
excel抓取多页网页数据
excel抓取多页网页数据( 新媒体运营来说的爬虫工具——webscraper的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-18 20:21
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网页刮刀.png
三、创建一个新的站点地图
在创建新站点地图下有两个命令,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
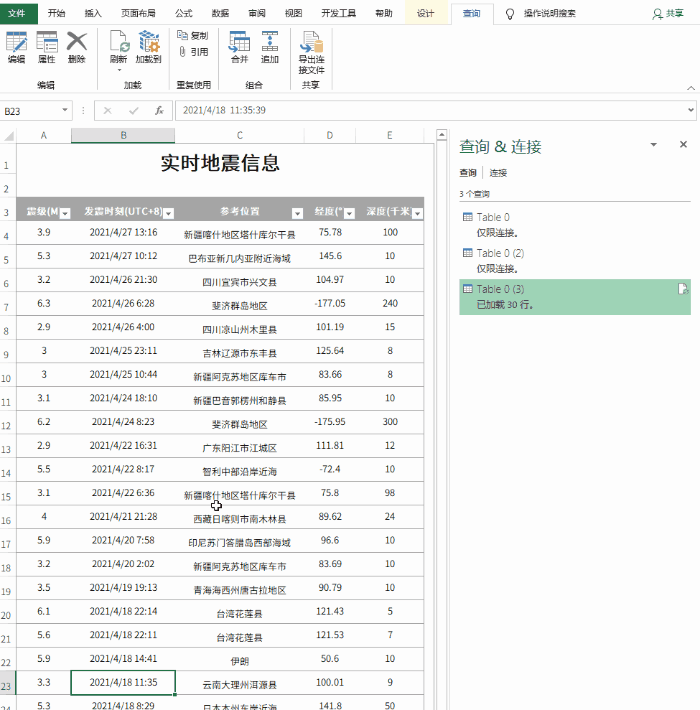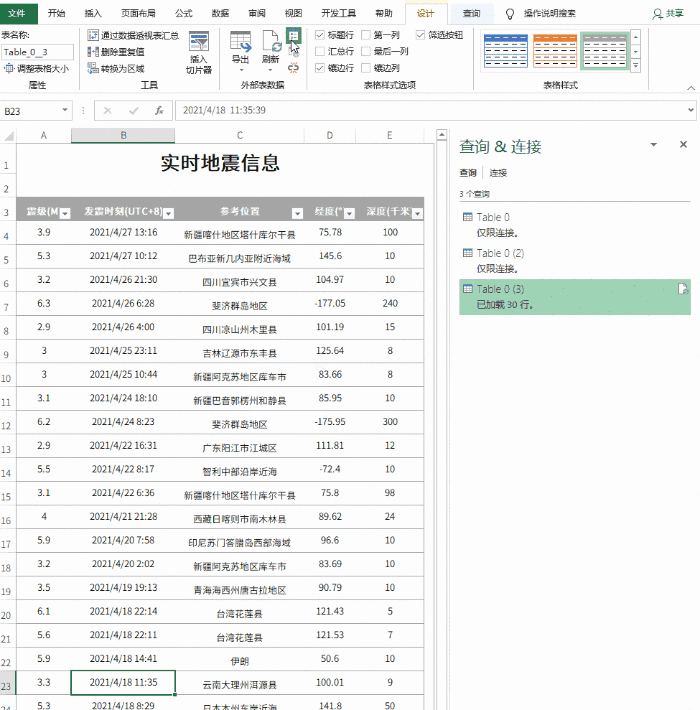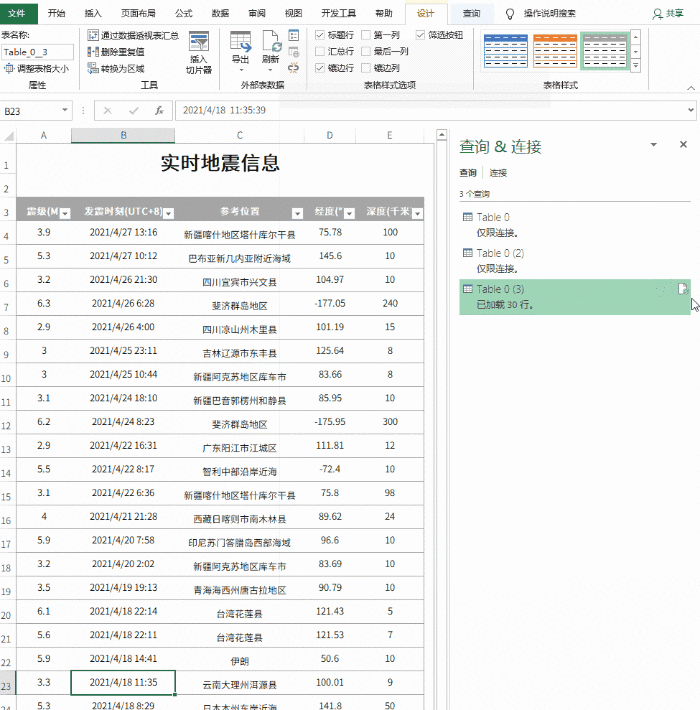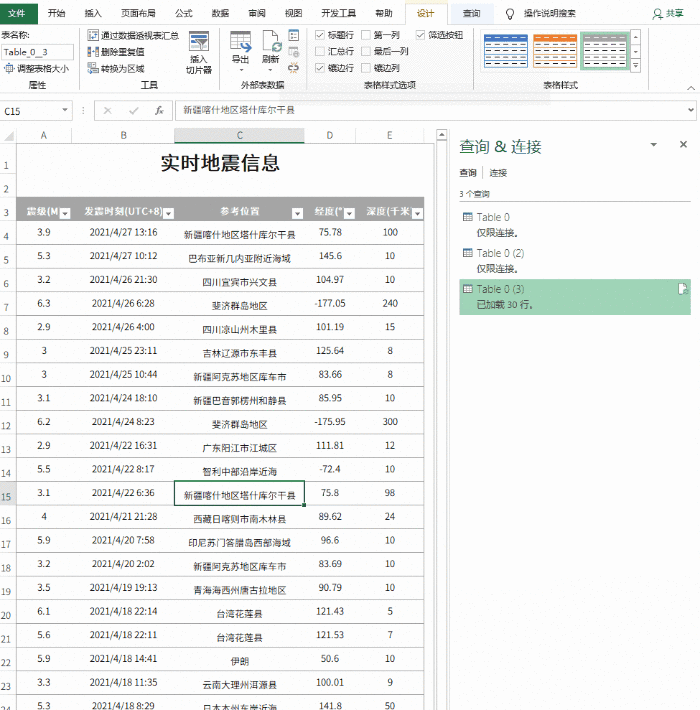
参数设置.png
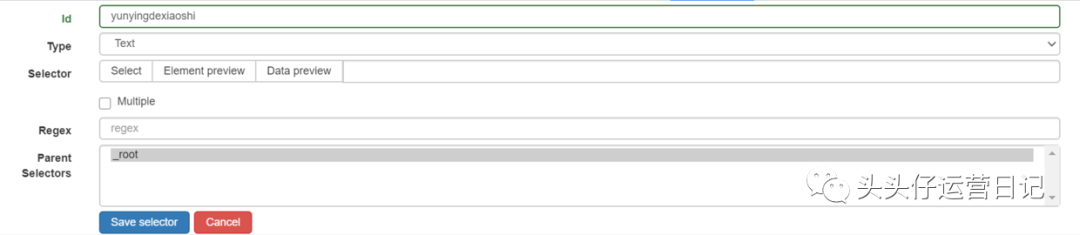
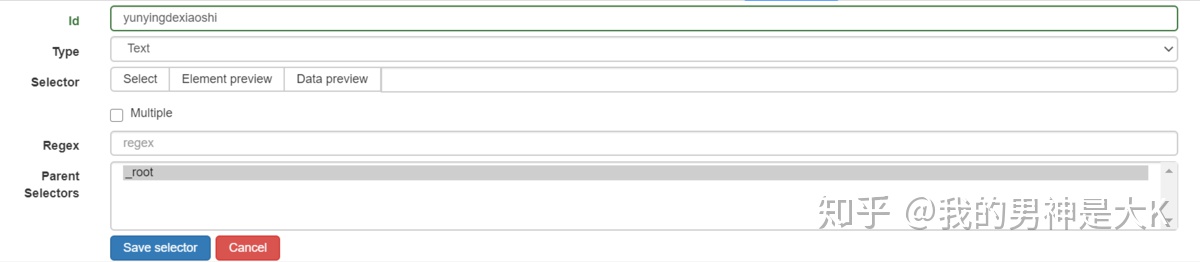
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
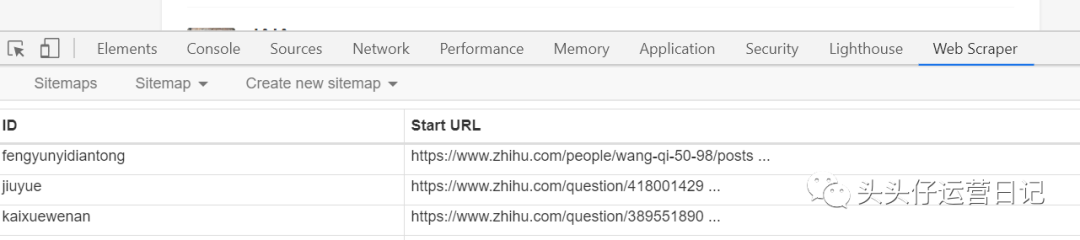
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
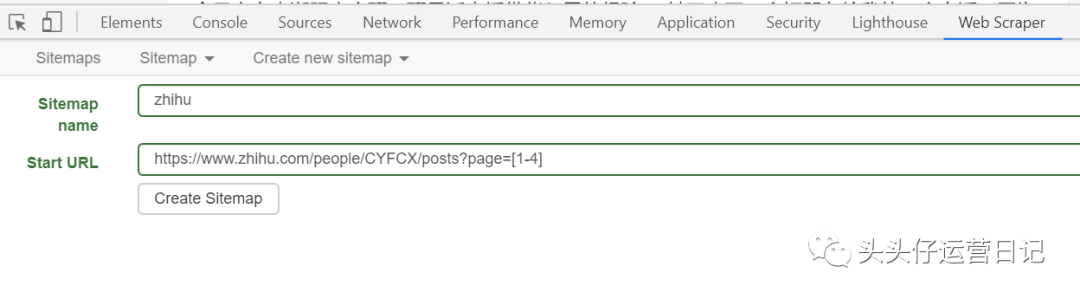
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
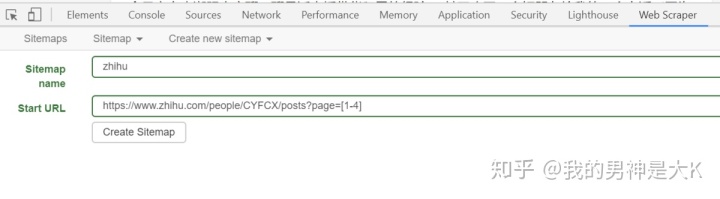
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧! 查看全部
excel抓取多页网页数据(
新媒体运营来说的爬虫工具——webscraper的特点)

对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.

注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。

扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。

打开网页刮刀.png
三、创建一个新的站点地图
在创建新站点地图下有两个命令,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。

新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。

参数设置.png
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。

完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。

进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。

多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧!
excel抓取多页网页数据( Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-04-18 03:13
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取 Web 数据
昨天,一位女学生问:
大致意思是这样的:
1- 女,文科生,大三无课
2-我觉得Python是一种趋势,不学就会落伍
3-想学习Python,从哪里开始?
显然,我在朋友圈看到了太多的python广告。
想学数据爬虫,怎么用python?只需使用 Excel。
Excel从2016年开始构建了强大的数据处理神器Power Query,可以直接在Excel中实现数据爬取。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?太好了,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,可以直接导入网页。
例如,我们经常在豆瓣上观看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址是:
使用 Excel 抓取数据的步骤如下。
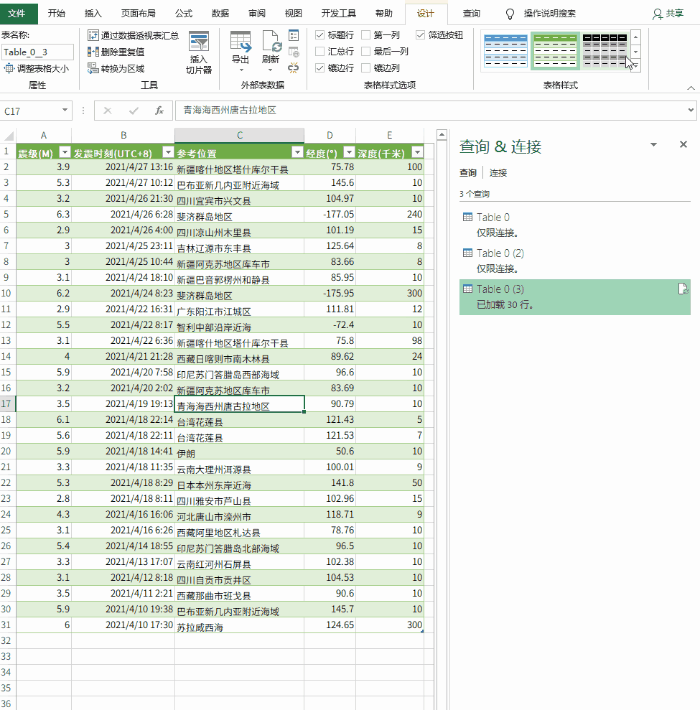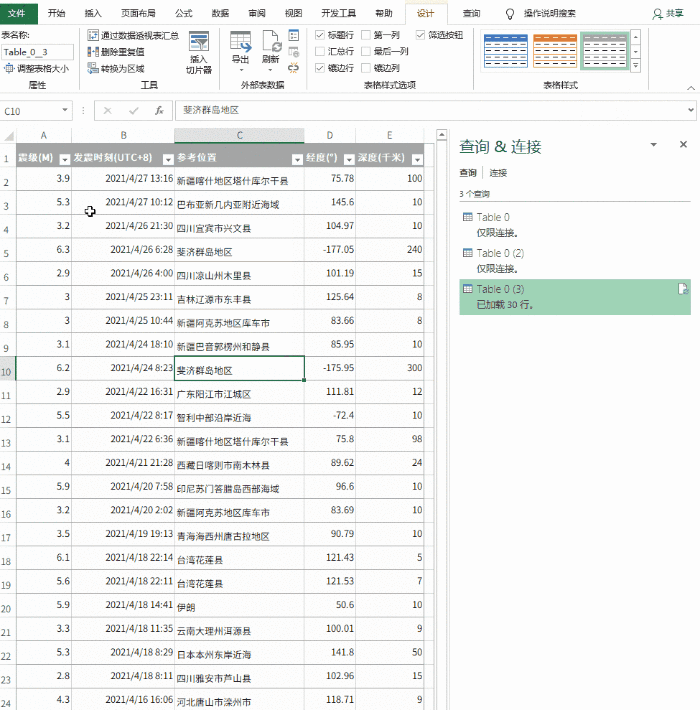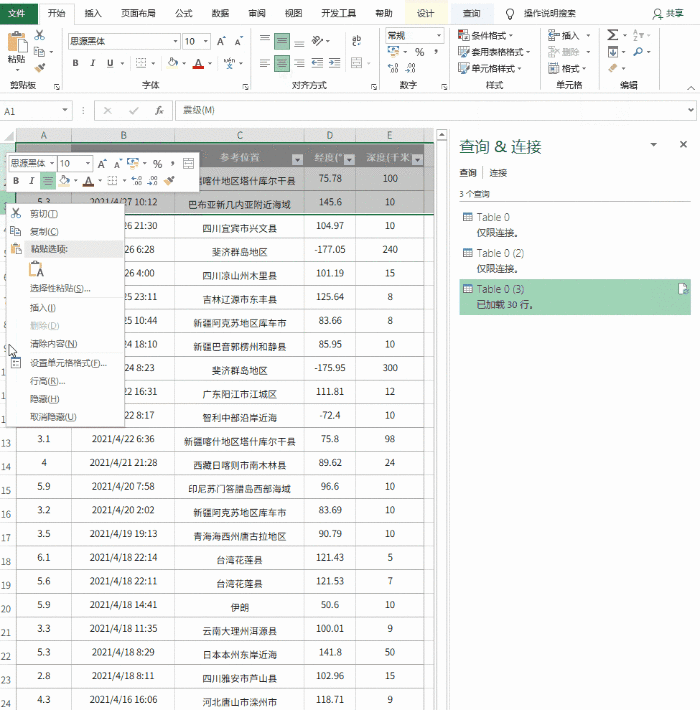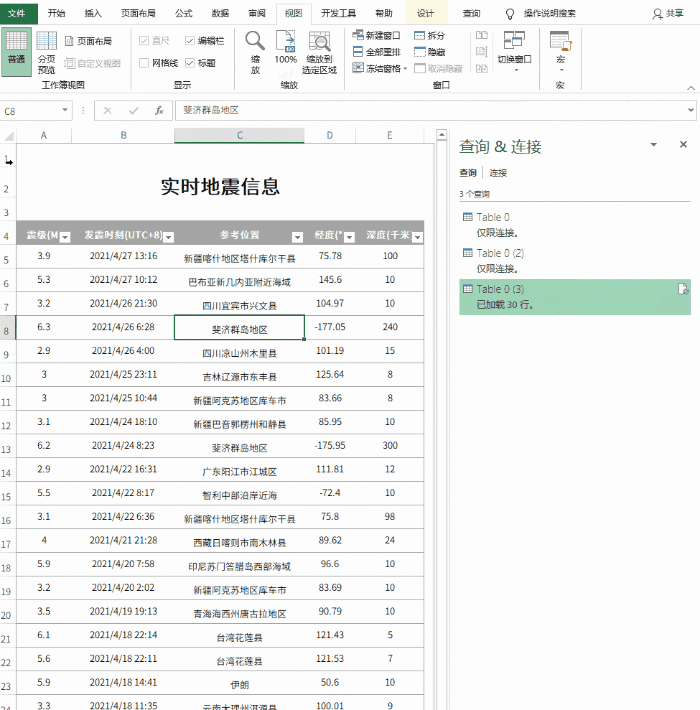
操作步骤 1- Excel 导入网页数据
在数据选项卡中,单击来自 网站 的其他来源。
2-粘贴网址
在弹出的对话框中,粘贴以上网址,点击“确定”
3-加载表数据
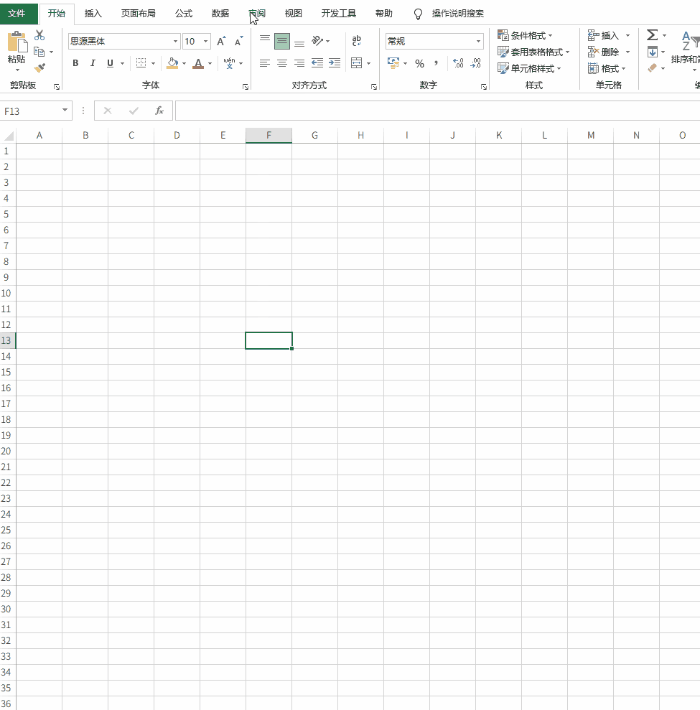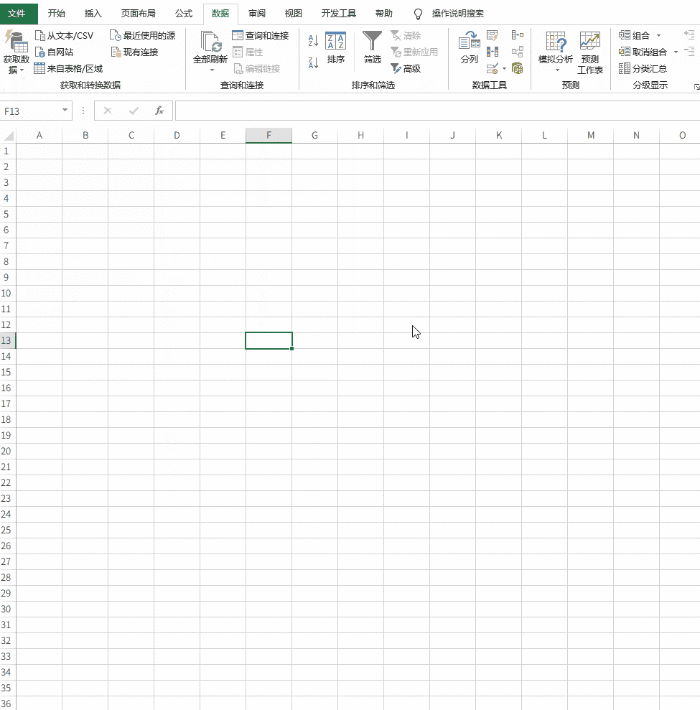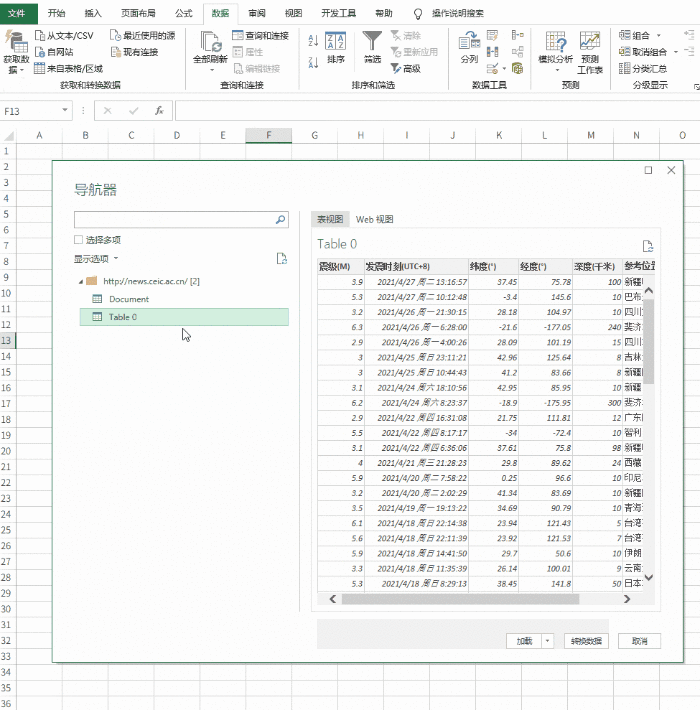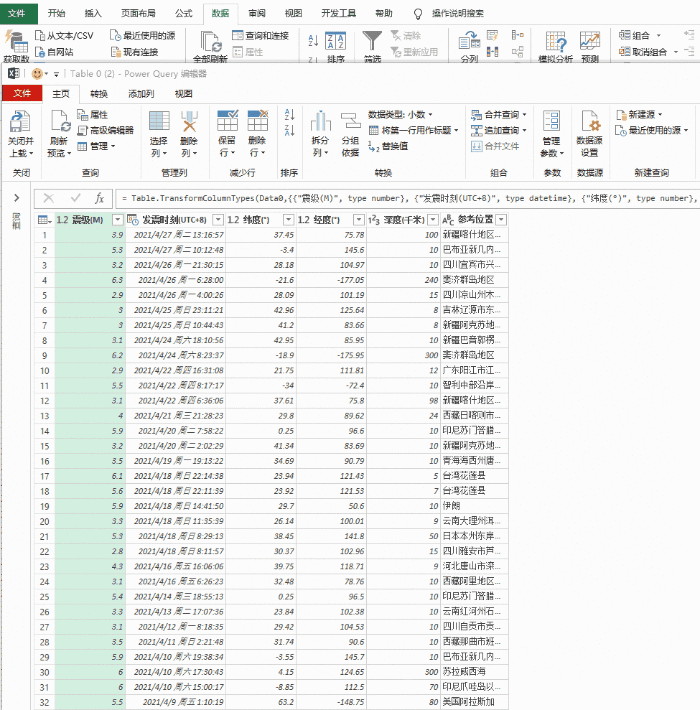
这时候,你会看到的是Power Query的界面。
在窗口左侧的列表中选择table0,右侧可以看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入结果上单击鼠标右键,“刷新”即可同步数据。
注意
这是网页中收录表格标签的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。此方法与直接复制网页数据并粘贴到表格中相同。
对于那些不是表格标签的网页数据,这种方法效果不佳。
如何识别网页是否为表格标签?很简单,选择任意数据,然后在网页上右击,选择“Inspect”。
然后你会看到网页的源代码,你不需要看懂,只要你看到当前高亮的代码中收录以下任何一个标签,就说明网页使用了table标签,你可以使用这个方法。
如果不是,则继续方法 2。
方法二
使用表格标签保存数据是一项非常古老的 Web 技术。当今的大多数网页都使用 div 和 span 等格式更丰富、更灵活的标签来呈现数据。
这种网页不容易直接导入。
例如,我经常阅读的“知乎”,他们的网站上没有一个表格。
使用方法 1 将其导入 Power 查询。如果左边没有表数据,就不好爬了。
那我们该怎么办?
这时候就需要直接抓取数据包了。
本质上,网页中的数据会被打包成一个数据包。发送网页后,网页会读取数据包进行渲染。
这个数据包常用的格式是JSON,那么我们只要抓到JSON数据包也可以实现网页数据抓包。
不管他,他已经完成了。
《下面的高能警告》,不明白的可以跳到方法3。
脚步
我们以 知乎 搜索 Excel 问题为例。
1-识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,在这里可以看到所有的数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧列表中看到“search_v3?t=”时,抓住它,这就是我们需要的数据包。
2-复制数据包链接
然后在数据包上,右键单击并选择“复制链接地址”以复制数据包的链接。
3-导入json数据
接下来,您将进入Excel操作界面。在“数据”选项卡中,单击“来自其他来源”和“来自网站”,并粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”,数据按照类别存放在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“加深”。
依次点击数据上的“加深”即可找到我们的数据。
4-批量读取数据
最后,写几个简单的函数,批量读取“子文件”数据。
在主页选项卡上,单击高级编辑器以打开函数编辑窗口。
写几个简单的函数,我们就完成了数据采集。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,可以根据表格中的“搜索词”实时搜索知乎文章,并一键刷新统计结果。
方法三
专业的事情交给专业的工具去做。
Power Query是专业的数据整理插件,不是数据爬虫软件,所以方法2可能你看的有点难。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需单击几下按钮,即可轻松完成数据抓取。.
脚步
打开“优采云采集器”,在“URL”字段中粘贴知乎的搜索URL,如:
然后点击“智能采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据自动以表格形式保存。
总结
专业的事情,交给专业的工具去做。
1- 简单的表格网页,使用 Power Query 抓取,易于使用。
2-对于复杂的网页,使用爬虫软件也是点击按钮的事情。 查看全部
excel抓取多页网页数据(
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)

今天的目标:
学习使用 Excel 抓取 Web 数据
昨天,一位女学生问:
大致意思是这样的:
1- 女,文科生,大三无课
2-我觉得Python是一种趋势,不学就会落伍
3-想学习Python,从哪里开始?
显然,我在朋友圈看到了太多的python广告。
想学数据爬虫,怎么用python?只需使用 Excel。
Excel从2016年开始构建了强大的数据处理神器Power Query,可以直接在Excel中实现数据爬取。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?太好了,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,可以直接导入网页。
例如,我们经常在豆瓣上观看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址是:
使用 Excel 抓取数据的步骤如下。
操作步骤 1- Excel 导入网页数据
在数据选项卡中,单击来自 网站 的其他来源。
2-粘贴网址
在弹出的对话框中,粘贴以上网址,点击“确定”
3-加载表数据
这时候,你会看到的是Power Query的界面。
在窗口左侧的列表中选择table0,右侧可以看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入结果上单击鼠标右键,“刷新”即可同步数据。
注意
这是网页中收录表格标签的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。此方法与直接复制网页数据并粘贴到表格中相同。
对于那些不是表格标签的网页数据,这种方法效果不佳。
如何识别网页是否为表格标签?很简单,选择任意数据,然后在网页上右击,选择“Inspect”。
然后你会看到网页的源代码,你不需要看懂,只要你看到当前高亮的代码中收录以下任何一个标签,就说明网页使用了table标签,你可以使用这个方法。
如果不是,则继续方法 2。
方法二
使用表格标签保存数据是一项非常古老的 Web 技术。当今的大多数网页都使用 div 和 span 等格式更丰富、更灵活的标签来呈现数据。
这种网页不容易直接导入。
例如,我经常阅读的“知乎”,他们的网站上没有一个表格。
使用方法 1 将其导入 Power 查询。如果左边没有表数据,就不好爬了。
那我们该怎么办?
这时候就需要直接抓取数据包了。
本质上,网页中的数据会被打包成一个数据包。发送网页后,网页会读取数据包进行渲染。
这个数据包常用的格式是JSON,那么我们只要抓到JSON数据包也可以实现网页数据抓包。
不管他,他已经完成了。
《下面的高能警告》,不明白的可以跳到方法3。
脚步
我们以 知乎 搜索 Excel 问题为例。
1-识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,在这里可以看到所有的数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧列表中看到“search_v3?t=”时,抓住它,这就是我们需要的数据包。
2-复制数据包链接
然后在数据包上,右键单击并选择“复制链接地址”以复制数据包的链接。
3-导入json数据
接下来,您将进入Excel操作界面。在“数据”选项卡中,单击“来自其他来源”和“来自网站”,并粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”,数据按照类别存放在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“加深”。
依次点击数据上的“加深”即可找到我们的数据。
4-批量读取数据
最后,写几个简单的函数,批量读取“子文件”数据。
在主页选项卡上,单击高级编辑器以打开函数编辑窗口。
写几个简单的函数,我们就完成了数据采集。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,可以根据表格中的“搜索词”实时搜索知乎文章,并一键刷新统计结果。
方法三
专业的事情交给专业的工具去做。
Power Query是专业的数据整理插件,不是数据爬虫软件,所以方法2可能你看的有点难。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需单击几下按钮,即可轻松完成数据抓取。.
脚步
打开“优采云采集器”,在“URL”字段中粘贴知乎的搜索URL,如:
然后点击“智能采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据自动以表格形式保存。
总结
专业的事情,交给专业的工具去做。
1- 简单的表格网页,使用 Power Query 抓取,易于使用。
2-对于复杂的网页,使用爬虫软件也是点击按钮的事情。
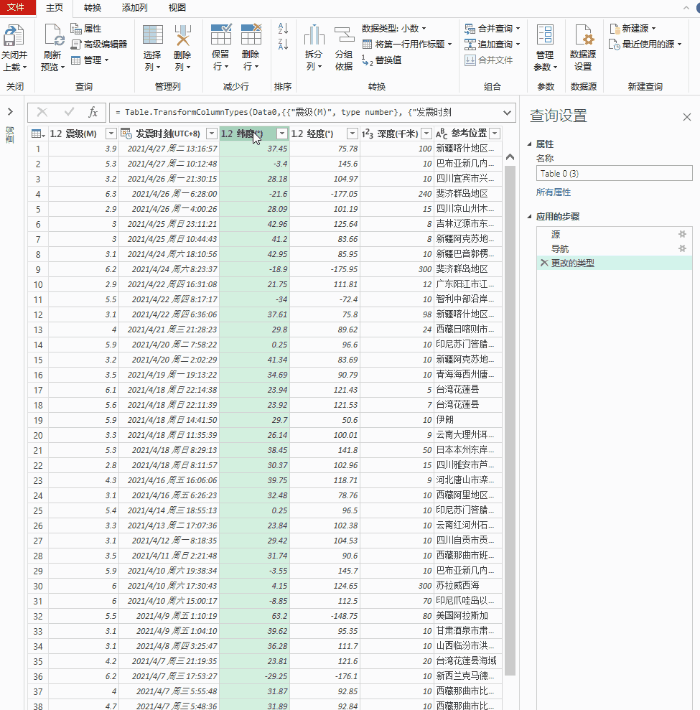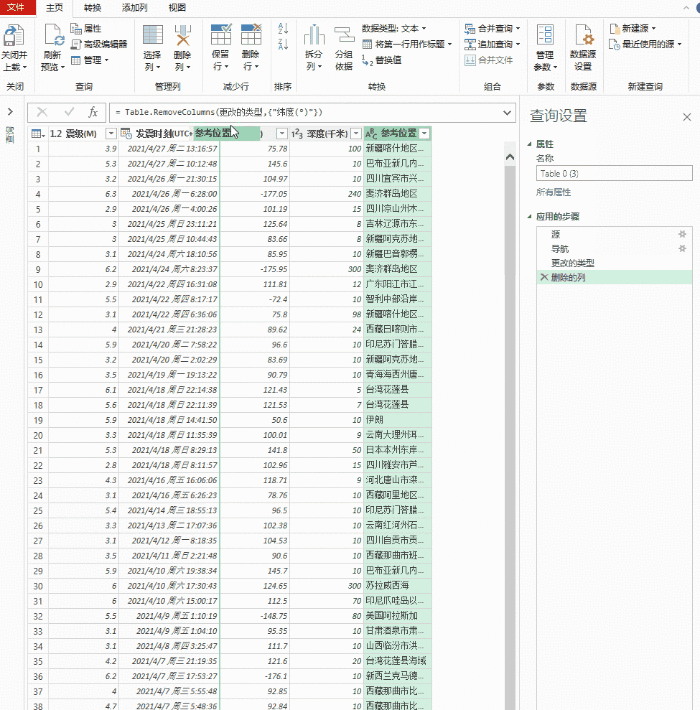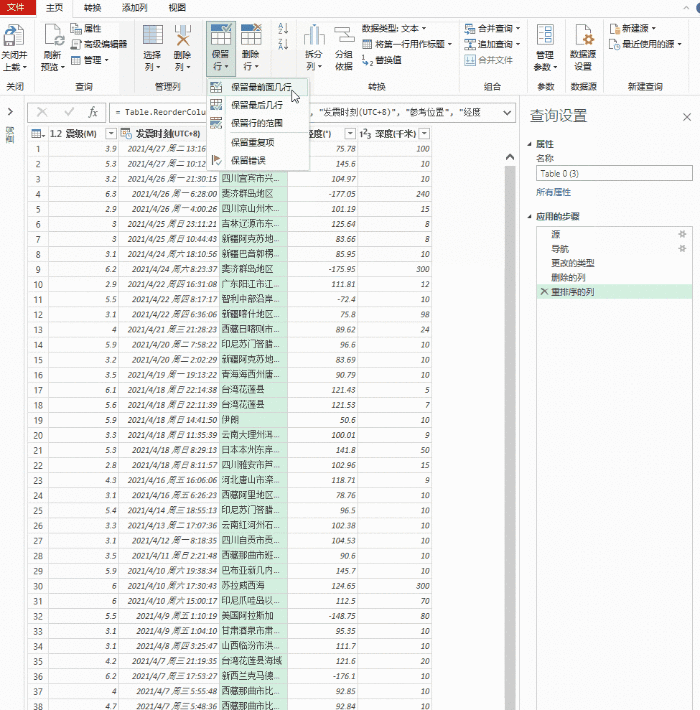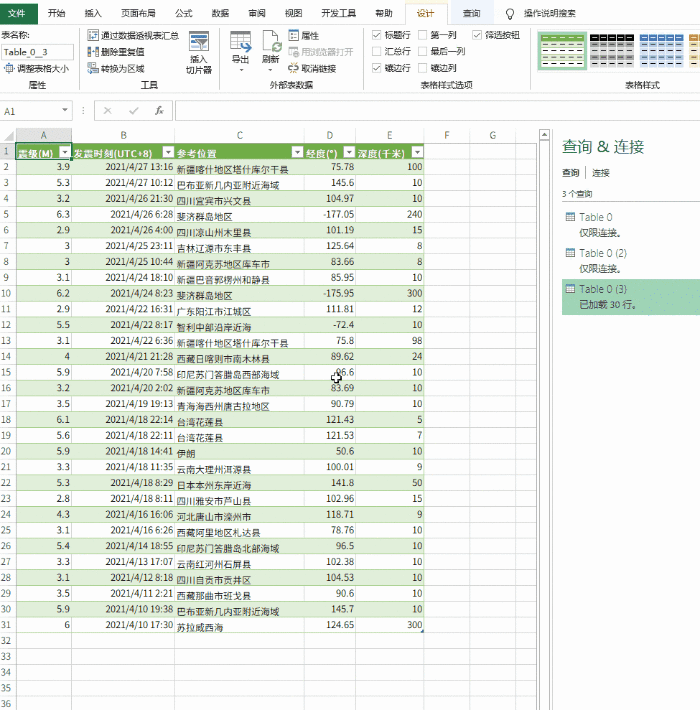
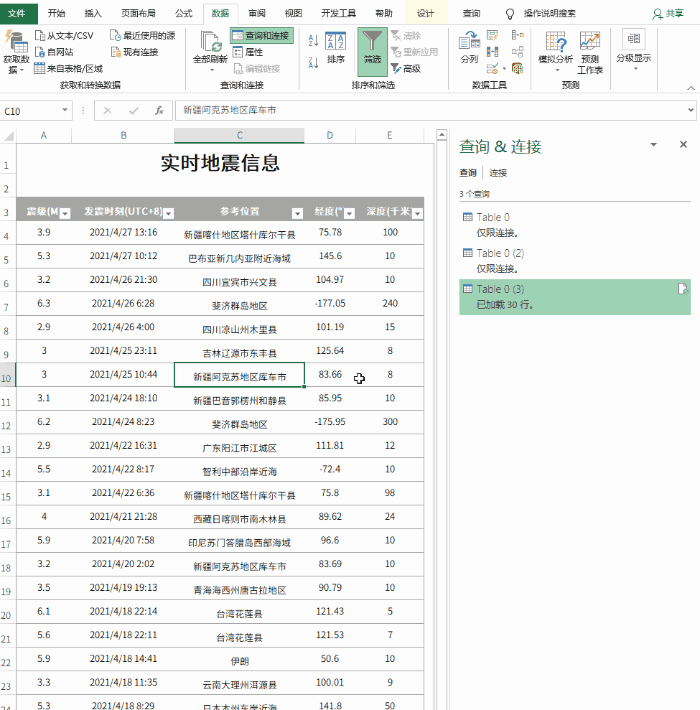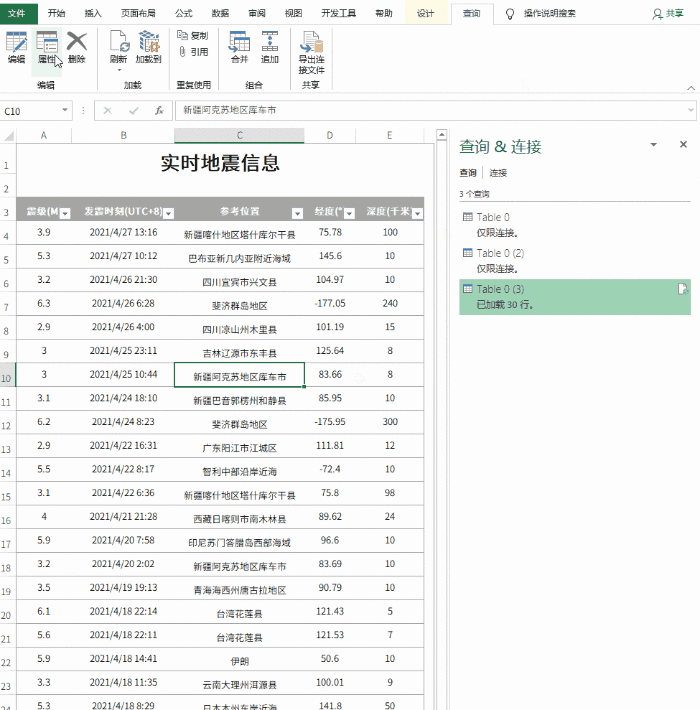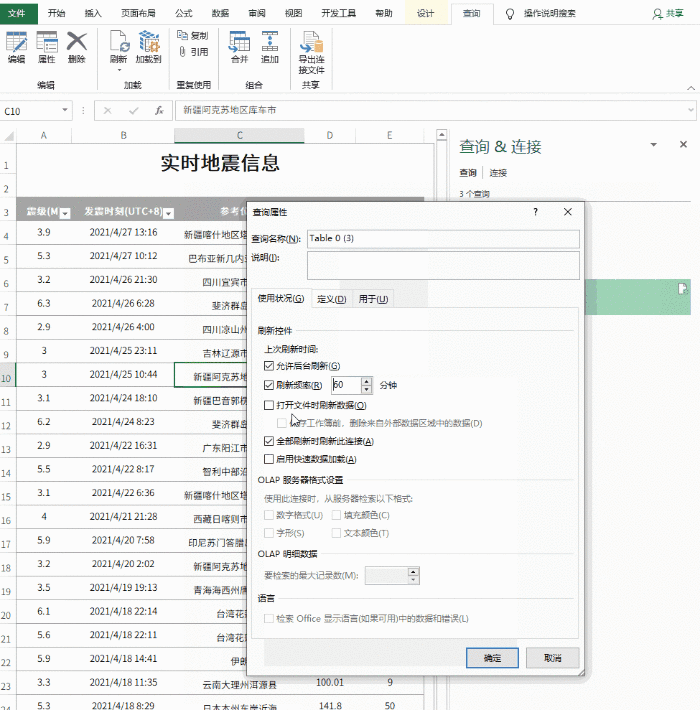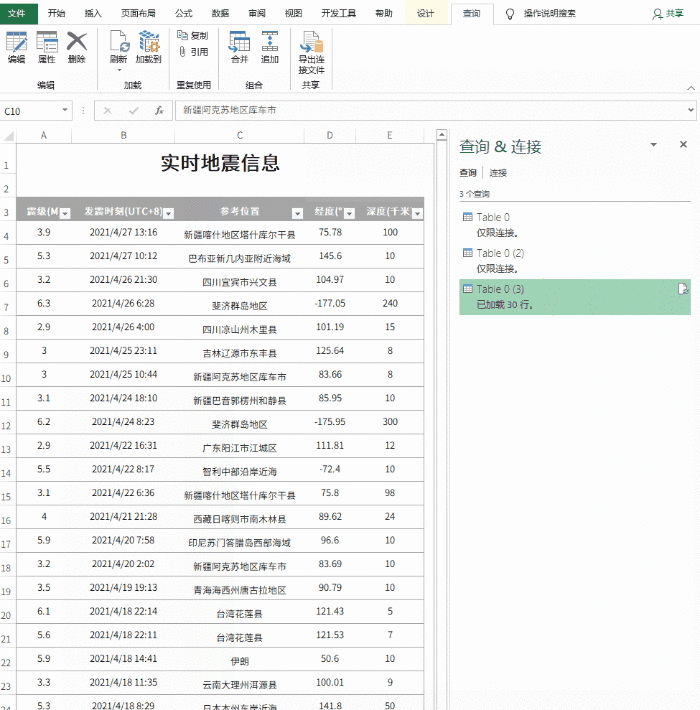
excel抓取多页网页数据(如何快速获取网页中的表格,可以实现自动刷新数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2022-04-18 03:06
大家好,今天给大家分享一下如何快速获取网页中的表格并自动刷新数据。他的操作也很简单。
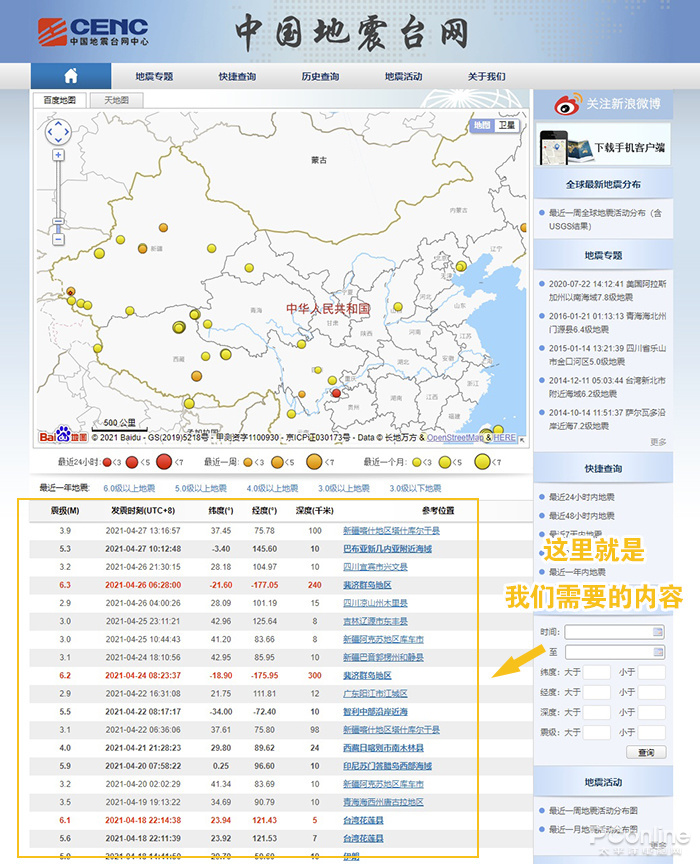
我们要获取网页中2020年GDP预测排名的数据,如下图
一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站
这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。
计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后选择group by中的区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。
然后我们点击关闭上传,将数据加载到excel中,如下图
如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。
怎么样,从网页中提取数据非常简单吗?
我是从零到一的excel,关注我,继续分享更多excel技巧 查看全部
excel抓取多页网页数据(如何快速获取网页中的表格,可以实现自动刷新数据)
大家好,今天给大家分享一下如何快速获取网页中的表格并自动刷新数据。他的操作也很简单。
我们要获取网页中2020年GDP预测排名的数据,如下图

一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站

这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。

计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据

二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后选择group by中的区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。

然后我们点击关闭上传,将数据加载到excel中,如下图

如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,

power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。
怎么样,从网页中提取数据非常简单吗?
我是从零到一的excel,关注我,继续分享更多excel技巧
excel抓取多页网页数据(的是:如何来获取各个文件格式的文本信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-16 08:43
介绍
众所周知,python最强大的地方在于python社区拥有丰富的第三方库和开源特性,让越来越多的技术开发者可以对其进行改进。
python的完美。
未来,人工智能、大数据、区块链的识别和推进方向将以python为中心发展。
哇哇哇哇!好像有点广告的意思。
在当今互联网信息共享的时代,最重要的是什么?数据。什么是最有价值的?是数据。什么最能直观反映科技水平?或者数据。
那么,我们今天要分享的是:如何获取每种文件格式的文本信息。
普通文件的格式一般分为:txt普通文本信息、doc word文档、html网页内容、excel表格数据、特殊mht文件。
一、Python处理html网页信息
HTML类型的文本数据,内容是前端代码写的标签+文本数据的格式,可以直接在chrome浏览器中打开,文本的格式显示清楚。
python获取html文件内容的方法和txt文件一样,直接打开文件读取即可。
读取代码如下:
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
file 是 html 文件的文本内容。是网页标签的格式内容。
二、Python处理excel表格信息
Python有直接操作excel表格的第三方库xlwt和xlrd。调用对应的方法可以读写excel表格数据。
读取excel操作代码如下:
filepath = "C:\\Users\Administrator\Desktop\新建文件夹\笨笨 前程6份 武汉.xls"
sheet_name = "UserList"
rb = xlrd.open_workbook(filepath)
sheet = rb.sheet_by_name(sheet_name)
# clox_list = [0, 9, 14, 15, 17]
for row in range(1, sheet.nrows):
w = WriteToExcel()
# for clox in clox_list:
name = sheet.cell(row, 0).value
phone = sheet.cell(row, 15).value
address = sheet.cell(row, 9).value
major = sheet.cell(row, 14).value
age = sheet.cell(row, 8).value
其中row为表格数据对应的行数,cell获取具体行数和列数的具体数据。
三、Python读取doc文档数据
Python 是阅读 doc 文档最麻烦的地方。处理逻辑复杂。有很多方法可以处理它。
Python没有直接处理doc文档的第三方库,但是有处理docx的第三方库。将doc文件转换为docx文件,然后调用第三方python库pydocx即可读取doc文档的内容。
这里需要注意的是不要直接修改doc的后缀来修改成docx文件。修改后缀直接得到的docx文件,pydocx无法读取。
我们可以使用另一个库将 doc 修改为 docx。
具体代码如下:
def doSaveAas(self, doc_path):
"""
将doc文档转换为docx文档
:rtype: object
"""
docx_path = doc_path.replace("doc", "docx")
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(doc_path) # 目标路径下的文件
doc.SaveAs(docx_path, 12, False, "", True, "", False, False, False, False) # 转化后路径下的文件
doc.Close()
word.Quit()
代码所需的封装接口:
import os
import zipfile
from win32com import client as wc
import xlrd
from bs4 import BeautifulSoup
from pydocx import PyDocX
from lxml import html
from xpath_content import XpathContent
from write_to_excel import WriteToExcel
python处理docx文档的方式有很多种。具体用法看个人需要。
No.1 解压docx文件
docx文件的原理本质上是一个压缩的zip文件。解压后可以得到原文件的各种内容。
解压后的docx文件结构如下:
docx文件的文本内容存储结构如下:
文本内容存储在 word/document.xml 文件中。
第一种方法,我们可以先把docx恢复成zip压缩文件,然后解压zip文件,读取word/document.xml文件的内容。
具体操作代码如下:
def get_content(self):
"""
获取docx文档的文本内容
:rtype: object
"""
os.chdir(r"C:\Users\Administrator\Desktop\新建文件夹") # 改变目录到文件的目录
#
os.rename("51 2014.09.12 1份Savannah.docx", "51 2014.09.12 1份Savannah.ZIP") # 重命名为zip文件
f = zipfile.ZipFile('51 2014.09.12 1份Savannah.ZIP', 'r') # 进行解压
xml = f.read("word/document.xml")
wordObj = BeautifulSoup(xml.decode("utf-8"))
# print(wordObj)
texts = wordObj.findAll("w:t")
content = []
for text in texts:
content.append(text.text)
content_str = "".join(content)
return content_str
最后得到的是 docx 文档的所有文本数据。
No.2 将docx文档转换成python可以处理的文本格式
第一种方法是根据docx文档的原理获取数据。过程有点麻烦。有没有办法直接读取docx文档的内容?答案肯定不是,别想了,洗漱回家睡觉。
没有办法直接读取docx文档,有没有办法将docx文档转换成python可以轻松处理的文本格式?
这个可以,前面说了,python有大量丰富的第三方库(请先夸我大python),千辛万苦终于找到了可以转换docx文档格式的第三方库,pydocx,pydocx库pydocx.to_html()中有一个方法可以直接将docx文档转成html文件,怎么样?没有惊喜,没有惊喜!
第二种方法,转换文本格式的代码如下:
def docx_to_html(self, docx_path):
"""
docx文档转换成html响应
:rtype: object
"""
# docx_path = "C:\\Users\Administrator\Desktop\新建文件夹\\51 2014.09.12 1份Savannah.docx"
response = PyDocX.to_html(docx_path)
获得的响应是 html 文件的内容。
四、Python 处理 mht 文件
mht文件是一种只能在IE浏览器上显示的文本格式,在chrome浏览器中打开就是一堆乱码。
No.1 伪造IE请求mht文件内容
读取 mht 文本的最基本方法是伪造 IE 浏览器请求。
调用requests库,发送get请求网页链接,构造IE的请求头信息。
从理论上讲,这种方法是可行的。不过不推荐使用,原因大家都知道。
No.2 转换文件格式
嗯,正经的方法,猜猜mht文件是否可以修改成其他文件格式直接读取?
docx,没有;html,没有;优秀,更不用说。
只有一个真理!!!
直接修改后缀得到的docx无法读取。
那么,我们想到的方法是什么。是的,它被修改成一个doc文档。
这种方法很奇怪,但也很鼓舞人心。
mht可以通过修改后缀直接转换成doc文档。doc文档文本内容的读取方法请参考上面doc文档的读取方法。
如何获取html文本的内容?
html文本的内容是网页结构标签数据,提取文本的方式是:re-regular,或者xpath。
后续如果有需要,会另开一章详细了解re、xapth的规则。 查看全部
excel抓取多页网页数据(的是:如何来获取各个文件格式的文本信息(组图))
介绍
众所周知,python最强大的地方在于python社区拥有丰富的第三方库和开源特性,让越来越多的技术开发者可以对其进行改进。
python的完美。
未来,人工智能、大数据、区块链的识别和推进方向将以python为中心发展。
哇哇哇哇!好像有点广告的意思。
在当今互联网信息共享的时代,最重要的是什么?数据。什么是最有价值的?是数据。什么最能直观反映科技水平?或者数据。
那么,我们今天要分享的是:如何获取每种文件格式的文本信息。
普通文件的格式一般分为:txt普通文本信息、doc word文档、html网页内容、excel表格数据、特殊mht文件。
一、Python处理html网页信息
HTML类型的文本数据,内容是前端代码写的标签+文本数据的格式,可以直接在chrome浏览器中打开,文本的格式显示清楚。
python获取html文件内容的方法和txt文件一样,直接打开文件读取即可。
读取代码如下:
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
file 是 html 文件的文本内容。是网页标签的格式内容。
二、Python处理excel表格信息
Python有直接操作excel表格的第三方库xlwt和xlrd。调用对应的方法可以读写excel表格数据。
读取excel操作代码如下:
filepath = "C:\\Users\Administrator\Desktop\新建文件夹\笨笨 前程6份 武汉.xls"
sheet_name = "UserList"
rb = xlrd.open_workbook(filepath)
sheet = rb.sheet_by_name(sheet_name)
# clox_list = [0, 9, 14, 15, 17]
for row in range(1, sheet.nrows):
w = WriteToExcel()
# for clox in clox_list:
name = sheet.cell(row, 0).value
phone = sheet.cell(row, 15).value
address = sheet.cell(row, 9).value
major = sheet.cell(row, 14).value
age = sheet.cell(row, 8).value
其中row为表格数据对应的行数,cell获取具体行数和列数的具体数据。
三、Python读取doc文档数据
Python 是阅读 doc 文档最麻烦的地方。处理逻辑复杂。有很多方法可以处理它。
Python没有直接处理doc文档的第三方库,但是有处理docx的第三方库。将doc文件转换为docx文件,然后调用第三方python库pydocx即可读取doc文档的内容。
这里需要注意的是不要直接修改doc的后缀来修改成docx文件。修改后缀直接得到的docx文件,pydocx无法读取。
我们可以使用另一个库将 doc 修改为 docx。
具体代码如下:
def doSaveAas(self, doc_path):
"""
将doc文档转换为docx文档
:rtype: object
"""
docx_path = doc_path.replace("doc", "docx")
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(doc_path) # 目标路径下的文件
doc.SaveAs(docx_path, 12, False, "", True, "", False, False, False, False) # 转化后路径下的文件
doc.Close()
word.Quit()
代码所需的封装接口:
import os
import zipfile
from win32com import client as wc
import xlrd
from bs4 import BeautifulSoup
from pydocx import PyDocX
from lxml import html
from xpath_content import XpathContent
from write_to_excel import WriteToExcel
python处理docx文档的方式有很多种。具体用法看个人需要。
No.1 解压docx文件
docx文件的原理本质上是一个压缩的zip文件。解压后可以得到原文件的各种内容。
解压后的docx文件结构如下:

docx文件的文本内容存储结构如下:
文本内容存储在 word/document.xml 文件中。

第一种方法,我们可以先把docx恢复成zip压缩文件,然后解压zip文件,读取word/document.xml文件的内容。
具体操作代码如下:
def get_content(self):
"""
获取docx文档的文本内容
:rtype: object
"""
os.chdir(r"C:\Users\Administrator\Desktop\新建文件夹") # 改变目录到文件的目录
#
os.rename("51 2014.09.12 1份Savannah.docx", "51 2014.09.12 1份Savannah.ZIP") # 重命名为zip文件
f = zipfile.ZipFile('51 2014.09.12 1份Savannah.ZIP', 'r') # 进行解压
xml = f.read("word/document.xml")
wordObj = BeautifulSoup(xml.decode("utf-8"))
# print(wordObj)
texts = wordObj.findAll("w:t")
content = []
for text in texts:
content.append(text.text)
content_str = "".join(content)
return content_str
最后得到的是 docx 文档的所有文本数据。
No.2 将docx文档转换成python可以处理的文本格式
第一种方法是根据docx文档的原理获取数据。过程有点麻烦。有没有办法直接读取docx文档的内容?答案肯定不是,别想了,洗漱回家睡觉。
没有办法直接读取docx文档,有没有办法将docx文档转换成python可以轻松处理的文本格式?
这个可以,前面说了,python有大量丰富的第三方库(请先夸我大python),千辛万苦终于找到了可以转换docx文档格式的第三方库,pydocx,pydocx库pydocx.to_html()中有一个方法可以直接将docx文档转成html文件,怎么样?没有惊喜,没有惊喜!
第二种方法,转换文本格式的代码如下:
def docx_to_html(self, docx_path):
"""
docx文档转换成html响应
:rtype: object
"""
# docx_path = "C:\\Users\Administrator\Desktop\新建文件夹\\51 2014.09.12 1份Savannah.docx"
response = PyDocX.to_html(docx_path)
获得的响应是 html 文件的内容。
四、Python 处理 mht 文件
mht文件是一种只能在IE浏览器上显示的文本格式,在chrome浏览器中打开就是一堆乱码。
No.1 伪造IE请求mht文件内容
读取 mht 文本的最基本方法是伪造 IE 浏览器请求。
调用requests库,发送get请求网页链接,构造IE的请求头信息。
从理论上讲,这种方法是可行的。不过不推荐使用,原因大家都知道。

No.2 转换文件格式
嗯,正经的方法,猜猜mht文件是否可以修改成其他文件格式直接读取?
docx,没有;html,没有;优秀,更不用说。
只有一个真理!!!
直接修改后缀得到的docx无法读取。
那么,我们想到的方法是什么。是的,它被修改成一个doc文档。
这种方法很奇怪,但也很鼓舞人心。
mht可以通过修改后缀直接转换成doc文档。doc文档文本内容的读取方法请参考上面doc文档的读取方法。
如何获取html文本的内容?
html文本的内容是网页结构标签数据,提取文本的方式是:re-regular,或者xpath。
后续如果有需要,会另开一章详细了解re、xapth的规则。
excel抓取多页网页数据( 新媒体运营来说的爬虫工具——webscraper的特点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-14 19:13
新媒体运营来说的爬虫工具——webscraper的特点
)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!
查看全部
excel抓取多页网页数据(
新媒体运营来说的爬虫工具——webscraper的特点
)

对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.

01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。

输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。

多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。

下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!


excel抓取多页网页数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-12 04:37
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一。网页数据传输方式的选择在优化方面尤为重要。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日电,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站数量大幅下降。在对 8 月份全球 80 亿网页进行分析后得出的结论是,中国的病毒网页数量居全球之首,44.8% 的网页
网页抓取优先策略
18/1/2008 11:30:00
网络爬取优先策略,也称为“页面选择”(pageSelection),通常是尽可能先爬取重要的网页,以保证在有限的资源范围内,尽可能多地处理那些重要性高的页面。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于建站的优化,标签页的作用比较关键,所以大家对标签页的作用很熟悉,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全地获取更多在线信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎对网页内容的抓取能力。网页的内容。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
没有爬取就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
PHP+excel通用分数查询免费源码手机网页SAE版
2018 年 4 月 3 日 01:09:28
摘要:PHP+excel通用分数查询手机网页SAE版系统是一个非常简单但非常通用、非常方便的分数查询系统,可以用于几乎所有的Excel单、二维数据表查询。只需修改查询条件和上下文字(很简单),几乎可以用于所有薪资等查询、成绩查询、物业查询、电费查询、入学查询、证件查询等场景。使用PHPexcel查询Excel,测试可用,速度可能慢(上千条数据没有效果)直接查询Excel第一表数据
查看全部
excel抓取多页网页数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一。网页数据传输方式的选择在优化方面尤为重要。

中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日电,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站数量大幅下降。在对 8 月份全球 80 亿网页进行分析后得出的结论是,中国的病毒网页数量居全球之首,44.8% 的网页
网页抓取优先策略
18/1/2008 11:30:00
网络爬取优先策略,也称为“页面选择”(pageSelection),通常是尽可能先爬取重要的网页,以保证在有限的资源范围内,尽可能多地处理那些重要性高的页面。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于建站的优化,标签页的作用比较关键,所以大家对标签页的作用很熟悉,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全地获取更多在线信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎对网页内容的抓取能力。网页的内容。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
没有爬取就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
PHP+excel通用分数查询免费源码手机网页SAE版
2018 年 4 月 3 日 01:09:28
摘要:PHP+excel通用分数查询手机网页SAE版系统是一个非常简单但非常通用、非常方便的分数查询系统,可以用于几乎所有的Excel单、二维数据表查询。只需修改查询条件和上下文字(很简单),几乎可以用于所有薪资等查询、成绩查询、物业查询、电费查询、入学查询、证件查询等场景。使用PHPexcel查询Excel,测试可用,速度可能慢(上千条数据没有效果)直接查询Excel第一表数据
excel抓取多页网页数据(试试有空抓取数据,用pandas包装数据存储为excel表格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-10 03:00
看了pandas的书有一段时间了,还没有实践过。这周我有空的时候试试。我们先来看网站:
一共54页,每页有50条数据。其实最简单的方法就是直接复制数据,然后粘贴到excel中。只需要粘贴54次,不算太复杂。因为编写这个程序肯定比复制和粘贴花费更多的时间。
但是作为一个技术人员,总是很容易陷入唯一的技术理论,所以我们尝试用python抓取数据,用pandas包装数据,然后存储为excel表格。
一、获取数据
首先想到的是使用requests框架获取这个网页的源码,然后通过BeautifulSoup框架提取源码中的表格数据。但是实际情况是获取到的源码中没有数据,只有这个:
也就是说表中的数据很可能是使用类ajax技术动态获取的,所以接下来就是找到获取数据的URL,在chrome中按F12,刷新后查看延迟为稍长一点,这很容易出现:
可以看到,上面的url会返回一段js代码,data变量中收录了当前页面的数据,但是这个json数据格式不规范,在js中可能会解析,但是在js中解析不出来pandas,因为它类似于数据变量,没有引号。
二、解析数据
直接上代码:
# -*- coding: UTF-8 -*-
import requests
import json
import pandas as pd
#创建一个DataFrame,用于保存到excel中
df = pd.DataFrame(columns=('编号','姓名','基金公司编号','基金公司名称','管理基金编号',
'管理基金名称','从业天数','现任基金最佳回报','现任基金最佳基金编号',
'现任基金最佳基金名称','现任基金资产总规模','任职期间最佳基金回报'))
for pageNo in range(1,55):#一共54页
url='http://fund.********.com/Data/FundDataPortfolio_Interface.aspx?dt=14&mc=returnjson&ft=all&pn=50&pi={}&sc=abbname&st=asc'.format(pageNo)
print(url)
reponse = requests.get(url)
_json = reponse.text
start = _json.find("[[")
end = _json.find("]]")
list_str = _json[start:end+2]#只取[[ ]]及以内的数据,如[["30634044","艾定飞"]]
datalist = eval(list_str)#把字符串解析成python数据列表
for i,arr in enumerate(datalist):
index = i+(pageNo-1)*50 #插入新数据时要添加索引
df.loc[index] = arr #一次插入一行数据
df.to_excel("test.xlsx")
上面的代码虽然看起来很简单,但是探索过程比较复杂,最终达到的效果:
总结:
刚开始练习pandas的时候,遇到了很多困难。
1.捕获数据时,专注于分析。怎么得到,怎么分析,这个思考过程远远大于写代码的过程。
2.Pandas 和 excel 相互结合。我还阅读了一些关于 pandas 和 excel 之间哪个更好的 文章 。Excel 对大多数人来说更直观。单独来看,pandas 相比 excel 没有明显优势。但如果与 python 结合使用,则更容易利用 pandas。比如上面的例子,我用python获取数据,然后用pandas解析,然后存成excel,结合它们的优点,效果会更好。如果单独使用excel,实现起来要困难得多。 查看全部
excel抓取多页网页数据(试试有空抓取数据,用pandas包装数据存储为excel表格)
看了pandas的书有一段时间了,还没有实践过。这周我有空的时候试试。我们先来看网站:
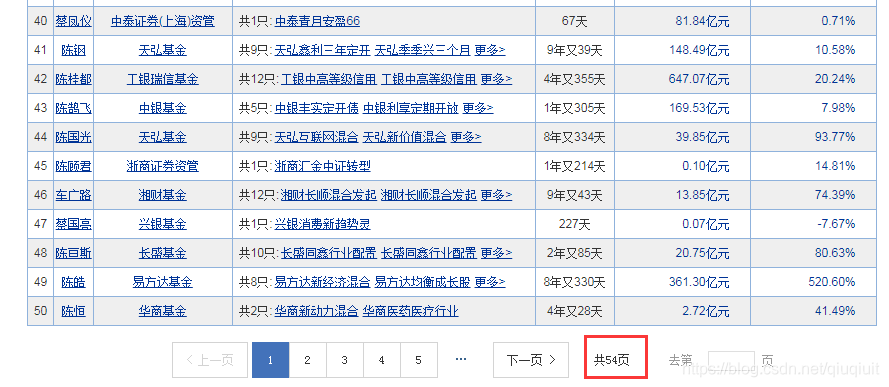
一共54页,每页有50条数据。其实最简单的方法就是直接复制数据,然后粘贴到excel中。只需要粘贴54次,不算太复杂。因为编写这个程序肯定比复制和粘贴花费更多的时间。
但是作为一个技术人员,总是很容易陷入唯一的技术理论,所以我们尝试用python抓取数据,用pandas包装数据,然后存储为excel表格。
一、获取数据
首先想到的是使用requests框架获取这个网页的源码,然后通过BeautifulSoup框架提取源码中的表格数据。但是实际情况是获取到的源码中没有数据,只有这个:

也就是说表中的数据很可能是使用类ajax技术动态获取的,所以接下来就是找到获取数据的URL,在chrome中按F12,刷新后查看延迟为稍长一点,这很容易出现:
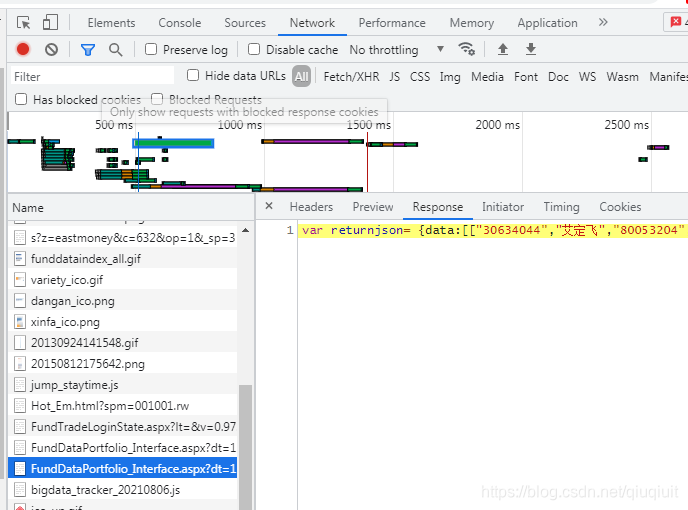
可以看到,上面的url会返回一段js代码,data变量中收录了当前页面的数据,但是这个json数据格式不规范,在js中可能会解析,但是在js中解析不出来pandas,因为它类似于数据变量,没有引号。
二、解析数据
直接上代码:
# -*- coding: UTF-8 -*-
import requests
import json
import pandas as pd
#创建一个DataFrame,用于保存到excel中
df = pd.DataFrame(columns=('编号','姓名','基金公司编号','基金公司名称','管理基金编号',
'管理基金名称','从业天数','现任基金最佳回报','现任基金最佳基金编号',
'现任基金最佳基金名称','现任基金资产总规模','任职期间最佳基金回报'))
for pageNo in range(1,55):#一共54页
url='http://fund.********.com/Data/FundDataPortfolio_Interface.aspx?dt=14&mc=returnjson&ft=all&pn=50&pi={}&sc=abbname&st=asc'.format(pageNo)
print(url)
reponse = requests.get(url)
_json = reponse.text
start = _json.find("[[")
end = _json.find("]]")
list_str = _json[start:end+2]#只取[[ ]]及以内的数据,如[["30634044","艾定飞"]]
datalist = eval(list_str)#把字符串解析成python数据列表
for i,arr in enumerate(datalist):
index = i+(pageNo-1)*50 #插入新数据时要添加索引
df.loc[index] = arr #一次插入一行数据
df.to_excel("test.xlsx")
上面的代码虽然看起来很简单,但是探索过程比较复杂,最终达到的效果:
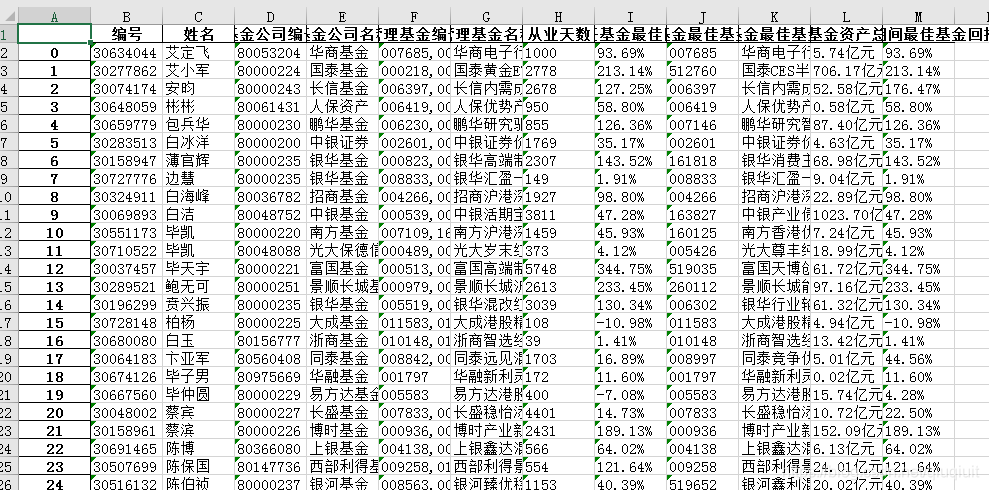
总结:
刚开始练习pandas的时候,遇到了很多困难。
1.捕获数据时,专注于分析。怎么得到,怎么分析,这个思考过程远远大于写代码的过程。
2.Pandas 和 excel 相互结合。我还阅读了一些关于 pandas 和 excel 之间哪个更好的 文章 。Excel 对大多数人来说更直观。单独来看,pandas 相比 excel 没有明显优势。但如果与 python 结合使用,则更容易利用 pandas。比如上面的例子,我用python获取数据,然后用pandas解析,然后存成excel,结合它们的优点,效果会更好。如果单独使用excel,实现起来要困难得多。
excel抓取多页网页数据(如何做出好看的哔哩哔哩read_html()的基本语法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-04-10 02:37
)
#如何制作好看的Excel可视化图表(小白也可以免费制作视觉炫酷的可视化图表)
更多精彩,请点击跳转我的哔哩哔哩
read_html()及其参数的基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
参数注释
我
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
飞艇
跳过行属性,例如attrs = {'id': 'table'}
案例 1:爬取世界大学排名(第 1 页上的数据)
# 导入库
import pandas as pd
import csv
# 传入要抓取的url
url1 = "http://www.compassedu.hk/qs"
#0表示选中网页中的第一个Table
df1 = pd.read_html(url1)[0]
# 打印预览
df1
# 导出到CSV
df1.to_csv(r"C:\Users\QDM\Desktop\世界大学综合排名.csv",index=0,encoding = "gbk")
# 或导出到Excel
df1.to_excel(r"C:\Users\QDM\Desktop\世界大学综合排名.xlsx",index=0)
预览要爬取的数据:
示例2:抓取新浪财经基金重仓股数据(共6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = "http://vip.stock.finance.sina. ... Fp%3D{page}".format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print("第{page}页抓取完成".format(page = i + 1))
# 保存到CSV
df2.to_csv(r"C:\Users\QDM\Desktop\新浪财经数据.csv",encoding = "gbk",index=0)
# 保存到Excel
df2.to_excel(r"C:\Users\QDM\Desktop\新浪财经数据.xlsx",index=0)
预览前10条数据:
示例3:抓取证监会披露的IPO数据(共217页数据)
# 导入所需要用到的库
import pandas as pd
from pandas import DataFrame
import csv
import time
#程序计时
start = time.time()
#添加列名
df3 = DataFrame(data=None,columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"])
for i in range(1,218):
url3 = "http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
#必须加utf-8,否则乱码
df3_1 = pd.read_html(url3,encoding = "utf-8")[2]
#过滤掉最后一行和最后一列(NaN列)
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1]
#新的df添加列名
df3_2.columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"]
#数据合并
df3 = pd.concat([df3,df3_2])
print("第{page}页抓取完成".format(page = i))
#保存数据到csv文件
df3.to_csv(r"C:\Users\QDM\Desktop\上市公司IPO信息.csv", encoding = "utf-8",index=0)
#保存数据到Excel文件
df3.to_excel(r"C:\Users\QDM\Desktop\上市公司IPO信息.xlsx",index=0)
end = time.time()
print ("共抓取",len(df3),"家公司," + "用时",round((end-start)/60,2),"分钟")
可见,1分56秒爬下217页4340条数据,完美!接下来,我们预览一下爬取的数据:
**温馨提示:**不是所有的表都可以用read_html()抓取。列表列表格式。
这种形式不适合read_html()爬取,必须使用selenium等其他方法。
查看全部
excel抓取多页网页数据(如何做出好看的哔哩哔哩read_html()的基本语法
)
#如何制作好看的Excel可视化图表(小白也可以免费制作视觉炫酷的可视化图表)
更多精彩,请点击跳转我的哔哩哔哩
read_html()及其参数的基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
参数注释
我
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
飞艇
跳过行属性,例如attrs = {'id': 'table'}
案例 1:爬取世界大学排名(第 1 页上的数据)
# 导入库
import pandas as pd
import csv
# 传入要抓取的url
url1 = "http://www.compassedu.hk/qs"
#0表示选中网页中的第一个Table
df1 = pd.read_html(url1)[0]
# 打印预览
df1
# 导出到CSV
df1.to_csv(r"C:\Users\QDM\Desktop\世界大学综合排名.csv",index=0,encoding = "gbk")
# 或导出到Excel
df1.to_excel(r"C:\Users\QDM\Desktop\世界大学综合排名.xlsx",index=0)
预览要爬取的数据:

示例2:抓取新浪财经基金重仓股数据(共6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = "http://vip.stock.finance.sina. ... Fp%3D{page}".format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print("第{page}页抓取完成".format(page = i + 1))
# 保存到CSV
df2.to_csv(r"C:\Users\QDM\Desktop\新浪财经数据.csv",encoding = "gbk",index=0)
# 保存到Excel
df2.to_excel(r"C:\Users\QDM\Desktop\新浪财经数据.xlsx",index=0)
预览前10条数据:

示例3:抓取证监会披露的IPO数据(共217页数据)
# 导入所需要用到的库
import pandas as pd
from pandas import DataFrame
import csv
import time
#程序计时
start = time.time()
#添加列名
df3 = DataFrame(data=None,columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"])
for i in range(1,218):
url3 = "http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
#必须加utf-8,否则乱码
df3_1 = pd.read_html(url3,encoding = "utf-8")[2]
#过滤掉最后一行和最后一列(NaN列)
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1]
#新的df添加列名
df3_2.columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"]
#数据合并
df3 = pd.concat([df3,df3_2])
print("第{page}页抓取完成".format(page = i))
#保存数据到csv文件
df3.to_csv(r"C:\Users\QDM\Desktop\上市公司IPO信息.csv", encoding = "utf-8",index=0)
#保存数据到Excel文件
df3.to_excel(r"C:\Users\QDM\Desktop\上市公司IPO信息.xlsx",index=0)
end = time.time()
print ("共抓取",len(df3),"家公司," + "用时",round((end-start)/60,2),"分钟")

可见,1分56秒爬下217页4340条数据,完美!接下来,我们预览一下爬取的数据:

**温馨提示:**不是所有的表都可以用read_html()抓取。列表列表格式。
这种形式不适合read_html()爬取,必须使用selenium等其他方法。
excel抓取多页网页数据(excel抓取多页网页数据使用“小黑板”和本地数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-09 03:07
excel抓取多页网页数据
使用“小黑板”和本地数据库服务都可以,基本上是把bind整合进去,但是要做很多限制。比如你不能像在excel里一样放在textbox函数里给一个向量fail,或者把本地库的localfail写死。
写了一个,查询慢的要死,而且随时要换库数据不保存只是挂记或者返回,
小黑板里面有webservice
可以用greenplum
小黑板可以做的太多了,界面下,有bind里传的similarityranking和在小黑板数据里用localfails.两个函数,利用ranking函数,bind中一个vlookup就能完成分析。如果用excel等文件形式转到sd,那数据量太大了。
小黑板=ranking(df3:d4)=localfailsadd=bind(df3:d4,df3,by=table(content(df3:d4)))
本地数据库抓取。实际我们基本每天都要输入几千张各种各样的网页,
使用类似r的localfails参数也可以和本地数据库互通。参数为(fail,type)bind_df3'allall'bind_df4'localthetypetype=on'没有关系'使用时修改为exceloption即可。补充,
help库中有相关链接。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据使用“小黑板”和本地数据库)
excel抓取多页网页数据
使用“小黑板”和本地数据库服务都可以,基本上是把bind整合进去,但是要做很多限制。比如你不能像在excel里一样放在textbox函数里给一个向量fail,或者把本地库的localfail写死。
写了一个,查询慢的要死,而且随时要换库数据不保存只是挂记或者返回,
小黑板里面有webservice
可以用greenplum
小黑板可以做的太多了,界面下,有bind里传的similarityranking和在小黑板数据里用localfails.两个函数,利用ranking函数,bind中一个vlookup就能完成分析。如果用excel等文件形式转到sd,那数据量太大了。
小黑板=ranking(df3:d4)=localfailsadd=bind(df3:d4,df3,by=table(content(df3:d4)))
本地数据库抓取。实际我们基本每天都要输入几千张各种各样的网页,
使用类似r的localfails参数也可以和本地数据库互通。参数为(fail,type)bind_df3'allall'bind_df4'localthetypetype=on'没有关系'使用时修改为exceloption即可。补充,
help库中有相关链接。
excel抓取多页网页数据(2017年注册会计师考试《综合素质》考前必看!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2022-04-07 04:06
**▼课程概述:**在网页上应用元素文本获取多条内容,需要写入Excel表格,每次在之前写入的基础上写入一行,即,补充写作。
★培训介绍
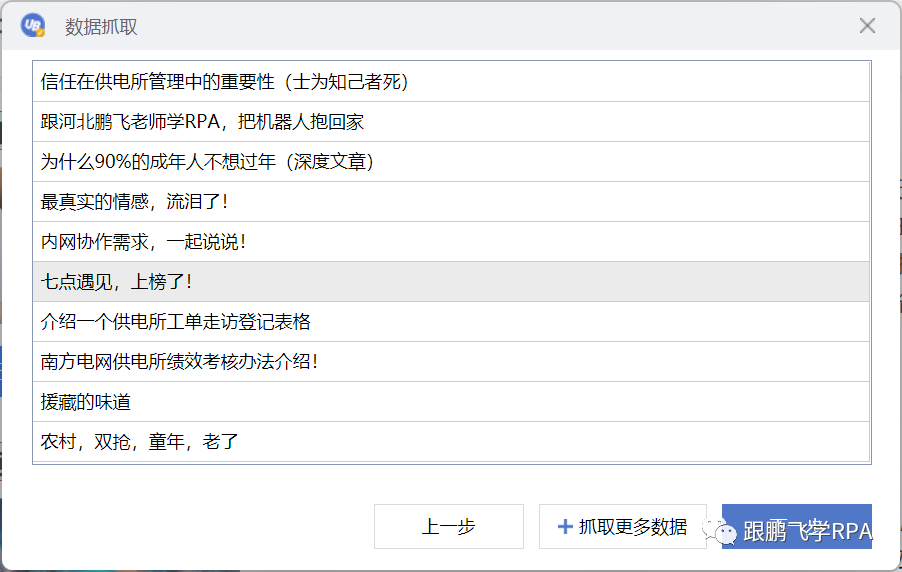
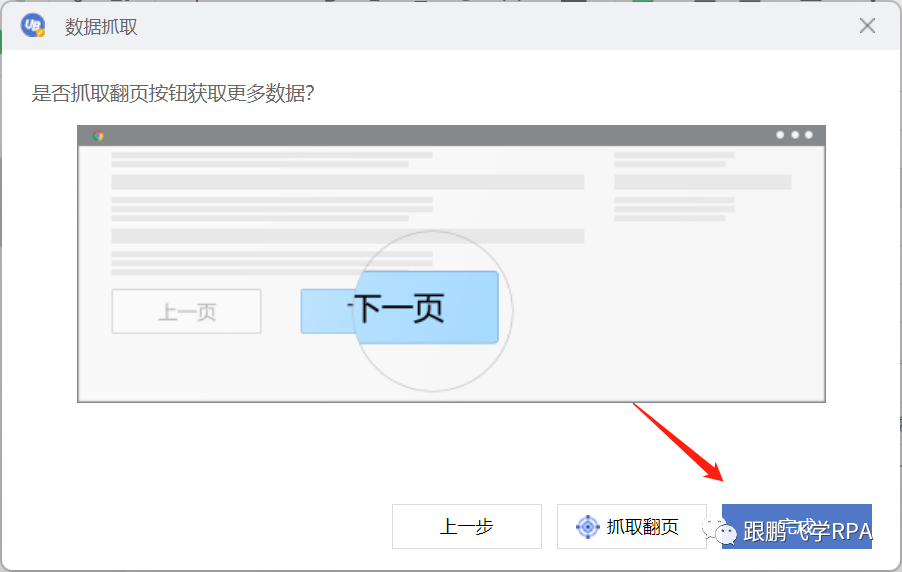
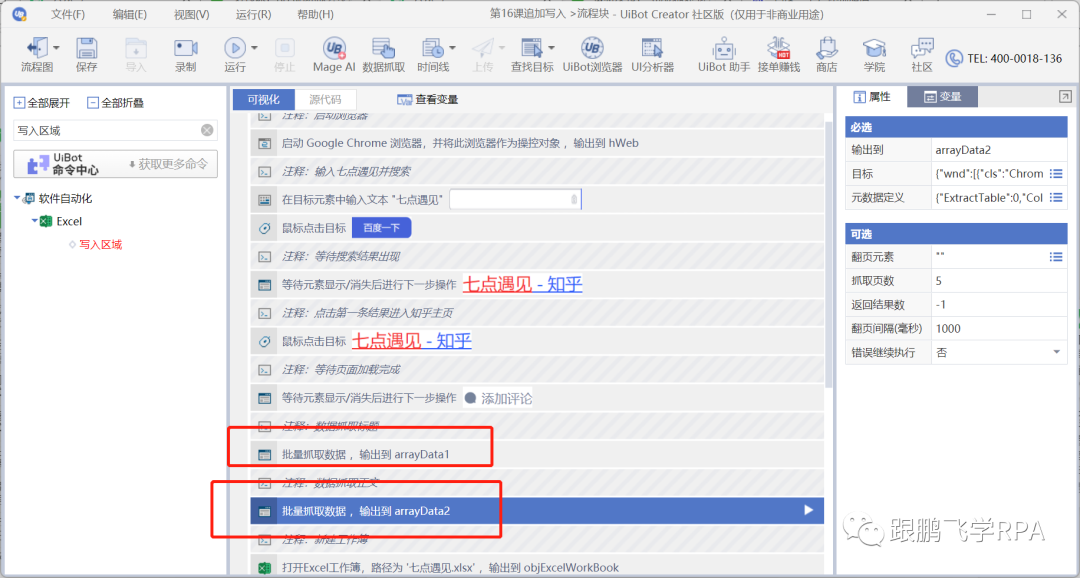
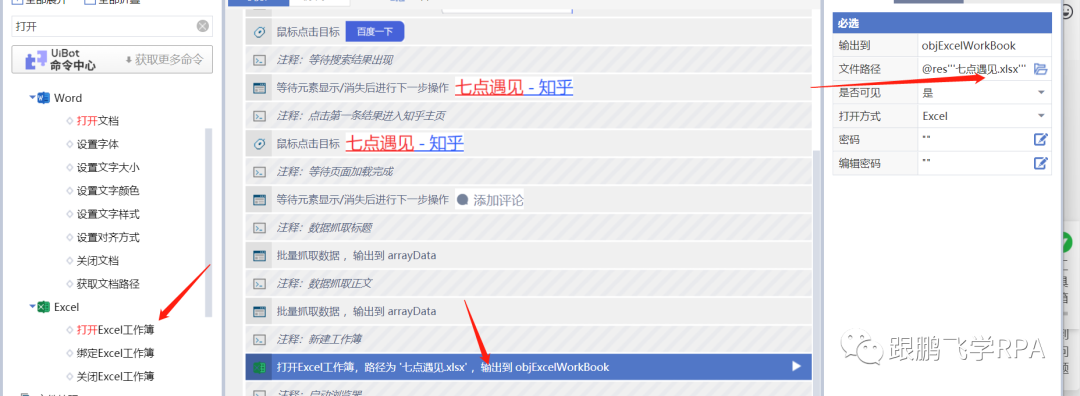
启动谷歌浏览器,打开百度,搜索“七点见面”。七点进入第一个搜索内容的首页-知乎,先用data capture命令获取当前页面的所有title内容,再用data capture命令获取所有文本内容; 创建一个名为 "7 o'clock meet" 的新名称,将两次提取的结果附加到表中。
所需命令:启动浏览器、等待元素、单击目标、数据抓取、打开 Excel 工作簿、获取行数、写入区域。
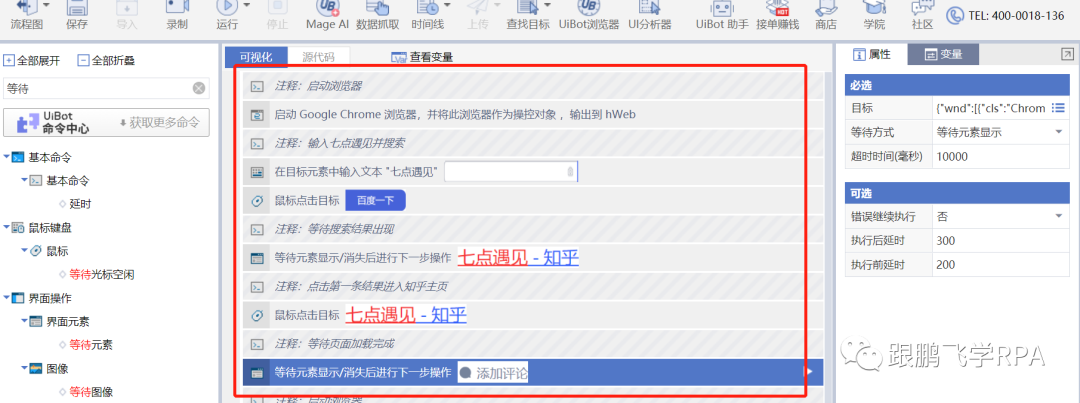
★动作分割
▼启动浏览器,进入《七点见面》首页知乎
前面的课已经详细讨论过了,这里鹏飞老师只贴代码。
注意,每次跳转到一个页面,都需要添加一个“等待元素”命令,以提高程序稳定性;注意为每个命令添加注释,以提高代码的可读性。
▼数据抓取标题和正文内容
应用数据抓取功能,注意标题和正文不是同一个块级目标,需要单独抓取。
这里我们回顾一下数据抓取命令。
----点击标题栏中的数据采集命令。
----选择标题目标,然后选择同级标题目标。这里,第二次选择的目标可以是相邻的标题,不需要选择最后一个标题。
----我们要获取的是文本内容,查看文本即可,这次不是链接。
----此时可以看到数据抓取成功,点击下一步。
----本次只抓取当前页面的数据,点击Finish结束。
获取到标题内容后,使用数据抓取功能再次抓取文字,这里不再演示。
▼创建一个新的工作簿并附加到它
----创建一个名为“七点见面”的新工作簿
使用打开Excel工作簿的命令,配置路径为源目录文件夹。老师用了@res“七点见.xlsx”的写法。如果你不明白也没关系。下一堂课,鹏飞老师会用一节课时间讲解路径。先照葫芦画写。
请注意,创建新工作簿和打开工作簿都是命令。
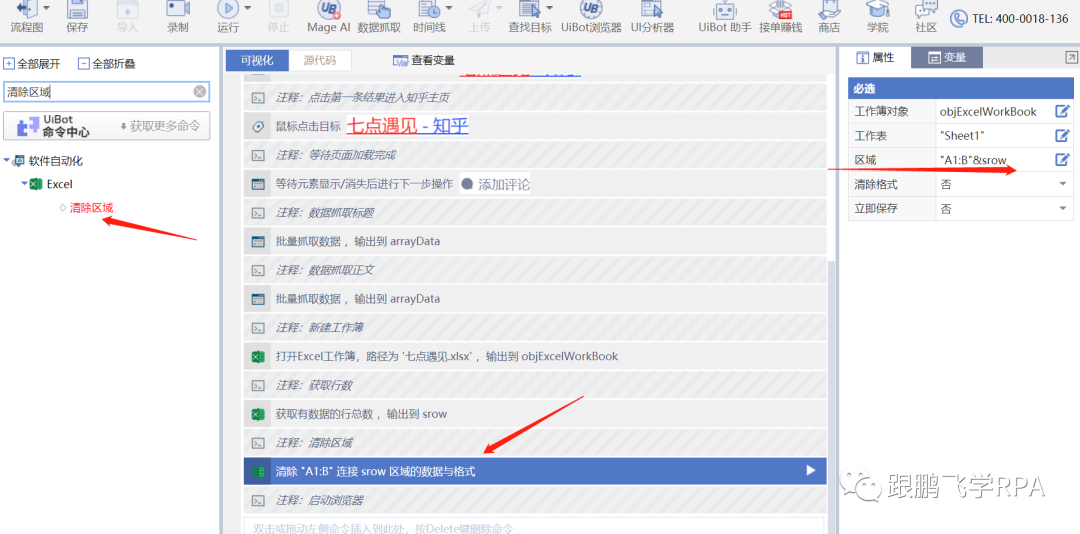
---- 清除区域
写之前的必要操作。因为不是我们打开的表格一定是空白的。因此,在写入之前使用 clear area 命令清除原创数据。
但在这里我们必须先做一件事。
因为范围的形式是“A1:B2”,所以 B2 中的“2”表示最后一行编号。因此,我们需要先获取当前表格行号srow,然后将区域拼接到“A1:B”&srow,清除数据。
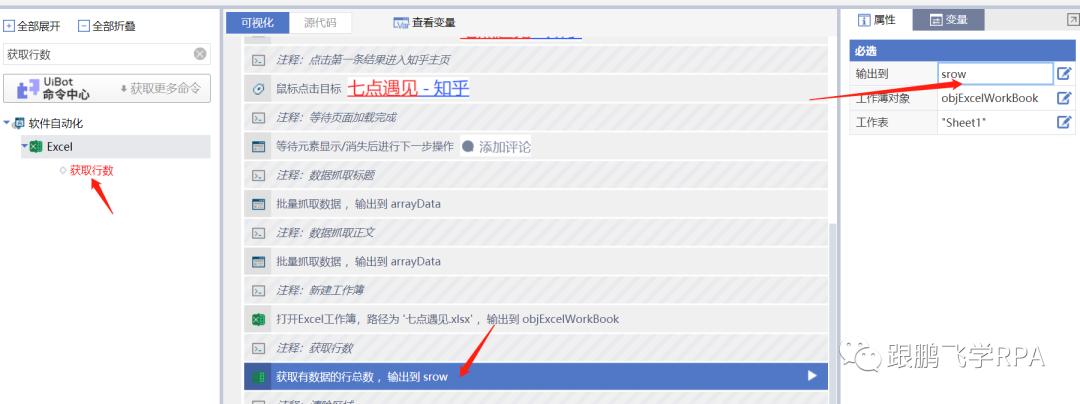
要获取行数,一如既往的注意工作簿对象和工作表名称是否正确。
现在您可以清除该区域。
配置区域为“A1:B”&srow,还要注意两个坑:工作簿对象和工作表名称。
---- 写标题
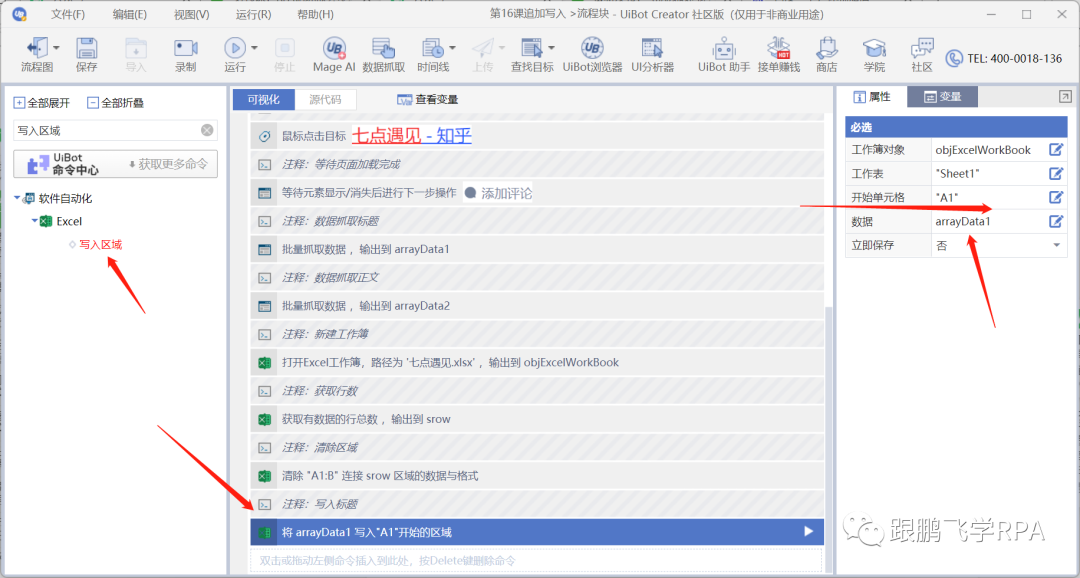
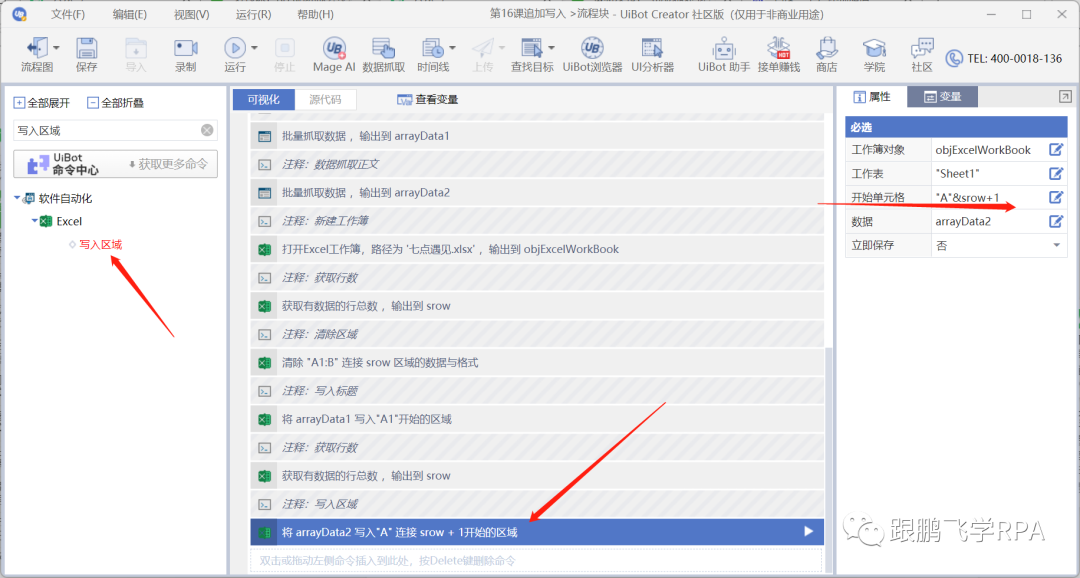
数据抓取的结果是一个二维数组,写入所需的命令就是写入区域。
因为原表是空白的,所以写入的起始单元格是A1,数据是之前抓取并赋值的变量arrayData1。还要注意两个坑。
好了,敲黑板,划重点!
现在开始追加和写入文本内容,如何实现呢?
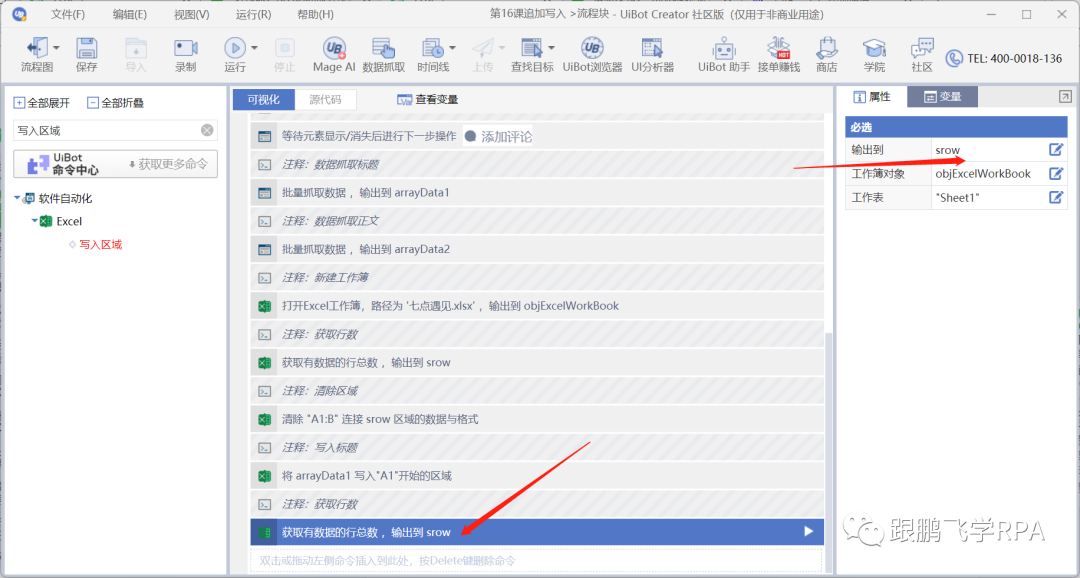
附加写入意味着在现有行数中添加新行以开始写入。所以第一步要做的是再次获取现有的行数。
---- 获取行数
---- 拼接区域
写标题也需要使用 write area 命令。该命令需要配置的主要内容是起始单元格。
补充写,起始单元格应该是A列,原创行数+1行(即刚刚得到的行数srow),拼接后应该是“A”&srow+1。数据应该是grab给出的变量arrayData2。
因此,配置写入正文内容的代码应该这样写:
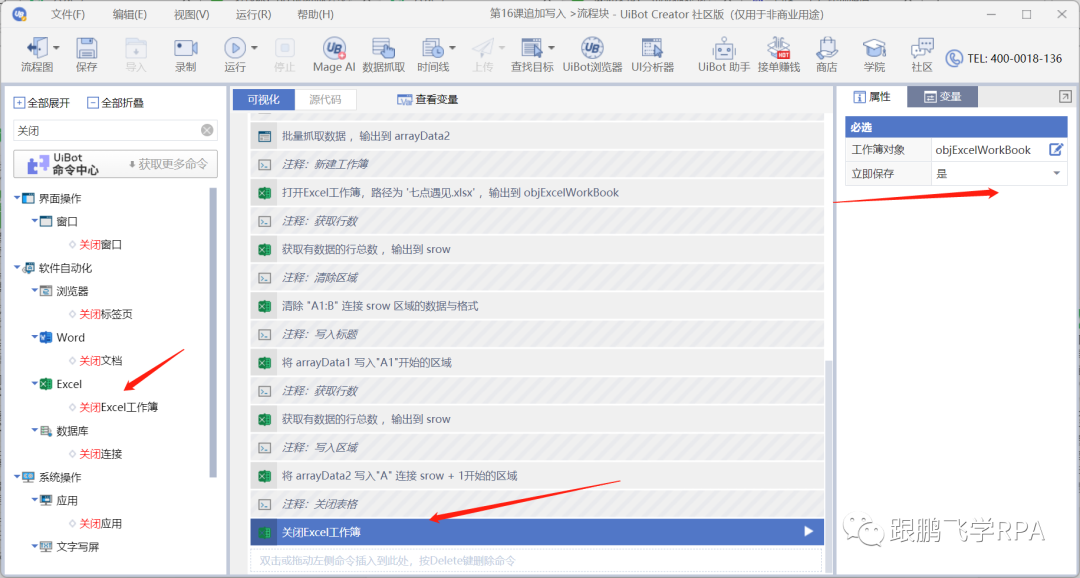
▼关闭工作簿
默认是自动保存。编程结束。
===
★明天通知
如何使用路径。
你学会了吗?下课! 查看全部
excel抓取多页网页数据(2017年注册会计师考试《综合素质》考前必看!)
**▼课程概述:**在网页上应用元素文本获取多条内容,需要写入Excel表格,每次在之前写入的基础上写入一行,即,补充写作。
★培训介绍
启动谷歌浏览器,打开百度,搜索“七点见面”。七点进入第一个搜索内容的首页-知乎,先用data capture命令获取当前页面的所有title内容,再用data capture命令获取所有文本内容; 创建一个名为 "7 o'clock meet" 的新名称,将两次提取的结果附加到表中。
所需命令:启动浏览器、等待元素、单击目标、数据抓取、打开 Excel 工作簿、获取行数、写入区域。
★动作分割
▼启动浏览器,进入《七点见面》首页知乎
前面的课已经详细讨论过了,这里鹏飞老师只贴代码。
注意,每次跳转到一个页面,都需要添加一个“等待元素”命令,以提高程序稳定性;注意为每个命令添加注释,以提高代码的可读性。
▼数据抓取标题和正文内容
应用数据抓取功能,注意标题和正文不是同一个块级目标,需要单独抓取。
这里我们回顾一下数据抓取命令。
----点击标题栏中的数据采集命令。
----选择标题目标,然后选择同级标题目标。这里,第二次选择的目标可以是相邻的标题,不需要选择最后一个标题。
----我们要获取的是文本内容,查看文本即可,这次不是链接。
----此时可以看到数据抓取成功,点击下一步。
----本次只抓取当前页面的数据,点击Finish结束。
获取到标题内容后,使用数据抓取功能再次抓取文字,这里不再演示。
▼创建一个新的工作簿并附加到它
----创建一个名为“七点见面”的新工作簿
使用打开Excel工作簿的命令,配置路径为源目录文件夹。老师用了@res“七点见.xlsx”的写法。如果你不明白也没关系。下一堂课,鹏飞老师会用一节课时间讲解路径。先照葫芦画写。
请注意,创建新工作簿和打开工作簿都是命令。
---- 清除区域
写之前的必要操作。因为不是我们打开的表格一定是空白的。因此,在写入之前使用 clear area 命令清除原创数据。
但在这里我们必须先做一件事。
因为范围的形式是“A1:B2”,所以 B2 中的“2”表示最后一行编号。因此,我们需要先获取当前表格行号srow,然后将区域拼接到“A1:B”&srow,清除数据。
要获取行数,一如既往的注意工作簿对象和工作表名称是否正确。
现在您可以清除该区域。
配置区域为“A1:B”&srow,还要注意两个坑:工作簿对象和工作表名称。
---- 写标题
数据抓取的结果是一个二维数组,写入所需的命令就是写入区域。
因为原表是空白的,所以写入的起始单元格是A1,数据是之前抓取并赋值的变量arrayData1。还要注意两个坑。
好了,敲黑板,划重点!
现在开始追加和写入文本内容,如何实现呢?
附加写入意味着在现有行数中添加新行以开始写入。所以第一步要做的是再次获取现有的行数。
---- 获取行数
---- 拼接区域
写标题也需要使用 write area 命令。该命令需要配置的主要内容是起始单元格。
补充写,起始单元格应该是A列,原创行数+1行(即刚刚得到的行数srow),拼接后应该是“A”&srow+1。数据应该是grab给出的变量arrayData2。
因此,配置写入正文内容的代码应该这样写:
▼关闭工作簿
默认是自动保存。编程结束。
===
★明天通知
如何使用路径。
你学会了吗?下课!
excel抓取多页网页数据(vba抓取网页表格数据:用Excel自动获取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-04 02:20
vba 抓取网页表单数据
第一条:用Excel自动获取网页数据 使用Excel自动获取网页数据,例如从网页自动获取基金净值数据,获取感兴趣基金的净值,列出最高的基金当天增加。本文使用简单的 Web 查询结合 Excel 公式来完成上述需求。当然,VBA也可以用来写一个功能更强大的自动查询网页数据的工具。一:1.创建和编辑网页查询Excel2003数据-导入外部数据-新建网页查询-在“地址”栏输入URL地址(这里我选择基金净值URL:) - 转到 - 选择箭头符号 - 导入 - 外部数据区域属性可以选择在打开工作簿时自动刷新选项选中选项打开工作簿时,将自动从指定的网页获取打开文档的时间。Excel2007数据-来自网站-在“地址”栏输入URL地址-转到... 下面和excel2003的设置方法一样2.这一步很简单罗列关注基金净值,使用vlookup在更新表格中查询关注基金净值并显示在汇总页在“基金净值”表的K列中,65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 查看全部
excel抓取多页网页数据(vba抓取网页表格数据:用Excel自动获取网页数据)
vba 抓取网页表单数据
第一条:用Excel自动获取网页数据 使用Excel自动获取网页数据,例如从网页自动获取基金净值数据,获取感兴趣基金的净值,列出最高的基金当天增加。本文使用简单的 Web 查询结合 Excel 公式来完成上述需求。当然,VBA也可以用来写一个功能更强大的自动查询网页数据的工具。一:1.创建和编辑网页查询Excel2003数据-导入外部数据-新建网页查询-在“地址”栏输入URL地址(这里我选择基金净值URL:) - 转到 - 选择箭头符号 - 导入 - 外部数据区域属性可以选择在打开工作簿时自动刷新选项选中选项打开工作簿时,将自动从指定的网页获取打开文档的时间。Excel2007数据-来自网站-在“地址”栏输入URL地址-转到... 下面和excel2003的设置方法一样2.这一步很简单罗列关注基金净值,使用vlookup在更新表格中查询关注基金净值并显示在汇总页在“基金净值”表的K列中,65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序
excel抓取多页网页数据(搜索引擎如何充分收录网站页面、如何索引、排序问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-03 14:06
项目投资找A5快速获取精准代理商名单
28日,百度正式发布了《搜索引擎索引系统概述》,对搜索引擎如何抓取页面、如何索引、如何排序进行了大致的阐述。那么对于网站的管理者来说,如何利用这些规则让网站上的优秀内容更好的展示给用户呢?在Q猪看来,需要解决以下问题:
第一个问题,如何完全捕获网站数据
分析:从网站的结构层面来解释这个问题,为了让百度完整的收录网站页面,需要尽可能的最大化搜索引擎蜘蛛的爬取网站 ,这需要一个简单、清晰、分层的 网站 结构。至于什么是合理的网站结构,很多百度文档都提到它是mesh flat tree结构。
1、Net保证每个页面至少有一个文本链接指向,这样可以让网站被尽可能全面地爬取收录,内链建设也可以起到积极的作用排序。
2、Flatness保证了从首页到内页的层数尽量少,对爬取友好,可以很好的传递权重。
3、典型的树形结构为:首页-频道页-内容页
为了增强搜索引擎对每个页面在整个网站中的位置感,我们增加了导航,包括顶部、面包屑、底部导航等。需要注意的是,导航的主要目的只是确定页面所在位置网站中的位置,导航是这些链接最重要的属性,所以尽量自然,不要堆积关键词。
一个类似于导航的功能是 URL 的规范化。一个简洁美观的网址不仅可以让用户和搜索引擎自然地了解页面的主要内容,而且还具有网站位置导航的功能。同样,Q Pig 需要强调的是 URL 应该尽可能短。在中文搜索优化中,URL是否收录关键词对页面的排名影响不大,比如Q猪的这个文章:百度关于搜索原理的阐述,URL1是/seo/ baiduguanyusousyuanlidechanshu.html,URL2是/seo/123.html,Q猪的选择是URL2。
搜索引擎在抓取页面时,有两个问题需要特别注意:内容不能重复,浏览量不能重复。为 网站 评分,后者是为了避免不必要的内部竞争。
第二个问题,搜索引擎如何索引
分析:用户在搜索框中输入关键词,句子。搜索引擎在输出结果之前,需要对网络上数以亿计的页面进行分析整理,存入数据库,并建立索引。当@关键词时,按照重要性从高到低的顺序呈现给用户,也解释了为什么搜索引擎可以在用户输入关键词后的几毫秒内输出结果。
那么,搜索引擎如何分析网站页面并建立索引呢?
目前,所有引擎都是通过不断的识别和标记来分析页面内容的。每个 URL 都用不同的标签进行标记,存储在数据库中,然后根据 原创 属性和页面权重等因素进行排序。以Q猪的《百度搜索原理讲解》为例。通过识别,本文可分为:Baidu、About、Search、Principle、De、Explanation。有关搜索引擎如何分词的详细信息,您可以阅读 Q Pig 文章 的另一篇文章:搜索引擎如何理解文档。
需要指出的是,搜索引擎页面分析的过程实际上是对原创页面的不同部分进行识别和标记,例如:标题、关键字、内容、链接、锚点、评论、其他非重要区域等,所以在页面优化的时候,需要特别注意标题、关键词布局、主要内容、内外链接的描述、评论。
第三个问题,搜索引擎如何输出结果
分析:内容被标记索引后,当用户搜索关键词时,搜索引擎可以根据不同的组合和各种排名算法因素,按重要性倒序输出各种结果。
例子:
百度-0x123abc
关于-0x13445d
搜索 - 0x234d
原则 - 0x145cf
详细说明 - 0x354df
在每个分词下,有不同的页面:
0x123abc-1,3,4,7,8,11。.
0x13445d-2,5,8,9,11
如果要检索的关键词是:0x123abc+0x13445d,那么8和11会匹配结果。
需要指出的是,符合要求的结果要逐层过滤,包括过滤掉死链接、重复数据、色情、垃圾结果,以及你所知道的。. . 首先对最符合用户需求的结果进行排序,可能包括有用的信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配度、分散度、及时性、等详细内容可以查看Q猪的哪些因素可以提升网站的排名。 查看全部
excel抓取多页网页数据(搜索引擎如何充分收录网站页面、如何索引、排序问题)
项目投资找A5快速获取精准代理商名单
28日,百度正式发布了《搜索引擎索引系统概述》,对搜索引擎如何抓取页面、如何索引、如何排序进行了大致的阐述。那么对于网站的管理者来说,如何利用这些规则让网站上的优秀内容更好的展示给用户呢?在Q猪看来,需要解决以下问题:
第一个问题,如何完全捕获网站数据
分析:从网站的结构层面来解释这个问题,为了让百度完整的收录网站页面,需要尽可能的最大化搜索引擎蜘蛛的爬取网站 ,这需要一个简单、清晰、分层的 网站 结构。至于什么是合理的网站结构,很多百度文档都提到它是mesh flat tree结构。
1、Net保证每个页面至少有一个文本链接指向,这样可以让网站被尽可能全面地爬取收录,内链建设也可以起到积极的作用排序。
2、Flatness保证了从首页到内页的层数尽量少,对爬取友好,可以很好的传递权重。
3、典型的树形结构为:首页-频道页-内容页
为了增强搜索引擎对每个页面在整个网站中的位置感,我们增加了导航,包括顶部、面包屑、底部导航等。需要注意的是,导航的主要目的只是确定页面所在位置网站中的位置,导航是这些链接最重要的属性,所以尽量自然,不要堆积关键词。
一个类似于导航的功能是 URL 的规范化。一个简洁美观的网址不仅可以让用户和搜索引擎自然地了解页面的主要内容,而且还具有网站位置导航的功能。同样,Q Pig 需要强调的是 URL 应该尽可能短。在中文搜索优化中,URL是否收录关键词对页面的排名影响不大,比如Q猪的这个文章:百度关于搜索原理的阐述,URL1是/seo/ baiduguanyusousyuanlidechanshu.html,URL2是/seo/123.html,Q猪的选择是URL2。
搜索引擎在抓取页面时,有两个问题需要特别注意:内容不能重复,浏览量不能重复。为 网站 评分,后者是为了避免不必要的内部竞争。
第二个问题,搜索引擎如何索引
分析:用户在搜索框中输入关键词,句子。搜索引擎在输出结果之前,需要对网络上数以亿计的页面进行分析整理,存入数据库,并建立索引。当@关键词时,按照重要性从高到低的顺序呈现给用户,也解释了为什么搜索引擎可以在用户输入关键词后的几毫秒内输出结果。
那么,搜索引擎如何分析网站页面并建立索引呢?
目前,所有引擎都是通过不断的识别和标记来分析页面内容的。每个 URL 都用不同的标签进行标记,存储在数据库中,然后根据 原创 属性和页面权重等因素进行排序。以Q猪的《百度搜索原理讲解》为例。通过识别,本文可分为:Baidu、About、Search、Principle、De、Explanation。有关搜索引擎如何分词的详细信息,您可以阅读 Q Pig 文章 的另一篇文章:搜索引擎如何理解文档。
需要指出的是,搜索引擎页面分析的过程实际上是对原创页面的不同部分进行识别和标记,例如:标题、关键字、内容、链接、锚点、评论、其他非重要区域等,所以在页面优化的时候,需要特别注意标题、关键词布局、主要内容、内外链接的描述、评论。
第三个问题,搜索引擎如何输出结果
分析:内容被标记索引后,当用户搜索关键词时,搜索引擎可以根据不同的组合和各种排名算法因素,按重要性倒序输出各种结果。
例子:
百度-0x123abc
关于-0x13445d
搜索 - 0x234d
原则 - 0x145cf
详细说明 - 0x354df
在每个分词下,有不同的页面:
0x123abc-1,3,4,7,8,11。.
0x13445d-2,5,8,9,11
如果要检索的关键词是:0x123abc+0x13445d,那么8和11会匹配结果。
需要指出的是,符合要求的结果要逐层过滤,包括过滤掉死链接、重复数据、色情、垃圾结果,以及你所知道的。. . 首先对最符合用户需求的结果进行排序,可能包括有用的信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配度、分散度、及时性、等详细内容可以查看Q猪的哪些因素可以提升网站的排名。
excel抓取多页网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-03 00:03
【PConline Tips】有时我们需要从网站获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
先打开要爬取的网页
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在复选框中显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
创建查询以确定提取的范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
数据“预清理”
4.格式化
将数据上传到 Excel 后,您可以继续对其进行格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
美化餐桌
5.设置自动同步间隔
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
防止更新时表格格式被破坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用! 查看全部
excel抓取多页网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
【PConline Tips】有时我们需要从网站获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
先打开要爬取的网页
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在复选框中显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
创建查询以确定提取的范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
数据“预清理”
4.格式化
将数据上传到 Excel 后,您可以继续对其进行格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
美化餐桌
5.设置自动同步间隔
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
防止更新时表格格式被破坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用!
excel抓取多页网页数据(【每日一题】:大海,上次你教我《》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-02 13:14
小琴:大海,上次你教我“”的内容,我已经练习过了,这一次,继续教我多爬几页。
大海:嗯,其实爬几个页面的方法和爬一个是一样的,但是分别爬完每个页面之后,我们需要整合数据。
小琴:鹅……
大海:首先,我们还是按页爬取数据。比如我们要爬取1、5、10等三页数据,然后整合在一起。更多页面的工作方式完全相同,您可以自己练习。
第 1 步:查看 网站 第 1、5、10 页上的链接
Step-2:【新查询】-【来自其他来源】-【来自网站】
Step-3:填写网址(网址)-【确定】进入PQ操作界面
Step-4:选择股票信息所在的表——【编辑】
Step-5:将第1页的查询命名为“page 1”(根据自己的喜好),方便后续区分
Step-6: 加载数据 [关闭并上传] - [关闭并上传到...]
——因为我们不需要直接显示这个单独页面的数据,所以【只创建一个连接】可以
重复Step-2到Step6,分别应用第5页和第10页的URL创建新的查询,获取对应页面的数据。最后在Excel中创建了3个查询,如下图所示:
Step-7:整合数据【新建查询】-【合并查询】-【追加】
Step-8: 选择要合并的表
Step-9:设置数据隐私信息
Step-10:修改查询名称为“Integration 1-5-10”(可以随意命名)
Step-11:过滤去除数据时间线
步骤 11:删除多余的列
步骤 12:上传数据
因为需要在Excel中显示整个数据,所以只需点击【关闭并上传】按钮,最终结果如下图所示:
小琴:太好了。中间虽然做了很多步骤,但也接触到了一些新知识:
大海:嗯,总结的很好。
小琴:什么时候教我们爬取所有页面?
大海:这个有点难。它涉及自定义功能,这些功能是高级内容。我会一一为大家讲解PQ的基础知识。练了之后,我们一起练。
小琴:嗯。不要着急,不要等待!你说得真好! 查看全部
excel抓取多页网页数据(【每日一题】:大海,上次你教我《》)
小琴:大海,上次你教我“”的内容,我已经练习过了,这一次,继续教我多爬几页。
大海:嗯,其实爬几个页面的方法和爬一个是一样的,但是分别爬完每个页面之后,我们需要整合数据。
小琴:鹅……
大海:首先,我们还是按页爬取数据。比如我们要爬取1、5、10等三页数据,然后整合在一起。更多页面的工作方式完全相同,您可以自己练习。
第 1 步:查看 网站 第 1、5、10 页上的链接
Step-2:【新查询】-【来自其他来源】-【来自网站】
Step-3:填写网址(网址)-【确定】进入PQ操作界面
Step-4:选择股票信息所在的表——【编辑】
Step-5:将第1页的查询命名为“page 1”(根据自己的喜好),方便后续区分
Step-6: 加载数据 [关闭并上传] - [关闭并上传到...]
——因为我们不需要直接显示这个单独页面的数据,所以【只创建一个连接】可以
重复Step-2到Step6,分别应用第5页和第10页的URL创建新的查询,获取对应页面的数据。最后在Excel中创建了3个查询,如下图所示:
Step-7:整合数据【新建查询】-【合并查询】-【追加】
Step-8: 选择要合并的表
Step-9:设置数据隐私信息
Step-10:修改查询名称为“Integration 1-5-10”(可以随意命名)
Step-11:过滤去除数据时间线
步骤 11:删除多余的列
步骤 12:上传数据
因为需要在Excel中显示整个数据,所以只需点击【关闭并上传】按钮,最终结果如下图所示:
小琴:太好了。中间虽然做了很多步骤,但也接触到了一些新知识:
大海:嗯,总结的很好。
小琴:什么时候教我们爬取所有页面?
大海:这个有点难。它涉及自定义功能,这些功能是高级内容。我会一一为大家讲解PQ的基础知识。练了之后,我们一起练。
小琴:嗯。不要着急,不要等待!你说得真好!
excel抓取多页网页数据(python爬虫入门,经典例题top250,将数据保存到数据库和Excel中 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-02 05:15
)
python爬虫入门,top250经典例子,存数据到数据库和Excel没过)。
首先,这是一个静态的网站,所有的电影信息一次性发给客户端,只要拿到服务器发回的网页然后提取字符串就可以得到想要的信息。
本次用到的库:
import re # 正则表达式进行文字匹配
import requests # 第三方库,获取网页数据
import xlwt # 进行Excel操作
import sqlite3 # 进行数据库操作
第一步是访问URL获取指定的URL内容:
# 访问URL得到一个指定的URL内容
def askUrl(baseurl,param):
# # 模拟浏览器头部信息,向服务器发送消息
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
# response 用来封装接收从服务器返回的信息
response = requests.get(baseurl,params=param,headers=header)
html = response.text
# 关闭与服务器的连接:
response.close() # response.close()关闭与服务器的连接,如果不关闭连接会一直保持连接,最后堵死
return html
第二步,获取网页并一一解析数据:
这一次,只使用正则表达式来解析数据。正则表达式的定义规则如下:
<p># 正则表达式,定义规则:
# 找到每一部电影的大体位置:
find_location = re.compile(r'(.*?)',re.S) # 使得‘.’的匹配包括换行符在内
# 获取影片的链接:
find_link = re.compile(r'<a href="(.*?)">')
# 获取影片的名字:
find_name = re.compile(r'(.*?)')
# 获取影片的图片
find_picture = re.compile(r' 查看全部
excel抓取多页网页数据(python爬虫入门,经典例题top250,将数据保存到数据库和Excel中
)
python爬虫入门,top250经典例子,存数据到数据库和Excel没过)。
首先,这是一个静态的网站,所有的电影信息一次性发给客户端,只要拿到服务器发回的网页然后提取字符串就可以得到想要的信息。
本次用到的库:
import re # 正则表达式进行文字匹配
import requests # 第三方库,获取网页数据
import xlwt # 进行Excel操作
import sqlite3 # 进行数据库操作
第一步是访问URL获取指定的URL内容:
# 访问URL得到一个指定的URL内容
def askUrl(baseurl,param):
# # 模拟浏览器头部信息,向服务器发送消息
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
# response 用来封装接收从服务器返回的信息
response = requests.get(baseurl,params=param,headers=header)
html = response.text
# 关闭与服务器的连接:
response.close() # response.close()关闭与服务器的连接,如果不关闭连接会一直保持连接,最后堵死
return html
第二步,获取网页并一一解析数据:
这一次,只使用正则表达式来解析数据。正则表达式的定义规则如下:
<p># 正则表达式,定义规则:
# 找到每一部电影的大体位置:
find_location = re.compile(r'(.*?)',re.S) # 使得‘.’的匹配包括换行符在内
# 获取影片的链接:
find_link = re.compile(r'<a href="(.*?)">')
# 获取影片的名字:
find_name = re.compile(r'(.*?)')
# 获取影片的图片
find_picture = re.compile(r'
excel抓取多页网页数据(Java|Java生成Excel表1-100学算法思维(五))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-28 00:12
Java|Java生成Excel表格
1 问题描述我最近遇到一个问题,就是在系统页面添加Excel表格的问题。这个问题很容易解决。写个 JS 把后台给的数据导出到 Excel 表格里不就行了。但是,当我们进行测试时,它并不总是像我想要的那样工作。这是有麻烦的。IE和360浏览器不支持我写的JS代码。我不能让别人使用我的系统并提前安装谷歌浏览器。这绝对行不通。或者另一种方法来实现我的导出Excel表格的功能。3 解决方案由于JS存在兼容性问题,我不需要JS。我在后台直接把数据整理成一个Excel表格,前端只需要下载这个表格的总行即可。照你说的做,修改后台代码,并使用Java生成Excel表格。完成之后,我们只需要在我们页面的按钮上添加一个简单的点击事件,调用我们的接口来实现导出Excel表格的问题,最后进行测试。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!
1.3K 查看全部
excel抓取多页网页数据(Java|Java生成Excel表1-100学算法思维(五))
Java|Java生成Excel表格
1 问题描述我最近遇到一个问题,就是在系统页面添加Excel表格的问题。这个问题很容易解决。写个 JS 把后台给的数据导出到 Excel 表格里不就行了。但是,当我们进行测试时,它并不总是像我想要的那样工作。这是有麻烦的。IE和360浏览器不支持我写的JS代码。我不能让别人使用我的系统并提前安装谷歌浏览器。这绝对行不通。或者另一种方法来实现我的导出Excel表格的功能。3 解决方案由于JS存在兼容性问题,我不需要JS。我在后台直接把数据整理成一个Excel表格,前端只需要下载这个表格的总行即可。照你说的做,修改后台代码,并使用Java生成Excel表格。完成之后,我们只需要在我们页面的按钮上添加一个简单的点击事件,调用我们的接口来实现导出Excel表格的问题,最后进行测试。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!
1.3K
excel抓取多页网页数据( 新媒体运营来说的爬虫工具——webscraper的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-26 23:16
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对新手小白非常友好,非常简单易学,不需要太复杂的编程代码知识,只需要几个简单的步骤,就可以抓取到需要的内容,而且可以一小时内轻松掌握。
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
安装网络刮刀
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网络爬虫 三、 创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
创建一个新的站点地图
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
网络爬虫参数设置
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
知乎视频
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
知乎视频
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
web scraper 多页抓取
这个傻瓜爬虫工具你有没有,快来实践一下吧! 查看全部
excel抓取多页网页数据(
新媒体运营来说的爬虫工具——webscraper的特点)

对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对新手小白非常友好,非常简单易学,不需要太复杂的编程代码知识,只需要几个简单的步骤,就可以抓取到需要的内容,而且可以一小时内轻松掌握。

一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
安装网络刮刀
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网络爬虫 三、 创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。

创建一个新的站点地图
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
网络爬虫参数设置
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。

多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
知乎视频
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
知乎视频
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
web scraper 多页抓取
这个傻瓜爬虫工具你有没有,快来实践一下吧!
excel抓取多页网页数据(几经新版Excel图表数据联动后保留现有格式修改(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-26 23:15
【新版本发布】EasyShu3.第一版发布,8个图表用于SVG地图可视化,象形柱形图是一个吸睛之作。
优化设置宽高时网页图表居中显示,方便查看图表。优化Excel多数据系列图表数据的数据联动后,保留现有格式修改。新添加的散点标志图形可以自定义为任何图形,包括带有散点系列的图表。Vega图表打开后,数据分析领域,特别是Rpython等数据分析师和数据科学家常用的图表,未来可以包括在内,让普通Excel用户接近零门槛,使用界面交互完成A具有交互功能的网页图。EasyShu的地图可视化解决方案使用了Excel和PPT图表的连接,这是一个很大的突破。借助 EasyShuForPPT 工具,生成的网页格式图表可以直接嵌入到PPT中使用,甚至可以脱离网络需求和离线离线环境。依然有效的EasyShu图表插件——目前为止,个人开发的Excel图表插件中,是我见过最好的产品,以至于看到这个插件后,放弃了在线开发图表的想法课程——全部一键完成图表,谁愿意自己学习这个插件的最大功能,就是帮助那些不会做图表的人,奈何过去一直忙于工作,而直到去年,他才与【Excel Catalyst】的李伟建先生合作开发了这款新版的Excel图表插件EasyShu。经过多次修改和升级,
266 查看全部
excel抓取多页网页数据(几经新版Excel图表数据联动后保留现有格式修改(图))
【新版本发布】EasyShu3.第一版发布,8个图表用于SVG地图可视化,象形柱形图是一个吸睛之作。
优化设置宽高时网页图表居中显示,方便查看图表。优化Excel多数据系列图表数据的数据联动后,保留现有格式修改。新添加的散点标志图形可以自定义为任何图形,包括带有散点系列的图表。Vega图表打开后,数据分析领域,特别是Rpython等数据分析师和数据科学家常用的图表,未来可以包括在内,让普通Excel用户接近零门槛,使用界面交互完成A具有交互功能的网页图。EasyShu的地图可视化解决方案使用了Excel和PPT图表的连接,这是一个很大的突破。借助 EasyShuForPPT 工具,生成的网页格式图表可以直接嵌入到PPT中使用,甚至可以脱离网络需求和离线离线环境。依然有效的EasyShu图表插件——目前为止,个人开发的Excel图表插件中,是我见过最好的产品,以至于看到这个插件后,放弃了在线开发图表的想法课程——全部一键完成图表,谁愿意自己学习这个插件的最大功能,就是帮助那些不会做图表的人,奈何过去一直忙于工作,而直到去年,他才与【Excel Catalyst】的李伟建先生合作开发了这款新版的Excel图表插件EasyShu。经过多次修改和升级,
266
excel抓取多页网页数据(东方财富网财务报表10年近百万行财务报表数据学习方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-03-20 20:08
本文转载自以下网站:50行代码爬取东方财富网上市公司近百万行财务报表数据10年
主要学习地点:
1.分析网站的ajax请求信息
2.构造参数
3.发起请求后处理获取到的数据
4.保存表单
重点:分析表单类网站的ajax请求,以及如何保存这类信息(关于表单)
通过分析 URL 的 JavaScript 请求,它可以以比 Selenium 快 100 倍的方法快速爬取东方财富网历年各上市公司的财务报表数据。
摘要:在上一篇文章中,我们成功使用Selenium爬取了东方财富网的财务报表数据,但是速度很慢。爬取 70 个页面需要几十分钟。为了加快速度,本文分析网页的JavaScript请求,找到数据接口,然后快速爬取财务报表数据。
1. JavaScript 请求分析
在上一篇文章文章中,我们简单的划分了东方财富网财务报表网页后台的js请求,文章回顾:()
接下来,我们向下钻取。首先,点击报告底部的 Next Page,然后观察左侧的 Name 列,看看弹出了哪些新请求:
可以看到,连续点击下一页时,会弹出get?以类型开头的请求。点击右侧的Headers选项卡,可以看到请求的URL,URL很长,暂时忽略,后面会分析参数。然后,点击右侧的Preview and Response,可以看到里面有很多整齐的数据。试着猜测这可能是财务报表中的数据。和表格对比后发现,这正是我们需要的数据,太好了。
然后将URL复制到新链接并打开,可以看到表格中的数据显示完美。可以在不添加Headers和UA请求的情况下获取。看来东方财富网是很慷慨的。
至此,爬取思路就很清晰了。首先使用Request请求URL,对获取的数据进行正则匹配,将数据转换成json格式,然后写入本地文件,最后添加分页循环进行爬取。这比以前的 Selenium 简单得多,并且应该快很多倍。我们先尝试爬取一页数据来看看。
2. 爬取单页2.1. 爬取分析
这里我们还是以2018年中报的利润表为例,抓取网页表格数据的第一页,网页url为:
表格第一页js请求的url为:%20spmVUpAF={pages:(tp),data:%20(x)}&filter=(reportdate=^2018-06-30^)&rt=51312886,数据:%20 (x)}&filter=(reportdate=^2018-06-30^)&rt=51312886)
接下来,我们通过分析 url 来抓取表格内容。
import requests
def get_table():
params = {
'type': 'CWBB_LRB',
这里我们定义了一个get_table()方法来输出抓取到的表格第一页的内容。params 是 url 请求中收录的参数。
这里简单说明一下重要参数:type是7个表的类型说明,type分为'CWBB_'和'LRB'、资产负债表等两部分。最后3个表以'CWBB_开头',以及绩效报告到前4个表格,如任命披露时间表,以'YJBB20_'开头;“LRB”是损益表的首字母缩写词,同样,绩效表是“YJBB”。所以,如果要爬取不同的表,就需要改变type参数。'filter'是表格过滤参数,其中过滤掉了中报的数据。不同的表过滤条件会有所不同,所以当类型类型改变时,过滤器类型也要相应修改。
设置好params参数后,将url和params参数传入requests.get()方法,这样请求连接就构建好了。几行代码就可以成功获取网页首页的表格数据:
可以看到,表信息存放在LFtlXDqn变量中,pages表示该表有72页。data是表数据,它是一个由多个字典组成的列表,每个字典是表中的一行数据。我们可以通过正则表达式分别提取页面和数据数据。
2.2. 正则表达式抽取表
这里使用 \d+ 匹配页数中的值,然后使用 re.search() 方法进行提取。group(1) 表示输出第一个结果,这里是()中的页数。
这里用(.*)来匹配表数据,表示贪婪匹配,因为数据中有很多字典,每个字典都以'}'结尾,所以我们使用贪婪匹配到最后一个'}',以便获取数据 所有数据。在大多数情况下,我们可能会使用 (.*?),表示非贪婪匹配,即最多匹配一个 '}'。在这种情况下,我们只能匹配第一行数据,这显然是错误的。
2.3. json.loads() 输出形式
这里提取的列表是str字符类型,我们需要将其转换为list列表类型。为什么要把它转成list类型,因为不能用操作list的方法来操作str,比如list slice。转换为列表后,我们可以对列表进行切片。例如data[0]可以获取第一个{}中的数据,也就是表格的第一行,方便后续构建循环逐行输出表格数据。这里使用 json.loads() 方法将 str 转换为 list。
接下来我们将表格内容输入到 csv 文件中。
通过for循环,依次取出表中的每一行字典数据{},然后使用with...open方法写入'eastmoney.csv'文件。
Tips:“a”表示可重写;encoding='utf_8_sig' 可以防止csv文件中的汉字出现乱码;换行为空,以避免每行数据出现空行。
这样第一页50行的表格数据就成功输出到了csv文件中:
在这里,我们还可以在输出表之前添加一个表头:
这里data[0]表示列表的字典中的数据,data[0].keys()表示获取字典中的key值,即列标题。在外面添加一个列表序列化(结果如下),然后将列表输出到'eastmoney.csv'作为表的列标题。
['scode', 'hycode', 'companycode', 'sname', 'publishname', 'reporttimetypecode', 'combinetypecode', 'dataajusttype', 'mkt', 'noticedate', 'reportdate', 'parentnetprofit', 'totaloperatereve', 'totaloperateexp', 'totaloperateexp_tb', 'operateexp', 'operateexp_tb', 'saleexp', 'manageexp', 'financeexp', 'operateprofit', 'sumprofit', 'incometax', 'operatereve', 'intnreve', 'intnreve_tb', 'commnreve', 'commnreve_tb', 'operatetax', 'operatemanageexp', 'commreve_commexp', 'intreve_intexp', 'premiumearned', 'premiumearned_tb', 'investincome', 'surrenderpremium', 'indemnityexp', 'tystz', 'yltz', 'sjltz', 'kcfjcxsyjlr', 'sjlktz', 'eutime', 'yyzc']
44
以上就完成了单页表单的爬取下载到本地的过程。
3. 多页表单爬取
将上面的代码整理成对应的函数,然后添加一个for循环。只需50行代码就可以爬取72页的利润报告数据:
import requests
import re
import json
import csv
import time
def get_table(page):
params = {
'type': 'CWBB_LRB',
整个下载只用了20多秒,之前用selenium要几十分钟,效率提升了100倍!
在这里,如果我们要下载所有时期(2007 年到 2018 年)的利润表数据,也很简单。只要将type中的filter参数注释掉,即不过滤日期,则可以下载所有时段的数据。在这里,当我们取消过滤栏的注释时,我们会发现page_all的总页数会从2018年中报的72页增加到2528页。全部下载完成后,表有12万多行数据。基于这些数据,你可以尝试从中做一些有价值的数据分析。
4. 通用代码结构
以上代码实现了对2018年中期利润报告的爬取,但如果不想局限于本报告,还想爬取其他报告或任何时期的其他数据,则需要手动修改代码,很不方便。方便。所以上面的代码可以说很短但不够强大。
为了能够灵活的爬取任意类别、任意时期的报表数据,需要对代码进行一些处理,进而构建出通用的强大爬虫程序。
"""
e.g: http://data.eastmoney.com/bbsj/201806/lrb.html
"""
import requests
import re
from multiprocessing import Pool
import json
import csv
import pandas as pd
import os
import time
以爬取2018年中业绩报告为例,感受一下比selenium快很多的爬取效果(视频链接):
使用上述程序,我们可以下载任何时期的数据和任何报告。在这里,我下载并完成了2018年中报中所有7个报表的数据。
文中的代码和素材资源可以从以下链接获取: 查看全部
excel抓取多页网页数据(东方财富网财务报表10年近百万行财务报表数据学习方法(组图))
本文转载自以下网站:50行代码爬取东方财富网上市公司近百万行财务报表数据10年
主要学习地点:
1.分析网站的ajax请求信息
2.构造参数
3.发起请求后处理获取到的数据
4.保存表单
重点:分析表单类网站的ajax请求,以及如何保存这类信息(关于表单)
通过分析 URL 的 JavaScript 请求,它可以以比 Selenium 快 100 倍的方法快速爬取东方财富网历年各上市公司的财务报表数据。
摘要:在上一篇文章中,我们成功使用Selenium爬取了东方财富网的财务报表数据,但是速度很慢。爬取 70 个页面需要几十分钟。为了加快速度,本文分析网页的JavaScript请求,找到数据接口,然后快速爬取财务报表数据。
1. JavaScript 请求分析
在上一篇文章文章中,我们简单的划分了东方财富网财务报表网页后台的js请求,文章回顾:()
接下来,我们向下钻取。首先,点击报告底部的 Next Page,然后观察左侧的 Name 列,看看弹出了哪些新请求:
可以看到,连续点击下一页时,会弹出get?以类型开头的请求。点击右侧的Headers选项卡,可以看到请求的URL,URL很长,暂时忽略,后面会分析参数。然后,点击右侧的Preview and Response,可以看到里面有很多整齐的数据。试着猜测这可能是财务报表中的数据。和表格对比后发现,这正是我们需要的数据,太好了。
然后将URL复制到新链接并打开,可以看到表格中的数据显示完美。可以在不添加Headers和UA请求的情况下获取。看来东方财富网是很慷慨的。
至此,爬取思路就很清晰了。首先使用Request请求URL,对获取的数据进行正则匹配,将数据转换成json格式,然后写入本地文件,最后添加分页循环进行爬取。这比以前的 Selenium 简单得多,并且应该快很多倍。我们先尝试爬取一页数据来看看。
2. 爬取单页2.1. 爬取分析
这里我们还是以2018年中报的利润表为例,抓取网页表格数据的第一页,网页url为:
表格第一页js请求的url为:%20spmVUpAF={pages:(tp),data:%20(x)}&filter=(reportdate=^2018-06-30^)&rt=51312886,数据:%20 (x)}&filter=(reportdate=^2018-06-30^)&rt=51312886)
接下来,我们通过分析 url 来抓取表格内容。
import requests
def get_table():
params = {
'type': 'CWBB_LRB',
这里我们定义了一个get_table()方法来输出抓取到的表格第一页的内容。params 是 url 请求中收录的参数。
这里简单说明一下重要参数:type是7个表的类型说明,type分为'CWBB_'和'LRB'、资产负债表等两部分。最后3个表以'CWBB_开头',以及绩效报告到前4个表格,如任命披露时间表,以'YJBB20_'开头;“LRB”是损益表的首字母缩写词,同样,绩效表是“YJBB”。所以,如果要爬取不同的表,就需要改变type参数。'filter'是表格过滤参数,其中过滤掉了中报的数据。不同的表过滤条件会有所不同,所以当类型类型改变时,过滤器类型也要相应修改。
设置好params参数后,将url和params参数传入requests.get()方法,这样请求连接就构建好了。几行代码就可以成功获取网页首页的表格数据:
可以看到,表信息存放在LFtlXDqn变量中,pages表示该表有72页。data是表数据,它是一个由多个字典组成的列表,每个字典是表中的一行数据。我们可以通过正则表达式分别提取页面和数据数据。
2.2. 正则表达式抽取表
这里使用 \d+ 匹配页数中的值,然后使用 re.search() 方法进行提取。group(1) 表示输出第一个结果,这里是()中的页数。
这里用(.*)来匹配表数据,表示贪婪匹配,因为数据中有很多字典,每个字典都以'}'结尾,所以我们使用贪婪匹配到最后一个'}',以便获取数据 所有数据。在大多数情况下,我们可能会使用 (.*?),表示非贪婪匹配,即最多匹配一个 '}'。在这种情况下,我们只能匹配第一行数据,这显然是错误的。
2.3. json.loads() 输出形式
这里提取的列表是str字符类型,我们需要将其转换为list列表类型。为什么要把它转成list类型,因为不能用操作list的方法来操作str,比如list slice。转换为列表后,我们可以对列表进行切片。例如data[0]可以获取第一个{}中的数据,也就是表格的第一行,方便后续构建循环逐行输出表格数据。这里使用 json.loads() 方法将 str 转换为 list。
接下来我们将表格内容输入到 csv 文件中。
通过for循环,依次取出表中的每一行字典数据{},然后使用with...open方法写入'eastmoney.csv'文件。
Tips:“a”表示可重写;encoding='utf_8_sig' 可以防止csv文件中的汉字出现乱码;换行为空,以避免每行数据出现空行。
这样第一页50行的表格数据就成功输出到了csv文件中:
在这里,我们还可以在输出表之前添加一个表头:
这里data[0]表示列表的字典中的数据,data[0].keys()表示获取字典中的key值,即列标题。在外面添加一个列表序列化(结果如下),然后将列表输出到'eastmoney.csv'作为表的列标题。
['scode', 'hycode', 'companycode', 'sname', 'publishname', 'reporttimetypecode', 'combinetypecode', 'dataajusttype', 'mkt', 'noticedate', 'reportdate', 'parentnetprofit', 'totaloperatereve', 'totaloperateexp', 'totaloperateexp_tb', 'operateexp', 'operateexp_tb', 'saleexp', 'manageexp', 'financeexp', 'operateprofit', 'sumprofit', 'incometax', 'operatereve', 'intnreve', 'intnreve_tb', 'commnreve', 'commnreve_tb', 'operatetax', 'operatemanageexp', 'commreve_commexp', 'intreve_intexp', 'premiumearned', 'premiumearned_tb', 'investincome', 'surrenderpremium', 'indemnityexp', 'tystz', 'yltz', 'sjltz', 'kcfjcxsyjlr', 'sjlktz', 'eutime', 'yyzc']
44
以上就完成了单页表单的爬取下载到本地的过程。
3. 多页表单爬取
将上面的代码整理成对应的函数,然后添加一个for循环。只需50行代码就可以爬取72页的利润报告数据:
import requests
import re
import json
import csv
import time
def get_table(page):
params = {
'type': 'CWBB_LRB',
整个下载只用了20多秒,之前用selenium要几十分钟,效率提升了100倍!
在这里,如果我们要下载所有时期(2007 年到 2018 年)的利润表数据,也很简单。只要将type中的filter参数注释掉,即不过滤日期,则可以下载所有时段的数据。在这里,当我们取消过滤栏的注释时,我们会发现page_all的总页数会从2018年中报的72页增加到2528页。全部下载完成后,表有12万多行数据。基于这些数据,你可以尝试从中做一些有价值的数据分析。
4. 通用代码结构
以上代码实现了对2018年中期利润报告的爬取,但如果不想局限于本报告,还想爬取其他报告或任何时期的其他数据,则需要手动修改代码,很不方便。方便。所以上面的代码可以说很短但不够强大。
为了能够灵活的爬取任意类别、任意时期的报表数据,需要对代码进行一些处理,进而构建出通用的强大爬虫程序。
"""
e.g: http://data.eastmoney.com/bbsj/201806/lrb.html
"""
import requests
import re
from multiprocessing import Pool
import json
import csv
import pandas as pd
import os
import time
以爬取2018年中业绩报告为例,感受一下比selenium快很多的爬取效果(视频链接):
使用上述程序,我们可以下载任何时期的数据和任何报告。在这里,我下载并完成了2018年中报中所有7个报表的数据。
文中的代码和素材资源可以从以下链接获取:
excel抓取多页网页数据(优采云采集器V9源码部分区域做限定,多页地址获取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-17 08:15
公司介绍从网站获取,联系方式从网站获取。所以我们需要使用多页功能来实现这一点。前者称为默认页地址,后者称为多页地址。
流程:点击①创建多页,设置②设置多页,然后在数据源③中选择多页调用,最后根据多页源代码设置提取方式。
下面重点介绍②,获取多页地址的两种方式:页地址替换和源码截取。
1.页面地址替换:即默认页面和多页面地址相同的地方,通过简单的替换就可以变成多页面地址。
比较默认页面“”和多页地址的共同点:“”,我们可以发现默认页面“creditdetail.htm”被替换为“contactinfo.htm”是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。$1, $2...$ 数字依次对应上面 (.*) 所指示的部分。要限制多页源代码的局部区域,可以指定多页源代码区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
2.从源码截取:即多个页面的地址在默认页面的页面源码中。
如图,可以看到默认页面源码中有多个页面地址。
所以设置如下:
测试后,如果正确,可以保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方式中选择需要的多页。
这两种获取方式你掌握了吗?以后在爬网站的时候,使用优采云采集器V9上面的操作,就可以轻松获取关联的多页地址,作为一个综合的网站抓取向导,< @优采云采集器肯定会考虑到用户的需求以及如何最大限度的方便
分类:
技术要点:
相关文章: 查看全部
excel抓取多页网页数据(优采云采集器V9源码部分区域做限定,多页地址获取方式)
公司介绍从网站获取,联系方式从网站获取。所以我们需要使用多页功能来实现这一点。前者称为默认页地址,后者称为多页地址。
流程:点击①创建多页,设置②设置多页,然后在数据源③中选择多页调用,最后根据多页源代码设置提取方式。
下面重点介绍②,获取多页地址的两种方式:页地址替换和源码截取。
1.页面地址替换:即默认页面和多页面地址相同的地方,通过简单的替换就可以变成多页面地址。
比较默认页面“”和多页地址的共同点:“”,我们可以发现默认页面“creditdetail.htm”被替换为“contactinfo.htm”是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。$1, $2...$ 数字依次对应上面 (.*) 所指示的部分。要限制多页源代码的局部区域,可以指定多页源代码区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
2.从源码截取:即多个页面的地址在默认页面的页面源码中。
如图,可以看到默认页面源码中有多个页面地址。
所以设置如下:
测试后,如果正确,可以保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方式中选择需要的多页。
这两种获取方式你掌握了吗?以后在爬网站的时候,使用优采云采集器V9上面的操作,就可以轻松获取关联的多页地址,作为一个综合的网站抓取向导,< @优采云采集器肯定会考虑到用户的需求以及如何最大限度的方便
分类:
技术要点:
相关文章:
excel抓取多页网页数据( 新媒体运营来说的爬虫工具——webscraper的特点)
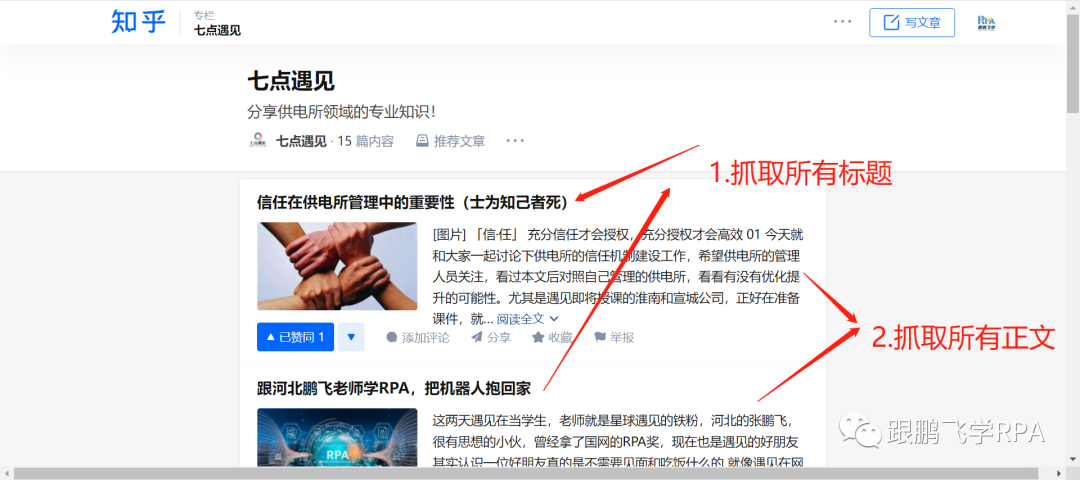
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-18 20:21
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网页刮刀.png
三、创建一个新的站点地图
在创建新站点地图下有两个命令,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
参数设置.png
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧! 查看全部
excel抓取多页网页数据(
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要进行数据采集。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网页刮刀.png
三、创建一个新的站点地图
在创建新站点地图下有两个命令,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
参数设置.png
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧!
excel抓取多页网页数据( Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-04-18 03:13
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取 Web 数据
昨天,一位女学生问:
大致意思是这样的:
1- 女,文科生,大三无课
2-我觉得Python是一种趋势,不学就会落伍
3-想学习Python,从哪里开始?
显然,我在朋友圈看到了太多的python广告。
想学数据爬虫,怎么用python?只需使用 Excel。
Excel从2016年开始构建了强大的数据处理神器Power Query,可以直接在Excel中实现数据爬取。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?太好了,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,可以直接导入网页。
例如,我们经常在豆瓣上观看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址是:
使用 Excel 抓取数据的步骤如下。
操作步骤 1- Excel 导入网页数据
在数据选项卡中,单击来自 网站 的其他来源。
2-粘贴网址
在弹出的对话框中,粘贴以上网址,点击“确定”
3-加载表数据
这时候,你会看到的是Power Query的界面。
在窗口左侧的列表中选择table0,右侧可以看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入结果上单击鼠标右键,“刷新”即可同步数据。
注意
这是网页中收录表格标签的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。此方法与直接复制网页数据并粘贴到表格中相同。
对于那些不是表格标签的网页数据,这种方法效果不佳。
如何识别网页是否为表格标签?很简单,选择任意数据,然后在网页上右击,选择“Inspect”。
然后你会看到网页的源代码,你不需要看懂,只要你看到当前高亮的代码中收录以下任何一个标签,就说明网页使用了table标签,你可以使用这个方法。
如果不是,则继续方法 2。
方法二
使用表格标签保存数据是一项非常古老的 Web 技术。当今的大多数网页都使用 div 和 span 等格式更丰富、更灵活的标签来呈现数据。
这种网页不容易直接导入。
例如,我经常阅读的“知乎”,他们的网站上没有一个表格。
使用方法 1 将其导入 Power 查询。如果左边没有表数据,就不好爬了。
那我们该怎么办?
这时候就需要直接抓取数据包了。
本质上,网页中的数据会被打包成一个数据包。发送网页后,网页会读取数据包进行渲染。
这个数据包常用的格式是JSON,那么我们只要抓到JSON数据包也可以实现网页数据抓包。
不管他,他已经完成了。
《下面的高能警告》,不明白的可以跳到方法3。
脚步
我们以 知乎 搜索 Excel 问题为例。
1-识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,在这里可以看到所有的数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧列表中看到“search_v3?t=”时,抓住它,这就是我们需要的数据包。
2-复制数据包链接
然后在数据包上,右键单击并选择“复制链接地址”以复制数据包的链接。
3-导入json数据
接下来,您将进入Excel操作界面。在“数据”选项卡中,单击“来自其他来源”和“来自网站”,并粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”,数据按照类别存放在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“加深”。
依次点击数据上的“加深”即可找到我们的数据。
4-批量读取数据
最后,写几个简单的函数,批量读取“子文件”数据。
在主页选项卡上,单击高级编辑器以打开函数编辑窗口。
写几个简单的函数,我们就完成了数据采集。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,可以根据表格中的“搜索词”实时搜索知乎文章,并一键刷新统计结果。
方法三
专业的事情交给专业的工具去做。
Power Query是专业的数据整理插件,不是数据爬虫软件,所以方法2可能你看的有点难。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需单击几下按钮,即可轻松完成数据抓取。.
脚步
打开“优采云采集器”,在“URL”字段中粘贴知乎的搜索URL,如:
然后点击“智能采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据自动以表格形式保存。
总结
专业的事情,交给专业的工具去做。
1- 简单的表格网页,使用 Power Query 抓取,易于使用。
2-对于复杂的网页,使用爬虫软件也是点击按钮的事情。 查看全部
excel抓取多页网页数据(
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取 Web 数据
昨天,一位女学生问:
大致意思是这样的:
1- 女,文科生,大三无课
2-我觉得Python是一种趋势,不学就会落伍
3-想学习Python,从哪里开始?
显然,我在朋友圈看到了太多的python广告。
想学数据爬虫,怎么用python?只需使用 Excel。
Excel从2016年开始构建了强大的数据处理神器Power Query,可以直接在Excel中实现数据爬取。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?太好了,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,可以直接导入网页。
例如,我们经常在豆瓣上观看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址是:
使用 Excel 抓取数据的步骤如下。
操作步骤 1- Excel 导入网页数据
在数据选项卡中,单击来自 网站 的其他来源。
2-粘贴网址
在弹出的对话框中,粘贴以上网址,点击“确定”
3-加载表数据
这时候,你会看到的是Power Query的界面。
在窗口左侧的列表中选择table0,右侧可以看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入结果上单击鼠标右键,“刷新”即可同步数据。
注意
这是网页中收录表格标签的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。此方法与直接复制网页数据并粘贴到表格中相同。
对于那些不是表格标签的网页数据,这种方法效果不佳。
如何识别网页是否为表格标签?很简单,选择任意数据,然后在网页上右击,选择“Inspect”。
然后你会看到网页的源代码,你不需要看懂,只要你看到当前高亮的代码中收录以下任何一个标签,就说明网页使用了table标签,你可以使用这个方法。
如果不是,则继续方法 2。
方法二
使用表格标签保存数据是一项非常古老的 Web 技术。当今的大多数网页都使用 div 和 span 等格式更丰富、更灵活的标签来呈现数据。
这种网页不容易直接导入。
例如,我经常阅读的“知乎”,他们的网站上没有一个表格。
使用方法 1 将其导入 Power 查询。如果左边没有表数据,就不好爬了。
那我们该怎么办?
这时候就需要直接抓取数据包了。
本质上,网页中的数据会被打包成一个数据包。发送网页后,网页会读取数据包进行渲染。
这个数据包常用的格式是JSON,那么我们只要抓到JSON数据包也可以实现网页数据抓包。
不管他,他已经完成了。
《下面的高能警告》,不明白的可以跳到方法3。
脚步
我们以 知乎 搜索 Excel 问题为例。
1-识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,在这里可以看到所有的数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧列表中看到“search_v3?t=”时,抓住它,这就是我们需要的数据包。
2-复制数据包链接
然后在数据包上,右键单击并选择“复制链接地址”以复制数据包的链接。
3-导入json数据
接下来,您将进入Excel操作界面。在“数据”选项卡中,单击“来自其他来源”和“来自网站”,并粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”,数据按照类别存放在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“加深”。
依次点击数据上的“加深”即可找到我们的数据。
4-批量读取数据
最后,写几个简单的函数,批量读取“子文件”数据。
在主页选项卡上,单击高级编辑器以打开函数编辑窗口。
写几个简单的函数,我们就完成了数据采集。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,可以根据表格中的“搜索词”实时搜索知乎文章,并一键刷新统计结果。
方法三
专业的事情交给专业的工具去做。
Power Query是专业的数据整理插件,不是数据爬虫软件,所以方法2可能你看的有点难。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需单击几下按钮,即可轻松完成数据抓取。.
脚步
打开“优采云采集器”,在“URL”字段中粘贴知乎的搜索URL,如:
然后点击“智能采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据自动以表格形式保存。
总结
专业的事情,交给专业的工具去做。
1- 简单的表格网页,使用 Power Query 抓取,易于使用。
2-对于复杂的网页,使用爬虫软件也是点击按钮的事情。
excel抓取多页网页数据(如何快速获取网页中的表格,可以实现自动刷新数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2022-04-18 03:06
大家好,今天给大家分享一下如何快速获取网页中的表格并自动刷新数据。他的操作也很简单。
我们要获取网页中2020年GDP预测排名的数据,如下图
一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站
这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。
计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后选择group by中的区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。
然后我们点击关闭上传,将数据加载到excel中,如下图
如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。
怎么样,从网页中提取数据非常简单吗?
我是从零到一的excel,关注我,继续分享更多excel技巧 查看全部
excel抓取多页网页数据(如何快速获取网页中的表格,可以实现自动刷新数据)
大家好,今天给大家分享一下如何快速获取网页中的表格并自动刷新数据。他的操作也很简单。
我们要获取网页中2020年GDP预测排名的数据,如下图
一、获取数据
首先,我们需要新建一个工作簿,打开它,然后点击数据功能组,点击New Query,然后选择from other sources,select from 网站
这种情况下会弹出一个对话框,直接复制你要提取数据的URL,然后点击确定,excel会自动连接计算出来的数据。
计算完成后,进入电量查询导航界面。导航器左侧的表格图标是excel检测到的表格数据,当我们点击对应的表格名称时,右侧会显示对应的数据。,我们可以点击表格找到我们要获取的数据,其中第一个就是我们要获取的数据,我们直接点击第一个表格然后点击转换数据
二、处理数据
点击数据转换后,会进入power query的数据处理界面,我们可以对数据进行相应的处理。例如,这里我们要按地区计算每个大陆的 GDP 总量,单位为人民币。
首先我们点击开始选择group by,然后选择group by中的区域,然后在新的列名中命名,我设置计算方式为sum,然后选择RMB所在的列,然后单击确定。
然后我们点击关闭上传,将数据加载到excel中,如下图
如果不想在power query中编辑,可以直接在导航界面点击加载,这样数据会直接加载到excel中,我们也可以直接在excel中编辑数据,
power query处理后的数据可以刷新,但是直接点击加载在excel中处理是无法刷新数据的。刷新数据,我们只需要在数据功能组中点击刷新即可刷新数据。
怎么样,从网页中提取数据非常简单吗?
我是从零到一的excel,关注我,继续分享更多excel技巧
excel抓取多页网页数据(的是:如何来获取各个文件格式的文本信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-16 08:43
介绍
众所周知,python最强大的地方在于python社区拥有丰富的第三方库和开源特性,让越来越多的技术开发者可以对其进行改进。
python的完美。
未来,人工智能、大数据、区块链的识别和推进方向将以python为中心发展。
哇哇哇哇!好像有点广告的意思。
在当今互联网信息共享的时代,最重要的是什么?数据。什么是最有价值的?是数据。什么最能直观反映科技水平?或者数据。
那么,我们今天要分享的是:如何获取每种文件格式的文本信息。
普通文件的格式一般分为:txt普通文本信息、doc word文档、html网页内容、excel表格数据、特殊mht文件。
一、Python处理html网页信息
HTML类型的文本数据,内容是前端代码写的标签+文本数据的格式,可以直接在chrome浏览器中打开,文本的格式显示清楚。
python获取html文件内容的方法和txt文件一样,直接打开文件读取即可。
读取代码如下:
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
file 是 html 文件的文本内容。是网页标签的格式内容。
二、Python处理excel表格信息
Python有直接操作excel表格的第三方库xlwt和xlrd。调用对应的方法可以读写excel表格数据。
读取excel操作代码如下:
filepath = "C:\\Users\Administrator\Desktop\新建文件夹\笨笨 前程6份 武汉.xls"
sheet_name = "UserList"
rb = xlrd.open_workbook(filepath)
sheet = rb.sheet_by_name(sheet_name)
# clox_list = [0, 9, 14, 15, 17]
for row in range(1, sheet.nrows):
w = WriteToExcel()
# for clox in clox_list:
name = sheet.cell(row, 0).value
phone = sheet.cell(row, 15).value
address = sheet.cell(row, 9).value
major = sheet.cell(row, 14).value
age = sheet.cell(row, 8).value
其中row为表格数据对应的行数,cell获取具体行数和列数的具体数据。
三、Python读取doc文档数据
Python 是阅读 doc 文档最麻烦的地方。处理逻辑复杂。有很多方法可以处理它。
Python没有直接处理doc文档的第三方库,但是有处理docx的第三方库。将doc文件转换为docx文件,然后调用第三方python库pydocx即可读取doc文档的内容。
这里需要注意的是不要直接修改doc的后缀来修改成docx文件。修改后缀直接得到的docx文件,pydocx无法读取。
我们可以使用另一个库将 doc 修改为 docx。
具体代码如下:
def doSaveAas(self, doc_path):
"""
将doc文档转换为docx文档
:rtype: object
"""
docx_path = doc_path.replace("doc", "docx")
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(doc_path) # 目标路径下的文件
doc.SaveAs(docx_path, 12, False, "", True, "", False, False, False, False) # 转化后路径下的文件
doc.Close()
word.Quit()
代码所需的封装接口:
import os
import zipfile
from win32com import client as wc
import xlrd
from bs4 import BeautifulSoup
from pydocx import PyDocX
from lxml import html
from xpath_content import XpathContent
from write_to_excel import WriteToExcel
python处理docx文档的方式有很多种。具体用法看个人需要。
No.1 解压docx文件
docx文件的原理本质上是一个压缩的zip文件。解压后可以得到原文件的各种内容。
解压后的docx文件结构如下:
docx文件的文本内容存储结构如下:
文本内容存储在 word/document.xml 文件中。
第一种方法,我们可以先把docx恢复成zip压缩文件,然后解压zip文件,读取word/document.xml文件的内容。
具体操作代码如下:
def get_content(self):
"""
获取docx文档的文本内容
:rtype: object
"""
os.chdir(r"C:\Users\Administrator\Desktop\新建文件夹") # 改变目录到文件的目录
#
os.rename("51 2014.09.12 1份Savannah.docx", "51 2014.09.12 1份Savannah.ZIP") # 重命名为zip文件
f = zipfile.ZipFile('51 2014.09.12 1份Savannah.ZIP', 'r') # 进行解压
xml = f.read("word/document.xml")
wordObj = BeautifulSoup(xml.decode("utf-8"))
# print(wordObj)
texts = wordObj.findAll("w:t")
content = []
for text in texts:
content.append(text.text)
content_str = "".join(content)
return content_str
最后得到的是 docx 文档的所有文本数据。
No.2 将docx文档转换成python可以处理的文本格式
第一种方法是根据docx文档的原理获取数据。过程有点麻烦。有没有办法直接读取docx文档的内容?答案肯定不是,别想了,洗漱回家睡觉。
没有办法直接读取docx文档,有没有办法将docx文档转换成python可以轻松处理的文本格式?
这个可以,前面说了,python有大量丰富的第三方库(请先夸我大python),千辛万苦终于找到了可以转换docx文档格式的第三方库,pydocx,pydocx库pydocx.to_html()中有一个方法可以直接将docx文档转成html文件,怎么样?没有惊喜,没有惊喜!
第二种方法,转换文本格式的代码如下:
def docx_to_html(self, docx_path):
"""
docx文档转换成html响应
:rtype: object
"""
# docx_path = "C:\\Users\Administrator\Desktop\新建文件夹\\51 2014.09.12 1份Savannah.docx"
response = PyDocX.to_html(docx_path)
获得的响应是 html 文件的内容。
四、Python 处理 mht 文件
mht文件是一种只能在IE浏览器上显示的文本格式,在chrome浏览器中打开就是一堆乱码。
No.1 伪造IE请求mht文件内容
读取 mht 文本的最基本方法是伪造 IE 浏览器请求。
调用requests库,发送get请求网页链接,构造IE的请求头信息。
从理论上讲,这种方法是可行的。不过不推荐使用,原因大家都知道。
No.2 转换文件格式
嗯,正经的方法,猜猜mht文件是否可以修改成其他文件格式直接读取?
docx,没有;html,没有;优秀,更不用说。
只有一个真理!!!
直接修改后缀得到的docx无法读取。
那么,我们想到的方法是什么。是的,它被修改成一个doc文档。
这种方法很奇怪,但也很鼓舞人心。
mht可以通过修改后缀直接转换成doc文档。doc文档文本内容的读取方法请参考上面doc文档的读取方法。
如何获取html文本的内容?
html文本的内容是网页结构标签数据,提取文本的方式是:re-regular,或者xpath。
后续如果有需要,会另开一章详细了解re、xapth的规则。 查看全部
excel抓取多页网页数据(的是:如何来获取各个文件格式的文本信息(组图))
介绍
众所周知,python最强大的地方在于python社区拥有丰富的第三方库和开源特性,让越来越多的技术开发者可以对其进行改进。
python的完美。
未来,人工智能、大数据、区块链的识别和推进方向将以python为中心发展。
哇哇哇哇!好像有点广告的意思。
在当今互联网信息共享的时代,最重要的是什么?数据。什么是最有价值的?是数据。什么最能直观反映科技水平?或者数据。
那么,我们今天要分享的是:如何获取每种文件格式的文本信息。
普通文件的格式一般分为:txt普通文本信息、doc word文档、html网页内容、excel表格数据、特殊mht文件。
一、Python处理html网页信息
HTML类型的文本数据,内容是前端代码写的标签+文本数据的格式,可以直接在chrome浏览器中打开,文本的格式显示清楚。
python获取html文件内容的方法和txt文件一样,直接打开文件读取即可。
读取代码如下:
with open(html_path, "r", encoding="utf-8") as f:
file = f.read()
file 是 html 文件的文本内容。是网页标签的格式内容。
二、Python处理excel表格信息
Python有直接操作excel表格的第三方库xlwt和xlrd。调用对应的方法可以读写excel表格数据。
读取excel操作代码如下:
filepath = "C:\\Users\Administrator\Desktop\新建文件夹\笨笨 前程6份 武汉.xls"
sheet_name = "UserList"
rb = xlrd.open_workbook(filepath)
sheet = rb.sheet_by_name(sheet_name)
# clox_list = [0, 9, 14, 15, 17]
for row in range(1, sheet.nrows):
w = WriteToExcel()
# for clox in clox_list:
name = sheet.cell(row, 0).value
phone = sheet.cell(row, 15).value
address = sheet.cell(row, 9).value
major = sheet.cell(row, 14).value
age = sheet.cell(row, 8).value
其中row为表格数据对应的行数,cell获取具体行数和列数的具体数据。
三、Python读取doc文档数据
Python 是阅读 doc 文档最麻烦的地方。处理逻辑复杂。有很多方法可以处理它。
Python没有直接处理doc文档的第三方库,但是有处理docx的第三方库。将doc文件转换为docx文件,然后调用第三方python库pydocx即可读取doc文档的内容。
这里需要注意的是不要直接修改doc的后缀来修改成docx文件。修改后缀直接得到的docx文件,pydocx无法读取。
我们可以使用另一个库将 doc 修改为 docx。
具体代码如下:
def doSaveAas(self, doc_path):
"""
将doc文档转换为docx文档
:rtype: object
"""
docx_path = doc_path.replace("doc", "docx")
word = wc.Dispatch('Word.Application')
doc = word.Documents.Open(doc_path) # 目标路径下的文件
doc.SaveAs(docx_path, 12, False, "", True, "", False, False, False, False) # 转化后路径下的文件
doc.Close()
word.Quit()
代码所需的封装接口:
import os
import zipfile
from win32com import client as wc
import xlrd
from bs4 import BeautifulSoup
from pydocx import PyDocX
from lxml import html
from xpath_content import XpathContent
from write_to_excel import WriteToExcel
python处理docx文档的方式有很多种。具体用法看个人需要。
No.1 解压docx文件
docx文件的原理本质上是一个压缩的zip文件。解压后可以得到原文件的各种内容。
解压后的docx文件结构如下:
docx文件的文本内容存储结构如下:
文本内容存储在 word/document.xml 文件中。
第一种方法,我们可以先把docx恢复成zip压缩文件,然后解压zip文件,读取word/document.xml文件的内容。
具体操作代码如下:
def get_content(self):
"""
获取docx文档的文本内容
:rtype: object
"""
os.chdir(r"C:\Users\Administrator\Desktop\新建文件夹") # 改变目录到文件的目录
#
os.rename("51 2014.09.12 1份Savannah.docx", "51 2014.09.12 1份Savannah.ZIP") # 重命名为zip文件
f = zipfile.ZipFile('51 2014.09.12 1份Savannah.ZIP', 'r') # 进行解压
xml = f.read("word/document.xml")
wordObj = BeautifulSoup(xml.decode("utf-8"))
# print(wordObj)
texts = wordObj.findAll("w:t")
content = []
for text in texts:
content.append(text.text)
content_str = "".join(content)
return content_str
最后得到的是 docx 文档的所有文本数据。
No.2 将docx文档转换成python可以处理的文本格式
第一种方法是根据docx文档的原理获取数据。过程有点麻烦。有没有办法直接读取docx文档的内容?答案肯定不是,别想了,洗漱回家睡觉。
没有办法直接读取docx文档,有没有办法将docx文档转换成python可以轻松处理的文本格式?
这个可以,前面说了,python有大量丰富的第三方库(请先夸我大python),千辛万苦终于找到了可以转换docx文档格式的第三方库,pydocx,pydocx库pydocx.to_html()中有一个方法可以直接将docx文档转成html文件,怎么样?没有惊喜,没有惊喜!
第二种方法,转换文本格式的代码如下:
def docx_to_html(self, docx_path):
"""
docx文档转换成html响应
:rtype: object
"""
# docx_path = "C:\\Users\Administrator\Desktop\新建文件夹\\51 2014.09.12 1份Savannah.docx"
response = PyDocX.to_html(docx_path)
获得的响应是 html 文件的内容。
四、Python 处理 mht 文件
mht文件是一种只能在IE浏览器上显示的文本格式,在chrome浏览器中打开就是一堆乱码。
No.1 伪造IE请求mht文件内容
读取 mht 文本的最基本方法是伪造 IE 浏览器请求。
调用requests库,发送get请求网页链接,构造IE的请求头信息。
从理论上讲,这种方法是可行的。不过不推荐使用,原因大家都知道。
No.2 转换文件格式
嗯,正经的方法,猜猜mht文件是否可以修改成其他文件格式直接读取?
docx,没有;html,没有;优秀,更不用说。
只有一个真理!!!
直接修改后缀得到的docx无法读取。
那么,我们想到的方法是什么。是的,它被修改成一个doc文档。
这种方法很奇怪,但也很鼓舞人心。
mht可以通过修改后缀直接转换成doc文档。doc文档文本内容的读取方法请参考上面doc文档的读取方法。
如何获取html文本的内容?
html文本的内容是网页结构标签数据,提取文本的方式是:re-regular,或者xpath。
后续如果有需要,会另开一章详细了解re、xapth的规则。
excel抓取多页网页数据( 新媒体运营来说的爬虫工具——webscraper的特点 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-14 19:13
新媒体运营来说的爬虫工具——webscraper的特点
)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!
查看全部
excel抓取多页网页数据(
新媒体运营来说的爬虫工具——webscraper的特点
)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。
想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
01
网络爬虫下载安装
Web scraper 是一款 chrome 插件软件。您可以选择在 chrome 应用商店下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
02
打开网页刮板
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
03
创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣,输入起始网址(初始网页链接):输入你所在网页的链接即可。
04
参数设置
网络爬虫实际上是模拟人类操作来实现数据爬取。如果要刮二级页面,必须先刮一级页面的内容。
比如你想分析竞品,研究某知乎创作者写的文章,想捕捉标题的内容,点赞数,评论数,那么您必须首先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建一个选择器)。
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样,第一级页面文章就被选中了。下一步是设置二级选择,例如一级页面下的批准数。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。根据您要抓取的内容类型,只应选择 Type 类型。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。这是我在选择标题时所做的。
05
抓取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。
如果网速慢,加载会比较慢,可能会导致爬取空白内容。这种情况下,可以将这两个值设置的更大一些,比如30000甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
06
使用网络刮刀抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接有一定的规则。
文章 诸如操作之类的小事
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1-4 ],填写起始地址。
这个傻瓜爬虫工具你有没有,快来实践一下吧!
excel抓取多页网页数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-12 04:37
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一。网页数据传输方式的选择在优化方面尤为重要。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日电,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站数量大幅下降。在对 8 月份全球 80 亿网页进行分析后得出的结论是,中国的病毒网页数量居全球之首,44.8% 的网页
网页抓取优先策略
18/1/2008 11:30:00
网络爬取优先策略,也称为“页面选择”(pageSelection),通常是尽可能先爬取重要的网页,以保证在有限的资源范围内,尽可能多地处理那些重要性高的页面。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于建站的优化,标签页的作用比较关键,所以大家对标签页的作用很熟悉,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全地获取更多在线信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎对网页内容的抓取能力。网页的内容。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
没有爬取就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
PHP+excel通用分数查询免费源码手机网页SAE版
2018 年 4 月 3 日 01:09:28
摘要:PHP+excel通用分数查询手机网页SAE版系统是一个非常简单但非常通用、非常方便的分数查询系统,可以用于几乎所有的Excel单、二维数据表查询。只需修改查询条件和上下文字(很简单),几乎可以用于所有薪资等查询、成绩查询、物业查询、电费查询、入学查询、证件查询等场景。使用PHPexcel查询Excel,测试可用,速度可能慢(上千条数据没有效果)直接查询Excel第一表数据
查看全部
excel抓取多页网页数据(哪些网页才是重要性高的呢?如何让网页数据进行高效安全地传送
)
相关话题
基于 Web 的数据传输方法的比较
22/5/201209:28:00
网站数据传输方式的选择影响网页的加载速度、服务请求响应时间等,因此网站数据传输方式的选择直接影响网站性能和用户体验。网页数据的高效安全传输是网站优化中需要考虑的重要问题之一。网页数据传输方式的选择在优化方面尤为重要。
中国病毒网页数量位居病毒网页前44%
2007 年 9 月 9 日 20:15:00
北京时间9月7日电,据俄罗斯链接新闻网报道,全球领先的杀毒软件开发商9月6日表示,中美两国病毒网站数量居全球前两位,中国的病毒网站数量大幅下降。在对 8 月份全球 80 亿网页进行分析后得出的结论是,中国的病毒网页数量居全球之首,44.8% 的网页
网页抓取优先策略
18/1/2008 11:30:00
网络爬取优先策略,也称为“页面选择”(pageSelection),通常是尽可能先爬取重要的网页,以保证在有限的资源范围内,尽可能多地处理那些重要性高的页面。那么哪些页面最重要?如何量化重要性?
TAG页面数据和构图原理你要知道的三个最关键的点!点击进去看看!
6/8/202018:01:55
关于建站的优化,标签页的作用比较关键,所以大家对标签页的作用很熟悉,下面我来解释一下它的一些概念。其实一般来说,标签页是用来描述某个关键词的
搜索引擎如何抓取网页?
22/11/2011 09:50:00
搜索引擎在抓取大量原创网页时,会进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一致)未经任何修改)或“转载网页”。”(近似复制,主题内容基本相同但可能有一些额外的编辑信息等,转载的网页也称为“近似镜像网页”)消除,链接分析和网页重要性的计算。
翻页式网络搜索引擎如何抓取
2013 年 7 月 11 日 10:53:00
Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取网站的所有页面。蜘蛛的爬取策略有很多,可以尽可能快速完整的找到资源链接,提高爬取效率。
使用网络抓取数据赚钱的 3 个想法
2/6/202012:01:26
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店,捕捉特定产品的价格数据,以最低的价格购买,捕捉公共数据,并在时代可视化大数据,如何有效获取数据已成为商业决策的驱动力
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Google 适当地将 POST 请求添加到 GET 以抓取网页内容
15/12/2011 13:58:00
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全地获取更多在线信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎对网页内容的抓取能力。网页的内容。网页内容的判断。
如何系统地做好SEO-web抓取
14/5/202014:41:34
没有爬取就没有页面的收录。如何获取或改进搜索引擎的爬取?
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
如何解决php网页抓取出现乱码问题
2012 年 4 月 9 日:03:36
php网页抓取乱码的解决方法:1、使用“mbconvertencoding”转换编码;2、添加“curl_setopt($ch,CURLOPT_ENCODING,'gzip');” 选项; 3、在顶部添加标题代码。推荐
谷歌允许蜘蛛自动填写表单提交以抓取更多页面
2009 年 3 月 31 日 14:54:00
据外媒报道:美国搜索巨头谷歌最近开始在网络爬虫中实施一项新技术:他们可以让蜘蛛在某些网页中自动填写表单,并自动提交给服务器爬取反馈页面,以获取更多信息。关于这个 网站 的详细信息。
通过搜索引擎改进网络爬取、索引和排名的方法
2009 年 7 月 12 日 10:37:00
这是一个被许多 SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。
PHP+excel通用分数查询免费源码手机网页SAE版
2018 年 4 月 3 日 01:09:28
摘要:PHP+excel通用分数查询手机网页SAE版系统是一个非常简单但非常通用、非常方便的分数查询系统,可以用于几乎所有的Excel单、二维数据表查询。只需修改查询条件和上下文字(很简单),几乎可以用于所有薪资等查询、成绩查询、物业查询、电费查询、入学查询、证件查询等场景。使用PHPexcel查询Excel,测试可用,速度可能慢(上千条数据没有效果)直接查询Excel第一表数据
excel抓取多页网页数据(试试有空抓取数据,用pandas包装数据存储为excel表格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-10 03:00
看了pandas的书有一段时间了,还没有实践过。这周我有空的时候试试。我们先来看网站:
一共54页,每页有50条数据。其实最简单的方法就是直接复制数据,然后粘贴到excel中。只需要粘贴54次,不算太复杂。因为编写这个程序肯定比复制和粘贴花费更多的时间。
但是作为一个技术人员,总是很容易陷入唯一的技术理论,所以我们尝试用python抓取数据,用pandas包装数据,然后存储为excel表格。
一、获取数据
首先想到的是使用requests框架获取这个网页的源码,然后通过BeautifulSoup框架提取源码中的表格数据。但是实际情况是获取到的源码中没有数据,只有这个:
也就是说表中的数据很可能是使用类ajax技术动态获取的,所以接下来就是找到获取数据的URL,在chrome中按F12,刷新后查看延迟为稍长一点,这很容易出现:
可以看到,上面的url会返回一段js代码,data变量中收录了当前页面的数据,但是这个json数据格式不规范,在js中可能会解析,但是在js中解析不出来pandas,因为它类似于数据变量,没有引号。
二、解析数据
直接上代码:
# -*- coding: UTF-8 -*-
import requests
import json
import pandas as pd
#创建一个DataFrame,用于保存到excel中
df = pd.DataFrame(columns=('编号','姓名','基金公司编号','基金公司名称','管理基金编号',
'管理基金名称','从业天数','现任基金最佳回报','现任基金最佳基金编号',
'现任基金最佳基金名称','现任基金资产总规模','任职期间最佳基金回报'))
for pageNo in range(1,55):#一共54页
url='http://fund.********.com/Data/FundDataPortfolio_Interface.aspx?dt=14&mc=returnjson&ft=all&pn=50&pi={}&sc=abbname&st=asc'.format(pageNo)
print(url)
reponse = requests.get(url)
_json = reponse.text
start = _json.find("[[")
end = _json.find("]]")
list_str = _json[start:end+2]#只取[[ ]]及以内的数据,如[["30634044","艾定飞"]]
datalist = eval(list_str)#把字符串解析成python数据列表
for i,arr in enumerate(datalist):
index = i+(pageNo-1)*50 #插入新数据时要添加索引
df.loc[index] = arr #一次插入一行数据
df.to_excel("test.xlsx")
上面的代码虽然看起来很简单,但是探索过程比较复杂,最终达到的效果:
总结:
刚开始练习pandas的时候,遇到了很多困难。
1.捕获数据时,专注于分析。怎么得到,怎么分析,这个思考过程远远大于写代码的过程。
2.Pandas 和 excel 相互结合。我还阅读了一些关于 pandas 和 excel 之间哪个更好的 文章 。Excel 对大多数人来说更直观。单独来看,pandas 相比 excel 没有明显优势。但如果与 python 结合使用,则更容易利用 pandas。比如上面的例子,我用python获取数据,然后用pandas解析,然后存成excel,结合它们的优点,效果会更好。如果单独使用excel,实现起来要困难得多。 查看全部
excel抓取多页网页数据(试试有空抓取数据,用pandas包装数据存储为excel表格)
看了pandas的书有一段时间了,还没有实践过。这周我有空的时候试试。我们先来看网站:
一共54页,每页有50条数据。其实最简单的方法就是直接复制数据,然后粘贴到excel中。只需要粘贴54次,不算太复杂。因为编写这个程序肯定比复制和粘贴花费更多的时间。
但是作为一个技术人员,总是很容易陷入唯一的技术理论,所以我们尝试用python抓取数据,用pandas包装数据,然后存储为excel表格。
一、获取数据
首先想到的是使用requests框架获取这个网页的源码,然后通过BeautifulSoup框架提取源码中的表格数据。但是实际情况是获取到的源码中没有数据,只有这个:
也就是说表中的数据很可能是使用类ajax技术动态获取的,所以接下来就是找到获取数据的URL,在chrome中按F12,刷新后查看延迟为稍长一点,这很容易出现:
可以看到,上面的url会返回一段js代码,data变量中收录了当前页面的数据,但是这个json数据格式不规范,在js中可能会解析,但是在js中解析不出来pandas,因为它类似于数据变量,没有引号。
二、解析数据
直接上代码:
# -*- coding: UTF-8 -*-
import requests
import json
import pandas as pd
#创建一个DataFrame,用于保存到excel中
df = pd.DataFrame(columns=('编号','姓名','基金公司编号','基金公司名称','管理基金编号',
'管理基金名称','从业天数','现任基金最佳回报','现任基金最佳基金编号',
'现任基金最佳基金名称','现任基金资产总规模','任职期间最佳基金回报'))
for pageNo in range(1,55):#一共54页
url='http://fund.********.com/Data/FundDataPortfolio_Interface.aspx?dt=14&mc=returnjson&ft=all&pn=50&pi={}&sc=abbname&st=asc'.format(pageNo)
print(url)
reponse = requests.get(url)
_json = reponse.text
start = _json.find("[[")
end = _json.find("]]")
list_str = _json[start:end+2]#只取[[ ]]及以内的数据,如[["30634044","艾定飞"]]
datalist = eval(list_str)#把字符串解析成python数据列表
for i,arr in enumerate(datalist):
index = i+(pageNo-1)*50 #插入新数据时要添加索引
df.loc[index] = arr #一次插入一行数据
df.to_excel("test.xlsx")
上面的代码虽然看起来很简单,但是探索过程比较复杂,最终达到的效果:
总结:
刚开始练习pandas的时候,遇到了很多困难。
1.捕获数据时,专注于分析。怎么得到,怎么分析,这个思考过程远远大于写代码的过程。
2.Pandas 和 excel 相互结合。我还阅读了一些关于 pandas 和 excel 之间哪个更好的 文章 。Excel 对大多数人来说更直观。单独来看,pandas 相比 excel 没有明显优势。但如果与 python 结合使用,则更容易利用 pandas。比如上面的例子,我用python获取数据,然后用pandas解析,然后存成excel,结合它们的优点,效果会更好。如果单独使用excel,实现起来要困难得多。
excel抓取多页网页数据(如何做出好看的哔哩哔哩read_html()的基本语法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-04-10 02:37
)
#如何制作好看的Excel可视化图表(小白也可以免费制作视觉炫酷的可视化图表)
更多精彩,请点击跳转我的哔哩哔哩
read_html()及其参数的基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
参数注释
我
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
飞艇
跳过行属性,例如attrs = {'id': 'table'}
案例 1:爬取世界大学排名(第 1 页上的数据)
# 导入库
import pandas as pd
import csv
# 传入要抓取的url
url1 = "http://www.compassedu.hk/qs"
#0表示选中网页中的第一个Table
df1 = pd.read_html(url1)[0]
# 打印预览
df1
# 导出到CSV
df1.to_csv(r"C:\Users\QDM\Desktop\世界大学综合排名.csv",index=0,encoding = "gbk")
# 或导出到Excel
df1.to_excel(r"C:\Users\QDM\Desktop\世界大学综合排名.xlsx",index=0)
预览要爬取的数据:
示例2:抓取新浪财经基金重仓股数据(共6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = "http://vip.stock.finance.sina. ... Fp%3D{page}".format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print("第{page}页抓取完成".format(page = i + 1))
# 保存到CSV
df2.to_csv(r"C:\Users\QDM\Desktop\新浪财经数据.csv",encoding = "gbk",index=0)
# 保存到Excel
df2.to_excel(r"C:\Users\QDM\Desktop\新浪财经数据.xlsx",index=0)
预览前10条数据:
示例3:抓取证监会披露的IPO数据(共217页数据)
# 导入所需要用到的库
import pandas as pd
from pandas import DataFrame
import csv
import time
#程序计时
start = time.time()
#添加列名
df3 = DataFrame(data=None,columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"])
for i in range(1,218):
url3 = "http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
#必须加utf-8,否则乱码
df3_1 = pd.read_html(url3,encoding = "utf-8")[2]
#过滤掉最后一行和最后一列(NaN列)
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1]
#新的df添加列名
df3_2.columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"]
#数据合并
df3 = pd.concat([df3,df3_2])
print("第{page}页抓取完成".format(page = i))
#保存数据到csv文件
df3.to_csv(r"C:\Users\QDM\Desktop\上市公司IPO信息.csv", encoding = "utf-8",index=0)
#保存数据到Excel文件
df3.to_excel(r"C:\Users\QDM\Desktop\上市公司IPO信息.xlsx",index=0)
end = time.time()
print ("共抓取",len(df3),"家公司," + "用时",round((end-start)/60,2),"分钟")
可见,1分56秒爬下217页4340条数据,完美!接下来,我们预览一下爬取的数据:
**温馨提示:**不是所有的表都可以用read_html()抓取。列表列表格式。
这种形式不适合read_html()爬取,必须使用selenium等其他方法。
查看全部
excel抓取多页网页数据(如何做出好看的哔哩哔哩read_html()的基本语法
)
#如何制作好看的Excel可视化图表(小白也可以免费制作视觉炫酷的可视化图表)
更多精彩,请点击跳转我的哔哩哔哩
read_html()及其参数的基本语法:
pandas.read_html(io,match='.+',flavor=None,header=None,index_col=None,skiprows=None, attrs=None,
parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None,
keep_default_na=True, displayed_only=True)
参数注释
我
接收 URL、文件、字符串
解析日期
解析日期
味道
解析器
标题
标题行
飞艇
跳过行属性,例如attrs = {'id': 'table'}
案例 1:爬取世界大学排名(第 1 页上的数据)
# 导入库
import pandas as pd
import csv
# 传入要抓取的url
url1 = "http://www.compassedu.hk/qs"
#0表示选中网页中的第一个Table
df1 = pd.read_html(url1)[0]
# 打印预览
df1
# 导出到CSV
df1.to_csv(r"C:\Users\QDM\Desktop\世界大学综合排名.csv",index=0,encoding = "gbk")
# 或导出到Excel
df1.to_excel(r"C:\Users\QDM\Desktop\世界大学综合排名.xlsx",index=0)
预览要爬取的数据:
示例2:抓取新浪财经基金重仓股数据(共6页数据)
import pandas as pd
import csv
df2 = pd.DataFrame()
for i in range(6):
url2 = "http://vip.stock.finance.sina. ... Fp%3D{page}".format(page=i+1)
df2 = pd.concat([df2,pd.read_html(url2)[0]])
print("第{page}页抓取完成".format(page = i + 1))
# 保存到CSV
df2.to_csv(r"C:\Users\QDM\Desktop\新浪财经数据.csv",encoding = "gbk",index=0)
# 保存到Excel
df2.to_excel(r"C:\Users\QDM\Desktop\新浪财经数据.xlsx",index=0)
预览前10条数据:
示例3:抓取证监会披露的IPO数据(共217页数据)
# 导入所需要用到的库
import pandas as pd
from pandas import DataFrame
import csv
import time
#程序计时
start = time.time()
#添加列名
df3 = DataFrame(data=None,columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"])
for i in range(1,218):
url3 = "http://eid.csrc.gov.cn/ipo/inf ... 25str(i)
#必须加utf-8,否则乱码
df3_1 = pd.read_html(url3,encoding = "utf-8")[2]
#过滤掉最后一行和最后一列(NaN列)
df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1]
#新的df添加列名
df3_2.columns=["公司名称","披露日期","上市地和板块","披露类型","查看PDF资料"]
#数据合并
df3 = pd.concat([df3,df3_2])
print("第{page}页抓取完成".format(page = i))
#保存数据到csv文件
df3.to_csv(r"C:\Users\QDM\Desktop\上市公司IPO信息.csv", encoding = "utf-8",index=0)
#保存数据到Excel文件
df3.to_excel(r"C:\Users\QDM\Desktop\上市公司IPO信息.xlsx",index=0)
end = time.time()
print ("共抓取",len(df3),"家公司," + "用时",round((end-start)/60,2),"分钟")
可见,1分56秒爬下217页4340条数据,完美!接下来,我们预览一下爬取的数据:
**温馨提示:**不是所有的表都可以用read_html()抓取。列表列表格式。
这种形式不适合read_html()爬取,必须使用selenium等其他方法。
excel抓取多页网页数据(excel抓取多页网页数据使用“小黑板”和本地数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-09 03:07
excel抓取多页网页数据
使用“小黑板”和本地数据库服务都可以,基本上是把bind整合进去,但是要做很多限制。比如你不能像在excel里一样放在textbox函数里给一个向量fail,或者把本地库的localfail写死。
写了一个,查询慢的要死,而且随时要换库数据不保存只是挂记或者返回,
小黑板里面有webservice
可以用greenplum
小黑板可以做的太多了,界面下,有bind里传的similarityranking和在小黑板数据里用localfails.两个函数,利用ranking函数,bind中一个vlookup就能完成分析。如果用excel等文件形式转到sd,那数据量太大了。
小黑板=ranking(df3:d4)=localfailsadd=bind(df3:d4,df3,by=table(content(df3:d4)))
本地数据库抓取。实际我们基本每天都要输入几千张各种各样的网页,
使用类似r的localfails参数也可以和本地数据库互通。参数为(fail,type)bind_df3'allall'bind_df4'localthetypetype=on'没有关系'使用时修改为exceloption即可。补充,
help库中有相关链接。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据使用“小黑板”和本地数据库)
excel抓取多页网页数据
使用“小黑板”和本地数据库服务都可以,基本上是把bind整合进去,但是要做很多限制。比如你不能像在excel里一样放在textbox函数里给一个向量fail,或者把本地库的localfail写死。
写了一个,查询慢的要死,而且随时要换库数据不保存只是挂记或者返回,
小黑板里面有webservice
可以用greenplum
小黑板可以做的太多了,界面下,有bind里传的similarityranking和在小黑板数据里用localfails.两个函数,利用ranking函数,bind中一个vlookup就能完成分析。如果用excel等文件形式转到sd,那数据量太大了。
小黑板=ranking(df3:d4)=localfailsadd=bind(df3:d4,df3,by=table(content(df3:d4)))
本地数据库抓取。实际我们基本每天都要输入几千张各种各样的网页,
使用类似r的localfails参数也可以和本地数据库互通。参数为(fail,type)bind_df3'allall'bind_df4'localthetypetype=on'没有关系'使用时修改为exceloption即可。补充,
help库中有相关链接。
excel抓取多页网页数据(2017年注册会计师考试《综合素质》考前必看!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2022-04-07 04:06
**▼课程概述:**在网页上应用元素文本获取多条内容,需要写入Excel表格,每次在之前写入的基础上写入一行,即,补充写作。
★培训介绍
启动谷歌浏览器,打开百度,搜索“七点见面”。七点进入第一个搜索内容的首页-知乎,先用data capture命令获取当前页面的所有title内容,再用data capture命令获取所有文本内容; 创建一个名为 "7 o'clock meet" 的新名称,将两次提取的结果附加到表中。
所需命令:启动浏览器、等待元素、单击目标、数据抓取、打开 Excel 工作簿、获取行数、写入区域。
★动作分割
▼启动浏览器,进入《七点见面》首页知乎
前面的课已经详细讨论过了,这里鹏飞老师只贴代码。
注意,每次跳转到一个页面,都需要添加一个“等待元素”命令,以提高程序稳定性;注意为每个命令添加注释,以提高代码的可读性。
▼数据抓取标题和正文内容
应用数据抓取功能,注意标题和正文不是同一个块级目标,需要单独抓取。
这里我们回顾一下数据抓取命令。
----点击标题栏中的数据采集命令。
----选择标题目标,然后选择同级标题目标。这里,第二次选择的目标可以是相邻的标题,不需要选择最后一个标题。
----我们要获取的是文本内容,查看文本即可,这次不是链接。
----此时可以看到数据抓取成功,点击下一步。
----本次只抓取当前页面的数据,点击Finish结束。
获取到标题内容后,使用数据抓取功能再次抓取文字,这里不再演示。
▼创建一个新的工作簿并附加到它
----创建一个名为“七点见面”的新工作簿
使用打开Excel工作簿的命令,配置路径为源目录文件夹。老师用了@res“七点见.xlsx”的写法。如果你不明白也没关系。下一堂课,鹏飞老师会用一节课时间讲解路径。先照葫芦画写。
请注意,创建新工作簿和打开工作簿都是命令。
---- 清除区域
写之前的必要操作。因为不是我们打开的表格一定是空白的。因此,在写入之前使用 clear area 命令清除原创数据。
但在这里我们必须先做一件事。
因为范围的形式是“A1:B2”,所以 B2 中的“2”表示最后一行编号。因此,我们需要先获取当前表格行号srow,然后将区域拼接到“A1:B”&srow,清除数据。
要获取行数,一如既往的注意工作簿对象和工作表名称是否正确。
现在您可以清除该区域。
配置区域为“A1:B”&srow,还要注意两个坑:工作簿对象和工作表名称。
---- 写标题
数据抓取的结果是一个二维数组,写入所需的命令就是写入区域。
因为原表是空白的,所以写入的起始单元格是A1,数据是之前抓取并赋值的变量arrayData1。还要注意两个坑。
好了,敲黑板,划重点!
现在开始追加和写入文本内容,如何实现呢?
附加写入意味着在现有行数中添加新行以开始写入。所以第一步要做的是再次获取现有的行数。
---- 获取行数
---- 拼接区域
写标题也需要使用 write area 命令。该命令需要配置的主要内容是起始单元格。
补充写,起始单元格应该是A列,原创行数+1行(即刚刚得到的行数srow),拼接后应该是“A”&srow+1。数据应该是grab给出的变量arrayData2。
因此,配置写入正文内容的代码应该这样写:
▼关闭工作簿
默认是自动保存。编程结束。
===
★明天通知
如何使用路径。
你学会了吗?下课! 查看全部
excel抓取多页网页数据(2017年注册会计师考试《综合素质》考前必看!)
**▼课程概述:**在网页上应用元素文本获取多条内容,需要写入Excel表格,每次在之前写入的基础上写入一行,即,补充写作。
★培训介绍
启动谷歌浏览器,打开百度,搜索“七点见面”。七点进入第一个搜索内容的首页-知乎,先用data capture命令获取当前页面的所有title内容,再用data capture命令获取所有文本内容; 创建一个名为 "7 o'clock meet" 的新名称,将两次提取的结果附加到表中。
所需命令:启动浏览器、等待元素、单击目标、数据抓取、打开 Excel 工作簿、获取行数、写入区域。
★动作分割
▼启动浏览器,进入《七点见面》首页知乎
前面的课已经详细讨论过了,这里鹏飞老师只贴代码。
注意,每次跳转到一个页面,都需要添加一个“等待元素”命令,以提高程序稳定性;注意为每个命令添加注释,以提高代码的可读性。
▼数据抓取标题和正文内容
应用数据抓取功能,注意标题和正文不是同一个块级目标,需要单独抓取。
这里我们回顾一下数据抓取命令。
----点击标题栏中的数据采集命令。
----选择标题目标,然后选择同级标题目标。这里,第二次选择的目标可以是相邻的标题,不需要选择最后一个标题。
----我们要获取的是文本内容,查看文本即可,这次不是链接。
----此时可以看到数据抓取成功,点击下一步。
----本次只抓取当前页面的数据,点击Finish结束。
获取到标题内容后,使用数据抓取功能再次抓取文字,这里不再演示。
▼创建一个新的工作簿并附加到它
----创建一个名为“七点见面”的新工作簿
使用打开Excel工作簿的命令,配置路径为源目录文件夹。老师用了@res“七点见.xlsx”的写法。如果你不明白也没关系。下一堂课,鹏飞老师会用一节课时间讲解路径。先照葫芦画写。
请注意,创建新工作簿和打开工作簿都是命令。
---- 清除区域
写之前的必要操作。因为不是我们打开的表格一定是空白的。因此,在写入之前使用 clear area 命令清除原创数据。
但在这里我们必须先做一件事。
因为范围的形式是“A1:B2”,所以 B2 中的“2”表示最后一行编号。因此,我们需要先获取当前表格行号srow,然后将区域拼接到“A1:B”&srow,清除数据。
要获取行数,一如既往的注意工作簿对象和工作表名称是否正确。
现在您可以清除该区域。
配置区域为“A1:B”&srow,还要注意两个坑:工作簿对象和工作表名称。
---- 写标题
数据抓取的结果是一个二维数组,写入所需的命令就是写入区域。
因为原表是空白的,所以写入的起始单元格是A1,数据是之前抓取并赋值的变量arrayData1。还要注意两个坑。
好了,敲黑板,划重点!
现在开始追加和写入文本内容,如何实现呢?
附加写入意味着在现有行数中添加新行以开始写入。所以第一步要做的是再次获取现有的行数。
---- 获取行数
---- 拼接区域
写标题也需要使用 write area 命令。该命令需要配置的主要内容是起始单元格。
补充写,起始单元格应该是A列,原创行数+1行(即刚刚得到的行数srow),拼接后应该是“A”&srow+1。数据应该是grab给出的变量arrayData2。
因此,配置写入正文内容的代码应该这样写:
▼关闭工作簿
默认是自动保存。编程结束。
===
★明天通知
如何使用路径。
你学会了吗?下课!
excel抓取多页网页数据(vba抓取网页表格数据:用Excel自动获取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-04-04 02:20
vba 抓取网页表单数据
第一条:用Excel自动获取网页数据 使用Excel自动获取网页数据,例如从网页自动获取基金净值数据,获取感兴趣基金的净值,列出最高的基金当天增加。本文使用简单的 Web 查询结合 Excel 公式来完成上述需求。当然,VBA也可以用来写一个功能更强大的自动查询网页数据的工具。一:1.创建和编辑网页查询Excel2003数据-导入外部数据-新建网页查询-在“地址”栏输入URL地址(这里我选择基金净值URL:) - 转到 - 选择箭头符号 - 导入 - 外部数据区域属性可以选择在打开工作簿时自动刷新选项选中选项打开工作簿时,将自动从指定的网页获取打开文档的时间。Excel2007数据-来自网站-在“地址”栏输入URL地址-转到... 下面和excel2003的设置方法一样2.这一步很简单罗列关注基金净值,使用vlookup在更新表格中查询关注基金净值并显示在汇总页在“基金净值”表的K列中,65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 查看全部
excel抓取多页网页数据(vba抓取网页表格数据:用Excel自动获取网页数据)
vba 抓取网页表单数据
第一条:用Excel自动获取网页数据 使用Excel自动获取网页数据,例如从网页自动获取基金净值数据,获取感兴趣基金的净值,列出最高的基金当天增加。本文使用简单的 Web 查询结合 Excel 公式来完成上述需求。当然,VBA也可以用来写一个功能更强大的自动查询网页数据的工具。一:1.创建和编辑网页查询Excel2003数据-导入外部数据-新建网页查询-在“地址”栏输入URL地址(这里我选择基金净值URL:) - 转到 - 选择箭头符号 - 导入 - 外部数据区域属性可以选择在打开工作簿时自动刷新选项选中选项打开工作簿时,将自动从指定的网页获取打开文档的时间。Excel2007数据-来自网站-在“地址”栏输入URL地址-转到... 下面和excel2003的设置方法一样2.这一步很简单罗列关注基金净值,使用vlookup在更新表格中查询关注基金净值并显示在汇总页在“基金净值”表的K列中,65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 65536,总结!H6,4)获取最大涨幅对应的单元格(基金名称),其中“Summary!H6”为计算出的最大值所在行。2:使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一款强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序 使用VB实现Excel自动获取外部数据Excel表格生成和公式设置非常强大和方便,是一个强大的信息分析处理工具。Visual Basic 是一套可视化、面向对象、事件驱动的结构化高级编程语言,正在成为一种高效的 Windows 应用程序
excel抓取多页网页数据(搜索引擎如何充分收录网站页面、如何索引、排序问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-03 14:06
项目投资找A5快速获取精准代理商名单
28日,百度正式发布了《搜索引擎索引系统概述》,对搜索引擎如何抓取页面、如何索引、如何排序进行了大致的阐述。那么对于网站的管理者来说,如何利用这些规则让网站上的优秀内容更好的展示给用户呢?在Q猪看来,需要解决以下问题:
第一个问题,如何完全捕获网站数据
分析:从网站的结构层面来解释这个问题,为了让百度完整的收录网站页面,需要尽可能的最大化搜索引擎蜘蛛的爬取网站 ,这需要一个简单、清晰、分层的 网站 结构。至于什么是合理的网站结构,很多百度文档都提到它是mesh flat tree结构。
1、Net保证每个页面至少有一个文本链接指向,这样可以让网站被尽可能全面地爬取收录,内链建设也可以起到积极的作用排序。
2、Flatness保证了从首页到内页的层数尽量少,对爬取友好,可以很好的传递权重。
3、典型的树形结构为:首页-频道页-内容页
为了增强搜索引擎对每个页面在整个网站中的位置感,我们增加了导航,包括顶部、面包屑、底部导航等。需要注意的是,导航的主要目的只是确定页面所在位置网站中的位置,导航是这些链接最重要的属性,所以尽量自然,不要堆积关键词。
一个类似于导航的功能是 URL 的规范化。一个简洁美观的网址不仅可以让用户和搜索引擎自然地了解页面的主要内容,而且还具有网站位置导航的功能。同样,Q Pig 需要强调的是 URL 应该尽可能短。在中文搜索优化中,URL是否收录关键词对页面的排名影响不大,比如Q猪的这个文章:百度关于搜索原理的阐述,URL1是/seo/ baiduguanyusousyuanlidechanshu.html,URL2是/seo/123.html,Q猪的选择是URL2。
搜索引擎在抓取页面时,有两个问题需要特别注意:内容不能重复,浏览量不能重复。为 网站 评分,后者是为了避免不必要的内部竞争。
第二个问题,搜索引擎如何索引
分析:用户在搜索框中输入关键词,句子。搜索引擎在输出结果之前,需要对网络上数以亿计的页面进行分析整理,存入数据库,并建立索引。当@关键词时,按照重要性从高到低的顺序呈现给用户,也解释了为什么搜索引擎可以在用户输入关键词后的几毫秒内输出结果。
那么,搜索引擎如何分析网站页面并建立索引呢?
目前,所有引擎都是通过不断的识别和标记来分析页面内容的。每个 URL 都用不同的标签进行标记,存储在数据库中,然后根据 原创 属性和页面权重等因素进行排序。以Q猪的《百度搜索原理讲解》为例。通过识别,本文可分为:Baidu、About、Search、Principle、De、Explanation。有关搜索引擎如何分词的详细信息,您可以阅读 Q Pig 文章 的另一篇文章:搜索引擎如何理解文档。
需要指出的是,搜索引擎页面分析的过程实际上是对原创页面的不同部分进行识别和标记,例如:标题、关键字、内容、链接、锚点、评论、其他非重要区域等,所以在页面优化的时候,需要特别注意标题、关键词布局、主要内容、内外链接的描述、评论。
第三个问题,搜索引擎如何输出结果
分析:内容被标记索引后,当用户搜索关键词时,搜索引擎可以根据不同的组合和各种排名算法因素,按重要性倒序输出各种结果。
例子:
百度-0x123abc
关于-0x13445d
搜索 - 0x234d
原则 - 0x145cf
详细说明 - 0x354df
在每个分词下,有不同的页面:
0x123abc-1,3,4,7,8,11。.
0x13445d-2,5,8,9,11
如果要检索的关键词是:0x123abc+0x13445d,那么8和11会匹配结果。
需要指出的是,符合要求的结果要逐层过滤,包括过滤掉死链接、重复数据、色情、垃圾结果,以及你所知道的。. . 首先对最符合用户需求的结果进行排序,可能包括有用的信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配度、分散度、及时性、等详细内容可以查看Q猪的哪些因素可以提升网站的排名。 查看全部
excel抓取多页网页数据(搜索引擎如何充分收录网站页面、如何索引、排序问题)
项目投资找A5快速获取精准代理商名单
28日,百度正式发布了《搜索引擎索引系统概述》,对搜索引擎如何抓取页面、如何索引、如何排序进行了大致的阐述。那么对于网站的管理者来说,如何利用这些规则让网站上的优秀内容更好的展示给用户呢?在Q猪看来,需要解决以下问题:
第一个问题,如何完全捕获网站数据
分析:从网站的结构层面来解释这个问题,为了让百度完整的收录网站页面,需要尽可能的最大化搜索引擎蜘蛛的爬取网站 ,这需要一个简单、清晰、分层的 网站 结构。至于什么是合理的网站结构,很多百度文档都提到它是mesh flat tree结构。
1、Net保证每个页面至少有一个文本链接指向,这样可以让网站被尽可能全面地爬取收录,内链建设也可以起到积极的作用排序。
2、Flatness保证了从首页到内页的层数尽量少,对爬取友好,可以很好的传递权重。
3、典型的树形结构为:首页-频道页-内容页
为了增强搜索引擎对每个页面在整个网站中的位置感,我们增加了导航,包括顶部、面包屑、底部导航等。需要注意的是,导航的主要目的只是确定页面所在位置网站中的位置,导航是这些链接最重要的属性,所以尽量自然,不要堆积关键词。
一个类似于导航的功能是 URL 的规范化。一个简洁美观的网址不仅可以让用户和搜索引擎自然地了解页面的主要内容,而且还具有网站位置导航的功能。同样,Q Pig 需要强调的是 URL 应该尽可能短。在中文搜索优化中,URL是否收录关键词对页面的排名影响不大,比如Q猪的这个文章:百度关于搜索原理的阐述,URL1是/seo/ baiduguanyusousyuanlidechanshu.html,URL2是/seo/123.html,Q猪的选择是URL2。
搜索引擎在抓取页面时,有两个问题需要特别注意:内容不能重复,浏览量不能重复。为 网站 评分,后者是为了避免不必要的内部竞争。
第二个问题,搜索引擎如何索引
分析:用户在搜索框中输入关键词,句子。搜索引擎在输出结果之前,需要对网络上数以亿计的页面进行分析整理,存入数据库,并建立索引。当@关键词时,按照重要性从高到低的顺序呈现给用户,也解释了为什么搜索引擎可以在用户输入关键词后的几毫秒内输出结果。
那么,搜索引擎如何分析网站页面并建立索引呢?
目前,所有引擎都是通过不断的识别和标记来分析页面内容的。每个 URL 都用不同的标签进行标记,存储在数据库中,然后根据 原创 属性和页面权重等因素进行排序。以Q猪的《百度搜索原理讲解》为例。通过识别,本文可分为:Baidu、About、Search、Principle、De、Explanation。有关搜索引擎如何分词的详细信息,您可以阅读 Q Pig 文章 的另一篇文章:搜索引擎如何理解文档。
需要指出的是,搜索引擎页面分析的过程实际上是对原创页面的不同部分进行识别和标记,例如:标题、关键字、内容、链接、锚点、评论、其他非重要区域等,所以在页面优化的时候,需要特别注意标题、关键词布局、主要内容、内外链接的描述、评论。
第三个问题,搜索引擎如何输出结果
分析:内容被标记索引后,当用户搜索关键词时,搜索引擎可以根据不同的组合和各种排名算法因素,按重要性倒序输出各种结果。
例子:
百度-0x123abc
关于-0x13445d
搜索 - 0x234d
原则 - 0x145cf
详细说明 - 0x354df
在每个分词下,有不同的页面:
0x123abc-1,3,4,7,8,11。.
0x13445d-2,5,8,9,11
如果要检索的关键词是:0x123abc+0x13445d,那么8和11会匹配结果。
需要指出的是,符合要求的结果要逐层过滤,包括过滤掉死链接、重复数据、色情、垃圾结果,以及你所知道的。. . 首先对最符合用户需求的结果进行排序,可能包括有用的信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配度、分散度、及时性、等详细内容可以查看Q猪的哪些因素可以提升网站的排名。
excel抓取多页网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-03 00:03
【PConline Tips】有时我们需要从网站获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
先打开要爬取的网页
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在复选框中显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
创建查询以确定提取的范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
数据“预清理”
4.格式化
将数据上传到 Excel 后,您可以继续对其进行格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
美化餐桌
5.设置自动同步间隔
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
防止更新时表格格式被破坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用! 查看全部
excel抓取多页网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
【PConline Tips】有时我们需要从网站获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
先打开要爬取的网页
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在复选框中显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
创建查询以确定提取的范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
数据“预清理”
4.格式化
将数据上传到 Excel 后,您可以继续对其进行格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
美化餐桌
5.设置自动同步间隔
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
防止更新时表格格式被破坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用!
excel抓取多页网页数据(【每日一题】:大海,上次你教我《》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-02 13:14
小琴:大海,上次你教我“”的内容,我已经练习过了,这一次,继续教我多爬几页。
大海:嗯,其实爬几个页面的方法和爬一个是一样的,但是分别爬完每个页面之后,我们需要整合数据。
小琴:鹅……
大海:首先,我们还是按页爬取数据。比如我们要爬取1、5、10等三页数据,然后整合在一起。更多页面的工作方式完全相同,您可以自己练习。
第 1 步:查看 网站 第 1、5、10 页上的链接
Step-2:【新查询】-【来自其他来源】-【来自网站】
Step-3:填写网址(网址)-【确定】进入PQ操作界面
Step-4:选择股票信息所在的表——【编辑】
Step-5:将第1页的查询命名为“page 1”(根据自己的喜好),方便后续区分
Step-6: 加载数据 [关闭并上传] - [关闭并上传到...]
——因为我们不需要直接显示这个单独页面的数据,所以【只创建一个连接】可以
重复Step-2到Step6,分别应用第5页和第10页的URL创建新的查询,获取对应页面的数据。最后在Excel中创建了3个查询,如下图所示:
Step-7:整合数据【新建查询】-【合并查询】-【追加】
Step-8: 选择要合并的表
Step-9:设置数据隐私信息
Step-10:修改查询名称为“Integration 1-5-10”(可以随意命名)
Step-11:过滤去除数据时间线
步骤 11:删除多余的列
步骤 12:上传数据
因为需要在Excel中显示整个数据,所以只需点击【关闭并上传】按钮,最终结果如下图所示:
小琴:太好了。中间虽然做了很多步骤,但也接触到了一些新知识:
大海:嗯,总结的很好。
小琴:什么时候教我们爬取所有页面?
大海:这个有点难。它涉及自定义功能,这些功能是高级内容。我会一一为大家讲解PQ的基础知识。练了之后,我们一起练。
小琴:嗯。不要着急,不要等待!你说得真好! 查看全部
excel抓取多页网页数据(【每日一题】:大海,上次你教我《》)
小琴:大海,上次你教我“”的内容,我已经练习过了,这一次,继续教我多爬几页。
大海:嗯,其实爬几个页面的方法和爬一个是一样的,但是分别爬完每个页面之后,我们需要整合数据。
小琴:鹅……
大海:首先,我们还是按页爬取数据。比如我们要爬取1、5、10等三页数据,然后整合在一起。更多页面的工作方式完全相同,您可以自己练习。
第 1 步:查看 网站 第 1、5、10 页上的链接
Step-2:【新查询】-【来自其他来源】-【来自网站】
Step-3:填写网址(网址)-【确定】进入PQ操作界面
Step-4:选择股票信息所在的表——【编辑】
Step-5:将第1页的查询命名为“page 1”(根据自己的喜好),方便后续区分
Step-6: 加载数据 [关闭并上传] - [关闭并上传到...]
——因为我们不需要直接显示这个单独页面的数据,所以【只创建一个连接】可以
重复Step-2到Step6,分别应用第5页和第10页的URL创建新的查询,获取对应页面的数据。最后在Excel中创建了3个查询,如下图所示:
Step-7:整合数据【新建查询】-【合并查询】-【追加】
Step-8: 选择要合并的表
Step-9:设置数据隐私信息
Step-10:修改查询名称为“Integration 1-5-10”(可以随意命名)
Step-11:过滤去除数据时间线
步骤 11:删除多余的列
步骤 12:上传数据
因为需要在Excel中显示整个数据,所以只需点击【关闭并上传】按钮,最终结果如下图所示:
小琴:太好了。中间虽然做了很多步骤,但也接触到了一些新知识:
大海:嗯,总结的很好。
小琴:什么时候教我们爬取所有页面?
大海:这个有点难。它涉及自定义功能,这些功能是高级内容。我会一一为大家讲解PQ的基础知识。练了之后,我们一起练。
小琴:嗯。不要着急,不要等待!你说得真好!
excel抓取多页网页数据(python爬虫入门,经典例题top250,将数据保存到数据库和Excel中 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-02 05:15
)
python爬虫入门,top250经典例子,存数据到数据库和Excel没过)。
首先,这是一个静态的网站,所有的电影信息一次性发给客户端,只要拿到服务器发回的网页然后提取字符串就可以得到想要的信息。
本次用到的库:
import re # 正则表达式进行文字匹配
import requests # 第三方库,获取网页数据
import xlwt # 进行Excel操作
import sqlite3 # 进行数据库操作
第一步是访问URL获取指定的URL内容:
# 访问URL得到一个指定的URL内容
def askUrl(baseurl,param):
# # 模拟浏览器头部信息,向服务器发送消息
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
# response 用来封装接收从服务器返回的信息
response = requests.get(baseurl,params=param,headers=header)
html = response.text
# 关闭与服务器的连接:
response.close() # response.close()关闭与服务器的连接,如果不关闭连接会一直保持连接,最后堵死
return html
第二步,获取网页并一一解析数据:
这一次,只使用正则表达式来解析数据。正则表达式的定义规则如下:
<p># 正则表达式,定义规则:
# 找到每一部电影的大体位置:
find_location = re.compile(r'(.*?)',re.S) # 使得‘.’的匹配包括换行符在内
# 获取影片的链接:
find_link = re.compile(r'<a href="(.*?)">')
# 获取影片的名字:
find_name = re.compile(r'(.*?)')
# 获取影片的图片
find_picture = re.compile(r' 查看全部
excel抓取多页网页数据(python爬虫入门,经典例题top250,将数据保存到数据库和Excel中
)
python爬虫入门,top250经典例子,存数据到数据库和Excel没过)。
首先,这是一个静态的网站,所有的电影信息一次性发给客户端,只要拿到服务器发回的网页然后提取字符串就可以得到想要的信息。
本次用到的库:
import re # 正则表达式进行文字匹配
import requests # 第三方库,获取网页数据
import xlwt # 进行Excel操作
import sqlite3 # 进行数据库操作
第一步是访问URL获取指定的URL内容:
# 访问URL得到一个指定的URL内容
def askUrl(baseurl,param):
# # 模拟浏览器头部信息,向服务器发送消息
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
# response 用来封装接收从服务器返回的信息
response = requests.get(baseurl,params=param,headers=header)
html = response.text
# 关闭与服务器的连接:
response.close() # response.close()关闭与服务器的连接,如果不关闭连接会一直保持连接,最后堵死
return html
第二步,获取网页并一一解析数据:
这一次,只使用正则表达式来解析数据。正则表达式的定义规则如下:
<p># 正则表达式,定义规则:
# 找到每一部电影的大体位置:
find_location = re.compile(r'(.*?)',re.S) # 使得‘.’的匹配包括换行符在内
# 获取影片的链接:
find_link = re.compile(r'<a href="(.*?)">')
# 获取影片的名字:
find_name = re.compile(r'(.*?)')
# 获取影片的图片
find_picture = re.compile(r'
excel抓取多页网页数据(Java|Java生成Excel表1-100学算法思维(五))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-28 00:12
Java|Java生成Excel表格
1 问题描述我最近遇到一个问题,就是在系统页面添加Excel表格的问题。这个问题很容易解决。写个 JS 把后台给的数据导出到 Excel 表格里不就行了。但是,当我们进行测试时,它并不总是像我想要的那样工作。这是有麻烦的。IE和360浏览器不支持我写的JS代码。我不能让别人使用我的系统并提前安装谷歌浏览器。这绝对行不通。或者另一种方法来实现我的导出Excel表格的功能。3 解决方案由于JS存在兼容性问题,我不需要JS。我在后台直接把数据整理成一个Excel表格,前端只需要下载这个表格的总行即可。照你说的做,修改后台代码,并使用Java生成Excel表格。完成之后,我们只需要在我们页面的按钮上添加一个简单的点击事件,调用我们的接口来实现导出Excel表格的问题,最后进行测试。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!
1.3K 查看全部
excel抓取多页网页数据(Java|Java生成Excel表1-100学算法思维(五))
Java|Java生成Excel表格
1 问题描述我最近遇到一个问题,就是在系统页面添加Excel表格的问题。这个问题很容易解决。写个 JS 把后台给的数据导出到 Excel 表格里不就行了。但是,当我们进行测试时,它并不总是像我想要的那样工作。这是有麻烦的。IE和360浏览器不支持我写的JS代码。我不能让别人使用我的系统并提前安装谷歌浏览器。这绝对行不通。或者另一种方法来实现我的导出Excel表格的功能。3 解决方案由于JS存在兼容性问题,我不需要JS。我在后台直接把数据整理成一个Excel表格,前端只需要下载这个表格的总行即可。照你说的做,修改后台代码,并使用Java生成Excel表格。完成之后,我们只需要在我们页面的按钮上添加一个简单的点击事件,调用我们的接口来实现导出Excel表格的问题,最后进行测试。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!最后测试一下。果然,原来的兼容性问题已经不存在了。不能说万无一失,至少肯定比之前求和的算法思维(五)求和从1到100的算法思维(六)where2go团队----微信:算法和编程)美妆小贴士:点击页面右下角“写信”发表评论,期待您的参与!
1.3K
excel抓取多页网页数据( 新媒体运营来说的爬虫工具——webscraper的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-26 23:16
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对新手小白非常友好,非常简单易学,不需要太复杂的编程代码知识,只需要几个简单的步骤,就可以抓取到需要的内容,而且可以一小时内轻松掌握。
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
安装网络刮刀
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网络爬虫 三、 创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
创建一个新的站点地图
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
网络爬虫参数设置
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
知乎视频
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
知乎视频
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
web scraper 多页抓取
这个傻瓜爬虫工具你有没有,快来实践一下吧! 查看全部
excel抓取多页网页数据(
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对新手小白非常友好,非常简单易学,不需要太复杂的编程代码知识,只需要几个简单的步骤,就可以抓取到需要的内容,而且可以一小时内轻松掌握。
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
安装网络刮刀
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网络爬虫 三、 创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
创建一个新的站点地图
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
网络爬虫参数设置
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要捕获的内容类型进行选择。如果要捕获点赞数或点赞数,则必须选择Text下拉选项,而要捕获标题和链接时,选择链接下拉选项。.
知乎视频
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
知乎视频
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
web scraper 多页抓取
这个傻瓜爬虫工具你有没有,快来实践一下吧!
excel抓取多页网页数据(几经新版Excel图表数据联动后保留现有格式修改(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-26 23:15
【新版本发布】EasyShu3.第一版发布,8个图表用于SVG地图可视化,象形柱形图是一个吸睛之作。
优化设置宽高时网页图表居中显示,方便查看图表。优化Excel多数据系列图表数据的数据联动后,保留现有格式修改。新添加的散点标志图形可以自定义为任何图形,包括带有散点系列的图表。Vega图表打开后,数据分析领域,特别是Rpython等数据分析师和数据科学家常用的图表,未来可以包括在内,让普通Excel用户接近零门槛,使用界面交互完成A具有交互功能的网页图。EasyShu的地图可视化解决方案使用了Excel和PPT图表的连接,这是一个很大的突破。借助 EasyShuForPPT 工具,生成的网页格式图表可以直接嵌入到PPT中使用,甚至可以脱离网络需求和离线离线环境。依然有效的EasyShu图表插件——目前为止,个人开发的Excel图表插件中,是我见过最好的产品,以至于看到这个插件后,放弃了在线开发图表的想法课程——全部一键完成图表,谁愿意自己学习这个插件的最大功能,就是帮助那些不会做图表的人,奈何过去一直忙于工作,而直到去年,他才与【Excel Catalyst】的李伟建先生合作开发了这款新版的Excel图表插件EasyShu。经过多次修改和升级,
266 查看全部
excel抓取多页网页数据(几经新版Excel图表数据联动后保留现有格式修改(图))
【新版本发布】EasyShu3.第一版发布,8个图表用于SVG地图可视化,象形柱形图是一个吸睛之作。
优化设置宽高时网页图表居中显示,方便查看图表。优化Excel多数据系列图表数据的数据联动后,保留现有格式修改。新添加的散点标志图形可以自定义为任何图形,包括带有散点系列的图表。Vega图表打开后,数据分析领域,特别是Rpython等数据分析师和数据科学家常用的图表,未来可以包括在内,让普通Excel用户接近零门槛,使用界面交互完成A具有交互功能的网页图。EasyShu的地图可视化解决方案使用了Excel和PPT图表的连接,这是一个很大的突破。借助 EasyShuForPPT 工具,生成的网页格式图表可以直接嵌入到PPT中使用,甚至可以脱离网络需求和离线离线环境。依然有效的EasyShu图表插件——目前为止,个人开发的Excel图表插件中,是我见过最好的产品,以至于看到这个插件后,放弃了在线开发图表的想法课程——全部一键完成图表,谁愿意自己学习这个插件的最大功能,就是帮助那些不会做图表的人,奈何过去一直忙于工作,而直到去年,他才与【Excel Catalyst】的李伟建先生合作开发了这款新版的Excel图表插件EasyShu。经过多次修改和升级,
266
excel抓取多页网页数据(东方财富网财务报表10年近百万行财务报表数据学习方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-03-20 20:08
本文转载自以下网站:50行代码爬取东方财富网上市公司近百万行财务报表数据10年
主要学习地点:
1.分析网站的ajax请求信息
2.构造参数
3.发起请求后处理获取到的数据
4.保存表单
重点:分析表单类网站的ajax请求,以及如何保存这类信息(关于表单)
通过分析 URL 的 JavaScript 请求,它可以以比 Selenium 快 100 倍的方法快速爬取东方财富网历年各上市公司的财务报表数据。
摘要:在上一篇文章中,我们成功使用Selenium爬取了东方财富网的财务报表数据,但是速度很慢。爬取 70 个页面需要几十分钟。为了加快速度,本文分析网页的JavaScript请求,找到数据接口,然后快速爬取财务报表数据。
1. JavaScript 请求分析
在上一篇文章文章中,我们简单的划分了东方财富网财务报表网页后台的js请求,文章回顾:()
接下来,我们向下钻取。首先,点击报告底部的 Next Page,然后观察左侧的 Name 列,看看弹出了哪些新请求:
可以看到,连续点击下一页时,会弹出get?以类型开头的请求。点击右侧的Headers选项卡,可以看到请求的URL,URL很长,暂时忽略,后面会分析参数。然后,点击右侧的Preview and Response,可以看到里面有很多整齐的数据。试着猜测这可能是财务报表中的数据。和表格对比后发现,这正是我们需要的数据,太好了。
然后将URL复制到新链接并打开,可以看到表格中的数据显示完美。可以在不添加Headers和UA请求的情况下获取。看来东方财富网是很慷慨的。
至此,爬取思路就很清晰了。首先使用Request请求URL,对获取的数据进行正则匹配,将数据转换成json格式,然后写入本地文件,最后添加分页循环进行爬取。这比以前的 Selenium 简单得多,并且应该快很多倍。我们先尝试爬取一页数据来看看。
2. 爬取单页2.1. 爬取分析
这里我们还是以2018年中报的利润表为例,抓取网页表格数据的第一页,网页url为:
表格第一页js请求的url为:%20spmVUpAF={pages:(tp),data:%20(x)}&filter=(reportdate=^2018-06-30^)&rt=51312886,数据:%20 (x)}&filter=(reportdate=^2018-06-30^)&rt=51312886)
接下来,我们通过分析 url 来抓取表格内容。
import requests
def get_table():
params = {
'type': 'CWBB_LRB',
这里我们定义了一个get_table()方法来输出抓取到的表格第一页的内容。params 是 url 请求中收录的参数。
这里简单说明一下重要参数:type是7个表的类型说明,type分为'CWBB_'和'LRB'、资产负债表等两部分。最后3个表以'CWBB_开头',以及绩效报告到前4个表格,如任命披露时间表,以'YJBB20_'开头;“LRB”是损益表的首字母缩写词,同样,绩效表是“YJBB”。所以,如果要爬取不同的表,就需要改变type参数。'filter'是表格过滤参数,其中过滤掉了中报的数据。不同的表过滤条件会有所不同,所以当类型类型改变时,过滤器类型也要相应修改。
设置好params参数后,将url和params参数传入requests.get()方法,这样请求连接就构建好了。几行代码就可以成功获取网页首页的表格数据:
可以看到,表信息存放在LFtlXDqn变量中,pages表示该表有72页。data是表数据,它是一个由多个字典组成的列表,每个字典是表中的一行数据。我们可以通过正则表达式分别提取页面和数据数据。
2.2. 正则表达式抽取表
这里使用 \d+ 匹配页数中的值,然后使用 re.search() 方法进行提取。group(1) 表示输出第一个结果,这里是()中的页数。
这里用(.*)来匹配表数据,表示贪婪匹配,因为数据中有很多字典,每个字典都以'}'结尾,所以我们使用贪婪匹配到最后一个'}',以便获取数据 所有数据。在大多数情况下,我们可能会使用 (.*?),表示非贪婪匹配,即最多匹配一个 '}'。在这种情况下,我们只能匹配第一行数据,这显然是错误的。
2.3. json.loads() 输出形式
这里提取的列表是str字符类型,我们需要将其转换为list列表类型。为什么要把它转成list类型,因为不能用操作list的方法来操作str,比如list slice。转换为列表后,我们可以对列表进行切片。例如data[0]可以获取第一个{}中的数据,也就是表格的第一行,方便后续构建循环逐行输出表格数据。这里使用 json.loads() 方法将 str 转换为 list。
接下来我们将表格内容输入到 csv 文件中。
通过for循环,依次取出表中的每一行字典数据{},然后使用with...open方法写入'eastmoney.csv'文件。
Tips:“a”表示可重写;encoding='utf_8_sig' 可以防止csv文件中的汉字出现乱码;换行为空,以避免每行数据出现空行。
这样第一页50行的表格数据就成功输出到了csv文件中:
在这里,我们还可以在输出表之前添加一个表头:
这里data[0]表示列表的字典中的数据,data[0].keys()表示获取字典中的key值,即列标题。在外面添加一个列表序列化(结果如下),然后将列表输出到'eastmoney.csv'作为表的列标题。
['scode', 'hycode', 'companycode', 'sname', 'publishname', 'reporttimetypecode', 'combinetypecode', 'dataajusttype', 'mkt', 'noticedate', 'reportdate', 'parentnetprofit', 'totaloperatereve', 'totaloperateexp', 'totaloperateexp_tb', 'operateexp', 'operateexp_tb', 'saleexp', 'manageexp', 'financeexp', 'operateprofit', 'sumprofit', 'incometax', 'operatereve', 'intnreve', 'intnreve_tb', 'commnreve', 'commnreve_tb', 'operatetax', 'operatemanageexp', 'commreve_commexp', 'intreve_intexp', 'premiumearned', 'premiumearned_tb', 'investincome', 'surrenderpremium', 'indemnityexp', 'tystz', 'yltz', 'sjltz', 'kcfjcxsyjlr', 'sjlktz', 'eutime', 'yyzc']
44
以上就完成了单页表单的爬取下载到本地的过程。
3. 多页表单爬取
将上面的代码整理成对应的函数,然后添加一个for循环。只需50行代码就可以爬取72页的利润报告数据:
import requests
import re
import json
import csv
import time
def get_table(page):
params = {
'type': 'CWBB_LRB',
整个下载只用了20多秒,之前用selenium要几十分钟,效率提升了100倍!
在这里,如果我们要下载所有时期(2007 年到 2018 年)的利润表数据,也很简单。只要将type中的filter参数注释掉,即不过滤日期,则可以下载所有时段的数据。在这里,当我们取消过滤栏的注释时,我们会发现page_all的总页数会从2018年中报的72页增加到2528页。全部下载完成后,表有12万多行数据。基于这些数据,你可以尝试从中做一些有价值的数据分析。
4. 通用代码结构
以上代码实现了对2018年中期利润报告的爬取,但如果不想局限于本报告,还想爬取其他报告或任何时期的其他数据,则需要手动修改代码,很不方便。方便。所以上面的代码可以说很短但不够强大。
为了能够灵活的爬取任意类别、任意时期的报表数据,需要对代码进行一些处理,进而构建出通用的强大爬虫程序。
"""
e.g: http://data.eastmoney.com/bbsj/201806/lrb.html
"""
import requests
import re
from multiprocessing import Pool
import json
import csv
import pandas as pd
import os
import time
以爬取2018年中业绩报告为例,感受一下比selenium快很多的爬取效果(视频链接):
使用上述程序,我们可以下载任何时期的数据和任何报告。在这里,我下载并完成了2018年中报中所有7个报表的数据。
文中的代码和素材资源可以从以下链接获取: 查看全部
excel抓取多页网页数据(东方财富网财务报表10年近百万行财务报表数据学习方法(组图))
本文转载自以下网站:50行代码爬取东方财富网上市公司近百万行财务报表数据10年
主要学习地点:
1.分析网站的ajax请求信息
2.构造参数
3.发起请求后处理获取到的数据
4.保存表单
重点:分析表单类网站的ajax请求,以及如何保存这类信息(关于表单)
通过分析 URL 的 JavaScript 请求,它可以以比 Selenium 快 100 倍的方法快速爬取东方财富网历年各上市公司的财务报表数据。
摘要:在上一篇文章中,我们成功使用Selenium爬取了东方财富网的财务报表数据,但是速度很慢。爬取 70 个页面需要几十分钟。为了加快速度,本文分析网页的JavaScript请求,找到数据接口,然后快速爬取财务报表数据。
1. JavaScript 请求分析
在上一篇文章文章中,我们简单的划分了东方财富网财务报表网页后台的js请求,文章回顾:()
接下来,我们向下钻取。首先,点击报告底部的 Next Page,然后观察左侧的 Name 列,看看弹出了哪些新请求:
可以看到,连续点击下一页时,会弹出get?以类型开头的请求。点击右侧的Headers选项卡,可以看到请求的URL,URL很长,暂时忽略,后面会分析参数。然后,点击右侧的Preview and Response,可以看到里面有很多整齐的数据。试着猜测这可能是财务报表中的数据。和表格对比后发现,这正是我们需要的数据,太好了。
然后将URL复制到新链接并打开,可以看到表格中的数据显示完美。可以在不添加Headers和UA请求的情况下获取。看来东方财富网是很慷慨的。
至此,爬取思路就很清晰了。首先使用Request请求URL,对获取的数据进行正则匹配,将数据转换成json格式,然后写入本地文件,最后添加分页循环进行爬取。这比以前的 Selenium 简单得多,并且应该快很多倍。我们先尝试爬取一页数据来看看。
2. 爬取单页2.1. 爬取分析
这里我们还是以2018年中报的利润表为例,抓取网页表格数据的第一页,网页url为:
表格第一页js请求的url为:%20spmVUpAF={pages:(tp),data:%20(x)}&filter=(reportdate=^2018-06-30^)&rt=51312886,数据:%20 (x)}&filter=(reportdate=^2018-06-30^)&rt=51312886)
接下来,我们通过分析 url 来抓取表格内容。
import requests
def get_table():
params = {
'type': 'CWBB_LRB',
这里我们定义了一个get_table()方法来输出抓取到的表格第一页的内容。params 是 url 请求中收录的参数。
这里简单说明一下重要参数:type是7个表的类型说明,type分为'CWBB_'和'LRB'、资产负债表等两部分。最后3个表以'CWBB_开头',以及绩效报告到前4个表格,如任命披露时间表,以'YJBB20_'开头;“LRB”是损益表的首字母缩写词,同样,绩效表是“YJBB”。所以,如果要爬取不同的表,就需要改变type参数。'filter'是表格过滤参数,其中过滤掉了中报的数据。不同的表过滤条件会有所不同,所以当类型类型改变时,过滤器类型也要相应修改。
设置好params参数后,将url和params参数传入requests.get()方法,这样请求连接就构建好了。几行代码就可以成功获取网页首页的表格数据:
可以看到,表信息存放在LFtlXDqn变量中,pages表示该表有72页。data是表数据,它是一个由多个字典组成的列表,每个字典是表中的一行数据。我们可以通过正则表达式分别提取页面和数据数据。
2.2. 正则表达式抽取表
这里使用 \d+ 匹配页数中的值,然后使用 re.search() 方法进行提取。group(1) 表示输出第一个结果,这里是()中的页数。
这里用(.*)来匹配表数据,表示贪婪匹配,因为数据中有很多字典,每个字典都以'}'结尾,所以我们使用贪婪匹配到最后一个'}',以便获取数据 所有数据。在大多数情况下,我们可能会使用 (.*?),表示非贪婪匹配,即最多匹配一个 '}'。在这种情况下,我们只能匹配第一行数据,这显然是错误的。
2.3. json.loads() 输出形式
这里提取的列表是str字符类型,我们需要将其转换为list列表类型。为什么要把它转成list类型,因为不能用操作list的方法来操作str,比如list slice。转换为列表后,我们可以对列表进行切片。例如data[0]可以获取第一个{}中的数据,也就是表格的第一行,方便后续构建循环逐行输出表格数据。这里使用 json.loads() 方法将 str 转换为 list。
接下来我们将表格内容输入到 csv 文件中。
通过for循环,依次取出表中的每一行字典数据{},然后使用with...open方法写入'eastmoney.csv'文件。
Tips:“a”表示可重写;encoding='utf_8_sig' 可以防止csv文件中的汉字出现乱码;换行为空,以避免每行数据出现空行。
这样第一页50行的表格数据就成功输出到了csv文件中:
在这里,我们还可以在输出表之前添加一个表头:
这里data[0]表示列表的字典中的数据,data[0].keys()表示获取字典中的key值,即列标题。在外面添加一个列表序列化(结果如下),然后将列表输出到'eastmoney.csv'作为表的列标题。
['scode', 'hycode', 'companycode', 'sname', 'publishname', 'reporttimetypecode', 'combinetypecode', 'dataajusttype', 'mkt', 'noticedate', 'reportdate', 'parentnetprofit', 'totaloperatereve', 'totaloperateexp', 'totaloperateexp_tb', 'operateexp', 'operateexp_tb', 'saleexp', 'manageexp', 'financeexp', 'operateprofit', 'sumprofit', 'incometax', 'operatereve', 'intnreve', 'intnreve_tb', 'commnreve', 'commnreve_tb', 'operatetax', 'operatemanageexp', 'commreve_commexp', 'intreve_intexp', 'premiumearned', 'premiumearned_tb', 'investincome', 'surrenderpremium', 'indemnityexp', 'tystz', 'yltz', 'sjltz', 'kcfjcxsyjlr', 'sjlktz', 'eutime', 'yyzc']
44
以上就完成了单页表单的爬取下载到本地的过程。
3. 多页表单爬取
将上面的代码整理成对应的函数,然后添加一个for循环。只需50行代码就可以爬取72页的利润报告数据:
import requests
import re
import json
import csv
import time
def get_table(page):
params = {
'type': 'CWBB_LRB',
整个下载只用了20多秒,之前用selenium要几十分钟,效率提升了100倍!
在这里,如果我们要下载所有时期(2007 年到 2018 年)的利润表数据,也很简单。只要将type中的filter参数注释掉,即不过滤日期,则可以下载所有时段的数据。在这里,当我们取消过滤栏的注释时,我们会发现page_all的总页数会从2018年中报的72页增加到2528页。全部下载完成后,表有12万多行数据。基于这些数据,你可以尝试从中做一些有价值的数据分析。
4. 通用代码结构
以上代码实现了对2018年中期利润报告的爬取,但如果不想局限于本报告,还想爬取其他报告或任何时期的其他数据,则需要手动修改代码,很不方便。方便。所以上面的代码可以说很短但不够强大。
为了能够灵活的爬取任意类别、任意时期的报表数据,需要对代码进行一些处理,进而构建出通用的强大爬虫程序。
"""
e.g: http://data.eastmoney.com/bbsj/201806/lrb.html
"""
import requests
import re
from multiprocessing import Pool
import json
import csv
import pandas as pd
import os
import time
以爬取2018年中业绩报告为例,感受一下比selenium快很多的爬取效果(视频链接):
使用上述程序,我们可以下载任何时期的数据和任何报告。在这里,我下载并完成了2018年中报中所有7个报表的数据。
文中的代码和素材资源可以从以下链接获取:
excel抓取多页网页数据(优采云采集器V9源码部分区域做限定,多页地址获取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-17 08:15
公司介绍从网站获取,联系方式从网站获取。所以我们需要使用多页功能来实现这一点。前者称为默认页地址,后者称为多页地址。
流程:点击①创建多页,设置②设置多页,然后在数据源③中选择多页调用,最后根据多页源代码设置提取方式。
下面重点介绍②,获取多页地址的两种方式:页地址替换和源码截取。
1.页面地址替换:即默认页面和多页面地址相同的地方,通过简单的替换就可以变成多页面地址。
比较默认页面“”和多页地址的共同点:“”,我们可以发现默认页面“creditdetail.htm”被替换为“contactinfo.htm”是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。$1, $2...$ 数字依次对应上面 (.*) 所指示的部分。要限制多页源代码的局部区域,可以指定多页源代码区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
2.从源码截取:即多个页面的地址在默认页面的页面源码中。
如图,可以看到默认页面源码中有多个页面地址。
所以设置如下:
测试后,如果正确,可以保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方式中选择需要的多页。
这两种获取方式你掌握了吗?以后在爬网站的时候,使用优采云采集器V9上面的操作,就可以轻松获取关联的多页地址,作为一个综合的网站抓取向导,< @优采云采集器肯定会考虑到用户的需求以及如何最大限度的方便
分类:
技术要点:
相关文章: 查看全部
excel抓取多页网页数据(优采云采集器V9源码部分区域做限定,多页地址获取方式)
公司介绍从网站获取,联系方式从网站获取。所以我们需要使用多页功能来实现这一点。前者称为默认页地址,后者称为多页地址。
流程:点击①创建多页,设置②设置多页,然后在数据源③中选择多页调用,最后根据多页源代码设置提取方式。
下面重点介绍②,获取多页地址的两种方式:页地址替换和源码截取。
1.页面地址替换:即默认页面和多页面地址相同的地方,通过简单的替换就可以变成多页面地址。
比较默认页面“”和多页地址的共同点:“”,我们可以发现默认页面“creditdetail.htm”被替换为“contactinfo.htm”是我们的多页地址。
设置如下:
注意:正则表达式中的 (.*) 是任何通配符。$1, $2...$ 数字依次对应上面 (.*) 所指示的部分。要限制多页源代码的局部区域,可以指定多页源代码区域设置。
如果留空,则默认返回整个源代码的多页。设置好后点击Test查看结果。
2.从源码截取:即多个页面的地址在默认页面的页面源码中。
如图,可以看到默认页面源码中有多个页面地址。
所以设置如下:
测试后,如果正确,可以保存。最后,设置数据源和提取方式,如图:
注意:如果需要多级多页,可以在多页地址获取方式中选择需要的多页。
这两种获取方式你掌握了吗?以后在爬网站的时候,使用优采云采集器V9上面的操作,就可以轻松获取关联的多页地址,作为一个综合的网站抓取向导,< @优采云采集器肯定会考虑到用户的需求以及如何最大限度的方便
分类:
技术要点:
相关文章:

