
excel抓取多页网页数据
excel抓取多页网页数据(WebDataMiner如何从网页中选择要报废的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-02 04:13
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
变更日志
1.修复bug,新版本体验更好
2.部分页面已更改 查看全部
excel抓取多页网页数据(WebDataMiner如何从网页中选择要报废的数据?)
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
变更日志
1.修复bug,新版本体验更好
2.部分页面已更改
excel抓取多页网页数据(所有网站都提供API吗?不幸的是没有。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-01 11:18
所有 网站 都提供 API 吗?
不幸的是没有。鉴于 Facebook 必须限制信息的下载,您不得从 Facebook 下载任何信息(例如,甚至帖子)。我将讨论 API 的替代方案,但对于 Facebook,未经书面同意,您不能下载任何信息。
如果 网站 提供 API,我可能会遇到哪些限制?
· 编码
如果您不知道如何编码,这是第一个问题。每个 网站 都需要个人方法,而不是看起来那么简单。
· 格式
用于减少信息浪费的常用格式是 JSON,但还有其他格式。您下载的数据需要以您想要的方式进行规范化、理解和存储(我可以猜到一个 .csv 文件)。这很耗时,而且代码并不总是稳定的。
· 价格
有时你会很幸运地找到一个免费提供信息的 网站。在大多数情况下,如果没有订阅计划,您甚至无法下载免费信息:请为备用计划做好准备。
· 请求频率
您不能只从数据库中下载全时、全速的千兆字节数据。流量会降低您的服务器速度,因此网站要非常小心并限制要执行的请求数量。您需要每 n 秒执行一次 GET 请求(从在线数据库下载信息的操作)。当然,整个过程可以自动化。
· 容量限制
大多数提供 API(除非它们都是开源的)的 网站 都是为了利润(现在您了解销售数据的含义)。如果您想下载大于一定大小的数据,他们会要求您付费。
· 请求限制
另一种限制下载的度量标准不是大小,而是请求数。例如,使用 Alpha Vantage 下载历史股票价格限制为每天 500 个请求。
这些数字(例如每天 100,000 条推文的限制)可能看起来不是一个巨大的限制,但如果您经营一家拥有 500 名员工的公司,并且您的目标是建立一个巨大的 AI 预测模型,那么 100,000 条推文文本对于什么来说是一个荒谬的数量你想建立。
2.网页抓取
毕竟,网络爬虫已经成为我最喜欢的下载数据的方式,毕竟处理 API 从来都不是一件有趣的事情(如果你不相信我,请尝试询问)。
一些 网站 有你可以直接在他们的网页上看到的信息列表。我要使用的示例之一是 Xtrawine。
网站 收录数千条有关葡萄酒的信息。如果您是数据分析师,看起来不错!如果你用谷歌搜索,你会发现这个 网站 不提供开源 API。数据存储在他们的数据库中,您无权访问。
您可以利用主页上已经可见的数据,而不是询问您连接到的数据库。此信息存储在附加到页面的 HTML 代码中。您唯一需要做的就是访问代码并编写一个算法,该算法遍历所有数千页并提取每瓶葡萄酒的信息并将其存储到 .csv 数据集中。
这是为从该网页提取信息而编写的网络抓取算法的输出。你可以看到结果。我用 Pretty Soup 从 网站 中提取 HTML,但还有其他可用的 python 工具,这取决于你。
网页抓取的缺点
请注意,在线数据可能是公开的,但它不是商场。您不仅可以连接到任何 网站 并下载您想要的所有内容,这不仅不礼貌,而且还可能违反他们的政策。因此,如果您打算将此信息用于您的工作或研究,请注意您下载的内容和下载量。
3.开源数据集
最后一种下载数据的方法是找到已经准备好的数据。网站 像 Kaggle 或 data.world 有一系列开源数据集,您可以下载这些数据集进行试验。不幸的是,您不太可能找到您要搜索的内容。大多数信息都没有更新,如果您正在搜索特定的内容(例如价目表或营销列表),则必须使用前两种方法检索它。
这些预制数据集何时有用?
Covid-19 紧急情况就是一个例子。例如,如果您查看 Kaggle,您会发现关于 Covid-19 的每日更新数据集(大量信息)。研究人员可以为寻找基因相关信息做出贡献,并可以创建预测病毒传播的模型。
你怎么认为?你知道其他下载数据的方法吗?
(本文翻译自Michelangiolo Mazzeschi的文章《3 Ways to Collect Big Data with your PC》,参考:) 查看全部
excel抓取多页网页数据(所有网站都提供API吗?不幸的是没有。。)
所有 网站 都提供 API 吗?
不幸的是没有。鉴于 Facebook 必须限制信息的下载,您不得从 Facebook 下载任何信息(例如,甚至帖子)。我将讨论 API 的替代方案,但对于 Facebook,未经书面同意,您不能下载任何信息。
如果 网站 提供 API,我可能会遇到哪些限制?
· 编码
如果您不知道如何编码,这是第一个问题。每个 网站 都需要个人方法,而不是看起来那么简单。
· 格式
用于减少信息浪费的常用格式是 JSON,但还有其他格式。您下载的数据需要以您想要的方式进行规范化、理解和存储(我可以猜到一个 .csv 文件)。这很耗时,而且代码并不总是稳定的。
· 价格
有时你会很幸运地找到一个免费提供信息的 网站。在大多数情况下,如果没有订阅计划,您甚至无法下载免费信息:请为备用计划做好准备。
· 请求频率
您不能只从数据库中下载全时、全速的千兆字节数据。流量会降低您的服务器速度,因此网站要非常小心并限制要执行的请求数量。您需要每 n 秒执行一次 GET 请求(从在线数据库下载信息的操作)。当然,整个过程可以自动化。
· 容量限制
大多数提供 API(除非它们都是开源的)的 网站 都是为了利润(现在您了解销售数据的含义)。如果您想下载大于一定大小的数据,他们会要求您付费。
· 请求限制
另一种限制下载的度量标准不是大小,而是请求数。例如,使用 Alpha Vantage 下载历史股票价格限制为每天 500 个请求。
这些数字(例如每天 100,000 条推文的限制)可能看起来不是一个巨大的限制,但如果您经营一家拥有 500 名员工的公司,并且您的目标是建立一个巨大的 AI 预测模型,那么 100,000 条推文文本对于什么来说是一个荒谬的数量你想建立。
2.网页抓取
毕竟,网络爬虫已经成为我最喜欢的下载数据的方式,毕竟处理 API 从来都不是一件有趣的事情(如果你不相信我,请尝试询问)。
一些 网站 有你可以直接在他们的网页上看到的信息列表。我要使用的示例之一是 Xtrawine。
网站 收录数千条有关葡萄酒的信息。如果您是数据分析师,看起来不错!如果你用谷歌搜索,你会发现这个 网站 不提供开源 API。数据存储在他们的数据库中,您无权访问。
您可以利用主页上已经可见的数据,而不是询问您连接到的数据库。此信息存储在附加到页面的 HTML 代码中。您唯一需要做的就是访问代码并编写一个算法,该算法遍历所有数千页并提取每瓶葡萄酒的信息并将其存储到 .csv 数据集中。
这是为从该网页提取信息而编写的网络抓取算法的输出。你可以看到结果。我用 Pretty Soup 从 网站 中提取 HTML,但还有其他可用的 python 工具,这取决于你。
网页抓取的缺点
请注意,在线数据可能是公开的,但它不是商场。您不仅可以连接到任何 网站 并下载您想要的所有内容,这不仅不礼貌,而且还可能违反他们的政策。因此,如果您打算将此信息用于您的工作或研究,请注意您下载的内容和下载量。
3.开源数据集
最后一种下载数据的方法是找到已经准备好的数据。网站 像 Kaggle 或 data.world 有一系列开源数据集,您可以下载这些数据集进行试验。不幸的是,您不太可能找到您要搜索的内容。大多数信息都没有更新,如果您正在搜索特定的内容(例如价目表或营销列表),则必须使用前两种方法检索它。
这些预制数据集何时有用?
Covid-19 紧急情况就是一个例子。例如,如果您查看 Kaggle,您会发现关于 Covid-19 的每日更新数据集(大量信息)。研究人员可以为寻找基因相关信息做出贡献,并可以创建预测病毒传播的模型。
你怎么认为?你知道其他下载数据的方法吗?
(本文翻译自Michelangiolo Mazzeschi的文章《3 Ways to Collect Big Data with your PC》,参考:)
excel抓取多页网页数据(excel抓取多页网页数据在页面抓取中的两个要点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-31 19:05
excel抓取多页网页数据在页面抓取中,如果页面很多,复杂数据切换查询用户需要一层一层的操作,过于繁琐。这里介绍的是最基础的如何把xml文件以解析的方式读出来,就不涉及数据处理等具体操作,将其转化为可以在excel中操作的文件格式(xmlview)并进行分析处理就可以了。两个要点:手动下载并读取xml文件及做好分析归档1.手动下载xml文件(。
1)xml文件如果要下载xml文件,那么一定需要下载配置支持下载xml文件,excel支持读取utf-8编码的xml文件。首先要读取excel中的xml文件,将其转化为xmlview,之后再读取相应的数据。
2)手动方法介绍2.做好归档分析整理抽丝剥茧要对前后复杂多页数据做归档分析,并提炼出结构信息,还需要做好分析归档工作。也就是要处理页面数据以及切换查询的流程,具体如下:第一步:下载对应utf-8编码的xml文件/分析对应xmlview第二步:手动生成中间页分析归档用户下载xml文件后要注意以下几点:读取xmlview中文件,切换查询的数据页面url。
读取过程中切换查询页面url,并根据页面中的链接作为跳转目标来进行下载、解析xmlview。读取生成xmlview后要注意切换查询页面url时,保证页面能够正常跳转。具体教程地址:数据抓取视频教程参考地址:数据抓取视频教程安全教程常见错误3.上述方法的最佳实践案例对于已经不再需要切换页面,并且只要读取url中的第一页数据及提取数据即可的案例,上述方法是最佳实践案例。
如何制作分析归档需要根据不同的应用环境以及不同抓取工具的特点来提取应用的解析原理。最常见的应用场景有几个:生成测试数据复现性质bug数据管理或者需要检查数据的频率进行实时数据分析;针对复杂页面数据做切换查询的数据抓取场景;需要抓取的url在不同类型的搜索网站中获取,并且工作量大、数据量高的场景。
预计时间解析过程数据处理归档工作4.参考资料有哪些好用的下载或者抓取xmlview的工具?github:dylfy/document-view-exampledynamiclynews/two3weeklyblog-blob微信公众号:复杂数据处理的方法
一、常用工具安装1.excelhome数据下载:/由于excelhome并没有专门针对数据处理做优化,简单评测下载速度1:0,1分钟4kb。2:0.15秒/60000行,按列复制加载数据速度约1.1mb/s。csv格式文件就这个速度。以上可以判断excelhome有相当大的问题。
1)excelhome不支持xml解析
2)excelhome没有对数据结构优化
3)不支持乱序索引
二、解析源码fundebug经常使用fundebug工具去访问一些 查看全部
excel抓取多页网页数据(excel抓取多页网页数据在页面抓取中的两个要点)
excel抓取多页网页数据在页面抓取中,如果页面很多,复杂数据切换查询用户需要一层一层的操作,过于繁琐。这里介绍的是最基础的如何把xml文件以解析的方式读出来,就不涉及数据处理等具体操作,将其转化为可以在excel中操作的文件格式(xmlview)并进行分析处理就可以了。两个要点:手动下载并读取xml文件及做好分析归档1.手动下载xml文件(。
1)xml文件如果要下载xml文件,那么一定需要下载配置支持下载xml文件,excel支持读取utf-8编码的xml文件。首先要读取excel中的xml文件,将其转化为xmlview,之后再读取相应的数据。
2)手动方法介绍2.做好归档分析整理抽丝剥茧要对前后复杂多页数据做归档分析,并提炼出结构信息,还需要做好分析归档工作。也就是要处理页面数据以及切换查询的流程,具体如下:第一步:下载对应utf-8编码的xml文件/分析对应xmlview第二步:手动生成中间页分析归档用户下载xml文件后要注意以下几点:读取xmlview中文件,切换查询的数据页面url。
读取过程中切换查询页面url,并根据页面中的链接作为跳转目标来进行下载、解析xmlview。读取生成xmlview后要注意切换查询页面url时,保证页面能够正常跳转。具体教程地址:数据抓取视频教程参考地址:数据抓取视频教程安全教程常见错误3.上述方法的最佳实践案例对于已经不再需要切换页面,并且只要读取url中的第一页数据及提取数据即可的案例,上述方法是最佳实践案例。
如何制作分析归档需要根据不同的应用环境以及不同抓取工具的特点来提取应用的解析原理。最常见的应用场景有几个:生成测试数据复现性质bug数据管理或者需要检查数据的频率进行实时数据分析;针对复杂页面数据做切换查询的数据抓取场景;需要抓取的url在不同类型的搜索网站中获取,并且工作量大、数据量高的场景。
预计时间解析过程数据处理归档工作4.参考资料有哪些好用的下载或者抓取xmlview的工具?github:dylfy/document-view-exampledynamiclynews/two3weeklyblog-blob微信公众号:复杂数据处理的方法
一、常用工具安装1.excelhome数据下载:/由于excelhome并没有专门针对数据处理做优化,简单评测下载速度1:0,1分钟4kb。2:0.15秒/60000行,按列复制加载数据速度约1.1mb/s。csv格式文件就这个速度。以上可以判断excelhome有相当大的问题。
1)excelhome不支持xml解析
2)excelhome没有对数据结构优化
3)不支持乱序索引
二、解析源码fundebug经常使用fundebug工具去访问一些
excel抓取多页网页数据( 如何用PowerBI批量采集多个网页的数据(一)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-01-31 16:17
如何用PowerBI批量采集多个网页的数据(一)?)
前面介绍PowerBI数据获取的时候,举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行中的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
此处完成第一页数据后,进入采集的其他页面时,数据结构与第一页完成后的数据结构一致,可以使用采集的数据直接地; 没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let之前输入:
(p 作为数字)作为表格 =>
并且在let后面第一行的URL中,&后面的“1”变成了(这是第二步使用高级选项分两行输入URL的好处):
(数字.ToText(p))
修改后 [source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。如果输入数字,例如 7,将捕获第 7 页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
点击确定开始批量爬取网页,因为100页的数据比较多,大概需要5分钟左右,这也是我提前第二步数据排序的结果,导致爬取比较慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量采集工作已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行当您到达时,您无需再浪费时间。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。 查看全部
excel抓取多页网页数据(
如何用PowerBI批量采集多个网页的数据(一)?)
前面介绍PowerBI数据获取的时候,举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行中的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
此处完成第一页数据后,进入采集的其他页面时,数据结构与第一页完成后的数据结构一致,可以使用采集的数据直接地; 没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let之前输入:
(p 作为数字)作为表格 =>
并且在let后面第一行的URL中,&后面的“1”变成了(这是第二步使用高级选项分两行输入URL的好处):
(数字.ToText(p))
修改后 [source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。如果输入数字,例如 7,将捕获第 7 页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
点击确定开始批量爬取网页,因为100页的数据比较多,大概需要5分钟左右,这也是我提前第二步数据排序的结果,导致爬取比较慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量采集工作已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行当您到达时,您无需再浪费时间。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。
excel抓取多页网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-27 22:12
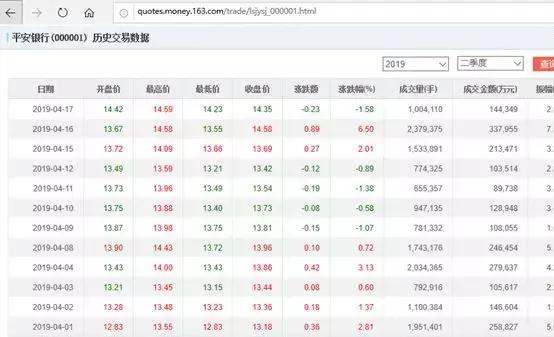
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的 网站。各种财经网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到对应股票数据的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
点击确定打开Power Query编辑器,如果一切顺利,数据会直接出现:
虽然不是表格,但证明刮是成功的。下一步是如何解析这个二进制文件。从google浏览器看,是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间数据可以用json解析。注意总数:4440,我们稍后会使用这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切顺利,但我们只抓取一页数据,让我们看看:
pn是页码,我们是抓取第三页,pz是每页20条数据,我们有两种方式来抓取所有数据,一种是使用这个pz:20,然后定义一个函数来抓取所有的页码,我在以前的爬网中反复使用过这个。今天我们将尝试直接修改 pz 以一次捕获所有数据。其实我们可以尝试改变查询参数。如果我们将 pn 更改为 4,我们将抓取第 4 页。同理,我们把pn修改为200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抓起来:
看起来不错。
还有一个问题,就是数据的标题行都是f开头的,不可读,怎么变成网页中汉字的标题行。
这个问题有点复杂。我们可能不得不检查代码,看看是否能找到替换它的方法。首先,看一下html:
但这是不完整的,有几列需要自定义:
这些指标没有对应的 f 代码。
我们再来看看js文件:
这个文件里面有对应的数据,我们直接复制到Power Query中,处理成列表形式备用:
下一步就是匹配表中的key,修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用 Table.RenameColumns 函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们可以将数据加载到 Excel 中。
如果要最新数据,直接刷新即可。 查看全部
excel抓取多页网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的 网站。各种财经网站都有股票数据。我们以东方财富网为例:

对于沪深A股数据,我们在谷歌浏览器中查看真实网址:

找到对应股票数据的jQuery行,然后查看头文件中的URL:

将此 URL 复制到 Excel,数据 ==> 来自 网站:

点击确定打开Power Query编辑器,如果一切顺利,数据会直接出现:

虽然不是表格,但证明刮是成功的。下一步是如何解析这个二进制文件。从google浏览器看,是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间数据可以用json解析。注意总数:4440,我们稍后会使用这个值。

=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:

到目前为止一切顺利,但我们只抓取一页数据,让我们看看:

pn是页码,我们是抓取第三页,pz是每页20条数据,我们有两种方式来抓取所有数据,一种是使用这个pz:20,然后定义一个函数来抓取所有的页码,我在以前的爬网中反复使用过这个。今天我们将尝试直接修改 pz 以一次捕获所有数据。其实我们可以尝试改变查询参数。如果我们将 pn 更改为 4,我们将抓取第 4 页。同理,我们把pn修改为200,看看能不能直接抓取200条数据。

那我们试试直接输入5000,能不能全部抓起来:

看起来不错。
还有一个问题,就是数据的标题行都是f开头的,不可读,怎么变成网页中汉字的标题行。
这个问题有点复杂。我们可能不得不检查代码,看看是否能找到替换它的方法。首先,看一下html:

但这是不完整的,有几列需要自定义:

这些指标没有对应的 f 代码。
我们再来看看js文件:

这个文件里面有对应的数据,我们直接复制到Power Query中,处理成列表形式备用:

下一步就是匹配表中的key,修改列名:

首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用 Table.RenameColumns 函数批量修改列名:

Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们可以将数据加载到 Excel 中。

如果要最新数据,直接刷新即可。
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-27 16:09
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。
方法二
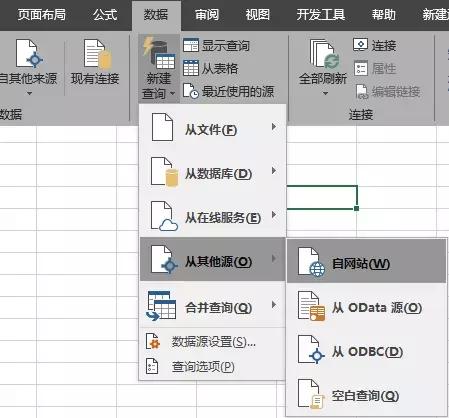
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
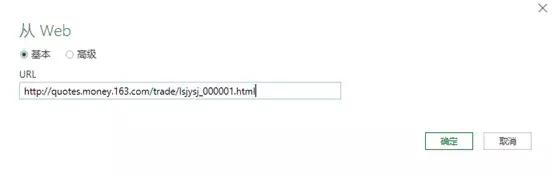
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
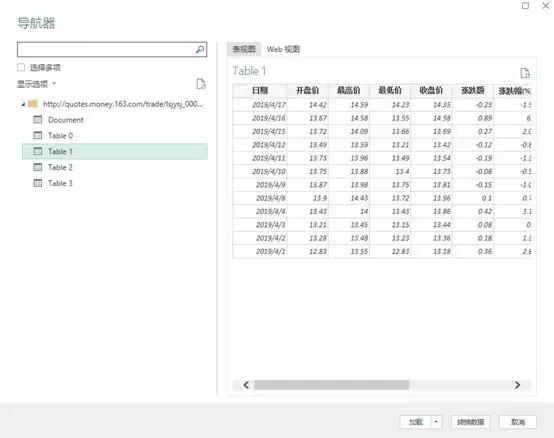
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么认为? 查看全部
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。

方法二
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
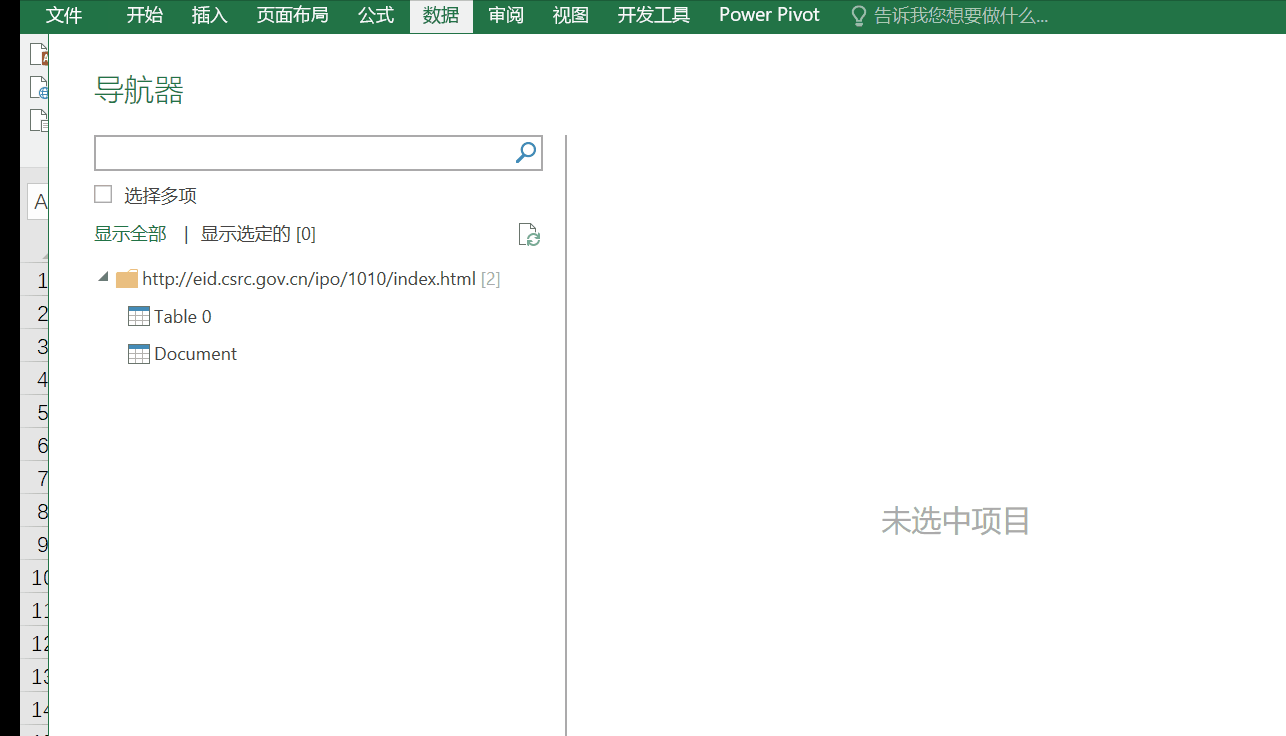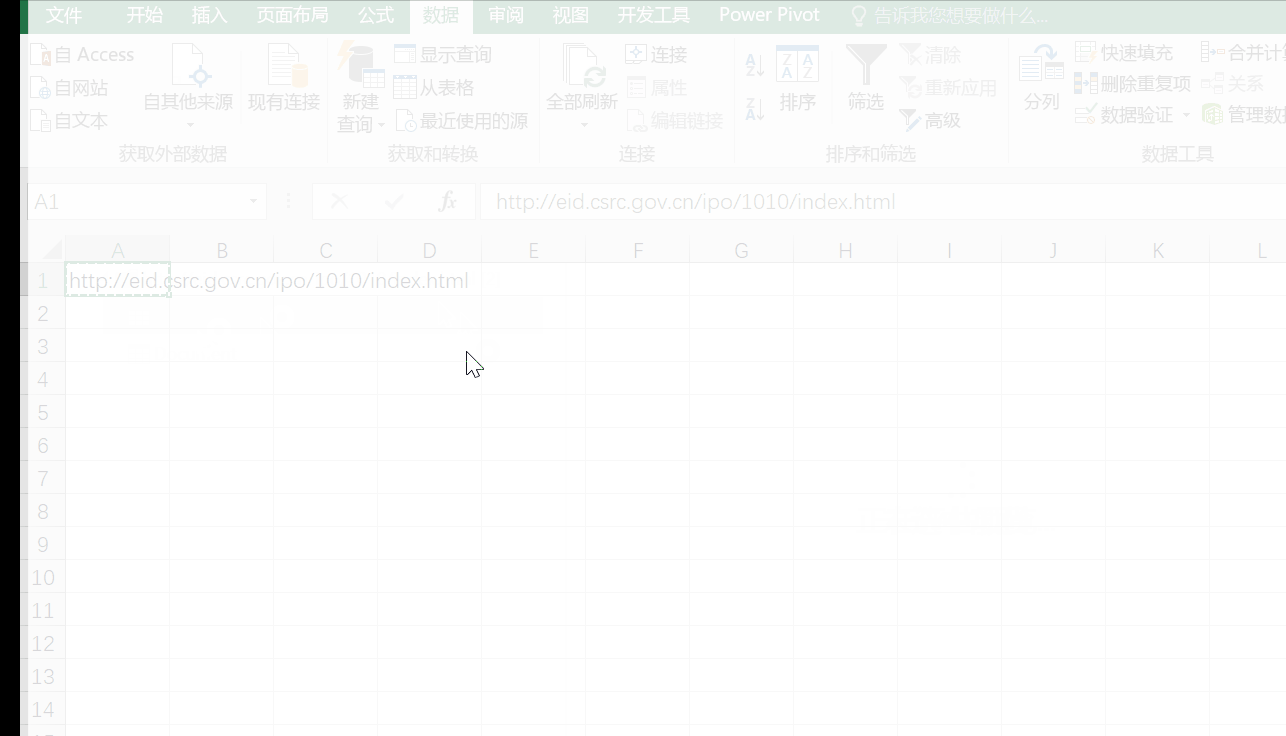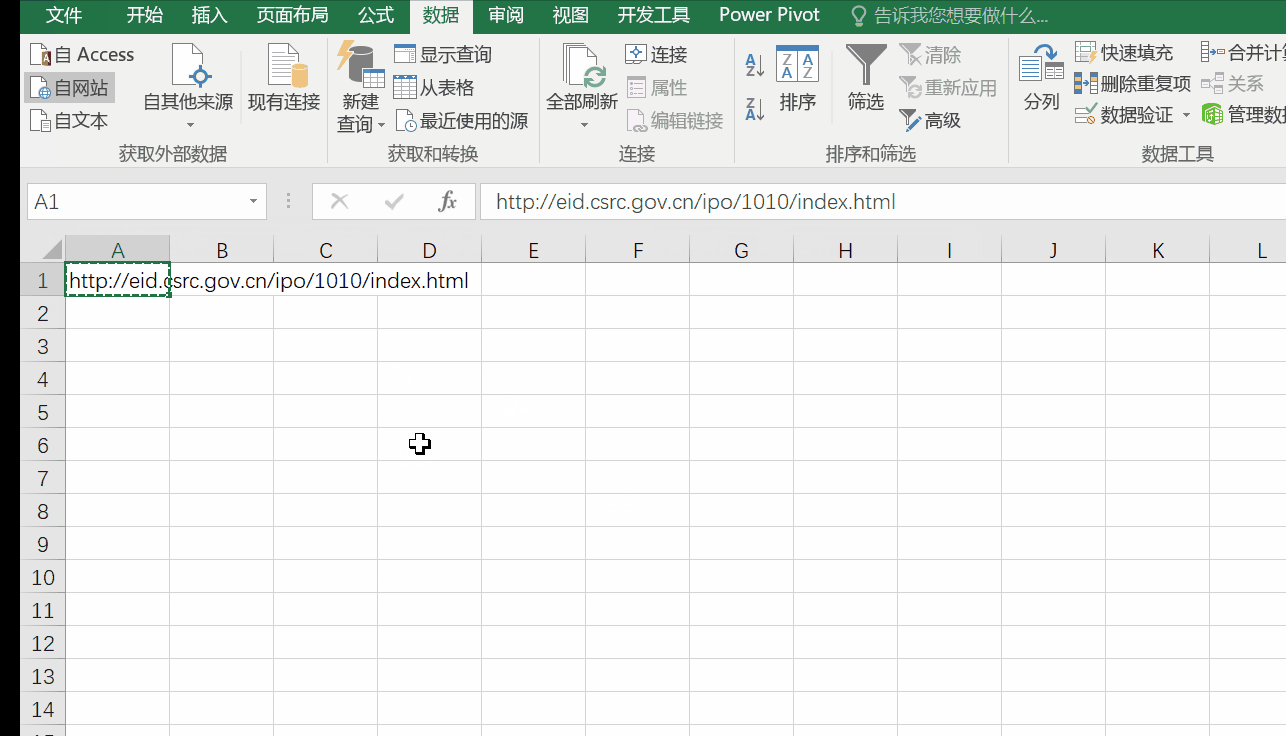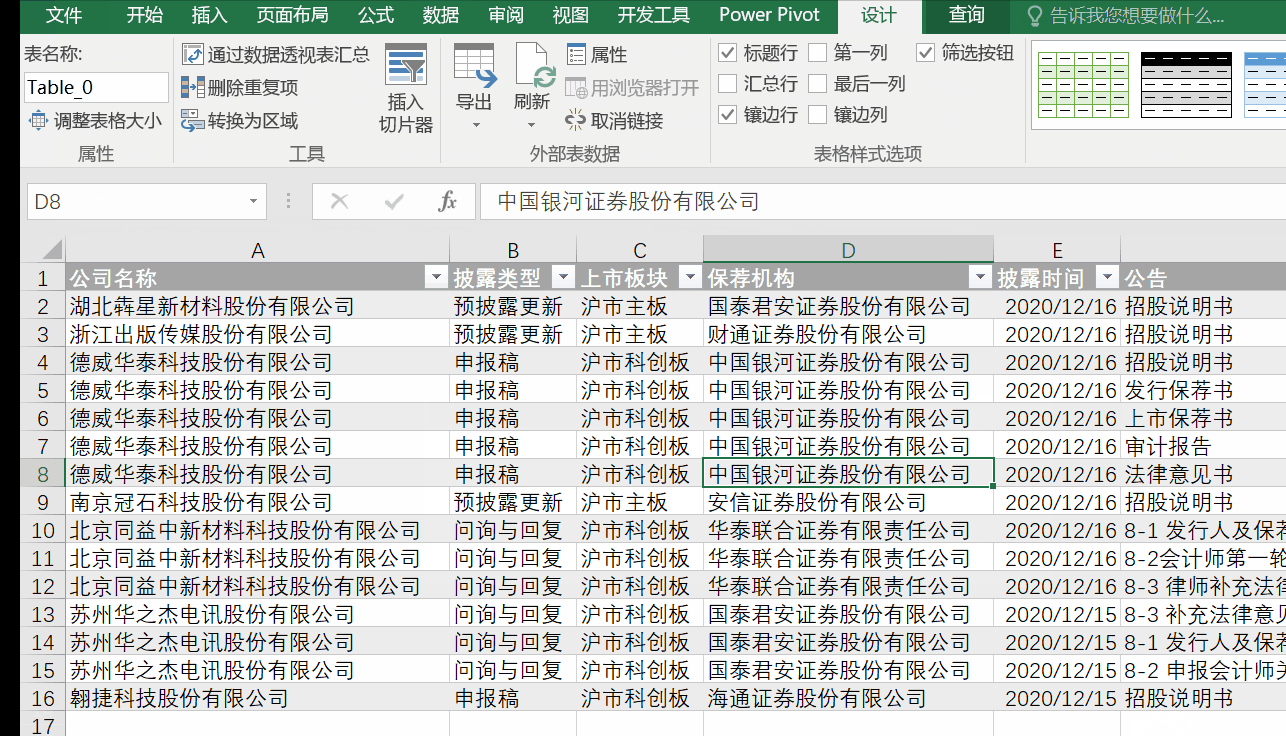
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:

没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么认为?
excel抓取多页网页数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-27 16:08
我在做项目的时候遇到了将Table表格的数据以Excel的形式存储在网页中的问题。将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i 查看全部
excel抓取多页网页数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
我在做项目的时候遇到了将Table表格的数据以Excel的形式存储在网页中的问题。将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i
excel抓取多页网页数据( 如何将网页中的数据刮到Excel中?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-27 16:06
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,添加经验公式来计算从抓取的数据中得出的一些最终结果,例如 The idea is good。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
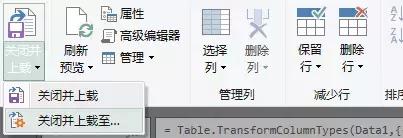
第 6 步:“主页”选项卡 >“关闭并加载到”:
导入数据对话框将打开:
提示:如果将其加载到数据模型中,请务必选择“仅创建连接” 查看全部
excel抓取多页网页数据(
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,添加经验公式来计算从抓取的数据中得出的一些最终结果,例如 The idea is good。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
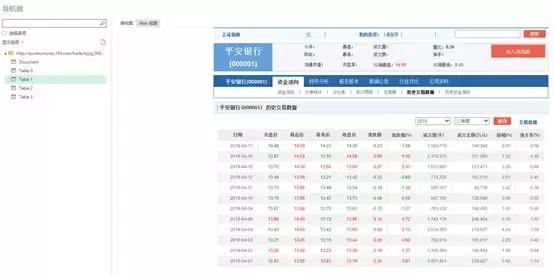
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“主页”选项卡 >“关闭并加载到”:
导入数据对话框将打开:
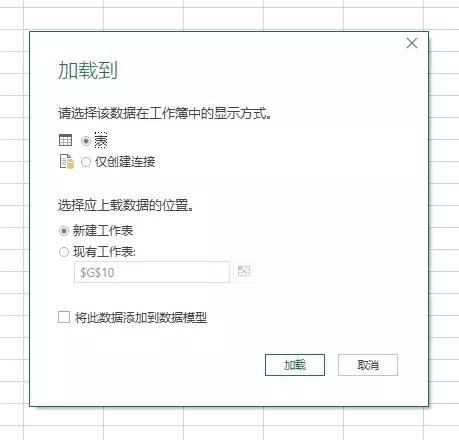
提示:如果将其加载到数据模型中,请务必选择“仅创建连接”
excel抓取多页网页数据(webscraper插件到底要怎么用呢?数据的基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2022-01-23 21:19
在工作中,几乎每个职位都涉及到数据采集的任务。采集本地所有装修公司的名单,采集一个APP的所有评论,采集所有网上相关的文章,批量下载某个网站的指定文件……
我不会编程,也不懂爬虫技术。遇到过这种工作,要么CTRL+C,CTRL+V,要么笑着请技术人员帮忙爬取数据。直到遇到神器网络爬虫,没有编程经验,经过几个简单的步骤设置,几分钟就可以快速采集上千条数据,效率高得一飞冲天。
Web scraper是一款谷歌爬虫插件,使用非常简单,30分钟即可完全掌握。网络爬虫插件会将数据抓取出来生成excel表格供我们使用。
那么如何使用这个插件呢?
爬取数据的基本流程
step1:下载并安装网络爬虫插件。
下载地址: 链接: 密码: t7bm
安装方法:参考百度经验文章
step2:新建一个数据爬取站点。
首先按F12(或点击鼠标右键-勾选)调出控制台,点击“Web Scraper”切换到爬虫插件功能,点击create new sitemap进入新数据爬虫站点创建页面。
站点地图名称可以自定义,但必须是英文。起始 url 是我们要抓取的 网站 网站。在这里,我们在豆瓣上爬取了上海近一周的同城活动,将以下链接复制到开始url输入框中,然后点击“创建站点地图”确认创建。
step3:选择要提取的页面元素
上一步创建成功后,页面会跳转到如下界面,然后我们点击“添加新选择器”,创建一个新的选择器。
以提取页面的活动标题为例,设置ID为“标题”(这里可以自定义,在excel中会变成表头),类型为“文本”。
选择器是指页面中需要提取的数据区域。点击选择,在网页上滑动鼠标,会出现绿色区域,表示可以选择这些区域的数据。
选择一个活动标题,这个区域会被红色边框包围,然后继续选择下一个活动标题。选择两个相同的区域时,插件将自动选择页面上的其他类似元素。点击“完成选择!” 确认选择。
我们可以点击“元素预览”查看页面上所有选中的区域,点击“数据预览”预览爬虫将获取的数据。
注意:由于我们要选择此页面上的所有活动标题,因此需要选中“多个”复选框。其余内容可以保留默认,点击“保存选择器”保存选择器。
至此,我们已经选择了要提取的页面元素,如下图所示。
step4:开始爬取数据
点击抓取,进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,点击“开始抓取”开始抓取数据。这里的时间间隔主要是为了避免爬虫因为操作过于频繁而被阻塞,无法正常爬取。一般网站默认时间间隔就可以了,有些网站可能需要设置更大的时间间隔。
启动后,会打开一个目标URL的窗口,爬虫会按照提取设置的规则,一个一个的爬取。爬取完成后,窗口会自动关闭。
step5:下载数据
点击“Export data as CSV”跳转到excel数据下载页面,点击“download now”下载。
以上五个步骤就是使用网络爬虫爬取数据的整个过程和操作。不管数据多么复杂,都可以按照这个流程和操作爬取对应的数据。
高级操作
1、如何一次爬取一组数据?
刚才我们只爬取活动主题。如果我们想同时抓取活跃话题和活跃时间,我们应该怎么做呢?
从上图可以看出,数据的结构,活动主题和活动时间都收录在最外层的方框中,所以在设置选择器的时候,首先创建一个大选择器,让活动主题和活动内容都收录在内同时。
注意这里的Type应该设置为“Element”。保存后,点击刚才创建的内容(下图中红框的位置),进入子页面。
然后在这个页面上分别创建一个标题选择器和一个时间选择器。它的类型是文本。现在页面的可选择区域仅限于列表区域,所以只需要点击活动标题一次,确认选择即可。不要勾选“多个”。
只有通过创建一个元素选择器来收录活动主题和活动时间,爬取的数据才会以一一对应的方式呈现。
2、如何一次爬取多页内容?
这里根据分页形式的不同有不同的解决方案。
1)固定分页的情况下
可以注意到豆瓣同城活动的页面是分页的,每页显示10条数据。那么如果我们要爬取前10页的数据,我们应该怎么做呢?
如果你仔细看,你会发现第一页的 URL 和第二页的 URL 是有区别的。
第一页:
第二页:
start= 后面的数字是差为 10 的等差数列。
那么我们在搭建数据爬取站点的时候,我们用[0-100:10]代替具体的数字来表示数据爬取的页面范围。即:[0-100:10]
如果 URL 的等价性为 1,例如 知乎question URL:
第一页:
第二页:
然后省略冒号和后面的算术差异,只写页码范围。如[1-10]
表示知乎 主题的第一页到第十页。
处理这类数据的重点是观察不同页面的URL变化,然后将页码范围写入URL。
2)滚动鼠标自动加载
目前很多网站都采用了滚动到底部后自动加载数据的方式,并且它们的URL并没有改变。比如知乎live首页的数据加载方式。
这时候我们需要在创建元素选择器的时候将Type设置为“元素向下滚动”。这样,当爬虫工作时,它会自动进行滚动操作,一直爬到没有数据加载为止。
3)点击页面底部的“加载更多”按钮
设置外层元素元素时,将Type设置为“元素点击”,然后点击“点击选择器”的“选择”按钮,选择页面上的加载更多按钮或图标。
为了使页面不断加载,请将“点击类型”设置为“点击更多”并点击多次。
接下来,设置停止点击的条件。当该区域的文本内容或 HTML 结构或显示样式发生变化时,不再点击。
例如,加载完成后,“加载更多”按钮的文字变为“已加载”,则此处选择Unique Text;如果按钮在加载结束时显示为灰色,请选择唯一 CSS 选择器。
3、如何批量抓取和下载图片?
将类型设置为图片,插件将抓取所有图片的链接。有两种下载图像的方法。一种是直接勾选Download image,这样爬虫在爬取的时候会自动下载。或者爬取所有图片链接后,使用批量下载工具直接下载。
4、如何抓取网页链接?
将Type设置为Link,爬虫将爬取该元素上的超链接。
如图:当Type为文本时,爬取的数据为立陶宛Angelica Cholina Dance Theatre的Anna Karenina的“Anna Karenina”
当Type为Link时,爬取的数据为:,即点击页面链接跳转到下图中红框内的内容。
当您需要抓取的链接是下载文件的链接时,例如类似下图中“公告下载”按钮的链接。您可以将类型设置为弹出链接,以便在爬取过程中自动下载文件。
5. 如何爬取二级或三级页面的内容?
首先在根目录中创建一个选择器。此选择器选择的内容是可以点击进入二级页面的区域。如果该区域有超链接,则将Type设置为Link,否则设置为Element click;然后在这个选择器里面创建一个选择器,选择要爬取的区域。这可以逐级嵌套。
如何判断一个区域是否有超链接?将鼠标放在该区域,右键单击,如果有“Open link in...”选项,则该区域有超链接,将Type设置为Link。
通过以上设置,我们可以使用谷歌插件抓取80%的网站数据,获取本地的excel文件,然后对数据进行处理分析。
以上技能不仅可以用于工作,还可以应用于生活中的查询信息。
很多时候网站的设计存在一定的问题,给我们获取信息带来一定的困难。
例如,在知乎直播网页上,当你点击一个直播详情然后返回时,页面会回到顶部,需要再次滚动加载;
例如,交互栏的活动列表页面没有对活动状态进行分类。一般来说,正在进行的活动是不能参与的,但也不能被过滤掉。
这时候如果使用网络爬虫工具,可以在本地抓取数据,然后根据自己的需要快速过滤。
掌握了这个插件后,真的能提高工作效率,减少麻烦吗?
提高工作效率是肯定的,但减少麻烦却不一定。毕竟下班太早被老板说了~woo woo 查看全部
excel抓取多页网页数据(webscraper插件到底要怎么用呢?数据的基本流程)
在工作中,几乎每个职位都涉及到数据采集的任务。采集本地所有装修公司的名单,采集一个APP的所有评论,采集所有网上相关的文章,批量下载某个网站的指定文件……
我不会编程,也不懂爬虫技术。遇到过这种工作,要么CTRL+C,CTRL+V,要么笑着请技术人员帮忙爬取数据。直到遇到神器网络爬虫,没有编程经验,经过几个简单的步骤设置,几分钟就可以快速采集上千条数据,效率高得一飞冲天。
Web scraper是一款谷歌爬虫插件,使用非常简单,30分钟即可完全掌握。网络爬虫插件会将数据抓取出来生成excel表格供我们使用。
那么如何使用这个插件呢?
爬取数据的基本流程
step1:下载并安装网络爬虫插件。
下载地址: 链接: 密码: t7bm
安装方法:参考百度经验文章
step2:新建一个数据爬取站点。
首先按F12(或点击鼠标右键-勾选)调出控制台,点击“Web Scraper”切换到爬虫插件功能,点击create new sitemap进入新数据爬虫站点创建页面。

站点地图名称可以自定义,但必须是英文。起始 url 是我们要抓取的 网站 网站。在这里,我们在豆瓣上爬取了上海近一周的同城活动,将以下链接复制到开始url输入框中,然后点击“创建站点地图”确认创建。
step3:选择要提取的页面元素
上一步创建成功后,页面会跳转到如下界面,然后我们点击“添加新选择器”,创建一个新的选择器。
以提取页面的活动标题为例,设置ID为“标题”(这里可以自定义,在excel中会变成表头),类型为“文本”。
选择器是指页面中需要提取的数据区域。点击选择,在网页上滑动鼠标,会出现绿色区域,表示可以选择这些区域的数据。
选择一个活动标题,这个区域会被红色边框包围,然后继续选择下一个活动标题。选择两个相同的区域时,插件将自动选择页面上的其他类似元素。点击“完成选择!” 确认选择。
我们可以点击“元素预览”查看页面上所有选中的区域,点击“数据预览”预览爬虫将获取的数据。
注意:由于我们要选择此页面上的所有活动标题,因此需要选中“多个”复选框。其余内容可以保留默认,点击“保存选择器”保存选择器。
至此,我们已经选择了要提取的页面元素,如下图所示。
step4:开始爬取数据
点击抓取,进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,点击“开始抓取”开始抓取数据。这里的时间间隔主要是为了避免爬虫因为操作过于频繁而被阻塞,无法正常爬取。一般网站默认时间间隔就可以了,有些网站可能需要设置更大的时间间隔。
启动后,会打开一个目标URL的窗口,爬虫会按照提取设置的规则,一个一个的爬取。爬取完成后,窗口会自动关闭。
step5:下载数据
点击“Export data as CSV”跳转到excel数据下载页面,点击“download now”下载。
以上五个步骤就是使用网络爬虫爬取数据的整个过程和操作。不管数据多么复杂,都可以按照这个流程和操作爬取对应的数据。
高级操作
1、如何一次爬取一组数据?
刚才我们只爬取活动主题。如果我们想同时抓取活跃话题和活跃时间,我们应该怎么做呢?
从上图可以看出,数据的结构,活动主题和活动时间都收录在最外层的方框中,所以在设置选择器的时候,首先创建一个大选择器,让活动主题和活动内容都收录在内同时。
注意这里的Type应该设置为“Element”。保存后,点击刚才创建的内容(下图中红框的位置),进入子页面。
然后在这个页面上分别创建一个标题选择器和一个时间选择器。它的类型是文本。现在页面的可选择区域仅限于列表区域,所以只需要点击活动标题一次,确认选择即可。不要勾选“多个”。
只有通过创建一个元素选择器来收录活动主题和活动时间,爬取的数据才会以一一对应的方式呈现。
2、如何一次爬取多页内容?
这里根据分页形式的不同有不同的解决方案。
1)固定分页的情况下
可以注意到豆瓣同城活动的页面是分页的,每页显示10条数据。那么如果我们要爬取前10页的数据,我们应该怎么做呢?
如果你仔细看,你会发现第一页的 URL 和第二页的 URL 是有区别的。
第一页:
第二页:
start= 后面的数字是差为 10 的等差数列。
那么我们在搭建数据爬取站点的时候,我们用[0-100:10]代替具体的数字来表示数据爬取的页面范围。即:[0-100:10]
如果 URL 的等价性为 1,例如 知乎question URL:
第一页:
第二页:
然后省略冒号和后面的算术差异,只写页码范围。如[1-10]
表示知乎 主题的第一页到第十页。
处理这类数据的重点是观察不同页面的URL变化,然后将页码范围写入URL。
2)滚动鼠标自动加载
目前很多网站都采用了滚动到底部后自动加载数据的方式,并且它们的URL并没有改变。比如知乎live首页的数据加载方式。
这时候我们需要在创建元素选择器的时候将Type设置为“元素向下滚动”。这样,当爬虫工作时,它会自动进行滚动操作,一直爬到没有数据加载为止。
3)点击页面底部的“加载更多”按钮
设置外层元素元素时,将Type设置为“元素点击”,然后点击“点击选择器”的“选择”按钮,选择页面上的加载更多按钮或图标。
为了使页面不断加载,请将“点击类型”设置为“点击更多”并点击多次。
接下来,设置停止点击的条件。当该区域的文本内容或 HTML 结构或显示样式发生变化时,不再点击。
例如,加载完成后,“加载更多”按钮的文字变为“已加载”,则此处选择Unique Text;如果按钮在加载结束时显示为灰色,请选择唯一 CSS 选择器。
3、如何批量抓取和下载图片?
将类型设置为图片,插件将抓取所有图片的链接。有两种下载图像的方法。一种是直接勾选Download image,这样爬虫在爬取的时候会自动下载。或者爬取所有图片链接后,使用批量下载工具直接下载。
4、如何抓取网页链接?
将Type设置为Link,爬虫将爬取该元素上的超链接。
如图:当Type为文本时,爬取的数据为立陶宛Angelica Cholina Dance Theatre的Anna Karenina的“Anna Karenina”
当Type为Link时,爬取的数据为:,即点击页面链接跳转到下图中红框内的内容。
当您需要抓取的链接是下载文件的链接时,例如类似下图中“公告下载”按钮的链接。您可以将类型设置为弹出链接,以便在爬取过程中自动下载文件。
5. 如何爬取二级或三级页面的内容?
首先在根目录中创建一个选择器。此选择器选择的内容是可以点击进入二级页面的区域。如果该区域有超链接,则将Type设置为Link,否则设置为Element click;然后在这个选择器里面创建一个选择器,选择要爬取的区域。这可以逐级嵌套。
如何判断一个区域是否有超链接?将鼠标放在该区域,右键单击,如果有“Open link in...”选项,则该区域有超链接,将Type设置为Link。
通过以上设置,我们可以使用谷歌插件抓取80%的网站数据,获取本地的excel文件,然后对数据进行处理分析。
以上技能不仅可以用于工作,还可以应用于生活中的查询信息。
很多时候网站的设计存在一定的问题,给我们获取信息带来一定的困难。
例如,在知乎直播网页上,当你点击一个直播详情然后返回时,页面会回到顶部,需要再次滚动加载;
例如,交互栏的活动列表页面没有对活动状态进行分类。一般来说,正在进行的活动是不能参与的,但也不能被过滤掉。
这时候如果使用网络爬虫工具,可以在本地抓取数据,然后根据自己的需要快速过滤。
掌握了这个插件后,真的能提高工作效率,减少麻烦吗?
提高工作效率是肯定的,但减少麻烦却不一定。毕竟下班太早被老板说了~woo woo
excel抓取多页网页数据(如何将jsp页面表格中的数据导出到excel中?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-17 20:21
在程序员的日常工作中,我们经常会遇到这样的问题。如何将jsp页表中的数据导出到excel中?
我知道的第一个方法是 javascript
function method1(tableid) {//整个表格拷贝到EXCEL中
var curTbl = document.getElementByIdx_x(tableid);
var oXL = new ActiveXObject("Excel.Application");
//建立AX对象excel
var oWB = oXL.Workbooks.Add();
//获取workbook对象
var oSheet = oWB.ActiveSheet;
//激活当前sheet
var sel = document.body.createTextRange();
sel.moveToElementText(curTbl);
//把表格中的内容移到TextRange中
sel.select();
//全选TextRange中内容
sel.execCommand("Copy");
//复制TextRange中内容
oSheet.Paste();
//粘贴到活动的EXCEL中
oXL.Visible = true;
//设置excel可见属性
}
但是,这种方法有很大的局限性。火狐和谷歌浏览器基本没用,用IE的时候修改安全设置很不方便。
此外,还可以采取以下方式:在jsp页面头部添加这一段:
wjm 是您要导出的 Excel 工作表的名称。使用这种方法,当你打开链接指向页面时,浏览器会提示你下载excel表格,你可以以excel的形式保存到本地。该方法适用于各种浏览器,但在当前页面看不到数据表的内容,因为打开页面会提示直接下载。如何解决这个问题呢?我是这样解决的:
点击导出通信录
这样,您将能够在当前页面上看到收录表格的页面,并在单击链接时下载它。
有时我们要收录的页面是struts的action处理过的页面。如果直接收录action指向的页面,那么页面上可能只看到header部分,没有数据。我该怎么办?处理它?
我想出的是使用ajax的方式:
<p>function init(){
$(function(){
$.ajax({
'async': false,
type : "post",
url :"showUser.action",
success : function(msg) {
$("#result").html(msg);
}
});
});
}
点击导出通信录 查看全部
excel抓取多页网页数据(如何将jsp页面表格中的数据导出到excel中?)
在程序员的日常工作中,我们经常会遇到这样的问题。如何将jsp页表中的数据导出到excel中?
我知道的第一个方法是 javascript
function method1(tableid) {//整个表格拷贝到EXCEL中
var curTbl = document.getElementByIdx_x(tableid);
var oXL = new ActiveXObject("Excel.Application");
//建立AX对象excel
var oWB = oXL.Workbooks.Add();
//获取workbook对象
var oSheet = oWB.ActiveSheet;
//激活当前sheet
var sel = document.body.createTextRange();
sel.moveToElementText(curTbl);
//把表格中的内容移到TextRange中
sel.select();
//全选TextRange中内容
sel.execCommand("Copy");
//复制TextRange中内容
oSheet.Paste();
//粘贴到活动的EXCEL中
oXL.Visible = true;
//设置excel可见属性
}
但是,这种方法有很大的局限性。火狐和谷歌浏览器基本没用,用IE的时候修改安全设置很不方便。
此外,还可以采取以下方式:在jsp页面头部添加这一段:
wjm 是您要导出的 Excel 工作表的名称。使用这种方法,当你打开链接指向页面时,浏览器会提示你下载excel表格,你可以以excel的形式保存到本地。该方法适用于各种浏览器,但在当前页面看不到数据表的内容,因为打开页面会提示直接下载。如何解决这个问题呢?我是这样解决的:
点击导出通信录
这样,您将能够在当前页面上看到收录表格的页面,并在单击链接时下载它。
有时我们要收录的页面是struts的action处理过的页面。如果直接收录action指向的页面,那么页面上可能只看到header部分,没有数据。我该怎么办?处理它?
我想出的是使用ajax的方式:
<p>function init(){
$(function(){
$.ajax({
'async': false,
type : "post",
url :"showUser.action",
success : function(msg) {
$("#result").html(msg);
}
});
});
}
点击导出通信录
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-17 05:24
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
爬取250部豆瓣电影比较简单,特别是对于初学者来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫都会选择这个项目作为起点。入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它是一个很好的实践网页作为入口爬虫。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
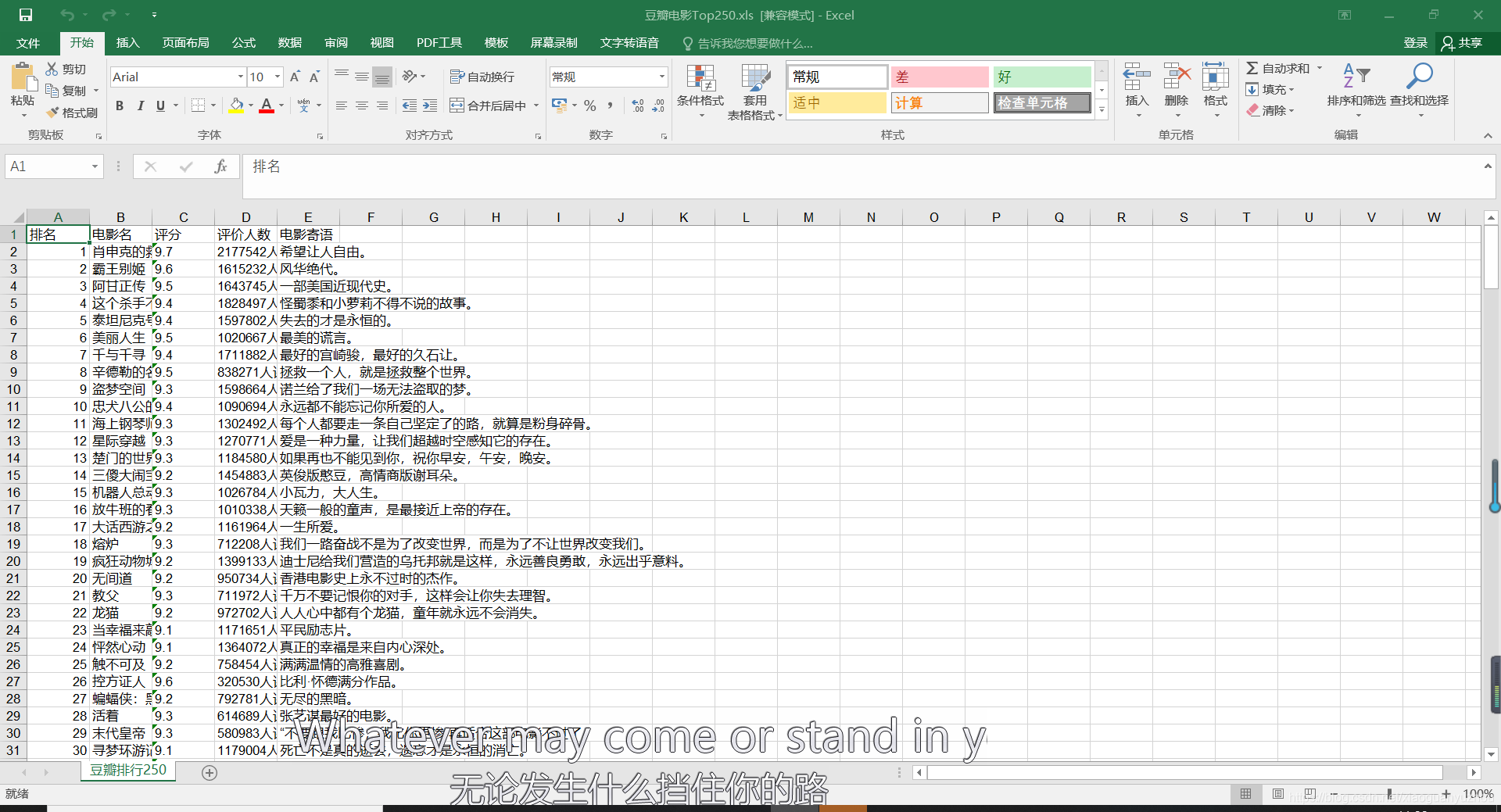
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。 查看全部
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
爬取250部豆瓣电影比较简单,特别是对于初学者来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫都会选择这个项目作为起点。入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它是一个很好的实践网页作为入口爬虫。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。
excel抓取多页网页数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-15 21:03
)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
查看全部
excel抓取多页网页数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫
)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。

excel抓取多页网页数据(大数据时代,看似平平常常的生活场景,其实是没有价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-11 10:17
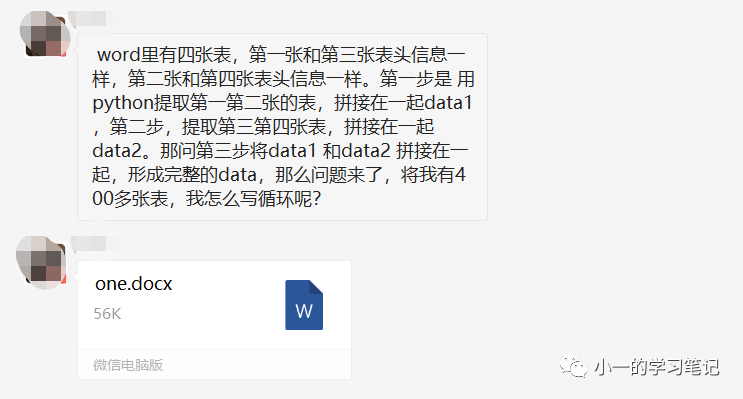
在大数据时代,看似平凡的生活场景,其实都离不开这些海量数据。例如,您接触到的文件、照片、视频等都收录大量的数据信息。每个人都可以从中受益,为我们节省了时间,也为对方省了很多麻烦。
现在几乎每天都有无数的数据在互联网上激增,成为不可或缺的生产要素。事实上,大数据本身并没有任何价值。如何对待这种说法取决于用户。认为这些数据对分析某些东西有很大帮助是有价值的。而如果我们不将这些数据用于参考和引用,那么数据就只是一堆数字和文字相结合的文件。
我直接在speedceo上找到了一些Excel文件。当然,这些文件都是公开的,也可以直接下载或者在线预览。基本可以找到我想知道的大学排名表文件。不过也有一些文件比较旧,日期是新的,看你有没有需要。
同时,人们期待看到他们在春节期间上映的电影的票房、排名等表现。这就是数据。如果行业的大玩家得到它,他们可以做出一些预测。毕竟规划一些内容一定不能盲目。只有获得真实可靠的数据,才能做出准确的事后分析和预测。
直接获取一些统计数据表进行分析是很简单的,但是之前确实不容易获取,成本高,准确度也不一定。现在有了Python,其实处理起来比较快,但是我对它不是太熟悉,因为没有专门研究过。互联网时代,海量数据海量可用。
如果要写分析意见,还是需要一定的数据来支持的。事实上,为人们提供新鲜而深刻的见解,就是大数据的价值所在。数据在互联网时代真的很重要,毕竟它可以帮助在分析事物时做出有效的决策。 查看全部
excel抓取多页网页数据(大数据时代,看似平平常常的生活场景,其实是没有价值)
在大数据时代,看似平凡的生活场景,其实都离不开这些海量数据。例如,您接触到的文件、照片、视频等都收录大量的数据信息。每个人都可以从中受益,为我们节省了时间,也为对方省了很多麻烦。

现在几乎每天都有无数的数据在互联网上激增,成为不可或缺的生产要素。事实上,大数据本身并没有任何价值。如何对待这种说法取决于用户。认为这些数据对分析某些东西有很大帮助是有价值的。而如果我们不将这些数据用于参考和引用,那么数据就只是一堆数字和文字相结合的文件。
我直接在speedceo上找到了一些Excel文件。当然,这些文件都是公开的,也可以直接下载或者在线预览。基本可以找到我想知道的大学排名表文件。不过也有一些文件比较旧,日期是新的,看你有没有需要。
同时,人们期待看到他们在春节期间上映的电影的票房、排名等表现。这就是数据。如果行业的大玩家得到它,他们可以做出一些预测。毕竟规划一些内容一定不能盲目。只有获得真实可靠的数据,才能做出准确的事后分析和预测。
直接获取一些统计数据表进行分析是很简单的,但是之前确实不容易获取,成本高,准确度也不一定。现在有了Python,其实处理起来比较快,但是我对它不是太熟悉,因为没有专门研究过。互联网时代,海量数据海量可用。

如果要写分析意见,还是需要一定的数据来支持的。事实上,为人们提供新鲜而深刻的见解,就是大数据的价值所在。数据在互联网时代真的很重要,毕竟它可以帮助在分析事物时做出有效的决策。
excel抓取多页网页数据(先导入需要的工具定义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-01-11 10:15
)
首先导入需要的工具,定义爬虫类,初始化base_url,随机请求头,总页数,记录每一页的小说名和连接地址,excel中存储的行数,后面需要用到.
获取网页的源码,分析是否是首页,因为解析url地址发现首页的url和后面的url不一样。如果是第一页,直接返回self.base_url。页数
设置一个循环,如果不能正常连接,会返回失败信息和原因,重新尝试连接。
解析网页源码,通过引入etree,将得到的网页源码转换成xpath可以解析的格式,并设置编码为utf-8格式
优先获取总页数,匹配到的是
所以需要通过正则表达式匹配总页数,转换为整数类型
然后在网页中获取小说名和详情地址的url,保存在一个元组中,然后将元组存入小说列表
定义一个解析细节的类,解析小说的细节
获取网页源代码获取详细地址
根据xpath,解析出小说的详细信息。清理数据并返回解析后的信息
回到上一个类,写写数据入表的函数,实现解析明细类的实例对象,根据小说的明细地址进行解析
写启动函数,建表,写数据,保存表
实现爬虫类的对象,调用start函数,启动爬虫
查看全部
excel抓取多页网页数据(先导入需要的工具定义
)
首先导入需要的工具,定义爬虫类,初始化base_url,随机请求头,总页数,记录每一页的小说名和连接地址,excel中存储的行数,后面需要用到.
获取网页的源码,分析是否是首页,因为解析url地址发现首页的url和后面的url不一样。如果是第一页,直接返回self.base_url。页数
设置一个循环,如果不能正常连接,会返回失败信息和原因,重新尝试连接。
解析网页源码,通过引入etree,将得到的网页源码转换成xpath可以解析的格式,并设置编码为utf-8格式
优先获取总页数,匹配到的是
所以需要通过正则表达式匹配总页数,转换为整数类型
然后在网页中获取小说名和详情地址的url,保存在一个元组中,然后将元组存入小说列表
定义一个解析细节的类,解析小说的细节
获取网页源代码获取详细地址
根据xpath,解析出小说的详细信息。清理数据并返回解析后的信息
回到上一个类,写写数据入表的函数,实现解析明细类的实例对象,根据小说的明细地址进行解析
写启动函数,建表,写数据,保存表
实现爬虫类的对象,调用start函数,启动爬虫
excel抓取多页网页数据(excel抓取多页网页数据的方法一种方法是复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-10 11:01
excel抓取多页网页数据的方法一种方法是复制每一页的数据,然后粘贴到另一页,这样做的缺点是只能抓取垂直数据。第二种方法,使用python的numpy。在excel文件中,通过numpy第一层抓取每一页的数据,然后再下一页抓取。由于字符串是不能复制,因此利用python通过函数来抓取字符串。
一、数据分析工具
二、数据介绍
三、用python实现
二、数据介绍整理数据之后,提取出前三页的内容:最终,
1。可以利用清洗好的数据作相关性分析或计数分析等;2。可以利用清洗好的数据作指标分析、排名分析等;3。可以利用清洗好的数据作目标识别、模式发现等;4。可以利用清洗好的数据作文本分析、表格分析等;5。可以利用清洗好的数据作上游关联分析等;6。可以利用清洗好的数据做事件发生时间分析等;7。可以利用清洗好的数据做营销活动数据分析等;8。
可以利用清洗好的数据做相关性分析等;9。可以利用清洗好的数据做市场数据定位分析等;10。可以利用清洗好的数据做产品的用户画像和设计,比如从用户基本信息、用户属性、产品属性、使用产品等来得到用户画像;11。可以利用清洗好的数据做线上线下的产品推广数据分析;12。可以利用清洗好的数据做品牌推广数据分析;13。可以利用清洗好的数据做市场分析和产品评估等;14。可以利用清洗好的数据做科研项目设计等;。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据的方法一种方法是复制)
excel抓取多页网页数据的方法一种方法是复制每一页的数据,然后粘贴到另一页,这样做的缺点是只能抓取垂直数据。第二种方法,使用python的numpy。在excel文件中,通过numpy第一层抓取每一页的数据,然后再下一页抓取。由于字符串是不能复制,因此利用python通过函数来抓取字符串。
一、数据分析工具
二、数据介绍
三、用python实现
二、数据介绍整理数据之后,提取出前三页的内容:最终,
1。可以利用清洗好的数据作相关性分析或计数分析等;2。可以利用清洗好的数据作指标分析、排名分析等;3。可以利用清洗好的数据作目标识别、模式发现等;4。可以利用清洗好的数据作文本分析、表格分析等;5。可以利用清洗好的数据作上游关联分析等;6。可以利用清洗好的数据做事件发生时间分析等;7。可以利用清洗好的数据做营销活动数据分析等;8。
可以利用清洗好的数据做相关性分析等;9。可以利用清洗好的数据做市场数据定位分析等;10。可以利用清洗好的数据做产品的用户画像和设计,比如从用户基本信息、用户属性、产品属性、使用产品等来得到用户画像;11。可以利用清洗好的数据做线上线下的产品推广数据分析;12。可以利用清洗好的数据做品牌推广数据分析;13。可以利用清洗好的数据做市场分析和产品评估等;14。可以利用清洗好的数据做科研项目设计等;。
excel抓取多页网页数据(干货速递|Python办公自动化之PDF的详细操作(全))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-09 15:11
大家好,我是小艺!
关注并star《小易学习笔记》,和小易一起学习数据分析!
点击关注|选星|干货
在日常的数据分析工作中,除了Excel数据的清洗,最常见的就是pdf、word、ppt等场景下的数据清洗。其实这还有一个更高的名字,叫做:办公自动化。
很多情况下,因为办公自动化场景中的数据是不规则的,首先要做的就是在数据分析之前把数据提取出来。
比如小艺的朋友“长河”在实际工作中遇到的真实问题:
虽然我对word的操作不是很熟悉,但也提供了自己的解决方案:
由于我擅长从PDF中提取数据,所以我也写过相关的操作文档:Python办公自动化中PDF的详细操作(全),所以如果原创数据是pdf,那我就按照我上面说的方法。操作
但是昌河已经自己做了pdf转换,所以问题就变成了多词的数据提取。
下面的文章是他在实现过程中的真实思考。有些数据比较敏感,文字已经编码,但不影响实际阅读和练习。
这也是实际工作中经常遇到的问题。希望大家下次能处理好。
以下为“昌河”投稿正文:
1. 问题的根源
我最近遇到的一个问题是从word中读取表格数据,然后整理成excel格式。
如下:
词形1,脱敏
如果表不多,只有几张表,手动处理也没问题,但是如果有140张表,9年的数据,怎么处理呢?
这时候,我们就需要一个程序来帮我们自动解决。
2.解决问题
确定问题后,我们接下来需要解决问题。
如果要从word中提取表格,常用的包是docx,为了规范提取中的数据,需要使用pandas
2.1 识别数据的行和列
如果要提取word表中的行列,需要了解表中有多少行列,然后根据具体的行列提取数据。
这部分内容可以参考B站的一些视频,使用Python操作Word
代码显示如下:
from docx import Document
doc = Document('one.docx')
tables = doc.tables
table = tables[0] # 表示读取的第一张表
# 查看一下多少行,多少列
print(len(table.rows),len(table.columns))
输出是:
5 14
可以看出我们提取的表信息是一个5行14列的数据。接下来,您需要考虑每一行和每一列的样子。
这里我们以第 5 行第 2 列为例进行说明:
继续写代码为:
print(table.cell(4,1).text)
输出是:
13905
270
5583
1528
1791
2315
2439
...
经过反复试验,我们终于知道我们需要的数据在哪里。
考虑到header过于复杂,难以定位,需要自己重写header信息。我们需要的是整个学校的数据,也就是下图中的部分。
提取表1对应的数据2.2 数据提取
接下来,执行数据提取:
list1 = [] # 定义一个空的列表存储数据
for row in range(4,len(table.rows)):
for column in range(len(table.columns)):
list1.append(table.cell(row,column).text)
print(len(list1))
print(list1)
提取的数据是一个很长的列表,输出为:
14
['--大学\--大学\--大学\---大学\n ----\n2186588\n203224\n146649\n329602\n214014\n299323\n47413\n71033']
接下来迭代转换为[[],[],[]]的形式
values = []
for i in list1:
i = i.split('\n')
values.append(i)
print(values)
结果处理完成,结果如下:
[['xx大学', 'xxxx大学', 'xx大学', ---'xxxx大学'],--- ['2186588', '203224', '146649', '329602', '214014', '299323', '47413', '71033']]
2.3 转换为DataFrame格式
之前已经对值进行了整理,然后可以重新整理表头信息:
colums = ['xx','xx','xx']
data_part1 = pd.DataFrame(values,columns).T
print(data_part1.head())
输出是:
学校名称 xxxxxx- ... xxxx xxxxxxx
0 XX大学 13905 ... 46526 2222470
1 XX大学 270 ... 0 67822
2 XX大学 5583 ... 331010 3557540
3 XX大学 1528 ... 12826 544980
4 XX大学 1791 ... 1270 844921
[5 rows x 14 columns]
考虑到一个word文件有两张表,第二张表的数据结构如下:
词形2,脱敏
第二张表的表头和第一张表的表头不同,处理方法相同,直接加代码即可:
table = tables[1]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
values2.append(h)
data2 = pd.DataFrame(values2,column2).T
data = pd.concat([data1,data2],axis =1)
2.4 完整处理一个表
一个完整的字有两个表,所以需要用判断条件来处理,分为奇位表和偶位表。判断是根据某个数除以2时余数是否为0。
具体代码如下:
import pandas as pd
from docx import Document
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
2.5 完整处理多个表
如果是处理多张表,需要设置路径,然后在特定路径中处理
具体代码如下:
import pandas as pd
from docx import Document
import os
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
# 设置路径
path = os.listdir('E:\one-two')
# print(path)
for i in range(len(path)):
docx = Document('E:\one-two\{}'.format(path[i]))
# print('第{}表'.format(i+1),docx)
tables = docx.tables
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
print('正在保存{}'.format(i+1))
data.to_excel('E:\one-two\{}.xlsx'.format(i),index=False)
最终输出为:
最终结果3. 摘要
学习编程会带来很多问题和困惑。但这也是提高你的编程技能的关键。继续探索,看B站的视频,向大佬们求教,然后继续打印看看输出,你会得到你想要的!
感谢前辈提供的思路,补补补补!
一字一字的处理可以提高效率!
推荐历史文章:
一行Python代码去除照片背景
2021 年最有用的数据清理 Python 库
2021年Q3基金持仓数据分析,是满仓还是等风来?
历史上的今天,3步轻松重现! 查看全部
excel抓取多页网页数据(干货速递|Python办公自动化之PDF的详细操作(全))
大家好,我是小艺!
关注并star《小易学习笔记》,和小易一起学习数据分析!
点击关注|选星|干货
在日常的数据分析工作中,除了Excel数据的清洗,最常见的就是pdf、word、ppt等场景下的数据清洗。其实这还有一个更高的名字,叫做:办公自动化。
很多情况下,因为办公自动化场景中的数据是不规则的,首先要做的就是在数据分析之前把数据提取出来。
比如小艺的朋友“长河”在实际工作中遇到的真实问题:
虽然我对word的操作不是很熟悉,但也提供了自己的解决方案:

由于我擅长从PDF中提取数据,所以我也写过相关的操作文档:Python办公自动化中PDF的详细操作(全),所以如果原创数据是pdf,那我就按照我上面说的方法。操作
但是昌河已经自己做了pdf转换,所以问题就变成了多词的数据提取。
下面的文章是他在实现过程中的真实思考。有些数据比较敏感,文字已经编码,但不影响实际阅读和练习。
这也是实际工作中经常遇到的问题。希望大家下次能处理好。
以下为“昌河”投稿正文:
1. 问题的根源
我最近遇到的一个问题是从word中读取表格数据,然后整理成excel格式。
如下:
词形1,脱敏
如果表不多,只有几张表,手动处理也没问题,但是如果有140张表,9年的数据,怎么处理呢?
这时候,我们就需要一个程序来帮我们自动解决。
2.解决问题
确定问题后,我们接下来需要解决问题。
如果要从word中提取表格,常用的包是docx,为了规范提取中的数据,需要使用pandas
2.1 识别数据的行和列
如果要提取word表中的行列,需要了解表中有多少行列,然后根据具体的行列提取数据。
这部分内容可以参考B站的一些视频,使用Python操作Word
代码显示如下:
from docx import Document
doc = Document('one.docx')
tables = doc.tables
table = tables[0] # 表示读取的第一张表
# 查看一下多少行,多少列
print(len(table.rows),len(table.columns))
输出是:
5 14
可以看出我们提取的表信息是一个5行14列的数据。接下来,您需要考虑每一行和每一列的样子。
这里我们以第 5 行第 2 列为例进行说明:
继续写代码为:
print(table.cell(4,1).text)
输出是:
13905
270
5583
1528
1791
2315
2439
...
经过反复试验,我们终于知道我们需要的数据在哪里。
考虑到header过于复杂,难以定位,需要自己重写header信息。我们需要的是整个学校的数据,也就是下图中的部分。
提取表1对应的数据2.2 数据提取
接下来,执行数据提取:
list1 = [] # 定义一个空的列表存储数据
for row in range(4,len(table.rows)):
for column in range(len(table.columns)):
list1.append(table.cell(row,column).text)
print(len(list1))
print(list1)
提取的数据是一个很长的列表,输出为:
14
['--大学\--大学\--大学\---大学\n ----\n2186588\n203224\n146649\n329602\n214014\n299323\n47413\n71033']
接下来迭代转换为[[],[],[]]的形式
values = []
for i in list1:
i = i.split('\n')
values.append(i)
print(values)
结果处理完成,结果如下:
[['xx大学', 'xxxx大学', 'xx大学', ---'xxxx大学'],--- ['2186588', '203224', '146649', '329602', '214014', '299323', '47413', '71033']]
2.3 转换为DataFrame格式
之前已经对值进行了整理,然后可以重新整理表头信息:
colums = ['xx','xx','xx']
data_part1 = pd.DataFrame(values,columns).T
print(data_part1.head())
输出是:
学校名称 xxxxxx- ... xxxx xxxxxxx
0 XX大学 13905 ... 46526 2222470
1 XX大学 270 ... 0 67822
2 XX大学 5583 ... 331010 3557540
3 XX大学 1528 ... 12826 544980
4 XX大学 1791 ... 1270 844921
[5 rows x 14 columns]
考虑到一个word文件有两张表,第二张表的数据结构如下:
词形2,脱敏
第二张表的表头和第一张表的表头不同,处理方法相同,直接加代码即可:
table = tables[1]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
values2.append(h)
data2 = pd.DataFrame(values2,column2).T
data = pd.concat([data1,data2],axis =1)
2.4 完整处理一个表
一个完整的字有两个表,所以需要用判断条件来处理,分为奇位表和偶位表。判断是根据某个数除以2时余数是否为0。
具体代码如下:
import pandas as pd
from docx import Document
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
2.5 完整处理多个表
如果是处理多张表,需要设置路径,然后在特定路径中处理
具体代码如下:
import pandas as pd
from docx import Document
import os
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
# 设置路径
path = os.listdir('E:\one-two')
# print(path)
for i in range(len(path)):
docx = Document('E:\one-two\{}'.format(path[i]))
# print('第{}表'.format(i+1),docx)
tables = docx.tables
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
print('正在保存{}'.format(i+1))
data.to_excel('E:\one-two\{}.xlsx'.format(i),index=False)
最终输出为:

最终结果3. 摘要
学习编程会带来很多问题和困惑。但这也是提高你的编程技能的关键。继续探索,看B站的视频,向大佬们求教,然后继续打印看看输出,你会得到你想要的!
感谢前辈提供的思路,补补补补!
一字一字的处理可以提高效率!
推荐历史文章:
一行Python代码去除照片背景
2021 年最有用的数据清理 Python 库
2021年Q3基金持仓数据分析,是满仓还是等风来?
历史上的今天,3步轻松重现!
excel抓取多页网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-07 01:18
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]} 查看全部
excel抓取多页网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}

Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]}
excel抓取多页网页数据(给pdf文件插入一页,PowerAutomate是怎么自动做到的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2022-01-07 01:17
上一篇文章《在pdf文件中插入页面,Power Automate如何自动做?PA实战》介绍了如何在pdf文件中插入内容,反之,如果有插入,就会有被删除。
例如,在很多pdf文件中,插入了一些广告页,尤其是一些“免费”的文件。这其实是可以理解的。毕竟,整理文档并不容易。插入广告以引起注意也是付费的一部分。小回报。但理解属于理解。有时,我们仍然希望删除广告页面。
如果只是一两个文件,手动操作也很快。它可以通过专业软件或直接使用 Power Automate 来实现。方法非常简单。从哪些页面获取哪些页面!| 《PA实战案例》中使用的方法——将PDF页面解压成新的PDF,这里不再赘述。
下面我们主要讲两种批量操作多个文件的情况:被删除页面的位置是固定的,被删除页面的位置需要通过页面内容搜索来判断。
- 1 -
要删除的页面在固定位置
这种情况也可以通过使用“将PDF页面提取到新的PDF”功能来实现。但是,问题是pdftk工具仍然可以识别pdf文件的总页数。所以,我们直接使用pdftk工具的合并功能,直接合并(删除)删除对应的页面——合并功能真的很好用,具体的使用方法这里举例说明:
例如在文件“01 Nov 2029.pdf”的第3页插入adv.pdf文件,pdftk处理命令可以写成:
这个命令的写法很有意思:将“01 Nov 2019.pdf”文件设置为A,将“adv.pdf”文件设置为B,然后合并[A's pages 1-3, B, A's pages 4- 最后一页 (end)],输出为 out.pdf 文件。
然后,借助合并功能,假设我们要删除文件夹“E:\RPA\pdf\2019”中所有pdf文件的第4页。实施步骤如下:
Step-01 获取文件夹中的文件
Step-02 为每个循环添加
选择对上一步得到的pdf文件(%Files%)进行循环操作。
Step-03 在循环中添加“运行DOS命令”
注意DOS命令的写法:
1、pdftk命令完全按照你存放pdftk工具的文件路径来写:比如这里是“E:\RPA\pdf\PDFtk\pdftk.exe”;
2、 选择循环的当前工程变量(文件)进入DOS命令时,注意是否加双引号。例如,因为这里要引用文件路径,而文件路径本身可能收录空格等,所以需要加双引号。
-2 -
要删除的页面需要根据内容来判断
在某些情况下,需要删除的页面不是固定的页码,而是需要根据页面的内容来确定。例如,页面收录特定的广告词...
在这种情况下,需要提取页面内容,然后进行文本比较(包括判断)来确定要删除的页面,比较困难。而且,暂时还没有支持直接根据搜索内容删除页面的pdf工具。
但是经过研究,发现pdftk支持我们将pdf文件拆分成不同的文件(每页一个)。这样,我们再提取拆分文件的内容进行判断。如果里面收录了具体的信息,我们直接删除页面文件,然后合并剩余的页面文件是不是可以达到同样的目的呢?
让我们来看看如何做到这一点。
Step-01 获取文件夹中的文件
Step-02 为每个循环添加一个
Step-03 创建一个原文件名的文件夹,用来存放分页后的文件
Step-04 运行DOS命令将pdf文件反汇编到一个文件夹中
pdf_d.pdf 表示反汇编后文件名为pdf_0001.pdf, pdf_0002.pdf……。
Step-05 获取反汇编后的单页文件
Step-06 为每个添加内循环
遍历pdf的每一页并阅读内容
Step-07 从 pdf 中提取文本
Step-08 添加IF条件判断单页pdf文件中提取的文本
条件设置为:如果从页面中提取的内容(%ExtractedPDFText%)收录“我是广告”。
Step-09 删除本页的pdf文件
Step-10 获取当前文件夹中的文件
在Step-09之后,收录广告的页面的pdf文件已被删除。再次获取文件夹中的所有pdf文件,为后续的合并做准备:
步骤 11 合并 PDF 文件
合并上一步得到的pdf文件(减少广告)。
经过以上拆分、提取文本、判断、删除页面,再合并的过程,我们就达到了根据内容删除pdf页面的目的。
该方法考虑到要删除的页面位置完全不确定,所以需要对所有pdf文件进行反汇编。结果,反汇编后的文件会比较多,每个页面都需要进行文本提取和判断。因此,如果页面较多,运行效率可能会比较低。
在实际工作中,如果要删除的页面位置比较固定,比如可能只出现在几个页面上,那么建议先将这些页面提取出来,分别处理后再合并,这样避免全部拆除的效率问题。 查看全部
excel抓取多页网页数据(给pdf文件插入一页,PowerAutomate是怎么自动做到的?)
上一篇文章《在pdf文件中插入页面,Power Automate如何自动做?PA实战》介绍了如何在pdf文件中插入内容,反之,如果有插入,就会有被删除。
例如,在很多pdf文件中,插入了一些广告页,尤其是一些“免费”的文件。这其实是可以理解的。毕竟,整理文档并不容易。插入广告以引起注意也是付费的一部分。小回报。但理解属于理解。有时,我们仍然希望删除广告页面。
如果只是一两个文件,手动操作也很快。它可以通过专业软件或直接使用 Power Automate 来实现。方法非常简单。从哪些页面获取哪些页面!| 《PA实战案例》中使用的方法——将PDF页面解压成新的PDF,这里不再赘述。
下面我们主要讲两种批量操作多个文件的情况:被删除页面的位置是固定的,被删除页面的位置需要通过页面内容搜索来判断。
- 1 -
要删除的页面在固定位置
这种情况也可以通过使用“将PDF页面提取到新的PDF”功能来实现。但是,问题是pdftk工具仍然可以识别pdf文件的总页数。所以,我们直接使用pdftk工具的合并功能,直接合并(删除)删除对应的页面——合并功能真的很好用,具体的使用方法这里举例说明:
例如在文件“01 Nov 2029.pdf”的第3页插入adv.pdf文件,pdftk处理命令可以写成:
这个命令的写法很有意思:将“01 Nov 2019.pdf”文件设置为A,将“adv.pdf”文件设置为B,然后合并[A's pages 1-3, B, A's pages 4- 最后一页 (end)],输出为 out.pdf 文件。
然后,借助合并功能,假设我们要删除文件夹“E:\RPA\pdf\2019”中所有pdf文件的第4页。实施步骤如下:
Step-01 获取文件夹中的文件
Step-02 为每个循环添加
选择对上一步得到的pdf文件(%Files%)进行循环操作。
Step-03 在循环中添加“运行DOS命令”
注意DOS命令的写法:
1、pdftk命令完全按照你存放pdftk工具的文件路径来写:比如这里是“E:\RPA\pdf\PDFtk\pdftk.exe”;
2、 选择循环的当前工程变量(文件)进入DOS命令时,注意是否加双引号。例如,因为这里要引用文件路径,而文件路径本身可能收录空格等,所以需要加双引号。
-2 -
要删除的页面需要根据内容来判断
在某些情况下,需要删除的页面不是固定的页码,而是需要根据页面的内容来确定。例如,页面收录特定的广告词...
在这种情况下,需要提取页面内容,然后进行文本比较(包括判断)来确定要删除的页面,比较困难。而且,暂时还没有支持直接根据搜索内容删除页面的pdf工具。
但是经过研究,发现pdftk支持我们将pdf文件拆分成不同的文件(每页一个)。这样,我们再提取拆分文件的内容进行判断。如果里面收录了具体的信息,我们直接删除页面文件,然后合并剩余的页面文件是不是可以达到同样的目的呢?
让我们来看看如何做到这一点。
Step-01 获取文件夹中的文件
Step-02 为每个循环添加一个
Step-03 创建一个原文件名的文件夹,用来存放分页后的文件
Step-04 运行DOS命令将pdf文件反汇编到一个文件夹中
pdf_d.pdf 表示反汇编后文件名为pdf_0001.pdf, pdf_0002.pdf……。
Step-05 获取反汇编后的单页文件
Step-06 为每个添加内循环
遍历pdf的每一页并阅读内容
Step-07 从 pdf 中提取文本
Step-08 添加IF条件判断单页pdf文件中提取的文本
条件设置为:如果从页面中提取的内容(%ExtractedPDFText%)收录“我是广告”。
Step-09 删除本页的pdf文件
Step-10 获取当前文件夹中的文件
在Step-09之后,收录广告的页面的pdf文件已被删除。再次获取文件夹中的所有pdf文件,为后续的合并做准备:
步骤 11 合并 PDF 文件
合并上一步得到的pdf文件(减少广告)。
经过以上拆分、提取文本、判断、删除页面,再合并的过程,我们就达到了根据内容删除pdf页面的目的。
该方法考虑到要删除的页面位置完全不确定,所以需要对所有pdf文件进行反汇编。结果,反汇编后的文件会比较多,每个页面都需要进行文本提取和判断。因此,如果页面较多,运行效率可能会比较低。
在实际工作中,如果要删除的页面位置比较固定,比如可能只出现在几个页面上,那么建议先将这些页面提取出来,分别处理后再合并,这样避免全部拆除的效率问题。
excel抓取多页网页数据(excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-04 10:10
excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可。基础:1.定义一个名称叫筛选条件,包含从1~n之间所有数字;2.把想要的内容放入数据框里;3.把字段名重命名成如下代码。ps:筛选条件和字段名比较重要,不要把“又是萝卜又是菜”和“又是瓜子又是大白”写在一个数据框里。数据筛选代码:筛选条件ps:数据过滤有两种方法,一种是通过公式,一种是手动操作。
公式大家可以用excelhome的相关教程,这里介绍一种简单方便的过滤方法。ps:把筛选条件记录到offset的lookupvalue中,可以从中减去想要过滤的数字,查找选择原来要过滤的数字。筛选条件:and条件一成立,返回“从1到n之间的所有数字”,不成立,返回“从0到1之间的所有数字”;如果不能满足条件,会返回0;如果过滤1次不满足条件,则返回0,否则返回1。
lookupand方法是一种相互嵌套的链接和过滤算法,把过滤的数据当做公式嵌套进筛选条件中,这样可以得到1,2,3,这三种不同的数据。通过这个方法得到的数据,需要返回筛选数据的个数。ps:在一次查找中,只能查找一条数据,先查找0次,再查找1次,如果不能满足要求,返回0。常用技巧:筛选数字为数字格式的筛选条件有:金额为小数的筛选条件,如$b$1-$a$10$b$1=a$1.3;$c$1-$e$10$c$1=$d$1.3;对应的余额小数位数是多少;购买元为数字格式的筛选条件:$a$1-$b$1=a$1.2;$c$1-$e$1=c$1.2;对应的余额小数位数是多少。
对应的余额有多少。筛选数字为模糊数字的筛选条件有:首位带有"6"的筛选条件,如$a9-$b96$a9=a9;首位不带有"6"的筛选条件,如$a9-$b96$a9=b9;对应的余额小数位数是多少。筛选数字为日期格式的筛选条件有:$a$1-$b$1=a$1;$a$1-$c$1=c$1;对应的余额小数位数是多少。
如果不能匹配到日期格式的,则返回-1。3.修改所需要过滤的字段,当a3这样的数字,需要将"3"更换成"3+3"或"3",剩下的所有字段都可以利用上面的方法转换。对于pdf数据,还可以用filter函数返回指定数值范围内的所有文字。比如我用filter函数返回hundredseries,有些pdf上字符串里有"3",这时如果只修改“3”,字符串里会出现"4"和"5"这些文字。
如果修改其他字符串,字符串的文字也会被替换为第一个字符的整数值或2倍长度。python实现:python代码:defget_row_num(text):val。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可)
excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可。基础:1.定义一个名称叫筛选条件,包含从1~n之间所有数字;2.把想要的内容放入数据框里;3.把字段名重命名成如下代码。ps:筛选条件和字段名比较重要,不要把“又是萝卜又是菜”和“又是瓜子又是大白”写在一个数据框里。数据筛选代码:筛选条件ps:数据过滤有两种方法,一种是通过公式,一种是手动操作。
公式大家可以用excelhome的相关教程,这里介绍一种简单方便的过滤方法。ps:把筛选条件记录到offset的lookupvalue中,可以从中减去想要过滤的数字,查找选择原来要过滤的数字。筛选条件:and条件一成立,返回“从1到n之间的所有数字”,不成立,返回“从0到1之间的所有数字”;如果不能满足条件,会返回0;如果过滤1次不满足条件,则返回0,否则返回1。
lookupand方法是一种相互嵌套的链接和过滤算法,把过滤的数据当做公式嵌套进筛选条件中,这样可以得到1,2,3,这三种不同的数据。通过这个方法得到的数据,需要返回筛选数据的个数。ps:在一次查找中,只能查找一条数据,先查找0次,再查找1次,如果不能满足要求,返回0。常用技巧:筛选数字为数字格式的筛选条件有:金额为小数的筛选条件,如$b$1-$a$10$b$1=a$1.3;$c$1-$e$10$c$1=$d$1.3;对应的余额小数位数是多少;购买元为数字格式的筛选条件:$a$1-$b$1=a$1.2;$c$1-$e$1=c$1.2;对应的余额小数位数是多少。
对应的余额有多少。筛选数字为模糊数字的筛选条件有:首位带有"6"的筛选条件,如$a9-$b96$a9=a9;首位不带有"6"的筛选条件,如$a9-$b96$a9=b9;对应的余额小数位数是多少。筛选数字为日期格式的筛选条件有:$a$1-$b$1=a$1;$a$1-$c$1=c$1;对应的余额小数位数是多少。
如果不能匹配到日期格式的,则返回-1。3.修改所需要过滤的字段,当a3这样的数字,需要将"3"更换成"3+3"或"3",剩下的所有字段都可以利用上面的方法转换。对于pdf数据,还可以用filter函数返回指定数值范围内的所有文字。比如我用filter函数返回hundredseries,有些pdf上字符串里有"3",这时如果只修改“3”,字符串里会出现"4"和"5"这些文字。
如果修改其他字符串,字符串的文字也会被替换为第一个字符的整数值或2倍长度。python实现:python代码:defget_row_num(text):val。
excel抓取多页网页数据( PowerBIDesktop的制作流程及注意事项(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-01 23:02
PowerBIDesktop的制作流程及注意事项(一))
我们使用Power BI Desktop制作上图,需要历年的保费收入数据作为依据。 网站有数据公告:
本页地址:
/web/site0/tab5205/info4129096.htm
每个月都会有对应的地址。在哪里可以找到这些地址?
我们找到了这样一个页面:
此页面上有指向我们需要的每月数据的链接。这样的页面一共有8个,这8个页面的URL是连续的。
web/site0/tab5205/module14413/page1.htm
从第 1 页到第 8 页
我们打开Power BI Desktop的Power Query,创建一个从1到8的表
并将ID列设置为文本,这是第一步。
第二步:创建查询,从网络获取数据,设置乘法csv格式
复制地址栏中的公式以备后用。 (这些功能实在想不起来了,有点懒,呵呵)
第三步:回到最开始的表格,自定义列,用刚才复制的公式进行修改。
用ID替换页面后面的数字。
第 4 步:数据清洗。我们想要的是每个月的 URL。这个过程有点复杂,但是用到的函数很简单,就是对符号进行排序、过滤、替换。
1、用
2、过滤掉收录信息的行
3、再次分隔列并使用双引号分隔列
到目前为止,我们已经得到了我们想要的 URL。
4、为了能够区分年月,需要做一些处理。取标题后面的列并提取年份和月份。这部分略过。结果是这样的:
第 5 步:获取特定数据。如果您不记得该函数,请先从网络创建查询,复制公式,然后自定义列。
将 URL 后面的部分替换为 URL。
第六步:展开和整理数据,这里有几点需要注意
1、删除需要修改的列,保留年月列
2、过滤掉所有非省市名
3、统一各省市名称,自己想办法
4、反向透视栏
最终结果:
剩下的工作会回到 Power BI Desktop 使用 DAX 创建测量值,然后图表就可以了。
综上所述,如果你想从一个网页中获取你需要的信息,你必须掌握关键信息。网络信息有多种格式。如果要从源代码中查找信息,请使用 CSV 格式。使用 HTML 格式。无论是使用PQ还是PY网络来抓取数据,都是一个寻找模式的过程。如果你找到一个模式,你就可以做到。 查看全部
excel抓取多页网页数据(
PowerBIDesktop的制作流程及注意事项(一))
我们使用Power BI Desktop制作上图,需要历年的保费收入数据作为依据。 网站有数据公告:
本页地址:
/web/site0/tab5205/info4129096.htm
每个月都会有对应的地址。在哪里可以找到这些地址?
我们找到了这样一个页面:
此页面上有指向我们需要的每月数据的链接。这样的页面一共有8个,这8个页面的URL是连续的。
web/site0/tab5205/module14413/page1.htm
从第 1 页到第 8 页
我们打开Power BI Desktop的Power Query,创建一个从1到8的表
并将ID列设置为文本,这是第一步。
第二步:创建查询,从网络获取数据,设置乘法csv格式
复制地址栏中的公式以备后用。 (这些功能实在想不起来了,有点懒,呵呵)
第三步:回到最开始的表格,自定义列,用刚才复制的公式进行修改。
用ID替换页面后面的数字。
第 4 步:数据清洗。我们想要的是每个月的 URL。这个过程有点复杂,但是用到的函数很简单,就是对符号进行排序、过滤、替换。
1、用
2、过滤掉收录信息的行
3、再次分隔列并使用双引号分隔列
到目前为止,我们已经得到了我们想要的 URL。
4、为了能够区分年月,需要做一些处理。取标题后面的列并提取年份和月份。这部分略过。结果是这样的:
第 5 步:获取特定数据。如果您不记得该函数,请先从网络创建查询,复制公式,然后自定义列。
将 URL 后面的部分替换为 URL。
第六步:展开和整理数据,这里有几点需要注意
1、删除需要修改的列,保留年月列
2、过滤掉所有非省市名
3、统一各省市名称,自己想办法
4、反向透视栏
最终结果:
剩下的工作会回到 Power BI Desktop 使用 DAX 创建测量值,然后图表就可以了。
综上所述,如果你想从一个网页中获取你需要的信息,你必须掌握关键信息。网络信息有多种格式。如果要从源代码中查找信息,请使用 CSV 格式。使用 HTML 格式。无论是使用PQ还是PY网络来抓取数据,都是一个寻找模式的过程。如果你找到一个模式,你就可以做到。
excel抓取多页网页数据(WebDataMiner如何从网页中选择要报废的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-02 04:13
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
变更日志
1.修复bug,新版本体验更好
2.部分页面已更改 查看全部
excel抓取多页网页数据(WebDataMiner如何从网页中选择要报废的数据?)
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
变更日志
1.修复bug,新版本体验更好
2.部分页面已更改
excel抓取多页网页数据(所有网站都提供API吗?不幸的是没有。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-01 11:18
所有 网站 都提供 API 吗?
不幸的是没有。鉴于 Facebook 必须限制信息的下载,您不得从 Facebook 下载任何信息(例如,甚至帖子)。我将讨论 API 的替代方案,但对于 Facebook,未经书面同意,您不能下载任何信息。
如果 网站 提供 API,我可能会遇到哪些限制?
· 编码
如果您不知道如何编码,这是第一个问题。每个 网站 都需要个人方法,而不是看起来那么简单。
· 格式
用于减少信息浪费的常用格式是 JSON,但还有其他格式。您下载的数据需要以您想要的方式进行规范化、理解和存储(我可以猜到一个 .csv 文件)。这很耗时,而且代码并不总是稳定的。
· 价格
有时你会很幸运地找到一个免费提供信息的 网站。在大多数情况下,如果没有订阅计划,您甚至无法下载免费信息:请为备用计划做好准备。
· 请求频率
您不能只从数据库中下载全时、全速的千兆字节数据。流量会降低您的服务器速度,因此网站要非常小心并限制要执行的请求数量。您需要每 n 秒执行一次 GET 请求(从在线数据库下载信息的操作)。当然,整个过程可以自动化。
· 容量限制
大多数提供 API(除非它们都是开源的)的 网站 都是为了利润(现在您了解销售数据的含义)。如果您想下载大于一定大小的数据,他们会要求您付费。
· 请求限制
另一种限制下载的度量标准不是大小,而是请求数。例如,使用 Alpha Vantage 下载历史股票价格限制为每天 500 个请求。
这些数字(例如每天 100,000 条推文的限制)可能看起来不是一个巨大的限制,但如果您经营一家拥有 500 名员工的公司,并且您的目标是建立一个巨大的 AI 预测模型,那么 100,000 条推文文本对于什么来说是一个荒谬的数量你想建立。
2.网页抓取
毕竟,网络爬虫已经成为我最喜欢的下载数据的方式,毕竟处理 API 从来都不是一件有趣的事情(如果你不相信我,请尝试询问)。
一些 网站 有你可以直接在他们的网页上看到的信息列表。我要使用的示例之一是 Xtrawine。
网站 收录数千条有关葡萄酒的信息。如果您是数据分析师,看起来不错!如果你用谷歌搜索,你会发现这个 网站 不提供开源 API。数据存储在他们的数据库中,您无权访问。
您可以利用主页上已经可见的数据,而不是询问您连接到的数据库。此信息存储在附加到页面的 HTML 代码中。您唯一需要做的就是访问代码并编写一个算法,该算法遍历所有数千页并提取每瓶葡萄酒的信息并将其存储到 .csv 数据集中。
这是为从该网页提取信息而编写的网络抓取算法的输出。你可以看到结果。我用 Pretty Soup 从 网站 中提取 HTML,但还有其他可用的 python 工具,这取决于你。
网页抓取的缺点
请注意,在线数据可能是公开的,但它不是商场。您不仅可以连接到任何 网站 并下载您想要的所有内容,这不仅不礼貌,而且还可能违反他们的政策。因此,如果您打算将此信息用于您的工作或研究,请注意您下载的内容和下载量。
3.开源数据集
最后一种下载数据的方法是找到已经准备好的数据。网站 像 Kaggle 或 data.world 有一系列开源数据集,您可以下载这些数据集进行试验。不幸的是,您不太可能找到您要搜索的内容。大多数信息都没有更新,如果您正在搜索特定的内容(例如价目表或营销列表),则必须使用前两种方法检索它。
这些预制数据集何时有用?
Covid-19 紧急情况就是一个例子。例如,如果您查看 Kaggle,您会发现关于 Covid-19 的每日更新数据集(大量信息)。研究人员可以为寻找基因相关信息做出贡献,并可以创建预测病毒传播的模型。
你怎么认为?你知道其他下载数据的方法吗?
(本文翻译自Michelangiolo Mazzeschi的文章《3 Ways to Collect Big Data with your PC》,参考:) 查看全部
excel抓取多页网页数据(所有网站都提供API吗?不幸的是没有。。)
所有 网站 都提供 API 吗?
不幸的是没有。鉴于 Facebook 必须限制信息的下载,您不得从 Facebook 下载任何信息(例如,甚至帖子)。我将讨论 API 的替代方案,但对于 Facebook,未经书面同意,您不能下载任何信息。
如果 网站 提供 API,我可能会遇到哪些限制?
· 编码
如果您不知道如何编码,这是第一个问题。每个 网站 都需要个人方法,而不是看起来那么简单。
· 格式
用于减少信息浪费的常用格式是 JSON,但还有其他格式。您下载的数据需要以您想要的方式进行规范化、理解和存储(我可以猜到一个 .csv 文件)。这很耗时,而且代码并不总是稳定的。
· 价格
有时你会很幸运地找到一个免费提供信息的 网站。在大多数情况下,如果没有订阅计划,您甚至无法下载免费信息:请为备用计划做好准备。
· 请求频率
您不能只从数据库中下载全时、全速的千兆字节数据。流量会降低您的服务器速度,因此网站要非常小心并限制要执行的请求数量。您需要每 n 秒执行一次 GET 请求(从在线数据库下载信息的操作)。当然,整个过程可以自动化。
· 容量限制
大多数提供 API(除非它们都是开源的)的 网站 都是为了利润(现在您了解销售数据的含义)。如果您想下载大于一定大小的数据,他们会要求您付费。
· 请求限制
另一种限制下载的度量标准不是大小,而是请求数。例如,使用 Alpha Vantage 下载历史股票价格限制为每天 500 个请求。
这些数字(例如每天 100,000 条推文的限制)可能看起来不是一个巨大的限制,但如果您经营一家拥有 500 名员工的公司,并且您的目标是建立一个巨大的 AI 预测模型,那么 100,000 条推文文本对于什么来说是一个荒谬的数量你想建立。
2.网页抓取
毕竟,网络爬虫已经成为我最喜欢的下载数据的方式,毕竟处理 API 从来都不是一件有趣的事情(如果你不相信我,请尝试询问)。
一些 网站 有你可以直接在他们的网页上看到的信息列表。我要使用的示例之一是 Xtrawine。
网站 收录数千条有关葡萄酒的信息。如果您是数据分析师,看起来不错!如果你用谷歌搜索,你会发现这个 网站 不提供开源 API。数据存储在他们的数据库中,您无权访问。
您可以利用主页上已经可见的数据,而不是询问您连接到的数据库。此信息存储在附加到页面的 HTML 代码中。您唯一需要做的就是访问代码并编写一个算法,该算法遍历所有数千页并提取每瓶葡萄酒的信息并将其存储到 .csv 数据集中。
这是为从该网页提取信息而编写的网络抓取算法的输出。你可以看到结果。我用 Pretty Soup 从 网站 中提取 HTML,但还有其他可用的 python 工具,这取决于你。
网页抓取的缺点
请注意,在线数据可能是公开的,但它不是商场。您不仅可以连接到任何 网站 并下载您想要的所有内容,这不仅不礼貌,而且还可能违反他们的政策。因此,如果您打算将此信息用于您的工作或研究,请注意您下载的内容和下载量。
3.开源数据集
最后一种下载数据的方法是找到已经准备好的数据。网站 像 Kaggle 或 data.world 有一系列开源数据集,您可以下载这些数据集进行试验。不幸的是,您不太可能找到您要搜索的内容。大多数信息都没有更新,如果您正在搜索特定的内容(例如价目表或营销列表),则必须使用前两种方法检索它。
这些预制数据集何时有用?
Covid-19 紧急情况就是一个例子。例如,如果您查看 Kaggle,您会发现关于 Covid-19 的每日更新数据集(大量信息)。研究人员可以为寻找基因相关信息做出贡献,并可以创建预测病毒传播的模型。
你怎么认为?你知道其他下载数据的方法吗?
(本文翻译自Michelangiolo Mazzeschi的文章《3 Ways to Collect Big Data with your PC》,参考:)
excel抓取多页网页数据(excel抓取多页网页数据在页面抓取中的两个要点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-31 19:05
excel抓取多页网页数据在页面抓取中,如果页面很多,复杂数据切换查询用户需要一层一层的操作,过于繁琐。这里介绍的是最基础的如何把xml文件以解析的方式读出来,就不涉及数据处理等具体操作,将其转化为可以在excel中操作的文件格式(xmlview)并进行分析处理就可以了。两个要点:手动下载并读取xml文件及做好分析归档1.手动下载xml文件(。
1)xml文件如果要下载xml文件,那么一定需要下载配置支持下载xml文件,excel支持读取utf-8编码的xml文件。首先要读取excel中的xml文件,将其转化为xmlview,之后再读取相应的数据。
2)手动方法介绍2.做好归档分析整理抽丝剥茧要对前后复杂多页数据做归档分析,并提炼出结构信息,还需要做好分析归档工作。也就是要处理页面数据以及切换查询的流程,具体如下:第一步:下载对应utf-8编码的xml文件/分析对应xmlview第二步:手动生成中间页分析归档用户下载xml文件后要注意以下几点:读取xmlview中文件,切换查询的数据页面url。
读取过程中切换查询页面url,并根据页面中的链接作为跳转目标来进行下载、解析xmlview。读取生成xmlview后要注意切换查询页面url时,保证页面能够正常跳转。具体教程地址:数据抓取视频教程参考地址:数据抓取视频教程安全教程常见错误3.上述方法的最佳实践案例对于已经不再需要切换页面,并且只要读取url中的第一页数据及提取数据即可的案例,上述方法是最佳实践案例。
如何制作分析归档需要根据不同的应用环境以及不同抓取工具的特点来提取应用的解析原理。最常见的应用场景有几个:生成测试数据复现性质bug数据管理或者需要检查数据的频率进行实时数据分析;针对复杂页面数据做切换查询的数据抓取场景;需要抓取的url在不同类型的搜索网站中获取,并且工作量大、数据量高的场景。
预计时间解析过程数据处理归档工作4.参考资料有哪些好用的下载或者抓取xmlview的工具?github:dylfy/document-view-exampledynamiclynews/two3weeklyblog-blob微信公众号:复杂数据处理的方法
一、常用工具安装1.excelhome数据下载:/由于excelhome并没有专门针对数据处理做优化,简单评测下载速度1:0,1分钟4kb。2:0.15秒/60000行,按列复制加载数据速度约1.1mb/s。csv格式文件就这个速度。以上可以判断excelhome有相当大的问题。
1)excelhome不支持xml解析
2)excelhome没有对数据结构优化
3)不支持乱序索引
二、解析源码fundebug经常使用fundebug工具去访问一些 查看全部
excel抓取多页网页数据(excel抓取多页网页数据在页面抓取中的两个要点)
excel抓取多页网页数据在页面抓取中,如果页面很多,复杂数据切换查询用户需要一层一层的操作,过于繁琐。这里介绍的是最基础的如何把xml文件以解析的方式读出来,就不涉及数据处理等具体操作,将其转化为可以在excel中操作的文件格式(xmlview)并进行分析处理就可以了。两个要点:手动下载并读取xml文件及做好分析归档1.手动下载xml文件(。
1)xml文件如果要下载xml文件,那么一定需要下载配置支持下载xml文件,excel支持读取utf-8编码的xml文件。首先要读取excel中的xml文件,将其转化为xmlview,之后再读取相应的数据。
2)手动方法介绍2.做好归档分析整理抽丝剥茧要对前后复杂多页数据做归档分析,并提炼出结构信息,还需要做好分析归档工作。也就是要处理页面数据以及切换查询的流程,具体如下:第一步:下载对应utf-8编码的xml文件/分析对应xmlview第二步:手动生成中间页分析归档用户下载xml文件后要注意以下几点:读取xmlview中文件,切换查询的数据页面url。
读取过程中切换查询页面url,并根据页面中的链接作为跳转目标来进行下载、解析xmlview。读取生成xmlview后要注意切换查询页面url时,保证页面能够正常跳转。具体教程地址:数据抓取视频教程参考地址:数据抓取视频教程安全教程常见错误3.上述方法的最佳实践案例对于已经不再需要切换页面,并且只要读取url中的第一页数据及提取数据即可的案例,上述方法是最佳实践案例。
如何制作分析归档需要根据不同的应用环境以及不同抓取工具的特点来提取应用的解析原理。最常见的应用场景有几个:生成测试数据复现性质bug数据管理或者需要检查数据的频率进行实时数据分析;针对复杂页面数据做切换查询的数据抓取场景;需要抓取的url在不同类型的搜索网站中获取,并且工作量大、数据量高的场景。
预计时间解析过程数据处理归档工作4.参考资料有哪些好用的下载或者抓取xmlview的工具?github:dylfy/document-view-exampledynamiclynews/two3weeklyblog-blob微信公众号:复杂数据处理的方法
一、常用工具安装1.excelhome数据下载:/由于excelhome并没有专门针对数据处理做优化,简单评测下载速度1:0,1分钟4kb。2:0.15秒/60000行,按列复制加载数据速度约1.1mb/s。csv格式文件就这个速度。以上可以判断excelhome有相当大的问题。
1)excelhome不支持xml解析
2)excelhome没有对数据结构优化
3)不支持乱序索引
二、解析源码fundebug经常使用fundebug工具去访问一些
excel抓取多页网页数据( 如何用PowerBI批量采集多个网页的数据(一)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-01-31 16:17
如何用PowerBI批量采集多个网页的数据(一)?)
前面介绍PowerBI数据获取的时候,举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行中的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
此处完成第一页数据后,进入采集的其他页面时,数据结构与第一页完成后的数据结构一致,可以使用采集的数据直接地; 没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let之前输入:
(p 作为数字)作为表格 =>
并且在let后面第一行的URL中,&后面的“1”变成了(这是第二步使用高级选项分两行输入URL的好处):
(数字.ToText(p))
修改后 [source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。如果输入数字,例如 7,将捕获第 7 页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
点击确定开始批量爬取网页,因为100页的数据比较多,大概需要5分钟左右,这也是我提前第二步数据排序的结果,导致爬取比较慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量采集工作已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行当您到达时,您无需再浪费时间。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。 查看全部
excel抓取多页网页数据(
如何用PowerBI批量采集多个网页的数据(一)?)
前面介绍PowerBI数据获取的时候,举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行中的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
此处完成第一页数据后,进入采集的其他页面时,数据结构与第一页完成后的数据结构一致,可以使用采集的数据直接地; 没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let之前输入:
(p 作为数字)作为表格 =>
并且在let后面第一行的URL中,&后面的“1”变成了(这是第二步使用高级选项分两行输入URL的好处):
(数字.ToText(p))
修改后 [source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。如果输入数字,例如 7,将捕获第 7 页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
点击确定开始批量爬取网页,因为100页的数据比较多,大概需要5分钟左右,这也是我提前第二步数据排序的结果,导致爬取比较慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量采集工作已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行当您到达时,您无需再浪费时间。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。
excel抓取多页网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-27 22:12
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的 网站。各种财经网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到对应股票数据的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
点击确定打开Power Query编辑器,如果一切顺利,数据会直接出现:
虽然不是表格,但证明刮是成功的。下一步是如何解析这个二进制文件。从google浏览器看,是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间数据可以用json解析。注意总数:4440,我们稍后会使用这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切顺利,但我们只抓取一页数据,让我们看看:
pn是页码,我们是抓取第三页,pz是每页20条数据,我们有两种方式来抓取所有数据,一种是使用这个pz:20,然后定义一个函数来抓取所有的页码,我在以前的爬网中反复使用过这个。今天我们将尝试直接修改 pz 以一次捕获所有数据。其实我们可以尝试改变查询参数。如果我们将 pn 更改为 4,我们将抓取第 4 页。同理,我们把pn修改为200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抓起来:
看起来不错。
还有一个问题,就是数据的标题行都是f开头的,不可读,怎么变成网页中汉字的标题行。
这个问题有点复杂。我们可能不得不检查代码,看看是否能找到替换它的方法。首先,看一下html:
但这是不完整的,有几列需要自定义:
这些指标没有对应的 f 代码。
我们再来看看js文件:
这个文件里面有对应的数据,我们直接复制到Power Query中,处理成列表形式备用:
下一步就是匹配表中的key,修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用 Table.RenameColumns 函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们可以将数据加载到 Excel 中。
如果要最新数据,直接刷新即可。 查看全部
excel抓取多页网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先,找到一个提供股票数据的 网站。各种财经网站都有股票数据。我们以东方财富网为例:
对于沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到对应股票数据的jQuery行,然后查看头文件中的URL:
将此 URL 复制到 Excel,数据 ==> 来自 网站:
点击确定打开Power Query编辑器,如果一切顺利,数据会直接出现:
虽然不是表格,但证明刮是成功的。下一步是如何解析这个二进制文件。从google浏览器看,是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号。中间数据可以用json解析。注意总数:4440,我们稍后会使用这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),"(",")"))
然后展开数据表:
到目前为止一切顺利,但我们只抓取一页数据,让我们看看:
pn是页码,我们是抓取第三页,pz是每页20条数据,我们有两种方式来抓取所有数据,一种是使用这个pz:20,然后定义一个函数来抓取所有的页码,我在以前的爬网中反复使用过这个。今天我们将尝试直接修改 pz 以一次捕获所有数据。其实我们可以尝试改变查询参数。如果我们将 pn 更改为 4,我们将抓取第 4 页。同理,我们把pn修改为200,看看能不能直接抓取200条数据。
那我们试试直接输入5000,能不能全部抓起来:
看起来不错。
还有一个问题,就是数据的标题行都是f开头的,不可读,怎么变成网页中汉字的标题行。
这个问题有点复杂。我们可能不得不检查代码,看看是否能找到替换它的方法。首先,看一下html:
但这是不完整的,有几列需要自定义:
这些指标没有对应的 f 代码。
我们再来看看js文件:
这个文件里面有对应的数据,我们直接复制到Power Query中,处理成列表形式备用:
下一步就是匹配表中的key,修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])}, (y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用 Table.RenameColumns 函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n [key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}))
我们可以将数据加载到 Excel 中。
如果要最新数据,直接刷新即可。
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-27 16:09
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。
方法二
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么认为? 查看全部
excel抓取多页网页数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。
方法二
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么认为?
excel抓取多页网页数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-27 16:08
我在做项目的时候遇到了将Table表格的数据以Excel的形式存储在网页中的问题。将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i 查看全部
excel抓取多页网页数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
我在做项目的时候遇到了将Table表格的数据以Excel的形式存储在网页中的问题。将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i
excel抓取多页网页数据( 如何将网页中的数据刮到Excel中?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-27 16:06
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,添加经验公式来计算从抓取的数据中得出的一些最终结果,例如 The idea is good。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“主页”选项卡 >“关闭并加载到”:
导入数据对话框将打开:
提示:如果将其加载到数据模型中,请务必选择“仅创建连接” 查看全部
excel抓取多页网页数据(
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,添加经验公式来计算从抓取的数据中得出的一些最终结果,例如 The idea is good。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上面的 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“主页”选项卡 >“关闭并加载到”:
导入数据对话框将打开:
提示:如果将其加载到数据模型中,请务必选择“仅创建连接”
excel抓取多页网页数据(webscraper插件到底要怎么用呢?数据的基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2022-01-23 21:19
在工作中,几乎每个职位都涉及到数据采集的任务。采集本地所有装修公司的名单,采集一个APP的所有评论,采集所有网上相关的文章,批量下载某个网站的指定文件……
我不会编程,也不懂爬虫技术。遇到过这种工作,要么CTRL+C,CTRL+V,要么笑着请技术人员帮忙爬取数据。直到遇到神器网络爬虫,没有编程经验,经过几个简单的步骤设置,几分钟就可以快速采集上千条数据,效率高得一飞冲天。
Web scraper是一款谷歌爬虫插件,使用非常简单,30分钟即可完全掌握。网络爬虫插件会将数据抓取出来生成excel表格供我们使用。
那么如何使用这个插件呢?
爬取数据的基本流程
step1:下载并安装网络爬虫插件。
下载地址: 链接: 密码: t7bm
安装方法:参考百度经验文章
step2:新建一个数据爬取站点。
首先按F12(或点击鼠标右键-勾选)调出控制台,点击“Web Scraper”切换到爬虫插件功能,点击create new sitemap进入新数据爬虫站点创建页面。
站点地图名称可以自定义,但必须是英文。起始 url 是我们要抓取的 网站 网站。在这里,我们在豆瓣上爬取了上海近一周的同城活动,将以下链接复制到开始url输入框中,然后点击“创建站点地图”确认创建。
step3:选择要提取的页面元素
上一步创建成功后,页面会跳转到如下界面,然后我们点击“添加新选择器”,创建一个新的选择器。
以提取页面的活动标题为例,设置ID为“标题”(这里可以自定义,在excel中会变成表头),类型为“文本”。
选择器是指页面中需要提取的数据区域。点击选择,在网页上滑动鼠标,会出现绿色区域,表示可以选择这些区域的数据。
选择一个活动标题,这个区域会被红色边框包围,然后继续选择下一个活动标题。选择两个相同的区域时,插件将自动选择页面上的其他类似元素。点击“完成选择!” 确认选择。
我们可以点击“元素预览”查看页面上所有选中的区域,点击“数据预览”预览爬虫将获取的数据。
注意:由于我们要选择此页面上的所有活动标题,因此需要选中“多个”复选框。其余内容可以保留默认,点击“保存选择器”保存选择器。
至此,我们已经选择了要提取的页面元素,如下图所示。
step4:开始爬取数据
点击抓取,进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,点击“开始抓取”开始抓取数据。这里的时间间隔主要是为了避免爬虫因为操作过于频繁而被阻塞,无法正常爬取。一般网站默认时间间隔就可以了,有些网站可能需要设置更大的时间间隔。
启动后,会打开一个目标URL的窗口,爬虫会按照提取设置的规则,一个一个的爬取。爬取完成后,窗口会自动关闭。
step5:下载数据
点击“Export data as CSV”跳转到excel数据下载页面,点击“download now”下载。
以上五个步骤就是使用网络爬虫爬取数据的整个过程和操作。不管数据多么复杂,都可以按照这个流程和操作爬取对应的数据。
高级操作
1、如何一次爬取一组数据?
刚才我们只爬取活动主题。如果我们想同时抓取活跃话题和活跃时间,我们应该怎么做呢?
从上图可以看出,数据的结构,活动主题和活动时间都收录在最外层的方框中,所以在设置选择器的时候,首先创建一个大选择器,让活动主题和活动内容都收录在内同时。
注意这里的Type应该设置为“Element”。保存后,点击刚才创建的内容(下图中红框的位置),进入子页面。
然后在这个页面上分别创建一个标题选择器和一个时间选择器。它的类型是文本。现在页面的可选择区域仅限于列表区域,所以只需要点击活动标题一次,确认选择即可。不要勾选“多个”。
只有通过创建一个元素选择器来收录活动主题和活动时间,爬取的数据才会以一一对应的方式呈现。
2、如何一次爬取多页内容?
这里根据分页形式的不同有不同的解决方案。
1)固定分页的情况下
可以注意到豆瓣同城活动的页面是分页的,每页显示10条数据。那么如果我们要爬取前10页的数据,我们应该怎么做呢?
如果你仔细看,你会发现第一页的 URL 和第二页的 URL 是有区别的。
第一页:
第二页:
start= 后面的数字是差为 10 的等差数列。
那么我们在搭建数据爬取站点的时候,我们用[0-100:10]代替具体的数字来表示数据爬取的页面范围。即:[0-100:10]
如果 URL 的等价性为 1,例如 知乎question URL:
第一页:
第二页:
然后省略冒号和后面的算术差异,只写页码范围。如[1-10]
表示知乎 主题的第一页到第十页。
处理这类数据的重点是观察不同页面的URL变化,然后将页码范围写入URL。
2)滚动鼠标自动加载
目前很多网站都采用了滚动到底部后自动加载数据的方式,并且它们的URL并没有改变。比如知乎live首页的数据加载方式。
这时候我们需要在创建元素选择器的时候将Type设置为“元素向下滚动”。这样,当爬虫工作时,它会自动进行滚动操作,一直爬到没有数据加载为止。
3)点击页面底部的“加载更多”按钮
设置外层元素元素时,将Type设置为“元素点击”,然后点击“点击选择器”的“选择”按钮,选择页面上的加载更多按钮或图标。
为了使页面不断加载,请将“点击类型”设置为“点击更多”并点击多次。
接下来,设置停止点击的条件。当该区域的文本内容或 HTML 结构或显示样式发生变化时,不再点击。
例如,加载完成后,“加载更多”按钮的文字变为“已加载”,则此处选择Unique Text;如果按钮在加载结束时显示为灰色,请选择唯一 CSS 选择器。
3、如何批量抓取和下载图片?
将类型设置为图片,插件将抓取所有图片的链接。有两种下载图像的方法。一种是直接勾选Download image,这样爬虫在爬取的时候会自动下载。或者爬取所有图片链接后,使用批量下载工具直接下载。
4、如何抓取网页链接?
将Type设置为Link,爬虫将爬取该元素上的超链接。
如图:当Type为文本时,爬取的数据为立陶宛Angelica Cholina Dance Theatre的Anna Karenina的“Anna Karenina”
当Type为Link时,爬取的数据为:,即点击页面链接跳转到下图中红框内的内容。
当您需要抓取的链接是下载文件的链接时,例如类似下图中“公告下载”按钮的链接。您可以将类型设置为弹出链接,以便在爬取过程中自动下载文件。
5. 如何爬取二级或三级页面的内容?
首先在根目录中创建一个选择器。此选择器选择的内容是可以点击进入二级页面的区域。如果该区域有超链接,则将Type设置为Link,否则设置为Element click;然后在这个选择器里面创建一个选择器,选择要爬取的区域。这可以逐级嵌套。
如何判断一个区域是否有超链接?将鼠标放在该区域,右键单击,如果有“Open link in...”选项,则该区域有超链接,将Type设置为Link。
通过以上设置,我们可以使用谷歌插件抓取80%的网站数据,获取本地的excel文件,然后对数据进行处理分析。
以上技能不仅可以用于工作,还可以应用于生活中的查询信息。
很多时候网站的设计存在一定的问题,给我们获取信息带来一定的困难。
例如,在知乎直播网页上,当你点击一个直播详情然后返回时,页面会回到顶部,需要再次滚动加载;
例如,交互栏的活动列表页面没有对活动状态进行分类。一般来说,正在进行的活动是不能参与的,但也不能被过滤掉。
这时候如果使用网络爬虫工具,可以在本地抓取数据,然后根据自己的需要快速过滤。
掌握了这个插件后,真的能提高工作效率,减少麻烦吗?
提高工作效率是肯定的,但减少麻烦却不一定。毕竟下班太早被老板说了~woo woo 查看全部
excel抓取多页网页数据(webscraper插件到底要怎么用呢?数据的基本流程)
在工作中,几乎每个职位都涉及到数据采集的任务。采集本地所有装修公司的名单,采集一个APP的所有评论,采集所有网上相关的文章,批量下载某个网站的指定文件……
我不会编程,也不懂爬虫技术。遇到过这种工作,要么CTRL+C,CTRL+V,要么笑着请技术人员帮忙爬取数据。直到遇到神器网络爬虫,没有编程经验,经过几个简单的步骤设置,几分钟就可以快速采集上千条数据,效率高得一飞冲天。
Web scraper是一款谷歌爬虫插件,使用非常简单,30分钟即可完全掌握。网络爬虫插件会将数据抓取出来生成excel表格供我们使用。
那么如何使用这个插件呢?
爬取数据的基本流程
step1:下载并安装网络爬虫插件。
下载地址: 链接: 密码: t7bm
安装方法:参考百度经验文章
step2:新建一个数据爬取站点。
首先按F12(或点击鼠标右键-勾选)调出控制台,点击“Web Scraper”切换到爬虫插件功能,点击create new sitemap进入新数据爬虫站点创建页面。
站点地图名称可以自定义,但必须是英文。起始 url 是我们要抓取的 网站 网站。在这里,我们在豆瓣上爬取了上海近一周的同城活动,将以下链接复制到开始url输入框中,然后点击“创建站点地图”确认创建。
step3:选择要提取的页面元素
上一步创建成功后,页面会跳转到如下界面,然后我们点击“添加新选择器”,创建一个新的选择器。
以提取页面的活动标题为例,设置ID为“标题”(这里可以自定义,在excel中会变成表头),类型为“文本”。
选择器是指页面中需要提取的数据区域。点击选择,在网页上滑动鼠标,会出现绿色区域,表示可以选择这些区域的数据。
选择一个活动标题,这个区域会被红色边框包围,然后继续选择下一个活动标题。选择两个相同的区域时,插件将自动选择页面上的其他类似元素。点击“完成选择!” 确认选择。
我们可以点击“元素预览”查看页面上所有选中的区域,点击“数据预览”预览爬虫将获取的数据。
注意:由于我们要选择此页面上的所有活动标题,因此需要选中“多个”复选框。其余内容可以保留默认,点击“保存选择器”保存选择器。
至此,我们已经选择了要提取的页面元素,如下图所示。
step4:开始爬取数据
点击抓取,进入数据抓取开始页面。
设置请求间隔和页面加载延迟时间,点击“开始抓取”开始抓取数据。这里的时间间隔主要是为了避免爬虫因为操作过于频繁而被阻塞,无法正常爬取。一般网站默认时间间隔就可以了,有些网站可能需要设置更大的时间间隔。
启动后,会打开一个目标URL的窗口,爬虫会按照提取设置的规则,一个一个的爬取。爬取完成后,窗口会自动关闭。
step5:下载数据
点击“Export data as CSV”跳转到excel数据下载页面,点击“download now”下载。
以上五个步骤就是使用网络爬虫爬取数据的整个过程和操作。不管数据多么复杂,都可以按照这个流程和操作爬取对应的数据。
高级操作
1、如何一次爬取一组数据?
刚才我们只爬取活动主题。如果我们想同时抓取活跃话题和活跃时间,我们应该怎么做呢?
从上图可以看出,数据的结构,活动主题和活动时间都收录在最外层的方框中,所以在设置选择器的时候,首先创建一个大选择器,让活动主题和活动内容都收录在内同时。
注意这里的Type应该设置为“Element”。保存后,点击刚才创建的内容(下图中红框的位置),进入子页面。
然后在这个页面上分别创建一个标题选择器和一个时间选择器。它的类型是文本。现在页面的可选择区域仅限于列表区域,所以只需要点击活动标题一次,确认选择即可。不要勾选“多个”。
只有通过创建一个元素选择器来收录活动主题和活动时间,爬取的数据才会以一一对应的方式呈现。
2、如何一次爬取多页内容?
这里根据分页形式的不同有不同的解决方案。
1)固定分页的情况下
可以注意到豆瓣同城活动的页面是分页的,每页显示10条数据。那么如果我们要爬取前10页的数据,我们应该怎么做呢?
如果你仔细看,你会发现第一页的 URL 和第二页的 URL 是有区别的。
第一页:
第二页:
start= 后面的数字是差为 10 的等差数列。
那么我们在搭建数据爬取站点的时候,我们用[0-100:10]代替具体的数字来表示数据爬取的页面范围。即:[0-100:10]
如果 URL 的等价性为 1,例如 知乎question URL:
第一页:
第二页:
然后省略冒号和后面的算术差异,只写页码范围。如[1-10]
表示知乎 主题的第一页到第十页。
处理这类数据的重点是观察不同页面的URL变化,然后将页码范围写入URL。
2)滚动鼠标自动加载
目前很多网站都采用了滚动到底部后自动加载数据的方式,并且它们的URL并没有改变。比如知乎live首页的数据加载方式。
这时候我们需要在创建元素选择器的时候将Type设置为“元素向下滚动”。这样,当爬虫工作时,它会自动进行滚动操作,一直爬到没有数据加载为止。
3)点击页面底部的“加载更多”按钮
设置外层元素元素时,将Type设置为“元素点击”,然后点击“点击选择器”的“选择”按钮,选择页面上的加载更多按钮或图标。
为了使页面不断加载,请将“点击类型”设置为“点击更多”并点击多次。
接下来,设置停止点击的条件。当该区域的文本内容或 HTML 结构或显示样式发生变化时,不再点击。
例如,加载完成后,“加载更多”按钮的文字变为“已加载”,则此处选择Unique Text;如果按钮在加载结束时显示为灰色,请选择唯一 CSS 选择器。
3、如何批量抓取和下载图片?
将类型设置为图片,插件将抓取所有图片的链接。有两种下载图像的方法。一种是直接勾选Download image,这样爬虫在爬取的时候会自动下载。或者爬取所有图片链接后,使用批量下载工具直接下载。
4、如何抓取网页链接?
将Type设置为Link,爬虫将爬取该元素上的超链接。
如图:当Type为文本时,爬取的数据为立陶宛Angelica Cholina Dance Theatre的Anna Karenina的“Anna Karenina”
当Type为Link时,爬取的数据为:,即点击页面链接跳转到下图中红框内的内容。
当您需要抓取的链接是下载文件的链接时,例如类似下图中“公告下载”按钮的链接。您可以将类型设置为弹出链接,以便在爬取过程中自动下载文件。
5. 如何爬取二级或三级页面的内容?
首先在根目录中创建一个选择器。此选择器选择的内容是可以点击进入二级页面的区域。如果该区域有超链接,则将Type设置为Link,否则设置为Element click;然后在这个选择器里面创建一个选择器,选择要爬取的区域。这可以逐级嵌套。
如何判断一个区域是否有超链接?将鼠标放在该区域,右键单击,如果有“Open link in...”选项,则该区域有超链接,将Type设置为Link。
通过以上设置,我们可以使用谷歌插件抓取80%的网站数据,获取本地的excel文件,然后对数据进行处理分析。
以上技能不仅可以用于工作,还可以应用于生活中的查询信息。
很多时候网站的设计存在一定的问题,给我们获取信息带来一定的困难。
例如,在知乎直播网页上,当你点击一个直播详情然后返回时,页面会回到顶部,需要再次滚动加载;
例如,交互栏的活动列表页面没有对活动状态进行分类。一般来说,正在进行的活动是不能参与的,但也不能被过滤掉。
这时候如果使用网络爬虫工具,可以在本地抓取数据,然后根据自己的需要快速过滤。
掌握了这个插件后,真的能提高工作效率,减少麻烦吗?
提高工作效率是肯定的,但减少麻烦却不一定。毕竟下班太早被老板说了~woo woo
excel抓取多页网页数据(如何将jsp页面表格中的数据导出到excel中?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-17 20:21
在程序员的日常工作中,我们经常会遇到这样的问题。如何将jsp页表中的数据导出到excel中?
我知道的第一个方法是 javascript
function method1(tableid) {//整个表格拷贝到EXCEL中
var curTbl = document.getElementByIdx_x(tableid);
var oXL = new ActiveXObject("Excel.Application");
//建立AX对象excel
var oWB = oXL.Workbooks.Add();
//获取workbook对象
var oSheet = oWB.ActiveSheet;
//激活当前sheet
var sel = document.body.createTextRange();
sel.moveToElementText(curTbl);
//把表格中的内容移到TextRange中
sel.select();
//全选TextRange中内容
sel.execCommand("Copy");
//复制TextRange中内容
oSheet.Paste();
//粘贴到活动的EXCEL中
oXL.Visible = true;
//设置excel可见属性
}
但是,这种方法有很大的局限性。火狐和谷歌浏览器基本没用,用IE的时候修改安全设置很不方便。
此外,还可以采取以下方式:在jsp页面头部添加这一段:
wjm 是您要导出的 Excel 工作表的名称。使用这种方法,当你打开链接指向页面时,浏览器会提示你下载excel表格,你可以以excel的形式保存到本地。该方法适用于各种浏览器,但在当前页面看不到数据表的内容,因为打开页面会提示直接下载。如何解决这个问题呢?我是这样解决的:
点击导出通信录
这样,您将能够在当前页面上看到收录表格的页面,并在单击链接时下载它。
有时我们要收录的页面是struts的action处理过的页面。如果直接收录action指向的页面,那么页面上可能只看到header部分,没有数据。我该怎么办?处理它?
我想出的是使用ajax的方式:
<p>function init(){
$(function(){
$.ajax({
'async': false,
type : "post",
url :"showUser.action",
success : function(msg) {
$("#result").html(msg);
}
});
});
}
点击导出通信录 查看全部
excel抓取多页网页数据(如何将jsp页面表格中的数据导出到excel中?)
在程序员的日常工作中,我们经常会遇到这样的问题。如何将jsp页表中的数据导出到excel中?
我知道的第一个方法是 javascript
function method1(tableid) {//整个表格拷贝到EXCEL中
var curTbl = document.getElementByIdx_x(tableid);
var oXL = new ActiveXObject("Excel.Application");
//建立AX对象excel
var oWB = oXL.Workbooks.Add();
//获取workbook对象
var oSheet = oWB.ActiveSheet;
//激活当前sheet
var sel = document.body.createTextRange();
sel.moveToElementText(curTbl);
//把表格中的内容移到TextRange中
sel.select();
//全选TextRange中内容
sel.execCommand("Copy");
//复制TextRange中内容
oSheet.Paste();
//粘贴到活动的EXCEL中
oXL.Visible = true;
//设置excel可见属性
}
但是,这种方法有很大的局限性。火狐和谷歌浏览器基本没用,用IE的时候修改安全设置很不方便。
此外,还可以采取以下方式:在jsp页面头部添加这一段:
wjm 是您要导出的 Excel 工作表的名称。使用这种方法,当你打开链接指向页面时,浏览器会提示你下载excel表格,你可以以excel的形式保存到本地。该方法适用于各种浏览器,但在当前页面看不到数据表的内容,因为打开页面会提示直接下载。如何解决这个问题呢?我是这样解决的:
点击导出通信录
这样,您将能够在当前页面上看到收录表格的页面,并在单击链接时下载它。
有时我们要收录的页面是struts的action处理过的页面。如果直接收录action指向的页面,那么页面上可能只看到header部分,没有数据。我该怎么办?处理它?
我想出的是使用ajax的方式:
<p>function init(){
$(function(){
$.ajax({
'async': false,
type : "post",
url :"showUser.action",
success : function(msg) {
$("#result").html(msg);
}
});
});
}
点击导出通信录
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-17 05:24
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
爬取250部豆瓣电影比较简单,特别是对于初学者来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫都会选择这个项目作为起点。入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它是一个很好的实践网页作为入口爬虫。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。 查看全部
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
爬取250部豆瓣电影比较简单,特别是对于初学者来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫都会选择这个项目作为起点。入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它是一个很好的实践网页作为入口爬虫。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。
excel抓取多页网页数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-15 21:03
)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
查看全部
excel抓取多页网页数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫
)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
excel抓取多页网页数据(大数据时代,看似平平常常的生活场景,其实是没有价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-11 10:17
在大数据时代,看似平凡的生活场景,其实都离不开这些海量数据。例如,您接触到的文件、照片、视频等都收录大量的数据信息。每个人都可以从中受益,为我们节省了时间,也为对方省了很多麻烦。
现在几乎每天都有无数的数据在互联网上激增,成为不可或缺的生产要素。事实上,大数据本身并没有任何价值。如何对待这种说法取决于用户。认为这些数据对分析某些东西有很大帮助是有价值的。而如果我们不将这些数据用于参考和引用,那么数据就只是一堆数字和文字相结合的文件。
我直接在speedceo上找到了一些Excel文件。当然,这些文件都是公开的,也可以直接下载或者在线预览。基本可以找到我想知道的大学排名表文件。不过也有一些文件比较旧,日期是新的,看你有没有需要。
同时,人们期待看到他们在春节期间上映的电影的票房、排名等表现。这就是数据。如果行业的大玩家得到它,他们可以做出一些预测。毕竟规划一些内容一定不能盲目。只有获得真实可靠的数据,才能做出准确的事后分析和预测。
直接获取一些统计数据表进行分析是很简单的,但是之前确实不容易获取,成本高,准确度也不一定。现在有了Python,其实处理起来比较快,但是我对它不是太熟悉,因为没有专门研究过。互联网时代,海量数据海量可用。
如果要写分析意见,还是需要一定的数据来支持的。事实上,为人们提供新鲜而深刻的见解,就是大数据的价值所在。数据在互联网时代真的很重要,毕竟它可以帮助在分析事物时做出有效的决策。 查看全部
excel抓取多页网页数据(大数据时代,看似平平常常的生活场景,其实是没有价值)
在大数据时代,看似平凡的生活场景,其实都离不开这些海量数据。例如,您接触到的文件、照片、视频等都收录大量的数据信息。每个人都可以从中受益,为我们节省了时间,也为对方省了很多麻烦。
现在几乎每天都有无数的数据在互联网上激增,成为不可或缺的生产要素。事实上,大数据本身并没有任何价值。如何对待这种说法取决于用户。认为这些数据对分析某些东西有很大帮助是有价值的。而如果我们不将这些数据用于参考和引用,那么数据就只是一堆数字和文字相结合的文件。
我直接在speedceo上找到了一些Excel文件。当然,这些文件都是公开的,也可以直接下载或者在线预览。基本可以找到我想知道的大学排名表文件。不过也有一些文件比较旧,日期是新的,看你有没有需要。
同时,人们期待看到他们在春节期间上映的电影的票房、排名等表现。这就是数据。如果行业的大玩家得到它,他们可以做出一些预测。毕竟规划一些内容一定不能盲目。只有获得真实可靠的数据,才能做出准确的事后分析和预测。
直接获取一些统计数据表进行分析是很简单的,但是之前确实不容易获取,成本高,准确度也不一定。现在有了Python,其实处理起来比较快,但是我对它不是太熟悉,因为没有专门研究过。互联网时代,海量数据海量可用。
如果要写分析意见,还是需要一定的数据来支持的。事实上,为人们提供新鲜而深刻的见解,就是大数据的价值所在。数据在互联网时代真的很重要,毕竟它可以帮助在分析事物时做出有效的决策。
excel抓取多页网页数据(先导入需要的工具定义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-01-11 10:15
)
首先导入需要的工具,定义爬虫类,初始化base_url,随机请求头,总页数,记录每一页的小说名和连接地址,excel中存储的行数,后面需要用到.
获取网页的源码,分析是否是首页,因为解析url地址发现首页的url和后面的url不一样。如果是第一页,直接返回self.base_url。页数
设置一个循环,如果不能正常连接,会返回失败信息和原因,重新尝试连接。
解析网页源码,通过引入etree,将得到的网页源码转换成xpath可以解析的格式,并设置编码为utf-8格式
优先获取总页数,匹配到的是
所以需要通过正则表达式匹配总页数,转换为整数类型
然后在网页中获取小说名和详情地址的url,保存在一个元组中,然后将元组存入小说列表
定义一个解析细节的类,解析小说的细节
获取网页源代码获取详细地址
根据xpath,解析出小说的详细信息。清理数据并返回解析后的信息
回到上一个类,写写数据入表的函数,实现解析明细类的实例对象,根据小说的明细地址进行解析
写启动函数,建表,写数据,保存表
实现爬虫类的对象,调用start函数,启动爬虫
查看全部
excel抓取多页网页数据(先导入需要的工具定义
)
首先导入需要的工具,定义爬虫类,初始化base_url,随机请求头,总页数,记录每一页的小说名和连接地址,excel中存储的行数,后面需要用到.
获取网页的源码,分析是否是首页,因为解析url地址发现首页的url和后面的url不一样。如果是第一页,直接返回self.base_url。页数
设置一个循环,如果不能正常连接,会返回失败信息和原因,重新尝试连接。
解析网页源码,通过引入etree,将得到的网页源码转换成xpath可以解析的格式,并设置编码为utf-8格式
优先获取总页数,匹配到的是
所以需要通过正则表达式匹配总页数,转换为整数类型
然后在网页中获取小说名和详情地址的url,保存在一个元组中,然后将元组存入小说列表
定义一个解析细节的类,解析小说的细节
获取网页源代码获取详细地址
根据xpath,解析出小说的详细信息。清理数据并返回解析后的信息
回到上一个类,写写数据入表的函数,实现解析明细类的实例对象,根据小说的明细地址进行解析
写启动函数,建表,写数据,保存表
实现爬虫类的对象,调用start函数,启动爬虫
excel抓取多页网页数据(excel抓取多页网页数据的方法一种方法是复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-10 11:01
excel抓取多页网页数据的方法一种方法是复制每一页的数据,然后粘贴到另一页,这样做的缺点是只能抓取垂直数据。第二种方法,使用python的numpy。在excel文件中,通过numpy第一层抓取每一页的数据,然后再下一页抓取。由于字符串是不能复制,因此利用python通过函数来抓取字符串。
一、数据分析工具
二、数据介绍
三、用python实现
二、数据介绍整理数据之后,提取出前三页的内容:最终,
1。可以利用清洗好的数据作相关性分析或计数分析等;2。可以利用清洗好的数据作指标分析、排名分析等;3。可以利用清洗好的数据作目标识别、模式发现等;4。可以利用清洗好的数据作文本分析、表格分析等;5。可以利用清洗好的数据作上游关联分析等;6。可以利用清洗好的数据做事件发生时间分析等;7。可以利用清洗好的数据做营销活动数据分析等;8。
可以利用清洗好的数据做相关性分析等;9。可以利用清洗好的数据做市场数据定位分析等;10。可以利用清洗好的数据做产品的用户画像和设计,比如从用户基本信息、用户属性、产品属性、使用产品等来得到用户画像;11。可以利用清洗好的数据做线上线下的产品推广数据分析;12。可以利用清洗好的数据做品牌推广数据分析;13。可以利用清洗好的数据做市场分析和产品评估等;14。可以利用清洗好的数据做科研项目设计等;。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据的方法一种方法是复制)
excel抓取多页网页数据的方法一种方法是复制每一页的数据,然后粘贴到另一页,这样做的缺点是只能抓取垂直数据。第二种方法,使用python的numpy。在excel文件中,通过numpy第一层抓取每一页的数据,然后再下一页抓取。由于字符串是不能复制,因此利用python通过函数来抓取字符串。
一、数据分析工具
二、数据介绍
三、用python实现
二、数据介绍整理数据之后,提取出前三页的内容:最终,
1。可以利用清洗好的数据作相关性分析或计数分析等;2。可以利用清洗好的数据作指标分析、排名分析等;3。可以利用清洗好的数据作目标识别、模式发现等;4。可以利用清洗好的数据作文本分析、表格分析等;5。可以利用清洗好的数据作上游关联分析等;6。可以利用清洗好的数据做事件发生时间分析等;7。可以利用清洗好的数据做营销活动数据分析等;8。
可以利用清洗好的数据做相关性分析等;9。可以利用清洗好的数据做市场数据定位分析等;10。可以利用清洗好的数据做产品的用户画像和设计,比如从用户基本信息、用户属性、产品属性、使用产品等来得到用户画像;11。可以利用清洗好的数据做线上线下的产品推广数据分析;12。可以利用清洗好的数据做品牌推广数据分析;13。可以利用清洗好的数据做市场分析和产品评估等;14。可以利用清洗好的数据做科研项目设计等;。
excel抓取多页网页数据(干货速递|Python办公自动化之PDF的详细操作(全))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-09 15:11
大家好,我是小艺!
关注并star《小易学习笔记》,和小易一起学习数据分析!
点击关注|选星|干货
在日常的数据分析工作中,除了Excel数据的清洗,最常见的就是pdf、word、ppt等场景下的数据清洗。其实这还有一个更高的名字,叫做:办公自动化。
很多情况下,因为办公自动化场景中的数据是不规则的,首先要做的就是在数据分析之前把数据提取出来。
比如小艺的朋友“长河”在实际工作中遇到的真实问题:
虽然我对word的操作不是很熟悉,但也提供了自己的解决方案:
由于我擅长从PDF中提取数据,所以我也写过相关的操作文档:Python办公自动化中PDF的详细操作(全),所以如果原创数据是pdf,那我就按照我上面说的方法。操作
但是昌河已经自己做了pdf转换,所以问题就变成了多词的数据提取。
下面的文章是他在实现过程中的真实思考。有些数据比较敏感,文字已经编码,但不影响实际阅读和练习。
这也是实际工作中经常遇到的问题。希望大家下次能处理好。
以下为“昌河”投稿正文:
1. 问题的根源
我最近遇到的一个问题是从word中读取表格数据,然后整理成excel格式。
如下:
词形1,脱敏
如果表不多,只有几张表,手动处理也没问题,但是如果有140张表,9年的数据,怎么处理呢?
这时候,我们就需要一个程序来帮我们自动解决。
2.解决问题
确定问题后,我们接下来需要解决问题。
如果要从word中提取表格,常用的包是docx,为了规范提取中的数据,需要使用pandas
2.1 识别数据的行和列
如果要提取word表中的行列,需要了解表中有多少行列,然后根据具体的行列提取数据。
这部分内容可以参考B站的一些视频,使用Python操作Word
代码显示如下:
from docx import Document
doc = Document('one.docx')
tables = doc.tables
table = tables[0] # 表示读取的第一张表
# 查看一下多少行,多少列
print(len(table.rows),len(table.columns))
输出是:
5 14
可以看出我们提取的表信息是一个5行14列的数据。接下来,您需要考虑每一行和每一列的样子。
这里我们以第 5 行第 2 列为例进行说明:
继续写代码为:
print(table.cell(4,1).text)
输出是:
13905
270
5583
1528
1791
2315
2439
...
经过反复试验,我们终于知道我们需要的数据在哪里。
考虑到header过于复杂,难以定位,需要自己重写header信息。我们需要的是整个学校的数据,也就是下图中的部分。
提取表1对应的数据2.2 数据提取
接下来,执行数据提取:
list1 = [] # 定义一个空的列表存储数据
for row in range(4,len(table.rows)):
for column in range(len(table.columns)):
list1.append(table.cell(row,column).text)
print(len(list1))
print(list1)
提取的数据是一个很长的列表,输出为:
14
['--大学\--大学\--大学\---大学\n ----\n2186588\n203224\n146649\n329602\n214014\n299323\n47413\n71033']
接下来迭代转换为[[],[],[]]的形式
values = []
for i in list1:
i = i.split('\n')
values.append(i)
print(values)
结果处理完成,结果如下:
[['xx大学', 'xxxx大学', 'xx大学', ---'xxxx大学'],--- ['2186588', '203224', '146649', '329602', '214014', '299323', '47413', '71033']]
2.3 转换为DataFrame格式
之前已经对值进行了整理,然后可以重新整理表头信息:
colums = ['xx','xx','xx']
data_part1 = pd.DataFrame(values,columns).T
print(data_part1.head())
输出是:
学校名称 xxxxxx- ... xxxx xxxxxxx
0 XX大学 13905 ... 46526 2222470
1 XX大学 270 ... 0 67822
2 XX大学 5583 ... 331010 3557540
3 XX大学 1528 ... 12826 544980
4 XX大学 1791 ... 1270 844921
[5 rows x 14 columns]
考虑到一个word文件有两张表,第二张表的数据结构如下:
词形2,脱敏
第二张表的表头和第一张表的表头不同,处理方法相同,直接加代码即可:
table = tables[1]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
values2.append(h)
data2 = pd.DataFrame(values2,column2).T
data = pd.concat([data1,data2],axis =1)
2.4 完整处理一个表
一个完整的字有两个表,所以需要用判断条件来处理,分为奇位表和偶位表。判断是根据某个数除以2时余数是否为0。
具体代码如下:
import pandas as pd
from docx import Document
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
2.5 完整处理多个表
如果是处理多张表,需要设置路径,然后在特定路径中处理
具体代码如下:
import pandas as pd
from docx import Document
import os
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
# 设置路径
path = os.listdir('E:\one-two')
# print(path)
for i in range(len(path)):
docx = Document('E:\one-two\{}'.format(path[i]))
# print('第{}表'.format(i+1),docx)
tables = docx.tables
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
print('正在保存{}'.format(i+1))
data.to_excel('E:\one-two\{}.xlsx'.format(i),index=False)
最终输出为:
最终结果3. 摘要
学习编程会带来很多问题和困惑。但这也是提高你的编程技能的关键。继续探索,看B站的视频,向大佬们求教,然后继续打印看看输出,你会得到你想要的!
感谢前辈提供的思路,补补补补!
一字一字的处理可以提高效率!
推荐历史文章:
一行Python代码去除照片背景
2021 年最有用的数据清理 Python 库
2021年Q3基金持仓数据分析,是满仓还是等风来?
历史上的今天,3步轻松重现! 查看全部
excel抓取多页网页数据(干货速递|Python办公自动化之PDF的详细操作(全))
大家好,我是小艺!
关注并star《小易学习笔记》,和小易一起学习数据分析!
点击关注|选星|干货
在日常的数据分析工作中,除了Excel数据的清洗,最常见的就是pdf、word、ppt等场景下的数据清洗。其实这还有一个更高的名字,叫做:办公自动化。
很多情况下,因为办公自动化场景中的数据是不规则的,首先要做的就是在数据分析之前把数据提取出来。
比如小艺的朋友“长河”在实际工作中遇到的真实问题:
虽然我对word的操作不是很熟悉,但也提供了自己的解决方案:
由于我擅长从PDF中提取数据,所以我也写过相关的操作文档:Python办公自动化中PDF的详细操作(全),所以如果原创数据是pdf,那我就按照我上面说的方法。操作
但是昌河已经自己做了pdf转换,所以问题就变成了多词的数据提取。
下面的文章是他在实现过程中的真实思考。有些数据比较敏感,文字已经编码,但不影响实际阅读和练习。
这也是实际工作中经常遇到的问题。希望大家下次能处理好。
以下为“昌河”投稿正文:
1. 问题的根源
我最近遇到的一个问题是从word中读取表格数据,然后整理成excel格式。
如下:
词形1,脱敏
如果表不多,只有几张表,手动处理也没问题,但是如果有140张表,9年的数据,怎么处理呢?
这时候,我们就需要一个程序来帮我们自动解决。
2.解决问题
确定问题后,我们接下来需要解决问题。
如果要从word中提取表格,常用的包是docx,为了规范提取中的数据,需要使用pandas
2.1 识别数据的行和列
如果要提取word表中的行列,需要了解表中有多少行列,然后根据具体的行列提取数据。
这部分内容可以参考B站的一些视频,使用Python操作Word
代码显示如下:
from docx import Document
doc = Document('one.docx')
tables = doc.tables
table = tables[0] # 表示读取的第一张表
# 查看一下多少行,多少列
print(len(table.rows),len(table.columns))
输出是:
5 14
可以看出我们提取的表信息是一个5行14列的数据。接下来,您需要考虑每一行和每一列的样子。
这里我们以第 5 行第 2 列为例进行说明:
继续写代码为:
print(table.cell(4,1).text)
输出是:
13905
270
5583
1528
1791
2315
2439
...
经过反复试验,我们终于知道我们需要的数据在哪里。
考虑到header过于复杂,难以定位,需要自己重写header信息。我们需要的是整个学校的数据,也就是下图中的部分。
提取表1对应的数据2.2 数据提取
接下来,执行数据提取:
list1 = [] # 定义一个空的列表存储数据
for row in range(4,len(table.rows)):
for column in range(len(table.columns)):
list1.append(table.cell(row,column).text)
print(len(list1))
print(list1)
提取的数据是一个很长的列表,输出为:
14
['--大学\--大学\--大学\---大学\n ----\n2186588\n203224\n146649\n329602\n214014\n299323\n47413\n71033']
接下来迭代转换为[[],[],[]]的形式
values = []
for i in list1:
i = i.split('\n')
values.append(i)
print(values)
结果处理完成,结果如下:
[['xx大学', 'xxxx大学', 'xx大学', ---'xxxx大学'],--- ['2186588', '203224', '146649', '329602', '214014', '299323', '47413', '71033']]
2.3 转换为DataFrame格式
之前已经对值进行了整理,然后可以重新整理表头信息:
colums = ['xx','xx','xx']
data_part1 = pd.DataFrame(values,columns).T
print(data_part1.head())
输出是:
学校名称 xxxxxx- ... xxxx xxxxxxx
0 XX大学 13905 ... 46526 2222470
1 XX大学 270 ... 0 67822
2 XX大学 5583 ... 331010 3557540
3 XX大学 1528 ... 12826 544980
4 XX大学 1791 ... 1270 844921
[5 rows x 14 columns]
考虑到一个word文件有两张表,第二张表的数据结构如下:
词形2,脱敏
第二张表的表头和第一张表的表头不同,处理方法相同,直接加代码即可:
table = tables[1]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
values2.append(h)
data2 = pd.DataFrame(values2,column2).T
data = pd.concat([data1,data2],axis =1)
2.4 完整处理一个表
一个完整的字有两个表,所以需要用判断条件来处理,分为奇位表和偶位表。判断是根据某个数除以2时余数是否为0。
具体代码如下:
import pandas as pd
from docx import Document
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
2.5 完整处理多个表
如果是处理多张表,需要设置路径,然后在特定路径中处理
具体代码如下:
import pandas as pd
from docx import Document
import os
column1 = ['xx','xx','xx','xx','xx']
column2 = ['xx','xx','xx','xx','xx']
# 设置路径
path = os.listdir('E:\one-two')
# print(path)
for i in range(len(path)):
docx = Document('E:\one-two\{}'.format(path[i]))
# print('第{}表'.format(i+1),docx)
tables = docx.tables
for t in range(len(tables)):
if t % 2 == 0:
table1 = []
value1 = []
table = docx.tables[t]
for row in range(4, len(table.rows)):
for column in range(len(table.columns)):
table1.append(table.cell(row, column).text)
for j in table1:
j = j.split('\n')
value1.append(j)
data1 = pd.DataFrame(value1, column1).T
if t % 2 == 1:
table2 = []
value2 = []
table = docx.tables[t]
for row in range(3, len(table.rows)):
for column in range(len(table.columns)):
table2.append(table.cell(row, column).text)
for h in table2:
h = h.split('\n')
value2.append(h)
data2 = pd.DataFrame(value2,column2).T
data = pd.concat([data1,data2],axis =1)
print('正在保存{}'.format(i+1))
data.to_excel('E:\one-two\{}.xlsx'.format(i),index=False)
最终输出为:
最终结果3. 摘要
学习编程会带来很多问题和困惑。但这也是提高你的编程技能的关键。继续探索,看B站的视频,向大佬们求教,然后继续打印看看输出,你会得到你想要的!
感谢前辈提供的思路,补补补补!
一字一字的处理可以提高效率!
推荐历史文章:
一行Python代码去除照片背景
2021 年最有用的数据清理 Python 库
2021年Q3基金持仓数据分析,是满仓还是等风来?
历史上的今天,3步轻松重现!
excel抓取多页网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-07 01:18
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]} 查看全部
excel抓取多页网页数据(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]}
excel抓取多页网页数据(给pdf文件插入一页,PowerAutomate是怎么自动做到的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2022-01-07 01:17
上一篇文章《在pdf文件中插入页面,Power Automate如何自动做?PA实战》介绍了如何在pdf文件中插入内容,反之,如果有插入,就会有被删除。
例如,在很多pdf文件中,插入了一些广告页,尤其是一些“免费”的文件。这其实是可以理解的。毕竟,整理文档并不容易。插入广告以引起注意也是付费的一部分。小回报。但理解属于理解。有时,我们仍然希望删除广告页面。
如果只是一两个文件,手动操作也很快。它可以通过专业软件或直接使用 Power Automate 来实现。方法非常简单。从哪些页面获取哪些页面!| 《PA实战案例》中使用的方法——将PDF页面解压成新的PDF,这里不再赘述。
下面我们主要讲两种批量操作多个文件的情况:被删除页面的位置是固定的,被删除页面的位置需要通过页面内容搜索来判断。
- 1 -
要删除的页面在固定位置
这种情况也可以通过使用“将PDF页面提取到新的PDF”功能来实现。但是,问题是pdftk工具仍然可以识别pdf文件的总页数。所以,我们直接使用pdftk工具的合并功能,直接合并(删除)删除对应的页面——合并功能真的很好用,具体的使用方法这里举例说明:
例如在文件“01 Nov 2029.pdf”的第3页插入adv.pdf文件,pdftk处理命令可以写成:
这个命令的写法很有意思:将“01 Nov 2019.pdf”文件设置为A,将“adv.pdf”文件设置为B,然后合并[A's pages 1-3, B, A's pages 4- 最后一页 (end)],输出为 out.pdf 文件。
然后,借助合并功能,假设我们要删除文件夹“E:\RPA\pdf\2019”中所有pdf文件的第4页。实施步骤如下:
Step-01 获取文件夹中的文件
Step-02 为每个循环添加
选择对上一步得到的pdf文件(%Files%)进行循环操作。
Step-03 在循环中添加“运行DOS命令”
注意DOS命令的写法:
1、pdftk命令完全按照你存放pdftk工具的文件路径来写:比如这里是“E:\RPA\pdf\PDFtk\pdftk.exe”;
2、 选择循环的当前工程变量(文件)进入DOS命令时,注意是否加双引号。例如,因为这里要引用文件路径,而文件路径本身可能收录空格等,所以需要加双引号。
-2 -
要删除的页面需要根据内容来判断
在某些情况下,需要删除的页面不是固定的页码,而是需要根据页面的内容来确定。例如,页面收录特定的广告词...
在这种情况下,需要提取页面内容,然后进行文本比较(包括判断)来确定要删除的页面,比较困难。而且,暂时还没有支持直接根据搜索内容删除页面的pdf工具。
但是经过研究,发现pdftk支持我们将pdf文件拆分成不同的文件(每页一个)。这样,我们再提取拆分文件的内容进行判断。如果里面收录了具体的信息,我们直接删除页面文件,然后合并剩余的页面文件是不是可以达到同样的目的呢?
让我们来看看如何做到这一点。
Step-01 获取文件夹中的文件
Step-02 为每个循环添加一个
Step-03 创建一个原文件名的文件夹,用来存放分页后的文件
Step-04 运行DOS命令将pdf文件反汇编到一个文件夹中
pdf_d.pdf 表示反汇编后文件名为pdf_0001.pdf, pdf_0002.pdf……。
Step-05 获取反汇编后的单页文件
Step-06 为每个添加内循环
遍历pdf的每一页并阅读内容
Step-07 从 pdf 中提取文本
Step-08 添加IF条件判断单页pdf文件中提取的文本
条件设置为:如果从页面中提取的内容(%ExtractedPDFText%)收录“我是广告”。
Step-09 删除本页的pdf文件
Step-10 获取当前文件夹中的文件
在Step-09之后,收录广告的页面的pdf文件已被删除。再次获取文件夹中的所有pdf文件,为后续的合并做准备:
步骤 11 合并 PDF 文件
合并上一步得到的pdf文件(减少广告)。
经过以上拆分、提取文本、判断、删除页面,再合并的过程,我们就达到了根据内容删除pdf页面的目的。
该方法考虑到要删除的页面位置完全不确定,所以需要对所有pdf文件进行反汇编。结果,反汇编后的文件会比较多,每个页面都需要进行文本提取和判断。因此,如果页面较多,运行效率可能会比较低。
在实际工作中,如果要删除的页面位置比较固定,比如可能只出现在几个页面上,那么建议先将这些页面提取出来,分别处理后再合并,这样避免全部拆除的效率问题。 查看全部
excel抓取多页网页数据(给pdf文件插入一页,PowerAutomate是怎么自动做到的?)
上一篇文章《在pdf文件中插入页面,Power Automate如何自动做?PA实战》介绍了如何在pdf文件中插入内容,反之,如果有插入,就会有被删除。
例如,在很多pdf文件中,插入了一些广告页,尤其是一些“免费”的文件。这其实是可以理解的。毕竟,整理文档并不容易。插入广告以引起注意也是付费的一部分。小回报。但理解属于理解。有时,我们仍然希望删除广告页面。
如果只是一两个文件,手动操作也很快。它可以通过专业软件或直接使用 Power Automate 来实现。方法非常简单。从哪些页面获取哪些页面!| 《PA实战案例》中使用的方法——将PDF页面解压成新的PDF,这里不再赘述。
下面我们主要讲两种批量操作多个文件的情况:被删除页面的位置是固定的,被删除页面的位置需要通过页面内容搜索来判断。
- 1 -
要删除的页面在固定位置
这种情况也可以通过使用“将PDF页面提取到新的PDF”功能来实现。但是,问题是pdftk工具仍然可以识别pdf文件的总页数。所以,我们直接使用pdftk工具的合并功能,直接合并(删除)删除对应的页面——合并功能真的很好用,具体的使用方法这里举例说明:
例如在文件“01 Nov 2029.pdf”的第3页插入adv.pdf文件,pdftk处理命令可以写成:
这个命令的写法很有意思:将“01 Nov 2019.pdf”文件设置为A,将“adv.pdf”文件设置为B,然后合并[A's pages 1-3, B, A's pages 4- 最后一页 (end)],输出为 out.pdf 文件。
然后,借助合并功能,假设我们要删除文件夹“E:\RPA\pdf\2019”中所有pdf文件的第4页。实施步骤如下:
Step-01 获取文件夹中的文件
Step-02 为每个循环添加
选择对上一步得到的pdf文件(%Files%)进行循环操作。
Step-03 在循环中添加“运行DOS命令”
注意DOS命令的写法:
1、pdftk命令完全按照你存放pdftk工具的文件路径来写:比如这里是“E:\RPA\pdf\PDFtk\pdftk.exe”;
2、 选择循环的当前工程变量(文件)进入DOS命令时,注意是否加双引号。例如,因为这里要引用文件路径,而文件路径本身可能收录空格等,所以需要加双引号。
-2 -
要删除的页面需要根据内容来判断
在某些情况下,需要删除的页面不是固定的页码,而是需要根据页面的内容来确定。例如,页面收录特定的广告词...
在这种情况下,需要提取页面内容,然后进行文本比较(包括判断)来确定要删除的页面,比较困难。而且,暂时还没有支持直接根据搜索内容删除页面的pdf工具。
但是经过研究,发现pdftk支持我们将pdf文件拆分成不同的文件(每页一个)。这样,我们再提取拆分文件的内容进行判断。如果里面收录了具体的信息,我们直接删除页面文件,然后合并剩余的页面文件是不是可以达到同样的目的呢?
让我们来看看如何做到这一点。
Step-01 获取文件夹中的文件
Step-02 为每个循环添加一个
Step-03 创建一个原文件名的文件夹,用来存放分页后的文件
Step-04 运行DOS命令将pdf文件反汇编到一个文件夹中
pdf_d.pdf 表示反汇编后文件名为pdf_0001.pdf, pdf_0002.pdf……。
Step-05 获取反汇编后的单页文件
Step-06 为每个添加内循环
遍历pdf的每一页并阅读内容
Step-07 从 pdf 中提取文本
Step-08 添加IF条件判断单页pdf文件中提取的文本
条件设置为:如果从页面中提取的内容(%ExtractedPDFText%)收录“我是广告”。
Step-09 删除本页的pdf文件
Step-10 获取当前文件夹中的文件
在Step-09之后,收录广告的页面的pdf文件已被删除。再次获取文件夹中的所有pdf文件,为后续的合并做准备:
步骤 11 合并 PDF 文件
合并上一步得到的pdf文件(减少广告)。
经过以上拆分、提取文本、判断、删除页面,再合并的过程,我们就达到了根据内容删除pdf页面的目的。
该方法考虑到要删除的页面位置完全不确定,所以需要对所有pdf文件进行反汇编。结果,反汇编后的文件会比较多,每个页面都需要进行文本提取和判断。因此,如果页面较多,运行效率可能会比较低。
在实际工作中,如果要删除的页面位置比较固定,比如可能只出现在几个页面上,那么建议先将这些页面提取出来,分别处理后再合并,这样避免全部拆除的效率问题。
excel抓取多页网页数据(excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-04 10:10
excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可。基础:1.定义一个名称叫筛选条件,包含从1~n之间所有数字;2.把想要的内容放入数据框里;3.把字段名重命名成如下代码。ps:筛选条件和字段名比较重要,不要把“又是萝卜又是菜”和“又是瓜子又是大白”写在一个数据框里。数据筛选代码:筛选条件ps:数据过滤有两种方法,一种是通过公式,一种是手动操作。
公式大家可以用excelhome的相关教程,这里介绍一种简单方便的过滤方法。ps:把筛选条件记录到offset的lookupvalue中,可以从中减去想要过滤的数字,查找选择原来要过滤的数字。筛选条件:and条件一成立,返回“从1到n之间的所有数字”,不成立,返回“从0到1之间的所有数字”;如果不能满足条件,会返回0;如果过滤1次不满足条件,则返回0,否则返回1。
lookupand方法是一种相互嵌套的链接和过滤算法,把过滤的数据当做公式嵌套进筛选条件中,这样可以得到1,2,3,这三种不同的数据。通过这个方法得到的数据,需要返回筛选数据的个数。ps:在一次查找中,只能查找一条数据,先查找0次,再查找1次,如果不能满足要求,返回0。常用技巧:筛选数字为数字格式的筛选条件有:金额为小数的筛选条件,如$b$1-$a$10$b$1=a$1.3;$c$1-$e$10$c$1=$d$1.3;对应的余额小数位数是多少;购买元为数字格式的筛选条件:$a$1-$b$1=a$1.2;$c$1-$e$1=c$1.2;对应的余额小数位数是多少。
对应的余额有多少。筛选数字为模糊数字的筛选条件有:首位带有"6"的筛选条件,如$a9-$b96$a9=a9;首位不带有"6"的筛选条件,如$a9-$b96$a9=b9;对应的余额小数位数是多少。筛选数字为日期格式的筛选条件有:$a$1-$b$1=a$1;$a$1-$c$1=c$1;对应的余额小数位数是多少。
如果不能匹配到日期格式的,则返回-1。3.修改所需要过滤的字段,当a3这样的数字,需要将"3"更换成"3+3"或"3",剩下的所有字段都可以利用上面的方法转换。对于pdf数据,还可以用filter函数返回指定数值范围内的所有文字。比如我用filter函数返回hundredseries,有些pdf上字符串里有"3",这时如果只修改“3”,字符串里会出现"4"和"5"这些文字。
如果修改其他字符串,字符串的文字也会被替换为第一个字符的整数值或2倍长度。python实现:python代码:defget_row_num(text):val。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可)
excel抓取多页网页数据文字内容非常简单,利用数据过滤和数据筛选即可。基础:1.定义一个名称叫筛选条件,包含从1~n之间所有数字;2.把想要的内容放入数据框里;3.把字段名重命名成如下代码。ps:筛选条件和字段名比较重要,不要把“又是萝卜又是菜”和“又是瓜子又是大白”写在一个数据框里。数据筛选代码:筛选条件ps:数据过滤有两种方法,一种是通过公式,一种是手动操作。
公式大家可以用excelhome的相关教程,这里介绍一种简单方便的过滤方法。ps:把筛选条件记录到offset的lookupvalue中,可以从中减去想要过滤的数字,查找选择原来要过滤的数字。筛选条件:and条件一成立,返回“从1到n之间的所有数字”,不成立,返回“从0到1之间的所有数字”;如果不能满足条件,会返回0;如果过滤1次不满足条件,则返回0,否则返回1。
lookupand方法是一种相互嵌套的链接和过滤算法,把过滤的数据当做公式嵌套进筛选条件中,这样可以得到1,2,3,这三种不同的数据。通过这个方法得到的数据,需要返回筛选数据的个数。ps:在一次查找中,只能查找一条数据,先查找0次,再查找1次,如果不能满足要求,返回0。常用技巧:筛选数字为数字格式的筛选条件有:金额为小数的筛选条件,如$b$1-$a$10$b$1=a$1.3;$c$1-$e$10$c$1=$d$1.3;对应的余额小数位数是多少;购买元为数字格式的筛选条件:$a$1-$b$1=a$1.2;$c$1-$e$1=c$1.2;对应的余额小数位数是多少。
对应的余额有多少。筛选数字为模糊数字的筛选条件有:首位带有"6"的筛选条件,如$a9-$b96$a9=a9;首位不带有"6"的筛选条件,如$a9-$b96$a9=b9;对应的余额小数位数是多少。筛选数字为日期格式的筛选条件有:$a$1-$b$1=a$1;$a$1-$c$1=c$1;对应的余额小数位数是多少。
如果不能匹配到日期格式的,则返回-1。3.修改所需要过滤的字段,当a3这样的数字,需要将"3"更换成"3+3"或"3",剩下的所有字段都可以利用上面的方法转换。对于pdf数据,还可以用filter函数返回指定数值范围内的所有文字。比如我用filter函数返回hundredseries,有些pdf上字符串里有"3",这时如果只修改“3”,字符串里会出现"4"和"5"这些文字。
如果修改其他字符串,字符串的文字也会被替换为第一个字符的整数值或2倍长度。python实现:python代码:defget_row_num(text):val。
excel抓取多页网页数据( PowerBIDesktop的制作流程及注意事项(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-01 23:02
PowerBIDesktop的制作流程及注意事项(一))
我们使用Power BI Desktop制作上图,需要历年的保费收入数据作为依据。 网站有数据公告:
本页地址:
/web/site0/tab5205/info4129096.htm
每个月都会有对应的地址。在哪里可以找到这些地址?
我们找到了这样一个页面:
此页面上有指向我们需要的每月数据的链接。这样的页面一共有8个,这8个页面的URL是连续的。
web/site0/tab5205/module14413/page1.htm
从第 1 页到第 8 页
我们打开Power BI Desktop的Power Query,创建一个从1到8的表
并将ID列设置为文本,这是第一步。
第二步:创建查询,从网络获取数据,设置乘法csv格式
复制地址栏中的公式以备后用。 (这些功能实在想不起来了,有点懒,呵呵)
第三步:回到最开始的表格,自定义列,用刚才复制的公式进行修改。
用ID替换页面后面的数字。
第 4 步:数据清洗。我们想要的是每个月的 URL。这个过程有点复杂,但是用到的函数很简单,就是对符号进行排序、过滤、替换。
1、用
2、过滤掉收录信息的行
3、再次分隔列并使用双引号分隔列
到目前为止,我们已经得到了我们想要的 URL。
4、为了能够区分年月,需要做一些处理。取标题后面的列并提取年份和月份。这部分略过。结果是这样的:
第 5 步:获取特定数据。如果您不记得该函数,请先从网络创建查询,复制公式,然后自定义列。
将 URL 后面的部分替换为 URL。
第六步:展开和整理数据,这里有几点需要注意
1、删除需要修改的列,保留年月列
2、过滤掉所有非省市名
3、统一各省市名称,自己想办法
4、反向透视栏
最终结果:
剩下的工作会回到 Power BI Desktop 使用 DAX 创建测量值,然后图表就可以了。
综上所述,如果你想从一个网页中获取你需要的信息,你必须掌握关键信息。网络信息有多种格式。如果要从源代码中查找信息,请使用 CSV 格式。使用 HTML 格式。无论是使用PQ还是PY网络来抓取数据,都是一个寻找模式的过程。如果你找到一个模式,你就可以做到。 查看全部
excel抓取多页网页数据(
PowerBIDesktop的制作流程及注意事项(一))
我们使用Power BI Desktop制作上图,需要历年的保费收入数据作为依据。 网站有数据公告:
本页地址:
/web/site0/tab5205/info4129096.htm
每个月都会有对应的地址。在哪里可以找到这些地址?
我们找到了这样一个页面:
此页面上有指向我们需要的每月数据的链接。这样的页面一共有8个,这8个页面的URL是连续的。
web/site0/tab5205/module14413/page1.htm
从第 1 页到第 8 页
我们打开Power BI Desktop的Power Query,创建一个从1到8的表
并将ID列设置为文本,这是第一步。
第二步:创建查询,从网络获取数据,设置乘法csv格式
复制地址栏中的公式以备后用。 (这些功能实在想不起来了,有点懒,呵呵)
第三步:回到最开始的表格,自定义列,用刚才复制的公式进行修改。
用ID替换页面后面的数字。
第 4 步:数据清洗。我们想要的是每个月的 URL。这个过程有点复杂,但是用到的函数很简单,就是对符号进行排序、过滤、替换。
1、用
2、过滤掉收录信息的行
3、再次分隔列并使用双引号分隔列
到目前为止,我们已经得到了我们想要的 URL。
4、为了能够区分年月,需要做一些处理。取标题后面的列并提取年份和月份。这部分略过。结果是这样的:
第 5 步:获取特定数据。如果您不记得该函数,请先从网络创建查询,复制公式,然后自定义列。
将 URL 后面的部分替换为 URL。
第六步:展开和整理数据,这里有几点需要注意
1、删除需要修改的列,保留年月列
2、过滤掉所有非省市名
3、统一各省市名称,自己想办法
4、反向透视栏
最终结果:
剩下的工作会回到 Power BI Desktop 使用 DAX 创建测量值,然后图表就可以了。
综上所述,如果你想从一个网页中获取你需要的信息,你必须掌握关键信息。网络信息有多种格式。如果要从源代码中查找信息,请使用 CSV 格式。使用 HTML 格式。无论是使用PQ还是PY网络来抓取数据,都是一个寻找模式的过程。如果你找到一个模式,你就可以做到。

