOf()}`;
fs.writeFile("./src/utils/buildTime.js", text, () => {});
然后在需要使用的地方直接导入buildTime.js文件,并使用默认暴露的时间戳
然后你需要调用 generateBuildTime 脚本来生成文件。有两种方式:
在 package.json 中配置 npm 脚本
"scripts": {
"serve": "node src/utils/genarateBuildTime.js && vue-cli-service serve",
"build": "node src/utils/genarateBuildTime.js && vue-cli-service build"
},
在项目配置文件中直接引入脚本,编译或打包时会执行该脚本
以vue-cli项目为例:
直接在vue.config.js中引入并执行脚本
// 每次编译打包之前设置打包时间
require("./src/utils/genarateBuildTime");
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-20 13:02
其实很早以前我做过即时理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码来执行,点这里。主要是通过定期爬取异步接口来获取数据。然后,通过一定的排序算法得到最终的数据。但这样做有以下缺点:
代码只能在浏览器窗口下运行,关闭浏览器或电脑无效
只能爬取一个页面的数据,不能整合其他页面的数据
爬取的数据无法存储在本地
上面的异步接口数据会被部分过滤掉,这会导致我们的重载算法失败。
由于最近学习了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我已经开通了阿里云服务器,可以把代码放到云端运行。这样,1、2、3就可以解决了。4是因为我不知道这个ajax接口每三分钟更新一次,所以我们可以按照这个来安排权重,保证数据不会重复。说到爬虫,大部分人都会想到python。确实,python有Scrapy等成熟的框架,可以实现强大的爬取功能。但是,节点也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单。让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经的每日销售额,并了解哪些产品被销售,哪些用户在什么时间购买了每个产品。首先介绍爬取的主要步骤:
1. 结构分析
如果我们要爬取页面的数据,第一步当然是分析页面的结构,要爬哪些页面,页面的结构是什么,是否登录;是否有ajax接口,返回什么样的数据等。
2. 数据抓取
分析好爬取哪些页面和ajax后,就需要爬取数据了。现在网页的数据大致分为同步页面和ajax接口。要获取同步页面数据,我们需要先分析网页的结构。Python取数据一般通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象,然后可以使用jquery强大的dom API来获取node相关的数据。其实看源码的话,这些API的本质就是正则匹配。Ajax接口数据一般为json格式,处理起来比较简单。
3. 数据存储
采集到数据后,会进行简单的筛选,然后将需要的数据保存下来,供后续分析处理。当然我们可以将数据存储在 MySQL 和 Mongodb 等数据库中。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要对原创数据按照一定的维度进行处理和分析,然后返回给客户端。这个过程可以在存储的时候进行处理,也可以在显示的时候,前端发送请求,后台取回存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果显示
做了这么多工作,一点显示输出都没有,怎么舍得?这又回到了我们的老业务,前端展示页面大家应该都很熟悉了。数据展示更加直观,方便我们进行统计分析。
二、爬虫公共库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求的时候,试试吧。
2. 谢里奥
Cheerio 可以理解为 jquery 的 Node.js 版本,用于从带有 css 选择器的网页中获取数据,方式与 jquery 完全相同。
3. 异步
Async 是一个流程控制工具包,提供了直接且强大的异步函数 mapLimit(arr, limit, iterator, callback)。我们主要使用这种方法。您可以在官方网站上查看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素方法的工具。可以通过传入一个由要删除的数组元素的索引组成的数组来执行一次性删除。
5. arr-排序
arr-sort 是我自己编写的用于对数组进行排序的工具。可以按一个或多个属性排序,支持嵌套属性。并且可以指定每个条件下的排序方向,并支持传入比较函数。
三、页面结构分析
让我们重复我们首先抓取的想法。利马理财在线的产品主要是普通的利马银行(光大银行最新的理财产品,手续复杂,前期投入大,基本没人买,这里不计)。定期我们可以爬取财务页面的ajax接口:. (更新:近期定期断货,可能看不到数据,可以看1月19日之前的数据)数据如下图:
这包括在线销售的所有常规产品。ajax数据只有产品本身相关的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,并没有哪些用户购买了产品的信息。. 所以我们需要到它的商品详情页面去爬取id参数,比如Lima Jucai-December issue HLB01239511。详情页有一栏投资记录,里面收录了我们需要的信息,如下图所示:
但是详情页需要我们登录才能查看,这就需要我们带着cookie来访问,而且cookie的有效期是有限的。如何让我们的cookie保持登录状态?请看下文。
其实Lima Vault也有类似的ajax接口:,但是里面的相关数据都写死了,没有意义。而且,金库的详情页没有投资记录信息。这就需要我们爬取开头提到的首页的ajax接口:. 但是后来发现这个接口每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。并且一次有10条数据,所以如果三分钟内购买产品的记录数超过10条,数据将被省略。没有办法绕过它,所以金库统计数据会立即低于真实数据。
四、爬虫代码分析1.获取登录cookie
因为商品详情页面需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机和密码参数是命令行传入的,就是你用手机号登录的账号和密码。我们使用superagent模拟即时财务管理登录界面的请求:. 传入相应的参数,在回调中我们获取到header的set-cookie信息,并发出setCookieie事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦获取到cookie,我们就会执行requestData方法。
2. 财务页面ajax的爬取
requestData 方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i 查看全部
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
其实很早以前我做过即时理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码来执行,点这里。主要是通过定期爬取异步接口来获取数据。然后,通过一定的排序算法得到最终的数据。但这样做有以下缺点:
代码只能在浏览器窗口下运行,关闭浏览器或电脑无效
只能爬取一个页面的数据,不能整合其他页面的数据
爬取的数据无法存储在本地
上面的异步接口数据会被部分过滤掉,这会导致我们的重载算法失败。
由于最近学习了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我已经开通了阿里云服务器,可以把代码放到云端运行。这样,1、2、3就可以解决了。4是因为我不知道这个ajax接口每三分钟更新一次,所以我们可以按照这个来安排权重,保证数据不会重复。说到爬虫,大部分人都会想到python。确实,python有Scrapy等成熟的框架,可以实现强大的爬取功能。但是,节点也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单。让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经的每日销售额,并了解哪些产品被销售,哪些用户在什么时间购买了每个产品。首先介绍爬取的主要步骤:
1. 结构分析
如果我们要爬取页面的数据,第一步当然是分析页面的结构,要爬哪些页面,页面的结构是什么,是否登录;是否有ajax接口,返回什么样的数据等。
2. 数据抓取
分析好爬取哪些页面和ajax后,就需要爬取数据了。现在网页的数据大致分为同步页面和ajax接口。要获取同步页面数据,我们需要先分析网页的结构。Python取数据一般通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象,然后可以使用jquery强大的dom API来获取node相关的数据。其实看源码的话,这些API的本质就是正则匹配。Ajax接口数据一般为json格式,处理起来比较简单。
3. 数据存储
采集到数据后,会进行简单的筛选,然后将需要的数据保存下来,供后续分析处理。当然我们可以将数据存储在 MySQL 和 Mongodb 等数据库中。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要对原创数据按照一定的维度进行处理和分析,然后返回给客户端。这个过程可以在存储的时候进行处理,也可以在显示的时候,前端发送请求,后台取回存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果显示
做了这么多工作,一点显示输出都没有,怎么舍得?这又回到了我们的老业务,前端展示页面大家应该都很熟悉了。数据展示更加直观,方便我们进行统计分析。
二、爬虫公共库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求的时候,试试吧。
2. 谢里奥
Cheerio 可以理解为 jquery 的 Node.js 版本,用于从带有 css 选择器的网页中获取数据,方式与 jquery 完全相同。
3. 异步
Async 是一个流程控制工具包,提供了直接且强大的异步函数 mapLimit(arr, limit, iterator, callback)。我们主要使用这种方法。您可以在官方网站上查看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素方法的工具。可以通过传入一个由要删除的数组元素的索引组成的数组来执行一次性删除。
5. arr-排序
arr-sort 是我自己编写的用于对数组进行排序的工具。可以按一个或多个属性排序,支持嵌套属性。并且可以指定每个条件下的排序方向,并支持传入比较函数。
三、页面结构分析
让我们重复我们首先抓取的想法。利马理财在线的产品主要是普通的利马银行(光大银行最新的理财产品,手续复杂,前期投入大,基本没人买,这里不计)。定期我们可以爬取财务页面的ajax接口:. (更新:近期定期断货,可能看不到数据,可以看1月19日之前的数据)数据如下图:
这包括在线销售的所有常规产品。ajax数据只有产品本身相关的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,并没有哪些用户购买了产品的信息。. 所以我们需要到它的商品详情页面去爬取id参数,比如Lima Jucai-December issue HLB01239511。详情页有一栏投资记录,里面收录了我们需要的信息,如下图所示:
但是详情页需要我们登录才能查看,这就需要我们带着cookie来访问,而且cookie的有效期是有限的。如何让我们的cookie保持登录状态?请看下文。
其实Lima Vault也有类似的ajax接口:,但是里面的相关数据都写死了,没有意义。而且,金库的详情页没有投资记录信息。这就需要我们爬取开头提到的首页的ajax接口:. 但是后来发现这个接口每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。并且一次有10条数据,所以如果三分钟内购买产品的记录数超过10条,数据将被省略。没有办法绕过它,所以金库统计数据会立即低于真实数据。
四、爬虫代码分析1.获取登录cookie
因为商品详情页面需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机和密码参数是命令行传入的,就是你用手机号登录的账号和密码。我们使用superagent模拟即时财务管理登录界面的请求:. 传入相应的参数,在回调中我们获取到header的set-cookie信息,并发出setCookieie事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦获取到cookie,我们就会执行requestData方法。
2. 财务页面ajax的爬取
requestData 方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-20 13:00
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫是一种被广泛使用的东西,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但是仔细看会发现它其实是用js动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。 查看全部
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫是一种被广泛使用的东西,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但是仔细看会发现它其实是用js动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。
nodejs抓取动态网页(先要搞懂对应的,访问url地址的背后的逻辑:需要你提供哪些内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-19 12:15
首先,我们要了解访问url地址背后的相应逻辑:
您需要什么:
网址
标题:一些可选的,一些必需的
饼干(可选)
发布数据
只有当它是POST方法时才需要
然后得到什么样的内容:
HTML源代码(或其他,json字符串,图片数据等)
cookie(可能):后续访问其他url,可能需要提供这里返回的(新的)cookie
暗示:
1.html 的字符集编码
关于html网页编码的背景知识,最好看看:
HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
了解您正在处理的网页执行的逻辑过程
简单来说就是你需要提供某个你要处理的url地址,需要提供哪些值,然后你就可以得到你需要的值了。
先了解自己关心的逻辑,才能用代码谈后续实现。
如果这个逻辑过程很简单,那么就不需要工具来分析了,自己看代码,自己分析就可以了。
但是这个过程往往非常复杂,所以一般需要使用相应的开发者工具来分析。
比如用IE9的F12捕捉对应的执行过程,然后分析一些你需要关心的网页的执行逻辑。
暗示:
1.其他各种分析工具
如果不熟悉IE9的F12等,可以先去看看:
浏览器中的开发者工具(IE9 中的 F12 和 Chrome 中的 Ctrl+Shift+I)——强大的网页分析工具
对于这部分内容,还有一个帖子供参考:
各种浏览器中的开发人员工具:IE9 的 F12、Chrome 的 Ctrl+Shift+J、Firefox 的 Firebug
2. 复杂参数值分析
在用工具分析的过程中,你会发现有些要分析的值比较复杂,无法直接获取,需要调试分析。
关于如何分析复杂的参数值是如何得到的,
登录过程中如何使用IE9的F12解析网站复杂的(参数、cookies等)值 (来源)
3.另一个例子
后来我写了一个例子来分析如何从songtaste的播放页面地址中找到歌曲的真实地址:
如何用IE9的F12抓取一首Songtaste歌曲的真实地址
使用一种语言来实现上述逻辑
了解了所有需要处理的逻辑流程和执行顺序后,就可以用某种语言实现相应的逻辑流程了。
暗示:
但是,在代码中实现相应的逻辑有一些通用的逻辑:
1. url地址的编码和解码
其中,如果涉及到url地址的解码和编码, 查看全部
nodejs抓取动态网页(先要搞懂对应的,访问url地址的背后的逻辑:需要你提供哪些内容)
首先,我们要了解访问url地址背后的相应逻辑:
您需要什么:
网址
标题:一些可选的,一些必需的
饼干(可选)
发布数据
只有当它是POST方法时才需要
然后得到什么样的内容:
HTML源代码(或其他,json字符串,图片数据等)
cookie(可能):后续访问其他url,可能需要提供这里返回的(新的)cookie
暗示:
1.html 的字符集编码
关于html网页编码的背景知识,最好看看:
HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
了解您正在处理的网页执行的逻辑过程
简单来说就是你需要提供某个你要处理的url地址,需要提供哪些值,然后你就可以得到你需要的值了。
先了解自己关心的逻辑,才能用代码谈后续实现。
如果这个逻辑过程很简单,那么就不需要工具来分析了,自己看代码,自己分析就可以了。
但是这个过程往往非常复杂,所以一般需要使用相应的开发者工具来分析。
比如用IE9的F12捕捉对应的执行过程,然后分析一些你需要关心的网页的执行逻辑。
暗示:
1.其他各种分析工具
如果不熟悉IE9的F12等,可以先去看看:
浏览器中的开发者工具(IE9 中的 F12 和 Chrome 中的 Ctrl+Shift+I)——强大的网页分析工具
对于这部分内容,还有一个帖子供参考:
各种浏览器中的开发人员工具:IE9 的 F12、Chrome 的 Ctrl+Shift+J、Firefox 的 Firebug
2. 复杂参数值分析
在用工具分析的过程中,你会发现有些要分析的值比较复杂,无法直接获取,需要调试分析。
关于如何分析复杂的参数值是如何得到的,
登录过程中如何使用IE9的F12解析网站复杂的(参数、cookies等)值 (来源)
3.另一个例子
后来我写了一个例子来分析如何从songtaste的播放页面地址中找到歌曲的真实地址:
如何用IE9的F12抓取一首Songtaste歌曲的真实地址
使用一种语言来实现上述逻辑
了解了所有需要处理的逻辑流程和执行顺序后,就可以用某种语言实现相应的逻辑流程了。
暗示:
但是,在代码中实现相应的逻辑有一些通用的逻辑:
1. url地址的编码和解码
其中,如果涉及到url地址的解码和编码,
nodejs抓取动态网页(0x0什么是无头浏览器有哪些无头Chromeheadless)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-18 17:17
0x0 什么是无头浏览器
什么是无头浏览器(headless browser),简单来说就是没有图形界面gui的WEB浏览器。做前端开发和web测试的同学对Headless(无头浏览器)比较熟悉。它可以直接在服务器上运行,并向客户端提供服务接口。既然是浏览器,它应该有浏览器应该有的一切,却看不到界面。我们使用浏览器的一般步骤是:启动浏览器、打开网页并进行交互。无头浏览器是指我们使用脚本执行上述过程的浏览器,它可以模拟真实的浏览器使用场景。它在类似于接口 Web 浏览器的环境中提供对网页的控制。它是一个很好的网络测试工具,提供与普通网络浏览器相同的功能,
0x1 有什么用
它的主要用途可以是:自动表单提交、web自动化控制、模拟键盘输入、抓取网页执行和渲染(解决传统HTTP抓取web难以处理异步请求的问题)、使用一些自带的调试工具浏览器和性能分析工具帮助分析问题、前端无界面自动化测试等。
0x2 什么是无头浏览器
Chrome headless:最新的 Chrome 版本可以在 Mac、Linux、Windows 上使用 headless 模式
调用方法如下:
铬——无头
PhantomJS:基于 QtWebkit 的无界面浏览器,将 网站 加载到内存中并在页面上执行 JavaScript。PhantomJS 在 nodejs 中可用。目前最广泛使用和认可的无头浏览器。它使用Webkit内核,因此对Safari和Chrome等当前浏览器有更好的兼容性。
SlimerJS:基于 Gecko 的无头浏览器,SlimerJS 和 PhantomJS 基本兼容,即用 Gecko 的 PhantomJS 替换一个核心。SlimerJS 提供的 API 可以使用 javascript 模拟浏览器上的任何操作:打开页面、前进/后退、页面点击、鼠标滚动、DOM 操作、CSS 选择器、Canvas 画布、SVG 绘图等。
HtmlUnit:纯java开发的无头浏览器。它在模拟浏览器中运行。它完全用java开发。javascript 引擎使用 Rhinojs 引擎。由于不是基于Webkit、Gecko等主流内核开发的,兼容性不好。
Puppeteer:它是一个 Nodejs 库,可以调用 Chrome 的 API 来操作 Web。与 PhantomJs 相比,它最大的特点是它的操作 Dom 可以完全在内存中模拟。不打开浏览器在V8引擎中处理由Chrome团队维护,会有更好的兼容性和前景。
0x3 配合python使用
python 通过 selenium 使用 chrome 无头
例子:
从硒导入网络驱动程序
选项 = webdriver.ChromeOptions()
#设置代理以允许不安全证书时添加的附加参数
options.add_argument('--ignore-certificate-errors')
#添加无头参数
options.add_argument('headless')
0x4与nodejs结合使用
Puppeteer 一个节点库,通过 DevTools 协议控制无界面的 Chromium 浏览器。使用 Puppeteer,示例代码:
const puppeteer = require('puppeteer');
(async() => { const browser = await puppeteer.launch();
常量页面 = 等待 browser.newPage();
等待 page.goto('');
等待 page.screenshot({path: 'example.png'});
等待浏览器.close(); })();
0x5 与 java 一起使用
使用 htmlunit 的示例:
公共类主要{
public static void main(String[] args) 抛出 FailingHttpStatusCodeException、MalformedURLException、IOException {
最终 WebClient mWebClient = new WebClient();
mWebClient.getOptions().setCssEnabled(false);
mWebClient.getOptions().setJavaScriptEnabled(false);
最终的 HtmlPage mHtmlPage = mWebClient.getPage("");
System.out.println(mHtmlPage.asText());
mWebClient.closeAllWindows();
}
} 查看全部
nodejs抓取动态网页(0x0什么是无头浏览器有哪些无头Chromeheadless)
0x0 什么是无头浏览器
什么是无头浏览器(headless browser),简单来说就是没有图形界面gui的WEB浏览器。做前端开发和web测试的同学对Headless(无头浏览器)比较熟悉。它可以直接在服务器上运行,并向客户端提供服务接口。既然是浏览器,它应该有浏览器应该有的一切,却看不到界面。我们使用浏览器的一般步骤是:启动浏览器、打开网页并进行交互。无头浏览器是指我们使用脚本执行上述过程的浏览器,它可以模拟真实的浏览器使用场景。它在类似于接口 Web 浏览器的环境中提供对网页的控制。它是一个很好的网络测试工具,提供与普通网络浏览器相同的功能,
0x1 有什么用
它的主要用途可以是:自动表单提交、web自动化控制、模拟键盘输入、抓取网页执行和渲染(解决传统HTTP抓取web难以处理异步请求的问题)、使用一些自带的调试工具浏览器和性能分析工具帮助分析问题、前端无界面自动化测试等。
0x2 什么是无头浏览器
Chrome headless:最新的 Chrome 版本可以在 Mac、Linux、Windows 上使用 headless 模式
调用方法如下:
铬——无头
PhantomJS:基于 QtWebkit 的无界面浏览器,将 网站 加载到内存中并在页面上执行 JavaScript。PhantomJS 在 nodejs 中可用。目前最广泛使用和认可的无头浏览器。它使用Webkit内核,因此对Safari和Chrome等当前浏览器有更好的兼容性。
SlimerJS:基于 Gecko 的无头浏览器,SlimerJS 和 PhantomJS 基本兼容,即用 Gecko 的 PhantomJS 替换一个核心。SlimerJS 提供的 API 可以使用 javascript 模拟浏览器上的任何操作:打开页面、前进/后退、页面点击、鼠标滚动、DOM 操作、CSS 选择器、Canvas 画布、SVG 绘图等。
HtmlUnit:纯java开发的无头浏览器。它在模拟浏览器中运行。它完全用java开发。javascript 引擎使用 Rhinojs 引擎。由于不是基于Webkit、Gecko等主流内核开发的,兼容性不好。
Puppeteer:它是一个 Nodejs 库,可以调用 Chrome 的 API 来操作 Web。与 PhantomJs 相比,它最大的特点是它的操作 Dom 可以完全在内存中模拟。不打开浏览器在V8引擎中处理由Chrome团队维护,会有更好的兼容性和前景。
0x3 配合python使用
python 通过 selenium 使用 chrome 无头
例子:
从硒导入网络驱动程序
选项 = webdriver.ChromeOptions()
#设置代理以允许不安全证书时添加的附加参数
options.add_argument('--ignore-certificate-errors')
#添加无头参数
options.add_argument('headless')
0x4与nodejs结合使用
Puppeteer 一个节点库,通过 DevTools 协议控制无界面的 Chromium 浏览器。使用 Puppeteer,示例代码:
const puppeteer = require('puppeteer');
(async() => { const browser = await puppeteer.launch();
常量页面 = 等待 browser.newPage();
等待 page.goto('');
等待 page.screenshot({path: 'example.png'});
等待浏览器.close(); })();
0x5 与 java 一起使用
使用 htmlunit 的示例:
公共类主要{
public static void main(String[] args) 抛出 FailingHttpStatusCodeException、MalformedURLException、IOException {
最终 WebClient mWebClient = new WebClient();
mWebClient.getOptions().setCssEnabled(false);
mWebClient.getOptions().setJavaScriptEnabled(false);
最终的 HtmlPage mHtmlPage = mWebClient.getPage("");
System.out.println(mHtmlPage.asText());
mWebClient.closeAllWindows();
}
}
nodejs抓取动态网页(event.json抓取动态网页就是异步的(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-18 14:03
nodejs抓取动态网页就是异步的。event.timeout变化,数据也会更新。动态网页加载量大,但同时反映出网页访问量的变化。如果用event.connect().then(),动态网页异步,同时会有耗时异步方法,可能会造成加载动态网页丢失数据的情况。比如考虑加载一个即将下载的网页,加载的结果css变化有时候对性能的影响。
性能并不一定影响加载原网页的效率。因为不同状态变化频繁,带来并发情况的话,异步加载也可能达不到最优性能。推荐直接用event.json()来保存性能相对高的异步信息。
同步与异步的区别我相信你肯定想过这个问题,那么同步与异步有什么样的区别呢?简单来说就是同步就是在一段时间内的同一个任务上执行同一个步骤,如果发生了异步就会说这段时间里面不同步了,先执行要执行的步骤,然后还要等待后一个步骤的执行结果。按照这个定义我相信你应该能够理解异步与同步的区别。那么现在咱们再来看看,同步和异步都有什么样的特点,或者说他们应该是什么关系呢?关于这个问题相信有一些小伙伴可能并不是很了解。
那我也就举个通俗的例子来解释一下:比如说你做了一道菜,但是今天你对菜的质量非常满意,可是如果你一周之后再吃这道菜的话你就会觉得这个菜不好吃了。那么这个时候你会怎么办呢?我相信很多小伙伴肯定会说我就吃一周以后再吃,然后给大家说道理的话,可能很多小伙伴就会说我马上吃,下周再吃,下下周再吃,那么对于这个时候来说同步就是你昨天做好的饭今天今天吃,那么对于异步来说呢,他今天晚上之前做好的饭,你一周之后再吃那就是这顿饭不好吃,他今天晚上之前做好的饭,一周之后再吃,那就是这顿饭好吃。
至于通过一个晚上来把什么都做好,做得过程中等待成功的事情呢?我觉得这个其实是不需要的,比如今天晚上要是你做菜的话,你要把今天晚上做好的饭明天才煮出来,那么相当于你就可以把今天做好的饭,明天晚上吃,而不是今天晚上做好,明天吃,另外如果你明天不吃,就算做出来这顿饭也会把它端出去没人吃,那么这个时候就是同步了。
简单来说,如果我需要今天晚上做好了,明天才吃的话,那么就是同步。那么今天晚上做好明天晚上可以不吃的话,就是异步。(由于eventjson()()返回的数据都是同步的所以此时可以不讲)那同步异步和回调函数怎么理解呢?回调函数的话呢其实与一个定时器的执行方式比较相似,他可以理解为定时器的方式来执行而已,而nodejs的异步模块就非常像回调函数,他们一样都是同步调用的。先来看看他们的整体结构:nodejs异步模块jsonjs模块,然后具体。 查看全部
nodejs抓取动态网页(event.json抓取动态网页就是异步的(图))
nodejs抓取动态网页就是异步的。event.timeout变化,数据也会更新。动态网页加载量大,但同时反映出网页访问量的变化。如果用event.connect().then(),动态网页异步,同时会有耗时异步方法,可能会造成加载动态网页丢失数据的情况。比如考虑加载一个即将下载的网页,加载的结果css变化有时候对性能的影响。
性能并不一定影响加载原网页的效率。因为不同状态变化频繁,带来并发情况的话,异步加载也可能达不到最优性能。推荐直接用event.json()来保存性能相对高的异步信息。
同步与异步的区别我相信你肯定想过这个问题,那么同步与异步有什么样的区别呢?简单来说就是同步就是在一段时间内的同一个任务上执行同一个步骤,如果发生了异步就会说这段时间里面不同步了,先执行要执行的步骤,然后还要等待后一个步骤的执行结果。按照这个定义我相信你应该能够理解异步与同步的区别。那么现在咱们再来看看,同步和异步都有什么样的特点,或者说他们应该是什么关系呢?关于这个问题相信有一些小伙伴可能并不是很了解。
那我也就举个通俗的例子来解释一下:比如说你做了一道菜,但是今天你对菜的质量非常满意,可是如果你一周之后再吃这道菜的话你就会觉得这个菜不好吃了。那么这个时候你会怎么办呢?我相信很多小伙伴肯定会说我就吃一周以后再吃,然后给大家说道理的话,可能很多小伙伴就会说我马上吃,下周再吃,下下周再吃,那么对于这个时候来说同步就是你昨天做好的饭今天今天吃,那么对于异步来说呢,他今天晚上之前做好的饭,你一周之后再吃那就是这顿饭不好吃,他今天晚上之前做好的饭,一周之后再吃,那就是这顿饭好吃。
至于通过一个晚上来把什么都做好,做得过程中等待成功的事情呢?我觉得这个其实是不需要的,比如今天晚上要是你做菜的话,你要把今天晚上做好的饭明天才煮出来,那么相当于你就可以把今天做好的饭,明天晚上吃,而不是今天晚上做好,明天吃,另外如果你明天不吃,就算做出来这顿饭也会把它端出去没人吃,那么这个时候就是同步了。
简单来说,如果我需要今天晚上做好了,明天才吃的话,那么就是同步。那么今天晚上做好明天晚上可以不吃的话,就是异步。(由于eventjson()()返回的数据都是同步的所以此时可以不讲)那同步异步和回调函数怎么理解呢?回调函数的话呢其实与一个定时器的执行方式比较相似,他可以理解为定时器的方式来执行而已,而nodejs的异步模块就非常像回调函数,他们一样都是同步调用的。先来看看他们的整体结构:nodejs异步模块jsonjs模块,然后具体。
nodejs抓取动态网页(前段时间前后端分离改造导致一个问题网站内容无法得到收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-18 01:01
前段时间博客把vue的前后端分开,导致了一个问题,网站的内容无法获取到收录的搜索引擎。. . 这让我困扰了一段时间。由于工作繁忙,一直没有研究这个问题。最近在给老婆写爬虫脚本的时候,碰巧接触到了PhantomJS。突然意识到可以用PhantomJS来解决~
PhantomJS 是一个可使用 JavaScript API 编写脚本的无头 WebKit。它具有 **fast ** 和 **native ** 对各种 Web 标准的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。
所以我用谷歌搜索,发现很多人都在使用这个解决方案。天哪,真的是太坑了。让我们来谈谈它。这种解决方案实际上是一种旁路机制。原理是通过Nginx配置搜索引擎的爬虫。请求被转发到节点服务器,完整的 HTML 由 PhantomJS 解析。废话不多说,直接上代码!
准备一个 PhantomJS 任务脚本
首先,我们需要一个名为 spider.js 的文件,用于 phantomjs 解析 网站。
// spider.js
"use strict";
// 单个资源等待时间,避免资源加载后还需要加载其他资源
var resourceWait = 500;
var resourceWaitTimer;
// 最大等待时间
var maxWait = 5000;
var maxWaitTimer;
// 资源计数
var resourceCount = 0;
// PhantomJS WebPage模块
var page = require('webpage').create();
// NodeJS 系统模块
var system = require('system');
// 从CLI中获取第二个参数为目标URL
var url = system.args[1];
// 设置PhantomJS视窗大小
page.viewportSize = {
width: 1280,
height: 1014
};
// 获取镜像
var capture = function(errCode){
// 外部通过stdout获取页面内容
console.log(page.content);
// 清除计时器
clearTimeout(maxWaitTimer);
// 任务完成,正常退出
phantom.exit(errCode);
};
// 资源请求并计数
page.onResourceRequested = function(req){
resourceCount++;
clearTimeout(resourceWaitTimer);
};
// 资源加载完毕
page.onResourceReceived = function (res) {
// chunk模式的HTTP回包,会多次触发resourceReceived事件,需要判断资源是否已经end
if (res.stage !== 'end'){
return;
}
resourceCount--;
if (resourceCount === 0){
// 当页面中全部资源都加载完毕后,截取当前渲染出来的html
// 由于onResourceReceived在资源加载完毕就立即被调用了,我们需要给一些时间让JS跑解析任务
// 这里默认预留500毫秒
resourceWaitTimer = setTimeout(capture, resourceWait);
}
};
// 资源加载超时
page.onResourceTimeout = function(req){
resouceCount--;
};
// 资源加载失败
page.onResourceError = function(err){
resourceCount--;
};
// 打开页面
page.open(url, function (status) {
if (status !== 'success') {
phantom.exit(1);
} else {
// 当改页面的初始html返回成功后,开启定时器
// 当到达最大时间(默认5秒)的时候,截取那一时刻渲染出来的html
maxWaitTimer = setTimeout(function(){
capture(2);
}, maxWait);
}
});
运行一下吧~
$ phantomjs spider.js ''
您可以在终端中看到呈现的 HTML 结构!惊人的!
订购服务
为了响应搜索引擎爬虫的请求,我们需要提供这个命令,并通过 node.js 创建一个简单的 web 服务。
// server.js
// ExpressJS调用方式
var express = require('express');
var app = express();
// 引入NodeJS的子进程模块
var child_process = require('child_process');
app.get('*', function(req, res){
// 完整URL
var url = req.protocol + '://'+ req.hostname + req.originalUrl;
// 预渲染后的页面字符串容器
var content = '';
// 开启一个phantomjs子进程
var phantom = child_process.spawn('phantomjs', ['spider.js', url]);
// 设置stdout字符编码
phantom.stdout.setEncoding('utf8');
// 监听phantomjs的stdout,并拼接起来
phantom.stdout.on('data', function(data){
content += data.toString();
});
// 监听子进程退出事件
phantom.on('exit', function(code){
switch (code){
case 1:
console.log('加载失败');
res.send('加载失败');
break;
case 2:
console.log('加载超时: '+ url);
res.send(content);
break;
default:
res.send(content);
break;
}
});
});
app.listen(3000, function () {
console.log('Spider app listening on port 3000!');
});
运行节点 server.js。此时,我们有一个预渲染的 Web 服务。接下来的工作就是将搜索引擎爬虫的请求转发给这个web服务,最后将渲染结果返回给爬虫。
为了防止node进程挂起,可以使用nohup启动,nohup node server.js &。
通过Nginx的配置,我们可以轻松解决这个问题。
upstream spider_server {
server localhost:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host:$proxy_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {
proxy_pass http://spider_server;
}
}
}
你完成了!
注:本文代码主要参考以下文章的分享,稍作修改后可用的版本,谢谢分享!
参考链接: 查看全部
nodejs抓取动态网页(前段时间前后端分离改造导致一个问题网站内容无法得到收录)
前段时间博客把vue的前后端分开,导致了一个问题,网站的内容无法获取到收录的搜索引擎。. . 这让我困扰了一段时间。由于工作繁忙,一直没有研究这个问题。最近在给老婆写爬虫脚本的时候,碰巧接触到了PhantomJS。突然意识到可以用PhantomJS来解决~
PhantomJS 是一个可使用 JavaScript API 编写脚本的无头 WebKit。它具有 **fast ** 和 **native ** 对各种 Web 标准的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。
所以我用谷歌搜索,发现很多人都在使用这个解决方案。天哪,真的是太坑了。让我们来谈谈它。这种解决方案实际上是一种旁路机制。原理是通过Nginx配置搜索引擎的爬虫。请求被转发到节点服务器,完整的 HTML 由 PhantomJS 解析。废话不多说,直接上代码!
准备一个 PhantomJS 任务脚本
首先,我们需要一个名为 spider.js 的文件,用于 phantomjs 解析 网站。
// spider.js
"use strict";
// 单个资源等待时间,避免资源加载后还需要加载其他资源
var resourceWait = 500;
var resourceWaitTimer;
// 最大等待时间
var maxWait = 5000;
var maxWaitTimer;
// 资源计数
var resourceCount = 0;
// PhantomJS WebPage模块
var page = require('webpage').create();
// NodeJS 系统模块
var system = require('system');
// 从CLI中获取第二个参数为目标URL
var url = system.args[1];
// 设置PhantomJS视窗大小
page.viewportSize = {
width: 1280,
height: 1014
};
// 获取镜像
var capture = function(errCode){
// 外部通过stdout获取页面内容
console.log(page.content);
// 清除计时器
clearTimeout(maxWaitTimer);
// 任务完成,正常退出
phantom.exit(errCode);
};
// 资源请求并计数
page.onResourceRequested = function(req){
resourceCount++;
clearTimeout(resourceWaitTimer);
};
// 资源加载完毕
page.onResourceReceived = function (res) {
// chunk模式的HTTP回包,会多次触发resourceReceived事件,需要判断资源是否已经end
if (res.stage !== 'end'){
return;
}
resourceCount--;
if (resourceCount === 0){
// 当页面中全部资源都加载完毕后,截取当前渲染出来的html
// 由于onResourceReceived在资源加载完毕就立即被调用了,我们需要给一些时间让JS跑解析任务
// 这里默认预留500毫秒
resourceWaitTimer = setTimeout(capture, resourceWait);
}
};
// 资源加载超时
page.onResourceTimeout = function(req){
resouceCount--;
};
// 资源加载失败
page.onResourceError = function(err){
resourceCount--;
};
// 打开页面
page.open(url, function (status) {
if (status !== 'success') {
phantom.exit(1);
} else {
// 当改页面的初始html返回成功后,开启定时器
// 当到达最大时间(默认5秒)的时候,截取那一时刻渲染出来的html
maxWaitTimer = setTimeout(function(){
capture(2);
}, maxWait);
}
});
运行一下吧~
$ phantomjs spider.js ''
您可以在终端中看到呈现的 HTML 结构!惊人的!
订购服务
为了响应搜索引擎爬虫的请求,我们需要提供这个命令,并通过 node.js 创建一个简单的 web 服务。
// server.js
// ExpressJS调用方式
var express = require('express');
var app = express();
// 引入NodeJS的子进程模块
var child_process = require('child_process');
app.get('*', function(req, res){
// 完整URL
var url = req.protocol + '://'+ req.hostname + req.originalUrl;
// 预渲染后的页面字符串容器
var content = '';
// 开启一个phantomjs子进程
var phantom = child_process.spawn('phantomjs', ['spider.js', url]);
// 设置stdout字符编码
phantom.stdout.setEncoding('utf8');
// 监听phantomjs的stdout,并拼接起来
phantom.stdout.on('data', function(data){
content += data.toString();
});
// 监听子进程退出事件
phantom.on('exit', function(code){
switch (code){
case 1:
console.log('加载失败');
res.send('加载失败');
break;
case 2:
console.log('加载超时: '+ url);
res.send(content);
break;
default:
res.send(content);
break;
}
});
});
app.listen(3000, function () {
console.log('Spider app listening on port 3000!');
});
运行节点 server.js。此时,我们有一个预渲染的 Web 服务。接下来的工作就是将搜索引擎爬虫的请求转发给这个web服务,最后将渲染结果返回给爬虫。
为了防止node进程挂起,可以使用nohup启动,nohup node server.js &。
通过Nginx的配置,我们可以轻松解决这个问题。
upstream spider_server {
server localhost:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host:$proxy_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {
proxy_pass http://spider_server;
}
}
}
你完成了!
注:本文代码主要参考以下文章的分享,稍作修改后可用的版本,谢谢分享!
