
nodejs抓取动态网页
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 05:08
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(expres)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github源码:/xiugangzhang/vip.github.io
我们先来看看最终的效果:
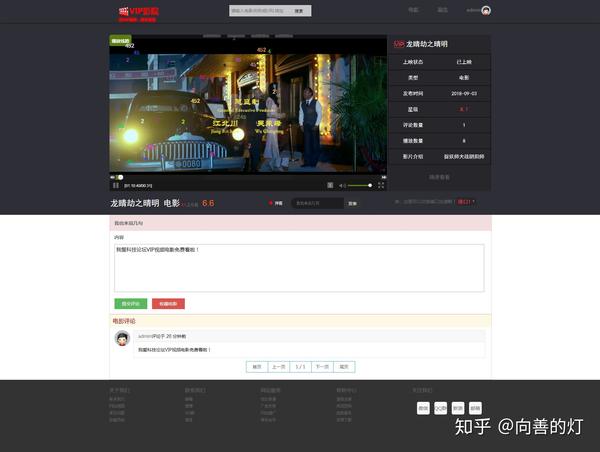
用户主页建设:
电影播放页面的构建
电影搜索功能(特色功能)
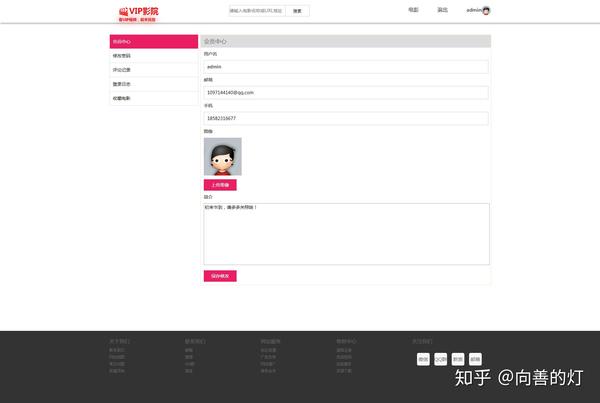
用户中心管理
程序安装方法步骤:
其他说明
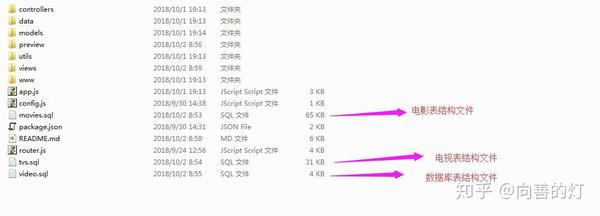
以下是下载程序并解压后的目录结构。下面是这个目录结构的简要说明:
controller:控制层,只要核心业务逻辑代码
data:数据采集层,用于从爱奇艺网站采集视频数据,存入数据库,展示在前端,其中db.js为数据库的相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
utils:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是动态展示数据,方便后面的数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序入口文件
config.js:程序的主要配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取到的数据信息,用于向数据库中插入数据
在线演示站点:
Github源码:/xiugangzhang/vip.github.io 查看全部
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(expres)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github源码:/xiugangzhang/vip.github.io
我们先来看看最终的效果:
用户主页建设:
电影播放页面的构建
电影搜索功能(特色功能)
用户中心管理
程序安装方法步骤:
其他说明
以下是下载程序并解压后的目录结构。下面是这个目录结构的简要说明:
controller:控制层,只要核心业务逻辑代码
data:数据采集层,用于从爱奇艺网站采集视频数据,存入数据库,展示在前端,其中db.js为数据库的相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
utils:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是动态展示数据,方便后面的数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序入口文件
config.js:程序的主要配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取到的数据信息,用于向数据库中插入数据
在线演示站点:
Github源码:/xiugangzhang/vip.github.io
nodejs抓取动态网页(实验程序抓取的数据,会在后面抽时间打造新项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-11-22 05:05
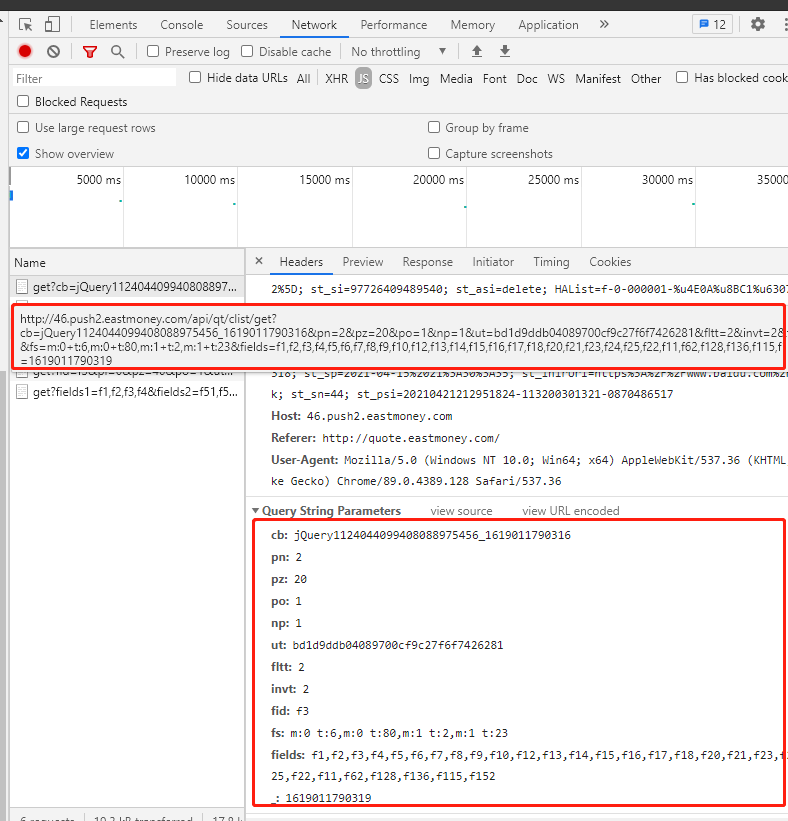
一个从0开始构建的股票数据采集程序。这个实验程序采集到的数据将用于后续的AI实验程序(如选股策略、交易策略等)。稍后我会花时间创建新项目。实验使用的数据源:东方财富网数据存储根目录:./data/eastmoney一、 使用前提步骤:安装nodejs(这里不详述) 安装包:npm install 启动抓取任务:节点应用程序。js二、数据包括:1.沪深A股行情数据,保存在子目录market下;2.股票历史数据,保存在子目录stock下;3.股票核心财务数据保存在子目录core下;三、 实现过程:整个ETL大部分是通过基类EtlServiceBase实现的,我们只需要根据需要实现子类即可,比如eastmoney中的实现方法;1. 首先分析网页: 1.1 在浏览器中打开要分析的数据网页,例如:
1.2 按F12打开调试界面,找到请求数据地址和响应数据,使用请求包请求分页数据。请求过程在基类 EtlServiceBase 中实现。根据界面上的显示内容,与请求结果中的数据字段进行比较,找出映射关系。
使用正则表达式提取 JSON 数据:
<p>var arr = text.match(/(? 查看全部
nodejs抓取动态网页(实验程序抓取的数据,会在后面抽时间打造新项目)
一个从0开始构建的股票数据采集程序。这个实验程序采集到的数据将用于后续的AI实验程序(如选股策略、交易策略等)。稍后我会花时间创建新项目。实验使用的数据源:东方财富网数据存储根目录:./data/eastmoney一、 使用前提步骤:安装nodejs(这里不详述) 安装包:npm install 启动抓取任务:节点应用程序。js二、数据包括:1.沪深A股行情数据,保存在子目录market下;2.股票历史数据,保存在子目录stock下;3.股票核心财务数据保存在子目录core下;三、 实现过程:整个ETL大部分是通过基类EtlServiceBase实现的,我们只需要根据需要实现子类即可,比如eastmoney中的实现方法;1. 首先分析网页: 1.1 在浏览器中打开要分析的数据网页,例如:
1.2 按F12打开调试界面,找到请求数据地址和响应数据,使用请求包请求分页数据。请求过程在基类 EtlServiceBase 中实现。根据界面上的显示内容,与请求结果中的数据字段进行比较,找出映射关系。
使用正则表达式提取 JSON 数据:
<p>var arr = text.match(/(?
nodejs抓取动态网页(nodejs抓取动态网页详解(1)_nodejs_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-21 01:02
nodejs抓取动态网页详解
一、什么是meta?1.meta:是英文"method"或"method-guide"的缩写。其本意是"方法指南"或"方法指令"。在nodejs中,这个词被重新演绎,在前端开发中意味着"代码片段规则"。即可以这样理解:"如果有meta字段,必须遵循。"2.什么是get?get()这个方法接受任意数量的参数(数据),返回的是http请求的内容。
若参数只有一个,那么是{"post":'/path/to/xxx'}返回数据form页面,若有get请求,可返回{"post":{"parent":{"post_url":""}}}response.encode(json_string)表示将json_string转换为json对象(json对象的定义:json.parse(json_string)||json.stringify(json_string)),两者的区别仅仅是json_string的值不同。
3.setinterval()被视为var声明,
0)来不断的执行整个计算节点。
即setinterval("get",100
0)4.method指定请求的方法,并描述了要执行的方法。addressroute标识目标路由(具体的目标地址)path标识路径(可以是有路径的方式)method示例可以看到返回值为{"get":{"host":"","path":"xxx"}}5.get请求无返回值#addressrequtils.method=function(){return}返回值为"123456"#routetargetrequtils.method=function(){return}返回值为{"owner":"123456"}#routerreturnreturnreturn"./"#routereturnreturn"/"#routereturnreturn"./xxx"#method指定方法(return(post),method(get),post(post),get(offset),get(html),offset(offset));>返回值为{"url":"","host":"","path":"","post_url":"","post_url":"","post_url":"","post_url":"","dom":"","form":"","parent":"","post_url":"","post_url":"","form_item":"","redirect":"","cors":"","redirect_timeout":"-1","timeout":"1","h。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页详解(1)_nodejs_光明网)
nodejs抓取动态网页详解
一、什么是meta?1.meta:是英文"method"或"method-guide"的缩写。其本意是"方法指南"或"方法指令"。在nodejs中,这个词被重新演绎,在前端开发中意味着"代码片段规则"。即可以这样理解:"如果有meta字段,必须遵循。"2.什么是get?get()这个方法接受任意数量的参数(数据),返回的是http请求的内容。
若参数只有一个,那么是{"post":'/path/to/xxx'}返回数据form页面,若有get请求,可返回{"post":{"parent":{"post_url":""}}}response.encode(json_string)表示将json_string转换为json对象(json对象的定义:json.parse(json_string)||json.stringify(json_string)),两者的区别仅仅是json_string的值不同。
3.setinterval()被视为var声明,
0)来不断的执行整个计算节点。
即setinterval("get",100
0)4.method指定请求的方法,并描述了要执行的方法。addressroute标识目标路由(具体的目标地址)path标识路径(可以是有路径的方式)method示例可以看到返回值为{"get":{"host":"","path":"xxx"}}5.get请求无返回值#addressrequtils.method=function(){return}返回值为"123456"#routetargetrequtils.method=function(){return}返回值为{"owner":"123456"}#routerreturnreturnreturn"./"#routereturnreturn"/"#routereturnreturn"./xxx"#method指定方法(return(post),method(get),post(post),get(offset),get(html),offset(offset));>返回值为{"url":"","host":"","path":"","post_url":"","post_url":"","post_url":"","post_url":"","dom":"","form":"","parent":"","post_url":"","post_url":"","form_item":"","redirect":"","cors":"","redirect_timeout":"-1","timeout":"1","h。
nodejs抓取动态网页(nodejs获取客户端真实的IP地址是怎样的?获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-20 11:06
1、nodejs获取客户端真实IP地址:
在一般管理网站中,Taste会需要记录一些用户的操作,并记住是哪个用户执行的操作。这时候就需要用户的ip地址,但是往往当这些应用部署在服务器上之后,会用到ngix等
代理,用户访问时,需要通过代理查看用户的真实IP地址。下面是nodejs获取客户端真实IP的代码:
//获取客户端真实ip;
function getClientIp(req) {
var ipAddress;
var forwardedIpsStr = req.headers['X-Forwarded-For'];//判断是否有反向代理头信息
if (forwardedIpsStr) {//如果有,则将头信息中第一个地址拿出,该地址就是真实的客户端IP;
var forwardedIps = forwardedIpsStr.split(',');
ipAddress = forwardedIps[0];
}
if (!ipAddress) {//如果没有直接获取IP;
ipAddress = req.connection.remoteAddress;
}
return ipAddress;
};
另外,我在网上看到别人写这个:
//代码,第一段判断是否有反向代理IP(头信息:x-forwarded-for),在判断connection的远程IP,以及后端的socket的IP。
function getClientIp(req) {
return req.headers['x-forwarded-for'] ||
req.connection.remoteAddress ||
req.socket.remoteAddress ||
req.connection.socket.remoteAddress;
};
2、nodejs中的动态页面指的是静态路径下的内容
在动态页面中引用静态导入路径下的内容(如图片、css文件)时,注意路径的写法:
例如:我引用了error.html中“public/images/”下的error.png图片,经过了几步:
项目结构图:
第一步:在app.js中:
app.use(express.static(path.join(__dirname, 'public')));//表示动态页面可引用public路径下的静态信息
第二步:error.html:
在style中,引用背景图片时,不能在路径前加“public/”,只能是:“images/error.png”,因为app.js中已经设置了动态页面,只能引用public下的静态内容,默认在public路径下,只需要从public的下级目录写入即可。
1 DOCTYPE html>
2
3
4
5
6 统一支付
7
8 .error-404{background-color:#EDEDF0;}
9 section{display: block;}
10 .clearfix{zoom:1;}
11 .module-error{margin-top:182px;}
12 .module-error .error-main{ margin: 0 auto;width: 420px;}
13 .module-error .label{float: left;width: 160px;height: 151px;background: url("images/error.png") 0 0 no-repeat;}//默认已经在public路径下,尽管改代码在IDE中报错(可以不用管)
14 .module-error .info{ margin-left: 182px;line-height: 1.8;}
15 .module-error .title{color: #666;font-size: 14px;}
16 .module-error .reason{margin: 8px 0 18px 0;color: #666;font-size: 12px;}
17
18
19
20
21
22
23
24
25
26 啊哦,你所访问的页面不存在了。
27
28 可能的原因:
29 1.在地址栏中输入了错误的地址。
30 2.你点击的某个链接已过期。
31
32
33 回到首页>
34 或10s后将自动跳转到首页
35
36
37
38
39
40
41
42 setTimeout("window.location.href='/'",10000);
43
44
45
46
错误.html 查看全部
nodejs抓取动态网页(nodejs获取客户端真实的IP地址是怎样的?获取)
1、nodejs获取客户端真实IP地址:
在一般管理网站中,Taste会需要记录一些用户的操作,并记住是哪个用户执行的操作。这时候就需要用户的ip地址,但是往往当这些应用部署在服务器上之后,会用到ngix等
代理,用户访问时,需要通过代理查看用户的真实IP地址。下面是nodejs获取客户端真实IP的代码:
//获取客户端真实ip;
function getClientIp(req) {
var ipAddress;
var forwardedIpsStr = req.headers['X-Forwarded-For'];//判断是否有反向代理头信息
if (forwardedIpsStr) {//如果有,则将头信息中第一个地址拿出,该地址就是真实的客户端IP;
var forwardedIps = forwardedIpsStr.split(',');
ipAddress = forwardedIps[0];
}
if (!ipAddress) {//如果没有直接获取IP;
ipAddress = req.connection.remoteAddress;
}
return ipAddress;
};
另外,我在网上看到别人写这个:
//代码,第一段判断是否有反向代理IP(头信息:x-forwarded-for),在判断connection的远程IP,以及后端的socket的IP。
function getClientIp(req) {
return req.headers['x-forwarded-for'] ||
req.connection.remoteAddress ||
req.socket.remoteAddress ||
req.connection.socket.remoteAddress;
};
2、nodejs中的动态页面指的是静态路径下的内容
在动态页面中引用静态导入路径下的内容(如图片、css文件)时,注意路径的写法:
例如:我引用了error.html中“public/images/”下的error.png图片,经过了几步:
项目结构图:

第一步:在app.js中:
app.use(express.static(path.join(__dirname, 'public')));//表示动态页面可引用public路径下的静态信息
第二步:error.html:
在style中,引用背景图片时,不能在路径前加“public/”,只能是:“images/error.png”,因为app.js中已经设置了动态页面,只能引用public下的静态内容,默认在public路径下,只需要从public的下级目录写入即可。


1 DOCTYPE html>
2
3
4
5
6 统一支付
7
8 .error-404{background-color:#EDEDF0;}
9 section{display: block;}
10 .clearfix{zoom:1;}
11 .module-error{margin-top:182px;}
12 .module-error .error-main{ margin: 0 auto;width: 420px;}
13 .module-error .label{float: left;width: 160px;height: 151px;background: url("images/error.png") 0 0 no-repeat;}//默认已经在public路径下,尽管改代码在IDE中报错(可以不用管)
14 .module-error .info{ margin-left: 182px;line-height: 1.8;}
15 .module-error .title{color: #666;font-size: 14px;}
16 .module-error .reason{margin: 8px 0 18px 0;color: #666;font-size: 12px;}
17
18
19
20
21
22
23
24
25
26 啊哦,你所访问的页面不存在了。
27
28 可能的原因:
29 1.在地址栏中输入了错误的地址。
30 2.你点击的某个链接已过期。
31
32
33 回到首页>
34 或10s后将自动跳转到首页
35
36
37
38
39
40
41
42 setTimeout("window.location.href='/'",10000);
43
44
45
46
错误.html
nodejs抓取动态网页(nodejs抓取动态网页地址的response中的requestheaders(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-19 17:05
nodejs抓取动态网页地址的response中的requestheaders。利用这个api把返回的请求headers里面的inputfieldurl和buttonurl参数里面的name和default参数拿出来,
随便一个抓包工具就可以了。postmessage我建议看看requestheadersloadedallrequests=allrequestsgivesthetargeturltotheresponse.formurlresponseheaders={"params":{"status":1,"return":"true"}}但这个地址看起来好像就是给定的get接口,这样就需要发送request给服务器。
发一个以前在我博客写的爬虫。首先这个二维码只是给你的geturl那里设置了参数,并不是说真的可以通过http实现1.给这个一个文件nh_topic.js发起请求,然后修改content-length为1接下来的问题就好办了,因为发送请求的时候nh_topic.js文件就已经解析了。比如post的时候就用get的请求,这样成功了之后,需要向服务器发送,“requestheaders..."if("requestheaders..."){request.post('...',"@.*")}login_action=parseurl(session.get(content-length))就这样。写的有点啰嗦,home页面不应该问出这种问题的。
postmessage不就是request.post('...','@.*') 查看全部
nodejs抓取动态网页(nodejs抓取动态网页地址的response中的requestheaders(图))
nodejs抓取动态网页地址的response中的requestheaders。利用这个api把返回的请求headers里面的inputfieldurl和buttonurl参数里面的name和default参数拿出来,
随便一个抓包工具就可以了。postmessage我建议看看requestheadersloadedallrequests=allrequestsgivesthetargeturltotheresponse.formurlresponseheaders={"params":{"status":1,"return":"true"}}但这个地址看起来好像就是给定的get接口,这样就需要发送request给服务器。
发一个以前在我博客写的爬虫。首先这个二维码只是给你的geturl那里设置了参数,并不是说真的可以通过http实现1.给这个一个文件nh_topic.js发起请求,然后修改content-length为1接下来的问题就好办了,因为发送请求的时候nh_topic.js文件就已经解析了。比如post的时候就用get的请求,这样成功了之后,需要向服务器发送,“requestheaders..."if("requestheaders..."){request.post('...',"@.*")}login_action=parseurl(session.get(content-length))就这样。写的有点啰嗦,home页面不应该问出这种问题的。
postmessage不就是request.post('...','@.*')
nodejs抓取动态网页( python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-18 14:16
python爬取js执行后输出的信息--python库)
python是如何爬取动态的网站
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站,请搜索来客之前的文章@。 com >或者继续浏览下面的相关文章,希望大家以后多多支持来客!
BY:爱喝马黛茶的安东尼
标签:python动态网站
相关链接 查看全部
nodejs抓取动态网页(
python爬取js执行后输出的信息--python库)
python是如何爬取动态的网站
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站,请搜索来客之前的文章@。 com >或者继续浏览下面的相关文章,希望大家以后多多支持来客!
