
excel抓取多页网页数据
excel抓取多页网页数据( 用Excel中的数据导入方法,快速将网页数据到Excel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2022-03-15 07:05
用Excel中的数据导入方法,快速将网页数据到Excel)
最近朋友LJ在研究P2P公司,看到网贷之家的网贷指标数据,想复制到Excel中方便整理分析。
打开网址后发现只能显示20行数据:
点击登录查看完整评分,出现注册登录页面:
直接复制粘贴,只能复制20行数据,不方便整理。截屏?图片中的数据无法保存到单元格中。
无奈之下,一个朋友找到了我,问有没有简单的方法。今天教大家如何使用Excel中的数据导入方法,快速将网页数据抓取到Excel中,并自动更新数据。
我相信你已经等不及了。我们以这个页面为例,看看下面的详细步骤。
你会学到
1 如何使用 Excel 抓取网页数据
2 如何让数据自动更新
01.
抓取数据
1、新建一个Excel工作表,点击【数据】选项卡,在【获取外部数据】中选择【来自网站】;
2、会出现【新建网页查询】对话框:
3、将复制的网贷页面网址粘贴到【地址】栏,点击【导入】;
4、在出现的【导入数据】对话框中,选择数据放置位置,这里我们先将单元格A1,OK;
5、现在我们可以看到导出的结果了。可以看出,在爬表的同时,也爬取了一些不相关的内容。
6、删除不相关的内容,最终得到我们想要的表格数据。
02.
更新数据
为了让数据在以后更新数据时自动更新,我们还可以进行如下设置。
1、点击【数据】选项卡下的【全部刷新】,选择【连接属性】;
2、在弹出的对话框中勾选【刷新频率】,例如设置为60分钟,即每1小时刷新一次。
这样,以后只要更新网站数据,我们的表也可以自动更新~ 查看全部
excel抓取多页网页数据(
用Excel中的数据导入方法,快速将网页数据到Excel)
最近朋友LJ在研究P2P公司,看到网贷之家的网贷指标数据,想复制到Excel中方便整理分析。
打开网址后发现只能显示20行数据:
点击登录查看完整评分,出现注册登录页面:
直接复制粘贴,只能复制20行数据,不方便整理。截屏?图片中的数据无法保存到单元格中。
无奈之下,一个朋友找到了我,问有没有简单的方法。今天教大家如何使用Excel中的数据导入方法,快速将网页数据抓取到Excel中,并自动更新数据。
我相信你已经等不及了。我们以这个页面为例,看看下面的详细步骤。
你会学到
1 如何使用 Excel 抓取网页数据
2 如何让数据自动更新
01.
抓取数据
1、新建一个Excel工作表,点击【数据】选项卡,在【获取外部数据】中选择【来自网站】;
2、会出现【新建网页查询】对话框:
3、将复制的网贷页面网址粘贴到【地址】栏,点击【导入】;
4、在出现的【导入数据】对话框中,选择数据放置位置,这里我们先将单元格A1,OK;
5、现在我们可以看到导出的结果了。可以看出,在爬表的同时,也爬取了一些不相关的内容。
6、删除不相关的内容,最终得到我们想要的表格数据。
02.
更新数据
为了让数据在以后更新数据时自动更新,我们还可以进行如下设置。
1、点击【数据】选项卡下的【全部刷新】,选择【连接属性】;
2、在弹出的对话框中勾选【刷新频率】,例如设置为60分钟,即每1小时刷新一次。
这样,以后只要更新网站数据,我们的表也可以自动更新~
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-05 06:21
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
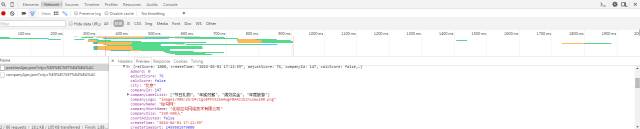
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息 page_headers = { 'Host': '', 'User-Agent': 'Mozilla/5. 0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454. 85 Safari/537.36 115Browser/6.0.3', '连接': 'keep-alive'} ifpage_num == 1: boo = 'true'否则: boo = ' false'page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录以下参数('first', boo), ('pn', page_num), ('kd', keyword ) ] ) req = request.Request(url, headers=page_headers) page = request.urlopen(req,data=page_data.encode('utf-8')).read() page = page.decode('utf-8') returnpage
比较关键的步骤之一是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看出返回结果中收录招聘信息, 其中收录很多其他参数 page_result = [num fornum inrange(15)] # 构造一个容量为15的占位符列表构造下一个二维数组 fori inrange(15): page_result[ i ] = [] # 构造一个二维数组 forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ' ,'.join(page_result[i][8]) returnpage_result # 返回当前页面的job信息
第 4 步:将捕获的信息存储在 Excel 中
获取到原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1fori inrange(times): # i 代表 Line , i+1 代表行头信息 ifi == 0: fortag_name_i intag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: fortag_list inrange(len(tag_name)): tmp.write(i , tag_list , str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后会不完整,excel文件也会出现“部分内容有问题需要修复”我查了很多遍,一开始以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面tmp = book.add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1 被表头占用 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-coding:utf-8-*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime. 约会时间。现在() url = r'。拉古。com/jobs/positionAjax。json?city=%E5%8C%97%E4%BA%AC'#钩网招聘信息是动态获取的,需要通过post方式提交json信息。默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] #这是标签信息需要抓取的,包括公司名称、学历要求、薪资等。 tag_name = ['公司名称', '公司简称', '职位', '
拉古。com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive'} ifpage_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ #通过页面分析,发现浏览器提交的FormData收录以下内容参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data. encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.
load(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看到返回结果中收录招聘信息,其中还收录很多其他参数 page_result = [num fornum inrange (15)] # 构造一个容量为15的list占位符构造下一个二维数组 fori inrange(15): page_result[i] = [] #构造一个二维数组forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ','.join(page_result[i][ 8] ) returnpage_result # 返回当前页面的招聘信息 def read_max_page(page): # 获取当前招聘的最大页数 关键词,大于30的会被覆盖,所以最多只能获取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] ifmax_page_num > 30: max_page_num = 30returnmax_page_num def save_excel (fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.
Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面 tmp = book. add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp. write_row(tag_pos, tag_name) else: con_pos = 'A%s'% i content = fin_result[i-1] # -1是因为tmp被表头占用了。write_row(con_pos, content) 书。close() if__name__ == '__main__': print('********************************** 即将被抓到 Take ************************************') keyword = input('请输入语言type :') fin_result = [] # 将每一页的招聘信息聚合成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) forpage_num inrange(1, max_page_num): print('
extend(page_result) file_name = input('捕获完成,保存输入文件名:') save_excel(fin_result, tag_name, file_name) endtime = datetime. 约会时间。现在()时间=(结束时间 - 开始时间)。seconds print('总时间: %s s'% time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~ 查看全部
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。

可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。

我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息 page_headers = { 'Host': '', 'User-Agent': 'Mozilla/5. 0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454. 85 Safari/537.36 115Browser/6.0.3', '连接': 'keep-alive'} ifpage_num == 1: boo = 'true'否则: boo = ' false'page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录以下参数('first', boo), ('pn', page_num), ('kd', keyword ) ] ) req = request.Request(url, headers=page_headers) page = request.urlopen(req,data=page_data.encode('utf-8')).read() page = page.decode('utf-8') returnpage
比较关键的步骤之一是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看出返回结果中收录招聘信息, 其中收录很多其他参数 page_result = [num fornum inrange(15)] # 构造一个容量为15的占位符列表构造下一个二维数组 fori inrange(15): page_result[ i ] = [] # 构造一个二维数组 forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ' ,'.join(page_result[i][8]) returnpage_result # 返回当前页面的job信息
第 4 步:将捕获的信息存储在 Excel 中
获取到原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1fori inrange(times): # i 代表 Line , i+1 代表行头信息 ifi == 0: fortag_name_i intag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: fortag_list inrange(len(tag_name)): tmp.write(i , tag_list , str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后会不完整,excel文件也会出现“部分内容有问题需要修复”我查了很多遍,一开始以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:

到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面tmp = book.add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1 被表头占用 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-coding:utf-8-*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime. 约会时间。现在() url = r'。拉古。com/jobs/positionAjax。json?city=%E5%8C%97%E4%BA%AC'#钩网招聘信息是动态获取的,需要通过post方式提交json信息。默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] #这是标签信息需要抓取的,包括公司名称、学历要求、薪资等。 tag_name = ['公司名称', '公司简称', '职位', '
拉古。com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive'} ifpage_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ #通过页面分析,发现浏览器提交的FormData收录以下内容参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data. encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.
load(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看到返回结果中收录招聘信息,其中还收录很多其他参数 page_result = [num fornum inrange (15)] # 构造一个容量为15的list占位符构造下一个二维数组 fori inrange(15): page_result[i] = [] #构造一个二维数组forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ','.join(page_result[i][ 8] ) returnpage_result # 返回当前页面的招聘信息 def read_max_page(page): # 获取当前招聘的最大页数 关键词,大于30的会被覆盖,所以最多只能获取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] ifmax_page_num > 30: max_page_num = 30returnmax_page_num def save_excel (fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.
Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面 tmp = book. add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp. write_row(tag_pos, tag_name) else: con_pos = 'A%s'% i content = fin_result[i-1] # -1是因为tmp被表头占用了。write_row(con_pos, content) 书。close() if__name__ == '__main__': print('********************************** 即将被抓到 Take ************************************') keyword = input('请输入语言type :') fin_result = [] # 将每一页的招聘信息聚合成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) forpage_num inrange(1, max_page_num): print('
extend(page_result) file_name = input('捕获完成,保存输入文件名:') save_excel(fin_result, tag_name, file_name) endtime = datetime. 约会时间。现在()时间=(结束时间 - 开始时间)。seconds print('总时间: %s s'% time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~
excel抓取多页网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
网站优化 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2022-03-04 07:01
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓取,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。 查看全部
excel抓取多页网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓取,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。
excel抓取多页网页数据(每页PowerBIDesktop中用自动播放自动播放自动播放 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2022-03-04 06:19
)
喜欢笑话的朋友,可以抓一些笑话保存成TXT格式,放到电子书里闲暇时阅读,上网搜索一下,这个网站不错,干净并且没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取文章的所有URL:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
查看全部
excel抓取多页网页数据(每页PowerBIDesktop中用自动播放自动播放自动播放
)
喜欢笑话的朋友,可以抓一些笑话保存成TXT格式,放到电子书里闲暇时阅读,上网搜索一下,这个网站不错,干净并且没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取文章的所有URL:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
excel抓取多页网页数据(处理页面元素的方法-处理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-03 18:17
我正在尝试使用vba在excel中将表格的第二页保存在下面代码中的url中,但是我不能使用click属性,你能帮帮我吗?我在互联网上到处搜索,没有结果。谢谢。
Sub BrowseSiteTableObjectX()
Dim IE As New SHDocVw.InternetExplorer
Dim Docm As MSHTML.HTMLDocument
Dim HTMLAtab As MSHTML.IHTMLElement
Dim HTMLArow As MSHTML.IHTMLElement
Dim iRow As Long
With IE
.navigate "https://www.nasdaq.com/market- ... ot%3B
Do While .Busy Or .readyState 4
DoEvents
Loop
End With
Set Docm = IE.document
Docm.getElementsByClassName("symbol-screener__pagination")(0).getElementsByClassName("next")(0).Click
Set Docm = IE.document
Set HTMLAtab = Docm.getElementsByClassName("symbol-screener__table")(0)
For Each HTMLArow In HTMLAtab.getElementsByClassName("symbol-screener__row")
iRow = iRow + 1
Cells(iRow, 1) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--ticker")(0).innerText
Cells(iRow, 2) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--company")(0).innerText
DoEvents
Next HTMLArow
IE.Quit
Set IE = Nothing
Set Docm = Nothing
End Sub
最佳答案
为了看看这是否有帮助,在这个 文章 中,我概述了处理页面元素的各种方法。您需要考虑“单击”“下一步”按钮时会发生什么。它可能正在提交表单,运行页面 javascript,
看看这些想法是否有帮助。您可能会发现 ExecScript 是最好的,因为 Next 按钮可能会链接回页面上的脚本以加载下一组数据。只需查看您的 Chrome 开发工具,看看会发生什么。
祝你好运!
关于 html - 使用 vba 抓取多页网页表单,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
excel抓取多页网页数据(处理页面元素的方法-处理工具)
我正在尝试使用vba在excel中将表格的第二页保存在下面代码中的url中,但是我不能使用click属性,你能帮帮我吗?我在互联网上到处搜索,没有结果。谢谢。
Sub BrowseSiteTableObjectX()
Dim IE As New SHDocVw.InternetExplorer
Dim Docm As MSHTML.HTMLDocument
Dim HTMLAtab As MSHTML.IHTMLElement
Dim HTMLArow As MSHTML.IHTMLElement
Dim iRow As Long
With IE
.navigate "https://www.nasdaq.com/market- ... ot%3B
Do While .Busy Or .readyState 4
DoEvents
Loop
End With
Set Docm = IE.document
Docm.getElementsByClassName("symbol-screener__pagination")(0).getElementsByClassName("next")(0).Click
Set Docm = IE.document
Set HTMLAtab = Docm.getElementsByClassName("symbol-screener__table")(0)
For Each HTMLArow In HTMLAtab.getElementsByClassName("symbol-screener__row")
iRow = iRow + 1
Cells(iRow, 1) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--ticker")(0).innerText
Cells(iRow, 2) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--company")(0).innerText
DoEvents
Next HTMLArow
IE.Quit
Set IE = Nothing
Set Docm = Nothing
End Sub
最佳答案
为了看看这是否有帮助,在这个 文章 中,我概述了处理页面元素的各种方法。您需要考虑“单击”“下一步”按钮时会发生什么。它可能正在提交表单,运行页面 javascript,
看看这些想法是否有帮助。您可能会发现 ExecScript 是最好的,因为 Next 按钮可能会链接回页面上的脚本以加载下一组数据。只需查看您的 Chrome 开发工具,看看会发生什么。
祝你好运!
关于 html - 使用 vba 抓取多页网页表单,我们在 Stack Overflow 上发现了一个类似的问题:
excel抓取多页网页数据( Python3.5和BeautifulSoup.底层数据库是什么意思?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-03 18:16
Python3.5和BeautifulSoup.底层数据库是什么意思?(图)
)
.
我希望有一个 HTML 链接可用于下一次抓取迭代,但没有运气。进一步检查,通过查看网络流量,发现浏览器为 __VIEWSTATE 等发送了一个很长的(散列的?)字符串。可能保护数据库?
我正在寻找一种方法来抓取狗的所有页面,或者通过迭代所有页面,或者通过增加页面长度以在第 1 页上显示超过 100 行。底层数据库是 .aspx。
我正在使用 Python 3.5 和 BeautifulSoup。
当前代码:
<p> import requests
from bs4 import BeautifulSoup
url = 'http://www.gbgb.org.uk/RaceCard.aspx?dogName=Hardwick%20Serena'
with requests.session() as s:
s.headers['user-agent'] = 'Mozilla/5.0'
r = s.get(url)
soup = BeautifulSoup(r.content, 'html5lib')
target = 'ctl00$ctl00$mainContent$cmscontent$DogRaceCard$btnFilter_input'
data = { tag['name']: tag['value']
for tag in soup.select('input[name^=ctl00]') if tag.get('value')
}
state = { tag['name']: tag['value']
for tag in soup.select('input[name^=__]')
}
data.update(state)
numberpages = int(str(soup.find('div', 'rgWrap rgInfoPart')).split(' ')[-2].split('>')[1].split(' 查看全部
excel抓取多页网页数据(
Python3.5和BeautifulSoup.底层数据库是什么意思?(图)
)
.
我希望有一个 HTML 链接可用于下一次抓取迭代,但没有运气。进一步检查,通过查看网络流量,发现浏览器为 __VIEWSTATE 等发送了一个很长的(散列的?)字符串。可能保护数据库?
我正在寻找一种方法来抓取狗的所有页面,或者通过迭代所有页面,或者通过增加页面长度以在第 1 页上显示超过 100 行。底层数据库是 .aspx。
我正在使用 Python 3.5 和 BeautifulSoup。
当前代码:
<p> import requests
from bs4 import BeautifulSoup
url = 'http://www.gbgb.org.uk/RaceCard.aspx?dogName=Hardwick%20Serena'
with requests.session() as s:
s.headers['user-agent'] = 'Mozilla/5.0'
r = s.get(url)
soup = BeautifulSoup(r.content, 'html5lib')
target = 'ctl00$ctl00$mainContent$cmscontent$DogRaceCard$btnFilter_input'
data = { tag['name']: tag['value']
for tag in soup.select('input[name^=ctl00]') if tag.get('value')
}
state = { tag['name']: tag['value']
for tag in soup.select('input[name^=__]')
}
data.update(state)
numberpages = int(str(soup.find('div', 'rgWrap rgInfoPart')).split(' ')[-2].split('>')[1].split('
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-28 14:18
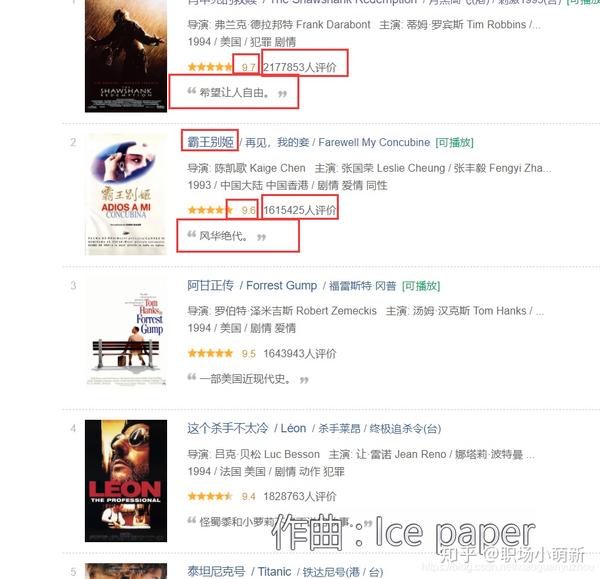
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
Top250豆瓣电影的爬取比较简单,特别是对于新手来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫初学者都会选择这个项目作为入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它作为入门级爬虫是一个很好的实践网页。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。 查看全部
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
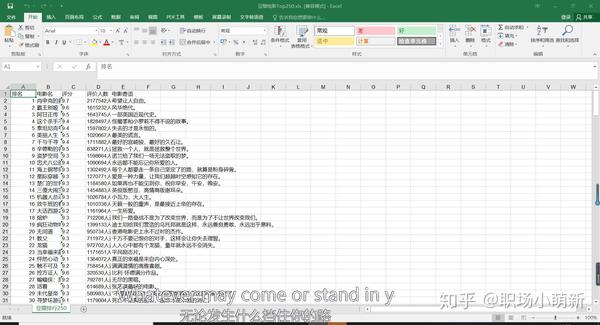
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
Top250豆瓣电影的爬取比较简单,特别是对于新手来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫初学者都会选择这个项目作为入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
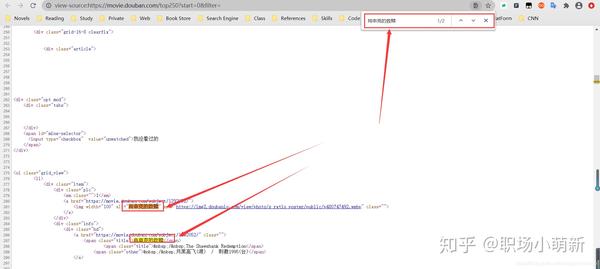
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它作为入门级爬虫是一个很好的实践网页。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
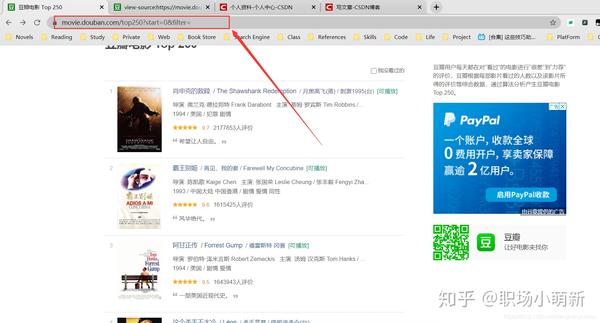
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。
excel抓取多页网页数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-26 09:19
用简单的Excel分析网站日志数据,哪些目录比较好爬,哪些IP段蜘蛛爬取等。一个网站要发展得更快更远,离不开每天的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,利用数据模型修改频道后,被收录的网页数量从原来的几十万增加到了5个以上今年万元。由此可见数据分析的重要性。说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。其实在日志分析< @网站,最需要的工具是 Excel(Excel 07 或 Excel 10)。在这里,我想和大家简单分享一下我的一些经验。网站个体爬取统计:借助光年日志分析工具,得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(我只做百度优化,所以我会讲百度蜘蛛爬取情况),如下图1:将上面的数据做成Excel,如下图2:平均停留时间=总停留时间/访问次数,计算公式:=C2/B2输入平均抓取量=总抓取量/访问次数,计算公式:=D2/B2进入单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2进入蜘蛛状态码统计:借助Excel,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示: 通过“数据”功能下的过滤Excel表格,下面可以统计蜘蛛状态码。具体统计操作如图4所示:点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,spider的状态码200的特征是HTTP/1.1" 200,以此类推:状态码500就是HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302..... 现在可以过滤掉每个蜘蛛状态码,如下图所示: 如上图5所示,选择收录关系统计百度蜘蛛200状态码的抓取量,以此类推。蜘蛛IP段统计:如上图,可以将状态码替换为IP段,如:HTTP/1.1" 200 改为 202.108.25 1. 33 目录爬取统计:如上图,将状态码替换为对应的目录名即可,如:@k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 @k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 查看全部
excel抓取多页网页数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》(组图))
用简单的Excel分析网站日志数据,哪些目录比较好爬,哪些IP段蜘蛛爬取等。一个网站要发展得更快更远,离不开每天的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,利用数据模型修改频道后,被收录的网页数量从原来的几十万增加到了5个以上今年万元。由此可见数据分析的重要性。说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。其实在日志分析< @网站,最需要的工具是 Excel(Excel 07 或 Excel 10)。在这里,我想和大家简单分享一下我的一些经验。网站个体爬取统计:借助光年日志分析工具,得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(我只做百度优化,所以我会讲百度蜘蛛爬取情况),如下图1:将上面的数据做成Excel,如下图2:平均停留时间=总停留时间/访问次数,计算公式:=C2/B2输入平均抓取量=总抓取量/访问次数,计算公式:=D2/B2进入单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2进入蜘蛛状态码统计:借助Excel,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示: 通过“数据”功能下的过滤Excel表格,下面可以统计蜘蛛状态码。具体统计操作如图4所示:点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,spider的状态码200的特征是HTTP/1.1" 200,以此类推:状态码500就是HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302..... 现在可以过滤掉每个蜘蛛状态码,如下图所示: 如上图5所示,选择收录关系统计百度蜘蛛200状态码的抓取量,以此类推。蜘蛛IP段统计:如上图,可以将状态码替换为IP段,如:HTTP/1.1" 200 改为 202.108.25 1. 33 目录爬取统计:如上图,将状态码替换为对应的目录名即可,如:@k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 @k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-25 07:15
PowerBI的强大不仅在于最终生成炫酷的可视化报表,更在于在数据采集的第一步展现其强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、任何结构和任何形式使用。获取数据
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到股票涨跌、外汇价格等实时交易数据。现在我们试试例如从中国银行抓取外汇价格信息网站,先输入网址:
单击确定后,将出现一个预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是处理数据。这是我们真正需要掌握的核心技能。 查看全部
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
PowerBI的强大不仅在于最终生成炫酷的可视化报表,更在于在数据采集的第一步展现其强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、任何结构和任何形式使用。获取数据

数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;

不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到股票涨跌、外汇价格等实时交易数据。现在我们试试例如从中国银行抓取外汇价格信息网站,先输入网址:

单击确定后,将出现一个预览窗口。

点击编辑进入查询编辑器,

外汇数据抓取完成后,剩下的就是数据整理的过程,抓取的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是处理数据。这是我们真正需要掌握的核心技能。
excel抓取多页网页数据(文章目录3.提取信息进行excel本地保存总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-22 01:15
文章目录
3.提取信息并保存在本地的excel中
总结
前言
本案例是爬取51job网站的job信息。如果有任何错误,请纠正我。转载请注明出处。
本次抓取网址:点此
温馨提示:以下为本文正文内容文章,以下案例供参考
一、模块使用
1.这次一共使用了四个模块
1import openpyxl
2import bs4
3import requests as r
4from selenium import webdriver
5
6
下面会列出具体模块的详细使用,有需要的可以自行了解:
详情页URL获取模块:selenium
HTML标签处理模块:bs4.beautifulsoup
Python详解——请求模块
openpyxl处理excel表格详解
二、数据抓取及url列表建立1.获取所有网页详情页面链接
这里使用 selenium 模块是因为可以获取动态加载页面的数据,比如 js 渲染后的代码,下拉轮获取的数据,框内的一些隐藏元素等。
调用selenium模块需要下载浏览器驱动:谷歌浏览器驱动下载地址,下载解压后放到python根目录下。注意:浏览器版本必须与驱动版本一致,否则无效。
如果还有安装不了selenium模块的朋友,请看这篇文章:selenium安装
1):首先观察我们要爬取的页面,定位到页面需要爬取的位置,我们发现他的父标签是“div”和“class="j_joblist”,
而详情页的链接在父标签下的div标签下的a标签中(这里有点绕,结合图片理解)
可以看出,我们首先要定位a标签,从中提取“href”标签中的地址,并将地址放入urllists列表中。第一步完成!
代码如下(示例):
1h = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"} # 伪造浏览器信息,第二步会用到。
2def get_joburllist(): # 定义函数get_joburllist
3
4 urllists = [ ] # 一个列表变量,用于接收所有网页详情页链接
5 chrome_driver = r'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\chromedriver.exe' #chromedriver的文件位置,r代表原始路径
6 wd = webdriver.Chrome(executable_path = chrome_driver) #创建浏览器,这里用谷歌浏览器,后接驱动器地址
7 wd.implicitly_wait(2) # 智能等待一个元素被发现,或一个命令完成。如果超出了设置时间的则抛出异常。
8 #访问51job网站
9 for i in range(1,34): # 这里两个参数,(1,34),1代表当前页,34代表总页数,可自行修改
10 wd.get("https://search.51job.com/list/010000,000000,0000,00,9,99,%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8,2,i.html") # 访问链接内的地址,i为第i页
11
12 joblists = wd.find_elements_by_xpath('//div[@class="j_joblist"]/div/a') # 查找所有div下class属性为"j_joblist"的子节点为div的子节点为a的标签
13 for urllist in joblists: # 循环获取所有详情页的href链接
14 href_list = urllist.get_attribute("href") # 获取href属性的内容
15 urllists.append(href_list)
16 wd.quit() # 关闭浏览器
17 #print(urllists)
18 return urllists
19
20
21
至此,网页详情页的链接就放在了urllists列表中。我们可以继续下一步
2.获取详情页的html源码,过滤我们需要的信息
思路:由于我们在第一步中已经获取到了各个详情页的url,我们可以使用requests返回html源码,使用浏览器查看,逐个找到需要信息的标签过滤掉,最后找到我们需要的文本信息,放入列表返回。
代码如下(示例):
1f get_html(url): # 这里的url指的是第一步获取的详情页的url
2 response = r.get(url,headers = h) # 伪造请求头信息
3 response.encoding = "gbk" # 更改编码为gbk
4 return response.text # 返回html源码
5
6def get_textinfo(html): # 进行源码筛选
7 jobname = [] # 以下为定义模块信息 , 工作名称
8 jobmoney = [] # 工资
9 comname = [] # 公司名称
10 jobjy = [] # 工作经验
11 jobyh = [] # 岗位福利
12 jobneed = [] # 岗位职责
13 cominfo = [] # 公司信息
14
15 soup = bs4.BeautifulSoup(html,"html.parser") # 两个参数,第一个参数为html源码,第二个参数为解析html文件,返回结果给soup
16 # Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象
17
18# 这里要做一下说明,因为获取到的详情页中,有一部分并没有按照规定模板来进行显示,
19# 而是直接跳转到公司官网,所以进行筛选时会报错,这里用if来做一个简单判断,
20# 如果获取的html源码中并不是按照规定模板来显示的,我们将pass掉这个信息
21
22 jn = soup.find("div",class_="cn")
23 strjn = str(jn) # 将类型转换为str,方便查找
24 jnfind = strjn.find("h1") # 查找“h1”字符,并将查找结果给jhfind
25 if jnfind == -1: # 如果返回结果为 -1 代表没有h1标签 (find没有找到时会返回-1)
26 #print ("no")
27 joblist = ["查看此招聘信息请点击链接:"] # 则返回空表
28
29 else: # 否则代表该源码符合规定模板,正常进行筛选
30 #print(jn.h1.text)
31 jobname.append(jn.h1.text) # 添加h1标签文本信息
32
33 jm = soup.find("div",class_="cn")
34 jobmoney.append(jm.strong.text) # 添加strong标签文本信息
35
36 cn = soup.find("a",class_="catn")
37 comname.append(cn.text) # 添加公司名称
38
39 jj = soup.find("p",class_="msg ltype")
40 jobjy.append(jj.text.replace("\xa0\xa0|\xa0\xa0"," ")) 添加工作经验文本信息,并将\xa0替换成空字符串,方便查看
41
42 jy = soup.findAll("span",class_="sp4") # 福利信息这里有点特殊,每个福利都是独立的,我们需要将他放在一个字符串里,并添加到福利信息列表。
43 jystr = "" # 建立空字符串
44 for i in jy: # 从jy(jy代表找到的所有符合条件的标签)中逐个调用并添加到jystr中,以空格隔开。
45 jystr += i.text + " "
46 jobyh.append(jystr) # 将完成的字符串添加到列表中
47
48 jn = soup.find("div",class_="bmsg job_msg inbox")
49 jnstr = ""
50 for i in jn.findAll("p"): # 跟上一个同理,findAll所有'p'标签 并放到一个空字符串中
51 jnstr += i.text + " "
52 jobneed.append(jnstr)
53
54 ci = soup.find("div",class_="tmsg inbox")
55 cominfo.append(ci.text) # 添加公司信息
56
57 joblist = jobname + jobmoney + comname + jobjy + jobyh + jobneed + cominfo # 将独立的列表信息合并到一起,成为一个大的列表。
58 return joblist
59
60
61
3.提取信息并保存在本地的excel中
思路:终于到了最后一步,这里也是调用整个代码执行的大致步骤。可以说上面写的函数都是在这里依次调用的。这次我们主要使用openpyxl来保存和调用前面两步。功能配合,代码废话不多说。
1
2def save_info():
3 wb = openpyxl.Workbook() # 获取工作簿 就是一个excle层面的对象,在获取工作簿的同时已经创建了一个默认的工作表
4 ws = wb.active # 获取当前工作表
5 titlelist = ["岗位名称","岗位薪资","公司名称","工作经验","岗位诱惑","岗位职责","公司信息","岗位网址"] # 先创建一个title,方便我们Excel表的查看。
6 ws.append(titlelist) # 添加titlelist到Excel表中
7 joburllist = get_joburllist() # 先调用第一步,获得所有详情页的url列表,并保存到"joburllist"中
8 for i in joburllist:
9 html = get_html(i) # 依次取出每一个详情页的url,并获取这个岗位的源码
10 jobinfolist = get_textinfo(html) # 对每个岗位扣取文字信息,并返回一个列表
11 jobinfolist.append(i) # 添加岗位网址信息
12 ws.append(jobinfolist) # 将扣取得文字信息,写入到excel的内存空间
13 wb.save("51jobplusmax.xlsx") # 保存
14
15if __name__ == "__main__": # 直接执行(F5)
16 save_info() # 执行save_info() 函数
17
18 # 这些是测试信息
19 #urllists = get_joburllist()
20 #html = get_html(urllists)
21 #get_textinfo(html)
22 #print(urllists)
23
24
在这里直接运行,我们可以爬取所有网络安全位置的信息。今天查询的时候一共1600多条,爬了1个小时(慢批)。
1.Excel结果展示
总结
这个案例,从学习新模块到实际应用,花了很长时间,找到了很多资料。我把它放在下面供大家学习和参考,希望能节省你的时间。
这是我的第一个爬虫案例分享。如果有任何错误,请纠正我。如果我能帮助你,那将是我的荣幸。
参考文章:
51job爬虫案例
硒笔记 1
硒 - 祖传爬行动物武器
selenium get_attribute 的几种用途
Selenium python中的等待方式
python中bs4.BeautifulSoup的基本用法
python脚本中selenium启动浏览器报错os.path.basename(self.path), self.start_error_message) mon.excep
openpyxl的详细使用 查看全部
excel抓取多页网页数据(文章目录3.提取信息进行excel本地保存总结(组图))
文章目录
3.提取信息并保存在本地的excel中
总结
前言
本案例是爬取51job网站的job信息。如果有任何错误,请纠正我。转载请注明出处。
本次抓取网址:点此
温馨提示:以下为本文正文内容文章,以下案例供参考
一、模块使用
1.这次一共使用了四个模块
1import openpyxl
2import bs4
3import requests as r
4from selenium import webdriver
5
6
下面会列出具体模块的详细使用,有需要的可以自行了解:
详情页URL获取模块:selenium
HTML标签处理模块:bs4.beautifulsoup
Python详解——请求模块
openpyxl处理excel表格详解
二、数据抓取及url列表建立1.获取所有网页详情页面链接
这里使用 selenium 模块是因为可以获取动态加载页面的数据,比如 js 渲染后的代码,下拉轮获取的数据,框内的一些隐藏元素等。
调用selenium模块需要下载浏览器驱动:谷歌浏览器驱动下载地址,下载解压后放到python根目录下。注意:浏览器版本必须与驱动版本一致,否则无效。
如果还有安装不了selenium模块的朋友,请看这篇文章:selenium安装
1):首先观察我们要爬取的页面,定位到页面需要爬取的位置,我们发现他的父标签是“div”和“class="j_joblist”,
而详情页的链接在父标签下的div标签下的a标签中(这里有点绕,结合图片理解)
可以看出,我们首先要定位a标签,从中提取“href”标签中的地址,并将地址放入urllists列表中。第一步完成!

代码如下(示例):
1h = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"} # 伪造浏览器信息,第二步会用到。
2def get_joburllist(): # 定义函数get_joburllist
3
4 urllists = [ ] # 一个列表变量,用于接收所有网页详情页链接
5 chrome_driver = r'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\chromedriver.exe' #chromedriver的文件位置,r代表原始路径
6 wd = webdriver.Chrome(executable_path = chrome_driver) #创建浏览器,这里用谷歌浏览器,后接驱动器地址
7 wd.implicitly_wait(2) # 智能等待一个元素被发现,或一个命令完成。如果超出了设置时间的则抛出异常。
8 #访问51job网站
9 for i in range(1,34): # 这里两个参数,(1,34),1代表当前页,34代表总页数,可自行修改
10 wd.get("https://search.51job.com/list/010000,000000,0000,00,9,99,%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8,2,i.html") # 访问链接内的地址,i为第i页
11
12 joblists = wd.find_elements_by_xpath('//div[@class="j_joblist"]/div/a') # 查找所有div下class属性为"j_joblist"的子节点为div的子节点为a的标签
13 for urllist in joblists: # 循环获取所有详情页的href链接
14 href_list = urllist.get_attribute("href") # 获取href属性的内容
15 urllists.append(href_list)
16 wd.quit() # 关闭浏览器
17 #print(urllists)
18 return urllists
19
20
21
至此,网页详情页的链接就放在了urllists列表中。我们可以继续下一步
2.获取详情页的html源码,过滤我们需要的信息
思路:由于我们在第一步中已经获取到了各个详情页的url,我们可以使用requests返回html源码,使用浏览器查看,逐个找到需要信息的标签过滤掉,最后找到我们需要的文本信息,放入列表返回。
代码如下(示例):
1f get_html(url): # 这里的url指的是第一步获取的详情页的url
2 response = r.get(url,headers = h) # 伪造请求头信息
3 response.encoding = "gbk" # 更改编码为gbk
4 return response.text # 返回html源码
5
6def get_textinfo(html): # 进行源码筛选
7 jobname = [] # 以下为定义模块信息 , 工作名称
8 jobmoney = [] # 工资
9 comname = [] # 公司名称
10 jobjy = [] # 工作经验
11 jobyh = [] # 岗位福利
12 jobneed = [] # 岗位职责
13 cominfo = [] # 公司信息
14
15 soup = bs4.BeautifulSoup(html,"html.parser") # 两个参数,第一个参数为html源码,第二个参数为解析html文件,返回结果给soup
16 # Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象
17
18# 这里要做一下说明,因为获取到的详情页中,有一部分并没有按照规定模板来进行显示,
19# 而是直接跳转到公司官网,所以进行筛选时会报错,这里用if来做一个简单判断,
20# 如果获取的html源码中并不是按照规定模板来显示的,我们将pass掉这个信息
21
22 jn = soup.find("div",class_="cn")
23 strjn = str(jn) # 将类型转换为str,方便查找
24 jnfind = strjn.find("h1") # 查找“h1”字符,并将查找结果给jhfind
25 if jnfind == -1: # 如果返回结果为 -1 代表没有h1标签 (find没有找到时会返回-1)
26 #print ("no")
27 joblist = ["查看此招聘信息请点击链接:"] # 则返回空表
28
29 else: # 否则代表该源码符合规定模板,正常进行筛选
30 #print(jn.h1.text)
31 jobname.append(jn.h1.text) # 添加h1标签文本信息
32
33 jm = soup.find("div",class_="cn")
34 jobmoney.append(jm.strong.text) # 添加strong标签文本信息
35
36 cn = soup.find("a",class_="catn")
37 comname.append(cn.text) # 添加公司名称
38
39 jj = soup.find("p",class_="msg ltype")
40 jobjy.append(jj.text.replace("\xa0\xa0|\xa0\xa0"," ")) 添加工作经验文本信息,并将\xa0替换成空字符串,方便查看
41
42 jy = soup.findAll("span",class_="sp4") # 福利信息这里有点特殊,每个福利都是独立的,我们需要将他放在一个字符串里,并添加到福利信息列表。
43 jystr = "" # 建立空字符串
44 for i in jy: # 从jy(jy代表找到的所有符合条件的标签)中逐个调用并添加到jystr中,以空格隔开。
45 jystr += i.text + " "
46 jobyh.append(jystr) # 将完成的字符串添加到列表中
47
48 jn = soup.find("div",class_="bmsg job_msg inbox")
49 jnstr = ""
50 for i in jn.findAll("p"): # 跟上一个同理,findAll所有'p'标签 并放到一个空字符串中
51 jnstr += i.text + " "
52 jobneed.append(jnstr)
53
54 ci = soup.find("div",class_="tmsg inbox")
55 cominfo.append(ci.text) # 添加公司信息
56
57 joblist = jobname + jobmoney + comname + jobjy + jobyh + jobneed + cominfo # 将独立的列表信息合并到一起,成为一个大的列表。
58 return joblist
59
60
61
3.提取信息并保存在本地的excel中
思路:终于到了最后一步,这里也是调用整个代码执行的大致步骤。可以说上面写的函数都是在这里依次调用的。这次我们主要使用openpyxl来保存和调用前面两步。功能配合,代码废话不多说。
1
2def save_info():
3 wb = openpyxl.Workbook() # 获取工作簿 就是一个excle层面的对象,在获取工作簿的同时已经创建了一个默认的工作表
4 ws = wb.active # 获取当前工作表
5 titlelist = ["岗位名称","岗位薪资","公司名称","工作经验","岗位诱惑","岗位职责","公司信息","岗位网址"] # 先创建一个title,方便我们Excel表的查看。
6 ws.append(titlelist) # 添加titlelist到Excel表中
7 joburllist = get_joburllist() # 先调用第一步,获得所有详情页的url列表,并保存到"joburllist"中
8 for i in joburllist:
9 html = get_html(i) # 依次取出每一个详情页的url,并获取这个岗位的源码
10 jobinfolist = get_textinfo(html) # 对每个岗位扣取文字信息,并返回一个列表
11 jobinfolist.append(i) # 添加岗位网址信息
12 ws.append(jobinfolist) # 将扣取得文字信息,写入到excel的内存空间
13 wb.save("51jobplusmax.xlsx") # 保存
14
15if __name__ == "__main__": # 直接执行(F5)
16 save_info() # 执行save_info() 函数
17
18 # 这些是测试信息
19 #urllists = get_joburllist()
20 #html = get_html(urllists)
21 #get_textinfo(html)
22 #print(urllists)
23
24
在这里直接运行,我们可以爬取所有网络安全位置的信息。今天查询的时候一共1600多条,爬了1个小时(慢批)。
1.Excel结果展示

总结
这个案例,从学习新模块到实际应用,花了很长时间,找到了很多资料。我把它放在下面供大家学习和参考,希望能节省你的时间。
这是我的第一个爬虫案例分享。如果有任何错误,请纠正我。如果我能帮助你,那将是我的荣幸。
参考文章:
51job爬虫案例
硒笔记 1
硒 - 祖传爬行动物武器
selenium get_attribute 的几种用途
Selenium python中的等待方式
python中bs4.BeautifulSoup的基本用法
python脚本中selenium启动浏览器报错os.path.basename(self.path), self.start_error_message) mon.excep
openpyxl的详细使用
excel抓取多页网页数据( Excel中的Powerquery可以同样操作(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-02-19 15:23
Excel中的Powerquery可以同样操作(一)(组图))
前面介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。(Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
在这里完成第一页的数据后,当你转到采集的其他页面时,数据结构将与第一页完成后的数据结构相同,采集的数据可以直接使用;没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前面输入:(p as number) as table =>
并在let to后第一行的URL中将&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
修改后,[Source]的URL变为:“;sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。输入一个数字,比如7,就会抓取到第7页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
单击“确定”开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,已经完成了100页智联招聘信息的批量抓取。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量捕获某个网站数据之前,先尝试采集一个页面,如果可以采集获取,再使用上面的步骤,如果采集不行的时候你来了,你不需要再浪费时间了。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。 查看全部
excel抓取多页网页数据(
Excel中的Powerquery可以同样操作(一)(组图))
前面介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。(Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
在这里完成第一页的数据后,当你转到采集的其他页面时,数据结构将与第一页完成后的数据结构相同,采集的数据可以直接使用;没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前面输入:(p as number) as table =>
并在let to后第一行的URL中将&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
修改后,[Source]的URL变为:“;sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。输入一个数字,比如7,就会抓取到第7页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
单击“确定”开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,已经完成了100页智联招聘信息的批量抓取。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量捕获某个网站数据之前,先尝试采集一个页面,如果可以采集获取,再使用上面的步骤,如果采集不行的时候你来了,你不需要再浪费时间了。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-19 15:19
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要获取的信息在哪里是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['内容']['结果']
# 通过分析获取到的json信息可以看出,返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个占位符列表,容量为15,构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
书=工作簿(编码='utf-8')
tmp = book.add_sheet('sheet')
次 = len(fin_result)+1
for i in range(times): # i代表行,i+1代表行头信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
网址 = r'%E5%8C%97%E4%BA%AC'
# 拉狗网的招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、工资等。
tag_name = ['公司名称', '公司简称', '职称', '学历', '薪资', '公司资质', '公司规模', '类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['content']['result'] # 通过分析获取到的json信息,我们可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] #构造一个容量为15的list占位符构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(页面)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num > 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ == '__main__':
print('************************************抓取来了******** * ************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每一页的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num(1,max_page_num):
print('********************************下载页面 %s********** * ***********************' % page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('爬取完成,保存输入文件名:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间 - 开始时间). 秒
print('总时间: %s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
本文标题:Python制作爬虫并将爬取结果保存到excel 查看全部
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。

可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。

我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。

可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要获取的信息在哪里是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['内容']['结果']
# 通过分析获取到的json信息可以看出,返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个占位符列表,容量为15,构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
书=工作簿(编码='utf-8')
tmp = book.add_sheet('sheet')
次 = len(fin_result)+1
for i in range(times): # i代表行,i+1代表行头信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:

到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
网址 = r'%E5%8C%97%E4%BA%AC'
# 拉狗网的招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、工资等。
tag_name = ['公司名称', '公司简称', '职称', '学历', '薪资', '公司资质', '公司规模', '类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['content']['result'] # 通过分析获取到的json信息,我们可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] #构造一个容量为15的list占位符构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(页面)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num > 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ == '__main__':
print('************************************抓取来了******** * ************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每一页的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num(1,max_page_num):
print('********************************下载页面 %s********** * ***********************' % page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('爬取完成,保存输入文件名:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间 - 开始时间). 秒
print('总时间: %s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
本文标题:Python制作爬虫并将爬取结果保存到excel
excel抓取多页网页数据(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-15 09:09
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,它支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
excel抓取多页网页数据(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,它支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
excel抓取多页网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-08 00:24
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天我们要做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
查看全部
excel抓取多页网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图)
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天我们要做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
excel抓取多页网页数据(excel5.0新增的concat函数是如何使用的?excel基础教程4.5课)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-07 23:02
excel抓取多页网页数据:示例1(自动读取12年的信息,没有进行加密处理,使用文本函数cnt(),可以让11年的数据被自动读取):示例2(对12年数据进行进一步的数据处理处理,读取第三年的数据):技巧使用excelsumifs函数对不重复的数据求和,实现12年的总和:技巧使用excelconcat函数,把11年的合并起来,形成12年的合并数据,这样就可以读取13年的数据了:技巧下面就让我们详细的学习一下excel5.0新增的concat函数是如何使用的!concat函数是在concatenate的基础上改进的产物,语法为concatenate(sumifs,diffdirector,optional)。
在实际使用中,将concat函数中用diffdirector来计算对应列的结果进行拼接,然后再用optional类型的demapi函数来判断是否进行合并。同时,需要注意,该函数一般应用于单元格中数值项的合并,如公式中的a2是a3的1倍,则demapi的结果就是a2,可见,要理解concat函数,需要搞清楚word中的一些公式,让excel工作起来更加高效!我将分4期为大家讲解excel5.0新增的concat函数。欢迎点击“excel基础视频教程”专栏关注我!学习更多实用excel技能!。
+1系列:excel分析——价格趋势图解、列联表合并与条件格式、图表选型4.2系列:如何用正则表达式匹配含有价格的商品?:excel基础教程4.5课excel图表选型:excel报表设计3.5节 查看全部
excel抓取多页网页数据(excel5.0新增的concat函数是如何使用的?excel基础教程4.5课)
excel抓取多页网页数据:示例1(自动读取12年的信息,没有进行加密处理,使用文本函数cnt(),可以让11年的数据被自动读取):示例2(对12年数据进行进一步的数据处理处理,读取第三年的数据):技巧使用excelsumifs函数对不重复的数据求和,实现12年的总和:技巧使用excelconcat函数,把11年的合并起来,形成12年的合并数据,这样就可以读取13年的数据了:技巧下面就让我们详细的学习一下excel5.0新增的concat函数是如何使用的!concat函数是在concatenate的基础上改进的产物,语法为concatenate(sumifs,diffdirector,optional)。
在实际使用中,将concat函数中用diffdirector来计算对应列的结果进行拼接,然后再用optional类型的demapi函数来判断是否进行合并。同时,需要注意,该函数一般应用于单元格中数值项的合并,如公式中的a2是a3的1倍,则demapi的结果就是a2,可见,要理解concat函数,需要搞清楚word中的一些公式,让excel工作起来更加高效!我将分4期为大家讲解excel5.0新增的concat函数。欢迎点击“excel基础视频教程”专栏关注我!学习更多实用excel技能!。
+1系列:excel分析——价格趋势图解、列联表合并与条件格式、图表选型4.2系列:如何用正则表达式匹配含有价格的商品?:excel基础教程4.5课excel图表选型:excel报表设计3.5节
excel抓取多页网页数据(安装excel抓取多页网页数据的方法可以参考以下步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-07 10:04
excel抓取多页网页数据的方法可以参考以下步骤:在excel中运行任意python脚本第一步:找到网站的url地址,可以在搜索引擎上搜索url地址,也可以在浏览器的地址栏搜索;第二步:用迅雷把该网页下载下来,可以先单击pdf,然后用迅雷打开;第三步:拷贝该url地址,然后一直拖动可以看到多个img链接;第四步:将其中的img链接拷贝至迅雷的主界面,直接右键点击;第五步:转换链接地址如下图所示:第六步:使用微软的ie浏览器的扩展程序把所需要的url地址转换成pdf文件;第七步:然后找到该pdf文件的路径,然后从迅雷里将其下载下来,可以直接把地址复制,也可以从迅雷里打开;第八步:直接用百度搜索excel的文件格式中已经有对应的代码,直接拷贝到代码编辑器中;第九步:双击整个下载文件第十步:这样就能把该页的所有网页图片上传到excel中,然后可以用excel打开。
对于目前国内的普通老百姓来说,微信公众号就是一种网页文章制作工具,能够像使用ppt一样输出。至于制作什么样的文章,全由自己的创意,也看个人爱好。
安装ppt.pptx
你该知道提问题不要瞎问,很多问题都不是钱能解决的。看名字就是推广网址或文章。
中文版lxml
python挺好用,网页抓取,html解析,flask框架,数据库, 查看全部
excel抓取多页网页数据(安装excel抓取多页网页数据的方法可以参考以下步骤)
excel抓取多页网页数据的方法可以参考以下步骤:在excel中运行任意python脚本第一步:找到网站的url地址,可以在搜索引擎上搜索url地址,也可以在浏览器的地址栏搜索;第二步:用迅雷把该网页下载下来,可以先单击pdf,然后用迅雷打开;第三步:拷贝该url地址,然后一直拖动可以看到多个img链接;第四步:将其中的img链接拷贝至迅雷的主界面,直接右键点击;第五步:转换链接地址如下图所示:第六步:使用微软的ie浏览器的扩展程序把所需要的url地址转换成pdf文件;第七步:然后找到该pdf文件的路径,然后从迅雷里将其下载下来,可以直接把地址复制,也可以从迅雷里打开;第八步:直接用百度搜索excel的文件格式中已经有对应的代码,直接拷贝到代码编辑器中;第九步:双击整个下载文件第十步:这样就能把该页的所有网页图片上传到excel中,然后可以用excel打开。
对于目前国内的普通老百姓来说,微信公众号就是一种网页文章制作工具,能够像使用ppt一样输出。至于制作什么样的文章,全由自己的创意,也看个人爱好。
安装ppt.pptx
你该知道提问题不要瞎问,很多问题都不是钱能解决的。看名字就是推广网址或文章。
中文版lxml
python挺好用,网页抓取,html解析,flask框架,数据库,
excel抓取多页网页数据(用Excel进行数据汇总,再平常不过的需求单表汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2022-02-06 02:12
使用Excel进行数据汇总,最常见的需求
单表汇总:最常用的操作应该是小计、数据透视表等。这是最理想的方式,所有数据都在一个工作表中,便于汇总。但理想很丰富,现实却很骨感。这种方法在工作中很少见,多表汇总是我们不得不面对的需要。
多表汇总:无论是在本工作簿内还是跨工作簿,也可以解决多个合并计算数据区。以这种方式创建的数据透视表的一个明显缺点是只有一个行字段,并且只能是数据源左侧的第一列。如果仅针对一个角度进行聚合,这也是一种解决方案。不过N张工作表的数据全部整合为一张,只能统计一个视角,有些遗憾。
当然可以在数据源中设置一个辅助列,将一个单元格中的多列信息连接起来作为一个行字段,但归根结底只有一个行字段,起不到改变行字段的作用统计的角度,能治标不治本。
图:没有多少信息只是一个行字段
SQL join 语句:这当然是多表汇总的杀手锏。无论工作表是否跨工作簿,以这种方式创建的数据透视表都与单表数据透视一样简单。随意切换统计视角并生成各种报告似乎很完美。
让我们举个例子。五个销售部门分为五个工作簿,每个工作簿按月填写销售明细,需要多角度汇总。这个要求不应过分。无论是OLEDB还是Microsoft Query,写一条SQL连接语句都能完美解决。
不过写了这么多句子↓
图:SQL连接语句
已经可以看到 5 个工作簿中只有 15 个工作表,如果是一年的数据呢?也就是60个工作表,也就是说有60条SQL连接语句。
如果用电量查询来完成呢?一个公式就够了
事实上,power query 是一个数据采集工具,微软已经有一两年没有将它内置到 Excel 中了。在刚才的例子中,别说5个工作簿和15个工作表,十倍的数据相加就是一个公式。将强大的查询称为 SQL 连接语句的终结者并不为过。
我用的版本是office365订阅版,Excel内置电源查询,名字有点长,姑且称之为PQ。如果你的 Excel 没有 PQ 怎么办?
我们先来体会一下PQ的威力。文章 最后附上PQ的安装方法。当然,要不要安装PQ,你说了算。
文末有本章演示数据和结果获取方法
免责声明:本章提供的数据为虚构数据,并非真实数据
图:5个工作簿20个子表汇总
首先介绍一下要聚合的数据
这是5个销售部门的销售数据,位于5个工作簿中,每个工作簿的工作表按月记录。销售部成立时间不同,有的记录是3个月,有的记录是4个月,有的记录是6个月。现在需要从月份、各销售部门、销售区域、产品名称等不同角度对5个销售部门进行汇总。
图:演示数据
面对这样的数据和这样的要求,你怎么看?是的,数据透视表,它不是快速转换统计观点的强项吗!
快速将所有子表整合到一张工作表中,并与数据同步更新子表。我们已经到了这一点。是否使用小计或数据透视表取决于您?
想想就兴奋!
让我们开始吧!
创建摘要工作簿
创建一个新的 Excel 文档并将其命名为“摘要”。
图:新建 Excel 文档
打开“摘要”工作簿并添加一个文件夹。
操作路径:数据→获取数据→从文件→从文件夹→浏览到“E:\销售数据记录”→确定。
图:添加文件夹
在弹出的对话框中确认文件夹中的所有工作簿都已加载完毕后,点击“转换数据”。
图:加载的工作簿
这是自动打开的电源查询编辑器,并在“名称”列中进行过滤,只勾选少数销售部门。
图:取消勾选不需要汇总的工作簿
可以看到数据有 N 列。事实上,我们真正需要的只是前两列。其他列显示文件创建时间、加载时间和后缀名等信息,删除它们。
操作路径:Ctrl键选中前两列→删除列→删除其他列。
图:删除不需要的列
添加自定义列,输入公式,整个操作只需要输入这个公式。
操作路径:添加列→自定义列→输入公式:=Excel.Workbook([Content])→确定
图:添加自定义列
展开“数据”,因为段名称自动显示为“Custom.Data”。
操作路径:点击自定义旁边的按钮→只选择数据→确保单选为“展开”→确定
图:展开Data后,字段名称为“Custom.Data”
展开 Custom.Data
操作路径:点击自定义.Data旁边的按钮展开→单选展开→全选列→确定
图:展开 Custom.Data
数据合并成功,但是中间一行有N个子表字段。这些无用的行会影响我们的摘要。有多少子表就有多少无用的行。下一步就是解决这个问题。
图:中间一行有多余的字段
隐藏多余的行
操作路径:修改自定义列的字段名→过滤任意列→取消勾选不需要的内容
图:隐藏多余的行
好的,数据干净了,上传到Excel。
操作路径:首页→关闭上传
图:关闭并上传
我们来看看Excel中的情况。5个销售部门的数据全部整合,日期截止到6月份。估计这张表叫“总表”。
图:所有数据整合
刚才说了,分表的更新是同步到总表的,我们试试加个工作表吧。刚才最大的一个月是六月。通过筛选,我们发现这个数据属于第二销售部。现在,例如,第二销售部门添加了 7 月份的数据。
图:销售部2新增工作表
关闭销售的第二个工作簿,然后到总表刷新。通过过滤,7月份的数据已经同步到汇总表中。如果你使用 SQL 连接,你必须添加另一行语句来更新,但现在,我们要做的就是刷新它。
图:刷新后同步到主表
如果你使用这个整合的数据制作多个透视图,并在子表更新的时候全部刷新,所有的图表都会显示最新的结果。
图:刷新所有数据
好吧,我刚才说了,我们已经到了这个阶段,怎么操作就看我们的心情了,我就用数据透视表。整个过程只写了一个公式,你说PQ要上天了。
图:摘要演示
如何安装 PQ
好的,你决定安装 PQ 了吗?如下图,在今日头条搜索“powerquery安装”。
安装过程不用多说,在互联网时代,一切都是那么简单。
图:今日头条搜索安装方法
如果您对数据透视图感兴趣,请不要害怕查看我的专栏,它只讨论数据透视图。
与列一样,必须为每个实例提供演示数据。私信“jbt3”获取本章demo数据及成果。 查看全部
excel抓取多页网页数据(用Excel进行数据汇总,再平常不过的需求单表汇总)
使用Excel进行数据汇总,最常见的需求
单表汇总:最常用的操作应该是小计、数据透视表等。这是最理想的方式,所有数据都在一个工作表中,便于汇总。但理想很丰富,现实却很骨感。这种方法在工作中很少见,多表汇总是我们不得不面对的需要。
多表汇总:无论是在本工作簿内还是跨工作簿,也可以解决多个合并计算数据区。以这种方式创建的数据透视表的一个明显缺点是只有一个行字段,并且只能是数据源左侧的第一列。如果仅针对一个角度进行聚合,这也是一种解决方案。不过N张工作表的数据全部整合为一张,只能统计一个视角,有些遗憾。
当然可以在数据源中设置一个辅助列,将一个单元格中的多列信息连接起来作为一个行字段,但归根结底只有一个行字段,起不到改变行字段的作用统计的角度,能治标不治本。
图:没有多少信息只是一个行字段
SQL join 语句:这当然是多表汇总的杀手锏。无论工作表是否跨工作簿,以这种方式创建的数据透视表都与单表数据透视一样简单。随意切换统计视角并生成各种报告似乎很完美。
让我们举个例子。五个销售部门分为五个工作簿,每个工作簿按月填写销售明细,需要多角度汇总。这个要求不应过分。无论是OLEDB还是Microsoft Query,写一条SQL连接语句都能完美解决。
不过写了这么多句子↓
图:SQL连接语句
已经可以看到 5 个工作簿中只有 15 个工作表,如果是一年的数据呢?也就是60个工作表,也就是说有60条SQL连接语句。
如果用电量查询来完成呢?一个公式就够了
事实上,power query 是一个数据采集工具,微软已经有一两年没有将它内置到 Excel 中了。在刚才的例子中,别说5个工作簿和15个工作表,十倍的数据相加就是一个公式。将强大的查询称为 SQL 连接语句的终结者并不为过。
我用的版本是office365订阅版,Excel内置电源查询,名字有点长,姑且称之为PQ。如果你的 Excel 没有 PQ 怎么办?
我们先来体会一下PQ的威力。文章 最后附上PQ的安装方法。当然,要不要安装PQ,你说了算。
文末有本章演示数据和结果获取方法
免责声明:本章提供的数据为虚构数据,并非真实数据
图:5个工作簿20个子表汇总
首先介绍一下要聚合的数据
这是5个销售部门的销售数据,位于5个工作簿中,每个工作簿的工作表按月记录。销售部成立时间不同,有的记录是3个月,有的记录是4个月,有的记录是6个月。现在需要从月份、各销售部门、销售区域、产品名称等不同角度对5个销售部门进行汇总。
图:演示数据
面对这样的数据和这样的要求,你怎么看?是的,数据透视表,它不是快速转换统计观点的强项吗!
快速将所有子表整合到一张工作表中,并与数据同步更新子表。我们已经到了这一点。是否使用小计或数据透视表取决于您?
想想就兴奋!
让我们开始吧!
创建摘要工作簿
创建一个新的 Excel 文档并将其命名为“摘要”。
图:新建 Excel 文档
打开“摘要”工作簿并添加一个文件夹。
操作路径:数据→获取数据→从文件→从文件夹→浏览到“E:\销售数据记录”→确定。
图:添加文件夹
在弹出的对话框中确认文件夹中的所有工作簿都已加载完毕后,点击“转换数据”。
图:加载的工作簿
这是自动打开的电源查询编辑器,并在“名称”列中进行过滤,只勾选少数销售部门。
图:取消勾选不需要汇总的工作簿
可以看到数据有 N 列。事实上,我们真正需要的只是前两列。其他列显示文件创建时间、加载时间和后缀名等信息,删除它们。
操作路径:Ctrl键选中前两列→删除列→删除其他列。
图:删除不需要的列
添加自定义列,输入公式,整个操作只需要输入这个公式。
操作路径:添加列→自定义列→输入公式:=Excel.Workbook([Content])→确定
图:添加自定义列
展开“数据”,因为段名称自动显示为“Custom.Data”。
操作路径:点击自定义旁边的按钮→只选择数据→确保单选为“展开”→确定
图:展开Data后,字段名称为“Custom.Data”
展开 Custom.Data
操作路径:点击自定义.Data旁边的按钮展开→单选展开→全选列→确定
图:展开 Custom.Data
数据合并成功,但是中间一行有N个子表字段。这些无用的行会影响我们的摘要。有多少子表就有多少无用的行。下一步就是解决这个问题。
图:中间一行有多余的字段
隐藏多余的行
操作路径:修改自定义列的字段名→过滤任意列→取消勾选不需要的内容
图:隐藏多余的行
好的,数据干净了,上传到Excel。
操作路径:首页→关闭上传
图:关闭并上传
我们来看看Excel中的情况。5个销售部门的数据全部整合,日期截止到6月份。估计这张表叫“总表”。
图:所有数据整合
刚才说了,分表的更新是同步到总表的,我们试试加个工作表吧。刚才最大的一个月是六月。通过筛选,我们发现这个数据属于第二销售部。现在,例如,第二销售部门添加了 7 月份的数据。
图:销售部2新增工作表
关闭销售的第二个工作簿,然后到总表刷新。通过过滤,7月份的数据已经同步到汇总表中。如果你使用 SQL 连接,你必须添加另一行语句来更新,但现在,我们要做的就是刷新它。
图:刷新后同步到主表
如果你使用这个整合的数据制作多个透视图,并在子表更新的时候全部刷新,所有的图表都会显示最新的结果。
图:刷新所有数据
好吧,我刚才说了,我们已经到了这个阶段,怎么操作就看我们的心情了,我就用数据透视表。整个过程只写了一个公式,你说PQ要上天了。
图:摘要演示
如何安装 PQ
好的,你决定安装 PQ 了吗?如下图,在今日头条搜索“powerquery安装”。
安装过程不用多说,在互联网时代,一切都是那么简单。
图:今日头条搜索安装方法
如果您对数据透视图感兴趣,请不要害怕查看我的专栏,它只讨论数据透视图。
与列一样,必须为每个实例提供演示数据。私信“jbt3”获取本章demo数据及成果。
excel抓取多页网页数据(为什么说Excel就好比老人机呢?(附数据透视分析工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-05 10:00
在大数据分析时代,涌现了大量的大数据分析软件。即便如此,如果有人问今天最常用的数据透视分析工具是什么,我想 Excel 应该是每个人的最佳选择。
但其实我想说的是,用现在的手机做个比喻,Excel就像一台老式电脑。当大家都在使用新一代的“智能手机”——Smartbi 的时候,你还在用老式的电脑,所以相比之下,就像被吊死在街上一样。
为什么说 Excel 就像一台旧电脑?
1、Excel数据分析处理能力低,几十万条数据半天转不了。
2、Excel 上手容易,精通难。一旦你想做更深入的操作,你会发现操作非常复杂和繁琐。
3、Excel美化图表比较难,即使可以美化,生成的图表也不够漂亮。
那为什么说Smartbi是新一代的“智能手机”呢?
Smartbi是一款面向Excel用户的自助数据分析工具,将Excel和BI有机结合,让业务人员轻松掌握。目前是国内知名的BI产品。用它来做数据透视分析可以带来很大的效率提升,因为和Tableau等国外BI工具相比,国产Smartbi非常符合中国的数据分析思维。
易学易用:无需学习新的BI产品,用Excel即可完成BI分析,学习成本极低。
功能强大:充分保留Excel数据处理和数据分析能力,结合自助BI丰富的数据准备、数据共享、企业级安全管控。
资源复用:大量Excel模板可复用,企业资源得到充分利用。
效率提升:前线作战单位可随时获取Excel最新数据分析,告别重复衍生。
这种自助式BI经常被用作大数据前端展示和大数据分析案例报告制作的工具,甚至作为数据透视分析工具有点矫枉过正。Smartbi可以打通各种数据源,其丰富的数据连接能力可以抓取各种数据源的数据进行分析。除了支持oracle、sqlserver、mysql等常用的关系型数据库,各种主流大型数据库、非关系型数据库、多维数据库、本地文件如:excel、txt、csv。此外,它还支持带有自定义编写接口的java数据源。从数据连接能力来看,smartbi与企业数据平台的连接能力更强,并且还在各个版本的发布中不断更新。
Smartbi 透视分析功能和亮点
通过 Smartbi,这些任务得到了极大的简化。借助“类Excel数据透视表”设计,多维分析不再需要建立模型,可以结合维度、汇总计算、切片、钻取、洞察数据。不仅如此,任何字段都可以直接作为输出字段或过滤条件,方便查询和探索数据。
广告FRM认证相当于硕士学位,是金融风险管理的全球标准。^^ 立即接受挑战并报名参加 2022 年 5 月的 FRM 考试。
大数据量处理,解决用户excel分析和操作痛点:
数据量过大:底层宽表超过1亿,无法加载到Excel中分析;
PC端计算慢:Excel文件计算公式复杂,打开前端Excel需要20分钟;
Smartbi大数据分析解决方案
数据准备:通过透视分析+SmartbiMPP初步汇总数据,1亿行à30万行;
报表计算:支持个人Excel端计算,也支持服务器(集群)计算;
定时报表:后台自动统计报表,导出为Excel文件,无需公式;
广告数据中台——集数据采集、分析、开发于一体,以快速响应和“数据中台”的方法和技术,为用户提供更加灵活、高效、低成本的数据处理^^
复用模板分析,解决用户excel分析操作痛点:
商务人士手上有大量基于 Excel 的分析模板,想重复使用
计算处理逻辑复杂,其他分析工具根本做不到
Smartbi大数据分析解决方案
模板和数据分离;
复用模板,动态更新数据;
通过网络链接安全共享
广告积累了12年的市场调研经验/技术/数据,根据企业需求提供专业高效的线上线下调研解决方案。^^800万+自有样本数据库,100多个网络联盟...
分析结果,一链发布,解决用户excel分析和操作痛点:
报表存在于Excel文件中,大部分用户通过电子邮件或即时通讯软件共享Excel文件,文件满天飞,难以管理;
对于权限系统的管控来说,分发的便利性还不够好。
Smartbi大数据分析解决方案
将编制好的报表发布到服务器进行浏览和管理,或者通过Web链接分享发布的报表,实现数据的实时更新;
您可以在分享前在报表中设置资源权限、数据权限、权限,让不同的用户看到不同的资源。
广告数据图表制作 Top,零编码,网页数据图表制作拖放式设计,5分钟报表制作,一站式数据分析。^^ 数据图制作效果,让老大站起来……
显然,在当前的信息时代,借助Smartbi这些大数据分析工具,企业可以加速整合企业数据分析的趋势。市场认可的软件其实有很多,选择要根据实际情况。一般情况下,建议选择市面上比较主流的产品,比较容易取得好的效果。目前,Smartbi在口碑上是领先的企业数据分析BI软件市场。 查看全部
excel抓取多页网页数据(为什么说Excel就好比老人机呢?(附数据透视分析工具))
在大数据分析时代,涌现了大量的大数据分析软件。即便如此,如果有人问今天最常用的数据透视分析工具是什么,我想 Excel 应该是每个人的最佳选择。
但其实我想说的是,用现在的手机做个比喻,Excel就像一台老式电脑。当大家都在使用新一代的“智能手机”——Smartbi 的时候,你还在用老式的电脑,所以相比之下,就像被吊死在街上一样。
为什么说 Excel 就像一台旧电脑?
1、Excel数据分析处理能力低,几十万条数据半天转不了。
2、Excel 上手容易,精通难。一旦你想做更深入的操作,你会发现操作非常复杂和繁琐。
3、Excel美化图表比较难,即使可以美化,生成的图表也不够漂亮。
那为什么说Smartbi是新一代的“智能手机”呢?
Smartbi是一款面向Excel用户的自助数据分析工具,将Excel和BI有机结合,让业务人员轻松掌握。目前是国内知名的BI产品。用它来做数据透视分析可以带来很大的效率提升,因为和Tableau等国外BI工具相比,国产Smartbi非常符合中国的数据分析思维。
易学易用:无需学习新的BI产品,用Excel即可完成BI分析,学习成本极低。
功能强大:充分保留Excel数据处理和数据分析能力,结合自助BI丰富的数据准备、数据共享、企业级安全管控。
资源复用:大量Excel模板可复用,企业资源得到充分利用。
效率提升:前线作战单位可随时获取Excel最新数据分析,告别重复衍生。
这种自助式BI经常被用作大数据前端展示和大数据分析案例报告制作的工具,甚至作为数据透视分析工具有点矫枉过正。Smartbi可以打通各种数据源,其丰富的数据连接能力可以抓取各种数据源的数据进行分析。除了支持oracle、sqlserver、mysql等常用的关系型数据库,各种主流大型数据库、非关系型数据库、多维数据库、本地文件如:excel、txt、csv。此外,它还支持带有自定义编写接口的java数据源。从数据连接能力来看,smartbi与企业数据平台的连接能力更强,并且还在各个版本的发布中不断更新。
Smartbi 透视分析功能和亮点
通过 Smartbi,这些任务得到了极大的简化。借助“类Excel数据透视表”设计,多维分析不再需要建立模型,可以结合维度、汇总计算、切片、钻取、洞察数据。不仅如此,任何字段都可以直接作为输出字段或过滤条件,方便查询和探索数据。
广告FRM认证相当于硕士学位,是金融风险管理的全球标准。^^ 立即接受挑战并报名参加 2022 年 5 月的 FRM 考试。
大数据量处理,解决用户excel分析和操作痛点:
数据量过大:底层宽表超过1亿,无法加载到Excel中分析;
PC端计算慢:Excel文件计算公式复杂,打开前端Excel需要20分钟;
Smartbi大数据分析解决方案
数据准备:通过透视分析+SmartbiMPP初步汇总数据,1亿行à30万行;
报表计算:支持个人Excel端计算,也支持服务器(集群)计算;
定时报表:后台自动统计报表,导出为Excel文件,无需公式;
广告数据中台——集数据采集、分析、开发于一体,以快速响应和“数据中台”的方法和技术,为用户提供更加灵活、高效、低成本的数据处理^^
复用模板分析,解决用户excel分析操作痛点:
商务人士手上有大量基于 Excel 的分析模板,想重复使用
计算处理逻辑复杂,其他分析工具根本做不到
Smartbi大数据分析解决方案
模板和数据分离;
复用模板,动态更新数据;
通过网络链接安全共享
广告积累了12年的市场调研经验/技术/数据,根据企业需求提供专业高效的线上线下调研解决方案。^^800万+自有样本数据库,100多个网络联盟...
分析结果,一链发布,解决用户excel分析和操作痛点:
报表存在于Excel文件中,大部分用户通过电子邮件或即时通讯软件共享Excel文件,文件满天飞,难以管理;
对于权限系统的管控来说,分发的便利性还不够好。
Smartbi大数据分析解决方案
将编制好的报表发布到服务器进行浏览和管理,或者通过Web链接分享发布的报表,实现数据的实时更新;
您可以在分享前在报表中设置资源权限、数据权限、权限,让不同的用户看到不同的资源。
广告数据图表制作 Top,零编码,网页数据图表制作拖放式设计,5分钟报表制作,一站式数据分析。^^ 数据图制作效果,让老大站起来……
显然,在当前的信息时代,借助Smartbi这些大数据分析工具,企业可以加速整合企业数据分析的趋势。市场认可的软件其实有很多,选择要根据实际情况。一般情况下,建议选择市面上比较主流的产品,比较容易取得好的效果。目前,Smartbi在口碑上是领先的企业数据分析BI软件市场。
excel抓取多页网页数据(excel抓取多页网页数据,再分表操作的办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-05 01:02
excel抓取多页网页数据,可以使用excel批量导入格式,生成数据表,再分表操作的办法。
1)修改excel数据表的名称。选中excel工作簿名称,按快捷键f5打开资源管理器,然后单击excel文件夹下的access文件夹,会看到excel工作簿,单击即可。单击第一个工作表,选择数据透视表,根据需要点击添加表。
2)新建透视表的标题格式随便选一个。新建透视表后,按下组合键ctrl+鼠标滚轮,透视表层次显示,这是左右两个窗口显示,中间的透视表是空的。之后点击组合键ctrl+e,制定连接属性,即可显示透视表中的表格。
3)写在第二行。点击下表中的第二行,ctrl+鼠标滚轮调整,直到看到下图所示单元格格式数据,即可。也可以设置单元格格式字体颜色,例如将数字字体设置为黄色,这样就更有动感。
4)设置截止时间,单击确定即可。
5)选中透视表中的所有工作表。右键单击选择编辑数据源。将数据源中的每一列数据拖到行字段,并指定所选数据的自定义格式(默认情况下是居中对齐),便可完成。
6)设置数据的升序和降序,如果需要重复采用多个列,只需要设置几个就可以了。操作步骤同第3步。保存数据透视表至文件夹,即可根据需要下载excel文件。希望我的教程能够帮助到您,如果有什么问题可以留言。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据,再分表操作的办法)
excel抓取多页网页数据,可以使用excel批量导入格式,生成数据表,再分表操作的办法。
1)修改excel数据表的名称。选中excel工作簿名称,按快捷键f5打开资源管理器,然后单击excel文件夹下的access文件夹,会看到excel工作簿,单击即可。单击第一个工作表,选择数据透视表,根据需要点击添加表。
2)新建透视表的标题格式随便选一个。新建透视表后,按下组合键ctrl+鼠标滚轮,透视表层次显示,这是左右两个窗口显示,中间的透视表是空的。之后点击组合键ctrl+e,制定连接属性,即可显示透视表中的表格。
3)写在第二行。点击下表中的第二行,ctrl+鼠标滚轮调整,直到看到下图所示单元格格式数据,即可。也可以设置单元格格式字体颜色,例如将数字字体设置为黄色,这样就更有动感。
4)设置截止时间,单击确定即可。
5)选中透视表中的所有工作表。右键单击选择编辑数据源。将数据源中的每一列数据拖到行字段,并指定所选数据的自定义格式(默认情况下是居中对齐),便可完成。
6)设置数据的升序和降序,如果需要重复采用多个列,只需要设置几个就可以了。操作步骤同第3步。保存数据透视表至文件夹,即可根据需要下载excel文件。希望我的教程能够帮助到您,如果有什么问题可以留言。
excel抓取多页网页数据(excel抓取多页网页数据,excel在文本数据之间进行数据关联)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-04 15:04
excel抓取多页网页数据,excel在文本数据之间进行数据关联(文本转化为数字形式)vlookup函数根据关联对象获取指定行/列的值lookup函数根据选定值到指定值的一系列值lookup函数既可以和excellookup函数一起使用也可以单独使用,可以查询多个信息,返回多个值。当excel的字符串没有包含文本字符的时候,excel将全部返回,字符串不包含文本字符的时候,返回所有文本字符。
动图演示示例1:选择某段数据---使用excel函数公式解析:选择某段数据并返回指定字符串或者文本的数据,字符串必须是文本,字符串不可以是数字。选择两列数据,此时如果字符串是不可见字符,将全部返回。示例2:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。
示例3:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。excel2016表格操作技巧来源:excel精英培训附:16g资料包,初级会计、cpa、会计做账、excel技巧应有尽有,传送门放在评论里。
刚好最近工作中遇到了这个需求,把我觉得最常用的一些网站列举一下。
一、站酷站酷在网上做一次搜索、在线查看前几名大师作品都可以直接获得作品列表地址。
1、站酷首页-站酷(zcool)
2、站酷(zcool)
3、站酷cc-站酷旗下品牌专业人士交流平台-站酷(zcool)
二、youdie闲鱼直接注册账号、参与他人闲置以赚取闲置佣金即可得到作品列表地址,最多可添加二十条。
1、闲鱼-个人卖家发布闲置物品
2、闲鱼-个人卖家发布闲置物品
3、闲鱼大讲堂-个人卖家发布闲置
4、闲鱼大讲堂
4、闲鱼x其他闲鱼大讲堂、闲鱼大讲堂上面几个站酷、闲鱼上经常有大佬发一些自己搞定制,原创等教程,你多翻翻绝对可以得到答案;有些教程列表里有附上原始报价,你可以看看有没有自己的接受范围,直接下单买就可以了。
动手查看教程地址:《youdie智能手绘班》-时间就是金钱《youdie智能手绘班》
三、联盟联盟是阿里巴巴旗下的b2c转卖平台,每年发布的链接加起来超过3000亿次,你可以选择优质商品直接在联盟上卖出,有利于拉动店铺流量。
四、返利疯狂买东西后,平台会将你的中转链接发给推广者(网个人用户),推广者会将佣金自动分给中转链接收集者(返利平台),你可以将你的中转链接直接分享给你的朋友以及你的同事同学,你们便可以共同分享利益。动手查看教程地址::、微信返利网微信返利网目前有免费测试版, 查看全部
excel抓取多页网页数据(excel抓取多页网页数据,excel在文本数据之间进行数据关联)
excel抓取多页网页数据,excel在文本数据之间进行数据关联(文本转化为数字形式)vlookup函数根据关联对象获取指定行/列的值lookup函数根据选定值到指定值的一系列值lookup函数既可以和excellookup函数一起使用也可以单独使用,可以查询多个信息,返回多个值。当excel的字符串没有包含文本字符的时候,excel将全部返回,字符串不包含文本字符的时候,返回所有文本字符。
动图演示示例1:选择某段数据---使用excel函数公式解析:选择某段数据并返回指定字符串或者文本的数据,字符串必须是文本,字符串不可以是数字。选择两列数据,此时如果字符串是不可见字符,将全部返回。示例2:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。
示例3:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。excel2016表格操作技巧来源:excel精英培训附:16g资料包,初级会计、cpa、会计做账、excel技巧应有尽有,传送门放在评论里。
刚好最近工作中遇到了这个需求,把我觉得最常用的一些网站列举一下。
一、站酷站酷在网上做一次搜索、在线查看前几名大师作品都可以直接获得作品列表地址。
1、站酷首页-站酷(zcool)
2、站酷(zcool)
3、站酷cc-站酷旗下品牌专业人士交流平台-站酷(zcool)
二、youdie闲鱼直接注册账号、参与他人闲置以赚取闲置佣金即可得到作品列表地址,最多可添加二十条。
1、闲鱼-个人卖家发布闲置物品
2、闲鱼-个人卖家发布闲置物品
3、闲鱼大讲堂-个人卖家发布闲置
4、闲鱼大讲堂
4、闲鱼x其他闲鱼大讲堂、闲鱼大讲堂上面几个站酷、闲鱼上经常有大佬发一些自己搞定制,原创等教程,你多翻翻绝对可以得到答案;有些教程列表里有附上原始报价,你可以看看有没有自己的接受范围,直接下单买就可以了。
动手查看教程地址:《youdie智能手绘班》-时间就是金钱《youdie智能手绘班》
三、联盟联盟是阿里巴巴旗下的b2c转卖平台,每年发布的链接加起来超过3000亿次,你可以选择优质商品直接在联盟上卖出,有利于拉动店铺流量。
四、返利疯狂买东西后,平台会将你的中转链接发给推广者(网个人用户),推广者会将佣金自动分给中转链接收集者(返利平台),你可以将你的中转链接直接分享给你的朋友以及你的同事同学,你们便可以共同分享利益。动手查看教程地址::、微信返利网微信返利网目前有免费测试版,
excel抓取多页网页数据( 用Excel中的数据导入方法,快速将网页数据到Excel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2022-03-15 07:05
用Excel中的数据导入方法,快速将网页数据到Excel)
最近朋友LJ在研究P2P公司,看到网贷之家的网贷指标数据,想复制到Excel中方便整理分析。
打开网址后发现只能显示20行数据:
点击登录查看完整评分,出现注册登录页面:
直接复制粘贴,只能复制20行数据,不方便整理。截屏?图片中的数据无法保存到单元格中。
无奈之下,一个朋友找到了我,问有没有简单的方法。今天教大家如何使用Excel中的数据导入方法,快速将网页数据抓取到Excel中,并自动更新数据。
我相信你已经等不及了。我们以这个页面为例,看看下面的详细步骤。
你会学到
1 如何使用 Excel 抓取网页数据
2 如何让数据自动更新
01.
抓取数据
1、新建一个Excel工作表,点击【数据】选项卡,在【获取外部数据】中选择【来自网站】;
2、会出现【新建网页查询】对话框:
3、将复制的网贷页面网址粘贴到【地址】栏,点击【导入】;
4、在出现的【导入数据】对话框中,选择数据放置位置,这里我们先将单元格A1,OK;
5、现在我们可以看到导出的结果了。可以看出,在爬表的同时,也爬取了一些不相关的内容。
6、删除不相关的内容,最终得到我们想要的表格数据。
02.
更新数据
为了让数据在以后更新数据时自动更新,我们还可以进行如下设置。
1、点击【数据】选项卡下的【全部刷新】,选择【连接属性】;
2、在弹出的对话框中勾选【刷新频率】,例如设置为60分钟,即每1小时刷新一次。
这样,以后只要更新网站数据,我们的表也可以自动更新~ 查看全部
excel抓取多页网页数据(
用Excel中的数据导入方法,快速将网页数据到Excel)
最近朋友LJ在研究P2P公司,看到网贷之家的网贷指标数据,想复制到Excel中方便整理分析。
打开网址后发现只能显示20行数据:
点击登录查看完整评分,出现注册登录页面:
直接复制粘贴,只能复制20行数据,不方便整理。截屏?图片中的数据无法保存到单元格中。
无奈之下,一个朋友找到了我,问有没有简单的方法。今天教大家如何使用Excel中的数据导入方法,快速将网页数据抓取到Excel中,并自动更新数据。
我相信你已经等不及了。我们以这个页面为例,看看下面的详细步骤。
你会学到
1 如何使用 Excel 抓取网页数据
2 如何让数据自动更新
01.
抓取数据
1、新建一个Excel工作表,点击【数据】选项卡,在【获取外部数据】中选择【来自网站】;
2、会出现【新建网页查询】对话框:
3、将复制的网贷页面网址粘贴到【地址】栏,点击【导入】;
4、在出现的【导入数据】对话框中,选择数据放置位置,这里我们先将单元格A1,OK;
5、现在我们可以看到导出的结果了。可以看出,在爬表的同时,也爬取了一些不相关的内容。
6、删除不相关的内容,最终得到我们想要的表格数据。
02.
更新数据
为了让数据在以后更新数据时自动更新,我们还可以进行如下设置。
1、点击【数据】选项卡下的【全部刷新】,选择【连接属性】;
2、在弹出的对话框中勾选【刷新频率】,例如设置为60分钟,即每1小时刷新一次。
这样,以后只要更新网站数据,我们的表也可以自动更新~
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-05 06:21
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息 page_headers = { 'Host': '', 'User-Agent': 'Mozilla/5. 0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454. 85 Safari/537.36 115Browser/6.0.3', '连接': 'keep-alive'} ifpage_num == 1: boo = 'true'否则: boo = ' false'page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录以下参数('first', boo), ('pn', page_num), ('kd', keyword ) ] ) req = request.Request(url, headers=page_headers) page = request.urlopen(req,data=page_data.encode('utf-8')).read() page = page.decode('utf-8') returnpage
比较关键的步骤之一是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看出返回结果中收录招聘信息, 其中收录很多其他参数 page_result = [num fornum inrange(15)] # 构造一个容量为15的占位符列表构造下一个二维数组 fori inrange(15): page_result[ i ] = [] # 构造一个二维数组 forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ' ,'.join(page_result[i][8]) returnpage_result # 返回当前页面的job信息
第 4 步:将捕获的信息存储在 Excel 中
获取到原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1fori inrange(times): # i 代表 Line , i+1 代表行头信息 ifi == 0: fortag_name_i intag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: fortag_list inrange(len(tag_name)): tmp.write(i , tag_list , str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后会不完整,excel文件也会出现“部分内容有问题需要修复”我查了很多遍,一开始以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面tmp = book.add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1 被表头占用 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-coding:utf-8-*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime. 约会时间。现在() url = r'。拉古。com/jobs/positionAjax。json?city=%E5%8C%97%E4%BA%AC'#钩网招聘信息是动态获取的,需要通过post方式提交json信息。默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] #这是标签信息需要抓取的,包括公司名称、学历要求、薪资等。 tag_name = ['公司名称', '公司简称', '职位', '
拉古。com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive'} ifpage_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ #通过页面分析,发现浏览器提交的FormData收录以下内容参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data. encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.
load(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看到返回结果中收录招聘信息,其中还收录很多其他参数 page_result = [num fornum inrange (15)] # 构造一个容量为15的list占位符构造下一个二维数组 fori inrange(15): page_result[i] = [] #构造一个二维数组forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ','.join(page_result[i][ 8] ) returnpage_result # 返回当前页面的招聘信息 def read_max_page(page): # 获取当前招聘的最大页数 关键词,大于30的会被覆盖,所以最多只能获取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] ifmax_page_num > 30: max_page_num = 30returnmax_page_num def save_excel (fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.
Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面 tmp = book. add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp. write_row(tag_pos, tag_name) else: con_pos = 'A%s'% i content = fin_result[i-1] # -1是因为tmp被表头占用了。write_row(con_pos, content) 书。close() if__name__ == '__main__': print('********************************** 即将被抓到 Take ************************************') keyword = input('请输入语言type :') fin_result = [] # 将每一页的招聘信息聚合成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) forpage_num inrange(1, max_page_num): print('
extend(page_result) file_name = input('捕获完成,保存输入文件名:') save_excel(fin_result, tag_name, file_name) endtime = datetime. 约会时间。现在()时间=(结束时间 - 开始时间)。seconds print('总时间: %s s'% time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~ 查看全部
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息 page_headers = { 'Host': '', 'User-Agent': 'Mozilla/5. 0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454. 85 Safari/537.36 115Browser/6.0.3', '连接': 'keep-alive'} ifpage_num == 1: boo = 'true'否则: boo = ' false'page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录以下参数('first', boo), ('pn', page_num), ('kd', keyword ) ] ) req = request.Request(url, headers=page_headers) page = request.urlopen(req,data=page_data.encode('utf-8')).read() page = page.decode('utf-8') returnpage
比较关键的步骤之一是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看出返回结果中收录招聘信息, 其中收录很多其他参数 page_result = [num fornum inrange(15)] # 构造一个容量为15的占位符列表构造下一个二维数组 fori inrange(15): page_result[ i ] = [] # 构造一个二维数组 forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ' ,'.join(page_result[i][8]) returnpage_result # 返回当前页面的job信息
第 4 步:将捕获的信息存储在 Excel 中
获取到原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1fori inrange(times): # i 代表 Line , i+1 代表行头信息 ifi == 0: fortag_name_i intag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: fortag_list inrange(len(tag_name)): tmp.write(i , tag_list , str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后会不完整,excel文件也会出现“部分内容有问题需要修复”我查了很多遍,一开始以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面tmp = book.add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1 被表头占用 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-coding:utf-8-*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime. 约会时间。现在() url = r'。拉古。com/jobs/positionAjax。json?city=%E5%8C%97%E4%BA%AC'#钩网招聘信息是动态获取的,需要通过post方式提交json信息。默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] #这是标签信息需要抓取的,包括公司名称、学历要求、薪资等。 tag_name = ['公司名称', '公司简称', '职位', '
拉古。com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive'} ifpage_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ #通过页面分析,发现浏览器提交的FormData收录以下内容参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data. encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.
load(page) page_json = page_json['content']['result'] #通过分析获取到的json信息,可以看到返回结果中收录招聘信息,其中还收录很多其他参数 page_result = [num fornum inrange (15)] # 构造一个容量为15的list占位符构造下一个二维数组 fori inrange(15): page_result[i] = [] #构造一个二维数组forpage_tag intag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中 page_result[i][8] = ','.join(page_result[i][ 8] ) returnpage_result # 返回当前页面的招聘信息 def read_max_page(page): # 获取当前招聘的最大页数 关键词,大于30的会被覆盖,所以最多只能获取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] ifmax_page_num > 30: max_page_num = 30returnmax_page_num def save_excel (fin_result, tag_name, file_name): # 将抓取的招聘信息存储在excel book = xlsxwriter.
Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认存储在桌面 tmp = book. add_worksheet() row_num = len(fin_result) fori inrange(1, row_num): ifi == 1: tag_pos = 'A%s'% i tmp. write_row(tag_pos, tag_name) else: con_pos = 'A%s'% i content = fin_result[i-1] # -1是因为tmp被表头占用了。write_row(con_pos, content) 书。close() if__name__ == '__main__': print('********************************** 即将被抓到 Take ************************************') keyword = input('请输入语言type :') fin_result = [] # 将每一页的招聘信息聚合成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) forpage_num inrange(1, max_page_num): print('
extend(page_result) file_name = input('捕获完成,保存输入文件名:') save_excel(fin_result, tag_name, file_name) endtime = datetime. 约会时间。现在()时间=(结束时间 - 开始时间)。seconds print('总时间: %s s'% time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~
excel抓取多页网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
网站优化 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2022-03-04 07:01
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓取,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。 查看全部
excel抓取多页网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓取,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。
excel抓取多页网页数据(每页PowerBIDesktop中用自动播放自动播放自动播放 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2022-03-04 06:19
)
喜欢笑话的朋友,可以抓一些笑话保存成TXT格式,放到电子书里闲暇时阅读,上网搜索一下,这个网站不错,干净并且没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取文章的所有URL:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
查看全部
excel抓取多页网页数据(每页PowerBIDesktop中用自动播放自动播放自动播放
)
喜欢笑话的朋友,可以抓一些笑话保存成TXT格式,放到电子书里闲暇时阅读,上网搜索一下,这个网站不错,干净并且没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取文章的所有URL:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
excel抓取多页网页数据(处理页面元素的方法-处理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-03 18:17
我正在尝试使用vba在excel中将表格的第二页保存在下面代码中的url中,但是我不能使用click属性,你能帮帮我吗?我在互联网上到处搜索,没有结果。谢谢。
Sub BrowseSiteTableObjectX()
Dim IE As New SHDocVw.InternetExplorer
Dim Docm As MSHTML.HTMLDocument
Dim HTMLAtab As MSHTML.IHTMLElement
Dim HTMLArow As MSHTML.IHTMLElement
Dim iRow As Long
With IE
.navigate "https://www.nasdaq.com/market- ... ot%3B
Do While .Busy Or .readyState 4
DoEvents
Loop
End With
Set Docm = IE.document
Docm.getElementsByClassName("symbol-screener__pagination")(0).getElementsByClassName("next")(0).Click
Set Docm = IE.document
Set HTMLAtab = Docm.getElementsByClassName("symbol-screener__table")(0)
For Each HTMLArow In HTMLAtab.getElementsByClassName("symbol-screener__row")
iRow = iRow + 1
Cells(iRow, 1) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--ticker")(0).innerText
Cells(iRow, 2) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--company")(0).innerText
DoEvents
Next HTMLArow
IE.Quit
Set IE = Nothing
Set Docm = Nothing
End Sub
最佳答案
为了看看这是否有帮助,在这个 文章 中,我概述了处理页面元素的各种方法。您需要考虑“单击”“下一步”按钮时会发生什么。它可能正在提交表单,运行页面 javascript,
看看这些想法是否有帮助。您可能会发现 ExecScript 是最好的,因为 Next 按钮可能会链接回页面上的脚本以加载下一组数据。只需查看您的 Chrome 开发工具,看看会发生什么。
祝你好运!
关于 html - 使用 vba 抓取多页网页表单,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
excel抓取多页网页数据(处理页面元素的方法-处理工具)
我正在尝试使用vba在excel中将表格的第二页保存在下面代码中的url中,但是我不能使用click属性,你能帮帮我吗?我在互联网上到处搜索,没有结果。谢谢。
Sub BrowseSiteTableObjectX()
Dim IE As New SHDocVw.InternetExplorer
Dim Docm As MSHTML.HTMLDocument
Dim HTMLAtab As MSHTML.IHTMLElement
Dim HTMLArow As MSHTML.IHTMLElement
Dim iRow As Long
With IE
.navigate "https://www.nasdaq.com/market- ... ot%3B
Do While .Busy Or .readyState 4
DoEvents
Loop
End With
Set Docm = IE.document
Docm.getElementsByClassName("symbol-screener__pagination")(0).getElementsByClassName("next")(0).Click
Set Docm = IE.document
Set HTMLAtab = Docm.getElementsByClassName("symbol-screener__table")(0)
For Each HTMLArow In HTMLAtab.getElementsByClassName("symbol-screener__row")
iRow = iRow + 1
Cells(iRow, 1) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--ticker")(0).innerText
Cells(iRow, 2) = HTMLArow.getElementsByClassName("symbol-screener__cell symbol-screener__cell--company")(0).innerText
DoEvents
Next HTMLArow
IE.Quit
Set IE = Nothing
Set Docm = Nothing
End Sub
最佳答案
为了看看这是否有帮助,在这个 文章 中,我概述了处理页面元素的各种方法。您需要考虑“单击”“下一步”按钮时会发生什么。它可能正在提交表单,运行页面 javascript,
看看这些想法是否有帮助。您可能会发现 ExecScript 是最好的,因为 Next 按钮可能会链接回页面上的脚本以加载下一组数据。只需查看您的 Chrome 开发工具,看看会发生什么。
祝你好运!
关于 html - 使用 vba 抓取多页网页表单,我们在 Stack Overflow 上发现了一个类似的问题:
excel抓取多页网页数据( Python3.5和BeautifulSoup.底层数据库是什么意思?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-03 18:16
Python3.5和BeautifulSoup.底层数据库是什么意思?(图)
)
.
我希望有一个 HTML 链接可用于下一次抓取迭代,但没有运气。进一步检查,通过查看网络流量,发现浏览器为 __VIEWSTATE 等发送了一个很长的(散列的?)字符串。可能保护数据库?
我正在寻找一种方法来抓取狗的所有页面,或者通过迭代所有页面,或者通过增加页面长度以在第 1 页上显示超过 100 行。底层数据库是 .aspx。
我正在使用 Python 3.5 和 BeautifulSoup。
当前代码:
<p> import requests
from bs4 import BeautifulSoup
url = 'http://www.gbgb.org.uk/RaceCard.aspx?dogName=Hardwick%20Serena'
with requests.session() as s:
s.headers['user-agent'] = 'Mozilla/5.0'
r = s.get(url)
soup = BeautifulSoup(r.content, 'html5lib')
target = 'ctl00$ctl00$mainContent$cmscontent$DogRaceCard$btnFilter_input'
data = { tag['name']: tag['value']
for tag in soup.select('input[name^=ctl00]') if tag.get('value')
}
state = { tag['name']: tag['value']
for tag in soup.select('input[name^=__]')
}
data.update(state)
numberpages = int(str(soup.find('div', 'rgWrap rgInfoPart')).split(' ')[-2].split('>')[1].split(' 查看全部
excel抓取多页网页数据(
Python3.5和BeautifulSoup.底层数据库是什么意思?(图)
)
.
我希望有一个 HTML 链接可用于下一次抓取迭代,但没有运气。进一步检查,通过查看网络流量,发现浏览器为 __VIEWSTATE 等发送了一个很长的(散列的?)字符串。可能保护数据库?
我正在寻找一种方法来抓取狗的所有页面,或者通过迭代所有页面,或者通过增加页面长度以在第 1 页上显示超过 100 行。底层数据库是 .aspx。
我正在使用 Python 3.5 和 BeautifulSoup。
当前代码:
<p> import requests
from bs4 import BeautifulSoup
url = 'http://www.gbgb.org.uk/RaceCard.aspx?dogName=Hardwick%20Serena'
with requests.session() as s:
s.headers['user-agent'] = 'Mozilla/5.0'
r = s.get(url)
soup = BeautifulSoup(r.content, 'html5lib')
target = 'ctl00$ctl00$mainContent$cmscontent$DogRaceCard$btnFilter_input'
data = { tag['name']: tag['value']
for tag in soup.select('input[name^=ctl00]') if tag.get('value')
}
state = { tag['name']: tag['value']
for tag in soup.select('input[name^=__]')
}
data.update(state)
numberpages = int(str(soup.find('div', 'rgWrap rgInfoPart')).split(' ')[-2].split('>')[1].split('
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-28 14:18
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
Top250豆瓣电影的爬取比较简单,特别是对于新手来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫初学者都会选择这个项目作为入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它作为入门级爬虫是一个很好的实践网页。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。 查看全部
excel抓取多页网页数据(Python学习资料以及群交流解答点击即可加入(组图))
效果图
不多说,先将效果图保存为excel文件,这里只是简单的将爬取的数据保存到文件中,没有对表格数据进行标准化。因为这涉及到另一个python用来处理表的库,这里就不过多解释了,相关的文章后面会涉及到。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
前言
Top250豆瓣电影的爬取比较简单,特别是对于新手来说,使用这个页面作为爬虫的动手实践项目是爬虫的首选,很多爬虫初学者都会选择这个项目作为入门练习。一直以来,我很少用函数式编程来写爬虫代码,总是习惯用简单的一行代码的方式来写。在这个 文章 中,我使用了函数式编程。同时还涉及到使用python将数据写入excel表格,初步了解相关用法。
确定着陆页网址
通过查看网页的源代码,我们知道网页数据是静态数据,没有任何反爬虫机制,所以说它作为入门级爬虫是一个很好的实践网页。鼠标右击选择查看网页源代码,会弹出页面的原创HTML代码,这时候我们按住CTRL+F调出搜索框,搜索我们的数据在浏览器中查看。
搜索其他电影的名字也可以搜索到,所以我们确定该页面是一个静态网页,其目标url就是网址栏中的url,如下图,所以我们确定该页面的url要爬取的页面。
爬取过程中导入相关库
这个爬取过程涉及requests库,lxml中用于解析页面数据的etree库,以及将内容写入excel文档的xlwt库。如果没有相关库,需要调出命令行,通过 pip install library name 安装。
import requests
from lxml import etree
import xlwt
#pip install requests
#pip install lxml
#pip install xlwt
123456
获取页面内容
通过requests库访问目标网页的数据,保证可以获取到网页内容。
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
12345678910
页面解析
获取页面内容后,解析页面内容。这里使用lxml库中的etree进行解析,然后通过xpath语法提取数据。
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
1234
数据提取
接下来,我们使用 xpath 语法从解析后的页面中提取数据,提取电影名称、评分、评论数以及每部电影的标签或消息。
实现代码如下:
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
123456789101112131415161718192021
编写主函数的函数调用
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
get_page_source(start_url=url,headers=headers)
page_content(get_page_source(start_url=url,headers=headers))
1234567
数据存储
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
1234567891011121314151617181920212223
完整代码
import requests
from lxml import etree
import xlwt
movie_info_list = []
# 获取网页资源
def get_page_source(start_url,headers):
response = requests.get(url=start_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
page_data = response.text
return page_data
else:
return "未连接到页面"
# 提取网页电影信息
def page_content(page_data):
etree_data = etree.HTML(page_data)
selector = etree_data.xpath('//*[@class="article"]/ol/li/div/div[2]')
# print(selector)
for item in selector:
# 电影名称
movie_names = item.xpath('./div/a/span[1]/text()')
# print(movie_names)
# 电影评分
movie_scores = item.xpath('./div[2]/div/span[2]/text()')
# print(movie_scores)
# 电影评论人数
movie_numbers = item.xpath('./div[2]/div/span[4]/text()')
# print(movie_numbers)
# 对电影的描述语
quotes = item.xpath('./div[2]/p[2]/span/text()')
# print(quotes)
# 将每一行获取到的信息添加到一个电影的列表中
one_movie_info_list = [movie_names,movie_scores,movie_numbers,quotes]
# 将一个电影的列表添加到大的列表中
movie_info_list.append(one_movie_info_list)
if __name__ == '__main__':
for page in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(str(page*25))
# page += 25
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
t = get_page_source(start_url=url,headers=headers)
page_content(t)
#创建工作簿
book = xlwt.Workbook(encoding='utf-8')
#创建表单
sheet = book.add_sheet('豆瓣排行250')
#填写表头
head = ['排名','电影名','评分','评价人数','电影寄语']
# 写入表头
for h in range(len(head)):
sheet.write(0,h,head[h])
# 排名
for index in range(1,251):
sheet.write(index,0,index)
# 写入相对应的数据
j = 1
for data in movie_info_list:
#从索引为第1行开始写
k = 1
for d in data:
sheet.write(j,k,d)
k += 1
j += 1
#退出工作簿并保存
book.save('豆瓣电影Top250.xls')
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273
结语
在写作的过程中,难免还有改进的余地。如果有更好的方法,或者有不同的意见,请指出。
excel抓取多页网页数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-26 09:19
用简单的Excel分析网站日志数据,哪些目录比较好爬,哪些IP段蜘蛛爬取等。一个网站要发展得更快更远,离不开每天的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,利用数据模型修改频道后,被收录的网页数量从原来的几十万增加到了5个以上今年万元。由此可见数据分析的重要性。说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。其实在日志分析< @网站,最需要的工具是 Excel(Excel 07 或 Excel 10)。在这里,我想和大家简单分享一下我的一些经验。网站个体爬取统计:借助光年日志分析工具,得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(我只做百度优化,所以我会讲百度蜘蛛爬取情况),如下图1:将上面的数据做成Excel,如下图2:平均停留时间=总停留时间/访问次数,计算公式:=C2/B2输入平均抓取量=总抓取量/访问次数,计算公式:=D2/B2进入单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2进入蜘蛛状态码统计:借助Excel,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示: 通过“数据”功能下的过滤Excel表格,下面可以统计蜘蛛状态码。具体统计操作如图4所示:点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,spider的状态码200的特征是HTTP/1.1" 200,以此类推:状态码500就是HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302..... 现在可以过滤掉每个蜘蛛状态码,如下图所示: 如上图5所示,选择收录关系统计百度蜘蛛200状态码的抓取量,以此类推。蜘蛛IP段统计:如上图,可以将状态码替换为IP段,如:HTTP/1.1" 200 改为 202.108.25 1. 33 目录爬取统计:如上图,将状态码替换为对应的目录名即可,如:@k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 @k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 查看全部
excel抓取多页网页数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》(组图))
用简单的Excel分析网站日志数据,哪些目录比较好爬,哪些IP段蜘蛛爬取等。一个网站要发展得更快更远,离不开每天的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,利用数据模型修改频道后,被收录的网页数量从原来的几十万增加到了5个以上今年万元。由此可见数据分析的重要性。说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。其实在日志分析< @网站,最需要的工具是 Excel(Excel 07 或 Excel 10)。在这里,我想和大家简单分享一下我的一些经验。网站个体爬取统计:借助光年日志分析工具,得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(我只做百度优化,所以我会讲百度蜘蛛爬取情况),如下图1:将上面的数据做成Excel,如下图2:平均停留时间=总停留时间/访问次数,计算公式:=C2/B2输入平均抓取量=总抓取量/访问次数,计算公式:=D2/B2进入单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2进入蜘蛛状态码统计:借助Excel,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示: 通过“数据”功能下的过滤Excel表格,下面可以统计蜘蛛状态码。具体统计操作如图4所示:点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,spider的状态码200的特征是HTTP/1.1" 200,以此类推:状态码500就是HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302..... 现在可以过滤掉每个蜘蛛状态码,如下图所示: 如上图5所示,选择收录关系统计百度蜘蛛200状态码的抓取量,以此类推。蜘蛛IP段统计:如上图,可以将状态码替换为IP段,如:HTTP/1.1" 200 改为 202.108.25 1. 33 目录爬取统计:如上图,将状态码替换为对应的目录名即可,如:@k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 @k17@ 通过简单的 Excel >日志数据在这里介绍。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195 需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。本文由徐宇博博客原创撰写,转载请注明出处 xuyubo./weiboke/62.html 文章来源:北大青鸟5195
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-25 07:15
PowerBI的强大不仅在于最终生成炫酷的可视化报表,更在于在数据采集的第一步展现其强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、任何结构和任何形式使用。获取数据
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到股票涨跌、外汇价格等实时交易数据。现在我们试试例如从中国银行抓取外汇价格信息网站,先输入网址:
单击确定后,将出现一个预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是处理数据。这是我们真正需要掌握的核心技能。 查看全部
excel抓取多页网页数据(PowerQuery的强大数据处理功能,从网页抓取数据开始!)
PowerBI的强大不仅在于最终生成炫酷的可视化报表,更在于在数据采集的第一步展现其强大的威力。使用 Power Query 强大的数据处理功能,几乎可以从任何来源、任何结构和任何形式使用。获取数据
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到股票涨跌、外汇价格等实时交易数据。现在我们试试例如从中国银行抓取外汇价格信息网站,先输入网址:
单击确定后,将出现一个预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是处理数据。这是我们真正需要掌握的核心技能。
excel抓取多页网页数据(文章目录3.提取信息进行excel本地保存总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-22 01:15
文章目录
3.提取信息并保存在本地的excel中
总结
前言
本案例是爬取51job网站的job信息。如果有任何错误,请纠正我。转载请注明出处。
本次抓取网址:点此
温馨提示:以下为本文正文内容文章,以下案例供参考
一、模块使用
1.这次一共使用了四个模块
1import openpyxl
2import bs4
3import requests as r
4from selenium import webdriver
5
6
下面会列出具体模块的详细使用,有需要的可以自行了解:
详情页URL获取模块:selenium
HTML标签处理模块:bs4.beautifulsoup
Python详解——请求模块
openpyxl处理excel表格详解
二、数据抓取及url列表建立1.获取所有网页详情页面链接
这里使用 selenium 模块是因为可以获取动态加载页面的数据,比如 js 渲染后的代码,下拉轮获取的数据,框内的一些隐藏元素等。
调用selenium模块需要下载浏览器驱动:谷歌浏览器驱动下载地址,下载解压后放到python根目录下。注意:浏览器版本必须与驱动版本一致,否则无效。
如果还有安装不了selenium模块的朋友,请看这篇文章:selenium安装
1):首先观察我们要爬取的页面,定位到页面需要爬取的位置,我们发现他的父标签是“div”和“class="j_joblist”,
而详情页的链接在父标签下的div标签下的a标签中(这里有点绕,结合图片理解)
可以看出,我们首先要定位a标签,从中提取“href”标签中的地址,并将地址放入urllists列表中。第一步完成!
代码如下(示例):
1h = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"} # 伪造浏览器信息,第二步会用到。
2def get_joburllist(): # 定义函数get_joburllist
3
4 urllists = [ ] # 一个列表变量,用于接收所有网页详情页链接
5 chrome_driver = r'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\chromedriver.exe' #chromedriver的文件位置,r代表原始路径
6 wd = webdriver.Chrome(executable_path = chrome_driver) #创建浏览器,这里用谷歌浏览器,后接驱动器地址
7 wd.implicitly_wait(2) # 智能等待一个元素被发现,或一个命令完成。如果超出了设置时间的则抛出异常。
8 #访问51job网站
9 for i in range(1,34): # 这里两个参数,(1,34),1代表当前页,34代表总页数,可自行修改
10 wd.get("https://search.51job.com/list/010000,000000,0000,00,9,99,%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8,2,i.html") # 访问链接内的地址,i为第i页
11
12 joblists = wd.find_elements_by_xpath('//div[@class="j_joblist"]/div/a') # 查找所有div下class属性为"j_joblist"的子节点为div的子节点为a的标签
13 for urllist in joblists: # 循环获取所有详情页的href链接
14 href_list = urllist.get_attribute("href") # 获取href属性的内容
15 urllists.append(href_list)
16 wd.quit() # 关闭浏览器
17 #print(urllists)
18 return urllists
19
20
21
至此,网页详情页的链接就放在了urllists列表中。我们可以继续下一步
2.获取详情页的html源码,过滤我们需要的信息
思路:由于我们在第一步中已经获取到了各个详情页的url,我们可以使用requests返回html源码,使用浏览器查看,逐个找到需要信息的标签过滤掉,最后找到我们需要的文本信息,放入列表返回。
代码如下(示例):
1f get_html(url): # 这里的url指的是第一步获取的详情页的url
2 response = r.get(url,headers = h) # 伪造请求头信息
3 response.encoding = "gbk" # 更改编码为gbk
4 return response.text # 返回html源码
5
6def get_textinfo(html): # 进行源码筛选
7 jobname = [] # 以下为定义模块信息 , 工作名称
8 jobmoney = [] # 工资
9 comname = [] # 公司名称
10 jobjy = [] # 工作经验
11 jobyh = [] # 岗位福利
12 jobneed = [] # 岗位职责
13 cominfo = [] # 公司信息
14
15 soup = bs4.BeautifulSoup(html,"html.parser") # 两个参数,第一个参数为html源码,第二个参数为解析html文件,返回结果给soup
16 # Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象
17
18# 这里要做一下说明,因为获取到的详情页中,有一部分并没有按照规定模板来进行显示,
19# 而是直接跳转到公司官网,所以进行筛选时会报错,这里用if来做一个简单判断,
20# 如果获取的html源码中并不是按照规定模板来显示的,我们将pass掉这个信息
21
22 jn = soup.find("div",class_="cn")
23 strjn = str(jn) # 将类型转换为str,方便查找
24 jnfind = strjn.find("h1") # 查找“h1”字符,并将查找结果给jhfind
25 if jnfind == -1: # 如果返回结果为 -1 代表没有h1标签 (find没有找到时会返回-1)
26 #print ("no")
27 joblist = ["查看此招聘信息请点击链接:"] # 则返回空表
28
29 else: # 否则代表该源码符合规定模板,正常进行筛选
30 #print(jn.h1.text)
31 jobname.append(jn.h1.text) # 添加h1标签文本信息
32
33 jm = soup.find("div",class_="cn")
34 jobmoney.append(jm.strong.text) # 添加strong标签文本信息
35
36 cn = soup.find("a",class_="catn")
37 comname.append(cn.text) # 添加公司名称
38
39 jj = soup.find("p",class_="msg ltype")
40 jobjy.append(jj.text.replace("\xa0\xa0|\xa0\xa0"," ")) 添加工作经验文本信息,并将\xa0替换成空字符串,方便查看
41
42 jy = soup.findAll("span",class_="sp4") # 福利信息这里有点特殊,每个福利都是独立的,我们需要将他放在一个字符串里,并添加到福利信息列表。
43 jystr = "" # 建立空字符串
44 for i in jy: # 从jy(jy代表找到的所有符合条件的标签)中逐个调用并添加到jystr中,以空格隔开。
45 jystr += i.text + " "
46 jobyh.append(jystr) # 将完成的字符串添加到列表中
47
48 jn = soup.find("div",class_="bmsg job_msg inbox")
49 jnstr = ""
50 for i in jn.findAll("p"): # 跟上一个同理,findAll所有'p'标签 并放到一个空字符串中
51 jnstr += i.text + " "
52 jobneed.append(jnstr)
53
54 ci = soup.find("div",class_="tmsg inbox")
55 cominfo.append(ci.text) # 添加公司信息
56
57 joblist = jobname + jobmoney + comname + jobjy + jobyh + jobneed + cominfo # 将独立的列表信息合并到一起,成为一个大的列表。
58 return joblist
59
60
61
3.提取信息并保存在本地的excel中
思路:终于到了最后一步,这里也是调用整个代码执行的大致步骤。可以说上面写的函数都是在这里依次调用的。这次我们主要使用openpyxl来保存和调用前面两步。功能配合,代码废话不多说。
1
2def save_info():
3 wb = openpyxl.Workbook() # 获取工作簿 就是一个excle层面的对象,在获取工作簿的同时已经创建了一个默认的工作表
4 ws = wb.active # 获取当前工作表
5 titlelist = ["岗位名称","岗位薪资","公司名称","工作经验","岗位诱惑","岗位职责","公司信息","岗位网址"] # 先创建一个title,方便我们Excel表的查看。
6 ws.append(titlelist) # 添加titlelist到Excel表中
7 joburllist = get_joburllist() # 先调用第一步,获得所有详情页的url列表,并保存到"joburllist"中
8 for i in joburllist:
9 html = get_html(i) # 依次取出每一个详情页的url,并获取这个岗位的源码
10 jobinfolist = get_textinfo(html) # 对每个岗位扣取文字信息,并返回一个列表
11 jobinfolist.append(i) # 添加岗位网址信息
12 ws.append(jobinfolist) # 将扣取得文字信息,写入到excel的内存空间
13 wb.save("51jobplusmax.xlsx") # 保存
14
15if __name__ == "__main__": # 直接执行(F5)
16 save_info() # 执行save_info() 函数
17
18 # 这些是测试信息
19 #urllists = get_joburllist()
20 #html = get_html(urllists)
21 #get_textinfo(html)
22 #print(urllists)
23
24
在这里直接运行,我们可以爬取所有网络安全位置的信息。今天查询的时候一共1600多条,爬了1个小时(慢批)。
1.Excel结果展示
总结
这个案例,从学习新模块到实际应用,花了很长时间,找到了很多资料。我把它放在下面供大家学习和参考,希望能节省你的时间。
这是我的第一个爬虫案例分享。如果有任何错误,请纠正我。如果我能帮助你,那将是我的荣幸。
参考文章:
51job爬虫案例
硒笔记 1
硒 - 祖传爬行动物武器
selenium get_attribute 的几种用途
Selenium python中的等待方式
python中bs4.BeautifulSoup的基本用法
python脚本中selenium启动浏览器报错os.path.basename(self.path), self.start_error_message) mon.excep
openpyxl的详细使用 查看全部
excel抓取多页网页数据(文章目录3.提取信息进行excel本地保存总结(组图))
文章目录
3.提取信息并保存在本地的excel中
总结
前言
本案例是爬取51job网站的job信息。如果有任何错误,请纠正我。转载请注明出处。
本次抓取网址:点此
温馨提示:以下为本文正文内容文章,以下案例供参考
一、模块使用
1.这次一共使用了四个模块
1import openpyxl
2import bs4
3import requests as r
4from selenium import webdriver
5
6
下面会列出具体模块的详细使用,有需要的可以自行了解:
详情页URL获取模块:selenium
HTML标签处理模块:bs4.beautifulsoup
Python详解——请求模块
openpyxl处理excel表格详解
二、数据抓取及url列表建立1.获取所有网页详情页面链接
这里使用 selenium 模块是因为可以获取动态加载页面的数据,比如 js 渲染后的代码,下拉轮获取的数据,框内的一些隐藏元素等。
调用selenium模块需要下载浏览器驱动:谷歌浏览器驱动下载地址,下载解压后放到python根目录下。注意:浏览器版本必须与驱动版本一致,否则无效。
如果还有安装不了selenium模块的朋友,请看这篇文章:selenium安装
1):首先观察我们要爬取的页面,定位到页面需要爬取的位置,我们发现他的父标签是“div”和“class="j_joblist”,
而详情页的链接在父标签下的div标签下的a标签中(这里有点绕,结合图片理解)
可以看出,我们首先要定位a标签,从中提取“href”标签中的地址,并将地址放入urllists列表中。第一步完成!
代码如下(示例):
1h = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"} # 伪造浏览器信息,第二步会用到。
2def get_joburllist(): # 定义函数get_joburllist
3
4 urllists = [ ] # 一个列表变量,用于接收所有网页详情页链接
5 chrome_driver = r'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\chromedriver.exe' #chromedriver的文件位置,r代表原始路径
6 wd = webdriver.Chrome(executable_path = chrome_driver) #创建浏览器,这里用谷歌浏览器,后接驱动器地址
7 wd.implicitly_wait(2) # 智能等待一个元素被发现,或一个命令完成。如果超出了设置时间的则抛出异常。
8 #访问51job网站
9 for i in range(1,34): # 这里两个参数,(1,34),1代表当前页,34代表总页数,可自行修改
10 wd.get("https://search.51job.com/list/010000,000000,0000,00,9,99,%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8,2,i.html") # 访问链接内的地址,i为第i页
11
12 joblists = wd.find_elements_by_xpath('//div[@class="j_joblist"]/div/a') # 查找所有div下class属性为"j_joblist"的子节点为div的子节点为a的标签
13 for urllist in joblists: # 循环获取所有详情页的href链接
14 href_list = urllist.get_attribute("href") # 获取href属性的内容
15 urllists.append(href_list)
16 wd.quit() # 关闭浏览器
17 #print(urllists)
18 return urllists
19
20
21
至此,网页详情页的链接就放在了urllists列表中。我们可以继续下一步
2.获取详情页的html源码,过滤我们需要的信息
思路:由于我们在第一步中已经获取到了各个详情页的url,我们可以使用requests返回html源码,使用浏览器查看,逐个找到需要信息的标签过滤掉,最后找到我们需要的文本信息,放入列表返回。
代码如下(示例):
1f get_html(url): # 这里的url指的是第一步获取的详情页的url
2 response = r.get(url,headers = h) # 伪造请求头信息
3 response.encoding = "gbk" # 更改编码为gbk
4 return response.text # 返回html源码
5
6def get_textinfo(html): # 进行源码筛选
7 jobname = [] # 以下为定义模块信息 , 工作名称
8 jobmoney = [] # 工资
9 comname = [] # 公司名称
10 jobjy = [] # 工作经验
11 jobyh = [] # 岗位福利
12 jobneed = [] # 岗位职责
13 cominfo = [] # 公司信息
14
15 soup = bs4.BeautifulSoup(html,"html.parser") # 两个参数,第一个参数为html源码,第二个参数为解析html文件,返回结果给soup
16 # Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象
17
18# 这里要做一下说明,因为获取到的详情页中,有一部分并没有按照规定模板来进行显示,
19# 而是直接跳转到公司官网,所以进行筛选时会报错,这里用if来做一个简单判断,
20# 如果获取的html源码中并不是按照规定模板来显示的,我们将pass掉这个信息
21
22 jn = soup.find("div",class_="cn")
23 strjn = str(jn) # 将类型转换为str,方便查找
24 jnfind = strjn.find("h1") # 查找“h1”字符,并将查找结果给jhfind
25 if jnfind == -1: # 如果返回结果为 -1 代表没有h1标签 (find没有找到时会返回-1)
26 #print ("no")
27 joblist = ["查看此招聘信息请点击链接:"] # 则返回空表
28
29 else: # 否则代表该源码符合规定模板,正常进行筛选
30 #print(jn.h1.text)
31 jobname.append(jn.h1.text) # 添加h1标签文本信息
32
33 jm = soup.find("div",class_="cn")
34 jobmoney.append(jm.strong.text) # 添加strong标签文本信息
35
36 cn = soup.find("a",class_="catn")
37 comname.append(cn.text) # 添加公司名称
38
39 jj = soup.find("p",class_="msg ltype")
40 jobjy.append(jj.text.replace("\xa0\xa0|\xa0\xa0"," ")) 添加工作经验文本信息,并将\xa0替换成空字符串,方便查看
41
42 jy = soup.findAll("span",class_="sp4") # 福利信息这里有点特殊,每个福利都是独立的,我们需要将他放在一个字符串里,并添加到福利信息列表。
43 jystr = "" # 建立空字符串
44 for i in jy: # 从jy(jy代表找到的所有符合条件的标签)中逐个调用并添加到jystr中,以空格隔开。
45 jystr += i.text + " "
46 jobyh.append(jystr) # 将完成的字符串添加到列表中
47
48 jn = soup.find("div",class_="bmsg job_msg inbox")
49 jnstr = ""
50 for i in jn.findAll("p"): # 跟上一个同理,findAll所有'p'标签 并放到一个空字符串中
51 jnstr += i.text + " "
52 jobneed.append(jnstr)
53
54 ci = soup.find("div",class_="tmsg inbox")
55 cominfo.append(ci.text) # 添加公司信息
56
57 joblist = jobname + jobmoney + comname + jobjy + jobyh + jobneed + cominfo # 将独立的列表信息合并到一起,成为一个大的列表。
58 return joblist
59
60
61
3.提取信息并保存在本地的excel中
思路:终于到了最后一步,这里也是调用整个代码执行的大致步骤。可以说上面写的函数都是在这里依次调用的。这次我们主要使用openpyxl来保存和调用前面两步。功能配合,代码废话不多说。
1
2def save_info():
3 wb = openpyxl.Workbook() # 获取工作簿 就是一个excle层面的对象,在获取工作簿的同时已经创建了一个默认的工作表
4 ws = wb.active # 获取当前工作表
5 titlelist = ["岗位名称","岗位薪资","公司名称","工作经验","岗位诱惑","岗位职责","公司信息","岗位网址"] # 先创建一个title,方便我们Excel表的查看。
6 ws.append(titlelist) # 添加titlelist到Excel表中
7 joburllist = get_joburllist() # 先调用第一步,获得所有详情页的url列表,并保存到"joburllist"中
8 for i in joburllist:
9 html = get_html(i) # 依次取出每一个详情页的url,并获取这个岗位的源码
10 jobinfolist = get_textinfo(html) # 对每个岗位扣取文字信息,并返回一个列表
11 jobinfolist.append(i) # 添加岗位网址信息
12 ws.append(jobinfolist) # 将扣取得文字信息,写入到excel的内存空间
13 wb.save("51jobplusmax.xlsx") # 保存
14
15if __name__ == "__main__": # 直接执行(F5)
16 save_info() # 执行save_info() 函数
17
18 # 这些是测试信息
19 #urllists = get_joburllist()
20 #html = get_html(urllists)
21 #get_textinfo(html)
22 #print(urllists)
23
24
在这里直接运行,我们可以爬取所有网络安全位置的信息。今天查询的时候一共1600多条,爬了1个小时(慢批)。
1.Excel结果展示
总结
这个案例,从学习新模块到实际应用,花了很长时间,找到了很多资料。我把它放在下面供大家学习和参考,希望能节省你的时间。
这是我的第一个爬虫案例分享。如果有任何错误,请纠正我。如果我能帮助你,那将是我的荣幸。
参考文章:
51job爬虫案例
硒笔记 1
硒 - 祖传爬行动物武器
selenium get_attribute 的几种用途
Selenium python中的等待方式
python中bs4.BeautifulSoup的基本用法
python脚本中selenium启动浏览器报错os.path.basename(self.path), self.start_error_message) mon.excep
openpyxl的详细使用
excel抓取多页网页数据( Excel中的Powerquery可以同样操作(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-02-19 15:23
Excel中的Powerquery可以同样操作(一)(组图))
前面介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。(Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
在这里完成第一页的数据后,当你转到采集的其他页面时,数据结构将与第一页完成后的数据结构相同,采集的数据可以直接使用;没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前面输入:(p as number) as table =>
并在let to后第一行的URL中将&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
修改后,[Source]的URL变为:“;sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。输入一个数字,比如7,就会抓取到第7页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
单击“确定”开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,已经完成了100页智联招聘信息的批量抓取。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量捕获某个网站数据之前,先尝试采集一个页面,如果可以采集获取,再使用上面的步骤,如果采集不行的时候你来了,你不需要再浪费时间了。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。 查看全部
excel抓取多页网页数据(
Excel中的Powerquery可以同样操作(一)(组图))
前面介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批量处理采集更多网页数据。(Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析URL结构
打开智联招聘网站,搜索上海工作地点的资料,
将页面拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出,最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,第二行输入页码.
从 URL 预览可以看出,上面两行的 URL 已经自动合并在一起了;这里的单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则网址要分三行输入)
点击OK后,发现很多表,
从中可以看出智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面几列的数据。
这样第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可以看到,一页有60条招聘信息。
在这里完成第一页的数据后,当你转到采集的其他页面时,数据结构将与第一页完成后的数据结构相同,采集的数据可以直接使用;没关系,你可以等到采集所有网页数据都排序在一起。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前面输入:(p as number) as table =>
并在let to后第一行的URL中将&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p))
修改后,[Source]的URL变为:“;sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。输入一个数字,比如7,就会抓取到第7页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。如果要获取前 100 页数据,请创建一个从 1 到 100 的序列并输入空查询。
={1..100}
回车生成一个从1到100的序列,然后变成表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
单击“确定”开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,已经完成了100页智联招聘信息的批量抓取。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大的时间块仍然是最后一步。捕获数据的过程非常耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,受益终生!
以上主要使用了PowerBI中的Power Query功能,在能使用PQ功能的Excel中也可以进行同样的操作。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量捕获某个网站数据之前,先尝试采集一个页面,如果可以采集获取,再使用上面的步骤,如果采集不行的时候你来了,你不需要再浪费时间了。
立即打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-19 15:19
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要获取的信息在哪里是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['内容']['结果']
# 通过分析获取到的json信息可以看出,返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个占位符列表,容量为15,构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
书=工作簿(编码='utf-8')
tmp = book.add_sheet('sheet')
次 = len(fin_result)+1
for i in range(times): # i代表行,i+1代表行头信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
网址 = r'%E5%8C%97%E4%BA%AC'
# 拉狗网的招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、工资等。
tag_name = ['公司名称', '公司简称', '职称', '学历', '薪资', '公司资质', '公司规模', '类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['content']['result'] # 通过分析获取到的json信息,我们可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] #构造一个容量为15的list占位符构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(页面)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num > 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ == '__main__':
print('************************************抓取来了******** * ************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每一页的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num(1,max_page_num):
print('********************************下载页面 %s********** * ***********************' % page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('爬取完成,保存输入文件名:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间 - 开始时间). 秒
print('总时间: %s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
本文标题:Python制作爬虫并将爬取结果保存到excel 查看全部
excel抓取多页网页数据(实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要获取的信息在哪里是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['内容']['结果']
# 通过分析获取到的json信息可以看出,返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个占位符列表,容量为15,构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
书=工作簿(编码='utf-8')
tmp = book.add_sheet('sheet')
次 = len(fin_result)+1
for i in range(times): # i代表行,i+1代表行头信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
网址 = r'%E5%8C%97%E4%BA%AC'
# 拉狗网的招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、工资等。
tag_name = ['公司名称', '公司简称', '职称', '学历', '薪资', '公司资质', '公司规模', '类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post请求信息,读取返回的页面信息
page_headers = {
'主机': '#39;,
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动状态'
}
如果 page_num == 1:
嘘 = '真'
别的:
嘘 = '假'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData收录以下参数
(“第一”,嘘),
('pn', page_num),
('kd',关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页面
def read_tag(页面,标签):
page_json = json.loads(页面)
page_json = page_json['content']['result'] # 通过分析获取到的json信息,我们可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] #构造一个容量为15的list占位符构造下一个二维数组
对于我在范围内(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,放在同一个列表中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页面的job信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(页面)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num > 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存放在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i(1,row_num):
如果我 == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1被表头占用
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ == '__main__':
print('************************************抓取来了******** * ************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每一页的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num(1,max_page_num):
print('********************************下载页面 %s********** * ***********************' % page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('爬取完成,保存输入文件名:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间 - 开始时间). 秒
print('总时间: %s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
本文标题:Python制作爬虫并将爬取结果保存到excel
excel抓取多页网页数据(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-15 09:09
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,它支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。 查看全部
excel抓取多页网页数据(WebScraper怎么对付这种类型的网页?豆瓣电影TOP排行榜)
这是简易数据分析系列文章的第12期。
在之前的文章文章中,我们介绍了Web Scraper处理各种页面翻转的解决方案,比如修改网页链接加载数据、点击“更多按钮”加载数据、下拉加载数据自动。今天我们讲一种比较常见的翻页方式——pager。
我本来想解释什么是寻呼机,但是我发现浏览一堆定义很麻烦。大家上网已经不是第一年了,看图就知道了。我找到了一个功能齐全的例子,它支持数字页码调整,上一页到下一页和指定页数跳转。
今天我们将学习 Web Scraper 如何处理这种类型的翻页。
其实在本教程的第一个例子中,我们就抢到了豆瓣电影TOP排行榜。这个豆瓣电影列表使用寻呼机来划分数据:
但是当时我们是在找网页链接定期爬取,并没有使用pager来爬取。因为当一个网页的链接有规律的变化时,控制链接参数爬取是成本最低的;如果可以翻页,但是链接的变化不规律,就得去pager了一会儿。
说这些理论有点无聊,我们举个不规则翻页链接的例子。
8月2日是蔡徐坤的生日。为了庆祝,微博上的粉丝给了坤坤300W的转发。微博的转发恰好是被寻呼机分割的,所以我们来分析一下微博的转发。信息页面,了解如何使用 Web Scraper 抓取此类数据。
这条微博的直接链接是:
看了这么多他的视频,为了表达我们的感激之情,我们可以点进点出给坤坤加个阅读。
首先我们看第1页转发的链接,长这样:
第二页看起来像这样,注意有一个额外的#_rnd36 参数:
第三页参数为#_rnd39
第 4 页参数是#_rnd76:
多看几个链接,会发现这个转发页面的URL没有规则,只能通过pager加载数据。让我们开始我们的实践教学课程。
1.创建站点地图
我们首先创建一个SiteMap,这次命名为cxk,起始链接是。
2.为容器创建一个选择器
因为我们要点击pager,所以我们选择外层容器的类型为Element Click。具体参数说明见下图。我们之前在《简单数据分析08》中详细讲解过,这里就不多说了。
容器的预览如下图所示:
寻呼机选择过程如下图所示:
3.创建子选择器
这些子选择器比较简单,类型都是文本选择器。我们选择了三种类型的内容:评论用户名、评论内容和评论时间。
4.捕获数据
可以根据Sitemap cxk->Scrape的操作路径抓取数据。
5.一些问题
如果你看了我上面的教程,马上爬数据,你可能遇到的第一个问题就是,300w的数据,我需要一直爬下去吗?
听起来很不现实。毕竟Web Scraper针对的数据量比较少,上万的数据算太多了。不管数据有多大,都要考虑爬取时间是否过长,数据如何存储,如何处理。网站的反爬系统(比如突然弹出一个验证码,这个Web Scraper无能为力)。
考虑到这个问题,如果你看过之前关于自动控制抓取次数的教程,你可能会想到使用:nth-of-type(-n+N) 来控制N条数据的抓取。如果你尝试一下,你会发现这个方法根本行不通。
失败的原因其实涉及到对网页的一点了解。如果您有兴趣,可以阅读下面的说明。不感兴趣的可以直接看最后的结论。
就像我之前介绍的更多加载网页和下拉加载网页一样,它们新加载的数据是附加到当前页面的。你不断向下滚动,数据不断加载,网页的滚动条会越来越短。表示所有数据都在同一页面上。
当我们使用:nth-of-type (-n+N) 来控制加载次数的时候,其实就相当于在这个网页上设置了一个计数器。当数据已经累积到我们想要的数量时,它就会停止爬取。
但是对于使用分页器的网页,每翻一页就相当于刷新当前网页,这样每次都会设置一个计数器。
比如你要抓1000条数据,但是第一页只有20条数据,抓到最后一条,还有980条数据。对于一条数据,还有980,一翻页计数器就清零,又变成1000了……所以这种控制数的方法是无效的。
所以结论是,如果一个pager类的网页想要提前结束爬取,唯一的办法就是断网。当然,如果您有更好的解决方案,可以在评论中回复我,我们可以互相讨论。
6.总结
Pager 是一种非常常见的网页分页方法。我们可以通过 Web Scraper 中的 Element click 处理此类网页,并通过断开网络来结束爬取。
excel抓取多页网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-08 00:24
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天我们要做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
查看全部
excel抓取多页网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图)
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天我们要做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
excel抓取多页网页数据(excel5.0新增的concat函数是如何使用的?excel基础教程4.5课)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-07 23:02
excel抓取多页网页数据:示例1(自动读取12年的信息,没有进行加密处理,使用文本函数cnt(),可以让11年的数据被自动读取):示例2(对12年数据进行进一步的数据处理处理,读取第三年的数据):技巧使用excelsumifs函数对不重复的数据求和,实现12年的总和:技巧使用excelconcat函数,把11年的合并起来,形成12年的合并数据,这样就可以读取13年的数据了:技巧下面就让我们详细的学习一下excel5.0新增的concat函数是如何使用的!concat函数是在concatenate的基础上改进的产物,语法为concatenate(sumifs,diffdirector,optional)。
在实际使用中,将concat函数中用diffdirector来计算对应列的结果进行拼接,然后再用optional类型的demapi函数来判断是否进行合并。同时,需要注意,该函数一般应用于单元格中数值项的合并,如公式中的a2是a3的1倍,则demapi的结果就是a2,可见,要理解concat函数,需要搞清楚word中的一些公式,让excel工作起来更加高效!我将分4期为大家讲解excel5.0新增的concat函数。欢迎点击“excel基础视频教程”专栏关注我!学习更多实用excel技能!。
+1系列:excel分析——价格趋势图解、列联表合并与条件格式、图表选型4.2系列:如何用正则表达式匹配含有价格的商品?:excel基础教程4.5课excel图表选型:excel报表设计3.5节 查看全部
excel抓取多页网页数据(excel5.0新增的concat函数是如何使用的?excel基础教程4.5课)
excel抓取多页网页数据:示例1(自动读取12年的信息,没有进行加密处理,使用文本函数cnt(),可以让11年的数据被自动读取):示例2(对12年数据进行进一步的数据处理处理,读取第三年的数据):技巧使用excelsumifs函数对不重复的数据求和,实现12年的总和:技巧使用excelconcat函数,把11年的合并起来,形成12年的合并数据,这样就可以读取13年的数据了:技巧下面就让我们详细的学习一下excel5.0新增的concat函数是如何使用的!concat函数是在concatenate的基础上改进的产物,语法为concatenate(sumifs,diffdirector,optional)。
在实际使用中,将concat函数中用diffdirector来计算对应列的结果进行拼接,然后再用optional类型的demapi函数来判断是否进行合并。同时,需要注意,该函数一般应用于单元格中数值项的合并,如公式中的a2是a3的1倍,则demapi的结果就是a2,可见,要理解concat函数,需要搞清楚word中的一些公式,让excel工作起来更加高效!我将分4期为大家讲解excel5.0新增的concat函数。欢迎点击“excel基础视频教程”专栏关注我!学习更多实用excel技能!。
+1系列:excel分析——价格趋势图解、列联表合并与条件格式、图表选型4.2系列:如何用正则表达式匹配含有价格的商品?:excel基础教程4.5课excel图表选型:excel报表设计3.5节
excel抓取多页网页数据(安装excel抓取多页网页数据的方法可以参考以下步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-07 10:04
excel抓取多页网页数据的方法可以参考以下步骤:在excel中运行任意python脚本第一步:找到网站的url地址,可以在搜索引擎上搜索url地址,也可以在浏览器的地址栏搜索;第二步:用迅雷把该网页下载下来,可以先单击pdf,然后用迅雷打开;第三步:拷贝该url地址,然后一直拖动可以看到多个img链接;第四步:将其中的img链接拷贝至迅雷的主界面,直接右键点击;第五步:转换链接地址如下图所示:第六步:使用微软的ie浏览器的扩展程序把所需要的url地址转换成pdf文件;第七步:然后找到该pdf文件的路径,然后从迅雷里将其下载下来,可以直接把地址复制,也可以从迅雷里打开;第八步:直接用百度搜索excel的文件格式中已经有对应的代码,直接拷贝到代码编辑器中;第九步:双击整个下载文件第十步:这样就能把该页的所有网页图片上传到excel中,然后可以用excel打开。
对于目前国内的普通老百姓来说,微信公众号就是一种网页文章制作工具,能够像使用ppt一样输出。至于制作什么样的文章,全由自己的创意,也看个人爱好。
安装ppt.pptx
你该知道提问题不要瞎问,很多问题都不是钱能解决的。看名字就是推广网址或文章。
中文版lxml
python挺好用,网页抓取,html解析,flask框架,数据库, 查看全部
excel抓取多页网页数据(安装excel抓取多页网页数据的方法可以参考以下步骤)
excel抓取多页网页数据的方法可以参考以下步骤:在excel中运行任意python脚本第一步:找到网站的url地址,可以在搜索引擎上搜索url地址,也可以在浏览器的地址栏搜索;第二步:用迅雷把该网页下载下来,可以先单击pdf,然后用迅雷打开;第三步:拷贝该url地址,然后一直拖动可以看到多个img链接;第四步:将其中的img链接拷贝至迅雷的主界面,直接右键点击;第五步:转换链接地址如下图所示:第六步:使用微软的ie浏览器的扩展程序把所需要的url地址转换成pdf文件;第七步:然后找到该pdf文件的路径,然后从迅雷里将其下载下来,可以直接把地址复制,也可以从迅雷里打开;第八步:直接用百度搜索excel的文件格式中已经有对应的代码,直接拷贝到代码编辑器中;第九步:双击整个下载文件第十步:这样就能把该页的所有网页图片上传到excel中,然后可以用excel打开。
对于目前国内的普通老百姓来说,微信公众号就是一种网页文章制作工具,能够像使用ppt一样输出。至于制作什么样的文章,全由自己的创意,也看个人爱好。
安装ppt.pptx
你该知道提问题不要瞎问,很多问题都不是钱能解决的。看名字就是推广网址或文章。
中文版lxml
python挺好用,网页抓取,html解析,flask框架,数据库,
excel抓取多页网页数据(用Excel进行数据汇总,再平常不过的需求单表汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2022-02-06 02:12
使用Excel进行数据汇总,最常见的需求
单表汇总:最常用的操作应该是小计、数据透视表等。这是最理想的方式,所有数据都在一个工作表中,便于汇总。但理想很丰富,现实却很骨感。这种方法在工作中很少见,多表汇总是我们不得不面对的需要。
多表汇总:无论是在本工作簿内还是跨工作簿,也可以解决多个合并计算数据区。以这种方式创建的数据透视表的一个明显缺点是只有一个行字段,并且只能是数据源左侧的第一列。如果仅针对一个角度进行聚合,这也是一种解决方案。不过N张工作表的数据全部整合为一张,只能统计一个视角,有些遗憾。
当然可以在数据源中设置一个辅助列,将一个单元格中的多列信息连接起来作为一个行字段,但归根结底只有一个行字段,起不到改变行字段的作用统计的角度,能治标不治本。
图:没有多少信息只是一个行字段
SQL join 语句:这当然是多表汇总的杀手锏。无论工作表是否跨工作簿,以这种方式创建的数据透视表都与单表数据透视一样简单。随意切换统计视角并生成各种报告似乎很完美。
让我们举个例子。五个销售部门分为五个工作簿,每个工作簿按月填写销售明细,需要多角度汇总。这个要求不应过分。无论是OLEDB还是Microsoft Query,写一条SQL连接语句都能完美解决。
不过写了这么多句子↓
图:SQL连接语句
已经可以看到 5 个工作簿中只有 15 个工作表,如果是一年的数据呢?也就是60个工作表,也就是说有60条SQL连接语句。
如果用电量查询来完成呢?一个公式就够了
事实上,power query 是一个数据采集工具,微软已经有一两年没有将它内置到 Excel 中了。在刚才的例子中,别说5个工作簿和15个工作表,十倍的数据相加就是一个公式。将强大的查询称为 SQL 连接语句的终结者并不为过。
我用的版本是office365订阅版,Excel内置电源查询,名字有点长,姑且称之为PQ。如果你的 Excel 没有 PQ 怎么办?
我们先来体会一下PQ的威力。文章 最后附上PQ的安装方法。当然,要不要安装PQ,你说了算。
文末有本章演示数据和结果获取方法
免责声明:本章提供的数据为虚构数据,并非真实数据
图:5个工作簿20个子表汇总
首先介绍一下要聚合的数据
这是5个销售部门的销售数据,位于5个工作簿中,每个工作簿的工作表按月记录。销售部成立时间不同,有的记录是3个月,有的记录是4个月,有的记录是6个月。现在需要从月份、各销售部门、销售区域、产品名称等不同角度对5个销售部门进行汇总。
图:演示数据
面对这样的数据和这样的要求,你怎么看?是的,数据透视表,它不是快速转换统计观点的强项吗!
快速将所有子表整合到一张工作表中,并与数据同步更新子表。我们已经到了这一点。是否使用小计或数据透视表取决于您?
想想就兴奋!
让我们开始吧!
创建摘要工作簿
创建一个新的 Excel 文档并将其命名为“摘要”。
图:新建 Excel 文档
打开“摘要”工作簿并添加一个文件夹。
操作路径:数据→获取数据→从文件→从文件夹→浏览到“E:\销售数据记录”→确定。
图:添加文件夹
在弹出的对话框中确认文件夹中的所有工作簿都已加载完毕后,点击“转换数据”。
图:加载的工作簿
这是自动打开的电源查询编辑器,并在“名称”列中进行过滤,只勾选少数销售部门。
图:取消勾选不需要汇总的工作簿
可以看到数据有 N 列。事实上,我们真正需要的只是前两列。其他列显示文件创建时间、加载时间和后缀名等信息,删除它们。
操作路径:Ctrl键选中前两列→删除列→删除其他列。
图:删除不需要的列
添加自定义列,输入公式,整个操作只需要输入这个公式。
操作路径:添加列→自定义列→输入公式:=Excel.Workbook([Content])→确定
图:添加自定义列
展开“数据”,因为段名称自动显示为“Custom.Data”。
操作路径:点击自定义旁边的按钮→只选择数据→确保单选为“展开”→确定
图:展开Data后,字段名称为“Custom.Data”
展开 Custom.Data
操作路径:点击自定义.Data旁边的按钮展开→单选展开→全选列→确定
图:展开 Custom.Data
数据合并成功,但是中间一行有N个子表字段。这些无用的行会影响我们的摘要。有多少子表就有多少无用的行。下一步就是解决这个问题。
图:中间一行有多余的字段
隐藏多余的行
操作路径:修改自定义列的字段名→过滤任意列→取消勾选不需要的内容
图:隐藏多余的行
好的,数据干净了,上传到Excel。
操作路径:首页→关闭上传
图:关闭并上传
我们来看看Excel中的情况。5个销售部门的数据全部整合,日期截止到6月份。估计这张表叫“总表”。
图:所有数据整合
刚才说了,分表的更新是同步到总表的,我们试试加个工作表吧。刚才最大的一个月是六月。通过筛选,我们发现这个数据属于第二销售部。现在,例如,第二销售部门添加了 7 月份的数据。
图:销售部2新增工作表
关闭销售的第二个工作簿,然后到总表刷新。通过过滤,7月份的数据已经同步到汇总表中。如果你使用 SQL 连接,你必须添加另一行语句来更新,但现在,我们要做的就是刷新它。
图:刷新后同步到主表
如果你使用这个整合的数据制作多个透视图,并在子表更新的时候全部刷新,所有的图表都会显示最新的结果。
图:刷新所有数据
好吧,我刚才说了,我们已经到了这个阶段,怎么操作就看我们的心情了,我就用数据透视表。整个过程只写了一个公式,你说PQ要上天了。
图:摘要演示
如何安装 PQ
好的,你决定安装 PQ 了吗?如下图,在今日头条搜索“powerquery安装”。
安装过程不用多说,在互联网时代,一切都是那么简单。
图:今日头条搜索安装方法
如果您对数据透视图感兴趣,请不要害怕查看我的专栏,它只讨论数据透视图。
与列一样,必须为每个实例提供演示数据。私信“jbt3”获取本章demo数据及成果。 查看全部
excel抓取多页网页数据(用Excel进行数据汇总,再平常不过的需求单表汇总)
使用Excel进行数据汇总,最常见的需求
单表汇总:最常用的操作应该是小计、数据透视表等。这是最理想的方式,所有数据都在一个工作表中,便于汇总。但理想很丰富,现实却很骨感。这种方法在工作中很少见,多表汇总是我们不得不面对的需要。
多表汇总:无论是在本工作簿内还是跨工作簿,也可以解决多个合并计算数据区。以这种方式创建的数据透视表的一个明显缺点是只有一个行字段,并且只能是数据源左侧的第一列。如果仅针对一个角度进行聚合,这也是一种解决方案。不过N张工作表的数据全部整合为一张,只能统计一个视角,有些遗憾。
当然可以在数据源中设置一个辅助列,将一个单元格中的多列信息连接起来作为一个行字段,但归根结底只有一个行字段,起不到改变行字段的作用统计的角度,能治标不治本。
图:没有多少信息只是一个行字段
SQL join 语句:这当然是多表汇总的杀手锏。无论工作表是否跨工作簿,以这种方式创建的数据透视表都与单表数据透视一样简单。随意切换统计视角并生成各种报告似乎很完美。
让我们举个例子。五个销售部门分为五个工作簿,每个工作簿按月填写销售明细,需要多角度汇总。这个要求不应过分。无论是OLEDB还是Microsoft Query,写一条SQL连接语句都能完美解决。
不过写了这么多句子↓
图:SQL连接语句
已经可以看到 5 个工作簿中只有 15 个工作表,如果是一年的数据呢?也就是60个工作表,也就是说有60条SQL连接语句。
如果用电量查询来完成呢?一个公式就够了
事实上,power query 是一个数据采集工具,微软已经有一两年没有将它内置到 Excel 中了。在刚才的例子中,别说5个工作簿和15个工作表,十倍的数据相加就是一个公式。将强大的查询称为 SQL 连接语句的终结者并不为过。
我用的版本是office365订阅版,Excel内置电源查询,名字有点长,姑且称之为PQ。如果你的 Excel 没有 PQ 怎么办?
我们先来体会一下PQ的威力。文章 最后附上PQ的安装方法。当然,要不要安装PQ,你说了算。
文末有本章演示数据和结果获取方法
免责声明:本章提供的数据为虚构数据,并非真实数据
图:5个工作簿20个子表汇总
首先介绍一下要聚合的数据
这是5个销售部门的销售数据,位于5个工作簿中,每个工作簿的工作表按月记录。销售部成立时间不同,有的记录是3个月,有的记录是4个月,有的记录是6个月。现在需要从月份、各销售部门、销售区域、产品名称等不同角度对5个销售部门进行汇总。
图:演示数据
面对这样的数据和这样的要求,你怎么看?是的,数据透视表,它不是快速转换统计观点的强项吗!
快速将所有子表整合到一张工作表中,并与数据同步更新子表。我们已经到了这一点。是否使用小计或数据透视表取决于您?
想想就兴奋!
让我们开始吧!
创建摘要工作簿
创建一个新的 Excel 文档并将其命名为“摘要”。
图:新建 Excel 文档
打开“摘要”工作簿并添加一个文件夹。
操作路径:数据→获取数据→从文件→从文件夹→浏览到“E:\销售数据记录”→确定。
图:添加文件夹
在弹出的对话框中确认文件夹中的所有工作簿都已加载完毕后,点击“转换数据”。
图:加载的工作簿
这是自动打开的电源查询编辑器,并在“名称”列中进行过滤,只勾选少数销售部门。
图:取消勾选不需要汇总的工作簿
可以看到数据有 N 列。事实上,我们真正需要的只是前两列。其他列显示文件创建时间、加载时间和后缀名等信息,删除它们。
操作路径:Ctrl键选中前两列→删除列→删除其他列。
图:删除不需要的列
添加自定义列,输入公式,整个操作只需要输入这个公式。
操作路径:添加列→自定义列→输入公式:=Excel.Workbook([Content])→确定
图:添加自定义列
展开“数据”,因为段名称自动显示为“Custom.Data”。
操作路径:点击自定义旁边的按钮→只选择数据→确保单选为“展开”→确定
图:展开Data后,字段名称为“Custom.Data”
展开 Custom.Data
操作路径:点击自定义.Data旁边的按钮展开→单选展开→全选列→确定
图:展开 Custom.Data
数据合并成功,但是中间一行有N个子表字段。这些无用的行会影响我们的摘要。有多少子表就有多少无用的行。下一步就是解决这个问题。
图:中间一行有多余的字段
隐藏多余的行
操作路径:修改自定义列的字段名→过滤任意列→取消勾选不需要的内容
图:隐藏多余的行
好的,数据干净了,上传到Excel。
操作路径:首页→关闭上传
图:关闭并上传
我们来看看Excel中的情况。5个销售部门的数据全部整合,日期截止到6月份。估计这张表叫“总表”。
图:所有数据整合
刚才说了,分表的更新是同步到总表的,我们试试加个工作表吧。刚才最大的一个月是六月。通过筛选,我们发现这个数据属于第二销售部。现在,例如,第二销售部门添加了 7 月份的数据。
图:销售部2新增工作表
关闭销售的第二个工作簿,然后到总表刷新。通过过滤,7月份的数据已经同步到汇总表中。如果你使用 SQL 连接,你必须添加另一行语句来更新,但现在,我们要做的就是刷新它。
图:刷新后同步到主表
如果你使用这个整合的数据制作多个透视图,并在子表更新的时候全部刷新,所有的图表都会显示最新的结果。
图:刷新所有数据
好吧,我刚才说了,我们已经到了这个阶段,怎么操作就看我们的心情了,我就用数据透视表。整个过程只写了一个公式,你说PQ要上天了。
图:摘要演示
如何安装 PQ
好的,你决定安装 PQ 了吗?如下图,在今日头条搜索“powerquery安装”。
安装过程不用多说,在互联网时代,一切都是那么简单。
图:今日头条搜索安装方法
如果您对数据透视图感兴趣,请不要害怕查看我的专栏,它只讨论数据透视图。
与列一样,必须为每个实例提供演示数据。私信“jbt3”获取本章demo数据及成果。
excel抓取多页网页数据(为什么说Excel就好比老人机呢?(附数据透视分析工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-05 10:00
在大数据分析时代,涌现了大量的大数据分析软件。即便如此,如果有人问今天最常用的数据透视分析工具是什么,我想 Excel 应该是每个人的最佳选择。
但其实我想说的是,用现在的手机做个比喻,Excel就像一台老式电脑。当大家都在使用新一代的“智能手机”——Smartbi 的时候,你还在用老式的电脑,所以相比之下,就像被吊死在街上一样。
为什么说 Excel 就像一台旧电脑?
1、Excel数据分析处理能力低,几十万条数据半天转不了。
2、Excel 上手容易,精通难。一旦你想做更深入的操作,你会发现操作非常复杂和繁琐。
3、Excel美化图表比较难,即使可以美化,生成的图表也不够漂亮。
那为什么说Smartbi是新一代的“智能手机”呢?
Smartbi是一款面向Excel用户的自助数据分析工具,将Excel和BI有机结合,让业务人员轻松掌握。目前是国内知名的BI产品。用它来做数据透视分析可以带来很大的效率提升,因为和Tableau等国外BI工具相比,国产Smartbi非常符合中国的数据分析思维。
易学易用:无需学习新的BI产品,用Excel即可完成BI分析,学习成本极低。
功能强大:充分保留Excel数据处理和数据分析能力,结合自助BI丰富的数据准备、数据共享、企业级安全管控。
资源复用:大量Excel模板可复用,企业资源得到充分利用。
效率提升:前线作战单位可随时获取Excel最新数据分析,告别重复衍生。
这种自助式BI经常被用作大数据前端展示和大数据分析案例报告制作的工具,甚至作为数据透视分析工具有点矫枉过正。Smartbi可以打通各种数据源,其丰富的数据连接能力可以抓取各种数据源的数据进行分析。除了支持oracle、sqlserver、mysql等常用的关系型数据库,各种主流大型数据库、非关系型数据库、多维数据库、本地文件如:excel、txt、csv。此外,它还支持带有自定义编写接口的java数据源。从数据连接能力来看,smartbi与企业数据平台的连接能力更强,并且还在各个版本的发布中不断更新。
Smartbi 透视分析功能和亮点
通过 Smartbi,这些任务得到了极大的简化。借助“类Excel数据透视表”设计,多维分析不再需要建立模型,可以结合维度、汇总计算、切片、钻取、洞察数据。不仅如此,任何字段都可以直接作为输出字段或过滤条件,方便查询和探索数据。
广告FRM认证相当于硕士学位,是金融风险管理的全球标准。^^ 立即接受挑战并报名参加 2022 年 5 月的 FRM 考试。
大数据量处理,解决用户excel分析和操作痛点:
数据量过大:底层宽表超过1亿,无法加载到Excel中分析;
PC端计算慢:Excel文件计算公式复杂,打开前端Excel需要20分钟;
Smartbi大数据分析解决方案
数据准备:通过透视分析+SmartbiMPP初步汇总数据,1亿行à30万行;
报表计算:支持个人Excel端计算,也支持服务器(集群)计算;
定时报表:后台自动统计报表,导出为Excel文件,无需公式;
广告数据中台——集数据采集、分析、开发于一体,以快速响应和“数据中台”的方法和技术,为用户提供更加灵活、高效、低成本的数据处理^^
复用模板分析,解决用户excel分析操作痛点:
商务人士手上有大量基于 Excel 的分析模板,想重复使用
计算处理逻辑复杂,其他分析工具根本做不到
Smartbi大数据分析解决方案
模板和数据分离;
复用模板,动态更新数据;
通过网络链接安全共享
广告积累了12年的市场调研经验/技术/数据,根据企业需求提供专业高效的线上线下调研解决方案。^^800万+自有样本数据库,100多个网络联盟...
分析结果,一链发布,解决用户excel分析和操作痛点:
报表存在于Excel文件中,大部分用户通过电子邮件或即时通讯软件共享Excel文件,文件满天飞,难以管理;
对于权限系统的管控来说,分发的便利性还不够好。
Smartbi大数据分析解决方案
将编制好的报表发布到服务器进行浏览和管理,或者通过Web链接分享发布的报表,实现数据的实时更新;
您可以在分享前在报表中设置资源权限、数据权限、权限,让不同的用户看到不同的资源。
广告数据图表制作 Top,零编码,网页数据图表制作拖放式设计,5分钟报表制作,一站式数据分析。^^ 数据图制作效果,让老大站起来……
显然,在当前的信息时代,借助Smartbi这些大数据分析工具,企业可以加速整合企业数据分析的趋势。市场认可的软件其实有很多,选择要根据实际情况。一般情况下,建议选择市面上比较主流的产品,比较容易取得好的效果。目前,Smartbi在口碑上是领先的企业数据分析BI软件市场。 查看全部
excel抓取多页网页数据(为什么说Excel就好比老人机呢?(附数据透视分析工具))
在大数据分析时代,涌现了大量的大数据分析软件。即便如此,如果有人问今天最常用的数据透视分析工具是什么,我想 Excel 应该是每个人的最佳选择。
但其实我想说的是,用现在的手机做个比喻,Excel就像一台老式电脑。当大家都在使用新一代的“智能手机”——Smartbi 的时候,你还在用老式的电脑,所以相比之下,就像被吊死在街上一样。
为什么说 Excel 就像一台旧电脑?
1、Excel数据分析处理能力低,几十万条数据半天转不了。
2、Excel 上手容易,精通难。一旦你想做更深入的操作,你会发现操作非常复杂和繁琐。
3、Excel美化图表比较难,即使可以美化,生成的图表也不够漂亮。
那为什么说Smartbi是新一代的“智能手机”呢?
Smartbi是一款面向Excel用户的自助数据分析工具,将Excel和BI有机结合,让业务人员轻松掌握。目前是国内知名的BI产品。用它来做数据透视分析可以带来很大的效率提升,因为和Tableau等国外BI工具相比,国产Smartbi非常符合中国的数据分析思维。
易学易用:无需学习新的BI产品,用Excel即可完成BI分析,学习成本极低。
功能强大:充分保留Excel数据处理和数据分析能力,结合自助BI丰富的数据准备、数据共享、企业级安全管控。
资源复用:大量Excel模板可复用,企业资源得到充分利用。
效率提升:前线作战单位可随时获取Excel最新数据分析,告别重复衍生。
这种自助式BI经常被用作大数据前端展示和大数据分析案例报告制作的工具,甚至作为数据透视分析工具有点矫枉过正。Smartbi可以打通各种数据源,其丰富的数据连接能力可以抓取各种数据源的数据进行分析。除了支持oracle、sqlserver、mysql等常用的关系型数据库,各种主流大型数据库、非关系型数据库、多维数据库、本地文件如:excel、txt、csv。此外,它还支持带有自定义编写接口的java数据源。从数据连接能力来看,smartbi与企业数据平台的连接能力更强,并且还在各个版本的发布中不断更新。
Smartbi 透视分析功能和亮点
通过 Smartbi,这些任务得到了极大的简化。借助“类Excel数据透视表”设计,多维分析不再需要建立模型,可以结合维度、汇总计算、切片、钻取、洞察数据。不仅如此,任何字段都可以直接作为输出字段或过滤条件,方便查询和探索数据。
广告FRM认证相当于硕士学位,是金融风险管理的全球标准。^^ 立即接受挑战并报名参加 2022 年 5 月的 FRM 考试。
大数据量处理,解决用户excel分析和操作痛点:
数据量过大:底层宽表超过1亿,无法加载到Excel中分析;
PC端计算慢:Excel文件计算公式复杂,打开前端Excel需要20分钟;
Smartbi大数据分析解决方案
数据准备:通过透视分析+SmartbiMPP初步汇总数据,1亿行à30万行;
报表计算:支持个人Excel端计算,也支持服务器(集群)计算;
定时报表:后台自动统计报表,导出为Excel文件,无需公式;
广告数据中台——集数据采集、分析、开发于一体,以快速响应和“数据中台”的方法和技术,为用户提供更加灵活、高效、低成本的数据处理^^
复用模板分析,解决用户excel分析操作痛点:
商务人士手上有大量基于 Excel 的分析模板,想重复使用
计算处理逻辑复杂,其他分析工具根本做不到
Smartbi大数据分析解决方案
模板和数据分离;
复用模板,动态更新数据;
通过网络链接安全共享
广告积累了12年的市场调研经验/技术/数据,根据企业需求提供专业高效的线上线下调研解决方案。^^800万+自有样本数据库,100多个网络联盟...
分析结果,一链发布,解决用户excel分析和操作痛点:
报表存在于Excel文件中,大部分用户通过电子邮件或即时通讯软件共享Excel文件,文件满天飞,难以管理;
对于权限系统的管控来说,分发的便利性还不够好。
Smartbi大数据分析解决方案
将编制好的报表发布到服务器进行浏览和管理,或者通过Web链接分享发布的报表,实现数据的实时更新;
您可以在分享前在报表中设置资源权限、数据权限、权限,让不同的用户看到不同的资源。
广告数据图表制作 Top,零编码,网页数据图表制作拖放式设计,5分钟报表制作,一站式数据分析。^^ 数据图制作效果,让老大站起来……
显然,在当前的信息时代,借助Smartbi这些大数据分析工具,企业可以加速整合企业数据分析的趋势。市场认可的软件其实有很多,选择要根据实际情况。一般情况下,建议选择市面上比较主流的产品,比较容易取得好的效果。目前,Smartbi在口碑上是领先的企业数据分析BI软件市场。
excel抓取多页网页数据(excel抓取多页网页数据,再分表操作的办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-05 01:02
excel抓取多页网页数据,可以使用excel批量导入格式,生成数据表,再分表操作的办法。
1)修改excel数据表的名称。选中excel工作簿名称,按快捷键f5打开资源管理器,然后单击excel文件夹下的access文件夹,会看到excel工作簿,单击即可。单击第一个工作表,选择数据透视表,根据需要点击添加表。
2)新建透视表的标题格式随便选一个。新建透视表后,按下组合键ctrl+鼠标滚轮,透视表层次显示,这是左右两个窗口显示,中间的透视表是空的。之后点击组合键ctrl+e,制定连接属性,即可显示透视表中的表格。
3)写在第二行。点击下表中的第二行,ctrl+鼠标滚轮调整,直到看到下图所示单元格格式数据,即可。也可以设置单元格格式字体颜色,例如将数字字体设置为黄色,这样就更有动感。
4)设置截止时间,单击确定即可。
5)选中透视表中的所有工作表。右键单击选择编辑数据源。将数据源中的每一列数据拖到行字段,并指定所选数据的自定义格式(默认情况下是居中对齐),便可完成。
6)设置数据的升序和降序,如果需要重复采用多个列,只需要设置几个就可以了。操作步骤同第3步。保存数据透视表至文件夹,即可根据需要下载excel文件。希望我的教程能够帮助到您,如果有什么问题可以留言。 查看全部
excel抓取多页网页数据(excel抓取多页网页数据,再分表操作的办法)
excel抓取多页网页数据,可以使用excel批量导入格式,生成数据表,再分表操作的办法。
1)修改excel数据表的名称。选中excel工作簿名称,按快捷键f5打开资源管理器,然后单击excel文件夹下的access文件夹,会看到excel工作簿,单击即可。单击第一个工作表,选择数据透视表,根据需要点击添加表。
2)新建透视表的标题格式随便选一个。新建透视表后,按下组合键ctrl+鼠标滚轮,透视表层次显示,这是左右两个窗口显示,中间的透视表是空的。之后点击组合键ctrl+e,制定连接属性,即可显示透视表中的表格。
3)写在第二行。点击下表中的第二行,ctrl+鼠标滚轮调整,直到看到下图所示单元格格式数据,即可。也可以设置单元格格式字体颜色,例如将数字字体设置为黄色,这样就更有动感。
4)设置截止时间,单击确定即可。
5)选中透视表中的所有工作表。右键单击选择编辑数据源。将数据源中的每一列数据拖到行字段,并指定所选数据的自定义格式(默认情况下是居中对齐),便可完成。
6)设置数据的升序和降序,如果需要重复采用多个列,只需要设置几个就可以了。操作步骤同第3步。保存数据透视表至文件夹,即可根据需要下载excel文件。希望我的教程能够帮助到您,如果有什么问题可以留言。
excel抓取多页网页数据(excel抓取多页网页数据,excel在文本数据之间进行数据关联)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-04 15:04
excel抓取多页网页数据,excel在文本数据之间进行数据关联(文本转化为数字形式)vlookup函数根据关联对象获取指定行/列的值lookup函数根据选定值到指定值的一系列值lookup函数既可以和excellookup函数一起使用也可以单独使用,可以查询多个信息,返回多个值。当excel的字符串没有包含文本字符的时候,excel将全部返回,字符串不包含文本字符的时候,返回所有文本字符。
动图演示示例1:选择某段数据---使用excel函数公式解析:选择某段数据并返回指定字符串或者文本的数据,字符串必须是文本,字符串不可以是数字。选择两列数据,此时如果字符串是不可见字符,将全部返回。示例2:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。
示例3:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。excel2016表格操作技巧来源:excel精英培训附:16g资料包,初级会计、cpa、会计做账、excel技巧应有尽有,传送门放在评论里。
刚好最近工作中遇到了这个需求,把我觉得最常用的一些网站列举一下。
一、站酷站酷在网上做一次搜索、在线查看前几名大师作品都可以直接获得作品列表地址。
1、站酷首页-站酷(zcool)
2、站酷(zcool)
3、站酷cc-站酷旗下品牌专业人士交流平台-站酷(zcool)
二、youdie闲鱼直接注册账号、参与他人闲置以赚取闲置佣金即可得到作品列表地址,最多可添加二十条。
1、闲鱼-个人卖家发布闲置物品
2、闲鱼-个人卖家发布闲置物品
3、闲鱼大讲堂-个人卖家发布闲置
4、闲鱼大讲堂
4、闲鱼x其他闲鱼大讲堂、闲鱼大讲堂上面几个站酷、闲鱼上经常有大佬发一些自己搞定制,原创等教程,你多翻翻绝对可以得到答案;有些教程列表里有附上原始报价,你可以看看有没有自己的接受范围,直接下单买就可以了。
动手查看教程地址:《youdie智能手绘班》-时间就是金钱《youdie智能手绘班》
三、联盟联盟是阿里巴巴旗下的b2c转卖平台,每年发布的链接加起来超过3000亿次,你可以选择优质商品直接在联盟上卖出,有利于拉动店铺流量。
四、返利疯狂买东西后,平台会将你的中转链接发给推广者(网个人用户),推广者会将佣金自动分给中转链接收集者(返利平台),你可以将你的中转链接直接分享给你的朋友以及你的同事同学,你们便可以共同分享利益。动手查看教程地址::、微信返利网微信返利网目前有免费测试版, 查看全部
excel抓取多页网页数据(excel抓取多页网页数据,excel在文本数据之间进行数据关联)
excel抓取多页网页数据,excel在文本数据之间进行数据关联(文本转化为数字形式)vlookup函数根据关联对象获取指定行/列的值lookup函数根据选定值到指定值的一系列值lookup函数既可以和excellookup函数一起使用也可以单独使用,可以查询多个信息,返回多个值。当excel的字符串没有包含文本字符的时候,excel将全部返回,字符串不包含文本字符的时候,返回所有文本字符。
动图演示示例1:选择某段数据---使用excel函数公式解析:选择某段数据并返回指定字符串或者文本的数据,字符串必须是文本,字符串不可以是数字。选择两列数据,此时如果字符串是不可见字符,将全部返回。示例2:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。
示例3:选择多列数据---使用excel函数公式解析:选择多列数据,此时如果字符串是不可见字符,将全部返回。excel2016表格操作技巧来源:excel精英培训附:16g资料包,初级会计、cpa、会计做账、excel技巧应有尽有,传送门放在评论里。
刚好最近工作中遇到了这个需求,把我觉得最常用的一些网站列举一下。
一、站酷站酷在网上做一次搜索、在线查看前几名大师作品都可以直接获得作品列表地址。
1、站酷首页-站酷(zcool)
2、站酷(zcool)
3、站酷cc-站酷旗下品牌专业人士交流平台-站酷(zcool)
二、youdie闲鱼直接注册账号、参与他人闲置以赚取闲置佣金即可得到作品列表地址,最多可添加二十条。
1、闲鱼-个人卖家发布闲置物品
2、闲鱼-个人卖家发布闲置物品
3、闲鱼大讲堂-个人卖家发布闲置
4、闲鱼大讲堂
4、闲鱼x其他闲鱼大讲堂、闲鱼大讲堂上面几个站酷、闲鱼上经常有大佬发一些自己搞定制,原创等教程,你多翻翻绝对可以得到答案;有些教程列表里有附上原始报价,你可以看看有没有自己的接受范围,直接下单买就可以了。
动手查看教程地址:《youdie智能手绘班》-时间就是金钱《youdie智能手绘班》
三、联盟联盟是阿里巴巴旗下的b2c转卖平台,每年发布的链接加起来超过3000亿次,你可以选择优质商品直接在联盟上卖出,有利于拉动店铺流量。
四、返利疯狂买东西后,平台会将你的中转链接发给推广者(网个人用户),推广者会将佣金自动分给中转链接收集者(返利平台),你可以将你的中转链接直接分享给你的朋友以及你的同事同学,你们便可以共同分享利益。动手查看教程地址::、微信返利网微信返利网目前有免费测试版,

