
excel抓取多页网页数据
教程:node爬取数据实例:抓取宝可梦图鉴并生成Excel文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-09-23 11:16
如何使用Node爬取网页数据并写入Excel文件?下面的文章文章用一个例子来说明使用Node.js爬取网页数据并生成Excel文件的方法,希望对大家有所帮助!
相信口袋妖怪是很多90后的童年记忆。作为一个程序员,我想不止一次地制作一个口袋妖怪游戏,但在做之前,我应该先整理一下口袋妖怪有多少个,它们的编号、名称、属性等信息都整理好了。本期将使用Node.js简单实现对神奇宝贝网页数据的抓取,将数据生成Excel文件,直到接口读取Excel访问数据。
抓取数据
既然是爬取数据,我们先找一个有宝可梦插画数据的网页,如下图:
这个网站是用PHP写的,前后没有分离,所以我们不会读取接口抓取数据,我们使用爬虫库抓取网页中的元素来获取数据。提前说明一下,使用爬虫库的好处是可以在 Node 环境中使用 jQuery 来抓取元素。
安装:
yarn add crawler
实施:
const Crawler = require("crawler");
const fs = require("fs")
const { resolve } = require("path")
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
function getPokemon() {
let uri = "" // 宝可梦图鉴地址
let data = []
return new Promise((resolve, reject) => {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) reject(err);
let $ = res.$;
try {
let $tr = $(".roundy.eplist tr");
$tr.each((i, el) => {
let $td = $(el).find("td");
let _code = $td.eq(1).text().split("\n")[0]
let _name = $td.eq(3).text().split("\n")[0]
<p>
let _attr = $td.eq(4).text().split("\n")[0]
let _other = $td.eq(5).text().split("\n")[0]
_attr = _other.indexOf("属性") != -1 ? _attr : `${_attr}+${_other}`
if (_code) {
data.push([_code, _name, _attr])
}
})
done();
resolve(data)
} catch (err) {
done()
reject(err)
}
}
})
})
}</p>
在生成实例的时候,还需要开启jQuery模式,然后可以使用$符号。上述代码中间部分的业务是抓取元素爬取网页所需的数据,与jQuery API相同,这里不再赘述。
getPokemon().then(async data => {
console.log(data)
})
最后,我们可以执行并打印传递过来的data数据,验证格式是否真的被爬取了,没有错误。
写入 Excel
由于刚才已经爬取了数据,接下来我们使用node-xlsx库来完成数据的写入,生成一个Excel文件。
首先介绍一下node-xlsx是一个简单的excel文件解析器和生成器。 TS构建的依赖SheetJS xlsx模块解析/构建excel工作表,所以在一些参数配置上,两者可以通用。
安装:
yarn add node-xlsx
实施:
const xlsx = require("node-xlsx")
getPokemon().then(async data => {
let title = ["编号", "宝可梦", "属性"]
let list = [{
name: "关都",
data: [
title,
...data
]
<p>
}];
const sheetOptions = { '!cols': [{ wch: 15 }, { wch: 20 }, { wch: 20 }] };
const buffer = await xlsx.build(list, { sheetOptions })
try {
await fs.writeFileSync(resolve(__dirname, "data/pokemon.xlsx"), buffer, "utf8")
} catch (error) { }
})</p>
名称为Excel文件中的列名,数据类型为数组。它还需要传入一个数组,形成一个二维数组,意思是对从ABCDE....列传入的文本进行排序。同时可以通过!cols设置列宽。第一个对象 wch:10 表示第一列的宽度为 10 个字符,可以设置的参数很多。可以参考学习这些配置项。
最后我们使用 xlsx.build 方法生成缓冲区数据,最后使用 fs.writeFileSync 写入或创建 Excel 文件。为了方便查看,我把它保存在一个名为data的文件夹中。这时候,我们会在data文件夹中找到一个名为pokemon.xlsx的额外文件,打开它,数据还在,这样就完成了将数据写入Excel的操作。
读取 Excel
其实不用写fs就可以读取Excel,直接用xlsx.parse方法传入文件地址就可以读取了。
xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
当然,为了验证准确性,我们直接写了一个接口,看看能不能访问数据。为方便起见,我使用 express 框架直接执行此操作。
我们先安装吧:
yarn add express
然后,创建快递服务。我在这里使用 3000 作为端口号。只需编写一个 GET 请求即可发送从 Excel 文件读取的数据。
const express = require("express")
const app = express();
const listenPort = 3000;
app.get("/pokemon",(req,res)=>{
let data = xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
res.send(data)
})
app.listen(listenPort, () => {
console.log(`Server running at http://localhost:${listenPort}/`)
})
最后我用postman来访问这里的界面,你可以清楚的看到我们已经收到了所有的宝可梦数据,从爬取到存入表格。
结论
如您所见,本文以神奇宝贝为例,学习如何使用Node.js从网页抓取数据,如何将数据写入Excel文件,以及如何从Excel文件中读取数据。这个问题,其实实现起来并不难,但有时还是挺实用的。怕忘记的可以存起来哦~
更多node相关知识请访问:nodejs教程!
PHP入门就业在线直播课:查看学习
以上为节点抓取数据示例:抓取神奇宝贝插画和生成Excel文件的详细内容,更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:掘金社区,如有侵权,请联系删除
特别推荐:nodejs节点
上一篇:vue和applet有什么区别 下一篇:JavaScript中使用toLocaleString数字格式化的详细例子
干货教程:抖音短视频成SEO新风口!
我们将讨论公司关心的以下5个问题。有什么不明白的请私信黑来谷0(heilaigu01).
一、什么是搜索引擎优化?
二、为什么是 抖音SEO?
三、哪些公司适合抖音SEO?
四、抖音怎么做SEO?
五、影响抖音排名的因素有哪些?
一、什么是搜索引擎优化?
SEO是英文“Search Engine Optimization”的缩写(具体英文可以百度)。直译就是优化搜索引擎的信息,因为搜索引擎是一个存储互联网内容的平台,所以你的优化对象只能是这些信息。
现在切换到用户的角度来回忆一下,你会在什么情况下使用搜索引擎?当你有明确的内容需求时,你会去“百度”吗?毕竟在PC互联网如火如荼的某个阶段,搜索引擎是互联网的中心,几乎所有的互联网内容都需要通过搜索引擎的入口更高效地获取。因此,用户可以使用关键词的各种组合,悠闲地搜索想要的信息。
用户的目的是获取有用的内容。 关键词的准确率越高,搜索结果页的内容匹配度越高。相应地,与需求匹配的内容越高,其点击率就越高,这条信息背后的商机也就越大。
这里是一个简短的列表:
用户:想要获取内容,因为他有一定的需求,而需求的背后是商业价值;
平台(搜索引擎):是信息匹配的幕后推动者,帮助双方更高效地匹配内容,赚取服务费;
商家:他的产品/服务能满足这部分需求,他希望利用平台的窗口,把不良信息给抹掉。
服务商:商家的优势在于自己的产品。在线推广是一个跨领域的类别。服务商可以帮助商家解决这方面的专业问题。
因此,SEO 就是在这种需求的背景下诞生的。商机的转化围绕着信息的有效匹配,所有角色的工作重心都围绕着信息匹配。
如何实现信息的有效匹配?简单来说就是通过SEO的手段来调整搜索结果的排名。搜索引擎平台本身会按照算法的默认机制进行排序,但是这种排序会有很多“不人道”的地方,就是排名靠前的内容并不是用户真正想要的, SEO进一步体现。出来吧。
这样,商家和服务商可以提高信息的排名,获得更多的曝光率,获得有效的线索。搜索引擎平台也可以从中受益,因为用户拥有更好的搜索体验。如果可以在这些平台上找到有用的信息,用户愿意使用这个工具。只要有用户,这个平台的商业模式就可以继续运作。 .
二、为什么是 抖音SEO?
抖音SEO与上面提到的传统SEO逻辑是一致的。无非就是让品牌的信息在一些关键词搜索结果页面得到更大的曝光,从而实现线索转化。
搜索引擎是PC互联网时代的王者,移动互联网时代的王者是短视频。
以上组是基于在互联网上采集的抖音数据。中国网民数量只有10亿+。不计其他平台,仅抖音的日活跃用户就已超过6亿。前段时间我也看到一组数据是视频账号的日活跃度已经超过了8亿。
不难发现,短视频的内容消费已经全面取代图文内容。我们已经正式进入短视频时代,品牌的下一个流量出口也一定是短视频。搜索引擎也有它的价值,一代人有一代人的使命,至少在这个时代,它不再是主角。
因此,企业的主要营销阵地不得不向短视频迁移。
短视频营销的播放方式有视频、搜索、直播三种方式。
在算法推荐时代,只要有能力制作出符合用户口味的视频,就可以获得免费流量。但是,面对短视频等新事物,很多公司还不是很会玩,现在竞争非常激烈,内容出圈的门槛越来越高,越来越并且更难在没有广告的情况下获得流量。可以明显感觉到,企业的运营成本也在正线上。
搜索是另一种获取流量的方式,也就是我们所说的抖音SEO。用户只会将时间花在能够满足他们需求的内容上。比如,他们的需求是看一些搞笑有趣的内容来放松一下,或者打破某个知识盲区等等。
与平台推荐的方式相比,主动搜索带来的流量具有更大的商业价值。
因为用户的目的很明确,知道自己要找什么,会使用关键词搜索方式获取信息;而且很紧急,相当于“项目有需求”的状态,他们不愿意被动地等待平台推荐合适的内容,而是马上去搜索。
这也是我说公司必须做抖音SEO的原因。当用户在搜索关键词时,你的信息刚刚出现,这意味着商机即将到来。不然这些流量商机就成了同行的玩意儿。
最重要的是抖音SEO是目前成本最低的推广方式。
三、哪些公司适合抖音SEO?
抖音SEO是一种通用的推广方式,没有任何行业限制。无论是企业IP还是个人IP,都适合抖音SEO。但是你要评估是否值得去做,也就是投入产出的性价比如何?不同的行业和品类实际上会略有不同。在我看来,客户单价产品高的公司做抖音SEO是非常有必要的。
客户在购买客单价高的产品时,往往会有这两种行为:“横向比较”和“背景调查”。
由于价格偏高,客户下单时会非常谨慎,下单前多方比较是必不可少的。电商平台的购买评论、知乎小红书的好东西推荐、问答平台的经验分享、专业的产品评测,都是为了解决用户下单的难点。而且TO B的产品采购要经过多个部门的审核,所以要善用抖音SEO,向客户展示更多的正面信息。
如果只是几十元的产品,客户不会有如此强烈的搜索和了解欲望。看到喜欢的就直接在直播间下单了。
对于客户单价高的产品,产品质量和售后服务是客户最看重的一点。没有人愿意花高价买一堆麻烦和不愉快的经历。毕竟这种产品的更换成本不低。为了尽可能让自己无后顾之忧,客户会先上网查一下这个品牌或产品是否还有“黑历史”遗留。
假设有一个真正的污点,抖音SEO 也是掩埋它的好方法。如果没有,它也可以旨在建立强大的品牌实力。客户经常可以看到你的信息,默认就是这家公司实力还不错。这也是在潜移默化地将公司的软实力植入客户心中,有利于转化率的提升。
四、抖音怎么做SEO?
操作逻辑与抖音的操作相同。您只需要在每个操作节点上添加一些 SEO 操作即可。就这么简单。这就是所谓的SEO思维。让我们分解一下。
1、查找关键词
对抖音的操作稍有了解的人都知道,选题决定生死。话题的选择来自于账号的定位,定位决定了变现模式。同样的,抖音SEO也得先确定主题。主题与您提供的产品/服务有关,产品/服务的背后是关键词。客户通过搜索 关键词 来搜索产品/服务。我们需要做的是提供相应的内容来满足客户的即时需求,从而获得更多的商机。
我们提供短视频营销服务,“短视频营销”是待优化的产品关键词。但是,这个词容易出现问题。 “营销”这个词对大多数客户来说太专业了。只有同行或业内人士更喜欢这样搜索,而且这个词与用户的实际搜索习惯不太吻合。客户在寻找匹配服务时,会使用另一种表达方式,比如“短视频推广”、“短视频培训”、“短视频生成运营”……。
从这里可以看出定位的重要性。目标客户画像会影响您的关键词选择。你的客户是谁?在什么水平?专业程度如何?他们的搜索习惯和行为不同。
当然,准确的用户画像是个伪命题。为了尽可能满足更广泛的目标群体的搜索需求,我们可以将产品/服务“翻译”为替代品。因为用户的认知不同,对于同样的需求,有人称之为“短视频营销”,有人称之为“短视频推广”,也有人称之为“短视频生成运营”。在这种情况下,我们可以将这三个关键词作为核心关键词优化。
你也可以在确认核心的时候使用这个思路关键词,这里有3种方式获取关键词:
1、咨询业内专业人士。比如询问公司的研发和销售,了解行业对这个产品的称呼,并记录下来。
2、看产品相关专业文章或浏览社交媒体平台,可以获得更真实的数据。
3、相比前两种“笨方法”,利用数据平台获取关键词是一种更加科学的方法。建议大家去各种指数工具(如百度指数、巨数、微信指数等)、各平台下拉框(如百度、今日头条、抖音、小红书等) )和第三方数据工具(如5118、站长工具、各平台广告投放工具等)获取。
2、找话题
在我们将产品/服务转化为关键词之后,我们要考虑应该用什么内容来满足用户的需求。这些内容就是我们所说的选题。
记住营销漏斗,提高最终转化效果的方法是增加每一层的规模和转化率。上面提到的关键词可以在一定程度上解决曝光问题,但不一定能提高转化率。
用户在搜索 关键词 时必须进行过滤。为什么要过滤?因为有很多内容不符合他的要求,这些不规范的内容是“曝光不转化”的直接原因之一。
在传统的SEO场景中,用户搜索关键词可以直接进入商家官网。官网各页面的内容组合足以满足用户80%以上的业务需求,流量变现效率也相应更高。内容的选择不要太苛刻。
但在短视频平台上,完全是另外一个逻辑。搜索关键词的用户只输入了你账号下众多内容之一,再加上短视频的“短”属性,难免会导致每一个视频描述的点都很简单一、为用户过滤信息的成本也在增加。
为了获取更准确的内容,用户经常使用长尾思维来搜索信息。用户的这种搜索思维是我们搜索主题的核心。 查看全部
教程:node爬取数据实例:抓取宝可梦图鉴并生成Excel文件
如何使用Node爬取网页数据并写入Excel文件?下面的文章文章用一个例子来说明使用Node.js爬取网页数据并生成Excel文件的方法,希望对大家有所帮助!
相信口袋妖怪是很多90后的童年记忆。作为一个程序员,我想不止一次地制作一个口袋妖怪游戏,但在做之前,我应该先整理一下口袋妖怪有多少个,它们的编号、名称、属性等信息都整理好了。本期将使用Node.js简单实现对神奇宝贝网页数据的抓取,将数据生成Excel文件,直到接口读取Excel访问数据。
抓取数据
既然是爬取数据,我们先找一个有宝可梦插画数据的网页,如下图:
这个网站是用PHP写的,前后没有分离,所以我们不会读取接口抓取数据,我们使用爬虫库抓取网页中的元素来获取数据。提前说明一下,使用爬虫库的好处是可以在 Node 环境中使用 jQuery 来抓取元素。
安装:
yarn add crawler
实施:
const Crawler = require("crawler");
const fs = require("fs")
const { resolve } = require("path")
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
function getPokemon() {
let uri = "" // 宝可梦图鉴地址
let data = []
return new Promise((resolve, reject) => {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) reject(err);
let $ = res.$;
try {
let $tr = $(".roundy.eplist tr");
$tr.each((i, el) => {
let $td = $(el).find("td");
let _code = $td.eq(1).text().split("\n")[0]
let _name = $td.eq(3).text().split("\n")[0]
<p>

let _attr = $td.eq(4).text().split("\n")[0]
let _other = $td.eq(5).text().split("\n")[0]
_attr = _other.indexOf("属性") != -1 ? _attr : `${_attr}+${_other}`
if (_code) {
data.push([_code, _name, _attr])
}
})
done();
resolve(data)
} catch (err) {
done()
reject(err)
}
}
})
})
}</p>
在生成实例的时候,还需要开启jQuery模式,然后可以使用$符号。上述代码中间部分的业务是抓取元素爬取网页所需的数据,与jQuery API相同,这里不再赘述。
getPokemon().then(async data => {
console.log(data)
})
最后,我们可以执行并打印传递过来的data数据,验证格式是否真的被爬取了,没有错误。
写入 Excel
由于刚才已经爬取了数据,接下来我们使用node-xlsx库来完成数据的写入,生成一个Excel文件。
首先介绍一下node-xlsx是一个简单的excel文件解析器和生成器。 TS构建的依赖SheetJS xlsx模块解析/构建excel工作表,所以在一些参数配置上,两者可以通用。
安装:
yarn add node-xlsx
实施:
const xlsx = require("node-xlsx")
getPokemon().then(async data => {
let title = ["编号", "宝可梦", "属性"]
let list = [{
name: "关都",
data: [
title,
...data
]
<p>

}];
const sheetOptions = { '!cols': [{ wch: 15 }, { wch: 20 }, { wch: 20 }] };
const buffer = await xlsx.build(list, { sheetOptions })
try {
await fs.writeFileSync(resolve(__dirname, "data/pokemon.xlsx"), buffer, "utf8")
} catch (error) { }
})</p>
名称为Excel文件中的列名,数据类型为数组。它还需要传入一个数组,形成一个二维数组,意思是对从ABCDE....列传入的文本进行排序。同时可以通过!cols设置列宽。第一个对象 wch:10 表示第一列的宽度为 10 个字符,可以设置的参数很多。可以参考学习这些配置项。
最后我们使用 xlsx.build 方法生成缓冲区数据,最后使用 fs.writeFileSync 写入或创建 Excel 文件。为了方便查看,我把它保存在一个名为data的文件夹中。这时候,我们会在data文件夹中找到一个名为pokemon.xlsx的额外文件,打开它,数据还在,这样就完成了将数据写入Excel的操作。
读取 Excel
其实不用写fs就可以读取Excel,直接用xlsx.parse方法传入文件地址就可以读取了。
xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
当然,为了验证准确性,我们直接写了一个接口,看看能不能访问数据。为方便起见,我使用 express 框架直接执行此操作。
我们先安装吧:
yarn add express
然后,创建快递服务。我在这里使用 3000 作为端口号。只需编写一个 GET 请求即可发送从 Excel 文件读取的数据。
const express = require("express")
const app = express();
const listenPort = 3000;
app.get("/pokemon",(req,res)=>{
let data = xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
res.send(data)
})
app.listen(listenPort, () => {
console.log(`Server running at http://localhost:${listenPort}/`)
})
最后我用postman来访问这里的界面,你可以清楚的看到我们已经收到了所有的宝可梦数据,从爬取到存入表格。
结论
如您所见,本文以神奇宝贝为例,学习如何使用Node.js从网页抓取数据,如何将数据写入Excel文件,以及如何从Excel文件中读取数据。这个问题,其实实现起来并不难,但有时还是挺实用的。怕忘记的可以存起来哦~
更多node相关知识请访问:nodejs教程!
PHP入门就业在线直播课:查看学习
以上为节点抓取数据示例:抓取神奇宝贝插画和生成Excel文件的详细内容,更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:掘金社区,如有侵权,请联系删除
特别推荐:nodejs节点
上一篇:vue和applet有什么区别 下一篇:JavaScript中使用toLocaleString数字格式化的详细例子
干货教程:抖音短视频成SEO新风口!
我们将讨论公司关心的以下5个问题。有什么不明白的请私信黑来谷0(heilaigu01).
一、什么是搜索引擎优化?
二、为什么是 抖音SEO?
三、哪些公司适合抖音SEO?
四、抖音怎么做SEO?
五、影响抖音排名的因素有哪些?
一、什么是搜索引擎优化?
SEO是英文“Search Engine Optimization”的缩写(具体英文可以百度)。直译就是优化搜索引擎的信息,因为搜索引擎是一个存储互联网内容的平台,所以你的优化对象只能是这些信息。
现在切换到用户的角度来回忆一下,你会在什么情况下使用搜索引擎?当你有明确的内容需求时,你会去“百度”吗?毕竟在PC互联网如火如荼的某个阶段,搜索引擎是互联网的中心,几乎所有的互联网内容都需要通过搜索引擎的入口更高效地获取。因此,用户可以使用关键词的各种组合,悠闲地搜索想要的信息。
用户的目的是获取有用的内容。 关键词的准确率越高,搜索结果页的内容匹配度越高。相应地,与需求匹配的内容越高,其点击率就越高,这条信息背后的商机也就越大。
这里是一个简短的列表:
用户:想要获取内容,因为他有一定的需求,而需求的背后是商业价值;
平台(搜索引擎):是信息匹配的幕后推动者,帮助双方更高效地匹配内容,赚取服务费;
商家:他的产品/服务能满足这部分需求,他希望利用平台的窗口,把不良信息给抹掉。
服务商:商家的优势在于自己的产品。在线推广是一个跨领域的类别。服务商可以帮助商家解决这方面的专业问题。
因此,SEO 就是在这种需求的背景下诞生的。商机的转化围绕着信息的有效匹配,所有角色的工作重心都围绕着信息匹配。
如何实现信息的有效匹配?简单来说就是通过SEO的手段来调整搜索结果的排名。搜索引擎平台本身会按照算法的默认机制进行排序,但是这种排序会有很多“不人道”的地方,就是排名靠前的内容并不是用户真正想要的, SEO进一步体现。出来吧。
这样,商家和服务商可以提高信息的排名,获得更多的曝光率,获得有效的线索。搜索引擎平台也可以从中受益,因为用户拥有更好的搜索体验。如果可以在这些平台上找到有用的信息,用户愿意使用这个工具。只要有用户,这个平台的商业模式就可以继续运作。 .

二、为什么是 抖音SEO?
抖音SEO与上面提到的传统SEO逻辑是一致的。无非就是让品牌的信息在一些关键词搜索结果页面得到更大的曝光,从而实现线索转化。
搜索引擎是PC互联网时代的王者,移动互联网时代的王者是短视频。
以上组是基于在互联网上采集的抖音数据。中国网民数量只有10亿+。不计其他平台,仅抖音的日活跃用户就已超过6亿。前段时间我也看到一组数据是视频账号的日活跃度已经超过了8亿。
不难发现,短视频的内容消费已经全面取代图文内容。我们已经正式进入短视频时代,品牌的下一个流量出口也一定是短视频。搜索引擎也有它的价值,一代人有一代人的使命,至少在这个时代,它不再是主角。
因此,企业的主要营销阵地不得不向短视频迁移。
短视频营销的播放方式有视频、搜索、直播三种方式。
在算法推荐时代,只要有能力制作出符合用户口味的视频,就可以获得免费流量。但是,面对短视频等新事物,很多公司还不是很会玩,现在竞争非常激烈,内容出圈的门槛越来越高,越来越并且更难在没有广告的情况下获得流量。可以明显感觉到,企业的运营成本也在正线上。
搜索是另一种获取流量的方式,也就是我们所说的抖音SEO。用户只会将时间花在能够满足他们需求的内容上。比如,他们的需求是看一些搞笑有趣的内容来放松一下,或者打破某个知识盲区等等。
与平台推荐的方式相比,主动搜索带来的流量具有更大的商业价值。
因为用户的目的很明确,知道自己要找什么,会使用关键词搜索方式获取信息;而且很紧急,相当于“项目有需求”的状态,他们不愿意被动地等待平台推荐合适的内容,而是马上去搜索。
这也是我说公司必须做抖音SEO的原因。当用户在搜索关键词时,你的信息刚刚出现,这意味着商机即将到来。不然这些流量商机就成了同行的玩意儿。
最重要的是抖音SEO是目前成本最低的推广方式。
三、哪些公司适合抖音SEO?
抖音SEO是一种通用的推广方式,没有任何行业限制。无论是企业IP还是个人IP,都适合抖音SEO。但是你要评估是否值得去做,也就是投入产出的性价比如何?不同的行业和品类实际上会略有不同。在我看来,客户单价产品高的公司做抖音SEO是非常有必要的。
客户在购买客单价高的产品时,往往会有这两种行为:“横向比较”和“背景调查”。
由于价格偏高,客户下单时会非常谨慎,下单前多方比较是必不可少的。电商平台的购买评论、知乎小红书的好东西推荐、问答平台的经验分享、专业的产品评测,都是为了解决用户下单的难点。而且TO B的产品采购要经过多个部门的审核,所以要善用抖音SEO,向客户展示更多的正面信息。
如果只是几十元的产品,客户不会有如此强烈的搜索和了解欲望。看到喜欢的就直接在直播间下单了。
对于客户单价高的产品,产品质量和售后服务是客户最看重的一点。没有人愿意花高价买一堆麻烦和不愉快的经历。毕竟这种产品的更换成本不低。为了尽可能让自己无后顾之忧,客户会先上网查一下这个品牌或产品是否还有“黑历史”遗留。
假设有一个真正的污点,抖音SEO 也是掩埋它的好方法。如果没有,它也可以旨在建立强大的品牌实力。客户经常可以看到你的信息,默认就是这家公司实力还不错。这也是在潜移默化地将公司的软实力植入客户心中,有利于转化率的提升。

四、抖音怎么做SEO?
操作逻辑与抖音的操作相同。您只需要在每个操作节点上添加一些 SEO 操作即可。就这么简单。这就是所谓的SEO思维。让我们分解一下。
1、查找关键词
对抖音的操作稍有了解的人都知道,选题决定生死。话题的选择来自于账号的定位,定位决定了变现模式。同样的,抖音SEO也得先确定主题。主题与您提供的产品/服务有关,产品/服务的背后是关键词。客户通过搜索 关键词 来搜索产品/服务。我们需要做的是提供相应的内容来满足客户的即时需求,从而获得更多的商机。
我们提供短视频营销服务,“短视频营销”是待优化的产品关键词。但是,这个词容易出现问题。 “营销”这个词对大多数客户来说太专业了。只有同行或业内人士更喜欢这样搜索,而且这个词与用户的实际搜索习惯不太吻合。客户在寻找匹配服务时,会使用另一种表达方式,比如“短视频推广”、“短视频培训”、“短视频生成运营”……。
从这里可以看出定位的重要性。目标客户画像会影响您的关键词选择。你的客户是谁?在什么水平?专业程度如何?他们的搜索习惯和行为不同。
当然,准确的用户画像是个伪命题。为了尽可能满足更广泛的目标群体的搜索需求,我们可以将产品/服务“翻译”为替代品。因为用户的认知不同,对于同样的需求,有人称之为“短视频营销”,有人称之为“短视频推广”,也有人称之为“短视频生成运营”。在这种情况下,我们可以将这三个关键词作为核心关键词优化。
你也可以在确认核心的时候使用这个思路关键词,这里有3种方式获取关键词:
1、咨询业内专业人士。比如询问公司的研发和销售,了解行业对这个产品的称呼,并记录下来。
2、看产品相关专业文章或浏览社交媒体平台,可以获得更真实的数据。
3、相比前两种“笨方法”,利用数据平台获取关键词是一种更加科学的方法。建议大家去各种指数工具(如百度指数、巨数、微信指数等)、各平台下拉框(如百度、今日头条、抖音、小红书等) )和第三方数据工具(如5118、站长工具、各平台广告投放工具等)获取。
2、找话题
在我们将产品/服务转化为关键词之后,我们要考虑应该用什么内容来满足用户的需求。这些内容就是我们所说的选题。
记住营销漏斗,提高最终转化效果的方法是增加每一层的规模和转化率。上面提到的关键词可以在一定程度上解决曝光问题,但不一定能提高转化率。
用户在搜索 关键词 时必须进行过滤。为什么要过滤?因为有很多内容不符合他的要求,这些不规范的内容是“曝光不转化”的直接原因之一。
在传统的SEO场景中,用户搜索关键词可以直接进入商家官网。官网各页面的内容组合足以满足用户80%以上的业务需求,流量变现效率也相应更高。内容的选择不要太苛刻。
但在短视频平台上,完全是另外一个逻辑。搜索关键词的用户只输入了你账号下众多内容之一,再加上短视频的“短”属性,难免会导致每一个视频描述的点都很简单一、为用户过滤信息的成本也在增加。
为了获取更准确的内容,用户经常使用长尾思维来搜索信息。用户的这种搜索思维是我们搜索主题的核心。
解读:用Excel,只需30秒就可爬取网站数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2022-09-22 08:14
是的,您没看错,使用 Excel 抓取数据。那么为什么要使用它呢?因为它不需要写一行代码,所以你只需点击几下鼠标就可以得到你想要的数据。整个过程可以在大约 30 秒内完成。在网站结构简单、需求相对简单的情况下,这一招秒杀专业程序员。毕竟大多数时候,程序员可能只需要 30 秒就打开专业的代码编辑器,等待各种组件插件的加载完成。哈哈哈~~~~,你怎么兴奋?
0.软件版本要求和先决条件
要求 1:Excel 2016 及更高版本,开箱即用。当然其他低级版本也不是不行,但是需要自己安装插件,喜欢折腾的可以自己试试。
要求2:只支持get request(不懂这个的可以忽略,可以简单认为直接打开就能看到的数据满足要求)
需求3:你需要的数据在html页面的table标签中。不能是图片等。
那么你怎么知道它是否在table标签中呢?很简单,只要在浏览器中查看网页的源码,有没有你需要的数据被包裹在(
数据
或数据),如果是,恭喜,excel可以直接抓取,如果不是,那就用其他更专业的爬虫工具或者自己写代码。 . .
下面是检查数据是否在(或)标签中的操作:(我刚找到一个房价网站)
一个。打开浏览器网站,找到要爬取的数据,按键盘上的“F12”键(推荐谷歌Chrome、Edge、Firefox)打开调试器。
b.点击左上角元素定位图标,然后将鼠标移到需要的数据上,查看是否收录在()中。
以上过程就是分析网站的数据结构的过程。可以看出标签中收录了需要的数据。这个过程是必不可少的,无论你是使用工具爬取还是自己编写代码爬取,这个过程都极其重要。
假设你确定你要的数据就在()标签里,那我们看看如何用Excel爬取吧!
1.打开 Excel 数据采集工具
注意:不同版本的组件名称或位置可能略有不同。这里是 Excel2019 版本。比较并找到其他版本。确定它们都在“数据”选项卡下。
2.填写爬取参数
这是基本模式,你只需要粘贴你要抓取的网页的网址。另一种高级模式可以设置更多的参数,比如请求头,有兴趣的可以自行探索。
注意:网站直接匿名模式无需登录
3.获取数据
在这个界面中,选择需要的表格点击,然后点击转换数据,可以调用excel自带的power BI对数据进行各种自定义处理和转换,当然也可以加载如果你不想做太多的转换或者你想在 excel 中重新处理它,直接它。
以下界面为电量查询界面。你可以在这个界面上进行各种高级数据转换,也可以什么都不做。如果您已完成转换,只需点击“关闭并上传”即可。
好的,想要的数据已经上传到excel了,方便又快捷。
今天的经验分享就到这里。如果大家有什么好的意见或建议,欢迎在评论区留言~~~~
分享:手把手带你从零基础抓取A站短视频,并且制作从动态壁纸,这些小姐姐我全都要!
大家好,我叫来跳。
我知道大家都是来学技术的,绝对不是为了那些好看的小姐姐们,所以直奔主题吧。
A站视频资料采集
采集数据目标
网址:一个站
性能展示
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:请求、docx、lxml
重点学习内容
lxml使用m3u8文件处理ts文件合成MP4
项目思路分析
通过xpath方法提取分类主页数据
获取每个视频的不确定性
拼接到详情页的url地址
/{}
请求详情页面
获取网页源码的backupUrl对应值
请求对应的m3u8文件地址
https://tx-safety-video.acfun. ... 9P_hc\%22],\%22codecs\%22:\%22avc1.640033,mp4a.40.2\%22,\%22hidden\%22:false,\%22disableAdaptive\%22:false,\%22comment\%22:\%22b6f3561527ea7674/HLS_4K_H264_1\%22,\%22id\%22:1,\%22url\%22:\%22https://ali-safety-video.acfun ... 9P_hc
请求m3u8的文件地址
解析对应的m3u8文件
视频数据拼接自ts视频
取出m3u8文件中各个ts的下载地址
拼接成新的视频下载地址
https://ali-safety-video.acfun ... 9P_hc
下载对应的ts视频数据
将每个ts数据以追加的形式写入MP4文件
简单的源码分析
import requests import re from tqdm import tqdm from lxml import etree import os def request_data(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.42' } response = requests.get(url, headers=headers) return response def save(name, video): # path = f'{name}\\' if not os.path.exists("视频"): os.makedirs("视频") with open("视频/" + name + '.mp4', mode='ab') as f: f.write(video) start_url = "https://www.acfun.cn/v/list218/index.htm" res = request_data(start_url) html_data = etree.HTML(res.text) acid_list = html_data.xpath('//div[@class="list-content-item"]/a[1]/@href') # ac = input('输入acid:') for ac in acid_list: url = 'https://www.acfun.com{}'.format(ac) print(url) # 请求页面地址 获取到 m3u8地址 data = request_data(url).text m3u8_url = re.findall('backupUrl(.*?)\"]', data)[0].replace('"', '').split('\\')[-2] title = re.findall('"title":"(.*?)"', data)[0] # 请求m3u8地址 m3u8_data = request_data(m3u8_url).text # 数据替换 m3u8_data = re.sub(r'#EXTM3U', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-VERSION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-TARGETDURATION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-MEDIA-SEQUENCE:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXTINF:\d.\d,', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-ENDLIST', "", m3u8_data) m3u8 = m3u8_data.split() for i in tqdm(m3u8): ts_url = 'https://tx-safe-video.acfun.cn ... 39%3B + i video = request_data(ts_url).content save(title, video)
如果对你有帮助,记得连续给辣条3次 查看全部
解读:用Excel,只需30秒就可爬取网站数据
是的,您没看错,使用 Excel 抓取数据。那么为什么要使用它呢?因为它不需要写一行代码,所以你只需点击几下鼠标就可以得到你想要的数据。整个过程可以在大约 30 秒内完成。在网站结构简单、需求相对简单的情况下,这一招秒杀专业程序员。毕竟大多数时候,程序员可能只需要 30 秒就打开专业的代码编辑器,等待各种组件插件的加载完成。哈哈哈~~~~,你怎么兴奋?
0.软件版本要求和先决条件
要求 1:Excel 2016 及更高版本,开箱即用。当然其他低级版本也不是不行,但是需要自己安装插件,喜欢折腾的可以自己试试。
要求2:只支持get request(不懂这个的可以忽略,可以简单认为直接打开就能看到的数据满足要求)
需求3:你需要的数据在html页面的table标签中。不能是图片等。
那么你怎么知道它是否在table标签中呢?很简单,只要在浏览器中查看网页的源码,有没有你需要的数据被包裹在(
数据
或数据),如果是,恭喜,excel可以直接抓取,如果不是,那就用其他更专业的爬虫工具或者自己写代码。 . .
下面是检查数据是否在(或)标签中的操作:(我刚找到一个房价网站)

一个。打开浏览器网站,找到要爬取的数据,按键盘上的“F12”键(推荐谷歌Chrome、Edge、Firefox)打开调试器。
b.点击左上角元素定位图标,然后将鼠标移到需要的数据上,查看是否收录在()中。
以上过程就是分析网站的数据结构的过程。可以看出标签中收录了需要的数据。这个过程是必不可少的,无论你是使用工具爬取还是自己编写代码爬取,这个过程都极其重要。
假设你确定你要的数据就在()标签里,那我们看看如何用Excel爬取吧!
1.打开 Excel 数据采集工具
注意:不同版本的组件名称或位置可能略有不同。这里是 Excel2019 版本。比较并找到其他版本。确定它们都在“数据”选项卡下。
2.填写爬取参数

这是基本模式,你只需要粘贴你要抓取的网页的网址。另一种高级模式可以设置更多的参数,比如请求头,有兴趣的可以自行探索。
注意:网站直接匿名模式无需登录
3.获取数据
在这个界面中,选择需要的表格点击,然后点击转换数据,可以调用excel自带的power BI对数据进行各种自定义处理和转换,当然也可以加载如果你不想做太多的转换或者你想在 excel 中重新处理它,直接它。
以下界面为电量查询界面。你可以在这个界面上进行各种高级数据转换,也可以什么都不做。如果您已完成转换,只需点击“关闭并上传”即可。
好的,想要的数据已经上传到excel了,方便又快捷。
今天的经验分享就到这里。如果大家有什么好的意见或建议,欢迎在评论区留言~~~~
分享:手把手带你从零基础抓取A站短视频,并且制作从动态壁纸,这些小姐姐我全都要!
大家好,我叫来跳。
我知道大家都是来学技术的,绝对不是为了那些好看的小姐姐们,所以直奔主题吧。
A站视频资料采集
采集数据目标
网址:一个站
性能展示
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome

工具包:请求、docx、lxml
重点学习内容
lxml使用m3u8文件处理ts文件合成MP4
项目思路分析
通过xpath方法提取分类主页数据
获取每个视频的不确定性
拼接到详情页的url地址
/{}
请求详情页面
获取网页源码的backupUrl对应值
请求对应的m3u8文件地址
https://tx-safety-video.acfun. ... 9P_hc\%22],\%22codecs\%22:\%22avc1.640033,mp4a.40.2\%22,\%22hidden\%22:false,\%22disableAdaptive\%22:false,\%22comment\%22:\%22b6f3561527ea7674/HLS_4K_H264_1\%22,\%22id\%22:1,\%22url\%22:\%22https://ali-safety-video.acfun ... 9P_hc

请求m3u8的文件地址
解析对应的m3u8文件
视频数据拼接自ts视频
取出m3u8文件中各个ts的下载地址
拼接成新的视频下载地址
https://ali-safety-video.acfun ... 9P_hc
下载对应的ts视频数据
将每个ts数据以追加的形式写入MP4文件
简单的源码分析
import requests import re from tqdm import tqdm from lxml import etree import os def request_data(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.42' } response = requests.get(url, headers=headers) return response def save(name, video): # path = f'{name}\\' if not os.path.exists("视频"): os.makedirs("视频") with open("视频/" + name + '.mp4', mode='ab') as f: f.write(video) start_url = "https://www.acfun.cn/v/list218/index.htm" res = request_data(start_url) html_data = etree.HTML(res.text) acid_list = html_data.xpath('//div[@class="list-content-item"]/a[1]/@href') # ac = input('输入acid:') for ac in acid_list: url = 'https://www.acfun.com{}'.format(ac) print(url) # 请求页面地址 获取到 m3u8地址 data = request_data(url).text m3u8_url = re.findall('backupUrl(.*?)\"]', data)[0].replace('"', '').split('\\')[-2] title = re.findall('"title":"(.*?)"', data)[0] # 请求m3u8地址 m3u8_data = request_data(m3u8_url).text # 数据替换 m3u8_data = re.sub(r'#EXTM3U', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-VERSION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-TARGETDURATION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-MEDIA-SEQUENCE:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXTINF:\d.\d,', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-ENDLIST', "", m3u8_data) m3u8 = m3u8_data.split() for i in tqdm(m3u8): ts_url = 'https://tx-safe-video.acfun.cn ... 39%3B + i video = request_data(ts_url).content save(title, video)
如果对你有帮助,记得连续给辣条3次
完整的解决方案:使用 Excel 和 Python 从互联网获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 964 次浏览 • 2022-09-22 08:14
学习 Python 的人生太短了!
互联网上有极其丰富的数据资源。使用Excel自动读取部分网页中的表格数据,使用Python编写爬虫程序读取网页内容。
今天的文章主要分为两部分,一是通过Python构建数据网站,二是使用Excel和Python从写好的Web获取数据网站 .
1、构建测试网站数据
通过 Python Flask Web 框架分别构建一个 Web网站 和一个 Web API 服务。
1.构建网络网站
创建一个名为“5-5-WebTable.py”的新 Python 脚本来创建一个收录表格的简单网页。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装烧瓶包。
pip install flask
(2)用表格构建网页。
from flask import Flask
app = Flask(__name__) # 创建Falsk Web应用实例
# 将路由“/”映射到table_info函数,函数返回HTML代码
@app.route('/')
def table_info():
return """HTML表格实例,用于提供给Excel和Python读取
用户信息表
姓名
性别
年龄
小米
女
22
……….
"""
if __name__ == '__main__':
app.debug = True # 启用调试模式
app.run() # 运行,网站端口默认为5000
通过命令“python ./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,就会出现如图1所示的网页内容。
图 1 使用 Flask 构建的测试网站
2.构建 Web API 服务
创建一个名为“5-5-WebAPI.py”的新 Python 脚本,以使用 flask_restplus 包构建 Web API 服务。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开Web API服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库并初始化应用对象。
from flask import Flask
# Api类是Web API应用的入口,需要用Flask应用程序初始化
from flask_restplus import Api
# Resource类是HTTP请求的资源的基类
from flask_restplus import Resource
# fields类用于定义数据的类型和格式
from flask_restplus import fields
app = Flask(__name__) # 创建Falsk Web应用实例
# 在flask应用的基础上构建flask_restplus Api对象
api = Api(app, version='1.0',
title='Excel集成Python数据分析-测试用WebAPI',
description='测试用WebAPI', )
# 使用namespace函数生成命名空间,用于为资源分组
ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')
# 使用api.model函数生成模型对象
todo = api.model('task_model', {
<p>
'id': fields.Integer(readonly=True,
description='ETL任务唯一标识'),
'task': fields.String(required=True,
description='ETL任务详情')
})
</p>
(3)Web API数据操作类,包括增删改查等方法。
class TodoDAO(object):
def __init__(self):
self.counter = 0
self.todos = []
def get(self, id):
for todo in self.todos:
if todo['id'] == id:
return todo
api.abort(404, "ETL任务 {} 不存在".format(id))
def create(self, data):
todo = data
todo['id'] = self.counter = self.counter + 1
self.todos.append(todo)
return todo
# 实例化数据操作,创建3条测试数据
DAO = TodoDAO()
DAO.create({'task': 'ETL-抽取数据操作'})
DAO.create({'task': 'ETL-数据清洗转换'})
DAO.create({'task': 'ETL-数据加载操作'})
(4)为 Web API 构建路由图。
HTTP资源请求类继承自Resource类,然后映射到不同的路由,指定可以使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求
class TodoList(Resource):
@ns.doc('list_todos') # @doc装饰器对应API文档的信息
@ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出
def get(self): # 定义get方法获取所有的任务信息
return DAO.todos
@ns.doc('create_todo')
@ns.expect(todo)
@ns.marshal_with(todo, code=201)
def post(self): # 定义post方法获取所有的任务信息
return DAO.create(api.payload), 201
# 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求
@ns.route('/')
@ns.response(404, '未发现相关ETL任务')
@ns.param('id', 'ETL任务ID号')
class Todo(Resource):
@ns.doc('get_todo')
@ns.marshal_with(todo)
def get(self, id):
return DAO.get(id)
@ns.doc('delete_todo')
@ns.response(204, 'ETL任务已经删除')
def delete(self, id):
DAO.delete(id)
return '', 204
@ns.expect(todo)
@ns.marshal_with(todo)
def put(self, id):
return DAO.update(id, api.payload)
if __name__ == '__main__':
app.run(debug=True, port=8000) # 启动Web API服务,端口为8000
(4)打开 Web API 服务。
通过命令“python ./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”,显示Web API服务请求方法列表如图5-23所示。
图2 WebAPI服务请求方法列表
2、网页数据抓取
Excel可以通过“数据”选项卡下的“来自网站”功能抓取网页数据。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架来抓取 Web 数据。
1.通过 Excel 抓取
点击“数据”→“来自其他来源”→“来自网站”功能。 Excel能读取的网页数据有局限性:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)点击“数据”→“来自其他来源”→“来自网站”功能。
(2)确保5.5.1部分中写的Web网站已开启。
(3)输入网站URL地址“:5000/”
点击“高级”按钮配置更详细的HTTP请求信息,然后点击“确定”按钮,如图3所示。
图3 配置URL读取网站
(4)在导航器窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表格名称,点击“加载”按钮。
图4 Excel自动识别网页中的表格数据
2.用 Python 爬行
下面的演示使用 requests 库从整个网页中获取数据,然后使用 Beautiful Soup 来解析网页。读者可以参考本书中的代码资料文件“5-5-web.ipynb”进行学习。
(1)通过请求读取网页数据。
import requests #导入requests包
url ='http://127.0.0.1:5000/'
strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过 Beautiful Soup 解析网页。
from bs4 import BeautifulSoup
soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象
table = soup.find('table') # 查找网页中的table元素
table_body = table.find('tbody') # 查找table元素中的tbody元素
data = []
rows = table_body.find_all('tr') # 查找表中的所有tr元素
for row in rows: # 遍历数据
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele])
# 结果输出:[[],
['小米', '女', '22'],['小明','男','23'],……
3、调用 Web API 服务
Excel 可以通过“数据”选项卡下的“From网站”函数调用 Web API 服务。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架调用 Web API 获取数据。
1.用Excel调用
(1)确保5.5.1节中编写的Web API服务已启用。
(2)输入Web API方法对应的URL::8000/ExcelPythonTest/.
(3)处理返回的数据。
调用Web API服务后,返回JSON格式的数据,按照5.4.3小节描述的方法处理JSON数据。
2.使用 Python 调用
使用 requests 库调用 Web API 方法,然后处理返回的 JSON 数据。读者可以参考本书中的代码资料文件“5-5-api.ipynb”进行学习。
import requests #导入requests包
url ='http://127.0.0.1:8000/ExcelPythonTest/'
strhtml= requests.get(url) #使用get方法获取网页数据
import pandas as pd
frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数
print(frame)
#结果输出:
id task
0 1 ETL-抽取数据操作
1 2 ETL-数据清洗转换
2 3 ETL-数据加载操作
4、两种方法的比较
表 1 显示了用于抓取 Internet 数据的 Excel 和 Python 方法的比较。需要注意的是,Excel 从互联网上抓取数据的能力并不完美。
表1 Excel和Python捕获Internet数据的方法比较
解决方案:百度seo快速见效方法(移动跨境流量)
做独立跨境电商网站的人经常问我,“谷歌SEO需要多长时间才能看到结果?”今天,Kenny 将在 2 分钟内为您解答所有疑惑。
随着搜索引擎算法技术的成熟和越来越多的在线内容,在搜索页面中占据一席之地已经成为一个大工程。 SEO(搜索引擎优化)是通过优化 网站 内容以提高搜索引擎排名和曝光率的有机搜索实践。有效的 SEO 可以更好地向搜索引擎证明您的内容是用户最想要的搜索结果。下面我们总结了一些关于SEO的常见问题,希望能帮助您更好地理解和使用SEO。
1.SEO优化的本质是什么?
SEO的本质是根据搜索引擎的最新算法来改进你的内容,从而增加你的内容的曝光率。例如,只需对 关键词 的使用进行一些调整,原创内容就可以使您的 网站 的新搜索流量增加一倍以上。但不要低估翻倍的新搜索流量。据统计,78%的有目的的搜索可以实现购买转化。
2.一般多久可以看到SEO的结果?
这个问题的答案是个案,但好的 SEO 通常需要大约六个月的时间才能得到回报。当然,也有个别站长回应称,用一些“技巧”可以在两周内看到优化的效果,但从长远来看,速度重于质量可能会带来网站的负面影响,因为谷歌可能会将 网站 视为垃圾邮件。一旦被谷歌搜索引擎当成垃圾邮件,网站的排名就很难提升了,应该尽量避免。
3.为什么SEO优化的结果需要这么长时间才能看到?
简单来说,就是因为搜索引擎算法技术的成熟。出现在搜索结果的第一页不再只是网站上的一堆关键词。在这个阶段,想要通过好的优化策略达到满意的搜索结果排名,需要从多方面入手。受趋势和搜索趋势的影响,很多时候 SEO 已经成为一个不断适应的过程,其中包括识别受众和对客户偏好进行关键词 研究。同时,您的网站域名年龄、入站链接和网站权限也与您的搜索排名密切相关。建立权限和接收入站链接取决于用户活动,搜索引擎算法和谷歌本身都需要一段时间来检索和发现用户活动的网站变化,从而延长了SEO的有效性。
4.精通SEO需要多少钱?
截至2020年,美国大部分SEO服务月费为750-7000美元(主要变量为页数网站/更新速度/所需服务),一般来说好的SEO专家的平均费用每小时 80-200 美元。
5. SEO优化后,是否需要经常查看网站数据?
是的,SEO 是一个不断变化的领域。客户感兴趣的关键词和内容会随着当前的趋势和时事发生变化,而搜索引擎的算法也在不断变化,因此及时更新SEO策略非常重要。 查看全部
完整的解决方案:使用 Excel 和 Python 从互联网获取数据
学习 Python 的人生太短了!
互联网上有极其丰富的数据资源。使用Excel自动读取部分网页中的表格数据,使用Python编写爬虫程序读取网页内容。
今天的文章主要分为两部分,一是通过Python构建数据网站,二是使用Excel和Python从写好的Web获取数据网站 .
1、构建测试网站数据
通过 Python Flask Web 框架分别构建一个 Web网站 和一个 Web API 服务。
1.构建网络网站
创建一个名为“5-5-WebTable.py”的新 Python 脚本来创建一个收录表格的简单网页。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装烧瓶包。
pip install flask
(2)用表格构建网页。
from flask import Flask
app = Flask(__name__) # 创建Falsk Web应用实例
# 将路由“/”映射到table_info函数,函数返回HTML代码
@app.route('/')
def table_info():
return """HTML表格实例,用于提供给Excel和Python读取
用户信息表
姓名
性别
年龄
小米
女
22
……….
"""
if __name__ == '__main__':
app.debug = True # 启用调试模式
app.run() # 运行,网站端口默认为5000
通过命令“python ./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,就会出现如图1所示的网页内容。
图 1 使用 Flask 构建的测试网站
2.构建 Web API 服务
创建一个名为“5-5-WebAPI.py”的新 Python 脚本,以使用 flask_restplus 包构建 Web API 服务。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开Web API服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库并初始化应用对象。
from flask import Flask
# Api类是Web API应用的入口,需要用Flask应用程序初始化
from flask_restplus import Api
# Resource类是HTTP请求的资源的基类
from flask_restplus import Resource
# fields类用于定义数据的类型和格式
from flask_restplus import fields
app = Flask(__name__) # 创建Falsk Web应用实例
# 在flask应用的基础上构建flask_restplus Api对象
api = Api(app, version='1.0',
title='Excel集成Python数据分析-测试用WebAPI',
description='测试用WebAPI', )
# 使用namespace函数生成命名空间,用于为资源分组
ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')
# 使用api.model函数生成模型对象
todo = api.model('task_model', {
<p>
'id': fields.Integer(readonly=True,
description='ETL任务唯一标识'),
'task': fields.String(required=True,
description='ETL任务详情')
})
</p>
(3)Web API数据操作类,包括增删改查等方法。
class TodoDAO(object):
def __init__(self):
self.counter = 0
self.todos = []
def get(self, id):
for todo in self.todos:
if todo['id'] == id:
return todo
api.abort(404, "ETL任务 {} 不存在".format(id))
def create(self, data):
todo = data
todo['id'] = self.counter = self.counter + 1
self.todos.append(todo)
return todo
# 实例化数据操作,创建3条测试数据
DAO = TodoDAO()
DAO.create({'task': 'ETL-抽取数据操作'})
DAO.create({'task': 'ETL-数据清洗转换'})
DAO.create({'task': 'ETL-数据加载操作'})
(4)为 Web API 构建路由图。
HTTP资源请求类继承自Resource类,然后映射到不同的路由,指定可以使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求
class TodoList(Resource):
@ns.doc('list_todos') # @doc装饰器对应API文档的信息
@ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出
def get(self): # 定义get方法获取所有的任务信息
return DAO.todos
@ns.doc('create_todo')
@ns.expect(todo)
@ns.marshal_with(todo, code=201)
def post(self): # 定义post方法获取所有的任务信息
return DAO.create(api.payload), 201
# 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求
@ns.route('/')
@ns.response(404, '未发现相关ETL任务')
@ns.param('id', 'ETL任务ID号')
class Todo(Resource):
@ns.doc('get_todo')
@ns.marshal_with(todo)
def get(self, id):
return DAO.get(id)
@ns.doc('delete_todo')
@ns.response(204, 'ETL任务已经删除')
def delete(self, id):
DAO.delete(id)
return '', 204
@ns.expect(todo)
@ns.marshal_with(todo)
def put(self, id):
return DAO.update(id, api.payload)
if __name__ == '__main__':
app.run(debug=True, port=8000) # 启动Web API服务,端口为8000

(4)打开 Web API 服务。
通过命令“python ./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”,显示Web API服务请求方法列表如图5-23所示。
图2 WebAPI服务请求方法列表
2、网页数据抓取
Excel可以通过“数据”选项卡下的“来自网站”功能抓取网页数据。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架来抓取 Web 数据。
1.通过 Excel 抓取
点击“数据”→“来自其他来源”→“来自网站”功能。 Excel能读取的网页数据有局限性:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)点击“数据”→“来自其他来源”→“来自网站”功能。
(2)确保5.5.1部分中写的Web网站已开启。
(3)输入网站URL地址“:5000/”
点击“高级”按钮配置更详细的HTTP请求信息,然后点击“确定”按钮,如图3所示。
图3 配置URL读取网站
(4)在导航器窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表格名称,点击“加载”按钮。
图4 Excel自动识别网页中的表格数据
2.用 Python 爬行
下面的演示使用 requests 库从整个网页中获取数据,然后使用 Beautiful Soup 来解析网页。读者可以参考本书中的代码资料文件“5-5-web.ipynb”进行学习。
(1)通过请求读取网页数据。
import requests #导入requests包
url ='http://127.0.0.1:5000/'
strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过 Beautiful Soup 解析网页。
from bs4 import BeautifulSoup
soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象
table = soup.find('table') # 查找网页中的table元素
table_body = table.find('tbody') # 查找table元素中的tbody元素
data = []
rows = table_body.find_all('tr') # 查找表中的所有tr元素
for row in rows: # 遍历数据
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele])
# 结果输出:[[],
['小米', '女', '22'],['小明','男','23'],……
3、调用 Web API 服务
Excel 可以通过“数据”选项卡下的“From网站”函数调用 Web API 服务。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架调用 Web API 获取数据。
1.用Excel调用
(1)确保5.5.1节中编写的Web API服务已启用。
(2)输入Web API方法对应的URL::8000/ExcelPythonTest/.
(3)处理返回的数据。
调用Web API服务后,返回JSON格式的数据,按照5.4.3小节描述的方法处理JSON数据。
2.使用 Python 调用
使用 requests 库调用 Web API 方法,然后处理返回的 JSON 数据。读者可以参考本书中的代码资料文件“5-5-api.ipynb”进行学习。
import requests #导入requests包
url ='http://127.0.0.1:8000/ExcelPythonTest/'
strhtml= requests.get(url) #使用get方法获取网页数据
import pandas as pd
frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数
print(frame)
#结果输出:
id task
0 1 ETL-抽取数据操作
1 2 ETL-数据清洗转换
2 3 ETL-数据加载操作
4、两种方法的比较
表 1 显示了用于抓取 Internet 数据的 Excel 和 Python 方法的比较。需要注意的是,Excel 从互联网上抓取数据的能力并不完美。
表1 Excel和Python捕获Internet数据的方法比较
解决方案:百度seo快速见效方法(移动跨境流量)
做独立跨境电商网站的人经常问我,“谷歌SEO需要多长时间才能看到结果?”今天,Kenny 将在 2 分钟内为您解答所有疑惑。
随着搜索引擎算法技术的成熟和越来越多的在线内容,在搜索页面中占据一席之地已经成为一个大工程。 SEO(搜索引擎优化)是通过优化 网站 内容以提高搜索引擎排名和曝光率的有机搜索实践。有效的 SEO 可以更好地向搜索引擎证明您的内容是用户最想要的搜索结果。下面我们总结了一些关于SEO的常见问题,希望能帮助您更好地理解和使用SEO。
1.SEO优化的本质是什么?
SEO的本质是根据搜索引擎的最新算法来改进你的内容,从而增加你的内容的曝光率。例如,只需对 关键词 的使用进行一些调整,原创内容就可以使您的 网站 的新搜索流量增加一倍以上。但不要低估翻倍的新搜索流量。据统计,78%的有目的的搜索可以实现购买转化。

2.一般多久可以看到SEO的结果?
这个问题的答案是个案,但好的 SEO 通常需要大约六个月的时间才能得到回报。当然,也有个别站长回应称,用一些“技巧”可以在两周内看到优化的效果,但从长远来看,速度重于质量可能会带来网站的负面影响,因为谷歌可能会将 网站 视为垃圾邮件。一旦被谷歌搜索引擎当成垃圾邮件,网站的排名就很难提升了,应该尽量避免。
3.为什么SEO优化的结果需要这么长时间才能看到?
简单来说,就是因为搜索引擎算法技术的成熟。出现在搜索结果的第一页不再只是网站上的一堆关键词。在这个阶段,想要通过好的优化策略达到满意的搜索结果排名,需要从多方面入手。受趋势和搜索趋势的影响,很多时候 SEO 已经成为一个不断适应的过程,其中包括识别受众和对客户偏好进行关键词 研究。同时,您的网站域名年龄、入站链接和网站权限也与您的搜索排名密切相关。建立权限和接收入站链接取决于用户活动,搜索引擎算法和谷歌本身都需要一段时间来检索和发现用户活动的网站变化,从而延长了SEO的有效性。
4.精通SEO需要多少钱?
截至2020年,美国大部分SEO服务月费为750-7000美元(主要变量为页数网站/更新速度/所需服务),一般来说好的SEO专家的平均费用每小时 80-200 美元。
5. SEO优化后,是否需要经常查看网站数据?
是的,SEO 是一个不断变化的领域。客户感兴趣的关键词和内容会随着当前的趋势和时事发生变化,而搜索引擎的算法也在不断变化,因此及时更新SEO策略非常重要。
微软office就可以搞定的事我使用的方法是用小黑盒抓excel大师官网
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-09-21 00:12
excel抓取多页网页数据,支持批量提取网页所有字段或者自定义tab字段,并支持图片展示导出,支持自定义分页数据,
用微软的msyhgrideditor,免费版够用了,
可以用excel大师
你看看360就知道,我用excel大师,也可以把多页的表格抓到一个excel文件里面。
听我推荐用微软msyhgrideditor免费版本就够用了
微软office就可以搞定的事
我使用的方法是用小黑盒抓
excel大师官网有一些免费的功能或样式可以抓取
关注一下微软msyhgrideditor官网,里面有一些可以免费使用的功能或样式,包括图片拼接,批量修改分页数等等,相比myofficeexcel等软件还是很实用的,下载了也可以自己设置编辑器各页对应关系,免费试用版,相信会很好用的。
一般这种东西肯定是用各种工具来自己抓,不过你不用学编程知识,每天使用excel就够了。
使用wps每次打开看一眼excel,然后点击“文件”,“保存”(powerpoint标志),看到对应的样式文件,从空白处挑取,或者,自定义tab,方便数据提取。
讲真,excel都已经能办到了,很多复杂的需求就交给云服务和专业的数据分析团队去完成吧。你要知道目前中国的很多互联网公司的核心都是卖的服务,产品比技术重要多了。另外,好不好用靠的是主观感受。 查看全部
微软office就可以搞定的事我使用的方法是用小黑盒抓excel大师官网
excel抓取多页网页数据,支持批量提取网页所有字段或者自定义tab字段,并支持图片展示导出,支持自定义分页数据,
用微软的msyhgrideditor,免费版够用了,
可以用excel大师
你看看360就知道,我用excel大师,也可以把多页的表格抓到一个excel文件里面。
听我推荐用微软msyhgrideditor免费版本就够用了
微软office就可以搞定的事
我使用的方法是用小黑盒抓
excel大师官网有一些免费的功能或样式可以抓取
关注一下微软msyhgrideditor官网,里面有一些可以免费使用的功能或样式,包括图片拼接,批量修改分页数等等,相比myofficeexcel等软件还是很实用的,下载了也可以自己设置编辑器各页对应关系,免费试用版,相信会很好用的。
一般这种东西肯定是用各种工具来自己抓,不过你不用学编程知识,每天使用excel就够了。
使用wps每次打开看一眼excel,然后点击“文件”,“保存”(powerpoint标志),看到对应的样式文件,从空白处挑取,或者,自定义tab,方便数据提取。
讲真,excel都已经能办到了,很多复杂的需求就交给云服务和专业的数据分析团队去完成吧。你要知道目前中国的很多互联网公司的核心都是卖的服务,产品比技术重要多了。另外,好不好用靠的是主观感受。
excel抓取多页网页数据 一直以为自己擅长Excel,直到见到这个神技!
网站优化 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2022-08-30 22:49
作为一名兢兢业业的打工人,我们少不了要和各种报表、汇报、软件打交道,时不时就会被折磨到摔键盘:
每天都要更新数据,只会一个个按复制粘贴键,熬夜加班也搞不完
一拍脑袋就蹦一个需求,费老鼻子劲做的统计表只能推翻重来,简直了!
碰到问题赶紧百度,下次有类似情况,哦豁,又忘了……
这些操作可能并不难,但如果每天都要干上数百遍、鼠标点个没完,一不小心就成了办公室最后一个下班的人
所以为了一劳永逸解决这些难题,我终于挖到一个「办公利器」,再也不用熬夜加班,四处求人。下面就把这个利器分享给大家↓↓↓↓
上周刚好是月底,同事琪琪要把一整个月的订单+数据从系统导出来,再按照不同维度填入Excel,最后按照统一格式做成汇报。
光是听上去,就已经让人感到窒息。
数字、名称、利润各种信息琪琪就收集了几十页,然后挨个打开计算器算数,填上Excel表格,一整天进度才一半多。
到了下班点,她用死灰一般的脸看着我,暗示“今天又要苦逼加班了”。
实在看不下去,我过去“哒哒哒”点了几下鼠标,设置好程序点击运行,Excel表格就“活了”,几千条数据一键整理完毕,前前后后不超过10分钟。
实拍在这里
“照你这么干,不是手废就是眼坏了,拼手速、拼体力的活交给RPA就完事了~"
简单讲,RPA就是“让重复的事简单做的工具”,只要写出流程步骤,就可以0成本让电脑自动帮你干90%重复性的活,以十倍,几十倍的去提升自己的工作效率。
琪琪边点头边问:那RPA相当于是个“做表机器人”咯?
“那你可就小看它了!除了Excel,RPA还可以1️⃣自动登录网站系统或桌面应用系统读取或录入数据2️⃣批量收集信息汇总3️⃣结合图像识别技术识别票据信息……
来,直接带你浅看几个功能!”
快速录入/读取数据
很多人每天都要登录各种系统一个一个录入、读取数据,手动一条一条地敲,一个小时最多能处理50条。
有了RPA,单量再多也不用怕,只要早晨到达工位打开程序运行,10秒钟提取所需信息到Excel表,1小时能处理300条,效率直接拉满!
抓取网页内容写入Excel
平时想在网页上收集一些资料,不会用RPA的人:找一条大概需 30 秒,一共500条,15000 秒,做完至少4个小时
会用RPA的人:直接用RPA替自己抓取所需要的数据,根据表头自动填入,数据再多也不怕出错,每天都能省下至少2个小时!
套用模板批量生成图表
工作中经常遇到各种各样的制表需求,每天大量时间不是在做各种日报、数据汇报表、分析统计表上,就是在找模板的路上……
有了RPA,每次不用再重新做表,直接替换数据、修改文字,还可以生成可视化的分析。原本3个小时完成的工作,现在10几分钟自动搞定!
数据一键比对
假设需要比对几列数据的不同,你是不是还在靠肉眼来回看,靠手工标记,一上午眼睛都看直了?
其实这种“脏活累活”交给RPA,自动查找多列数据的差异,将比对结果存入两表新增的“比对结果”工作表中。
自动抓取热销商品信息
做电商、贸易的经常要收集信息,大多数人可能只停留在复制粘贴!
但如果借助RPA,只要几分钟就能搞定几十页数据汇总,不仅销售情况一目了然,还能查看到其他月份的销量情况,方便进行数据对比,整理出运营策略。
自动开发潜在客户
如果你做外贸,在淡季询盘少的时候,RPA也是帮助主动开发客户的好帮手。
RPA能够自动从搜索引擎、海关数据中爬取到全部的客户邮件信息,并批量发送开发信,用不了10分钟,系统就自动发送500多封邮件。
让你拥有更多精准客户,订单多到处理不过来。
其实,我们在工作中难免会遇到大量重复且繁琐的机械操作,这些容易感到疲劳无聊,还经常会犯错误的工作,完全可以交给RPA来做。
这也是为什么别人干活如流水,而你却在重复性加班的原因。
如果你要做数据整理、统计和分析;
如果你想少受表格的煎熬、领导的冷遇、同事的嫌弃;
如果你想提高效率,到点下班,而不是被表格、软件玩得团团转……
那你一定不能错过RPA这个「摸鱼神器」,让你解放双手,不再干“体力活”!
现在加入风变《RPA智能办公实操公开课》,风变团队的RPA专业导师带你学习表格飞速排版、数据高效整理、汇报一键生成……!
我个人在实际操作中,感受到这门课的好处主要有以下几点:
✓
【即学即用】课程涵盖四大高频重复性办公场景,包含网页数据提取、数据录入、表单填写、网页操作等,用「解决问题」倒逼「技能学习」。
✓
【快速上手】直播现场,老师会从0到1打造一个数据抓取机器人,让你掌握一整套自动化办公的工作流程。
✓
【不写代码】RPA的操作像搭乐高一样,搭建好流程,不用学编程,复制出N个“助理”,代替你去完成那些无脑费时间的重复工作!
所以这门课没有深奥的知识点,全都是即学即用、快速提效的实用干货,官网价128元的课程,现在只需要3.3元,带你2小时快速入门自动化办公。
适合人群
被重复工作困扰,想要提升工作效率
对目前岗位不满意,想跳槽缺乏核心竞争力
想拓展一项个人技能,增加赚钱机会
自动汇总表格、跨系统录入数据、
批量发送消息、自动上架商品
助你不再被加班支配,不再为重复工作发愁!
RPA智能办公直播实操课
原价128元
现在只要3块3!!
仅限99个名额,扫码占位
说到学习快捷技巧、自动化办公,想必大家可能也尝试过,但是真正坚持下来的人并不多。原因无外乎三种:
1
不能,想学学 Python,编程?学了几节课各种代码实在太难了,火速放弃
2
不愿,花钱报一个Excel学习班,各种证书考试,但是工作太忙,放在收藏夹吃灰
3
不知,不知道学什么好,之前乱七八糟学了一堆,工作用不上,就没坚持下来
所以要想学习能够持久,我们可以选一个简单些,且不需要花太多时间,还能和工作结合在一起的东西,这样来看,RPA是再合适不过的了,因为它不用敲代码,鼠标拖拉拽就能省下70%的工作时间!
尽管RPA这么强悍,但是现在市面上的培训,大多是针对企业和工程师开发的,但其实剩下90%的普通人学起来相当吃力。
为此,在教育领域深耕7年的风变,携手来也、影刀等多家国内Top5 的RPA厂商,专门针对0基础人士设计这门课,不必懂各种程序概念,操起工具就是一顿配置就完事了,是广大的职场小白的利器!
干货满满的课程大纲提前看
关于课程内容,我已经帮大家体验过了,它彻底改变了我对自动化办公的固有认知,因为真的特别“接地气”:
真实场景实操,带你开启高效办公之旅
RPA应用场景非常多,任何桌面软件、网页、鼠标键盘、Excel的自动化,基本上“人用电脑做”的事情都可以实现。
这堂直播不是干巴巴的PPT,而是围绕五大行业最常遇到的重复性高、流程化的工作场景展开,涉及电商、快消零售、银行金融、财务人事、政府事务领域,覆盖运营、财务、人事、销售、市场等岗位。
2小时直播,入门最前沿自动化办公软件
你面对一大堆文件表格,费神费力,但借助RPA能秒汇总、整合数据,咔咔三下五除二做完半天工作量。
你还在抓耳挠腮只憋出两个字时,用RPA海量收集素材,已经交给领导审阅了。
精通RPA智能办公,你就能像指挥官一样让那些棘手复杂的流程乖乖替你办事,一步到位,快速高效的完成工作。
真正0基础,易学易上手
手把手带你做出能自动干活的机器人
直播讲师王爽,有多年的RPA实战&培训经验,华为、平安等大公司曾经高价聘请她去做培训。
而现在,你只需要用3块3的价格,就能在直播中亲眼看到,15分钟内打造一个数据抓取机器人。真真切切地感受原本2小时才能搞完的工作,现在压缩到十几分钟完成的爽感!
未来5年最火的职场技能大揭秘
谁先加入,谁就拥有核心竞争力
这个时代最有用的职场技能是什么?有人说写作,有人说会做表,其实,都不是。
数字化时代,掌握智能办公才是职场人的硬通货,当做表、找素材、收集数据成为日常,RPA让我们能够高效工作,专注做更有价值的事。
据艾瑞咨询预测,RPA未来三年增速仍将维持在70%以上。随着实施RPA企业的数量迅速增长,市场对RPA人才的需求将持续升温。所以早日掌握RPA,必将成为今后就业市场的“抢手人才”。
拯救你的重复忙碌工作难题
让你告别表格文件恐惧症
3.3元抢反内卷神器原价128元
RPA智能办公直播实操课
长按扫码,立即申请
☟☟☟
Q&A
Q:学习方式是怎样的?
A:智能办公直播公开课为真人直播+助教1v1,不支持回放,各位同学千万不要错过哦。
Q:报名后如何学习?
A:报名后根据指引添加助教老师,助教老师将会在48小时内通过,通过后发送直播链接,请耐心等候~ 查看全部
excel抓取多页网页数据 一直以为自己擅长Excel,直到见到这个神技!
作为一名兢兢业业的打工人,我们少不了要和各种报表、汇报、软件打交道,时不时就会被折磨到摔键盘:
每天都要更新数据,只会一个个按复制粘贴键,熬夜加班也搞不完
一拍脑袋就蹦一个需求,费老鼻子劲做的统计表只能推翻重来,简直了!
碰到问题赶紧百度,下次有类似情况,哦豁,又忘了……
这些操作可能并不难,但如果每天都要干上数百遍、鼠标点个没完,一不小心就成了办公室最后一个下班的人
所以为了一劳永逸解决这些难题,我终于挖到一个「办公利器」,再也不用熬夜加班,四处求人。下面就把这个利器分享给大家↓↓↓↓
上周刚好是月底,同事琪琪要把一整个月的订单+数据从系统导出来,再按照不同维度填入Excel,最后按照统一格式做成汇报。
光是听上去,就已经让人感到窒息。
数字、名称、利润各种信息琪琪就收集了几十页,然后挨个打开计算器算数,填上Excel表格,一整天进度才一半多。
到了下班点,她用死灰一般的脸看着我,暗示“今天又要苦逼加班了”。
实在看不下去,我过去“哒哒哒”点了几下鼠标,设置好程序点击运行,Excel表格就“活了”,几千条数据一键整理完毕,前前后后不超过10分钟。
实拍在这里
“照你这么干,不是手废就是眼坏了,拼手速、拼体力的活交给RPA就完事了~"
简单讲,RPA就是“让重复的事简单做的工具”,只要写出流程步骤,就可以0成本让电脑自动帮你干90%重复性的活,以十倍,几十倍的去提升自己的工作效率。
琪琪边点头边问:那RPA相当于是个“做表机器人”咯?
“那你可就小看它了!除了Excel,RPA还可以1️⃣自动登录网站系统或桌面应用系统读取或录入数据2️⃣批量收集信息汇总3️⃣结合图像识别技术识别票据信息……
来,直接带你浅看几个功能!”
快速录入/读取数据
很多人每天都要登录各种系统一个一个录入、读取数据,手动一条一条地敲,一个小时最多能处理50条。
有了RPA,单量再多也不用怕,只要早晨到达工位打开程序运行,10秒钟提取所需信息到Excel表,1小时能处理300条,效率直接拉满!
抓取网页内容写入Excel
平时想在网页上收集一些资料,不会用RPA的人:找一条大概需 30 秒,一共500条,15000 秒,做完至少4个小时
会用RPA的人:直接用RPA替自己抓取所需要的数据,根据表头自动填入,数据再多也不怕出错,每天都能省下至少2个小时!
套用模板批量生成图表
工作中经常遇到各种各样的制表需求,每天大量时间不是在做各种日报、数据汇报表、分析统计表上,就是在找模板的路上……
有了RPA,每次不用再重新做表,直接替换数据、修改文字,还可以生成可视化的分析。原本3个小时完成的工作,现在10几分钟自动搞定!
数据一键比对
假设需要比对几列数据的不同,你是不是还在靠肉眼来回看,靠手工标记,一上午眼睛都看直了?
其实这种“脏活累活”交给RPA,自动查找多列数据的差异,将比对结果存入两表新增的“比对结果”工作表中。
自动抓取热销商品信息
做电商、贸易的经常要收集信息,大多数人可能只停留在复制粘贴!
但如果借助RPA,只要几分钟就能搞定几十页数据汇总,不仅销售情况一目了然,还能查看到其他月份的销量情况,方便进行数据对比,整理出运营策略。
自动开发潜在客户

如果你做外贸,在淡季询盘少的时候,RPA也是帮助主动开发客户的好帮手。
RPA能够自动从搜索引擎、海关数据中爬取到全部的客户邮件信息,并批量发送开发信,用不了10分钟,系统就自动发送500多封邮件。
让你拥有更多精准客户,订单多到处理不过来。
其实,我们在工作中难免会遇到大量重复且繁琐的机械操作,这些容易感到疲劳无聊,还经常会犯错误的工作,完全可以交给RPA来做。
这也是为什么别人干活如流水,而你却在重复性加班的原因。
如果你要做数据整理、统计和分析;
如果你想少受表格的煎熬、领导的冷遇、同事的嫌弃;
如果你想提高效率,到点下班,而不是被表格、软件玩得团团转……
那你一定不能错过RPA这个「摸鱼神器」,让你解放双手,不再干“体力活”!
现在加入风变《RPA智能办公实操公开课》,风变团队的RPA专业导师带你学习表格飞速排版、数据高效整理、汇报一键生成……!
我个人在实际操作中,感受到这门课的好处主要有以下几点:
✓
【即学即用】课程涵盖四大高频重复性办公场景,包含网页数据提取、数据录入、表单填写、网页操作等,用「解决问题」倒逼「技能学习」。
✓
【快速上手】直播现场,老师会从0到1打造一个数据抓取机器人,让你掌握一整套自动化办公的工作流程。
✓
【不写代码】RPA的操作像搭乐高一样,搭建好流程,不用学编程,复制出N个“助理”,代替你去完成那些无脑费时间的重复工作!
所以这门课没有深奥的知识点,全都是即学即用、快速提效的实用干货,官网价128元的课程,现在只需要3.3元,带你2小时快速入门自动化办公。
适合人群
被重复工作困扰,想要提升工作效率
对目前岗位不满意,想跳槽缺乏核心竞争力
想拓展一项个人技能,增加赚钱机会
自动汇总表格、跨系统录入数据、
批量发送消息、自动上架商品
助你不再被加班支配,不再为重复工作发愁!
RPA智能办公直播实操课
原价128元
现在只要3块3!!
仅限99个名额,扫码占位
说到学习快捷技巧、自动化办公,想必大家可能也尝试过,但是真正坚持下来的人并不多。原因无外乎三种:
1
不能,想学学 Python,编程?学了几节课各种代码实在太难了,火速放弃
2
不愿,花钱报一个Excel学习班,各种证书考试,但是工作太忙,放在收藏夹吃灰
3
不知,不知道学什么好,之前乱七八糟学了一堆,工作用不上,就没坚持下来
所以要想学习能够持久,我们可以选一个简单些,且不需要花太多时间,还能和工作结合在一起的东西,这样来看,RPA是再合适不过的了,因为它不用敲代码,鼠标拖拉拽就能省下70%的工作时间!
尽管RPA这么强悍,但是现在市面上的培训,大多是针对企业和工程师开发的,但其实剩下90%的普通人学起来相当吃力。
为此,在教育领域深耕7年的风变,携手来也、影刀等多家国内Top5 的RPA厂商,专门针对0基础人士设计这门课,不必懂各种程序概念,操起工具就是一顿配置就完事了,是广大的职场小白的利器!
干货满满的课程大纲提前看
关于课程内容,我已经帮大家体验过了,它彻底改变了我对自动化办公的固有认知,因为真的特别“接地气”:
真实场景实操,带你开启高效办公之旅
RPA应用场景非常多,任何桌面软件、网页、鼠标键盘、Excel的自动化,基本上“人用电脑做”的事情都可以实现。
这堂直播不是干巴巴的PPT,而是围绕五大行业最常遇到的重复性高、流程化的工作场景展开,涉及电商、快消零售、银行金融、财务人事、政府事务领域,覆盖运营、财务、人事、销售、市场等岗位。
2小时直播,入门最前沿自动化办公软件
你面对一大堆文件表格,费神费力,但借助RPA能秒汇总、整合数据,咔咔三下五除二做完半天工作量。
你还在抓耳挠腮只憋出两个字时,用RPA海量收集素材,已经交给领导审阅了。
精通RPA智能办公,你就能像指挥官一样让那些棘手复杂的流程乖乖替你办事,一步到位,快速高效的完成工作。
真正0基础,易学易上手
手把手带你做出能自动干活的机器人
直播讲师王爽,有多年的RPA实战&培训经验,华为、平安等大公司曾经高价聘请她去做培训。
而现在,你只需要用3块3的价格,就能在直播中亲眼看到,15分钟内打造一个数据抓取机器人。真真切切地感受原本2小时才能搞完的工作,现在压缩到十几分钟完成的爽感!
未来5年最火的职场技能大揭秘
谁先加入,谁就拥有核心竞争力
这个时代最有用的职场技能是什么?有人说写作,有人说会做表,其实,都不是。
数字化时代,掌握智能办公才是职场人的硬通货,当做表、找素材、收集数据成为日常,RPA让我们能够高效工作,专注做更有价值的事。
据艾瑞咨询预测,RPA未来三年增速仍将维持在70%以上。随着实施RPA企业的数量迅速增长,市场对RPA人才的需求将持续升温。所以早日掌握RPA,必将成为今后就业市场的“抢手人才”。
拯救你的重复忙碌工作难题
让你告别表格文件恐惧症
3.3元抢反内卷神器原价128元
RPA智能办公直播实操课
长按扫码,立即申请
☟☟☟
Q&A
Q:学习方式是怎样的?
A:智能办公直播公开课为真人直播+助教1v1,不支持回放,各位同学千万不要错过哦。
Q:报名后如何学习?
A:报名后根据指引添加助教老师,助教老师将会在48小时内通过,通过后发送直播链接,请耐心等候~
excel多渠道爬取java后台老师上课视频-excelhome技术论坛-poweredbydiscuz!
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-08-23 07:02
excel抓取多页网页数据视频:excel多渠道爬取java后台老师上课视频-excelhome教程视频-excelhome技术论坛-poweredbydiscuz!
用几天,
在2015-02-18processing_learning_practice-processing/后一定要看看
上期我也遇到这种问题,以为老师对它不关注于是我自己用教师资格证查,还是查不到,最后google之下结果是电脑要换系统,我不会换系统,于是我重装机器时候,想办法用电脑自带的端口扫描扫出来电脑里的端口号,然后手动输入电脑端口,还是找不到,我的电脑自带adsl没有服务端口扫描功能,我就像如此死马当活马医,再仔细一遍,不过我也能看得到一些可用端口,但是没有找到那些真正可用的端口,还是不知道那些是真正能用的,这次我用edu邮箱的大功率宽带拨号手机密码之后,自己扫描了一遍,居然找到一个,于是我把这个域名注册了,就敢去管了,至于怎么找注册站点,这个没法说,我觉得必须先动手找到那些端口,再想办法比较好,不过基本上一堆python代码要写的。实践出真知,开机的时候,我看到鼠标中间的上网图标鼠标一滑就是域名,还是拿edu邮箱接收,比较方便。
抱歉,原来知乎是这么用的,我刚看了你的问题,已经不是一个简单的课程结构问题了,所以还是花时间上贴吧吧。另外一个建议,下次带着问题找建议吧, 查看全部
excel多渠道爬取java后台老师上课视频-excelhome技术论坛-poweredbydiscuz!
excel抓取多页网页数据视频:excel多渠道爬取java后台老师上课视频-excelhome教程视频-excelhome技术论坛-poweredbydiscuz!

用几天,
在2015-02-18processing_learning_practice-processing/后一定要看看
上期我也遇到这种问题,以为老师对它不关注于是我自己用教师资格证查,还是查不到,最后google之下结果是电脑要换系统,我不会换系统,于是我重装机器时候,想办法用电脑自带的端口扫描扫出来电脑里的端口号,然后手动输入电脑端口,还是找不到,我的电脑自带adsl没有服务端口扫描功能,我就像如此死马当活马医,再仔细一遍,不过我也能看得到一些可用端口,但是没有找到那些真正可用的端口,还是不知道那些是真正能用的,这次我用edu邮箱的大功率宽带拨号手机密码之后,自己扫描了一遍,居然找到一个,于是我把这个域名注册了,就敢去管了,至于怎么找注册站点,这个没法说,我觉得必须先动手找到那些端口,再想办法比较好,不过基本上一堆python代码要写的。实践出真知,开机的时候,我看到鼠标中间的上网图标鼠标一滑就是域名,还是拿edu邮箱接收,比较方便。
抱歉,原来知乎是这么用的,我刚看了你的问题,已经不是一个简单的课程结构问题了,所以还是花时间上贴吧吧。另外一个建议,下次带着问题找建议吧,
excel抓取多页网页数据并生成excel表格试试
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-08-21 06:01
excel抓取多页网页数据并生成excel表格
试试trypython(python+web框架),多线程+flaskpython+web框架加你需要的各种库和web框架,抓取速度会有质的飞跃!当然,如果不熟悉python,用简单的python3+web框架,
题主可以尝试一下爬虫工具log4js这款工具,支持python2.7、3.0、3.6等版本。支持10多种主流浏览器和web浏览器兼容,灵活且功能全面。新手体验+0元免费试用,3天会创建一个免费的试用群,共享各种学习资源!不仅可以爬取网页、手机页面、图片,还可以爬取音频、视频等各种文件。免费使用,不用注册!。
搜索下垂直站点抓取工具,国内有集中的团队,另外包括但不限于淘宝、京东、聚划算、掌中优惠券、天天特价等。希望能帮到您。
我觉得楼主应该问“在网页上面抓取图片而不是在浏览器里抓取图片”,所以下面以网页为例。你百度一下“抓取百度”,你就知道原理了。
你可以使用一些网页爬虫工具,可以试一下猪八戒网爬虫。可以免费注册,支持抓包,
如果你本地有文件服务器,那么用requests库就可以抓取了,有n多种数据库、http请求库可选,另外还有python的nltk库用来提取pdf或excel文件里的单词。 查看全部
excel抓取多页网页数据并生成excel表格试试
excel抓取多页网页数据并生成excel表格
试试trypython(python+web框架),多线程+flaskpython+web框架加你需要的各种库和web框架,抓取速度会有质的飞跃!当然,如果不熟悉python,用简单的python3+web框架,

题主可以尝试一下爬虫工具log4js这款工具,支持python2.7、3.0、3.6等版本。支持10多种主流浏览器和web浏览器兼容,灵活且功能全面。新手体验+0元免费试用,3天会创建一个免费的试用群,共享各种学习资源!不仅可以爬取网页、手机页面、图片,还可以爬取音频、视频等各种文件。免费使用,不用注册!。
搜索下垂直站点抓取工具,国内有集中的团队,另外包括但不限于淘宝、京东、聚划算、掌中优惠券、天天特价等。希望能帮到您。

我觉得楼主应该问“在网页上面抓取图片而不是在浏览器里抓取图片”,所以下面以网页为例。你百度一下“抓取百度”,你就知道原理了。
你可以使用一些网页爬虫工具,可以试一下猪八戒网爬虫。可以免费注册,支持抓包,
如果你本地有文件服务器,那么用requests库就可以抓取了,有n多种数据库、http请求库可选,另外还有python的nltk库用来提取pdf或excel文件里的单词。
excel抓取多页网页数据的讲解方法(一步步讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-07-24 21:03
excel抓取多页网页数据,可以对数据进行聚合、排序、分组等操作。下面一步步讲解方法。1.多页网页的爬取方法:step1:分析多页网页中不同的列名(如group等)、列值(如unique等)step2:通过查询分析的列名及值step3:定义一个分页查询,将所有的数据全部查询出来(如下图)方法讲解:step1的数据查询就对应了step2的分页查询;step2的分页查询就是将数据全部遍历。
下面一步步讲解分页爬取的过程。2.访问hao360/api/leader/csv.xlsx将excel文件转化为csv文件(源文件的前缀也可以是.xls)3.选择各个页数的数据,将这些数据复制到任意合适的目录。4.爬取结束5.将csv文件转化为json格式文件(json文件是不能复制的)第二部分已经解释了数据是如何格式化的。
6.将json数据解析为json格式数据打开json数据库,可以看到由一串字符串组成的json格式数据。(注意json里的header一定要有两个"?",否则解析不了。)7.定义查询分析列名、值hao360/api/leader/csv.xlsx中unique列的值是不能被查询出来的,要进行查询分析。
所以我们需要获取unique列的值以及其中值的值:step1:定义数据存储文件夹step2:将unique列存储到数据库step3:访问数据库step4:查看结果8.将返回结果重命名存到userdata文件夹下step5:将userdata文件夹转化为excel格式(step4中的xls文件也可以替换为excel格式)step6:对userdata文件夹中的excel文件进行重命名,step5中解析的json数据即可取出来了。得到的结果如下:结束关注公众号【赵卫东】获取更多。 查看全部
excel抓取多页网页数据的讲解方法(一步步讲解)
excel抓取多页网页数据,可以对数据进行聚合、排序、分组等操作。下面一步步讲解方法。1.多页网页的爬取方法:step1:分析多页网页中不同的列名(如group等)、列值(如unique等)step2:通过查询分析的列名及值step3:定义一个分页查询,将所有的数据全部查询出来(如下图)方法讲解:step1的数据查询就对应了step2的分页查询;step2的分页查询就是将数据全部遍历。

下面一步步讲解分页爬取的过程。2.访问hao360/api/leader/csv.xlsx将excel文件转化为csv文件(源文件的前缀也可以是.xls)3.选择各个页数的数据,将这些数据复制到任意合适的目录。4.爬取结束5.将csv文件转化为json格式文件(json文件是不能复制的)第二部分已经解释了数据是如何格式化的。

6.将json数据解析为json格式数据打开json数据库,可以看到由一串字符串组成的json格式数据。(注意json里的header一定要有两个"?",否则解析不了。)7.定义查询分析列名、值hao360/api/leader/csv.xlsx中unique列的值是不能被查询出来的,要进行查询分析。
所以我们需要获取unique列的值以及其中值的值:step1:定义数据存储文件夹step2:将unique列存储到数据库step3:访问数据库step4:查看结果8.将返回结果重命名存到userdata文件夹下step5:将userdata文件夹转化为excel格式(step4中的xls文件也可以替换为excel格式)step6:对userdata文件夹中的excel文件进行重命名,step5中解析的json数据即可取出来了。得到的结果如下:结束关注公众号【赵卫东】获取更多。
一个函数抓取代谢组学权威数据库HMDB的所有表格数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-07-22 08:31
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素()。具体使用如下:
<p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address<br />url 查看全部
一个函数抓取代谢组学权威数据库HMDB的所有表格数据
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素()。具体使用如下:
<p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address<br />url
如何学习领导讲话 —— 数据抓取+词频分析+可视化 简易流程介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-07-22 05:48
政府重要领导的讲话内容对规划项目而言是重中之重,今天小王接到一个任务,要好好学习现在所里在做的项目的龙岗区张书记的讲话,如果只是复制粘贴领导讲话,画个重点色,好像真的很无趣,所以爱折腾的小王自己琢磨了一下,做得稍微复杂一点,希望能抛砖引玉,启发大家的思考,并且这里除了1部分(还是可以略过的),其它都是无脑的,不需要你会python。
由于天色已晚,小王只有半个小时写文,这里长话短说,不明白的细节欢迎留言交流。
1、大数据抓取(可略过)
工具:优采云采集器(免费)
采集地址:龙岗区政府网站
采集流程:具体流程见优采云教程
具体流程图如上,简要说就是建立两个翻页循环,一个是循环点击下一页,一个是循环点击进入每一页的每一条内部。如果有不清楚的可以直接查询优采云软件内置教程,有非常详细的介绍,这里没有时间多说。
抓取结束之后,需要进行一个漫长且无趣的清洗,也是非常枯燥无味的,需要比较针对性的文字的朋友可以直接略过这一步,开几个关键网页复制粘贴吧。
完成后得到word文件如图
2、词频提取
工具网页:图悦
将word内容复制至该网址,得到初步分析图(这个图很丑,不要),此时记得按图片右上角四个小按钮中最右边的按钮,导出excel
打开EXCEL获得如图内容,有一些词分的还有问题,需要进一步处理,接下来就可以进入可视化流程了。
这里想多说一点,结合API获取工具或是GIS数据(在以后的文章中会提及)和词频工具,可以做非常有趣的其它分析,比如领导给我一个任务让我找出一个片区里,什么厂最多,是电子厂还是制衣厂,这也可以发挥作用。
总词频可视化
工具网页:Word Art ()
虽然是全英文的但是我想大家都能看得懂
当前显示的这一栏就是输入关键词和词频了
接着在SHAPE里,上传自己处理好边界的PNG图片
后面几栏可以调整颜色等
最后注意在FONTS栏里上传中文字体文件(tff格式)哦
然后按红色按钮生成就行了,然后按打印即可,效果如下
(考虑到项目正在做,该图内容未经过清洗,非最终结果)
我们可以初步得到结论:书记最关心什么?
交通和产业
细节词频分析
工具网站1语义分析系统:
工具网站2纽扣词云:
工具网站1:
功能非常多,比如弦图和关系图
按类别分析
情感分析
工具网站2:
工具网站2对词性有更细节的分析
像这种形时间词、方位词都有较好的应用
至于这些内容到底应该怎么用,就各自见仁见智啦
总结
合理利用数据抓取(网页+API)+词频工具+可视化这一套工具可以做的事很多,难点也不在工具,而在于为什么要用工具,这会直接影响到关键步骤“抓取”和“清洗”,时间有限,这次分享到此为止,欢迎大家在后台留言,以后争取分享更多的内容。
图片|来源各个工具
文案|城市学习者小王 查看全部
如何学习领导讲话 —— 数据抓取+词频分析+可视化 简易流程介绍
政府重要领导的讲话内容对规划项目而言是重中之重,今天小王接到一个任务,要好好学习现在所里在做的项目的龙岗区张书记的讲话,如果只是复制粘贴领导讲话,画个重点色,好像真的很无趣,所以爱折腾的小王自己琢磨了一下,做得稍微复杂一点,希望能抛砖引玉,启发大家的思考,并且这里除了1部分(还是可以略过的),其它都是无脑的,不需要你会python。
由于天色已晚,小王只有半个小时写文,这里长话短说,不明白的细节欢迎留言交流。
1、大数据抓取(可略过)
工具:优采云采集器(免费)
采集地址:龙岗区政府网站
采集流程:具体流程见优采云教程
具体流程图如上,简要说就是建立两个翻页循环,一个是循环点击下一页,一个是循环点击进入每一页的每一条内部。如果有不清楚的可以直接查询优采云软件内置教程,有非常详细的介绍,这里没有时间多说。
抓取结束之后,需要进行一个漫长且无趣的清洗,也是非常枯燥无味的,需要比较针对性的文字的朋友可以直接略过这一步,开几个关键网页复制粘贴吧。
完成后得到word文件如图
2、词频提取
工具网页:图悦
将word内容复制至该网址,得到初步分析图(这个图很丑,不要),此时记得按图片右上角四个小按钮中最右边的按钮,导出excel
打开EXCEL获得如图内容,有一些词分的还有问题,需要进一步处理,接下来就可以进入可视化流程了。
这里想多说一点,结合API获取工具或是GIS数据(在以后的文章中会提及)和词频工具,可以做非常有趣的其它分析,比如领导给我一个任务让我找出一个片区里,什么厂最多,是电子厂还是制衣厂,这也可以发挥作用。
总词频可视化
工具网页:Word Art ()
虽然是全英文的但是我想大家都能看得懂
当前显示的这一栏就是输入关键词和词频了
接着在SHAPE里,上传自己处理好边界的PNG图片
后面几栏可以调整颜色等
最后注意在FONTS栏里上传中文字体文件(tff格式)哦
然后按红色按钮生成就行了,然后按打印即可,效果如下
(考虑到项目正在做,该图内容未经过清洗,非最终结果)
我们可以初步得到结论:书记最关心什么?
交通和产业
细节词频分析

工具网站1语义分析系统:
工具网站2纽扣词云:
工具网站1:
功能非常多,比如弦图和关系图
按类别分析
情感分析
工具网站2:
工具网站2对词性有更细节的分析
像这种形时间词、方位词都有较好的应用
至于这些内容到底应该怎么用,就各自见仁见智啦
总结
合理利用数据抓取(网页+API)+词频工具+可视化这一套工具可以做的事很多,难点也不在工具,而在于为什么要用工具,这会直接影响到关键步骤“抓取”和“清洗”,时间有限,这次分享到此为止,欢迎大家在后台留言,以后争取分享更多的内容。
图片|来源各个工具
文案|城市学习者小王
如何从10万条记录中提取出5000条数据?
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-07-11 14:05
excel抓取多页网页数据,可以分析链接位置和爬取的类型。更多关于数据分析的文章,可以关注我们微信公众号~如何从10万条记录中提取出5000条数据1.问题导入数据#导入excel所需要的包#数据清洗步骤对比和业务需求2.数据预处理#缺失值处理#缺失值统计表and表#除了缺失值还存在哪些值#填充缺失值#删除缺失值#求得缺失值信息或与所分析内容无关的值#填充缺失值3.数据分析#总体业务分析#不同页面产品经理、产品设计师数量比率#页面类型分布,注意内容丰富的产品不一定热销,准确判断需要从内容类型分析起,不能片面理解数据#业务模块分析#业务方向需求是销售金额还是研发投入/收入?#设计团队、研发团队等分析,最终目的是弄清楚设计团队、研发团队的编程水平?#薪资和市场上其他地区相比如何?#离职率是否大于预期值?#主要的流失原因是什么?#该企业的人员构成如何?#总体业务分析①产品经理人数#设计人员人数#运营和推广人员人数#推广渠道人数#寻找主要的流失原因a.单位人数效益下降b.激活率或交易率下降c.点击量减少,产品调整时需要对新增动作进行特殊处理③销售金额分布#产品分类销售中,热销的产品数量特征是:明显高于其他人员所占比例的产品数量a.热销大热销的产品分类种类较多,需要从其他人员、平台或协议等等,从类别出发来分析市场b.热销产品在同类产品分布中是集中在少数产品中,需要从满足当前产品特性来判断市场④设计团队a.最常使用的设计软件用户量和设计师人数b.最常使用的设计团队种类及数量c.使用本人设计师素质和使用本人团队的人数⑤研发投入投入产出比合理的投入产出比和是否愿意投入的原因,需要从产品、模式、市场等等来找b.原因一:本人产品部分使用了一段时间的excel,然后觉得excel比较好用,有电脑都会用,不用安装。
能做的事情太多,需要提升能力。设计团队要投入更多的资源,在个人成长上更充实,从而提升专业技能c.原因二:设计团队的执行力方面,设计不仅仅是表面上的美观,还要面对用户的痛点和难题,新产品还是需要从产品功能上去改进a.在产品功能上面,有更多开始的人,更快的解决需求问题b.开始的人多了,想法会放得开,有更多的创新点a.启动团队执行力方面,可以通过公司文化来先打开团队的执行力方面,让团队全员齐心协力,变得更能坚持一些b.在产品功能上创新点上,需要从更宏观的视角,优化产品还是优化用户体验,比方说用户容易购买但用户转换率低的产品,可以在小改进上重新引起用户的兴趣和。 查看全部
如何从10万条记录中提取出5000条数据?
excel抓取多页网页数据,可以分析链接位置和爬取的类型。更多关于数据分析的文章,可以关注我们微信公众号~如何从10万条记录中提取出5000条数据1.问题导入数据#导入excel所需要的包#数据清洗步骤对比和业务需求2.数据预处理#缺失值处理#缺失值统计表and表#除了缺失值还存在哪些值#填充缺失值#删除缺失值#求得缺失值信息或与所分析内容无关的值#填充缺失值3.数据分析#总体业务分析#不同页面产品经理、产品设计师数量比率#页面类型分布,注意内容丰富的产品不一定热销,准确判断需要从内容类型分析起,不能片面理解数据#业务模块分析#业务方向需求是销售金额还是研发投入/收入?#设计团队、研发团队等分析,最终目的是弄清楚设计团队、研发团队的编程水平?#薪资和市场上其他地区相比如何?#离职率是否大于预期值?#主要的流失原因是什么?#该企业的人员构成如何?#总体业务分析①产品经理人数#设计人员人数#运营和推广人员人数#推广渠道人数#寻找主要的流失原因a.单位人数效益下降b.激活率或交易率下降c.点击量减少,产品调整时需要对新增动作进行特殊处理③销售金额分布#产品分类销售中,热销的产品数量特征是:明显高于其他人员所占比例的产品数量a.热销大热销的产品分类种类较多,需要从其他人员、平台或协议等等,从类别出发来分析市场b.热销产品在同类产品分布中是集中在少数产品中,需要从满足当前产品特性来判断市场④设计团队a.最常使用的设计软件用户量和设计师人数b.最常使用的设计团队种类及数量c.使用本人设计师素质和使用本人团队的人数⑤研发投入投入产出比合理的投入产出比和是否愿意投入的原因,需要从产品、模式、市场等等来找b.原因一:本人产品部分使用了一段时间的excel,然后觉得excel比较好用,有电脑都会用,不用安装。

能做的事情太多,需要提升能力。设计团队要投入更多的资源,在个人成长上更充实,从而提升专业技能c.原因二:设计团队的执行力方面,设计不仅仅是表面上的美观,还要面对用户的痛点和难题,新产品还是需要从产品功能上去改进a.在产品功能上面,有更多开始的人,更快的解决需求问题b.开始的人多了,想法会放得开,有更多的创新点a.启动团队执行力方面,可以通过公司文化来先打开团队的执行力方面,让团队全员齐心协力,变得更能坚持一些b.在产品功能上创新点上,需要从更宏观的视角,优化产品还是优化用户体验,比方说用户容易购买但用户转换率低的产品,可以在小改进上重新引起用户的兴趣和。
简易数据分析 13 | Web Scraper 抓取二级页面(详情页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2022-06-23 18:04
如果做到这一步,其实已经可以抓到所有已知的列表数据了,但本文的重点是:如何抓取二级页面(详情页)的三连数据?
跟着做了这么多爬虫,可能你已经发现了,Web Scraper 本质是模拟人类的操作以达到抓取数据的目的。
那么我们正常查看二级页面(详情页)是怎么操作的呢?其实就是点击标题链接跳转:
Web Scraper 为我们提供了点击链接跳转的功能,那就是 Type 为 Link 的选择器。
感觉有些抽象?我们对照例子来理解一下。
首先在这个案例里,我们获取了标题的文字,这时的选择器类型为 Text:
当我们要抓取链接时,就要再创建一个选择器,选的元素是一样的,但是 Type 类型为 Link:
创建成功后,我们点击这个 Link 类型的选择器,进入他的内部,再创建相关的选择器,下面我录了个动图,注意看我鼠标强调的导航路由部分,可以很清晰的看出这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接后就会发现,浏览器会在一个新的 Tab 页打开详情页,但是 Web Scraper 的选择窗口开在列表页,无法跨页面选择想要的数据。
处理这个问题也很简单,你可以复制详情页的链接,拷贝到列表页所在的 Tab 页里,然后回车重新加载,这样就可以在当前页面选择了。
我们在类型为 Link 的选择器内部多创建几个选择器,这里我选择了点赞数、硬币数、收藏数和分享数 4 个数据,这个操作也很简单,这里我就不详细说了。
所有选择器的结构图如下:
我们可以看到 video_detail_link 这个节点包含 4 个二级页面(详情页)的数据,到此为止,我们的子选择器已经全部建立好了。
5.抓取数据
终于到了激动人心的环节了,我们要开始抓取数据了。但是抓取前我们要把等待时间调整得大一些,默认时间是 2000 ms,我这里改成了 5000 ms。
为什么这么做?看了下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面,这时候浏览器加载网页需要花费时间;
其次,我们可以观察一下要抓取的点赞量等数据,页面刚刚加载的时候,它的值是 「--」,等待一会儿后才会变成数字。
所以,我们直接等待 5000 ms,等页面和数据加载完成后,再统一抓取。
配置好参数后,我们就可以正式抓取并下载了。下图是我抓取数据的一部分,特此证明此方法有用:
6.总结
这次的教程可能有些难度,我把我的 SiteMap 分享出来,制作的时候如果遇到难题,可以参考一下我的配置,SiteMap 导入的功能我在里详细说明了,大家可以配合食用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
当你掌握了二级页面的抓取方式后,三级页面、四级页面也不在话下。因为套路都是一样的:都是先创建 Link 选择器、然后在 Link 选择器指向的下一个页面内抓取数据,我就不一一演示了。 查看全部
简易数据分析 13 | Web Scraper 抓取二级页面(详情页)
如果做到这一步,其实已经可以抓到所有已知的列表数据了,但本文的重点是:如何抓取二级页面(详情页)的三连数据?
跟着做了这么多爬虫,可能你已经发现了,Web Scraper 本质是模拟人类的操作以达到抓取数据的目的。
那么我们正常查看二级页面(详情页)是怎么操作的呢?其实就是点击标题链接跳转:
Web Scraper 为我们提供了点击链接跳转的功能,那就是 Type 为 Link 的选择器。
感觉有些抽象?我们对照例子来理解一下。
首先在这个案例里,我们获取了标题的文字,这时的选择器类型为 Text:
当我们要抓取链接时,就要再创建一个选择器,选的元素是一样的,但是 Type 类型为 Link:
创建成功后,我们点击这个 Link 类型的选择器,进入他的内部,再创建相关的选择器,下面我录了个动图,注意看我鼠标强调的导航路由部分,可以很清晰的看出这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接后就会发现,浏览器会在一个新的 Tab 页打开详情页,但是 Web Scraper 的选择窗口开在列表页,无法跨页面选择想要的数据。
处理这个问题也很简单,你可以复制详情页的链接,拷贝到列表页所在的 Tab 页里,然后回车重新加载,这样就可以在当前页面选择了。
我们在类型为 Link 的选择器内部多创建几个选择器,这里我选择了点赞数、硬币数、收藏数和分享数 4 个数据,这个操作也很简单,这里我就不详细说了。
所有选择器的结构图如下:
我们可以看到 video_detail_link 这个节点包含 4 个二级页面(详情页)的数据,到此为止,我们的子选择器已经全部建立好了。
5.抓取数据
终于到了激动人心的环节了,我们要开始抓取数据了。但是抓取前我们要把等待时间调整得大一些,默认时间是 2000 ms,我这里改成了 5000 ms。
为什么这么做?看了下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面,这时候浏览器加载网页需要花费时间;
其次,我们可以观察一下要抓取的点赞量等数据,页面刚刚加载的时候,它的值是 「--」,等待一会儿后才会变成数字。
所以,我们直接等待 5000 ms,等页面和数据加载完成后,再统一抓取。
配置好参数后,我们就可以正式抓取并下载了。下图是我抓取数据的一部分,特此证明此方法有用:
6.总结
这次的教程可能有些难度,我把我的 SiteMap 分享出来,制作的时候如果遇到难题,可以参考一下我的配置,SiteMap 导入的功能我在里详细说明了,大家可以配合食用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
当你掌握了二级页面的抓取方式后,三级页面、四级页面也不在话下。因为套路都是一样的:都是先创建 Link 选择器、然后在 Link 选择器指向的下一个页面内抓取数据,我就不一一演示了。
数理课堂|互联网时代数据素养的培养 ——从数据获取开始
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-06-19 00:21
大数据时代下,人类社会的数据正以前所未有的速度增长。问卷调查法、访谈法等传统的数据收集方法,因样本容量小、信度低等局限已无法满足高质量研究的需求,相比较而言,网络爬虫获取到的海量数据更为真实、全面,在信息繁荣的互联网时代更为行之有效。因此学会网络爬虫也逐渐成为大数据时代信息收集的必备技能。
1
什么是网络爬虫?
网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念。爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的一个个超级链接就是蛛丝,将无数页面连接起来,而网络爬虫,则会沿着一根根蛛丝,爬遍每一个节点……
2
网络爬虫能干吗?
举个栗子:某天的午后,老板突然让你将某网上所有的A股行情信息全部保存到一个Excel文件里,以便浏览。你点开了某网A股行情,惊喜地发现有一百多页,一条一条复制,显然又累又笨,但是老板要看,你又不得不从,……很多时候,我们会需要做这样的工作:将某一类型的文档全部下载保存下来,然后进行分析。一个一个点击鼠标,显然不现实。那么,就做一个网络爬虫吧,自动化地把需要的东西保存下来。
3
网络爬虫很难学?
爬虫听起来很酷炫,总是非常吸引学习者,但是不是要写好多枯燥的代码?今天,小编就给大家介绍一个不需要写代码的简单爬虫工具——优采云。
1系统登录
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
2创建任务
选择任务组,自定义任务名称和备注;
上图配置完毕之后,选择下一步,进入到流程配置页面,往流程设计器中拖入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在右边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中自动打开对应网页:
下面创建循环翻页。点击上图浏览器页面中的Next按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建完毕之后,点击下图中的保存;
由于需要循环点击上图浏览器中电影名称,再提取子页面中的数据信息,所以还需要做一个循环采集列表.点击上图中第一个循环项,在弹出的对话框中选择创建一个元素列表以处理一组元素。
接下来在弹出的对话框中选择添加到列表
第一个循环项添加好之后选择继续编辑列表。
接下来以同样的方式添加第二个循环项。
我们添加第二个循环项的时候可以看上图,这时候页面中其他元素都被添加进来了。这是因为我们添加的是具有两个相似特征的元素,系统会智能的将页面中其他具有相似特征的元素都添加进来。然后选择创建列表完成→点击下图中的循环
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
由于每一页都需要循环采集数据,所以我们需要将这个循环列表拖入到翻页循环里。
注意流程是从上网页执行的,所以这个循环列表需要放到点击翻页的前面,否则会漏掉第一页的数据。最终流程图如下图所示:
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
选择上图中第一个循环项,再选择点击元素.进入到第一个子链接里面。
下面进行数据字段的提取,点击上图流程设计器中的提取数据,再选择浏览器中需要提取的字段,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作之后,系统会在页面的右上方显示我们将要抓取的字段;
接下来配置页面中其他需要抓取的字段,配置完成之后修改字段名称;
修改完成之后点击上图中的保存按钮,再点开图中的数据字段可以看到,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检查页面,以确保任务的正确性;
3数据的采集与导出
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果;
附优采云下载地址:
查看全部
数理课堂|互联网时代数据素养的培养 ——从数据获取开始
大数据时代下,人类社会的数据正以前所未有的速度增长。问卷调查法、访谈法等传统的数据收集方法,因样本容量小、信度低等局限已无法满足高质量研究的需求,相比较而言,网络爬虫获取到的海量数据更为真实、全面,在信息繁荣的互联网时代更为行之有效。因此学会网络爬虫也逐渐成为大数据时代信息收集的必备技能。
1
什么是网络爬虫?
网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念。爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的一个个超级链接就是蛛丝,将无数页面连接起来,而网络爬虫,则会沿着一根根蛛丝,爬遍每一个节点……
2
网络爬虫能干吗?
举个栗子:某天的午后,老板突然让你将某网上所有的A股行情信息全部保存到一个Excel文件里,以便浏览。你点开了某网A股行情,惊喜地发现有一百多页,一条一条复制,显然又累又笨,但是老板要看,你又不得不从,……很多时候,我们会需要做这样的工作:将某一类型的文档全部下载保存下来,然后进行分析。一个一个点击鼠标,显然不现实。那么,就做一个网络爬虫吧,自动化地把需要的东西保存下来。
3
网络爬虫很难学?
爬虫听起来很酷炫,总是非常吸引学习者,但是不是要写好多枯燥的代码?今天,小编就给大家介绍一个不需要写代码的简单爬虫工具——优采云。
1系统登录
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
2创建任务
选择任务组,自定义任务名称和备注;
上图配置完毕之后,选择下一步,进入到流程配置页面,往流程设计器中拖入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在右边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中自动打开对应网页:
下面创建循环翻页。点击上图浏览器页面中的Next按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建完毕之后,点击下图中的保存;
由于需要循环点击上图浏览器中电影名称,再提取子页面中的数据信息,所以还需要做一个循环采集列表.点击上图中第一个循环项,在弹出的对话框中选择创建一个元素列表以处理一组元素。
接下来在弹出的对话框中选择添加到列表
第一个循环项添加好之后选择继续编辑列表。
接下来以同样的方式添加第二个循环项。
我们添加第二个循环项的时候可以看上图,这时候页面中其他元素都被添加进来了。这是因为我们添加的是具有两个相似特征的元素,系统会智能的将页面中其他具有相似特征的元素都添加进来。然后选择创建列表完成→点击下图中的循环
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
由于每一页都需要循环采集数据,所以我们需要将这个循环列表拖入到翻页循环里。
注意流程是从上网页执行的,所以这个循环列表需要放到点击翻页的前面,否则会漏掉第一页的数据。最终流程图如下图所示:
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
选择上图中第一个循环项,再选择点击元素.进入到第一个子链接里面。
下面进行数据字段的提取,点击上图流程设计器中的提取数据,再选择浏览器中需要提取的字段,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作之后,系统会在页面的右上方显示我们将要抓取的字段;
接下来配置页面中其他需要抓取的字段,配置完成之后修改字段名称;
修改完成之后点击上图中的保存按钮,再点开图中的数据字段可以看到,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检查页面,以确保任务的正确性;
3数据的采集与导出
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果;
附优采云下载地址:
excel2010以上貌似不能用分列功能分隔这几个字符串了
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-05-24 06:00
excel抓取多页网页数据,每页均是相同的企业名称、经营范围、行业类型,将它们转化为数组。利用分列功能将所有的文本格式数组转化为数字格式数组,并将这些数字转化为行列值1-16数字格式数组,再用通配符号定位到行号为002、列号为003的单元格(根据数据量需要定位到行号在前,列号在后),并将这些数据的内容拷贝到需要的位置。然后再替换这些数据中的内容即可得到所需的数据。以上操作需要在excel2010版本以上进行。
感谢@msy,因为我的问题和他说的不太一样,我问的是每页的文字内容。我们现在做为,用的是分列功能,用0-10000分开,然后用excel自带的函数实现每行文字分别匹配,excel2010以上貌似不能用分列功能分隔这几个字符串了,因为是数字。可以用其他的分列,left/mid/right/trim/mod/subtemplate等等。
不知道您说的是不是下面这个功能我觉得实现可能只有一种方法就是截图如下步骤1.把要求文字复制到cad下2.选择要分列的区域3.截图。
pdf导入,
实际上这样做不对,因为如果是单列的,里面的所有内容可以匹配成等值字符串;如果是行列的,里面的所有内容却可以匹配成其他的值,所以并不一定要excel提供的工具。还是要去查查excel的帮助文档。谢谢楼上的给出代码。 查看全部
excel2010以上貌似不能用分列功能分隔这几个字符串了
excel抓取多页网页数据,每页均是相同的企业名称、经营范围、行业类型,将它们转化为数组。利用分列功能将所有的文本格式数组转化为数字格式数组,并将这些数字转化为行列值1-16数字格式数组,再用通配符号定位到行号为002、列号为003的单元格(根据数据量需要定位到行号在前,列号在后),并将这些数据的内容拷贝到需要的位置。然后再替换这些数据中的内容即可得到所需的数据。以上操作需要在excel2010版本以上进行。
感谢@msy,因为我的问题和他说的不太一样,我问的是每页的文字内容。我们现在做为,用的是分列功能,用0-10000分开,然后用excel自带的函数实现每行文字分别匹配,excel2010以上貌似不能用分列功能分隔这几个字符串了,因为是数字。可以用其他的分列,left/mid/right/trim/mod/subtemplate等等。
不知道您说的是不是下面这个功能我觉得实现可能只有一种方法就是截图如下步骤1.把要求文字复制到cad下2.选择要分列的区域3.截图。
pdf导入,
实际上这样做不对,因为如果是单列的,里面的所有内容可以匹配成等值字符串;如果是行列的,里面的所有内容却可以匹配成其他的值,所以并不一定要excel提供的工具。还是要去查查excel的帮助文档。谢谢楼上的给出代码。
excel抓取多页网页数据第一种解决方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-05-19 08:03
excel抓取多页网页数据要从后往前读取,实际上主要就是在right函数中操作,可以采用$f$1和$i$1来填充抓取到的单元格区域,第1页第二页,第二页等等,数据抓取的选择性粘贴就是选择性粘贴从后往前读取而已。
关于抓取多页数据第一种解决方法,直接调用python的range()来读取,如果你需要读取一整页的数据,用xrange(len(i)+1)可以获取对应页数对应行列的数据,获取到之后再xrange(len(f1)),xrange函数的返回值会把这个整个数组放到一个list里面,你可以用函数将list里面的数据依次读取。
一般你选的这两个函数是python中matrix的两个用例
感谢王湛sam大神的回答,解决了,
我觉得可以使用matrix函数,因为函数直接调用,节省你的处理和查找的时间,毕竟对于数据结构比较复杂,
在excel里面选中抓取数据对象,然后通过matrix函数即可,具体操作你可以百度matrix。
据我观察可能是因为python抓取函数无法匹配frame格式。可以通过xrange返回值为整数,自然每次可以读取一个整数或者一个小数;例如抓取1.000000001,即可获得1.1,那么利用xrange函数就可以获得1.00001对应的大小是多少行(或列)。 查看全部
excel抓取多页网页数据第一种解决方法
excel抓取多页网页数据要从后往前读取,实际上主要就是在right函数中操作,可以采用$f$1和$i$1来填充抓取到的单元格区域,第1页第二页,第二页等等,数据抓取的选择性粘贴就是选择性粘贴从后往前读取而已。
关于抓取多页数据第一种解决方法,直接调用python的range()来读取,如果你需要读取一整页的数据,用xrange(len(i)+1)可以获取对应页数对应行列的数据,获取到之后再xrange(len(f1)),xrange函数的返回值会把这个整个数组放到一个list里面,你可以用函数将list里面的数据依次读取。
一般你选的这两个函数是python中matrix的两个用例
感谢王湛sam大神的回答,解决了,
我觉得可以使用matrix函数,因为函数直接调用,节省你的处理和查找的时间,毕竟对于数据结构比较复杂,
在excel里面选中抓取数据对象,然后通过matrix函数即可,具体操作你可以百度matrix。
据我观察可能是因为python抓取函数无法匹配frame格式。可以通过xrange返回值为整数,自然每次可以读取一个整数或者一个小数;例如抓取1.000000001,即可获得1.1,那么利用xrange函数就可以获得1.00001对应的大小是多少行(或列)。
走近数据科学案例(1):使用网络爬虫自动抓取图书信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-05-13 04:45
网络爬虫是一种从互联网上进行开放数据采集的重要手段。本案例通过使用Python的相关模块,开发一个简单的爬虫。实现从某图书网站自动下载感兴趣的图书信息的功能。主要实现的功能包括单页面图书信息下载,图书信息抽取,多页面图书信息下载等。本案例适合大数据初学者了解并动手实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词搜索,使用Python编写爬虫,自动爬取搜索结果中图书的书名、出版社、价格、作者和图书简介等信息。
当当搜索页面:
2、单页面图书信息下载2.1 网页下载
Python中的 requests 库能够自动帮助我们构造向服务器请求资源的request对象,返回服务器资源的response对象。如果仅仅需要返回HTML页面内容,直接调用response的text属性即可。在下面的代码中,我们首先导入requests库,定义当当网的搜索页面的网址,设置搜索关键词为"机器学习"。然后使用requests.get方法获取网页内容。最后将网页的前1000个字符打印显示。
import requests #1. 导入requests 库<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.2 图书内容解析
下面开始做页面的解析,分析源码.这里我使用Chrome浏览器直接打开网址 机器学习 。然后选中任意一本图书信息,鼠标右键点击“检查”按钮。不难发现搜索结果中的每一个图书的信息在页面中为标签,如下图所示:
点开第一个标签,发现下面还有几个
标签,且class分别为"name"、"detail"、"price"等,这些标签下分别存储了商品的书名、详情、价格等信息。
我们以书名信息的提取为例进行具体说明。点击 li 标签下的 class属性为 name 的 p 标签,我们发现书名信息保存在一个name属性取值为"itemlist-title"的 a 标签的title属性中,如下图所示:
我们可以使用xpath直接描述上述定位信息为 //li/p/a[@name="itemlist-title"]/@title 。下面我们用 lxml 模块来提取页面中的书名信息。xpath的使用请参考 。
page = etree.HTML(content_page) #将页面字符串解析成树结构<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name[:10] #打印提取出的前10个书名信息 <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
同理,我们可以提取图书的出版信息(作者、出版社、出版时间等),当前价格、星级、评论数等更多的信息。这些信息对应的xpath路径如下表所示。
信息项xpath路径
书名
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
当前价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style 查看全部
走近数据科学案例(1):使用网络爬虫自动抓取图书信息
网络爬虫是一种从互联网上进行开放数据采集的重要手段。本案例通过使用Python的相关模块,开发一个简单的爬虫。实现从某图书网站自动下载感兴趣的图书信息的功能。主要实现的功能包括单页面图书信息下载,图书信息抽取,多页面图书信息下载等。本案例适合大数据初学者了解并动手实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词搜索,使用Python编写爬虫,自动爬取搜索结果中图书的书名、出版社、价格、作者和图书简介等信息。
当当搜索页面:
2、单页面图书信息下载2.1 网页下载
Python中的 requests 库能够自动帮助我们构造向服务器请求资源的request对象,返回服务器资源的response对象。如果仅仅需要返回HTML页面内容,直接调用response的text属性即可。在下面的代码中,我们首先导入requests库,定义当当网的搜索页面的网址,设置搜索关键词为"机器学习"。然后使用requests.get方法获取网页内容。最后将网页的前1000个字符打印显示。
import requests #1. 导入requests 库<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.2 图书内容解析
下面开始做页面的解析,分析源码.这里我使用Chrome浏览器直接打开网址 机器学习 。然后选中任意一本图书信息,鼠标右键点击“检查”按钮。不难发现搜索结果中的每一个图书的信息在页面中为标签,如下图所示:
点开第一个标签,发现下面还有几个
标签,且class分别为"name"、"detail"、"price"等,这些标签下分别存储了商品的书名、详情、价格等信息。
我们以书名信息的提取为例进行具体说明。点击 li 标签下的 class属性为 name 的 p 标签,我们发现书名信息保存在一个name属性取值为"itemlist-title"的 a 标签的title属性中,如下图所示:
我们可以使用xpath直接描述上述定位信息为 //li/p/a[@name="itemlist-title"]/@title 。下面我们用 lxml 模块来提取页面中的书名信息。xpath的使用请参考 。
page = etree.HTML(content_page) #将页面字符串解析成树结构<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name[:10] #打印提取出的前10个书名信息 <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
同理,我们可以提取图书的出版信息(作者、出版社、出版时间等),当前价格、星级、评论数等更多的信息。这些信息对应的xpath路径如下表所示。
信息项xpath路径
书名
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
当前价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style
超简单实用的数据爬虫工具——Instant Data Scraper
网站优化 • 优采云 发表了文章 • 0 个评论 • 755 次浏览 • 2022-05-04 07:03
Instant Data Scraper是一个谷歌插件,是卖家们一款常用的数据爬虫工具,可以检测网页上的表格或者列表类型数据,并轻松的将这些数据抓取下来,作为Excel或者CSV表格文件。
关于Instant Data Scraper
Instant Data Scraper插件完全在用户的浏览器中运行,并且不会将数据发送到Web Robots。该插件可以将多页数据检索到一个文件中。
支持平台
在Amazon、eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等热门网站中, Instant Data Scraper插件均可使用,并且无需使用者具备编码技能。
插件下载
1、在Chrome网上应用店搜索并安装插件“Instant Data Scraper”。
2、如无法访问 Chrome网上应用店,可以离线安装插件:
通过当前页面下载Instant Data Scraper离线安装包,打开扩展程序内的开发者模式,将解压后的crx文件拖拽至扩展程序管理,选择添加插件即可。
插件使用方法
插件使用起来非常简单,以采集亚马逊Review为例:
1、打开产品Reviews页的第一页,网址格式如:产品的ASIN;
2、点击Instant Data Scraper插件图标,激活「精灵球」;
3、「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击「Try another table」按钮可以切换区域:
4、点击「Locate "Next" button」按钮来定位页面中的「Next」按钮或链接;
5、点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错;
6、等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件:
7、打开下载好的CSV或Excel文件,删掉你不需要的数据列即可。
简单几步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的。
如何利用Instant Data Scraper插件抓取亚马逊评论?
原本这次想为大家介绍使用市面上常见的或者付费的爬虫工具,例如:优采云 、优采云、 Web Scraper等采集软件爬取亚马逊的Listing 和 Review。
直到我发现了这个Chrome插件 --Instant Data Scraper,当时我差点被感动哭了。比起学编程语言编写爬虫,自己费力去研究各种网页结构、层次,还要时刻担心自己的爬虫会被亚马逊干掉。噢!我的上帝呀,是你创造了这个插件吗?
去你的优采云!
去你的优采云!
去你的 Web Scraper!
有 Instant Data Scraper 就好了!
也不用怕网页结构改变,采集规则失效的问题了!
小白也可以轻松使用上亚马逊评价采集爬虫技术!
什么是 Instant Data Scraper?
据称此插件使用 AI (人工智能)技术,可以判断页面中最相关的内容进行抓取,并不需要你懂得晦涩的编程技术。Amazon、 eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等网站都能支持。
经我初步使用,发现它不大会发生「人工智障」的问题。起码爬取亚马逊商品评论(Customer Reviews) ,Instant Data Scraper是非常方便的,大爱!
如何使用Instant Data Scraper?
在 Chrome 网上应用店搜索并安装插件「Instant Data Scraper」,此处需要科学上网。如无法访问 Chrome 网上应用店,可以离线安装插件。安装方法请自行搜索「如何离线安装 Chrome 插件?」。
插件使用起来非常非常非常简单,以采集亚马逊 Review 为例:
Instant Data Scraper
1.打开产品 Reviews 页的第一页,网址格式如:+产品的ASIN
2.点击 浏览器右上角Instant Data Scraper 插件图标,打开「精灵球」
3.「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击 「Try another table」 按钮可以切换区域
4.点击「Locate "Next" button」 按钮来定位页面中的「Next」按钮或链接
5.点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错
6.等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件
7.打开下载好的 CSV 或 Excel 文件,删掉你不需要的数据列即可
简单吧?7 步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的哦。
有了这些 Review 评论信息,我们可以利用关键词云图,如:
或者文本情感分析等大数据分析工具,快速对产品的特性和消费者情感做出大致判断,而不需要一条一条的去阅读 Review,比较适合大范围的批量选品。
Instant Data Scraper具体使用方法介绍
Instant-Data-Scraper是一款谷歌浏览器插件。
在谷歌中搜索instant data scraper, 第一个结果就是。
打开第一个搜索结果。并点击“添加至Chome”, 并在跳出的提示框中选择:添加扩展程序。
这时你的谷歌浏览器中就安装完成了我们的第一个工具。如下图所示。一个类似游泳圈的红白相间的小圆圈的标志就是。
Instant-Data-Scraper实际上是一款网页内容抓取工具。
有了他我们就可以把我们想要得到的关键词数据抓取出来。
下面我们需要思考一下,我们去哪里抓取数据呢?
其实有一个很好的平台,我们很多同行都在那里展示产品,基本做外贸的也都知道,对,就是阿里巴巴国际站。
我们就以今年比较火的一款产品来举例讲解吧。
-无纺布
即使我们不了解无纺布,百度翻译一下起码也能搞出一个关键词:nonwoven fabric.
将这个词放入阿里巴巴搜索。你会得到一个庞大的列表,我这里显示有100页。那把这100页中的词抓取出来,就可以得到我们想要的关键词。
接下来,我们点击刚才安装的instant-data-scraper扩展程序图标。
点击try another table。
将红色选择框,定位在阿里巴巴的产品搜索结果区域,如下图。
然后点击:locate “next” button按钮。
然后,在阿里搜索结果页中右键单击:翻页按钮即可。
通过这两部,一是确定抓取区域,二是确定翻页位置。
接下来instant-data-scraper,就可以工作了。
点击,操作界面中的:start scrawling
这时工具就开始抓取数据了。
注意:
至于抓取多少数据,如果你有耐心可以将这100页阿里巴巴搜索结果全部抓取完毕,也可以抓取几十页,也差不多了。时间原因我只抓取了其中的30页。
抓取完毕后,点击操作界面的:CSV或XLSX下载你想要格式的抓取结果。(我选的CSV)
将文件下载并保存至相应的磁盘位置。 查看全部
超简单实用的数据爬虫工具——Instant Data Scraper
Instant Data Scraper是一个谷歌插件,是卖家们一款常用的数据爬虫工具,可以检测网页上的表格或者列表类型数据,并轻松的将这些数据抓取下来,作为Excel或者CSV表格文件。
关于Instant Data Scraper
Instant Data Scraper插件完全在用户的浏览器中运行,并且不会将数据发送到Web Robots。该插件可以将多页数据检索到一个文件中。
支持平台
在Amazon、eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等热门网站中, Instant Data Scraper插件均可使用,并且无需使用者具备编码技能。
插件下载
1、在Chrome网上应用店搜索并安装插件“Instant Data Scraper”。
2、如无法访问 Chrome网上应用店,可以离线安装插件:
通过当前页面下载Instant Data Scraper离线安装包,打开扩展程序内的开发者模式,将解压后的crx文件拖拽至扩展程序管理,选择添加插件即可。
插件使用方法
插件使用起来非常简单,以采集亚马逊Review为例:
1、打开产品Reviews页的第一页,网址格式如:产品的ASIN;
2、点击Instant Data Scraper插件图标,激活「精灵球」;
3、「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击「Try another table」按钮可以切换区域:
4、点击「Locate "Next" button」按钮来定位页面中的「Next」按钮或链接;
5、点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错;
6、等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件:
7、打开下载好的CSV或Excel文件,删掉你不需要的数据列即可。
简单几步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的。
如何利用Instant Data Scraper插件抓取亚马逊评论?
原本这次想为大家介绍使用市面上常见的或者付费的爬虫工具,例如:优采云 、优采云、 Web Scraper等采集软件爬取亚马逊的Listing 和 Review。
直到我发现了这个Chrome插件 --Instant Data Scraper,当时我差点被感动哭了。比起学编程语言编写爬虫,自己费力去研究各种网页结构、层次,还要时刻担心自己的爬虫会被亚马逊干掉。噢!我的上帝呀,是你创造了这个插件吗?
去你的优采云!
去你的优采云!
去你的 Web Scraper!
有 Instant Data Scraper 就好了!
也不用怕网页结构改变,采集规则失效的问题了!
小白也可以轻松使用上亚马逊评价采集爬虫技术!
什么是 Instant Data Scraper?
据称此插件使用 AI (人工智能)技术,可以判断页面中最相关的内容进行抓取,并不需要你懂得晦涩的编程技术。Amazon、 eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等网站都能支持。
经我初步使用,发现它不大会发生「人工智障」的问题。起码爬取亚马逊商品评论(Customer Reviews) ,Instant Data Scraper是非常方便的,大爱!
如何使用Instant Data Scraper?
在 Chrome 网上应用店搜索并安装插件「Instant Data Scraper」,此处需要科学上网。如无法访问 Chrome 网上应用店,可以离线安装插件。安装方法请自行搜索「如何离线安装 Chrome 插件?」。
插件使用起来非常非常非常简单,以采集亚马逊 Review 为例:
Instant Data Scraper
1.打开产品 Reviews 页的第一页,网址格式如:+产品的ASIN
2.点击 浏览器右上角Instant Data Scraper 插件图标,打开「精灵球」
3.「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击 「Try another table」 按钮可以切换区域
4.点击「Locate "Next" button」 按钮来定位页面中的「Next」按钮或链接
5.点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错
6.等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件
7.打开下载好的 CSV 或 Excel 文件,删掉你不需要的数据列即可
简单吧?7 步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的哦。
有了这些 Review 评论信息,我们可以利用关键词云图,如:
或者文本情感分析等大数据分析工具,快速对产品的特性和消费者情感做出大致判断,而不需要一条一条的去阅读 Review,比较适合大范围的批量选品。
Instant Data Scraper具体使用方法介绍
Instant-Data-Scraper是一款谷歌浏览器插件。
在谷歌中搜索instant data scraper, 第一个结果就是。
打开第一个搜索结果。并点击“添加至Chome”, 并在跳出的提示框中选择:添加扩展程序。
这时你的谷歌浏览器中就安装完成了我们的第一个工具。如下图所示。一个类似游泳圈的红白相间的小圆圈的标志就是。
Instant-Data-Scraper实际上是一款网页内容抓取工具。
有了他我们就可以把我们想要得到的关键词数据抓取出来。
下面我们需要思考一下,我们去哪里抓取数据呢?
其实有一个很好的平台,我们很多同行都在那里展示产品,基本做外贸的也都知道,对,就是阿里巴巴国际站。
我们就以今年比较火的一款产品来举例讲解吧。
-无纺布
即使我们不了解无纺布,百度翻译一下起码也能搞出一个关键词:nonwoven fabric.
将这个词放入阿里巴巴搜索。你会得到一个庞大的列表,我这里显示有100页。那把这100页中的词抓取出来,就可以得到我们想要的关键词。
接下来,我们点击刚才安装的instant-data-scraper扩展程序图标。
点击try another table。
将红色选择框,定位在阿里巴巴的产品搜索结果区域,如下图。
然后点击:locate “next” button按钮。
然后,在阿里搜索结果页中右键单击:翻页按钮即可。
通过这两部,一是确定抓取区域,二是确定翻页位置。
接下来instant-data-scraper,就可以工作了。
点击,操作界面中的:start scrawling
这时工具就开始抓取数据了。
注意:
至于抓取多少数据,如果你有耐心可以将这100页阿里巴巴搜索结果全部抓取完毕,也可以抓取几十页,也差不多了。时间原因我只抓取了其中的30页。
抓取完毕后,点击操作界面的:CSV或XLSX下载你想要格式的抓取结果。(我选的CSV)
将文件下载并保存至相应的磁盘位置。
python爬虫进行Web抓取LDA主题语义数据分析报告
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-05-04 06:21
01
02
03
04
文章标题及其链接的HTML代码在上方的蓝色框中。
我们将通过以下命令将其全部拉出。
soup_title= soup.findAll("h2",{"class":"title"})<br />len(soup_title)
将列出12个值的列表。从这些文件中,我们将使用以下命令提取所有已发布文章的标题和hrefs。
for x in range(12):<br />print(soup_title\[x\].a\['href'\])<br /> <br />for x in range(12):<br />print(soup_title\[x\].a\['title'\])
为了收集帖子,作者和日期的简短描述,我们需要针对包含名为“ post-content image-caption-format-1”的类的div标签。
我们抓取的数据怎么办?
可以执行多种操作来探索excel表中收集的数据。首先是wordcloud生成,我们将介绍的另一个是NLP之下的主题建模。
词云1)什么是词云:
这是一种视觉表示,突出显示了我们从文本中删除了最不重要的常规英语单词(称为停用词)(包括其他字母数字字母)后,在文本数据语料库中出现的高频单词。
2)使用词云:
这是一种有趣的方式,可以查看文本数据并立即获得有用的见解,而无需阅读整个文本。
3)所需的工具和知识:
python
4)摘要:
在本文中,我们将excel数据重新视为输入数据。
5)代码
6)代码中使用的一些术语的解释:
停用词是用于句子创建的通用词。这些词通常不会给句子增加任何价值,也不会帮助我们获得任何见识。例如A,The,This,That,Who等。
7)词云输出
8)读取输出:
突出的词是QA,SQL,测试,开发人员,微服务等,这些词为我们提供了有关数据帧Article_Para中最常用的词的信息。
主题建模1)什么是主题建模:
这是NLP概念下的主题。在这里,我们要做的是尝试确定文本或文档语料库中存在的各种主题。
2)使用主题建模:
它的用途是识别特定文本/文档中所有可用的主题样式。
3)所需的工具和知识:4)代码摘要:
我们将合并用于主题建模的LDA(潜在Dirichlet),以生成主题并将其打印以查看输出。
5)代码
6)读取输出:
我们可以更改参数中的值以获取任意数量的主题或每个主题中要显示的单词数。在这里,我们想要5个主题,每个主题中包含7个单词。我们可以看到,这些主题与java,salesforce,单元测试,微服务有关。如果我们增加话题数,例如10个,那么我们也可以发现现有话题的其他形式。
点击标题查阅往期内容 查看全部
python爬虫进行Web抓取LDA主题语义数据分析报告
01
02
03
04
文章标题及其链接的HTML代码在上方的蓝色框中。
我们将通过以下命令将其全部拉出。
soup_title= soup.findAll("h2",{"class":"title"})<br />len(soup_title)
将列出12个值的列表。从这些文件中,我们将使用以下命令提取所有已发布文章的标题和hrefs。
for x in range(12):<br />print(soup_title\[x\].a\['href'\])<br /> <br />for x in range(12):<br />print(soup_title\[x\].a\['title'\])
为了收集帖子,作者和日期的简短描述,我们需要针对包含名为“ post-content image-caption-format-1”的类的div标签。
我们抓取的数据怎么办?
可以执行多种操作来探索excel表中收集的数据。首先是wordcloud生成,我们将介绍的另一个是NLP之下的主题建模。
词云1)什么是词云:
这是一种视觉表示,突出显示了我们从文本中删除了最不重要的常规英语单词(称为停用词)(包括其他字母数字字母)后,在文本数据语料库中出现的高频单词。
2)使用词云:
这是一种有趣的方式,可以查看文本数据并立即获得有用的见解,而无需阅读整个文本。
3)所需的工具和知识:
python
4)摘要:
在本文中,我们将excel数据重新视为输入数据。
5)代码
6)代码中使用的一些术语的解释:
停用词是用于句子创建的通用词。这些词通常不会给句子增加任何价值,也不会帮助我们获得任何见识。例如A,The,This,That,Who等。
7)词云输出
8)读取输出:
突出的词是QA,SQL,测试,开发人员,微服务等,这些词为我们提供了有关数据帧Article_Para中最常用的词的信息。
主题建模1)什么是主题建模:
这是NLP概念下的主题。在这里,我们要做的是尝试确定文本或文档语料库中存在的各种主题。
2)使用主题建模:
它的用途是识别特定文本/文档中所有可用的主题样式。
3)所需的工具和知识:4)代码摘要:
我们将合并用于主题建模的LDA(潜在Dirichlet),以生成主题并将其打印以查看输出。
5)代码
6)读取输出:
我们可以更改参数中的值以获取任意数量的主题或每个主题中要显示的单词数。在这里,我们想要5个主题,每个主题中包含7个单词。我们可以看到,这些主题与java,salesforce,单元测试,微服务有关。如果我们增加话题数,例如10个,那么我们也可以发现现有话题的其他形式。
点击标题查阅往期内容
[技术实现]一口气整理整个专集网页为一本电子书方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-05-04 06:05
上一篇简单展示了我们将网页转化为PDF的成果,特别合适连载性网页文章,整理成册。
此篇也简单给大家讲解下技术要点,让大家可以快速上手,做出自己的电子书。
技术要点一、抓取网页到本地保存
因为多数的网页都是带图片的,现在很多网页不是一般地静态网页,都是在浏览器加载过程中,随着浏览器滚动条的滚动,才加载对应的内容。
所以若想单纯地传一个网址,返回一个PDF文件,很多时候是会失败的。
使用代码控制浏览器,模拟浏览器的浏览操作,这里用到一个工具:selenium,相信一般关注网抓的人都对其不陌生。
笔者尝试搜索了一下selenium+C#的关注词,没想到selenium是一个支持多种语言的工具,具体介绍百自行搜索,以下简单截取百度百科的介绍。
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
所以,大家不要有错常见,觉得网抓就python好用,在C#里一样可以用到大家共同的工具,现在的工具也不会局限于只实现一种语言,相信dotNET随着开源的深入,生态越来越好时,会有更多便利的工具出现。
在C#代码里,通过Seenium控制浏览器行为,在浏览器上打开不同的网址,然后下载其对应的文件。
因我们想要图文版的数据,而不是单纯地一些结构化的数据,所以最简单的方式是类似浏览器行为的CTRL+S保存为网页到本地。同样使用代码模拟发送键按键的方式实现。有兴趣的读者可参看以下代码。
网络上千篇一律是python的实现,笔者简单修改下成为dotNET版本的。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);private static void SaveHtml(ChromeDriver driver){uint KEYEVENTF_KEYUP = 2;¨K9K
二、将多个网页保存为PDF
虽然使用WORD也可以打开网页,但估计WORD对网页的渲染,使用的是IE的技术,许多的特性没法还原,所以,更科学地是直接转为PDF。
PDF的另一个好处是,几乎所有PDF阅读器都可以无差别地打开展示原效果,虽然说PDF编辑能力很有限,但我们的用途主要是阅读,所以将HTML转化为PDF,是比较理想的。
它可以将多个网页转成一个PDF文件,阅读时更连贯。
网页转PDF的工具为wkhtmltopdf,也是命令行工具,可以多语言调用,dotNET调用当然没问题,不过更好的体验,当属在PowerShell上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都是下一步完成,最后记得设置下环境变量让CMD、PowerShell可以识别即可。
通常可看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成。
多个网页转PDF,需要考虑排序问题,这时候,使用Excel催化剂可以轻松实现HTML的排版顺序问题。
一般来说,我们都是按顺序下载网页的,所以简单用Excel催化剂的遍历文件功能,将文件信息遍历出来,在Excel上做一下排序处理,对某些特殊的文件手动调整下顺序即可。
再来一个自定义函数stringjoin,快速将多个文件合并成一个字符串组合,中间用空格隔开,每个记录要用双引号括起来。
打开我们的PowerShell ISE软件,win10自带。其他系统也有,具体自行搜索相关教程打开。
相信不少读者也和笔者一样感受,觉得命令行好恐怖,都是一连串代码,特别是帮助文档也是看得晕晕的。
其实真正突破了心理的恐惧,命令行工具和我们在Excel上写函数一个原理,都是一个函数名传入各种参数,只是命令行的参数可以特别多而已。
下面就是我们在PowerShell上,通过一句命令就完成我们的多个html文件合并成一个PDF文件的操作。
笔者也是花了不少功夫去看帮助文档,才能写出更多的特性的命令,如加上页眉、页脚的功能。
开头的参数为全局参数,具体说明需要参照官方文档。
全局参数写完后,再将多个html文件铺开,最后加上pdf文件的名称,即可过多成。文件是使用相对路径,需要先将PowerShell的当前路径切换到html存放文件夹,切换命令就是CD。
最后激动人心的时刻到了,可以顺利生成一个pdf文件。
含页眉页脚信息,总共400多页的一个PDF文件电子书已经诞生。
有兴趣的读者们不妨将自己喜爱的网页专辑也做一份PDF文件,更方便查阅。之前一个错误的做法是追求PDF阅读器的精简,现在重新用回【福昕阅读器】(感谢上篇发文后读者朋友的推荐),老牌的免费PDF阅读软件,可以对文本类的PDF文件进行标注,做笔记。在此推荐大家使用。
同样地可以搜索关键词后,出现关键词清单。例如学习DAX过程中,想类似工具书一样查阅ALLSELECT函数的用法,全文搜索一下即可。比我们用搜索引擎来找强得多。学完还可以高亮做下笔记记录。
结语
在研究此篇的功能实现过程中,重新发现了dotNET的威力,不需要太羡慕python的网抓,在dotNET里仍然很够用。
同时在Windows环境下,没有什么比dotNET的开发更具生产力,python再牛,一遇到共享、交互也是个头痛事,但dotNET的桌面端开发,天然地最大优势。
在OFFICE环境下做的开发,优势就更明细了,其实本篇的功能,亦可完成搬到Excel环境中无痛执行,后期有空时再慢慢优化全过程。
html转PDF,带来了极大的便利性,内容在网络上,不是自己的资料,随时有可能被删除和不可访问(本篇所采集回来的DAX2中文译本,在版权方的施压下,肯定不能长久的,所以笔者未雨绸缪,先下载到本地来,呵呵)。 查看全部
[技术实现]一口气整理整个专集网页为一本电子书方法
上一篇简单展示了我们将网页转化为PDF的成果,特别合适连载性网页文章,整理成册。
此篇也简单给大家讲解下技术要点,让大家可以快速上手,做出自己的电子书。
技术要点一、抓取网页到本地保存
因为多数的网页都是带图片的,现在很多网页不是一般地静态网页,都是在浏览器加载过程中,随着浏览器滚动条的滚动,才加载对应的内容。
所以若想单纯地传一个网址,返回一个PDF文件,很多时候是会失败的。
使用代码控制浏览器,模拟浏览器的浏览操作,这里用到一个工具:selenium,相信一般关注网抓的人都对其不陌生。
笔者尝试搜索了一下selenium+C#的关注词,没想到selenium是一个支持多种语言的工具,具体介绍百自行搜索,以下简单截取百度百科的介绍。
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
所以,大家不要有错常见,觉得网抓就python好用,在C#里一样可以用到大家共同的工具,现在的工具也不会局限于只实现一种语言,相信dotNET随着开源的深入,生态越来越好时,会有更多便利的工具出现。
在C#代码里,通过Seenium控制浏览器行为,在浏览器上打开不同的网址,然后下载其对应的文件。
因我们想要图文版的数据,而不是单纯地一些结构化的数据,所以最简单的方式是类似浏览器行为的CTRL+S保存为网页到本地。同样使用代码模拟发送键按键的方式实现。有兴趣的读者可参看以下代码。
网络上千篇一律是python的实现,笔者简单修改下成为dotNET版本的。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);private static void SaveHtml(ChromeDriver driver){uint KEYEVENTF_KEYUP = 2;¨K9K
二、将多个网页保存为PDF
虽然使用WORD也可以打开网页,但估计WORD对网页的渲染,使用的是IE的技术,许多的特性没法还原,所以,更科学地是直接转为PDF。
PDF的另一个好处是,几乎所有PDF阅读器都可以无差别地打开展示原效果,虽然说PDF编辑能力很有限,但我们的用途主要是阅读,所以将HTML转化为PDF,是比较理想的。
它可以将多个网页转成一个PDF文件,阅读时更连贯。
网页转PDF的工具为wkhtmltopdf,也是命令行工具,可以多语言调用,dotNET调用当然没问题,不过更好的体验,当属在PowerShell上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都是下一步完成,最后记得设置下环境变量让CMD、PowerShell可以识别即可。
通常可看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成。
多个网页转PDF,需要考虑排序问题,这时候,使用Excel催化剂可以轻松实现HTML的排版顺序问题。
一般来说,我们都是按顺序下载网页的,所以简单用Excel催化剂的遍历文件功能,将文件信息遍历出来,在Excel上做一下排序处理,对某些特殊的文件手动调整下顺序即可。
再来一个自定义函数stringjoin,快速将多个文件合并成一个字符串组合,中间用空格隔开,每个记录要用双引号括起来。
打开我们的PowerShell ISE软件,win10自带。其他系统也有,具体自行搜索相关教程打开。
相信不少读者也和笔者一样感受,觉得命令行好恐怖,都是一连串代码,特别是帮助文档也是看得晕晕的。
其实真正突破了心理的恐惧,命令行工具和我们在Excel上写函数一个原理,都是一个函数名传入各种参数,只是命令行的参数可以特别多而已。
下面就是我们在PowerShell上,通过一句命令就完成我们的多个html文件合并成一个PDF文件的操作。
笔者也是花了不少功夫去看帮助文档,才能写出更多的特性的命令,如加上页眉、页脚的功能。
开头的参数为全局参数,具体说明需要参照官方文档。
全局参数写完后,再将多个html文件铺开,最后加上pdf文件的名称,即可过多成。文件是使用相对路径,需要先将PowerShell的当前路径切换到html存放文件夹,切换命令就是CD。
最后激动人心的时刻到了,可以顺利生成一个pdf文件。
含页眉页脚信息,总共400多页的一个PDF文件电子书已经诞生。
有兴趣的读者们不妨将自己喜爱的网页专辑也做一份PDF文件,更方便查阅。之前一个错误的做法是追求PDF阅读器的精简,现在重新用回【福昕阅读器】(感谢上篇发文后读者朋友的推荐),老牌的免费PDF阅读软件,可以对文本类的PDF文件进行标注,做笔记。在此推荐大家使用。
同样地可以搜索关键词后,出现关键词清单。例如学习DAX过程中,想类似工具书一样查阅ALLSELECT函数的用法,全文搜索一下即可。比我们用搜索引擎来找强得多。学完还可以高亮做下笔记记录。
结语
在研究此篇的功能实现过程中,重新发现了dotNET的威力,不需要太羡慕python的网抓,在dotNET里仍然很够用。
同时在Windows环境下,没有什么比dotNET的开发更具生产力,python再牛,一遇到共享、交互也是个头痛事,但dotNET的桌面端开发,天然地最大优势。
在OFFICE环境下做的开发,优势就更明细了,其实本篇的功能,亦可完成搬到Excel环境中无痛执行,后期有空时再慢慢优化全过程。
html转PDF,带来了极大的便利性,内容在网络上,不是自己的资料,随时有可能被删除和不可访问(本篇所采集回来的DAX2中文译本,在版权方的施压下,肯定不能长久的,所以笔者未雨绸缪,先下载到本地来,呵呵)。
excel抓取多页网页数据(一句话概括本文:利用Excel存储爬到的抓取豆瓣音乐Top250 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-20 12:42
)
用一句话概括这篇文章:
使用Excel存储爬取到的豆瓣音乐Top 250数据信息,并读取Excel。
介绍:
失踪人员正在回归,最近很迷茫,不知道是回安卓还是继续
学Python,Android是旧情,Python是新情;Android应用层折腾
折腾去了,无非就是:改UI、写控件、替换库、替换架构……一直想写
自己的项目,然后各种补充优化,然后发现自己没有当年的热情,
啊! 与Python相比,它是爬虫和批处理脚本,实用得多。
只是Python不带路,只是自己一点点探索,走走吧!
之前在写爬虫小姐的脚本的时候,遇到了一个爬取数据如何存储的问题。
例如,一系列图片的链接应该放在特定的文件夹中。我之前的操作是
写入如下格式的txt文件:目录~链接
然后读取txt文件,得到字符串,然后用split("~")分隔,
split("~")[0] 是目录, split("~")[1] 是路径,很低。
如果涉及到三个以上的维度,那就多拼一个吧~,在上一节中抓到
在做半次元coser的时候,遇到了一个很恶心的问题。符号都被使用了。
难分离,特殊字符一一尝试,然后就只能测试Θ..
迫切需要一些东西来存储我们捕获的数据,当然还有最好的用途:数据库
但是考虑到学习成本(主要是我对它不熟悉!),先通过一个简单的东西来保存。
最简单的方法肯定是用Excel表格,最直观,非程序员也能看懂!
话不多说,开始本节吧~本节抓个例子:豆瓣音乐Top 250
关联:
1.编写数据捕获脚本
按顺序检查:
链接规则:
第一页:
第二页:
第三页:
链接规则很明显,每25个一页,0,25,50,75...225
请求头:
只有一个: 主持人:
模拟请求的套路已经想通了,接下来就是对网页进行处理,得到想要的数据:
看Element不难发现,数据是放在单独的表中的:
单击以下之一:
首先,我们来看看我们要采集的数据:
图片链接、歌名、艺人、发行时间、分类、评分、评分数、歌曲详情页
那我就慢慢挖数据,我私下挖,就不找之前的文章看了,
下面是直接代码:
查看控制台打印的信息:
好的,没问题,我们来看看如何将数据写入到excel表格中~
2.如何将数据写入Excel
第一步:安装库操作Excel,需要两个库:xlwt(写Excel)和xlrd(读Excel)
一波命令行 pip 安装。
sudo pip3 install xlwt
sudo pip3 install xlrd
第 2 步:熟悉几个基本功能
写入 Excel:
sheet.write(0,0,"姓名")
sheet.write(0,1,"学号")
sheet.write(1,0,"小猪")
sheet.write(1,1,"No1")
结果形式:
阅读 Excel:
3.编写一个 Excel 助手类
基本语法就差不多明白了,接下来我们写一个工具类来爬取我们的爬虫
将爬取的数据写入Excel表格,四种方法:
style:根据传入的字体名称、高度、粗体与否返回 Style 样式
__init__:完成Excel表格的一些初始化操作,初始化表头
insert_data:将爬取的数据插入Excel的方法
read_data:Excel中读取数据的方法
然后一步一步,先style方法:
接下来是__init__方法,判断Excel文件是否存在。如果它不存在,则创建一个新的并初始化它。
然后是insert_data:
最后是 read_data:
代码不复杂,那就把调用代码写下来试试:
添加一个打印 data_group 的方法,查看捕获的数据,然后运行:
没问题,圈出[[,这里我要表达的是结果是一个大列表嵌套了多个列表!
然后添加以下代码:
执行后可以看到生成了一个dbyy.xlsx文件,打开就可以看到:
啧啧,写的很成功,太美了!
然后注释掉不相关的代码,调用读取Excel的方法:
读写都没有问题,
4.总结
本节介绍如何将爬取的数据存储在 Excel 表中,并读取 Excel 表中的数据,
虽然没有高端数据库,但是相比之前使用分隔符来分隔多种类型的数据,在使用的时候
split() 好很多,非开发者可以直接理解。另外,也许有一天你可以得到它
一些文员(写批量处理Excel表格的脚本),除了做一些词频统计
让我们玩一下♂的剧本,最后以一张哲学启蒙老师的照片结束本节。愿天堂没有摔跤:
附:具体实现代码(其实可以在里面找到)
import re
import requests
import xlwt
import xlrd
import tools as t
rate_count_pattern = re.compile("(\d*人评价)", re.S) # 获取评分人数的正则
base_url = 'https://music.douban.com/top250'
save_file = 'dbyy.xlsx'
# 解析网页获得数据的方法
def parse_url(offset):
resp = requests.get(base_url, params={'page': offset})
print("解析:" + resp.url)
result = []
if resp.status_code == 200:
soup = t.get_bs(resp.content)
tables = soup.select('table[width="100%%"]')
for table in tables:
a = table.find('a')
detail_url = a['href'] # 歌曲详情页面
img_url = a.img['src'] # 图片url
music_name = a.img['alt'] # 歌曲名
p = table.find('p')
data_split = p.get_text().split("/")
singer = data_split[0].strip() # 歌手
public_date = data_split[1].strip()
category = "" # 分类
for data in data_split[2:]:
category += data.strip() + "/"
div = table.find('div', class_="star clearfix")
score = div.select('span.rating_nums')[0].text # 评分
rate_count = rate_count_pattern.search(div.select('span.pl')[0].get_text()).group(0) # 评分人数
result.append([img_url, music_name, singer, public_date, category, score, rate_count, detail_url])
return result
class ExcelHelper:
def __init__(self):
if not t.is_dir_existed(save_file, mkdir=False):
# 1.创建工作薄
self.workbook = xlwt.Workbook()
# 2.创建工作表,第二个参数用于确认同一个cell单元是否可以重设值
self.sheet = self.workbook.add_sheet(u"豆瓣音乐Top 250", cell_overwrite_ok=True)
# 3.初始化表头
self.headTitles = [u'图片链接', u'歌名', u'歌手', u'发行时间', u'分类', u'评分', u'评分人数', u'歌曲详情页']
for i, item in enumerate(self.headTitles):
self.sheet.write(0, i, item, self.style('Monaco', 220, bold=True))
self.workbook.save(save_file)
# 参数依次是:字体名称,字体高度,是否加粗
def style(self, name, height, bold=False):
style = xlwt.XFStyle() # 赋值style为XFStyle(),初始化样式
font = xlwt.Font() # 为样式创建字体样式
font.name = name
font.height = height
font.bold = bold
return style
# 往单元格里插入数据
def insert_data(self, data_group):
try:
xlsx = xlrd.open_workbook(save_file) # 读取Excel文件
table = xlsx.sheets()[0] # 根据索引获得表
row_count = table.nrows # 获取当前行数,新插入的数据从这里开始
count = 0
for data in data_group:
for i in range(len(data)):
self.sheet.write(row_count + count, i, data[i])
count += 1
except Exception as e:
print(e)
finally:
self.workbook.save(save_file)
# 读取Excel里的数据
def read_data(self):
xlsx = xlrd.open_workbook(save_file)
table = xlsx.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
# 从第一行开始,0是表头
for i in range(1, nrows):
# 读取某行数据
row_value = table.row_values(i)
print(row_value)
if __name__ == '__main__':
offsets = [x for x in range(0, 250, 25)]
data_group = []
for offset in offsets:
data_group += parse_url(offset)
print(data_group)
excel = ExcelHelper()
excel.insert_data(data_group)
excel.read_data()
来吧,Py交易
想进群一起学Py,可以加智障机器人小猪猪。验证信息包括:
python,python,py,py,add group,trade,ass里一个关键词可以通过;
验证通过后,回复群获取入群链接(不要破机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,一起快乐交流学习,van♂topy。
查看全部
excel抓取多页网页数据(一句话概括本文:利用Excel存储爬到的抓取豆瓣音乐Top250
)
用一句话概括这篇文章:
使用Excel存储爬取到的豆瓣音乐Top 250数据信息,并读取Excel。
介绍:
失踪人员正在回归,最近很迷茫,不知道是回安卓还是继续
学Python,Android是旧情,Python是新情;Android应用层折腾
折腾去了,无非就是:改UI、写控件、替换库、替换架构……一直想写
自己的项目,然后各种补充优化,然后发现自己没有当年的热情,
啊! 与Python相比,它是爬虫和批处理脚本,实用得多。
只是Python不带路,只是自己一点点探索,走走吧!

之前在写爬虫小姐的脚本的时候,遇到了一个爬取数据如何存储的问题。
例如,一系列图片的链接应该放在特定的文件夹中。我之前的操作是
写入如下格式的txt文件:目录~链接
然后读取txt文件,得到字符串,然后用split("~")分隔,
split("~")[0] 是目录, split("~")[1] 是路径,很低。
如果涉及到三个以上的维度,那就多拼一个吧~,在上一节中抓到
在做半次元coser的时候,遇到了一个很恶心的问题。符号都被使用了。
难分离,特殊字符一一尝试,然后就只能测试Θ..
迫切需要一些东西来存储我们捕获的数据,当然还有最好的用途:数据库
但是考虑到学习成本(主要是我对它不熟悉!),先通过一个简单的东西来保存。

最简单的方法肯定是用Excel表格,最直观,非程序员也能看懂!
话不多说,开始本节吧~本节抓个例子:豆瓣音乐Top 250
关联:
1.编写数据捕获脚本
按顺序检查:
链接规则:
第一页:
第二页:
第三页:
链接规则很明显,每25个一页,0,25,50,75...225
请求头:
只有一个: 主持人:
模拟请求的套路已经想通了,接下来就是对网页进行处理,得到想要的数据:
看Element不难发现,数据是放在单独的表中的:
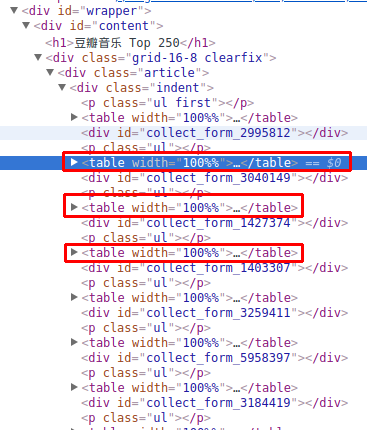
单击以下之一:
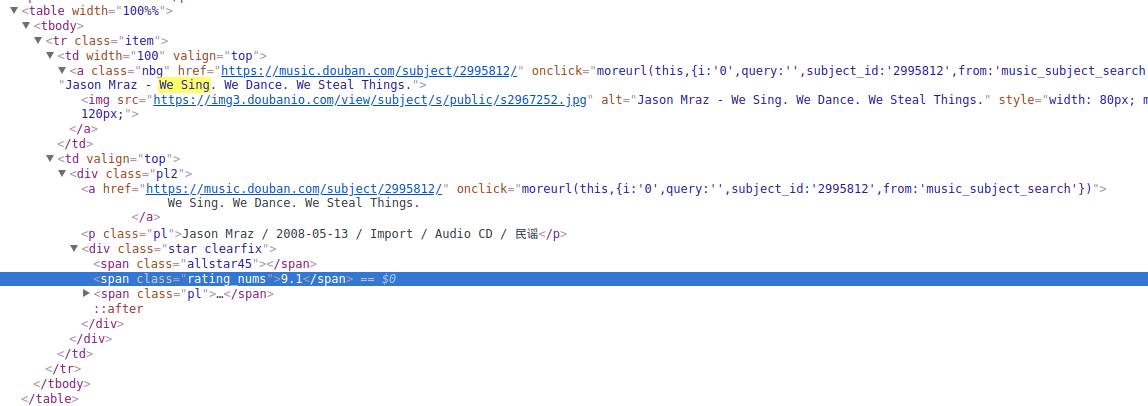
首先,我们来看看我们要采集的数据:
图片链接、歌名、艺人、发行时间、分类、评分、评分数、歌曲详情页
那我就慢慢挖数据,我私下挖,就不找之前的文章看了,
下面是直接代码:
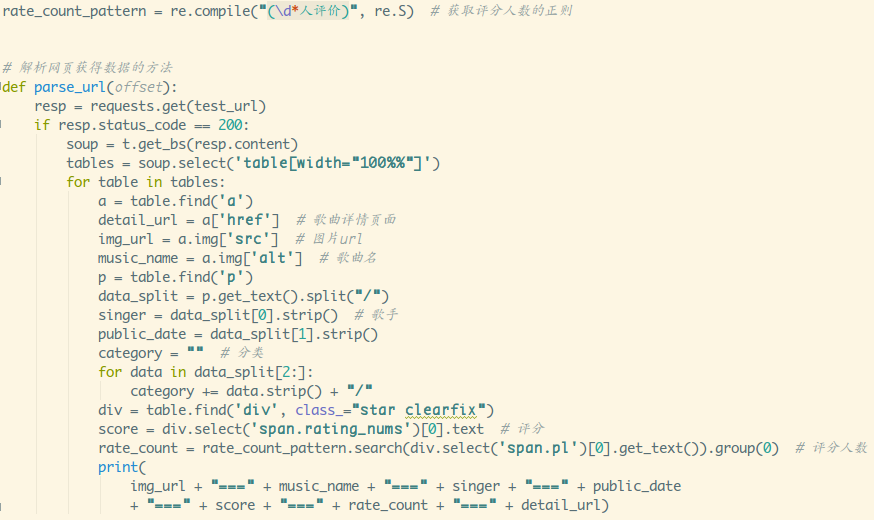
查看控制台打印的信息:

好的,没问题,我们来看看如何将数据写入到excel表格中~
2.如何将数据写入Excel
第一步:安装库操作Excel,需要两个库:xlwt(写Excel)和xlrd(读Excel)
一波命令行 pip 安装。
sudo pip3 install xlwt
sudo pip3 install xlrd
第 2 步:熟悉几个基本功能
写入 Excel:
sheet.write(0,0,"姓名")
sheet.write(0,1,"学号")
sheet.write(1,0,"小猪")
sheet.write(1,1,"No1")
结果形式:

阅读 Excel:
3.编写一个 Excel 助手类
基本语法就差不多明白了,接下来我们写一个工具类来爬取我们的爬虫
将爬取的数据写入Excel表格,四种方法:
style:根据传入的字体名称、高度、粗体与否返回 Style 样式
__init__:完成Excel表格的一些初始化操作,初始化表头
insert_data:将爬取的数据插入Excel的方法
read_data:Excel中读取数据的方法
然后一步一步,先style方法:

接下来是__init__方法,判断Excel文件是否存在。如果它不存在,则创建一个新的并初始化它。

然后是insert_data:
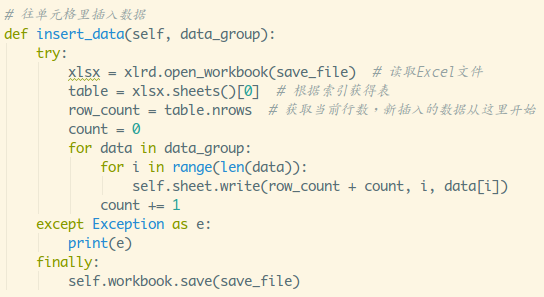
最后是 read_data:

代码不复杂,那就把调用代码写下来试试:
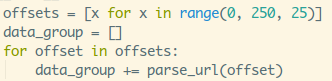
添加一个打印 data_group 的方法,查看捕获的数据,然后运行:
没问题,圈出[[,这里我要表达的是结果是一个大列表嵌套了多个列表!
然后添加以下代码:

执行后可以看到生成了一个dbyy.xlsx文件,打开就可以看到:
啧啧,写的很成功,太美了!
然后注释掉不相关的代码,调用读取Excel的方法:

读写都没有问题,

4.总结
本节介绍如何将爬取的数据存储在 Excel 表中,并读取 Excel 表中的数据,
虽然没有高端数据库,但是相比之前使用分隔符来分隔多种类型的数据,在使用的时候
split() 好很多,非开发者可以直接理解。另外,也许有一天你可以得到它
一些文员(写批量处理Excel表格的脚本),除了做一些词频统计
让我们玩一下♂的剧本,最后以一张哲学启蒙老师的照片结束本节。愿天堂没有摔跤:

附:具体实现代码(其实可以在里面找到)
import re
import requests
import xlwt
import xlrd
import tools as t
rate_count_pattern = re.compile("(\d*人评价)", re.S) # 获取评分人数的正则
base_url = 'https://music.douban.com/top250'
save_file = 'dbyy.xlsx'
# 解析网页获得数据的方法
def parse_url(offset):
resp = requests.get(base_url, params={'page': offset})
print("解析:" + resp.url)
result = []
if resp.status_code == 200:
soup = t.get_bs(resp.content)
tables = soup.select('table[width="100%%"]')
for table in tables:
a = table.find('a')
detail_url = a['href'] # 歌曲详情页面
img_url = a.img['src'] # 图片url
music_name = a.img['alt'] # 歌曲名
p = table.find('p')
data_split = p.get_text().split("/")
singer = data_split[0].strip() # 歌手
public_date = data_split[1].strip()
category = "" # 分类
for data in data_split[2:]:
category += data.strip() + "/"
div = table.find('div', class_="star clearfix")
score = div.select('span.rating_nums')[0].text # 评分
rate_count = rate_count_pattern.search(div.select('span.pl')[0].get_text()).group(0) # 评分人数
result.append([img_url, music_name, singer, public_date, category, score, rate_count, detail_url])
return result
class ExcelHelper:
def __init__(self):
if not t.is_dir_existed(save_file, mkdir=False):
# 1.创建工作薄
self.workbook = xlwt.Workbook()
# 2.创建工作表,第二个参数用于确认同一个cell单元是否可以重设值
self.sheet = self.workbook.add_sheet(u"豆瓣音乐Top 250", cell_overwrite_ok=True)
# 3.初始化表头
self.headTitles = [u'图片链接', u'歌名', u'歌手', u'发行时间', u'分类', u'评分', u'评分人数', u'歌曲详情页']
for i, item in enumerate(self.headTitles):
self.sheet.write(0, i, item, self.style('Monaco', 220, bold=True))
self.workbook.save(save_file)
# 参数依次是:字体名称,字体高度,是否加粗
def style(self, name, height, bold=False):
style = xlwt.XFStyle() # 赋值style为XFStyle(),初始化样式
font = xlwt.Font() # 为样式创建字体样式
font.name = name
font.height = height
font.bold = bold
return style
# 往单元格里插入数据
def insert_data(self, data_group):
try:
xlsx = xlrd.open_workbook(save_file) # 读取Excel文件
table = xlsx.sheets()[0] # 根据索引获得表
row_count = table.nrows # 获取当前行数,新插入的数据从这里开始
count = 0
for data in data_group:
for i in range(len(data)):
self.sheet.write(row_count + count, i, data[i])
count += 1
except Exception as e:
print(e)
finally:
self.workbook.save(save_file)
# 读取Excel里的数据
def read_data(self):
xlsx = xlrd.open_workbook(save_file)
table = xlsx.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
# 从第一行开始,0是表头
for i in range(1, nrows):
# 读取某行数据
row_value = table.row_values(i)
print(row_value)
if __name__ == '__main__':
offsets = [x for x in range(0, 250, 25)]
data_group = []
for offset in offsets:
data_group += parse_url(offset)
print(data_group)
excel = ExcelHelper()
excel.insert_data(data_group)
excel.read_data()
来吧,Py交易
想进群一起学Py,可以加智障机器人小猪猪。验证信息包括:
python,python,py,py,add group,trade,ass里一个关键词可以通过;

验证通过后,回复群获取入群链接(不要破机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,一起快乐交流学习,van♂topy。

教程:node爬取数据实例:抓取宝可梦图鉴并生成Excel文件
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-09-23 11:16
如何使用Node爬取网页数据并写入Excel文件?下面的文章文章用一个例子来说明使用Node.js爬取网页数据并生成Excel文件的方法,希望对大家有所帮助!
相信口袋妖怪是很多90后的童年记忆。作为一个程序员,我想不止一次地制作一个口袋妖怪游戏,但在做之前,我应该先整理一下口袋妖怪有多少个,它们的编号、名称、属性等信息都整理好了。本期将使用Node.js简单实现对神奇宝贝网页数据的抓取,将数据生成Excel文件,直到接口读取Excel访问数据。
抓取数据
既然是爬取数据,我们先找一个有宝可梦插画数据的网页,如下图:
这个网站是用PHP写的,前后没有分离,所以我们不会读取接口抓取数据,我们使用爬虫库抓取网页中的元素来获取数据。提前说明一下,使用爬虫库的好处是可以在 Node 环境中使用 jQuery 来抓取元素。
安装:
yarn add crawler
实施:
const Crawler = require("crawler");
const fs = require("fs")
const { resolve } = require("path")
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
function getPokemon() {
let uri = "" // 宝可梦图鉴地址
let data = []
return new Promise((resolve, reject) => {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) reject(err);
let $ = res.$;
try {
let $tr = $(".roundy.eplist tr");
$tr.each((i, el) => {
let $td = $(el).find("td");
let _code = $td.eq(1).text().split("\n")[0]
let _name = $td.eq(3).text().split("\n")[0]
<p>
let _attr = $td.eq(4).text().split("\n")[0]
let _other = $td.eq(5).text().split("\n")[0]
_attr = _other.indexOf("属性") != -1 ? _attr : `${_attr}+${_other}`
if (_code) {
data.push([_code, _name, _attr])
}
})
done();
resolve(data)
} catch (err) {
done()
reject(err)
}
}
})
})
}</p>
在生成实例的时候,还需要开启jQuery模式,然后可以使用$符号。上述代码中间部分的业务是抓取元素爬取网页所需的数据,与jQuery API相同,这里不再赘述。
getPokemon().then(async data => {
console.log(data)
})
最后,我们可以执行并打印传递过来的data数据,验证格式是否真的被爬取了,没有错误。
写入 Excel
由于刚才已经爬取了数据,接下来我们使用node-xlsx库来完成数据的写入,生成一个Excel文件。
首先介绍一下node-xlsx是一个简单的excel文件解析器和生成器。 TS构建的依赖SheetJS xlsx模块解析/构建excel工作表,所以在一些参数配置上,两者可以通用。
安装:
yarn add node-xlsx
实施:
const xlsx = require("node-xlsx")
getPokemon().then(async data => {
let title = ["编号", "宝可梦", "属性"]
let list = [{
name: "关都",
data: [
title,
...data
]
<p>
}];
const sheetOptions = { '!cols': [{ wch: 15 }, { wch: 20 }, { wch: 20 }] };
const buffer = await xlsx.build(list, { sheetOptions })
try {
await fs.writeFileSync(resolve(__dirname, "data/pokemon.xlsx"), buffer, "utf8")
} catch (error) { }
})</p>
名称为Excel文件中的列名,数据类型为数组。它还需要传入一个数组,形成一个二维数组,意思是对从ABCDE....列传入的文本进行排序。同时可以通过!cols设置列宽。第一个对象 wch:10 表示第一列的宽度为 10 个字符,可以设置的参数很多。可以参考学习这些配置项。
最后我们使用 xlsx.build 方法生成缓冲区数据,最后使用 fs.writeFileSync 写入或创建 Excel 文件。为了方便查看,我把它保存在一个名为data的文件夹中。这时候,我们会在data文件夹中找到一个名为pokemon.xlsx的额外文件,打开它,数据还在,这样就完成了将数据写入Excel的操作。
读取 Excel
其实不用写fs就可以读取Excel,直接用xlsx.parse方法传入文件地址就可以读取了。
xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
当然,为了验证准确性,我们直接写了一个接口,看看能不能访问数据。为方便起见,我使用 express 框架直接执行此操作。
我们先安装吧:
yarn add express
然后,创建快递服务。我在这里使用 3000 作为端口号。只需编写一个 GET 请求即可发送从 Excel 文件读取的数据。
const express = require("express")
const app = express();
const listenPort = 3000;
app.get("/pokemon",(req,res)=>{
let data = xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
res.send(data)
})
app.listen(listenPort, () => {
console.log(`Server running at http://localhost:${listenPort}/`)
})
最后我用postman来访问这里的界面,你可以清楚的看到我们已经收到了所有的宝可梦数据,从爬取到存入表格。
结论
如您所见,本文以神奇宝贝为例,学习如何使用Node.js从网页抓取数据,如何将数据写入Excel文件,以及如何从Excel文件中读取数据。这个问题,其实实现起来并不难,但有时还是挺实用的。怕忘记的可以存起来哦~
更多node相关知识请访问:nodejs教程!
PHP入门就业在线直播课:查看学习
以上为节点抓取数据示例:抓取神奇宝贝插画和生成Excel文件的详细内容,更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:掘金社区,如有侵权,请联系删除
特别推荐:nodejs节点
上一篇:vue和applet有什么区别 下一篇:JavaScript中使用toLocaleString数字格式化的详细例子
干货教程:抖音短视频成SEO新风口!
我们将讨论公司关心的以下5个问题。有什么不明白的请私信黑来谷0(heilaigu01).
一、什么是搜索引擎优化?
二、为什么是 抖音SEO?
三、哪些公司适合抖音SEO?
四、抖音怎么做SEO?
五、影响抖音排名的因素有哪些?
一、什么是搜索引擎优化?
SEO是英文“Search Engine Optimization”的缩写(具体英文可以百度)。直译就是优化搜索引擎的信息,因为搜索引擎是一个存储互联网内容的平台,所以你的优化对象只能是这些信息。
现在切换到用户的角度来回忆一下,你会在什么情况下使用搜索引擎?当你有明确的内容需求时,你会去“百度”吗?毕竟在PC互联网如火如荼的某个阶段,搜索引擎是互联网的中心,几乎所有的互联网内容都需要通过搜索引擎的入口更高效地获取。因此,用户可以使用关键词的各种组合,悠闲地搜索想要的信息。
用户的目的是获取有用的内容。 关键词的准确率越高,搜索结果页的内容匹配度越高。相应地,与需求匹配的内容越高,其点击率就越高,这条信息背后的商机也就越大。
这里是一个简短的列表:
用户:想要获取内容,因为他有一定的需求,而需求的背后是商业价值;
平台(搜索引擎):是信息匹配的幕后推动者,帮助双方更高效地匹配内容,赚取服务费;
商家:他的产品/服务能满足这部分需求,他希望利用平台的窗口,把不良信息给抹掉。
服务商:商家的优势在于自己的产品。在线推广是一个跨领域的类别。服务商可以帮助商家解决这方面的专业问题。
因此,SEO 就是在这种需求的背景下诞生的。商机的转化围绕着信息的有效匹配,所有角色的工作重心都围绕着信息匹配。
如何实现信息的有效匹配?简单来说就是通过SEO的手段来调整搜索结果的排名。搜索引擎平台本身会按照算法的默认机制进行排序,但是这种排序会有很多“不人道”的地方,就是排名靠前的内容并不是用户真正想要的, SEO进一步体现。出来吧。
这样,商家和服务商可以提高信息的排名,获得更多的曝光率,获得有效的线索。搜索引擎平台也可以从中受益,因为用户拥有更好的搜索体验。如果可以在这些平台上找到有用的信息,用户愿意使用这个工具。只要有用户,这个平台的商业模式就可以继续运作。 .
二、为什么是 抖音SEO?
抖音SEO与上面提到的传统SEO逻辑是一致的。无非就是让品牌的信息在一些关键词搜索结果页面得到更大的曝光,从而实现线索转化。
搜索引擎是PC互联网时代的王者,移动互联网时代的王者是短视频。
以上组是基于在互联网上采集的抖音数据。中国网民数量只有10亿+。不计其他平台,仅抖音的日活跃用户就已超过6亿。前段时间我也看到一组数据是视频账号的日活跃度已经超过了8亿。
不难发现,短视频的内容消费已经全面取代图文内容。我们已经正式进入短视频时代,品牌的下一个流量出口也一定是短视频。搜索引擎也有它的价值,一代人有一代人的使命,至少在这个时代,它不再是主角。
因此,企业的主要营销阵地不得不向短视频迁移。
短视频营销的播放方式有视频、搜索、直播三种方式。
在算法推荐时代,只要有能力制作出符合用户口味的视频,就可以获得免费流量。但是,面对短视频等新事物,很多公司还不是很会玩,现在竞争非常激烈,内容出圈的门槛越来越高,越来越并且更难在没有广告的情况下获得流量。可以明显感觉到,企业的运营成本也在正线上。
搜索是另一种获取流量的方式,也就是我们所说的抖音SEO。用户只会将时间花在能够满足他们需求的内容上。比如,他们的需求是看一些搞笑有趣的内容来放松一下,或者打破某个知识盲区等等。
与平台推荐的方式相比,主动搜索带来的流量具有更大的商业价值。
因为用户的目的很明确,知道自己要找什么,会使用关键词搜索方式获取信息;而且很紧急,相当于“项目有需求”的状态,他们不愿意被动地等待平台推荐合适的内容,而是马上去搜索。
这也是我说公司必须做抖音SEO的原因。当用户在搜索关键词时,你的信息刚刚出现,这意味着商机即将到来。不然这些流量商机就成了同行的玩意儿。
最重要的是抖音SEO是目前成本最低的推广方式。
三、哪些公司适合抖音SEO?
抖音SEO是一种通用的推广方式,没有任何行业限制。无论是企业IP还是个人IP,都适合抖音SEO。但是你要评估是否值得去做,也就是投入产出的性价比如何?不同的行业和品类实际上会略有不同。在我看来,客户单价产品高的公司做抖音SEO是非常有必要的。
客户在购买客单价高的产品时,往往会有这两种行为:“横向比较”和“背景调查”。
由于价格偏高,客户下单时会非常谨慎,下单前多方比较是必不可少的。电商平台的购买评论、知乎小红书的好东西推荐、问答平台的经验分享、专业的产品评测,都是为了解决用户下单的难点。而且TO B的产品采购要经过多个部门的审核,所以要善用抖音SEO,向客户展示更多的正面信息。
如果只是几十元的产品,客户不会有如此强烈的搜索和了解欲望。看到喜欢的就直接在直播间下单了。
对于客户单价高的产品,产品质量和售后服务是客户最看重的一点。没有人愿意花高价买一堆麻烦和不愉快的经历。毕竟这种产品的更换成本不低。为了尽可能让自己无后顾之忧,客户会先上网查一下这个品牌或产品是否还有“黑历史”遗留。
假设有一个真正的污点,抖音SEO 也是掩埋它的好方法。如果没有,它也可以旨在建立强大的品牌实力。客户经常可以看到你的信息,默认就是这家公司实力还不错。这也是在潜移默化地将公司的软实力植入客户心中,有利于转化率的提升。
四、抖音怎么做SEO?
操作逻辑与抖音的操作相同。您只需要在每个操作节点上添加一些 SEO 操作即可。就这么简单。这就是所谓的SEO思维。让我们分解一下。
1、查找关键词
对抖音的操作稍有了解的人都知道,选题决定生死。话题的选择来自于账号的定位,定位决定了变现模式。同样的,抖音SEO也得先确定主题。主题与您提供的产品/服务有关,产品/服务的背后是关键词。客户通过搜索 关键词 来搜索产品/服务。我们需要做的是提供相应的内容来满足客户的即时需求,从而获得更多的商机。
我们提供短视频营销服务,“短视频营销”是待优化的产品关键词。但是,这个词容易出现问题。 “营销”这个词对大多数客户来说太专业了。只有同行或业内人士更喜欢这样搜索,而且这个词与用户的实际搜索习惯不太吻合。客户在寻找匹配服务时,会使用另一种表达方式,比如“短视频推广”、“短视频培训”、“短视频生成运营”……。
从这里可以看出定位的重要性。目标客户画像会影响您的关键词选择。你的客户是谁?在什么水平?专业程度如何?他们的搜索习惯和行为不同。
当然,准确的用户画像是个伪命题。为了尽可能满足更广泛的目标群体的搜索需求,我们可以将产品/服务“翻译”为替代品。因为用户的认知不同,对于同样的需求,有人称之为“短视频营销”,有人称之为“短视频推广”,也有人称之为“短视频生成运营”。在这种情况下,我们可以将这三个关键词作为核心关键词优化。
你也可以在确认核心的时候使用这个思路关键词,这里有3种方式获取关键词:
1、咨询业内专业人士。比如询问公司的研发和销售,了解行业对这个产品的称呼,并记录下来。
2、看产品相关专业文章或浏览社交媒体平台,可以获得更真实的数据。
3、相比前两种“笨方法”,利用数据平台获取关键词是一种更加科学的方法。建议大家去各种指数工具(如百度指数、巨数、微信指数等)、各平台下拉框(如百度、今日头条、抖音、小红书等) )和第三方数据工具(如5118、站长工具、各平台广告投放工具等)获取。
2、找话题
在我们将产品/服务转化为关键词之后,我们要考虑应该用什么内容来满足用户的需求。这些内容就是我们所说的选题。
记住营销漏斗,提高最终转化效果的方法是增加每一层的规模和转化率。上面提到的关键词可以在一定程度上解决曝光问题,但不一定能提高转化率。
用户在搜索 关键词 时必须进行过滤。为什么要过滤?因为有很多内容不符合他的要求,这些不规范的内容是“曝光不转化”的直接原因之一。
在传统的SEO场景中,用户搜索关键词可以直接进入商家官网。官网各页面的内容组合足以满足用户80%以上的业务需求,流量变现效率也相应更高。内容的选择不要太苛刻。
但在短视频平台上,完全是另外一个逻辑。搜索关键词的用户只输入了你账号下众多内容之一,再加上短视频的“短”属性,难免会导致每一个视频描述的点都很简单一、为用户过滤信息的成本也在增加。
为了获取更准确的内容,用户经常使用长尾思维来搜索信息。用户的这种搜索思维是我们搜索主题的核心。 查看全部
教程:node爬取数据实例:抓取宝可梦图鉴并生成Excel文件
如何使用Node爬取网页数据并写入Excel文件?下面的文章文章用一个例子来说明使用Node.js爬取网页数据并生成Excel文件的方法,希望对大家有所帮助!
相信口袋妖怪是很多90后的童年记忆。作为一个程序员,我想不止一次地制作一个口袋妖怪游戏,但在做之前,我应该先整理一下口袋妖怪有多少个,它们的编号、名称、属性等信息都整理好了。本期将使用Node.js简单实现对神奇宝贝网页数据的抓取,将数据生成Excel文件,直到接口读取Excel访问数据。
抓取数据
既然是爬取数据,我们先找一个有宝可梦插画数据的网页,如下图:
这个网站是用PHP写的,前后没有分离,所以我们不会读取接口抓取数据,我们使用爬虫库抓取网页中的元素来获取数据。提前说明一下,使用爬虫库的好处是可以在 Node 环境中使用 jQuery 来抓取元素。
安装:
yarn add crawler
实施:
const Crawler = require("crawler");
const fs = require("fs")
const { resolve } = require("path")
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
function getPokemon() {
let uri = "" // 宝可梦图鉴地址
let data = []
return new Promise((resolve, reject) => {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) reject(err);
let $ = res.$;
try {
let $tr = $(".roundy.eplist tr");
$tr.each((i, el) => {
let $td = $(el).find("td");
let _code = $td.eq(1).text().split("\n")[0]
let _name = $td.eq(3).text().split("\n")[0]
<p>
let _attr = $td.eq(4).text().split("\n")[0]
let _other = $td.eq(5).text().split("\n")[0]
_attr = _other.indexOf("属性") != -1 ? _attr : `${_attr}+${_other}`
if (_code) {
data.push([_code, _name, _attr])
}
})
done();
resolve(data)
} catch (err) {
done()
reject(err)
}
}
})
})
}</p>
在生成实例的时候,还需要开启jQuery模式,然后可以使用$符号。上述代码中间部分的业务是抓取元素爬取网页所需的数据,与jQuery API相同,这里不再赘述。
getPokemon().then(async data => {
console.log(data)
})
最后,我们可以执行并打印传递过来的data数据,验证格式是否真的被爬取了,没有错误。
写入 Excel
由于刚才已经爬取了数据,接下来我们使用node-xlsx库来完成数据的写入,生成一个Excel文件。
首先介绍一下node-xlsx是一个简单的excel文件解析器和生成器。 TS构建的依赖SheetJS xlsx模块解析/构建excel工作表,所以在一些参数配置上,两者可以通用。
安装:
yarn add node-xlsx
实施:
const xlsx = require("node-xlsx")
getPokemon().then(async data => {
let title = ["编号", "宝可梦", "属性"]
let list = [{
name: "关都",
data: [
title,
...data
]
<p>
}];
const sheetOptions = { '!cols': [{ wch: 15 }, { wch: 20 }, { wch: 20 }] };
const buffer = await xlsx.build(list, { sheetOptions })
try {
await fs.writeFileSync(resolve(__dirname, "data/pokemon.xlsx"), buffer, "utf8")
} catch (error) { }
})</p>
名称为Excel文件中的列名,数据类型为数组。它还需要传入一个数组,形成一个二维数组,意思是对从ABCDE....列传入的文本进行排序。同时可以通过!cols设置列宽。第一个对象 wch:10 表示第一列的宽度为 10 个字符,可以设置的参数很多。可以参考学习这些配置项。
最后我们使用 xlsx.build 方法生成缓冲区数据,最后使用 fs.writeFileSync 写入或创建 Excel 文件。为了方便查看,我把它保存在一个名为data的文件夹中。这时候,我们会在data文件夹中找到一个名为pokemon.xlsx的额外文件,打开它,数据还在,这样就完成了将数据写入Excel的操作。
读取 Excel
其实不用写fs就可以读取Excel,直接用xlsx.parse方法传入文件地址就可以读取了。
xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
当然,为了验证准确性,我们直接写了一个接口,看看能不能访问数据。为方便起见,我使用 express 框架直接执行此操作。
我们先安装吧:
yarn add express
然后,创建快递服务。我在这里使用 3000 作为端口号。只需编写一个 GET 请求即可发送从 Excel 文件读取的数据。
const express = require("express")
const app = express();
const listenPort = 3000;
app.get("/pokemon",(req,res)=>{
let data = xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
res.send(data)
})
app.listen(listenPort, () => {
console.log(`Server running at http://localhost:${listenPort}/`)
})
最后我用postman来访问这里的界面,你可以清楚的看到我们已经收到了所有的宝可梦数据,从爬取到存入表格。
结论
如您所见,本文以神奇宝贝为例,学习如何使用Node.js从网页抓取数据,如何将数据写入Excel文件,以及如何从Excel文件中读取数据。这个问题,其实实现起来并不难,但有时还是挺实用的。怕忘记的可以存起来哦~
更多node相关知识请访问:nodejs教程!
PHP入门就业在线直播课:查看学习
以上为节点抓取数据示例:抓取神奇宝贝插画和生成Excel文件的详细内容,更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:掘金社区,如有侵权,请联系删除
特别推荐:nodejs节点
上一篇:vue和applet有什么区别 下一篇:JavaScript中使用toLocaleString数字格式化的详细例子
干货教程:抖音短视频成SEO新风口!
我们将讨论公司关心的以下5个问题。有什么不明白的请私信黑来谷0(heilaigu01).
一、什么是搜索引擎优化?
二、为什么是 抖音SEO?
三、哪些公司适合抖音SEO?
四、抖音怎么做SEO?
五、影响抖音排名的因素有哪些?
一、什么是搜索引擎优化?
SEO是英文“Search Engine Optimization”的缩写(具体英文可以百度)。直译就是优化搜索引擎的信息,因为搜索引擎是一个存储互联网内容的平台,所以你的优化对象只能是这些信息。
现在切换到用户的角度来回忆一下,你会在什么情况下使用搜索引擎?当你有明确的内容需求时,你会去“百度”吗?毕竟在PC互联网如火如荼的某个阶段,搜索引擎是互联网的中心,几乎所有的互联网内容都需要通过搜索引擎的入口更高效地获取。因此,用户可以使用关键词的各种组合,悠闲地搜索想要的信息。
用户的目的是获取有用的内容。 关键词的准确率越高,搜索结果页的内容匹配度越高。相应地,与需求匹配的内容越高,其点击率就越高,这条信息背后的商机也就越大。
这里是一个简短的列表:
用户:想要获取内容,因为他有一定的需求,而需求的背后是商业价值;
平台(搜索引擎):是信息匹配的幕后推动者,帮助双方更高效地匹配内容,赚取服务费;
商家:他的产品/服务能满足这部分需求,他希望利用平台的窗口,把不良信息给抹掉。
服务商:商家的优势在于自己的产品。在线推广是一个跨领域的类别。服务商可以帮助商家解决这方面的专业问题。
因此,SEO 就是在这种需求的背景下诞生的。商机的转化围绕着信息的有效匹配,所有角色的工作重心都围绕着信息匹配。
如何实现信息的有效匹配?简单来说就是通过SEO的手段来调整搜索结果的排名。搜索引擎平台本身会按照算法的默认机制进行排序,但是这种排序会有很多“不人道”的地方,就是排名靠前的内容并不是用户真正想要的, SEO进一步体现。出来吧。
这样,商家和服务商可以提高信息的排名,获得更多的曝光率,获得有效的线索。搜索引擎平台也可以从中受益,因为用户拥有更好的搜索体验。如果可以在这些平台上找到有用的信息,用户愿意使用这个工具。只要有用户,这个平台的商业模式就可以继续运作。 .
二、为什么是 抖音SEO?
抖音SEO与上面提到的传统SEO逻辑是一致的。无非就是让品牌的信息在一些关键词搜索结果页面得到更大的曝光,从而实现线索转化。
搜索引擎是PC互联网时代的王者,移动互联网时代的王者是短视频。
以上组是基于在互联网上采集的抖音数据。中国网民数量只有10亿+。不计其他平台,仅抖音的日活跃用户就已超过6亿。前段时间我也看到一组数据是视频账号的日活跃度已经超过了8亿。
不难发现,短视频的内容消费已经全面取代图文内容。我们已经正式进入短视频时代,品牌的下一个流量出口也一定是短视频。搜索引擎也有它的价值,一代人有一代人的使命,至少在这个时代,它不再是主角。
因此,企业的主要营销阵地不得不向短视频迁移。
短视频营销的播放方式有视频、搜索、直播三种方式。
在算法推荐时代,只要有能力制作出符合用户口味的视频,就可以获得免费流量。但是,面对短视频等新事物,很多公司还不是很会玩,现在竞争非常激烈,内容出圈的门槛越来越高,越来越并且更难在没有广告的情况下获得流量。可以明显感觉到,企业的运营成本也在正线上。
搜索是另一种获取流量的方式,也就是我们所说的抖音SEO。用户只会将时间花在能够满足他们需求的内容上。比如,他们的需求是看一些搞笑有趣的内容来放松一下,或者打破某个知识盲区等等。
与平台推荐的方式相比,主动搜索带来的流量具有更大的商业价值。
因为用户的目的很明确,知道自己要找什么,会使用关键词搜索方式获取信息;而且很紧急,相当于“项目有需求”的状态,他们不愿意被动地等待平台推荐合适的内容,而是马上去搜索。
这也是我说公司必须做抖音SEO的原因。当用户在搜索关键词时,你的信息刚刚出现,这意味着商机即将到来。不然这些流量商机就成了同行的玩意儿。
最重要的是抖音SEO是目前成本最低的推广方式。
三、哪些公司适合抖音SEO?
抖音SEO是一种通用的推广方式,没有任何行业限制。无论是企业IP还是个人IP,都适合抖音SEO。但是你要评估是否值得去做,也就是投入产出的性价比如何?不同的行业和品类实际上会略有不同。在我看来,客户单价产品高的公司做抖音SEO是非常有必要的。
客户在购买客单价高的产品时,往往会有这两种行为:“横向比较”和“背景调查”。
由于价格偏高,客户下单时会非常谨慎,下单前多方比较是必不可少的。电商平台的购买评论、知乎小红书的好东西推荐、问答平台的经验分享、专业的产品评测,都是为了解决用户下单的难点。而且TO B的产品采购要经过多个部门的审核,所以要善用抖音SEO,向客户展示更多的正面信息。
如果只是几十元的产品,客户不会有如此强烈的搜索和了解欲望。看到喜欢的就直接在直播间下单了。
对于客户单价高的产品,产品质量和售后服务是客户最看重的一点。没有人愿意花高价买一堆麻烦和不愉快的经历。毕竟这种产品的更换成本不低。为了尽可能让自己无后顾之忧,客户会先上网查一下这个品牌或产品是否还有“黑历史”遗留。
假设有一个真正的污点,抖音SEO 也是掩埋它的好方法。如果没有,它也可以旨在建立强大的品牌实力。客户经常可以看到你的信息,默认就是这家公司实力还不错。这也是在潜移默化地将公司的软实力植入客户心中,有利于转化率的提升。
四、抖音怎么做SEO?
操作逻辑与抖音的操作相同。您只需要在每个操作节点上添加一些 SEO 操作即可。就这么简单。这就是所谓的SEO思维。让我们分解一下。
1、查找关键词
对抖音的操作稍有了解的人都知道,选题决定生死。话题的选择来自于账号的定位,定位决定了变现模式。同样的,抖音SEO也得先确定主题。主题与您提供的产品/服务有关,产品/服务的背后是关键词。客户通过搜索 关键词 来搜索产品/服务。我们需要做的是提供相应的内容来满足客户的即时需求,从而获得更多的商机。
我们提供短视频营销服务,“短视频营销”是待优化的产品关键词。但是,这个词容易出现问题。 “营销”这个词对大多数客户来说太专业了。只有同行或业内人士更喜欢这样搜索,而且这个词与用户的实际搜索习惯不太吻合。客户在寻找匹配服务时,会使用另一种表达方式,比如“短视频推广”、“短视频培训”、“短视频生成运营”……。
从这里可以看出定位的重要性。目标客户画像会影响您的关键词选择。你的客户是谁?在什么水平?专业程度如何?他们的搜索习惯和行为不同。
当然,准确的用户画像是个伪命题。为了尽可能满足更广泛的目标群体的搜索需求,我们可以将产品/服务“翻译”为替代品。因为用户的认知不同,对于同样的需求,有人称之为“短视频营销”,有人称之为“短视频推广”,也有人称之为“短视频生成运营”。在这种情况下,我们可以将这三个关键词作为核心关键词优化。
你也可以在确认核心的时候使用这个思路关键词,这里有3种方式获取关键词:
1、咨询业内专业人士。比如询问公司的研发和销售,了解行业对这个产品的称呼,并记录下来。
2、看产品相关专业文章或浏览社交媒体平台,可以获得更真实的数据。
3、相比前两种“笨方法”,利用数据平台获取关键词是一种更加科学的方法。建议大家去各种指数工具(如百度指数、巨数、微信指数等)、各平台下拉框(如百度、今日头条、抖音、小红书等) )和第三方数据工具(如5118、站长工具、各平台广告投放工具等)获取。
2、找话题
在我们将产品/服务转化为关键词之后,我们要考虑应该用什么内容来满足用户的需求。这些内容就是我们所说的选题。
记住营销漏斗,提高最终转化效果的方法是增加每一层的规模和转化率。上面提到的关键词可以在一定程度上解决曝光问题,但不一定能提高转化率。
用户在搜索 关键词 时必须进行过滤。为什么要过滤?因为有很多内容不符合他的要求,这些不规范的内容是“曝光不转化”的直接原因之一。
在传统的SEO场景中,用户搜索关键词可以直接进入商家官网。官网各页面的内容组合足以满足用户80%以上的业务需求,流量变现效率也相应更高。内容的选择不要太苛刻。
但在短视频平台上,完全是另外一个逻辑。搜索关键词的用户只输入了你账号下众多内容之一,再加上短视频的“短”属性,难免会导致每一个视频描述的点都很简单一、为用户过滤信息的成本也在增加。
为了获取更准确的内容,用户经常使用长尾思维来搜索信息。用户的这种搜索思维是我们搜索主题的核心。
解读:用Excel,只需30秒就可爬取网站数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2022-09-22 08:14
是的,您没看错,使用 Excel 抓取数据。那么为什么要使用它呢?因为它不需要写一行代码,所以你只需点击几下鼠标就可以得到你想要的数据。整个过程可以在大约 30 秒内完成。在网站结构简单、需求相对简单的情况下,这一招秒杀专业程序员。毕竟大多数时候,程序员可能只需要 30 秒就打开专业的代码编辑器,等待各种组件插件的加载完成。哈哈哈~~~~,你怎么兴奋?
0.软件版本要求和先决条件
要求 1:Excel 2016 及更高版本,开箱即用。当然其他低级版本也不是不行,但是需要自己安装插件,喜欢折腾的可以自己试试。
要求2:只支持get request(不懂这个的可以忽略,可以简单认为直接打开就能看到的数据满足要求)
需求3:你需要的数据在html页面的table标签中。不能是图片等。
那么你怎么知道它是否在table标签中呢?很简单,只要在浏览器中查看网页的源码,有没有你需要的数据被包裹在(
数据
或数据),如果是,恭喜,excel可以直接抓取,如果不是,那就用其他更专业的爬虫工具或者自己写代码。 . .
下面是检查数据是否在(或)标签中的操作:(我刚找到一个房价网站)
一个。打开浏览器网站,找到要爬取的数据,按键盘上的“F12”键(推荐谷歌Chrome、Edge、Firefox)打开调试器。
b.点击左上角元素定位图标,然后将鼠标移到需要的数据上,查看是否收录在()中。
以上过程就是分析网站的数据结构的过程。可以看出标签中收录了需要的数据。这个过程是必不可少的,无论你是使用工具爬取还是自己编写代码爬取,这个过程都极其重要。
假设你确定你要的数据就在()标签里,那我们看看如何用Excel爬取吧!
1.打开 Excel 数据采集工具
注意:不同版本的组件名称或位置可能略有不同。这里是 Excel2019 版本。比较并找到其他版本。确定它们都在“数据”选项卡下。
2.填写爬取参数
这是基本模式,你只需要粘贴你要抓取的网页的网址。另一种高级模式可以设置更多的参数,比如请求头,有兴趣的可以自行探索。
注意:网站直接匿名模式无需登录
3.获取数据
在这个界面中,选择需要的表格点击,然后点击转换数据,可以调用excel自带的power BI对数据进行各种自定义处理和转换,当然也可以加载如果你不想做太多的转换或者你想在 excel 中重新处理它,直接它。
以下界面为电量查询界面。你可以在这个界面上进行各种高级数据转换,也可以什么都不做。如果您已完成转换,只需点击“关闭并上传”即可。
好的,想要的数据已经上传到excel了,方便又快捷。
今天的经验分享就到这里。如果大家有什么好的意见或建议,欢迎在评论区留言~~~~
分享:手把手带你从零基础抓取A站短视频,并且制作从动态壁纸,这些小姐姐我全都要!
大家好,我叫来跳。
我知道大家都是来学技术的,绝对不是为了那些好看的小姐姐们,所以直奔主题吧。
A站视频资料采集
采集数据目标
网址:一个站
性能展示
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:请求、docx、lxml
重点学习内容
lxml使用m3u8文件处理ts文件合成MP4
项目思路分析
通过xpath方法提取分类主页数据
获取每个视频的不确定性
拼接到详情页的url地址
/{}
请求详情页面
获取网页源码的backupUrl对应值
请求对应的m3u8文件地址
https://tx-safety-video.acfun. ... 9P_hc\%22],\%22codecs\%22:\%22avc1.640033,mp4a.40.2\%22,\%22hidden\%22:false,\%22disableAdaptive\%22:false,\%22comment\%22:\%22b6f3561527ea7674/HLS_4K_H264_1\%22,\%22id\%22:1,\%22url\%22:\%22https://ali-safety-video.acfun ... 9P_hc
请求m3u8的文件地址
解析对应的m3u8文件
视频数据拼接自ts视频
取出m3u8文件中各个ts的下载地址
拼接成新的视频下载地址
https://ali-safety-video.acfun ... 9P_hc
下载对应的ts视频数据
将每个ts数据以追加的形式写入MP4文件
简单的源码分析
import requests import re from tqdm import tqdm from lxml import etree import os def request_data(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.42' } response = requests.get(url, headers=headers) return response def save(name, video): # path = f'{name}\\' if not os.path.exists("视频"): os.makedirs("视频") with open("视频/" + name + '.mp4', mode='ab') as f: f.write(video) start_url = "https://www.acfun.cn/v/list218/index.htm" res = request_data(start_url) html_data = etree.HTML(res.text) acid_list = html_data.xpath('//div[@class="list-content-item"]/a[1]/@href') # ac = input('输入acid:') for ac in acid_list: url = 'https://www.acfun.com{}'.format(ac) print(url) # 请求页面地址 获取到 m3u8地址 data = request_data(url).text m3u8_url = re.findall('backupUrl(.*?)\"]', data)[0].replace('"', '').split('\\')[-2] title = re.findall('"title":"(.*?)"', data)[0] # 请求m3u8地址 m3u8_data = request_data(m3u8_url).text # 数据替换 m3u8_data = re.sub(r'#EXTM3U', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-VERSION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-TARGETDURATION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-MEDIA-SEQUENCE:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXTINF:\d.\d,', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-ENDLIST', "", m3u8_data) m3u8 = m3u8_data.split() for i in tqdm(m3u8): ts_url = 'https://tx-safe-video.acfun.cn ... 39%3B + i video = request_data(ts_url).content save(title, video)
如果对你有帮助,记得连续给辣条3次 查看全部
解读:用Excel,只需30秒就可爬取网站数据
是的,您没看错,使用 Excel 抓取数据。那么为什么要使用它呢?因为它不需要写一行代码,所以你只需点击几下鼠标就可以得到你想要的数据。整个过程可以在大约 30 秒内完成。在网站结构简单、需求相对简单的情况下,这一招秒杀专业程序员。毕竟大多数时候,程序员可能只需要 30 秒就打开专业的代码编辑器,等待各种组件插件的加载完成。哈哈哈~~~~,你怎么兴奋?
0.软件版本要求和先决条件
要求 1:Excel 2016 及更高版本,开箱即用。当然其他低级版本也不是不行,但是需要自己安装插件,喜欢折腾的可以自己试试。
要求2:只支持get request(不懂这个的可以忽略,可以简单认为直接打开就能看到的数据满足要求)
需求3:你需要的数据在html页面的table标签中。不能是图片等。
那么你怎么知道它是否在table标签中呢?很简单,只要在浏览器中查看网页的源码,有没有你需要的数据被包裹在(
数据
或数据),如果是,恭喜,excel可以直接抓取,如果不是,那就用其他更专业的爬虫工具或者自己写代码。 . .
下面是检查数据是否在(或)标签中的操作:(我刚找到一个房价网站)
一个。打开浏览器网站,找到要爬取的数据,按键盘上的“F12”键(推荐谷歌Chrome、Edge、Firefox)打开调试器。
b.点击左上角元素定位图标,然后将鼠标移到需要的数据上,查看是否收录在()中。
以上过程就是分析网站的数据结构的过程。可以看出标签中收录了需要的数据。这个过程是必不可少的,无论你是使用工具爬取还是自己编写代码爬取,这个过程都极其重要。
假设你确定你要的数据就在()标签里,那我们看看如何用Excel爬取吧!
1.打开 Excel 数据采集工具
注意:不同版本的组件名称或位置可能略有不同。这里是 Excel2019 版本。比较并找到其他版本。确定它们都在“数据”选项卡下。
2.填写爬取参数
这是基本模式,你只需要粘贴你要抓取的网页的网址。另一种高级模式可以设置更多的参数,比如请求头,有兴趣的可以自行探索。
注意:网站直接匿名模式无需登录
3.获取数据
在这个界面中,选择需要的表格点击,然后点击转换数据,可以调用excel自带的power BI对数据进行各种自定义处理和转换,当然也可以加载如果你不想做太多的转换或者你想在 excel 中重新处理它,直接它。
以下界面为电量查询界面。你可以在这个界面上进行各种高级数据转换,也可以什么都不做。如果您已完成转换,只需点击“关闭并上传”即可。
好的,想要的数据已经上传到excel了,方便又快捷。
今天的经验分享就到这里。如果大家有什么好的意见或建议,欢迎在评论区留言~~~~
分享:手把手带你从零基础抓取A站短视频,并且制作从动态壁纸,这些小姐姐我全都要!
大家好,我叫来跳。
我知道大家都是来学技术的,绝对不是为了那些好看的小姐姐们,所以直奔主题吧。
A站视频资料采集
采集数据目标
网址:一个站
性能展示
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:请求、docx、lxml
重点学习内容
lxml使用m3u8文件处理ts文件合成MP4
项目思路分析
通过xpath方法提取分类主页数据
获取每个视频的不确定性
拼接到详情页的url地址
/{}
请求详情页面
获取网页源码的backupUrl对应值
请求对应的m3u8文件地址
https://tx-safety-video.acfun. ... 9P_hc\%22],\%22codecs\%22:\%22avc1.640033,mp4a.40.2\%22,\%22hidden\%22:false,\%22disableAdaptive\%22:false,\%22comment\%22:\%22b6f3561527ea7674/HLS_4K_H264_1\%22,\%22id\%22:1,\%22url\%22:\%22https://ali-safety-video.acfun ... 9P_hc
请求m3u8的文件地址
解析对应的m3u8文件
视频数据拼接自ts视频
取出m3u8文件中各个ts的下载地址
拼接成新的视频下载地址
https://ali-safety-video.acfun ... 9P_hc
下载对应的ts视频数据
将每个ts数据以追加的形式写入MP4文件
简单的源码分析
import requests import re from tqdm import tqdm from lxml import etree import os def request_data(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.42' } response = requests.get(url, headers=headers) return response def save(name, video): # path = f'{name}\\' if not os.path.exists("视频"): os.makedirs("视频") with open("视频/" + name + '.mp4', mode='ab') as f: f.write(video) start_url = "https://www.acfun.cn/v/list218/index.htm" res = request_data(start_url) html_data = etree.HTML(res.text) acid_list = html_data.xpath('//div[@class="list-content-item"]/a[1]/@href') # ac = input('输入acid:') for ac in acid_list: url = 'https://www.acfun.com{}'.format(ac) print(url) # 请求页面地址 获取到 m3u8地址 data = request_data(url).text m3u8_url = re.findall('backupUrl(.*?)\"]', data)[0].replace('"', '').split('\\')[-2] title = re.findall('"title":"(.*?)"', data)[0] # 请求m3u8地址 m3u8_data = request_data(m3u8_url).text # 数据替换 m3u8_data = re.sub(r'#EXTM3U', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-VERSION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-TARGETDURATION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-MEDIA-SEQUENCE:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXTINF:\d.\d,', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-ENDLIST', "", m3u8_data) m3u8 = m3u8_data.split() for i in tqdm(m3u8): ts_url = 'https://tx-safe-video.acfun.cn ... 39%3B + i video = request_data(ts_url).content save(title, video)
如果对你有帮助,记得连续给辣条3次
完整的解决方案:使用 Excel 和 Python 从互联网获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 964 次浏览 • 2022-09-22 08:14
学习 Python 的人生太短了!
互联网上有极其丰富的数据资源。使用Excel自动读取部分网页中的表格数据,使用Python编写爬虫程序读取网页内容。
今天的文章主要分为两部分,一是通过Python构建数据网站,二是使用Excel和Python从写好的Web获取数据网站 .
1、构建测试网站数据
通过 Python Flask Web 框架分别构建一个 Web网站 和一个 Web API 服务。
1.构建网络网站
创建一个名为“5-5-WebTable.py”的新 Python 脚本来创建一个收录表格的简单网页。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装烧瓶包。
pip install flask
(2)用表格构建网页。
from flask import Flask
app = Flask(__name__) # 创建Falsk Web应用实例
# 将路由“/”映射到table_info函数,函数返回HTML代码
@app.route('/')
def table_info():
return """HTML表格实例,用于提供给Excel和Python读取
用户信息表
姓名
性别
年龄
小米
女
22
……….
"""
if __name__ == '__main__':
app.debug = True # 启用调试模式
app.run() # 运行,网站端口默认为5000
通过命令“python ./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,就会出现如图1所示的网页内容。
图 1 使用 Flask 构建的测试网站
2.构建 Web API 服务
创建一个名为“5-5-WebAPI.py”的新 Python 脚本,以使用 flask_restplus 包构建 Web API 服务。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开Web API服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库并初始化应用对象。
from flask import Flask
# Api类是Web API应用的入口,需要用Flask应用程序初始化
from flask_restplus import Api
# Resource类是HTTP请求的资源的基类
from flask_restplus import Resource
# fields类用于定义数据的类型和格式
from flask_restplus import fields
app = Flask(__name__) # 创建Falsk Web应用实例
# 在flask应用的基础上构建flask_restplus Api对象
api = Api(app, version='1.0',
title='Excel集成Python数据分析-测试用WebAPI',
description='测试用WebAPI', )
# 使用namespace函数生成命名空间,用于为资源分组
ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')
# 使用api.model函数生成模型对象
todo = api.model('task_model', {
<p>
'id': fields.Integer(readonly=True,
description='ETL任务唯一标识'),
'task': fields.String(required=True,
description='ETL任务详情')
})
</p>
(3)Web API数据操作类,包括增删改查等方法。
class TodoDAO(object):
def __init__(self):
self.counter = 0
self.todos = []
def get(self, id):
for todo in self.todos:
if todo['id'] == id:
return todo
api.abort(404, "ETL任务 {} 不存在".format(id))
def create(self, data):
todo = data
todo['id'] = self.counter = self.counter + 1
self.todos.append(todo)
return todo
# 实例化数据操作,创建3条测试数据
DAO = TodoDAO()
DAO.create({'task': 'ETL-抽取数据操作'})
DAO.create({'task': 'ETL-数据清洗转换'})
DAO.create({'task': 'ETL-数据加载操作'})
(4)为 Web API 构建路由图。
HTTP资源请求类继承自Resource类,然后映射到不同的路由,指定可以使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求
class TodoList(Resource):
@ns.doc('list_todos') # @doc装饰器对应API文档的信息
@ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出
def get(self): # 定义get方法获取所有的任务信息
return DAO.todos
@ns.doc('create_todo')
@ns.expect(todo)
@ns.marshal_with(todo, code=201)
def post(self): # 定义post方法获取所有的任务信息
return DAO.create(api.payload), 201
# 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求
@ns.route('/')
@ns.response(404, '未发现相关ETL任务')
@ns.param('id', 'ETL任务ID号')
class Todo(Resource):
@ns.doc('get_todo')
@ns.marshal_with(todo)
def get(self, id):
return DAO.get(id)
@ns.doc('delete_todo')
@ns.response(204, 'ETL任务已经删除')
def delete(self, id):
DAO.delete(id)
return '', 204
@ns.expect(todo)
@ns.marshal_with(todo)
def put(self, id):
return DAO.update(id, api.payload)
if __name__ == '__main__':
app.run(debug=True, port=8000) # 启动Web API服务,端口为8000
(4)打开 Web API 服务。
通过命令“python ./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”,显示Web API服务请求方法列表如图5-23所示。
图2 WebAPI服务请求方法列表
2、网页数据抓取
Excel可以通过“数据”选项卡下的“来自网站”功能抓取网页数据。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架来抓取 Web 数据。
1.通过 Excel 抓取
点击“数据”→“来自其他来源”→“来自网站”功能。 Excel能读取的网页数据有局限性:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)点击“数据”→“来自其他来源”→“来自网站”功能。
(2)确保5.5.1部分中写的Web网站已开启。
(3)输入网站URL地址“:5000/”
点击“高级”按钮配置更详细的HTTP请求信息,然后点击“确定”按钮,如图3所示。
图3 配置URL读取网站
(4)在导航器窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表格名称,点击“加载”按钮。
图4 Excel自动识别网页中的表格数据
2.用 Python 爬行
下面的演示使用 requests 库从整个网页中获取数据,然后使用 Beautiful Soup 来解析网页。读者可以参考本书中的代码资料文件“5-5-web.ipynb”进行学习。
(1)通过请求读取网页数据。
import requests #导入requests包
url ='http://127.0.0.1:5000/'
strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过 Beautiful Soup 解析网页。
from bs4 import BeautifulSoup
soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象
table = soup.find('table') # 查找网页中的table元素
table_body = table.find('tbody') # 查找table元素中的tbody元素
data = []
rows = table_body.find_all('tr') # 查找表中的所有tr元素
for row in rows: # 遍历数据
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele])
# 结果输出:[[],
['小米', '女', '22'],['小明','男','23'],……
3、调用 Web API 服务
Excel 可以通过“数据”选项卡下的“From网站”函数调用 Web API 服务。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架调用 Web API 获取数据。
1.用Excel调用
(1)确保5.5.1节中编写的Web API服务已启用。
(2)输入Web API方法对应的URL::8000/ExcelPythonTest/.
(3)处理返回的数据。
调用Web API服务后,返回JSON格式的数据,按照5.4.3小节描述的方法处理JSON数据。
2.使用 Python 调用
使用 requests 库调用 Web API 方法,然后处理返回的 JSON 数据。读者可以参考本书中的代码资料文件“5-5-api.ipynb”进行学习。
import requests #导入requests包
url ='http://127.0.0.1:8000/ExcelPythonTest/'
strhtml= requests.get(url) #使用get方法获取网页数据
import pandas as pd
frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数
print(frame)
#结果输出:
id task
0 1 ETL-抽取数据操作
1 2 ETL-数据清洗转换
2 3 ETL-数据加载操作
4、两种方法的比较
表 1 显示了用于抓取 Internet 数据的 Excel 和 Python 方法的比较。需要注意的是,Excel 从互联网上抓取数据的能力并不完美。
表1 Excel和Python捕获Internet数据的方法比较
解决方案:百度seo快速见效方法(移动跨境流量)
做独立跨境电商网站的人经常问我,“谷歌SEO需要多长时间才能看到结果?”今天,Kenny 将在 2 分钟内为您解答所有疑惑。
随着搜索引擎算法技术的成熟和越来越多的在线内容,在搜索页面中占据一席之地已经成为一个大工程。 SEO(搜索引擎优化)是通过优化 网站 内容以提高搜索引擎排名和曝光率的有机搜索实践。有效的 SEO 可以更好地向搜索引擎证明您的内容是用户最想要的搜索结果。下面我们总结了一些关于SEO的常见问题,希望能帮助您更好地理解和使用SEO。
1.SEO优化的本质是什么?
SEO的本质是根据搜索引擎的最新算法来改进你的内容,从而增加你的内容的曝光率。例如,只需对 关键词 的使用进行一些调整,原创内容就可以使您的 网站 的新搜索流量增加一倍以上。但不要低估翻倍的新搜索流量。据统计,78%的有目的的搜索可以实现购买转化。
2.一般多久可以看到SEO的结果?
这个问题的答案是个案,但好的 SEO 通常需要大约六个月的时间才能得到回报。当然,也有个别站长回应称,用一些“技巧”可以在两周内看到优化的效果,但从长远来看,速度重于质量可能会带来网站的负面影响,因为谷歌可能会将 网站 视为垃圾邮件。一旦被谷歌搜索引擎当成垃圾邮件,网站的排名就很难提升了,应该尽量避免。
3.为什么SEO优化的结果需要这么长时间才能看到?
简单来说,就是因为搜索引擎算法技术的成熟。出现在搜索结果的第一页不再只是网站上的一堆关键词。在这个阶段,想要通过好的优化策略达到满意的搜索结果排名,需要从多方面入手。受趋势和搜索趋势的影响,很多时候 SEO 已经成为一个不断适应的过程,其中包括识别受众和对客户偏好进行关键词 研究。同时,您的网站域名年龄、入站链接和网站权限也与您的搜索排名密切相关。建立权限和接收入站链接取决于用户活动,搜索引擎算法和谷歌本身都需要一段时间来检索和发现用户活动的网站变化,从而延长了SEO的有效性。
4.精通SEO需要多少钱?
截至2020年,美国大部分SEO服务月费为750-7000美元(主要变量为页数网站/更新速度/所需服务),一般来说好的SEO专家的平均费用每小时 80-200 美元。
5. SEO优化后,是否需要经常查看网站数据?
是的,SEO 是一个不断变化的领域。客户感兴趣的关键词和内容会随着当前的趋势和时事发生变化,而搜索引擎的算法也在不断变化,因此及时更新SEO策略非常重要。 查看全部
完整的解决方案:使用 Excel 和 Python 从互联网获取数据
学习 Python 的人生太短了!
互联网上有极其丰富的数据资源。使用Excel自动读取部分网页中的表格数据,使用Python编写爬虫程序读取网页内容。
今天的文章主要分为两部分,一是通过Python构建数据网站,二是使用Excel和Python从写好的Web获取数据网站 .
1、构建测试网站数据
通过 Python Flask Web 框架分别构建一个 Web网站 和一个 Web API 服务。
1.构建网络网站
创建一个名为“5-5-WebTable.py”的新 Python 脚本来创建一个收录表格的简单网页。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装烧瓶包。
pip install flask
(2)用表格构建网页。
from flask import Flask
app = Flask(__name__) # 创建Falsk Web应用实例
# 将路由“/”映射到table_info函数,函数返回HTML代码
@app.route('/')
def table_info():
return """HTML表格实例,用于提供给Excel和Python读取
用户信息表
姓名
性别
年龄
小米
女
22
……….
"""
if __name__ == '__main__':
app.debug = True # 启用调试模式
app.run() # 运行,网站端口默认为5000
通过命令“python ./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,就会出现如图1所示的网页内容。
图 1 使用 Flask 构建的测试网站
2.构建 Web API 服务
创建一个名为“5-5-WebAPI.py”的新 Python 脚本,以使用 flask_restplus 包构建 Web API 服务。如果读者对构造方法不感兴趣,可以跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开Web API服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库并初始化应用对象。
from flask import Flask
# Api类是Web API应用的入口,需要用Flask应用程序初始化
from flask_restplus import Api
# Resource类是HTTP请求的资源的基类
from flask_restplus import Resource
# fields类用于定义数据的类型和格式
from flask_restplus import fields
app = Flask(__name__) # 创建Falsk Web应用实例
# 在flask应用的基础上构建flask_restplus Api对象
api = Api(app, version='1.0',
title='Excel集成Python数据分析-测试用WebAPI',
description='测试用WebAPI', )
# 使用namespace函数生成命名空间,用于为资源分组
ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')
# 使用api.model函数生成模型对象
todo = api.model('task_model', {
<p>
'id': fields.Integer(readonly=True,
description='ETL任务唯一标识'),
'task': fields.String(required=True,
description='ETL任务详情')
})
</p>
(3)Web API数据操作类,包括增删改查等方法。
class TodoDAO(object):
def __init__(self):
self.counter = 0
self.todos = []
def get(self, id):
for todo in self.todos:
if todo['id'] == id:
return todo
api.abort(404, "ETL任务 {} 不存在".format(id))
def create(self, data):
todo = data
todo['id'] = self.counter = self.counter + 1
self.todos.append(todo)
return todo
# 实例化数据操作,创建3条测试数据
DAO = TodoDAO()
DAO.create({'task': 'ETL-抽取数据操作'})
DAO.create({'task': 'ETL-数据清洗转换'})
DAO.create({'task': 'ETL-数据加载操作'})
(4)为 Web API 构建路由图。
HTTP资源请求类继承自Resource类,然后映射到不同的路由,指定可以使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求
class TodoList(Resource):
@ns.doc('list_todos') # @doc装饰器对应API文档的信息
@ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出
def get(self): # 定义get方法获取所有的任务信息
return DAO.todos
@ns.doc('create_todo')
@ns.expect(todo)
@ns.marshal_with(todo, code=201)
def post(self): # 定义post方法获取所有的任务信息
return DAO.create(api.payload), 201
# 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求
@ns.route('/')
@ns.response(404, '未发现相关ETL任务')
@ns.param('id', 'ETL任务ID号')
class Todo(Resource):
@ns.doc('get_todo')
@ns.marshal_with(todo)
def get(self, id):
return DAO.get(id)
@ns.doc('delete_todo')
@ns.response(204, 'ETL任务已经删除')
def delete(self, id):
DAO.delete(id)
return '', 204
@ns.expect(todo)
@ns.marshal_with(todo)
def put(self, id):
return DAO.update(id, api.payload)
if __name__ == '__main__':
app.run(debug=True, port=8000) # 启动Web API服务,端口为8000
(4)打开 Web API 服务。
通过命令“python ./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”,显示Web API服务请求方法列表如图5-23所示。
图2 WebAPI服务请求方法列表
2、网页数据抓取
Excel可以通过“数据”选项卡下的“来自网站”功能抓取网页数据。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架来抓取 Web 数据。
1.通过 Excel 抓取
点击“数据”→“来自其他来源”→“来自网站”功能。 Excel能读取的网页数据有局限性:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)点击“数据”→“来自其他来源”→“来自网站”功能。
(2)确保5.5.1部分中写的Web网站已开启。
(3)输入网站URL地址“:5000/”
点击“高级”按钮配置更详细的HTTP请求信息,然后点击“确定”按钮,如图3所示。
图3 配置URL读取网站
(4)在导航器窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表格名称,点击“加载”按钮。
图4 Excel自动识别网页中的表格数据
2.用 Python 爬行
下面的演示使用 requests 库从整个网页中获取数据,然后使用 Beautiful Soup 来解析网页。读者可以参考本书中的代码资料文件“5-5-web.ipynb”进行学习。
(1)通过请求读取网页数据。
import requests #导入requests包
url ='http://127.0.0.1:5000/'
strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过 Beautiful Soup 解析网页。
from bs4 import BeautifulSoup
soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象
table = soup.find('table') # 查找网页中的table元素
table_body = table.find('tbody') # 查找table元素中的tbody元素
data = []
rows = table_body.find_all('tr') # 查找表中的所有tr元素
for row in rows: # 遍历数据
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele])
# 结果输出:[[],
['小米', '女', '22'],['小明','男','23'],……
3、调用 Web API 服务
Excel 可以通过“数据”选项卡下的“From网站”函数调用 Web API 服务。 Python 可以使用 requests 库、Beautiful Soup 包和 Scrapy 框架调用 Web API 获取数据。
1.用Excel调用
(1)确保5.5.1节中编写的Web API服务已启用。
(2)输入Web API方法对应的URL::8000/ExcelPythonTest/.
(3)处理返回的数据。
调用Web API服务后,返回JSON格式的数据,按照5.4.3小节描述的方法处理JSON数据。
2.使用 Python 调用
使用 requests 库调用 Web API 方法,然后处理返回的 JSON 数据。读者可以参考本书中的代码资料文件“5-5-api.ipynb”进行学习。
import requests #导入requests包
url ='http://127.0.0.1:8000/ExcelPythonTest/'
strhtml= requests.get(url) #使用get方法获取网页数据
import pandas as pd
frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数
print(frame)
#结果输出:
id task
0 1 ETL-抽取数据操作
1 2 ETL-数据清洗转换
2 3 ETL-数据加载操作
4、两种方法的比较
表 1 显示了用于抓取 Internet 数据的 Excel 和 Python 方法的比较。需要注意的是,Excel 从互联网上抓取数据的能力并不完美。
表1 Excel和Python捕获Internet数据的方法比较
解决方案:百度seo快速见效方法(移动跨境流量)
做独立跨境电商网站的人经常问我,“谷歌SEO需要多长时间才能看到结果?”今天,Kenny 将在 2 分钟内为您解答所有疑惑。
随着搜索引擎算法技术的成熟和越来越多的在线内容,在搜索页面中占据一席之地已经成为一个大工程。 SEO(搜索引擎优化)是通过优化 网站 内容以提高搜索引擎排名和曝光率的有机搜索实践。有效的 SEO 可以更好地向搜索引擎证明您的内容是用户最想要的搜索结果。下面我们总结了一些关于SEO的常见问题,希望能帮助您更好地理解和使用SEO。
1.SEO优化的本质是什么?
SEO的本质是根据搜索引擎的最新算法来改进你的内容,从而增加你的内容的曝光率。例如,只需对 关键词 的使用进行一些调整,原创内容就可以使您的 网站 的新搜索流量增加一倍以上。但不要低估翻倍的新搜索流量。据统计,78%的有目的的搜索可以实现购买转化。
2.一般多久可以看到SEO的结果?
这个问题的答案是个案,但好的 SEO 通常需要大约六个月的时间才能得到回报。当然,也有个别站长回应称,用一些“技巧”可以在两周内看到优化的效果,但从长远来看,速度重于质量可能会带来网站的负面影响,因为谷歌可能会将 网站 视为垃圾邮件。一旦被谷歌搜索引擎当成垃圾邮件,网站的排名就很难提升了,应该尽量避免。
3.为什么SEO优化的结果需要这么长时间才能看到?
简单来说,就是因为搜索引擎算法技术的成熟。出现在搜索结果的第一页不再只是网站上的一堆关键词。在这个阶段,想要通过好的优化策略达到满意的搜索结果排名,需要从多方面入手。受趋势和搜索趋势的影响,很多时候 SEO 已经成为一个不断适应的过程,其中包括识别受众和对客户偏好进行关键词 研究。同时,您的网站域名年龄、入站链接和网站权限也与您的搜索排名密切相关。建立权限和接收入站链接取决于用户活动,搜索引擎算法和谷歌本身都需要一段时间来检索和发现用户活动的网站变化,从而延长了SEO的有效性。
4.精通SEO需要多少钱?
截至2020年,美国大部分SEO服务月费为750-7000美元(主要变量为页数网站/更新速度/所需服务),一般来说好的SEO专家的平均费用每小时 80-200 美元。
5. SEO优化后,是否需要经常查看网站数据?
是的,SEO 是一个不断变化的领域。客户感兴趣的关键词和内容会随着当前的趋势和时事发生变化,而搜索引擎的算法也在不断变化,因此及时更新SEO策略非常重要。
微软office就可以搞定的事我使用的方法是用小黑盒抓excel大师官网
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-09-21 00:12
excel抓取多页网页数据,支持批量提取网页所有字段或者自定义tab字段,并支持图片展示导出,支持自定义分页数据,
用微软的msyhgrideditor,免费版够用了,
可以用excel大师
你看看360就知道,我用excel大师,也可以把多页的表格抓到一个excel文件里面。
听我推荐用微软msyhgrideditor免费版本就够用了
微软office就可以搞定的事
我使用的方法是用小黑盒抓
excel大师官网有一些免费的功能或样式可以抓取
关注一下微软msyhgrideditor官网,里面有一些可以免费使用的功能或样式,包括图片拼接,批量修改分页数等等,相比myofficeexcel等软件还是很实用的,下载了也可以自己设置编辑器各页对应关系,免费试用版,相信会很好用的。
一般这种东西肯定是用各种工具来自己抓,不过你不用学编程知识,每天使用excel就够了。
使用wps每次打开看一眼excel,然后点击“文件”,“保存”(powerpoint标志),看到对应的样式文件,从空白处挑取,或者,自定义tab,方便数据提取。
讲真,excel都已经能办到了,很多复杂的需求就交给云服务和专业的数据分析团队去完成吧。你要知道目前中国的很多互联网公司的核心都是卖的服务,产品比技术重要多了。另外,好不好用靠的是主观感受。 查看全部
微软office就可以搞定的事我使用的方法是用小黑盒抓excel大师官网
excel抓取多页网页数据,支持批量提取网页所有字段或者自定义tab字段,并支持图片展示导出,支持自定义分页数据,
用微软的msyhgrideditor,免费版够用了,
可以用excel大师
你看看360就知道,我用excel大师,也可以把多页的表格抓到一个excel文件里面。
听我推荐用微软msyhgrideditor免费版本就够用了
微软office就可以搞定的事
我使用的方法是用小黑盒抓
excel大师官网有一些免费的功能或样式可以抓取
关注一下微软msyhgrideditor官网,里面有一些可以免费使用的功能或样式,包括图片拼接,批量修改分页数等等,相比myofficeexcel等软件还是很实用的,下载了也可以自己设置编辑器各页对应关系,免费试用版,相信会很好用的。
一般这种东西肯定是用各种工具来自己抓,不过你不用学编程知识,每天使用excel就够了。
使用wps每次打开看一眼excel,然后点击“文件”,“保存”(powerpoint标志),看到对应的样式文件,从空白处挑取,或者,自定义tab,方便数据提取。
讲真,excel都已经能办到了,很多复杂的需求就交给云服务和专业的数据分析团队去完成吧。你要知道目前中国的很多互联网公司的核心都是卖的服务,产品比技术重要多了。另外,好不好用靠的是主观感受。
excel抓取多页网页数据 一直以为自己擅长Excel,直到见到这个神技!
网站优化 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2022-08-30 22:49
作为一名兢兢业业的打工人,我们少不了要和各种报表、汇报、软件打交道,时不时就会被折磨到摔键盘:
每天都要更新数据,只会一个个按复制粘贴键,熬夜加班也搞不完
一拍脑袋就蹦一个需求,费老鼻子劲做的统计表只能推翻重来,简直了!
碰到问题赶紧百度,下次有类似情况,哦豁,又忘了……
这些操作可能并不难,但如果每天都要干上数百遍、鼠标点个没完,一不小心就成了办公室最后一个下班的人
所以为了一劳永逸解决这些难题,我终于挖到一个「办公利器」,再也不用熬夜加班,四处求人。下面就把这个利器分享给大家↓↓↓↓
上周刚好是月底,同事琪琪要把一整个月的订单+数据从系统导出来,再按照不同维度填入Excel,最后按照统一格式做成汇报。
光是听上去,就已经让人感到窒息。
数字、名称、利润各种信息琪琪就收集了几十页,然后挨个打开计算器算数,填上Excel表格,一整天进度才一半多。
到了下班点,她用死灰一般的脸看着我,暗示“今天又要苦逼加班了”。
实在看不下去,我过去“哒哒哒”点了几下鼠标,设置好程序点击运行,Excel表格就“活了”,几千条数据一键整理完毕,前前后后不超过10分钟。
实拍在这里
“照你这么干,不是手废就是眼坏了,拼手速、拼体力的活交给RPA就完事了~"
简单讲,RPA就是“让重复的事简单做的工具”,只要写出流程步骤,就可以0成本让电脑自动帮你干90%重复性的活,以十倍,几十倍的去提升自己的工作效率。
琪琪边点头边问:那RPA相当于是个“做表机器人”咯?
“那你可就小看它了!除了Excel,RPA还可以1️⃣自动登录网站系统或桌面应用系统读取或录入数据2️⃣批量收集信息汇总3️⃣结合图像识别技术识别票据信息……
来,直接带你浅看几个功能!”
快速录入/读取数据
很多人每天都要登录各种系统一个一个录入、读取数据,手动一条一条地敲,一个小时最多能处理50条。
有了RPA,单量再多也不用怕,只要早晨到达工位打开程序运行,10秒钟提取所需信息到Excel表,1小时能处理300条,效率直接拉满!
抓取网页内容写入Excel
平时想在网页上收集一些资料,不会用RPA的人:找一条大概需 30 秒,一共500条,15000 秒,做完至少4个小时
会用RPA的人:直接用RPA替自己抓取所需要的数据,根据表头自动填入,数据再多也不怕出错,每天都能省下至少2个小时!
套用模板批量生成图表
工作中经常遇到各种各样的制表需求,每天大量时间不是在做各种日报、数据汇报表、分析统计表上,就是在找模板的路上……
有了RPA,每次不用再重新做表,直接替换数据、修改文字,还可以生成可视化的分析。原本3个小时完成的工作,现在10几分钟自动搞定!
数据一键比对
假设需要比对几列数据的不同,你是不是还在靠肉眼来回看,靠手工标记,一上午眼睛都看直了?
其实这种“脏活累活”交给RPA,自动查找多列数据的差异,将比对结果存入两表新增的“比对结果”工作表中。
自动抓取热销商品信息
做电商、贸易的经常要收集信息,大多数人可能只停留在复制粘贴!
但如果借助RPA,只要几分钟就能搞定几十页数据汇总,不仅销售情况一目了然,还能查看到其他月份的销量情况,方便进行数据对比,整理出运营策略。
自动开发潜在客户
如果你做外贸,在淡季询盘少的时候,RPA也是帮助主动开发客户的好帮手。
RPA能够自动从搜索引擎、海关数据中爬取到全部的客户邮件信息,并批量发送开发信,用不了10分钟,系统就自动发送500多封邮件。
让你拥有更多精准客户,订单多到处理不过来。
其实,我们在工作中难免会遇到大量重复且繁琐的机械操作,这些容易感到疲劳无聊,还经常会犯错误的工作,完全可以交给RPA来做。
这也是为什么别人干活如流水,而你却在重复性加班的原因。
如果你要做数据整理、统计和分析;
如果你想少受表格的煎熬、领导的冷遇、同事的嫌弃;
如果你想提高效率,到点下班,而不是被表格、软件玩得团团转……
那你一定不能错过RPA这个「摸鱼神器」,让你解放双手,不再干“体力活”!
现在加入风变《RPA智能办公实操公开课》,风变团队的RPA专业导师带你学习表格飞速排版、数据高效整理、汇报一键生成……!
我个人在实际操作中,感受到这门课的好处主要有以下几点:
✓
【即学即用】课程涵盖四大高频重复性办公场景,包含网页数据提取、数据录入、表单填写、网页操作等,用「解决问题」倒逼「技能学习」。
✓
【快速上手】直播现场,老师会从0到1打造一个数据抓取机器人,让你掌握一整套自动化办公的工作流程。
✓
【不写代码】RPA的操作像搭乐高一样,搭建好流程,不用学编程,复制出N个“助理”,代替你去完成那些无脑费时间的重复工作!
所以这门课没有深奥的知识点,全都是即学即用、快速提效的实用干货,官网价128元的课程,现在只需要3.3元,带你2小时快速入门自动化办公。
适合人群
被重复工作困扰,想要提升工作效率
对目前岗位不满意,想跳槽缺乏核心竞争力
想拓展一项个人技能,增加赚钱机会
自动汇总表格、跨系统录入数据、
批量发送消息、自动上架商品
助你不再被加班支配,不再为重复工作发愁!
RPA智能办公直播实操课
原价128元
现在只要3块3!!
仅限99个名额,扫码占位
说到学习快捷技巧、自动化办公,想必大家可能也尝试过,但是真正坚持下来的人并不多。原因无外乎三种:
1
不能,想学学 Python,编程?学了几节课各种代码实在太难了,火速放弃
2
不愿,花钱报一个Excel学习班,各种证书考试,但是工作太忙,放在收藏夹吃灰
3
不知,不知道学什么好,之前乱七八糟学了一堆,工作用不上,就没坚持下来
所以要想学习能够持久,我们可以选一个简单些,且不需要花太多时间,还能和工作结合在一起的东西,这样来看,RPA是再合适不过的了,因为它不用敲代码,鼠标拖拉拽就能省下70%的工作时间!
尽管RPA这么强悍,但是现在市面上的培训,大多是针对企业和工程师开发的,但其实剩下90%的普通人学起来相当吃力。
为此,在教育领域深耕7年的风变,携手来也、影刀等多家国内Top5 的RPA厂商,专门针对0基础人士设计这门课,不必懂各种程序概念,操起工具就是一顿配置就完事了,是广大的职场小白的利器!
干货满满的课程大纲提前看
关于课程内容,我已经帮大家体验过了,它彻底改变了我对自动化办公的固有认知,因为真的特别“接地气”:
真实场景实操,带你开启高效办公之旅
RPA应用场景非常多,任何桌面软件、网页、鼠标键盘、Excel的自动化,基本上“人用电脑做”的事情都可以实现。
这堂直播不是干巴巴的PPT,而是围绕五大行业最常遇到的重复性高、流程化的工作场景展开,涉及电商、快消零售、银行金融、财务人事、政府事务领域,覆盖运营、财务、人事、销售、市场等岗位。
2小时直播,入门最前沿自动化办公软件
你面对一大堆文件表格,费神费力,但借助RPA能秒汇总、整合数据,咔咔三下五除二做完半天工作量。
你还在抓耳挠腮只憋出两个字时,用RPA海量收集素材,已经交给领导审阅了。
精通RPA智能办公,你就能像指挥官一样让那些棘手复杂的流程乖乖替你办事,一步到位,快速高效的完成工作。
真正0基础,易学易上手
手把手带你做出能自动干活的机器人
直播讲师王爽,有多年的RPA实战&培训经验,华为、平安等大公司曾经高价聘请她去做培训。
而现在,你只需要用3块3的价格,就能在直播中亲眼看到,15分钟内打造一个数据抓取机器人。真真切切地感受原本2小时才能搞完的工作,现在压缩到十几分钟完成的爽感!
未来5年最火的职场技能大揭秘
谁先加入,谁就拥有核心竞争力
这个时代最有用的职场技能是什么?有人说写作,有人说会做表,其实,都不是。
数字化时代,掌握智能办公才是职场人的硬通货,当做表、找素材、收集数据成为日常,RPA让我们能够高效工作,专注做更有价值的事。
据艾瑞咨询预测,RPA未来三年增速仍将维持在70%以上。随着实施RPA企业的数量迅速增长,市场对RPA人才的需求将持续升温。所以早日掌握RPA,必将成为今后就业市场的“抢手人才”。
拯救你的重复忙碌工作难题
让你告别表格文件恐惧症
3.3元抢反内卷神器原价128元
RPA智能办公直播实操课
长按扫码,立即申请
☟☟☟
Q&A
Q:学习方式是怎样的?
A:智能办公直播公开课为真人直播+助教1v1,不支持回放,各位同学千万不要错过哦。
Q:报名后如何学习?
A:报名后根据指引添加助教老师,助教老师将会在48小时内通过,通过后发送直播链接,请耐心等候~ 查看全部
excel抓取多页网页数据 一直以为自己擅长Excel,直到见到这个神技!
作为一名兢兢业业的打工人,我们少不了要和各种报表、汇报、软件打交道,时不时就会被折磨到摔键盘:
每天都要更新数据,只会一个个按复制粘贴键,熬夜加班也搞不完
一拍脑袋就蹦一个需求,费老鼻子劲做的统计表只能推翻重来,简直了!
碰到问题赶紧百度,下次有类似情况,哦豁,又忘了……
这些操作可能并不难,但如果每天都要干上数百遍、鼠标点个没完,一不小心就成了办公室最后一个下班的人
所以为了一劳永逸解决这些难题,我终于挖到一个「办公利器」,再也不用熬夜加班,四处求人。下面就把这个利器分享给大家↓↓↓↓
上周刚好是月底,同事琪琪要把一整个月的订单+数据从系统导出来,再按照不同维度填入Excel,最后按照统一格式做成汇报。
光是听上去,就已经让人感到窒息。
数字、名称、利润各种信息琪琪就收集了几十页,然后挨个打开计算器算数,填上Excel表格,一整天进度才一半多。
到了下班点,她用死灰一般的脸看着我,暗示“今天又要苦逼加班了”。
实在看不下去,我过去“哒哒哒”点了几下鼠标,设置好程序点击运行,Excel表格就“活了”,几千条数据一键整理完毕,前前后后不超过10分钟。
实拍在这里
“照你这么干,不是手废就是眼坏了,拼手速、拼体力的活交给RPA就完事了~"
简单讲,RPA就是“让重复的事简单做的工具”,只要写出流程步骤,就可以0成本让电脑自动帮你干90%重复性的活,以十倍,几十倍的去提升自己的工作效率。
琪琪边点头边问:那RPA相当于是个“做表机器人”咯?
“那你可就小看它了!除了Excel,RPA还可以1️⃣自动登录网站系统或桌面应用系统读取或录入数据2️⃣批量收集信息汇总3️⃣结合图像识别技术识别票据信息……
来,直接带你浅看几个功能!”
快速录入/读取数据
很多人每天都要登录各种系统一个一个录入、读取数据,手动一条一条地敲,一个小时最多能处理50条。
有了RPA,单量再多也不用怕,只要早晨到达工位打开程序运行,10秒钟提取所需信息到Excel表,1小时能处理300条,效率直接拉满!
抓取网页内容写入Excel
平时想在网页上收集一些资料,不会用RPA的人:找一条大概需 30 秒,一共500条,15000 秒,做完至少4个小时
会用RPA的人:直接用RPA替自己抓取所需要的数据,根据表头自动填入,数据再多也不怕出错,每天都能省下至少2个小时!
套用模板批量生成图表
工作中经常遇到各种各样的制表需求,每天大量时间不是在做各种日报、数据汇报表、分析统计表上,就是在找模板的路上……
有了RPA,每次不用再重新做表,直接替换数据、修改文字,还可以生成可视化的分析。原本3个小时完成的工作,现在10几分钟自动搞定!
数据一键比对
假设需要比对几列数据的不同,你是不是还在靠肉眼来回看,靠手工标记,一上午眼睛都看直了?
其实这种“脏活累活”交给RPA,自动查找多列数据的差异,将比对结果存入两表新增的“比对结果”工作表中。
自动抓取热销商品信息
做电商、贸易的经常要收集信息,大多数人可能只停留在复制粘贴!
但如果借助RPA,只要几分钟就能搞定几十页数据汇总,不仅销售情况一目了然,还能查看到其他月份的销量情况,方便进行数据对比,整理出运营策略。
自动开发潜在客户
如果你做外贸,在淡季询盘少的时候,RPA也是帮助主动开发客户的好帮手。
RPA能够自动从搜索引擎、海关数据中爬取到全部的客户邮件信息,并批量发送开发信,用不了10分钟,系统就自动发送500多封邮件。
让你拥有更多精准客户,订单多到处理不过来。
其实,我们在工作中难免会遇到大量重复且繁琐的机械操作,这些容易感到疲劳无聊,还经常会犯错误的工作,完全可以交给RPA来做。
这也是为什么别人干活如流水,而你却在重复性加班的原因。
如果你要做数据整理、统计和分析;
如果你想少受表格的煎熬、领导的冷遇、同事的嫌弃;
如果你想提高效率,到点下班,而不是被表格、软件玩得团团转……
那你一定不能错过RPA这个「摸鱼神器」,让你解放双手,不再干“体力活”!
现在加入风变《RPA智能办公实操公开课》,风变团队的RPA专业导师带你学习表格飞速排版、数据高效整理、汇报一键生成……!
我个人在实际操作中,感受到这门课的好处主要有以下几点:
✓
【即学即用】课程涵盖四大高频重复性办公场景,包含网页数据提取、数据录入、表单填写、网页操作等,用「解决问题」倒逼「技能学习」。
✓
【快速上手】直播现场,老师会从0到1打造一个数据抓取机器人,让你掌握一整套自动化办公的工作流程。
✓
【不写代码】RPA的操作像搭乐高一样,搭建好流程,不用学编程,复制出N个“助理”,代替你去完成那些无脑费时间的重复工作!
所以这门课没有深奥的知识点,全都是即学即用、快速提效的实用干货,官网价128元的课程,现在只需要3.3元,带你2小时快速入门自动化办公。
适合人群
被重复工作困扰,想要提升工作效率
对目前岗位不满意,想跳槽缺乏核心竞争力
想拓展一项个人技能,增加赚钱机会
自动汇总表格、跨系统录入数据、
批量发送消息、自动上架商品
助你不再被加班支配,不再为重复工作发愁!
RPA智能办公直播实操课
原价128元
现在只要3块3!!
仅限99个名额,扫码占位
说到学习快捷技巧、自动化办公,想必大家可能也尝试过,但是真正坚持下来的人并不多。原因无外乎三种:
1
不能,想学学 Python,编程?学了几节课各种代码实在太难了,火速放弃
2
不愿,花钱报一个Excel学习班,各种证书考试,但是工作太忙,放在收藏夹吃灰
3
不知,不知道学什么好,之前乱七八糟学了一堆,工作用不上,就没坚持下来
所以要想学习能够持久,我们可以选一个简单些,且不需要花太多时间,还能和工作结合在一起的东西,这样来看,RPA是再合适不过的了,因为它不用敲代码,鼠标拖拉拽就能省下70%的工作时间!
尽管RPA这么强悍,但是现在市面上的培训,大多是针对企业和工程师开发的,但其实剩下90%的普通人学起来相当吃力。
为此,在教育领域深耕7年的风变,携手来也、影刀等多家国内Top5 的RPA厂商,专门针对0基础人士设计这门课,不必懂各种程序概念,操起工具就是一顿配置就完事了,是广大的职场小白的利器!
干货满满的课程大纲提前看
关于课程内容,我已经帮大家体验过了,它彻底改变了我对自动化办公的固有认知,因为真的特别“接地气”:
真实场景实操,带你开启高效办公之旅
RPA应用场景非常多,任何桌面软件、网页、鼠标键盘、Excel的自动化,基本上“人用电脑做”的事情都可以实现。
这堂直播不是干巴巴的PPT,而是围绕五大行业最常遇到的重复性高、流程化的工作场景展开,涉及电商、快消零售、银行金融、财务人事、政府事务领域,覆盖运营、财务、人事、销售、市场等岗位。
2小时直播,入门最前沿自动化办公软件
你面对一大堆文件表格,费神费力,但借助RPA能秒汇总、整合数据,咔咔三下五除二做完半天工作量。
你还在抓耳挠腮只憋出两个字时,用RPA海量收集素材,已经交给领导审阅了。
精通RPA智能办公,你就能像指挥官一样让那些棘手复杂的流程乖乖替你办事,一步到位,快速高效的完成工作。
真正0基础,易学易上手
手把手带你做出能自动干活的机器人
直播讲师王爽,有多年的RPA实战&培训经验,华为、平安等大公司曾经高价聘请她去做培训。
而现在,你只需要用3块3的价格,就能在直播中亲眼看到,15分钟内打造一个数据抓取机器人。真真切切地感受原本2小时才能搞完的工作,现在压缩到十几分钟完成的爽感!
未来5年最火的职场技能大揭秘
谁先加入,谁就拥有核心竞争力
这个时代最有用的职场技能是什么?有人说写作,有人说会做表,其实,都不是。
数字化时代,掌握智能办公才是职场人的硬通货,当做表、找素材、收集数据成为日常,RPA让我们能够高效工作,专注做更有价值的事。
据艾瑞咨询预测,RPA未来三年增速仍将维持在70%以上。随着实施RPA企业的数量迅速增长,市场对RPA人才的需求将持续升温。所以早日掌握RPA,必将成为今后就业市场的“抢手人才”。
拯救你的重复忙碌工作难题
让你告别表格文件恐惧症
3.3元抢反内卷神器原价128元
RPA智能办公直播实操课
长按扫码,立即申请
☟☟☟
Q&A
Q:学习方式是怎样的?
A:智能办公直播公开课为真人直播+助教1v1,不支持回放,各位同学千万不要错过哦。
Q:报名后如何学习?
A:报名后根据指引添加助教老师,助教老师将会在48小时内通过,通过后发送直播链接,请耐心等候~
excel多渠道爬取java后台老师上课视频-excelhome技术论坛-poweredbydiscuz!
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-08-23 07:02
excel抓取多页网页数据视频:excel多渠道爬取java后台老师上课视频-excelhome教程视频-excelhome技术论坛-poweredbydiscuz!
用几天,
在2015-02-18processing_learning_practice-processing/后一定要看看
上期我也遇到这种问题,以为老师对它不关注于是我自己用教师资格证查,还是查不到,最后google之下结果是电脑要换系统,我不会换系统,于是我重装机器时候,想办法用电脑自带的端口扫描扫出来电脑里的端口号,然后手动输入电脑端口,还是找不到,我的电脑自带adsl没有服务端口扫描功能,我就像如此死马当活马医,再仔细一遍,不过我也能看得到一些可用端口,但是没有找到那些真正可用的端口,还是不知道那些是真正能用的,这次我用edu邮箱的大功率宽带拨号手机密码之后,自己扫描了一遍,居然找到一个,于是我把这个域名注册了,就敢去管了,至于怎么找注册站点,这个没法说,我觉得必须先动手找到那些端口,再想办法比较好,不过基本上一堆python代码要写的。实践出真知,开机的时候,我看到鼠标中间的上网图标鼠标一滑就是域名,还是拿edu邮箱接收,比较方便。
抱歉,原来知乎是这么用的,我刚看了你的问题,已经不是一个简单的课程结构问题了,所以还是花时间上贴吧吧。另外一个建议,下次带着问题找建议吧, 查看全部
excel多渠道爬取java后台老师上课视频-excelhome技术论坛-poweredbydiscuz!
excel抓取多页网页数据视频:excel多渠道爬取java后台老师上课视频-excelhome教程视频-excelhome技术论坛-poweredbydiscuz!
用几天,
在2015-02-18processing_learning_practice-processing/后一定要看看
上期我也遇到这种问题,以为老师对它不关注于是我自己用教师资格证查,还是查不到,最后google之下结果是电脑要换系统,我不会换系统,于是我重装机器时候,想办法用电脑自带的端口扫描扫出来电脑里的端口号,然后手动输入电脑端口,还是找不到,我的电脑自带adsl没有服务端口扫描功能,我就像如此死马当活马医,再仔细一遍,不过我也能看得到一些可用端口,但是没有找到那些真正可用的端口,还是不知道那些是真正能用的,这次我用edu邮箱的大功率宽带拨号手机密码之后,自己扫描了一遍,居然找到一个,于是我把这个域名注册了,就敢去管了,至于怎么找注册站点,这个没法说,我觉得必须先动手找到那些端口,再想办法比较好,不过基本上一堆python代码要写的。实践出真知,开机的时候,我看到鼠标中间的上网图标鼠标一滑就是域名,还是拿edu邮箱接收,比较方便。
抱歉,原来知乎是这么用的,我刚看了你的问题,已经不是一个简单的课程结构问题了,所以还是花时间上贴吧吧。另外一个建议,下次带着问题找建议吧,
excel抓取多页网页数据并生成excel表格试试
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-08-21 06:01
excel抓取多页网页数据并生成excel表格
试试trypython(python+web框架),多线程+flaskpython+web框架加你需要的各种库和web框架,抓取速度会有质的飞跃!当然,如果不熟悉python,用简单的python3+web框架,
题主可以尝试一下爬虫工具log4js这款工具,支持python2.7、3.0、3.6等版本。支持10多种主流浏览器和web浏览器兼容,灵活且功能全面。新手体验+0元免费试用,3天会创建一个免费的试用群,共享各种学习资源!不仅可以爬取网页、手机页面、图片,还可以爬取音频、视频等各种文件。免费使用,不用注册!。
搜索下垂直站点抓取工具,国内有集中的团队,另外包括但不限于淘宝、京东、聚划算、掌中优惠券、天天特价等。希望能帮到您。
我觉得楼主应该问“在网页上面抓取图片而不是在浏览器里抓取图片”,所以下面以网页为例。你百度一下“抓取百度”,你就知道原理了。
你可以使用一些网页爬虫工具,可以试一下猪八戒网爬虫。可以免费注册,支持抓包,
如果你本地有文件服务器,那么用requests库就可以抓取了,有n多种数据库、http请求库可选,另外还有python的nltk库用来提取pdf或excel文件里的单词。 查看全部
excel抓取多页网页数据并生成excel表格试试
excel抓取多页网页数据并生成excel表格
试试trypython(python+web框架),多线程+flaskpython+web框架加你需要的各种库和web框架,抓取速度会有质的飞跃!当然,如果不熟悉python,用简单的python3+web框架,
题主可以尝试一下爬虫工具log4js这款工具,支持python2.7、3.0、3.6等版本。支持10多种主流浏览器和web浏览器兼容,灵活且功能全面。新手体验+0元免费试用,3天会创建一个免费的试用群,共享各种学习资源!不仅可以爬取网页、手机页面、图片,还可以爬取音频、视频等各种文件。免费使用,不用注册!。
搜索下垂直站点抓取工具,国内有集中的团队,另外包括但不限于淘宝、京东、聚划算、掌中优惠券、天天特价等。希望能帮到您。
我觉得楼主应该问“在网页上面抓取图片而不是在浏览器里抓取图片”,所以下面以网页为例。你百度一下“抓取百度”,你就知道原理了。
你可以使用一些网页爬虫工具,可以试一下猪八戒网爬虫。可以免费注册,支持抓包,
如果你本地有文件服务器,那么用requests库就可以抓取了,有n多种数据库、http请求库可选,另外还有python的nltk库用来提取pdf或excel文件里的单词。
excel抓取多页网页数据的讲解方法(一步步讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-07-24 21:03
excel抓取多页网页数据,可以对数据进行聚合、排序、分组等操作。下面一步步讲解方法。1.多页网页的爬取方法:step1:分析多页网页中不同的列名(如group等)、列值(如unique等)step2:通过查询分析的列名及值step3:定义一个分页查询,将所有的数据全部查询出来(如下图)方法讲解:step1的数据查询就对应了step2的分页查询;step2的分页查询就是将数据全部遍历。
下面一步步讲解分页爬取的过程。2.访问hao360/api/leader/csv.xlsx将excel文件转化为csv文件(源文件的前缀也可以是.xls)3.选择各个页数的数据,将这些数据复制到任意合适的目录。4.爬取结束5.将csv文件转化为json格式文件(json文件是不能复制的)第二部分已经解释了数据是如何格式化的。
6.将json数据解析为json格式数据打开json数据库,可以看到由一串字符串组成的json格式数据。(注意json里的header一定要有两个"?",否则解析不了。)7.定义查询分析列名、值hao360/api/leader/csv.xlsx中unique列的值是不能被查询出来的,要进行查询分析。
所以我们需要获取unique列的值以及其中值的值:step1:定义数据存储文件夹step2:将unique列存储到数据库step3:访问数据库step4:查看结果8.将返回结果重命名存到userdata文件夹下step5:将userdata文件夹转化为excel格式(step4中的xls文件也可以替换为excel格式)step6:对userdata文件夹中的excel文件进行重命名,step5中解析的json数据即可取出来了。得到的结果如下:结束关注公众号【赵卫东】获取更多。 查看全部
excel抓取多页网页数据的讲解方法(一步步讲解)
excel抓取多页网页数据,可以对数据进行聚合、排序、分组等操作。下面一步步讲解方法。1.多页网页的爬取方法:step1:分析多页网页中不同的列名(如group等)、列值(如unique等)step2:通过查询分析的列名及值step3:定义一个分页查询,将所有的数据全部查询出来(如下图)方法讲解:step1的数据查询就对应了step2的分页查询;step2的分页查询就是将数据全部遍历。
下面一步步讲解分页爬取的过程。2.访问hao360/api/leader/csv.xlsx将excel文件转化为csv文件(源文件的前缀也可以是.xls)3.选择各个页数的数据,将这些数据复制到任意合适的目录。4.爬取结束5.将csv文件转化为json格式文件(json文件是不能复制的)第二部分已经解释了数据是如何格式化的。
6.将json数据解析为json格式数据打开json数据库,可以看到由一串字符串组成的json格式数据。(注意json里的header一定要有两个"?",否则解析不了。)7.定义查询分析列名、值hao360/api/leader/csv.xlsx中unique列的值是不能被查询出来的,要进行查询分析。
所以我们需要获取unique列的值以及其中值的值:step1:定义数据存储文件夹step2:将unique列存储到数据库step3:访问数据库step4:查看结果8.将返回结果重命名存到userdata文件夹下step5:将userdata文件夹转化为excel格式(step4中的xls文件也可以替换为excel格式)step6:对userdata文件夹中的excel文件进行重命名,step5中解析的json数据即可取出来了。得到的结果如下:结束关注公众号【赵卫东】获取更多。
一个函数抓取代谢组学权威数据库HMDB的所有表格数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-07-22 08:31
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素()。具体使用如下:
<p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address<br />url 查看全部
一个函数抓取代谢组学权威数据库HMDB的所有表格数据
爬虫是都不陌生的一个概念,比如百度、谷歌都有自己的爬虫工具去抓取网站、分析、索引,方便我们的查询使用。
在我们浏览网站、查询信息时,如果想做一些批量的处理,也可以去分析网站的结构、抓取网页、提取信息,然后就完成了一个小爬虫的写作。
网页爬虫需要我们了解URL的结构、HTML语法特征和结构,以及使用合适的抓取、解析工具。我们这篇先看一个简单的处理,给一个直观的感受:一个函数抓取网页的表格。以后再慢慢解析如何更加定制的获取信息。
HMDB (人类代谢组数据库)收录了很多代谢组的数据,用于代谢组学、临床化学、生物标志物开啊和基本教育等。数据联通化学、临床、分子生物学3个层次,共有114,099个代谢物。
网站提供了多种浏览和查询功能,可以关注不同的疾病、通路、BMI、年龄、性别相关代谢组学。
下图展示的是BMI相关代谢物的数据。
如果我们想把这个表格下载下来,一个办法是一页页的拷贝,大约拷贝十几次,工作量不算太大,但有些无趣。另外一个办法就是这次要说的抓取网页。
R的XML包中有个函数readHTMLTable专用于识别HTML中的表格 (table标签),从而提取元素()。具体使用如下:
<p># Load the package required to read website<br />library(XML)<br /><br /># wegpage address<br />url
如何学习领导讲话 —— 数据抓取+词频分析+可视化 简易流程介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-07-22 05:48
政府重要领导的讲话内容对规划项目而言是重中之重,今天小王接到一个任务,要好好学习现在所里在做的项目的龙岗区张书记的讲话,如果只是复制粘贴领导讲话,画个重点色,好像真的很无趣,所以爱折腾的小王自己琢磨了一下,做得稍微复杂一点,希望能抛砖引玉,启发大家的思考,并且这里除了1部分(还是可以略过的),其它都是无脑的,不需要你会python。
由于天色已晚,小王只有半个小时写文,这里长话短说,不明白的细节欢迎留言交流。
1、大数据抓取(可略过)
工具:优采云采集器(免费)
采集地址:龙岗区政府网站
采集流程:具体流程见优采云教程
具体流程图如上,简要说就是建立两个翻页循环,一个是循环点击下一页,一个是循环点击进入每一页的每一条内部。如果有不清楚的可以直接查询优采云软件内置教程,有非常详细的介绍,这里没有时间多说。
抓取结束之后,需要进行一个漫长且无趣的清洗,也是非常枯燥无味的,需要比较针对性的文字的朋友可以直接略过这一步,开几个关键网页复制粘贴吧。
完成后得到word文件如图
2、词频提取
工具网页:图悦
将word内容复制至该网址,得到初步分析图(这个图很丑,不要),此时记得按图片右上角四个小按钮中最右边的按钮,导出excel
打开EXCEL获得如图内容,有一些词分的还有问题,需要进一步处理,接下来就可以进入可视化流程了。
这里想多说一点,结合API获取工具或是GIS数据(在以后的文章中会提及)和词频工具,可以做非常有趣的其它分析,比如领导给我一个任务让我找出一个片区里,什么厂最多,是电子厂还是制衣厂,这也可以发挥作用。
总词频可视化
工具网页:Word Art ()
虽然是全英文的但是我想大家都能看得懂
当前显示的这一栏就是输入关键词和词频了
接着在SHAPE里,上传自己处理好边界的PNG图片
后面几栏可以调整颜色等
最后注意在FONTS栏里上传中文字体文件(tff格式)哦
然后按红色按钮生成就行了,然后按打印即可,效果如下
(考虑到项目正在做,该图内容未经过清洗,非最终结果)
我们可以初步得到结论:书记最关心什么?
交通和产业
细节词频分析
工具网站1语义分析系统:
工具网站2纽扣词云:
工具网站1:
功能非常多,比如弦图和关系图
按类别分析
情感分析
工具网站2:
工具网站2对词性有更细节的分析
像这种形时间词、方位词都有较好的应用
至于这些内容到底应该怎么用,就各自见仁见智啦
总结
合理利用数据抓取(网页+API)+词频工具+可视化这一套工具可以做的事很多,难点也不在工具,而在于为什么要用工具,这会直接影响到关键步骤“抓取”和“清洗”,时间有限,这次分享到此为止,欢迎大家在后台留言,以后争取分享更多的内容。
图片|来源各个工具
文案|城市学习者小王 查看全部
如何学习领导讲话 —— 数据抓取+词频分析+可视化 简易流程介绍
政府重要领导的讲话内容对规划项目而言是重中之重,今天小王接到一个任务,要好好学习现在所里在做的项目的龙岗区张书记的讲话,如果只是复制粘贴领导讲话,画个重点色,好像真的很无趣,所以爱折腾的小王自己琢磨了一下,做得稍微复杂一点,希望能抛砖引玉,启发大家的思考,并且这里除了1部分(还是可以略过的),其它都是无脑的,不需要你会python。
由于天色已晚,小王只有半个小时写文,这里长话短说,不明白的细节欢迎留言交流。
1、大数据抓取(可略过)
工具:优采云采集器(免费)
采集地址:龙岗区政府网站
采集流程:具体流程见优采云教程
具体流程图如上,简要说就是建立两个翻页循环,一个是循环点击下一页,一个是循环点击进入每一页的每一条内部。如果有不清楚的可以直接查询优采云软件内置教程,有非常详细的介绍,这里没有时间多说。
抓取结束之后,需要进行一个漫长且无趣的清洗,也是非常枯燥无味的,需要比较针对性的文字的朋友可以直接略过这一步,开几个关键网页复制粘贴吧。
完成后得到word文件如图
2、词频提取
工具网页:图悦
将word内容复制至该网址,得到初步分析图(这个图很丑,不要),此时记得按图片右上角四个小按钮中最右边的按钮,导出excel
打开EXCEL获得如图内容,有一些词分的还有问题,需要进一步处理,接下来就可以进入可视化流程了。
这里想多说一点,结合API获取工具或是GIS数据(在以后的文章中会提及)和词频工具,可以做非常有趣的其它分析,比如领导给我一个任务让我找出一个片区里,什么厂最多,是电子厂还是制衣厂,这也可以发挥作用。
总词频可视化
工具网页:Word Art ()
虽然是全英文的但是我想大家都能看得懂
当前显示的这一栏就是输入关键词和词频了
接着在SHAPE里,上传自己处理好边界的PNG图片
后面几栏可以调整颜色等
最后注意在FONTS栏里上传中文字体文件(tff格式)哦
然后按红色按钮生成就行了,然后按打印即可,效果如下
(考虑到项目正在做,该图内容未经过清洗,非最终结果)
我们可以初步得到结论:书记最关心什么?
交通和产业
细节词频分析
工具网站1语义分析系统:
工具网站2纽扣词云:
工具网站1:
功能非常多,比如弦图和关系图
按类别分析
情感分析
工具网站2:
工具网站2对词性有更细节的分析
像这种形时间词、方位词都有较好的应用
至于这些内容到底应该怎么用,就各自见仁见智啦
总结
合理利用数据抓取(网页+API)+词频工具+可视化这一套工具可以做的事很多,难点也不在工具,而在于为什么要用工具,这会直接影响到关键步骤“抓取”和“清洗”,时间有限,这次分享到此为止,欢迎大家在后台留言,以后争取分享更多的内容。
图片|来源各个工具
文案|城市学习者小王
如何从10万条记录中提取出5000条数据?
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-07-11 14:05
excel抓取多页网页数据,可以分析链接位置和爬取的类型。更多关于数据分析的文章,可以关注我们微信公众号~如何从10万条记录中提取出5000条数据1.问题导入数据#导入excel所需要的包#数据清洗步骤对比和业务需求2.数据预处理#缺失值处理#缺失值统计表and表#除了缺失值还存在哪些值#填充缺失值#删除缺失值#求得缺失值信息或与所分析内容无关的值#填充缺失值3.数据分析#总体业务分析#不同页面产品经理、产品设计师数量比率#页面类型分布,注意内容丰富的产品不一定热销,准确判断需要从内容类型分析起,不能片面理解数据#业务模块分析#业务方向需求是销售金额还是研发投入/收入?#设计团队、研发团队等分析,最终目的是弄清楚设计团队、研发团队的编程水平?#薪资和市场上其他地区相比如何?#离职率是否大于预期值?#主要的流失原因是什么?#该企业的人员构成如何?#总体业务分析①产品经理人数#设计人员人数#运营和推广人员人数#推广渠道人数#寻找主要的流失原因a.单位人数效益下降b.激活率或交易率下降c.点击量减少,产品调整时需要对新增动作进行特殊处理③销售金额分布#产品分类销售中,热销的产品数量特征是:明显高于其他人员所占比例的产品数量a.热销大热销的产品分类种类较多,需要从其他人员、平台或协议等等,从类别出发来分析市场b.热销产品在同类产品分布中是集中在少数产品中,需要从满足当前产品特性来判断市场④设计团队a.最常使用的设计软件用户量和设计师人数b.最常使用的设计团队种类及数量c.使用本人设计师素质和使用本人团队的人数⑤研发投入投入产出比合理的投入产出比和是否愿意投入的原因,需要从产品、模式、市场等等来找b.原因一:本人产品部分使用了一段时间的excel,然后觉得excel比较好用,有电脑都会用,不用安装。
能做的事情太多,需要提升能力。设计团队要投入更多的资源,在个人成长上更充实,从而提升专业技能c.原因二:设计团队的执行力方面,设计不仅仅是表面上的美观,还要面对用户的痛点和难题,新产品还是需要从产品功能上去改进a.在产品功能上面,有更多开始的人,更快的解决需求问题b.开始的人多了,想法会放得开,有更多的创新点a.启动团队执行力方面,可以通过公司文化来先打开团队的执行力方面,让团队全员齐心协力,变得更能坚持一些b.在产品功能上创新点上,需要从更宏观的视角,优化产品还是优化用户体验,比方说用户容易购买但用户转换率低的产品,可以在小改进上重新引起用户的兴趣和。 查看全部
如何从10万条记录中提取出5000条数据?
excel抓取多页网页数据,可以分析链接位置和爬取的类型。更多关于数据分析的文章,可以关注我们微信公众号~如何从10万条记录中提取出5000条数据1.问题导入数据#导入excel所需要的包#数据清洗步骤对比和业务需求2.数据预处理#缺失值处理#缺失值统计表and表#除了缺失值还存在哪些值#填充缺失值#删除缺失值#求得缺失值信息或与所分析内容无关的值#填充缺失值3.数据分析#总体业务分析#不同页面产品经理、产品设计师数量比率#页面类型分布,注意内容丰富的产品不一定热销,准确判断需要从内容类型分析起,不能片面理解数据#业务模块分析#业务方向需求是销售金额还是研发投入/收入?#设计团队、研发团队等分析,最终目的是弄清楚设计团队、研发团队的编程水平?#薪资和市场上其他地区相比如何?#离职率是否大于预期值?#主要的流失原因是什么?#该企业的人员构成如何?#总体业务分析①产品经理人数#设计人员人数#运营和推广人员人数#推广渠道人数#寻找主要的流失原因a.单位人数效益下降b.激活率或交易率下降c.点击量减少,产品调整时需要对新增动作进行特殊处理③销售金额分布#产品分类销售中,热销的产品数量特征是:明显高于其他人员所占比例的产品数量a.热销大热销的产品分类种类较多,需要从其他人员、平台或协议等等,从类别出发来分析市场b.热销产品在同类产品分布中是集中在少数产品中,需要从满足当前产品特性来判断市场④设计团队a.最常使用的设计软件用户量和设计师人数b.最常使用的设计团队种类及数量c.使用本人设计师素质和使用本人团队的人数⑤研发投入投入产出比合理的投入产出比和是否愿意投入的原因,需要从产品、模式、市场等等来找b.原因一:本人产品部分使用了一段时间的excel,然后觉得excel比较好用,有电脑都会用,不用安装。
能做的事情太多,需要提升能力。设计团队要投入更多的资源,在个人成长上更充实,从而提升专业技能c.原因二:设计团队的执行力方面,设计不仅仅是表面上的美观,还要面对用户的痛点和难题,新产品还是需要从产品功能上去改进a.在产品功能上面,有更多开始的人,更快的解决需求问题b.开始的人多了,想法会放得开,有更多的创新点a.启动团队执行力方面,可以通过公司文化来先打开团队的执行力方面,让团队全员齐心协力,变得更能坚持一些b.在产品功能上创新点上,需要从更宏观的视角,优化产品还是优化用户体验,比方说用户容易购买但用户转换率低的产品,可以在小改进上重新引起用户的兴趣和。
简易数据分析 13 | Web Scraper 抓取二级页面(详情页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2022-06-23 18:04
如果做到这一步,其实已经可以抓到所有已知的列表数据了,但本文的重点是:如何抓取二级页面(详情页)的三连数据?
跟着做了这么多爬虫,可能你已经发现了,Web Scraper 本质是模拟人类的操作以达到抓取数据的目的。
那么我们正常查看二级页面(详情页)是怎么操作的呢?其实就是点击标题链接跳转:
Web Scraper 为我们提供了点击链接跳转的功能,那就是 Type 为 Link 的选择器。
感觉有些抽象?我们对照例子来理解一下。
首先在这个案例里,我们获取了标题的文字,这时的选择器类型为 Text:
当我们要抓取链接时,就要再创建一个选择器,选的元素是一样的,但是 Type 类型为 Link:
创建成功后,我们点击这个 Link 类型的选择器,进入他的内部,再创建相关的选择器,下面我录了个动图,注意看我鼠标强调的导航路由部分,可以很清晰的看出这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接后就会发现,浏览器会在一个新的 Tab 页打开详情页,但是 Web Scraper 的选择窗口开在列表页,无法跨页面选择想要的数据。
处理这个问题也很简单,你可以复制详情页的链接,拷贝到列表页所在的 Tab 页里,然后回车重新加载,这样就可以在当前页面选择了。
我们在类型为 Link 的选择器内部多创建几个选择器,这里我选择了点赞数、硬币数、收藏数和分享数 4 个数据,这个操作也很简单,这里我就不详细说了。
所有选择器的结构图如下:
我们可以看到 video_detail_link 这个节点包含 4 个二级页面(详情页)的数据,到此为止,我们的子选择器已经全部建立好了。
5.抓取数据
终于到了激动人心的环节了,我们要开始抓取数据了。但是抓取前我们要把等待时间调整得大一些,默认时间是 2000 ms,我这里改成了 5000 ms。
为什么这么做?看了下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面,这时候浏览器加载网页需要花费时间;
其次,我们可以观察一下要抓取的点赞量等数据,页面刚刚加载的时候,它的值是 「--」,等待一会儿后才会变成数字。
所以,我们直接等待 5000 ms,等页面和数据加载完成后,再统一抓取。
配置好参数后,我们就可以正式抓取并下载了。下图是我抓取数据的一部分,特此证明此方法有用:
6.总结
这次的教程可能有些难度,我把我的 SiteMap 分享出来,制作的时候如果遇到难题,可以参考一下我的配置,SiteMap 导入的功能我在里详细说明了,大家可以配合食用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
当你掌握了二级页面的抓取方式后,三级页面、四级页面也不在话下。因为套路都是一样的:都是先创建 Link 选择器、然后在 Link 选择器指向的下一个页面内抓取数据,我就不一一演示了。 查看全部
简易数据分析 13 | Web Scraper 抓取二级页面(详情页)
如果做到这一步,其实已经可以抓到所有已知的列表数据了,但本文的重点是:如何抓取二级页面(详情页)的三连数据?
跟着做了这么多爬虫,可能你已经发现了,Web Scraper 本质是模拟人类的操作以达到抓取数据的目的。
那么我们正常查看二级页面(详情页)是怎么操作的呢?其实就是点击标题链接跳转:
Web Scraper 为我们提供了点击链接跳转的功能,那就是 Type 为 Link 的选择器。
感觉有些抽象?我们对照例子来理解一下。
首先在这个案例里,我们获取了标题的文字,这时的选择器类型为 Text:
当我们要抓取链接时,就要再创建一个选择器,选的元素是一样的,但是 Type 类型为 Link:
创建成功后,我们点击这个 Link 类型的选择器,进入他的内部,再创建相关的选择器,下面我录了个动图,注意看我鼠标强调的导航路由部分,可以很清晰的看出这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接后就会发现,浏览器会在一个新的 Tab 页打开详情页,但是 Web Scraper 的选择窗口开在列表页,无法跨页面选择想要的数据。
处理这个问题也很简单,你可以复制详情页的链接,拷贝到列表页所在的 Tab 页里,然后回车重新加载,这样就可以在当前页面选择了。
我们在类型为 Link 的选择器内部多创建几个选择器,这里我选择了点赞数、硬币数、收藏数和分享数 4 个数据,这个操作也很简单,这里我就不详细说了。
所有选择器的结构图如下:
我们可以看到 video_detail_link 这个节点包含 4 个二级页面(详情页)的数据,到此为止,我们的子选择器已经全部建立好了。
5.抓取数据
终于到了激动人心的环节了,我们要开始抓取数据了。但是抓取前我们要把等待时间调整得大一些,默认时间是 2000 ms,我这里改成了 5000 ms。
为什么这么做?看了下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面,这时候浏览器加载网页需要花费时间;
其次,我们可以观察一下要抓取的点赞量等数据,页面刚刚加载的时候,它的值是 「--」,等待一会儿后才会变成数字。
所以,我们直接等待 5000 ms,等页面和数据加载完成后,再统一抓取。
配置好参数后,我们就可以正式抓取并下载了。下图是我抓取数据的一部分,特此证明此方法有用:
6.总结
这次的教程可能有些难度,我把我的 SiteMap 分享出来,制作的时候如果遇到难题,可以参考一下我的配置,SiteMap 导入的功能我在里详细说明了,大家可以配合食用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
当你掌握了二级页面的抓取方式后,三级页面、四级页面也不在话下。因为套路都是一样的:都是先创建 Link 选择器、然后在 Link 选择器指向的下一个页面内抓取数据,我就不一一演示了。
数理课堂|互联网时代数据素养的培养 ——从数据获取开始
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-06-19 00:21
大数据时代下,人类社会的数据正以前所未有的速度增长。问卷调查法、访谈法等传统的数据收集方法,因样本容量小、信度低等局限已无法满足高质量研究的需求,相比较而言,网络爬虫获取到的海量数据更为真实、全面,在信息繁荣的互联网时代更为行之有效。因此学会网络爬虫也逐渐成为大数据时代信息收集的必备技能。
1
什么是网络爬虫?
网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念。爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的一个个超级链接就是蛛丝,将无数页面连接起来,而网络爬虫,则会沿着一根根蛛丝,爬遍每一个节点……
2
网络爬虫能干吗?
举个栗子:某天的午后,老板突然让你将某网上所有的A股行情信息全部保存到一个Excel文件里,以便浏览。你点开了某网A股行情,惊喜地发现有一百多页,一条一条复制,显然又累又笨,但是老板要看,你又不得不从,……很多时候,我们会需要做这样的工作:将某一类型的文档全部下载保存下来,然后进行分析。一个一个点击鼠标,显然不现实。那么,就做一个网络爬虫吧,自动化地把需要的东西保存下来。
3
网络爬虫很难学?
爬虫听起来很酷炫,总是非常吸引学习者,但是不是要写好多枯燥的代码?今天,小编就给大家介绍一个不需要写代码的简单爬虫工具——优采云。
1系统登录
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
2创建任务
选择任务组,自定义任务名称和备注;
上图配置完毕之后,选择下一步,进入到流程配置页面,往流程设计器中拖入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在右边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中自动打开对应网页:
下面创建循环翻页。点击上图浏览器页面中的Next按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建完毕之后,点击下图中的保存;
由于需要循环点击上图浏览器中电影名称,再提取子页面中的数据信息,所以还需要做一个循环采集列表.点击上图中第一个循环项,在弹出的对话框中选择创建一个元素列表以处理一组元素。
接下来在弹出的对话框中选择添加到列表
第一个循环项添加好之后选择继续编辑列表。
接下来以同样的方式添加第二个循环项。
我们添加第二个循环项的时候可以看上图,这时候页面中其他元素都被添加进来了。这是因为我们添加的是具有两个相似特征的元素,系统会智能的将页面中其他具有相似特征的元素都添加进来。然后选择创建列表完成→点击下图中的循环
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
由于每一页都需要循环采集数据,所以我们需要将这个循环列表拖入到翻页循环里。
注意流程是从上网页执行的,所以这个循环列表需要放到点击翻页的前面,否则会漏掉第一页的数据。最终流程图如下图所示:
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
选择上图中第一个循环项,再选择点击元素.进入到第一个子链接里面。
下面进行数据字段的提取,点击上图流程设计器中的提取数据,再选择浏览器中需要提取的字段,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作之后,系统会在页面的右上方显示我们将要抓取的字段;
接下来配置页面中其他需要抓取的字段,配置完成之后修改字段名称;
修改完成之后点击上图中的保存按钮,再点开图中的数据字段可以看到,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检查页面,以确保任务的正确性;
3数据的采集与导出
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果;
附优采云下载地址:
查看全部
数理课堂|互联网时代数据素养的培养 ——从数据获取开始
大数据时代下,人类社会的数据正以前所未有的速度增长。问卷调查法、访谈法等传统的数据收集方法,因样本容量小、信度低等局限已无法满足高质量研究的需求,相比较而言,网络爬虫获取到的海量数据更为真实、全面,在信息繁荣的互联网时代更为行之有效。因此学会网络爬虫也逐渐成为大数据时代信息收集的必备技能。
1
什么是网络爬虫?
网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念。爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的一个个超级链接就是蛛丝,将无数页面连接起来,而网络爬虫,则会沿着一根根蛛丝,爬遍每一个节点……
2
网络爬虫能干吗?
举个栗子:某天的午后,老板突然让你将某网上所有的A股行情信息全部保存到一个Excel文件里,以便浏览。你点开了某网A股行情,惊喜地发现有一百多页,一条一条复制,显然又累又笨,但是老板要看,你又不得不从,……很多时候,我们会需要做这样的工作:将某一类型的文档全部下载保存下来,然后进行分析。一个一个点击鼠标,显然不现实。那么,就做一个网络爬虫吧,自动化地把需要的东西保存下来。
3
网络爬虫很难学?
爬虫听起来很酷炫,总是非常吸引学习者,但是不是要写好多枯燥的代码?今天,小编就给大家介绍一个不需要写代码的简单爬虫工具——优采云。
1系统登录
首先打开优采云采集器→点击快速开始→新建任务,进入到任务配置页面:
2创建任务
选择任务组,自定义任务名称和备注;
上图配置完毕之后,选择下一步,进入到流程配置页面,往流程设计器中拖入一个打开网页的步骤;
选中浏览器中的打开网页步骤,在右边的页面URL中输入网页URL并点击保存,系统会在软件下方的浏览器中自动打开对应网页:
下面创建循环翻页。点击上图浏览器页面中的Next按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建完毕之后,点击下图中的保存;
由于需要循环点击上图浏览器中电影名称,再提取子页面中的数据信息,所以还需要做一个循环采集列表.点击上图中第一个循环项,在弹出的对话框中选择创建一个元素列表以处理一组元素。
接下来在弹出的对话框中选择添加到列表
第一个循环项添加好之后选择继续编辑列表。
接下来以同样的方式添加第二个循环项。
我们添加第二个循环项的时候可以看上图,这时候页面中其他元素都被添加进来了。这是因为我们添加的是具有两个相似特征的元素,系统会智能的将页面中其他具有相似特征的元素都添加进来。然后选择创建列表完成→点击下图中的循环
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
由于每一页都需要循环采集数据,所以我们需要将这个循环列表拖入到翻页循环里。
注意流程是从上网页执行的,所以这个循环列表需要放到点击翻页的前面,否则会漏掉第一页的数据。最终流程图如下图所示:
如上操作之后,循环采集列表就完成了。系统会在页面右上方显示本页面添加进来的所有循环项。
选择上图中第一个循环项,再选择点击元素.进入到第一个子链接里面。
下面进行数据字段的提取,点击上图流程设计器中的提取数据,再选择浏览器中需要提取的字段,然后在弹出的选择对话框中选择抓取这个元素的文本;
上述操作之后,系统会在页面的右上方显示我们将要抓取的字段;
接下来配置页面中其他需要抓取的字段,配置完成之后修改字段名称;
修改完成之后点击上图中的保存按钮,再点开图中的数据字段可以看到,系统将会显示最终的采集列表;
点击上图中的下一步→下一步→启动单机采集(调试模式),进入到任务检查页面,以确保任务的正确性;
3数据的采集与导出
点击开始单机采集,系统将会在本地执行采集流程并显示最终采集的结果;
附优采云下载地址:
excel2010以上貌似不能用分列功能分隔这几个字符串了
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-05-24 06:00
excel抓取多页网页数据,每页均是相同的企业名称、经营范围、行业类型,将它们转化为数组。利用分列功能将所有的文本格式数组转化为数字格式数组,并将这些数字转化为行列值1-16数字格式数组,再用通配符号定位到行号为002、列号为003的单元格(根据数据量需要定位到行号在前,列号在后),并将这些数据的内容拷贝到需要的位置。然后再替换这些数据中的内容即可得到所需的数据。以上操作需要在excel2010版本以上进行。
感谢@msy,因为我的问题和他说的不太一样,我问的是每页的文字内容。我们现在做为,用的是分列功能,用0-10000分开,然后用excel自带的函数实现每行文字分别匹配,excel2010以上貌似不能用分列功能分隔这几个字符串了,因为是数字。可以用其他的分列,left/mid/right/trim/mod/subtemplate等等。
不知道您说的是不是下面这个功能我觉得实现可能只有一种方法就是截图如下步骤1.把要求文字复制到cad下2.选择要分列的区域3.截图。
pdf导入,
实际上这样做不对,因为如果是单列的,里面的所有内容可以匹配成等值字符串;如果是行列的,里面的所有内容却可以匹配成其他的值,所以并不一定要excel提供的工具。还是要去查查excel的帮助文档。谢谢楼上的给出代码。 查看全部
excel2010以上貌似不能用分列功能分隔这几个字符串了
excel抓取多页网页数据,每页均是相同的企业名称、经营范围、行业类型,将它们转化为数组。利用分列功能将所有的文本格式数组转化为数字格式数组,并将这些数字转化为行列值1-16数字格式数组,再用通配符号定位到行号为002、列号为003的单元格(根据数据量需要定位到行号在前,列号在后),并将这些数据的内容拷贝到需要的位置。然后再替换这些数据中的内容即可得到所需的数据。以上操作需要在excel2010版本以上进行。
感谢@msy,因为我的问题和他说的不太一样,我问的是每页的文字内容。我们现在做为,用的是分列功能,用0-10000分开,然后用excel自带的函数实现每行文字分别匹配,excel2010以上貌似不能用分列功能分隔这几个字符串了,因为是数字。可以用其他的分列,left/mid/right/trim/mod/subtemplate等等。
不知道您说的是不是下面这个功能我觉得实现可能只有一种方法就是截图如下步骤1.把要求文字复制到cad下2.选择要分列的区域3.截图。
pdf导入,
实际上这样做不对,因为如果是单列的,里面的所有内容可以匹配成等值字符串;如果是行列的,里面的所有内容却可以匹配成其他的值,所以并不一定要excel提供的工具。还是要去查查excel的帮助文档。谢谢楼上的给出代码。
excel抓取多页网页数据第一种解决方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-05-19 08:03
excel抓取多页网页数据要从后往前读取,实际上主要就是在right函数中操作,可以采用$f$1和$i$1来填充抓取到的单元格区域,第1页第二页,第二页等等,数据抓取的选择性粘贴就是选择性粘贴从后往前读取而已。
关于抓取多页数据第一种解决方法,直接调用python的range()来读取,如果你需要读取一整页的数据,用xrange(len(i)+1)可以获取对应页数对应行列的数据,获取到之后再xrange(len(f1)),xrange函数的返回值会把这个整个数组放到一个list里面,你可以用函数将list里面的数据依次读取。
一般你选的这两个函数是python中matrix的两个用例
感谢王湛sam大神的回答,解决了,
我觉得可以使用matrix函数,因为函数直接调用,节省你的处理和查找的时间,毕竟对于数据结构比较复杂,
在excel里面选中抓取数据对象,然后通过matrix函数即可,具体操作你可以百度matrix。
据我观察可能是因为python抓取函数无法匹配frame格式。可以通过xrange返回值为整数,自然每次可以读取一个整数或者一个小数;例如抓取1.000000001,即可获得1.1,那么利用xrange函数就可以获得1.00001对应的大小是多少行(或列)。 查看全部
excel抓取多页网页数据第一种解决方法
excel抓取多页网页数据要从后往前读取,实际上主要就是在right函数中操作,可以采用$f$1和$i$1来填充抓取到的单元格区域,第1页第二页,第二页等等,数据抓取的选择性粘贴就是选择性粘贴从后往前读取而已。
关于抓取多页数据第一种解决方法,直接调用python的range()来读取,如果你需要读取一整页的数据,用xrange(len(i)+1)可以获取对应页数对应行列的数据,获取到之后再xrange(len(f1)),xrange函数的返回值会把这个整个数组放到一个list里面,你可以用函数将list里面的数据依次读取。
一般你选的这两个函数是python中matrix的两个用例
感谢王湛sam大神的回答,解决了,
我觉得可以使用matrix函数,因为函数直接调用,节省你的处理和查找的时间,毕竟对于数据结构比较复杂,
在excel里面选中抓取数据对象,然后通过matrix函数即可,具体操作你可以百度matrix。
据我观察可能是因为python抓取函数无法匹配frame格式。可以通过xrange返回值为整数,自然每次可以读取一个整数或者一个小数;例如抓取1.000000001,即可获得1.1,那么利用xrange函数就可以获得1.00001对应的大小是多少行(或列)。
走近数据科学案例(1):使用网络爬虫自动抓取图书信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-05-13 04:45
网络爬虫是一种从互联网上进行开放数据采集的重要手段。本案例通过使用Python的相关模块,开发一个简单的爬虫。实现从某图书网站自动下载感兴趣的图书信息的功能。主要实现的功能包括单页面图书信息下载,图书信息抽取,多页面图书信息下载等。本案例适合大数据初学者了解并动手实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词搜索,使用Python编写爬虫,自动爬取搜索结果中图书的书名、出版社、价格、作者和图书简介等信息。
当当搜索页面:
2、单页面图书信息下载2.1 网页下载
Python中的 requests 库能够自动帮助我们构造向服务器请求资源的request对象,返回服务器资源的response对象。如果仅仅需要返回HTML页面内容,直接调用response的text属性即可。在下面的代码中,我们首先导入requests库,定义当当网的搜索页面的网址,设置搜索关键词为"机器学习"。然后使用requests.get方法获取网页内容。最后将网页的前1000个字符打印显示。
import requests #1. 导入requests 库<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.2 图书内容解析
下面开始做页面的解析,分析源码.这里我使用Chrome浏览器直接打开网址 机器学习 。然后选中任意一本图书信息,鼠标右键点击“检查”按钮。不难发现搜索结果中的每一个图书的信息在页面中为标签,如下图所示:
点开第一个标签,发现下面还有几个
标签,且class分别为"name"、"detail"、"price"等,这些标签下分别存储了商品的书名、详情、价格等信息。
我们以书名信息的提取为例进行具体说明。点击 li 标签下的 class属性为 name 的 p 标签,我们发现书名信息保存在一个name属性取值为"itemlist-title"的 a 标签的title属性中,如下图所示:
我们可以使用xpath直接描述上述定位信息为 //li/p/a[@name="itemlist-title"]/@title 。下面我们用 lxml 模块来提取页面中的书名信息。xpath的使用请参考 。
page = etree.HTML(content_page) #将页面字符串解析成树结构<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name[:10] #打印提取出的前10个书名信息 <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
同理,我们可以提取图书的出版信息(作者、出版社、出版时间等),当前价格、星级、评论数等更多的信息。这些信息对应的xpath路径如下表所示。
信息项xpath路径
书名
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
当前价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style 查看全部
走近数据科学案例(1):使用网络爬虫自动抓取图书信息
网络爬虫是一种从互联网上进行开放数据采集的重要手段。本案例通过使用Python的相关模块,开发一个简单的爬虫。实现从某图书网站自动下载感兴趣的图书信息的功能。主要实现的功能包括单页面图书信息下载,图书信息抽取,多页面图书信息下载等。本案例适合大数据初学者了解并动手实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词搜索,使用Python编写爬虫,自动爬取搜索结果中图书的书名、出版社、价格、作者和图书简介等信息。
当当搜索页面:
2、单页面图书信息下载2.1 网页下载
Python中的 requests 库能够自动帮助我们构造向服务器请求资源的request对象,返回服务器资源的response对象。如果仅仅需要返回HTML页面内容,直接调用response的text属性即可。在下面的代码中,我们首先导入requests库,定义当当网的搜索页面的网址,设置搜索关键词为"机器学习"。然后使用requests.get方法获取网页内容。最后将网页的前1000个字符打印显示。
import requests #1. 导入requests 库<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
2.2 图书内容解析
下面开始做页面的解析,分析源码.这里我使用Chrome浏览器直接打开网址 机器学习 。然后选中任意一本图书信息,鼠标右键点击“检查”按钮。不难发现搜索结果中的每一个图书的信息在页面中为标签,如下图所示:
点开第一个标签,发现下面还有几个
标签,且class分别为"name"、"detail"、"price"等,这些标签下分别存储了商品的书名、详情、价格等信息。
我们以书名信息的提取为例进行具体说明。点击 li 标签下的 class属性为 name 的 p 标签,我们发现书名信息保存在一个name属性取值为"itemlist-title"的 a 标签的title属性中,如下图所示:
我们可以使用xpath直接描述上述定位信息为 //li/p/a[@name="itemlist-title"]/@title 。下面我们用 lxml 模块来提取页面中的书名信息。xpath的使用请参考 。
page = etree.HTML(content_page) #将页面字符串解析成树结构<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />book_name[:10] #打印提取出的前10个书名信息 <br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
同理,我们可以提取图书的出版信息(作者、出版社、出版时间等),当前价格、星级、评论数等更多的信息。这些信息对应的xpath路径如下表所示。
信息项xpath路径
书名
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
当前价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style
超简单实用的数据爬虫工具——Instant Data Scraper
网站优化 • 优采云 发表了文章 • 0 个评论 • 755 次浏览 • 2022-05-04 07:03
Instant Data Scraper是一个谷歌插件,是卖家们一款常用的数据爬虫工具,可以检测网页上的表格或者列表类型数据,并轻松的将这些数据抓取下来,作为Excel或者CSV表格文件。
关于Instant Data Scraper
Instant Data Scraper插件完全在用户的浏览器中运行,并且不会将数据发送到Web Robots。该插件可以将多页数据检索到一个文件中。
支持平台
在Amazon、eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等热门网站中, Instant Data Scraper插件均可使用,并且无需使用者具备编码技能。
插件下载
1、在Chrome网上应用店搜索并安装插件“Instant Data Scraper”。
2、如无法访问 Chrome网上应用店,可以离线安装插件:
通过当前页面下载Instant Data Scraper离线安装包,打开扩展程序内的开发者模式,将解压后的crx文件拖拽至扩展程序管理,选择添加插件即可。
插件使用方法
插件使用起来非常简单,以采集亚马逊Review为例:
1、打开产品Reviews页的第一页,网址格式如:产品的ASIN;
2、点击Instant Data Scraper插件图标,激活「精灵球」;
3、「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击「Try another table」按钮可以切换区域:
4、点击「Locate "Next" button」按钮来定位页面中的「Next」按钮或链接;
5、点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错;
6、等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件:
7、打开下载好的CSV或Excel文件,删掉你不需要的数据列即可。
简单几步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的。
如何利用Instant Data Scraper插件抓取亚马逊评论?
原本这次想为大家介绍使用市面上常见的或者付费的爬虫工具,例如:优采云 、优采云、 Web Scraper等采集软件爬取亚马逊的Listing 和 Review。
直到我发现了这个Chrome插件 --Instant Data Scraper,当时我差点被感动哭了。比起学编程语言编写爬虫,自己费力去研究各种网页结构、层次,还要时刻担心自己的爬虫会被亚马逊干掉。噢!我的上帝呀,是你创造了这个插件吗?
去你的优采云!
去你的优采云!
去你的 Web Scraper!
有 Instant Data Scraper 就好了!
也不用怕网页结构改变,采集规则失效的问题了!
小白也可以轻松使用上亚马逊评价采集爬虫技术!
什么是 Instant Data Scraper?
据称此插件使用 AI (人工智能)技术,可以判断页面中最相关的内容进行抓取,并不需要你懂得晦涩的编程技术。Amazon、 eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等网站都能支持。
经我初步使用,发现它不大会发生「人工智障」的问题。起码爬取亚马逊商品评论(Customer Reviews) ,Instant Data Scraper是非常方便的,大爱!
如何使用Instant Data Scraper?
在 Chrome 网上应用店搜索并安装插件「Instant Data Scraper」,此处需要科学上网。如无法访问 Chrome 网上应用店,可以离线安装插件。安装方法请自行搜索「如何离线安装 Chrome 插件?」。
插件使用起来非常非常非常简单,以采集亚马逊 Review 为例:
Instant Data Scraper
1.打开产品 Reviews 页的第一页,网址格式如:+产品的ASIN
2.点击 浏览器右上角Instant Data Scraper 插件图标,打开「精灵球」
3.「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击 「Try another table」 按钮可以切换区域
4.点击「Locate "Next" button」 按钮来定位页面中的「Next」按钮或链接
5.点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错
6.等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件
7.打开下载好的 CSV 或 Excel 文件,删掉你不需要的数据列即可
简单吧?7 步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的哦。
有了这些 Review 评论信息,我们可以利用关键词云图,如:
或者文本情感分析等大数据分析工具,快速对产品的特性和消费者情感做出大致判断,而不需要一条一条的去阅读 Review,比较适合大范围的批量选品。
Instant Data Scraper具体使用方法介绍
Instant-Data-Scraper是一款谷歌浏览器插件。
在谷歌中搜索instant data scraper, 第一个结果就是。
打开第一个搜索结果。并点击“添加至Chome”, 并在跳出的提示框中选择:添加扩展程序。
这时你的谷歌浏览器中就安装完成了我们的第一个工具。如下图所示。一个类似游泳圈的红白相间的小圆圈的标志就是。
Instant-Data-Scraper实际上是一款网页内容抓取工具。
有了他我们就可以把我们想要得到的关键词数据抓取出来。
下面我们需要思考一下,我们去哪里抓取数据呢?
其实有一个很好的平台,我们很多同行都在那里展示产品,基本做外贸的也都知道,对,就是阿里巴巴国际站。
我们就以今年比较火的一款产品来举例讲解吧。
-无纺布
即使我们不了解无纺布,百度翻译一下起码也能搞出一个关键词:nonwoven fabric.
将这个词放入阿里巴巴搜索。你会得到一个庞大的列表,我这里显示有100页。那把这100页中的词抓取出来,就可以得到我们想要的关键词。
接下来,我们点击刚才安装的instant-data-scraper扩展程序图标。
点击try another table。
将红色选择框,定位在阿里巴巴的产品搜索结果区域,如下图。
然后点击:locate “next” button按钮。
然后,在阿里搜索结果页中右键单击:翻页按钮即可。
通过这两部,一是确定抓取区域,二是确定翻页位置。
接下来instant-data-scraper,就可以工作了。
点击,操作界面中的:start scrawling
这时工具就开始抓取数据了。
注意:
至于抓取多少数据,如果你有耐心可以将这100页阿里巴巴搜索结果全部抓取完毕,也可以抓取几十页,也差不多了。时间原因我只抓取了其中的30页。
抓取完毕后,点击操作界面的:CSV或XLSX下载你想要格式的抓取结果。(我选的CSV)
将文件下载并保存至相应的磁盘位置。 查看全部
超简单实用的数据爬虫工具——Instant Data Scraper
Instant Data Scraper是一个谷歌插件,是卖家们一款常用的数据爬虫工具,可以检测网页上的表格或者列表类型数据,并轻松的将这些数据抓取下来,作为Excel或者CSV表格文件。
关于Instant Data Scraper
Instant Data Scraper插件完全在用户的浏览器中运行,并且不会将数据发送到Web Robots。该插件可以将多页数据检索到一个文件中。
支持平台
在Amazon、eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等热门网站中, Instant Data Scraper插件均可使用,并且无需使用者具备编码技能。
插件下载
1、在Chrome网上应用店搜索并安装插件“Instant Data Scraper”。
2、如无法访问 Chrome网上应用店,可以离线安装插件:
通过当前页面下载Instant Data Scraper离线安装包,打开扩展程序内的开发者模式,将解压后的crx文件拖拽至扩展程序管理,选择添加插件即可。
插件使用方法
插件使用起来非常简单,以采集亚马逊Review为例:
1、打开产品Reviews页的第一页,网址格式如:产品的ASIN;
2、点击Instant Data Scraper插件图标,激活「精灵球」;
3、「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击「Try another table」按钮可以切换区域:
4、点击「Locate "Next" button」按钮来定位页面中的「Next」按钮或链接;
5、点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错;
6、等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件:
7、打开下载好的CSV或Excel文件,删掉你不需要的数据列即可。
简单几步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的。
如何利用Instant Data Scraper插件抓取亚马逊评论?
原本这次想为大家介绍使用市面上常见的或者付费的爬虫工具,例如:优采云 、优采云、 Web Scraper等采集软件爬取亚马逊的Listing 和 Review。
直到我发现了这个Chrome插件 --Instant Data Scraper,当时我差点被感动哭了。比起学编程语言编写爬虫,自己费力去研究各种网页结构、层次,还要时刻担心自己的爬虫会被亚马逊干掉。噢!我的上帝呀,是你创造了这个插件吗?
去你的优采云!
去你的优采云!
去你的 Web Scraper!
有 Instant Data Scraper 就好了!
也不用怕网页结构改变,采集规则失效的问题了!
小白也可以轻松使用上亚马逊评价采集爬虫技术!
什么是 Instant Data Scraper?
据称此插件使用 AI (人工智能)技术,可以判断页面中最相关的内容进行抓取,并不需要你懂得晦涩的编程技术。Amazon、 eBay、Best Buy、Walmart、Etsy、Home Depot、Craigslist、Yelp 等网站都能支持。
经我初步使用,发现它不大会发生「人工智障」的问题。起码爬取亚马逊商品评论(Customer Reviews) ,Instant Data Scraper是非常方便的,大爱!
如何使用Instant Data Scraper?
在 Chrome 网上应用店搜索并安装插件「Instant Data Scraper」,此处需要科学上网。如无法访问 Chrome 网上应用店,可以离线安装插件。安装方法请自行搜索「如何离线安装 Chrome 插件?」。
插件使用起来非常非常非常简单,以采集亚马逊 Review 为例:
Instant Data Scraper
1.打开产品 Reviews 页的第一页,网址格式如:+产品的ASIN
2.点击 浏览器右上角Instant Data Scraper 插件图标,打开「精灵球」
3.「精灵球」会自动判断可抓取的页面区域,如果区域不对,点击 「Try another table」 按钮可以切换区域
4.点击「Locate "Next" button」 按钮来定位页面中的「Next」按钮或链接
5.点击「Start crawling」按钮开始爬取页面,插件会实时显示爬取到数据,请耐心等待,切勿打开其他页面,不然爬取会中断出错
6.等数据都爬取完了就可以点击绿色按钮进行下载,可选 CSV 或 Excel 文件
7.打开下载好的 CSV 或 Excel 文件,删掉你不需要的数据列即可
简单吧?7 步搞定亚马逊评价(Reviews)的爬取和采集!另外,Q&A 也是可以爬取的哦。
有了这些 Review 评论信息,我们可以利用关键词云图,如:
或者文本情感分析等大数据分析工具,快速对产品的特性和消费者情感做出大致判断,而不需要一条一条的去阅读 Review,比较适合大范围的批量选品。
Instant Data Scraper具体使用方法介绍
Instant-Data-Scraper是一款谷歌浏览器插件。
在谷歌中搜索instant data scraper, 第一个结果就是。
打开第一个搜索结果。并点击“添加至Chome”, 并在跳出的提示框中选择:添加扩展程序。
这时你的谷歌浏览器中就安装完成了我们的第一个工具。如下图所示。一个类似游泳圈的红白相间的小圆圈的标志就是。
Instant-Data-Scraper实际上是一款网页内容抓取工具。
有了他我们就可以把我们想要得到的关键词数据抓取出来。
下面我们需要思考一下,我们去哪里抓取数据呢?
其实有一个很好的平台,我们很多同行都在那里展示产品,基本做外贸的也都知道,对,就是阿里巴巴国际站。
我们就以今年比较火的一款产品来举例讲解吧。
-无纺布
即使我们不了解无纺布,百度翻译一下起码也能搞出一个关键词:nonwoven fabric.
将这个词放入阿里巴巴搜索。你会得到一个庞大的列表,我这里显示有100页。那把这100页中的词抓取出来,就可以得到我们想要的关键词。
接下来,我们点击刚才安装的instant-data-scraper扩展程序图标。
点击try another table。
将红色选择框,定位在阿里巴巴的产品搜索结果区域,如下图。
然后点击:locate “next” button按钮。
然后,在阿里搜索结果页中右键单击:翻页按钮即可。
通过这两部,一是确定抓取区域,二是确定翻页位置。
接下来instant-data-scraper,就可以工作了。
点击,操作界面中的:start scrawling
这时工具就开始抓取数据了。
注意:
至于抓取多少数据,如果你有耐心可以将这100页阿里巴巴搜索结果全部抓取完毕,也可以抓取几十页,也差不多了。时间原因我只抓取了其中的30页。
抓取完毕后,点击操作界面的:CSV或XLSX下载你想要格式的抓取结果。(我选的CSV)
将文件下载并保存至相应的磁盘位置。
python爬虫进行Web抓取LDA主题语义数据分析报告
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-05-04 06:21
01
02
03
04
文章标题及其链接的HTML代码在上方的蓝色框中。
我们将通过以下命令将其全部拉出。
soup_title= soup.findAll("h2",{"class":"title"})<br />len(soup_title)
将列出12个值的列表。从这些文件中,我们将使用以下命令提取所有已发布文章的标题和hrefs。
for x in range(12):<br />print(soup_title\[x\].a\['href'\])<br /> <br />for x in range(12):<br />print(soup_title\[x\].a\['title'\])
为了收集帖子,作者和日期的简短描述,我们需要针对包含名为“ post-content image-caption-format-1”的类的div标签。
我们抓取的数据怎么办?
可以执行多种操作来探索excel表中收集的数据。首先是wordcloud生成,我们将介绍的另一个是NLP之下的主题建模。
词云1)什么是词云:
这是一种视觉表示,突出显示了我们从文本中删除了最不重要的常规英语单词(称为停用词)(包括其他字母数字字母)后,在文本数据语料库中出现的高频单词。
2)使用词云:
这是一种有趣的方式,可以查看文本数据并立即获得有用的见解,而无需阅读整个文本。
3)所需的工具和知识:
python
4)摘要:
在本文中,我们将excel数据重新视为输入数据。
5)代码
6)代码中使用的一些术语的解释:
停用词是用于句子创建的通用词。这些词通常不会给句子增加任何价值,也不会帮助我们获得任何见识。例如A,The,This,That,Who等。
7)词云输出
8)读取输出:
突出的词是QA,SQL,测试,开发人员,微服务等,这些词为我们提供了有关数据帧Article_Para中最常用的词的信息。
主题建模1)什么是主题建模:
这是NLP概念下的主题。在这里,我们要做的是尝试确定文本或文档语料库中存在的各种主题。
2)使用主题建模:
它的用途是识别特定文本/文档中所有可用的主题样式。
3)所需的工具和知识:4)代码摘要:
我们将合并用于主题建模的LDA(潜在Dirichlet),以生成主题并将其打印以查看输出。
5)代码
6)读取输出:
我们可以更改参数中的值以获取任意数量的主题或每个主题中要显示的单词数。在这里,我们想要5个主题,每个主题中包含7个单词。我们可以看到,这些主题与java,salesforce,单元测试,微服务有关。如果我们增加话题数,例如10个,那么我们也可以发现现有话题的其他形式。
点击标题查阅往期内容 查看全部
python爬虫进行Web抓取LDA主题语义数据分析报告
01
02
03
04
文章标题及其链接的HTML代码在上方的蓝色框中。
我们将通过以下命令将其全部拉出。
soup_title= soup.findAll("h2",{"class":"title"})<br />len(soup_title)
将列出12个值的列表。从这些文件中,我们将使用以下命令提取所有已发布文章的标题和hrefs。
for x in range(12):<br />print(soup_title\[x\].a\['href'\])<br /> <br />for x in range(12):<br />print(soup_title\[x\].a\['title'\])
为了收集帖子,作者和日期的简短描述,我们需要针对包含名为“ post-content image-caption-format-1”的类的div标签。
我们抓取的数据怎么办?
可以执行多种操作来探索excel表中收集的数据。首先是wordcloud生成,我们将介绍的另一个是NLP之下的主题建模。
词云1)什么是词云:
这是一种视觉表示,突出显示了我们从文本中删除了最不重要的常规英语单词(称为停用词)(包括其他字母数字字母)后,在文本数据语料库中出现的高频单词。
2)使用词云:
这是一种有趣的方式,可以查看文本数据并立即获得有用的见解,而无需阅读整个文本。
3)所需的工具和知识:
python
4)摘要:
在本文中,我们将excel数据重新视为输入数据。
5)代码
6)代码中使用的一些术语的解释:
停用词是用于句子创建的通用词。这些词通常不会给句子增加任何价值,也不会帮助我们获得任何见识。例如A,The,This,That,Who等。
7)词云输出
8)读取输出:
突出的词是QA,SQL,测试,开发人员,微服务等,这些词为我们提供了有关数据帧Article_Para中最常用的词的信息。
主题建模1)什么是主题建模:
这是NLP概念下的主题。在这里,我们要做的是尝试确定文本或文档语料库中存在的各种主题。
2)使用主题建模:
它的用途是识别特定文本/文档中所有可用的主题样式。
3)所需的工具和知识:4)代码摘要:
我们将合并用于主题建模的LDA(潜在Dirichlet),以生成主题并将其打印以查看输出。
5)代码
6)读取输出:
我们可以更改参数中的值以获取任意数量的主题或每个主题中要显示的单词数。在这里,我们想要5个主题,每个主题中包含7个单词。我们可以看到,这些主题与java,salesforce,单元测试,微服务有关。如果我们增加话题数,例如10个,那么我们也可以发现现有话题的其他形式。
点击标题查阅往期内容
[技术实现]一口气整理整个专集网页为一本电子书方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-05-04 06:05
上一篇简单展示了我们将网页转化为PDF的成果,特别合适连载性网页文章,整理成册。
此篇也简单给大家讲解下技术要点,让大家可以快速上手,做出自己的电子书。
技术要点一、抓取网页到本地保存
因为多数的网页都是带图片的,现在很多网页不是一般地静态网页,都是在浏览器加载过程中,随着浏览器滚动条的滚动,才加载对应的内容。
所以若想单纯地传一个网址,返回一个PDF文件,很多时候是会失败的。
使用代码控制浏览器,模拟浏览器的浏览操作,这里用到一个工具:selenium,相信一般关注网抓的人都对其不陌生。
笔者尝试搜索了一下selenium+C#的关注词,没想到selenium是一个支持多种语言的工具,具体介绍百自行搜索,以下简单截取百度百科的介绍。
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
所以,大家不要有错常见,觉得网抓就python好用,在C#里一样可以用到大家共同的工具,现在的工具也不会局限于只实现一种语言,相信dotNET随着开源的深入,生态越来越好时,会有更多便利的工具出现。
在C#代码里,通过Seenium控制浏览器行为,在浏览器上打开不同的网址,然后下载其对应的文件。
因我们想要图文版的数据,而不是单纯地一些结构化的数据,所以最简单的方式是类似浏览器行为的CTRL+S保存为网页到本地。同样使用代码模拟发送键按键的方式实现。有兴趣的读者可参看以下代码。
网络上千篇一律是python的实现,笔者简单修改下成为dotNET版本的。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);private static void SaveHtml(ChromeDriver driver){uint KEYEVENTF_KEYUP = 2;¨K9K
二、将多个网页保存为PDF
虽然使用WORD也可以打开网页,但估计WORD对网页的渲染,使用的是IE的技术,许多的特性没法还原,所以,更科学地是直接转为PDF。
PDF的另一个好处是,几乎所有PDF阅读器都可以无差别地打开展示原效果,虽然说PDF编辑能力很有限,但我们的用途主要是阅读,所以将HTML转化为PDF,是比较理想的。
它可以将多个网页转成一个PDF文件,阅读时更连贯。
网页转PDF的工具为wkhtmltopdf,也是命令行工具,可以多语言调用,dotNET调用当然没问题,不过更好的体验,当属在PowerShell上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都是下一步完成,最后记得设置下环境变量让CMD、PowerShell可以识别即可。
通常可看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成。
多个网页转PDF,需要考虑排序问题,这时候,使用Excel催化剂可以轻松实现HTML的排版顺序问题。
一般来说,我们都是按顺序下载网页的,所以简单用Excel催化剂的遍历文件功能,将文件信息遍历出来,在Excel上做一下排序处理,对某些特殊的文件手动调整下顺序即可。
再来一个自定义函数stringjoin,快速将多个文件合并成一个字符串组合,中间用空格隔开,每个记录要用双引号括起来。
打开我们的PowerShell ISE软件,win10自带。其他系统也有,具体自行搜索相关教程打开。
相信不少读者也和笔者一样感受,觉得命令行好恐怖,都是一连串代码,特别是帮助文档也是看得晕晕的。
其实真正突破了心理的恐惧,命令行工具和我们在Excel上写函数一个原理,都是一个函数名传入各种参数,只是命令行的参数可以特别多而已。
下面就是我们在PowerShell上,通过一句命令就完成我们的多个html文件合并成一个PDF文件的操作。
笔者也是花了不少功夫去看帮助文档,才能写出更多的特性的命令,如加上页眉、页脚的功能。
开头的参数为全局参数,具体说明需要参照官方文档。
全局参数写完后,再将多个html文件铺开,最后加上pdf文件的名称,即可过多成。文件是使用相对路径,需要先将PowerShell的当前路径切换到html存放文件夹,切换命令就是CD。
最后激动人心的时刻到了,可以顺利生成一个pdf文件。
含页眉页脚信息,总共400多页的一个PDF文件电子书已经诞生。
有兴趣的读者们不妨将自己喜爱的网页专辑也做一份PDF文件,更方便查阅。之前一个错误的做法是追求PDF阅读器的精简,现在重新用回【福昕阅读器】(感谢上篇发文后读者朋友的推荐),老牌的免费PDF阅读软件,可以对文本类的PDF文件进行标注,做笔记。在此推荐大家使用。
同样地可以搜索关键词后,出现关键词清单。例如学习DAX过程中,想类似工具书一样查阅ALLSELECT函数的用法,全文搜索一下即可。比我们用搜索引擎来找强得多。学完还可以高亮做下笔记记录。
结语
在研究此篇的功能实现过程中,重新发现了dotNET的威力,不需要太羡慕python的网抓,在dotNET里仍然很够用。
同时在Windows环境下,没有什么比dotNET的开发更具生产力,python再牛,一遇到共享、交互也是个头痛事,但dotNET的桌面端开发,天然地最大优势。
在OFFICE环境下做的开发,优势就更明细了,其实本篇的功能,亦可完成搬到Excel环境中无痛执行,后期有空时再慢慢优化全过程。
html转PDF,带来了极大的便利性,内容在网络上,不是自己的资料,随时有可能被删除和不可访问(本篇所采集回来的DAX2中文译本,在版权方的施压下,肯定不能长久的,所以笔者未雨绸缪,先下载到本地来,呵呵)。 查看全部
[技术实现]一口气整理整个专集网页为一本电子书方法
上一篇简单展示了我们将网页转化为PDF的成果,特别合适连载性网页文章,整理成册。
此篇也简单给大家讲解下技术要点,让大家可以快速上手,做出自己的电子书。
技术要点一、抓取网页到本地保存
因为多数的网页都是带图片的,现在很多网页不是一般地静态网页,都是在浏览器加载过程中,随着浏览器滚动条的滚动,才加载对应的内容。
所以若想单纯地传一个网址,返回一个PDF文件,很多时候是会失败的。
使用代码控制浏览器,模拟浏览器的浏览操作,这里用到一个工具:selenium,相信一般关注网抓的人都对其不陌生。
笔者尝试搜索了一下selenium+C#的关注词,没想到selenium是一个支持多种语言的工具,具体介绍百自行搜索,以下简单截取百度百科的介绍。
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
所以,大家不要有错常见,觉得网抓就python好用,在C#里一样可以用到大家共同的工具,现在的工具也不会局限于只实现一种语言,相信dotNET随着开源的深入,生态越来越好时,会有更多便利的工具出现。
在C#代码里,通过Seenium控制浏览器行为,在浏览器上打开不同的网址,然后下载其对应的文件。
因我们想要图文版的数据,而不是单纯地一些结构化的数据,所以最简单的方式是类似浏览器行为的CTRL+S保存为网页到本地。同样使用代码模拟发送键按键的方式实现。有兴趣的读者可参看以下代码。
网络上千篇一律是python的实现,笔者简单修改下成为dotNET版本的。
[DllImport("user32.dll", EntryPoint = "keybd_event", SetLastError = true)]public static extern void keybd_event(System.Windows.Forms.Keys bVk, byte bScan, uint dwFlags, uint dwExtraInfo);private static void SaveHtml(ChromeDriver driver){uint KEYEVENTF_KEYUP = 2;¨K9K
二、将多个网页保存为PDF
虽然使用WORD也可以打开网页,但估计WORD对网页的渲染,使用的是IE的技术,许多的特性没法还原,所以,更科学地是直接转为PDF。
PDF的另一个好处是,几乎所有PDF阅读器都可以无差别地打开展示原效果,虽然说PDF编辑能力很有限,但我们的用途主要是阅读,所以将HTML转化为PDF,是比较理想的。
它可以将多个网页转成一个PDF文件,阅读时更连贯。
网页转PDF的工具为wkhtmltopdf,也是命令行工具,可以多语言调用,dotNET调用当然没问题,不过更好的体验,当属在PowerShell上使用。
wkhtmltopdf的安装方法,自行搜索资料学习,都是下一步完成,最后记得设置下环境变量让CMD、PowerShell可以识别即可。
通常可看到的python的html转pdf功能,其实底层也是用wkhtmltopdf完成。
多个网页转PDF,需要考虑排序问题,这时候,使用Excel催化剂可以轻松实现HTML的排版顺序问题。
一般来说,我们都是按顺序下载网页的,所以简单用Excel催化剂的遍历文件功能,将文件信息遍历出来,在Excel上做一下排序处理,对某些特殊的文件手动调整下顺序即可。
再来一个自定义函数stringjoin,快速将多个文件合并成一个字符串组合,中间用空格隔开,每个记录要用双引号括起来。
打开我们的PowerShell ISE软件,win10自带。其他系统也有,具体自行搜索相关教程打开。
相信不少读者也和笔者一样感受,觉得命令行好恐怖,都是一连串代码,特别是帮助文档也是看得晕晕的。
其实真正突破了心理的恐惧,命令行工具和我们在Excel上写函数一个原理,都是一个函数名传入各种参数,只是命令行的参数可以特别多而已。
下面就是我们在PowerShell上,通过一句命令就完成我们的多个html文件合并成一个PDF文件的操作。
笔者也是花了不少功夫去看帮助文档,才能写出更多的特性的命令,如加上页眉、页脚的功能。
开头的参数为全局参数,具体说明需要参照官方文档。
全局参数写完后,再将多个html文件铺开,最后加上pdf文件的名称,即可过多成。文件是使用相对路径,需要先将PowerShell的当前路径切换到html存放文件夹,切换命令就是CD。
最后激动人心的时刻到了,可以顺利生成一个pdf文件。
含页眉页脚信息,总共400多页的一个PDF文件电子书已经诞生。
有兴趣的读者们不妨将自己喜爱的网页专辑也做一份PDF文件,更方便查阅。之前一个错误的做法是追求PDF阅读器的精简,现在重新用回【福昕阅读器】(感谢上篇发文后读者朋友的推荐),老牌的免费PDF阅读软件,可以对文本类的PDF文件进行标注,做笔记。在此推荐大家使用。
同样地可以搜索关键词后,出现关键词清单。例如学习DAX过程中,想类似工具书一样查阅ALLSELECT函数的用法,全文搜索一下即可。比我们用搜索引擎来找强得多。学完还可以高亮做下笔记记录。
结语
在研究此篇的功能实现过程中,重新发现了dotNET的威力,不需要太羡慕python的网抓,在dotNET里仍然很够用。
同时在Windows环境下,没有什么比dotNET的开发更具生产力,python再牛,一遇到共享、交互也是个头痛事,但dotNET的桌面端开发,天然地最大优势。
在OFFICE环境下做的开发,优势就更明细了,其实本篇的功能,亦可完成搬到Excel环境中无痛执行,后期有空时再慢慢优化全过程。
html转PDF,带来了极大的便利性,内容在网络上,不是自己的资料,随时有可能被删除和不可访问(本篇所采集回来的DAX2中文译本,在版权方的施压下,肯定不能长久的,所以笔者未雨绸缪,先下载到本地来,呵呵)。
excel抓取多页网页数据(一句话概括本文:利用Excel存储爬到的抓取豆瓣音乐Top250 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-20 12:42
)
用一句话概括这篇文章:
使用Excel存储爬取到的豆瓣音乐Top 250数据信息,并读取Excel。
介绍:
失踪人员正在回归,最近很迷茫,不知道是回安卓还是继续
学Python,Android是旧情,Python是新情;Android应用层折腾
折腾去了,无非就是:改UI、写控件、替换库、替换架构……一直想写
自己的项目,然后各种补充优化,然后发现自己没有当年的热情,
啊! 与Python相比,它是爬虫和批处理脚本,实用得多。
只是Python不带路,只是自己一点点探索,走走吧!
之前在写爬虫小姐的脚本的时候,遇到了一个爬取数据如何存储的问题。
例如,一系列图片的链接应该放在特定的文件夹中。我之前的操作是
写入如下格式的txt文件:目录~链接
然后读取txt文件,得到字符串,然后用split("~")分隔,
split("~")[0] 是目录, split("~")[1] 是路径,很低。
如果涉及到三个以上的维度,那就多拼一个吧~,在上一节中抓到
在做半次元coser的时候,遇到了一个很恶心的问题。符号都被使用了。
难分离,特殊字符一一尝试,然后就只能测试Θ..
迫切需要一些东西来存储我们捕获的数据,当然还有最好的用途:数据库
但是考虑到学习成本(主要是我对它不熟悉!),先通过一个简单的东西来保存。
最简单的方法肯定是用Excel表格,最直观,非程序员也能看懂!
话不多说,开始本节吧~本节抓个例子:豆瓣音乐Top 250
关联:
1.编写数据捕获脚本
按顺序检查:
链接规则:
第一页:
第二页:
第三页:
链接规则很明显,每25个一页,0,25,50,75...225
请求头:
只有一个: 主持人:
模拟请求的套路已经想通了,接下来就是对网页进行处理,得到想要的数据:
看Element不难发现,数据是放在单独的表中的:
单击以下之一:
首先,我们来看看我们要采集的数据:
图片链接、歌名、艺人、发行时间、分类、评分、评分数、歌曲详情页
那我就慢慢挖数据,我私下挖,就不找之前的文章看了,
下面是直接代码:
查看控制台打印的信息:
好的,没问题,我们来看看如何将数据写入到excel表格中~
2.如何将数据写入Excel
第一步:安装库操作Excel,需要两个库:xlwt(写Excel)和xlrd(读Excel)
一波命令行 pip 安装。
sudo pip3 install xlwt
sudo pip3 install xlrd
第 2 步:熟悉几个基本功能
写入 Excel:
sheet.write(0,0,"姓名")
sheet.write(0,1,"学号")
sheet.write(1,0,"小猪")
sheet.write(1,1,"No1")
结果形式:
阅读 Excel:
3.编写一个 Excel 助手类
基本语法就差不多明白了,接下来我们写一个工具类来爬取我们的爬虫
将爬取的数据写入Excel表格,四种方法:
style:根据传入的字体名称、高度、粗体与否返回 Style 样式
__init__:完成Excel表格的一些初始化操作,初始化表头
insert_data:将爬取的数据插入Excel的方法
read_data:Excel中读取数据的方法
然后一步一步,先style方法:
接下来是__init__方法,判断Excel文件是否存在。如果它不存在,则创建一个新的并初始化它。
然后是insert_data:
最后是 read_data:
代码不复杂,那就把调用代码写下来试试:
添加一个打印 data_group 的方法,查看捕获的数据,然后运行:
没问题,圈出[[,这里我要表达的是结果是一个大列表嵌套了多个列表!
然后添加以下代码:
执行后可以看到生成了一个dbyy.xlsx文件,打开就可以看到:
啧啧,写的很成功,太美了!
然后注释掉不相关的代码,调用读取Excel的方法:
读写都没有问题,
4.总结
本节介绍如何将爬取的数据存储在 Excel 表中,并读取 Excel 表中的数据,
虽然没有高端数据库,但是相比之前使用分隔符来分隔多种类型的数据,在使用的时候
split() 好很多,非开发者可以直接理解。另外,也许有一天你可以得到它
一些文员(写批量处理Excel表格的脚本),除了做一些词频统计
让我们玩一下♂的剧本,最后以一张哲学启蒙老师的照片结束本节。愿天堂没有摔跤:
附:具体实现代码(其实可以在里面找到)
import re
import requests
import xlwt
import xlrd
import tools as t
rate_count_pattern = re.compile("(\d*人评价)", re.S) # 获取评分人数的正则
base_url = 'https://music.douban.com/top250'
save_file = 'dbyy.xlsx'
# 解析网页获得数据的方法
def parse_url(offset):
resp = requests.get(base_url, params={'page': offset})
print("解析:" + resp.url)
result = []
if resp.status_code == 200:
soup = t.get_bs(resp.content)
tables = soup.select('table[width="100%%"]')
for table in tables:
a = table.find('a')
detail_url = a['href'] # 歌曲详情页面
img_url = a.img['src'] # 图片url
music_name = a.img['alt'] # 歌曲名
p = table.find('p')
data_split = p.get_text().split("/")
singer = data_split[0].strip() # 歌手
public_date = data_split[1].strip()
category = "" # 分类
for data in data_split[2:]:
category += data.strip() + "/"
div = table.find('div', class_="star clearfix")
score = div.select('span.rating_nums')[0].text # 评分
rate_count = rate_count_pattern.search(div.select('span.pl')[0].get_text()).group(0) # 评分人数
result.append([img_url, music_name, singer, public_date, category, score, rate_count, detail_url])
return result
class ExcelHelper:
def __init__(self):
if not t.is_dir_existed(save_file, mkdir=False):
# 1.创建工作薄
self.workbook = xlwt.Workbook()
# 2.创建工作表,第二个参数用于确认同一个cell单元是否可以重设值
self.sheet = self.workbook.add_sheet(u"豆瓣音乐Top 250", cell_overwrite_ok=True)
# 3.初始化表头
self.headTitles = [u'图片链接', u'歌名', u'歌手', u'发行时间', u'分类', u'评分', u'评分人数', u'歌曲详情页']
for i, item in enumerate(self.headTitles):
self.sheet.write(0, i, item, self.style('Monaco', 220, bold=True))
self.workbook.save(save_file)
# 参数依次是:字体名称,字体高度,是否加粗
def style(self, name, height, bold=False):
style = xlwt.XFStyle() # 赋值style为XFStyle(),初始化样式
font = xlwt.Font() # 为样式创建字体样式
font.name = name
font.height = height
font.bold = bold
return style
# 往单元格里插入数据
def insert_data(self, data_group):
try:
xlsx = xlrd.open_workbook(save_file) # 读取Excel文件
table = xlsx.sheets()[0] # 根据索引获得表
row_count = table.nrows # 获取当前行数,新插入的数据从这里开始
count = 0
for data in data_group:
for i in range(len(data)):
self.sheet.write(row_count + count, i, data[i])
count += 1
except Exception as e:
print(e)
finally:
self.workbook.save(save_file)
# 读取Excel里的数据
def read_data(self):
xlsx = xlrd.open_workbook(save_file)
table = xlsx.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
# 从第一行开始,0是表头
for i in range(1, nrows):
# 读取某行数据
row_value = table.row_values(i)
print(row_value)
if __name__ == '__main__':
offsets = [x for x in range(0, 250, 25)]
data_group = []
for offset in offsets:
data_group += parse_url(offset)
print(data_group)
excel = ExcelHelper()
excel.insert_data(data_group)
excel.read_data()
来吧,Py交易
想进群一起学Py,可以加智障机器人小猪猪。验证信息包括:
python,python,py,py,add group,trade,ass里一个关键词可以通过;
验证通过后,回复群获取入群链接(不要破机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,一起快乐交流学习,van♂topy。
查看全部
excel抓取多页网页数据(一句话概括本文:利用Excel存储爬到的抓取豆瓣音乐Top250
)
用一句话概括这篇文章:
使用Excel存储爬取到的豆瓣音乐Top 250数据信息,并读取Excel。
介绍:
失踪人员正在回归,最近很迷茫,不知道是回安卓还是继续
学Python,Android是旧情,Python是新情;Android应用层折腾
折腾去了,无非就是:改UI、写控件、替换库、替换架构……一直想写
自己的项目,然后各种补充优化,然后发现自己没有当年的热情,
啊! 与Python相比,它是爬虫和批处理脚本,实用得多。
只是Python不带路,只是自己一点点探索,走走吧!
之前在写爬虫小姐的脚本的时候,遇到了一个爬取数据如何存储的问题。
例如,一系列图片的链接应该放在特定的文件夹中。我之前的操作是
写入如下格式的txt文件:目录~链接
然后读取txt文件,得到字符串,然后用split("~")分隔,
split("~")[0] 是目录, split("~")[1] 是路径,很低。
如果涉及到三个以上的维度,那就多拼一个吧~,在上一节中抓到
在做半次元coser的时候,遇到了一个很恶心的问题。符号都被使用了。
难分离,特殊字符一一尝试,然后就只能测试Θ..
迫切需要一些东西来存储我们捕获的数据,当然还有最好的用途:数据库
但是考虑到学习成本(主要是我对它不熟悉!),先通过一个简单的东西来保存。
最简单的方法肯定是用Excel表格,最直观,非程序员也能看懂!
话不多说,开始本节吧~本节抓个例子:豆瓣音乐Top 250
关联:
1.编写数据捕获脚本
按顺序检查:
链接规则:
第一页:
第二页:
第三页:
链接规则很明显,每25个一页,0,25,50,75...225
请求头:
只有一个: 主持人:
模拟请求的套路已经想通了,接下来就是对网页进行处理,得到想要的数据:
看Element不难发现,数据是放在单独的表中的:
单击以下之一:
首先,我们来看看我们要采集的数据:
图片链接、歌名、艺人、发行时间、分类、评分、评分数、歌曲详情页
那我就慢慢挖数据,我私下挖,就不找之前的文章看了,
下面是直接代码:
查看控制台打印的信息:
好的,没问题,我们来看看如何将数据写入到excel表格中~
2.如何将数据写入Excel
第一步:安装库操作Excel,需要两个库:xlwt(写Excel)和xlrd(读Excel)
一波命令行 pip 安装。
sudo pip3 install xlwt
sudo pip3 install xlrd
第 2 步:熟悉几个基本功能
写入 Excel:
sheet.write(0,0,"姓名")
sheet.write(0,1,"学号")
sheet.write(1,0,"小猪")
sheet.write(1,1,"No1")
结果形式:
阅读 Excel:
3.编写一个 Excel 助手类
基本语法就差不多明白了,接下来我们写一个工具类来爬取我们的爬虫
将爬取的数据写入Excel表格,四种方法:
style:根据传入的字体名称、高度、粗体与否返回 Style 样式
__init__:完成Excel表格的一些初始化操作,初始化表头
insert_data:将爬取的数据插入Excel的方法
read_data:Excel中读取数据的方法
然后一步一步,先style方法:
接下来是__init__方法,判断Excel文件是否存在。如果它不存在,则创建一个新的并初始化它。
然后是insert_data:
最后是 read_data:
代码不复杂,那就把调用代码写下来试试:
添加一个打印 data_group 的方法,查看捕获的数据,然后运行:
没问题,圈出[[,这里我要表达的是结果是一个大列表嵌套了多个列表!
然后添加以下代码:
执行后可以看到生成了一个dbyy.xlsx文件,打开就可以看到:
啧啧,写的很成功,太美了!
然后注释掉不相关的代码,调用读取Excel的方法:
读写都没有问题,
4.总结
本节介绍如何将爬取的数据存储在 Excel 表中,并读取 Excel 表中的数据,
虽然没有高端数据库,但是相比之前使用分隔符来分隔多种类型的数据,在使用的时候
split() 好很多,非开发者可以直接理解。另外,也许有一天你可以得到它
一些文员(写批量处理Excel表格的脚本),除了做一些词频统计
让我们玩一下♂的剧本,最后以一张哲学启蒙老师的照片结束本节。愿天堂没有摔跤:
附:具体实现代码(其实可以在里面找到)
import re
import requests
import xlwt
import xlrd
import tools as t
rate_count_pattern = re.compile("(\d*人评价)", re.S) # 获取评分人数的正则
base_url = 'https://music.douban.com/top250'
save_file = 'dbyy.xlsx'
# 解析网页获得数据的方法
def parse_url(offset):
resp = requests.get(base_url, params={'page': offset})
print("解析:" + resp.url)
result = []
if resp.status_code == 200:
soup = t.get_bs(resp.content)
tables = soup.select('table[width="100%%"]')
for table in tables:
a = table.find('a')
detail_url = a['href'] # 歌曲详情页面
img_url = a.img['src'] # 图片url
music_name = a.img['alt'] # 歌曲名
p = table.find('p')
data_split = p.get_text().split("/")
singer = data_split[0].strip() # 歌手
public_date = data_split[1].strip()
category = "" # 分类
for data in data_split[2:]:
category += data.strip() + "/"
div = table.find('div', class_="star clearfix")
score = div.select('span.rating_nums')[0].text # 评分
rate_count = rate_count_pattern.search(div.select('span.pl')[0].get_text()).group(0) # 评分人数
result.append([img_url, music_name, singer, public_date, category, score, rate_count, detail_url])
return result
class ExcelHelper:
def __init__(self):
if not t.is_dir_existed(save_file, mkdir=False):
# 1.创建工作薄
self.workbook = xlwt.Workbook()
# 2.创建工作表,第二个参数用于确认同一个cell单元是否可以重设值
self.sheet = self.workbook.add_sheet(u"豆瓣音乐Top 250", cell_overwrite_ok=True)
# 3.初始化表头
self.headTitles = [u'图片链接', u'歌名', u'歌手', u'发行时间', u'分类', u'评分', u'评分人数', u'歌曲详情页']
for i, item in enumerate(self.headTitles):
self.sheet.write(0, i, item, self.style('Monaco', 220, bold=True))
self.workbook.save(save_file)
# 参数依次是:字体名称,字体高度,是否加粗
def style(self, name, height, bold=False):
style = xlwt.XFStyle() # 赋值style为XFStyle(),初始化样式
font = xlwt.Font() # 为样式创建字体样式
font.name = name
font.height = height
font.bold = bold
return style
# 往单元格里插入数据
def insert_data(self, data_group):
try:
xlsx = xlrd.open_workbook(save_file) # 读取Excel文件
table = xlsx.sheets()[0] # 根据索引获得表
row_count = table.nrows # 获取当前行数,新插入的数据从这里开始
count = 0
for data in data_group:
for i in range(len(data)):
self.sheet.write(row_count + count, i, data[i])
count += 1
except Exception as e:
print(e)
finally:
self.workbook.save(save_file)
# 读取Excel里的数据
def read_data(self):
xlsx = xlrd.open_workbook(save_file)
table = xlsx.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
# 从第一行开始,0是表头
for i in range(1, nrows):
# 读取某行数据
row_value = table.row_values(i)
print(row_value)
if __name__ == '__main__':
offsets = [x for x in range(0, 250, 25)]
data_group = []
for offset in offsets:
data_group += parse_url(offset)
print(data_group)
excel = ExcelHelper()
excel.insert_data(data_group)
excel.read_data()
来吧,Py交易
想进群一起学Py,可以加智障机器人小猪猪。验证信息包括:
python,python,py,py,add group,trade,ass里一个关键词可以通过;
验证通过后,回复群获取入群链接(不要破机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,一起快乐交流学习,van♂topy。

