
nodejs抓取动态网页
nodejs抓取动态网页(使用搭建服务器的Hello程序使用postnodeapp.js启动应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-08 10:04
标签: reqartNodejs--resappexpressconst 页面
一、Express 框架介绍
在之前的Node基础中,我们学习了Node.js中的http模块,虽然我们知道使用Node.js中的http模块可以开发Web应用,处理静态资源,处理动态资源,请求分发(路由)等,也可以让开发者对HTTP协议的理解更加清晰,但是使用起来比较复杂,开发效率低。
npm 提供了大量的第三方模块,包括很多 web 框架,我们不需要重新发明轮子,所以我们选择使用 Express 作为开发框架,因为它是目前最稳定和使用最广泛的,也是唯一的Node.js 官方推荐的一个 Web 开发框架。除了为 http 模块提供更高级别的接口外,还实现了许多功能,包括:
官方网站:
express 是基于内置核心 http 模块的第三方包,专注于构建 web 服务器。
二、使用Express搭建服务器Hello world程序
// 1、引入express模块并创建express对象
const express = require('express');
const app = express();
// 2、书写处理请求的方法,来响应请求
app.get('/', (req, res) => {
// 这里的代码在浏览器以get请求/的时候执行,
// 这个函数就是用来处理浏览器的 对于/的get请求 的
// 第一个参数req是请求头对象,里面包含请求头信息
// 第二个参数res用来做响应
console.log(req);
res.send('Hello World!222');
});
// 3、监听端口
app.listen(3000, () => {
//这里的代码服务器刚启动的时候执行1次
console.log('Example app listening on port 3000!')
});
使用node app.js启动应用,访问:3000/查看效果。
三、使用Express处理get请求方法3.1、返回页面
在myapp目录下新建views文件夹,放入register.html页面。
在 register.html 中:
注册页面11
<p>
用户名:
邮箱:
密码:
确认密码:
</p>
在 app.js 中:
const express = require('express');
const app = express();
// 1、引入fs和path模块
const fs = require("fs");
const path = require("path");
// 2、处理/register的get请求
app.get('/register', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "register.html");
const regPage = fs.readFileSync(pathName, "utf-8");
res.send(regPage);
});
app.listen(3000, () => {
console.log('Example app listening on port 3000!')
});
3.2、获取查询参数
app.get('/index', (req, res) => {
let ret = req.query // 获取到一个对象
res.send(ret.curPage);
//可以在请求的时候传入查询参数:
//http://localhost:3000/index%3F ... %3D10
});
四、使用Express处理post请求方法4.1、post请求处理格式
app.post('/register', (req, res) => {
//可以在回调函数中,获取请求参数(用户在页面填写的信息),并进行处理
res.send("post---");
});
4.2、获取请求参数
我们使用第三方包body-parser来处理请求参数更简单更专业
首先,在项目目录下安装body-parser:
yarn add body-parser 或者 npm install body-parser
使用 body-parser 获取请求参数:
// 1、引入body-parser
const bodyParser = require('body-parser')
// 2、bodyParser功能添加到项目app中
// parse application/x-www-form-urlencoded 针对普通页面提交功能
app.use(bodyParser.urlencoded({ extended: false })) //false接收的值为字符串或者数组,true则为任意类型
// parse application/json
app.use(bodyParser.json()) // 解析json格式
// 3、在接口中获取请求参数 req.body
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body);
// 获取到请求参数之后就可以在这里处理这些请求参数,比如保存到数据库中(后面我们学习数据库知识)
res.send("post ok");
});
五、重定向到其他界面
一般注册成功后可以跳转到登录页面,也就是重定向
我们使用 res.redirect('/login'); 跳转到另一个界面进行处理
// 添加登录页面的接口
app.get('/login', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "login.html");
const loginPage = fs.readFileSync(pathName, "utf-8");
res.send(loginPage);
});
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body.username);
// 一般注册成功之后可以跳转到登录页面,这就是重定向
res.redirect('/login'); // 重定向到'/login'接口,对应的接口函数会执行
});
六、all() 方法组合同一请求路径的不同方式
对于上面的case/register请求,有两种方式:GET和POST。Express 提供了 all() 方法来组合写接口:
app.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, 'views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })
七、使用Express获取静态资源
const express = require('express');const app = express();// 获取静态资源// app.use(express.static("public")) // "public"表示指定在本地public下找静态资源 // 请求: localhost:3000/images/01.jpg // 如果想要在请求的路径里面添加前缀app.use("/static", express.static("public"))// localhost:3000/static/images/01.jpg // 可能有延迟,如果延迟尝试重启服务器或者浏览器app.listen(3000, () => { console.log('Example app listening on port 3000!')});
八、使用 Express 渲染模板页面
我们使用 art-templates 模板引擎
文档网址:
使用前需要安装 art-template 和 express-art-template
yarn add art-template 或者 npm install art-templateyarn add express-art-template 或者 npm install express-art-template
在views目录下新建一个index.html
// 1、修改模板引擎为html,导入express-art-templateapp.engine('html', require('express-art-template'));// 2、设置运行的模式为生产模式// production 生产模式,线上模式// development 开发模式app.set('view options', { debug: process.env.NODE_ENV !== 'production'});// 3、设置模板存放目录为views文件夹app.set('views', path.join(__dirname, 'views'));// 4、设置引擎后缀为htmlapp.set('view engine', 'html');app.get('/', (req, res) => { res.render('index') //通过render返回该模板});
九、art-templates模板引擎的使用
使用语法:
我们可以将数据从后端界面传递到前端页面,这就是我们使用模板引擎的原因。
app.engine('html', require('express-art-template'));app.set('view options', { debug: process.env.NODE_ENV !== 'production'});app.set('views', path.join(__dirname, 'views'));app.set('view engine', 'html');app.get('/', (req, res) => { let data = { user:{ id:1, name: "Jack", age:18, job: "coder" }, books:["《西游记》", "《三国演义》","《红楼梦》", "《水浒传》"], num1:20, num2:30 } res.render('index', data); // 把data数据传入到index.html页面中。});
在视图下的 index.html 中:
这是首页 {{ user.id }} {{ user.name }} {{ user.age }} {{ user['age'] }} {{each books}} {{$index}}、{{$value}} {{/each}} <p>num1和num2中比较大的那个数是: {{num1>num2?num1:num2}} {{ if user.name === "Jacka"}}
{{ user.name }}的年龄是{{ user.age }} {{/if}}
</p>
类似的模板引擎和ejs模板引擎
十、在项目中使用路由
在项目中,我们不会直接在项目入口文件中编写路由接口。
我们提取第 6 节中的路由,在项目文件夹下新建一个 routes 文件夹,并新建一个 passport.js:
// 抽取路由const express = require('express');const router = express.Router();const fs = require("fs");const path = require("path");router.get('/login', (req, res) => { //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "login.html"); const loginPage = fs.readFileSync(pathName, "utf-8"); res.send(loginPage);});router.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })module.exports = router
在项目入口文件 app.js 中:
const express = require('express');const app = express();// 1、引入对应的路由模块const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、书写的路由添加到app上app.use(passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
处理请求前的十个一、钩子函数
这里先了解一下这个功能,以后在项目中使用。
如果你想在执行处理请求的函数之前执行一些代码,比如验证你是否登录的工作。
你可以在 app.use(utils.checkLogin, routers); 之前添加一个函数
创建一个新的 utils 文件夹并创建一个新的 index.js 文件:
function checkLogin(req, res, next){ console.log("执行接口代码之前会执行这里的代码"); next(); //直接跳入请求的接口执行代码}module.exports = { checkLogin}
在项目入口函数app.js中:
// 项目中使用路由const express = require('express');const app = express();// 1、引入对应工具模块const utils = require('./utils/index.js');const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、补上执行接口函数之前所执行的函数app.use(utils.checkLogin, passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
作用:在执行路由器下的各个接口之前,都会执行checkLogin函数中的代码。
应用程序:这可用于稍后在项目中进行身份验证和登录。
标签:req,art,Nodejs,--,res,app,express,const,page 查看全部
nodejs抓取动态网页(使用搭建服务器的Hello程序使用postnodeapp.js启动应用)
标签: reqartNodejs--resappexpressconst 页面
一、Express 框架介绍
在之前的Node基础中,我们学习了Node.js中的http模块,虽然我们知道使用Node.js中的http模块可以开发Web应用,处理静态资源,处理动态资源,请求分发(路由)等,也可以让开发者对HTTP协议的理解更加清晰,但是使用起来比较复杂,开发效率低。
npm 提供了大量的第三方模块,包括很多 web 框架,我们不需要重新发明轮子,所以我们选择使用 Express 作为开发框架,因为它是目前最稳定和使用最广泛的,也是唯一的Node.js 官方推荐的一个 Web 开发框架。除了为 http 模块提供更高级别的接口外,还实现了许多功能,包括:
官方网站:
express 是基于内置核心 http 模块的第三方包,专注于构建 web 服务器。
二、使用Express搭建服务器Hello world程序
// 1、引入express模块并创建express对象
const express = require('express');
const app = express();
// 2、书写处理请求的方法,来响应请求
app.get('/', (req, res) => {
// 这里的代码在浏览器以get请求/的时候执行,
// 这个函数就是用来处理浏览器的 对于/的get请求 的
// 第一个参数req是请求头对象,里面包含请求头信息
// 第二个参数res用来做响应
console.log(req);
res.send('Hello World!222');
});
// 3、监听端口
app.listen(3000, () => {
//这里的代码服务器刚启动的时候执行1次
console.log('Example app listening on port 3000!')
});
使用node app.js启动应用,访问:3000/查看效果。
三、使用Express处理get请求方法3.1、返回页面
在myapp目录下新建views文件夹,放入register.html页面。
在 register.html 中:
注册页面11
<p>
用户名:
邮箱:
密码:
确认密码:
</p>
在 app.js 中:
const express = require('express');
const app = express();
// 1、引入fs和path模块
const fs = require("fs");
const path = require("path");
// 2、处理/register的get请求
app.get('/register', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "register.html");
const regPage = fs.readFileSync(pathName, "utf-8");
res.send(regPage);
});
app.listen(3000, () => {
console.log('Example app listening on port 3000!')
});
3.2、获取查询参数
app.get('/index', (req, res) => {
let ret = req.query // 获取到一个对象
res.send(ret.curPage);
//可以在请求的时候传入查询参数:
//http://localhost:3000/index%3F ... %3D10
});
四、使用Express处理post请求方法4.1、post请求处理格式
app.post('/register', (req, res) => {
//可以在回调函数中,获取请求参数(用户在页面填写的信息),并进行处理
res.send("post---");
});
4.2、获取请求参数
我们使用第三方包body-parser来处理请求参数更简单更专业
首先,在项目目录下安装body-parser:
yarn add body-parser 或者 npm install body-parser
使用 body-parser 获取请求参数:
// 1、引入body-parser
const bodyParser = require('body-parser')
// 2、bodyParser功能添加到项目app中
// parse application/x-www-form-urlencoded 针对普通页面提交功能
app.use(bodyParser.urlencoded({ extended: false })) //false接收的值为字符串或者数组,true则为任意类型
// parse application/json
app.use(bodyParser.json()) // 解析json格式
// 3、在接口中获取请求参数 req.body
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body);
// 获取到请求参数之后就可以在这里处理这些请求参数,比如保存到数据库中(后面我们学习数据库知识)
res.send("post ok");
});
五、重定向到其他界面
一般注册成功后可以跳转到登录页面,也就是重定向
我们使用 res.redirect('/login'); 跳转到另一个界面进行处理
// 添加登录页面的接口
app.get('/login', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "login.html");
const loginPage = fs.readFileSync(pathName, "utf-8");
res.send(loginPage);
});
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body.username);
// 一般注册成功之后可以跳转到登录页面,这就是重定向
res.redirect('/login'); // 重定向到'/login'接口,对应的接口函数会执行
});
六、all() 方法组合同一请求路径的不同方式
对于上面的case/register请求,有两种方式:GET和POST。Express 提供了 all() 方法来组合写接口:
app.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, 'views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })
七、使用Express获取静态资源
const express = require('express');const app = express();// 获取静态资源// app.use(express.static("public")) // "public"表示指定在本地public下找静态资源 // 请求: localhost:3000/images/01.jpg // 如果想要在请求的路径里面添加前缀app.use("/static", express.static("public"))// localhost:3000/static/images/01.jpg // 可能有延迟,如果延迟尝试重启服务器或者浏览器app.listen(3000, () => { console.log('Example app listening on port 3000!')});
八、使用 Express 渲染模板页面
我们使用 art-templates 模板引擎
文档网址:
使用前需要安装 art-template 和 express-art-template
yarn add art-template 或者 npm install art-templateyarn add express-art-template 或者 npm install express-art-template
在views目录下新建一个index.html
// 1、修改模板引擎为html,导入express-art-templateapp.engine('html', require('express-art-template'));// 2、设置运行的模式为生产模式// production 生产模式,线上模式// development 开发模式app.set('view options', { debug: process.env.NODE_ENV !== 'production'});// 3、设置模板存放目录为views文件夹app.set('views', path.join(__dirname, 'views'));// 4、设置引擎后缀为htmlapp.set('view engine', 'html');app.get('/', (req, res) => { res.render('index') //通过render返回该模板});
九、art-templates模板引擎的使用
使用语法:
我们可以将数据从后端界面传递到前端页面,这就是我们使用模板引擎的原因。
app.engine('html', require('express-art-template'));app.set('view options', { debug: process.env.NODE_ENV !== 'production'});app.set('views', path.join(__dirname, 'views'));app.set('view engine', 'html');app.get('/', (req, res) => { let data = { user:{ id:1, name: "Jack", age:18, job: "coder" }, books:["《西游记》", "《三国演义》","《红楼梦》", "《水浒传》"], num1:20, num2:30 } res.render('index', data); // 把data数据传入到index.html页面中。});
在视图下的 index.html 中:
这是首页 {{ user.id }} {{ user.name }} {{ user.age }} {{ user['age'] }} {{each books}} {{$index}}、{{$value}} {{/each}} <p>num1和num2中比较大的那个数是: {{num1>num2?num1:num2}} {{ if user.name === "Jacka"}}
{{ user.name }}的年龄是{{ user.age }} {{/if}}
</p>
类似的模板引擎和ejs模板引擎
十、在项目中使用路由
在项目中,我们不会直接在项目入口文件中编写路由接口。
我们提取第 6 节中的路由,在项目文件夹下新建一个 routes 文件夹,并新建一个 passport.js:
// 抽取路由const express = require('express');const router = express.Router();const fs = require("fs");const path = require("path");router.get('/login', (req, res) => { //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "login.html"); const loginPage = fs.readFileSync(pathName, "utf-8"); res.send(loginPage);});router.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })module.exports = router
在项目入口文件 app.js 中:
const express = require('express');const app = express();// 1、引入对应的路由模块const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、书写的路由添加到app上app.use(passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
处理请求前的十个一、钩子函数
这里先了解一下这个功能,以后在项目中使用。
如果你想在执行处理请求的函数之前执行一些代码,比如验证你是否登录的工作。
你可以在 app.use(utils.checkLogin, routers); 之前添加一个函数
创建一个新的 utils 文件夹并创建一个新的 index.js 文件:
function checkLogin(req, res, next){ console.log("执行接口代码之前会执行这里的代码"); next(); //直接跳入请求的接口执行代码}module.exports = { checkLogin}
在项目入口函数app.js中:
// 项目中使用路由const express = require('express');const app = express();// 1、引入对应工具模块const utils = require('./utils/index.js');const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、补上执行接口函数之前所执行的函数app.use(utils.checkLogin, passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
作用:在执行路由器下的各个接口之前,都会执行checkLogin函数中的代码。
应用程序:这可用于稍后在项目中进行身份验证和登录。
标签:req,art,Nodejs,--,res,app,express,const,page
nodejs抓取动态网页(JS模块原生拓展1.需要注意哪些区别?|诊断报告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-07 15:00
提供诊断报告
Node12 有一个实验性的功能,可以根据用户的需求提供诊断报告,包括崩溃、性能下降、内存泄漏、高 CPU 使用率等等。
堆内存转储
以前如果要从堆内存中生成dump文件,需要在生产环境中安装额外的模块,Node12集成了这个功能。
更好的原生模块支持
C++扩展升级到版本4。同时,可以用C++编写一个native模块并发布到npm,就像一个普通的JS模块一样被引用。但是,有一些区别需要注意:
JS 模块原生扩展
1.
… 需要编译
不
如果预编译不要使用它
2.
... 可以在所有平台上运行吗
是的
如果是预编译的,你可以
3.
... 是否兼容所有 Node 版本
是的
不
4.
... 将被多次加载
是的
不
5.
...如果没有明确使用多线程,它是线程安全的
是的
不
6.
......可以被摧毁
是的
不
Worker 正式激活
--experimental-worker 取消了实验性开关,默认支持worker_threads。
需要注意的是,worker 适合执行 CPU 密集型任务(大量计算),但是在执行 I/O 密集型任务时,Worker 不如 Node 内置的 I/O 操作(读和写)文件)。
启动速度优化
通过在构建时提前为内置库生成代码缓存,启动时间最终加快了 30%。
支持 ES6 模块
Node12 对 ES6 模块的支持仍处于实验阶段,需要通过 --experimental-modules 启用。
简单来说就是支持Import Export语法,不需要转换成require!如果在 package.json 中添加了 "type": "module" 配置,Node 会像 ES6 模块一样处理它。
新的编译器和平台要求
由于升级到新的 V8 引擎和内部改造,Node12 在 Mac 和 Windows 以外的平台上至少需要 GCC6 和 glibc 2.17。
3. 精读
V8引擎升级、TLS升级、堆配置自动化、http-parser升级到llhttp、启动速度优化等都是被动优化。代码不需要改,只要升级Node版本,就可以享受了。
支持 ES6 模块特性其实挺鸡肋的。毕竟如果源码是用Ts写的,这些升级不会影响源码。
worker_threads 可以默认开启,就像之前支持 async/await 一样,会带来 Nodejs 多线程的更广泛使用。
Node12 更新了 V8 引擎。随着V8的更新,也实现了很多新的ES规范,比如Class成员函数、私有成员变量等等。
4. 总结
Nodejs只有10年的历史,但它越来越受到开发者的欢迎,因为它允许JS在服务器端运行,这是扩展JS生态系统的重要组成部分。从Node的更新历史可以看出,性能和语法能力都得到了稳步提升。一些服务器环境所需的诊断报告和堆栈分析能力正在逐步完善。社区也有Alinode和egg、express、koa等有用的服务框架。相比前端的翻天覆地的变化,对Node的评价只有一个字:稳定性。
讨论地址:《Nodejs V12》精读·Issue #184·dt-fe/weekly 查看全部
nodejs抓取动态网页(JS模块原生拓展1.需要注意哪些区别?|诊断报告)
提供诊断报告
Node12 有一个实验性的功能,可以根据用户的需求提供诊断报告,包括崩溃、性能下降、内存泄漏、高 CPU 使用率等等。
堆内存转储
以前如果要从堆内存中生成dump文件,需要在生产环境中安装额外的模块,Node12集成了这个功能。
更好的原生模块支持
C++扩展升级到版本4。同时,可以用C++编写一个native模块并发布到npm,就像一个普通的JS模块一样被引用。但是,有一些区别需要注意:
JS 模块原生扩展
1.
… 需要编译
不
如果预编译不要使用它
2.
... 可以在所有平台上运行吗
是的
如果是预编译的,你可以
3.
... 是否兼容所有 Node 版本
是的
不
4.
... 将被多次加载
是的
不
5.
...如果没有明确使用多线程,它是线程安全的
是的
不
6.
......可以被摧毁
是的
不
Worker 正式激活
--experimental-worker 取消了实验性开关,默认支持worker_threads。
需要注意的是,worker 适合执行 CPU 密集型任务(大量计算),但是在执行 I/O 密集型任务时,Worker 不如 Node 内置的 I/O 操作(读和写)文件)。
启动速度优化
通过在构建时提前为内置库生成代码缓存,启动时间最终加快了 30%。
支持 ES6 模块
Node12 对 ES6 模块的支持仍处于实验阶段,需要通过 --experimental-modules 启用。
简单来说就是支持Import Export语法,不需要转换成require!如果在 package.json 中添加了 "type": "module" 配置,Node 会像 ES6 模块一样处理它。
新的编译器和平台要求
由于升级到新的 V8 引擎和内部改造,Node12 在 Mac 和 Windows 以外的平台上至少需要 GCC6 和 glibc 2.17。
3. 精读
V8引擎升级、TLS升级、堆配置自动化、http-parser升级到llhttp、启动速度优化等都是被动优化。代码不需要改,只要升级Node版本,就可以享受了。
支持 ES6 模块特性其实挺鸡肋的。毕竟如果源码是用Ts写的,这些升级不会影响源码。
worker_threads 可以默认开启,就像之前支持 async/await 一样,会带来 Nodejs 多线程的更广泛使用。
Node12 更新了 V8 引擎。随着V8的更新,也实现了很多新的ES规范,比如Class成员函数、私有成员变量等等。
4. 总结
Nodejs只有10年的历史,但它越来越受到开发者的欢迎,因为它允许JS在服务器端运行,这是扩展JS生态系统的重要组成部分。从Node的更新历史可以看出,性能和语法能力都得到了稳步提升。一些服务器环境所需的诊断报告和堆栈分析能力正在逐步完善。社区也有Alinode和egg、express、koa等有用的服务框架。相比前端的翻天覆地的变化,对Node的评价只有一个字:稳定性。
讨论地址:《Nodejs V12》精读·Issue #184·dt-fe/weekly
nodejs抓取动态网页(1.为什么需要一个前端监控系统?技术选型监控的意义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-07 06:14
1. 为什么需要前端监控系统
通常大型web项目中的监控系统很多,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是,这些监控并不能准确反映用户看到的前端页面的状态,例如:页面调用第三方系统数据失败、模块加载异常、数据错误、天窗空白等。
这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题。
2. 监控系统需要解决的问题
一般页面出现以下问题时,您需要及时通过邮件或短信报告,通知相关人员修复问题。
3. 技术选型
监控的意义和测试的意义本质上是一样的。两者都对上线功能进行回归测试,但不同的是监控需要长期持续的循环回归测试,上线后只需进行一次测试。回归测试。
既然监控和测试的本质是一样的,我们就可以用测试来制作监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具。我们只需要集成这些自动化工具供我们使用。
节点
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非集群 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,使可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,比如网络监控、网页截图、无需浏览器的网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,而且使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。在后期,性能优化、系统改造和扩展等也可以提高简单性。
5. 解决方案(1)前台规则条目
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于和正则。
这样做的好处是,输入规则的人只需要了解一点DOM选择器的知识就可以上手,而我们通常把它交给测试工程师来完成规则的输入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。从而准确抓取页面信息。
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。键入任务。
(2) 主动报错页面脚本执行错误监控
页面引入了监控脚本,用于采集页面产生的错误事件信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面爬取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染数据。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行采集结果。
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器将规则系统采集的规则转换成消息队列,然后依次交给长期连续处理器处理。
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用。
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。其实队列的产生可以参考数据接口-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和抽取数据。
当然,类消息队列的中间介质可以根据自己的实际情况选择,当然也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存。
长时处理器
长期持久化处理器是作为消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲惫的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。之后,返回的结果将被统一处理,例如电子邮件或短信报警。
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演变为规则转换器。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理 查看全部
nodejs抓取动态网页(1.为什么需要一个前端监控系统?技术选型监控的意义)
1. 为什么需要前端监控系统
通常大型web项目中的监控系统很多,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是,这些监控并不能准确反映用户看到的前端页面的状态,例如:页面调用第三方系统数据失败、模块加载异常、数据错误、天窗空白等。
这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题。
2. 监控系统需要解决的问题
一般页面出现以下问题时,您需要及时通过邮件或短信报告,通知相关人员修复问题。
3. 技术选型
监控的意义和测试的意义本质上是一样的。两者都对上线功能进行回归测试,但不同的是监控需要长期持续的循环回归测试,上线后只需进行一次测试。回归测试。
既然监控和测试的本质是一样的,我们就可以用测试来制作监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具。我们只需要集成这些自动化工具供我们使用。
节点
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非集群 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,使可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,比如网络监控、网页截图、无需浏览器的网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,而且使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)

架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。在后期,性能优化、系统改造和扩展等也可以提高简单性。
5. 解决方案(1)前台规则条目
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于和正则。
这样做的好处是,输入规则的人只需要了解一点DOM选择器的知识就可以上手,而我们通常把它交给测试工程师来完成规则的输入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。从而准确抓取页面信息。
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。键入任务。
(2) 主动报错页面脚本执行错误监控
页面引入了监控脚本,用于采集页面产生的错误事件信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面爬取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染数据。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行采集结果。
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器将规则系统采集的规则转换成消息队列,然后依次交给长期连续处理器处理。
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用。
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。其实队列的产生可以参考数据接口-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和抽取数据。
当然,类消息队列的中间介质可以根据自己的实际情况选择,当然也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存。
长时处理器
长期持久化处理器是作为消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲惫的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。之后,返回的结果将被统一处理,例如电子邮件或短信报警。
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演变为规则转换器。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理
nodejs抓取动态网页( 一个、path和url模块的确定文件的路径这就要依赖于 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-07 06:13
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000') 查看全部
nodejs抓取动态网页(
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000')
nodejs抓取动态网页( 一个、path和url模块的确定文件的路径这就要依赖于 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-05 12:11
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000') 查看全部
nodejs抓取动态网页(
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000')
nodejs抓取动态网页(nodejs抓取动态网页必须用python!不用换别的啦!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 09:15
nodejs抓取动态网页必须用python!不用换别的啦!下面就来告诉你这个代码能做什么:步骤如下:打开浏览器输入进入首页按f12或者chrome的开发者工具把network拖动到浏览器的调试工具里右键进行搜索-navigate检查network,需要看哪个网页的动态首页的文字信息。
一、谷歌浏览器下载安装,推荐使用谷歌浏览器。1.下载我测试下载最新版chrome浏览器,如果版本不对需要下载对应的chrome版本。chrome54版本,在chrome商店里搜索谷歌浏览器-安装,基本上都能安装chrome浏览器,我安装时就有提示。2.打开谷歌浏览器,打开此页面。将searchtools(谷歌搜索工具)点击右键,选择“选项”并确定,登录上你谷歌的账号。3.把谷歌网页中的关键词拉出来:以“阿拉丁”为例,打开之后是这样:。
二、百度、搜狗、360。
三、神奇的网页分析工具可以直接使用【飞渡看雪】工具,可以抓取你想要的网页。选择你要看的网页,点击工具,进行搜索:打开该工具后,选择“全部网页搜索”,
四、神奇的浏览器扩展javascript特效-plot
可以使用javascript调试器来进行,这个浏览器插件不仅可以抓取网页的动态代码,还可以抓取单页信息, 查看全部
nodejs抓取动态网页(nodejs抓取动态网页必须用python!不用换别的啦!)
nodejs抓取动态网页必须用python!不用换别的啦!下面就来告诉你这个代码能做什么:步骤如下:打开浏览器输入进入首页按f12或者chrome的开发者工具把network拖动到浏览器的调试工具里右键进行搜索-navigate检查network,需要看哪个网页的动态首页的文字信息。
一、谷歌浏览器下载安装,推荐使用谷歌浏览器。1.下载我测试下载最新版chrome浏览器,如果版本不对需要下载对应的chrome版本。chrome54版本,在chrome商店里搜索谷歌浏览器-安装,基本上都能安装chrome浏览器,我安装时就有提示。2.打开谷歌浏览器,打开此页面。将searchtools(谷歌搜索工具)点击右键,选择“选项”并确定,登录上你谷歌的账号。3.把谷歌网页中的关键词拉出来:以“阿拉丁”为例,打开之后是这样:。
二、百度、搜狗、360。
三、神奇的网页分析工具可以直接使用【飞渡看雪】工具,可以抓取你想要的网页。选择你要看的网页,点击工具,进行搜索:打开该工具后,选择“全部网页搜索”,
四、神奇的浏览器扩展javascript特效-plot
可以使用javascript调试器来进行,这个浏览器插件不仅可以抓取网页的动态代码,还可以抓取单页信息,
nodejs抓取动态网页( 你眼中的JavaScript是干什么?特效?or只是与客户端的交互?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-04 07:14
你眼中的JavaScript是干什么?特效?or只是与客户端的交互?)
在nodejs中实现路由功能
更新时间:2014年12月29日08:55:07 投稿:俊杰
本文文章主要介绍nodejs中的路由功能。顾名思义,路由是指我们必须以不同的方式处理不同的 URL。本文将教你在node.js中实现路由功能。有需要的朋友可以参考
一个 Node 初学者,我发现了一个与我之前的观点完全不同的场景——JavaScript 在你眼中的目的是什么?特殊效果?还是只是与客户的互动?可以说 JavaScript 最初是在浏览器中运行的,但如果你这样想,浏览器只是提供了一个上下文(context),它定义了你可以用 JavaScript 做什么。这可以被认为是一个类似的企业,企业定义了你在这里可以做什么,但并没有多说 JavaScript 语言本身可以做什么。事实上,作为一门完整的语言,JavaScript 可以用在不同的上下文中,体现出不同的能力。这里提到的Nodejs其实就是提供一个上下文,一个运行环境,让JavaScript代码可以在后端(浏览器环境之外)运行。
路由的核心是路由。顾名思义,路由就是我们要以不同的方式处理不同的URL,比如处理/启动业务逻辑,处理/上传模块业务;逻辑不一致。在实际实现中,路由过程会在路由模块中“结束”,而路由模块并不是真正对请求“采取行动”的模块,否则当我们的应用变得更复杂时,它就无法使用了。非常好的扩展。
这里我们首先创建一个名为 requestHandlers 的模块,并为每个请求处理程序添加一个占位符函数:
复制代码代码如下:
函数开始(){
console.log("请求处理程序'start'被调用。");
函数睡眠(毫秒){
var startTime=new Date().getTime();
while(new Date().getTime() }
睡眠(10000);
return "Hello Start";
}
函数上传(){
console.log("请求处理程序'上传'被调用。");
返回“你好上传”;
}
exports.start=start;
exports.upload=upload;
这样,我们就可以连接请求处理程序和路由模块,让路由“有路径可走”。之后,我们决定通过一个对象传递一系列请求处理程序,我们需要使用松耦合将这个对象注入到router()函数中,主文件index.js:
复制代码代码如下:
var server=require("./server");
var router=require("./router");
var requestHandlers=require("./requestHandlers");
var handle={};
handle["/"]=requestHandlers.start;
handle["/start"]=requestHandlers.start;
handle["/upload"]=requestHandlers.upload;
server.start(router.route,handle);
如上所示,很容易将不同的 URL 映射到同一个请求处理程序:只需在对象中添加一个键为“/”的属性,对应 requestHandlers.start。这样,我们就可以简洁地配置 /start 和 / 由 start 处理程序处理的请求。完成查看对象的定义后,我们将其作为附加参数传递给服务器,参见server.js:
复制代码代码如下: 查看全部
nodejs抓取动态网页(
你眼中的JavaScript是干什么?特效?or只是与客户端的交互?)