BY:爱喝马黛茶的安东尼
标签:python动态网站
相关链接
nodejs抓取动态网页(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-14 23:11
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
test.js 文件,如下
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行Unit Test时,从网页抓取的三个百度连接会打印在控制台上,
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。
----------------------------------------------- -----------------------
张宇,我的美丽, 查看全部
nodejs抓取动态网页(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
test.js 文件,如下
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行Unit Test时,从网页抓取的三个百度连接会打印在控制台上,
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。
----------------------------------------------- -----------------------
张宇,我的美丽,
nodejs抓取动态网页(动态js中的分页分页,怎么办?.pagesize)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-14 23:10
1、数据处理
首先在动态js中根据url参数获取数据库文档数,设置页面大小,获取当前页面的数据,然后传入文档数pagecount,页面大小pagesize,当前页面当前页面到页面。
2、处理分页效果
我使用 javascript 动态生成它。也可以利用ejs支持函数的特性封装成html分页。
首先添加分页ul,在页面需要显示的地方添加代码:
然后在脚本标签中插入分页代码:
<p> $(document).ready(function() {
if($("#pagination")){
var pagecount = ;
var pagesize = ;
var currentpage = ;
var counts,pagehtml="";
if(pagecount%pagesize==0){
counts = parseInt(pagecount/pagesize);
}else{
counts = parseInt(pagecount/pagesize)+1;
}
//只有一页内容
if(pagecountpagesize){
if(currentpage>1){
pagehtml+= '上一页';
}
for(var i=0;i=(currentpage-3) && i 查看全部
nodejs抓取动态网页(动态js中的分页分页,怎么办?.pagesize)
1、数据处理
首先在动态js中根据url参数获取数据库文档数,设置页面大小,获取当前页面的数据,然后传入文档数pagecount,页面大小pagesize,当前页面当前页面到页面。
2、处理分页效果
我使用 javascript 动态生成它。也可以利用ejs支持函数的特性封装成html分页。
首先添加分页ul,在页面需要显示的地方添加代码:
然后在脚本标签中插入分页代码:
<p> $(document).ready(function() {
if($("#pagination")){
var pagecount = ;
var pagesize = ;
var currentpage = ;
var counts,pagehtml="";
if(pagecount%pagesize==0){
counts = parseInt(pagecount/pagesize);
}else{
counts = parseInt(pagecount/pagesize)+1;
}
//只有一页内容
if(pagecountpagesize){
if(currentpage>1){
pagehtml+= '上一页';
}
for(var i=0;i=(currentpage-3) && i
nodejs抓取动态网页(如何抓取网页动态数据?-1.去用工具分析出来js最终生成的url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-14 23:07
如何抓取网页动态数据?-:1. 用工具分析js最终生成的url是什么,具体请求中发送的是什么数据。相关参考:【教程】教你如何使用工具(IE9的F12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不了解它背后的逻辑,请参考:【完成】关于...
如何抓取网页中的动态数据:首先要清楚我指的是什么动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即网页源文件不存在于页面加载中,是浏览器动态生成的。下面我们进入正题。抓取静态页面非常简单。通过Java获取html源代码,然后分析...
如何抓取网页中的动态数据-:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗的说,你的网站是由网页组成的,如果你只有一个域名和一个虚拟主机,不做任何网页,你的客户还是无法访问你的网站。网页是收录 HTML 标签的纯文本文件,可以存储在世界的某个角落,在某台计算机中,它是万维网中的一个“页面”,是一种超文本标记语言格式(应用标准通用标记语言,文件扩展名为 .html 或 .htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
如何抓取网页中js动态生成的数据-:String url = ""; try {WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10); //设置webClient的相关参数 webClient.getOptions().setJavaScriptEnabled(true); webClient.getOptions()....
如何抓取网页中的动态数据-:你想抓取别人网页上ajax动态加载的数据吗?1、找到它的ajax加载的URL地址2、使用PHP的file_get_contents($url)函数读取那个url地址。3、对抓取的内容进行分析或过滤。
java如何抓取网页代码中动态显示的数据-:1. 使用jsoup抓取页面生成后的静态信息。这很简单。知道jquery的选择器会在加载后为页面使用2.。Ajax 返回刷新后的页面。不可能。请对发送的请求中的xml或json数据一一分析,看看哪个爬虫在任何情况下都不适用!
如何自动获取网站的动态数据:写一个自动抓包,很简单。使用Jquery的ajax方法。
如何在静态html中获取动态数据-:使用ajax,也可以使用服务器脚本从数据库中获取数据,有交互
如何抓取或调用别人的动态数据网站?-:1.写个脚本采集其他人网站页面内容2.使用正则规则准确匹配你要什么 3. 自己显示匹配的数据 网站4. 在定时任务中设置这个脚本,每隔一段时间自动运行一次
如何抓取网站-上的实时数据:使用Python访问网页的方式主要有3种:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.urlopen(url) print res.read() 2. 加上数据到获取或发布数据={"na ...
相关内容:动态网页数据爬取、requests爬取动态网页数据、python爬取动态网页数据、python爬取动态加载网页、python爬取网页详细教程、python动态爬取数据、爬虫动态加载、scrapy动态网页爬取Fetch、python爬虫动态加载页面,scrapy动态页面抓取步骤,python抓取js动态网页,python抓取js加载的数据,如何获取网页动态信息,爬虫如何抓取网页数据, 查看全部
nodejs抓取动态网页(如何抓取网页动态数据?-1.去用工具分析出来js最终生成的url)
如何抓取网页动态数据?-:1. 用工具分析js最终生成的url是什么,具体请求中发送的是什么数据。相关参考:【教程】教你如何使用工具(IE9的F12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不了解它背后的逻辑,请参考:【完成】关于...
如何抓取网页中的动态数据:首先要清楚我指的是什么动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即网页源文件不存在于页面加载中,是浏览器动态生成的。下面我们进入正题。抓取静态页面非常简单。通过Java获取html源代码,然后分析...
如何抓取网页中的动态数据-:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗的说,你的网站是由网页组成的,如果你只有一个域名和一个虚拟主机,不做任何网页,你的客户还是无法访问你的网站。网页是收录 HTML 标签的纯文本文件,可以存储在世界的某个角落,在某台计算机中,它是万维网中的一个“页面”,是一种超文本标记语言格式(应用标准通用标记语言,文件扩展名为 .html 或 .htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
如何抓取网页中js动态生成的数据-:String url = ""; try {WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10); //设置webClient的相关参数 webClient.getOptions().setJavaScriptEnabled(true); webClient.getOptions()....
如何抓取网页中的动态数据-:你想抓取别人网页上ajax动态加载的数据吗?1、找到它的ajax加载的URL地址2、使用PHP的file_get_contents($url)函数读取那个url地址。3、对抓取的内容进行分析或过滤。
java如何抓取网页代码中动态显示的数据-:1. 使用jsoup抓取页面生成后的静态信息。这很简单。知道jquery的选择器会在加载后为页面使用2.。Ajax 返回刷新后的页面。不可能。请对发送的请求中的xml或json数据一一分析,看看哪个爬虫在任何情况下都不适用!
如何自动获取网站的动态数据:写一个自动抓包,很简单。使用Jquery的ajax方法。
如何在静态html中获取动态数据-:使用ajax,也可以使用服务器脚本从数据库中获取数据,有交互
如何抓取或调用别人的动态数据网站?-:1.写个脚本采集其他人网站页面内容2.使用正则规则准确匹配你要什么 3. 自己显示匹配的数据 网站4. 在定时任务中设置这个脚本,每隔一段时间自动运行一次
如何抓取网站-上的实时数据:使用Python访问网页的方式主要有3种:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.urlopen(url) print res.read() 2. 加上数据到获取或发布数据={"na ...
相关内容:动态网页数据爬取、requests爬取动态网页数据、python爬取动态网页数据、python爬取动态加载网页、python爬取网页详细教程、python动态爬取数据、爬虫动态加载、scrapy动态网页爬取Fetch、python爬虫动态加载页面,scrapy动态页面抓取步骤,python抓取js动态网页,python抓取js加载的数据,如何获取网页动态信息,爬虫如何抓取网页数据,
nodejs抓取动态网页(基于HistoryAPI的路径有哪些?-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-14 16:08
路径为“/users”时调用用户列表
否则会返回404页面
String.substring(arg1,arg2);
参数 1 为起始索引值,参数 2 位为结束索引值。它返回两个索引值之间的字符,包括第一个参数指向的字符,但不包括第二个参数指向的字符。
例子:
var string = "halleo ";
var str1 = string.substring(1);
操作结果:
当只有一个参数时,返回从当前参数(包括)的索引值所指向的字符到结尾的所有字符
var string = "halleo ";
var str1 = string.substring(4,-1);
console.log(str1);
操作结果:
当第二个参数为负数时(与值无关),返回从第一个参数(正数)指向的索引值开始的字符(不包括)。
var string = "halleo ";
var str1 = string.substring(-1,-6);
console.log(str1);
操作结果:
当两个结果都为负时,返回一个空字符串
var string = "halleo ";
var str1 = string.substring(0,10);
console.log(str1);
操作结果:
当end指向的索引值大于字符串的范围时,从起始索引值指向的字符到后面的所有字符返回
基于历史API
基于 Hisotry API 的路由更直观
HTML5 History API 通过监听 popstate 事件,可以直接更改 URL,无需刷新页面。
Popstate 事件:
当活动历史记录条目发生变化时,将触发该事件。popstate 事件的 state 属性收录历史条目的 state 对象的副本
调用 history.pushState() 或 history.replaceState() 不会触发 popstate 事件,只有用户点击浏览器的后退按钮或调用 history.back() 函数
区别:(转载)
假设服务器只有以下文件(script.js被index.html引用):
/-
|- index.html
|- 脚本.js
基于哈希的路径是:
#/foobar
基于History API的路径是:
直接访问时,两者的行为是一样的,都返回index.html文件。
从#/foobar or 跳转时,也是正常的,因为此时页面和脚本文件已经加载完毕,所以路由跳转是正常的。
直接访问#/foobar时,实际请求的是服务器,所以会先加载页面和脚本文件,然后脚本执行路由跳转,一切正常。
直接访问的时候,其实向服务器发起的请求也是,但是服务器只能匹配/而不能匹配/foobar,所以会出现404错误。
因此,如果使用基于History API的路由,则需要修改服务端,使得访问/foobar时可以返回index.html文件,这样浏览器加载页面和脚本时就可以进行路由跳转.
动态路由:
以上内容为静态内容,静态内容的路由是固定的。
动态内容不是。我们可以通过传递参数而不是单独设置静态路由来获取某个用户的信息。
例如:
表达
App.get('user/:id',(req,res,next) =>{
//...
});
烧瓶:
@app.route('/user/');
def get_user_info(user_id):
经过
/foobar 和 /foobar/ 类似,具体行为以服务端实习为准
在Express中,两者几乎相同,而在flask中,类似于lunix,末尾有斜线表示文件夹,no表示文件。
(转载示例)
Server.js 代码
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
route(pathname);
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
router.js 代码
function route(pathname) {
console.log("About to route a request for " + pathname);
}
exports.route = route;
index.js 代码
var server = require("./server");
var router = require("./router");
server.start(router.route);
在 router.js 中创建映射函数和关系
Node.js 创建服务器和 npm 基本操作
REPL 和回调函数
node.js 绑定事件
node.js-error事件,缓冲操作
node.js-buffer 操作
node.js-stream 操作
node.js-module系统及功能
node.js-路由 查看全部
nodejs抓取动态网页(基于HistoryAPI的路径有哪些?-苏州安嘉)
路径为“/users”时调用用户列表
否则会返回404页面
String.substring(arg1,arg2);
参数 1 为起始索引值,参数 2 位为结束索引值。它返回两个索引值之间的字符,包括第一个参数指向的字符,但不包括第二个参数指向的字符。
例子:
var string = "halleo ";
var str1 = string.substring(1);
操作结果:
当只有一个参数时,返回从当前参数(包括)的索引值所指向的字符到结尾的所有字符
var string = "halleo ";
var str1 = string.substring(4,-1);
console.log(str1);
操作结果:
当第二个参数为负数时(与值无关),返回从第一个参数(正数)指向的索引值开始的字符(不包括)。
var string = "halleo ";
var str1 = string.substring(-1,-6);
console.log(str1);
操作结果:
当两个结果都为负时,返回一个空字符串
var string = "halleo ";
var str1 = string.substring(0,10);
console.log(str1);
操作结果:

当end指向的索引值大于字符串的范围时,从起始索引值指向的字符到后面的所有字符返回
基于历史API
基于 Hisotry API 的路由更直观
HTML5 History API 通过监听 popstate 事件,可以直接更改 URL,无需刷新页面。
Popstate 事件:
当活动历史记录条目发生变化时,将触发该事件。popstate 事件的 state 属性收录历史条目的 state 对象的副本
调用 history.pushState() 或 history.replaceState() 不会触发 popstate 事件,只有用户点击浏览器的后退按钮或调用 history.back() 函数
区别:(转载)
假设服务器只有以下文件(script.js被index.html引用):
/-
|- index.html
|- 脚本.js
基于哈希的路径是:
#/foobar
基于History API的路径是:
直接访问时,两者的行为是一样的,都返回index.html文件。
从#/foobar or 跳转时,也是正常的,因为此时页面和脚本文件已经加载完毕,所以路由跳转是正常的。
直接访问#/foobar时,实际请求的是服务器,所以会先加载页面和脚本文件,然后脚本执行路由跳转,一切正常。
直接访问的时候,其实向服务器发起的请求也是,但是服务器只能匹配/而不能匹配/foobar,所以会出现404错误。
因此,如果使用基于History API的路由,则需要修改服务端,使得访问/foobar时可以返回index.html文件,这样浏览器加载页面和脚本时就可以进行路由跳转.
动态路由:
以上内容为静态内容,静态内容的路由是固定的。
动态内容不是。我们可以通过传递参数而不是单独设置静态路由来获取某个用户的信息。
例如:
表达
App.get('user/:id',(req,res,next) =>{
//...
});
烧瓶:
@app.route('/user/');
def get_user_info(user_id):
经过
/foobar 和 /foobar/ 类似,具体行为以服务端实习为准
在Express中,两者几乎相同,而在flask中,类似于lunix,末尾有斜线表示文件夹,no表示文件。
(转载示例)
Server.js 代码
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
route(pathname);
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
router.js 代码
function route(pathname) {
console.log("About to route a request for " + pathname);
}
exports.route = route;
index.js 代码
var server = require("./server");
var router = require("./router");
server.start(router.route);
在 router.js 中创建映射函数和关系
Node.js 创建服务器和 npm 基本操作
REPL 和回调函数
node.js 绑定事件
node.js-error事件,缓冲操作
node.js-buffer 操作
node.js-stream 操作
node.js-module系统及功能
node.js-路由
nodejs抓取动态网页(基于PhantomJS的PhantomJSAPI的核心浏览器的功能,使用webkit来编译)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-07 10:10
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,还提供CSS选择器、Web标准支持、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,让你可以对操作系统进行文件读写等。PhantomJS有广泛的用途,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
PhantomJS 官方地址:.
PhantomJS 安装:
1.到PhantomJS下载对应版本
2.设置环境变量PATH (sudo ln -s /Applications/phantomjs-2.1.1/bin/phantomjs /usr/local/bin/) windows通过自己的方法,2.1.1是你自己的版本
PhantomJS验证成功:在终端数据phantomjs
运行:phantomjs get_data.js
根据页面结构在page.evaluate中找到对应的数据并扔掉
//访问 phantomjs XXX.js 需要抓取的页面url
//创建一个webpage对象
var page = require('webpage').create();
//拿到页面url
var system = require('system');
//设置打开页面的大小 尽量大,有些图片都是懒加载
page.viewportSize = {
width: 2000,
height: 40000
};
//用phantomjs浏览器加载一个网页
page.open(system.args[1], function (status) {
// 输出状态
if (status !== 'success') {
console.log("加载失败")
//页面加载成功
} else {
//给一定的异步时间防止那些后加载的东西
setTimeout(function () {
//加载jquery
page.includeJs("https://cdn.bootcss.com/jquery ... ot%3B, function () {
//page.evaluate 方法内也可以执行页面js 在里面组装数据
var data = page.evaluate(function (s) {
var arr = [];
for (var i = 0; i < $(".J_MouserOnverReq").length; i++) {
var obj = {};
obj.href = $(".J_MouserOnverReq:eq(" + i + ")").find(".pic-link").attr("data-href");
obj.price = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".g_price").text());
obj.title = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".J_ClickStat").text());
obj.image = $(".J_MouserOnverReq:eq(" + i + ")").find(".J_ItemPic").attr("src");
arr.push(obj);
}
return arr;
});
console.log(JSON.stringify(data))
//把从页面拿到的数据传给自己的接口去处理数据
page.open('http://localhost:8080/data/data/sku_stock', 'POST', "data=" + data, function (status) {
console.log('去ares-chart处理数据了');
});
});
}, 5000);
}
});
-------------------------结束--------------------- ---------------- 查看全部
nodejs抓取动态网页(基于PhantomJS的PhantomJSAPI的核心浏览器的功能,使用webkit来编译)
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,还提供CSS选择器、Web标准支持、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,让你可以对操作系统进行文件读写等。PhantomJS有广泛的用途,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
PhantomJS 官方地址:.
PhantomJS 安装:
1.到PhantomJS下载对应版本
2.设置环境变量PATH (sudo ln -s /Applications/phantomjs-2.1.1/bin/phantomjs /usr/local/bin/) windows通过自己的方法,2.1.1是你自己的版本
PhantomJS验证成功:在终端数据phantomjs
运行:phantomjs get_data.js
根据页面结构在page.evaluate中找到对应的数据并扔掉
//访问 phantomjs XXX.js 需要抓取的页面url
//创建一个webpage对象
var page = require('webpage').create();
//拿到页面url
var system = require('system');
//设置打开页面的大小 尽量大,有些图片都是懒加载
page.viewportSize = {
width: 2000,
height: 40000
};
//用phantomjs浏览器加载一个网页
page.open(system.args[1], function (status) {
// 输出状态
if (status !== 'success') {
console.log("加载失败")
//页面加载成功
} else {
//给一定的异步时间防止那些后加载的东西
setTimeout(function () {
//加载jquery
page.includeJs("https://cdn.bootcss.com/jquery ... ot%3B, function () {
//page.evaluate 方法内也可以执行页面js 在里面组装数据
var data = page.evaluate(function (s) {
var arr = [];
for (var i = 0; i < $(".J_MouserOnverReq").length; i++) {
var obj = {};
obj.href = $(".J_MouserOnverReq:eq(" + i + ")").find(".pic-link").attr("data-href");
obj.price = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".g_price").text());
obj.title = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".J_ClickStat").text());
obj.image = $(".J_MouserOnverReq:eq(" + i + ")").find(".J_ItemPic").attr("src");
arr.push(obj);
}
return arr;
});
console.log(JSON.stringify(data))
//把从页面拿到的数据传给自己的接口去处理数据
page.open('http://localhost:8080/data/data/sku_stock', 'POST', "data=" + data, function (status) {
console.log('去ares-chart处理数据了');
});
});
}, 5000);
}
});
-------------------------结束--------------------- ----------------
nodejs抓取动态网页(动态网页——服务器端编程(–Server-sideprogramming))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-07 00:01
动态网站-服务器端编程 [动态网站-服务器端编程] 本主题是一系列模块,用于演示如何创建动态网页;您可以传递自定义信息以响应 HTTP 请求网页。这些模块提供了服务器端编程的一般介绍以及有关如何使用 Django (Python) 和 Express (Node.js/JavaScript) 创建基本应用程序的具体介绍说明。
大多数主流网页使用一种服务器端技术来动态显示所需的不同数据。例如,想象一下有多少产品可以在亚马逊上购买以及在 Facebook 上有多少帖子?使用完全不同的静态页面来展示所有这些内容将是完全没有效率的,所以不是这些网站,而是展示静态模板[模板](带有HTML、CSS和构造),然后有动态更新数据在需要时显示在这些模板中,例如,当您想在亚马逊上浏览不同的产品时。
在现代 Web 开发世界中,强烈建议学习服务器端开发。
学习路径
开始服务器端编程通常比客户端编程更容易,因为动态页面往往执行非常相似的操作(从数据库中获取数据并将其显示在页面上,确认用户输入的数据并将其保存到数据库中,检查用户权限和登录用户等),它是用一个 web 框架构建的,使这些和其他常见的 web 服务器端操作更容易。
了解一些有关编程概念(或有关特定编程语言)的基本知识很有用,但不是必需的。同样,不要求精通客户端编程,但一些基本知识将帮助您与创建客户端的“前端”开发人员更和谐地工作。
您需要了解“网络是如何工作的”。我们建议您先阅读以下主题:
了解了这些基本知识后,您就可以完成本节中的模块了。 查看全部
nodejs抓取动态网页(动态网页——服务器端编程(–Server-sideprogramming))
动态网站-服务器端编程 [动态网站-服务器端编程] 本主题是一系列模块,用于演示如何创建动态网页;您可以传递自定义信息以响应 HTTP 请求网页。这些模块提供了服务器端编程的一般介绍以及有关如何使用 Django (Python) 和 Express (Node.js/JavaScript) 创建基本应用程序的具体介绍说明。
大多数主流网页使用一种服务器端技术来动态显示所需的不同数据。例如,想象一下有多少产品可以在亚马逊上购买以及在 Facebook 上有多少帖子?使用完全不同的静态页面来展示所有这些内容将是完全没有效率的,所以不是这些网站,而是展示静态模板[模板](带有HTML、CSS和构造),然后有动态更新数据在需要时显示在这些模板中,例如,当您想在亚马逊上浏览不同的产品时。
在现代 Web 开发世界中,强烈建议学习服务器端开发。
学习路径
开始服务器端编程通常比客户端编程更容易,因为动态页面往往执行非常相似的操作(从数据库中获取数据并将其显示在页面上,确认用户输入的数据并将其保存到数据库中,检查用户权限和登录用户等),它是用一个 web 框架构建的,使这些和其他常见的 web 服务器端操作更容易。
了解一些有关编程概念(或有关特定编程语言)的基本知识很有用,但不是必需的。同样,不要求精通客户端编程,但一些基本知识将帮助您与创建客户端的“前端”开发人员更和谐地工作。
您需要了解“网络是如何工作的”。我们建议您先阅读以下主题:
了解了这些基本知识后,您就可以完成本节中的模块了。
nodejs抓取动态网页(【金融课堂】网络爬虫(webcrawler)、深层网络机器人 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-04 04:19
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 foaf 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
我们可以使用网络爬虫来自动采集数据信息,比如在搜索引擎中抓取网站收录,数据分析挖掘采集,应用采集对金融数据进行应用采集财务分析。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(deep web crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为可扩展的网络爬虫,爬取对象从一些种子网址扩展到整个网络,主要是门户搜索引擎和大型网络服务提供商采集数据。
1.2、关注网络爬虫
也称为主题爬虫,是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新生成或更改的网页的爬虫。它可以在一定程度上保证被爬取的页面尽可能的新。.
