
nodejs抓取动态网页
nodejs抓取动态网页新建一个dateparser,看你的后端用什么语言
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-29 05:01
nodejs抓取动态网页
新建一个dateparser,然后看你的后端用什么语言,drupal,用qml可以用qt的事件机制把你要抓取的时间点输出,直接转换成json。之后直接post给你要抓取的网页就行了。
同意@rickzhao的,单独来抓,抓完直接格式化存起来就好了,你可以在datepicker下写你的代码,把时间点嵌入到一个队列中。其实时间本身应该是没有意义的,它只是一个常量。但是从量化角度看,如果要增加时间纬度的话,如何取值也要确定才行。
用drupal之类可以用事件监听吧,也可以用drupal生成jsonparser,如redis/redis.js·github的time_guide模块。
1).setimes('yyyy-mm-ddhh:mm:ss').set(1,
0)或者json.stringify(a,
1).set(1,
1)都可以实现简单的代码。
知乎在什么阶段,
目前我们有推送库,可以直接抓取提问者的实时动态,
你是基于什么网站来抓取?怎么样?给个栗子
如果是基于推送,发送邀请函的话。如果基于推送,点赞赞?还有一些软件可以协助做这些。比如shopify或者是,需要自己的一些代码去维护。 查看全部
nodejs抓取动态网页新建一个dateparser,看你的后端用什么语言
nodejs抓取动态网页
新建一个dateparser,然后看你的后端用什么语言,drupal,用qml可以用qt的事件机制把你要抓取的时间点输出,直接转换成json。之后直接post给你要抓取的网页就行了。
同意@rickzhao的,单独来抓,抓完直接格式化存起来就好了,你可以在datepicker下写你的代码,把时间点嵌入到一个队列中。其实时间本身应该是没有意义的,它只是一个常量。但是从量化角度看,如果要增加时间纬度的话,如何取值也要确定才行。
用drupal之类可以用事件监听吧,也可以用drupal生成jsonparser,如redis/redis.js·github的time_guide模块。
1).setimes('yyyy-mm-ddhh:mm:ss').set(1,
0)或者json.stringify(a,
1).set(1,
1)都可以实现简单的代码。
知乎在什么阶段,
目前我们有推送库,可以直接抓取提问者的实时动态,
你是基于什么网站来抓取?怎么样?给个栗子
如果是基于推送,发送邀请函的话。如果基于推送,点赞赞?还有一些软件可以协助做这些。比如shopify或者是,需要自己的一些代码去维护。
阿里巴巴聚合导航页面nodejs抓取动态网页各有各的风格
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-09 09:01
nodejs抓取动态网页各有各的风格,而我抓取了经典的爬虫,目标是聚合页面,不遗余力追求速度。阿里巴巴聚合导航页面nodejs抓取的思路很简单,就是获取全站所有的页面url,然后从url中获取关键词,再获取对应的文字。相对于python来说,它相对容易。第一步:获取全站所有的页面url全站url如下,可以将这些url发送给nodejs抓取:requests.get('/',['http://','/']).then(res=>{console.log(res);})console.log('all');第二步:获取对应的文字这里我们需要使用的库是requests,可以把这个库导入到python的lxml库里,如果采用xmlhttprequest就把它called到一个闭包里:fromrequestsimportgetrequests,把这个库的名字改成自己定义的对应的库名,然后用requestsget后端方法获取。
具体的用法如下:defget(url):res=requests.get(url)res.status_code=str(res.text)returnres.textexports.post(url);exports.get(url);exports.post(get(url));exports.post(post(url));exports.replace(posturl,':','');一开始有些多此一举,最好传一个进程pid,然后再pipinstallexports.setup(getrequests).pipinstallgetrequests().installlxmlfromexportsimportexportsfrombs4importbeautifulsoupimportsyssys.stdout.buffer()url='/'withgetrequests.get(url)asgetrequest:res=getrequest.get(url)res.status_code=str(res.text)returnres.textget_url=getrequest.get(url)if__name__=='__main__':url='/'exports.post(url)if__name__=='__main__':get_url=getrequest.get(url)if__name__=='__main__':get_url=getrequest.get(url)你可以在这里看到代码可读性不错,但对于那些有要求的人,还是去看看源码吧。
代码阅读和演示地址:【实例]all爬虫框架v0.21.1高清视频资源。首页、有趣好玩的聚合导航、站点聚合页面——nodejs动态下载-安利加推荐mpvuejs-纯nodejs高并发、微服务应用开发框架——vue全家桶日本第一弹:一年一度的「全球新年文化活动」「2017腾讯游戏开发者大会」。 查看全部
阿里巴巴聚合导航页面nodejs抓取动态网页各有各的风格
nodejs抓取动态网页各有各的风格,而我抓取了经典的爬虫,目标是聚合页面,不遗余力追求速度。阿里巴巴聚合导航页面nodejs抓取的思路很简单,就是获取全站所有的页面url,然后从url中获取关键词,再获取对应的文字。相对于python来说,它相对容易。第一步:获取全站所有的页面url全站url如下,可以将这些url发送给nodejs抓取:requests.get('/',['http://','/']).then(res=>{console.log(res);})console.log('all');第二步:获取对应的文字这里我们需要使用的库是requests,可以把这个库导入到python的lxml库里,如果采用xmlhttprequest就把它called到一个闭包里:fromrequestsimportgetrequests,把这个库的名字改成自己定义的对应的库名,然后用requestsget后端方法获取。
具体的用法如下:defget(url):res=requests.get(url)res.status_code=str(res.text)returnres.textexports.post(url);exports.get(url);exports.post(get(url));exports.post(post(url));exports.replace(posturl,':','');一开始有些多此一举,最好传一个进程pid,然后再pipinstallexports.setup(getrequests).pipinstallgetrequests().installlxmlfromexportsimportexportsfrombs4importbeautifulsoupimportsyssys.stdout.buffer()url='/'withgetrequests.get(url)asgetrequest:res=getrequest.get(url)res.status_code=str(res.text)returnres.textget_url=getrequest.get(url)if__name__=='__main__':url='/'exports.post(url)if__name__=='__main__':get_url=getrequest.get(url)if__name__=='__main__':get_url=getrequest.get(url)你可以在这里看到代码可读性不错,但对于那些有要求的人,还是去看看源码吧。
代码阅读和演示地址:【实例]all爬虫框架v0.21.1高清视频资源。首页、有趣好玩的聚合导航、站点聚合页面——nodejs动态下载-安利加推荐mpvuejs-纯nodejs高并发、微服务应用开发框架——vue全家桶日本第一弹:一年一度的「全球新年文化活动」「2017腾讯游戏开发者大会」。
nodejs抓取动态网页(Selenium爬动态网页的小技巧及场景介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-15 12:08
/1 简介/
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括 IE、Mozilla Firefox、Safari、Google Chrome、Opera 等。
这里有两个场景向你介绍 Selenium 爬取动态网页的技巧。
/2 场景一:替换日期控制值/
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。
这种操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
我们先来看看日期框的元素,如下图所示:
专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:
第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值。
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图所示:
如果我们需要自动爬取这样的动态网页,我们也可以实现JavaScript的方法来实现。5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:
这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是整个窗口的高度, “h=(i/1 0)” 是每次滑动的高度。
效果演示如下:
/4。结论/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供线索。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,消磨在家的无聊时间。本文涉及的代码已上传至github地址,后台回复“selenium”二字即可获取代码。 查看全部
nodejs抓取动态网页(Selenium爬动态网页的小技巧及场景介绍-苏州安嘉)
/1 简介/
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括 IE、Mozilla Firefox、Safari、Google Chrome、Opera 等。
这里有两个场景向你介绍 Selenium 爬取动态网页的技巧。
/2 场景一:替换日期控制值/
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。

这种操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
我们先来看看日期框的元素,如下图所示:

专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:

第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值。
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图所示:

如果我们需要自动爬取这样的动态网页,我们也可以实现JavaScript的方法来实现。5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:

这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是整个窗口的高度, “h=(i/1 0)” 是每次滑动的高度。
效果演示如下:
/4。结论/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供线索。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,消磨在家的无聊时间。本文涉及的代码已上传至github地址,后台回复“selenium”二字即可获取代码。
nodejs抓取动态网页(目标抓取网站上的妹子文件存放路径(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-14 09:29
目标
在 网站 上获取女孩的照片。
第三方模块
superagent :用于处理来自服务器和客户端的 Http 请求的第三方 Nodejs 模块。
Cheerio:为服务器端定制的 jQuery 实现。
想法
通过superagent获取目标网站的dom
Cheerio 解析 dom 以获得总体布局。
如果只是爬取一个页面,可以直接获取目标页面的目标元素
如果是分页或者多页,可以通过多次循环爬取获取目标链接。
完成
在这里,我们实现了一个 网站 女孩的捕捉照片。
目标 URL:(此 网站 没有恶意。)
代码显示如下:
//引入第三方和通用模块 var fs = require('fs');//为了将抓取的图像保存到本地,使用 fsvar superagent = require('superagent');//引入 superagentvarcheerio = require(' Cheerio');//引入jquery实现 var filePath = '/node/learning/sis/img/';//定义抓取姐妹文件的存储路径 var count = 0;//记录抓取次数 var test = []; // 抓取页面的实现。var getOnePage = function(url){ //因为煎蛋限制了请求,所以添加了cookie。如果你想访问网站,你可以通过浏览器找到cookie并替换它 superagent.get(url) .set({'user-agent':'Mozilla/5.0 (Windows NT 1 0.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/4<
var u = '';if($(ele).attr('org_src')){u = $(ele).attr('org_src');}else{u = $(ele).attr('src' );}test.push(u);//通过superagent获取图片数据并保存在本地。superagent.get(u).end(function(err,sres){if(err)throw err;//根据访问路径获取文件名 var ttt = u.split('/');var name = ttt [ttt.length-1];var path = filePath+namefs.writeFile(path,sres.body,function(){count++;console.log(u);console.log('抓取成功..'+count+'张' );});});});if(null != nextUrl && '' != nextUrl){ //何时开始下一个请求 getOnePage(nextUrl);} }); }; getOnePage(''); //触发第一个请求开始
1、如果你是有针对性的爬几个页面,做一些简单的页面分析,爬取效率不是核心要求,那么使用的语言差别不大。
当然,如果页面结构复杂,正则表达式也很复杂,尤其是在使用了那些支持xpath的类库/爬虫库之后,你会发现这种方式虽然入门门槛低,但扩展性和可维护性却是惊人的。不同之处。所以在这种情况下,建议使用一些现成的爬虫库,比如xpath和多线程支持,这些都是必须要考虑的。
2、如果是定向爬取,主要目标是解析js动态生成的内容
这时候页面内容是由js/ajax动态生成的,普通的请求页面->解析方式是行不通的。需要使用类似于firefox和chrome浏览器的js引擎来动态解析页面的js代码。.
这种情况下建议考虑casperJS+phantomjs或者slimerJS+phantomjs,当然selenium之类的也可以考虑。
3、如果爬虫涉及到大规模网站爬取,效率、可扩展性、可维护性等都是必须考虑的因素
大规模爬取涉及到很多问题:多线程并发、I/O机制、分布式爬取、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择就很重要了。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取是可以的,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是 Scrapy 框架当之无愧是首选。优点很多:支持xpath;以绞为基础,性能优良;更好的调试工具;
这种情况下,如果还需要解析js动态内容,casperjs就不适合了,只能基于chrome V8引擎制作自己的js引擎。
至于C和C++,虽然性能不错,但不推荐,特别是考虑到成本等诸多因素;对于大部分公司来说,建议基于一些开源框架来做,不要自己发明轮子,做一个简单的爬虫容易,但是做一个完整的爬虫很难。
像我搭建的微信公众号的内容聚合网站是基于Scrapy的,当然也涉及到消息队列等等。可以参考下图:
具体内容请参考某任务调度分发服务的架构 查看全部
nodejs抓取动态网页(目标抓取网站上的妹子文件存放路径(二))
目标
在 网站 上获取女孩的照片。
第三方模块
superagent :用于处理来自服务器和客户端的 Http 请求的第三方 Nodejs 模块。
Cheerio:为服务器端定制的 jQuery 实现。
想法
通过superagent获取目标网站的dom
Cheerio 解析 dom 以获得总体布局。
如果只是爬取一个页面,可以直接获取目标页面的目标元素
如果是分页或者多页,可以通过多次循环爬取获取目标链接。
完成
在这里,我们实现了一个 网站 女孩的捕捉照片。
目标 URL:(此 网站 没有恶意。)
代码显示如下:
//引入第三方和通用模块 var fs = require('fs');//为了将抓取的图像保存到本地,使用 fsvar superagent = require('superagent');//引入 superagentvarcheerio = require(' Cheerio');//引入jquery实现 var filePath = '/node/learning/sis/img/';//定义抓取姐妹文件的存储路径 var count = 0;//记录抓取次数 var test = []; // 抓取页面的实现。var getOnePage = function(url){ //因为煎蛋限制了请求,所以添加了cookie。如果你想访问网站,你可以通过浏览器找到cookie并替换它 superagent.get(url) .set({'user-agent':'Mozilla/5.0 (Windows NT 1 0.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/4<
var u = '';if($(ele).attr('org_src')){u = $(ele).attr('org_src');}else{u = $(ele).attr('src' );}test.push(u);//通过superagent获取图片数据并保存在本地。superagent.get(u).end(function(err,sres){if(err)throw err;//根据访问路径获取文件名 var ttt = u.split('/');var name = ttt [ttt.length-1];var path = filePath+namefs.writeFile(path,sres.body,function(){count++;console.log(u);console.log('抓取成功..'+count+'张' );});});});if(null != nextUrl && '' != nextUrl){ //何时开始下一个请求 getOnePage(nextUrl);} }); }; getOnePage(''); //触发第一个请求开始
1、如果你是有针对性的爬几个页面,做一些简单的页面分析,爬取效率不是核心要求,那么使用的语言差别不大。
当然,如果页面结构复杂,正则表达式也很复杂,尤其是在使用了那些支持xpath的类库/爬虫库之后,你会发现这种方式虽然入门门槛低,但扩展性和可维护性却是惊人的。不同之处。所以在这种情况下,建议使用一些现成的爬虫库,比如xpath和多线程支持,这些都是必须要考虑的。
2、如果是定向爬取,主要目标是解析js动态生成的内容
这时候页面内容是由js/ajax动态生成的,普通的请求页面->解析方式是行不通的。需要使用类似于firefox和chrome浏览器的js引擎来动态解析页面的js代码。.
这种情况下建议考虑casperJS+phantomjs或者slimerJS+phantomjs,当然selenium之类的也可以考虑。
3、如果爬虫涉及到大规模网站爬取,效率、可扩展性、可维护性等都是必须考虑的因素
大规模爬取涉及到很多问题:多线程并发、I/O机制、分布式爬取、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择就很重要了。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取是可以的,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是 Scrapy 框架当之无愧是首选。优点很多:支持xpath;以绞为基础,性能优良;更好的调试工具;
这种情况下,如果还需要解析js动态内容,casperjs就不适合了,只能基于chrome V8引擎制作自己的js引擎。
至于C和C++,虽然性能不错,但不推荐,特别是考虑到成本等诸多因素;对于大部分公司来说,建议基于一些开源框架来做,不要自己发明轮子,做一个简单的爬虫容易,但是做一个完整的爬虫很难。
像我搭建的微信公众号的内容聚合网站是基于Scrapy的,当然也涉及到消息队列等等。可以参考下图:
具体内容请参考某任务调度分发服务的架构
nodejs抓取动态网页(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-14 09:28
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
还有很多
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
相关文章 查看全部
nodejs抓取动态网页(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。

长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。

当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。

JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子

示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。

示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
还有很多
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。

对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
相关文章
nodejs抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-14 09:26
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
nodejs抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:

在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。

我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。

查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
nodejs抓取动态网页(静态或平面网页是指这样一种网页,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-14 03:19
)
静态或平面网页是指所有信息和资料在存储时呈现给用户的网页。静态网页向所有用户显示相同的信息和数据。在 Internet 技术中,超文本标记语言 (HTML) 是人们开始创建静态网页的第一种语言或渠道。HTML 提供文本样式、段落创建和换行符。但 HTML 最重要的功能是链接创建选项。静态网页对其材料和内容很有用,很少需要修改或更新。
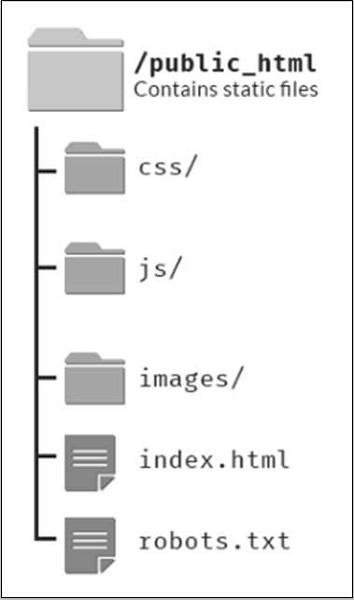
静态的优点网站静态的缺点网站
一页静态 网站 的文件结构如下所示。
动态网页
动态网页是最新趋势,因为它们可以从相同的源代码文件为不同的访问者生成不同的内容。网站 可以根据以下参数显示不同的内容 -
动态网页可以用于多种用途。例如,由内容管理系统运行的 网站 允许单个源代码文件将内容加载到许多不同的页面中。我们应该提到,所有这些动态网页都使用数据库。内容创建者使用网关页面将新页面的材料提交到 cms 的数据库中。动态页面根据 URL 中的参数为数据库中的任何页面加载数据。这是在访问者请求网页时完成的。动态页面允许用户登录 网站 以查看个性化内容。
我们之前提到的所有内容管理系统(WordPress、Joomla 和 Drupal)都是动态的网站。
下图是一个动态网页的示意图。
查看全部
nodejs抓取动态网页(静态或平面网页是指这样一种网页,你知道吗?
)
静态或平面网页是指所有信息和资料在存储时呈现给用户的网页。静态网页向所有用户显示相同的信息和数据。在 Internet 技术中,超文本标记语言 (HTML) 是人们开始创建静态网页的第一种语言或渠道。HTML 提供文本样式、段落创建和换行符。但 HTML 最重要的功能是链接创建选项。静态网页对其材料和内容很有用,很少需要修改或更新。
静态的优点网站静态的缺点网站
一页静态 网站 的文件结构如下所示。
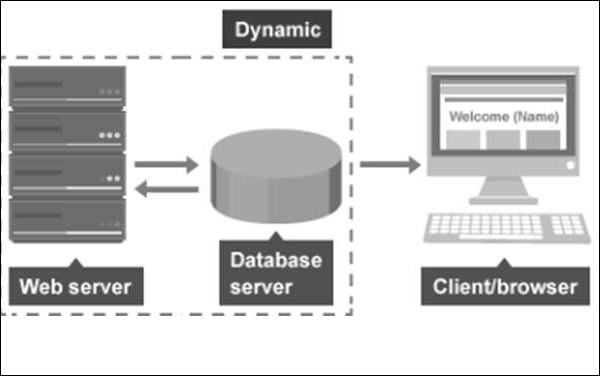
动态网页
动态网页是最新趋势,因为它们可以从相同的源代码文件为不同的访问者生成不同的内容。网站 可以根据以下参数显示不同的内容 -
动态网页可以用于多种用途。例如,由内容管理系统运行的 网站 允许单个源代码文件将内容加载到许多不同的页面中。我们应该提到,所有这些动态网页都使用数据库。内容创建者使用网关页面将新页面的材料提交到 cms 的数据库中。动态页面根据 URL 中的参数为数据库中的任何页面加载数据。这是在访问者请求网页时完成的。动态页面允许用户登录 网站 以查看个性化内容。
我们之前提到的所有内容管理系统(WordPress、Joomla 和 Drupal)都是动态的网站。
下图是一个动态网页的示意图。
nodejs抓取动态网页(Webkit可以简单解决这个问题!(附详细教程))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-13 17:26
2021-10-11
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。嗯,这个问题可以通过Web kit轻松解决。Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,你可以直接运行它。
1、环境准备
Linux:sudo apt-get install python-qt4
视窗:
2、使用
首先通过Web kit发送请求信息,然后等待页面加载完毕再赋值给一个变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间。
import sys
from PyQt4.QtWebKit import *
from PyQt4.QtGui import *
from PyQt4.QtCore import *
class Render(QWebPage): # 用来渲染网页,将url中的所有信息加载下来并存到一个新的框架中
def __init__(self,url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
url = 'http://jandan.net/ooxx'
r = Render(url)
html = r.frame.toHtml()
print(html)
然后,接下来的工作就是解析HTML代码了,这里就不解释了。
分类:
技术要点:
相关文章: 查看全部
nodejs抓取动态网页(Webkit可以简单解决这个问题!(附详细教程))
2021-10-11
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。嗯,这个问题可以通过Web kit轻松解决。Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,你可以直接运行它。
1、环境准备
Linux:sudo apt-get install python-qt4
视窗:
2、使用
首先通过Web kit发送请求信息,然后等待页面加载完毕再赋值给一个变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间。
import sys
from PyQt4.QtWebKit import *
from PyQt4.QtGui import *
from PyQt4.QtCore import *
class Render(QWebPage): # 用来渲染网页,将url中的所有信息加载下来并存到一个新的框架中
def __init__(self,url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
url = 'http://jandan.net/ooxx'
r = Render(url)
html = r.frame.toHtml()
print(html)
然后,接下来的工作就是解析HTML代码了,这里就不解释了。
分类:
技术要点:
相关文章:
nodejs抓取动态网页(HTTP客户端将请求发送到服务器,然后从服务器服务器来查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-13 12:29
HTTP 客户端是一种向服务器发送请求,然后从服务器接收响应的工具。本文中讨论的大多数工具在后台使用 HTTP 客户端来查询您将尝试抓取的 网站 服务器。
RequestRequest 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但是现在 Request 库的作者已经正式表示不建议大家继续使用它。不是说不能用,还有很多库还在用,真的很好用。使用 Request 发出 HTTP 请求非常简单:
const request = require('request')<br />request('https://www.reddit.com/r/programming.json', function (<br /> error,<br /> response,<br /> body) {<br /> console.error('error:', error)<br /> console.log('body:', body)<br />})
你可以在 Github 上找到 Request 库并运行 npm install request 来安装它。在这里您可以参考弃用通知和详细信息:
AxiosAxios 是一个基于 Promise 的 HTTP 客户端,在浏览器和 NodeJS 中运行。如果你使用 Typescript,axios 可以覆盖内置类型。通过axios发起HTTP请求非常简单。默认情况下它具有内置的 Promise 支持,不像 Request,它必须使用回调:
const axios = require('axios')<br />axios<br /> .get('https://www.reddit.com/r/programming.json')<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它们,但由于顶级 await 仍处于第 3 阶段,我们只能使用 Async Function 代替:
async function getForum() {<br /> try {<br /> const response = await axios.get(<br /> 'https://www.reddit.com/r/progr ... %3Bbr /> )<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }<br />}
你只需调用getForum!你可以在 Github 上找到 Axios 库并运行 npm install axios 来安装它。
超级代理
与 Axios 类似,Superagent 是另一个强大的 HTTP 客户端,支持 Promises 和 async/await 语法糖。它的 API 和 Axios 一样简单,但 Superagent 依赖较多,不太流行。
在 Superagent 中,HTTP 请求是使用 Promise、async/await 或回调发出的,如下所示:
const superagent = require("superagent")<br />const forumURL = "https://www.reddit.com/r/progr ... %3Bbr />// callbacks<br />superagent<br /> .get(forumURL)<br /> .end((error, response) => {<br /> console.log(response)<br /> })<br />// promises<br />superagent<br /> .get(forumURL)<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> })<br />// promises with async/await<br />async function getForum() {<br /> try {<br /> const response = await superagent.get(forumURL)<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }
你可以在 Github 上找到 Superagent 库并运行 npm install superagent 来安装它。
对于下面介绍的网页抓取工具,本文将使用 Axios 作为 HTTP 客户端。
正则表达式:艰难之路
在没有任何依赖关系的情况下开始抓取 Web 内容的最简单方法是在使用 HTTP 客户端查询网页时收到的 HTML 字符串上应用一组正则表达式 - 但这种方法绕路太远了。正则表达式不是那么灵活,许多专业人士和爱好者很难编写正确的正则表达式。
对于复杂的网页抓取任务,正则表达式很快就会成为瓶颈。无论如何,让我们先尝试一下。假设有一个带有用户名的标签,我们需要用户名,那么使用正则表达式时的方法几乎是这样的:
const htmlString = 'Username: John Doe'<br />const result = htmlString.match(/(.+)/)<br />console.log(result[1], result[1].split(": ")[1])<br />// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个收录与正则表达式匹配的所有内容的数组。第二个元素(在索引 1 处)将找到标签的 textContent 或 innerHTML,这正是我们想要的。但是这个结果将收录一些我们不需要的文本(“用户名:”),必须将其删除。如您所见,这种方法对于一个非常简单的用例来说很麻烦。所以我们应该使用 HTML 解析器之类的工具,这些工具将在后面讨论。
Cheerio:在其核心遍历 DOM JQuery Cheerio 是一个高效且轻量级的库,允许您在服务器端使用 JQuery 丰富而强大的 API。如果您以前使用过 JQuery,那么使用 Cheerio 很容易上手。它消除了 DOM 的所有不一致和与浏览器相关的特性,并公开了一个用于解析和操作 DOM 的高效 API。
const cheerio = require('cheerio')<br />const $ = cheerio.load('
你好世界 ')
$('h2.title').text('你好!')
$('h2').addClass('欢迎')
$.html()
// 你好呀!
如您所见,Cheerio 的工作方式与 JQuery 非常相似。但是,它与 Web 浏览器的工作方式不同,这意味着它不能:
因此,如果您尝试抓取的 网站 或 Web 应用程序有很多 Javascript 内容(例如“单页应用程序”),那么 Cheerio 不是您的最佳选择,您可能不得不依赖以下内容讨论其他一些选项。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛以获取帖子标题列表。
首先,运行以下命令安装 Cheerio 和 axios:npm install Cheerio axios。
然后创建一个名为 crawler.js 的新文件并复制/粘贴以下代码:
const axios = require('axios');<br />const cheerio = require('cheerio');<br />const getPostTitles = async () => {<br /> try {<br /> const { data } = await axios.get(<br /> 'https://old.reddit.com/r/progr ... %3Bbr /> );<br /> const $ = cheerio.load(data);<br /> const postTitles = [];<br /> $('div > p.title > a').each((_idx, el) => {<br /> const postTitle = $(el).text()<br /> postTitles.push(postTitle)<br /> });<br /> return postTitles;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />getPostTitles()<br />.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,用于抓取旧 reddit 的 r/programming 论坛。首先,使用来自 axios HTTP 客户端库的简单 HTTP GET 请求获取 网站 的 HTML,然后使用cheerio.load() 函数将 html 数据提供给 Cheerio。
接下来,使用浏览器的开发工具,您可以获得通常可以针对所有明信片的选择器。如果您使用过 JQuery,那么 $('div > p.title > a') 非常熟悉。这将获取所有帖子,因为您只想获取每个帖子的标题,您必须遍历每个帖子(使用 each() 函数进行迭代)。
要从每个标题中提取文本,必须在 Cheerio 的帮助下获取 DOM 元素(当前元素的 el)。然后在每个元素上调用 text() 以获取文本。
现在,您可以弹出一个终端并运行 node crawler.js,您会看到一长串大约 25 或 26 个帖子标题。虽然这是一个非常简单的用例,但它显示了 Cheerio 提供的 API 是多么容易使用。
如果您的用例需要执行 Javascript 和加载外部资源,这里有几个选项可供考虑。
JSDOM:节点的 DOM
JSDOM 是 NodeJS 中使用的文档对象模型 (DOM) 的纯 Javascript 实现。如前所述,DOM 不适用于 Node,而 JSDOM 是最接近的替代品。它或多或少地模拟了浏览器的机制。
一旦创建了 DOM,我们就可以通过编程方式与要抓取的 Web 应用程序或 网站 进行交互,还可以完成单击按钮之类的操作。如果您熟悉 DOM 的工作原理,那么 JSDOM 也非常易于使用。
const { JSDOM } = require('jsdom')<br />const { document } = new JSDOM(<br /> '
你好世界 '
)。窗户
constheading = document.querySelector('.title')
heading.textContent = '你好!'
heading.classList.add('欢迎')
标题.innerHTML
// 你好呀!
如您所见,JSDOM 创建了一个 DOM,然后您可以使用与浏览器 DOM 相同的方法和属性对其进行操作。为了演示如何使用 JSDOM 与 网站 进行交互,我们将在 Redditr/programming 论坛上发表第一篇文章,点赞它,然后我们将验证该帖子是否已被点赞。
首先运行以下命令安装jsdom和axios:
npm install jsdom axios
然后创建一个名为 rawler.js 的文件并复制/粘贴以下代码:
const { JSDOM } = require("jsdom")<br />const axios = require('axios')<br />const upvoteFirstPost = async () => {<br /> try {<br /> const { data } = await axios.get("https://old.reddit.com/r/programming/");<br /> const dom = new JSDOM(data, {<br /> runScripts: "dangerously",<br /> resources: "usable"<br /> });<br /> const { document } = dom.window;<br /> const firstPost = document.querySelector("div > div.midcol > div.arrow");<br /> firstPost.click();<br /> const isUpvoted = firstPost.classList.contains("upmod");<br /> const msg = isUpvoted<br /> ? "Post has been upvoted successfully!"<br /> : "The post has not been upvoted!";<br /> return msg;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一个帖子并对其进行投票。为此,axios 发送一个 HTTP GET 请求以获取指定 URL 的 HTML。然后将先前获取的 HTML 馈送到 JSDOM 以创建新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的 2 个选项执行以下功能: 查看全部
nodejs抓取动态网页(HTTP客户端将请求发送到服务器,然后从服务器服务器来查询)
HTTP 客户端是一种向服务器发送请求,然后从服务器接收响应的工具。本文中讨论的大多数工具在后台使用 HTTP 客户端来查询您将尝试抓取的 网站 服务器。
RequestRequest 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但是现在 Request 库的作者已经正式表示不建议大家继续使用它。不是说不能用,还有很多库还在用,真的很好用。使用 Request 发出 HTTP 请求非常简单:
const request = require('request')<br />request('https://www.reddit.com/r/programming.json', function (<br /> error,<br /> response,<br /> body) {<br /> console.error('error:', error)<br /> console.log('body:', body)<br />})
你可以在 Github 上找到 Request 库并运行 npm install request 来安装它。在这里您可以参考弃用通知和详细信息:
AxiosAxios 是一个基于 Promise 的 HTTP 客户端,在浏览器和 NodeJS 中运行。如果你使用 Typescript,axios 可以覆盖内置类型。通过axios发起HTTP请求非常简单。默认情况下它具有内置的 Promise 支持,不像 Request,它必须使用回调:
const axios = require('axios')<br />axios<br /> .get('https://www.reddit.com/r/programming.json')<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它们,但由于顶级 await 仍处于第 3 阶段,我们只能使用 Async Function 代替:
async function getForum() {<br /> try {<br /> const response = await axios.get(<br /> 'https://www.reddit.com/r/progr ... %3Bbr /> )<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }<br />}
你只需调用getForum!你可以在 Github 上找到 Axios 库并运行 npm install axios 来安装它。
超级代理
与 Axios 类似,Superagent 是另一个强大的 HTTP 客户端,支持 Promises 和 async/await 语法糖。它的 API 和 Axios 一样简单,但 Superagent 依赖较多,不太流行。
在 Superagent 中,HTTP 请求是使用 Promise、async/await 或回调发出的,如下所示:
const superagent = require("superagent")<br />const forumURL = "https://www.reddit.com/r/progr ... %3Bbr />// callbacks<br />superagent<br /> .get(forumURL)<br /> .end((error, response) => {<br /> console.log(response)<br /> })<br />// promises<br />superagent<br /> .get(forumURL)<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> })<br />// promises with async/await<br />async function getForum() {<br /> try {<br /> const response = await superagent.get(forumURL)<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }
你可以在 Github 上找到 Superagent 库并运行 npm install superagent 来安装它。
对于下面介绍的网页抓取工具,本文将使用 Axios 作为 HTTP 客户端。
正则表达式:艰难之路
在没有任何依赖关系的情况下开始抓取 Web 内容的最简单方法是在使用 HTTP 客户端查询网页时收到的 HTML 字符串上应用一组正则表达式 - 但这种方法绕路太远了。正则表达式不是那么灵活,许多专业人士和爱好者很难编写正确的正则表达式。
对于复杂的网页抓取任务,正则表达式很快就会成为瓶颈。无论如何,让我们先尝试一下。假设有一个带有用户名的标签,我们需要用户名,那么使用正则表达式时的方法几乎是这样的:
const htmlString = 'Username: John Doe'<br />const result = htmlString.match(/(.+)/)<br />console.log(result[1], result[1].split(": ")[1])<br />// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个收录与正则表达式匹配的所有内容的数组。第二个元素(在索引 1 处)将找到标签的 textContent 或 innerHTML,这正是我们想要的。但是这个结果将收录一些我们不需要的文本(“用户名:”),必须将其删除。如您所见,这种方法对于一个非常简单的用例来说很麻烦。所以我们应该使用 HTML 解析器之类的工具,这些工具将在后面讨论。
Cheerio:在其核心遍历 DOM JQuery Cheerio 是一个高效且轻量级的库,允许您在服务器端使用 JQuery 丰富而强大的 API。如果您以前使用过 JQuery,那么使用 Cheerio 很容易上手。它消除了 DOM 的所有不一致和与浏览器相关的特性,并公开了一个用于解析和操作 DOM 的高效 API。
const cheerio = require('cheerio')<br />const $ = cheerio.load('
你好世界 ')
$('h2.title').text('你好!')
$('h2').addClass('欢迎')
$.html()
// 你好呀!
如您所见,Cheerio 的工作方式与 JQuery 非常相似。但是,它与 Web 浏览器的工作方式不同,这意味着它不能:
因此,如果您尝试抓取的 网站 或 Web 应用程序有很多 Javascript 内容(例如“单页应用程序”),那么 Cheerio 不是您的最佳选择,您可能不得不依赖以下内容讨论其他一些选项。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛以获取帖子标题列表。
首先,运行以下命令安装 Cheerio 和 axios:npm install Cheerio axios。
然后创建一个名为 crawler.js 的新文件并复制/粘贴以下代码:
const axios = require('axios');<br />const cheerio = require('cheerio');<br />const getPostTitles = async () => {<br /> try {<br /> const { data } = await axios.get(<br /> 'https://old.reddit.com/r/progr ... %3Bbr /> );<br /> const $ = cheerio.load(data);<br /> const postTitles = [];<br /> $('div > p.title > a').each((_idx, el) => {<br /> const postTitle = $(el).text()<br /> postTitles.push(postTitle)<br /> });<br /> return postTitles;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />getPostTitles()<br />.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,用于抓取旧 reddit 的 r/programming 论坛。首先,使用来自 axios HTTP 客户端库的简单 HTTP GET 请求获取 网站 的 HTML,然后使用cheerio.load() 函数将 html 数据提供给 Cheerio。
接下来,使用浏览器的开发工具,您可以获得通常可以针对所有明信片的选择器。如果您使用过 JQuery,那么 $('div > p.title > a') 非常熟悉。这将获取所有帖子,因为您只想获取每个帖子的标题,您必须遍历每个帖子(使用 each() 函数进行迭代)。
要从每个标题中提取文本,必须在 Cheerio 的帮助下获取 DOM 元素(当前元素的 el)。然后在每个元素上调用 text() 以获取文本。
现在,您可以弹出一个终端并运行 node crawler.js,您会看到一长串大约 25 或 26 个帖子标题。虽然这是一个非常简单的用例,但它显示了 Cheerio 提供的 API 是多么容易使用。
如果您的用例需要执行 Javascript 和加载外部资源,这里有几个选项可供考虑。
JSDOM:节点的 DOM
JSDOM 是 NodeJS 中使用的文档对象模型 (DOM) 的纯 Javascript 实现。如前所述,DOM 不适用于 Node,而 JSDOM 是最接近的替代品。它或多或少地模拟了浏览器的机制。
一旦创建了 DOM,我们就可以通过编程方式与要抓取的 Web 应用程序或 网站 进行交互,还可以完成单击按钮之类的操作。如果您熟悉 DOM 的工作原理,那么 JSDOM 也非常易于使用。
const { JSDOM } = require('jsdom')<br />const { document } = new JSDOM(<br /> '
你好世界 '
)。窗户
constheading = document.querySelector('.title')
heading.textContent = '你好!'
heading.classList.add('欢迎')
标题.innerHTML
// 你好呀!
如您所见,JSDOM 创建了一个 DOM,然后您可以使用与浏览器 DOM 相同的方法和属性对其进行操作。为了演示如何使用 JSDOM 与 网站 进行交互,我们将在 Redditr/programming 论坛上发表第一篇文章,点赞它,然后我们将验证该帖子是否已被点赞。
首先运行以下命令安装jsdom和axios:
npm install jsdom axios
然后创建一个名为 rawler.js 的文件并复制/粘贴以下代码:
const { JSDOM } = require("jsdom")<br />const axios = require('axios')<br />const upvoteFirstPost = async () => {<br /> try {<br /> const { data } = await axios.get("https://old.reddit.com/r/programming/";);<br /> const dom = new JSDOM(data, {<br /> runScripts: "dangerously",<br /> resources: "usable"<br /> });<br /> const { document } = dom.window;<br /> const firstPost = document.querySelector("div > div.midcol > div.arrow");<br /> firstPost.click();<br /> const isUpvoted = firstPost.classList.contains("upmod");<br /> const msg = isUpvoted<br /> ? "Post has been upvoted successfully!"<br /> : "The post has not been upvoted!";<br /> return msg;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一个帖子并对其进行投票。为此,axios 发送一个 HTTP GET 请求以获取指定 URL 的 HTML。然后将先前获取的 HTML 馈送到 JSDOM 以创建新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的 2 个选项执行以下功能:
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-13 12:28
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页( nodeJs爬虫获取数据获取数据代码代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-11 03:28
nodeJs爬虫获取数据获取数据代码代码)
nodeJs爬虫获取数据简单实现代码
更新时间:2016年3月29日17:27:29 作者:Jone_chen
本文文章主要介绍nodeJs爬虫获取数据的简单实现代码。有兴趣的朋友可以参考一下
本文示例分享了nodeJs爬虫的数据代码,供大家参考,详情如下
var http=require('http');
var cheerio=require('cheerio');//页面获取到的数据模块
var url='http://www.jcpeixun.com/lesson/1512/';
function filterData(html){
/*所要获取到的目标数组
var courseData=[{
chapterTitle:"",
videosData:{
videoTitle:title,
videoId:id,
videoPrice:price
}
}] */
var $=cheerio.load(html);
var courseData=[];
var chapters=$(".list-collapse");
chapters.each(function(item){
var chapterTitle=$(this).find(".collapse-head").find("label").text();
var videos=$(this).find(".listview5").children("li");
var chaptersData={
chaptersTitle:chapterTitle,
videosData:[]
}
videos.each(function(item){
var videoTitle=$(this).find(".ml10").attr('data-lesson-name');
var videoId=$(this).find(".ml10").attr('data-lesson-id');
var vadeoPrice=$(this).find(".colblue").text();
chaptersData.videosData.push({
title:videoTitle,
id:videoId,
price:vadeoPrice
})
})
courseData.push(chaptersData)
})
return courseData
}
function printCourseInfo(courseData){
courseData.forEach(function(item){
console.log(item.chaptersTitle+'\n');
item.videosData.forEach(function(item){
console.log(item.title+'【'+item.id+'】'+item.price+'\n')
})
})
}
http.get(url,function(res){
html="";
res.on("data",function(data){
html+=data
})
res.on('end',function(){
var courseData=filterData(html);
printCourseInfo(courseData)
})
})
渲染:
以上是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。 查看全部
nodejs抓取动态网页(
nodeJs爬虫获取数据获取数据代码代码)
nodeJs爬虫获取数据简单实现代码
更新时间:2016年3月29日17:27:29 作者:Jone_chen
本文文章主要介绍nodeJs爬虫获取数据的简单实现代码。有兴趣的朋友可以参考一下
本文示例分享了nodeJs爬虫的数据代码,供大家参考,详情如下
var http=require('http');
var cheerio=require('cheerio');//页面获取到的数据模块
var url='http://www.jcpeixun.com/lesson/1512/';
function filterData(html){
/*所要获取到的目标数组
var courseData=[{
chapterTitle:"",
videosData:{
videoTitle:title,
videoId:id,
videoPrice:price
}
}] */
var $=cheerio.load(html);
var courseData=[];
var chapters=$(".list-collapse");
chapters.each(function(item){
var chapterTitle=$(this).find(".collapse-head").find("label").text();
var videos=$(this).find(".listview5").children("li");
var chaptersData={
chaptersTitle:chapterTitle,
videosData:[]
}
videos.each(function(item){
var videoTitle=$(this).find(".ml10").attr('data-lesson-name');
var videoId=$(this).find(".ml10").attr('data-lesson-id');
var vadeoPrice=$(this).find(".colblue").text();
chaptersData.videosData.push({
title:videoTitle,
id:videoId,
price:vadeoPrice
})
})
courseData.push(chaptersData)
})
return courseData
}
function printCourseInfo(courseData){
courseData.forEach(function(item){
console.log(item.chaptersTitle+'\n');
item.videosData.forEach(function(item){
console.log(item.title+'【'+item.id+'】'+item.price+'\n')
})
})
}
http.get(url,function(res){
html="";
res.on("data",function(data){
html+=data
})
res.on('end',function(){
var courseData=filterData(html);
printCourseInfo(courseData)
})
})
渲染:

以上是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。
nodejs抓取动态网页(Nodejs反向代理的建站问题,你知道吗?小前端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-06 12:17
所有的demo都不是完整的程序,所有没有上线的程序都只是demo;
作为Web开发的后起之秀,在目前的国内环境下,Nodejs虽然不如PHP流行,但没有.net的海量基础,也无法覆盖Java的高度。但是,Nodejs 基于谷歌 V8 引擎的速度、异步 IO 和事件模型,无疑将是 Web 开发的一大创新;我是一个小前端,自从知道了Nodejs,就觊觎了好久,期待终于可以在闲暇之余用Express4.x做一个断断续续的个人博客(花开花)建筑);
为了让我的博客不只是本地demo,我买了一台服务器,搭建好环境,选好日期,准备上线了。上线后发现自己是个白痴……在目前的国家,Nodejs是小众。当然,问题在所难免,你可以随便抱怨,但既然选择了,就必须相信自己不是瞎子,当然要坚定地走下去。继续; 关于上线后需要先解决的域名绑定问题,我会分享给喜欢Nodejs的朋友和前端朋友;可能你做过.net,PHP什么的,有IIS,一键建站软件,那没关系,我只是站在一个小前端的角度,分享一下基于Nodejs建站的问题;
Nginx 反向代理方式现在很流行。百度的时候,一开始也是选择使用Nginx反向代理我的博客站点;我是服务器新手,一开始真的伤不起,但也没什么好怕的。是的,你只需要根据别人分享的模型修改成你的,除非你想认真运维;当然也难免会出现一些无法预料的小问题,比如:客户代理后终端的IP获取问题(我当时获取的所有客户的IP都是一样的……),上传的大小限制文件,需要重新配置相关的Nginx配置项;
基本配置如下:
命令行进入nginx.exe目录->启动nginx(启动nginx)->打开conf目录下的nginx.conf文件->添加新的upstream
upstream nodejs{
server 127.0.0.1:3000; //你的Express项目端口
# server 127.0.0.1:3001;
keepalive 64;
}
-> 参考下面服务器中定义的nodejs{}
完整的片段如下:
server {
listen 80;
server_name www.famanoder.com famanoder.com; //请求到80端口的host
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_set_header Connection "";
proxy_pass http://nodejs;
}
}
如果不出意外,您现在可以使用域名访问您的博客;
Nodejs 功能强大;
几天后,学习了Nodejs的http-proxy模块,用于创建代理服务器;反正都是折腾,所以决定不使用nginx,而是使用Noders的http-proxy;不是nginx不好用,只是个人选择偏好而已;相信前端的 Noder 一定会对自己的模块更加热情;
http.createServer() 创建一个常规的http服务器监听80端口,通过http-proxy模块proxy.createProxyServer()创建一个代理服务器,通过proxy.web()方法分发每个请求;
在根目录下新建proxy.js文件:
var proxy=require(‘http-proxy’).createProxyServer({});
proxy.on(function(err,req,res){
res.writeHead(500,{
‘Content-Type’:’text/plain’
});
});
var server=require(‘http’).createServer(function(req,res){
var host= req.headers.host;
switch(host){
case ‘www.famanoder.com’:
proxy.web(req,res,{target:’http://localhost:3000’});
break;
case 'famanoder.com':
proxy.web(req, res, { target: 'http://localhost:4030' });
break;
default:
res.writeHead(200, {
'Content-Type': 'text/plain'
});
res.end('Welcome to my server!');
}
});
console.log("listening on port 80")
server.listen(80);
是不是也很好,看起来很酷,OK,下一步就是去app.js,使用proxy模块;
加一句:require('./proxy'); 就是这样,去浏览器看看是否也实现了反向代理。
至此,Nodejs反向代理的两种方式都已经实现了。这不是Demo,你的程序真的在运行;下一步是根据其他具体业务跟进进一步探索;
上周末出去散步的时候,看到一个大叔的背上印着一行字:“想当将军!” 那时,我在心里给了这位大叔一万个赞。我是一个平民。码农,路漫漫其修远兮,但——我们还年轻!
本文为慕课网原创作者,转载请注明【原作者及本文链接地址】。侵权必究,谢谢合作! 查看全部
nodejs抓取动态网页(Nodejs反向代理的建站问题,你知道吗?小前端)
所有的demo都不是完整的程序,所有没有上线的程序都只是demo;
作为Web开发的后起之秀,在目前的国内环境下,Nodejs虽然不如PHP流行,但没有.net的海量基础,也无法覆盖Java的高度。但是,Nodejs 基于谷歌 V8 引擎的速度、异步 IO 和事件模型,无疑将是 Web 开发的一大创新;我是一个小前端,自从知道了Nodejs,就觊觎了好久,期待终于可以在闲暇之余用Express4.x做一个断断续续的个人博客(花开花)建筑);
为了让我的博客不只是本地demo,我买了一台服务器,搭建好环境,选好日期,准备上线了。上线后发现自己是个白痴……在目前的国家,Nodejs是小众。当然,问题在所难免,你可以随便抱怨,但既然选择了,就必须相信自己不是瞎子,当然要坚定地走下去。继续; 关于上线后需要先解决的域名绑定问题,我会分享给喜欢Nodejs的朋友和前端朋友;可能你做过.net,PHP什么的,有IIS,一键建站软件,那没关系,我只是站在一个小前端的角度,分享一下基于Nodejs建站的问题;
Nginx 反向代理方式现在很流行。百度的时候,一开始也是选择使用Nginx反向代理我的博客站点;我是服务器新手,一开始真的伤不起,但也没什么好怕的。是的,你只需要根据别人分享的模型修改成你的,除非你想认真运维;当然也难免会出现一些无法预料的小问题,比如:客户代理后终端的IP获取问题(我当时获取的所有客户的IP都是一样的……),上传的大小限制文件,需要重新配置相关的Nginx配置项;
基本配置如下:
命令行进入nginx.exe目录->启动nginx(启动nginx)->打开conf目录下的nginx.conf文件->添加新的upstream
upstream nodejs{
server 127.0.0.1:3000; //你的Express项目端口
# server 127.0.0.1:3001;
keepalive 64;
}
-> 参考下面服务器中定义的nodejs{}
完整的片段如下:
server {
listen 80;
server_name www.famanoder.com famanoder.com; //请求到80端口的host
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_set_header Connection "";
proxy_pass http://nodejs;
}
}
如果不出意外,您现在可以使用域名访问您的博客;
Nodejs 功能强大;
几天后,学习了Nodejs的http-proxy模块,用于创建代理服务器;反正都是折腾,所以决定不使用nginx,而是使用Noders的http-proxy;不是nginx不好用,只是个人选择偏好而已;相信前端的 Noder 一定会对自己的模块更加热情;
http.createServer() 创建一个常规的http服务器监听80端口,通过http-proxy模块proxy.createProxyServer()创建一个代理服务器,通过proxy.web()方法分发每个请求;
在根目录下新建proxy.js文件:
var proxy=require(‘http-proxy’).createProxyServer({});
proxy.on(function(err,req,res){
res.writeHead(500,{
‘Content-Type’:’text/plain’
});
});
var server=require(‘http’).createServer(function(req,res){
var host= req.headers.host;
switch(host){
case ‘www.famanoder.com’:
proxy.web(req,res,{target:’http://localhost:3000’});
break;
case 'famanoder.com':
proxy.web(req, res, { target: 'http://localhost:4030' });
break;
default:
res.writeHead(200, {
'Content-Type': 'text/plain'
});
res.end('Welcome to my server!');
}
});
console.log("listening on port 80")
server.listen(80);
是不是也很好,看起来很酷,OK,下一步就是去app.js,使用proxy模块;
加一句:require('./proxy'); 就是这样,去浏览器看看是否也实现了反向代理。
至此,Nodejs反向代理的两种方式都已经实现了。这不是Demo,你的程序真的在运行;下一步是根据其他具体业务跟进进一步探索;
上周末出去散步的时候,看到一个大叔的背上印着一行字:“想当将军!” 那时,我在心里给了这位大叔一万个赞。我是一个平民。码农,路漫漫其修远兮,但——我们还年轻!
本文为慕课网原创作者,转载请注明【原作者及本文链接地址】。侵权必究,谢谢合作!
nodejs抓取动态网页(2017年江南大学本文参考书目复试题目推荐院校)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-04-06 00:18
Linux挂载lvm磁盘
江南大学计算机科学复试题,2019江南大学计算机入学考试初试科目,参考书目,复试线..._dongyu大麦的博客-程序员的秘密
该推荐院校位于江苏省无锡市江南大学。学校地理位置优越,具有一定的区域影响力。当然,最重要的是录取分数低。对于一些考生来说,这所学校更适合他们的需要。本文主要有以下几个部分:院校介绍、专业介绍、2019年招生分析、考研科目介绍、专业课程参考书和备考指导。一、学院介绍 江南大学是教育部直属、国家“211工程”重点建设大学和一流学科建设大学。学校办学历史悠久,
3.1 webpack的插件_鑫迅的博客-程序员的秘密
什么是插件?插件是指插件,通常用于扩展现有架构。webpack中的插件是对webpack现有功能的各种扩展,比如打包优化、文件压缩等。loader和plugin的区别Loader主要用于转换某些类型的模块,它是一个转换器。plugin 是一个插件,它是 webpack 本身的扩展,它是一个扩展器。插件使用流程步骤一:通过npm(一些webpack...
Qt应用开发框架-快速入门-Henrik-Yao的博客-程序员的秘密-Qt应用开发框架
文章目录一.Qt介绍及安装二.QtCreator介绍三.QtDesigner介绍四.Qt信号与槽一.Qt介绍及安装Qt是一个Qt公司于1991年开发的跨平台C++图形用户界面应用程序开发框架,既可以开发GUI程序,也可以开发控制台工具、服务器等非GUI程序。Qt 是一个面向对象的框架,使用特殊的代码生成扩展(称为 Meta Object Compiler (moc))和一些宏,Qt 易于扩展并允许真正的组件编程。Qt使用效果Qt下载地址
python程序的绘图扩展包matplotlib如何安装_自知博客-程序员秘籍_python绘图包安装
**如何安装python程序的matplotlib扩展包**对于编程初学者,一般推荐使用pip自动安装。步骤如下。首先找到python的安装路径,看是否安装了pip,pip是否在python下。使用Win+R进入电脑cmd界面。(要特别注意路径问题,如图,默认路径是C:\Users\16009. 并且为我们安装python,如果安装到这个路径,下一步可以执行。)如果。..
ThinkPHP3.2开发流程_weixin_33720452的博客-程序员的秘密
原文:ThinkPHP 3.2 开发过程设置所有项目的通用配置Application\Common\Conf\config.php,SAE模式下的配置文件是config_sae.php配置默认模块'DEFAULT_MODULE' => ' Home',配置模块'MODULE_DENY_LIS... 查看全部
nodejs抓取动态网页(2017年江南大学本文参考书目复试题目推荐院校)
Linux挂载lvm磁盘
江南大学计算机科学复试题,2019江南大学计算机入学考试初试科目,参考书目,复试线..._dongyu大麦的博客-程序员的秘密
该推荐院校位于江苏省无锡市江南大学。学校地理位置优越,具有一定的区域影响力。当然,最重要的是录取分数低。对于一些考生来说,这所学校更适合他们的需要。本文主要有以下几个部分:院校介绍、专业介绍、2019年招生分析、考研科目介绍、专业课程参考书和备考指导。一、学院介绍 江南大学是教育部直属、国家“211工程”重点建设大学和一流学科建设大学。学校办学历史悠久,
3.1 webpack的插件_鑫迅的博客-程序员的秘密
什么是插件?插件是指插件,通常用于扩展现有架构。webpack中的插件是对webpack现有功能的各种扩展,比如打包优化、文件压缩等。loader和plugin的区别Loader主要用于转换某些类型的模块,它是一个转换器。plugin 是一个插件,它是 webpack 本身的扩展,它是一个扩展器。插件使用流程步骤一:通过npm(一些webpack...
Qt应用开发框架-快速入门-Henrik-Yao的博客-程序员的秘密-Qt应用开发框架
文章目录一.Qt介绍及安装二.QtCreator介绍三.QtDesigner介绍四.Qt信号与槽一.Qt介绍及安装Qt是一个Qt公司于1991年开发的跨平台C++图形用户界面应用程序开发框架,既可以开发GUI程序,也可以开发控制台工具、服务器等非GUI程序。Qt 是一个面向对象的框架,使用特殊的代码生成扩展(称为 Meta Object Compiler (moc))和一些宏,Qt 易于扩展并允许真正的组件编程。Qt使用效果Qt下载地址
python程序的绘图扩展包matplotlib如何安装_自知博客-程序员秘籍_python绘图包安装
**如何安装python程序的matplotlib扩展包**对于编程初学者,一般推荐使用pip自动安装。步骤如下。首先找到python的安装路径,看是否安装了pip,pip是否在python下。使用Win+R进入电脑cmd界面。(要特别注意路径问题,如图,默认路径是C:\Users\16009. 并且为我们安装python,如果安装到这个路径,下一步可以执行。)如果。..
ThinkPHP3.2开发流程_weixin_33720452的博客-程序员的秘密
原文:ThinkPHP 3.2 开发过程设置所有项目的通用配置Application\Common\Conf\config.php,SAE模式下的配置文件是config_sae.php配置默认模块'DEFAULT_MODULE' => ' Home',配置模块'MODULE_DENY_LIS...
nodejs抓取动态网页(通过使用node.js我试图抓取一个网页(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-04 14:14
通过使用 node.js,我正在尝试抓取网页。为此,我使用cheerio 和 tinyreq 模块。我的源代码如下:
// scrape function
function scrape(url, data, cb) {
req(url, (err, body) => {
if (err) { return cb(err); }
let $ = cheerio.load(body)
, pageData = {};
Object.keys(data).forEach(k => {
pageData[k] = $(data[k]).text();
});
cb(null, pageData);
});
}
scrape("https://www.activecubs.com/activity-wheel/", {
title: ".row h1"
, description: ".row h2"
}, (err, data) => {
console.log(err || data);
});
在我的代码中,h1 标签中的文本是静态的,而在 h2 标签中它是动态的。当我运行代码时,我只得到静态数据,即描述字段数据为空。从以前的 StackOverflow 问题中,我尝试使用 phantom j 来克服这个问题,但它对我不起作用。这里的动态数据是通过转动轮子得到的数据。对于我正在使用的 网站 的任何查询,您可以查看它。 查看全部
nodejs抓取动态网页(通过使用node.js我试图抓取一个网页(图))
通过使用 node.js,我正在尝试抓取网页。为此,我使用cheerio 和 tinyreq 模块。我的源代码如下:
// scrape function
function scrape(url, data, cb) {
req(url, (err, body) => {
if (err) { return cb(err); }
let $ = cheerio.load(body)
, pageData = {};
Object.keys(data).forEach(k => {
pageData[k] = $(data[k]).text();
});
cb(null, pageData);
});
}
scrape("https://www.activecubs.com/activity-wheel/", {
title: ".row h1"
, description: ".row h2"
}, (err, data) => {
console.log(err || data);
});
在我的代码中,h1 标签中的文本是静态的,而在 h2 标签中它是动态的。当我运行代码时,我只得到静态数据,即描述字段数据为空。从以前的 StackOverflow 问题中,我尝试使用 phantom j 来克服这个问题,但它对我不起作用。这里的动态数据是通过转动轮子得到的数据。对于我正在使用的 网站 的任何查询,您可以查看它。
nodejs抓取动态网页(利用Python/.NET语言实现一个糗事百科的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-03 13:14
1.前言分析
通常爬虫都是用 Python/.NET 语言实现的,但现在作为前端开发者,自然需要精通 NodeJS。下面我们用NodeJS语言来实现一个尴尬事百科的爬虫。此外,本文中使用的一些代码是 es6 语法。
实现爬虫所需的依赖库如下。
request:使用get或post获取网页源代码。Cheerio:解析网页源代码,获取需要的数据。
本文首先介绍爬虫所需的依赖库及其使用方法,然后利用这些依赖库来实现一个网络爬虫,用于网络爬虫百科。
2. 请求库
request 是一个轻量级的 http 库,非常强大且易于使用。可以用来实现Http请求,支持HTTP认证、自定义请求头等。下面介绍请求库中的部分功能。
安装请求模块如下:
npm install request
安装好请求后,就可以使用了。接下来,使用请求请求百度的网页。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
未设置 options 参数时,请求方法默认为 get 请求。而且我喜欢使用请求对象的具体方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
但是在很多情况下,直接请求一个URL获取的html源代码,往往并不能得到我们需要的信息。一般来说,需要考虑请求头和网页编码。
网页请求头的编码
下面介绍如何在请求时添加网页请求头并设置正确的编码。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
设置options参数,添加headers属性设置请求头;添加 encoding 属性来设置网页的编码。需要注意的是,如果encoding:null,则get请求得到的内容是一个Buffer对象,即body是一个Buffer对象。
上述功能足以满足以下需求。
3.cheerio 库
Cheerio 是一个服务器端的 Jquery,因其轻量、快速和易于学习的特性而受到开发人员的喜爱。掌握了 Jquery 的基础知识之后,学习 Cheerio 库就很容易了。可以快速定位网页中的元素,其规则与jquery定位元素的方法相同;它还可以修改html中元素的内容,并以非常方便的形式获取它们的数据。下面主要介绍cheerio快速定位网页中的元素并获取其内容。
首先安装cheerio库
npm install cheerio
下面给出一段代码,然后代码说明cheerio库的用法。分析博客园的首页,然后提取每个页面中文章的标题。
首先,分析博客园的首页。如下所示:
分析完html源码,首先通过.post_item获取所有title,然后分析每个.post_item,并使用a.titlelnk匹配每个title的a标签。代码在下面实现。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
当然,cheerio 库也支持链式调用,上面的代码也可以改写为:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
上面的代码很简单,不用文字重复了。下面总结了一些我认为比较重要的点。
使用find()方法得到的节点集A,如果将A集中的元素作为根节点定位其子节点并获取子元素的内容和属性,则需要执行$(A [i ]) 包装器,如上面的 $(ele) 。上面代码中使用$(ele),其实也可以使用$(this),但是由于我使用的是es6箭头函数,所以我在每个方法中更改了回调函数的this指针,所以我使用了$(ele ); Cheerio 库还支持链式调用,例如上面的 $('.post_item').find('a.titlelnk')。需要注意的是,cheerio 对象 A 调用了 find() 方法。如果 A 是一个集合,那么 A 集合中的每个子元素都会调用 find() 方法并放回一个结果组合。如果 A 调用 text(),那么 A' 中的每个子元素
最后,我总结了一些比较常用的方法。
first() last() children([selector]):这个方法和find类似,只是这个方法只搜索子节点,而find搜索整个后代节点。
4. 尴尬的百科全书爬虫
通过上面对request和cheerio类库的介绍,下面两个类库是用来爬取尴尬事百科的页面的。
1、在项目目录下新建httpHelper.js文件,通过url获取尴尬百科的源码。代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2、在项目目录下,新建一个Splitter.js文件,分析糗事百科的网页代码,提取你需要的信息,通过改变id建立爬取不同页面数据的逻辑的网址。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到需要的标签,然后提取标签的文字或属性值,从而完成网页的解析。
Spliter.js 文件的入口是 spliter 方法。首先根据传入方法的index索引,构造出糗大百科的url,然后得到url的网页源码,最后将得到的源码传入getQBJok方法进行分析。本文只分析每一个文字笑话的作者、内容和点赞数。
直接运行Slider.js文件,爬取第一页的笑话信息。然后可以改变slider方法的参数来爬取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0搭建一个浏览文本的页面,效果如下:
源代码已经上传到github。下载链接: ;
项目的运行依赖节点v7.6.0或以上。首先从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录并运行以下命令。
node app.js
5. 总结
通过实现一个完整的爬虫功能,可以加深对Node的理解,部分实现的语言使用es6语法,这样可以加快es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node 中,有几种方法可以实现异步控制。关于具体的方法和原则,有时间再总结。 查看全部
nodejs抓取动态网页(利用Python/.NET语言实现一个糗事百科的爬虫)
1.前言分析
通常爬虫都是用 Python/.NET 语言实现的,但现在作为前端开发者,自然需要精通 NodeJS。下面我们用NodeJS语言来实现一个尴尬事百科的爬虫。此外,本文中使用的一些代码是 es6 语法。
实现爬虫所需的依赖库如下。
request:使用get或post获取网页源代码。Cheerio:解析网页源代码,获取需要的数据。
本文首先介绍爬虫所需的依赖库及其使用方法,然后利用这些依赖库来实现一个网络爬虫,用于网络爬虫百科。
2. 请求库
request 是一个轻量级的 http 库,非常强大且易于使用。可以用来实现Http请求,支持HTTP认证、自定义请求头等。下面介绍请求库中的部分功能。
安装请求模块如下:
npm install request
安装好请求后,就可以使用了。接下来,使用请求请求百度的网页。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
未设置 options 参数时,请求方法默认为 get 请求。而且我喜欢使用请求对象的具体方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
但是在很多情况下,直接请求一个URL获取的html源代码,往往并不能得到我们需要的信息。一般来说,需要考虑请求头和网页编码。
网页请求头的编码
下面介绍如何在请求时添加网页请求头并设置正确的编码。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
设置options参数,添加headers属性设置请求头;添加 encoding 属性来设置网页的编码。需要注意的是,如果encoding:null,则get请求得到的内容是一个Buffer对象,即body是一个Buffer对象。
上述功能足以满足以下需求。
3.cheerio 库
Cheerio 是一个服务器端的 Jquery,因其轻量、快速和易于学习的特性而受到开发人员的喜爱。掌握了 Jquery 的基础知识之后,学习 Cheerio 库就很容易了。可以快速定位网页中的元素,其规则与jquery定位元素的方法相同;它还可以修改html中元素的内容,并以非常方便的形式获取它们的数据。下面主要介绍cheerio快速定位网页中的元素并获取其内容。
首先安装cheerio库
npm install cheerio
下面给出一段代码,然后代码说明cheerio库的用法。分析博客园的首页,然后提取每个页面中文章的标题。
首先,分析博客园的首页。如下所示:

分析完html源码,首先通过.post_item获取所有title,然后分析每个.post_item,并使用a.titlelnk匹配每个title的a标签。代码在下面实现。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
当然,cheerio 库也支持链式调用,上面的代码也可以改写为:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
上面的代码很简单,不用文字重复了。下面总结了一些我认为比较重要的点。
使用find()方法得到的节点集A,如果将A集中的元素作为根节点定位其子节点并获取子元素的内容和属性,则需要执行$(A [i ]) 包装器,如上面的 $(ele) 。上面代码中使用$(ele),其实也可以使用$(this),但是由于我使用的是es6箭头函数,所以我在每个方法中更改了回调函数的this指针,所以我使用了$(ele ); Cheerio 库还支持链式调用,例如上面的 $('.post_item').find('a.titlelnk')。需要注意的是,cheerio 对象 A 调用了 find() 方法。如果 A 是一个集合,那么 A 集合中的每个子元素都会调用 find() 方法并放回一个结果组合。如果 A 调用 text(),那么 A' 中的每个子元素
最后,我总结了一些比较常用的方法。
first() last() children([selector]):这个方法和find类似,只是这个方法只搜索子节点,而find搜索整个后代节点。
4. 尴尬的百科全书爬虫
通过上面对request和cheerio类库的介绍,下面两个类库是用来爬取尴尬事百科的页面的。
1、在项目目录下新建httpHelper.js文件,通过url获取尴尬百科的源码。代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2、在项目目录下,新建一个Splitter.js文件,分析糗事百科的网页代码,提取你需要的信息,通过改变id建立爬取不同页面数据的逻辑的网址。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到需要的标签,然后提取标签的文字或属性值,从而完成网页的解析。
Spliter.js 文件的入口是 spliter 方法。首先根据传入方法的index索引,构造出糗大百科的url,然后得到url的网页源码,最后将得到的源码传入getQBJok方法进行分析。本文只分析每一个文字笑话的作者、内容和点赞数。
直接运行Slider.js文件,爬取第一页的笑话信息。然后可以改变slider方法的参数来爬取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0搭建一个浏览文本的页面,效果如下:

源代码已经上传到github。下载链接: ;
项目的运行依赖节点v7.6.0或以上。首先从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录并运行以下命令。
node app.js
5. 总结
通过实现一个完整的爬虫功能,可以加深对Node的理解,部分实现的语言使用es6语法,这样可以加快es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node 中,有几种方法可以实现异步控制。关于具体的方法和原则,有时间再总结。
nodejs抓取动态网页(思路可以看之前bodyRun的抓取应用版的内容介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-03 13:12
思路可以看前面的文章,我就不多说了。
因为AppStore的页面版只显示3天的评论,所以这次就介绍一下app版的内容。
我们编写一个简单的爬虫,以在 AppStore 上抓取一个新的超级马里奥跑的评论为例
var request=require('request');
var url='http://itunes.apple.com/WebObjects/MZStore.woa/wa/userReviewsRow?cc=us&id=1145275343&displayable-kind=11&startIndex=0&endIndex=100&sort=0&appVersion=all'
var options = {
port: 80,
uri: url,
method: 'GET',
headers: {
'User-Agent': 'iTunes/11.0 (Windows; Microsoft Windows 7 Business Edition Service Pack 1 (Build 7601)) AppleWebKit/536.27.1'
}
};
request(options,(error, response, body)=>{
console.log(body);
})
节点运行后,控制台打印如下:
正文打印结果
这个链接是专门用来获取评论相关数据的,我们可以整理一下,看看每条评论的结构
收到的内容
function formatJson(contentsDate){
content=contentsDate.userReviewList;
content.forEach(function(item){
console.log('orginId:'+item.userReviewId);
console.log('username: ' + item.name + ' time:' + item.date);
console.log('star: ' + item.rating);
console.log('title: ' + item.title);
console.log('content: ' + item.body);
console.log('------------------------------------');
})
}
在之前打印body的地方调用formatJson,传入body转换成json
request(options,(error, response, body)=>{
var datas=JSON.parse(body)
formatJson(datas);
})
运行文件,可以看到打印结果:
超级马里奥跑酷评测结果
因为这个游戏在中国不可用,所以你需要翻墙。不翻墙的话,可以在中国的商店里找一个app,把链接里的cc换成cn。不明白具体可以参考上一篇文章文章。 查看全部
nodejs抓取动态网页(思路可以看之前bodyRun的抓取应用版的内容介绍)
思路可以看前面的文章,我就不多说了。
因为AppStore的页面版只显示3天的评论,所以这次就介绍一下app版的内容。
我们编写一个简单的爬虫,以在 AppStore 上抓取一个新的超级马里奥跑的评论为例
var request=require('request');
var url='http://itunes.apple.com/WebObjects/MZStore.woa/wa/userReviewsRow?cc=us&id=1145275343&displayable-kind=11&startIndex=0&endIndex=100&sort=0&appVersion=all'
var options = {
port: 80,
uri: url,
method: 'GET',
headers: {
'User-Agent': 'iTunes/11.0 (Windows; Microsoft Windows 7 Business Edition Service Pack 1 (Build 7601)) AppleWebKit/536.27.1'
}
};
request(options,(error, response, body)=>{
console.log(body);
})
节点运行后,控制台打印如下:

正文打印结果
这个链接是专门用来获取评论相关数据的,我们可以整理一下,看看每条评论的结构
收到的内容
function formatJson(contentsDate){
content=contentsDate.userReviewList;
content.forEach(function(item){
console.log('orginId:'+item.userReviewId);
console.log('username: ' + item.name + ' time:' + item.date);
console.log('star: ' + item.rating);
console.log('title: ' + item.title);
console.log('content: ' + item.body);
console.log('------------------------------------');
})
}
在之前打印body的地方调用formatJson,传入body转换成json
request(options,(error, response, body)=>{
var datas=JSON.parse(body)
formatJson(datas);
})
运行文件,可以看到打印结果:
超级马里奥跑酷评测结果
因为这个游戏在中国不可用,所以你需要翻墙。不翻墙的话,可以在中国的商店里找一个app,把链接里的cc换成cn。不明白具体可以参考上一篇文章文章。
nodejs抓取动态网页( 易百教程:Js更新MySQL中的数据.js程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-31 07:12
易百教程:Js更新MySQL中的数据.js程序)
<p>转载地址:https://www.yiibai.com/mysql/nodejs-update.html
在本教程中,您将学习如何从node.js应用程序更新MySQL数据库中的数据。
要从node.js应用程序更新数据,请使用以下步骤:
连接到MySQL数据库服务器。通过在Connection对象上调用query()方法来执行UPDATE语句。关闭数据库连接。
要连接到MySQL数据库,我们将使用以下config.js模块,其中包含MySQL数据库服务器的必要信息,包括主机,用户,密码和数据库。
let config = {
host : 'localhost',
user : 'root',
password: '123456',
database: 'todoapp'
};
module.exports = config;
</p>
Js
更新数据示例
以下 update.js 程序根据特定 ID 更新托管状态。
let mysql = require('mysql');
let config = require('./config.js');
let connection = mysql.createConnection(config);
// update statment
let sql = `UPDATE todos
SET completed = ?
WHERE id = ?`;
let data = [false, 1];
// execute the UPDATE statement
connection.query(sql, data, (error, results, fields) => {
if (error){
return console.error(error.message);
}
console.log('Rows affected:', results.affectedRows);
});
connection.end();
Js
在本例中,我们在 UPDATE 语句中使用了占位符 (?)。
当通过调用连接对象的query()方法执行UPDATE语句时,数据以数组的形式传递给UPDATE语句。占位符会用数组中的值替换成数组。在本例中,id 为 1 的记录的已完成列将设置为 false。
回调函数的results参数有属性affectedRows,返回UPDATE语句更新的行数。
在执行程序之前,请查看todos表中id为1的行的记录信息:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 1 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
现在,让我们运行上面的 update.js 程序。
F:\worksp\mysql\nodejs\nodejs-connect>node update.js
openssl config failed: error:02001003:system library:fopen:No such process
Rows affected: 1
壳
程序返回一条消息,表示受影响的行数为1,我们可以在数据库中再次查看如下:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 0 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
可以看到完成列中的值已经更新为0,在node.js中为false。
在本教程中,我们向您展示了如何从 node.js 应用程序更新 MySQL 中的数据。
原文来自【Ebay教程】。如需商业转载,请联系作者授权。非商业转载请保留原链接: 查看全部
nodejs抓取动态网页(
易百教程:Js更新MySQL中的数据.js程序)
<p>转载地址:https://www.yiibai.com/mysql/nodejs-update.html
在本教程中,您将学习如何从node.js应用程序更新MySQL数据库中的数据。
要从node.js应用程序更新数据,请使用以下步骤:
连接到MySQL数据库服务器。通过在Connection对象上调用query()方法来执行UPDATE语句。关闭数据库连接。
要连接到MySQL数据库,我们将使用以下config.js模块,其中包含MySQL数据库服务器的必要信息,包括主机,用户,密码和数据库。
let config = {
host : 'localhost',
user : 'root',
password: '123456',
database: 'todoapp'
};
module.exports = config;
</p>
Js
更新数据示例
以下 update.js 程序根据特定 ID 更新托管状态。
let mysql = require('mysql');
let config = require('./config.js');
let connection = mysql.createConnection(config);
// update statment
let sql = `UPDATE todos
SET completed = ?
WHERE id = ?`;
let data = [false, 1];
// execute the UPDATE statement
connection.query(sql, data, (error, results, fields) => {
if (error){
return console.error(error.message);
}
console.log('Rows affected:', results.affectedRows);
});
connection.end();
Js
在本例中,我们在 UPDATE 语句中使用了占位符 (?)。
当通过调用连接对象的query()方法执行UPDATE语句时,数据以数组的形式传递给UPDATE语句。占位符会用数组中的值替换成数组。在本例中,id 为 1 的记录的已完成列将设置为 false。
回调函数的results参数有属性affectedRows,返回UPDATE语句更新的行数。
在执行程序之前,请查看todos表中id为1的行的记录信息:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 1 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
现在,让我们运行上面的 update.js 程序。
F:\worksp\mysql\nodejs\nodejs-connect>node update.js
openssl config failed: error:02001003:system library:fopen:No such process
Rows affected: 1
壳
程序返回一条消息,表示受影响的行数为1,我们可以在数据库中再次查看如下:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 0 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
可以看到完成列中的值已经更新为0,在node.js中为false。
在本教程中,我们向您展示了如何从 node.js 应用程序更新 MySQL 中的数据。
原文来自【Ebay教程】。如需商业转载,请联系作者授权。非商业转载请保留原链接:
nodejs抓取动态网页(为什么要上https呢,全站https是一个的思路?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-31 06:20
为什么要为整个站点使用 https?这主要是因为https可以防止中间人攻击和内容劫持,提高网站的访问安全性。但是由于增加了SSL/TLS服务器端和浏览器端的处理,性能会有相应的下降,不过我们也启用了HTTP/2,主要特点:多路复用(Multiplexing) Multiplexing 使用允许多个请求-通过单个 HTTP/2 连接同时发出的响应消息。另外,PWA 中的 service worker 还必须要求 网站 的协议是 https,也为此打下了基础。HTTPS是现代WEB的发展趋势。由于 PWA 不是本文的重点,以后可以在其他主题上展开。
浏览器端优化
移动端有多种,导致浏览器处理和效果过度,会导致体验不一致,尤其是安卓手机,所以我们在浏览器端的策略是尽量减少网页的权重,目前page 只处理当前必要的内容和多个页面。方式。这是谷歌现在提出的开源项目AMP的一个想法。
首屏直出优化
从用户发出请求到页面完整展示,一般来说网络正常需要1s以上,但如果页面打开时间超过1s,用户流失的概率会线性增加。所以手机端秒开是很重要的,所以我们的想法是减少白屏时间,尽快显示浏览器的可视区域,也就是所谓的首屏。我们从以下几个方面对其进行了优化。
直出文档,简化DOM结构服务器进行HTML渲染输出,只处理首屏需要的HTML,简化DOM树结构,如:
可以简化为
页面上只保留必要的 DOM。另外,可以估计手机的分辨率,可以确定最大首屏输出可视区域的DOM。如果需要滚动到第二个屏幕,可以通过 Ajax 延迟内容加载。减少 DOM 可以减少 HTML 的输出,当然更重要的浏览器布局和渲染时间也大大减少。当然,首先要加载首屏的静态资源和样式。下一个关键点是在第一个屏幕上只加载所需的样式和静态资源。
仅在首屏加载所需的样式和静态资源是远远不够的。DOM 处理是不够的。要从白屏显示完整的第一屏,还需要样式和静态资源。所以需要先加载样式和静态资源,所以直接提取公共样式的首屏使用的样式,直接将首屏使用的样式内置到html页面中。另外先加载其他需要显示的部分,比如图片、字体等,方便首页快速显示。
首屏渲染,js延迟执行
第一屏渲染的时候,这个时候js的执行可能会阻塞渲染线程,所以为了减少浏览器主线程的渲染过程,尽量延迟js的执行,尤其是在操作的情况下DOM,否则,在首屏显示过程中,会在页面底部,body之后,html之前直接生成额外的re-layout和repaint,js导入或者code。
优化直出服务器的处理时间,突出直出的关键。服务器的处理等待被最小化,这对于第一屏的直出非常重要。
图像优化
画质和音量控制 对于移动终端来说,分辨率比桌面要小很多。首先,图片的分辨率和图片的DPI值会降低。第二步会降低图片的质量,保证图片的体积变小。.
提高CDN缓存命中率,一是缩小缩略图的尺寸规格,二是尽量与其他终端的图片规格保持一致,如APP、小程序。
使用WEBP webp并不是所有的浏览器都支持,所以我们的做法是判断需要js加载的图片,如果支持就直接加载webp格式的图片。如果没有,请使用默认的 jpg 格式。格式。
浏览器端缓存优化
当有缓存时,可以减少浏览器的重新请求,大大提高网页的打开速度。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,而且由于缓存的文件可以重复使用,还可以减少带宽,减少网络负载。那么我们来看看服务器端缓存的原理。
缓存优化(max-age)
页面的缓存状态由http协议的头部决定。我们主要使用max-age(单位S)来设置缓存的最长有效时间,也就是时间长度。比如我设置了max-age=60,也就是在请求发出后的60秒内,浏览器再次请求时不会再次请求服务器,而是从浏览器缓存中读取数据。
预加载和延迟加载
预加载和延迟加载是一对好兄弟。如果使用得当,它们可以极大地改善浏览器端的体验。就是决定什么时候预加载,什么时候懒加载。我们主要是在浏览器首屏结束后,当浏览器比较空闲时,预加载下一屏要显示的内容。
当用户即将触发下一屏的时候,下一屏的数据或者DOM已经留了下来,自然体验会流畅很多,但是预加载需要一定的度数,因为一个页面的DOM太多了,而且浏览器占用内存也会太多。最好预加载用户会触发浏览的内容,比如第二屏、轮播后面的内容、标签页等。
延迟加载的应用场景主要是减少单个 DOM 渲染的大小。对于当前页面的非可视区域,只有在需要显示或被用户事件触发时才加载。所以,懒加载和预加载在不同的场景下会有不同的应用,只要保证页面的流畅度。
DNS 预取
DNS预读配置的DNS解析,可以减少DNS次数,加快不同域名资源的加载。目前,仍然有很多浏览器支持。
配置也很简单:
当然,减少DNS的最佳时机是减少使用DNS的站点数量,我们会去掉一些二级域名。
CSS、JS优化
项目建设主要采用webpack的工具链,管理依赖,构建打包CSS,最小化CSS和JS,对我们现有的多页面项目进行多入口分包管理。
多页面 css 和 js 构建
打包代码如下,方便js的源文件目录,构建各个页面模块的js。所有页面都将收录两个 js 文件,libjs(全局公共 js)、xxx.js(当前页面特定的 js)和 css。. 这样每个页面的js和css都会最小化。同时,我们也对这些静态字符串文件进行gzip压缩。当然,这些文件会根据版本进行静态存储,并通过 CDN 进行缓存。
DOM 优化
页面流畅度与 DOM 渲染和操作密切相关。渲染过程大致如下:
处理 HTML 标记并构建 DOM 树。
处理 CSS 标记并构建 CSSOM 树。
将 DOM 和 CSSOM 组合成一个渲染树。
根据渲染树布局计算每个节点的几何形状。
将每个节点绘制到屏幕上。
您可以使用 DEVTOOLS 来分析整个渲染过程中的性能问题。
简化DOM,DOM操作优化
简化 DOM 可以减少渲染过程的时间,优化 DOM 操作可以减少重新布局和重绘的时间。简化 DOM 相应的方法已经在首屏引入。
这里主要讲DOM操作的优化。首先,减少 DOM 操作的数量。你可以在 js 执行过程中多次 DOM 操作生成好的 HTML 结果,一次性插入到 DOM 中。其次,尽量不要在页面的 DOM 树中使用它们。直接操作,可以在文档流的DOM外进行操作,也可以使用fragment一次性插入到文档流中。
当然,react 和 vue 现在都使用虚拟 DOM 技术,通过 diff 算法进行泛化的 DOM 操作。这也是一种高效高效的方法,但是对于一些不容易优化的页面,还是需要人为的干预和操作 DOM 才能让性能达到最佳。
减少重新布局和重绘
首先,为了减少布局调整,当您更改样式时,浏览器会检查是否有任何更改需要计算布局,以及是否需要更新渲染树。对“几何属性”(例如宽度、高度、左侧或顶部)的更改需要布局计算。第二,绘图的复杂性,减少绘图区域:改变transform或opacity属性以外的任何属性都会触发绘图。绘图通常是像素管道中最昂贵的部分;应尽可能避免。
通过提升图层和编排动画来减少绘图区域。Chrome DevTools 可用于快速确定正在绘制的区域。打开 DevTools 并按键盘上的 Esc 键。在出现的面板中,转到“渲染”选项卡并选中“显示绘制矩形”。每次绘图时,Chrome 都会将屏幕闪烁绿色。如果您看到整个屏幕呈绿色闪烁,或者看到您认为不应绘制的屏幕区域,则应进一步调查。
页面动画优化
尽可能使用 CSS3 动画,使用 transform 和 opacity 属性更改来制作动画。使用 will-change 或 translateZ 来促进移动元素。避免过度使用提升规则;每一层都需要内存和管理开销。另外,动画的层数需要减少,每增加一层都会增加内存占用和管理的开销。
如果一定要用js动画,推荐使用:requestAnimationFrame。另外,在不能使用页面动画的场景中尽量不要使用动画。如果一定要使用,可以简化动画渲染过程。
我们之前用过一个js插件,iScroll就是一个例子,在页面中初始化了多个iScroll的实例,尤其是安卓手机上,特别卡顿。最后,我们的解决方案是使用css3动画和触摸事件来实现简单轻量。对于需要滚动的部分,页面的滚动部分使用原生滚动,保证了不同终端的体验一致。
总结
移动端的优化如果对以上几点展开,可以单独写一篇文章文章,我们对以上几个方面进行了优化,也产生了比较好的效果,移动端的打开速度和体验终端有了不错的提升,一般开放时间增加了30-50%。在网络稳定的情况下,服务器的耗时基本在50ms以内,首屏时间在500ms以内,但是从来没有优化过。没有限制,没有最好,只有更好。它需要开发者从根本上去探索,勇于创新,以达到越来越好的局面。
后续我们还可以深入挖掘web的基本技术点。同时,我们可以积极面对PWA、AMP等现代web新思维的诸多方面,不断探索,在web前端的未来我们可以走的更好。提供更好的用户体验,创造更高的社会价值。
亲爱的“攻城狮”,如果你喜欢这篇文章,请在文末点个赞,也欢迎你去51Testing软件测试网掌握更多IT技术文章 ~ 查看全部
nodejs抓取动态网页(为什么要上https呢,全站https是一个的思路?)
为什么要为整个站点使用 https?这主要是因为https可以防止中间人攻击和内容劫持,提高网站的访问安全性。但是由于增加了SSL/TLS服务器端和浏览器端的处理,性能会有相应的下降,不过我们也启用了HTTP/2,主要特点:多路复用(Multiplexing) Multiplexing 使用允许多个请求-通过单个 HTTP/2 连接同时发出的响应消息。另外,PWA 中的 service worker 还必须要求 网站 的协议是 https,也为此打下了基础。HTTPS是现代WEB的发展趋势。由于 PWA 不是本文的重点,以后可以在其他主题上展开。
浏览器端优化
移动端有多种,导致浏览器处理和效果过度,会导致体验不一致,尤其是安卓手机,所以我们在浏览器端的策略是尽量减少网页的权重,目前page 只处理当前必要的内容和多个页面。方式。这是谷歌现在提出的开源项目AMP的一个想法。
首屏直出优化
从用户发出请求到页面完整展示,一般来说网络正常需要1s以上,但如果页面打开时间超过1s,用户流失的概率会线性增加。所以手机端秒开是很重要的,所以我们的想法是减少白屏时间,尽快显示浏览器的可视区域,也就是所谓的首屏。我们从以下几个方面对其进行了优化。
直出文档,简化DOM结构服务器进行HTML渲染输出,只处理首屏需要的HTML,简化DOM树结构,如:
可以简化为
页面上只保留必要的 DOM。另外,可以估计手机的分辨率,可以确定最大首屏输出可视区域的DOM。如果需要滚动到第二个屏幕,可以通过 Ajax 延迟内容加载。减少 DOM 可以减少 HTML 的输出,当然更重要的浏览器布局和渲染时间也大大减少。当然,首先要加载首屏的静态资源和样式。下一个关键点是在第一个屏幕上只加载所需的样式和静态资源。
仅在首屏加载所需的样式和静态资源是远远不够的。DOM 处理是不够的。要从白屏显示完整的第一屏,还需要样式和静态资源。所以需要先加载样式和静态资源,所以直接提取公共样式的首屏使用的样式,直接将首屏使用的样式内置到html页面中。另外先加载其他需要显示的部分,比如图片、字体等,方便首页快速显示。
首屏渲染,js延迟执行
第一屏渲染的时候,这个时候js的执行可能会阻塞渲染线程,所以为了减少浏览器主线程的渲染过程,尽量延迟js的执行,尤其是在操作的情况下DOM,否则,在首屏显示过程中,会在页面底部,body之后,html之前直接生成额外的re-layout和repaint,js导入或者code。
优化直出服务器的处理时间,突出直出的关键。服务器的处理等待被最小化,这对于第一屏的直出非常重要。
图像优化
画质和音量控制 对于移动终端来说,分辨率比桌面要小很多。首先,图片的分辨率和图片的DPI值会降低。第二步会降低图片的质量,保证图片的体积变小。.
提高CDN缓存命中率,一是缩小缩略图的尺寸规格,二是尽量与其他终端的图片规格保持一致,如APP、小程序。
使用WEBP webp并不是所有的浏览器都支持,所以我们的做法是判断需要js加载的图片,如果支持就直接加载webp格式的图片。如果没有,请使用默认的 jpg 格式。格式。
浏览器端缓存优化
当有缓存时,可以减少浏览器的重新请求,大大提高网页的打开速度。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,而且由于缓存的文件可以重复使用,还可以减少带宽,减少网络负载。那么我们来看看服务器端缓存的原理。
缓存优化(max-age)
页面的缓存状态由http协议的头部决定。我们主要使用max-age(单位S)来设置缓存的最长有效时间,也就是时间长度。比如我设置了max-age=60,也就是在请求发出后的60秒内,浏览器再次请求时不会再次请求服务器,而是从浏览器缓存中读取数据。
预加载和延迟加载
预加载和延迟加载是一对好兄弟。如果使用得当,它们可以极大地改善浏览器端的体验。就是决定什么时候预加载,什么时候懒加载。我们主要是在浏览器首屏结束后,当浏览器比较空闲时,预加载下一屏要显示的内容。
当用户即将触发下一屏的时候,下一屏的数据或者DOM已经留了下来,自然体验会流畅很多,但是预加载需要一定的度数,因为一个页面的DOM太多了,而且浏览器占用内存也会太多。最好预加载用户会触发浏览的内容,比如第二屏、轮播后面的内容、标签页等。
延迟加载的应用场景主要是减少单个 DOM 渲染的大小。对于当前页面的非可视区域,只有在需要显示或被用户事件触发时才加载。所以,懒加载和预加载在不同的场景下会有不同的应用,只要保证页面的流畅度。
DNS 预取
DNS预读配置的DNS解析,可以减少DNS次数,加快不同域名资源的加载。目前,仍然有很多浏览器支持。
配置也很简单:
当然,减少DNS的最佳时机是减少使用DNS的站点数量,我们会去掉一些二级域名。
CSS、JS优化
项目建设主要采用webpack的工具链,管理依赖,构建打包CSS,最小化CSS和JS,对我们现有的多页面项目进行多入口分包管理。
多页面 css 和 js 构建
打包代码如下,方便js的源文件目录,构建各个页面模块的js。所有页面都将收录两个 js 文件,libjs(全局公共 js)、xxx.js(当前页面特定的 js)和 css。. 这样每个页面的js和css都会最小化。同时,我们也对这些静态字符串文件进行gzip压缩。当然,这些文件会根据版本进行静态存储,并通过 CDN 进行缓存。
DOM 优化
页面流畅度与 DOM 渲染和操作密切相关。渲染过程大致如下:
处理 HTML 标记并构建 DOM 树。
处理 CSS 标记并构建 CSSOM 树。
将 DOM 和 CSSOM 组合成一个渲染树。
根据渲染树布局计算每个节点的几何形状。
将每个节点绘制到屏幕上。
您可以使用 DEVTOOLS 来分析整个渲染过程中的性能问题。
简化DOM,DOM操作优化
简化 DOM 可以减少渲染过程的时间,优化 DOM 操作可以减少重新布局和重绘的时间。简化 DOM 相应的方法已经在首屏引入。
这里主要讲DOM操作的优化。首先,减少 DOM 操作的数量。你可以在 js 执行过程中多次 DOM 操作生成好的 HTML 结果,一次性插入到 DOM 中。其次,尽量不要在页面的 DOM 树中使用它们。直接操作,可以在文档流的DOM外进行操作,也可以使用fragment一次性插入到文档流中。
当然,react 和 vue 现在都使用虚拟 DOM 技术,通过 diff 算法进行泛化的 DOM 操作。这也是一种高效高效的方法,但是对于一些不容易优化的页面,还是需要人为的干预和操作 DOM 才能让性能达到最佳。
减少重新布局和重绘
首先,为了减少布局调整,当您更改样式时,浏览器会检查是否有任何更改需要计算布局,以及是否需要更新渲染树。对“几何属性”(例如宽度、高度、左侧或顶部)的更改需要布局计算。第二,绘图的复杂性,减少绘图区域:改变transform或opacity属性以外的任何属性都会触发绘图。绘图通常是像素管道中最昂贵的部分;应尽可能避免。
通过提升图层和编排动画来减少绘图区域。Chrome DevTools 可用于快速确定正在绘制的区域。打开 DevTools 并按键盘上的 Esc 键。在出现的面板中,转到“渲染”选项卡并选中“显示绘制矩形”。每次绘图时,Chrome 都会将屏幕闪烁绿色。如果您看到整个屏幕呈绿色闪烁,或者看到您认为不应绘制的屏幕区域,则应进一步调查。
页面动画优化
尽可能使用 CSS3 动画,使用 transform 和 opacity 属性更改来制作动画。使用 will-change 或 translateZ 来促进移动元素。避免过度使用提升规则;每一层都需要内存和管理开销。另外,动画的层数需要减少,每增加一层都会增加内存占用和管理的开销。
如果一定要用js动画,推荐使用:requestAnimationFrame。另外,在不能使用页面动画的场景中尽量不要使用动画。如果一定要使用,可以简化动画渲染过程。
我们之前用过一个js插件,iScroll就是一个例子,在页面中初始化了多个iScroll的实例,尤其是安卓手机上,特别卡顿。最后,我们的解决方案是使用css3动画和触摸事件来实现简单轻量。对于需要滚动的部分,页面的滚动部分使用原生滚动,保证了不同终端的体验一致。
总结
移动端的优化如果对以上几点展开,可以单独写一篇文章文章,我们对以上几个方面进行了优化,也产生了比较好的效果,移动端的打开速度和体验终端有了不错的提升,一般开放时间增加了30-50%。在网络稳定的情况下,服务器的耗时基本在50ms以内,首屏时间在500ms以内,但是从来没有优化过。没有限制,没有最好,只有更好。它需要开发者从根本上去探索,勇于创新,以达到越来越好的局面。
后续我们还可以深入挖掘web的基本技术点。同时,我们可以积极面对PWA、AMP等现代web新思维的诸多方面,不断探索,在web前端的未来我们可以走的更好。提供更好的用户体验,创造更高的社会价值。
亲爱的“攻城狮”,如果你喜欢这篇文章,请在文末点个赞,也欢迎你去51Testing软件测试网掌握更多IT技术文章 ~
nodejs抓取动态网页(cheerio抓取页面后操作来提取页面中的数据,api及用法跟jquery)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-29 10:18
切里奥
抓取页面后,操作dom提取页面中的数据,api和用法类似jquery
表示
用于启动一个简单的服务,在浏览器中查看爬虫爬取的数据
玉
页面模板引擎
使用方法将仓库克隆到本地,然后安装相应模块并执行node app启动服务。打开浏览器输入localhost:3000查看效果分析。
整个爬虫其实很简单。主要功能是发送请求以采集数据,然后对其进行分析。当然,这一步分析不一定收录在爬虫中。您可以自己编写其他模块来分析和处理数据。使用superagent请求知乎接口获取具体数据,但是有些接口有限制,有些数据是通过服务端渲染直接显示在页面上的,不能直接通过知乎接口获取,所以需要从渲染的页面中抓取,所以需要使用cheerio模块进行dom操作,获取对应的dom结构然后获取值。这里需要注意的是,这种需要登录的网站请求可能有权限验证,
目录说明
主要步骤
登录和获取授权的过程有点繁琐,而且有验证码,所以只能通过快递做转发。有兴趣的可以直接看github代码和对应的注释。代码在此不详述。
演示测试效果
github地址
知乎 带登录功能的爬虫 查看全部
nodejs抓取动态网页(cheerio抓取页面后操作来提取页面中的数据,api及用法跟jquery)
切里奥
抓取页面后,操作dom提取页面中的数据,api和用法类似jquery
表示
用于启动一个简单的服务,在浏览器中查看爬虫爬取的数据
玉
页面模板引擎
使用方法将仓库克隆到本地,然后安装相应模块并执行node app启动服务。打开浏览器输入localhost:3000查看效果分析。
整个爬虫其实很简单。主要功能是发送请求以采集数据,然后对其进行分析。当然,这一步分析不一定收录在爬虫中。您可以自己编写其他模块来分析和处理数据。使用superagent请求知乎接口获取具体数据,但是有些接口有限制,有些数据是通过服务端渲染直接显示在页面上的,不能直接通过知乎接口获取,所以需要从渲染的页面中抓取,所以需要使用cheerio模块进行dom操作,获取对应的dom结构然后获取值。这里需要注意的是,这种需要登录的网站请求可能有权限验证,
目录说明

