
通过关键词采集文章采集api
微信公众号文章搜索导入助手软件破解版微信公众号文章搜索导入助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-29 18:06
摘要:微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
微信公众号文章搜索导入助手软件破解版
微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
软件功能
1、一键采集指定微信公众号所有群发文章,并通过关键词搜索所有公众号相关文章,支持按时间段采集;
2、微信文章可一键导入pdf、word、Excel、txt和html格式,并下载音频和视频文件,图片和文章留言,导出文档排版可保持和原文一样;
3、内置开放插口,可一键同步所有陌陌文章到自己网站,并保证陌陌图片正常显示;
4、可实时查看文章阅读量、在看量和留言;
5、软件提供逾80项其他附加功能,非常强悍实用;
软件特色
1、微信公众号文章搜索导入助手提供简单的文章采集功能
2、在软件界面登陆陌陌就可以开始采集数据
3、支持公众号输入,可以对指定的公众号数据采集
4、提供多种文章采集,只要是公众号内的文章就可以全部采集
5、支持列表显示,在软件界面显示采集的内容
6、支持文章查看,可以通过外置的浏览器查看文章
7、支持生成文章二维码,方便将当前的文章制作为二维码
8、支持将列表重复的文章删除,支持公众号过滤
使用说明
1、打开微信公众号文章搜索导入助手显示软件的功能界面
2、如果你须要学习软件就可以打开官方提供的视频教程
3、卡密目前售价29.9元/永久,只要有用户,软件将保持不断更新,优化升级!具体价钱以购买页为准
4、在软件输入关键词就可以查询公众号文章
5、如图所示,这里是软件的登入界面,您须要登陆陌陌 查看全部
微信公众号文章搜索导入助手软件破解版微信公众号文章搜索导入助手
摘要:微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
微信公众号文章搜索导入助手软件破解版

微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
软件功能
1、一键采集指定微信公众号所有群发文章,并通过关键词搜索所有公众号相关文章,支持按时间段采集;
2、微信文章可一键导入pdf、word、Excel、txt和html格式,并下载音频和视频文件,图片和文章留言,导出文档排版可保持和原文一样;
3、内置开放插口,可一键同步所有陌陌文章到自己网站,并保证陌陌图片正常显示;
4、可实时查看文章阅读量、在看量和留言;
5、软件提供逾80项其他附加功能,非常强悍实用;
软件特色
1、微信公众号文章搜索导入助手提供简单的文章采集功能
2、在软件界面登陆陌陌就可以开始采集数据
3、支持公众号输入,可以对指定的公众号数据采集
4、提供多种文章采集,只要是公众号内的文章就可以全部采集
5、支持列表显示,在软件界面显示采集的内容
6、支持文章查看,可以通过外置的浏览器查看文章
7、支持生成文章二维码,方便将当前的文章制作为二维码
8、支持将列表重复的文章删除,支持公众号过滤
使用说明
1、打开微信公众号文章搜索导入助手显示软件的功能界面
2、如果你须要学习软件就可以打开官方提供的视频教程
3、卡密目前售价29.9元/永久,只要有用户,软件将保持不断更新,优化升级!具体价钱以购买页为准
4、在软件输入关键词就可以查询公众号文章
5、如图所示,这里是软件的登入界面,您须要登陆陌陌
总结:seo优化六步走网站优化基础策略分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2020-08-28 20:25
seo优化一般是一个漫长又剌激的过程,依次把握好以下几点才能做好!
第一步,关键词策略。挖掘、分析、筛选关键词,整理关键词列表。
首先,选择核心关键词,seo最直接的目的就是获得定向的转化,转化率很低的词句不予考虑!
其次,判断关键词的竞争度,看关键词搜索次数、百度指数。
再次,挖掘长尾词,具体工具查看《seo优化干货分享(一)如何挖掘长尾关键词》一文。
第二步,架构策略。针对关键词设计好的网站架构,这个阶段是极其重要的,因为设计的网站架构、URL构架、内容构架决定了前面的SEO工作是否更容易。对于刚上线的新站来说,网站目录结构设计的浅些,能便捷蜘蛛抓取。
第三步,内容建设策略。持续更新内容保持网站活力,需要思索什么样的内容是用户最须要、最喜欢的,此时可以忘记SEO,纯粹从用户角度考虑内容。想要内容愈加受欢迎,可以从分享性、交流性、互助性考虑。想要降低用户点击行为,就要提高相关文章的关联性、增加页面数目、操作步骤,适当的添加娱乐化内容。
第四步,内链策略。如果你第2步做好了,内链就很容易解决。此时的重点是考虑每位关键词须要多少内链支持,主要可以通过面包屑导航、自动内链(Tag标签)、全站链接等形式提供内链。
第五步,外链策略。俗话说“外链为皇”,虽然当下外链的SEO疗效没有曾经显著,但是还是发挥着重要的作用。高质量的外链主要通过友情链接、商业合作(购买门户网站合作伙伴的外链)、软文链接、用户自然转发的链接(此时须要做好链接诱饵)来解决。至于以前十分流行的发外链可以不用考虑了,因为疗效差并且风险大,至于峰会推广作用还是有,只是流量被分散早已没先前作用这么大。
第六步,广告引流策略。可以找一些流量较高的网站或自媒体进行合作,在合作方的平台进行设置广告位,为我们的网站进行引流,或做品牌推广。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化 查看全部
seo优化六步走网站优化基础策略分享
seo优化一般是一个漫长又剌激的过程,依次把握好以下几点才能做好!
第一步,关键词策略。挖掘、分析、筛选关键词,整理关键词列表。
首先,选择核心关键词,seo最直接的目的就是获得定向的转化,转化率很低的词句不予考虑!
其次,判断关键词的竞争度,看关键词搜索次数、百度指数。
再次,挖掘长尾词,具体工具查看《seo优化干货分享(一)如何挖掘长尾关键词》一文。
第二步,架构策略。针对关键词设计好的网站架构,这个阶段是极其重要的,因为设计的网站架构、URL构架、内容构架决定了前面的SEO工作是否更容易。对于刚上线的新站来说,网站目录结构设计的浅些,能便捷蜘蛛抓取。
第三步,内容建设策略。持续更新内容保持网站活力,需要思索什么样的内容是用户最须要、最喜欢的,此时可以忘记SEO,纯粹从用户角度考虑内容。想要内容愈加受欢迎,可以从分享性、交流性、互助性考虑。想要降低用户点击行为,就要提高相关文章的关联性、增加页面数目、操作步骤,适当的添加娱乐化内容。
第四步,内链策略。如果你第2步做好了,内链就很容易解决。此时的重点是考虑每位关键词须要多少内链支持,主要可以通过面包屑导航、自动内链(Tag标签)、全站链接等形式提供内链。
第五步,外链策略。俗话说“外链为皇”,虽然当下外链的SEO疗效没有曾经显著,但是还是发挥着重要的作用。高质量的外链主要通过友情链接、商业合作(购买门户网站合作伙伴的外链)、软文链接、用户自然转发的链接(此时须要做好链接诱饵)来解决。至于以前十分流行的发外链可以不用考虑了,因为疗效差并且风险大,至于峰会推广作用还是有,只是流量被分散早已没先前作用这么大。
第六步,广告引流策略。可以找一些流量较高的网站或自媒体进行合作,在合作方的平台进行设置广告位,为我们的网站进行引流,或做品牌推广。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化
【seo建设】关于网站关键词被百度快速索引的问题讨论
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-08-27 21:41
经常会有SEO人员讨论,为什么我的SEO关键词总是不被快速索引,而实际上这儿主要指的是,针对特定关键词的核心内容,那么,它主要涉及如下两个指标:
①索引
②快速收录
这里值得说明的是:索引并不等于收录,索引只是被百度抓取后,进入百度的索引库中,它并不一定会在百度搜索结果中显露。
而经过算法评估后,搜索引擎觉得它可以展现今搜索结果中的时侯,它才弄成我们一般所谈论的百度收录。
那么,SEO关键词优化,如何使百度快速索引?
根据往年的工作经验,我们觉得我们首要须要先解决索引的问题,而进一步在解决快速收录的问题,为此我们须要:
1、索引
针对百度索引的问题,我们主要须要审视如下指标:
页面加载速率
对应搜索引擎而言,索引的前提,通常是抓取,只有保持一定的抓取频度,才可以被有效的索引,而抓取的前提,则是保持页面加载速率符合百度官方标准。
通常,百度给出的建议是在3秒以内,而对于移动端才能达到1.5秒则最优。
为此,你可能须要:
①优选服务器,保障服务器性能适配高频度的访问与抓取。
②开启页面加速器,比如:MIP、服务器缓存、CDN等。
页面内容原创
为什么要指出,内容索引是须要保持页面内容原创度,道理很简单,基于百度搜索算法,如果你递交的是采集内容,百度早已索引过的内容。
当你的网站权重相当较低的时侯,搜索引擎觉得,即使你采集的内容被索引与收录,并不能提供潜在的搜索价值。
这个时侯,搜索引擎都会舍弃,索引你的内容。
2、快速收录
在被百度索引后,如何实现百度快速收录,它一般须要审视如下几个指标:
内容原创且高质量
前文提及在索引阶段,内容一定是要原创的,而达到快速收录的标准,我们须要在一次进阶,确保内容是高质量的,并且满足一定搜索需求,比如:
①内容页面核心主题的关键词,需要具备一定的搜索量。
②内容段落具有一定的逻辑结构。
③内容页面,具有极高的参考价值,合理的相关内容推荐。
推进百度索引速率
当我们创作完满足快速收录的文章内容时,我们须要将该内容,快速被搜索引擎索引,为此,我们须要增强,百度蜘蛛发觉目标内容的可能性,可以尝试如下渠道:
①利用API接口主动递交。
②建立网站地图,并在百度搜索资源平台递交。
③配置熊掌号,利用熊掌号递交内容。
④在高权重网站引蜘蛛,利用投稿与软文的方式,在高权重站点发布优质内容,并收录目标URL。
总结:SEO关键词优化,快速达到索引的目的,通常可以根据上述流程操作,一般都可以实现。 查看全部
【seo建设】关于网站关键词被百度快速索引的问题讨论
经常会有SEO人员讨论,为什么我的SEO关键词总是不被快速索引,而实际上这儿主要指的是,针对特定关键词的核心内容,那么,它主要涉及如下两个指标:
①索引
②快速收录
这里值得说明的是:索引并不等于收录,索引只是被百度抓取后,进入百度的索引库中,它并不一定会在百度搜索结果中显露。
而经过算法评估后,搜索引擎觉得它可以展现今搜索结果中的时侯,它才弄成我们一般所谈论的百度收录。
那么,SEO关键词优化,如何使百度快速索引?
根据往年的工作经验,我们觉得我们首要须要先解决索引的问题,而进一步在解决快速收录的问题,为此我们须要:
1、索引
针对百度索引的问题,我们主要须要审视如下指标:
页面加载速率
对应搜索引擎而言,索引的前提,通常是抓取,只有保持一定的抓取频度,才可以被有效的索引,而抓取的前提,则是保持页面加载速率符合百度官方标准。
通常,百度给出的建议是在3秒以内,而对于移动端才能达到1.5秒则最优。
为此,你可能须要:
①优选服务器,保障服务器性能适配高频度的访问与抓取。
②开启页面加速器,比如:MIP、服务器缓存、CDN等。
页面内容原创
为什么要指出,内容索引是须要保持页面内容原创度,道理很简单,基于百度搜索算法,如果你递交的是采集内容,百度早已索引过的内容。
当你的网站权重相当较低的时侯,搜索引擎觉得,即使你采集的内容被索引与收录,并不能提供潜在的搜索价值。
这个时侯,搜索引擎都会舍弃,索引你的内容。

2、快速收录
在被百度索引后,如何实现百度快速收录,它一般须要审视如下几个指标:
内容原创且高质量
前文提及在索引阶段,内容一定是要原创的,而达到快速收录的标准,我们须要在一次进阶,确保内容是高质量的,并且满足一定搜索需求,比如:
①内容页面核心主题的关键词,需要具备一定的搜索量。
②内容段落具有一定的逻辑结构。
③内容页面,具有极高的参考价值,合理的相关内容推荐。
推进百度索引速率
当我们创作完满足快速收录的文章内容时,我们须要将该内容,快速被搜索引擎索引,为此,我们须要增强,百度蜘蛛发觉目标内容的可能性,可以尝试如下渠道:
①利用API接口主动递交。
②建立网站地图,并在百度搜索资源平台递交。
③配置熊掌号,利用熊掌号递交内容。
④在高权重网站引蜘蛛,利用投稿与软文的方式,在高权重站点发布优质内容,并收录目标URL。
总结:SEO关键词优化,快速达到索引的目的,通常可以根据上述流程操作,一般都可以实现。
程序里的后端和前端是哪些意思?
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2020-08-27 05:18
可以这样理解:能看到的都是后端,看不见的就是前端。
前端包括设计、html、css、JavaScript。设计挺好理解,就是产品的风格、布局,完成后它只是一张图片,它为我们前面的工作“打了个样”,让我们一开始就晓得产品完成后是哪些样子。然后通过html+css实现与设计图疗效一样的静态页面,html是超文本标记,比如设计图上面有一个文字超链接,我们就用超文本标记中的标签表示这是一个超链接,用href属性指定超链接地址,完整写法是这是超链接文字内容。css是样式表,比如前面超链接文字是哪些颜色、需不需要顿号等,都由css控制。JavaScript能实现一些动漫疗效或后端交互,比如一个注册页面上面要求填写手机号,但用户填写的是英文字符,那么可以通过JavaScript来判定并提醒用户输入11位阿拉伯数字。
后端是指通过程序语言(、php、jsp、java、c++等)实现动态数据。这里的动态数据不是指文字或图片在跳动,而是指数据能通过数据库完成新增、删除、编辑等指令。比如前面我举的文字超链接事例,如果这个文字超链接每晚都要更新,就可以通过程序语言来实现在管理后台进行更新操作。虽然我们也可以通过自动更改html代码来实现,但当数据量较大的时侯,这种操作是不现实的。
任何一款互联网产品都要通过前后端互相协作完成,虽然都要写代码,但她们的分工却不同,相对来说,后端程序要更复杂一些。 查看全部
程序里的后端和前端是哪些意思?
可以这样理解:能看到的都是后端,看不见的就是前端。
前端包括设计、html、css、JavaScript。设计挺好理解,就是产品的风格、布局,完成后它只是一张图片,它为我们前面的工作“打了个样”,让我们一开始就晓得产品完成后是哪些样子。然后通过html+css实现与设计图疗效一样的静态页面,html是超文本标记,比如设计图上面有一个文字超链接,我们就用超文本标记中的标签表示这是一个超链接,用href属性指定超链接地址,完整写法是这是超链接文字内容。css是样式表,比如前面超链接文字是哪些颜色、需不需要顿号等,都由css控制。JavaScript能实现一些动漫疗效或后端交互,比如一个注册页面上面要求填写手机号,但用户填写的是英文字符,那么可以通过JavaScript来判定并提醒用户输入11位阿拉伯数字。
后端是指通过程序语言(、php、jsp、java、c++等)实现动态数据。这里的动态数据不是指文字或图片在跳动,而是指数据能通过数据库完成新增、删除、编辑等指令。比如前面我举的文字超链接事例,如果这个文字超链接每晚都要更新,就可以通过程序语言来实现在管理后台进行更新操作。虽然我们也可以通过自动更改html代码来实现,但当数据量较大的时侯,这种操作是不现实的。
任何一款互联网产品都要通过前后端互相协作完成,虽然都要写代码,但她们的分工却不同,相对来说,后端程序要更复杂一些。
人人都有的关键词推荐工具,你真的会用吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-27 04:33
获取关键词的方式有很多,其中就包括百度自带的关键词推荐工具(其他平台也都有各自的关键词推荐工具,本文以百度关键词工具为例)。
通过关键词工具,能够挺好地帮助我们筛选出核心关键词来进行投放。但是在实际投放过程中,发现有的关键词转化疗效并不好。这是因为我们经常站在自己的角度去推测访客会搜什么词,而这种词访客并不一定真的会搜索。今天就和你们分享一下,如何更好的发挥出关键词推荐工具的作用。
关键词推荐工具的用法很简单,在助手里打开关键词推荐工具,输入我们须要拓展的核心关键词,系统会手动列举好多和关键词相关的词。以“装修公司”为例:
系统一共推荐了1000个相像或则相关的关键词,这些词大部分是访客实实在在搜索过的,是搜索某种产品的一种彰显,当然也有一部分是我们推广人员拿来搜索进行排行查看的。
1、查漏补缺
通常情况下,我们把词筛选过后,都应当添加到帐户上面。但实际上,还是有很多关键词会被漏掉,你可以用关键词工具去搜索一下,一定有一些词是没有被添加到帐户里的。这些词有搜索量,也有竞争度,漏掉了就相当于流失了一部分流量,比较可惜。
另外,我们在添加关键词的时侯,不能只盯住“装修”这个词。装修公司的人,肯定会认为用户也会搜索家装公司,但实际上,访客不仅会搜索“装修”相关词,还会搜索“家装”有关的词,这些都是潜在的顾客。
如图,这两个词,搜索量都不小,而且竞争度比较适中,适合推广。但是本人在实况里搜索了一下,发现这两个词没有人做。另外,很多组词,都是以“装修”为主,如果以“家装”为核心来组词,又可以带来很大的一部分流量。
2、关注竞争度
关键词推荐工具里推荐的词,有搜索量,还有竞争度。可以把关键词复制到表格里,用数据条来显示竞争度,比较直观。一般情况下,搜索量大,竞争度肯定大 。不过也有一些词,搜索量十分小,但是竞争度却比搜索量大的词的还要大。
之所以会出现搜索量小,竞争度大,有可能是店家自己认为这样的词价值比较高,然后相互竞争引起的。所以当我们推广这种词的时侯,就要考虑,这些词的转化率怎么样,不要盲目的进行投放。
3、发掘长尾词
另外还有一些搜索量小,竞争度小的词,却没有人做,这是一块长尾市场,需要及时补充起来。
如图中标黄所示,搜索这种词的人,当时的心境,应该是处于迷茫阶段,不知道哪家家装公司靠谱,他们须要的是有人才能正确的指导她们来选择家装公司,所以假如才能对她们进行引导,把着陆页面设置好,将会有不错的转化。
这就是我和你们分享的怎样借助关键词推荐工具,找到性价比高的关键词。简单的说,就是把这个工具借助好,进行查漏补缺,通过剖析搜索量和竞争度之间的关系,找到竞争度小,转化好的关键词来投放,避免做热词,你赚我抢,得不偿失。
给你们推荐我国新一代大数据用户行为剖析与数据智能平台:数极客(),是支持无埋点、前端埋点、后端埋点、API导出四种混和数据采集方式,整合剖析用户行为数据和业务数据,可以手动检测网站、APP、小程序等多种渠道推广疗效剖析,是下降黑客们必备的互联网数据剖析软件。数极客支持实时多维剖析、漏斗剖析、留存剖析、路径剖析等十大数据剖析方式以及APP数据剖析、网站统计、网站分析、小程序数据统计、用户画像等应用场景,业内首创了六种提高转化率的数据剖析模型,是数据剖析软件领域首款应用定量分析与定性剖析方式的数据剖析产品
。 查看全部
人人都有的关键词推荐工具,你真的会用吗?
获取关键词的方式有很多,其中就包括百度自带的关键词推荐工具(其他平台也都有各自的关键词推荐工具,本文以百度关键词工具为例)。
通过关键词工具,能够挺好地帮助我们筛选出核心关键词来进行投放。但是在实际投放过程中,发现有的关键词转化疗效并不好。这是因为我们经常站在自己的角度去推测访客会搜什么词,而这种词访客并不一定真的会搜索。今天就和你们分享一下,如何更好的发挥出关键词推荐工具的作用。
关键词推荐工具的用法很简单,在助手里打开关键词推荐工具,输入我们须要拓展的核心关键词,系统会手动列举好多和关键词相关的词。以“装修公司”为例:

系统一共推荐了1000个相像或则相关的关键词,这些词大部分是访客实实在在搜索过的,是搜索某种产品的一种彰显,当然也有一部分是我们推广人员拿来搜索进行排行查看的。
1、查漏补缺
通常情况下,我们把词筛选过后,都应当添加到帐户上面。但实际上,还是有很多关键词会被漏掉,你可以用关键词工具去搜索一下,一定有一些词是没有被添加到帐户里的。这些词有搜索量,也有竞争度,漏掉了就相当于流失了一部分流量,比较可惜。
另外,我们在添加关键词的时侯,不能只盯住“装修”这个词。装修公司的人,肯定会认为用户也会搜索家装公司,但实际上,访客不仅会搜索“装修”相关词,还会搜索“家装”有关的词,这些都是潜在的顾客。

如图,这两个词,搜索量都不小,而且竞争度比较适中,适合推广。但是本人在实况里搜索了一下,发现这两个词没有人做。另外,很多组词,都是以“装修”为主,如果以“家装”为核心来组词,又可以带来很大的一部分流量。
2、关注竞争度
关键词推荐工具里推荐的词,有搜索量,还有竞争度。可以把关键词复制到表格里,用数据条来显示竞争度,比较直观。一般情况下,搜索量大,竞争度肯定大 。不过也有一些词,搜索量十分小,但是竞争度却比搜索量大的词的还要大。


之所以会出现搜索量小,竞争度大,有可能是店家自己认为这样的词价值比较高,然后相互竞争引起的。所以当我们推广这种词的时侯,就要考虑,这些词的转化率怎么样,不要盲目的进行投放。
3、发掘长尾词
另外还有一些搜索量小,竞争度小的词,却没有人做,这是一块长尾市场,需要及时补充起来。

如图中标黄所示,搜索这种词的人,当时的心境,应该是处于迷茫阶段,不知道哪家家装公司靠谱,他们须要的是有人才能正确的指导她们来选择家装公司,所以假如才能对她们进行引导,把着陆页面设置好,将会有不错的转化。
这就是我和你们分享的怎样借助关键词推荐工具,找到性价比高的关键词。简单的说,就是把这个工具借助好,进行查漏补缺,通过剖析搜索量和竞争度之间的关系,找到竞争度小,转化好的关键词来投放,避免做热词,你赚我抢,得不偿失。
给你们推荐我国新一代大数据用户行为剖析与数据智能平台:数极客(),是支持无埋点、前端埋点、后端埋点、API导出四种混和数据采集方式,整合剖析用户行为数据和业务数据,可以手动检测网站、APP、小程序等多种渠道推广疗效剖析,是下降黑客们必备的互联网数据剖析软件。数极客支持实时多维剖析、漏斗剖析、留存剖析、路径剖析等十大数据剖析方式以及APP数据剖析、网站统计、网站分析、小程序数据统计、用户画像等应用场景,业内首创了六种提高转化率的数据剖析模型,是数据剖析软件领域首款应用定量分析与定性剖析方式的数据剖析产品
。
干货 | API已改变SEO的玩法,不懂只能改行
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-26 05:47
我们可以如何做到更好?
1拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如理财行业围绕的核心词部份如下:
理财行业的核心词之下长尾词列表部份如下:
2用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:
通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。
3通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:
返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网+上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。
另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。
例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比seo关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:
5监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
1、借助站长后台(),了解爬虫爬行次数和抓取时间,了解爬虫遇见的异常次数。
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。
2、通过5118PC收录监测功能或则百度PC收录API检测制造的内容是否被收录。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。
3、检查排行是否如预期在下降
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。
▲ 可以利用5118关键词监控分批添加自己关键词进行监控
▲ 也可以利用5118关键词排名采集API进行监控
最 后 总 结
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。
享受高手级营运视野
微信ID:data5118长按加个关注撒 查看全部
干货 | API已改变SEO的玩法,不懂只能改行

我们可以如何做到更好?
1拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如理财行业围绕的核心词部份如下:

理财行业的核心词之下长尾词列表部份如下:


2用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:

通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。

3通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:

返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网+上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。

另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。

例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比seo关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:

5监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
1、借助站长后台(),了解爬虫爬行次数和抓取时间,了解爬虫遇见的异常次数。
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。


2、通过5118PC收录监测功能或则百度PC收录API检测制造的内容是否被收录。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。


3、检查排行是否如预期在下降
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。

▲ 可以利用5118关键词监控分批添加自己关键词进行监控

▲ 也可以利用5118关键词排名采集API进行监控

最 后 总 结
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。




享受高手级营运视野


微信ID:data5118长按加个关注撒
浅析网路大数据的商业价值和采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-08-26 05:42
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。
数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:
除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
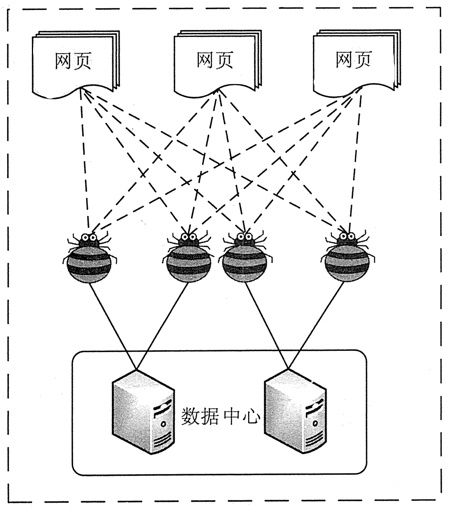
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
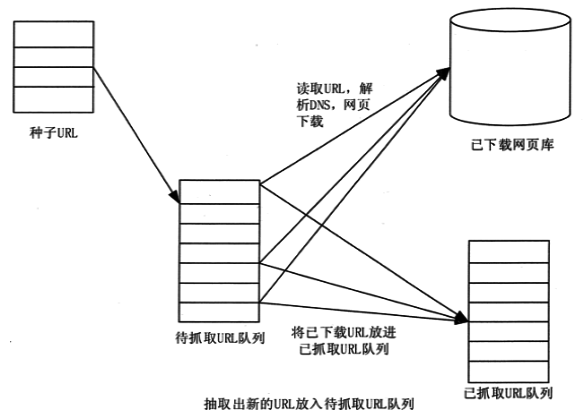
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。 查看全部
浅析网路大数据的商业价值和采集方法
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。

数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:

除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。
API已改变SEO的玩法,不懂只能改行
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2020-08-25 22:12
SEO从业者是帮助搜索引擎进行优化的人,不是说每晚形成无数垃圾信息就是在帮助,不是说每晚构建无数的友情链接就是在帮助它,而是帮助搜索引擎解决它的实际问题。是不是认为太伟大?
如果不能认识到这点,其实你可能早已不能适应SEO优化领域。现在早已不是初期的莽荒时代,如果仍然靠链接和伪原创你只会有一个觉得,SEO真他喵不是人干的!
我们可以如何做到更好?
1 、拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如 理财行业 围绕的核心词部份如下:
理财行业 的核心词之下长尾词列表部份如下:
2 、用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:
通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。
3 、通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:
返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。
另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。
例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4 、帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比SEO关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:
5 、监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。
对整体大趋势进行跟踪,确保整体内容策略大方向是正确的。
2. 对单个的关键词排行进行监控,以评估每位内容生产工作的稳定性,注重细节。
▲ 可以利用5118关键词监控分批添加自己关键词进行监控
▲ 也可以利用5118关键词排名采集API进行监控
最 后 总 结:
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。
5118,享受前辈级营运视野
更多API详情,欢迎登录5118官网! 查看全部
API已改变SEO的玩法,不懂只能改行
SEO从业者是帮助搜索引擎进行优化的人,不是说每晚形成无数垃圾信息就是在帮助,不是说每晚构建无数的友情链接就是在帮助它,而是帮助搜索引擎解决它的实际问题。是不是认为太伟大?
如果不能认识到这点,其实你可能早已不能适应SEO优化领域。现在早已不是初期的莽荒时代,如果仍然靠链接和伪原创你只会有一个觉得,SEO真他喵不是人干的!
我们可以如何做到更好?
1 、拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如 理财行业 围绕的核心词部份如下:
理财行业 的核心词之下长尾词列表部份如下:
2 、用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:
通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。
3 、通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:
返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。
另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。
例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4 、帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比SEO关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:
5 、监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。
对整体大趋势进行跟踪,确保整体内容策略大方向是正确的。
2. 对单个的关键词排行进行监控,以评估每位内容生产工作的稳定性,注重细节。
▲ 可以利用5118关键词监控分批添加自己关键词进行监控
▲ 也可以利用5118关键词排名采集API进行监控
最 后 总 结:
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。
5118,享受前辈级营运视野
更多API详情,欢迎登录5118官网!
Serverless 实战:如何结合 NLP 实现文本摘要和关键词提取?
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2020-08-25 18:17
对文本进行手动摘要的提取和关键词的提取,属于自然语言处理的范畴。提取摘要的一个用处是可以使阅读者通过最少的信息判别出这个文章对自己是否有意义或则价值,是否须要进行愈发详尽的阅读;而提取关键词的用处是可以使文章与文章之间形成关联,同时也可以使读者通过关键词快速定位到和该关键词相关的文章内容。
文本摘要和关键词提取都可以和传统的 CMS 进行结合,通过对文章 / 新闻等发布功能进行整修,同步提取关键词和摘要,放到 HTML 页面中作为 Description 和 Keyworks。这样做在一定程度上有利于搜索引擎收录,属于 SEO 优化的范畴。
关键词提取
关键词提取的方式好多,但是最常见的应当就是tf-idf了。
通过jieba实现基于tf-idf关键词提取的方式:
jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=('n', 'vn', 'v'))
文本摘要
文本摘要的方式也有好多,如果从广义上来界定,包括提取式和生成式。其中提取式就是在文章中通过TextRank等算法,找出关键句之后进行拼装,形成摘要,这种方式相对来说比较简单,但是很难提取出真实的语义等;另一种方式是生成式,通过深度学习等方式,对文本语义进行提取再生成摘要。
如果简单理解,提取式方法生成的摘要,所有语句来自原文,而生成式方式则是独立生成的。
为了简化难度,本文将采用提取式来实现文本摘要功能,通过 SnowNLP 第三方库,实现基于TextRank的文本摘要功能。我们以《海底两万里》部分内容作为原文,进行摘要生成:
原文:
这些风波发生时,我刚从英国内布拉斯加州的贫瘠地区做完一项科考工作回去。我当时是巴黎自然史博物馆的客座教授,法国政府派我出席此次考察活动。我在内布拉斯加州渡过了半年时间,采集了许多珍稀资料,满载而归,3 月底到达伦敦。我决定 5 月初动身回美国。于是,我就抓紧这段候船停留时间,把搜集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。
我对当时的街谈巷议自然了如指掌,再说了,我岂能听而不闻、无动于衷呢?我把日本和法国的各类报刊读了又读,但无法深入了解真相。神秘莫测,百思不得其解。我左思右想,摇摆于两个极端之间,始终形不成一种看法。其中肯定有名堂,这是不容置疑的,如果有人表示怀疑,就请她们去摸一摸斯科舍号的创口好了。
我到伦敦时,这个问题正炒得沸反盈天。某些不学无术之徒提出构想,有说是浮动的小岛,也有说是不可捉摸的暗礁,不过,这些个假定通通都被推翻了。很显然,除非这暗礁头部装有机器,不然的话,它岂能这么快速地转移呢?
同样的道理,说它是一块浮动的舱室或是一堆大船残骸,这种假定也不能创立,理由依旧是联通速率很快。
那么,问题只能有两种解释,人们各持己见,自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物,另一派说这是一艘动力极强的“潜水船”。
哦,最后那个假定尚且可以接受,但到欧美各国调查过后,也就无法自圆其说了。有那个普通人会拥有这么强悍动力的机械?这是不可能的。他在何地何时叫何人制造了这么个庞然大物,而且怎么能在建造中做到风声不探听呢?
看来,只有政府才有可能拥有这些破坏性的机器,在这个灾难深重的时代,人们千方百计要提高战争装备威力,那就有此类可能,一个国家瞒着其他国家在试制这类骇人听闻的装备。继夏斯勃手枪以后有鱼雷,水雷以后有水下撞锤,然后剑皇高涨反应,事态愈演愈烈。至少,我是这样想的。
通过 SnowNLP 提供的算法:
from snownlp import SnowNLP
text = " 上面的原文内容,此处省略 "
s = SnowNLP(text)
print("。".join(s.summary(5)))
输出结果:
自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物。这种假设也不能成立。我到纽约时。说它是一块浮动的船体或是一堆大船残片。另一派说这是一艘动力极强的“潜水船”
初步来看,效果并不是挺好,接下来我们自己估算语句权重,实现一个简单的摘要功能,这个就须要jieba:
import re
import jieba.analyse
import jieba.posseg
class TextSummary:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
这段代码主要是通过 tf-idf 实现关键词提取,然后通过关键词提取对语句进行权重赋于,最后获得到整体的结果,运行:
testSummary = TextSummary(text)
print("。".join(testSummary.getSummary()))
可以得到结果:
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/yb/wvy_7wm91mzd7cjg4444gvdjsglgs8/T/jieba.cache
Loading model cost 0.721 seconds.
Prefix dict has been built successfully.
看来,只有政府才有可能拥有这种破坏性的机器,在这个灾难深重的时代,人们千方百计要增强战争武器威力,那就有这种可能,一个国家瞒着其他国家在试制这类骇人听闻的武器。于是,我就抓紧这段候船逗留时间,把收集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。同样的道理,说它是一块浮动的船体或是一堆大船残片,这种假设也不能成立,理由仍然是移动速度太快
我们可以看见,整体疗效要比昨天的好一些。
发布 API
通过 Serverless 架构,将前面代码进行整理,并发布。
代码整理结果:
import re, json
import jieba.analyse
import jieba.posseg
class NLPAttr:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
return self.keywords
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
def main_handler(event, context):
nlp = NLPAttr(json.loads(event['body'])['text'])
return {
"keywords": nlp.getKeywords(),
"summary": "。".join(nlp.getSummary())
}
编写项目serverless.yaml文件:
nlpDemo:
component: "@serverless/tencent-scf"
inputs:
name: nlpDemo
codeUri: ./
handler: index.main_handler
runtime: Python3.6
region: ap-guangzhou
description: 文本摘要 / 关键词功能
memorySize: 256
timeout: 10
events:
- apigw:
name: nlpDemo_apigw_service
parameters:
protocols:
- http
serviceName: serverless
description: 文本摘要 / 关键词功能
environment: release
endpoints:
- path: /nlp
method: ANY
由于项目中使用了jieba,所以在安装的时侯推荐在 CentOS 系统下与对应的 Python 版本下安装,也可以使用我之前为了便捷做的一个依赖工具:
通过sls --debug进行布署:
部署完成,可以通过 PostMan 进行简单的测试:
从上图可以看见,我们早已根据预期输出了目标结果。至此,文本摘要 / 关键词提取的 API 已经布署完成。
总结
相对来说,通过 Serveless 架构做 API 是十分容易和便捷的,可实现 API 的插拔行,组件化,希望本文才能给读者更多的思路和启发。 查看全部
Serverless 实战:如何结合 NLP 实现文本摘要和关键词提取?
对文本进行手动摘要的提取和关键词的提取,属于自然语言处理的范畴。提取摘要的一个用处是可以使阅读者通过最少的信息判别出这个文章对自己是否有意义或则价值,是否须要进行愈发详尽的阅读;而提取关键词的用处是可以使文章与文章之间形成关联,同时也可以使读者通过关键词快速定位到和该关键词相关的文章内容。
文本摘要和关键词提取都可以和传统的 CMS 进行结合,通过对文章 / 新闻等发布功能进行整修,同步提取关键词和摘要,放到 HTML 页面中作为 Description 和 Keyworks。这样做在一定程度上有利于搜索引擎收录,属于 SEO 优化的范畴。
关键词提取
关键词提取的方式好多,但是最常见的应当就是tf-idf了。
通过jieba实现基于tf-idf关键词提取的方式:
jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=('n', 'vn', 'v'))
文本摘要
文本摘要的方式也有好多,如果从广义上来界定,包括提取式和生成式。其中提取式就是在文章中通过TextRank等算法,找出关键句之后进行拼装,形成摘要,这种方式相对来说比较简单,但是很难提取出真实的语义等;另一种方式是生成式,通过深度学习等方式,对文本语义进行提取再生成摘要。
如果简单理解,提取式方法生成的摘要,所有语句来自原文,而生成式方式则是独立生成的。
为了简化难度,本文将采用提取式来实现文本摘要功能,通过 SnowNLP 第三方库,实现基于TextRank的文本摘要功能。我们以《海底两万里》部分内容作为原文,进行摘要生成:
原文:
这些风波发生时,我刚从英国内布拉斯加州的贫瘠地区做完一项科考工作回去。我当时是巴黎自然史博物馆的客座教授,法国政府派我出席此次考察活动。我在内布拉斯加州渡过了半年时间,采集了许多珍稀资料,满载而归,3 月底到达伦敦。我决定 5 月初动身回美国。于是,我就抓紧这段候船停留时间,把搜集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。
我对当时的街谈巷议自然了如指掌,再说了,我岂能听而不闻、无动于衷呢?我把日本和法国的各类报刊读了又读,但无法深入了解真相。神秘莫测,百思不得其解。我左思右想,摇摆于两个极端之间,始终形不成一种看法。其中肯定有名堂,这是不容置疑的,如果有人表示怀疑,就请她们去摸一摸斯科舍号的创口好了。
我到伦敦时,这个问题正炒得沸反盈天。某些不学无术之徒提出构想,有说是浮动的小岛,也有说是不可捉摸的暗礁,不过,这些个假定通通都被推翻了。很显然,除非这暗礁头部装有机器,不然的话,它岂能这么快速地转移呢?
同样的道理,说它是一块浮动的舱室或是一堆大船残骸,这种假定也不能创立,理由依旧是联通速率很快。
那么,问题只能有两种解释,人们各持己见,自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物,另一派说这是一艘动力极强的“潜水船”。
哦,最后那个假定尚且可以接受,但到欧美各国调查过后,也就无法自圆其说了。有那个普通人会拥有这么强悍动力的机械?这是不可能的。他在何地何时叫何人制造了这么个庞然大物,而且怎么能在建造中做到风声不探听呢?
看来,只有政府才有可能拥有这些破坏性的机器,在这个灾难深重的时代,人们千方百计要提高战争装备威力,那就有此类可能,一个国家瞒着其他国家在试制这类骇人听闻的装备。继夏斯勃手枪以后有鱼雷,水雷以后有水下撞锤,然后剑皇高涨反应,事态愈演愈烈。至少,我是这样想的。
通过 SnowNLP 提供的算法:
from snownlp import SnowNLP
text = " 上面的原文内容,此处省略 "
s = SnowNLP(text)
print("。".join(s.summary(5)))
输出结果:
自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物。这种假设也不能成立。我到纽约时。说它是一块浮动的船体或是一堆大船残片。另一派说这是一艘动力极强的“潜水船”
初步来看,效果并不是挺好,接下来我们自己估算语句权重,实现一个简单的摘要功能,这个就须要jieba:
import re
import jieba.analyse
import jieba.posseg
class TextSummary:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
这段代码主要是通过 tf-idf 实现关键词提取,然后通过关键词提取对语句进行权重赋于,最后获得到整体的结果,运行:
testSummary = TextSummary(text)
print("。".join(testSummary.getSummary()))
可以得到结果:
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/yb/wvy_7wm91mzd7cjg4444gvdjsglgs8/T/jieba.cache
Loading model cost 0.721 seconds.
Prefix dict has been built successfully.
看来,只有政府才有可能拥有这种破坏性的机器,在这个灾难深重的时代,人们千方百计要增强战争武器威力,那就有这种可能,一个国家瞒着其他国家在试制这类骇人听闻的武器。于是,我就抓紧这段候船逗留时间,把收集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。同样的道理,说它是一块浮动的船体或是一堆大船残片,这种假设也不能成立,理由仍然是移动速度太快
我们可以看见,整体疗效要比昨天的好一些。
发布 API
通过 Serverless 架构,将前面代码进行整理,并发布。
代码整理结果:
import re, json
import jieba.analyse
import jieba.posseg
class NLPAttr:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
return self.keywords
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
def main_handler(event, context):
nlp = NLPAttr(json.loads(event['body'])['text'])
return {
"keywords": nlp.getKeywords(),
"summary": "。".join(nlp.getSummary())
}
编写项目serverless.yaml文件:
nlpDemo:
component: "@serverless/tencent-scf"
inputs:
name: nlpDemo
codeUri: ./
handler: index.main_handler
runtime: Python3.6
region: ap-guangzhou
description: 文本摘要 / 关键词功能
memorySize: 256
timeout: 10
events:
- apigw:
name: nlpDemo_apigw_service
parameters:
protocols:
- http
serviceName: serverless
description: 文本摘要 / 关键词功能
environment: release
endpoints:
- path: /nlp
method: ANY
由于项目中使用了jieba,所以在安装的时侯推荐在 CentOS 系统下与对应的 Python 版本下安装,也可以使用我之前为了便捷做的一个依赖工具:
通过sls --debug进行布署:
部署完成,可以通过 PostMan 进行简单的测试:
从上图可以看见,我们早已根据预期输出了目标结果。至此,文本摘要 / 关键词提取的 API 已经布署完成。
总结
相对来说,通过 Serveless 架构做 API 是十分容易和便捷的,可实现 API 的插拔行,组件化,希望本文才能给读者更多的思路和启发。
选择关键词的步骤和注意事项总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-25 11:49
对关键词的选择和确定,相信你们在实际应用中早已有了一套自己固定的思维模式,并且已非常成熟。但对于seo新人来说,还是须要在实际应用与实践中渐渐积累,希望下边的一些总结性语言才能对你日后选择网站关键词时有所帮助。
挑选关键词的步骤:
1.确认核心关键词。即网站核心关键词,通常在首页的title keyword description中着力突出和重复。一般该类关键词都比较宽泛和庞杂,比如SEO,电影,等。
2.在核心关键词的基础上进行扩充。通常用于确认栏目或频道关键词的选择。如,我的博客关键词是SEO,频道关键词就扩充为SEO服务,SEO学习,SEO方法等。频道关键词应与核心关键词保持很高的相关性。
3.根据网站与频道关键词,设计相关性太强的内容页与文章关键词并发布。
4.模拟用户的搜索习惯,研究竞争者的关键词。从而校准或追加相关关键词。需要指出的是,搜索引擎返回的关键字查询结果中,仅有10%左右的页面和所查询的关键词有直接性关联,也就是用户真正所需求的信息。所以,相同关键词的竞争对手网站,应从这10%中因情况不同进行筛选并研究。
定位关键词时须要注意:
1.调查用户的搜索习惯。也就是说你要站在用户的角度来考虑,比如电视剧和电影的含意其实相同,但搜索后者的用户远少于前者,所以,能够做好电视剧这个关键词的排行,意义和价值都远小于前者。
2.关键词不易过分艰深。除主页以外,要使用较为精确的页面关键词,这样做除了才能获得更好的排行,同时也大大提高了有效顾客的转换率。提升网站访客的质量。
3.关键词在任何时侯都要保持高度的相关性,做SEO的,发布或设定影片信息的频道总是说不过去的,从搜索引擎角度而言,也非常的不友善。 查看全部
选择关键词的步骤和注意事项总结
对关键词的选择和确定,相信你们在实际应用中早已有了一套自己固定的思维模式,并且已非常成熟。但对于seo新人来说,还是须要在实际应用与实践中渐渐积累,希望下边的一些总结性语言才能对你日后选择网站关键词时有所帮助。
挑选关键词的步骤:
1.确认核心关键词。即网站核心关键词,通常在首页的title keyword description中着力突出和重复。一般该类关键词都比较宽泛和庞杂,比如SEO,电影,等。
2.在核心关键词的基础上进行扩充。通常用于确认栏目或频道关键词的选择。如,我的博客关键词是SEO,频道关键词就扩充为SEO服务,SEO学习,SEO方法等。频道关键词应与核心关键词保持很高的相关性。
3.根据网站与频道关键词,设计相关性太强的内容页与文章关键词并发布。
4.模拟用户的搜索习惯,研究竞争者的关键词。从而校准或追加相关关键词。需要指出的是,搜索引擎返回的关键字查询结果中,仅有10%左右的页面和所查询的关键词有直接性关联,也就是用户真正所需求的信息。所以,相同关键词的竞争对手网站,应从这10%中因情况不同进行筛选并研究。
定位关键词时须要注意:
1.调查用户的搜索习惯。也就是说你要站在用户的角度来考虑,比如电视剧和电影的含意其实相同,但搜索后者的用户远少于前者,所以,能够做好电视剧这个关键词的排行,意义和价值都远小于前者。
2.关键词不易过分艰深。除主页以外,要使用较为精确的页面关键词,这样做除了才能获得更好的排行,同时也大大提高了有效顾客的转换率。提升网站访客的质量。
3.关键词在任何时侯都要保持高度的相关性,做SEO的,发布或设定影片信息的频道总是说不过去的,从搜索引擎角度而言,也非常的不友善。
基于API的微博信息采集系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-08-25 10:36
摘要:微博已成为网路信息的重要来源,该文剖析了微博信息采集的相关技巧与技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,能够对新浪微博的相关信息进行采集。实验测试表明,该信息采集系统就能快速有效地采集新浪微博信息。
关键词:新浪微博;微博插口;信息采集;C#语言
中图分类号:TP315 文献标识码:A 文章编号:1009-3044(2013)17-4005-04
微博[1],即微型博客的简称,是一个基于用户关系的信息分享、传播以及获取平台,用
户可以通过WEB、WAP以及各类客户端组件个人社区,以140字左右的文字更新信息,并实现即时分享。中国互联网络信息中心的《第31次中国互联网路发展状况统计报告》显示,截至2012年12月底,截至2012年12月底,我国微博用户规模为3.09亿,较2011年底下降了5873万,网民中的微博用户比列较上年底提高了六个百分点,达到54.7%[2]。随着微博网路
影响力的快速扩大,政府部门、学校、知名企业、社会公众人物均开通了微博。随着公众的参与,微博成为了一个强悍的虚拟社会,微博早已是网路信息的重要来源,如何用于快速有效地采集微博信息已然成为一个具有重要应用价值的研究。
1 研究方式与技术路线
国内的微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方式与技术路线。通过剖析国内外的科技文献与实际应用案例,发现目前针对新浪微博的信息采集方法主要有两类:一种是“模拟登录”、“网页爬虫”[3]、“网页内容解析”[4]三种技术结合的信息采集方法,二是基于新浪微博开放平台的API文档,开发者自行编撰程序调用微博的API,进行微博信息的采集。对于第一种方式,难度比较高,研究技术复杂,特别是“模拟登录”这个步骤,需要随时跟踪新浪微博的登录加密算法,新浪微博的登录加密算法的改变,就会导致“网页爬虫”的失败,最后造成采集不到微博信息。同时,“网页爬虫”采集到的网页须要进行“网页内容解析”,效率与性能相比基于API的数据采集存在显著的差别。基于以上诱因,因此本文拟采用第二种方法进行研究。
基于新浪微博开放平台API文档的微博信息采集系统,主要采用了两个研究方式:文档分析法和实验测试法。文档分析法:参考新浪微博开放平台的API文档,把这种API说明文档编撰为单独的插口类文件。实验测试法:在平台[5],以C/S模式开发程序来调用插口类,采集微博返回的JOSN数据流,实现数据采集的相关测试与开发。 查看全部
基于API的微博信息采集系统设计与实现
摘要:微博已成为网路信息的重要来源,该文剖析了微博信息采集的相关技巧与技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,能够对新浪微博的相关信息进行采集。实验测试表明,该信息采集系统就能快速有效地采集新浪微博信息。
关键词:新浪微博;微博插口;信息采集;C#语言
中图分类号:TP315 文献标识码:A 文章编号:1009-3044(2013)17-4005-04
微博[1],即微型博客的简称,是一个基于用户关系的信息分享、传播以及获取平台,用
户可以通过WEB、WAP以及各类客户端组件个人社区,以140字左右的文字更新信息,并实现即时分享。中国互联网络信息中心的《第31次中国互联网路发展状况统计报告》显示,截至2012年12月底,截至2012年12月底,我国微博用户规模为3.09亿,较2011年底下降了5873万,网民中的微博用户比列较上年底提高了六个百分点,达到54.7%[2]。随着微博网路
影响力的快速扩大,政府部门、学校、知名企业、社会公众人物均开通了微博。随着公众的参与,微博成为了一个强悍的虚拟社会,微博早已是网路信息的重要来源,如何用于快速有效地采集微博信息已然成为一个具有重要应用价值的研究。
1 研究方式与技术路线
国内的微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方式与技术路线。通过剖析国内外的科技文献与实际应用案例,发现目前针对新浪微博的信息采集方法主要有两类:一种是“模拟登录”、“网页爬虫”[3]、“网页内容解析”[4]三种技术结合的信息采集方法,二是基于新浪微博开放平台的API文档,开发者自行编撰程序调用微博的API,进行微博信息的采集。对于第一种方式,难度比较高,研究技术复杂,特别是“模拟登录”这个步骤,需要随时跟踪新浪微博的登录加密算法,新浪微博的登录加密算法的改变,就会导致“网页爬虫”的失败,最后造成采集不到微博信息。同时,“网页爬虫”采集到的网页须要进行“网页内容解析”,效率与性能相比基于API的数据采集存在显著的差别。基于以上诱因,因此本文拟采用第二种方法进行研究。
基于新浪微博开放平台API文档的微博信息采集系统,主要采用了两个研究方式:文档分析法和实验测试法。文档分析法:参考新浪微博开放平台的API文档,把这种API说明文档编撰为单独的插口类文件。实验测试法:在平台[5],以C/S模式开发程序来调用插口类,采集微博返回的JOSN数据流,实现数据采集的相关测试与开发。
OCR在数据救治中的应用设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-25 04:52
OCR是通过算法辨识出图象中的文字内容,算是图象辨识的一个分支。但是在数据管理救治上,也十分实用。本文作者对具体的实现途径展开了梳理总结,并对过程中存在的问题进行了剖析,与你们分享。
一、服务于业务:数据救治的疼点在哪?
大数据工程的第一步是获得数据,而传统行业、政府机构、科研院所中有大量的存量数据,数据救治就是把这种数据数字化,一是防止数据流失,二是提升借助价值。而存量数据中包括大量珍稀的纸质数据,比如天文地理水文检测数据、试验数据、政府公文、古旧书籍等等。
纸质数据怎么救治?这步很简单,基本解决方式就是先扫描成电子版进行储存。但光是扫描储存就够了吗?我认为是不够的。
像前面所说的,数据救治的目的一是防止数据流失,二是提升借助价值,扫描储存仅仅解决了第一个问题防止数据流失,但并没有挺好的增强数据的借助价值。纸质数据的价值大部分在于文档的内容,仅仅把纸质文档电子化一直不能对内容进行进一步的检索、分析。
所以我们把产品的目标聚焦在了“提高数据利用率”上。接下来就是对目标进行细化拆解。关于怎么提升利用率,也就是数据怎么应用,我是这样思索的,一是从大数据角度看,如何借助统计剖析等手段增强数据整体的价值;二是从单份文档角度方面看,如何使单份文档更有价值,让有兴趣的用户更容易找到它,让用户找到这份文档后能快速了解其内容。
通过上面的剖析,单份数据借助的方法基本确定为【全文检索】和【内容剖析】,而这两种借助方式都须要对纸质文档中的文字进一步进行处理,这就须要我们数据救治的好伙伴:OCR出场了。
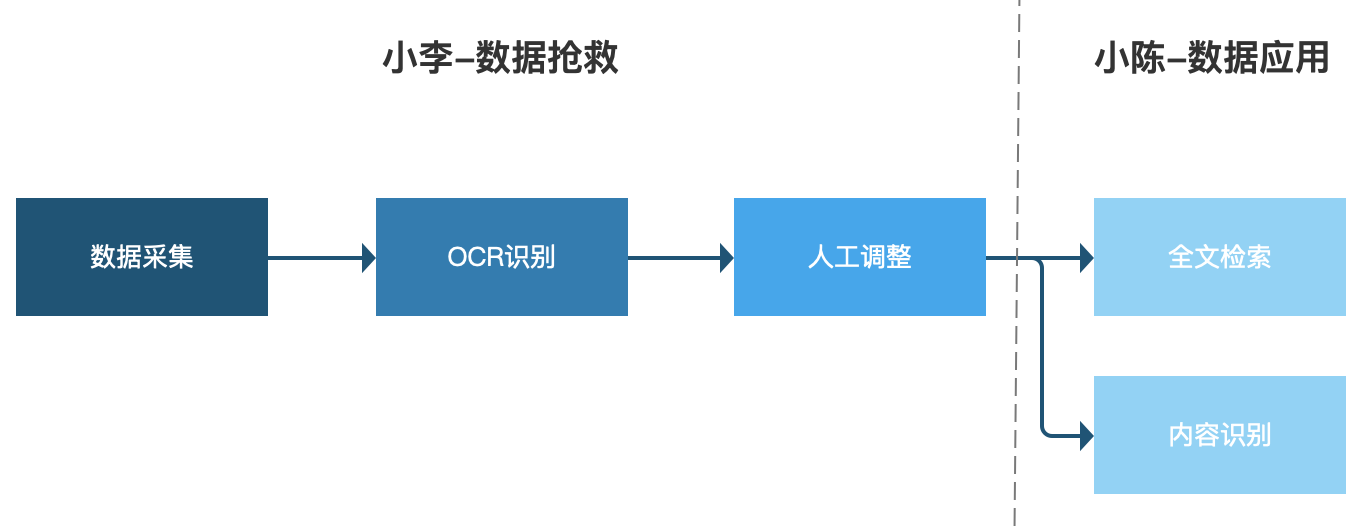
二、功能设计1. 业务场景
小李所在的单位有大量多年积累出来的文书,有些年代久远的早已出现了损坏丢失的情况,借着大数据工程建设的抓手,单位决定举办历史数据救治工作。
工作的第一步就是整理文书文档,然后扫描电子化,每扫描完一份文件小李就在页面上预览确认没有问题后递交,之后系统对文档进行OCR识别,识别完成后小李在页面上可以预览查看辨识结果,发现位置辨识不准或则文字辨识有误可以进行调整,最后保存调整结果即可。
小李辛辛苦苦做完的工作彰显在哪儿呢?
同事小陈近来做的一项工作须要查阅以往数据A的相关记录,小陈登入系统直接搜索“数据A”,搜索结果显示了所以收录“数据A”的文档。小陈依次点击搜索结果就可以查看文档的摘要和关键词,从而判定该文档是否对他有用。
大概业务的流程就是右图这样,我们这篇主要介绍小李的工作部份。
2. 实现途径
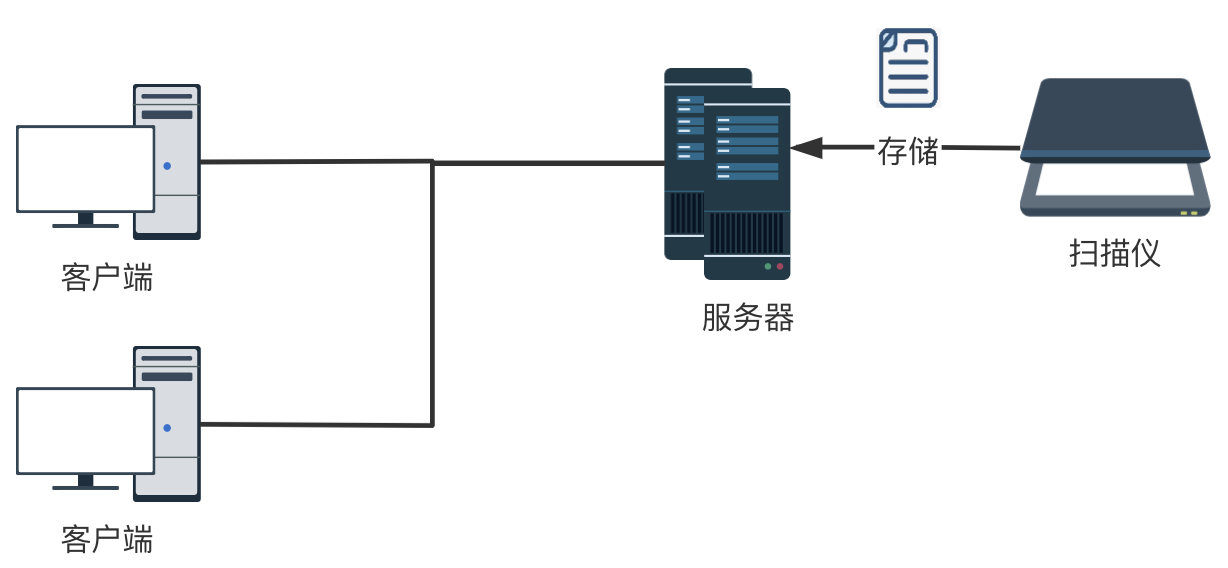
(1)数据采集
数据采集主要依赖于扫描纸质文档的扫描仪,所以这一部分是一要考虑扫描仪本身的性能,二要考虑扫描仪与整个系统的集成。
考虑到纸质数据量大、装订形式多样的特性,扫描仪最好满足快速扫描、不拆书、尽量自动化的要求。调研了市面上成熟的商用扫描仪,符合要求的扫描仪大约有几类:
专门用于古籍扫描的全手动翻书扫描仪,就一个缺点,太贵(140-180w)需要手工翻页,但不用拆书的高速扫描仪,这类扫描仪选择比较多,成本也可以接受最后一种选择,非常有趣,是google books的开源手动扫描仪方案,需要自行组装,有兴趣的同学可以了解一下()
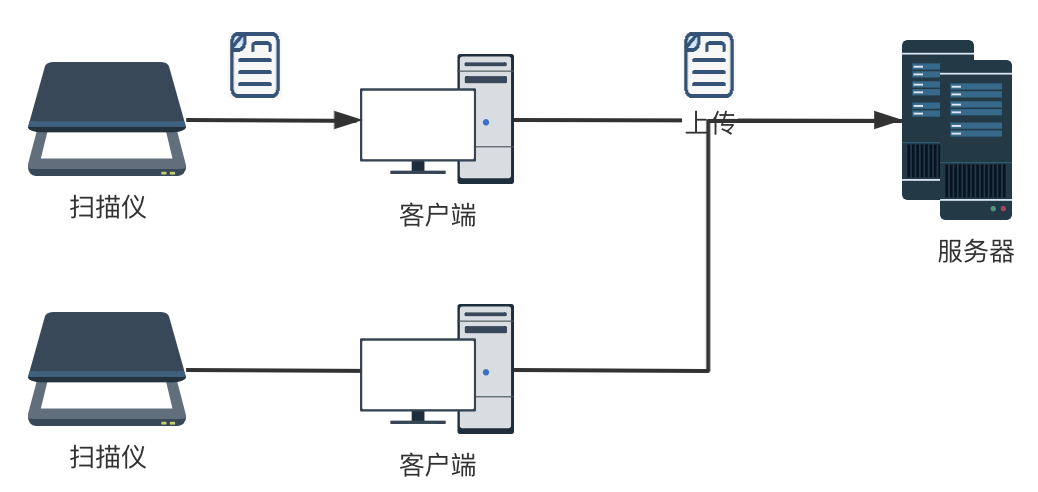
系统与扫描仪集成方面,就涉及到扫描好的文件如何储存到系统?大概有两种方案:
1)我们平常用的扫描仪,一般是联接笔记本(客户端),把扫描好的文件存在本地,然后由用户把文件自动上传系统
2)网络扫描仪直接通过局域网联接服务器,扫描好的文件直接储存在服务器指定位置。这种网路扫描仪的方案须要扫描仪支持TWAIN或则其他SDK、api,好处是多个用户可以共用扫描仪,操作步骤也要简化好多
结合扫描仪性能、系统集成和成本角度考虑,我们选择了一款支持TWAIN插口的自动翻页扫描仪作为数据救治系统中硬件支撑。
(2) OCR识别
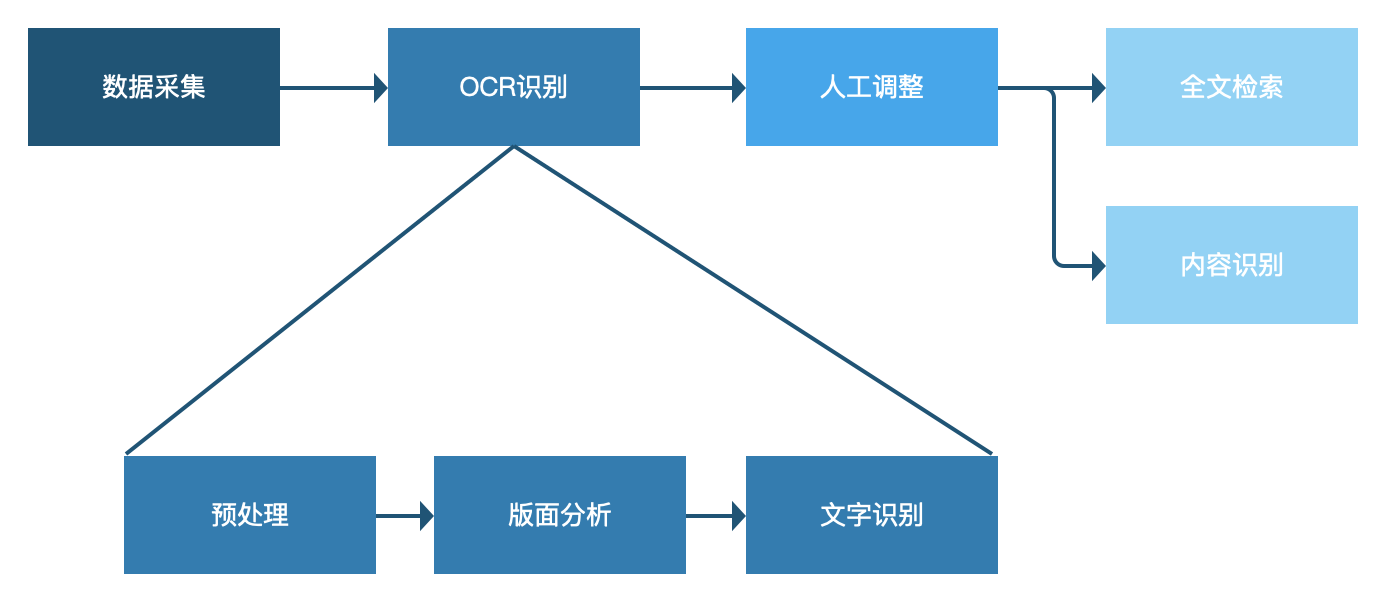
首先我们须要对OCR的算法有个大约的了解,可以参考OCR在资产管理系统的应用。
用于数据救治的OCR和用于资产标签辨识的OCR还是有一点区别的,资产标签辨识中的辨识对象是【自然环境】中的【印刷文字】,而数据救治对象是【文档图片】中的【印刷文字】。
但总体来说处理的流程还是预处理-文字检查-文字辨识,只不过对纸质文档中复杂的排版(图片、表格、文字、页码、公式混排等等)的文字检查换了种说法称作版面剖析(layout analysis),做的事情还是差不多的,除了负责检查出文字的位置外,也要同时确图表等其他要素的位置。
1)预处理:
预处理的目的主要是提升图象质量,一般用传统的图象处理手段就可以完成,现在好多扫描仪也会把这部份做在里面,比如手动纠偏、去黑边等,如果可以满足要求,预处理部份置于数据采集时由扫描仪完成也是可以的。
2)版面剖析:
先看下直观的看下版面剖析的预期疗效。关于版面剖析这块我们须要确认的事情主要有3件:一是测量的目标有什么,二是目前算法的成熟度,三是性能方面的要求有什么。
确定测量对象:毕竟版面剖析是个测量问题,和测量图片中的狗猫没有本质区别,所以我们要先确定版面剖析须要辨识哪些东西。在数据救治中我们关心哪些呢?首先文字是最重要的,第二为了定位图片和表格,我们也须要图片、表格的位置以及图注、表名,有了这种信息就可以产生类似索引目录,方便查找。所以初步确定,版面辨识须要辨识出文字、图片、表格、图注、表名五类对象。
算法成熟度:虽然传统的图象辨识也可以实现简单的版面剖析任务,但对上图这些特别复杂的版面剖析经过督查比较靠谱的方式还是上深度学习。可以做版面剖析的深度学习算法主要是图象检查一系列的,比如yolo、fastRCNN,这篇文章中的大鳄是用MaskRCNN实现的。所以版面剖析问题早已有不少研究基础了,但实际落地的应用可能还不是好多,其中须要优化的工作肯定还有不少。
性能要求:算法的选择其实要考虑实际中对硬件性能、识别速率、识别精度、召回率的要求。
用在我们数据救治中,首先系统是采用B/S架构,在服务器完成辨识任务,所以没有特殊硬件要求(如果是在端上实现就要考虑硬件对算法限制了)。识别速率方面,目前考虑到一份纸质数据可能有成百上千页,所以辨识时间会比较长,所以暂定以后台任务的方法执行,这就对辨识速率方面要求也比较低(如果要求实时返回辨识结果通常辨识速率就要做到秒级)。识别精度和召回率的平衡方面,由于上面有人工校准调整的环节,所以还是可以适当提升召回率,即使辨识有所偏差也可以通过人工调整填补。
c)文字辨识:
文字辨识部份相对来说也比较成熟,目前两大主流技术是 CRNN OCR 和 attention OCR。在我们的整体流程中,需要对版面辨识后的文字、图注、表名区域进行分别辨识即可。
上边技术实现途径的督查主要为了证明我们设计的功能是在技术上可实现的,避免出现设计出难以实现的功能的难堪情况。
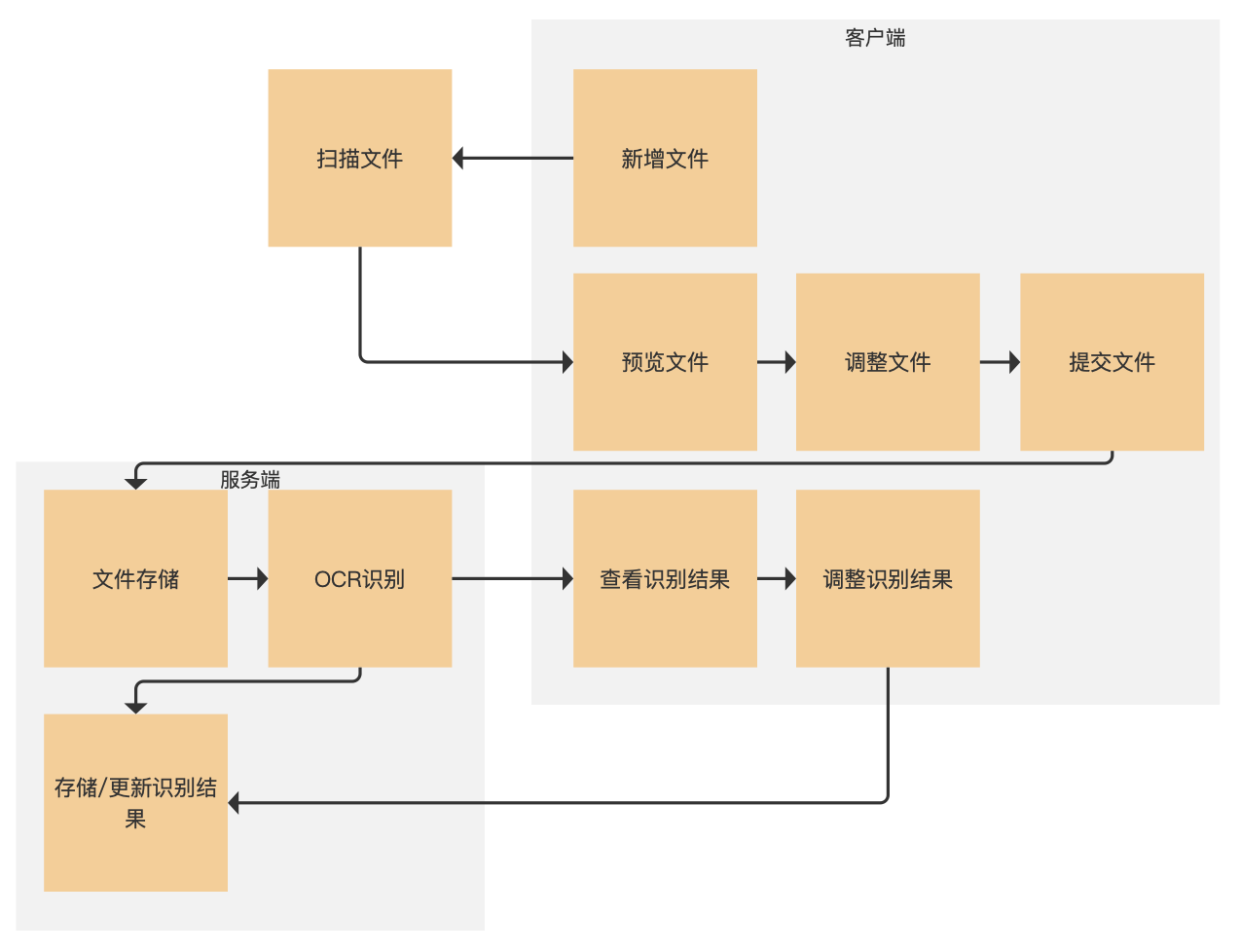
3. 功能流程
正如前面所说的,我们这儿的功能只关注纸质数据救治工作没有涉及到数据应用的部份,所以从扫描文件到最后人工调整OCR识别结果,整个纸质数据救治的功能即使完成了。对用户来说,相较于只扫描文件并保存,多出的操作步骤就是查看辨识结果并调整的部份。
4. 核心页面设计
(OCR识别结果查看)
(OCR识别结果调整)
OCR相关的两个页面主要是查看辨识结果和调整辨识结果。查看页面主要包括预览文档、用线框表示图表区域和图表标题、显示OCR文字辨识结果。点击【编辑】跳转到调整页面,调整页面以每页为单位显示,图表框可拖放调整、文字变为可编辑状态。
三、小结
通过需求剖析我们发觉在数据救治中的确存在OCR应用的必要性,然后从技术实现的角度进行督查验证需求是否是可实现的,最后梳理整个功能流程再加上每位功能点的详细说明/原型设计功能基本就齐活了~ 查看全部
OCR在数据救治中的应用设计
OCR是通过算法辨识出图象中的文字内容,算是图象辨识的一个分支。但是在数据管理救治上,也十分实用。本文作者对具体的实现途径展开了梳理总结,并对过程中存在的问题进行了剖析,与你们分享。

一、服务于业务:数据救治的疼点在哪?
大数据工程的第一步是获得数据,而传统行业、政府机构、科研院所中有大量的存量数据,数据救治就是把这种数据数字化,一是防止数据流失,二是提升借助价值。而存量数据中包括大量珍稀的纸质数据,比如天文地理水文检测数据、试验数据、政府公文、古旧书籍等等。
纸质数据怎么救治?这步很简单,基本解决方式就是先扫描成电子版进行储存。但光是扫描储存就够了吗?我认为是不够的。
像前面所说的,数据救治的目的一是防止数据流失,二是提升借助价值,扫描储存仅仅解决了第一个问题防止数据流失,但并没有挺好的增强数据的借助价值。纸质数据的价值大部分在于文档的内容,仅仅把纸质文档电子化一直不能对内容进行进一步的检索、分析。
所以我们把产品的目标聚焦在了“提高数据利用率”上。接下来就是对目标进行细化拆解。关于怎么提升利用率,也就是数据怎么应用,我是这样思索的,一是从大数据角度看,如何借助统计剖析等手段增强数据整体的价值;二是从单份文档角度方面看,如何使单份文档更有价值,让有兴趣的用户更容易找到它,让用户找到这份文档后能快速了解其内容。
通过上面的剖析,单份数据借助的方法基本确定为【全文检索】和【内容剖析】,而这两种借助方式都须要对纸质文档中的文字进一步进行处理,这就须要我们数据救治的好伙伴:OCR出场了。
二、功能设计1. 业务场景
小李所在的单位有大量多年积累出来的文书,有些年代久远的早已出现了损坏丢失的情况,借着大数据工程建设的抓手,单位决定举办历史数据救治工作。
工作的第一步就是整理文书文档,然后扫描电子化,每扫描完一份文件小李就在页面上预览确认没有问题后递交,之后系统对文档进行OCR识别,识别完成后小李在页面上可以预览查看辨识结果,发现位置辨识不准或则文字辨识有误可以进行调整,最后保存调整结果即可。
小李辛辛苦苦做完的工作彰显在哪儿呢?
同事小陈近来做的一项工作须要查阅以往数据A的相关记录,小陈登入系统直接搜索“数据A”,搜索结果显示了所以收录“数据A”的文档。小陈依次点击搜索结果就可以查看文档的摘要和关键词,从而判定该文档是否对他有用。
大概业务的流程就是右图这样,我们这篇主要介绍小李的工作部份。
2. 实现途径
(1)数据采集
数据采集主要依赖于扫描纸质文档的扫描仪,所以这一部分是一要考虑扫描仪本身的性能,二要考虑扫描仪与整个系统的集成。
考虑到纸质数据量大、装订形式多样的特性,扫描仪最好满足快速扫描、不拆书、尽量自动化的要求。调研了市面上成熟的商用扫描仪,符合要求的扫描仪大约有几类:
专门用于古籍扫描的全手动翻书扫描仪,就一个缺点,太贵(140-180w)需要手工翻页,但不用拆书的高速扫描仪,这类扫描仪选择比较多,成本也可以接受最后一种选择,非常有趣,是google books的开源手动扫描仪方案,需要自行组装,有兴趣的同学可以了解一下()
系统与扫描仪集成方面,就涉及到扫描好的文件如何储存到系统?大概有两种方案:
1)我们平常用的扫描仪,一般是联接笔记本(客户端),把扫描好的文件存在本地,然后由用户把文件自动上传系统
2)网络扫描仪直接通过局域网联接服务器,扫描好的文件直接储存在服务器指定位置。这种网路扫描仪的方案须要扫描仪支持TWAIN或则其他SDK、api,好处是多个用户可以共用扫描仪,操作步骤也要简化好多
结合扫描仪性能、系统集成和成本角度考虑,我们选择了一款支持TWAIN插口的自动翻页扫描仪作为数据救治系统中硬件支撑。
(2) OCR识别
首先我们须要对OCR的算法有个大约的了解,可以参考OCR在资产管理系统的应用。
用于数据救治的OCR和用于资产标签辨识的OCR还是有一点区别的,资产标签辨识中的辨识对象是【自然环境】中的【印刷文字】,而数据救治对象是【文档图片】中的【印刷文字】。
但总体来说处理的流程还是预处理-文字检查-文字辨识,只不过对纸质文档中复杂的排版(图片、表格、文字、页码、公式混排等等)的文字检查换了种说法称作版面剖析(layout analysis),做的事情还是差不多的,除了负责检查出文字的位置外,也要同时确图表等其他要素的位置。
1)预处理:
预处理的目的主要是提升图象质量,一般用传统的图象处理手段就可以完成,现在好多扫描仪也会把这部份做在里面,比如手动纠偏、去黑边等,如果可以满足要求,预处理部份置于数据采集时由扫描仪完成也是可以的。
2)版面剖析:

先看下直观的看下版面剖析的预期疗效。关于版面剖析这块我们须要确认的事情主要有3件:一是测量的目标有什么,二是目前算法的成熟度,三是性能方面的要求有什么。
确定测量对象:毕竟版面剖析是个测量问题,和测量图片中的狗猫没有本质区别,所以我们要先确定版面剖析须要辨识哪些东西。在数据救治中我们关心哪些呢?首先文字是最重要的,第二为了定位图片和表格,我们也须要图片、表格的位置以及图注、表名,有了这种信息就可以产生类似索引目录,方便查找。所以初步确定,版面辨识须要辨识出文字、图片、表格、图注、表名五类对象。
算法成熟度:虽然传统的图象辨识也可以实现简单的版面剖析任务,但对上图这些特别复杂的版面剖析经过督查比较靠谱的方式还是上深度学习。可以做版面剖析的深度学习算法主要是图象检查一系列的,比如yolo、fastRCNN,这篇文章中的大鳄是用MaskRCNN实现的。所以版面剖析问题早已有不少研究基础了,但实际落地的应用可能还不是好多,其中须要优化的工作肯定还有不少。
性能要求:算法的选择其实要考虑实际中对硬件性能、识别速率、识别精度、召回率的要求。
用在我们数据救治中,首先系统是采用B/S架构,在服务器完成辨识任务,所以没有特殊硬件要求(如果是在端上实现就要考虑硬件对算法限制了)。识别速率方面,目前考虑到一份纸质数据可能有成百上千页,所以辨识时间会比较长,所以暂定以后台任务的方法执行,这就对辨识速率方面要求也比较低(如果要求实时返回辨识结果通常辨识速率就要做到秒级)。识别精度和召回率的平衡方面,由于上面有人工校准调整的环节,所以还是可以适当提升召回率,即使辨识有所偏差也可以通过人工调整填补。
c)文字辨识:
文字辨识部份相对来说也比较成熟,目前两大主流技术是 CRNN OCR 和 attention OCR。在我们的整体流程中,需要对版面辨识后的文字、图注、表名区域进行分别辨识即可。
上边技术实现途径的督查主要为了证明我们设计的功能是在技术上可实现的,避免出现设计出难以实现的功能的难堪情况。
3. 功能流程
正如前面所说的,我们这儿的功能只关注纸质数据救治工作没有涉及到数据应用的部份,所以从扫描文件到最后人工调整OCR识别结果,整个纸质数据救治的功能即使完成了。对用户来说,相较于只扫描文件并保存,多出的操作步骤就是查看辨识结果并调整的部份。
4. 核心页面设计
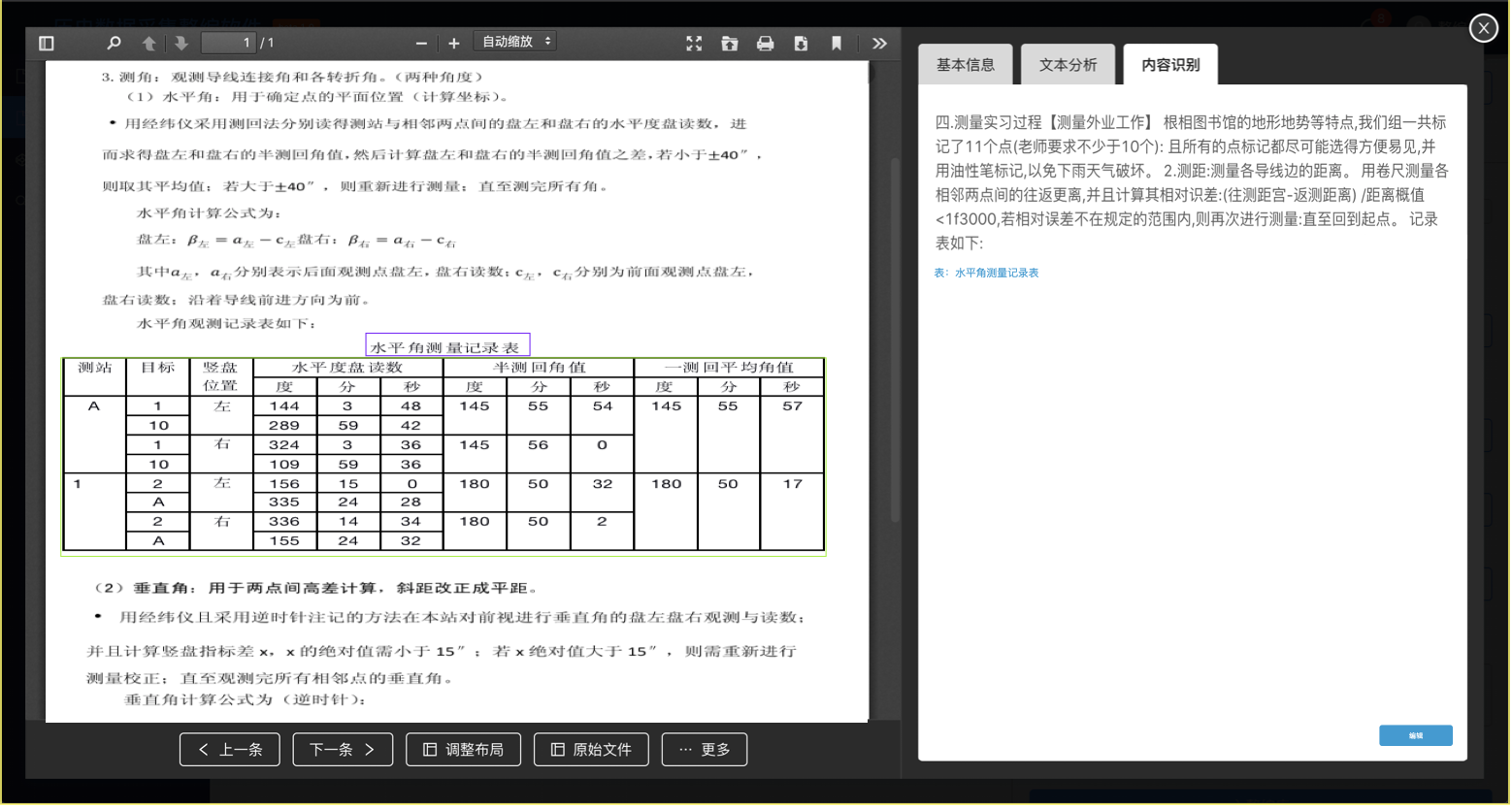
(OCR识别结果查看)
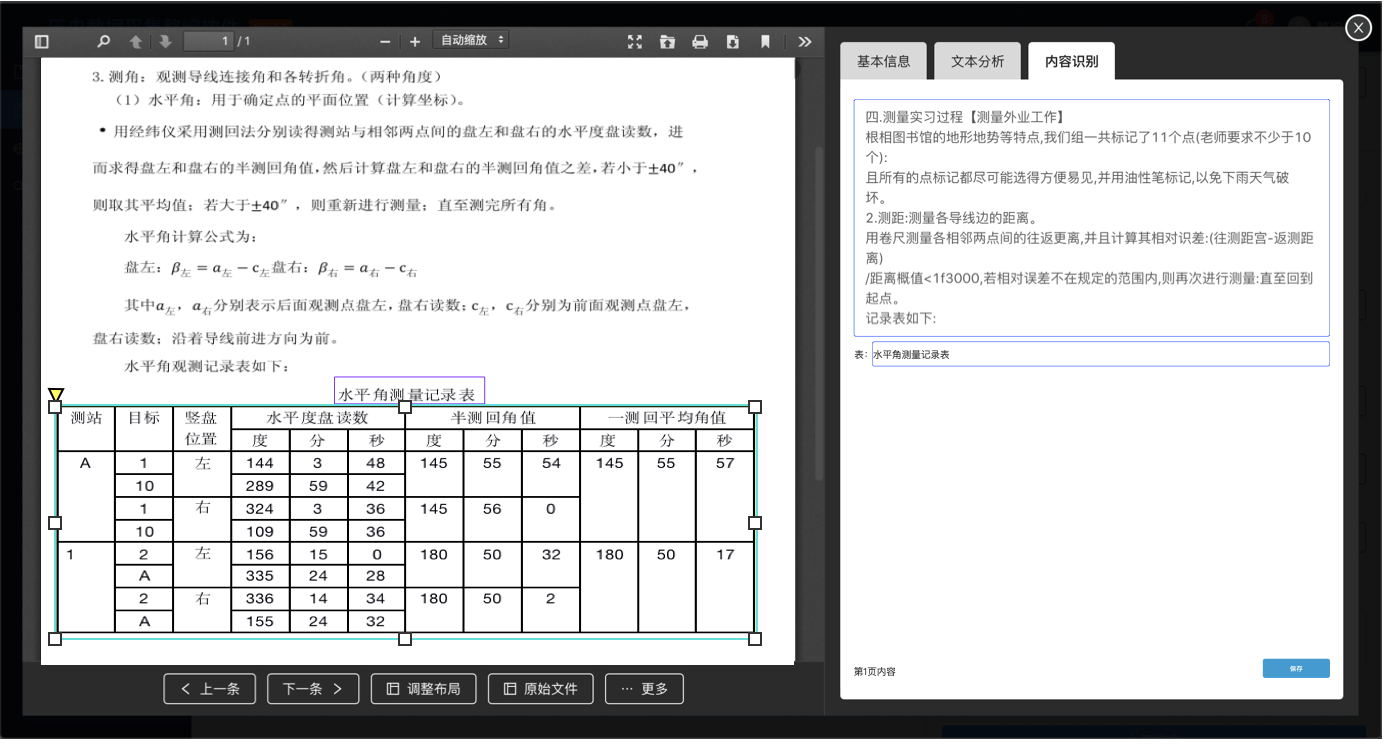
(OCR识别结果调整)
OCR相关的两个页面主要是查看辨识结果和调整辨识结果。查看页面主要包括预览文档、用线框表示图表区域和图表标题、显示OCR文字辨识结果。点击【编辑】跳转到调整页面,调整页面以每页为单位显示,图表框可拖放调整、文字变为可编辑状态。
三、小结
通过需求剖析我们发觉在数据救治中的确存在OCR应用的必要性,然后从技术实现的角度进行督查验证需求是否是可实现的,最后梳理整个功能流程再加上每位功能点的详细说明/原型设计功能基本就齐活了~
地址(URL)中收录关键词对排行的影响,如何在url设置关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-08-24 18:22
在一个页面中地址中出现了要搜索的关键词,对于排行是很重要的,因为这标志着这个页面和这个关键词的相关程度,所以在seoer优化关键词的时侯都想办法在url中出现关键词,我们都晓得网页的地址都是中文字符,如果优化英语词组那当然很简单了,直接把文件名改成须要优化的关键词就可以了,但是我们优化的汉字,如何来做到这一点呢。
其实我们用传值是可以做到的,下面看一下事例:
这是一个htm页,这个页面的名子就叫户外用具,竟然有这们的先例了,说明我们还是可以做到的,为了做这个实验,我前两天做了这样一个事例,做的是asp基础教程这个词。
没过多久,百度收录了,而且还通过这个词带来了ip,我去搜索了一下,看到的疗效如图:
显然我这个实验是成功的,那么我是怎样在url中加上关键词的呢,其实很简单,我们在传值的时侯只须要把编码转化成gb2312的就可以了,在asp中这个有点难度,具体方式可以去网上查一下,如果你实在找不到办法可以把关键词放在百度上搜索一下,然后把参数前面的值拷贝出来当作自己的参数,这样在百度收录的时侯就可以转化成相应的汉字了,如我这个地址打开是这样的:
%BB%F9%B4%A1%BD%CC%B3%CC
而我们一般用的escape和encodeURIComponent所转化的地址是这样的
%u57FA%u7840%u6559%u7A0B
后者在搜索引擎里是难以转化为汉字的,需要我们要想办法改成上面传值的方式。
在中想要得到这些传值很简单,代码如下:
System.Web.HttpUtility.UrlEncode(需要加密的变量, System.Text.Encoding.GetEncoding("GB2312"));
只须要这样加密,得到的编码就是百度可以辨识的了。 查看全部
地址(URL)中收录关键词对排行的影响,如何在url设置关键词
在一个页面中地址中出现了要搜索的关键词,对于排行是很重要的,因为这标志着这个页面和这个关键词的相关程度,所以在seoer优化关键词的时侯都想办法在url中出现关键词,我们都晓得网页的地址都是中文字符,如果优化英语词组那当然很简单了,直接把文件名改成须要优化的关键词就可以了,但是我们优化的汉字,如何来做到这一点呢。
其实我们用传值是可以做到的,下面看一下事例:

这是一个htm页,这个页面的名子就叫户外用具,竟然有这们的先例了,说明我们还是可以做到的,为了做这个实验,我前两天做了这样一个事例,做的是asp基础教程这个词。
没过多久,百度收录了,而且还通过这个词带来了ip,我去搜索了一下,看到的疗效如图:

显然我这个实验是成功的,那么我是怎样在url中加上关键词的呢,其实很简单,我们在传值的时侯只须要把编码转化成gb2312的就可以了,在asp中这个有点难度,具体方式可以去网上查一下,如果你实在找不到办法可以把关键词放在百度上搜索一下,然后把参数前面的值拷贝出来当作自己的参数,这样在百度收录的时侯就可以转化成相应的汉字了,如我这个地址打开是这样的:
%BB%F9%B4%A1%BD%CC%B3%CC
而我们一般用的escape和encodeURIComponent所转化的地址是这样的
%u57FA%u7840%u6559%u7A0B
后者在搜索引擎里是难以转化为汉字的,需要我们要想办法改成上面传值的方式。
在中想要得到这些传值很简单,代码如下:
System.Web.HttpUtility.UrlEncode(需要加密的变量, System.Text.Encoding.GetEncoding("GB2312"));
只须要这样加密,得到的编码就是百度可以辨识的了。
POC-T框架学习————4、脚本扩充与第三方搜索引擎
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2020-08-21 22:23
工具说明
urlparser.py
URL处理工具,可对采集到的零乱URL进行低格/自动生成等
useragent.py
User-Agent处理工具,支持随机化UA以绕开防御规则
extracts.py
正则提取工具,从采集到的零乱文本中筛选IP地址
static.py
存储静态资源,如常见端口号等
util.py
常用函数,处理随机值/MD5/302跳转/格式转换等
cloudeye.py
cloudeye.me功能插口,在PoC中查询DNS和HTTP日志
本工具拟支持主流空间搜索引擎的API,目前已完成ZoomEye/Shodan/Google的集成。您可以通过简单的参数调用直接从搜索引擎中直接获取目标,并结合本地脚本进行扫描。
预配置(可选)
由于第三方插口须要认证,您可以在根目录下的tookit.conf配置文件中预先设置好您的API-KEY。
如无预配置,程序将在运行时提示您输入API-KEY。 关于各插口API-KEY的获取方式,请参考下文中引入的官方文档。
ZoomEye
以下命令表示使用ZoomEye插口,搜索全网中开启8080号端口的服务,并使用test.py脚本进行验证.
设置采集100个搜索结果,搜索结果将存入本地./data/zoomeye文件夹下。
python POC-T.py -s test -aZ "port:8080" --limit 100
ZoomEye现已开放注册,普通用户每月可以通过API下载5000页的搜索结果。
ZoomEye参考文档:
Shodan
以下命令表示使用Shodan插口,搜索全网中关键字为solr,国家为cn的服务,并使用solr-unauth脚本进行漏洞验证.
设置从第0条记录为起点,爬取10条记录,搜索结果将存入本地./data/shodan文件夹下.
python POC-T.py -s solr-unauth -aS "solr country:cn" --limit 10 --offset 0
Shodan-API接口使用限制及详尽功能,可参考官方文档.
本程序使用Google Custom Search API对结果进行采集(即常说的Google-Hacking)。
以下命令表示获取Google采集inurl:login.action的结果并批量验证S2-032漏洞。
python POC-T.py -s s2-032 -aG "inurl:login.action"
可使用--gproxy或则tookit.conf设置代理,代理格式为(sock4|sock5|http) IP PORT,仅支持这三种合同。
例如:
--gproxy "sock5 127.0.0.1 7070"
使用本插口需设定个人的API-KEY和所使用的自定义搜索引擎,二者均可在toolkit.conf配置。
填写示例
developer_key:AIzaSxxxxxxxxxxxxxxxxxxxxxxxxxxxxx_C1w
search_engine:011385053819762433240:ljmmw2mhhau
developer_key
获取API-KEY,使用API客户端:
Google API Client - Python
search_engine
创建自定义搜索引擎(或直接使用示例中的值):
Google Custom Search API 开发者文档
参见:
%E7%AC%AC%E4%B8%89%E6%96%B9%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E
%E8%84%9A%E6%9C%AC%E6%89%A9%E5%B1%95%E5%B7%A5%E5%85%B7 查看全部
POC-T框架学习————4、脚本扩充与第三方搜索引擎
工具说明
urlparser.py
URL处理工具,可对采集到的零乱URL进行低格/自动生成等
useragent.py
User-Agent处理工具,支持随机化UA以绕开防御规则
extracts.py
正则提取工具,从采集到的零乱文本中筛选IP地址
static.py
存储静态资源,如常见端口号等
util.py
常用函数,处理随机值/MD5/302跳转/格式转换等
cloudeye.py
cloudeye.me功能插口,在PoC中查询DNS和HTTP日志
本工具拟支持主流空间搜索引擎的API,目前已完成ZoomEye/Shodan/Google的集成。您可以通过简单的参数调用直接从搜索引擎中直接获取目标,并结合本地脚本进行扫描。
预配置(可选)
由于第三方插口须要认证,您可以在根目录下的tookit.conf配置文件中预先设置好您的API-KEY。
如无预配置,程序将在运行时提示您输入API-KEY。 关于各插口API-KEY的获取方式,请参考下文中引入的官方文档。
ZoomEye
以下命令表示使用ZoomEye插口,搜索全网中开启8080号端口的服务,并使用test.py脚本进行验证.
设置采集100个搜索结果,搜索结果将存入本地./data/zoomeye文件夹下。
python POC-T.py -s test -aZ "port:8080" --limit 100
ZoomEye现已开放注册,普通用户每月可以通过API下载5000页的搜索结果。
ZoomEye参考文档:
Shodan
以下命令表示使用Shodan插口,搜索全网中关键字为solr,国家为cn的服务,并使用solr-unauth脚本进行漏洞验证.
设置从第0条记录为起点,爬取10条记录,搜索结果将存入本地./data/shodan文件夹下.
python POC-T.py -s solr-unauth -aS "solr country:cn" --limit 10 --offset 0
Shodan-API接口使用限制及详尽功能,可参考官方文档.
本程序使用Google Custom Search API对结果进行采集(即常说的Google-Hacking)。
以下命令表示获取Google采集inurl:login.action的结果并批量验证S2-032漏洞。
python POC-T.py -s s2-032 -aG "inurl:login.action"
可使用--gproxy或则tookit.conf设置代理,代理格式为(sock4|sock5|http) IP PORT,仅支持这三种合同。
例如:
--gproxy "sock5 127.0.0.1 7070"
使用本插口需设定个人的API-KEY和所使用的自定义搜索引擎,二者均可在toolkit.conf配置。
填写示例
developer_key:AIzaSxxxxxxxxxxxxxxxxxxxxxxxxxxxxx_C1w
search_engine:011385053819762433240:ljmmw2mhhau
developer_key
获取API-KEY,使用API客户端:
Google API Client - Python
search_engine
创建自定义搜索引擎(或直接使用示例中的值):
Google Custom Search API 开发者文档
参见:
%E7%AC%AC%E4%B8%89%E6%96%B9%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E
%E8%84%9A%E6%9C%AC%E6%89%A9%E5%B1%95%E5%B7%A5%E5%85%B7
怎么爬取网路数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-08-21 13:06
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。
数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:
除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。 查看全部
怎么爬取网路数据
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。
数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:
除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。
基于兴趣轻博客网站拓扑特点剖析.doc 6页
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2020-08-20 23:15
基于兴趣轻博客网站拓扑特点剖析 摘要:为了了解新型在线社会网路——轻博客网站的拓扑特点,该文以国外最大的轻博客网站——点点网为研究对象,根据用户间兴趣关系建立兴趣网路,从小世界效应、无标度特点和中心度等角度对该网路进行了实证剖析,为进一步认识和研究轻博客网站奠定了基础。 关键词:轻博客;社会网路剖析;复杂网路;拓扑特点;中心性 中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2013)22-5033-04 根据Garry Tan 2013年一月的调查报告表明,2007创立的轻博客网站Tumblr早已赶超Facebook,成为日本年轻人访问最多的社交网站[1]。随着Tumblr的迅速崛起,国内也出现了各类类Tumblr的网站。2011年,许朝军创立了点点网,此后新浪Qing网,网易的lofter、人人网的人人小站、盛大推他等一批Tumblr的追随者都朝着轻博客的方向大步前进。轻博客这些新型的在线社会网路(Online Social Network, 简称OSN)极可能迎来一个高速发展期。同时,轻博客在中国还是一个新生事物,国内尚未见相关研究。因此,结合社会网路剖析和复杂网路理论,研究轻博客网站的拓扑特点,不仅能建立国内外对OSN拓扑特点的理论探求,而且有助于了解轻博客中人际关系和信息传播的特点,同时也对实现轻博客舆论的检测、引导、控制等提供重要根据和基础。
1 点点网的数据采集 本文选定国外典型的轻博客网站——点点网作为研究对象,这是因为相比其他,被称为“Tumblr中文版”的点点网是最纯粹的轻博客,其网路结构特点具有太强的代表性。 1.1面向点点网的网路爬虫 采集网站数据的方式有基于API的数据采集和基于网路爬虫的数据采集。通过调用网站提供的API接口可以实现网站数据的方便抓取与解析,但也要注意:一是API内容开放不全面,例如点点网API是在2011年12月才对外开放,API的种类也极少,目前不到30个;二是API服务商对用户的API接口调用频度与查询的返回结果的最大数目有限制,点点网就规定查询的返回结果不超过20个;三是使用API接口须要解决用户认证问题,如果待获取用户条目太多则会占用大量系统开支等待用户授权许可。因此,该文在开源软件Heritrix的基础上,采用基于网路爬虫的数据采集技术来获取点点网的数据。 从图1可以发觉,点点网在整篇轻博文下边都有“热度”,标注喜欢、转载和推荐该文的用户列表。查看源码,发现“热度”是一个内嵌网页,页面源码中内容比较少,更多的内容实际上是采用AJAX(Asynchronous Javascript and XML)技术[2]加载下来的。
如果直接用Heritirx原有的抓取方式,抓取不到真正的用户列表。所以,必须对Heritirx的Extracotr类进行扩充,扩展后的新类DiandianExtractor重载extract方式,在抓取页面、抽取链接的时侯,直接对“热度”部分进行剖析,通过Selenium WebDriver API驱动浏览器内核PhantomJS,模拟浏览器获取AJAX内容,得到和页面呈现一致的页面内容,再通过Jsoup解析页面内容,并把剖析结果存到MYSQL数据库里。至此,AJAX页面采集问题得到真正解决。 1.2 数据集 据点点网自身统计数据显示,目前点点网注册用户数早已达到1919万,帖子数达到3547万,数据采集量非常庞大且处于动态变化之中,要获取整个网路的拓扑数据非常困难,因此本文采用滚雪球采样法,依据“兴趣标签”,随机选择两个标签下边的“杰出轻博客”的某篇轻博文作为种子,利用点点网用户之间的兴趣关系进行广度优先搜索。搜索页面的URL富含“post/”和“n/common/comment”,前一种页面主要由某用户发表的所有博文组成;后一种页面包括所有“喜欢”、“转载”、“推荐”该用户博文的其他用户列表。
数据采集器最终抓取逾600万页面,总容量接近60G。通过对这逾600万页面信息的实时抽取,共1898356条记录储存到MySQL数据库里。其中,数据表结构包括id、username(用户名)、inname(链入用户名)、type(链入用户是哪种类型用户:喜欢、转载还是推荐)、link(该记录从那个链接得来的)。经过去重(从数据表中删掉username和inname都相同的记录),得到825057条可用记录用于后续网路拓扑检测。 2 点点网的拓扑特点 2.1网路拓扑检测 3 结论 本文选定国外最大的轻博客平台——点点网作为研究对象,根据采集下来的点点网样本数据,构造一个基于“发文←喜欢、转载和推荐”互动的兴趣关系网路。通过开源工具Pajek统计点点网的拓扑特点,如平均路径宽度、聚集系数、出入度分布、连接度相关性及中心性等,发现点点网存在小世界效应和无标度特点,网络中存在中心节点,即少量用户在信息发布和传播中起着至关重要的作用,这为进一步研究轻博客的人际关系和信息传播特点奠定了基础。 参考文献: [1] 果子. 影子大亨Tumblr的成功之道 [EB/OL]. [2013-02-21]. http:///p/201458.html?ref=weixin0222m. [2] 罗兵.支持AJAX的互联网搜索引擎爬虫设计与实现[D].杭州:浙江大学,2007:14-40. [3] Alan Mislove, Massimiliano Marcon, Krishna P.Gummadi. Measurement and Analysis of Online Social Networks[C]// IMC'07: Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement. New York: ACM Press, 2007: 29-42. [4] Feng Fu,Lianghuan Liu,Long Wang.Empirical analysis of online social networks in the age of Web 2.0[J]. Physica A, 2008(387):675–684. [5] 樊鹏翼,王晖,姜志宏,等.微博网路检测研究[J].计算机研究与发展, 2012,49(4):691-699. [6] Albert R, Barabasi A L.Statistical mechanics of complex networks[J]. Reviews of Modern Physics, 2002, 74(1):47-97. [7] Wilson C,Boe B,Sala A,et a1.User interactions in social networks and their implications[C]//Proceedings of the 4th ACM European Conference on Computer Systems.New York:ACM, 2009:205-218. [8] 陈静,孙林夫.复杂网路中节点重要度评估[J].西南交通大学学报,2009,44(3):426-429. 查看全部
基于兴趣轻博客网站拓扑特点剖析.doc 6页
基于兴趣轻博客网站拓扑特点剖析 摘要:为了了解新型在线社会网路——轻博客网站的拓扑特点,该文以国外最大的轻博客网站——点点网为研究对象,根据用户间兴趣关系建立兴趣网路,从小世界效应、无标度特点和中心度等角度对该网路进行了实证剖析,为进一步认识和研究轻博客网站奠定了基础。 关键词:轻博客;社会网路剖析;复杂网路;拓扑特点;中心性 中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2013)22-5033-04 根据Garry Tan 2013年一月的调查报告表明,2007创立的轻博客网站Tumblr早已赶超Facebook,成为日本年轻人访问最多的社交网站[1]。随着Tumblr的迅速崛起,国内也出现了各类类Tumblr的网站。2011年,许朝军创立了点点网,此后新浪Qing网,网易的lofter、人人网的人人小站、盛大推他等一批Tumblr的追随者都朝着轻博客的方向大步前进。轻博客这些新型的在线社会网路(Online Social Network, 简称OSN)极可能迎来一个高速发展期。同时,轻博客在中国还是一个新生事物,国内尚未见相关研究。因此,结合社会网路剖析和复杂网路理论,研究轻博客网站的拓扑特点,不仅能建立国内外对OSN拓扑特点的理论探求,而且有助于了解轻博客中人际关系和信息传播的特点,同时也对实现轻博客舆论的检测、引导、控制等提供重要根据和基础。
1 点点网的数据采集 本文选定国外典型的轻博客网站——点点网作为研究对象,这是因为相比其他,被称为“Tumblr中文版”的点点网是最纯粹的轻博客,其网路结构特点具有太强的代表性。 1.1面向点点网的网路爬虫 采集网站数据的方式有基于API的数据采集和基于网路爬虫的数据采集。通过调用网站提供的API接口可以实现网站数据的方便抓取与解析,但也要注意:一是API内容开放不全面,例如点点网API是在2011年12月才对外开放,API的种类也极少,目前不到30个;二是API服务商对用户的API接口调用频度与查询的返回结果的最大数目有限制,点点网就规定查询的返回结果不超过20个;三是使用API接口须要解决用户认证问题,如果待获取用户条目太多则会占用大量系统开支等待用户授权许可。因此,该文在开源软件Heritrix的基础上,采用基于网路爬虫的数据采集技术来获取点点网的数据。 从图1可以发觉,点点网在整篇轻博文下边都有“热度”,标注喜欢、转载和推荐该文的用户列表。查看源码,发现“热度”是一个内嵌网页,页面源码中内容比较少,更多的内容实际上是采用AJAX(Asynchronous Javascript and XML)技术[2]加载下来的。
如果直接用Heritirx原有的抓取方式,抓取不到真正的用户列表。所以,必须对Heritirx的Extracotr类进行扩充,扩展后的新类DiandianExtractor重载extract方式,在抓取页面、抽取链接的时侯,直接对“热度”部分进行剖析,通过Selenium WebDriver API驱动浏览器内核PhantomJS,模拟浏览器获取AJAX内容,得到和页面呈现一致的页面内容,再通过Jsoup解析页面内容,并把剖析结果存到MYSQL数据库里。至此,AJAX页面采集问题得到真正解决。 1.2 数据集 据点点网自身统计数据显示,目前点点网注册用户数早已达到1919万,帖子数达到3547万,数据采集量非常庞大且处于动态变化之中,要获取整个网路的拓扑数据非常困难,因此本文采用滚雪球采样法,依据“兴趣标签”,随机选择两个标签下边的“杰出轻博客”的某篇轻博文作为种子,利用点点网用户之间的兴趣关系进行广度优先搜索。搜索页面的URL富含“post/”和“n/common/comment”,前一种页面主要由某用户发表的所有博文组成;后一种页面包括所有“喜欢”、“转载”、“推荐”该用户博文的其他用户列表。
数据采集器最终抓取逾600万页面,总容量接近60G。通过对这逾600万页面信息的实时抽取,共1898356条记录储存到MySQL数据库里。其中,数据表结构包括id、username(用户名)、inname(链入用户名)、type(链入用户是哪种类型用户:喜欢、转载还是推荐)、link(该记录从那个链接得来的)。经过去重(从数据表中删掉username和inname都相同的记录),得到825057条可用记录用于后续网路拓扑检测。 2 点点网的拓扑特点 2.1网路拓扑检测 3 结论 本文选定国外最大的轻博客平台——点点网作为研究对象,根据采集下来的点点网样本数据,构造一个基于“发文←喜欢、转载和推荐”互动的兴趣关系网路。通过开源工具Pajek统计点点网的拓扑特点,如平均路径宽度、聚集系数、出入度分布、连接度相关性及中心性等,发现点点网存在小世界效应和无标度特点,网络中存在中心节点,即少量用户在信息发布和传播中起着至关重要的作用,这为进一步研究轻博客的人际关系和信息传播特点奠定了基础。 参考文献: [1] 果子. 影子大亨Tumblr的成功之道 [EB/OL]. [2013-02-21]. http:///p/201458.html?ref=weixin0222m. [2] 罗兵.支持AJAX的互联网搜索引擎爬虫设计与实现[D].杭州:浙江大学,2007:14-40. [3] Alan Mislove, Massimiliano Marcon, Krishna P.Gummadi. Measurement and Analysis of Online Social Networks[C]// IMC'07: Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement. New York: ACM Press, 2007: 29-42. [4] Feng Fu,Lianghuan Liu,Long Wang.Empirical analysis of online social networks in the age of Web 2.0[J]. Physica A, 2008(387):675–684. [5] 樊鹏翼,王晖,姜志宏,等.微博网路检测研究[J].计算机研究与发展, 2012,49(4):691-699. [6] Albert R, Barabasi A L.Statistical mechanics of complex networks[J]. Reviews of Modern Physics, 2002, 74(1):47-97. [7] Wilson C,Boe B,Sala A,et a1.User interactions in social networks and their implications[C]//Proceedings of the 4th ACM European Conference on Computer Systems.New York:ACM, 2009:205-218. [8] 陈静,孙林夫.复杂网路中节点重要度评估[J].西南交通大学学报,2009,44(3):426-429.
3.kettle实现不同数据库的数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 599 次浏览 • 2020-08-20 12:38
「深度学习福利」大神带你进阶工程师,立即查看>>>
基于kettle实现数据采集
1.kettle简介
Kettle 是一款美国开源的 ETL 工具,纯 Java 编写,通过提供一个图形化的用户环境来描述你想做哪些,而不是你想怎样做,它的数据抽取高效稳定(数据迁移工具)。Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。
2.kettle下载
下面两个案例是使用kettle7.1进行操作,分享一下国外的下载地址:
kettle下载
无需安装,双击根目录下的Spoon.bat文件即可
3.kettle实现不同数据库的数据采集
这个案例是实现oracle数据库的数据采集到mysql上面去
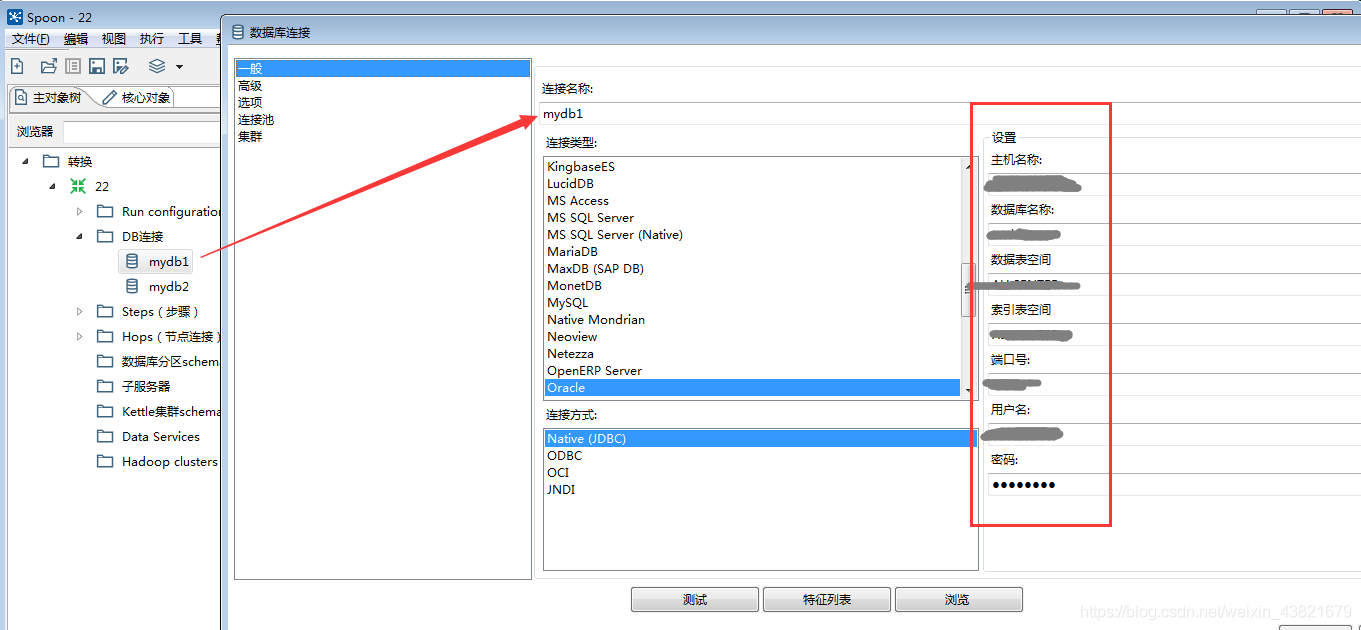
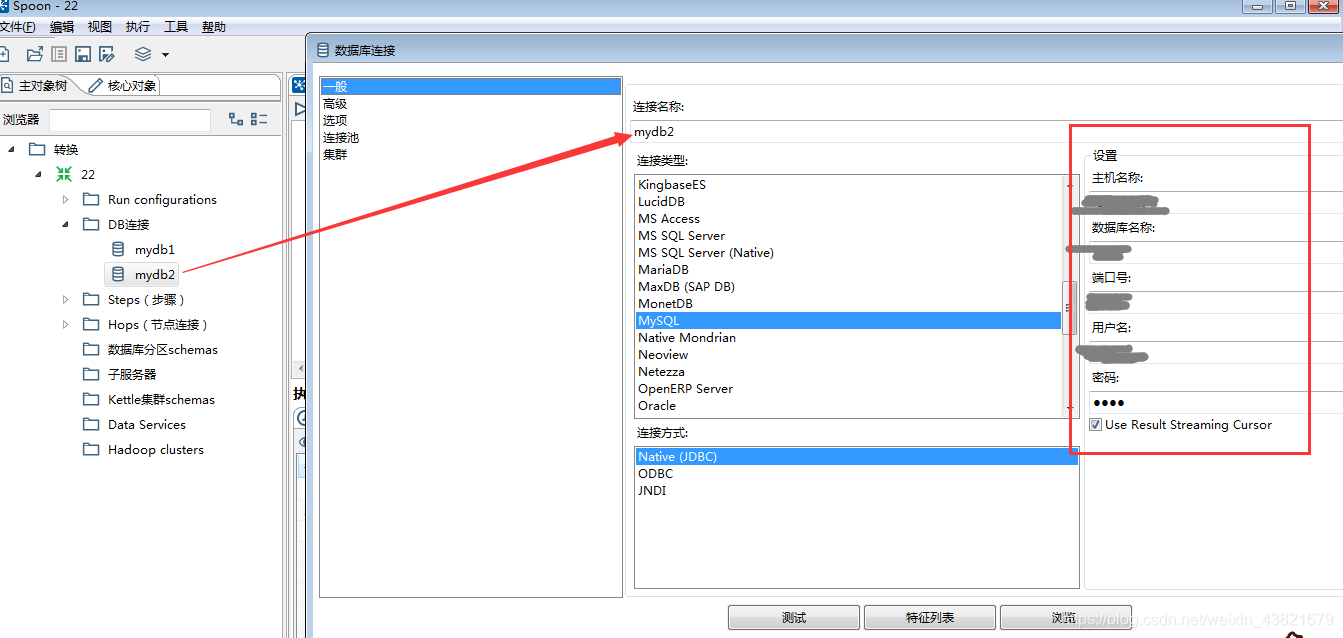
3.1创建对应数据库的DB联接
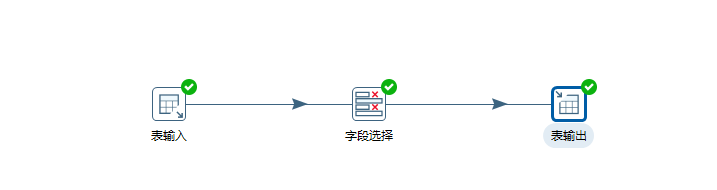
3.2使用图形工具完成表输入->字段选择->表输出的流线设计
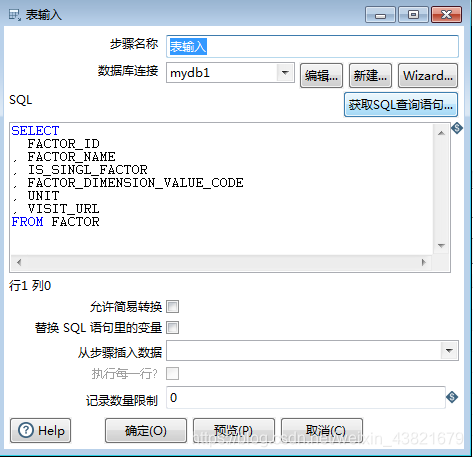
3.3配置表输入信息:用于编撰sql获取数据源的数据
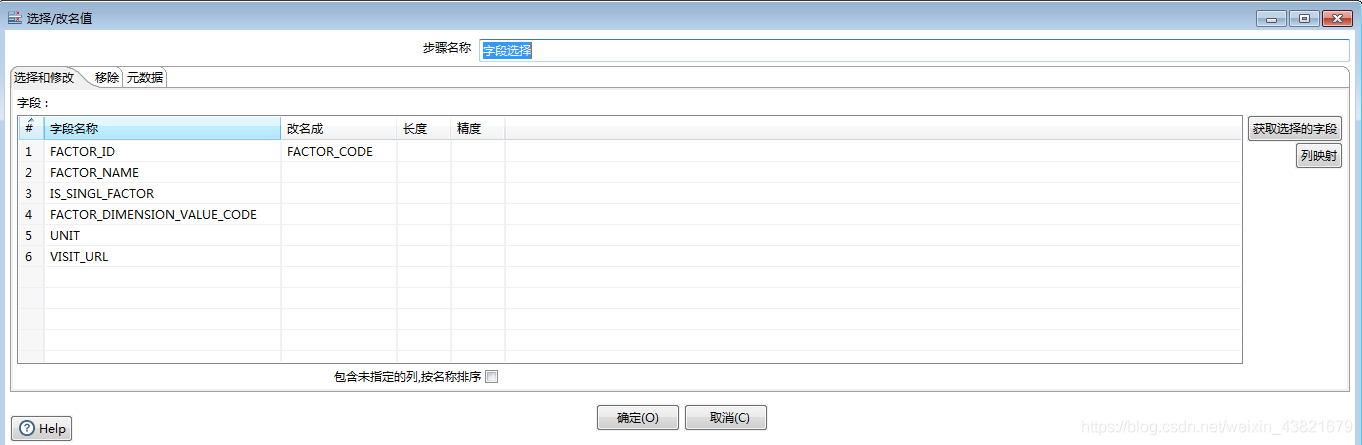
3.4配置数组选择信息:用于数据源和目标表数组名不一致的一个转换
3.5配置表输出信息:用于目标表的主键映射
3.6运行这个转换,并查看结果
4.kettle实现插口的数据采集
接口地址(可直接复制):%E8%A7%92%E7%BE%8E&region=%E6%BC%B3%E5%B7%9E%E5%B8%82&output=json&ak=n0lHarpY3QZx6xXXIaWMFLxj
通过访问插口可以获知返回的json数据结构,可考虑做两层json解析来获取对应的数组,当然也可以使用:$…result[*].name的表达式来获取,这里不做演示,有兴趣的朋友可以试一下!
4.1配置目标表的DB联接(上面有oracle和mysql的不同示例)
4.2使用图形工具插口采集的流线图
4.3配置生成记录信息:填写对应的url地址和定义url名称,类型 查看全部
3.kettle实现不同数据库的数据采集
「深度学习福利」大神带你进阶工程师,立即查看>>>

基于kettle实现数据采集
1.kettle简介
Kettle 是一款美国开源的 ETL 工具,纯 Java 编写,通过提供一个图形化的用户环境来描述你想做哪些,而不是你想怎样做,它的数据抽取高效稳定(数据迁移工具)。Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。
2.kettle下载
下面两个案例是使用kettle7.1进行操作,分享一下国外的下载地址:
kettle下载
无需安装,双击根目录下的Spoon.bat文件即可
3.kettle实现不同数据库的数据采集
这个案例是实现oracle数据库的数据采集到mysql上面去
3.1创建对应数据库的DB联接
3.2使用图形工具完成表输入->字段选择->表输出的流线设计
3.3配置表输入信息:用于编撰sql获取数据源的数据
3.4配置数组选择信息:用于数据源和目标表数组名不一致的一个转换
3.5配置表输出信息:用于目标表的主键映射
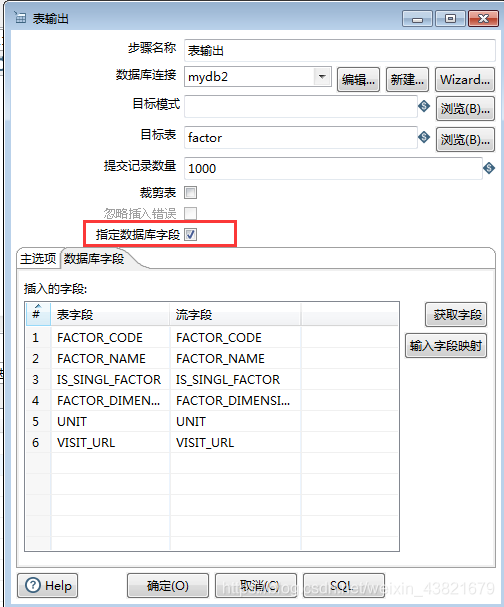
3.6运行这个转换,并查看结果
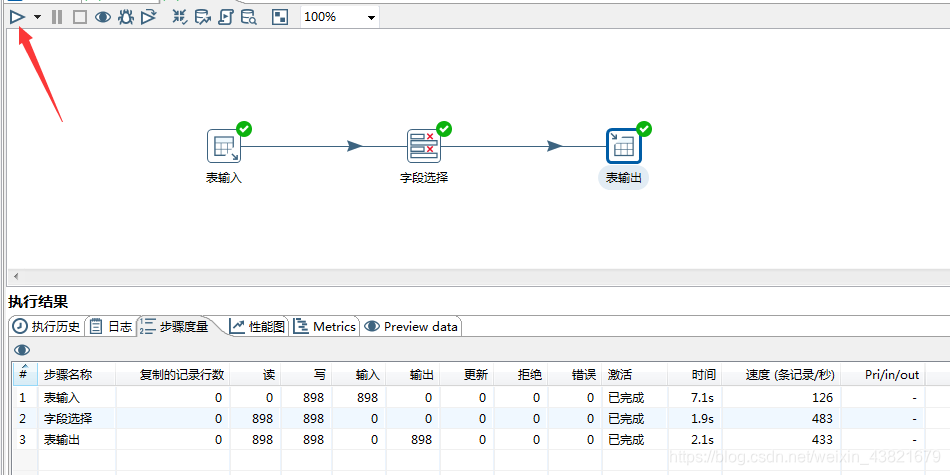
4.kettle实现插口的数据采集
接口地址(可直接复制):%E8%A7%92%E7%BE%8E&region=%E6%BC%B3%E5%B7%9E%E5%B8%82&output=json&ak=n0lHarpY3QZx6xXXIaWMFLxj
通过访问插口可以获知返回的json数据结构,可考虑做两层json解析来获取对应的数组,当然也可以使用:$…result[*].name的表达式来获取,这里不做演示,有兴趣的朋友可以试一下!

4.1配置目标表的DB联接(上面有oracle和mysql的不同示例)
4.2使用图形工具插口采集的流线图
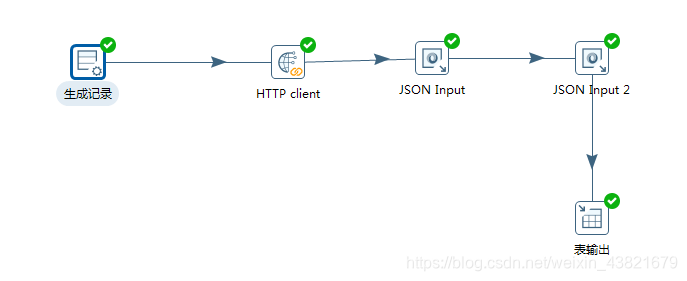
4.3配置生成记录信息:填写对应的url地址和定义url名称,类型
Python爬虫总结(CSS,Xpath,JsonLoad;静态网页,JS加载
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-18 21:25
前言
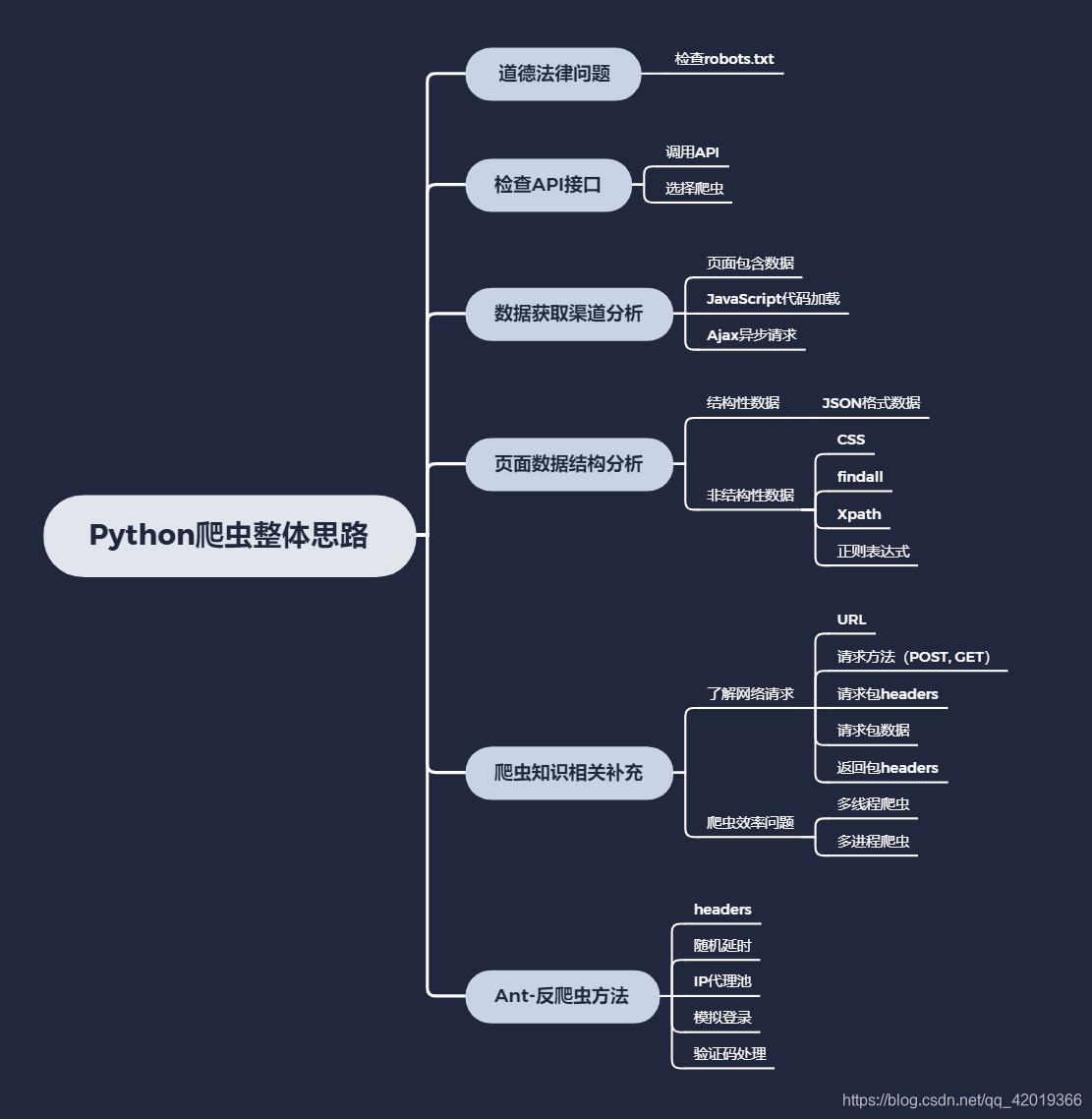
随着人类社会的高速发展,数据对各行各业的重要性,愈加突出。爬虫,也称为数据采集器,是指通过程序设计,机械化地对网路上的数据,进行批量爬取,以取代低效的人工获取信息的手段。
1. 道德法律问题
爬虫目前在法律上尚属黑色地段,但爬别的网站用于自己的商业化用途也可能存在着法律风险。非法抓取使用“新浪微博”用户信息被判赔200万元,这是国外的一条因爬虫被判败诉的新闻。所以各商业公司还是悠着点,特别是涉及隐私数据。
大型的网站一般还会有robot.txt,这算是与爬虫者的一个合同。只要在robot.txt容许的范围内爬虫就不存在道德和法律风险。
2. 网络爬虫步骤2.1 检查API接口
API是网站官方提供的数据插口,如果通过调用API采集数据,则相当于在网站允许的范围内采集。这样既不会有道德法律风险,也没有网站故意设置的障碍;不过调用API插口的访问则处于网站的控制中,网站可以拿来收费,可以拿来限制访问上限等。整体来看,如果数据采集的需求并不是太奇特,那么有API则应优先采用调用API的形式。如果没有,则选择爬虫。
2.2 数据获取渠道剖析
页面收录数据
这种情况是最容易解决的,一般来讲基本上是静态网页,或者动态网页,采用模板渲染,浏览器获取到HTML的时侯早已是收录所有的关键信息,所以直接在网页上见到的内容都可以通过特定的HTML标签得到。
JavaScript代码加载内容
虽然网页显示的数据在HTML标签上面,但是指定HTML标签下内容为空。这是因为数据在js代码上面,而js的执行是在浏览器端的操作。当我们用程序去恳求网页地址的时侯,得到的response是网页代码和js的代码,因此自己在浏览器端能看到数据,解析时因为js未执行,指定HTML标签下数据肯定为空。这个时侯的处理办法:找到收录内容的js代码串,然后通过正则表达式获得相应的内容,而不是解析HTML标签。
Ajax异步恳求
这种情况是现今太常见的,尤其是在数据以分页方式显示在网页上,并且页面无刷新,或者是对网页进行某个交互操作后得到数据。所以当我们开始刷新页面的时侯就要开始跟踪所有的恳求,观察数据究竟是在哪一步加载进来的。然后当我们找到核心的异步恳求的时侯,就只用抓取这个异步恳求就可以了,如果原创网页没有任何有用信息,也没必要去抓取原创网页了。
2.3 页面数据结构剖析
结构性数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键数组即可。
page = requests.get(url)
headers = {}
page.encoding = 'utf-8'
data =re.findall(r'__INITIAL_STATE__=(.*?)',page.text)[0]
json_data = json.loads(data)
print(json_data)
#f = open('结果2.txt', 'w',
encoding='utf-8') # 以'w'方式打开文件
#for k, v in json_data.items():
# 遍历字典中的键值
#s2 = str(v) # 把字典的值转换成字符型
#f.write(k + '\n') # 键和值分行放,键在单数行,值在双数行
#f.write(s2 + '\n')
jobList = json_data['souresult']['Items'] #打印json_data,抓到关键词
for element in jobList:
print(f"===公司名称:{element['CompanyName']}:===\n"
f"岗位名称:{element['DateCreated']}\n"
f"招聘人数:{element['JobTitle']}\n"
f"工作代码:{element['JobTypeName']}\n"
f"公司代码:{element['RecruitCount']}\n"
f"详细信息URL:{element['SocialCompanyUrl']}")
非结构性数据-HTML文本数据
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时侯会碰到的情况。例如抓取一个网页,得到的是HTML,然后须要解析一些常见的元素,提取一些关键的信息。HTML虽然理应属于结构化的文本组织,但是又由于通常我们须要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作就能得到,所以还是归类于非结构化的数据处理中。常见解析方式:
CSS选择器
现在的网页式样比较多,所以通常的网页就会有一些CSS的定位,例如class,id等等,或者我们按照常见的节点路径进行定位。
item = soup.select('#u1 > a')
#选择指定目录下所有css数据
#print([i for i in item]) #print里添加循环时,记得加方括号
item = soup.select_one('#u1 > a') #选择指定目录下第一条 css数据
print(item)
Findall
##招聘人数
recru_num = soup.find_all('div', attrs={'class':'cityfn-left'}) #找到页面中a元素的所有元素,并找到a元素中 属性为'class=value'———————— attrs={"class": 'value'}
print(recru_num)
dr = re.compile(r']+>', re.S)
data = dr.sub('', str(recru_num)) #过滤HTML标签
print(data)
Xpath
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()') #获取某个标签的内容(基本使用)
正则表达式
正则表达式,用标准正则解析,一般会把HTML当作普通文本,用指定格式匹配。当相关文本是小片断文本,或者某一串字符,或者HTML收录javascript的代码,无法用CSS选择器或则XPATH。
import re
a = '<p>[Aero, Animals, Architecture,Wallpapers">Artistic</a>, ........(省略)......... Vintage]'
titles = re.findall(' 查看全部
Python爬虫总结(CSS,Xpath,JsonLoad;静态网页,JS加载
前言
随着人类社会的高速发展,数据对各行各业的重要性,愈加突出。爬虫,也称为数据采集器,是指通过程序设计,机械化地对网路上的数据,进行批量爬取,以取代低效的人工获取信息的手段。
1. 道德法律问题
爬虫目前在法律上尚属黑色地段,但爬别的网站用于自己的商业化用途也可能存在着法律风险。非法抓取使用“新浪微博”用户信息被判赔200万元,这是国外的一条因爬虫被判败诉的新闻。所以各商业公司还是悠着点,特别是涉及隐私数据。
大型的网站一般还会有robot.txt,这算是与爬虫者的一个合同。只要在robot.txt容许的范围内爬虫就不存在道德和法律风险。
2. 网络爬虫步骤2.1 检查API接口
API是网站官方提供的数据插口,如果通过调用API采集数据,则相当于在网站允许的范围内采集。这样既不会有道德法律风险,也没有网站故意设置的障碍;不过调用API插口的访问则处于网站的控制中,网站可以拿来收费,可以拿来限制访问上限等。整体来看,如果数据采集的需求并不是太奇特,那么有API则应优先采用调用API的形式。如果没有,则选择爬虫。
2.2 数据获取渠道剖析
页面收录数据
这种情况是最容易解决的,一般来讲基本上是静态网页,或者动态网页,采用模板渲染,浏览器获取到HTML的时侯早已是收录所有的关键信息,所以直接在网页上见到的内容都可以通过特定的HTML标签得到。
JavaScript代码加载内容
虽然网页显示的数据在HTML标签上面,但是指定HTML标签下内容为空。这是因为数据在js代码上面,而js的执行是在浏览器端的操作。当我们用程序去恳求网页地址的时侯,得到的response是网页代码和js的代码,因此自己在浏览器端能看到数据,解析时因为js未执行,指定HTML标签下数据肯定为空。这个时侯的处理办法:找到收录内容的js代码串,然后通过正则表达式获得相应的内容,而不是解析HTML标签。
Ajax异步恳求
这种情况是现今太常见的,尤其是在数据以分页方式显示在网页上,并且页面无刷新,或者是对网页进行某个交互操作后得到数据。所以当我们开始刷新页面的时侯就要开始跟踪所有的恳求,观察数据究竟是在哪一步加载进来的。然后当我们找到核心的异步恳求的时侯,就只用抓取这个异步恳求就可以了,如果原创网页没有任何有用信息,也没必要去抓取原创网页了。
2.3 页面数据结构剖析
结构性数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键数组即可。
page = requests.get(url)
headers = {}
page.encoding = 'utf-8'
data =re.findall(r'__INITIAL_STATE__=(.*?)',page.text)[0]
json_data = json.loads(data)
print(json_data)
#f = open('结果2.txt', 'w',
encoding='utf-8') # 以'w'方式打开文件
#for k, v in json_data.items():
# 遍历字典中的键值
#s2 = str(v) # 把字典的值转换成字符型
#f.write(k + '\n') # 键和值分行放,键在单数行,值在双数行
#f.write(s2 + '\n')
jobList = json_data['souresult']['Items'] #打印json_data,抓到关键词
for element in jobList:
print(f"===公司名称:{element['CompanyName']}:===\n"
f"岗位名称:{element['DateCreated']}\n"
f"招聘人数:{element['JobTitle']}\n"
f"工作代码:{element['JobTypeName']}\n"
f"公司代码:{element['RecruitCount']}\n"
f"详细信息URL:{element['SocialCompanyUrl']}")
非结构性数据-HTML文本数据
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时侯会碰到的情况。例如抓取一个网页,得到的是HTML,然后须要解析一些常见的元素,提取一些关键的信息。HTML虽然理应属于结构化的文本组织,但是又由于通常我们须要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作就能得到,所以还是归类于非结构化的数据处理中。常见解析方式:
CSS选择器
现在的网页式样比较多,所以通常的网页就会有一些CSS的定位,例如class,id等等,或者我们按照常见的节点路径进行定位。
item = soup.select('#u1 > a')
#选择指定目录下所有css数据
#print([i for i in item]) #print里添加循环时,记得加方括号
item = soup.select_one('#u1 > a') #选择指定目录下第一条 css数据
print(item)
Findall
##招聘人数
recru_num = soup.find_all('div', attrs={'class':'cityfn-left'}) #找到页面中a元素的所有元素,并找到a元素中 属性为'class=value'———————— attrs={"class": 'value'}
print(recru_num)
dr = re.compile(r']+>', re.S)
data = dr.sub('', str(recru_num)) #过滤HTML标签
print(data)
Xpath
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()') #获取某个标签的内容(基本使用)
正则表达式
正则表达式,用标准正则解析,一般会把HTML当作普通文本,用指定格式匹配。当相关文本是小片断文本,或者某一串字符,或者HTML收录javascript的代码,无法用CSS选择器或则XPATH。
import re
a = '<p>[Aero, Animals, Architecture,Wallpapers">Artistic</a>, ........(省略)......... Vintage]'
titles = re.findall('
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推
采集交流 • 优采云 发表了文章 • 0 个评论 • 725 次浏览 • 2020-08-18 10:02
蜘蛛池引流 站群蜘蛛池 2019seo优化超级蜘蛛池 自动采集 网站优化必备
seo优化站群特色
安全、高效,化的优化借助php性能,使得运行流畅稳定
独创内容无缓存刷新不变,节省硬碟。防止搜索引擎辨识蜘蛛池
蜘蛛池算法,轻松建立站点(电影、资讯、图片、论坛等等)
可以个性化每位网站的风格、内容、站点模式、关键词、外链等
(自定义tkd、自定义外链关键词、自定义泛域名前缀)
什么是蜘蛛池? 蜘蛛池是一种通过借助小型平台权重来获得百度收录以及排行的一种程序,程序员常称为“蜘蛛池”。这是一种可以快速提高网站排名的一种程序,值得一提的是,它是手动提高网站的排行和网站的收录,这个疗效是极其出色的。蜘蛛池程序可以帮助我们做哪些? 发了外链了贴子还不收录,可竞争对手人家一样是发同样的站,人家没发外链也收录了,是吧!答:(因为人家养有了数目庞大的百度收录蜘蛛爬虫,有了蜘蛛池你也可以做到) CNmmm.Com
有些老手会说,我自己也养有百度蜘蛛如何我的也不收录呢?
答:(因为你的百度收录蜘蛛不够多,不够广,来来回回都是这些低质量的百度收录爬虫,收录慢,而且甚至是根本不收录了!——-蜘蛛池拥有多服务器,多域名,正规内容站点养着百度收录蜘蛛,分布广,域名多,团队化养着蜘蛛,来源站点多,质量高,每天都有新来的蜘蛛进行爬取收录您的外推贴子) 内容来自新手源码CNmmm.Com
蜘蛛池超级强悍的功能,全手动采集,支持api二次开发!
也可以当作站群的源程序使用。
支持给用户开帐号,全手动发布,可用于租用蜘蛛池,发布外链使用!
支持关键词跳转,全局跳转! 内容来自新手源码CNmmm.Com
自动采集(腾讯新闻(国内,军事),新浪新闻(国际,军事))
新闻伪原创,加快收录!
支持导出txt外推网址,蜘蛛日记,索引池,权重池等等等,更多功能自行发觉!
商业源码下载
售价 :80.00(元)会员价钱 :0.00(元) VIP会员登入 后即可免费下载!
资源信息 :
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推,支持降低用户 api
下载链接:*** 隐藏内容订购后可见 ***下载密码:*** 隐藏内容订购后可见 ***
开通VIP会员后,全站源码即可免费下载!活动期间会员仅需28元 - 马上开通VIP会员 查看全部
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推
蜘蛛池引流 站群蜘蛛池 2019seo优化超级蜘蛛池 自动采集 网站优化必备
seo优化站群特色
安全、高效,化的优化借助php性能,使得运行流畅稳定
独创内容无缓存刷新不变,节省硬碟。防止搜索引擎辨识蜘蛛池
蜘蛛池算法,轻松建立站点(电影、资讯、图片、论坛等等)
可以个性化每位网站的风格、内容、站点模式、关键词、外链等
(自定义tkd、自定义外链关键词、自定义泛域名前缀)
什么是蜘蛛池? 蜘蛛池是一种通过借助小型平台权重来获得百度收录以及排行的一种程序,程序员常称为“蜘蛛池”。这是一种可以快速提高网站排名的一种程序,值得一提的是,它是手动提高网站的排行和网站的收录,这个疗效是极其出色的。蜘蛛池程序可以帮助我们做哪些? 发了外链了贴子还不收录,可竞争对手人家一样是发同样的站,人家没发外链也收录了,是吧!答:(因为人家养有了数目庞大的百度收录蜘蛛爬虫,有了蜘蛛池你也可以做到) CNmmm.Com
有些老手会说,我自己也养有百度蜘蛛如何我的也不收录呢?
答:(因为你的百度收录蜘蛛不够多,不够广,来来回回都是这些低质量的百度收录爬虫,收录慢,而且甚至是根本不收录了!——-蜘蛛池拥有多服务器,多域名,正规内容站点养着百度收录蜘蛛,分布广,域名多,团队化养着蜘蛛,来源站点多,质量高,每天都有新来的蜘蛛进行爬取收录您的外推贴子) 内容来自新手源码CNmmm.Com
蜘蛛池超级强悍的功能,全手动采集,支持api二次开发!
也可以当作站群的源程序使用。
支持给用户开帐号,全手动发布,可用于租用蜘蛛池,发布外链使用!
支持关键词跳转,全局跳转! 内容来自新手源码CNmmm.Com
自动采集(腾讯新闻(国内,军事),新浪新闻(国际,军事))
新闻伪原创,加快收录!
支持导出txt外推网址,蜘蛛日记,索引池,权重池等等等,更多功能自行发觉!

商业源码下载
售价 :80.00(元)会员价钱 :0.00(元) VIP会员登入 后即可免费下载!
资源信息 :
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推,支持降低用户 api
下载链接:*** 隐藏内容订购后可见 ***下载密码:*** 隐藏内容订购后可见 ***
开通VIP会员后,全站源码即可免费下载!活动期间会员仅需28元 - 马上开通VIP会员
销帮帮数据处理工具开发说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-17 01:26
目录
开发背景:
公司CRM采购了销帮帮的CRM系统,由于CRM系统不健全,导出功能不能满足公司对数据进行剖析的需求。每次整理数据,分析人员部门等各类情况,再有假如人员重名,销帮帮不能分辨出具体是谁,必须去依据人员或其他数据进行分辨。
解决方案:
由于销帮帮数据的人员是有UserID的,而该UserID对应钉钉的UserID,所以可以按照钉钉提供的API接口轻松的判别出人员部门、分公司等信息,不用关心人员重名的情况。
开发环境:
软件使用C#+SQLSERVER进行开发。
使用教程:
开始前先给你们瞧瞧软件的整体界面。
软件主要包括清空明日数据,采集、数据剖析、同步用户信息、获取数据 5部份功能。
创建并配置SQLServer数据库
在安装好的SQLServer服务器上,创建数据库,数据库名称按照须要定义,此处我定义的数据库名称是xbb,如下图的配置[1],正确配置数据库联接
获取销帮帮的组织编码和Token
根据销帮帮提供的网址[]获取对应的组织编码和token.,如下图配置[2]配置销帮帮石药使用的组织编码和Token.
创建企业内部应用
在钉钉的【开发者后台】创建企业内部应用。开放查询部门、人员信息的权限即可。并配置对应的appkey/appsecret到右图【3】处。
清空明日数据
开始采集前,如果明天的数据早已采集过,请点击【清空明日数据】,会手动清空明天早已采集的数据,重新开始采集。
采集
点击【开始】进行数据采集,采集的内容主要包括功能上勾选的数据。等待最下边的状态栏采集后待处理数据变为0条,则代表采集完成。
数据剖析
采集后会把数据统计分配到一张表里,点击数据剖析会手动依据采集到的数据创建表,并把数据插入到对应的表上面。
同步用户数据
同步用户数据是为了增量备份钉钉的所有的用户信息。
获取数据
点击【获取数据】按钮,自动导入销帮帮销售机会、合同、跟进记录等信息。
备注:如果哪天销帮帮数据发生变化,可以在软件的ExecSQL文件夹下更改对应的导入SQL句子,不用更改代码。
软件技能更新
第一次在开发中使用了dynamic关键字,通过对Json进行反序列化挺好用。减少了好多Model的创建工作,也降低了先前通过正则表达式匹配的方法的工作量。
通过下边的句子更改当前显示的文字做的颜色。
rtbContent.SelectionColor = Color.Red;
rtbContent.SelectedText = msg+"\r\n";
为了备份每晚的数据,所有的表都带上了年月日yyyyMMdd格式结尾。所有的查询都是通过{Date}关键字,用明天的日期替换{Date}关键字后产生SQL查询句子
每次抓取分页数据时,由于是异步的,不能马上确定是否有下一页的时侯,尤其是抓取第一页的时侯,由于数据分类不同,以前都是按照不同的数据分页设置一下队列,然后依次从队列中进行数据弹出、采集等。现在采用字典Dic> 可以通过统一的方式,设置不同的关键字插入分页或则弹出分页。
以前的加密方式大多是md5/AES等加密方法,最近大多都在改成sha256,可能与统一的后端构架有关系把。
C#的sha256加密方法:
public static string sha256(string data)
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
byte[] hash = SHA256Managed.Create().ComputeHash(bytes);
StringBuilder builder = new StringBuilder();
for (int i = 0; i < hash.Length; i++)
{
builder.Append(hash[i].ToString("X2"));
}
return builder.ToString();
}
以前处理数据库都是自己自动写个简单的DbHelper,由于用不到各类复杂的处理。所以还算够用。
后来发觉通过Dapper可以轻松实现数据的批量处理,而且总体来说效率还可以,毕竟写的代码少了,还是很高兴的。
轻量级的ORM工具,我选Dapper.。但是ADO.NET原理不能忘。
NPOI仍然是最好的处理Excel的工具
不再使用Model,正则表达式,把所有Json格式的数据通过,数据字段ID、列名、列值、数据类型 插入到一张表,通过统一的SQL创建插入规则把数据在统一插入到对应的表中,不需要提早晓得表的列名。
自动创建、增加列。自动插入数据。 查看全部
销帮帮数据处理工具开发说明
目录
开发背景:
公司CRM采购了销帮帮的CRM系统,由于CRM系统不健全,导出功能不能满足公司对数据进行剖析的需求。每次整理数据,分析人员部门等各类情况,再有假如人员重名,销帮帮不能分辨出具体是谁,必须去依据人员或其他数据进行分辨。
解决方案:
由于销帮帮数据的人员是有UserID的,而该UserID对应钉钉的UserID,所以可以按照钉钉提供的API接口轻松的判别出人员部门、分公司等信息,不用关心人员重名的情况。
开发环境:
软件使用C#+SQLSERVER进行开发。
使用教程:
开始前先给你们瞧瞧软件的整体界面。
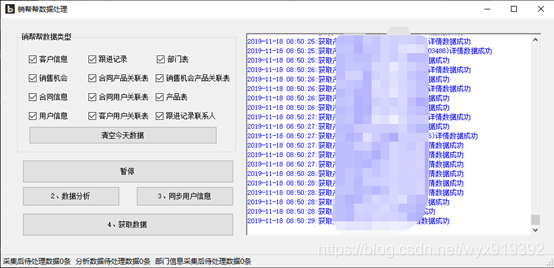
软件主要包括清空明日数据,采集、数据剖析、同步用户信息、获取数据 5部份功能。
创建并配置SQLServer数据库
在安装好的SQLServer服务器上,创建数据库,数据库名称按照须要定义,此处我定义的数据库名称是xbb,如下图的配置[1],正确配置数据库联接
获取销帮帮的组织编码和Token
根据销帮帮提供的网址[]获取对应的组织编码和token.,如下图配置[2]配置销帮帮石药使用的组织编码和Token.
创建企业内部应用
在钉钉的【开发者后台】创建企业内部应用。开放查询部门、人员信息的权限即可。并配置对应的appkey/appsecret到右图【3】处。
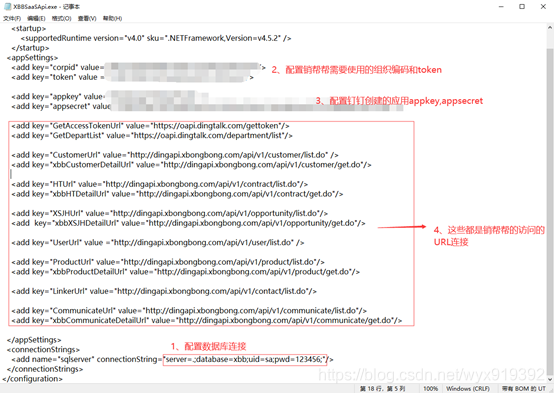
清空明日数据
开始采集前,如果明天的数据早已采集过,请点击【清空明日数据】,会手动清空明天早已采集的数据,重新开始采集。
采集
点击【开始】进行数据采集,采集的内容主要包括功能上勾选的数据。等待最下边的状态栏采集后待处理数据变为0条,则代表采集完成。
数据剖析
采集后会把数据统计分配到一张表里,点击数据剖析会手动依据采集到的数据创建表,并把数据插入到对应的表上面。
同步用户数据
同步用户数据是为了增量备份钉钉的所有的用户信息。
获取数据
点击【获取数据】按钮,自动导入销帮帮销售机会、合同、跟进记录等信息。
备注:如果哪天销帮帮数据发生变化,可以在软件的ExecSQL文件夹下更改对应的导入SQL句子,不用更改代码。
软件技能更新
第一次在开发中使用了dynamic关键字,通过对Json进行反序列化挺好用。减少了好多Model的创建工作,也降低了先前通过正则表达式匹配的方法的工作量。
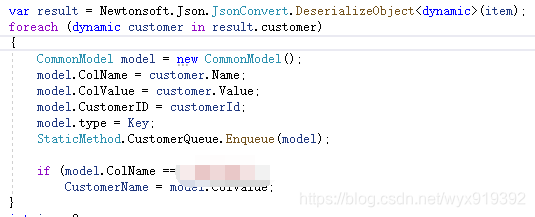
通过下边的句子更改当前显示的文字做的颜色。
rtbContent.SelectionColor = Color.Red;
rtbContent.SelectedText = msg+"\r\n";
为了备份每晚的数据,所有的表都带上了年月日yyyyMMdd格式结尾。所有的查询都是通过{Date}关键字,用明天的日期替换{Date}关键字后产生SQL查询句子
每次抓取分页数据时,由于是异步的,不能马上确定是否有下一页的时侯,尤其是抓取第一页的时侯,由于数据分类不同,以前都是按照不同的数据分页设置一下队列,然后依次从队列中进行数据弹出、采集等。现在采用字典Dic> 可以通过统一的方式,设置不同的关键字插入分页或则弹出分页。
以前的加密方式大多是md5/AES等加密方法,最近大多都在改成sha256,可能与统一的后端构架有关系把。
C#的sha256加密方法:
public static string sha256(string data)
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
byte[] hash = SHA256Managed.Create().ComputeHash(bytes);
StringBuilder builder = new StringBuilder();
for (int i = 0; i < hash.Length; i++)
{
builder.Append(hash[i].ToString("X2"));
}
return builder.ToString();
}
以前处理数据库都是自己自动写个简单的DbHelper,由于用不到各类复杂的处理。所以还算够用。
后来发觉通过Dapper可以轻松实现数据的批量处理,而且总体来说效率还可以,毕竟写的代码少了,还是很高兴的。
轻量级的ORM工具,我选Dapper.。但是ADO.NET原理不能忘。
NPOI仍然是最好的处理Excel的工具
不再使用Model,正则表达式,把所有Json格式的数据通过,数据字段ID、列名、列值、数据类型 插入到一张表,通过统一的SQL创建插入规则把数据在统一插入到对应的表中,不需要提早晓得表的列名。
自动创建、增加列。自动插入数据。
微信公众号文章搜索导入助手软件破解版微信公众号文章搜索导入助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-29 18:06
摘要:微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
微信公众号文章搜索导入助手软件破解版
微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
软件功能
1、一键采集指定微信公众号所有群发文章,并通过关键词搜索所有公众号相关文章,支持按时间段采集;
2、微信文章可一键导入pdf、word、Excel、txt和html格式,并下载音频和视频文件,图片和文章留言,导出文档排版可保持和原文一样;
3、内置开放插口,可一键同步所有陌陌文章到自己网站,并保证陌陌图片正常显示;
4、可实时查看文章阅读量、在看量和留言;
5、软件提供逾80项其他附加功能,非常强悍实用;
软件特色
1、微信公众号文章搜索导入助手提供简单的文章采集功能
2、在软件界面登陆陌陌就可以开始采集数据
3、支持公众号输入,可以对指定的公众号数据采集
4、提供多种文章采集,只要是公众号内的文章就可以全部采集
5、支持列表显示,在软件界面显示采集的内容
6、支持文章查看,可以通过外置的浏览器查看文章
7、支持生成文章二维码,方便将当前的文章制作为二维码
8、支持将列表重复的文章删除,支持公众号过滤
使用说明
1、打开微信公众号文章搜索导入助手显示软件的功能界面
2、如果你须要学习软件就可以打开官方提供的视频教程
3、卡密目前售价29.9元/永久,只要有用户,软件将保持不断更新,优化升级!具体价钱以购买页为准
4、在软件输入关键词就可以查询公众号文章
5、如图所示,这里是软件的登入界面,您须要登陆陌陌 查看全部
微信公众号文章搜索导入助手软件破解版微信公众号文章搜索导入助手
摘要:微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
微信公众号文章搜索导入助手软件破解版
微信公众号文章搜索导入助手可以在软件直接查询公众号文章,可以将文章下载到笔记本保存,方便之后使用,大家多晓得公众号可以编辑文章发送,也可以添加音视频以及图片,如果你须要使用公众号资源,可以通过这款软件下载,本软件可以快速采集文章内容,支持文章搜索,输入关键词就可以查询对应的文章,支持号内采集,直接对公众号全部数据采集,支持本地搜索,从历史搜索文章中采集,通过这款软件就可以快速对文章采集,并且可以将采集到的文字保存docx、PDF、html,采集过程也可以下载音视频!
软件功能
1、一键采集指定微信公众号所有群发文章,并通过关键词搜索所有公众号相关文章,支持按时间段采集;
2、微信文章可一键导入pdf、word、Excel、txt和html格式,并下载音频和视频文件,图片和文章留言,导出文档排版可保持和原文一样;
3、内置开放插口,可一键同步所有陌陌文章到自己网站,并保证陌陌图片正常显示;
4、可实时查看文章阅读量、在看量和留言;
5、软件提供逾80项其他附加功能,非常强悍实用;
软件特色
1、微信公众号文章搜索导入助手提供简单的文章采集功能
2、在软件界面登陆陌陌就可以开始采集数据
3、支持公众号输入,可以对指定的公众号数据采集
4、提供多种文章采集,只要是公众号内的文章就可以全部采集
5、支持列表显示,在软件界面显示采集的内容
6、支持文章查看,可以通过外置的浏览器查看文章
7、支持生成文章二维码,方便将当前的文章制作为二维码
8、支持将列表重复的文章删除,支持公众号过滤
使用说明
1、打开微信公众号文章搜索导入助手显示软件的功能界面
2、如果你须要学习软件就可以打开官方提供的视频教程
3、卡密目前售价29.9元/永久,只要有用户,软件将保持不断更新,优化升级!具体价钱以购买页为准
4、在软件输入关键词就可以查询公众号文章
5、如图所示,这里是软件的登入界面,您须要登陆陌陌
总结:seo优化六步走网站优化基础策略分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2020-08-28 20:25
seo优化一般是一个漫长又剌激的过程,依次把握好以下几点才能做好!
第一步,关键词策略。挖掘、分析、筛选关键词,整理关键词列表。
首先,选择核心关键词,seo最直接的目的就是获得定向的转化,转化率很低的词句不予考虑!
其次,判断关键词的竞争度,看关键词搜索次数、百度指数。
再次,挖掘长尾词,具体工具查看《seo优化干货分享(一)如何挖掘长尾关键词》一文。
第二步,架构策略。针对关键词设计好的网站架构,这个阶段是极其重要的,因为设计的网站架构、URL构架、内容构架决定了前面的SEO工作是否更容易。对于刚上线的新站来说,网站目录结构设计的浅些,能便捷蜘蛛抓取。
第三步,内容建设策略。持续更新内容保持网站活力,需要思索什么样的内容是用户最须要、最喜欢的,此时可以忘记SEO,纯粹从用户角度考虑内容。想要内容愈加受欢迎,可以从分享性、交流性、互助性考虑。想要降低用户点击行为,就要提高相关文章的关联性、增加页面数目、操作步骤,适当的添加娱乐化内容。
第四步,内链策略。如果你第2步做好了,内链就很容易解决。此时的重点是考虑每位关键词须要多少内链支持,主要可以通过面包屑导航、自动内链(Tag标签)、全站链接等形式提供内链。
第五步,外链策略。俗话说“外链为皇”,虽然当下外链的SEO疗效没有曾经显著,但是还是发挥着重要的作用。高质量的外链主要通过友情链接、商业合作(购买门户网站合作伙伴的外链)、软文链接、用户自然转发的链接(此时须要做好链接诱饵)来解决。至于以前十分流行的发外链可以不用考虑了,因为疗效差并且风险大,至于峰会推广作用还是有,只是流量被分散早已没先前作用这么大。
第六步,广告引流策略。可以找一些流量较高的网站或自媒体进行合作,在合作方的平台进行设置广告位,为我们的网站进行引流,或做品牌推广。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化 查看全部
seo优化六步走网站优化基础策略分享
seo优化一般是一个漫长又剌激的过程,依次把握好以下几点才能做好!
第一步,关键词策略。挖掘、分析、筛选关键词,整理关键词列表。
首先,选择核心关键词,seo最直接的目的就是获得定向的转化,转化率很低的词句不予考虑!
其次,判断关键词的竞争度,看关键词搜索次数、百度指数。
再次,挖掘长尾词,具体工具查看《seo优化干货分享(一)如何挖掘长尾关键词》一文。
第二步,架构策略。针对关键词设计好的网站架构,这个阶段是极其重要的,因为设计的网站架构、URL构架、内容构架决定了前面的SEO工作是否更容易。对于刚上线的新站来说,网站目录结构设计的浅些,能便捷蜘蛛抓取。
第三步,内容建设策略。持续更新内容保持网站活力,需要思索什么样的内容是用户最须要、最喜欢的,此时可以忘记SEO,纯粹从用户角度考虑内容。想要内容愈加受欢迎,可以从分享性、交流性、互助性考虑。想要降低用户点击行为,就要提高相关文章的关联性、增加页面数目、操作步骤,适当的添加娱乐化内容。
第四步,内链策略。如果你第2步做好了,内链就很容易解决。此时的重点是考虑每位关键词须要多少内链支持,主要可以通过面包屑导航、自动内链(Tag标签)、全站链接等形式提供内链。
第五步,外链策略。俗话说“外链为皇”,虽然当下外链的SEO疗效没有曾经显著,但是还是发挥着重要的作用。高质量的外链主要通过友情链接、商业合作(购买门户网站合作伙伴的外链)、软文链接、用户自然转发的链接(此时须要做好链接诱饵)来解决。至于以前十分流行的发外链可以不用考虑了,因为疗效差并且风险大,至于峰会推广作用还是有,只是流量被分散早已没先前作用这么大。
第六步,广告引流策略。可以找一些流量较高的网站或自媒体进行合作,在合作方的平台进行设置广告位,为我们的网站进行引流,或做品牌推广。
好推达人 抖音、小红书推广利器
购买短视频粉丝/网店/网站 到a5交易
10W+新媒体资源 低投入高转化
【seo建设】关于网站关键词被百度快速索引的问题讨论
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-08-27 21:41
经常会有SEO人员讨论,为什么我的SEO关键词总是不被快速索引,而实际上这儿主要指的是,针对特定关键词的核心内容,那么,它主要涉及如下两个指标:
①索引
②快速收录
这里值得说明的是:索引并不等于收录,索引只是被百度抓取后,进入百度的索引库中,它并不一定会在百度搜索结果中显露。
而经过算法评估后,搜索引擎觉得它可以展现今搜索结果中的时侯,它才弄成我们一般所谈论的百度收录。
那么,SEO关键词优化,如何使百度快速索引?
根据往年的工作经验,我们觉得我们首要须要先解决索引的问题,而进一步在解决快速收录的问题,为此我们须要:
1、索引
针对百度索引的问题,我们主要须要审视如下指标:
页面加载速率
对应搜索引擎而言,索引的前提,通常是抓取,只有保持一定的抓取频度,才可以被有效的索引,而抓取的前提,则是保持页面加载速率符合百度官方标准。
通常,百度给出的建议是在3秒以内,而对于移动端才能达到1.5秒则最优。
为此,你可能须要:
①优选服务器,保障服务器性能适配高频度的访问与抓取。
②开启页面加速器,比如:MIP、服务器缓存、CDN等。
页面内容原创
为什么要指出,内容索引是须要保持页面内容原创度,道理很简单,基于百度搜索算法,如果你递交的是采集内容,百度早已索引过的内容。
当你的网站权重相当较低的时侯,搜索引擎觉得,即使你采集的内容被索引与收录,并不能提供潜在的搜索价值。
这个时侯,搜索引擎都会舍弃,索引你的内容。
2、快速收录
在被百度索引后,如何实现百度快速收录,它一般须要审视如下几个指标:
内容原创且高质量
前文提及在索引阶段,内容一定是要原创的,而达到快速收录的标准,我们须要在一次进阶,确保内容是高质量的,并且满足一定搜索需求,比如:
①内容页面核心主题的关键词,需要具备一定的搜索量。
②内容段落具有一定的逻辑结构。
③内容页面,具有极高的参考价值,合理的相关内容推荐。
推进百度索引速率
当我们创作完满足快速收录的文章内容时,我们须要将该内容,快速被搜索引擎索引,为此,我们须要增强,百度蜘蛛发觉目标内容的可能性,可以尝试如下渠道:
①利用API接口主动递交。
②建立网站地图,并在百度搜索资源平台递交。
③配置熊掌号,利用熊掌号递交内容。
④在高权重网站引蜘蛛,利用投稿与软文的方式,在高权重站点发布优质内容,并收录目标URL。
总结:SEO关键词优化,快速达到索引的目的,通常可以根据上述流程操作,一般都可以实现。 查看全部
【seo建设】关于网站关键词被百度快速索引的问题讨论
经常会有SEO人员讨论,为什么我的SEO关键词总是不被快速索引,而实际上这儿主要指的是,针对特定关键词的核心内容,那么,它主要涉及如下两个指标:
①索引
②快速收录
这里值得说明的是:索引并不等于收录,索引只是被百度抓取后,进入百度的索引库中,它并不一定会在百度搜索结果中显露。
而经过算法评估后,搜索引擎觉得它可以展现今搜索结果中的时侯,它才弄成我们一般所谈论的百度收录。
那么,SEO关键词优化,如何使百度快速索引?
根据往年的工作经验,我们觉得我们首要须要先解决索引的问题,而进一步在解决快速收录的问题,为此我们须要:
1、索引
针对百度索引的问题,我们主要须要审视如下指标:
页面加载速率
对应搜索引擎而言,索引的前提,通常是抓取,只有保持一定的抓取频度,才可以被有效的索引,而抓取的前提,则是保持页面加载速率符合百度官方标准。
通常,百度给出的建议是在3秒以内,而对于移动端才能达到1.5秒则最优。
为此,你可能须要:
①优选服务器,保障服务器性能适配高频度的访问与抓取。
②开启页面加速器,比如:MIP、服务器缓存、CDN等。
页面内容原创
为什么要指出,内容索引是须要保持页面内容原创度,道理很简单,基于百度搜索算法,如果你递交的是采集内容,百度早已索引过的内容。
当你的网站权重相当较低的时侯,搜索引擎觉得,即使你采集的内容被索引与收录,并不能提供潜在的搜索价值。
这个时侯,搜索引擎都会舍弃,索引你的内容。
2、快速收录
在被百度索引后,如何实现百度快速收录,它一般须要审视如下几个指标:
内容原创且高质量
前文提及在索引阶段,内容一定是要原创的,而达到快速收录的标准,我们须要在一次进阶,确保内容是高质量的,并且满足一定搜索需求,比如:
①内容页面核心主题的关键词,需要具备一定的搜索量。
②内容段落具有一定的逻辑结构。
③内容页面,具有极高的参考价值,合理的相关内容推荐。
推进百度索引速率
当我们创作完满足快速收录的文章内容时,我们须要将该内容,快速被搜索引擎索引,为此,我们须要增强,百度蜘蛛发觉目标内容的可能性,可以尝试如下渠道:
①利用API接口主动递交。
②建立网站地图,并在百度搜索资源平台递交。
③配置熊掌号,利用熊掌号递交内容。
④在高权重网站引蜘蛛,利用投稿与软文的方式,在高权重站点发布优质内容,并收录目标URL。
总结:SEO关键词优化,快速达到索引的目的,通常可以根据上述流程操作,一般都可以实现。
程序里的后端和前端是哪些意思?
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2020-08-27 05:18
可以这样理解:能看到的都是后端,看不见的就是前端。
前端包括设计、html、css、JavaScript。设计挺好理解,就是产品的风格、布局,完成后它只是一张图片,它为我们前面的工作“打了个样”,让我们一开始就晓得产品完成后是哪些样子。然后通过html+css实现与设计图疗效一样的静态页面,html是超文本标记,比如设计图上面有一个文字超链接,我们就用超文本标记中的标签表示这是一个超链接,用href属性指定超链接地址,完整写法是这是超链接文字内容。css是样式表,比如前面超链接文字是哪些颜色、需不需要顿号等,都由css控制。JavaScript能实现一些动漫疗效或后端交互,比如一个注册页面上面要求填写手机号,但用户填写的是英文字符,那么可以通过JavaScript来判定并提醒用户输入11位阿拉伯数字。
后端是指通过程序语言(、php、jsp、java、c++等)实现动态数据。这里的动态数据不是指文字或图片在跳动,而是指数据能通过数据库完成新增、删除、编辑等指令。比如前面我举的文字超链接事例,如果这个文字超链接每晚都要更新,就可以通过程序语言来实现在管理后台进行更新操作。虽然我们也可以通过自动更改html代码来实现,但当数据量较大的时侯,这种操作是不现实的。
任何一款互联网产品都要通过前后端互相协作完成,虽然都要写代码,但她们的分工却不同,相对来说,后端程序要更复杂一些。 查看全部
程序里的后端和前端是哪些意思?
可以这样理解:能看到的都是后端,看不见的就是前端。
前端包括设计、html、css、JavaScript。设计挺好理解,就是产品的风格、布局,完成后它只是一张图片,它为我们前面的工作“打了个样”,让我们一开始就晓得产品完成后是哪些样子。然后通过html+css实现与设计图疗效一样的静态页面,html是超文本标记,比如设计图上面有一个文字超链接,我们就用超文本标记中的标签表示这是一个超链接,用href属性指定超链接地址,完整写法是这是超链接文字内容。css是样式表,比如前面超链接文字是哪些颜色、需不需要顿号等,都由css控制。JavaScript能实现一些动漫疗效或后端交互,比如一个注册页面上面要求填写手机号,但用户填写的是英文字符,那么可以通过JavaScript来判定并提醒用户输入11位阿拉伯数字。
后端是指通过程序语言(、php、jsp、java、c++等)实现动态数据。这里的动态数据不是指文字或图片在跳动,而是指数据能通过数据库完成新增、删除、编辑等指令。比如前面我举的文字超链接事例,如果这个文字超链接每晚都要更新,就可以通过程序语言来实现在管理后台进行更新操作。虽然我们也可以通过自动更改html代码来实现,但当数据量较大的时侯,这种操作是不现实的。
任何一款互联网产品都要通过前后端互相协作完成,虽然都要写代码,但她们的分工却不同,相对来说,后端程序要更复杂一些。
人人都有的关键词推荐工具,你真的会用吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-27 04:33
获取关键词的方式有很多,其中就包括百度自带的关键词推荐工具(其他平台也都有各自的关键词推荐工具,本文以百度关键词工具为例)。
通过关键词工具,能够挺好地帮助我们筛选出核心关键词来进行投放。但是在实际投放过程中,发现有的关键词转化疗效并不好。这是因为我们经常站在自己的角度去推测访客会搜什么词,而这种词访客并不一定真的会搜索。今天就和你们分享一下,如何更好的发挥出关键词推荐工具的作用。
关键词推荐工具的用法很简单,在助手里打开关键词推荐工具,输入我们须要拓展的核心关键词,系统会手动列举好多和关键词相关的词。以“装修公司”为例:
系统一共推荐了1000个相像或则相关的关键词,这些词大部分是访客实实在在搜索过的,是搜索某种产品的一种彰显,当然也有一部分是我们推广人员拿来搜索进行排行查看的。
1、查漏补缺
通常情况下,我们把词筛选过后,都应当添加到帐户上面。但实际上,还是有很多关键词会被漏掉,你可以用关键词工具去搜索一下,一定有一些词是没有被添加到帐户里的。这些词有搜索量,也有竞争度,漏掉了就相当于流失了一部分流量,比较可惜。
另外,我们在添加关键词的时侯,不能只盯住“装修”这个词。装修公司的人,肯定会认为用户也会搜索家装公司,但实际上,访客不仅会搜索“装修”相关词,还会搜索“家装”有关的词,这些都是潜在的顾客。
如图,这两个词,搜索量都不小,而且竞争度比较适中,适合推广。但是本人在实况里搜索了一下,发现这两个词没有人做。另外,很多组词,都是以“装修”为主,如果以“家装”为核心来组词,又可以带来很大的一部分流量。
2、关注竞争度
关键词推荐工具里推荐的词,有搜索量,还有竞争度。可以把关键词复制到表格里,用数据条来显示竞争度,比较直观。一般情况下,搜索量大,竞争度肯定大 。不过也有一些词,搜索量十分小,但是竞争度却比搜索量大的词的还要大。
之所以会出现搜索量小,竞争度大,有可能是店家自己认为这样的词价值比较高,然后相互竞争引起的。所以当我们推广这种词的时侯,就要考虑,这些词的转化率怎么样,不要盲目的进行投放。
3、发掘长尾词
另外还有一些搜索量小,竞争度小的词,却没有人做,这是一块长尾市场,需要及时补充起来。
如图中标黄所示,搜索这种词的人,当时的心境,应该是处于迷茫阶段,不知道哪家家装公司靠谱,他们须要的是有人才能正确的指导她们来选择家装公司,所以假如才能对她们进行引导,把着陆页面设置好,将会有不错的转化。
这就是我和你们分享的怎样借助关键词推荐工具,找到性价比高的关键词。简单的说,就是把这个工具借助好,进行查漏补缺,通过剖析搜索量和竞争度之间的关系,找到竞争度小,转化好的关键词来投放,避免做热词,你赚我抢,得不偿失。
给你们推荐我国新一代大数据用户行为剖析与数据智能平台:数极客(),是支持无埋点、前端埋点、后端埋点、API导出四种混和数据采集方式,整合剖析用户行为数据和业务数据,可以手动检测网站、APP、小程序等多种渠道推广疗效剖析,是下降黑客们必备的互联网数据剖析软件。数极客支持实时多维剖析、漏斗剖析、留存剖析、路径剖析等十大数据剖析方式以及APP数据剖析、网站统计、网站分析、小程序数据统计、用户画像等应用场景,业内首创了六种提高转化率的数据剖析模型,是数据剖析软件领域首款应用定量分析与定性剖析方式的数据剖析产品
。 查看全部
人人都有的关键词推荐工具,你真的会用吗?
获取关键词的方式有很多,其中就包括百度自带的关键词推荐工具(其他平台也都有各自的关键词推荐工具,本文以百度关键词工具为例)。
通过关键词工具,能够挺好地帮助我们筛选出核心关键词来进行投放。但是在实际投放过程中,发现有的关键词转化疗效并不好。这是因为我们经常站在自己的角度去推测访客会搜什么词,而这种词访客并不一定真的会搜索。今天就和你们分享一下,如何更好的发挥出关键词推荐工具的作用。
关键词推荐工具的用法很简单,在助手里打开关键词推荐工具,输入我们须要拓展的核心关键词,系统会手动列举好多和关键词相关的词。以“装修公司”为例:
系统一共推荐了1000个相像或则相关的关键词,这些词大部分是访客实实在在搜索过的,是搜索某种产品的一种彰显,当然也有一部分是我们推广人员拿来搜索进行排行查看的。
1、查漏补缺
通常情况下,我们把词筛选过后,都应当添加到帐户上面。但实际上,还是有很多关键词会被漏掉,你可以用关键词工具去搜索一下,一定有一些词是没有被添加到帐户里的。这些词有搜索量,也有竞争度,漏掉了就相当于流失了一部分流量,比较可惜。
另外,我们在添加关键词的时侯,不能只盯住“装修”这个词。装修公司的人,肯定会认为用户也会搜索家装公司,但实际上,访客不仅会搜索“装修”相关词,还会搜索“家装”有关的词,这些都是潜在的顾客。
如图,这两个词,搜索量都不小,而且竞争度比较适中,适合推广。但是本人在实况里搜索了一下,发现这两个词没有人做。另外,很多组词,都是以“装修”为主,如果以“家装”为核心来组词,又可以带来很大的一部分流量。
2、关注竞争度
关键词推荐工具里推荐的词,有搜索量,还有竞争度。可以把关键词复制到表格里,用数据条来显示竞争度,比较直观。一般情况下,搜索量大,竞争度肯定大 。不过也有一些词,搜索量十分小,但是竞争度却比搜索量大的词的还要大。
之所以会出现搜索量小,竞争度大,有可能是店家自己认为这样的词价值比较高,然后相互竞争引起的。所以当我们推广这种词的时侯,就要考虑,这些词的转化率怎么样,不要盲目的进行投放。
3、发掘长尾词
另外还有一些搜索量小,竞争度小的词,却没有人做,这是一块长尾市场,需要及时补充起来。
如图中标黄所示,搜索这种词的人,当时的心境,应该是处于迷茫阶段,不知道哪家家装公司靠谱,他们须要的是有人才能正确的指导她们来选择家装公司,所以假如才能对她们进行引导,把着陆页面设置好,将会有不错的转化。
这就是我和你们分享的怎样借助关键词推荐工具,找到性价比高的关键词。简单的说,就是把这个工具借助好,进行查漏补缺,通过剖析搜索量和竞争度之间的关系,找到竞争度小,转化好的关键词来投放,避免做热词,你赚我抢,得不偿失。
给你们推荐我国新一代大数据用户行为剖析与数据智能平台:数极客(),是支持无埋点、前端埋点、后端埋点、API导出四种混和数据采集方式,整合剖析用户行为数据和业务数据,可以手动检测网站、APP、小程序等多种渠道推广疗效剖析,是下降黑客们必备的互联网数据剖析软件。数极客支持实时多维剖析、漏斗剖析、留存剖析、路径剖析等十大数据剖析方式以及APP数据剖析、网站统计、网站分析、小程序数据统计、用户画像等应用场景,业内首创了六种提高转化率的数据剖析模型,是数据剖析软件领域首款应用定量分析与定性剖析方式的数据剖析产品
。
干货 | API已改变SEO的玩法,不懂只能改行
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-26 05:47
我们可以如何做到更好?
1拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如理财行业围绕的核心词部份如下:
理财行业的核心词之下长尾词列表部份如下:
2用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:
通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。
3通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:
返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网+上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。
另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。
例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比seo关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:
5监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
1、借助站长后台(),了解爬虫爬行次数和抓取时间,了解爬虫遇见的异常次数。
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。
2、通过5118PC收录监测功能或则百度PC收录API检测制造的内容是否被收录。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。
3、检查排行是否如预期在下降
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。
▲ 可以利用5118关键词监控分批添加自己关键词进行监控
▲ 也可以利用5118关键词排名采集API进行监控
最 后 总 结
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。
享受高手级营运视野
微信ID:data5118长按加个关注撒 查看全部
干货 | API已改变SEO的玩法,不懂只能改行
我们可以如何做到更好?
1拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如理财行业围绕的核心词部份如下:
理财行业的核心词之下长尾词列表部份如下:
2用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:
通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。
3通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:
返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网+上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。
另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。
例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比seo关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:
5监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
1、借助站长后台(),了解爬虫爬行次数和抓取时间,了解爬虫遇见的异常次数。
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。
2、通过5118PC收录监测功能或则百度PC收录API检测制造的内容是否被收录。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。
3、检查排行是否如预期在下降
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。
▲ 可以利用5118关键词监控分批添加自己关键词进行监控
▲ 也可以利用5118关键词排名采集API进行监控
最 后 总 结
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。
享受高手级营运视野
微信ID:data5118长按加个关注撒
浅析网路大数据的商业价值和采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-08-26 05:42
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。
数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:
除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。 查看全部
浅析网路大数据的商业价值和采集方法
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。
数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:
除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。
API已改变SEO的玩法,不懂只能改行
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2020-08-25 22:12
SEO从业者是帮助搜索引擎进行优化的人,不是说每晚形成无数垃圾信息就是在帮助,不是说每晚构建无数的友情链接就是在帮助它,而是帮助搜索引擎解决它的实际问题。是不是认为太伟大?
如果不能认识到这点,其实你可能早已不能适应SEO优化领域。现在早已不是初期的莽荒时代,如果仍然靠链接和伪原创你只会有一个觉得,SEO真他喵不是人干的!
我们可以如何做到更好?
1 、拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如 理财行业 围绕的核心词部份如下:
理财行业 的核心词之下长尾词列表部份如下:
2 、用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:
通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。
3 、通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:
返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。
另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。
例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4 、帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比SEO关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:
5 、监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。
对整体大趋势进行跟踪,确保整体内容策略大方向是正确的。
2. 对单个的关键词排行进行监控,以评估每位内容生产工作的稳定性,注重细节。
▲ 可以利用5118关键词监控分批添加自己关键词进行监控
▲ 也可以利用5118关键词排名采集API进行监控
最 后 总 结:
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。
5118,享受前辈级营运视野
更多API详情,欢迎登录5118官网! 查看全部
API已改变SEO的玩法,不懂只能改行
SEO从业者是帮助搜索引擎进行优化的人,不是说每晚形成无数垃圾信息就是在帮助,不是说每晚构建无数的友情链接就是在帮助它,而是帮助搜索引擎解决它的实际问题。是不是认为太伟大?
如果不能认识到这点,其实你可能早已不能适应SEO优化领域。现在早已不是初期的莽荒时代,如果仍然靠链接和伪原创你只会有一个觉得,SEO真他喵不是人干的!
我们可以如何做到更好?
1 、拥有最全面确切的行业词库
我们在营运某个网站或者栏目时,往往会垂直于一个行业。每个行业都有自己的范围,如果浅显的讲,实际上每位行业都有自己一批核心关键词+长尾词,由这种词汇划分了一个行业的范围,所以拥有一个行业词库是对一个行业充分把握的必备品。
例如 理财行业 围绕的核心词部份如下:
理财行业 的核心词之下长尾词列表部份如下:
2 、用词库找出搜索引擎最须要的内容
当我们拥有一个行业的所有词汇后,我们能够真正意义上懂得这个行业,懂得这个行业用户的需求。
接下来我们要在这近百万的理财词库中,找到最能带来流量的词汇,这里我们借助百度PC指数、360指数、百度移动指数、竞价规划师PC搜索量、竞价规划师联通搜索量、竞价规划师竞争度:
通过以上公式我们可以筛选出行业中最能带来流量的一批词,从百万词库中筛选出104635个流量词。
3 、通过 API 筛选出搜索引擎最缺少内容的关键词
有了前面筛选下来的104635个流量词,我们便可以装入百度、360等搜索引擎进行模拟查询,了解排位在前20位的网页对应的url级别和标题情况,了解搜索引擎是否早已内容饱和。
通过API商城中的百度PC端TOP 50位排行情况API(),我们可以轻松获得JSON格式的排行情况。
下图中我们以“什么是指数基金”这个词为例来获取TOP20搜索结果排行情况:
返回的排行信息中比较重要的有两种信息,域名权重信息和Title信息。
域名权重信息代表着是否排名前50的域名中是不是都是有权重还比较低的域名,这样你才有机会挤进去。
Title信息的剖析意味着互联网上关于这个关键词的内容是否饱和,是不是由于百度为了填充信息而选择了一些补充信息来填充搜索结果。
通过剖析这两个信息,我们能够决定这个关键词是否优先值得去做内容。
这里做个假定,如果我的网站5118的权重是A,那么我们就要找寻TOP20排行结果中是否还有好多5118权重B级甚至C级的网站排名结果,如果有这么我们就还有机会攻打她们的位置。
另外还有一种情况,如果通过域名发觉不了机会,还有另一个机会,就是虽然这种高权重域名的内容并没有完全符合搜索要求,也就是说结果中一些内容标题没有完全匹配关键词。
例如上图中的Title,就没有完全收录“什么是指数基金”这个词,只不过是搜索引擎为了补充结果而装入的索引,那我们也可以把这种位置标记为有机会。
通过类似前面的算法,每个词我们都可以得到一个机会分值,我们可以设置一个筛选的阀值,例如设置为8,如果TOP 20的结果中有8个以上是有机会的位置,我们就将这种关键词保留出来,进入到第四阶段。
4 、帮助搜索引擎建立这种内容
当我们通过上面三步完成了最高性价比SEO关键词筛选过后,我们便可以安排编辑人员进行文章或者专题的编撰,或是安排技术部进行文章的采集,亦或是安排营运部门引导用户制造内容。
通过这四个步骤的层层过滤,我们的内容营运工作将会十分有针对性,虽然里面写了这么多文字,但是毕竟就是下边三个目的:
5 、监控SEO疗效
随着内容的不断建立,我们须要整体评估前面确定的内容策略的成效,可能要对一些参数和阀值甚至算法进行微调:
因为只有监控那些参数能够晓得你的内容制造下来以后百度爬虫是否如期而来,并且没有碰到任何障碍,这样确保你的内容策略没有由于其他技术运维的干扰诱因引起策略没有发挥作用。
收录是有排行的前提,如果内容不能收录,爬虫爬行再多也没有意义。内容做下来不收录,对于内容策略也将会是一个严打,所以收录的监控也至关重要。
随着内容和收录的不断降低,我们SEO终极目的就是要获得好的排行。
对整体大趋势进行跟踪,确保整体内容策略大方向是正确的。
2. 对单个的关键词排行进行监控,以评估每位内容生产工作的稳定性,注重细节。
▲ 可以利用5118关键词监控分批添加自己关键词进行监控
▲ 也可以利用5118关键词排名采集API进行监控
最 后 总 结:
人类近代文明的发展就是一个追求极其自动化过程,无人工厂、无人超市、无人机、作为大数据时代的SEO管理人员,同样要追求SEO的自动化,与时俱进能够实现自我的突破。
通过这样的内容生产过程,我们可以逐渐优化我们的内容策略,做到内容生产流量疗效的最大化。所以你还在等哪些,赶快用起这种可以使你轻松晋升的大数据API。
5118,享受前辈级营运视野
更多API详情,欢迎登录5118官网!
Serverless 实战:如何结合 NLP 实现文本摘要和关键词提取?
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2020-08-25 18:17
对文本进行手动摘要的提取和关键词的提取,属于自然语言处理的范畴。提取摘要的一个用处是可以使阅读者通过最少的信息判别出这个文章对自己是否有意义或则价值,是否须要进行愈发详尽的阅读;而提取关键词的用处是可以使文章与文章之间形成关联,同时也可以使读者通过关键词快速定位到和该关键词相关的文章内容。
文本摘要和关键词提取都可以和传统的 CMS 进行结合,通过对文章 / 新闻等发布功能进行整修,同步提取关键词和摘要,放到 HTML 页面中作为 Description 和 Keyworks。这样做在一定程度上有利于搜索引擎收录,属于 SEO 优化的范畴。
关键词提取
关键词提取的方式好多,但是最常见的应当就是tf-idf了。
通过jieba实现基于tf-idf关键词提取的方式:
jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=('n', 'vn', 'v'))
文本摘要
文本摘要的方式也有好多,如果从广义上来界定,包括提取式和生成式。其中提取式就是在文章中通过TextRank等算法,找出关键句之后进行拼装,形成摘要,这种方式相对来说比较简单,但是很难提取出真实的语义等;另一种方式是生成式,通过深度学习等方式,对文本语义进行提取再生成摘要。
如果简单理解,提取式方法生成的摘要,所有语句来自原文,而生成式方式则是独立生成的。
为了简化难度,本文将采用提取式来实现文本摘要功能,通过 SnowNLP 第三方库,实现基于TextRank的文本摘要功能。我们以《海底两万里》部分内容作为原文,进行摘要生成:
原文:
这些风波发生时,我刚从英国内布拉斯加州的贫瘠地区做完一项科考工作回去。我当时是巴黎自然史博物馆的客座教授,法国政府派我出席此次考察活动。我在内布拉斯加州渡过了半年时间,采集了许多珍稀资料,满载而归,3 月底到达伦敦。我决定 5 月初动身回美国。于是,我就抓紧这段候船停留时间,把搜集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。
我对当时的街谈巷议自然了如指掌,再说了,我岂能听而不闻、无动于衷呢?我把日本和法国的各类报刊读了又读,但无法深入了解真相。神秘莫测,百思不得其解。我左思右想,摇摆于两个极端之间,始终形不成一种看法。其中肯定有名堂,这是不容置疑的,如果有人表示怀疑,就请她们去摸一摸斯科舍号的创口好了。
我到伦敦时,这个问题正炒得沸反盈天。某些不学无术之徒提出构想,有说是浮动的小岛,也有说是不可捉摸的暗礁,不过,这些个假定通通都被推翻了。很显然,除非这暗礁头部装有机器,不然的话,它岂能这么快速地转移呢?
同样的道理,说它是一块浮动的舱室或是一堆大船残骸,这种假定也不能创立,理由依旧是联通速率很快。
那么,问题只能有两种解释,人们各持己见,自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物,另一派说这是一艘动力极强的“潜水船”。
哦,最后那个假定尚且可以接受,但到欧美各国调查过后,也就无法自圆其说了。有那个普通人会拥有这么强悍动力的机械?这是不可能的。他在何地何时叫何人制造了这么个庞然大物,而且怎么能在建造中做到风声不探听呢?
看来,只有政府才有可能拥有这些破坏性的机器,在这个灾难深重的时代,人们千方百计要提高战争装备威力,那就有此类可能,一个国家瞒着其他国家在试制这类骇人听闻的装备。继夏斯勃手枪以后有鱼雷,水雷以后有水下撞锤,然后剑皇高涨反应,事态愈演愈烈。至少,我是这样想的。
通过 SnowNLP 提供的算法:
from snownlp import SnowNLP
text = " 上面的原文内容,此处省略 "
s = SnowNLP(text)
print("。".join(s.summary(5)))
输出结果:
自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物。这种假设也不能成立。我到纽约时。说它是一块浮动的船体或是一堆大船残片。另一派说这是一艘动力极强的“潜水船”
初步来看,效果并不是挺好,接下来我们自己估算语句权重,实现一个简单的摘要功能,这个就须要jieba:
import re
import jieba.analyse
import jieba.posseg
class TextSummary:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
这段代码主要是通过 tf-idf 实现关键词提取,然后通过关键词提取对语句进行权重赋于,最后获得到整体的结果,运行:
testSummary = TextSummary(text)
print("。".join(testSummary.getSummary()))
可以得到结果:
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/yb/wvy_7wm91mzd7cjg4444gvdjsglgs8/T/jieba.cache
Loading model cost 0.721 seconds.
Prefix dict has been built successfully.
看来,只有政府才有可能拥有这种破坏性的机器,在这个灾难深重的时代,人们千方百计要增强战争武器威力,那就有这种可能,一个国家瞒着其他国家在试制这类骇人听闻的武器。于是,我就抓紧这段候船逗留时间,把收集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。同样的道理,说它是一块浮动的船体或是一堆大船残片,这种假设也不能成立,理由仍然是移动速度太快
我们可以看见,整体疗效要比昨天的好一些。
发布 API
通过 Serverless 架构,将前面代码进行整理,并发布。
代码整理结果:
import re, json
import jieba.analyse
import jieba.posseg
class NLPAttr:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
return self.keywords
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
def main_handler(event, context):
nlp = NLPAttr(json.loads(event['body'])['text'])
return {
"keywords": nlp.getKeywords(),
"summary": "。".join(nlp.getSummary())
}
编写项目serverless.yaml文件:
nlpDemo:
component: "@serverless/tencent-scf"
inputs:
name: nlpDemo
codeUri: ./
handler: index.main_handler
runtime: Python3.6
region: ap-guangzhou
description: 文本摘要 / 关键词功能
memorySize: 256
timeout: 10
events:
- apigw:
name: nlpDemo_apigw_service
parameters:
protocols:
- http
serviceName: serverless
description: 文本摘要 / 关键词功能
environment: release
endpoints:
- path: /nlp
method: ANY
由于项目中使用了jieba,所以在安装的时侯推荐在 CentOS 系统下与对应的 Python 版本下安装,也可以使用我之前为了便捷做的一个依赖工具:
通过sls --debug进行布署:
部署完成,可以通过 PostMan 进行简单的测试:
从上图可以看见,我们早已根据预期输出了目标结果。至此,文本摘要 / 关键词提取的 API 已经布署完成。
总结
相对来说,通过 Serveless 架构做 API 是十分容易和便捷的,可实现 API 的插拔行,组件化,希望本文才能给读者更多的思路和启发。 查看全部
Serverless 实战:如何结合 NLP 实现文本摘要和关键词提取?
对文本进行手动摘要的提取和关键词的提取,属于自然语言处理的范畴。提取摘要的一个用处是可以使阅读者通过最少的信息判别出这个文章对自己是否有意义或则价值,是否须要进行愈发详尽的阅读;而提取关键词的用处是可以使文章与文章之间形成关联,同时也可以使读者通过关键词快速定位到和该关键词相关的文章内容。
文本摘要和关键词提取都可以和传统的 CMS 进行结合,通过对文章 / 新闻等发布功能进行整修,同步提取关键词和摘要,放到 HTML 页面中作为 Description 和 Keyworks。这样做在一定程度上有利于搜索引擎收录,属于 SEO 优化的范畴。
关键词提取
关键词提取的方式好多,但是最常见的应当就是tf-idf了。
通过jieba实现基于tf-idf关键词提取的方式:
jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=('n', 'vn', 'v'))
文本摘要
文本摘要的方式也有好多,如果从广义上来界定,包括提取式和生成式。其中提取式就是在文章中通过TextRank等算法,找出关键句之后进行拼装,形成摘要,这种方式相对来说比较简单,但是很难提取出真实的语义等;另一种方式是生成式,通过深度学习等方式,对文本语义进行提取再生成摘要。
如果简单理解,提取式方法生成的摘要,所有语句来自原文,而生成式方式则是独立生成的。
为了简化难度,本文将采用提取式来实现文本摘要功能,通过 SnowNLP 第三方库,实现基于TextRank的文本摘要功能。我们以《海底两万里》部分内容作为原文,进行摘要生成:
原文:
这些风波发生时,我刚从英国内布拉斯加州的贫瘠地区做完一项科考工作回去。我当时是巴黎自然史博物馆的客座教授,法国政府派我出席此次考察活动。我在内布拉斯加州渡过了半年时间,采集了许多珍稀资料,满载而归,3 月底到达伦敦。我决定 5 月初动身回美国。于是,我就抓紧这段候船停留时间,把搜集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。
我对当时的街谈巷议自然了如指掌,再说了,我岂能听而不闻、无动于衷呢?我把日本和法国的各类报刊读了又读,但无法深入了解真相。神秘莫测,百思不得其解。我左思右想,摇摆于两个极端之间,始终形不成一种看法。其中肯定有名堂,这是不容置疑的,如果有人表示怀疑,就请她们去摸一摸斯科舍号的创口好了。
我到伦敦时,这个问题正炒得沸反盈天。某些不学无术之徒提出构想,有说是浮动的小岛,也有说是不可捉摸的暗礁,不过,这些个假定通通都被推翻了。很显然,除非这暗礁头部装有机器,不然的话,它岂能这么快速地转移呢?
同样的道理,说它是一块浮动的舱室或是一堆大船残骸,这种假定也不能创立,理由依旧是联通速率很快。
那么,问题只能有两种解释,人们各持己见,自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物,另一派说这是一艘动力极强的“潜水船”。
哦,最后那个假定尚且可以接受,但到欧美各国调查过后,也就无法自圆其说了。有那个普通人会拥有这么强悍动力的机械?这是不可能的。他在何地何时叫何人制造了这么个庞然大物,而且怎么能在建造中做到风声不探听呢?
看来,只有政府才有可能拥有这些破坏性的机器,在这个灾难深重的时代,人们千方百计要提高战争装备威力,那就有此类可能,一个国家瞒着其他国家在试制这类骇人听闻的装备。继夏斯勃手枪以后有鱼雷,水雷以后有水下撞锤,然后剑皇高涨反应,事态愈演愈烈。至少,我是这样想的。
通过 SnowNLP 提供的算法:
from snownlp import SnowNLP
text = " 上面的原文内容,此处省略 "
s = SnowNLP(text)
print("。".join(s.summary(5)))
输出结果:
自然就分成观点截然不同的两派:一派说这是一个力大无比的怪物。这种假设也不能成立。我到纽约时。说它是一块浮动的船体或是一堆大船残片。另一派说这是一艘动力极强的“潜水船”
初步来看,效果并不是挺好,接下来我们自己估算语句权重,实现一个简单的摘要功能,这个就须要jieba:
import re
import jieba.analyse
import jieba.posseg
class TextSummary:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
这段代码主要是通过 tf-idf 实现关键词提取,然后通过关键词提取对语句进行权重赋于,最后获得到整体的结果,运行:
testSummary = TextSummary(text)
print("。".join(testSummary.getSummary()))
可以得到结果:
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/yb/wvy_7wm91mzd7cjg4444gvdjsglgs8/T/jieba.cache
Loading model cost 0.721 seconds.
Prefix dict has been built successfully.
看来,只有政府才有可能拥有这种破坏性的机器,在这个灾难深重的时代,人们千方百计要增强战争武器威力,那就有这种可能,一个国家瞒着其他国家在试制这类骇人听闻的武器。于是,我就抓紧这段候船逗留时间,把收集到的矿物和动植物标本进行分类整理,可就在这时,斯科舍号出事了。同样的道理,说它是一块浮动的船体或是一堆大船残片,这种假设也不能成立,理由仍然是移动速度太快
我们可以看见,整体疗效要比昨天的好一些。
发布 API
通过 Serverless 架构,将前面代码进行整理,并发布。
代码整理结果:
import re, json
import jieba.analyse
import jieba.posseg
class NLPAttr:
def __init__(self, text):
self.text = text
def splitSentence(self):
sectionNum = 0
self.sentences = []
for eveSection in self.text.split("\n"):
if eveSection:
sentenceNum = 0
for eveSentence in re.split("!|。|?", eveSection):
if eveSentence:
mark = []
if sectionNum == 0:
mark.append("FIRSTSECTION")
if sentenceNum == 0:
mark.append("FIRSTSENTENCE")
self.sentences.append({
"text": eveSentence,
"pos": {
"x": sectionNum,
"y": sentenceNum,
"mark": mark
}
})
sentenceNum = sentenceNum + 1
sectionNum = sectionNum + 1
self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE")
for i in range(0, len(self.sentences)):
if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]:
self.sentences[i]["pos"]["mark"].append("LASTSECTION")
def getKeywords(self):
self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v'))
return self.keywords
def sentenceWeight(self):
# 计算句子的位置权重
for sentence in self.sentences:
mark = sentence["pos"]["mark"]
weightPos = 0
if "FIRSTSECTION" in mark:
weightPos = weightPos + 2
if "FIRSTSENTENCE" in mark:
weightPos = weightPos + 2
if "LASTSENTENCE" in mark:
weightPos = weightPos + 1
if "LASTSECTION" in mark:
weightPos = weightPos + 1
sentence["weightPos"] = weightPos
# 计算句子的线索词权重
index = [" 总之 ", " 总而言之 "]
for sentence in self.sentences:
sentence["weightCueWords"] = 0
sentence["weightKeywords"] = 0
for i in index:
for sentence in self.sentences:
if sentence["text"].find(i) >= 0:
sentence["weightCueWords"] = 1
for keyword in self.keywords:
for sentence in self.sentences:
if sentence["text"].find(keyword) >= 0:
sentence["weightKeywords"] = sentence["weightKeywords"] + 1
for sentence in self.sentences:
sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"]
def getSummary(self, ratio=0.1):
self.keywords = list()
self.sentences = list()
self.summary = list()
# 调用方法,分别计算关键词、分句,计算权重
self.getKeywords()
self.splitSentence()
self.sentenceWeight()
# 对句子的权重值进行排序
self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True)
# 根据排序结果,取排名占前 ratio% 的句子作为摘要
for i in range(len(self.sentences)):
if i < ratio * len(self.sentences):
sentence = self.sentences[i]
self.summary.append(sentence["text"])
return self.summary
def main_handler(event, context):
nlp = NLPAttr(json.loads(event['body'])['text'])
return {
"keywords": nlp.getKeywords(),
"summary": "。".join(nlp.getSummary())
}
编写项目serverless.yaml文件:
nlpDemo:
component: "@serverless/tencent-scf"
inputs:
name: nlpDemo
codeUri: ./
handler: index.main_handler
runtime: Python3.6
region: ap-guangzhou
description: 文本摘要 / 关键词功能
memorySize: 256
timeout: 10
events:
- apigw:
name: nlpDemo_apigw_service
parameters:
protocols:
- http
serviceName: serverless
description: 文本摘要 / 关键词功能
environment: release
endpoints:
- path: /nlp
method: ANY
由于项目中使用了jieba,所以在安装的时侯推荐在 CentOS 系统下与对应的 Python 版本下安装,也可以使用我之前为了便捷做的一个依赖工具:
通过sls --debug进行布署:
部署完成,可以通过 PostMan 进行简单的测试:
从上图可以看见,我们早已根据预期输出了目标结果。至此,文本摘要 / 关键词提取的 API 已经布署完成。
总结
相对来说,通过 Serveless 架构做 API 是十分容易和便捷的,可实现 API 的插拔行,组件化,希望本文才能给读者更多的思路和启发。
选择关键词的步骤和注意事项总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-25 11:49
对关键词的选择和确定,相信你们在实际应用中早已有了一套自己固定的思维模式,并且已非常成熟。但对于seo新人来说,还是须要在实际应用与实践中渐渐积累,希望下边的一些总结性语言才能对你日后选择网站关键词时有所帮助。
挑选关键词的步骤:
1.确认核心关键词。即网站核心关键词,通常在首页的title keyword description中着力突出和重复。一般该类关键词都比较宽泛和庞杂,比如SEO,电影,等。
2.在核心关键词的基础上进行扩充。通常用于确认栏目或频道关键词的选择。如,我的博客关键词是SEO,频道关键词就扩充为SEO服务,SEO学习,SEO方法等。频道关键词应与核心关键词保持很高的相关性。
3.根据网站与频道关键词,设计相关性太强的内容页与文章关键词并发布。
4.模拟用户的搜索习惯,研究竞争者的关键词。从而校准或追加相关关键词。需要指出的是,搜索引擎返回的关键字查询结果中,仅有10%左右的页面和所查询的关键词有直接性关联,也就是用户真正所需求的信息。所以,相同关键词的竞争对手网站,应从这10%中因情况不同进行筛选并研究。
定位关键词时须要注意:
1.调查用户的搜索习惯。也就是说你要站在用户的角度来考虑,比如电视剧和电影的含意其实相同,但搜索后者的用户远少于前者,所以,能够做好电视剧这个关键词的排行,意义和价值都远小于前者。
2.关键词不易过分艰深。除主页以外,要使用较为精确的页面关键词,这样做除了才能获得更好的排行,同时也大大提高了有效顾客的转换率。提升网站访客的质量。
3.关键词在任何时侯都要保持高度的相关性,做SEO的,发布或设定影片信息的频道总是说不过去的,从搜索引擎角度而言,也非常的不友善。 查看全部
选择关键词的步骤和注意事项总结
对关键词的选择和确定,相信你们在实际应用中早已有了一套自己固定的思维模式,并且已非常成熟。但对于seo新人来说,还是须要在实际应用与实践中渐渐积累,希望下边的一些总结性语言才能对你日后选择网站关键词时有所帮助。
挑选关键词的步骤:
1.确认核心关键词。即网站核心关键词,通常在首页的title keyword description中着力突出和重复。一般该类关键词都比较宽泛和庞杂,比如SEO,电影,等。
2.在核心关键词的基础上进行扩充。通常用于确认栏目或频道关键词的选择。如,我的博客关键词是SEO,频道关键词就扩充为SEO服务,SEO学习,SEO方法等。频道关键词应与核心关键词保持很高的相关性。
3.根据网站与频道关键词,设计相关性太强的内容页与文章关键词并发布。
4.模拟用户的搜索习惯,研究竞争者的关键词。从而校准或追加相关关键词。需要指出的是,搜索引擎返回的关键字查询结果中,仅有10%左右的页面和所查询的关键词有直接性关联,也就是用户真正所需求的信息。所以,相同关键词的竞争对手网站,应从这10%中因情况不同进行筛选并研究。
定位关键词时须要注意:
1.调查用户的搜索习惯。也就是说你要站在用户的角度来考虑,比如电视剧和电影的含意其实相同,但搜索后者的用户远少于前者,所以,能够做好电视剧这个关键词的排行,意义和价值都远小于前者。
2.关键词不易过分艰深。除主页以外,要使用较为精确的页面关键词,这样做除了才能获得更好的排行,同时也大大提高了有效顾客的转换率。提升网站访客的质量。
3.关键词在任何时侯都要保持高度的相关性,做SEO的,发布或设定影片信息的频道总是说不过去的,从搜索引擎角度而言,也非常的不友善。
基于API的微博信息采集系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-08-25 10:36
摘要:微博已成为网路信息的重要来源,该文剖析了微博信息采集的相关技巧与技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,能够对新浪微博的相关信息进行采集。实验测试表明,该信息采集系统就能快速有效地采集新浪微博信息。
关键词:新浪微博;微博插口;信息采集;C#语言
中图分类号:TP315 文献标识码:A 文章编号:1009-3044(2013)17-4005-04
微博[1],即微型博客的简称,是一个基于用户关系的信息分享、传播以及获取平台,用
户可以通过WEB、WAP以及各类客户端组件个人社区,以140字左右的文字更新信息,并实现即时分享。中国互联网络信息中心的《第31次中国互联网路发展状况统计报告》显示,截至2012年12月底,截至2012年12月底,我国微博用户规模为3.09亿,较2011年底下降了5873万,网民中的微博用户比列较上年底提高了六个百分点,达到54.7%[2]。随着微博网路
影响力的快速扩大,政府部门、学校、知名企业、社会公众人物均开通了微博。随着公众的参与,微博成为了一个强悍的虚拟社会,微博早已是网路信息的重要来源,如何用于快速有效地采集微博信息已然成为一个具有重要应用价值的研究。
1 研究方式与技术路线
国内的微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方式与技术路线。通过剖析国内外的科技文献与实际应用案例,发现目前针对新浪微博的信息采集方法主要有两类:一种是“模拟登录”、“网页爬虫”[3]、“网页内容解析”[4]三种技术结合的信息采集方法,二是基于新浪微博开放平台的API文档,开发者自行编撰程序调用微博的API,进行微博信息的采集。对于第一种方式,难度比较高,研究技术复杂,特别是“模拟登录”这个步骤,需要随时跟踪新浪微博的登录加密算法,新浪微博的登录加密算法的改变,就会导致“网页爬虫”的失败,最后造成采集不到微博信息。同时,“网页爬虫”采集到的网页须要进行“网页内容解析”,效率与性能相比基于API的数据采集存在显著的差别。基于以上诱因,因此本文拟采用第二种方法进行研究。
基于新浪微博开放平台API文档的微博信息采集系统,主要采用了两个研究方式:文档分析法和实验测试法。文档分析法:参考新浪微博开放平台的API文档,把这种API说明文档编撰为单独的插口类文件。实验测试法:在平台[5],以C/S模式开发程序来调用插口类,采集微博返回的JOSN数据流,实现数据采集的相关测试与开发。 查看全部
基于API的微博信息采集系统设计与实现
摘要:微博已成为网路信息的重要来源,该文剖析了微博信息采集的相关技巧与技术,提出了基于API的信息采集方法,然后设计了一个信息采集系统,能够对新浪微博的相关信息进行采集。实验测试表明,该信息采集系统就能快速有效地采集新浪微博信息。
关键词:新浪微博;微博插口;信息采集;C#语言
中图分类号:TP315 文献标识码:A 文章编号:1009-3044(2013)17-4005-04
微博[1],即微型博客的简称,是一个基于用户关系的信息分享、传播以及获取平台,用
户可以通过WEB、WAP以及各类客户端组件个人社区,以140字左右的文字更新信息,并实现即时分享。中国互联网络信息中心的《第31次中国互联网路发展状况统计报告》显示,截至2012年12月底,截至2012年12月底,我国微博用户规模为3.09亿,较2011年底下降了5873万,网民中的微博用户比列较上年底提高了六个百分点,达到54.7%[2]。随着微博网路
影响力的快速扩大,政府部门、学校、知名企业、社会公众人物均开通了微博。随着公众的参与,微博成为了一个强悍的虚拟社会,微博早已是网路信息的重要来源,如何用于快速有效地采集微博信息已然成为一个具有重要应用价值的研究。
1 研究方式与技术路线
国内的微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方式与技术路线。通过剖析国内外的科技文献与实际应用案例,发现目前针对新浪微博的信息采集方法主要有两类:一种是“模拟登录”、“网页爬虫”[3]、“网页内容解析”[4]三种技术结合的信息采集方法,二是基于新浪微博开放平台的API文档,开发者自行编撰程序调用微博的API,进行微博信息的采集。对于第一种方式,难度比较高,研究技术复杂,特别是“模拟登录”这个步骤,需要随时跟踪新浪微博的登录加密算法,新浪微博的登录加密算法的改变,就会导致“网页爬虫”的失败,最后造成采集不到微博信息。同时,“网页爬虫”采集到的网页须要进行“网页内容解析”,效率与性能相比基于API的数据采集存在显著的差别。基于以上诱因,因此本文拟采用第二种方法进行研究。
基于新浪微博开放平台API文档的微博信息采集系统,主要采用了两个研究方式:文档分析法和实验测试法。文档分析法:参考新浪微博开放平台的API文档,把这种API说明文档编撰为单独的插口类文件。实验测试法:在平台[5],以C/S模式开发程序来调用插口类,采集微博返回的JOSN数据流,实现数据采集的相关测试与开发。
OCR在数据救治中的应用设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-25 04:52
OCR是通过算法辨识出图象中的文字内容,算是图象辨识的一个分支。但是在数据管理救治上,也十分实用。本文作者对具体的实现途径展开了梳理总结,并对过程中存在的问题进行了剖析,与你们分享。
一、服务于业务:数据救治的疼点在哪?
大数据工程的第一步是获得数据,而传统行业、政府机构、科研院所中有大量的存量数据,数据救治就是把这种数据数字化,一是防止数据流失,二是提升借助价值。而存量数据中包括大量珍稀的纸质数据,比如天文地理水文检测数据、试验数据、政府公文、古旧书籍等等。
纸质数据怎么救治?这步很简单,基本解决方式就是先扫描成电子版进行储存。但光是扫描储存就够了吗?我认为是不够的。
像前面所说的,数据救治的目的一是防止数据流失,二是提升借助价值,扫描储存仅仅解决了第一个问题防止数据流失,但并没有挺好的增强数据的借助价值。纸质数据的价值大部分在于文档的内容,仅仅把纸质文档电子化一直不能对内容进行进一步的检索、分析。
所以我们把产品的目标聚焦在了“提高数据利用率”上。接下来就是对目标进行细化拆解。关于怎么提升利用率,也就是数据怎么应用,我是这样思索的,一是从大数据角度看,如何借助统计剖析等手段增强数据整体的价值;二是从单份文档角度方面看,如何使单份文档更有价值,让有兴趣的用户更容易找到它,让用户找到这份文档后能快速了解其内容。
通过上面的剖析,单份数据借助的方法基本确定为【全文检索】和【内容剖析】,而这两种借助方式都须要对纸质文档中的文字进一步进行处理,这就须要我们数据救治的好伙伴:OCR出场了。
二、功能设计1. 业务场景
小李所在的单位有大量多年积累出来的文书,有些年代久远的早已出现了损坏丢失的情况,借着大数据工程建设的抓手,单位决定举办历史数据救治工作。
工作的第一步就是整理文书文档,然后扫描电子化,每扫描完一份文件小李就在页面上预览确认没有问题后递交,之后系统对文档进行OCR识别,识别完成后小李在页面上可以预览查看辨识结果,发现位置辨识不准或则文字辨识有误可以进行调整,最后保存调整结果即可。
小李辛辛苦苦做完的工作彰显在哪儿呢?
同事小陈近来做的一项工作须要查阅以往数据A的相关记录,小陈登入系统直接搜索“数据A”,搜索结果显示了所以收录“数据A”的文档。小陈依次点击搜索结果就可以查看文档的摘要和关键词,从而判定该文档是否对他有用。
大概业务的流程就是右图这样,我们这篇主要介绍小李的工作部份。
2. 实现途径
(1)数据采集
数据采集主要依赖于扫描纸质文档的扫描仪,所以这一部分是一要考虑扫描仪本身的性能,二要考虑扫描仪与整个系统的集成。
考虑到纸质数据量大、装订形式多样的特性,扫描仪最好满足快速扫描、不拆书、尽量自动化的要求。调研了市面上成熟的商用扫描仪,符合要求的扫描仪大约有几类:
专门用于古籍扫描的全手动翻书扫描仪,就一个缺点,太贵(140-180w)需要手工翻页,但不用拆书的高速扫描仪,这类扫描仪选择比较多,成本也可以接受最后一种选择,非常有趣,是google books的开源手动扫描仪方案,需要自行组装,有兴趣的同学可以了解一下()
系统与扫描仪集成方面,就涉及到扫描好的文件如何储存到系统?大概有两种方案:
1)我们平常用的扫描仪,一般是联接笔记本(客户端),把扫描好的文件存在本地,然后由用户把文件自动上传系统
2)网络扫描仪直接通过局域网联接服务器,扫描好的文件直接储存在服务器指定位置。这种网路扫描仪的方案须要扫描仪支持TWAIN或则其他SDK、api,好处是多个用户可以共用扫描仪,操作步骤也要简化好多
结合扫描仪性能、系统集成和成本角度考虑,我们选择了一款支持TWAIN插口的自动翻页扫描仪作为数据救治系统中硬件支撑。
(2) OCR识别
首先我们须要对OCR的算法有个大约的了解,可以参考OCR在资产管理系统的应用。
用于数据救治的OCR和用于资产标签辨识的OCR还是有一点区别的,资产标签辨识中的辨识对象是【自然环境】中的【印刷文字】,而数据救治对象是【文档图片】中的【印刷文字】。
但总体来说处理的流程还是预处理-文字检查-文字辨识,只不过对纸质文档中复杂的排版(图片、表格、文字、页码、公式混排等等)的文字检查换了种说法称作版面剖析(layout analysis),做的事情还是差不多的,除了负责检查出文字的位置外,也要同时确图表等其他要素的位置。
1)预处理:
预处理的目的主要是提升图象质量,一般用传统的图象处理手段就可以完成,现在好多扫描仪也会把这部份做在里面,比如手动纠偏、去黑边等,如果可以满足要求,预处理部份置于数据采集时由扫描仪完成也是可以的。
2)版面剖析:
先看下直观的看下版面剖析的预期疗效。关于版面剖析这块我们须要确认的事情主要有3件:一是测量的目标有什么,二是目前算法的成熟度,三是性能方面的要求有什么。
确定测量对象:毕竟版面剖析是个测量问题,和测量图片中的狗猫没有本质区别,所以我们要先确定版面剖析须要辨识哪些东西。在数据救治中我们关心哪些呢?首先文字是最重要的,第二为了定位图片和表格,我们也须要图片、表格的位置以及图注、表名,有了这种信息就可以产生类似索引目录,方便查找。所以初步确定,版面辨识须要辨识出文字、图片、表格、图注、表名五类对象。
算法成熟度:虽然传统的图象辨识也可以实现简单的版面剖析任务,但对上图这些特别复杂的版面剖析经过督查比较靠谱的方式还是上深度学习。可以做版面剖析的深度学习算法主要是图象检查一系列的,比如yolo、fastRCNN,这篇文章中的大鳄是用MaskRCNN实现的。所以版面剖析问题早已有不少研究基础了,但实际落地的应用可能还不是好多,其中须要优化的工作肯定还有不少。
性能要求:算法的选择其实要考虑实际中对硬件性能、识别速率、识别精度、召回率的要求。
用在我们数据救治中,首先系统是采用B/S架构,在服务器完成辨识任务,所以没有特殊硬件要求(如果是在端上实现就要考虑硬件对算法限制了)。识别速率方面,目前考虑到一份纸质数据可能有成百上千页,所以辨识时间会比较长,所以暂定以后台任务的方法执行,这就对辨识速率方面要求也比较低(如果要求实时返回辨识结果通常辨识速率就要做到秒级)。识别精度和召回率的平衡方面,由于上面有人工校准调整的环节,所以还是可以适当提升召回率,即使辨识有所偏差也可以通过人工调整填补。
c)文字辨识:
文字辨识部份相对来说也比较成熟,目前两大主流技术是 CRNN OCR 和 attention OCR。在我们的整体流程中,需要对版面辨识后的文字、图注、表名区域进行分别辨识即可。
上边技术实现途径的督查主要为了证明我们设计的功能是在技术上可实现的,避免出现设计出难以实现的功能的难堪情况。
3. 功能流程
正如前面所说的,我们这儿的功能只关注纸质数据救治工作没有涉及到数据应用的部份,所以从扫描文件到最后人工调整OCR识别结果,整个纸质数据救治的功能即使完成了。对用户来说,相较于只扫描文件并保存,多出的操作步骤就是查看辨识结果并调整的部份。
4. 核心页面设计
(OCR识别结果查看)
(OCR识别结果调整)
OCR相关的两个页面主要是查看辨识结果和调整辨识结果。查看页面主要包括预览文档、用线框表示图表区域和图表标题、显示OCR文字辨识结果。点击【编辑】跳转到调整页面,调整页面以每页为单位显示,图表框可拖放调整、文字变为可编辑状态。
三、小结
通过需求剖析我们发觉在数据救治中的确存在OCR应用的必要性,然后从技术实现的角度进行督查验证需求是否是可实现的,最后梳理整个功能流程再加上每位功能点的详细说明/原型设计功能基本就齐活了~ 查看全部
OCR在数据救治中的应用设计
OCR是通过算法辨识出图象中的文字内容,算是图象辨识的一个分支。但是在数据管理救治上,也十分实用。本文作者对具体的实现途径展开了梳理总结,并对过程中存在的问题进行了剖析,与你们分享。
一、服务于业务:数据救治的疼点在哪?
大数据工程的第一步是获得数据,而传统行业、政府机构、科研院所中有大量的存量数据,数据救治就是把这种数据数字化,一是防止数据流失,二是提升借助价值。而存量数据中包括大量珍稀的纸质数据,比如天文地理水文检测数据、试验数据、政府公文、古旧书籍等等。
纸质数据怎么救治?这步很简单,基本解决方式就是先扫描成电子版进行储存。但光是扫描储存就够了吗?我认为是不够的。
像前面所说的,数据救治的目的一是防止数据流失,二是提升借助价值,扫描储存仅仅解决了第一个问题防止数据流失,但并没有挺好的增强数据的借助价值。纸质数据的价值大部分在于文档的内容,仅仅把纸质文档电子化一直不能对内容进行进一步的检索、分析。
所以我们把产品的目标聚焦在了“提高数据利用率”上。接下来就是对目标进行细化拆解。关于怎么提升利用率,也就是数据怎么应用,我是这样思索的,一是从大数据角度看,如何借助统计剖析等手段增强数据整体的价值;二是从单份文档角度方面看,如何使单份文档更有价值,让有兴趣的用户更容易找到它,让用户找到这份文档后能快速了解其内容。
通过上面的剖析,单份数据借助的方法基本确定为【全文检索】和【内容剖析】,而这两种借助方式都须要对纸质文档中的文字进一步进行处理,这就须要我们数据救治的好伙伴:OCR出场了。
二、功能设计1. 业务场景
小李所在的单位有大量多年积累出来的文书,有些年代久远的早已出现了损坏丢失的情况,借着大数据工程建设的抓手,单位决定举办历史数据救治工作。
工作的第一步就是整理文书文档,然后扫描电子化,每扫描完一份文件小李就在页面上预览确认没有问题后递交,之后系统对文档进行OCR识别,识别完成后小李在页面上可以预览查看辨识结果,发现位置辨识不准或则文字辨识有误可以进行调整,最后保存调整结果即可。
小李辛辛苦苦做完的工作彰显在哪儿呢?
同事小陈近来做的一项工作须要查阅以往数据A的相关记录,小陈登入系统直接搜索“数据A”,搜索结果显示了所以收录“数据A”的文档。小陈依次点击搜索结果就可以查看文档的摘要和关键词,从而判定该文档是否对他有用。
大概业务的流程就是右图这样,我们这篇主要介绍小李的工作部份。
2. 实现途径
(1)数据采集
数据采集主要依赖于扫描纸质文档的扫描仪,所以这一部分是一要考虑扫描仪本身的性能,二要考虑扫描仪与整个系统的集成。
考虑到纸质数据量大、装订形式多样的特性,扫描仪最好满足快速扫描、不拆书、尽量自动化的要求。调研了市面上成熟的商用扫描仪,符合要求的扫描仪大约有几类:
专门用于古籍扫描的全手动翻书扫描仪,就一个缺点,太贵(140-180w)需要手工翻页,但不用拆书的高速扫描仪,这类扫描仪选择比较多,成本也可以接受最后一种选择,非常有趣,是google books的开源手动扫描仪方案,需要自行组装,有兴趣的同学可以了解一下()
系统与扫描仪集成方面,就涉及到扫描好的文件如何储存到系统?大概有两种方案:
1)我们平常用的扫描仪,一般是联接笔记本(客户端),把扫描好的文件存在本地,然后由用户把文件自动上传系统
2)网络扫描仪直接通过局域网联接服务器,扫描好的文件直接储存在服务器指定位置。这种网路扫描仪的方案须要扫描仪支持TWAIN或则其他SDK、api,好处是多个用户可以共用扫描仪,操作步骤也要简化好多
结合扫描仪性能、系统集成和成本角度考虑,我们选择了一款支持TWAIN插口的自动翻页扫描仪作为数据救治系统中硬件支撑。
(2) OCR识别
首先我们须要对OCR的算法有个大约的了解,可以参考OCR在资产管理系统的应用。
用于数据救治的OCR和用于资产标签辨识的OCR还是有一点区别的,资产标签辨识中的辨识对象是【自然环境】中的【印刷文字】,而数据救治对象是【文档图片】中的【印刷文字】。
但总体来说处理的流程还是预处理-文字检查-文字辨识,只不过对纸质文档中复杂的排版(图片、表格、文字、页码、公式混排等等)的文字检查换了种说法称作版面剖析(layout analysis),做的事情还是差不多的,除了负责检查出文字的位置外,也要同时确图表等其他要素的位置。
1)预处理:
预处理的目的主要是提升图象质量,一般用传统的图象处理手段就可以完成,现在好多扫描仪也会把这部份做在里面,比如手动纠偏、去黑边等,如果可以满足要求,预处理部份置于数据采集时由扫描仪完成也是可以的。
2)版面剖析:
先看下直观的看下版面剖析的预期疗效。关于版面剖析这块我们须要确认的事情主要有3件:一是测量的目标有什么,二是目前算法的成熟度,三是性能方面的要求有什么。
确定测量对象:毕竟版面剖析是个测量问题,和测量图片中的狗猫没有本质区别,所以我们要先确定版面剖析须要辨识哪些东西。在数据救治中我们关心哪些呢?首先文字是最重要的,第二为了定位图片和表格,我们也须要图片、表格的位置以及图注、表名,有了这种信息就可以产生类似索引目录,方便查找。所以初步确定,版面辨识须要辨识出文字、图片、表格、图注、表名五类对象。
算法成熟度:虽然传统的图象辨识也可以实现简单的版面剖析任务,但对上图这些特别复杂的版面剖析经过督查比较靠谱的方式还是上深度学习。可以做版面剖析的深度学习算法主要是图象检查一系列的,比如yolo、fastRCNN,这篇文章中的大鳄是用MaskRCNN实现的。所以版面剖析问题早已有不少研究基础了,但实际落地的应用可能还不是好多,其中须要优化的工作肯定还有不少。
性能要求:算法的选择其实要考虑实际中对硬件性能、识别速率、识别精度、召回率的要求。
用在我们数据救治中,首先系统是采用B/S架构,在服务器完成辨识任务,所以没有特殊硬件要求(如果是在端上实现就要考虑硬件对算法限制了)。识别速率方面,目前考虑到一份纸质数据可能有成百上千页,所以辨识时间会比较长,所以暂定以后台任务的方法执行,这就对辨识速率方面要求也比较低(如果要求实时返回辨识结果通常辨识速率就要做到秒级)。识别精度和召回率的平衡方面,由于上面有人工校准调整的环节,所以还是可以适当提升召回率,即使辨识有所偏差也可以通过人工调整填补。
c)文字辨识:
文字辨识部份相对来说也比较成熟,目前两大主流技术是 CRNN OCR 和 attention OCR。在我们的整体流程中,需要对版面辨识后的文字、图注、表名区域进行分别辨识即可。
上边技术实现途径的督查主要为了证明我们设计的功能是在技术上可实现的,避免出现设计出难以实现的功能的难堪情况。
3. 功能流程
正如前面所说的,我们这儿的功能只关注纸质数据救治工作没有涉及到数据应用的部份,所以从扫描文件到最后人工调整OCR识别结果,整个纸质数据救治的功能即使完成了。对用户来说,相较于只扫描文件并保存,多出的操作步骤就是查看辨识结果并调整的部份。
4. 核心页面设计
(OCR识别结果查看)
(OCR识别结果调整)
OCR相关的两个页面主要是查看辨识结果和调整辨识结果。查看页面主要包括预览文档、用线框表示图表区域和图表标题、显示OCR文字辨识结果。点击【编辑】跳转到调整页面,调整页面以每页为单位显示,图表框可拖放调整、文字变为可编辑状态。
三、小结
通过需求剖析我们发觉在数据救治中的确存在OCR应用的必要性,然后从技术实现的角度进行督查验证需求是否是可实现的,最后梳理整个功能流程再加上每位功能点的详细说明/原型设计功能基本就齐活了~
地址(URL)中收录关键词对排行的影响,如何在url设置关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-08-24 18:22
在一个页面中地址中出现了要搜索的关键词,对于排行是很重要的,因为这标志着这个页面和这个关键词的相关程度,所以在seoer优化关键词的时侯都想办法在url中出现关键词,我们都晓得网页的地址都是中文字符,如果优化英语词组那当然很简单了,直接把文件名改成须要优化的关键词就可以了,但是我们优化的汉字,如何来做到这一点呢。
其实我们用传值是可以做到的,下面看一下事例:
这是一个htm页,这个页面的名子就叫户外用具,竟然有这们的先例了,说明我们还是可以做到的,为了做这个实验,我前两天做了这样一个事例,做的是asp基础教程这个词。
没过多久,百度收录了,而且还通过这个词带来了ip,我去搜索了一下,看到的疗效如图:
显然我这个实验是成功的,那么我是怎样在url中加上关键词的呢,其实很简单,我们在传值的时侯只须要把编码转化成gb2312的就可以了,在asp中这个有点难度,具体方式可以去网上查一下,如果你实在找不到办法可以把关键词放在百度上搜索一下,然后把参数前面的值拷贝出来当作自己的参数,这样在百度收录的时侯就可以转化成相应的汉字了,如我这个地址打开是这样的:
%BB%F9%B4%A1%BD%CC%B3%CC
而我们一般用的escape和encodeURIComponent所转化的地址是这样的
%u57FA%u7840%u6559%u7A0B
后者在搜索引擎里是难以转化为汉字的,需要我们要想办法改成上面传值的方式。
在中想要得到这些传值很简单,代码如下:
System.Web.HttpUtility.UrlEncode(需要加密的变量, System.Text.Encoding.GetEncoding("GB2312"));
只须要这样加密,得到的编码就是百度可以辨识的了。 查看全部
地址(URL)中收录关键词对排行的影响,如何在url设置关键词
在一个页面中地址中出现了要搜索的关键词,对于排行是很重要的,因为这标志着这个页面和这个关键词的相关程度,所以在seoer优化关键词的时侯都想办法在url中出现关键词,我们都晓得网页的地址都是中文字符,如果优化英语词组那当然很简单了,直接把文件名改成须要优化的关键词就可以了,但是我们优化的汉字,如何来做到这一点呢。
其实我们用传值是可以做到的,下面看一下事例:
这是一个htm页,这个页面的名子就叫户外用具,竟然有这们的先例了,说明我们还是可以做到的,为了做这个实验,我前两天做了这样一个事例,做的是asp基础教程这个词。
没过多久,百度收录了,而且还通过这个词带来了ip,我去搜索了一下,看到的疗效如图:
显然我这个实验是成功的,那么我是怎样在url中加上关键词的呢,其实很简单,我们在传值的时侯只须要把编码转化成gb2312的就可以了,在asp中这个有点难度,具体方式可以去网上查一下,如果你实在找不到办法可以把关键词放在百度上搜索一下,然后把参数前面的值拷贝出来当作自己的参数,这样在百度收录的时侯就可以转化成相应的汉字了,如我这个地址打开是这样的:
%BB%F9%B4%A1%BD%CC%B3%CC
而我们一般用的escape和encodeURIComponent所转化的地址是这样的
%u57FA%u7840%u6559%u7A0B
后者在搜索引擎里是难以转化为汉字的,需要我们要想办法改成上面传值的方式。
在中想要得到这些传值很简单,代码如下:
System.Web.HttpUtility.UrlEncode(需要加密的变量, System.Text.Encoding.GetEncoding("GB2312"));
只须要这样加密,得到的编码就是百度可以辨识的了。
POC-T框架学习————4、脚本扩充与第三方搜索引擎
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2020-08-21 22:23
工具说明
urlparser.py
URL处理工具,可对采集到的零乱URL进行低格/自动生成等
useragent.py
User-Agent处理工具,支持随机化UA以绕开防御规则
extracts.py
正则提取工具,从采集到的零乱文本中筛选IP地址
static.py
存储静态资源,如常见端口号等
util.py
常用函数,处理随机值/MD5/302跳转/格式转换等
cloudeye.py
cloudeye.me功能插口,在PoC中查询DNS和HTTP日志
本工具拟支持主流空间搜索引擎的API,目前已完成ZoomEye/Shodan/Google的集成。您可以通过简单的参数调用直接从搜索引擎中直接获取目标,并结合本地脚本进行扫描。
预配置(可选)
由于第三方插口须要认证,您可以在根目录下的tookit.conf配置文件中预先设置好您的API-KEY。
如无预配置,程序将在运行时提示您输入API-KEY。 关于各插口API-KEY的获取方式,请参考下文中引入的官方文档。
ZoomEye
以下命令表示使用ZoomEye插口,搜索全网中开启8080号端口的服务,并使用test.py脚本进行验证.
设置采集100个搜索结果,搜索结果将存入本地./data/zoomeye文件夹下。
python POC-T.py -s test -aZ "port:8080" --limit 100
ZoomEye现已开放注册,普通用户每月可以通过API下载5000页的搜索结果。
ZoomEye参考文档:
Shodan
以下命令表示使用Shodan插口,搜索全网中关键字为solr,国家为cn的服务,并使用solr-unauth脚本进行漏洞验证.
设置从第0条记录为起点,爬取10条记录,搜索结果将存入本地./data/shodan文件夹下.
python POC-T.py -s solr-unauth -aS "solr country:cn" --limit 10 --offset 0
Shodan-API接口使用限制及详尽功能,可参考官方文档.
本程序使用Google Custom Search API对结果进行采集(即常说的Google-Hacking)。
以下命令表示获取Google采集inurl:login.action的结果并批量验证S2-032漏洞。
python POC-T.py -s s2-032 -aG "inurl:login.action"
可使用--gproxy或则tookit.conf设置代理,代理格式为(sock4|sock5|http) IP PORT,仅支持这三种合同。
例如:
--gproxy "sock5 127.0.0.1 7070"
使用本插口需设定个人的API-KEY和所使用的自定义搜索引擎,二者均可在toolkit.conf配置。
填写示例
developer_key:AIzaSxxxxxxxxxxxxxxxxxxxxxxxxxxxxx_C1w
search_engine:011385053819762433240:ljmmw2mhhau
developer_key
获取API-KEY,使用API客户端:
Google API Client - Python
search_engine
创建自定义搜索引擎(或直接使用示例中的值):
Google Custom Search API 开发者文档
参见:
%E7%AC%AC%E4%B8%89%E6%96%B9%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E
%E8%84%9A%E6%9C%AC%E6%89%A9%E5%B1%95%E5%B7%A5%E5%85%B7 查看全部
POC-T框架学习————4、脚本扩充与第三方搜索引擎
工具说明
urlparser.py
URL处理工具,可对采集到的零乱URL进行低格/自动生成等
useragent.py
User-Agent处理工具,支持随机化UA以绕开防御规则
extracts.py
正则提取工具,从采集到的零乱文本中筛选IP地址
static.py
存储静态资源,如常见端口号等
util.py
常用函数,处理随机值/MD5/302跳转/格式转换等
cloudeye.py
cloudeye.me功能插口,在PoC中查询DNS和HTTP日志
本工具拟支持主流空间搜索引擎的API,目前已完成ZoomEye/Shodan/Google的集成。您可以通过简单的参数调用直接从搜索引擎中直接获取目标,并结合本地脚本进行扫描。
预配置(可选)
由于第三方插口须要认证,您可以在根目录下的tookit.conf配置文件中预先设置好您的API-KEY。
如无预配置,程序将在运行时提示您输入API-KEY。 关于各插口API-KEY的获取方式,请参考下文中引入的官方文档。
ZoomEye
以下命令表示使用ZoomEye插口,搜索全网中开启8080号端口的服务,并使用test.py脚本进行验证.
设置采集100个搜索结果,搜索结果将存入本地./data/zoomeye文件夹下。
python POC-T.py -s test -aZ "port:8080" --limit 100
ZoomEye现已开放注册,普通用户每月可以通过API下载5000页的搜索结果。
ZoomEye参考文档:
Shodan
以下命令表示使用Shodan插口,搜索全网中关键字为solr,国家为cn的服务,并使用solr-unauth脚本进行漏洞验证.
设置从第0条记录为起点,爬取10条记录,搜索结果将存入本地./data/shodan文件夹下.
python POC-T.py -s solr-unauth -aS "solr country:cn" --limit 10 --offset 0
Shodan-API接口使用限制及详尽功能,可参考官方文档.
本程序使用Google Custom Search API对结果进行采集(即常说的Google-Hacking)。
以下命令表示获取Google采集inurl:login.action的结果并批量验证S2-032漏洞。
python POC-T.py -s s2-032 -aG "inurl:login.action"
可使用--gproxy或则tookit.conf设置代理,代理格式为(sock4|sock5|http) IP PORT,仅支持这三种合同。
例如:
--gproxy "sock5 127.0.0.1 7070"
使用本插口需设定个人的API-KEY和所使用的自定义搜索引擎,二者均可在toolkit.conf配置。
填写示例
developer_key:AIzaSxxxxxxxxxxxxxxxxxxxxxxxxxxxxx_C1w
search_engine:011385053819762433240:ljmmw2mhhau
developer_key
获取API-KEY,使用API客户端:
Google API Client - Python
search_engine
创建自定义搜索引擎(或直接使用示例中的值):
Google Custom Search API 开发者文档
参见:
%E7%AC%AC%E4%B8%89%E6%96%B9%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E
%E8%84%9A%E6%9C%AC%E6%89%A9%E5%B1%95%E5%B7%A5%E5%85%B7
怎么爬取网路数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-08-21 13:06
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。
数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:
除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。 查看全部
怎么爬取网路数据
据赛迪顾问统计,在技术领域中近来10,000条专利中常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热词汇。其中,数据采集是提及最多的词汇。
数据采集是进行大数据剖析的前提也是必要条件,在整个数据借助流程中抢占重要地位。数据采集方式分为三种:系统日志采集法、网络数据采集法以及其他数据采集法。随着Web2.0的发展,整个Web系统囊括了大量的价值化数据,目前针对Web系统的数据采集通常通过网路爬虫来实现,本文将对网路大数据和网路爬虫进行系统描述。
什么是网路大数据
网络大数据,是指非传统数据源,例如通过抓取搜索引擎获得的不同方式的数据。网络大数据也可以是从数据聚合商或搜索引擎网站购买的数据,用于改善目标营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络构成了现今提供给我们的大部分数据,根据许多研究可知,非结构化数据抢占了其中的80%。尽管这种方式的数据较早被忽视了,但是竞争激化以及须要更多数据的需求促使必须使用尽可能多的数据源。
网络大数据可以拿来干哪些
互联网拥有数十亿页的数据,网络大数据作为潜在的数据来源,对于行业的战略性业务发展来说拥有巨大的借助潜力。
以下举例说明网路大数据在不同行业的借助价值:
除此之外,在《How Web Scraping is Transforming the World with its Applications》文章中详尽得列举出网路大数据在制造业、金融研究、风险管理等诸多领域的借助价值。
如何搜集网路数据
目前网路数据采集有两种方式:一种是API,另一种是网路爬虫法。API又叫应用程序插口,是网站的管理者为了使用者便捷,编写的一种程序插口。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术虽然受限于平台开发者,为了减少网站(平台)的负荷,一般平台均会对每晚插口调用上限做限制,这给我们带来极大的不便利。为此我们一般采用第二种形式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指根据一定的规则手动地抓取万维网信息的程序或则脚本。该方式可以将非结构化数据从网页中抽取下来,将其储存为统一的本地数据文件,并以结构化的形式储存。它支持图片、音频、视频等文件或附件的采集,附件与正文可以手动关联。
在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。
网络爬虫原理
网络爬虫是一种根据一定的规则,自动地抓取网路信息的程序或则脚本。网络爬虫可以手动采集所有其才能访问到的页面内容,为搜索引擎和大数据剖析提供数据来源。从功能上来讲,爬虫通常有网路数据采集、处理和储存 3 部分功能,如图所示:
网络爬虫采集
网络爬虫通过定义采集字段对网页中的文本信息、图片信息等进行爬取。并且在网页中还收录一些超链接信息,网络爬虫系统正是通过网页中的超链接信息不断获得网路上的其他网页。网络爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,爬虫将网页中所须要提取的资源进行提取并保存,同时提取出网站中存在的其他网站链接,经过发送恳求,接收网站响应以及再度解析页面,再将网页中所需资源进行提取......以此类推,通过网页爬虫便可将搜索引擎上的相关数据完全爬取下来。
数据处理
数据处理是对数据(包括数值的和非数值的)进行剖析和加工的技术过程。网络爬虫爬取的初始数据是须要“清洗”的,在数据处理步骤,对各类原创数据的剖析、整理、计算、编辑等的加工和处理,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推论出有价值、有意义的数据。
数据中心
所谓的数据中心也就是数据存储,是指在获得所需的数据并将其分解为有用的组件以后,通过可扩充的方式来将所有提取和解析的数据储存在数据库或集群中,然后创建一个容许用户可及时查找相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选定一部分种子 URL。
总结
当前,网络大数据在规模与复杂度上的快速下降对现有IT构架的处理和估算能力提出了挑战,据IDC发布的研究报告,预计到2020年,网络大数据总数将达到35ZB,网络大数据将成为行业数字化、信息化的重要推手。
基于兴趣轻博客网站拓扑特点剖析.doc 6页
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2020-08-20 23:15
基于兴趣轻博客网站拓扑特点剖析 摘要:为了了解新型在线社会网路——轻博客网站的拓扑特点,该文以国外最大的轻博客网站——点点网为研究对象,根据用户间兴趣关系建立兴趣网路,从小世界效应、无标度特点和中心度等角度对该网路进行了实证剖析,为进一步认识和研究轻博客网站奠定了基础。 关键词:轻博客;社会网路剖析;复杂网路;拓扑特点;中心性 中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2013)22-5033-04 根据Garry Tan 2013年一月的调查报告表明,2007创立的轻博客网站Tumblr早已赶超Facebook,成为日本年轻人访问最多的社交网站[1]。随着Tumblr的迅速崛起,国内也出现了各类类Tumblr的网站。2011年,许朝军创立了点点网,此后新浪Qing网,网易的lofter、人人网的人人小站、盛大推他等一批Tumblr的追随者都朝着轻博客的方向大步前进。轻博客这些新型的在线社会网路(Online Social Network, 简称OSN)极可能迎来一个高速发展期。同时,轻博客在中国还是一个新生事物,国内尚未见相关研究。因此,结合社会网路剖析和复杂网路理论,研究轻博客网站的拓扑特点,不仅能建立国内外对OSN拓扑特点的理论探求,而且有助于了解轻博客中人际关系和信息传播的特点,同时也对实现轻博客舆论的检测、引导、控制等提供重要根据和基础。
1 点点网的数据采集 本文选定国外典型的轻博客网站——点点网作为研究对象,这是因为相比其他,被称为“Tumblr中文版”的点点网是最纯粹的轻博客,其网路结构特点具有太强的代表性。 1.1面向点点网的网路爬虫 采集网站数据的方式有基于API的数据采集和基于网路爬虫的数据采集。通过调用网站提供的API接口可以实现网站数据的方便抓取与解析,但也要注意:一是API内容开放不全面,例如点点网API是在2011年12月才对外开放,API的种类也极少,目前不到30个;二是API服务商对用户的API接口调用频度与查询的返回结果的最大数目有限制,点点网就规定查询的返回结果不超过20个;三是使用API接口须要解决用户认证问题,如果待获取用户条目太多则会占用大量系统开支等待用户授权许可。因此,该文在开源软件Heritrix的基础上,采用基于网路爬虫的数据采集技术来获取点点网的数据。 从图1可以发觉,点点网在整篇轻博文下边都有“热度”,标注喜欢、转载和推荐该文的用户列表。查看源码,发现“热度”是一个内嵌网页,页面源码中内容比较少,更多的内容实际上是采用AJAX(Asynchronous Javascript and XML)技术[2]加载下来的。
如果直接用Heritirx原有的抓取方式,抓取不到真正的用户列表。所以,必须对Heritirx的Extracotr类进行扩充,扩展后的新类DiandianExtractor重载extract方式,在抓取页面、抽取链接的时侯,直接对“热度”部分进行剖析,通过Selenium WebDriver API驱动浏览器内核PhantomJS,模拟浏览器获取AJAX内容,得到和页面呈现一致的页面内容,再通过Jsoup解析页面内容,并把剖析结果存到MYSQL数据库里。至此,AJAX页面采集问题得到真正解决。 1.2 数据集 据点点网自身统计数据显示,目前点点网注册用户数早已达到1919万,帖子数达到3547万,数据采集量非常庞大且处于动态变化之中,要获取整个网路的拓扑数据非常困难,因此本文采用滚雪球采样法,依据“兴趣标签”,随机选择两个标签下边的“杰出轻博客”的某篇轻博文作为种子,利用点点网用户之间的兴趣关系进行广度优先搜索。搜索页面的URL富含“post/”和“n/common/comment”,前一种页面主要由某用户发表的所有博文组成;后一种页面包括所有“喜欢”、“转载”、“推荐”该用户博文的其他用户列表。
数据采集器最终抓取逾600万页面,总容量接近60G。通过对这逾600万页面信息的实时抽取,共1898356条记录储存到MySQL数据库里。其中,数据表结构包括id、username(用户名)、inname(链入用户名)、type(链入用户是哪种类型用户:喜欢、转载还是推荐)、link(该记录从那个链接得来的)。经过去重(从数据表中删掉username和inname都相同的记录),得到825057条可用记录用于后续网路拓扑检测。 2 点点网的拓扑特点 2.1网路拓扑检测 3 结论 本文选定国外最大的轻博客平台——点点网作为研究对象,根据采集下来的点点网样本数据,构造一个基于“发文←喜欢、转载和推荐”互动的兴趣关系网路。通过开源工具Pajek统计点点网的拓扑特点,如平均路径宽度、聚集系数、出入度分布、连接度相关性及中心性等,发现点点网存在小世界效应和无标度特点,网络中存在中心节点,即少量用户在信息发布和传播中起着至关重要的作用,这为进一步研究轻博客的人际关系和信息传播特点奠定了基础。 参考文献: [1] 果子. 影子大亨Tumblr的成功之道 [EB/OL]. [2013-02-21]. http:///p/201458.html?ref=weixin0222m. [2] 罗兵.支持AJAX的互联网搜索引擎爬虫设计与实现[D].杭州:浙江大学,2007:14-40. [3] Alan Mislove, Massimiliano Marcon, Krishna P.Gummadi. Measurement and Analysis of Online Social Networks[C]// IMC'07: Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement. New York: ACM Press, 2007: 29-42. [4] Feng Fu,Lianghuan Liu,Long Wang.Empirical analysis of online social networks in the age of Web 2.0[J]. Physica A, 2008(387):675–684. [5] 樊鹏翼,王晖,姜志宏,等.微博网路检测研究[J].计算机研究与发展, 2012,49(4):691-699. [6] Albert R, Barabasi A L.Statistical mechanics of complex networks[J]. Reviews of Modern Physics, 2002, 74(1):47-97. [7] Wilson C,Boe B,Sala A,et a1.User interactions in social networks and their implications[C]//Proceedings of the 4th ACM European Conference on Computer Systems.New York:ACM, 2009:205-218. [8] 陈静,孙林夫.复杂网路中节点重要度评估[J].西南交通大学学报,2009,44(3):426-429. 查看全部
基于兴趣轻博客网站拓扑特点剖析.doc 6页
基于兴趣轻博客网站拓扑特点剖析 摘要:为了了解新型在线社会网路——轻博客网站的拓扑特点,该文以国外最大的轻博客网站——点点网为研究对象,根据用户间兴趣关系建立兴趣网路,从小世界效应、无标度特点和中心度等角度对该网路进行了实证剖析,为进一步认识和研究轻博客网站奠定了基础。 关键词:轻博客;社会网路剖析;复杂网路;拓扑特点;中心性 中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2013)22-5033-04 根据Garry Tan 2013年一月的调查报告表明,2007创立的轻博客网站Tumblr早已赶超Facebook,成为日本年轻人访问最多的社交网站[1]。随着Tumblr的迅速崛起,国内也出现了各类类Tumblr的网站。2011年,许朝军创立了点点网,此后新浪Qing网,网易的lofter、人人网的人人小站、盛大推他等一批Tumblr的追随者都朝着轻博客的方向大步前进。轻博客这些新型的在线社会网路(Online Social Network, 简称OSN)极可能迎来一个高速发展期。同时,轻博客在中国还是一个新生事物,国内尚未见相关研究。因此,结合社会网路剖析和复杂网路理论,研究轻博客网站的拓扑特点,不仅能建立国内外对OSN拓扑特点的理论探求,而且有助于了解轻博客中人际关系和信息传播的特点,同时也对实现轻博客舆论的检测、引导、控制等提供重要根据和基础。
1 点点网的数据采集 本文选定国外典型的轻博客网站——点点网作为研究对象,这是因为相比其他,被称为“Tumblr中文版”的点点网是最纯粹的轻博客,其网路结构特点具有太强的代表性。 1.1面向点点网的网路爬虫 采集网站数据的方式有基于API的数据采集和基于网路爬虫的数据采集。通过调用网站提供的API接口可以实现网站数据的方便抓取与解析,但也要注意:一是API内容开放不全面,例如点点网API是在2011年12月才对外开放,API的种类也极少,目前不到30个;二是API服务商对用户的API接口调用频度与查询的返回结果的最大数目有限制,点点网就规定查询的返回结果不超过20个;三是使用API接口须要解决用户认证问题,如果待获取用户条目太多则会占用大量系统开支等待用户授权许可。因此,该文在开源软件Heritrix的基础上,采用基于网路爬虫的数据采集技术来获取点点网的数据。 从图1可以发觉,点点网在整篇轻博文下边都有“热度”,标注喜欢、转载和推荐该文的用户列表。查看源码,发现“热度”是一个内嵌网页,页面源码中内容比较少,更多的内容实际上是采用AJAX(Asynchronous Javascript and XML)技术[2]加载下来的。
如果直接用Heritirx原有的抓取方式,抓取不到真正的用户列表。所以,必须对Heritirx的Extracotr类进行扩充,扩展后的新类DiandianExtractor重载extract方式,在抓取页面、抽取链接的时侯,直接对“热度”部分进行剖析,通过Selenium WebDriver API驱动浏览器内核PhantomJS,模拟浏览器获取AJAX内容,得到和页面呈现一致的页面内容,再通过Jsoup解析页面内容,并把剖析结果存到MYSQL数据库里。至此,AJAX页面采集问题得到真正解决。 1.2 数据集 据点点网自身统计数据显示,目前点点网注册用户数早已达到1919万,帖子数达到3547万,数据采集量非常庞大且处于动态变化之中,要获取整个网路的拓扑数据非常困难,因此本文采用滚雪球采样法,依据“兴趣标签”,随机选择两个标签下边的“杰出轻博客”的某篇轻博文作为种子,利用点点网用户之间的兴趣关系进行广度优先搜索。搜索页面的URL富含“post/”和“n/common/comment”,前一种页面主要由某用户发表的所有博文组成;后一种页面包括所有“喜欢”、“转载”、“推荐”该用户博文的其他用户列表。
数据采集器最终抓取逾600万页面,总容量接近60G。通过对这逾600万页面信息的实时抽取,共1898356条记录储存到MySQL数据库里。其中,数据表结构包括id、username(用户名)、inname(链入用户名)、type(链入用户是哪种类型用户:喜欢、转载还是推荐)、link(该记录从那个链接得来的)。经过去重(从数据表中删掉username和inname都相同的记录),得到825057条可用记录用于后续网路拓扑检测。 2 点点网的拓扑特点 2.1网路拓扑检测 3 结论 本文选定国外最大的轻博客平台——点点网作为研究对象,根据采集下来的点点网样本数据,构造一个基于“发文←喜欢、转载和推荐”互动的兴趣关系网路。通过开源工具Pajek统计点点网的拓扑特点,如平均路径宽度、聚集系数、出入度分布、连接度相关性及中心性等,发现点点网存在小世界效应和无标度特点,网络中存在中心节点,即少量用户在信息发布和传播中起着至关重要的作用,这为进一步研究轻博客的人际关系和信息传播特点奠定了基础。 参考文献: [1] 果子. 影子大亨Tumblr的成功之道 [EB/OL]. [2013-02-21]. http:///p/201458.html?ref=weixin0222m. [2] 罗兵.支持AJAX的互联网搜索引擎爬虫设计与实现[D].杭州:浙江大学,2007:14-40. [3] Alan Mislove, Massimiliano Marcon, Krishna P.Gummadi. Measurement and Analysis of Online Social Networks[C]// IMC'07: Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement. New York: ACM Press, 2007: 29-42. [4] Feng Fu,Lianghuan Liu,Long Wang.Empirical analysis of online social networks in the age of Web 2.0[J]. Physica A, 2008(387):675–684. [5] 樊鹏翼,王晖,姜志宏,等.微博网路检测研究[J].计算机研究与发展, 2012,49(4):691-699. [6] Albert R, Barabasi A L.Statistical mechanics of complex networks[J]. Reviews of Modern Physics, 2002, 74(1):47-97. [7] Wilson C,Boe B,Sala A,et a1.User interactions in social networks and their implications[C]//Proceedings of the 4th ACM European Conference on Computer Systems.New York:ACM, 2009:205-218. [8] 陈静,孙林夫.复杂网路中节点重要度评估[J].西南交通大学学报,2009,44(3):426-429.
3.kettle实现不同数据库的数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 599 次浏览 • 2020-08-20 12:38
「深度学习福利」大神带你进阶工程师,立即查看>>>
基于kettle实现数据采集
1.kettle简介
Kettle 是一款美国开源的 ETL 工具,纯 Java 编写,通过提供一个图形化的用户环境来描述你想做哪些,而不是你想怎样做,它的数据抽取高效稳定(数据迁移工具)。Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。
2.kettle下载
下面两个案例是使用kettle7.1进行操作,分享一下国外的下载地址:
kettle下载
无需安装,双击根目录下的Spoon.bat文件即可
3.kettle实现不同数据库的数据采集
这个案例是实现oracle数据库的数据采集到mysql上面去
3.1创建对应数据库的DB联接
3.2使用图形工具完成表输入->字段选择->表输出的流线设计
3.3配置表输入信息:用于编撰sql获取数据源的数据
3.4配置数组选择信息:用于数据源和目标表数组名不一致的一个转换
3.5配置表输出信息:用于目标表的主键映射
3.6运行这个转换,并查看结果
4.kettle实现插口的数据采集
接口地址(可直接复制):%E8%A7%92%E7%BE%8E&region=%E6%BC%B3%E5%B7%9E%E5%B8%82&output=json&ak=n0lHarpY3QZx6xXXIaWMFLxj
通过访问插口可以获知返回的json数据结构,可考虑做两层json解析来获取对应的数组,当然也可以使用:$…result[*].name的表达式来获取,这里不做演示,有兴趣的朋友可以试一下!
4.1配置目标表的DB联接(上面有oracle和mysql的不同示例)
4.2使用图形工具插口采集的流线图
4.3配置生成记录信息:填写对应的url地址和定义url名称,类型 查看全部
3.kettle实现不同数据库的数据采集
「深度学习福利」大神带你进阶工程师,立即查看>>>
基于kettle实现数据采集
1.kettle简介
Kettle 是一款美国开源的 ETL 工具,纯 Java 编写,通过提供一个图形化的用户环境来描述你想做哪些,而不是你想怎样做,它的数据抽取高效稳定(数据迁移工具)。Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。
2.kettle下载
下面两个案例是使用kettle7.1进行操作,分享一下国外的下载地址:
kettle下载
无需安装,双击根目录下的Spoon.bat文件即可
3.kettle实现不同数据库的数据采集
这个案例是实现oracle数据库的数据采集到mysql上面去
3.1创建对应数据库的DB联接
3.2使用图形工具完成表输入->字段选择->表输出的流线设计
3.3配置表输入信息:用于编撰sql获取数据源的数据
3.4配置数组选择信息:用于数据源和目标表数组名不一致的一个转换
3.5配置表输出信息:用于目标表的主键映射
3.6运行这个转换,并查看结果
4.kettle实现插口的数据采集
接口地址(可直接复制):%E8%A7%92%E7%BE%8E&region=%E6%BC%B3%E5%B7%9E%E5%B8%82&output=json&ak=n0lHarpY3QZx6xXXIaWMFLxj
通过访问插口可以获知返回的json数据结构,可考虑做两层json解析来获取对应的数组,当然也可以使用:$…result[*].name的表达式来获取,这里不做演示,有兴趣的朋友可以试一下!
4.1配置目标表的DB联接(上面有oracle和mysql的不同示例)
4.2使用图形工具插口采集的流线图
4.3配置生成记录信息:填写对应的url地址和定义url名称,类型
Python爬虫总结(CSS,Xpath,JsonLoad;静态网页,JS加载
采集交流 • 优采云 发表了文章 • 0 个评论 • 389 次浏览 • 2020-08-18 21:25
前言
随着人类社会的高速发展,数据对各行各业的重要性,愈加突出。爬虫,也称为数据采集器,是指通过程序设计,机械化地对网路上的数据,进行批量爬取,以取代低效的人工获取信息的手段。
1. 道德法律问题
爬虫目前在法律上尚属黑色地段,但爬别的网站用于自己的商业化用途也可能存在着法律风险。非法抓取使用“新浪微博”用户信息被判赔200万元,这是国外的一条因爬虫被判败诉的新闻。所以各商业公司还是悠着点,特别是涉及隐私数据。
大型的网站一般还会有robot.txt,这算是与爬虫者的一个合同。只要在robot.txt容许的范围内爬虫就不存在道德和法律风险。
2. 网络爬虫步骤2.1 检查API接口
API是网站官方提供的数据插口,如果通过调用API采集数据,则相当于在网站允许的范围内采集。这样既不会有道德法律风险,也没有网站故意设置的障碍;不过调用API插口的访问则处于网站的控制中,网站可以拿来收费,可以拿来限制访问上限等。整体来看,如果数据采集的需求并不是太奇特,那么有API则应优先采用调用API的形式。如果没有,则选择爬虫。
2.2 数据获取渠道剖析
页面收录数据
这种情况是最容易解决的,一般来讲基本上是静态网页,或者动态网页,采用模板渲染,浏览器获取到HTML的时侯早已是收录所有的关键信息,所以直接在网页上见到的内容都可以通过特定的HTML标签得到。
JavaScript代码加载内容
虽然网页显示的数据在HTML标签上面,但是指定HTML标签下内容为空。这是因为数据在js代码上面,而js的执行是在浏览器端的操作。当我们用程序去恳求网页地址的时侯,得到的response是网页代码和js的代码,因此自己在浏览器端能看到数据,解析时因为js未执行,指定HTML标签下数据肯定为空。这个时侯的处理办法:找到收录内容的js代码串,然后通过正则表达式获得相应的内容,而不是解析HTML标签。
Ajax异步恳求
这种情况是现今太常见的,尤其是在数据以分页方式显示在网页上,并且页面无刷新,或者是对网页进行某个交互操作后得到数据。所以当我们开始刷新页面的时侯就要开始跟踪所有的恳求,观察数据究竟是在哪一步加载进来的。然后当我们找到核心的异步恳求的时侯,就只用抓取这个异步恳求就可以了,如果原创网页没有任何有用信息,也没必要去抓取原创网页了。
2.3 页面数据结构剖析
结构性数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键数组即可。
page = requests.get(url)
headers = {}
page.encoding = 'utf-8'
data =re.findall(r'__INITIAL_STATE__=(.*?)',page.text)[0]
json_data = json.loads(data)
print(json_data)
#f = open('结果2.txt', 'w',
encoding='utf-8') # 以'w'方式打开文件
#for k, v in json_data.items():
# 遍历字典中的键值
#s2 = str(v) # 把字典的值转换成字符型
#f.write(k + '\n') # 键和值分行放,键在单数行,值在双数行
#f.write(s2 + '\n')
jobList = json_data['souresult']['Items'] #打印json_data,抓到关键词
for element in jobList:
print(f"===公司名称:{element['CompanyName']}:===\n"
f"岗位名称:{element['DateCreated']}\n"
f"招聘人数:{element['JobTitle']}\n"
f"工作代码:{element['JobTypeName']}\n"
f"公司代码:{element['RecruitCount']}\n"
f"详细信息URL:{element['SocialCompanyUrl']}")
非结构性数据-HTML文本数据
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时侯会碰到的情况。例如抓取一个网页,得到的是HTML,然后须要解析一些常见的元素,提取一些关键的信息。HTML虽然理应属于结构化的文本组织,但是又由于通常我们须要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作就能得到,所以还是归类于非结构化的数据处理中。常见解析方式:
CSS选择器
现在的网页式样比较多,所以通常的网页就会有一些CSS的定位,例如class,id等等,或者我们按照常见的节点路径进行定位。
item = soup.select('#u1 > a')
#选择指定目录下所有css数据
#print([i for i in item]) #print里添加循环时,记得加方括号
item = soup.select_one('#u1 > a') #选择指定目录下第一条 css数据
print(item)
Findall
##招聘人数
recru_num = soup.find_all('div', attrs={'class':'cityfn-left'}) #找到页面中a元素的所有元素,并找到a元素中 属性为'class=value'———————— attrs={"class": 'value'}
print(recru_num)
dr = re.compile(r']+>', re.S)
data = dr.sub('', str(recru_num)) #过滤HTML标签
print(data)
Xpath
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()') #获取某个标签的内容(基本使用)
正则表达式
正则表达式,用标准正则解析,一般会把HTML当作普通文本,用指定格式匹配。当相关文本是小片断文本,或者某一串字符,或者HTML收录javascript的代码,无法用CSS选择器或则XPATH。
import re
a = '<p>[Aero, Animals, Architecture,Wallpapers">Artistic</a>, ........(省略)......... Vintage]'
titles = re.findall(' 查看全部
Python爬虫总结(CSS,Xpath,JsonLoad;静态网页,JS加载
前言
随着人类社会的高速发展,数据对各行各业的重要性,愈加突出。爬虫,也称为数据采集器,是指通过程序设计,机械化地对网路上的数据,进行批量爬取,以取代低效的人工获取信息的手段。
1. 道德法律问题
爬虫目前在法律上尚属黑色地段,但爬别的网站用于自己的商业化用途也可能存在着法律风险。非法抓取使用“新浪微博”用户信息被判赔200万元,这是国外的一条因爬虫被判败诉的新闻。所以各商业公司还是悠着点,特别是涉及隐私数据。
大型的网站一般还会有robot.txt,这算是与爬虫者的一个合同。只要在robot.txt容许的范围内爬虫就不存在道德和法律风险。
2. 网络爬虫步骤2.1 检查API接口
API是网站官方提供的数据插口,如果通过调用API采集数据,则相当于在网站允许的范围内采集。这样既不会有道德法律风险,也没有网站故意设置的障碍;不过调用API插口的访问则处于网站的控制中,网站可以拿来收费,可以拿来限制访问上限等。整体来看,如果数据采集的需求并不是太奇特,那么有API则应优先采用调用API的形式。如果没有,则选择爬虫。
2.2 数据获取渠道剖析
页面收录数据
这种情况是最容易解决的,一般来讲基本上是静态网页,或者动态网页,采用模板渲染,浏览器获取到HTML的时侯早已是收录所有的关键信息,所以直接在网页上见到的内容都可以通过特定的HTML标签得到。
JavaScript代码加载内容
虽然网页显示的数据在HTML标签上面,但是指定HTML标签下内容为空。这是因为数据在js代码上面,而js的执行是在浏览器端的操作。当我们用程序去恳求网页地址的时侯,得到的response是网页代码和js的代码,因此自己在浏览器端能看到数据,解析时因为js未执行,指定HTML标签下数据肯定为空。这个时侯的处理办法:找到收录内容的js代码串,然后通过正则表达式获得相应的内容,而不是解析HTML标签。
Ajax异步恳求
这种情况是现今太常见的,尤其是在数据以分页方式显示在网页上,并且页面无刷新,或者是对网页进行某个交互操作后得到数据。所以当我们开始刷新页面的时侯就要开始跟踪所有的恳求,观察数据究竟是在哪一步加载进来的。然后当我们找到核心的异步恳求的时侯,就只用抓取这个异步恳求就可以了,如果原创网页没有任何有用信息,也没必要去抓取原创网页了。
2.3 页面数据结构剖析
结构性数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键数组即可。
page = requests.get(url)
headers = {}
page.encoding = 'utf-8'
data =re.findall(r'__INITIAL_STATE__=(.*?)',page.text)[0]
json_data = json.loads(data)
print(json_data)
#f = open('结果2.txt', 'w',
encoding='utf-8') # 以'w'方式打开文件
#for k, v in json_data.items():
# 遍历字典中的键值
#s2 = str(v) # 把字典的值转换成字符型
#f.write(k + '\n') # 键和值分行放,键在单数行,值在双数行
#f.write(s2 + '\n')
jobList = json_data['souresult']['Items'] #打印json_data,抓到关键词
for element in jobList:
print(f"===公司名称:{element['CompanyName']}:===\n"
f"岗位名称:{element['DateCreated']}\n"
f"招聘人数:{element['JobTitle']}\n"
f"工作代码:{element['JobTypeName']}\n"
f"公司代码:{element['RecruitCount']}\n"
f"详细信息URL:{element['SocialCompanyUrl']}")
非结构性数据-HTML文本数据
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时侯会碰到的情况。例如抓取一个网页,得到的是HTML,然后须要解析一些常见的元素,提取一些关键的信息。HTML虽然理应属于结构化的文本组织,但是又由于通常我们须要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作就能得到,所以还是归类于非结构化的数据处理中。常见解析方式:
CSS选择器
现在的网页式样比较多,所以通常的网页就会有一些CSS的定位,例如class,id等等,或者我们按照常见的节点路径进行定位。
item = soup.select('#u1 > a')
#选择指定目录下所有css数据
#print([i for i in item]) #print里添加循环时,记得加方括号
item = soup.select_one('#u1 > a') #选择指定目录下第一条 css数据
print(item)
Findall
##招聘人数
recru_num = soup.find_all('div', attrs={'class':'cityfn-left'}) #找到页面中a元素的所有元素,并找到a元素中 属性为'class=value'———————— attrs={"class": 'value'}
print(recru_num)
dr = re.compile(r']+>', re.S)
data = dr.sub('', str(recru_num)) #过滤HTML标签
print(data)
Xpath
html = etree.HTML(wb_data)
html_data = html.xpath('/html/body/div/ul/li/a/text()') #获取某个标签的内容(基本使用)
正则表达式
正则表达式,用标准正则解析,一般会把HTML当作普通文本,用指定格式匹配。当相关文本是小片断文本,或者某一串字符,或者HTML收录javascript的代码,无法用CSS选择器或则XPATH。
import re
a = '<p>[Aero, Animals, Architecture,Wallpapers">Artistic</a>, ........(省略)......... Vintage]'
titles = re.findall('
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推
采集交流 • 优采云 发表了文章 • 0 个评论 • 725 次浏览 • 2020-08-18 10:02
蜘蛛池引流 站群蜘蛛池 2019seo优化超级蜘蛛池 自动采集 网站优化必备
seo优化站群特色
安全、高效,化的优化借助php性能,使得运行流畅稳定
独创内容无缓存刷新不变,节省硬碟。防止搜索引擎辨识蜘蛛池
蜘蛛池算法,轻松建立站点(电影、资讯、图片、论坛等等)
可以个性化每位网站的风格、内容、站点模式、关键词、外链等
(自定义tkd、自定义外链关键词、自定义泛域名前缀)
什么是蜘蛛池? 蜘蛛池是一种通过借助小型平台权重来获得百度收录以及排行的一种程序,程序员常称为“蜘蛛池”。这是一种可以快速提高网站排名的一种程序,值得一提的是,它是手动提高网站的排行和网站的收录,这个疗效是极其出色的。蜘蛛池程序可以帮助我们做哪些? 发了外链了贴子还不收录,可竞争对手人家一样是发同样的站,人家没发外链也收录了,是吧!答:(因为人家养有了数目庞大的百度收录蜘蛛爬虫,有了蜘蛛池你也可以做到) CNmmm.Com
有些老手会说,我自己也养有百度蜘蛛如何我的也不收录呢?
答:(因为你的百度收录蜘蛛不够多,不够广,来来回回都是这些低质量的百度收录爬虫,收录慢,而且甚至是根本不收录了!——-蜘蛛池拥有多服务器,多域名,正规内容站点养着百度收录蜘蛛,分布广,域名多,团队化养着蜘蛛,来源站点多,质量高,每天都有新来的蜘蛛进行爬取收录您的外推贴子) 内容来自新手源码CNmmm.Com
蜘蛛池超级强悍的功能,全手动采集,支持api二次开发!
也可以当作站群的源程序使用。
支持给用户开帐号,全手动发布,可用于租用蜘蛛池,发布外链使用!
支持关键词跳转,全局跳转! 内容来自新手源码CNmmm.Com
自动采集(腾讯新闻(国内,军事),新浪新闻(国际,军事))
新闻伪原创,加快收录!
支持导出txt外推网址,蜘蛛日记,索引池,权重池等等等,更多功能自行发觉!
商业源码下载
售价 :80.00(元)会员价钱 :0.00(元) VIP会员登入 后即可免费下载!
资源信息 :
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推,支持降低用户 api
下载链接:*** 隐藏内容订购后可见 ***下载密码:*** 隐藏内容订购后可见 ***
开通VIP会员后,全站源码即可免费下载!活动期间会员仅需28元 - 马上开通VIP会员 查看全部
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推
蜘蛛池引流 站群蜘蛛池 2019seo优化超级蜘蛛池 自动采集 网站优化必备
seo优化站群特色
安全、高效,化的优化借助php性能,使得运行流畅稳定
独创内容无缓存刷新不变,节省硬碟。防止搜索引擎辨识蜘蛛池
蜘蛛池算法,轻松建立站点(电影、资讯、图片、论坛等等)
可以个性化每位网站的风格、内容、站点模式、关键词、外链等
(自定义tkd、自定义外链关键词、自定义泛域名前缀)
什么是蜘蛛池? 蜘蛛池是一种通过借助小型平台权重来获得百度收录以及排行的一种程序,程序员常称为“蜘蛛池”。这是一种可以快速提高网站排名的一种程序,值得一提的是,它是手动提高网站的排行和网站的收录,这个疗效是极其出色的。蜘蛛池程序可以帮助我们做哪些? 发了外链了贴子还不收录,可竞争对手人家一样是发同样的站,人家没发外链也收录了,是吧!答:(因为人家养有了数目庞大的百度收录蜘蛛爬虫,有了蜘蛛池你也可以做到) CNmmm.Com
有些老手会说,我自己也养有百度蜘蛛如何我的也不收录呢?
答:(因为你的百度收录蜘蛛不够多,不够广,来来回回都是这些低质量的百度收录爬虫,收录慢,而且甚至是根本不收录了!——-蜘蛛池拥有多服务器,多域名,正规内容站点养着百度收录蜘蛛,分布广,域名多,团队化养着蜘蛛,来源站点多,质量高,每天都有新来的蜘蛛进行爬取收录您的外推贴子) 内容来自新手源码CNmmm.Com
蜘蛛池超级强悍的功能,全手动采集,支持api二次开发!
也可以当作站群的源程序使用。
支持给用户开帐号,全手动发布,可用于租用蜘蛛池,发布外链使用!
支持关键词跳转,全局跳转! 内容来自新手源码CNmmm.Com
自动采集(腾讯新闻(国内,军事),新浪新闻(国际,军事))
新闻伪原创,加快收录!
支持导出txt外推网址,蜘蛛日记,索引池,权重池等等等,更多功能自行发觉!
商业源码下载
售价 :80.00(元)会员价钱 :0.00(元) VIP会员登入 后即可免费下载!
资源信息 :
2019最新站群优化超级蜘蛛池 引流必备,可转让后台,自动采集,支持外推,支持降低用户 api
下载链接:*** 隐藏内容订购后可见 ***下载密码:*** 隐藏内容订购后可见 ***
开通VIP会员后,全站源码即可免费下载!活动期间会员仅需28元 - 马上开通VIP会员
销帮帮数据处理工具开发说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-17 01:26
目录
开发背景:
公司CRM采购了销帮帮的CRM系统,由于CRM系统不健全,导出功能不能满足公司对数据进行剖析的需求。每次整理数据,分析人员部门等各类情况,再有假如人员重名,销帮帮不能分辨出具体是谁,必须去依据人员或其他数据进行分辨。
解决方案:
由于销帮帮数据的人员是有UserID的,而该UserID对应钉钉的UserID,所以可以按照钉钉提供的API接口轻松的判别出人员部门、分公司等信息,不用关心人员重名的情况。
开发环境:
软件使用C#+SQLSERVER进行开发。
使用教程:
开始前先给你们瞧瞧软件的整体界面。
软件主要包括清空明日数据,采集、数据剖析、同步用户信息、获取数据 5部份功能。
创建并配置SQLServer数据库
在安装好的SQLServer服务器上,创建数据库,数据库名称按照须要定义,此处我定义的数据库名称是xbb,如下图的配置[1],正确配置数据库联接
获取销帮帮的组织编码和Token
根据销帮帮提供的网址[]获取对应的组织编码和token.,如下图配置[2]配置销帮帮石药使用的组织编码和Token.
创建企业内部应用
在钉钉的【开发者后台】创建企业内部应用。开放查询部门、人员信息的权限即可。并配置对应的appkey/appsecret到右图【3】处。
清空明日数据
开始采集前,如果明天的数据早已采集过,请点击【清空明日数据】,会手动清空明天早已采集的数据,重新开始采集。
采集
点击【开始】进行数据采集,采集的内容主要包括功能上勾选的数据。等待最下边的状态栏采集后待处理数据变为0条,则代表采集完成。
数据剖析
采集后会把数据统计分配到一张表里,点击数据剖析会手动依据采集到的数据创建表,并把数据插入到对应的表上面。
同步用户数据
同步用户数据是为了增量备份钉钉的所有的用户信息。
获取数据
点击【获取数据】按钮,自动导入销帮帮销售机会、合同、跟进记录等信息。
备注:如果哪天销帮帮数据发生变化,可以在软件的ExecSQL文件夹下更改对应的导入SQL句子,不用更改代码。
软件技能更新
第一次在开发中使用了dynamic关键字,通过对Json进行反序列化挺好用。减少了好多Model的创建工作,也降低了先前通过正则表达式匹配的方法的工作量。
通过下边的句子更改当前显示的文字做的颜色。
rtbContent.SelectionColor = Color.Red;
rtbContent.SelectedText = msg+"\r\n";
为了备份每晚的数据,所有的表都带上了年月日yyyyMMdd格式结尾。所有的查询都是通过{Date}关键字,用明天的日期替换{Date}关键字后产生SQL查询句子
每次抓取分页数据时,由于是异步的,不能马上确定是否有下一页的时侯,尤其是抓取第一页的时侯,由于数据分类不同,以前都是按照不同的数据分页设置一下队列,然后依次从队列中进行数据弹出、采集等。现在采用字典Dic> 可以通过统一的方式,设置不同的关键字插入分页或则弹出分页。
以前的加密方式大多是md5/AES等加密方法,最近大多都在改成sha256,可能与统一的后端构架有关系把。
C#的sha256加密方法:
public static string sha256(string data)
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
byte[] hash = SHA256Managed.Create().ComputeHash(bytes);
StringBuilder builder = new StringBuilder();
for (int i = 0; i < hash.Length; i++)
{
builder.Append(hash[i].ToString("X2"));
}
return builder.ToString();
}
以前处理数据库都是自己自动写个简单的DbHelper,由于用不到各类复杂的处理。所以还算够用。
后来发觉通过Dapper可以轻松实现数据的批量处理,而且总体来说效率还可以,毕竟写的代码少了,还是很高兴的。
轻量级的ORM工具,我选Dapper.。但是ADO.NET原理不能忘。
NPOI仍然是最好的处理Excel的工具
不再使用Model,正则表达式,把所有Json格式的数据通过,数据字段ID、列名、列值、数据类型 插入到一张表,通过统一的SQL创建插入规则把数据在统一插入到对应的表中,不需要提早晓得表的列名。
自动创建、增加列。自动插入数据。 查看全部
销帮帮数据处理工具开发说明
目录
开发背景:
公司CRM采购了销帮帮的CRM系统,由于CRM系统不健全,导出功能不能满足公司对数据进行剖析的需求。每次整理数据,分析人员部门等各类情况,再有假如人员重名,销帮帮不能分辨出具体是谁,必须去依据人员或其他数据进行分辨。
解决方案:
由于销帮帮数据的人员是有UserID的,而该UserID对应钉钉的UserID,所以可以按照钉钉提供的API接口轻松的判别出人员部门、分公司等信息,不用关心人员重名的情况。
开发环境:
软件使用C#+SQLSERVER进行开发。
使用教程:
开始前先给你们瞧瞧软件的整体界面。
软件主要包括清空明日数据,采集、数据剖析、同步用户信息、获取数据 5部份功能。
创建并配置SQLServer数据库
在安装好的SQLServer服务器上,创建数据库,数据库名称按照须要定义,此处我定义的数据库名称是xbb,如下图的配置[1],正确配置数据库联接
获取销帮帮的组织编码和Token
根据销帮帮提供的网址[]获取对应的组织编码和token.,如下图配置[2]配置销帮帮石药使用的组织编码和Token.
创建企业内部应用
在钉钉的【开发者后台】创建企业内部应用。开放查询部门、人员信息的权限即可。并配置对应的appkey/appsecret到右图【3】处。
清空明日数据
开始采集前,如果明天的数据早已采集过,请点击【清空明日数据】,会手动清空明天早已采集的数据,重新开始采集。
采集
点击【开始】进行数据采集,采集的内容主要包括功能上勾选的数据。等待最下边的状态栏采集后待处理数据变为0条,则代表采集完成。
数据剖析
采集后会把数据统计分配到一张表里,点击数据剖析会手动依据采集到的数据创建表,并把数据插入到对应的表上面。
同步用户数据
同步用户数据是为了增量备份钉钉的所有的用户信息。
获取数据
点击【获取数据】按钮,自动导入销帮帮销售机会、合同、跟进记录等信息。
备注:如果哪天销帮帮数据发生变化,可以在软件的ExecSQL文件夹下更改对应的导入SQL句子,不用更改代码。
软件技能更新
第一次在开发中使用了dynamic关键字,通过对Json进行反序列化挺好用。减少了好多Model的创建工作,也降低了先前通过正则表达式匹配的方法的工作量。
通过下边的句子更改当前显示的文字做的颜色。
rtbContent.SelectionColor = Color.Red;
rtbContent.SelectedText = msg+"\r\n";
为了备份每晚的数据,所有的表都带上了年月日yyyyMMdd格式结尾。所有的查询都是通过{Date}关键字,用明天的日期替换{Date}关键字后产生SQL查询句子
每次抓取分页数据时,由于是异步的,不能马上确定是否有下一页的时侯,尤其是抓取第一页的时侯,由于数据分类不同,以前都是按照不同的数据分页设置一下队列,然后依次从队列中进行数据弹出、采集等。现在采用字典Dic> 可以通过统一的方式,设置不同的关键字插入分页或则弹出分页。
以前的加密方式大多是md5/AES等加密方法,最近大多都在改成sha256,可能与统一的后端构架有关系把。
C#的sha256加密方法:
public static string sha256(string data)
{
byte[] bytes = Encoding.UTF8.GetBytes(data);
byte[] hash = SHA256Managed.Create().ComputeHash(bytes);
StringBuilder builder = new StringBuilder();
for (int i = 0; i < hash.Length; i++)
{
builder.Append(hash[i].ToString("X2"));
}
return builder.ToString();
}
以前处理数据库都是自己自动写个简单的DbHelper,由于用不到各类复杂的处理。所以还算够用。
后来发觉通过Dapper可以轻松实现数据的批量处理,而且总体来说效率还可以,毕竟写的代码少了,还是很高兴的。
轻量级的ORM工具,我选Dapper.。但是ADO.NET原理不能忘。
NPOI仍然是最好的处理Excel的工具
不再使用Model,正则表达式,把所有Json格式的数据通过,数据字段ID、列名、列值、数据类型 插入到一张表,通过统一的SQL创建插入规则把数据在统一插入到对应的表中,不需要提早晓得表的列名。
自动创建、增加列。自动插入数据。