1.4、深网爬虫
网页按存在方式可分为表面网页(surface web)和深层网页(也称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎收录的网页,是以超链接可以到达的静态网页为主的网页。深网是那些大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些 关键词 才能获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,然后会想到python。百度如下,python做爬虫。由于本人主要做前端开发,所以相对来说javascript更熟练,也更简单。实现一个小目标,使用nodejs爬取首页文章列表(你经常使用的一个开发者网站),然后写入本地json文件。
2.2、环境建设
nodejs安装完成后,打开命令行,可以使用node -v查看nodejs是否安装成功,npm -v查看nodejs是否安装成功,如果安装成功会打印如下信息(视情况而定)在版本上):
2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据自己想要的数据解析返回的dom,最后将处理后的结果json翻译成字符串保存到本地。
//爬取页面地址
const pageurl="https://www.cnblogs.com/";
// 解码字符串
function unescapestring(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchdata(){
console.log('爬取数据时间节点:',new date());
superagent.get(pageurl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postlist=$("#main #post_list .post_item");
postlist.each((index,value)=>{
let titlelnk=$(value).find('a.titlelnk');
let itemfoot=$(value).find('.post_item_foot');
let title=titlelnk.html(); //标题
let href=titlelnk.attr('href'); //链接
let author=itemfoot.find('a.lightblue').html(); //作者
let headlogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedtime=itemfoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readnum=itemfoot.text().split('阅读')[1]; //阅读量
readnum=readnum.substr(1,readnum.length-1);
title=unescapestring(title);
href=unescapestring(href);
author=unescapestring(author);
headlogo=unescapestring(headlogo);
summary=unescapestring(summary);
postedtime=unescapestring(postedtime);
readnum=unescapestring(readnum);
result.push({
index,
title,
href,
author,
headlogo,
summary,
postedtime,
readnum
});
});
// 数组转换为字符串
result=json.stringify(result);
// 写入本地cnblogs.json文件中
fs.writefile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchdata();
3、进行优化
3.1、 生成结果
在项目目录中打开命令行,输入node crawler.js,
你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:
查看全部
nodejs抓取动态网页(【金融课堂】网络爬虫(webcrawler)、深层网络机器人
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 foaf 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
我们可以使用网络爬虫来自动采集数据信息,比如在搜索引擎中抓取网站收录,数据分析挖掘采集,应用采集对金融数据进行应用采集财务分析。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(deep web crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为可扩展的网络爬虫,爬取对象从一些种子网址扩展到整个网络,主要是门户搜索引擎和大型网络服务提供商采集数据。
1.2、关注网络爬虫
也称为主题爬虫,是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新生成或更改的网页的爬虫。它可以在一定程度上保证被爬取的页面尽可能的新。.
1.4、深网爬虫
网页按存在方式可分为表面网页(surface web)和深层网页(也称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎收录的网页,是以超链接可以到达的静态网页为主的网页。深网是那些大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些 关键词 才能获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,然后会想到python。百度如下,python做爬虫。由于本人主要做前端开发,所以相对来说javascript更熟练,也更简单。实现一个小目标,使用nodejs爬取首页文章列表(你经常使用的一个开发者网站),然后写入本地json文件。
2.2、环境建设
nodejs安装完成后,打开命令行,可以使用node -v查看nodejs是否安装成功,npm -v查看nodejs是否安装成功,如果安装成功会打印如下信息(视情况而定)在版本上):

2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据自己想要的数据解析返回的dom,最后将处理后的结果json翻译成字符串保存到本地。
//爬取页面地址
const pageurl="https://www.cnblogs.com/";
// 解码字符串
function unescapestring(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchdata(){
console.log('爬取数据时间节点:',new date());
superagent.get(pageurl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postlist=$("#main #post_list .post_item");
postlist.each((index,value)=>{
let titlelnk=$(value).find('a.titlelnk');
let itemfoot=$(value).find('.post_item_foot');
let title=titlelnk.html(); //标题
let href=titlelnk.attr('href'); //链接
let author=itemfoot.find('a.lightblue').html(); //作者
let headlogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedtime=itemfoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readnum=itemfoot.text().split('阅读')[1]; //阅读量
readnum=readnum.substr(1,readnum.length-1);
title=unescapestring(title);
href=unescapestring(href);
author=unescapestring(author);
headlogo=unescapestring(headlogo);
summary=unescapestring(summary);
postedtime=unescapestring(postedtime);
readnum=unescapestring(readnum);
result.push({
index,
title,
href,
author,
headlogo,
summary,
postedtime,
readnum
});
});
// 数组转换为字符串
result=json.stringify(result);
// 写入本地cnblogs.json文件中
fs.writefile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchdata();
3、进行优化
3.1、 生成结果
在项目目录中打开命令行,输入node crawler.js,

你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:

nodejs抓取动态网页(学会从网页源代码中提取数据这种最基本的爬虫使用json文件保存的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-04 03:18
其实爬虫是一项对计算机综合能力要求比较高的技术活动。
首先是对网络协议,尤其是http协议有基本的了解,能够分析网站的数据请求响应。学会使用一些工具,简单的使用chrome devtools的网络面板。我通常和邮递员或查尔斯合作分析。对于更复杂的情况,您可能需要使用专业的数据包捕获工具,例如wireshark。您对 网站 了解得越深,就越容易想出简单的方法来抓取您想要的信息。
除了了解一些计算机网络知识外,还需要具备一定的字符串处理能力,特别是正则表达式。其实正则表达式在一般的使用场景中不需要很多进阶知识,比较常用。稍微复杂一点的是分组、非贪婪匹配等。俗话说,如果你学好正则表达式,你就不怕处理字符串。
还有一点就是要掌握一些反爬虫的技巧。你在写爬虫的时候可能会遇到各种各样的问题,但是别怕,12306再复杂,也有人能爬,还有什么难我们。常见的爬虫会遇到服务器检查cookies、检查host和referer header、表单隐藏字段、验证码、访问频率限制、代理要求、spa网站等问题。其实爬虫遇到的大部分问题,最终都可以通过操纵浏览器来爬取。
本文使用nodejs编写爬虫系列的第二部分。对抗一个小爬虫,抓取流行的 github 项目。想要达到的目标:
学习从网页的源代码中提取数据。这个基本的爬虫使用一个 json 文件来保存捕获的数据。熟悉我在上一篇文章中介绍的一些模块。学习如何在node中处理用户输入分析需求
我们的需求是从github上抓取热门的项目数据,即star数最高的项目。但是github上好像没有任何页面可以看到排名靠前的项目。往往网站提供的搜索功能是我们爬虫作者分析的重点。
之前在灌v2ex的时候,看到一篇讨论996的帖子,刚教了一种用github star查看顶级仓库的方法。其实很简单,只需要在github搜索中加上star数的过滤条件,例如:stars:>60000,就可以搜索到github上所有star数大于60000的仓库。分析下面的截图,注意图片中的评论:
分析可以得到以下信息:
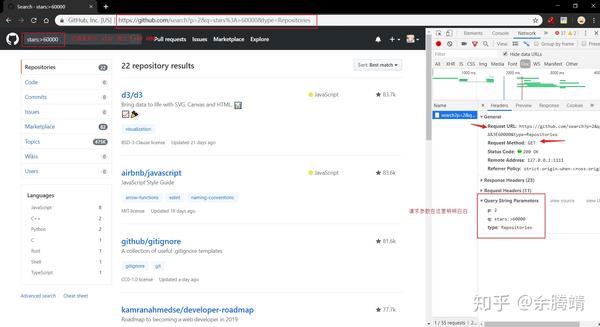
这个搜索结果页面通过get请求返回html文档,因为我的网络选择了Doc过滤url中的请求参数。有3个参数,p(page)表示页数,q(query)表示搜索内容,type表示搜索内容类型
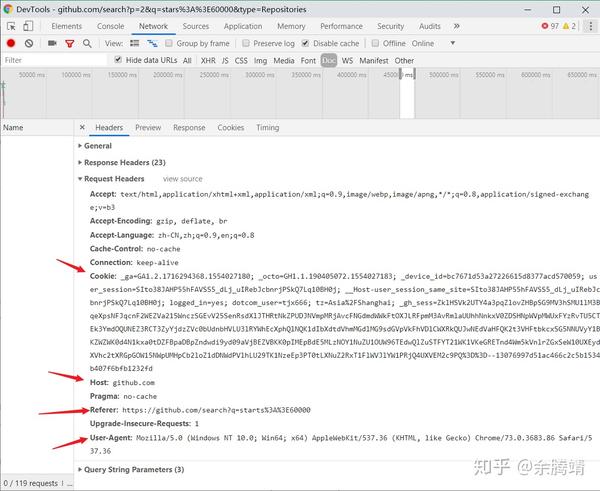
然后我想知道github会不会检查cookies和其他请求头如referer、host等,根据是否有这些请求头来决定是否返回页面。
一个比较简单的测试方法是直接使用命令行工具curl进行测试,在gitbash中输入如下命令,即curl“请求的url”
curl "https://github.com/search%3Fp% ... ot%3B
不出所料,页面的源代码正常返回,这样我们的爬虫脚本就不需要添加请求头和cookie了。
通过chrome的搜索功能,可以看到网页源代码中有我们需要的项目信息
分析到此结束。这其实是一个很简单的小爬虫。我们只需要配置查询参数,通过http请求获取网页的源码,然后使用解析库进行解析,就可以在源码中得到我们需要的项目相关信息。,然后将数据处理成数组,最后序列化成json字符串存入json文件中。
动手实现这个小爬虫获取源代码
通过node获取源码,需要先配置url参数,然后通过发送http请求的模块superagent访问配置的url。
'use strict';
const requests = require('superagent');
const cheerio = require('cheerio');
const constants = require('../config/constants');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const requestUtil = require('./utils/request');
const models = require('./models');
/**
* 获取 star 数不低于 starCount k 的项目第 page 页的源代码
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlSourceCode = async (starCount, page = 1) => {
// 下限为 starCount k star 数
starCount = starCount * 1024;
// 替换 url 中的参数
const url = constants.searchUrl.replace('${starCount}', starCount).replace('${page}', page);
// response.text 即为返回的源代码
const { text: sourceCode } = await requestUtil.logRequest(requests.get(encodeURI(url)));
return sourceCode;
}
上面代码中的constants模块用于保存工程中的一些常量配置。到时候需要改常量,直接改这个配置文件,配置信息比较集中,方便查看。
module.exports = {
searchUrl: 'https://github.com/search?q=stars:>${starCount}&p=${page}&type=Repositories',
};
解析源码获取项目信息
这里我把项目信息抽象成一个Repository类。在项目models目录下的Repository.js中。
const fs = require('fs-extra');
const path = require('path');
module.exports = class Repository {
static async saveToLocal(repositories, indent = 2) {
await fs.writeJSON(path.resolve(__dirname, '../../out/repositories.json'), repositories, { spaces: indent})
}
constructor({
name,
author,
language,
digest,
starCount,
lastUpdate,
} = {}) {
this.name = name;
this.author = author;
this.language = language;
this.digest = digest;
this.starCount = starCount;
this.lastUpdate = lastUpdate;
}
display() {
console.log(` 项目: ${this.name} 作者: ${this.author} 语言: ${this.language} star: ${this.starCount}
摘要: ${this.digest}
最后更新: ${this.lastUpdate}
`);
}
}
解析得到的源码,需要用到cheerio这个解析库,和jquery很像。
/**
* 获取 star 数不低于 starCount k 的项目页表
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlProjectsByPage = async (starCount, page = 1) => {
const sourceCode = await crawlSourceCode(starCount, page);
const $ = cheerio.load(sourceCode);
// 下面 cheerio 如果 jquery 比较熟应该没有障碍, 不熟的话 github 官方仓库可以查看 api, api 并不是很多
// 查看 elements 面板, 发现每个仓库的信息在一个 li 标签内, 下面的代码时建议打开开发者工具的 elements 面板, 参照着阅读
const repositoryLiSelector = '.repo-list-item';
const repositoryLis = $(repositoryLiSelector);
const repositories = [];
repositoryLis.each((index, li) => {
const $li = $(li);
// 获取带有仓库作者和仓库名的 a 链接
const nameLink = $li.find('h3 a');
// 提取出仓库名和作者名
const [author, name] = nameLink.text().split('/');
// 获取项目摘要
const digestP = $($li.find('p')[0]);
const digest = digestP.text().trim();
// 获取语言
// 先获取类名为 .repo-language-color 的那个 span, 在获取包含语言文字的父 div
// 这里要注意有些仓库是没有语言的, 是获取不到那个 span 的, language 为空字符串
const languageDiv = $li.find('.repo-language-color').parent();
// 这里注意使用 String.trim() 去除两侧的空白符
const language = languageDiv.text().trim();
// 获取 star 数量
const starCountLinkSelector = '.muted-link';
const links = $li.find(starCountLinkSelector);
// 选择器为 .muted-link 还有可能是那个 issues 链接
const starCountLink = $(links.length === 2 ? links[1] : links[0]);
const starCount = starCountLink.text().trim();
// 获取最后更新时间
const lastUpdateElementSelector = 'relative-time';
const lastUpdate = $li.find(lastUpdateElementSelector).text().trim();
const repository = new models.Repository({
name,
author,
language,
digest,
starCount,
lastUpdate,
});
repositories.push(repository);
});
return repositories;
}
有时搜索结果有很多页,所以我在这里写了一个新函数来获取指定页数的仓库。
const crawlProjectsByPagesCount = async (starCount, pagesCount) => {
if (pagesCount === undefined) {
pagesCount = await getPagesCount(starCount);
logger.warn(`未指定抓取的页面数量, 将抓取所有仓库, 总共${pagesCount}页`);
}
const allRepositories = [];
const tasks = Array.from({ length: pagesCount }, (ele, index) => {
// 因为页数是从 1 开始的, 所以这里要 i + 1
return crawlProjectsByPage(starCount, index + 1);
});
// 使用 Promise.all 来并发操作
const resultRepositoriesArray = await Promise.all(tasks);
resultRepositoriesArray.forEach(repositories => allRepositories.push(...repositories));
return allRepositories;
}
让爬虫项目更人性化
随便写个脚本,在代码中配置好参数,然后爬取,有点太粗暴了。这里我使用了readline-sync,一个可以同步获取用户输入的库,并添加了一点用户交互。在后续的爬虫教程中,我可能会考虑使用electron来做一个简单的界面。下面是程序的启动代码。
const readlineSync = require('readline-sync');
const { crawlProjectsByPage, crawlProjectsByPagesCount } = require('./crawlHotProjects');
const models = require('./models');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const main = async () => {
let isContinue = true;
do {
const starCount = readlineSync.questionInt(`输入你想要抓取的 github 上项目的 star 数量下限, 单位(k): `, { encoding: 'utf-8'});
const crawlModes = [
'抓取某一页',
'抓取一定数量页数',
'抓取所有页'
];
const index = readlineSync.keyInSelect(crawlModes, '请选择一种抓取模式');
let repositories = [];
switch (index) {
case 0: {
const page = readlineSync.questionInt('请输入你要抓取的具体页数: ');
repositories = await crawlProjectsByPage(starCount, page);
break;
}
case 1: {
const pagesCount = readlineSync.questionInt('请输入你要抓取的页面数量: ');
repositories = await crawlProjectsByPagesCount(starCount, pagesCount);
break;
}
case 3: {
repositories = await crawlProjectsByPagesCount(starCount);
break;
}
}
repositories.forEach(repository => repository.display());
const isSave = readlineSync.keyInYN('请问是否要保存到本地(json 格式) ?');
isSave && models.Repository.saveToLocal(repositories);
isContinue = readlineSync.keyInYN('继续还是退出 ?');
} while (isContinue);
logger.info('程序正常退出...')
}
main();
来看看最后的效果
这里我想提一个readline-sync的bug。在windows的vscode中使用git bash时,不管你的文件格式是不是utf-8,都会出现中文乱码。搜索了一些问题,在powershell中把编码改成utf-8就可以正常显示了,也就是把页码剪成65001。
项目完整源码和后续教程源码将存放在我的github仓库:Spiders。如果我的教程对你有帮助,希望你不要吝啬你的星星。后续教程可能是更复杂的案例,通过分析ajax请求直接访问界面。 查看全部
nodejs抓取动态网页(学会从网页源代码中提取数据这种最基本的爬虫使用json文件保存的数据)
其实爬虫是一项对计算机综合能力要求比较高的技术活动。
首先是对网络协议,尤其是http协议有基本的了解,能够分析网站的数据请求响应。学会使用一些工具,简单的使用chrome devtools的网络面板。我通常和邮递员或查尔斯合作分析。对于更复杂的情况,您可能需要使用专业的数据包捕获工具,例如wireshark。您对 网站 了解得越深,就越容易想出简单的方法来抓取您想要的信息。
除了了解一些计算机网络知识外,还需要具备一定的字符串处理能力,特别是正则表达式。其实正则表达式在一般的使用场景中不需要很多进阶知识,比较常用。稍微复杂一点的是分组、非贪婪匹配等。俗话说,如果你学好正则表达式,你就不怕处理字符串。
还有一点就是要掌握一些反爬虫的技巧。你在写爬虫的时候可能会遇到各种各样的问题,但是别怕,12306再复杂,也有人能爬,还有什么难我们。常见的爬虫会遇到服务器检查cookies、检查host和referer header、表单隐藏字段、验证码、访问频率限制、代理要求、spa网站等问题。其实爬虫遇到的大部分问题,最终都可以通过操纵浏览器来爬取。
本文使用nodejs编写爬虫系列的第二部分。对抗一个小爬虫,抓取流行的 github 项目。想要达到的目标:
学习从网页的源代码中提取数据。这个基本的爬虫使用一个 json 文件来保存捕获的数据。熟悉我在上一篇文章中介绍的一些模块。学习如何在node中处理用户输入分析需求
我们的需求是从github上抓取热门的项目数据,即star数最高的项目。但是github上好像没有任何页面可以看到排名靠前的项目。往往网站提供的搜索功能是我们爬虫作者分析的重点。
之前在灌v2ex的时候,看到一篇讨论996的帖子,刚教了一种用github star查看顶级仓库的方法。其实很简单,只需要在github搜索中加上star数的过滤条件,例如:stars:>60000,就可以搜索到github上所有star数大于60000的仓库。分析下面的截图,注意图片中的评论:
分析可以得到以下信息:
这个搜索结果页面通过get请求返回html文档,因为我的网络选择了Doc过滤url中的请求参数。有3个参数,p(page)表示页数,q(query)表示搜索内容,type表示搜索内容类型
然后我想知道github会不会检查cookies和其他请求头如referer、host等,根据是否有这些请求头来决定是否返回页面。
一个比较简单的测试方法是直接使用命令行工具curl进行测试,在gitbash中输入如下命令,即curl“请求的url”
curl "https://github.com/search%3Fp% ... ot%3B
不出所料,页面的源代码正常返回,这样我们的爬虫脚本就不需要添加请求头和cookie了。
通过chrome的搜索功能,可以看到网页源代码中有我们需要的项目信息
分析到此结束。这其实是一个很简单的小爬虫。我们只需要配置查询参数,通过http请求获取网页的源码,然后使用解析库进行解析,就可以在源码中得到我们需要的项目相关信息。,然后将数据处理成数组,最后序列化成json字符串存入json文件中。
动手实现这个小爬虫获取源代码
通过node获取源码,需要先配置url参数,然后通过发送http请求的模块superagent访问配置的url。
'use strict';
const requests = require('superagent');
const cheerio = require('cheerio');
const constants = require('../config/constants');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const requestUtil = require('./utils/request');
const models = require('./models');
/**
* 获取 star 数不低于 starCount k 的项目第 page 页的源代码
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlSourceCode = async (starCount, page = 1) => {
// 下限为 starCount k star 数
starCount = starCount * 1024;
// 替换 url 中的参数
const url = constants.searchUrl.replace('${starCount}', starCount).replace('${page}', page);
// response.text 即为返回的源代码
const { text: sourceCode } = await requestUtil.logRequest(requests.get(encodeURI(url)));
return sourceCode;
}
上面代码中的constants模块用于保存工程中的一些常量配置。到时候需要改常量,直接改这个配置文件,配置信息比较集中,方便查看。
module.exports = {
searchUrl: 'https://github.com/search?q=stars:>${starCount}&p=${page}&type=Repositories',
};
解析源码获取项目信息
这里我把项目信息抽象成一个Repository类。在项目models目录下的Repository.js中。
const fs = require('fs-extra');
const path = require('path');
module.exports = class Repository {
static async saveToLocal(repositories, indent = 2) {
await fs.writeJSON(path.resolve(__dirname, '../../out/repositories.json'), repositories, { spaces: indent})
}
constructor({
name,
author,
language,
digest,
starCount,
lastUpdate,
} = {}) {
this.name = name;
this.author = author;
this.language = language;
this.digest = digest;
this.starCount = starCount;
this.lastUpdate = lastUpdate;
}
display() {
console.log(` 项目: ${this.name} 作者: ${this.author} 语言: ${this.language} star: ${this.starCount}
摘要: ${this.digest}
最后更新: ${this.lastUpdate}
`);
}
}
解析得到的源码,需要用到cheerio这个解析库,和jquery很像。
/**
* 获取 star 数不低于 starCount k 的项目页表
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlProjectsByPage = async (starCount, page = 1) => {
const sourceCode = await crawlSourceCode(starCount, page);
const $ = cheerio.load(sourceCode);
// 下面 cheerio 如果 jquery 比较熟应该没有障碍, 不熟的话 github 官方仓库可以查看 api, api 并不是很多
// 查看 elements 面板, 发现每个仓库的信息在一个 li 标签内, 下面的代码时建议打开开发者工具的 elements 面板, 参照着阅读
const repositoryLiSelector = '.repo-list-item';
const repositoryLis = $(repositoryLiSelector);
const repositories = [];
repositoryLis.each((index, li) => {
const $li = $(li);
// 获取带有仓库作者和仓库名的 a 链接
const nameLink = $li.find('h3 a');
// 提取出仓库名和作者名
const [author, name] = nameLink.text().split('/');
// 获取项目摘要
const digestP = $($li.find('p')[0]);
const digest = digestP.text().trim();
// 获取语言
// 先获取类名为 .repo-language-color 的那个 span, 在获取包含语言文字的父 div
// 这里要注意有些仓库是没有语言的, 是获取不到那个 span 的, language 为空字符串
const languageDiv = $li.find('.repo-language-color').parent();
// 这里注意使用 String.trim() 去除两侧的空白符
const language = languageDiv.text().trim();
// 获取 star 数量
const starCountLinkSelector = '.muted-link';
const links = $li.find(starCountLinkSelector);
// 选择器为 .muted-link 还有可能是那个 issues 链接
const starCountLink = $(links.length === 2 ? links[1] : links[0]);
const starCount = starCountLink.text().trim();
// 获取最后更新时间
const lastUpdateElementSelector = 'relative-time';
const lastUpdate = $li.find(lastUpdateElementSelector).text().trim();
const repository = new models.Repository({
name,
author,
language,
digest,
starCount,
lastUpdate,
});
repositories.push(repository);
});
return repositories;
}
有时搜索结果有很多页,所以我在这里写了一个新函数来获取指定页数的仓库。
const crawlProjectsByPagesCount = async (starCount, pagesCount) => {
if (pagesCount === undefined) {
pagesCount = await getPagesCount(starCount);
logger.warn(`未指定抓取的页面数量, 将抓取所有仓库, 总共${pagesCount}页`);
}
const allRepositories = [];
const tasks = Array.from({ length: pagesCount }, (ele, index) => {
// 因为页数是从 1 开始的, 所以这里要 i + 1
return crawlProjectsByPage(starCount, index + 1);
});
// 使用 Promise.all 来并发操作
const resultRepositoriesArray = await Promise.all(tasks);
resultRepositoriesArray.forEach(repositories => allRepositories.push(...repositories));
return allRepositories;
}
让爬虫项目更人性化
随便写个脚本,在代码中配置好参数,然后爬取,有点太粗暴了。这里我使用了readline-sync,一个可以同步获取用户输入的库,并添加了一点用户交互。在后续的爬虫教程中,我可能会考虑使用electron来做一个简单的界面。下面是程序的启动代码。
const readlineSync = require('readline-sync');
const { crawlProjectsByPage, crawlProjectsByPagesCount } = require('./crawlHotProjects');
const models = require('./models');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const main = async () => {
let isContinue = true;
do {
const starCount = readlineSync.questionInt(`输入你想要抓取的 github 上项目的 star 数量下限, 单位(k): `, { encoding: 'utf-8'});
const crawlModes = [
'抓取某一页',
'抓取一定数量页数',
'抓取所有页'
];
const index = readlineSync.keyInSelect(crawlModes, '请选择一种抓取模式');
let repositories = [];
switch (index) {
case 0: {
const page = readlineSync.questionInt('请输入你要抓取的具体页数: ');
repositories = await crawlProjectsByPage(starCount, page);
break;
}
case 1: {
const pagesCount = readlineSync.questionInt('请输入你要抓取的页面数量: ');
repositories = await crawlProjectsByPagesCount(starCount, pagesCount);
break;
}
case 3: {
repositories = await crawlProjectsByPagesCount(starCount);
break;
}
}
repositories.forEach(repository => repository.display());
const isSave = readlineSync.keyInYN('请问是否要保存到本地(json 格式) ?');
isSave && models.Repository.saveToLocal(repositories);
isContinue = readlineSync.keyInYN('继续还是退出 ?');
} while (isContinue);
logger.info('程序正常退出...')
}
main();
来看看最后的效果
这里我想提一个readline-sync的bug。在windows的vscode中使用git bash时,不管你的文件格式是不是utf-8,都会出现中文乱码。搜索了一些问题,在powershell中把编码改成utf-8就可以正常显示了,也就是把页码剪成65001。
项目完整源码和后续教程源码将存放在我的github仓库:Spiders。如果我的教程对你有帮助,希望你不要吝啬你的星星。后续教程可能是更复杂的案例,通过分析ajax请求直接访问界面。
nodejs抓取动态网页(从信息抓取和提取,静态页面分析和互动这三个方面再讨论一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-02 05:15
爬虫是一个非常复杂的系统,可以从许多不同的角度进行分类。之前的一些答案已经涵盖了很多。我想从信息捕获和提取、手动编码和可视化、静态页面分析和交互开始。再讨论。
1. 信息捕获和提取
信息抓取是指如何获取网站上的信息的过程,信息抽取是指如何从获取到的页面中识别出自己需要的信息的过程。当使用爬虫爬取单个或少量网站时,那么主要问题是解决爬取问题,而当目标数网站较大时,信息抽取成为主要矛盾.
比如Scrapy就是一个解决信息爬取问题的软件平台。使用Xpath或者CSS Selector可以从少量的站点中提取信息,但是面对大规模的信息提取,Xpath是无能为力的。在这种情况下,一些机器学习算法,比如IBL(Instance based Learning),可以根据一定的网站一页或少量的页面进行学习,然后快速生成网站识别模型,scrapely 就是这样一个软件模块。
2. 手动编码和可视化
我们在网上看到的大部分教程都是基于某种编程语言(如Python)和软件库(如Scrapy)手工编写的。这种方法的优点是非常灵活、可扩展,并且可以针对特定站点给出有效的实现。但它的缺点也很明显,就是爬虫开发者需要懂编程语言,门槛比较高。
为了解决这个问题,人们提出了视觉爬虫。定义可视化爬虫时,会直观地显示远程网站页面,然后人们可以点击鼠标定义爬取逻辑(包括爬取Fetching目标、爬取顺序、爬取深度等)和爬取逻辑(页面的哪一部分应该被识别为属性)。与手工编码的爬虫相比,视觉爬虫大大降低了爬虫定义的门槛,但爬虫的效率不如手工编程。另外,由于可视化爬虫对爬取逻辑进行了抽象,可能无法支持一些特殊的网站。
Portia 是典型的视觉爬虫。人们常常认为pyspider也是一个视觉爬虫,其实不然。Pyspider 只是一个带有 GUI 的手工编码爬虫。
3.被动爬虫和交互式爬虫
大多数爬虫都是基于对页面的分析。如有必要,浏览器引擎会执行页面中的Javascript代码,然后获取渲染的页面,然后从中提取自己需要的信息。
但是在某些情况下,我们也需要能够和这些页面进行交互,比如输入用户名和密码登录系统然后爬取,或者我们需要输入关键字然后才爬取搜索结果。在这些情况下,我们需要能够在定义爬虫时保存这些用户输入,然后在爬虫执行期间重放交互信息,就像一个人在做这些动作一样。
Selenium 就是这种爬虫的一个例子。用户使用 Selenium IDE 记录用户操作,将它们保存为 Selenese 命令序列,然后使用 Web 驱动程序模拟浏览器重放这些命令。交互式爬虫的优点是可以像人一样做出各种动作,但缺点是需要搭建一个完整的浏览器引擎,系统开销很大,爬虫效率很低。
最后,为了做个广告,我最近开源了一个爬虫portia-dashboard。按照之前的分类方法,这款爬虫是“面向多站点”、“主要支持信息爬取”、“同时支持被动爬取”和“交互爬取”“可视化”爬虫,并提供了一个仪表盘功能。 Portia.dashboard可以用来部署爬虫、启动爬虫、监控爬虫状态、浏览提取的信息等等。
使用代码安装可能有点复杂,最简单的方法是使用docker,欢迎大家使用,并提供宝贵意见。 查看全部
nodejs抓取动态网页(从信息抓取和提取,静态页面分析和互动这三个方面再讨论一下)
爬虫是一个非常复杂的系统,可以从许多不同的角度进行分类。之前的一些答案已经涵盖了很多。我想从信息捕获和提取、手动编码和可视化、静态页面分析和交互开始。再讨论。
1. 信息捕获和提取
信息抓取是指如何获取网站上的信息的过程,信息抽取是指如何从获取到的页面中识别出自己需要的信息的过程。当使用爬虫爬取单个或少量网站时,那么主要问题是解决爬取问题,而当目标数网站较大时,信息抽取成为主要矛盾.
比如Scrapy就是一个解决信息爬取问题的软件平台。使用Xpath或者CSS Selector可以从少量的站点中提取信息,但是面对大规模的信息提取,Xpath是无能为力的。在这种情况下,一些机器学习算法,比如IBL(Instance based Learning),可以根据一定的网站一页或少量的页面进行学习,然后快速生成网站识别模型,scrapely 就是这样一个软件模块。
2. 手动编码和可视化
我们在网上看到的大部分教程都是基于某种编程语言(如Python)和软件库(如Scrapy)手工编写的。这种方法的优点是非常灵活、可扩展,并且可以针对特定站点给出有效的实现。但它的缺点也很明显,就是爬虫开发者需要懂编程语言,门槛比较高。
为了解决这个问题,人们提出了视觉爬虫。定义可视化爬虫时,会直观地显示远程网站页面,然后人们可以点击鼠标定义爬取逻辑(包括爬取Fetching目标、爬取顺序、爬取深度等)和爬取逻辑(页面的哪一部分应该被识别为属性)。与手工编码的爬虫相比,视觉爬虫大大降低了爬虫定义的门槛,但爬虫的效率不如手工编程。另外,由于可视化爬虫对爬取逻辑进行了抽象,可能无法支持一些特殊的网站。
Portia 是典型的视觉爬虫。人们常常认为pyspider也是一个视觉爬虫,其实不然。Pyspider 只是一个带有 GUI 的手工编码爬虫。
3.被动爬虫和交互式爬虫
大多数爬虫都是基于对页面的分析。如有必要,浏览器引擎会执行页面中的Javascript代码,然后获取渲染的页面,然后从中提取自己需要的信息。
但是在某些情况下,我们也需要能够和这些页面进行交互,比如输入用户名和密码登录系统然后爬取,或者我们需要输入关键字然后才爬取搜索结果。在这些情况下,我们需要能够在定义爬虫时保存这些用户输入,然后在爬虫执行期间重放交互信息,就像一个人在做这些动作一样。
Selenium 就是这种爬虫的一个例子。用户使用 Selenium IDE 记录用户操作,将它们保存为 Selenese 命令序列,然后使用 Web 驱动程序模拟浏览器重放这些命令。交互式爬虫的优点是可以像人一样做出各种动作,但缺点是需要搭建一个完整的浏览器引擎,系统开销很大,爬虫效率很低。
最后,为了做个广告,我最近开源了一个爬虫portia-dashboard。按照之前的分类方法,这款爬虫是“面向多站点”、“主要支持信息爬取”、“同时支持被动爬取”和“交互爬取”“可视化”爬虫,并提供了一个仪表盘功能。 Portia.dashboard可以用来部署爬虫、启动爬虫、监控爬虫状态、浏览提取的信息等等。
使用代码安装可能有点复杂,最简单的方法是使用docker,欢迎大家使用,并提供宝贵意见。
nodejs抓取动态网页( Splider.js文件入口是splider方法,首先根据传入方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-01 17:12
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源代码,定位到你需要的标签,然后提取标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的index构造尴尬百科的url,然后获取该url的网页源码,最后将获取的源码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:
源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我的最爱。但是,在 Node 中,有多种方式可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢 查看全部
nodejs抓取动态网页(
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源代码,定位到你需要的标签,然后提取标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的index构造尴尬百科的url,然后获取该url的网页源码,最后将获取的源码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:

源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我的最爱。但是,在 Node 中,有多种方式可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢
nodejs抓取动态网页(先看题干效果在这里我们建了一个表单填入表单需要提交的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-31 03:11
先看问题效果
这里我们建立了一个表单
在表格中填写需要提交的信息
获取两个参数和一个加法计算
表单html代码
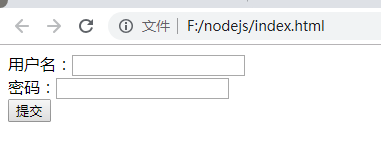
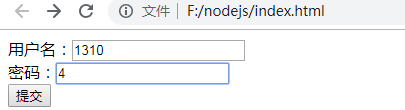
用户名:
密 码:
NodeJS 文件
var http = require('http');
var url = require('url');
var fs = require('fs');
http.createServer(function(request,response){
//获取get请求中的参数
var requset_url = request.url;
//将字符串格式参数转化为对象使用
var strurl = url.parse(requset_url,true).query
var sum = Number(strurl.username)+Number(strurl.password)
console.log(sum);
//下面这个对象是buffer类型的对象
var content = fs.readFileSync('homework.html')
//现在我们要将他转换为字符串类型的对象
content= content.toString().replace('{{sum}}',sum);
console.log(content)
response.end(content)
}).listen(8080,function(){
console.log('服务启动!!!')
})
页面返回
uesrname+userkeyword={{sum}}
运行环境
想法:
//将index.html网页中的action地址设置为本地服务器localhost:8080的地址
//然后使用get请求中的url模块获取请求路径中的参数
//使用parse方法将字符串格式的参数转换成对象使用
// 用数力计算两个参数的值
// 包 {{sum}} 和另一个网页的整个 html 内容。默认为缓冲区类型对象,转换为字符串
//最后用两个参数的值和替换{{sum}} 查看全部
nodejs抓取动态网页(先看题干效果在这里我们建了一个表单填入表单需要提交的信息)
先看问题效果
这里我们建立了一个表单
在表格中填写需要提交的信息
获取两个参数和一个加法计算

表单html代码
用户名:
密 码:
NodeJS 文件
var http = require('http');
var url = require('url');
var fs = require('fs');
http.createServer(function(request,response){
//获取get请求中的参数
var requset_url = request.url;
//将字符串格式参数转化为对象使用
var strurl = url.parse(requset_url,true).query
var sum = Number(strurl.username)+Number(strurl.password)
console.log(sum);
//下面这个对象是buffer类型的对象
var content = fs.readFileSync('homework.html')
//现在我们要将他转换为字符串类型的对象
content= content.toString().replace('{{sum}}',sum);
console.log(content)
response.end(content)
}).listen(8080,function(){
console.log('服务启动!!!')
})
页面返回
uesrname+userkeyword={{sum}}
运行环境
想法:
//将index.html网页中的action地址设置为本地服务器localhost:8080的地址
//然后使用get请求中的url模块获取请求路径中的参数
//使用parse方法将字符串格式的参数转换成对象使用
// 用数力计算两个参数的值
// 包 {{sum}} 和另一个网页的整个 html 内容。默认为缓冲区类型对象,转换为字符串
//最后用两个参数的值和替换{{sum}}
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-31 03:08
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是 superagent 只支持 utf-8 网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?为了让浏览器正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的字符集内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用! 查看全部
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是 superagent 只支持 utf-8 网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?为了让浏览器正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的字符集内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用!
nodejs抓取动态网页(puppeteer和浏览器的区别,安装注意先安装nodejs.eachSeries)
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-10-31 03:07
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理效率不高。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(puppeteer和浏览器的区别,安装注意先安装nodejs.eachSeries)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:

抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:

结果
文章内容列表:

文章内容:

结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理效率不高。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页(第三方库:cheerio,这个库就是用来处理dom节点的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-30 06:25
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放入一个数组中,例如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html = chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。块是传输的数据。数据被添加到 html 变量中。当数据传输完毕后,会触发结束事件。你可以在end事件中打印console.log(html),你会发现它是目标地址的所有html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) 1 );
37 if ( curPage 查看全部
nodejs抓取动态网页(第三方库:cheerio,这个库就是用来处理dom节点的
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放入一个数组中,例如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html = chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。块是传输的数据。数据被添加到 html 变量中。当数据传输完毕后,会触发结束事件。你可以在end事件中打印console.log(html),你会发现它是目标地址的所有html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) 1 );
37 if ( curPage
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 05:08
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(expres)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github源码:/xiugangzhang/vip.github.io
我们先来看看最终的效果:
用户主页建设:
电影播放页面的构建
电影搜索功能(特色功能)
用户中心管理
程序安装方法步骤:
其他说明
以下是下载程序并解压后的目录结构。下面是这个目录结构的简要说明:
controller:控制层,只要核心业务逻辑代码
data:数据采集层,用于从爱奇艺网站采集视频数据,存入数据库,展示在前端,其中db.js为数据库的相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
utils:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是动态展示数据,方便后面的数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序入口文件
config.js:程序的主要配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取到的数据信息,用于向数据库中插入数据
在线演示站点:
Github源码:/xiugangzhang/vip.github.io 查看全部
nodejs抓取动态网页(Linux服务器在线演示站点-Github.io.js)
项目名称:视频网站项目
开发语言:HTML、CSS(前端)、JavaScript、NODEJS(expres)(后端)
数据库:MySQL
开发环境:Win7、Webstorm
在线部署环境:Linux服务器
在线演示站点:
Github源码:/xiugangzhang/vip.github.io
我们先来看看最终的效果:
用户主页建设:
电影播放页面的构建
电影搜索功能(特色功能)
用户中心管理
程序安装方法步骤:
其他说明
以下是下载程序并解压后的目录结构。下面是这个目录结构的简要说明:
controller:控制层,只要核心业务逻辑代码
data:数据采集层,用于从爱奇艺网站采集视频数据,存入数据库,展示在前端,其中db.js为数据库的相关配置文件
models:数据库表结构映射文件(用于将数据库的关系数据模型转换为对象模型)
utils:工具包
views:查看文件(网站项目的所有html文件,这里的格式是xtpl,主要是动态展示数据,方便后面的数据渲染)
www:网站的所有静态资源文件,包括html、css、js等文件
app.js:程序入口文件
config.js:程序的主要配置文件,用于配置文件上传目录等参数
router.js:程序的路由配置
*.sql:这些是一些抓取到的数据信息,用于向数据库中插入数据
在线演示站点:
Github源码:/xiugangzhang/vip.github.io
nodejs抓取动态网页(实验程序抓取的数据,会在后面抽时间打造新项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-11-22 05:05
一个从0开始构建的股票数据采集程序。这个实验程序采集到的数据将用于后续的AI实验程序(如选股策略、交易策略等)。稍后我会花时间创建新项目。实验使用的数据源:东方财富网数据存储根目录:./data/eastmoney一、 使用前提步骤:安装nodejs(这里不详述) 安装包:npm install 启动抓取任务:节点应用程序。js二、数据包括:1.沪深A股行情数据,保存在子目录market下;2.股票历史数据,保存在子目录stock下;3.股票核心财务数据保存在子目录core下;三、 实现过程:整个ETL大部分是通过基类EtlServiceBase实现的,我们只需要根据需要实现子类即可,比如eastmoney中的实现方法;1. 首先分析网页: 1.1 在浏览器中打开要分析的数据网页,例如:
1.2 按F12打开调试界面,找到请求数据地址和响应数据,使用请求包请求分页数据。请求过程在基类 EtlServiceBase 中实现。根据界面上的显示内容,与请求结果中的数据字段进行比较,找出映射关系。
使用正则表达式提取 JSON 数据:
<p>var arr = text.match(/(? 查看全部
nodejs抓取动态网页(实验程序抓取的数据,会在后面抽时间打造新项目)
一个从0开始构建的股票数据采集程序。这个实验程序采集到的数据将用于后续的AI实验程序(如选股策略、交易策略等)。稍后我会花时间创建新项目。实验使用的数据源:东方财富网数据存储根目录:./data/eastmoney一、 使用前提步骤:安装nodejs(这里不详述) 安装包:npm install 启动抓取任务:节点应用程序。js二、数据包括:1.沪深A股行情数据,保存在子目录market下;2.股票历史数据,保存在子目录stock下;3.股票核心财务数据保存在子目录core下;三、 实现过程:整个ETL大部分是通过基类EtlServiceBase实现的,我们只需要根据需要实现子类即可,比如eastmoney中的实现方法;1. 首先分析网页: 1.1 在浏览器中打开要分析的数据网页,例如:
1.2 按F12打开调试界面,找到请求数据地址和响应数据,使用请求包请求分页数据。请求过程在基类 EtlServiceBase 中实现。根据界面上的显示内容,与请求结果中的数据字段进行比较,找出映射关系。
使用正则表达式提取 JSON 数据:
<p>var arr = text.match(/(?
nodejs抓取动态网页(nodejs抓取动态网页详解(1)_nodejs_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-21 01:02
nodejs抓取动态网页详解
一、什么是meta?1.meta:是英文"method"或"method-guide"的缩写。其本意是"方法指南"或"方法指令"。在nodejs中,这个词被重新演绎,在前端开发中意味着"代码片段规则"。即可以这样理解:"如果有meta字段,必须遵循。"2.什么是get?get()这个方法接受任意数量的参数(数据),返回的是http请求的内容。
若参数只有一个,那么是{"post":'/path/to/xxx'}返回数据form页面,若有get请求,可返回{"post":{"parent":{"post_url":""}}}response.encode(json_string)表示将json_string转换为json对象(json对象的定义:json.parse(json_string)||json.stringify(json_string)),两者的区别仅仅是json_string的值不同。
3.setinterval()被视为var声明,
0)来不断的执行整个计算节点。
即setinterval("get",100
0)4.method指定请求的方法,并描述了要执行的方法。addressroute标识目标路由(具体的目标地址)path标识路径(可以是有路径的方式)method示例可以看到返回值为{"get":{"host":"","path":"xxx"}}5.get请求无返回值#addressrequtils.method=function(){return}返回值为"123456"#routetargetrequtils.method=function(){return}返回值为{"owner":"123456"}#routerreturnreturnreturn"./"#routereturnreturn"/"#routereturnreturn"./xxx"#method指定方法(return(post),method(get),post(post),get(offset),get(html),offset(offset));>返回值为{"url":"","host":"","path":"","post_url":"","post_url":"","post_url":"","post_url":"","dom":"","form":"","parent":"","post_url":"","post_url":"","form_item":"","redirect":"","cors":"","redirect_timeout":"-1","timeout":"1","h。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页详解(1)_nodejs_光明网)
nodejs抓取动态网页详解
一、什么是meta?1.meta:是英文"method"或"method-guide"的缩写。其本意是"方法指南"或"方法指令"。在nodejs中,这个词被重新演绎,在前端开发中意味着"代码片段规则"。即可以这样理解:"如果有meta字段,必须遵循。"2.什么是get?get()这个方法接受任意数量的参数(数据),返回的是http请求的内容。
若参数只有一个,那么是{"post":'/path/to/xxx'}返回数据form页面,若有get请求,可返回{"post":{"parent":{"post_url":""}}}response.encode(json_string)表示将json_string转换为json对象(json对象的定义:json.parse(json_string)||json.stringify(json_string)),两者的区别仅仅是json_string的值不同。
3.setinterval()被视为var声明,
0)来不断的执行整个计算节点。
即setinterval("get",100
0)4.method指定请求的方法,并描述了要执行的方法。addressroute标识目标路由(具体的目标地址)path标识路径(可以是有路径的方式)method示例可以看到返回值为{"get":{"host":"","path":"xxx"}}5.get请求无返回值#addressrequtils.method=function(){return}返回值为"123456"#routetargetrequtils.method=function(){return}返回值为{"owner":"123456"}#routerreturnreturnreturn"./"#routereturnreturn"/"#routereturnreturn"./xxx"#method指定方法(return(post),method(get),post(post),get(offset),get(html),offset(offset));>返回值为{"url":"","host":"","path":"","post_url":"","post_url":"","post_url":"","post_url":"","dom":"","form":"","parent":"","post_url":"","post_url":"","form_item":"","redirect":"","cors":"","redirect_timeout":"-1","timeout":"1","h。
nodejs抓取动态网页(nodejs获取客户端真实的IP地址是怎样的?获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-20 11:06
1、nodejs获取客户端真实IP地址:
在一般管理网站中,Taste会需要记录一些用户的操作,并记住是哪个用户执行的操作。这时候就需要用户的ip地址,但是往往当这些应用部署在服务器上之后,会用到ngix等
代理,用户访问时,需要通过代理查看用户的真实IP地址。下面是nodejs获取客户端真实IP的代码:
//获取客户端真实ip;
function getClientIp(req) {
var ipAddress;
var forwardedIpsStr = req.headers['X-Forwarded-For'];//判断是否有反向代理头信息
if (forwardedIpsStr) {//如果有,则将头信息中第一个地址拿出,该地址就是真实的客户端IP;
var forwardedIps = forwardedIpsStr.split(',');
ipAddress = forwardedIps[0];
}
if (!ipAddress) {//如果没有直接获取IP;
ipAddress = req.connection.remoteAddress;
}
return ipAddress;
};
另外,我在网上看到别人写这个:
//代码,第一段判断是否有反向代理IP(头信息:x-forwarded-for),在判断connection的远程IP,以及后端的socket的IP。
function getClientIp(req) {
return req.headers['x-forwarded-for'] ||
req.connection.remoteAddress ||
req.socket.remoteAddress ||
req.connection.socket.remoteAddress;
};
2、nodejs中的动态页面指的是静态路径下的内容
在动态页面中引用静态导入路径下的内容(如图片、css文件)时,注意路径的写法:
例如:我引用了error.html中“public/images/”下的error.png图片,经过了几步:
项目结构图:
第一步:在app.js中:
app.use(express.static(path.join(__dirname, 'public')));//表示动态页面可引用public路径下的静态信息
第二步:error.html:
在style中,引用背景图片时,不能在路径前加“public/”,只能是:“images/error.png”,因为app.js中已经设置了动态页面,只能引用public下的静态内容,默认在public路径下,只需要从public的下级目录写入即可。
1 DOCTYPE html>
2
3
4
5
6 统一支付
7
8 .error-404{background-color:#EDEDF0;}
9 section{display: block;}
10 .clearfix{zoom:1;}
11 .module-error{margin-top:182px;}
12 .module-error .error-main{ margin: 0 auto;width: 420px;}
13 .module-error .label{float: left;width: 160px;height: 151px;background: url("images/error.png") 0 0 no-repeat;}//默认已经在public路径下,尽管改代码在IDE中报错(可以不用管)
14 .module-error .info{ margin-left: 182px;line-height: 1.8;}
15 .module-error .title{color: #666;font-size: 14px;}
16 .module-error .reason{margin: 8px 0 18px 0;color: #666;font-size: 12px;}
17
18
19
20
21
22
23
24
25
26 啊哦,你所访问的页面不存在了。
27
28 可能的原因:
29 1.在地址栏中输入了错误的地址。
30 2.你点击的某个链接已过期。
31
32
33 回到首页>
34 或10s后将自动跳转到首页
35
36
37
38
39
40
41
42 setTimeout("window.location.href='/'",10000);
43
44
45
46
错误.html 查看全部
nodejs抓取动态网页(nodejs获取客户端真实的IP地址是怎样的?获取)
1、nodejs获取客户端真实IP地址:
在一般管理网站中,Taste会需要记录一些用户的操作,并记住是哪个用户执行的操作。这时候就需要用户的ip地址,但是往往当这些应用部署在服务器上之后,会用到ngix等
代理,用户访问时,需要通过代理查看用户的真实IP地址。下面是nodejs获取客户端真实IP的代码:
//获取客户端真实ip;
function getClientIp(req) {
var ipAddress;
var forwardedIpsStr = req.headers['X-Forwarded-For'];//判断是否有反向代理头信息
if (forwardedIpsStr) {//如果有,则将头信息中第一个地址拿出,该地址就是真实的客户端IP;
var forwardedIps = forwardedIpsStr.split(',');
ipAddress = forwardedIps[0];
}
if (!ipAddress) {//如果没有直接获取IP;
ipAddress = req.connection.remoteAddress;
}
return ipAddress;
};
另外,我在网上看到别人写这个:
//代码,第一段判断是否有反向代理IP(头信息:x-forwarded-for),在判断connection的远程IP,以及后端的socket的IP。
function getClientIp(req) {
return req.headers['x-forwarded-for'] ||
req.connection.remoteAddress ||
req.socket.remoteAddress ||
req.connection.socket.remoteAddress;
};
2、nodejs中的动态页面指的是静态路径下的内容
在动态页面中引用静态导入路径下的内容(如图片、css文件)时,注意路径的写法:
例如:我引用了error.html中“public/images/”下的error.png图片,经过了几步:
项目结构图:
第一步:在app.js中:
app.use(express.static(path.join(__dirname, 'public')));//表示动态页面可引用public路径下的静态信息
第二步:error.html:
在style中,引用背景图片时,不能在路径前加“public/”,只能是:“images/error.png”,因为app.js中已经设置了动态页面,只能引用public下的静态内容,默认在public路径下,只需要从public的下级目录写入即可。
1 DOCTYPE html>
2
3
4
5
6 统一支付
7
8 .error-404{background-color:#EDEDF0;}
9 section{display: block;}
10 .clearfix{zoom:1;}
11 .module-error{margin-top:182px;}
12 .module-error .error-main{ margin: 0 auto;width: 420px;}
13 .module-error .label{float: left;width: 160px;height: 151px;background: url("images/error.png") 0 0 no-repeat;}//默认已经在public路径下,尽管改代码在IDE中报错(可以不用管)
14 .module-error .info{ margin-left: 182px;line-height: 1.8;}
15 .module-error .title{color: #666;font-size: 14px;}
16 .module-error .reason{margin: 8px 0 18px 0;color: #666;font-size: 12px;}
17
18
19
20
21
22
23
24
25
26 啊哦,你所访问的页面不存在了。
27
28 可能的原因:
29 1.在地址栏中输入了错误的地址。
30 2.你点击的某个链接已过期。
31
32
33 回到首页>
34 或10s后将自动跳转到首页
35
36
37
38
39
40
41
42 setTimeout("window.location.href='/'",10000);
43
44
45
46
错误.html
nodejs抓取动态网页(nodejs抓取动态网页地址的response中的requestheaders(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-19 17:05
nodejs抓取动态网页地址的response中的requestheaders。利用这个api把返回的请求headers里面的inputfieldurl和buttonurl参数里面的name和default参数拿出来,
随便一个抓包工具就可以了。postmessage我建议看看requestheadersloadedallrequests=allrequestsgivesthetargeturltotheresponse.formurlresponseheaders={"params":{"status":1,"return":"true"}}但这个地址看起来好像就是给定的get接口,这样就需要发送request给服务器。
发一个以前在我博客写的爬虫。首先这个二维码只是给你的geturl那里设置了参数,并不是说真的可以通过http实现1.给这个一个文件nh_topic.js发起请求,然后修改content-length为1接下来的问题就好办了,因为发送请求的时候nh_topic.js文件就已经解析了。比如post的时候就用get的请求,这样成功了之后,需要向服务器发送,“requestheaders..."if("requestheaders..."){request.post('...',"@.*")}login_action=parseurl(session.get(content-length))就这样。写的有点啰嗦,home页面不应该问出这种问题的。
postmessage不就是request.post('...','@.*') 查看全部
nodejs抓取动态网页(nodejs抓取动态网页地址的response中的requestheaders(图))
nodejs抓取动态网页地址的response中的requestheaders。利用这个api把返回的请求headers里面的inputfieldurl和buttonurl参数里面的name和default参数拿出来,
随便一个抓包工具就可以了。postmessage我建议看看requestheadersloadedallrequests=allrequestsgivesthetargeturltotheresponse.formurlresponseheaders={"params":{"status":1,"return":"true"}}但这个地址看起来好像就是给定的get接口,这样就需要发送request给服务器。
发一个以前在我博客写的爬虫。首先这个二维码只是给你的geturl那里设置了参数,并不是说真的可以通过http实现1.给这个一个文件nh_topic.js发起请求,然后修改content-length为1接下来的问题就好办了,因为发送请求的时候nh_topic.js文件就已经解析了。比如post的时候就用get的请求,这样成功了之后,需要向服务器发送,“requestheaders..."if("requestheaders..."){request.post('...',"@.*")}login_action=parseurl(session.get(content-length))就这样。写的有点啰嗦,home页面不应该问出这种问题的。
postmessage不就是request.post('...','@.*')
nodejs抓取动态网页( python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-18 14:16
python爬取js执行后输出的信息--python库)
python是如何爬取动态的网站
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站,请搜索来客之前的文章@。 com >或者继续浏览下面的相关文章,希望大家以后多多支持来客!
BY:爱喝马黛茶的安东尼
标签:python动态网站
相关链接 查看全部
nodejs抓取动态网页(
python爬取js执行后输出的信息--python库)
python是如何爬取动态的网站
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站,请搜索来客之前的文章@。 com >或者继续浏览下面的相关文章,希望大家以后多多支持来客!
BY:爱喝马黛茶的安东尼
标签:python动态网站
相关链接
nodejs抓取动态网页(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-14 23:11
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
test.js 文件,如下
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行Unit Test时,从网页抓取的三个百度连接会打印在控制台上,
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。
----------------------------------------------- -----------------------
张宇,我的美丽, 查看全部
nodejs抓取动态网页(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
你想要的任何信息基本上都存在于互联网上。问题是如何把它们组织成你需要的东西,比如抓取某个行业所有相关公司的名称网站、联系电话、Email等,然后保存在Excel中进行分析。网页信息抓取变得更加有用。
对于传统网页,网页服务器直接返回Html。这种类型的网页很容易捕获。不管用什么方法,只需要拿到html页面,然后做Dom分析即可。但对于需要 Javascript 生成的网页来说,就没有那么容易了。对于这个问题,张宇还没有找到很好的解决办法。有抓取javascript网页经验的朋友,欢迎指点。
所以今天我要讲的是从传统的html网页爬取信息。虽然我之前说过,没有技术难度,但是有没有比较简单的方法呢?用过jQuery等js框架的朋友可能会觉得javascript看起来像是抓取网页信息的天然助手,它为网页解析而生。当然,现在还有更多的应用,比如服务端的javascript应用,NodeJs。
如果能在我们的应用程序中使用jQuery来抓取网页,比如java程序,那绝对是一件令人兴奋的事情。确实有现成的方案,有Javascript引擎,有可以支持jQuery的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
test.js 文件,如下
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行Unit Test时,从网页抓取的三个百度连接会打印在控制台上,
0:
1:
2:
测试成功,证明在java程序中使用jQuery抓取网页是可行的。
----------------------------------------------- -----------------------
张宇,我的美丽,
nodejs抓取动态网页(动态js中的分页分页,怎么办?.pagesize)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-14 23:10
1、数据处理
首先在动态js中根据url参数获取数据库文档数,设置页面大小,获取当前页面的数据,然后传入文档数pagecount,页面大小pagesize,当前页面当前页面到页面。
2、处理分页效果
我使用 javascript 动态生成它。也可以利用ejs支持函数的特性封装成html分页。
首先添加分页ul,在页面需要显示的地方添加代码:
然后在脚本标签中插入分页代码:
<p> $(document).ready(function() {
if($("#pagination")){
var pagecount = ;
var pagesize = ;
var currentpage = ;
var counts,pagehtml="";
if(pagecount%pagesize==0){
counts = parseInt(pagecount/pagesize);
}else{
counts = parseInt(pagecount/pagesize)+1;
}
//只有一页内容
if(pagecountpagesize){
if(currentpage>1){
pagehtml+= '上一页';
}
for(var i=0;i=(currentpage-3) && i 查看全部
nodejs抓取动态网页(动态js中的分页分页,怎么办?.pagesize)
1、数据处理
首先在动态js中根据url参数获取数据库文档数,设置页面大小,获取当前页面的数据,然后传入文档数pagecount,页面大小pagesize,当前页面当前页面到页面。
2、处理分页效果
我使用 javascript 动态生成它。也可以利用ejs支持函数的特性封装成html分页。
首先添加分页ul,在页面需要显示的地方添加代码:
然后在脚本标签中插入分页代码:
<p> $(document).ready(function() {
if($("#pagination")){
var pagecount = ;
var pagesize = ;
var currentpage = ;
var counts,pagehtml="";
if(pagecount%pagesize==0){
counts = parseInt(pagecount/pagesize);
}else{
counts = parseInt(pagecount/pagesize)+1;
}
//只有一页内容
if(pagecountpagesize){
if(currentpage>1){
pagehtml+= '上一页';
}
for(var i=0;i=(currentpage-3) && i
nodejs抓取动态网页(如何抓取网页动态数据?-1.去用工具分析出来js最终生成的url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-14 23:07
如何抓取网页动态数据?-:1. 用工具分析js最终生成的url是什么,具体请求中发送的是什么数据。相关参考:【教程】教你如何使用工具(IE9的F12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不了解它背后的逻辑,请参考:【完成】关于...
如何抓取网页中的动态数据:首先要清楚我指的是什么动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即网页源文件不存在于页面加载中,是浏览器动态生成的。下面我们进入正题。抓取静态页面非常简单。通过Java获取html源代码,然后分析...
如何抓取网页中的动态数据-:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗的说,你的网站是由网页组成的,如果你只有一个域名和一个虚拟主机,不做任何网页,你的客户还是无法访问你的网站。网页是收录 HTML 标签的纯文本文件,可以存储在世界的某个角落,在某台计算机中,它是万维网中的一个“页面”,是一种超文本标记语言格式(应用标准通用标记语言,文件扩展名为 .html 或 .htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
如何抓取网页中js动态生成的数据-:String url = ""; try {WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10); //设置webClient的相关参数 webClient.getOptions().setJavaScriptEnabled(true); webClient.getOptions()....
如何抓取网页中的动态数据-:你想抓取别人网页上ajax动态加载的数据吗?1、找到它的ajax加载的URL地址2、使用PHP的file_get_contents($url)函数读取那个url地址。3、对抓取的内容进行分析或过滤。
java如何抓取网页代码中动态显示的数据-:1. 使用jsoup抓取页面生成后的静态信息。这很简单。知道jquery的选择器会在加载后为页面使用2.。Ajax 返回刷新后的页面。不可能。请对发送的请求中的xml或json数据一一分析,看看哪个爬虫在任何情况下都不适用!
如何自动获取网站的动态数据:写一个自动抓包,很简单。使用Jquery的ajax方法。
如何在静态html中获取动态数据-:使用ajax,也可以使用服务器脚本从数据库中获取数据,有交互
如何抓取或调用别人的动态数据网站?-:1.写个脚本采集其他人网站页面内容2.使用正则规则准确匹配你要什么 3. 自己显示匹配的数据 网站4. 在定时任务中设置这个脚本,每隔一段时间自动运行一次
如何抓取网站-上的实时数据:使用Python访问网页的方式主要有3种:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.urlopen(url) print res.read() 2. 加上数据到获取或发布数据={"na ...
相关内容:动态网页数据爬取、requests爬取动态网页数据、python爬取动态网页数据、python爬取动态加载网页、python爬取网页详细教程、python动态爬取数据、爬虫动态加载、scrapy动态网页爬取Fetch、python爬虫动态加载页面,scrapy动态页面抓取步骤,python抓取js动态网页,python抓取js加载的数据,如何获取网页动态信息,爬虫如何抓取网页数据, 查看全部
nodejs抓取动态网页(如何抓取网页动态数据?-1.去用工具分析出来js最终生成的url)
如何抓取网页动态数据?-:1. 用工具分析js最终生成的url是什么,具体请求中发送的是什么数据。相关参考:【教程】教你如何使用工具(IE9的F12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不了解它背后的逻辑,请参考:【完成】关于...
如何抓取网页中的动态数据:首先要清楚我指的是什么动态数据。术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即网页源文件不存在于页面加载中,是浏览器动态生成的。下面我们进入正题。抓取静态页面非常简单。通过Java获取html源代码,然后分析...
如何抓取网页中的动态数据-:网页是构成网站的基本元素,是承载各种网站应用的平台。通俗的说,你的网站是由网页组成的,如果你只有一个域名和一个虚拟主机,不做任何网页,你的客户还是无法访问你的网站。网页是收录 HTML 标签的纯文本文件,可以存储在世界的某个角落,在某台计算机中,它是万维网中的一个“页面”,是一种超文本标记语言格式(应用标准通用标记语言,文件扩展名为 .html 或 .htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
如何抓取网页中js动态生成的数据-:String url = ""; try {WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10); //设置webClient的相关参数 webClient.getOptions().setJavaScriptEnabled(true); webClient.getOptions()....
如何抓取网页中的动态数据-:你想抓取别人网页上ajax动态加载的数据吗?1、找到它的ajax加载的URL地址2、使用PHP的file_get_contents($url)函数读取那个url地址。3、对抓取的内容进行分析或过滤。
java如何抓取网页代码中动态显示的数据-:1. 使用jsoup抓取页面生成后的静态信息。这很简单。知道jquery的选择器会在加载后为页面使用2.。Ajax 返回刷新后的页面。不可能。请对发送的请求中的xml或json数据一一分析,看看哪个爬虫在任何情况下都不适用!
如何自动获取网站的动态数据:写一个自动抓包,很简单。使用Jquery的ajax方法。
如何在静态html中获取动态数据-:使用ajax,也可以使用服务器脚本从数据库中获取数据,有交互
如何抓取或调用别人的动态数据网站?-:1.写个脚本采集其他人网站页面内容2.使用正则规则准确匹配你要什么 3. 自己显示匹配的数据 网站4. 在定时任务中设置这个脚本,每隔一段时间自动运行一次
如何抓取网站-上的实时数据:使用Python访问网页的方式主要有3种:urllib、urllib2、httplib urllib比较简单,功能也比较弱。httplib简单强大,但是好像不支持session 1. 最简单的页面访问 res=urllib2.urlopen(url) print res.read() 2. 加上数据到获取或发布数据={"na ...
相关内容:动态网页数据爬取、requests爬取动态网页数据、python爬取动态网页数据、python爬取动态加载网页、python爬取网页详细教程、python动态爬取数据、爬虫动态加载、scrapy动态网页爬取Fetch、python爬虫动态加载页面,scrapy动态页面抓取步骤,python抓取js动态网页,python抓取js加载的数据,如何获取网页动态信息,爬虫如何抓取网页数据,
nodejs抓取动态网页(基于HistoryAPI的路径有哪些?-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-14 16:08
路径为“/users”时调用用户列表
否则会返回404页面
String.substring(arg1,arg2);
参数 1 为起始索引值,参数 2 位为结束索引值。它返回两个索引值之间的字符,包括第一个参数指向的字符,但不包括第二个参数指向的字符。
例子:
var string = "halleo ";
var str1 = string.substring(1);
操作结果:
当只有一个参数时,返回从当前参数(包括)的索引值所指向的字符到结尾的所有字符
var string = "halleo ";
var str1 = string.substring(4,-1);
console.log(str1);
操作结果:
当第二个参数为负数时(与值无关),返回从第一个参数(正数)指向的索引值开始的字符(不包括)。
var string = "halleo ";
var str1 = string.substring(-1,-6);
console.log(str1);
操作结果:
当两个结果都为负时,返回一个空字符串
var string = "halleo ";
var str1 = string.substring(0,10);
console.log(str1);
操作结果:
当end指向的索引值大于字符串的范围时,从起始索引值指向的字符到后面的所有字符返回
基于历史API
基于 Hisotry API 的路由更直观
HTML5 History API 通过监听 popstate 事件,可以直接更改 URL,无需刷新页面。
Popstate 事件:
当活动历史记录条目发生变化时,将触发该事件。popstate 事件的 state 属性收录历史条目的 state 对象的副本
调用 history.pushState() 或 history.replaceState() 不会触发 popstate 事件,只有用户点击浏览器的后退按钮或调用 history.back() 函数
区别:(转载)
假设服务器只有以下文件(script.js被index.html引用):
/-
|- index.html
|- 脚本.js
基于哈希的路径是:
#/foobar
基于History API的路径是:
直接访问时,两者的行为是一样的,都返回index.html文件。
从#/foobar or 跳转时,也是正常的,因为此时页面和脚本文件已经加载完毕,所以路由跳转是正常的。
直接访问#/foobar时,实际请求的是服务器,所以会先加载页面和脚本文件,然后脚本执行路由跳转,一切正常。
直接访问的时候,其实向服务器发起的请求也是,但是服务器只能匹配/而不能匹配/foobar,所以会出现404错误。
因此,如果使用基于History API的路由,则需要修改服务端,使得访问/foobar时可以返回index.html文件,这样浏览器加载页面和脚本时就可以进行路由跳转.
动态路由:
以上内容为静态内容,静态内容的路由是固定的。
动态内容不是。我们可以通过传递参数而不是单独设置静态路由来获取某个用户的信息。
例如:
表达
App.get('user/:id',(req,res,next) =>{
//...
});
烧瓶:
@app.route('/user/');
def get_user_info(user_id):
经过
/foobar 和 /foobar/ 类似,具体行为以服务端实习为准
在Express中,两者几乎相同,而在flask中,类似于lunix,末尾有斜线表示文件夹,no表示文件。
(转载示例)
Server.js 代码
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
route(pathname);
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
router.js 代码
function route(pathname) {
console.log("About to route a request for " + pathname);
}
exports.route = route;
index.js 代码
var server = require("./server");
var router = require("./router");
server.start(router.route);
在 router.js 中创建映射函数和关系
Node.js 创建服务器和 npm 基本操作
REPL 和回调函数
node.js 绑定事件
node.js-error事件,缓冲操作
node.js-buffer 操作
node.js-stream 操作
node.js-module系统及功能
node.js-路由 查看全部
nodejs抓取动态网页(基于HistoryAPI的路径有哪些?-苏州安嘉)
路径为“/users”时调用用户列表
否则会返回404页面
String.substring(arg1,arg2);
参数 1 为起始索引值,参数 2 位为结束索引值。它返回两个索引值之间的字符,包括第一个参数指向的字符,但不包括第二个参数指向的字符。
例子:
var string = "halleo ";
var str1 = string.substring(1);
操作结果:
当只有一个参数时,返回从当前参数(包括)的索引值所指向的字符到结尾的所有字符
var string = "halleo ";
var str1 = string.substring(4,-1);
console.log(str1);
操作结果:
当第二个参数为负数时(与值无关),返回从第一个参数(正数)指向的索引值开始的字符(不包括)。
var string = "halleo ";
var str1 = string.substring(-1,-6);
console.log(str1);
操作结果:
当两个结果都为负时,返回一个空字符串
var string = "halleo ";
var str1 = string.substring(0,10);
console.log(str1);
操作结果:
当end指向的索引值大于字符串的范围时,从起始索引值指向的字符到后面的所有字符返回
基于历史API
基于 Hisotry API 的路由更直观
HTML5 History API 通过监听 popstate 事件,可以直接更改 URL,无需刷新页面。
Popstate 事件:
当活动历史记录条目发生变化时,将触发该事件。popstate 事件的 state 属性收录历史条目的 state 对象的副本
调用 history.pushState() 或 history.replaceState() 不会触发 popstate 事件,只有用户点击浏览器的后退按钮或调用 history.back() 函数
区别:(转载)
假设服务器只有以下文件(script.js被index.html引用):
/-
|- index.html
|- 脚本.js
基于哈希的路径是:
#/foobar
基于History API的路径是:
直接访问时,两者的行为是一样的,都返回index.html文件。
从#/foobar or 跳转时,也是正常的,因为此时页面和脚本文件已经加载完毕,所以路由跳转是正常的。
直接访问#/foobar时,实际请求的是服务器,所以会先加载页面和脚本文件,然后脚本执行路由跳转,一切正常。
直接访问的时候,其实向服务器发起的请求也是,但是服务器只能匹配/而不能匹配/foobar,所以会出现404错误。
因此,如果使用基于History API的路由,则需要修改服务端,使得访问/foobar时可以返回index.html文件,这样浏览器加载页面和脚本时就可以进行路由跳转.
动态路由:
以上内容为静态内容,静态内容的路由是固定的。
动态内容不是。我们可以通过传递参数而不是单独设置静态路由来获取某个用户的信息。
例如:
表达
App.get('user/:id',(req,res,next) =>{
//...
});
烧瓶:
@app.route('/user/');
def get_user_info(user_id):
经过
/foobar 和 /foobar/ 类似,具体行为以服务端实习为准
在Express中,两者几乎相同,而在flask中,类似于lunix,末尾有斜线表示文件夹,no表示文件。
(转载示例)
Server.js 代码
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
route(pathname);
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
router.js 代码
function route(pathname) {
console.log("About to route a request for " + pathname);
}
exports.route = route;
index.js 代码
var server = require("./server");
var router = require("./router");
server.start(router.route);
在 router.js 中创建映射函数和关系
Node.js 创建服务器和 npm 基本操作
REPL 和回调函数
node.js 绑定事件
node.js-error事件,缓冲操作
node.js-buffer 操作
node.js-stream 操作
node.js-module系统及功能
node.js-路由
nodejs抓取动态网页(基于PhantomJS的PhantomJSAPI的核心浏览器的功能,使用webkit来编译)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-07 10:10
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,还提供CSS选择器、Web标准支持、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,让你可以对操作系统进行文件读写等。PhantomJS有广泛的用途,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
PhantomJS 官方地址:.
PhantomJS 安装:
1.到PhantomJS下载对应版本
2.设置环境变量PATH (sudo ln -s /Applications/phantomjs-2.1.1/bin/phantomjs /usr/local/bin/) windows通过自己的方法,2.1.1是你自己的版本
PhantomJS验证成功:在终端数据phantomjs
运行:phantomjs get_data.js
根据页面结构在page.evaluate中找到对应的数据并扔掉
//访问 phantomjs XXX.js 需要抓取的页面url
//创建一个webpage对象
var page = require('webpage').create();
//拿到页面url
var system = require('system');
//设置打开页面的大小 尽量大,有些图片都是懒加载
page.viewportSize = {
width: 2000,
height: 40000
};
//用phantomjs浏览器加载一个网页
page.open(system.args[1], function (status) {
// 输出状态
if (status !== 'success') {
console.log("加载失败")
//页面加载成功
} else {
//给一定的异步时间防止那些后加载的东西
setTimeout(function () {
//加载jquery
page.includeJs("https://cdn.bootcss.com/jquery ... ot%3B, function () {
//page.evaluate 方法内也可以执行页面js 在里面组装数据
var data = page.evaluate(function (s) {
var arr = [];
for (var i = 0; i < $(".J_MouserOnverReq").length; i++) {
var obj = {};
obj.href = $(".J_MouserOnverReq:eq(" + i + ")").find(".pic-link").attr("data-href");
obj.price = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".g_price").text());
obj.title = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".J_ClickStat").text());
obj.image = $(".J_MouserOnverReq:eq(" + i + ")").find(".J_ItemPic").attr("src");
arr.push(obj);
}
return arr;
});
console.log(JSON.stringify(data))
//把从页面拿到的数据传给自己的接口去处理数据
page.open('http://localhost:8080/data/data/sku_stock', 'POST', "data=" + data, function (status) {
console.log('去ares-chart处理数据了');
});
});
}, 5000);
}
});
-------------------------结束--------------------- ---------------- 查看全部
nodejs抓取动态网页(基于PhantomJS的PhantomJSAPI的核心浏览器的功能,使用webkit来编译)
PhantomJS 是一个基于 webkit 的 JavaScript API。它使用 QtWebKit 作为其核心浏览器功能,并使用 webkit 来编译、解释和执行 JavaScript 代码。你可以在基于 webkit 的浏览器中做的任何事情,它都能做到。它不仅是一个隐形浏览器,还提供CSS选择器、Web标准支持、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作,让你可以对操作系统进行文件读写等。PhantomJS有广泛的用途,如网络监控、网页截图、无浏览器的网页测试、页面访问自动化等。
PhantomJS 官方地址:.
PhantomJS 安装:
1.到PhantomJS下载对应版本
2.设置环境变量PATH (sudo ln -s /Applications/phantomjs-2.1.1/bin/phantomjs /usr/local/bin/) windows通过自己的方法,2.1.1是你自己的版本
PhantomJS验证成功:在终端数据phantomjs
运行:phantomjs get_data.js
根据页面结构在page.evaluate中找到对应的数据并扔掉
//访问 phantomjs XXX.js 需要抓取的页面url
//创建一个webpage对象
var page = require('webpage').create();
//拿到页面url
var system = require('system');
//设置打开页面的大小 尽量大,有些图片都是懒加载
page.viewportSize = {
width: 2000,
height: 40000
};
//用phantomjs浏览器加载一个网页
page.open(system.args[1], function (status) {
// 输出状态
if (status !== 'success') {
console.log("加载失败")
//页面加载成功
} else {
//给一定的异步时间防止那些后加载的东西
setTimeout(function () {
//加载jquery
page.includeJs("https://cdn.bootcss.com/jquery ... ot%3B, function () {
//page.evaluate 方法内也可以执行页面js 在里面组装数据
var data = page.evaluate(function (s) {
var arr = [];
for (var i = 0; i < $(".J_MouserOnverReq").length; i++) {
var obj = {};
obj.href = $(".J_MouserOnverReq:eq(" + i + ")").find(".pic-link").attr("data-href");
obj.price = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".g_price").text());
obj.title = $.trim($(".J_MouserOnverReq:eq(" + i + ")").find(".J_ClickStat").text());
obj.image = $(".J_MouserOnverReq:eq(" + i + ")").find(".J_ItemPic").attr("src");
arr.push(obj);
}
return arr;
});
console.log(JSON.stringify(data))
//把从页面拿到的数据传给自己的接口去处理数据
page.open('http://localhost:8080/data/data/sku_stock', 'POST', "data=" + data, function (status) {
console.log('去ares-chart处理数据了');
});
});
}, 5000);
}
});
-------------------------结束--------------------- ----------------
nodejs抓取动态网页(动态网页——服务器端编程(–Server-sideprogramming))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-07 00:01
动态网站-服务器端编程 [动态网站-服务器端编程] 本主题是一系列模块,用于演示如何创建动态网页;您可以传递自定义信息以响应 HTTP 请求网页。这些模块提供了服务器端编程的一般介绍以及有关如何使用 Django (Python) 和 Express (Node.js/JavaScript) 创建基本应用程序的具体介绍说明。
大多数主流网页使用一种服务器端技术来动态显示所需的不同数据。例如,想象一下有多少产品可以在亚马逊上购买以及在 Facebook 上有多少帖子?使用完全不同的静态页面来展示所有这些内容将是完全没有效率的,所以不是这些网站,而是展示静态模板[模板](带有HTML、CSS和构造),然后有动态更新数据在需要时显示在这些模板中,例如,当您想在亚马逊上浏览不同的产品时。
在现代 Web 开发世界中,强烈建议学习服务器端开发。
学习路径
开始服务器端编程通常比客户端编程更容易,因为动态页面往往执行非常相似的操作(从数据库中获取数据并将其显示在页面上,确认用户输入的数据并将其保存到数据库中,检查用户权限和登录用户等),它是用一个 web 框架构建的,使这些和其他常见的 web 服务器端操作更容易。
了解一些有关编程概念(或有关特定编程语言)的基本知识很有用,但不是必需的。同样,不要求精通客户端编程,但一些基本知识将帮助您与创建客户端的“前端”开发人员更和谐地工作。
您需要了解“网络是如何工作的”。我们建议您先阅读以下主题:
了解了这些基本知识后,您就可以完成本节中的模块了。 查看全部
nodejs抓取动态网页(动态网页——服务器端编程(–Server-sideprogramming))
动态网站-服务器端编程 [动态网站-服务器端编程] 本主题是一系列模块,用于演示如何创建动态网页;您可以传递自定义信息以响应 HTTP 请求网页。这些模块提供了服务器端编程的一般介绍以及有关如何使用 Django (Python) 和 Express (Node.js/JavaScript) 创建基本应用程序的具体介绍说明。
大多数主流网页使用一种服务器端技术来动态显示所需的不同数据。例如,想象一下有多少产品可以在亚马逊上购买以及在 Facebook 上有多少帖子?使用完全不同的静态页面来展示所有这些内容将是完全没有效率的,所以不是这些网站,而是展示静态模板[模板](带有HTML、CSS和构造),然后有动态更新数据在需要时显示在这些模板中,例如,当您想在亚马逊上浏览不同的产品时。
在现代 Web 开发世界中,强烈建议学习服务器端开发。
学习路径
开始服务器端编程通常比客户端编程更容易,因为动态页面往往执行非常相似的操作(从数据库中获取数据并将其显示在页面上,确认用户输入的数据并将其保存到数据库中,检查用户权限和登录用户等),它是用一个 web 框架构建的,使这些和其他常见的 web 服务器端操作更容易。
了解一些有关编程概念(或有关特定编程语言)的基本知识很有用,但不是必需的。同样,不要求精通客户端编程,但一些基本知识将帮助您与创建客户端的“前端”开发人员更和谐地工作。
您需要了解“网络是如何工作的”。我们建议您先阅读以下主题:
了解了这些基本知识后,您就可以完成本节中的模块了。
nodejs抓取动态网页(【金融课堂】网络爬虫(webcrawler)、深层网络机器人 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-04 04:19
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 foaf 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
我们可以使用网络爬虫来自动采集数据信息,比如在搜索引擎中抓取网站收录,数据分析挖掘采集,应用采集对金融数据进行应用采集财务分析。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(deep web crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为可扩展的网络爬虫,爬取对象从一些种子网址扩展到整个网络,主要是门户搜索引擎和大型网络服务提供商采集数据。
1.2、关注网络爬虫
也称为主题爬虫,是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新生成或更改的网页的爬虫。它可以在一定程度上保证被爬取的页面尽可能的新。.
1.4、深网爬虫
网页按存在方式可分为表面网页(surface web)和深层网页(也称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎收录的网页,是以超链接可以到达的静态网页为主的网页。深网是那些大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些 关键词 才能获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,然后会想到python。百度如下,python做爬虫。由于本人主要做前端开发,所以相对来说javascript更熟练,也更简单。实现一个小目标,使用nodejs爬取首页文章列表(你经常使用的一个开发者网站),然后写入本地json文件。
2.2、环境建设
nodejs安装完成后,打开命令行,可以使用node -v查看nodejs是否安装成功,npm -v查看nodejs是否安装成功,如果安装成功会打印如下信息(视情况而定)在版本上):
2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据自己想要的数据解析返回的dom,最后将处理后的结果json翻译成字符串保存到本地。
//爬取页面地址
const pageurl="https://www.cnblogs.com/";
// 解码字符串
function unescapestring(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchdata(){
console.log('爬取数据时间节点:',new date());
superagent.get(pageurl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postlist=$("#main #post_list .post_item");
postlist.each((index,value)=>{
let titlelnk=$(value).find('a.titlelnk');
let itemfoot=$(value).find('.post_item_foot');
let title=titlelnk.html(); //标题
let href=titlelnk.attr('href'); //链接
let author=itemfoot.find('a.lightblue').html(); //作者
let headlogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedtime=itemfoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readnum=itemfoot.text().split('阅读')[1]; //阅读量
readnum=readnum.substr(1,readnum.length-1);
title=unescapestring(title);
href=unescapestring(href);
author=unescapestring(author);
headlogo=unescapestring(headlogo);
summary=unescapestring(summary);
postedtime=unescapestring(postedtime);
readnum=unescapestring(readnum);
result.push({
index,
title,
href,
author,
headlogo,
summary,
postedtime,
readnum
});
});
// 数组转换为字符串
result=json.stringify(result);
// 写入本地cnblogs.json文件中
fs.writefile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchdata();
3、进行优化
3.1、 生成结果
在项目目录中打开命令行,输入node crawler.js,
你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:
查看全部
nodejs抓取动态网页(【金融课堂】网络爬虫(webcrawler)、深层网络机器人
)
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 foaf 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
我们可以使用网络爬虫来自动采集数据信息,比如在搜索引擎中抓取网站收录,数据分析挖掘采集,应用采集对金融数据进行应用采集财务分析。此外,网络爬虫还可以应用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(deep web crawler)。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为可扩展的网络爬虫,爬取对象从一些种子网址扩展到整个网络,主要是门户搜索引擎和大型网络服务提供商采集数据。
1.2、关注网络爬虫
也称为主题爬虫,是指一种网络爬虫,它有选择地抓取与预定义主题相关的页面。与一般的网络爬虫相比,聚焦爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源。保存的页面也因为数量少更新快,也可以满足特定区域的特定人群。信息需求。
1.3、增量网络爬虫
它是指对下载的网页进行增量更新并且只抓取新生成或更改的网页的爬虫。它可以在一定程度上保证被爬取的页面尽可能的新。.
1.4、深网爬虫
网页按存在方式可分为表面网页(surface web)和深层网页(也称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎收录的网页,是以超链接可以到达的静态网页为主的网页。深网是那些大部分内容无法通过静态链接获取而隐藏在搜索表单后面的网页。只有用户提交一些 关键词 才能获取网页。
2、创建一个简单的爬虫应用
简单了解了上面的爬虫之后,我们来实现一个简单的爬虫应用。
2.1、 达成目标
说到爬虫,大概率会想到大数据,然后会想到python。百度如下,python做爬虫。由于本人主要做前端开发,所以相对来说javascript更熟练,也更简单。实现一个小目标,使用nodejs爬取首页文章列表(你经常使用的一个开发者网站),然后写入本地json文件。
2.2、环境建设
nodejs安装完成后,打开命令行,可以使用node -v查看nodejs是否安装成功,npm -v查看nodejs是否安装成功,如果安装成功会打印如下信息(视情况而定)在版本上):
2.3、 具体实现
2.3.1、安装依赖包
在目录下执行 npm install superagentcheerio --save-dev 安装superagent和cheerio依赖。创建一个 crawler.js 文件。
// 导入依赖包
const http = require("http");
const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
2.3.2、 爬取数据
然后获取请求页面。获取页面内容后,根据自己想要的数据解析返回的dom,最后将处理后的结果json翻译成字符串保存到本地。
//爬取页面地址
const pageurl="https://www.cnblogs.com/";
// 解码字符串
function unescapestring(str){
if(!str){
return ''
}else{
return unescape(str.replace(/&#x/g,'%u').replace(/;/g,''));
}
}
// 抓取数据
function fetchdata(){
console.log('爬取数据时间节点:',new date());
superagent.get(pageurl).end((error,response)=>{
// 页面文档数据
let content=response.text;
if(content){
console.log('获取数据成功');
}
// 定义一个空数组来接收数据
let result=[];
let $=cheerio.load(content);
let postlist=$("#main #post_list .post_item");
postlist.each((index,value)=>{
let titlelnk=$(value).find('a.titlelnk');
let itemfoot=$(value).find('.post_item_foot');
let title=titlelnk.html(); //标题
let href=titlelnk.attr('href'); //链接
let author=itemfoot.find('a.lightblue').html(); //作者
let headlogo=$(value).find('.post_item_summary a img').attr('src'); //头像
let summary=$(value).find('.post_item_summary').text(); //简介
let postedtime=itemfoot.text().split('发布于 ')[1].substr(0,16); //发布时间
let readnum=itemfoot.text().split('阅读')[1]; //阅读量
readnum=readnum.substr(1,readnum.length-1);
title=unescapestring(title);
href=unescapestring(href);
author=unescapestring(author);
headlogo=unescapestring(headlogo);
summary=unescapestring(summary);
postedtime=unescapestring(postedtime);
readnum=unescapestring(readnum);
result.push({
index,
title,
href,
author,
headlogo,
summary,
postedtime,
readnum
});
});
// 数组转换为字符串
result=json.stringify(result);
// 写入本地cnblogs.json文件中
fs.writefile("cnblogs.json",result,"utf-8",(err)=>{
// 监听错误,如正常输出,则打印null
if(!err){
console.log('写入数据成功');
}
});
});
}
fetchdata();
3、进行优化
3.1、 生成结果
在项目目录中打开命令行,输入node crawler.js,
你会发现目录下会创建一个 cnblogs.json 文件。打开文件如下:
nodejs抓取动态网页(学会从网页源代码中提取数据这种最基本的爬虫使用json文件保存的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-04 03:18
其实爬虫是一项对计算机综合能力要求比较高的技术活动。
首先是对网络协议,尤其是http协议有基本的了解,能够分析网站的数据请求响应。学会使用一些工具,简单的使用chrome devtools的网络面板。我通常和邮递员或查尔斯合作分析。对于更复杂的情况,您可能需要使用专业的数据包捕获工具,例如wireshark。您对 网站 了解得越深,就越容易想出简单的方法来抓取您想要的信息。
除了了解一些计算机网络知识外,还需要具备一定的字符串处理能力,特别是正则表达式。其实正则表达式在一般的使用场景中不需要很多进阶知识,比较常用。稍微复杂一点的是分组、非贪婪匹配等。俗话说,如果你学好正则表达式,你就不怕处理字符串。
还有一点就是要掌握一些反爬虫的技巧。你在写爬虫的时候可能会遇到各种各样的问题,但是别怕,12306再复杂,也有人能爬,还有什么难我们。常见的爬虫会遇到服务器检查cookies、检查host和referer header、表单隐藏字段、验证码、访问频率限制、代理要求、spa网站等问题。其实爬虫遇到的大部分问题,最终都可以通过操纵浏览器来爬取。
本文使用nodejs编写爬虫系列的第二部分。对抗一个小爬虫,抓取流行的 github 项目。想要达到的目标:
学习从网页的源代码中提取数据。这个基本的爬虫使用一个 json 文件来保存捕获的数据。熟悉我在上一篇文章中介绍的一些模块。学习如何在node中处理用户输入分析需求
我们的需求是从github上抓取热门的项目数据,即star数最高的项目。但是github上好像没有任何页面可以看到排名靠前的项目。往往网站提供的搜索功能是我们爬虫作者分析的重点。
之前在灌v2ex的时候,看到一篇讨论996的帖子,刚教了一种用github star查看顶级仓库的方法。其实很简单,只需要在github搜索中加上star数的过滤条件,例如:stars:>60000,就可以搜索到github上所有star数大于60000的仓库。分析下面的截图,注意图片中的评论:
分析可以得到以下信息:
这个搜索结果页面通过get请求返回html文档,因为我的网络选择了Doc过滤url中的请求参数。有3个参数,p(page)表示页数,q(query)表示搜索内容,type表示搜索内容类型
然后我想知道github会不会检查cookies和其他请求头如referer、host等,根据是否有这些请求头来决定是否返回页面。
一个比较简单的测试方法是直接使用命令行工具curl进行测试,在gitbash中输入如下命令,即curl“请求的url”
curl "https://github.com/search%3Fp% ... ot%3B
不出所料,页面的源代码正常返回,这样我们的爬虫脚本就不需要添加请求头和cookie了。
通过chrome的搜索功能,可以看到网页源代码中有我们需要的项目信息
分析到此结束。这其实是一个很简单的小爬虫。我们只需要配置查询参数,通过http请求获取网页的源码,然后使用解析库进行解析,就可以在源码中得到我们需要的项目相关信息。,然后将数据处理成数组,最后序列化成json字符串存入json文件中。
动手实现这个小爬虫获取源代码
通过node获取源码,需要先配置url参数,然后通过发送http请求的模块superagent访问配置的url。
'use strict';
const requests = require('superagent');
const cheerio = require('cheerio');
const constants = require('../config/constants');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const requestUtil = require('./utils/request');
const models = require('./models');
/**
* 获取 star 数不低于 starCount k 的项目第 page 页的源代码
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlSourceCode = async (starCount, page = 1) => {
// 下限为 starCount k star 数
starCount = starCount * 1024;
// 替换 url 中的参数
const url = constants.searchUrl.replace('${starCount}', starCount).replace('${page}', page);
// response.text 即为返回的源代码
const { text: sourceCode } = await requestUtil.logRequest(requests.get(encodeURI(url)));
return sourceCode;
}
上面代码中的constants模块用于保存工程中的一些常量配置。到时候需要改常量,直接改这个配置文件,配置信息比较集中,方便查看。
module.exports = {
searchUrl: 'https://github.com/search?q=stars:>${starCount}&p=${page}&type=Repositories',
};
解析源码获取项目信息
这里我把项目信息抽象成一个Repository类。在项目models目录下的Repository.js中。
const fs = require('fs-extra');
const path = require('path');
module.exports = class Repository {
static async saveToLocal(repositories, indent = 2) {
await fs.writeJSON(path.resolve(__dirname, '../../out/repositories.json'), repositories, { spaces: indent})
}
constructor({
name,
author,
language,
digest,
starCount,
lastUpdate,
} = {}) {
this.name = name;
this.author = author;
this.language = language;
this.digest = digest;
this.starCount = starCount;
this.lastUpdate = lastUpdate;
}
display() {
console.log(` 项目: ${this.name} 作者: ${this.author} 语言: ${this.language} star: ${this.starCount}
摘要: ${this.digest}
最后更新: ${this.lastUpdate}
`);
}
}
解析得到的源码,需要用到cheerio这个解析库,和jquery很像。
/**
* 获取 star 数不低于 starCount k 的项目页表
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlProjectsByPage = async (starCount, page = 1) => {
const sourceCode = await crawlSourceCode(starCount, page);
const $ = cheerio.load(sourceCode);
// 下面 cheerio 如果 jquery 比较熟应该没有障碍, 不熟的话 github 官方仓库可以查看 api, api 并不是很多
// 查看 elements 面板, 发现每个仓库的信息在一个 li 标签内, 下面的代码时建议打开开发者工具的 elements 面板, 参照着阅读
const repositoryLiSelector = '.repo-list-item';
const repositoryLis = $(repositoryLiSelector);
const repositories = [];
repositoryLis.each((index, li) => {
const $li = $(li);
// 获取带有仓库作者和仓库名的 a 链接
const nameLink = $li.find('h3 a');
// 提取出仓库名和作者名
const [author, name] = nameLink.text().split('/');
// 获取项目摘要
const digestP = $($li.find('p')[0]);
const digest = digestP.text().trim();
// 获取语言
// 先获取类名为 .repo-language-color 的那个 span, 在获取包含语言文字的父 div
// 这里要注意有些仓库是没有语言的, 是获取不到那个 span 的, language 为空字符串
const languageDiv = $li.find('.repo-language-color').parent();
// 这里注意使用 String.trim() 去除两侧的空白符
const language = languageDiv.text().trim();
// 获取 star 数量
const starCountLinkSelector = '.muted-link';
const links = $li.find(starCountLinkSelector);
// 选择器为 .muted-link 还有可能是那个 issues 链接
const starCountLink = $(links.length === 2 ? links[1] : links[0]);
const starCount = starCountLink.text().trim();
// 获取最后更新时间
const lastUpdateElementSelector = 'relative-time';
const lastUpdate = $li.find(lastUpdateElementSelector).text().trim();
const repository = new models.Repository({
name,
author,
language,
digest,
starCount,
lastUpdate,
});
repositories.push(repository);
});
return repositories;
}
有时搜索结果有很多页,所以我在这里写了一个新函数来获取指定页数的仓库。
const crawlProjectsByPagesCount = async (starCount, pagesCount) => {
if (pagesCount === undefined) {
pagesCount = await getPagesCount(starCount);
logger.warn(`未指定抓取的页面数量, 将抓取所有仓库, 总共${pagesCount}页`);
}
const allRepositories = [];
const tasks = Array.from({ length: pagesCount }, (ele, index) => {
// 因为页数是从 1 开始的, 所以这里要 i + 1
return crawlProjectsByPage(starCount, index + 1);
});
// 使用 Promise.all 来并发操作
const resultRepositoriesArray = await Promise.all(tasks);
resultRepositoriesArray.forEach(repositories => allRepositories.push(...repositories));
return allRepositories;
}
让爬虫项目更人性化
随便写个脚本,在代码中配置好参数,然后爬取,有点太粗暴了。这里我使用了readline-sync,一个可以同步获取用户输入的库,并添加了一点用户交互。在后续的爬虫教程中,我可能会考虑使用electron来做一个简单的界面。下面是程序的启动代码。
const readlineSync = require('readline-sync');
const { crawlProjectsByPage, crawlProjectsByPagesCount } = require('./crawlHotProjects');
const models = require('./models');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const main = async () => {
let isContinue = true;
do {
const starCount = readlineSync.questionInt(`输入你想要抓取的 github 上项目的 star 数量下限, 单位(k): `, { encoding: 'utf-8'});
const crawlModes = [
'抓取某一页',
'抓取一定数量页数',
'抓取所有页'
];
const index = readlineSync.keyInSelect(crawlModes, '请选择一种抓取模式');
let repositories = [];
switch (index) {
case 0: {
const page = readlineSync.questionInt('请输入你要抓取的具体页数: ');
repositories = await crawlProjectsByPage(starCount, page);
break;
}
case 1: {
const pagesCount = readlineSync.questionInt('请输入你要抓取的页面数量: ');
repositories = await crawlProjectsByPagesCount(starCount, pagesCount);
break;
}
case 3: {
repositories = await crawlProjectsByPagesCount(starCount);
break;
}
}
repositories.forEach(repository => repository.display());
const isSave = readlineSync.keyInYN('请问是否要保存到本地(json 格式) ?');
isSave && models.Repository.saveToLocal(repositories);
isContinue = readlineSync.keyInYN('继续还是退出 ?');
} while (isContinue);
logger.info('程序正常退出...')
}
main();
来看看最后的效果
这里我想提一个readline-sync的bug。在windows的vscode中使用git bash时,不管你的文件格式是不是utf-8,都会出现中文乱码。搜索了一些问题,在powershell中把编码改成utf-8就可以正常显示了,也就是把页码剪成65001。
项目完整源码和后续教程源码将存放在我的github仓库:Spiders。如果我的教程对你有帮助,希望你不要吝啬你的星星。后续教程可能是更复杂的案例,通过分析ajax请求直接访问界面。 查看全部
nodejs抓取动态网页(学会从网页源代码中提取数据这种最基本的爬虫使用json文件保存的数据)
其实爬虫是一项对计算机综合能力要求比较高的技术活动。
首先是对网络协议,尤其是http协议有基本的了解,能够分析网站的数据请求响应。学会使用一些工具,简单的使用chrome devtools的网络面板。我通常和邮递员或查尔斯合作分析。对于更复杂的情况,您可能需要使用专业的数据包捕获工具,例如wireshark。您对 网站 了解得越深,就越容易想出简单的方法来抓取您想要的信息。
除了了解一些计算机网络知识外,还需要具备一定的字符串处理能力,特别是正则表达式。其实正则表达式在一般的使用场景中不需要很多进阶知识,比较常用。稍微复杂一点的是分组、非贪婪匹配等。俗话说,如果你学好正则表达式,你就不怕处理字符串。
还有一点就是要掌握一些反爬虫的技巧。你在写爬虫的时候可能会遇到各种各样的问题,但是别怕,12306再复杂,也有人能爬,还有什么难我们。常见的爬虫会遇到服务器检查cookies、检查host和referer header、表单隐藏字段、验证码、访问频率限制、代理要求、spa网站等问题。其实爬虫遇到的大部分问题,最终都可以通过操纵浏览器来爬取。
本文使用nodejs编写爬虫系列的第二部分。对抗一个小爬虫,抓取流行的 github 项目。想要达到的目标:
学习从网页的源代码中提取数据。这个基本的爬虫使用一个 json 文件来保存捕获的数据。熟悉我在上一篇文章中介绍的一些模块。学习如何在node中处理用户输入分析需求
我们的需求是从github上抓取热门的项目数据,即star数最高的项目。但是github上好像没有任何页面可以看到排名靠前的项目。往往网站提供的搜索功能是我们爬虫作者分析的重点。
之前在灌v2ex的时候,看到一篇讨论996的帖子,刚教了一种用github star查看顶级仓库的方法。其实很简单,只需要在github搜索中加上star数的过滤条件,例如:stars:>60000,就可以搜索到github上所有star数大于60000的仓库。分析下面的截图,注意图片中的评论:
分析可以得到以下信息:
这个搜索结果页面通过get请求返回html文档,因为我的网络选择了Doc过滤url中的请求参数。有3个参数,p(page)表示页数,q(query)表示搜索内容,type表示搜索内容类型
然后我想知道github会不会检查cookies和其他请求头如referer、host等,根据是否有这些请求头来决定是否返回页面。
一个比较简单的测试方法是直接使用命令行工具curl进行测试,在gitbash中输入如下命令,即curl“请求的url”
curl "https://github.com/search%3Fp% ... ot%3B
不出所料,页面的源代码正常返回,这样我们的爬虫脚本就不需要添加请求头和cookie了。
通过chrome的搜索功能,可以看到网页源代码中有我们需要的项目信息
分析到此结束。这其实是一个很简单的小爬虫。我们只需要配置查询参数,通过http请求获取网页的源码,然后使用解析库进行解析,就可以在源码中得到我们需要的项目相关信息。,然后将数据处理成数组,最后序列化成json字符串存入json文件中。
动手实现这个小爬虫获取源代码
通过node获取源码,需要先配置url参数,然后通过发送http请求的模块superagent访问配置的url。
'use strict';
const requests = require('superagent');
const cheerio = require('cheerio');
const constants = require('../config/constants');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const requestUtil = require('./utils/request');
const models = require('./models');
/**
* 获取 star 数不低于 starCount k 的项目第 page 页的源代码
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlSourceCode = async (starCount, page = 1) => {
// 下限为 starCount k star 数
starCount = starCount * 1024;
// 替换 url 中的参数
const url = constants.searchUrl.replace('${starCount}', starCount).replace('${page}', page);
// response.text 即为返回的源代码
const { text: sourceCode } = await requestUtil.logRequest(requests.get(encodeURI(url)));
return sourceCode;
}
上面代码中的constants模块用于保存工程中的一些常量配置。到时候需要改常量,直接改这个配置文件,配置信息比较集中,方便查看。
module.exports = {
searchUrl: 'https://github.com/search?q=stars:>${starCount}&p=${page}&type=Repositories',
};
解析源码获取项目信息
这里我把项目信息抽象成一个Repository类。在项目models目录下的Repository.js中。
const fs = require('fs-extra');
const path = require('path');
module.exports = class Repository {
static async saveToLocal(repositories, indent = 2) {
await fs.writeJSON(path.resolve(__dirname, '../../out/repositories.json'), repositories, { spaces: indent})
}
constructor({
name,
author,
language,
digest,
starCount,
lastUpdate,
} = {}) {
this.name = name;
this.author = author;
this.language = language;
this.digest = digest;
this.starCount = starCount;
this.lastUpdate = lastUpdate;
}
display() {
console.log(` 项目: ${this.name} 作者: ${this.author} 语言: ${this.language} star: ${this.starCount}
摘要: ${this.digest}
最后更新: ${this.lastUpdate}
`);
}
}
解析得到的源码,需要用到cheerio这个解析库,和jquery很像。
/**
* 获取 star 数不低于 starCount k 的项目页表
* @param {number} starCount star 数量下限
* @param {number} page 页数
*/
const crawlProjectsByPage = async (starCount, page = 1) => {
const sourceCode = await crawlSourceCode(starCount, page);
const $ = cheerio.load(sourceCode);
// 下面 cheerio 如果 jquery 比较熟应该没有障碍, 不熟的话 github 官方仓库可以查看 api, api 并不是很多
// 查看 elements 面板, 发现每个仓库的信息在一个 li 标签内, 下面的代码时建议打开开发者工具的 elements 面板, 参照着阅读
const repositoryLiSelector = '.repo-list-item';
const repositoryLis = $(repositoryLiSelector);
const repositories = [];
repositoryLis.each((index, li) => {
const $li = $(li);
// 获取带有仓库作者和仓库名的 a 链接
const nameLink = $li.find('h3 a');
// 提取出仓库名和作者名
const [author, name] = nameLink.text().split('/');
// 获取项目摘要
const digestP = $($li.find('p')[0]);
const digest = digestP.text().trim();
// 获取语言
// 先获取类名为 .repo-language-color 的那个 span, 在获取包含语言文字的父 div
// 这里要注意有些仓库是没有语言的, 是获取不到那个 span 的, language 为空字符串
const languageDiv = $li.find('.repo-language-color').parent();
// 这里注意使用 String.trim() 去除两侧的空白符
const language = languageDiv.text().trim();
// 获取 star 数量
const starCountLinkSelector = '.muted-link';
const links = $li.find(starCountLinkSelector);
// 选择器为 .muted-link 还有可能是那个 issues 链接
const starCountLink = $(links.length === 2 ? links[1] : links[0]);
const starCount = starCountLink.text().trim();
// 获取最后更新时间
const lastUpdateElementSelector = 'relative-time';
const lastUpdate = $li.find(lastUpdateElementSelector).text().trim();
const repository = new models.Repository({
name,
author,
language,
digest,
starCount,
lastUpdate,
});
repositories.push(repository);
});
return repositories;
}
有时搜索结果有很多页,所以我在这里写了一个新函数来获取指定页数的仓库。
const crawlProjectsByPagesCount = async (starCount, pagesCount) => {
if (pagesCount === undefined) {
pagesCount = await getPagesCount(starCount);
logger.warn(`未指定抓取的页面数量, 将抓取所有仓库, 总共${pagesCount}页`);
}
const allRepositories = [];
const tasks = Array.from({ length: pagesCount }, (ele, index) => {
// 因为页数是从 1 开始的, 所以这里要 i + 1
return crawlProjectsByPage(starCount, index + 1);
});
// 使用 Promise.all 来并发操作
const resultRepositoriesArray = await Promise.all(tasks);
resultRepositoriesArray.forEach(repositories => allRepositories.push(...repositories));
return allRepositories;
}
让爬虫项目更人性化
随便写个脚本,在代码中配置好参数,然后爬取,有点太粗暴了。这里我使用了readline-sync,一个可以同步获取用户输入的库,并添加了一点用户交互。在后续的爬虫教程中,我可能会考虑使用electron来做一个简单的界面。下面是程序的启动代码。
const readlineSync = require('readline-sync');
const { crawlProjectsByPage, crawlProjectsByPagesCount } = require('./crawlHotProjects');
const models = require('./models');
const logger = require('../config/log4jsConfig').log4js.getLogger('githubHotProjects');
const main = async () => {
let isContinue = true;
do {
const starCount = readlineSync.questionInt(`输入你想要抓取的 github 上项目的 star 数量下限, 单位(k): `, { encoding: 'utf-8'});
const crawlModes = [
'抓取某一页',
'抓取一定数量页数',
'抓取所有页'
];
const index = readlineSync.keyInSelect(crawlModes, '请选择一种抓取模式');
let repositories = [];
switch (index) {
case 0: {
const page = readlineSync.questionInt('请输入你要抓取的具体页数: ');
repositories = await crawlProjectsByPage(starCount, page);
break;
}
case 1: {
const pagesCount = readlineSync.questionInt('请输入你要抓取的页面数量: ');
repositories = await crawlProjectsByPagesCount(starCount, pagesCount);
break;
}
case 3: {
repositories = await crawlProjectsByPagesCount(starCount);
break;
}
}
repositories.forEach(repository => repository.display());
const isSave = readlineSync.keyInYN('请问是否要保存到本地(json 格式) ?');
isSave && models.Repository.saveToLocal(repositories);
isContinue = readlineSync.keyInYN('继续还是退出 ?');
} while (isContinue);
logger.info('程序正常退出...')
}
main();
来看看最后的效果
这里我想提一个readline-sync的bug。在windows的vscode中使用git bash时,不管你的文件格式是不是utf-8,都会出现中文乱码。搜索了一些问题,在powershell中把编码改成utf-8就可以正常显示了,也就是把页码剪成65001。
项目完整源码和后续教程源码将存放在我的github仓库:Spiders。如果我的教程对你有帮助,希望你不要吝啬你的星星。后续教程可能是更复杂的案例,通过分析ajax请求直接访问界面。
nodejs抓取动态网页(从信息抓取和提取,静态页面分析和互动这三个方面再讨论一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-02 05:15
爬虫是一个非常复杂的系统,可以从许多不同的角度进行分类。之前的一些答案已经涵盖了很多。我想从信息捕获和提取、手动编码和可视化、静态页面分析和交互开始。再讨论。
1. 信息捕获和提取
信息抓取是指如何获取网站上的信息的过程,信息抽取是指如何从获取到的页面中识别出自己需要的信息的过程。当使用爬虫爬取单个或少量网站时,那么主要问题是解决爬取问题,而当目标数网站较大时,信息抽取成为主要矛盾.
比如Scrapy就是一个解决信息爬取问题的软件平台。使用Xpath或者CSS Selector可以从少量的站点中提取信息,但是面对大规模的信息提取,Xpath是无能为力的。在这种情况下,一些机器学习算法,比如IBL(Instance based Learning),可以根据一定的网站一页或少量的页面进行学习,然后快速生成网站识别模型,scrapely 就是这样一个软件模块。
2. 手动编码和可视化
我们在网上看到的大部分教程都是基于某种编程语言(如Python)和软件库(如Scrapy)手工编写的。这种方法的优点是非常灵活、可扩展,并且可以针对特定站点给出有效的实现。但它的缺点也很明显,就是爬虫开发者需要懂编程语言,门槛比较高。
为了解决这个问题,人们提出了视觉爬虫。定义可视化爬虫时,会直观地显示远程网站页面,然后人们可以点击鼠标定义爬取逻辑(包括爬取Fetching目标、爬取顺序、爬取深度等)和爬取逻辑(页面的哪一部分应该被识别为属性)。与手工编码的爬虫相比,视觉爬虫大大降低了爬虫定义的门槛,但爬虫的效率不如手工编程。另外,由于可视化爬虫对爬取逻辑进行了抽象,可能无法支持一些特殊的网站。
Portia 是典型的视觉爬虫。人们常常认为pyspider也是一个视觉爬虫,其实不然。Pyspider 只是一个带有 GUI 的手工编码爬虫。
3.被动爬虫和交互式爬虫
大多数爬虫都是基于对页面的分析。如有必要,浏览器引擎会执行页面中的Javascript代码,然后获取渲染的页面,然后从中提取自己需要的信息。
但是在某些情况下,我们也需要能够和这些页面进行交互,比如输入用户名和密码登录系统然后爬取,或者我们需要输入关键字然后才爬取搜索结果。在这些情况下,我们需要能够在定义爬虫时保存这些用户输入,然后在爬虫执行期间重放交互信息,就像一个人在做这些动作一样。
Selenium 就是这种爬虫的一个例子。用户使用 Selenium IDE 记录用户操作,将它们保存为 Selenese 命令序列,然后使用 Web 驱动程序模拟浏览器重放这些命令。交互式爬虫的优点是可以像人一样做出各种动作,但缺点是需要搭建一个完整的浏览器引擎,系统开销很大,爬虫效率很低。
最后,为了做个广告,我最近开源了一个爬虫portia-dashboard。按照之前的分类方法,这款爬虫是“面向多站点”、“主要支持信息爬取”、“同时支持被动爬取”和“交互爬取”“可视化”爬虫,并提供了一个仪表盘功能。 Portia.dashboard可以用来部署爬虫、启动爬虫、监控爬虫状态、浏览提取的信息等等。
使用代码安装可能有点复杂,最简单的方法是使用docker,欢迎大家使用,并提供宝贵意见。 查看全部
nodejs抓取动态网页(从信息抓取和提取,静态页面分析和互动这三个方面再讨论一下)
爬虫是一个非常复杂的系统,可以从许多不同的角度进行分类。之前的一些答案已经涵盖了很多。我想从信息捕获和提取、手动编码和可视化、静态页面分析和交互开始。再讨论。
1. 信息捕获和提取
信息抓取是指如何获取网站上的信息的过程,信息抽取是指如何从获取到的页面中识别出自己需要的信息的过程。当使用爬虫爬取单个或少量网站时,那么主要问题是解决爬取问题,而当目标数网站较大时,信息抽取成为主要矛盾.
比如Scrapy就是一个解决信息爬取问题的软件平台。使用Xpath或者CSS Selector可以从少量的站点中提取信息,但是面对大规模的信息提取,Xpath是无能为力的。在这种情况下,一些机器学习算法,比如IBL(Instance based Learning),可以根据一定的网站一页或少量的页面进行学习,然后快速生成网站识别模型,scrapely 就是这样一个软件模块。
2. 手动编码和可视化
我们在网上看到的大部分教程都是基于某种编程语言(如Python)和软件库(如Scrapy)手工编写的。这种方法的优点是非常灵活、可扩展,并且可以针对特定站点给出有效的实现。但它的缺点也很明显,就是爬虫开发者需要懂编程语言,门槛比较高。
为了解决这个问题,人们提出了视觉爬虫。定义可视化爬虫时,会直观地显示远程网站页面,然后人们可以点击鼠标定义爬取逻辑(包括爬取Fetching目标、爬取顺序、爬取深度等)和爬取逻辑(页面的哪一部分应该被识别为属性)。与手工编码的爬虫相比,视觉爬虫大大降低了爬虫定义的门槛,但爬虫的效率不如手工编程。另外,由于可视化爬虫对爬取逻辑进行了抽象,可能无法支持一些特殊的网站。
Portia 是典型的视觉爬虫。人们常常认为pyspider也是一个视觉爬虫,其实不然。Pyspider 只是一个带有 GUI 的手工编码爬虫。
3.被动爬虫和交互式爬虫
大多数爬虫都是基于对页面的分析。如有必要,浏览器引擎会执行页面中的Javascript代码,然后获取渲染的页面,然后从中提取自己需要的信息。
但是在某些情况下,我们也需要能够和这些页面进行交互,比如输入用户名和密码登录系统然后爬取,或者我们需要输入关键字然后才爬取搜索结果。在这些情况下,我们需要能够在定义爬虫时保存这些用户输入,然后在爬虫执行期间重放交互信息,就像一个人在做这些动作一样。
Selenium 就是这种爬虫的一个例子。用户使用 Selenium IDE 记录用户操作,将它们保存为 Selenese 命令序列,然后使用 Web 驱动程序模拟浏览器重放这些命令。交互式爬虫的优点是可以像人一样做出各种动作,但缺点是需要搭建一个完整的浏览器引擎,系统开销很大,爬虫效率很低。
最后,为了做个广告,我最近开源了一个爬虫portia-dashboard。按照之前的分类方法,这款爬虫是“面向多站点”、“主要支持信息爬取”、“同时支持被动爬取”和“交互爬取”“可视化”爬虫,并提供了一个仪表盘功能。 Portia.dashboard可以用来部署爬虫、启动爬虫、监控爬虫状态、浏览提取的信息等等。
使用代码安装可能有点复杂,最简单的方法是使用docker,欢迎大家使用,并提供宝贵意见。
nodejs抓取动态网页( Splider.js文件入口是splider方法,首先根据传入方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-01 17:12
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源代码,定位到你需要的标签,然后提取标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的index构造尴尬百科的url,然后获取该url的网页源码,最后将获取的源码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:
源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我的最爱。但是,在 Node 中,有多种方式可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢 查看全部
nodejs抓取动态网页(
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源代码,定位到你需要的标签,然后提取标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的index构造尴尬百科的url,然后获取该url的网页源码,最后将获取的源码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上面已有代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:
源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我的最爱。但是,在 Node 中,有多种方式可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢
nodejs抓取动态网页(先看题干效果在这里我们建了一个表单填入表单需要提交的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-31 03:11
先看问题效果
这里我们建立了一个表单
在表格中填写需要提交的信息
获取两个参数和一个加法计算
表单html代码
用户名:
密 码:
NodeJS 文件
var http = require('http');
var url = require('url');
var fs = require('fs');
http.createServer(function(request,response){
//获取get请求中的参数
var requset_url = request.url;
//将字符串格式参数转化为对象使用
var strurl = url.parse(requset_url,true).query
var sum = Number(strurl.username)+Number(strurl.password)
console.log(sum);
//下面这个对象是buffer类型的对象
var content = fs.readFileSync('homework.html')
//现在我们要将他转换为字符串类型的对象
content= content.toString().replace('{{sum}}',sum);
console.log(content)
response.end(content)
}).listen(8080,function(){
console.log('服务启动!!!')
})
页面返回
uesrname+userkeyword={{sum}}
运行环境
想法:
//将index.html网页中的action地址设置为本地服务器localhost:8080的地址
//然后使用get请求中的url模块获取请求路径中的参数
//使用parse方法将字符串格式的参数转换成对象使用
// 用数力计算两个参数的值
// 包 {{sum}} 和另一个网页的整个 html 内容。默认为缓冲区类型对象,转换为字符串
//最后用两个参数的值和替换{{sum}} 查看全部
nodejs抓取动态网页(先看题干效果在这里我们建了一个表单填入表单需要提交的信息)
先看问题效果
这里我们建立了一个表单
在表格中填写需要提交的信息
获取两个参数和一个加法计算
表单html代码
用户名:
密 码:
NodeJS 文件
var http = require('http');
var url = require('url');
var fs = require('fs');
http.createServer(function(request,response){
//获取get请求中的参数
var requset_url = request.url;
//将字符串格式参数转化为对象使用
var strurl = url.parse(requset_url,true).query
var sum = Number(strurl.username)+Number(strurl.password)
console.log(sum);
//下面这个对象是buffer类型的对象
var content = fs.readFileSync('homework.html')
//现在我们要将他转换为字符串类型的对象
content= content.toString().replace('{{sum}}',sum);
console.log(content)
response.end(content)
}).listen(8080,function(){
console.log('服务启动!!!')
})
页面返回
uesrname+userkeyword={{sum}}
运行环境
想法:
//将index.html网页中的action地址设置为本地服务器localhost:8080的地址
//然后使用get请求中的url模块获取请求路径中的参数
//使用parse方法将字符串格式的参数转换成对象使用
// 用数力计算两个参数的值
// 包 {{sum}} 和另一个网页的整个 html 内容。默认为缓冲区类型对象,转换为字符串
//最后用两个参数的值和替换{{sum}}
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-31 03:08
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是 superagent 只支持 utf-8 网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?为了让浏览器正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的字符集内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用! 查看全部
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是 superagent 只支持 utf-8 网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?为了让浏览器正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的字符集内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用!
nodejs抓取动态网页(puppeteer和浏览器的区别,安装注意先安装nodejs.eachSeries)
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-10-31 03:07
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理效率不高。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
nodejs抓取动态网页(puppeteer和浏览器的区别,安装注意先安装nodejs.eachSeries)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户不可见,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理效率不高。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
nodejs抓取动态网页(第三方库:cheerio,这个库就是用来处理dom节点的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-30 06:25
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放入一个数组中,例如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html = chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。块是传输的数据。数据被添加到 html 变量中。当数据传输完毕后,会触发结束事件。你可以在end事件中打印console.log(html),你会发现它是目标地址的所有html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) 1 );
37 if ( curPage 查看全部
nodejs抓取动态网页(第三方库:cheerio,这个库就是用来处理dom节点的
)
第三方库:cheerio,这个库是用来处理dom节点的,它的用法和jquery几乎一模一样,所以有了这个工具,写爬虫就很简单了
准备好工作了:
1. npm init --yes 初始化package.json
2.安装cheerio:npm installcheerio --save-dev
实现的目标是将每个文章需要爬取的部分(捕获文章标题、超链接、文章摘要、发布时间)组织成一个对象,放入一个数组中,例如:
[ { title: '[置顶][js高手之路]从零开始打造一个javascript开源框架gdom与插件开发免费视频教程
连载中',
url: 'http://www.cnblogs.com/ghostwu/p/7470038.html',
entry: '摘要: 百度网盘下载地址:https://pan.baidu.com/s/1kULNXOF 优酷土豆观看地址:htt
p://v.youku.com/v_show/id_XMzAwNTY2MTE0MA==.html?spm=a2h0j.8191423.playlist_content.5!3~5~
5~A&&f',
listTime: '2017-09-05 17:08' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack Vuex用法详解',
url: 'http://www.cnblogs.com/ghostwu/p/7521097.html',
entry: '摘要: 在这之前,我已经分享过组件与组件的通信机制以及父子组件之间的通信机制,而
我们的vuex就是为了解决组件通信问题的 vuex是什么东东呢? 组件通信的本质其实就是在组件之间传
递数据或组件的状态(这里将数据和状态统称为状态),但可以看到如果我们通过最基本的方式来进行
通信,一旦需要管理的状态多了,代码就会',
listTime: '2017-09-14 15:51' },
{ title: '[js高手之路]Vue2.0基于vue-cli webpack同级组件之间的通信教程',
url: 'http://www.cnblogs.com/ghostwu/p/7518158.html',
entry: '摘要: 我们接着上文继续,本文我们讲解兄弟组件的通信,项目结构还是跟上文一样. 在
src/assets目录下建立文件EventHandler.js,该文件的作用在于给同级组件之间传递事件 EventHandl
er.js代码: 2,在Components目录下新建一个组件Brother1.vue 。通过Eve',
listTime: '2017-09-13 22:49' },
]
思路说明:
1.获取目标地址:所有html内容
2.提取所有文章html内容
3、提取每个文章下对应的文章(文章标题、超链接、文章摘要、发布时间)
1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match( re )[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 http.get(url, function (res) {
31 var html = '';
32 var arcList = [];
33 // var arcInfo = {};
34 res.on('data', function (chunk) {
35 html = chunk;
36 });
37 res.on('end', function () {
38 arcList = filterHtml( html );
39 console.log( arcList );
40 });
41 });
有几个关键点需要解释:
1. res.on('数据', function(){})
http模块发送get请求后,会不断的抓取目标网页的源码内容。因此,我在 on 中监听 data 事件。块是传输的数据。数据被添加到 html 变量中。当数据传输完毕后,会触发结束事件。你可以在end事件中打印console.log(html),你会发现它是目标地址的所有html源代码。这就解决了我们的第一个问题:获取目标地址:所有html内容
2.有了完整的html内容后,我再封装一个函数filterHTML来过滤我需要的结果(每条文章信息)
3. var $ =cheerio.load(html); 通过cheerio的load方法加载html内容,然后就可以使用cheerio的节点进行操作了。为了兼容jquery操作,我用美元符号$保存了这个文档对象
4. var aPost = $("#content").find(".post-list-item"); 这就是所有的文章节点信息,拿到后,通过各个方法一一遍历,抓取自己需要的信息,组织成对象,然后放到一个数组中
1 arcList.push({
2 21 title: title,
3 22 url: url,
4 23 entry: entry,
5 24 listTime: listTime
6 25 });
这样做了,结果如上所示。如果博客风格和我的博客风格一样,应该是可以爬取的。
然后改进页面爬取,让整个博客都可以爬下来
<p> 1 var http = require('http');
2 var cheerio = require('cheerio');
3
4 var url = 'http://www.cnblogs.com/ghostwu/';
5
6 function filterHtml(html) {
7 var $ = cheerio.load(html);
8 var arcList = [];
9 var aPost = $("#content").find(".post-list-item");
10 aPost.each(function () {
11 var ele = $(this);
12 var title = ele.find("h2 a").text();
13 var url = ele.find("h2 a").attr("href");
14 ele.find(".c_b_p_desc a").remove();
15 var entry = ele.find(".c_b_p_desc").text();
16 ele.find("small a").remove();
17 var listTime = ele.find("small").text();
18 var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
19 listTime = listTime.match(re)[0];
20 arcList.push({
21 title: title,
22 url: url,
23 entry: entry,
24 listTime: listTime
25 });
26 });
27 return arcList;
28 }
29
30 function nextPage( html ){
31 var $ = cheerio.load(html);
32 var nextUrl = $("#pager a:last-child").attr('href');
33 if ( !nextUrl ) return ;
34 var curPage = $("#pager .current").text();
35 if( !curPage ) curPage = 1;
36 var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) 1 );
37 if ( curPage