主要步骤
登录和获取授权的过程有点繁琐,而且有验证码,所以只能通过快递做转发。有兴趣的可以直接看github代码和对应的注释。代码在此不详述。
演示测试效果
github地址
知乎 带登录功能的爬虫
nodejs抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-29 10:13
现在越来越多的网页使用前端渲染页面,给爬取工作带来了很大的麻烦。通过通常的方法,我们只能得到一堆js方法或者api接口。当然,我们不希望每个 网站 都如此努力地探索他们的 api。
那么有什么更好的方式称呼全能的谷歌老爸,puppeteer可以模拟chrome打开网页,可以截图,转换成pdf文件,当然还可以抓取数据,因为截图的前提是模拟前端渲染效果就像真的打开了网站。
本文章主要介绍如何通过puppeteer简单爬取
下载
1
$ yarn add puppeteer
采用
我们先看一个简单的例子,不问为什么,直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行之后,你会发现它打印出了文档的宽度、高度和标题。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取页面的头像信息。通过开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这个时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样,我们就可以轻松分析一个dom元素。当然,这样的粘贴复制并不是万能的。很多情况下,我们需要分析页面样式来寻找更好的解析方式。
完整用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
去检查一个数组是否收录一个项目
Vim 高级功能 vimgrep 全局搜索文件
在北京申请工作和居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置 查看全部
nodejs抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
现在越来越多的网页使用前端渲染页面,给爬取工作带来了很大的麻烦。通过通常的方法,我们只能得到一堆js方法或者api接口。当然,我们不希望每个 网站 都如此努力地探索他们的 api。
那么有什么更好的方式称呼全能的谷歌老爸,puppeteer可以模拟chrome打开网页,可以截图,转换成pdf文件,当然还可以抓取数据,因为截图的前提是模拟前端渲染效果就像真的打开了网站。
本文章主要介绍如何通过puppeteer简单爬取
下载
1
$ yarn add puppeteer
采用
我们先看一个简单的例子,不问为什么,直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行之后,你会发现它打印出了文档的宽度、高度和标题。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取页面的头像信息。通过开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这个时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样,我们就可以轻松分析一个dom元素。当然,这样的粘贴复制并不是万能的。很多情况下,我们需要分析页面样式来寻找更好的解析方式。
完整用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
去检查一个数组是否收录一个项目
Vim 高级功能 vimgrep 全局搜索文件
在北京申请工作和居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置
nodejs抓取动态网页新建一个dateparser,看你的后端用什么语言
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-29 05:01
nodejs抓取动态网页
新建一个dateparser,然后看你的后端用什么语言,drupal,用qml可以用qt的事件机制把你要抓取的时间点输出,直接转换成json。之后直接post给你要抓取的网页就行了。
同意@rickzhao的,单独来抓,抓完直接格式化存起来就好了,你可以在datepicker下写你的代码,把时间点嵌入到一个队列中。其实时间本身应该是没有意义的,它只是一个常量。但是从量化角度看,如果要增加时间纬度的话,如何取值也要确定才行。
用drupal之类可以用事件监听吧,也可以用drupal生成jsonparser,如redis/redis.js·github的time_guide模块。
1).setimes('yyyy-mm-ddhh:mm:ss').set(1,
0)或者json.stringify(a,
1).set(1,
1)都可以实现简单的代码。
知乎在什么阶段,
目前我们有推送库,可以直接抓取提问者的实时动态,
你是基于什么网站来抓取?怎么样?给个栗子
如果是基于推送,发送邀请函的话。如果基于推送,点赞赞?还有一些软件可以协助做这些。比如shopify或者是,需要自己的一些代码去维护。 查看全部
nodejs抓取动态网页新建一个dateparser,看你的后端用什么语言
nodejs抓取动态网页
新建一个dateparser,然后看你的后端用什么语言,drupal,用qml可以用qt的事件机制把你要抓取的时间点输出,直接转换成json。之后直接post给你要抓取的网页就行了。
同意@rickzhao的,单独来抓,抓完直接格式化存起来就好了,你可以在datepicker下写你的代码,把时间点嵌入到一个队列中。其实时间本身应该是没有意义的,它只是一个常量。但是从量化角度看,如果要增加时间纬度的话,如何取值也要确定才行。
用drupal之类可以用事件监听吧,也可以用drupal生成jsonparser,如redis/redis.js·github的time_guide模块。
1).setimes('yyyy-mm-ddhh:mm:ss').set(1,
0)或者json.stringify(a,
1).set(1,
1)都可以实现简单的代码。
知乎在什么阶段,
目前我们有推送库,可以直接抓取提问者的实时动态,
你是基于什么网站来抓取?怎么样?给个栗子
如果是基于推送,发送邀请函的话。如果基于推送,点赞赞?还有一些软件可以协助做这些。比如shopify或者是,需要自己的一些代码去维护。
阿里巴巴聚合导航页面nodejs抓取动态网页各有各的风格
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-09 09:01
nodejs抓取动态网页各有各的风格,而我抓取了经典的爬虫,目标是聚合页面,不遗余力追求速度。阿里巴巴聚合导航页面nodejs抓取的思路很简单,就是获取全站所有的页面url,然后从url中获取关键词,再获取对应的文字。相对于python来说,它相对容易。第一步:获取全站所有的页面url全站url如下,可以将这些url发送给nodejs抓取:requests.get('/',['http://','/']).then(res=>{console.log(res);})console.log('all');第二步:获取对应的文字这里我们需要使用的库是requests,可以把这个库导入到python的lxml库里,如果采用xmlhttprequest就把它called到一个闭包里:fromrequestsimportgetrequests,把这个库的名字改成自己定义的对应的库名,然后用requestsget后端方法获取。
具体的用法如下:defget(url):res=requests.get(url)res.status_code=str(res.text)returnres.textexports.post(url);exports.get(url);exports.post(get(url));exports.post(post(url));exports.replace(posturl,':','');一开始有些多此一举,最好传一个进程pid,然后再pipinstallexports.setup(getrequests).pipinstallgetrequests().installlxmlfromexportsimportexportsfrombs4importbeautifulsoupimportsyssys.stdout.buffer()url='/'withgetrequests.get(url)asgetrequest:res=getrequest.get(url)res.status_code=str(res.text)returnres.textget_url=getrequest.get(url)if__name__=='__main__':url='/'exports.post(url)if__name__=='__main__':get_url=getrequest.get(url)if__name__=='__main__':get_url=getrequest.get(url)你可以在这里看到代码可读性不错,但对于那些有要求的人,还是去看看源码吧。
代码阅读和演示地址:【实例]all爬虫框架v0.21.1高清视频资源。首页、有趣好玩的聚合导航、站点聚合页面——nodejs动态下载-安利加推荐mpvuejs-纯nodejs高并发、微服务应用开发框架——vue全家桶日本第一弹:一年一度的「全球新年文化活动」「2017腾讯游戏开发者大会」。 查看全部
阿里巴巴聚合导航页面nodejs抓取动态网页各有各的风格
nodejs抓取动态网页各有各的风格,而我抓取了经典的爬虫,目标是聚合页面,不遗余力追求速度。阿里巴巴聚合导航页面nodejs抓取的思路很简单,就是获取全站所有的页面url,然后从url中获取关键词,再获取对应的文字。相对于python来说,它相对容易。第一步:获取全站所有的页面url全站url如下,可以将这些url发送给nodejs抓取:requests.get('/',['http://','/']).then(res=>{console.log(res);})console.log('all');第二步:获取对应的文字这里我们需要使用的库是requests,可以把这个库导入到python的lxml库里,如果采用xmlhttprequest就把它called到一个闭包里:fromrequestsimportgetrequests,把这个库的名字改成自己定义的对应的库名,然后用requestsget后端方法获取。
具体的用法如下:defget(url):res=requests.get(url)res.status_code=str(res.text)returnres.textexports.post(url);exports.get(url);exports.post(get(url));exports.post(post(url));exports.replace(posturl,':','');一开始有些多此一举,最好传一个进程pid,然后再pipinstallexports.setup(getrequests).pipinstallgetrequests().installlxmlfromexportsimportexportsfrombs4importbeautifulsoupimportsyssys.stdout.buffer()url='/'withgetrequests.get(url)asgetrequest:res=getrequest.get(url)res.status_code=str(res.text)returnres.textget_url=getrequest.get(url)if__name__=='__main__':url='/'exports.post(url)if__name__=='__main__':get_url=getrequest.get(url)if__name__=='__main__':get_url=getrequest.get(url)你可以在这里看到代码可读性不错,但对于那些有要求的人,还是去看看源码吧。
代码阅读和演示地址:【实例]all爬虫框架v0.21.1高清视频资源。首页、有趣好玩的聚合导航、站点聚合页面——nodejs动态下载-安利加推荐mpvuejs-纯nodejs高并发、微服务应用开发框架——vue全家桶日本第一弹:一年一度的「全球新年文化活动」「2017腾讯游戏开发者大会」。
nodejs抓取动态网页(Selenium爬动态网页的小技巧及场景介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-15 12:08
/1 简介/
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括 IE、Mozilla Firefox、Safari、Google Chrome、Opera 等。
这里有两个场景向你介绍 Selenium 爬取动态网页的技巧。
/2 场景一:替换日期控制值/
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。
这种操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
我们先来看看日期框的元素,如下图所示:
专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:
第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值。
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图所示:
如果我们需要自动爬取这样的动态网页,我们也可以实现JavaScript的方法来实现。5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:
这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是整个窗口的高度, “h=(i/1 0)” 是每次滑动的高度。
效果演示如下:
/4。结论/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供线索。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,消磨在家的无聊时间。本文涉及的代码已上传至github地址,后台回复“selenium”二字即可获取代码。 查看全部
nodejs抓取动态网页(Selenium爬动态网页的小技巧及场景介绍-苏州安嘉)
/1 简介/
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户一样,是爬取复杂动态网页的必备工具。支持的浏览器包括 IE、Mozilla Firefox、Safari、Google Chrome、Opera 等。
这里有两个场景向你介绍 Selenium 爬取动态网页的技巧。
/2 场景一:替换日期控制值/
以12306网站为例,如下图,按照正常的方法,我们首先需要定位到时间元素,然后调用selenium的click()方法进行点击。
这种操作也是可以的。但是,过了一会儿,当我们再次运行自动化代码时,我们发现该功能无法正常工作。因为日历控件的布局会随着日期的变化而变化,操作起来很麻烦。
我们先来看看日期框的元素,如下图所示:
专注于价值='文本'。此属性值可以通过 JavaScript 更改。三行代码就可以解决这个问题,如下图所示:
第一行是要输入的日期,第二行是JavaScript代码,“documen.getElementById”通过HTML的“id”定位元素,通过改变元素的“值”来改变值。
效果演示如下:
/3 场景二:动态网页自动下拉/
一些复杂的动态网页需要下拉才能完整展示元素,比如腾讯视频首页,如下图所示:
如果我们需要自动爬取这样的动态网页,我们也可以实现JavaScript的方法来实现。5行代码,我们就可以连续滑动网页,显示所有动态网页元素。代码如下图所示:
这里小编采用的一步一步下拉的方式,每次滚动1/10,“window.scrollTo”是向下滑动的命令,“document.body.clientHeight”是整个窗口的高度, “h=(i/1 0)” 是每次滑动的高度。
效果演示如下:
/4。结论/
将 JavaScript 应用到 selenium 可以帮助我们解决很多问题。这里有两个小例子,只是为了提供线索。希望以后遇到 selenium 无法解决的问题时,可以考虑在 JavaScript 中寻找突破口。
欢迎大家积极尝试,消磨在家的无聊时间。本文涉及的代码已上传至github地址,后台回复“selenium”二字即可获取代码。
nodejs抓取动态网页(目标抓取网站上的妹子文件存放路径(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-14 09:29
目标
在 网站 上获取女孩的照片。
第三方模块
superagent :用于处理来自服务器和客户端的 Http 请求的第三方 Nodejs 模块。
Cheerio:为服务器端定制的 jQuery 实现。
想法
通过superagent获取目标网站的dom
Cheerio 解析 dom 以获得总体布局。
如果只是爬取一个页面,可以直接获取目标页面的目标元素
如果是分页或者多页,可以通过多次循环爬取获取目标链接。
完成
在这里,我们实现了一个 网站 女孩的捕捉照片。
目标 URL:(此 网站 没有恶意。)
代码显示如下:
//引入第三方和通用模块 var fs = require('fs');//为了将抓取的图像保存到本地,使用 fsvar superagent = require('superagent');//引入 superagentvarcheerio = require(' Cheerio');//引入jquery实现 var filePath = '/node/learning/sis/img/';//定义抓取姐妹文件的存储路径 var count = 0;//记录抓取次数 var test = []; // 抓取页面的实现。var getOnePage = function(url){ //因为煎蛋限制了请求,所以添加了cookie。如果你想访问网站,你可以通过浏览器找到cookie并替换它 superagent.get(url) .set({'user-agent':'Mozilla/5.0 (Windows NT 1 0.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/4<
var u = '';if($(ele).attr('org_src')){u = $(ele).attr('org_src');}else{u = $(ele).attr('src' );}test.push(u);//通过superagent获取图片数据并保存在本地。superagent.get(u).end(function(err,sres){if(err)throw err;//根据访问路径获取文件名 var ttt = u.split('/');var name = ttt [ttt.length-1];var path = filePath+namefs.writeFile(path,sres.body,function(){count++;console.log(u);console.log('抓取成功..'+count+'张' );});});});if(null != nextUrl && '' != nextUrl){ //何时开始下一个请求 getOnePage(nextUrl);} }); }; getOnePage(''); //触发第一个请求开始
1、如果你是有针对性的爬几个页面,做一些简单的页面分析,爬取效率不是核心要求,那么使用的语言差别不大。
当然,如果页面结构复杂,正则表达式也很复杂,尤其是在使用了那些支持xpath的类库/爬虫库之后,你会发现这种方式虽然入门门槛低,但扩展性和可维护性却是惊人的。不同之处。所以在这种情况下,建议使用一些现成的爬虫库,比如xpath和多线程支持,这些都是必须要考虑的。
2、如果是定向爬取,主要目标是解析js动态生成的内容
这时候页面内容是由js/ajax动态生成的,普通的请求页面->解析方式是行不通的。需要使用类似于firefox和chrome浏览器的js引擎来动态解析页面的js代码。.
这种情况下建议考虑casperJS+phantomjs或者slimerJS+phantomjs,当然selenium之类的也可以考虑。
3、如果爬虫涉及到大规模网站爬取,效率、可扩展性、可维护性等都是必须考虑的因素
大规模爬取涉及到很多问题:多线程并发、I/O机制、分布式爬取、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择就很重要了。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取是可以的,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是 Scrapy 框架当之无愧是首选。优点很多:支持xpath;以绞为基础,性能优良;更好的调试工具;
这种情况下,如果还需要解析js动态内容,casperjs就不适合了,只能基于chrome V8引擎制作自己的js引擎。
至于C和C++,虽然性能不错,但不推荐,特别是考虑到成本等诸多因素;对于大部分公司来说,建议基于一些开源框架来做,不要自己发明轮子,做一个简单的爬虫容易,但是做一个完整的爬虫很难。
像我搭建的微信公众号的内容聚合网站是基于Scrapy的,当然也涉及到消息队列等等。可以参考下图:
具体内容请参考某任务调度分发服务的架构 查看全部
nodejs抓取动态网页(目标抓取网站上的妹子文件存放路径(二))
目标
在 网站 上获取女孩的照片。
第三方模块
superagent :用于处理来自服务器和客户端的 Http 请求的第三方 Nodejs 模块。
Cheerio:为服务器端定制的 jQuery 实现。
想法
通过superagent获取目标网站的dom
Cheerio 解析 dom 以获得总体布局。
如果只是爬取一个页面,可以直接获取目标页面的目标元素
如果是分页或者多页,可以通过多次循环爬取获取目标链接。
完成
在这里,我们实现了一个 网站 女孩的捕捉照片。
目标 URL:(此 网站 没有恶意。)
代码显示如下:
//引入第三方和通用模块 var fs = require('fs');//为了将抓取的图像保存到本地,使用 fsvar superagent = require('superagent');//引入 superagentvarcheerio = require(' Cheerio');//引入jquery实现 var filePath = '/node/learning/sis/img/';//定义抓取姐妹文件的存储路径 var count = 0;//记录抓取次数 var test = []; // 抓取页面的实现。var getOnePage = function(url){ //因为煎蛋限制了请求,所以添加了cookie。如果你想访问网站,你可以通过浏览器找到cookie并替换它 superagent.get(url) .set({'user-agent':'Mozilla/5.0 (Windows NT 1 0.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/4<
var u = '';if($(ele).attr('org_src')){u = $(ele).attr('org_src');}else{u = $(ele).attr('src' );}test.push(u);//通过superagent获取图片数据并保存在本地。superagent.get(u).end(function(err,sres){if(err)throw err;//根据访问路径获取文件名 var ttt = u.split('/');var name = ttt [ttt.length-1];var path = filePath+namefs.writeFile(path,sres.body,function(){count++;console.log(u);console.log('抓取成功..'+count+'张' );});});});if(null != nextUrl && '' != nextUrl){ //何时开始下一个请求 getOnePage(nextUrl);} }); }; getOnePage(''); //触发第一个请求开始
1、如果你是有针对性的爬几个页面,做一些简单的页面分析,爬取效率不是核心要求,那么使用的语言差别不大。
当然,如果页面结构复杂,正则表达式也很复杂,尤其是在使用了那些支持xpath的类库/爬虫库之后,你会发现这种方式虽然入门门槛低,但扩展性和可维护性却是惊人的。不同之处。所以在这种情况下,建议使用一些现成的爬虫库,比如xpath和多线程支持,这些都是必须要考虑的。
2、如果是定向爬取,主要目标是解析js动态生成的内容
这时候页面内容是由js/ajax动态生成的,普通的请求页面->解析方式是行不通的。需要使用类似于firefox和chrome浏览器的js引擎来动态解析页面的js代码。.
这种情况下建议考虑casperJS+phantomjs或者slimerJS+phantomjs,当然selenium之类的也可以考虑。
3、如果爬虫涉及到大规模网站爬取,效率、可扩展性、可维护性等都是必须考虑的因素
大规模爬取涉及到很多问题:多线程并发、I/O机制、分布式爬取、消息通信、权重判断机制、任务调度等,这时候语言和框架的选择就很重要了。
PHP 对多线程和异步的支持较差,不推荐使用。
NodeJS:对于一些垂直的网站爬取是可以的,但是由于对分布式爬取、消息通信等支持较弱,请根据自己的情况判断。
Python:强烈推荐,对上述问题有很好的支持。尤其是 Scrapy 框架当之无愧是首选。优点很多:支持xpath;以绞为基础,性能优良;更好的调试工具;
这种情况下,如果还需要解析js动态内容,casperjs就不适合了,只能基于chrome V8引擎制作自己的js引擎。
至于C和C++,虽然性能不错,但不推荐,特别是考虑到成本等诸多因素;对于大部分公司来说,建议基于一些开源框架来做,不要自己发明轮子,做一个简单的爬虫容易,但是做一个完整的爬虫很难。
像我搭建的微信公众号的内容聚合网站是基于Scrapy的,当然也涉及到消息队列等等。可以参考下图:
具体内容请参考某任务调度分发服务的架构
nodejs抓取动态网页(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-14 09:28
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
还有很多
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
相关文章 查看全部
nodejs抓取动态网页(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
还有很多
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
相关文章
nodejs抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-14 09:26
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
nodejs抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
nodejs抓取动态网页(静态或平面网页是指这样一种网页,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-14 03:19
)
静态或平面网页是指所有信息和资料在存储时呈现给用户的网页。静态网页向所有用户显示相同的信息和数据。在 Internet 技术中,超文本标记语言 (HTML) 是人们开始创建静态网页的第一种语言或渠道。HTML 提供文本样式、段落创建和换行符。但 HTML 最重要的功能是链接创建选项。静态网页对其材料和内容很有用,很少需要修改或更新。
静态的优点网站静态的缺点网站
一页静态 网站 的文件结构如下所示。
动态网页
动态网页是最新趋势,因为它们可以从相同的源代码文件为不同的访问者生成不同的内容。网站 可以根据以下参数显示不同的内容 -
动态网页可以用于多种用途。例如,由内容管理系统运行的 网站 允许单个源代码文件将内容加载到许多不同的页面中。我们应该提到,所有这些动态网页都使用数据库。内容创建者使用网关页面将新页面的材料提交到 cms 的数据库中。动态页面根据 URL 中的参数为数据库中的任何页面加载数据。这是在访问者请求网页时完成的。动态页面允许用户登录 网站 以查看个性化内容。
我们之前提到的所有内容管理系统(WordPress、Joomla 和 Drupal)都是动态的网站。
下图是一个动态网页的示意图。
查看全部
nodejs抓取动态网页(静态或平面网页是指这样一种网页,你知道吗?
)
静态或平面网页是指所有信息和资料在存储时呈现给用户的网页。静态网页向所有用户显示相同的信息和数据。在 Internet 技术中,超文本标记语言 (HTML) 是人们开始创建静态网页的第一种语言或渠道。HTML 提供文本样式、段落创建和换行符。但 HTML 最重要的功能是链接创建选项。静态网页对其材料和内容很有用,很少需要修改或更新。
静态的优点网站静态的缺点网站
一页静态 网站 的文件结构如下所示。
动态网页
动态网页是最新趋势,因为它们可以从相同的源代码文件为不同的访问者生成不同的内容。网站 可以根据以下参数显示不同的内容 -
动态网页可以用于多种用途。例如,由内容管理系统运行的 网站 允许单个源代码文件将内容加载到许多不同的页面中。我们应该提到,所有这些动态网页都使用数据库。内容创建者使用网关页面将新页面的材料提交到 cms 的数据库中。动态页面根据 URL 中的参数为数据库中的任何页面加载数据。这是在访问者请求网页时完成的。动态页面允许用户登录 网站 以查看个性化内容。
我们之前提到的所有内容管理系统(WordPress、Joomla 和 Drupal)都是动态的网站。
下图是一个动态网页的示意图。
nodejs抓取动态网页(Webkit可以简单解决这个问题!(附详细教程))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-13 17:26
2021-10-11
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。嗯,这个问题可以通过Web kit轻松解决。Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,你可以直接运行它。
1、环境准备
Linux:sudo apt-get install python-qt4
视窗:
2、使用
首先通过Web kit发送请求信息,然后等待页面加载完毕再赋值给一个变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间。
import sys
from PyQt4.QtWebKit import *
from PyQt4.QtGui import *
from PyQt4.QtCore import *
class Render(QWebPage): # 用来渲染网页,将url中的所有信息加载下来并存到一个新的框架中
def __init__(self,url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
url = 'http://jandan.net/ooxx'
r = Render(url)
html = r.frame.toHtml()
print(html)
然后,接下来的工作就是解析HTML代码了,这里就不解释了。
分类:
技术要点:
相关文章: 查看全部
nodejs抓取动态网页(Webkit可以简单解决这个问题!(附详细教程))
2021-10-11
当我们进行网络爬取时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页收录 JavaScript 代码,我们必须渲染它以获取原创数据。在这一点上,如果我们仍然以通常的方式从中抓取数据,我们将一无所获。嗯,这个问题可以通过Web kit轻松解决。Web 工具包可以做任何浏览器可以处理的事情。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,你可以直接运行它。
1、环境准备
Linux:sudo apt-get install python-qt4
视窗:
2、使用
首先通过Web kit发送请求信息,然后等待页面加载完毕再赋值给一个变量。接下来我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一点时间。
import sys
from PyQt4.QtWebKit import *
from PyQt4.QtGui import *
from PyQt4.QtCore import *
class Render(QWebPage): # 用来渲染网页,将url中的所有信息加载下来并存到一个新的框架中
def __init__(self,url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
url = 'http://jandan.net/ooxx'
r = Render(url)
html = r.frame.toHtml()
print(html)
然后,接下来的工作就是解析HTML代码了,这里就不解释了。
分类:
技术要点:
相关文章:
nodejs抓取动态网页(HTTP客户端将请求发送到服务器,然后从服务器服务器来查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-13 12:29
