解读:用Excel,只需30秒就可爬取网站数据
优采云 发布时间: 2022-09-22 08:14解读:用Excel,只需30秒就可爬取网站数据
是的,您没看错,使用 Excel 抓取数据。那么为什么要使用它呢?因为它不需要写一行代码,所以你只需点击几下鼠标就可以得到你想要的数据。整个过程可以在大约 30 秒内完成。在网站结构简单、需求相对简单的情况下,这一招秒杀专业程序员。毕竟大多数时候,程序员可能只需要 30 秒就打开专业的代码编辑器,等待各种组件插件的加载完成。哈哈哈~~~~,你怎么兴奋?
0.软件版本要求和先决条件
要求 1:Excel 2016 及更高版本,开箱即用。当然其他低级版本也不是不行,但是需要自己安装插件,喜欢折腾的可以自己试试。
要求2:只支持get request(不懂这个的可以忽略,可以简单认为直接打开就能看到的数据满足要求)
需求3:你需要的数据在html页面的table标签中。不能是图片等。
那么你怎么知道它是否在table标签中呢?很简单,只要在浏览器中查看网页的源码,有没有你需要的数据被包裹在(
数据
或数据),如果是,恭喜,excel可以直接抓取,如果不是,那就用其他更专业的爬虫工具或者自己写代码。 . .
下面是检查数据是否在(或)标签中的操作:(我刚找到一个房价网站)
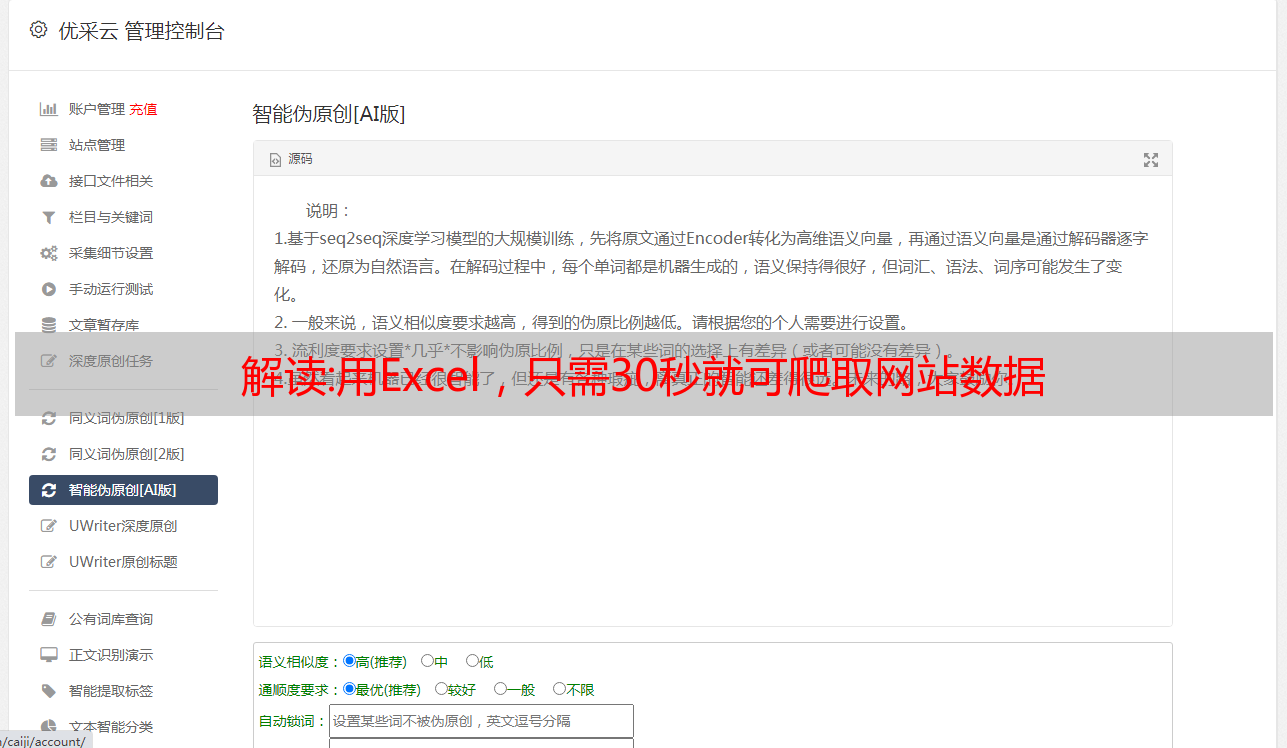
一个。打开浏览器网站,找到要爬取的数据,按键盘上的“F12”键(推荐谷歌Chrome、Edge、Firefox)打开调试器。
b.点击左上角元素定位图标,然后将鼠标移到需要的数据上,查看是否收录在()中。
以上过程就是分析网站的数据结构的过程。可以看出标签中收录了需要的数据。这个过程是必不可少的,无论你是使用工具爬取还是自己编写代码爬取,这个过程都极其重要。
假设你确定你要的数据就在()标签里,那我们看看如何用Excel爬取吧!
1.打开 Excel 数据采集工具
注意:不同版本的组件名称或位置可能略有不同。这里是 Excel2019 版本。比较并找到其他版本。确定它们都在“数据”选项卡下。
2.填写爬取参数
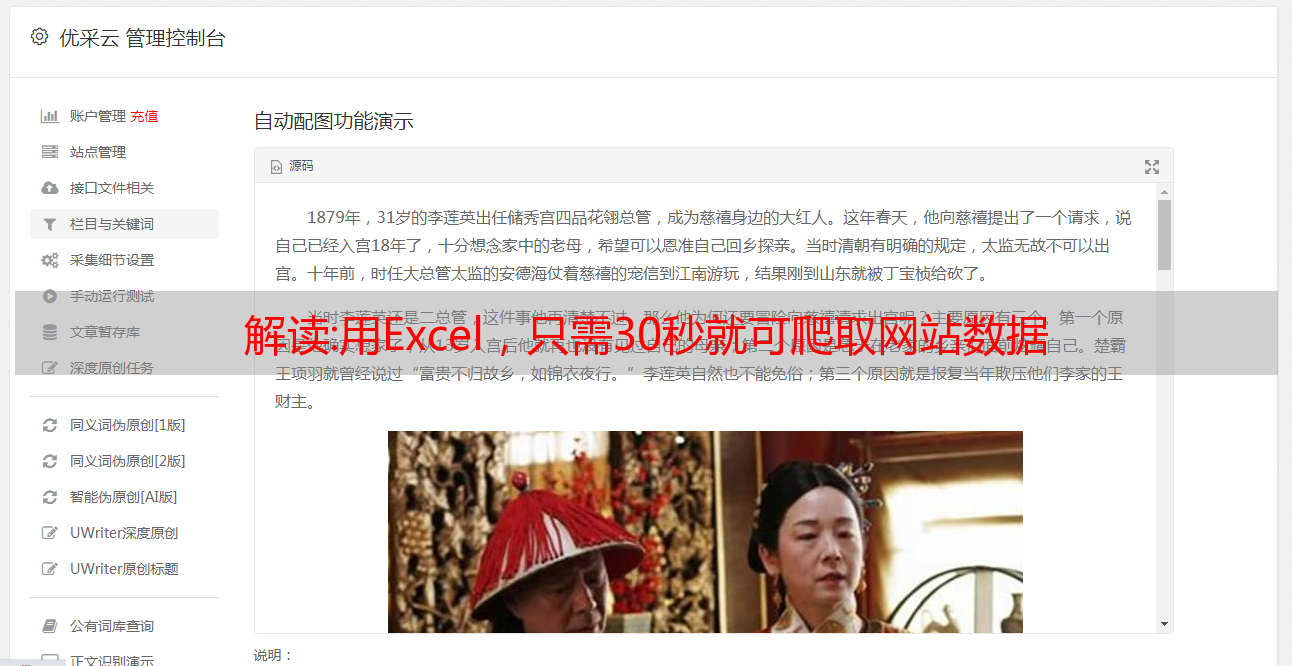
这是基本模式,你只需要粘贴你要抓取的网页的网址。另一种高级模式可以设置更多的参数,比如请求头,有兴趣的可以自行探索。
注意:网站直接匿名模式无需登录
3.获取数据
在这个界面中,选择需要的表格点击,然后点击转换数据,可以调用excel自带的power BI对数据进行各种自定义处理和转换,当然也可以加载如果你不想做太多的转换或者你想在 excel 中重新处理它,直接它。
以下界面为电量查询界面。你可以在这个界面上进行各种高级数据转换,也可以什么都不做。如果您已完成转换,只需点击“关闭并上传”即可。
好的,想要的数据已经上传到excel了,方便又快捷。
今天的经验分享就到这里。如果大家有什么好的意见或建议,欢迎在评论区留言~~~~
分享:*敏*感*词*带你从零基础抓取A站短视频,并且制作从动态壁纸,这些*敏*感*词*姐我全都要!
大家好,我叫来跳。
我知道大家都是来学技术的,绝对不是为了那些好看的*敏*感*词*姐们,所以直奔主题吧。
A站视频资料采集
采集数据目标
网址:一个站
性能展示
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:请求、docx、lxml
重点学习内容
lxml使用m3u8文件处理ts文件合成MP4
项目思路分析
通过xpath方法提取分类主页数据
获取每个视频的不确定性
拼接到详情页的url地址
/{}
请求详情页面
获取网页源码的backupUrl对应值
请求对应的m3u8文件地址
https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/hls/b6f3561527ea7674-4c05d717a155db2cd75c5e3455bcc285-hls_4k_h264_1.m3u8?pkey=ABCVjggV-526Eqfc2aQQzGQs8FaP_JPEFMV8eoqWKXmTZNXICw3L3XRSv0vwV-O7fLtKIhIyZzMNqkxhT_7BJ8X0gLmIuej3RM1T37Wg7iIGLBDUcMNB27vJ8DIX0F2_QAyLKZ7DGb4h7C_7MvCIy1arBJWk0OVyDm5Gvn7iS1clxQbLPd9N1J-yRHeuoMAQ-bF-cQca4Dpi0jz2XSyxAqvj1U-kNkybrP2xBwTxT1gG5CRLcOu0uBvjVryvdLm_bwQ&safety_id=AAKL9ykXaHfy4Hgj44E9P_hc\%22],\%22codecs\%22:\%22avc1.640033,mp4a.40.2\%22,\%22hidden\%22:false,\%22disableAdaptive\%22:false,\%22comment\%22:\%22b6f3561527ea7674/HLS_4K_H264_1\%22,\%22id\%22:1,\%22url\%22:\%22https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/hls/b6f3561527ea7674-4c05d717a155db2cd75c5e3455bcc285-hls_4k_h264_1.m3u8?pkey=ABCVjggV-526Eqfc2aQQzGQs8FaP_JPEFMV8eoqWKXmTZAnICSBGjLT_PyFsslJJXiOP2eQEO--qVGdx3RAVv2u-HzgG2V3aGkpXflsVIfuLURk-uyEAGOvuDvQoIX64vgGt9w5oTxJ1X_6LoiSXl2Z-7Kb5ytDpExAACRaRMSOqDcxaB-Q9niMjCa9yuAs40UKwxyIzZdmKyRjL2GRFwBqH0CjM9ZKxkjmQ7nuTn4bfnFyWP2LIrkeW6RDFLuG1mgc&safety_id=AAKL9ykXaHfy4Hgj44E9P_hc
请求m3u8的文件地址
解析对应的m3u8文件
视频数据拼接自ts视频
取出m3u8文件中各个ts的下载地址
拼接成新的视频下载地址
https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/hls/b6f3561527ea7674-723550b3c6b1ff9a4b05be736acd7098-hls_720p_2.00000.ts?pkey=ABClqkBWwxUgoTqPKsnjoZ5X2vsyNNN9F0mDGRhhZMiyRUZkfurznShxCBqmWZWTtj2M2zCGcFwL-F30xT89BkrNoA4QT7yBQ9q4sjyRJpmBrVqcd2vQHWZhjTzkUsPY2hQuWtSoYHBrWJbqTgNbWVF-k0vjXxbDsN311gKd358IpcQnTvboQDX1wOKspWfm_OHyXMkPJqdCulUQ6wVBA6i5kE9RGNnVVgyFKxbRzPiKzyKfCnzYo6x723CCbbRNnBM&safety_id=AAKL9ykXaHfy4Hgj44E9P_hc
下载对应的ts视频数据
将每个ts数据以追加的形式写入MP4文件
简单的源码分析
import requests import re from tqdm import tqdm from lxml import etree import os def request_data(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.42' } response = requests.get(url, headers=headers) return response def save(name, video): # path = f'{name}\' if not os.path.exists("视频"): os.makedirs("视频") with open("视频/" + name + '.mp4', mode='ab') as f: f.write(video) start_url = "https://www.acfun.cn/v/list218/index.htm" res = request_data(start_url) html_data = etree.HTML(res.text) acid_list = html_data.xpath('//div[@class="list-content-item"]/a[1]/@href') # ac = input('输入acid:') for ac in acid_list: url = 'https://www.acfun.com{}'.format(ac) print(url) # 请求页面地址 获取到 m3u8地址 data = request_data(url).text m3u8_url = re.findall('backupUrl(.*?)\"]', data)[0].replace('"', '').split('\')[-2] title = re.findall('"title":"(.*?)"', data)[0] # 请求m3u8地址 m3u8_data = request_data(m3u8_url).text # 数据替换 m3u8_data = re.sub(r'#EXTM3U', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-VERSION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-TARGETDURATION:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-MEDIA-SEQUENCE:\d', "", m3u8_data) m3u8_data = re.sub(r'#EXTINF:\d.\d,', "", m3u8_data) m3u8_data = re.sub(r'#EXT-X-ENDLIST', "", m3u8_data) m3u8 = m3u8_data.split() for i in tqdm(m3u8): ts_url = 'https://tx-safe-video.acfun.cn/mediacloud/acfun/acfun_video/hls/' + i video = request_data(ts_url).content save(title, video)
如果对你有帮助,记得连续给辣条3次

