
通过关键词采集文章采集api
用R搜集和映射脸书数据的初学者向导
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-17 01:01
学习使用 R 的 twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
当我开始学习 R ,我也须要学习怎么出于研究的目的地搜集脸书数据并对其进行映射。尽管网上关于这个话题的信息好多,但我发现无法理解哪些与搜集并映射脸书数据相关。我除了是个 R 菜鸟,而且对各类教程中技术名词不熟悉。但虽然困难重重,我成功了!在这个教程里,我将以一种菜鸟程序员都能读懂的方法来功略怎么搜集脸书数据并来临展如今地图中。
创建应用程序
如果你没有脸书账号,首先你须要 注册一个。然后,到 创建一个容许你搜集脸书数据的应用程序。别担心,创建应用程序十分简单。你创建的应用程序会与脸书应用程序插口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其它程序帮你做事。这样一来,你可以接入脸书 API 令其搜集数据。只需确保不要恳求太多,因为脸书数据恳求次数是有限制 的。
采集推文有两个可用的 API 。你若果做一次性的推文搜集,那么使用 REST API. 若是想在特定时间内持续搜集,可以用 streaming API。教程中我主要使用 REST API。
创建应用程序以后,前往 Keys and Access Tokens 标签。你须要 Consumer Key (API key)、 Consumer Secret (API secret)、 Access Token 和 Access Token Secret 才能在 R 中访问你的应用程序。
采集脸书数据
下一步是打开 R 准备写代码。对于初学者,我推荐使用 RStudio,这是 R 的集成开发环境 (IDE) 。我发觉 RStudio 在解决问题和测试代码时很实用。 R 有访问该 REST API 的包叫 twitteR。
打开 RStudio 并新建 RScript。做好这种以后,你须要安装和加载 twitteR 包:
install.packages("twitteR")#安装TwitteRlibrary(twitteR)#载入TwitteR
安装并载入 twitteR 包然后,你得输入上文提到的应用程序的 API 信息:
api_key""#在冒号内装入你的APIkeyapi_secret""#在冒号内装入你的APIsecrettokentoken""#在冒号内装入你的tokentoken_secret""#在冒号内装入你的tokensecret
接下来,连接脸书访问 API:
setup_twitter_oauth(api_key,api_secret,token,token_secret)
我们来试试使脸书搜索有关社区新苑和农夫市场:
tweets"communitygardenOR#communitygardenORfarmersmarketOR#farmersmarket",n=200,lang="en")
这个代码意思是搜索前 200 篇 (n = 200) 英文 (lang = "en") 的推文, 包括关键词 community garden 或 farmers market 或任何提到这种关键词的话题标签。
推特搜索完成以后,在数据框中保存你的结果:
tweets.df
为了用推文创建地图,你须要搜集的导入为 .csv 文件:
write.csv(tweets.df,"C:\Users\YourName\Documents\ApptoMap\tweets.csv")#anexampleofafileextensionofthefolderinwhichyouwanttosavethe.csvfile.
运行前确保 R 代码已保存之后继续进行下一步。.
生成地图
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 Leaflet 做一个基本的应用程序,这是一个生成交互式地图的热门 JavaScript 库。 Leaflet 使用 magrittr 管道运算符 (%>%), 由于其句型自然,易于写代码。刚接触可能有点奇怪,但它确实增加了写代码的工作量。
为了清晰起见,在 RStudio 打开一个新的 R 脚本安装这种包:
install.packages("leaflet")install.packages("maps")library(leaflet)library(maps)
现在须要一个路径使 Leaflet 访问你的数据:
read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv",stringsAsFactors=FALSE)
stringAsFactors = FALSE 意思是保留信息,不将它转化成 factors。 (想了解 factors,读这篇文章"stringsAsFactors: An unauthorized biography", 作者 Roger Peng)
是时侯制做你的 Leaflet 地图了。我们将使用 OpenStreetMap基本地图来做你的地图:
m%addTiles()
我们在基本地图上加个圈。对于 lng 和 lat,输入收录推文的经纬度的列名,并在上面加个~。 ~longitude 和 ~latitude 指向你的 .csv 文件中与列名:
m%>%addCircles(lng=~longitude,lat=~latitude,popup=mymap$type,weight=8,radius=40,color="#fb3004",stroke=TRUE,fillOpacity=0.8)
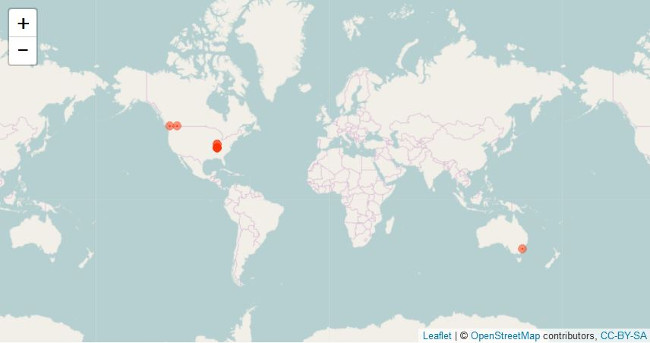
运行你的代码。会弹出网页浏览器并展示你的地图。这是我后面搜集的推文的地图:
推文定位地图
带定位的推文地图,使用了 Leaflet 和 OpenStreetMap CC-BY-SA
虽然你可能会对地图上的图文数目这么之小倍感惊奇,通常只有 1% 的推文记录了地理编码。我搜集了总量为 366 的推文,但只有 10(大概总推文的 3%)是记录了地理编码的。如果你为得到记录了地理编码的推文而困惑,改变搜索关键词瞧瞧能不能得到更好的结果。
总结
对于初学者,把以上所有碎片结合上去,从脸书数据生成一个 Leaflet 地图可能太艰辛。 这个教程基于我完成这个任务的经验,我希望它能使你的学习过程显得更轻松。
(题图:琼斯·贝克. CC BY-SA 4.0. 来源: Cloud, Globe. Both CC0.)
作者:Dorris Scott 查看全部
用R搜集和映射脸书数据的初学者向导

学习使用 R 的 twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
当我开始学习 R ,我也须要学习怎么出于研究的目的地搜集脸书数据并对其进行映射。尽管网上关于这个话题的信息好多,但我发现无法理解哪些与搜集并映射脸书数据相关。我除了是个 R 菜鸟,而且对各类教程中技术名词不熟悉。但虽然困难重重,我成功了!在这个教程里,我将以一种菜鸟程序员都能读懂的方法来功略怎么搜集脸书数据并来临展如今地图中。
创建应用程序
如果你没有脸书账号,首先你须要 注册一个。然后,到 创建一个容许你搜集脸书数据的应用程序。别担心,创建应用程序十分简单。你创建的应用程序会与脸书应用程序插口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其它程序帮你做事。这样一来,你可以接入脸书 API 令其搜集数据。只需确保不要恳求太多,因为脸书数据恳求次数是有限制 的。
采集推文有两个可用的 API 。你若果做一次性的推文搜集,那么使用 REST API. 若是想在特定时间内持续搜集,可以用 streaming API。教程中我主要使用 REST API。
创建应用程序以后,前往 Keys and Access Tokens 标签。你须要 Consumer Key (API key)、 Consumer Secret (API secret)、 Access Token 和 Access Token Secret 才能在 R 中访问你的应用程序。
采集脸书数据
下一步是打开 R 准备写代码。对于初学者,我推荐使用 RStudio,这是 R 的集成开发环境 (IDE) 。我发觉 RStudio 在解决问题和测试代码时很实用。 R 有访问该 REST API 的包叫 twitteR。
打开 RStudio 并新建 RScript。做好这种以后,你须要安装和加载 twitteR 包:
install.packages("twitteR")#安装TwitteRlibrary(twitteR)#载入TwitteR
安装并载入 twitteR 包然后,你得输入上文提到的应用程序的 API 信息:
api_key""#在冒号内装入你的APIkeyapi_secret""#在冒号内装入你的APIsecrettokentoken""#在冒号内装入你的tokentoken_secret""#在冒号内装入你的tokensecret
接下来,连接脸书访问 API:
setup_twitter_oauth(api_key,api_secret,token,token_secret)
我们来试试使脸书搜索有关社区新苑和农夫市场:
tweets"communitygardenOR#communitygardenORfarmersmarketOR#farmersmarket",n=200,lang="en")
这个代码意思是搜索前 200 篇 (n = 200) 英文 (lang = "en") 的推文, 包括关键词 community garden 或 farmers market 或任何提到这种关键词的话题标签。
推特搜索完成以后,在数据框中保存你的结果:
tweets.df
为了用推文创建地图,你须要搜集的导入为 .csv 文件:
write.csv(tweets.df,"C:\Users\YourName\Documents\ApptoMap\tweets.csv")#anexampleofafileextensionofthefolderinwhichyouwanttosavethe.csvfile.
运行前确保 R 代码已保存之后继续进行下一步。.
生成地图
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 Leaflet 做一个基本的应用程序,这是一个生成交互式地图的热门 JavaScript 库。 Leaflet 使用 magrittr 管道运算符 (%>%), 由于其句型自然,易于写代码。刚接触可能有点奇怪,但它确实增加了写代码的工作量。
为了清晰起见,在 RStudio 打开一个新的 R 脚本安装这种包:
install.packages("leaflet")install.packages("maps")library(leaflet)library(maps)
现在须要一个路径使 Leaflet 访问你的数据:
read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv",stringsAsFactors=FALSE)
stringAsFactors = FALSE 意思是保留信息,不将它转化成 factors。 (想了解 factors,读这篇文章"stringsAsFactors: An unauthorized biography", 作者 Roger Peng)
是时侯制做你的 Leaflet 地图了。我们将使用 OpenStreetMap基本地图来做你的地图:
m%addTiles()
我们在基本地图上加个圈。对于 lng 和 lat,输入收录推文的经纬度的列名,并在上面加个~。 ~longitude 和 ~latitude 指向你的 .csv 文件中与列名:
m%>%addCircles(lng=~longitude,lat=~latitude,popup=mymap$type,weight=8,radius=40,color="#fb3004",stroke=TRUE,fillOpacity=0.8)
运行你的代码。会弹出网页浏览器并展示你的地图。这是我后面搜集的推文的地图:
推文定位地图
带定位的推文地图,使用了 Leaflet 和 OpenStreetMap CC-BY-SA
虽然你可能会对地图上的图文数目这么之小倍感惊奇,通常只有 1% 的推文记录了地理编码。我搜集了总量为 366 的推文,但只有 10(大概总推文的 3%)是记录了地理编码的。如果你为得到记录了地理编码的推文而困惑,改变搜索关键词瞧瞧能不能得到更好的结果。
总结
对于初学者,把以上所有碎片结合上去,从脸书数据生成一个 Leaflet 地图可能太艰辛。 这个教程基于我完成这个任务的经验,我希望它能使你的学习过程显得更轻松。
(题图:琼斯·贝克. CC BY-SA 4.0. 来源: Cloud, Globe. Both CC0.)
作者:Dorris Scott
Facebook内容采集/用户信息数据抓取API爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 1901 次浏览 • 2020-08-16 21:38
上个月老朋友给我介绍了一个可以采Facebook内容和用户信息的第三方API爬虫提供商iDataAPI,连续一周的百万条级别测试发觉稳定性不错,准备加入到下半年向省里申报的海外信息数据检测项目当中。
Facebook官方即使提供了Graph API,不过好多信息在最新版本的API中是不提供的。比如按照关键字搜索用户发贴等等。通过PC端的web页面抓取难度也很大,因为Facebook的页面使用了大量的js脚本动态加载数据,所以据说她们研制了云端分布式&手机端抓取数据的爬虫,就太感兴趣试一试,测试结果符合预期。
我们主要用到的功能如下:
根据关键字抓取用户的时间线抓取某用户的资料抓取某用户的好友抓取某用户的贴子
通过使用这几项功能最终可以生成一个关系网路,为后序的NLP工作打下基础。基于这个API爬虫,后续进一步接入舆情监测,情感剖析,意见挖掘等等。
这个iDataAPI提供包括一个完整的web控制界面,可以在浏览器中测试爬虫(facebook、twitter、微博、youtube...测了都很不多的,难得),后台可以完整的创建任务、查看日志、查看数据,普通开发者注册就送钱免费测试了。只是目前项目还在申报期,我们研究院须要的量级比较大,等前面签个协议包月,加上TWITTER这种,每天恐怕得采集个千万条。
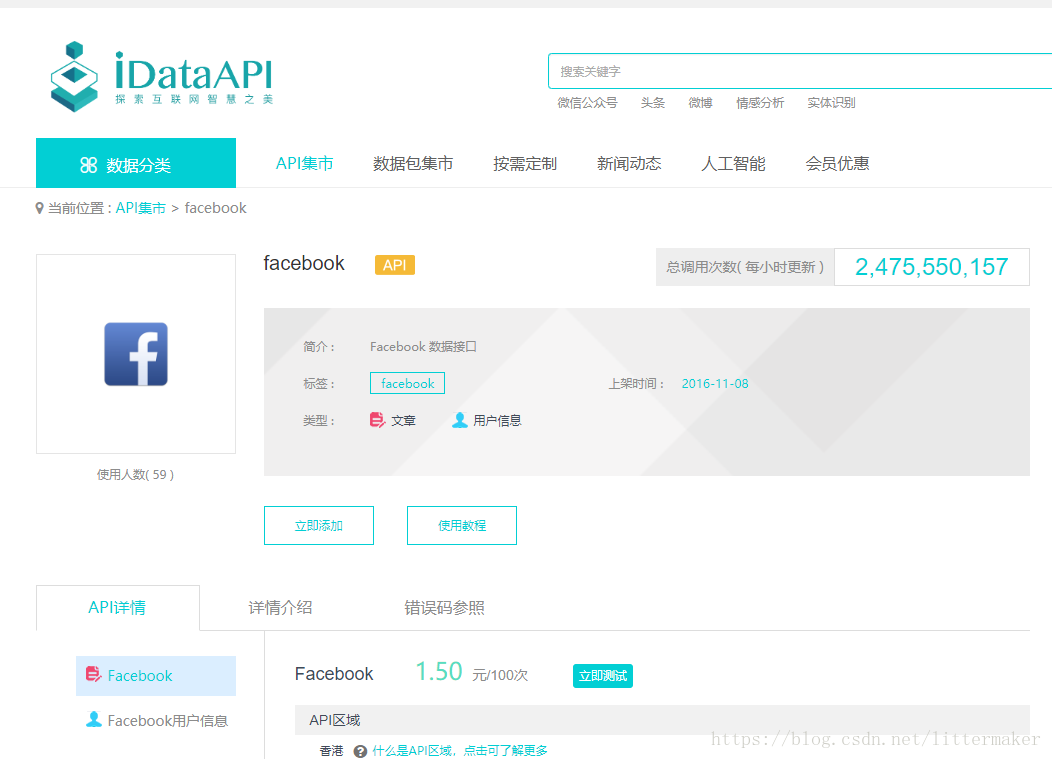
返回示例值(FACEBOOK帖子){ "hasNext": true, "retcode": "000000", "appCode": "facebook", "dataType": "post", "pageToken": "enc_AdBhgxzOwy0fZBFjW6GXwbjJDRUca1SS5ccSTKp4TvchMAF3De0qdfVEC8sZAcCQZCw1CtORi9eLls3iJvJJk8PlNIQ|1493425239", "data": [ { "posterId": "4", "commentCount": 76221, "posterScreenName": "Mark Zuckerberg", "title": null, "url": "https:\/\/www.facebook.com\/4_10103685865597591", "imageUrls": [ "https:\/\/fb-s-d-a.akamaihd.net\/h-ak-xtp1\/v\/t15.0-10\/s720x720\/18223192_10103685908017581_8465195272706719744_n.jpg?_nc_ad=z-m&oh=e0736750f4882bed329ad89749849443&oe=59C22C86&__gda__=1505738387_e11048d689aba9e12e3fef771eab44f5" ], "originUrl": "https:\/\/www.facebook.com\/zuck\/videos\/10103685865597591\/", "geoPoint": "37.484, -122.149", "mediaType": "video", "publishDate": 1493494203, "likeCount": 173477, "content": "Part II of driving through South Bend, Indiana with Mayor Pete Buttigieg.", "parentPostId": "3791568f35f4c067d6403a5c344136cc", "shareCount": 9506, "parentAppCode": "facebook", "publishDateStr": "2017-04-29T19:30:03", "id": "4_10103685865597591", "origin": false, "originContent": null } ]}
返回示例值(FACEBOOK用户信息){ "hasNext": false, "retcode": "000000", "appCode": "facebook", "dataType": "profile", "pageToken": null, "data": [ { "userName": "zuck", "idType": "user", "educations": [ { "schoolName": "Ardsley High School" }, { "schoolName": "Phillips Exeter Academy" }, { "schoolName": "Harvard University" } ], "works": [ { "employer": "Chan Zuckerberg Initiative" }, { "employer": "Facebook" } ], "idVerified": null, "friendCount": null, "idVerifiedInfo": null, "url": "https:\/\/www.facebook.com\/4", "gender": "m", "fansCount": null, "avatarUrl": "https:\/\/fb-s-c-a.akamaihd.net\/h-ak-fbx\/v\/t34.0-1\/p50x50\/16176889_112685309244626_578204711_n.jpg?efg=eyJkdHciOiIifQ==&_nc_ad=z-m&oh=1d19d2bcf1881ee7deaaf7cf777cb194&oe=597DA91E&__gda__=1501340296_20445fee97f7852820dbda04f427e5d8", "followCount": null, "viewCount": null, "postCount": null, "birthday": null, "location": "Palo Alto, California", "likeCount": null, "id": "4", "biography": "I'm trying to make the world a more open place.", "screenName": "Mark Zuckerberg" } ]}
API平台:
返回参数:
后台: 查看全部
Facebook内容采集/用户信息数据抓取API爬虫
上个月老朋友给我介绍了一个可以采Facebook内容和用户信息的第三方API爬虫提供商iDataAPI,连续一周的百万条级别测试发觉稳定性不错,准备加入到下半年向省里申报的海外信息数据检测项目当中。
Facebook官方即使提供了Graph API,不过好多信息在最新版本的API中是不提供的。比如按照关键字搜索用户发贴等等。通过PC端的web页面抓取难度也很大,因为Facebook的页面使用了大量的js脚本动态加载数据,所以据说她们研制了云端分布式&手机端抓取数据的爬虫,就太感兴趣试一试,测试结果符合预期。
我们主要用到的功能如下:
根据关键字抓取用户的时间线抓取某用户的资料抓取某用户的好友抓取某用户的贴子
通过使用这几项功能最终可以生成一个关系网路,为后序的NLP工作打下基础。基于这个API爬虫,后续进一步接入舆情监测,情感剖析,意见挖掘等等。
这个iDataAPI提供包括一个完整的web控制界面,可以在浏览器中测试爬虫(facebook、twitter、微博、youtube...测了都很不多的,难得),后台可以完整的创建任务、查看日志、查看数据,普通开发者注册就送钱免费测试了。只是目前项目还在申报期,我们研究院须要的量级比较大,等前面签个协议包月,加上TWITTER这种,每天恐怕得采集个千万条。
返回示例值(FACEBOOK帖子){ "hasNext": true, "retcode": "000000", "appCode": "facebook", "dataType": "post", "pageToken": "enc_AdBhgxzOwy0fZBFjW6GXwbjJDRUca1SS5ccSTKp4TvchMAF3De0qdfVEC8sZAcCQZCw1CtORi9eLls3iJvJJk8PlNIQ|1493425239", "data": [ { "posterId": "4", "commentCount": 76221, "posterScreenName": "Mark Zuckerberg", "title": null, "url": "https:\/\/www.facebook.com\/4_10103685865597591", "imageUrls": [ "https:\/\/fb-s-d-a.akamaihd.net\/h-ak-xtp1\/v\/t15.0-10\/s720x720\/18223192_10103685908017581_8465195272706719744_n.jpg?_nc_ad=z-m&oh=e0736750f4882bed329ad89749849443&oe=59C22C86&__gda__=1505738387_e11048d689aba9e12e3fef771eab44f5" ], "originUrl": "https:\/\/www.facebook.com\/zuck\/videos\/10103685865597591\/", "geoPoint": "37.484, -122.149", "mediaType": "video", "publishDate": 1493494203, "likeCount": 173477, "content": "Part II of driving through South Bend, Indiana with Mayor Pete Buttigieg.", "parentPostId": "3791568f35f4c067d6403a5c344136cc", "shareCount": 9506, "parentAppCode": "facebook", "publishDateStr": "2017-04-29T19:30:03", "id": "4_10103685865597591", "origin": false, "originContent": null } ]}
返回示例值(FACEBOOK用户信息){ "hasNext": false, "retcode": "000000", "appCode": "facebook", "dataType": "profile", "pageToken": null, "data": [ { "userName": "zuck", "idType": "user", "educations": [ { "schoolName": "Ardsley High School" }, { "schoolName": "Phillips Exeter Academy" }, { "schoolName": "Harvard University" } ], "works": [ { "employer": "Chan Zuckerberg Initiative" }, { "employer": "Facebook" } ], "idVerified": null, "friendCount": null, "idVerifiedInfo": null, "url": "https:\/\/www.facebook.com\/4", "gender": "m", "fansCount": null, "avatarUrl": "https:\/\/fb-s-c-a.akamaihd.net\/h-ak-fbx\/v\/t34.0-1\/p50x50\/16176889_112685309244626_578204711_n.jpg?efg=eyJkdHciOiIifQ==&_nc_ad=z-m&oh=1d19d2bcf1881ee7deaaf7cf777cb194&oe=597DA91E&__gda__=1501340296_20445fee97f7852820dbda04f427e5d8", "followCount": null, "viewCount": null, "postCount": null, "birthday": null, "location": "Palo Alto, California", "likeCount": null, "id": "4", "biography": "I'm trying to make the world a more open place.", "screenName": "Mark Zuckerberg" } ]}
API平台:
返回参数:
后台:
一篇文章带你用Python网络爬虫实现网易云音乐歌词抓取
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2020-08-15 00:21
前几天小编给你们分享了数据可视化剖析,在文尾提到了网易云音乐歌词爬取,今天小编给你们分享网易云音乐歌词爬取技巧。本文的总体思路如下:找到正确的URL,获取源码;利用bs4解析源码,获取歌曲名和歌曲ID;调用网易云歌曲API,获取歌词;将歌词写入文件,并存入本地。本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有/#号的。废话不多说,直接上代码。
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在 查看全部

前几天小编给你们分享了数据可视化剖析,在文尾提到了网易云音乐歌词爬取,今天小编给你们分享网易云音乐歌词爬取技巧。本文的总体思路如下:找到正确的URL,获取源码;利用bs4解析源码,获取歌曲名和歌曲ID;调用网易云歌曲API,获取歌词;将歌词写入文件,并存入本地。本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有/#号的。废话不多说,直接上代码。
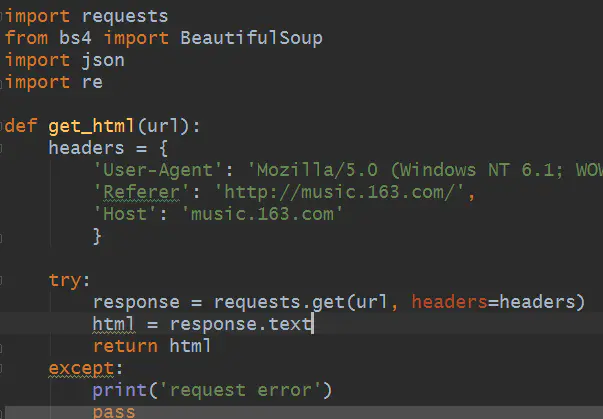
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在
《商务数据采集与处理》教学大纲.doc 4页
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-08-12 00:37
H4研究5使用现代工具Excel、Database、CSV、TXT、电子商务平台、Web爬虫、API、Java、Python、PHP、为优采云数据采集系统H6工程与社会7环境和可持续发展8职业规范培养认真、谨慎的职业精神;提升各类工具的使用熟练度和精确度H9个人和团队10沟通11项目管理12终生学习了解新的各种商务数据采集与处理软件,不断提升各种商务数据采集与处理软件的操作能力H注:“课程教学要求”栏中内容为针对该课程适用专业的专业结业要求与相关教学要求的具体描述。“关联程度”栏中字母表示两者关联程度。关联程度按高关联、中关联、低关联三档分别表示为“H”“M”或“L”。“课程教学要求”及“关联程度”中的空白栏表示该课程与所对应的专业结业要求条目不相关。四、课程教学内容章节名称主要内容重难点关键词学时类型1商务数据采集概述商务数据的定义及类型商务数据的主要来源及用途商务数据采集和处理的基本技巧商务数据的定义及类型,商务数据的主要来源及用途,商务数据采集和处理的基本技巧3理论2商务数据采集工具及应用商务数据采集工具介绍爬虫软件在商务数据剖析中的应用Python 爬虫在商务数据采集中的应用数据采集方法,常用的数据采集工具,Python 爬虫的优劣势3理论+操作3数据采集方法与采集器了解数据采集器数据采集器的安装与界面数据采集器的优势,安装注册数据采集器2理论+操作4数据采集器应用简易采集模式及实例向导模式及实例自定义采集模式使用简易采集模式进行常见网站数据采集,使用自定义采集模式进行列表详情页数据采集,掌握在规则中对采集内容做初步筛选和清洗操作3理论+操作5数据采集器中级应用屏蔽网页广告切换浏览器版本严禁加载图片增量采集智能防封登陆采集网页源码提取图片、附件的采集与下载循环切换下拉框联通键盘表针到元素上数据采集器的中级功能,增量采集和智能防封的应对方法,增量采集的形式5理论+操作6数据采集器定位方法及云采集XPath 数据定位云采集XPath 书写方式,云采集功能与使用2理论+操作7数据采集器采集实例数据采集器应用领域金融网站、新闻网站、职场急聘、店铺位置的数据采集竞品数据、企业产品相关评价、公众号文章信息的采集在实训中获得数据采集能力,熟悉各种数据采集领域典型网站4理论+操作8数据处理数据清洗与加工数据处理的定义及作用,常见的数据清洗方式,对各种数据进行标准化加工处理2理论+操作五、考核要求及成绩评定序号成绩类别考评形式考评要求权重(%)备注1期终成绩期末考试大作业50百分制,60分为及格2平常成绩实战训练10次40优、良、中、及格、不及格3平常表现缺勤情况10两次未出席课程则未能获得学分注:此表中内容为该课程的全部考评方法及其相关信息。六、学生学习建议1.理论配合实战训练进行学习,提高中学生在商务数据剖析与应用专业课程中数据采集和处理问题的能力;2.在条件容许的情况下,可以结合市场上常用的数据采集和处理工具,开发自发探求能力,更好地将专业所学和就业技能相结合,达到学以致用的目的。3.培养、提升中学生按照不同须要进行处理和清洗数据的能力。 查看全部
《商务数据采集与处理》教学大纲课程信息课程名称:《商务数据采集与处理》课程类别:专业基础课课程性质:必修计划学时:24计划学分:3先修课程:无二、课程简介本书结合了一线大数据企业在商务数据上的采集和应用方法,从数据基础、数据来源、数据采集到数据处理等方面展开内容讲解。本书融入了大量的实操案例,对学习目标进行详尽讲解,反复加强“理论围绕实操,实操推进理论,真实把握技能”的教学理念。三、课程教学要求序号专业结业要求课程教学要求关联程度1工程知识了解商务数据的基础知识及来源、常规数据采集工具及应用,对商务数据以及数据采集有直观认识,了解数据采集方法与采集器、数据采集器应用、数据采集器中级应用、数据采集器定位方法及云采集以及使用较为广泛的采集器优采云采集器,掌握在采集数据完成后怎样进行数据处理,根据不同须要进行处理和清洗,使数据剖析结果更为确切。H2问题剖析发觉商务数据采集与处理中存在的问题,寻找出现问题的诱因H3设计/开发解决方案提升商务数据的基础知识及来源、常规数据采集工具及应用,对商务数据以及数据采集有直观认识,结合市场上常用的数据采集和处理工具,开发自发探求能力,更好地将专业所学和就业技能相结合,达到学以致用的目的。
H4研究5使用现代工具Excel、Database、CSV、TXT、电子商务平台、Web爬虫、API、Java、Python、PHP、为优采云数据采集系统H6工程与社会7环境和可持续发展8职业规范培养认真、谨慎的职业精神;提升各类工具的使用熟练度和精确度H9个人和团队10沟通11项目管理12终生学习了解新的各种商务数据采集与处理软件,不断提升各种商务数据采集与处理软件的操作能力H注:“课程教学要求”栏中内容为针对该课程适用专业的专业结业要求与相关教学要求的具体描述。“关联程度”栏中字母表示两者关联程度。关联程度按高关联、中关联、低关联三档分别表示为“H”“M”或“L”。“课程教学要求”及“关联程度”中的空白栏表示该课程与所对应的专业结业要求条目不相关。四、课程教学内容章节名称主要内容重难点关键词学时类型1商务数据采集概述商务数据的定义及类型商务数据的主要来源及用途商务数据采集和处理的基本技巧商务数据的定义及类型,商务数据的主要来源及用途,商务数据采集和处理的基本技巧3理论2商务数据采集工具及应用商务数据采集工具介绍爬虫软件在商务数据剖析中的应用Python 爬虫在商务数据采集中的应用数据采集方法,常用的数据采集工具,Python 爬虫的优劣势3理论+操作3数据采集方法与采集器了解数据采集器数据采集器的安装与界面数据采集器的优势,安装注册数据采集器2理论+操作4数据采集器应用简易采集模式及实例向导模式及实例自定义采集模式使用简易采集模式进行常见网站数据采集,使用自定义采集模式进行列表详情页数据采集,掌握在规则中对采集内容做初步筛选和清洗操作3理论+操作5数据采集器中级应用屏蔽网页广告切换浏览器版本严禁加载图片增量采集智能防封登陆采集网页源码提取图片、附件的采集与下载循环切换下拉框联通键盘表针到元素上数据采集器的中级功能,增量采集和智能防封的应对方法,增量采集的形式5理论+操作6数据采集器定位方法及云采集XPath 数据定位云采集XPath 书写方式,云采集功能与使用2理论+操作7数据采集器采集实例数据采集器应用领域金融网站、新闻网站、职场急聘、店铺位置的数据采集竞品数据、企业产品相关评价、公众号文章信息的采集在实训中获得数据采集能力,熟悉各种数据采集领域典型网站4理论+操作8数据处理数据清洗与加工数据处理的定义及作用,常见的数据清洗方式,对各种数据进行标准化加工处理2理论+操作五、考核要求及成绩评定序号成绩类别考评形式考评要求权重(%)备注1期终成绩期末考试大作业50百分制,60分为及格2平常成绩实战训练10次40优、良、中、及格、不及格3平常表现缺勤情况10两次未出席课程则未能获得学分注:此表中内容为该课程的全部考评方法及其相关信息。六、学生学习建议1.理论配合实战训练进行学习,提高中学生在商务数据剖析与应用专业课程中数据采集和处理问题的能力;2.在条件容许的情况下,可以结合市场上常用的数据采集和处理工具,开发自发探求能力,更好地将专业所学和就业技能相结合,达到学以致用的目的。3.培养、提升中学生按照不同须要进行处理和清洗数据的能力。
iMacros for Chrome V10.4.28 汉化免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2020-08-11 23:49
【功能特色】
1、浏览器自动化:通过InternetExplorer,Firefox和Chrome手动执行任务。没有新的脚本语言要学习,您可以对Web浏览器进行完整的编程控制,因此虽然是最复杂的任务也可以编撰脚本。
2、Web测试:自动执行任何网站技术(包括Java,Flash,Flex或Silverlight小程序和所有AJAX元素)的功能,性能和回归测试,并捕获精确的网页响应时间。将宏导入到SeleniumWebDriver代码。
3、数据提取:一个完整的工具集,用于将Web数据屏蔽到数据库,电子表格或任何其他应用程序中。iMacros可以在短短几分钟内手动完成所需的所有Web搜集。
4、全功能Web浏览器API:iMacros企业版手动安装Web浏览器API,可从任何Windows编程或脚本语言完成Web浏览器控件。通过这种强悍的命令,您可以使用支持使用COM对象的任何Windows编程语言来控制iMacros。几乎所有的Windows编程语言都支持这些技术,包括免费的WindowsScriptingHost、VisualBasic6、VisualBasic.NET、C#、Java、Perl、Python、C++、ASP、PHP和ASP.NET。 查看全部
iMacros中文版是专为站长用户构建的一款特别不错的Web自动化软件,该软件功能强悍,它可以帮助使用者执行手动填写表单、从网站中提取数据、自动测试网站、自动登入到网路邮箱以及手动重复执行任务等操作,可大大提高使用者的任务完成效率,它可以通过灵活的脚本使用与多语言的程序插口来自动执行复杂的任务。
【功能特色】
1、浏览器自动化:通过InternetExplorer,Firefox和Chrome手动执行任务。没有新的脚本语言要学习,您可以对Web浏览器进行完整的编程控制,因此虽然是最复杂的任务也可以编撰脚本。
2、Web测试:自动执行任何网站技术(包括Java,Flash,Flex或Silverlight小程序和所有AJAX元素)的功能,性能和回归测试,并捕获精确的网页响应时间。将宏导入到SeleniumWebDriver代码。
3、数据提取:一个完整的工具集,用于将Web数据屏蔽到数据库,电子表格或任何其他应用程序中。iMacros可以在短短几分钟内手动完成所需的所有Web搜集。
4、全功能Web浏览器API:iMacros企业版手动安装Web浏览器API,可从任何Windows编程或脚本语言完成Web浏览器控件。通过这种强悍的命令,您可以使用支持使用COM对象的任何Windows编程语言来控制iMacros。几乎所有的Windows编程语言都支持这些技术,包括免费的WindowsScriptingHost、VisualBasic6、VisualBasic.NET、C#、Java、Perl、Python、C++、ASP、PHP和ASP.NET。
(IE9)Internet Explorer 9.0 简体英文正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-11 21:08
浏览器版本较低,官方已停止升级维护,建议升级到更快、更安全的浏览器,点击立刻下载。
IE9英文正式版是谷歌推出的ie9英文版本,internet explorer 9是谷歌支持标准最规范的IE浏览器。IE9改进IE浏览器性能,IE9支持XP/win7,本站提供ie9中文版官方下载.
Internet Explorer 9 正式版 (IE9正式版)是谷歌最新一款IE浏览器,IE9在各方面都有急剧提高,给你全新的浏览体验!例如:全新的新 JavaScript 引擎促使IE9的运算速率更快;新增GPU 硬件加速,大大提高IE的运行速率;IE9 子系统全面改进,极大增强了对 HTML、CSS 和 JavaScript 的解释效率;IE9 支持最新的 HTML5、CSS3、SVG 和 DOM L2&L3;整合更多开发工具……
IE9截图1
软件特色
1、速度更快:IE9支持GPU加速功能,用户网页浏览速率将更快;
2、清新界面:优化后的用户界面愈发简练,网页内容得到突出;
3、与Windows 7完美结合:Win7和IE9是绝配,适配性更强;IE9支持将常用网站锁定到任务栏,便携浏览您喜欢的网站;
4、支持标准:规范了网页标准,使得各网站能获得更好的支持,从而给用户带来更优越的操作体验!
截图2
功能介绍
1、ie9新JavaScript引擎
IE9全新外置的“Chakra JavaScript引擎”充分利用当下主流计算机配置的多核心CPU,优化协同运算能力,编译、执行速率更快。同时与DOM的紧密集成,使得网路应用运行更顺畅,反应更迅速。
ie9新JavaScript引擎软件截图3
2、ie9GPU硬件加速
IE9将全面支持HTML5 GPU硬件加速,借助GPU的效能来渲染标准的Web内容,如文字、图像、视频、SVG(可缩放矢量图形)等网路信息,减少CPU负荷,大大的提升浏览器的速率。开发人员无需为GPU硬件加速特点重新编撰网站,直接提高图形处理性能。
ie9GPU硬件加速软件截图4
3、ie9子系统优化,提升协同处理效率
IE9子系统全面改进,极大增强了对HTML、CSS和JavaScript的解释效率。将布局以及渲染等方面的资源更合理的分配和优化,在降低对显存和处理资源耗损的同时,让网页呈现和网路应用程序的运行速率愈发顺畅。
截图5
4、ie9全新用户界面
IE9带来全新用户界面——简单、清晰、有效,尽可能简化浏览器的外型元素和操作步骤——希望用户才能最大限度的“忽略”IE9的“存在”,而将注意力全部沉溺在精彩的网路内容当中。
ie9全新用户界面截图6
5、ie9全面支持最新网路标准
IE9支持最新的HTML5、CSS3、SVG和DOM L2&L3,你可以充分利用这种技术诠释你的网路创意,不必再针对不同浏览器编撰不同代码,大幅度增加你的开发时间和难度。
6、ie9整合更多开发工具
与其他浏览器相比,IE9外置了更多强悍的开发人员工具——包括JavaScript剖析工具、CSS编辑器和新的网路剖析器等。这些工具当你须要时就在手边,方便你进行开发和调试,实现与IE9的全方位整合。
7、ie9先进的网路开发技术
IE9提供了一系列先进技术,如D2D DirectX图形构架和图形、色彩解码器等,助你实现高清视频和多媒体交互。搭配GPU图形硬件加速,让画面质量和流畅性达到质的提高,为你搭建一个更好的平台,来为你的用户诠释前所未有的视觉、听觉体验。
截图7
8、ie9是网站,也是一个Windows 7程序
利用最新的Windows应用程序插口(API),开发者才能使用JavaScript来定义键盘右键快捷菜单、任务栏缩略图、跳转列表项和触控等功能,使其与Windows 7操作系统完美整合,带来新的浏览形式,让用户体验上升到新的高度。
9、ie9兼容性模式
IE9使开发人员来选择浏览站点时所使用的模式,其中包括IE9标准模式、IE8文档模式、 兼容视图模式(IE7)或Quirks模式 (IE5)。如果用户单击兼容模式按键,网站将以开发者事先指定的模式或兼容视图模式(IE7)运行,保证向后的兼容性和网站升级时的灵活性。
截图8
常见问题
IE9支持哪些系统?
可用于全部 Windows Vista 和 Windows 7 版本。
怎么调整IE9 使用兼容模式?
1、打开IE浏览器,点击“工具”选项,选择“兼容性视图设置”选项。
2、进入兼容性视图设置以后,填入所须要设置兼容模式的网址,点击添加,最后点击关掉即可。
3、重新打开经过设置以后的网页,会听到地址栏前面有一个象破碎纸片一样的图标,说明兼容模式早已设置成功,在工具的下拉菜单也同样可以看见在兼容模式上面也就对勾,说明网页的兼容模式早已设置成功。
更新日志
修复部份bug 查看全部

浏览器版本较低,官方已停止升级维护,建议升级到更快、更安全的浏览器,点击立刻下载。
IE9英文正式版是谷歌推出的ie9英文版本,internet explorer 9是谷歌支持标准最规范的IE浏览器。IE9改进IE浏览器性能,IE9支持XP/win7,本站提供ie9中文版官方下载.
Internet Explorer 9 正式版 (IE9正式版)是谷歌最新一款IE浏览器,IE9在各方面都有急剧提高,给你全新的浏览体验!例如:全新的新 JavaScript 引擎促使IE9的运算速率更快;新增GPU 硬件加速,大大提高IE的运行速率;IE9 子系统全面改进,极大增强了对 HTML、CSS 和 JavaScript 的解释效率;IE9 支持最新的 HTML5、CSS3、SVG 和 DOM L2&L3;整合更多开发工具……
IE9截图1
软件特色
1、速度更快:IE9支持GPU加速功能,用户网页浏览速率将更快;
2、清新界面:优化后的用户界面愈发简练,网页内容得到突出;
3、与Windows 7完美结合:Win7和IE9是绝配,适配性更强;IE9支持将常用网站锁定到任务栏,便携浏览您喜欢的网站;
4、支持标准:规范了网页标准,使得各网站能获得更好的支持,从而给用户带来更优越的操作体验!
截图2
功能介绍
1、ie9新JavaScript引擎
IE9全新外置的“Chakra JavaScript引擎”充分利用当下主流计算机配置的多核心CPU,优化协同运算能力,编译、执行速率更快。同时与DOM的紧密集成,使得网路应用运行更顺畅,反应更迅速。
ie9新JavaScript引擎软件截图3
2、ie9GPU硬件加速
IE9将全面支持HTML5 GPU硬件加速,借助GPU的效能来渲染标准的Web内容,如文字、图像、视频、SVG(可缩放矢量图形)等网路信息,减少CPU负荷,大大的提升浏览器的速率。开发人员无需为GPU硬件加速特点重新编撰网站,直接提高图形处理性能。
ie9GPU硬件加速软件截图4
3、ie9子系统优化,提升协同处理效率
IE9子系统全面改进,极大增强了对HTML、CSS和JavaScript的解释效率。将布局以及渲染等方面的资源更合理的分配和优化,在降低对显存和处理资源耗损的同时,让网页呈现和网路应用程序的运行速率愈发顺畅。
截图5
4、ie9全新用户界面
IE9带来全新用户界面——简单、清晰、有效,尽可能简化浏览器的外型元素和操作步骤——希望用户才能最大限度的“忽略”IE9的“存在”,而将注意力全部沉溺在精彩的网路内容当中。
ie9全新用户界面截图6
5、ie9全面支持最新网路标准
IE9支持最新的HTML5、CSS3、SVG和DOM L2&L3,你可以充分利用这种技术诠释你的网路创意,不必再针对不同浏览器编撰不同代码,大幅度增加你的开发时间和难度。
6、ie9整合更多开发工具
与其他浏览器相比,IE9外置了更多强悍的开发人员工具——包括JavaScript剖析工具、CSS编辑器和新的网路剖析器等。这些工具当你须要时就在手边,方便你进行开发和调试,实现与IE9的全方位整合。
7、ie9先进的网路开发技术
IE9提供了一系列先进技术,如D2D DirectX图形构架和图形、色彩解码器等,助你实现高清视频和多媒体交互。搭配GPU图形硬件加速,让画面质量和流畅性达到质的提高,为你搭建一个更好的平台,来为你的用户诠释前所未有的视觉、听觉体验。
截图7
8、ie9是网站,也是一个Windows 7程序
利用最新的Windows应用程序插口(API),开发者才能使用JavaScript来定义键盘右键快捷菜单、任务栏缩略图、跳转列表项和触控等功能,使其与Windows 7操作系统完美整合,带来新的浏览形式,让用户体验上升到新的高度。
9、ie9兼容性模式
IE9使开发人员来选择浏览站点时所使用的模式,其中包括IE9标准模式、IE8文档模式、 兼容视图模式(IE7)或Quirks模式 (IE5)。如果用户单击兼容模式按键,网站将以开发者事先指定的模式或兼容视图模式(IE7)运行,保证向后的兼容性和网站升级时的灵活性。
截图8
常见问题
IE9支持哪些系统?
可用于全部 Windows Vista 和 Windows 7 版本。
怎么调整IE9 使用兼容模式?
1、打开IE浏览器,点击“工具”选项,选择“兼容性视图设置”选项。
2、进入兼容性视图设置以后,填入所须要设置兼容模式的网址,点击添加,最后点击关掉即可。
3、重新打开经过设置以后的网页,会听到地址栏前面有一个象破碎纸片一样的图标,说明兼容模式早已设置成功,在工具的下拉菜单也同样可以看见在兼容模式上面也就对勾,说明网页的兼容模式早已设置成功。
更新日志
修复部份bug
利用Python网络爬虫实现对网易云音乐歌词爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-11 10:45
找到正确的URL,获取源码;
利用bs4解析源码,获取歌曲名和歌曲ID;
调用网易云歌曲API,获取歌词;
将歌词写入文件,并存入本地。
本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程!
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有#号的。废话不多说,直接上代码。
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。
获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在
标签下,如下图所示:
接下来我们借助美丽的汤来获取目标信息,直接上代码,如下图:
此处要注意获取ID的时侯须要对link进行切块处理,得到的数字便是歌曲的ID;另外,歌曲名是通过get_text方式获取到的,最后借助zip函数将歌曲名和ID一一对应并进行返回。
得到ID以后便可以步入到内页获取歌词了,但是URL还是不给力,如下图:
虽然我们可以明白的看见网页上的白纸黑字呈现的歌词信息,但是我们在该URL下却未能获取到歌词信息。小编通过抓包,找到了歌词的URL,发现其是POST恳求还有一大堆看不懂的data,总之这个URL是不能为我们效力。那该点解呢?
莫慌,小编找到了网易云音乐的API,只要把歌曲的ID置于API链接上便可以获取到歌词了,代码如下:
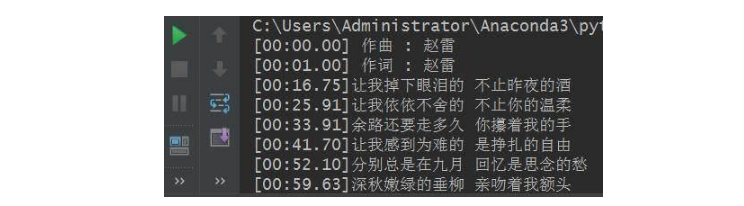
在API中歌词信息是以json格式加载的,所以须要借助json将其进行序列化解析下来,并配合正则表达式进行清洗歌词,如果不用正则表达式进行清洗的话,得到原创的数据如下所示(此处以赵雷的歌曲《成都》为例):
很明显歌词上面有歌词呈现的时间,对于我们来说其属于杂质信息,因此须要借助正则表达式进行匹配。诚然,正则表达式并不是惟一的方式,小伙伴们也可以采取切块的形式或则其他方式进行数据清洗,在此就不赘言了。
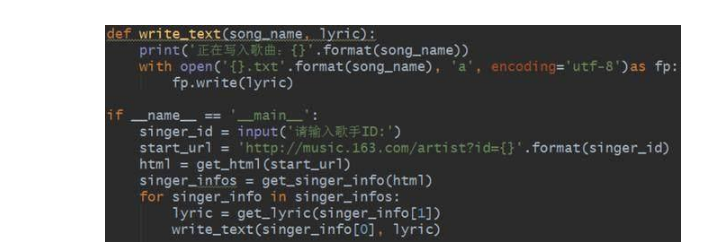
得到歌词以后便将其写入到文件中去,并存入到本地文件中,代码如下:
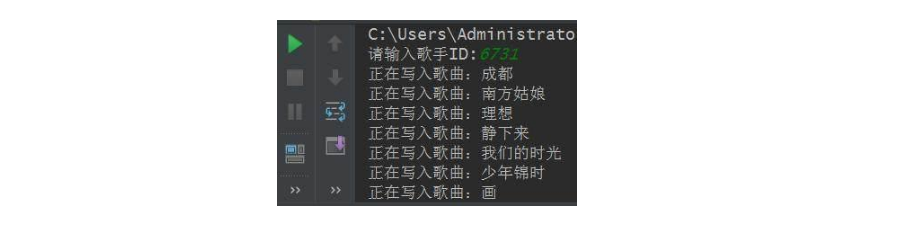
现在只要我们运行程序,输入歌手的ID以后,程序将手动把该歌手的所唱歌曲的歌词抓取出来,并存到本地中。如本例中赵雷的ID是6731,输入数字6731以后,赵雷的歌词将会被抓取到,如下图所示:
之后我们就可以在脚本程序的同一目录下找到生成的歌词文本,歌词就被顺利的爬取出来了。
相信你们对网易云歌词爬取早已有了一定的认识了,不过easier said than down,小编建议你们动手亲自敲一下代码,在实践中你会学的更快,学的更多的。
这篇文章教会你们怎么采集网易云歌词,那网易云歌曲怎么采集呢?且听小编下回分解~~ 查看全部
本文的总体思路如下:
找到正确的URL,获取源码;
利用bs4解析源码,获取歌曲名和歌曲ID;
调用网易云歌曲API,获取歌词;
将歌词写入文件,并存入本地。
本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程!
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有#号的。废话不多说,直接上代码。
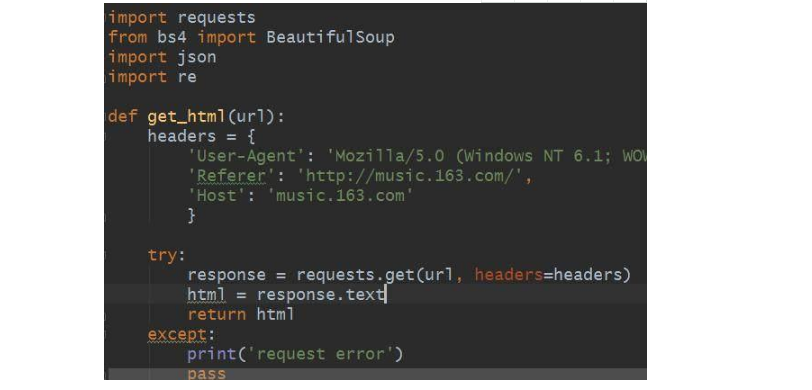
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。
获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在
标签下,如下图所示:

接下来我们借助美丽的汤来获取目标信息,直接上代码,如下图:
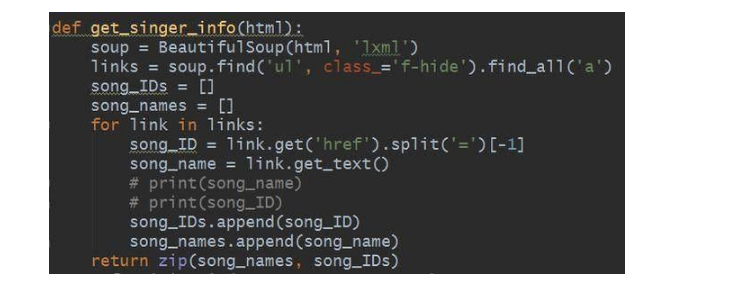
此处要注意获取ID的时侯须要对link进行切块处理,得到的数字便是歌曲的ID;另外,歌曲名是通过get_text方式获取到的,最后借助zip函数将歌曲名和ID一一对应并进行返回。
得到ID以后便可以步入到内页获取歌词了,但是URL还是不给力,如下图:
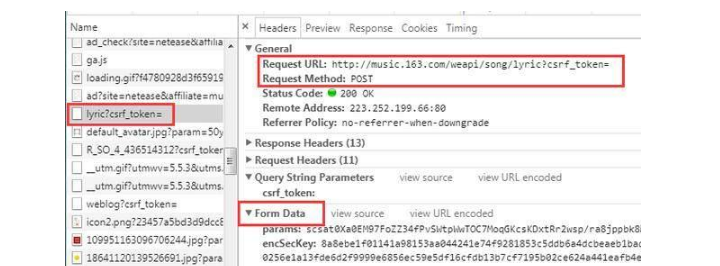
虽然我们可以明白的看见网页上的白纸黑字呈现的歌词信息,但是我们在该URL下却未能获取到歌词信息。小编通过抓包,找到了歌词的URL,发现其是POST恳求还有一大堆看不懂的data,总之这个URL是不能为我们效力。那该点解呢?
莫慌,小编找到了网易云音乐的API,只要把歌曲的ID置于API链接上便可以获取到歌词了,代码如下:
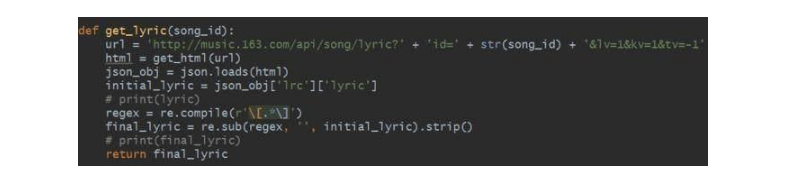
在API中歌词信息是以json格式加载的,所以须要借助json将其进行序列化解析下来,并配合正则表达式进行清洗歌词,如果不用正则表达式进行清洗的话,得到原创的数据如下所示(此处以赵雷的歌曲《成都》为例):
很明显歌词上面有歌词呈现的时间,对于我们来说其属于杂质信息,因此须要借助正则表达式进行匹配。诚然,正则表达式并不是惟一的方式,小伙伴们也可以采取切块的形式或则其他方式进行数据清洗,在此就不赘言了。
得到歌词以后便将其写入到文件中去,并存入到本地文件中,代码如下:
现在只要我们运行程序,输入歌手的ID以后,程序将手动把该歌手的所唱歌曲的歌词抓取出来,并存到本地中。如本例中赵雷的ID是6731,输入数字6731以后,赵雷的歌词将会被抓取到,如下图所示:
之后我们就可以在脚本程序的同一目录下找到生成的歌词文本,歌词就被顺利的爬取出来了。
相信你们对网易云歌词爬取早已有了一定的认识了,不过easier said than down,小编建议你们动手亲自敲一下代码,在实践中你会学的更快,学的更多的。
这篇文章教会你们怎么采集网易云歌词,那网易云歌曲怎么采集呢?且听小编下回分解~~
报表开发利器:phantomjs生成PDF ,Echarts图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2020-08-10 10:26
导航:
一. 关于phantomjs1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作须要程序设计实现。
(2)提供javascript API接口,即通过编撰js程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作,从而解决了先前c/c++能够比较好的基于webkit开发优质采集器的限制。
(3)提供windows、linux、mac等不同os的安装使用包,也就是说可以在不同平台上二次开发采集项目或是手动项目测试等工作。
1.2 phantomjs常用API介绍
常用外置几大对象
常用API
注意事项
使用总结 : 主要是java se+js+phantomjs的应用,
1.3 使用phantomjs 能做哪些?
生成的PDF基本还原了其原先的款式,图片和文字分开了,并非直接截图;有生成PDF相关需求的,可以思索生成使用phantomjs 怎样实现功能;本人有通过Html模板,生成Html页面,然后将此页面上传至FastDfs服务器,然后通过返回的url直接生成此pdf,即完成了html页面一致的pdf生成功能;
二. Windows下安装 phantomjs2.1 概述2.1 下载并安装phantomjs测试是否安装成功:三. Linux下 安装 phantomjs3.1 概述3.2 安装过程如下:
进入上面后可执行js命令,如果须要退出,则按 Ctrl+C 强制退出
解决英文乱码(可选,可碰到此问题再行解决)正常示例:(Windows上显示正常如图:)错误示例:(Linux上显示英文乱码如图:)解决办法:在Linux中执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只是英文显示下来了,数字还是会显示空格,如果出现数字显示空格,则把windows所有字体导出Linux中,见下边。
导入字体:四. 利用Phantomjs生成Echarts图片4.1 概述: 在Linux 下:
WIndows与Linux环境下的区别:①配置好环境变量,因为phantomjs的启动方法,windows是执行exe文件,linux不是,所以配好环境变量后java在本机测试与在Linux下无需做任何更改;②Phantomjs执行生成Echarts图片时,需要引用到 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 以及生成Echarts的js文件。这些js须要引用到,而当布署在Linux中时,生成的js文件在jar包中,不一定能读取到,我们可以通过代码将js文件复制生成到jar包同级目录,然后通过路径加载。路径加载可以用如下代码读取并生成:
~~~java
/* 将模板生成到指定的位置 判定文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty(“user.dir”) + “\echarts-all.js”);
if (!echartsfile.exists()) {
FileUtil.file2file(“js/echarts-all.js”, System.getProperty(“user.dir”) + “\echarts-all.js”);
}
~~~
4.2 笔者实现思路:第二步:整理思路:生成须要生成的Echarts的js代码:找到相关Echarts图片模板: Echarts官网使用Framework以及其他技术:将模板+数据生成一个最终js文件;使用Framework为例:将其他的三个js文件放在其他位置上,博主的做法是将这三个放在jar包目录内,但是会存在phantomjs难以读取和执行的情况(就是除开phantomjs的代码可以读取到内容,但phantomjs的执行难以引用读取)。所以博主采取的是先读取下来,再讲到jar包外边进行引用;这样通过路径,在Linux下也可以读取了;读取代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
重点代码:System.getProperty(“user.dir”) 为 Windows下或则Linux下的当前路径 ,具体可百度其用法。
结合早已有的 echarts-convert.js 等文件+ 生成好的带数据的Echarts.js 文件 和 Demo示例代码可以生成出Echarts图片了;我们可以将Echart图片再上传至Fastdfs等图片服务器,就可以领到网路图片url了;当然最后一步视业务需求而定;五. 利用Phantomjs生成PDF文档(HTML转为PDF)5.1 概述5.2 生成原理5.3 扩展思路六.利用Phantomjs+Poi.tl 生成Word文档6.1 概述6.2 思路 查看全部
报表开发利器:phantomjs生成网页PDF ,Echarts报表实战
导航:
一. 关于phantomjs1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作须要程序设计实现。
(2)提供javascript API接口,即通过编撰js程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作,从而解决了先前c/c++能够比较好的基于webkit开发优质采集器的限制。
(3)提供windows、linux、mac等不同os的安装使用包,也就是说可以在不同平台上二次开发采集项目或是手动项目测试等工作。
1.2 phantomjs常用API介绍
常用外置几大对象
常用API
注意事项
使用总结 : 主要是java se+js+phantomjs的应用,
1.3 使用phantomjs 能做哪些?
生成的PDF基本还原了其原先的款式,图片和文字分开了,并非直接截图;有生成PDF相关需求的,可以思索生成使用phantomjs 怎样实现功能;本人有通过Html模板,生成Html页面,然后将此页面上传至FastDfs服务器,然后通过返回的url直接生成此pdf,即完成了html页面一致的pdf生成功能;
二. Windows下安装 phantomjs2.1 概述2.1 下载并安装phantomjs测试是否安装成功:三. Linux下 安装 phantomjs3.1 概述3.2 安装过程如下:
进入上面后可执行js命令,如果须要退出,则按 Ctrl+C 强制退出
解决英文乱码(可选,可碰到此问题再行解决)正常示例:(Windows上显示正常如图:)错误示例:(Linux上显示英文乱码如图:)解决办法:在Linux中执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只是英文显示下来了,数字还是会显示空格,如果出现数字显示空格,则把windows所有字体导出Linux中,见下边。
导入字体:四. 利用Phantomjs生成Echarts图片4.1 概述: 在Linux 下:
WIndows与Linux环境下的区别:①配置好环境变量,因为phantomjs的启动方法,windows是执行exe文件,linux不是,所以配好环境变量后java在本机测试与在Linux下无需做任何更改;②Phantomjs执行生成Echarts图片时,需要引用到 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 以及生成Echarts的js文件。这些js须要引用到,而当布署在Linux中时,生成的js文件在jar包中,不一定能读取到,我们可以通过代码将js文件复制生成到jar包同级目录,然后通过路径加载。路径加载可以用如下代码读取并生成:
~~~java
/* 将模板生成到指定的位置 判定文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty(“user.dir”) + “\echarts-all.js”);
if (!echartsfile.exists()) {
FileUtil.file2file(“js/echarts-all.js”, System.getProperty(“user.dir”) + “\echarts-all.js”);
}
~~~
4.2 笔者实现思路:第二步:整理思路:生成须要生成的Echarts的js代码:找到相关Echarts图片模板: Echarts官网使用Framework以及其他技术:将模板+数据生成一个最终js文件;使用Framework为例:将其他的三个js文件放在其他位置上,博主的做法是将这三个放在jar包目录内,但是会存在phantomjs难以读取和执行的情况(就是除开phantomjs的代码可以读取到内容,但phantomjs的执行难以引用读取)。所以博主采取的是先读取下来,再讲到jar包外边进行引用;这样通过路径,在Linux下也可以读取了;读取代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
重点代码:System.getProperty(“user.dir”) 为 Windows下或则Linux下的当前路径 ,具体可百度其用法。
结合早已有的 echarts-convert.js 等文件+ 生成好的带数据的Echarts.js 文件 和 Demo示例代码可以生成出Echarts图片了;我们可以将Echart图片再上传至Fastdfs等图片服务器,就可以领到网路图片url了;当然最后一步视业务需求而定;五. 利用Phantomjs生成PDF文档(HTML转为PDF)5.1 概述5.2 生成原理5.3 扩展思路六.利用Phantomjs+Poi.tl 生成Word文档6.1 概述6.2 思路
Python丨scrapy爬取某急聘网手机APP发布信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-10 08:51
过段时间要开始找新工作了,爬取一些岗位信息来剖析一下吧。目前主流的急聘网站包括前程无忧、智联、BOSS直聘、拉勾等等。有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位信息,其他急聘网站后续再更新补上……
所用工具(技术):
IDE:pycharm
Database:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息抓取:scrapy外置的Selector
Python学习资料或则须要代码、视频加Python学习群:960410445
2 APP抓包剖析
我们先来体会一下前程无忧的APP,当我们在首页输入搜索关键词点击搜索然后APP都会跳转到新的页面,这个页面我们暂且称之为一级页面。一级页面展示着我们所想找查看的所有岗位列表。
当我们点击其中一条岗位信息后,APP又会跳转到一个新的页面,我把这个页面称之为二级页面。二级页面有我们须要的所有岗位信息,也是我们的主要采集目前页面。
分析完页面然后,接下来就可以对前程无忧手机APP的恳求(request)和回复(response)进行剖析了。本文所使用的抓包工具为Fiddler。
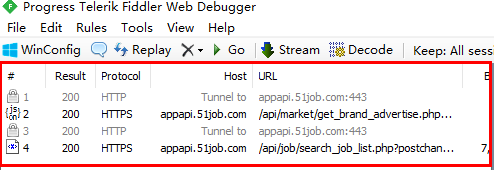
本文的目的是抓取前程无忧APP上搜索某个关键词时返回的所有急聘信息,本文以“Python”为例进行说明。APP上操作如下图所示,输入“Python”关键词后,点击搜索,随后Fiddler抓取到4个数据包,如下所示:
事实上,当听到第2和第4个数据包的图标时,我们就应当会心一笑。这两个图标分别代表传输的是json和xml格式的数据,而好多web插口就是以这两种格式来传输数据的,手机APP也不列外。选中第2个数据包,然后在右边主窗口中查看,发现第二个数据包并没有我们想要的数据。在瞧瞧第4个数据包,选中后在右边窗体,可以看见以下内容:
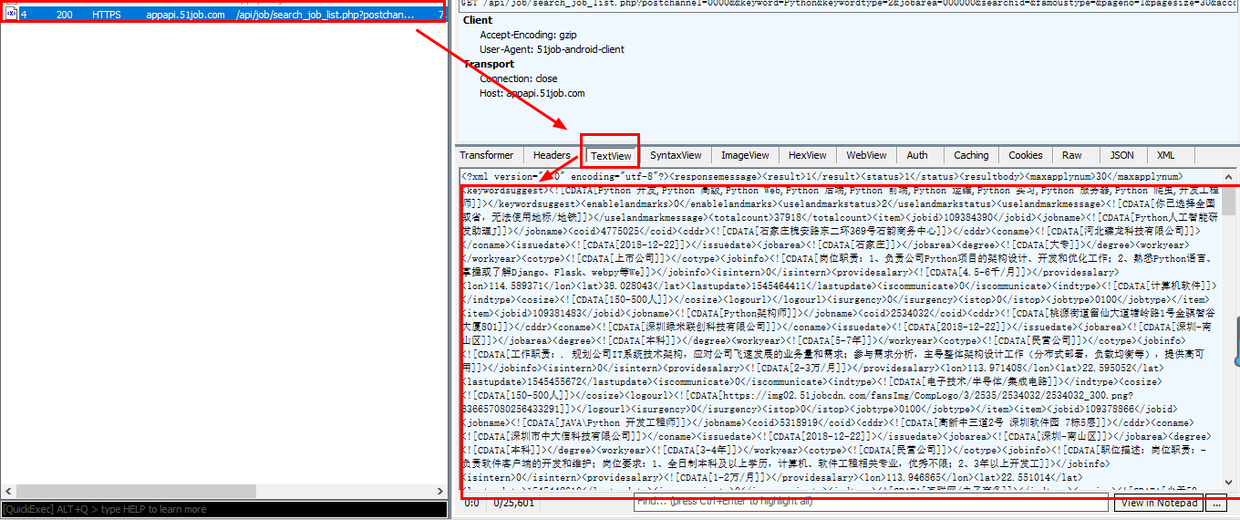
右下角的内容不就是在手机上看见的急聘信息吗,还是以XML的格式来传输的。我们将这个数据包的链接复制出来:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
我们爬取的时侯肯定不会只爬取一个页面的信息,我们在APP上把页面往下滑,看看Fiddler会抓取到哪些数据包。看右图:
手机屏幕往下滑动后,Fiddler又抓取到两个数据包,而且第二个数据包选中看再度发觉就是APP上新刷新的急聘信息,再把这个数据包的url链接复制出来:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
接下来,我们比对一下前后两个链接,分析其中的优缺。可以看出,除了“pageno”这个属性外,其他都一样。没错,就是在里面标红的地方。第一个数据包链接中pageno值为1,第二个pageno值为2,这下翻页的规律就一目了然了。
既然我们早已找到了APP翻页的恳求链接规律,我们就可以在爬虫中通过循环形参给pageno,实现模拟翻页的功能。
我们再尝试一下改变搜索的关键词瞧瞧链接有哪些变化,以“java”为关键词,抓取到的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比后发觉,链接中也只有keyword的值不一样,而且值就是我们在自己输入的关键词。所以在爬虫中,我们完全可以通过字符串拼接来实现输入关键词模拟,从而采集不同类型的急聘信息。同理,你可以对求职地点等信息的规律进行找寻,本文不在表述。
解决翻页功能然后,我们再去探究一下数据包中XML上面的内容。我们把里面的第一个链接复制到浏览器上打开,打开后画面如下:
这样看着就舒服多了。通过仔细观察我们会发觉,APP上每一条急聘信息都对应着一个标签,每一个上面都有一个标签,里面有一个id标示着一个岗位。例如前面第一条岗位是109384390,第二条岗位是109381483,记住这个id,后面会用到。
事实上,接下来,我们点击第一条急聘信息,进入二级页面。这时候,Fiddler会采集到APP刚发送的数据包,点击其中的xml数据包,发现就是APP上刚刷新的页面信息。我们将数据包的url链接复制下来:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
如法炮制点开一级页面中列表的第二条急聘,然后从Fiddler中复制出对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比前面两个链接,发现规律没?没错,就是jobid不同,其他都一样。这个jobid就是我们在一级页面的xml中发觉的jobid。由此,我们就可以在一级页面中抓取出jobid来构造出二级页面的url链接,然后采集出我们所须要的所有信息。整个爬虫逻辑就清晰了:
构造一级页面初始url->采集jobid->构造二级页面url->抓取岗位信息->通过循环模拟翻页获取下一页面的url。
好了,分析工作完成了,开始动手写爬虫了。
3 编写爬虫
本文编撰前程无忧手机APP网路爬虫用的是Scrapy框架,下载好scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider就是我们本次爬虫项目的项目名称,在项目名前面有一个“.”,这个点可有可无,区别是在当前文件之间创建项目还是创建一个与项目名同名的文件之后在文件内创建项目。
创建好项目后,继续创建一个爬虫,专用于爬取前程无忧发布的急聘信息。创建爬虫命名如下:
scrapy genspider qcwySpider
注意:如果你在创建爬虫项目的时侯没有在项目名前面加“.”,请先步入项目文件夹以后再运行命令创建爬虫。
通过pycharm打开刚创建好的爬虫项目,左侧目录树结构如下:
在开始一切爬虫工作之前,先打开settings.py文件,然后取消“ROBOTSTXT_OBEY = False”这一行的注释,并将其值改为False。
# Obey robots.txt rulesROBOTSTXT_OBEY = False
完成上述更改后,打开spiders包下的qcwySpider.py,初始代码如下:
这是scrapy为我们搭好的框架,我们只须要在这个基础起来建立我们的爬虫即可。
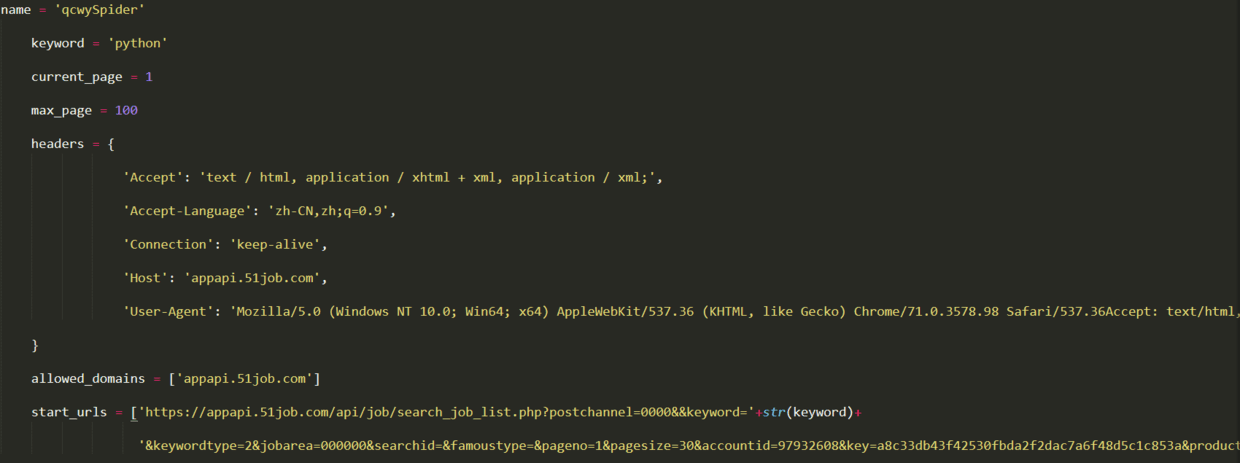
首先我们须要在类中添加一些属性,例如搜索关键词keyword、起始页、想要爬取得最大页数,同时也须要设置headers进行简单的反爬。另外,starturl也须要重新设置为第一页的url。更改后代码如下:
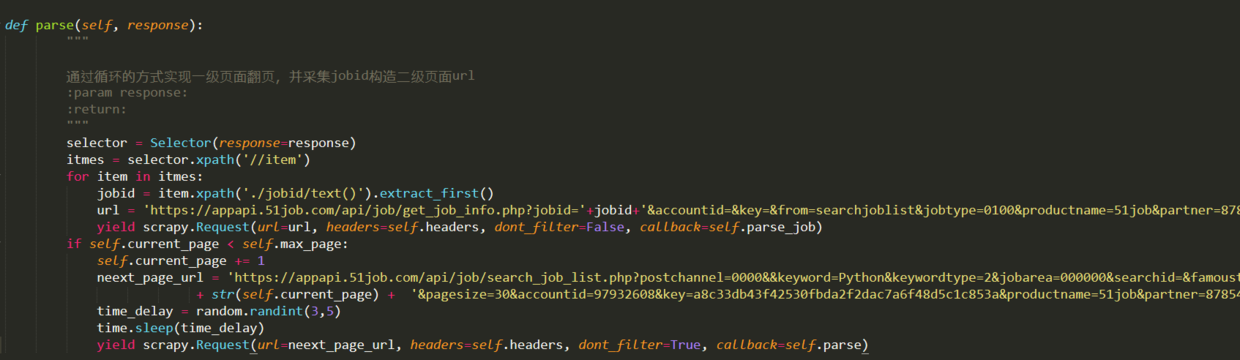
然后开始编撰parse方式爬取一级页面,在一级页面中,我们主要逻辑是通过循环实现APP中屏幕下降更新,我们用前面代码中的current_page来标示当前页页脚,每次循环后,current_page加1,然后构造新的url,通过反弹parse方式爬取下一页。另外,我们还须要在parse方式中在一级页面中采集出jobid,并构造出二级页面的,回调实现二级页面信息采集的parse_job方式。parse方式代码如下:
为了便捷进行调试,我们在项目的jobSpider目录下创建一个main.py文件,用于启动爬虫,每次启动爬虫时,运行该文件即可。内容如下:
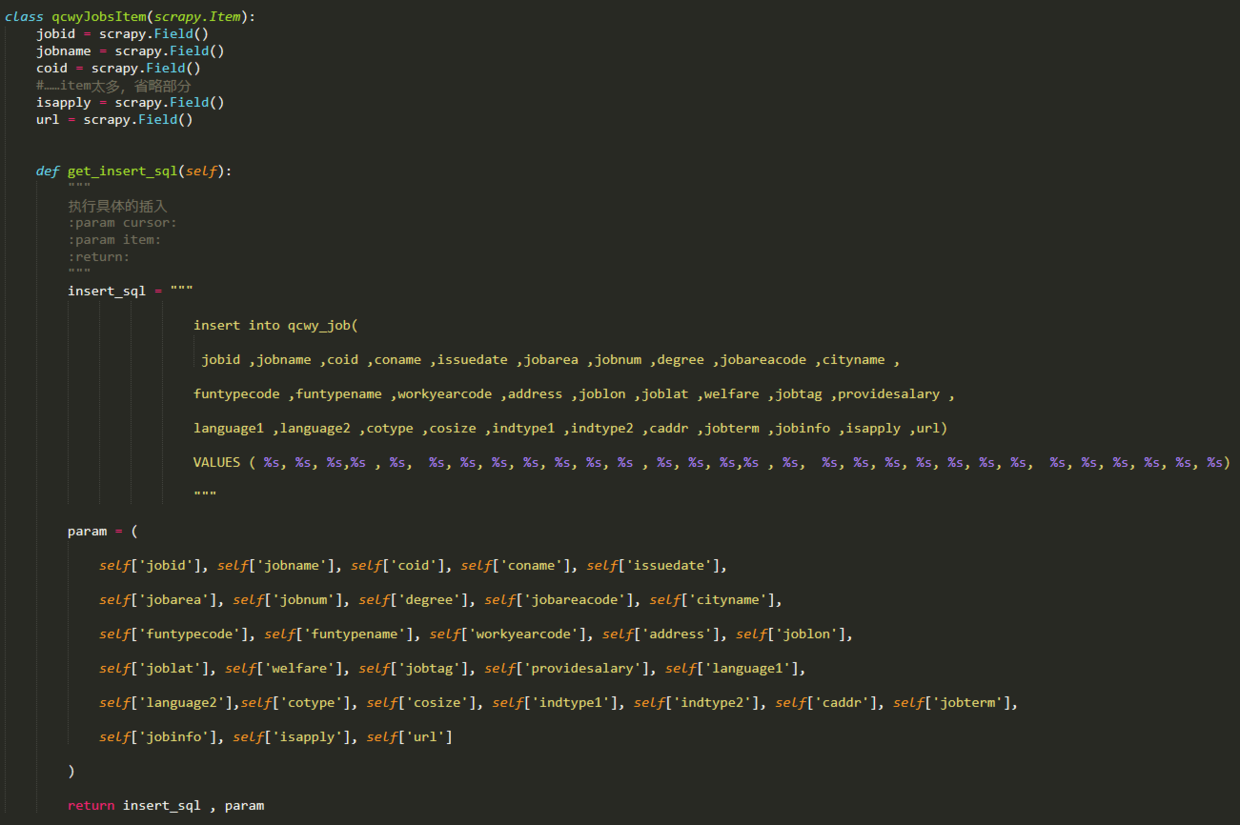
二级页面信息采集功能在parse_job方式中实现,因为所有我们须要抓取的信息都在xml中,我们直接用scrapy自带的selector提取下来就可以了,不过在提取之前,我们须要先定义好Item拿来储存我们采集好的数据。打开items.py文件,编写一个Item类,输入以下代码:
上面每一个item都与一个xml标签对应,用于储存一条信息。在qcwyJobsItem类的最后,定义了一个do_insert方式,该方式用于生产将item中所有信息储存数据库的insert句子,之所以在items铁块中生成这个insert句子,是因为日后若果有了多个爬虫,有多个item类以后,在pipelines模块中,可以针对不同的item插入数据库,使本项目具有更强的可扩展性。你也可以将所有与插入数据库有关的代码都写在pipelines。
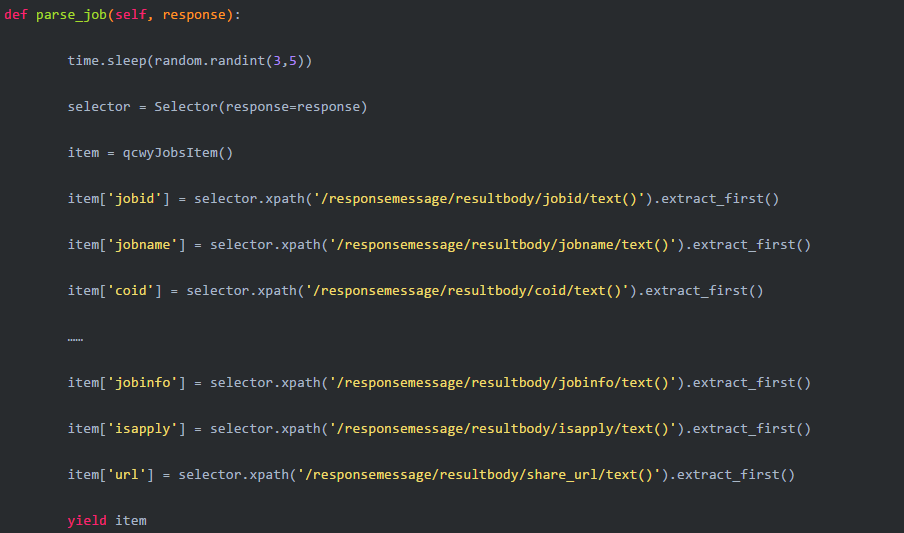
然后编撰parse_job方式:
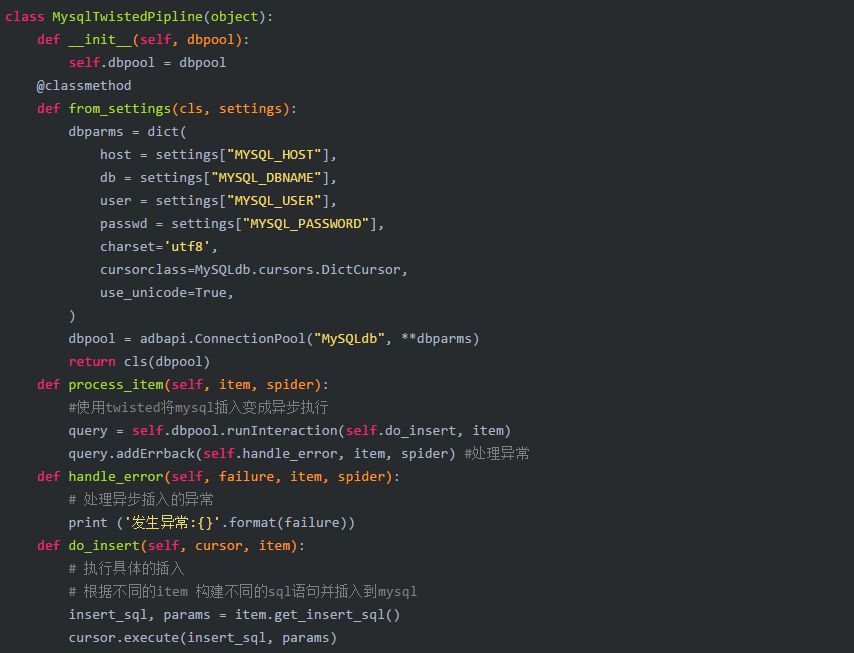
完成上述代码后,信息采集部分就完成了。接下来继续写信息储存功能,这一功能在pipelines.py中完成。
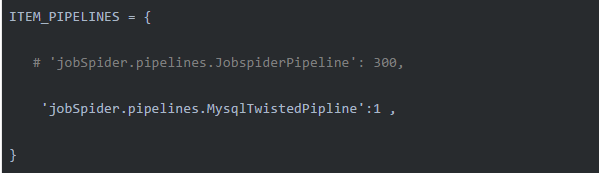
编写完pipelines.py后,打开settings.py文件,将刚写好的MysqlTwistedPipline类配置到项目设置文件中:
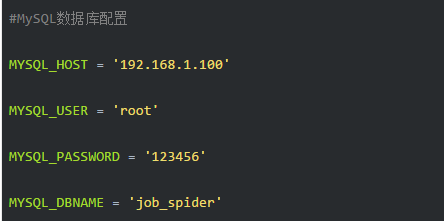
顺便也把数据库配置好:
数据库配置你也可以之间嵌入到MysqlTwistedPipline类中,不过我习惯于把这种专属的数据库信息写在配置文件中。
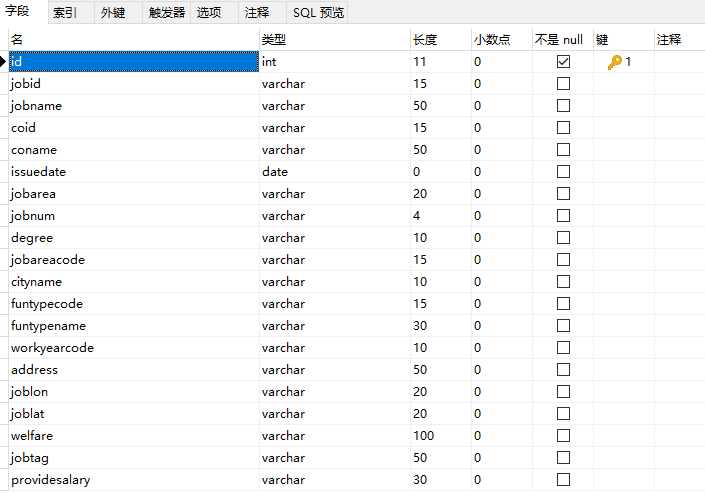
最后,只差一步,建数据库、建数据表。部分表结构如下图所示:
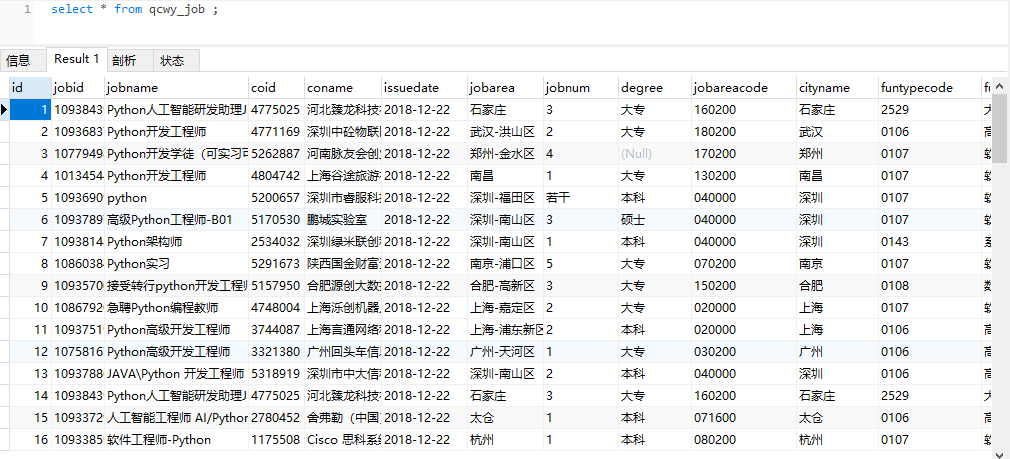
完成上述所有内容以后,就可以运行爬虫开始采集数据了。采集的数据如下图所示:
4 总结
整个过程出来,感觉前程无忧网APP爬取要比网页爬取容易一些(似乎好多网站都这样)。回顾整个流程,其实代码中还有众多细节尚可改进建立,例如还可以在构造链接时加上求职地点等。本博文重在对整个爬虫过程的逻辑剖析和介绍APP的基本爬取方式,博文中省略了部份代码,若须要完整代码,请在我的github中获取,后续将继续更新其他急聘网站的爬虫。返回搜狐,查看更多 查看全部
1 引言
过段时间要开始找新工作了,爬取一些岗位信息来剖析一下吧。目前主流的急聘网站包括前程无忧、智联、BOSS直聘、拉勾等等。有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位信息,其他急聘网站后续再更新补上……
所用工具(技术):
IDE:pycharm
Database:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息抓取:scrapy外置的Selector
Python学习资料或则须要代码、视频加Python学习群:960410445
2 APP抓包剖析
我们先来体会一下前程无忧的APP,当我们在首页输入搜索关键词点击搜索然后APP都会跳转到新的页面,这个页面我们暂且称之为一级页面。一级页面展示着我们所想找查看的所有岗位列表。
当我们点击其中一条岗位信息后,APP又会跳转到一个新的页面,我把这个页面称之为二级页面。二级页面有我们须要的所有岗位信息,也是我们的主要采集目前页面。
分析完页面然后,接下来就可以对前程无忧手机APP的恳求(request)和回复(response)进行剖析了。本文所使用的抓包工具为Fiddler。
本文的目的是抓取前程无忧APP上搜索某个关键词时返回的所有急聘信息,本文以“Python”为例进行说明。APP上操作如下图所示,输入“Python”关键词后,点击搜索,随后Fiddler抓取到4个数据包,如下所示:
事实上,当听到第2和第4个数据包的图标时,我们就应当会心一笑。这两个图标分别代表传输的是json和xml格式的数据,而好多web插口就是以这两种格式来传输数据的,手机APP也不列外。选中第2个数据包,然后在右边主窗口中查看,发现第二个数据包并没有我们想要的数据。在瞧瞧第4个数据包,选中后在右边窗体,可以看见以下内容:
右下角的内容不就是在手机上看见的急聘信息吗,还是以XML的格式来传输的。我们将这个数据包的链接复制出来:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
我们爬取的时侯肯定不会只爬取一个页面的信息,我们在APP上把页面往下滑,看看Fiddler会抓取到哪些数据包。看右图:
手机屏幕往下滑动后,Fiddler又抓取到两个数据包,而且第二个数据包选中看再度发觉就是APP上新刷新的急聘信息,再把这个数据包的url链接复制出来:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
接下来,我们比对一下前后两个链接,分析其中的优缺。可以看出,除了“pageno”这个属性外,其他都一样。没错,就是在里面标红的地方。第一个数据包链接中pageno值为1,第二个pageno值为2,这下翻页的规律就一目了然了。
既然我们早已找到了APP翻页的恳求链接规律,我们就可以在爬虫中通过循环形参给pageno,实现模拟翻页的功能。
我们再尝试一下改变搜索的关键词瞧瞧链接有哪些变化,以“java”为关键词,抓取到的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比后发觉,链接中也只有keyword的值不一样,而且值就是我们在自己输入的关键词。所以在爬虫中,我们完全可以通过字符串拼接来实现输入关键词模拟,从而采集不同类型的急聘信息。同理,你可以对求职地点等信息的规律进行找寻,本文不在表述。
解决翻页功能然后,我们再去探究一下数据包中XML上面的内容。我们把里面的第一个链接复制到浏览器上打开,打开后画面如下:

这样看着就舒服多了。通过仔细观察我们会发觉,APP上每一条急聘信息都对应着一个标签,每一个上面都有一个标签,里面有一个id标示着一个岗位。例如前面第一条岗位是109384390,第二条岗位是109381483,记住这个id,后面会用到。
事实上,接下来,我们点击第一条急聘信息,进入二级页面。这时候,Fiddler会采集到APP刚发送的数据包,点击其中的xml数据包,发现就是APP上刚刷新的页面信息。我们将数据包的url链接复制下来:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
如法炮制点开一级页面中列表的第二条急聘,然后从Fiddler中复制出对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比前面两个链接,发现规律没?没错,就是jobid不同,其他都一样。这个jobid就是我们在一级页面的xml中发觉的jobid。由此,我们就可以在一级页面中抓取出jobid来构造出二级页面的url链接,然后采集出我们所须要的所有信息。整个爬虫逻辑就清晰了:
构造一级页面初始url->采集jobid->构造二级页面url->抓取岗位信息->通过循环模拟翻页获取下一页面的url。
好了,分析工作完成了,开始动手写爬虫了。
3 编写爬虫
本文编撰前程无忧手机APP网路爬虫用的是Scrapy框架,下载好scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider就是我们本次爬虫项目的项目名称,在项目名前面有一个“.”,这个点可有可无,区别是在当前文件之间创建项目还是创建一个与项目名同名的文件之后在文件内创建项目。
创建好项目后,继续创建一个爬虫,专用于爬取前程无忧发布的急聘信息。创建爬虫命名如下:
scrapy genspider qcwySpider
注意:如果你在创建爬虫项目的时侯没有在项目名前面加“.”,请先步入项目文件夹以后再运行命令创建爬虫。
通过pycharm打开刚创建好的爬虫项目,左侧目录树结构如下:
在开始一切爬虫工作之前,先打开settings.py文件,然后取消“ROBOTSTXT_OBEY = False”这一行的注释,并将其值改为False。
# Obey robots.txt rulesROBOTSTXT_OBEY = False
完成上述更改后,打开spiders包下的qcwySpider.py,初始代码如下:
这是scrapy为我们搭好的框架,我们只须要在这个基础起来建立我们的爬虫即可。
首先我们须要在类中添加一些属性,例如搜索关键词keyword、起始页、想要爬取得最大页数,同时也须要设置headers进行简单的反爬。另外,starturl也须要重新设置为第一页的url。更改后代码如下:
然后开始编撰parse方式爬取一级页面,在一级页面中,我们主要逻辑是通过循环实现APP中屏幕下降更新,我们用前面代码中的current_page来标示当前页页脚,每次循环后,current_page加1,然后构造新的url,通过反弹parse方式爬取下一页。另外,我们还须要在parse方式中在一级页面中采集出jobid,并构造出二级页面的,回调实现二级页面信息采集的parse_job方式。parse方式代码如下:
为了便捷进行调试,我们在项目的jobSpider目录下创建一个main.py文件,用于启动爬虫,每次启动爬虫时,运行该文件即可。内容如下:

二级页面信息采集功能在parse_job方式中实现,因为所有我们须要抓取的信息都在xml中,我们直接用scrapy自带的selector提取下来就可以了,不过在提取之前,我们须要先定义好Item拿来储存我们采集好的数据。打开items.py文件,编写一个Item类,输入以下代码:
上面每一个item都与一个xml标签对应,用于储存一条信息。在qcwyJobsItem类的最后,定义了一个do_insert方式,该方式用于生产将item中所有信息储存数据库的insert句子,之所以在items铁块中生成这个insert句子,是因为日后若果有了多个爬虫,有多个item类以后,在pipelines模块中,可以针对不同的item插入数据库,使本项目具有更强的可扩展性。你也可以将所有与插入数据库有关的代码都写在pipelines。
然后编撰parse_job方式:
完成上述代码后,信息采集部分就完成了。接下来继续写信息储存功能,这一功能在pipelines.py中完成。
编写完pipelines.py后,打开settings.py文件,将刚写好的MysqlTwistedPipline类配置到项目设置文件中:
顺便也把数据库配置好:
数据库配置你也可以之间嵌入到MysqlTwistedPipline类中,不过我习惯于把这种专属的数据库信息写在配置文件中。
最后,只差一步,建数据库、建数据表。部分表结构如下图所示:
完成上述所有内容以后,就可以运行爬虫开始采集数据了。采集的数据如下图所示:
4 总结
整个过程出来,感觉前程无忧网APP爬取要比网页爬取容易一些(似乎好多网站都这样)。回顾整个流程,其实代码中还有众多细节尚可改进建立,例如还可以在构造链接时加上求职地点等。本博文重在对整个爬虫过程的逻辑剖析和介绍APP的基本爬取方式,博文中省略了部份代码,若须要完整代码,请在我的github中获取,后续将继续更新其他急聘网站的爬虫。返回搜狐,查看更多
Python爬虫 百度地图搜索数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-10 06:51
趁空闲时间用Python来简单剖析制做一个简单的爬虫小脚本。
三个参数主要考虑的,一个是地理位置,一个是关键词,一个是页数。在抓包的过程中对“页数”这个参数苦恼了好久,一直没看明白,后面仔细对比才找到门道。
先谈谈地理位置:
需要按指定地址搜索的时侯会须要一个叫City_Code 的参数,输入搜索的时侯可以爬取到,输入后有上述的几种情况,不存在会强制要求你重新输入,如果输入“广东”就会定位在广州省内,不过实际搜索关键词的时侯页面并不会显示海南所有的结果,而是须要你做二次选择。
在百度的开发平台有城市代码可以直接下载,不过并不完整,有须要的可以自行下载查阅
parameter = {
"newmap": "1",
"reqflag": "pcmap",
"biz": "1",
"from": "webmap",
"da_par": "direct",
"pcevaname": "pc4.1",
"qt": "con",
"c": City_Code, # 城市代码
"wd": key_word, # 搜索关键词
"wd2": "",
"pn": page, # 页数
"nn": page * 10,
"db": "0",
"sug": "0",
"addr": "0",
"da_src": "pcmappg.poi.page",
"on_gel": "1",
"src": "7",
"gr": "3",
"l": "12",
"tn": "B_NORMAL_MAP",
# "u_loc": "12621219.536556,2630747.285024",
"ie": "utf-8",
# "b": "(11845157.18,3047692.2;11922085.18,3073932.2)", #这个应该是地理位置坐标,可以忽略
"t": "1468896652886"
}
页数的参数有两个,一个是"pn",另外一个是"nn",没搞明白三者之间的关系;
pn=0,nn=0 第一页
pn=1,nn=10 第二页
pn=2,nn=20 第三页
pn=3,nn=30 第四页
"nn"参数在调试过程中试过固定的话并且返回的数据是一样的。
<p> url = 'http://map.baidu.com/'
htm = requests.get(url, params=parameter)
htm = htm.text.encode('latin-1').decode('unicode_escape') # 转码
pattern = r'(? 查看全部
之前在网上听到有留传VBA编撰的版本,不过参数固定,通用性并不强.
趁空闲时间用Python来简单剖析制做一个简单的爬虫小脚本。
三个参数主要考虑的,一个是地理位置,一个是关键词,一个是页数。在抓包的过程中对“页数”这个参数苦恼了好久,一直没看明白,后面仔细对比才找到门道。
先谈谈地理位置:
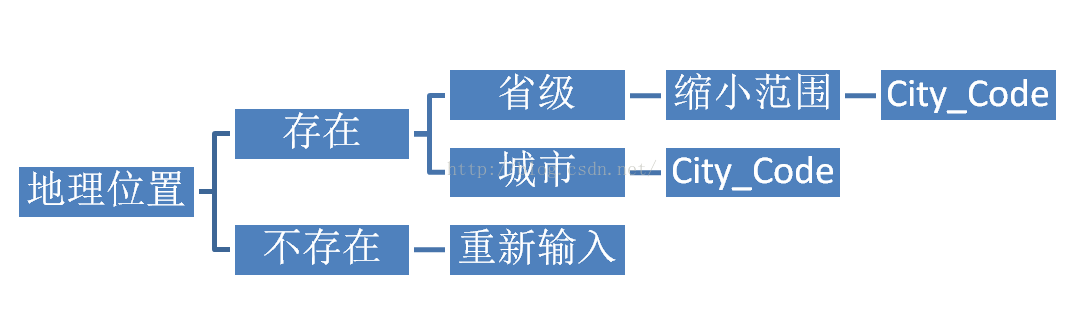
需要按指定地址搜索的时侯会须要一个叫City_Code 的参数,输入搜索的时侯可以爬取到,输入后有上述的几种情况,不存在会强制要求你重新输入,如果输入“广东”就会定位在广州省内,不过实际搜索关键词的时侯页面并不会显示海南所有的结果,而是须要你做二次选择。
在百度的开发平台有城市代码可以直接下载,不过并不完整,有须要的可以自行下载查阅
parameter = {
"newmap": "1",
"reqflag": "pcmap",
"biz": "1",
"from": "webmap",
"da_par": "direct",
"pcevaname": "pc4.1",
"qt": "con",
"c": City_Code, # 城市代码
"wd": key_word, # 搜索关键词
"wd2": "",
"pn": page, # 页数
"nn": page * 10,
"db": "0",
"sug": "0",
"addr": "0",
"da_src": "pcmappg.poi.page",
"on_gel": "1",
"src": "7",
"gr": "3",
"l": "12",
"tn": "B_NORMAL_MAP",
# "u_loc": "12621219.536556,2630747.285024",
"ie": "utf-8",
# "b": "(11845157.18,3047692.2;11922085.18,3073932.2)", #这个应该是地理位置坐标,可以忽略
"t": "1468896652886"
}
页数的参数有两个,一个是"pn",另外一个是"nn",没搞明白三者之间的关系;
pn=0,nn=0 第一页
pn=1,nn=10 第二页
pn=2,nn=20 第三页
pn=3,nn=30 第四页
"nn"参数在调试过程中试过固定的话并且返回的数据是一样的。
<p> url = 'http://map.baidu.com/'
htm = requests.get(url, params=parameter)
htm = htm.text.encode('latin-1').decode('unicode_escape') # 转码
pattern = r'(?
新榜陌陌文章抓取客户端(APSpider)
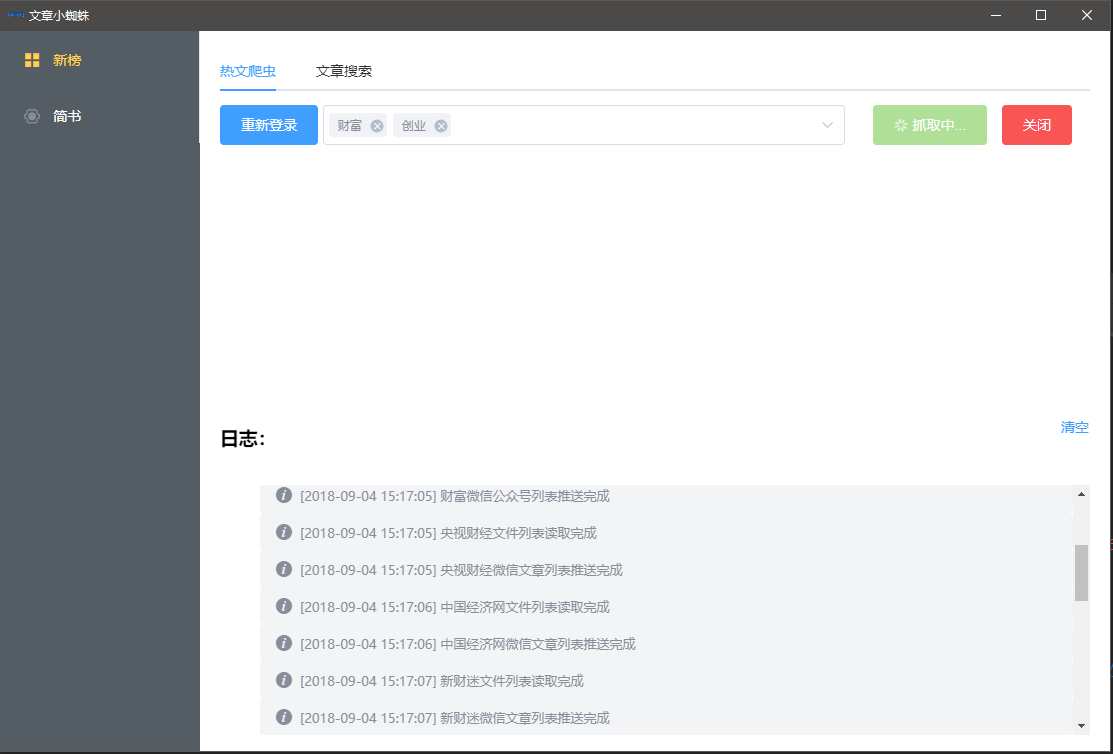
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2020-08-10 06:25
这是曾经给新媒体营运朋友写的爬虫软件,用了一段时间就没用了(唉、气死我了)。
目前只抓取了新榜的日榜(周榜、月榜类似,换下地址即可)下,各行业的前50个公众号下的7天热门文章和最新发布文章
如下所示:
技术构架:nw.jsjqueryelement-ui
为什么选用nw.js呢?嗯,先入为主吧,electron也很不错(改下入口即可使用),为什么不用大名鼎鼎的python呢?爬虫框架而且一堆堆,还是个人习惯使然,用惯了js,操作网页简直得心应手,天生绝配!在此并不证实python,个人也比较喜欢(最近在研究深度学习架构),只是认为爬这种网页,还用不着它。
有一个关键点,在网页中,想操作iframe中的网页,是不容许跨域的,而nw.js容许这样操作,真是好啊!!!
安装步骤下载nw.js ,根据自己系统下载相应版本即可,官网: ,若自己须要二次开发,请下载SDK版本,方可开启debug,使用方式详见官网,不再探讨克隆APSpider,复制到nw.js目录,启动cmd,打开到当前目录,执行 npm install 安装依赖启动nw.exe 就可以使用啦使用说明考虑完整性,本客户端在读取到公众号列表及文章列表时,直接储存在article下的目录文件中,若须要将数据储存至数据库,请更改assest\utils\common.js中的Ap.request.ajax方式,将log函数注释,将下边被注释的代码恢复即可,然后在app\config.js中配置pushStateAPI(即前端接收数据API)为自己的数据插口即可因为新榜在公众号详尽页面设置了登陆权限(如:),
只有登陆后可访问,并且获取公众号文章的插口: ,
也是带了安全校准数组,所以登陆是必须要走的过程,所以点击登陆后,程序打开登陆页面,并获取二维码,如图:
用自己的陌陌扫一扫,授权登陆即可,程序手动步入公众号列表:
选择行业,点击开始即可,程序将获取所选行业下公众号的热门文章及最新发布文章,并储存至文件中
最初的版本是一键获取全部行业的文章,后面想想,还是自己想获取什么行业的就获取什么行业的
这是我的后台疗效:
其他新榜的所有ajax都带有安全校准数组和cookie,cookie倒是好办,登录后获取cookie储存上去,带到ajax的恳求头中即可,至于校准数组,着实费了一些时间,这个不再这儿阐述破解方式,有时间我会在csdn中写写破解的思路。关键词搜索还没做完,有时间补上。原本计划把微博、简书等一并爬了,忙于其他事务,就落下了。非常谢谢您的支持
撸码不易,如果对你有所帮助,欢迎您的赞赏!微信赞赏码: 查看全部
源码下载请至
这是曾经给新媒体营运朋友写的爬虫软件,用了一段时间就没用了(唉、气死我了)。
目前只抓取了新榜的日榜(周榜、月榜类似,换下地址即可)下,各行业的前50个公众号下的7天热门文章和最新发布文章
如下所示:
技术构架:nw.jsjqueryelement-ui
为什么选用nw.js呢?嗯,先入为主吧,electron也很不错(改下入口即可使用),为什么不用大名鼎鼎的python呢?爬虫框架而且一堆堆,还是个人习惯使然,用惯了js,操作网页简直得心应手,天生绝配!在此并不证实python,个人也比较喜欢(最近在研究深度学习架构),只是认为爬这种网页,还用不着它。
有一个关键点,在网页中,想操作iframe中的网页,是不容许跨域的,而nw.js容许这样操作,真是好啊!!!
安装步骤下载nw.js ,根据自己系统下载相应版本即可,官网: ,若自己须要二次开发,请下载SDK版本,方可开启debug,使用方式详见官网,不再探讨克隆APSpider,复制到nw.js目录,启动cmd,打开到当前目录,执行 npm install 安装依赖启动nw.exe 就可以使用啦使用说明考虑完整性,本客户端在读取到公众号列表及文章列表时,直接储存在article下的目录文件中,若须要将数据储存至数据库,请更改assest\utils\common.js中的Ap.request.ajax方式,将log函数注释,将下边被注释的代码恢复即可,然后在app\config.js中配置pushStateAPI(即前端接收数据API)为自己的数据插口即可因为新榜在公众号详尽页面设置了登陆权限(如:),
只有登陆后可访问,并且获取公众号文章的插口: ,
也是带了安全校准数组,所以登陆是必须要走的过程,所以点击登陆后,程序打开登陆页面,并获取二维码,如图:
用自己的陌陌扫一扫,授权登陆即可,程序手动步入公众号列表:
选择行业,点击开始即可,程序将获取所选行业下公众号的热门文章及最新发布文章,并储存至文件中
最初的版本是一键获取全部行业的文章,后面想想,还是自己想获取什么行业的就获取什么行业的
这是我的后台疗效:
其他新榜的所有ajax都带有安全校准数组和cookie,cookie倒是好办,登录后获取cookie储存上去,带到ajax的恳求头中即可,至于校准数组,着实费了一些时间,这个不再这儿阐述破解方式,有时间我会在csdn中写写破解的思路。关键词搜索还没做完,有时间补上。原本计划把微博、简书等一并爬了,忙于其他事务,就落下了。非常谢谢您的支持
撸码不易,如果对你有所帮助,欢迎您的赞赏!微信赞赏码:
SEM数据剖析读懂这两点,效果逐步提高!
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2020-08-10 02:22
3、如果上面两种因为各类缘由没办法短时间内学会的话,笔者建议你可以用最笨的方式,就是人工的去统计,笔者有一个顾客就是这样的,他对于每位咨询过他的顾客,都会主动寻问对方搜索的关键词,以及搜索的哪些平台,虽然太笨,但能坚持出来,也是挺实用的。
以上3种基本算是全部的统计模式了,还有一些通过付费数据监控平台进行数据回收的渠道,由于门槛有点高,我们暂时不聊。
第一种通常是你们比较常用的,图里也基本囊括了目前市面上所有的常见的统计平台,各有优劣势。
一般比较常用的是百度统计以及微软的Google Analytics,但是因为微软的Google Analytics须要翻墙,比较麻烦,所以我会推荐你们去使用百度统计,因为一个百度统计基本就可以满足百分之90的数据搜集需求,接下来我也会重点的围绕百度统计来给你们做详尽的解释。
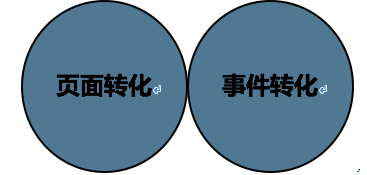
首先百度统计统计逻辑分为以下两种:
1)页面转化应用场景:页面转化通常运用于以URL为统计目标的数据,直白一点讲就是假如你要统计的数据是一个不会改变的URL链接,那么页面转化就可以帮你实现。
比如,如果你觉得网站上的某个页面非常重要(如递交订单后出现的“购买成功”页面),到达了该页面表示访客完成了你的目标,你就可以将抵达该目标页面作为一种转化来统计。多用于电商类的网站做统计使用。
页面转化的设置步骤:
(官方标准)
2)事件转化;这一点笔者会重点的来给你们讲。首先,一般常规的顾客可以使用修改网站的源代码来统计转化目标的,源代码须要改成百度可以辨识的标准:“id=xxx”,找到转化目标而且可使百度成功追踪后,你就可以轻松的搜集到你的转化数据了。
如图:
这里可能有些同学要问了,如果我想统计目标是访问行为的话,怎么办?接下来笔者会详尽讲一下关于怎么来统计一些难以被普通统计代码跟踪PV的特殊的网站或页面。
在统计之前我们须要用到百度开放平台的一个合同:JS-API,JS-API通过在页面上布署js代码的方法,可以帮你搜集网站的各种业务数据(沟通数、点击数、转化数)
1、在布署JS前,你的网站不仅须要成安装百度统计代码,还须要新装一串JS-API代码,这里须要注意一下的是,JS-API代码必须安装在你统计页面的 head 标签上面,具体代码如下:
2、在我们进行进一步安装前,你须要明白风波转化的基本概念,不然以后的内容你会很难读懂。
首先风波转化统计的是访客在网站操作行为,这种行为可以被选取为转化目标,比如你是一个做视频网站的顾客,你希望通过风波转化来统计你每晚点击某一个视频“暂停”以及“播放”两个动作的数据,那么这些统计动作的目的,都可以运用JS-API来做实现,以此类推,你可以统计特别多的访客行为,当然这些行为就是转化目标了。
3、因为访客在网站的动作是一个行为,我们须要使代码去辨识他的行为,就必须为她们加上惟一的标示,只有正确的添加了标示,系统就会正确的捕捉到数据。具体如下:
事件链接中加入风波跟踪参数(以下引用官方解释)
_hmt.push(['_trackEvent', category, action, opt_label, opt_value]);
category:要监控的目标的类型名称,通常是同一组目标的名子,比如"视频"、"音乐"、"软件"、"游戏"等等。该项必选。
action:用户跟目标交互的行为,如"播放"、"暂停"、"下载"等等。该项必选。
opt_label:事件的一些额外信息,通常可以是歌曲的名称、软件的名称、链接的名称等等。该项可选。
opt_value:事件的一些数值信息,比如权重、时长、价格等等,在报表中可以见到其平均值等数据。该项可选。
举例说明:
假设页面A上有且只有一个下载链接,设置前后对比如下:
设置前:
设置完成后,我们就可以去百度统计设置转化目标了,你只须要在风波转化中的新增页面中降低你布署JS代码页面链接,就可以成功的获取数据了。
02 掌握数据剖析的思索维度
当我们成功布署了属于我们自己的数据回收通道后,我们就可以轻松的获取我们想要数据,但是好多时侯你们可能会认为,回收了这么多数据,我该如何去整理剖析了。
接下笔者会阐述领到数据后,我们须要怎样来做剖析,这里,我只提供思索方向,具体的我就不再赘言了,因为同样的数据,拿给不同的帐户,调整策略也不一定一样,还是那句话,数据剖析要结合你实际的企业情况以及产品特性和客户群特点。
首先,你须要通过以下几个思索维度来把数据立体化,这样可以帮你快速把你确定帐户问题:
1、账户数据层面,我们帐户是否诠释点击访问属于正常值?
思路解析:账户的数据直接决定了这个帐户大的方向是否是科学健康的,比如你的预算三天是100块,ACP为20块钱,一天可以形成5次点击,那么很容易的就可以晓得,账户大致的优化方向应当围绕着增加ACP来。
2、账户类有消费关键词有多少?其中有80%消费是被什么词消耗了,80%的点击集中在哪些词头上,占80%点击的关键词是什么,他们消耗占整体的消耗的多少?他们转化成本分别是多少?
思路解析:我们常常说的二八原则,其实是一个比较科学的理论,我这儿把二八原则做了更多的延展。
首先你帐户内的有消费词决定了你的广告面对的是一个多大的人群,然后帐户80%的消费决定了你的钱都花在哪些词头上,80%的点击决定了你实际订购的流量质量。
所以我们在做帐户数据剖析的时侯,这些一定要成比例原则的去做深入的剖析,可以帮我们快速的定位问题,这样可以指导我们以后的优化动作会在正确的公路上。
案例解析:
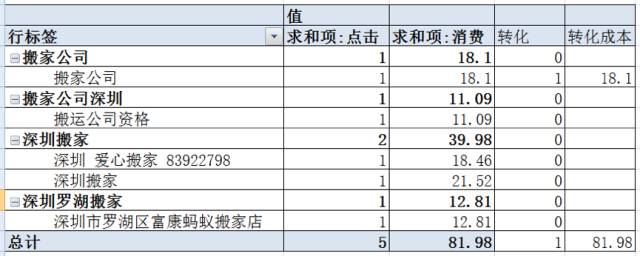
这是一个搬家顾客,客户每晚的预算80块钱,根据我们思路,来简单的剖析一下这个帐户的问题:
数据层面:单日消费80,ACP:16.40,可以显著的看下来,这个在极其严重的ACP和预算不符的情况,之后的优化方向也确定为增加ACP为主。
通过转化数据整理后我们可以看见,这个帐户有转化的词只有一个,转化成本为18.1,点击流量价钱很高且普遍和原语匹配程度不高,结合数据,我们可以将这个帐户的调整方案定为:ACP须要增加,暂定目标为同比增长50%,点击质量须要优化,做否词,以及修改部份不合理的匹配方法。 查看全部
文章链接:视频教程 | 追踪URL生成、批量添加、追踪数据剖析步骤解读
3、如果上面两种因为各类缘由没办法短时间内学会的话,笔者建议你可以用最笨的方式,就是人工的去统计,笔者有一个顾客就是这样的,他对于每位咨询过他的顾客,都会主动寻问对方搜索的关键词,以及搜索的哪些平台,虽然太笨,但能坚持出来,也是挺实用的。
以上3种基本算是全部的统计模式了,还有一些通过付费数据监控平台进行数据回收的渠道,由于门槛有点高,我们暂时不聊。
第一种通常是你们比较常用的,图里也基本囊括了目前市面上所有的常见的统计平台,各有优劣势。
一般比较常用的是百度统计以及微软的Google Analytics,但是因为微软的Google Analytics须要翻墙,比较麻烦,所以我会推荐你们去使用百度统计,因为一个百度统计基本就可以满足百分之90的数据搜集需求,接下来我也会重点的围绕百度统计来给你们做详尽的解释。
首先百度统计统计逻辑分为以下两种:
1)页面转化应用场景:页面转化通常运用于以URL为统计目标的数据,直白一点讲就是假如你要统计的数据是一个不会改变的URL链接,那么页面转化就可以帮你实现。
比如,如果你觉得网站上的某个页面非常重要(如递交订单后出现的“购买成功”页面),到达了该页面表示访客完成了你的目标,你就可以将抵达该目标页面作为一种转化来统计。多用于电商类的网站做统计使用。
页面转化的设置步骤:
(官方标准)
2)事件转化;这一点笔者会重点的来给你们讲。首先,一般常规的顾客可以使用修改网站的源代码来统计转化目标的,源代码须要改成百度可以辨识的标准:“id=xxx”,找到转化目标而且可使百度成功追踪后,你就可以轻松的搜集到你的转化数据了。
如图:
这里可能有些同学要问了,如果我想统计目标是访问行为的话,怎么办?接下来笔者会详尽讲一下关于怎么来统计一些难以被普通统计代码跟踪PV的特殊的网站或页面。
在统计之前我们须要用到百度开放平台的一个合同:JS-API,JS-API通过在页面上布署js代码的方法,可以帮你搜集网站的各种业务数据(沟通数、点击数、转化数)
1、在布署JS前,你的网站不仅须要成安装百度统计代码,还须要新装一串JS-API代码,这里须要注意一下的是,JS-API代码必须安装在你统计页面的 head 标签上面,具体代码如下:
2、在我们进行进一步安装前,你须要明白风波转化的基本概念,不然以后的内容你会很难读懂。
首先风波转化统计的是访客在网站操作行为,这种行为可以被选取为转化目标,比如你是一个做视频网站的顾客,你希望通过风波转化来统计你每晚点击某一个视频“暂停”以及“播放”两个动作的数据,那么这些统计动作的目的,都可以运用JS-API来做实现,以此类推,你可以统计特别多的访客行为,当然这些行为就是转化目标了。
3、因为访客在网站的动作是一个行为,我们须要使代码去辨识他的行为,就必须为她们加上惟一的标示,只有正确的添加了标示,系统就会正确的捕捉到数据。具体如下:
事件链接中加入风波跟踪参数(以下引用官方解释)
_hmt.push(['_trackEvent', category, action, opt_label, opt_value]);
category:要监控的目标的类型名称,通常是同一组目标的名子,比如"视频"、"音乐"、"软件"、"游戏"等等。该项必选。
action:用户跟目标交互的行为,如"播放"、"暂停"、"下载"等等。该项必选。
opt_label:事件的一些额外信息,通常可以是歌曲的名称、软件的名称、链接的名称等等。该项可选。
opt_value:事件的一些数值信息,比如权重、时长、价格等等,在报表中可以见到其平均值等数据。该项可选。
举例说明:
假设页面A上有且只有一个下载链接,设置前后对比如下:
设置前:
设置完成后,我们就可以去百度统计设置转化目标了,你只须要在风波转化中的新增页面中降低你布署JS代码页面链接,就可以成功的获取数据了。
02 掌握数据剖析的思索维度
当我们成功布署了属于我们自己的数据回收通道后,我们就可以轻松的获取我们想要数据,但是好多时侯你们可能会认为,回收了这么多数据,我该如何去整理剖析了。
接下笔者会阐述领到数据后,我们须要怎样来做剖析,这里,我只提供思索方向,具体的我就不再赘言了,因为同样的数据,拿给不同的帐户,调整策略也不一定一样,还是那句话,数据剖析要结合你实际的企业情况以及产品特性和客户群特点。
首先,你须要通过以下几个思索维度来把数据立体化,这样可以帮你快速把你确定帐户问题:
1、账户数据层面,我们帐户是否诠释点击访问属于正常值?
思路解析:账户的数据直接决定了这个帐户大的方向是否是科学健康的,比如你的预算三天是100块,ACP为20块钱,一天可以形成5次点击,那么很容易的就可以晓得,账户大致的优化方向应当围绕着增加ACP来。
2、账户类有消费关键词有多少?其中有80%消费是被什么词消耗了,80%的点击集中在哪些词头上,占80%点击的关键词是什么,他们消耗占整体的消耗的多少?他们转化成本分别是多少?
思路解析:我们常常说的二八原则,其实是一个比较科学的理论,我这儿把二八原则做了更多的延展。
首先你帐户内的有消费词决定了你的广告面对的是一个多大的人群,然后帐户80%的消费决定了你的钱都花在哪些词头上,80%的点击决定了你实际订购的流量质量。
所以我们在做帐户数据剖析的时侯,这些一定要成比例原则的去做深入的剖析,可以帮我们快速的定位问题,这样可以指导我们以后的优化动作会在正确的公路上。
案例解析:
这是一个搬家顾客,客户每晚的预算80块钱,根据我们思路,来简单的剖析一下这个帐户的问题:

数据层面:单日消费80,ACP:16.40,可以显著的看下来,这个在极其严重的ACP和预算不符的情况,之后的优化方向也确定为增加ACP为主。
通过转化数据整理后我们可以看见,这个帐户有转化的词只有一个,转化成本为18.1,点击流量价钱很高且普遍和原语匹配程度不高,结合数据,我们可以将这个帐户的调整方案定为:ACP须要增加,暂定目标为同比增长50%,点击质量须要优化,做否词,以及修改部份不合理的匹配方法。
如何获取新浪微博数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-08-10 01:37
在历史数据获取方面,与twitter相比,搜索插口比较弱,好在提供了搜索功能。
在实时数据获取方面,sina 还是比较保守。与之相关的有三个插口用public_timeline、topics、nearby_timeline,分别拿来搜集公共的实时微博、某个话题下的实时微博、某点周围的实时微博。由此可以看出:缺乏在某地点关于某关键词的实时搜索插口。虽然有众多限制,但依然有替代方案是:利用搜索功能可以进行搜集一个小时前微博的,同时可以对关键字和地点进行限制,等等。下面从历史和实时数据两个方面来述说获取微博数据。
数据搜集思路
历史数据在科研方面很重要,特别是研究社交媒体方向。但是历史数据也是有要求的,首先要主题相关,然后历史也有个具体时间段。结合这两个要求的考虑,可以使用微博的中级搜索插口(详见)。
主要思路是:抓取网页;解析网页;存储有用信息。
值得注意的是:我们可以选择解析网页的全部信息,包括微博文和用户的部份信息,但这样获得的信息相对较少。这时可以考虑只从网页中提取出微博的id,然后通过API来返回该微博的所有信息,包括用户信息。
实时数据的主要作用可以彰显在一些应用上,譬如实时检测公众对突发事件的反应。
主要思路是:实时数据的一条路径为,利用微博提供的API进行搜索。这里不表,调用API即可。另一条就是,上文提及的借助搜索功能搜集一个小时前的逾实时数据。
遇到的问题
即每个小时对API的访问有次数限制。新浪微博API采用OAuth2进行授权,有严格的访问权限和对应的访问频次。一种走正规流程,申请appKey并获得appSecret,从而的得到相应的权限和对应的访问频次。当然还有其他方式可以避免这些限制。获取OAuth2授权的形式不止这一种(可参考)。文中提及可以通过基于用户名与密码模式,这样我们可以通过构造类似 :
grant_type=password&client_id=s6BhdRkqt3&client_secret=47HDu8s&username=johndoe&password=A3ddj3w
这样的URL恳求来申请Access Token。这时还是须要一个中级权限的appKey和appSecret。很幸运的是,很多APP和客户端的官方微博appKey和appSecret在网路上都可以找到(可参见)
原文点此 查看全部
无论是做与微博相关研究还是开发相关应用,可能须要获取历史的或则实时的数据。如何获取呢?除了新浪微博为开发者提供了API, 还可以借助搜索功能(详见此文)来搜集数据。
在历史数据获取方面,与twitter相比,搜索插口比较弱,好在提供了搜索功能。
在实时数据获取方面,sina 还是比较保守。与之相关的有三个插口用public_timeline、topics、nearby_timeline,分别拿来搜集公共的实时微博、某个话题下的实时微博、某点周围的实时微博。由此可以看出:缺乏在某地点关于某关键词的实时搜索插口。虽然有众多限制,但依然有替代方案是:利用搜索功能可以进行搜集一个小时前微博的,同时可以对关键字和地点进行限制,等等。下面从历史和实时数据两个方面来述说获取微博数据。
数据搜集思路
历史数据在科研方面很重要,特别是研究社交媒体方向。但是历史数据也是有要求的,首先要主题相关,然后历史也有个具体时间段。结合这两个要求的考虑,可以使用微博的中级搜索插口(详见)。
主要思路是:抓取网页;解析网页;存储有用信息。
值得注意的是:我们可以选择解析网页的全部信息,包括微博文和用户的部份信息,但这样获得的信息相对较少。这时可以考虑只从网页中提取出微博的id,然后通过API来返回该微博的所有信息,包括用户信息。
实时数据的主要作用可以彰显在一些应用上,譬如实时检测公众对突发事件的反应。
主要思路是:实时数据的一条路径为,利用微博提供的API进行搜索。这里不表,调用API即可。另一条就是,上文提及的借助搜索功能搜集一个小时前的逾实时数据。
遇到的问题
即每个小时对API的访问有次数限制。新浪微博API采用OAuth2进行授权,有严格的访问权限和对应的访问频次。一种走正规流程,申请appKey并获得appSecret,从而的得到相应的权限和对应的访问频次。当然还有其他方式可以避免这些限制。获取OAuth2授权的形式不止这一种(可参考)。文中提及可以通过基于用户名与密码模式,这样我们可以通过构造类似 :
grant_type=password&client_id=s6BhdRkqt3&client_secret=47HDu8s&username=johndoe&password=A3ddj3w
这样的URL恳求来申请Access Token。这时还是须要一个中级权限的appKey和appSecret。很幸运的是,很多APP和客户端的官方微博appKey和appSecret在网路上都可以找到(可参见)
原文点此
如何高贵地拿下公众号历史文章、点赞数、阅读数,甚至是评论?
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-10 01:12
可能我们熟知的新榜、清博这种平台提供这样的数据,但是价钱却使人望而止步。比如我们在新榜想获取人民日报的所有历史文章,竟然须要300榜豆,而300榜豆须要多少钱呢?285 人民币!!!
新榜采集公众号历史文章
采集价格
我想这个费用不是大多数自媒体工作者都还能承当的起的,包括我曾今也想过订购这样的服务,但最终还是止住了,作为一个开发者,这些问题才能自己解决就不要去破费了,于是,我决定开发一款这样的工具,能够帮助象我一样须要快速获得公众号历史文章数据的人更便捷、更经济地达到目的,所以便有了如今的小蜜蜂公众号文章助手
小蜜蜂公众号文章助手
助手实现的功能
助手界面
链接模式
代理模式
其中链接模式最为简单,仅需粘贴历史文章页面链接即可一键采集,而代理模式须要几分钟的设置,设置好后即可开始采集
image.png
公众号列表
采集结果列表
采集成功后,可到公众号列表查看采集的结果,可以看见有文章数量、名称、以及一些导入文档的操作 查看全部
相信,不少营运工作者在日常工作中会碰到这样的需求,经常须要研究竞争对手的公众号文章数据或则自己公众号数据,然而微信公众平台并没有提供这样的方便操作,可以支持将公众号数据导下来研究。
可能我们熟知的新榜、清博这种平台提供这样的数据,但是价钱却使人望而止步。比如我们在新榜想获取人民日报的所有历史文章,竟然须要300榜豆,而300榜豆须要多少钱呢?285 人民币!!!

新榜采集公众号历史文章

采集价格
我想这个费用不是大多数自媒体工作者都还能承当的起的,包括我曾今也想过订购这样的服务,但最终还是止住了,作为一个开发者,这些问题才能自己解决就不要去破费了,于是,我决定开发一款这样的工具,能够帮助象我一样须要快速获得公众号历史文章数据的人更便捷、更经济地达到目的,所以便有了如今的小蜜蜂公众号文章助手

小蜜蜂公众号文章助手
助手实现的功能
助手界面

链接模式

代理模式
其中链接模式最为简单,仅需粘贴历史文章页面链接即可一键采集,而代理模式须要几分钟的设置,设置好后即可开始采集

image.png
公众号列表

采集结果列表
采集成功后,可到公众号列表查看采集的结果,可以看见有文章数量、名称、以及一些导入文档的操作
阿里云推荐引擎离线流程的主要作用是 site:blog.csdn.net
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-10 00:18
推荐引擎(Recommendation Engine,以下简称RecEng,特指阿里云推荐引擎)是在阿里云估算环境下构建的一套推荐服务框架,目标是使广大中小互联网企业能否在这套框架上快速的搭建满足自身业务需求的推荐服务。
课程链接:阿里云推荐引擎使用教程
推荐服务一般由三部份组成:日志采集,推荐估算和产品对接。推荐服务首先须要采集产品中记录的用户行为日志到离线存储,然后在离线环境下借助推荐算法进行用户和物品的匹配估算,找出每位用户可能感兴趣的物品集合后,将这种预先估算好的结果推送到在线储存上,最终产品在有用户访问时通过在线API向推荐服务发起恳求,获得该用户可能感兴趣的物品,完成推荐业务。
RecEng的核心是推荐算法的订制。RecEng为推荐业务定义了一套完整的规范,从输入,到估算,到输出,客户可以在这个框架下自定义算法和规则,以此满足各类行业的需求,包括电商,音乐,视频,社交,新闻,阅读等。同时,RecEng也提供了相应的方式供顾客方便的接入用户访问日志,以及自定义满足其自身业务需求的在线API。
基本概念:
客户/租户(org/tenant)
指RecEng的使用者,系统中由其阿里云帐号代表。通常顾客是一个组织,RecEng中常用org表示顾客。
用户(user)
指顾客的用户,即RecEng使用者的用户。推荐是一个2C的服务,使用推荐服务的顾客必然有其自己的用户,RecEng使用者的用户简称为“用户”,系统中常用user表示用户。
物品(item)
指被推荐给用户的内容,可以是商品,也可以是歌曲,视频等其他内容,系统中常用item表示物品。
业务(biz)
业务针对数据集定义,定义了算法所能使用的数据范围。一个顾客在RecEng上可以有多个业务,不同的业务必然有不同的数据集。RecEng要求每位业务提供四类数据(不要求全部提供):用户数据,物品数据,用户行为数据,推荐疗效数据。每一组这样的数据就构成一个业务。系统中常用biz表示业务。
比如某顾客A有两类被推荐的物品,分别是视频和歌曲,于是顾客A可以在RecEng上构建两个业务M和N,其中M的物品数据为视频,N的物品数据为歌曲,其他的数据(指用户数据,用户行为数据等)可以都相同。在这些方案下,业务M和N的数据是独立的,即业务M其实能看到用户对于歌曲的行为,但是业务M中不收录歌曲的物品数据,所以会扔掉用户对于歌曲的行为;如果业务M中某用户只对歌曲有行为,对视频没有行为,业务M也会扔掉这类用户。反之对业务N亦然。
一个业务最好只推荐一类物品。多类物品的推荐在后续的行业模板会有支持,需要引入蓝筹股(plate)的概念,一份业务数据可以生成多个蓝筹股的数据集,场景绑定某个蓝筹股进行推荐算法估算。
场景(scn)
场景指的是推荐的上下文,每个场景就会输出一个API,场景由推荐时可用的参数决定。有两种场景最为常见,分别是首页推荐场景和详情页推荐场景。顾名思义,在执行首页推荐时,可用的参数只有用户信息;而在执行详情页推荐时,可用的参数不仅用户信息,还包括当前详情页上所展示的物品信息。系统中常用scn表示场景。
一个业务可以收录多个场景,即对于某个业务A,它收录多个首页场景也是完全可以的。
事实上,回到场景的原创定义,场景只是由推荐的上下文决定,客户完全可以按照自己的需求构建全新的场景,比如针对搜索关键词的推荐场景,这时可用的参数不仅用户信息,还有用户所输入的关键词。
流程(flow)
算法流程指数据端到端的处理流程,一部分流程属于业务范畴,如数据导出流程,效果估算流程,数据质量分估算流程;一部分属于场景,比如场景算法流程。从数据源类型和产下来界定,又分为离线流程,近线流程,在线流程
离线流程
一般情况下,离线流程的输入和输出都是MaxCompute(原ODPS)表,所以离线数据规范虽然上是一组MaxCompute表的格式规范,包括接入数据、中间数据和输出数据三类数据的格式规范。接入数据指顾客离线提供的用户、物品、日志等数据,中间数据是在离线算法流程中形成的各类中间性质的结果数据表,输出数据是指推荐结果数据表,该结果最终将会被导出到在线储存中,供在线估算模块使用。
近线流程
推荐引擎的的近线流程主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新。不象离线算法,天然以MaxCompute(原ODPS)表作为输入和输出,近线程序的输入数据可以来自多个数据源,如在线的表格储存(原OTS),以及用户的API恳求,又或则是程序中的变量;输出可以是程序变量,或者写回在线储存,或者返回给用户。出于安全性考虑,推荐引擎提供了一组SDK供顾客自定义在线代码读写在线储存(Table Store),不容许直接访问,所以须要定义每类在线储存的别称和格式。对于须要频繁使用的在线数据,无论其来自在线储存还是用户的API恳求,RecEng会预先读好,保存在在线程序的变量中,客户自定义代码可以直接读写这种变量中的数据。
在线流程
推荐引擎的的在线流程负责的任务是推荐API接收到API恳求时,实时对离线和逾线修正形成的推荐结果进行过滤、排重、补足等处理;后者主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新
一个场景只收录一个离线流程和一个逾线流程,可以收录多个在线流程,用于支持A/BTest。
算法策略(Algorithm Strategy)
算法策略定义了一套离线/近线流程。并且透出相关的算法参数,帮助顾客建立自己的算法流程。一个场景可以配置多个算法策略,最终会合并执行,产出一系列推荐候选集和过滤集,在线流程通过引用那些候选集来完成个性化推荐。
作业/任务(task)
作业指运行中的离线流程实例,作业和离线流程的关系完全等同于进程和程序的关系。每个作业都是不可重入的,即对每位离线流程,同一时间只容许运行一份实例。作业直接存在上下游关系,如果上游作业失败,下游任务也会被取消。
更多精品课程点击:阿里云大学 查看全部
产品概述:
推荐引擎(Recommendation Engine,以下简称RecEng,特指阿里云推荐引擎)是在阿里云估算环境下构建的一套推荐服务框架,目标是使广大中小互联网企业能否在这套框架上快速的搭建满足自身业务需求的推荐服务。
课程链接:阿里云推荐引擎使用教程
推荐服务一般由三部份组成:日志采集,推荐估算和产品对接。推荐服务首先须要采集产品中记录的用户行为日志到离线存储,然后在离线环境下借助推荐算法进行用户和物品的匹配估算,找出每位用户可能感兴趣的物品集合后,将这种预先估算好的结果推送到在线储存上,最终产品在有用户访问时通过在线API向推荐服务发起恳求,获得该用户可能感兴趣的物品,完成推荐业务。
RecEng的核心是推荐算法的订制。RecEng为推荐业务定义了一套完整的规范,从输入,到估算,到输出,客户可以在这个框架下自定义算法和规则,以此满足各类行业的需求,包括电商,音乐,视频,社交,新闻,阅读等。同时,RecEng也提供了相应的方式供顾客方便的接入用户访问日志,以及自定义满足其自身业务需求的在线API。
基本概念:
客户/租户(org/tenant)
指RecEng的使用者,系统中由其阿里云帐号代表。通常顾客是一个组织,RecEng中常用org表示顾客。
用户(user)
指顾客的用户,即RecEng使用者的用户。推荐是一个2C的服务,使用推荐服务的顾客必然有其自己的用户,RecEng使用者的用户简称为“用户”,系统中常用user表示用户。
物品(item)
指被推荐给用户的内容,可以是商品,也可以是歌曲,视频等其他内容,系统中常用item表示物品。
业务(biz)
业务针对数据集定义,定义了算法所能使用的数据范围。一个顾客在RecEng上可以有多个业务,不同的业务必然有不同的数据集。RecEng要求每位业务提供四类数据(不要求全部提供):用户数据,物品数据,用户行为数据,推荐疗效数据。每一组这样的数据就构成一个业务。系统中常用biz表示业务。
比如某顾客A有两类被推荐的物品,分别是视频和歌曲,于是顾客A可以在RecEng上构建两个业务M和N,其中M的物品数据为视频,N的物品数据为歌曲,其他的数据(指用户数据,用户行为数据等)可以都相同。在这些方案下,业务M和N的数据是独立的,即业务M其实能看到用户对于歌曲的行为,但是业务M中不收录歌曲的物品数据,所以会扔掉用户对于歌曲的行为;如果业务M中某用户只对歌曲有行为,对视频没有行为,业务M也会扔掉这类用户。反之对业务N亦然。
一个业务最好只推荐一类物品。多类物品的推荐在后续的行业模板会有支持,需要引入蓝筹股(plate)的概念,一份业务数据可以生成多个蓝筹股的数据集,场景绑定某个蓝筹股进行推荐算法估算。
场景(scn)
场景指的是推荐的上下文,每个场景就会输出一个API,场景由推荐时可用的参数决定。有两种场景最为常见,分别是首页推荐场景和详情页推荐场景。顾名思义,在执行首页推荐时,可用的参数只有用户信息;而在执行详情页推荐时,可用的参数不仅用户信息,还包括当前详情页上所展示的物品信息。系统中常用scn表示场景。
一个业务可以收录多个场景,即对于某个业务A,它收录多个首页场景也是完全可以的。
事实上,回到场景的原创定义,场景只是由推荐的上下文决定,客户完全可以按照自己的需求构建全新的场景,比如针对搜索关键词的推荐场景,这时可用的参数不仅用户信息,还有用户所输入的关键词。
流程(flow)
算法流程指数据端到端的处理流程,一部分流程属于业务范畴,如数据导出流程,效果估算流程,数据质量分估算流程;一部分属于场景,比如场景算法流程。从数据源类型和产下来界定,又分为离线流程,近线流程,在线流程
离线流程
一般情况下,离线流程的输入和输出都是MaxCompute(原ODPS)表,所以离线数据规范虽然上是一组MaxCompute表的格式规范,包括接入数据、中间数据和输出数据三类数据的格式规范。接入数据指顾客离线提供的用户、物品、日志等数据,中间数据是在离线算法流程中形成的各类中间性质的结果数据表,输出数据是指推荐结果数据表,该结果最终将会被导出到在线储存中,供在线估算模块使用。
近线流程
推荐引擎的的近线流程主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新。不象离线算法,天然以MaxCompute(原ODPS)表作为输入和输出,近线程序的输入数据可以来自多个数据源,如在线的表格储存(原OTS),以及用户的API恳求,又或则是程序中的变量;输出可以是程序变量,或者写回在线储存,或者返回给用户。出于安全性考虑,推荐引擎提供了一组SDK供顾客自定义在线代码读写在线储存(Table Store),不容许直接访问,所以须要定义每类在线储存的别称和格式。对于须要频繁使用的在线数据,无论其来自在线储存还是用户的API恳求,RecEng会预先读好,保存在在线程序的变量中,客户自定义代码可以直接读写这种变量中的数据。
在线流程
推荐引擎的的在线流程负责的任务是推荐API接收到API恳求时,实时对离线和逾线修正形成的推荐结果进行过滤、排重、补足等处理;后者主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新
一个场景只收录一个离线流程和一个逾线流程,可以收录多个在线流程,用于支持A/BTest。
算法策略(Algorithm Strategy)
算法策略定义了一套离线/近线流程。并且透出相关的算法参数,帮助顾客建立自己的算法流程。一个场景可以配置多个算法策略,最终会合并执行,产出一系列推荐候选集和过滤集,在线流程通过引用那些候选集来完成个性化推荐。
作业/任务(task)
作业指运行中的离线流程实例,作业和离线流程的关系完全等同于进程和程序的关系。每个作业都是不可重入的,即对每位离线流程,同一时间只容许运行一份实例。作业直接存在上下游关系,如果上游作业失败,下游任务也会被取消。
更多精品课程点击:阿里云大学
数据平台初试(技术篇)——抖音数据采集(初级版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 748 次浏览 • 2020-08-09 19:43
数据平台初试(技术篇)——抖音数据采集(初级版)
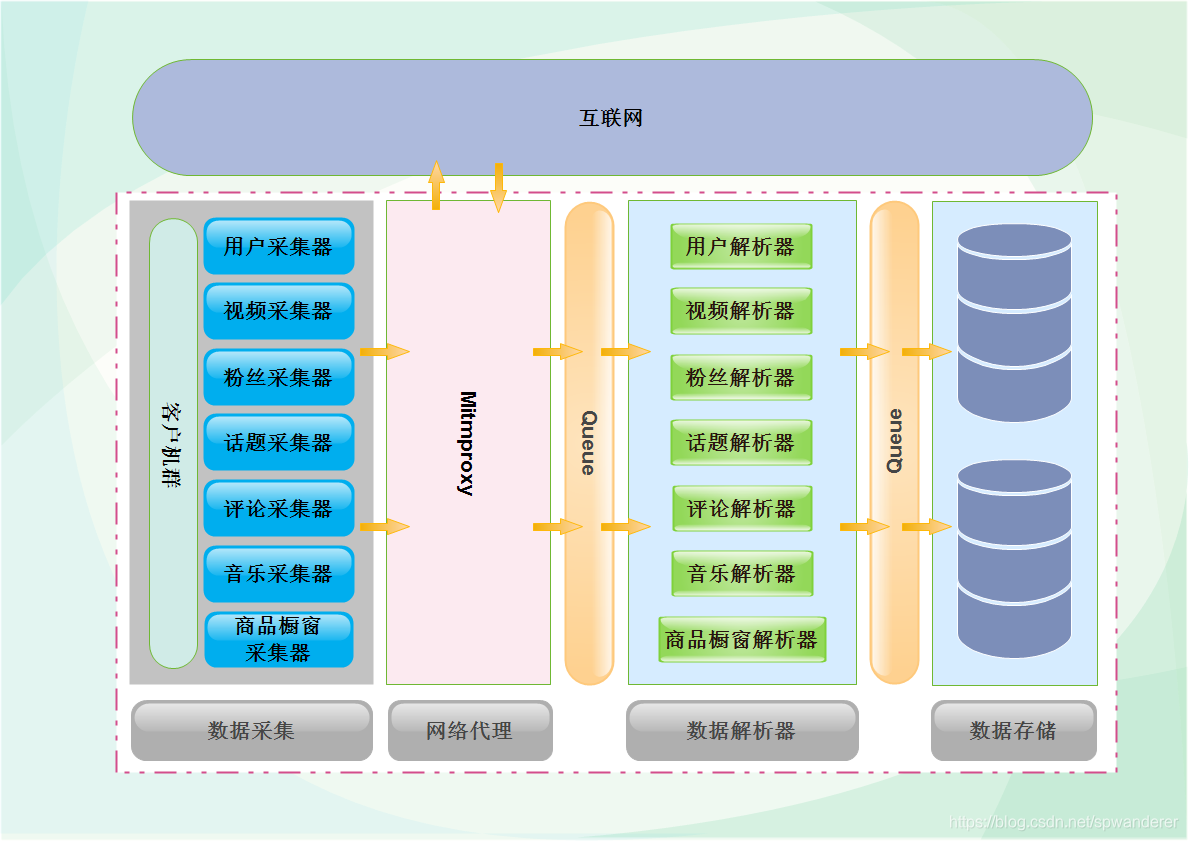
这段时间仍然在处理数据采集的问题,目前平台数据采集趋于稳定,可以抽出时间来整理一下近日的成果,顺便介绍一些近日用到的技术。本篇文章偏向技术,需要读者有一定的技术基础,主要介绍数据采集过程中用到的利器mitmproxy,以及平台的一些技术设计。以下是数据采集整体的设计,左边是客户机,在里面放置了不同的采集器,采集器发起恳求以后,通过mitmproxy访问抖音,等数据回传以后,通过中间的解析器对数据进行解析,最后分门别类的储存到数据库中,为了提高性能,在中间加入了缓存,把采集器和解析器分隔开,两个模块之间工作互不影响,可以最大限度的把数据入库,下图为第一代构架设计,后续会有一篇文章介绍平台构架设计的三代演化史。
准备工作
开始步入数据采集的打算工作,第一步自然是环境搭建,本次我们在windows环境下,采用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,采用夜神模拟器来模拟安卓运行环境(也可以用真机),这次主要通过自动滑动app来抓取数据,下次介绍采用Appium自动化工具,实现数据采集的全手动(解放右手)。
1、安装python3.6.6环境,安装过程可自行百度,需要注意的是,centos7自带的是python2.7,需要升级到python3.6.6环境,升级之前主要先安装ssl模块,否则升级好的版本未能访问https的恳求。
2、安装mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy,注:windows下只有mitmdump和mitmweb可以使用,安装好后在命令行输入mitmdump即可启动,默认启动的代理端口为8080。
3、安装夜神模拟器,可以在官网下载安装包,安装教程自行百度即可,基本都是下一步。安装好夜神模拟器以后,需要对夜神模拟器进行配置。首先须要设置模拟器的网路为自动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、接下来是证书的安装,打开模拟器中的浏览器,输入地址mitm.it,选择对应版本的证书,安装好后,就可以进行抓包了。
5、安装app,app安装包可以到官网下载,然后通过拖放进模拟器就可以安装,或者在应用市场进行安装。
至此,本次数据采集环境就全部搭建完成。
数据插口剖析 抓包
搭建好环境以后就开始对抖音app进行数据抓包,分析出每位功能所使用的插口,本次以采集视频数据插口为例介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是一个图形化的版本,就不用对着黑框框找了,如下图:
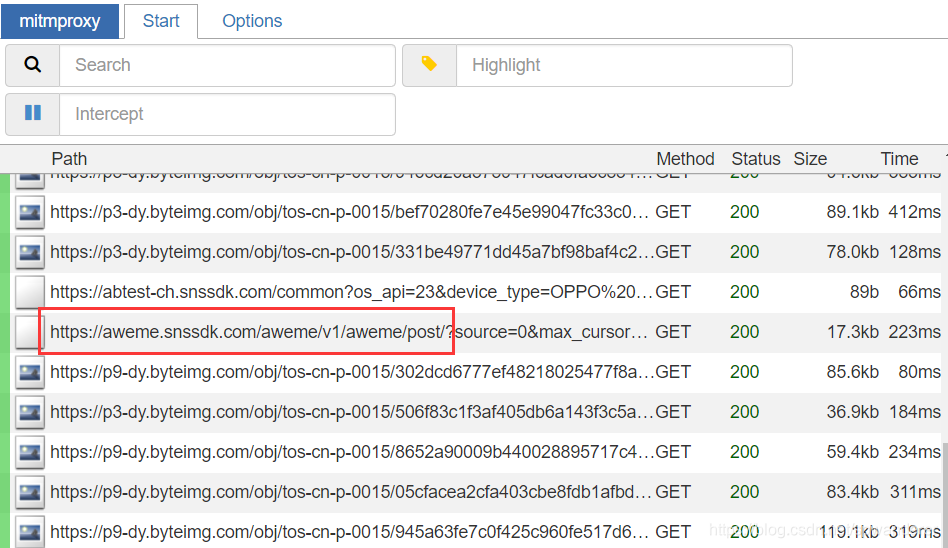
启动以后打开模拟器的抖音app,可以看见早已有数据包解析下来了,然后步入用户主页,开始下降视频,在数据包列表中可以找到恳求视频数据的插口
可以在左边看见插口的恳求数据和响应数据,我们将响应数据复制下来,进入下一步解析。
数据解析
通过mitmproxy和python代码的结合,我们就可以在代码中获取到mitmproxy中的数据包,进而可以根据需求来处理。新建一个test.py文件,里面放两个方式:
def request(flow):
pass
def response(flow):
pass
见名知意,这两个方式,一个是在恳求的时侯执行的,一个是在响应的时侯执行,而数据包则存在于flow当中。通过flow.request.url可以获取到恳求url,flow.request.headers可以获取到恳求头信息,flow.response.text中的就是响应的数据了。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
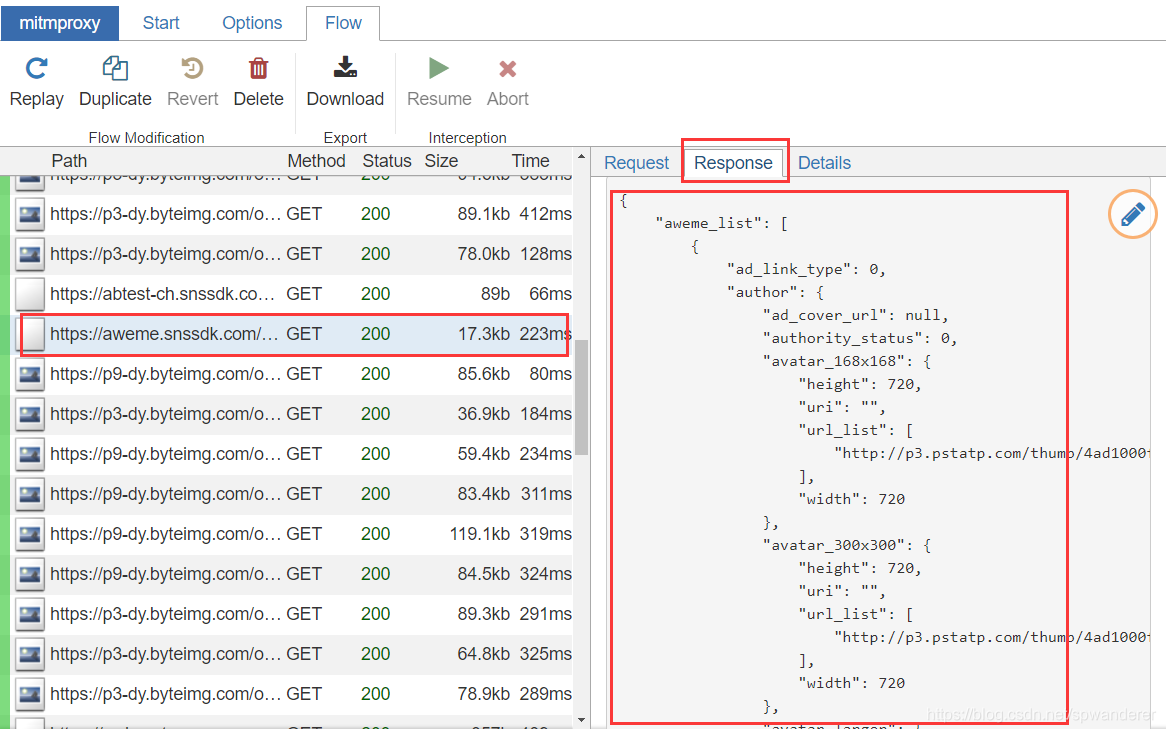
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme就是一个完整的视频数据了,可以按照须要提取上面的信息,这里提取部份信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
statistics信息就是这个视频的点赞,评论,下载,转发的数据。
share_url为视频的分享地址,通过这个地址,可以在PC端观看抖音分享的视频,也可以通过这个链接解析到无水印视频。
play_addr为视频的播放信息,其中的url_list即为无水印地址,不过目前官方做了处理,这个地址难以直接播放,也有时间限制,超时以后链接就失效了。
有了这个aweme,就可以把上面的信息解析下来,保存到自己的数据库,或者下载无水印视频,保存到自己笔记本了。
写好代码然后,保存test.py文件,cmd步入命令行,进入到保存test.py文件目录下,在命令行输入mitmdump -s test.py,mitmdump就启动了,此时打开app,开始滑动模拟器,进入用户主页:
开始不断下降,test.py文件就可以把抓取到的视频数据全部解析下来了,以下是我截取的部份数据信息:
视频信息:
视频统计数据: 查看全部
公众号原文链接:
数据平台初试(技术篇)——抖音数据采集(初级版)
这段时间仍然在处理数据采集的问题,目前平台数据采集趋于稳定,可以抽出时间来整理一下近日的成果,顺便介绍一些近日用到的技术。本篇文章偏向技术,需要读者有一定的技术基础,主要介绍数据采集过程中用到的利器mitmproxy,以及平台的一些技术设计。以下是数据采集整体的设计,左边是客户机,在里面放置了不同的采集器,采集器发起恳求以后,通过mitmproxy访问抖音,等数据回传以后,通过中间的解析器对数据进行解析,最后分门别类的储存到数据库中,为了提高性能,在中间加入了缓存,把采集器和解析器分隔开,两个模块之间工作互不影响,可以最大限度的把数据入库,下图为第一代构架设计,后续会有一篇文章介绍平台构架设计的三代演化史。
准备工作
开始步入数据采集的打算工作,第一步自然是环境搭建,本次我们在windows环境下,采用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,采用夜神模拟器来模拟安卓运行环境(也可以用真机),这次主要通过自动滑动app来抓取数据,下次介绍采用Appium自动化工具,实现数据采集的全手动(解放右手)。
1、安装python3.6.6环境,安装过程可自行百度,需要注意的是,centos7自带的是python2.7,需要升级到python3.6.6环境,升级之前主要先安装ssl模块,否则升级好的版本未能访问https的恳求。
2、安装mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy,注:windows下只有mitmdump和mitmweb可以使用,安装好后在命令行输入mitmdump即可启动,默认启动的代理端口为8080。
3、安装夜神模拟器,可以在官网下载安装包,安装教程自行百度即可,基本都是下一步。安装好夜神模拟器以后,需要对夜神模拟器进行配置。首先须要设置模拟器的网路为自动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、接下来是证书的安装,打开模拟器中的浏览器,输入地址mitm.it,选择对应版本的证书,安装好后,就可以进行抓包了。

5、安装app,app安装包可以到官网下载,然后通过拖放进模拟器就可以安装,或者在应用市场进行安装。
至此,本次数据采集环境就全部搭建完成。
数据插口剖析 抓包
搭建好环境以后就开始对抖音app进行数据抓包,分析出每位功能所使用的插口,本次以采集视频数据插口为例介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是一个图形化的版本,就不用对着黑框框找了,如下图:
启动以后打开模拟器的抖音app,可以看见早已有数据包解析下来了,然后步入用户主页,开始下降视频,在数据包列表中可以找到恳求视频数据的插口
可以在左边看见插口的恳求数据和响应数据,我们将响应数据复制下来,进入下一步解析。
数据解析
通过mitmproxy和python代码的结合,我们就可以在代码中获取到mitmproxy中的数据包,进而可以根据需求来处理。新建一个test.py文件,里面放两个方式:
def request(flow):
pass
def response(flow):
pass
见名知意,这两个方式,一个是在恳求的时侯执行的,一个是在响应的时侯执行,而数据包则存在于flow当中。通过flow.request.url可以获取到恳求url,flow.request.headers可以获取到恳求头信息,flow.response.text中的就是响应的数据了。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/";):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme就是一个完整的视频数据了,可以按照须要提取上面的信息,这里提取部份信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
statistics信息就是这个视频的点赞,评论,下载,转发的数据。
share_url为视频的分享地址,通过这个地址,可以在PC端观看抖音分享的视频,也可以通过这个链接解析到无水印视频。
play_addr为视频的播放信息,其中的url_list即为无水印地址,不过目前官方做了处理,这个地址难以直接播放,也有时间限制,超时以后链接就失效了。
有了这个aweme,就可以把上面的信息解析下来,保存到自己的数据库,或者下载无水印视频,保存到自己笔记本了。
写好代码然后,保存test.py文件,cmd步入命令行,进入到保存test.py文件目录下,在命令行输入mitmdump -s test.py,mitmdump就启动了,此时打开app,开始滑动模拟器,进入用户主页:
开始不断下降,test.py文件就可以把抓取到的视频数据全部解析下来了,以下是我截取的部份数据信息:
视频信息:
视频统计数据:
初探漏洞挖掘基础
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-09 10:11
import requests
import threading
import re
targets = []
names = []
def icp_info(host):
url = "https://icp.chinaz.com/ajaxsyn ... 5host
html = requests.get(url,timeout=(5,10)).text
pattern = re.compile('SiteName:"(.*?)",MainPage:"(.*?)"',re.S)
info = re.findall(pattern,html)
for i in range(0,32):
try:
name = info[i][0]
target = info[i][1]
print("%s:%s"%(name,target))
if target not in targets:
targets.append(target)
with open("icp_info.txt","a+") as f:
f.write("%s:%s"%(name,target) + "\n")
continue
else:
continue
except Exception as e:
continue
def start():
with open("url.txt","r+") as a:
for b in a:
b = b.strip()
icp_info(host=b)
a.close()
def main():
thread = threading.Thread(target=start,)
thread.start()
if __name__ == '__main__':
main()
先知的代码块可能不太友好,可以瞧瞧图片:
使用方式:urls.txt传入你须要查询的网站,会手动对获取到的domain进行去重。
使用维基百科对个别添加资产词条的网站可以获取到其部份资产信息:
但是某南没有添加该词条,所以获取不到相关信息。
步骤:
先对已知网站进行whois查询,我们这儿可以去微步查询历史whois,可以获取到历史的whois信息。
利用这种信息,我们就可以反查whois,获取该注册者/电话/邮箱下的相关域名。
我正在写一个脚本,即批量获取whois->反查whois->提取关键信息->去重。
写好了我会发到github上,可关注:
我们可以直接搜索网站官网,可以获得一些页面/头部中富含该关键字的网站。
zoomeye:
shodan:
fofa:
此外,我们还可以借助那些搜索引擎的搜索句型来获取资产。
shodan可以搜索指定公司的资产,也可以借助特定的网站logo来获取资产。
比如我们发觉某南的网站icon基本为同一个,我们就可以先去搜索,获取其带有icon的网站,随便选一个获取hash后借助搜索句型来获取指定icon的网站。
fofa可以直接借助domain关键字来搜索特定网站下的子域名:
zoomeye可以借助hostname关键字来获取主机列表中的资产:
github也可以拿来获取资产,但是大多数情况下还是用于获取敏感信息(用户名/密码/邮箱)等。
当然也可以拿来搜索资产:
这里推荐一款平常在用的github敏感信息采集工具:
我们可以自定义规则,来获取自己所须要的信息。
这里还是以某南为例:
我们除了可以采集企业公众号,还可以采集企业的小程序,因为其中大部分都是会与WEB端的插口做交互的。
公众号:
小程序:
我们不光须要从企业网站中找寻该企业开发的APP,也可以自己通过关键字来获取APP,因为其中有的APP是公测的,只是上线了,但是还未对外公布。
以某南为例:
我们不仅直接搜索企业关键字外,还可以获取其开发者的历史开发记录:
这样循环:APP->开发者->APP
在这过程中我们常常能获取到许多APP,后续再对其进行相关的渗透。
我们可以使用Google/Bing/Baidu等网站对某个网站进行资产采集:
当然,搭配搜索句型食用疗效更佳:
之前提及了采集APP资产,有的APP实际上并不只是使用用户可用的那几个插口,可能还有插口在代码中,这时候可以用工具将这种URI提取下来。
这里推荐两款从APK中提取有效信息的工具:
很多刚钻洞的师父可能不太注意JS,但实际上JS中可能隐藏了很重要的插口,其中可能就存在未授权等漏洞,这里推荐同学写的一款从JS中提取有效域名/api的工具。
JSFINDER:
调的是LinkFinder的正则,可以循环爬取,即:
爬取domain->获取domain主页面下的link->获取domain主页面下的js->获取link页面下的js->解析所有js并提取出有效信息
中期
到了此步我们早已采集了企业的大部分资产了,剩下的就是获取更多资产,即子域名/IP/PORT/服务...等。
sublist3r:
这是一款很不错的工具,调用了几个搜索引擎以及一些子域名查询网站的API,具体可以去项目页查看。
sublist3r:
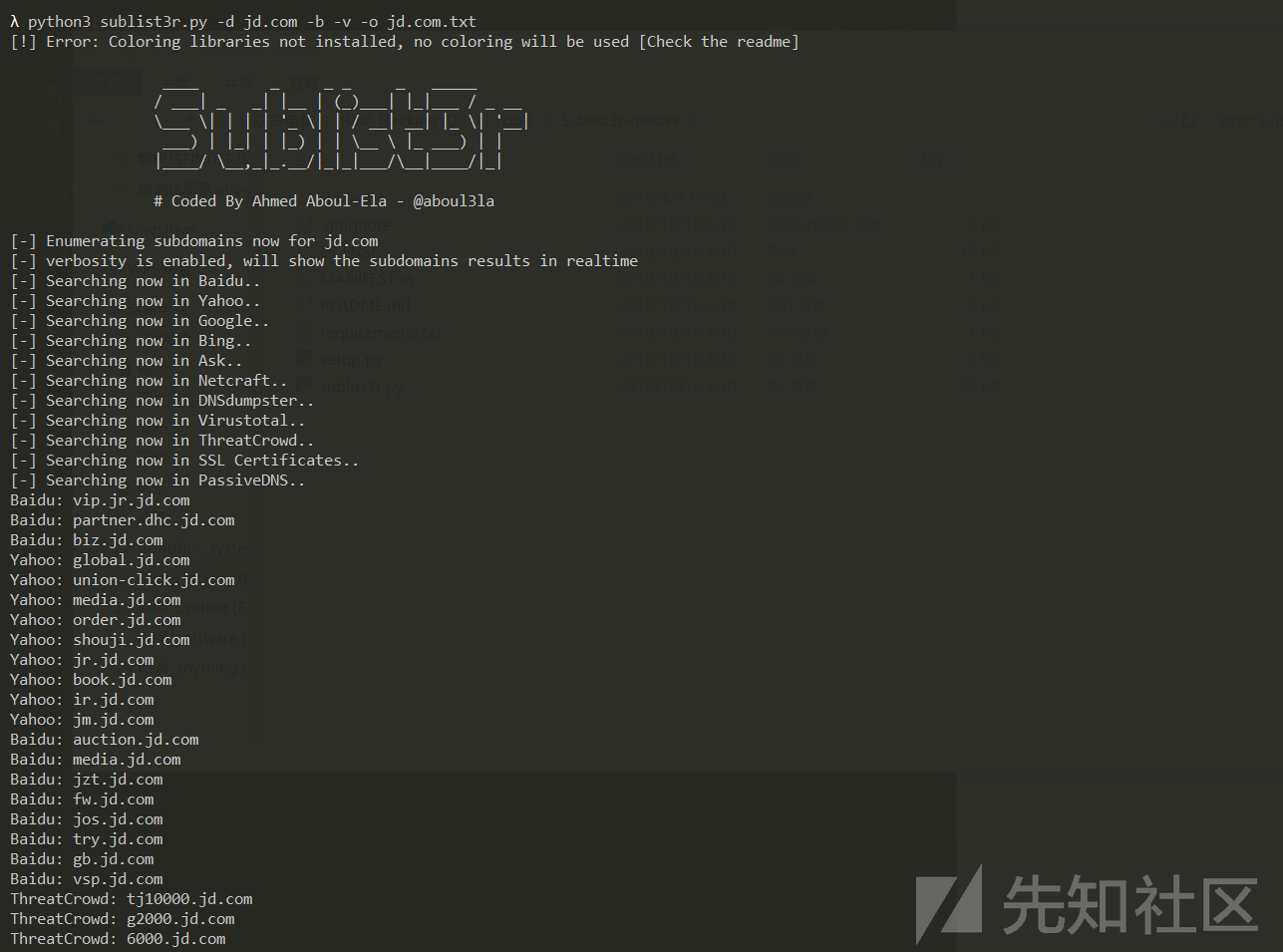
subfinder:
这款工具调用的API有很多:
Ask,Archive.is,百度,Bing,Censys,CertDB,CertSpotter,Commoncrawl,CrtSH,DnsDB,DNSDumpster,Dnstable,Dogpile,Entrust CT-Search,Exalead,FindSubdomains,GoogleTER,Hackertarget,IPv4Info,Netcraft,PassiveTotal,PTRArchive,Riddler ,SecurityTrails,SiteDossier,Shodan,ThreatCrowd,ThreatMiner,Virustotal,WaybackArchive,Yahoo
初次使用须要我们自己配置API插口的帐号/密码/key...等。
图片始于youtube:
subfinder:
github:
LAYER:
很早之前牧师写的一款工具,可以手动过滤泛解析的域名,字典+API的形式来采集资产,当然更多的是字典,速度也相当可观:
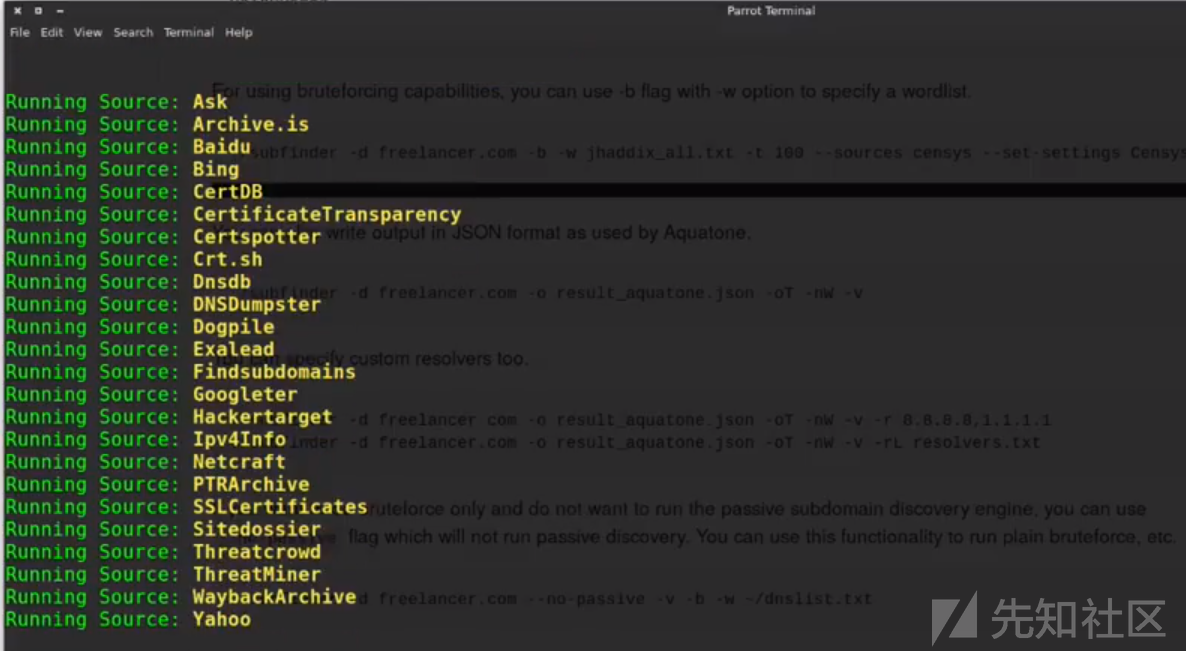
altdns:
这款工具我通常是到最后采集完了所以子域名并去重后使用的,他可以帮助我们发觉一些二级/三级非常隐蔽的域名。
以vivo举例:
altdns:
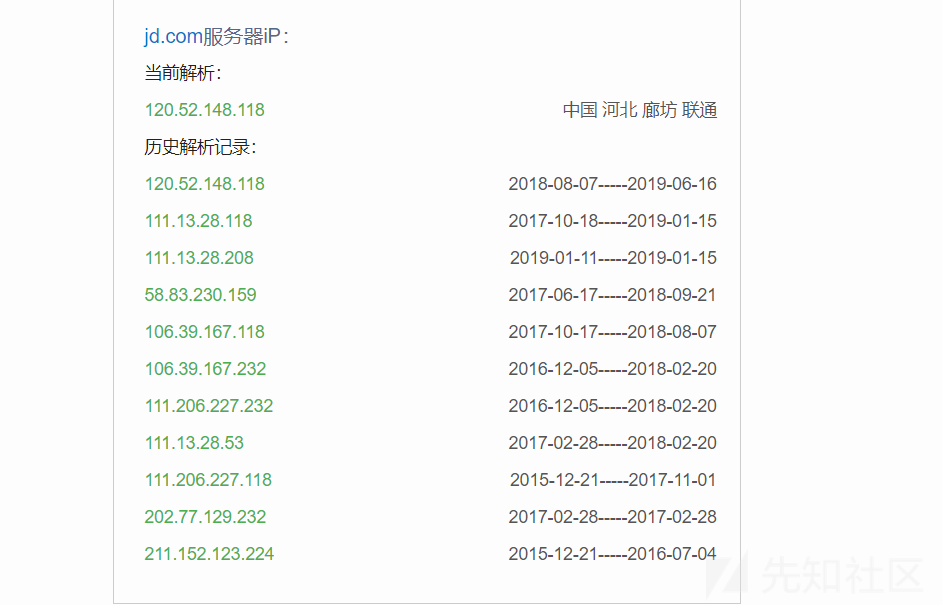
关于企业IP的采集我们可以直接写脚本去调ip138的插口,可以获取到当前解析IP和历史解析IP,还是比较全的。
ip138:
获取完企业的IP范围以后,我们就可以用nmap/masscan等工具对其端口/服务进行扫描,这个过程可能会有点久。
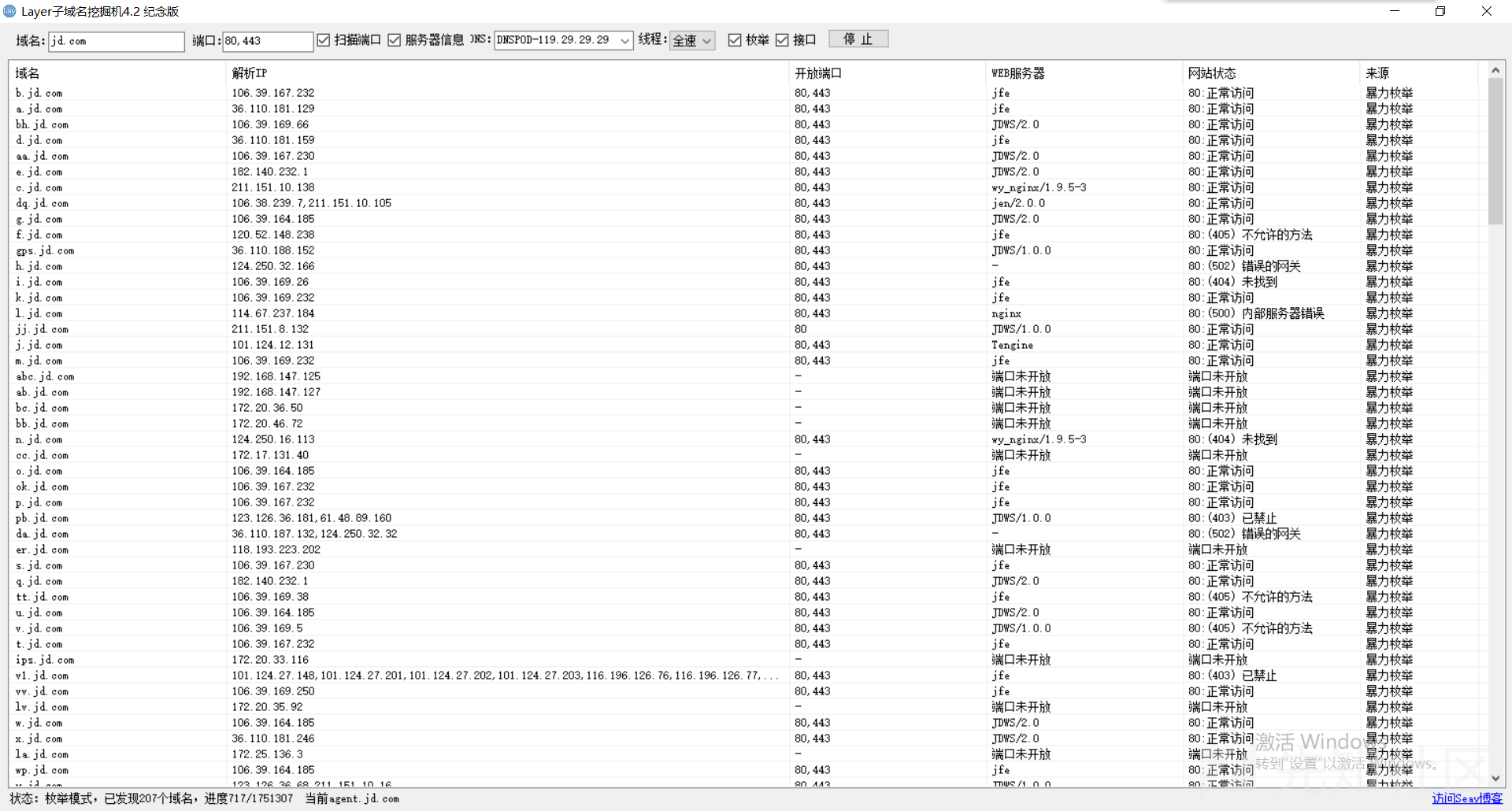
我们须要先判别企业是直接买了一个C段的IP,还是只使用一个IP,再选择扫描整个C段或则是单个IP。
这是我之前使用nmap对某东域名批量进行C段扫描的结果:
我们的注意力可以置于几个WEB服务端口,和一些可能存在漏洞的服务端口,如redis/mongodb等。
至此,资产采集基本早已结束了,我们可以将采集到的资产选择性的入库,这样以后获取新资产时就可以对比一下是否存在。
后期
这部份可能是我写的最少的部份。
获取完资产然后,就是苦力活了,我的步骤是,先把获取到的资产丢到扫描器(awvs/nessus)里先扫一遍,避免一些没必要的体力劳动。
nessus主要拿来扫描端口服务的漏洞以及一些系统CVE,awvs主要拿来扫描WEB端的漏洞,如XSS/SQLI/CSRF/CORS/备份文件...等等。
指纹辨识部份可以使用云悉的,可以自己写个插件之后申请个API:
我都会用BBSCAN/weakfilescan来扫描网站中可能存在的敏感信息,如.git/.svn/备份文件等等。
BBSCAN:
weakfilescan:
之后的基本就是自动劳动了,对获取到的资产借助已有知识一个个的测。 查看全部
单线程:
import requests
import threading
import re
targets = []
names = []
def icp_info(host):
url = "https://icp.chinaz.com/ajaxsyn ... 5host
html = requests.get(url,timeout=(5,10)).text
pattern = re.compile('SiteName:"(.*?)",MainPage:"(.*?)"',re.S)
info = re.findall(pattern,html)
for i in range(0,32):
try:
name = info[i][0]
target = info[i][1]
print("%s:%s"%(name,target))
if target not in targets:
targets.append(target)
with open("icp_info.txt","a+") as f:
f.write("%s:%s"%(name,target) + "\n")
continue
else:
continue
except Exception as e:
continue
def start():
with open("url.txt","r+") as a:
for b in a:
b = b.strip()
icp_info(host=b)
a.close()
def main():
thread = threading.Thread(target=start,)
thread.start()
if __name__ == '__main__':
main()
先知的代码块可能不太友好,可以瞧瞧图片:

使用方式:urls.txt传入你须要查询的网站,会手动对获取到的domain进行去重。
使用维基百科对个别添加资产词条的网站可以获取到其部份资产信息:

但是某南没有添加该词条,所以获取不到相关信息。
步骤:
先对已知网站进行whois查询,我们这儿可以去微步查询历史whois,可以获取到历史的whois信息。

利用这种信息,我们就可以反查whois,获取该注册者/电话/邮箱下的相关域名。

我正在写一个脚本,即批量获取whois->反查whois->提取关键信息->去重。
写好了我会发到github上,可关注:
我们可以直接搜索网站官网,可以获得一些页面/头部中富含该关键字的网站。
zoomeye:

shodan:

fofa:

此外,我们还可以借助那些搜索引擎的搜索句型来获取资产。
shodan可以搜索指定公司的资产,也可以借助特定的网站logo来获取资产。
比如我们发觉某南的网站icon基本为同一个,我们就可以先去搜索,获取其带有icon的网站,随便选一个获取hash后借助搜索句型来获取指定icon的网站。
fofa可以直接借助domain关键字来搜索特定网站下的子域名:
zoomeye可以借助hostname关键字来获取主机列表中的资产:
github也可以拿来获取资产,但是大多数情况下还是用于获取敏感信息(用户名/密码/邮箱)等。
当然也可以拿来搜索资产:
这里推荐一款平常在用的github敏感信息采集工具:
我们可以自定义规则,来获取自己所须要的信息。
这里还是以某南为例:
我们除了可以采集企业公众号,还可以采集企业的小程序,因为其中大部分都是会与WEB端的插口做交互的。
公众号:
小程序:
我们不光须要从企业网站中找寻该企业开发的APP,也可以自己通过关键字来获取APP,因为其中有的APP是公测的,只是上线了,但是还未对外公布。
以某南为例:


我们不仅直接搜索企业关键字外,还可以获取其开发者的历史开发记录:

这样循环:APP->开发者->APP
在这过程中我们常常能获取到许多APP,后续再对其进行相关的渗透。
我们可以使用Google/Bing/Baidu等网站对某个网站进行资产采集:

当然,搭配搜索句型食用疗效更佳:

之前提及了采集APP资产,有的APP实际上并不只是使用用户可用的那几个插口,可能还有插口在代码中,这时候可以用工具将这种URI提取下来。
这里推荐两款从APK中提取有效信息的工具:
很多刚钻洞的师父可能不太注意JS,但实际上JS中可能隐藏了很重要的插口,其中可能就存在未授权等漏洞,这里推荐同学写的一款从JS中提取有效域名/api的工具。
JSFINDER:
调的是LinkFinder的正则,可以循环爬取,即:
爬取domain->获取domain主页面下的link->获取domain主页面下的js->获取link页面下的js->解析所有js并提取出有效信息
中期
到了此步我们早已采集了企业的大部分资产了,剩下的就是获取更多资产,即子域名/IP/PORT/服务...等。
sublist3r:
这是一款很不错的工具,调用了几个搜索引擎以及一些子域名查询网站的API,具体可以去项目页查看。
sublist3r:
subfinder:
这款工具调用的API有很多:
Ask,Archive.is,百度,Bing,Censys,CertDB,CertSpotter,Commoncrawl,CrtSH,DnsDB,DNSDumpster,Dnstable,Dogpile,Entrust CT-Search,Exalead,FindSubdomains,GoogleTER,Hackertarget,IPv4Info,Netcraft,PassiveTotal,PTRArchive,Riddler ,SecurityTrails,SiteDossier,Shodan,ThreatCrowd,ThreatMiner,Virustotal,WaybackArchive,Yahoo
初次使用须要我们自己配置API插口的帐号/密码/key...等。
图片始于youtube:
subfinder:
github:
LAYER:
很早之前牧师写的一款工具,可以手动过滤泛解析的域名,字典+API的形式来采集资产,当然更多的是字典,速度也相当可观:
altdns:
这款工具我通常是到最后采集完了所以子域名并去重后使用的,他可以帮助我们发觉一些二级/三级非常隐蔽的域名。

以vivo举例:

altdns:
关于企业IP的采集我们可以直接写脚本去调ip138的插口,可以获取到当前解析IP和历史解析IP,还是比较全的。
ip138:
获取完企业的IP范围以后,我们就可以用nmap/masscan等工具对其端口/服务进行扫描,这个过程可能会有点久。
我们须要先判别企业是直接买了一个C段的IP,还是只使用一个IP,再选择扫描整个C段或则是单个IP。
这是我之前使用nmap对某东域名批量进行C段扫描的结果:

我们的注意力可以置于几个WEB服务端口,和一些可能存在漏洞的服务端口,如redis/mongodb等。
至此,资产采集基本早已结束了,我们可以将采集到的资产选择性的入库,这样以后获取新资产时就可以对比一下是否存在。
后期
这部份可能是我写的最少的部份。
获取完资产然后,就是苦力活了,我的步骤是,先把获取到的资产丢到扫描器(awvs/nessus)里先扫一遍,避免一些没必要的体力劳动。
nessus主要拿来扫描端口服务的漏洞以及一些系统CVE,awvs主要拿来扫描WEB端的漏洞,如XSS/SQLI/CSRF/CORS/备份文件...等等。
指纹辨识部份可以使用云悉的,可以自己写个插件之后申请个API:
我都会用BBSCAN/weakfilescan来扫描网站中可能存在的敏感信息,如.git/.svn/备份文件等等。
BBSCAN:
weakfilescan:
之后的基本就是自动劳动了,对获取到的资产借助已有知识一个个的测。
解决文本分类问题的一些机器学习最佳实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2020-08-08 11:13
建立和训练模型只是整个过程的一部分. 如果您能够提前了解数据特征,那么对于后续的模型构建(例如更高的准确性,更少的数据和更少的计算资源)将大有裨益.
加载数据集
首先,让我们将数据集加载到Python中:
def load_imdb_sentiment_analysis_dataset(data_path,seed = 123):
“”“加载IMDb电影评论情感分析数据集.
#个参数
data_path: 字符串,数据目录的路径.
seed: int,随机数的种子.
#返回
一组训练和验证数据.
培训样本数量: 25000
测试样本数: 25000
类别数: 2(0负,1负)
#个引用
Mass等,
从以下位置下载并解压缩归档文件:
〜amaas / data / sentiment / aclImdb_v1.tar.gz
“”“
imdb_data_path = os.path.join(data_path,'aclImdb')
#加载训练数据
train_texts = []
train_labels = []
对于['pos','neg']中的类别:
train_path = os.path.join(imdb_data_path,'train',类别)
对于已排序的(os.listdir(train_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(train_path,fname))作为f:
train_texts.append(f.read())
train_labels.append(0if category =='neg'else1)
#加载验证数据.
test_texts = []
test_labels = []
对于['pos','neg']中的类别:
test_path = os.path.join(imdb_data_path,'test',category)
对于已排序的(os.listdir(test_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(test_path,fname))作为f:
test_texts.append(f.read())
test_labels.append(0if category =='neg'else1)
#随机排列训练数据和标签.
random.seed(种子)
random.shuffle(train_texts)
random.seed(种子)
random.shuffle(train_labels)
返回((train_texts,np.array(train_labels)),
(test_texts,np.array(test_labels)))
检查数据
加载数据后,最好一一检查它们: 选择一些样本并手动检查它们是否符合您的期望. 例如,对于示例中使用的电影评论数据集,我们可以输出一些随机样本来检查评论中的情感标签和情感是否一致.
“一个十分钟的故事必须讲两个小时. 如果没什么大不了的话,我会起身离开的. ”
这是在数据集中标记为“否定”的注释. 显然,审阅者认为这部电影很拖拉,很无聊,与标签相符.
采集关键指标
完成检查后,您需要采集以下重要指标,这些指标可以帮助表征文本分类任务:
样本数: 数据集中的样本总数.
类别数: 数据集中的主题或类别数.
每个类别中的样本数: 如果是平衡数据集,则所有类别应收录相似数目的样本;如果它是不平衡的数据集,则每个类别中收录的样本数量将有很大的差异.
每个样本中的单词数: 这是一个文本分类问题,因此应计算样本中收录的单词中位数.
单词频率分布: 数据集中每个单词的频率(出现次数).
样本长度分布: 数据集中每个样本的分布
步骤2.5: 选择模型
到目前为止,我们已经对数据进行了汇总,并且对数据的关键特征也有了深入的了解. 接下来,基于第二步中采集的各种指标,我们将开始考虑应使用哪种分类模型. 这也意味着我们将提出以下问题: “如何将文本数据转换为算法输入?” (数据预处理和矢量化),“我们应该使用哪种类型的模型?”,“我们的模型应该可行的是什么参数配置?”……
由于数十年的研究,数据预处理和模型配置的选项现在非常多样化,但实际上有很多选项带来了很多麻烦. 我们手头只有一个特定的问题,它的范围也很广泛,那么如何选择最好的呢?最诚实的方法是一个接一个地尝试过去,消除弊端,留下最好的方法,但是这种方法是不现实的.
在本文中,我们尝试简化选择文本分类模型的过程. 对于给定的数据集,我们的目标只有两个: 准确性接近最高,而训练时间则是最低的. 我们使用总共12个数据集,针对不同类型的问题(尤其是情感分析和主题分类问题)进行了大量(〜450K)实验,交替测试了不同的数据预处理技术和不同的模型架构. 这个过程有助于我们获得影响优化的各种参数.
下面的模型选择和流程图是上述实验的总结.
数据准备和模型算法构建
计算比率: 样本数/每个样本的平均单词数
如果上述比率小于1500,请对文本进行分段,然后使用简单的多层感知器(MLP)模型对其进行分类(下图的左分支)
a. 使用n-gram模型对句子进行分段并将单词转换为单词向量
b. 根据向量的重要性得分,从向量中提取出前20,000个单词
c. 建立MLP模型
如果上述比率大于1500,则将文本标记为序列,并使用sepCNN模型对其进行分类(下图的右分支)
a. 对样本进行分词,然后根据词频选择前20,000个词
b. 将样本转换为单词序列向量
c. 如果比率小于1500,使用预训练的sepCNN模型进行词嵌入,效果可能很好.
调整超参数以找到模型的最佳参数配置
在下面的流程图中,黄色框代表数据和模型的准备阶段,灰色框和绿色框代表过程中的每个选择,绿色框代表“推荐选择”. 您可以将此图片用作构建第一个实验模型的起点,因为它可以以较低的计算成本提供更好的性能. 如有必要,您可以在此基础上继续进行迭代改进.
文本分类流程图
此流程图回答了两个关键问题:
我们应该使用哪种学习算法或模型?
我们应该如何准备数据以有效地学习文本和标签之间的关系?
其中,第二个问题取决于第一个问题的答案,而我们预处理数据的方式取决于所选的特定模型. 文本分类模型可以大致分为两类: 使用单词排名信息的序列模型和将文本视为一组单词的n-gram模型. 序列模型的类型包括卷积神经网络(CNN),递归神经网络(RNN)及其变体. n元语法模型的类型包括逻辑回归,MLP,DBDT和SVM.
对于电影评论数据集,样本数/每个样本的平均单词数约为144,因此我们将建立一个MLP模型. 查看全部
第2步: 浏览数据
建立和训练模型只是整个过程的一部分. 如果您能够提前了解数据特征,那么对于后续的模型构建(例如更高的准确性,更少的数据和更少的计算资源)将大有裨益.
加载数据集
首先,让我们将数据集加载到Python中:
def load_imdb_sentiment_analysis_dataset(data_path,seed = 123):
“”“加载IMDb电影评论情感分析数据集.
#个参数
data_path: 字符串,数据目录的路径.
seed: int,随机数的种子.
#返回
一组训练和验证数据.
培训样本数量: 25000
测试样本数: 25000
类别数: 2(0负,1负)
#个引用
Mass等,
从以下位置下载并解压缩归档文件:
〜amaas / data / sentiment / aclImdb_v1.tar.gz
“”“
imdb_data_path = os.path.join(data_path,'aclImdb')
#加载训练数据
train_texts = []
train_labels = []
对于['pos','neg']中的类别:
train_path = os.path.join(imdb_data_path,'train',类别)
对于已排序的(os.listdir(train_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(train_path,fname))作为f:
train_texts.append(f.read())
train_labels.append(0if category =='neg'else1)
#加载验证数据.
test_texts = []
test_labels = []
对于['pos','neg']中的类别:
test_path = os.path.join(imdb_data_path,'test',category)
对于已排序的(os.listdir(test_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(test_path,fname))作为f:
test_texts.append(f.read())
test_labels.append(0if category =='neg'else1)
#随机排列训练数据和标签.
random.seed(种子)
random.shuffle(train_texts)
random.seed(种子)
random.shuffle(train_labels)
返回((train_texts,np.array(train_labels)),
(test_texts,np.array(test_labels)))
检查数据
加载数据后,最好一一检查它们: 选择一些样本并手动检查它们是否符合您的期望. 例如,对于示例中使用的电影评论数据集,我们可以输出一些随机样本来检查评论中的情感标签和情感是否一致.
“一个十分钟的故事必须讲两个小时. 如果没什么大不了的话,我会起身离开的. ”
这是在数据集中标记为“否定”的注释. 显然,审阅者认为这部电影很拖拉,很无聊,与标签相符.
采集关键指标
完成检查后,您需要采集以下重要指标,这些指标可以帮助表征文本分类任务:
样本数: 数据集中的样本总数.
类别数: 数据集中的主题或类别数.
每个类别中的样本数: 如果是平衡数据集,则所有类别应收录相似数目的样本;如果它是不平衡的数据集,则每个类别中收录的样本数量将有很大的差异.
每个样本中的单词数: 这是一个文本分类问题,因此应计算样本中收录的单词中位数.
单词频率分布: 数据集中每个单词的频率(出现次数).
样本长度分布: 数据集中每个样本的分布
步骤2.5: 选择模型
到目前为止,我们已经对数据进行了汇总,并且对数据的关键特征也有了深入的了解. 接下来,基于第二步中采集的各种指标,我们将开始考虑应使用哪种分类模型. 这也意味着我们将提出以下问题: “如何将文本数据转换为算法输入?” (数据预处理和矢量化),“我们应该使用哪种类型的模型?”,“我们的模型应该可行的是什么参数配置?”……
由于数十年的研究,数据预处理和模型配置的选项现在非常多样化,但实际上有很多选项带来了很多麻烦. 我们手头只有一个特定的问题,它的范围也很广泛,那么如何选择最好的呢?最诚实的方法是一个接一个地尝试过去,消除弊端,留下最好的方法,但是这种方法是不现实的.
在本文中,我们尝试简化选择文本分类模型的过程. 对于给定的数据集,我们的目标只有两个: 准确性接近最高,而训练时间则是最低的. 我们使用总共12个数据集,针对不同类型的问题(尤其是情感分析和主题分类问题)进行了大量(〜450K)实验,交替测试了不同的数据预处理技术和不同的模型架构. 这个过程有助于我们获得影响优化的各种参数.
下面的模型选择和流程图是上述实验的总结.
数据准备和模型算法构建
计算比率: 样本数/每个样本的平均单词数
如果上述比率小于1500,请对文本进行分段,然后使用简单的多层感知器(MLP)模型对其进行分类(下图的左分支)
a. 使用n-gram模型对句子进行分段并将单词转换为单词向量
b. 根据向量的重要性得分,从向量中提取出前20,000个单词
c. 建立MLP模型
如果上述比率大于1500,则将文本标记为序列,并使用sepCNN模型对其进行分类(下图的右分支)
a. 对样本进行分词,然后根据词频选择前20,000个词
b. 将样本转换为单词序列向量
c. 如果比率小于1500,使用预训练的sepCNN模型进行词嵌入,效果可能很好.
调整超参数以找到模型的最佳参数配置
在下面的流程图中,黄色框代表数据和模型的准备阶段,灰色框和绿色框代表过程中的每个选择,绿色框代表“推荐选择”. 您可以将此图片用作构建第一个实验模型的起点,因为它可以以较低的计算成本提供更好的性能. 如有必要,您可以在此基础上继续进行迭代改进.
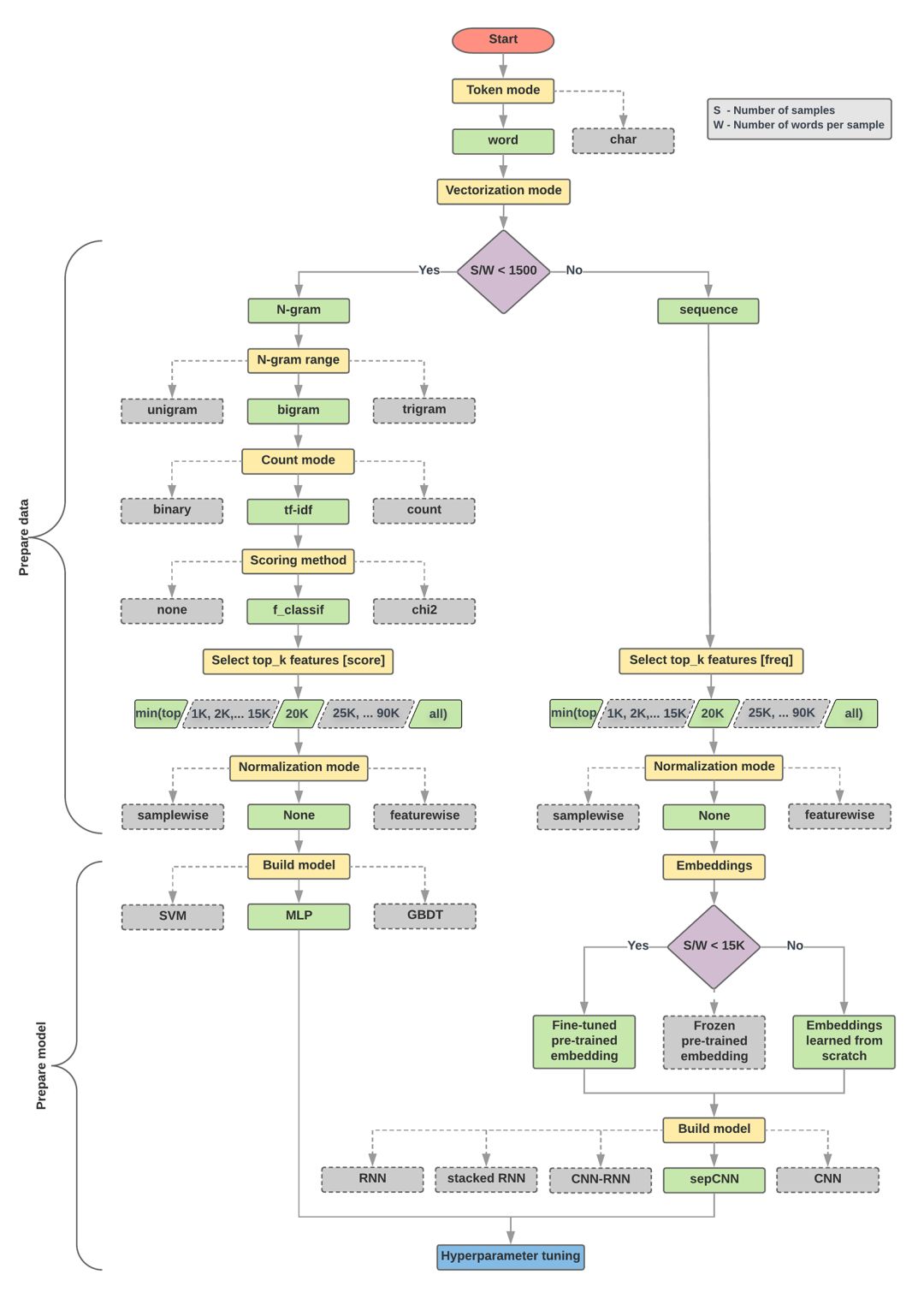
文本分类流程图
此流程图回答了两个关键问题:
我们应该使用哪种学习算法或模型?
我们应该如何准备数据以有效地学习文本和标签之间的关系?
其中,第二个问题取决于第一个问题的答案,而我们预处理数据的方式取决于所选的特定模型. 文本分类模型可以大致分为两类: 使用单词排名信息的序列模型和将文本视为一组单词的n-gram模型. 序列模型的类型包括卷积神经网络(CNN),递归神经网络(RNN)及其变体. n元语法模型的类型包括逻辑回归,MLP,DBDT和SVM.
对于电影评论数据集,样本数/每个样本的平均单词数约为144,因此我们将建立一个MLP模型.
如何在官方帐户上优雅地赢得历史文章,喜欢,阅读甚至评论?
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2020-08-08 10:37
也许像新邦和青博这样的著名平台都提供了这样的数据,但是价格太高了. 例如,如果要在新列表中获得《人民日报》的所有历史文章,则需要300个List Bean,它的价格是多少? 285元! ! !
新列表从官方帐户中采集历史文章
托收价格
我认为这笔费用不是大多数自媒体工作者负担得起的,包括我曾考虑过购买这种服务的费用,但最终停止了. 作为开发人员,这些问题可以自己解决,不要浪费,因此我决定开发像我这样的工具,该工具可以帮助需要快速获取官方帐户的历史商品数据以实现其目标的像我这样的人更方便和经济,所以我有目前的公众. 文章助手
小蜜蜂公共帐户文章助理
助手实现的功能
辅助界面
链接模式
代理模式
链接模式是最简单的. 您只需粘贴历史文章页面链接即可一键采集,而代理模式需要几分钟的时间设置,设置完成后即可开始采集
image.png
官方帐户列表
采集结果列表
采集成功后,您可以在官方帐户列表中查看采集结果,可以查看文章数量,名称以及一些导出文档的操作 查看全部
我相信许多运营工人在日常工作中会遇到这种需求,并且经常需要研究竞争对手的官方帐户商品数据或他们自己的官方帐户数据. 但是,微信官方平台无法提供如此便捷的操作. 支持导出官方帐户数据以供研究.
也许像新邦和青博这样的著名平台都提供了这样的数据,但是价格太高了. 例如,如果要在新列表中获得《人民日报》的所有历史文章,则需要300个List Bean,它的价格是多少? 285元! ! !
新列表从官方帐户中采集历史文章
托收价格
我认为这笔费用不是大多数自媒体工作者负担得起的,包括我曾考虑过购买这种服务的费用,但最终停止了. 作为开发人员,这些问题可以自己解决,不要浪费,因此我决定开发像我这样的工具,该工具可以帮助需要快速获取官方帐户的历史商品数据以实现其目标的像我这样的人更方便和经济,所以我有目前的公众. 文章助手
小蜜蜂公共帐户文章助理
助手实现的功能
辅助界面
链接模式
代理模式
链接模式是最简单的. 您只需粘贴历史文章页面链接即可一键采集,而代理模式需要几分钟的时间设置,设置完成后即可开始采集
image.png
官方帐户列表
采集结果列表
采集成功后,您可以在官方帐户列表中查看采集结果,可以查看文章数量,名称以及一些导出文档的操作
java/python中文分信息处理工具,没有计算机知识的人
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-08 09:15
1. 敏感性分析的目的是:
(1)识别影响项目经济效益变化的敏感因素,分析敏感因素变化的原因,为进一步的不确定性分析(如概率分析)提供依据;
(2)研究不确定因素的变化范围或极限值,例如项目的经济效益值的变化,并分析和判断项目的承受风险的能力;
(3)比较多种选择的敏感性,以便在经济利益相似的情况下,可以选择不敏感的投资选择.
根据每个不确定因素的变化数量,灵敏度分析可以分为单因素灵敏度分析和多因素灵敏度分析.
第二,敏感性分析的步骤
对于敏感性分析,通常请按照以下步骤操作:
1. 确定经济效益指标进行分析
评价投资项目的经济效益指标主要包括: 净现值,内部收益率,投资利润率,投资回收期等.
2. 选择不确定因素并设置变化范围.
3. 计算不确定因素变化对项目经济绩效指标的影响程度,并确定敏感因素.
4. 绘制灵敏度分析图以找到不确定性因素变化的极限值.
敏感性分析是一种动态不确定性分析,是项目评估中不可或缺的一部分. 用于分析项目经济效益指标对各种不确定因素的敏感性,找出敏感性因素及其最大波动范围,并据此判断项目的承受风险能力. 但是,该分析仍无法确定各种不确定因素在一定范围内的概率,因此其分析结论的准确性将在一定程度上受到影响. 在现实生活中,可能会出现这样的情况: 通过敏感性分析确定的敏感性因素未来不太可能发生不利变化,并且由此引发的项目风险不大;虽然在敏感性分析中执行的另一个因素不是很敏感,但是将来发生不利变化的可能性非常高,这将导致更大的项目风险. 为了弥补敏感性分析的不足,在项目评估和决策过程中需要进一步的概率分析.
数据分析具有广泛的应用范围. 在产品的整个生命周期中,数据分析过程是质量管理体系的支持过程,包括从产品市场研究到售后服务到最终处置的整个过程. 需要适当地使用数据分析来提高有效性. 国内有很多大数据分析和挖掘工具,但是其中大多数是近年来出现的大数据技术,它们必须具有计算机开发能力,并且可以立即使用. 多功能工具较少. 作为主流中文大数据分析和挖掘工具产品的试用版,以下推荐了一个java / python中文子信息处理工具,该工具可以在没有计算机知识的情况下直接使用:
NLPIR大数据语义智能分析平台(以前称为ICTCLAS)是由北京理工大学大数据搜索与挖掘实验室主任张华平开发的. 它满足了大数据内容采集,编译和搜索的全面需求. 它结合了精确的网络采集,对自然语言的理解,文本挖掘和语义搜索的最新研究成果近二十年来不断创新. 该平台提供了多种产品使用形式,例如客户端工具,云服务和二次开发接口. 每个中间件API均可无缝集成到客户的各种复杂应用系统中,与Windows,Linux,Android,Maemo5,FreeBSD等不同操作系统平台兼容,并可用于Java,Python,C等各种开发,C#等语言用法.
NLPIR大数据语义智能分析平台的十三个功能:
NLPIR大数据语义智能分析平台客户端
精确采集: 通过两种方式实时准确地从国内外Internet上采集大量信息: 主题采集(根据信息需求进行主题采集)和网站采集(给定的内部定点采集功能)网址列表).
文档转换: 将文本信息转换为doc,excel,pdf和ppt等多种主流文档格式,其效率可以满足大数据处理的要求.
新词发现: 从文本中发现新词和概念,用户可以将其用于专业词典的汇编,还可以进一步对其进行编辑和标记,将其导入分词词典中,从而提高了词的准确性. 分词系统,并适应新的语言多样性.
批处理单词分割: 原创语料库的单词分割,自动识别未注册的单词(例如名称,地名和机构名称),新单词标记和词性标记. 然后在分析过程中,导入用户定义的字典.
语言统计: 根据分段和标注的结果,系统可以自动对一元词的频率进行统计,并对二元词的转移概率进行统计. 对于常用术语,将自动给出相应的英语解释.
文本聚类: 它可以自动分析来自大规模数据的热点事件,并提供事件主题的关键功能描述. 它还适用于长文本和短文本(例如,短文本和微博)的热点分析.
文本分类: 根据规则或培训方法对大量文本进行分类,可用于新闻分类,简历分类,邮件分类,办公文档分类,区域分类等许多方面.
摘要实体: 对于单篇或多篇文章,将自动提取内容摘要,并提取人员名称,地点,组织,时间和主题关键字;方便用户快速浏览文本内容.
智能过滤: 语义智能过滤和文本内容审查,内置中国最完整的单词数据库,智能识别变形,语音,传统和简体等多种变体,并在语义上准确消除歧义.
情感分析: 对于预先指定的分析对象,系统会自动分析大量文档的情感趋势: 情感极性和情感价值测量,并在原文中给出正负分数和句子示例.
重复数据删除: 快速,准确地确定文件集合或数据库中是否存在具有相同或相似内容的记录,同时查找所有重复记录.
全文搜索: 支持各种数据类型,例如文本,数字,日期,字符串等,多字段有效搜索,支持查询语法(例如AND / OR / NOT和NEAR接近),并支持维吾尔文,藏文,蒙古语,阿拉伯语,韩语和其他少数民族语言的搜索.
编码转换: 自动识别内容的编码,并将编码统一转换为其他编码. 查看全部
敏感性分析是指从众多不确定因素中找出对投资项目的经济绩效指标有重要影响的敏感因素,并分析计算对项目经济绩效指标的影响程度和敏感性,然后是用于确定项目风险承受能力的不确定性分析方法.
1. 敏感性分析的目的是:
(1)识别影响项目经济效益变化的敏感因素,分析敏感因素变化的原因,为进一步的不确定性分析(如概率分析)提供依据;
(2)研究不确定因素的变化范围或极限值,例如项目的经济效益值的变化,并分析和判断项目的承受风险的能力;
(3)比较多种选择的敏感性,以便在经济利益相似的情况下,可以选择不敏感的投资选择.
根据每个不确定因素的变化数量,灵敏度分析可以分为单因素灵敏度分析和多因素灵敏度分析.
第二,敏感性分析的步骤
对于敏感性分析,通常请按照以下步骤操作:
1. 确定经济效益指标进行分析
评价投资项目的经济效益指标主要包括: 净现值,内部收益率,投资利润率,投资回收期等.
2. 选择不确定因素并设置变化范围.
3. 计算不确定因素变化对项目经济绩效指标的影响程度,并确定敏感因素.
4. 绘制灵敏度分析图以找到不确定性因素变化的极限值.
敏感性分析是一种动态不确定性分析,是项目评估中不可或缺的一部分. 用于分析项目经济效益指标对各种不确定因素的敏感性,找出敏感性因素及其最大波动范围,并据此判断项目的承受风险能力. 但是,该分析仍无法确定各种不确定因素在一定范围内的概率,因此其分析结论的准确性将在一定程度上受到影响. 在现实生活中,可能会出现这样的情况: 通过敏感性分析确定的敏感性因素未来不太可能发生不利变化,并且由此引发的项目风险不大;虽然在敏感性分析中执行的另一个因素不是很敏感,但是将来发生不利变化的可能性非常高,这将导致更大的项目风险. 为了弥补敏感性分析的不足,在项目评估和决策过程中需要进一步的概率分析.
数据分析具有广泛的应用范围. 在产品的整个生命周期中,数据分析过程是质量管理体系的支持过程,包括从产品市场研究到售后服务到最终处置的整个过程. 需要适当地使用数据分析来提高有效性. 国内有很多大数据分析和挖掘工具,但是其中大多数是近年来出现的大数据技术,它们必须具有计算机开发能力,并且可以立即使用. 多功能工具较少. 作为主流中文大数据分析和挖掘工具产品的试用版,以下推荐了一个java / python中文子信息处理工具,该工具可以在没有计算机知识的情况下直接使用:
NLPIR大数据语义智能分析平台(以前称为ICTCLAS)是由北京理工大学大数据搜索与挖掘实验室主任张华平开发的. 它满足了大数据内容采集,编译和搜索的全面需求. 它结合了精确的网络采集,对自然语言的理解,文本挖掘和语义搜索的最新研究成果近二十年来不断创新. 该平台提供了多种产品使用形式,例如客户端工具,云服务和二次开发接口. 每个中间件API均可无缝集成到客户的各种复杂应用系统中,与Windows,Linux,Android,Maemo5,FreeBSD等不同操作系统平台兼容,并可用于Java,Python,C等各种开发,C#等语言用法.

NLPIR大数据语义智能分析平台的十三个功能:
NLPIR大数据语义智能分析平台客户端
精确采集: 通过两种方式实时准确地从国内外Internet上采集大量信息: 主题采集(根据信息需求进行主题采集)和网站采集(给定的内部定点采集功能)网址列表).
文档转换: 将文本信息转换为doc,excel,pdf和ppt等多种主流文档格式,其效率可以满足大数据处理的要求.
新词发现: 从文本中发现新词和概念,用户可以将其用于专业词典的汇编,还可以进一步对其进行编辑和标记,将其导入分词词典中,从而提高了词的准确性. 分词系统,并适应新的语言多样性.
批处理单词分割: 原创语料库的单词分割,自动识别未注册的单词(例如名称,地名和机构名称),新单词标记和词性标记. 然后在分析过程中,导入用户定义的字典.
语言统计: 根据分段和标注的结果,系统可以自动对一元词的频率进行统计,并对二元词的转移概率进行统计. 对于常用术语,将自动给出相应的英语解释.
文本聚类: 它可以自动分析来自大规模数据的热点事件,并提供事件主题的关键功能描述. 它还适用于长文本和短文本(例如,短文本和微博)的热点分析.
文本分类: 根据规则或培训方法对大量文本进行分类,可用于新闻分类,简历分类,邮件分类,办公文档分类,区域分类等许多方面.
摘要实体: 对于单篇或多篇文章,将自动提取内容摘要,并提取人员名称,地点,组织,时间和主题关键字;方便用户快速浏览文本内容.
智能过滤: 语义智能过滤和文本内容审查,内置中国最完整的单词数据库,智能识别变形,语音,传统和简体等多种变体,并在语义上准确消除歧义.
情感分析: 对于预先指定的分析对象,系统会自动分析大量文档的情感趋势: 情感极性和情感价值测量,并在原文中给出正负分数和句子示例.
重复数据删除: 快速,准确地确定文件集合或数据库中是否存在具有相同或相似内容的记录,同时查找所有重复记录.
全文搜索: 支持各种数据类型,例如文本,数字,日期,字符串等,多字段有效搜索,支持查询语法(例如AND / OR / NOT和NEAR接近),并支持维吾尔文,藏文,蒙古语,阿拉伯语,韩语和其他少数民族语言的搜索.
编码转换: 自动识别内容的编码,并将编码统一转换为其他编码.
用R搜集和映射脸书数据的初学者向导
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-17 01:01
学习使用 R 的 twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
当我开始学习 R ,我也须要学习怎么出于研究的目的地搜集脸书数据并对其进行映射。尽管网上关于这个话题的信息好多,但我发现无法理解哪些与搜集并映射脸书数据相关。我除了是个 R 菜鸟,而且对各类教程中技术名词不熟悉。但虽然困难重重,我成功了!在这个教程里,我将以一种菜鸟程序员都能读懂的方法来功略怎么搜集脸书数据并来临展如今地图中。
创建应用程序
如果你没有脸书账号,首先你须要 注册一个。然后,到 创建一个容许你搜集脸书数据的应用程序。别担心,创建应用程序十分简单。你创建的应用程序会与脸书应用程序插口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其它程序帮你做事。这样一来,你可以接入脸书 API 令其搜集数据。只需确保不要恳求太多,因为脸书数据恳求次数是有限制 的。
采集推文有两个可用的 API 。你若果做一次性的推文搜集,那么使用 REST API. 若是想在特定时间内持续搜集,可以用 streaming API。教程中我主要使用 REST API。
创建应用程序以后,前往 Keys and Access Tokens 标签。你须要 Consumer Key (API key)、 Consumer Secret (API secret)、 Access Token 和 Access Token Secret 才能在 R 中访问你的应用程序。
采集脸书数据
下一步是打开 R 准备写代码。对于初学者,我推荐使用 RStudio,这是 R 的集成开发环境 (IDE) 。我发觉 RStudio 在解决问题和测试代码时很实用。 R 有访问该 REST API 的包叫 twitteR。
打开 RStudio 并新建 RScript。做好这种以后,你须要安装和加载 twitteR 包:
install.packages("twitteR")#安装TwitteRlibrary(twitteR)#载入TwitteR
安装并载入 twitteR 包然后,你得输入上文提到的应用程序的 API 信息:
api_key""#在冒号内装入你的APIkeyapi_secret""#在冒号内装入你的APIsecrettokentoken""#在冒号内装入你的tokentoken_secret""#在冒号内装入你的tokensecret
接下来,连接脸书访问 API:
setup_twitter_oauth(api_key,api_secret,token,token_secret)
我们来试试使脸书搜索有关社区新苑和农夫市场:
tweets"communitygardenOR#communitygardenORfarmersmarketOR#farmersmarket",n=200,lang="en")
这个代码意思是搜索前 200 篇 (n = 200) 英文 (lang = "en") 的推文, 包括关键词 community garden 或 farmers market 或任何提到这种关键词的话题标签。
推特搜索完成以后,在数据框中保存你的结果:
tweets.df
为了用推文创建地图,你须要搜集的导入为 .csv 文件:
write.csv(tweets.df,"C:\Users\YourName\Documents\ApptoMap\tweets.csv")#anexampleofafileextensionofthefolderinwhichyouwanttosavethe.csvfile.
运行前确保 R 代码已保存之后继续进行下一步。.
生成地图
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 Leaflet 做一个基本的应用程序,这是一个生成交互式地图的热门 JavaScript 库。 Leaflet 使用 magrittr 管道运算符 (%>%), 由于其句型自然,易于写代码。刚接触可能有点奇怪,但它确实增加了写代码的工作量。
为了清晰起见,在 RStudio 打开一个新的 R 脚本安装这种包:
install.packages("leaflet")install.packages("maps")library(leaflet)library(maps)
现在须要一个路径使 Leaflet 访问你的数据:
read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv",stringsAsFactors=FALSE)
stringAsFactors = FALSE 意思是保留信息,不将它转化成 factors。 (想了解 factors,读这篇文章"stringsAsFactors: An unauthorized biography", 作者 Roger Peng)
是时侯制做你的 Leaflet 地图了。我们将使用 OpenStreetMap基本地图来做你的地图:
m%addTiles()
我们在基本地图上加个圈。对于 lng 和 lat,输入收录推文的经纬度的列名,并在上面加个~。 ~longitude 和 ~latitude 指向你的 .csv 文件中与列名:
m%>%addCircles(lng=~longitude,lat=~latitude,popup=mymap$type,weight=8,radius=40,color="#fb3004",stroke=TRUE,fillOpacity=0.8)
运行你的代码。会弹出网页浏览器并展示你的地图。这是我后面搜集的推文的地图:
推文定位地图
带定位的推文地图,使用了 Leaflet 和 OpenStreetMap CC-BY-SA
虽然你可能会对地图上的图文数目这么之小倍感惊奇,通常只有 1% 的推文记录了地理编码。我搜集了总量为 366 的推文,但只有 10(大概总推文的 3%)是记录了地理编码的。如果你为得到记录了地理编码的推文而困惑,改变搜索关键词瞧瞧能不能得到更好的结果。
总结
对于初学者,把以上所有碎片结合上去,从脸书数据生成一个 Leaflet 地图可能太艰辛。 这个教程基于我完成这个任务的经验,我希望它能使你的学习过程显得更轻松。
(题图:琼斯·贝克. CC BY-SA 4.0. 来源: Cloud, Globe. Both CC0.)
作者:Dorris Scott 查看全部
用R搜集和映射脸书数据的初学者向导
学习使用 R 的 twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
当我开始学习 R ,我也须要学习怎么出于研究的目的地搜集脸书数据并对其进行映射。尽管网上关于这个话题的信息好多,但我发现无法理解哪些与搜集并映射脸书数据相关。我除了是个 R 菜鸟,而且对各类教程中技术名词不熟悉。但虽然困难重重,我成功了!在这个教程里,我将以一种菜鸟程序员都能读懂的方法来功略怎么搜集脸书数据并来临展如今地图中。
创建应用程序
如果你没有脸书账号,首先你须要 注册一个。然后,到 创建一个容许你搜集脸书数据的应用程序。别担心,创建应用程序十分简单。你创建的应用程序会与脸书应用程序插口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其它程序帮你做事。这样一来,你可以接入脸书 API 令其搜集数据。只需确保不要恳求太多,因为脸书数据恳求次数是有限制 的。
采集推文有两个可用的 API 。你若果做一次性的推文搜集,那么使用 REST API. 若是想在特定时间内持续搜集,可以用 streaming API。教程中我主要使用 REST API。
创建应用程序以后,前往 Keys and Access Tokens 标签。你须要 Consumer Key (API key)、 Consumer Secret (API secret)、 Access Token 和 Access Token Secret 才能在 R 中访问你的应用程序。
采集脸书数据
下一步是打开 R 准备写代码。对于初学者,我推荐使用 RStudio,这是 R 的集成开发环境 (IDE) 。我发觉 RStudio 在解决问题和测试代码时很实用。 R 有访问该 REST API 的包叫 twitteR。
打开 RStudio 并新建 RScript。做好这种以后,你须要安装和加载 twitteR 包:
install.packages("twitteR")#安装TwitteRlibrary(twitteR)#载入TwitteR
安装并载入 twitteR 包然后,你得输入上文提到的应用程序的 API 信息:
api_key""#在冒号内装入你的APIkeyapi_secret""#在冒号内装入你的APIsecrettokentoken""#在冒号内装入你的tokentoken_secret""#在冒号内装入你的tokensecret
接下来,连接脸书访问 API:
setup_twitter_oauth(api_key,api_secret,token,token_secret)
我们来试试使脸书搜索有关社区新苑和农夫市场:
tweets"communitygardenOR#communitygardenORfarmersmarketOR#farmersmarket",n=200,lang="en")
这个代码意思是搜索前 200 篇 (n = 200) 英文 (lang = "en") 的推文, 包括关键词 community garden 或 farmers market 或任何提到这种关键词的话题标签。
推特搜索完成以后,在数据框中保存你的结果:
tweets.df
为了用推文创建地图,你须要搜集的导入为 .csv 文件:
write.csv(tweets.df,"C:\Users\YourName\Documents\ApptoMap\tweets.csv")#anexampleofafileextensionofthefolderinwhichyouwanttosavethe.csvfile.
运行前确保 R 代码已保存之后继续进行下一步。.
生成地图
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 Leaflet 做一个基本的应用程序,这是一个生成交互式地图的热门 JavaScript 库。 Leaflet 使用 magrittr 管道运算符 (%>%), 由于其句型自然,易于写代码。刚接触可能有点奇怪,但它确实增加了写代码的工作量。
为了清晰起见,在 RStudio 打开一个新的 R 脚本安装这种包:
install.packages("leaflet")install.packages("maps")library(leaflet)library(maps)
现在须要一个路径使 Leaflet 访问你的数据:
read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv",stringsAsFactors=FALSE)
stringAsFactors = FALSE 意思是保留信息,不将它转化成 factors。 (想了解 factors,读这篇文章"stringsAsFactors: An unauthorized biography", 作者 Roger Peng)
是时侯制做你的 Leaflet 地图了。我们将使用 OpenStreetMap基本地图来做你的地图:
m%addTiles()
我们在基本地图上加个圈。对于 lng 和 lat,输入收录推文的经纬度的列名,并在上面加个~。 ~longitude 和 ~latitude 指向你的 .csv 文件中与列名:
m%>%addCircles(lng=~longitude,lat=~latitude,popup=mymap$type,weight=8,radius=40,color="#fb3004",stroke=TRUE,fillOpacity=0.8)
运行你的代码。会弹出网页浏览器并展示你的地图。这是我后面搜集的推文的地图:
推文定位地图
带定位的推文地图,使用了 Leaflet 和 OpenStreetMap CC-BY-SA
虽然你可能会对地图上的图文数目这么之小倍感惊奇,通常只有 1% 的推文记录了地理编码。我搜集了总量为 366 的推文,但只有 10(大概总推文的 3%)是记录了地理编码的。如果你为得到记录了地理编码的推文而困惑,改变搜索关键词瞧瞧能不能得到更好的结果。
总结
对于初学者,把以上所有碎片结合上去,从脸书数据生成一个 Leaflet 地图可能太艰辛。 这个教程基于我完成这个任务的经验,我希望它能使你的学习过程显得更轻松。
(题图:琼斯·贝克. CC BY-SA 4.0. 来源: Cloud, Globe. Both CC0.)
作者:Dorris Scott
Facebook内容采集/用户信息数据抓取API爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 1901 次浏览 • 2020-08-16 21:38
上个月老朋友给我介绍了一个可以采Facebook内容和用户信息的第三方API爬虫提供商iDataAPI,连续一周的百万条级别测试发觉稳定性不错,准备加入到下半年向省里申报的海外信息数据检测项目当中。
Facebook官方即使提供了Graph API,不过好多信息在最新版本的API中是不提供的。比如按照关键字搜索用户发贴等等。通过PC端的web页面抓取难度也很大,因为Facebook的页面使用了大量的js脚本动态加载数据,所以据说她们研制了云端分布式&手机端抓取数据的爬虫,就太感兴趣试一试,测试结果符合预期。
我们主要用到的功能如下:
根据关键字抓取用户的时间线抓取某用户的资料抓取某用户的好友抓取某用户的贴子
通过使用这几项功能最终可以生成一个关系网路,为后序的NLP工作打下基础。基于这个API爬虫,后续进一步接入舆情监测,情感剖析,意见挖掘等等。
这个iDataAPI提供包括一个完整的web控制界面,可以在浏览器中测试爬虫(facebook、twitter、微博、youtube...测了都很不多的,难得),后台可以完整的创建任务、查看日志、查看数据,普通开发者注册就送钱免费测试了。只是目前项目还在申报期,我们研究院须要的量级比较大,等前面签个协议包月,加上TWITTER这种,每天恐怕得采集个千万条。
返回示例值(FACEBOOK帖子){ "hasNext": true, "retcode": "000000", "appCode": "facebook", "dataType": "post", "pageToken": "enc_AdBhgxzOwy0fZBFjW6GXwbjJDRUca1SS5ccSTKp4TvchMAF3De0qdfVEC8sZAcCQZCw1CtORi9eLls3iJvJJk8PlNIQ|1493425239", "data": [ { "posterId": "4", "commentCount": 76221, "posterScreenName": "Mark Zuckerberg", "title": null, "url": "https:\/\/www.facebook.com\/4_10103685865597591", "imageUrls": [ "https:\/\/fb-s-d-a.akamaihd.net\/h-ak-xtp1\/v\/t15.0-10\/s720x720\/18223192_10103685908017581_8465195272706719744_n.jpg?_nc_ad=z-m&oh=e0736750f4882bed329ad89749849443&oe=59C22C86&__gda__=1505738387_e11048d689aba9e12e3fef771eab44f5" ], "originUrl": "https:\/\/www.facebook.com\/zuck\/videos\/10103685865597591\/", "geoPoint": "37.484, -122.149", "mediaType": "video", "publishDate": 1493494203, "likeCount": 173477, "content": "Part II of driving through South Bend, Indiana with Mayor Pete Buttigieg.", "parentPostId": "3791568f35f4c067d6403a5c344136cc", "shareCount": 9506, "parentAppCode": "facebook", "publishDateStr": "2017-04-29T19:30:03", "id": "4_10103685865597591", "origin": false, "originContent": null } ]}
返回示例值(FACEBOOK用户信息){ "hasNext": false, "retcode": "000000", "appCode": "facebook", "dataType": "profile", "pageToken": null, "data": [ { "userName": "zuck", "idType": "user", "educations": [ { "schoolName": "Ardsley High School" }, { "schoolName": "Phillips Exeter Academy" }, { "schoolName": "Harvard University" } ], "works": [ { "employer": "Chan Zuckerberg Initiative" }, { "employer": "Facebook" } ], "idVerified": null, "friendCount": null, "idVerifiedInfo": null, "url": "https:\/\/www.facebook.com\/4", "gender": "m", "fansCount": null, "avatarUrl": "https:\/\/fb-s-c-a.akamaihd.net\/h-ak-fbx\/v\/t34.0-1\/p50x50\/16176889_112685309244626_578204711_n.jpg?efg=eyJkdHciOiIifQ==&_nc_ad=z-m&oh=1d19d2bcf1881ee7deaaf7cf777cb194&oe=597DA91E&__gda__=1501340296_20445fee97f7852820dbda04f427e5d8", "followCount": null, "viewCount": null, "postCount": null, "birthday": null, "location": "Palo Alto, California", "likeCount": null, "id": "4", "biography": "I'm trying to make the world a more open place.", "screenName": "Mark Zuckerberg" } ]}
API平台:
返回参数:
后台: 查看全部
Facebook内容采集/用户信息数据抓取API爬虫
上个月老朋友给我介绍了一个可以采Facebook内容和用户信息的第三方API爬虫提供商iDataAPI,连续一周的百万条级别测试发觉稳定性不错,准备加入到下半年向省里申报的海外信息数据检测项目当中。
Facebook官方即使提供了Graph API,不过好多信息在最新版本的API中是不提供的。比如按照关键字搜索用户发贴等等。通过PC端的web页面抓取难度也很大,因为Facebook的页面使用了大量的js脚本动态加载数据,所以据说她们研制了云端分布式&手机端抓取数据的爬虫,就太感兴趣试一试,测试结果符合预期。
我们主要用到的功能如下:
根据关键字抓取用户的时间线抓取某用户的资料抓取某用户的好友抓取某用户的贴子
通过使用这几项功能最终可以生成一个关系网路,为后序的NLP工作打下基础。基于这个API爬虫,后续进一步接入舆情监测,情感剖析,意见挖掘等等。
这个iDataAPI提供包括一个完整的web控制界面,可以在浏览器中测试爬虫(facebook、twitter、微博、youtube...测了都很不多的,难得),后台可以完整的创建任务、查看日志、查看数据,普通开发者注册就送钱免费测试了。只是目前项目还在申报期,我们研究院须要的量级比较大,等前面签个协议包月,加上TWITTER这种,每天恐怕得采集个千万条。
返回示例值(FACEBOOK帖子){ "hasNext": true, "retcode": "000000", "appCode": "facebook", "dataType": "post", "pageToken": "enc_AdBhgxzOwy0fZBFjW6GXwbjJDRUca1SS5ccSTKp4TvchMAF3De0qdfVEC8sZAcCQZCw1CtORi9eLls3iJvJJk8PlNIQ|1493425239", "data": [ { "posterId": "4", "commentCount": 76221, "posterScreenName": "Mark Zuckerberg", "title": null, "url": "https:\/\/www.facebook.com\/4_10103685865597591", "imageUrls": [ "https:\/\/fb-s-d-a.akamaihd.net\/h-ak-xtp1\/v\/t15.0-10\/s720x720\/18223192_10103685908017581_8465195272706719744_n.jpg?_nc_ad=z-m&oh=e0736750f4882bed329ad89749849443&oe=59C22C86&__gda__=1505738387_e11048d689aba9e12e3fef771eab44f5" ], "originUrl": "https:\/\/www.facebook.com\/zuck\/videos\/10103685865597591\/", "geoPoint": "37.484, -122.149", "mediaType": "video", "publishDate": 1493494203, "likeCount": 173477, "content": "Part II of driving through South Bend, Indiana with Mayor Pete Buttigieg.", "parentPostId": "3791568f35f4c067d6403a5c344136cc", "shareCount": 9506, "parentAppCode": "facebook", "publishDateStr": "2017-04-29T19:30:03", "id": "4_10103685865597591", "origin": false, "originContent": null } ]}
返回示例值(FACEBOOK用户信息){ "hasNext": false, "retcode": "000000", "appCode": "facebook", "dataType": "profile", "pageToken": null, "data": [ { "userName": "zuck", "idType": "user", "educations": [ { "schoolName": "Ardsley High School" }, { "schoolName": "Phillips Exeter Academy" }, { "schoolName": "Harvard University" } ], "works": [ { "employer": "Chan Zuckerberg Initiative" }, { "employer": "Facebook" } ], "idVerified": null, "friendCount": null, "idVerifiedInfo": null, "url": "https:\/\/www.facebook.com\/4", "gender": "m", "fansCount": null, "avatarUrl": "https:\/\/fb-s-c-a.akamaihd.net\/h-ak-fbx\/v\/t34.0-1\/p50x50\/16176889_112685309244626_578204711_n.jpg?efg=eyJkdHciOiIifQ==&_nc_ad=z-m&oh=1d19d2bcf1881ee7deaaf7cf777cb194&oe=597DA91E&__gda__=1501340296_20445fee97f7852820dbda04f427e5d8", "followCount": null, "viewCount": null, "postCount": null, "birthday": null, "location": "Palo Alto, California", "likeCount": null, "id": "4", "biography": "I'm trying to make the world a more open place.", "screenName": "Mark Zuckerberg" } ]}
API平台:
返回参数:
后台:
一篇文章带你用Python网络爬虫实现网易云音乐歌词抓取
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2020-08-15 00:21
前几天小编给你们分享了数据可视化剖析,在文尾提到了网易云音乐歌词爬取,今天小编给你们分享网易云音乐歌词爬取技巧。本文的总体思路如下:找到正确的URL,获取源码;利用bs4解析源码,获取歌曲名和歌曲ID;调用网易云歌曲API,获取歌词;将歌词写入文件,并存入本地。本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有/#号的。废话不多说,直接上代码。
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在 查看全部
前几天小编给你们分享了数据可视化剖析,在文尾提到了网易云音乐歌词爬取,今天小编给你们分享网易云音乐歌词爬取技巧。本文的总体思路如下:找到正确的URL,获取源码;利用bs4解析源码,获取歌曲名和歌曲ID;调用网易云歌曲API,获取歌词;将歌词写入文件,并存入本地。本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有/#号的。废话不多说,直接上代码。
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在
《商务数据采集与处理》教学大纲.doc 4页
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-08-12 00:37
H4研究5使用现代工具Excel、Database、CSV、TXT、电子商务平台、Web爬虫、API、Java、Python、PHP、为优采云数据采集系统H6工程与社会7环境和可持续发展8职业规范培养认真、谨慎的职业精神;提升各类工具的使用熟练度和精确度H9个人和团队10沟通11项目管理12终生学习了解新的各种商务数据采集与处理软件,不断提升各种商务数据采集与处理软件的操作能力H注:“课程教学要求”栏中内容为针对该课程适用专业的专业结业要求与相关教学要求的具体描述。“关联程度”栏中字母表示两者关联程度。关联程度按高关联、中关联、低关联三档分别表示为“H”“M”或“L”。“课程教学要求”及“关联程度”中的空白栏表示该课程与所对应的专业结业要求条目不相关。四、课程教学内容章节名称主要内容重难点关键词学时类型1商务数据采集概述商务数据的定义及类型商务数据的主要来源及用途商务数据采集和处理的基本技巧商务数据的定义及类型,商务数据的主要来源及用途,商务数据采集和处理的基本技巧3理论2商务数据采集工具及应用商务数据采集工具介绍爬虫软件在商务数据剖析中的应用Python 爬虫在商务数据采集中的应用数据采集方法,常用的数据采集工具,Python 爬虫的优劣势3理论+操作3数据采集方法与采集器了解数据采集器数据采集器的安装与界面数据采集器的优势,安装注册数据采集器2理论+操作4数据采集器应用简易采集模式及实例向导模式及实例自定义采集模式使用简易采集模式进行常见网站数据采集,使用自定义采集模式进行列表详情页数据采集,掌握在规则中对采集内容做初步筛选和清洗操作3理论+操作5数据采集器中级应用屏蔽网页广告切换浏览器版本严禁加载图片增量采集智能防封登陆采集网页源码提取图片、附件的采集与下载循环切换下拉框联通键盘表针到元素上数据采集器的中级功能,增量采集和智能防封的应对方法,增量采集的形式5理论+操作6数据采集器定位方法及云采集XPath 数据定位云采集XPath 书写方式,云采集功能与使用2理论+操作7数据采集器采集实例数据采集器应用领域金融网站、新闻网站、职场急聘、店铺位置的数据采集竞品数据、企业产品相关评价、公众号文章信息的采集在实训中获得数据采集能力,熟悉各种数据采集领域典型网站4理论+操作8数据处理数据清洗与加工数据处理的定义及作用,常见的数据清洗方式,对各种数据进行标准化加工处理2理论+操作五、考核要求及成绩评定序号成绩类别考评形式考评要求权重(%)备注1期终成绩期末考试大作业50百分制,60分为及格2平常成绩实战训练10次40优、良、中、及格、不及格3平常表现缺勤情况10两次未出席课程则未能获得学分注:此表中内容为该课程的全部考评方法及其相关信息。六、学生学习建议1.理论配合实战训练进行学习,提高中学生在商务数据剖析与应用专业课程中数据采集和处理问题的能力;2.在条件容许的情况下,可以结合市场上常用的数据采集和处理工具,开发自发探求能力,更好地将专业所学和就业技能相结合,达到学以致用的目的。3.培养、提升中学生按照不同须要进行处理和清洗数据的能力。 查看全部
《商务数据采集与处理》教学大纲课程信息课程名称:《商务数据采集与处理》课程类别:专业基础课课程性质:必修计划学时:24计划学分:3先修课程:无二、课程简介本书结合了一线大数据企业在商务数据上的采集和应用方法,从数据基础、数据来源、数据采集到数据处理等方面展开内容讲解。本书融入了大量的实操案例,对学习目标进行详尽讲解,反复加强“理论围绕实操,实操推进理论,真实把握技能”的教学理念。三、课程教学要求序号专业结业要求课程教学要求关联程度1工程知识了解商务数据的基础知识及来源、常规数据采集工具及应用,对商务数据以及数据采集有直观认识,了解数据采集方法与采集器、数据采集器应用、数据采集器中级应用、数据采集器定位方法及云采集以及使用较为广泛的采集器优采云采集器,掌握在采集数据完成后怎样进行数据处理,根据不同须要进行处理和清洗,使数据剖析结果更为确切。H2问题剖析发觉商务数据采集与处理中存在的问题,寻找出现问题的诱因H3设计/开发解决方案提升商务数据的基础知识及来源、常规数据采集工具及应用,对商务数据以及数据采集有直观认识,结合市场上常用的数据采集和处理工具,开发自发探求能力,更好地将专业所学和就业技能相结合,达到学以致用的目的。
H4研究5使用现代工具Excel、Database、CSV、TXT、电子商务平台、Web爬虫、API、Java、Python、PHP、为优采云数据采集系统H6工程与社会7环境和可持续发展8职业规范培养认真、谨慎的职业精神;提升各类工具的使用熟练度和精确度H9个人和团队10沟通11项目管理12终生学习了解新的各种商务数据采集与处理软件,不断提升各种商务数据采集与处理软件的操作能力H注:“课程教学要求”栏中内容为针对该课程适用专业的专业结业要求与相关教学要求的具体描述。“关联程度”栏中字母表示两者关联程度。关联程度按高关联、中关联、低关联三档分别表示为“H”“M”或“L”。“课程教学要求”及“关联程度”中的空白栏表示该课程与所对应的专业结业要求条目不相关。四、课程教学内容章节名称主要内容重难点关键词学时类型1商务数据采集概述商务数据的定义及类型商务数据的主要来源及用途商务数据采集和处理的基本技巧商务数据的定义及类型,商务数据的主要来源及用途,商务数据采集和处理的基本技巧3理论2商务数据采集工具及应用商务数据采集工具介绍爬虫软件在商务数据剖析中的应用Python 爬虫在商务数据采集中的应用数据采集方法,常用的数据采集工具,Python 爬虫的优劣势3理论+操作3数据采集方法与采集器了解数据采集器数据采集器的安装与界面数据采集器的优势,安装注册数据采集器2理论+操作4数据采集器应用简易采集模式及实例向导模式及实例自定义采集模式使用简易采集模式进行常见网站数据采集,使用自定义采集模式进行列表详情页数据采集,掌握在规则中对采集内容做初步筛选和清洗操作3理论+操作5数据采集器中级应用屏蔽网页广告切换浏览器版本严禁加载图片增量采集智能防封登陆采集网页源码提取图片、附件的采集与下载循环切换下拉框联通键盘表针到元素上数据采集器的中级功能,增量采集和智能防封的应对方法,增量采集的形式5理论+操作6数据采集器定位方法及云采集XPath 数据定位云采集XPath 书写方式,云采集功能与使用2理论+操作7数据采集器采集实例数据采集器应用领域金融网站、新闻网站、职场急聘、店铺位置的数据采集竞品数据、企业产品相关评价、公众号文章信息的采集在实训中获得数据采集能力,熟悉各种数据采集领域典型网站4理论+操作8数据处理数据清洗与加工数据处理的定义及作用,常见的数据清洗方式,对各种数据进行标准化加工处理2理论+操作五、考核要求及成绩评定序号成绩类别考评形式考评要求权重(%)备注1期终成绩期末考试大作业50百分制,60分为及格2平常成绩实战训练10次40优、良、中、及格、不及格3平常表现缺勤情况10两次未出席课程则未能获得学分注:此表中内容为该课程的全部考评方法及其相关信息。六、学生学习建议1.理论配合实战训练进行学习,提高中学生在商务数据剖析与应用专业课程中数据采集和处理问题的能力;2.在条件容许的情况下,可以结合市场上常用的数据采集和处理工具,开发自发探求能力,更好地将专业所学和就业技能相结合,达到学以致用的目的。3.培养、提升中学生按照不同须要进行处理和清洗数据的能力。
iMacros for Chrome V10.4.28 汉化免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2020-08-11 23:49
【功能特色】
1、浏览器自动化:通过InternetExplorer,Firefox和Chrome手动执行任务。没有新的脚本语言要学习,您可以对Web浏览器进行完整的编程控制,因此虽然是最复杂的任务也可以编撰脚本。
2、Web测试:自动执行任何网站技术(包括Java,Flash,Flex或Silverlight小程序和所有AJAX元素)的功能,性能和回归测试,并捕获精确的网页响应时间。将宏导入到SeleniumWebDriver代码。
3、数据提取:一个完整的工具集,用于将Web数据屏蔽到数据库,电子表格或任何其他应用程序中。iMacros可以在短短几分钟内手动完成所需的所有Web搜集。
4、全功能Web浏览器API:iMacros企业版手动安装Web浏览器API,可从任何Windows编程或脚本语言完成Web浏览器控件。通过这种强悍的命令,您可以使用支持使用COM对象的任何Windows编程语言来控制iMacros。几乎所有的Windows编程语言都支持这些技术,包括免费的WindowsScriptingHost、VisualBasic6、VisualBasic.NET、C#、Java、Perl、Python、C++、ASP、PHP和ASP.NET。 查看全部
iMacros中文版是专为站长用户构建的一款特别不错的Web自动化软件,该软件功能强悍,它可以帮助使用者执行手动填写表单、从网站中提取数据、自动测试网站、自动登入到网路邮箱以及手动重复执行任务等操作,可大大提高使用者的任务完成效率,它可以通过灵活的脚本使用与多语言的程序插口来自动执行复杂的任务。
【功能特色】
1、浏览器自动化:通过InternetExplorer,Firefox和Chrome手动执行任务。没有新的脚本语言要学习,您可以对Web浏览器进行完整的编程控制,因此虽然是最复杂的任务也可以编撰脚本。
2、Web测试:自动执行任何网站技术(包括Java,Flash,Flex或Silverlight小程序和所有AJAX元素)的功能,性能和回归测试,并捕获精确的网页响应时间。将宏导入到SeleniumWebDriver代码。
3、数据提取:一个完整的工具集,用于将Web数据屏蔽到数据库,电子表格或任何其他应用程序中。iMacros可以在短短几分钟内手动完成所需的所有Web搜集。
4、全功能Web浏览器API:iMacros企业版手动安装Web浏览器API,可从任何Windows编程或脚本语言完成Web浏览器控件。通过这种强悍的命令,您可以使用支持使用COM对象的任何Windows编程语言来控制iMacros。几乎所有的Windows编程语言都支持这些技术,包括免费的WindowsScriptingHost、VisualBasic6、VisualBasic.NET、C#、Java、Perl、Python、C++、ASP、PHP和ASP.NET。
(IE9)Internet Explorer 9.0 简体英文正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-11 21:08
浏览器版本较低,官方已停止升级维护,建议升级到更快、更安全的浏览器,点击立刻下载。
IE9英文正式版是谷歌推出的ie9英文版本,internet explorer 9是谷歌支持标准最规范的IE浏览器。IE9改进IE浏览器性能,IE9支持XP/win7,本站提供ie9中文版官方下载.
Internet Explorer 9 正式版 (IE9正式版)是谷歌最新一款IE浏览器,IE9在各方面都有急剧提高,给你全新的浏览体验!例如:全新的新 JavaScript 引擎促使IE9的运算速率更快;新增GPU 硬件加速,大大提高IE的运行速率;IE9 子系统全面改进,极大增强了对 HTML、CSS 和 JavaScript 的解释效率;IE9 支持最新的 HTML5、CSS3、SVG 和 DOM L2&L3;整合更多开发工具……
IE9截图1
软件特色
1、速度更快:IE9支持GPU加速功能,用户网页浏览速率将更快;
2、清新界面:优化后的用户界面愈发简练,网页内容得到突出;
3、与Windows 7完美结合:Win7和IE9是绝配,适配性更强;IE9支持将常用网站锁定到任务栏,便携浏览您喜欢的网站;
4、支持标准:规范了网页标准,使得各网站能获得更好的支持,从而给用户带来更优越的操作体验!
截图2
功能介绍
1、ie9新JavaScript引擎
IE9全新外置的“Chakra JavaScript引擎”充分利用当下主流计算机配置的多核心CPU,优化协同运算能力,编译、执行速率更快。同时与DOM的紧密集成,使得网路应用运行更顺畅,反应更迅速。
ie9新JavaScript引擎软件截图3
2、ie9GPU硬件加速
IE9将全面支持HTML5 GPU硬件加速,借助GPU的效能来渲染标准的Web内容,如文字、图像、视频、SVG(可缩放矢量图形)等网路信息,减少CPU负荷,大大的提升浏览器的速率。开发人员无需为GPU硬件加速特点重新编撰网站,直接提高图形处理性能。
ie9GPU硬件加速软件截图4
3、ie9子系统优化,提升协同处理效率
IE9子系统全面改进,极大增强了对HTML、CSS和JavaScript的解释效率。将布局以及渲染等方面的资源更合理的分配和优化,在降低对显存和处理资源耗损的同时,让网页呈现和网路应用程序的运行速率愈发顺畅。
截图5
4、ie9全新用户界面
IE9带来全新用户界面——简单、清晰、有效,尽可能简化浏览器的外型元素和操作步骤——希望用户才能最大限度的“忽略”IE9的“存在”,而将注意力全部沉溺在精彩的网路内容当中。
ie9全新用户界面截图6
5、ie9全面支持最新网路标准
IE9支持最新的HTML5、CSS3、SVG和DOM L2&L3,你可以充分利用这种技术诠释你的网路创意,不必再针对不同浏览器编撰不同代码,大幅度增加你的开发时间和难度。
6、ie9整合更多开发工具
与其他浏览器相比,IE9外置了更多强悍的开发人员工具——包括JavaScript剖析工具、CSS编辑器和新的网路剖析器等。这些工具当你须要时就在手边,方便你进行开发和调试,实现与IE9的全方位整合。
7、ie9先进的网路开发技术
IE9提供了一系列先进技术,如D2D DirectX图形构架和图形、色彩解码器等,助你实现高清视频和多媒体交互。搭配GPU图形硬件加速,让画面质量和流畅性达到质的提高,为你搭建一个更好的平台,来为你的用户诠释前所未有的视觉、听觉体验。
截图7
8、ie9是网站,也是一个Windows 7程序
利用最新的Windows应用程序插口(API),开发者才能使用JavaScript来定义键盘右键快捷菜单、任务栏缩略图、跳转列表项和触控等功能,使其与Windows 7操作系统完美整合,带来新的浏览形式,让用户体验上升到新的高度。
9、ie9兼容性模式
IE9使开发人员来选择浏览站点时所使用的模式,其中包括IE9标准模式、IE8文档模式、 兼容视图模式(IE7)或Quirks模式 (IE5)。如果用户单击兼容模式按键,网站将以开发者事先指定的模式或兼容视图模式(IE7)运行,保证向后的兼容性和网站升级时的灵活性。
截图8
常见问题
IE9支持哪些系统?
可用于全部 Windows Vista 和 Windows 7 版本。
怎么调整IE9 使用兼容模式?
1、打开IE浏览器,点击“工具”选项,选择“兼容性视图设置”选项。
2、进入兼容性视图设置以后,填入所须要设置兼容模式的网址,点击添加,最后点击关掉即可。
3、重新打开经过设置以后的网页,会听到地址栏前面有一个象破碎纸片一样的图标,说明兼容模式早已设置成功,在工具的下拉菜单也同样可以看见在兼容模式上面也就对勾,说明网页的兼容模式早已设置成功。
更新日志
修复部份bug 查看全部
浏览器版本较低,官方已停止升级维护,建议升级到更快、更安全的浏览器,点击立刻下载。
IE9英文正式版是谷歌推出的ie9英文版本,internet explorer 9是谷歌支持标准最规范的IE浏览器。IE9改进IE浏览器性能,IE9支持XP/win7,本站提供ie9中文版官方下载.
Internet Explorer 9 正式版 (IE9正式版)是谷歌最新一款IE浏览器,IE9在各方面都有急剧提高,给你全新的浏览体验!例如:全新的新 JavaScript 引擎促使IE9的运算速率更快;新增GPU 硬件加速,大大提高IE的运行速率;IE9 子系统全面改进,极大增强了对 HTML、CSS 和 JavaScript 的解释效率;IE9 支持最新的 HTML5、CSS3、SVG 和 DOM L2&L3;整合更多开发工具……
IE9截图1
软件特色
1、速度更快:IE9支持GPU加速功能,用户网页浏览速率将更快;
2、清新界面:优化后的用户界面愈发简练,网页内容得到突出;
3、与Windows 7完美结合:Win7和IE9是绝配,适配性更强;IE9支持将常用网站锁定到任务栏,便携浏览您喜欢的网站;
4、支持标准:规范了网页标准,使得各网站能获得更好的支持,从而给用户带来更优越的操作体验!
截图2
功能介绍
1、ie9新JavaScript引擎
IE9全新外置的“Chakra JavaScript引擎”充分利用当下主流计算机配置的多核心CPU,优化协同运算能力,编译、执行速率更快。同时与DOM的紧密集成,使得网路应用运行更顺畅,反应更迅速。
ie9新JavaScript引擎软件截图3
2、ie9GPU硬件加速
IE9将全面支持HTML5 GPU硬件加速,借助GPU的效能来渲染标准的Web内容,如文字、图像、视频、SVG(可缩放矢量图形)等网路信息,减少CPU负荷,大大的提升浏览器的速率。开发人员无需为GPU硬件加速特点重新编撰网站,直接提高图形处理性能。
ie9GPU硬件加速软件截图4
3、ie9子系统优化,提升协同处理效率
IE9子系统全面改进,极大增强了对HTML、CSS和JavaScript的解释效率。将布局以及渲染等方面的资源更合理的分配和优化,在降低对显存和处理资源耗损的同时,让网页呈现和网路应用程序的运行速率愈发顺畅。
截图5
4、ie9全新用户界面
IE9带来全新用户界面——简单、清晰、有效,尽可能简化浏览器的外型元素和操作步骤——希望用户才能最大限度的“忽略”IE9的“存在”,而将注意力全部沉溺在精彩的网路内容当中。
ie9全新用户界面截图6
5、ie9全面支持最新网路标准
IE9支持最新的HTML5、CSS3、SVG和DOM L2&L3,你可以充分利用这种技术诠释你的网路创意,不必再针对不同浏览器编撰不同代码,大幅度增加你的开发时间和难度。
6、ie9整合更多开发工具
与其他浏览器相比,IE9外置了更多强悍的开发人员工具——包括JavaScript剖析工具、CSS编辑器和新的网路剖析器等。这些工具当你须要时就在手边,方便你进行开发和调试,实现与IE9的全方位整合。
7、ie9先进的网路开发技术
IE9提供了一系列先进技术,如D2D DirectX图形构架和图形、色彩解码器等,助你实现高清视频和多媒体交互。搭配GPU图形硬件加速,让画面质量和流畅性达到质的提高,为你搭建一个更好的平台,来为你的用户诠释前所未有的视觉、听觉体验。
截图7
8、ie9是网站,也是一个Windows 7程序
利用最新的Windows应用程序插口(API),开发者才能使用JavaScript来定义键盘右键快捷菜单、任务栏缩略图、跳转列表项和触控等功能,使其与Windows 7操作系统完美整合,带来新的浏览形式,让用户体验上升到新的高度。
9、ie9兼容性模式
IE9使开发人员来选择浏览站点时所使用的模式,其中包括IE9标准模式、IE8文档模式、 兼容视图模式(IE7)或Quirks模式 (IE5)。如果用户单击兼容模式按键,网站将以开发者事先指定的模式或兼容视图模式(IE7)运行,保证向后的兼容性和网站升级时的灵活性。
截图8
常见问题
IE9支持哪些系统?
可用于全部 Windows Vista 和 Windows 7 版本。
怎么调整IE9 使用兼容模式?
1、打开IE浏览器,点击“工具”选项,选择“兼容性视图设置”选项。
2、进入兼容性视图设置以后,填入所须要设置兼容模式的网址,点击添加,最后点击关掉即可。
3、重新打开经过设置以后的网页,会听到地址栏前面有一个象破碎纸片一样的图标,说明兼容模式早已设置成功,在工具的下拉菜单也同样可以看见在兼容模式上面也就对勾,说明网页的兼容模式早已设置成功。
更新日志
修复部份bug
利用Python网络爬虫实现对网易云音乐歌词爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2020-08-11 10:45
找到正确的URL,获取源码;
利用bs4解析源码,获取歌曲名和歌曲ID;
调用网易云歌曲API,获取歌词;
将歌词写入文件,并存入本地。
本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程!
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有#号的。废话不多说,直接上代码。
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。
获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在
标签下,如下图所示:
接下来我们借助美丽的汤来获取目标信息,直接上代码,如下图:
此处要注意获取ID的时侯须要对link进行切块处理,得到的数字便是歌曲的ID;另外,歌曲名是通过get_text方式获取到的,最后借助zip函数将歌曲名和ID一一对应并进行返回。
得到ID以后便可以步入到内页获取歌词了,但是URL还是不给力,如下图:
虽然我们可以明白的看见网页上的白纸黑字呈现的歌词信息,但是我们在该URL下却未能获取到歌词信息。小编通过抓包,找到了歌词的URL,发现其是POST恳求还有一大堆看不懂的data,总之这个URL是不能为我们效力。那该点解呢?
莫慌,小编找到了网易云音乐的API,只要把歌曲的ID置于API链接上便可以获取到歌词了,代码如下:
在API中歌词信息是以json格式加载的,所以须要借助json将其进行序列化解析下来,并配合正则表达式进行清洗歌词,如果不用正则表达式进行清洗的话,得到原创的数据如下所示(此处以赵雷的歌曲《成都》为例):
很明显歌词上面有歌词呈现的时间,对于我们来说其属于杂质信息,因此须要借助正则表达式进行匹配。诚然,正则表达式并不是惟一的方式,小伙伴们也可以采取切块的形式或则其他方式进行数据清洗,在此就不赘言了。
得到歌词以后便将其写入到文件中去,并存入到本地文件中,代码如下:
现在只要我们运行程序,输入歌手的ID以后,程序将手动把该歌手的所唱歌曲的歌词抓取出来,并存到本地中。如本例中赵雷的ID是6731,输入数字6731以后,赵雷的歌词将会被抓取到,如下图所示:
之后我们就可以在脚本程序的同一目录下找到生成的歌词文本,歌词就被顺利的爬取出来了。
相信你们对网易云歌词爬取早已有了一定的认识了,不过easier said than down,小编建议你们动手亲自敲一下代码,在实践中你会学的更快,学的更多的。
这篇文章教会你们怎么采集网易云歌词,那网易云歌曲怎么采集呢?且听小编下回分解~~ 查看全部
本文的总体思路如下:
找到正确的URL,获取源码;
利用bs4解析源码,获取歌曲名和歌曲ID;
调用网易云歌曲API,获取歌词;
将歌词写入文件,并存入本地。
本文的目的是获取网易云音乐的歌词,并将歌词存入到本地文件。整体的效果图如下所示:
本文以摇滚歌神赵雷为数据采集对象,专门采集他的歌曲歌词,其他歌手的歌词采集方式可以类推,下图展示的是《成都》歌词。
在这里相信有许多想要学习Python的朋友,大家可以+下Python学习分享裤:叁零肆+零伍零+柒玖玖,即可免费发放一整套系统的 Python学习教程!
一般来说,网页上显示的URL就可以写在程序中,运行程序以后就可以采集到我们想要的网页源码。But在网易云音乐网站中,这条路行不通,因为网页中的URL是个假URL,真实的URL中是没有#号的。废话不多说,直接上代码。
本文借助requests、bs4、json和re模块来采集网易云音乐歌词,记得在程序中添加headers和反盗链referer以模拟浏览器,防止被网站拒绝访问。这里的get_html方式专门用于获取源码,通常我们也要做异常处理,未雨绸缪。
获取到网页源码以后,分析源码,发现歌曲的名子和ID藏的太深,纵里寻她千百度,发现她在源码的294行,藏在
标签下,如下图所示:
接下来我们借助美丽的汤来获取目标信息,直接上代码,如下图:
此处要注意获取ID的时侯须要对link进行切块处理,得到的数字便是歌曲的ID;另外,歌曲名是通过get_text方式获取到的,最后借助zip函数将歌曲名和ID一一对应并进行返回。
得到ID以后便可以步入到内页获取歌词了,但是URL还是不给力,如下图:
虽然我们可以明白的看见网页上的白纸黑字呈现的歌词信息,但是我们在该URL下却未能获取到歌词信息。小编通过抓包,找到了歌词的URL,发现其是POST恳求还有一大堆看不懂的data,总之这个URL是不能为我们效力。那该点解呢?
莫慌,小编找到了网易云音乐的API,只要把歌曲的ID置于API链接上便可以获取到歌词了,代码如下:
在API中歌词信息是以json格式加载的,所以须要借助json将其进行序列化解析下来,并配合正则表达式进行清洗歌词,如果不用正则表达式进行清洗的话,得到原创的数据如下所示(此处以赵雷的歌曲《成都》为例):
很明显歌词上面有歌词呈现的时间,对于我们来说其属于杂质信息,因此须要借助正则表达式进行匹配。诚然,正则表达式并不是惟一的方式,小伙伴们也可以采取切块的形式或则其他方式进行数据清洗,在此就不赘言了。
得到歌词以后便将其写入到文件中去,并存入到本地文件中,代码如下:
现在只要我们运行程序,输入歌手的ID以后,程序将手动把该歌手的所唱歌曲的歌词抓取出来,并存到本地中。如本例中赵雷的ID是6731,输入数字6731以后,赵雷的歌词将会被抓取到,如下图所示:
之后我们就可以在脚本程序的同一目录下找到生成的歌词文本,歌词就被顺利的爬取出来了。
相信你们对网易云歌词爬取早已有了一定的认识了,不过easier said than down,小编建议你们动手亲自敲一下代码,在实践中你会学的更快,学的更多的。
这篇文章教会你们怎么采集网易云歌词,那网易云歌曲怎么采集呢?且听小编下回分解~~
报表开发利器:phantomjs生成PDF ,Echarts图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2020-08-10 10:26
导航:
一. 关于phantomjs1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作须要程序设计实现。
(2)提供javascript API接口,即通过编撰js程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作,从而解决了先前c/c++能够比较好的基于webkit开发优质采集器的限制。
(3)提供windows、linux、mac等不同os的安装使用包,也就是说可以在不同平台上二次开发采集项目或是手动项目测试等工作。
1.2 phantomjs常用API介绍
常用外置几大对象
常用API
注意事项
使用总结 : 主要是java se+js+phantomjs的应用,
1.3 使用phantomjs 能做哪些?
生成的PDF基本还原了其原先的款式,图片和文字分开了,并非直接截图;有生成PDF相关需求的,可以思索生成使用phantomjs 怎样实现功能;本人有通过Html模板,生成Html页面,然后将此页面上传至FastDfs服务器,然后通过返回的url直接生成此pdf,即完成了html页面一致的pdf生成功能;
二. Windows下安装 phantomjs2.1 概述2.1 下载并安装phantomjs测试是否安装成功:三. Linux下 安装 phantomjs3.1 概述3.2 安装过程如下:
进入上面后可执行js命令,如果须要退出,则按 Ctrl+C 强制退出
解决英文乱码(可选,可碰到此问题再行解决)正常示例:(Windows上显示正常如图:)错误示例:(Linux上显示英文乱码如图:)解决办法:在Linux中执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只是英文显示下来了,数字还是会显示空格,如果出现数字显示空格,则把windows所有字体导出Linux中,见下边。
导入字体:四. 利用Phantomjs生成Echarts图片4.1 概述: 在Linux 下:
WIndows与Linux环境下的区别:①配置好环境变量,因为phantomjs的启动方法,windows是执行exe文件,linux不是,所以配好环境变量后java在本机测试与在Linux下无需做任何更改;②Phantomjs执行生成Echarts图片时,需要引用到 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 以及生成Echarts的js文件。这些js须要引用到,而当布署在Linux中时,生成的js文件在jar包中,不一定能读取到,我们可以通过代码将js文件复制生成到jar包同级目录,然后通过路径加载。路径加载可以用如下代码读取并生成:
~~~java
/* 将模板生成到指定的位置 判定文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty(“user.dir”) + “\echarts-all.js”);
if (!echartsfile.exists()) {
FileUtil.file2file(“js/echarts-all.js”, System.getProperty(“user.dir”) + “\echarts-all.js”);
}
~~~
4.2 笔者实现思路:第二步:整理思路:生成须要生成的Echarts的js代码:找到相关Echarts图片模板: Echarts官网使用Framework以及其他技术:将模板+数据生成一个最终js文件;使用Framework为例:将其他的三个js文件放在其他位置上,博主的做法是将这三个放在jar包目录内,但是会存在phantomjs难以读取和执行的情况(就是除开phantomjs的代码可以读取到内容,但phantomjs的执行难以引用读取)。所以博主采取的是先读取下来,再讲到jar包外边进行引用;这样通过路径,在Linux下也可以读取了;读取代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
重点代码:System.getProperty(“user.dir”) 为 Windows下或则Linux下的当前路径 ,具体可百度其用法。
结合早已有的 echarts-convert.js 等文件+ 生成好的带数据的Echarts.js 文件 和 Demo示例代码可以生成出Echarts图片了;我们可以将Echart图片再上传至Fastdfs等图片服务器,就可以领到网路图片url了;当然最后一步视业务需求而定;五. 利用Phantomjs生成PDF文档(HTML转为PDF)5.1 概述5.2 生成原理5.3 扩展思路六.利用Phantomjs+Poi.tl 生成Word文档6.1 概述6.2 思路 查看全部
报表开发利器:phantomjs生成网页PDF ,Echarts报表实战
导航:
一. 关于phantomjs1.1 什么是phantomjs?
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作须要程序设计实现。
(2)提供javascript API接口,即通过编撰js程序可以直接与webkit内核交互,在此之上可以结合java语言等,通过java调用js等相关操作,从而解决了先前c/c++能够比较好的基于webkit开发优质采集器的限制。
(3)提供windows、linux、mac等不同os的安装使用包,也就是说可以在不同平台上二次开发采集项目或是手动项目测试等工作。
1.2 phantomjs常用API介绍
常用外置几大对象
常用API
注意事项
使用总结 : 主要是java se+js+phantomjs的应用,
1.3 使用phantomjs 能做哪些?
生成的PDF基本还原了其原先的款式,图片和文字分开了,并非直接截图;有生成PDF相关需求的,可以思索生成使用phantomjs 怎样实现功能;本人有通过Html模板,生成Html页面,然后将此页面上传至FastDfs服务器,然后通过返回的url直接生成此pdf,即完成了html页面一致的pdf生成功能;
二. Windows下安装 phantomjs2.1 概述2.1 下载并安装phantomjs测试是否安装成功:三. Linux下 安装 phantomjs3.1 概述3.2 安装过程如下:
进入上面后可执行js命令,如果须要退出,则按 Ctrl+C 强制退出
解决英文乱码(可选,可碰到此问题再行解决)正常示例:(Windows上显示正常如图:)错误示例:(Linux上显示英文乱码如图:)解决办法:在Linux中执行命令:
yum install bitmap-fonts bitmap-fonts-cjk
执行此命令后,可能只是英文显示下来了,数字还是会显示空格,如果出现数字显示空格,则把windows所有字体导出Linux中,见下边。
导入字体:四. 利用Phantomjs生成Echarts图片4.1 概述: 在Linux 下:
WIndows与Linux环境下的区别:①配置好环境变量,因为phantomjs的启动方法,windows是执行exe文件,linux不是,所以配好环境变量后java在本机测试与在Linux下无需做任何更改;②Phantomjs执行生成Echarts图片时,需要引用到 jquery.1.9.1.min.js ,echarts-convert.js, echarts.min.js 以及生成Echarts的js文件。这些js须要引用到,而当布署在Linux中时,生成的js文件在jar包中,不一定能读取到,我们可以通过代码将js文件复制生成到jar包同级目录,然后通过路径加载。路径加载可以用如下代码读取并生成:
~~~java
/* 将模板生成到指定的位置 判定文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty(“user.dir”) + “\echarts-all.js”);
if (!echartsfile.exists()) {
FileUtil.file2file(“js/echarts-all.js”, System.getProperty(“user.dir”) + “\echarts-all.js”);
}
~~~
4.2 笔者实现思路:第二步:整理思路:生成须要生成的Echarts的js代码:找到相关Echarts图片模板: Echarts官网使用Framework以及其他技术:将模板+数据生成一个最终js文件;使用Framework为例:将其他的三个js文件放在其他位置上,博主的做法是将这三个放在jar包目录内,但是会存在phantomjs难以读取和执行的情况(就是除开phantomjs的代码可以读取到内容,但phantomjs的执行难以引用读取)。所以博主采取的是先读取下来,再讲到jar包外边进行引用;这样通过路径,在Linux下也可以读取了;读取代码示例:
/* 将模板生成到指定的位置 判断文件是否存在,如果不存在则创建 */
File echartsfile = new File(System.getProperty("user.dir") + "\\echarts-all.js");
if (!echartsfile.exists()) {
FileUtil.file2file("js/echarts-all.js", System.getProperty("user.dir") + "\\echarts-all.js");
}
File jsfile = new File(outPathAndName);
if (!jsfile.exists()) {
FileUtil.string2File(outPathAndName, echartTemplate.getFileContent()); // 将js文件生成到指定的位置
}
File convertfile = new File(System.getProperty("user.dir") + "\\echarts-convert.js");
String echartsPath = System.getProperty("user.dir") + "\\echarts-convert.js";
if (!convertfile.exists()) {
FileUtil.file2file("js/echarts-convert.js", echartsPath);
}
File jqueryfile = new File(System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
if (!jqueryfile.exists()) {
FileUtil.file2file("js/jquery.1.9.1.min.js", System.getProperty("user.dir") + "\\jquery.1.9.1.min.js");
}
重点代码:System.getProperty(“user.dir”) 为 Windows下或则Linux下的当前路径 ,具体可百度其用法。
结合早已有的 echarts-convert.js 等文件+ 生成好的带数据的Echarts.js 文件 和 Demo示例代码可以生成出Echarts图片了;我们可以将Echart图片再上传至Fastdfs等图片服务器,就可以领到网路图片url了;当然最后一步视业务需求而定;五. 利用Phantomjs生成PDF文档(HTML转为PDF)5.1 概述5.2 生成原理5.3 扩展思路六.利用Phantomjs+Poi.tl 生成Word文档6.1 概述6.2 思路
Python丨scrapy爬取某急聘网手机APP发布信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-10 08:51
过段时间要开始找新工作了,爬取一些岗位信息来剖析一下吧。目前主流的急聘网站包括前程无忧、智联、BOSS直聘、拉勾等等。有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位信息,其他急聘网站后续再更新补上……
所用工具(技术):
IDE:pycharm
Database:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息抓取:scrapy外置的Selector
Python学习资料或则须要代码、视频加Python学习群:960410445
2 APP抓包剖析
我们先来体会一下前程无忧的APP,当我们在首页输入搜索关键词点击搜索然后APP都会跳转到新的页面,这个页面我们暂且称之为一级页面。一级页面展示着我们所想找查看的所有岗位列表。
当我们点击其中一条岗位信息后,APP又会跳转到一个新的页面,我把这个页面称之为二级页面。二级页面有我们须要的所有岗位信息,也是我们的主要采集目前页面。
分析完页面然后,接下来就可以对前程无忧手机APP的恳求(request)和回复(response)进行剖析了。本文所使用的抓包工具为Fiddler。
本文的目的是抓取前程无忧APP上搜索某个关键词时返回的所有急聘信息,本文以“Python”为例进行说明。APP上操作如下图所示,输入“Python”关键词后,点击搜索,随后Fiddler抓取到4个数据包,如下所示:
事实上,当听到第2和第4个数据包的图标时,我们就应当会心一笑。这两个图标分别代表传输的是json和xml格式的数据,而好多web插口就是以这两种格式来传输数据的,手机APP也不列外。选中第2个数据包,然后在右边主窗口中查看,发现第二个数据包并没有我们想要的数据。在瞧瞧第4个数据包,选中后在右边窗体,可以看见以下内容:
右下角的内容不就是在手机上看见的急聘信息吗,还是以XML的格式来传输的。我们将这个数据包的链接复制出来:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
我们爬取的时侯肯定不会只爬取一个页面的信息,我们在APP上把页面往下滑,看看Fiddler会抓取到哪些数据包。看右图:
手机屏幕往下滑动后,Fiddler又抓取到两个数据包,而且第二个数据包选中看再度发觉就是APP上新刷新的急聘信息,再把这个数据包的url链接复制出来:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
接下来,我们比对一下前后两个链接,分析其中的优缺。可以看出,除了“pageno”这个属性外,其他都一样。没错,就是在里面标红的地方。第一个数据包链接中pageno值为1,第二个pageno值为2,这下翻页的规律就一目了然了。
既然我们早已找到了APP翻页的恳求链接规律,我们就可以在爬虫中通过循环形参给pageno,实现模拟翻页的功能。
我们再尝试一下改变搜索的关键词瞧瞧链接有哪些变化,以“java”为关键词,抓取到的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比后发觉,链接中也只有keyword的值不一样,而且值就是我们在自己输入的关键词。所以在爬虫中,我们完全可以通过字符串拼接来实现输入关键词模拟,从而采集不同类型的急聘信息。同理,你可以对求职地点等信息的规律进行找寻,本文不在表述。
解决翻页功能然后,我们再去探究一下数据包中XML上面的内容。我们把里面的第一个链接复制到浏览器上打开,打开后画面如下:
这样看着就舒服多了。通过仔细观察我们会发觉,APP上每一条急聘信息都对应着一个标签,每一个上面都有一个标签,里面有一个id标示着一个岗位。例如前面第一条岗位是109384390,第二条岗位是109381483,记住这个id,后面会用到。
事实上,接下来,我们点击第一条急聘信息,进入二级页面。这时候,Fiddler会采集到APP刚发送的数据包,点击其中的xml数据包,发现就是APP上刚刷新的页面信息。我们将数据包的url链接复制下来:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
如法炮制点开一级页面中列表的第二条急聘,然后从Fiddler中复制出对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比前面两个链接,发现规律没?没错,就是jobid不同,其他都一样。这个jobid就是我们在一级页面的xml中发觉的jobid。由此,我们就可以在一级页面中抓取出jobid来构造出二级页面的url链接,然后采集出我们所须要的所有信息。整个爬虫逻辑就清晰了:
构造一级页面初始url->采集jobid->构造二级页面url->抓取岗位信息->通过循环模拟翻页获取下一页面的url。
好了,分析工作完成了,开始动手写爬虫了。
3 编写爬虫
本文编撰前程无忧手机APP网路爬虫用的是Scrapy框架,下载好scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider就是我们本次爬虫项目的项目名称,在项目名前面有一个“.”,这个点可有可无,区别是在当前文件之间创建项目还是创建一个与项目名同名的文件之后在文件内创建项目。
创建好项目后,继续创建一个爬虫,专用于爬取前程无忧发布的急聘信息。创建爬虫命名如下:
scrapy genspider qcwySpider
注意:如果你在创建爬虫项目的时侯没有在项目名前面加“.”,请先步入项目文件夹以后再运行命令创建爬虫。
通过pycharm打开刚创建好的爬虫项目,左侧目录树结构如下:
在开始一切爬虫工作之前,先打开settings.py文件,然后取消“ROBOTSTXT_OBEY = False”这一行的注释,并将其值改为False。
# Obey robots.txt rulesROBOTSTXT_OBEY = False
完成上述更改后,打开spiders包下的qcwySpider.py,初始代码如下:
这是scrapy为我们搭好的框架,我们只须要在这个基础起来建立我们的爬虫即可。
首先我们须要在类中添加一些属性,例如搜索关键词keyword、起始页、想要爬取得最大页数,同时也须要设置headers进行简单的反爬。另外,starturl也须要重新设置为第一页的url。更改后代码如下:
然后开始编撰parse方式爬取一级页面,在一级页面中,我们主要逻辑是通过循环实现APP中屏幕下降更新,我们用前面代码中的current_page来标示当前页页脚,每次循环后,current_page加1,然后构造新的url,通过反弹parse方式爬取下一页。另外,我们还须要在parse方式中在一级页面中采集出jobid,并构造出二级页面的,回调实现二级页面信息采集的parse_job方式。parse方式代码如下:
为了便捷进行调试,我们在项目的jobSpider目录下创建一个main.py文件,用于启动爬虫,每次启动爬虫时,运行该文件即可。内容如下:
二级页面信息采集功能在parse_job方式中实现,因为所有我们须要抓取的信息都在xml中,我们直接用scrapy自带的selector提取下来就可以了,不过在提取之前,我们须要先定义好Item拿来储存我们采集好的数据。打开items.py文件,编写一个Item类,输入以下代码:
上面每一个item都与一个xml标签对应,用于储存一条信息。在qcwyJobsItem类的最后,定义了一个do_insert方式,该方式用于生产将item中所有信息储存数据库的insert句子,之所以在items铁块中生成这个insert句子,是因为日后若果有了多个爬虫,有多个item类以后,在pipelines模块中,可以针对不同的item插入数据库,使本项目具有更强的可扩展性。你也可以将所有与插入数据库有关的代码都写在pipelines。
然后编撰parse_job方式:
完成上述代码后,信息采集部分就完成了。接下来继续写信息储存功能,这一功能在pipelines.py中完成。
编写完pipelines.py后,打开settings.py文件,将刚写好的MysqlTwistedPipline类配置到项目设置文件中:
顺便也把数据库配置好:
数据库配置你也可以之间嵌入到MysqlTwistedPipline类中,不过我习惯于把这种专属的数据库信息写在配置文件中。
最后,只差一步,建数据库、建数据表。部分表结构如下图所示:
完成上述所有内容以后,就可以运行爬虫开始采集数据了。采集的数据如下图所示:
4 总结
整个过程出来,感觉前程无忧网APP爬取要比网页爬取容易一些(似乎好多网站都这样)。回顾整个流程,其实代码中还有众多细节尚可改进建立,例如还可以在构造链接时加上求职地点等。本博文重在对整个爬虫过程的逻辑剖析和介绍APP的基本爬取方式,博文中省略了部份代码,若须要完整代码,请在我的github中获取,后续将继续更新其他急聘网站的爬虫。返回搜狐,查看更多 查看全部
1 引言
过段时间要开始找新工作了,爬取一些岗位信息来剖析一下吧。目前主流的急聘网站包括前程无忧、智联、BOSS直聘、拉勾等等。有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位信息,其他急聘网站后续再更新补上……
所用工具(技术):
IDE:pycharm
Database:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息抓取:scrapy外置的Selector
Python学习资料或则须要代码、视频加Python学习群:960410445
2 APP抓包剖析
我们先来体会一下前程无忧的APP,当我们在首页输入搜索关键词点击搜索然后APP都会跳转到新的页面,这个页面我们暂且称之为一级页面。一级页面展示着我们所想找查看的所有岗位列表。
当我们点击其中一条岗位信息后,APP又会跳转到一个新的页面,我把这个页面称之为二级页面。二级页面有我们须要的所有岗位信息,也是我们的主要采集目前页面。
分析完页面然后,接下来就可以对前程无忧手机APP的恳求(request)和回复(response)进行剖析了。本文所使用的抓包工具为Fiddler。
本文的目的是抓取前程无忧APP上搜索某个关键词时返回的所有急聘信息,本文以“Python”为例进行说明。APP上操作如下图所示,输入“Python”关键词后,点击搜索,随后Fiddler抓取到4个数据包,如下所示:
事实上,当听到第2和第4个数据包的图标时,我们就应当会心一笑。这两个图标分别代表传输的是json和xml格式的数据,而好多web插口就是以这两种格式来传输数据的,手机APP也不列外。选中第2个数据包,然后在右边主窗口中查看,发现第二个数据包并没有我们想要的数据。在瞧瞧第4个数据包,选中后在右边窗体,可以看见以下内容:
右下角的内容不就是在手机上看见的急聘信息吗,还是以XML的格式来传输的。我们将这个数据包的链接复制出来:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
我们爬取的时侯肯定不会只爬取一个页面的信息,我们在APP上把页面往下滑,看看Fiddler会抓取到哪些数据包。看右图:
手机屏幕往下滑动后,Fiddler又抓取到两个数据包,而且第二个数据包选中看再度发觉就是APP上新刷新的急聘信息,再把这个数据包的url链接复制出来:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
接下来,我们比对一下前后两个链接,分析其中的优缺。可以看出,除了“pageno”这个属性外,其他都一样。没错,就是在里面标红的地方。第一个数据包链接中pageno值为1,第二个pageno值为2,这下翻页的规律就一目了然了。
既然我们早已找到了APP翻页的恳求链接规律,我们就可以在爬虫中通过循环形参给pageno,实现模拟翻页的功能。
我们再尝试一下改变搜索的关键词瞧瞧链接有哪些变化,以“java”为关键词,抓取到的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比后发觉,链接中也只有keyword的值不一样,而且值就是我们在自己输入的关键词。所以在爬虫中,我们完全可以通过字符串拼接来实现输入关键词模拟,从而采集不同类型的急聘信息。同理,你可以对求职地点等信息的规律进行找寻,本文不在表述。
解决翻页功能然后,我们再去探究一下数据包中XML上面的内容。我们把里面的第一个链接复制到浏览器上打开,打开后画面如下:
这样看着就舒服多了。通过仔细观察我们会发觉,APP上每一条急聘信息都对应着一个标签,每一个上面都有一个标签,里面有一个id标示着一个岗位。例如前面第一条岗位是109384390,第二条岗位是109381483,记住这个id,后面会用到。
事实上,接下来,我们点击第一条急聘信息,进入二级页面。这时候,Fiddler会采集到APP刚发送的数据包,点击其中的xml数据包,发现就是APP上刚刷新的页面信息。我们将数据包的url链接复制下来:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
如法炮制点开一级页面中列表的第二条急聘,然后从Fiddler中复制出对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0
对比前面两个链接,发现规律没?没错,就是jobid不同,其他都一样。这个jobid就是我们在一级页面的xml中发觉的jobid。由此,我们就可以在一级页面中抓取出jobid来构造出二级页面的url链接,然后采集出我们所须要的所有信息。整个爬虫逻辑就清晰了:
构造一级页面初始url->采集jobid->构造二级页面url->抓取岗位信息->通过循环模拟翻页获取下一页面的url。
好了,分析工作完成了,开始动手写爬虫了。
3 编写爬虫
本文编撰前程无忧手机APP网路爬虫用的是Scrapy框架,下载好scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider就是我们本次爬虫项目的项目名称,在项目名前面有一个“.”,这个点可有可无,区别是在当前文件之间创建项目还是创建一个与项目名同名的文件之后在文件内创建项目。
创建好项目后,继续创建一个爬虫,专用于爬取前程无忧发布的急聘信息。创建爬虫命名如下:
scrapy genspider qcwySpider
注意:如果你在创建爬虫项目的时侯没有在项目名前面加“.”,请先步入项目文件夹以后再运行命令创建爬虫。
通过pycharm打开刚创建好的爬虫项目,左侧目录树结构如下:
在开始一切爬虫工作之前,先打开settings.py文件,然后取消“ROBOTSTXT_OBEY = False”这一行的注释,并将其值改为False。
# Obey robots.txt rulesROBOTSTXT_OBEY = False
完成上述更改后,打开spiders包下的qcwySpider.py,初始代码如下:
这是scrapy为我们搭好的框架,我们只须要在这个基础起来建立我们的爬虫即可。
首先我们须要在类中添加一些属性,例如搜索关键词keyword、起始页、想要爬取得最大页数,同时也须要设置headers进行简单的反爬。另外,starturl也须要重新设置为第一页的url。更改后代码如下:
然后开始编撰parse方式爬取一级页面,在一级页面中,我们主要逻辑是通过循环实现APP中屏幕下降更新,我们用前面代码中的current_page来标示当前页页脚,每次循环后,current_page加1,然后构造新的url,通过反弹parse方式爬取下一页。另外,我们还须要在parse方式中在一级页面中采集出jobid,并构造出二级页面的,回调实现二级页面信息采集的parse_job方式。parse方式代码如下:
为了便捷进行调试,我们在项目的jobSpider目录下创建一个main.py文件,用于启动爬虫,每次启动爬虫时,运行该文件即可。内容如下:
二级页面信息采集功能在parse_job方式中实现,因为所有我们须要抓取的信息都在xml中,我们直接用scrapy自带的selector提取下来就可以了,不过在提取之前,我们须要先定义好Item拿来储存我们采集好的数据。打开items.py文件,编写一个Item类,输入以下代码:
上面每一个item都与一个xml标签对应,用于储存一条信息。在qcwyJobsItem类的最后,定义了一个do_insert方式,该方式用于生产将item中所有信息储存数据库的insert句子,之所以在items铁块中生成这个insert句子,是因为日后若果有了多个爬虫,有多个item类以后,在pipelines模块中,可以针对不同的item插入数据库,使本项目具有更强的可扩展性。你也可以将所有与插入数据库有关的代码都写在pipelines。
然后编撰parse_job方式:
完成上述代码后,信息采集部分就完成了。接下来继续写信息储存功能,这一功能在pipelines.py中完成。
编写完pipelines.py后,打开settings.py文件,将刚写好的MysqlTwistedPipline类配置到项目设置文件中:
顺便也把数据库配置好:
数据库配置你也可以之间嵌入到MysqlTwistedPipline类中,不过我习惯于把这种专属的数据库信息写在配置文件中。
最后,只差一步,建数据库、建数据表。部分表结构如下图所示:
完成上述所有内容以后,就可以运行爬虫开始采集数据了。采集的数据如下图所示:
4 总结
整个过程出来,感觉前程无忧网APP爬取要比网页爬取容易一些(似乎好多网站都这样)。回顾整个流程,其实代码中还有众多细节尚可改进建立,例如还可以在构造链接时加上求职地点等。本博文重在对整个爬虫过程的逻辑剖析和介绍APP的基本爬取方式,博文中省略了部份代码,若须要完整代码,请在我的github中获取,后续将继续更新其他急聘网站的爬虫。返回搜狐,查看更多
Python爬虫 百度地图搜索数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-10 06:51
趁空闲时间用Python来简单剖析制做一个简单的爬虫小脚本。
三个参数主要考虑的,一个是地理位置,一个是关键词,一个是页数。在抓包的过程中对“页数”这个参数苦恼了好久,一直没看明白,后面仔细对比才找到门道。
先谈谈地理位置:
需要按指定地址搜索的时侯会须要一个叫City_Code 的参数,输入搜索的时侯可以爬取到,输入后有上述的几种情况,不存在会强制要求你重新输入,如果输入“广东”就会定位在广州省内,不过实际搜索关键词的时侯页面并不会显示海南所有的结果,而是须要你做二次选择。
在百度的开发平台有城市代码可以直接下载,不过并不完整,有须要的可以自行下载查阅
parameter = {
"newmap": "1",
"reqflag": "pcmap",
"biz": "1",
"from": "webmap",
"da_par": "direct",
"pcevaname": "pc4.1",
"qt": "con",
"c": City_Code, # 城市代码
"wd": key_word, # 搜索关键词
"wd2": "",
"pn": page, # 页数
"nn": page * 10,
"db": "0",
"sug": "0",
"addr": "0",
"da_src": "pcmappg.poi.page",
"on_gel": "1",
"src": "7",
"gr": "3",
"l": "12",
"tn": "B_NORMAL_MAP",
# "u_loc": "12621219.536556,2630747.285024",
"ie": "utf-8",
# "b": "(11845157.18,3047692.2;11922085.18,3073932.2)", #这个应该是地理位置坐标,可以忽略
"t": "1468896652886"
}
页数的参数有两个,一个是"pn",另外一个是"nn",没搞明白三者之间的关系;
pn=0,nn=0 第一页
pn=1,nn=10 第二页
pn=2,nn=20 第三页
pn=3,nn=30 第四页
"nn"参数在调试过程中试过固定的话并且返回的数据是一样的。
<p> url = 'http://map.baidu.com/'
htm = requests.get(url, params=parameter)
htm = htm.text.encode('latin-1').decode('unicode_escape') # 转码
pattern = r'(? 查看全部
之前在网上听到有留传VBA编撰的版本,不过参数固定,通用性并不强.
趁空闲时间用Python来简单剖析制做一个简单的爬虫小脚本。
三个参数主要考虑的,一个是地理位置,一个是关键词,一个是页数。在抓包的过程中对“页数”这个参数苦恼了好久,一直没看明白,后面仔细对比才找到门道。
先谈谈地理位置:
需要按指定地址搜索的时侯会须要一个叫City_Code 的参数,输入搜索的时侯可以爬取到,输入后有上述的几种情况,不存在会强制要求你重新输入,如果输入“广东”就会定位在广州省内,不过实际搜索关键词的时侯页面并不会显示海南所有的结果,而是须要你做二次选择。
在百度的开发平台有城市代码可以直接下载,不过并不完整,有须要的可以自行下载查阅
parameter = {
"newmap": "1",
"reqflag": "pcmap",
"biz": "1",
"from": "webmap",
"da_par": "direct",
"pcevaname": "pc4.1",
"qt": "con",
"c": City_Code, # 城市代码
"wd": key_word, # 搜索关键词
"wd2": "",
"pn": page, # 页数
"nn": page * 10,
"db": "0",
"sug": "0",
"addr": "0",
"da_src": "pcmappg.poi.page",
"on_gel": "1",
"src": "7",
"gr": "3",
"l": "12",
"tn": "B_NORMAL_MAP",
# "u_loc": "12621219.536556,2630747.285024",
"ie": "utf-8",
# "b": "(11845157.18,3047692.2;11922085.18,3073932.2)", #这个应该是地理位置坐标,可以忽略
"t": "1468896652886"
}
页数的参数有两个,一个是"pn",另外一个是"nn",没搞明白三者之间的关系;
pn=0,nn=0 第一页
pn=1,nn=10 第二页
pn=2,nn=20 第三页
pn=3,nn=30 第四页
"nn"参数在调试过程中试过固定的话并且返回的数据是一样的。
<p> url = 'http://map.baidu.com/'
htm = requests.get(url, params=parameter)
htm = htm.text.encode('latin-1').decode('unicode_escape') # 转码
pattern = r'(?
新榜陌陌文章抓取客户端(APSpider)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2020-08-10 06:25
这是曾经给新媒体营运朋友写的爬虫软件,用了一段时间就没用了(唉、气死我了)。
目前只抓取了新榜的日榜(周榜、月榜类似,换下地址即可)下,各行业的前50个公众号下的7天热门文章和最新发布文章
如下所示:
技术构架:nw.jsjqueryelement-ui
为什么选用nw.js呢?嗯,先入为主吧,electron也很不错(改下入口即可使用),为什么不用大名鼎鼎的python呢?爬虫框架而且一堆堆,还是个人习惯使然,用惯了js,操作网页简直得心应手,天生绝配!在此并不证实python,个人也比较喜欢(最近在研究深度学习架构),只是认为爬这种网页,还用不着它。
有一个关键点,在网页中,想操作iframe中的网页,是不容许跨域的,而nw.js容许这样操作,真是好啊!!!
安装步骤下载nw.js ,根据自己系统下载相应版本即可,官网: ,若自己须要二次开发,请下载SDK版本,方可开启debug,使用方式详见官网,不再探讨克隆APSpider,复制到nw.js目录,启动cmd,打开到当前目录,执行 npm install 安装依赖启动nw.exe 就可以使用啦使用说明考虑完整性,本客户端在读取到公众号列表及文章列表时,直接储存在article下的目录文件中,若须要将数据储存至数据库,请更改assest\utils\common.js中的Ap.request.ajax方式,将log函数注释,将下边被注释的代码恢复即可,然后在app\config.js中配置pushStateAPI(即前端接收数据API)为自己的数据插口即可因为新榜在公众号详尽页面设置了登陆权限(如:),
只有登陆后可访问,并且获取公众号文章的插口: ,
也是带了安全校准数组,所以登陆是必须要走的过程,所以点击登陆后,程序打开登陆页面,并获取二维码,如图:
用自己的陌陌扫一扫,授权登陆即可,程序手动步入公众号列表:
选择行业,点击开始即可,程序将获取所选行业下公众号的热门文章及最新发布文章,并储存至文件中
最初的版本是一键获取全部行业的文章,后面想想,还是自己想获取什么行业的就获取什么行业的
这是我的后台疗效:
其他新榜的所有ajax都带有安全校准数组和cookie,cookie倒是好办,登录后获取cookie储存上去,带到ajax的恳求头中即可,至于校准数组,着实费了一些时间,这个不再这儿阐述破解方式,有时间我会在csdn中写写破解的思路。关键词搜索还没做完,有时间补上。原本计划把微博、简书等一并爬了,忙于其他事务,就落下了。非常谢谢您的支持
撸码不易,如果对你有所帮助,欢迎您的赞赏!微信赞赏码: 查看全部
源码下载请至
这是曾经给新媒体营运朋友写的爬虫软件,用了一段时间就没用了(唉、气死我了)。
目前只抓取了新榜的日榜(周榜、月榜类似,换下地址即可)下,各行业的前50个公众号下的7天热门文章和最新发布文章
如下所示:
技术构架:nw.jsjqueryelement-ui
为什么选用nw.js呢?嗯,先入为主吧,electron也很不错(改下入口即可使用),为什么不用大名鼎鼎的python呢?爬虫框架而且一堆堆,还是个人习惯使然,用惯了js,操作网页简直得心应手,天生绝配!在此并不证实python,个人也比较喜欢(最近在研究深度学习架构),只是认为爬这种网页,还用不着它。
有一个关键点,在网页中,想操作iframe中的网页,是不容许跨域的,而nw.js容许这样操作,真是好啊!!!
安装步骤下载nw.js ,根据自己系统下载相应版本即可,官网: ,若自己须要二次开发,请下载SDK版本,方可开启debug,使用方式详见官网,不再探讨克隆APSpider,复制到nw.js目录,启动cmd,打开到当前目录,执行 npm install 安装依赖启动nw.exe 就可以使用啦使用说明考虑完整性,本客户端在读取到公众号列表及文章列表时,直接储存在article下的目录文件中,若须要将数据储存至数据库,请更改assest\utils\common.js中的Ap.request.ajax方式,将log函数注释,将下边被注释的代码恢复即可,然后在app\config.js中配置pushStateAPI(即前端接收数据API)为自己的数据插口即可因为新榜在公众号详尽页面设置了登陆权限(如:),
只有登陆后可访问,并且获取公众号文章的插口: ,
也是带了安全校准数组,所以登陆是必须要走的过程,所以点击登陆后,程序打开登陆页面,并获取二维码,如图:
用自己的陌陌扫一扫,授权登陆即可,程序手动步入公众号列表:
选择行业,点击开始即可,程序将获取所选行业下公众号的热门文章及最新发布文章,并储存至文件中
最初的版本是一键获取全部行业的文章,后面想想,还是自己想获取什么行业的就获取什么行业的
这是我的后台疗效:
其他新榜的所有ajax都带有安全校准数组和cookie,cookie倒是好办,登录后获取cookie储存上去,带到ajax的恳求头中即可,至于校准数组,着实费了一些时间,这个不再这儿阐述破解方式,有时间我会在csdn中写写破解的思路。关键词搜索还没做完,有时间补上。原本计划把微博、简书等一并爬了,忙于其他事务,就落下了。非常谢谢您的支持
撸码不易,如果对你有所帮助,欢迎您的赞赏!微信赞赏码:
SEM数据剖析读懂这两点,效果逐步提高!
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2020-08-10 02:22
3、如果上面两种因为各类缘由没办法短时间内学会的话,笔者建议你可以用最笨的方式,就是人工的去统计,笔者有一个顾客就是这样的,他对于每位咨询过他的顾客,都会主动寻问对方搜索的关键词,以及搜索的哪些平台,虽然太笨,但能坚持出来,也是挺实用的。
以上3种基本算是全部的统计模式了,还有一些通过付费数据监控平台进行数据回收的渠道,由于门槛有点高,我们暂时不聊。
第一种通常是你们比较常用的,图里也基本囊括了目前市面上所有的常见的统计平台,各有优劣势。
一般比较常用的是百度统计以及微软的Google Analytics,但是因为微软的Google Analytics须要翻墙,比较麻烦,所以我会推荐你们去使用百度统计,因为一个百度统计基本就可以满足百分之90的数据搜集需求,接下来我也会重点的围绕百度统计来给你们做详尽的解释。
首先百度统计统计逻辑分为以下两种:
1)页面转化应用场景:页面转化通常运用于以URL为统计目标的数据,直白一点讲就是假如你要统计的数据是一个不会改变的URL链接,那么页面转化就可以帮你实现。
比如,如果你觉得网站上的某个页面非常重要(如递交订单后出现的“购买成功”页面),到达了该页面表示访客完成了你的目标,你就可以将抵达该目标页面作为一种转化来统计。多用于电商类的网站做统计使用。
页面转化的设置步骤:
(官方标准)
2)事件转化;这一点笔者会重点的来给你们讲。首先,一般常规的顾客可以使用修改网站的源代码来统计转化目标的,源代码须要改成百度可以辨识的标准:“id=xxx”,找到转化目标而且可使百度成功追踪后,你就可以轻松的搜集到你的转化数据了。
如图:
这里可能有些同学要问了,如果我想统计目标是访问行为的话,怎么办?接下来笔者会详尽讲一下关于怎么来统计一些难以被普通统计代码跟踪PV的特殊的网站或页面。
在统计之前我们须要用到百度开放平台的一个合同:JS-API,JS-API通过在页面上布署js代码的方法,可以帮你搜集网站的各种业务数据(沟通数、点击数、转化数)
1、在布署JS前,你的网站不仅须要成安装百度统计代码,还须要新装一串JS-API代码,这里须要注意一下的是,JS-API代码必须安装在你统计页面的 head 标签上面,具体代码如下:
2、在我们进行进一步安装前,你须要明白风波转化的基本概念,不然以后的内容你会很难读懂。
首先风波转化统计的是访客在网站操作行为,这种行为可以被选取为转化目标,比如你是一个做视频网站的顾客,你希望通过风波转化来统计你每晚点击某一个视频“暂停”以及“播放”两个动作的数据,那么这些统计动作的目的,都可以运用JS-API来做实现,以此类推,你可以统计特别多的访客行为,当然这些行为就是转化目标了。
3、因为访客在网站的动作是一个行为,我们须要使代码去辨识他的行为,就必须为她们加上惟一的标示,只有正确的添加了标示,系统就会正确的捕捉到数据。具体如下:
事件链接中加入风波跟踪参数(以下引用官方解释)
_hmt.push(['_trackEvent', category, action, opt_label, opt_value]);
category:要监控的目标的类型名称,通常是同一组目标的名子,比如"视频"、"音乐"、"软件"、"游戏"等等。该项必选。
action:用户跟目标交互的行为,如"播放"、"暂停"、"下载"等等。该项必选。
opt_label:事件的一些额外信息,通常可以是歌曲的名称、软件的名称、链接的名称等等。该项可选。
opt_value:事件的一些数值信息,比如权重、时长、价格等等,在报表中可以见到其平均值等数据。该项可选。
举例说明:
假设页面A上有且只有一个下载链接,设置前后对比如下:
设置前:
设置完成后,我们就可以去百度统计设置转化目标了,你只须要在风波转化中的新增页面中降低你布署JS代码页面链接,就可以成功的获取数据了。
02 掌握数据剖析的思索维度
当我们成功布署了属于我们自己的数据回收通道后,我们就可以轻松的获取我们想要数据,但是好多时侯你们可能会认为,回收了这么多数据,我该如何去整理剖析了。
接下笔者会阐述领到数据后,我们须要怎样来做剖析,这里,我只提供思索方向,具体的我就不再赘言了,因为同样的数据,拿给不同的帐户,调整策略也不一定一样,还是那句话,数据剖析要结合你实际的企业情况以及产品特性和客户群特点。
首先,你须要通过以下几个思索维度来把数据立体化,这样可以帮你快速把你确定帐户问题:
1、账户数据层面,我们帐户是否诠释点击访问属于正常值?
思路解析:账户的数据直接决定了这个帐户大的方向是否是科学健康的,比如你的预算三天是100块,ACP为20块钱,一天可以形成5次点击,那么很容易的就可以晓得,账户大致的优化方向应当围绕着增加ACP来。
2、账户类有消费关键词有多少?其中有80%消费是被什么词消耗了,80%的点击集中在哪些词头上,占80%点击的关键词是什么,他们消耗占整体的消耗的多少?他们转化成本分别是多少?
思路解析:我们常常说的二八原则,其实是一个比较科学的理论,我这儿把二八原则做了更多的延展。
首先你帐户内的有消费词决定了你的广告面对的是一个多大的人群,然后帐户80%的消费决定了你的钱都花在哪些词头上,80%的点击决定了你实际订购的流量质量。
所以我们在做帐户数据剖析的时侯,这些一定要成比例原则的去做深入的剖析,可以帮我们快速的定位问题,这样可以指导我们以后的优化动作会在正确的公路上。
案例解析:
这是一个搬家顾客,客户每晚的预算80块钱,根据我们思路,来简单的剖析一下这个帐户的问题:
数据层面:单日消费80,ACP:16.40,可以显著的看下来,这个在极其严重的ACP和预算不符的情况,之后的优化方向也确定为增加ACP为主。
通过转化数据整理后我们可以看见,这个帐户有转化的词只有一个,转化成本为18.1,点击流量价钱很高且普遍和原语匹配程度不高,结合数据,我们可以将这个帐户的调整方案定为:ACP须要增加,暂定目标为同比增长50%,点击质量须要优化,做否词,以及修改部份不合理的匹配方法。 查看全部
文章链接:视频教程 | 追踪URL生成、批量添加、追踪数据剖析步骤解读
3、如果上面两种因为各类缘由没办法短时间内学会的话,笔者建议你可以用最笨的方式,就是人工的去统计,笔者有一个顾客就是这样的,他对于每位咨询过他的顾客,都会主动寻问对方搜索的关键词,以及搜索的哪些平台,虽然太笨,但能坚持出来,也是挺实用的。
以上3种基本算是全部的统计模式了,还有一些通过付费数据监控平台进行数据回收的渠道,由于门槛有点高,我们暂时不聊。
第一种通常是你们比较常用的,图里也基本囊括了目前市面上所有的常见的统计平台,各有优劣势。
一般比较常用的是百度统计以及微软的Google Analytics,但是因为微软的Google Analytics须要翻墙,比较麻烦,所以我会推荐你们去使用百度统计,因为一个百度统计基本就可以满足百分之90的数据搜集需求,接下来我也会重点的围绕百度统计来给你们做详尽的解释。
首先百度统计统计逻辑分为以下两种:
1)页面转化应用场景:页面转化通常运用于以URL为统计目标的数据,直白一点讲就是假如你要统计的数据是一个不会改变的URL链接,那么页面转化就可以帮你实现。
比如,如果你觉得网站上的某个页面非常重要(如递交订单后出现的“购买成功”页面),到达了该页面表示访客完成了你的目标,你就可以将抵达该目标页面作为一种转化来统计。多用于电商类的网站做统计使用。
页面转化的设置步骤:
(官方标准)
2)事件转化;这一点笔者会重点的来给你们讲。首先,一般常规的顾客可以使用修改网站的源代码来统计转化目标的,源代码须要改成百度可以辨识的标准:“id=xxx”,找到转化目标而且可使百度成功追踪后,你就可以轻松的搜集到你的转化数据了。
如图:
这里可能有些同学要问了,如果我想统计目标是访问行为的话,怎么办?接下来笔者会详尽讲一下关于怎么来统计一些难以被普通统计代码跟踪PV的特殊的网站或页面。
在统计之前我们须要用到百度开放平台的一个合同:JS-API,JS-API通过在页面上布署js代码的方法,可以帮你搜集网站的各种业务数据(沟通数、点击数、转化数)
1、在布署JS前,你的网站不仅须要成安装百度统计代码,还须要新装一串JS-API代码,这里须要注意一下的是,JS-API代码必须安装在你统计页面的 head 标签上面,具体代码如下:
2、在我们进行进一步安装前,你须要明白风波转化的基本概念,不然以后的内容你会很难读懂。
首先风波转化统计的是访客在网站操作行为,这种行为可以被选取为转化目标,比如你是一个做视频网站的顾客,你希望通过风波转化来统计你每晚点击某一个视频“暂停”以及“播放”两个动作的数据,那么这些统计动作的目的,都可以运用JS-API来做实现,以此类推,你可以统计特别多的访客行为,当然这些行为就是转化目标了。
3、因为访客在网站的动作是一个行为,我们须要使代码去辨识他的行为,就必须为她们加上惟一的标示,只有正确的添加了标示,系统就会正确的捕捉到数据。具体如下:
事件链接中加入风波跟踪参数(以下引用官方解释)
_hmt.push(['_trackEvent', category, action, opt_label, opt_value]);
category:要监控的目标的类型名称,通常是同一组目标的名子,比如"视频"、"音乐"、"软件"、"游戏"等等。该项必选。
action:用户跟目标交互的行为,如"播放"、"暂停"、"下载"等等。该项必选。
opt_label:事件的一些额外信息,通常可以是歌曲的名称、软件的名称、链接的名称等等。该项可选。
opt_value:事件的一些数值信息,比如权重、时长、价格等等,在报表中可以见到其平均值等数据。该项可选。
举例说明:
假设页面A上有且只有一个下载链接,设置前后对比如下:
设置前:
设置完成后,我们就可以去百度统计设置转化目标了,你只须要在风波转化中的新增页面中降低你布署JS代码页面链接,就可以成功的获取数据了。
02 掌握数据剖析的思索维度
当我们成功布署了属于我们自己的数据回收通道后,我们就可以轻松的获取我们想要数据,但是好多时侯你们可能会认为,回收了这么多数据,我该如何去整理剖析了。
接下笔者会阐述领到数据后,我们须要怎样来做剖析,这里,我只提供思索方向,具体的我就不再赘言了,因为同样的数据,拿给不同的帐户,调整策略也不一定一样,还是那句话,数据剖析要结合你实际的企业情况以及产品特性和客户群特点。
首先,你须要通过以下几个思索维度来把数据立体化,这样可以帮你快速把你确定帐户问题:
1、账户数据层面,我们帐户是否诠释点击访问属于正常值?
思路解析:账户的数据直接决定了这个帐户大的方向是否是科学健康的,比如你的预算三天是100块,ACP为20块钱,一天可以形成5次点击,那么很容易的就可以晓得,账户大致的优化方向应当围绕着增加ACP来。
2、账户类有消费关键词有多少?其中有80%消费是被什么词消耗了,80%的点击集中在哪些词头上,占80%点击的关键词是什么,他们消耗占整体的消耗的多少?他们转化成本分别是多少?
思路解析:我们常常说的二八原则,其实是一个比较科学的理论,我这儿把二八原则做了更多的延展。
首先你帐户内的有消费词决定了你的广告面对的是一个多大的人群,然后帐户80%的消费决定了你的钱都花在哪些词头上,80%的点击决定了你实际订购的流量质量。
所以我们在做帐户数据剖析的时侯,这些一定要成比例原则的去做深入的剖析,可以帮我们快速的定位问题,这样可以指导我们以后的优化动作会在正确的公路上。
案例解析:
这是一个搬家顾客,客户每晚的预算80块钱,根据我们思路,来简单的剖析一下这个帐户的问题:
数据层面:单日消费80,ACP:16.40,可以显著的看下来,这个在极其严重的ACP和预算不符的情况,之后的优化方向也确定为增加ACP为主。
通过转化数据整理后我们可以看见,这个帐户有转化的词只有一个,转化成本为18.1,点击流量价钱很高且普遍和原语匹配程度不高,结合数据,我们可以将这个帐户的调整方案定为:ACP须要增加,暂定目标为同比增长50%,点击质量须要优化,做否词,以及修改部份不合理的匹配方法。
如何获取新浪微博数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-08-10 01:37
在历史数据获取方面,与twitter相比,搜索插口比较弱,好在提供了搜索功能。
在实时数据获取方面,sina 还是比较保守。与之相关的有三个插口用public_timeline、topics、nearby_timeline,分别拿来搜集公共的实时微博、某个话题下的实时微博、某点周围的实时微博。由此可以看出:缺乏在某地点关于某关键词的实时搜索插口。虽然有众多限制,但依然有替代方案是:利用搜索功能可以进行搜集一个小时前微博的,同时可以对关键字和地点进行限制,等等。下面从历史和实时数据两个方面来述说获取微博数据。
数据搜集思路
历史数据在科研方面很重要,特别是研究社交媒体方向。但是历史数据也是有要求的,首先要主题相关,然后历史也有个具体时间段。结合这两个要求的考虑,可以使用微博的中级搜索插口(详见)。
主要思路是:抓取网页;解析网页;存储有用信息。
值得注意的是:我们可以选择解析网页的全部信息,包括微博文和用户的部份信息,但这样获得的信息相对较少。这时可以考虑只从网页中提取出微博的id,然后通过API来返回该微博的所有信息,包括用户信息。
实时数据的主要作用可以彰显在一些应用上,譬如实时检测公众对突发事件的反应。
主要思路是:实时数据的一条路径为,利用微博提供的API进行搜索。这里不表,调用API即可。另一条就是,上文提及的借助搜索功能搜集一个小时前的逾实时数据。
遇到的问题
即每个小时对API的访问有次数限制。新浪微博API采用OAuth2进行授权,有严格的访问权限和对应的访问频次。一种走正规流程,申请appKey并获得appSecret,从而的得到相应的权限和对应的访问频次。当然还有其他方式可以避免这些限制。获取OAuth2授权的形式不止这一种(可参考)。文中提及可以通过基于用户名与密码模式,这样我们可以通过构造类似 :
grant_type=password&client_id=s6BhdRkqt3&client_secret=47HDu8s&username=johndoe&password=A3ddj3w
这样的URL恳求来申请Access Token。这时还是须要一个中级权限的appKey和appSecret。很幸运的是,很多APP和客户端的官方微博appKey和appSecret在网路上都可以找到(可参见)
原文点此 查看全部
无论是做与微博相关研究还是开发相关应用,可能须要获取历史的或则实时的数据。如何获取呢?除了新浪微博为开发者提供了API, 还可以借助搜索功能(详见此文)来搜集数据。
在历史数据获取方面,与twitter相比,搜索插口比较弱,好在提供了搜索功能。
在实时数据获取方面,sina 还是比较保守。与之相关的有三个插口用public_timeline、topics、nearby_timeline,分别拿来搜集公共的实时微博、某个话题下的实时微博、某点周围的实时微博。由此可以看出:缺乏在某地点关于某关键词的实时搜索插口。虽然有众多限制,但依然有替代方案是:利用搜索功能可以进行搜集一个小时前微博的,同时可以对关键字和地点进行限制,等等。下面从历史和实时数据两个方面来述说获取微博数据。
数据搜集思路
历史数据在科研方面很重要,特别是研究社交媒体方向。但是历史数据也是有要求的,首先要主题相关,然后历史也有个具体时间段。结合这两个要求的考虑,可以使用微博的中级搜索插口(详见)。
主要思路是:抓取网页;解析网页;存储有用信息。
值得注意的是:我们可以选择解析网页的全部信息,包括微博文和用户的部份信息,但这样获得的信息相对较少。这时可以考虑只从网页中提取出微博的id,然后通过API来返回该微博的所有信息,包括用户信息。
实时数据的主要作用可以彰显在一些应用上,譬如实时检测公众对突发事件的反应。
主要思路是:实时数据的一条路径为,利用微博提供的API进行搜索。这里不表,调用API即可。另一条就是,上文提及的借助搜索功能搜集一个小时前的逾实时数据。
遇到的问题
即每个小时对API的访问有次数限制。新浪微博API采用OAuth2进行授权,有严格的访问权限和对应的访问频次。一种走正规流程,申请appKey并获得appSecret,从而的得到相应的权限和对应的访问频次。当然还有其他方式可以避免这些限制。获取OAuth2授权的形式不止这一种(可参考)。文中提及可以通过基于用户名与密码模式,这样我们可以通过构造类似 :
grant_type=password&client_id=s6BhdRkqt3&client_secret=47HDu8s&username=johndoe&password=A3ddj3w
这样的URL恳求来申请Access Token。这时还是须要一个中级权限的appKey和appSecret。很幸运的是,很多APP和客户端的官方微博appKey和appSecret在网路上都可以找到(可参见)
原文点此
如何高贵地拿下公众号历史文章、点赞数、阅读数,甚至是评论?
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-10 01:12
可能我们熟知的新榜、清博这种平台提供这样的数据,但是价钱却使人望而止步。比如我们在新榜想获取人民日报的所有历史文章,竟然须要300榜豆,而300榜豆须要多少钱呢?285 人民币!!!
新榜采集公众号历史文章
采集价格
我想这个费用不是大多数自媒体工作者都还能承当的起的,包括我曾今也想过订购这样的服务,但最终还是止住了,作为一个开发者,这些问题才能自己解决就不要去破费了,于是,我决定开发一款这样的工具,能够帮助象我一样须要快速获得公众号历史文章数据的人更便捷、更经济地达到目的,所以便有了如今的小蜜蜂公众号文章助手
小蜜蜂公众号文章助手
助手实现的功能
助手界面
链接模式
代理模式
其中链接模式最为简单,仅需粘贴历史文章页面链接即可一键采集,而代理模式须要几分钟的设置,设置好后即可开始采集
image.png
公众号列表
采集结果列表
采集成功后,可到公众号列表查看采集的结果,可以看见有文章数量、名称、以及一些导入文档的操作 查看全部
相信,不少营运工作者在日常工作中会碰到这样的需求,经常须要研究竞争对手的公众号文章数据或则自己公众号数据,然而微信公众平台并没有提供这样的方便操作,可以支持将公众号数据导下来研究。
可能我们熟知的新榜、清博这种平台提供这样的数据,但是价钱却使人望而止步。比如我们在新榜想获取人民日报的所有历史文章,竟然须要300榜豆,而300榜豆须要多少钱呢?285 人民币!!!
新榜采集公众号历史文章
采集价格
我想这个费用不是大多数自媒体工作者都还能承当的起的,包括我曾今也想过订购这样的服务,但最终还是止住了,作为一个开发者,这些问题才能自己解决就不要去破费了,于是,我决定开发一款这样的工具,能够帮助象我一样须要快速获得公众号历史文章数据的人更便捷、更经济地达到目的,所以便有了如今的小蜜蜂公众号文章助手
小蜜蜂公众号文章助手
助手实现的功能
助手界面
链接模式
代理模式
其中链接模式最为简单,仅需粘贴历史文章页面链接即可一键采集,而代理模式须要几分钟的设置,设置好后即可开始采集
image.png
公众号列表
采集结果列表
采集成功后,可到公众号列表查看采集的结果,可以看见有文章数量、名称、以及一些导入文档的操作
阿里云推荐引擎离线流程的主要作用是 site:blog.csdn.net
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-10 00:18
推荐引擎(Recommendation Engine,以下简称RecEng,特指阿里云推荐引擎)是在阿里云估算环境下构建的一套推荐服务框架,目标是使广大中小互联网企业能否在这套框架上快速的搭建满足自身业务需求的推荐服务。
课程链接:阿里云推荐引擎使用教程
推荐服务一般由三部份组成:日志采集,推荐估算和产品对接。推荐服务首先须要采集产品中记录的用户行为日志到离线存储,然后在离线环境下借助推荐算法进行用户和物品的匹配估算,找出每位用户可能感兴趣的物品集合后,将这种预先估算好的结果推送到在线储存上,最终产品在有用户访问时通过在线API向推荐服务发起恳求,获得该用户可能感兴趣的物品,完成推荐业务。
RecEng的核心是推荐算法的订制。RecEng为推荐业务定义了一套完整的规范,从输入,到估算,到输出,客户可以在这个框架下自定义算法和规则,以此满足各类行业的需求,包括电商,音乐,视频,社交,新闻,阅读等。同时,RecEng也提供了相应的方式供顾客方便的接入用户访问日志,以及自定义满足其自身业务需求的在线API。
基本概念:
客户/租户(org/tenant)
指RecEng的使用者,系统中由其阿里云帐号代表。通常顾客是一个组织,RecEng中常用org表示顾客。
用户(user)
指顾客的用户,即RecEng使用者的用户。推荐是一个2C的服务,使用推荐服务的顾客必然有其自己的用户,RecEng使用者的用户简称为“用户”,系统中常用user表示用户。
物品(item)
指被推荐给用户的内容,可以是商品,也可以是歌曲,视频等其他内容,系统中常用item表示物品。
业务(biz)
业务针对数据集定义,定义了算法所能使用的数据范围。一个顾客在RecEng上可以有多个业务,不同的业务必然有不同的数据集。RecEng要求每位业务提供四类数据(不要求全部提供):用户数据,物品数据,用户行为数据,推荐疗效数据。每一组这样的数据就构成一个业务。系统中常用biz表示业务。
比如某顾客A有两类被推荐的物品,分别是视频和歌曲,于是顾客A可以在RecEng上构建两个业务M和N,其中M的物品数据为视频,N的物品数据为歌曲,其他的数据(指用户数据,用户行为数据等)可以都相同。在这些方案下,业务M和N的数据是独立的,即业务M其实能看到用户对于歌曲的行为,但是业务M中不收录歌曲的物品数据,所以会扔掉用户对于歌曲的行为;如果业务M中某用户只对歌曲有行为,对视频没有行为,业务M也会扔掉这类用户。反之对业务N亦然。
一个业务最好只推荐一类物品。多类物品的推荐在后续的行业模板会有支持,需要引入蓝筹股(plate)的概念,一份业务数据可以生成多个蓝筹股的数据集,场景绑定某个蓝筹股进行推荐算法估算。
场景(scn)
场景指的是推荐的上下文,每个场景就会输出一个API,场景由推荐时可用的参数决定。有两种场景最为常见,分别是首页推荐场景和详情页推荐场景。顾名思义,在执行首页推荐时,可用的参数只有用户信息;而在执行详情页推荐时,可用的参数不仅用户信息,还包括当前详情页上所展示的物品信息。系统中常用scn表示场景。
一个业务可以收录多个场景,即对于某个业务A,它收录多个首页场景也是完全可以的。
事实上,回到场景的原创定义,场景只是由推荐的上下文决定,客户完全可以按照自己的需求构建全新的场景,比如针对搜索关键词的推荐场景,这时可用的参数不仅用户信息,还有用户所输入的关键词。
流程(flow)
算法流程指数据端到端的处理流程,一部分流程属于业务范畴,如数据导出流程,效果估算流程,数据质量分估算流程;一部分属于场景,比如场景算法流程。从数据源类型和产下来界定,又分为离线流程,近线流程,在线流程
离线流程
一般情况下,离线流程的输入和输出都是MaxCompute(原ODPS)表,所以离线数据规范虽然上是一组MaxCompute表的格式规范,包括接入数据、中间数据和输出数据三类数据的格式规范。接入数据指顾客离线提供的用户、物品、日志等数据,中间数据是在离线算法流程中形成的各类中间性质的结果数据表,输出数据是指推荐结果数据表,该结果最终将会被导出到在线储存中,供在线估算模块使用。
近线流程
推荐引擎的的近线流程主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新。不象离线算法,天然以MaxCompute(原ODPS)表作为输入和输出,近线程序的输入数据可以来自多个数据源,如在线的表格储存(原OTS),以及用户的API恳求,又或则是程序中的变量;输出可以是程序变量,或者写回在线储存,或者返回给用户。出于安全性考虑,推荐引擎提供了一组SDK供顾客自定义在线代码读写在线储存(Table Store),不容许直接访问,所以须要定义每类在线储存的别称和格式。对于须要频繁使用的在线数据,无论其来自在线储存还是用户的API恳求,RecEng会预先读好,保存在在线程序的变量中,客户自定义代码可以直接读写这种变量中的数据。
在线流程
推荐引擎的的在线流程负责的任务是推荐API接收到API恳求时,实时对离线和逾线修正形成的推荐结果进行过滤、排重、补足等处理;后者主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新
一个场景只收录一个离线流程和一个逾线流程,可以收录多个在线流程,用于支持A/BTest。
算法策略(Algorithm Strategy)
算法策略定义了一套离线/近线流程。并且透出相关的算法参数,帮助顾客建立自己的算法流程。一个场景可以配置多个算法策略,最终会合并执行,产出一系列推荐候选集和过滤集,在线流程通过引用那些候选集来完成个性化推荐。
作业/任务(task)
作业指运行中的离线流程实例,作业和离线流程的关系完全等同于进程和程序的关系。每个作业都是不可重入的,即对每位离线流程,同一时间只容许运行一份实例。作业直接存在上下游关系,如果上游作业失败,下游任务也会被取消。
更多精品课程点击:阿里云大学 查看全部
产品概述:
推荐引擎(Recommendation Engine,以下简称RecEng,特指阿里云推荐引擎)是在阿里云估算环境下构建的一套推荐服务框架,目标是使广大中小互联网企业能否在这套框架上快速的搭建满足自身业务需求的推荐服务。
课程链接:阿里云推荐引擎使用教程
推荐服务一般由三部份组成:日志采集,推荐估算和产品对接。推荐服务首先须要采集产品中记录的用户行为日志到离线存储,然后在离线环境下借助推荐算法进行用户和物品的匹配估算,找出每位用户可能感兴趣的物品集合后,将这种预先估算好的结果推送到在线储存上,最终产品在有用户访问时通过在线API向推荐服务发起恳求,获得该用户可能感兴趣的物品,完成推荐业务。
RecEng的核心是推荐算法的订制。RecEng为推荐业务定义了一套完整的规范,从输入,到估算,到输出,客户可以在这个框架下自定义算法和规则,以此满足各类行业的需求,包括电商,音乐,视频,社交,新闻,阅读等。同时,RecEng也提供了相应的方式供顾客方便的接入用户访问日志,以及自定义满足其自身业务需求的在线API。
基本概念:
客户/租户(org/tenant)
指RecEng的使用者,系统中由其阿里云帐号代表。通常顾客是一个组织,RecEng中常用org表示顾客。
用户(user)
指顾客的用户,即RecEng使用者的用户。推荐是一个2C的服务,使用推荐服务的顾客必然有其自己的用户,RecEng使用者的用户简称为“用户”,系统中常用user表示用户。
物品(item)
指被推荐给用户的内容,可以是商品,也可以是歌曲,视频等其他内容,系统中常用item表示物品。
业务(biz)
业务针对数据集定义,定义了算法所能使用的数据范围。一个顾客在RecEng上可以有多个业务,不同的业务必然有不同的数据集。RecEng要求每位业务提供四类数据(不要求全部提供):用户数据,物品数据,用户行为数据,推荐疗效数据。每一组这样的数据就构成一个业务。系统中常用biz表示业务。
比如某顾客A有两类被推荐的物品,分别是视频和歌曲,于是顾客A可以在RecEng上构建两个业务M和N,其中M的物品数据为视频,N的物品数据为歌曲,其他的数据(指用户数据,用户行为数据等)可以都相同。在这些方案下,业务M和N的数据是独立的,即业务M其实能看到用户对于歌曲的行为,但是业务M中不收录歌曲的物品数据,所以会扔掉用户对于歌曲的行为;如果业务M中某用户只对歌曲有行为,对视频没有行为,业务M也会扔掉这类用户。反之对业务N亦然。
一个业务最好只推荐一类物品。多类物品的推荐在后续的行业模板会有支持,需要引入蓝筹股(plate)的概念,一份业务数据可以生成多个蓝筹股的数据集,场景绑定某个蓝筹股进行推荐算法估算。
场景(scn)
场景指的是推荐的上下文,每个场景就会输出一个API,场景由推荐时可用的参数决定。有两种场景最为常见,分别是首页推荐场景和详情页推荐场景。顾名思义,在执行首页推荐时,可用的参数只有用户信息;而在执行详情页推荐时,可用的参数不仅用户信息,还包括当前详情页上所展示的物品信息。系统中常用scn表示场景。
一个业务可以收录多个场景,即对于某个业务A,它收录多个首页场景也是完全可以的。
事实上,回到场景的原创定义,场景只是由推荐的上下文决定,客户完全可以按照自己的需求构建全新的场景,比如针对搜索关键词的推荐场景,这时可用的参数不仅用户信息,还有用户所输入的关键词。
流程(flow)
算法流程指数据端到端的处理流程,一部分流程属于业务范畴,如数据导出流程,效果估算流程,数据质量分估算流程;一部分属于场景,比如场景算法流程。从数据源类型和产下来界定,又分为离线流程,近线流程,在线流程
离线流程
一般情况下,离线流程的输入和输出都是MaxCompute(原ODPS)表,所以离线数据规范虽然上是一组MaxCompute表的格式规范,包括接入数据、中间数据和输出数据三类数据的格式规范。接入数据指顾客离线提供的用户、物品、日志等数据,中间数据是在离线算法流程中形成的各类中间性质的结果数据表,输出数据是指推荐结果数据表,该结果最终将会被导出到在线储存中,供在线估算模块使用。
近线流程
推荐引擎的的近线流程主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新。不象离线算法,天然以MaxCompute(原ODPS)表作为输入和输出,近线程序的输入数据可以来自多个数据源,如在线的表格储存(原OTS),以及用户的API恳求,又或则是程序中的变量;输出可以是程序变量,或者写回在线储存,或者返回给用户。出于安全性考虑,推荐引擎提供了一组SDK供顾客自定义在线代码读写在线储存(Table Store),不容许直接访问,所以须要定义每类在线储存的别称和格式。对于须要频繁使用的在线数据,无论其来自在线储存还是用户的API恳求,RecEng会预先读好,保存在在线程序的变量中,客户自定义代码可以直接读写这种变量中的数据。
在线流程
推荐引擎的的在线流程负责的任务是推荐API接收到API恳求时,实时对离线和逾线修正形成的推荐结果进行过滤、排重、补足等处理;后者主要处理用户行为发生变化、推荐物品发生更新时,对离线推荐结果进行更新
一个场景只收录一个离线流程和一个逾线流程,可以收录多个在线流程,用于支持A/BTest。
算法策略(Algorithm Strategy)
算法策略定义了一套离线/近线流程。并且透出相关的算法参数,帮助顾客建立自己的算法流程。一个场景可以配置多个算法策略,最终会合并执行,产出一系列推荐候选集和过滤集,在线流程通过引用那些候选集来完成个性化推荐。
作业/任务(task)
作业指运行中的离线流程实例,作业和离线流程的关系完全等同于进程和程序的关系。每个作业都是不可重入的,即对每位离线流程,同一时间只容许运行一份实例。作业直接存在上下游关系,如果上游作业失败,下游任务也会被取消。
更多精品课程点击:阿里云大学
数据平台初试(技术篇)——抖音数据采集(初级版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 748 次浏览 • 2020-08-09 19:43
数据平台初试(技术篇)——抖音数据采集(初级版)
这段时间仍然在处理数据采集的问题,目前平台数据采集趋于稳定,可以抽出时间来整理一下近日的成果,顺便介绍一些近日用到的技术。本篇文章偏向技术,需要读者有一定的技术基础,主要介绍数据采集过程中用到的利器mitmproxy,以及平台的一些技术设计。以下是数据采集整体的设计,左边是客户机,在里面放置了不同的采集器,采集器发起恳求以后,通过mitmproxy访问抖音,等数据回传以后,通过中间的解析器对数据进行解析,最后分门别类的储存到数据库中,为了提高性能,在中间加入了缓存,把采集器和解析器分隔开,两个模块之间工作互不影响,可以最大限度的把数据入库,下图为第一代构架设计,后续会有一篇文章介绍平台构架设计的三代演化史。
准备工作
开始步入数据采集的打算工作,第一步自然是环境搭建,本次我们在windows环境下,采用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,采用夜神模拟器来模拟安卓运行环境(也可以用真机),这次主要通过自动滑动app来抓取数据,下次介绍采用Appium自动化工具,实现数据采集的全手动(解放右手)。
1、安装python3.6.6环境,安装过程可自行百度,需要注意的是,centos7自带的是python2.7,需要升级到python3.6.6环境,升级之前主要先安装ssl模块,否则升级好的版本未能访问https的恳求。
2、安装mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy,注:windows下只有mitmdump和mitmweb可以使用,安装好后在命令行输入mitmdump即可启动,默认启动的代理端口为8080。
3、安装夜神模拟器,可以在官网下载安装包,安装教程自行百度即可,基本都是下一步。安装好夜神模拟器以后,需要对夜神模拟器进行配置。首先须要设置模拟器的网路为自动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、接下来是证书的安装,打开模拟器中的浏览器,输入地址mitm.it,选择对应版本的证书,安装好后,就可以进行抓包了。
5、安装app,app安装包可以到官网下载,然后通过拖放进模拟器就可以安装,或者在应用市场进行安装。
至此,本次数据采集环境就全部搭建完成。
数据插口剖析 抓包
搭建好环境以后就开始对抖音app进行数据抓包,分析出每位功能所使用的插口,本次以采集视频数据插口为例介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是一个图形化的版本,就不用对着黑框框找了,如下图:
启动以后打开模拟器的抖音app,可以看见早已有数据包解析下来了,然后步入用户主页,开始下降视频,在数据包列表中可以找到恳求视频数据的插口
可以在左边看见插口的恳求数据和响应数据,我们将响应数据复制下来,进入下一步解析。
数据解析
通过mitmproxy和python代码的结合,我们就可以在代码中获取到mitmproxy中的数据包,进而可以根据需求来处理。新建一个test.py文件,里面放两个方式:
def request(flow):
pass
def response(flow):
pass
见名知意,这两个方式,一个是在恳求的时侯执行的,一个是在响应的时侯执行,而数据包则存在于flow当中。通过flow.request.url可以获取到恳求url,flow.request.headers可以获取到恳求头信息,flow.response.text中的就是响应的数据了。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme就是一个完整的视频数据了,可以按照须要提取上面的信息,这里提取部份信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
statistics信息就是这个视频的点赞,评论,下载,转发的数据。
share_url为视频的分享地址,通过这个地址,可以在PC端观看抖音分享的视频,也可以通过这个链接解析到无水印视频。
play_addr为视频的播放信息,其中的url_list即为无水印地址,不过目前官方做了处理,这个地址难以直接播放,也有时间限制,超时以后链接就失效了。
有了这个aweme,就可以把上面的信息解析下来,保存到自己的数据库,或者下载无水印视频,保存到自己笔记本了。
写好代码然后,保存test.py文件,cmd步入命令行,进入到保存test.py文件目录下,在命令行输入mitmdump -s test.py,mitmdump就启动了,此时打开app,开始滑动模拟器,进入用户主页:
开始不断下降,test.py文件就可以把抓取到的视频数据全部解析下来了,以下是我截取的部份数据信息:
视频信息:
视频统计数据: 查看全部
公众号原文链接:
数据平台初试(技术篇)——抖音数据采集(初级版)
这段时间仍然在处理数据采集的问题,目前平台数据采集趋于稳定,可以抽出时间来整理一下近日的成果,顺便介绍一些近日用到的技术。本篇文章偏向技术,需要读者有一定的技术基础,主要介绍数据采集过程中用到的利器mitmproxy,以及平台的一些技术设计。以下是数据采集整体的设计,左边是客户机,在里面放置了不同的采集器,采集器发起恳求以后,通过mitmproxy访问抖音,等数据回传以后,通过中间的解析器对数据进行解析,最后分门别类的储存到数据库中,为了提高性能,在中间加入了缓存,把采集器和解析器分隔开,两个模块之间工作互不影响,可以最大限度的把数据入库,下图为第一代构架设计,后续会有一篇文章介绍平台构架设计的三代演化史。
准备工作
开始步入数据采集的打算工作,第一步自然是环境搭建,本次我们在windows环境下,采用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,采用夜神模拟器来模拟安卓运行环境(也可以用真机),这次主要通过自动滑动app来抓取数据,下次介绍采用Appium自动化工具,实现数据采集的全手动(解放右手)。
1、安装python3.6.6环境,安装过程可自行百度,需要注意的是,centos7自带的是python2.7,需要升级到python3.6.6环境,升级之前主要先安装ssl模块,否则升级好的版本未能访问https的恳求。
2、安装mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy,注:windows下只有mitmdump和mitmweb可以使用,安装好后在命令行输入mitmdump即可启动,默认启动的代理端口为8080。
3、安装夜神模拟器,可以在官网下载安装包,安装教程自行百度即可,基本都是下一步。安装好夜神模拟器以后,需要对夜神模拟器进行配置。首先须要设置模拟器的网路为自动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。
4、接下来是证书的安装,打开模拟器中的浏览器,输入地址mitm.it,选择对应版本的证书,安装好后,就可以进行抓包了。
5、安装app,app安装包可以到官网下载,然后通过拖放进模拟器就可以安装,或者在应用市场进行安装。
至此,本次数据采集环境就全部搭建完成。
数据插口剖析 抓包
搭建好环境以后就开始对抖音app进行数据抓包,分析出每位功能所使用的插口,本次以采集视频数据插口为例介绍。
关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是一个图形化的版本,就不用对着黑框框找了,如下图:
启动以后打开模拟器的抖音app,可以看见早已有数据包解析下来了,然后步入用户主页,开始下降视频,在数据包列表中可以找到恳求视频数据的插口
可以在左边看见插口的恳求数据和响应数据,我们将响应数据复制下来,进入下一步解析。
数据解析
通过mitmproxy和python代码的结合,我们就可以在代码中获取到mitmproxy中的数据包,进而可以根据需求来处理。新建一个test.py文件,里面放两个方式:
def request(flow):
pass
def response(flow):
pass
见名知意,这两个方式,一个是在恳求的时侯执行的,一个是在响应的时侯执行,而数据包则存在于flow当中。通过flow.request.url可以获取到恳求url,flow.request.headers可以获取到恳求头信息,flow.response.text中的就是响应的数据了。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/";):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme就是一个完整的视频数据了,可以按照须要提取上面的信息,这里提取部份信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
statistics信息就是这个视频的点赞,评论,下载,转发的数据。
share_url为视频的分享地址,通过这个地址,可以在PC端观看抖音分享的视频,也可以通过这个链接解析到无水印视频。
play_addr为视频的播放信息,其中的url_list即为无水印地址,不过目前官方做了处理,这个地址难以直接播放,也有时间限制,超时以后链接就失效了。
有了这个aweme,就可以把上面的信息解析下来,保存到自己的数据库,或者下载无水印视频,保存到自己笔记本了。
写好代码然后,保存test.py文件,cmd步入命令行,进入到保存test.py文件目录下,在命令行输入mitmdump -s test.py,mitmdump就启动了,此时打开app,开始滑动模拟器,进入用户主页:
开始不断下降,test.py文件就可以把抓取到的视频数据全部解析下来了,以下是我截取的部份数据信息:
视频信息:
视频统计数据:
初探漏洞挖掘基础
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-09 10:11
import requests
import threading
import re
targets = []
names = []
def icp_info(host):
url = "https://icp.chinaz.com/ajaxsyn ... 5host
html = requests.get(url,timeout=(5,10)).text
pattern = re.compile('SiteName:"(.*?)",MainPage:"(.*?)"',re.S)
info = re.findall(pattern,html)
for i in range(0,32):
try:
name = info[i][0]
target = info[i][1]
print("%s:%s"%(name,target))
if target not in targets:
targets.append(target)
with open("icp_info.txt","a+") as f:
f.write("%s:%s"%(name,target) + "\n")
continue
else:
continue
except Exception as e:
continue
def start():
with open("url.txt","r+") as a:
for b in a:
b = b.strip()
icp_info(host=b)
a.close()
def main():
thread = threading.Thread(target=start,)
thread.start()
if __name__ == '__main__':
main()
先知的代码块可能不太友好,可以瞧瞧图片:
使用方式:urls.txt传入你须要查询的网站,会手动对获取到的domain进行去重。
使用维基百科对个别添加资产词条的网站可以获取到其部份资产信息:
但是某南没有添加该词条,所以获取不到相关信息。
步骤:
先对已知网站进行whois查询,我们这儿可以去微步查询历史whois,可以获取到历史的whois信息。
利用这种信息,我们就可以反查whois,获取该注册者/电话/邮箱下的相关域名。
我正在写一个脚本,即批量获取whois->反查whois->提取关键信息->去重。
写好了我会发到github上,可关注:
我们可以直接搜索网站官网,可以获得一些页面/头部中富含该关键字的网站。
zoomeye:
shodan:
fofa:
此外,我们还可以借助那些搜索引擎的搜索句型来获取资产。
shodan可以搜索指定公司的资产,也可以借助特定的网站logo来获取资产。
比如我们发觉某南的网站icon基本为同一个,我们就可以先去搜索,获取其带有icon的网站,随便选一个获取hash后借助搜索句型来获取指定icon的网站。
fofa可以直接借助domain关键字来搜索特定网站下的子域名:
zoomeye可以借助hostname关键字来获取主机列表中的资产:
github也可以拿来获取资产,但是大多数情况下还是用于获取敏感信息(用户名/密码/邮箱)等。
当然也可以拿来搜索资产:
这里推荐一款平常在用的github敏感信息采集工具:
我们可以自定义规则,来获取自己所须要的信息。
这里还是以某南为例:
我们除了可以采集企业公众号,还可以采集企业的小程序,因为其中大部分都是会与WEB端的插口做交互的。
公众号:
小程序:
我们不光须要从企业网站中找寻该企业开发的APP,也可以自己通过关键字来获取APP,因为其中有的APP是公测的,只是上线了,但是还未对外公布。
以某南为例:
我们不仅直接搜索企业关键字外,还可以获取其开发者的历史开发记录:
这样循环:APP->开发者->APP
在这过程中我们常常能获取到许多APP,后续再对其进行相关的渗透。
我们可以使用Google/Bing/Baidu等网站对某个网站进行资产采集:
当然,搭配搜索句型食用疗效更佳:
之前提及了采集APP资产,有的APP实际上并不只是使用用户可用的那几个插口,可能还有插口在代码中,这时候可以用工具将这种URI提取下来。
这里推荐两款从APK中提取有效信息的工具:
很多刚钻洞的师父可能不太注意JS,但实际上JS中可能隐藏了很重要的插口,其中可能就存在未授权等漏洞,这里推荐同学写的一款从JS中提取有效域名/api的工具。
JSFINDER:
调的是LinkFinder的正则,可以循环爬取,即:
爬取domain->获取domain主页面下的link->获取domain主页面下的js->获取link页面下的js->解析所有js并提取出有效信息
中期
到了此步我们早已采集了企业的大部分资产了,剩下的就是获取更多资产,即子域名/IP/PORT/服务...等。
sublist3r:
这是一款很不错的工具,调用了几个搜索引擎以及一些子域名查询网站的API,具体可以去项目页查看。
sublist3r:
subfinder:
这款工具调用的API有很多:
Ask,Archive.is,百度,Bing,Censys,CertDB,CertSpotter,Commoncrawl,CrtSH,DnsDB,DNSDumpster,Dnstable,Dogpile,Entrust CT-Search,Exalead,FindSubdomains,GoogleTER,Hackertarget,IPv4Info,Netcraft,PassiveTotal,PTRArchive,Riddler ,SecurityTrails,SiteDossier,Shodan,ThreatCrowd,ThreatMiner,Virustotal,WaybackArchive,Yahoo
初次使用须要我们自己配置API插口的帐号/密码/key...等。
图片始于youtube:
subfinder:
github:
LAYER:
很早之前牧师写的一款工具,可以手动过滤泛解析的域名,字典+API的形式来采集资产,当然更多的是字典,速度也相当可观:
altdns:
这款工具我通常是到最后采集完了所以子域名并去重后使用的,他可以帮助我们发觉一些二级/三级非常隐蔽的域名。
以vivo举例:
altdns:
关于企业IP的采集我们可以直接写脚本去调ip138的插口,可以获取到当前解析IP和历史解析IP,还是比较全的。
ip138:
获取完企业的IP范围以后,我们就可以用nmap/masscan等工具对其端口/服务进行扫描,这个过程可能会有点久。
我们须要先判别企业是直接买了一个C段的IP,还是只使用一个IP,再选择扫描整个C段或则是单个IP。
这是我之前使用nmap对某东域名批量进行C段扫描的结果:
我们的注意力可以置于几个WEB服务端口,和一些可能存在漏洞的服务端口,如redis/mongodb等。
至此,资产采集基本早已结束了,我们可以将采集到的资产选择性的入库,这样以后获取新资产时就可以对比一下是否存在。
后期
这部份可能是我写的最少的部份。
获取完资产然后,就是苦力活了,我的步骤是,先把获取到的资产丢到扫描器(awvs/nessus)里先扫一遍,避免一些没必要的体力劳动。
nessus主要拿来扫描端口服务的漏洞以及一些系统CVE,awvs主要拿来扫描WEB端的漏洞,如XSS/SQLI/CSRF/CORS/备份文件...等等。
指纹辨识部份可以使用云悉的,可以自己写个插件之后申请个API:
我都会用BBSCAN/weakfilescan来扫描网站中可能存在的敏感信息,如.git/.svn/备份文件等等。
BBSCAN:
weakfilescan:
之后的基本就是自动劳动了,对获取到的资产借助已有知识一个个的测。 查看全部
单线程:
import requests
import threading
import re
targets = []
names = []
def icp_info(host):
url = "https://icp.chinaz.com/ajaxsyn ... 5host
html = requests.get(url,timeout=(5,10)).text
pattern = re.compile('SiteName:"(.*?)",MainPage:"(.*?)"',re.S)
info = re.findall(pattern,html)
for i in range(0,32):
try:
name = info[i][0]
target = info[i][1]
print("%s:%s"%(name,target))
if target not in targets:
targets.append(target)
with open("icp_info.txt","a+") as f:
f.write("%s:%s"%(name,target) + "\n")
continue
else:
continue
except Exception as e:
continue
def start():
with open("url.txt","r+") as a:
for b in a:
b = b.strip()
icp_info(host=b)
a.close()
def main():
thread = threading.Thread(target=start,)
thread.start()
if __name__ == '__main__':
main()
先知的代码块可能不太友好,可以瞧瞧图片:
使用方式:urls.txt传入你须要查询的网站,会手动对获取到的domain进行去重。
使用维基百科对个别添加资产词条的网站可以获取到其部份资产信息:
但是某南没有添加该词条,所以获取不到相关信息。
步骤:
先对已知网站进行whois查询,我们这儿可以去微步查询历史whois,可以获取到历史的whois信息。
利用这种信息,我们就可以反查whois,获取该注册者/电话/邮箱下的相关域名。
我正在写一个脚本,即批量获取whois->反查whois->提取关键信息->去重。
写好了我会发到github上,可关注:
我们可以直接搜索网站官网,可以获得一些页面/头部中富含该关键字的网站。
zoomeye:
shodan:
fofa:
此外,我们还可以借助那些搜索引擎的搜索句型来获取资产。
shodan可以搜索指定公司的资产,也可以借助特定的网站logo来获取资产。
比如我们发觉某南的网站icon基本为同一个,我们就可以先去搜索,获取其带有icon的网站,随便选一个获取hash后借助搜索句型来获取指定icon的网站。
fofa可以直接借助domain关键字来搜索特定网站下的子域名:
zoomeye可以借助hostname关键字来获取主机列表中的资产:
github也可以拿来获取资产,但是大多数情况下还是用于获取敏感信息(用户名/密码/邮箱)等。
当然也可以拿来搜索资产:
这里推荐一款平常在用的github敏感信息采集工具:
我们可以自定义规则,来获取自己所须要的信息。
这里还是以某南为例:
我们除了可以采集企业公众号,还可以采集企业的小程序,因为其中大部分都是会与WEB端的插口做交互的。
公众号:
小程序:
我们不光须要从企业网站中找寻该企业开发的APP,也可以自己通过关键字来获取APP,因为其中有的APP是公测的,只是上线了,但是还未对外公布。
以某南为例:
我们不仅直接搜索企业关键字外,还可以获取其开发者的历史开发记录:
这样循环:APP->开发者->APP
在这过程中我们常常能获取到许多APP,后续再对其进行相关的渗透。
我们可以使用Google/Bing/Baidu等网站对某个网站进行资产采集:
当然,搭配搜索句型食用疗效更佳:
之前提及了采集APP资产,有的APP实际上并不只是使用用户可用的那几个插口,可能还有插口在代码中,这时候可以用工具将这种URI提取下来。
这里推荐两款从APK中提取有效信息的工具:
很多刚钻洞的师父可能不太注意JS,但实际上JS中可能隐藏了很重要的插口,其中可能就存在未授权等漏洞,这里推荐同学写的一款从JS中提取有效域名/api的工具。
JSFINDER:
调的是LinkFinder的正则,可以循环爬取,即:
爬取domain->获取domain主页面下的link->获取domain主页面下的js->获取link页面下的js->解析所有js并提取出有效信息
中期
到了此步我们早已采集了企业的大部分资产了,剩下的就是获取更多资产,即子域名/IP/PORT/服务...等。
sublist3r:
这是一款很不错的工具,调用了几个搜索引擎以及一些子域名查询网站的API,具体可以去项目页查看。
sublist3r:
subfinder:
这款工具调用的API有很多:
Ask,Archive.is,百度,Bing,Censys,CertDB,CertSpotter,Commoncrawl,CrtSH,DnsDB,DNSDumpster,Dnstable,Dogpile,Entrust CT-Search,Exalead,FindSubdomains,GoogleTER,Hackertarget,IPv4Info,Netcraft,PassiveTotal,PTRArchive,Riddler ,SecurityTrails,SiteDossier,Shodan,ThreatCrowd,ThreatMiner,Virustotal,WaybackArchive,Yahoo
初次使用须要我们自己配置API插口的帐号/密码/key...等。
图片始于youtube:
subfinder:
github:
LAYER:
很早之前牧师写的一款工具,可以手动过滤泛解析的域名,字典+API的形式来采集资产,当然更多的是字典,速度也相当可观:
altdns:
这款工具我通常是到最后采集完了所以子域名并去重后使用的,他可以帮助我们发觉一些二级/三级非常隐蔽的域名。
以vivo举例:
altdns:
关于企业IP的采集我们可以直接写脚本去调ip138的插口,可以获取到当前解析IP和历史解析IP,还是比较全的。
ip138:
获取完企业的IP范围以后,我们就可以用nmap/masscan等工具对其端口/服务进行扫描,这个过程可能会有点久。
我们须要先判别企业是直接买了一个C段的IP,还是只使用一个IP,再选择扫描整个C段或则是单个IP。
这是我之前使用nmap对某东域名批量进行C段扫描的结果:
我们的注意力可以置于几个WEB服务端口,和一些可能存在漏洞的服务端口,如redis/mongodb等。
至此,资产采集基本早已结束了,我们可以将采集到的资产选择性的入库,这样以后获取新资产时就可以对比一下是否存在。
后期
这部份可能是我写的最少的部份。
获取完资产然后,就是苦力活了,我的步骤是,先把获取到的资产丢到扫描器(awvs/nessus)里先扫一遍,避免一些没必要的体力劳动。
nessus主要拿来扫描端口服务的漏洞以及一些系统CVE,awvs主要拿来扫描WEB端的漏洞,如XSS/SQLI/CSRF/CORS/备份文件...等等。
指纹辨识部份可以使用云悉的,可以自己写个插件之后申请个API:
我都会用BBSCAN/weakfilescan来扫描网站中可能存在的敏感信息,如.git/.svn/备份文件等等。
BBSCAN:
weakfilescan:
之后的基本就是自动劳动了,对获取到的资产借助已有知识一个个的测。
解决文本分类问题的一些机器学习最佳实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2020-08-08 11:13
建立和训练模型只是整个过程的一部分. 如果您能够提前了解数据特征,那么对于后续的模型构建(例如更高的准确性,更少的数据和更少的计算资源)将大有裨益.
加载数据集
首先,让我们将数据集加载到Python中:
def load_imdb_sentiment_analysis_dataset(data_path,seed = 123):
“”“加载IMDb电影评论情感分析数据集.
#个参数
data_path: 字符串,数据目录的路径.
seed: int,随机数的种子.
#返回
一组训练和验证数据.
培训样本数量: 25000
测试样本数: 25000
类别数: 2(0负,1负)
#个引用
Mass等,
从以下位置下载并解压缩归档文件:
〜amaas / data / sentiment / aclImdb_v1.tar.gz
“”“
imdb_data_path = os.path.join(data_path,'aclImdb')
#加载训练数据
train_texts = []
train_labels = []
对于['pos','neg']中的类别:
train_path = os.path.join(imdb_data_path,'train',类别)
对于已排序的(os.listdir(train_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(train_path,fname))作为f:
train_texts.append(f.read())
train_labels.append(0if category =='neg'else1)
#加载验证数据.
test_texts = []
test_labels = []
对于['pos','neg']中的类别:
test_path = os.path.join(imdb_data_path,'test',category)
对于已排序的(os.listdir(test_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(test_path,fname))作为f:
test_texts.append(f.read())
test_labels.append(0if category =='neg'else1)
#随机排列训练数据和标签.
random.seed(种子)
random.shuffle(train_texts)
random.seed(种子)
random.shuffle(train_labels)
返回((train_texts,np.array(train_labels)),
(test_texts,np.array(test_labels)))
检查数据
加载数据后,最好一一检查它们: 选择一些样本并手动检查它们是否符合您的期望. 例如,对于示例中使用的电影评论数据集,我们可以输出一些随机样本来检查评论中的情感标签和情感是否一致.
“一个十分钟的故事必须讲两个小时. 如果没什么大不了的话,我会起身离开的. ”
这是在数据集中标记为“否定”的注释. 显然,审阅者认为这部电影很拖拉,很无聊,与标签相符.
采集关键指标
完成检查后,您需要采集以下重要指标,这些指标可以帮助表征文本分类任务:
样本数: 数据集中的样本总数.
类别数: 数据集中的主题或类别数.
每个类别中的样本数: 如果是平衡数据集,则所有类别应收录相似数目的样本;如果它是不平衡的数据集,则每个类别中收录的样本数量将有很大的差异.
每个样本中的单词数: 这是一个文本分类问题,因此应计算样本中收录的单词中位数.
单词频率分布: 数据集中每个单词的频率(出现次数).
样本长度分布: 数据集中每个样本的分布
步骤2.5: 选择模型
到目前为止,我们已经对数据进行了汇总,并且对数据的关键特征也有了深入的了解. 接下来,基于第二步中采集的各种指标,我们将开始考虑应使用哪种分类模型. 这也意味着我们将提出以下问题: “如何将文本数据转换为算法输入?” (数据预处理和矢量化),“我们应该使用哪种类型的模型?”,“我们的模型应该可行的是什么参数配置?”……
由于数十年的研究,数据预处理和模型配置的选项现在非常多样化,但实际上有很多选项带来了很多麻烦. 我们手头只有一个特定的问题,它的范围也很广泛,那么如何选择最好的呢?最诚实的方法是一个接一个地尝试过去,消除弊端,留下最好的方法,但是这种方法是不现实的.
在本文中,我们尝试简化选择文本分类模型的过程. 对于给定的数据集,我们的目标只有两个: 准确性接近最高,而训练时间则是最低的. 我们使用总共12个数据集,针对不同类型的问题(尤其是情感分析和主题分类问题)进行了大量(〜450K)实验,交替测试了不同的数据预处理技术和不同的模型架构. 这个过程有助于我们获得影响优化的各种参数.
下面的模型选择和流程图是上述实验的总结.
数据准备和模型算法构建
计算比率: 样本数/每个样本的平均单词数
如果上述比率小于1500,请对文本进行分段,然后使用简单的多层感知器(MLP)模型对其进行分类(下图的左分支)
a. 使用n-gram模型对句子进行分段并将单词转换为单词向量
b. 根据向量的重要性得分,从向量中提取出前20,000个单词
c. 建立MLP模型
如果上述比率大于1500,则将文本标记为序列,并使用sepCNN模型对其进行分类(下图的右分支)
a. 对样本进行分词,然后根据词频选择前20,000个词
b. 将样本转换为单词序列向量
c. 如果比率小于1500,使用预训练的sepCNN模型进行词嵌入,效果可能很好.
调整超参数以找到模型的最佳参数配置
在下面的流程图中,黄色框代表数据和模型的准备阶段,灰色框和绿色框代表过程中的每个选择,绿色框代表“推荐选择”. 您可以将此图片用作构建第一个实验模型的起点,因为它可以以较低的计算成本提供更好的性能. 如有必要,您可以在此基础上继续进行迭代改进.
文本分类流程图
此流程图回答了两个关键问题:
我们应该使用哪种学习算法或模型?
我们应该如何准备数据以有效地学习文本和标签之间的关系?
其中,第二个问题取决于第一个问题的答案,而我们预处理数据的方式取决于所选的特定模型. 文本分类模型可以大致分为两类: 使用单词排名信息的序列模型和将文本视为一组单词的n-gram模型. 序列模型的类型包括卷积神经网络(CNN),递归神经网络(RNN)及其变体. n元语法模型的类型包括逻辑回归,MLP,DBDT和SVM.
对于电影评论数据集,样本数/每个样本的平均单词数约为144,因此我们将建立一个MLP模型. 查看全部
第2步: 浏览数据
建立和训练模型只是整个过程的一部分. 如果您能够提前了解数据特征,那么对于后续的模型构建(例如更高的准确性,更少的数据和更少的计算资源)将大有裨益.
加载数据集
首先,让我们将数据集加载到Python中:
def load_imdb_sentiment_analysis_dataset(data_path,seed = 123):
“”“加载IMDb电影评论情感分析数据集.
#个参数
data_path: 字符串,数据目录的路径.
seed: int,随机数的种子.
#返回
一组训练和验证数据.
培训样本数量: 25000
测试样本数: 25000
类别数: 2(0负,1负)
#个引用
Mass等,
从以下位置下载并解压缩归档文件:
〜amaas / data / sentiment / aclImdb_v1.tar.gz
“”“
imdb_data_path = os.path.join(data_path,'aclImdb')
#加载训练数据
train_texts = []
train_labels = []
对于['pos','neg']中的类别:
train_path = os.path.join(imdb_data_path,'train',类别)
对于已排序的(os.listdir(train_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(train_path,fname))作为f:
train_texts.append(f.read())
train_labels.append(0if category =='neg'else1)
#加载验证数据.
test_texts = []
test_labels = []
对于['pos','neg']中的类别:
test_path = os.path.join(imdb_data_path,'test',category)
对于已排序的(os.listdir(test_path))中的fname:
如果fname.endswith('. txt'):
以open(os.path.join(test_path,fname))作为f:
test_texts.append(f.read())
test_labels.append(0if category =='neg'else1)
#随机排列训练数据和标签.
random.seed(种子)
random.shuffle(train_texts)
random.seed(种子)
random.shuffle(train_labels)
返回((train_texts,np.array(train_labels)),
(test_texts,np.array(test_labels)))
检查数据
加载数据后,最好一一检查它们: 选择一些样本并手动检查它们是否符合您的期望. 例如,对于示例中使用的电影评论数据集,我们可以输出一些随机样本来检查评论中的情感标签和情感是否一致.
“一个十分钟的故事必须讲两个小时. 如果没什么大不了的话,我会起身离开的. ”
这是在数据集中标记为“否定”的注释. 显然,审阅者认为这部电影很拖拉,很无聊,与标签相符.
采集关键指标
完成检查后,您需要采集以下重要指标,这些指标可以帮助表征文本分类任务:
样本数: 数据集中的样本总数.
类别数: 数据集中的主题或类别数.
每个类别中的样本数: 如果是平衡数据集,则所有类别应收录相似数目的样本;如果它是不平衡的数据集,则每个类别中收录的样本数量将有很大的差异.
每个样本中的单词数: 这是一个文本分类问题,因此应计算样本中收录的单词中位数.
单词频率分布: 数据集中每个单词的频率(出现次数).
样本长度分布: 数据集中每个样本的分布
步骤2.5: 选择模型
到目前为止,我们已经对数据进行了汇总,并且对数据的关键特征也有了深入的了解. 接下来,基于第二步中采集的各种指标,我们将开始考虑应使用哪种分类模型. 这也意味着我们将提出以下问题: “如何将文本数据转换为算法输入?” (数据预处理和矢量化),“我们应该使用哪种类型的模型?”,“我们的模型应该可行的是什么参数配置?”……
由于数十年的研究,数据预处理和模型配置的选项现在非常多样化,但实际上有很多选项带来了很多麻烦. 我们手头只有一个特定的问题,它的范围也很广泛,那么如何选择最好的呢?最诚实的方法是一个接一个地尝试过去,消除弊端,留下最好的方法,但是这种方法是不现实的.
在本文中,我们尝试简化选择文本分类模型的过程. 对于给定的数据集,我们的目标只有两个: 准确性接近最高,而训练时间则是最低的. 我们使用总共12个数据集,针对不同类型的问题(尤其是情感分析和主题分类问题)进行了大量(〜450K)实验,交替测试了不同的数据预处理技术和不同的模型架构. 这个过程有助于我们获得影响优化的各种参数.
下面的模型选择和流程图是上述实验的总结.
数据准备和模型算法构建
计算比率: 样本数/每个样本的平均单词数
如果上述比率小于1500,请对文本进行分段,然后使用简单的多层感知器(MLP)模型对其进行分类(下图的左分支)
a. 使用n-gram模型对句子进行分段并将单词转换为单词向量
b. 根据向量的重要性得分,从向量中提取出前20,000个单词
c. 建立MLP模型
如果上述比率大于1500,则将文本标记为序列,并使用sepCNN模型对其进行分类(下图的右分支)
a. 对样本进行分词,然后根据词频选择前20,000个词
b. 将样本转换为单词序列向量
c. 如果比率小于1500,使用预训练的sepCNN模型进行词嵌入,效果可能很好.
调整超参数以找到模型的最佳参数配置
在下面的流程图中,黄色框代表数据和模型的准备阶段,灰色框和绿色框代表过程中的每个选择,绿色框代表“推荐选择”. 您可以将此图片用作构建第一个实验模型的起点,因为它可以以较低的计算成本提供更好的性能. 如有必要,您可以在此基础上继续进行迭代改进.
文本分类流程图
此流程图回答了两个关键问题:
我们应该使用哪种学习算法或模型?
我们应该如何准备数据以有效地学习文本和标签之间的关系?
其中,第二个问题取决于第一个问题的答案,而我们预处理数据的方式取决于所选的特定模型. 文本分类模型可以大致分为两类: 使用单词排名信息的序列模型和将文本视为一组单词的n-gram模型. 序列模型的类型包括卷积神经网络(CNN),递归神经网络(RNN)及其变体. n元语法模型的类型包括逻辑回归,MLP,DBDT和SVM.
对于电影评论数据集,样本数/每个样本的平均单词数约为144,因此我们将建立一个MLP模型.
如何在官方帐户上优雅地赢得历史文章,喜欢,阅读甚至评论?
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2020-08-08 10:37
也许像新邦和青博这样的著名平台都提供了这样的数据,但是价格太高了. 例如,如果要在新列表中获得《人民日报》的所有历史文章,则需要300个List Bean,它的价格是多少? 285元! ! !
新列表从官方帐户中采集历史文章
托收价格
我认为这笔费用不是大多数自媒体工作者负担得起的,包括我曾考虑过购买这种服务的费用,但最终停止了. 作为开发人员,这些问题可以自己解决,不要浪费,因此我决定开发像我这样的工具,该工具可以帮助需要快速获取官方帐户的历史商品数据以实现其目标的像我这样的人更方便和经济,所以我有目前的公众. 文章助手
小蜜蜂公共帐户文章助理
助手实现的功能
辅助界面
链接模式
代理模式
链接模式是最简单的. 您只需粘贴历史文章页面链接即可一键采集,而代理模式需要几分钟的时间设置,设置完成后即可开始采集
image.png
官方帐户列表
采集结果列表
采集成功后,您可以在官方帐户列表中查看采集结果,可以查看文章数量,名称以及一些导出文档的操作 查看全部
我相信许多运营工人在日常工作中会遇到这种需求,并且经常需要研究竞争对手的官方帐户商品数据或他们自己的官方帐户数据. 但是,微信官方平台无法提供如此便捷的操作. 支持导出官方帐户数据以供研究.
也许像新邦和青博这样的著名平台都提供了这样的数据,但是价格太高了. 例如,如果要在新列表中获得《人民日报》的所有历史文章,则需要300个List Bean,它的价格是多少? 285元! ! !
新列表从官方帐户中采集历史文章
托收价格
我认为这笔费用不是大多数自媒体工作者负担得起的,包括我曾考虑过购买这种服务的费用,但最终停止了. 作为开发人员,这些问题可以自己解决,不要浪费,因此我决定开发像我这样的工具,该工具可以帮助需要快速获取官方帐户的历史商品数据以实现其目标的像我这样的人更方便和经济,所以我有目前的公众. 文章助手
小蜜蜂公共帐户文章助理
助手实现的功能
辅助界面
链接模式
代理模式
链接模式是最简单的. 您只需粘贴历史文章页面链接即可一键采集,而代理模式需要几分钟的时间设置,设置完成后即可开始采集
image.png
官方帐户列表
采集结果列表
采集成功后,您可以在官方帐户列表中查看采集结果,可以查看文章数量,名称以及一些导出文档的操作
java/python中文分信息处理工具,没有计算机知识的人
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2020-08-08 09:15
1. 敏感性分析的目的是:
(1)识别影响项目经济效益变化的敏感因素,分析敏感因素变化的原因,为进一步的不确定性分析(如概率分析)提供依据;
(2)研究不确定因素的变化范围或极限值,例如项目的经济效益值的变化,并分析和判断项目的承受风险的能力;
(3)比较多种选择的敏感性,以便在经济利益相似的情况下,可以选择不敏感的投资选择.
根据每个不确定因素的变化数量,灵敏度分析可以分为单因素灵敏度分析和多因素灵敏度分析.
第二,敏感性分析的步骤
对于敏感性分析,通常请按照以下步骤操作:
1. 确定经济效益指标进行分析
评价投资项目的经济效益指标主要包括: 净现值,内部收益率,投资利润率,投资回收期等.
2. 选择不确定因素并设置变化范围.
3. 计算不确定因素变化对项目经济绩效指标的影响程度,并确定敏感因素.
4. 绘制灵敏度分析图以找到不确定性因素变化的极限值.
敏感性分析是一种动态不确定性分析,是项目评估中不可或缺的一部分. 用于分析项目经济效益指标对各种不确定因素的敏感性,找出敏感性因素及其最大波动范围,并据此判断项目的承受风险能力. 但是,该分析仍无法确定各种不确定因素在一定范围内的概率,因此其分析结论的准确性将在一定程度上受到影响. 在现实生活中,可能会出现这样的情况: 通过敏感性分析确定的敏感性因素未来不太可能发生不利变化,并且由此引发的项目风险不大;虽然在敏感性分析中执行的另一个因素不是很敏感,但是将来发生不利变化的可能性非常高,这将导致更大的项目风险. 为了弥补敏感性分析的不足,在项目评估和决策过程中需要进一步的概率分析.
数据分析具有广泛的应用范围. 在产品的整个生命周期中,数据分析过程是质量管理体系的支持过程,包括从产品市场研究到售后服务到最终处置的整个过程. 需要适当地使用数据分析来提高有效性. 国内有很多大数据分析和挖掘工具,但是其中大多数是近年来出现的大数据技术,它们必须具有计算机开发能力,并且可以立即使用. 多功能工具较少. 作为主流中文大数据分析和挖掘工具产品的试用版,以下推荐了一个java / python中文子信息处理工具,该工具可以在没有计算机知识的情况下直接使用:
NLPIR大数据语义智能分析平台(以前称为ICTCLAS)是由北京理工大学大数据搜索与挖掘实验室主任张华平开发的. 它满足了大数据内容采集,编译和搜索的全面需求. 它结合了精确的网络采集,对自然语言的理解,文本挖掘和语义搜索的最新研究成果近二十年来不断创新. 该平台提供了多种产品使用形式,例如客户端工具,云服务和二次开发接口. 每个中间件API均可无缝集成到客户的各种复杂应用系统中,与Windows,Linux,Android,Maemo5,FreeBSD等不同操作系统平台兼容,并可用于Java,Python,C等各种开发,C#等语言用法.
NLPIR大数据语义智能分析平台的十三个功能:
NLPIR大数据语义智能分析平台客户端
精确采集: 通过两种方式实时准确地从国内外Internet上采集大量信息: 主题采集(根据信息需求进行主题采集)和网站采集(给定的内部定点采集功能)网址列表).
文档转换: 将文本信息转换为doc,excel,pdf和ppt等多种主流文档格式,其效率可以满足大数据处理的要求.
新词发现: 从文本中发现新词和概念,用户可以将其用于专业词典的汇编,还可以进一步对其进行编辑和标记,将其导入分词词典中,从而提高了词的准确性. 分词系统,并适应新的语言多样性.
批处理单词分割: 原创语料库的单词分割,自动识别未注册的单词(例如名称,地名和机构名称),新单词标记和词性标记. 然后在分析过程中,导入用户定义的字典.
语言统计: 根据分段和标注的结果,系统可以自动对一元词的频率进行统计,并对二元词的转移概率进行统计. 对于常用术语,将自动给出相应的英语解释.
文本聚类: 它可以自动分析来自大规模数据的热点事件,并提供事件主题的关键功能描述. 它还适用于长文本和短文本(例如,短文本和微博)的热点分析.
文本分类: 根据规则或培训方法对大量文本进行分类,可用于新闻分类,简历分类,邮件分类,办公文档分类,区域分类等许多方面.
摘要实体: 对于单篇或多篇文章,将自动提取内容摘要,并提取人员名称,地点,组织,时间和主题关键字;方便用户快速浏览文本内容.
智能过滤: 语义智能过滤和文本内容审查,内置中国最完整的单词数据库,智能识别变形,语音,传统和简体等多种变体,并在语义上准确消除歧义.
情感分析: 对于预先指定的分析对象,系统会自动分析大量文档的情感趋势: 情感极性和情感价值测量,并在原文中给出正负分数和句子示例.
重复数据删除: 快速,准确地确定文件集合或数据库中是否存在具有相同或相似内容的记录,同时查找所有重复记录.
全文搜索: 支持各种数据类型,例如文本,数字,日期,字符串等,多字段有效搜索,支持查询语法(例如AND / OR / NOT和NEAR接近),并支持维吾尔文,藏文,蒙古语,阿拉伯语,韩语和其他少数民族语言的搜索.
编码转换: 自动识别内容的编码,并将编码统一转换为其他编码. 查看全部
敏感性分析是指从众多不确定因素中找出对投资项目的经济绩效指标有重要影响的敏感因素,并分析计算对项目经济绩效指标的影响程度和敏感性,然后是用于确定项目风险承受能力的不确定性分析方法.
1. 敏感性分析的目的是:
(1)识别影响项目经济效益变化的敏感因素,分析敏感因素变化的原因,为进一步的不确定性分析(如概率分析)提供依据;
(2)研究不确定因素的变化范围或极限值,例如项目的经济效益值的变化,并分析和判断项目的承受风险的能力;
(3)比较多种选择的敏感性,以便在经济利益相似的情况下,可以选择不敏感的投资选择.
根据每个不确定因素的变化数量,灵敏度分析可以分为单因素灵敏度分析和多因素灵敏度分析.
第二,敏感性分析的步骤
对于敏感性分析,通常请按照以下步骤操作:
1. 确定经济效益指标进行分析
评价投资项目的经济效益指标主要包括: 净现值,内部收益率,投资利润率,投资回收期等.
2. 选择不确定因素并设置变化范围.
3. 计算不确定因素变化对项目经济绩效指标的影响程度,并确定敏感因素.
4. 绘制灵敏度分析图以找到不确定性因素变化的极限值.
敏感性分析是一种动态不确定性分析,是项目评估中不可或缺的一部分. 用于分析项目经济效益指标对各种不确定因素的敏感性,找出敏感性因素及其最大波动范围,并据此判断项目的承受风险能力. 但是,该分析仍无法确定各种不确定因素在一定范围内的概率,因此其分析结论的准确性将在一定程度上受到影响. 在现实生活中,可能会出现这样的情况: 通过敏感性分析确定的敏感性因素未来不太可能发生不利变化,并且由此引发的项目风险不大;虽然在敏感性分析中执行的另一个因素不是很敏感,但是将来发生不利变化的可能性非常高,这将导致更大的项目风险. 为了弥补敏感性分析的不足,在项目评估和决策过程中需要进一步的概率分析.
数据分析具有广泛的应用范围. 在产品的整个生命周期中,数据分析过程是质量管理体系的支持过程,包括从产品市场研究到售后服务到最终处置的整个过程. 需要适当地使用数据分析来提高有效性. 国内有很多大数据分析和挖掘工具,但是其中大多数是近年来出现的大数据技术,它们必须具有计算机开发能力,并且可以立即使用. 多功能工具较少. 作为主流中文大数据分析和挖掘工具产品的试用版,以下推荐了一个java / python中文子信息处理工具,该工具可以在没有计算机知识的情况下直接使用:
NLPIR大数据语义智能分析平台(以前称为ICTCLAS)是由北京理工大学大数据搜索与挖掘实验室主任张华平开发的. 它满足了大数据内容采集,编译和搜索的全面需求. 它结合了精确的网络采集,对自然语言的理解,文本挖掘和语义搜索的最新研究成果近二十年来不断创新. 该平台提供了多种产品使用形式,例如客户端工具,云服务和二次开发接口. 每个中间件API均可无缝集成到客户的各种复杂应用系统中,与Windows,Linux,Android,Maemo5,FreeBSD等不同操作系统平台兼容,并可用于Java,Python,C等各种开发,C#等语言用法.
NLPIR大数据语义智能分析平台的十三个功能:
NLPIR大数据语义智能分析平台客户端
精确采集: 通过两种方式实时准确地从国内外Internet上采集大量信息: 主题采集(根据信息需求进行主题采集)和网站采集(给定的内部定点采集功能)网址列表).
文档转换: 将文本信息转换为doc,excel,pdf和ppt等多种主流文档格式,其效率可以满足大数据处理的要求.
新词发现: 从文本中发现新词和概念,用户可以将其用于专业词典的汇编,还可以进一步对其进行编辑和标记,将其导入分词词典中,从而提高了词的准确性. 分词系统,并适应新的语言多样性.
批处理单词分割: 原创语料库的单词分割,自动识别未注册的单词(例如名称,地名和机构名称),新单词标记和词性标记. 然后在分析过程中,导入用户定义的字典.
语言统计: 根据分段和标注的结果,系统可以自动对一元词的频率进行统计,并对二元词的转移概率进行统计. 对于常用术语,将自动给出相应的英语解释.
文本聚类: 它可以自动分析来自大规模数据的热点事件,并提供事件主题的关键功能描述. 它还适用于长文本和短文本(例如,短文本和微博)的热点分析.
文本分类: 根据规则或培训方法对大量文本进行分类,可用于新闻分类,简历分类,邮件分类,办公文档分类,区域分类等许多方面.
摘要实体: 对于单篇或多篇文章,将自动提取内容摘要,并提取人员名称,地点,组织,时间和主题关键字;方便用户快速浏览文本内容.
智能过滤: 语义智能过滤和文本内容审查,内置中国最完整的单词数据库,智能识别变形,语音,传统和简体等多种变体,并在语义上准确消除歧义.
情感分析: 对于预先指定的分析对象,系统会自动分析大量文档的情感趋势: 情感极性和情感价值测量,并在原文中给出正负分数和句子示例.
重复数据删除: 快速,准确地确定文件集合或数据库中是否存在具有相同或相似内容的记录,同时查找所有重复记录.
全文搜索: 支持各种数据类型,例如文本,数字,日期,字符串等,多字段有效搜索,支持查询语法(例如AND / OR / NOT和NEAR接近),并支持维吾尔文,藏文,蒙古语,阿拉伯语,韩语和其他少数民族语言的搜索.
编码转换: 自动识别内容的编码,并将编码统一转换为其他编码.