HTTP 客户端是一种向服务器发送请求,然后从服务器接收响应的工具。本文中讨论的大多数工具在后台使用 HTTP 客户端来查询您将尝试抓取的 网站 服务器。
RequestRequest 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但是现在 Request 库的作者已经正式表示不建议大家继续使用它。不是说不能用,还有很多库还在用,真的很好用。使用 Request 发出 HTTP 请求非常简单:
const request = require('request')<br />request('https://www.reddit.com/r/programming.json', function (<br /> error,<br /> response,<br /> body) {<br /> console.error('error:', error)<br /> console.log('body:', body)<br />})
你可以在 Github 上找到 Request 库并运行 npm install request 来安装它。在这里您可以参考弃用通知和详细信息:
AxiosAxios 是一个基于 Promise 的 HTTP 客户端,在浏览器和 NodeJS 中运行。如果你使用 Typescript,axios 可以覆盖内置类型。通过axios发起HTTP请求非常简单。默认情况下它具有内置的 Promise 支持,不像 Request,它必须使用回调:
const axios = require('axios')<br />axios<br /> .get('https://www.reddit.com/r/programming.json')<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它们,但由于顶级 await 仍处于第 3 阶段,我们只能使用 Async Function 代替:
async function getForum() {<br /> try {<br /> const response = await axios.get(<br /> 'https://www.reddit.com/r/progr ... %3Bbr /> )<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }<br />}
你只需调用getForum!你可以在 Github 上找到 Axios 库并运行 npm install axios 来安装它。
超级代理
与 Axios 类似,Superagent 是另一个强大的 HTTP 客户端,支持 Promises 和 async/await 语法糖。它的 API 和 Axios 一样简单,但 Superagent 依赖较多,不太流行。
在 Superagent 中,HTTP 请求是使用 Promise、async/await 或回调发出的,如下所示:
const superagent = require("superagent")<br />const forumURL = "https://www.reddit.com/r/progr ... %3Bbr />// callbacks<br />superagent<br /> .get(forumURL)<br /> .end((error, response) => {<br /> console.log(response)<br /> })<br />// promises<br />superagent<br /> .get(forumURL)<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> })<br />// promises with async/await<br />async function getForum() {<br /> try {<br /> const response = await superagent.get(forumURL)<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }
你可以在 Github 上找到 Superagent 库并运行 npm install superagent 来安装它。
对于下面介绍的网页抓取工具,本文将使用 Axios 作为 HTTP 客户端。
正则表达式:艰难之路
在没有任何依赖关系的情况下开始抓取 Web 内容的最简单方法是在使用 HTTP 客户端查询网页时收到的 HTML 字符串上应用一组正则表达式 - 但这种方法绕路太远了。正则表达式不是那么灵活,许多专业人士和爱好者很难编写正确的正则表达式。
对于复杂的网页抓取任务,正则表达式很快就会成为瓶颈。无论如何,让我们先尝试一下。假设有一个带有用户名的标签,我们需要用户名,那么使用正则表达式时的方法几乎是这样的:
const htmlString = 'Username: John Doe'<br />const result = htmlString.match(/(.+)/)<br />console.log(result[1], result[1].split(": ")[1])<br />// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个收录与正则表达式匹配的所有内容的数组。第二个元素(在索引 1 处)将找到标签的 textContent 或 innerHTML,这正是我们想要的。但是这个结果将收录一些我们不需要的文本(“用户名:”),必须将其删除。如您所见,这种方法对于一个非常简单的用例来说很麻烦。所以我们应该使用 HTML 解析器之类的工具,这些工具将在后面讨论。
Cheerio:在其核心遍历 DOM JQuery Cheerio 是一个高效且轻量级的库,允许您在服务器端使用 JQuery 丰富而强大的 API。如果您以前使用过 JQuery,那么使用 Cheerio 很容易上手。它消除了 DOM 的所有不一致和与浏览器相关的特性,并公开了一个用于解析和操作 DOM 的高效 API。
const cheerio = require('cheerio')<br />const $ = cheerio.load('
你好世界 ')
$('h2.title').text('你好!')
$('h2').addClass('欢迎')
$.html()
// 你好呀!
如您所见,Cheerio 的工作方式与 JQuery 非常相似。但是,它与 Web 浏览器的工作方式不同,这意味着它不能:
因此,如果您尝试抓取的 网站 或 Web 应用程序有很多 Javascript 内容(例如“单页应用程序”),那么 Cheerio 不是您的最佳选择,您可能不得不依赖以下内容讨论其他一些选项。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛以获取帖子标题列表。
首先,运行以下命令安装 Cheerio 和 axios:npm install Cheerio axios。
然后创建一个名为 crawler.js 的新文件并复制/粘贴以下代码:
const axios = require('axios');<br />const cheerio = require('cheerio');<br />const getPostTitles = async () => {<br /> try {<br /> const { data } = await axios.get(<br /> 'https://old.reddit.com/r/progr ... %3Bbr /> );<br /> const $ = cheerio.load(data);<br /> const postTitles = [];<br /> $('div > p.title > a').each((_idx, el) => {<br /> const postTitle = $(el).text()<br /> postTitles.push(postTitle)<br /> });<br /> return postTitles;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />getPostTitles()<br />.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,用于抓取旧 reddit 的 r/programming 论坛。首先,使用来自 axios HTTP 客户端库的简单 HTTP GET 请求获取 网站 的 HTML,然后使用cheerio.load() 函数将 html 数据提供给 Cheerio。
接下来,使用浏览器的开发工具,您可以获得通常可以针对所有明信片的选择器。如果您使用过 JQuery,那么 $('div > p.title > a') 非常熟悉。这将获取所有帖子,因为您只想获取每个帖子的标题,您必须遍历每个帖子(使用 each() 函数进行迭代)。
要从每个标题中提取文本,必须在 Cheerio 的帮助下获取 DOM 元素(当前元素的 el)。然后在每个元素上调用 text() 以获取文本。
现在,您可以弹出一个终端并运行 node crawler.js,您会看到一长串大约 25 或 26 个帖子标题。虽然这是一个非常简单的用例,但它显示了 Cheerio 提供的 API 是多么容易使用。
如果您的用例需要执行 Javascript 和加载外部资源,这里有几个选项可供考虑。
JSDOM:节点的 DOM
JSDOM 是 NodeJS 中使用的文档对象模型 (DOM) 的纯 Javascript 实现。如前所述,DOM 不适用于 Node,而 JSDOM 是最接近的替代品。它或多或少地模拟了浏览器的机制。
一旦创建了 DOM,我们就可以通过编程方式与要抓取的 Web 应用程序或 网站 进行交互,还可以完成单击按钮之类的操作。如果您熟悉 DOM 的工作原理,那么 JSDOM 也非常易于使用。
const { JSDOM } = require('jsdom')<br />const { document } = new JSDOM(<br /> '
你好世界 '
)。窗户
constheading = document.querySelector('.title')
heading.textContent = '你好!'
heading.classList.add('欢迎')
标题.innerHTML
// 你好呀!
如您所见,JSDOM 创建了一个 DOM,然后您可以使用与浏览器 DOM 相同的方法和属性对其进行操作。为了演示如何使用 JSDOM 与 网站 进行交互,我们将在 Redditr/programming 论坛上发表第一篇文章,点赞它,然后我们将验证该帖子是否已被点赞。
首先运行以下命令安装jsdom和axios:
npm install jsdom axios
然后创建一个名为 rawler.js 的文件并复制/粘贴以下代码:
const { JSDOM } = require("jsdom")<br />const axios = require('axios')<br />const upvoteFirstPost = async () => {<br /> try {<br /> const { data } = await axios.get("https://old.reddit.com/r/programming/");<br /> const dom = new JSDOM(data, {<br /> runScripts: "dangerously",<br /> resources: "usable"<br /> });<br /> const { document } = dom.window;<br /> const firstPost = document.querySelector("div > div.midcol > div.arrow");<br /> firstPost.click();<br /> const isUpvoted = firstPost.classList.contains("upmod");<br /> const msg = isUpvoted<br /> ? "Post has been upvoted successfully!"<br /> : "The post has not been upvoted!";<br /> return msg;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一个帖子并对其进行投票。为此,axios 发送一个 HTTP GET 请求以获取指定 URL 的 HTML。然后将先前获取的 HTML 馈送到 JSDOM 以创建新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的 2 个选项执行以下功能: 查看全部
nodejs抓取动态网页(HTTP客户端将请求发送到服务器,然后从服务器服务器来查询)
HTTP 客户端是一种向服务器发送请求,然后从服务器接收响应的工具。本文中讨论的大多数工具在后台使用 HTTP 客户端来查询您将尝试抓取的 网站 服务器。
RequestRequest 是 Javascript 生态系统中使用最广泛的 HTTP 客户端之一,但是现在 Request 库的作者已经正式表示不建议大家继续使用它。不是说不能用,还有很多库还在用,真的很好用。使用 Request 发出 HTTP 请求非常简单:
const request = require('request')<br />request('https://www.reddit.com/r/programming.json', function (<br /> error,<br /> response,<br /> body) {<br /> console.error('error:', error)<br /> console.log('body:', body)<br />})
你可以在 Github 上找到 Request 库并运行 npm install request 来安装它。在这里您可以参考弃用通知和详细信息:
AxiosAxios 是一个基于 Promise 的 HTTP 客户端,在浏览器和 NodeJS 中运行。如果你使用 Typescript,axios 可以覆盖内置类型。通过axios发起HTTP请求非常简单。默认情况下它具有内置的 Promise 支持,不像 Request,它必须使用回调:
const axios = require('axios')<br />axios<br /> .get('https://www.reddit.com/r/programming.json')<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> });
如果你喜欢 Promises API 的 async/await 语法糖,你也可以使用它们,但由于顶级 await 仍处于第 3 阶段,我们只能使用 Async Function 代替:
async function getForum() {<br /> try {<br /> const response = await axios.get(<br /> 'https://www.reddit.com/r/progr ... %3Bbr /> )<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }<br />}
你只需调用getForum!你可以在 Github 上找到 Axios 库并运行 npm install axios 来安装它。
超级代理
与 Axios 类似,Superagent 是另一个强大的 HTTP 客户端,支持 Promises 和 async/await 语法糖。它的 API 和 Axios 一样简单,但 Superagent 依赖较多,不太流行。
在 Superagent 中,HTTP 请求是使用 Promise、async/await 或回调发出的,如下所示:
const superagent = require("superagent")<br />const forumURL = "https://www.reddit.com/r/progr ... %3Bbr />// callbacks<br />superagent<br /> .get(forumURL)<br /> .end((error, response) => {<br /> console.log(response)<br /> })<br />// promises<br />superagent<br /> .get(forumURL)<br /> .then((response) => {<br /> console.log(response)<br /> })<br /> .catch((error) => {<br /> console.error(error)<br /> })<br />// promises with async/await<br />async function getForum() {<br /> try {<br /> const response = await superagent.get(forumURL)<br /> console.log(response)<br /> } catch (error) {<br /> console.error(error)<br /> }
你可以在 Github 上找到 Superagent 库并运行 npm install superagent 来安装它。
对于下面介绍的网页抓取工具,本文将使用 Axios 作为 HTTP 客户端。
正则表达式:艰难之路
在没有任何依赖关系的情况下开始抓取 Web 内容的最简单方法是在使用 HTTP 客户端查询网页时收到的 HTML 字符串上应用一组正则表达式 - 但这种方法绕路太远了。正则表达式不是那么灵活,许多专业人士和爱好者很难编写正确的正则表达式。
对于复杂的网页抓取任务,正则表达式很快就会成为瓶颈。无论如何,让我们先尝试一下。假设有一个带有用户名的标签,我们需要用户名,那么使用正则表达式时的方法几乎是这样的:
const htmlString = 'Username: John Doe'<br />const result = htmlString.match(/(.+)/)<br />console.log(result[1], result[1].split(": ")[1])<br />// Username: John Doe, John Doe
在 Javascript 中,match() 通常返回一个收录与正则表达式匹配的所有内容的数组。第二个元素(在索引 1 处)将找到标签的 textContent 或 innerHTML,这正是我们想要的。但是这个结果将收录一些我们不需要的文本(“用户名:”),必须将其删除。如您所见,这种方法对于一个非常简单的用例来说很麻烦。所以我们应该使用 HTML 解析器之类的工具,这些工具将在后面讨论。
Cheerio:在其核心遍历 DOM JQuery Cheerio 是一个高效且轻量级的库,允许您在服务器端使用 JQuery 丰富而强大的 API。如果您以前使用过 JQuery,那么使用 Cheerio 很容易上手。它消除了 DOM 的所有不一致和与浏览器相关的特性,并公开了一个用于解析和操作 DOM 的高效 API。
const cheerio = require('cheerio')<br />const $ = cheerio.load('
你好世界 ')
$('h2.title').text('你好!')
$('h2').addClass('欢迎')
$.html()
// 你好呀!
如您所见,Cheerio 的工作方式与 JQuery 非常相似。但是,它与 Web 浏览器的工作方式不同,这意味着它不能:
因此,如果您尝试抓取的 网站 或 Web 应用程序有很多 Javascript 内容(例如“单页应用程序”),那么 Cheerio 不是您的最佳选择,您可能不得不依赖以下内容讨论其他一些选项。
为了展示 Cheerio 的强大功能,我们将尝试爬取 Reddit 中的 r/programming 论坛以获取帖子标题列表。
首先,运行以下命令安装 Cheerio 和 axios:npm install Cheerio axios。
然后创建一个名为 crawler.js 的新文件并复制/粘贴以下代码:
const axios = require('axios');<br />const cheerio = require('cheerio');<br />const getPostTitles = async () => {<br /> try {<br /> const { data } = await axios.get(<br /> 'https://old.reddit.com/r/progr ... %3Bbr /> );<br /> const $ = cheerio.load(data);<br /> const postTitles = [];<br /> $('div > p.title > a').each((_idx, el) => {<br /> const postTitle = $(el).text()<br /> postTitles.push(postTitle)<br /> });<br /> return postTitles;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />getPostTitles()<br />.then((postTitles) => console.log(postTitles));
getPostTitles() 是一个异步函数,用于抓取旧 reddit 的 r/programming 论坛。首先,使用来自 axios HTTP 客户端库的简单 HTTP GET 请求获取 网站 的 HTML,然后使用cheerio.load() 函数将 html 数据提供给 Cheerio。
接下来,使用浏览器的开发工具,您可以获得通常可以针对所有明信片的选择器。如果您使用过 JQuery,那么 $('div > p.title > a') 非常熟悉。这将获取所有帖子,因为您只想获取每个帖子的标题,您必须遍历每个帖子(使用 each() 函数进行迭代)。
要从每个标题中提取文本,必须在 Cheerio 的帮助下获取 DOM 元素(当前元素的 el)。然后在每个元素上调用 text() 以获取文本。
现在,您可以弹出一个终端并运行 node crawler.js,您会看到一长串大约 25 或 26 个帖子标题。虽然这是一个非常简单的用例,但它显示了 Cheerio 提供的 API 是多么容易使用。
如果您的用例需要执行 Javascript 和加载外部资源,这里有几个选项可供考虑。
JSDOM:节点的 DOM
JSDOM 是 NodeJS 中使用的文档对象模型 (DOM) 的纯 Javascript 实现。如前所述,DOM 不适用于 Node,而 JSDOM 是最接近的替代品。它或多或少地模拟了浏览器的机制。
一旦创建了 DOM,我们就可以通过编程方式与要抓取的 Web 应用程序或 网站 进行交互,还可以完成单击按钮之类的操作。如果您熟悉 DOM 的工作原理,那么 JSDOM 也非常易于使用。
const { JSDOM } = require('jsdom')<br />const { document } = new JSDOM(<br /> '
你好世界 '
)。窗户
constheading = document.querySelector('.title')
heading.textContent = '你好!'
heading.classList.add('欢迎')
标题.innerHTML
// 你好呀!
如您所见,JSDOM 创建了一个 DOM,然后您可以使用与浏览器 DOM 相同的方法和属性对其进行操作。为了演示如何使用 JSDOM 与 网站 进行交互,我们将在 Redditr/programming 论坛上发表第一篇文章,点赞它,然后我们将验证该帖子是否已被点赞。
首先运行以下命令安装jsdom和axios:
npm install jsdom axios
然后创建一个名为 rawler.js 的文件并复制/粘贴以下代码:
const { JSDOM } = require("jsdom")<br />const axios = require('axios')<br />const upvoteFirstPost = async () => {<br /> try {<br /> const { data } = await axios.get("https://old.reddit.com/r/programming/";);<br /> const dom = new JSDOM(data, {<br /> runScripts: "dangerously",<br /> resources: "usable"<br /> });<br /> const { document } = dom.window;<br /> const firstPost = document.querySelector("div > div.midcol > div.arrow");<br /> firstPost.click();<br /> const isUpvoted = firstPost.classList.contains("upmod");<br /> const msg = isUpvoted<br /> ? "Post has been upvoted successfully!"<br /> : "The post has not been upvoted!";<br /> return msg;<br /> } catch (error) {<br /> throw error;<br /> }<br />};<br />upvoteFirstPost().then(msg => console.log(msg));
upvoteFirstPost() 是一个异步函数,它将获得 r/programming 中的第一个帖子并对其进行投票。为此,axios 发送一个 HTTP GET 请求以获取指定 URL 的 HTML。然后将先前获取的 HTML 馈送到 JSDOM 以创建新的 DOM。JSDOM 构造函数将 HTML 作为第一个参数,将选项作为第二个参数。添加的 2 个选项执行以下功能:
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-13 12:28
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页( nodeJs爬虫获取数据获取数据代码代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-11 03:28
nodeJs爬虫获取数据获取数据代码代码)
nodeJs爬虫获取数据简单实现代码
更新时间:2016年3月29日17:27:29 作者:Jone_chen
本文文章主要介绍nodeJs爬虫获取数据的简单实现代码。有兴趣的朋友可以参考一下
本文示例分享了nodeJs爬虫的数据代码,供大家参考,详情如下
var http=require('http');
var cheerio=require('cheerio');//页面获取到的数据模块
var url='http://www.jcpeixun.com/lesson/1512/';
function filterData(html){
/*所要获取到的目标数组
var courseData=[{
chapterTitle:"",
videosData:{
videoTitle:title,
videoId:id,
videoPrice:price
}
}] */
var $=cheerio.load(html);
var courseData=[];
var chapters=$(".list-collapse");
chapters.each(function(item){
var chapterTitle=$(this).find(".collapse-head").find("label").text();
var videos=$(this).find(".listview5").children("li");
var chaptersData={
chaptersTitle:chapterTitle,
videosData:[]
}
videos.each(function(item){
var videoTitle=$(this).find(".ml10").attr('data-lesson-name');
var videoId=$(this).find(".ml10").attr('data-lesson-id');
var vadeoPrice=$(this).find(".colblue").text();
chaptersData.videosData.push({
title:videoTitle,
id:videoId,
price:vadeoPrice
})
})
courseData.push(chaptersData)
})
return courseData
}
function printCourseInfo(courseData){
courseData.forEach(function(item){
console.log(item.chaptersTitle+'\n');
item.videosData.forEach(function(item){
console.log(item.title+'【'+item.id+'】'+item.price+'\n')
})
})
}
http.get(url,function(res){
html="";
res.on("data",function(data){
html+=data
})
res.on('end',function(){
var courseData=filterData(html);
printCourseInfo(courseData)
})
})
渲染:
以上是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。 查看全部
nodejs抓取动态网页(
nodeJs爬虫获取数据获取数据代码代码)
nodeJs爬虫获取数据简单实现代码
更新时间:2016年3月29日17:27:29 作者:Jone_chen
本文文章主要介绍nodeJs爬虫获取数据的简单实现代码。有兴趣的朋友可以参考一下
本文示例分享了nodeJs爬虫的数据代码,供大家参考,详情如下
var http=require('http');
var cheerio=require('cheerio');//页面获取到的数据模块
var url='http://www.jcpeixun.com/lesson/1512/';
function filterData(html){
/*所要获取到的目标数组
var courseData=[{
chapterTitle:"",
videosData:{
videoTitle:title,
videoId:id,
videoPrice:price
}
}] */
var $=cheerio.load(html);
var courseData=[];
var chapters=$(".list-collapse");
chapters.each(function(item){
var chapterTitle=$(this).find(".collapse-head").find("label").text();
var videos=$(this).find(".listview5").children("li");
var chaptersData={
chaptersTitle:chapterTitle,
videosData:[]
}
videos.each(function(item){
var videoTitle=$(this).find(".ml10").attr('data-lesson-name');
var videoId=$(this).find(".ml10").attr('data-lesson-id');
var vadeoPrice=$(this).find(".colblue").text();
chaptersData.videosData.push({
title:videoTitle,
id:videoId,
price:vadeoPrice
})
})
courseData.push(chaptersData)
})
return courseData
}
function printCourseInfo(courseData){
courseData.forEach(function(item){
console.log(item.chaptersTitle+'\n');
item.videosData.forEach(function(item){
console.log(item.title+'【'+item.id+'】'+item.price+'\n')
})
})
}
http.get(url,function(res){
html="";
res.on("data",function(data){
html+=data
})
res.on('end',function(){
var courseData=filterData(html);
printCourseInfo(courseData)
})
})
渲染:
以上是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。
nodejs抓取动态网页(Nodejs反向代理的建站问题,你知道吗?小前端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-06 12:17
所有的demo都不是完整的程序,所有没有上线的程序都只是demo;
作为Web开发的后起之秀,在目前的国内环境下,Nodejs虽然不如PHP流行,但没有.net的海量基础,也无法覆盖Java的高度。但是,Nodejs 基于谷歌 V8 引擎的速度、异步 IO 和事件模型,无疑将是 Web 开发的一大创新;我是一个小前端,自从知道了Nodejs,就觊觎了好久,期待终于可以在闲暇之余用Express4.x做一个断断续续的个人博客(花开花)建筑);
为了让我的博客不只是本地demo,我买了一台服务器,搭建好环境,选好日期,准备上线了。上线后发现自己是个白痴……在目前的国家,Nodejs是小众。当然,问题在所难免,你可以随便抱怨,但既然选择了,就必须相信自己不是瞎子,当然要坚定地走下去。继续; 关于上线后需要先解决的域名绑定问题,我会分享给喜欢Nodejs的朋友和前端朋友;可能你做过.net,PHP什么的,有IIS,一键建站软件,那没关系,我只是站在一个小前端的角度,分享一下基于Nodejs建站的问题;
Nginx 反向代理方式现在很流行。百度的时候,一开始也是选择使用Nginx反向代理我的博客站点;我是服务器新手,一开始真的伤不起,但也没什么好怕的。是的,你只需要根据别人分享的模型修改成你的,除非你想认真运维;当然也难免会出现一些无法预料的小问题,比如:客户代理后终端的IP获取问题(我当时获取的所有客户的IP都是一样的……),上传的大小限制文件,需要重新配置相关的Nginx配置项;
基本配置如下:
命令行进入nginx.exe目录->启动nginx(启动nginx)->打开conf目录下的nginx.conf文件->添加新的upstream
upstream nodejs{
server 127.0.0.1:3000; //你的Express项目端口
# server 127.0.0.1:3001;
keepalive 64;
}
-> 参考下面服务器中定义的nodejs{}
完整的片段如下:
server {
listen 80;
server_name www.famanoder.com famanoder.com; //请求到80端口的host
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_set_header Connection "";
proxy_pass http://nodejs;
}
}
如果不出意外,您现在可以使用域名访问您的博客;
Nodejs 功能强大;
几天后,学习了Nodejs的http-proxy模块,用于创建代理服务器;反正都是折腾,所以决定不使用nginx,而是使用Noders的http-proxy;不是nginx不好用,只是个人选择偏好而已;相信前端的 Noder 一定会对自己的模块更加热情;
http.createServer() 创建一个常规的http服务器监听80端口,通过http-proxy模块proxy.createProxyServer()创建一个代理服务器,通过proxy.web()方法分发每个请求;
在根目录下新建proxy.js文件:
var proxy=require(‘http-proxy’).createProxyServer({});
proxy.on(function(err,req,res){
res.writeHead(500,{
‘Content-Type’:’text/plain’
});
});
var server=require(‘http’).createServer(function(req,res){
var host= req.headers.host;
switch(host){
case ‘www.famanoder.com’:
proxy.web(req,res,{target:’http://localhost:3000’});
break;
case 'famanoder.com':
proxy.web(req, res, { target: 'http://localhost:4030' });
break;
default:
res.writeHead(200, {
'Content-Type': 'text/plain'
});
res.end('Welcome to my server!');
}
});
console.log("listening on port 80")
server.listen(80);
是不是也很好,看起来很酷,OK,下一步就是去app.js,使用proxy模块;
加一句:require('./proxy'); 就是这样,去浏览器看看是否也实现了反向代理。
至此,Nodejs反向代理的两种方式都已经实现了。这不是Demo,你的程序真的在运行;下一步是根据其他具体业务跟进进一步探索;
上周末出去散步的时候,看到一个大叔的背上印着一行字:“想当将军!” 那时,我在心里给了这位大叔一万个赞。我是一个平民。码农,路漫漫其修远兮,但——我们还年轻!
本文为慕课网原创作者,转载请注明【原作者及本文链接地址】。侵权必究,谢谢合作! 查看全部
nodejs抓取动态网页(Nodejs反向代理的建站问题,你知道吗?小前端)
所有的demo都不是完整的程序,所有没有上线的程序都只是demo;
作为Web开发的后起之秀,在目前的国内环境下,Nodejs虽然不如PHP流行,但没有.net的海量基础,也无法覆盖Java的高度。但是,Nodejs 基于谷歌 V8 引擎的速度、异步 IO 和事件模型,无疑将是 Web 开发的一大创新;我是一个小前端,自从知道了Nodejs,就觊觎了好久,期待终于可以在闲暇之余用Express4.x做一个断断续续的个人博客(花开花)建筑);
为了让我的博客不只是本地demo,我买了一台服务器,搭建好环境,选好日期,准备上线了。上线后发现自己是个白痴……在目前的国家,Nodejs是小众。当然,问题在所难免,你可以随便抱怨,但既然选择了,就必须相信自己不是瞎子,当然要坚定地走下去。继续; 关于上线后需要先解决的域名绑定问题,我会分享给喜欢Nodejs的朋友和前端朋友;可能你做过.net,PHP什么的,有IIS,一键建站软件,那没关系,我只是站在一个小前端的角度,分享一下基于Nodejs建站的问题;
Nginx 反向代理方式现在很流行。百度的时候,一开始也是选择使用Nginx反向代理我的博客站点;我是服务器新手,一开始真的伤不起,但也没什么好怕的。是的,你只需要根据别人分享的模型修改成你的,除非你想认真运维;当然也难免会出现一些无法预料的小问题,比如:客户代理后终端的IP获取问题(我当时获取的所有客户的IP都是一样的……),上传的大小限制文件,需要重新配置相关的Nginx配置项;
基本配置如下:
命令行进入nginx.exe目录->启动nginx(启动nginx)->打开conf目录下的nginx.conf文件->添加新的upstream
upstream nodejs{
server 127.0.0.1:3000; //你的Express项目端口
# server 127.0.0.1:3001;
keepalive 64;
}
-> 参考下面服务器中定义的nodejs{}
完整的片段如下:
server {
listen 80;
server_name www.famanoder.com famanoder.com; //请求到80端口的host
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_set_header Connection "";
proxy_pass http://nodejs;
}
}
如果不出意外,您现在可以使用域名访问您的博客;
Nodejs 功能强大;
几天后,学习了Nodejs的http-proxy模块,用于创建代理服务器;反正都是折腾,所以决定不使用nginx,而是使用Noders的http-proxy;不是nginx不好用,只是个人选择偏好而已;相信前端的 Noder 一定会对自己的模块更加热情;
http.createServer() 创建一个常规的http服务器监听80端口,通过http-proxy模块proxy.createProxyServer()创建一个代理服务器,通过proxy.web()方法分发每个请求;
在根目录下新建proxy.js文件:
var proxy=require(‘http-proxy’).createProxyServer({});
proxy.on(function(err,req,res){
res.writeHead(500,{
‘Content-Type’:’text/plain’
});
});
var server=require(‘http’).createServer(function(req,res){
var host= req.headers.host;
switch(host){
case ‘www.famanoder.com’:
proxy.web(req,res,{target:’http://localhost:3000’});
break;
case 'famanoder.com':
proxy.web(req, res, { target: 'http://localhost:4030' });
break;
default:
res.writeHead(200, {
'Content-Type': 'text/plain'
});
res.end('Welcome to my server!');
}
});
console.log("listening on port 80")
server.listen(80);
是不是也很好,看起来很酷,OK,下一步就是去app.js,使用proxy模块;
加一句:require('./proxy'); 就是这样,去浏览器看看是否也实现了反向代理。
至此,Nodejs反向代理的两种方式都已经实现了。这不是Demo,你的程序真的在运行;下一步是根据其他具体业务跟进进一步探索;
上周末出去散步的时候,看到一个大叔的背上印着一行字:“想当将军!” 那时,我在心里给了这位大叔一万个赞。我是一个平民。码农,路漫漫其修远兮,但——我们还年轻!
本文为慕课网原创作者,转载请注明【原作者及本文链接地址】。侵权必究,谢谢合作!
nodejs抓取动态网页(2017年江南大学本文参考书目复试题目推荐院校)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-04-06 00:18
Linux挂载lvm磁盘
江南大学计算机科学复试题,2019江南大学计算机入学考试初试科目,参考书目,复试线..._dongyu大麦的博客-程序员的秘密
该推荐院校位于江苏省无锡市江南大学。学校地理位置优越,具有一定的区域影响力。当然,最重要的是录取分数低。对于一些考生来说,这所学校更适合他们的需要。本文主要有以下几个部分:院校介绍、专业介绍、2019年招生分析、考研科目介绍、专业课程参考书和备考指导。一、学院介绍 江南大学是教育部直属、国家“211工程”重点建设大学和一流学科建设大学。学校办学历史悠久,
3.1 webpack的插件_鑫迅的博客-程序员的秘密
什么是插件?插件是指插件,通常用于扩展现有架构。webpack中的插件是对webpack现有功能的各种扩展,比如打包优化、文件压缩等。loader和plugin的区别Loader主要用于转换某些类型的模块,它是一个转换器。plugin 是一个插件,它是 webpack 本身的扩展,它是一个扩展器。插件使用流程步骤一:通过npm(一些webpack...
Qt应用开发框架-快速入门-Henrik-Yao的博客-程序员的秘密-Qt应用开发框架
文章目录一.Qt介绍及安装二.QtCreator介绍三.QtDesigner介绍四.Qt信号与槽一.Qt介绍及安装Qt是一个Qt公司于1991年开发的跨平台C++图形用户界面应用程序开发框架,既可以开发GUI程序,也可以开发控制台工具、服务器等非GUI程序。Qt 是一个面向对象的框架,使用特殊的代码生成扩展(称为 Meta Object Compiler (moc))和一些宏,Qt 易于扩展并允许真正的组件编程。Qt使用效果Qt下载地址
python程序的绘图扩展包matplotlib如何安装_自知博客-程序员秘籍_python绘图包安装
**如何安装python程序的matplotlib扩展包**对于编程初学者,一般推荐使用pip自动安装。步骤如下。首先找到python的安装路径,看是否安装了pip,pip是否在python下。使用Win+R进入电脑cmd界面。(要特别注意路径问题,如图,默认路径是C:\Users\16009. 并且为我们安装python,如果安装到这个路径,下一步可以执行。)如果。..
ThinkPHP3.2开发流程_weixin_33720452的博客-程序员的秘密
原文:ThinkPHP 3.2 开发过程设置所有项目的通用配置Application\Common\Conf\config.php,SAE模式下的配置文件是config_sae.php配置默认模块'DEFAULT_MODULE' => ' Home',配置模块'MODULE_DENY_LIS... 查看全部
nodejs抓取动态网页(2017年江南大学本文参考书目复试题目推荐院校)
Linux挂载lvm磁盘
江南大学计算机科学复试题,2019江南大学计算机入学考试初试科目,参考书目,复试线..._dongyu大麦的博客-程序员的秘密
该推荐院校位于江苏省无锡市江南大学。学校地理位置优越,具有一定的区域影响力。当然,最重要的是录取分数低。对于一些考生来说,这所学校更适合他们的需要。本文主要有以下几个部分:院校介绍、专业介绍、2019年招生分析、考研科目介绍、专业课程参考书和备考指导。一、学院介绍 江南大学是教育部直属、国家“211工程”重点建设大学和一流学科建设大学。学校办学历史悠久,
3.1 webpack的插件_鑫迅的博客-程序员的秘密
什么是插件?插件是指插件,通常用于扩展现有架构。webpack中的插件是对webpack现有功能的各种扩展,比如打包优化、文件压缩等。loader和plugin的区别Loader主要用于转换某些类型的模块,它是一个转换器。plugin 是一个插件,它是 webpack 本身的扩展,它是一个扩展器。插件使用流程步骤一:通过npm(一些webpack...
Qt应用开发框架-快速入门-Henrik-Yao的博客-程序员的秘密-Qt应用开发框架
文章目录一.Qt介绍及安装二.QtCreator介绍三.QtDesigner介绍四.Qt信号与槽一.Qt介绍及安装Qt是一个Qt公司于1991年开发的跨平台C++图形用户界面应用程序开发框架,既可以开发GUI程序,也可以开发控制台工具、服务器等非GUI程序。Qt 是一个面向对象的框架,使用特殊的代码生成扩展(称为 Meta Object Compiler (moc))和一些宏,Qt 易于扩展并允许真正的组件编程。Qt使用效果Qt下载地址
python程序的绘图扩展包matplotlib如何安装_自知博客-程序员秘籍_python绘图包安装
**如何安装python程序的matplotlib扩展包**对于编程初学者,一般推荐使用pip自动安装。步骤如下。首先找到python的安装路径,看是否安装了pip,pip是否在python下。使用Win+R进入电脑cmd界面。(要特别注意路径问题,如图,默认路径是C:\Users\16009. 并且为我们安装python,如果安装到这个路径,下一步可以执行。)如果。..
ThinkPHP3.2开发流程_weixin_33720452的博客-程序员的秘密
原文:ThinkPHP 3.2 开发过程设置所有项目的通用配置Application\Common\Conf\config.php,SAE模式下的配置文件是config_sae.php配置默认模块'DEFAULT_MODULE' => ' Home',配置模块'MODULE_DENY_LIS...
nodejs抓取动态网页(通过使用node.js我试图抓取一个网页(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-04 14:14
通过使用 node.js,我正在尝试抓取网页。为此,我使用cheerio 和 tinyreq 模块。我的源代码如下:
// scrape function
function scrape(url, data, cb) {
req(url, (err, body) => {
if (err) { return cb(err); }
let $ = cheerio.load(body)
, pageData = {};
Object.keys(data).forEach(k => {
pageData[k] = $(data[k]).text();
});
cb(null, pageData);
});
}
scrape("https://www.activecubs.com/activity-wheel/", {
title: ".row h1"
, description: ".row h2"
}, (err, data) => {
console.log(err || data);
});
在我的代码中,h1 标签中的文本是静态的,而在 h2 标签中它是动态的。当我运行代码时,我只得到静态数据,即描述字段数据为空。从以前的 StackOverflow 问题中,我尝试使用 phantom j 来克服这个问题,但它对我不起作用。这里的动态数据是通过转动轮子得到的数据。对于我正在使用的 网站 的任何查询,您可以查看它。 查看全部
nodejs抓取动态网页(通过使用node.js我试图抓取一个网页(图))
通过使用 node.js,我正在尝试抓取网页。为此,我使用cheerio 和 tinyreq 模块。我的源代码如下:
// scrape function
function scrape(url, data, cb) {
req(url, (err, body) => {
if (err) { return cb(err); }
let $ = cheerio.load(body)
, pageData = {};
Object.keys(data).forEach(k => {
pageData[k] = $(data[k]).text();
});
cb(null, pageData);
});
}
scrape("https://www.activecubs.com/activity-wheel/", {
title: ".row h1"
, description: ".row h2"
}, (err, data) => {
console.log(err || data);
});
在我的代码中,h1 标签中的文本是静态的,而在 h2 标签中它是动态的。当我运行代码时,我只得到静态数据,即描述字段数据为空。从以前的 StackOverflow 问题中,我尝试使用 phantom j 来克服这个问题,但它对我不起作用。这里的动态数据是通过转动轮子得到的数据。对于我正在使用的 网站 的任何查询,您可以查看它。
nodejs抓取动态网页(利用Python/.NET语言实现一个糗事百科的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-03 13:14
1.前言分析
通常爬虫都是用 Python/.NET 语言实现的,但现在作为前端开发者,自然需要精通 NodeJS。下面我们用NodeJS语言来实现一个尴尬事百科的爬虫。此外,本文中使用的一些代码是 es6 语法。
实现爬虫所需的依赖库如下。
request:使用get或post获取网页源代码。Cheerio:解析网页源代码,获取需要的数据。
本文首先介绍爬虫所需的依赖库及其使用方法,然后利用这些依赖库来实现一个网络爬虫,用于网络爬虫百科。
2. 请求库
request 是一个轻量级的 http 库,非常强大且易于使用。可以用来实现Http请求,支持HTTP认证、自定义请求头等。下面介绍请求库中的部分功能。
安装请求模块如下:
npm install request
安装好请求后,就可以使用了。接下来,使用请求请求百度的网页。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
未设置 options 参数时,请求方法默认为 get 请求。而且我喜欢使用请求对象的具体方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
但是在很多情况下,直接请求一个URL获取的html源代码,往往并不能得到我们需要的信息。一般来说,需要考虑请求头和网页编码。
网页请求头的编码
下面介绍如何在请求时添加网页请求头并设置正确的编码。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
设置options参数,添加headers属性设置请求头;添加 encoding 属性来设置网页的编码。需要注意的是,如果encoding:null,则get请求得到的内容是一个Buffer对象,即body是一个Buffer对象。
上述功能足以满足以下需求。
3.cheerio 库
Cheerio 是一个服务器端的 Jquery,因其轻量、快速和易于学习的特性而受到开发人员的喜爱。掌握了 Jquery 的基础知识之后,学习 Cheerio 库就很容易了。可以快速定位网页中的元素,其规则与jquery定位元素的方法相同;它还可以修改html中元素的内容,并以非常方便的形式获取它们的数据。下面主要介绍cheerio快速定位网页中的元素并获取其内容。
首先安装cheerio库
npm install cheerio
下面给出一段代码,然后代码说明cheerio库的用法。分析博客园的首页,然后提取每个页面中文章的标题。
首先,分析博客园的首页。如下所示:
分析完html源码,首先通过.post_item获取所有title,然后分析每个.post_item,并使用a.titlelnk匹配每个title的a标签。代码在下面实现。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
当然,cheerio 库也支持链式调用,上面的代码也可以改写为:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
上面的代码很简单,不用文字重复了。下面总结了一些我认为比较重要的点。
使用find()方法得到的节点集A,如果将A集中的元素作为根节点定位其子节点并获取子元素的内容和属性,则需要执行$(A [i ]) 包装器,如上面的 $(ele) 。上面代码中使用$(ele),其实也可以使用$(this),但是由于我使用的是es6箭头函数,所以我在每个方法中更改了回调函数的this指针,所以我使用了$(ele ); Cheerio 库还支持链式调用,例如上面的 $('.post_item').find('a.titlelnk')。需要注意的是,cheerio 对象 A 调用了 find() 方法。如果 A 是一个集合,那么 A 集合中的每个子元素都会调用 find() 方法并放回一个结果组合。如果 A 调用 text(),那么 A' 中的每个子元素
最后,我总结了一些比较常用的方法。
first() last() children([selector]):这个方法和find类似,只是这个方法只搜索子节点,而find搜索整个后代节点。
4. 尴尬的百科全书爬虫
通过上面对request和cheerio类库的介绍,下面两个类库是用来爬取尴尬事百科的页面的。
1、在项目目录下新建httpHelper.js文件,通过url获取尴尬百科的源码。代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2、在项目目录下,新建一个Splitter.js文件,分析糗事百科的网页代码,提取你需要的信息,通过改变id建立爬取不同页面数据的逻辑的网址。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到需要的标签,然后提取标签的文字或属性值,从而完成网页的解析。
Spliter.js 文件的入口是 spliter 方法。首先根据传入方法的index索引,构造出糗大百科的url,然后得到url的网页源码,最后将得到的源码传入getQBJok方法进行分析。本文只分析每一个文字笑话的作者、内容和点赞数。
直接运行Slider.js文件,爬取第一页的笑话信息。然后可以改变slider方法的参数来爬取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0搭建一个浏览文本的页面,效果如下:
源代码已经上传到github。下载链接: ;
项目的运行依赖节点v7.6.0或以上。首先从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录并运行以下命令。
node app.js
5. 总结
通过实现一个完整的爬虫功能,可以加深对Node的理解,部分实现的语言使用es6语法,这样可以加快es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node 中,有几种方法可以实现异步控制。关于具体的方法和原则,有时间再总结。 查看全部
nodejs抓取动态网页(利用Python/.NET语言实现一个糗事百科的爬虫)
1.前言分析
通常爬虫都是用 Python/.NET 语言实现的,但现在作为前端开发者,自然需要精通 NodeJS。下面我们用NodeJS语言来实现一个尴尬事百科的爬虫。此外,本文中使用的一些代码是 es6 语法。
实现爬虫所需的依赖库如下。
request:使用get或post获取网页源代码。Cheerio:解析网页源代码,获取需要的数据。
本文首先介绍爬虫所需的依赖库及其使用方法,然后利用这些依赖库来实现一个网络爬虫,用于网络爬虫百科。
2. 请求库
request 是一个轻量级的 http 库,非常强大且易于使用。可以用来实现Http请求,支持HTTP认证、自定义请求头等。下面介绍请求库中的部分功能。
安装请求模块如下:
npm install request
安装好请求后,就可以使用了。接下来,使用请求请求百度的网页。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
未设置 options 参数时,请求方法默认为 get 请求。而且我喜欢使用请求对象的具体方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
但是在很多情况下,直接请求一个URL获取的html源代码,往往并不能得到我们需要的信息。一般来说,需要考虑请求头和网页编码。
网页请求头的编码
下面介绍如何在请求时添加网页请求头并设置正确的编码。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
设置options参数,添加headers属性设置请求头;添加 encoding 属性来设置网页的编码。需要注意的是,如果encoding:null,则get请求得到的内容是一个Buffer对象,即body是一个Buffer对象。
上述功能足以满足以下需求。
3.cheerio 库
Cheerio 是一个服务器端的 Jquery,因其轻量、快速和易于学习的特性而受到开发人员的喜爱。掌握了 Jquery 的基础知识之后,学习 Cheerio 库就很容易了。可以快速定位网页中的元素,其规则与jquery定位元素的方法相同;它还可以修改html中元素的内容,并以非常方便的形式获取它们的数据。下面主要介绍cheerio快速定位网页中的元素并获取其内容。
首先安装cheerio库
npm install cheerio
下面给出一段代码,然后代码说明cheerio库的用法。分析博客园的首页,然后提取每个页面中文章的标题。
首先,分析博客园的首页。如下所示:
分析完html源码,首先通过.post_item获取所有title,然后分析每个.post_item,并使用a.titlelnk匹配每个title的a标签。代码在下面实现。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
当然,cheerio 库也支持链式调用,上面的代码也可以改写为:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
上面的代码很简单,不用文字重复了。下面总结了一些我认为比较重要的点。
使用find()方法得到的节点集A,如果将A集中的元素作为根节点定位其子节点并获取子元素的内容和属性,则需要执行$(A [i ]) 包装器,如上面的 $(ele) 。上面代码中使用$(ele),其实也可以使用$(this),但是由于我使用的是es6箭头函数,所以我在每个方法中更改了回调函数的this指针,所以我使用了$(ele ); Cheerio 库还支持链式调用,例如上面的 $('.post_item').find('a.titlelnk')。需要注意的是,cheerio 对象 A 调用了 find() 方法。如果 A 是一个集合,那么 A 集合中的每个子元素都会调用 find() 方法并放回一个结果组合。如果 A 调用 text(),那么 A' 中的每个子元素
最后,我总结了一些比较常用的方法。
first() last() children([selector]):这个方法和find类似,只是这个方法只搜索子节点,而find搜索整个后代节点。
4. 尴尬的百科全书爬虫
通过上面对request和cheerio类库的介绍,下面两个类库是用来爬取尴尬事百科的页面的。
1、在项目目录下新建httpHelper.js文件,通过url获取尴尬百科的源码。代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2、在项目目录下,新建一个Splitter.js文件,分析糗事百科的网页代码,提取你需要的信息,通过改变id建立爬取不同页面数据的逻辑的网址。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到需要的标签,然后提取标签的文字或属性值,从而完成网页的解析。
Spliter.js 文件的入口是 spliter 方法。首先根据传入方法的index索引,构造出糗大百科的url,然后得到url的网页源码,最后将得到的源码传入getQBJok方法进行分析。本文只分析每一个文字笑话的作者、内容和点赞数。
直接运行Slider.js文件,爬取第一页的笑话信息。然后可以改变slider方法的参数来爬取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0搭建一个浏览文本的页面,效果如下:
源代码已经上传到github。下载链接: ;
项目的运行依赖节点v7.6.0或以上。首先从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录并运行以下命令。
node app.js
5. 总结
通过实现一个完整的爬虫功能,可以加深对Node的理解,部分实现的语言使用es6语法,这样可以加快es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node 中,有几种方法可以实现异步控制。关于具体的方法和原则,有时间再总结。
nodejs抓取动态网页(思路可以看之前bodyRun的抓取应用版的内容介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-03 13:12
思路可以看前面的文章,我就不多说了。
因为AppStore的页面版只显示3天的评论,所以这次就介绍一下app版的内容。
我们编写一个简单的爬虫,以在 AppStore 上抓取一个新的超级马里奥跑的评论为例
var request=require('request');
var url='http://itunes.apple.com/WebObjects/MZStore.woa/wa/userReviewsRow?cc=us&id=1145275343&displayable-kind=11&startIndex=0&endIndex=100&sort=0&appVersion=all'
var options = {
port: 80,
uri: url,
method: 'GET',
headers: {
'User-Agent': 'iTunes/11.0 (Windows; Microsoft Windows 7 Business Edition Service Pack 1 (Build 7601)) AppleWebKit/536.27.1'
}
};
request(options,(error, response, body)=>{
console.log(body);
})
节点运行后,控制台打印如下:
正文打印结果
这个链接是专门用来获取评论相关数据的,我们可以整理一下,看看每条评论的结构
收到的内容
function formatJson(contentsDate){
content=contentsDate.userReviewList;
content.forEach(function(item){
console.log('orginId:'+item.userReviewId);
console.log('username: ' + item.name + ' time:' + item.date);
console.log('star: ' + item.rating);
console.log('title: ' + item.title);
console.log('content: ' + item.body);
console.log('------------------------------------');
})
}
在之前打印body的地方调用formatJson,传入body转换成json
request(options,(error, response, body)=>{
var datas=JSON.parse(body)
formatJson(datas);
})
运行文件,可以看到打印结果:
超级马里奥跑酷评测结果
因为这个游戏在中国不可用,所以你需要翻墙。不翻墙的话,可以在中国的商店里找一个app,把链接里的cc换成cn。不明白具体可以参考上一篇文章文章。 查看全部
nodejs抓取动态网页(思路可以看之前bodyRun的抓取应用版的内容介绍)
思路可以看前面的文章,我就不多说了。
因为AppStore的页面版只显示3天的评论,所以这次就介绍一下app版的内容。
我们编写一个简单的爬虫,以在 AppStore 上抓取一个新的超级马里奥跑的评论为例
var request=require('request');
var url='http://itunes.apple.com/WebObjects/MZStore.woa/wa/userReviewsRow?cc=us&id=1145275343&displayable-kind=11&startIndex=0&endIndex=100&sort=0&appVersion=all'
var options = {
port: 80,
uri: url,
method: 'GET',
headers: {
'User-Agent': 'iTunes/11.0 (Windows; Microsoft Windows 7 Business Edition Service Pack 1 (Build 7601)) AppleWebKit/536.27.1'
}
};
request(options,(error, response, body)=>{
console.log(body);
})
节点运行后,控制台打印如下:
正文打印结果
这个链接是专门用来获取评论相关数据的,我们可以整理一下,看看每条评论的结构
收到的内容
function formatJson(contentsDate){
content=contentsDate.userReviewList;
content.forEach(function(item){
console.log('orginId:'+item.userReviewId);
console.log('username: ' + item.name + ' time:' + item.date);
console.log('star: ' + item.rating);
console.log('title: ' + item.title);
console.log('content: ' + item.body);
console.log('------------------------------------');
})
}
在之前打印body的地方调用formatJson,传入body转换成json
request(options,(error, response, body)=>{
var datas=JSON.parse(body)
formatJson(datas);
})
运行文件,可以看到打印结果:
超级马里奥跑酷评测结果
因为这个游戏在中国不可用,所以你需要翻墙。不翻墙的话,可以在中国的商店里找一个app,把链接里的cc换成cn。不明白具体可以参考上一篇文章文章。
nodejs抓取动态网页( 易百教程:Js更新MySQL中的数据.js程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-31 07:12
易百教程:Js更新MySQL中的数据.js程序)
<p>转载地址:https://www.yiibai.com/mysql/nodejs-update.html
在本教程中,您将学习如何从node.js应用程序更新MySQL数据库中的数据。
要从node.js应用程序更新数据,请使用以下步骤:
连接到MySQL数据库服务器。通过在Connection对象上调用query()方法来执行UPDATE语句。关闭数据库连接。
要连接到MySQL数据库,我们将使用以下config.js模块,其中包含MySQL数据库服务器的必要信息,包括主机,用户,密码和数据库。
let config = {
host : 'localhost',
user : 'root',
password: '123456',
database: 'todoapp'
};
module.exports = config;
</p>
Js
更新数据示例
以下 update.js 程序根据特定 ID 更新托管状态。
let mysql = require('mysql');
let config = require('./config.js');
let connection = mysql.createConnection(config);
// update statment
let sql = `UPDATE todos
SET completed = ?
WHERE id = ?`;
let data = [false, 1];
// execute the UPDATE statement
connection.query(sql, data, (error, results, fields) => {
if (error){
return console.error(error.message);
}
console.log('Rows affected:', results.affectedRows);
});
connection.end();
Js
在本例中,我们在 UPDATE 语句中使用了占位符 (?)。
当通过调用连接对象的query()方法执行UPDATE语句时,数据以数组的形式传递给UPDATE语句。占位符会用数组中的值替换成数组。在本例中,id 为 1 的记录的已完成列将设置为 false。
回调函数的results参数有属性affectedRows,返回UPDATE语句更新的行数。
在执行程序之前,请查看todos表中id为1的行的记录信息:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 1 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
现在,让我们运行上面的 update.js 程序。
F:\worksp\mysql\nodejs\nodejs-connect>node update.js
openssl config failed: error:02001003:system library:fopen:No such process
Rows affected: 1
壳
程序返回一条消息,表示受影响的行数为1,我们可以在数据库中再次查看如下:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 0 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
可以看到完成列中的值已经更新为0,在node.js中为false。
在本教程中,我们向您展示了如何从 node.js 应用程序更新 MySQL 中的数据。
原文来自【Ebay教程】。如需商业转载,请联系作者授权。非商业转载请保留原链接: 查看全部
nodejs抓取动态网页(
易百教程:Js更新MySQL中的数据.js程序)
<p>转载地址:https://www.yiibai.com/mysql/nodejs-update.html
在本教程中,您将学习如何从node.js应用程序更新MySQL数据库中的数据。
要从node.js应用程序更新数据,请使用以下步骤:
连接到MySQL数据库服务器。通过在Connection对象上调用query()方法来执行UPDATE语句。关闭数据库连接。
要连接到MySQL数据库,我们将使用以下config.js模块,其中包含MySQL数据库服务器的必要信息,包括主机,用户,密码和数据库。
let config = {
host : 'localhost',
user : 'root',
password: '123456',
database: 'todoapp'
};
module.exports = config;
</p>
Js
更新数据示例
以下 update.js 程序根据特定 ID 更新托管状态。
let mysql = require('mysql');
let config = require('./config.js');
let connection = mysql.createConnection(config);
// update statment
let sql = `UPDATE todos
SET completed = ?
WHERE id = ?`;
let data = [false, 1];
// execute the UPDATE statement
connection.query(sql, data, (error, results, fields) => {
if (error){
return console.error(error.message);
}
console.log('Rows affected:', results.affectedRows);
});
connection.end();
Js
在本例中,我们在 UPDATE 语句中使用了占位符 (?)。
当通过调用连接对象的query()方法执行UPDATE语句时,数据以数组的形式传递给UPDATE语句。占位符会用数组中的值替换成数组。在本例中,id 为 1 的记录的已完成列将设置为 false。
回调函数的results参数有属性affectedRows,返回UPDATE语句更新的行数。
在执行程序之前,请查看todos表中id为1的行的记录信息:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 1 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
现在,让我们运行上面的 update.js 程序。
F:\worksp\mysql\nodejs\nodejs-connect>node update.js
openssl config failed: error:02001003:system library:fopen:No such process
Rows affected: 1
壳
程序返回一条消息,表示受影响的行数为1,我们可以在数据库中再次查看如下:
mysql> SELECT * FROM todos WHERE id = 1;
+----+-------------------------------+-----------+
| id | title | completed |
+----+-------------------------------+-----------+
| 1 | Learn how to insert a new row | 0 |
+----+-------------------------------+-----------+
1 row in set (0.00 sec)
壳
可以看到完成列中的值已经更新为0,在node.js中为false。
在本教程中,我们向您展示了如何从 node.js 应用程序更新 MySQL 中的数据。
原文来自【Ebay教程】。如需商业转载,请联系作者授权。非商业转载请保留原链接:
nodejs抓取动态网页(为什么要上https呢,全站https是一个的思路?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-31 06:20
为什么要为整个站点使用 https?这主要是因为https可以防止中间人攻击和内容劫持,提高网站的访问安全性。但是由于增加了SSL/TLS服务器端和浏览器端的处理,性能会有相应的下降,不过我们也启用了HTTP/2,主要特点:多路复用(Multiplexing) Multiplexing 使用允许多个请求-通过单个 HTTP/2 连接同时发出的响应消息。另外,PWA 中的 service worker 还必须要求 网站 的协议是 https,也为此打下了基础。HTTPS是现代WEB的发展趋势。由于 PWA 不是本文的重点,以后可以在其他主题上展开。
浏览器端优化
移动端有多种,导致浏览器处理和效果过度,会导致体验不一致,尤其是安卓手机,所以我们在浏览器端的策略是尽量减少网页的权重,目前page 只处理当前必要的内容和多个页面。方式。这是谷歌现在提出的开源项目AMP的一个想法。
首屏直出优化
从用户发出请求到页面完整展示,一般来说网络正常需要1s以上,但如果页面打开时间超过1s,用户流失的概率会线性增加。所以手机端秒开是很重要的,所以我们的想法是减少白屏时间,尽快显示浏览器的可视区域,也就是所谓的首屏。我们从以下几个方面对其进行了优化。
直出文档,简化DOM结构服务器进行HTML渲染输出,只处理首屏需要的HTML,简化DOM树结构,如:
可以简化为
页面上只保留必要的 DOM。另外,可以估计手机的分辨率,可以确定最大首屏输出可视区域的DOM。如果需要滚动到第二个屏幕,可以通过 Ajax 延迟内容加载。减少 DOM 可以减少 HTML 的输出,当然更重要的浏览器布局和渲染时间也大大减少。当然,首先要加载首屏的静态资源和样式。下一个关键点是在第一个屏幕上只加载所需的样式和静态资源。
仅在首屏加载所需的样式和静态资源是远远不够的。DOM 处理是不够的。要从白屏显示完整的第一屏,还需要样式和静态资源。所以需要先加载样式和静态资源,所以直接提取公共样式的首屏使用的样式,直接将首屏使用的样式内置到html页面中。另外先加载其他需要显示的部分,比如图片、字体等,方便首页快速显示。
首屏渲染,js延迟执行
第一屏渲染的时候,这个时候js的执行可能会阻塞渲染线程,所以为了减少浏览器主线程的渲染过程,尽量延迟js的执行,尤其是在操作的情况下DOM,否则,在首屏显示过程中,会在页面底部,body之后,html之前直接生成额外的re-layout和repaint,js导入或者code。
优化直出服务器的处理时间,突出直出的关键。服务器的处理等待被最小化,这对于第一屏的直出非常重要。
图像优化
画质和音量控制 对于移动终端来说,分辨率比桌面要小很多。首先,图片的分辨率和图片的DPI值会降低。第二步会降低图片的质量,保证图片的体积变小。.
提高CDN缓存命中率,一是缩小缩略图的尺寸规格,二是尽量与其他终端的图片规格保持一致,如APP、小程序。
使用WEBP webp并不是所有的浏览器都支持,所以我们的做法是判断需要js加载的图片,如果支持就直接加载webp格式的图片。如果没有,请使用默认的 jpg 格式。格式。
浏览器端缓存优化
当有缓存时,可以减少浏览器的重新请求,大大提高网页的打开速度。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,而且由于缓存的文件可以重复使用,还可以减少带宽,减少网络负载。那么我们来看看服务器端缓存的原理。
缓存优化(max-age)
页面的缓存状态由http协议的头部决定。我们主要使用max-age(单位S)来设置缓存的最长有效时间,也就是时间长度。比如我设置了max-age=60,也就是在请求发出后的60秒内,浏览器再次请求时不会再次请求服务器,而是从浏览器缓存中读取数据。
预加载和延迟加载
预加载和延迟加载是一对好兄弟。如果使用得当,它们可以极大地改善浏览器端的体验。就是决定什么时候预加载,什么时候懒加载。我们主要是在浏览器首屏结束后,当浏览器比较空闲时,预加载下一屏要显示的内容。
当用户即将触发下一屏的时候,下一屏的数据或者DOM已经留了下来,自然体验会流畅很多,但是预加载需要一定的度数,因为一个页面的DOM太多了,而且浏览器占用内存也会太多。最好预加载用户会触发浏览的内容,比如第二屏、轮播后面的内容、标签页等。
延迟加载的应用场景主要是减少单个 DOM 渲染的大小。对于当前页面的非可视区域,只有在需要显示或被用户事件触发时才加载。所以,懒加载和预加载在不同的场景下会有不同的应用,只要保证页面的流畅度。
DNS 预取
DNS预读配置的DNS解析,可以减少DNS次数,加快不同域名资源的加载。目前,仍然有很多浏览器支持。
配置也很简单:
当然,减少DNS的最佳时机是减少使用DNS的站点数量,我们会去掉一些二级域名。
CSS、JS优化
项目建设主要采用webpack的工具链,管理依赖,构建打包CSS,最小化CSS和JS,对我们现有的多页面项目进行多入口分包管理。
多页面 css 和 js 构建
打包代码如下,方便js的源文件目录,构建各个页面模块的js。所有页面都将收录两个 js 文件,libjs(全局公共 js)、xxx.js(当前页面特定的 js)和 css。. 这样每个页面的js和css都会最小化。同时,我们也对这些静态字符串文件进行gzip压缩。当然,这些文件会根据版本进行静态存储,并通过 CDN 进行缓存。
DOM 优化
页面流畅度与 DOM 渲染和操作密切相关。渲染过程大致如下:
处理 HTML 标记并构建 DOM 树。
处理 CSS 标记并构建 CSSOM 树。
将 DOM 和 CSSOM 组合成一个渲染树。
根据渲染树布局计算每个节点的几何形状。
将每个节点绘制到屏幕上。
您可以使用 DEVTOOLS 来分析整个渲染过程中的性能问题。
简化DOM,DOM操作优化
简化 DOM 可以减少渲染过程的时间,优化 DOM 操作可以减少重新布局和重绘的时间。简化 DOM 相应的方法已经在首屏引入。
这里主要讲DOM操作的优化。首先,减少 DOM 操作的数量。你可以在 js 执行过程中多次 DOM 操作生成好的 HTML 结果,一次性插入到 DOM 中。其次,尽量不要在页面的 DOM 树中使用它们。直接操作,可以在文档流的DOM外进行操作,也可以使用fragment一次性插入到文档流中。
当然,react 和 vue 现在都使用虚拟 DOM 技术,通过 diff 算法进行泛化的 DOM 操作。这也是一种高效高效的方法,但是对于一些不容易优化的页面,还是需要人为的干预和操作 DOM 才能让性能达到最佳。
减少重新布局和重绘
首先,为了减少布局调整,当您更改样式时,浏览器会检查是否有任何更改需要计算布局,以及是否需要更新渲染树。对“几何属性”(例如宽度、高度、左侧或顶部)的更改需要布局计算。第二,绘图的复杂性,减少绘图区域:改变transform或opacity属性以外的任何属性都会触发绘图。绘图通常是像素管道中最昂贵的部分;应尽可能避免。
通过提升图层和编排动画来减少绘图区域。Chrome DevTools 可用于快速确定正在绘制的区域。打开 DevTools 并按键盘上的 Esc 键。在出现的面板中,转到“渲染”选项卡并选中“显示绘制矩形”。每次绘图时,Chrome 都会将屏幕闪烁绿色。如果您看到整个屏幕呈绿色闪烁,或者看到您认为不应绘制的屏幕区域,则应进一步调查。
页面动画优化
尽可能使用 CSS3 动画,使用 transform 和 opacity 属性更改来制作动画。使用 will-change 或 translateZ 来促进移动元素。避免过度使用提升规则;每一层都需要内存和管理开销。另外,动画的层数需要减少,每增加一层都会增加内存占用和管理的开销。
如果一定要用js动画,推荐使用:requestAnimationFrame。另外,在不能使用页面动画的场景中尽量不要使用动画。如果一定要使用,可以简化动画渲染过程。
我们之前用过一个js插件,iScroll就是一个例子,在页面中初始化了多个iScroll的实例,尤其是安卓手机上,特别卡顿。最后,我们的解决方案是使用css3动画和触摸事件来实现简单轻量。对于需要滚动的部分,页面的滚动部分使用原生滚动,保证了不同终端的体验一致。
总结
移动端的优化如果对以上几点展开,可以单独写一篇文章文章,我们对以上几个方面进行了优化,也产生了比较好的效果,移动端的打开速度和体验终端有了不错的提升,一般开放时间增加了30-50%。在网络稳定的情况下,服务器的耗时基本在50ms以内,首屏时间在500ms以内,但是从来没有优化过。没有限制,没有最好,只有更好。它需要开发者从根本上去探索,勇于创新,以达到越来越好的局面。
后续我们还可以深入挖掘web的基本技术点。同时,我们可以积极面对PWA、AMP等现代web新思维的诸多方面,不断探索,在web前端的未来我们可以走的更好。提供更好的用户体验,创造更高的社会价值。
亲爱的“攻城狮”,如果你喜欢这篇文章,请在文末点个赞,也欢迎你去51Testing软件测试网掌握更多IT技术文章 ~ 查看全部
nodejs抓取动态网页(为什么要上https呢,全站https是一个的思路?)
为什么要为整个站点使用 https?这主要是因为https可以防止中间人攻击和内容劫持,提高网站的访问安全性。但是由于增加了SSL/TLS服务器端和浏览器端的处理,性能会有相应的下降,不过我们也启用了HTTP/2,主要特点:多路复用(Multiplexing) Multiplexing 使用允许多个请求-通过单个 HTTP/2 连接同时发出的响应消息。另外,PWA 中的 service worker 还必须要求 网站 的协议是 https,也为此打下了基础。HTTPS是现代WEB的发展趋势。由于 PWA 不是本文的重点,以后可以在其他主题上展开。
浏览器端优化
移动端有多种,导致浏览器处理和效果过度,会导致体验不一致,尤其是安卓手机,所以我们在浏览器端的策略是尽量减少网页的权重,目前page 只处理当前必要的内容和多个页面。方式。这是谷歌现在提出的开源项目AMP的一个想法。
首屏直出优化
从用户发出请求到页面完整展示,一般来说网络正常需要1s以上,但如果页面打开时间超过1s,用户流失的概率会线性增加。所以手机端秒开是很重要的,所以我们的想法是减少白屏时间,尽快显示浏览器的可视区域,也就是所谓的首屏。我们从以下几个方面对其进行了优化。
直出文档,简化DOM结构服务器进行HTML渲染输出,只处理首屏需要的HTML,简化DOM树结构,如:
可以简化为
页面上只保留必要的 DOM。另外,可以估计手机的分辨率,可以确定最大首屏输出可视区域的DOM。如果需要滚动到第二个屏幕,可以通过 Ajax 延迟内容加载。减少 DOM 可以减少 HTML 的输出,当然更重要的浏览器布局和渲染时间也大大减少。当然,首先要加载首屏的静态资源和样式。下一个关键点是在第一个屏幕上只加载所需的样式和静态资源。
仅在首屏加载所需的样式和静态资源是远远不够的。DOM 处理是不够的。要从白屏显示完整的第一屏,还需要样式和静态资源。所以需要先加载样式和静态资源,所以直接提取公共样式的首屏使用的样式,直接将首屏使用的样式内置到html页面中。另外先加载其他需要显示的部分,比如图片、字体等,方便首页快速显示。
首屏渲染,js延迟执行
第一屏渲染的时候,这个时候js的执行可能会阻塞渲染线程,所以为了减少浏览器主线程的渲染过程,尽量延迟js的执行,尤其是在操作的情况下DOM,否则,在首屏显示过程中,会在页面底部,body之后,html之前直接生成额外的re-layout和repaint,js导入或者code。
优化直出服务器的处理时间,突出直出的关键。服务器的处理等待被最小化,这对于第一屏的直出非常重要。
图像优化
画质和音量控制 对于移动终端来说,分辨率比桌面要小很多。首先,图片的分辨率和图片的DPI值会降低。第二步会降低图片的质量,保证图片的体积变小。.
提高CDN缓存命中率,一是缩小缩略图的尺寸规格,二是尽量与其他终端的图片规格保持一致,如APP、小程序。
使用WEBP webp并不是所有的浏览器都支持,所以我们的做法是判断需要js加载的图片,如果支持就直接加载webp格式的图片。如果没有,请使用默认的 jpg 格式。格式。
浏览器端缓存优化
当有缓存时,可以减少浏览器的重新请求,大大提高网页的打开速度。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,而且由于缓存的文件可以重复使用,还可以减少带宽,减少网络负载。那么我们来看看服务器端缓存的原理。
缓存优化(max-age)
页面的缓存状态由http协议的头部决定。我们主要使用max-age(单位S)来设置缓存的最长有效时间,也就是时间长度。比如我设置了max-age=60,也就是在请求发出后的60秒内,浏览器再次请求时不会再次请求服务器,而是从浏览器缓存中读取数据。
预加载和延迟加载
预加载和延迟加载是一对好兄弟。如果使用得当,它们可以极大地改善浏览器端的体验。就是决定什么时候预加载,什么时候懒加载。我们主要是在浏览器首屏结束后,当浏览器比较空闲时,预加载下一屏要显示的内容。
当用户即将触发下一屏的时候,下一屏的数据或者DOM已经留了下来,自然体验会流畅很多,但是预加载需要一定的度数,因为一个页面的DOM太多了,而且浏览器占用内存也会太多。最好预加载用户会触发浏览的内容,比如第二屏、轮播后面的内容、标签页等。
延迟加载的应用场景主要是减少单个 DOM 渲染的大小。对于当前页面的非可视区域,只有在需要显示或被用户事件触发时才加载。所以,懒加载和预加载在不同的场景下会有不同的应用,只要保证页面的流畅度。
DNS 预取
DNS预读配置的DNS解析,可以减少DNS次数,加快不同域名资源的加载。目前,仍然有很多浏览器支持。
配置也很简单:
当然,减少DNS的最佳时机是减少使用DNS的站点数量,我们会去掉一些二级域名。
CSS、JS优化
项目建设主要采用webpack的工具链,管理依赖,构建打包CSS,最小化CSS和JS,对我们现有的多页面项目进行多入口分包管理。
多页面 css 和 js 构建
打包代码如下,方便js的源文件目录,构建各个页面模块的js。所有页面都将收录两个 js 文件,libjs(全局公共 js)、xxx.js(当前页面特定的 js)和 css。. 这样每个页面的js和css都会最小化。同时,我们也对这些静态字符串文件进行gzip压缩。当然,这些文件会根据版本进行静态存储,并通过 CDN 进行缓存。
DOM 优化
页面流畅度与 DOM 渲染和操作密切相关。渲染过程大致如下:
处理 HTML 标记并构建 DOM 树。
处理 CSS 标记并构建 CSSOM 树。
将 DOM 和 CSSOM 组合成一个渲染树。
根据渲染树布局计算每个节点的几何形状。
将每个节点绘制到屏幕上。
您可以使用 DEVTOOLS 来分析整个渲染过程中的性能问题。
简化DOM,DOM操作优化
简化 DOM 可以减少渲染过程的时间,优化 DOM 操作可以减少重新布局和重绘的时间。简化 DOM 相应的方法已经在首屏引入。
这里主要讲DOM操作的优化。首先,减少 DOM 操作的数量。你可以在 js 执行过程中多次 DOM 操作生成好的 HTML 结果,一次性插入到 DOM 中。其次,尽量不要在页面的 DOM 树中使用它们。直接操作,可以在文档流的DOM外进行操作,也可以使用fragment一次性插入到文档流中。
当然,react 和 vue 现在都使用虚拟 DOM 技术,通过 diff 算法进行泛化的 DOM 操作。这也是一种高效高效的方法,但是对于一些不容易优化的页面,还是需要人为的干预和操作 DOM 才能让性能达到最佳。
减少重新布局和重绘
首先,为了减少布局调整,当您更改样式时,浏览器会检查是否有任何更改需要计算布局,以及是否需要更新渲染树。对“几何属性”(例如宽度、高度、左侧或顶部)的更改需要布局计算。第二,绘图的复杂性,减少绘图区域:改变transform或opacity属性以外的任何属性都会触发绘图。绘图通常是像素管道中最昂贵的部分;应尽可能避免。
通过提升图层和编排动画来减少绘图区域。Chrome DevTools 可用于快速确定正在绘制的区域。打开 DevTools 并按键盘上的 Esc 键。在出现的面板中,转到“渲染”选项卡并选中“显示绘制矩形”。每次绘图时,Chrome 都会将屏幕闪烁绿色。如果您看到整个屏幕呈绿色闪烁,或者看到您认为不应绘制的屏幕区域,则应进一步调查。
页面动画优化
尽可能使用 CSS3 动画,使用 transform 和 opacity 属性更改来制作动画。使用 will-change 或 translateZ 来促进移动元素。避免过度使用提升规则;每一层都需要内存和管理开销。另外,动画的层数需要减少,每增加一层都会增加内存占用和管理的开销。
如果一定要用js动画,推荐使用:requestAnimationFrame。另外,在不能使用页面动画的场景中尽量不要使用动画。如果一定要使用,可以简化动画渲染过程。
我们之前用过一个js插件,iScroll就是一个例子,在页面中初始化了多个iScroll的实例,尤其是安卓手机上,特别卡顿。最后,我们的解决方案是使用css3动画和触摸事件来实现简单轻量。对于需要滚动的部分,页面的滚动部分使用原生滚动,保证了不同终端的体验一致。
总结
移动端的优化如果对以上几点展开,可以单独写一篇文章文章,我们对以上几个方面进行了优化,也产生了比较好的效果,移动端的打开速度和体验终端有了不错的提升,一般开放时间增加了30-50%。在网络稳定的情况下,服务器的耗时基本在50ms以内,首屏时间在500ms以内,但是从来没有优化过。没有限制,没有最好,只有更好。它需要开发者从根本上去探索,勇于创新,以达到越来越好的局面。
后续我们还可以深入挖掘web的基本技术点。同时,我们可以积极面对PWA、AMP等现代web新思维的诸多方面,不断探索,在web前端的未来我们可以走的更好。提供更好的用户体验,创造更高的社会价值。
亲爱的“攻城狮”,如果你喜欢这篇文章,请在文末点个赞,也欢迎你去51Testing软件测试网掌握更多IT技术文章 ~
nodejs抓取动态网页(cheerio抓取页面后操作来提取页面中的数据,api及用法跟jquery)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-29 10:18
切里奥
抓取页面后,操作dom提取页面中的数据,api和用法类似jquery
表示
用于启动一个简单的服务,在浏览器中查看爬虫爬取的数据
玉
页面模板引擎
使用方法将仓库克隆到本地,然后安装相应模块并执行node app启动服务。打开浏览器输入localhost:3000查看效果分析。
整个爬虫其实很简单。主要功能是发送请求以采集数据,然后对其进行分析。当然,这一步分析不一定收录在爬虫中。您可以自己编写其他模块来分析和处理数据。使用superagent请求知乎接口获取具体数据,但是有些接口有限制,有些数据是通过服务端渲染直接显示在页面上的,不能直接通过知乎接口获取,所以需要从渲染的页面中抓取,所以需要使用cheerio模块进行dom操作,获取对应的dom结构然后获取值。这里需要注意的是,这种需要登录的网站请求可能有权限验证,
目录说明
主要步骤
登录和获取授权的过程有点繁琐,而且有验证码,所以只能通过快递做转发。有兴趣的可以直接看github代码和对应的注释。代码在此不详述。
演示测试效果
github地址
知乎 带登录功能的爬虫 查看全部
nodejs抓取动态网页(cheerio抓取页面后操作来提取页面中的数据,api及用法跟jquery)
切里奥
抓取页面后,操作dom提取页面中的数据,api和用法类似jquery
表示
用于启动一个简单的服务,在浏览器中查看爬虫爬取的数据
玉
页面模板引擎
使用方法将仓库克隆到本地,然后安装相应模块并执行node app启动服务。打开浏览器输入localhost:3000查看效果分析。
整个爬虫其实很简单。主要功能是发送请求以采集数据,然后对其进行分析。当然,这一步分析不一定收录在爬虫中。您可以自己编写其他模块来分析和处理数据。使用superagent请求知乎接口获取具体数据,但是有些接口有限制,有些数据是通过服务端渲染直接显示在页面上的,不能直接通过知乎接口获取,所以需要从渲染的页面中抓取,所以需要使用cheerio模块进行dom操作,获取对应的dom结构然后获取值。这里需要注意的是,这种需要登录的网站请求可能有权限验证,
目录说明
主要步骤
登录和获取授权的过程有点繁琐,而且有验证码,所以只能通过快递做转发。有兴趣的可以直接看github代码和对应的注释。代码在此不详述。
演示测试效果
github地址
知乎 带登录功能的爬虫
nodejs抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-29 10:13
现在越来越多的网页使用前端渲染页面,给爬取工作带来了很大的麻烦。通过通常的方法,我们只能得到一堆js方法或者api接口。当然,我们不希望每个 网站 都如此努力地探索他们的 api。
那么有什么更好的方式称呼全能的谷歌老爸,puppeteer可以模拟chrome打开网页,可以截图,转换成pdf文件,当然还可以抓取数据,因为截图的前提是模拟前端渲染效果就像真的打开了网站。
本文章主要介绍如何通过puppeteer简单爬取
下载
1
$ yarn add puppeteer
采用
我们先看一个简单的例子,不问为什么,直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行之后,你会发现它打印出了文档的宽度、高度和标题。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取页面的头像信息。通过开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这个时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样,我们就可以轻松分析一个dom元素。当然,这样的粘贴复制并不是万能的。很多情况下,我们需要分析页面样式来寻找更好的解析方式。
完整用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
去检查一个数组是否收录一个项目
Vim 高级功能 vimgrep 全局搜索文件
在北京申请工作和居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置 查看全部
nodejs抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
现在越来越多的网页使用前端渲染页面,给爬取工作带来了很大的麻烦。通过通常的方法,我们只能得到一堆js方法或者api接口。当然,我们不希望每个 网站 都如此努力地探索他们的 api。
那么有什么更好的方式称呼全能的谷歌老爸,puppeteer可以模拟chrome打开网页,可以截图,转换成pdf文件,当然还可以抓取数据,因为截图的前提是模拟前端渲染效果就像真的打开了网站。
本文章主要介绍如何通过puppeteer简单爬取
下载
1
$ yarn add puppeteer
采用
我们先看一个简单的例子,不问为什么,直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行之后,你会发现它打印出了文档的宽度、高度和标题。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取页面的头像信息。通过开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这个时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样,我们就可以轻松分析一个dom元素。当然,这样的粘贴复制并不是万能的。很多情况下,我们需要分析页面样式来寻找更好的解析方式。
完整用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
去检查一个数组是否收录一个项目
Vim 高级功能 vimgrep 全局搜索文件
在北京申请工作和居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置