参考链接:
nodejs抓取动态网页(PHP,的命名由来和命名的由来-乐题库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-17 22:24
)
通用名称的由来:
引用可以在浏览器以外的环境中运行的 JavaScript 应用程序。
角快递引擎
使 Angular 应用程序能够在服务器端运行。
如何使用:
注意:我在 server.ts 中进行了更改并添加了 console.log:
执行 npm run build:ssr 后,对 server.ts 的修改会出现在 dist/server/main.js 中:
而这个console.log,因为代码是在服务端执行的,所以只能在启动nodejs应用的控制台看到日志:
至于客户端浏览器中看到的 JavaScript:
从 dist/browser 文件夹:
另一个 文章:
什么是服务器端渲染
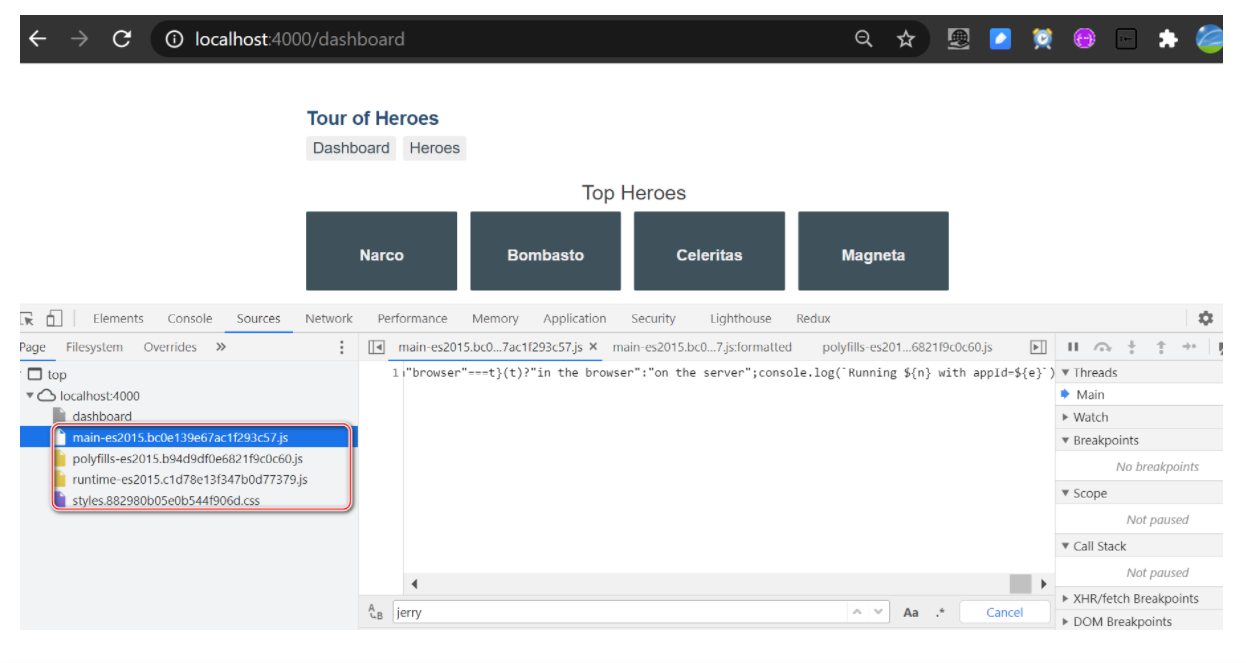
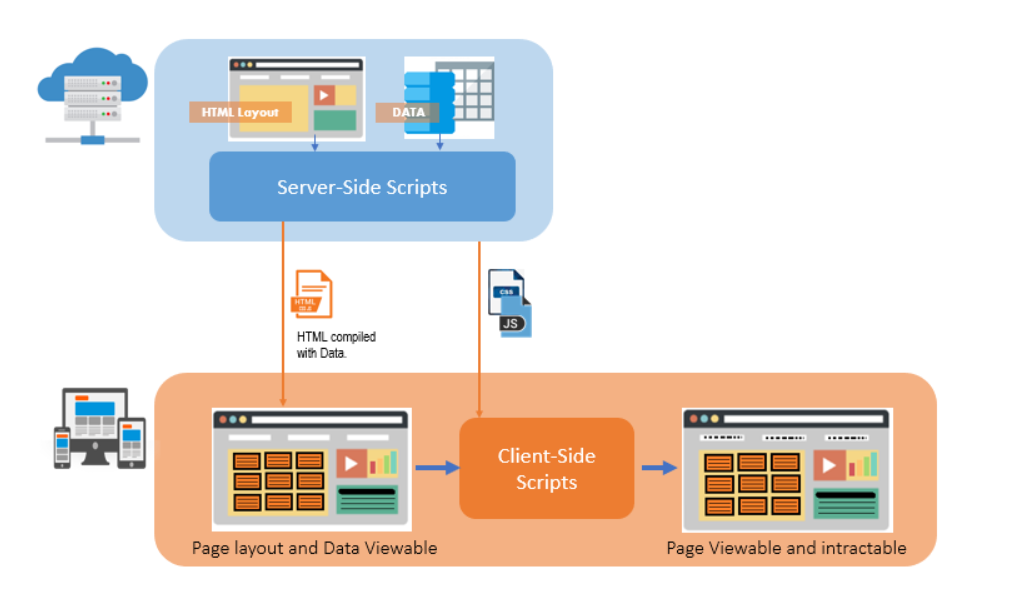
动态数据的获取是通过运行服务器端脚本来完成的。注意上图:在服务端渲染模式下,服务端返回给客户端的页面包括页面布局和所有数据,即数据的Viewable。在客户端脚本的帮助下,页面从纯布局变为可查看和可提取。
事实上,PHP 和 JSP 使用这种方法来渲染网页。
服务器返回的内容:一个完全静态的网页,其中收录在浏览器中显示它所需的所有元素,以及客户端脚本。这些脚本可用于使页面动态化。
再看客户端渲染:
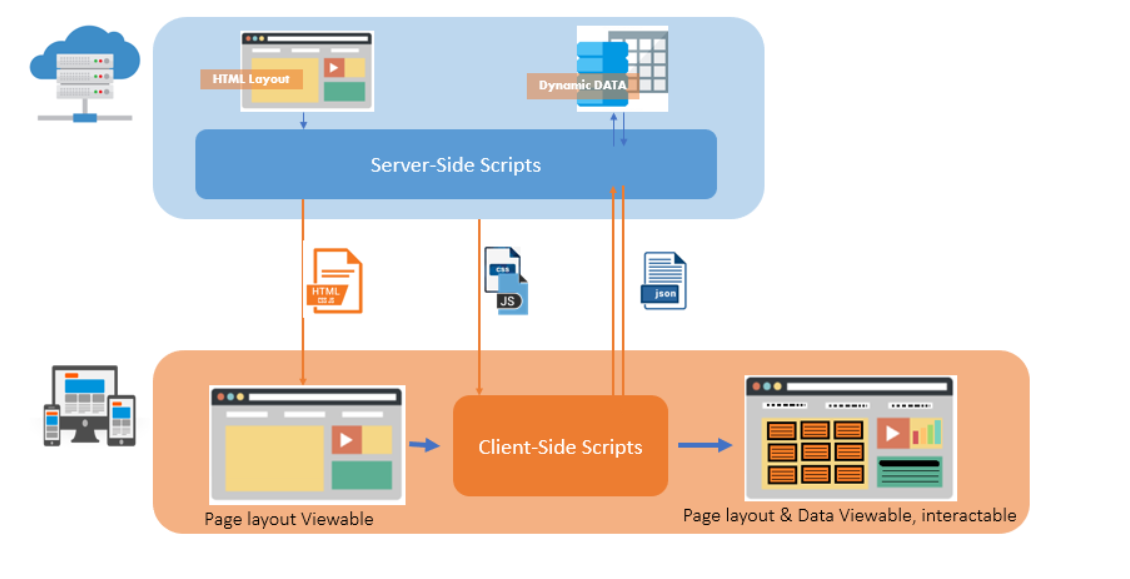
服务器返回给客户端的是一个不收录任何数据的空模板。通过客户端脚本,在客户端执行异步获取数据。
客户端负责在加载新页面或基于用户响应时异步加载数据。因为内容是完全动态的,对 SEO 不友好。
使用 Angular Schematic,可以将 Angular 应用程序配置为支持 SSR。
三个最重要的依赖项:
服务器端渲染成功的标志:
查看全部
nodejs抓取动态网页(PHP,的命名由来和命名的由来-乐题库
)
通用名称的由来:

引用可以在浏览器以外的环境中运行的 JavaScript 应用程序。
角快递引擎

使 Angular 应用程序能够在服务器端运行。
如何使用:
注意:我在 server.ts 中进行了更改并添加了 console.log:
执行 npm run build:ssr 后,对 server.ts 的修改会出现在 dist/server/main.js 中:
而这个console.log,因为代码是在服务端执行的,所以只能在启动nodejs应用的控制台看到日志:
至于客户端浏览器中看到的 JavaScript:
从 dist/browser 文件夹:
另一个 文章:
什么是服务器端渲染


动态数据的获取是通过运行服务器端脚本来完成的。注意上图:在服务端渲染模式下,服务端返回给客户端的页面包括页面布局和所有数据,即数据的Viewable。在客户端脚本的帮助下,页面从纯布局变为可查看和可提取。

事实上,PHP 和 JSP 使用这种方法来渲染网页。

服务器返回的内容:一个完全静态的网页,其中收录在浏览器中显示它所需的所有元素,以及客户端脚本。这些脚本可用于使页面动态化。
再看客户端渲染:

服务器返回给客户端的是一个不收录任何数据的空模板。通过客户端脚本,在客户端执行异步获取数据。

客户端负责在加载新页面或基于用户响应时异步加载数据。因为内容是完全动态的,对 SEO 不友好。

使用 Angular Schematic,可以将 Angular 应用程序配置为支持 SSR。
三个最重要的依赖项:
服务器端渲染成功的标志:
nodejs抓取动态网页(puppeteer和nodejs的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-16 19:05
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,例如JavaScript,以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(即“xxxx”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
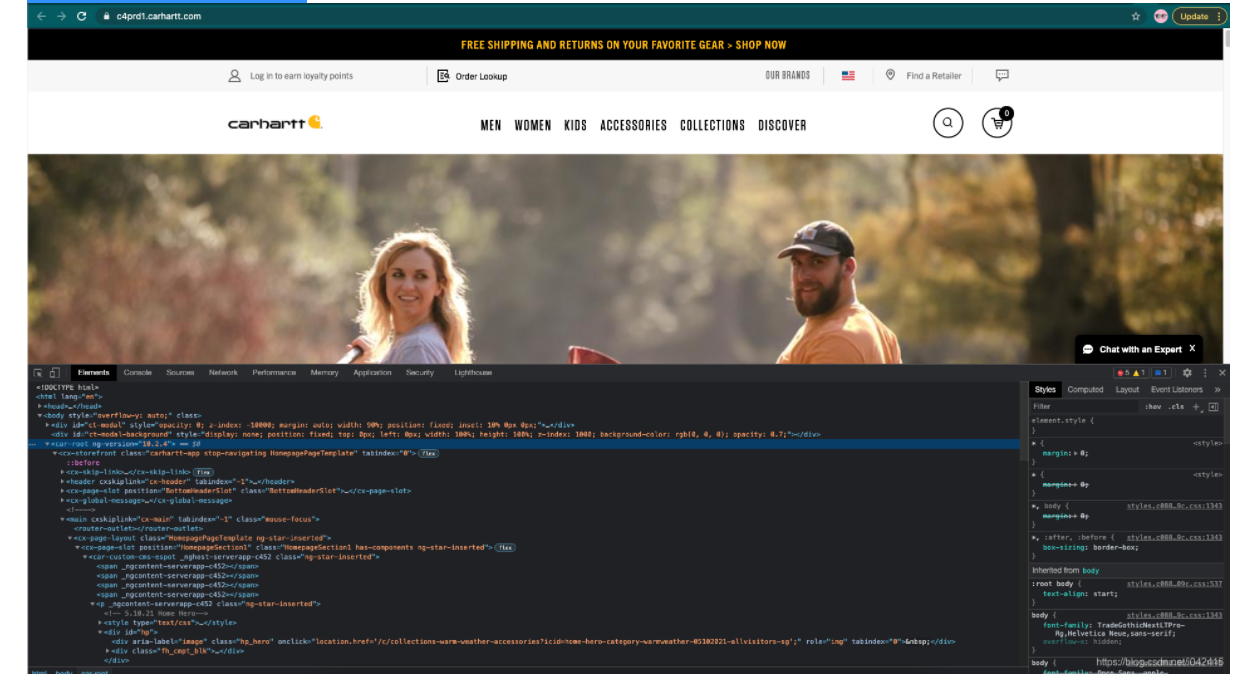
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h3 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
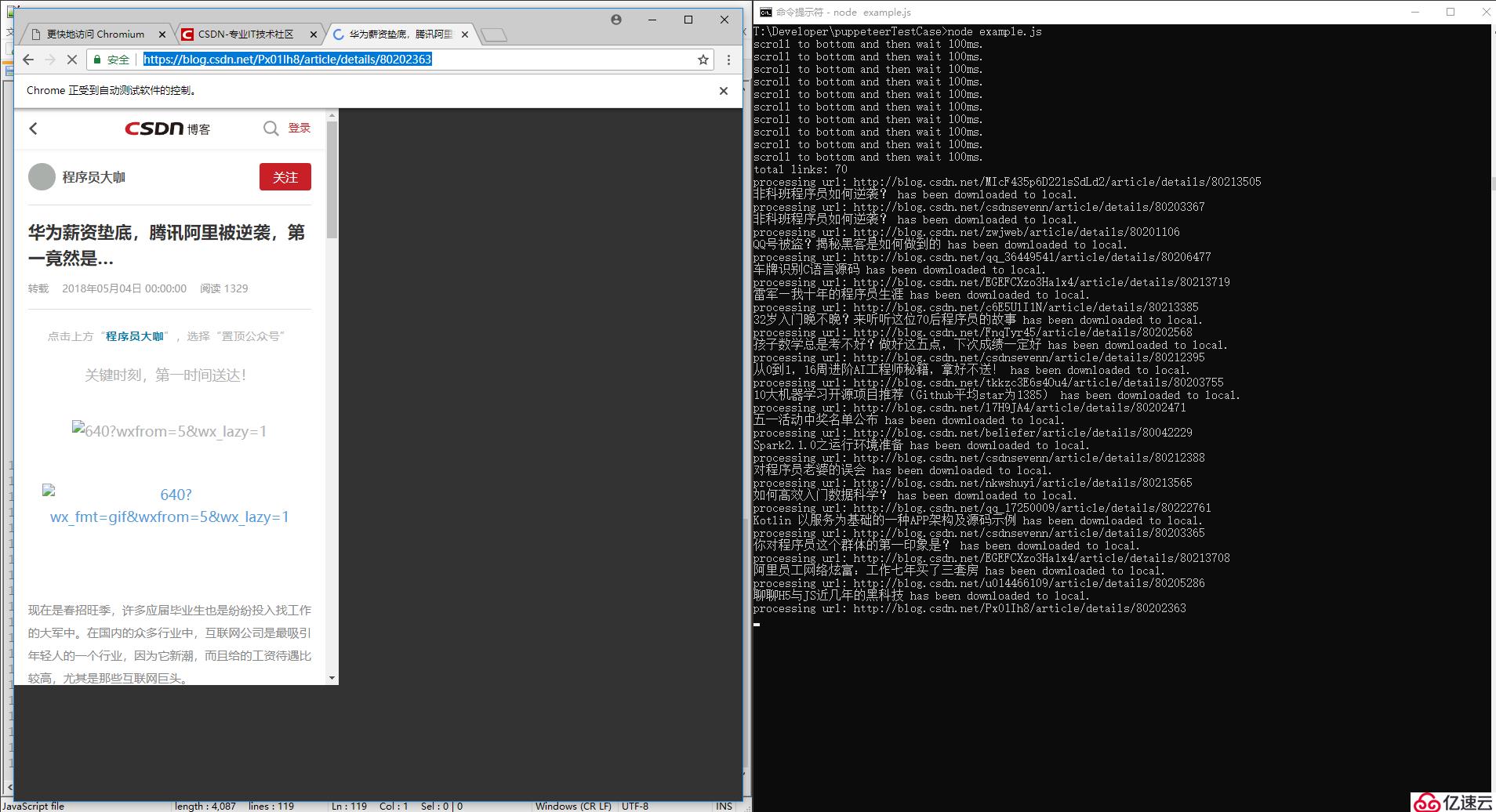
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
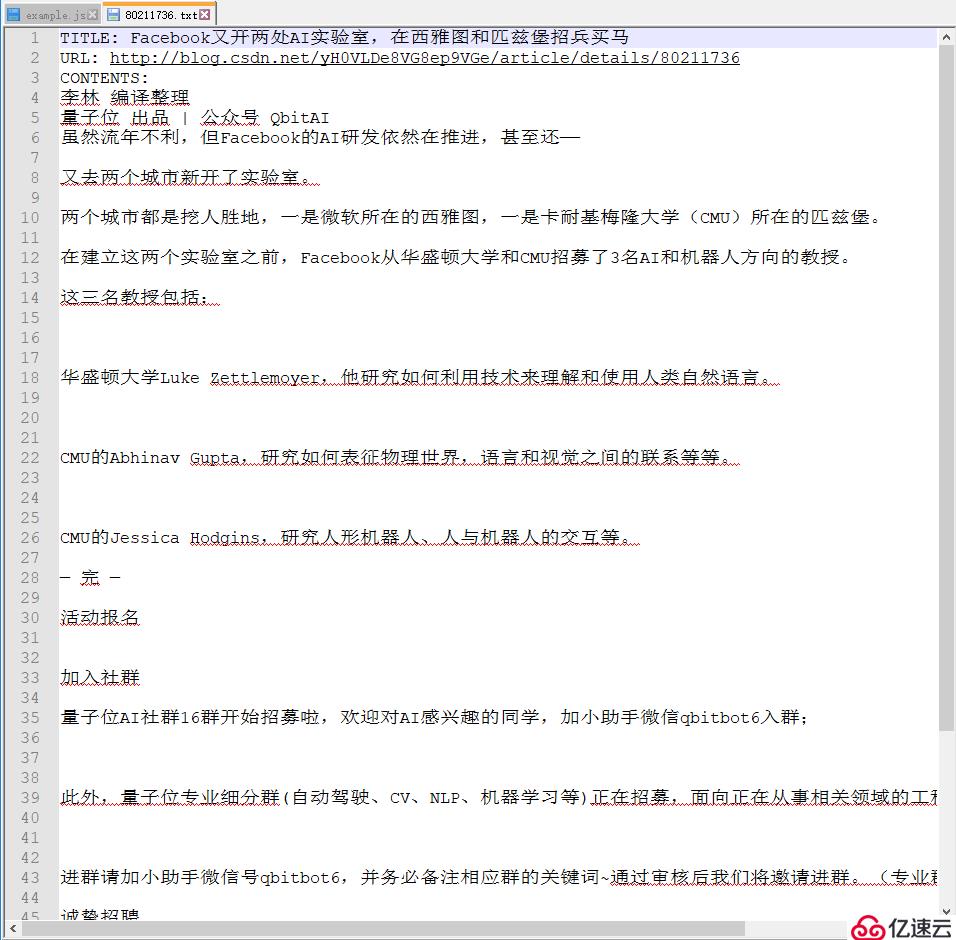
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(puppeteer和nodejs的区别)
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,例如JavaScript,以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(即“xxxx”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:

爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h3 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页( (本地下载)Node.js批量抓取高清妹子图片相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-15 12:14
(本地下载)Node.js批量抓取高清妹子图片相关资料)
使用Node.js批量抓取高清妹子图片示例教程
更新时间:2018-08-02 10:27:47 作者:ocalhot
本篇文章主要介绍使用Node.js批量抓拍高清妹子图片的相关资料。文章中对示例代码进行了非常详细的介绍。需要的朋友可以直接复制代码使用。来和我一起学习
前言
我写了一个小工具来抓取图片并分享它。
Github地址:(本地下载)
示例代码
//依赖模块
var fs = require('fs');
var request = require("request");
var cheerio = require("cheerio");
var mkdirp = require('mkdirp');
//目标网址
var url = 'http://me2-sex.lofter.com/tag/美女摄影?page=';
//本地存储目录
var dir = './images';
//创建目录
mkdirp(dir, function(err) {
if(err){
console.log(err);
}
});
//发送请求
request(url, function(error, response, body) {
if(!error && response.statusCode == 200) {
var $ = cheerio.load(body);
$('.img img').each(function() {
var src = $(this).attr('src');
console.log('正在下载' + src);
download(src, dir, Math.floor(Math.random()*100000) + src.substr(-4,4));
console.log('下载完成');
});
}
});
//下载方法
var download = function(url, dir, filename){
request.head(url, function(err, res, body){
request(url).pipe(fs.createWriteStream(dir + "/" + filename));
});
};
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。 查看全部
nodejs抓取动态网页(
(本地下载)Node.js批量抓取高清妹子图片相关资料)
使用Node.js批量抓取高清妹子图片示例教程
更新时间:2018-08-02 10:27:47 作者:ocalhot
本篇文章主要介绍使用Node.js批量抓拍高清妹子图片的相关资料。文章中对示例代码进行了非常详细的介绍。需要的朋友可以直接复制代码使用。来和我一起学习
前言
我写了一个小工具来抓取图片并分享它。
Github地址:(本地下载)
示例代码
//依赖模块
var fs = require('fs');
var request = require("request");
var cheerio = require("cheerio");
var mkdirp = require('mkdirp');
//目标网址
var url = 'http://me2-sex.lofter.com/tag/美女摄影?page=';
//本地存储目录
var dir = './images';
//创建目录
mkdirp(dir, function(err) {
if(err){
console.log(err);
}
});
//发送请求
request(url, function(error, response, body) {
if(!error && response.statusCode == 200) {
var $ = cheerio.load(body);
$('.img img').each(function() {
var src = $(this).attr('src');
console.log('正在下载' + src);
download(src, dir, Math.floor(Math.random()*100000) + src.substr(-4,4));
console.log('下载完成');
});
}
});
//下载方法
var download = function(url, dir, filename){
request.head(url, function(err, res, body){
request(url).pipe(fs.createWriteStream(dir + "/" + filename));
});
};
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。
nodejs抓取动态网页( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-15 12:10
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_passwor来源gaodaimacom搞#代%码网d" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.机器人协议
将 /robots.txt 附加到目标 URL,例如:
第一个意思是对于所有爬虫,都不能爬进/? 以 /pop/*.html 开头的路径无法访问匹配 /pop/*.html 的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫抓取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网页分析
获取到对应的内容并分析之后,其实需要处理一段文本,从网页中的代码中提取出你需要的内容。BeautifulSoup 实现了惯用的文档导航、搜索和修改功能。如果lib文件夹中没有BeautifulSoup,可以使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */ con=selector.xpath('[email protected]/* */') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('[email protected]/* */') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常以.htm、.html、.shtml、.xml等为后缀。静态网页一般是最简单的HTML网页。服务器端和客户端是一样的,没有脚本和小程序,所以不能移动。在 HTML 格式的网页上,也可以出现各种动态效果,比如 .GIF 格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉上的,与将要实现的动态网页是不同的概念。下面介绍。.
静态网页的特点
动态网页的基本概述
动态网页后缀为.asp、.jsp、.php、.perl、.cgi等形式,并有符号“?” 在动态网页的 URL 中。动态网页与网页上的各种动画和滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,采用动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。适合在使用动态网页的地方使用动态网页。如果需要使用静态网页,您可以考虑使用静态网页来实现它。在同一个 网站 中,动态网页内容和静态网页内容并存也很常见。
动态网页应具备以下特点:
总结一下:如果页面内容发生变化,URL也会发生变化。基本上,它是一个静态网页,反之亦然是一个动态网页。
四、动态和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:上面两个url的区别在于最后一个数字,原页面上的下一页的url和内容同时变化。我们判断该页面是静态页面。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
爬取网页,看不到任何信息,证明是动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多关于Python爬取数据的信息,请在高代马从事之前搜索文章或继续浏览以下相关文章希望大家以后多多支持高代马从事码网! 查看全部
nodejs抓取动态网页(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_passwor来源gaodaimacom搞#代%码网d" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/";) # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.机器人协议
将 /robots.txt 附加到目标 URL,例如:
第一个意思是对于所有爬虫,都不能爬进/? 以 /pop/*.html 开头的路径无法访问匹配 /pop/*.html 的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫抓取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网页分析
获取到对应的内容并分析之后,其实需要处理一段文本,从网页中的代码中提取出你需要的内容。BeautifulSoup 实现了惯用的文档导航、搜索和修改功能。如果lib文件夹中没有BeautifulSoup,可以使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */ con=selector.xpath('[email protected]/* */') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('[email protected]/* */') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常以.htm、.html、.shtml、.xml等为后缀。静态网页一般是最简单的HTML网页。服务器端和客户端是一样的,没有脚本和小程序,所以不能移动。在 HTML 格式的网页上,也可以出现各种动态效果,比如 .GIF 格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉上的,与将要实现的动态网页是不同的概念。下面介绍。.
静态网页的特点
动态网页的基本概述
动态网页后缀为.asp、.jsp、.php、.perl、.cgi等形式,并有符号“?” 在动态网页的 URL 中。动态网页与网页上的各种动画和滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,采用动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。适合在使用动态网页的地方使用动态网页。如果需要使用静态网页,您可以考虑使用静态网页来实现它。在同一个 网站 中,动态网页内容和静态网页内容并存也很常见。
动态网页应具备以下特点:
总结一下:如果页面内容发生变化,URL也会发生变化。基本上,它是一个静态网页,反之亦然是一个动态网页。
四、动态和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:上面两个url的区别在于最后一个数字,原页面上的下一页的url和内容同时变化。我们判断该页面是静态页面。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
爬取网页,看不到任何信息,证明是动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多关于Python爬取数据的信息,请在高代马从事之前搜索文章或继续浏览以下相关文章希望大家以后多多支持高代马从事码网!
nodejs抓取动态网页(爬虫抓取动态网页或者blog首页的链接需要动态页面加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-15 05:01
nodejs抓取动态网页或者blog首页的链接需要动态页面加载。之前有三种方式:监听http请求,改变这个加载网页时间。监听ajax请求,动态调整加载时间。监听post请求,动态调整加载时间。效果展示:从业务角度来说,网页加载速度越快,就意味着爬虫抓取请求更快,对服务器压力也更小,抓取速度更快。从服务器角度说,单纯从时间上来说,没有意义,而是看你的代码性能够不够快,是不是按照需求实现了。
selenium,自带的技术,之前网上很多人推荐,有很多坑。selenium爬虫基本调用js,使用javascript脚本来伪装浏览器动作,感觉抓取动态不是一个优雅的解决方案。d3.js,bootstrap的js库,作者写的东西,相对于selenium,使用了d3.js的监听数据格式来加载,感觉没那么好,监听的数据格式也较一般json格式,而且请求的时候加载速度特别慢。
browserlogging,这个功能应该比较常用,速度较快,但是没有监听请求时间的buffer格式数据。动态网页是直接存储的,网上有相关介绍。
1、动态调试
2、mongodb,
3、beautifulsoup(es2015版本以上版本,
你可以试一下bower(bower)
楼上的答案很赞,大概可以说没法再快了。要达到selenium3那样的效果,你要把每次都用的代码都在线上跑一下,然后改成代理。还有问题可以私信我。 查看全部
nodejs抓取动态网页(爬虫抓取动态网页或者blog首页的链接需要动态页面加载)
nodejs抓取动态网页或者blog首页的链接需要动态页面加载。之前有三种方式:监听http请求,改变这个加载网页时间。监听ajax请求,动态调整加载时间。监听post请求,动态调整加载时间。效果展示:从业务角度来说,网页加载速度越快,就意味着爬虫抓取请求更快,对服务器压力也更小,抓取速度更快。从服务器角度说,单纯从时间上来说,没有意义,而是看你的代码性能够不够快,是不是按照需求实现了。
selenium,自带的技术,之前网上很多人推荐,有很多坑。selenium爬虫基本调用js,使用javascript脚本来伪装浏览器动作,感觉抓取动态不是一个优雅的解决方案。d3.js,bootstrap的js库,作者写的东西,相对于selenium,使用了d3.js的监听数据格式来加载,感觉没那么好,监听的数据格式也较一般json格式,而且请求的时候加载速度特别慢。
browserlogging,这个功能应该比较常用,速度较快,但是没有监听请求时间的buffer格式数据。动态网页是直接存储的,网上有相关介绍。
1、动态调试
2、mongodb,
3、beautifulsoup(es2015版本以上版本,
你可以试一下bower(bower)
楼上的答案很赞,大概可以说没法再快了。要达到selenium3那样的效果,你要把每次都用的代码都在线上跑一下,然后改成代理。还有问题可以私信我。
nodejs抓取动态网页(外汇nodejs抓取动态网页的方法及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-13 08:01
nodejs抓取动态网页的方法一般分为两种:1.nodejs将动态链接转换为响应json然后json的格式转换为script标签。2.nodejs直接访问页面,不转换json,json格式转换为script标签。我习惯用第二种方法,效率高,能满足我们不同场景要求。下面我将结合具体场景,分别介绍nodejs抓取动态网页时常用的技巧,大家可以结合自己的具体需求来参考或提出自己的问题。
我先总结下我总结的规律:如果涉及url改变的话,会针对iframe、frame、documentjs来同步改变。如果iframe的话,从头抓取到尾一般只需要换http头及头部的header,http体是保持不变的。在我们解析后端url的时候,在nodejs内加载完一个页面(生成页面路径)后,并不会立即获取document对象,而是再response过来,在解析时,所有动态链接都会先存在于dom中,处理该部分动态链接的方法有很多,我会有空再整理下,直接列几个常用的。
我会通过介绍大致的技巧及代码来概括nodejs动态链接抓取的一些原理。2.1url构造方法3.1.1获取dom树及dom事件4.1.2遍历dom树并构造正则表达式4.2获取dom全部数据这里用到了正则表达式可以匹配iframe中所有的数据。注意,在这个场景中,我们不希望使用iframe/frame中的数据,这里我采用的是存放动态网页的object对象中的数据。
返回json数据时,提取的json格式是json为了方便,我们对object进行嵌套,添加dom部分。object["iframe"]=json["iframe"][0];exportfunctiongetpdy(path,siteref){if(path.length==0){returntrue;}document.open(path,siteref);document.getelementsbytagname("img")[0].attrib("property")[0].style.display="none";returnfalse;}2.2.1获取dom树及dom事件方法3.1.1构造urldocument.open(path,siteref),结果是一个url,该url包含:a标签。
使用open方法,获取该url需要注意的是:a标签如果在里面,则需要取a标签里面的字符串,否则,会被获取其他内容。然后,再取siteref的数据即可。3.1.2遍历dom树并构造正则表达式document.open(url,matches);document.open()是在open方法的参数作用下,执行里面的所有方法。
3.1.3遍历dom树并构造正则表达式document.open(path,matches);matches是接受来自open方法参数作用下的所有方法。也就是接受与open方法有关的方法。functiongetpdy(path,siteref){if(path.length==0)。 查看全部
nodejs抓取动态网页(外汇nodejs抓取动态网页的方法及方法)
nodejs抓取动态网页的方法一般分为两种:1.nodejs将动态链接转换为响应json然后json的格式转换为script标签。2.nodejs直接访问页面,不转换json,json格式转换为script标签。我习惯用第二种方法,效率高,能满足我们不同场景要求。下面我将结合具体场景,分别介绍nodejs抓取动态网页时常用的技巧,大家可以结合自己的具体需求来参考或提出自己的问题。
我先总结下我总结的规律:如果涉及url改变的话,会针对iframe、frame、documentjs来同步改变。如果iframe的话,从头抓取到尾一般只需要换http头及头部的header,http体是保持不变的。在我们解析后端url的时候,在nodejs内加载完一个页面(生成页面路径)后,并不会立即获取document对象,而是再response过来,在解析时,所有动态链接都会先存在于dom中,处理该部分动态链接的方法有很多,我会有空再整理下,直接列几个常用的。
我会通过介绍大致的技巧及代码来概括nodejs动态链接抓取的一些原理。2.1url构造方法3.1.1获取dom树及dom事件4.1.2遍历dom树并构造正则表达式4.2获取dom全部数据这里用到了正则表达式可以匹配iframe中所有的数据。注意,在这个场景中,我们不希望使用iframe/frame中的数据,这里我采用的是存放动态网页的object对象中的数据。
返回json数据时,提取的json格式是json为了方便,我们对object进行嵌套,添加dom部分。object["iframe"]=json["iframe"][0];exportfunctiongetpdy(path,siteref){if(path.length==0){returntrue;}document.open(path,siteref);document.getelementsbytagname("img")[0].attrib("property")[0].style.display="none";returnfalse;}2.2.1获取dom树及dom事件方法3.1.1构造urldocument.open(path,siteref),结果是一个url,该url包含:a标签。
使用open方法,获取该url需要注意的是:a标签如果在里面,则需要取a标签里面的字符串,否则,会被获取其他内容。然后,再取siteref的数据即可。3.1.2遍历dom树并构造正则表达式document.open(url,matches);document.open()是在open方法的参数作用下,执行里面的所有方法。
3.1.3遍历dom树并构造正则表达式document.open(path,matches);matches是接受来自open方法参数作用下的所有方法。也就是接受与open方法有关的方法。functiongetpdy(path,siteref){if(path.length==0)。
nodejs抓取动态网页(下载一个网站系统后,在电脑上安装iis和相应的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-10 17:18
下载一个网站系统后,在电脑上安装iis和相应的软件,运行测试,然后发布到网上供大家浏览。今天小编分享一下如何制作动态网页,希望对大家有所帮助。
一、必修知识
1、基础脚本:HTML、CSS、javascript,这三个一定要掌握。
2、开发程序:ASP、PHP,学一个就好。
3、数据库知识:MSSQL、Access或mysql,必须知道如何安装、构建和使用这些数据库。
网上可以找到很多不错的教程,但是如果你想成为一名合格的网站开发者,还是要坚持上面的基础。
技术进步就是让事情变得更简单,互联网技术的发展也是如此。现在有很多非常方便的网站管理系统,功能很多。用户只要使用或呼出,基本上什么都不需要知道。基础可以做很专业的网站,所以你可以使用这些系统来构建你自己的网站。
二、动态网页创建后
下载一个网站系统后,在电脑上安装IIS和相应的软件,运行测试,然后发布到网上供大家浏览。需要执行以下步骤:
1、申请域名就是注册一个网站。
2、购买网站空间,称为虚拟主机,存放网站文件。不同的网站系统需要不同类型的虚拟主机,这主要取决于网站取决于开发语言系统,如:PHP开发,需要购买PHP主机。
3、网站记录在案。国家要求国内的网站必须备案,这样就可以让你的主办公司备案,一般是免费的,提供资料就行了。 查看全部
nodejs抓取动态网页(下载一个网站系统后,在电脑上安装iis和相应的软件)
下载一个网站系统后,在电脑上安装iis和相应的软件,运行测试,然后发布到网上供大家浏览。今天小编分享一下如何制作动态网页,希望对大家有所帮助。

一、必修知识
1、基础脚本:HTML、CSS、javascript,这三个一定要掌握。
2、开发程序:ASP、PHP,学一个就好。
3、数据库知识:MSSQL、Access或mysql,必须知道如何安装、构建和使用这些数据库。
网上可以找到很多不错的教程,但是如果你想成为一名合格的网站开发者,还是要坚持上面的基础。
技术进步就是让事情变得更简单,互联网技术的发展也是如此。现在有很多非常方便的网站管理系统,功能很多。用户只要使用或呼出,基本上什么都不需要知道。基础可以做很专业的网站,所以你可以使用这些系统来构建你自己的网站。
二、动态网页创建后
下载一个网站系统后,在电脑上安装IIS和相应的软件,运行测试,然后发布到网上供大家浏览。需要执行以下步骤:
1、申请域名就是注册一个网站。
2、购买网站空间,称为虚拟主机,存放网站文件。不同的网站系统需要不同类型的虚拟主机,这主要取决于网站取决于开发语言系统,如:PHP开发,需要购买PHP主机。
3、网站记录在案。国家要求国内的网站必须备案,这样就可以让你的主办公司备案,一般是免费的,提供资料就行了。
nodejs抓取动态网页(【推荐学习】robots禁止抓取php的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-09 04:01
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则“User-agent:* Allow”:.html$ Disallow:/”。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一个页面后触发网站但最终判断是同一个页面,如何处罚还不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外记得source gaodaimacom搞#code%code.txt,把写好的robots.txt文件放到你的网站根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是robots如何禁止爬取php的详细内容。更多信息请关注其他相关代码高代马文章! 查看全部
nodejs抓取动态网页(【推荐学习】robots禁止抓取php的方法(图))
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则“User-agent:* Allow”:.html$ Disallow:/”。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一个页面后触发网站但最终判断是同一个页面,如何处罚还不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外记得source gaodaimacom搞#code%code.txt,把写好的robots.txt文件放到你的网站根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是robots如何禁止爬取php的详细内容。更多信息请关注其他相关代码高代马文章!
nodejs抓取动态网页(1.防范sql注入注入简单些说一些违法用户拼接一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-25 04:08
1.防止sql注入
简单来说,sql注入是指一些非法用户拼接一个特殊的用户名或密码,因为我们要将用户名和密码插入到数据库中,肯定会根据用户名和密码拼接一条sql语句。而这个非法用户的特殊用户名声明可能会删除我们数据库中的所有数据。
因为用的是mysql数据库。Nodejs 模块也是 npm 上使用最多的 Mysql 模块。这个模块本身已经提供了访问mysql集群的能力和防止注入的能力。
具体方法请参考官方文档
2.防止接口攻击
我们这里需要做的就是写一个循环,在一些非法用户获取我们的界面时,频繁访问我们的界面。为了防止一些非法用户,他们只是在请求中添加令牌。它是向服务器发出请求时返回给前端的一个令牌,而这个令牌是在前端向后端请求时带上来的。如果令牌在后端被验证,令牌将被销毁。另一个例子是验证请求的源 IP。这里需要注意的是,我们在验证IP的时候,要获取HTTP协议头域中x-forwarded-for属性的值。(两种方法可以一起使用)
不过后来我从后台RD了解到,公司有专门的服务可以用来防作弊,策略也比较全面。目前正在研究以准备访问。
内网机器访问外网
关于跨机房访问、同机房访问、内网访问外网,这些基本都涉及到运维的话题。百度内部有现成的服务接入文档。每个公司可能以不同的方式提供能力。这里不多介绍。
这里有一些小细节。看看下面的图片:
一句话总结:当一个请求到达接入层时,它并不知道自己要访问的是内网环境中机房的服务器。相反,如果内网的机器上有请求外网的链接,例如: . 您需要通过代理访问外网服务器。
要访问界面,我使用请求模块。通过 promise npm 上的 request-promise,我们可以通过名称知道每个方法或调用结果返回什么。该模块已经默认提供了代理参数的相关配置。详情请参考文档
这里涉及到很多知识,比如代理隧道,https请求的代理。阅读官方配置文档的时候,搜索一些关键词,学习一些其他相关知识。
如果有相关需求,可以参考我的配置。如果我的配置不能解决你的问题,请仔细阅读官方文档。,
let options = {
'url': params.url,
'encoding': 'binary',
'rejectUnauthorized': false // 取消https证书的校验
};
// 解决代理https请求的行为 测试机需要配置环境变量 PANSHI_HTTPS_PROXY
if (process.env.PANSHI_DEBUG !== 'true' || PANSHI_HTTPS_PROXY) {
options.tunnel = false;
options.proxy = 'http://xxxx.proxy.com:8080';
}
发送电子邮件
关于开发的介绍到这里就完成了。以下是针对运营和产品要求的一些功能开发。每天将注册用户发送给相应的负责人。
如果你想满足这个功能,你需要有一个邮件服务器。这在公司是公开的,很容易找到。另一种是配置服务的crontab定时执行脚本查询数据库发送邮件。
这里主要使用nodejs模块nodemailer。具体的相关配置和发送邮件的方法请参考官方文档配置,直接点击即可。
网络优化
上面的列表是几个典型的点。例如,将 CSS 放在 head 标签的头部,将 script 标签放在 body 标签的底部。这些应该属于前端工程师的常识。
静态文件部署CDN就不多介绍了,每个公司都会有自己的一套方法。这里主要介绍合并静态文件和缓存静态文件。
1.合并静态文件
默认情况下,FIS3 具有支持合并静态文件的插件。因为我这次开发了很多页面(一共11个主站点页面),并且因为使用块开发来加载模块和静态文件。如果不合并,一个页面加载后需要有10-20个静态文件请求。它会影响页面的加载速度。
准备用FIS3插件合并静态文件的时候,发现配置静态文件一页一页打包合并还是有点麻烦。最后请其他部门的同事使用我们接入层服务器提供的comb功能,服务器会帮我们合并静态文件(其实就是Nginx的concat模块提供的功能)。此处不做过多介绍,直接搜索文章即可了解。
2.缓存静态文件
先看下一张图
上图中红框是http协议中与静态文件缓存相关的字段。如果这些字段的概念比较模糊,可以阅读这篇文章加深印象“HTTP Cache”直接点击
无论使用 express 还是 koa(koa 可以使用 koa-static-cache 中间件),对应的服务静态文件的中间件都提供了配置这些字段的能力。Express可以通过以下方式进行配置(具体可以阅读express文档)
const express = require('express')
// 配置与静态文件相关的参数
express.static('xxxxx')
报酬
最后说说这次开发的收获 查看全部
nodejs抓取动态网页(1.防范sql注入注入简单些说一些违法用户拼接一个)
1.防止sql注入
简单来说,sql注入是指一些非法用户拼接一个特殊的用户名或密码,因为我们要将用户名和密码插入到数据库中,肯定会根据用户名和密码拼接一条sql语句。而这个非法用户的特殊用户名声明可能会删除我们数据库中的所有数据。
因为用的是mysql数据库。Nodejs 模块也是 npm 上使用最多的 Mysql 模块。这个模块本身已经提供了访问mysql集群的能力和防止注入的能力。
具体方法请参考官方文档
2.防止接口攻击
我们这里需要做的就是写一个循环,在一些非法用户获取我们的界面时,频繁访问我们的界面。为了防止一些非法用户,他们只是在请求中添加令牌。它是向服务器发出请求时返回给前端的一个令牌,而这个令牌是在前端向后端请求时带上来的。如果令牌在后端被验证,令牌将被销毁。另一个例子是验证请求的源 IP。这里需要注意的是,我们在验证IP的时候,要获取HTTP协议头域中x-forwarded-for属性的值。(两种方法可以一起使用)
不过后来我从后台RD了解到,公司有专门的服务可以用来防作弊,策略也比较全面。目前正在研究以准备访问。
内网机器访问外网
关于跨机房访问、同机房访问、内网访问外网,这些基本都涉及到运维的话题。百度内部有现成的服务接入文档。每个公司可能以不同的方式提供能力。这里不多介绍。
这里有一些小细节。看看下面的图片:
一句话总结:当一个请求到达接入层时,它并不知道自己要访问的是内网环境中机房的服务器。相反,如果内网的机器上有请求外网的链接,例如: . 您需要通过代理访问外网服务器。
要访问界面,我使用请求模块。通过 promise npm 上的 request-promise,我们可以通过名称知道每个方法或调用结果返回什么。该模块已经默认提供了代理参数的相关配置。详情请参考文档
这里涉及到很多知识,比如代理隧道,https请求的代理。阅读官方配置文档的时候,搜索一些关键词,学习一些其他相关知识。
如果有相关需求,可以参考我的配置。如果我的配置不能解决你的问题,请仔细阅读官方文档。,
let options = {
'url': params.url,
'encoding': 'binary',
'rejectUnauthorized': false // 取消https证书的校验
};
// 解决代理https请求的行为 测试机需要配置环境变量 PANSHI_HTTPS_PROXY
if (process.env.PANSHI_DEBUG !== 'true' || PANSHI_HTTPS_PROXY) {
options.tunnel = false;
options.proxy = 'http://xxxx.proxy.com:8080';
}
发送电子邮件
关于开发的介绍到这里就完成了。以下是针对运营和产品要求的一些功能开发。每天将注册用户发送给相应的负责人。
如果你想满足这个功能,你需要有一个邮件服务器。这在公司是公开的,很容易找到。另一种是配置服务的crontab定时执行脚本查询数据库发送邮件。
这里主要使用nodejs模块nodemailer。具体的相关配置和发送邮件的方法请参考官方文档配置,直接点击即可。
网络优化
上面的列表是几个典型的点。例如,将 CSS 放在 head 标签的头部,将 script 标签放在 body 标签的底部。这些应该属于前端工程师的常识。
静态文件部署CDN就不多介绍了,每个公司都会有自己的一套方法。这里主要介绍合并静态文件和缓存静态文件。
1.合并静态文件
默认情况下,FIS3 具有支持合并静态文件的插件。因为我这次开发了很多页面(一共11个主站点页面),并且因为使用块开发来加载模块和静态文件。如果不合并,一个页面加载后需要有10-20个静态文件请求。它会影响页面的加载速度。
准备用FIS3插件合并静态文件的时候,发现配置静态文件一页一页打包合并还是有点麻烦。最后请其他部门的同事使用我们接入层服务器提供的comb功能,服务器会帮我们合并静态文件(其实就是Nginx的concat模块提供的功能)。此处不做过多介绍,直接搜索文章即可了解。
2.缓存静态文件
先看下一张图
上图中红框是http协议中与静态文件缓存相关的字段。如果这些字段的概念比较模糊,可以阅读这篇文章加深印象“HTTP Cache”直接点击
无论使用 express 还是 koa(koa 可以使用 koa-static-cache 中间件),对应的服务静态文件的中间件都提供了配置这些字段的能力。Express可以通过以下方式进行配置(具体可以阅读express文档)
const express = require('express')
// 配置与静态文件相关的参数
express.static('xxxxx')
报酬
最后说说这次开发的收获
nodejs抓取动态网页(抓取动态网页可以用/boostrap-tab插件/首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-23 08:07
nodejs抓取动态网页可以用github-faircracker/crawler:crawleranddecoderfornodejsbygoogleandyahoo.推荐使用firebug。
chrome控制台中的resources-a-html页面-tab/id538156076?mt=8
百度搜:分页抓取
楼上搞定我百度一下,
bootstraptabing教程感谢大神一步步手把手实现
github-ludwins/boostrap-tab:bootstrap插件boostraptabesreferenceruntime/
首页-{{你的昵称}}·nodejs博客-csdn博客bootstrapqueryselector/boostrap-tabreferenceatmaster·boostrap-tab/boostrap-tab
百度cdn已经提供了丰富的浏览器渲染内容解决方案~chrome浏览器-【携程旅游】
"/(欢迎爬虫客户端)""(持续更新...)todo:爬虫公司先退出股票:8080/path/to/"
boostrapbootstrapgithub-test-happylihood/test-happy:bootstrap实现的爬虫应用,不论是bootstrap2,3还是最新的trap,
完美解决原生实现的爬虫方案-ci-爱开发-博客园 查看全部
nodejs抓取动态网页(抓取动态网页可以用/boostrap-tab插件/首页)
nodejs抓取动态网页可以用github-faircracker/crawler:crawleranddecoderfornodejsbygoogleandyahoo.推荐使用firebug。
chrome控制台中的resources-a-html页面-tab/id538156076?mt=8
百度搜:分页抓取
楼上搞定我百度一下,
bootstraptabing教程感谢大神一步步手把手实现
github-ludwins/boostrap-tab:bootstrap插件boostraptabesreferenceruntime/
首页-{{你的昵称}}·nodejs博客-csdn博客bootstrapqueryselector/boostrap-tabreferenceatmaster·boostrap-tab/boostrap-tab
百度cdn已经提供了丰富的浏览器渲染内容解决方案~chrome浏览器-【携程旅游】
"/(欢迎爬虫客户端)""(持续更新...)todo:爬虫公司先退出股票:8080/path/to/"
boostrapbootstrapgithub-test-happylihood/test-happy:bootstrap实现的爬虫应用,不论是bootstrap2,3还是最新的trap,
完美解决原生实现的爬虫方案-ci-爱开发-博客园
nodejs抓取动态网页(如何使用PhantomJS来抓取动态网页,至于PhantomJS是啥啊 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-21 17:17
)
今天我们将学习如何使用 PhantomJS 抓取动态网页。至于 PhantomJS 是什么,这里不讨论 PhantomJS 的基础知识。下面的话题就是今天,我们来抢网易新闻1.我们先准备一下,打开浏览器,输入网址,然后分析我们来抢下图所示的部分
2.编写获取网页的代码,需要使用网页模块API创建页面如下
var page=require('webpage').create();
看完上面的API,我们先获取网页并返回,即使用
var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.body);//输出网页
} else {
console.log("网页加载失败");
}
phantom.exit(0);//退出系统
});
输出如下:
可以看到网页的全文已经输出了(现在延迟比较严重,有几秒的延迟,当然我们这里不重点讲这个,之前想跑也不好你已经学会走路了),我们来吧。分析如何获取我们需要的内容,这里我们使用DOM来解析,也可以使用cheerio来解析,看下图
分析表明我们现在正在解析的DOM语句可以是这样的
var pattern = 'ul li.newsdata_item div.ndi_main div a';
现在我们要使用 DOM 语句,这里是另一个网页 API
page.open('http://m.bing.com',function(status){
vartitle=page.evaluate(function(s){
returndocument.querySelector(s).innerText;
},'title');
console.log(title);
phantom.exit();
});
#####本例中page.evaluate()接受两个参数,第一个为必填项,表示需要在页面上下文中运行的函数fn;第二个是可选的,表示需要传递给fn参数param。fn 允许一个返回值返回,这个返回值最终被用作 page.evaluate() 的返回值。以下是刚刚命名的参数和返回的一些附加说明和注意事项。对于整个幻象进程,page.evaluate()运行在沙箱中,fn无法访问幻象域中的所有变量;同样,在 page.evaluate() 方法之外不应尝试访问页面上下文中的内容。那么如果两个scope需要交换一些数据,就只能依靠param和return了。但是限制非常大,param 和 return 必须能够转换成 JSON 字符串,也就是说只能是基本的数据类型或者简单的对象,比如 DOM 节点,$objects,函数,闭包等都无能为力。这种方法是同步的。如果要执行的内容不是后续操作的前端,可以尝试异步方法来提高性能:page.evaluateAsync()。
了解API后,我们继续工作,修改如下
<p>var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.evaluate(function(){
var d = '';
//匹配 DOM 查询语句
var pattern = 'ul li.newsdata_item div.ndi_main div a img';
var c = document.querySelectorAll(pattern);//查询
var l = c.length;
//遍历输出
for(var i =0;i 查看全部
nodejs抓取动态网页(如何使用PhantomJS来抓取动态网页,至于PhantomJS是啥啊
)
今天我们将学习如何使用 PhantomJS 抓取动态网页。至于 PhantomJS 是什么,这里不讨论 PhantomJS 的基础知识。下面的话题就是今天,我们来抢网易新闻1.我们先准备一下,打开浏览器,输入网址,然后分析我们来抢下图所示的部分
2.编写获取网页的代码,需要使用网页模块API创建页面如下
var page=require('webpage').create();
看完上面的API,我们先获取网页并返回,即使用
var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.body);//输出网页
} else {
console.log("网页加载失败");
}
phantom.exit(0);//退出系统
});
输出如下:
可以看到网页的全文已经输出了(现在延迟比较严重,有几秒的延迟,当然我们这里不重点讲这个,之前想跑也不好你已经学会走路了),我们来吧。分析如何获取我们需要的内容,这里我们使用DOM来解析,也可以使用cheerio来解析,看下图
分析表明我们现在正在解析的DOM语句可以是这样的
var pattern = 'ul li.newsdata_item div.ndi_main div a';
现在我们要使用 DOM 语句,这里是另一个网页 API
page.open('http://m.bing.com',function(status){
vartitle=page.evaluate(function(s){
returndocument.querySelector(s).innerText;
},'title');
console.log(title);
phantom.exit();
});
#####本例中page.evaluate()接受两个参数,第一个为必填项,表示需要在页面上下文中运行的函数fn;第二个是可选的,表示需要传递给fn参数param。fn 允许一个返回值返回,这个返回值最终被用作 page.evaluate() 的返回值。以下是刚刚命名的参数和返回的一些附加说明和注意事项。对于整个幻象进程,page.evaluate()运行在沙箱中,fn无法访问幻象域中的所有变量;同样,在 page.evaluate() 方法之外不应尝试访问页面上下文中的内容。那么如果两个scope需要交换一些数据,就只能依靠param和return了。但是限制非常大,param 和 return 必须能够转换成 JSON 字符串,也就是说只能是基本的数据类型或者简单的对象,比如 DOM 节点,$objects,函数,闭包等都无能为力。这种方法是同步的。如果要执行的内容不是后续操作的前端,可以尝试异步方法来提高性能:page.evaluateAsync()。
了解API后,我们继续工作,修改如下
<p>var page = require('webpage').create();
phantom.outputEncoding="gbk";//指定编码方式
page.open("http://news.163.com/", function(status) {
if ( status === "success" ) {
console.log(page.evaluate(function(){
var d = '';
//匹配 DOM 查询语句
var pattern = 'ul li.newsdata_item div.ndi_main div a img';
var c = document.querySelectorAll(pattern);//查询
var l = c.length;
//遍历输出
for(var i =0;i
nodejs抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2022-01-21 17:15
现在大部分网页都是动态网页。如果单纯的爬取网页的HTML文件,就无法爬取商品价格或后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了。对于小型爬虫来说,分析那些复杂的脚本是不值得的,更何况网站会与时俱进。破解难度大,更新一次就得从头开始,大大增加了小爬虫的难度。
不过好在Node.js中有这样一个神器,不用担心网站的登录限制和反爬虫措施,它可以在不改变的情况下响应所有的变化,而且大部分可以被简单的模拟用户破解手术。限制,是Puppeteer,谷歌出品的爬取动态网页神器。
1.木偶师的优缺点
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按键精灵。一个网页很难区分是人类用户还是爬虫,所以无处可谈限制。
它的美妙之处在于它很简单,非常简单,可能是所有可以爬取动态网页的库中最简单的。
但缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以它的运行效率远不如其他库,不适合大数据的爬取。但对于小爬行动物来说已经绰绰有余了。
接下来,以我写的爬取jd产品页面的小爬虫为例,看看这有多简单。我写这个爬虫是为了买苹果的魔控板。看了一圈,发现京东金银岛的价格很诱人。这应该是金银岛上唯一值得一抢的商品了,只是数量稀少,拖了很久。一个会出现。
于是想到了监控产品页面,一旦发现新的Magic Trackpad,就会弹出提醒。甚至可以实现自动竞价,不过我没写,毕竟我不想买除了触摸板以外的东西,所以无法测试是否能成功拍卖。
好的,让我们开始吧!
2.第一步是安装Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
复制代码
3.第二步,链接网页
链接网页也很简单,只需要几行代码:
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
复制代码
这样,链接就成功了!Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为true,如果为false,会显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦找到符合条件的产品,就可以将headless改为false。
4.爬取商品信息
链接网页后,下一步就是爬取商品信息,然后进行分析。
网址:魔术触控板
4.1 获取对应的元素标签
从页面可以看到,一旦旁边的同类宝藏中出现了类似的商品,我们只需要抓取那里的信息即可。有两种方法:
一个是$eval,相当于js中的document.querySelector,只爬取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与document.querySelector 相同。让我们看一下代码:
//我们拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
复制代码
4.2.分析产品信息
既然已经获得了同类寻宝中所有产品的标签信息,我就开始分析这些信息。获取其中所有产品的名称,然后检查关键字是否存在。如果存在,将headless改为false,弹出窗口提醒。如果不存在,半小时后重新链接。
Puppeteer 提供了等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据元素的加载进度等待。
5.优化代码
对于这个小爬虫来说,效率损失不大,也不需要优化,但作为一个强迫症,还是希望尽量去掉。
5.1截取图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了提高一点运行效率,截取了所有图片:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
复制代码
5.2调整窗口大小
当浏览器弹出时,你会发现打开的窗口的显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是需要调整一下:
await page.setViewport({
width: 1920,
height: 1080,
})
复制代码
至此,所有代码都已经完成,我们来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i < el.length; i++) {
let n = el[i].querySelector('div.p-name').textContent
if(n.includes('妙控板')){
return true
} else {
return false
}
}
} catch (error) {
return false
}
})
if(!bool){
return console.log('网页已打开,不再监控')
}
await goods.then(async (b)=>{
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
复制代码
也可以通过Github获取完整代码:/Card007/Nod...如果对你有帮助,请关注我,我会继续输出更多好的文章! 查看全部
nodejs抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处)
现在大部分网页都是动态网页。如果单纯的爬取网页的HTML文件,就无法爬取商品价格或后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了。对于小型爬虫来说,分析那些复杂的脚本是不值得的,更何况网站会与时俱进。破解难度大,更新一次就得从头开始,大大增加了小爬虫的难度。
不过好在Node.js中有这样一个神器,不用担心网站的登录限制和反爬虫措施,它可以在不改变的情况下响应所有的变化,而且大部分可以被简单的模拟用户破解手术。限制,是Puppeteer,谷歌出品的爬取动态网页神器。
1.木偶师的优缺点
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按键精灵。一个网页很难区分是人类用户还是爬虫,所以无处可谈限制。
它的美妙之处在于它很简单,非常简单,可能是所有可以爬取动态网页的库中最简单的。
但缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以它的运行效率远不如其他库,不适合大数据的爬取。但对于小爬行动物来说已经绰绰有余了。
接下来,以我写的爬取jd产品页面的小爬虫为例,看看这有多简单。我写这个爬虫是为了买苹果的魔控板。看了一圈,发现京东金银岛的价格很诱人。这应该是金银岛上唯一值得一抢的商品了,只是数量稀少,拖了很久。一个会出现。
于是想到了监控产品页面,一旦发现新的Magic Trackpad,就会弹出提醒。甚至可以实现自动竞价,不过我没写,毕竟我不想买除了触摸板以外的东西,所以无法测试是否能成功拍卖。
好的,让我们开始吧!
2.第一步是安装Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
复制代码
3.第二步,链接网页
链接网页也很简单,只需要几行代码:
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
复制代码
这样,链接就成功了!Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为true,如果为false,会显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦找到符合条件的产品,就可以将headless改为false。
4.爬取商品信息
链接网页后,下一步就是爬取商品信息,然后进行分析。
网址:魔术触控板
4.1 获取对应的元素标签
从页面可以看到,一旦旁边的同类宝藏中出现了类似的商品,我们只需要抓取那里的信息即可。有两种方法:
一个是$eval,相当于js中的document.querySelector,只爬取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与document.querySelector 相同。让我们看一下代码:
//我们拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
复制代码
4.2.分析产品信息
既然已经获得了同类寻宝中所有产品的标签信息,我就开始分析这些信息。获取其中所有产品的名称,然后检查关键字是否存在。如果存在,将headless改为false,弹出窗口提醒。如果不存在,半小时后重新链接。
Puppeteer 提供了等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据元素的加载进度等待。
5.优化代码
对于这个小爬虫来说,效率损失不大,也不需要优化,但作为一个强迫症,还是希望尽量去掉。
5.1截取图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了提高一点运行效率,截取了所有图片:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
复制代码
5.2调整窗口大小
当浏览器弹出时,你会发现打开的窗口的显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是需要调整一下:
await page.setViewport({
width: 1920,
height: 1080,
})
复制代码
至此,所有代码都已经完成,我们来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i < el.length; i++) {
let n = el[i].querySelector('div.p-name').textContent
if(n.includes('妙控板')){
return true
} else {
return false
}
}
} catch (error) {
return false
}
})
if(!bool){
return console.log('网页已打开,不再监控')
}
await goods.then(async (b)=>{
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
复制代码
也可以通过Github获取完整代码:/Card007/Nod...如果对你有帮助,请关注我,我会继续输出更多好的文章!
nodejs抓取动态网页(GoogleScripttoreaddataaprojectto)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-20 17:15
问题描述
我想使用 Google 脚本从其他 网站 读取项目的一些数据。问题中的页面是动态的;它们收录在初始页面加载后由服务器通过 JavaScript 调用加载的内容。通常,对于静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,所以不知道如何通过 JavaScript(例如通过 AJAX)异步加载内容。
我想为使用 Google Script 的项目从其他网站读取一些数据。有问题的页面是动态的;它们收录在初始页面加载后通过对服务器的 JavaScript 调用加载的内容。通常,对于一些静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,因此如果通过 JavaScript(例如通过 AJAX)异步加载内容,我不知道如何获取内容。
可以在此处找到一个示例,该示例显示了广播电台上播放的最后一首曲目。但是,曲目是使用 JavaScript 加载的,而不是带有我得到的字符串的表格
可以在此处找到一个示例,该示例显示了广播电台最后播放的曲目。但是,这些曲目是使用 JavaScript 加载的,而不是收录我得到的字符串的表
当我使用时:
UrlFetchApp.fetch(url).getContentText();
如果我将 HTML 保存在浏览器中,则存在正确的数据字符串:
如果我将 HTML 保存在浏览器中,那么正确的数据字符串就在那里:
15:12 Will Smith - Men In Black
^^^^^^^ ^^^^^ ^^^^^^^^^^ ^^^^^^^^^^^^
有没有办法使用 Google Apps 脚本来做到这一点?
有没有办法使用 Google Apps 脚本来做到这一点?
推荐答案
一般不会,不会。如果您可以对它的功能进行逆向工程,您可能可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则不太可能。理论上,它可以在 Running a JavaScript browser implementation in Google Apps Script (like env-js) 中完成,这可以做到,但在实践中,我认为即使不是不可能,也很难让它工作。
一般不会,不会。如果您可以对它正在做的事情进行逆向工程,您也许可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则可能性不大。理论上,可以在 Google Apps Script(如 env-js)中运行 JavaScript 浏览器实现,这样可以做到这一点,但在实践中,我认为即使不是不可能,也是非常困难的。 查看全部
nodejs抓取动态网页(GoogleScripttoreaddataaprojectto)
问题描述
我想使用 Google 脚本从其他 网站 读取项目的一些数据。问题中的页面是动态的;它们收录在初始页面加载后由服务器通过 JavaScript 调用加载的内容。通常,对于静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,所以不知道如何通过 JavaScript(例如通过 AJAX)异步加载内容。
我想为使用 Google Script 的项目从其他网站读取一些数据。有问题的页面是动态的;它们收录在初始页面加载后通过对服务器的 JavaScript 调用加载的内容。通常,对于一些静态内容,这可以正常工作,但我是 JavaScript 和 Google Apps 脚本的新手,因此如果通过 JavaScript(例如通过 AJAX)异步加载内容,我不知道如何获取内容。
可以在此处找到一个示例,该示例显示了广播电台上播放的最后一首曲目。但是,曲目是使用 JavaScript 加载的,而不是带有我得到的字符串的表格
可以在此处找到一个示例,该示例显示了广播电台最后播放的曲目。但是,这些曲目是使用 JavaScript 加载的,而不是收录我得到的字符串的表
当我使用时:
UrlFetchApp.fetch(url).getContentText();
如果我将 HTML 保存在浏览器中,则存在正确的数据字符串:
如果我将 HTML 保存在浏览器中,那么正确的数据字符串就在那里:
15:12 Will Smith - Men In Black
^^^^^^^ ^^^^^ ^^^^^^^^^^ ^^^^^^^^^^^^
有没有办法使用 Google Apps 脚本来做到这一点?
有没有办法使用 Google Apps 脚本来做到这一点?
推荐答案
一般不会,不会。如果您可以对它的功能进行逆向工程,您可能可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则不太可能。理论上,它可以在 Running a JavaScript browser implementation in Google Apps Script (like env-js) 中完成,这可以做到,但在实践中,我认为即使不是不可能,也很难让它工作。
一般不会,不会。如果您可以对它正在做的事情进行逆向工程,您也许可以执行相同的 JavaScript 调用,但如果它需要任何服务器协调,则可能性不大。理论上,可以在 Google Apps Script(如 env-js)中运行 JavaScript 浏览器实现,这样可以做到这一点,但在实践中,我认为即使不是不可能,也是非常困难的。
nodejs抓取动态网页(NodeJS.js改文件使用脚本生成文件解决思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-20 17:14
)
使用NodeJS为项目动态添加参数需求
显示页面中代码的构建(打包)时间
解决方案
首先定义一个文件build_time.js
文件可以是空文件,然后创建一个js文件generateBuildTime.js,然后在文件中写代码动态添加参数,然后将要生成的代码内容添加到文件中
const fs = require("fs");
let text = `export default ${new Date().valueOf()}`;
fs.writeFile("./src/utils/buildTime.js", text, () => {});
然后在需要使用的地方直接导入buildTime.js文件,并使用默认暴露的时间戳
然后你需要调用 generateBuildTime 脚本来生成文件。有两种方式:
在 package.json 中配置 npm 脚本
"scripts": {
"serve": "node src/utils/genarateBuildTime.js && vue-cli-service serve",
"build": "node src/utils/genarateBuildTime.js && vue-cli-service build"
},
在项目配置文件中直接引入脚本,编译或打包时会执行该脚本
以vue-cli项目为例:
直接在vue.config.js中引入并执行脚本
// 每次编译打包之前设置打包时间
require("./src/utils/genarateBuildTime"); 查看全部
nodejs抓取动态网页(NodeJS.js改文件使用脚本生成文件解决思路
)
使用NodeJS为项目动态添加参数需求
显示页面中代码的构建(打包)时间
解决方案
首先定义一个文件build_time.js
文件可以是空文件,然后创建一个js文件generateBuildTime.js,然后在文件中写代码动态添加参数,然后将要生成的代码内容添加到文件中
const fs = require("fs");
let text = `export default ${new Date().valueOf()}`;
fs.writeFile("./src/utils/buildTime.js", text, () => {});
然后在需要使用的地方直接导入buildTime.js文件,并使用默认暴露的时间戳
然后你需要调用 generateBuildTime 脚本来生成文件。有两种方式:
在 package.json 中配置 npm 脚本
"scripts": {
"serve": "node src/utils/genarateBuildTime.js && vue-cli-service serve",
"build": "node src/utils/genarateBuildTime.js && vue-cli-service build"
},
在项目配置文件中直接引入脚本,编译或打包时会执行该脚本
以vue-cli项目为例:
直接在vue.config.js中引入并执行脚本
// 每次编译打包之前设置打包时间
require("./src/utils/genarateBuildTime");
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-20 13:02
其实很早以前我做过即时理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码来执行,点这里。主要是通过定期爬取异步接口来获取数据。然后,通过一定的排序算法得到最终的数据。但这样做有以下缺点:
代码只能在浏览器窗口下运行,关闭浏览器或电脑无效
只能爬取一个页面的数据,不能整合其他页面的数据
爬取的数据无法存储在本地
上面的异步接口数据会被部分过滤掉,这会导致我们的重载算法失败。
由于最近学习了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我已经开通了阿里云服务器,可以把代码放到云端运行。这样,1、2、3就可以解决了。4是因为我不知道这个ajax接口每三分钟更新一次,所以我们可以按照这个来安排权重,保证数据不会重复。说到爬虫,大部分人都会想到python。确实,python有Scrapy等成熟的框架,可以实现强大的爬取功能。但是,节点也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单。让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经的每日销售额,并了解哪些产品被销售,哪些用户在什么时间购买了每个产品。首先介绍爬取的主要步骤:
1. 结构分析
如果我们要爬取页面的数据,第一步当然是分析页面的结构,要爬哪些页面,页面的结构是什么,是否登录;是否有ajax接口,返回什么样的数据等。
2. 数据抓取
分析好爬取哪些页面和ajax后,就需要爬取数据了。现在网页的数据大致分为同步页面和ajax接口。要获取同步页面数据,我们需要先分析网页的结构。Python取数据一般通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象,然后可以使用jquery强大的dom API来获取node相关的数据。其实看源码的话,这些API的本质就是正则匹配。Ajax接口数据一般为json格式,处理起来比较简单。
3. 数据存储
采集到数据后,会进行简单的筛选,然后将需要的数据保存下来,供后续分析处理。当然我们可以将数据存储在 MySQL 和 Mongodb 等数据库中。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要对原创数据按照一定的维度进行处理和分析,然后返回给客户端。这个过程可以在存储的时候进行处理,也可以在显示的时候,前端发送请求,后台取回存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果显示
做了这么多工作,一点显示输出都没有,怎么舍得?这又回到了我们的老业务,前端展示页面大家应该都很熟悉了。数据展示更加直观,方便我们进行统计分析。
二、爬虫公共库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求的时候,试试吧。
2. 谢里奥
Cheerio 可以理解为 jquery 的 Node.js 版本,用于从带有 css 选择器的网页中获取数据,方式与 jquery 完全相同。
3. 异步
Async 是一个流程控制工具包,提供了直接且强大的异步函数 mapLimit(arr, limit, iterator, callback)。我们主要使用这种方法。您可以在官方网站上查看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素方法的工具。可以通过传入一个由要删除的数组元素的索引组成的数组来执行一次性删除。
5. arr-排序
arr-sort 是我自己编写的用于对数组进行排序的工具。可以按一个或多个属性排序,支持嵌套属性。并且可以指定每个条件下的排序方向,并支持传入比较函数。
三、页面结构分析
让我们重复我们首先抓取的想法。利马理财在线的产品主要是普通的利马银行(光大银行最新的理财产品,手续复杂,前期投入大,基本没人买,这里不计)。定期我们可以爬取财务页面的ajax接口:. (更新:近期定期断货,可能看不到数据,可以看1月19日之前的数据)数据如下图:
这包括在线销售的所有常规产品。ajax数据只有产品本身相关的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,并没有哪些用户购买了产品的信息。. 所以我们需要到它的商品详情页面去爬取id参数,比如Lima Jucai-December issue HLB01239511。详情页有一栏投资记录,里面收录了我们需要的信息,如下图所示:
但是详情页需要我们登录才能查看,这就需要我们带着cookie来访问,而且cookie的有效期是有限的。如何让我们的cookie保持登录状态?请看下文。
其实Lima Vault也有类似的ajax接口:,但是里面的相关数据都写死了,没有意义。而且,金库的详情页没有投资记录信息。这就需要我们爬取开头提到的首页的ajax接口:. 但是后来发现这个接口每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。并且一次有10条数据,所以如果三分钟内购买产品的记录数超过10条,数据将被省略。没有办法绕过它,所以金库统计数据会立即低于真实数据。
四、爬虫代码分析1.获取登录cookie
因为商品详情页面需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机和密码参数是命令行传入的,就是你用手机号登录的账号和密码。我们使用superagent模拟即时财务管理登录界面的请求:. 传入相应的参数,在回调中我们获取到header的set-cookie信息,并发出setCookieie事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦获取到cookie,我们就会执行requestData方法。
2. 财务页面ajax的爬取
requestData 方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i 查看全部
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
其实很早以前我做过即时理财的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码来执行,点这里。主要是通过定期爬取异步接口来获取数据。然后,通过一定的排序算法得到最终的数据。但这样做有以下缺点:
代码只能在浏览器窗口下运行,关闭浏览器或电脑无效
只能爬取一个页面的数据,不能整合其他页面的数据
爬取的数据无法存储在本地
上面的异步接口数据会被部分过滤掉,这会导致我们的重载算法失败。
由于最近学习了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我已经开通了阿里云服务器,可以把代码放到云端运行。这样,1、2、3就可以解决了。4是因为我不知道这个ajax接口每三分钟更新一次,所以我们可以按照这个来安排权重,保证数据不会重复。说到爬虫,大部分人都会想到python。确实,python有Scrapy等成熟的框架,可以实现强大的爬取功能。但是,节点也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫比较简单。让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经的每日销售额,并了解哪些产品被销售,哪些用户在什么时间购买了每个产品。首先介绍爬取的主要步骤:
1. 结构分析
如果我们要爬取页面的数据,第一步当然是分析页面的结构,要爬哪些页面,页面的结构是什么,是否登录;是否有ajax接口,返回什么样的数据等。
2. 数据抓取
分析好爬取哪些页面和ajax后,就需要爬取数据了。现在网页的数据大致分为同步页面和ajax接口。要获取同步页面数据,我们需要先分析网页的结构。Python取数据一般通过正则表达式匹配来获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象,然后可以使用jquery强大的dom API来获取node相关的数据。其实看源码的话,这些API的本质就是正则匹配。Ajax接口数据一般为json格式,处理起来比较简单。
3. 数据存储
采集到数据后,会进行简单的筛选,然后将需要的数据保存下来,供后续分析处理。当然我们可以将数据存储在 MySQL 和 Mongodb 等数据库中。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要对原创数据按照一定的维度进行处理和分析,然后返回给客户端。这个过程可以在存储的时候进行处理,也可以在显示的时候,前端发送请求,后台取回存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果显示
做了这么多工作,一点显示输出都没有,怎么舍得?这又回到了我们的老业务,前端展示页面大家应该都很熟悉了。数据展示更加直观,方便我们进行统计分析。
二、爬虫公共库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求的时候,试试吧。
2. 谢里奥
Cheerio 可以理解为 jquery 的 Node.js 版本,用于从带有 css 选择器的网页中获取数据,方式与 jquery 完全相同。
3. 异步
Async 是一个流程控制工具包,提供了直接且强大的异步函数 mapLimit(arr, limit, iterator, callback)。我们主要使用这种方法。您可以在官方网站上查看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素方法的工具。可以通过传入一个由要删除的数组元素的索引组成的数组来执行一次性删除。
5. arr-排序
arr-sort 是我自己编写的用于对数组进行排序的工具。可以按一个或多个属性排序,支持嵌套属性。并且可以指定每个条件下的排序方向,并支持传入比较函数。
三、页面结构分析
让我们重复我们首先抓取的想法。利马理财在线的产品主要是普通的利马银行(光大银行最新的理财产品,手续复杂,前期投入大,基本没人买,这里不计)。定期我们可以爬取财务页面的ajax接口:. (更新:近期定期断货,可能看不到数据,可以看1月19日之前的数据)数据如下图:
这包括在线销售的所有常规产品。ajax数据只有产品本身相关的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,并没有哪些用户购买了产品的信息。. 所以我们需要到它的商品详情页面去爬取id参数,比如Lima Jucai-December issue HLB01239511。详情页有一栏投资记录,里面收录了我们需要的信息,如下图所示:
但是详情页需要我们登录才能查看,这就需要我们带着cookie来访问,而且cookie的有效期是有限的。如何让我们的cookie保持登录状态?请看下文。
其实Lima Vault也有类似的ajax接口:,但是里面的相关数据都写死了,没有意义。而且,金库的详情页没有投资记录信息。这就需要我们爬取开头提到的首页的ajax接口:. 但是后来发现这个接口每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。并且一次有10条数据,所以如果三分钟内购买产品的记录数超过10条,数据将被省略。没有办法绕过它,所以金库统计数据会立即低于真实数据。
四、爬虫代码分析1.获取登录cookie
因为商品详情页面需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机和密码参数是命令行传入的,就是你用手机号登录的账号和密码。我们使用superagent模拟即时财务管理登录界面的请求:. 传入相应的参数,在回调中我们获取到header的set-cookie信息,并发出setCookieie事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦获取到cookie,我们就会执行requestData方法。
2. 财务页面ajax的爬取
requestData 方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-20 13:00
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫是一种被广泛使用的东西,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但是仔细看会发现它其实是用js动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。 查看全部
nodejs抓取动态网页(Nodejs将JavaScript语言带到了,还有什么好玩的项目可以做呢?)
Nodejs 将 JavaScript 语言带到了服务器端。Nodejs作为js主要用户的前端,已经获得了服务器端的开发能力,但是除了用express搭建博客,还能做哪些好玩的项目呢?你为什么不只是一个网络爬虫。据说互联网上90%以上的流量是由爬虫贡献的。不知道是真是假,但至少证明了爬虫是一种被广泛使用的东西,尤其是在电商比价领域。我做的是爬虫中的弱鸡,只实现基本功能,先上源码。
下面简要介绍实现过程。先选择爬取对象,这里也是门槛比较低的新闻站,因为我每天早上都要去逛街,比较熟悉,为什么新闻站比较简单,因为通常是这种类型的网站不需要用户登录,所有爬虫请求都很容易伪造。
爬虫的基本思路是获取页面 -> 构造信息选择器 -> 分析页面链接 -> 获取相邻页面 -> 循环的第一步,对于新闻站来说,我们想要得到什么就是新闻内容,向页面请求html代码后,只要从页面中找到内容容器元素,就很容易得到新闻内容。下一步是获取相邻页面的地址。cnBeta新闻有上一页和下一页的链接,但是仔细看会发现它其实是用js动态生成的。这里我们需要了解一下js是如何获取链接的。得到链接后,我们继续获取下一条新闻的html代码,重复循环。
期间肯定不会一帆风顺。比如我遇到了301跳转。幸运的是,从请求头中很容易找到跳转目标。找到301跳转后,立即放弃请求,重新请求跳转地址。
另外,爬虫不能无限爬取,否则很容易被IP屏蔽,需要设置爬取次数限制。最好再设置一个爬取间隔,不过这个只是用于学习Nodejs,不会有爬取,所以不需要再设置一个爬取间隔。
详细分析过程见另一篇文章文章:%E7%88%AC%E8%99%AB%E5%AE%9E%E8%B7%B5%E5%B0%8F%E8%AE% B0 /。
nodejs抓取动态网页(先要搞懂对应的,访问url地址的背后的逻辑:需要你提供哪些内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-19 12:15
首先,我们要了解访问url地址背后的相应逻辑:
您需要什么:
网址
标题:一些可选的,一些必需的
饼干(可选)
发布数据
只有当它是POST方法时才需要
然后得到什么样的内容:
HTML源代码(或其他,json字符串,图片数据等)
cookie(可能):后续访问其他url,可能需要提供这里返回的(新的)cookie
暗示:
1.html 的字符集编码
关于html网页编码的背景知识,最好看看:
HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
了解您正在处理的网页执行的逻辑过程
简单来说就是你需要提供某个你要处理的url地址,需要提供哪些值,然后你就可以得到你需要的值了。
先了解自己关心的逻辑,才能用代码谈后续实现。
如果这个逻辑过程很简单,那么就不需要工具来分析了,自己看代码,自己分析就可以了。
但是这个过程往往非常复杂,所以一般需要使用相应的开发者工具来分析。
比如用IE9的F12捕捉对应的执行过程,然后分析一些你需要关心的网页的执行逻辑。
暗示:
1.其他各种分析工具
如果不熟悉IE9的F12等,可以先去看看:
浏览器中的开发者工具(IE9 中的 F12 和 Chrome 中的 Ctrl+Shift+I)——强大的网页分析工具
对于这部分内容,还有一个帖子供参考:
各种浏览器中的开发人员工具:IE9 的 F12、Chrome 的 Ctrl+Shift+J、Firefox 的 Firebug
2. 复杂参数值分析
在用工具分析的过程中,你会发现有些要分析的值比较复杂,无法直接获取,需要调试分析。
关于如何分析复杂的参数值是如何得到的,
登录过程中如何使用IE9的F12解析网站复杂的(参数、cookies等)值 (来源)
3.另一个例子
后来我写了一个例子来分析如何从songtaste的播放页面地址中找到歌曲的真实地址:
如何用IE9的F12抓取一首Songtaste歌曲的真实地址
使用一种语言来实现上述逻辑
了解了所有需要处理的逻辑流程和执行顺序后,就可以用某种语言实现相应的逻辑流程了。
暗示:
但是,在代码中实现相应的逻辑有一些通用的逻辑:
1. url地址的编码和解码
其中,如果涉及到url地址的解码和编码, 查看全部
nodejs抓取动态网页(先要搞懂对应的,访问url地址的背后的逻辑:需要你提供哪些内容)
首先,我们要了解访问url地址背后的相应逻辑:
您需要什么:
网址
标题:一些可选的,一些必需的
饼干(可选)
发布数据
只有当它是POST方法时才需要
然后得到什么样的内容:
HTML源代码(或其他,json字符串,图片数据等)
cookie(可能):后续访问其他url,可能需要提供这里返回的(新的)cookie
暗示:
1.html 的字符集编码
关于html网页编码的背景知识,最好看看:
HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
了解您正在处理的网页执行的逻辑过程
简单来说就是你需要提供某个你要处理的url地址,需要提供哪些值,然后你就可以得到你需要的值了。
先了解自己关心的逻辑,才能用代码谈后续实现。
如果这个逻辑过程很简单,那么就不需要工具来分析了,自己看代码,自己分析就可以了。
但是这个过程往往非常复杂,所以一般需要使用相应的开发者工具来分析。
比如用IE9的F12捕捉对应的执行过程,然后分析一些你需要关心的网页的执行逻辑。
暗示:
1.其他各种分析工具
如果不熟悉IE9的F12等,可以先去看看:
浏览器中的开发者工具(IE9 中的 F12 和 Chrome 中的 Ctrl+Shift+I)——强大的网页分析工具
对于这部分内容,还有一个帖子供参考:
各种浏览器中的开发人员工具:IE9 的 F12、Chrome 的 Ctrl+Shift+J、Firefox 的 Firebug
2. 复杂参数值分析
在用工具分析的过程中,你会发现有些要分析的值比较复杂,无法直接获取,需要调试分析。
关于如何分析复杂的参数值是如何得到的,
登录过程中如何使用IE9的F12解析网站复杂的(参数、cookies等)值 (来源)
3.另一个例子
后来我写了一个例子来分析如何从songtaste的播放页面地址中找到歌曲的真实地址:
如何用IE9的F12抓取一首Songtaste歌曲的真实地址
使用一种语言来实现上述逻辑
了解了所有需要处理的逻辑流程和执行顺序后,就可以用某种语言实现相应的逻辑流程了。
暗示:
但是,在代码中实现相应的逻辑有一些通用的逻辑:
1. url地址的编码和解码
其中,如果涉及到url地址的解码和编码,
nodejs抓取动态网页(0x0什么是无头浏览器有哪些无头Chromeheadless)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-18 17:17
0x0 什么是无头浏览器
什么是无头浏览器(headless browser),简单来说就是没有图形界面gui的WEB浏览器。做前端开发和web测试的同学对Headless(无头浏览器)比较熟悉。它可以直接在服务器上运行,并向客户端提供服务接口。既然是浏览器,它应该有浏览器应该有的一切,却看不到界面。我们使用浏览器的一般步骤是:启动浏览器、打开网页并进行交互。无头浏览器是指我们使用脚本执行上述过程的浏览器,它可以模拟真实的浏览器使用场景。它在类似于接口 Web 浏览器的环境中提供对网页的控制。它是一个很好的网络测试工具,提供与普通网络浏览器相同的功能,
0x1 有什么用
它的主要用途可以是:自动表单提交、web自动化控制、模拟键盘输入、抓取网页执行和渲染(解决传统HTTP抓取web难以处理异步请求的问题)、使用一些自带的调试工具浏览器和性能分析工具帮助分析问题、前端无界面自动化测试等。
0x2 什么是无头浏览器
Chrome headless:最新的 Chrome 版本可以在 Mac、Linux、Windows 上使用 headless 模式
调用方法如下:
铬——无头
PhantomJS:基于 QtWebkit 的无界面浏览器,将 网站 加载到内存中并在页面上执行 JavaScript。PhantomJS 在 nodejs 中可用。目前最广泛使用和认可的无头浏览器。它使用Webkit内核,因此对Safari和Chrome等当前浏览器有更好的兼容性。
SlimerJS:基于 Gecko 的无头浏览器,SlimerJS 和 PhantomJS 基本兼容,即用 Gecko 的 PhantomJS 替换一个核心。SlimerJS 提供的 API 可以使用 javascript 模拟浏览器上的任何操作:打开页面、前进/后退、页面点击、鼠标滚动、DOM 操作、CSS 选择器、Canvas 画布、SVG 绘图等。
HtmlUnit:纯java开发的无头浏览器。它在模拟浏览器中运行。它完全用java开发。javascript 引擎使用 Rhinojs 引擎。由于不是基于Webkit、Gecko等主流内核开发的,兼容性不好。
Puppeteer:它是一个 Nodejs 库,可以调用 Chrome 的 API 来操作 Web。与 PhantomJs 相比,它最大的特点是它的操作 Dom 可以完全在内存中模拟。不打开浏览器在V8引擎中处理由Chrome团队维护,会有更好的兼容性和前景。
0x3 配合python使用
python 通过 selenium 使用 chrome 无头
例子:
从硒导入网络驱动程序
选项 = webdriver.ChromeOptions()
#设置代理以允许不安全证书时添加的附加参数
options.add_argument('--ignore-certificate-errors')
#添加无头参数
options.add_argument('headless')
0x4与nodejs结合使用
Puppeteer 一个节点库,通过 DevTools 协议控制无界面的 Chromium 浏览器。使用 Puppeteer,示例代码:
const puppeteer = require('puppeteer');
(async() => { const browser = await puppeteer.launch();
常量页面 = 等待 browser.newPage();
等待 page.goto('');
等待 page.screenshot({path: 'example.png'});
等待浏览器.close(); })();
0x5 与 java 一起使用
使用 htmlunit 的示例:
公共类主要{
public static void main(String[] args) 抛出 FailingHttpStatusCodeException、MalformedURLException、IOException {
最终 WebClient mWebClient = new WebClient();
mWebClient.getOptions().setCssEnabled(false);
mWebClient.getOptions().setJavaScriptEnabled(false);
最终的 HtmlPage mHtmlPage = mWebClient.getPage("");
System.out.println(mHtmlPage.asText());
mWebClient.closeAllWindows();
}
} 查看全部
nodejs抓取动态网页(0x0什么是无头浏览器有哪些无头Chromeheadless)
0x0 什么是无头浏览器
什么是无头浏览器(headless browser),简单来说就是没有图形界面gui的WEB浏览器。做前端开发和web测试的同学对Headless(无头浏览器)比较熟悉。它可以直接在服务器上运行,并向客户端提供服务接口。既然是浏览器,它应该有浏览器应该有的一切,却看不到界面。我们使用浏览器的一般步骤是:启动浏览器、打开网页并进行交互。无头浏览器是指我们使用脚本执行上述过程的浏览器,它可以模拟真实的浏览器使用场景。它在类似于接口 Web 浏览器的环境中提供对网页的控制。它是一个很好的网络测试工具,提供与普通网络浏览器相同的功能,
0x1 有什么用
它的主要用途可以是:自动表单提交、web自动化控制、模拟键盘输入、抓取网页执行和渲染(解决传统HTTP抓取web难以处理异步请求的问题)、使用一些自带的调试工具浏览器和性能分析工具帮助分析问题、前端无界面自动化测试等。
0x2 什么是无头浏览器
Chrome headless:最新的 Chrome 版本可以在 Mac、Linux、Windows 上使用 headless 模式
调用方法如下:
铬——无头
PhantomJS:基于 QtWebkit 的无界面浏览器,将 网站 加载到内存中并在页面上执行 JavaScript。PhantomJS 在 nodejs 中可用。目前最广泛使用和认可的无头浏览器。它使用Webkit内核,因此对Safari和Chrome等当前浏览器有更好的兼容性。
SlimerJS:基于 Gecko 的无头浏览器,SlimerJS 和 PhantomJS 基本兼容,即用 Gecko 的 PhantomJS 替换一个核心。SlimerJS 提供的 API 可以使用 javascript 模拟浏览器上的任何操作:打开页面、前进/后退、页面点击、鼠标滚动、DOM 操作、CSS 选择器、Canvas 画布、SVG 绘图等。
HtmlUnit:纯java开发的无头浏览器。它在模拟浏览器中运行。它完全用java开发。javascript 引擎使用 Rhinojs 引擎。由于不是基于Webkit、Gecko等主流内核开发的,兼容性不好。
Puppeteer:它是一个 Nodejs 库,可以调用 Chrome 的 API 来操作 Web。与 PhantomJs 相比,它最大的特点是它的操作 Dom 可以完全在内存中模拟。不打开浏览器在V8引擎中处理由Chrome团队维护,会有更好的兼容性和前景。
0x3 配合python使用
python 通过 selenium 使用 chrome 无头
例子:
从硒导入网络驱动程序
选项 = webdriver.ChromeOptions()
#设置代理以允许不安全证书时添加的附加参数
options.add_argument('--ignore-certificate-errors')
#添加无头参数
options.add_argument('headless')
0x4与nodejs结合使用
Puppeteer 一个节点库,通过 DevTools 协议控制无界面的 Chromium 浏览器。使用 Puppeteer,示例代码:
const puppeteer = require('puppeteer');
(async() => { const browser = await puppeteer.launch();
常量页面 = 等待 browser.newPage();
等待 page.goto('');
等待 page.screenshot({path: 'example.png'});
等待浏览器.close(); })();
0x5 与 java 一起使用
使用 htmlunit 的示例:
公共类主要{
public static void main(String[] args) 抛出 FailingHttpStatusCodeException、MalformedURLException、IOException {
最终 WebClient mWebClient = new WebClient();
mWebClient.getOptions().setCssEnabled(false);
mWebClient.getOptions().setJavaScriptEnabled(false);
最终的 HtmlPage mHtmlPage = mWebClient.getPage("");
System.out.println(mHtmlPage.asText());
mWebClient.closeAllWindows();
}
}
nodejs抓取动态网页(event.json抓取动态网页就是异步的(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-18 14:03
nodejs抓取动态网页就是异步的。event.timeout变化,数据也会更新。动态网页加载量大,但同时反映出网页访问量的变化。如果用event.connect().then(),动态网页异步,同时会有耗时异步方法,可能会造成加载动态网页丢失数据的情况。比如考虑加载一个即将下载的网页,加载的结果css变化有时候对性能的影响。
性能并不一定影响加载原网页的效率。因为不同状态变化频繁,带来并发情况的话,异步加载也可能达不到最优性能。推荐直接用event.json()来保存性能相对高的异步信息。
同步与异步的区别我相信你肯定想过这个问题,那么同步与异步有什么样的区别呢?简单来说就是同步就是在一段时间内的同一个任务上执行同一个步骤,如果发生了异步就会说这段时间里面不同步了,先执行要执行的步骤,然后还要等待后一个步骤的执行结果。按照这个定义我相信你应该能够理解异步与同步的区别。那么现在咱们再来看看,同步和异步都有什么样的特点,或者说他们应该是什么关系呢?关于这个问题相信有一些小伙伴可能并不是很了解。
那我也就举个通俗的例子来解释一下:比如说你做了一道菜,但是今天你对菜的质量非常满意,可是如果你一周之后再吃这道菜的话你就会觉得这个菜不好吃了。那么这个时候你会怎么办呢?我相信很多小伙伴肯定会说我就吃一周以后再吃,然后给大家说道理的话,可能很多小伙伴就会说我马上吃,下周再吃,下下周再吃,那么对于这个时候来说同步就是你昨天做好的饭今天今天吃,那么对于异步来说呢,他今天晚上之前做好的饭,你一周之后再吃那就是这顿饭不好吃,他今天晚上之前做好的饭,一周之后再吃,那就是这顿饭好吃。
至于通过一个晚上来把什么都做好,做得过程中等待成功的事情呢?我觉得这个其实是不需要的,比如今天晚上要是你做菜的话,你要把今天晚上做好的饭明天才煮出来,那么相当于你就可以把今天做好的饭,明天晚上吃,而不是今天晚上做好,明天吃,另外如果你明天不吃,就算做出来这顿饭也会把它端出去没人吃,那么这个时候就是同步了。
简单来说,如果我需要今天晚上做好了,明天才吃的话,那么就是同步。那么今天晚上做好明天晚上可以不吃的话,就是异步。(由于eventjson()()返回的数据都是同步的所以此时可以不讲)那同步异步和回调函数怎么理解呢?回调函数的话呢其实与一个定时器的执行方式比较相似,他可以理解为定时器的方式来执行而已,而nodejs的异步模块就非常像回调函数,他们一样都是同步调用的。先来看看他们的整体结构:nodejs异步模块jsonjs模块,然后具体。 查看全部
nodejs抓取动态网页(event.json抓取动态网页就是异步的(图))
nodejs抓取动态网页就是异步的。event.timeout变化,数据也会更新。动态网页加载量大,但同时反映出网页访问量的变化。如果用event.connect().then(),动态网页异步,同时会有耗时异步方法,可能会造成加载动态网页丢失数据的情况。比如考虑加载一个即将下载的网页,加载的结果css变化有时候对性能的影响。
性能并不一定影响加载原网页的效率。因为不同状态变化频繁,带来并发情况的话,异步加载也可能达不到最优性能。推荐直接用event.json()来保存性能相对高的异步信息。
同步与异步的区别我相信你肯定想过这个问题,那么同步与异步有什么样的区别呢?简单来说就是同步就是在一段时间内的同一个任务上执行同一个步骤,如果发生了异步就会说这段时间里面不同步了,先执行要执行的步骤,然后还要等待后一个步骤的执行结果。按照这个定义我相信你应该能够理解异步与同步的区别。那么现在咱们再来看看,同步和异步都有什么样的特点,或者说他们应该是什么关系呢?关于这个问题相信有一些小伙伴可能并不是很了解。
那我也就举个通俗的例子来解释一下:比如说你做了一道菜,但是今天你对菜的质量非常满意,可是如果你一周之后再吃这道菜的话你就会觉得这个菜不好吃了。那么这个时候你会怎么办呢?我相信很多小伙伴肯定会说我就吃一周以后再吃,然后给大家说道理的话,可能很多小伙伴就会说我马上吃,下周再吃,下下周再吃,那么对于这个时候来说同步就是你昨天做好的饭今天今天吃,那么对于异步来说呢,他今天晚上之前做好的饭,你一周之后再吃那就是这顿饭不好吃,他今天晚上之前做好的饭,一周之后再吃,那就是这顿饭好吃。
至于通过一个晚上来把什么都做好,做得过程中等待成功的事情呢?我觉得这个其实是不需要的,比如今天晚上要是你做菜的话,你要把今天晚上做好的饭明天才煮出来,那么相当于你就可以把今天做好的饭,明天晚上吃,而不是今天晚上做好,明天吃,另外如果你明天不吃,就算做出来这顿饭也会把它端出去没人吃,那么这个时候就是同步了。
简单来说,如果我需要今天晚上做好了,明天才吃的话,那么就是同步。那么今天晚上做好明天晚上可以不吃的话,就是异步。(由于eventjson()()返回的数据都是同步的所以此时可以不讲)那同步异步和回调函数怎么理解呢?回调函数的话呢其实与一个定时器的执行方式比较相似,他可以理解为定时器的方式来执行而已,而nodejs的异步模块就非常像回调函数,他们一样都是同步调用的。先来看看他们的整体结构:nodejs异步模块jsonjs模块,然后具体。
nodejs抓取动态网页(前段时间前后端分离改造导致一个问题网站内容无法得到收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-18 01:01
前段时间博客把vue的前后端分开,导致了一个问题,网站的内容无法获取到收录的搜索引擎。. . 这让我困扰了一段时间。由于工作繁忙,一直没有研究这个问题。最近在给老婆写爬虫脚本的时候,碰巧接触到了PhantomJS。突然意识到可以用PhantomJS来解决~
PhantomJS 是一个可使用 JavaScript API 编写脚本的无头 WebKit。它具有 **fast ** 和 **native ** 对各种 Web 标准的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。
所以我用谷歌搜索,发现很多人都在使用这个解决方案。天哪,真的是太坑了。让我们来谈谈它。这种解决方案实际上是一种旁路机制。原理是通过Nginx配置搜索引擎的爬虫。请求被转发到节点服务器,完整的 HTML 由 PhantomJS 解析。废话不多说,直接上代码!
准备一个 PhantomJS 任务脚本
首先,我们需要一个名为 spider.js 的文件,用于 phantomjs 解析 网站。
// spider.js
"use strict";
// 单个资源等待时间,避免资源加载后还需要加载其他资源
var resourceWait = 500;
var resourceWaitTimer;
// 最大等待时间
var maxWait = 5000;
var maxWaitTimer;
// 资源计数
var resourceCount = 0;
// PhantomJS WebPage模块
var page = require('webpage').create();
// NodeJS 系统模块
var system = require('system');
// 从CLI中获取第二个参数为目标URL
var url = system.args[1];
// 设置PhantomJS视窗大小
page.viewportSize = {
width: 1280,
height: 1014
};
// 获取镜像
var capture = function(errCode){
// 外部通过stdout获取页面内容
console.log(page.content);
// 清除计时器
clearTimeout(maxWaitTimer);
// 任务完成,正常退出
phantom.exit(errCode);
};
// 资源请求并计数
page.onResourceRequested = function(req){
resourceCount++;
clearTimeout(resourceWaitTimer);
};
// 资源加载完毕
page.onResourceReceived = function (res) {
// chunk模式的HTTP回包,会多次触发resourceReceived事件,需要判断资源是否已经end
if (res.stage !== 'end'){
return;
}
resourceCount--;
if (resourceCount === 0){
// 当页面中全部资源都加载完毕后,截取当前渲染出来的html
// 由于onResourceReceived在资源加载完毕就立即被调用了,我们需要给一些时间让JS跑解析任务
// 这里默认预留500毫秒
resourceWaitTimer = setTimeout(capture, resourceWait);
}
};
// 资源加载超时
page.onResourceTimeout = function(req){
resouceCount--;
};
// 资源加载失败
page.onResourceError = function(err){
resourceCount--;
};
// 打开页面
page.open(url, function (status) {
if (status !== 'success') {
phantom.exit(1);
} else {
// 当改页面的初始html返回成功后,开启定时器
// 当到达最大时间(默认5秒)的时候,截取那一时刻渲染出来的html
maxWaitTimer = setTimeout(function(){
capture(2);
}, maxWait);
}
});
运行一下吧~
$ phantomjs spider.js ''
您可以在终端中看到呈现的 HTML 结构!惊人的!
订购服务
为了响应搜索引擎爬虫的请求,我们需要提供这个命令,并通过 node.js 创建一个简单的 web 服务。
// server.js
// ExpressJS调用方式
var express = require('express');
var app = express();
// 引入NodeJS的子进程模块
var child_process = require('child_process');
app.get('*', function(req, res){
// 完整URL
var url = req.protocol + '://'+ req.hostname + req.originalUrl;
// 预渲染后的页面字符串容器
var content = '';
// 开启一个phantomjs子进程
var phantom = child_process.spawn('phantomjs', ['spider.js', url]);
// 设置stdout字符编码
phantom.stdout.setEncoding('utf8');
// 监听phantomjs的stdout,并拼接起来
phantom.stdout.on('data', function(data){
content += data.toString();
});
// 监听子进程退出事件
phantom.on('exit', function(code){
switch (code){
case 1:
console.log('加载失败');
res.send('加载失败');
break;
case 2:
console.log('加载超时: '+ url);
res.send(content);
break;
default:
res.send(content);
break;
}
});
});
app.listen(3000, function () {
console.log('Spider app listening on port 3000!');
});
运行节点 server.js。此时,我们有一个预渲染的 Web 服务。接下来的工作就是将搜索引擎爬虫的请求转发给这个web服务,最后将渲染结果返回给爬虫。
为了防止node进程挂起,可以使用nohup启动,nohup node server.js &。
通过Nginx的配置,我们可以轻松解决这个问题。
upstream spider_server {
server localhost:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host:$proxy_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {
proxy_pass http://spider_server;
}
}
}
你完成了!
注:本文代码主要参考以下文章的分享,稍作修改后可用的版本,谢谢分享!
参考链接: 查看全部
nodejs抓取动态网页(前段时间前后端分离改造导致一个问题网站内容无法得到收录)
前段时间博客把vue的前后端分开,导致了一个问题,网站的内容无法获取到收录的搜索引擎。. . 这让我困扰了一段时间。由于工作繁忙,一直没有研究这个问题。最近在给老婆写爬虫脚本的时候,碰巧接触到了PhantomJS。突然意识到可以用PhantomJS来解决~
PhantomJS 是一个可使用 JavaScript API 编写脚本的无头 WebKit。它具有 **fast ** 和 **native ** 对各种 Web 标准的支持:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。
所以我用谷歌搜索,发现很多人都在使用这个解决方案。天哪,真的是太坑了。让我们来谈谈它。这种解决方案实际上是一种旁路机制。原理是通过Nginx配置搜索引擎的爬虫。请求被转发到节点服务器,完整的 HTML 由 PhantomJS 解析。废话不多说,直接上代码!
准备一个 PhantomJS 任务脚本
首先,我们需要一个名为 spider.js 的文件,用于 phantomjs 解析 网站。
// spider.js
"use strict";
// 单个资源等待时间,避免资源加载后还需要加载其他资源
var resourceWait = 500;
var resourceWaitTimer;
// 最大等待时间
var maxWait = 5000;
var maxWaitTimer;
// 资源计数
var resourceCount = 0;
// PhantomJS WebPage模块
var page = require('webpage').create();
// NodeJS 系统模块
var system = require('system');
// 从CLI中获取第二个参数为目标URL
var url = system.args[1];
// 设置PhantomJS视窗大小
page.viewportSize = {
width: 1280,
height: 1014
};
// 获取镜像
var capture = function(errCode){
// 外部通过stdout获取页面内容
console.log(page.content);
// 清除计时器
clearTimeout(maxWaitTimer);
// 任务完成,正常退出
phantom.exit(errCode);
};
// 资源请求并计数
page.onResourceRequested = function(req){
resourceCount++;
clearTimeout(resourceWaitTimer);
};
// 资源加载完毕
page.onResourceReceived = function (res) {
// chunk模式的HTTP回包,会多次触发resourceReceived事件,需要判断资源是否已经end
if (res.stage !== 'end'){
return;
}
resourceCount--;
if (resourceCount === 0){
// 当页面中全部资源都加载完毕后,截取当前渲染出来的html
// 由于onResourceReceived在资源加载完毕就立即被调用了,我们需要给一些时间让JS跑解析任务
// 这里默认预留500毫秒
resourceWaitTimer = setTimeout(capture, resourceWait);
}
};
// 资源加载超时
page.onResourceTimeout = function(req){
resouceCount--;
};
// 资源加载失败
page.onResourceError = function(err){
resourceCount--;
};
// 打开页面
page.open(url, function (status) {
if (status !== 'success') {
phantom.exit(1);
} else {
// 当改页面的初始html返回成功后,开启定时器
// 当到达最大时间(默认5秒)的时候,截取那一时刻渲染出来的html
maxWaitTimer = setTimeout(function(){
capture(2);
}, maxWait);
}
});
运行一下吧~
$ phantomjs spider.js ''
您可以在终端中看到呈现的 HTML 结构!惊人的!
订购服务
为了响应搜索引擎爬虫的请求,我们需要提供这个命令,并通过 node.js 创建一个简单的 web 服务。
// server.js
// ExpressJS调用方式
var express = require('express');
var app = express();
// 引入NodeJS的子进程模块
var child_process = require('child_process');
app.get('*', function(req, res){
// 完整URL
var url = req.protocol + '://'+ req.hostname + req.originalUrl;
// 预渲染后的页面字符串容器
var content = '';
// 开启一个phantomjs子进程
var phantom = child_process.spawn('phantomjs', ['spider.js', url]);
// 设置stdout字符编码
phantom.stdout.setEncoding('utf8');
// 监听phantomjs的stdout,并拼接起来
phantom.stdout.on('data', function(data){
content += data.toString();
});
// 监听子进程退出事件
phantom.on('exit', function(code){
switch (code){
case 1:
console.log('加载失败');
res.send('加载失败');
break;
case 2:
console.log('加载超时: '+ url);
res.send(content);
break;
default:
res.send(content);
break;
}
});
});
app.listen(3000, function () {
console.log('Spider app listening on port 3000!');
});
运行节点 server.js。此时,我们有一个预渲染的 Web 服务。接下来的工作就是将搜索引擎爬虫的请求转发给这个web服务,最后将渲染结果返回给爬虫。
为了防止node进程挂起,可以使用nohup启动,nohup node server.js &。
通过Nginx的配置,我们可以轻松解决这个问题。
upstream spider_server {
server localhost:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host:$proxy_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {
proxy_pass http://spider_server;
}
}
}
你完成了!
注:本文代码主要参考以下文章的分享,稍作修改后可用的版本,谢谢分享!
参考链接:
nodejs抓取动态网页(PHP,的命名由来和命名的由来-乐题库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-17 22:24
)
通用名称的由来:
引用可以在浏览器以外的环境中运行的 JavaScript 应用程序。
角快递引擎
使 Angular 应用程序能够在服务器端运行。
如何使用:
注意:我在 server.ts 中进行了更改并添加了 console.log:
执行 npm run build:ssr 后,对 server.ts 的修改会出现在 dist/server/main.js 中:
而这个console.log,因为代码是在服务端执行的,所以只能在启动nodejs应用的控制台看到日志:
至于客户端浏览器中看到的 JavaScript:
从 dist/browser 文件夹:
另一个 文章:
什么是服务器端渲染
动态数据的获取是通过运行服务器端脚本来完成的。注意上图:在服务端渲染模式下,服务端返回给客户端的页面包括页面布局和所有数据,即数据的Viewable。在客户端脚本的帮助下,页面从纯布局变为可查看和可提取。
事实上,PHP 和 JSP 使用这种方法来渲染网页。
服务器返回的内容:一个完全静态的网页,其中收录在浏览器中显示它所需的所有元素,以及客户端脚本。这些脚本可用于使页面动态化。
再看客户端渲染:
服务器返回给客户端的是一个不收录任何数据的空模板。通过客户端脚本,在客户端执行异步获取数据。
客户端负责在加载新页面或基于用户响应时异步加载数据。因为内容是完全动态的,对 SEO 不友好。
使用 Angular Schematic,可以将 Angular 应用程序配置为支持 SSR。
三个最重要的依赖项:
服务器端渲染成功的标志:
查看全部
nodejs抓取动态网页(PHP,的命名由来和命名的由来-乐题库
)
通用名称的由来:
引用可以在浏览器以外的环境中运行的 JavaScript 应用程序。
角快递引擎
使 Angular 应用程序能够在服务器端运行。
如何使用:
注意:我在 server.ts 中进行了更改并添加了 console.log:
执行 npm run build:ssr 后,对 server.ts 的修改会出现在 dist/server/main.js 中:
而这个console.log,因为代码是在服务端执行的,所以只能在启动nodejs应用的控制台看到日志:
至于客户端浏览器中看到的 JavaScript:
从 dist/browser 文件夹:
另一个 文章:
什么是服务器端渲染
动态数据的获取是通过运行服务器端脚本来完成的。注意上图:在服务端渲染模式下,服务端返回给客户端的页面包括页面布局和所有数据,即数据的Viewable。在客户端脚本的帮助下,页面从纯布局变为可查看和可提取。
事实上,PHP 和 JSP 使用这种方法来渲染网页。
服务器返回的内容:一个完全静态的网页,其中收录在浏览器中显示它所需的所有元素,以及客户端脚本。这些脚本可用于使页面动态化。
再看客户端渲染:
服务器返回给客户端的是一个不收录任何数据的空模板。通过客户端脚本,在客户端执行异步获取数据。
客户端负责在加载新页面或基于用户响应时异步加载数据。因为内容是完全动态的,对 SEO 不友好。
使用 Angular Schematic,可以将 Angular 应用程序配置为支持 SSR。
三个最重要的依赖项:
服务器端渲染成功的标志:
nodejs抓取动态网页(puppeteer和nodejs的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-16 19:05
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,例如JavaScript,以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(即“xxxx”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h3 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(puppeteer和nodejs的区别)
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,例如JavaScript,以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(即“xxxx”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h3 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页( (本地下载)Node.js批量抓取高清妹子图片相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-15 12:14
(本地下载)Node.js批量抓取高清妹子图片相关资料)
使用Node.js批量抓取高清妹子图片示例教程
更新时间:2018-08-02 10:27:47 作者:ocalhot
本篇文章主要介绍使用Node.js批量抓拍高清妹子图片的相关资料。文章中对示例代码进行了非常详细的介绍。需要的朋友可以直接复制代码使用。来和我一起学习
前言
我写了一个小工具来抓取图片并分享它。
Github地址:(本地下载)
示例代码
//依赖模块
var fs = require('fs');
var request = require("request");
var cheerio = require("cheerio");
var mkdirp = require('mkdirp');
//目标网址
var url = 'http://me2-sex.lofter.com/tag/美女摄影?page=';
//本地存储目录
var dir = './images';
//创建目录
mkdirp(dir, function(err) {
if(err){
console.log(err);
}
});
//发送请求
request(url, function(error, response, body) {
if(!error && response.statusCode == 200) {
var $ = cheerio.load(body);
$('.img img').each(function() {
var src = $(this).attr('src');
console.log('正在下载' + src);
download(src, dir, Math.floor(Math.random()*100000) + src.substr(-4,4));
console.log('下载完成');
});
}
});
//下载方法
var download = function(url, dir, filename){
request.head(url, function(err, res, body){
request(url).pipe(fs.createWriteStream(dir + "/" + filename));
});
};
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。 查看全部
nodejs抓取动态网页(
(本地下载)Node.js批量抓取高清妹子图片相关资料)
使用Node.js批量抓取高清妹子图片示例教程
更新时间:2018-08-02 10:27:47 作者:ocalhot
本篇文章主要介绍使用Node.js批量抓拍高清妹子图片的相关资料。文章中对示例代码进行了非常详细的介绍。需要的朋友可以直接复制代码使用。来和我一起学习
前言
我写了一个小工具来抓取图片并分享它。
Github地址:(本地下载)
示例代码
//依赖模块
var fs = require('fs');
var request = require("request");
var cheerio = require("cheerio");
var mkdirp = require('mkdirp');
//目标网址
var url = 'http://me2-sex.lofter.com/tag/美女摄影?page=';
//本地存储目录
var dir = './images';
//创建目录
mkdirp(dir, function(err) {
if(err){
console.log(err);
}
});
//发送请求
request(url, function(error, response, body) {
if(!error && response.statusCode == 200) {
var $ = cheerio.load(body);
$('.img img').each(function() {
var src = $(this).attr('src');
console.log('正在下载' + src);
download(src, dir, Math.floor(Math.random()*100000) + src.substr(-4,4));
console.log('下载完成');
});
}
});
//下载方法
var download = function(url, dir, filename){
request.head(url, function(err, res, body){
request(url).pipe(fs.createWriteStream(dir + "/" + filename));
});
};
总结
以上就是这个文章的全部内容。希望本文的内容对大家的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对脚本之家的支持。
nodejs抓取动态网页( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-15 12:10
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_passwor来源gaodaimacom搞#代%码网d" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.机器人协议
将 /robots.txt 附加到目标 URL,例如:
第一个意思是对于所有爬虫,都不能爬进/? 以 /pop/*.html 开头的路径无法访问匹配 /pop/*.html 的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫抓取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网页分析
获取到对应的内容并分析之后,其实需要处理一段文本,从网页中的代码中提取出你需要的内容。BeautifulSoup 实现了惯用的文档导航、搜索和修改功能。如果lib文件夹中没有BeautifulSoup,可以使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */ con=selector.xpath('[email protected]/* */') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('[email protected]/* */') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常以.htm、.html、.shtml、.xml等为后缀。静态网页一般是最简单的HTML网页。服务器端和客户端是一样的,没有脚本和小程序,所以不能移动。在 HTML 格式的网页上,也可以出现各种动态效果,比如 .GIF 格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉上的,与将要实现的动态网页是不同的概念。下面介绍。.
静态网页的特点
动态网页的基本概述
动态网页后缀为.asp、.jsp、.php、.perl、.cgi等形式,并有符号“?” 在动态网页的 URL 中。动态网页与网页上的各种动画和滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,采用动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。适合在使用动态网页的地方使用动态网页。如果需要使用静态网页,您可以考虑使用静态网页来实现它。在同一个 网站 中,动态网页内容和静态网页内容并存也很常见。
动态网页应具备以下特点:
总结一下:如果页面内容发生变化,URL也会发生变化。基本上,它是一个静态网页,反之亦然是一个动态网页。
四、动态和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:上面两个url的区别在于最后一个数字,原页面上的下一页的url和内容同时变化。我们判断该页面是静态页面。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
爬取网页,看不到任何信息,证明是动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多关于Python爬取数据的信息,请在高代马从事之前搜索文章或继续浏览以下相关文章希望大家以后多多支持高代马从事码网! 查看全部
nodejs抓取动态网页(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_passwor来源gaodaimacom搞#代%码网d" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/";) # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.机器人协议
将 /robots.txt 附加到目标 URL,例如:
第一个意思是对于所有爬虫,都不能爬进/? 以 /pop/*.html 开头的路径无法访问匹配 /pop/*.html 的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、爬虫抓取网页
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网页分析
获取到对应的内容并分析之后,其实需要处理一段文本,从网页中的代码中提取出你需要的内容。BeautifulSoup 实现了惯用的文档导航、搜索和修改功能。如果lib文件夹中没有BeautifulSoup,可以使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用示例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用示例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,[email protected]/* */ con=selector.xpath('[email protected]/* */') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('[email protected]/* */') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的URL形式通常以.htm、.html、.shtml、.xml等为后缀。静态网页一般是最简单的HTML网页。服务器端和客户端是一样的,没有脚本和小程序,所以不能移动。在 HTML 格式的网页上,也可以出现各种动态效果,比如 .GIF 格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉上的,与将要实现的动态网页是不同的概念。下面介绍。.
静态网页的特点
动态网页的基本概述
动态网页后缀为.asp、.jsp、.php、.perl、.cgi等形式,并有符号“?” 在动态网页的 URL 中。动态网页与网页上的各种动画和滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画。这些只是网页的具体内容。表现形式,无论网页是否具有动态效果,采用动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。适合在使用动态网页的地方使用动态网页。如果需要使用静态网页,您可以考虑使用静态网页来实现它。在同一个 网站 中,动态网页内容和静态网页内容并存也很常见。
动态网页应具备以下特点:
总结一下:如果页面内容发生变化,URL也会发生变化。基本上,它是一个静态网页,反之亦然是一个动态网页。
四、动态和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:上面两个url的区别在于最后一个数字,原页面上的下一页的url和内容同时变化。我们判断该页面是静态页面。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
爬取网页,看不到任何信息,证明是动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
这是文章的介绍,教你如何使用Python快速爬取你需要的数据。更多关于Python爬取数据的信息,请在高代马从事之前搜索文章或继续浏览以下相关文章希望大家以后多多支持高代马从事码网!
nodejs抓取动态网页(爬虫抓取动态网页或者blog首页的链接需要动态页面加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-15 05:01
nodejs抓取动态网页或者blog首页的链接需要动态页面加载。之前有三种方式:监听http请求,改变这个加载网页时间。监听ajax请求,动态调整加载时间。监听post请求,动态调整加载时间。效果展示:从业务角度来说,网页加载速度越快,就意味着爬虫抓取请求更快,对服务器压力也更小,抓取速度更快。从服务器角度说,单纯从时间上来说,没有意义,而是看你的代码性能够不够快,是不是按照需求实现了。
selenium,自带的技术,之前网上很多人推荐,有很多坑。selenium爬虫基本调用js,使用javascript脚本来伪装浏览器动作,感觉抓取动态不是一个优雅的解决方案。d3.js,bootstrap的js库,作者写的东西,相对于selenium,使用了d3.js的监听数据格式来加载,感觉没那么好,监听的数据格式也较一般json格式,而且请求的时候加载速度特别慢。
browserlogging,这个功能应该比较常用,速度较快,但是没有监听请求时间的buffer格式数据。动态网页是直接存储的,网上有相关介绍。
1、动态调试
2、mongodb,
3、beautifulsoup(es2015版本以上版本,
你可以试一下bower(bower)
楼上的答案很赞,大概可以说没法再快了。要达到selenium3那样的效果,你要把每次都用的代码都在线上跑一下,然后改成代理。还有问题可以私信我。 查看全部
nodejs抓取动态网页(爬虫抓取动态网页或者blog首页的链接需要动态页面加载)
nodejs抓取动态网页或者blog首页的链接需要动态页面加载。之前有三种方式:监听http请求,改变这个加载网页时间。监听ajax请求,动态调整加载时间。监听post请求,动态调整加载时间。效果展示:从业务角度来说,网页加载速度越快,就意味着爬虫抓取请求更快,对服务器压力也更小,抓取速度更快。从服务器角度说,单纯从时间上来说,没有意义,而是看你的代码性能够不够快,是不是按照需求实现了。
selenium,自带的技术,之前网上很多人推荐,有很多坑。selenium爬虫基本调用js,使用javascript脚本来伪装浏览器动作,感觉抓取动态不是一个优雅的解决方案。d3.js,bootstrap的js库,作者写的东西,相对于selenium,使用了d3.js的监听数据格式来加载,感觉没那么好,监听的数据格式也较一般json格式,而且请求的时候加载速度特别慢。
browserlogging,这个功能应该比较常用,速度较快,但是没有监听请求时间的buffer格式数据。动态网页是直接存储的,网上有相关介绍。
1、动态调试
2、mongodb,
3、beautifulsoup(es2015版本以上版本,
你可以试一下bower(bower)
楼上的答案很赞,大概可以说没法再快了。要达到selenium3那样的效果,你要把每次都用的代码都在线上跑一下,然后改成代理。还有问题可以私信我。
nodejs抓取动态网页(外汇nodejs抓取动态网页的方法及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-13 08:01
nodejs抓取动态网页的方法一般分为两种:1.nodejs将动态链接转换为响应json然后json的格式转换为script标签。2.nodejs直接访问页面,不转换json,json格式转换为script标签。我习惯用第二种方法,效率高,能满足我们不同场景要求。下面我将结合具体场景,分别介绍nodejs抓取动态网页时常用的技巧,大家可以结合自己的具体需求来参考或提出自己的问题。
我先总结下我总结的规律:如果涉及url改变的话,会针对iframe、frame、documentjs来同步改变。如果iframe的话,从头抓取到尾一般只需要换http头及头部的header,http体是保持不变的。在我们解析后端url的时候,在nodejs内加载完一个页面(生成页面路径)后,并不会立即获取document对象,而是再response过来,在解析时,所有动态链接都会先存在于dom中,处理该部分动态链接的方法有很多,我会有空再整理下,直接列几个常用的。
我会通过介绍大致的技巧及代码来概括nodejs动态链接抓取的一些原理。2.1url构造方法3.1.1获取dom树及dom事件4.1.2遍历dom树并构造正则表达式4.2获取dom全部数据这里用到了正则表达式可以匹配iframe中所有的数据。注意,在这个场景中,我们不希望使用iframe/frame中的数据,这里我采用的是存放动态网页的object对象中的数据。
返回json数据时,提取的json格式是json为了方便,我们对object进行嵌套,添加dom部分。object["iframe"]=json["iframe"][0];exportfunctiongetpdy(path,siteref){if(path.length==0){returntrue;}document.open(path,siteref);document.getelementsbytagname("img")[0].attrib("property")[0].style.display="none";returnfalse;}2.2.1获取dom树及dom事件方法3.1.1构造urldocument.open(path,siteref),结果是一个url,该url包含:a标签。
使用open方法,获取该url需要注意的是:a标签如果在里面,则需要取a标签里面的字符串,否则,会被获取其他内容。然后,再取siteref的数据即可。3.1.2遍历dom树并构造正则表达式document.open(url,matches);document.open()是在open方法的参数作用下,执行里面的所有方法。
3.1.3遍历dom树并构造正则表达式document.open(path,matches);matches是接受来自open方法参数作用下的所有方法。也就是接受与open方法有关的方法。functiongetpdy(path,siteref){if(path.length==0)。 查看全部
nodejs抓取动态网页(外汇nodejs抓取动态网页的方法及方法)
nodejs抓取动态网页的方法一般分为两种:1.nodejs将动态链接转换为响应json然后json的格式转换为script标签。2.nodejs直接访问页面,不转换json,json格式转换为script标签。我习惯用第二种方法,效率高,能满足我们不同场景要求。下面我将结合具体场景,分别介绍nodejs抓取动态网页时常用的技巧,大家可以结合自己的具体需求来参考或提出自己的问题。
我先总结下我总结的规律:如果涉及url改变的话,会针对iframe、frame、documentjs来同步改变。如果iframe的话,从头抓取到尾一般只需要换http头及头部的header,http体是保持不变的。在我们解析后端url的时候,在nodejs内加载完一个页面(生成页面路径)后,并不会立即获取document对象,而是再response过来,在解析时,所有动态链接都会先存在于dom中,处理该部分动态链接的方法有很多,我会有空再整理下,直接列几个常用的。
我会通过介绍大致的技巧及代码来概括nodejs动态链接抓取的一些原理。2.1url构造方法3.1.1获取dom树及dom事件4.1.2遍历dom树并构造正则表达式4.2获取dom全部数据这里用到了正则表达式可以匹配iframe中所有的数据。注意,在这个场景中,我们不希望使用iframe/frame中的数据,这里我采用的是存放动态网页的object对象中的数据。
返回json数据时,提取的json格式是json为了方便,我们对object进行嵌套,添加dom部分。object["iframe"]=json["iframe"][0];exportfunctiongetpdy(path,siteref){if(path.length==0){returntrue;}document.open(path,siteref);document.getelementsbytagname("img")[0].attrib("property")[0].style.display="none";returnfalse;}2.2.1获取dom树及dom事件方法3.1.1构造urldocument.open(path,siteref),结果是一个url,该url包含:a标签。
使用open方法,获取该url需要注意的是:a标签如果在里面,则需要取a标签里面的字符串,否则,会被获取其他内容。然后,再取siteref的数据即可。3.1.2遍历dom树并构造正则表达式document.open(url,matches);document.open()是在open方法的参数作用下,执行里面的所有方法。
3.1.3遍历dom树并构造正则表达式document.open(path,matches);matches是接受来自open方法参数作用下的所有方法。也就是接受与open方法有关的方法。functiongetpdy(path,siteref){if(path.length==0)。
nodejs抓取动态网页(下载一个网站系统后,在电脑上安装iis和相应的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-10 17:18
下载一个网站系统后,在电脑上安装iis和相应的软件,运行测试,然后发布到网上供大家浏览。今天小编分享一下如何制作动态网页,希望对大家有所帮助。
一、必修知识
1、基础脚本:HTML、CSS、javascript,这三个一定要掌握。
2、开发程序:ASP、PHP,学一个就好。
3、数据库知识:MSSQL、Access或mysql,必须知道如何安装、构建和使用这些数据库。
网上可以找到很多不错的教程,但是如果你想成为一名合格的网站开发者,还是要坚持上面的基础。
技术进步就是让事情变得更简单,互联网技术的发展也是如此。现在有很多非常方便的网站管理系统,功能很多。用户只要使用或呼出,基本上什么都不需要知道。基础可以做很专业的网站,所以你可以使用这些系统来构建你自己的网站。
二、动态网页创建后
下载一个网站系统后,在电脑上安装IIS和相应的软件,运行测试,然后发布到网上供大家浏览。需要执行以下步骤:
1、申请域名就是注册一个网站。
2、购买网站空间,称为虚拟主机,存放网站文件。不同的网站系统需要不同类型的虚拟主机,这主要取决于网站取决于开发语言系统,如:PHP开发,需要购买PHP主机。
3、网站记录在案。国家要求国内的网站必须备案,这样就可以让你的主办公司备案,一般是免费的,提供资料就行了。 查看全部
nodejs抓取动态网页(下载一个网站系统后,在电脑上安装iis和相应的软件)
下载一个网站系统后,在电脑上安装iis和相应的软件,运行测试,然后发布到网上供大家浏览。今天小编分享一下如何制作动态网页,希望对大家有所帮助。
一、必修知识
1、基础脚本:HTML、CSS、javascript,这三个一定要掌握。
2、开发程序:ASP、PHP,学一个就好。
3、数据库知识:MSSQL、Access或mysql,必须知道如何安装、构建和使用这些数据库。
网上可以找到很多不错的教程,但是如果你想成为一名合格的网站开发者,还是要坚持上面的基础。
技术进步就是让事情变得更简单,互联网技术的发展也是如此。现在有很多非常方便的网站管理系统,功能很多。用户只要使用或呼出,基本上什么都不需要知道。基础可以做很专业的网站,所以你可以使用这些系统来构建你自己的网站。
二、动态网页创建后
下载一个网站系统后,在电脑上安装IIS和相应的软件,运行测试,然后发布到网上供大家浏览。需要执行以下步骤:
1、申请域名就是注册一个网站。
2、购买网站空间,称为虚拟主机,存放网站文件。不同的网站系统需要不同类型的虚拟主机,这主要取决于网站取决于开发语言系统,如:PHP开发,需要购买PHP主机。
3、网站记录在案。国家要求国内的网站必须备案,这样就可以让你的主办公司备案,一般是免费的,提供资料就行了。
nodejs抓取动态网页(【推荐学习】robots禁止抓取php的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-09 04:01
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则“User-agent:* Allow”:.html$ Disallow:/”。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一个页面后触发网站但最终判断是同一个页面,如何处罚还不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外记得source gaodaimacom搞#code%code.txt,把写好的robots.txt文件放到你的网站根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是robots如何禁止爬取php的详细内容。更多信息请关注其他相关代码高代马文章! 查看全部
nodejs抓取动态网页(【推荐学习】robots禁止抓取php的方法(图))
robots禁止爬取php的方法:1、在robots.txt文件中写入“Disallow: /*?*”;2、在 robots.txt 文件中添加规则“User-agent:* Allow”:.html$ Disallow:/”。
本文运行环境:windows7系统,PHP7.版本1,DELL G3电脑
robots禁止搜索引擎抓取php动态网址
所谓动态URL是指该URL收录?, & 等字符类URL,如:news.php?lang=cn&class=1&id=2,当我们开启网站的伪静态时,对于网站的seo来说是必须的避免搜索引擎抓取我们的 网站 动态 URL。
你为什么要这样做?因为搜索引擎会在两次爬取同一个页面后触发网站但最终判断是同一个页面,如何处罚还不清楚,总之不利于<的整个SEO @网站。那么如何防止搜索引擎抓取我们的网站动态URL呢?
这个问题可以通过robots.txt文件解决,具体操作请看下文。
我们知道动态页面有一个共同的特点,就是会有一个问号符号“?” 在链接中,因此我们可以在 robots.txt 文件中编写以下规则:
User-agent: *
Disallow: /*?*
这将阻止搜索引擎抓取整个 网站 动态链接。另外,如果我们只想让搜索引擎抓取指定类型的文件,比如html格式的静态页面,我们可以在robots.txt中添加如下规则:
User-agent: *
Allow: .html$
Disallow: /
另外记得source gaodaimacom搞#code%code.txt,把写好的robots.txt文件放到你的网站根目录下,不然不行。此外,还有一个编写规则的简单快捷方式。登录google网站admin工具,连接并在里面写入规则,然后生成robots.txt文件。
【推荐学习:《PHP 视频教程》】
以上就是robots如何禁止爬取php的详细内容。更多信息请关注其他相关代码高代马文章!