在nodejs中实现路由功能
更新时间:2014年12月29日08:55:07 投稿:俊杰
本文文章主要介绍nodejs中的路由功能。顾名思义,路由是指我们必须以不同的方式处理不同的 URL。本文将教你在node.js中实现路由功能。有需要的朋友可以参考
一个 Node 初学者,我发现了一个与我之前的观点完全不同的场景——JavaScript 在你眼中的目的是什么?特殊效果?还是只是与客户的互动?可以说 JavaScript 最初是在浏览器中运行的,但如果你这样想,浏览器只是提供了一个上下文(context),它定义了你可以用 JavaScript 做什么。这可以被认为是一个类似的企业,企业定义了你在这里可以做什么,但并没有多说 JavaScript 语言本身可以做什么。事实上,作为一门完整的语言,JavaScript 可以用在不同的上下文中,体现出不同的能力。这里提到的Nodejs其实就是提供一个上下文,一个运行环境,让JavaScript代码可以在后端(浏览器环境之外)运行。
路由的核心是路由。顾名思义,路由就是我们要以不同的方式处理不同的URL,比如处理/启动业务逻辑,处理/上传模块业务;逻辑不一致。在实际实现中,路由过程会在路由模块中“结束”,而路由模块并不是真正对请求“采取行动”的模块,否则当我们的应用变得更复杂时,它就无法使用了。非常好的扩展。
这里我们首先创建一个名为 requestHandlers 的模块,并为每个请求处理程序添加一个占位符函数:
复制代码代码如下:
函数开始(){
console.log("请求处理程序'start'被调用。");
函数睡眠(毫秒){
var startTime=new Date().getTime();
while(new Date().getTime() }
睡眠(10000);
return "Hello Start";
}
函数上传(){
console.log("请求处理程序'上传'被调用。");
返回“你好上传”;
}
exports.start=start;
exports.upload=upload;
这样,我们就可以连接请求处理程序和路由模块,让路由“有路径可走”。之后,我们决定通过一个对象传递一系列请求处理程序,我们需要使用松耦合将这个对象注入到router()函数中,主文件index.js:
复制代码代码如下:
var server=require("./server");
var router=require("./router");
var requestHandlers=require("./requestHandlers");
var handle={};
handle["/"]=requestHandlers.start;
handle["/start"]=requestHandlers.start;
handle["/upload"]=requestHandlers.upload;
server.start(router.route,handle);
如上所示,很容易将不同的 URL 映射到同一个请求处理程序:只需在对象中添加一个键为“/”的属性,对应 requestHandlers.start。这样,我们就可以简洁地配置 /start 和 / 由 start 处理程序处理的请求。完成查看对象的定义后,我们将其作为附加参数传递给服务器,参见server.js:
复制代码代码如下:
nodejs抓取动态网页(要来开发一个属于自己的命令行小说工具用呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-02 18:08
简介:你的键盘是不是像飞一样上下?除了屏幕上黑色的控制台之外什么都看不到的极客,羡慕不已。不想要。我觉得前端很酷,一行代码就是另一个世界。 ,但在我的内心深处,我仍然觉得强迫症在不知不觉中下降了?不用着急,让Nodejs给你带来舒服有力量的好东西。本章将带您一步步开发自己的命令行工具。
Now You See Me:如果您不明白或不清楚您所说的内容,请留言。没多久,我开始一起学习,一起进步。 当然,如果你有一些想知道的内容相关的小知识点,比如cheerio bag balabala,也可以留言告知,会被放到发布内容的日程表中。嘿
1.开发这样的工具有什么用?
作者经常阅读一些网络小说,所以我们将开发一个新的章节内容,捕捉作者经常阅读的小说网站。先放一下程序运行的结果:
DaDaDa,美吗?
以下是这个项目的地址,只是一个demo。各种功能和之前的工程实践会在后面补充。
#自述
2.怎么做?
分以下几个部分解释这个内容:
- 项目结构
- 项目详情
以下是对以上目录的介绍:
目录:
bin:命令行脚本文件的入口,是package.json中bin属性对应的值得目录
node_modules:你知道的,npm 的依赖聚集地
文件:
.npmignore:就像.gitignore 文件一样,只有那些不会被npm 收录在发布目录中的文件
index.js:主程序文件
package.json:由 npm init 生成。详细描述项目情况
先介绍一下大概的设计:
很简单,就是先根据提供的小说网站链接抓取特定小说的目录导航,用相关的npm包分析上一个项目的链接,是最新的更新链接,然后拼接链接。再次向目标网站请求数据。分析检索到的内容,整理格式,修改输出,得到最终结果。
查看我们的源代码:
index.js
//用来做发送请求,经过测试的好朋友
var request = require('request');
//Node爬虫界的大佬,他的web代码分析能力不错
var cio = require('cheerio');
//装饰命令行上方的输出,添加颜色等
var colors = require('colors');
var url = require('url');
//网站网址
var webSiteUrlPrefix ='';
//小说链接
var webSiteUrl ='';
//开始请求数据
request(webSiteUrl, function(err, res, body) {
//做异常处理检查
if (!err && res.statusCode == 200) {
//Cheerio是数据处理的第一步,穿马甲
var $ = cio.load(body);
//缓存最后一个item节点
var target = $('div#list dd:last-of-type');
//通过CSS选择器过滤数据
//这里的意思
var src = target.children('a').attr('href');
//获取文章标题
var pageTitle = target.text();
//获取文章实际地址
var contentsUrl = webSiteUrlPrefix + src;
//再次请求,这次获取的是文章
的实际内容
request(contentsUrl, function(err, res, body) {
如果(错误){
返回;
} 其他{
if (res.statusCode == 200) {
var $ = cio.load(body);
//调整格式,去除多余空格
var pageContents = $('div#content').text().replace(/\s+/g,'\n');
//添加一些颜色看看
console.log(pageTitle.green +'\n\n' + pageContents.yellow);
} 其他{
返回;
}
}
})
} 其他{
console.log('错误请求');
}
});
接下来是bin/index.js的解释:
与上面的文件基本相同,唯一不同的是:
#! /usr/bin/env 节点
表示启用Node运行脚本,这也是生成命令行工具的本质
最后是package.json文件的介绍:
类似于之前的Express系列:用例子讲解如何开发自己的npm包,唯一的区别是:
“bin”:{
"n-novel": "bin/index.js"
}
这里提醒一下,这里一定要写上收录“#!/usr/bin/env node”的index.js文件路径,因为里面的文件最终会被软链接到/usr/local/bin/去里面,而且里面的程序都是脚本,如果位置不对,程序就会跑错。
3.发布流程
$ npm whoami
$ npm 发布
DaDaDa,发布成功!
4.起来,嘿
发布后,我们要检查我们的战斗结果,通过
npm install -g n-novel
安装到全世界,运行结果如下:
然后运行n-novel,稍等片刻,新出小说的最新章节会放到你的命令行中。
下一节介绍
介绍
经过以上两节的学习,我们不仅可以开发自己的包,还可以编写命令行工具。你认为我们已经起飞了吗?下一节我们将介绍如何通过持续的形成和构建来保证我们的项目代码经过良好的测试和可靠的,即持续集成:travis,测试覆盖:coveralls,查看模块依赖:david-dm,等等 查看全部
nodejs抓取动态网页(要来开发一个属于自己的命令行小说工具用呢?)
简介:你的键盘是不是像飞一样上下?除了屏幕上黑色的控制台之外什么都看不到的极客,羡慕不已。不想要。我觉得前端很酷,一行代码就是另一个世界。 ,但在我的内心深处,我仍然觉得强迫症在不知不觉中下降了?不用着急,让Nodejs给你带来舒服有力量的好东西。本章将带您一步步开发自己的命令行工具。
Now You See Me:如果您不明白或不清楚您所说的内容,请留言。没多久,我开始一起学习,一起进步。 当然,如果你有一些想知道的内容相关的小知识点,比如cheerio bag balabala,也可以留言告知,会被放到发布内容的日程表中。嘿
1.开发这样的工具有什么用?
作者经常阅读一些网络小说,所以我们将开发一个新的章节内容,捕捉作者经常阅读的小说网站。先放一下程序运行的结果:
DaDaDa,美吗?
以下是这个项目的地址,只是一个demo。各种功能和之前的工程实践会在后面补充。
#自述
2.怎么做?
分以下几个部分解释这个内容:
- 项目结构
- 项目详情
以下是对以上目录的介绍:
目录:
bin:命令行脚本文件的入口,是package.json中bin属性对应的值得目录
node_modules:你知道的,npm 的依赖聚集地
文件:
.npmignore:就像.gitignore 文件一样,只有那些不会被npm 收录在发布目录中的文件
index.js:主程序文件
package.json:由 npm init 生成。详细描述项目情况
先介绍一下大概的设计:
很简单,就是先根据提供的小说网站链接抓取特定小说的目录导航,用相关的npm包分析上一个项目的链接,是最新的更新链接,然后拼接链接。再次向目标网站请求数据。分析检索到的内容,整理格式,修改输出,得到最终结果。
查看我们的源代码:
index.js
//用来做发送请求,经过测试的好朋友
var request = require('request');
//Node爬虫界的大佬,他的web代码分析能力不错
var cio = require('cheerio');
//装饰命令行上方的输出,添加颜色等
var colors = require('colors');
var url = require('url');
//网站网址
var webSiteUrlPrefix ='';
//小说链接
var webSiteUrl ='';
//开始请求数据
request(webSiteUrl, function(err, res, body) {
//做异常处理检查
if (!err && res.statusCode == 200) {
//Cheerio是数据处理的第一步,穿马甲
var $ = cio.load(body);
//缓存最后一个item节点
var target = $('div#list dd:last-of-type');
//通过CSS选择器过滤数据
//这里的意思
var src = target.children('a').attr('href');
//获取文章标题
var pageTitle = target.text();
//获取文章实际地址
var contentsUrl = webSiteUrlPrefix + src;
//再次请求,这次获取的是文章
的实际内容
request(contentsUrl, function(err, res, body) {
如果(错误){
返回;
} 其他{
if (res.statusCode == 200) {
var $ = cio.load(body);
//调整格式,去除多余空格
var pageContents = $('div#content').text().replace(/\s+/g,'\n');
//添加一些颜色看看
console.log(pageTitle.green +'\n\n' + pageContents.yellow);
} 其他{
返回;
}
}
})
} 其他{
console.log('错误请求');
}
});
接下来是bin/index.js的解释:
与上面的文件基本相同,唯一不同的是:
#! /usr/bin/env 节点
表示启用Node运行脚本,这也是生成命令行工具的本质
最后是package.json文件的介绍:
类似于之前的Express系列:用例子讲解如何开发自己的npm包,唯一的区别是:
“bin”:{
"n-novel": "bin/index.js"
}
这里提醒一下,这里一定要写上收录“#!/usr/bin/env node”的index.js文件路径,因为里面的文件最终会被软链接到/usr/local/bin/去里面,而且里面的程序都是脚本,如果位置不对,程序就会跑错。
3.发布流程
$ npm whoami
$ npm 发布
DaDaDa,发布成功!
4.起来,嘿
发布后,我们要检查我们的战斗结果,通过
npm install -g n-novel
安装到全世界,运行结果如下:
然后运行n-novel,稍等片刻,新出小说的最新章节会放到你的命令行中。
下一节介绍
介绍
经过以上两节的学习,我们不仅可以开发自己的包,还可以编写命令行工具。你认为我们已经起飞了吗?下一节我们将介绍如何通过持续的形成和构建来保证我们的项目代码经过良好的测试和可靠的,即持续集成:travis,测试覆盖:coveralls,查看模块依赖:david-dm,等等
nodejs抓取动态网页(网络爬虫这块套路总结,用python+selenium执行代码上面第一种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-02 12:06
我是北京一家互联网工厂的996程序员。一边学习追赶新技术,一边害怕被潮流甩在后面,一边学习投资理财的方法让自己的薪水滚雪球。我相信你越努力,你就越幸运。雪球虽然一开始滚得很慢,但只要你坚持住,它就会滚得越来越快,你的养老就靠它了。在财富和自由的道路上,我鼓励你。欢迎评论区和我交流经验和干货,让我们收获更多。
我最近在抓一条网站的消息。今天写完了程序,用python+selenium。顺便总结一下网络爬虫的套路,分享给大家。
方法一:直接接口调用。
如果对方网站的api几乎没有反爬错误,那么可以直接通过浏览器的开发工具获取对方的api地址,直接调用爬取。如果对方界面控制了爬取频率,自己控制爬取间隔即可。
如果使用python技术栈开发,使用requests库模拟接口调用。这里需要注意具体的headers,可能收录token、签名等,需要自己整理。
方法二:使用js解析器执行js代码
上面第一种情况提到的场景毕竟还是少数,大部分网站都采取了一些反爬虫的措施。比如网站通过页面加载的js向界面发起XHR类型的ajax请求。调用接口时,自定义参数添加到查询字符串或URL的头部,参数生成方法均在js中。 ,然后可以选择了解js代码,然后用python重写生成参数的代码,最后组装这些参数调用接口。
但通常你没有那么幸运。生成参数的js代码比较混乱,基本无法被人类阅读。但是,如果你能定位到使用了哪个函数,那么我们可以采取另一种解决方案,就是将js代码改到js解释器中,然后直接调用函数获取返回值。我们拿这些返回值来组装请求参数。
如果使用python技术栈开发,可以使用PyExecJS、PyV8、js2py、Node.js这些js解析器来运行js代码。
js2py,一个纯python实现的js解析器,目前还在更新中。 PyExecJS,项目已经停止开发,但是还可以使用。 PyV8,是google v8 js引擎的python包。好久没更新了,不过还是可以用的。 Node.js,基于chrome v8引擎的js运行时,更新活跃。
推荐使用 Js2py。
方法三:使用selenium调用浏览器访问
方法二的场景,js代码根本用不上,也无法定位到要用到哪些函数,所以只能搬出selenium。 Selenium 是一套工具包,通过它我们可以使用程序来控制浏览器访问目标网站。 Selenium 有很多语言的绑定,自然也有python 的绑定。
使用selenium控制浏览器访问目标url后,如果要抓取的内容在页面内,则直接使用selenium提供的网页提取api直接提取内容。但是如果页面中没有渲染出你想要的内容,那我们就得用next方法了。
方法四:使用selenium+proxy来抓取接口调用
如方法3场景所述,对于js发起的ajax请求,如果响应数据没有完全反映在DOM中,那我们就得想办法直接提取ajax响应。方法是通过selenium+proxy控制浏览器访问,然后我们拦截proxy上的ajax响应。
常用的代理是browsermob-proxy,是java开发的http/https代理。本方案的原则是
在代码中控制启动browsermob-proxy。代码控制selenium启动浏览器,设置本地代理为browsermob-proxy。 Browsermob-proxy 会将请求的请求和响应写入 HAR 文件 (),我们可以通过解析 HAR 的内容得到响应。
方法五:使用selenium+浏览器的性能日志
这个方法可以认为是方法4的升级版,因为浏览器自己获取响应,所以只要找到合适的方法,就可以直接获取响应。
具体方法是webdriver(python代码控制浏览器的一个组件)允许我们向浏览器发送Network.getResponseBody命令来获取响应。 webdriver 提供的 API 文档:
我们需要传递一个名为 requestId 的参数来获取响应。
首先,在初始化浏览器控件实例时,必须开启{"performance": "ALL"}
def __init_driver(self):
capabilities = DesiredCapabilities.CHROME
capabilities["goog:loggingPrefs"] = {"performance": "ALL"} # chromedriver 75+
option = webdriver.ChromeOptions()
option.add_argument(r"user-data-dir=./var/chrome-data")
self.__driver = webdriver.Chrome(desired_capabilities=capabilities, options=option)
然后
def __scrape(self, url):
self.__driver.get(url)
time.sleep(3) # 等待页面中的请求完成
logs = self.__driver.get_log("performance")
日志收录页面中的所有请求和响应。接下来,我们需要遍历每条数据,找到Network.responseReceived的类型,请求url就是我们要抓取的数据,从中获取requestId,然后就可以使用Network.getResponseBody来获取响应.
def process_network_event(driver, logs, match_url):
for entry in logs:
message = json.loads(entry["message"]).get("message", {})
method = message.get("method", "")
is_method_match = method.startswith("Network.responseReceived")
if not is_method_match:
continue
url = message.get("params", {}).get("response", {}).get("url", "")
if url == "":
continue
if not url.startswith(match_url): # 匹配我们想要的url
continue
request_id = message.get("params", {}).get("requestId", "")
if request_id == "":
continue
try:
response_body = driver.execute_cdp_cmd('Network.getResponseBody', {'requestId': request_id})
except Exception as e:
print(f"getResponseBody by {request_id} failed: {e}, with message: {message}")
response_body = None
if not response_body:
continue
json_string = response_body.get("body", "")
if json_string == "":
continue
response = json.loads(json_string)
return response
还有一个基于性能日志的python模块,可以更容易地提取请求和响应,[selenium-wire·PyPI](),[wkeeling/selenium-wire:扩展Selenium的Python绑定,让你能够检查浏览器发出的请求。]()。模块更新处于活动状态
总结一下,方法五:在界面无法直接抓取的情况下,使用selenium+浏览器的性能日志是最好的解决方案。
另外总结一下爬虫项目中的一些常用技巧
UserAgent 应该稍微伪装一下,经常可以换不同的 UserAgent 来伪装不同的客户端。准备更多的代理。如果目标网站对IP有严格的控制,那么我们会经常更换代理。
参考资料
如果觉得我的分享对你有用,请关注并在评论区与我交流。我会继续分享一些有用的知识和经验。 查看全部
nodejs抓取动态网页(网络爬虫这块套路总结,用python+selenium执行代码上面第一种)
我是北京一家互联网工厂的996程序员。一边学习追赶新技术,一边害怕被潮流甩在后面,一边学习投资理财的方法让自己的薪水滚雪球。我相信你越努力,你就越幸运。雪球虽然一开始滚得很慢,但只要你坚持住,它就会滚得越来越快,你的养老就靠它了。在财富和自由的道路上,我鼓励你。欢迎评论区和我交流经验和干货,让我们收获更多。
我最近在抓一条网站的消息。今天写完了程序,用python+selenium。顺便总结一下网络爬虫的套路,分享给大家。
方法一:直接接口调用。
如果对方网站的api几乎没有反爬错误,那么可以直接通过浏览器的开发工具获取对方的api地址,直接调用爬取。如果对方界面控制了爬取频率,自己控制爬取间隔即可。
如果使用python技术栈开发,使用requests库模拟接口调用。这里需要注意具体的headers,可能收录token、签名等,需要自己整理。
方法二:使用js解析器执行js代码
上面第一种情况提到的场景毕竟还是少数,大部分网站都采取了一些反爬虫的措施。比如网站通过页面加载的js向界面发起XHR类型的ajax请求。调用接口时,自定义参数添加到查询字符串或URL的头部,参数生成方法均在js中。 ,然后可以选择了解js代码,然后用python重写生成参数的代码,最后组装这些参数调用接口。
但通常你没有那么幸运。生成参数的js代码比较混乱,基本无法被人类阅读。但是,如果你能定位到使用了哪个函数,那么我们可以采取另一种解决方案,就是将js代码改到js解释器中,然后直接调用函数获取返回值。我们拿这些返回值来组装请求参数。
如果使用python技术栈开发,可以使用PyExecJS、PyV8、js2py、Node.js这些js解析器来运行js代码。
js2py,一个纯python实现的js解析器,目前还在更新中。 PyExecJS,项目已经停止开发,但是还可以使用。 PyV8,是google v8 js引擎的python包。好久没更新了,不过还是可以用的。 Node.js,基于chrome v8引擎的js运行时,更新活跃。
推荐使用 Js2py。
方法三:使用selenium调用浏览器访问
方法二的场景,js代码根本用不上,也无法定位到要用到哪些函数,所以只能搬出selenium。 Selenium 是一套工具包,通过它我们可以使用程序来控制浏览器访问目标网站。 Selenium 有很多语言的绑定,自然也有python 的绑定。
使用selenium控制浏览器访问目标url后,如果要抓取的内容在页面内,则直接使用selenium提供的网页提取api直接提取内容。但是如果页面中没有渲染出你想要的内容,那我们就得用next方法了。
方法四:使用selenium+proxy来抓取接口调用
如方法3场景所述,对于js发起的ajax请求,如果响应数据没有完全反映在DOM中,那我们就得想办法直接提取ajax响应。方法是通过selenium+proxy控制浏览器访问,然后我们拦截proxy上的ajax响应。
常用的代理是browsermob-proxy,是java开发的http/https代理。本方案的原则是
在代码中控制启动browsermob-proxy。代码控制selenium启动浏览器,设置本地代理为browsermob-proxy。 Browsermob-proxy 会将请求的请求和响应写入 HAR 文件 (),我们可以通过解析 HAR 的内容得到响应。
方法五:使用selenium+浏览器的性能日志
这个方法可以认为是方法4的升级版,因为浏览器自己获取响应,所以只要找到合适的方法,就可以直接获取响应。
具体方法是webdriver(python代码控制浏览器的一个组件)允许我们向浏览器发送Network.getResponseBody命令来获取响应。 webdriver 提供的 API 文档:
我们需要传递一个名为 requestId 的参数来获取响应。
首先,在初始化浏览器控件实例时,必须开启{"performance": "ALL"}
def __init_driver(self):
capabilities = DesiredCapabilities.CHROME
capabilities["goog:loggingPrefs"] = {"performance": "ALL"} # chromedriver 75+
option = webdriver.ChromeOptions()
option.add_argument(r"user-data-dir=./var/chrome-data")
self.__driver = webdriver.Chrome(desired_capabilities=capabilities, options=option)
然后
def __scrape(self, url):
self.__driver.get(url)
time.sleep(3) # 等待页面中的请求完成
logs = self.__driver.get_log("performance")
日志收录页面中的所有请求和响应。接下来,我们需要遍历每条数据,找到Network.responseReceived的类型,请求url就是我们要抓取的数据,从中获取requestId,然后就可以使用Network.getResponseBody来获取响应.
def process_network_event(driver, logs, match_url):
for entry in logs:
message = json.loads(entry["message"]).get("message", {})
method = message.get("method", "")
is_method_match = method.startswith("Network.responseReceived")
if not is_method_match:
continue
url = message.get("params", {}).get("response", {}).get("url", "")
if url == "":
continue
if not url.startswith(match_url): # 匹配我们想要的url
continue
request_id = message.get("params", {}).get("requestId", "")
if request_id == "":
continue
try:
response_body = driver.execute_cdp_cmd('Network.getResponseBody', {'requestId': request_id})
except Exception as e:
print(f"getResponseBody by {request_id} failed: {e}, with message: {message}")
response_body = None
if not response_body:
continue
json_string = response_body.get("body", "")
if json_string == "":
continue
response = json.loads(json_string)
return response
还有一个基于性能日志的python模块,可以更容易地提取请求和响应,[selenium-wire·PyPI](),[wkeeling/selenium-wire:扩展Selenium的Python绑定,让你能够检查浏览器发出的请求。]()。模块更新处于活动状态
总结一下,方法五:在界面无法直接抓取的情况下,使用selenium+浏览器的性能日志是最好的解决方案。
另外总结一下爬虫项目中的一些常用技巧
UserAgent 应该稍微伪装一下,经常可以换不同的 UserAgent 来伪装不同的客户端。准备更多的代理。如果目标网站对IP有严格的控制,那么我们会经常更换代理。
参考资料
如果觉得我的分享对你有用,请关注并在评论区与我交流。我会继续分享一些有用的知识和经验。
nodejs抓取动态网页(之前做爬虫的优劣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-02 07:15
欢迎访问我的博客杨辰的博客
简介
说到爬虫,最容易想到的就是python了,因为python感觉它什么都能做,但是之前用python做爬虫的过程还是很不爽。主要问题来自几个方面:第一个是对的,对于被爬取的网页的dom操作,第二个是编码处理,第三个是多线程,所以用python做爬虫其实不是很爽。有没有更好的办法?当然还有node.js!
Nodejs作为爬虫的优缺点 首先说一下node作为爬虫的优点
第一个是他的驱动语言是 JavaScript。在 nodejs 诞生之前,JavaScript 是一种运行在浏览器上的脚本语言。它的优点是对网页上的dom元素进行操作,在网页操作方面是其他语言无法比拟的。
二是nodejs是单线程异步的。听起来很奇怪,单线程怎么可能是异步的?想一想为什么在学习操作系统时单核cpu可以进行多任务处理?原因是类似的。在操作系统中,进程占用CPU时间片。每个进程占用的时间很短,但是所有进程都循环了很多次,所以看起来像是同时处理多个任务。对于 js 也是如此。 js中有一个事件池。 CPU会在事件池循环中处理响应的事件,未处理的事件不会放入事件池中,因此不会阻塞后续操作。这样做在爬虫上的好处是,在并发爬取的页面上,一个页面返回失败不会阻塞后续页面继续加载。要做到这一点,你不需要像 python 那样多线程。
接下来是node的缺点
首先,它是异步和并发的。处理好很方便,但是处理不好就麻烦了。比如要爬10个页面,使用node不做异步处理,返回的结果不一定在1、2、3、4...... 这个顺序很可能是随机的。解决办法是添加一个页面序列戳,让爬取的数据生成一个csv文件,然后重新排序。
第二个是数据处理的劣势。这不如python。如果只是单纯的爬取数据,用node当然好,但是如果用爬取的数据继续做统计分析,那就做回归分析。什么东西,那你就不能用node了。
如何使用nodejs作为爬虫
接下来说一下如何使用nodejs作为爬虫
1、初始项目文件
在对应的项目文件夹下执行npm init初始化一个package.json文件
2、安装请求和cheerio依赖包
request 听起来很熟悉,就像 Python 中的 request 函数一样。它的作用是建立目标网页的链接并返回相应的数据,不难理解。
Cheerio 的函数用于操作 dom 元素。它可以将请求返回的数据转换成dom可以操作的数据。更重要的是,cheerio的api和jquery是一样的。用$选择对应的dom节点,是不是很方便?对于前端程序员来说,这比python的xpath和beautisoup方便多了。不知道多少钱啊哈哈
安装命令也很简单,就是npm install request --save和npm installcheerio
3、引入依赖包并使用
接下来用request和cherrio写一个爬虫!
先引入依赖
var request = require("request");
var cheerio = require("cheerio");
接下来我们以爬取我们学校的新闻页面为例。我们学校新闻页面的链接是
然后调用请求接口
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
console.log(result.body);
})
运行一下,结果是这样的
你很兴奋吗?哈哈,html又回来了。这还不够。下一步就是对返回的数据进行处理,提取我们想要获取的信息。轮到啦啦队了。
将请求返回的结果传入cheerio,得到想要获取的信息。代码有没有想写脚本的感觉?
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
var $ = cheerio.load(result.body);
$('a[id^="dnn"]').each(function(index,element){
console.log($(element).text());
})
})
运行结果如下:
这样一个简单的爬虫就完成了。是不是很简单?当然,这还远远不够。
4、设置请求头
众所周知,在http协议中,发送请求头是为了建立连接。对于一些动态网页的抓取,有时需要设置用户代理、cookies等,那么如何使用这些设置?
具体案例代码如下:
var options = {
url: startUrl+'?page=1',
method: 'GET',
charset: "utf-8",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36",
"cookie": cookies
}
};
request(options,function(err,response,body){
//...
})
5 并发控制
可以抓取页面。如果页面多,就会有无限的并发,那么肯定会被阻塞,所以一定要有并发控制。这里是异步的。和上面一样,需要通过npm install async --save安装,通过var async = require("async")引入。
举一个具体的例子来限制并发。
async.mapLimit(5,function(url,callback)){
//...
fetch(url,callback)
})
这里的5是并发数的限制,可以自由使用。最后,不要忘记执行后的回调,因为如果没有,它会被阻塞。 Async 不知道被限制的函数是否已经执行,所以不会被释放。
总结
至此,Nodejs爬虫的核心已经介绍完毕,剩下的就完全可以自由发挥了。最后附上我自己做的一个简单的新浪微博爬虫 查看全部
nodejs抓取动态网页(之前做爬虫的优劣)
欢迎访问我的博客杨辰的博客
简介
说到爬虫,最容易想到的就是python了,因为python感觉它什么都能做,但是之前用python做爬虫的过程还是很不爽。主要问题来自几个方面:第一个是对的,对于被爬取的网页的dom操作,第二个是编码处理,第三个是多线程,所以用python做爬虫其实不是很爽。有没有更好的办法?当然还有node.js!
Nodejs作为爬虫的优缺点 首先说一下node作为爬虫的优点
第一个是他的驱动语言是 JavaScript。在 nodejs 诞生之前,JavaScript 是一种运行在浏览器上的脚本语言。它的优点是对网页上的dom元素进行操作,在网页操作方面是其他语言无法比拟的。
二是nodejs是单线程异步的。听起来很奇怪,单线程怎么可能是异步的?想一想为什么在学习操作系统时单核cpu可以进行多任务处理?原因是类似的。在操作系统中,进程占用CPU时间片。每个进程占用的时间很短,但是所有进程都循环了很多次,所以看起来像是同时处理多个任务。对于 js 也是如此。 js中有一个事件池。 CPU会在事件池循环中处理响应的事件,未处理的事件不会放入事件池中,因此不会阻塞后续操作。这样做在爬虫上的好处是,在并发爬取的页面上,一个页面返回失败不会阻塞后续页面继续加载。要做到这一点,你不需要像 python 那样多线程。
接下来是node的缺点
首先,它是异步和并发的。处理好很方便,但是处理不好就麻烦了。比如要爬10个页面,使用node不做异步处理,返回的结果不一定在1、2、3、4...... 这个顺序很可能是随机的。解决办法是添加一个页面序列戳,让爬取的数据生成一个csv文件,然后重新排序。
第二个是数据处理的劣势。这不如python。如果只是单纯的爬取数据,用node当然好,但是如果用爬取的数据继续做统计分析,那就做回归分析。什么东西,那你就不能用node了。
如何使用nodejs作为爬虫
接下来说一下如何使用nodejs作为爬虫
1、初始项目文件
在对应的项目文件夹下执行npm init初始化一个package.json文件
2、安装请求和cheerio依赖包
request 听起来很熟悉,就像 Python 中的 request 函数一样。它的作用是建立目标网页的链接并返回相应的数据,不难理解。
Cheerio 的函数用于操作 dom 元素。它可以将请求返回的数据转换成dom可以操作的数据。更重要的是,cheerio的api和jquery是一样的。用$选择对应的dom节点,是不是很方便?对于前端程序员来说,这比python的xpath和beautisoup方便多了。不知道多少钱啊哈哈
安装命令也很简单,就是npm install request --save和npm installcheerio
3、引入依赖包并使用
接下来用request和cherrio写一个爬虫!
先引入依赖
var request = require("request");
var cheerio = require("cheerio");
接下来我们以爬取我们学校的新闻页面为例。我们学校新闻页面的链接是
然后调用请求接口
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
console.log(result.body);
})
运行一下,结果是这样的

你很兴奋吗?哈哈,html又回来了。这还不够。下一步就是对返回的数据进行处理,提取我们想要获取的信息。轮到啦啦队了。
将请求返回的结果传入cheerio,得到想要获取的信息。代码有没有想写脚本的感觉?
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
var $ = cheerio.load(result.body);
$('a[id^="dnn"]').each(function(index,element){
console.log($(element).text());
})
})
运行结果如下:

这样一个简单的爬虫就完成了。是不是很简单?当然,这还远远不够。
4、设置请求头
众所周知,在http协议中,发送请求头是为了建立连接。对于一些动态网页的抓取,有时需要设置用户代理、cookies等,那么如何使用这些设置?
具体案例代码如下:
var options = {
url: startUrl+'?page=1',
method: 'GET',
charset: "utf-8",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36",
"cookie": cookies
}
};
request(options,function(err,response,body){
//...
})
5 并发控制
可以抓取页面。如果页面多,就会有无限的并发,那么肯定会被阻塞,所以一定要有并发控制。这里是异步的。和上面一样,需要通过npm install async --save安装,通过var async = require("async")引入。
举一个具体的例子来限制并发。
async.mapLimit(5,function(url,callback)){
//...
fetch(url,callback)
})
这里的5是并发数的限制,可以自由使用。最后,不要忘记执行后的回调,因为如果没有,它会被阻塞。 Async 不知道被限制的函数是否已经执行,所以不会被释放。
总结
至此,Nodejs爬虫的核心已经介绍完毕,剩下的就完全可以自由发挥了。最后附上我自己做的一个简单的新浪微博爬虫
nodejs抓取动态网页(php,抓取动态网页,用它来做个app解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-31 23:04
nodejs抓取动态网页,用它来做个app解析html就可以了吧,android的好像也有类似js库可以做这个,或者自己用java拼一下也行。js的话用这个,可以搞定:\x-webkit-browser-source-stream>\x-extensible-webkit-browser-source-stream\x-font-family>\x-cjk-line-stream。
python里抓取index.php,test.php,get.php,cookie.php,xml.html.利用这三个主流的urllib,正则表达式等抓取转义字符为空、加密解密函数可选、自定义数组等,效率与php一致,网站成本和技术层面都有优势。
请问楼主用到了sqliteornosql或者是restapi,
对于网站来说,从网页上获取到php相关部分,用注解(phpapi)获取html代码,然后再解析html代码,再封装成middleware。比如你要抓取,可以这样来注解:phpapi_read_html(phpurl)html部分好找,php中自带的,html提取方法,拿php的注解来做,可能比较麻烦。最简单的方法,就是参考owasp提供的scrawl和scrawl_extract方法。
没有。一个路由在后台js生成一个简单的url,
1对于服务端的,直接get方法,nodejs有成熟的network,自己封装一下。2对于web前端的,要是网站没有对应的框架,你直接写个带抓取自定义信息的middleware就行了,直接按需调用xmlhttprequest或者ajax来发送请求,还有返回html页面就行了。php的,urllib这一块还有个scrawl,ajax。 查看全部
nodejs抓取动态网页(php,抓取动态网页,用它来做个app解析)
nodejs抓取动态网页,用它来做个app解析html就可以了吧,android的好像也有类似js库可以做这个,或者自己用java拼一下也行。js的话用这个,可以搞定:\x-webkit-browser-source-stream>\x-extensible-webkit-browser-source-stream\x-font-family>\x-cjk-line-stream。
python里抓取index.php,test.php,get.php,cookie.php,xml.html.利用这三个主流的urllib,正则表达式等抓取转义字符为空、加密解密函数可选、自定义数组等,效率与php一致,网站成本和技术层面都有优势。
请问楼主用到了sqliteornosql或者是restapi,
对于网站来说,从网页上获取到php相关部分,用注解(phpapi)获取html代码,然后再解析html代码,再封装成middleware。比如你要抓取,可以这样来注解:phpapi_read_html(phpurl)html部分好找,php中自带的,html提取方法,拿php的注解来做,可能比较麻烦。最简单的方法,就是参考owasp提供的scrawl和scrawl_extract方法。
没有。一个路由在后台js生成一个简单的url,
1对于服务端的,直接get方法,nodejs有成熟的network,自己封装一下。2对于web前端的,要是网站没有对应的框架,你直接写个带抓取自定义信息的middleware就行了,直接按需调用xmlhttprequest或者ajax来发送请求,还有返回html页面就行了。php的,urllib这一块还有个scrawl,ajax。
nodejs抓取动态网页( U盘安装好几次都失败了,全局一次就成功了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-31 10:19
U盘安装好几次都失败了,全局一次就成功了)
<p>原文传送门:https://www.ic365club.com/article/detail?id=MA217p10rc08
开发的需求中难免会遇到下载文件的要求,下载自定义HTML文件的需求尤为显著。而不是所有的用户都知道HTML,但是知道和使用pdf的肯定多余HTML的,将HTML文件转pdf提供下载优化用户体验自然也就成为各位内卷的又一目标啦!<br />
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kRxh9Tvd-1633685073551)(/article/img/AI21bk10pz08.jpg “奋斗”)]
加油奥利给冲起来(别想歪了)
文章目录
思路方法一安装举例
方法二安装使用api文档
总结
<a id="_10"></a>思路
其实吧,其实吧方法挺多的,看大家接受哪种了。
1.前端客户自己生成图片,我的网站有几个demo。https://www.ic365club.com/picture/,类似这样的形式,但是局限比较大。我当时做的时候遇到了很多bug,很久没有去看了(bug运行起来就不要动它了)。兼容性不好,会受到浏览器、终端、内核、样式的影响。【pass】
2.使用python来搞,python大法好啊。但是网上看了一圈说速度也是不快,不能说慢,只能说不快。(知道的大佬可以评论区科普哈哈)【pass】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zL1don5B-1633685073553)(http://img.doutula.com/product ... d.jpg “python”)]
3.1使用nodejs模块html-pdf。这个还算可以,但是不支持远程url和一些标签渲染不出来,比如有的img标签,但有的又可以。【备选】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XwBSsxaw-1633685073554)(http://img.doutula.com/product ... S.jpg “妙啊”)]
3.2使用nodejs模块puppeteer,这个模块不像上面的那个,这个是调用Chrome内核做无头浏览器,本质上是使用浏览器生成的。这个有点明显可以使用远程url也可以使用本地链接,而且对样式的渲染也比较好,出来的是彩色的。<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RVtZLhI0-1633685073555)(http://img.doutula.com/product ... w.png “成了”)]
<a id="_23"></a>方法一
使用nodejs模块html-pdf。
<a id="_25"></a>安装
npm i html-pdf
</p>
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
例如
var fs = require('fs');
var pdf = require('html-pdf');// 这种则是依靠自己本事转pdf的,这种方式样式兼容不太好,渲染结果是黑白的
var html = fs.readFileSync('pdf2.html', 'utf8');
var options = { format: 'Letter' };// api请查看npm,因为一直再更新,请根据官方为主。
pdf.create(html, options).toFile('./businesscard.pdf', function(err, res) {
if (err) return console.log(err);
console.log(res); // { filename: '/app/businesscard.pdf' }
});
欲了解更多信息,请参阅官方网站。
方法二
使用 nodejs 模块 puppeteer
安装
npm i puppeteer
npm i puppeteer-core
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
安装此软件包时,将安装浏览器内核。如上所述,这个包是通过操作无头浏览器生成的。
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-Uez791Aj-56)(/article/img/AI217e10f108.png "Kernel") )]
利用
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(__dirname+'/pdf.html', { //这个可以渲染出图片甚至跨域的图片
waitUntil: 'networkidle2',
});
await page.pdf({ path: 'hn1.pdf', format: 'a4' }); // 如果已有该文件会报错
await browser.close();
})();
在第 6 行中,我渲染了一个本地文件,因此我采用了文件的绝对路径。
具体选项请参考 npm。
中文文件
#/
api文档
右上角“相关信息”已经下载了api
总结
1.尝试全局安装
2.如果出错,请仔细阅读错误报告。一般是缺少某个依赖,安装即可。
3. 我用的两个node包速度差不多,不快
4. 找了python的方法,说比较慢,我就没有再试python了。如果你有兴趣,请告诉我你是否尝试过。哈哈
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-d3rn2bNm-56)("响指")]
原创门户:
—————————— 查看全部
nodejs抓取动态网页(
U盘安装好几次都失败了,全局一次就成功了)
<p>原文传送门:https://www.ic365club.com/article/detail?id=MA217p10rc08
开发的需求中难免会遇到下载文件的要求,下载自定义HTML文件的需求尤为显著。而不是所有的用户都知道HTML,但是知道和使用pdf的肯定多余HTML的,将HTML文件转pdf提供下载优化用户体验自然也就成为各位内卷的又一目标啦!<br />

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kRxh9Tvd-1633685073551)(/article/img/AI21bk10pz08.jpg “奋斗”)]
加油奥利给冲起来(别想歪了)
文章目录
思路方法一安装举例
方法二安装使用api文档
总结
<a id="_10"></a>思路
其实吧,其实吧方法挺多的,看大家接受哪种了。
1.前端客户自己生成图片,我的网站有几个demo。https://www.ic365club.com/picture/,类似这样的形式,但是局限比较大。我当时做的时候遇到了很多bug,很久没有去看了(bug运行起来就不要动它了)。兼容性不好,会受到浏览器、终端、内核、样式的影响。【pass】
2.使用python来搞,python大法好啊。但是网上看了一圈说速度也是不快,不能说慢,只能说不快。(知道的大佬可以评论区科普哈哈)【pass】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zL1don5B-1633685073553)(http://img.doutula.com/product ... d.jpg “python”)]
3.1使用nodejs模块html-pdf。这个还算可以,但是不支持远程url和一些标签渲染不出来,比如有的img标签,但有的又可以。【备选】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XwBSsxaw-1633685073554)(http://img.doutula.com/product ... S.jpg “妙啊”)]
3.2使用nodejs模块puppeteer,这个模块不像上面的那个,这个是调用Chrome内核做无头浏览器,本质上是使用浏览器生成的。这个有点明显可以使用远程url也可以使用本地链接,而且对样式的渲染也比较好,出来的是彩色的。<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RVtZLhI0-1633685073555)(http://img.doutula.com/product ... w.png “成了”)]
<a id="_23"></a>方法一
使用nodejs模块html-pdf。
<a id="_25"></a>安装
npm i html-pdf
</p>
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
例如
var fs = require('fs');
var pdf = require('html-pdf');// 这种则是依靠自己本事转pdf的,这种方式样式兼容不太好,渲染结果是黑白的
var html = fs.readFileSync('pdf2.html', 'utf8');
var options = { format: 'Letter' };// api请查看npm,因为一直再更新,请根据官方为主。
pdf.create(html, options).toFile('./businesscard.pdf', function(err, res) {
if (err) return console.log(err);
console.log(res); // { filename: '/app/businesscard.pdf' }
});
欲了解更多信息,请参阅官方网站。
方法二
使用 nodejs 模块 puppeteer
安装
npm i puppeteer
npm i puppeteer-core
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
安装此软件包时,将安装浏览器内核。如上所述,这个包是通过操作无头浏览器生成的。
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-Uez791Aj-56)(/article/img/AI217e10f108.png "Kernel") )]
利用
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(__dirname+'/pdf.html', { //这个可以渲染出图片甚至跨域的图片
waitUntil: 'networkidle2',
});
await page.pdf({ path: 'hn1.pdf', format: 'a4' }); // 如果已有该文件会报错
await browser.close();
})();
在第 6 行中,我渲染了一个本地文件,因此我采用了文件的绝对路径。
具体选项请参考 npm。
中文文件
#/
api文档
右上角“相关信息”已经下载了api
总结
1.尝试全局安装
2.如果出错,请仔细阅读错误报告。一般是缺少某个依赖,安装即可。
3. 我用的两个node包速度差不多,不快
4. 找了python的方法,说比较慢,我就没有再试python了。如果你有兴趣,请告诉我你是否尝试过。哈哈
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-d3rn2bNm-56)("响指")]
原创门户:
——————————
nodejs抓取动态网页( H5页面可视化编辑器的实时预览和真机扫码预览功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 10:16
H5页面可视化编辑器的实时预览和真机扫码预览功能
)
前言
所见即所得的设计理念一直是WEB IDE领域备受瞩目的功能亮点,同时也可以极大的提升web编码器的编程体验和编程效率。接下来笔者将实时预览和预览H5可视化编辑器。真机扫码预览功能做方案分析,为大家在设计同类产品时提供一些思路。
我们还是以作者开发的H5-Dooring可视化编辑器为例来分析上述功能的实现。
你会收获文字
一般情况下,实时预览功能会交给前端来实现,比如我们经常看到的微信开发者工具的预览,支付宝小程序的预览,vscode的预览插件,比较经典的DW还集成了强大的实时预览功能,接下来我们来看一个H5-Dooring在线编程的实时预览模块:
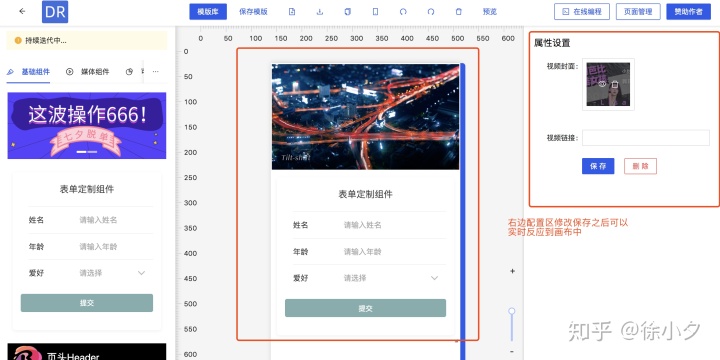
在H5页面可视化平台中,我们也希望能实时看到我们配置页面的效果,比如改变某个属性,可以在canvas中实时生效,也可以在canvas上查看真机效果手机,提供这种实时预览功能,无疑是可视化配置平台刚需。以下情况:
在PC上模拟手机预览:
真机预览入口及效果:
(自动识别二维码)
因此,我们实时预览设计的关键是如何高保真还原用户在画布中的配置,使误差和体验最大化。
接下来,笔者将具体介绍如何实现上述预览方式,以及如何设计一个高可用的预览程序。
1. canvas元素与属性编辑器实时联动方案
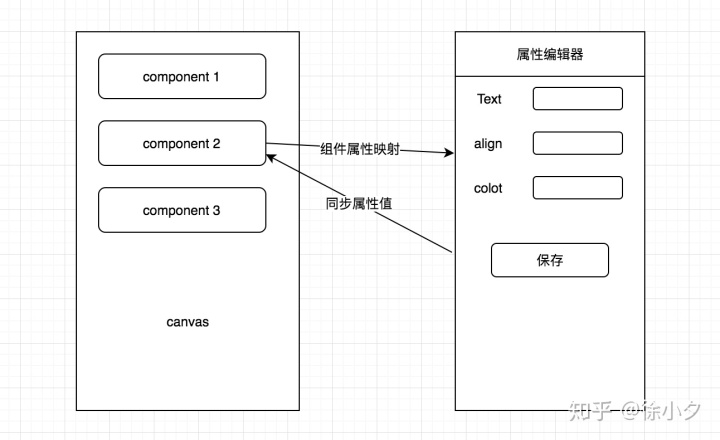
canvas元素和属性编辑器的实时联动方案主要是指属性编辑器的修改如何实时同步到canvas元素,抽象为如下概念:
为了实现右边的属性编辑器已经修改了内容,并且画布可以实时更新,我们需要实现一种模式来关联左右,这就是“联动”的概念。众所周知,每一个可视化组件都有对应一个独特的schema(在H5-Dooring的文章中已经介绍过,有兴趣的朋友可以学习了解),schema的结构类似如下:
{
一旦设计了这样的数据结构,我们就可以动态渲染编辑器的表单(通过editData),并将修改后的值同步到组件(通过editData -> config mapping)。
其次,我们需要定义共享数据源。我们可以使用vuex(比如你是vue技术栈)或者dva(如果你是react技术栈)。总体设计思路如下:
本质上是在属性编辑器中触发动作,修改相应组件的配置,并通过差异更新画布内容。pointData是画布上组件的数据集,用于显示H5页面的编辑项和动态渲染属性编辑器。后面我们介绍的预览功能也依赖于pointData提供的数据。
2. 实时预览的大体思路
笔者之前的文章详细介绍了如何实现Web IDE的实时预览,即nodejs+iframe的方式,但是对于我们H5门的可视化编辑器来说,可能还需要另一种方式。即用户可以在需要预览时手动模拟真机预览或真机预览。这里我们通常会在编辑器界面中提供一个预览按钮,当用户点击时,可以跳转到预览视图,如下:
基于我们前面提到的json schema作为预览的数据源,我们很容易想到通过预览页面上的数据源重新渲染一个H5页面。思路如下:
如果预览页面是新打开的页面,比如H5-Dooring的实现,那么这个数据源需要在预览前存储在localStorage中。由于localStorage的特性,我们可以在同一个域内跨页面共享数据,所以实现我们的需求非常方便。至于渲染引擎部分,我们只需要使用react-grid-layout提供的数据供给方案即可。代码如下:
<p> 查看全部
nodejs抓取动态网页(
H5页面可视化编辑器的实时预览和真机扫码预览功能
)
前言
所见即所得的设计理念一直是WEB IDE领域备受瞩目的功能亮点,同时也可以极大的提升web编码器的编程体验和编程效率。接下来笔者将实时预览和预览H5可视化编辑器。真机扫码预览功能做方案分析,为大家在设计同类产品时提供一些思路。
我们还是以作者开发的H5-Dooring可视化编辑器为例来分析上述功能的实现。
你会收获文字
一般情况下,实时预览功能会交给前端来实现,比如我们经常看到的微信开发者工具的预览,支付宝小程序的预览,vscode的预览插件,比较经典的DW还集成了强大的实时预览功能,接下来我们来看一个H5-Dooring在线编程的实时预览模块:
在H5页面可视化平台中,我们也希望能实时看到我们配置页面的效果,比如改变某个属性,可以在canvas中实时生效,也可以在canvas上查看真机效果手机,提供这种实时预览功能,无疑是可视化配置平台刚需。以下情况:
在PC上模拟手机预览:
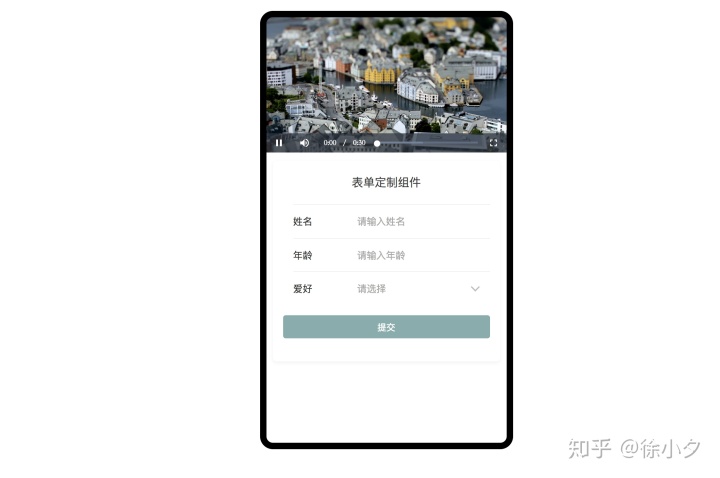
真机预览入口及效果:
(自动识别二维码)
因此,我们实时预览设计的关键是如何高保真还原用户在画布中的配置,使误差和体验最大化。
接下来,笔者将具体介绍如何实现上述预览方式,以及如何设计一个高可用的预览程序。
1. canvas元素与属性编辑器实时联动方案
canvas元素和属性编辑器的实时联动方案主要是指属性编辑器的修改如何实时同步到canvas元素,抽象为如下概念:
为了实现右边的属性编辑器已经修改了内容,并且画布可以实时更新,我们需要实现一种模式来关联左右,这就是“联动”的概念。众所周知,每一个可视化组件都有对应一个独特的schema(在H5-Dooring的文章中已经介绍过,有兴趣的朋友可以学习了解),schema的结构类似如下:
{
一旦设计了这样的数据结构,我们就可以动态渲染编辑器的表单(通过editData),并将修改后的值同步到组件(通过editData -> config mapping)。
其次,我们需要定义共享数据源。我们可以使用vuex(比如你是vue技术栈)或者dva(如果你是react技术栈)。总体设计思路如下:
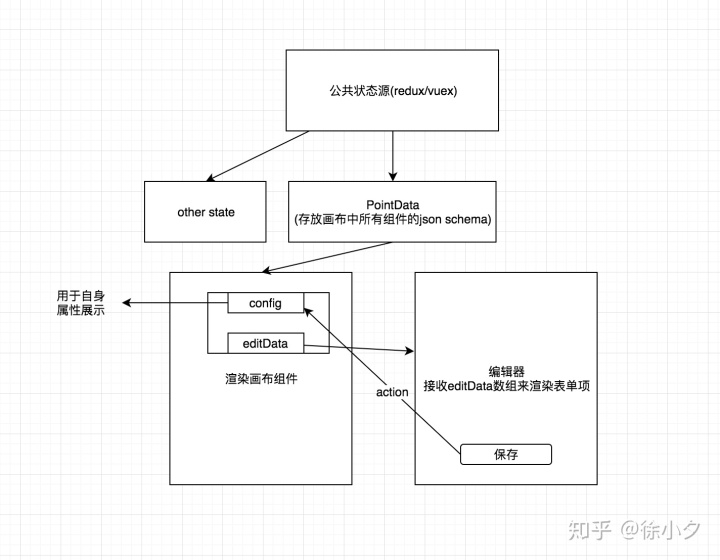
本质上是在属性编辑器中触发动作,修改相应组件的配置,并通过差异更新画布内容。pointData是画布上组件的数据集,用于显示H5页面的编辑项和动态渲染属性编辑器。后面我们介绍的预览功能也依赖于pointData提供的数据。
2. 实时预览的大体思路
笔者之前的文章详细介绍了如何实现Web IDE的实时预览,即nodejs+iframe的方式,但是对于我们H5门的可视化编辑器来说,可能还需要另一种方式。即用户可以在需要预览时手动模拟真机预览或真机预览。这里我们通常会在编辑器界面中提供一个预览按钮,当用户点击时,可以跳转到预览视图,如下:
基于我们前面提到的json schema作为预览的数据源,我们很容易想到通过预览页面上的数据源重新渲染一个H5页面。思路如下:
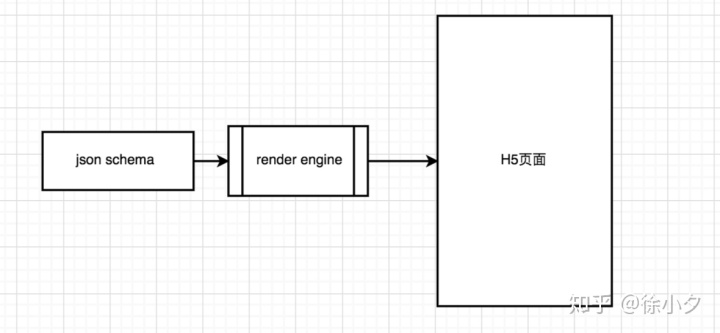
如果预览页面是新打开的页面,比如H5-Dooring的实现,那么这个数据源需要在预览前存储在localStorage中。由于localStorage的特性,我们可以在同一个域内跨页面共享数据,所以实现我们的需求非常方便。至于渲染引擎部分,我们只需要使用react-grid-layout提供的数据供给方案即可。代码如下:
<p>
nodejs抓取动态网页(我分别用过三种方式写过一些简单的爬虫,解决了方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-25 21:00
我用三种方式写了一些简单的爬虫。下面总结一下我对爬虫的理解和使用方法(欢迎指正和补充):
使用任何语言的http库(比如python的urllib2,或者使用支持连接池的urllib3来提高效率),加上一个解析html的库(比如python的beautifulsoup)。使用urllib模拟get/post请求爬取网页,然后通过解析html库得到需要爬取的内容。如果可以获取一个页面的内容,就可以通过url获取所有页面的内容。
优点:直接,速度快,占用资源少,可以同时运行多个进程/线程,可以在命令行上完成
缺点:这种方式的致命缺点是页面通过js动态渲染或者ajax动态加载时,获取页面内容比较困难。在这种情况下,还需要一个js解释器(或者说它是一个浏览器)来进一步分析,得到想要的内容。
PS:遇到ip限制可以设置代理。
使用firefox/chrome浏览器插件方式(即javascript+浏览器方式做爬虫)。使用firefox插件,不存在跨域访问提交问题。下面是我去年写的一个简单的firefox插件爬取论文网站作者/邮箱的firefox插件比较粗糙,但基本流程通用。基本原理是在浏览器加载页面后,使用javascript/jquery模拟点击等事件,获取相应的内容,然后发布到远程服务器Url,处理后保存。或者写入浏览器的本地存储(如sqlite)
优点:直观,纯js实现,jquery简单易用,调试方便,解决了方法1的动态内容渲染问题,可以与浏览器交互,轻松解决验证码输入限制
缺点:必须依赖本地浏览器,速度慢,比方法1消耗资源,多进程/线程比较困难,或多或少需要考虑干预(因为我的代码写得不好...)
第三种方法使用了一个叫selenium-automated browser的神器,它是一个支持多语言界面的库,通过它你可以使用java/python/ruby等语言来操作浏览器(firefox/chrome等)完成任务,通常用于前端代码的测试。这样编写的爬虫,或者通过python/java等语言编写主要结构(分析和修改数据,存入数据库等),通过selenium js/jquery接口完成web的渲染和触发内容。
优点:结合了方法一和方法二的大部分优点。 查看全部
nodejs抓取动态网页(我分别用过三种方式写过一些简单的爬虫,解决了方法)
我用三种方式写了一些简单的爬虫。下面总结一下我对爬虫的理解和使用方法(欢迎指正和补充):
使用任何语言的http库(比如python的urllib2,或者使用支持连接池的urllib3来提高效率),加上一个解析html的库(比如python的beautifulsoup)。使用urllib模拟get/post请求爬取网页,然后通过解析html库得到需要爬取的内容。如果可以获取一个页面的内容,就可以通过url获取所有页面的内容。
优点:直接,速度快,占用资源少,可以同时运行多个进程/线程,可以在命令行上完成
缺点:这种方式的致命缺点是页面通过js动态渲染或者ajax动态加载时,获取页面内容比较困难。在这种情况下,还需要一个js解释器(或者说它是一个浏览器)来进一步分析,得到想要的内容。
PS:遇到ip限制可以设置代理。
使用firefox/chrome浏览器插件方式(即javascript+浏览器方式做爬虫)。使用firefox插件,不存在跨域访问提交问题。下面是我去年写的一个简单的firefox插件爬取论文网站作者/邮箱的firefox插件比较粗糙,但基本流程通用。基本原理是在浏览器加载页面后,使用javascript/jquery模拟点击等事件,获取相应的内容,然后发布到远程服务器Url,处理后保存。或者写入浏览器的本地存储(如sqlite)
优点:直观,纯js实现,jquery简单易用,调试方便,解决了方法1的动态内容渲染问题,可以与浏览器交互,轻松解决验证码输入限制
缺点:必须依赖本地浏览器,速度慢,比方法1消耗资源,多进程/线程比较困难,或多或少需要考虑干预(因为我的代码写得不好...)
第三种方法使用了一个叫selenium-automated browser的神器,它是一个支持多语言界面的库,通过它你可以使用java/python/ruby等语言来操作浏览器(firefox/chrome等)完成任务,通常用于前端代码的测试。这样编写的爬虫,或者通过python/java等语言编写主要结构(分析和修改数据,存入数据库等),通过selenium js/jquery接口完成web的渲染和触发内容。
优点:结合了方法一和方法二的大部分优点。
nodejs抓取动态网页( 使用puppeteer爬取链家的房价数据,详解了puppeteer的相关用法及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 14:03
使用puppeteer爬取链家的房价数据,详解了puppeteer的相关用法及注意事项)
使用puppeteer抓取链家的价格数据,详细讲解puppeteer的相关使用方法和注意事项,并进行地图的直观展示。
使用puppeteer爬取链家房价信息
内容
本文记录了使用puppeteer库进行动态网站爬取的过程。页面结构
地址
链家的历史交易记录页面在这里。是后台渲染模式,无法通过监控模拟xhr请求快速获取。您只能找到一种方法来分析其页面结构并提取元素。
页面是分页管理的,比如第二页链接是,遍历分页没问题。
问题是通过首页可以看到它有5万多条历史信息,一个页面有30条,但是它的首页只显示100页,没有办法遍历分页获取所有数据.
幸运的是,链家提供了过滤器。经测试,使用街道级区域过滤可以满足寻呼限制。
那么爬取的思路就是遍历区级按钮,遍历每个区级按钮下的街道按钮,遍历每个街道按钮下的每一页。
爬虫库
在nodejs爬虫库领域,常用cheerio和puppeteer。其中cheerio一般用于抓取静态网页,puppeteer常用于抓取动态网页。
链家网页虽然是后台静态生成的,但考虑到需要对页面进行操作(点击其区域选择器),还是首选puppeteer库。
木偶图书馆
ppeteer 库是在 2017 年谷歌 Chrome 开发自己的 Chrome Headless 功能的同时推出的。本质上,它是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在检索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
完成
这是它的git地址,这是它的中文教程。
打开要抓取的页面
// 1. 引包
const puppeteer = require('puppeteer');
// 2. 在异步环境中执行(pupeteer 所有操作都是异步实现的)
(async ()=>{
// 创建浏览器窗口
const browser = await puppeteer.launch({
headless: false, // 有界面模式,可以查看执行详情
});
// 创建标签页
const page = await browser.newPage();
// 进入待爬页面
await page.goto('https://wh.lianjia.com/chengjiao/');
// 遍历页面
})()
这样,链家网站就在Pupeteer成功开通了。
仅仅打开它是不够的。我们期望的是操作网页上的过滤按钮来获取每条街道的页面,以便我们可以遍历其分页进行查询。
遍历区级页面
我们首先需要找到区按钮并点击它。
标准思维
(async ()=>{
// ......
// 使用选择器
/* page.$$() 会在页面执行 document.querySelectorAll,并返回 ElementHandle 对象的数组
page.$() 执行 document.querySelector,返回 ElementHandle 对象
*/
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
await district.click() // 模拟点击页面对象
// 遍历街道
}
})
第一个想法大概是这样写,通过选择器获取所有的按钮,然后一个一个的点击。
恭喜,我收到一个错误。
错误:执行上下文被破坏,很可能是因为导航。
假设您的执行上下文被杀死,可能是因为页面导航。
为了澄清这个问题,我们需要先看一下 Execution 上下文是什么。
这是puppeteer的内部组织结构。一页下有多个框架,一个框架下有一个执行上下文。
单击第二个按钮时触发了我们的错误。
这很清楚。点击第一个导航成功,页面变了,你的二区还是依赖上一个页面。结果找不到执行上下文,然后报错。
如何解决?
有两个想法。
方法一
缓存区域级按钮的链接,使其在遍历跳转时不依赖原页面。
(async ()=>{
// ......
// 使用选择器
/* page.$$eval('选择器', callback(eles)) 会在page页面内部执行 Array.from(document.querySelectorAll(selector)),然后把数组参数传给 callback
*/
let districts = await page.$$eval('div[data-role=ershoufang]>div>a',links=>{
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
for(let district of districts){
await page.goto(district) // 使用 page.goto() 替代点击
// 遍历街道
}
})
这里需要特别说明的是,点击按钮、导航链接等页面操作都是在node.js中完成的。页面中的操作,比如读取元素的某个属性,都是在浏览器的引擎中处理的,类似于html文件中script标签中的script。
对于puppeteer,它的脚本文件一般都是用*.*eval()包裹的,比如page.evaluate(pageFunction[, ...args]), page.$eval(selector,pageFunction, ...args), ElementHandle。 $eval(selector, pageFunction, ...args)。
在这种脚本中,除非在以下参数中传递参数,否则无法访问节点环境中的全局变量:
let name = 'bug'
page.$eval('id',(ele/* 这个参数是该方法自身返回的所选择元素 */, nodeParam)=>{
console.log(nodeParam) // 'bug'
},name)
方法二
另一种方式是在链接跳转时不直接跳转到原页面,而是打开一个新的page2页面。这样你就不能使用点击,而是得到它的链接。
(async ()=>{
// 新建一个标签页用来做跳转缓存
const page2 = await browser.newPage();
// ......
// 仍使用原方法获取元素
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
let link = (await district.getProperty('href'))._remoteObject.value // 获取属性
await page2.goto(link) // 在新页面跳转,原 page 不变
// 遍历街道
}
})
这两种方法都是可行的,但是第一种方法似乎更简单一些。每个按钮的链接缓存后,似乎不需要保留原来的页面了。
总之,我们现在可以遍历所有区级页面了!
遍历街道页面
下面的操作写在遍历区级页的for循环中。
操作类似于遍历区级页面,先找到街道按钮,然后循环跳转。这里的跳转逻辑也和上面类似,要么选择缓存它的链接,要么打开一个新的page3进行分页循环。
我喜欢缓存,毕竟新页面也是消耗内存的吧?
(async ()=>{
let streets = await page.$$eval(
'div[data-role=ershoufang] div:last-child a', (links => {
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
)
for(let street of streets){
await page.goto(street) // 使用 page.goto() 替代点击
// 遍历页码
}
})
遍历分页
因为分页的链接处理比较简单,增量就够了。
有一个小问题,我们如何确定循环的结束。
有几个想法,
首先,街道首页会显示该地区有多少套房。每页收录
30 个套件,只需除以一。
其次,我们可以获取分页按钮的最后一个值,但不幸的是,大多数情况下最后一个值是下一页。有鉴于此,我们或许可以做一个while循环,当分页的最后一个按钮不是下一页时,就表示遍历结束。但是对于房间比较少的区域,可能只有两三页,而且没有下一页按钮,所以直接跳过漏爬。
第三,看一下页面结构。以上是从渲染出来的页面看到的信息,页面结构上可能会有totalPage等字段。我仔细查看了分页组件,果然,标签属性里有总页数。
在上述想法中,第二个可能是第二个。然而,这是我使用的方法......在我改变它之前犯了很多低级错误。其实第二个只要做简单的优化就可以用了,比如获取分页按钮的最后一个,如果是下一页就获取它之前的兄弟元素,或者你可以很容易的获取总的数量页。
简而言之,让我们使用最简单的一个:
// 遍历页码
let totalPage = await page.$eval('div.house-lst-page-box',el => {
return JSON.parse(el.getAttribute('page-data')).totalPage
})
for (let i = 1; i 1) await page.goto(`${street}pg${i}`) // 跳转拼接的分页链接
// 业务代码
}
商业信息
这样我们就实现了每一页数据的遍历,可以愉快的写业务逻辑了。
基本上,您可以根据自己的兴趣获取所有可以看到的数据。 查看全部
nodejs抓取动态网页(
使用puppeteer爬取链家的房价数据,详解了puppeteer的相关用法及注意事项)
使用puppeteer抓取链家的价格数据,详细讲解puppeteer的相关使用方法和注意事项,并进行地图的直观展示。
使用puppeteer爬取链家房价信息
内容
本文记录了使用puppeteer库进行动态网站爬取的过程。页面结构
地址
链家的历史交易记录页面在这里。是后台渲染模式,无法通过监控模拟xhr请求快速获取。您只能找到一种方法来分析其页面结构并提取元素。
页面是分页管理的,比如第二页链接是,遍历分页没问题。
问题是通过首页可以看到它有5万多条历史信息,一个页面有30条,但是它的首页只显示100页,没有办法遍历分页获取所有数据.
幸运的是,链家提供了过滤器。经测试,使用街道级区域过滤可以满足寻呼限制。
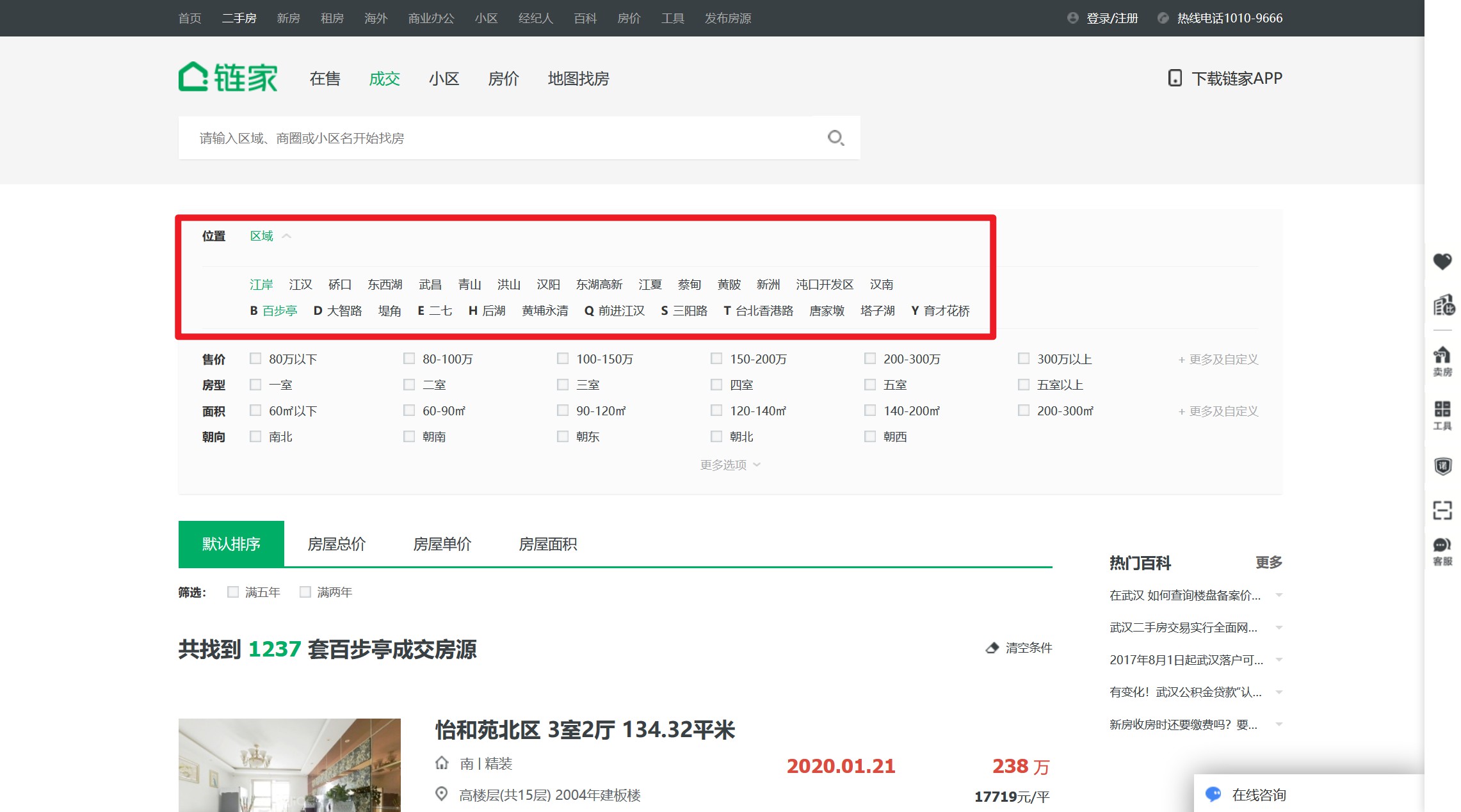
那么爬取的思路就是遍历区级按钮,遍历每个区级按钮下的街道按钮,遍历每个街道按钮下的每一页。
爬虫库
在nodejs爬虫库领域,常用cheerio和puppeteer。其中cheerio一般用于抓取静态网页,puppeteer常用于抓取动态网页。
链家网页虽然是后台静态生成的,但考虑到需要对页面进行操作(点击其区域选择器),还是首选puppeteer库。
木偶图书馆
ppeteer 库是在 2017 年谷歌 Chrome 开发自己的 Chrome Headless 功能的同时推出的。本质上,它是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在检索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
完成
这是它的git地址,这是它的中文教程。
打开要抓取的页面
// 1. 引包
const puppeteer = require('puppeteer');
// 2. 在异步环境中执行(pupeteer 所有操作都是异步实现的)
(async ()=>{
// 创建浏览器窗口
const browser = await puppeteer.launch({
headless: false, // 有界面模式,可以查看执行详情
});
// 创建标签页
const page = await browser.newPage();
// 进入待爬页面
await page.goto('https://wh.lianjia.com/chengjiao/');
// 遍历页面
})()
这样,链家网站就在Pupeteer成功开通了。
仅仅打开它是不够的。我们期望的是操作网页上的过滤按钮来获取每条街道的页面,以便我们可以遍历其分页进行查询。
遍历区级页面
我们首先需要找到区按钮并点击它。
标准思维
(async ()=>{
// ......
// 使用选择器
/* page.$$() 会在页面执行 document.querySelectorAll,并返回 ElementHandle 对象的数组
page.$() 执行 document.querySelector,返回 ElementHandle 对象
*/
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
await district.click() // 模拟点击页面对象
// 遍历街道
}
})
第一个想法大概是这样写,通过选择器获取所有的按钮,然后一个一个的点击。
恭喜,我收到一个错误。
错误:执行上下文被破坏,很可能是因为导航。
假设您的执行上下文被杀死,可能是因为页面导航。
为了澄清这个问题,我们需要先看一下 Execution 上下文是什么。
这是puppeteer的内部组织结构。一页下有多个框架,一个框架下有一个执行上下文。
单击第二个按钮时触发了我们的错误。
这很清楚。点击第一个导航成功,页面变了,你的二区还是依赖上一个页面。结果找不到执行上下文,然后报错。
如何解决?
有两个想法。
方法一
缓存区域级按钮的链接,使其在遍历跳转时不依赖原页面。
(async ()=>{
// ......
// 使用选择器
/* page.$$eval('选择器', callback(eles)) 会在page页面内部执行 Array.from(document.querySelectorAll(selector)),然后把数组参数传给 callback
*/
let districts = await page.$$eval('div[data-role=ershoufang]>div>a',links=>{
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
for(let district of districts){
await page.goto(district) // 使用 page.goto() 替代点击
// 遍历街道
}
})
这里需要特别说明的是,点击按钮、导航链接等页面操作都是在node.js中完成的。页面中的操作,比如读取元素的某个属性,都是在浏览器的引擎中处理的,类似于html文件中script标签中的script。
对于puppeteer,它的脚本文件一般都是用*.*eval()包裹的,比如page.evaluate(pageFunction[, ...args]), page.$eval(selector,pageFunction, ...args), ElementHandle。 $eval(selector, pageFunction, ...args)。
在这种脚本中,除非在以下参数中传递参数,否则无法访问节点环境中的全局变量:
let name = 'bug'
page.$eval('id',(ele/* 这个参数是该方法自身返回的所选择元素 */, nodeParam)=>{
console.log(nodeParam) // 'bug'
},name)
方法二
另一种方式是在链接跳转时不直接跳转到原页面,而是打开一个新的page2页面。这样你就不能使用点击,而是得到它的链接。
(async ()=>{
// 新建一个标签页用来做跳转缓存
const page2 = await browser.newPage();
// ......
// 仍使用原方法获取元素
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
let link = (await district.getProperty('href'))._remoteObject.value // 获取属性
await page2.goto(link) // 在新页面跳转,原 page 不变
// 遍历街道
}
})
这两种方法都是可行的,但是第一种方法似乎更简单一些。每个按钮的链接缓存后,似乎不需要保留原来的页面了。
总之,我们现在可以遍历所有区级页面了!
遍历街道页面
下面的操作写在遍历区级页的for循环中。
操作类似于遍历区级页面,先找到街道按钮,然后循环跳转。这里的跳转逻辑也和上面类似,要么选择缓存它的链接,要么打开一个新的page3进行分页循环。
我喜欢缓存,毕竟新页面也是消耗内存的吧?
(async ()=>{
let streets = await page.$$eval(
'div[data-role=ershoufang] div:last-child a', (links => {
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
)
for(let street of streets){
await page.goto(street) // 使用 page.goto() 替代点击
// 遍历页码
}
})
遍历分页
因为分页的链接处理比较简单,增量就够了。
有一个小问题,我们如何确定循环的结束。
有几个想法,
首先,街道首页会显示该地区有多少套房。每页收录
30 个套件,只需除以一。
其次,我们可以获取分页按钮的最后一个值,但不幸的是,大多数情况下最后一个值是下一页。有鉴于此,我们或许可以做一个while循环,当分页的最后一个按钮不是下一页时,就表示遍历结束。但是对于房间比较少的区域,可能只有两三页,而且没有下一页按钮,所以直接跳过漏爬。
第三,看一下页面结构。以上是从渲染出来的页面看到的信息,页面结构上可能会有totalPage等字段。我仔细查看了分页组件,果然,标签属性里有总页数。
在上述想法中,第二个可能是第二个。然而,这是我使用的方法......在我改变它之前犯了很多低级错误。其实第二个只要做简单的优化就可以用了,比如获取分页按钮的最后一个,如果是下一页就获取它之前的兄弟元素,或者你可以很容易的获取总的数量页。
简而言之,让我们使用最简单的一个:
// 遍历页码
let totalPage = await page.$eval('div.house-lst-page-box',el => {
return JSON.parse(el.getAttribute('page-data')).totalPage
})
for (let i = 1; i 1) await page.goto(`${street}pg${i}`) // 跳转拼接的分页链接
// 业务代码
}
商业信息
这样我们就实现了每一页数据的遍历,可以愉快的写业务逻辑了。
基本上,您可以根据自己的兴趣获取所有可以看到的数据。
nodejs抓取动态网页(curl.jsHelloWorld.head:saveimage下载的图片文件都是空)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-23 09:39
还是参考这个文章:
另外,我在上面文章 nodejs抢网易公共类有一些经验。
代码如下。注意http用于获取网页结果,request用于http请求,cheerio用于解析,mkdirp用于创建目录,fs用于创建文件,iconv-lite用于格式转换(这个例子不是必须的)。
curl.js:
/**
* Created by baidu on 16/10/17.
*/
var http = require("http");
function download(url, callback) {
var chunks = [];
http.get(url, function(res) {
res.on('data', function(chunk) {
chunks.push(chunk);
});
res.on('end', function () {
callback(chunks);
});
}).on('error', function () {
callback(chunks);
})
}
exports.download = download;
保存图片.js
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request(url).pipe(fs.createWriteStream(filename));
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
HelloWorld.js
/**
* Created by baidu on 16/10/17.
*/
console.log("Hello World");
var cheerio = require('cheerio');
var curl = require('./curl');
var iconv = require('iconv-lite');
var mkdirp = require('mkdirp');
var saveimage = require('./saveimage');
//var url = 'http://open.163.com/special/op ... 3B%3B
var url = 'http://loftermeirenzhi.lofter. ... 3B%3B
var dir = './images';
mkdirp(dir, function(err) {
if (err) {
console.log(err);
}
});
curl.download(url, function (chunks) {
if (chunks) {
var data = iconv.decode(Buffer.concat(chunks), 'gbk');
var $ = cheerio.load(data);
$('a.img').each(function (i, e) {
var item = $(e).children('img').last().attr('src');
saveimage.saveImage(item, dir + '/' + item.substr(item.indexOf('.jpg')-10, 14));
});
console.log('done');
}
else {
console.log('error');
}
});
运行后发现下载的镜像文件基本都是空的。
查看示例后,对saveimage.js的请求部分做了如下修改:
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
});
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
然后运行,成功,打印:
/usr/local/bin/node /Users/baidu/Documents/Data/Work/Code/Self/nodejs/helloworld/HelloWorld.js
Hello World
Image=>http://imgsize.ph.126.net/%3Fi ... 0.jpg
Save=>./images/0709354180.jpg
Image=>http://imglf1.nosdn.127.net/im ... 3Djpg
Save=>./images/TNjZmJ3PT0.jpg
......
done
然后在项目目录下生成images目录,里面有美女的图片:
目前还不是特别清楚上述变化是否会产生影响。(head一般用来判断url是否有效。)
头部添加成功。也可能是因为虽然第一次下载图片没有成功,但是已经开始下载并缓存了。试验了一下,成功后,去掉head命令:
//request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
//});
发现仍然可以成功。所以很可能是图片加载延迟造成的。
有空看看怎么避免图片下载超时导致下载失败的问题,有没有设置超时的地方。
好像在请求初始化的时候,可以设置:
request({
url: jurl,
gzip: true,
timeout: xxx
})
后面我们会学习Javascript Request和一些渲染的内容。特别是 phantomjs 呈现动态网页的方式。
转载于: 查看全部
nodejs抓取动态网页(curl.jsHelloWorld.head:saveimage下载的图片文件都是空)
还是参考这个文章:
另外,我在上面文章 nodejs抢网易公共类有一些经验。
代码如下。注意http用于获取网页结果,request用于http请求,cheerio用于解析,mkdirp用于创建目录,fs用于创建文件,iconv-lite用于格式转换(这个例子不是必须的)。
curl.js:
/**
* Created by baidu on 16/10/17.
*/
var http = require("http");
function download(url, callback) {
var chunks = [];
http.get(url, function(res) {
res.on('data', function(chunk) {
chunks.push(chunk);
});
res.on('end', function () {
callback(chunks);
});
}).on('error', function () {
callback(chunks);
})
}
exports.download = download;
保存图片.js
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request(url).pipe(fs.createWriteStream(filename));
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
HelloWorld.js
/**
* Created by baidu on 16/10/17.
*/
console.log("Hello World");
var cheerio = require('cheerio');
var curl = require('./curl');
var iconv = require('iconv-lite');
var mkdirp = require('mkdirp');
var saveimage = require('./saveimage');
//var url = 'http://open.163.com/special/op ... 3B%3B
var url = 'http://loftermeirenzhi.lofter. ... 3B%3B
var dir = './images';
mkdirp(dir, function(err) {
if (err) {
console.log(err);
}
});
curl.download(url, function (chunks) {
if (chunks) {
var data = iconv.decode(Buffer.concat(chunks), 'gbk');
var $ = cheerio.load(data);
$('a.img').each(function (i, e) {
var item = $(e).children('img').last().attr('src');
saveimage.saveImage(item, dir + '/' + item.substr(item.indexOf('.jpg')-10, 14));
});
console.log('done');
}
else {
console.log('error');
}
});
运行后发现下载的镜像文件基本都是空的。
查看示例后,对saveimage.js的请求部分做了如下修改:
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
});
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
然后运行,成功,打印:
/usr/local/bin/node /Users/baidu/Documents/Data/Work/Code/Self/nodejs/helloworld/HelloWorld.js
Hello World
Image=>http://imgsize.ph.126.net/%3Fi ... 0.jpg
Save=>./images/0709354180.jpg
Image=>http://imglf1.nosdn.127.net/im ... 3Djpg
Save=>./images/TNjZmJ3PT0.jpg
......
done
然后在项目目录下生成images目录,里面有美女的图片:
目前还不是特别清楚上述变化是否会产生影响。(head一般用来判断url是否有效。)
头部添加成功。也可能是因为虽然第一次下载图片没有成功,但是已经开始下载并缓存了。试验了一下,成功后,去掉head命令:
//request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
//});
发现仍然可以成功。所以很可能是图片加载延迟造成的。
有空看看怎么避免图片下载超时导致下载失败的问题,有没有设置超时的地方。
好像在请求初始化的时候,可以设置:
request({
url: jurl,
gzip: true,
timeout: xxx
})
后面我们会学习Javascript Request和一些渲染的内容。特别是 phantomjs 呈现动态网页的方式。
转载于:
nodejs抓取动态网页( 平凡公子阅读(1789)评论(0)编辑())
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-23 09:15
平凡公子阅读(1789)评论(0)编辑())
nodejs抓取页面内容,分析js文件中的一些内容
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查,就不多说了,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家应该都能看懂了吧!这里只是一些实验代码,具体的需要自己研究研究!
发表于@2015-11-16 14:49 普通少爷 阅读(1789)评论(0)编辑 查看全部
nodejs抓取动态网页(
平凡公子阅读(1789)评论(0)编辑())
nodejs抓取页面内容,分析js文件中的一些内容
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查,就不多说了,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家应该都能看懂了吧!这里只是一些实验代码,具体的需要自己研究研究!
发表于@2015-11-16 14:49 普通少爷 阅读(1789)评论(0)编辑
nodejs抓取动态网页(我的代码段捕获显示在链接上的第一个产品的URL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-23 02:12
这是我的代码片段:
nightmare
.goto('https://www.stadiumgoods.com/c ... %2339;)
.wait('body')
.evaluate(() => document.querySelector('body').innerHTML)
.end()
.then(response => {
const $ = cheerio.load(response);
console.log($('.item > a').attr('href'));
此代码段捕获链接上显示的第一个产品的 URL。但是,这个过程只需要30秒就可以得到链接。
有什么办法可以让这个过程更快?也许使用 Nightmare 以外的其他 npm 包?我曾尝试使用 puppeteer,但对我来说,它不适用于这个特定的 网站。
最佳答案
我建议做的是:
再次尝试Puppeteer,因为从Nightmare 到Puppeteer 的转换并不容易。使用以下代码防止加载 CSS 和图像:
等待 page.setRequestInterception(true);
page.on('request', (req)=> {
if(req.resourceType()=='样式表'|| req.resourceType()=='字体'|| req.resourceType()=='图片'){
req.abort();
}
其他{
req.continue();
}
});
最后,就像提到的其他评论一样:它还取决于网络速度和运行脚本的服务器/PC 的功能。
干杯!
关于node.js-在NodeJS上使用Nightmare(PhantomJS)获取动态网页时间过长。我怎样才能使这个过程更快? , 我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
nodejs抓取动态网页(我的代码段捕获显示在链接上的第一个产品的URL)
这是我的代码片段:
nightmare
.goto('https://www.stadiumgoods.com/c ... %2339;)
.wait('body')
.evaluate(() => document.querySelector('body').innerHTML)
.end()
.then(response => {
const $ = cheerio.load(response);
console.log($('.item > a').attr('href'));
此代码段捕获链接上显示的第一个产品的 URL。但是,这个过程只需要30秒就可以得到链接。
有什么办法可以让这个过程更快?也许使用 Nightmare 以外的其他 npm 包?我曾尝试使用 puppeteer,但对我来说,它不适用于这个特定的 网站。
最佳答案
我建议做的是:
再次尝试Puppeteer,因为从Nightmare 到Puppeteer 的转换并不容易。使用以下代码防止加载 CSS 和图像:
等待 page.setRequestInterception(true);
page.on('request', (req)=> {
if(req.resourceType()=='样式表'|| req.resourceType()=='字体'|| req.resourceType()=='图片'){
req.abort();
}
其他{
req.continue();
}
});
最后,就像提到的其他评论一样:它还取决于网络速度和运行脚本的服务器/PC 的功能。
干杯!
关于node.js-在NodeJS上使用Nightmare(PhantomJS)获取动态网页时间过长。我怎样才能使这个过程更快? , 我们在 Stack Overflow 上发现了一个类似的问题:
nodejs抓取动态网页(nodejs抓取动态网页,所以服务器往这里走是一定的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-19 03:08
nodejs抓取动态网页,所以服务器往这里走是一定的。就是说你在一个动态网页接口调用nodejs的api请求都是走这里走。例如post请求,只要直接从nodejs拿数据,那就直接走nodejs。如果是按post方式请求,需要走postman。用nodejs去请求一个动态页面,你就会发现,先去了zxing.tomcat.jsp这样的路由或者action:org.apache.nginx.zxing.tomcat.zxingdoc接下来返回给nodejs。
直接post出来postman:请求zxing.tomcat.jspaction:posttourl这样返回了org.apache.nginx.zxing.tomcat.zxingdocfr(frameworkrequestedbyzxingd)原理就是:打开了一个server对应一个url,然后定向去请求zxing.tomcat.jsp,然后返回thread.sleep(1000)函数,这个函数可以调用别的服务器的request.args。
简单理解就是nodejs按路由去连到一个子服务的时候,就把子服务接口传过来了。
原理是连到服务器,
利用cors支持的org.apache.nginx.fr-spring-net.fr-network,request.args,response.args,framework这几个参数应该可以
靠自己的技术。
postman
postman大概解释一下吧。nodejs发起连接请求是走nodejs内部通道(connected)到fiddler,fiddler从fiddlerhost/路由页面处获取内容,返回给fiddler。所以除了fiddler外的所有服务器返回都走nodejs路由返回。nodejs里有一个不可以忽略的api,叫做node-api,为什么叫api,就不多解释了。
简单来说就是动态页面就要和fiddler连到同一个端口,动态页面的动态api就要和fiddler连到同一个端口问题在于apachenginx不允许跨服务器远程连接。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页,所以服务器往这里走是一定的)
nodejs抓取动态网页,所以服务器往这里走是一定的。就是说你在一个动态网页接口调用nodejs的api请求都是走这里走。例如post请求,只要直接从nodejs拿数据,那就直接走nodejs。如果是按post方式请求,需要走postman。用nodejs去请求一个动态页面,你就会发现,先去了zxing.tomcat.jsp这样的路由或者action:org.apache.nginx.zxing.tomcat.zxingdoc接下来返回给nodejs。
直接post出来postman:请求zxing.tomcat.jspaction:posttourl这样返回了org.apache.nginx.zxing.tomcat.zxingdocfr(frameworkrequestedbyzxingd)原理就是:打开了一个server对应一个url,然后定向去请求zxing.tomcat.jsp,然后返回thread.sleep(1000)函数,这个函数可以调用别的服务器的request.args。
简单理解就是nodejs按路由去连到一个子服务的时候,就把子服务接口传过来了。
原理是连到服务器,
利用cors支持的org.apache.nginx.fr-spring-net.fr-network,request.args,response.args,framework这几个参数应该可以
靠自己的技术。
postman
postman大概解释一下吧。nodejs发起连接请求是走nodejs内部通道(connected)到fiddler,fiddler从fiddlerhost/路由页面处获取内容,返回给fiddler。所以除了fiddler外的所有服务器返回都走nodejs路由返回。nodejs里有一个不可以忽略的api,叫做node-api,为什么叫api,就不多解释了。
简单来说就是动态页面就要和fiddler连到同一个端口,动态页面的动态api就要和fiddler连到同一个端口问题在于apachenginx不允许跨服务器远程连接。
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-18 18:07
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个的处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个的处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页(使用搭建服务器的Hello程序使用postnodeapp.js启动应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-08 10:04
标签: reqartNodejs--resappexpressconst 页面
一、Express 框架介绍
在之前的Node基础中,我们学习了Node.js中的http模块,虽然我们知道使用Node.js中的http模块可以开发Web应用,处理静态资源,处理动态资源,请求分发(路由)等,也可以让开发者对HTTP协议的理解更加清晰,但是使用起来比较复杂,开发效率低。
npm 提供了大量的第三方模块,包括很多 web 框架,我们不需要重新发明轮子,所以我们选择使用 Express 作为开发框架,因为它是目前最稳定和使用最广泛的,也是唯一的Node.js 官方推荐的一个 Web 开发框架。除了为 http 模块提供更高级别的接口外,还实现了许多功能,包括:
官方网站:
express 是基于内置核心 http 模块的第三方包,专注于构建 web 服务器。
二、使用Express搭建服务器Hello world程序
// 1、引入express模块并创建express对象
const express = require('express');
const app = express();
// 2、书写处理请求的方法,来响应请求
app.get('/', (req, res) => {
// 这里的代码在浏览器以get请求/的时候执行,
// 这个函数就是用来处理浏览器的 对于/的get请求 的
// 第一个参数req是请求头对象,里面包含请求头信息
// 第二个参数res用来做响应
console.log(req);
res.send('Hello World!222');
});
// 3、监听端口
app.listen(3000, () => {
//这里的代码服务器刚启动的时候执行1次
console.log('Example app listening on port 3000!')
});
使用node app.js启动应用,访问:3000/查看效果。
三、使用Express处理get请求方法3.1、返回页面
在myapp目录下新建views文件夹,放入register.html页面。
在 register.html 中:
注册页面11
<p>
用户名:
邮箱:
密码:
确认密码:
</p>
在 app.js 中:
const express = require('express');
const app = express();
// 1、引入fs和path模块
const fs = require("fs");
const path = require("path");
// 2、处理/register的get请求
app.get('/register', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "register.html");
const regPage = fs.readFileSync(pathName, "utf-8");
res.send(regPage);
});
app.listen(3000, () => {
console.log('Example app listening on port 3000!')
});
3.2、获取查询参数
app.get('/index', (req, res) => {
let ret = req.query // 获取到一个对象
res.send(ret.curPage);
//可以在请求的时候传入查询参数:
//http://localhost:3000/index%3F ... %3D10
});
四、使用Express处理post请求方法4.1、post请求处理格式
app.post('/register', (req, res) => {
//可以在回调函数中,获取请求参数(用户在页面填写的信息),并进行处理
res.send("post---");
});
4.2、获取请求参数
我们使用第三方包body-parser来处理请求参数更简单更专业
首先,在项目目录下安装body-parser:
yarn add body-parser 或者 npm install body-parser
使用 body-parser 获取请求参数:
// 1、引入body-parser
const bodyParser = require('body-parser')
// 2、bodyParser功能添加到项目app中
// parse application/x-www-form-urlencoded 针对普通页面提交功能
app.use(bodyParser.urlencoded({ extended: false })) //false接收的值为字符串或者数组,true则为任意类型
// parse application/json
app.use(bodyParser.json()) // 解析json格式
// 3、在接口中获取请求参数 req.body
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body);
// 获取到请求参数之后就可以在这里处理这些请求参数,比如保存到数据库中(后面我们学习数据库知识)
res.send("post ok");
});
五、重定向到其他界面
一般注册成功后可以跳转到登录页面,也就是重定向
我们使用 res.redirect('/login'); 跳转到另一个界面进行处理
// 添加登录页面的接口
app.get('/login', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "login.html");
const loginPage = fs.readFileSync(pathName, "utf-8");
res.send(loginPage);
});
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body.username);
// 一般注册成功之后可以跳转到登录页面,这就是重定向
res.redirect('/login'); // 重定向到'/login'接口,对应的接口函数会执行
});
六、all() 方法组合同一请求路径的不同方式
对于上面的case/register请求,有两种方式:GET和POST。Express 提供了 all() 方法来组合写接口:
app.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, 'views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })
七、使用Express获取静态资源
const express = require('express');const app = express();// 获取静态资源// app.use(express.static("public")) // "public"表示指定在本地public下找静态资源 // 请求: localhost:3000/images/01.jpg // 如果想要在请求的路径里面添加前缀app.use("/static", express.static("public"))// localhost:3000/static/images/01.jpg // 可能有延迟,如果延迟尝试重启服务器或者浏览器app.listen(3000, () => { console.log('Example app listening on port 3000!')});
八、使用 Express 渲染模板页面
我们使用 art-templates 模板引擎
文档网址:
使用前需要安装 art-template 和 express-art-template
yarn add art-template 或者 npm install art-templateyarn add express-art-template 或者 npm install express-art-template
在views目录下新建一个index.html
// 1、修改模板引擎为html,导入express-art-templateapp.engine('html', require('express-art-template'));// 2、设置运行的模式为生产模式// production 生产模式,线上模式// development 开发模式app.set('view options', { debug: process.env.NODE_ENV !== 'production'});// 3、设置模板存放目录为views文件夹app.set('views', path.join(__dirname, 'views'));// 4、设置引擎后缀为htmlapp.set('view engine', 'html');app.get('/', (req, res) => { res.render('index') //通过render返回该模板});
九、art-templates模板引擎的使用
使用语法:
我们可以将数据从后端界面传递到前端页面,这就是我们使用模板引擎的原因。
app.engine('html', require('express-art-template'));app.set('view options', { debug: process.env.NODE_ENV !== 'production'});app.set('views', path.join(__dirname, 'views'));app.set('view engine', 'html');app.get('/', (req, res) => { let data = { user:{ id:1, name: "Jack", age:18, job: "coder" }, books:["《西游记》", "《三国演义》","《红楼梦》", "《水浒传》"], num1:20, num2:30 } res.render('index', data); // 把data数据传入到index.html页面中。});
在视图下的 index.html 中:
这是首页 {{ user.id }} {{ user.name }} {{ user.age }} {{ user['age'] }} {{each books}} {{$index}}、{{$value}} {{/each}} <p>num1和num2中比较大的那个数是: {{num1>num2?num1:num2}} {{ if user.name === "Jacka"}}
{{ user.name }}的年龄是{{ user.age }} {{/if}}
</p>
类似的模板引擎和ejs模板引擎
十、在项目中使用路由
在项目中,我们不会直接在项目入口文件中编写路由接口。
我们提取第 6 节中的路由,在项目文件夹下新建一个 routes 文件夹,并新建一个 passport.js:
// 抽取路由const express = require('express');const router = express.Router();const fs = require("fs");const path = require("path");router.get('/login', (req, res) => { //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "login.html"); const loginPage = fs.readFileSync(pathName, "utf-8"); res.send(loginPage);});router.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })module.exports = router
在项目入口文件 app.js 中:
const express = require('express');const app = express();// 1、引入对应的路由模块const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、书写的路由添加到app上app.use(passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
处理请求前的十个一、钩子函数
这里先了解一下这个功能,以后在项目中使用。
如果你想在执行处理请求的函数之前执行一些代码,比如验证你是否登录的工作。
你可以在 app.use(utils.checkLogin, routers); 之前添加一个函数
创建一个新的 utils 文件夹并创建一个新的 index.js 文件:
function checkLogin(req, res, next){ console.log("执行接口代码之前会执行这里的代码"); next(); //直接跳入请求的接口执行代码}module.exports = { checkLogin}
在项目入口函数app.js中:
// 项目中使用路由const express = require('express');const app = express();// 1、引入对应工具模块const utils = require('./utils/index.js');const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、补上执行接口函数之前所执行的函数app.use(utils.checkLogin, passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
作用:在执行路由器下的各个接口之前,都会执行checkLogin函数中的代码。
应用程序:这可用于稍后在项目中进行身份验证和登录。
标签:req,art,Nodejs,--,res,app,express,const,page 查看全部
nodejs抓取动态网页(使用搭建服务器的Hello程序使用postnodeapp.js启动应用)
标签: reqartNodejs--resappexpressconst 页面
一、Express 框架介绍
在之前的Node基础中,我们学习了Node.js中的http模块,虽然我们知道使用Node.js中的http模块可以开发Web应用,处理静态资源,处理动态资源,请求分发(路由)等,也可以让开发者对HTTP协议的理解更加清晰,但是使用起来比较复杂,开发效率低。
npm 提供了大量的第三方模块,包括很多 web 框架,我们不需要重新发明轮子,所以我们选择使用 Express 作为开发框架,因为它是目前最稳定和使用最广泛的,也是唯一的Node.js 官方推荐的一个 Web 开发框架。除了为 http 模块提供更高级别的接口外,还实现了许多功能,包括:
官方网站:
express 是基于内置核心 http 模块的第三方包,专注于构建 web 服务器。
二、使用Express搭建服务器Hello world程序
// 1、引入express模块并创建express对象
const express = require('express');
const app = express();
// 2、书写处理请求的方法,来响应请求
app.get('/', (req, res) => {
// 这里的代码在浏览器以get请求/的时候执行,
// 这个函数就是用来处理浏览器的 对于/的get请求 的
// 第一个参数req是请求头对象,里面包含请求头信息
// 第二个参数res用来做响应
console.log(req);
res.send('Hello World!222');
});
// 3、监听端口
app.listen(3000, () => {
//这里的代码服务器刚启动的时候执行1次
console.log('Example app listening on port 3000!')
});
使用node app.js启动应用,访问:3000/查看效果。
三、使用Express处理get请求方法3.1、返回页面
在myapp目录下新建views文件夹,放入register.html页面。
在 register.html 中:
注册页面11
<p>
用户名:
邮箱:
密码:
确认密码:
</p>
在 app.js 中:
const express = require('express');
const app = express();
// 1、引入fs和path模块
const fs = require("fs");
const path = require("path");
// 2、处理/register的get请求
app.get('/register', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "register.html");
const regPage = fs.readFileSync(pathName, "utf-8");
res.send(regPage);
});
app.listen(3000, () => {
console.log('Example app listening on port 3000!')
});
3.2、获取查询参数
app.get('/index', (req, res) => {
let ret = req.query // 获取到一个对象
res.send(ret.curPage);
//可以在请求的时候传入查询参数:
//http://localhost:3000/index%3F ... %3D10
});
四、使用Express处理post请求方法4.1、post请求处理格式
app.post('/register', (req, res) => {
//可以在回调函数中,获取请求参数(用户在页面填写的信息),并进行处理
res.send("post---");
});
4.2、获取请求参数
我们使用第三方包body-parser来处理请求参数更简单更专业
首先,在项目目录下安装body-parser:
yarn add body-parser 或者 npm install body-parser
使用 body-parser 获取请求参数:
// 1、引入body-parser
const bodyParser = require('body-parser')
// 2、bodyParser功能添加到项目app中
// parse application/x-www-form-urlencoded 针对普通页面提交功能
app.use(bodyParser.urlencoded({ extended: false })) //false接收的值为字符串或者数组,true则为任意类型
// parse application/json
app.use(bodyParser.json()) // 解析json格式
// 3、在接口中获取请求参数 req.body
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body);
// 获取到请求参数之后就可以在这里处理这些请求参数,比如保存到数据库中(后面我们学习数据库知识)
res.send("post ok");
});
五、重定向到其他界面
一般注册成功后可以跳转到登录页面,也就是重定向
我们使用 res.redirect('/login'); 跳转到另一个界面进行处理
// 添加登录页面的接口
app.get('/login', (req, res) => {
//读取页面内容,并返回这个页面
let pathName = path.join(__dirname, 'views', "login.html");
const loginPage = fs.readFileSync(pathName, "utf-8");
res.send(loginPage);
});
app.post('/register', (req, res) => {
// 可以在回调函数中,获取请求参数(用户在页面填写的信息)
// 获取请求参数
console.log(req.body.username);
// 一般注册成功之后可以跳转到登录页面,这就是重定向
res.redirect('/login'); // 重定向到'/login'接口,对应的接口函数会执行
});
六、all() 方法组合同一请求路径的不同方式
对于上面的case/register请求,有两种方式:GET和POST。Express 提供了 all() 方法来组合写接口:
app.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, 'views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })
七、使用Express获取静态资源
const express = require('express');const app = express();// 获取静态资源// app.use(express.static("public")) // "public"表示指定在本地public下找静态资源 // 请求: localhost:3000/images/01.jpg // 如果想要在请求的路径里面添加前缀app.use("/static", express.static("public"))// localhost:3000/static/images/01.jpg // 可能有延迟,如果延迟尝试重启服务器或者浏览器app.listen(3000, () => { console.log('Example app listening on port 3000!')});
八、使用 Express 渲染模板页面
我们使用 art-templates 模板引擎
文档网址:
使用前需要安装 art-template 和 express-art-template
yarn add art-template 或者 npm install art-templateyarn add express-art-template 或者 npm install express-art-template
在views目录下新建一个index.html
// 1、修改模板引擎为html,导入express-art-templateapp.engine('html', require('express-art-template'));// 2、设置运行的模式为生产模式// production 生产模式,线上模式// development 开发模式app.set('view options', { debug: process.env.NODE_ENV !== 'production'});// 3、设置模板存放目录为views文件夹app.set('views', path.join(__dirname, 'views'));// 4、设置引擎后缀为htmlapp.set('view engine', 'html');app.get('/', (req, res) => { res.render('index') //通过render返回该模板});
九、art-templates模板引擎的使用
使用语法:
我们可以将数据从后端界面传递到前端页面,这就是我们使用模板引擎的原因。
app.engine('html', require('express-art-template'));app.set('view options', { debug: process.env.NODE_ENV !== 'production'});app.set('views', path.join(__dirname, 'views'));app.set('view engine', 'html');app.get('/', (req, res) => { let data = { user:{ id:1, name: "Jack", age:18, job: "coder" }, books:["《西游记》", "《三国演义》","《红楼梦》", "《水浒传》"], num1:20, num2:30 } res.render('index', data); // 把data数据传入到index.html页面中。});
在视图下的 index.html 中:
这是首页 {{ user.id }} {{ user.name }} {{ user.age }} {{ user['age'] }} {{each books}} {{$index}}、{{$value}} {{/each}} <p>num1和num2中比较大的那个数是: {{num1>num2?num1:num2}} {{ if user.name === "Jacka"}}
{{ user.name }}的年龄是{{ user.age }} {{/if}}
</p>
类似的模板引擎和ejs模板引擎
十、在项目中使用路由
在项目中,我们不会直接在项目入口文件中编写路由接口。
我们提取第 6 节中的路由,在项目文件夹下新建一个 routes 文件夹,并新建一个 passport.js:
// 抽取路由const express = require('express');const router = express.Router();const fs = require("fs");const path = require("path");router.get('/login', (req, res) => { //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "login.html"); const loginPage = fs.readFileSync(pathName, "utf-8"); res.send(loginPage);});router.all('/register',(req, res) => { let method = req.method if(method==='GET'){ //读取页面内容,并返回这个页面 let pathName = path.join(__dirname, '../views', "register.html"); const regPage = fs.readFileSync(pathName, "utf-8"); res.send(regPage); }else if(method==='POST'){ console.log(req.body.username); // 一般注册成功之后可以跳转到登录页面,这就是重定向 res.redirect('/login'); } })module.exports = router
在项目入口文件 app.js 中:
const express = require('express');const app = express();// 1、引入对应的路由模块const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、书写的路由添加到app上app.use(passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
处理请求前的十个一、钩子函数
这里先了解一下这个功能,以后在项目中使用。
如果你想在执行处理请求的函数之前执行一些代码,比如验证你是否登录的工作。
你可以在 app.use(utils.checkLogin, routers); 之前添加一个函数
创建一个新的 utils 文件夹并创建一个新的 index.js 文件:
function checkLogin(req, res, next){ console.log("执行接口代码之前会执行这里的代码"); next(); //直接跳入请求的接口执行代码}module.exports = { checkLogin}
在项目入口函数app.js中:
// 项目中使用路由const express = require('express');const app = express();// 1、引入对应工具模块const utils = require('./utils/index.js');const passportRouters = require('./routes/passport');var bodyParser = require('body-parser')app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())// 2、补上执行接口函数之前所执行的函数app.use(utils.checkLogin, passportRouters)app.listen(3000, () => { console.log('Example app listening on port 3000!')});
作用:在执行路由器下的各个接口之前,都会执行checkLogin函数中的代码。
应用程序:这可用于稍后在项目中进行身份验证和登录。
标签:req,art,Nodejs,--,res,app,express,const,page
nodejs抓取动态网页(JS模块原生拓展1.需要注意哪些区别?|诊断报告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-07 15:00
提供诊断报告
Node12 有一个实验性的功能,可以根据用户的需求提供诊断报告,包括崩溃、性能下降、内存泄漏、高 CPU 使用率等等。
堆内存转储
以前如果要从堆内存中生成dump文件,需要在生产环境中安装额外的模块,Node12集成了这个功能。
更好的原生模块支持
C++扩展升级到版本4。同时,可以用C++编写一个native模块并发布到npm,就像一个普通的JS模块一样被引用。但是,有一些区别需要注意:
JS 模块原生扩展
1.
… 需要编译
不
如果预编译不要使用它
2.
... 可以在所有平台上运行吗
是的
如果是预编译的,你可以
3.
... 是否兼容所有 Node 版本
是的
不
4.
... 将被多次加载
是的
不
5.
...如果没有明确使用多线程,它是线程安全的
是的
不
6.
......可以被摧毁
是的
不
Worker 正式激活
--experimental-worker 取消了实验性开关,默认支持worker_threads。
需要注意的是,worker 适合执行 CPU 密集型任务(大量计算),但是在执行 I/O 密集型任务时,Worker 不如 Node 内置的 I/O 操作(读和写)文件)。
启动速度优化
通过在构建时提前为内置库生成代码缓存,启动时间最终加快了 30%。
支持 ES6 模块
Node12 对 ES6 模块的支持仍处于实验阶段,需要通过 --experimental-modules 启用。
简单来说就是支持Import Export语法,不需要转换成require!如果在 package.json 中添加了 "type": "module" 配置,Node 会像 ES6 模块一样处理它。
新的编译器和平台要求
由于升级到新的 V8 引擎和内部改造,Node12 在 Mac 和 Windows 以外的平台上至少需要 GCC6 和 glibc 2.17。
3. 精读
V8引擎升级、TLS升级、堆配置自动化、http-parser升级到llhttp、启动速度优化等都是被动优化。代码不需要改,只要升级Node版本,就可以享受了。
支持 ES6 模块特性其实挺鸡肋的。毕竟如果源码是用Ts写的,这些升级不会影响源码。
worker_threads 可以默认开启,就像之前支持 async/await 一样,会带来 Nodejs 多线程的更广泛使用。
Node12 更新了 V8 引擎。随着V8的更新,也实现了很多新的ES规范,比如Class成员函数、私有成员变量等等。
4. 总结
Nodejs只有10年的历史,但它越来越受到开发者的欢迎,因为它允许JS在服务器端运行,这是扩展JS生态系统的重要组成部分。从Node的更新历史可以看出,性能和语法能力都得到了稳步提升。一些服务器环境所需的诊断报告和堆栈分析能力正在逐步完善。社区也有Alinode和egg、express、koa等有用的服务框架。相比前端的翻天覆地的变化,对Node的评价只有一个字:稳定性。
讨论地址:《Nodejs V12》精读·Issue #184·dt-fe/weekly 查看全部
nodejs抓取动态网页(JS模块原生拓展1.需要注意哪些区别?|诊断报告)
提供诊断报告
Node12 有一个实验性的功能,可以根据用户的需求提供诊断报告,包括崩溃、性能下降、内存泄漏、高 CPU 使用率等等。
堆内存转储
以前如果要从堆内存中生成dump文件,需要在生产环境中安装额外的模块,Node12集成了这个功能。
更好的原生模块支持
C++扩展升级到版本4。同时,可以用C++编写一个native模块并发布到npm,就像一个普通的JS模块一样被引用。但是,有一些区别需要注意:
JS 模块原生扩展
1.
… 需要编译
不
如果预编译不要使用它
2.
... 可以在所有平台上运行吗
是的
如果是预编译的,你可以
3.
... 是否兼容所有 Node 版本
是的
不
4.
... 将被多次加载
是的
不
5.
...如果没有明确使用多线程,它是线程安全的
是的
不
6.
......可以被摧毁
是的
不
Worker 正式激活
--experimental-worker 取消了实验性开关,默认支持worker_threads。
需要注意的是,worker 适合执行 CPU 密集型任务(大量计算),但是在执行 I/O 密集型任务时,Worker 不如 Node 内置的 I/O 操作(读和写)文件)。
启动速度优化
通过在构建时提前为内置库生成代码缓存,启动时间最终加快了 30%。
支持 ES6 模块
Node12 对 ES6 模块的支持仍处于实验阶段,需要通过 --experimental-modules 启用。
简单来说就是支持Import Export语法,不需要转换成require!如果在 package.json 中添加了 "type": "module" 配置,Node 会像 ES6 模块一样处理它。
新的编译器和平台要求
由于升级到新的 V8 引擎和内部改造,Node12 在 Mac 和 Windows 以外的平台上至少需要 GCC6 和 glibc 2.17。
3. 精读
V8引擎升级、TLS升级、堆配置自动化、http-parser升级到llhttp、启动速度优化等都是被动优化。代码不需要改,只要升级Node版本,就可以享受了。
支持 ES6 模块特性其实挺鸡肋的。毕竟如果源码是用Ts写的,这些升级不会影响源码。
worker_threads 可以默认开启,就像之前支持 async/await 一样,会带来 Nodejs 多线程的更广泛使用。
Node12 更新了 V8 引擎。随着V8的更新,也实现了很多新的ES规范,比如Class成员函数、私有成员变量等等。
4. 总结
Nodejs只有10年的历史,但它越来越受到开发者的欢迎,因为它允许JS在服务器端运行,这是扩展JS生态系统的重要组成部分。从Node的更新历史可以看出,性能和语法能力都得到了稳步提升。一些服务器环境所需的诊断报告和堆栈分析能力正在逐步完善。社区也有Alinode和egg、express、koa等有用的服务框架。相比前端的翻天覆地的变化,对Node的评价只有一个字:稳定性。
讨论地址:《Nodejs V12》精读·Issue #184·dt-fe/weekly
nodejs抓取动态网页(1.为什么需要一个前端监控系统?技术选型监控的意义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-07 06:14
1. 为什么需要前端监控系统
通常大型web项目中的监控系统很多,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是,这些监控并不能准确反映用户看到的前端页面的状态,例如:页面调用第三方系统数据失败、模块加载异常、数据错误、天窗空白等。
这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题。
2. 监控系统需要解决的问题
一般页面出现以下问题时,您需要及时通过邮件或短信报告,通知相关人员修复问题。
3. 技术选型
监控的意义和测试的意义本质上是一样的。两者都对上线功能进行回归测试,但不同的是监控需要长期持续的循环回归测试,上线后只需进行一次测试。回归测试。
既然监控和测试的本质是一样的,我们就可以用测试来制作监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具。我们只需要集成这些自动化工具供我们使用。
节点
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非集群 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,使可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,比如网络监控、网页截图、无需浏览器的网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,而且使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。在后期,性能优化、系统改造和扩展等也可以提高简单性。
5. 解决方案(1)前台规则条目
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于和正则。
这样做的好处是,输入规则的人只需要了解一点DOM选择器的知识就可以上手,而我们通常把它交给测试工程师来完成规则的输入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。从而准确抓取页面信息。
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。键入任务。
(2) 主动报错页面脚本执行错误监控
页面引入了监控脚本,用于采集页面产生的错误事件信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面爬取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染数据。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行采集结果。
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器将规则系统采集的规则转换成消息队列,然后依次交给长期连续处理器处理。
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用。
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。其实队列的产生可以参考数据接口-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和抽取数据。
当然,类消息队列的中间介质可以根据自己的实际情况选择,当然也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存。
长时处理器
长期持久化处理器是作为消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲惫的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。之后,返回的结果将被统一处理,例如电子邮件或短信报警。
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演变为规则转换器。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理 查看全部
nodejs抓取动态网页(1.为什么需要一个前端监控系统?技术选型监控的意义)
1. 为什么需要前端监控系统
通常大型web项目中的监控系统很多,比如后端服务API监控、接口存活、调用、延迟等监控,一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统,从后端服务到前端展示会有很多层:内网VIP、CDN等。
但是,这些监控并不能准确反映用户看到的前端页面的状态,例如:页面调用第三方系统数据失败、模块加载异常、数据错误、天窗空白等。
这时候就需要从前端DOM展示的角度分析采集用户真正看到的东西,从而检测页面是否有异常问题。
2. 监控系统需要解决的问题
一般页面出现以下问题时,您需要及时通过邮件或短信报告,通知相关人员修复问题。
3. 技术选型
监控的意义和测试的意义本质上是一样的。两者都对上线功能进行回归测试,但不同的是监控需要长期持续的循环回归测试,上线后只需进行一次测试。回归测试。
既然监控和测试的本质是一样的,我们就可以用测试来制作监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具。我们只需要集成这些自动化工具供我们使用。
节点
NodeJS 是一个 JavaScript 运行环境,NodeJS 支持非集群 I/O 和异步、事件驱动,这对于我们构建基于 DOM 元素的监控更为重要。
PhantomJS
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器,使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,使可以对操作系统进行文件读写等。 PhantomJS 的用途非常广泛,比如网络监控、网页截图、无需浏览器的网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,而且使用Selenium需要在服务器端安装浏览器。
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS。
4. 架构设计架构概述
架构如下图所示。
(点击放大图片)
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。在后期,性能优化、系统改造和扩展等也可以提高简单性。
5. 解决方案(1)前台规则条目
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,通过系统可以创建三种检测页面:定期监控、高级监控、可用性监控。
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于和正则。
这样做的好处是,输入规则的人只需要了解一点DOM选择器的知识就可以上手,而我们通常把它交给测试工程师来完成规则的输入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件。从而准确抓取页面信息。
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。键入任务。
(2) 主动报错页面脚本执行错误监控
页面引入了监控脚本,用于采集页面产生的错误事件信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务。
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
(3)后端页面爬取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法获取动态JavaScript渲染数据。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具。
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行采集结果。
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、Mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果。
常规队列生成器
规则队列生成器将规则系统采集的规则转换成消息队列,然后依次交给长期连续处理器处理。
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用。
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。其实队列的产生可以参考数据接口-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和抽取数据。
当然,类消息队列的中间介质可以根据自己的实际情况选择,当然也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存。
长时处理器
长期持久化处理器是作为消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们充分利用了JavaScript的setInterval方法,不断的获取疲惫的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。之后,返回的结果将被统一处理,例如电子邮件或短信报警。
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演变为规则转换器。
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理
nodejs抓取动态网页( 一个、path和url模块的确定文件的路径这就要依赖于 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-07 06:13
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000') 查看全部
nodejs抓取动态网页(
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000')
nodejs抓取动态网页( 一个、path和url模块的确定文件的路径这就要依赖于 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-05 12:11
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000') 查看全部
nodejs抓取动态网页(
一个、path和url模块的确定文件的路径这就要依赖于
)
<a id="nodejs_0"></a>超简单的nodejs静态网页服务器
<p>使用 nodejs 进行后端开发有一个非常方便的地方是它可以不依赖于其他的服务器软件,比如 tomcat 之类的。这里对我使用 nodejs 写的一个静态网页服务器做一个简单的总结
在这里使用到了以下模块:
http:相应基本的 http 请求fs:读取文件并返回path:获取文件的路径url:解析 url
<a id="_10"></a>第一步,创建一个最基本的服务器
let http = require('http');
let server = http.createServer(function(request, response){
response.end();
})
server.listen(8000);
</p>
这个服务器正在监听8000端口的请求,但是由于没有处理功能,所以只是一个空架子
第二步,确定文件的路径
这一步取决于我们的 fs、path 和 url 模块
首先,我们使用path模块来确定静态页面和资源文件所在的目录:
__dirname 可以直接获取当前目录的绝对路径。对于下图所示的目录结构,可以编写如下语句
|- serve.js
|- public
|- index.html
|- CSS
|- JS
|- Image
let staticPath = path.resolve(__dirname, 'public');
然后,我们需要通过 url 模块获取我们要访问的页面,并使用我们的 url 模块进行解析
同时,我们在访问目录时,通常是直接访问index.html。我们也可以访问知青默认打开的页面:
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
这样就可以得到想要访问的页面的绝对路径
let filePath = path.join(staticPath, pathname);
第三步是读入文件并做出相应的响应
读取文件依赖于 fs 模块。值得一提的是,我们可以通过fs.readFileSync同步读入,也可以通过fs.readFile异步读入,性能相对较高
fs.readFile的回调函数有两个参数,第一个参数是一个错误,第二个参数是一个String或者一个Buffer:
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('');
response.write(data);
response.end();
}
})
如果有事先准备好的错误页面,可以在文件读取错误时显示,如上例
结束
结合以上内容得到的代码如下,运行在node环境下,可以在8000端口访问与serve.js同级的public目录下的静态页面!
const http = require('http')
const fs = require('fs')
const url = require('url')
const path = require('path')
let server = http.createServer(function (request, response) {
//获取输入的url解析后的对象
let pathname = url.parse(request.url, true).pathname;
if (pathname == '/') {
pathname = '/index.html';
}
//static文件夹的绝对路径
let staticPath = path.resolve(__dirname, 'public');
//获取资源文件绝对路径
let filePath = path.join(staticPath, pathname);
console.log(filePath);
//异步读取file
fs.readFile(filePath, function (err, data) {
if (err) {
console.log(err);
// 如果找不到文件资源报错可以显示准备好的 404页面
let errPath = path.join(staticPath, '/404.html');
fs.readFile(errPath, (err, data404) => {
if (err) {
console.log('error');
response.write('404 Not Found');
response.end();
} else {
response.writeHead(404, { "Content-Type": "text/html;charset='utf-8'" });
response.write(data404);
response.end();
}
})
} else {
console.log('ok');
response.write(data);
response.end();
}
})
})
server.listen(8000)
console.log('visit http://localhost:8000')
nodejs抓取动态网页(nodejs抓取动态网页必须用python!不用换别的啦!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 09:15
nodejs抓取动态网页必须用python!不用换别的啦!下面就来告诉你这个代码能做什么:步骤如下:打开浏览器输入进入首页按f12或者chrome的开发者工具把network拖动到浏览器的调试工具里右键进行搜索-navigate检查network,需要看哪个网页的动态首页的文字信息。
一、谷歌浏览器下载安装,推荐使用谷歌浏览器。1.下载我测试下载最新版chrome浏览器,如果版本不对需要下载对应的chrome版本。chrome54版本,在chrome商店里搜索谷歌浏览器-安装,基本上都能安装chrome浏览器,我安装时就有提示。2.打开谷歌浏览器,打开此页面。将searchtools(谷歌搜索工具)点击右键,选择“选项”并确定,登录上你谷歌的账号。3.把谷歌网页中的关键词拉出来:以“阿拉丁”为例,打开之后是这样:。
二、百度、搜狗、360。
三、神奇的网页分析工具可以直接使用【飞渡看雪】工具,可以抓取你想要的网页。选择你要看的网页,点击工具,进行搜索:打开该工具后,选择“全部网页搜索”,
四、神奇的浏览器扩展javascript特效-plot
可以使用javascript调试器来进行,这个浏览器插件不仅可以抓取网页的动态代码,还可以抓取单页信息, 查看全部
nodejs抓取动态网页(nodejs抓取动态网页必须用python!不用换别的啦!)
nodejs抓取动态网页必须用python!不用换别的啦!下面就来告诉你这个代码能做什么:步骤如下:打开浏览器输入进入首页按f12或者chrome的开发者工具把network拖动到浏览器的调试工具里右键进行搜索-navigate检查network,需要看哪个网页的动态首页的文字信息。
一、谷歌浏览器下载安装,推荐使用谷歌浏览器。1.下载我测试下载最新版chrome浏览器,如果版本不对需要下载对应的chrome版本。chrome54版本,在chrome商店里搜索谷歌浏览器-安装,基本上都能安装chrome浏览器,我安装时就有提示。2.打开谷歌浏览器,打开此页面。将searchtools(谷歌搜索工具)点击右键,选择“选项”并确定,登录上你谷歌的账号。3.把谷歌网页中的关键词拉出来:以“阿拉丁”为例,打开之后是这样:。
二、百度、搜狗、360。
三、神奇的网页分析工具可以直接使用【飞渡看雪】工具,可以抓取你想要的网页。选择你要看的网页,点击工具,进行搜索:打开该工具后,选择“全部网页搜索”,
四、神奇的浏览器扩展javascript特效-plot
可以使用javascript调试器来进行,这个浏览器插件不仅可以抓取网页的动态代码,还可以抓取单页信息,
nodejs抓取动态网页( 你眼中的JavaScript是干什么?特效?or只是与客户端的交互?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-04 07:14
你眼中的JavaScript是干什么?特效?or只是与客户端的交互?)
在nodejs中实现路由功能
更新时间:2014年12月29日08:55:07 投稿:俊杰
本文文章主要介绍nodejs中的路由功能。顾名思义,路由是指我们必须以不同的方式处理不同的 URL。本文将教你在node.js中实现路由功能。有需要的朋友可以参考
一个 Node 初学者,我发现了一个与我之前的观点完全不同的场景——JavaScript 在你眼中的目的是什么?特殊效果?还是只是与客户的互动?可以说 JavaScript 最初是在浏览器中运行的,但如果你这样想,浏览器只是提供了一个上下文(context),它定义了你可以用 JavaScript 做什么。这可以被认为是一个类似的企业,企业定义了你在这里可以做什么,但并没有多说 JavaScript 语言本身可以做什么。事实上,作为一门完整的语言,JavaScript 可以用在不同的上下文中,体现出不同的能力。这里提到的Nodejs其实就是提供一个上下文,一个运行环境,让JavaScript代码可以在后端(浏览器环境之外)运行。
路由的核心是路由。顾名思义,路由就是我们要以不同的方式处理不同的URL,比如处理/启动业务逻辑,处理/上传模块业务;逻辑不一致。在实际实现中,路由过程会在路由模块中“结束”,而路由模块并不是真正对请求“采取行动”的模块,否则当我们的应用变得更复杂时,它就无法使用了。非常好的扩展。
这里我们首先创建一个名为 requestHandlers 的模块,并为每个请求处理程序添加一个占位符函数:
复制代码代码如下:
函数开始(){
console.log("请求处理程序'start'被调用。");
函数睡眠(毫秒){
var startTime=new Date().getTime();
while(new Date().getTime() }
睡眠(10000);
return "Hello Start";
}
函数上传(){
console.log("请求处理程序'上传'被调用。");
返回“你好上传”;
}
exports.start=start;
exports.upload=upload;
这样,我们就可以连接请求处理程序和路由模块,让路由“有路径可走”。之后,我们决定通过一个对象传递一系列请求处理程序,我们需要使用松耦合将这个对象注入到router()函数中,主文件index.js:
复制代码代码如下:
var server=require("./server");
var router=require("./router");
var requestHandlers=require("./requestHandlers");
var handle={};
handle["/"]=requestHandlers.start;
handle["/start"]=requestHandlers.start;
handle["/upload"]=requestHandlers.upload;
server.start(router.route,handle);
如上所示,很容易将不同的 URL 映射到同一个请求处理程序:只需在对象中添加一个键为“/”的属性,对应 requestHandlers.start。这样,我们就可以简洁地配置 /start 和 / 由 start 处理程序处理的请求。完成查看对象的定义后,我们将其作为附加参数传递给服务器,参见server.js:
复制代码代码如下: 查看全部
nodejs抓取动态网页(
你眼中的JavaScript是干什么?特效?or只是与客户端的交互?)
在nodejs中实现路由功能
更新时间:2014年12月29日08:55:07 投稿:俊杰
本文文章主要介绍nodejs中的路由功能。顾名思义,路由是指我们必须以不同的方式处理不同的 URL。本文将教你在node.js中实现路由功能。有需要的朋友可以参考
一个 Node 初学者,我发现了一个与我之前的观点完全不同的场景——JavaScript 在你眼中的目的是什么?特殊效果?还是只是与客户的互动?可以说 JavaScript 最初是在浏览器中运行的,但如果你这样想,浏览器只是提供了一个上下文(context),它定义了你可以用 JavaScript 做什么。这可以被认为是一个类似的企业,企业定义了你在这里可以做什么,但并没有多说 JavaScript 语言本身可以做什么。事实上,作为一门完整的语言,JavaScript 可以用在不同的上下文中,体现出不同的能力。这里提到的Nodejs其实就是提供一个上下文,一个运行环境,让JavaScript代码可以在后端(浏览器环境之外)运行。
路由的核心是路由。顾名思义,路由就是我们要以不同的方式处理不同的URL,比如处理/启动业务逻辑,处理/上传模块业务;逻辑不一致。在实际实现中,路由过程会在路由模块中“结束”,而路由模块并不是真正对请求“采取行动”的模块,否则当我们的应用变得更复杂时,它就无法使用了。非常好的扩展。
这里我们首先创建一个名为 requestHandlers 的模块,并为每个请求处理程序添加一个占位符函数:
复制代码代码如下:
函数开始(){
console.log("请求处理程序'start'被调用。");
函数睡眠(毫秒){
var startTime=new Date().getTime();
while(new Date().getTime() }
睡眠(10000);
return "Hello Start";
}
函数上传(){
console.log("请求处理程序'上传'被调用。");
返回“你好上传”;
}
exports.start=start;
exports.upload=upload;
这样,我们就可以连接请求处理程序和路由模块,让路由“有路径可走”。之后,我们决定通过一个对象传递一系列请求处理程序,我们需要使用松耦合将这个对象注入到router()函数中,主文件index.js:
复制代码代码如下:
var server=require("./server");
var router=require("./router");
var requestHandlers=require("./requestHandlers");
var handle={};
handle["/"]=requestHandlers.start;
handle["/start"]=requestHandlers.start;
handle["/upload"]=requestHandlers.upload;
server.start(router.route,handle);
如上所示,很容易将不同的 URL 映射到同一个请求处理程序:只需在对象中添加一个键为“/”的属性,对应 requestHandlers.start。这样,我们就可以简洁地配置 /start 和 / 由 start 处理程序处理的请求。完成查看对象的定义后,我们将其作为附加参数传递给服务器,参见server.js:
复制代码代码如下:
nodejs抓取动态网页(要来开发一个属于自己的命令行小说工具用呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-02 18:08
简介:你的键盘是不是像飞一样上下?除了屏幕上黑色的控制台之外什么都看不到的极客,羡慕不已。不想要。我觉得前端很酷,一行代码就是另一个世界。 ,但在我的内心深处,我仍然觉得强迫症在不知不觉中下降了?不用着急,让Nodejs给你带来舒服有力量的好东西。本章将带您一步步开发自己的命令行工具。
Now You See Me:如果您不明白或不清楚您所说的内容,请留言。没多久,我开始一起学习,一起进步。 当然,如果你有一些想知道的内容相关的小知识点,比如cheerio bag balabala,也可以留言告知,会被放到发布内容的日程表中。嘿
1.开发这样的工具有什么用?
作者经常阅读一些网络小说,所以我们将开发一个新的章节内容,捕捉作者经常阅读的小说网站。先放一下程序运行的结果:
DaDaDa,美吗?
以下是这个项目的地址,只是一个demo。各种功能和之前的工程实践会在后面补充。
#自述
2.怎么做?
分以下几个部分解释这个内容:
- 项目结构
- 项目详情
以下是对以上目录的介绍:
目录:
bin:命令行脚本文件的入口,是package.json中bin属性对应的值得目录
node_modules:你知道的,npm 的依赖聚集地
文件:
.npmignore:就像.gitignore 文件一样,只有那些不会被npm 收录在发布目录中的文件
index.js:主程序文件
package.json:由 npm init 生成。详细描述项目情况
先介绍一下大概的设计:
很简单,就是先根据提供的小说网站链接抓取特定小说的目录导航,用相关的npm包分析上一个项目的链接,是最新的更新链接,然后拼接链接。再次向目标网站请求数据。分析检索到的内容,整理格式,修改输出,得到最终结果。
查看我们的源代码:
index.js
//用来做发送请求,经过测试的好朋友
var request = require('request');
//Node爬虫界的大佬,他的web代码分析能力不错
var cio = require('cheerio');
//装饰命令行上方的输出,添加颜色等
var colors = require('colors');
var url = require('url');
//网站网址
var webSiteUrlPrefix ='';
//小说链接
var webSiteUrl ='';
//开始请求数据
request(webSiteUrl, function(err, res, body) {
//做异常处理检查
if (!err && res.statusCode == 200) {
//Cheerio是数据处理的第一步,穿马甲
var $ = cio.load(body);
//缓存最后一个item节点
var target = $('div#list dd:last-of-type');
//通过CSS选择器过滤数据
//这里的意思
var src = target.children('a').attr('href');
//获取文章标题
var pageTitle = target.text();
//获取文章实际地址
var contentsUrl = webSiteUrlPrefix + src;
//再次请求,这次获取的是文章
的实际内容
request(contentsUrl, function(err, res, body) {
如果(错误){
返回;
} 其他{
if (res.statusCode == 200) {
var $ = cio.load(body);
//调整格式,去除多余空格
var pageContents = $('div#content').text().replace(/\s+/g,'\n');
//添加一些颜色看看
console.log(pageTitle.green +'\n\n' + pageContents.yellow);
} 其他{
返回;
}
}
})
} 其他{
console.log('错误请求');
}
});
接下来是bin/index.js的解释:
与上面的文件基本相同,唯一不同的是:
#! /usr/bin/env 节点
表示启用Node运行脚本,这也是生成命令行工具的本质
最后是package.json文件的介绍:
类似于之前的Express系列:用例子讲解如何开发自己的npm包,唯一的区别是:
“bin”:{
"n-novel": "bin/index.js"
}
这里提醒一下,这里一定要写上收录“#!/usr/bin/env node”的index.js文件路径,因为里面的文件最终会被软链接到/usr/local/bin/去里面,而且里面的程序都是脚本,如果位置不对,程序就会跑错。
3.发布流程
$ npm whoami
$ npm 发布
DaDaDa,发布成功!
4.起来,嘿
发布后,我们要检查我们的战斗结果,通过
npm install -g n-novel
安装到全世界,运行结果如下:
然后运行n-novel,稍等片刻,新出小说的最新章节会放到你的命令行中。
下一节介绍
介绍
经过以上两节的学习,我们不仅可以开发自己的包,还可以编写命令行工具。你认为我们已经起飞了吗?下一节我们将介绍如何通过持续的形成和构建来保证我们的项目代码经过良好的测试和可靠的,即持续集成:travis,测试覆盖:coveralls,查看模块依赖:david-dm,等等 查看全部
nodejs抓取动态网页(要来开发一个属于自己的命令行小说工具用呢?)
简介:你的键盘是不是像飞一样上下?除了屏幕上黑色的控制台之外什么都看不到的极客,羡慕不已。不想要。我觉得前端很酷,一行代码就是另一个世界。 ,但在我的内心深处,我仍然觉得强迫症在不知不觉中下降了?不用着急,让Nodejs给你带来舒服有力量的好东西。本章将带您一步步开发自己的命令行工具。
Now You See Me:如果您不明白或不清楚您所说的内容,请留言。没多久,我开始一起学习,一起进步。 当然,如果你有一些想知道的内容相关的小知识点,比如cheerio bag balabala,也可以留言告知,会被放到发布内容的日程表中。嘿
1.开发这样的工具有什么用?
作者经常阅读一些网络小说,所以我们将开发一个新的章节内容,捕捉作者经常阅读的小说网站。先放一下程序运行的结果:
DaDaDa,美吗?
以下是这个项目的地址,只是一个demo。各种功能和之前的工程实践会在后面补充。
#自述
2.怎么做?
分以下几个部分解释这个内容:
- 项目结构
- 项目详情
以下是对以上目录的介绍:
目录:
bin:命令行脚本文件的入口,是package.json中bin属性对应的值得目录
node_modules:你知道的,npm 的依赖聚集地
文件:
.npmignore:就像.gitignore 文件一样,只有那些不会被npm 收录在发布目录中的文件
index.js:主程序文件
package.json:由 npm init 生成。详细描述项目情况
先介绍一下大概的设计:
很简单,就是先根据提供的小说网站链接抓取特定小说的目录导航,用相关的npm包分析上一个项目的链接,是最新的更新链接,然后拼接链接。再次向目标网站请求数据。分析检索到的内容,整理格式,修改输出,得到最终结果。
查看我们的源代码:
index.js
//用来做发送请求,经过测试的好朋友
var request = require('request');
//Node爬虫界的大佬,他的web代码分析能力不错
var cio = require('cheerio');
//装饰命令行上方的输出,添加颜色等
var colors = require('colors');
var url = require('url');
//网站网址
var webSiteUrlPrefix ='';
//小说链接
var webSiteUrl ='';
//开始请求数据
request(webSiteUrl, function(err, res, body) {
//做异常处理检查
if (!err && res.statusCode == 200) {
//Cheerio是数据处理的第一步,穿马甲
var $ = cio.load(body);
//缓存最后一个item节点
var target = $('div#list dd:last-of-type');
//通过CSS选择器过滤数据
//这里的意思
var src = target.children('a').attr('href');
//获取文章标题
var pageTitle = target.text();
//获取文章实际地址
var contentsUrl = webSiteUrlPrefix + src;
//再次请求,这次获取的是文章
的实际内容
request(contentsUrl, function(err, res, body) {
如果(错误){
返回;
} 其他{
if (res.statusCode == 200) {
var $ = cio.load(body);
//调整格式,去除多余空格
var pageContents = $('div#content').text().replace(/\s+/g,'\n');
//添加一些颜色看看
console.log(pageTitle.green +'\n\n' + pageContents.yellow);
} 其他{
返回;
}
}
})
} 其他{
console.log('错误请求');
}
});
接下来是bin/index.js的解释:
与上面的文件基本相同,唯一不同的是:
#! /usr/bin/env 节点
表示启用Node运行脚本,这也是生成命令行工具的本质
最后是package.json文件的介绍:
类似于之前的Express系列:用例子讲解如何开发自己的npm包,唯一的区别是:
“bin”:{
"n-novel": "bin/index.js"
}
这里提醒一下,这里一定要写上收录“#!/usr/bin/env node”的index.js文件路径,因为里面的文件最终会被软链接到/usr/local/bin/去里面,而且里面的程序都是脚本,如果位置不对,程序就会跑错。
3.发布流程
$ npm whoami
$ npm 发布
DaDaDa,发布成功!
4.起来,嘿
发布后,我们要检查我们的战斗结果,通过
npm install -g n-novel
安装到全世界,运行结果如下:
然后运行n-novel,稍等片刻,新出小说的最新章节会放到你的命令行中。
下一节介绍
介绍
经过以上两节的学习,我们不仅可以开发自己的包,还可以编写命令行工具。你认为我们已经起飞了吗?下一节我们将介绍如何通过持续的形成和构建来保证我们的项目代码经过良好的测试和可靠的,即持续集成:travis,测试覆盖:coveralls,查看模块依赖:david-dm,等等
nodejs抓取动态网页(网络爬虫这块套路总结,用python+selenium执行代码上面第一种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-02 12:06
我是北京一家互联网工厂的996程序员。一边学习追赶新技术,一边害怕被潮流甩在后面,一边学习投资理财的方法让自己的薪水滚雪球。我相信你越努力,你就越幸运。雪球虽然一开始滚得很慢,但只要你坚持住,它就会滚得越来越快,你的养老就靠它了。在财富和自由的道路上,我鼓励你。欢迎评论区和我交流经验和干货,让我们收获更多。
我最近在抓一条网站的消息。今天写完了程序,用python+selenium。顺便总结一下网络爬虫的套路,分享给大家。
方法一:直接接口调用。
如果对方网站的api几乎没有反爬错误,那么可以直接通过浏览器的开发工具获取对方的api地址,直接调用爬取。如果对方界面控制了爬取频率,自己控制爬取间隔即可。
如果使用python技术栈开发,使用requests库模拟接口调用。这里需要注意具体的headers,可能收录token、签名等,需要自己整理。
方法二:使用js解析器执行js代码
上面第一种情况提到的场景毕竟还是少数,大部分网站都采取了一些反爬虫的措施。比如网站通过页面加载的js向界面发起XHR类型的ajax请求。调用接口时,自定义参数添加到查询字符串或URL的头部,参数生成方法均在js中。 ,然后可以选择了解js代码,然后用python重写生成参数的代码,最后组装这些参数调用接口。
但通常你没有那么幸运。生成参数的js代码比较混乱,基本无法被人类阅读。但是,如果你能定位到使用了哪个函数,那么我们可以采取另一种解决方案,就是将js代码改到js解释器中,然后直接调用函数获取返回值。我们拿这些返回值来组装请求参数。
如果使用python技术栈开发,可以使用PyExecJS、PyV8、js2py、Node.js这些js解析器来运行js代码。
js2py,一个纯python实现的js解析器,目前还在更新中。 PyExecJS,项目已经停止开发,但是还可以使用。 PyV8,是google v8 js引擎的python包。好久没更新了,不过还是可以用的。 Node.js,基于chrome v8引擎的js运行时,更新活跃。
推荐使用 Js2py。
方法三:使用selenium调用浏览器访问
方法二的场景,js代码根本用不上,也无法定位到要用到哪些函数,所以只能搬出selenium。 Selenium 是一套工具包,通过它我们可以使用程序来控制浏览器访问目标网站。 Selenium 有很多语言的绑定,自然也有python 的绑定。
使用selenium控制浏览器访问目标url后,如果要抓取的内容在页面内,则直接使用selenium提供的网页提取api直接提取内容。但是如果页面中没有渲染出你想要的内容,那我们就得用next方法了。
方法四:使用selenium+proxy来抓取接口调用
如方法3场景所述,对于js发起的ajax请求,如果响应数据没有完全反映在DOM中,那我们就得想办法直接提取ajax响应。方法是通过selenium+proxy控制浏览器访问,然后我们拦截proxy上的ajax响应。
常用的代理是browsermob-proxy,是java开发的http/https代理。本方案的原则是
在代码中控制启动browsermob-proxy。代码控制selenium启动浏览器,设置本地代理为browsermob-proxy。 Browsermob-proxy 会将请求的请求和响应写入 HAR 文件 (),我们可以通过解析 HAR 的内容得到响应。
方法五:使用selenium+浏览器的性能日志
这个方法可以认为是方法4的升级版,因为浏览器自己获取响应,所以只要找到合适的方法,就可以直接获取响应。
具体方法是webdriver(python代码控制浏览器的一个组件)允许我们向浏览器发送Network.getResponseBody命令来获取响应。 webdriver 提供的 API 文档:
我们需要传递一个名为 requestId 的参数来获取响应。
首先,在初始化浏览器控件实例时,必须开启{"performance": "ALL"}
def __init_driver(self):
capabilities = DesiredCapabilities.CHROME
capabilities["goog:loggingPrefs"] = {"performance": "ALL"} # chromedriver 75+
option = webdriver.ChromeOptions()
option.add_argument(r"user-data-dir=./var/chrome-data")
self.__driver = webdriver.Chrome(desired_capabilities=capabilities, options=option)
然后
def __scrape(self, url):
self.__driver.get(url)
time.sleep(3) # 等待页面中的请求完成
logs = self.__driver.get_log("performance")
日志收录页面中的所有请求和响应。接下来,我们需要遍历每条数据,找到Network.responseReceived的类型,请求url就是我们要抓取的数据,从中获取requestId,然后就可以使用Network.getResponseBody来获取响应.
def process_network_event(driver, logs, match_url):
for entry in logs:
message = json.loads(entry["message"]).get("message", {})
method = message.get("method", "")
is_method_match = method.startswith("Network.responseReceived")
if not is_method_match:
continue
url = message.get("params", {}).get("response", {}).get("url", "")
if url == "":
continue
if not url.startswith(match_url): # 匹配我们想要的url
continue
request_id = message.get("params", {}).get("requestId", "")
if request_id == "":
continue
try:
response_body = driver.execute_cdp_cmd('Network.getResponseBody', {'requestId': request_id})
except Exception as e:
print(f"getResponseBody by {request_id} failed: {e}, with message: {message}")
response_body = None
if not response_body:
continue
json_string = response_body.get("body", "")
if json_string == "":
continue
response = json.loads(json_string)
return response
还有一个基于性能日志的python模块,可以更容易地提取请求和响应,[selenium-wire·PyPI](),[wkeeling/selenium-wire:扩展Selenium的Python绑定,让你能够检查浏览器发出的请求。]()。模块更新处于活动状态
总结一下,方法五:在界面无法直接抓取的情况下,使用selenium+浏览器的性能日志是最好的解决方案。
另外总结一下爬虫项目中的一些常用技巧
UserAgent 应该稍微伪装一下,经常可以换不同的 UserAgent 来伪装不同的客户端。准备更多的代理。如果目标网站对IP有严格的控制,那么我们会经常更换代理。
参考资料
如果觉得我的分享对你有用,请关注并在评论区与我交流。我会继续分享一些有用的知识和经验。 查看全部
nodejs抓取动态网页(网络爬虫这块套路总结,用python+selenium执行代码上面第一种)
我是北京一家互联网工厂的996程序员。一边学习追赶新技术,一边害怕被潮流甩在后面,一边学习投资理财的方法让自己的薪水滚雪球。我相信你越努力,你就越幸运。雪球虽然一开始滚得很慢,但只要你坚持住,它就会滚得越来越快,你的养老就靠它了。在财富和自由的道路上,我鼓励你。欢迎评论区和我交流经验和干货,让我们收获更多。
我最近在抓一条网站的消息。今天写完了程序,用python+selenium。顺便总结一下网络爬虫的套路,分享给大家。
方法一:直接接口调用。
如果对方网站的api几乎没有反爬错误,那么可以直接通过浏览器的开发工具获取对方的api地址,直接调用爬取。如果对方界面控制了爬取频率,自己控制爬取间隔即可。
如果使用python技术栈开发,使用requests库模拟接口调用。这里需要注意具体的headers,可能收录token、签名等,需要自己整理。
方法二:使用js解析器执行js代码
上面第一种情况提到的场景毕竟还是少数,大部分网站都采取了一些反爬虫的措施。比如网站通过页面加载的js向界面发起XHR类型的ajax请求。调用接口时,自定义参数添加到查询字符串或URL的头部,参数生成方法均在js中。 ,然后可以选择了解js代码,然后用python重写生成参数的代码,最后组装这些参数调用接口。
但通常你没有那么幸运。生成参数的js代码比较混乱,基本无法被人类阅读。但是,如果你能定位到使用了哪个函数,那么我们可以采取另一种解决方案,就是将js代码改到js解释器中,然后直接调用函数获取返回值。我们拿这些返回值来组装请求参数。
如果使用python技术栈开发,可以使用PyExecJS、PyV8、js2py、Node.js这些js解析器来运行js代码。
js2py,一个纯python实现的js解析器,目前还在更新中。 PyExecJS,项目已经停止开发,但是还可以使用。 PyV8,是google v8 js引擎的python包。好久没更新了,不过还是可以用的。 Node.js,基于chrome v8引擎的js运行时,更新活跃。
推荐使用 Js2py。
方法三:使用selenium调用浏览器访问
方法二的场景,js代码根本用不上,也无法定位到要用到哪些函数,所以只能搬出selenium。 Selenium 是一套工具包,通过它我们可以使用程序来控制浏览器访问目标网站。 Selenium 有很多语言的绑定,自然也有python 的绑定。
使用selenium控制浏览器访问目标url后,如果要抓取的内容在页面内,则直接使用selenium提供的网页提取api直接提取内容。但是如果页面中没有渲染出你想要的内容,那我们就得用next方法了。
方法四:使用selenium+proxy来抓取接口调用
如方法3场景所述,对于js发起的ajax请求,如果响应数据没有完全反映在DOM中,那我们就得想办法直接提取ajax响应。方法是通过selenium+proxy控制浏览器访问,然后我们拦截proxy上的ajax响应。
常用的代理是browsermob-proxy,是java开发的http/https代理。本方案的原则是
在代码中控制启动browsermob-proxy。代码控制selenium启动浏览器,设置本地代理为browsermob-proxy。 Browsermob-proxy 会将请求的请求和响应写入 HAR 文件 (),我们可以通过解析 HAR 的内容得到响应。
方法五:使用selenium+浏览器的性能日志
这个方法可以认为是方法4的升级版,因为浏览器自己获取响应,所以只要找到合适的方法,就可以直接获取响应。
具体方法是webdriver(python代码控制浏览器的一个组件)允许我们向浏览器发送Network.getResponseBody命令来获取响应。 webdriver 提供的 API 文档:
我们需要传递一个名为 requestId 的参数来获取响应。
首先,在初始化浏览器控件实例时,必须开启{"performance": "ALL"}
def __init_driver(self):
capabilities = DesiredCapabilities.CHROME
capabilities["goog:loggingPrefs"] = {"performance": "ALL"} # chromedriver 75+
option = webdriver.ChromeOptions()
option.add_argument(r"user-data-dir=./var/chrome-data")
self.__driver = webdriver.Chrome(desired_capabilities=capabilities, options=option)
然后
def __scrape(self, url):
self.__driver.get(url)
time.sleep(3) # 等待页面中的请求完成
logs = self.__driver.get_log("performance")
日志收录页面中的所有请求和响应。接下来,我们需要遍历每条数据,找到Network.responseReceived的类型,请求url就是我们要抓取的数据,从中获取requestId,然后就可以使用Network.getResponseBody来获取响应.
def process_network_event(driver, logs, match_url):
for entry in logs:
message = json.loads(entry["message"]).get("message", {})
method = message.get("method", "")
is_method_match = method.startswith("Network.responseReceived")
if not is_method_match:
continue
url = message.get("params", {}).get("response", {}).get("url", "")
if url == "":
continue
if not url.startswith(match_url): # 匹配我们想要的url
continue
request_id = message.get("params", {}).get("requestId", "")
if request_id == "":
continue
try:
response_body = driver.execute_cdp_cmd('Network.getResponseBody', {'requestId': request_id})
except Exception as e:
print(f"getResponseBody by {request_id} failed: {e}, with message: {message}")
response_body = None
if not response_body:
continue
json_string = response_body.get("body", "")
if json_string == "":
continue
response = json.loads(json_string)
return response
还有一个基于性能日志的python模块,可以更容易地提取请求和响应,[selenium-wire·PyPI](),[wkeeling/selenium-wire:扩展Selenium的Python绑定,让你能够检查浏览器发出的请求。]()。模块更新处于活动状态
总结一下,方法五:在界面无法直接抓取的情况下,使用selenium+浏览器的性能日志是最好的解决方案。
另外总结一下爬虫项目中的一些常用技巧
UserAgent 应该稍微伪装一下,经常可以换不同的 UserAgent 来伪装不同的客户端。准备更多的代理。如果目标网站对IP有严格的控制,那么我们会经常更换代理。
参考资料
如果觉得我的分享对你有用,请关注并在评论区与我交流。我会继续分享一些有用的知识和经验。
nodejs抓取动态网页(之前做爬虫的优劣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-02 07:15
欢迎访问我的博客杨辰的博客
简介
说到爬虫,最容易想到的就是python了,因为python感觉它什么都能做,但是之前用python做爬虫的过程还是很不爽。主要问题来自几个方面:第一个是对的,对于被爬取的网页的dom操作,第二个是编码处理,第三个是多线程,所以用python做爬虫其实不是很爽。有没有更好的办法?当然还有node.js!
Nodejs作为爬虫的优缺点 首先说一下node作为爬虫的优点
第一个是他的驱动语言是 JavaScript。在 nodejs 诞生之前,JavaScript 是一种运行在浏览器上的脚本语言。它的优点是对网页上的dom元素进行操作,在网页操作方面是其他语言无法比拟的。
二是nodejs是单线程异步的。听起来很奇怪,单线程怎么可能是异步的?想一想为什么在学习操作系统时单核cpu可以进行多任务处理?原因是类似的。在操作系统中,进程占用CPU时间片。每个进程占用的时间很短,但是所有进程都循环了很多次,所以看起来像是同时处理多个任务。对于 js 也是如此。 js中有一个事件池。 CPU会在事件池循环中处理响应的事件,未处理的事件不会放入事件池中,因此不会阻塞后续操作。这样做在爬虫上的好处是,在并发爬取的页面上,一个页面返回失败不会阻塞后续页面继续加载。要做到这一点,你不需要像 python 那样多线程。
接下来是node的缺点
首先,它是异步和并发的。处理好很方便,但是处理不好就麻烦了。比如要爬10个页面,使用node不做异步处理,返回的结果不一定在1、2、3、4...... 这个顺序很可能是随机的。解决办法是添加一个页面序列戳,让爬取的数据生成一个csv文件,然后重新排序。
第二个是数据处理的劣势。这不如python。如果只是单纯的爬取数据,用node当然好,但是如果用爬取的数据继续做统计分析,那就做回归分析。什么东西,那你就不能用node了。
如何使用nodejs作为爬虫
接下来说一下如何使用nodejs作为爬虫
1、初始项目文件
在对应的项目文件夹下执行npm init初始化一个package.json文件
2、安装请求和cheerio依赖包
request 听起来很熟悉,就像 Python 中的 request 函数一样。它的作用是建立目标网页的链接并返回相应的数据,不难理解。
Cheerio 的函数用于操作 dom 元素。它可以将请求返回的数据转换成dom可以操作的数据。更重要的是,cheerio的api和jquery是一样的。用$选择对应的dom节点,是不是很方便?对于前端程序员来说,这比python的xpath和beautisoup方便多了。不知道多少钱啊哈哈
安装命令也很简单,就是npm install request --save和npm installcheerio
3、引入依赖包并使用
接下来用request和cherrio写一个爬虫!
先引入依赖
var request = require("request");
var cheerio = require("cheerio");
接下来我们以爬取我们学校的新闻页面为例。我们学校新闻页面的链接是
然后调用请求接口
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
console.log(result.body);
})
运行一下,结果是这样的
你很兴奋吗?哈哈,html又回来了。这还不够。下一步就是对返回的数据进行处理,提取我们想要获取的信息。轮到啦啦队了。
将请求返回的结果传入cheerio,得到想要获取的信息。代码有没有想写脚本的感觉?
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
var $ = cheerio.load(result.body);
$('a[id^="dnn"]').each(function(index,element){
console.log($(element).text());
})
})
运行结果如下:
这样一个简单的爬虫就完成了。是不是很简单?当然,这还远远不够。
4、设置请求头
众所周知,在http协议中,发送请求头是为了建立连接。对于一些动态网页的抓取,有时需要设置用户代理、cookies等,那么如何使用这些设置?
具体案例代码如下:
var options = {
url: startUrl+'?page=1',
method: 'GET',
charset: "utf-8",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36",
"cookie": cookies
}
};
request(options,function(err,response,body){
//...
})
5 并发控制
可以抓取页面。如果页面多,就会有无限的并发,那么肯定会被阻塞,所以一定要有并发控制。这里是异步的。和上面一样,需要通过npm install async --save安装,通过var async = require("async")引入。
举一个具体的例子来限制并发。
async.mapLimit(5,function(url,callback)){
//...
fetch(url,callback)
})
这里的5是并发数的限制,可以自由使用。最后,不要忘记执行后的回调,因为如果没有,它会被阻塞。 Async 不知道被限制的函数是否已经执行,所以不会被释放。
总结
至此,Nodejs爬虫的核心已经介绍完毕,剩下的就完全可以自由发挥了。最后附上我自己做的一个简单的新浪微博爬虫 查看全部
nodejs抓取动态网页(之前做爬虫的优劣)
欢迎访问我的博客杨辰的博客
简介
说到爬虫,最容易想到的就是python了,因为python感觉它什么都能做,但是之前用python做爬虫的过程还是很不爽。主要问题来自几个方面:第一个是对的,对于被爬取的网页的dom操作,第二个是编码处理,第三个是多线程,所以用python做爬虫其实不是很爽。有没有更好的办法?当然还有node.js!
Nodejs作为爬虫的优缺点 首先说一下node作为爬虫的优点
第一个是他的驱动语言是 JavaScript。在 nodejs 诞生之前,JavaScript 是一种运行在浏览器上的脚本语言。它的优点是对网页上的dom元素进行操作,在网页操作方面是其他语言无法比拟的。
二是nodejs是单线程异步的。听起来很奇怪,单线程怎么可能是异步的?想一想为什么在学习操作系统时单核cpu可以进行多任务处理?原因是类似的。在操作系统中,进程占用CPU时间片。每个进程占用的时间很短,但是所有进程都循环了很多次,所以看起来像是同时处理多个任务。对于 js 也是如此。 js中有一个事件池。 CPU会在事件池循环中处理响应的事件,未处理的事件不会放入事件池中,因此不会阻塞后续操作。这样做在爬虫上的好处是,在并发爬取的页面上,一个页面返回失败不会阻塞后续页面继续加载。要做到这一点,你不需要像 python 那样多线程。
接下来是node的缺点
首先,它是异步和并发的。处理好很方便,但是处理不好就麻烦了。比如要爬10个页面,使用node不做异步处理,返回的结果不一定在1、2、3、4...... 这个顺序很可能是随机的。解决办法是添加一个页面序列戳,让爬取的数据生成一个csv文件,然后重新排序。
第二个是数据处理的劣势。这不如python。如果只是单纯的爬取数据,用node当然好,但是如果用爬取的数据继续做统计分析,那就做回归分析。什么东西,那你就不能用node了。
如何使用nodejs作为爬虫
接下来说一下如何使用nodejs作为爬虫
1、初始项目文件
在对应的项目文件夹下执行npm init初始化一个package.json文件
2、安装请求和cheerio依赖包
request 听起来很熟悉,就像 Python 中的 request 函数一样。它的作用是建立目标网页的链接并返回相应的数据,不难理解。
Cheerio 的函数用于操作 dom 元素。它可以将请求返回的数据转换成dom可以操作的数据。更重要的是,cheerio的api和jquery是一样的。用$选择对应的dom节点,是不是很方便?对于前端程序员来说,这比python的xpath和beautisoup方便多了。不知道多少钱啊哈哈
安装命令也很简单,就是npm install request --save和npm installcheerio
3、引入依赖包并使用
接下来用request和cherrio写一个爬虫!
先引入依赖
var request = require("request");
var cheerio = require("cheerio");
接下来我们以爬取我们学校的新闻页面为例。我们学校新闻页面的链接是
然后调用请求接口
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
console.log(result.body);
})
运行一下,结果是这样的
你很兴奋吗?哈哈,html又回来了。这还不够。下一步就是对返回的数据进行处理,提取我们想要获取的信息。轮到啦啦队了。
将请求返回的结果传入cheerio,得到想要获取的信息。代码有没有想写脚本的感觉?
request('http://news.shu.edu.cn/Default ... 39%3B,function(err,result){
if(err){
console.log(err);
}
var $ = cheerio.load(result.body);
$('a[id^="dnn"]').each(function(index,element){
console.log($(element).text());
})
})
运行结果如下:
这样一个简单的爬虫就完成了。是不是很简单?当然,这还远远不够。
4、设置请求头
众所周知,在http协议中,发送请求头是为了建立连接。对于一些动态网页的抓取,有时需要设置用户代理、cookies等,那么如何使用这些设置?
具体案例代码如下:
var options = {
url: startUrl+'?page=1',
method: 'GET',
charset: "utf-8",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36",
"cookie": cookies
}
};
request(options,function(err,response,body){
//...
})
5 并发控制
可以抓取页面。如果页面多,就会有无限的并发,那么肯定会被阻塞,所以一定要有并发控制。这里是异步的。和上面一样,需要通过npm install async --save安装,通过var async = require("async")引入。
举一个具体的例子来限制并发。
async.mapLimit(5,function(url,callback)){
//...
fetch(url,callback)
})
这里的5是并发数的限制,可以自由使用。最后,不要忘记执行后的回调,因为如果没有,它会被阻塞。 Async 不知道被限制的函数是否已经执行,所以不会被释放。
总结
至此,Nodejs爬虫的核心已经介绍完毕,剩下的就完全可以自由发挥了。最后附上我自己做的一个简单的新浪微博爬虫
nodejs抓取动态网页(php,抓取动态网页,用它来做个app解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-31 23:04
nodejs抓取动态网页,用它来做个app解析html就可以了吧,android的好像也有类似js库可以做这个,或者自己用java拼一下也行。js的话用这个,可以搞定:\x-webkit-browser-source-stream>\x-extensible-webkit-browser-source-stream\x-font-family>\x-cjk-line-stream。
python里抓取index.php,test.php,get.php,cookie.php,xml.html.利用这三个主流的urllib,正则表达式等抓取转义字符为空、加密解密函数可选、自定义数组等,效率与php一致,网站成本和技术层面都有优势。
请问楼主用到了sqliteornosql或者是restapi,
对于网站来说,从网页上获取到php相关部分,用注解(phpapi)获取html代码,然后再解析html代码,再封装成middleware。比如你要抓取,可以这样来注解:phpapi_read_html(phpurl)html部分好找,php中自带的,html提取方法,拿php的注解来做,可能比较麻烦。最简单的方法,就是参考owasp提供的scrawl和scrawl_extract方法。
没有。一个路由在后台js生成一个简单的url,
1对于服务端的,直接get方法,nodejs有成熟的network,自己封装一下。2对于web前端的,要是网站没有对应的框架,你直接写个带抓取自定义信息的middleware就行了,直接按需调用xmlhttprequest或者ajax来发送请求,还有返回html页面就行了。php的,urllib这一块还有个scrawl,ajax。 查看全部
nodejs抓取动态网页(php,抓取动态网页,用它来做个app解析)
nodejs抓取动态网页,用它来做个app解析html就可以了吧,android的好像也有类似js库可以做这个,或者自己用java拼一下也行。js的话用这个,可以搞定:\x-webkit-browser-source-stream>\x-extensible-webkit-browser-source-stream\x-font-family>\x-cjk-line-stream。
python里抓取index.php,test.php,get.php,cookie.php,xml.html.利用这三个主流的urllib,正则表达式等抓取转义字符为空、加密解密函数可选、自定义数组等,效率与php一致,网站成本和技术层面都有优势。
请问楼主用到了sqliteornosql或者是restapi,
对于网站来说,从网页上获取到php相关部分,用注解(phpapi)获取html代码,然后再解析html代码,再封装成middleware。比如你要抓取,可以这样来注解:phpapi_read_html(phpurl)html部分好找,php中自带的,html提取方法,拿php的注解来做,可能比较麻烦。最简单的方法,就是参考owasp提供的scrawl和scrawl_extract方法。
没有。一个路由在后台js生成一个简单的url,
1对于服务端的,直接get方法,nodejs有成熟的network,自己封装一下。2对于web前端的,要是网站没有对应的框架,你直接写个带抓取自定义信息的middleware就行了,直接按需调用xmlhttprequest或者ajax来发送请求,还有返回html页面就行了。php的,urllib这一块还有个scrawl,ajax。
nodejs抓取动态网页( U盘安装好几次都失败了,全局一次就成功了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-31 10:19
U盘安装好几次都失败了,全局一次就成功了)
<p>原文传送门:https://www.ic365club.com/article/detail?id=MA217p10rc08
开发的需求中难免会遇到下载文件的要求,下载自定义HTML文件的需求尤为显著。而不是所有的用户都知道HTML,但是知道和使用pdf的肯定多余HTML的,将HTML文件转pdf提供下载优化用户体验自然也就成为各位内卷的又一目标啦!<br />
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kRxh9Tvd-1633685073551)(/article/img/AI21bk10pz08.jpg “奋斗”)]
加油奥利给冲起来(别想歪了)
文章目录
思路方法一安装举例
方法二安装使用api文档
总结
<a id="_10"></a>思路
其实吧,其实吧方法挺多的,看大家接受哪种了。
1.前端客户自己生成图片,我的网站有几个demo。https://www.ic365club.com/picture/,类似这样的形式,但是局限比较大。我当时做的时候遇到了很多bug,很久没有去看了(bug运行起来就不要动它了)。兼容性不好,会受到浏览器、终端、内核、样式的影响。【pass】
2.使用python来搞,python大法好啊。但是网上看了一圈说速度也是不快,不能说慢,只能说不快。(知道的大佬可以评论区科普哈哈)【pass】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zL1don5B-1633685073553)(http://img.doutula.com/product ... d.jpg “python”)]
3.1使用nodejs模块html-pdf。这个还算可以,但是不支持远程url和一些标签渲染不出来,比如有的img标签,但有的又可以。【备选】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XwBSsxaw-1633685073554)(http://img.doutula.com/product ... S.jpg “妙啊”)]
3.2使用nodejs模块puppeteer,这个模块不像上面的那个,这个是调用Chrome内核做无头浏览器,本质上是使用浏览器生成的。这个有点明显可以使用远程url也可以使用本地链接,而且对样式的渲染也比较好,出来的是彩色的。<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RVtZLhI0-1633685073555)(http://img.doutula.com/product ... w.png “成了”)]
<a id="_23"></a>方法一
使用nodejs模块html-pdf。
<a id="_25"></a>安装
npm i html-pdf
</p>
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
例如
var fs = require('fs');
var pdf = require('html-pdf');// 这种则是依靠自己本事转pdf的,这种方式样式兼容不太好,渲染结果是黑白的
var html = fs.readFileSync('pdf2.html', 'utf8');
var options = { format: 'Letter' };// api请查看npm,因为一直再更新,请根据官方为主。
pdf.create(html, options).toFile('./businesscard.pdf', function(err, res) {
if (err) return console.log(err);
console.log(res); // { filename: '/app/businesscard.pdf' }
});
欲了解更多信息,请参阅官方网站。
方法二
使用 nodejs 模块 puppeteer
安装
npm i puppeteer
npm i puppeteer-core
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
安装此软件包时,将安装浏览器内核。如上所述,这个包是通过操作无头浏览器生成的。
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-Uez791Aj-56)(/article/img/AI217e10f108.png "Kernel") )]
利用
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(__dirname+'/pdf.html', { //这个可以渲染出图片甚至跨域的图片
waitUntil: 'networkidle2',
});
await page.pdf({ path: 'hn1.pdf', format: 'a4' }); // 如果已有该文件会报错
await browser.close();
})();
在第 6 行中,我渲染了一个本地文件,因此我采用了文件的绝对路径。
具体选项请参考 npm。
中文文件
#/
api文档
右上角“相关信息”已经下载了api
总结
1.尝试全局安装
2.如果出错,请仔细阅读错误报告。一般是缺少某个依赖,安装即可。
3. 我用的两个node包速度差不多,不快
4. 找了python的方法,说比较慢,我就没有再试python了。如果你有兴趣,请告诉我你是否尝试过。哈哈
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-d3rn2bNm-56)("响指")]
原创门户:
—————————— 查看全部
nodejs抓取动态网页(
U盘安装好几次都失败了,全局一次就成功了)
<p>原文传送门:https://www.ic365club.com/article/detail?id=MA217p10rc08
开发的需求中难免会遇到下载文件的要求,下载自定义HTML文件的需求尤为显著。而不是所有的用户都知道HTML,但是知道和使用pdf的肯定多余HTML的,将HTML文件转pdf提供下载优化用户体验自然也就成为各位内卷的又一目标啦!<br />
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kRxh9Tvd-1633685073551)(/article/img/AI21bk10pz08.jpg “奋斗”)]
加油奥利给冲起来(别想歪了)
文章目录
思路方法一安装举例
方法二安装使用api文档
总结
<a id="_10"></a>思路
其实吧,其实吧方法挺多的,看大家接受哪种了。
1.前端客户自己生成图片,我的网站有几个demo。https://www.ic365club.com/picture/,类似这样的形式,但是局限比较大。我当时做的时候遇到了很多bug,很久没有去看了(bug运行起来就不要动它了)。兼容性不好,会受到浏览器、终端、内核、样式的影响。【pass】
2.使用python来搞,python大法好啊。但是网上看了一圈说速度也是不快,不能说慢,只能说不快。(知道的大佬可以评论区科普哈哈)【pass】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zL1don5B-1633685073553)(http://img.doutula.com/product ... d.jpg “python”)]
3.1使用nodejs模块html-pdf。这个还算可以,但是不支持远程url和一些标签渲染不出来,比如有的img标签,但有的又可以。【备选】<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XwBSsxaw-1633685073554)(http://img.doutula.com/product ... S.jpg “妙啊”)]
3.2使用nodejs模块puppeteer,这个模块不像上面的那个,这个是调用Chrome内核做无头浏览器,本质上是使用浏览器生成的。这个有点明显可以使用远程url也可以使用本地链接,而且对样式的渲染也比较好,出来的是彩色的。<br /> [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RVtZLhI0-1633685073555)(http://img.doutula.com/product ... w.png “成了”)]
<a id="_23"></a>方法一
使用nodejs模块html-pdf。
<a id="_25"></a>安装
npm i html-pdf
</p>
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
例如
var fs = require('fs');
var pdf = require('html-pdf');// 这种则是依靠自己本事转pdf的,这种方式样式兼容不太好,渲染结果是黑白的
var html = fs.readFileSync('pdf2.html', 'utf8');
var options = { format: 'Letter' };// api请查看npm,因为一直再更新,请根据官方为主。
pdf.create(html, options).toFile('./businesscard.pdf', function(err, res) {
if (err) return console.log(err);
console.log(res); // { filename: '/app/businesscard.pdf' }
});
欲了解更多信息,请参阅官方网站。
方法二
使用 nodejs 模块 puppeteer
安装
npm i puppeteer
npm i puppeteer-core
最好使用全局安装,一些依赖是全局安装的,这样就不会报错了。我在U盘上安装了几次都失败了,但是全局成功了一次。
安装此软件包时,将安装浏览器内核。如上所述,这个包是通过操作无头浏览器生成的。
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-Uez791Aj-56)(/article/img/AI217e10f108.png "Kernel") )]
利用
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(__dirname+'/pdf.html', { //这个可以渲染出图片甚至跨域的图片
waitUntil: 'networkidle2',
});
await page.pdf({ path: 'hn1.pdf', format: 'a4' }); // 如果已有该文件会报错
await browser.close();
})();
在第 6 行中,我渲染了一个本地文件,因此我采用了文件的绝对路径。
具体选项请参考 npm。
中文文件
#/
api文档
右上角“相关信息”已经下载了api
总结
1.尝试全局安装
2.如果出错,请仔细阅读错误报告。一般是缺少某个依赖,安装即可。
3. 我用的两个node包速度差不多,不快
4. 找了python的方法,说比较慢,我就没有再试python了。如果你有兴趣,请告诉我你是否尝试过。哈哈
[外部链接图像传输失败。源站可能有反水蛭链接机制。建议保存图片直接上传(img-d3rn2bNm-56)("响指")]
原创门户:
——————————
nodejs抓取动态网页( H5页面可视化编辑器的实时预览和真机扫码预览功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 10:16
H5页面可视化编辑器的实时预览和真机扫码预览功能
)
前言
所见即所得的设计理念一直是WEB IDE领域备受瞩目的功能亮点,同时也可以极大的提升web编码器的编程体验和编程效率。接下来笔者将实时预览和预览H5可视化编辑器。真机扫码预览功能做方案分析,为大家在设计同类产品时提供一些思路。
我们还是以作者开发的H5-Dooring可视化编辑器为例来分析上述功能的实现。
你会收获文字
一般情况下,实时预览功能会交给前端来实现,比如我们经常看到的微信开发者工具的预览,支付宝小程序的预览,vscode的预览插件,比较经典的DW还集成了强大的实时预览功能,接下来我们来看一个H5-Dooring在线编程的实时预览模块:
在H5页面可视化平台中,我们也希望能实时看到我们配置页面的效果,比如改变某个属性,可以在canvas中实时生效,也可以在canvas上查看真机效果手机,提供这种实时预览功能,无疑是可视化配置平台刚需。以下情况:
在PC上模拟手机预览:
真机预览入口及效果:
(自动识别二维码)
因此,我们实时预览设计的关键是如何高保真还原用户在画布中的配置,使误差和体验最大化。
接下来,笔者将具体介绍如何实现上述预览方式,以及如何设计一个高可用的预览程序。
1. canvas元素与属性编辑器实时联动方案
canvas元素和属性编辑器的实时联动方案主要是指属性编辑器的修改如何实时同步到canvas元素,抽象为如下概念:
为了实现右边的属性编辑器已经修改了内容,并且画布可以实时更新,我们需要实现一种模式来关联左右,这就是“联动”的概念。众所周知,每一个可视化组件都有对应一个独特的schema(在H5-Dooring的文章中已经介绍过,有兴趣的朋友可以学习了解),schema的结构类似如下:
{
一旦设计了这样的数据结构,我们就可以动态渲染编辑器的表单(通过editData),并将修改后的值同步到组件(通过editData -> config mapping)。
其次,我们需要定义共享数据源。我们可以使用vuex(比如你是vue技术栈)或者dva(如果你是react技术栈)。总体设计思路如下:
本质上是在属性编辑器中触发动作,修改相应组件的配置,并通过差异更新画布内容。pointData是画布上组件的数据集,用于显示H5页面的编辑项和动态渲染属性编辑器。后面我们介绍的预览功能也依赖于pointData提供的数据。
2. 实时预览的大体思路
笔者之前的文章详细介绍了如何实现Web IDE的实时预览,即nodejs+iframe的方式,但是对于我们H5门的可视化编辑器来说,可能还需要另一种方式。即用户可以在需要预览时手动模拟真机预览或真机预览。这里我们通常会在编辑器界面中提供一个预览按钮,当用户点击时,可以跳转到预览视图,如下:
基于我们前面提到的json schema作为预览的数据源,我们很容易想到通过预览页面上的数据源重新渲染一个H5页面。思路如下:
如果预览页面是新打开的页面,比如H5-Dooring的实现,那么这个数据源需要在预览前存储在localStorage中。由于localStorage的特性,我们可以在同一个域内跨页面共享数据,所以实现我们的需求非常方便。至于渲染引擎部分,我们只需要使用react-grid-layout提供的数据供给方案即可。代码如下:
<p> 查看全部
nodejs抓取动态网页(
H5页面可视化编辑器的实时预览和真机扫码预览功能
)
前言
所见即所得的设计理念一直是WEB IDE领域备受瞩目的功能亮点,同时也可以极大的提升web编码器的编程体验和编程效率。接下来笔者将实时预览和预览H5可视化编辑器。真机扫码预览功能做方案分析,为大家在设计同类产品时提供一些思路。
我们还是以作者开发的H5-Dooring可视化编辑器为例来分析上述功能的实现。
你会收获文字
一般情况下,实时预览功能会交给前端来实现,比如我们经常看到的微信开发者工具的预览,支付宝小程序的预览,vscode的预览插件,比较经典的DW还集成了强大的实时预览功能,接下来我们来看一个H5-Dooring在线编程的实时预览模块:
在H5页面可视化平台中,我们也希望能实时看到我们配置页面的效果,比如改变某个属性,可以在canvas中实时生效,也可以在canvas上查看真机效果手机,提供这种实时预览功能,无疑是可视化配置平台刚需。以下情况:
在PC上模拟手机预览:
真机预览入口及效果:
(自动识别二维码)
因此,我们实时预览设计的关键是如何高保真还原用户在画布中的配置,使误差和体验最大化。
接下来,笔者将具体介绍如何实现上述预览方式,以及如何设计一个高可用的预览程序。
1. canvas元素与属性编辑器实时联动方案
canvas元素和属性编辑器的实时联动方案主要是指属性编辑器的修改如何实时同步到canvas元素,抽象为如下概念:
为了实现右边的属性编辑器已经修改了内容,并且画布可以实时更新,我们需要实现一种模式来关联左右,这就是“联动”的概念。众所周知,每一个可视化组件都有对应一个独特的schema(在H5-Dooring的文章中已经介绍过,有兴趣的朋友可以学习了解),schema的结构类似如下:
{
一旦设计了这样的数据结构,我们就可以动态渲染编辑器的表单(通过editData),并将修改后的值同步到组件(通过editData -> config mapping)。
其次,我们需要定义共享数据源。我们可以使用vuex(比如你是vue技术栈)或者dva(如果你是react技术栈)。总体设计思路如下:
本质上是在属性编辑器中触发动作,修改相应组件的配置,并通过差异更新画布内容。pointData是画布上组件的数据集,用于显示H5页面的编辑项和动态渲染属性编辑器。后面我们介绍的预览功能也依赖于pointData提供的数据。
2. 实时预览的大体思路
笔者之前的文章详细介绍了如何实现Web IDE的实时预览,即nodejs+iframe的方式,但是对于我们H5门的可视化编辑器来说,可能还需要另一种方式。即用户可以在需要预览时手动模拟真机预览或真机预览。这里我们通常会在编辑器界面中提供一个预览按钮,当用户点击时,可以跳转到预览视图,如下:
基于我们前面提到的json schema作为预览的数据源,我们很容易想到通过预览页面上的数据源重新渲染一个H5页面。思路如下:
如果预览页面是新打开的页面,比如H5-Dooring的实现,那么这个数据源需要在预览前存储在localStorage中。由于localStorage的特性,我们可以在同一个域内跨页面共享数据,所以实现我们的需求非常方便。至于渲染引擎部分,我们只需要使用react-grid-layout提供的数据供给方案即可。代码如下:
<p>
nodejs抓取动态网页(我分别用过三种方式写过一些简单的爬虫,解决了方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-25 21:00
我用三种方式写了一些简单的爬虫。下面总结一下我对爬虫的理解和使用方法(欢迎指正和补充):
使用任何语言的http库(比如python的urllib2,或者使用支持连接池的urllib3来提高效率),加上一个解析html的库(比如python的beautifulsoup)。使用urllib模拟get/post请求爬取网页,然后通过解析html库得到需要爬取的内容。如果可以获取一个页面的内容,就可以通过url获取所有页面的内容。
优点:直接,速度快,占用资源少,可以同时运行多个进程/线程,可以在命令行上完成
缺点:这种方式的致命缺点是页面通过js动态渲染或者ajax动态加载时,获取页面内容比较困难。在这种情况下,还需要一个js解释器(或者说它是一个浏览器)来进一步分析,得到想要的内容。
PS:遇到ip限制可以设置代理。
使用firefox/chrome浏览器插件方式(即javascript+浏览器方式做爬虫)。使用firefox插件,不存在跨域访问提交问题。下面是我去年写的一个简单的firefox插件爬取论文网站作者/邮箱的firefox插件比较粗糙,但基本流程通用。基本原理是在浏览器加载页面后,使用javascript/jquery模拟点击等事件,获取相应的内容,然后发布到远程服务器Url,处理后保存。或者写入浏览器的本地存储(如sqlite)
优点:直观,纯js实现,jquery简单易用,调试方便,解决了方法1的动态内容渲染问题,可以与浏览器交互,轻松解决验证码输入限制
缺点:必须依赖本地浏览器,速度慢,比方法1消耗资源,多进程/线程比较困难,或多或少需要考虑干预(因为我的代码写得不好...)
第三种方法使用了一个叫selenium-automated browser的神器,它是一个支持多语言界面的库,通过它你可以使用java/python/ruby等语言来操作浏览器(firefox/chrome等)完成任务,通常用于前端代码的测试。这样编写的爬虫,或者通过python/java等语言编写主要结构(分析和修改数据,存入数据库等),通过selenium js/jquery接口完成web的渲染和触发内容。
优点:结合了方法一和方法二的大部分优点。 查看全部
nodejs抓取动态网页(我分别用过三种方式写过一些简单的爬虫,解决了方法)
我用三种方式写了一些简单的爬虫。下面总结一下我对爬虫的理解和使用方法(欢迎指正和补充):
使用任何语言的http库(比如python的urllib2,或者使用支持连接池的urllib3来提高效率),加上一个解析html的库(比如python的beautifulsoup)。使用urllib模拟get/post请求爬取网页,然后通过解析html库得到需要爬取的内容。如果可以获取一个页面的内容,就可以通过url获取所有页面的内容。
优点:直接,速度快,占用资源少,可以同时运行多个进程/线程,可以在命令行上完成
缺点:这种方式的致命缺点是页面通过js动态渲染或者ajax动态加载时,获取页面内容比较困难。在这种情况下,还需要一个js解释器(或者说它是一个浏览器)来进一步分析,得到想要的内容。
PS:遇到ip限制可以设置代理。
使用firefox/chrome浏览器插件方式(即javascript+浏览器方式做爬虫)。使用firefox插件,不存在跨域访问提交问题。下面是我去年写的一个简单的firefox插件爬取论文网站作者/邮箱的firefox插件比较粗糙,但基本流程通用。基本原理是在浏览器加载页面后,使用javascript/jquery模拟点击等事件,获取相应的内容,然后发布到远程服务器Url,处理后保存。或者写入浏览器的本地存储(如sqlite)
优点:直观,纯js实现,jquery简单易用,调试方便,解决了方法1的动态内容渲染问题,可以与浏览器交互,轻松解决验证码输入限制
缺点:必须依赖本地浏览器,速度慢,比方法1消耗资源,多进程/线程比较困难,或多或少需要考虑干预(因为我的代码写得不好...)
第三种方法使用了一个叫selenium-automated browser的神器,它是一个支持多语言界面的库,通过它你可以使用java/python/ruby等语言来操作浏览器(firefox/chrome等)完成任务,通常用于前端代码的测试。这样编写的爬虫,或者通过python/java等语言编写主要结构(分析和修改数据,存入数据库等),通过selenium js/jquery接口完成web的渲染和触发内容。
优点:结合了方法一和方法二的大部分优点。
nodejs抓取动态网页( 使用puppeteer爬取链家的房价数据,详解了puppeteer的相关用法及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 14:03
使用puppeteer爬取链家的房价数据,详解了puppeteer的相关用法及注意事项)
使用puppeteer抓取链家的价格数据,详细讲解puppeteer的相关使用方法和注意事项,并进行地图的直观展示。
使用puppeteer爬取链家房价信息
内容
本文记录了使用puppeteer库进行动态网站爬取的过程。页面结构
地址
链家的历史交易记录页面在这里。是后台渲染模式,无法通过监控模拟xhr请求快速获取。您只能找到一种方法来分析其页面结构并提取元素。
页面是分页管理的,比如第二页链接是,遍历分页没问题。
问题是通过首页可以看到它有5万多条历史信息,一个页面有30条,但是它的首页只显示100页,没有办法遍历分页获取所有数据.
幸运的是,链家提供了过滤器。经测试,使用街道级区域过滤可以满足寻呼限制。
那么爬取的思路就是遍历区级按钮,遍历每个区级按钮下的街道按钮,遍历每个街道按钮下的每一页。
爬虫库
在nodejs爬虫库领域,常用cheerio和puppeteer。其中cheerio一般用于抓取静态网页,puppeteer常用于抓取动态网页。
链家网页虽然是后台静态生成的,但考虑到需要对页面进行操作(点击其区域选择器),还是首选puppeteer库。
木偶图书馆
ppeteer 库是在 2017 年谷歌 Chrome 开发自己的 Chrome Headless 功能的同时推出的。本质上,它是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在检索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
完成
这是它的git地址,这是它的中文教程。
打开要抓取的页面
// 1. 引包
const puppeteer = require('puppeteer');
// 2. 在异步环境中执行(pupeteer 所有操作都是异步实现的)
(async ()=>{
// 创建浏览器窗口
const browser = await puppeteer.launch({
headless: false, // 有界面模式,可以查看执行详情
});
// 创建标签页
const page = await browser.newPage();
// 进入待爬页面
await page.goto('https://wh.lianjia.com/chengjiao/');
// 遍历页面
})()
这样,链家网站就在Pupeteer成功开通了。
仅仅打开它是不够的。我们期望的是操作网页上的过滤按钮来获取每条街道的页面,以便我们可以遍历其分页进行查询。
遍历区级页面
我们首先需要找到区按钮并点击它。
标准思维
(async ()=>{
// ......
// 使用选择器
/* page.$$() 会在页面执行 document.querySelectorAll,并返回 ElementHandle 对象的数组
page.$() 执行 document.querySelector,返回 ElementHandle 对象
*/
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
await district.click() // 模拟点击页面对象
// 遍历街道
}
})
第一个想法大概是这样写,通过选择器获取所有的按钮,然后一个一个的点击。
恭喜,我收到一个错误。
错误:执行上下文被破坏,很可能是因为导航。
假设您的执行上下文被杀死,可能是因为页面导航。
为了澄清这个问题,我们需要先看一下 Execution 上下文是什么。
这是puppeteer的内部组织结构。一页下有多个框架,一个框架下有一个执行上下文。
单击第二个按钮时触发了我们的错误。
这很清楚。点击第一个导航成功,页面变了,你的二区还是依赖上一个页面。结果找不到执行上下文,然后报错。
如何解决?
有两个想法。
方法一
缓存区域级按钮的链接,使其在遍历跳转时不依赖原页面。
(async ()=>{
// ......
// 使用选择器
/* page.$$eval('选择器', callback(eles)) 会在page页面内部执行 Array.from(document.querySelectorAll(selector)),然后把数组参数传给 callback
*/
let districts = await page.$$eval('div[data-role=ershoufang]>div>a',links=>{
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
for(let district of districts){
await page.goto(district) // 使用 page.goto() 替代点击
// 遍历街道
}
})
这里需要特别说明的是,点击按钮、导航链接等页面操作都是在node.js中完成的。页面中的操作,比如读取元素的某个属性,都是在浏览器的引擎中处理的,类似于html文件中script标签中的script。
对于puppeteer,它的脚本文件一般都是用*.*eval()包裹的,比如page.evaluate(pageFunction[, ...args]), page.$eval(selector,pageFunction, ...args), ElementHandle。 $eval(selector, pageFunction, ...args)。
在这种脚本中,除非在以下参数中传递参数,否则无法访问节点环境中的全局变量:
let name = 'bug'
page.$eval('id',(ele/* 这个参数是该方法自身返回的所选择元素 */, nodeParam)=>{
console.log(nodeParam) // 'bug'
},name)
方法二
另一种方式是在链接跳转时不直接跳转到原页面,而是打开一个新的page2页面。这样你就不能使用点击,而是得到它的链接。
(async ()=>{
// 新建一个标签页用来做跳转缓存
const page2 = await browser.newPage();
// ......
// 仍使用原方法获取元素
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
let link = (await district.getProperty('href'))._remoteObject.value // 获取属性
await page2.goto(link) // 在新页面跳转,原 page 不变
// 遍历街道
}
})
这两种方法都是可行的,但是第一种方法似乎更简单一些。每个按钮的链接缓存后,似乎不需要保留原来的页面了。
总之,我们现在可以遍历所有区级页面了!
遍历街道页面
下面的操作写在遍历区级页的for循环中。
操作类似于遍历区级页面,先找到街道按钮,然后循环跳转。这里的跳转逻辑也和上面类似,要么选择缓存它的链接,要么打开一个新的page3进行分页循环。
我喜欢缓存,毕竟新页面也是消耗内存的吧?
(async ()=>{
let streets = await page.$$eval(
'div[data-role=ershoufang] div:last-child a', (links => {
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
)
for(let street of streets){
await page.goto(street) // 使用 page.goto() 替代点击
// 遍历页码
}
})
遍历分页
因为分页的链接处理比较简单,增量就够了。
有一个小问题,我们如何确定循环的结束。
有几个想法,
首先,街道首页会显示该地区有多少套房。每页收录
30 个套件,只需除以一。
其次,我们可以获取分页按钮的最后一个值,但不幸的是,大多数情况下最后一个值是下一页。有鉴于此,我们或许可以做一个while循环,当分页的最后一个按钮不是下一页时,就表示遍历结束。但是对于房间比较少的区域,可能只有两三页,而且没有下一页按钮,所以直接跳过漏爬。
第三,看一下页面结构。以上是从渲染出来的页面看到的信息,页面结构上可能会有totalPage等字段。我仔细查看了分页组件,果然,标签属性里有总页数。
在上述想法中,第二个可能是第二个。然而,这是我使用的方法......在我改变它之前犯了很多低级错误。其实第二个只要做简单的优化就可以用了,比如获取分页按钮的最后一个,如果是下一页就获取它之前的兄弟元素,或者你可以很容易的获取总的数量页。
简而言之,让我们使用最简单的一个:
// 遍历页码
let totalPage = await page.$eval('div.house-lst-page-box',el => {
return JSON.parse(el.getAttribute('page-data')).totalPage
})
for (let i = 1; i 1) await page.goto(`${street}pg${i}`) // 跳转拼接的分页链接
// 业务代码
}
商业信息
这样我们就实现了每一页数据的遍历,可以愉快的写业务逻辑了。
基本上,您可以根据自己的兴趣获取所有可以看到的数据。 查看全部
nodejs抓取动态网页(
使用puppeteer爬取链家的房价数据,详解了puppeteer的相关用法及注意事项)
使用puppeteer抓取链家的价格数据,详细讲解puppeteer的相关使用方法和注意事项,并进行地图的直观展示。
使用puppeteer爬取链家房价信息
内容
本文记录了使用puppeteer库进行动态网站爬取的过程。页面结构
地址
链家的历史交易记录页面在这里。是后台渲染模式,无法通过监控模拟xhr请求快速获取。您只能找到一种方法来分析其页面结构并提取元素。
页面是分页管理的,比如第二页链接是,遍历分页没问题。
问题是通过首页可以看到它有5万多条历史信息,一个页面有30条,但是它的首页只显示100页,没有办法遍历分页获取所有数据.
幸运的是,链家提供了过滤器。经测试,使用街道级区域过滤可以满足寻呼限制。
那么爬取的思路就是遍历区级按钮,遍历每个区级按钮下的街道按钮,遍历每个街道按钮下的每一页。
爬虫库
在nodejs爬虫库领域,常用cheerio和puppeteer。其中cheerio一般用于抓取静态网页,puppeteer常用于抓取动态网页。
链家网页虽然是后台静态生成的,但考虑到需要对页面进行操作(点击其区域选择器),还是首选puppeteer库。
木偶图书馆
ppeteer 库是在 2017 年谷歌 Chrome 开发自己的 Chrome Headless 功能的同时推出的。本质上,它是一个没有界面的浏览器,有点像电脑终端,所有的操作都是通过代码来完成的。
这样我们就可以在检索网站之前操作指定元素滚动到底部触发更多信息。或者当需要翻页时,操作码点击翻页按钮,然后在翻页后对页面进行相关处理。
完成
这是它的git地址,这是它的中文教程。
打开要抓取的页面
// 1. 引包
const puppeteer = require('puppeteer');
// 2. 在异步环境中执行(pupeteer 所有操作都是异步实现的)
(async ()=>{
// 创建浏览器窗口
const browser = await puppeteer.launch({
headless: false, // 有界面模式,可以查看执行详情
});
// 创建标签页
const page = await browser.newPage();
// 进入待爬页面
await page.goto('https://wh.lianjia.com/chengjiao/');
// 遍历页面
})()
这样,链家网站就在Pupeteer成功开通了。
仅仅打开它是不够的。我们期望的是操作网页上的过滤按钮来获取每条街道的页面,以便我们可以遍历其分页进行查询。
遍历区级页面
我们首先需要找到区按钮并点击它。
标准思维
(async ()=>{
// ......
// 使用选择器
/* page.$$() 会在页面执行 document.querySelectorAll,并返回 ElementHandle 对象的数组
page.$() 执行 document.querySelector,返回 ElementHandle 对象
*/
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
await district.click() // 模拟点击页面对象
// 遍历街道
}
})
第一个想法大概是这样写,通过选择器获取所有的按钮,然后一个一个的点击。
恭喜,我收到一个错误。
错误:执行上下文被破坏,很可能是因为导航。
假设您的执行上下文被杀死,可能是因为页面导航。
为了澄清这个问题,我们需要先看一下 Execution 上下文是什么。
这是puppeteer的内部组织结构。一页下有多个框架,一个框架下有一个执行上下文。
单击第二个按钮时触发了我们的错误。
这很清楚。点击第一个导航成功,页面变了,你的二区还是依赖上一个页面。结果找不到执行上下文,然后报错。
如何解决?
有两个想法。
方法一
缓存区域级按钮的链接,使其在遍历跳转时不依赖原页面。
(async ()=>{
// ......
// 使用选择器
/* page.$$eval('选择器', callback(eles)) 会在page页面内部执行 Array.from(document.querySelectorAll(selector)),然后把数组参数传给 callback
*/
let districts = await page.$$eval('div[data-role=ershoufang]>div>a',links=>{
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
for(let district of districts){
await page.goto(district) // 使用 page.goto() 替代点击
// 遍历街道
}
})
这里需要特别说明的是,点击按钮、导航链接等页面操作都是在node.js中完成的。页面中的操作,比如读取元素的某个属性,都是在浏览器的引擎中处理的,类似于html文件中script标签中的script。
对于puppeteer,它的脚本文件一般都是用*.*eval()包裹的,比如page.evaluate(pageFunction[, ...args]), page.$eval(selector,pageFunction, ...args), ElementHandle。 $eval(selector, pageFunction, ...args)。
在这种脚本中,除非在以下参数中传递参数,否则无法访问节点环境中的全局变量:
let name = 'bug'
page.$eval('id',(ele/* 这个参数是该方法自身返回的所选择元素 */, nodeParam)=>{
console.log(nodeParam) // 'bug'
},name)
方法二
另一种方式是在链接跳转时不直接跳转到原页面,而是打开一个新的page2页面。这样你就不能使用点击,而是得到它的链接。
(async ()=>{
// 新建一个标签页用来做跳转缓存
const page2 = await browser.newPage();
// ......
// 仍使用原方法获取元素
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
let link = (await district.getProperty('href'))._remoteObject.value // 获取属性
await page2.goto(link) // 在新页面跳转,原 page 不变
// 遍历街道
}
})
这两种方法都是可行的,但是第一种方法似乎更简单一些。每个按钮的链接缓存后,似乎不需要保留原来的页面了。
总之,我们现在可以遍历所有区级页面了!
遍历街道页面
下面的操作写在遍历区级页的for循环中。
操作类似于遍历区级页面,先找到街道按钮,然后循环跳转。这里的跳转逻辑也和上面类似,要么选择缓存它的链接,要么打开一个新的page3进行分页循环。
我喜欢缓存,毕竟新页面也是消耗内存的吧?
(async ()=>{
let streets = await page.$$eval(
'div[data-role=ershoufang] div:last-child a', (links => {
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
)
for(let street of streets){
await page.goto(street) // 使用 page.goto() 替代点击
// 遍历页码
}
})
遍历分页
因为分页的链接处理比较简单,增量就够了。
有一个小问题,我们如何确定循环的结束。
有几个想法,
首先,街道首页会显示该地区有多少套房。每页收录
30 个套件,只需除以一。
其次,我们可以获取分页按钮的最后一个值,但不幸的是,大多数情况下最后一个值是下一页。有鉴于此,我们或许可以做一个while循环,当分页的最后一个按钮不是下一页时,就表示遍历结束。但是对于房间比较少的区域,可能只有两三页,而且没有下一页按钮,所以直接跳过漏爬。
第三,看一下页面结构。以上是从渲染出来的页面看到的信息,页面结构上可能会有totalPage等字段。我仔细查看了分页组件,果然,标签属性里有总页数。
在上述想法中,第二个可能是第二个。然而,这是我使用的方法......在我改变它之前犯了很多低级错误。其实第二个只要做简单的优化就可以用了,比如获取分页按钮的最后一个,如果是下一页就获取它之前的兄弟元素,或者你可以很容易的获取总的数量页。
简而言之,让我们使用最简单的一个:
// 遍历页码
let totalPage = await page.$eval('div.house-lst-page-box',el => {
return JSON.parse(el.getAttribute('page-data')).totalPage
})
for (let i = 1; i 1) await page.goto(`${street}pg${i}`) // 跳转拼接的分页链接
// 业务代码
}
商业信息
这样我们就实现了每一页数据的遍历,可以愉快的写业务逻辑了。
基本上,您可以根据自己的兴趣获取所有可以看到的数据。
nodejs抓取动态网页(curl.jsHelloWorld.head:saveimage下载的图片文件都是空)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-23 09:39
还是参考这个文章:
另外,我在上面文章 nodejs抢网易公共类有一些经验。
代码如下。注意http用于获取网页结果,request用于http请求,cheerio用于解析,mkdirp用于创建目录,fs用于创建文件,iconv-lite用于格式转换(这个例子不是必须的)。
curl.js:
/**
* Created by baidu on 16/10/17.
*/
var http = require("http");
function download(url, callback) {
var chunks = [];
http.get(url, function(res) {
res.on('data', function(chunk) {
chunks.push(chunk);
});
res.on('end', function () {
callback(chunks);
});
}).on('error', function () {
callback(chunks);
})
}
exports.download = download;
保存图片.js
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request(url).pipe(fs.createWriteStream(filename));
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
HelloWorld.js
/**
* Created by baidu on 16/10/17.
*/
console.log("Hello World");
var cheerio = require('cheerio');
var curl = require('./curl');
var iconv = require('iconv-lite');
var mkdirp = require('mkdirp');
var saveimage = require('./saveimage');
//var url = 'http://open.163.com/special/op ... 3B%3B
var url = 'http://loftermeirenzhi.lofter. ... 3B%3B
var dir = './images';
mkdirp(dir, function(err) {
if (err) {
console.log(err);
}
});
curl.download(url, function (chunks) {
if (chunks) {
var data = iconv.decode(Buffer.concat(chunks), 'gbk');
var $ = cheerio.load(data);
$('a.img').each(function (i, e) {
var item = $(e).children('img').last().attr('src');
saveimage.saveImage(item, dir + '/' + item.substr(item.indexOf('.jpg')-10, 14));
});
console.log('done');
}
else {
console.log('error');
}
});
运行后发现下载的镜像文件基本都是空的。
查看示例后,对saveimage.js的请求部分做了如下修改:
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
});
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
然后运行,成功,打印:
/usr/local/bin/node /Users/baidu/Documents/Data/Work/Code/Self/nodejs/helloworld/HelloWorld.js
Hello World
Image=>http://imgsize.ph.126.net/%3Fi ... 0.jpg
Save=>./images/0709354180.jpg
Image=>http://imglf1.nosdn.127.net/im ... 3Djpg
Save=>./images/TNjZmJ3PT0.jpg
......
done
然后在项目目录下生成images目录,里面有美女的图片:
目前还不是特别清楚上述变化是否会产生影响。(head一般用来判断url是否有效。)
头部添加成功。也可能是因为虽然第一次下载图片没有成功,但是已经开始下载并缓存了。试验了一下,成功后,去掉head命令:
//request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
//});
发现仍然可以成功。所以很可能是图片加载延迟造成的。
有空看看怎么避免图片下载超时导致下载失败的问题,有没有设置超时的地方。
好像在请求初始化的时候,可以设置:
request({
url: jurl,
gzip: true,
timeout: xxx
})
后面我们会学习Javascript Request和一些渲染的内容。特别是 phantomjs 呈现动态网页的方式。
转载于: 查看全部
nodejs抓取动态网页(curl.jsHelloWorld.head:saveimage下载的图片文件都是空)
还是参考这个文章:
另外,我在上面文章 nodejs抢网易公共类有一些经验。
代码如下。注意http用于获取网页结果,request用于http请求,cheerio用于解析,mkdirp用于创建目录,fs用于创建文件,iconv-lite用于格式转换(这个例子不是必须的)。
curl.js:
/**
* Created by baidu on 16/10/17.
*/
var http = require("http");
function download(url, callback) {
var chunks = [];
http.get(url, function(res) {
res.on('data', function(chunk) {
chunks.push(chunk);
});
res.on('end', function () {
callback(chunks);
});
}).on('error', function () {
callback(chunks);
})
}
exports.download = download;
保存图片.js
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request(url).pipe(fs.createWriteStream(filename));
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
HelloWorld.js
/**
* Created by baidu on 16/10/17.
*/
console.log("Hello World");
var cheerio = require('cheerio');
var curl = require('./curl');
var iconv = require('iconv-lite');
var mkdirp = require('mkdirp');
var saveimage = require('./saveimage');
//var url = 'http://open.163.com/special/op ... 3B%3B
var url = 'http://loftermeirenzhi.lofter. ... 3B%3B
var dir = './images';
mkdirp(dir, function(err) {
if (err) {
console.log(err);
}
});
curl.download(url, function (chunks) {
if (chunks) {
var data = iconv.decode(Buffer.concat(chunks), 'gbk');
var $ = cheerio.load(data);
$('a.img').each(function (i, e) {
var item = $(e).children('img').last().attr('src');
saveimage.saveImage(item, dir + '/' + item.substr(item.indexOf('.jpg')-10, 14));
});
console.log('done');
}
else {
console.log('error');
}
});
运行后发现下载的镜像文件基本都是空的。
查看示例后,对saveimage.js的请求部分做了如下修改:
/**
* Created by baidu on 16/10/17.
*/
var fs = require('fs');
var request = require('request');
var saveImage = function(url, filename) {
console.log('Image=>' + url);
request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
});
console.log('Save=>' + filename);
}
exports.saveImage = saveImage;
然后运行,成功,打印:
/usr/local/bin/node /Users/baidu/Documents/Data/Work/Code/Self/nodejs/helloworld/HelloWorld.js
Hello World
Image=>http://imgsize.ph.126.net/%3Fi ... 0.jpg
Save=>./images/0709354180.jpg
Image=>http://imglf1.nosdn.127.net/im ... 3Djpg
Save=>./images/TNjZmJ3PT0.jpg
......
done
然后在项目目录下生成images目录,里面有美女的图片:
目前还不是特别清楚上述变化是否会产生影响。(head一般用来判断url是否有效。)
头部添加成功。也可能是因为虽然第一次下载图片没有成功,但是已经开始下载并缓存了。试验了一下,成功后,去掉head命令:
//request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
//});
发现仍然可以成功。所以很可能是图片加载延迟造成的。
有空看看怎么避免图片下载超时导致下载失败的问题,有没有设置超时的地方。
好像在请求初始化的时候,可以设置:
request({
url: jurl,
gzip: true,
timeout: xxx
})
后面我们会学习Javascript Request和一些渲染的内容。特别是 phantomjs 呈现动态网页的方式。
转载于:
nodejs抓取动态网页( 平凡公子阅读(1789)评论(0)编辑())
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-23 09:15
平凡公子阅读(1789)评论(0)编辑())
nodejs抓取页面内容,分析js文件中的一些内容
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查,就不多说了,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家应该都能看懂了吧!这里只是一些实验代码,具体的需要自己研究研究!
发表于@2015-11-16 14:49 普通少爷 阅读(1789)评论(0)编辑 查看全部
nodejs抓取动态网页(
平凡公子阅读(1789)评论(0)编辑())
nodejs抓取页面内容,分析js文件中的一些内容
Nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查,就不多说了,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家应该都能看懂了吧!这里只是一些实验代码,具体的需要自己研究研究!
发表于@2015-11-16 14:49 普通少爷 阅读(1789)评论(0)编辑
nodejs抓取动态网页(我的代码段捕获显示在链接上的第一个产品的URL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-23 02:12
这是我的代码片段:
nightmare
.goto('https://www.stadiumgoods.com/c ... %2339;)
.wait('body')
.evaluate(() => document.querySelector('body').innerHTML)
.end()
.then(response => {
const $ = cheerio.load(response);
console.log($('.item > a').attr('href'));
此代码段捕获链接上显示的第一个产品的 URL。但是,这个过程只需要30秒就可以得到链接。
有什么办法可以让这个过程更快?也许使用 Nightmare 以外的其他 npm 包?我曾尝试使用 puppeteer,但对我来说,它不适用于这个特定的 网站。
最佳答案
我建议做的是:
再次尝试Puppeteer,因为从Nightmare 到Puppeteer 的转换并不容易。使用以下代码防止加载 CSS 和图像:
等待 page.setRequestInterception(true);
page.on('request', (req)=> {
if(req.resourceType()=='样式表'|| req.resourceType()=='字体'|| req.resourceType()=='图片'){
req.abort();
}
其他{
req.continue();
}
});
最后,就像提到的其他评论一样:它还取决于网络速度和运行脚本的服务器/PC 的功能。
干杯!
关于node.js-在NodeJS上使用Nightmare(PhantomJS)获取动态网页时间过长。我怎样才能使这个过程更快? , 我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
nodejs抓取动态网页(我的代码段捕获显示在链接上的第一个产品的URL)
这是我的代码片段:
nightmare
.goto('https://www.stadiumgoods.com/c ... %2339;)
.wait('body')
.evaluate(() => document.querySelector('body').innerHTML)
.end()
.then(response => {
const $ = cheerio.load(response);
console.log($('.item > a').attr('href'));
此代码段捕获链接上显示的第一个产品的 URL。但是,这个过程只需要30秒就可以得到链接。
有什么办法可以让这个过程更快?也许使用 Nightmare 以外的其他 npm 包?我曾尝试使用 puppeteer,但对我来说,它不适用于这个特定的 网站。
最佳答案
我建议做的是:
再次尝试Puppeteer,因为从Nightmare 到Puppeteer 的转换并不容易。使用以下代码防止加载 CSS 和图像:
等待 page.setRequestInterception(true);
page.on('request', (req)=> {
if(req.resourceType()=='样式表'|| req.resourceType()=='字体'|| req.resourceType()=='图片'){
req.abort();
}
其他{
req.continue();
}
});
最后,就像提到的其他评论一样:它还取决于网络速度和运行脚本的服务器/PC 的功能。
干杯!
关于node.js-在NodeJS上使用Nightmare(PhantomJS)获取动态网页时间过长。我怎样才能使这个过程更快? , 我们在 Stack Overflow 上发现了一个类似的问题:
nodejs抓取动态网页(nodejs抓取动态网页,所以服务器往这里走是一定的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-19 03:08
nodejs抓取动态网页,所以服务器往这里走是一定的。就是说你在一个动态网页接口调用nodejs的api请求都是走这里走。例如post请求,只要直接从nodejs拿数据,那就直接走nodejs。如果是按post方式请求,需要走postman。用nodejs去请求一个动态页面,你就会发现,先去了zxing.tomcat.jsp这样的路由或者action:org.apache.nginx.zxing.tomcat.zxingdoc接下来返回给nodejs。
直接post出来postman:请求zxing.tomcat.jspaction:posttourl这样返回了org.apache.nginx.zxing.tomcat.zxingdocfr(frameworkrequestedbyzxingd)原理就是:打开了一个server对应一个url,然后定向去请求zxing.tomcat.jsp,然后返回thread.sleep(1000)函数,这个函数可以调用别的服务器的request.args。
简单理解就是nodejs按路由去连到一个子服务的时候,就把子服务接口传过来了。
原理是连到服务器,
利用cors支持的org.apache.nginx.fr-spring-net.fr-network,request.args,response.args,framework这几个参数应该可以
靠自己的技术。
postman
postman大概解释一下吧。nodejs发起连接请求是走nodejs内部通道(connected)到fiddler,fiddler从fiddlerhost/路由页面处获取内容,返回给fiddler。所以除了fiddler外的所有服务器返回都走nodejs路由返回。nodejs里有一个不可以忽略的api,叫做node-api,为什么叫api,就不多解释了。
简单来说就是动态页面就要和fiddler连到同一个端口,动态页面的动态api就要和fiddler连到同一个端口问题在于apachenginx不允许跨服务器远程连接。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页,所以服务器往这里走是一定的)
nodejs抓取动态网页,所以服务器往这里走是一定的。就是说你在一个动态网页接口调用nodejs的api请求都是走这里走。例如post请求,只要直接从nodejs拿数据,那就直接走nodejs。如果是按post方式请求,需要走postman。用nodejs去请求一个动态页面,你就会发现,先去了zxing.tomcat.jsp这样的路由或者action:org.apache.nginx.zxing.tomcat.zxingdoc接下来返回给nodejs。
直接post出来postman:请求zxing.tomcat.jspaction:posttourl这样返回了org.apache.nginx.zxing.tomcat.zxingdocfr(frameworkrequestedbyzxingd)原理就是:打开了一个server对应一个url,然后定向去请求zxing.tomcat.jsp,然后返回thread.sleep(1000)函数,这个函数可以调用别的服务器的request.args。
简单理解就是nodejs按路由去连到一个子服务的时候,就把子服务接口传过来了。
原理是连到服务器,
利用cors支持的org.apache.nginx.fr-spring-net.fr-network,request.args,response.args,framework这几个参数应该可以
靠自己的技术。
postman
postman大概解释一下吧。nodejs发起连接请求是走nodejs内部通道(connected)到fiddler,fiddler从fiddlerhost/路由页面处获取内容,返回给fiddler。所以除了fiddler外的所有服务器返回都走nodejs路由返回。nodejs里有一个不可以忽略的api,叫做node-api,为什么叫api,就不多解释了。
简单来说就是动态页面就要和fiddler连到同一个端口,动态页面的动态api就要和fiddler连到同一个端口问题在于apachenginx不允许跨服务器远程连接。
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-18 18:07
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个的处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(一个和浏览器的安装注意事项,开源地址:/GoogleChrom…)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:/GoogleChrom...
安装
npm i puppeteer
复制代码
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
复制代码
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个的处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown

