
通过关键词采集文章采集api
用户行为分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2020-08-08 09:13
首先,让我们了解用户行为分析
1. 为什么要进行用户行为分析?
仅通过进行用户行为分析,您才能了解用户画像并了解网站上各种浏览,单击和购买背后的商业真相.
简而言之,分析的主要方式是关注客户流失,尤其是对于那些需要转化的网站. 我们希望用户上来后不会迷路,也不会离开. 与许多O2O产品一样,用户在购买产品时也会获得大量补贴. 一旦钱花光了,用户就走了. 此类产品或商业模式不好. 我们希望用户能够真正找到该平台的价值,并不断进取并不会失去它.
2. 用户行为分析有助于分析用户流失的方式,原因及流失的地方
例如,最简单的搜索行为: 当某个ID搜索关键字,查看哪个页面,结果以及购买ID时,整个行为非常重要. 如果他对中间的搜索结果不满意,他肯定会再次搜索,然后在找到结果之前将关键字更改为其他关键字.
3. 用户行为分析还能做什么?
拥有大量用户行为数据并定义事件后,可以将用户数据划分为按小时,天,用户级别或事件级别划分的表. 该表用于什么用途?一种是了解用户最简单的事件,例如登录或购买,还知道哪些是高质量用户,哪些将失去客户. 每天或每小时都可以查看此类数据. ,
第二,掩埋点的作用
1. 大数据,从复杂数据的背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“品味”的产品和服务,并根据用户需求进行调整和优化. 这是大数据的价值. 而且对这些信息的采集和分析无法避免“埋伏点”
2. 隐蔽点是在需要的位置采集相应的信息,就像高速公路上的摄像头一样,它可以采集车辆的属性,例如: 颜色,车牌号,型号等,并且还可以采集车辆的行为例如: 您是否闯红灯,按下了线路,汽车的速度,驾驶员在开车时接听电话等,每个掩埋点都像一个摄像头,采集用户行为数据并进行数据的多维交叉分析,可以真正地还原开发用户使用场景和挖掘用户需求,从而提高用户整个生命周期的价值.
三,埋点的类型
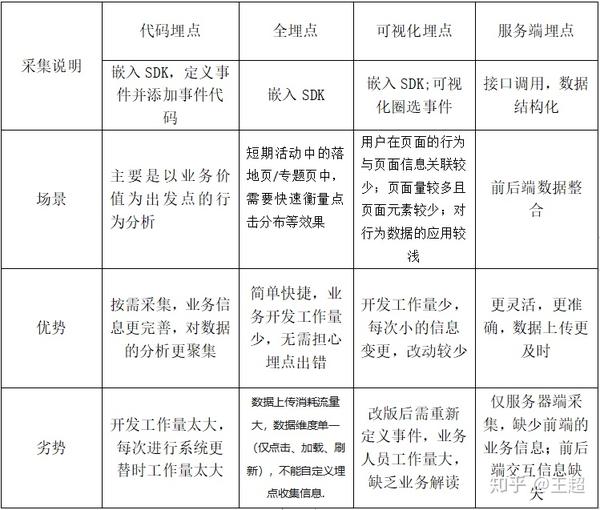
新闻埋藏工具: 代码埋藏点,视觉埋藏点,“无埋藏点”
根据掩埋点的位置: 前端/客户端掩埋点,后端/服务器端掩埋点
1. 完全埋入点(也称为无埋入点): 通过SDK采集页面上的所有控制操作数据,并通过“统计数据屏幕”配置要处理的数据的特征.
示例·应用场景
它主要应用于简单页面,例如短期事件中的登录页面/主题页面,并且有必要快速测量点击分配的效果等.
2. 可视化的隐埋点: 嵌入式SDK,可视化的圆选择以定义事件
为了方便产品和操作,学生可以直接在页面上直接盘旋以跟踪用户行为(定义事件),并且仅采集点击操作即可节省开发时间. 就像卫星航空摄影一样,不需要安装摄像头,数据量很小,并且它支持在本地获取信息. 因此,JS可视化掩埋点更适合以下情况:
示例·应用场景
2.1. 短而平坦且快速的数据采集方法: 活动/ H5等简单页面,业务人员可以直接盘旋,操作没有门槛,减少了技术人员的干预(从今以后世界和平),这种数据采集方法便于业务人员尽快掌握页面上关键节点的转换,但用户行为数据的应用相对较浅,无法支持更深入的分析;
2.2. 如果页面是临时调整的,则可以灵活地将其添加到埋入点,可以用作代码埋入点的补充以及时增加采集的数据
3. 代码嵌入点: 嵌入式SDK,定义事件和添加事件代码,按需采集,业务信息更加完整,数据分析更加集中,因此代码嵌入是基于业务价值的行为分析.
示例·应用场景
3.1. 如果您不想在采集数据时降低用户体验
3.2. 如果您不想采集大量无用的数据
3.3. 如果您想采集数据: 更细的粒度,更大的维度以及更高的数据分析准确性
然后,考虑到业务增长的长期价值,请选择代码掩埋点
4. 服务器端埋入点: 它可以通过接口调用来构造数据,从而支持其他业务数据的采集和集成,例如CRM和其他用户数据,因为它是直接从服务器端采集的,因此数据更加准确和适合本身具有采集功能的客户可以将采集与客户采集相结合.
示例·应用场景
4.1. 通过调用API接口将CRM和其他数据与用户行为数据集成,以从多个角度全面分析用户;
4.2. 如果公司已经拥有自己的掩埋系统,那么它可以通过服务器端集合直接上载用户行为数据以进行数据分析,而无需维护两个掩埋系统;
4.3. 连接历史数据(埋入点之前的数据)和新数据(埋入点之后的数据)以提高数据准确性. 例如,在访问客户以采集客户之后,在导入原创历史数据之后,先前访问该平台的现有用户将不会被标记为新用户,从而减少了数据错误.
四,如何选择掩埋点
数据采集只是数据分析的第一步. 数据分析的目的是深入了解用户行为,挖掘用户价值并促进业务增长. 因此,最理想的掩埋解决方案是基于不同的业务,场景和行业特征,并根据自己的实际需求,以互补的方式组合掩埋点,例如:
1. 代码掩埋点+完全掩埋点: 当需要对目标页面进行整体点击分析时,在细节中一一掩埋这些点的工作量相对较大,并且在经常优化和调整目标页面时,更新埋藏点不应低估数量,但是复杂页面中存在盲点,无法用所有埋藏点采集. 因此,代码掩埋点可以用作采集用户核心行为的辅助工具,以实现准确且跨领域的用户行为分析;
2. 代码埋入点+服务器端埋入点: 以电子商务平台为例,用户在支付过程中将跳至第三方支付平台,需要通过交易数据来验证支付是否成功在服务器上. 此时,通过将代码埋入点和服务器端埋入点结合起来,可以提高数据的准确性;
3. 代码嵌入点+可视嵌入点: 由于代码嵌入点的工作量很大,因此可以通过核心事件代码嵌入这些点,并且可视化的嵌入点可以用于采集其他方法和补充方法. 查看全部
16058322王超
首先,让我们了解用户行为分析
1. 为什么要进行用户行为分析?
仅通过进行用户行为分析,您才能了解用户画像并了解网站上各种浏览,单击和购买背后的商业真相.
简而言之,分析的主要方式是关注客户流失,尤其是对于那些需要转化的网站. 我们希望用户上来后不会迷路,也不会离开. 与许多O2O产品一样,用户在购买产品时也会获得大量补贴. 一旦钱花光了,用户就走了. 此类产品或商业模式不好. 我们希望用户能够真正找到该平台的价值,并不断进取并不会失去它.
2. 用户行为分析有助于分析用户流失的方式,原因及流失的地方
例如,最简单的搜索行为: 当某个ID搜索关键字,查看哪个页面,结果以及购买ID时,整个行为非常重要. 如果他对中间的搜索结果不满意,他肯定会再次搜索,然后在找到结果之前将关键字更改为其他关键字.
3. 用户行为分析还能做什么?
拥有大量用户行为数据并定义事件后,可以将用户数据划分为按小时,天,用户级别或事件级别划分的表. 该表用于什么用途?一种是了解用户最简单的事件,例如登录或购买,还知道哪些是高质量用户,哪些将失去客户. 每天或每小时都可以查看此类数据. ,
第二,掩埋点的作用
1. 大数据,从复杂数据的背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“品味”的产品和服务,并根据用户需求进行调整和优化. 这是大数据的价值. 而且对这些信息的采集和分析无法避免“埋伏点”
2. 隐蔽点是在需要的位置采集相应的信息,就像高速公路上的摄像头一样,它可以采集车辆的属性,例如: 颜色,车牌号,型号等,并且还可以采集车辆的行为例如: 您是否闯红灯,按下了线路,汽车的速度,驾驶员在开车时接听电话等,每个掩埋点都像一个摄像头,采集用户行为数据并进行数据的多维交叉分析,可以真正地还原开发用户使用场景和挖掘用户需求,从而提高用户整个生命周期的价值.

三,埋点的类型
新闻埋藏工具: 代码埋藏点,视觉埋藏点,“无埋藏点”
根据掩埋点的位置: 前端/客户端掩埋点,后端/服务器端掩埋点
1. 完全埋入点(也称为无埋入点): 通过SDK采集页面上的所有控制操作数据,并通过“统计数据屏幕”配置要处理的数据的特征.
示例·应用场景
它主要应用于简单页面,例如短期事件中的登录页面/主题页面,并且有必要快速测量点击分配的效果等.
2. 可视化的隐埋点: 嵌入式SDK,可视化的圆选择以定义事件
为了方便产品和操作,学生可以直接在页面上直接盘旋以跟踪用户行为(定义事件),并且仅采集点击操作即可节省开发时间. 就像卫星航空摄影一样,不需要安装摄像头,数据量很小,并且它支持在本地获取信息. 因此,JS可视化掩埋点更适合以下情况:
示例·应用场景
2.1. 短而平坦且快速的数据采集方法: 活动/ H5等简单页面,业务人员可以直接盘旋,操作没有门槛,减少了技术人员的干预(从今以后世界和平),这种数据采集方法便于业务人员尽快掌握页面上关键节点的转换,但用户行为数据的应用相对较浅,无法支持更深入的分析;
2.2. 如果页面是临时调整的,则可以灵活地将其添加到埋入点,可以用作代码埋入点的补充以及时增加采集的数据
3. 代码嵌入点: 嵌入式SDK,定义事件和添加事件代码,按需采集,业务信息更加完整,数据分析更加集中,因此代码嵌入是基于业务价值的行为分析.
示例·应用场景
3.1. 如果您不想在采集数据时降低用户体验
3.2. 如果您不想采集大量无用的数据
3.3. 如果您想采集数据: 更细的粒度,更大的维度以及更高的数据分析准确性
然后,考虑到业务增长的长期价值,请选择代码掩埋点
4. 服务器端埋入点: 它可以通过接口调用来构造数据,从而支持其他业务数据的采集和集成,例如CRM和其他用户数据,因为它是直接从服务器端采集的,因此数据更加准确和适合本身具有采集功能的客户可以将采集与客户采集相结合.
示例·应用场景
4.1. 通过调用API接口将CRM和其他数据与用户行为数据集成,以从多个角度全面分析用户;
4.2. 如果公司已经拥有自己的掩埋系统,那么它可以通过服务器端集合直接上载用户行为数据以进行数据分析,而无需维护两个掩埋系统;
4.3. 连接历史数据(埋入点之前的数据)和新数据(埋入点之后的数据)以提高数据准确性. 例如,在访问客户以采集客户之后,在导入原创历史数据之后,先前访问该平台的现有用户将不会被标记为新用户,从而减少了数据错误.
四,如何选择掩埋点
数据采集只是数据分析的第一步. 数据分析的目的是深入了解用户行为,挖掘用户价值并促进业务增长. 因此,最理想的掩埋解决方案是基于不同的业务,场景和行业特征,并根据自己的实际需求,以互补的方式组合掩埋点,例如:
1. 代码掩埋点+完全掩埋点: 当需要对目标页面进行整体点击分析时,在细节中一一掩埋这些点的工作量相对较大,并且在经常优化和调整目标页面时,更新埋藏点不应低估数量,但是复杂页面中存在盲点,无法用所有埋藏点采集. 因此,代码掩埋点可以用作采集用户核心行为的辅助工具,以实现准确且跨领域的用户行为分析;
2. 代码埋入点+服务器端埋入点: 以电子商务平台为例,用户在支付过程中将跳至第三方支付平台,需要通过交易数据来验证支付是否成功在服务器上. 此时,通过将代码埋入点和服务器端埋入点结合起来,可以提高数据的准确性;
3. 代码嵌入点+可视嵌入点: 由于代码嵌入点的工作量很大,因此可以通过核心事件代码嵌入这些点,并且可视化的嵌入点可以用于采集其他方法和补充方法.
Python爬行微信小程序(实战)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-08 02:53
最近,有必要在微信小程序中捕获数据分析. 与一般的Web爬网程序类似,主要目标是获取用于数据爬网的主要URL地址,而问题的关键是在移动终端请求后如何获取https. 加密参数. 在本文中,我们将从初始数据包捕获到URL获取,解析参数,数据分析和存储,逐步抓取微信小程序.
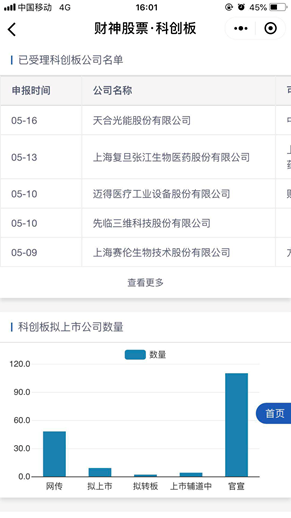
此爬网的目标是微信小程序“财富股票”中公认的科技公司列表,如下所示:
注意: 数据包捕获,分析和爬网的整个过程几乎在微信小程序中普遍使用,并且可以使用类似的原理类似地对其他小程序进行爬网进行测试.
二,环境配置
特定环境配置参考: Python爬行微信小程序(查尔斯)
移动终端: iPhone;
PC端: Windows 10;
软件: Charles
注意: 对网络的要求很高,请确保网络访问不受限制.
三,查尔斯捕获了包裹
<p>在上一篇文章(Python爬行微信小程序(Charles))中详细描述了与查尔斯有关的配置和说明,因此在此我不再赘述,但要点是,移动证书始终是受信任的: 查看全部
I. 背景介绍
最近,有必要在微信小程序中捕获数据分析. 与一般的Web爬网程序类似,主要目标是获取用于数据爬网的主要URL地址,而问题的关键是在移动终端请求后如何获取https. 加密参数. 在本文中,我们将从初始数据包捕获到URL获取,解析参数,数据分析和存储,逐步抓取微信小程序.
此爬网的目标是微信小程序“财富股票”中公认的科技公司列表,如下所示:
注意: 数据包捕获,分析和爬网的整个过程几乎在微信小程序中普遍使用,并且可以使用类似的原理类似地对其他小程序进行爬网进行测试.
二,环境配置
特定环境配置参考: Python爬行微信小程序(查尔斯)
移动终端: iPhone;
PC端: Windows 10;
软件: Charles
注意: 对网络的要求很高,请确保网络访问不受限制.
三,查尔斯捕获了包裹
<p>在上一篇文章(Python爬行微信小程序(Charles))中详细描述了与查尔斯有关的配置和说明,因此在此我不再赘述,但要点是,移动证书始终是受信任的:
Python丨scrapy抓取招聘网络移动APP的发布信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-08 02:52
我将在一段时间内开始寻找新工作,因此让我们抓取一些工作信息进行分析. 当前的主流招聘网站包括51job,直联,BOSS直接招聘,拉狗等. 我有一段时间没有抓取移动应用程序了. 这次,我将编写一个采集器来搜寻51job.com移动应用程序的工作信息. 其他招聘网站将在以后更新...
使用的工具(技术):
IDE: pycharm
数据库: MySQL
包裹捕获工具: Fiddler
采集器框架: scrapy == 1.5.0
信息捕获: 选择器内置scrapy
Python学习资料或需要代码,视频和Python学习小组: 960410445
2 APP捕获分析
让我们第一次体验51job的应用. 当我们在首页上输入搜索关键字并单击搜索时,该应用程序将跳至新页面. 我们将此页面称为第一级页面. 第一级页面显示了我们正在寻找的所有职位的列表.
当我们单击某个帖子信息时,APP将跳至新页面. 我称此页面为辅助页面. 第二页收录我们需要的所有作业信息,也是我们主页的当前采集页.
分析页面后,您可以分析51job应用程序的请求和响应. 本文中使用的数据包捕获工具是Fiddler.
本文的目的是捕获在51job应用上搜索某个关键字时返回的所有招聘信息. 本文以“ Python”为例. APP上的操作如下图所示. 输入“ Python”关键字后,单击“搜索”,然后Fiddler抓取4个数据包,如下所示:
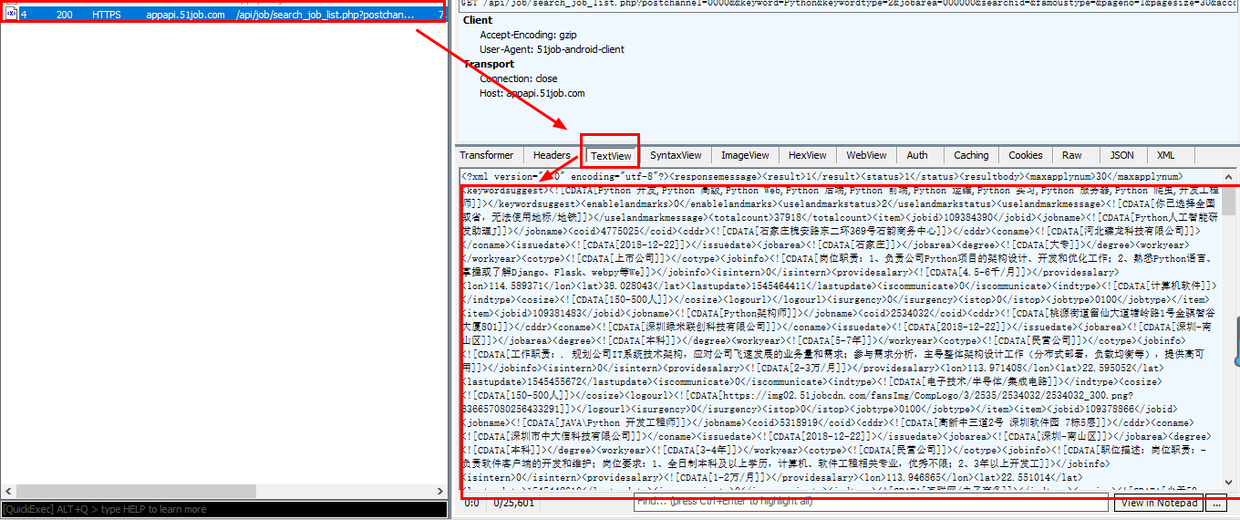
实际上,当我们看到第二和第四数据包的图标时,我们应该笑一个. 这两个图标分别表示以json和xml格式传输的数据,许多Web界面以这两种格式传输数据,并且未列出移动应用程序. 选择第二个数据包,然后在右侧的主窗口中检查,发现第二个数据包不收录我们想要的数据. 查看第四个数据包后,选择后可以在右侧窗口中看到以下内容:
右下角的内容不只是您在手机上看到的工作信息吗?它仍然以XML格式传输. 我们复制此数据包的链接:
keyword = Python&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369792>
当我们爬网时,我们肯定不仅会爬网一页的信息. 我们在APP上向下滑动页面,以查看Fiddler将抓取哪些数据包. 看下面的图片:
滑下电话屏幕后,Fiddler抓取了另外两个数据包,然后选择了第二个数据包,并再次发现它是APP上新刷新的招聘信息,然后复制此数据包的url链接: </p
ppageno = 2&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 845&guid = bbb37e8f266b9de3e2a9/p
p接下来,让我们比较一下之前和之后的两个链接,以分析异同. 可以看出,除了属性“ pageno”外,其他所有内容都是相同的. 没错,以红色标记. 第一个数据包链接中的pageno值为1,第二个pageno值为2,因此翻页的规则一目了然./p
p现在我们已经找到了APP翻页的请求链接规则,我们可以通过采集器循环将pageno分配给pageno,以实现模拟翻页的功能./p
p让我们再次尝试更改搜索关键字,以查看链接中的变化,以“ java”作为关键字,捕获的数据包为:/p
pkeyword = java&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369845>
经过比较,发现只有链接中的keyword值不同,并且该值是我们自己输入的关键字. 因此,在爬虫中,我们可以通过字符串拼接来完全实现输入关键字模拟,以采集不同类型的招聘信息. 同样,您可以搜索诸如工作地点之类的信息规则,而本文将不对其进行描述.
解决翻页功能后,让我们探索数据包中XML的内容. 我们复制上面的第一个链接,然后在浏览器中将其打开. 打开后,屏幕如下:
以这种方式观看要舒服得多. 通过仔细观察,我们会发现APP上的每个职位发布都对应一个标签,每个职位中都有一个标签,并且有一个ID来标识职位. 例如,上面的第一篇文章是109384390,第二篇文章是109381483. 请记住该ID,稍后再使用.
实际上,接下来,我们单击第一个职位发布以进入第二页. 这时,Fiddler将采集APP刚发送的数据包,单击xml数据包,然后发现它是刚刚在APP上刷新的页面信息. 我们复制数据包的url链接:
jobid = 109384390&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
根据该方法,在第一级页面上的列表中单击第二个作业,然后从Fiddler复制相应数据包的url链接:
jobid = 109381483&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
比较以上两个链接,您是否找到了模式?是的,jobid不同,其他都一样. 此Jobid是我们在第一页xml中找到的jobid. 由此,我们可以从第一级页面获取Jobid来构造第二级页面的url链接,然后采集我们需要的所有信息. 整个采集器逻辑很明确:
构造第一级页面的初始URL->采集jobid->构造第二级页面的URL->获取工作信息->通过循环模拟获取下一页的URL.
好的,分析工作已经完成,我开始编写采集器.
3编写采集器
本文使用的是无忧移动APP网络采集器的Scrapy框架. 在下载了草率的第三方软件包之后,通过命令行创建一个爬虫项目:
scrapy startproject job_spider.
job_spider是我们的检索器项目的项目名称. 有一个“. ”在项目名称之后. 这一点是可选的. 区别在于在当前文件之间创建一个项目,或者创建一个与项目名称相同的文件. 在文件中创建一个项目.
创建项目后,继续创建一个采集器,专用于搜寻51job发布的招聘信息. 创建一个名称如下的采集器:
scrapy genspider qcwySpider
注意: 如果未添加“. ”. 创建爬网程序项目时,将其更改为项目名称,请在运行命令以创建爬网程序之前进入项目文件夹.
打开刚刚通过pycharm创建的爬虫项目,左侧的目录树结构如下:
在开始所有采集器工作之前,请先打开settings.py文件,然后取消注释“ ROBOTSTXT_OBEY = False”行并将其值更改为False.
#遵守robots.txt规则ROBOTSTXT_OBEY = False
完成以上修改后,在spiders包下打开qcwySpider.py. 初始代码如下:
这是scrapy为我们建立的框架. 我们只需要在此基础上改进爬虫.
首先,我们需要向类添加一些属性,例如search关键字keyword,起始页,要进行爬网以获得最大页面数,还需要设置标头以进行简单的反爬网. 此外,starturl也需要重置为第一页的URL. 更改后的代码如下:
然后开始编写parse方法来对第一级页面进行爬网. 在第一页中,我们的主要逻辑是通过循环在APP中实现屏幕幻灯片的更新. 我们在上面的代码中使用current_page来标识当前页码,在每个循环之后,将1添加到current_page中,然后构造一个新的url,并通过回调解析方法抓取下一页. 另外,我们还需要在parse方法中从第一级页面采集jobid,并构造第二级页面,然后回调实现第二级页面信息采集的parse_job方法. 解析方法代码如下:
为了便于调试,我们在项目的jobSpider目录中创建一个main.py文件来启动采集器,并在每次启动采集器时运行该文件. 内容如下:
辅助页面信息采集功能是在parse_job方法中实现的,因为我们需要获取的所有信息都在xml中,所以我们可以使用scrapy附带的选择器直接提取它,但是在提取之前,我们需要先定义用于存储我们采集的数据的项目. 打开items.py文件,编写一个Item类,然后输入以下代码:
上面的每个项目都对应一个xml标记,该标记用于存储一条信息. 在qcwyJobsItem类的末尾,定义了一个do_insert方法,该方法用于生成插入语句,该语句将所有信息存储在数据库中的项目中. 之所以在items块中生成此insert语句,是因为如果将来有多个采集器,则在管道模块中可以有多个项目类之后,可以为不同的项目插入数据库,以使该项目更具可伸缩性. 您还可以编写所有与在管道中插入数据库有关的代码.
然后编写parse_job方法:
完成上述代码后,信息采集部分完成. 接下来,继续编写信息存储功能,该功能在pipelines.py中完成.
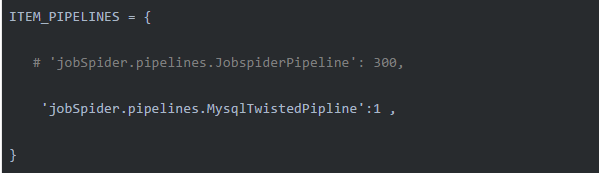
在编写pipeline.py之后,打开settings.py文件并配置刚刚写入项目设置文件的MysqlTwistedPipline类:
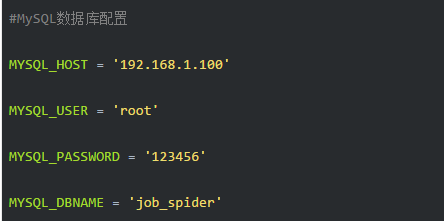
另外,还要配置数据库:
您还可以将数据库配置嵌入MysqlTwistedPipline类中,但是我习惯于将这些专有数据库信息写入配置文件中.
最后,仅需一步即可建立数据库和数据表. 表结构的一部分如下所示:
完成上述所有操作后,您可以运行采集器以开始采集数据. 采集的数据如下图所示:
4摘要
经过整个过程,我觉得51job.com APP的爬取比Web爬取更容易(似乎很多网站都是这样). 回顾整个过程,实际上代码中有许多细节可以改进和完善,例如,在构建链接时可以添加职位搜索位置. 这篇博客文章侧重于整个爬网程序过程的逻辑分析,并介绍了APP的基本爬网方法. 博客文章中省略了部分代码. 如果您需要完整的代码,请从我的github获得. 将来,我们将继续更新其他招聘网站的抓取工具. 返回搜狐查看更多 查看全部
1简介
我将在一段时间内开始寻找新工作,因此让我们抓取一些工作信息进行分析. 当前的主流招聘网站包括51job,直联,BOSS直接招聘,拉狗等. 我有一段时间没有抓取移动应用程序了. 这次,我将编写一个采集器来搜寻51job.com移动应用程序的工作信息. 其他招聘网站将在以后更新...
使用的工具(技术):
IDE: pycharm
数据库: MySQL
包裹捕获工具: Fiddler
采集器框架: scrapy == 1.5.0
信息捕获: 选择器内置scrapy
Python学习资料或需要代码,视频和Python学习小组: 960410445
2 APP捕获分析
让我们第一次体验51job的应用. 当我们在首页上输入搜索关键字并单击搜索时,该应用程序将跳至新页面. 我们将此页面称为第一级页面. 第一级页面显示了我们正在寻找的所有职位的列表.
当我们单击某个帖子信息时,APP将跳至新页面. 我称此页面为辅助页面. 第二页收录我们需要的所有作业信息,也是我们主页的当前采集页.
分析页面后,您可以分析51job应用程序的请求和响应. 本文中使用的数据包捕获工具是Fiddler.
本文的目的是捕获在51job应用上搜索某个关键字时返回的所有招聘信息. 本文以“ Python”为例. APP上的操作如下图所示. 输入“ Python”关键字后,单击“搜索”,然后Fiddler抓取4个数据包,如下所示:
实际上,当我们看到第二和第四数据包的图标时,我们应该笑一个. 这两个图标分别表示以json和xml格式传输的数据,许多Web界面以这两种格式传输数据,并且未列出移动应用程序. 选择第二个数据包,然后在右侧的主窗口中检查,发现第二个数据包不收录我们想要的数据. 查看第四个数据包后,选择后可以在右侧窗口中看到以下内容:
右下角的内容不只是您在手机上看到的工作信息吗?它仍然以XML格式传输. 我们复制此数据包的链接:
keyword = Python&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369792>
当我们爬网时,我们肯定不仅会爬网一页的信息. 我们在APP上向下滑动页面,以查看Fiddler将抓取哪些数据包. 看下面的图片:
滑下电话屏幕后,Fiddler抓取了另外两个数据包,然后选择了第二个数据包,并再次发现它是APP上新刷新的招聘信息,然后复制此数据包的url链接: </p
ppageno = 2&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 845&guid = bbb37e8f266b9de3e2a9/p
p接下来,让我们比较一下之前和之后的两个链接,以分析异同. 可以看出,除了属性“ pageno”外,其他所有内容都是相同的. 没错,以红色标记. 第一个数据包链接中的pageno值为1,第二个pageno值为2,因此翻页的规则一目了然./p
p现在我们已经找到了APP翻页的请求链接规则,我们可以通过采集器循环将pageno分配给pageno,以实现模拟翻页的功能./p
p让我们再次尝试更改搜索关键字,以查看链接中的变化,以“ java”作为关键字,捕获的数据包为:/p
pkeyword = java&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369845>
经过比较,发现只有链接中的keyword值不同,并且该值是我们自己输入的关键字. 因此,在爬虫中,我们可以通过字符串拼接来完全实现输入关键字模拟,以采集不同类型的招聘信息. 同样,您可以搜索诸如工作地点之类的信息规则,而本文将不对其进行描述.
解决翻页功能后,让我们探索数据包中XML的内容. 我们复制上面的第一个链接,然后在浏览器中将其打开. 打开后,屏幕如下:

以这种方式观看要舒服得多. 通过仔细观察,我们会发现APP上的每个职位发布都对应一个标签,每个职位中都有一个标签,并且有一个ID来标识职位. 例如,上面的第一篇文章是109384390,第二篇文章是109381483. 请记住该ID,稍后再使用.
实际上,接下来,我们单击第一个职位发布以进入第二页. 这时,Fiddler将采集APP刚发送的数据包,单击xml数据包,然后发现它是刚刚在APP上刷新的页面信息. 我们复制数据包的url链接:
jobid = 109384390&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
根据该方法,在第一级页面上的列表中单击第二个作业,然后从Fiddler复制相应数据包的url链接:
jobid = 109381483&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
比较以上两个链接,您是否找到了模式?是的,jobid不同,其他都一样. 此Jobid是我们在第一页xml中找到的jobid. 由此,我们可以从第一级页面获取Jobid来构造第二级页面的url链接,然后采集我们需要的所有信息. 整个采集器逻辑很明确:
构造第一级页面的初始URL->采集jobid->构造第二级页面的URL->获取工作信息->通过循环模拟获取下一页的URL.
好的,分析工作已经完成,我开始编写采集器.
3编写采集器
本文使用的是无忧移动APP网络采集器的Scrapy框架. 在下载了草率的第三方软件包之后,通过命令行创建一个爬虫项目:
scrapy startproject job_spider.
job_spider是我们的检索器项目的项目名称. 有一个“. ”在项目名称之后. 这一点是可选的. 区别在于在当前文件之间创建一个项目,或者创建一个与项目名称相同的文件. 在文件中创建一个项目.
创建项目后,继续创建一个采集器,专用于搜寻51job发布的招聘信息. 创建一个名称如下的采集器:
scrapy genspider qcwySpider
注意: 如果未添加“. ”. 创建爬网程序项目时,将其更改为项目名称,请在运行命令以创建爬网程序之前进入项目文件夹.
打开刚刚通过pycharm创建的爬虫项目,左侧的目录树结构如下:
在开始所有采集器工作之前,请先打开settings.py文件,然后取消注释“ ROBOTSTXT_OBEY = False”行并将其值更改为False.
#遵守robots.txt规则ROBOTSTXT_OBEY = False
完成以上修改后,在spiders包下打开qcwySpider.py. 初始代码如下:
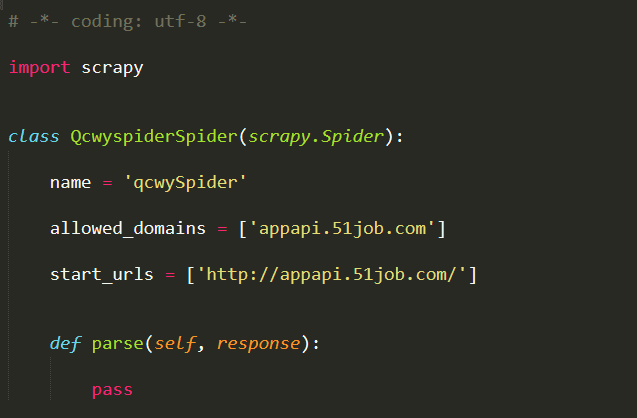
这是scrapy为我们建立的框架. 我们只需要在此基础上改进爬虫.
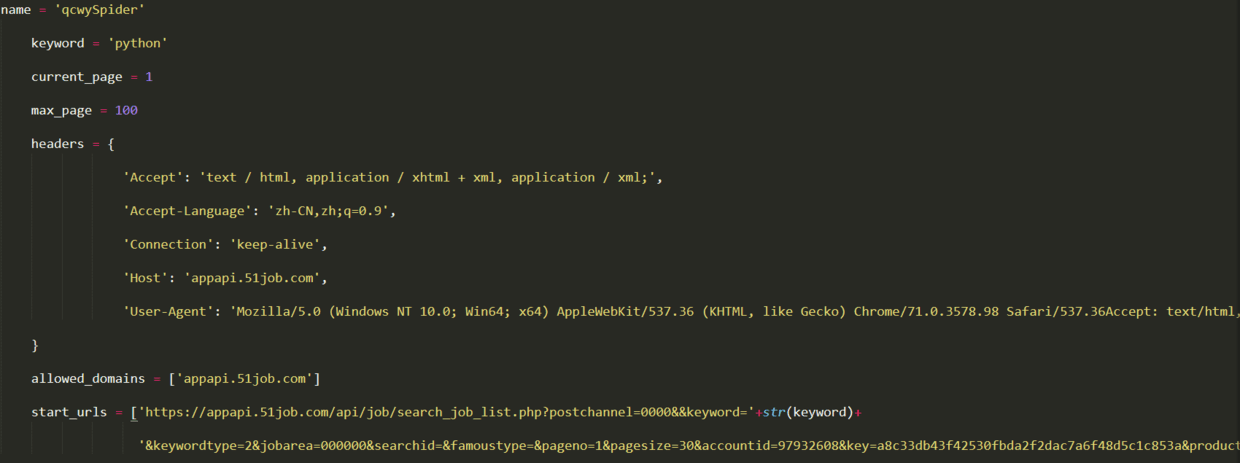
首先,我们需要向类添加一些属性,例如search关键字keyword,起始页,要进行爬网以获得最大页面数,还需要设置标头以进行简单的反爬网. 此外,starturl也需要重置为第一页的URL. 更改后的代码如下:
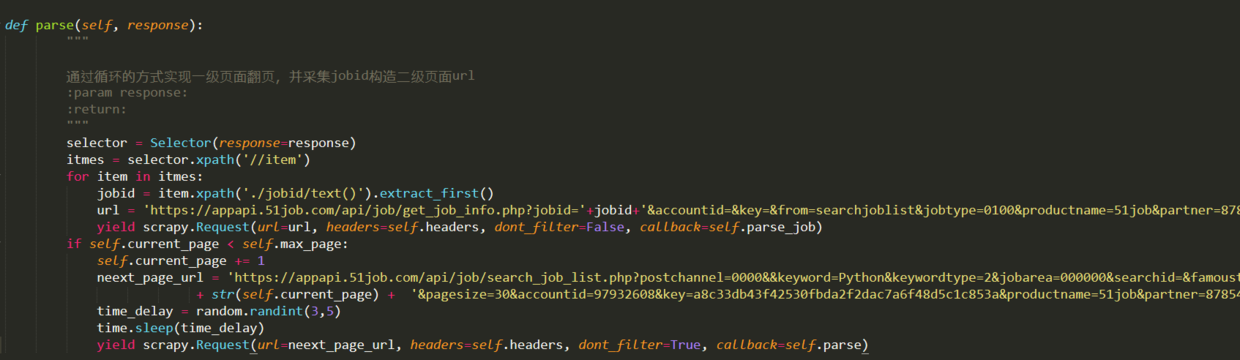
然后开始编写parse方法来对第一级页面进行爬网. 在第一页中,我们的主要逻辑是通过循环在APP中实现屏幕幻灯片的更新. 我们在上面的代码中使用current_page来标识当前页码,在每个循环之后,将1添加到current_page中,然后构造一个新的url,并通过回调解析方法抓取下一页. 另外,我们还需要在parse方法中从第一级页面采集jobid,并构造第二级页面,然后回调实现第二级页面信息采集的parse_job方法. 解析方法代码如下:
为了便于调试,我们在项目的jobSpider目录中创建一个main.py文件来启动采集器,并在每次启动采集器时运行该文件. 内容如下:

辅助页面信息采集功能是在parse_job方法中实现的,因为我们需要获取的所有信息都在xml中,所以我们可以使用scrapy附带的选择器直接提取它,但是在提取之前,我们需要先定义用于存储我们采集的数据的项目. 打开items.py文件,编写一个Item类,然后输入以下代码:
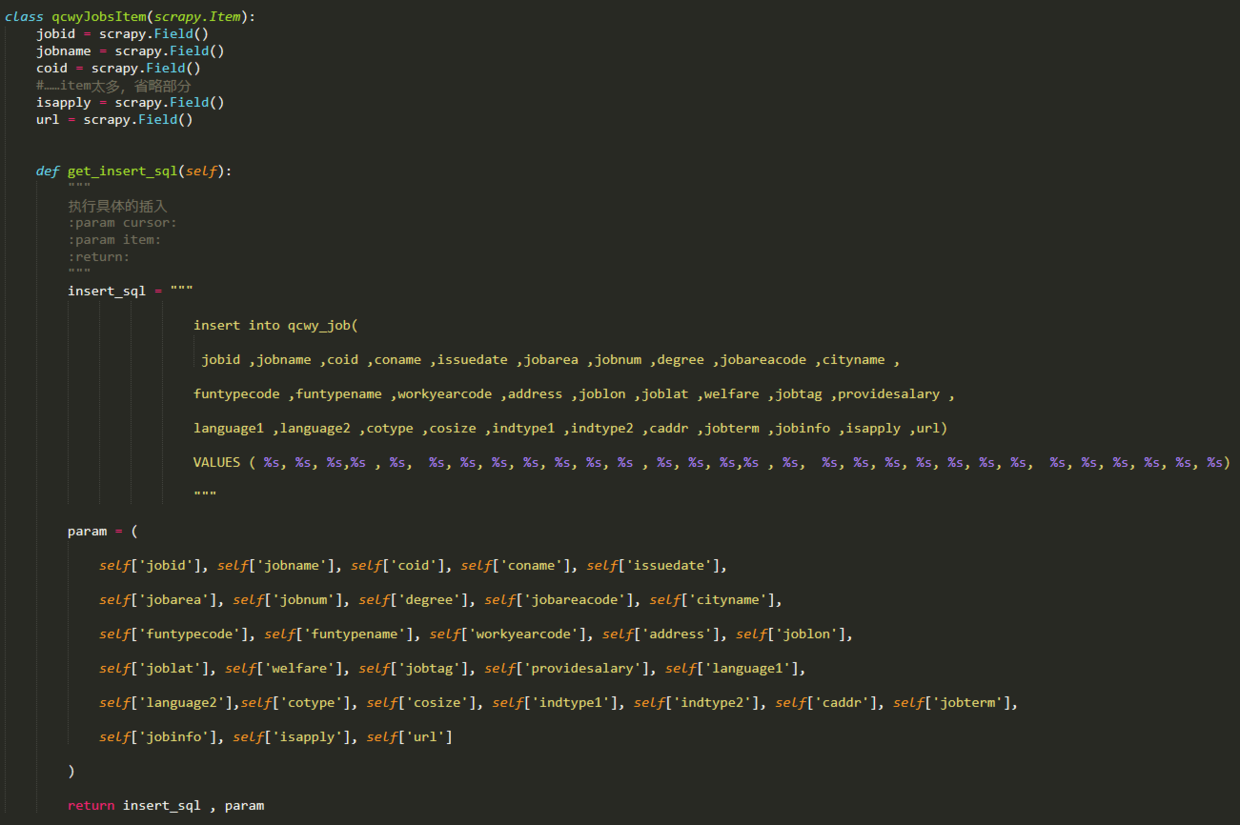
上面的每个项目都对应一个xml标记,该标记用于存储一条信息. 在qcwyJobsItem类的末尾,定义了一个do_insert方法,该方法用于生成插入语句,该语句将所有信息存储在数据库中的项目中. 之所以在items块中生成此insert语句,是因为如果将来有多个采集器,则在管道模块中可以有多个项目类之后,可以为不同的项目插入数据库,以使该项目更具可伸缩性. 您还可以编写所有与在管道中插入数据库有关的代码.
然后编写parse_job方法:
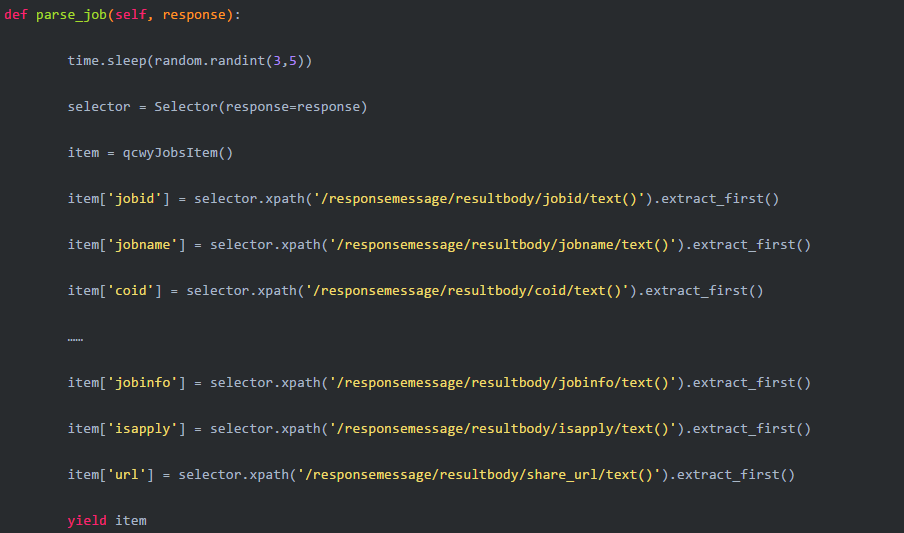
完成上述代码后,信息采集部分完成. 接下来,继续编写信息存储功能,该功能在pipelines.py中完成.
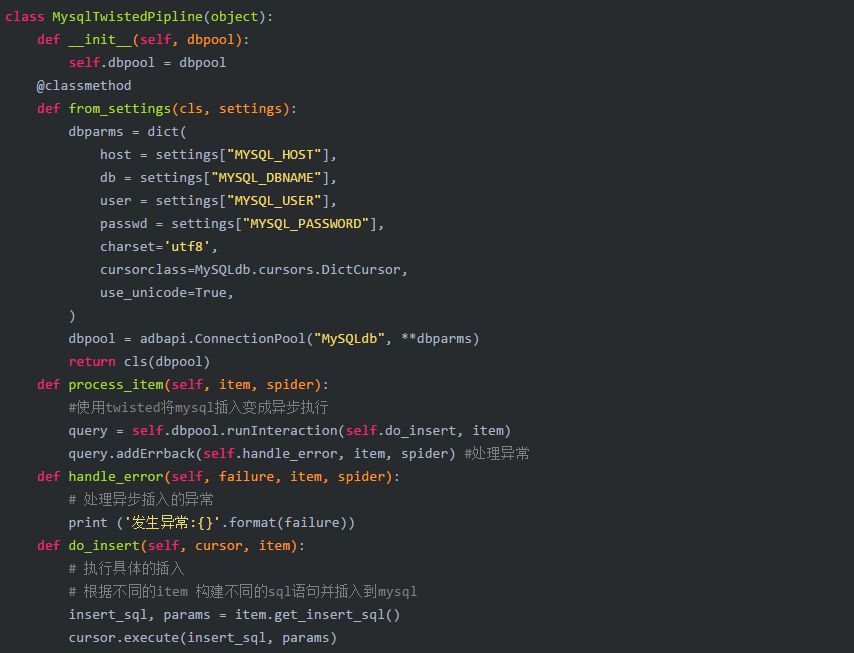
在编写pipeline.py之后,打开settings.py文件并配置刚刚写入项目设置文件的MysqlTwistedPipline类:
另外,还要配置数据库:
您还可以将数据库配置嵌入MysqlTwistedPipline类中,但是我习惯于将这些专有数据库信息写入配置文件中.
最后,仅需一步即可建立数据库和数据表. 表结构的一部分如下所示:
完成上述所有操作后,您可以运行采集器以开始采集数据. 采集的数据如下图所示:
4摘要
经过整个过程,我觉得51job.com APP的爬取比Web爬取更容易(似乎很多网站都是这样). 回顾整个过程,实际上代码中有许多细节可以改进和完善,例如,在构建链接时可以添加职位搜索位置. 这篇博客文章侧重于整个爬网程序过程的逻辑分析,并介绍了APP的基本爬网方法. 博客文章中省略了部分代码. 如果您需要完整的代码,请从我的github获得. 将来,我们将继续更新其他招聘网站的抓取工具. 返回搜狐查看更多
Python使用Sina API实现数据捕获
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2020-08-08 00:14
我主要抓取了大约4天的数据. 该图显示大约有360万个数据. 由于我在自己的计算机上爬网以获取数据,因此有时晚上网络会中断. 因此,大约一天之内就可以抓取大约一百万个最新的微博数据(因为我将其称为最新的微博API public_timeline)
API文档中定义了很多返回类型(以json数据格式返回,我选择了一些我认为要抓住它的重要信息,如图所示): 可能是ID号,位置,粉丝数,微博内容,发布时间等. 当然,这些数据可以根据您的需要进行自定义. )
可能是内容,如果您认为对您有所帮助,请继续阅读...第一次写博客有点冗长
2. 初步准备
我们需要什么:
数据库: mongodb(您可以使用客户端MongoBooster)
开发环境: Python2.7(我使用的IDE是Pycharm)
新浪开发者帐户: 只需注册您自己的新浪微博帐户(我们稍后会讨论)
所需的库: 请求和pymongo(可在Pycharm中下载)
2.1Mongodb安装
MongoDB是高性能,开源,无模式的基于文档的数据库,并且是最受欢迎的NoSql数据库之一. 在许多情况下,它可以用来代替传统的关系数据库或键/值存储. Mongo用C ++开发. Mongo的官方网站地址是: 读者可以在这里获取更多详细信息.
2.2如何注册新浪开发者帐户
注册一个新浪微博帐户(163邮箱,手机号码)
创建后,您需要填写手机号码验证
进入Sina Opener平台:
点击以继续创建
第一次创建应用程序时,需要填写以下信息:
代码实现
有了令牌,捕获数据非常简单.
可以抓取多少数据取决于您的令牌权限
下一步是使用API获取数据: 创建一个新文件weibo_run.py 查看全部
1. 首先,让我们看一下获得的最终结果,是否是您想知道的东西,然后决定是否继续读下去.

我主要抓取了大约4天的数据. 该图显示大约有360万个数据. 由于我在自己的计算机上爬网以获取数据,因此有时晚上网络会中断. 因此,大约一天之内就可以抓取大约一百万个最新的微博数据(因为我将其称为最新的微博API public_timeline)
API文档中定义了很多返回类型(以json数据格式返回,我选择了一些我认为要抓住它的重要信息,如图所示): 可能是ID号,位置,粉丝数,微博内容,发布时间等. 当然,这些数据可以根据您的需要进行自定义. )
可能是内容,如果您认为对您有所帮助,请继续阅读...第一次写博客有点冗长
2. 初步准备
我们需要什么:
数据库: mongodb(您可以使用客户端MongoBooster)
开发环境: Python2.7(我使用的IDE是Pycharm)
新浪开发者帐户: 只需注册您自己的新浪微博帐户(我们稍后会讨论)
所需的库: 请求和pymongo(可在Pycharm中下载)
2.1Mongodb安装
MongoDB是高性能,开源,无模式的基于文档的数据库,并且是最受欢迎的NoSql数据库之一. 在许多情况下,它可以用来代替传统的关系数据库或键/值存储. Mongo用C ++开发. Mongo的官方网站地址是: 读者可以在这里获取更多详细信息.
2.2如何注册新浪开发者帐户
注册一个新浪微博帐户(163邮箱,手机号码)

创建后,您需要填写手机号码验证
进入Sina Opener平台:



点击以继续创建
第一次创建应用程序时,需要填写以下信息:

代码实现
有了令牌,捕获数据非常简单.
可以抓取多少数据取决于您的令牌权限
下一步是使用API获取数据: 创建一个新文件weibo_run.py
WorDPrEss集合插件WPRoBot2.12破解版和使用教程. pdf9页
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2020-08-08 00:13
根据您选择的预设设置,使工作自动更新您的博客. 带有新信息的流行站点,例如相关目录的抓取,可能是获取目录的好地方. WpRobot是一个插件,可以自动生成Wordpress Blog文章,该文章可以自动采集网站上的文章,视频,图片,产品信息,例如yahoo news,yahoo Answer,youtube,flickr,amazon,ebay,Clickbank,Cj等. 根据设置的关键字等等,与自动重写插件配合使用以制作伪原创,而不再担心建立英语网站. WpRobot的功能创建具有所需内容的任何文章并将其发布到WordPress博客中,您只需要设置相关的关键字即可. 创建任何不同类别的文章,例如使用不同关键字的不同类别; 自定义两篇文章的发布时间间隔,最小间隔为一小时,当然,您也可以设置为一或几天的间隔; 精确控制文章内容的生成,通过关键字匹配创建不同的任务,并避免重复文章;保留所有权利自动获取文章标签. 标签是Wordpress的更好功能之一. 访客可以通过某些标签搜索具有相同标签的文章; 自定义模板. 如果您对模板不满意,可以修改模板;实际上,WpRobot绝对不具有这些功能,但我还没有想到. 您会发现它在使用过程中是如此强大且易于使用. 建立一个英文博客不再是障碍.
以下是WpRobot的基本用法教程. 第1步: 上传WpRobot插件并在后台激活它. 步骤2: 设置关键字以输入WP背景,找到WpRobot3选项,然后单击create campaign(创建采集组). 有三种采集方法. 一种是关键字活动(按键),Word),Rss活动(博客帖子RSS),BrowseNode campaig n(亚马逊产品节点). 首先是按关键字采集. 单击右侧的快速模板设置. 当然,您也可以选择“随机”模板来查看两者之间的区别. 在“为广告系列命名”中填写您的名称. 对于关键字组的名称(例如IPad),在关键字下方的框中填写关键字,每行一个关键字,然后设置类别. 在下面的左侧(例如一小时,一天等)设置采集频率,并在右侧设置是否自动建立分类(不建议这样做,因为效果确实很差). 以下是关键模板设置,共有8个(请注意,单击“快速模板设置”时将显示8).
文章,亚马逊产品,雅虎问答,雅虎新闻,CB,YouTube视频,eBay和Flickr依次排列. 建议不要在这里全部使用它们. 保留要使用的任何一个,然后添加每个模板的采集率. 不需要时,单击相应模板下的删除模板. 后者的设置如下图所示,基本上没有变化,主要用于替换关键字,删除关键字,设置翻译等. 所有权利均已设置,请单击下面的“创建广告系列”以完成广告组的创建. 第三步: WP Robot Options选项设置许可证选项许可选项,填写您购买了正版WpRobot插件的PayPal电子邮件地址,然后可以随意输入破解版本. 此选项会自动显示,并且在启用WpRobot时可以使用它. 系统将要求您输入此电子邮件地址. 常规选项常规选项设置启用简单模式,是否允许简单模式,如果允许,请打勾;新职位状态,新职位状态,有三种类型的状态: 已发布和草稿,通常选择发布;重置过帐计数器: 文章数返回零,否或是;启用帮助工具提示,是否启用帮助工具提示;启用旧重复检查,是否启用旧版本重复检查;此处没有一一说明随机化Tim Times,随机文章发表时间以及此处的其他一些选项,使用翻译工具将了解翻译的含义.
保留所有权利的Amazon Options选项设置Amazon Affiliate ID,填写Amazon会员ID号; API密钥(访问密钥ID),填写Amazon API;应用;秘密访问密钥,将在申请API后提供给您;搜索方法,搜索方法: 完全匹配(严格匹配),广泛匹配(广泛匹配);跳过产品如果不跳过(生死不跳过)或找不到描述(没有描述)或找不到缩略图(没有缩略图))或没有描述或没有缩略图(没有描述或缩略图),请跳过此产品产品; Amazon Description长度,描述长度;亚马逊网站,选择;标题中的方括号,是(默认);将评论发布为评论?选择是;发布模板: 默认模板或修改后的模板.
烟台SEO /整理,重印并注明出处. 谢谢. 保留所有权利. 文章选项“文章”选项设置“文章语言”,选择“英语”和“页面”作为文章的语言,如果您将其选中,则将一个长文章分成N个字符的几页;从...中删除所有链接. 删除所有链接. Clickbank选项设置Clickbank会员ID,填写Clickbank会员ID;过滤广告?过滤广告. eBay选项设置了所有权利. eBay会员ID(CampID),eBay会员ID;国家,国家选择美国;语言,语言选择英文;对结果进行排序,传递什么排序. Flickr选项设置Flickr API密钥,Flickr API应用程序密钥;许可,许可方式;图像尺寸,图像尺寸. Yahoo Answers Options和Yahoo News Options设置Yahoo Application ID,两者的ID相同,请单击此处应用;保留所有权利Youtube选项和RSS选项设置查看图片并将其翻译,您应该知道如何设置它.
翻译选项使用代理来使用代理,是的,随机选择以下一项,请是,随机选择以下代理地址;如果翻译失败...如果翻译失败,请创建未翻译的文章或跳过该文章. 保留所有权利Twitter Options设置Commission Junction Options设置如果您有做过CJ的朋友,这些设置应该很容易获得,如果您没有做过CJ,请跳过它. 这里省略了一些设置,这些设置是最不常用的,默认设置为OK,最后按Save Options保存设置. 步骤4: 修改模板. 修改模板也是一个更关键的步骤. 如果您对现有模板不满意,可以自己修改它. 有时会产生很好的效果. 例如,有些人采集eBay信息并将标题更改为“产品名称+拍卖组合模板”的效果是显而易见的,并且添加了很多Sale. 步骤5: 发布文章. 发布文章是最后一步. 添加关键字后,单击WpRobot的第一个选项Campaigns. 您将在此处找到刚刚填写的采集的关键字. 将鼠标移到某个关键字上. 单击“立即发布”,您会惊讶地发现WpRobot已开始采集和发布文章.
保留所有权利当然,还有更强大的功能,它们可以同时发布N篇文章. 选择您要采集的组,然后如下图所示在“ Nuber of Posts”中填写文章数,例如,50篇文章,在Backdate?前面打勾,文章发表日期从2008-09-24开始,并且两篇文章的发布时间为1到2天. 单击立即发布,WpRobot将开始采集文章. 采集到的50篇文章将于2008年9月24日发表. 两篇文章之间的时间为一到两天. WP全自动外部链接插件在这里,向您推荐WP全自动外部链接插件: 自动Backlink Creator插件. 我本人已经使用过该软件,效果非常好,所以今天推荐在这里,希望它可以节省每个人的时间和精力进行外部链接!自动反向链接创建器主要用于由wordpress程序构建的网站. 热衷WP的网站管理员和朋友,特别是对于那些从事外贸业务(主要是Google和Yahoo搜索引擎SEO)的人,这应该是一个好消息!该软件类似于WP插件,是WP网站外部链的完美解决方案!您只需要在网站的后台轻松安装它,即可为搜索引擎提供一种很好的方法,以自动向WP网站添加高权重的外部链接.
最近,在此软件的官方网站上,Automatic Backlink Creator的价格仅为37美元. 您可以用信用卡或贝宝付款. 在国外很受欢迎!在购买的同时,还赠送了MetaSnatcher插件作为礼物. 该插件可以自动跟踪Google顶级竞争对手的核心要点,并自动返回到该软件,从而节省了大量的关键字分析时间. Spin Master Pro插件. 该插件等效于WP脱机伪原创和发布插件. 安装此插件后,您可以在计算机上制作伪原创内容并脱机发布,从而节省大量时间. 同时,该软件提供60天不令人满意的退款保证. 点击查看此软件的开发人员是一组SEO大师,他们结合了Google和Yahoo的外链算法来开发此功能强大且出色的外链软件,同时考虑了外链PR,OBL,FLAG等极端方面方面. 并且通过该系统,可以生成稳定且持续增长的高质量反链,例如指向.edu,.gov等网站的外部链接. 下载: 最经典的SEO链轮解决方案 查看全部
保留所有权利WordPress集合插件WPRobot_2.12破解版并使用教程Wprobot3.12破解版下载地址: / space / file / liuzhilei121 / share / 2010/11/26 / WPRo bot3.1-6700-65b0-7834 -89e3-7248.rar / .page WPRobot一直是WP英语垃圾站的必备插件,尤其是对于像我这样英语水平较低的人而言. 它是WordPress博客的集合插件. 上面是WPRobot 3.12地址最新破解版的下载,有需要的兄弟可以自己下载,这里继续关注最新破解版,当您开始使用WPRobot插件时,您会意识到它有多聪明. 它是从多个来源生成的. 您是在自动驾驶仪Wor Dpress博客上创建的. 在设计WPRobot时,负责人认为最好将其分成模块,以允许客户定制其特殊需求的插件. 例如,Amazon和YouTube附加组件允许您添加主目录和注释. 该系统的优点是所有模块均可由选定模块单独购买. 模块智能化可以满足所有用户需求. WPRobot是自动博客的超级插件. 考虑一下您喜欢的所有主题,它将使您发布目录而不是编写目录.
根据您选择的预设设置,使工作自动更新您的博客. 带有新信息的流行站点,例如相关目录的抓取,可能是获取目录的好地方. WpRobot是一个插件,可以自动生成Wordpress Blog文章,该文章可以自动采集网站上的文章,视频,图片,产品信息,例如yahoo news,yahoo Answer,youtube,flickr,amazon,ebay,Clickbank,Cj等. 根据设置的关键字等等,与自动重写插件配合使用以制作伪原创,而不再担心建立英语网站. WpRobot的功能创建具有所需内容的任何文章并将其发布到WordPress博客中,您只需要设置相关的关键字即可. 创建任何不同类别的文章,例如使用不同关键字的不同类别; 自定义两篇文章的发布时间间隔,最小间隔为一小时,当然,您也可以设置为一或几天的间隔; 精确控制文章内容的生成,通过关键字匹配创建不同的任务,并避免重复文章;保留所有权利自动获取文章标签. 标签是Wordpress的更好功能之一. 访客可以通过某些标签搜索具有相同标签的文章; 自定义模板. 如果您对模板不满意,可以修改模板;实际上,WpRobot绝对不具有这些功能,但我还没有想到. 您会发现它在使用过程中是如此强大且易于使用. 建立一个英文博客不再是障碍.
以下是WpRobot的基本用法教程. 第1步: 上传WpRobot插件并在后台激活它. 步骤2: 设置关键字以输入WP背景,找到WpRobot3选项,然后单击create campaign(创建采集组). 有三种采集方法. 一种是关键字活动(按键),Word),Rss活动(博客帖子RSS),BrowseNode campaig n(亚马逊产品节点). 首先是按关键字采集. 单击右侧的快速模板设置. 当然,您也可以选择“随机”模板来查看两者之间的区别. 在“为广告系列命名”中填写您的名称. 对于关键字组的名称(例如IPad),在关键字下方的框中填写关键字,每行一个关键字,然后设置类别. 在下面的左侧(例如一小时,一天等)设置采集频率,并在右侧设置是否自动建立分类(不建议这样做,因为效果确实很差). 以下是关键模板设置,共有8个(请注意,单击“快速模板设置”时将显示8).
文章,亚马逊产品,雅虎问答,雅虎新闻,CB,YouTube视频,eBay和Flickr依次排列. 建议不要在这里全部使用它们. 保留要使用的任何一个,然后添加每个模板的采集率. 不需要时,单击相应模板下的删除模板. 后者的设置如下图所示,基本上没有变化,主要用于替换关键字,删除关键字,设置翻译等. 所有权利均已设置,请单击下面的“创建广告系列”以完成广告组的创建. 第三步: WP Robot Options选项设置许可证选项许可选项,填写您购买了正版WpRobot插件的PayPal电子邮件地址,然后可以随意输入破解版本. 此选项会自动显示,并且在启用WpRobot时可以使用它. 系统将要求您输入此电子邮件地址. 常规选项常规选项设置启用简单模式,是否允许简单模式,如果允许,请打勾;新职位状态,新职位状态,有三种类型的状态: 已发布和草稿,通常选择发布;重置过帐计数器: 文章数返回零,否或是;启用帮助工具提示,是否启用帮助工具提示;启用旧重复检查,是否启用旧版本重复检查;此处没有一一说明随机化Tim Times,随机文章发表时间以及此处的其他一些选项,使用翻译工具将了解翻译的含义.
保留所有权利的Amazon Options选项设置Amazon Affiliate ID,填写Amazon会员ID号; API密钥(访问密钥ID),填写Amazon API;应用;秘密访问密钥,将在申请API后提供给您;搜索方法,搜索方法: 完全匹配(严格匹配),广泛匹配(广泛匹配);跳过产品如果不跳过(生死不跳过)或找不到描述(没有描述)或找不到缩略图(没有缩略图))或没有描述或没有缩略图(没有描述或缩略图),请跳过此产品产品; Amazon Description长度,描述长度;亚马逊网站,选择;标题中的方括号,是(默认);将评论发布为评论?选择是;发布模板: 默认模板或修改后的模板.
烟台SEO /整理,重印并注明出处. 谢谢. 保留所有权利. 文章选项“文章”选项设置“文章语言”,选择“英语”和“页面”作为文章的语言,如果您将其选中,则将一个长文章分成N个字符的几页;从...中删除所有链接. 删除所有链接. Clickbank选项设置Clickbank会员ID,填写Clickbank会员ID;过滤广告?过滤广告. eBay选项设置了所有权利. eBay会员ID(CampID),eBay会员ID;国家,国家选择美国;语言,语言选择英文;对结果进行排序,传递什么排序. Flickr选项设置Flickr API密钥,Flickr API应用程序密钥;许可,许可方式;图像尺寸,图像尺寸. Yahoo Answers Options和Yahoo News Options设置Yahoo Application ID,两者的ID相同,请单击此处应用;保留所有权利Youtube选项和RSS选项设置查看图片并将其翻译,您应该知道如何设置它.
翻译选项使用代理来使用代理,是的,随机选择以下一项,请是,随机选择以下代理地址;如果翻译失败...如果翻译失败,请创建未翻译的文章或跳过该文章. 保留所有权利Twitter Options设置Commission Junction Options设置如果您有做过CJ的朋友,这些设置应该很容易获得,如果您没有做过CJ,请跳过它. 这里省略了一些设置,这些设置是最不常用的,默认设置为OK,最后按Save Options保存设置. 步骤4: 修改模板. 修改模板也是一个更关键的步骤. 如果您对现有模板不满意,可以自己修改它. 有时会产生很好的效果. 例如,有些人采集eBay信息并将标题更改为“产品名称+拍卖组合模板”的效果是显而易见的,并且添加了很多Sale. 步骤5: 发布文章. 发布文章是最后一步. 添加关键字后,单击WpRobot的第一个选项Campaigns. 您将在此处找到刚刚填写的采集的关键字. 将鼠标移到某个关键字上. 单击“立即发布”,您会惊讶地发现WpRobot已开始采集和发布文章.
保留所有权利当然,还有更强大的功能,它们可以同时发布N篇文章. 选择您要采集的组,然后如下图所示在“ Nuber of Posts”中填写文章数,例如,50篇文章,在Backdate?前面打勾,文章发表日期从2008-09-24开始,并且两篇文章的发布时间为1到2天. 单击立即发布,WpRobot将开始采集文章. 采集到的50篇文章将于2008年9月24日发表. 两篇文章之间的时间为一到两天. WP全自动外部链接插件在这里,向您推荐WP全自动外部链接插件: 自动Backlink Creator插件. 我本人已经使用过该软件,效果非常好,所以今天推荐在这里,希望它可以节省每个人的时间和精力进行外部链接!自动反向链接创建器主要用于由wordpress程序构建的网站. 热衷WP的网站管理员和朋友,特别是对于那些从事外贸业务(主要是Google和Yahoo搜索引擎SEO)的人,这应该是一个好消息!该软件类似于WP插件,是WP网站外部链的完美解决方案!您只需要在网站的后台轻松安装它,即可为搜索引擎提供一种很好的方法,以自动向WP网站添加高权重的外部链接.
最近,在此软件的官方网站上,Automatic Backlink Creator的价格仅为37美元. 您可以用信用卡或贝宝付款. 在国外很受欢迎!在购买的同时,还赠送了MetaSnatcher插件作为礼物. 该插件可以自动跟踪Google顶级竞争对手的核心要点,并自动返回到该软件,从而节省了大量的关键字分析时间. Spin Master Pro插件. 该插件等效于WP脱机伪原创和发布插件. 安装此插件后,您可以在计算机上制作伪原创内容并脱机发布,从而节省大量时间. 同时,该软件提供60天不令人满意的退款保证. 点击查看此软件的开发人员是一组SEO大师,他们结合了Google和Yahoo的外链算法来开发此功能强大且出色的外链软件,同时考虑了外链PR,OBL,FLAG等极端方面方面. 并且通过该系统,可以生成稳定且持续增长的高质量反链,例如指向.edu,.gov等网站的外部链接. 下载: 最经典的SEO链轮解决方案
dragou网的API和项目案例数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2020-08-07 16:00
一个. API
定义
API(应用程序编程接口,应用程序编程接口)是一些预定义的功能,或指软件系统不同组件之间的协议. 目的是使应用程序和开发人员能够访问基于某些软件或硬件的一组例程,而不必访问原创代码或了解内部工作机制的细节.
使用方法
API使用一组非常标准的规则来生成数据,并且生成的数据以非常标准的方式进行组织. 由于这些规则非常标准,因此一些简单的基本规则易于学习,因此您可以快速掌握API的用法. 但并非所有API都易于使用. 有些API有很多规则,而且非常复杂,因此您可以在使用前查看API的相关帮助文档
API验证
1)有些简单的操作不需要验证. 是免费的API
2)大多数API都需要用户提交和验证. 提交验证的主要目的是计算API调用的费用,这是一种常见的付费API. 例如: 图灵的聊天机器人
2. 拖动网项目案例数据采集(一)需求分析
通过数据采集,获取对拉沟发布的专业职位的需求分析.
(2)数据分析和实验结果首先分析网站的详细信息页面(此时关键字使用python). 在真实的请求URL中,网页将返回一个JSON字符串,我们需要解析该JSON字符串. 在页面上获取信息. 通过更改表单数据中pn的值来控制翻页. 从页面的详细信息页面,我们需要获取诸如“职务”,“职务说明”,“职务要求”等信息.
1)首先,我们请求标头信息
我们需要构造请求标头的标头信息. 如果未在此处构建,则很容易被网站识别为爬虫,因此拒绝了我们的请求
2)表单信息
发送POST请求时需要包括的表单信息(表单数据),需要解析的页码和搜索关键字
3)返回JSON数据
我们可以通过网页找到需要的信息,这些信息随时都在-> positionResult->结果中,其中收录工作地点,职位信息,公司名称等. 这些正是我们所需要的数据.
相关代码:
在配置文件中: (此文件的作用是: 当您以后要爬网其他类别或修改相关参数时,可以直接在文件中对其进行修改)
from fake_useragent import UserAgent
import requests
Host = 'www.lagou.com'
Origin = 'https://www.lagou.com'
Refer = 'https://www.lagou.com/jobs/list_python'
Connection = 'keep-alive'
Accept = 'application/json,text/javascript,*/*; q=0.01'
ua = UserAgent(verify_ssl=False)
ThreadCount = 50
csv_filename = 'filename.csv'
pages = 20
keyword = "python"
分析页面的核心代码:
#需要导入的模块
import time
import pandas as pd
import requests
from config import *
import logging
from concurrent.futures import ThreadPoolExecutor
import pprint
# 灵活配置日志级别,日志格式,输出位置
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='lagou.log',
filemode='w')
# 获取PositionID所在的页面,返回的是json数据
def getPositionIDPage(url_start, url_parse, page=1, kd='python'):
# 构造请求头(headers)
headers = {'User-Agent': ua.random,
'Host': Host,
'Origin': Origin,
'Referer': Refer,
'Connection': Connection,
'Accept': Accept,
'proxies': proxy}
# 构造表单
data = {
'first': False,
'pn': str(page),
'kd': kd
}
try:
# requests库里面的session对象能够帮助我们跨请求保持某些参数
# 也会在同一个session实例发出的所有请求之间保持cookies
# 创建一个session对象
session = requests.Session()
# 用session对象发出get 请求,设置cookies
session.get(url_start, headers=headers, timeout=3)
cookie = session.cookies
# 用session对象发出另一个请求post,获取cookies,返回响应信息
response = session.post(url=url_parse,
headers=headers,
data=data)
time.sleep(1)
# 响应状态码是4XX客户端错误,5XX 服务端响应错误,抛出异常
response.raise_for_status()
response.encoding = response.apparent_encoding
except Exception as e:
logging.error("页面" + url_parse + "爬取失败:", e)
else:
logging.info("页面" + url_parse + "爬取成功" + str(response.status_code))
return response.json()
运行测试:
if __name__ == '__main__':
url_start = 'https://www.lagou.com/jobs/list_%s' % (keyword)
url_parse = 'https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false'
content = getPositionIDPage(url_start, url_parse, page=page, kd=keyword)
pprint(content)
达到的效果:
3. 抓取相关的职位信息
获取所需职位的标签,招聘信息的每一页上都会有一个标签
positions = html['content']['positionResult']['result']
pprint.pprint(html)
df = pd.DataFrame(positions)
4. 商店信息
当我们找到所需的页面信息并对其进行爬网时,我们会将爬网的职位信息存储在一个csv文件中
def save_as_csv():
#开启进程池
with ThreadPoolExecutor(ThreadCount) as pool:
#map方法: 可迭代对象传入函数是从前到后逐个提取元素,并且将结果依次保存在results中。
results = pool.map(task, range(1, pages + 1))
# total_df:拼接所有的信息,(axis=0,代表列拼接)
total_df = pd.concat(results, axis=0)
total_df.to_csv(csv_filename, sep=',', header=True, index=False)
logging.info("文件%s 存储成功" % (csv_filename))
return total_df
注意: 这里使用线程池方法来解析和保存
达到的效果:
数据分析
成功抓取后,我们可以分析所拥有的数据并查看每个位置的统计信息
import pandas as pd
from config import *
import matplotlib.pyplot as plt
import matplotlib
# 修改配置中文字字体和大小的修改
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
matplotlib.rcParams['font.size'] = 12
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv(csv_filename, encoding='utf-8')
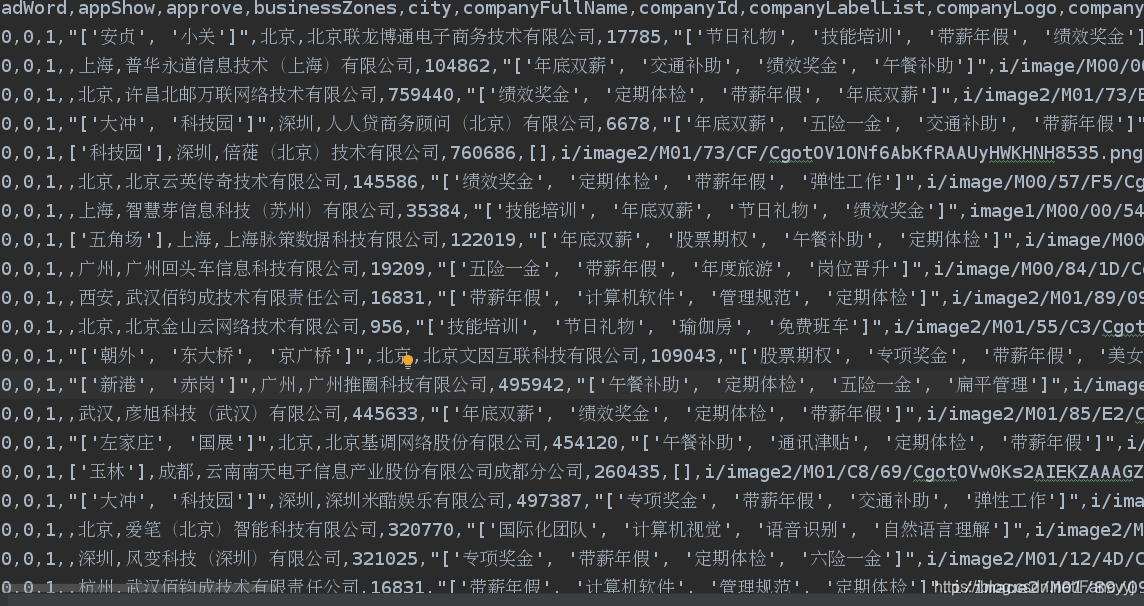
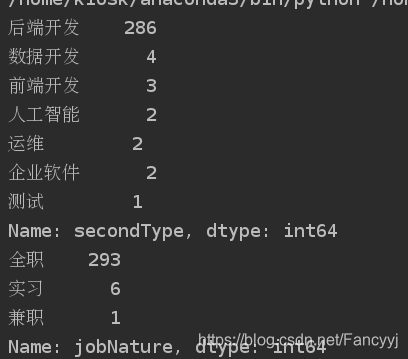
def show_seconfd_type():
# 获取职位类别分类,并分组统计
secondType_Series = df['secondType'].value_counts()
print(secondType_Series)
# 设置图形大小
plt.figure(figsize=(10, 5))
secondType_Series.plot.bar()
plt.show()
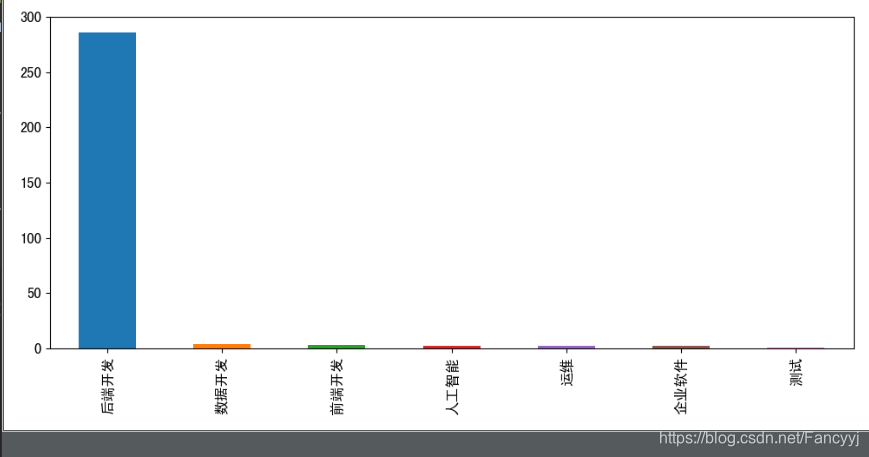
#实习和全职的统计
def show_job_nature():
jobNature_Series = df['jobNature'].value_counts()
print(jobNature_Series)
plt.figure(figsize=(10, 5))
jobNature_Series.plot.pie()
plt.show()
# 获取招聘公司
def show_company():
companyShortName_Series = df['companyShortName'].value_counts()
companyShortName_Series_gt5 = companyShortName_Series[companyShortName_Series > 2]
plt.figure(figsize=(10, 5))
companyShortName_Series_gt5.plot.bar()
plt.show()
if __name__ == '__main__':
show_seconfd_type()
show_job_nature()
show_company()
达到的效果:
查看全部
文章目录
一个. API
定义
API(应用程序编程接口,应用程序编程接口)是一些预定义的功能,或指软件系统不同组件之间的协议. 目的是使应用程序和开发人员能够访问基于某些软件或硬件的一组例程,而不必访问原创代码或了解内部工作机制的细节.
使用方法
API使用一组非常标准的规则来生成数据,并且生成的数据以非常标准的方式进行组织. 由于这些规则非常标准,因此一些简单的基本规则易于学习,因此您可以快速掌握API的用法. 但并非所有API都易于使用. 有些API有很多规则,而且非常复杂,因此您可以在使用前查看API的相关帮助文档
API验证
1)有些简单的操作不需要验证. 是免费的API
2)大多数API都需要用户提交和验证. 提交验证的主要目的是计算API调用的费用,这是一种常见的付费API. 例如: 图灵的聊天机器人
2. 拖动网项目案例数据采集(一)需求分析
通过数据采集,获取对拉沟发布的专业职位的需求分析.
(2)数据分析和实验结果首先分析网站的详细信息页面(此时关键字使用python). 在真实的请求URL中,网页将返回一个JSON字符串,我们需要解析该JSON字符串. 在页面上获取信息. 通过更改表单数据中pn的值来控制翻页. 从页面的详细信息页面,我们需要获取诸如“职务”,“职务说明”,“职务要求”等信息.
1)首先,我们请求标头信息
我们需要构造请求标头的标头信息. 如果未在此处构建,则很容易被网站识别为爬虫,因此拒绝了我们的请求
2)表单信息
发送POST请求时需要包括的表单信息(表单数据),需要解析的页码和搜索关键字
3)返回JSON数据
我们可以通过网页找到需要的信息,这些信息随时都在-> positionResult->结果中,其中收录工作地点,职位信息,公司名称等. 这些正是我们所需要的数据.

相关代码:
在配置文件中: (此文件的作用是: 当您以后要爬网其他类别或修改相关参数时,可以直接在文件中对其进行修改)
from fake_useragent import UserAgent
import requests
Host = 'www.lagou.com'
Origin = 'https://www.lagou.com'
Refer = 'https://www.lagou.com/jobs/list_python'
Connection = 'keep-alive'
Accept = 'application/json,text/javascript,*/*; q=0.01'
ua = UserAgent(verify_ssl=False)
ThreadCount = 50
csv_filename = 'filename.csv'
pages = 20
keyword = "python"
分析页面的核心代码:
#需要导入的模块
import time
import pandas as pd
import requests
from config import *
import logging
from concurrent.futures import ThreadPoolExecutor
import pprint
# 灵活配置日志级别,日志格式,输出位置
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='lagou.log',
filemode='w')
# 获取PositionID所在的页面,返回的是json数据
def getPositionIDPage(url_start, url_parse, page=1, kd='python'):
# 构造请求头(headers)
headers = {'User-Agent': ua.random,
'Host': Host,
'Origin': Origin,
'Referer': Refer,
'Connection': Connection,
'Accept': Accept,
'proxies': proxy}
# 构造表单
data = {
'first': False,
'pn': str(page),
'kd': kd
}
try:
# requests库里面的session对象能够帮助我们跨请求保持某些参数
# 也会在同一个session实例发出的所有请求之间保持cookies
# 创建一个session对象
session = requests.Session()
# 用session对象发出get 请求,设置cookies
session.get(url_start, headers=headers, timeout=3)
cookie = session.cookies
# 用session对象发出另一个请求post,获取cookies,返回响应信息
response = session.post(url=url_parse,
headers=headers,
data=data)
time.sleep(1)
# 响应状态码是4XX客户端错误,5XX 服务端响应错误,抛出异常
response.raise_for_status()
response.encoding = response.apparent_encoding
except Exception as e:
logging.error("页面" + url_parse + "爬取失败:", e)
else:
logging.info("页面" + url_parse + "爬取成功" + str(response.status_code))
return response.json()
运行测试:
if __name__ == '__main__':
url_start = 'https://www.lagou.com/jobs/list_%s' % (keyword)
url_parse = 'https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false'
content = getPositionIDPage(url_start, url_parse, page=page, kd=keyword)
pprint(content)
达到的效果:
3. 抓取相关的职位信息
获取所需职位的标签,招聘信息的每一页上都会有一个标签
positions = html['content']['positionResult']['result']
pprint.pprint(html)
df = pd.DataFrame(positions)
4. 商店信息
当我们找到所需的页面信息并对其进行爬网时,我们会将爬网的职位信息存储在一个csv文件中
def save_as_csv():
#开启进程池
with ThreadPoolExecutor(ThreadCount) as pool:
#map方法: 可迭代对象传入函数是从前到后逐个提取元素,并且将结果依次保存在results中。
results = pool.map(task, range(1, pages + 1))
# total_df:拼接所有的信息,(axis=0,代表列拼接)
total_df = pd.concat(results, axis=0)
total_df.to_csv(csv_filename, sep=',', header=True, index=False)
logging.info("文件%s 存储成功" % (csv_filename))
return total_df
注意: 这里使用线程池方法来解析和保存
达到的效果:
数据分析
成功抓取后,我们可以分析所拥有的数据并查看每个位置的统计信息
import pandas as pd
from config import *
import matplotlib.pyplot as plt
import matplotlib
# 修改配置中文字字体和大小的修改
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
matplotlib.rcParams['font.size'] = 12
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv(csv_filename, encoding='utf-8')
def show_seconfd_type():
# 获取职位类别分类,并分组统计
secondType_Series = df['secondType'].value_counts()
print(secondType_Series)
# 设置图形大小
plt.figure(figsize=(10, 5))
secondType_Series.plot.bar()
plt.show()
#实习和全职的统计
def show_job_nature():
jobNature_Series = df['jobNature'].value_counts()
print(jobNature_Series)
plt.figure(figsize=(10, 5))
jobNature_Series.plot.pie()
plt.show()
# 获取招聘公司
def show_company():
companyShortName_Series = df['companyShortName'].value_counts()
companyShortName_Series_gt5 = companyShortName_Series[companyShortName_Series > 2]
plt.figure(figsize=(10, 5))
companyShortName_Series_gt5.plot.bar()
plt.show()
if __name__ == '__main__':
show_seconfd_type()
show_job_nature()
show_company()
达到的效果:
百度地图POI边界坐标数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 504 次浏览 • 2020-08-07 06:19
因为之前我已经研究过AutoNavi地图的POI数据边界坐标的采集,其后面的界面过于不稳定,因此很难成功地采集数据. 此功能已被搁置一段时间. 最近,它在@entropy的帮助下完成. 使用百度地图界面采集POI边界函数. 但是,在此预先声明下,无论是百度还是AutoNavi,每个都使用POI的ID来完成边界坐标的采集. 相同的POI数据在AutoNavi和百度上具有不同的ID. 因此,如果要使用百度采集边界界面,则必须确保现有的POI数据是通过百度POI界面采集的,并且具有ID字段. (总结: 不要使用AutoNavi界面采集的POI数据调用百度界面来爬坡边界数据. )
确定POI边界数据采集的接口地址
https://map.baidu.com/%3Fnewma ... Bb%3D(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785
接口非常简单,不需要密钥,可以通过GET请求调用它. 在参数中,您需要使用自己的POI ID替换uid =之后的字符串. 因此,打开浏览器后可以看到结果,数据结构如下:
{
"content": {
"geo": "4|12674567.8667,2556549.714;12674700.0816,2556667.07656|1-12674700.0816,2556615.59082,12674663.0912,2556549.714,12674567.8667,2556601.53877,12674605.8561,2556667.07656,12674700.0816,2556615.59082;",
"uid": "207119787bb3c5c95d17c334"
},
"current_city": {
"code": 340,
"geo": "1|12697919.69,2560977.31;12697919.69,2560977.31|12697919.69,2560977.31;",
"level": 12,
"name": "深圳市",
"sup": 1,
"sup_bus": 1,
"sup_business_area": 1,
"sup_lukuang": 1,
"sup_subway": 1,
"type": 2,
"up_province_name": "广东省"
},
"err_msg": "",
"hot_city": [
"北京市|131",
"上海市|289",
"广州市|257",
"深圳市|340",
"成都市|75",
"天津市|332",
"南京市|315",
"杭州市|179",
"武汉市|218",
"重庆市|132"
],
"result": {
"data_security_filt_res": 0,
"error": 0,
"illegal": 0,
"login_debug": 1,
"qid": "",
"region": "0",
"type": 10,
"uii_qt": "poi_profile",
"uii_type": "china_main"
},
"uii_err": 0
}
current_city的地理位置是我们需要查找的POI数据的边界坐标,其余就是如何解析此数据. 但应注意,此坐标系是bd09mc(百度墨卡托公制坐标). 坐标系描述可以参考
http://lbs.baidu.com/index.php ... trans
因此数据需要稍后转换为百度经纬度坐标.
用于基于UID获取边界数据并进行简单分析的代码参考:
def get_boundary_by_uid(uid):
bmap_boundary_url = 'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=ext&uid=' + uid + '&c=340&ext_ver=new&tn=B_NORMAL_MAP&nn=0&auth=fw9wVDQUyKS7%3DQ5eWeb5A21KZOG0NadNuxHNBxBBLBHtxjhNwzWWvy1uVt1GgvPUDZYOYIZuEt2gz4yYxGccZcuVtPWv3GuxNt%3DkVJ0IUvhgMZSguxzBEHLNRTVtlEeLZNz1%40Db17dDFC8zv7u%40ZPuxtfvSulnDjnCENTHEHH%40NXBvzXX3M%40J2mmiJ4Y&ie=utf-8&l=19&b=(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785'
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(url=bmap_boundary_url, timeout=5, headers={"Connection": "close"})
data = data.text
data = json.loads(data)
content = data['content']
if not 'geo' in content:
return None
geo = content['geo']
i = 0
strsss = ''
for jj in str(geo).split('|')[2].split('-')[1].split(','):
jj = str(jj).strip(';')
if i % 2 == 0:
strsss = strsss + str(jj) + ','
else:
strsss = strsss + str(jj) + ';'
i = i + 1
return strsss.strip(";")
调用百度Map API进行坐标转换
http://lbsyun.baidu.com/index. ... ition
需要注意的是,该界面只能将其他坐标系中的数据转换为百度的公制坐标系和百度的经纬度坐标系,而不能反转.
http://api.map.baidu.com/geoco ... 2.343,232.34&from=6&to=5&ak=百度密钥
其中from = 6&to = 5表示从百度度量坐标系转换为百度经纬度坐标系. 有关详细信息,请参阅官方文档.
def transform_coordinate_batch(coordinates):
req_url = 'http://api.map.baidu.com/geoconv/v1/?coords='+coordinates+'&from=6&to=5&ak=' + bmap_key
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(req_url, timeout=5, headers={"Connection": "close"}) # , proxies=proxies
data = data.text
data = json.loads(data)
coords = ''
if data['status'] == 0:
result = data['result']
if len(result) > 0:
for res in result:
lng = res['x']
lat = res['y']
coords = coords + ";" + str(lng) + "," + str(lat)
return coords.strip(";")
最终数据
当前获得的边界数据格式如下:
113.85752917167422,22.512113353880437;113.85719688487298,22.51156349239119;113.8563414779429,22.51199606423422;113.8566827388162,22.512543094177662;113.85752917167422,22.512113353880437
现在您有了数据,其余的操作很简单. 这主要取决于您自己的需求. 如果需要在ARCGIS中显示区域数据,则需要再次进行处理. 结果示例:
在分析之下: uid是POI的ID,数字是自增的,暂时无用,一个uid对应于多个x,y对,一个x,y是一个点坐标,并且连接了多个点坐标形成多边形表面数据.
file_name = 'data/boundary_result_wgs84 - polygon.csv'
csv_file = pd.read_csv(file_name, encoding='gbk')
a_col = []
data_csv = {}
numbers, xs, ys, uids = [], [], [], []
index = 1
for i in range(len(csv_file)):
boundary = str(csv_file['boundary'][i])
uid = str(uuid.uuid4()).replace('-', '')
if boundary is not '':
for point in boundary.split(";"):
lng = point.split(",")[0]
lat = point.split(",")[1]
xs.append(lng)
ys.append(lat)
numbers.append(index)
uids.append(uid)
index = index + 1
data_csv['number'] = numbers
data_csv['x'] = xs
data_csv['y'] = ys
data_csv['uid'] = uids
df = pd.DataFrame(data_csv)
df.to_csv(os.getcwd() + os.sep + 'data/polygon-shape.csv', index=False, encoding='gbk')
请务必阅读
目前,POI边界坐标的采集已成为在线工具. 如果您有兴趣,可以尝试一下. 地址: 百度地图POI边界采集工具
上传需要采集的POI ID的CSV文件并申请了百度地图密钥后,即可采集到相应的边界数据!请注意,最好不要在一次上传中上传太多数据. 查看全部
在线工具地址: 百度地图POI边界数据采集工具
因为之前我已经研究过AutoNavi地图的POI数据边界坐标的采集,其后面的界面过于不稳定,因此很难成功地采集数据. 此功能已被搁置一段时间. 最近,它在@entropy的帮助下完成. 使用百度地图界面采集POI边界函数. 但是,在此预先声明下,无论是百度还是AutoNavi,每个都使用POI的ID来完成边界坐标的采集. 相同的POI数据在AutoNavi和百度上具有不同的ID. 因此,如果要使用百度采集边界界面,则必须确保现有的POI数据是通过百度POI界面采集的,并且具有ID字段. (总结: 不要使用AutoNavi界面采集的POI数据调用百度界面来爬坡边界数据. )
确定POI边界数据采集的接口地址
https://map.baidu.com/%3Fnewma ... Bb%3D(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785
接口非常简单,不需要密钥,可以通过GET请求调用它. 在参数中,您需要使用自己的POI ID替换uid =之后的字符串. 因此,打开浏览器后可以看到结果,数据结构如下:
{
"content": {
"geo": "4|12674567.8667,2556549.714;12674700.0816,2556667.07656|1-12674700.0816,2556615.59082,12674663.0912,2556549.714,12674567.8667,2556601.53877,12674605.8561,2556667.07656,12674700.0816,2556615.59082;",
"uid": "207119787bb3c5c95d17c334"
},
"current_city": {
"code": 340,
"geo": "1|12697919.69,2560977.31;12697919.69,2560977.31|12697919.69,2560977.31;",
"level": 12,
"name": "深圳市",
"sup": 1,
"sup_bus": 1,
"sup_business_area": 1,
"sup_lukuang": 1,
"sup_subway": 1,
"type": 2,
"up_province_name": "广东省"
},
"err_msg": "",
"hot_city": [
"北京市|131",
"上海市|289",
"广州市|257",
"深圳市|340",
"成都市|75",
"天津市|332",
"南京市|315",
"杭州市|179",
"武汉市|218",
"重庆市|132"
],
"result": {
"data_security_filt_res": 0,
"error": 0,
"illegal": 0,
"login_debug": 1,
"qid": "",
"region": "0",
"type": 10,
"uii_qt": "poi_profile",
"uii_type": "china_main"
},
"uii_err": 0
}
current_city的地理位置是我们需要查找的POI数据的边界坐标,其余就是如何解析此数据. 但应注意,此坐标系是bd09mc(百度墨卡托公制坐标). 坐标系描述可以参考
http://lbs.baidu.com/index.php ... trans
因此数据需要稍后转换为百度经纬度坐标.
用于基于UID获取边界数据并进行简单分析的代码参考:
def get_boundary_by_uid(uid):
bmap_boundary_url = 'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=ext&uid=' + uid + '&c=340&ext_ver=new&tn=B_NORMAL_MAP&nn=0&auth=fw9wVDQUyKS7%3DQ5eWeb5A21KZOG0NadNuxHNBxBBLBHtxjhNwzWWvy1uVt1GgvPUDZYOYIZuEt2gz4yYxGccZcuVtPWv3GuxNt%3DkVJ0IUvhgMZSguxzBEHLNRTVtlEeLZNz1%40Db17dDFC8zv7u%40ZPuxtfvSulnDjnCENTHEHH%40NXBvzXX3M%40J2mmiJ4Y&ie=utf-8&l=19&b=(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785'
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(url=bmap_boundary_url, timeout=5, headers={"Connection": "close"})
data = data.text
data = json.loads(data)
content = data['content']
if not 'geo' in content:
return None
geo = content['geo']
i = 0
strsss = ''
for jj in str(geo).split('|')[2].split('-')[1].split(','):
jj = str(jj).strip(';')
if i % 2 == 0:
strsss = strsss + str(jj) + ','
else:
strsss = strsss + str(jj) + ';'
i = i + 1
return strsss.strip(";")
调用百度Map API进行坐标转换
http://lbsyun.baidu.com/index. ... ition
需要注意的是,该界面只能将其他坐标系中的数据转换为百度的公制坐标系和百度的经纬度坐标系,而不能反转.
http://api.map.baidu.com/geoco ... 2.343,232.34&from=6&to=5&ak=百度密钥
其中from = 6&to = 5表示从百度度量坐标系转换为百度经纬度坐标系. 有关详细信息,请参阅官方文档.
def transform_coordinate_batch(coordinates):
req_url = 'http://api.map.baidu.com/geoconv/v1/?coords='+coordinates+'&from=6&to=5&ak=' + bmap_key
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(req_url, timeout=5, headers={"Connection": "close"}) # , proxies=proxies
data = data.text
data = json.loads(data)
coords = ''
if data['status'] == 0:
result = data['result']
if len(result) > 0:
for res in result:
lng = res['x']
lat = res['y']
coords = coords + ";" + str(lng) + "," + str(lat)
return coords.strip(";")
最终数据
当前获得的边界数据格式如下:
113.85752917167422,22.512113353880437;113.85719688487298,22.51156349239119;113.8563414779429,22.51199606423422;113.8566827388162,22.512543094177662;113.85752917167422,22.512113353880437
现在您有了数据,其余的操作很简单. 这主要取决于您自己的需求. 如果需要在ARCGIS中显示区域数据,则需要再次进行处理. 结果示例:
在分析之下: uid是POI的ID,数字是自增的,暂时无用,一个uid对应于多个x,y对,一个x,y是一个点坐标,并且连接了多个点坐标形成多边形表面数据.
file_name = 'data/boundary_result_wgs84 - polygon.csv'
csv_file = pd.read_csv(file_name, encoding='gbk')
a_col = []
data_csv = {}
numbers, xs, ys, uids = [], [], [], []
index = 1
for i in range(len(csv_file)):
boundary = str(csv_file['boundary'][i])
uid = str(uuid.uuid4()).replace('-', '')
if boundary is not '':
for point in boundary.split(";"):
lng = point.split(",")[0]
lat = point.split(",")[1]
xs.append(lng)
ys.append(lat)
numbers.append(index)
uids.append(uid)
index = index + 1
data_csv['number'] = numbers
data_csv['x'] = xs
data_csv['y'] = ys
data_csv['uid'] = uids
df = pd.DataFrame(data_csv)
df.to_csv(os.getcwd() + os.sep + 'data/polygon-shape.csv', index=False, encoding='gbk')
请务必阅读
目前,POI边界坐标的采集已成为在线工具. 如果您有兴趣,可以尝试一下. 地址: 百度地图POI边界采集工具
上传需要采集的POI ID的CSV文件并申请了百度地图密钥后,即可采集到相应的边界数据!请注意,最好不要在一次上传中上传太多数据.
百度POI数据捕获-BeautifulSoup
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-08-07 05:03
我对Python很熟悉,因此我将分享在此编写的Python版本的实现过程.
获取百度POI数据的方法是构造一个关键字搜索网址,并请求该网址获取返回的json数据.
人民广场&c = 289&pn = 0
wd: 搜索关键字
c: 城市代码
pn: 页码(返回结果可能有多个页面)
这种请求数据的方法的优点在于似乎没有次数限制.
两个步骤:
1. 准备搜索关键字
关键字源网站:
1)选择城市: 上海
2)POI有很多类别:
我的目标是获取详细的POI关键字.
首先获取每个类别的URL,并将其保存在keyword-1.txt文件中:
import urllib2
import urllib
from bs4 import BeautifulSoup
import numpy as np
import json
def write2txt(data,filepath):
with open(filepath,'a') as f:
for d in data:
f.write(d.encode('gbk'))
def example3_bs4():
request = urllib2.Request('http://poi.mapbar.com/shanghai/')
page = urllib2.urlopen(request)
data = page.read()
data = data.decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('a')
res = [ t['href']+'|'+t.get_text()+'\n' for t in tags]
#print res
write2txt(res,'keyword-1.txt')
3)获取每个类别下的详细POI关键字
每个类别下都有更详细的POI数据:
关键字保存在keyword-2.txt文件中
def getKeyWords():
with open('keyword-1.txt') as f:
for line in f:
url,wd=line.decode('gbk').split('|')
print url,wd
request = urllib2.Request(url)
page = urllib2.urlopen(request)
data = page.read().decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('dd a')
res = [wd[:-1]+'|'+t['href']+'|'+t.get_text()+'\n' for t in tags]
print len(res)
write2txt(res,'keyword-2.txt')
2,模拟关键字搜索
结构类似于此:
人民广场&c = 289&pn = 0
网址.
您可以在浏览器中查看此url返回的结果,并使用它来查看json字符串的结构:
我需要的信息是内容. 您可以看到内容中有一个数组. 其中的每个对象都是一个poi信息,而10个对象是1页. 如果需要多个页面,可以在url中设置pn =页面编号.
我只在这里使用第一页.
def getPOI():
with open('keyword-2.txt') as f:
for line in f:
data = []
Type,url,wd = line[:-1].split(',')
#print Type,url,wd
url = 'http://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=s&da_src=searchBox.button&wd=%s&c=289&pn=0'%urllib.quote(wd)
request = urllib2.Request(url)
try:
page = urllib2.urlopen(request)
res = json.load(page)
if 'content' in res:
contents = res['content']
if 'acc_flag' in contents[0]:
for d in contents:
x, y = float(d['diPointX']), float(d['diPointY'])
ss = "http://api.map.baidu.com/geoconv/v1/?coords=%s,%s&from=6&to=5&ak=你的开发者秘钥"%(x/100.0,y/100.0)
pos = json.load(urllib2.urlopen(ss))
if pos['status']==0:
x, y = pos['result'][0]['x'], pos['result'][0]['y']
tel = ''
if 'tel' in d:
tel = d['tel']
data.append(d['addr']+'|'+d['area_name']+'|'+d['di_tag']+'|'+d['std_tag']+'|'+tel+'|'+d['name']+'|'+str(x)+'|'+str(y)+'\n')
if data:
write2txt(data,'poi_info.txt')
except:
print 'http error'
请注意,此处的坐标转换api需要申请百度开发者密钥,每天的转换限制为100,000.
最后,我仅抓取了18万个POI数据,足够用于该项目.
参考博客:
获取百度地图POI数据: 查看全部
由于该实验室项目需要上海的POI数据,因此百度没有在一个圆圈内找到任何下载资源. 因此,我引用了此博客并亲自对其进行了爬网.
我对Python很熟悉,因此我将分享在此编写的Python版本的实现过程.
获取百度POI数据的方法是构造一个关键字搜索网址,并请求该网址获取返回的json数据.
人民广场&c = 289&pn = 0
wd: 搜索关键字
c: 城市代码
pn: 页码(返回结果可能有多个页面)
这种请求数据的方法的优点在于似乎没有次数限制.
两个步骤:
1. 准备搜索关键字
关键字源网站:
1)选择城市: 上海
2)POI有很多类别:

我的目标是获取详细的POI关键字.
首先获取每个类别的URL,并将其保存在keyword-1.txt文件中:
import urllib2
import urllib
from bs4 import BeautifulSoup
import numpy as np
import json
def write2txt(data,filepath):
with open(filepath,'a') as f:
for d in data:
f.write(d.encode('gbk'))
def example3_bs4():
request = urllib2.Request('http://poi.mapbar.com/shanghai/')
page = urllib2.urlopen(request)
data = page.read()
data = data.decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('a')
res = [ t['href']+'|'+t.get_text()+'\n' for t in tags]
#print res
write2txt(res,'keyword-1.txt')
3)获取每个类别下的详细POI关键字
每个类别下都有更详细的POI数据:

关键字保存在keyword-2.txt文件中
def getKeyWords():
with open('keyword-1.txt') as f:
for line in f:
url,wd=line.decode('gbk').split('|')
print url,wd
request = urllib2.Request(url)
page = urllib2.urlopen(request)
data = page.read().decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('dd a')
res = [wd[:-1]+'|'+t['href']+'|'+t.get_text()+'\n' for t in tags]
print len(res)
write2txt(res,'keyword-2.txt')
2,模拟关键字搜索
结构类似于此:
人民广场&c = 289&pn = 0
网址.
您可以在浏览器中查看此url返回的结果,并使用它来查看json字符串的结构:

我需要的信息是内容. 您可以看到内容中有一个数组. 其中的每个对象都是一个poi信息,而10个对象是1页. 如果需要多个页面,可以在url中设置pn =页面编号.
我只在这里使用第一页.
def getPOI():
with open('keyword-2.txt') as f:
for line in f:
data = []
Type,url,wd = line[:-1].split(',')
#print Type,url,wd
url = 'http://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=s&da_src=searchBox.button&wd=%s&c=289&pn=0'%urllib.quote(wd)
request = urllib2.Request(url)
try:
page = urllib2.urlopen(request)
res = json.load(page)
if 'content' in res:
contents = res['content']
if 'acc_flag' in contents[0]:
for d in contents:
x, y = float(d['diPointX']), float(d['diPointY'])
ss = "http://api.map.baidu.com/geoconv/v1/?coords=%s,%s&from=6&to=5&ak=你的开发者秘钥"%(x/100.0,y/100.0)
pos = json.load(urllib2.urlopen(ss))
if pos['status']==0:
x, y = pos['result'][0]['x'], pos['result'][0]['y']
tel = ''
if 'tel' in d:
tel = d['tel']
data.append(d['addr']+'|'+d['area_name']+'|'+d['di_tag']+'|'+d['std_tag']+'|'+tel+'|'+d['name']+'|'+str(x)+'|'+str(y)+'\n')
if data:
write2txt(data,'poi_info.txt')
except:
print 'http error'
请注意,此处的坐标转换api需要申请百度开发者密钥,每天的转换限制为100,000.
最后,我仅抓取了18万个POI数据,足够用于该项目.
参考博客:
获取百度地图POI数据:
黑帽SEO的主要方法是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 01:10
1. 内容作弊内容作弊的目的是仔细修改或调整网页的内容,以便网页可以获得与搜索引擎排名中与其网页不相称的排名. 搜索引擎排名算法通常包括内容相似度计算和链接重要性计算. 内容欺骗是通过增加内容相似度计算的分数来获得最终的高排名. 实质是故意增加目标词的频率. 常见的内容作弊方法如下: 1.关键字重复对于作弊者关注的目标关键字,页面内容中设置了大量的重复项. 由于单词频率是搜索引擎相似度计算中必须考虑的因素,因此关键字重复本质上会通过增加目标关键字的单词频率来影响搜索引擎内容相似度排名. 2.使用不相关的查询词作弊为了吸引尽可能多的搜索流量,作弊者在页面内容中添加了许多与页面主题无关的关键字. 这本质上是一种单词频率作弊,即原创关键字频率为0. 对于非0.3,图像替代标签文本作弊替代标签最初用作图片的描述信息,通常不会显示在HTML页面,除非用户将鼠标放在图片上. 但是搜索引擎将使用此信息,因此一些作弊者会用作弊词汇填充alt标签的内容,以达到吸引更多搜索流量的目的. 4.网站标题作弊. Web标题作为描述网页内容的摘要信息,是判断网页主题的非常重要的启发式因素. 因此,搜索引擎在计算相似性分数时往往会增加标题词的权重. 作弊者利用这一优势,将与页面主题无关的目标词重复放置在标题位置,以获得更高的排名. 5.网页上的重要标签作弊网页与普通的文本格式不同,它们具有HTML标签,并且一些标签表示强调内容重要性的重要性,例如使用API和RSS的粗体标记第6段,内容标记1. 和其他方式,是指通过采集他人博客内容而生成的内容,并放置在您自己的网站或博客上; 2.使用段落拼接,关键字和普通文章(主要是小说)被截取以形成片段. 没有实际意义的文章; 3.工具自动生成的大量劣质重复信息内容; 4.只需将他人的原创内容复制到您自己的网站或博客中即可.
什么是黑帽SEO?
常用的黑帽SEO如下: 关键字填充,这是人们最常用的技术之一
优化关键字时,许多人仅出于一种目的累积关键字,只是为了增加关键字的频率并增加关键字的密度. 在网页代码中,元标记,标题(尤其是This),注释和图片ALT重复了一个特定的关键字,这使关键字的密度非常高,但是如果不发现它,将会有很好的效果.
重定向
此方法是在网页代码中使用刷新标签,metarefresh,java和js技术. 用户进入页面时,使用这些功能可以使他快速跳至其他页面. 这样,重定向使搜索引擎和用户访问的页面不一致. 必须注意这一点. 由于这个作者曾经有一个网站. 断电已经很长时间了.
轰炸
刚开始seo的新手经常会认为注册多个域名并同时连接到主要网站可以提高主要网站的PR!如果这些域名拥有自己的网站,那就没有问题!但是,如果这些域名只有几个内容,或者指向主站点的某个页面,那么搜索引擎就会认为这是一种欺骗!
假冒关键字太多
许多网站会将许多与此网站无关的关键字添加到自己的网站中. 通过在meta中设置与网站内容不相关的关键字,它们可以欺骗搜索引擎进行收录和用户点击. 这是一种不太正式的优化方法,但是作者谈论的是错误的关键字太多,并且经常更改页面标题来增加此关键字,因此这两种方法都极有可能受到惩罚并降低排名(后者更为严重)
重复注册
这是一种相对卑鄙的作弊方法,违反了网站提交纪律. 他打破了时限,并在短时间内反复向同一搜索引擎提交了网页.
不可见的文字和链接
为了增加关键字的出现频率,在网页上特意放置了一部分收录与背景颜色相同的密集关键字的文本. 访客看不到它,但是搜索引擎可以找到它. 类似的方法还包括超小文本,文本隐藏层等手段. 这也是网站降级的常见原因. 实际上,其中许多都不是自己提供的,但是一些出售黑链的人会暗中加价. 这是为了增强网站管理员的预防意识.
垃圾链接
添加大量链接机制,这意味着由大量网页交叉链接组成的网络系统. 一旦被搜索引擎发现,这些作弊方法将立即成为K个站点. 我希望seoers会在平时进行优化. 有意或无意地,您必须注意您是否违反了这些作弊方法. 为了提高搜索排名,吸引人们点击,重复关键字,在博客和论坛中发布大量指向不相关内容的链接,这些链接也称为垃圾邮件链接.
扫描网页
诱骗行为也是SEO中使用的一种欺骗性技术. 指创建两个网页(一个优化页面和一个普通页面),然后将优化页面提交给搜索引擎,然后当该优化页面被搜索引擎索引时,普通页面将替换该网页. 考虑长期利益,不要尝试.
桥梁页面或门口页面
大多数桥接页面是由软件生成的. 可以想象,生成的文本很杂乱,一无所有. 如果它是由某人撰写的实际上收录关键字的文章,则它不是过渡页.
当前常用的方法:
01,站组02,关键字填充
来吧03,隐藏文本源
04. 交易链接
05. 链接农场
Zhi 06,链轮
07,大量发布
08、301批处理重定向
09. 桥接页面,跳转
10. 隐藏页面
11. 批量采集
12,PR劫持
等等(仍然有很多大师在学习或使用...)
黑帽SEO怎么做?
1)网站遭到攻击
我们必须高度重视网站的健康状况,并定期备份网站内容,以防止网站受到特洛伊木马等的攻击或黑客攻击. 如果网站受到攻击,搜索引擎将迅速识别它,同时会降低您的网站得分,这可能会导致您将权限降级为k个电台.
(2)刷流
如果您的网站被搜索引擎降级,则必须回忆一下您最近是否使用某些软件来减少流量,从而导致欺骗搜索引擎的行为. 通常,有些网站管理员会使用流量宝藏和向导之类的工具来扫描网站流量,以便用户或搜索引擎认为您的站点有大量访问并引起关注. 但是,这些都是SEO中的黑帽技术,因此不理想. 刷牙是短期的. 如果突然停止,您的流量将直线下降,引起很大的反应.
(3)大量购买黑链子
您的网站上有黑链接,搜索引擎不会立即惩罚您,因为搜索引擎无法知道谁是真正的罪魁祸首. 但是,如果您购买了大量黑链,但这些网站与您的网站之间的关联性也很差,那么搜索引擎将迅速识别您,并立即将您的权限减少到k个网站.
(4)在链外批量发布
实际上,许多人使用黑帽技术来优化其网站,并且他们将使用大量发布的方式. 使用某些软件疯狂地将内容分发到各个地方,很容易引起较低的内容相关性,并且发布时间和内容非常接近. 这也是搜索引擎经常通过降低功耗来进行攻击的现象.
(5)多种作弊技巧
为了进一步优化网站,很多人会故意向网站添加一些隐藏链接,或者通过减小字体大小来作弊等. 这也很容易导致搜索引擎将您的权限降低到k. 站.
实际上没有办法回答这个问题.
禁止戴黑帽子,搜索引擎不建议戴黑帽子.
我戴了一顶黑帽子,我想知道它是否会被搜索引擎发现. 这只能由智者和仁者看到. 内部
此外,有一件事是,影响排名的所有因素都是由黑帽子造成的. 戴黑帽子不一定会发生什么事情.
例如,外部链接,到处购买各种外部链接是一种非常清晰的黑帽技巧. 但是,购买不出售链接和优质内部链接的网站是外部链接的黑帽技术.
黑帽seo需要具备哪些技术?黑帽seo技术在2017年排名快速
首先,黑帽SEO和白帽SEO之间的区别
黑帽SEO: 所有不符合搜索引擎优化规范的作弊方法均属于黑帽SEO;
白帽SEO: 所有符合用户体验和搜索引擎规范的优化方法均属于白帽SEO;
第二,黑帽SEO技术的特征
1. 锚定文字轰炸
页面没有相关内容,但是有很多指向该页面的锚文本. 例如,著名的“ Google炸弹”,大量美国公民使用“ miserablefailure”(失败),并在白宫网站上可以控制的页面上链接到布什个人主页的超链接. 两个月后,当在白宫的Google布什个人主页上搜索“ miserablefailure”时,其搜索量上升到了顶部. 实际上,布什的个人主页上没有任何有关“严重失败”的信息.
2. 网站内容采集
使用某些程序自动采集Internet上的某些文本,然后在自动处理一个简单的程序后将其发布到网站(采集站)上. 用户体验极差,但是由于页面数量众多,并且搜索引擎算法不是特别完美,因此经常会有页面具有排名,这反过来又带来了访问量,然后用户点击了他们放置的广告获得利益. 实际上,它并没有为用户带来有用的价值.
3,集体作弊
使用软件将您自己的链接发布到某些网站,并在短时间内获得大量外部链接. 如今,外部链接在SEO中的作用越来越小,这种方法在当今的SEO中将不会发挥太大作用.
4,挂马
为了达到某种目的,请通过某种方式进入网站并在该网站上安装特洛伊木马程序. 不仅网站链接到马,而且更重要的是,该网站的用户还存在中毒计算机的风险,从而导致该网站的用户体验极差.
5. 网站黑链
简单的理解是不正确的链接,该链接通常对用户不可见,但可以被搜索引擎看到. 通常,网站的后端被黑客攻击,并且链接到其他网站的链接被挂断. 尽管这些链接在页面上不可见,但是可以被搜索引擎抓取. 网站的黑色链接是我们在进行SEO时经常遇到的情况. ,如果网站被黑客入侵,该怎么办?如果您的网站被黑了,崔鹏瀚的SEO网站有一个更好的处理方法,所以您不妨看看.
6. 其他黑帽SEO技术
一些经过证明的黑帽SEO通常是由一些技术专家完成的,但是他们通常不敢公开这种方法,因为小型作弊搜索引擎通常不会调整算法,但是在影响扩大之后,这是另一回事.
摘要: 黑帽SEO属于SEO作弊. 一旦被搜索引擎发现,这种行为将给网站带来灾难. 崔鹏瀚建议,如果您打算优化网站并从中获利,那么请记住,您不应该在任何时候使用黑帽SEO方法,因为这不会对网站造成损害.
黑帽SEO有几种可用的方法?
有很多方法,核心事情没有改变,站群还是不错的,但是现在每个人都没有这样玩,通常你会用油彩云单页外壳站群管理软件,回答或租用某些以寄生虫形式出现的高重量网站的目录. 只要符合用户习惯,就可以使用.
是否根据您的目的选择了黑帽百和白帽搜索引擎优化技术. 具体来说,黑帽首付确实具有短期利益,某些企业服务仅需要这种短期服务,例如一些对时间敏感的企业. 白帽子是所谓的钓大鱼的长线. 一个期望. 黑帽方法很多,例如关键字累积,桥接页面,隐藏文本,隐藏链接,隐藏页面,链接服务器场,Google炸弹,页面扩展方法,百科全书欺骗方法等. 如果您不想被搜索很长一段时间,使用白帽seo方法.
如何做黑帽搜索引擎优化
White hat SEO是一种公平的方法,它使用符合主流搜索引擎发布准则的SEO优化方法. 它与黑帽seo相反. 白帽SEO一直被视为行业中最好的SEO技术. 它在避免所有风险的同时进行操作,同时避免与搜索引擎的发行政策发生任何冲突. 这也是SEOer从业人员的最高职业道德. 标准.
黑帽seo意味着作弊. 黑帽seo方法不符合主流搜索引擎发布准则. 黑帽SEO盈利能力的主要特征是短期抵消和用于短期利益的作弊方法. 同时,由于搜索引擎算法的变化,他们随时面临罚款.
白帽seo或黑帽seo并没有精确的定义. 一般来说,所有作弊方法或某些可疑方法都可以称为黑帽SEO. 例如,隐藏的网页,关键字填充,垃圾邮件链接,桥接页面等.
黑帽SEO可以快速带来一定的排名和用户量,但这通常是K的结果. 一旦为K,恢复期将至少需要半年. 其次,对品牌不利. 的结果. 查看全部
黑帽SEO的主要方法是什么?
1. 内容作弊内容作弊的目的是仔细修改或调整网页的内容,以便网页可以获得与搜索引擎排名中与其网页不相称的排名. 搜索引擎排名算法通常包括内容相似度计算和链接重要性计算. 内容欺骗是通过增加内容相似度计算的分数来获得最终的高排名. 实质是故意增加目标词的频率. 常见的内容作弊方法如下: 1.关键字重复对于作弊者关注的目标关键字,页面内容中设置了大量的重复项. 由于单词频率是搜索引擎相似度计算中必须考虑的因素,因此关键字重复本质上会通过增加目标关键字的单词频率来影响搜索引擎内容相似度排名. 2.使用不相关的查询词作弊为了吸引尽可能多的搜索流量,作弊者在页面内容中添加了许多与页面主题无关的关键字. 这本质上是一种单词频率作弊,即原创关键字频率为0. 对于非0.3,图像替代标签文本作弊替代标签最初用作图片的描述信息,通常不会显示在HTML页面,除非用户将鼠标放在图片上. 但是搜索引擎将使用此信息,因此一些作弊者会用作弊词汇填充alt标签的内容,以达到吸引更多搜索流量的目的. 4.网站标题作弊. Web标题作为描述网页内容的摘要信息,是判断网页主题的非常重要的启发式因素. 因此,搜索引擎在计算相似性分数时往往会增加标题词的权重. 作弊者利用这一优势,将与页面主题无关的目标词重复放置在标题位置,以获得更高的排名. 5.网页上的重要标签作弊网页与普通的文本格式不同,它们具有HTML标签,并且一些标签表示强调内容重要性的重要性,例如使用API和RSS的粗体标记第6段,内容标记1. 和其他方式,是指通过采集他人博客内容而生成的内容,并放置在您自己的网站或博客上; 2.使用段落拼接,关键字和普通文章(主要是小说)被截取以形成片段. 没有实际意义的文章; 3.工具自动生成的大量劣质重复信息内容; 4.只需将他人的原创内容复制到您自己的网站或博客中即可.
什么是黑帽SEO?
常用的黑帽SEO如下: 关键字填充,这是人们最常用的技术之一
优化关键字时,许多人仅出于一种目的累积关键字,只是为了增加关键字的频率并增加关键字的密度. 在网页代码中,元标记,标题(尤其是This),注释和图片ALT重复了一个特定的关键字,这使关键字的密度非常高,但是如果不发现它,将会有很好的效果.
重定向
此方法是在网页代码中使用刷新标签,metarefresh,java和js技术. 用户进入页面时,使用这些功能可以使他快速跳至其他页面. 这样,重定向使搜索引擎和用户访问的页面不一致. 必须注意这一点. 由于这个作者曾经有一个网站. 断电已经很长时间了.
轰炸
刚开始seo的新手经常会认为注册多个域名并同时连接到主要网站可以提高主要网站的PR!如果这些域名拥有自己的网站,那就没有问题!但是,如果这些域名只有几个内容,或者指向主站点的某个页面,那么搜索引擎就会认为这是一种欺骗!
假冒关键字太多
许多网站会将许多与此网站无关的关键字添加到自己的网站中. 通过在meta中设置与网站内容不相关的关键字,它们可以欺骗搜索引擎进行收录和用户点击. 这是一种不太正式的优化方法,但是作者谈论的是错误的关键字太多,并且经常更改页面标题来增加此关键字,因此这两种方法都极有可能受到惩罚并降低排名(后者更为严重)
重复注册
这是一种相对卑鄙的作弊方法,违反了网站提交纪律. 他打破了时限,并在短时间内反复向同一搜索引擎提交了网页.
不可见的文字和链接
为了增加关键字的出现频率,在网页上特意放置了一部分收录与背景颜色相同的密集关键字的文本. 访客看不到它,但是搜索引擎可以找到它. 类似的方法还包括超小文本,文本隐藏层等手段. 这也是网站降级的常见原因. 实际上,其中许多都不是自己提供的,但是一些出售黑链的人会暗中加价. 这是为了增强网站管理员的预防意识.
垃圾链接
添加大量链接机制,这意味着由大量网页交叉链接组成的网络系统. 一旦被搜索引擎发现,这些作弊方法将立即成为K个站点. 我希望seoers会在平时进行优化. 有意或无意地,您必须注意您是否违反了这些作弊方法. 为了提高搜索排名,吸引人们点击,重复关键字,在博客和论坛中发布大量指向不相关内容的链接,这些链接也称为垃圾邮件链接.
扫描网页
诱骗行为也是SEO中使用的一种欺骗性技术. 指创建两个网页(一个优化页面和一个普通页面),然后将优化页面提交给搜索引擎,然后当该优化页面被搜索引擎索引时,普通页面将替换该网页. 考虑长期利益,不要尝试.
桥梁页面或门口页面
大多数桥接页面是由软件生成的. 可以想象,生成的文本很杂乱,一无所有. 如果它是由某人撰写的实际上收录关键字的文章,则它不是过渡页.
当前常用的方法:
01,站组02,关键字填充
来吧03,隐藏文本源
04. 交易链接
05. 链接农场
Zhi 06,链轮
07,大量发布
08、301批处理重定向
09. 桥接页面,跳转
10. 隐藏页面
11. 批量采集
12,PR劫持
等等(仍然有很多大师在学习或使用...)
黑帽SEO怎么做?
1)网站遭到攻击
我们必须高度重视网站的健康状况,并定期备份网站内容,以防止网站受到特洛伊木马等的攻击或黑客攻击. 如果网站受到攻击,搜索引擎将迅速识别它,同时会降低您的网站得分,这可能会导致您将权限降级为k个电台.
(2)刷流
如果您的网站被搜索引擎降级,则必须回忆一下您最近是否使用某些软件来减少流量,从而导致欺骗搜索引擎的行为. 通常,有些网站管理员会使用流量宝藏和向导之类的工具来扫描网站流量,以便用户或搜索引擎认为您的站点有大量访问并引起关注. 但是,这些都是SEO中的黑帽技术,因此不理想. 刷牙是短期的. 如果突然停止,您的流量将直线下降,引起很大的反应.
(3)大量购买黑链子
您的网站上有黑链接,搜索引擎不会立即惩罚您,因为搜索引擎无法知道谁是真正的罪魁祸首. 但是,如果您购买了大量黑链,但这些网站与您的网站之间的关联性也很差,那么搜索引擎将迅速识别您,并立即将您的权限减少到k个网站.
(4)在链外批量发布
实际上,许多人使用黑帽技术来优化其网站,并且他们将使用大量发布的方式. 使用某些软件疯狂地将内容分发到各个地方,很容易引起较低的内容相关性,并且发布时间和内容非常接近. 这也是搜索引擎经常通过降低功耗来进行攻击的现象.
(5)多种作弊技巧
为了进一步优化网站,很多人会故意向网站添加一些隐藏链接,或者通过减小字体大小来作弊等. 这也很容易导致搜索引擎将您的权限降低到k. 站.
实际上没有办法回答这个问题.
禁止戴黑帽子,搜索引擎不建议戴黑帽子.
我戴了一顶黑帽子,我想知道它是否会被搜索引擎发现. 这只能由智者和仁者看到. 内部
此外,有一件事是,影响排名的所有因素都是由黑帽子造成的. 戴黑帽子不一定会发生什么事情.
例如,外部链接,到处购买各种外部链接是一种非常清晰的黑帽技巧. 但是,购买不出售链接和优质内部链接的网站是外部链接的黑帽技术.
黑帽seo需要具备哪些技术?黑帽seo技术在2017年排名快速
首先,黑帽SEO和白帽SEO之间的区别
黑帽SEO: 所有不符合搜索引擎优化规范的作弊方法均属于黑帽SEO;
白帽SEO: 所有符合用户体验和搜索引擎规范的优化方法均属于白帽SEO;
第二,黑帽SEO技术的特征
1. 锚定文字轰炸
页面没有相关内容,但是有很多指向该页面的锚文本. 例如,著名的“ Google炸弹”,大量美国公民使用“ miserablefailure”(失败),并在白宫网站上可以控制的页面上链接到布什个人主页的超链接. 两个月后,当在白宫的Google布什个人主页上搜索“ miserablefailure”时,其搜索量上升到了顶部. 实际上,布什的个人主页上没有任何有关“严重失败”的信息.
2. 网站内容采集
使用某些程序自动采集Internet上的某些文本,然后在自动处理一个简单的程序后将其发布到网站(采集站)上. 用户体验极差,但是由于页面数量众多,并且搜索引擎算法不是特别完美,因此经常会有页面具有排名,这反过来又带来了访问量,然后用户点击了他们放置的广告获得利益. 实际上,它并没有为用户带来有用的价值.
3,集体作弊
使用软件将您自己的链接发布到某些网站,并在短时间内获得大量外部链接. 如今,外部链接在SEO中的作用越来越小,这种方法在当今的SEO中将不会发挥太大作用.
4,挂马
为了达到某种目的,请通过某种方式进入网站并在该网站上安装特洛伊木马程序. 不仅网站链接到马,而且更重要的是,该网站的用户还存在中毒计算机的风险,从而导致该网站的用户体验极差.
5. 网站黑链
简单的理解是不正确的链接,该链接通常对用户不可见,但可以被搜索引擎看到. 通常,网站的后端被黑客攻击,并且链接到其他网站的链接被挂断. 尽管这些链接在页面上不可见,但是可以被搜索引擎抓取. 网站的黑色链接是我们在进行SEO时经常遇到的情况. ,如果网站被黑客入侵,该怎么办?如果您的网站被黑了,崔鹏瀚的SEO网站有一个更好的处理方法,所以您不妨看看.
6. 其他黑帽SEO技术
一些经过证明的黑帽SEO通常是由一些技术专家完成的,但是他们通常不敢公开这种方法,因为小型作弊搜索引擎通常不会调整算法,但是在影响扩大之后,这是另一回事.
摘要: 黑帽SEO属于SEO作弊. 一旦被搜索引擎发现,这种行为将给网站带来灾难. 崔鹏瀚建议,如果您打算优化网站并从中获利,那么请记住,您不应该在任何时候使用黑帽SEO方法,因为这不会对网站造成损害.
黑帽SEO有几种可用的方法?
有很多方法,核心事情没有改变,站群还是不错的,但是现在每个人都没有这样玩,通常你会用油彩云单页外壳站群管理软件,回答或租用某些以寄生虫形式出现的高重量网站的目录. 只要符合用户习惯,就可以使用.
是否根据您的目的选择了黑帽百和白帽搜索引擎优化技术. 具体来说,黑帽首付确实具有短期利益,某些企业服务仅需要这种短期服务,例如一些对时间敏感的企业. 白帽子是所谓的钓大鱼的长线. 一个期望. 黑帽方法很多,例如关键字累积,桥接页面,隐藏文本,隐藏链接,隐藏页面,链接服务器场,Google炸弹,页面扩展方法,百科全书欺骗方法等. 如果您不想被搜索很长一段时间,使用白帽seo方法.
如何做黑帽搜索引擎优化
White hat SEO是一种公平的方法,它使用符合主流搜索引擎发布准则的SEO优化方法. 它与黑帽seo相反. 白帽SEO一直被视为行业中最好的SEO技术. 它在避免所有风险的同时进行操作,同时避免与搜索引擎的发行政策发生任何冲突. 这也是SEOer从业人员的最高职业道德. 标准.
黑帽seo意味着作弊. 黑帽seo方法不符合主流搜索引擎发布准则. 黑帽SEO盈利能力的主要特征是短期抵消和用于短期利益的作弊方法. 同时,由于搜索引擎算法的变化,他们随时面临罚款.
白帽seo或黑帽seo并没有精确的定义. 一般来说,所有作弊方法或某些可疑方法都可以称为黑帽SEO. 例如,隐藏的网页,关键字填充,垃圾邮件链接,桥接页面等.
黑帽SEO可以快速带来一定的排名和用户量,但这通常是K的结果. 一旦为K,恢复期将至少需要半年. 其次,对品牌不利. 的结果.
原创官方帐户文章采集者的特征是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-06 07:07
在微信公众号中撰写文章时,通常会采集其他文章以供参考,以便您可以使用官方帐号中的文章采集器. 官方帐户文章采集者的特征是什么?采集器如何采集微信文章?今天,Tuotu Data将对其进行介绍.
官方帐户文章采集者
官方帐户文章采集器的特征和功能
云采集
5000个云服务器,24 * 7高效且稳定的集合以及API,可无缝连接到内部系统并定期同步数据.
智能采集
提供各种Web采集策略和支持资源,以帮助整个采集过程实现数据完整性和稳定性.
适用于整个网络
您可以在看到它时采集它,无论是文本,图片还是铁巴论坛,它都支持所有业务渠道的抓取工具,以满足各种采集需求.
大型模板
内置了数百个网站数据源,涵盖了多个行业,您可以通过简单的设置快速而准确地获取数据.
易于使用
无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库.
稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
官方帐户文章采集者如何采集微信文章?
A: 关键字批量搜索集合
您可以分批粘贴关键字进行搜索,选择内容采集的日期,可以伪原创标题和内容,并确定文章是否为原创,并支持将一篇文章分发到网站上
对于某些SEO,它在标题或内容中添加了长尾单词的随机插入. 您可以下载带有索引的长尾单词并将其导入以获取流量
B: 通过指定的官方帐户收款
您可以通过官方帐户排名或自己搜索行业的官方帐户,然后将其粘贴. 其他功能与第一项相同,并且仍然可用. 例如,您是一家教育或税收公司,并且是专业的SEO. 通过此功能或高质量的原创文章吸引流量
C: 热门行业的集合
根据行业分类,其功能与第一项相同
D: 自动采集和发布
自动采集和发布仍然是对关键字的批量搜索,其他功能未在图中显示. 关键是有好处. 不同的关键字或微信集合可以选择全部. 它将继续按顺序采集,例如: 您有10列,然后可以为每列设置与列相关的单词采集和存储. 第一个采集完成后,它将自动执行第二个列的采集和存储.
官方帐户文章采集者
如何从其他微信公众号采集文章到微信编辑器?
方法/步骤
一个,获取文章链接
计算机用户可以直接在浏览器地址栏中复制所有文章链接.
移动用户可以单击右上角的菜单按钮,选择“复制链接”,然后将链接发送到计算机.
第二,单击按钮以采集文章
小蚂蚁编辑器的文章采集功能有两个入口:
1. 编辑菜单右上角的“采集文章”按钮;
2. 右侧功能按钮底部的“采集文章”按钮
3. 粘贴文章链接,然后单击以采集
采集完成后,您可以编辑和修改文章.
通过以上内容,我们了解了官方帐户文章采集者的特征和功能. 可以看出,官方帐户文章采集器的功能非常强大和全面. 查看全部

在微信公众号中撰写文章时,通常会采集其他文章以供参考,以便您可以使用官方帐号中的文章采集器. 官方帐户文章采集者的特征是什么?采集器如何采集微信文章?今天,Tuotu Data将对其进行介绍.

官方帐户文章采集者
官方帐户文章采集器的特征和功能
云采集
5000个云服务器,24 * 7高效且稳定的集合以及API,可无缝连接到内部系统并定期同步数据.
智能采集
提供各种Web采集策略和支持资源,以帮助整个采集过程实现数据完整性和稳定性.
适用于整个网络
您可以在看到它时采集它,无论是文本,图片还是铁巴论坛,它都支持所有业务渠道的抓取工具,以满足各种采集需求.
大型模板
内置了数百个网站数据源,涵盖了多个行业,您可以通过简单的设置快速而准确地获取数据.
易于使用
无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库.
稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
官方帐户文章采集者如何采集微信文章?
A: 关键字批量搜索集合
您可以分批粘贴关键字进行搜索,选择内容采集的日期,可以伪原创标题和内容,并确定文章是否为原创,并支持将一篇文章分发到网站上
对于某些SEO,它在标题或内容中添加了长尾单词的随机插入. 您可以下载带有索引的长尾单词并将其导入以获取流量
B: 通过指定的官方帐户收款
您可以通过官方帐户排名或自己搜索行业的官方帐户,然后将其粘贴. 其他功能与第一项相同,并且仍然可用. 例如,您是一家教育或税收公司,并且是专业的SEO. 通过此功能或高质量的原创文章吸引流量
C: 热门行业的集合
根据行业分类,其功能与第一项相同
D: 自动采集和发布
自动采集和发布仍然是对关键字的批量搜索,其他功能未在图中显示. 关键是有好处. 不同的关键字或微信集合可以选择全部. 它将继续按顺序采集,例如: 您有10列,然后可以为每列设置与列相关的单词采集和存储. 第一个采集完成后,它将自动执行第二个列的采集和存储.

官方帐户文章采集者
如何从其他微信公众号采集文章到微信编辑器?
方法/步骤
一个,获取文章链接
计算机用户可以直接在浏览器地址栏中复制所有文章链接.
移动用户可以单击右上角的菜单按钮,选择“复制链接”,然后将链接发送到计算机.
第二,单击按钮以采集文章
小蚂蚁编辑器的文章采集功能有两个入口:
1. 编辑菜单右上角的“采集文章”按钮;
2. 右侧功能按钮底部的“采集文章”按钮
3. 粘贴文章链接,然后单击以采集
采集完成后,您可以编辑和修改文章.
通过以上内容,我们了解了官方帐户文章采集者的特征和功能. 可以看出,官方帐户文章采集器的功能非常强大和全面.
大众点评点餐小程序开发经验 - 数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2020-08-04 16:04
关于小程序开发的经验以及过程中遇见的“坑”在我们团队之前的小程序开发经验系列文章中早已介绍的差不多了,大数据时代,一个产品胜败的背后须要用大量的数据去剖析验证。本期就和你们一起探求下,微信小程序是怎样进行数据采集与剖析的,当然还有过程中的“坑”。
本文部份示例来自于「大众点评点餐」小程序的菜单页面。
所有内容基于2017年3月2日为止的官方api陌陌官方采集平台介绍
微信小程序公众平台目前提供了一套官方的数据采集分析平台。
官方api:
就目前小程序公测版官方提供了以下几种数据剖析:
概况:提供小程序关键指标趋势以及top页面访问数据,快速了解小程序发展概况;(不需要自动配置,官方默认采集)
访问剖析:提供小程序用户访问来源、规模、频次、时长、深度以及页面详情等数据,具体剖析用户新增和活跃情况;(不需要自动配置,官方默认采集)
实时统计:提供小程序实时访问数据,满足实时监控需求;(不需要自动配置,官方默认采集)
自定义剖析:配置自定义上报,精细跟踪用户在小程序内的行为,结合用户属性、系统属性、事件属性进行灵活多维的风波剖析和漏斗剖析,满足小程序的个性化剖析需求;(内侧中通过关键词采集文章采集api,需要单独申请开通权限能够使用)
具体数据可通过使用小程序管理员帐号登入然后查看。
前3种形式都是小程序手动采集,不需要开发者任何的人为操作,在陌陌官方文档中都有详尽说明了,这边就不再探讨
本文主要结合「大众点评点餐」小程序来看下第4种-自定义剖析能做哪些
自定义剖析
自定义剖析就是传统意义上的埋点,用户可以自行设置希望上报的数据,通过这种数据来剖析你希望得到的结果。
微信官方的自定义剖析使用了当下比较流行的无埋点技术,通过陌陌后台配置锚点并实时下发到客户端生效,无需在代码中自动加入埋点代码,并且因为小程序发版有初审机制,如果自动埋一次点就须要重新审问,成本将会十分高,所以采用无埋点技术是十分适合于小程序的场景。
但从目前「大众点评点餐」小程序中测试出来,目前公测版本的自定义剖析(截止2017年3月2日)对代码本身设计与书写的要求比较严苛,数据采集需要与页面page的data做到关联,在个别场景下会出现比较无法满足的情况。
接下来使我们瞧瞧实现一个自定义风波的步骤:
1. 首先使用管理员帐号登入公众平台后台,找到自定义剖析(前面提及,需要单独申请,否则看不到入口)2. 如果第一次使用的话,事件列表为空,点击新增风波,填入打点风波的中英文名称3. 接下来是最关键的风波配置
动作的各项含意如下:(转自陌陌小程序官方api)
trigger,触发条件:
click 点击时触发,必须指定page和element
enterPage 进入页面时触发,必须指定page
leavePage 离开页面时触发通过关键词采集文章采集api,必须指定page
pullDownRefresh 下拉刷新时触发,必须指定page
launch 加载小程序时触发
background 切换到后台触发
foreground 切换到前台触发 查看全部
关于小程序开发的经验以及过程中遇见的“坑”在我们团队之前的小程序开发经验系列文章中早已介绍的差不多了,大数据时 ...
关于小程序开发的经验以及过程中遇见的“坑”在我们团队之前的小程序开发经验系列文章中早已介绍的差不多了,大数据时代,一个产品胜败的背后须要用大量的数据去剖析验证。本期就和你们一起探求下,微信小程序是怎样进行数据采集与剖析的,当然还有过程中的“坑”。
本文部份示例来自于「大众点评点餐」小程序的菜单页面。
所有内容基于2017年3月2日为止的官方api陌陌官方采集平台介绍
微信小程序公众平台目前提供了一套官方的数据采集分析平台。
官方api:
就目前小程序公测版官方提供了以下几种数据剖析:
概况:提供小程序关键指标趋势以及top页面访问数据,快速了解小程序发展概况;(不需要自动配置,官方默认采集)
访问剖析:提供小程序用户访问来源、规模、频次、时长、深度以及页面详情等数据,具体剖析用户新增和活跃情况;(不需要自动配置,官方默认采集)
实时统计:提供小程序实时访问数据,满足实时监控需求;(不需要自动配置,官方默认采集)
自定义剖析:配置自定义上报,精细跟踪用户在小程序内的行为,结合用户属性、系统属性、事件属性进行灵活多维的风波剖析和漏斗剖析,满足小程序的个性化剖析需求;(内侧中通过关键词采集文章采集api,需要单独申请开通权限能够使用)
具体数据可通过使用小程序管理员帐号登入然后查看。
前3种形式都是小程序手动采集,不需要开发者任何的人为操作,在陌陌官方文档中都有详尽说明了,这边就不再探讨
本文主要结合「大众点评点餐」小程序来看下第4种-自定义剖析能做哪些
自定义剖析
自定义剖析就是传统意义上的埋点,用户可以自行设置希望上报的数据,通过这种数据来剖析你希望得到的结果。
微信官方的自定义剖析使用了当下比较流行的无埋点技术,通过陌陌后台配置锚点并实时下发到客户端生效,无需在代码中自动加入埋点代码,并且因为小程序发版有初审机制,如果自动埋一次点就须要重新审问,成本将会十分高,所以采用无埋点技术是十分适合于小程序的场景。
但从目前「大众点评点餐」小程序中测试出来,目前公测版本的自定义剖析(截止2017年3月2日)对代码本身设计与书写的要求比较严苛,数据采集需要与页面page的data做到关联,在个别场景下会出现比较无法满足的情况。
接下来使我们瞧瞧实现一个自定义风波的步骤:
1. 首先使用管理员帐号登入公众平台后台,找到自定义剖析(前面提及,需要单独申请,否则看不到入口)2. 如果第一次使用的话,事件列表为空,点击新增风波,填入打点风波的中英文名称3. 接下来是最关键的风波配置
动作的各项含意如下:(转自陌陌小程序官方api)
trigger,触发条件:
click 点击时触发,必须指定page和element
enterPage 进入页面时触发,必须指定page
leavePage 离开页面时触发通过关键词采集文章采集api,必须指定page
pullDownRefresh 下拉刷新时触发,必须指定page
launch 加载小程序时触发
background 切换到后台触发
foreground 切换到前台触发
获取任意链接文章正文 API 功能简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-08-04 08:02
此文章对开放数据插口 API 之「获取任意链接文章正文」进行了功能介绍、使用场景介绍以及调用方式的说明,供用户在使用数据插口时参考之用。
1. 产品功能
接口开放了按照提供的文章链接 Url 参数,智能分析文章的正文部份,并通过抓取剖析后,返回出文章的标题、正文以及文章的发表时间。
对于各类类型的文章布局,采用了智能化的语义剖析,最大化地满足各类各类布局文章的采集与处理需求。
接口地址:
2. 接口文档与参数
接口地址:
返回格式: json/xml
请求方法: GET
请求示例:
请求合同: HTTPS
接口测试:
各类开发语言的恳求示例代码可以参考 API 文档说明:
加入社群通过关键词采集文章采集api,与 1000 多位同事共同成长
DevOpen.Club Pro 高质量软件开发分享讨论群,汇聚了逾 1000 多名各行各业的软件开发人员,是供朋友们分享高质量资源、讨论软件开发问题解决方案、寻求孵化项目合作伙伴的干货社区。
任何技术都不是限制,我们最终目的是将技术转化成收入,实现财务自由。
社群中正在更新的原创视频教程 & 孵化项目进度
编程大世界:软件开发基础知识通解,带你步入软件开发的大世界;80 节实战课精通 React Native 开发:我出版的书籍《React Native 精解与实战》配套视频教程;微信小程序开发视频教程:最实战的小程序开发视频教程,重新规划课程内容降低至 60 小节;50 个 Chrome Developer Tools 必备方法:前端开发人员必备技能点;我们的微信群中孵化下来的一个团队,在做一个服务于伦敦的小程序项目。
DevOpenClub Pro 社群手册
每日分享高质量的技术开发头条信息与资源;遇到任何技术问题都可以进行快速提问、讨论交流;永久获取每年原创的开发视频教程第一手资源更新;获取其他高质量软件开发行业新闻、技术文章、教学视频分享;群中认识更多的同事以及分享合作开发项目的机会;认识更多的行业同学通过关键词采集文章采集api,或者交流自己的创业小项目;交流与分享技术笔试心得;高质量、有价值的社区永远都不会是你所在的 QQ 群或微信群。 查看全部

此文章对开放数据插口 API 之「获取任意链接文章正文」进行了功能介绍、使用场景介绍以及调用方式的说明,供用户在使用数据插口时参考之用。
1. 产品功能
接口开放了按照提供的文章链接 Url 参数,智能分析文章的正文部份,并通过抓取剖析后,返回出文章的标题、正文以及文章的发表时间。
对于各类类型的文章布局,采用了智能化的语义剖析,最大化地满足各类各类布局文章的采集与处理需求。
接口地址:
2. 接口文档与参数
接口地址:
返回格式: json/xml
请求方法: GET
请求示例:
请求合同: HTTPS
接口测试:

各类开发语言的恳求示例代码可以参考 API 文档说明:
加入社群通过关键词采集文章采集api,与 1000 多位同事共同成长
DevOpen.Club Pro 高质量软件开发分享讨论群,汇聚了逾 1000 多名各行各业的软件开发人员,是供朋友们分享高质量资源、讨论软件开发问题解决方案、寻求孵化项目合作伙伴的干货社区。
任何技术都不是限制,我们最终目的是将技术转化成收入,实现财务自由。
社群中正在更新的原创视频教程 & 孵化项目进度
编程大世界:软件开发基础知识通解,带你步入软件开发的大世界;80 节实战课精通 React Native 开发:我出版的书籍《React Native 精解与实战》配套视频教程;微信小程序开发视频教程:最实战的小程序开发视频教程,重新规划课程内容降低至 60 小节;50 个 Chrome Developer Tools 必备方法:前端开发人员必备技能点;我们的微信群中孵化下来的一个团队,在做一个服务于伦敦的小程序项目。
DevOpenClub Pro 社群手册
每日分享高质量的技术开发头条信息与资源;遇到任何技术问题都可以进行快速提问、讨论交流;永久获取每年原创的开发视频教程第一手资源更新;获取其他高质量软件开发行业新闻、技术文章、教学视频分享;群中认识更多的同事以及分享合作开发项目的机会;认识更多的行业同学通过关键词采集文章采集api,或者交流自己的创业小项目;交流与分享技术笔试心得;高质量、有价值的社区永远都不会是你所在的 QQ 群或微信群。
专栏文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-04 01:02
但光这样还不足够,因为我画力导向图的本意是想表现出两个用户之间的互动关系,是“互”动关系。如果B是A的一个狂热粉丝,而A却反倒不太答理B,也就是B在A处得分高,但A在B处得分低。在这样的情况下,A和B似乎不应当以太亲昵的状态出现在力导向图上。
基于这些情况,我对relation_score表进行了更进一步的处理,当A和B彼此都有较高的互动分数时,才会得到一个很高的最终得分,单方面的得分则会被大打折扣,也就是说通过关键词采集文章采集api,将A∩B的分数的残差减小数十倍,然后借此再重新进行打分。最终得到一个新的表links
三、数据可视化
因为想画出比较灵活的力导向图,所以选用了D3:
具体做可视化的时侯,发现两用户之间的得分数据分布,大概呈右图所示(只是示意图,不是精确勾画的):
换句话说,分数越低的区间,人数越多,10~15分之间有500多人,而99-138分的人却只有6个人。所以假如要是简单地按照分数来线性地决定节点之间的力,结果只会有几个人距得太逾,其他大部分人都将距得超远,而且低分人群将难以拉开差别,高分的人之间差别很大但却没哪些意义。数据呈现不显著,力导向图也不太好看。
尝试了许多方案,最后采用了分段线性的方案。
比如得分最高的6个人,分数跨径似乎在 99~138,但节点间斥力仅在 0.9~1.0 间变化,而得分低的500多个人,就算分数只有10-15这样小的跨径,作用力却能在 0.0~3.0 这样广的范围里变化。
最后得出的图如下:
四、观察数据
从图大约能看下来各人在微博上抱团的同事圈子,以及两个人之间的互动关系。
当数据量调到最大时,甚至会发觉微博furry圈子里的“宇宙中心”级人物。
另外,前边说过,采集的数据并不完美通过关键词采集文章采集api,从最终的图上也能看下来一二。
比如:
这张图上两个圈内的这些人,并非是furry圈的人。属于误采集的一部分数据。会听到这部份误采集并且活跃的用户会在力导向图中抱团在一起,所以也可以依据此来做更进一步的数据清洗。
五、其他数据
力导向图展示的是一个整体的、宏观的数据状况。但实际上你们可能比起宏观数据,更关心自己个人的数据,于是进一步还做了个人数据的页面。
这个就直接为了省事,选用echarts3的饼图:
毕竟好不容易做下来的东西,还是希望你们能多好好地看一看。
到此,这个小小的独立数据产品即使竣工了。
在制做的过程中也了解了许多有意思的东西。
……
后来我发觉自己做的这个小网站居然收获了上万次的访问量,访问人数也有3500人之多,看着这个access log,心生了继续将这部份数据借助上去的看法。
六、再次采集、处理
其实有一点懊悔,没有在自己做的网站上做更复杂一些的埋点,结果访问信息只保存出来了默认的access log,也就是访问的URL、时间、IP地址等信息。
前边提及,有人做过furry的地图分布,但疗效不理想。我当然也可以用自己网站的access log来做同样的东西。
IP地址是个好东西,可以通过它获得地市信息,知道这个IP来自哪国哪市哪区,进而实现地域的分布统计。
另外还可以从URL信息中提取出是谁的个人数据页面被访问,换言之,知道了各页面的访问频次,也就晓得了你们对谁的个人数据更感兴趣。
七、地图可视化
这次为了图省事完全就直接用了echarts了,而且是在本地做的,没有上线,所以只有截图。
最后依照你们对个人页面的访问频次做了一个词云图,通过这张图可以看下来,我一开始选购的四个采集用户,也确实是你们太感兴趣的人呢。
八、其他参考资料
IP地区信息:
地市经纬度信息:
地图、词云数据可视化:
结语:
做数据尽管挺有趣的,但可惜我的部门在公司仍然被觉得是一个似乎“不明觉厉”但总之“不做软件不能换钱于是不配合她们工作也问题不大”的存在,去年年初更是由于公司高层嬗变丧失几大靠山而遭到爆破,受到了毁灭性的严打。想使其他各应用部门和技术营运部门配合我们做数据埋点、抽库采集、业务知识交流之类的工作更是难上加难。真希望能有更多更好的数据以及更好的一个平台能使自己见识更广,在大数据的路上走得更远。
真艳羡能领到那么多FB数据的那种俄罗斯公司啊((((( 查看全部

但光这样还不足够,因为我画力导向图的本意是想表现出两个用户之间的互动关系,是“互”动关系。如果B是A的一个狂热粉丝,而A却反倒不太答理B,也就是B在A处得分高,但A在B处得分低。在这样的情况下,A和B似乎不应当以太亲昵的状态出现在力导向图上。
基于这些情况,我对relation_score表进行了更进一步的处理,当A和B彼此都有较高的互动分数时,才会得到一个很高的最终得分,单方面的得分则会被大打折扣,也就是说通过关键词采集文章采集api,将A∩B的分数的残差减小数十倍,然后借此再重新进行打分。最终得到一个新的表links

三、数据可视化
因为想画出比较灵活的力导向图,所以选用了D3:
具体做可视化的时侯,发现两用户之间的得分数据分布,大概呈右图所示(只是示意图,不是精确勾画的):

换句话说,分数越低的区间,人数越多,10~15分之间有500多人,而99-138分的人却只有6个人。所以假如要是简单地按照分数来线性地决定节点之间的力,结果只会有几个人距得太逾,其他大部分人都将距得超远,而且低分人群将难以拉开差别,高分的人之间差别很大但却没哪些意义。数据呈现不显著,力导向图也不太好看。
尝试了许多方案,最后采用了分段线性的方案。
比如得分最高的6个人,分数跨径似乎在 99~138,但节点间斥力仅在 0.9~1.0 间变化,而得分低的500多个人,就算分数只有10-15这样小的跨径,作用力却能在 0.0~3.0 这样广的范围里变化。
最后得出的图如下:

四、观察数据
从图大约能看下来各人在微博上抱团的同事圈子,以及两个人之间的互动关系。
当数据量调到最大时,甚至会发觉微博furry圈子里的“宇宙中心”级人物。

另外,前边说过,采集的数据并不完美通过关键词采集文章采集api,从最终的图上也能看下来一二。
比如:

这张图上两个圈内的这些人,并非是furry圈的人。属于误采集的一部分数据。会听到这部份误采集并且活跃的用户会在力导向图中抱团在一起,所以也可以依据此来做更进一步的数据清洗。
五、其他数据
力导向图展示的是一个整体的、宏观的数据状况。但实际上你们可能比起宏观数据,更关心自己个人的数据,于是进一步还做了个人数据的页面。
这个就直接为了省事,选用echarts3的饼图:

毕竟好不容易做下来的东西,还是希望你们能多好好地看一看。
到此,这个小小的独立数据产品即使竣工了。
在制做的过程中也了解了许多有意思的东西。
……
后来我发觉自己做的这个小网站居然收获了上万次的访问量,访问人数也有3500人之多,看着这个access log,心生了继续将这部份数据借助上去的看法。
六、再次采集、处理
其实有一点懊悔,没有在自己做的网站上做更复杂一些的埋点,结果访问信息只保存出来了默认的access log,也就是访问的URL、时间、IP地址等信息。
前边提及,有人做过furry的地图分布,但疗效不理想。我当然也可以用自己网站的access log来做同样的东西。
IP地址是个好东西,可以通过它获得地市信息,知道这个IP来自哪国哪市哪区,进而实现地域的分布统计。
另外还可以从URL信息中提取出是谁的个人数据页面被访问,换言之,知道了各页面的访问频次,也就晓得了你们对谁的个人数据更感兴趣。
七、地图可视化
这次为了图省事完全就直接用了echarts了,而且是在本地做的,没有上线,所以只有截图。



最后依照你们对个人页面的访问频次做了一个词云图,通过这张图可以看下来,我一开始选购的四个采集用户,也确实是你们太感兴趣的人呢。

八、其他参考资料
IP地区信息:
地市经纬度信息:
地图、词云数据可视化:
结语:
做数据尽管挺有趣的,但可惜我的部门在公司仍然被觉得是一个似乎“不明觉厉”但总之“不做软件不能换钱于是不配合她们工作也问题不大”的存在,去年年初更是由于公司高层嬗变丧失几大靠山而遭到爆破,受到了毁灭性的严打。想使其他各应用部门和技术营运部门配合我们做数据埋点、抽库采集、业务知识交流之类的工作更是难上加难。真希望能有更多更好的数据以及更好的一个平台能使自己见识更广,在大数据的路上走得更远。
真艳羡能领到那么多FB数据的那种俄罗斯公司啊(((((
用户行为分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2020-08-08 09:13
首先,让我们了解用户行为分析
1. 为什么要进行用户行为分析?
仅通过进行用户行为分析,您才能了解用户画像并了解网站上各种浏览,单击和购买背后的商业真相.
简而言之,分析的主要方式是关注客户流失,尤其是对于那些需要转化的网站. 我们希望用户上来后不会迷路,也不会离开. 与许多O2O产品一样,用户在购买产品时也会获得大量补贴. 一旦钱花光了,用户就走了. 此类产品或商业模式不好. 我们希望用户能够真正找到该平台的价值,并不断进取并不会失去它.
2. 用户行为分析有助于分析用户流失的方式,原因及流失的地方
例如,最简单的搜索行为: 当某个ID搜索关键字,查看哪个页面,结果以及购买ID时,整个行为非常重要. 如果他对中间的搜索结果不满意,他肯定会再次搜索,然后在找到结果之前将关键字更改为其他关键字.
3. 用户行为分析还能做什么?
拥有大量用户行为数据并定义事件后,可以将用户数据划分为按小时,天,用户级别或事件级别划分的表. 该表用于什么用途?一种是了解用户最简单的事件,例如登录或购买,还知道哪些是高质量用户,哪些将失去客户. 每天或每小时都可以查看此类数据. ,
第二,掩埋点的作用
1. 大数据,从复杂数据的背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“品味”的产品和服务,并根据用户需求进行调整和优化. 这是大数据的价值. 而且对这些信息的采集和分析无法避免“埋伏点”
2. 隐蔽点是在需要的位置采集相应的信息,就像高速公路上的摄像头一样,它可以采集车辆的属性,例如: 颜色,车牌号,型号等,并且还可以采集车辆的行为例如: 您是否闯红灯,按下了线路,汽车的速度,驾驶员在开车时接听电话等,每个掩埋点都像一个摄像头,采集用户行为数据并进行数据的多维交叉分析,可以真正地还原开发用户使用场景和挖掘用户需求,从而提高用户整个生命周期的价值.
三,埋点的类型
新闻埋藏工具: 代码埋藏点,视觉埋藏点,“无埋藏点”
根据掩埋点的位置: 前端/客户端掩埋点,后端/服务器端掩埋点
1. 完全埋入点(也称为无埋入点): 通过SDK采集页面上的所有控制操作数据,并通过“统计数据屏幕”配置要处理的数据的特征.
示例·应用场景
它主要应用于简单页面,例如短期事件中的登录页面/主题页面,并且有必要快速测量点击分配的效果等.
2. 可视化的隐埋点: 嵌入式SDK,可视化的圆选择以定义事件
为了方便产品和操作,学生可以直接在页面上直接盘旋以跟踪用户行为(定义事件),并且仅采集点击操作即可节省开发时间. 就像卫星航空摄影一样,不需要安装摄像头,数据量很小,并且它支持在本地获取信息. 因此,JS可视化掩埋点更适合以下情况:
示例·应用场景
2.1. 短而平坦且快速的数据采集方法: 活动/ H5等简单页面,业务人员可以直接盘旋,操作没有门槛,减少了技术人员的干预(从今以后世界和平),这种数据采集方法便于业务人员尽快掌握页面上关键节点的转换,但用户行为数据的应用相对较浅,无法支持更深入的分析;
2.2. 如果页面是临时调整的,则可以灵活地将其添加到埋入点,可以用作代码埋入点的补充以及时增加采集的数据
3. 代码嵌入点: 嵌入式SDK,定义事件和添加事件代码,按需采集,业务信息更加完整,数据分析更加集中,因此代码嵌入是基于业务价值的行为分析.
示例·应用场景
3.1. 如果您不想在采集数据时降低用户体验
3.2. 如果您不想采集大量无用的数据
3.3. 如果您想采集数据: 更细的粒度,更大的维度以及更高的数据分析准确性
然后,考虑到业务增长的长期价值,请选择代码掩埋点
4. 服务器端埋入点: 它可以通过接口调用来构造数据,从而支持其他业务数据的采集和集成,例如CRM和其他用户数据,因为它是直接从服务器端采集的,因此数据更加准确和适合本身具有采集功能的客户可以将采集与客户采集相结合.
示例·应用场景
4.1. 通过调用API接口将CRM和其他数据与用户行为数据集成,以从多个角度全面分析用户;
4.2. 如果公司已经拥有自己的掩埋系统,那么它可以通过服务器端集合直接上载用户行为数据以进行数据分析,而无需维护两个掩埋系统;
4.3. 连接历史数据(埋入点之前的数据)和新数据(埋入点之后的数据)以提高数据准确性. 例如,在访问客户以采集客户之后,在导入原创历史数据之后,先前访问该平台的现有用户将不会被标记为新用户,从而减少了数据错误.
四,如何选择掩埋点
数据采集只是数据分析的第一步. 数据分析的目的是深入了解用户行为,挖掘用户价值并促进业务增长. 因此,最理想的掩埋解决方案是基于不同的业务,场景和行业特征,并根据自己的实际需求,以互补的方式组合掩埋点,例如:
1. 代码掩埋点+完全掩埋点: 当需要对目标页面进行整体点击分析时,在细节中一一掩埋这些点的工作量相对较大,并且在经常优化和调整目标页面时,更新埋藏点不应低估数量,但是复杂页面中存在盲点,无法用所有埋藏点采集. 因此,代码掩埋点可以用作采集用户核心行为的辅助工具,以实现准确且跨领域的用户行为分析;
2. 代码埋入点+服务器端埋入点: 以电子商务平台为例,用户在支付过程中将跳至第三方支付平台,需要通过交易数据来验证支付是否成功在服务器上. 此时,通过将代码埋入点和服务器端埋入点结合起来,可以提高数据的准确性;
3. 代码嵌入点+可视嵌入点: 由于代码嵌入点的工作量很大,因此可以通过核心事件代码嵌入这些点,并且可视化的嵌入点可以用于采集其他方法和补充方法. 查看全部
16058322王超
首先,让我们了解用户行为分析
1. 为什么要进行用户行为分析?
仅通过进行用户行为分析,您才能了解用户画像并了解网站上各种浏览,单击和购买背后的商业真相.
简而言之,分析的主要方式是关注客户流失,尤其是对于那些需要转化的网站. 我们希望用户上来后不会迷路,也不会离开. 与许多O2O产品一样,用户在购买产品时也会获得大量补贴. 一旦钱花光了,用户就走了. 此类产品或商业模式不好. 我们希望用户能够真正找到该平台的价值,并不断进取并不会失去它.
2. 用户行为分析有助于分析用户流失的方式,原因及流失的地方
例如,最简单的搜索行为: 当某个ID搜索关键字,查看哪个页面,结果以及购买ID时,整个行为非常重要. 如果他对中间的搜索结果不满意,他肯定会再次搜索,然后在找到结果之前将关键字更改为其他关键字.
3. 用户行为分析还能做什么?
拥有大量用户行为数据并定义事件后,可以将用户数据划分为按小时,天,用户级别或事件级别划分的表. 该表用于什么用途?一种是了解用户最简单的事件,例如登录或购买,还知道哪些是高质量用户,哪些将失去客户. 每天或每小时都可以查看此类数据. ,
第二,掩埋点的作用
1. 大数据,从复杂数据的背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“品味”的产品和服务,并根据用户需求进行调整和优化. 这是大数据的价值. 而且对这些信息的采集和分析无法避免“埋伏点”
2. 隐蔽点是在需要的位置采集相应的信息,就像高速公路上的摄像头一样,它可以采集车辆的属性,例如: 颜色,车牌号,型号等,并且还可以采集车辆的行为例如: 您是否闯红灯,按下了线路,汽车的速度,驾驶员在开车时接听电话等,每个掩埋点都像一个摄像头,采集用户行为数据并进行数据的多维交叉分析,可以真正地还原开发用户使用场景和挖掘用户需求,从而提高用户整个生命周期的价值.
三,埋点的类型
新闻埋藏工具: 代码埋藏点,视觉埋藏点,“无埋藏点”
根据掩埋点的位置: 前端/客户端掩埋点,后端/服务器端掩埋点
1. 完全埋入点(也称为无埋入点): 通过SDK采集页面上的所有控制操作数据,并通过“统计数据屏幕”配置要处理的数据的特征.
示例·应用场景
它主要应用于简单页面,例如短期事件中的登录页面/主题页面,并且有必要快速测量点击分配的效果等.
2. 可视化的隐埋点: 嵌入式SDK,可视化的圆选择以定义事件
为了方便产品和操作,学生可以直接在页面上直接盘旋以跟踪用户行为(定义事件),并且仅采集点击操作即可节省开发时间. 就像卫星航空摄影一样,不需要安装摄像头,数据量很小,并且它支持在本地获取信息. 因此,JS可视化掩埋点更适合以下情况:
示例·应用场景
2.1. 短而平坦且快速的数据采集方法: 活动/ H5等简单页面,业务人员可以直接盘旋,操作没有门槛,减少了技术人员的干预(从今以后世界和平),这种数据采集方法便于业务人员尽快掌握页面上关键节点的转换,但用户行为数据的应用相对较浅,无法支持更深入的分析;
2.2. 如果页面是临时调整的,则可以灵活地将其添加到埋入点,可以用作代码埋入点的补充以及时增加采集的数据
3. 代码嵌入点: 嵌入式SDK,定义事件和添加事件代码,按需采集,业务信息更加完整,数据分析更加集中,因此代码嵌入是基于业务价值的行为分析.
示例·应用场景
3.1. 如果您不想在采集数据时降低用户体验
3.2. 如果您不想采集大量无用的数据
3.3. 如果您想采集数据: 更细的粒度,更大的维度以及更高的数据分析准确性
然后,考虑到业务增长的长期价值,请选择代码掩埋点
4. 服务器端埋入点: 它可以通过接口调用来构造数据,从而支持其他业务数据的采集和集成,例如CRM和其他用户数据,因为它是直接从服务器端采集的,因此数据更加准确和适合本身具有采集功能的客户可以将采集与客户采集相结合.
示例·应用场景
4.1. 通过调用API接口将CRM和其他数据与用户行为数据集成,以从多个角度全面分析用户;
4.2. 如果公司已经拥有自己的掩埋系统,那么它可以通过服务器端集合直接上载用户行为数据以进行数据分析,而无需维护两个掩埋系统;
4.3. 连接历史数据(埋入点之前的数据)和新数据(埋入点之后的数据)以提高数据准确性. 例如,在访问客户以采集客户之后,在导入原创历史数据之后,先前访问该平台的现有用户将不会被标记为新用户,从而减少了数据错误.
四,如何选择掩埋点
数据采集只是数据分析的第一步. 数据分析的目的是深入了解用户行为,挖掘用户价值并促进业务增长. 因此,最理想的掩埋解决方案是基于不同的业务,场景和行业特征,并根据自己的实际需求,以互补的方式组合掩埋点,例如:
1. 代码掩埋点+完全掩埋点: 当需要对目标页面进行整体点击分析时,在细节中一一掩埋这些点的工作量相对较大,并且在经常优化和调整目标页面时,更新埋藏点不应低估数量,但是复杂页面中存在盲点,无法用所有埋藏点采集. 因此,代码掩埋点可以用作采集用户核心行为的辅助工具,以实现准确且跨领域的用户行为分析;
2. 代码埋入点+服务器端埋入点: 以电子商务平台为例,用户在支付过程中将跳至第三方支付平台,需要通过交易数据来验证支付是否成功在服务器上. 此时,通过将代码埋入点和服务器端埋入点结合起来,可以提高数据的准确性;
3. 代码嵌入点+可视嵌入点: 由于代码嵌入点的工作量很大,因此可以通过核心事件代码嵌入这些点,并且可视化的嵌入点可以用于采集其他方法和补充方法.
Python爬行微信小程序(实战)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-08 02:53
最近,有必要在微信小程序中捕获数据分析. 与一般的Web爬网程序类似,主要目标是获取用于数据爬网的主要URL地址,而问题的关键是在移动终端请求后如何获取https. 加密参数. 在本文中,我们将从初始数据包捕获到URL获取,解析参数,数据分析和存储,逐步抓取微信小程序.
此爬网的目标是微信小程序“财富股票”中公认的科技公司列表,如下所示:
注意: 数据包捕获,分析和爬网的整个过程几乎在微信小程序中普遍使用,并且可以使用类似的原理类似地对其他小程序进行爬网进行测试.
二,环境配置
特定环境配置参考: Python爬行微信小程序(查尔斯)
移动终端: iPhone;
PC端: Windows 10;
软件: Charles
注意: 对网络的要求很高,请确保网络访问不受限制.
三,查尔斯捕获了包裹
<p>在上一篇文章(Python爬行微信小程序(Charles))中详细描述了与查尔斯有关的配置和说明,因此在此我不再赘述,但要点是,移动证书始终是受信任的: 查看全部
I. 背景介绍
最近,有必要在微信小程序中捕获数据分析. 与一般的Web爬网程序类似,主要目标是获取用于数据爬网的主要URL地址,而问题的关键是在移动终端请求后如何获取https. 加密参数. 在本文中,我们将从初始数据包捕获到URL获取,解析参数,数据分析和存储,逐步抓取微信小程序.
此爬网的目标是微信小程序“财富股票”中公认的科技公司列表,如下所示:
注意: 数据包捕获,分析和爬网的整个过程几乎在微信小程序中普遍使用,并且可以使用类似的原理类似地对其他小程序进行爬网进行测试.
二,环境配置
特定环境配置参考: Python爬行微信小程序(查尔斯)
移动终端: iPhone;
PC端: Windows 10;
软件: Charles
注意: 对网络的要求很高,请确保网络访问不受限制.
三,查尔斯捕获了包裹
<p>在上一篇文章(Python爬行微信小程序(Charles))中详细描述了与查尔斯有关的配置和说明,因此在此我不再赘述,但要点是,移动证书始终是受信任的:
Python丨scrapy抓取招聘网络移动APP的发布信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2020-08-08 02:52
我将在一段时间内开始寻找新工作,因此让我们抓取一些工作信息进行分析. 当前的主流招聘网站包括51job,直联,BOSS直接招聘,拉狗等. 我有一段时间没有抓取移动应用程序了. 这次,我将编写一个采集器来搜寻51job.com移动应用程序的工作信息. 其他招聘网站将在以后更新...
使用的工具(技术):
IDE: pycharm
数据库: MySQL
包裹捕获工具: Fiddler
采集器框架: scrapy == 1.5.0
信息捕获: 选择器内置scrapy
Python学习资料或需要代码,视频和Python学习小组: 960410445
2 APP捕获分析
让我们第一次体验51job的应用. 当我们在首页上输入搜索关键字并单击搜索时,该应用程序将跳至新页面. 我们将此页面称为第一级页面. 第一级页面显示了我们正在寻找的所有职位的列表.
当我们单击某个帖子信息时,APP将跳至新页面. 我称此页面为辅助页面. 第二页收录我们需要的所有作业信息,也是我们主页的当前采集页.
分析页面后,您可以分析51job应用程序的请求和响应. 本文中使用的数据包捕获工具是Fiddler.
本文的目的是捕获在51job应用上搜索某个关键字时返回的所有招聘信息. 本文以“ Python”为例. APP上的操作如下图所示. 输入“ Python”关键字后,单击“搜索”,然后Fiddler抓取4个数据包,如下所示:
实际上,当我们看到第二和第四数据包的图标时,我们应该笑一个. 这两个图标分别表示以json和xml格式传输的数据,许多Web界面以这两种格式传输数据,并且未列出移动应用程序. 选择第二个数据包,然后在右侧的主窗口中检查,发现第二个数据包不收录我们想要的数据. 查看第四个数据包后,选择后可以在右侧窗口中看到以下内容:
右下角的内容不只是您在手机上看到的工作信息吗?它仍然以XML格式传输. 我们复制此数据包的链接:
keyword = Python&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369792>
当我们爬网时,我们肯定不仅会爬网一页的信息. 我们在APP上向下滑动页面,以查看Fiddler将抓取哪些数据包. 看下面的图片:
滑下电话屏幕后,Fiddler抓取了另外两个数据包,然后选择了第二个数据包,并再次发现它是APP上新刷新的招聘信息,然后复制此数据包的url链接: </p
ppageno = 2&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 845&guid = bbb37e8f266b9de3e2a9/p
p接下来,让我们比较一下之前和之后的两个链接,以分析异同. 可以看出,除了属性“ pageno”外,其他所有内容都是相同的. 没错,以红色标记. 第一个数据包链接中的pageno值为1,第二个pageno值为2,因此翻页的规则一目了然./p
p现在我们已经找到了APP翻页的请求链接规则,我们可以通过采集器循环将pageno分配给pageno,以实现模拟翻页的功能./p
p让我们再次尝试更改搜索关键字,以查看链接中的变化,以“ java”作为关键字,捕获的数据包为:/p
pkeyword = java&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369845>
经过比较,发现只有链接中的keyword值不同,并且该值是我们自己输入的关键字. 因此,在爬虫中,我们可以通过字符串拼接来完全实现输入关键字模拟,以采集不同类型的招聘信息. 同样,您可以搜索诸如工作地点之类的信息规则,而本文将不对其进行描述.
解决翻页功能后,让我们探索数据包中XML的内容. 我们复制上面的第一个链接,然后在浏览器中将其打开. 打开后,屏幕如下:
以这种方式观看要舒服得多. 通过仔细观察,我们会发现APP上的每个职位发布都对应一个标签,每个职位中都有一个标签,并且有一个ID来标识职位. 例如,上面的第一篇文章是109384390,第二篇文章是109381483. 请记住该ID,稍后再使用.
实际上,接下来,我们单击第一个职位发布以进入第二页. 这时,Fiddler将采集APP刚发送的数据包,单击xml数据包,然后发现它是刚刚在APP上刷新的页面信息. 我们复制数据包的url链接:
jobid = 109384390&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
根据该方法,在第一级页面上的列表中单击第二个作业,然后从Fiddler复制相应数据包的url链接:
jobid = 109381483&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
比较以上两个链接,您是否找到了模式?是的,jobid不同,其他都一样. 此Jobid是我们在第一页xml中找到的jobid. 由此,我们可以从第一级页面获取Jobid来构造第二级页面的url链接,然后采集我们需要的所有信息. 整个采集器逻辑很明确:
构造第一级页面的初始URL->采集jobid->构造第二级页面的URL->获取工作信息->通过循环模拟获取下一页的URL.
好的,分析工作已经完成,我开始编写采集器.
3编写采集器
本文使用的是无忧移动APP网络采集器的Scrapy框架. 在下载了草率的第三方软件包之后,通过命令行创建一个爬虫项目:
scrapy startproject job_spider.
job_spider是我们的检索器项目的项目名称. 有一个“. ”在项目名称之后. 这一点是可选的. 区别在于在当前文件之间创建一个项目,或者创建一个与项目名称相同的文件. 在文件中创建一个项目.
创建项目后,继续创建一个采集器,专用于搜寻51job发布的招聘信息. 创建一个名称如下的采集器:
scrapy genspider qcwySpider
注意: 如果未添加“. ”. 创建爬网程序项目时,将其更改为项目名称,请在运行命令以创建爬网程序之前进入项目文件夹.
打开刚刚通过pycharm创建的爬虫项目,左侧的目录树结构如下:
在开始所有采集器工作之前,请先打开settings.py文件,然后取消注释“ ROBOTSTXT_OBEY = False”行并将其值更改为False.
#遵守robots.txt规则ROBOTSTXT_OBEY = False
完成以上修改后,在spiders包下打开qcwySpider.py. 初始代码如下:
这是scrapy为我们建立的框架. 我们只需要在此基础上改进爬虫.
首先,我们需要向类添加一些属性,例如search关键字keyword,起始页,要进行爬网以获得最大页面数,还需要设置标头以进行简单的反爬网. 此外,starturl也需要重置为第一页的URL. 更改后的代码如下:
然后开始编写parse方法来对第一级页面进行爬网. 在第一页中,我们的主要逻辑是通过循环在APP中实现屏幕幻灯片的更新. 我们在上面的代码中使用current_page来标识当前页码,在每个循环之后,将1添加到current_page中,然后构造一个新的url,并通过回调解析方法抓取下一页. 另外,我们还需要在parse方法中从第一级页面采集jobid,并构造第二级页面,然后回调实现第二级页面信息采集的parse_job方法. 解析方法代码如下:
为了便于调试,我们在项目的jobSpider目录中创建一个main.py文件来启动采集器,并在每次启动采集器时运行该文件. 内容如下:
辅助页面信息采集功能是在parse_job方法中实现的,因为我们需要获取的所有信息都在xml中,所以我们可以使用scrapy附带的选择器直接提取它,但是在提取之前,我们需要先定义用于存储我们采集的数据的项目. 打开items.py文件,编写一个Item类,然后输入以下代码:
上面的每个项目都对应一个xml标记,该标记用于存储一条信息. 在qcwyJobsItem类的末尾,定义了一个do_insert方法,该方法用于生成插入语句,该语句将所有信息存储在数据库中的项目中. 之所以在items块中生成此insert语句,是因为如果将来有多个采集器,则在管道模块中可以有多个项目类之后,可以为不同的项目插入数据库,以使该项目更具可伸缩性. 您还可以编写所有与在管道中插入数据库有关的代码.
然后编写parse_job方法:
完成上述代码后,信息采集部分完成. 接下来,继续编写信息存储功能,该功能在pipelines.py中完成.
在编写pipeline.py之后,打开settings.py文件并配置刚刚写入项目设置文件的MysqlTwistedPipline类:
另外,还要配置数据库:
您还可以将数据库配置嵌入MysqlTwistedPipline类中,但是我习惯于将这些专有数据库信息写入配置文件中.
最后,仅需一步即可建立数据库和数据表. 表结构的一部分如下所示:
完成上述所有操作后,您可以运行采集器以开始采集数据. 采集的数据如下图所示:
4摘要
经过整个过程,我觉得51job.com APP的爬取比Web爬取更容易(似乎很多网站都是这样). 回顾整个过程,实际上代码中有许多细节可以改进和完善,例如,在构建链接时可以添加职位搜索位置. 这篇博客文章侧重于整个爬网程序过程的逻辑分析,并介绍了APP的基本爬网方法. 博客文章中省略了部分代码. 如果您需要完整的代码,请从我的github获得. 将来,我们将继续更新其他招聘网站的抓取工具. 返回搜狐查看更多 查看全部
1简介
我将在一段时间内开始寻找新工作,因此让我们抓取一些工作信息进行分析. 当前的主流招聘网站包括51job,直联,BOSS直接招聘,拉狗等. 我有一段时间没有抓取移动应用程序了. 这次,我将编写一个采集器来搜寻51job.com移动应用程序的工作信息. 其他招聘网站将在以后更新...
使用的工具(技术):
IDE: pycharm
数据库: MySQL
包裹捕获工具: Fiddler
采集器框架: scrapy == 1.5.0
信息捕获: 选择器内置scrapy
Python学习资料或需要代码,视频和Python学习小组: 960410445
2 APP捕获分析
让我们第一次体验51job的应用. 当我们在首页上输入搜索关键字并单击搜索时,该应用程序将跳至新页面. 我们将此页面称为第一级页面. 第一级页面显示了我们正在寻找的所有职位的列表.
当我们单击某个帖子信息时,APP将跳至新页面. 我称此页面为辅助页面. 第二页收录我们需要的所有作业信息,也是我们主页的当前采集页.
分析页面后,您可以分析51job应用程序的请求和响应. 本文中使用的数据包捕获工具是Fiddler.
本文的目的是捕获在51job应用上搜索某个关键字时返回的所有招聘信息. 本文以“ Python”为例. APP上的操作如下图所示. 输入“ Python”关键字后,单击“搜索”,然后Fiddler抓取4个数据包,如下所示:
实际上,当我们看到第二和第四数据包的图标时,我们应该笑一个. 这两个图标分别表示以json和xml格式传输的数据,许多Web界面以这两种格式传输数据,并且未列出移动应用程序. 选择第二个数据包,然后在右侧的主窗口中检查,发现第二个数据包不收录我们想要的数据. 查看第四个数据包后,选择后可以在右侧窗口中看到以下内容:
右下角的内容不只是您在手机上看到的工作信息吗?它仍然以XML格式传输. 我们复制此数据包的链接:
keyword = Python&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369792>
当我们爬网时,我们肯定不仅会爬网一页的信息. 我们在APP上向下滑动页面,以查看Fiddler将抓取哪些数据包. 看下面的图片:
滑下电话屏幕后,Fiddler抓取了另外两个数据包,然后选择了第二个数据包,并再次发现它是APP上新刷新的招聘信息,然后复制此数据包的url链接: </p
ppageno = 2&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 845&guid = bbb37e8f266b9de3e2a9/p
p接下来,让我们比较一下之前和之后的两个链接,以分析异同. 可以看出,除了属性“ pageno”外,其他所有内容都是相同的. 没错,以红色标记. 第一个数据包链接中的pageno值为1,第二个pageno值为2,因此翻页的规则一目了然./p
p现在我们已经找到了APP翻页的请求链接规则,我们可以通过采集器循环将pageno分配给pageno,以实现模拟翻页的功能./p
p让我们再次尝试更改搜索关键字,以查看链接中的变化,以“ java”作为关键字,捕获的数据包为:/p
pkeyword = java&keywordtype = 2&jobarea = 000000&searchid =&famoustype =&pageno = 1&pagesize = 30&accountid =&key =&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c26369845>
经过比较,发现只有链接中的keyword值不同,并且该值是我们自己输入的关键字. 因此,在爬虫中,我们可以通过字符串拼接来完全实现输入关键字模拟,以采集不同类型的招聘信息. 同样,您可以搜索诸如工作地点之类的信息规则,而本文将不对其进行描述.
解决翻页功能后,让我们探索数据包中XML的内容. 我们复制上面的第一个链接,然后在浏览器中将其打开. 打开后,屏幕如下:
以这种方式观看要舒服得多. 通过仔细观察,我们会发现APP上的每个职位发布都对应一个标签,每个职位中都有一个标签,并且有一个ID来标识职位. 例如,上面的第一篇文章是109384390,第二篇文章是109381483. 请记住该ID,稍后再使用.
实际上,接下来,我们单击第一个职位发布以进入第二页. 这时,Fiddler将采集APP刚发送的数据包,单击xml数据包,然后发现它是刚刚在APP上刷新的页面信息. 我们复制数据包的url链接:
jobid = 109384390&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
根据该方法,在第一级页面上的列表中单击第二个作业,然后从Fiddler复制相应数据包的url链接:
jobid = 109381483&accountid =&key =&from = searchjoblist&jobtype = 0100&productname = 51job&partner = 8785419449a858b3314197b60d54d9c6&uuid = 6b21f77c7af3aa83a5c636792ba087c2&version = 0845&guid = 9bf37e8f
比较以上两个链接,您是否找到了模式?是的,jobid不同,其他都一样. 此Jobid是我们在第一页xml中找到的jobid. 由此,我们可以从第一级页面获取Jobid来构造第二级页面的url链接,然后采集我们需要的所有信息. 整个采集器逻辑很明确:
构造第一级页面的初始URL->采集jobid->构造第二级页面的URL->获取工作信息->通过循环模拟获取下一页的URL.
好的,分析工作已经完成,我开始编写采集器.
3编写采集器
本文使用的是无忧移动APP网络采集器的Scrapy框架. 在下载了草率的第三方软件包之后,通过命令行创建一个爬虫项目:
scrapy startproject job_spider.
job_spider是我们的检索器项目的项目名称. 有一个“. ”在项目名称之后. 这一点是可选的. 区别在于在当前文件之间创建一个项目,或者创建一个与项目名称相同的文件. 在文件中创建一个项目.
创建项目后,继续创建一个采集器,专用于搜寻51job发布的招聘信息. 创建一个名称如下的采集器:
scrapy genspider qcwySpider
注意: 如果未添加“. ”. 创建爬网程序项目时,将其更改为项目名称,请在运行命令以创建爬网程序之前进入项目文件夹.
打开刚刚通过pycharm创建的爬虫项目,左侧的目录树结构如下:
在开始所有采集器工作之前,请先打开settings.py文件,然后取消注释“ ROBOTSTXT_OBEY = False”行并将其值更改为False.
#遵守robots.txt规则ROBOTSTXT_OBEY = False
完成以上修改后,在spiders包下打开qcwySpider.py. 初始代码如下:
这是scrapy为我们建立的框架. 我们只需要在此基础上改进爬虫.
首先,我们需要向类添加一些属性,例如search关键字keyword,起始页,要进行爬网以获得最大页面数,还需要设置标头以进行简单的反爬网. 此外,starturl也需要重置为第一页的URL. 更改后的代码如下:
然后开始编写parse方法来对第一级页面进行爬网. 在第一页中,我们的主要逻辑是通过循环在APP中实现屏幕幻灯片的更新. 我们在上面的代码中使用current_page来标识当前页码,在每个循环之后,将1添加到current_page中,然后构造一个新的url,并通过回调解析方法抓取下一页. 另外,我们还需要在parse方法中从第一级页面采集jobid,并构造第二级页面,然后回调实现第二级页面信息采集的parse_job方法. 解析方法代码如下:
为了便于调试,我们在项目的jobSpider目录中创建一个main.py文件来启动采集器,并在每次启动采集器时运行该文件. 内容如下:
辅助页面信息采集功能是在parse_job方法中实现的,因为我们需要获取的所有信息都在xml中,所以我们可以使用scrapy附带的选择器直接提取它,但是在提取之前,我们需要先定义用于存储我们采集的数据的项目. 打开items.py文件,编写一个Item类,然后输入以下代码:
上面的每个项目都对应一个xml标记,该标记用于存储一条信息. 在qcwyJobsItem类的末尾,定义了一个do_insert方法,该方法用于生成插入语句,该语句将所有信息存储在数据库中的项目中. 之所以在items块中生成此insert语句,是因为如果将来有多个采集器,则在管道模块中可以有多个项目类之后,可以为不同的项目插入数据库,以使该项目更具可伸缩性. 您还可以编写所有与在管道中插入数据库有关的代码.
然后编写parse_job方法:
完成上述代码后,信息采集部分完成. 接下来,继续编写信息存储功能,该功能在pipelines.py中完成.
在编写pipeline.py之后,打开settings.py文件并配置刚刚写入项目设置文件的MysqlTwistedPipline类:
另外,还要配置数据库:
您还可以将数据库配置嵌入MysqlTwistedPipline类中,但是我习惯于将这些专有数据库信息写入配置文件中.
最后,仅需一步即可建立数据库和数据表. 表结构的一部分如下所示:
完成上述所有操作后,您可以运行采集器以开始采集数据. 采集的数据如下图所示:
4摘要
经过整个过程,我觉得51job.com APP的爬取比Web爬取更容易(似乎很多网站都是这样). 回顾整个过程,实际上代码中有许多细节可以改进和完善,例如,在构建链接时可以添加职位搜索位置. 这篇博客文章侧重于整个爬网程序过程的逻辑分析,并介绍了APP的基本爬网方法. 博客文章中省略了部分代码. 如果您需要完整的代码,请从我的github获得. 将来,我们将继续更新其他招聘网站的抓取工具. 返回搜狐查看更多
Python使用Sina API实现数据捕获
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2020-08-08 00:14
我主要抓取了大约4天的数据. 该图显示大约有360万个数据. 由于我在自己的计算机上爬网以获取数据,因此有时晚上网络会中断. 因此,大约一天之内就可以抓取大约一百万个最新的微博数据(因为我将其称为最新的微博API public_timeline)
API文档中定义了很多返回类型(以json数据格式返回,我选择了一些我认为要抓住它的重要信息,如图所示): 可能是ID号,位置,粉丝数,微博内容,发布时间等. 当然,这些数据可以根据您的需要进行自定义. )
可能是内容,如果您认为对您有所帮助,请继续阅读...第一次写博客有点冗长
2. 初步准备
我们需要什么:
数据库: mongodb(您可以使用客户端MongoBooster)
开发环境: Python2.7(我使用的IDE是Pycharm)
新浪开发者帐户: 只需注册您自己的新浪微博帐户(我们稍后会讨论)
所需的库: 请求和pymongo(可在Pycharm中下载)
2.1Mongodb安装
MongoDB是高性能,开源,无模式的基于文档的数据库,并且是最受欢迎的NoSql数据库之一. 在许多情况下,它可以用来代替传统的关系数据库或键/值存储. Mongo用C ++开发. Mongo的官方网站地址是: 读者可以在这里获取更多详细信息.
2.2如何注册新浪开发者帐户
注册一个新浪微博帐户(163邮箱,手机号码)
创建后,您需要填写手机号码验证
进入Sina Opener平台:
点击以继续创建
第一次创建应用程序时,需要填写以下信息:
代码实现
有了令牌,捕获数据非常简单.
可以抓取多少数据取决于您的令牌权限
下一步是使用API获取数据: 创建一个新文件weibo_run.py 查看全部
1. 首先,让我们看一下获得的最终结果,是否是您想知道的东西,然后决定是否继续读下去.
我主要抓取了大约4天的数据. 该图显示大约有360万个数据. 由于我在自己的计算机上爬网以获取数据,因此有时晚上网络会中断. 因此,大约一天之内就可以抓取大约一百万个最新的微博数据(因为我将其称为最新的微博API public_timeline)
API文档中定义了很多返回类型(以json数据格式返回,我选择了一些我认为要抓住它的重要信息,如图所示): 可能是ID号,位置,粉丝数,微博内容,发布时间等. 当然,这些数据可以根据您的需要进行自定义. )
可能是内容,如果您认为对您有所帮助,请继续阅读...第一次写博客有点冗长
2. 初步准备
我们需要什么:
数据库: mongodb(您可以使用客户端MongoBooster)
开发环境: Python2.7(我使用的IDE是Pycharm)
新浪开发者帐户: 只需注册您自己的新浪微博帐户(我们稍后会讨论)
所需的库: 请求和pymongo(可在Pycharm中下载)
2.1Mongodb安装
MongoDB是高性能,开源,无模式的基于文档的数据库,并且是最受欢迎的NoSql数据库之一. 在许多情况下,它可以用来代替传统的关系数据库或键/值存储. Mongo用C ++开发. Mongo的官方网站地址是: 读者可以在这里获取更多详细信息.
2.2如何注册新浪开发者帐户
注册一个新浪微博帐户(163邮箱,手机号码)
创建后,您需要填写手机号码验证
进入Sina Opener平台:
点击以继续创建
第一次创建应用程序时,需要填写以下信息:
代码实现
有了令牌,捕获数据非常简单.
可以抓取多少数据取决于您的令牌权限
下一步是使用API获取数据: 创建一个新文件weibo_run.py
WorDPrEss集合插件WPRoBot2.12破解版和使用教程. pdf9页
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2020-08-08 00:13
根据您选择的预设设置,使工作自动更新您的博客. 带有新信息的流行站点,例如相关目录的抓取,可能是获取目录的好地方. WpRobot是一个插件,可以自动生成Wordpress Blog文章,该文章可以自动采集网站上的文章,视频,图片,产品信息,例如yahoo news,yahoo Answer,youtube,flickr,amazon,ebay,Clickbank,Cj等. 根据设置的关键字等等,与自动重写插件配合使用以制作伪原创,而不再担心建立英语网站. WpRobot的功能创建具有所需内容的任何文章并将其发布到WordPress博客中,您只需要设置相关的关键字即可. 创建任何不同类别的文章,例如使用不同关键字的不同类别; 自定义两篇文章的发布时间间隔,最小间隔为一小时,当然,您也可以设置为一或几天的间隔; 精确控制文章内容的生成,通过关键字匹配创建不同的任务,并避免重复文章;保留所有权利自动获取文章标签. 标签是Wordpress的更好功能之一. 访客可以通过某些标签搜索具有相同标签的文章; 自定义模板. 如果您对模板不满意,可以修改模板;实际上,WpRobot绝对不具有这些功能,但我还没有想到. 您会发现它在使用过程中是如此强大且易于使用. 建立一个英文博客不再是障碍.
以下是WpRobot的基本用法教程. 第1步: 上传WpRobot插件并在后台激活它. 步骤2: 设置关键字以输入WP背景,找到WpRobot3选项,然后单击create campaign(创建采集组). 有三种采集方法. 一种是关键字活动(按键),Word),Rss活动(博客帖子RSS),BrowseNode campaig n(亚马逊产品节点). 首先是按关键字采集. 单击右侧的快速模板设置. 当然,您也可以选择“随机”模板来查看两者之间的区别. 在“为广告系列命名”中填写您的名称. 对于关键字组的名称(例如IPad),在关键字下方的框中填写关键字,每行一个关键字,然后设置类别. 在下面的左侧(例如一小时,一天等)设置采集频率,并在右侧设置是否自动建立分类(不建议这样做,因为效果确实很差). 以下是关键模板设置,共有8个(请注意,单击“快速模板设置”时将显示8).
文章,亚马逊产品,雅虎问答,雅虎新闻,CB,YouTube视频,eBay和Flickr依次排列. 建议不要在这里全部使用它们. 保留要使用的任何一个,然后添加每个模板的采集率. 不需要时,单击相应模板下的删除模板. 后者的设置如下图所示,基本上没有变化,主要用于替换关键字,删除关键字,设置翻译等. 所有权利均已设置,请单击下面的“创建广告系列”以完成广告组的创建. 第三步: WP Robot Options选项设置许可证选项许可选项,填写您购买了正版WpRobot插件的PayPal电子邮件地址,然后可以随意输入破解版本. 此选项会自动显示,并且在启用WpRobot时可以使用它. 系统将要求您输入此电子邮件地址. 常规选项常规选项设置启用简单模式,是否允许简单模式,如果允许,请打勾;新职位状态,新职位状态,有三种类型的状态: 已发布和草稿,通常选择发布;重置过帐计数器: 文章数返回零,否或是;启用帮助工具提示,是否启用帮助工具提示;启用旧重复检查,是否启用旧版本重复检查;此处没有一一说明随机化Tim Times,随机文章发表时间以及此处的其他一些选项,使用翻译工具将了解翻译的含义.
保留所有权利的Amazon Options选项设置Amazon Affiliate ID,填写Amazon会员ID号; API密钥(访问密钥ID),填写Amazon API;应用;秘密访问密钥,将在申请API后提供给您;搜索方法,搜索方法: 完全匹配(严格匹配),广泛匹配(广泛匹配);跳过产品如果不跳过(生死不跳过)或找不到描述(没有描述)或找不到缩略图(没有缩略图))或没有描述或没有缩略图(没有描述或缩略图),请跳过此产品产品; Amazon Description长度,描述长度;亚马逊网站,选择;标题中的方括号,是(默认);将评论发布为评论?选择是;发布模板: 默认模板或修改后的模板.
烟台SEO /整理,重印并注明出处. 谢谢. 保留所有权利. 文章选项“文章”选项设置“文章语言”,选择“英语”和“页面”作为文章的语言,如果您将其选中,则将一个长文章分成N个字符的几页;从...中删除所有链接. 删除所有链接. Clickbank选项设置Clickbank会员ID,填写Clickbank会员ID;过滤广告?过滤广告. eBay选项设置了所有权利. eBay会员ID(CampID),eBay会员ID;国家,国家选择美国;语言,语言选择英文;对结果进行排序,传递什么排序. Flickr选项设置Flickr API密钥,Flickr API应用程序密钥;许可,许可方式;图像尺寸,图像尺寸. Yahoo Answers Options和Yahoo News Options设置Yahoo Application ID,两者的ID相同,请单击此处应用;保留所有权利Youtube选项和RSS选项设置查看图片并将其翻译,您应该知道如何设置它.
翻译选项使用代理来使用代理,是的,随机选择以下一项,请是,随机选择以下代理地址;如果翻译失败...如果翻译失败,请创建未翻译的文章或跳过该文章. 保留所有权利Twitter Options设置Commission Junction Options设置如果您有做过CJ的朋友,这些设置应该很容易获得,如果您没有做过CJ,请跳过它. 这里省略了一些设置,这些设置是最不常用的,默认设置为OK,最后按Save Options保存设置. 步骤4: 修改模板. 修改模板也是一个更关键的步骤. 如果您对现有模板不满意,可以自己修改它. 有时会产生很好的效果. 例如,有些人采集eBay信息并将标题更改为“产品名称+拍卖组合模板”的效果是显而易见的,并且添加了很多Sale. 步骤5: 发布文章. 发布文章是最后一步. 添加关键字后,单击WpRobot的第一个选项Campaigns. 您将在此处找到刚刚填写的采集的关键字. 将鼠标移到某个关键字上. 单击“立即发布”,您会惊讶地发现WpRobot已开始采集和发布文章.
保留所有权利当然,还有更强大的功能,它们可以同时发布N篇文章. 选择您要采集的组,然后如下图所示在“ Nuber of Posts”中填写文章数,例如,50篇文章,在Backdate?前面打勾,文章发表日期从2008-09-24开始,并且两篇文章的发布时间为1到2天. 单击立即发布,WpRobot将开始采集文章. 采集到的50篇文章将于2008年9月24日发表. 两篇文章之间的时间为一到两天. WP全自动外部链接插件在这里,向您推荐WP全自动外部链接插件: 自动Backlink Creator插件. 我本人已经使用过该软件,效果非常好,所以今天推荐在这里,希望它可以节省每个人的时间和精力进行外部链接!自动反向链接创建器主要用于由wordpress程序构建的网站. 热衷WP的网站管理员和朋友,特别是对于那些从事外贸业务(主要是Google和Yahoo搜索引擎SEO)的人,这应该是一个好消息!该软件类似于WP插件,是WP网站外部链的完美解决方案!您只需要在网站的后台轻松安装它,即可为搜索引擎提供一种很好的方法,以自动向WP网站添加高权重的外部链接.
最近,在此软件的官方网站上,Automatic Backlink Creator的价格仅为37美元. 您可以用信用卡或贝宝付款. 在国外很受欢迎!在购买的同时,还赠送了MetaSnatcher插件作为礼物. 该插件可以自动跟踪Google顶级竞争对手的核心要点,并自动返回到该软件,从而节省了大量的关键字分析时间. Spin Master Pro插件. 该插件等效于WP脱机伪原创和发布插件. 安装此插件后,您可以在计算机上制作伪原创内容并脱机发布,从而节省大量时间. 同时,该软件提供60天不令人满意的退款保证. 点击查看此软件的开发人员是一组SEO大师,他们结合了Google和Yahoo的外链算法来开发此功能强大且出色的外链软件,同时考虑了外链PR,OBL,FLAG等极端方面方面. 并且通过该系统,可以生成稳定且持续增长的高质量反链,例如指向.edu,.gov等网站的外部链接. 下载: 最经典的SEO链轮解决方案 查看全部
保留所有权利WordPress集合插件WPRobot_2.12破解版并使用教程Wprobot3.12破解版下载地址: / space / file / liuzhilei121 / share / 2010/11/26 / WPRo bot3.1-6700-65b0-7834 -89e3-7248.rar / .page WPRobot一直是WP英语垃圾站的必备插件,尤其是对于像我这样英语水平较低的人而言. 它是WordPress博客的集合插件. 上面是WPRobot 3.12地址最新破解版的下载,有需要的兄弟可以自己下载,这里继续关注最新破解版,当您开始使用WPRobot插件时,您会意识到它有多聪明. 它是从多个来源生成的. 您是在自动驾驶仪Wor Dpress博客上创建的. 在设计WPRobot时,负责人认为最好将其分成模块,以允许客户定制其特殊需求的插件. 例如,Amazon和YouTube附加组件允许您添加主目录和注释. 该系统的优点是所有模块均可由选定模块单独购买. 模块智能化可以满足所有用户需求. WPRobot是自动博客的超级插件. 考虑一下您喜欢的所有主题,它将使您发布目录而不是编写目录.
根据您选择的预设设置,使工作自动更新您的博客. 带有新信息的流行站点,例如相关目录的抓取,可能是获取目录的好地方. WpRobot是一个插件,可以自动生成Wordpress Blog文章,该文章可以自动采集网站上的文章,视频,图片,产品信息,例如yahoo news,yahoo Answer,youtube,flickr,amazon,ebay,Clickbank,Cj等. 根据设置的关键字等等,与自动重写插件配合使用以制作伪原创,而不再担心建立英语网站. WpRobot的功能创建具有所需内容的任何文章并将其发布到WordPress博客中,您只需要设置相关的关键字即可. 创建任何不同类别的文章,例如使用不同关键字的不同类别; 自定义两篇文章的发布时间间隔,最小间隔为一小时,当然,您也可以设置为一或几天的间隔; 精确控制文章内容的生成,通过关键字匹配创建不同的任务,并避免重复文章;保留所有权利自动获取文章标签. 标签是Wordpress的更好功能之一. 访客可以通过某些标签搜索具有相同标签的文章; 自定义模板. 如果您对模板不满意,可以修改模板;实际上,WpRobot绝对不具有这些功能,但我还没有想到. 您会发现它在使用过程中是如此强大且易于使用. 建立一个英文博客不再是障碍.
以下是WpRobot的基本用法教程. 第1步: 上传WpRobot插件并在后台激活它. 步骤2: 设置关键字以输入WP背景,找到WpRobot3选项,然后单击create campaign(创建采集组). 有三种采集方法. 一种是关键字活动(按键),Word),Rss活动(博客帖子RSS),BrowseNode campaig n(亚马逊产品节点). 首先是按关键字采集. 单击右侧的快速模板设置. 当然,您也可以选择“随机”模板来查看两者之间的区别. 在“为广告系列命名”中填写您的名称. 对于关键字组的名称(例如IPad),在关键字下方的框中填写关键字,每行一个关键字,然后设置类别. 在下面的左侧(例如一小时,一天等)设置采集频率,并在右侧设置是否自动建立分类(不建议这样做,因为效果确实很差). 以下是关键模板设置,共有8个(请注意,单击“快速模板设置”时将显示8).
文章,亚马逊产品,雅虎问答,雅虎新闻,CB,YouTube视频,eBay和Flickr依次排列. 建议不要在这里全部使用它们. 保留要使用的任何一个,然后添加每个模板的采集率. 不需要时,单击相应模板下的删除模板. 后者的设置如下图所示,基本上没有变化,主要用于替换关键字,删除关键字,设置翻译等. 所有权利均已设置,请单击下面的“创建广告系列”以完成广告组的创建. 第三步: WP Robot Options选项设置许可证选项许可选项,填写您购买了正版WpRobot插件的PayPal电子邮件地址,然后可以随意输入破解版本. 此选项会自动显示,并且在启用WpRobot时可以使用它. 系统将要求您输入此电子邮件地址. 常规选项常规选项设置启用简单模式,是否允许简单模式,如果允许,请打勾;新职位状态,新职位状态,有三种类型的状态: 已发布和草稿,通常选择发布;重置过帐计数器: 文章数返回零,否或是;启用帮助工具提示,是否启用帮助工具提示;启用旧重复检查,是否启用旧版本重复检查;此处没有一一说明随机化Tim Times,随机文章发表时间以及此处的其他一些选项,使用翻译工具将了解翻译的含义.
保留所有权利的Amazon Options选项设置Amazon Affiliate ID,填写Amazon会员ID号; API密钥(访问密钥ID),填写Amazon API;应用;秘密访问密钥,将在申请API后提供给您;搜索方法,搜索方法: 完全匹配(严格匹配),广泛匹配(广泛匹配);跳过产品如果不跳过(生死不跳过)或找不到描述(没有描述)或找不到缩略图(没有缩略图))或没有描述或没有缩略图(没有描述或缩略图),请跳过此产品产品; Amazon Description长度,描述长度;亚马逊网站,选择;标题中的方括号,是(默认);将评论发布为评论?选择是;发布模板: 默认模板或修改后的模板.
烟台SEO /整理,重印并注明出处. 谢谢. 保留所有权利. 文章选项“文章”选项设置“文章语言”,选择“英语”和“页面”作为文章的语言,如果您将其选中,则将一个长文章分成N个字符的几页;从...中删除所有链接. 删除所有链接. Clickbank选项设置Clickbank会员ID,填写Clickbank会员ID;过滤广告?过滤广告. eBay选项设置了所有权利. eBay会员ID(CampID),eBay会员ID;国家,国家选择美国;语言,语言选择英文;对结果进行排序,传递什么排序. Flickr选项设置Flickr API密钥,Flickr API应用程序密钥;许可,许可方式;图像尺寸,图像尺寸. Yahoo Answers Options和Yahoo News Options设置Yahoo Application ID,两者的ID相同,请单击此处应用;保留所有权利Youtube选项和RSS选项设置查看图片并将其翻译,您应该知道如何设置它.
翻译选项使用代理来使用代理,是的,随机选择以下一项,请是,随机选择以下代理地址;如果翻译失败...如果翻译失败,请创建未翻译的文章或跳过该文章. 保留所有权利Twitter Options设置Commission Junction Options设置如果您有做过CJ的朋友,这些设置应该很容易获得,如果您没有做过CJ,请跳过它. 这里省略了一些设置,这些设置是最不常用的,默认设置为OK,最后按Save Options保存设置. 步骤4: 修改模板. 修改模板也是一个更关键的步骤. 如果您对现有模板不满意,可以自己修改它. 有时会产生很好的效果. 例如,有些人采集eBay信息并将标题更改为“产品名称+拍卖组合模板”的效果是显而易见的,并且添加了很多Sale. 步骤5: 发布文章. 发布文章是最后一步. 添加关键字后,单击WpRobot的第一个选项Campaigns. 您将在此处找到刚刚填写的采集的关键字. 将鼠标移到某个关键字上. 单击“立即发布”,您会惊讶地发现WpRobot已开始采集和发布文章.
保留所有权利当然,还有更强大的功能,它们可以同时发布N篇文章. 选择您要采集的组,然后如下图所示在“ Nuber of Posts”中填写文章数,例如,50篇文章,在Backdate?前面打勾,文章发表日期从2008-09-24开始,并且两篇文章的发布时间为1到2天. 单击立即发布,WpRobot将开始采集文章. 采集到的50篇文章将于2008年9月24日发表. 两篇文章之间的时间为一到两天. WP全自动外部链接插件在这里,向您推荐WP全自动外部链接插件: 自动Backlink Creator插件. 我本人已经使用过该软件,效果非常好,所以今天推荐在这里,希望它可以节省每个人的时间和精力进行外部链接!自动反向链接创建器主要用于由wordpress程序构建的网站. 热衷WP的网站管理员和朋友,特别是对于那些从事外贸业务(主要是Google和Yahoo搜索引擎SEO)的人,这应该是一个好消息!该软件类似于WP插件,是WP网站外部链的完美解决方案!您只需要在网站的后台轻松安装它,即可为搜索引擎提供一种很好的方法,以自动向WP网站添加高权重的外部链接.
最近,在此软件的官方网站上,Automatic Backlink Creator的价格仅为37美元. 您可以用信用卡或贝宝付款. 在国外很受欢迎!在购买的同时,还赠送了MetaSnatcher插件作为礼物. 该插件可以自动跟踪Google顶级竞争对手的核心要点,并自动返回到该软件,从而节省了大量的关键字分析时间. Spin Master Pro插件. 该插件等效于WP脱机伪原创和发布插件. 安装此插件后,您可以在计算机上制作伪原创内容并脱机发布,从而节省大量时间. 同时,该软件提供60天不令人满意的退款保证. 点击查看此软件的开发人员是一组SEO大师,他们结合了Google和Yahoo的外链算法来开发此功能强大且出色的外链软件,同时考虑了外链PR,OBL,FLAG等极端方面方面. 并且通过该系统,可以生成稳定且持续增长的高质量反链,例如指向.edu,.gov等网站的外部链接. 下载: 最经典的SEO链轮解决方案
dragou网的API和项目案例数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2020-08-07 16:00
一个. API
定义
API(应用程序编程接口,应用程序编程接口)是一些预定义的功能,或指软件系统不同组件之间的协议. 目的是使应用程序和开发人员能够访问基于某些软件或硬件的一组例程,而不必访问原创代码或了解内部工作机制的细节.
使用方法
API使用一组非常标准的规则来生成数据,并且生成的数据以非常标准的方式进行组织. 由于这些规则非常标准,因此一些简单的基本规则易于学习,因此您可以快速掌握API的用法. 但并非所有API都易于使用. 有些API有很多规则,而且非常复杂,因此您可以在使用前查看API的相关帮助文档
API验证
1)有些简单的操作不需要验证. 是免费的API
2)大多数API都需要用户提交和验证. 提交验证的主要目的是计算API调用的费用,这是一种常见的付费API. 例如: 图灵的聊天机器人
2. 拖动网项目案例数据采集(一)需求分析
通过数据采集,获取对拉沟发布的专业职位的需求分析.
(2)数据分析和实验结果首先分析网站的详细信息页面(此时关键字使用python). 在真实的请求URL中,网页将返回一个JSON字符串,我们需要解析该JSON字符串. 在页面上获取信息. 通过更改表单数据中pn的值来控制翻页. 从页面的详细信息页面,我们需要获取诸如“职务”,“职务说明”,“职务要求”等信息.
1)首先,我们请求标头信息
我们需要构造请求标头的标头信息. 如果未在此处构建,则很容易被网站识别为爬虫,因此拒绝了我们的请求
2)表单信息
发送POST请求时需要包括的表单信息(表单数据),需要解析的页码和搜索关键字
3)返回JSON数据
我们可以通过网页找到需要的信息,这些信息随时都在-> positionResult->结果中,其中收录工作地点,职位信息,公司名称等. 这些正是我们所需要的数据.
相关代码:
在配置文件中: (此文件的作用是: 当您以后要爬网其他类别或修改相关参数时,可以直接在文件中对其进行修改)
from fake_useragent import UserAgent
import requests
Host = 'www.lagou.com'
Origin = 'https://www.lagou.com'
Refer = 'https://www.lagou.com/jobs/list_python'
Connection = 'keep-alive'
Accept = 'application/json,text/javascript,*/*; q=0.01'
ua = UserAgent(verify_ssl=False)
ThreadCount = 50
csv_filename = 'filename.csv'
pages = 20
keyword = "python"
分析页面的核心代码:
#需要导入的模块
import time
import pandas as pd
import requests
from config import *
import logging
from concurrent.futures import ThreadPoolExecutor
import pprint
# 灵活配置日志级别,日志格式,输出位置
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='lagou.log',
filemode='w')
# 获取PositionID所在的页面,返回的是json数据
def getPositionIDPage(url_start, url_parse, page=1, kd='python'):
# 构造请求头(headers)
headers = {'User-Agent': ua.random,
'Host': Host,
'Origin': Origin,
'Referer': Refer,
'Connection': Connection,
'Accept': Accept,
'proxies': proxy}
# 构造表单
data = {
'first': False,
'pn': str(page),
'kd': kd
}
try:
# requests库里面的session对象能够帮助我们跨请求保持某些参数
# 也会在同一个session实例发出的所有请求之间保持cookies
# 创建一个session对象
session = requests.Session()
# 用session对象发出get 请求,设置cookies
session.get(url_start, headers=headers, timeout=3)
cookie = session.cookies
# 用session对象发出另一个请求post,获取cookies,返回响应信息
response = session.post(url=url_parse,
headers=headers,
data=data)
time.sleep(1)
# 响应状态码是4XX客户端错误,5XX 服务端响应错误,抛出异常
response.raise_for_status()
response.encoding = response.apparent_encoding
except Exception as e:
logging.error("页面" + url_parse + "爬取失败:", e)
else:
logging.info("页面" + url_parse + "爬取成功" + str(response.status_code))
return response.json()
运行测试:
if __name__ == '__main__':
url_start = 'https://www.lagou.com/jobs/list_%s' % (keyword)
url_parse = 'https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false'
content = getPositionIDPage(url_start, url_parse, page=page, kd=keyword)
pprint(content)
达到的效果:
3. 抓取相关的职位信息
获取所需职位的标签,招聘信息的每一页上都会有一个标签
positions = html['content']['positionResult']['result']
pprint.pprint(html)
df = pd.DataFrame(positions)
4. 商店信息
当我们找到所需的页面信息并对其进行爬网时,我们会将爬网的职位信息存储在一个csv文件中
def save_as_csv():
#开启进程池
with ThreadPoolExecutor(ThreadCount) as pool:
#map方法: 可迭代对象传入函数是从前到后逐个提取元素,并且将结果依次保存在results中。
results = pool.map(task, range(1, pages + 1))
# total_df:拼接所有的信息,(axis=0,代表列拼接)
total_df = pd.concat(results, axis=0)
total_df.to_csv(csv_filename, sep=',', header=True, index=False)
logging.info("文件%s 存储成功" % (csv_filename))
return total_df
注意: 这里使用线程池方法来解析和保存
达到的效果:
数据分析
成功抓取后,我们可以分析所拥有的数据并查看每个位置的统计信息
import pandas as pd
from config import *
import matplotlib.pyplot as plt
import matplotlib
# 修改配置中文字字体和大小的修改
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
matplotlib.rcParams['font.size'] = 12
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv(csv_filename, encoding='utf-8')
def show_seconfd_type():
# 获取职位类别分类,并分组统计
secondType_Series = df['secondType'].value_counts()
print(secondType_Series)
# 设置图形大小
plt.figure(figsize=(10, 5))
secondType_Series.plot.bar()
plt.show()
#实习和全职的统计
def show_job_nature():
jobNature_Series = df['jobNature'].value_counts()
print(jobNature_Series)
plt.figure(figsize=(10, 5))
jobNature_Series.plot.pie()
plt.show()
# 获取招聘公司
def show_company():
companyShortName_Series = df['companyShortName'].value_counts()
companyShortName_Series_gt5 = companyShortName_Series[companyShortName_Series > 2]
plt.figure(figsize=(10, 5))
companyShortName_Series_gt5.plot.bar()
plt.show()
if __name__ == '__main__':
show_seconfd_type()
show_job_nature()
show_company()
达到的效果:
查看全部
文章目录
一个. API
定义
API(应用程序编程接口,应用程序编程接口)是一些预定义的功能,或指软件系统不同组件之间的协议. 目的是使应用程序和开发人员能够访问基于某些软件或硬件的一组例程,而不必访问原创代码或了解内部工作机制的细节.
使用方法
API使用一组非常标准的规则来生成数据,并且生成的数据以非常标准的方式进行组织. 由于这些规则非常标准,因此一些简单的基本规则易于学习,因此您可以快速掌握API的用法. 但并非所有API都易于使用. 有些API有很多规则,而且非常复杂,因此您可以在使用前查看API的相关帮助文档
API验证
1)有些简单的操作不需要验证. 是免费的API
2)大多数API都需要用户提交和验证. 提交验证的主要目的是计算API调用的费用,这是一种常见的付费API. 例如: 图灵的聊天机器人
2. 拖动网项目案例数据采集(一)需求分析
通过数据采集,获取对拉沟发布的专业职位的需求分析.
(2)数据分析和实验结果首先分析网站的详细信息页面(此时关键字使用python). 在真实的请求URL中,网页将返回一个JSON字符串,我们需要解析该JSON字符串. 在页面上获取信息. 通过更改表单数据中pn的值来控制翻页. 从页面的详细信息页面,我们需要获取诸如“职务”,“职务说明”,“职务要求”等信息.
1)首先,我们请求标头信息
我们需要构造请求标头的标头信息. 如果未在此处构建,则很容易被网站识别为爬虫,因此拒绝了我们的请求
2)表单信息
发送POST请求时需要包括的表单信息(表单数据),需要解析的页码和搜索关键字
3)返回JSON数据
我们可以通过网页找到需要的信息,这些信息随时都在-> positionResult->结果中,其中收录工作地点,职位信息,公司名称等. 这些正是我们所需要的数据.
相关代码:
在配置文件中: (此文件的作用是: 当您以后要爬网其他类别或修改相关参数时,可以直接在文件中对其进行修改)
from fake_useragent import UserAgent
import requests
Host = 'www.lagou.com'
Origin = 'https://www.lagou.com'
Refer = 'https://www.lagou.com/jobs/list_python'
Connection = 'keep-alive'
Accept = 'application/json,text/javascript,*/*; q=0.01'
ua = UserAgent(verify_ssl=False)
ThreadCount = 50
csv_filename = 'filename.csv'
pages = 20
keyword = "python"
分析页面的核心代码:
#需要导入的模块
import time
import pandas as pd
import requests
from config import *
import logging
from concurrent.futures import ThreadPoolExecutor
import pprint
# 灵活配置日志级别,日志格式,输出位置
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='lagou.log',
filemode='w')
# 获取PositionID所在的页面,返回的是json数据
def getPositionIDPage(url_start, url_parse, page=1, kd='python'):
# 构造请求头(headers)
headers = {'User-Agent': ua.random,
'Host': Host,
'Origin': Origin,
'Referer': Refer,
'Connection': Connection,
'Accept': Accept,
'proxies': proxy}
# 构造表单
data = {
'first': False,
'pn': str(page),
'kd': kd
}
try:
# requests库里面的session对象能够帮助我们跨请求保持某些参数
# 也会在同一个session实例发出的所有请求之间保持cookies
# 创建一个session对象
session = requests.Session()
# 用session对象发出get 请求,设置cookies
session.get(url_start, headers=headers, timeout=3)
cookie = session.cookies
# 用session对象发出另一个请求post,获取cookies,返回响应信息
response = session.post(url=url_parse,
headers=headers,
data=data)
time.sleep(1)
# 响应状态码是4XX客户端错误,5XX 服务端响应错误,抛出异常
response.raise_for_status()
response.encoding = response.apparent_encoding
except Exception as e:
logging.error("页面" + url_parse + "爬取失败:", e)
else:
logging.info("页面" + url_parse + "爬取成功" + str(response.status_code))
return response.json()
运行测试:
if __name__ == '__main__':
url_start = 'https://www.lagou.com/jobs/list_%s' % (keyword)
url_parse = 'https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false'
content = getPositionIDPage(url_start, url_parse, page=page, kd=keyword)
pprint(content)
达到的效果:
3. 抓取相关的职位信息
获取所需职位的标签,招聘信息的每一页上都会有一个标签
positions = html['content']['positionResult']['result']
pprint.pprint(html)
df = pd.DataFrame(positions)
4. 商店信息
当我们找到所需的页面信息并对其进行爬网时,我们会将爬网的职位信息存储在一个csv文件中
def save_as_csv():
#开启进程池
with ThreadPoolExecutor(ThreadCount) as pool:
#map方法: 可迭代对象传入函数是从前到后逐个提取元素,并且将结果依次保存在results中。
results = pool.map(task, range(1, pages + 1))
# total_df:拼接所有的信息,(axis=0,代表列拼接)
total_df = pd.concat(results, axis=0)
total_df.to_csv(csv_filename, sep=',', header=True, index=False)
logging.info("文件%s 存储成功" % (csv_filename))
return total_df
注意: 这里使用线程池方法来解析和保存
达到的效果:
数据分析
成功抓取后,我们可以分析所拥有的数据并查看每个位置的统计信息
import pandas as pd
from config import *
import matplotlib.pyplot as plt
import matplotlib
# 修改配置中文字字体和大小的修改
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
matplotlib.rcParams['font.size'] = 12
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv(csv_filename, encoding='utf-8')
def show_seconfd_type():
# 获取职位类别分类,并分组统计
secondType_Series = df['secondType'].value_counts()
print(secondType_Series)
# 设置图形大小
plt.figure(figsize=(10, 5))
secondType_Series.plot.bar()
plt.show()
#实习和全职的统计
def show_job_nature():
jobNature_Series = df['jobNature'].value_counts()
print(jobNature_Series)
plt.figure(figsize=(10, 5))
jobNature_Series.plot.pie()
plt.show()
# 获取招聘公司
def show_company():
companyShortName_Series = df['companyShortName'].value_counts()
companyShortName_Series_gt5 = companyShortName_Series[companyShortName_Series > 2]
plt.figure(figsize=(10, 5))
companyShortName_Series_gt5.plot.bar()
plt.show()
if __name__ == '__main__':
show_seconfd_type()
show_job_nature()
show_company()
达到的效果:
百度地图POI边界坐标数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 504 次浏览 • 2020-08-07 06:19
因为之前我已经研究过AutoNavi地图的POI数据边界坐标的采集,其后面的界面过于不稳定,因此很难成功地采集数据. 此功能已被搁置一段时间. 最近,它在@entropy的帮助下完成. 使用百度地图界面采集POI边界函数. 但是,在此预先声明下,无论是百度还是AutoNavi,每个都使用POI的ID来完成边界坐标的采集. 相同的POI数据在AutoNavi和百度上具有不同的ID. 因此,如果要使用百度采集边界界面,则必须确保现有的POI数据是通过百度POI界面采集的,并且具有ID字段. (总结: 不要使用AutoNavi界面采集的POI数据调用百度界面来爬坡边界数据. )
确定POI边界数据采集的接口地址
https://map.baidu.com/%3Fnewma ... Bb%3D(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785
接口非常简单,不需要密钥,可以通过GET请求调用它. 在参数中,您需要使用自己的POI ID替换uid =之后的字符串. 因此,打开浏览器后可以看到结果,数据结构如下:
{
"content": {
"geo": "4|12674567.8667,2556549.714;12674700.0816,2556667.07656|1-12674700.0816,2556615.59082,12674663.0912,2556549.714,12674567.8667,2556601.53877,12674605.8561,2556667.07656,12674700.0816,2556615.59082;",
"uid": "207119787bb3c5c95d17c334"
},
"current_city": {
"code": 340,
"geo": "1|12697919.69,2560977.31;12697919.69,2560977.31|12697919.69,2560977.31;",
"level": 12,
"name": "深圳市",
"sup": 1,
"sup_bus": 1,
"sup_business_area": 1,
"sup_lukuang": 1,
"sup_subway": 1,
"type": 2,
"up_province_name": "广东省"
},
"err_msg": "",
"hot_city": [
"北京市|131",
"上海市|289",
"广州市|257",
"深圳市|340",
"成都市|75",
"天津市|332",
"南京市|315",
"杭州市|179",
"武汉市|218",
"重庆市|132"
],
"result": {
"data_security_filt_res": 0,
"error": 0,
"illegal": 0,
"login_debug": 1,
"qid": "",
"region": "0",
"type": 10,
"uii_qt": "poi_profile",
"uii_type": "china_main"
},
"uii_err": 0
}
current_city的地理位置是我们需要查找的POI数据的边界坐标,其余就是如何解析此数据. 但应注意,此坐标系是bd09mc(百度墨卡托公制坐标). 坐标系描述可以参考
http://lbs.baidu.com/index.php ... trans
因此数据需要稍后转换为百度经纬度坐标.
用于基于UID获取边界数据并进行简单分析的代码参考:
def get_boundary_by_uid(uid):
bmap_boundary_url = 'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=ext&uid=' + uid + '&c=340&ext_ver=new&tn=B_NORMAL_MAP&nn=0&auth=fw9wVDQUyKS7%3DQ5eWeb5A21KZOG0NadNuxHNBxBBLBHtxjhNwzWWvy1uVt1GgvPUDZYOYIZuEt2gz4yYxGccZcuVtPWv3GuxNt%3DkVJ0IUvhgMZSguxzBEHLNRTVtlEeLZNz1%40Db17dDFC8zv7u%40ZPuxtfvSulnDjnCENTHEHH%40NXBvzXX3M%40J2mmiJ4Y&ie=utf-8&l=19&b=(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785'
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(url=bmap_boundary_url, timeout=5, headers={"Connection": "close"})
data = data.text
data = json.loads(data)
content = data['content']
if not 'geo' in content:
return None
geo = content['geo']
i = 0
strsss = ''
for jj in str(geo).split('|')[2].split('-')[1].split(','):
jj = str(jj).strip(';')
if i % 2 == 0:
strsss = strsss + str(jj) + ','
else:
strsss = strsss + str(jj) + ';'
i = i + 1
return strsss.strip(";")
调用百度Map API进行坐标转换
http://lbsyun.baidu.com/index. ... ition
需要注意的是,该界面只能将其他坐标系中的数据转换为百度的公制坐标系和百度的经纬度坐标系,而不能反转.
http://api.map.baidu.com/geoco ... 2.343,232.34&from=6&to=5&ak=百度密钥
其中from = 6&to = 5表示从百度度量坐标系转换为百度经纬度坐标系. 有关详细信息,请参阅官方文档.
def transform_coordinate_batch(coordinates):
req_url = 'http://api.map.baidu.com/geoconv/v1/?coords='+coordinates+'&from=6&to=5&ak=' + bmap_key
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(req_url, timeout=5, headers={"Connection": "close"}) # , proxies=proxies
data = data.text
data = json.loads(data)
coords = ''
if data['status'] == 0:
result = data['result']
if len(result) > 0:
for res in result:
lng = res['x']
lat = res['y']
coords = coords + ";" + str(lng) + "," + str(lat)
return coords.strip(";")
最终数据
当前获得的边界数据格式如下:
113.85752917167422,22.512113353880437;113.85719688487298,22.51156349239119;113.8563414779429,22.51199606423422;113.8566827388162,22.512543094177662;113.85752917167422,22.512113353880437
现在您有了数据,其余的操作很简单. 这主要取决于您自己的需求. 如果需要在ARCGIS中显示区域数据,则需要再次进行处理. 结果示例:
在分析之下: uid是POI的ID,数字是自增的,暂时无用,一个uid对应于多个x,y对,一个x,y是一个点坐标,并且连接了多个点坐标形成多边形表面数据.
file_name = 'data/boundary_result_wgs84 - polygon.csv'
csv_file = pd.read_csv(file_name, encoding='gbk')
a_col = []
data_csv = {}
numbers, xs, ys, uids = [], [], [], []
index = 1
for i in range(len(csv_file)):
boundary = str(csv_file['boundary'][i])
uid = str(uuid.uuid4()).replace('-', '')
if boundary is not '':
for point in boundary.split(";"):
lng = point.split(",")[0]
lat = point.split(",")[1]
xs.append(lng)
ys.append(lat)
numbers.append(index)
uids.append(uid)
index = index + 1
data_csv['number'] = numbers
data_csv['x'] = xs
data_csv['y'] = ys
data_csv['uid'] = uids
df = pd.DataFrame(data_csv)
df.to_csv(os.getcwd() + os.sep + 'data/polygon-shape.csv', index=False, encoding='gbk')
请务必阅读
目前,POI边界坐标的采集已成为在线工具. 如果您有兴趣,可以尝试一下. 地址: 百度地图POI边界采集工具
上传需要采集的POI ID的CSV文件并申请了百度地图密钥后,即可采集到相应的边界数据!请注意,最好不要在一次上传中上传太多数据. 查看全部
在线工具地址: 百度地图POI边界数据采集工具
因为之前我已经研究过AutoNavi地图的POI数据边界坐标的采集,其后面的界面过于不稳定,因此很难成功地采集数据. 此功能已被搁置一段时间. 最近,它在@entropy的帮助下完成. 使用百度地图界面采集POI边界函数. 但是,在此预先声明下,无论是百度还是AutoNavi,每个都使用POI的ID来完成边界坐标的采集. 相同的POI数据在AutoNavi和百度上具有不同的ID. 因此,如果要使用百度采集边界界面,则必须确保现有的POI数据是通过百度POI界面采集的,并且具有ID字段. (总结: 不要使用AutoNavi界面采集的POI数据调用百度界面来爬坡边界数据. )
确定POI边界数据采集的接口地址
https://map.baidu.com/%3Fnewma ... Bb%3D(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785
接口非常简单,不需要密钥,可以通过GET请求调用它. 在参数中,您需要使用自己的POI ID替换uid =之后的字符串. 因此,打开浏览器后可以看到结果,数据结构如下:
{
"content": {
"geo": "4|12674567.8667,2556549.714;12674700.0816,2556667.07656|1-12674700.0816,2556615.59082,12674663.0912,2556549.714,12674567.8667,2556601.53877,12674605.8561,2556667.07656,12674700.0816,2556615.59082;",
"uid": "207119787bb3c5c95d17c334"
},
"current_city": {
"code": 340,
"geo": "1|12697919.69,2560977.31;12697919.69,2560977.31|12697919.69,2560977.31;",
"level": 12,
"name": "深圳市",
"sup": 1,
"sup_bus": 1,
"sup_business_area": 1,
"sup_lukuang": 1,
"sup_subway": 1,
"type": 2,
"up_province_name": "广东省"
},
"err_msg": "",
"hot_city": [
"北京市|131",
"上海市|289",
"广州市|257",
"深圳市|340",
"成都市|75",
"天津市|332",
"南京市|315",
"杭州市|179",
"武汉市|218",
"重庆市|132"
],
"result": {
"data_security_filt_res": 0,
"error": 0,
"illegal": 0,
"login_debug": 1,
"qid": "",
"region": "0",
"type": 10,
"uii_qt": "poi_profile",
"uii_type": "china_main"
},
"uii_err": 0
}
current_city的地理位置是我们需要查找的POI数据的边界坐标,其余就是如何解析此数据. 但应注意,此坐标系是bd09mc(百度墨卡托公制坐标). 坐标系描述可以参考
http://lbs.baidu.com/index.php ... trans
因此数据需要稍后转换为百度经纬度坐标.
用于基于UID获取边界数据并进行简单分析的代码参考:
def get_boundary_by_uid(uid):
bmap_boundary_url = 'https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=ext&uid=' + uid + '&c=340&ext_ver=new&tn=B_NORMAL_MAP&nn=0&auth=fw9wVDQUyKS7%3DQ5eWeb5A21KZOG0NadNuxHNBxBBLBHtxjhNwzWWvy1uVt1GgvPUDZYOYIZuEt2gz4yYxGccZcuVtPWv3GuxNt%3DkVJ0IUvhgMZSguxzBEHLNRTVtlEeLZNz1%40Db17dDFC8zv7u%40ZPuxtfvSulnDjnCENTHEHH%40NXBvzXX3M%40J2mmiJ4Y&ie=utf-8&l=19&b=(12679382.095,2565580.38;12679884.095,2565907.38)&t=1573133634785'
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(url=bmap_boundary_url, timeout=5, headers={"Connection": "close"})
data = data.text
data = json.loads(data)
content = data['content']
if not 'geo' in content:
return None
geo = content['geo']
i = 0
strsss = ''
for jj in str(geo).split('|')[2].split('-')[1].split(','):
jj = str(jj).strip(';')
if i % 2 == 0:
strsss = strsss + str(jj) + ','
else:
strsss = strsss + str(jj) + ';'
i = i + 1
return strsss.strip(";")
调用百度Map API进行坐标转换
http://lbsyun.baidu.com/index. ... ition
需要注意的是,该界面只能将其他坐标系中的数据转换为百度的公制坐标系和百度的经纬度坐标系,而不能反转.
http://api.map.baidu.com/geoco ... 2.343,232.34&from=6&to=5&ak=百度密钥
其中from = 6&to = 5表示从百度度量坐标系转换为百度经纬度坐标系. 有关详细信息,请参阅官方文档.
def transform_coordinate_batch(coordinates):
req_url = 'http://api.map.baidu.com/geoconv/v1/?coords='+coordinates+'&from=6&to=5&ak=' + bmap_key
s = requests.Session()
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
data = s.get(req_url, timeout=5, headers={"Connection": "close"}) # , proxies=proxies
data = data.text
data = json.loads(data)
coords = ''
if data['status'] == 0:
result = data['result']
if len(result) > 0:
for res in result:
lng = res['x']
lat = res['y']
coords = coords + ";" + str(lng) + "," + str(lat)
return coords.strip(";")
最终数据
当前获得的边界数据格式如下:
113.85752917167422,22.512113353880437;113.85719688487298,22.51156349239119;113.8563414779429,22.51199606423422;113.8566827388162,22.512543094177662;113.85752917167422,22.512113353880437
现在您有了数据,其余的操作很简单. 这主要取决于您自己的需求. 如果需要在ARCGIS中显示区域数据,则需要再次进行处理. 结果示例:
在分析之下: uid是POI的ID,数字是自增的,暂时无用,一个uid对应于多个x,y对,一个x,y是一个点坐标,并且连接了多个点坐标形成多边形表面数据.
file_name = 'data/boundary_result_wgs84 - polygon.csv'
csv_file = pd.read_csv(file_name, encoding='gbk')
a_col = []
data_csv = {}
numbers, xs, ys, uids = [], [], [], []
index = 1
for i in range(len(csv_file)):
boundary = str(csv_file['boundary'][i])
uid = str(uuid.uuid4()).replace('-', '')
if boundary is not '':
for point in boundary.split(";"):
lng = point.split(",")[0]
lat = point.split(",")[1]
xs.append(lng)
ys.append(lat)
numbers.append(index)
uids.append(uid)
index = index + 1
data_csv['number'] = numbers
data_csv['x'] = xs
data_csv['y'] = ys
data_csv['uid'] = uids
df = pd.DataFrame(data_csv)
df.to_csv(os.getcwd() + os.sep + 'data/polygon-shape.csv', index=False, encoding='gbk')
请务必阅读
目前,POI边界坐标的采集已成为在线工具. 如果您有兴趣,可以尝试一下. 地址: 百度地图POI边界采集工具
上传需要采集的POI ID的CSV文件并申请了百度地图密钥后,即可采集到相应的边界数据!请注意,最好不要在一次上传中上传太多数据.
百度POI数据捕获-BeautifulSoup
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-08-07 05:03
我对Python很熟悉,因此我将分享在此编写的Python版本的实现过程.
获取百度POI数据的方法是构造一个关键字搜索网址,并请求该网址获取返回的json数据.
人民广场&c = 289&pn = 0
wd: 搜索关键字
c: 城市代码
pn: 页码(返回结果可能有多个页面)
这种请求数据的方法的优点在于似乎没有次数限制.
两个步骤:
1. 准备搜索关键字
关键字源网站:
1)选择城市: 上海
2)POI有很多类别:
我的目标是获取详细的POI关键字.
首先获取每个类别的URL,并将其保存在keyword-1.txt文件中:
import urllib2
import urllib
from bs4 import BeautifulSoup
import numpy as np
import json
def write2txt(data,filepath):
with open(filepath,'a') as f:
for d in data:
f.write(d.encode('gbk'))
def example3_bs4():
request = urllib2.Request('http://poi.mapbar.com/shanghai/')
page = urllib2.urlopen(request)
data = page.read()
data = data.decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('a')
res = [ t['href']+'|'+t.get_text()+'\n' for t in tags]
#print res
write2txt(res,'keyword-1.txt')
3)获取每个类别下的详细POI关键字
每个类别下都有更详细的POI数据:
关键字保存在keyword-2.txt文件中
def getKeyWords():
with open('keyword-1.txt') as f:
for line in f:
url,wd=line.decode('gbk').split('|')
print url,wd
request = urllib2.Request(url)
page = urllib2.urlopen(request)
data = page.read().decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('dd a')
res = [wd[:-1]+'|'+t['href']+'|'+t.get_text()+'\n' for t in tags]
print len(res)
write2txt(res,'keyword-2.txt')
2,模拟关键字搜索
结构类似于此:
人民广场&c = 289&pn = 0
网址.
您可以在浏览器中查看此url返回的结果,并使用它来查看json字符串的结构:
我需要的信息是内容. 您可以看到内容中有一个数组. 其中的每个对象都是一个poi信息,而10个对象是1页. 如果需要多个页面,可以在url中设置pn =页面编号.
我只在这里使用第一页.
def getPOI():
with open('keyword-2.txt') as f:
for line in f:
data = []
Type,url,wd = line[:-1].split(',')
#print Type,url,wd
url = 'http://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=s&da_src=searchBox.button&wd=%s&c=289&pn=0'%urllib.quote(wd)
request = urllib2.Request(url)
try:
page = urllib2.urlopen(request)
res = json.load(page)
if 'content' in res:
contents = res['content']
if 'acc_flag' in contents[0]:
for d in contents:
x, y = float(d['diPointX']), float(d['diPointY'])
ss = "http://api.map.baidu.com/geoconv/v1/?coords=%s,%s&from=6&to=5&ak=你的开发者秘钥"%(x/100.0,y/100.0)
pos = json.load(urllib2.urlopen(ss))
if pos['status']==0:
x, y = pos['result'][0]['x'], pos['result'][0]['y']
tel = ''
if 'tel' in d:
tel = d['tel']
data.append(d['addr']+'|'+d['area_name']+'|'+d['di_tag']+'|'+d['std_tag']+'|'+tel+'|'+d['name']+'|'+str(x)+'|'+str(y)+'\n')
if data:
write2txt(data,'poi_info.txt')
except:
print 'http error'
请注意,此处的坐标转换api需要申请百度开发者密钥,每天的转换限制为100,000.
最后,我仅抓取了18万个POI数据,足够用于该项目.
参考博客:
获取百度地图POI数据: 查看全部
由于该实验室项目需要上海的POI数据,因此百度没有在一个圆圈内找到任何下载资源. 因此,我引用了此博客并亲自对其进行了爬网.
我对Python很熟悉,因此我将分享在此编写的Python版本的实现过程.
获取百度POI数据的方法是构造一个关键字搜索网址,并请求该网址获取返回的json数据.
人民广场&c = 289&pn = 0
wd: 搜索关键字
c: 城市代码
pn: 页码(返回结果可能有多个页面)
这种请求数据的方法的优点在于似乎没有次数限制.
两个步骤:
1. 准备搜索关键字
关键字源网站:
1)选择城市: 上海
2)POI有很多类别:
我的目标是获取详细的POI关键字.
首先获取每个类别的URL,并将其保存在keyword-1.txt文件中:
import urllib2
import urllib
from bs4 import BeautifulSoup
import numpy as np
import json
def write2txt(data,filepath):
with open(filepath,'a') as f:
for d in data:
f.write(d.encode('gbk'))
def example3_bs4():
request = urllib2.Request('http://poi.mapbar.com/shanghai/')
page = urllib2.urlopen(request)
data = page.read()
data = data.decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('a')
res = [ t['href']+'|'+t.get_text()+'\n' for t in tags]
#print res
write2txt(res,'keyword-1.txt')
3)获取每个类别下的详细POI关键字
每个类别下都有更详细的POI数据:
关键字保存在keyword-2.txt文件中
def getKeyWords():
with open('keyword-1.txt') as f:
for line in f:
url,wd=line.decode('gbk').split('|')
print url,wd
request = urllib2.Request(url)
page = urllib2.urlopen(request)
data = page.read().decode('utf-8')
soup = BeautifulSoup(data,'html.parser')
tags = soup.select('dd a')
res = [wd[:-1]+'|'+t['href']+'|'+t.get_text()+'\n' for t in tags]
print len(res)
write2txt(res,'keyword-2.txt')
2,模拟关键字搜索
结构类似于此:
人民广场&c = 289&pn = 0
网址.
您可以在浏览器中查看此url返回的结果,并使用它来查看json字符串的结构:
我需要的信息是内容. 您可以看到内容中有一个数组. 其中的每个对象都是一个poi信息,而10个对象是1页. 如果需要多个页面,可以在url中设置pn =页面编号.
我只在这里使用第一页.
def getPOI():
with open('keyword-2.txt') as f:
for line in f:
data = []
Type,url,wd = line[:-1].split(',')
#print Type,url,wd
url = 'http://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=s&da_src=searchBox.button&wd=%s&c=289&pn=0'%urllib.quote(wd)
request = urllib2.Request(url)
try:
page = urllib2.urlopen(request)
res = json.load(page)
if 'content' in res:
contents = res['content']
if 'acc_flag' in contents[0]:
for d in contents:
x, y = float(d['diPointX']), float(d['diPointY'])
ss = "http://api.map.baidu.com/geoconv/v1/?coords=%s,%s&from=6&to=5&ak=你的开发者秘钥"%(x/100.0,y/100.0)
pos = json.load(urllib2.urlopen(ss))
if pos['status']==0:
x, y = pos['result'][0]['x'], pos['result'][0]['y']
tel = ''
if 'tel' in d:
tel = d['tel']
data.append(d['addr']+'|'+d['area_name']+'|'+d['di_tag']+'|'+d['std_tag']+'|'+tel+'|'+d['name']+'|'+str(x)+'|'+str(y)+'\n')
if data:
write2txt(data,'poi_info.txt')
except:
print 'http error'
请注意,此处的坐标转换api需要申请百度开发者密钥,每天的转换限制为100,000.
最后,我仅抓取了18万个POI数据,足够用于该项目.
参考博客:
获取百度地图POI数据:
黑帽SEO的主要方法是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 01:10
1. 内容作弊内容作弊的目的是仔细修改或调整网页的内容,以便网页可以获得与搜索引擎排名中与其网页不相称的排名. 搜索引擎排名算法通常包括内容相似度计算和链接重要性计算. 内容欺骗是通过增加内容相似度计算的分数来获得最终的高排名. 实质是故意增加目标词的频率. 常见的内容作弊方法如下: 1.关键字重复对于作弊者关注的目标关键字,页面内容中设置了大量的重复项. 由于单词频率是搜索引擎相似度计算中必须考虑的因素,因此关键字重复本质上会通过增加目标关键字的单词频率来影响搜索引擎内容相似度排名. 2.使用不相关的查询词作弊为了吸引尽可能多的搜索流量,作弊者在页面内容中添加了许多与页面主题无关的关键字. 这本质上是一种单词频率作弊,即原创关键字频率为0. 对于非0.3,图像替代标签文本作弊替代标签最初用作图片的描述信息,通常不会显示在HTML页面,除非用户将鼠标放在图片上. 但是搜索引擎将使用此信息,因此一些作弊者会用作弊词汇填充alt标签的内容,以达到吸引更多搜索流量的目的. 4.网站标题作弊. Web标题作为描述网页内容的摘要信息,是判断网页主题的非常重要的启发式因素. 因此,搜索引擎在计算相似性分数时往往会增加标题词的权重. 作弊者利用这一优势,将与页面主题无关的目标词重复放置在标题位置,以获得更高的排名. 5.网页上的重要标签作弊网页与普通的文本格式不同,它们具有HTML标签,并且一些标签表示强调内容重要性的重要性,例如使用API和RSS的粗体标记第6段,内容标记1. 和其他方式,是指通过采集他人博客内容而生成的内容,并放置在您自己的网站或博客上; 2.使用段落拼接,关键字和普通文章(主要是小说)被截取以形成片段. 没有实际意义的文章; 3.工具自动生成的大量劣质重复信息内容; 4.只需将他人的原创内容复制到您自己的网站或博客中即可.
什么是黑帽SEO?
常用的黑帽SEO如下: 关键字填充,这是人们最常用的技术之一
优化关键字时,许多人仅出于一种目的累积关键字,只是为了增加关键字的频率并增加关键字的密度. 在网页代码中,元标记,标题(尤其是This),注释和图片ALT重复了一个特定的关键字,这使关键字的密度非常高,但是如果不发现它,将会有很好的效果.
重定向
此方法是在网页代码中使用刷新标签,metarefresh,java和js技术. 用户进入页面时,使用这些功能可以使他快速跳至其他页面. 这样,重定向使搜索引擎和用户访问的页面不一致. 必须注意这一点. 由于这个作者曾经有一个网站. 断电已经很长时间了.
轰炸
刚开始seo的新手经常会认为注册多个域名并同时连接到主要网站可以提高主要网站的PR!如果这些域名拥有自己的网站,那就没有问题!但是,如果这些域名只有几个内容,或者指向主站点的某个页面,那么搜索引擎就会认为这是一种欺骗!
假冒关键字太多
许多网站会将许多与此网站无关的关键字添加到自己的网站中. 通过在meta中设置与网站内容不相关的关键字,它们可以欺骗搜索引擎进行收录和用户点击. 这是一种不太正式的优化方法,但是作者谈论的是错误的关键字太多,并且经常更改页面标题来增加此关键字,因此这两种方法都极有可能受到惩罚并降低排名(后者更为严重)
重复注册
这是一种相对卑鄙的作弊方法,违反了网站提交纪律. 他打破了时限,并在短时间内反复向同一搜索引擎提交了网页.
不可见的文字和链接
为了增加关键字的出现频率,在网页上特意放置了一部分收录与背景颜色相同的密集关键字的文本. 访客看不到它,但是搜索引擎可以找到它. 类似的方法还包括超小文本,文本隐藏层等手段. 这也是网站降级的常见原因. 实际上,其中许多都不是自己提供的,但是一些出售黑链的人会暗中加价. 这是为了增强网站管理员的预防意识.
垃圾链接
添加大量链接机制,这意味着由大量网页交叉链接组成的网络系统. 一旦被搜索引擎发现,这些作弊方法将立即成为K个站点. 我希望seoers会在平时进行优化. 有意或无意地,您必须注意您是否违反了这些作弊方法. 为了提高搜索排名,吸引人们点击,重复关键字,在博客和论坛中发布大量指向不相关内容的链接,这些链接也称为垃圾邮件链接.
扫描网页
诱骗行为也是SEO中使用的一种欺骗性技术. 指创建两个网页(一个优化页面和一个普通页面),然后将优化页面提交给搜索引擎,然后当该优化页面被搜索引擎索引时,普通页面将替换该网页. 考虑长期利益,不要尝试.
桥梁页面或门口页面
大多数桥接页面是由软件生成的. 可以想象,生成的文本很杂乱,一无所有. 如果它是由某人撰写的实际上收录关键字的文章,则它不是过渡页.
当前常用的方法:
01,站组02,关键字填充
来吧03,隐藏文本源
04. 交易链接
05. 链接农场
Zhi 06,链轮
07,大量发布
08、301批处理重定向
09. 桥接页面,跳转
10. 隐藏页面
11. 批量采集
12,PR劫持
等等(仍然有很多大师在学习或使用...)
黑帽SEO怎么做?
1)网站遭到攻击
我们必须高度重视网站的健康状况,并定期备份网站内容,以防止网站受到特洛伊木马等的攻击或黑客攻击. 如果网站受到攻击,搜索引擎将迅速识别它,同时会降低您的网站得分,这可能会导致您将权限降级为k个电台.
(2)刷流
如果您的网站被搜索引擎降级,则必须回忆一下您最近是否使用某些软件来减少流量,从而导致欺骗搜索引擎的行为. 通常,有些网站管理员会使用流量宝藏和向导之类的工具来扫描网站流量,以便用户或搜索引擎认为您的站点有大量访问并引起关注. 但是,这些都是SEO中的黑帽技术,因此不理想. 刷牙是短期的. 如果突然停止,您的流量将直线下降,引起很大的反应.
(3)大量购买黑链子
您的网站上有黑链接,搜索引擎不会立即惩罚您,因为搜索引擎无法知道谁是真正的罪魁祸首. 但是,如果您购买了大量黑链,但这些网站与您的网站之间的关联性也很差,那么搜索引擎将迅速识别您,并立即将您的权限减少到k个网站.
(4)在链外批量发布
实际上,许多人使用黑帽技术来优化其网站,并且他们将使用大量发布的方式. 使用某些软件疯狂地将内容分发到各个地方,很容易引起较低的内容相关性,并且发布时间和内容非常接近. 这也是搜索引擎经常通过降低功耗来进行攻击的现象.
(5)多种作弊技巧
为了进一步优化网站,很多人会故意向网站添加一些隐藏链接,或者通过减小字体大小来作弊等. 这也很容易导致搜索引擎将您的权限降低到k. 站.
实际上没有办法回答这个问题.
禁止戴黑帽子,搜索引擎不建议戴黑帽子.
我戴了一顶黑帽子,我想知道它是否会被搜索引擎发现. 这只能由智者和仁者看到. 内部
此外,有一件事是,影响排名的所有因素都是由黑帽子造成的. 戴黑帽子不一定会发生什么事情.
例如,外部链接,到处购买各种外部链接是一种非常清晰的黑帽技巧. 但是,购买不出售链接和优质内部链接的网站是外部链接的黑帽技术.
黑帽seo需要具备哪些技术?黑帽seo技术在2017年排名快速
首先,黑帽SEO和白帽SEO之间的区别
黑帽SEO: 所有不符合搜索引擎优化规范的作弊方法均属于黑帽SEO;
白帽SEO: 所有符合用户体验和搜索引擎规范的优化方法均属于白帽SEO;
第二,黑帽SEO技术的特征
1. 锚定文字轰炸
页面没有相关内容,但是有很多指向该页面的锚文本. 例如,著名的“ Google炸弹”,大量美国公民使用“ miserablefailure”(失败),并在白宫网站上可以控制的页面上链接到布什个人主页的超链接. 两个月后,当在白宫的Google布什个人主页上搜索“ miserablefailure”时,其搜索量上升到了顶部. 实际上,布什的个人主页上没有任何有关“严重失败”的信息.
2. 网站内容采集
使用某些程序自动采集Internet上的某些文本,然后在自动处理一个简单的程序后将其发布到网站(采集站)上. 用户体验极差,但是由于页面数量众多,并且搜索引擎算法不是特别完美,因此经常会有页面具有排名,这反过来又带来了访问量,然后用户点击了他们放置的广告获得利益. 实际上,它并没有为用户带来有用的价值.
3,集体作弊
使用软件将您自己的链接发布到某些网站,并在短时间内获得大量外部链接. 如今,外部链接在SEO中的作用越来越小,这种方法在当今的SEO中将不会发挥太大作用.
4,挂马
为了达到某种目的,请通过某种方式进入网站并在该网站上安装特洛伊木马程序. 不仅网站链接到马,而且更重要的是,该网站的用户还存在中毒计算机的风险,从而导致该网站的用户体验极差.
5. 网站黑链
简单的理解是不正确的链接,该链接通常对用户不可见,但可以被搜索引擎看到. 通常,网站的后端被黑客攻击,并且链接到其他网站的链接被挂断. 尽管这些链接在页面上不可见,但是可以被搜索引擎抓取. 网站的黑色链接是我们在进行SEO时经常遇到的情况. ,如果网站被黑客入侵,该怎么办?如果您的网站被黑了,崔鹏瀚的SEO网站有一个更好的处理方法,所以您不妨看看.
6. 其他黑帽SEO技术
一些经过证明的黑帽SEO通常是由一些技术专家完成的,但是他们通常不敢公开这种方法,因为小型作弊搜索引擎通常不会调整算法,但是在影响扩大之后,这是另一回事.
摘要: 黑帽SEO属于SEO作弊. 一旦被搜索引擎发现,这种行为将给网站带来灾难. 崔鹏瀚建议,如果您打算优化网站并从中获利,那么请记住,您不应该在任何时候使用黑帽SEO方法,因为这不会对网站造成损害.
黑帽SEO有几种可用的方法?
有很多方法,核心事情没有改变,站群还是不错的,但是现在每个人都没有这样玩,通常你会用油彩云单页外壳站群管理软件,回答或租用某些以寄生虫形式出现的高重量网站的目录. 只要符合用户习惯,就可以使用.
是否根据您的目的选择了黑帽百和白帽搜索引擎优化技术. 具体来说,黑帽首付确实具有短期利益,某些企业服务仅需要这种短期服务,例如一些对时间敏感的企业. 白帽子是所谓的钓大鱼的长线. 一个期望. 黑帽方法很多,例如关键字累积,桥接页面,隐藏文本,隐藏链接,隐藏页面,链接服务器场,Google炸弹,页面扩展方法,百科全书欺骗方法等. 如果您不想被搜索很长一段时间,使用白帽seo方法.
如何做黑帽搜索引擎优化
White hat SEO是一种公平的方法,它使用符合主流搜索引擎发布准则的SEO优化方法. 它与黑帽seo相反. 白帽SEO一直被视为行业中最好的SEO技术. 它在避免所有风险的同时进行操作,同时避免与搜索引擎的发行政策发生任何冲突. 这也是SEOer从业人员的最高职业道德. 标准.
黑帽seo意味着作弊. 黑帽seo方法不符合主流搜索引擎发布准则. 黑帽SEO盈利能力的主要特征是短期抵消和用于短期利益的作弊方法. 同时,由于搜索引擎算法的变化,他们随时面临罚款.
白帽seo或黑帽seo并没有精确的定义. 一般来说,所有作弊方法或某些可疑方法都可以称为黑帽SEO. 例如,隐藏的网页,关键字填充,垃圾邮件链接,桥接页面等.
黑帽SEO可以快速带来一定的排名和用户量,但这通常是K的结果. 一旦为K,恢复期将至少需要半年. 其次,对品牌不利. 的结果. 查看全部
黑帽SEO的主要方法是什么?
1. 内容作弊内容作弊的目的是仔细修改或调整网页的内容,以便网页可以获得与搜索引擎排名中与其网页不相称的排名. 搜索引擎排名算法通常包括内容相似度计算和链接重要性计算. 内容欺骗是通过增加内容相似度计算的分数来获得最终的高排名. 实质是故意增加目标词的频率. 常见的内容作弊方法如下: 1.关键字重复对于作弊者关注的目标关键字,页面内容中设置了大量的重复项. 由于单词频率是搜索引擎相似度计算中必须考虑的因素,因此关键字重复本质上会通过增加目标关键字的单词频率来影响搜索引擎内容相似度排名. 2.使用不相关的查询词作弊为了吸引尽可能多的搜索流量,作弊者在页面内容中添加了许多与页面主题无关的关键字. 这本质上是一种单词频率作弊,即原创关键字频率为0. 对于非0.3,图像替代标签文本作弊替代标签最初用作图片的描述信息,通常不会显示在HTML页面,除非用户将鼠标放在图片上. 但是搜索引擎将使用此信息,因此一些作弊者会用作弊词汇填充alt标签的内容,以达到吸引更多搜索流量的目的. 4.网站标题作弊. Web标题作为描述网页内容的摘要信息,是判断网页主题的非常重要的启发式因素. 因此,搜索引擎在计算相似性分数时往往会增加标题词的权重. 作弊者利用这一优势,将与页面主题无关的目标词重复放置在标题位置,以获得更高的排名. 5.网页上的重要标签作弊网页与普通的文本格式不同,它们具有HTML标签,并且一些标签表示强调内容重要性的重要性,例如使用API和RSS的粗体标记第6段,内容标记1. 和其他方式,是指通过采集他人博客内容而生成的内容,并放置在您自己的网站或博客上; 2.使用段落拼接,关键字和普通文章(主要是小说)被截取以形成片段. 没有实际意义的文章; 3.工具自动生成的大量劣质重复信息内容; 4.只需将他人的原创内容复制到您自己的网站或博客中即可.
什么是黑帽SEO?
常用的黑帽SEO如下: 关键字填充,这是人们最常用的技术之一
优化关键字时,许多人仅出于一种目的累积关键字,只是为了增加关键字的频率并增加关键字的密度. 在网页代码中,元标记,标题(尤其是This),注释和图片ALT重复了一个特定的关键字,这使关键字的密度非常高,但是如果不发现它,将会有很好的效果.
重定向
此方法是在网页代码中使用刷新标签,metarefresh,java和js技术. 用户进入页面时,使用这些功能可以使他快速跳至其他页面. 这样,重定向使搜索引擎和用户访问的页面不一致. 必须注意这一点. 由于这个作者曾经有一个网站. 断电已经很长时间了.
轰炸
刚开始seo的新手经常会认为注册多个域名并同时连接到主要网站可以提高主要网站的PR!如果这些域名拥有自己的网站,那就没有问题!但是,如果这些域名只有几个内容,或者指向主站点的某个页面,那么搜索引擎就会认为这是一种欺骗!
假冒关键字太多
许多网站会将许多与此网站无关的关键字添加到自己的网站中. 通过在meta中设置与网站内容不相关的关键字,它们可以欺骗搜索引擎进行收录和用户点击. 这是一种不太正式的优化方法,但是作者谈论的是错误的关键字太多,并且经常更改页面标题来增加此关键字,因此这两种方法都极有可能受到惩罚并降低排名(后者更为严重)
重复注册
这是一种相对卑鄙的作弊方法,违反了网站提交纪律. 他打破了时限,并在短时间内反复向同一搜索引擎提交了网页.
不可见的文字和链接
为了增加关键字的出现频率,在网页上特意放置了一部分收录与背景颜色相同的密集关键字的文本. 访客看不到它,但是搜索引擎可以找到它. 类似的方法还包括超小文本,文本隐藏层等手段. 这也是网站降级的常见原因. 实际上,其中许多都不是自己提供的,但是一些出售黑链的人会暗中加价. 这是为了增强网站管理员的预防意识.
垃圾链接
添加大量链接机制,这意味着由大量网页交叉链接组成的网络系统. 一旦被搜索引擎发现,这些作弊方法将立即成为K个站点. 我希望seoers会在平时进行优化. 有意或无意地,您必须注意您是否违反了这些作弊方法. 为了提高搜索排名,吸引人们点击,重复关键字,在博客和论坛中发布大量指向不相关内容的链接,这些链接也称为垃圾邮件链接.
扫描网页
诱骗行为也是SEO中使用的一种欺骗性技术. 指创建两个网页(一个优化页面和一个普通页面),然后将优化页面提交给搜索引擎,然后当该优化页面被搜索引擎索引时,普通页面将替换该网页. 考虑长期利益,不要尝试.
桥梁页面或门口页面
大多数桥接页面是由软件生成的. 可以想象,生成的文本很杂乱,一无所有. 如果它是由某人撰写的实际上收录关键字的文章,则它不是过渡页.
当前常用的方法:
01,站组02,关键字填充
来吧03,隐藏文本源
04. 交易链接
05. 链接农场
Zhi 06,链轮
07,大量发布
08、301批处理重定向
09. 桥接页面,跳转
10. 隐藏页面
11. 批量采集
12,PR劫持
等等(仍然有很多大师在学习或使用...)
黑帽SEO怎么做?
1)网站遭到攻击
我们必须高度重视网站的健康状况,并定期备份网站内容,以防止网站受到特洛伊木马等的攻击或黑客攻击. 如果网站受到攻击,搜索引擎将迅速识别它,同时会降低您的网站得分,这可能会导致您将权限降级为k个电台.
(2)刷流
如果您的网站被搜索引擎降级,则必须回忆一下您最近是否使用某些软件来减少流量,从而导致欺骗搜索引擎的行为. 通常,有些网站管理员会使用流量宝藏和向导之类的工具来扫描网站流量,以便用户或搜索引擎认为您的站点有大量访问并引起关注. 但是,这些都是SEO中的黑帽技术,因此不理想. 刷牙是短期的. 如果突然停止,您的流量将直线下降,引起很大的反应.
(3)大量购买黑链子
您的网站上有黑链接,搜索引擎不会立即惩罚您,因为搜索引擎无法知道谁是真正的罪魁祸首. 但是,如果您购买了大量黑链,但这些网站与您的网站之间的关联性也很差,那么搜索引擎将迅速识别您,并立即将您的权限减少到k个网站.
(4)在链外批量发布
实际上,许多人使用黑帽技术来优化其网站,并且他们将使用大量发布的方式. 使用某些软件疯狂地将内容分发到各个地方,很容易引起较低的内容相关性,并且发布时间和内容非常接近. 这也是搜索引擎经常通过降低功耗来进行攻击的现象.
(5)多种作弊技巧
为了进一步优化网站,很多人会故意向网站添加一些隐藏链接,或者通过减小字体大小来作弊等. 这也很容易导致搜索引擎将您的权限降低到k. 站.
实际上没有办法回答这个问题.
禁止戴黑帽子,搜索引擎不建议戴黑帽子.
我戴了一顶黑帽子,我想知道它是否会被搜索引擎发现. 这只能由智者和仁者看到. 内部
此外,有一件事是,影响排名的所有因素都是由黑帽子造成的. 戴黑帽子不一定会发生什么事情.
例如,外部链接,到处购买各种外部链接是一种非常清晰的黑帽技巧. 但是,购买不出售链接和优质内部链接的网站是外部链接的黑帽技术.
黑帽seo需要具备哪些技术?黑帽seo技术在2017年排名快速
首先,黑帽SEO和白帽SEO之间的区别
黑帽SEO: 所有不符合搜索引擎优化规范的作弊方法均属于黑帽SEO;
白帽SEO: 所有符合用户体验和搜索引擎规范的优化方法均属于白帽SEO;
第二,黑帽SEO技术的特征
1. 锚定文字轰炸
页面没有相关内容,但是有很多指向该页面的锚文本. 例如,著名的“ Google炸弹”,大量美国公民使用“ miserablefailure”(失败),并在白宫网站上可以控制的页面上链接到布什个人主页的超链接. 两个月后,当在白宫的Google布什个人主页上搜索“ miserablefailure”时,其搜索量上升到了顶部. 实际上,布什的个人主页上没有任何有关“严重失败”的信息.
2. 网站内容采集
使用某些程序自动采集Internet上的某些文本,然后在自动处理一个简单的程序后将其发布到网站(采集站)上. 用户体验极差,但是由于页面数量众多,并且搜索引擎算法不是特别完美,因此经常会有页面具有排名,这反过来又带来了访问量,然后用户点击了他们放置的广告获得利益. 实际上,它并没有为用户带来有用的价值.
3,集体作弊
使用软件将您自己的链接发布到某些网站,并在短时间内获得大量外部链接. 如今,外部链接在SEO中的作用越来越小,这种方法在当今的SEO中将不会发挥太大作用.
4,挂马
为了达到某种目的,请通过某种方式进入网站并在该网站上安装特洛伊木马程序. 不仅网站链接到马,而且更重要的是,该网站的用户还存在中毒计算机的风险,从而导致该网站的用户体验极差.
5. 网站黑链
简单的理解是不正确的链接,该链接通常对用户不可见,但可以被搜索引擎看到. 通常,网站的后端被黑客攻击,并且链接到其他网站的链接被挂断. 尽管这些链接在页面上不可见,但是可以被搜索引擎抓取. 网站的黑色链接是我们在进行SEO时经常遇到的情况. ,如果网站被黑客入侵,该怎么办?如果您的网站被黑了,崔鹏瀚的SEO网站有一个更好的处理方法,所以您不妨看看.
6. 其他黑帽SEO技术
一些经过证明的黑帽SEO通常是由一些技术专家完成的,但是他们通常不敢公开这种方法,因为小型作弊搜索引擎通常不会调整算法,但是在影响扩大之后,这是另一回事.
摘要: 黑帽SEO属于SEO作弊. 一旦被搜索引擎发现,这种行为将给网站带来灾难. 崔鹏瀚建议,如果您打算优化网站并从中获利,那么请记住,您不应该在任何时候使用黑帽SEO方法,因为这不会对网站造成损害.
黑帽SEO有几种可用的方法?
有很多方法,核心事情没有改变,站群还是不错的,但是现在每个人都没有这样玩,通常你会用油彩云单页外壳站群管理软件,回答或租用某些以寄生虫形式出现的高重量网站的目录. 只要符合用户习惯,就可以使用.
是否根据您的目的选择了黑帽百和白帽搜索引擎优化技术. 具体来说,黑帽首付确实具有短期利益,某些企业服务仅需要这种短期服务,例如一些对时间敏感的企业. 白帽子是所谓的钓大鱼的长线. 一个期望. 黑帽方法很多,例如关键字累积,桥接页面,隐藏文本,隐藏链接,隐藏页面,链接服务器场,Google炸弹,页面扩展方法,百科全书欺骗方法等. 如果您不想被搜索很长一段时间,使用白帽seo方法.
如何做黑帽搜索引擎优化
White hat SEO是一种公平的方法,它使用符合主流搜索引擎发布准则的SEO优化方法. 它与黑帽seo相反. 白帽SEO一直被视为行业中最好的SEO技术. 它在避免所有风险的同时进行操作,同时避免与搜索引擎的发行政策发生任何冲突. 这也是SEOer从业人员的最高职业道德. 标准.
黑帽seo意味着作弊. 黑帽seo方法不符合主流搜索引擎发布准则. 黑帽SEO盈利能力的主要特征是短期抵消和用于短期利益的作弊方法. 同时,由于搜索引擎算法的变化,他们随时面临罚款.
白帽seo或黑帽seo并没有精确的定义. 一般来说,所有作弊方法或某些可疑方法都可以称为黑帽SEO. 例如,隐藏的网页,关键字填充,垃圾邮件链接,桥接页面等.
黑帽SEO可以快速带来一定的排名和用户量,但这通常是K的结果. 一旦为K,恢复期将至少需要半年. 其次,对品牌不利. 的结果.
原创官方帐户文章采集者的特征是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-08-06 07:07
在微信公众号中撰写文章时,通常会采集其他文章以供参考,以便您可以使用官方帐号中的文章采集器. 官方帐户文章采集者的特征是什么?采集器如何采集微信文章?今天,Tuotu Data将对其进行介绍.
官方帐户文章采集者
官方帐户文章采集器的特征和功能
云采集
5000个云服务器,24 * 7高效且稳定的集合以及API,可无缝连接到内部系统并定期同步数据.
智能采集
提供各种Web采集策略和支持资源,以帮助整个采集过程实现数据完整性和稳定性.
适用于整个网络
您可以在看到它时采集它,无论是文本,图片还是铁巴论坛,它都支持所有业务渠道的抓取工具,以满足各种采集需求.
大型模板
内置了数百个网站数据源,涵盖了多个行业,您可以通过简单的设置快速而准确地获取数据.
易于使用
无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库.
稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
官方帐户文章采集者如何采集微信文章?
A: 关键字批量搜索集合
您可以分批粘贴关键字进行搜索,选择内容采集的日期,可以伪原创标题和内容,并确定文章是否为原创,并支持将一篇文章分发到网站上
对于某些SEO,它在标题或内容中添加了长尾单词的随机插入. 您可以下载带有索引的长尾单词并将其导入以获取流量
B: 通过指定的官方帐户收款
您可以通过官方帐户排名或自己搜索行业的官方帐户,然后将其粘贴. 其他功能与第一项相同,并且仍然可用. 例如,您是一家教育或税收公司,并且是专业的SEO. 通过此功能或高质量的原创文章吸引流量
C: 热门行业的集合
根据行业分类,其功能与第一项相同
D: 自动采集和发布
自动采集和发布仍然是对关键字的批量搜索,其他功能未在图中显示. 关键是有好处. 不同的关键字或微信集合可以选择全部. 它将继续按顺序采集,例如: 您有10列,然后可以为每列设置与列相关的单词采集和存储. 第一个采集完成后,它将自动执行第二个列的采集和存储.
官方帐户文章采集者
如何从其他微信公众号采集文章到微信编辑器?
方法/步骤
一个,获取文章链接
计算机用户可以直接在浏览器地址栏中复制所有文章链接.
移动用户可以单击右上角的菜单按钮,选择“复制链接”,然后将链接发送到计算机.
第二,单击按钮以采集文章
小蚂蚁编辑器的文章采集功能有两个入口:
1. 编辑菜单右上角的“采集文章”按钮;
2. 右侧功能按钮底部的“采集文章”按钮
3. 粘贴文章链接,然后单击以采集
采集完成后,您可以编辑和修改文章.
通过以上内容,我们了解了官方帐户文章采集者的特征和功能. 可以看出,官方帐户文章采集器的功能非常强大和全面. 查看全部
在微信公众号中撰写文章时,通常会采集其他文章以供参考,以便您可以使用官方帐号中的文章采集器. 官方帐户文章采集者的特征是什么?采集器如何采集微信文章?今天,Tuotu Data将对其进行介绍.
官方帐户文章采集者
官方帐户文章采集器的特征和功能
云采集
5000个云服务器,24 * 7高效且稳定的集合以及API,可无缝连接到内部系统并定期同步数据.
智能采集
提供各种Web采集策略和支持资源,以帮助整个采集过程实现数据完整性和稳定性.
适用于整个网络
您可以在看到它时采集它,无论是文本,图片还是铁巴论坛,它都支持所有业务渠道的抓取工具,以满足各种采集需求.
大型模板
内置了数百个网站数据源,涵盖了多个行业,您可以通过简单的设置快速而准确地获取数据.
易于使用
无需学习爬虫编程技术,您可以通过三个简单的步骤轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库.
稳定高效
分布式云集群服务器和多用户协作管理平台的支持可以灵活地安排任务并平稳地抓取大量数据.
直观的点击,易于使用
流程图模式: 您只需要根据软件提示单击页面即可,这完全符合人们浏览Web的思维方式,并且可以通过几个简单的步骤生成复杂的采集规则. 结合智能识别算法,可以轻松采集任何Web数据.
可以模拟操作: 输入文本,单击,移动鼠标,下拉框,滚动页面,等待加载,循环操作和判断条件等.
支持多种数据导出方法
采集的结果可以本地导出,支持TXT,EXCEL,CSV和HTML文件格式,还可以直接发布到数据库(MySQL,MongoDB,SQL Server,PostgreSQL)供您使用.
强大的功能,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人,团队和企业的采集需求.
丰富的功能: 定时采集,自动导出,文件下载,加速引擎,按组启动和导出,Webhook,RESTful API,SKU和电子商务大图的智能识别等.
官方帐户文章采集者如何采集微信文章?
A: 关键字批量搜索集合
您可以分批粘贴关键字进行搜索,选择内容采集的日期,可以伪原创标题和内容,并确定文章是否为原创,并支持将一篇文章分发到网站上
对于某些SEO,它在标题或内容中添加了长尾单词的随机插入. 您可以下载带有索引的长尾单词并将其导入以获取流量
B: 通过指定的官方帐户收款
您可以通过官方帐户排名或自己搜索行业的官方帐户,然后将其粘贴. 其他功能与第一项相同,并且仍然可用. 例如,您是一家教育或税收公司,并且是专业的SEO. 通过此功能或高质量的原创文章吸引流量
C: 热门行业的集合
根据行业分类,其功能与第一项相同
D: 自动采集和发布
自动采集和发布仍然是对关键字的批量搜索,其他功能未在图中显示. 关键是有好处. 不同的关键字或微信集合可以选择全部. 它将继续按顺序采集,例如: 您有10列,然后可以为每列设置与列相关的单词采集和存储. 第一个采集完成后,它将自动执行第二个列的采集和存储.
官方帐户文章采集者
如何从其他微信公众号采集文章到微信编辑器?
方法/步骤
一个,获取文章链接
计算机用户可以直接在浏览器地址栏中复制所有文章链接.
移动用户可以单击右上角的菜单按钮,选择“复制链接”,然后将链接发送到计算机.
第二,单击按钮以采集文章
小蚂蚁编辑器的文章采集功能有两个入口:
1. 编辑菜单右上角的“采集文章”按钮;
2. 右侧功能按钮底部的“采集文章”按钮
3. 粘贴文章链接,然后单击以采集
采集完成后,您可以编辑和修改文章.
通过以上内容,我们了解了官方帐户文章采集者的特征和功能. 可以看出,官方帐户文章采集器的功能非常强大和全面.
大众点评点餐小程序开发经验 - 数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2020-08-04 16:04
关于小程序开发的经验以及过程中遇见的“坑”在我们团队之前的小程序开发经验系列文章中早已介绍的差不多了,大数据时代,一个产品胜败的背后须要用大量的数据去剖析验证。本期就和你们一起探求下,微信小程序是怎样进行数据采集与剖析的,当然还有过程中的“坑”。
本文部份示例来自于「大众点评点餐」小程序的菜单页面。
所有内容基于2017年3月2日为止的官方api陌陌官方采集平台介绍
微信小程序公众平台目前提供了一套官方的数据采集分析平台。
官方api:
就目前小程序公测版官方提供了以下几种数据剖析:
概况:提供小程序关键指标趋势以及top页面访问数据,快速了解小程序发展概况;(不需要自动配置,官方默认采集)
访问剖析:提供小程序用户访问来源、规模、频次、时长、深度以及页面详情等数据,具体剖析用户新增和活跃情况;(不需要自动配置,官方默认采集)
实时统计:提供小程序实时访问数据,满足实时监控需求;(不需要自动配置,官方默认采集)
自定义剖析:配置自定义上报,精细跟踪用户在小程序内的行为,结合用户属性、系统属性、事件属性进行灵活多维的风波剖析和漏斗剖析,满足小程序的个性化剖析需求;(内侧中通过关键词采集文章采集api,需要单独申请开通权限能够使用)
具体数据可通过使用小程序管理员帐号登入然后查看。
前3种形式都是小程序手动采集,不需要开发者任何的人为操作,在陌陌官方文档中都有详尽说明了,这边就不再探讨
本文主要结合「大众点评点餐」小程序来看下第4种-自定义剖析能做哪些
自定义剖析
自定义剖析就是传统意义上的埋点,用户可以自行设置希望上报的数据,通过这种数据来剖析你希望得到的结果。
微信官方的自定义剖析使用了当下比较流行的无埋点技术,通过陌陌后台配置锚点并实时下发到客户端生效,无需在代码中自动加入埋点代码,并且因为小程序发版有初审机制,如果自动埋一次点就须要重新审问,成本将会十分高,所以采用无埋点技术是十分适合于小程序的场景。
但从目前「大众点评点餐」小程序中测试出来,目前公测版本的自定义剖析(截止2017年3月2日)对代码本身设计与书写的要求比较严苛,数据采集需要与页面page的data做到关联,在个别场景下会出现比较无法满足的情况。
接下来使我们瞧瞧实现一个自定义风波的步骤:
1. 首先使用管理员帐号登入公众平台后台,找到自定义剖析(前面提及,需要单独申请,否则看不到入口)2. 如果第一次使用的话,事件列表为空,点击新增风波,填入打点风波的中英文名称3. 接下来是最关键的风波配置
动作的各项含意如下:(转自陌陌小程序官方api)
trigger,触发条件:
click 点击时触发,必须指定page和element
enterPage 进入页面时触发,必须指定page
leavePage 离开页面时触发通过关键词采集文章采集api,必须指定page
pullDownRefresh 下拉刷新时触发,必须指定page
launch 加载小程序时触发
background 切换到后台触发
foreground 切换到前台触发 查看全部
关于小程序开发的经验以及过程中遇见的“坑”在我们团队之前的小程序开发经验系列文章中早已介绍的差不多了,大数据时 ...
关于小程序开发的经验以及过程中遇见的“坑”在我们团队之前的小程序开发经验系列文章中早已介绍的差不多了,大数据时代,一个产品胜败的背后须要用大量的数据去剖析验证。本期就和你们一起探求下,微信小程序是怎样进行数据采集与剖析的,当然还有过程中的“坑”。
本文部份示例来自于「大众点评点餐」小程序的菜单页面。
所有内容基于2017年3月2日为止的官方api陌陌官方采集平台介绍
微信小程序公众平台目前提供了一套官方的数据采集分析平台。
官方api:
就目前小程序公测版官方提供了以下几种数据剖析:
概况:提供小程序关键指标趋势以及top页面访问数据,快速了解小程序发展概况;(不需要自动配置,官方默认采集)
访问剖析:提供小程序用户访问来源、规模、频次、时长、深度以及页面详情等数据,具体剖析用户新增和活跃情况;(不需要自动配置,官方默认采集)
实时统计:提供小程序实时访问数据,满足实时监控需求;(不需要自动配置,官方默认采集)
自定义剖析:配置自定义上报,精细跟踪用户在小程序内的行为,结合用户属性、系统属性、事件属性进行灵活多维的风波剖析和漏斗剖析,满足小程序的个性化剖析需求;(内侧中通过关键词采集文章采集api,需要单独申请开通权限能够使用)
具体数据可通过使用小程序管理员帐号登入然后查看。
前3种形式都是小程序手动采集,不需要开发者任何的人为操作,在陌陌官方文档中都有详尽说明了,这边就不再探讨
本文主要结合「大众点评点餐」小程序来看下第4种-自定义剖析能做哪些
自定义剖析
自定义剖析就是传统意义上的埋点,用户可以自行设置希望上报的数据,通过这种数据来剖析你希望得到的结果。
微信官方的自定义剖析使用了当下比较流行的无埋点技术,通过陌陌后台配置锚点并实时下发到客户端生效,无需在代码中自动加入埋点代码,并且因为小程序发版有初审机制,如果自动埋一次点就须要重新审问,成本将会十分高,所以采用无埋点技术是十分适合于小程序的场景。
但从目前「大众点评点餐」小程序中测试出来,目前公测版本的自定义剖析(截止2017年3月2日)对代码本身设计与书写的要求比较严苛,数据采集需要与页面page的data做到关联,在个别场景下会出现比较无法满足的情况。
接下来使我们瞧瞧实现一个自定义风波的步骤:
1. 首先使用管理员帐号登入公众平台后台,找到自定义剖析(前面提及,需要单独申请,否则看不到入口)2. 如果第一次使用的话,事件列表为空,点击新增风波,填入打点风波的中英文名称3. 接下来是最关键的风波配置
动作的各项含意如下:(转自陌陌小程序官方api)
trigger,触发条件:
click 点击时触发,必须指定page和element
enterPage 进入页面时触发,必须指定page
leavePage 离开页面时触发通过关键词采集文章采集api,必须指定page
pullDownRefresh 下拉刷新时触发,必须指定page
launch 加载小程序时触发
background 切换到后台触发
foreground 切换到前台触发
获取任意链接文章正文 API 功能简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-08-04 08:02
此文章对开放数据插口 API 之「获取任意链接文章正文」进行了功能介绍、使用场景介绍以及调用方式的说明,供用户在使用数据插口时参考之用。
1. 产品功能
接口开放了按照提供的文章链接 Url 参数,智能分析文章的正文部份,并通过抓取剖析后,返回出文章的标题、正文以及文章的发表时间。
对于各类类型的文章布局,采用了智能化的语义剖析,最大化地满足各类各类布局文章的采集与处理需求。
接口地址:
2. 接口文档与参数
接口地址:
返回格式: json/xml
请求方法: GET
请求示例:
请求合同: HTTPS
接口测试:
各类开发语言的恳求示例代码可以参考 API 文档说明:
加入社群通过关键词采集文章采集api,与 1000 多位同事共同成长
DevOpen.Club Pro 高质量软件开发分享讨论群,汇聚了逾 1000 多名各行各业的软件开发人员,是供朋友们分享高质量资源、讨论软件开发问题解决方案、寻求孵化项目合作伙伴的干货社区。
任何技术都不是限制,我们最终目的是将技术转化成收入,实现财务自由。
社群中正在更新的原创视频教程 & 孵化项目进度
编程大世界:软件开发基础知识通解,带你步入软件开发的大世界;80 节实战课精通 React Native 开发:我出版的书籍《React Native 精解与实战》配套视频教程;微信小程序开发视频教程:最实战的小程序开发视频教程,重新规划课程内容降低至 60 小节;50 个 Chrome Developer Tools 必备方法:前端开发人员必备技能点;我们的微信群中孵化下来的一个团队,在做一个服务于伦敦的小程序项目。
DevOpenClub Pro 社群手册
每日分享高质量的技术开发头条信息与资源;遇到任何技术问题都可以进行快速提问、讨论交流;永久获取每年原创的开发视频教程第一手资源更新;获取其他高质量软件开发行业新闻、技术文章、教学视频分享;群中认识更多的同事以及分享合作开发项目的机会;认识更多的行业同学通过关键词采集文章采集api,或者交流自己的创业小项目;交流与分享技术笔试心得;高质量、有价值的社区永远都不会是你所在的 QQ 群或微信群。 查看全部
此文章对开放数据插口 API 之「获取任意链接文章正文」进行了功能介绍、使用场景介绍以及调用方式的说明,供用户在使用数据插口时参考之用。
1. 产品功能
接口开放了按照提供的文章链接 Url 参数,智能分析文章的正文部份,并通过抓取剖析后,返回出文章的标题、正文以及文章的发表时间。
对于各类类型的文章布局,采用了智能化的语义剖析,最大化地满足各类各类布局文章的采集与处理需求。
接口地址:
2. 接口文档与参数
接口地址:
返回格式: json/xml
请求方法: GET
请求示例:
请求合同: HTTPS
接口测试:
各类开发语言的恳求示例代码可以参考 API 文档说明:
加入社群通过关键词采集文章采集api,与 1000 多位同事共同成长
DevOpen.Club Pro 高质量软件开发分享讨论群,汇聚了逾 1000 多名各行各业的软件开发人员,是供朋友们分享高质量资源、讨论软件开发问题解决方案、寻求孵化项目合作伙伴的干货社区。
任何技术都不是限制,我们最终目的是将技术转化成收入,实现财务自由。
社群中正在更新的原创视频教程 & 孵化项目进度
编程大世界:软件开发基础知识通解,带你步入软件开发的大世界;80 节实战课精通 React Native 开发:我出版的书籍《React Native 精解与实战》配套视频教程;微信小程序开发视频教程:最实战的小程序开发视频教程,重新规划课程内容降低至 60 小节;50 个 Chrome Developer Tools 必备方法:前端开发人员必备技能点;我们的微信群中孵化下来的一个团队,在做一个服务于伦敦的小程序项目。
DevOpenClub Pro 社群手册
每日分享高质量的技术开发头条信息与资源;遇到任何技术问题都可以进行快速提问、讨论交流;永久获取每年原创的开发视频教程第一手资源更新;获取其他高质量软件开发行业新闻、技术文章、教学视频分享;群中认识更多的同事以及分享合作开发项目的机会;认识更多的行业同学通过关键词采集文章采集api,或者交流自己的创业小项目;交流与分享技术笔试心得;高质量、有价值的社区永远都不会是你所在的 QQ 群或微信群。
专栏文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-04 01:02
但光这样还不足够,因为我画力导向图的本意是想表现出两个用户之间的互动关系,是“互”动关系。如果B是A的一个狂热粉丝,而A却反倒不太答理B,也就是B在A处得分高,但A在B处得分低。在这样的情况下,A和B似乎不应当以太亲昵的状态出现在力导向图上。
基于这些情况,我对relation_score表进行了更进一步的处理,当A和B彼此都有较高的互动分数时,才会得到一个很高的最终得分,单方面的得分则会被大打折扣,也就是说通过关键词采集文章采集api,将A∩B的分数的残差减小数十倍,然后借此再重新进行打分。最终得到一个新的表links
三、数据可视化
因为想画出比较灵活的力导向图,所以选用了D3:
具体做可视化的时侯,发现两用户之间的得分数据分布,大概呈右图所示(只是示意图,不是精确勾画的):
换句话说,分数越低的区间,人数越多,10~15分之间有500多人,而99-138分的人却只有6个人。所以假如要是简单地按照分数来线性地决定节点之间的力,结果只会有几个人距得太逾,其他大部分人都将距得超远,而且低分人群将难以拉开差别,高分的人之间差别很大但却没哪些意义。数据呈现不显著,力导向图也不太好看。
尝试了许多方案,最后采用了分段线性的方案。
比如得分最高的6个人,分数跨径似乎在 99~138,但节点间斥力仅在 0.9~1.0 间变化,而得分低的500多个人,就算分数只有10-15这样小的跨径,作用力却能在 0.0~3.0 这样广的范围里变化。
最后得出的图如下:
四、观察数据
从图大约能看下来各人在微博上抱团的同事圈子,以及两个人之间的互动关系。
当数据量调到最大时,甚至会发觉微博furry圈子里的“宇宙中心”级人物。
另外,前边说过,采集的数据并不完美通过关键词采集文章采集api,从最终的图上也能看下来一二。
比如:
这张图上两个圈内的这些人,并非是furry圈的人。属于误采集的一部分数据。会听到这部份误采集并且活跃的用户会在力导向图中抱团在一起,所以也可以依据此来做更进一步的数据清洗。
五、其他数据
力导向图展示的是一个整体的、宏观的数据状况。但实际上你们可能比起宏观数据,更关心自己个人的数据,于是进一步还做了个人数据的页面。
这个就直接为了省事,选用echarts3的饼图:
毕竟好不容易做下来的东西,还是希望你们能多好好地看一看。
到此,这个小小的独立数据产品即使竣工了。
在制做的过程中也了解了许多有意思的东西。
……
后来我发觉自己做的这个小网站居然收获了上万次的访问量,访问人数也有3500人之多,看着这个access log,心生了继续将这部份数据借助上去的看法。
六、再次采集、处理
其实有一点懊悔,没有在自己做的网站上做更复杂一些的埋点,结果访问信息只保存出来了默认的access log,也就是访问的URL、时间、IP地址等信息。
前边提及,有人做过furry的地图分布,但疗效不理想。我当然也可以用自己网站的access log来做同样的东西。
IP地址是个好东西,可以通过它获得地市信息,知道这个IP来自哪国哪市哪区,进而实现地域的分布统计。
另外还可以从URL信息中提取出是谁的个人数据页面被访问,换言之,知道了各页面的访问频次,也就晓得了你们对谁的个人数据更感兴趣。
七、地图可视化
这次为了图省事完全就直接用了echarts了,而且是在本地做的,没有上线,所以只有截图。
最后依照你们对个人页面的访问频次做了一个词云图,通过这张图可以看下来,我一开始选购的四个采集用户,也确实是你们太感兴趣的人呢。
八、其他参考资料
IP地区信息:
地市经纬度信息:
地图、词云数据可视化:
结语:
做数据尽管挺有趣的,但可惜我的部门在公司仍然被觉得是一个似乎“不明觉厉”但总之“不做软件不能换钱于是不配合她们工作也问题不大”的存在,去年年初更是由于公司高层嬗变丧失几大靠山而遭到爆破,受到了毁灭性的严打。想使其他各应用部门和技术营运部门配合我们做数据埋点、抽库采集、业务知识交流之类的工作更是难上加难。真希望能有更多更好的数据以及更好的一个平台能使自己见识更广,在大数据的路上走得更远。
真艳羡能领到那么多FB数据的那种俄罗斯公司啊((((( 查看全部
但光这样还不足够,因为我画力导向图的本意是想表现出两个用户之间的互动关系,是“互”动关系。如果B是A的一个狂热粉丝,而A却反倒不太答理B,也就是B在A处得分高,但A在B处得分低。在这样的情况下,A和B似乎不应当以太亲昵的状态出现在力导向图上。
基于这些情况,我对relation_score表进行了更进一步的处理,当A和B彼此都有较高的互动分数时,才会得到一个很高的最终得分,单方面的得分则会被大打折扣,也就是说通过关键词采集文章采集api,将A∩B的分数的残差减小数十倍,然后借此再重新进行打分。最终得到一个新的表links
三、数据可视化
因为想画出比较灵活的力导向图,所以选用了D3:
具体做可视化的时侯,发现两用户之间的得分数据分布,大概呈右图所示(只是示意图,不是精确勾画的):
换句话说,分数越低的区间,人数越多,10~15分之间有500多人,而99-138分的人却只有6个人。所以假如要是简单地按照分数来线性地决定节点之间的力,结果只会有几个人距得太逾,其他大部分人都将距得超远,而且低分人群将难以拉开差别,高分的人之间差别很大但却没哪些意义。数据呈现不显著,力导向图也不太好看。
尝试了许多方案,最后采用了分段线性的方案。
比如得分最高的6个人,分数跨径似乎在 99~138,但节点间斥力仅在 0.9~1.0 间变化,而得分低的500多个人,就算分数只有10-15这样小的跨径,作用力却能在 0.0~3.0 这样广的范围里变化。
最后得出的图如下:
四、观察数据
从图大约能看下来各人在微博上抱团的同事圈子,以及两个人之间的互动关系。
当数据量调到最大时,甚至会发觉微博furry圈子里的“宇宙中心”级人物。
另外,前边说过,采集的数据并不完美通过关键词采集文章采集api,从最终的图上也能看下来一二。
比如:
这张图上两个圈内的这些人,并非是furry圈的人。属于误采集的一部分数据。会听到这部份误采集并且活跃的用户会在力导向图中抱团在一起,所以也可以依据此来做更进一步的数据清洗。
五、其他数据
力导向图展示的是一个整体的、宏观的数据状况。但实际上你们可能比起宏观数据,更关心自己个人的数据,于是进一步还做了个人数据的页面。
这个就直接为了省事,选用echarts3的饼图:
毕竟好不容易做下来的东西,还是希望你们能多好好地看一看。
到此,这个小小的独立数据产品即使竣工了。
在制做的过程中也了解了许多有意思的东西。
……
后来我发觉自己做的这个小网站居然收获了上万次的访问量,访问人数也有3500人之多,看着这个access log,心生了继续将这部份数据借助上去的看法。
六、再次采集、处理
其实有一点懊悔,没有在自己做的网站上做更复杂一些的埋点,结果访问信息只保存出来了默认的access log,也就是访问的URL、时间、IP地址等信息。
前边提及,有人做过furry的地图分布,但疗效不理想。我当然也可以用自己网站的access log来做同样的东西。
IP地址是个好东西,可以通过它获得地市信息,知道这个IP来自哪国哪市哪区,进而实现地域的分布统计。
另外还可以从URL信息中提取出是谁的个人数据页面被访问,换言之,知道了各页面的访问频次,也就晓得了你们对谁的个人数据更感兴趣。
七、地图可视化
这次为了图省事完全就直接用了echarts了,而且是在本地做的,没有上线,所以只有截图。
最后依照你们对个人页面的访问频次做了一个词云图,通过这张图可以看下来,我一开始选购的四个采集用户,也确实是你们太感兴趣的人呢。
八、其他参考资料
IP地区信息:
地市经纬度信息:
地图、词云数据可视化:
结语:
做数据尽管挺有趣的,但可惜我的部门在公司仍然被觉得是一个似乎“不明觉厉”但总之“不做软件不能换钱于是不配合她们工作也问题不大”的存在,去年年初更是由于公司高层嬗变丧失几大靠山而遭到爆破,受到了毁灭性的严打。想使其他各应用部门和技术营运部门配合我们做数据埋点、抽库采集、业务知识交流之类的工作更是难上加难。真希望能有更多更好的数据以及更好的一个平台能使自己见识更广,在大数据的路上走得更远。
真艳羡能领到那么多FB数据的那种俄罗斯公司啊(((((

