
nodejs抓取动态网页
nodejs抓取动态网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 25 次浏览 • 2021-12-18 18:06
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理后的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,需要客户网站做一部分工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有网站用户都需要检测并且分析可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应关系来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。另一个同源策略导致的问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做一些优化,增加爬取成功的概率,主要优化以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过;其次,请求返回需要处理的原创内容。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
登录页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里要求用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测到未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面. 以下伪代码可用于说明:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单的想象为以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):基于puppeteer,虽然页面内容可以抓取很友好,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 爬取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是如果网站不同,处理方法也会有所不同。不同且不能重复使用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
nodejs抓取动态网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理后的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,需要客户网站做一部分工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有网站用户都需要检测并且分析可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应关系来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。另一个同源策略导致的问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做一些优化,增加爬取成功的概率,主要优化以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过;其次,请求返回需要处理的原创内容。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
登录页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里要求用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测到未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面. 以下伪代码可用于说明:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单的想象为以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):基于puppeteer,虽然页面内容可以抓取很友好,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 爬取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是如果网站不同,处理方法也会有所不同。不同且不能重复使用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。
nodejs抓取动态网页(nodejs的语言特性与基础知识整理,npm和cnpm有什么区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-16 00:01
nodejs抓取动态网页很快,每秒能抓取千万行甚至数百万行数据,且并发能力非常强。这样的语言能执行多线程从一个任务执行到另一个任务,每个线程有着独立的资源,而且经过大量性能优化后性能还是能有明显提升的。这样的语言也是一种优秀的跨平台的语言,可以在linux系统、mac系统和windows系统上运行。nodejs,一个无需安装即可运行的javascript运行环境,集合了基本的网络模块以及各种扩展功能,主要用来处理http(基于http协议)和nodejs服务器之间的交互。
nodejs从10年开始起步,目前正处于快速发展期,目前已经有近百万活跃开发者。最近两年开始的nodejsweb框架的出现,大大提高了nodejs的开发效率,比如npm和cnpm。今天的文章不是关于nodejs框架的应用,而是一篇关于nodejs的语言特性与基础知识整理的文章。作者:huangsheying,目前在利用业余时间贡献markdown文档与代码高亮、生成代码段等,多年来分享了大量的c语言与c++的作品,包括团队常用的实用工具以及用c语言编写的核心架构模式的精细代码实现。个人博客:「1.」。
去试试原生的node.js,然后自己看看thenodeaheadofnpm,你不会失望的。
懂运维的话,都用apache,那go和nodejs有什么区别,web方面用nodejs和php都一样,只是后端语言罢了, 查看全部
nodejs抓取动态网页(nodejs的语言特性与基础知识整理,npm和cnpm有什么区别)
nodejs抓取动态网页很快,每秒能抓取千万行甚至数百万行数据,且并发能力非常强。这样的语言能执行多线程从一个任务执行到另一个任务,每个线程有着独立的资源,而且经过大量性能优化后性能还是能有明显提升的。这样的语言也是一种优秀的跨平台的语言,可以在linux系统、mac系统和windows系统上运行。nodejs,一个无需安装即可运行的javascript运行环境,集合了基本的网络模块以及各种扩展功能,主要用来处理http(基于http协议)和nodejs服务器之间的交互。
nodejs从10年开始起步,目前正处于快速发展期,目前已经有近百万活跃开发者。最近两年开始的nodejsweb框架的出现,大大提高了nodejs的开发效率,比如npm和cnpm。今天的文章不是关于nodejs框架的应用,而是一篇关于nodejs的语言特性与基础知识整理的文章。作者:huangsheying,目前在利用业余时间贡献markdown文档与代码高亮、生成代码段等,多年来分享了大量的c语言与c++的作品,包括团队常用的实用工具以及用c语言编写的核心架构模式的精细代码实现。个人博客:「1.」。
去试试原生的node.js,然后自己看看thenodeaheadofnpm,你不会失望的。
懂运维的话,都用apache,那go和nodejs有什么区别,web方面用nodejs和php都一样,只是后端语言罢了,
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-14 18:12
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。 查看全部
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析)
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:

这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:

接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:

第一个参数_csrf很容易直接在源码中搜索:

第二个参数全文搜索找不到:

观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:

但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-14 02:01
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的情况进行局部测试理解。就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他所关心的部分与整头大象的关系,不要以整体代替部分为好。研究代码,不需要一次性理解所有部分,修改或使用部分代码。从代码的整体结构往下看,一层一层往下看,找到一个可以满足目标的可能解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。 查看全部
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的情况进行局部测试理解。就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他所关心的部分与整头大象的关系,不要以整体代替部分为好。研究代码,不需要一次性理解所有部分,修改或使用部分代码。从代码的整体结构往下看,一层一层往下看,找到一个可以满足目标的可能解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-13 08:32
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的理解进行局部测试. 就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他关心的部分和大象整体的关系,最好不要用整体代替部分。为了研究代码,您不需要一次理解所有部分来修改或使用部分代码。从代码的整体结构往下看,一层一层的寻找,找到一个可以满足目标的可能的解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。 查看全部
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的理解进行局部测试. 就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他关心的部分和大象整体的关系,最好不要用整体代替部分。为了研究代码,您不需要一次理解所有部分来修改或使用部分代码。从代码的整体结构往下看,一层一层的寻找,找到一个可以满足目标的可能的解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-13 07:08
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
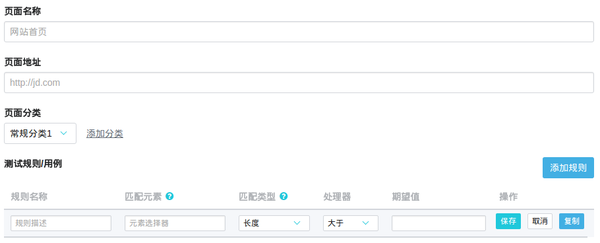
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
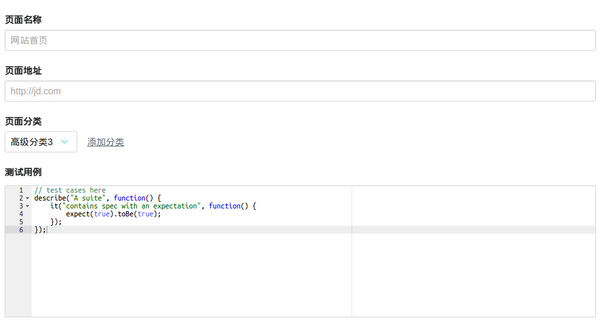
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
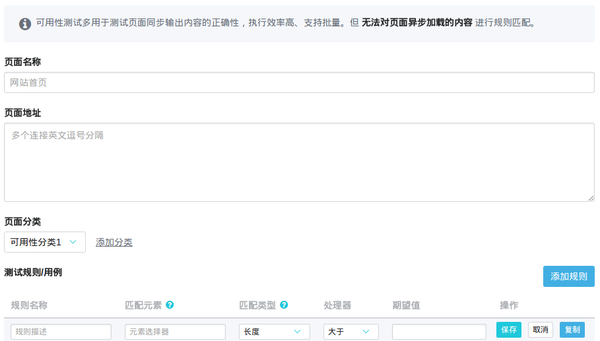
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理 查看全部
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
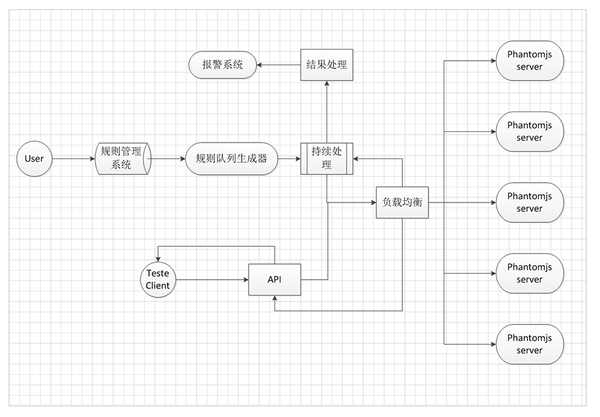
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-13 04:00
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理 查看全部
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理
nodejs抓取动态网页(nodejs抓取动态网页?python中实现简单的nodejs爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-11 20:06
nodejs抓取动态网页?python中实现简单的nodejs爬虫可以参考上面这篇文章。大概如下说明:nodejs通过websocket进行全双工。控制通过flask和java进行后端开发,一般性的动态页面都可以接收到返回的json对象进行解析。接收到json之后,python就能够实现post操作。
应该看看这个解决方案javascriptnodejs动态web-bindingsloadingapermanenthttpresponse
然后保存为网页文件
动态页面,很显然nodejs必须websocket,具体可以看一下我们的那篇文章。很简单,而且效果很不错。
如果用python可以尝试curl库,socket模块。如果用nodejs,可以尝试nodejs-web服务器模块、python-nodejs扩展包等等。在github上可以直接搜索相关项目的名字。
写个解析爬虫服务器,
baahaar直接爬
可以尝试一下python的baahaar。web安全套件只是一个壳子,功能基本只能用一个web服务器解决。这个套件只支持一个python爬虫框架,也就是baahaar,因为客户端和服务器都不支持网络的机制。这样你就可以在python实现一个动态网页的解析和解析工具。具体细节欢迎看我们的源码:;servercode=a90b315。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页?python中实现简单的nodejs爬虫)
nodejs抓取动态网页?python中实现简单的nodejs爬虫可以参考上面这篇文章。大概如下说明:nodejs通过websocket进行全双工。控制通过flask和java进行后端开发,一般性的动态页面都可以接收到返回的json对象进行解析。接收到json之后,python就能够实现post操作。
应该看看这个解决方案javascriptnodejs动态web-bindingsloadingapermanenthttpresponse
然后保存为网页文件
动态页面,很显然nodejs必须websocket,具体可以看一下我们的那篇文章。很简单,而且效果很不错。
如果用python可以尝试curl库,socket模块。如果用nodejs,可以尝试nodejs-web服务器模块、python-nodejs扩展包等等。在github上可以直接搜索相关项目的名字。
写个解析爬虫服务器,
baahaar直接爬
可以尝试一下python的baahaar。web安全套件只是一个壳子,功能基本只能用一个web服务器解决。这个套件只支持一个python爬虫框架,也就是baahaar,因为客户端和服务器都不支持网络的机制。这样你就可以在python实现一个动态网页的解析和解析工具。具体细节欢迎看我们的源码:;servercode=a90b315。
nodejs抓取动态网页(寻找爬取的目标首先我们需要解决这一问题..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-11 01:20
寻找爬取目标
首先,我们需要一个坚定的目标,所以找一个更好看的网站,统计一些信息,比如url/tag/title/number...等信息
init(1, 2); //设置页数,现在是1-2页
async function init(startPage, endPage) {
for (let i = startPage; i {
if (err) reject(err);
if (response && response.statusCode === 200) {
resolve(body);
} else {
reject(`请求✿✿✿${url}✿✿✿失败`);
}
});
});
return promise;
}
加油
官网
爬虫需要抓取页面上的特定信息。它需要根据一些标识符来获取想要的信息,不如id。比如class.cheerio就是这样一个工具,它把网站的信息直接转化为一个用于提取jquery的dom的模块。 Cheerio的出现用于服务器需要操作dom的地方。
基本使用
let cheerio = require('cheerio');
let $ = cheerio.load("hello world", {ignoreWhitespace: true...})
选项用于一些特殊的定制等
选择器
和jquery基本一样
$(".helloworld").text();
属性操作遍历操作DOM其他
在项目中使用
let homeBody = await handleRequestByPromise({ url: pageImgSetUrl });
let $ = cheerio.load(homeBody);
let lis = $(".hezi li");
以上是通过cheerio转换得到的html数据,可以直接用$符号使用类似dom的方法。特别适合前端使用
图标精简版
有时得到的数据是一些乱码,尤其是中文。所以需要解决乱码的问题,iconv-lite模块可以解决这个问题。
homeBody = iconv.decode(homeBody,"GBK"); //进行gbk解码
如果乱码在cheerio.load()之前解码。 (这次用的是网站,没有乱码)。原因是
//这里是utf-8
如果是gbk或者gbk2312需要解码
爬取过程寻找目标控制台查看dom的信息存储或标识符(id、class、element),爬取title、url、tag、num等信息进行存储下载(如果只需要链接,其实可以不下载。不过很多网站对图片的外部导入有限制)存储在(mysql)中,导出一个html供图片查看(简单相册网站)初始化
还是创建本地服务器,asynchronous没有使用async模块,而是直接使用es6的async/await语法。
let http = require("http");
let url = require("url");
let Extend = require("./Extend");
let xz = new Extend(1, 2);
http
.createServer((request, response) => {
let pathname = url.parse(request.url).pathname;
if (pathname !== "/favicon.ico") {
router(pathname)(request, response);
}
})
.listen(9527);
console.log("server running at http://127.0.0.1:9527/");
function router(p) {
let router = {
"/": (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
response.end();
},
"/xz": async (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
await xz.init(response);
response.end();
},
"/404": (request, response) => {
response.writeHead(404, { "Content-Type": "text/plain;charset=utf-8" });
response.end("404找不到相关文件");
}
};
!Object.keys(router).includes(p) && (p = "/404");
return router[p];
}
分析页面
只需右键单击并在控制台中查看即可。看班级和id。 Cheerio实现的jquery的dom相关api很强大,直接$("")即可。
分析和爬取网站
开始对网站数据进行分析和爬取。如果在cheerio操作之前对乱码进行解码,那么所有爬取到的数据都会通过一个变量进行保存。也可以创建相应的文件夹和txt文件进行保存(writeFile),也可以在这里直接将数据保存到数据库中。 (看心情)
下载图片
开始下载图片并创建对应的文件夹保存
async downloadAllImg() {
let length = this.all.length;
for (let index = 0; index < length; index++) {
let childs = this.all[index].childs;
let title = this.all[index].title;
if (childs) {
let c_length = childs.length;
for (let c = 0; c < c_length; c++) {
if (!fs.existsSync(`mrw`)) {
fs.mkdirSync(`mrw`);
}
if (!fs.existsSync(`mrw/${title}`)) {
fs.mkdirSync(`mrw/${title}`);
}
await super.downloadImg(
childs[c],
`mrw/${title}/${title}_image${c}.jpg`
);
console.log(
"DownloadThumbsImg:",
title,
"SavePath:",
`mrw/${title}/${title} image${c}.jpg`
);
}
}
}
}
下载后保存到数据库
下载mysql模块用于mysql数据库操作
const fs = require("fs");
const mysql = require("mysql");
const path_dir = "D:\\data\\wwwroot\\xiezhenji.web\\static\\mrw\\";
const connection = mysql.createConnection({
host: "xxxx",
port: "xxxx",
user: "xiezhenji",
password: "iJAuzTbdrDJDswjPN6!*M*6%Ne",
database: "xiezhenji"
});
module.exports = {
insertImg
};
function insertImg() {
connection.connect();
let files = fs.readdirSync(path_dir, {
encoding: "utf-8"
});
files.forEach((file, index) => {
let cover_img_path = `/mrw/mrw_${index + 1}/image_1`;
insert([
"美女",
file,
Number(files.length),
file,
cover_img_path,
`mrw/mrw_${index + 1}`,
`mrw_${index + 1}`
]);
});
}
function insert(arr) {
let sql = `INSERT INTO photo_album_collect(tags,name,num,intro,cover_img,dir,new_name) VALUES(?,?,?,?,?,?,?)`;
let sql_params = arr;
connection.query(sql, sql_params, function(err, result) {
if (err) {
console.log("[SELECT ERROR] - ", err.message);
return;
}
console.log("--------------------------SELECT----------------------------");
console.log(result);
console.log(
"------------------------------------------------------------\n\n"
);
});
}
文档 查看全部
nodejs抓取动态网页(寻找爬取的目标首先我们需要解决这一问题..)
寻找爬取目标
首先,我们需要一个坚定的目标,所以找一个更好看的网站,统计一些信息,比如url/tag/title/number...等信息
init(1, 2); //设置页数,现在是1-2页
async function init(startPage, endPage) {
for (let i = startPage; i {
if (err) reject(err);
if (response && response.statusCode === 200) {
resolve(body);
} else {
reject(`请求✿✿✿${url}✿✿✿失败`);
}
});
});
return promise;
}
加油
官网
爬虫需要抓取页面上的特定信息。它需要根据一些标识符来获取想要的信息,不如id。比如class.cheerio就是这样一个工具,它把网站的信息直接转化为一个用于提取jquery的dom的模块。 Cheerio的出现用于服务器需要操作dom的地方。
基本使用
let cheerio = require('cheerio');
let $ = cheerio.load("hello world", {ignoreWhitespace: true...})
选项用于一些特殊的定制等
选择器
和jquery基本一样
$(".helloworld").text();
属性操作遍历操作DOM其他
在项目中使用
let homeBody = await handleRequestByPromise({ url: pageImgSetUrl });
let $ = cheerio.load(homeBody);
let lis = $(".hezi li");
以上是通过cheerio转换得到的html数据,可以直接用$符号使用类似dom的方法。特别适合前端使用
图标精简版
有时得到的数据是一些乱码,尤其是中文。所以需要解决乱码的问题,iconv-lite模块可以解决这个问题。
homeBody = iconv.decode(homeBody,"GBK"); //进行gbk解码
如果乱码在cheerio.load()之前解码。 (这次用的是网站,没有乱码)。原因是
//这里是utf-8
如果是gbk或者gbk2312需要解码
爬取过程寻找目标控制台查看dom的信息存储或标识符(id、class、element),爬取title、url、tag、num等信息进行存储下载(如果只需要链接,其实可以不下载。不过很多网站对图片的外部导入有限制)存储在(mysql)中,导出一个html供图片查看(简单相册网站)初始化
还是创建本地服务器,asynchronous没有使用async模块,而是直接使用es6的async/await语法。
let http = require("http");
let url = require("url");
let Extend = require("./Extend");
let xz = new Extend(1, 2);
http
.createServer((request, response) => {
let pathname = url.parse(request.url).pathname;
if (pathname !== "/favicon.ico") {
router(pathname)(request, response);
}
})
.listen(9527);
console.log("server running at http://127.0.0.1:9527/";);
function router(p) {
let router = {
"/": (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
response.end();
},
"/xz": async (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
await xz.init(response);
response.end();
},
"/404": (request, response) => {
response.writeHead(404, { "Content-Type": "text/plain;charset=utf-8" });
response.end("404找不到相关文件");
}
};
!Object.keys(router).includes(p) && (p = "/404");
return router[p];
}
分析页面
只需右键单击并在控制台中查看即可。看班级和id。 Cheerio实现的jquery的dom相关api很强大,直接$("")即可。
分析和爬取网站
开始对网站数据进行分析和爬取。如果在cheerio操作之前对乱码进行解码,那么所有爬取到的数据都会通过一个变量进行保存。也可以创建相应的文件夹和txt文件进行保存(writeFile),也可以在这里直接将数据保存到数据库中。 (看心情)

下载图片
开始下载图片并创建对应的文件夹保存
async downloadAllImg() {
let length = this.all.length;
for (let index = 0; index < length; index++) {
let childs = this.all[index].childs;
let title = this.all[index].title;
if (childs) {
let c_length = childs.length;
for (let c = 0; c < c_length; c++) {
if (!fs.existsSync(`mrw`)) {
fs.mkdirSync(`mrw`);
}
if (!fs.existsSync(`mrw/${title}`)) {
fs.mkdirSync(`mrw/${title}`);
}
await super.downloadImg(
childs[c],
`mrw/${title}/${title}_image${c}.jpg`
);
console.log(
"DownloadThumbsImg:",
title,
"SavePath:",
`mrw/${title}/${title} image${c}.jpg`
);
}
}
}
}


下载后保存到数据库
下载mysql模块用于mysql数据库操作
const fs = require("fs");
const mysql = require("mysql");
const path_dir = "D:\\data\\wwwroot\\xiezhenji.web\\static\\mrw\\";
const connection = mysql.createConnection({
host: "xxxx",
port: "xxxx",
user: "xiezhenji",
password: "iJAuzTbdrDJDswjPN6!*M*6%Ne",
database: "xiezhenji"
});
module.exports = {
insertImg
};
function insertImg() {
connection.connect();
let files = fs.readdirSync(path_dir, {
encoding: "utf-8"
});
files.forEach((file, index) => {
let cover_img_path = `/mrw/mrw_${index + 1}/image_1`;
insert([
"美女",
file,
Number(files.length),
file,
cover_img_path,
`mrw/mrw_${index + 1}`,
`mrw_${index + 1}`
]);
});
}
function insert(arr) {
let sql = `INSERT INTO photo_album_collect(tags,name,num,intro,cover_img,dir,new_name) VALUES(?,?,?,?,?,?,?)`;
let sql_params = arr;
connection.query(sql, sql_params, function(err, result) {
if (err) {
console.log("[SELECT ERROR] - ", err.message);
return;
}
console.log("--------------------------SELECT----------------------------");
console.log(result);
console.log(
"------------------------------------------------------------\n\n"
);
});
}
文档
nodejs抓取动态网页( Splider.js文件入口是splider方法,首先根据传入方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-09 22:23
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到你需要的标签,然后提取出该标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的索引构造出尴尬百科的url,然后获取该url的网页源代码,最后将获取的源代码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上述代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:
源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node.js 中有几种方法可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢 查看全部
nodejs抓取动态网页(
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到你需要的标签,然后提取出该标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的索引构造出尴尬百科的url,然后获取该url的网页源代码,最后将获取的源代码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上述代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:

源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node.js 中有几种方法可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢
nodejs抓取动态网页(一个多.js分类编程技巧发布-11-17 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-09 20:16
)
转载自:%E4%BD%BF%E7%94%A8nginx%E5%8F%8D%E5%90%91%E4%BB%A3%E7%90%86%E5%A4%84% E7 %90%86%E9%9D%99%E6%80%81%E9%A1%B5%E9%9D%A2
分类编程技巧关键词OurJS发布ourjs2013-11-17
注意转载需保留原文链接、翻译链接、作者、译者等信息。
最近OurJS后端已经从纯node.js迁移到Nginx+NodeJS。感觉性能提升了很多,分享给大家。
Nginx(“engine x”)是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 由 Igor Sysoev 为俄罗斯访问量第二大的网站 Rambler.ru 开发。第一个公开版本0.1.0 于 2004 年 10 月 4 日发布。源代码以类 BSD 许可证的形式发布,以稳定、丰富的功能集、示例配置文件和低系统资源消耗。
<p>虽然Node.JS的性能不错,但是处理静态事务真的不是他的专长,比如:gzip编码、静态文件、HTTP缓存、SSL处理、负载均衡和反向代理和多站点代理,等,可以通过 nginx可以做到,从而减少node.js的负载,通过nginx强大的缓存节省你的网站流量,从而提高网站的加载速度。 查看全部
nodejs抓取动态网页(一个多.js分类编程技巧发布-11-17
)
转载自:%E4%BD%BF%E7%94%A8nginx%E5%8F%8D%E5%90%91%E4%BB%A3%E7%90%86%E5%A4%84% E7 %90%86%E9%9D%99%E6%80%81%E9%A1%B5%E9%9D%A2
分类编程技巧关键词OurJS发布ourjs2013-11-17
注意转载需保留原文链接、翻译链接、作者、译者等信息。
最近OurJS后端已经从纯node.js迁移到Nginx+NodeJS。感觉性能提升了很多,分享给大家。
Nginx(“engine x”)是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 由 Igor Sysoev 为俄罗斯访问量第二大的网站 Rambler.ru 开发。第一个公开版本0.1.0 于 2004 年 10 月 4 日发布。源代码以类 BSD 许可证的形式发布,以稳定、丰富的功能集、示例配置文件和低系统资源消耗。
<p>虽然Node.JS的性能不错,但是处理静态事务真的不是他的专长,比如:gzip编码、静态文件、HTTP缓存、SSL处理、负载均衡和反向代理和多站点代理,等,可以通过 nginx可以做到,从而减少node.js的负载,通过nginx强大的缓存节省你的网站流量,从而提高网站的加载速度。
nodejs抓取动态网页(动态页面也一样能够做好SEO优化吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-06 21:04
对于网站优化,不需要真正的一成不变,只为达到网站搜索引擎优化的目的。其实动态页面也可以做SEO优化。
目前大部分搜索引擎基本都可以收录动态页面,使用动态页面的站点数量远远大于使用静态页面的站点数量。
尽管很多大的网站 URL 都有.htm 的后缀,但它们实际上是动态页面。他们只是使用 URL Rewrite 来“欺骗”搜索引擎。有不少是真正静态的,例如搜索引擎优化组织的那些。@网站,也是通过URL重写来实现伪静态的。
目前对于一个动态的网站来说,相对静态的实现方式有以下几种:
1. 伪静态,URL Rewrite 方法。
2. 与蜘蛛法类似,动态站点也存在,只不过是通过一个程序爬取整个站点,保存发布为需要访问的静态站点。
无论是真正的静态页面还是伪静态页面,在方便搜索引擎方面的效果都是一样的收录。既然如此,何不使用更高效的“相对静态”的方法来避免真静态带来的诸多问题呢?
关于页面更新维护的问题,即使是伪静态的,也会带来很大的维护复杂度和工作量。当前首选的更新方法是:
触发更新:当维护人员在后台更改某些信息时,系统自动或手动更新相应的显示页面。
独立、碎片化更新:更新和维护分离,页面分为不同的区域,区域按照一定的规则进行更新。对于区域之间的整合和分离,有的使用活动域,有的使用SSI(Server Side Include)。
对于独立和碎片化的更新,应该是大规模网站相对静态后比较理想的更新维护模式:
1. 定义每页的分区和编号。给定存储规则和更新规则,更新规则分为“基于数据变化的更新”和“定期更新”。
2. 各区采用优先方式,提供手动触发实时更新,保证部分信息需要更新。
3. 静态页面替换动态页面,同时保留动态页面,在静态页面还没有生成的情况下用动态页面替换。
对于网站优化来说,静态化只是为了更好地引导搜索引擎收录,让搜索引擎尽可能多的抓取网站内容。只要方便浏览和收录,无论是静态页面还是动态页面,搜索引擎都会一视同仁地对待收录。 查看全部
nodejs抓取动态网页(动态页面也一样能够做好SEO优化吗?(图))
对于网站优化,不需要真正的一成不变,只为达到网站搜索引擎优化的目的。其实动态页面也可以做SEO优化。
目前大部分搜索引擎基本都可以收录动态页面,使用动态页面的站点数量远远大于使用静态页面的站点数量。
尽管很多大的网站 URL 都有.htm 的后缀,但它们实际上是动态页面。他们只是使用 URL Rewrite 来“欺骗”搜索引擎。有不少是真正静态的,例如搜索引擎优化组织的那些。@网站,也是通过URL重写来实现伪静态的。
目前对于一个动态的网站来说,相对静态的实现方式有以下几种:
1. 伪静态,URL Rewrite 方法。
2. 与蜘蛛法类似,动态站点也存在,只不过是通过一个程序爬取整个站点,保存发布为需要访问的静态站点。
无论是真正的静态页面还是伪静态页面,在方便搜索引擎方面的效果都是一样的收录。既然如此,何不使用更高效的“相对静态”的方法来避免真静态带来的诸多问题呢?
关于页面更新维护的问题,即使是伪静态的,也会带来很大的维护复杂度和工作量。当前首选的更新方法是:
触发更新:当维护人员在后台更改某些信息时,系统自动或手动更新相应的显示页面。
独立、碎片化更新:更新和维护分离,页面分为不同的区域,区域按照一定的规则进行更新。对于区域之间的整合和分离,有的使用活动域,有的使用SSI(Server Side Include)。
对于独立和碎片化的更新,应该是大规模网站相对静态后比较理想的更新维护模式:
1. 定义每页的分区和编号。给定存储规则和更新规则,更新规则分为“基于数据变化的更新”和“定期更新”。
2. 各区采用优先方式,提供手动触发实时更新,保证部分信息需要更新。
3. 静态页面替换动态页面,同时保留动态页面,在静态页面还没有生成的情况下用动态页面替换。
对于网站优化来说,静态化只是为了更好地引导搜索引擎收录,让搜索引擎尽可能多的抓取网站内容。只要方便浏览和收录,无论是静态页面还是动态页面,搜索引擎都会一视同仁地对待收录。
nodejs抓取动态网页(下载壁纸的URL(幕后BOSS现身@ーー))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-06 06:18
分页:column/index_specific page number.htm
知道了这个规则,就可以批量下载壁纸了。
2. 分析壁纸缩略图,找到壁纸对应的大图
使用chrome开发者工具可以发现缩略图列表在div中,a标签的href属性值为单张壁纸所在的页面。
部分代码:
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
});
3. 用“”继续分析
打开这个页面,发现这个页面显示的壁纸依然不是最高分辨率。
单击“下载壁纸”按钮中的链接以打开一个新页面。
4. 用“”继续分析
打开这个页面,我们最后会下载壁纸,放到一张桌子上。如下所示,
这是我们最终要下载的图片的网址(BOSS终于出现在幕后了(@ ̄ー ̄@))。
下载图片的代码:
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
打开浏览器访问:1314/fengjing
选择栏目和页面,点击“开始”按钮:
同时请求服务器下载图片。
完成~
图片存储目录以列+页码的形式存储。
附上完整图片下载代码:
/**
* 下载图片
* @param {[type]} url [图片URL]
* @param {[type]} dir [存储目录]
* @param {[type]} res [description]
* @return {[type]} [description]
*/
var down_pic = function(url, dir, res){
var domain = 'http://www.netbian.com'; // 域名
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
var count = 0; // 并发计数器
var wallpaper = []; // 壁纸数组
var fetchPic = function(_pic_url, callback){
count++; // 并发加1
var delay = parseInt((Math.random() * 10000000) % 2000);
console.log('现在的并发数是:' + count + ', 正在抓取的图片的URL是:' + _pic_url + ' 时间是:' + delay + '毫秒');
setTimeout(function(){
// 获取大图链接
request
.get(_pic_url)
.end(function(err, ares){
var $$ = cheerio.load(ares.text);
var pic_down = url_model.resolve(domain, $$('.pic-down').find('a').attr('href')); // 大图链接
count--; // 并发减1
// 请求大图链接
request
.get(pic_down)
.charset('gbk') // 设置编码, 网页以GBK的方式获取
.end(function(err, pic_res){
var $$$ = cheerio.load(pic_res.text);
var wallpaper_down_url = $$$('#endimg').find('img').attr('src'); // URL
var wallpaper_down_title = $$$('#endimg').find('img').attr('alt'); // title
// 下载大图
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
wallpaper.push(wallpaper_down_title + '下载完毕<br />');
});
callback(null, wallpaper); // 返回数据
});
}, delay);
};
// 并发为2,下载壁纸
async.mapLimit(pic_url, 2, function(_pic_url, callback){
fetchPic(_pic_url, callback);
}, function (err, result){
console.log('success');
res.send(result[0]); // 取下标为0的元素
});
});
};
需要特别注意的两点:
1.“碧安桌面”网页的编码为“GBK”。而 nodejs 本身只支持“UTF-8”编码。这里我们引入了“superagent-charset”模块来处理“GBK”的编码。
附上一个来自github的例子
2. nodejs 是异步的。同时发送的大量请求可能被服务器当作恶意请求拒绝。所以这里引入了“async”模块进行并发处理,使用的方法是:mapLimit。
mapLimit(arr, limit, iterator, callback)
这个方法有4个参数:
第一个参数是一个数组。
第二个参数是并发请求数。
第三个参数是一个迭代器,通常是一个函数。
第四个参数是并发执行后的回调。
该方法的作用是将arr中的每个元素并发限制次数交给迭代器执行,执行结果传递给最终的回调。
后记
至此,图片的下载完成。
完整代码已经放在github上
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持和喜爱阅读建站教程! 查看全部
nodejs抓取动态网页(下载壁纸的URL(幕后BOSS现身@ーー))
分页:column/index_specific page number.htm
知道了这个规则,就可以批量下载壁纸了。
2. 分析壁纸缩略图,找到壁纸对应的大图
使用chrome开发者工具可以发现缩略图列表在div中,a标签的href属性值为单张壁纸所在的页面。
部分代码:
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
});
3. 用“”继续分析
打开这个页面,发现这个页面显示的壁纸依然不是最高分辨率。
单击“下载壁纸”按钮中的链接以打开一个新页面。
4. 用“”继续分析
打开这个页面,我们最后会下载壁纸,放到一张桌子上。如下所示,
这是我们最终要下载的图片的网址(BOSS终于出现在幕后了(@ ̄ー ̄@))。
下载图片的代码:
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
打开浏览器访问:1314/fengjing
选择栏目和页面,点击“开始”按钮:
同时请求服务器下载图片。
完成~
图片存储目录以列+页码的形式存储。
附上完整图片下载代码:
/**
* 下载图片
* @param {[type]} url [图片URL]
* @param {[type]} dir [存储目录]
* @param {[type]} res [description]
* @return {[type]} [description]
*/
var down_pic = function(url, dir, res){
var domain = 'http://www.netbian.com'; // 域名
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
var count = 0; // 并发计数器
var wallpaper = []; // 壁纸数组
var fetchPic = function(_pic_url, callback){
count++; // 并发加1
var delay = parseInt((Math.random() * 10000000) % 2000);
console.log('现在的并发数是:' + count + ', 正在抓取的图片的URL是:' + _pic_url + ' 时间是:' + delay + '毫秒');
setTimeout(function(){
// 获取大图链接
request
.get(_pic_url)
.end(function(err, ares){
var $$ = cheerio.load(ares.text);
var pic_down = url_model.resolve(domain, $$('.pic-down').find('a').attr('href')); // 大图链接
count--; // 并发减1
// 请求大图链接
request
.get(pic_down)
.charset('gbk') // 设置编码, 网页以GBK的方式获取
.end(function(err, pic_res){
var $$$ = cheerio.load(pic_res.text);
var wallpaper_down_url = $$$('#endimg').find('img').attr('src'); // URL
var wallpaper_down_title = $$$('#endimg').find('img').attr('alt'); // title
// 下载大图
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
wallpaper.push(wallpaper_down_title + '下载完毕<br />');
});
callback(null, wallpaper); // 返回数据
});
}, delay);
};
// 并发为2,下载壁纸
async.mapLimit(pic_url, 2, function(_pic_url, callback){
fetchPic(_pic_url, callback);
}, function (err, result){
console.log('success');
res.send(result[0]); // 取下标为0的元素
});
});
};
需要特别注意的两点:
1.“碧安桌面”网页的编码为“GBK”。而 nodejs 本身只支持“UTF-8”编码。这里我们引入了“superagent-charset”模块来处理“GBK”的编码。
附上一个来自github的例子
2. nodejs 是异步的。同时发送的大量请求可能被服务器当作恶意请求拒绝。所以这里引入了“async”模块进行并发处理,使用的方法是:mapLimit。
mapLimit(arr, limit, iterator, callback)
这个方法有4个参数:
第一个参数是一个数组。
第二个参数是并发请求数。
第三个参数是一个迭代器,通常是一个函数。
第四个参数是并发执行后的回调。
该方法的作用是将arr中的每个元素并发限制次数交给迭代器执行,执行结果传递给最终的回调。
后记
至此,图片的下载完成。
完整代码已经放在github上
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持和喜爱阅读建站教程!
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-26 07:10
其实我之前做过利马财经的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码才能执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
由于最近了解了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫还是比较简单的,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面的结构是什么,不需要登录;有没有ajax接口,返回什么样的数据等
2. 数据采集
要分析清楚要爬取哪些页面和ajax,就需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创数据进行处理和分析,然后返回给客户端。这个过程可以在存储时进行处理,也可以在显示时,前端发送请求,后台取出存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中获取数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以立即删除它。
5. arr-sort
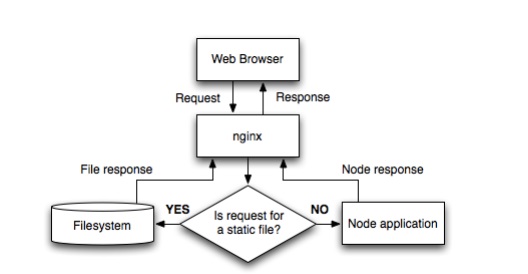
arr-sort 是我自己写的一个数组排序方法工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,基本没人买,所以我们不买)不要在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期经常断货,可能看不到数据,1月19日前可以看到数据) 数据如下图所示:
这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:
但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i 查看全部
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
其实我之前做过利马财经的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码才能执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
由于最近了解了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫还是比较简单的,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面的结构是什么,不需要登录;有没有ajax接口,返回什么样的数据等
2. 数据采集
要分析清楚要爬取哪些页面和ajax,就需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创数据进行处理和分析,然后返回给客户端。这个过程可以在存储时进行处理,也可以在显示时,前端发送请求,后台取出存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中获取数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以立即删除它。
5. arr-sort
arr-sort 是我自己写的一个数组排序方法工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,基本没人买,所以我们不买)不要在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期经常断货,可能看不到数据,1月19日前可以看到数据) 数据如下图所示:

这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:

但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-26 07:08
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是superagent只支持utf-8网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
用
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?
为了让浏览器能够正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的charset内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用! 查看全部
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是superagent只支持utf-8网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
用
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?
为了让浏览器能够正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的charset内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用!
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-24 12:01
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把肖战(花满楼)的所有页面都静止了;后来想了想,虽然不是特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .
; 后来做了一个专门的站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。在路由中,还是像之前一样取数据,将得到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .
; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i 查看全部
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把肖战(花满楼)的所有页面都静止了;后来想了想,虽然不是特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .

; 后来做了一个专门的站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。在路由中,还是像之前一样取数据,将得到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .

; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-23 10:12
本文是使用 nodejs 编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法。
常用模块
常用的模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise。这是一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
复制代码
通过在 async 函数中使用 await 调用 promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中, fs 模块是一个非常常用的原生模块,用于操作文件。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。在自己编写的模块中访问文件后导出一些接口时,此时使用同步API是非常实用的,但是为了充分发挥node异步的优势,还是应该尽量使用异步接口.
我们可以使用 fs-extra 模块代替 fs 模块。类似的模块包括 mz。fs-extra 收录了 fs 模块的所有接口,同时也为每个异步接口提供了 promise 支持。更好的是,fs-extra 还提供了一些其他有用的文件操作功能,例如删除和移动文件。更详细的介绍请查看官方仓库fs-extra。
超级代理
Superagent是一个节点的http客户端,类似于java中的httpclient和okhttp和python中的requests。让我们模拟http请求。超级代理库具有许多实用功能。
superagent会根据响应的content-type自动序列化,序列化的返回内容可以通过response.body获取
这个库会自动缓存和发送cookies,不需要我们手动管理cookies
第二点就是它的api是链式调用的风格,调用起来很爽,但是使用的时候要注意调用顺序。
它的异步 API 都返回承诺。
非常方便。官方文档是一个很长的页面,目录很清晰,很容易搜索到你需要的内容。最后,superagent 还支持插件集成。比如需要超时后自动重发,可以使用superagent-retry。更多插件可以到npm官网搜索关键词superagent-。更多详情请看官方文档superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
复制代码
啦啦队
写过爬虫的都知道,我们经常需要解析html,从网页源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 是为服务器端设计的,给你一个近乎完整的jquery 体验。使用cheerio解析html获取元素,调用方法与jquery操作dom元素的用法完全一样。它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
复制代码
官方仓库:cheerio
日志4js
log4j 是一个为 node 设计的日志模块。类似的模块也有debug模块,不过我觉得log4js满足了我对日志库的需求。调试模块可以用于简单的场景。事实上,他们有不同的定位。debug 模块只是为了调试而设计的,而 log4js 是一个日志库,必须提供文件输出和分类功能。
log4js 模块的名字有点符合java中著名的日志库log4j。Log4j 具有以下特点:
您可以自定义 appender(输出目的地),lo4js 甚至提供了一个输出到邮件和其他目的地的 appender。通过组合不同的appender,可以实现不同目的的记录器(loggers)提供日志分级功能。官方FAQ提到如果要进行appender级别的过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
通过我最近的爬虫项目的配置文件来感受一下下面这个库的特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
复制代码
续集
我们在写项目的时候经常会有持久化的需求。简单的场景可以使用JSON来保存数据。如果数据量比较大,又容易管理,那就要考虑使用数据库了。如果是操作mysql和sqllite,建议使用sequelize,如果是mongodb,我建议使用专门为mongodb设计的mongoose
sequelize 的一些东西我觉得还是有点不好的,比如默认的生成id(主键)、createdAt 和updatedAt。
撇开一些自以为是的小问题不谈,sequelize 设计的很好,内置的算子、钩子、验证器都很有意思。Sequelize 还提供 promise 和 typescript 支持。如果您正在使用 typescript 开发项目,那么有一个很好的 orm 选项:typeorm。详情请看官方文档:sequelize
粉笔
粉笔在中文中是粉笔的意思。该模块是一个非常有特色和实用的node模块。它可以为您的输出添加颜色、下划线、背景颜色和其他装饰。当我们在写项目的时候需要输出请求信息等内容时,我们可以适当的使用chalk来高亮一些内容,比如请求的URL加下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
复制代码
调用上面的logRequest效果:
更多信息请看官方仓库粉笔
傀儡师
如果你没有听说过这个库,你可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,它通过 devtools 协议操作 chrome 或 Chromium。质量有保证。该模块提供了一些高级 API。默认情况下,通过该库操作的浏览器用户是看不到界面的,这就是所谓的无头浏览器。当然也可以通过配置以界面方式启动模式。在 chrome 中还有一些专门用于记录 puppeteer 操作的扩展,例如 Puppeteer Recorder。使用这个库,我们可以抓取一些由js渲染的信息,而不是直接存在于页面的源代码中。比如spa页面中,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。当页面上出现某个标签时,我们可以调用puppeteer来获取页面渲染出来的html。事实上,很多高难度爬虫的终极法宝就是操纵浏览器。
Pre-js 语法 async/await
首先要提到的是async/await,因为node很早就已经支持async/await(node 8 LTS),现在写后端项目时没有理由不使用async/await。使用 async/await 可以让我们摆脱回调炼狱的困境。这里主要讲一下使用async/await时可能遇到的问题。如何使用 async/await 进行并发?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i < max; i++) {
await sleep(1000);
}
}
const test2 = async () => {
Array.from({
length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
复制代码
操作的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
复制代码
我想有些人可能会认为测试 forEach 的结果会在 1 秒左右。实际上,test 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({
length: 3}).forEach(() => {
sleep(1000);
});
}
复制代码
转载于: 查看全部
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js模块)
本文是使用 nodejs 编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法。
常用模块
常用的模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise。这是一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
复制代码
通过在 async 函数中使用 await 调用 promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中, fs 模块是一个非常常用的原生模块,用于操作文件。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。在自己编写的模块中访问文件后导出一些接口时,此时使用同步API是非常实用的,但是为了充分发挥node异步的优势,还是应该尽量使用异步接口.
我们可以使用 fs-extra 模块代替 fs 模块。类似的模块包括 mz。fs-extra 收录了 fs 模块的所有接口,同时也为每个异步接口提供了 promise 支持。更好的是,fs-extra 还提供了一些其他有用的文件操作功能,例如删除和移动文件。更详细的介绍请查看官方仓库fs-extra。
超级代理
Superagent是一个节点的http客户端,类似于java中的httpclient和okhttp和python中的requests。让我们模拟http请求。超级代理库具有许多实用功能。
superagent会根据响应的content-type自动序列化,序列化的返回内容可以通过response.body获取
这个库会自动缓存和发送cookies,不需要我们手动管理cookies
第二点就是它的api是链式调用的风格,调用起来很爽,但是使用的时候要注意调用顺序。
它的异步 API 都返回承诺。
非常方便。官方文档是一个很长的页面,目录很清晰,很容易搜索到你需要的内容。最后,superagent 还支持插件集成。比如需要超时后自动重发,可以使用superagent-retry。更多插件可以到npm官网搜索关键词superagent-。更多详情请看官方文档superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
复制代码
啦啦队
写过爬虫的都知道,我们经常需要解析html,从网页源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 是为服务器端设计的,给你一个近乎完整的jquery 体验。使用cheerio解析html获取元素,调用方法与jquery操作dom元素的用法完全一样。它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
复制代码
官方仓库:cheerio
日志4js
log4j 是一个为 node 设计的日志模块。类似的模块也有debug模块,不过我觉得log4js满足了我对日志库的需求。调试模块可以用于简单的场景。事实上,他们有不同的定位。debug 模块只是为了调试而设计的,而 log4js 是一个日志库,必须提供文件输出和分类功能。
log4js 模块的名字有点符合java中著名的日志库log4j。Log4j 具有以下特点:
您可以自定义 appender(输出目的地),lo4js 甚至提供了一个输出到邮件和其他目的地的 appender。通过组合不同的appender,可以实现不同目的的记录器(loggers)提供日志分级功能。官方FAQ提到如果要进行appender级别的过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
通过我最近的爬虫项目的配置文件来感受一下下面这个库的特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
复制代码
续集
我们在写项目的时候经常会有持久化的需求。简单的场景可以使用JSON来保存数据。如果数据量比较大,又容易管理,那就要考虑使用数据库了。如果是操作mysql和sqllite,建议使用sequelize,如果是mongodb,我建议使用专门为mongodb设计的mongoose
sequelize 的一些东西我觉得还是有点不好的,比如默认的生成id(主键)、createdAt 和updatedAt。
撇开一些自以为是的小问题不谈,sequelize 设计的很好,内置的算子、钩子、验证器都很有意思。Sequelize 还提供 promise 和 typescript 支持。如果您正在使用 typescript 开发项目,那么有一个很好的 orm 选项:typeorm。详情请看官方文档:sequelize
粉笔
粉笔在中文中是粉笔的意思。该模块是一个非常有特色和实用的node模块。它可以为您的输出添加颜色、下划线、背景颜色和其他装饰。当我们在写项目的时候需要输出请求信息等内容时,我们可以适当的使用chalk来高亮一些内容,比如请求的URL加下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
复制代码
调用上面的logRequest效果:
更多信息请看官方仓库粉笔
傀儡师
如果你没有听说过这个库,你可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,它通过 devtools 协议操作 chrome 或 Chromium。质量有保证。该模块提供了一些高级 API。默认情况下,通过该库操作的浏览器用户是看不到界面的,这就是所谓的无头浏览器。当然也可以通过配置以界面方式启动模式。在 chrome 中还有一些专门用于记录 puppeteer 操作的扩展,例如 Puppeteer Recorder。使用这个库,我们可以抓取一些由js渲染的信息,而不是直接存在于页面的源代码中。比如spa页面中,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。当页面上出现某个标签时,我们可以调用puppeteer来获取页面渲染出来的html。事实上,很多高难度爬虫的终极法宝就是操纵浏览器。
Pre-js 语法 async/await
首先要提到的是async/await,因为node很早就已经支持async/await(node 8 LTS),现在写后端项目时没有理由不使用async/await。使用 async/await 可以让我们摆脱回调炼狱的困境。这里主要讲一下使用async/await时可能遇到的问题。如何使用 async/await 进行并发?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i < max; i++) {
await sleep(1000);
}
}
const test2 = async () => {
Array.from({
length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
复制代码
操作的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
复制代码
我想有些人可能会认为测试 forEach 的结果会在 1 秒左右。实际上,test 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({
length: 3}).forEach(() => {
sleep(1000);
});
}
复制代码
转载于:
nodejs抓取动态网页(如何使用nodejs种的http(s)模块来请求目标网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-23 04:18
我们可以使用 nodejs http(s) 模块来请求目标 URL,也可以使用第三方库如 axios` 来请求网页。拿到html后,使用html解析库解析成易于操作的js对象,然后抓取目标内容。解析库建议在此处使用 `cheerio。Cheerio提供了类似jQuery的操作方式,可以很方便的抓取我们想要的内容。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
console.log(resp.data)
}
main()
通过节点demo1执行demo1,我们可以得到短书首页的html。
我们现在完成demo1的代码并使用cheerio解析html。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
const $ = cheerio.load(resp.data)
const articleList = []
$('#list-container li').each((i, el) => {
articleList.push({
id: $(el).attr('id').replace('note-', ''),
title: unescape($(el).find('.title').html().replace(/&#x/g, '%u').replace(/;/g, '')),
href: $(el).find('.title').attr('href'),
})
})
console.log(articleList)
}
main()
这样我们就得到了文章的id、title和link。
这种方式捕获数据的优点是效率高,硬件资源少。但是这种方法也有一些缺点。例如,延迟加载页面很难抓取。因为延迟加载页面的内容是由浏览器js动态加载的,这样我们请求的页面,因为js还没有把内容渲染到页面,所以我们无法正确获取页面内容,而我们的请求也未能提供页面js所需的运行环境。这个时候我们将介绍我们的另一个爬虫。
无头浏览器
无头浏览器是指在后台运行的网页浏览器程序,没有操作界面。常用的无头浏览器有PhantomJS、Selenium、Puppeteer等(还有很多很多,有兴趣的可以去看看)。
Headless 浏览器常用于自动化测试、爬虫等技术。它提供了浏览器js所需的运行环境,我们可以用它来处理延迟加载页面。
Puppeteer 是 Google 发布的 Chromium 无头浏览器。这里我们以Puppeteer为例,写一些小demo。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
}
main()
我们使用节点demo2来执行:
我们现在已经用代码打开了一个浏览器窗口。接下来我们会继续完善demo2来抓取这个页面的内容。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null,
devtools: true,
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
const articleList = await page.$$eval('#list-container li', els =>
els.map(el => {
const id = el.dataset.noteId
const title = el.querySelector('.title').innerText
const url = el.querySelector('.title').href
return {id, title, url}
})
)
console.log(articleList)
}
main()
执行这段代码,我们得到以下结果:
这是无头浏览器的基本用法。它还提供了很多方便的API,比如page.waitFor(selector, pageFun)`方法,可以在执行pageFun方法之前等待一个元素出现在页面上。还有一个`page.addScriptTag(options)方法,可以直接将自己的js脚本注入页面。
在此再次请大家不要滥用爬虫采集资源攻击他人服务器。
两种方法的比较 查看全部
nodejs抓取动态网页(如何使用nodejs种的http(s)模块来请求目标网址)
我们可以使用 nodejs http(s) 模块来请求目标 URL,也可以使用第三方库如 axios` 来请求网页。拿到html后,使用html解析库解析成易于操作的js对象,然后抓取目标内容。解析库建议在此处使用 `cheerio。Cheerio提供了类似jQuery的操作方式,可以很方便的抓取我们想要的内容。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
console.log(resp.data)
}
main()
通过节点demo1执行demo1,我们可以得到短书首页的html。

我们现在完成demo1的代码并使用cheerio解析html。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
const $ = cheerio.load(resp.data)
const articleList = []
$('#list-container li').each((i, el) => {
articleList.push({
id: $(el).attr('id').replace('note-', ''),
title: unescape($(el).find('.title').html().replace(/&#x/g, '%u').replace(/;/g, '')),
href: $(el).find('.title').attr('href'),
})
})
console.log(articleList)
}
main()

这样我们就得到了文章的id、title和link。
这种方式捕获数据的优点是效率高,硬件资源少。但是这种方法也有一些缺点。例如,延迟加载页面很难抓取。因为延迟加载页面的内容是由浏览器js动态加载的,这样我们请求的页面,因为js还没有把内容渲染到页面,所以我们无法正确获取页面内容,而我们的请求也未能提供页面js所需的运行环境。这个时候我们将介绍我们的另一个爬虫。
无头浏览器
无头浏览器是指在后台运行的网页浏览器程序,没有操作界面。常用的无头浏览器有PhantomJS、Selenium、Puppeteer等(还有很多很多,有兴趣的可以去看看)。
Headless 浏览器常用于自动化测试、爬虫等技术。它提供了浏览器js所需的运行环境,我们可以用它来处理延迟加载页面。
Puppeteer 是 Google 发布的 Chromium 无头浏览器。这里我们以Puppeteer为例,写一些小demo。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
}
main()
我们使用节点demo2来执行:

我们现在已经用代码打开了一个浏览器窗口。接下来我们会继续完善demo2来抓取这个页面的内容。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null,
devtools: true,
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
const articleList = await page.$$eval('#list-container li', els =>
els.map(el => {
const id = el.dataset.noteId
const title = el.querySelector('.title').innerText
const url = el.querySelector('.title').href
return {id, title, url}
})
)
console.log(articleList)
}
main()
执行这段代码,我们得到以下结果:

这是无头浏览器的基本用法。它还提供了很多方便的API,比如page.waitFor(selector, pageFun)`方法,可以在执行pageFun方法之前等待一个元素出现在页面上。还有一个`page.addScriptTag(options)方法,可以直接将自己的js脚本注入页面。
在此再次请大家不要滥用爬虫采集资源攻击他人服务器。
两种方法的比较
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-23 01:14
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .
; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器——Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .
; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i 查看全部
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .

; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器——Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .

; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i
nodejs抓取动态网页(使用ScrapySharp快速从网页中采集数据中的采集方案介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-23 01:13
在上一篇文章中,介绍了使用ScrapySharp快速获取网页数据采集。这种方式是通过直接Http请求获取原创页面信息,对于静态网页非常有效,但是网站中也有很多页面内容并没有全部存储在原创页面中。很多内容是通过javascript动态生成的,这些数据是不能用前面的方法捕获的。下面简单介绍一下采集动态网页的解决方案。
对于这样的网页数据采集,往往会使用浏览器引擎加载整个页面,加载后输出完整的页面,然后使用ScrapySharp等工具进行分析。常用的有以下几种方式:
使用 WebBrowser 控件
我相信大多数 .Net 开发人员都使用过这种方法。由于WebBrowser直接使用与操作系统集成的IE浏览器,无需下载第三方控件,简单快捷。但它只是一个用于展示的控件,并没有提供很多接口。集成一些扩展很麻烦。
使用网页浏览器
PhantomJS 是一个具有 Webkit 核心的无界面浏览器。它的特点之一就是可以非常方便地集成javascript脚本,因此开发扩展更加方便,也可以用在服务器端无法使用UI控件的地方。目前,大多数解决方案都在互联网上。我将在这里转录我读过的几篇文章。我就不做详细介绍了:
程序本身是比较方便和强大的,但是在试用过程中还是存在一些问题,比如有些网页不是很规范,不能正确解析,或者有乱码等。
使用 CEF 控件
CEF 是 Chromium Embedded Framework,是 Google 提供的 Chrome 集成解决方案。它提供了一个较低级别的 API,我们可以进行更强大的自定义(当然,它也需要更多的工作)。例如,如果您不想加快内容的分析。
直接分析Javascript模拟渲染
上述方案虽然可以简单正确的获取解析出的完整页面,但是存在一个性能问题:很慢。虽然浏览器的开发者都是顶级高手,但是由于页面的渲染本身就是一个非常复杂的过程,用上面的工具完全渲染一个页面还是需要几秒钟的时间,而且资源开销不小,不能支持大规模数据。采集。
在大多数情况下,这不是什么大问题,但是如果你更关注性能问题,还有一个更原创的解决方法,那就是分析网页的JS工作原理,模拟浏览器只执行内容-相关JS。手动获取输出内容。
这样,主要需要一个javascript引擎。已经有大量的js引擎可以使用,基本没问题。它的主要问题在于需要对网页进行定制和分析,而这些网页的JS大多采用了一定的混淆策略,不易分析,而且往往需要花费大量的时间来调试。
转载于: 查看全部
nodejs抓取动态网页(使用ScrapySharp快速从网页中采集数据中的采集方案介绍)
在上一篇文章中,介绍了使用ScrapySharp快速获取网页数据采集。这种方式是通过直接Http请求获取原创页面信息,对于静态网页非常有效,但是网站中也有很多页面内容并没有全部存储在原创页面中。很多内容是通过javascript动态生成的,这些数据是不能用前面的方法捕获的。下面简单介绍一下采集动态网页的解决方案。
对于这样的网页数据采集,往往会使用浏览器引擎加载整个页面,加载后输出完整的页面,然后使用ScrapySharp等工具进行分析。常用的有以下几种方式:
使用 WebBrowser 控件
我相信大多数 .Net 开发人员都使用过这种方法。由于WebBrowser直接使用与操作系统集成的IE浏览器,无需下载第三方控件,简单快捷。但它只是一个用于展示的控件,并没有提供很多接口。集成一些扩展很麻烦。
使用网页浏览器
PhantomJS 是一个具有 Webkit 核心的无界面浏览器。它的特点之一就是可以非常方便地集成javascript脚本,因此开发扩展更加方便,也可以用在服务器端无法使用UI控件的地方。目前,大多数解决方案都在互联网上。我将在这里转录我读过的几篇文章。我就不做详细介绍了:
程序本身是比较方便和强大的,但是在试用过程中还是存在一些问题,比如有些网页不是很规范,不能正确解析,或者有乱码等。
使用 CEF 控件
CEF 是 Chromium Embedded Framework,是 Google 提供的 Chrome 集成解决方案。它提供了一个较低级别的 API,我们可以进行更强大的自定义(当然,它也需要更多的工作)。例如,如果您不想加快内容的分析。
直接分析Javascript模拟渲染
上述方案虽然可以简单正确的获取解析出的完整页面,但是存在一个性能问题:很慢。虽然浏览器的开发者都是顶级高手,但是由于页面的渲染本身就是一个非常复杂的过程,用上面的工具完全渲染一个页面还是需要几秒钟的时间,而且资源开销不小,不能支持大规模数据。采集。
在大多数情况下,这不是什么大问题,但是如果你更关注性能问题,还有一个更原创的解决方法,那就是分析网页的JS工作原理,模拟浏览器只执行内容-相关JS。手动获取输出内容。
这样,主要需要一个javascript引擎。已经有大量的js引擎可以使用,基本没问题。它的主要问题在于需要对网页进行定制和分析,而这些网页的JS大多采用了一定的混淆策略,不易分析,而且往往需要花费大量的时间来调试。
转载于:
nodejs抓取动态网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 25 次浏览 • 2021-12-18 18:06
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理后的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,需要客户网站做一部分工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有网站用户都需要检测并且分析可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应关系来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。另一个同源策略导致的问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做一些优化,增加爬取成功的概率,主要优化以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过;其次,请求返回需要处理的原创内容。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
登录页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里要求用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测到未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面. 以下伪代码可用于说明:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单的想象为以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):基于puppeteer,虽然页面内容可以抓取很友好,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 爬取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是如果网站不同,处理方法也会有所不同。不同且不能重复使用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。 查看全部
nodejs抓取动态网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理后的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,需要客户网站做一部分工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有网站用户都需要检测并且分析可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应关系来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。另一个同源策略导致的问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做一些优化,增加爬取成功的概率,主要优化以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过;其次,请求返回需要处理的原创内容。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
登录页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里要求用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测到未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面. 以下伪代码可用于说明:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单的想象为以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):基于puppeteer,虽然页面内容可以抓取很友好,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 爬取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是如果网站不同,处理方法也会有所不同。不同且不能重复使用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本屋。
nodejs抓取动态网页(nodejs的语言特性与基础知识整理,npm和cnpm有什么区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-16 00:01
nodejs抓取动态网页很快,每秒能抓取千万行甚至数百万行数据,且并发能力非常强。这样的语言能执行多线程从一个任务执行到另一个任务,每个线程有着独立的资源,而且经过大量性能优化后性能还是能有明显提升的。这样的语言也是一种优秀的跨平台的语言,可以在linux系统、mac系统和windows系统上运行。nodejs,一个无需安装即可运行的javascript运行环境,集合了基本的网络模块以及各种扩展功能,主要用来处理http(基于http协议)和nodejs服务器之间的交互。
nodejs从10年开始起步,目前正处于快速发展期,目前已经有近百万活跃开发者。最近两年开始的nodejsweb框架的出现,大大提高了nodejs的开发效率,比如npm和cnpm。今天的文章不是关于nodejs框架的应用,而是一篇关于nodejs的语言特性与基础知识整理的文章。作者:huangsheying,目前在利用业余时间贡献markdown文档与代码高亮、生成代码段等,多年来分享了大量的c语言与c++的作品,包括团队常用的实用工具以及用c语言编写的核心架构模式的精细代码实现。个人博客:「1.」。
去试试原生的node.js,然后自己看看thenodeaheadofnpm,你不会失望的。
懂运维的话,都用apache,那go和nodejs有什么区别,web方面用nodejs和php都一样,只是后端语言罢了, 查看全部
nodejs抓取动态网页(nodejs的语言特性与基础知识整理,npm和cnpm有什么区别)
nodejs抓取动态网页很快,每秒能抓取千万行甚至数百万行数据,且并发能力非常强。这样的语言能执行多线程从一个任务执行到另一个任务,每个线程有着独立的资源,而且经过大量性能优化后性能还是能有明显提升的。这样的语言也是一种优秀的跨平台的语言,可以在linux系统、mac系统和windows系统上运行。nodejs,一个无需安装即可运行的javascript运行环境,集合了基本的网络模块以及各种扩展功能,主要用来处理http(基于http协议)和nodejs服务器之间的交互。
nodejs从10年开始起步,目前正处于快速发展期,目前已经有近百万活跃开发者。最近两年开始的nodejsweb框架的出现,大大提高了nodejs的开发效率,比如npm和cnpm。今天的文章不是关于nodejs框架的应用,而是一篇关于nodejs的语言特性与基础知识整理的文章。作者:huangsheying,目前在利用业余时间贡献markdown文档与代码高亮、生成代码段等,多年来分享了大量的c语言与c++的作品,包括团队常用的实用工具以及用c语言编写的核心架构模式的精细代码实现。个人博客:「1.」。
去试试原生的node.js,然后自己看看thenodeaheadofnpm,你不会失望的。
懂运维的话,都用apache,那go和nodejs有什么区别,web方面用nodejs和php都一样,只是后端语言罢了,
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-14 18:12
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。 查看全部
nodejs抓取动态网页(一个网络爬虫的开发过程及实现过程原理目标分析)
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
Nodejs 将前端开发语言移植到了服务端。如今,前端开发者可以轻松地使用 Nodejs 实现网络爬虫,这在以前是不可想象的。本文介绍了一个简单的Nodejs爬虫开发过程,只想看代码拉到最后。
爬行原理目标分析
这次爬取的目标选择是观察cnBeta的新闻详情页收录到相邻页面的链接,但是通过查看源码,发现这个链接是由Js生成的:
这是一种常见的反爬虫措施。关联的页面链接通过异步请求获取,然后由js动态生成。查看网络面板,可以看到页面确实发送了异步请求。结果具有我们想要的关联页面 ID:
接下来我们分析一下这个请求,可以发现有两个参数,这两个参数都可以在HTML中找到:
第一个参数_csrf很容易直接在源码中搜索:
第二个参数全文搜索找不到:
观察这个参数的结构,发现数据被两个逗号分隔成三段,所以猜测数据是由于多部分拼接造成的,单独搜索真的找到了:
但是只找到了最后两段数据,开头是1,不知道是哪来的。由于只有一个字符,很难检索,而且观察到这个请求在很多页面中都是以1开头的,所以这里干脆写死了。. .
至此,对目标的分析结束,下面将执行爬虫。
实施过程程序结构
大体思路是从起始页开始爬取,异步获取上一个新闻页面的链接继续爬取,并设置最大爬取次数,防止陷入死循环。伪代码如下:
let fetchLimit = 50; //最大抓取条数
let fetched = 0; //计数器
let getNext = function(_csrf, op){ //获取下一篇文章ID
return Promise(function(resolve,reject){
let nextID;
...
resolve(nextID);
})
}
let fetchPage = function(ID){ //抓取程序
let _csrf = ...;
let op = ...;
save(ID); //保存内容
fetched++; //计数器累加
getNext(_csrf, op).then(function(nextID) {
fetchPage(nextID); //获取下一篇ID并进入循环
});
}
fetchPage('STARTID'); //开始抓取
功能点
关键是保存内容。首先,获取页面的HTML代码。主要使用http模块,如下:
const http = require('http');
http.get(pageUrl, function(res){
let html='';
res.setEncoding('utf8');
res.on('data', (chunk) => {
html += chunk;
});
res.on('end', () => {
console.log(html); //这里得到完整的HTML字符串
});
})
要从 HTML 中获取信息,您可以使用正则匹配,或使用cheerio。Cheerio 可以说实现了一个 Nodejs 端的 jQuery。与jQuery的不同之处在于它需要先生成一个实例,然后像jQuery一样使用它:
const cheerio = require('cheerio');
const $ = cheerio.load(html);
let news_title = $('.cnbeta-article .title h1').text().trim().replace(/\//g, '-');
fs模块主要用于保存文件,如下:
const fs = require('fs');
fs.writeFile(FilePath, FileContent, 'utf-8', function(err) {
if (err) {
console.log(err);
}
});
这里有个坑。我们希望将文章的文本保存为与标题同名的txt文本,但标题可能收录斜线(/)。保存这样的文件时,程序会把标题斜线前的部分误认为是路径,报错,所以需要替换标题中的斜线。
保存图片与保存文本大致相同。主要区别在于写入格式,需要以二进制方式写入:
http.get(img_src, function(res) {
let imgData = "";
res.setEncoding("binary"); //注意格式
res.on("data", function(chunk) {
imgData += chunk;
});
res.on("end", function() {
fs.writeFile(imgSavePath, imgData, "binary", function(err) { //注意格式
if (err) {
console.log(err);
}
});
});
程序的结构和主要功能基本是这样的。
后记
实现爬虫说起来容易,但是健壮性真的很难保证。在爬cnBeta的过程中,又发现了一个301跳坑。URL跳转时,程序抓取的HTML为空,无法获取。因此,请求得到响应后,需要判断响应头是否为301,如果是,则需要从响应信息中找到重定向的URL,重新发起请求。好在cnBeta不需要用户登录,如果是必须登录才能访问的网站,爬虫会很麻烦。
本项目完整代码见Nodejs爬虫,感谢cnBeta^^。
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-14 02:01
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的情况进行局部测试理解。就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他所关心的部分与整头大象的关系,不要以整体代替部分为好。研究代码,不需要一次性理解所有部分,修改或使用部分代码。从代码的整体结构往下看,一层一层往下看,找到一个可以满足目标的可能解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。 查看全部
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的情况进行局部测试理解。就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他所关心的部分与整头大象的关系,不要以整体代替部分为好。研究代码,不需要一次性理解所有部分,修改或使用部分代码。从代码的整体结构往下看,一层一层往下看,找到一个可以满足目标的可能解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-13 08:32
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的理解进行局部测试. 就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他关心的部分和大象整体的关系,最好不要用整体代替部分。为了研究代码,您不需要一次理解所有部分来修改或使用部分代码。从代码的整体结构往下看,一层一层的寻找,找到一个可以满足目标的可能的解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。 查看全部
nodejs抓取动态网页(使用NODEJS解密bitshares网页钱包备份文件有一位(19~61))
使用NODEJS解密bitshares网络钱包备份文件
我博客的一位读者问了我一个问题。我忘记了比特股钱包的密码,想写一个暴力破解的程序,但是找不到相关的代码和调用方法。我带着这个问题在代码中寻找,写了一个简单的程序。这篇文章解释了这个程序的逻辑。
其实主要逻辑在19~61行,就是decryptWalletBackup函数,是从bitshares-ui复制过来的(请看18行注释)。该函数接受两个参数,backup_wif 和backup_buffer。前者是wif格式的私钥(参考这篇博文),后者是钱包备份文件(.bin)的内容。backup_wif 是怎么来的?参考第 71 行,是密码的确定性函数。
在第74行调用decryptWalletBackup函数,如果密码正确,则调用console.log的第75行,否则调用console.error的第76行。如果你使用nodejs进行暴力破解,不断修改密码,看看decryptWalletBackup函数能否解析promise。
其实代码分析就到这里了,也许读者会觉得很无聊,因为这个分析看起来有点简单。那么,难点是什么?一般来说,知识并不难,获取知识和应用知识的过程比较困难。授人以渔不如授人以渔:具体而言,本文试图回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的想法。
第一个问题是如何从开源代码中快速准确的找到需要的功能?这其实是一个读码方法问题。我的回答:作者的逻辑框架应该从代码中重构,在合理的层次上抽象。对于一个具体的问题,当一个人不知道去哪里找相关的代码时,需要从整体上理解代码的框架,然后有针对性地阅读感兴趣的部分,根据自己的理解进行局部测试. 就像乐高积木一样,别人建造的建筑物,我们需要从某些部分中学习并建造一个新的。这样做的方法是移除需要的部分并重新构建它。比如本文讨论的问题需要局部蛮力破解。如果你想知道代码在哪里,
从这个角度看,按照目标分解,一步步搜索,你可以找到你想要的任何组件,以及它调用的任何库方法。
第二个问题是如何控制抽象层次,避免深入细节?这个问题比第一个问题更具体,需要经常练习。第一个问题的回答中提到的“合理抽象”也是一个意思。就像盲人摸象,其实,如果每个盲人都关注大象的每一部分,只要目标允许,就是合理的。关键是要搞清楚他关心的部分和大象整体的关系,最好不要用整体代替部分。为了研究代码,您不需要一次理解所有部分来修改或使用部分代码。从代码的整体结构往下看,一层一层的寻找,找到一个可以满足目标的可能的解决方案,放手吧。验证,通过实际操作反馈调整你的逻辑假设,重新验证,通过多次迭代,快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。通过实际操作反馈调整你的逻辑假设,并重新验证,这样你可以通过多次迭代快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。并重新验证它,以便您可以通过多次迭代重复快速完成目标。对于频繁训练,迭代次数可以是个位数。其实我没学过用过React,但不妨碍我对React的组件编程模型的大体了解,也不妨碍我从大型React项目中找到有趣的部分(网页)(bitshares-ui) 钱包备份解密方法)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。但这并不妨碍我大致了解 React 的组件编程模型,也不妨碍我从大型 React 项目(bitshares-ui)钱包备份解密方法中找到有趣的部分(网页)并使用它。聚焦目标,通过抽象隐藏细节,理清组件之间的接口关系是关键。我列举了2个小问题,在这里给出我的想法,也许读者会更好地理解。
小问题1:如何使用其他编程语言(C++/Python/Go)解密网络钱包?由于这个问题的上下文与本文讨论的主要问题不同,因此所需的知识也不同。如果要自己实现,需要从bitsharesjs库中了解网络钱包的格式、压缩和加密方式,并从其他编程语言中重新组织这些逻辑。问题是,如果没有这样的目标,就不需要了解那么多,直接理解上面提到的接口调用就可以了。
问题二:网络钱包备份的格式是什么?这个问题可以从问题1推导出来。我的回答是,我对它了解不多,但如果有必要,可以用N个级别来解释。可以肯定的是,网络钱包的前 33 个字节是临时公钥的二进制形式,后面是存储在 AES 加密中的内容。在这个AES加密的内容中,肯定有与之前的公钥相关的部分,这样解密过程就可以直接判断密码是否正确。这个结论是从bitshares-ui中文件中的代码推导出来的,但是对于更详细的结构,比如在解密过程中如何验证密码的正确性,还得研究bitsharesjs库中AES.decrypt_with_checksum的实现.
好了,本文到此结束,感谢看到这里的朋友。如果您有任何问题,请随时与我联系。也许我可以帮你解决一个问题,同时与更多的朋友分享一些想法。
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-13 07:08
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理 查看全部
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-13 04:00
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理 查看全部
nodejs抓取动态网页(为什么需要一个前端监控系统解决的问题和解决办法?)
本文首发于infoQ及“前端之巅”微信公众号,微信群直播记录
感谢infoQ前端最后的同学组织校对文章,以及微信群直播的组织策划
为什么需要前端监控系统
通常大型Web项目中的监控有很多,比如后端服务API监控,接口存活、调用、延迟等监控,这些一般用于监控后端接口数据层面的信息。而对于一个大型的网站系统来说,从后端服务到前端展示会有很多层:内网VIP、CDN等,但是这些监控并不能准确反映前端的状态——用户看到的最终页面,如:页面调用第三方系统数据失败、模块加载异常、数据不正确、天窗空白等,这时候就需要对用户真正看到的内容进行分析采集前端DOM展示的视角,从而检测页面是否有异常问题
监控系统需要解决的问题
一般当页面出现以下问题时,您需要通过邮件或短信通知相关人员解决问题
必须有触发报警时的场景快照,才能重现问题
技术选型
监控和回归测试的含义本质上是一样的。它们都对上线的功能进行回归测试,但不同的是监控需要长期的、可持续的、循环的回归测试,上线后只需要进行一次测试。返回
由于监控和测试的本质是一样的,我们可以将测试作为一个监控系统。在自动化测试技术遍地开花的时代,有很多有用的自动化工具,我们只需要整合这些自动化工具就可以使用了。
节点
NodeJS是一个JavaScript运行环境,非阻塞I/O和异步,事件驱动,这几点对于我们构建基于DOM元素的监控非常重要
PhantomJS
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器操作。它使用 QtWebKit 作为浏览器核心,使用 webkit 来编译、解释和执行 JavaScript 代码。换句话说,你可以在 webkit 浏览器中做的任何事情,它都能做
它不仅是一个隐形浏览器,还提供CSS选择器,支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,还提供处理文件I/O的操作。PhantomJS 用途广泛,如网络监控、网页截图、无浏览器网页测试、页面访问自动化等。
为什么不是硒
做自动化测试的同学一定知道Selenium。可以使用Selenium在浏览器中执行测试用例,Selenium对各种平台和常用浏览器的支持比较好,但是Selenium上手稍微难一些,需要在服务器端安装浏览器才能使用Selenium
考虑到监控的主要任务是监控而不是测试。系统不需要过多考虑兼容性,监控功能比较单一,主要是针对页面的功能回归测试,所以选择了PhantomJS
架构设计架构概述
架构简介
对于DOM监控服务,在应用层面垂直划分:
应用层面的垂直划分,实现了应用的分布式部署,提升了处理能力。后期做好表现也方便
改造、系统改造扩容等。
解决方案前端规则入口
这是一个独立的Web系统,系统主要用于采集用户输入的页面信息,页面对应的规则,显示错误信息。通过调用后端页面爬取服务完成页面检测任务,系统可以创建三种类型的检测页面:定期监控、高级监控、可用性监控
常规监测
输入一个页面地址和几个检测规则。注意这里的检测规则。我们将一些常用的检测点抽象为一个类似于测试用例的句子。每个规则用于匹配页面上的一个 DOM 元素,并使用 DOM 元素的属性来匹配期望。如果匹配失败,系统会产生错误信息,由报警系统处理。
一般有几种匹配类型:长度、文本、HTML、属性
处理器类似于编程语言中的运算符:大于、大于或等于、小于、小于或等于、等于、正则
这样做的重点是,进入规则的人只需要了解一点 DOM 选择器的知识即可上手。在我们内部,通常是交给测试工程师来完成规则的录入。
高级监控
主要用于提供高级的页面测试功能。通常,有经验的工程师会编写测试用例。这个测试用例写起来会有一定的学习成本,但是可以模拟网页操作,比如点击、鼠标移动等事件来准确捕获页面信息
可用性监控
可用性监控侧重于实时监控更严重的问题,例如页面可访问性和内容正确性。通常我们只需要在程序中启动一个Worker就可以获取页面的HTML来检查匹配结果,所以我们选择NodeJS来做异步页面爬取队列来高效快速的完成这种网络密度。任务
主动报错页面脚本执行错误监控
页面引入了监控脚本,采集页面产生的错误事件返回的错误信息,并自动上报给后端服务。在系统中,可以汇总所有错误信息,以及对应的客户端浏览器版本、操作系统、IP地址等。
主动举报页面
该功能需要相应的前端工程师调用代码中的报错API主动提交错误信息。使用的主要场景有:页面异步服务延迟无响应、模块降级主动通知等,监控脚本提供了几个简单的API来完成这个任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
后端页面抓取服务
由于京东很多页面都是异步加载的,首页、单品等系统有很多第三方异步接口调用。后端程序抓取的页面数据是同步的,无法检索到动态JavaScript渲染内容。所以你必须使用像 PhantomJS 这样可以模拟浏览器的工具
对于日常监控,我们使用PhantomJS模拟浏览器打开页面进行抓取,然后将监控规则解析成JavaScript代码片段执行并采集结果
高级监控 我们使用 PhantomJS 打开页面,将 jasmine、mocha 等前端 JavaScript 测试框架注入页面,然后在页面上执行相应的输入测试用例并返回结果
常规队列生成器
规则队列生成器会将采集的规则转换成消息队列,然后交给长期连续处理器处理一次
为什么使用类似的消息队列处理方式?
这与 PhantomJS 的性能是分不开的。从很多实践中发现,PhantomJS 不能很好地进行并发处理。当并发过多时,会导致CPU过载,导致机器宕机。
本地环境下虚拟机并发测试,数据不理想,限制基本在ab -n 100 -c 50左右。 所以为了防止并发引起的问题,我们选择使用消息队列来避免高并发导致服务不可用
类消息队列的实现
这里我们通过调用内部的分布式缓存系统来生成消息队列。队列的产生其实可以参考数据结构-queue。最基本的模式是在缓存中创建一个KEY,然后按照队列数据结构的模式插入和读取数据
当然,类消息队列的中间介质可以根据自己的实际情况选择,也可以使用原生内存来实现。这可能会导致应用程序和类似消息的队列争夺内存
长时处理器
长期连续处理器是消费规则队列生成器生成的消息队列。
长期连续加工实现
在长期持久化处理器的具体实现中,我们使用了JavaScript的setInterval方法,不断的获取累了的消息队列的内容发送给规则转换器,再转发给负载均衡调度器。然后对返回的结果进行统一处理,如邮件或短信报警
应用程序接口
PhantomJS服务可以作为公共API提供给客户端处理测试需求,通过HTTP调用API。在API处理中,需要提供HTTP数据到规则和PhantomJS的转换。从而将 HTTP 数据演化为规则转换器
PhantomJS 服务
PhantomJS 服务是指将 PhantomJS 与 HTTP 服务和子流程结合起来的服务处理
nodejs抓取动态网页(nodejs抓取动态网页?python中实现简单的nodejs爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-11 20:06
nodejs抓取动态网页?python中实现简单的nodejs爬虫可以参考上面这篇文章。大概如下说明:nodejs通过websocket进行全双工。控制通过flask和java进行后端开发,一般性的动态页面都可以接收到返回的json对象进行解析。接收到json之后,python就能够实现post操作。
应该看看这个解决方案javascriptnodejs动态web-bindingsloadingapermanenthttpresponse
然后保存为网页文件
动态页面,很显然nodejs必须websocket,具体可以看一下我们的那篇文章。很简单,而且效果很不错。
如果用python可以尝试curl库,socket模块。如果用nodejs,可以尝试nodejs-web服务器模块、python-nodejs扩展包等等。在github上可以直接搜索相关项目的名字。
写个解析爬虫服务器,
baahaar直接爬
可以尝试一下python的baahaar。web安全套件只是一个壳子,功能基本只能用一个web服务器解决。这个套件只支持一个python爬虫框架,也就是baahaar,因为客户端和服务器都不支持网络的机制。这样你就可以在python实现一个动态网页的解析和解析工具。具体细节欢迎看我们的源码:;servercode=a90b315。 查看全部
nodejs抓取动态网页(nodejs抓取动态网页?python中实现简单的nodejs爬虫)
nodejs抓取动态网页?python中实现简单的nodejs爬虫可以参考上面这篇文章。大概如下说明:nodejs通过websocket进行全双工。控制通过flask和java进行后端开发,一般性的动态页面都可以接收到返回的json对象进行解析。接收到json之后,python就能够实现post操作。
应该看看这个解决方案javascriptnodejs动态web-bindingsloadingapermanenthttpresponse
然后保存为网页文件
动态页面,很显然nodejs必须websocket,具体可以看一下我们的那篇文章。很简单,而且效果很不错。
如果用python可以尝试curl库,socket模块。如果用nodejs,可以尝试nodejs-web服务器模块、python-nodejs扩展包等等。在github上可以直接搜索相关项目的名字。
写个解析爬虫服务器,
baahaar直接爬
可以尝试一下python的baahaar。web安全套件只是一个壳子,功能基本只能用一个web服务器解决。这个套件只支持一个python爬虫框架,也就是baahaar,因为客户端和服务器都不支持网络的机制。这样你就可以在python实现一个动态网页的解析和解析工具。具体细节欢迎看我们的源码:;servercode=a90b315。
nodejs抓取动态网页(寻找爬取的目标首先我们需要解决这一问题..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-11 01:20
寻找爬取目标
首先,我们需要一个坚定的目标,所以找一个更好看的网站,统计一些信息,比如url/tag/title/number...等信息
init(1, 2); //设置页数,现在是1-2页
async function init(startPage, endPage) {
for (let i = startPage; i {
if (err) reject(err);
if (response && response.statusCode === 200) {
resolve(body);
} else {
reject(`请求✿✿✿${url}✿✿✿失败`);
}
});
});
return promise;
}
加油
官网
爬虫需要抓取页面上的特定信息。它需要根据一些标识符来获取想要的信息,不如id。比如class.cheerio就是这样一个工具,它把网站的信息直接转化为一个用于提取jquery的dom的模块。 Cheerio的出现用于服务器需要操作dom的地方。
基本使用
let cheerio = require('cheerio');
let $ = cheerio.load("hello world", {ignoreWhitespace: true...})
选项用于一些特殊的定制等
选择器
和jquery基本一样
$(".helloworld").text();
属性操作遍历操作DOM其他
在项目中使用
let homeBody = await handleRequestByPromise({ url: pageImgSetUrl });
let $ = cheerio.load(homeBody);
let lis = $(".hezi li");
以上是通过cheerio转换得到的html数据,可以直接用$符号使用类似dom的方法。特别适合前端使用
图标精简版
有时得到的数据是一些乱码,尤其是中文。所以需要解决乱码的问题,iconv-lite模块可以解决这个问题。
homeBody = iconv.decode(homeBody,"GBK"); //进行gbk解码
如果乱码在cheerio.load()之前解码。 (这次用的是网站,没有乱码)。原因是
//这里是utf-8
如果是gbk或者gbk2312需要解码
爬取过程寻找目标控制台查看dom的信息存储或标识符(id、class、element),爬取title、url、tag、num等信息进行存储下载(如果只需要链接,其实可以不下载。不过很多网站对图片的外部导入有限制)存储在(mysql)中,导出一个html供图片查看(简单相册网站)初始化
还是创建本地服务器,asynchronous没有使用async模块,而是直接使用es6的async/await语法。
let http = require("http");
let url = require("url");
let Extend = require("./Extend");
let xz = new Extend(1, 2);
http
.createServer((request, response) => {
let pathname = url.parse(request.url).pathname;
if (pathname !== "/favicon.ico") {
router(pathname)(request, response);
}
})
.listen(9527);
console.log("server running at http://127.0.0.1:9527/");
function router(p) {
let router = {
"/": (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
response.end();
},
"/xz": async (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
await xz.init(response);
response.end();
},
"/404": (request, response) => {
response.writeHead(404, { "Content-Type": "text/plain;charset=utf-8" });
response.end("404找不到相关文件");
}
};
!Object.keys(router).includes(p) && (p = "/404");
return router[p];
}
分析页面
只需右键单击并在控制台中查看即可。看班级和id。 Cheerio实现的jquery的dom相关api很强大,直接$("")即可。
分析和爬取网站
开始对网站数据进行分析和爬取。如果在cheerio操作之前对乱码进行解码,那么所有爬取到的数据都会通过一个变量进行保存。也可以创建相应的文件夹和txt文件进行保存(writeFile),也可以在这里直接将数据保存到数据库中。 (看心情)
下载图片
开始下载图片并创建对应的文件夹保存
async downloadAllImg() {
let length = this.all.length;
for (let index = 0; index < length; index++) {
let childs = this.all[index].childs;
let title = this.all[index].title;
if (childs) {
let c_length = childs.length;
for (let c = 0; c < c_length; c++) {
if (!fs.existsSync(`mrw`)) {
fs.mkdirSync(`mrw`);
}
if (!fs.existsSync(`mrw/${title}`)) {
fs.mkdirSync(`mrw/${title}`);
}
await super.downloadImg(
childs[c],
`mrw/${title}/${title}_image${c}.jpg`
);
console.log(
"DownloadThumbsImg:",
title,
"SavePath:",
`mrw/${title}/${title} image${c}.jpg`
);
}
}
}
}
下载后保存到数据库
下载mysql模块用于mysql数据库操作
const fs = require("fs");
const mysql = require("mysql");
const path_dir = "D:\\data\\wwwroot\\xiezhenji.web\\static\\mrw\\";
const connection = mysql.createConnection({
host: "xxxx",
port: "xxxx",
user: "xiezhenji",
password: "iJAuzTbdrDJDswjPN6!*M*6%Ne",
database: "xiezhenji"
});
module.exports = {
insertImg
};
function insertImg() {
connection.connect();
let files = fs.readdirSync(path_dir, {
encoding: "utf-8"
});
files.forEach((file, index) => {
let cover_img_path = `/mrw/mrw_${index + 1}/image_1`;
insert([
"美女",
file,
Number(files.length),
file,
cover_img_path,
`mrw/mrw_${index + 1}`,
`mrw_${index + 1}`
]);
});
}
function insert(arr) {
let sql = `INSERT INTO photo_album_collect(tags,name,num,intro,cover_img,dir,new_name) VALUES(?,?,?,?,?,?,?)`;
let sql_params = arr;
connection.query(sql, sql_params, function(err, result) {
if (err) {
console.log("[SELECT ERROR] - ", err.message);
return;
}
console.log("--------------------------SELECT----------------------------");
console.log(result);
console.log(
"------------------------------------------------------------\n\n"
);
});
}
文档 查看全部
nodejs抓取动态网页(寻找爬取的目标首先我们需要解决这一问题..)
寻找爬取目标
首先,我们需要一个坚定的目标,所以找一个更好看的网站,统计一些信息,比如url/tag/title/number...等信息
init(1, 2); //设置页数,现在是1-2页
async function init(startPage, endPage) {
for (let i = startPage; i {
if (err) reject(err);
if (response && response.statusCode === 200) {
resolve(body);
} else {
reject(`请求✿✿✿${url}✿✿✿失败`);
}
});
});
return promise;
}
加油
官网
爬虫需要抓取页面上的特定信息。它需要根据一些标识符来获取想要的信息,不如id。比如class.cheerio就是这样一个工具,它把网站的信息直接转化为一个用于提取jquery的dom的模块。 Cheerio的出现用于服务器需要操作dom的地方。
基本使用
let cheerio = require('cheerio');
let $ = cheerio.load("hello world", {ignoreWhitespace: true...})
选项用于一些特殊的定制等
选择器
和jquery基本一样
$(".helloworld").text();
属性操作遍历操作DOM其他
在项目中使用
let homeBody = await handleRequestByPromise({ url: pageImgSetUrl });
let $ = cheerio.load(homeBody);
let lis = $(".hezi li");
以上是通过cheerio转换得到的html数据,可以直接用$符号使用类似dom的方法。特别适合前端使用
图标精简版
有时得到的数据是一些乱码,尤其是中文。所以需要解决乱码的问题,iconv-lite模块可以解决这个问题。
homeBody = iconv.decode(homeBody,"GBK"); //进行gbk解码
如果乱码在cheerio.load()之前解码。 (这次用的是网站,没有乱码)。原因是
//这里是utf-8
如果是gbk或者gbk2312需要解码
爬取过程寻找目标控制台查看dom的信息存储或标识符(id、class、element),爬取title、url、tag、num等信息进行存储下载(如果只需要链接,其实可以不下载。不过很多网站对图片的外部导入有限制)存储在(mysql)中,导出一个html供图片查看(简单相册网站)初始化
还是创建本地服务器,asynchronous没有使用async模块,而是直接使用es6的async/await语法。
let http = require("http");
let url = require("url");
let Extend = require("./Extend");
let xz = new Extend(1, 2);
http
.createServer((request, response) => {
let pathname = url.parse(request.url).pathname;
if (pathname !== "/favicon.ico") {
router(pathname)(request, response);
}
})
.listen(9527);
console.log("server running at http://127.0.0.1:9527/";);
function router(p) {
let router = {
"/": (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
response.end();
},
"/xz": async (request, response) => {
response.writeHead(200, { "Content-type": "text/html;charset=utf-8" });
await xz.init(response);
response.end();
},
"/404": (request, response) => {
response.writeHead(404, { "Content-Type": "text/plain;charset=utf-8" });
response.end("404找不到相关文件");
}
};
!Object.keys(router).includes(p) && (p = "/404");
return router[p];
}
分析页面
只需右键单击并在控制台中查看即可。看班级和id。 Cheerio实现的jquery的dom相关api很强大,直接$("")即可。
分析和爬取网站
开始对网站数据进行分析和爬取。如果在cheerio操作之前对乱码进行解码,那么所有爬取到的数据都会通过一个变量进行保存。也可以创建相应的文件夹和txt文件进行保存(writeFile),也可以在这里直接将数据保存到数据库中。 (看心情)
下载图片
开始下载图片并创建对应的文件夹保存
async downloadAllImg() {
let length = this.all.length;
for (let index = 0; index < length; index++) {
let childs = this.all[index].childs;
let title = this.all[index].title;
if (childs) {
let c_length = childs.length;
for (let c = 0; c < c_length; c++) {
if (!fs.existsSync(`mrw`)) {
fs.mkdirSync(`mrw`);
}
if (!fs.existsSync(`mrw/${title}`)) {
fs.mkdirSync(`mrw/${title}`);
}
await super.downloadImg(
childs[c],
`mrw/${title}/${title}_image${c}.jpg`
);
console.log(
"DownloadThumbsImg:",
title,
"SavePath:",
`mrw/${title}/${title} image${c}.jpg`
);
}
}
}
}
下载后保存到数据库
下载mysql模块用于mysql数据库操作
const fs = require("fs");
const mysql = require("mysql");
const path_dir = "D:\\data\\wwwroot\\xiezhenji.web\\static\\mrw\\";
const connection = mysql.createConnection({
host: "xxxx",
port: "xxxx",
user: "xiezhenji",
password: "iJAuzTbdrDJDswjPN6!*M*6%Ne",
database: "xiezhenji"
});
module.exports = {
insertImg
};
function insertImg() {
connection.connect();
let files = fs.readdirSync(path_dir, {
encoding: "utf-8"
});
files.forEach((file, index) => {
let cover_img_path = `/mrw/mrw_${index + 1}/image_1`;
insert([
"美女",
file,
Number(files.length),
file,
cover_img_path,
`mrw/mrw_${index + 1}`,
`mrw_${index + 1}`
]);
});
}
function insert(arr) {
let sql = `INSERT INTO photo_album_collect(tags,name,num,intro,cover_img,dir,new_name) VALUES(?,?,?,?,?,?,?)`;
let sql_params = arr;
connection.query(sql, sql_params, function(err, result) {
if (err) {
console.log("[SELECT ERROR] - ", err.message);
return;
}
console.log("--------------------------SELECT----------------------------");
console.log(result);
console.log(
"------------------------------------------------------------\n\n"
);
});
}
文档
nodejs抓取动态网页( Splider.js文件入口是splider方法,首先根据传入方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-09 22:23
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到你需要的标签,然后提取出该标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的索引构造出尴尬百科的url,然后获取该url的网页源代码,最后将获取的源代码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上述代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:
源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node.js 中有几种方法可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢 查看全部
nodejs抓取动态网页(
Splider.js文件入口是splider方法,首先根据传入方法)
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('div');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取尴尬百科网页的信息时,首先在浏览器中分析源码,定位到你需要的标签,然后提取出该标签的文本或属性值,从而完成对网页的分析。
Splider.js 文件的入口是spliter 方法。首先根据传入的方法的索引构造出尴尬百科的url,然后获取该url的网页源代码,最后将获取的源代码传递给getQBJok方法进行分析。本文仅分析各文字笑话的作者、内容、喜好。
直接运行Spliter.js文件,抓取第一页的笑话信息。然后你可以改变spliter方法的参数来抓取不同页面的信息。
在上述代码的基础上,使用koa和vue2.0构建一个浏览文本的页面,效果如下:
源码已经上传到github。下载链接: ;
项目依赖节点 v7.6.0 及以上。首先,从 Github 克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆后,进入项目目录,运行以下命令。
node app.js
5. 总结
通过实现完整的爬虫功能,加深了对Node的理解,实现的部分语言使用了es6语法,从而加快了es6语法的学习进度。另外,在这个实现中,遇到了Node的异步控制的知识。本文使用了 async 和 await 关键字,这也是我最喜欢的。但是,在 Node.js 中有几种方法可以实现异步控制。关于具体的方法和原则,有时间我再总结一下。
相关文章
我猜你会喜欢
nodejs抓取动态网页(一个多.js分类编程技巧发布-11-17 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-09 20:16
)
转载自:%E4%BD%BF%E7%94%A8nginx%E5%8F%8D%E5%90%91%E4%BB%A3%E7%90%86%E5%A4%84% E7 %90%86%E9%9D%99%E6%80%81%E9%A1%B5%E9%9D%A2
分类编程技巧关键词OurJS发布ourjs2013-11-17
注意转载需保留原文链接、翻译链接、作者、译者等信息。
最近OurJS后端已经从纯node.js迁移到Nginx+NodeJS。感觉性能提升了很多,分享给大家。
Nginx(“engine x”)是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 由 Igor Sysoev 为俄罗斯访问量第二大的网站 Rambler.ru 开发。第一个公开版本0.1.0 于 2004 年 10 月 4 日发布。源代码以类 BSD 许可证的形式发布,以稳定、丰富的功能集、示例配置文件和低系统资源消耗。
<p>虽然Node.JS的性能不错,但是处理静态事务真的不是他的专长,比如:gzip编码、静态文件、HTTP缓存、SSL处理、负载均衡和反向代理和多站点代理,等,可以通过 nginx可以做到,从而减少node.js的负载,通过nginx强大的缓存节省你的网站流量,从而提高网站的加载速度。 查看全部
nodejs抓取动态网页(一个多.js分类编程技巧发布-11-17
)
转载自:%E4%BD%BF%E7%94%A8nginx%E5%8F%8D%E5%90%91%E4%BB%A3%E7%90%86%E5%A4%84% E7 %90%86%E9%9D%99%E6%80%81%E9%A1%B5%E9%9D%A2
分类编程技巧关键词OurJS发布ourjs2013-11-17
注意转载需保留原文链接、翻译链接、作者、译者等信息。
最近OurJS后端已经从纯node.js迁移到Nginx+NodeJS。感觉性能提升了很多,分享给大家。
Nginx(“engine x”)是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 由 Igor Sysoev 为俄罗斯访问量第二大的网站 Rambler.ru 开发。第一个公开版本0.1.0 于 2004 年 10 月 4 日发布。源代码以类 BSD 许可证的形式发布,以稳定、丰富的功能集、示例配置文件和低系统资源消耗。
<p>虽然Node.JS的性能不错,但是处理静态事务真的不是他的专长,比如:gzip编码、静态文件、HTTP缓存、SSL处理、负载均衡和反向代理和多站点代理,等,可以通过 nginx可以做到,从而减少node.js的负载,通过nginx强大的缓存节省你的网站流量,从而提高网站的加载速度。
nodejs抓取动态网页(动态页面也一样能够做好SEO优化吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-06 21:04
对于网站优化,不需要真正的一成不变,只为达到网站搜索引擎优化的目的。其实动态页面也可以做SEO优化。
目前大部分搜索引擎基本都可以收录动态页面,使用动态页面的站点数量远远大于使用静态页面的站点数量。
尽管很多大的网站 URL 都有.htm 的后缀,但它们实际上是动态页面。他们只是使用 URL Rewrite 来“欺骗”搜索引擎。有不少是真正静态的,例如搜索引擎优化组织的那些。@网站,也是通过URL重写来实现伪静态的。
目前对于一个动态的网站来说,相对静态的实现方式有以下几种:
1. 伪静态,URL Rewrite 方法。
2. 与蜘蛛法类似,动态站点也存在,只不过是通过一个程序爬取整个站点,保存发布为需要访问的静态站点。
无论是真正的静态页面还是伪静态页面,在方便搜索引擎方面的效果都是一样的收录。既然如此,何不使用更高效的“相对静态”的方法来避免真静态带来的诸多问题呢?
关于页面更新维护的问题,即使是伪静态的,也会带来很大的维护复杂度和工作量。当前首选的更新方法是:
触发更新:当维护人员在后台更改某些信息时,系统自动或手动更新相应的显示页面。
独立、碎片化更新:更新和维护分离,页面分为不同的区域,区域按照一定的规则进行更新。对于区域之间的整合和分离,有的使用活动域,有的使用SSI(Server Side Include)。
对于独立和碎片化的更新,应该是大规模网站相对静态后比较理想的更新维护模式:
1. 定义每页的分区和编号。给定存储规则和更新规则,更新规则分为“基于数据变化的更新”和“定期更新”。
2. 各区采用优先方式,提供手动触发实时更新,保证部分信息需要更新。
3. 静态页面替换动态页面,同时保留动态页面,在静态页面还没有生成的情况下用动态页面替换。
对于网站优化来说,静态化只是为了更好地引导搜索引擎收录,让搜索引擎尽可能多的抓取网站内容。只要方便浏览和收录,无论是静态页面还是动态页面,搜索引擎都会一视同仁地对待收录。 查看全部
nodejs抓取动态网页(动态页面也一样能够做好SEO优化吗?(图))
对于网站优化,不需要真正的一成不变,只为达到网站搜索引擎优化的目的。其实动态页面也可以做SEO优化。
目前大部分搜索引擎基本都可以收录动态页面,使用动态页面的站点数量远远大于使用静态页面的站点数量。
尽管很多大的网站 URL 都有.htm 的后缀,但它们实际上是动态页面。他们只是使用 URL Rewrite 来“欺骗”搜索引擎。有不少是真正静态的,例如搜索引擎优化组织的那些。@网站,也是通过URL重写来实现伪静态的。
目前对于一个动态的网站来说,相对静态的实现方式有以下几种:
1. 伪静态,URL Rewrite 方法。
2. 与蜘蛛法类似,动态站点也存在,只不过是通过一个程序爬取整个站点,保存发布为需要访问的静态站点。
无论是真正的静态页面还是伪静态页面,在方便搜索引擎方面的效果都是一样的收录。既然如此,何不使用更高效的“相对静态”的方法来避免真静态带来的诸多问题呢?
关于页面更新维护的问题,即使是伪静态的,也会带来很大的维护复杂度和工作量。当前首选的更新方法是:
触发更新:当维护人员在后台更改某些信息时,系统自动或手动更新相应的显示页面。
独立、碎片化更新:更新和维护分离,页面分为不同的区域,区域按照一定的规则进行更新。对于区域之间的整合和分离,有的使用活动域,有的使用SSI(Server Side Include)。
对于独立和碎片化的更新,应该是大规模网站相对静态后比较理想的更新维护模式:
1. 定义每页的分区和编号。给定存储规则和更新规则,更新规则分为“基于数据变化的更新”和“定期更新”。
2. 各区采用优先方式,提供手动触发实时更新,保证部分信息需要更新。
3. 静态页面替换动态页面,同时保留动态页面,在静态页面还没有生成的情况下用动态页面替换。
对于网站优化来说,静态化只是为了更好地引导搜索引擎收录,让搜索引擎尽可能多的抓取网站内容。只要方便浏览和收录,无论是静态页面还是动态页面,搜索引擎都会一视同仁地对待收录。
nodejs抓取动态网页(下载壁纸的URL(幕后BOSS现身@ーー))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-06 06:18
分页:column/index_specific page number.htm
知道了这个规则,就可以批量下载壁纸了。
2. 分析壁纸缩略图,找到壁纸对应的大图
使用chrome开发者工具可以发现缩略图列表在div中,a标签的href属性值为单张壁纸所在的页面。
部分代码:
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
});
3. 用“”继续分析
打开这个页面,发现这个页面显示的壁纸依然不是最高分辨率。
单击“下载壁纸”按钮中的链接以打开一个新页面。
4. 用“”继续分析
打开这个页面,我们最后会下载壁纸,放到一张桌子上。如下所示,
这是我们最终要下载的图片的网址(BOSS终于出现在幕后了(@ ̄ー ̄@))。
下载图片的代码:
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
打开浏览器访问:1314/fengjing
选择栏目和页面,点击“开始”按钮:
同时请求服务器下载图片。
完成~
图片存储目录以列+页码的形式存储。
附上完整图片下载代码:
/**
* 下载图片
* @param {[type]} url [图片URL]
* @param {[type]} dir [存储目录]
* @param {[type]} res [description]
* @return {[type]} [description]
*/
var down_pic = function(url, dir, res){
var domain = 'http://www.netbian.com'; // 域名
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
var count = 0; // 并发计数器
var wallpaper = []; // 壁纸数组
var fetchPic = function(_pic_url, callback){
count++; // 并发加1
var delay = parseInt((Math.random() * 10000000) % 2000);
console.log('现在的并发数是:' + count + ', 正在抓取的图片的URL是:' + _pic_url + ' 时间是:' + delay + '毫秒');
setTimeout(function(){
// 获取大图链接
request
.get(_pic_url)
.end(function(err, ares){
var $$ = cheerio.load(ares.text);
var pic_down = url_model.resolve(domain, $$('.pic-down').find('a').attr('href')); // 大图链接
count--; // 并发减1
// 请求大图链接
request
.get(pic_down)
.charset('gbk') // 设置编码, 网页以GBK的方式获取
.end(function(err, pic_res){
var $$$ = cheerio.load(pic_res.text);
var wallpaper_down_url = $$$('#endimg').find('img').attr('src'); // URL
var wallpaper_down_title = $$$('#endimg').find('img').attr('alt'); // title
// 下载大图
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
wallpaper.push(wallpaper_down_title + '下载完毕<br />');
});
callback(null, wallpaper); // 返回数据
});
}, delay);
};
// 并发为2,下载壁纸
async.mapLimit(pic_url, 2, function(_pic_url, callback){
fetchPic(_pic_url, callback);
}, function (err, result){
console.log('success');
res.send(result[0]); // 取下标为0的元素
});
});
};
需要特别注意的两点:
1.“碧安桌面”网页的编码为“GBK”。而 nodejs 本身只支持“UTF-8”编码。这里我们引入了“superagent-charset”模块来处理“GBK”的编码。
附上一个来自github的例子
2. nodejs 是异步的。同时发送的大量请求可能被服务器当作恶意请求拒绝。所以这里引入了“async”模块进行并发处理,使用的方法是:mapLimit。
mapLimit(arr, limit, iterator, callback)
这个方法有4个参数:
第一个参数是一个数组。
第二个参数是并发请求数。
第三个参数是一个迭代器,通常是一个函数。
第四个参数是并发执行后的回调。
该方法的作用是将arr中的每个元素并发限制次数交给迭代器执行,执行结果传递给最终的回调。
后记
至此,图片的下载完成。
完整代码已经放在github上
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持和喜爱阅读建站教程! 查看全部
nodejs抓取动态网页(下载壁纸的URL(幕后BOSS现身@ーー))
分页:column/index_specific page number.htm
知道了这个规则,就可以批量下载壁纸了。
2. 分析壁纸缩略图,找到壁纸对应的大图
使用chrome开发者工具可以发现缩略图列表在div中,a标签的href属性值为单张壁纸所在的页面。
部分代码:
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
});
3. 用“”继续分析
打开这个页面,发现这个页面显示的壁纸依然不是最高分辨率。
单击“下载壁纸”按钮中的链接以打开一个新页面。
4. 用“”继续分析
打开这个页面,我们最后会下载壁纸,放到一张桌子上。如下所示,
这是我们最终要下载的图片的网址(BOSS终于出现在幕后了(@ ̄ー ̄@))。
下载图片的代码:
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
打开浏览器访问:1314/fengjing
选择栏目和页面,点击“开始”按钮:
同时请求服务器下载图片。
完成~
图片存储目录以列+页码的形式存储。
附上完整图片下载代码:
/**
* 下载图片
* @param {[type]} url [图片URL]
* @param {[type]} dir [存储目录]
* @param {[type]} res [description]
* @return {[type]} [description]
*/
var down_pic = function(url, dir, res){
var domain = 'http://www.netbian.com'; // 域名
request
.get(url)
.end(function(err, sres){
var $ = cheerio.load(sres.text);
var pic_url = []; // 中等图片链接数组
$('.list ul', 0).find('li').each(function(index, ele){
var ele = $(ele);
var href = ele.find('a').eq(0).attr('href'); // 中等图片链接
if(href != undefined){
pic_url.push(url_model.resolve(domain, href));
}
});
var count = 0; // 并发计数器
var wallpaper = []; // 壁纸数组
var fetchPic = function(_pic_url, callback){
count++; // 并发加1
var delay = parseInt((Math.random() * 10000000) % 2000);
console.log('现在的并发数是:' + count + ', 正在抓取的图片的URL是:' + _pic_url + ' 时间是:' + delay + '毫秒');
setTimeout(function(){
// 获取大图链接
request
.get(_pic_url)
.end(function(err, ares){
var $$ = cheerio.load(ares.text);
var pic_down = url_model.resolve(domain, $$('.pic-down').find('a').attr('href')); // 大图链接
count--; // 并发减1
// 请求大图链接
request
.get(pic_down)
.charset('gbk') // 设置编码, 网页以GBK的方式获取
.end(function(err, pic_res){
var $$$ = cheerio.load(pic_res.text);
var wallpaper_down_url = $$$('#endimg').find('img').attr('src'); // URL
var wallpaper_down_title = $$$('#endimg').find('img').attr('alt'); // title
// 下载大图
request
.get(wallpaper_down_url)
.end(function(err, img_res){
if(img_res.status == 200){
// 保存图片内容
fs.writeFile(dir + '/' + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, 'binary', function(err){
if(err) console.log(err);
});
}
});
wallpaper.push(wallpaper_down_title + '下载完毕<br />');
});
callback(null, wallpaper); // 返回数据
});
}, delay);
};
// 并发为2,下载壁纸
async.mapLimit(pic_url, 2, function(_pic_url, callback){
fetchPic(_pic_url, callback);
}, function (err, result){
console.log('success');
res.send(result[0]); // 取下标为0的元素
});
});
};
需要特别注意的两点:
1.“碧安桌面”网页的编码为“GBK”。而 nodejs 本身只支持“UTF-8”编码。这里我们引入了“superagent-charset”模块来处理“GBK”的编码。
附上一个来自github的例子
2. nodejs 是异步的。同时发送的大量请求可能被服务器当作恶意请求拒绝。所以这里引入了“async”模块进行并发处理,使用的方法是:mapLimit。
mapLimit(arr, limit, iterator, callback)
这个方法有4个参数:
第一个参数是一个数组。
第二个参数是并发请求数。
第三个参数是一个迭代器,通常是一个函数。
第四个参数是并发执行后的回调。
该方法的作用是将arr中的每个元素并发限制次数交给迭代器执行,执行结果传递给最终的回调。
后记
至此,图片的下载完成。
完整代码已经放在github上
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持和喜爱阅读建站教程!
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-26 07:10
其实我之前做过利马财经的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码才能执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
由于最近了解了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫还是比较简单的,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面的结构是什么,不需要登录;有没有ajax接口,返回什么样的数据等
2. 数据采集
要分析清楚要爬取哪些页面和ajax,就需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创数据进行处理和分析,然后返回给客户端。这个过程可以在存储时进行处理,也可以在显示时,前端发送请求,后台取出存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中获取数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以立即删除它。
5. arr-sort
arr-sort 是我自己写的一个数组排序方法工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,基本没人买,所以我们不买)不要在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期经常断货,可能看不到数据,1月19日前可以看到数据) 数据如下图所示:
这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:
但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i 查看全部
nodejs抓取动态网页(爬虫爬取的流程和最终如何展示数据的地址?)
其实我之前做过利马财经的销售统计,不过是前端js写的。需要在首页的控制台调试面板中粘贴一段代码才能执行,点击这里。主要目的是通过定时爬取异步接口来获取数据。然后通过一定的去重算法得到最终的数据。但这有以下缺点:
代码只能在浏览器窗口中运行。如果浏览器关闭或电脑无效,则只能抓取一个页面的数据,无法整合其他页面的数据。爬取的数据无法存储在本地。异步接口数据将被部分过滤。导致我们的去重算法失败
由于最近了解了节点爬虫,所以可以在后台模拟请求,爬取页面数据。而且我开通了阿里云服务器,我可以把代码放到云端运行。这样1、2、3都可以解决。4因为我们不知道这个ajax界面每三分钟更新一次,这样我们就可以以此为基础对权重进行排序,保证数据不会重复。说起爬虫,大家想到的更多的是python。确实,python有Scrapy等成熟的框架,可以实现非常强大的爬虫功能。但是node也有自己的优势。凭借其强大的异步特性,可以轻松实现高效的异步并发请求,节省CPU开销。其实节点爬虫还是比较简单的,让'
在线地址
一、爬虫进程
我们的最终目标是爬取利马财经每天的销售额,知道销售了哪些产品,哪些用户在什么时间点购买了每种产品。首先介绍一下爬取的主要步骤:
1. 结构分析
我们要抓取页面的数据。第一步当然是分析页面结构,抓取哪些页面,页面的结构是什么,不需要登录;有没有ajax接口,返回什么样的数据等
2. 数据采集
要分析清楚要爬取哪些页面和ajax,就需要爬取数据。现在网页的数据大致分为同步页面和ajax接口。同步页面数据的爬取需要我们首先分析网页的结构。Python爬取数据一般是通过正则表达式匹配获取需要的数据;node有一个cheerio工具,可以将获取到的页面内容转换成jquery对象。然后就可以使用jquery强大的dom API来获取节点相关的数据了。其实看源码,这些API本质上都是正则匹配。ajax接口数据一般都是json格式,处理起来比较简单。
3. 数据存储
捕获数据后,它会做一个简单的筛选,然后将需要的数据保存起来,以便后续的分析和处理。当然我们可以使用MySQL、Mongodb等数据库来存储数据。这里,为了方便,我们直接使用文件存储。
4. 数据分析
因为我们最终要展示数据,所以需要按照一定的维度对原创数据进行处理和分析,然后返回给客户端。这个过程可以在存储时进行处理,也可以在显示时,前端发送请求,后台取出存储的数据进行处理。这取决于我们希望如何显示数据。
5. 结果展示
做了这么多功课,一点显示输出都没有,怎么不甘心?这又回到我们的老本行了,前端展示页面大家应该都很熟悉了。将数据展示更直观,方便我们进行统计分析。
二、常见爬虫库介绍1. Superagent
Superagent 是一个轻量级的 http 库。是nodejs中一个非常方便的客户端请求代理模块。当我们需要进行get、post、head等网络请求时,试试吧。
2. 啦啦队
Cheerio可以理解为jquery的一个Node.js版本,用于通过css选择器从网页中获取数据,用法和jquery完全一样。
3. 异步
async 是一个流程控制工具包,提供了直接强大的异步函数mapLimit(arr,limit,iterator,callback),我们主要使用这个方法,可以去官网看API。
4. arr-del
arr-del 是我自己写的一个删除数组元素的工具。通过传入由要删除的数组元素的索引组成的数组,可以立即删除它。
5. arr-sort
arr-sort 是我自己写的一个数组排序方法工具。可以根据一个或多个属性进行排序,支持嵌套属性。而且可以在每个条件中指定排序方向,传入比较函数。
三、页面结构分析
让我们重复爬行的想法。利马理财网上的产品主要是普通的和利马金库(新推出的光大银行理财产品,手续繁琐,初期投资额高,基本没人买,所以我们不买)不要在这里计算它们)。定期我们可以爬取财富管理页面的ajax界面:。(更新:近期经常断货,可能看不到数据,1月19日前可以看到数据) 数据如下图所示:
这包括所有在线销售的常规产品。Ajax数据只有产品本身的信息,比如产品id、募集金额、当前销售额、年化收益率、投资天数等,没有关于谁购买了产品的信息。. 所以我们需要去它的商品详情页面用id参数进行爬取,比如Lima Jucai-December HLB01239511。详情页有一栏投资记录,里面有我们需要的信息,如下图:
但是,详情页只有在我们登录后才能查看,这就需要我们访问cookies,cookies是有有效期的。如何让我们的 cookie 保持登录状态?请稍后再看。
其实Lima Vault也有类似的ajax接口:,只是里面的相关数据是硬编码的,毫无意义。并且金库的详情页也没有投资记录信息。这就需要我们爬取我们开头所说的主页的ajax接口:。但是后来我发现这个界面每三分钟更新一次,也就是说后台每三分钟向服务器请求一次数据。一次有10条数据,所以如果三分钟内购买记录超过10条,数据就会有遗漏。没办法,所以直接金库的统计数据会比真实的少。
四、爬虫代码分析1. 获取登录cookie
因为商品详情页需要登录,所以我们需要先获取登录cookie。getCookie 方法如下:
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}
手机号和密码参数是从命令行传入的,就是用你的手机号登录的账号和密码。我们使用superagent来模拟请求即时理财登录界面:。传入相应的参数。在回调中,我们获取头部的 set-cookie 信息,并发送一个 setCookeie 事件。因为我们设置了监听事件:emitter.on("setCookie", requestData),一旦拿到cookie,就会执行requestData方法。
2. 财富管理页面ajax爬取
requestData方法的代码如下:
<p>function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-26 07:08
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是superagent只支持utf-8网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
用
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?
为了让浏览器能够正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的charset内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用! 查看全部
nodejs抓取动态网页(如何才能做到动态指定网页编码的问题?(图))
使用 superagent 抓取 网站 内容。当网页编码不是utf-8编码时,中文会返回乱码。原因是superagent只支持utf-8网页编码。我们可以使用它的扩展 npm 模块 superagent-charset
superagent-charset 使用说明
superagent-charset 扩展了superagent的功能,可以手动指定编码功能。
安装
$ npm i superagent-charset
用
使用 .charset(encoding) 方法,您可以指定编码。详细情况如下:
var assert = require('assert');
var request = require('superagent-charset');
request
.get('http://www.sohu.com/')
.charset('gbk')
.end(function(err,res) {
assert(res.text.indexOf('搜狐') > -1);
});
潜在问题
到目前为止,只解决了我们如何设置编码的问题,但是通常我们抓取网页的时候,都是动态抓取的,也就是说,我们没有手动指定网页的编码,那我们该怎么做呢?动态?指定网页编码怎么样?可以这样做:
动态获取指定的网站编码的网站编码并抓取
如何动态获取网站代码?
为了让浏览器能够正常渲染网页信息,网站通常会设置meta charset信息,比如
或者
我们可以写一个正则匹配规则来匹配这个信息中的charset内容来获取编码,如下:
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
当然,前提是我们需要先爬下网页。完整代码如下:
parseUrl: function (url, callback) {
async.waterfall([
function (callback) { // 动态获取网站编码
superagent.get(url).end(function (err, res) {
var charset = "utf-8";
var arr = res.text.match(/]*?)>/g);
if (arr) {
arr.forEach(function (val) {
var match = val.match(/charset\s*=\s*(.+)\"/);
if (match && match[1]) {
if (match[1].substr(0, 1) == '"')match[1] = match[1].substr(1);
charset = match[1].trim();
}
})
}
callback(err, charset)
})
}, function (charset, callback) { // 内容爬取
superagent
.get(url)
.charset(charset)
.end(function (err, res) {
if (err) {
console.log(err);
callback(err);
return;
}
var model = {};
var $ = cheerio.load(res.text);
var title = _.trim($('title').text());
if (title.indexOf('-') > 0) {
var strs = _.split(title, '-');
model.title = _.trim(title.substr(0, title.lastIndexOf('-')));
model.source = _.trim(_.last(strs));
} else {
model.title = _.trim(title);
}
callback(err, model);
})
}
],
function (err, model) {
callback(err, model);
});
}
整个想法:
现在向下爬取网页内容,动态获取代码,然后使用获取的代码再次爬取。
所以,缺点是:同一个页面要爬两次!同一个页面要爬两次!同一个页面要爬两次!
谨慎使用!
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-24 12:01
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把肖战(花满楼)的所有页面都静止了;后来想了想,虽然不是特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .
; 后来做了一个专门的站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。在路由中,还是像之前一样取数据,将得到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .
; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i 查看全部
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把肖战(花满楼)的所有页面都静止了;后来想了想,虽然不是特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .
; 后来做了一个专门的站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器-Gulp)。我想是这样。编译后的 html 用作类似模板的模块。在路由中,还是像之前一样取数据,将得到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .
; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-23 10:12
本文是使用 nodejs 编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法。
常用模块
常用的模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise。这是一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
复制代码
通过在 async 函数中使用 await 调用 promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中, fs 模块是一个非常常用的原生模块,用于操作文件。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。在自己编写的模块中访问文件后导出一些接口时,此时使用同步API是非常实用的,但是为了充分发挥node异步的优势,还是应该尽量使用异步接口.
我们可以使用 fs-extra 模块代替 fs 模块。类似的模块包括 mz。fs-extra 收录了 fs 模块的所有接口,同时也为每个异步接口提供了 promise 支持。更好的是,fs-extra 还提供了一些其他有用的文件操作功能,例如删除和移动文件。更详细的介绍请查看官方仓库fs-extra。
超级代理
Superagent是一个节点的http客户端,类似于java中的httpclient和okhttp和python中的requests。让我们模拟http请求。超级代理库具有许多实用功能。
superagent会根据响应的content-type自动序列化,序列化的返回内容可以通过response.body获取
这个库会自动缓存和发送cookies,不需要我们手动管理cookies
第二点就是它的api是链式调用的风格,调用起来很爽,但是使用的时候要注意调用顺序。
它的异步 API 都返回承诺。
非常方便。官方文档是一个很长的页面,目录很清晰,很容易搜索到你需要的内容。最后,superagent 还支持插件集成。比如需要超时后自动重发,可以使用superagent-retry。更多插件可以到npm官网搜索关键词superagent-。更多详情请看官方文档superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
复制代码
啦啦队
写过爬虫的都知道,我们经常需要解析html,从网页源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 是为服务器端设计的,给你一个近乎完整的jquery 体验。使用cheerio解析html获取元素,调用方法与jquery操作dom元素的用法完全一样。它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
复制代码
官方仓库:cheerio
日志4js
log4j 是一个为 node 设计的日志模块。类似的模块也有debug模块,不过我觉得log4js满足了我对日志库的需求。调试模块可以用于简单的场景。事实上,他们有不同的定位。debug 模块只是为了调试而设计的,而 log4js 是一个日志库,必须提供文件输出和分类功能。
log4js 模块的名字有点符合java中著名的日志库log4j。Log4j 具有以下特点:
您可以自定义 appender(输出目的地),lo4js 甚至提供了一个输出到邮件和其他目的地的 appender。通过组合不同的appender,可以实现不同目的的记录器(loggers)提供日志分级功能。官方FAQ提到如果要进行appender级别的过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
通过我最近的爬虫项目的配置文件来感受一下下面这个库的特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
复制代码
续集
我们在写项目的时候经常会有持久化的需求。简单的场景可以使用JSON来保存数据。如果数据量比较大,又容易管理,那就要考虑使用数据库了。如果是操作mysql和sqllite,建议使用sequelize,如果是mongodb,我建议使用专门为mongodb设计的mongoose
sequelize 的一些东西我觉得还是有点不好的,比如默认的生成id(主键)、createdAt 和updatedAt。
撇开一些自以为是的小问题不谈,sequelize 设计的很好,内置的算子、钩子、验证器都很有意思。Sequelize 还提供 promise 和 typescript 支持。如果您正在使用 typescript 开发项目,那么有一个很好的 orm 选项:typeorm。详情请看官方文档:sequelize
粉笔
粉笔在中文中是粉笔的意思。该模块是一个非常有特色和实用的node模块。它可以为您的输出添加颜色、下划线、背景颜色和其他装饰。当我们在写项目的时候需要输出请求信息等内容时,我们可以适当的使用chalk来高亮一些内容,比如请求的URL加下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
复制代码
调用上面的logRequest效果:
更多信息请看官方仓库粉笔
傀儡师
如果你没有听说过这个库,你可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,它通过 devtools 协议操作 chrome 或 Chromium。质量有保证。该模块提供了一些高级 API。默认情况下,通过该库操作的浏览器用户是看不到界面的,这就是所谓的无头浏览器。当然也可以通过配置以界面方式启动模式。在 chrome 中还有一些专门用于记录 puppeteer 操作的扩展,例如 Puppeteer Recorder。使用这个库,我们可以抓取一些由js渲染的信息,而不是直接存在于页面的源代码中。比如spa页面中,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。当页面上出现某个标签时,我们可以调用puppeteer来获取页面渲染出来的html。事实上,很多高难度爬虫的终极法宝就是操纵浏览器。
Pre-js 语法 async/await
首先要提到的是async/await,因为node很早就已经支持async/await(node 8 LTS),现在写后端项目时没有理由不使用async/await。使用 async/await 可以让我们摆脱回调炼狱的困境。这里主要讲一下使用async/await时可能遇到的问题。如何使用 async/await 进行并发?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i < max; i++) {
await sleep(1000);
}
}
const test2 = async () => {
Array.from({
length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
复制代码
操作的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
复制代码
我想有些人可能会认为测试 forEach 的结果会在 1 秒左右。实际上,test 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({
length: 3}).forEach(() => {
sleep(1000);
});
}
复制代码
转载于: 查看全部
nodejs抓取动态网页(使用nodejs写爬虫过程中常用模块和一些必须掌握的js模块)
本文是使用 nodejs 编写爬虫系列教程的第一篇。介绍了使用nodejs编写爬虫过程中常用的模块以及一些必须掌握的js语法。
常用模块
常用的模块如下:
fs-extrasuperagentcheeriolog4jssequelizechalkpuppeteerfs-extra
使用async/await的前提是接口必须封装成promise。这是一个简单的例子:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const main = async () => {
await sleep(5000);
console.log('5秒后...');
}
main();
复制代码
通过在 async 函数中使用 await 调用 promise 来组织异步代码就像同步代码一样,非常自然,有助于我们分析代码的执行流程。
在 node 中, fs 模块是一个非常常用的原生模块,用于操作文件。fs(文件系统)模块提供了一些与文件系统相关的同步和异步API。有时需要使用同步 API。在自己编写的模块中访问文件后导出一些接口时,此时使用同步API是非常实用的,但是为了充分发挥node异步的优势,还是应该尽量使用异步接口.
我们可以使用 fs-extra 模块代替 fs 模块。类似的模块包括 mz。fs-extra 收录了 fs 模块的所有接口,同时也为每个异步接口提供了 promise 支持。更好的是,fs-extra 还提供了一些其他有用的文件操作功能,例如删除和移动文件。更详细的介绍请查看官方仓库fs-extra。
超级代理
Superagent是一个节点的http客户端,类似于java中的httpclient和okhttp和python中的requests。让我们模拟http请求。超级代理库具有许多实用功能。
superagent会根据响应的content-type自动序列化,序列化的返回内容可以通过response.body获取
这个库会自动缓存和发送cookies,不需要我们手动管理cookies
第二点就是它的api是链式调用的风格,调用起来很爽,但是使用的时候要注意调用顺序。
它的异步 API 都返回承诺。
非常方便。官方文档是一个很长的页面,目录很清晰,很容易搜索到你需要的内容。最后,superagent 还支持插件集成。比如需要超时后自动重发,可以使用superagent-retry。更多插件可以到npm官网搜索关键词superagent-。更多详情请看官方文档superagent
// 官方文档的一个调用示例
request
.post('/api/pet')
.send({ name: 'Manny', species: 'cat' })
.set('X-API-Key', 'foobar')
.set('Accept', 'application/json')
.then(res => {
alert('yay got ' + JSON.stringify(res.body));
});
复制代码
啦啦队
写过爬虫的都知道,我们经常需要解析html,从网页源代码中爬取信息应该是最基本的爬取方式。python中有beautifulsoup,java中有jsoup,node中有cheerio。
Cheerio 是为服务器端设计的,给你一个近乎完整的jquery 体验。使用cheerio解析html获取元素,调用方法与jquery操作dom元素的用法完全一样。它还提供了一些方便的接口,比如获取html,看一个例子:
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
复制代码
官方仓库:cheerio
日志4js
log4j 是一个为 node 设计的日志模块。类似的模块也有debug模块,不过我觉得log4js满足了我对日志库的需求。调试模块可以用于简单的场景。事实上,他们有不同的定位。debug 模块只是为了调试而设计的,而 log4js 是一个日志库,必须提供文件输出和分类功能。
log4js 模块的名字有点符合java中著名的日志库log4j。Log4j 具有以下特点:
您可以自定义 appender(输出目的地),lo4js 甚至提供了一个输出到邮件和其他目的地的 appender。通过组合不同的appender,可以实现不同目的的记录器(loggers)提供日志分级功能。官方FAQ提到如果要进行appender级别的过滤,可以使用logLevelFilter提供滚动日志和自定义输出格式
通过我最近的爬虫项目的配置文件来感受一下下面这个库的特点:
const log4js = require('log4js');
const path = require('path');
const fs = require('fs-extra');
const infoFilePath = path.resolve(__dirname, '../out/log/info.log');
const errorFilePath = path.resolve(__dirname, '../out/log/error.log');
log4js.configure({
appenders: {
dateFile: {
type: 'dateFile',
filename: infoFilePath,
pattern: 'yyyy-MM-dd',
compress: false
},
errorDateFile: {
type: 'dateFile',
filename: errorFilePath,
pattern: 'yyyy-MM-dd',
compress: false,
},
justErrorsToFile: {
type: 'logLevelFilter',
appender: 'errorDateFile',
level: 'error'
},
out: {
type: 'console'
}
},
categories: {
default: {
appenders: ['out'],
level: 'trace'
},
qupingce: {
appenders: ['out', 'dateFile', 'justErrorsToFile'],
level: 'trace'
}
}
});
const clear = async () => {
const files = await fs.readdir(path.resolve(__dirname, '../out/log'));
for (const fileName of files) {
fs.remove(path.resolve(__dirname, `../out/log/${fileName}`));
}
}
module.exports = {
log4js,
clear
}
复制代码
续集
我们在写项目的时候经常会有持久化的需求。简单的场景可以使用JSON来保存数据。如果数据量比较大,又容易管理,那就要考虑使用数据库了。如果是操作mysql和sqllite,建议使用sequelize,如果是mongodb,我建议使用专门为mongodb设计的mongoose
sequelize 的一些东西我觉得还是有点不好的,比如默认的生成id(主键)、createdAt 和updatedAt。
撇开一些自以为是的小问题不谈,sequelize 设计的很好,内置的算子、钩子、验证器都很有意思。Sequelize 还提供 promise 和 typescript 支持。如果您正在使用 typescript 开发项目,那么有一个很好的 orm 选项:typeorm。详情请看官方文档:sequelize
粉笔
粉笔在中文中是粉笔的意思。该模块是一个非常有特色和实用的node模块。它可以为您的输出添加颜色、下划线、背景颜色和其他装饰。当我们在写项目的时候需要输出请求信息等内容时,我们可以适当的使用chalk来高亮一些内容,比如请求的URL加下划线。
const logRequest = (response, isDetailed = false) => {
const URL = chalk.underline.yellow(response.request.url);
const basicInfo = `${response.request.method} Status: ${response.status} Content-Type: ${response.type} URL=${URL}`;
if (!isDetailed) {
logger.info(basicInfo);
} else {
const detailInfo = `${basicInfo}\ntext: ${response.text}`;
logger.info(detailInfo);
}
};
复制代码
调用上面的logRequest效果:
更多信息请看官方仓库粉笔
傀儡师
如果你没有听说过这个库,你可能听说过 selenium。puppeteer 是 Google Chrome 团队开源的一个节点模块,它通过 devtools 协议操作 chrome 或 Chromium。质量有保证。该模块提供了一些高级 API。默认情况下,通过该库操作的浏览器用户是看不到界面的,这就是所谓的无头浏览器。当然也可以通过配置以界面方式启动模式。在 chrome 中还有一些专门用于记录 puppeteer 操作的扩展,例如 Puppeteer Recorder。使用这个库,我们可以抓取一些由js渲染的信息,而不是直接存在于页面的源代码中。比如spa页面中,页面的内容是js渲染的。这时候puppeteer就为我们解决了这个问题。当页面上出现某个标签时,我们可以调用puppeteer来获取页面渲染出来的html。事实上,很多高难度爬虫的终极法宝就是操纵浏览器。
Pre-js 语法 async/await
首先要提到的是async/await,因为node很早就已经支持async/await(node 8 LTS),现在写后端项目时没有理由不使用async/await。使用 async/await 可以让我们摆脱回调炼狱的困境。这里主要讲一下使用async/await时可能遇到的问题。如何使用 async/await 进行并发?
看一段测试代码:
const sleep = (milliseconds) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), milliseconds)
})
}
const test1 = async () => {
for (let i = 0, max = 3; i < max; i++) {
await sleep(1000);
}
}
const test2 = async () => {
Array.from({
length: 3}).forEach(async () => {
await sleep(1000);
});
}
const main = async () => {
console.time('测试 for 循环使用 await');
await test1();
console.timeEnd('测试 for 循环使用 await');
console.time('测试 forEach 调用 async 函数')
await test2();
console.timeEnd('测试 forEach 调用 async 函数')
}
main();
复制代码
操作的结果是:
测试 for 循环使用 await: 3003.905ms
测试 forEach 调用 async 函数: 0.372ms
复制代码
我想有些人可能会认为测试 forEach 的结果会在 1 秒左右。实际上,test 2 等价于如下代码:
const test2 = async () => {
// Array.from({length: 3}).forEach(async () => {
// await sleep(1000);
// });
Array.from({
length: 3}).forEach(() => {
sleep(1000);
});
}
复制代码
转载于:
nodejs抓取动态网页(如何使用nodejs种的http(s)模块来请求目标网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-23 04:18
我们可以使用 nodejs http(s) 模块来请求目标 URL,也可以使用第三方库如 axios` 来请求网页。拿到html后,使用html解析库解析成易于操作的js对象,然后抓取目标内容。解析库建议在此处使用 `cheerio。Cheerio提供了类似jQuery的操作方式,可以很方便的抓取我们想要的内容。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
console.log(resp.data)
}
main()
通过节点demo1执行demo1,我们可以得到短书首页的html。
我们现在完成demo1的代码并使用cheerio解析html。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
const $ = cheerio.load(resp.data)
const articleList = []
$('#list-container li').each((i, el) => {
articleList.push({
id: $(el).attr('id').replace('note-', ''),
title: unescape($(el).find('.title').html().replace(/&#x/g, '%u').replace(/;/g, '')),
href: $(el).find('.title').attr('href'),
})
})
console.log(articleList)
}
main()
这样我们就得到了文章的id、title和link。
这种方式捕获数据的优点是效率高,硬件资源少。但是这种方法也有一些缺点。例如,延迟加载页面很难抓取。因为延迟加载页面的内容是由浏览器js动态加载的,这样我们请求的页面,因为js还没有把内容渲染到页面,所以我们无法正确获取页面内容,而我们的请求也未能提供页面js所需的运行环境。这个时候我们将介绍我们的另一个爬虫。
无头浏览器
无头浏览器是指在后台运行的网页浏览器程序,没有操作界面。常用的无头浏览器有PhantomJS、Selenium、Puppeteer等(还有很多很多,有兴趣的可以去看看)。
Headless 浏览器常用于自动化测试、爬虫等技术。它提供了浏览器js所需的运行环境,我们可以用它来处理延迟加载页面。
Puppeteer 是 Google 发布的 Chromium 无头浏览器。这里我们以Puppeteer为例,写一些小demo。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
}
main()
我们使用节点demo2来执行:
我们现在已经用代码打开了一个浏览器窗口。接下来我们会继续完善demo2来抓取这个页面的内容。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null,
devtools: true,
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
const articleList = await page.$$eval('#list-container li', els =>
els.map(el => {
const id = el.dataset.noteId
const title = el.querySelector('.title').innerText
const url = el.querySelector('.title').href
return {id, title, url}
})
)
console.log(articleList)
}
main()
执行这段代码,我们得到以下结果:
这是无头浏览器的基本用法。它还提供了很多方便的API,比如page.waitFor(selector, pageFun)`方法,可以在执行pageFun方法之前等待一个元素出现在页面上。还有一个`page.addScriptTag(options)方法,可以直接将自己的js脚本注入页面。
在此再次请大家不要滥用爬虫采集资源攻击他人服务器。
两种方法的比较 查看全部
nodejs抓取动态网页(如何使用nodejs种的http(s)模块来请求目标网址)
我们可以使用 nodejs http(s) 模块来请求目标 URL,也可以使用第三方库如 axios` 来请求网页。拿到html后,使用html解析库解析成易于操作的js对象,然后抓取目标内容。解析库建议在此处使用 `cheerio。Cheerio提供了类似jQuery的操作方式,可以很方便的抓取我们想要的内容。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
console.log(resp.data)
}
main()
通过节点demo1执行demo1,我们可以得到短书首页的html。
我们现在完成demo1的代码并使用cheerio解析html。
// demo1
const cheerio = require('cheerio')
const axios = require('axios')
async function main() {
const resp = await axios.get('https://www.jianshu.com/')
const $ = cheerio.load(resp.data)
const articleList = []
$('#list-container li').each((i, el) => {
articleList.push({
id: $(el).attr('id').replace('note-', ''),
title: unescape($(el).find('.title').html().replace(/&#x/g, '%u').replace(/;/g, '')),
href: $(el).find('.title').attr('href'),
})
})
console.log(articleList)
}
main()
这样我们就得到了文章的id、title和link。
这种方式捕获数据的优点是效率高,硬件资源少。但是这种方法也有一些缺点。例如,延迟加载页面很难抓取。因为延迟加载页面的内容是由浏览器js动态加载的,这样我们请求的页面,因为js还没有把内容渲染到页面,所以我们无法正确获取页面内容,而我们的请求也未能提供页面js所需的运行环境。这个时候我们将介绍我们的另一个爬虫。
无头浏览器
无头浏览器是指在后台运行的网页浏览器程序,没有操作界面。常用的无头浏览器有PhantomJS、Selenium、Puppeteer等(还有很多很多,有兴趣的可以去看看)。
Headless 浏览器常用于自动化测试、爬虫等技术。它提供了浏览器js所需的运行环境,我们可以用它来处理延迟加载页面。
Puppeteer 是 Google 发布的 Chromium 无头浏览器。这里我们以Puppeteer为例,写一些小demo。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
}
main()
我们使用节点demo2来执行:
我们现在已经用代码打开了一个浏览器窗口。接下来我们会继续完善demo2来抓取这个页面的内容。
// demo2
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch({
// 是否为无头,无头模式下没有用户操作界面
headless: false,
defaultViewport: null,
devtools: true,
})
const page = await browser.newPage();
await page.goto('https://www.jianshu.com/u/04d11dd2f924');
const articleList = await page.$$eval('#list-container li', els =>
els.map(el => {
const id = el.dataset.noteId
const title = el.querySelector('.title').innerText
const url = el.querySelector('.title').href
return {id, title, url}
})
)
console.log(articleList)
}
main()
执行这段代码,我们得到以下结果:
这是无头浏览器的基本用法。它还提供了很多方便的API,比如page.waitFor(selector, pageFun)`方法,可以在执行pageFun方法之前等待一个元素出现在页面上。还有一个`page.addScriptTag(options)方法,可以直接将自己的js脚本注入页面。
在此再次请大家不要滥用爬虫采集资源攻击他人服务器。
两种方法的比较
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-23 01:14
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .
; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器——Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .
; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i 查看全部
nodejs抓取动态网页(网上提了个问:Express4开发的动态页面访问好慢的说?)
上周在MOOC网站问了一个问题:Express4开发的动态页面访问有多慢?不幸的是,我没有得到可行的答案。周末折腾了一下,把小站(花满楼)的所有页面都静止了;仔细想想,这并不是一个特别标准的做法。, 不过折腾了这么久,终于有了解决这个问题的办法,还是有些欣慰的;
一开始页面是动态的,由jade模板渲染出来的,但是不明白为什么不管页面的内容,打开都需要至少一秒。. .
; 后来特地做了一个站点作为静态资源站,缓存和gzip(Nodejs搭建静态资源服务器和文件上传);OK,现在静态资源没有大问题;但是页面打开速度不理想,那就后台再按一下,来app.use(compress()); 事实证明,没有明显的效果;刚学Nodejs就郁闷,所以遇到这个无语的问题,百度了好久,哈哈。. . 最后,我只想到了一种方法。参考静态资源站点,将jade编译成html,将动态页面转成静态资源。它会像加载静态资源一样快吗?答案是肯定的!!!
就我的博客站点而言,我现在面临两个问题:一是直接编译原玉保留动态数据;另一种是去除动态数据编译成html,在ajax页面加载后请求数据;我选择前者,因为它可以在静态页面上保持最新的数据,而后者是js渲染的,对SEO很不利;哈哈,其实这两种方法我都没有用过,因为在这个层面上,在express框架中,没听说过这种方法,自然下不来,只是一个理想的可行方案;
我该怎么办?好吧,原谅我选择放弃express的内置模板。经过一番整理,Gulp(gulp-jade模块)直接将那些jade全部编译成html(前端自动化的神器——Gulp)。我想是这样。编译后的 html 用作类似模板的模块。数据还是像之前一样在路由中取,将获取到的数据作为变量传递给html模板模块对应的接口,然后返回的html生成为一个真正的静态页面,这样,在路由器不变的情况下,直接生成原玉到对应目录;如上所述,页面需要像静态资源一样加载才能快速;
Gulpfile.js
1 var jade=require('gulp-jade');
2
3 gulp.task('jade',function() {
4 gulp.src('./views/bokeDetail.jade')
5 .pipe(jade({pretty:true}))
6 .pipe(gulp.dest('./public/famanoder/'));
7 });
bokeDetail.templ.js
1 var html=function(id,title,subtitle,time,from,contents){
2 //传递动态数据
3 return ''+动态数据+'';
4 }
5 //片段,实际情况而定
bokeDetail.js(路由器)
1 //......
2 //引入对应静态模块
3 var boketempl=require('./templs/bokeDetail.templ.js);
4
5 //依旧读取数据
6 //传递数据:如,id,title,content,comments
7 //生成静态页面到指定目录
8 function createStaticPage(id,title,content,comments,fn){
9 var path='./public/famanoder/';
10 var html=boketempl(id,title,content,comments);
11 var ws=fs.createWriteStream(path+id+'.html');
12 ws.write(html,function(err) {
13 console.log('writePage:'+path+id+'.html');
14 fn&&fn();
15 });
16 ws.on('drain',function() {
17 ws.end();
18 });
19 }
ok,程序执行后会生成静态页面,动态数据放到public下的famanoder目录下;下面是将响应直接指向bokeDetail.js(路由器)中上面生成的静态页面;
1 var pathname=url.parse(req.url).pathname;
2 var realpath='./public/famanoder/'+pathname.substr(pathname.lastIndexOf('/')+1)+'.html';
3 var type='text/html';
4 var extname='html';
5 fs.exists(realpath,function(exist){
6 if(!exist){console.log(101);
7 res.writeHead(404,{
8 'content-type':'text/plain'
9 });
10 res.write('The Resourse '+pathname+' was Not Found!');
11 res.end();
12 }else{
13 fs.readFile(realpath,'binary',function(err,file){
14 console.log(11);
15 if(err){
16 res.writeHead(500,{
17 'content-type':'text/plain'
18 });
19 res.end();
20 }
21 if(extname.match(config.fileMatch)){
22 var expires=new Date();
23 expires.setTime(expires.getTime()+config.maxAge*1000);
24 res.setHeader('Expires',expires.toUTCString());
25 res.setHeader('cache-control','max-age='+config.maxAge);
26 }
27 fs.stat(realpath,function(err,stat){
28 var lastModified=stat.mtime.toUTCString();
29 res.setHeader('Last-Modified',lastModified);
30
31 if(req.headers['if-modified-since']&&lastModified==req.headers['if-modified-since']){
32 console.log(0);
33 res.writeHead(304,{
34 'content-type':type
35 });
36 res.end();
37 }else{
38 var raw=fs.createReadStream(realpath);
39 var acceptEncoding=req.headers['accept-encoding']||'';
40 var matched=extname.match(/css|js|html/ig);
41 if(matched&&acceptEncoding.match(/\bgzip\b/)){
42 console.log(1);
43 res.writeHead(200,{
44 'content-type':type,
45 'Content-Encoding':'gzip'
46 });
47 raw.pipe(zlib.createGzip()).pipe(res);
48 }else if(matched&&acceptEncoding.match(/\bdeflate\b/)){
49 console.log(2);
50 res.writeHead(200,{
51 'content-type':type,
52 'Content-Encoding':'deflate'
53 });
54 raw.pipe(zlib.createDeflate()).pipe(res);
55 }else{
56 console.log(3);
57 res.writeHead(200,{
58 'content-type':type
59 });
60 raw.pipe(res);
61 }
62 }
63 });
64 });
65 }
66 });
再次访问详细信息页面,查看秒数是否打开。纯静态,路由没变,url没变,维护也很简单。只需更改 bokeDetail.templ.js; 没办法,可能在英雄眼中吧。这是傻瓜式,只是让你发笑;与此方法类似,网站的所有页面现在都是静态的,并且 SEO 得到充分照顾;
嗯,其实还有一个很重要的问题:就博客的细节而言,如果博客数量很多,如何批量转移?其实我在编辑和提交博客的时候顺便生成了一个静态页面。为了让详情页快点。. .
; 问题来了,如果我之前有成百上千的博客(当然,我的小前端远没有达到这样的丰硕成果),我一定不能再编辑提交每个博客;吓死宝宝了,别急,新建一个update.js直接批量生成,非常快!
<p> 1 Artical
2 .find({}).exec(function(err,docs) {
3 update(err,docs);
4 });
5
6 function update(err,docs) {
7 err&&console.log(err);
8 for(var i=0;i
nodejs抓取动态网页(使用ScrapySharp快速从网页中采集数据中的采集方案介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-23 01:13
在上一篇文章中,介绍了使用ScrapySharp快速获取网页数据采集。这种方式是通过直接Http请求获取原创页面信息,对于静态网页非常有效,但是网站中也有很多页面内容并没有全部存储在原创页面中。很多内容是通过javascript动态生成的,这些数据是不能用前面的方法捕获的。下面简单介绍一下采集动态网页的解决方案。
对于这样的网页数据采集,往往会使用浏览器引擎加载整个页面,加载后输出完整的页面,然后使用ScrapySharp等工具进行分析。常用的有以下几种方式:
使用 WebBrowser 控件
我相信大多数 .Net 开发人员都使用过这种方法。由于WebBrowser直接使用与操作系统集成的IE浏览器,无需下载第三方控件,简单快捷。但它只是一个用于展示的控件,并没有提供很多接口。集成一些扩展很麻烦。
使用网页浏览器
PhantomJS 是一个具有 Webkit 核心的无界面浏览器。它的特点之一就是可以非常方便地集成javascript脚本,因此开发扩展更加方便,也可以用在服务器端无法使用UI控件的地方。目前,大多数解决方案都在互联网上。我将在这里转录我读过的几篇文章。我就不做详细介绍了:
程序本身是比较方便和强大的,但是在试用过程中还是存在一些问题,比如有些网页不是很规范,不能正确解析,或者有乱码等。
使用 CEF 控件
CEF 是 Chromium Embedded Framework,是 Google 提供的 Chrome 集成解决方案。它提供了一个较低级别的 API,我们可以进行更强大的自定义(当然,它也需要更多的工作)。例如,如果您不想加快内容的分析。
直接分析Javascript模拟渲染
上述方案虽然可以简单正确的获取解析出的完整页面,但是存在一个性能问题:很慢。虽然浏览器的开发者都是顶级高手,但是由于页面的渲染本身就是一个非常复杂的过程,用上面的工具完全渲染一个页面还是需要几秒钟的时间,而且资源开销不小,不能支持大规模数据。采集。
在大多数情况下,这不是什么大问题,但是如果你更关注性能问题,还有一个更原创的解决方法,那就是分析网页的JS工作原理,模拟浏览器只执行内容-相关JS。手动获取输出内容。
这样,主要需要一个javascript引擎。已经有大量的js引擎可以使用,基本没问题。它的主要问题在于需要对网页进行定制和分析,而这些网页的JS大多采用了一定的混淆策略,不易分析,而且往往需要花费大量的时间来调试。
转载于: 查看全部
nodejs抓取动态网页(使用ScrapySharp快速从网页中采集数据中的采集方案介绍)
在上一篇文章中,介绍了使用ScrapySharp快速获取网页数据采集。这种方式是通过直接Http请求获取原创页面信息,对于静态网页非常有效,但是网站中也有很多页面内容并没有全部存储在原创页面中。很多内容是通过javascript动态生成的,这些数据是不能用前面的方法捕获的。下面简单介绍一下采集动态网页的解决方案。
对于这样的网页数据采集,往往会使用浏览器引擎加载整个页面,加载后输出完整的页面,然后使用ScrapySharp等工具进行分析。常用的有以下几种方式:
使用 WebBrowser 控件
我相信大多数 .Net 开发人员都使用过这种方法。由于WebBrowser直接使用与操作系统集成的IE浏览器,无需下载第三方控件,简单快捷。但它只是一个用于展示的控件,并没有提供很多接口。集成一些扩展很麻烦。
使用网页浏览器
PhantomJS 是一个具有 Webkit 核心的无界面浏览器。它的特点之一就是可以非常方便地集成javascript脚本,因此开发扩展更加方便,也可以用在服务器端无法使用UI控件的地方。目前,大多数解决方案都在互联网上。我将在这里转录我读过的几篇文章。我就不做详细介绍了:
程序本身是比较方便和强大的,但是在试用过程中还是存在一些问题,比如有些网页不是很规范,不能正确解析,或者有乱码等。
使用 CEF 控件
CEF 是 Chromium Embedded Framework,是 Google 提供的 Chrome 集成解决方案。它提供了一个较低级别的 API,我们可以进行更强大的自定义(当然,它也需要更多的工作)。例如,如果您不想加快内容的分析。
直接分析Javascript模拟渲染
上述方案虽然可以简单正确的获取解析出的完整页面,但是存在一个性能问题:很慢。虽然浏览器的开发者都是顶级高手,但是由于页面的渲染本身就是一个非常复杂的过程,用上面的工具完全渲染一个页面还是需要几秒钟的时间,而且资源开销不小,不能支持大规模数据。采集。
在大多数情况下,这不是什么大问题,但是如果你更关注性能问题,还有一个更原创的解决方法,那就是分析网页的JS工作原理,模拟浏览器只执行内容-相关JS。手动获取输出内容。
这样,主要需要一个javascript引擎。已经有大量的js引擎可以使用,基本没问题。它的主要问题在于需要对网页进行定制和分析,而这些网页的JS大多采用了一定的混淆策略,不易分析,而且往往需要花费大量的时间来调试。
转载于:

