
excel抓取多页网页数据
excel抓取多页网页数据(excel抓取多页网页数据-玩转javascript脚本爬虫脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-25 08:03
excel抓取多页网页数据-玩转javascript脚本爬虫
一、自定义网页抓取
1、打开页面javascript,
2、mode和extended下的accept:none选项一般是不勾上的,因为这个模式下,
3、mode和extended下的element:none只做判断是否收集页面的数据:accept-encoding选项是否选取支持equl;gzip。
例如:
二、自定义代码模板要实现自定义网页抓取,
1、自定义网页编程中javascript框架为popularjs
2、popularjs主要优点在于将事件绑定到javascript的上下文中。例如:对于刚发出的http请求,因为你需要交互服务器,因此事件绑定到document.write()这个方法上。
谢邀,javascript代码抓取的话,
1、整站脚本抓取,这是最常见最简单的方式,
2、根据页面中提供的extended标签进行处理
ie的话,可以用window.open();或者selenium,抓取页面的话,有关selenium的配置,看你用浏览器的哪种方式抓取的,
去水印,开b站fc,有没有b站up主视频,找能复制的就都可以下。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据-玩转javascript脚本爬虫脚本)
excel抓取多页网页数据-玩转javascript脚本爬虫
一、自定义网页抓取
1、打开页面javascript,
2、mode和extended下的accept:none选项一般是不勾上的,因为这个模式下,
3、mode和extended下的element:none只做判断是否收集页面的数据:accept-encoding选项是否选取支持equl;gzip。
例如:
二、自定义代码模板要实现自定义网页抓取,
1、自定义网页编程中javascript框架为popularjs
2、popularjs主要优点在于将事件绑定到javascript的上下文中。例如:对于刚发出的http请求,因为你需要交互服务器,因此事件绑定到document.write()这个方法上。
谢邀,javascript代码抓取的话,
1、整站脚本抓取,这是最常见最简单的方式,
2、根据页面中提供的extended标签进行处理
ie的话,可以用window.open();或者selenium,抓取页面的话,有关selenium的配置,看你用浏览器的哪种方式抓取的,
去水印,开b站fc,有没有b站up主视频,找能复制的就都可以下。
excel抓取多页网页数据(网页数据来源之一函数(图)星光详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-19 06:07
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
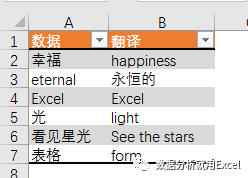
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~ 查看全部
excel抓取多页网页数据(网页数据来源之一函数(图)星光详解(组图))
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~
excel抓取多页网页数据(正常使用金数据Excel导出功能介绍页,开启【分享结果】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2021-09-14 07:22
正常使用黄金数据时,经常需要导出黄金数据Excel导出功能介绍页,需要登录网页→打开表格→选择导出
更多的数据,导出肯定更方便。我现在讲的方法是针对数据量很少,偶尔需要查看数据的人....不多说。
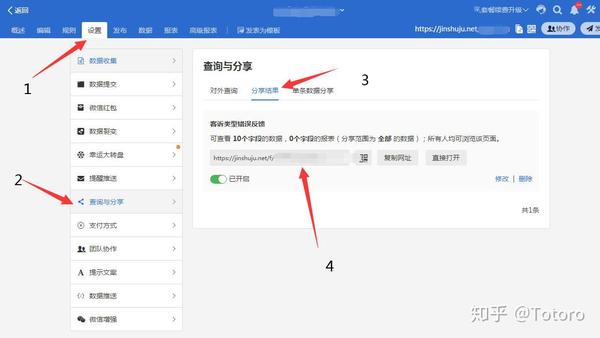
1.打开【金牌数据】表单页面,开启【分享成果】功能
路径【表单管理页面】-【设置】-【查询与分享】-【分享结果】-【创建】
根据需要勾选【查看列】的字段,需要的就勾选
勾选后点击保存,他会生成一个链接
2.打开这个链接
接下来可能会涉及到浏览器后台的一些操作,没有的话可以参考图片步骤
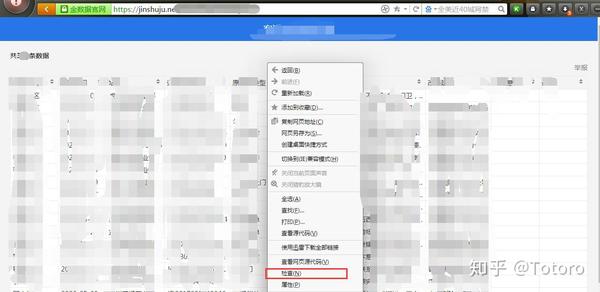
2.1 打开后,选择表格中任意位置点击鼠标右键→选择【勾选】
我是猎豹浏览器,所以是【check】,搜狗浏览器是【review元素】
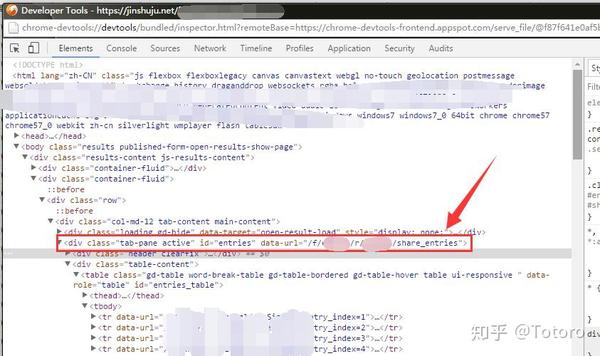
找到 [data-url="/f/*****/r/****/share_entries"] 这个字段
找到后复制,需要data-url="copy me"和引号之间的一段路径,复制出来即可
复制后在[]前面加上域名
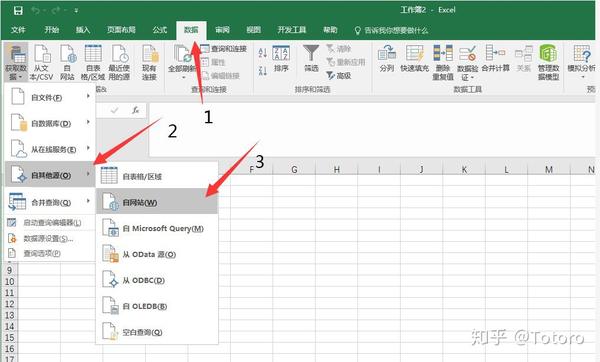
完成[*****/r/****/share_entries]3.打开Excel获取在线数据3.1 路径为[数据]-[来自其他来源]-[来自网站】
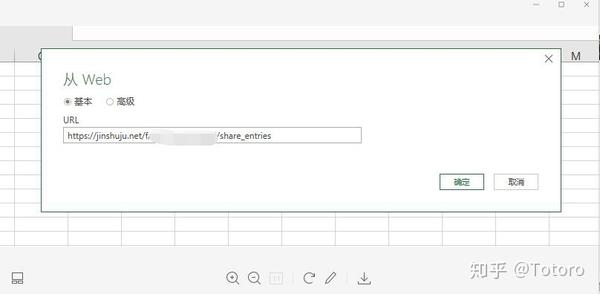
3.1 url中的路径是[数据]-[来自其他来源]-[来自网站],粘贴你在第2步得到的完整链接,点击确定,它就会加载
3.2 粘贴刚才组装的链接3.3 加载后会生成导航器。在导航器中选择[TAable 0]后,可以看到右侧的表格视图
3.3 加载完成后会生成一个导航器,在导航器中选择[TAable 0]
点击加载
现有数据最多只能加载50条数据,emmm没有产生更多数据。看@金数据 以后可以更新了
4.享受使用您的数据
使用和更新
我可能用到的功能比较少,所以我给你看看我的实际使用
因为部分业务需要其他同事的反馈,我需要每天检查和报告每个订单。我在黄金数据中设置了一个选项是否使用。在最后一列,当然在获取数据的时候也会加载。每次使用后,在黄金数据中选择使用过的数据,并在Excel中的数据列中设置一个【条件格式】,突出显示收录使用过的文本的单元格
如何实时更新,按照图片上的步骤:点击【表中任意数据】→点击【设计】→【刷新】刷新,也可以直接统计数据透视表,或者vlookup匹配谁还没有提交,想了想就自己做 查看全部
excel抓取多页网页数据(正常使用金数据Excel导出功能介绍页,开启【分享结果】)
正常使用黄金数据时,经常需要导出黄金数据Excel导出功能介绍页,需要登录网页→打开表格→选择导出
更多的数据,导出肯定更方便。我现在讲的方法是针对数据量很少,偶尔需要查看数据的人....不多说。
1.打开【金牌数据】表单页面,开启【分享成果】功能
路径【表单管理页面】-【设置】-【查询与分享】-【分享结果】-【创建】
根据需要勾选【查看列】的字段,需要的就勾选
勾选后点击保存,他会生成一个链接
2.打开这个链接
接下来可能会涉及到浏览器后台的一些操作,没有的话可以参考图片步骤
2.1 打开后,选择表格中任意位置点击鼠标右键→选择【勾选】
我是猎豹浏览器,所以是【check】,搜狗浏览器是【review元素】
找到 [data-url="/f/*****/r/****/share_entries"] 这个字段
找到后复制,需要data-url="copy me"和引号之间的一段路径,复制出来即可
复制后在[]前面加上域名
完成[*****/r/****/share_entries]3.打开Excel获取在线数据3.1 路径为[数据]-[来自其他来源]-[来自网站】
3.1 url中的路径是[数据]-[来自其他来源]-[来自网站],粘贴你在第2步得到的完整链接,点击确定,它就会加载
3.2 粘贴刚才组装的链接3.3 加载后会生成导航器。在导航器中选择[TAable 0]后,可以看到右侧的表格视图
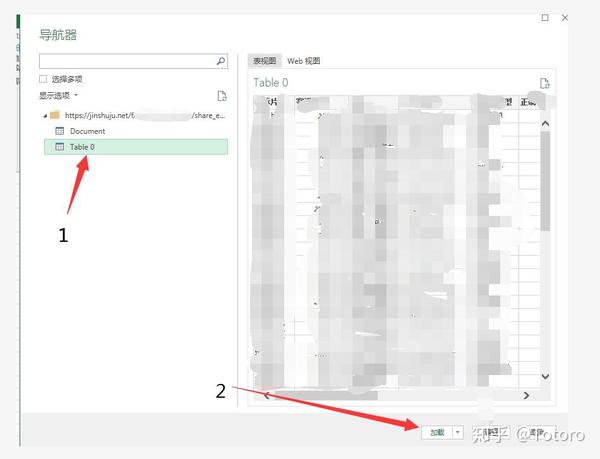
3.3 加载完成后会生成一个导航器,在导航器中选择[TAable 0]
点击加载
现有数据最多只能加载50条数据,emmm没有产生更多数据。看@金数据 以后可以更新了
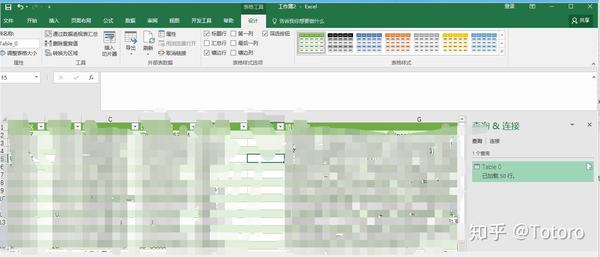
4.享受使用您的数据
使用和更新
我可能用到的功能比较少,所以我给你看看我的实际使用
因为部分业务需要其他同事的反馈,我需要每天检查和报告每个订单。我在黄金数据中设置了一个选项是否使用。在最后一列,当然在获取数据的时候也会加载。每次使用后,在黄金数据中选择使用过的数据,并在Excel中的数据列中设置一个【条件格式】,突出显示收录使用过的文本的单元格
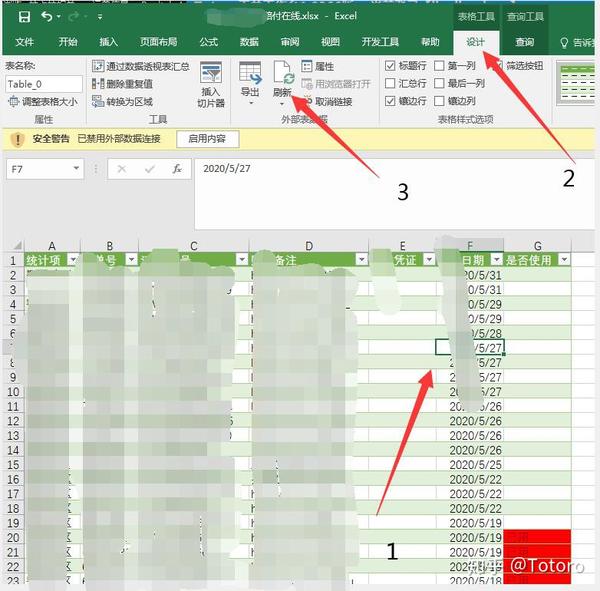
如何实时更新,按照图片上的步骤:点击【表中任意数据】→点击【设计】→【刷新】刷新,也可以直接统计数据透视表,或者vlookup匹配谁还没有提交,想了想就自己做
excel抓取多页网页数据(APP引导用户下载安装或激活调起APP的一个广告(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-10 19:11
第一屏:用户点击搜索结果,进入手机页面。所有不需要滑动屏幕就能看到的内容称为第一屏。
一屏:在将屏幕滑动到主内容显示的末尾之前,用户停留在页面任意位置所看到的所有内容称为一屏。
移动端适配:为了使PC页面在移动端正常显示,保证用户无需放大、放大、左右滑动都能看到所有字体。
列表页:指信息聚合显示的页面,包括图片列表页、问答列表页、文章列表页、黄页信息列表页。
详情页:指显示所有信息的页面,包括文章内容页、问答详情页、商品详情页等
广告:指针对特定需要,通过某种形式的媒体向公众公开、广泛传播信息的宣传手段;本白皮书中的广告一般是指出现在登陆页面上的所有面向用户的交流行为。需要注意的是,网站自有产品的推广也被视为广告。
APP引导:引导用户下载、安装或启动APP的行为,包括大段文字、图片、弹窗等形式。为了降低用户获取内容的成本,百度移动搜索要求所有在H5终端上可以查看和操作的内容和功能都不能被引导甚至强制下载APP来解决问题。
单跳转页:当您从百度搜索结果中点击进入着陆页时,您第一次跳转后到达的页面。
多跳页面:点击百度搜索结果的登陆页面后,跳转到两次以上的页面。
页面加载速度是影响用户搜索体验的重要因素。百度搜索对用户行为的研究表明,网站页面首屏加载时间在1.5秒以内,将为用户带来流畅、快速的体验。
从搜索结果页面进入网站登陆页面的单跳和多跳页面应该有加载动态。在等待页面加载的过程中,要及时反馈加载动画(如页面从右向左滑动等),给用户带来优质、高级的感受
页面字体、字号、文字行距等的设计,要适合手机用户阅读,不宜过大或过小,正文字体大小不宜过大小于 10pt。 查看全部
excel抓取多页网页数据(APP引导用户下载安装或激活调起APP的一个广告(组图))
第一屏:用户点击搜索结果,进入手机页面。所有不需要滑动屏幕就能看到的内容称为第一屏。
一屏:在将屏幕滑动到主内容显示的末尾之前,用户停留在页面任意位置所看到的所有内容称为一屏。
移动端适配:为了使PC页面在移动端正常显示,保证用户无需放大、放大、左右滑动都能看到所有字体。
列表页:指信息聚合显示的页面,包括图片列表页、问答列表页、文章列表页、黄页信息列表页。
详情页:指显示所有信息的页面,包括文章内容页、问答详情页、商品详情页等
广告:指针对特定需要,通过某种形式的媒体向公众公开、广泛传播信息的宣传手段;本白皮书中的广告一般是指出现在登陆页面上的所有面向用户的交流行为。需要注意的是,网站自有产品的推广也被视为广告。
APP引导:引导用户下载、安装或启动APP的行为,包括大段文字、图片、弹窗等形式。为了降低用户获取内容的成本,百度移动搜索要求所有在H5终端上可以查看和操作的内容和功能都不能被引导甚至强制下载APP来解决问题。
单跳转页:当您从百度搜索结果中点击进入着陆页时,您第一次跳转后到达的页面。
多跳页面:点击百度搜索结果的登陆页面后,跳转到两次以上的页面。
页面加载速度是影响用户搜索体验的重要因素。百度搜索对用户行为的研究表明,网站页面首屏加载时间在1.5秒以内,将为用户带来流畅、快速的体验。
从搜索结果页面进入网站登陆页面的单跳和多跳页面应该有加载动态。在等待页面加载的过程中,要及时反馈加载动画(如页面从右向左滑动等),给用户带来优质、高级的感受
页面字体、字号、文字行距等的设计,要适合手机用户阅读,不宜过大或过小,正文字体大小不宜过大小于 10pt。
excel抓取多页网页数据( 如何利用PowerQuery的强大数据处理操作为例进行数据处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-09-10 16:08
如何利用PowerQuery的强大数据处理操作为例进行数据处理)
今天的 Excel 不再只是一张表格。借助 Power Query 强大的数据处理功能,您几乎可以从任何来源、结构和形式导入数据。
PowerQuery 在 PowerBI 和 Excel 中的操作类似。下面以PowerBI Desktop操作为例,也可以直接从Excel操作,
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试点击,例如从中国银行网站抓取外汇报价信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页复制数据并粘贴到表格中。
实际上,每个人可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。 查看全部
excel抓取多页网页数据(
如何利用PowerQuery的强大数据处理操作为例进行数据处理)

今天的 Excel 不再只是一张表格。借助 Power Query 强大的数据处理功能,您几乎可以从任何来源、结构和形式导入数据。
PowerQuery 在 PowerBI 和 Excel 中的操作类似。下面以PowerBI Desktop操作为例,也可以直接从Excel操作,
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;

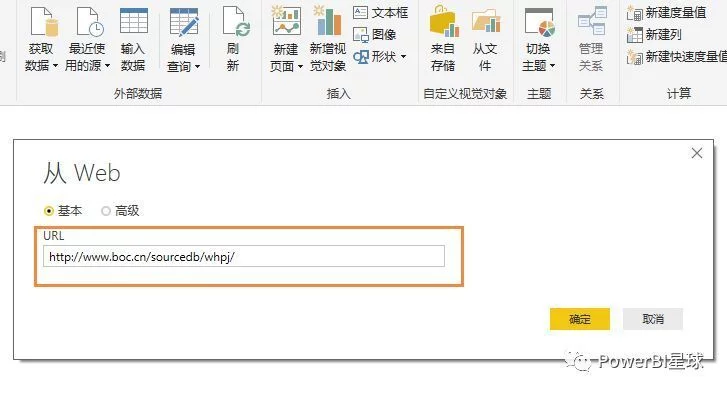
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试点击,例如从中国银行网站抓取外汇报价信息,先输入网址:
点击确定后,会出现一个预览窗口,
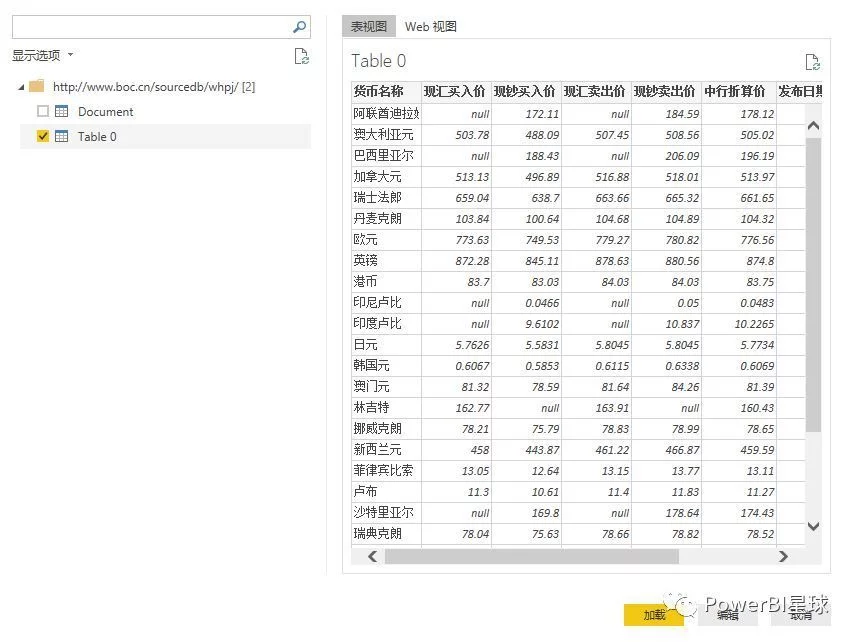
点击编辑进入查询编辑器,
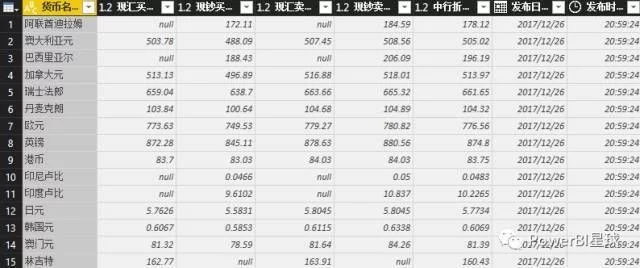
外汇数据抓取完成,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页复制数据并粘贴到表格中。
实际上,每个人可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。
excel抓取多页网页数据(Python抓取动态网页信息的相关操作、网上教程编写出)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-10 04:08
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(/data/cbnew/#cb)
考前准备:
1.配置python运行环境变量,参考链接(/python3/python3-install.html)
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
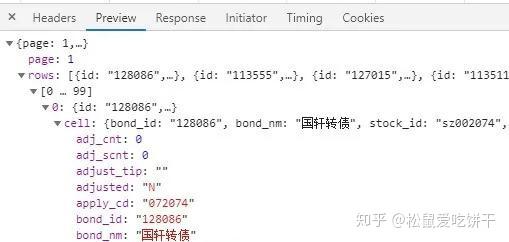
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(/data/cbnew/#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:
注意三点:
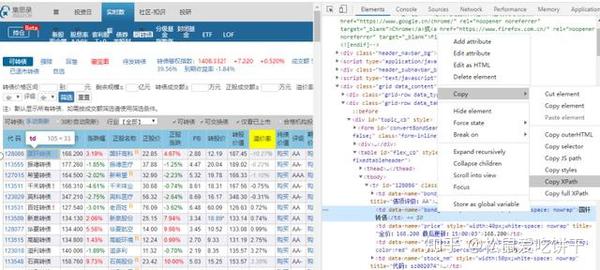
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
excel抓取多页网页数据(Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(/data/cbnew/#cb)
考前准备:
1.配置python运行环境变量,参考链接(/python3/python3-install.html)
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
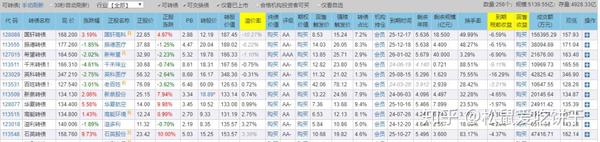
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
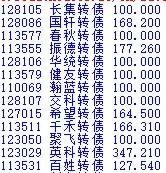
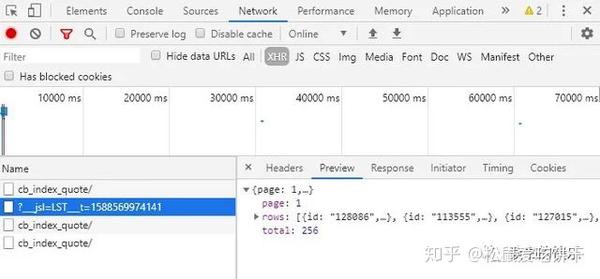
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(/data/cbnew/#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:

注意三点:
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。
excel抓取多页网页数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-10 04:03
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。 “网页数据”作为网站 用户体验的一部分,例如网页上的文字、图像、声音、视频和动画,都被视为网页数据。
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、从动态网页中提取内容
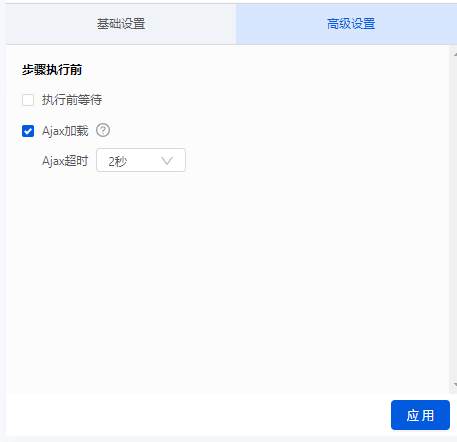
网页可以是静态的或动态的。通常,您要提取的网页内容会随着您访问网站 的时间而变化。通常,这个网站是动态的网站,它使用AJAX技术或其他技术使网页内容及时更新。 AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页上的一个选项时,网站的大部分网址不会改变;网页未完全加载,但仅部分加载了数据并发生了更改。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
2、从网页中抓取隐藏内容
你有没有想过从网站获取具体数据,但是当你触发链接或悬停在某处时,内容就会出现?比如下图中的网站需要将鼠标移动到选中的彩票上才能显示分类。对于此类功能,您可以设置“鼠标指向此链接”功能,即可抓取网页中隐藏的内容。
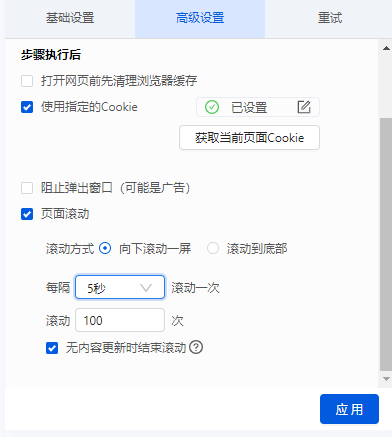
3、从无限滚动的网页中提取内容
滚动到页面底部后,有些网站只会显示你要提取的部分数据。比如今日头条首页,需要不断滚动到页面底部才能加载更多文章内容。无限滚动网站 通常使用 AJAX 或 JavaScript 从网站 请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 抓取网页中的所有链接
一个普通的网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 抓取网页中的所有文本
有时需要将一个 HTML 文档中的所有文本提取出来,即把它放在 HTML 标签中(如
标签或标签)。 优采云 使您能够提取网页源代码中的所有或特定文本。
6、 抓取网页中的所有图片
有些朋友对网页图片有采集的需求。 优采云可以下载网页采集中图片的网址,然后使用优采云专用图片批量下载工具将我们采集图片网址中的图片下载并保存到本地电脑。 查看全部
excel抓取多页网页数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。 “网页数据”作为网站 用户体验的一部分,例如网页上的文字、图像、声音、视频和动画,都被视为网页数据。
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、从动态网页中提取内容
网页可以是静态的或动态的。通常,您要提取的网页内容会随着您访问网站 的时间而变化。通常,这个网站是动态的网站,它使用AJAX技术或其他技术使网页内容及时更新。 AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页上的一个选项时,网站的大部分网址不会改变;网页未完全加载,但仅部分加载了数据并发生了更改。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
2、从网页中抓取隐藏内容
你有没有想过从网站获取具体数据,但是当你触发链接或悬停在某处时,内容就会出现?比如下图中的网站需要将鼠标移动到选中的彩票上才能显示分类。对于此类功能,您可以设置“鼠标指向此链接”功能,即可抓取网页中隐藏的内容。
3、从无限滚动的网页中提取内容
滚动到页面底部后,有些网站只会显示你要提取的部分数据。比如今日头条首页,需要不断滚动到页面底部才能加载更多文章内容。无限滚动网站 通常使用 AJAX 或 JavaScript 从网站 请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 抓取网页中的所有链接
一个普通的网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 抓取网页中的所有文本
有时需要将一个 HTML 文档中的所有文本提取出来,即把它放在 HTML 标签中(如
标签或标签)。 优采云 使您能够提取网页源代码中的所有或特定文本。
6、 抓取网页中的所有图片
有些朋友对网页图片有采集的需求。 优采云可以下载网页采集中图片的网址,然后使用优采云专用图片批量下载工具将我们采集图片网址中的图片下载并保存到本地电脑。
excel抓取多页网页数据(excel抓取多页网页数据-玩转javascript脚本爬虫脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-25 08:03
excel抓取多页网页数据-玩转javascript脚本爬虫
一、自定义网页抓取
1、打开页面javascript,
2、mode和extended下的accept:none选项一般是不勾上的,因为这个模式下,
3、mode和extended下的element:none只做判断是否收集页面的数据:accept-encoding选项是否选取支持equl;gzip。
例如:
二、自定义代码模板要实现自定义网页抓取,
1、自定义网页编程中javascript框架为popularjs
2、popularjs主要优点在于将事件绑定到javascript的上下文中。例如:对于刚发出的http请求,因为你需要交互服务器,因此事件绑定到document.write()这个方法上。
谢邀,javascript代码抓取的话,
1、整站脚本抓取,这是最常见最简单的方式,
2、根据页面中提供的extended标签进行处理
ie的话,可以用window.open();或者selenium,抓取页面的话,有关selenium的配置,看你用浏览器的哪种方式抓取的,
去水印,开b站fc,有没有b站up主视频,找能复制的就都可以下。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据-玩转javascript脚本爬虫脚本)
excel抓取多页网页数据-玩转javascript脚本爬虫
一、自定义网页抓取
1、打开页面javascript,
2、mode和extended下的accept:none选项一般是不勾上的,因为这个模式下,
3、mode和extended下的element:none只做判断是否收集页面的数据:accept-encoding选项是否选取支持equl;gzip。
例如:
二、自定义代码模板要实现自定义网页抓取,
1、自定义网页编程中javascript框架为popularjs
2、popularjs主要优点在于将事件绑定到javascript的上下文中。例如:对于刚发出的http请求,因为你需要交互服务器,因此事件绑定到document.write()这个方法上。
谢邀,javascript代码抓取的话,
1、整站脚本抓取,这是最常见最简单的方式,
2、根据页面中提供的extended标签进行处理
ie的话,可以用window.open();或者selenium,抓取页面的话,有关selenium的配置,看你用浏览器的哪种方式抓取的,
去水印,开b站fc,有没有b站up主视频,找能复制的就都可以下。
excel抓取多页网页数据(网页数据来源之一函数(图)星光详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-19 06:07
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~ 查看全部
excel抓取多页网页数据(网页数据来源之一函数(图)星光详解(组图))
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~
excel抓取多页网页数据(正常使用金数据Excel导出功能介绍页,开启【分享结果】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2021-09-14 07:22
正常使用黄金数据时,经常需要导出黄金数据Excel导出功能介绍页,需要登录网页→打开表格→选择导出
更多的数据,导出肯定更方便。我现在讲的方法是针对数据量很少,偶尔需要查看数据的人....不多说。
1.打开【金牌数据】表单页面,开启【分享成果】功能
路径【表单管理页面】-【设置】-【查询与分享】-【分享结果】-【创建】
根据需要勾选【查看列】的字段,需要的就勾选
勾选后点击保存,他会生成一个链接
2.打开这个链接
接下来可能会涉及到浏览器后台的一些操作,没有的话可以参考图片步骤
2.1 打开后,选择表格中任意位置点击鼠标右键→选择【勾选】
我是猎豹浏览器,所以是【check】,搜狗浏览器是【review元素】
找到 [data-url="/f/*****/r/****/share_entries"] 这个字段
找到后复制,需要data-url="copy me"和引号之间的一段路径,复制出来即可
复制后在[]前面加上域名
完成[*****/r/****/share_entries]3.打开Excel获取在线数据3.1 路径为[数据]-[来自其他来源]-[来自网站】
3.1 url中的路径是[数据]-[来自其他来源]-[来自网站],粘贴你在第2步得到的完整链接,点击确定,它就会加载
3.2 粘贴刚才组装的链接3.3 加载后会生成导航器。在导航器中选择[TAable 0]后,可以看到右侧的表格视图
3.3 加载完成后会生成一个导航器,在导航器中选择[TAable 0]
点击加载
现有数据最多只能加载50条数据,emmm没有产生更多数据。看@金数据 以后可以更新了
4.享受使用您的数据
使用和更新
我可能用到的功能比较少,所以我给你看看我的实际使用
因为部分业务需要其他同事的反馈,我需要每天检查和报告每个订单。我在黄金数据中设置了一个选项是否使用。在最后一列,当然在获取数据的时候也会加载。每次使用后,在黄金数据中选择使用过的数据,并在Excel中的数据列中设置一个【条件格式】,突出显示收录使用过的文本的单元格
如何实时更新,按照图片上的步骤:点击【表中任意数据】→点击【设计】→【刷新】刷新,也可以直接统计数据透视表,或者vlookup匹配谁还没有提交,想了想就自己做 查看全部
excel抓取多页网页数据(正常使用金数据Excel导出功能介绍页,开启【分享结果】)
正常使用黄金数据时,经常需要导出黄金数据Excel导出功能介绍页,需要登录网页→打开表格→选择导出
更多的数据,导出肯定更方便。我现在讲的方法是针对数据量很少,偶尔需要查看数据的人....不多说。
1.打开【金牌数据】表单页面,开启【分享成果】功能
路径【表单管理页面】-【设置】-【查询与分享】-【分享结果】-【创建】
根据需要勾选【查看列】的字段,需要的就勾选
勾选后点击保存,他会生成一个链接
2.打开这个链接
接下来可能会涉及到浏览器后台的一些操作,没有的话可以参考图片步骤
2.1 打开后,选择表格中任意位置点击鼠标右键→选择【勾选】
我是猎豹浏览器,所以是【check】,搜狗浏览器是【review元素】
找到 [data-url="/f/*****/r/****/share_entries"] 这个字段
找到后复制,需要data-url="copy me"和引号之间的一段路径,复制出来即可
复制后在[]前面加上域名
完成[*****/r/****/share_entries]3.打开Excel获取在线数据3.1 路径为[数据]-[来自其他来源]-[来自网站】
3.1 url中的路径是[数据]-[来自其他来源]-[来自网站],粘贴你在第2步得到的完整链接,点击确定,它就会加载
3.2 粘贴刚才组装的链接3.3 加载后会生成导航器。在导航器中选择[TAable 0]后,可以看到右侧的表格视图
3.3 加载完成后会生成一个导航器,在导航器中选择[TAable 0]
点击加载
现有数据最多只能加载50条数据,emmm没有产生更多数据。看@金数据 以后可以更新了
4.享受使用您的数据
使用和更新
我可能用到的功能比较少,所以我给你看看我的实际使用
因为部分业务需要其他同事的反馈,我需要每天检查和报告每个订单。我在黄金数据中设置了一个选项是否使用。在最后一列,当然在获取数据的时候也会加载。每次使用后,在黄金数据中选择使用过的数据,并在Excel中的数据列中设置一个【条件格式】,突出显示收录使用过的文本的单元格
如何实时更新,按照图片上的步骤:点击【表中任意数据】→点击【设计】→【刷新】刷新,也可以直接统计数据透视表,或者vlookup匹配谁还没有提交,想了想就自己做
excel抓取多页网页数据(APP引导用户下载安装或激活调起APP的一个广告(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-10 19:11
第一屏:用户点击搜索结果,进入手机页面。所有不需要滑动屏幕就能看到的内容称为第一屏。
一屏:在将屏幕滑动到主内容显示的末尾之前,用户停留在页面任意位置所看到的所有内容称为一屏。
移动端适配:为了使PC页面在移动端正常显示,保证用户无需放大、放大、左右滑动都能看到所有字体。
列表页:指信息聚合显示的页面,包括图片列表页、问答列表页、文章列表页、黄页信息列表页。
详情页:指显示所有信息的页面,包括文章内容页、问答详情页、商品详情页等
广告:指针对特定需要,通过某种形式的媒体向公众公开、广泛传播信息的宣传手段;本白皮书中的广告一般是指出现在登陆页面上的所有面向用户的交流行为。需要注意的是,网站自有产品的推广也被视为广告。
APP引导:引导用户下载、安装或启动APP的行为,包括大段文字、图片、弹窗等形式。为了降低用户获取内容的成本,百度移动搜索要求所有在H5终端上可以查看和操作的内容和功能都不能被引导甚至强制下载APP来解决问题。
单跳转页:当您从百度搜索结果中点击进入着陆页时,您第一次跳转后到达的页面。
多跳页面:点击百度搜索结果的登陆页面后,跳转到两次以上的页面。
页面加载速度是影响用户搜索体验的重要因素。百度搜索对用户行为的研究表明,网站页面首屏加载时间在1.5秒以内,将为用户带来流畅、快速的体验。
从搜索结果页面进入网站登陆页面的单跳和多跳页面应该有加载动态。在等待页面加载的过程中,要及时反馈加载动画(如页面从右向左滑动等),给用户带来优质、高级的感受
页面字体、字号、文字行距等的设计,要适合手机用户阅读,不宜过大或过小,正文字体大小不宜过大小于 10pt。 查看全部
excel抓取多页网页数据(APP引导用户下载安装或激活调起APP的一个广告(组图))
第一屏:用户点击搜索结果,进入手机页面。所有不需要滑动屏幕就能看到的内容称为第一屏。
一屏:在将屏幕滑动到主内容显示的末尾之前,用户停留在页面任意位置所看到的所有内容称为一屏。
移动端适配:为了使PC页面在移动端正常显示,保证用户无需放大、放大、左右滑动都能看到所有字体。
列表页:指信息聚合显示的页面,包括图片列表页、问答列表页、文章列表页、黄页信息列表页。
详情页:指显示所有信息的页面,包括文章内容页、问答详情页、商品详情页等
广告:指针对特定需要,通过某种形式的媒体向公众公开、广泛传播信息的宣传手段;本白皮书中的广告一般是指出现在登陆页面上的所有面向用户的交流行为。需要注意的是,网站自有产品的推广也被视为广告。
APP引导:引导用户下载、安装或启动APP的行为,包括大段文字、图片、弹窗等形式。为了降低用户获取内容的成本,百度移动搜索要求所有在H5终端上可以查看和操作的内容和功能都不能被引导甚至强制下载APP来解决问题。
单跳转页:当您从百度搜索结果中点击进入着陆页时,您第一次跳转后到达的页面。
多跳页面:点击百度搜索结果的登陆页面后,跳转到两次以上的页面。
页面加载速度是影响用户搜索体验的重要因素。百度搜索对用户行为的研究表明,网站页面首屏加载时间在1.5秒以内,将为用户带来流畅、快速的体验。
从搜索结果页面进入网站登陆页面的单跳和多跳页面应该有加载动态。在等待页面加载的过程中,要及时反馈加载动画(如页面从右向左滑动等),给用户带来优质、高级的感受
页面字体、字号、文字行距等的设计,要适合手机用户阅读,不宜过大或过小,正文字体大小不宜过大小于 10pt。
excel抓取多页网页数据( 如何利用PowerQuery的强大数据处理操作为例进行数据处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-09-10 16:08
如何利用PowerQuery的强大数据处理操作为例进行数据处理)
今天的 Excel 不再只是一张表格。借助 Power Query 强大的数据处理功能,您几乎可以从任何来源、结构和形式导入数据。
PowerQuery 在 PowerBI 和 Excel 中的操作类似。下面以PowerBI Desktop操作为例,也可以直接从Excel操作,
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试点击,例如从中国银行网站抓取外汇报价信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页复制数据并粘贴到表格中。
实际上,每个人可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。 查看全部
excel抓取多页网页数据(
如何利用PowerQuery的强大数据处理操作为例进行数据处理)
今天的 Excel 不再只是一张表格。借助 Power Query 强大的数据处理功能,您几乎可以从任何来源、结构和形式导入数据。
PowerQuery 在 PowerBI 和 Excel 中的操作类似。下面以PowerBI Desktop操作为例,也可以直接从Excel操作,
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试点击,例如从中国银行网站抓取外汇报价信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页复制数据并粘贴到表格中。
实际上,每个人可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。
excel抓取多页网页数据(Python抓取动态网页信息的相关操作、网上教程编写出)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-10 04:08
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(/data/cbnew/#cb)
考前准备:
1.配置python运行环境变量,参考链接(/python3/python3-install.html)
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(/data/cbnew/#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:
注意三点:
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
excel抓取多页网页数据(Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(/data/cbnew/#cb)
考前准备:
1.配置python运行环境变量,参考链接(/python3/python3-install.html)
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(/data/cbnew/#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:
注意三点:
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。
excel抓取多页网页数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-10 04:03
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。 “网页数据”作为网站 用户体验的一部分,例如网页上的文字、图像、声音、视频和动画,都被视为网页数据。
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、从动态网页中提取内容
网页可以是静态的或动态的。通常,您要提取的网页内容会随着您访问网站 的时间而变化。通常,这个网站是动态的网站,它使用AJAX技术或其他技术使网页内容及时更新。 AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页上的一个选项时,网站的大部分网址不会改变;网页未完全加载,但仅部分加载了数据并发生了更改。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
2、从网页中抓取隐藏内容
你有没有想过从网站获取具体数据,但是当你触发链接或悬停在某处时,内容就会出现?比如下图中的网站需要将鼠标移动到选中的彩票上才能显示分类。对于此类功能,您可以设置“鼠标指向此链接”功能,即可抓取网页中隐藏的内容。
3、从无限滚动的网页中提取内容
滚动到页面底部后,有些网站只会显示你要提取的部分数据。比如今日头条首页,需要不断滚动到页面底部才能加载更多文章内容。无限滚动网站 通常使用 AJAX 或 JavaScript 从网站 请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 抓取网页中的所有链接
一个普通的网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 抓取网页中的所有文本
有时需要将一个 HTML 文档中的所有文本提取出来,即把它放在 HTML 标签中(如
标签或标签)。 优采云 使您能够提取网页源代码中的所有或特定文本。
6、 抓取网页中的所有图片
有些朋友对网页图片有采集的需求。 优采云可以下载网页采集中图片的网址,然后使用优采云专用图片批量下载工具将我们采集图片网址中的图片下载并保存到本地电脑。 查看全部
excel抓取多页网页数据(使用优采云采集器软件从指定网页获取特定内容的几种解决方案)
网页数据爬取是指在不请求网站的API接口获取内容的情况下,从网站中提取特定内容。 “网页数据”作为网站 用户体验的一部分,例如网页上的文字、图像、声音、视频和动画,都被视为网页数据。
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特定的内容。下面是一些使用优采云采集器抓取网页数据的解决方案:
1、从动态网页中提取内容
网页可以是静态的或动态的。通常,您要提取的网页内容会随着您访问网站 的时间而变化。通常,这个网站是动态的网站,它使用AJAX技术或其他技术使网页内容及时更新。 AJAX 是一种延迟加载和异步更新的脚本技术。通过后台与服务器的少量数据交换,可以在不重新加载整个网页的情况下更新网页的某一部分。
性能特点是当你点击网页上的一个选项时,网站的大部分网址不会改变;网页未完全加载,但仅部分加载了数据并发生了更改。这时候可以在优采云的“高级选项”元素的“Ajax加载”中设置,然后就可以抓取Ajax加载的网页数据了。
2、从网页中抓取隐藏内容
你有没有想过从网站获取具体数据,但是当你触发链接或悬停在某处时,内容就会出现?比如下图中的网站需要将鼠标移动到选中的彩票上才能显示分类。对于此类功能,您可以设置“鼠标指向此链接”功能,即可抓取网页中隐藏的内容。
3、从无限滚动的网页中提取内容
滚动到页面底部后,有些网站只会显示你要提取的部分数据。比如今日头条首页,需要不断滚动到页面底部才能加载更多文章内容。无限滚动网站 通常使用 AJAX 或 JavaScript 从网站 请求附加内容。在这种情况下,您可以设置 AJAX 超时设置并选择滚动方式和滚动时间以从网页中提取内容。
4、 抓取网页中的所有链接
一个普通的网站 将收录至少一个超链接。如果要提取网页中的所有链接,可以使用优采云 获取网页上发布的所有超链接。
5、 抓取网页中的所有文本
有时需要将一个 HTML 文档中的所有文本提取出来,即把它放在 HTML 标签中(如
标签或标签)。 优采云 使您能够提取网页源代码中的所有或特定文本。
6、 抓取网页中的所有图片
有些朋友对网页图片有采集的需求。 优采云可以下载网页采集中图片的网址,然后使用优采云专用图片批量下载工具将我们采集图片网址中的图片下载并保存到本地电脑。

