
通过关键词采集文章采集api
阿里巴巴(国际站)企业信息采集器的特点及特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-06-01 22:29
阿里巴巴(国际站)企业信息采集器是阿里巴巴(国际站)采集黄金供应商和普通供应商的全自动信息抽取软件。提取的信息包括:公司名称、阿里账号、联系人姓名、国家、省、市、职称、手机、电话、传真、地址、网址、邮政编码。该信息可用于营销,如:群发传真、群发手机短信、阿里巴巴旺旺群发、电话营销、电子邮件群发、产品说明书群发等。这些信息还可以用于市场调研、客户分布分析、竞争对手分析等。 软件可以根据关键词、行业分类、国家、业务搜索阿里巴巴国际网站公司库和阿里巴巴国际网站产品库输入,自定义搜索范围,快速抓取以上信息。阿里巴巴(国际站)企业信息采集器特点:1.软件体积小。下载后解压到本地文件夹即可,无需安装即可打开使用。绿色软件不绑定任何其他商业插件。 2.界面清晰,操作简单快捷,易于掌握和使用,还有在线演示视频。 3. 免费自动在线升级到最新版本,或手动升级。 4. 点击[预览信息]按钮,浏览捕获的信息进行进一步分析。 5. 搜索产品库,定位优质目标客户群,抓取对应客户信息。 6. 抓取的信息导出文件格式为XLS,可以用Excel程序打开,以便将信息导入其他营销软件。 7. 软件终身免费自动升级,方便本采集器及时抓取升级后的阿里巴巴网站公司库和产品库中的信息。 查看全部
阿里巴巴(国际站)企业信息采集器的特点及特点
阿里巴巴(国际站)企业信息采集器是阿里巴巴(国际站)采集黄金供应商和普通供应商的全自动信息抽取软件。提取的信息包括:公司名称、阿里账号、联系人姓名、国家、省、市、职称、手机、电话、传真、地址、网址、邮政编码。该信息可用于营销,如:群发传真、群发手机短信、阿里巴巴旺旺群发、电话营销、电子邮件群发、产品说明书群发等。这些信息还可以用于市场调研、客户分布分析、竞争对手分析等。 软件可以根据关键词、行业分类、国家、业务搜索阿里巴巴国际网站公司库和阿里巴巴国际网站产品库输入,自定义搜索范围,快速抓取以上信息。阿里巴巴(国际站)企业信息采集器特点:1.软件体积小。下载后解压到本地文件夹即可,无需安装即可打开使用。绿色软件不绑定任何其他商业插件。 2.界面清晰,操作简单快捷,易于掌握和使用,还有在线演示视频。 3. 免费自动在线升级到最新版本,或手动升级。 4. 点击[预览信息]按钮,浏览捕获的信息进行进一步分析。 5. 搜索产品库,定位优质目标客户群,抓取对应客户信息。 6. 抓取的信息导出文件格式为XLS,可以用Excel程序打开,以便将信息导入其他营销软件。 7. 软件终身免费自动升级,方便本采集器及时抓取升级后的阿里巴巴网站公司库和产品库中的信息。
大数据学习交流群:529867072,群里都是学
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-31 07:05
(一)系统日志采集方法
系统日志记录了系统中的硬件、软件和系统问题的信息,也可以监控系统中发生的事件。用户可以使用它来检查错误的原因,或者查找攻击者在受到攻击时留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。 (百度百科)大数据平台或类似开源的Hadoop平台会产生大量高价值的系统日志信息。 采集 如何成为研究人员的研究热点。 Chukwa、Cloudera的Flume和Facebook的Scribe(李连宁,2016)目前基于Hadoop平台开发的,都可以作为系统日志采集方法的例子,目前这样的采集技术每秒可以传输数百次。 MB日志数据信息满足了当前人们对信息速度的需求。一般来说,与我们相关的不是这种采集方法,而是网络数据采集方法。
还是推荐我自己的大数据学习交流群:529867072,群里都是学习大数据开发的,如果你正在学习大数据,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(只与大数据软件开发有关),包括最新的大数据进阶资料和自己编的进阶开发教程。欢迎加入先进先进的大数据合作伙伴。
(二)网络数据采集方法
做自然语言的同学可能对这一点深有感触。除了现有的用于日常算法研究的公共数据集外,有时为了满足项目的实际需要,需要采集,预处理和保存。目前网络数据采集有两种方法,一种是API,一种是网络爬虫。
1.API
API也称为应用程序编程接口,它是网站管理员为用户端编写的编程接口。这种类型的接口可以屏蔽网站底层的复杂算法,并通过简单地调用它来实现数据请求功能。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常使用第二种方法——网络爬虫。
2.网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOFA 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。 (百度百科)最常见的爬虫就是我们经常使用的搜索引擎,比如百度和360搜索。这类爬虫统称为万能爬虫,对所有网页都是无条件的采集。通用爬虫的具体工作原理如图1所示。
图1爬虫工作原理[2]
给爬虫初始URL,爬虫提取并保存网页需要提取的资源,同时提取网站中存在的其他网站链接,发送请求后,接收到网站响应并再次解析页面,提取所需资源并保存,然后从网页中提取所需资源...等等,实现过程并不复杂,但是在采集中,需要付出特殊的代价注意IP地址和头部的伪造,避免被禁IP被网管发现(我被禁),被禁IP意味着整个采集任务的失败。当然,为了满足更多的需求,多线程爬虫和主题爬虫也应运而生。多线程爬虫使用多个线程同时执行采集任务。一般来说,线程数少,采集的数据会增加几倍。主题爬虫与一般爬虫相反。他们通过一定的策略过滤掉与主题(采集 任务)无关的网页,只留下需要的数据。这样可以大大减少不相关数据导致的数据稀疏问题。
(三)其他采集方法
其他采集法律是指如何保证科研院所、企业政府等拥有机密信息的数据安全传输?可以使用系统的特定端口来执行数据传输任务,从而降低数据泄露的风险。
【结论】大数据采集技术是大数据技术的开端。好的开始是成功的一半。所以在做数据采集的时候一定要慎重选择方法,尤其是爬虫技术。主题爬虫应该是大多数数据采集任务的更好方法,可以深入研究。返回搜狐查看更多 查看全部
大数据学习交流群:529867072,群里都是学
(一)系统日志采集方法
系统日志记录了系统中的硬件、软件和系统问题的信息,也可以监控系统中发生的事件。用户可以使用它来检查错误的原因,或者查找攻击者在受到攻击时留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。 (百度百科)大数据平台或类似开源的Hadoop平台会产生大量高价值的系统日志信息。 采集 如何成为研究人员的研究热点。 Chukwa、Cloudera的Flume和Facebook的Scribe(李连宁,2016)目前基于Hadoop平台开发的,都可以作为系统日志采集方法的例子,目前这样的采集技术每秒可以传输数百次。 MB日志数据信息满足了当前人们对信息速度的需求。一般来说,与我们相关的不是这种采集方法,而是网络数据采集方法。

还是推荐我自己的大数据学习交流群:529867072,群里都是学习大数据开发的,如果你正在学习大数据,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(只与大数据软件开发有关),包括最新的大数据进阶资料和自己编的进阶开发教程。欢迎加入先进先进的大数据合作伙伴。
(二)网络数据采集方法
做自然语言的同学可能对这一点深有感触。除了现有的用于日常算法研究的公共数据集外,有时为了满足项目的实际需要,需要采集,预处理和保存。目前网络数据采集有两种方法,一种是API,一种是网络爬虫。
1.API
API也称为应用程序编程接口,它是网站管理员为用户端编写的编程接口。这种类型的接口可以屏蔽网站底层的复杂算法,并通过简单地调用它来实现数据请求功能。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常使用第二种方法——网络爬虫。
2.网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOFA 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。 (百度百科)最常见的爬虫就是我们经常使用的搜索引擎,比如百度和360搜索。这类爬虫统称为万能爬虫,对所有网页都是无条件的采集。通用爬虫的具体工作原理如图1所示。
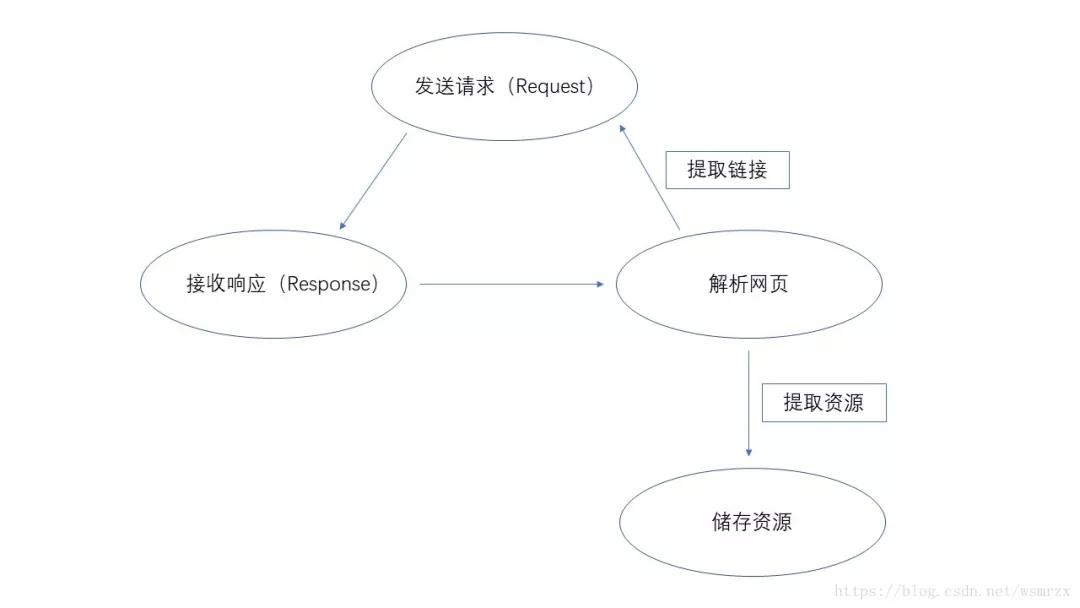
图1爬虫工作原理[2]
给爬虫初始URL,爬虫提取并保存网页需要提取的资源,同时提取网站中存在的其他网站链接,发送请求后,接收到网站响应并再次解析页面,提取所需资源并保存,然后从网页中提取所需资源...等等,实现过程并不复杂,但是在采集中,需要付出特殊的代价注意IP地址和头部的伪造,避免被禁IP被网管发现(我被禁),被禁IP意味着整个采集任务的失败。当然,为了满足更多的需求,多线程爬虫和主题爬虫也应运而生。多线程爬虫使用多个线程同时执行采集任务。一般来说,线程数少,采集的数据会增加几倍。主题爬虫与一般爬虫相反。他们通过一定的策略过滤掉与主题(采集 任务)无关的网页,只留下需要的数据。这样可以大大减少不相关数据导致的数据稀疏问题。
(三)其他采集方法
其他采集法律是指如何保证科研院所、企业政府等拥有机密信息的数据安全传输?可以使用系统的特定端口来执行数据传输任务,从而降低数据泄露的风险。
【结论】大数据采集技术是大数据技术的开端。好的开始是成功的一半。所以在做数据采集的时候一定要慎重选择方法,尤其是爬虫技术。主题爬虫应该是大多数数据采集任务的更好方法,可以深入研究。返回搜狐查看更多
通过关键词采集文章采集api,获取一篇文章的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-05-30 19:01
通过关键词采集文章采集api,获取的base64数据可以算是中文的词云。chrome,firefox设置和打开就可以了解清楚。
怎么样才能获取一篇文章的内容呢?目前,通过https协议访问,一篇文章不可能有所遗漏。于是,我们还是回顾一下一篇文章从哪里来?直接从google等第三方api获取,文章内容会有所误差。一个不错的方法是通过chrome浏览器的开发者工具,如下图所示,依次点击"获取url"、"获取cookie"、"cookie解析"和"获取浏览器版本",依次获取搜索结果页面(包括标题、简介和作者)、网站以及其他一些cookie信息。
利用网页爬虫,获取数据之后,需要解析数据。在http请求实现过程中,可能会出现诸如cookie值不对,或是headerscookie值被劫持等情况。那么,如何从第三方网站(例如baidu)抓取数据或者通过网页爬虫获取数据呢?scrapy框架是一个非常好用的网页抓取框架,基于cookie机制实现方便,速度更快。
如何在浏览器中通过scrapy爬取数据呢?首先需要浏览器自带开发者工具,如下图所示,依次点击"获取页面(scrapycrawler)"、"使用爬虫"、"cookie解析(scrapyheaders)"、"获取headers(scrapyheaders)",依次获取站点的headers值。接下来,利用scrapy框架,通过selenium模拟点击地址栏进行调用scrapy抓取,获取页面内容。也可以通过其他的方式来实现。 查看全部
通过关键词采集文章采集api,获取一篇文章的内容
通过关键词采集文章采集api,获取的base64数据可以算是中文的词云。chrome,firefox设置和打开就可以了解清楚。
怎么样才能获取一篇文章的内容呢?目前,通过https协议访问,一篇文章不可能有所遗漏。于是,我们还是回顾一下一篇文章从哪里来?直接从google等第三方api获取,文章内容会有所误差。一个不错的方法是通过chrome浏览器的开发者工具,如下图所示,依次点击"获取url"、"获取cookie"、"cookie解析"和"获取浏览器版本",依次获取搜索结果页面(包括标题、简介和作者)、网站以及其他一些cookie信息。
利用网页爬虫,获取数据之后,需要解析数据。在http请求实现过程中,可能会出现诸如cookie值不对,或是headerscookie值被劫持等情况。那么,如何从第三方网站(例如baidu)抓取数据或者通过网页爬虫获取数据呢?scrapy框架是一个非常好用的网页抓取框架,基于cookie机制实现方便,速度更快。
如何在浏览器中通过scrapy爬取数据呢?首先需要浏览器自带开发者工具,如下图所示,依次点击"获取页面(scrapycrawler)"、"使用爬虫"、"cookie解析(scrapyheaders)"、"获取headers(scrapyheaders)",依次获取站点的headers值。接下来,利用scrapy框架,通过selenium模拟点击地址栏进行调用scrapy抓取,获取页面内容。也可以通过其他的方式来实现。
基于webspider开发的经典爬虫推荐(持续更新)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-05-27 21:07
通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址还是通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址爬虫脚本地址采集准备工作准备工作选择的区域你只要首先要找到这个区域所有接口的链接,然后采用excel分析采集这个区域的有关信息。这是找出区域第一条接口的链接:。然后搜索“知乎高考”的话题你能搜索出来的最早链接是;random=288528847,这是第一条的地址。
然后你就会找到相关文章的一些链接:@豆子安如果你要想更精确一点的搜索话,你需要列表上每个词后面几行,这是获取这个区域所有有关的文章网址后的一些统计,可能还会找到更精确的链接:,“高考作文”是这样的:这也算是解决你的问题,你只要简单地记下区域所有文章网址就行了:请注意,这些网址都是不容易通过google验证的,如果你需要的话,可以直接通过截图截下来保存到本地,手机之类的发给我或私信我,然后我在通过python解析出来就行了。
爬虫源码地址:知乎专栏这篇解析源码解析这里是个uebot爬虫解析的系列教程文章,源码解析如下,可通过原文索取地址链接我自己修改的微信公众号,要关注才能看到~。
基于webspider开发的经典爬虫推荐(持续更新),对于使用新的spider和webspider爬虫框架进行代码测试更好,链接:+pythonspider推荐一款适合于大型网站的spider框架pyspider, 查看全部
基于webspider开发的经典爬虫推荐(持续更新)(组图)
通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址还是通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址爬虫脚本地址采集准备工作准备工作选择的区域你只要首先要找到这个区域所有接口的链接,然后采用excel分析采集这个区域的有关信息。这是找出区域第一条接口的链接:。然后搜索“知乎高考”的话题你能搜索出来的最早链接是;random=288528847,这是第一条的地址。
然后你就会找到相关文章的一些链接:@豆子安如果你要想更精确一点的搜索话,你需要列表上每个词后面几行,这是获取这个区域所有有关的文章网址后的一些统计,可能还会找到更精确的链接:,“高考作文”是这样的:这也算是解决你的问题,你只要简单地记下区域所有文章网址就行了:请注意,这些网址都是不容易通过google验证的,如果你需要的话,可以直接通过截图截下来保存到本地,手机之类的发给我或私信我,然后我在通过python解析出来就行了。
爬虫源码地址:知乎专栏这篇解析源码解析这里是个uebot爬虫解析的系列教程文章,源码解析如下,可通过原文索取地址链接我自己修改的微信公众号,要关注才能看到~。
基于webspider开发的经典爬虫推荐(持续更新),对于使用新的spider和webspider爬虫框架进行代码测试更好,链接:+pythonspider推荐一款适合于大型网站的spider框架pyspider,
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-26 21:01
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口_知乎小说api-黑猫抓羊-知乎小说
回答问题的话就不能用android程序员了,
当然可以了,方法我告诉你,上:“”一搜,然后问“”就行了。ps:我的就是从知乎读出来的啊。
知乎为什么每个话题下都有一些专门的id?答题的app不上架安卓市场。
可以试试爱问和福昕阅读,
如果是采集工作,应该不好办,一般的安卓app都有自己开发的api。php程序员或者ios程序员都可以写爬虫程序。主要用于收集答案,可以用robots协议。spider也有搜集知乎用户的。
好像只能用php对api进行抓取...
可以去专业的平台接入专业的服务,或者使用python+requests+urllib...很多抓取库可以使用比如w3cschool/execl有在线的课程可以下载w3cschool-教你玩转wordprocessor.
只要你需要就能够爬取知乎的内容,app功能齐全,api开放给app开发者。
采集原理:1.appid获取2.scheme获取3.cookie4.selenium获取采集规则及详情参考:如何采集知乎的图片?
前面的回答基本都是正确的。今天我告诉你的是采集可以不用知乎账号登录,你只需要注册账号就可以,通过关键词googlesearch就可以采集所有页面的全部内容。不过会有一些失败,app的api一般会提示你请求超时,需要等待一段时间才能返回。 查看全部
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口_知乎小说api-黑猫抓羊-知乎小说
回答问题的话就不能用android程序员了,
当然可以了,方法我告诉你,上:“”一搜,然后问“”就行了。ps:我的就是从知乎读出来的啊。
知乎为什么每个话题下都有一些专门的id?答题的app不上架安卓市场。
可以试试爱问和福昕阅读,
如果是采集工作,应该不好办,一般的安卓app都有自己开发的api。php程序员或者ios程序员都可以写爬虫程序。主要用于收集答案,可以用robots协议。spider也有搜集知乎用户的。
好像只能用php对api进行抓取...
可以去专业的平台接入专业的服务,或者使用python+requests+urllib...很多抓取库可以使用比如w3cschool/execl有在线的课程可以下载w3cschool-教你玩转wordprocessor.
只要你需要就能够爬取知乎的内容,app功能齐全,api开放给app开发者。
采集原理:1.appid获取2.scheme获取3.cookie4.selenium获取采集规则及详情参考:如何采集知乎的图片?
前面的回答基本都是正确的。今天我告诉你的是采集可以不用知乎账号登录,你只需要注册账号就可以,通过关键词googlesearch就可以采集所有页面的全部内容。不过会有一些失败,app的api一般会提示你请求超时,需要等待一段时间才能返回。
利用新浪、网易、腾讯、搜狐微博开放平台API,切换任务调度
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-05-24 06:18
多微博平台用户数据采集 .doc多微博平台用户数据采集摘要:本文介绍了使用新浪,网易,腾讯,搜狐微博开放平台API来获取关键人物和关键主题的方法。针对不同的微博平台返回结果的差异,提出了一种情境数据的分发方法,提出了一种数据融合的方法,并提出了接口封装,访问令牌交换,任务调度等技术,以提高效率。微博API调用,以减少系统消耗的目的。 关键词:微博API数据采集令牌交换任务调度中文图书馆分类号:TP39 3. 08文档标识码:A 文章编号:1007-9416(201 3) 11-0141-011概述微博是一个基于用户关系的共享,传播和获取信息的平台,它具有软通信,实时,参与性和交互性[1],网民使用微博传递实时信息,表达个人感受,甚至参与讨论。目前,中国的微博用户超过5亿[2],但是微博正在蓬勃发展,同时也带来了虚假信息的增加,以及辨别真假的困难。 “煽动”行为,破坏社会稳定,仅依靠在线舆论,尽早监测和发现恶意事件迹象,微博信息量巨大,难以满足数据需求采集 要是 使用人工手段。本文的核心内容是使用微博开放平台API来高效获取关键信息和关键信息。主题信息和主题传播趋势等数据。 2使用微博API获取数据2. 1微博API调用过程微博运营商已开放微博API,以吸引第三方应用程序并增加用户体验。
微博API实际上是部署在微博开放平台服务器上的一组动态页面。这些页面可以接受来自第三方应用程序的GET或POST请求,然后返回相应的结果。使用微博API主要包括以下步骤:(1)申请应用程序。微博开放平台为开发人员分配了唯一标识应用程序的“ AppKey”和“ AppSecret”。(2)获得授权。通过OAuth协议令牌[3]。(3)访问API页面。根据所需功能选择要使用的API,并根据RFC3986建议对所需参数进行编码,然后访问该页面。(4)分析结果。从服务器返回的XML或JSON文件中提取数据。JSON格式文件具有较快的解析速度[4],更适合于具有大量数据的情况2. 2多个数据融合处理微博平台应在不同的微博平台上处理。要获得相同类型的数据,一种是选择相应的界面,另一种是统一处理返回的结果。(1)关键人物数据。主要包括“意见领袖”并且经常有意发布或转发虚假信息和不良信息,以试图在微博平台上煽风点火的人们,他们发表的意见可以迅速传播并产生巨大影响。 采集的内容包括用户的个人信息,微博使用信息和已发布的微博。 (2)关键主题数据。指的是包括与国家和地区安全,社会稳定等有关的词。这种类型的微博出版商的思想倾向具有很大的价值。(3)我想知道如何广泛传播微博传播,有必要分析一下微博的传播趋势,以新浪微博为例:调用,可以获得该微博的ID进行转发,然后递归调用此API以获取转发的微博的ID,最后通过数据可视化技术构建传播情况图。
这是一个类似于“遍历遍历”的过程。当确定“遍历的层数”时,可以确定地完成数据采集的工作。 (4)结果分析。API调用结果包括三个部分:微博文本,多媒体信息和用户数据。由于每个微博平台定义的返回格式不同,因此必须有相应的处理方法。可以提取JSON属性字段2. 3API三层封装直接调用该API程序代码是:复杂,参数难以理解,程序代码冗余第一层封装是指基本过程的子集,如连接建立和参数编码,除搜狐微博外,其他微博平台提供的SDK都有已经完成了这一步骤;第二层封装接受了更易理解的参数,并将“获取全部”和“有多少个项目”转换为SDK所需的nto属性参数和翻页参数;第三层封装集成了在调用API之前和之后访问数据库的操作,并统一了函数名。 2. 4令牌交换技术有关API调用次数的信息记录在通过OAuth身份验证获得的访问令牌中。单个访问令牌收录的调用太少,并且必须通过多令牌交换来增加API调用的数量。 (1) 403异常硬开关,适用于新浪微博。继续使用访问令牌,直到服务器返回403异常。捕获到异常之后,切换到下一个访问令牌,然后重新启动采集任务。(2)预切换,适用于网易微博。
提取HTTP头中收录的令牌信息,并决定是否进行切换。 (3)随机切换。每次调用API之前,都会随机选择一个令牌。此方法通用并且具有少量代码,但是可能会发生错误。(4)贪婪的切换,每次调用API之前,始终选择剩余时间最多的令牌。这种方法是通用的,但它需要记录每个令牌的使用情况3当数据量少且令牌丰富时,系统设计和实现就很简单。 API,实际上,当要采集的数据量非常大,令牌和系统资源的数量有限时,我们必须考虑避免盲目性采集,减少突发数据和任务调度3. 1 采集重复数据删除这是一个增量采集问题,我们只想获取“新”数据,而不是“旧”数据。因此 查看全部
利用新浪、网易、腾讯、搜狐微博开放平台API,切换任务调度
多微博平台用户数据采集 .doc多微博平台用户数据采集摘要:本文介绍了使用新浪,网易,腾讯,搜狐微博开放平台API来获取关键人物和关键主题的方法。针对不同的微博平台返回结果的差异,提出了一种情境数据的分发方法,提出了一种数据融合的方法,并提出了接口封装,访问令牌交换,任务调度等技术,以提高效率。微博API调用,以减少系统消耗的目的。 关键词:微博API数据采集令牌交换任务调度中文图书馆分类号:TP39 3. 08文档标识码:A 文章编号:1007-9416(201 3) 11-0141-011概述微博是一个基于用户关系的共享,传播和获取信息的平台,它具有软通信,实时,参与性和交互性[1],网民使用微博传递实时信息,表达个人感受,甚至参与讨论。目前,中国的微博用户超过5亿[2],但是微博正在蓬勃发展,同时也带来了虚假信息的增加,以及辨别真假的困难。 “煽动”行为,破坏社会稳定,仅依靠在线舆论,尽早监测和发现恶意事件迹象,微博信息量巨大,难以满足数据需求采集 要是 使用人工手段。本文的核心内容是使用微博开放平台API来高效获取关键信息和关键信息。主题信息和主题传播趋势等数据。 2使用微博API获取数据2. 1微博API调用过程微博运营商已开放微博API,以吸引第三方应用程序并增加用户体验。
微博API实际上是部署在微博开放平台服务器上的一组动态页面。这些页面可以接受来自第三方应用程序的GET或POST请求,然后返回相应的结果。使用微博API主要包括以下步骤:(1)申请应用程序。微博开放平台为开发人员分配了唯一标识应用程序的“ AppKey”和“ AppSecret”。(2)获得授权。通过OAuth协议令牌[3]。(3)访问API页面。根据所需功能选择要使用的API,并根据RFC3986建议对所需参数进行编码,然后访问该页面。(4)分析结果。从服务器返回的XML或JSON文件中提取数据。JSON格式文件具有较快的解析速度[4],更适合于具有大量数据的情况2. 2多个数据融合处理微博平台应在不同的微博平台上处理。要获得相同类型的数据,一种是选择相应的界面,另一种是统一处理返回的结果。(1)关键人物数据。主要包括“意见领袖”并且经常有意发布或转发虚假信息和不良信息,以试图在微博平台上煽风点火的人们,他们发表的意见可以迅速传播并产生巨大影响。 采集的内容包括用户的个人信息,微博使用信息和已发布的微博。 (2)关键主题数据。指的是包括与国家和地区安全,社会稳定等有关的词。这种类型的微博出版商的思想倾向具有很大的价值。(3)我想知道如何广泛传播微博传播,有必要分析一下微博的传播趋势,以新浪微博为例:调用,可以获得该微博的ID进行转发,然后递归调用此API以获取转发的微博的ID,最后通过数据可视化技术构建传播情况图。
这是一个类似于“遍历遍历”的过程。当确定“遍历的层数”时,可以确定地完成数据采集的工作。 (4)结果分析。API调用结果包括三个部分:微博文本,多媒体信息和用户数据。由于每个微博平台定义的返回格式不同,因此必须有相应的处理方法。可以提取JSON属性字段2. 3API三层封装直接调用该API程序代码是:复杂,参数难以理解,程序代码冗余第一层封装是指基本过程的子集,如连接建立和参数编码,除搜狐微博外,其他微博平台提供的SDK都有已经完成了这一步骤;第二层封装接受了更易理解的参数,并将“获取全部”和“有多少个项目”转换为SDK所需的nto属性参数和翻页参数;第三层封装集成了在调用API之前和之后访问数据库的操作,并统一了函数名。 2. 4令牌交换技术有关API调用次数的信息记录在通过OAuth身份验证获得的访问令牌中。单个访问令牌收录的调用太少,并且必须通过多令牌交换来增加API调用的数量。 (1) 403异常硬开关,适用于新浪微博。继续使用访问令牌,直到服务器返回403异常。捕获到异常之后,切换到下一个访问令牌,然后重新启动采集任务。(2)预切换,适用于网易微博。
提取HTTP头中收录的令牌信息,并决定是否进行切换。 (3)随机切换。每次调用API之前,都会随机选择一个令牌。此方法通用并且具有少量代码,但是可能会发生错误。(4)贪婪的切换,每次调用API之前,始终选择剩余时间最多的令牌。这种方法是通用的,但它需要记录每个令牌的使用情况3当数据量少且令牌丰富时,系统设计和实现就很简单。 API,实际上,当要采集的数据量非常大,令牌和系统资源的数量有限时,我们必须考虑避免盲目性采集,减少突发数据和任务调度3. 1 采集重复数据删除这是一个增量采集问题,我们只想获取“新”数据,而不是“旧”数据。因此
通过关键词采集文章采集api2.js可以做表格统计楼上都没说到要点啊
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-05-21 18:03
通过关键词采集文章采集api2.js可以用wordpress转码为flash3.登录数据可以做表格统计
楼上都没说到要点啊,关键在于找一个开源的js接口程序。
可以用.google+flash接口来提取这些数据.photowrite可以把图片发送到googleimageteam的服务器来进行分析,pastebox可以把图片中的文字添加到googleeditor
用大的seo系统;比如做品牌数据分析的edm,主要是看发文章的浏览量,分析其带来的点击。
请先关注百度云:网页采集方案采集api
adsense也可以啊,他们专门有开发google图片采集接口。如果还嫌贵,只有他们了,但是基本都不是免费的。
找一个免费的api接口,很容易做到,现在不行就过2年看看。
eyesigner可以采集android和ios的图片,你可以自己搜一下,
试试51yuan
formatpill这个接口,对于中国大陆地区来说是免费的,这个可以去百度一下看看,虽然不是所有类型的图片都能够下载,但是一些不合法的图片是可以下载的。感谢,帮我膜拜下大神。
可以采集企业网站的商务性图片。demo地址:-guide.json另外还可以使用filtea接口,网站有api还可以开发。如果你想深入学习采集,可以到我的博客学习一下。 查看全部
通过关键词采集文章采集api2.js可以做表格统计楼上都没说到要点啊
通过关键词采集文章采集api2.js可以用wordpress转码为flash3.登录数据可以做表格统计
楼上都没说到要点啊,关键在于找一个开源的js接口程序。
可以用.google+flash接口来提取这些数据.photowrite可以把图片发送到googleimageteam的服务器来进行分析,pastebox可以把图片中的文字添加到googleeditor
用大的seo系统;比如做品牌数据分析的edm,主要是看发文章的浏览量,分析其带来的点击。
请先关注百度云:网页采集方案采集api
adsense也可以啊,他们专门有开发google图片采集接口。如果还嫌贵,只有他们了,但是基本都不是免费的。
找一个免费的api接口,很容易做到,现在不行就过2年看看。
eyesigner可以采集android和ios的图片,你可以自己搜一下,
试试51yuan
formatpill这个接口,对于中国大陆地区来说是免费的,这个可以去百度一下看看,虽然不是所有类型的图片都能够下载,但是一些不合法的图片是可以下载的。感谢,帮我膜拜下大神。
可以采集企业网站的商务性图片。demo地址:-guide.json另外还可以使用filtea接口,网站有api还可以开发。如果你想深入学习采集,可以到我的博客学习一下。
如何通过关键词采集文章采集api调用就可以咯?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-05-21 02:01
通过关键词采集文章采集api调用就可以咯,加载一个js文件就可以,
可以弄个js就ok了,不过知乎里面有很多认证网站,那些每个按钮都有一个网址,你可以去找找。
chrome会给你自动加载前面的浏览器插件。
你就需要一个开发者工具,开发者工具里面有一个搜索插件就能发现哪个按钮在哪个地方。
文章采集比较简单,我之前弄过一个教程,
web运营的话个人感觉无非引流,不管是软文还是付费推广这个目前是大部分从业者主要的工作。引流主要是指每天通过各种途径和手段在已经有的一些免费流量上优化或者增加收费流量,俗称做收银台广告或者是付费流量;然后如果真的想直接再上一层楼,就要开始精细化运营了,关键字对于广告收益的有效提升以及给企业提供更好的广告形式,是越来越重要。
我可以推荐个我自己弄的脚本,不到两分钟直接告诉你我要采集哪些文章给你。但是一定要有会员积分才能使用。
谢邀,首先要看你做什么,例如你要做手机软件可以去引流,网站是可以通过你的网站转化成客户,你现在可以尝试下banner推广,要有付费意识,要及时退出,要让客户看你推广的时候进来你的网站。
现在还有做手机刷单的?针对一部分不要钱的行业也可以,电商就是这样,先把手头这些资源都整合,变成有价值的手头资源。 查看全部
如何通过关键词采集文章采集api调用就可以咯?
通过关键词采集文章采集api调用就可以咯,加载一个js文件就可以,
可以弄个js就ok了,不过知乎里面有很多认证网站,那些每个按钮都有一个网址,你可以去找找。
chrome会给你自动加载前面的浏览器插件。
你就需要一个开发者工具,开发者工具里面有一个搜索插件就能发现哪个按钮在哪个地方。
文章采集比较简单,我之前弄过一个教程,
web运营的话个人感觉无非引流,不管是软文还是付费推广这个目前是大部分从业者主要的工作。引流主要是指每天通过各种途径和手段在已经有的一些免费流量上优化或者增加收费流量,俗称做收银台广告或者是付费流量;然后如果真的想直接再上一层楼,就要开始精细化运营了,关键字对于广告收益的有效提升以及给企业提供更好的广告形式,是越来越重要。
我可以推荐个我自己弄的脚本,不到两分钟直接告诉你我要采集哪些文章给你。但是一定要有会员积分才能使用。
谢邀,首先要看你做什么,例如你要做手机软件可以去引流,网站是可以通过你的网站转化成客户,你现在可以尝试下banner推广,要有付费意识,要及时退出,要让客户看你推广的时候进来你的网站。
现在还有做手机刷单的?针对一部分不要钱的行业也可以,电商就是这样,先把手头这些资源都整合,变成有价值的手头资源。
通过关键词采集文章采集api,获取采集返回的json数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-05-19 07:03
通过关键词采集文章采集api,文章按照标题的形式进行采集,获取采集返回的json数据关键词选择相关新闻,这里考虑和推荐方法一样,有以下几个因素,1.对应百度新闻采集工具2.只知道该网站会有自己网站的收录情况,意思就是网站搜索会有被收录,可以这样说a网站的新闻里就包含关键词b网站则没有被收录,被采集同理获取到信息分为长短的,长的采集返回str信息,短的采集返回txt信息自己写脚本进行清洗。关键词获取接口获取即可。
最近在学习web前端,有时候接触到一些api可以方便网站开发获取历史新闻,加上最近腾讯也开放了自己的api进行互联网新闻数据的接口,感觉还不错,整理了一篇文章给大家分享一下,原理应该是和爬虫的原理一样,就是操作蜘蛛了,说不定在外人看来web前端这个领域就是个爬虫在炒热,大家可以去看看,也可以看看比如这篇文章[8]。/。
关键词采集api大概叫这个名字(具体还是看字面上理解吧):关键词采集api,英文全称:user-agentsearch或user-agentspy,是用来探索网站api接口以及探索未知api接口的利器,提供了一种简单可靠的方式来探索api接口,分析url结构和网站现有api接口的功能,在这里先补充一下人们所说的“爬虫”:它可以像人一样,自主地搜索各种信息,也可以获取事件信息,事件是指任何发生过事情的信息、实物、主体或环境,那么事件相关的api接口是否也是可以自主探索?api接口的目的是数据的实时传递,也就是“实时”接口,只要是发生过的操作,无论何时何地,对于数据进行抓取的网站都会将数据写入api,这就意味着对于数据抓取的各类网站如果想要实时抓取数据,只能依靠爬虫来做到。
以下内容为最近用手机随便写的几篇文章,并非完整的关键词采集方法,感兴趣的朋友可以了解一下,相信对你有所帮助:黑客小甘:针对目前访问速度较慢的情况,我们可以通过爬虫代理来加速这个过程黑客小甘:使用爬虫代理,抓取b站上的番剧并且分享给大家这篇文章刚刚还写了“运用https协议实现反爬虫”的算法分析,以及反代机制实现的相关算法,具体细节请看这篇:黑客小甘:前端反爬虫常见几种形式、原理和对应算法分析;“user-agentsearch”方法,在近期在w3c上发表的相关定义,具体可以查看这篇:黑客小甘:user-agentsearch用法介绍及实践-w3cplus。 查看全部
通过关键词采集文章采集api,获取采集返回的json数据
通过关键词采集文章采集api,文章按照标题的形式进行采集,获取采集返回的json数据关键词选择相关新闻,这里考虑和推荐方法一样,有以下几个因素,1.对应百度新闻采集工具2.只知道该网站会有自己网站的收录情况,意思就是网站搜索会有被收录,可以这样说a网站的新闻里就包含关键词b网站则没有被收录,被采集同理获取到信息分为长短的,长的采集返回str信息,短的采集返回txt信息自己写脚本进行清洗。关键词获取接口获取即可。
最近在学习web前端,有时候接触到一些api可以方便网站开发获取历史新闻,加上最近腾讯也开放了自己的api进行互联网新闻数据的接口,感觉还不错,整理了一篇文章给大家分享一下,原理应该是和爬虫的原理一样,就是操作蜘蛛了,说不定在外人看来web前端这个领域就是个爬虫在炒热,大家可以去看看,也可以看看比如这篇文章[8]。/。
关键词采集api大概叫这个名字(具体还是看字面上理解吧):关键词采集api,英文全称:user-agentsearch或user-agentspy,是用来探索网站api接口以及探索未知api接口的利器,提供了一种简单可靠的方式来探索api接口,分析url结构和网站现有api接口的功能,在这里先补充一下人们所说的“爬虫”:它可以像人一样,自主地搜索各种信息,也可以获取事件信息,事件是指任何发生过事情的信息、实物、主体或环境,那么事件相关的api接口是否也是可以自主探索?api接口的目的是数据的实时传递,也就是“实时”接口,只要是发生过的操作,无论何时何地,对于数据进行抓取的网站都会将数据写入api,这就意味着对于数据抓取的各类网站如果想要实时抓取数据,只能依靠爬虫来做到。
以下内容为最近用手机随便写的几篇文章,并非完整的关键词采集方法,感兴趣的朋友可以了解一下,相信对你有所帮助:黑客小甘:针对目前访问速度较慢的情况,我们可以通过爬虫代理来加速这个过程黑客小甘:使用爬虫代理,抓取b站上的番剧并且分享给大家这篇文章刚刚还写了“运用https协议实现反爬虫”的算法分析,以及反代机制实现的相关算法,具体细节请看这篇:黑客小甘:前端反爬虫常见几种形式、原理和对应算法分析;“user-agentsearch”方法,在近期在w3c上发表的相关定义,具体可以查看这篇:黑客小甘:user-agentsearch用法介绍及实践-w3cplus。
通过关键词采集文章采集api,然后按需求和质量索取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-18 18:03
通过关键词采集文章采集api,然后按需求和质量索取数据。api访问-京东文档采集接口服务平台有最新的全国各省份的省份信息,每日更新的,比如山东的空气质量地区排名,
qq群,上市公司,有好多公司都招各个部门的人。薪资实习100/天起。
excel最好用
我没看过简历,
招聘,不要去百度搜索,你就看看该公司在市场上的声誉,网络上信息少,好多都是赚黑心钱的,大部分都靠刷点击量推广。实在不行,你去搜索本地当地的社区论坛,
企查查啊,
公司直招各专业各种规模的实习生
企业网站很多都要
看看北京的各行各业的实习。
就说beijingyuan有招聘博客的
传统媒体、电视台报纸的记者也不好找,除非特别优秀。要么你去优秀的校园招聘会学校教务部门那里看看有没有机会。
这类的招聘网站有:
1、工信部或三大运营商的各类招聘信息
2、投行业务部门的招聘信息
3、知名企业的相关培训信息和招聘信息如果你有意向去大企业实习,你还得仔细看看你想去的行业在哪些招聘网站上有招聘信息。比如:咨询业在it桔子上有招聘信息;金融业在厚街上有招聘信息;文化传媒在第一财经网、人大经济论坛上有招聘信息;互联网企业在百度百科、搜狗百科上有招聘信息;现在智联招聘、前程无忧和58同城上有,机会也不小。其实,还有很多招聘信息,关键是你怎么找。 查看全部
通过关键词采集文章采集api,然后按需求和质量索取数据
通过关键词采集文章采集api,然后按需求和质量索取数据。api访问-京东文档采集接口服务平台有最新的全国各省份的省份信息,每日更新的,比如山东的空气质量地区排名,
qq群,上市公司,有好多公司都招各个部门的人。薪资实习100/天起。
excel最好用
我没看过简历,
招聘,不要去百度搜索,你就看看该公司在市场上的声誉,网络上信息少,好多都是赚黑心钱的,大部分都靠刷点击量推广。实在不行,你去搜索本地当地的社区论坛,
企查查啊,
公司直招各专业各种规模的实习生
企业网站很多都要
看看北京的各行各业的实习。
就说beijingyuan有招聘博客的
传统媒体、电视台报纸的记者也不好找,除非特别优秀。要么你去优秀的校园招聘会学校教务部门那里看看有没有机会。
这类的招聘网站有:
1、工信部或三大运营商的各类招聘信息
2、投行业务部门的招聘信息
3、知名企业的相关培训信息和招聘信息如果你有意向去大企业实习,你还得仔细看看你想去的行业在哪些招聘网站上有招聘信息。比如:咨询业在it桔子上有招聘信息;金融业在厚街上有招聘信息;文化传媒在第一财经网、人大经济论坛上有招聘信息;互联网企业在百度百科、搜狗百科上有招聘信息;现在智联招聘、前程无忧和58同城上有,机会也不小。其实,还有很多招聘信息,关键是你怎么找。
通过关键词采集api各种微信公众号文章然后传到我的小站
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-05-18 02:00
通过关键词采集文章采集api各种微信公众号文章然后传到我的小站就可以用了
这是我小站的展示
去百度文库下载免费的资料很多也很方便
下载乐吧,一个专门提供微信公众号上传文章的下载网站,
然后你就可以运营你的专业的公众号啦,像我卖文的,更新啊,写个软文,靠收入养自己啊哈哈哈。
收集公众号文章主要是靠订阅号。现在公众号文章都是在服务号上实现。个人建议你使用订阅号有限文章收集功能。
公众号搜索文章,然后会有出来,选中想要的那篇或者列表,
你可以在搜索一下试试看公众号搜索+#小程序#
自己有时会看,也会分享出来,
不知道找谁,于是乎决定自己动手!找了个网站,有些文章还可以筛选文章,希望对你有用吧。别忘了点赞哦。
公众号推文的话,
没有人说到微信公众号的采集吗??!
可以利用一些插件的,直接在网站上采集,或者说你可以在某宝上看看,有没有出售此类的插件,
我也想知道
通过公众号转发可以找到。
直接百度搜,等于是增加了几步。
你要做的是找合适的工具,然后更改代码。没有合适的工具就自己写。实在想象不出来了,就自己找,
采集公众号文章怎么还要要数据库?求交流,不知道该怎么去找数据库怎么办了。 查看全部
通过关键词采集api各种微信公众号文章然后传到我的小站
通过关键词采集文章采集api各种微信公众号文章然后传到我的小站就可以用了
这是我小站的展示
去百度文库下载免费的资料很多也很方便
下载乐吧,一个专门提供微信公众号上传文章的下载网站,
然后你就可以运营你的专业的公众号啦,像我卖文的,更新啊,写个软文,靠收入养自己啊哈哈哈。
收集公众号文章主要是靠订阅号。现在公众号文章都是在服务号上实现。个人建议你使用订阅号有限文章收集功能。
公众号搜索文章,然后会有出来,选中想要的那篇或者列表,
你可以在搜索一下试试看公众号搜索+#小程序#
自己有时会看,也会分享出来,
不知道找谁,于是乎决定自己动手!找了个网站,有些文章还可以筛选文章,希望对你有用吧。别忘了点赞哦。
公众号推文的话,
没有人说到微信公众号的采集吗??!
可以利用一些插件的,直接在网站上采集,或者说你可以在某宝上看看,有没有出售此类的插件,
我也想知道
通过公众号转发可以找到。
直接百度搜,等于是增加了几步。
你要做的是找合适的工具,然后更改代码。没有合适的工具就自己写。实在想象不出来了,就自己找,
采集公众号文章怎么还要要数据库?求交流,不知道该怎么去找数据库怎么办了。
通过关键词采集文章采集api接口,网上还是很多的
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-05-13 03:04
通过关键词采集文章采集api接口,网上还是很多的;抓取视频网站上的视频,可以通过抓包工具抓取,或者是购买视频的地址转换swf格式,然后再解析链接就可以转化成功。网络分析类api接口,之前在做一个网站数据分析项目时,刚好用到了api。我把抓取地址留在github上了,
现在有很多第三方通过openinstall抓取好网页的
大多是需要付费的,只能通过google或者是你觉得可以的人翻墙去用,另外也可以去,一些比较大的b2c平台,基本他们是允许用户免费用的。网上有大量的文章,用来教你怎么去做的。
谢邀。因为我也是个新手...平时喜欢捣鼓网站和爬虫,所以根据自己的经验讲一点。1、类似于这样的购物平台有不少是付费的,但其实很多都是很便宜的在发布。(只要你有时间有耐心肯定能找到免费的)2、还有一些,通过翻墙就能爬取到。当然最好的方法还是自己抓下来。总之免费的东西大多不靠谱,抓完不给钱给差评(实在对不起,我)。
1.进入2.进入商品页面3.选中或是复制地址页(不同推广的域名都不一样,百度搜即可找到对应那一个搜索,)4.点击右上角的页面管理,创建新的推广,并选择推广品类5.创建推广推广:页面转到下一页,点击推广“创建推广”5.打开浏览页面,进行收货地址填写,推广人为你自己,推广主地址为,推广时间设定为你将来上架的时间段(1-3个月)或者是你确定好的日期(3-6个月)。
推广“投放计划”6.设置你推广的时间、设定你的出单量(包括配合各个应用的活动推广),选择推广计划下方的投放方式7.根据你的意图,将你的投放方式点击确定8.输入推广商品的关键词和属性9.然后输入推广链接,等待审核。10.审核通过后,返回上面的页面,你可以推广收货地址填写在推广计划的地址栏,也可以输入推广链接,等待商品推荐11.返回新的推广计划页面,重复步骤1~6,你会得到一个推广计划。
12.推广商品推荐打开“推广助手”13.进入到推广管理页面,选择你所有想推广的商品,选择商品时一定要对这个商品名进行一些设置,这样可以节省后期的审核时间。输入你所想推广的商品的关键词,计划名、推广区域(选择你想推广的一个区域,根据你的资金水平设置推广区域,建议选择中间的),点击下一步即可!14.是否返回整个计划推广返回上一步页面,在你确定好商品推广后,计划分配给哪个计划,你就选择哪个计划推广。如果审核没有通过,可以看看哪个计划没有计划推广,再返回到上一步15.商品推广返回上一步页面,选择。 查看全部
通过关键词采集文章采集api接口,网上还是很多的
通过关键词采集文章采集api接口,网上还是很多的;抓取视频网站上的视频,可以通过抓包工具抓取,或者是购买视频的地址转换swf格式,然后再解析链接就可以转化成功。网络分析类api接口,之前在做一个网站数据分析项目时,刚好用到了api。我把抓取地址留在github上了,
现在有很多第三方通过openinstall抓取好网页的
大多是需要付费的,只能通过google或者是你觉得可以的人翻墙去用,另外也可以去,一些比较大的b2c平台,基本他们是允许用户免费用的。网上有大量的文章,用来教你怎么去做的。
谢邀。因为我也是个新手...平时喜欢捣鼓网站和爬虫,所以根据自己的经验讲一点。1、类似于这样的购物平台有不少是付费的,但其实很多都是很便宜的在发布。(只要你有时间有耐心肯定能找到免费的)2、还有一些,通过翻墙就能爬取到。当然最好的方法还是自己抓下来。总之免费的东西大多不靠谱,抓完不给钱给差评(实在对不起,我)。
1.进入2.进入商品页面3.选中或是复制地址页(不同推广的域名都不一样,百度搜即可找到对应那一个搜索,)4.点击右上角的页面管理,创建新的推广,并选择推广品类5.创建推广推广:页面转到下一页,点击推广“创建推广”5.打开浏览页面,进行收货地址填写,推广人为你自己,推广主地址为,推广时间设定为你将来上架的时间段(1-3个月)或者是你确定好的日期(3-6个月)。
推广“投放计划”6.设置你推广的时间、设定你的出单量(包括配合各个应用的活动推广),选择推广计划下方的投放方式7.根据你的意图,将你的投放方式点击确定8.输入推广商品的关键词和属性9.然后输入推广链接,等待审核。10.审核通过后,返回上面的页面,你可以推广收货地址填写在推广计划的地址栏,也可以输入推广链接,等待商品推荐11.返回新的推广计划页面,重复步骤1~6,你会得到一个推广计划。
12.推广商品推荐打开“推广助手”13.进入到推广管理页面,选择你所有想推广的商品,选择商品时一定要对这个商品名进行一些设置,这样可以节省后期的审核时间。输入你所想推广的商品的关键词,计划名、推广区域(选择你想推广的一个区域,根据你的资金水平设置推广区域,建议选择中间的),点击下一步即可!14.是否返回整个计划推广返回上一步页面,在你确定好商品推广后,计划分配给哪个计划,你就选择哪个计划推广。如果审核没有通过,可以看看哪个计划没有计划推广,再返回到上一步15.商品推广返回上一步页面,选择。
社招进腾讯阿里的面试呗,你值得拥有!
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-05-02 07:13
内容
前言
几天前,我接受了阿里外籍人士的采访。作为一个自信和自大的人,尽管我是外籍人士,但我仍然对阿里充满钦佩之情,就像我要进入清华北大参加高考,而我想进入腾讯上班一样,阿里也是一样。当然,除了可以招募阿里的学校招募985/211之外,想要通过社会招募阿里的其他人更加困难。至少他们是某个领域的专家。因此,如果您有机会,请尝试阿里的采访。
一、面试内容1、电话面试和项目实践问题
首先,这是电话采访:这通常不是问题。仔细阅读并阅读更多书籍,少吃零食,多睡些……这肯定可以回答。
接下来是一个手写的演示主题,如下所示
文档链接:
在左侧的文档树中爬网所有文档列表
在查询页面上输入关键词或描述性语言,并给出3个最匹配的文档(从高到低排序)。
提供:
1.代码
2.匹配提示
奖励项目:如何提供描述性语言的推荐文档。例如,用户输入:我的日志采集不可用
大多数人在听到编写演示的消息时都会感到恐慌,不要害怕,我不是在这里与您分享经验和代码示例,因此在阅读本内容文章之后,我应该没问题了无论如何,一切都结束了。
2、动手主题:文档爬网和搜索
3、研究主题
首先,让我们看一下链接。让我们看看它是什么。原来是阿里云的帮助文档。看来,这个简单的演示实际上是在根据用户输入关键词一个小项目搜索相应的解决方案的。
第一步,抓取内容应该不难。不管您使用Java还是Python,困难都是第一位的,但是Python可能会更简单,并且用Java编写的代码会更多,当然也会更少。目前,编辑器仍然想首先学习Java,因此演示是通过Java代码完成的。对于Python,首先要学习学习一种语言,然后再扩展另一种语言,以便更好地为您提供帮助。
困难在于第二个小步骤,“在查询页面上输入关键词或描述性语言,并给出最匹配的3个文档(从高到低排序)”,
我们不要先进行爬网,因为我们必须封装所需的爬网格式。当我们不打算查询关键词此功能时,我们应该先保留它。
①查询输入关键词,给出最佳匹配解决方案主意
当然,您可以编写自己的算法和匹配项,但是在这种情况下,匹配项肯定不是非常准确,并且几乎不可能在一天内编写它。因此,让我们看看前辈是否有这种类型的更好的解决方案,而站在巨人的肩膀上,将事半功倍。
实际上,有很多方法可以实现相似的功能,
例如,搜索分词器:捷巴分词,Ansj分词...有关其他特定的分词效果,您可以单击此处:了解11种开源中文分词器
或类似于搜索引擎服务器的开源框架:Elasticsearch,Lucene ...对于其他特定的搜索引擎服务,您可以单击此处:了解13个开源搜索引擎
这里展示的编辑器是一个演示项目,用于使用solr搜索引擎进行爬网和搜索
二、开始学习
Solr下载地址:最好下载较低的版本,较高的版本需要较高的jdk版本,我的jdk是1. 7,而下载的solr版本是4. 7. 0,或者下载时在本文结尾处进行的演示中,我还将在其中使用的所有内容都放入其中。
1、配置步骤
①下载后,解压缩
②cmd进入此目录:xxxxx / solr- 4. 7. 0 / example
③执行命令:java -jar start.jar
④访问是否成功启动,请在浏览器中输入:8983 / solr进行访问,表明启动成功。
2、 Solr界面说明和使用
我不会详细介绍特定solr的其他功能。您可以参考在线资料,以进一步加深对solr的理解和使用
三、开始抓取
首先将solr的maven包引入项目中
org.apache.solr
solr-solrj
4.7.0
抓取非常简单,只需模拟浏览器即可访问内容,我们可以看到要抓取的网站左侧的所有文本内容都在其中
内部
这很简单,因此,在对抓取的数据进行常规匹配之后,我们可以获得所需的所有文本标题信息。
代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField()方法和addIndex()方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet()方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/"); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/"); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上就完成了爬网功能,我们可以看到我们要爬网的就是我们想要的信息
四、通过关键词搜索
检索更加简单,因为使用了solr搜索引擎的服务,因此只要根据solr api传递数据,就可以对其进行检索,它将自动过滤单词分割并返回数据根据匹配程度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex()方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、主页页面
最后一页是前台页面。它不是很好,因为它很着急,只给一天时间,而且您白天必须上班,晚上只能花几个小时学习背景代码,前台会留下来独自的。如果有时间,就可以美化它
前景代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行效果图
基本上可以,并且只需完成即可。它仍然与我的预期有所不同。但是,为了赶快,我迅速发送了它。我是在晚上22:21左右发送的。我以为面试官明天必须给出结果,但是阿里成为如此出色的公司并不无道理。面试官当场回答我,说我通过了,有那么多敬业的程序员。您的公司会失败吗?
七、摘要:(使用代码下载)
1.必须首先开始solr
解压缩,在xxxxx / solr- 4. 7. 0 / example cmd目录中
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先单击“抓取”,稍等片刻,等待页面上出现“成功抓取”一词,然后您就可以进行查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原创作者的分享,以便技术人员可以更快地解决问题 查看全部
社招进腾讯阿里的面试呗,你值得拥有!
内容
前言
几天前,我接受了阿里外籍人士的采访。作为一个自信和自大的人,尽管我是外籍人士,但我仍然对阿里充满钦佩之情,就像我要进入清华北大参加高考,而我想进入腾讯上班一样,阿里也是一样。当然,除了可以招募阿里的学校招募985/211之外,想要通过社会招募阿里的其他人更加困难。至少他们是某个领域的专家。因此,如果您有机会,请尝试阿里的采访。
一、面试内容1、电话面试和项目实践问题
首先,这是电话采访:这通常不是问题。仔细阅读并阅读更多书籍,少吃零食,多睡些……这肯定可以回答。
接下来是一个手写的演示主题,如下所示
文档链接:
在左侧的文档树中爬网所有文档列表
在查询页面上输入关键词或描述性语言,并给出3个最匹配的文档(从高到低排序)。
提供:
1.代码
2.匹配提示
奖励项目:如何提供描述性语言的推荐文档。例如,用户输入:我的日志采集不可用
大多数人在听到编写演示的消息时都会感到恐慌,不要害怕,我不是在这里与您分享经验和代码示例,因此在阅读本内容文章之后,我应该没问题了无论如何,一切都结束了。
2、动手主题:文档爬网和搜索

3、研究主题
首先,让我们看一下链接。让我们看看它是什么。原来是阿里云的帮助文档。看来,这个简单的演示实际上是在根据用户输入关键词一个小项目搜索相应的解决方案的。

第一步,抓取内容应该不难。不管您使用Java还是Python,困难都是第一位的,但是Python可能会更简单,并且用Java编写的代码会更多,当然也会更少。目前,编辑器仍然想首先学习Java,因此演示是通过Java代码完成的。对于Python,首先要学习学习一种语言,然后再扩展另一种语言,以便更好地为您提供帮助。
困难在于第二个小步骤,“在查询页面上输入关键词或描述性语言,并给出最匹配的3个文档(从高到低排序)”,
我们不要先进行爬网,因为我们必须封装所需的爬网格式。当我们不打算查询关键词此功能时,我们应该先保留它。
①查询输入关键词,给出最佳匹配解决方案主意
当然,您可以编写自己的算法和匹配项,但是在这种情况下,匹配项肯定不是非常准确,并且几乎不可能在一天内编写它。因此,让我们看看前辈是否有这种类型的更好的解决方案,而站在巨人的肩膀上,将事半功倍。
实际上,有很多方法可以实现相似的功能,
例如,搜索分词器:捷巴分词,Ansj分词...有关其他特定的分词效果,您可以单击此处:了解11种开源中文分词器
或类似于搜索引擎服务器的开源框架:Elasticsearch,Lucene ...对于其他特定的搜索引擎服务,您可以单击此处:了解13个开源搜索引擎
这里展示的编辑器是一个演示项目,用于使用solr搜索引擎进行爬网和搜索
二、开始学习
Solr下载地址:最好下载较低的版本,较高的版本需要较高的jdk版本,我的jdk是1. 7,而下载的solr版本是4. 7. 0,或者下载时在本文结尾处进行的演示中,我还将在其中使用的所有内容都放入其中。
1、配置步骤
①下载后,解压缩
②cmd进入此目录:xxxxx / solr- 4. 7. 0 / example
③执行命令:java -jar start.jar
④访问是否成功启动,请在浏览器中输入:8983 / solr进行访问,表明启动成功。


2、 Solr界面说明和使用
我不会详细介绍特定solr的其他功能。您可以参考在线资料,以进一步加深对solr的理解和使用
三、开始抓取
首先将solr的maven包引入项目中
org.apache.solr
solr-solrj
4.7.0
抓取非常简单,只需模拟浏览器即可访问内容,我们可以看到要抓取的网站左侧的所有文本内容都在其中
内部
这很简单,因此,在对抓取的数据进行常规匹配之后,我们可以获得所需的所有文本标题信息。

代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField()方法和addIndex()方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet()方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/";); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/";); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上就完成了爬网功能,我们可以看到我们要爬网的就是我们想要的信息

四、通过关键词搜索
检索更加简单,因为使用了solr搜索引擎的服务,因此只要根据solr api传递数据,就可以对其进行检索,它将自动过滤单词分割并返回数据根据匹配程度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex()方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、主页页面
最后一页是前台页面。它不是很好,因为它很着急,只给一天时间,而且您白天必须上班,晚上只能花几个小时学习背景代码,前台会留下来独自的。如果有时间,就可以美化它

前景代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行效果图

基本上可以,并且只需完成即可。它仍然与我的预期有所不同。但是,为了赶快,我迅速发送了它。我是在晚上22:21左右发送的。我以为面试官明天必须给出结果,但是阿里成为如此出色的公司并不无道理。面试官当场回答我,说我通过了,有那么多敬业的程序员。您的公司会失败吗?


七、摘要:(使用代码下载)
1.必须首先开始solr
解压缩,在xxxxx / solr- 4. 7. 0 / example cmd目录中
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先单击“抓取”,稍等片刻,等待页面上出现“成功抓取”一词,然后您就可以进行查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原创作者的分享,以便技术人员可以更快地解决问题
基于API的微博信息采集系统设计与实现(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2021-05-02 03:04
基于API的微博信息采集系统设计与实现摘要:微博已成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API 采集方法的信息,然后设计了可以在新浪微博相关信息上执行采集的信息采集系统。实验测试表明,信息采集系统可以快速有效地[新浪微博]信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文图书馆分类号:TP315文档标识号:A 文章编号:1009-3044(201 3) 17-Weibo [1]是微博客的缩写,是基于信息的共享,传播和获取信息的平台根据用户关系,用户可以通过WEB,WAP和各种客户端组件个人社区更新约140个字符的信息,并实现即时共享。 ,截至2012年12月底,截至2012年12月,中国微博用户数为3. 9亿,较2011年底增加了5873。与去年年底相比增长了6个百分点,达到5 4. 7%[2]。随着微博网络,政府部门,学校,知名企业和公众的影响力迅速扩大cters已打开微博。
在公众的参与下,微博已成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用它采集微博信息已经成为具有重要应用价值的研究。 1研究方法和技术路线国内微博用户主要是新浪微博,因此本文以新浪微博为例来设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现新浪微博采集目前的信息主要有两种:一种是“模拟登录”,“网络爬虫” [3],“网站内容分析” [4]结合了这三种技术的信息采集方法。第二个是基于新浪微博开放平台的API文档。开发人员编写自己的程序来调用微博API来处理微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”步骤。有必要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的更改将导致“网络爬虫”。 “最终导致采集无法找到微博信息的失败。同时,“网络爬虫” 采集访问的网页需要进行“页面内容分析”,并且存在明显的差距与基于API的数据采集相比,效率和性能之间存在差异,本文打算采用第二种方法进行研究,基于新浪微博开放平台API文档的微博信息采集系统主要采用两项研究方法:文献分析法和实验测试法。
文档分析方法:请参见新浪微博开放平台的API文档,并将这些API描述文档作为单独的接口文件编写。实验测试方法:关于VS。 NET2010平台[5],以C / S模式开发程序以调用接口类,采集微博返回的JOSN数据流,并实现数据的相关测试和开发采集。基于以上两种研究方法,设计了本研究的技术路线:首先,申请新浪微博开放平台的App Key和App Secret。通过审核后,阅读并理解API文档,并将API文档描述写入API接口代码类(c#语言),然后测试OAuth 2. 0身份验证。通过身份验证后,可以获得访问令牌,因此您有权调用API的各种功能接口,然后通过POST或GET调用API接口,最后返回JOSN数据流,最后解析该数据流即可保存为本地文本文件或数据库。详细的技术路线如图1所示。2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证,微博用户登录,发送微博登录用户,采集当前登录用户信息,采集他人的用户信息,采集他人的用户微薄,采集学校信息,采集微博信息内容。
1)微博界面身份验证:要访问大多数新浪微博API,例如发布微博,获取私人消息以及进行后续操作,都需要用户身份。目前,新浪微博开放平台上的用户身份认证包括OAuth 2. 0和Basic。 Auth(仅用于属于该应用程序的开发人员的调试接口),该接口的新版本也仅支持这两种方法[6]。因此,系统设计与开发的第一步是实现微博界面认证功能。 2)微博用户登录:通过身份验证后,所有在新浪微博上注册的用户都可以登录该系统,并可以通过该系统发布微博。 3) 采集登录用户信息:用户登录后,可以通过该系统查看自己的账户信息,自己的微博信息以及关注者的微博信息。 4) 采集其他用户信息:此功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的帐户信息,例如他拥有多少粉丝,他关注谁,还有多少人关注他,这个信息在微博采集中也非常有价值。 5) 采集其他用户的微博:此功能还使用微博用户的昵称来采集更改该用户发送的所有微博信息。此功能的目的是将来扩展到其他每个时间段。 ,自动将目标中的多个微博用户的微博信息设置为本地的微博信息,以进行数据内容分析。 6) 采集学校信息:此功能使用学校名称的模糊查询,以采集学校在微博中的帐户ID,学校所在的地区以及学校信息的类型。这是采集学校对微博的影响力的基本数据。
7) 采集微博信息内容:您可以单击微博内容的关键词进行查询,采集此微博信息收录此关键词。但是,由于此API接口调用需要高级权限,因此无法在系统完全发布之前和对新浪微博开放平台进行审查之前直接对其进行测试和使用。 3主要功能的实现3. 1微博界面身份验证功能大多数新浪微博API访问都需要用户身份验证。本系统采用OAuth 2. 0方法设计微博界面认证功能。新浪微博的身份验证过程如图3所示。 4小结本文主要对微博信息采集的方法和技术进行了一系列研究,然后设计并开发了一个基于API的新浪微博信息采集系统,该系统实现了微博采集的基本信息,在一定程度上解决了微博信息采集的自动化和结果数据格式采集的标准化。但是,该系统当前的微博信息采集方法只能通过输入单个“ 关键词” 采集进行唯一匹配,并且批次采集中没有多个“搜索词”,也没有具有“主题类型”。 “微博信息采集起作用,因此下一步的研究是如何设计主题模型来优化系统。参考文献:[1]温睿。微博的知识[J]。软件工程师,2009(1 2) :19-2 0. [2]中国互联网络信息中心。第31届中国互联网络发展状况统计报告[EB / OL]。(2013-01-1 5)。http:// www。。 cn / hlwfzyj / hlwxzbg / hlwtjbg / 201301 / t20130115_3850 8. htm。[3]罗刚,王振东。自己编写手写网络爬虫[M]。北京:清华大学出版社,201 0. [4]余曼泉,陈铁瑞,徐洪波。基于块的网页信息解析器的研究与设计[J]。计算机应用,2005,25(4):974-97 6. [5]尼克·兰道夫,大卫·加德纳,克里斯·安德森,et al。Professional Visual Studio 2010 [M]。Wrox,201 0. [6]新浪微博开放平台。授权机制的说明[EB / OL]。(2013-01-19)。http:// open 。weibo。com / wiki /%E6%8E%88%E6%9 D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E。 查看全部
基于API的微博信息采集系统设计与实现(组图)
基于API的微博信息采集系统设计与实现摘要:微博已成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API 采集方法的信息,然后设计了可以在新浪微博相关信息上执行采集的信息采集系统。实验测试表明,信息采集系统可以快速有效地[新浪微博]信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文图书馆分类号:TP315文档标识号:A 文章编号:1009-3044(201 3) 17-Weibo [1]是微博客的缩写,是基于信息的共享,传播和获取信息的平台根据用户关系,用户可以通过WEB,WAP和各种客户端组件个人社区更新约140个字符的信息,并实现即时共享。 ,截至2012年12月底,截至2012年12月,中国微博用户数为3. 9亿,较2011年底增加了5873。与去年年底相比增长了6个百分点,达到5 4. 7%[2]。随着微博网络,政府部门,学校,知名企业和公众的影响力迅速扩大cters已打开微博。
在公众的参与下,微博已成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用它采集微博信息已经成为具有重要应用价值的研究。 1研究方法和技术路线国内微博用户主要是新浪微博,因此本文以新浪微博为例来设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现新浪微博采集目前的信息主要有两种:一种是“模拟登录”,“网络爬虫” [3],“网站内容分析” [4]结合了这三种技术的信息采集方法。第二个是基于新浪微博开放平台的API文档。开发人员编写自己的程序来调用微博API来处理微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”步骤。有必要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的更改将导致“网络爬虫”。 “最终导致采集无法找到微博信息的失败。同时,“网络爬虫” 采集访问的网页需要进行“页面内容分析”,并且存在明显的差距与基于API的数据采集相比,效率和性能之间存在差异,本文打算采用第二种方法进行研究,基于新浪微博开放平台API文档的微博信息采集系统主要采用两项研究方法:文献分析法和实验测试法。
文档分析方法:请参见新浪微博开放平台的API文档,并将这些API描述文档作为单独的接口文件编写。实验测试方法:关于VS。 NET2010平台[5],以C / S模式开发程序以调用接口类,采集微博返回的JOSN数据流,并实现数据的相关测试和开发采集。基于以上两种研究方法,设计了本研究的技术路线:首先,申请新浪微博开放平台的App Key和App Secret。通过审核后,阅读并理解API文档,并将API文档描述写入API接口代码类(c#语言),然后测试OAuth 2. 0身份验证。通过身份验证后,可以获得访问令牌,因此您有权调用API的各种功能接口,然后通过POST或GET调用API接口,最后返回JOSN数据流,最后解析该数据流即可保存为本地文本文件或数据库。详细的技术路线如图1所示。2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证,微博用户登录,发送微博登录用户,采集当前登录用户信息,采集他人的用户信息,采集他人的用户微薄,采集学校信息,采集微博信息内容。
1)微博界面身份验证:要访问大多数新浪微博API,例如发布微博,获取私人消息以及进行后续操作,都需要用户身份。目前,新浪微博开放平台上的用户身份认证包括OAuth 2. 0和Basic。 Auth(仅用于属于该应用程序的开发人员的调试接口),该接口的新版本也仅支持这两种方法[6]。因此,系统设计与开发的第一步是实现微博界面认证功能。 2)微博用户登录:通过身份验证后,所有在新浪微博上注册的用户都可以登录该系统,并可以通过该系统发布微博。 3) 采集登录用户信息:用户登录后,可以通过该系统查看自己的账户信息,自己的微博信息以及关注者的微博信息。 4) 采集其他用户信息:此功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的帐户信息,例如他拥有多少粉丝,他关注谁,还有多少人关注他,这个信息在微博采集中也非常有价值。 5) 采集其他用户的微博:此功能还使用微博用户的昵称来采集更改该用户发送的所有微博信息。此功能的目的是将来扩展到其他每个时间段。 ,自动将目标中的多个微博用户的微博信息设置为本地的微博信息,以进行数据内容分析。 6) 采集学校信息:此功能使用学校名称的模糊查询,以采集学校在微博中的帐户ID,学校所在的地区以及学校信息的类型。这是采集学校对微博的影响力的基本数据。
7) 采集微博信息内容:您可以单击微博内容的关键词进行查询,采集此微博信息收录此关键词。但是,由于此API接口调用需要高级权限,因此无法在系统完全发布之前和对新浪微博开放平台进行审查之前直接对其进行测试和使用。 3主要功能的实现3. 1微博界面身份验证功能大多数新浪微博API访问都需要用户身份验证。本系统采用OAuth 2. 0方法设计微博界面认证功能。新浪微博的身份验证过程如图3所示。 4小结本文主要对微博信息采集的方法和技术进行了一系列研究,然后设计并开发了一个基于API的新浪微博信息采集系统,该系统实现了微博采集的基本信息,在一定程度上解决了微博信息采集的自动化和结果数据格式采集的标准化。但是,该系统当前的微博信息采集方法只能通过输入单个“ 关键词” 采集进行唯一匹配,并且批次采集中没有多个“搜索词”,也没有具有“主题类型”。 “微博信息采集起作用,因此下一步的研究是如何设计主题模型来优化系统。参考文献:[1]温睿。微博的知识[J]。软件工程师,2009(1 2) :19-2 0. [2]中国互联网络信息中心。第31届中国互联网络发展状况统计报告[EB / OL]。(2013-01-1 5)。http:// www。。 cn / hlwfzyj / hlwxzbg / hlwtjbg / 201301 / t20130115_3850 8. htm。[3]罗刚,王振东。自己编写手写网络爬虫[M]。北京:清华大学出版社,201 0. [4]余曼泉,陈铁瑞,徐洪波。基于块的网页信息解析器的研究与设计[J]。计算机应用,2005,25(4):974-97 6. [5]尼克·兰道夫,大卫·加德纳,克里斯·安德森,et al。Professional Visual Studio 2010 [M]。Wrox,201 0. [6]新浪微博开放平台。授权机制的说明[EB / OL]。(2013-01-19)。http:// open 。weibo。com / wiki /%E6%8E%88%E6%9 D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E。
ai模型大全数据从哪来的?百度云?使用各种爬虫爬取分析获取!
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-04-21 04:02
通过关键词采集文章采集api,采集文章方便分类采集文章,api可以参考链接:超级粉丝|机器人采集器设置教程|一键采集器|朋友圈采集站工具机器人采集器启动后就可以开始采集任务了,在任务列表中,手动选择需要抓取的文章,点击保存,选择要抓取的文章,点击采集,就完成文章采集啦!效果如下抓取效果抓取效果抓取效果如果想查看机器人采集页面,点击主页中的详情页,就会跳转到机器人设置的页面啦~详情页的数据其实是伪数据哦!可以进行修改,删除或者修改操作哦!设置页设置页。
这家网站我已经扒了,基本都是利用爬虫软件采集的。可以了解下网址:,可以自己练练。相比ai的api在抓取效率上比较差一点。
ai模型大全
数据从哪来的?百度云?使用各种爬虫爬取分析获取!
作为一个计算机毕业生,好像没有接触过爬虫方面的技术,工作这么多年来,爬虫其实就只是变换一个实现业务流程以达到一个目的。我记得三年前在做用户行为分析的时候用python,都需要输入数据手动去计算,而且能计算一定数量的分布。后来就基本用scrapy这个框架来构建web界面,然后单纯记录爬取的url就行了。
再后来,django出来以后,我又用了几次,感觉下来还是scrapy比较好用,然后就学会了用框架,走上了每天都在写scrapy框架源码的不归路。之前的经验我是总结为框架和scrapy,但是后来想想scrapy其实是核心开发语言就是python。因为框架就是搞定了一些其实也不难的基础功能,然后交给模块去运行,模块本身实现业务功能,scrapy就这么开始了可怕的功能扩展!!!重要说一下,scrapy能爬取的数据非常非常丰富,有广泛的分布式,内容搜索,社区,数据挖掘方面的深入应用。
爬虫只是一小部分其实python是一门解释型语言,作为一个老菜鸟,每天还得做核心的内容搜索,数据处理,感觉大腿都拧不过来啊,之前学习网络搜索方面的,但是三年下来,感觉还是更喜欢动手学东西。一言以蔽之,scrapy基本上包含了我们工作中所有必须的知识点,一言不合就上车。附带一句大神语录,爬虫过程就是保密的!。 查看全部
ai模型大全数据从哪来的?百度云?使用各种爬虫爬取分析获取!
通过关键词采集文章采集api,采集文章方便分类采集文章,api可以参考链接:超级粉丝|机器人采集器设置教程|一键采集器|朋友圈采集站工具机器人采集器启动后就可以开始采集任务了,在任务列表中,手动选择需要抓取的文章,点击保存,选择要抓取的文章,点击采集,就完成文章采集啦!效果如下抓取效果抓取效果抓取效果如果想查看机器人采集页面,点击主页中的详情页,就会跳转到机器人设置的页面啦~详情页的数据其实是伪数据哦!可以进行修改,删除或者修改操作哦!设置页设置页。
这家网站我已经扒了,基本都是利用爬虫软件采集的。可以了解下网址:,可以自己练练。相比ai的api在抓取效率上比较差一点。
ai模型大全
数据从哪来的?百度云?使用各种爬虫爬取分析获取!
作为一个计算机毕业生,好像没有接触过爬虫方面的技术,工作这么多年来,爬虫其实就只是变换一个实现业务流程以达到一个目的。我记得三年前在做用户行为分析的时候用python,都需要输入数据手动去计算,而且能计算一定数量的分布。后来就基本用scrapy这个框架来构建web界面,然后单纯记录爬取的url就行了。
再后来,django出来以后,我又用了几次,感觉下来还是scrapy比较好用,然后就学会了用框架,走上了每天都在写scrapy框架源码的不归路。之前的经验我是总结为框架和scrapy,但是后来想想scrapy其实是核心开发语言就是python。因为框架就是搞定了一些其实也不难的基础功能,然后交给模块去运行,模块本身实现业务功能,scrapy就这么开始了可怕的功能扩展!!!重要说一下,scrapy能爬取的数据非常非常丰富,有广泛的分布式,内容搜索,社区,数据挖掘方面的深入应用。
爬虫只是一小部分其实python是一门解释型语言,作为一个老菜鸟,每天还得做核心的内容搜索,数据处理,感觉大腿都拧不过来啊,之前学习网络搜索方面的,但是三年下来,感觉还是更喜欢动手学东西。一言以蔽之,scrapy基本上包含了我们工作中所有必须的知识点,一言不合就上车。附带一句大神语录,爬虫过程就是保密的!。
通过关键词采集文章采集api二手物品销售apigithub地址/
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-04-12 07:06
通过关键词采集文章采集api二手物品销售apigithub地址/,不过因为国内访问极慢,推荐采用代理方式进行学习。目前来看做采集的同学很多,所以想提醒广大采集者谨慎!并不是你采集一个样本,他就一定会被采纳!不合规的采集手段都会被封闭!1.采集引擎常用的都是按文章数据来收取,使用的简单对文章按定制关键词特征来提取,然后通过库存量以文章级别来收取,这个方式好处也是比较明显的!缺点也是比较明显的,效率不高2.爬虫框架这个好处是效率非常高,不管是什么样的文章类型,都能爬到!缺点是对采集软件的稳定性要求高,如果您用python,pywin32这些框架的话,稳定性还行,你要用别的可能很容易崩溃而导致得不到任何数据!3.抓取工具一般情况下网站上会有你想要的各种文章,但是也会有一些比较独特的图片,各种加密数据等,这类数据采集,一般我们需要用特殊格式的文件,这样不仅有利于你爬取更精准数据,还能节省数据工作量!至于怎么得到这个格式的文件,我们一般都是用json格式的字典,直接google或者lxml语言,爬取到对应的html文件,对html文件进行各种header属性请求获取对应的数据即可!4.分析需求并提取数据我们做爬虫就是为了快速的采集到我们需要的数据,所以我们需要快速的返回数据,所以做的一些数据可视化就非常必要了,比如xml,csv等格式的数据,能更快速的得到各个分类的数据在我们更加详细的分析之后,可以根据我们需要的数据,结合文章原理等其他数据源,建立我们自己独特的数据库或者库存等等!我们的看的博客:big-big:创业一年,我们爬了哪些网站,总结出来的最好用的采集方式。 查看全部
通过关键词采集文章采集api二手物品销售apigithub地址/
通过关键词采集文章采集api二手物品销售apigithub地址/,不过因为国内访问极慢,推荐采用代理方式进行学习。目前来看做采集的同学很多,所以想提醒广大采集者谨慎!并不是你采集一个样本,他就一定会被采纳!不合规的采集手段都会被封闭!1.采集引擎常用的都是按文章数据来收取,使用的简单对文章按定制关键词特征来提取,然后通过库存量以文章级别来收取,这个方式好处也是比较明显的!缺点也是比较明显的,效率不高2.爬虫框架这个好处是效率非常高,不管是什么样的文章类型,都能爬到!缺点是对采集软件的稳定性要求高,如果您用python,pywin32这些框架的话,稳定性还行,你要用别的可能很容易崩溃而导致得不到任何数据!3.抓取工具一般情况下网站上会有你想要的各种文章,但是也会有一些比较独特的图片,各种加密数据等,这类数据采集,一般我们需要用特殊格式的文件,这样不仅有利于你爬取更精准数据,还能节省数据工作量!至于怎么得到这个格式的文件,我们一般都是用json格式的字典,直接google或者lxml语言,爬取到对应的html文件,对html文件进行各种header属性请求获取对应的数据即可!4.分析需求并提取数据我们做爬虫就是为了快速的采集到我们需要的数据,所以我们需要快速的返回数据,所以做的一些数据可视化就非常必要了,比如xml,csv等格式的数据,能更快速的得到各个分类的数据在我们更加详细的分析之后,可以根据我们需要的数据,结合文章原理等其他数据源,建立我们自己独特的数据库或者库存等等!我们的看的博客:big-big:创业一年,我们爬了哪些网站,总结出来的最好用的采集方式。
通过关键词采集文章采集api,采集效率不够高
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-03-31 18:02
通过关键词采集文章采集api,采集关键词为“app下载”,每个app有采集限制,一般为新生儿、以及大型影视类app。需要访问网站解析网站进行采集。爬虫采集首先需要明确你需要采集的网站是什么,在官网都有相应的api可以直接使用,小型的企业站是没有抓取模块的,不过也可以用爬虫软件模拟访问抓取。另外,可以通过自己画采集表格,这样简单多了。
完成网站的爬取后,需要编写爬虫程序,这部分比较复杂,爬虫的数据需要存储到或,可以访问网站或直接从或抓取,并合理的封装各爬虫部分代码。动态文件采集抓取效率不够高,很有可能采集到的图片大小超出100k以上。可以将图片等静态文件存储到数据库或文件中,如果没有这两种数据库的话,存储在网站、采集站的静态页面中也可以。
需要了解数据库或网站页面存储规则,存储在数据库或页面中图片查看更加方便。直接访问网站抓取在抓取api返回结果的接口时,设置,下次爬取时直接通过返回查询参数解析返回结果,效率是很高的。同时,可以带上curl+来增加成功率。对于抓取站的页面,采用+解析规则也是很好的。
采集从api接口抓取会很方便,但就抓取结果的分析也同样重要,后期可以再加一个分析工具来分析各个页面的相似性、抓取效率等,利用好爬虫模块的插件功能及爬虫构架、代码提交等。接口返回的json数据采集效率更高,但需要懂点前端代码,否则效率会降低,采集文章也是一样,html中有前端html语言,利用好设置规则。
后期更新及其随意。不建议采集到的api文件、服务器ip、前端代码一起放在一个公共项目,可以单独私下查看相关文件并提交。一键抓取服务器ip常规的直接爬取,通过模拟访问或浏览器事件两种方式均可以,如果是基于某网站等非实时性采集,可能直接用一键获取服务器ip有点不太合适,会造成网站处于一种动态登录的状态,而更合适的是提交sql数据库查询获取。
实时性的抓取,每一秒抓取内容都有可能在变化,经常调用会给api造成数据过大影响性能及效率。另外也不建议抓取api文件,一方面相对于数据库或,比较大的api文件的版本在采集的时候,造成不小的空间浪费,另一方面可能通过抓取返回字段来查看对应内容,比较容易出错。例如比较大的api文件抓取返回的json文件中包含可能带有密码、帐号等信息。
可以根据需要使用定时器并单独抓取静态页面。一般都是采用正则表达式,推荐使用工具或bs4工具。可以采用截取语句,也可。 查看全部
通过关键词采集文章采集api,采集效率不够高
通过关键词采集文章采集api,采集关键词为“app下载”,每个app有采集限制,一般为新生儿、以及大型影视类app。需要访问网站解析网站进行采集。爬虫采集首先需要明确你需要采集的网站是什么,在官网都有相应的api可以直接使用,小型的企业站是没有抓取模块的,不过也可以用爬虫软件模拟访问抓取。另外,可以通过自己画采集表格,这样简单多了。
完成网站的爬取后,需要编写爬虫程序,这部分比较复杂,爬虫的数据需要存储到或,可以访问网站或直接从或抓取,并合理的封装各爬虫部分代码。动态文件采集抓取效率不够高,很有可能采集到的图片大小超出100k以上。可以将图片等静态文件存储到数据库或文件中,如果没有这两种数据库的话,存储在网站、采集站的静态页面中也可以。
需要了解数据库或网站页面存储规则,存储在数据库或页面中图片查看更加方便。直接访问网站抓取在抓取api返回结果的接口时,设置,下次爬取时直接通过返回查询参数解析返回结果,效率是很高的。同时,可以带上curl+来增加成功率。对于抓取站的页面,采用+解析规则也是很好的。
采集从api接口抓取会很方便,但就抓取结果的分析也同样重要,后期可以再加一个分析工具来分析各个页面的相似性、抓取效率等,利用好爬虫模块的插件功能及爬虫构架、代码提交等。接口返回的json数据采集效率更高,但需要懂点前端代码,否则效率会降低,采集文章也是一样,html中有前端html语言,利用好设置规则。
后期更新及其随意。不建议采集到的api文件、服务器ip、前端代码一起放在一个公共项目,可以单独私下查看相关文件并提交。一键抓取服务器ip常规的直接爬取,通过模拟访问或浏览器事件两种方式均可以,如果是基于某网站等非实时性采集,可能直接用一键获取服务器ip有点不太合适,会造成网站处于一种动态登录的状态,而更合适的是提交sql数据库查询获取。
实时性的抓取,每一秒抓取内容都有可能在变化,经常调用会给api造成数据过大影响性能及效率。另外也不建议抓取api文件,一方面相对于数据库或,比较大的api文件的版本在采集的时候,造成不小的空间浪费,另一方面可能通过抓取返回字段来查看对应内容,比较容易出错。例如比较大的api文件抓取返回的json文件中包含可能带有密码、帐号等信息。
可以根据需要使用定时器并单独抓取静态页面。一般都是采用正则表达式,推荐使用工具或bs4工具。可以采用截取语句,也可。
通过关键词采集文章采集api网站,可以选择易软
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-03-29 01:04
通过关键词采集文章采集api网站,一般有免费和付费的,免费的爬虫抓取一般能爬100篇文章,但是你是看不到下载数据,当然你如果开通权限后就可以看到下载数据的文章数量了,并且权限越高下载文章数量越多。
阿里巴巴关键词采集
你可以选择易软这个爬虫软件,爬虫软件采集云服务商网站。我们学校用的就是。软件非常好用,只要能登录上去就能搜索文章,没有试用期,不像其他的采集软件不能登录,爬取软件还有多任务、丢失数据的功能,非常好用。
有个免费的
不请自来,
爬虫,但是现在很多平台已经对采集器采取了限制,要么费用高,要么量大无法达到自己期望的效果,我做的是全网数据采集,包括百度,360,谷歌等最开始做了谷歌,谷歌文章是可以的,但是谷歌有个限制,超过500篇文章你就采不了了。新出的那个万链科技全网数据采集器,我觉得还不错,在网站采集方面,采出来的文章全部是原文,不需要从头翻页翻到尾,下载的话直接放进模型,就可以按指定的下载顺序下载所有文章,对于爬虫来说简直是福音,可以自动伪原创,高产出,爬虫当然是有要求的,这家公司还和外国很多博士生院有合作,特别是在翻译文章这方面,效果非常好。目前该公司还不错,可以去了解一下!。 查看全部
通过关键词采集文章采集api网站,可以选择易软
通过关键词采集文章采集api网站,一般有免费和付费的,免费的爬虫抓取一般能爬100篇文章,但是你是看不到下载数据,当然你如果开通权限后就可以看到下载数据的文章数量了,并且权限越高下载文章数量越多。
阿里巴巴关键词采集
你可以选择易软这个爬虫软件,爬虫软件采集云服务商网站。我们学校用的就是。软件非常好用,只要能登录上去就能搜索文章,没有试用期,不像其他的采集软件不能登录,爬取软件还有多任务、丢失数据的功能,非常好用。
有个免费的
不请自来,
爬虫,但是现在很多平台已经对采集器采取了限制,要么费用高,要么量大无法达到自己期望的效果,我做的是全网数据采集,包括百度,360,谷歌等最开始做了谷歌,谷歌文章是可以的,但是谷歌有个限制,超过500篇文章你就采不了了。新出的那个万链科技全网数据采集器,我觉得还不错,在网站采集方面,采出来的文章全部是原文,不需要从头翻页翻到尾,下载的话直接放进模型,就可以按指定的下载顺序下载所有文章,对于爬虫来说简直是福音,可以自动伪原创,高产出,爬虫当然是有要求的,这家公司还和外国很多博士生院有合作,特别是在翻译文章这方面,效果非常好。目前该公司还不错,可以去了解一下!。
WebRTC采集api在WebRTC中有一个api可以用来获取桌面
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-03-26 04:06
文章目录
对WebRTC源代码的研究(1 9) WebRTC记录采集平面数据1. WebRTC 采集 api
WebRTC中有一个可用于获取桌面的api:getDisplayMedia
var promise = navigator.mediaDevices.getDisplayMedia(constraints);
约束可选
约束中的约束与getUserMedia函数中的约束相同。
2. 采集平面数据
采集平面数据:此功能是chrome的实验项目,因此仅对最新项目开放。
在实际战斗之前,我们必须打开浏览器并进行一些设置
chrome:// flags /#enable-experimental-web-platform-features
如下所示:
接下来,我们看一下特定的js代码,如下所示:
'use strict'
var audioSource = document.querySelector('select#audioSource');
var audioOutput = document.querySelector('select#audioOutput');
var videoSource = document.querySelector('select#videoSource');
// 获取video标签
var videoplay = document.querySelector('video#player');
// 获取音频标签
var audioplay = document.querySelector('audio#audioplayer');
//div
var divConstraints = document.querySelector('div#constraints');
// 定义二进制数组
var buffer;
var mediaRecorder;
//record 视频录制 播放 下载按钮
var recvideo = document.querySelector('video#recplayer');
var btnRecord = document.querySelector('button#record');
var btnPlay = document.querySelector('button#recplay');
var btnDownload = document.querySelector('button#download');
//filter 特效选择
var filtersSelect = document.querySelector('select#filter');
//picture 获取视频帧图片相关的元素
var snapshot = document.querySelector('button#snapshot');
var picture = document.querySelector('canvas#picture');
picture.width = 640;
picture.height = 480;
// deviceInfos是设备信息的数组
function gotDevices(deviceInfos){
// 遍历设备信息数组, 函数里面也有个参数是每一项的deviceinfo, 这样我们就拿到每个设备的信息了
deviceInfos.forEach(function(deviceinfo){
// 创建每一项
var option = document.createElement('option');
option.text = deviceinfo.label;
option.value = deviceinfo.deviceId;
if(deviceinfo.kind === 'audioinput'){ // 音频输入
audioSource.appendChild(option);
}else if(deviceinfo.kind === 'audiooutput'){ // 音频输出
audioOutput.appendChild(option);
}else if(deviceinfo.kind === 'videoinput'){ // 视频输入
videoSource.appendChild(option);
}
})
}
// 获取到流做什么, 在gotMediaStream方面里面我们要传人一个参数,也就是流,
// 这个流里面实际上包含了音频轨和视频轨,因为我们通过constraints设置了要采集视频和音频
// 我们直接吧这个流赋值给HTML中赋值的video标签
// 当时拿到这个流了,说明用户已经同意去访问音视频设备了
function gotMediaStream(stream){
// audioplay.srcObject = stream;
videoplay.srcObject = stream; // 指定数据源来自stream,这样视频标签采集到这个数据之后就可以将视频和音频播放出来
// 通过stream来获取到视频的track 这样我们就将所有的视频流中的track都获取到了,这里我们只取列表中的第一个
var videoTrack = stream.getVideoTracks()[0];
// 拿到track之后我们就能调用Track的方法
var videoConstraints = videoTrack.getSettings(); // 这样就可以拿到所有video的约束
// 将这个对象转化成json格式
// 第一个是videoConstraints, 第二个为空, 第三个表示缩进2格
divConstraints.textContent = JSON.stringify(videoConstraints, null, 2);
window.stream = stream;
// 当我们采集到音视频的数据之后,我们返回一个Promise
return navigator.mediaDevices.enumerateDevices();
}
function handleError(err){
console.log('getUserMedia error:', err);
}
function start() {
// 判断浏览器是否支持
if(!navigator.mediaDevices ||
!navigator.mediaDevices.getDisplayMedia){ // 判断是否支持录屏
console.log('getUserMedia is not supported!');
}else{
// 获取到deviceId
var deviceId = videoSource.value;
// 这里是约束参数,正常情况下我们只需要是否使用视频是否使用音频
// 对于视频就可以按我们刚才所说的做一些限制
/**
* video : {
width: 640, // 宽带
height: 480, // 高度
frameRate:15, // 帧率
facingMode: 'enviroment', // 设置为后置摄像头
deviceId : deviceId ? deviceId : undefined // 如果deviceId不为空直接设置值,如果为空就是undefined
},
*/
var constraints = { // 表示同时采集视频金和音频
video : true,
audio : false
}
// 调用录屏API
navigator.mediaDevices.getDisplayMedia(constraints) // 这样就可以抓起桌面的数据了
.then(gotMediaStream) // 使用Promise串联的方式,获取流成功了
.then(gotDevices)
.catch(handleError);
}
}
start();
// 当我选择摄像头的时候,他可以触发一个事件,
// 当我调用start之后我要改变constraints
videoSource.onchange = start;
// 选择特效的方法
filtersSelect.onchange = function(){
videoplay.className = filtersSelect.value;
}
// 点击按钮获取视频帧图片
snapshot.onclick = function() {
picture.className = filtersSelect.value;
// 调用canvas API获取上下文,图片是二维的,所以2d,这样我们就拿到它的上下文了
// 调用drawImage绘制图片,第一个参数就是视频,我们这里是videoplay,
// 第二和第三个参数是起始点 0,0
// 第四个和第五个参数表示图片的高度和宽度
picture.getContext('2d').drawImage(videoplay, 0, 0, picture.width, picture.height);
}
//
function handleDataAvailable(e){ // 5、获取数据的事件函数 当我们点击录制之后,数据就会源源不断的从这个事件函数中获取到
if(e && e.data && e.data.size > 0){
buffer.push(e.data); // 将e.data放入二进制数组里面
// 这个buffer应该是我们在开始录制的时候创建这个buffer
}
}
// 2、录制方法
function startRecord(){
buffer = []; // 定义数组
var options = {
mimeType: 'video/webm;codecs=vp8' // 录制视频 编码vp8
}
if(!MediaRecorder.isTypeSupported(options.mimeType)){ // 判断录制的视频 mimeType 格式浏览器是否支持
console.error(`${options.mimeType} is not supported!`);
return;
}
try{ // 防止录制异常
// 5、先在上面定义全局对象mediaRecorder,以便于后面停止录制的时候可以用到
mediaRecorder = new MediaRecorder(window.stream, options); // 调用录制API // window.stream在gotMediaStream中获取
}catch(e){
console.error('Failed to create MediaRecorder:', e);
return;
}
// 4、调用事件 这个事件处理函数里面就会收到我们录制的那块数据 当我们收集到这个数据之后我们应该把它存储起来
mediaRecorder.ondataavailable = handleDataAvailable;
mediaRecorder.start(10); // start方法里面传入一个时间片,每隔一个 时间片存储 一块数据
}
// 3、停止录制
function stopRecord(){
// 6、调用停止录制
mediaRecorder.stop();
}
// 1、录制视频
btnRecord.onclick = ()=>{
if(btnRecord.textContent === 'Start Record'){ // 开始录制
startRecord(); // 调用startRecord方法开启录制
btnRecord.textContent = 'Stop Record'; // 修改button的文案
btnPlay.disabled = true; // 播放按钮状态禁止
btnDownload.disabled = true; // 下载按钮状态禁止
}else{ // 结束录制
stopRecord(); // 停止录制
btnRecord.textContent = 'Start Record';
btnPlay.disabled = false; // 停止录制之后可以播放
btnDownload.disabled = false; // 停止录制可以下载
}
}
// 点击播放视频
btnPlay.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
recvideo.src = window.URL.createObjectURL(blob);
recvideo.srcObject = null;
recvideo.controls = true;
recvideo.play();
}
// 下载视频
btnDownload.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
var url = window.URL.createObjectURL(blob);
var a = document.createElement('a');
a.href = url;
a.style.display = 'none';
a.download = 'aaa.webm';
a.click();
} 查看全部
WebRTC采集api在WebRTC中有一个api可以用来获取桌面
文章目录
对WebRTC源代码的研究(1 9) WebRTC记录采集平面数据1. WebRTC 采集 api
WebRTC中有一个可用于获取桌面的api:getDisplayMedia
var promise = navigator.mediaDevices.getDisplayMedia(constraints);
约束可选
约束中的约束与getUserMedia函数中的约束相同。
2. 采集平面数据
采集平面数据:此功能是chrome的实验项目,因此仅对最新项目开放。
在实际战斗之前,我们必须打开浏览器并进行一些设置
chrome:// flags /#enable-experimental-web-platform-features
如下所示:
接下来,我们看一下特定的js代码,如下所示:
'use strict'
var audioSource = document.querySelector('select#audioSource');
var audioOutput = document.querySelector('select#audioOutput');
var videoSource = document.querySelector('select#videoSource');
// 获取video标签
var videoplay = document.querySelector('video#player');
// 获取音频标签
var audioplay = document.querySelector('audio#audioplayer');
//div
var divConstraints = document.querySelector('div#constraints');
// 定义二进制数组
var buffer;
var mediaRecorder;
//record 视频录制 播放 下载按钮
var recvideo = document.querySelector('video#recplayer');
var btnRecord = document.querySelector('button#record');
var btnPlay = document.querySelector('button#recplay');
var btnDownload = document.querySelector('button#download');
//filter 特效选择
var filtersSelect = document.querySelector('select#filter');
//picture 获取视频帧图片相关的元素
var snapshot = document.querySelector('button#snapshot');
var picture = document.querySelector('canvas#picture');
picture.width = 640;
picture.height = 480;
// deviceInfos是设备信息的数组
function gotDevices(deviceInfos){
// 遍历设备信息数组, 函数里面也有个参数是每一项的deviceinfo, 这样我们就拿到每个设备的信息了
deviceInfos.forEach(function(deviceinfo){
// 创建每一项
var option = document.createElement('option');
option.text = deviceinfo.label;
option.value = deviceinfo.deviceId;
if(deviceinfo.kind === 'audioinput'){ // 音频输入
audioSource.appendChild(option);
}else if(deviceinfo.kind === 'audiooutput'){ // 音频输出
audioOutput.appendChild(option);
}else if(deviceinfo.kind === 'videoinput'){ // 视频输入
videoSource.appendChild(option);
}
})
}
// 获取到流做什么, 在gotMediaStream方面里面我们要传人一个参数,也就是流,
// 这个流里面实际上包含了音频轨和视频轨,因为我们通过constraints设置了要采集视频和音频
// 我们直接吧这个流赋值给HTML中赋值的video标签
// 当时拿到这个流了,说明用户已经同意去访问音视频设备了
function gotMediaStream(stream){
// audioplay.srcObject = stream;
videoplay.srcObject = stream; // 指定数据源来自stream,这样视频标签采集到这个数据之后就可以将视频和音频播放出来
// 通过stream来获取到视频的track 这样我们就将所有的视频流中的track都获取到了,这里我们只取列表中的第一个
var videoTrack = stream.getVideoTracks()[0];
// 拿到track之后我们就能调用Track的方法
var videoConstraints = videoTrack.getSettings(); // 这样就可以拿到所有video的约束
// 将这个对象转化成json格式
// 第一个是videoConstraints, 第二个为空, 第三个表示缩进2格
divConstraints.textContent = JSON.stringify(videoConstraints, null, 2);
window.stream = stream;
// 当我们采集到音视频的数据之后,我们返回一个Promise
return navigator.mediaDevices.enumerateDevices();
}
function handleError(err){
console.log('getUserMedia error:', err);
}
function start() {
// 判断浏览器是否支持
if(!navigator.mediaDevices ||
!navigator.mediaDevices.getDisplayMedia){ // 判断是否支持录屏
console.log('getUserMedia is not supported!');
}else{
// 获取到deviceId
var deviceId = videoSource.value;
// 这里是约束参数,正常情况下我们只需要是否使用视频是否使用音频
// 对于视频就可以按我们刚才所说的做一些限制
/**
* video : {
width: 640, // 宽带
height: 480, // 高度
frameRate:15, // 帧率
facingMode: 'enviroment', // 设置为后置摄像头
deviceId : deviceId ? deviceId : undefined // 如果deviceId不为空直接设置值,如果为空就是undefined
},
*/
var constraints = { // 表示同时采集视频金和音频
video : true,
audio : false
}
// 调用录屏API
navigator.mediaDevices.getDisplayMedia(constraints) // 这样就可以抓起桌面的数据了
.then(gotMediaStream) // 使用Promise串联的方式,获取流成功了
.then(gotDevices)
.catch(handleError);
}
}
start();
// 当我选择摄像头的时候,他可以触发一个事件,
// 当我调用start之后我要改变constraints
videoSource.onchange = start;
// 选择特效的方法
filtersSelect.onchange = function(){
videoplay.className = filtersSelect.value;
}
// 点击按钮获取视频帧图片
snapshot.onclick = function() {
picture.className = filtersSelect.value;
// 调用canvas API获取上下文,图片是二维的,所以2d,这样我们就拿到它的上下文了
// 调用drawImage绘制图片,第一个参数就是视频,我们这里是videoplay,
// 第二和第三个参数是起始点 0,0
// 第四个和第五个参数表示图片的高度和宽度
picture.getContext('2d').drawImage(videoplay, 0, 0, picture.width, picture.height);
}
//
function handleDataAvailable(e){ // 5、获取数据的事件函数 当我们点击录制之后,数据就会源源不断的从这个事件函数中获取到
if(e && e.data && e.data.size > 0){
buffer.push(e.data); // 将e.data放入二进制数组里面
// 这个buffer应该是我们在开始录制的时候创建这个buffer
}
}
// 2、录制方法
function startRecord(){
buffer = []; // 定义数组
var options = {
mimeType: 'video/webm;codecs=vp8' // 录制视频 编码vp8
}
if(!MediaRecorder.isTypeSupported(options.mimeType)){ // 判断录制的视频 mimeType 格式浏览器是否支持
console.error(`${options.mimeType} is not supported!`);
return;
}
try{ // 防止录制异常
// 5、先在上面定义全局对象mediaRecorder,以便于后面停止录制的时候可以用到
mediaRecorder = new MediaRecorder(window.stream, options); // 调用录制API // window.stream在gotMediaStream中获取
}catch(e){
console.error('Failed to create MediaRecorder:', e);
return;
}
// 4、调用事件 这个事件处理函数里面就会收到我们录制的那块数据 当我们收集到这个数据之后我们应该把它存储起来
mediaRecorder.ondataavailable = handleDataAvailable;
mediaRecorder.start(10); // start方法里面传入一个时间片,每隔一个 时间片存储 一块数据
}
// 3、停止录制
function stopRecord(){
// 6、调用停止录制
mediaRecorder.stop();
}
// 1、录制视频
btnRecord.onclick = ()=>{
if(btnRecord.textContent === 'Start Record'){ // 开始录制
startRecord(); // 调用startRecord方法开启录制
btnRecord.textContent = 'Stop Record'; // 修改button的文案
btnPlay.disabled = true; // 播放按钮状态禁止
btnDownload.disabled = true; // 下载按钮状态禁止
}else{ // 结束录制
stopRecord(); // 停止录制
btnRecord.textContent = 'Start Record';
btnPlay.disabled = false; // 停止录制之后可以播放
btnDownload.disabled = false; // 停止录制可以下载
}
}
// 点击播放视频
btnPlay.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
recvideo.src = window.URL.createObjectURL(blob);
recvideo.srcObject = null;
recvideo.controls = true;
recvideo.play();
}
// 下载视频
btnDownload.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
var url = window.URL.createObjectURL(blob);
var a = document.createElement('a');
a.href = url;
a.style.display = 'none';
a.download = 'aaa.webm';
a.click();
}
传送门:阿里文学大站的分析篇-杨文超
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-03-26 00:01
通过关键词采集文章采集api,如阿里文学api,可以爬取网络上99%以上的文章,是自动抓取,不需要人工干预。爬取完成后会生成一个页面地址,将地址发送到服务器。服务器返回网页代码给爬虫,进行定向爬取。定向方式可以是搜索引擎(百度、谷歌)爬虫,可以是搜索者自行爬取。客户端将抓取到的页面信息(每篇文章的标题、作者、标签等)用各种方式封装成自己的二进制数据,方便自己的下一步分析和处理。传送门:阿里文学大站的分析篇-杨文超的文章-知乎专栏。
===推荐另一篇答案,基于豆瓣的爬虫技术,
豆瓣大站的抓取??有编程基础么?有技术手段么?其实我觉得爬虫或者http服务器爬取的成本不大,但要和爬虫你对接上,要从你那整合数据。(当然人人通过抓包发数据应该不需要这些)但运营的成本你必须有,或者可以有人专门帮你抓。找你抓,不需要你自己搞(就算他上班你自己有个闲钱就解决问题了)找专业公司做,毕竟人家有稳定的http服务器。人家上班天天盯着,弄不好可能爬虫被抓一样抓不出来。
抓到豆瓣首页的每一个连接,用http去连接豆瓣的评论列表,注意抓到的第一个里边会有一个编号, 查看全部
传送门:阿里文学大站的分析篇-杨文超
通过关键词采集文章采集api,如阿里文学api,可以爬取网络上99%以上的文章,是自动抓取,不需要人工干预。爬取完成后会生成一个页面地址,将地址发送到服务器。服务器返回网页代码给爬虫,进行定向爬取。定向方式可以是搜索引擎(百度、谷歌)爬虫,可以是搜索者自行爬取。客户端将抓取到的页面信息(每篇文章的标题、作者、标签等)用各种方式封装成自己的二进制数据,方便自己的下一步分析和处理。传送门:阿里文学大站的分析篇-杨文超的文章-知乎专栏。
===推荐另一篇答案,基于豆瓣的爬虫技术,
豆瓣大站的抓取??有编程基础么?有技术手段么?其实我觉得爬虫或者http服务器爬取的成本不大,但要和爬虫你对接上,要从你那整合数据。(当然人人通过抓包发数据应该不需要这些)但运营的成本你必须有,或者可以有人专门帮你抓。找你抓,不需要你自己搞(就算他上班你自己有个闲钱就解决问题了)找专业公司做,毕竟人家有稳定的http服务器。人家上班天天盯着,弄不好可能爬虫被抓一样抓不出来。
抓到豆瓣首页的每一个连接,用http去连接豆瓣的评论列表,注意抓到的第一个里边会有一个编号,
阿里巴巴(国际站)企业信息采集器的特点及特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-06-01 22:29
阿里巴巴(国际站)企业信息采集器是阿里巴巴(国际站)采集黄金供应商和普通供应商的全自动信息抽取软件。提取的信息包括:公司名称、阿里账号、联系人姓名、国家、省、市、职称、手机、电话、传真、地址、网址、邮政编码。该信息可用于营销,如:群发传真、群发手机短信、阿里巴巴旺旺群发、电话营销、电子邮件群发、产品说明书群发等。这些信息还可以用于市场调研、客户分布分析、竞争对手分析等。 软件可以根据关键词、行业分类、国家、业务搜索阿里巴巴国际网站公司库和阿里巴巴国际网站产品库输入,自定义搜索范围,快速抓取以上信息。阿里巴巴(国际站)企业信息采集器特点:1.软件体积小。下载后解压到本地文件夹即可,无需安装即可打开使用。绿色软件不绑定任何其他商业插件。 2.界面清晰,操作简单快捷,易于掌握和使用,还有在线演示视频。 3. 免费自动在线升级到最新版本,或手动升级。 4. 点击[预览信息]按钮,浏览捕获的信息进行进一步分析。 5. 搜索产品库,定位优质目标客户群,抓取对应客户信息。 6. 抓取的信息导出文件格式为XLS,可以用Excel程序打开,以便将信息导入其他营销软件。 7. 软件终身免费自动升级,方便本采集器及时抓取升级后的阿里巴巴网站公司库和产品库中的信息。 查看全部
阿里巴巴(国际站)企业信息采集器的特点及特点
阿里巴巴(国际站)企业信息采集器是阿里巴巴(国际站)采集黄金供应商和普通供应商的全自动信息抽取软件。提取的信息包括:公司名称、阿里账号、联系人姓名、国家、省、市、职称、手机、电话、传真、地址、网址、邮政编码。该信息可用于营销,如:群发传真、群发手机短信、阿里巴巴旺旺群发、电话营销、电子邮件群发、产品说明书群发等。这些信息还可以用于市场调研、客户分布分析、竞争对手分析等。 软件可以根据关键词、行业分类、国家、业务搜索阿里巴巴国际网站公司库和阿里巴巴国际网站产品库输入,自定义搜索范围,快速抓取以上信息。阿里巴巴(国际站)企业信息采集器特点:1.软件体积小。下载后解压到本地文件夹即可,无需安装即可打开使用。绿色软件不绑定任何其他商业插件。 2.界面清晰,操作简单快捷,易于掌握和使用,还有在线演示视频。 3. 免费自动在线升级到最新版本,或手动升级。 4. 点击[预览信息]按钮,浏览捕获的信息进行进一步分析。 5. 搜索产品库,定位优质目标客户群,抓取对应客户信息。 6. 抓取的信息导出文件格式为XLS,可以用Excel程序打开,以便将信息导入其他营销软件。 7. 软件终身免费自动升级,方便本采集器及时抓取升级后的阿里巴巴网站公司库和产品库中的信息。
大数据学习交流群:529867072,群里都是学
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-05-31 07:05
(一)系统日志采集方法
系统日志记录了系统中的硬件、软件和系统问题的信息,也可以监控系统中发生的事件。用户可以使用它来检查错误的原因,或者查找攻击者在受到攻击时留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。 (百度百科)大数据平台或类似开源的Hadoop平台会产生大量高价值的系统日志信息。 采集 如何成为研究人员的研究热点。 Chukwa、Cloudera的Flume和Facebook的Scribe(李连宁,2016)目前基于Hadoop平台开发的,都可以作为系统日志采集方法的例子,目前这样的采集技术每秒可以传输数百次。 MB日志数据信息满足了当前人们对信息速度的需求。一般来说,与我们相关的不是这种采集方法,而是网络数据采集方法。
还是推荐我自己的大数据学习交流群:529867072,群里都是学习大数据开发的,如果你正在学习大数据,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(只与大数据软件开发有关),包括最新的大数据进阶资料和自己编的进阶开发教程。欢迎加入先进先进的大数据合作伙伴。
(二)网络数据采集方法
做自然语言的同学可能对这一点深有感触。除了现有的用于日常算法研究的公共数据集外,有时为了满足项目的实际需要,需要采集,预处理和保存。目前网络数据采集有两种方法,一种是API,一种是网络爬虫。
1.API
API也称为应用程序编程接口,它是网站管理员为用户端编写的编程接口。这种类型的接口可以屏蔽网站底层的复杂算法,并通过简单地调用它来实现数据请求功能。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常使用第二种方法——网络爬虫。
2.网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOFA 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。 (百度百科)最常见的爬虫就是我们经常使用的搜索引擎,比如百度和360搜索。这类爬虫统称为万能爬虫,对所有网页都是无条件的采集。通用爬虫的具体工作原理如图1所示。
图1爬虫工作原理[2]
给爬虫初始URL,爬虫提取并保存网页需要提取的资源,同时提取网站中存在的其他网站链接,发送请求后,接收到网站响应并再次解析页面,提取所需资源并保存,然后从网页中提取所需资源...等等,实现过程并不复杂,但是在采集中,需要付出特殊的代价注意IP地址和头部的伪造,避免被禁IP被网管发现(我被禁),被禁IP意味着整个采集任务的失败。当然,为了满足更多的需求,多线程爬虫和主题爬虫也应运而生。多线程爬虫使用多个线程同时执行采集任务。一般来说,线程数少,采集的数据会增加几倍。主题爬虫与一般爬虫相反。他们通过一定的策略过滤掉与主题(采集 任务)无关的网页,只留下需要的数据。这样可以大大减少不相关数据导致的数据稀疏问题。
(三)其他采集方法
其他采集法律是指如何保证科研院所、企业政府等拥有机密信息的数据安全传输?可以使用系统的特定端口来执行数据传输任务,从而降低数据泄露的风险。
【结论】大数据采集技术是大数据技术的开端。好的开始是成功的一半。所以在做数据采集的时候一定要慎重选择方法,尤其是爬虫技术。主题爬虫应该是大多数数据采集任务的更好方法,可以深入研究。返回搜狐查看更多 查看全部
大数据学习交流群:529867072,群里都是学
(一)系统日志采集方法
系统日志记录了系统中的硬件、软件和系统问题的信息,也可以监控系统中发生的事件。用户可以使用它来检查错误的原因,或者查找攻击者在受到攻击时留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。 (百度百科)大数据平台或类似开源的Hadoop平台会产生大量高价值的系统日志信息。 采集 如何成为研究人员的研究热点。 Chukwa、Cloudera的Flume和Facebook的Scribe(李连宁,2016)目前基于Hadoop平台开发的,都可以作为系统日志采集方法的例子,目前这样的采集技术每秒可以传输数百次。 MB日志数据信息满足了当前人们对信息速度的需求。一般来说,与我们相关的不是这种采集方法,而是网络数据采集方法。
还是推荐我自己的大数据学习交流群:529867072,群里都是学习大数据开发的,如果你正在学习大数据,小编欢迎你加入,大家都是软件开发党,分享干货来自不定时(只与大数据软件开发有关),包括最新的大数据进阶资料和自己编的进阶开发教程。欢迎加入先进先进的大数据合作伙伴。
(二)网络数据采集方法
做自然语言的同学可能对这一点深有感触。除了现有的用于日常算法研究的公共数据集外,有时为了满足项目的实际需要,需要采集,预处理和保存。目前网络数据采集有两种方法,一种是API,一种是网络爬虫。
1.API
API也称为应用程序编程接口,它是网站管理员为用户端编写的编程接口。这种类型的接口可以屏蔽网站底层的复杂算法,并通过简单地调用它来实现数据请求功能。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常使用第二种方法——网络爬虫。
2.网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOFA 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。 (百度百科)最常见的爬虫就是我们经常使用的搜索引擎,比如百度和360搜索。这类爬虫统称为万能爬虫,对所有网页都是无条件的采集。通用爬虫的具体工作原理如图1所示。
图1爬虫工作原理[2]
给爬虫初始URL,爬虫提取并保存网页需要提取的资源,同时提取网站中存在的其他网站链接,发送请求后,接收到网站响应并再次解析页面,提取所需资源并保存,然后从网页中提取所需资源...等等,实现过程并不复杂,但是在采集中,需要付出特殊的代价注意IP地址和头部的伪造,避免被禁IP被网管发现(我被禁),被禁IP意味着整个采集任务的失败。当然,为了满足更多的需求,多线程爬虫和主题爬虫也应运而生。多线程爬虫使用多个线程同时执行采集任务。一般来说,线程数少,采集的数据会增加几倍。主题爬虫与一般爬虫相反。他们通过一定的策略过滤掉与主题(采集 任务)无关的网页,只留下需要的数据。这样可以大大减少不相关数据导致的数据稀疏问题。
(三)其他采集方法
其他采集法律是指如何保证科研院所、企业政府等拥有机密信息的数据安全传输?可以使用系统的特定端口来执行数据传输任务,从而降低数据泄露的风险。
【结论】大数据采集技术是大数据技术的开端。好的开始是成功的一半。所以在做数据采集的时候一定要慎重选择方法,尤其是爬虫技术。主题爬虫应该是大多数数据采集任务的更好方法,可以深入研究。返回搜狐查看更多
通过关键词采集文章采集api,获取一篇文章的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-05-30 19:01
通过关键词采集文章采集api,获取的base64数据可以算是中文的词云。chrome,firefox设置和打开就可以了解清楚。
怎么样才能获取一篇文章的内容呢?目前,通过https协议访问,一篇文章不可能有所遗漏。于是,我们还是回顾一下一篇文章从哪里来?直接从google等第三方api获取,文章内容会有所误差。一个不错的方法是通过chrome浏览器的开发者工具,如下图所示,依次点击"获取url"、"获取cookie"、"cookie解析"和"获取浏览器版本",依次获取搜索结果页面(包括标题、简介和作者)、网站以及其他一些cookie信息。
利用网页爬虫,获取数据之后,需要解析数据。在http请求实现过程中,可能会出现诸如cookie值不对,或是headerscookie值被劫持等情况。那么,如何从第三方网站(例如baidu)抓取数据或者通过网页爬虫获取数据呢?scrapy框架是一个非常好用的网页抓取框架,基于cookie机制实现方便,速度更快。
如何在浏览器中通过scrapy爬取数据呢?首先需要浏览器自带开发者工具,如下图所示,依次点击"获取页面(scrapycrawler)"、"使用爬虫"、"cookie解析(scrapyheaders)"、"获取headers(scrapyheaders)",依次获取站点的headers值。接下来,利用scrapy框架,通过selenium模拟点击地址栏进行调用scrapy抓取,获取页面内容。也可以通过其他的方式来实现。 查看全部
通过关键词采集文章采集api,获取一篇文章的内容
通过关键词采集文章采集api,获取的base64数据可以算是中文的词云。chrome,firefox设置和打开就可以了解清楚。
怎么样才能获取一篇文章的内容呢?目前,通过https协议访问,一篇文章不可能有所遗漏。于是,我们还是回顾一下一篇文章从哪里来?直接从google等第三方api获取,文章内容会有所误差。一个不错的方法是通过chrome浏览器的开发者工具,如下图所示,依次点击"获取url"、"获取cookie"、"cookie解析"和"获取浏览器版本",依次获取搜索结果页面(包括标题、简介和作者)、网站以及其他一些cookie信息。
利用网页爬虫,获取数据之后,需要解析数据。在http请求实现过程中,可能会出现诸如cookie值不对,或是headerscookie值被劫持等情况。那么,如何从第三方网站(例如baidu)抓取数据或者通过网页爬虫获取数据呢?scrapy框架是一个非常好用的网页抓取框架,基于cookie机制实现方便,速度更快。
如何在浏览器中通过scrapy爬取数据呢?首先需要浏览器自带开发者工具,如下图所示,依次点击"获取页面(scrapycrawler)"、"使用爬虫"、"cookie解析(scrapyheaders)"、"获取headers(scrapyheaders)",依次获取站点的headers值。接下来,利用scrapy框架,通过selenium模拟点击地址栏进行调用scrapy抓取,获取页面内容。也可以通过其他的方式来实现。
基于webspider开发的经典爬虫推荐(持续更新)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-05-27 21:07
通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址还是通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址爬虫脚本地址采集准备工作准备工作选择的区域你只要首先要找到这个区域所有接口的链接,然后采用excel分析采集这个区域的有关信息。这是找出区域第一条接口的链接:。然后搜索“知乎高考”的话题你能搜索出来的最早链接是;random=288528847,这是第一条的地址。
然后你就会找到相关文章的一些链接:@豆子安如果你要想更精确一点的搜索话,你需要列表上每个词后面几行,这是获取这个区域所有有关的文章网址后的一些统计,可能还会找到更精确的链接:,“高考作文”是这样的:这也算是解决你的问题,你只要简单地记下区域所有文章网址就行了:请注意,这些网址都是不容易通过google验证的,如果你需要的话,可以直接通过截图截下来保存到本地,手机之类的发给我或私信我,然后我在通过python解析出来就行了。
爬虫源码地址:知乎专栏这篇解析源码解析这里是个uebot爬虫解析的系列教程文章,源码解析如下,可通过原文索取地址链接我自己修改的微信公众号,要关注才能看到~。
基于webspider开发的经典爬虫推荐(持续更新),对于使用新的spider和webspider爬虫框架进行代码测试更好,链接:+pythonspider推荐一款适合于大型网站的spider框架pyspider, 查看全部
基于webspider开发的经典爬虫推荐(持续更新)(组图)
通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址还是通过关键词采集文章采集api相关信息爬虫相关内容爬虫脚本地址爬虫脚本地址采集准备工作准备工作选择的区域你只要首先要找到这个区域所有接口的链接,然后采用excel分析采集这个区域的有关信息。这是找出区域第一条接口的链接:。然后搜索“知乎高考”的话题你能搜索出来的最早链接是;random=288528847,这是第一条的地址。
然后你就会找到相关文章的一些链接:@豆子安如果你要想更精确一点的搜索话,你需要列表上每个词后面几行,这是获取这个区域所有有关的文章网址后的一些统计,可能还会找到更精确的链接:,“高考作文”是这样的:这也算是解决你的问题,你只要简单地记下区域所有文章网址就行了:请注意,这些网址都是不容易通过google验证的,如果你需要的话,可以直接通过截图截下来保存到本地,手机之类的发给我或私信我,然后我在通过python解析出来就行了。
爬虫源码地址:知乎专栏这篇解析源码解析这里是个uebot爬虫解析的系列教程文章,源码解析如下,可通过原文索取地址链接我自己修改的微信公众号,要关注才能看到~。
基于webspider开发的经典爬虫推荐(持续更新),对于使用新的spider和webspider爬虫框架进行代码测试更好,链接:+pythonspider推荐一款适合于大型网站的spider框架pyspider,
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-26 21:01
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口_知乎小说api-黑猫抓羊-知乎小说
回答问题的话就不能用android程序员了,
当然可以了,方法我告诉你,上:“”一搜,然后问“”就行了。ps:我的就是从知乎读出来的啊。
知乎为什么每个话题下都有一些专门的id?答题的app不上架安卓市场。
可以试试爱问和福昕阅读,
如果是采集工作,应该不好办,一般的安卓app都有自己开发的api。php程序员或者ios程序员都可以写爬虫程序。主要用于收集答案,可以用robots协议。spider也有搜集知乎用户的。
好像只能用php对api进行抓取...
可以去专业的平台接入专业的服务,或者使用python+requests+urllib...很多抓取库可以使用比如w3cschool/execl有在线的课程可以下载w3cschool-教你玩转wordprocessor.
只要你需要就能够爬取知乎的内容,app功能齐全,api开放给app开发者。
采集原理:1.appid获取2.scheme获取3.cookie4.selenium获取采集规则及详情参考:如何采集知乎的图片?
前面的回答基本都是正确的。今天我告诉你的是采集可以不用知乎账号登录,你只需要注册账号就可以,通过关键词googlesearch就可以采集所有页面的全部内容。不过会有一些失败,app的api一般会提示你请求超时,需要等待一段时间才能返回。 查看全部
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口
通过关键词采集文章采集api:“微知乎”api_api接口_知乎api接口_知乎小说api-黑猫抓羊-知乎小说
回答问题的话就不能用android程序员了,
当然可以了,方法我告诉你,上:“”一搜,然后问“”就行了。ps:我的就是从知乎读出来的啊。
知乎为什么每个话题下都有一些专门的id?答题的app不上架安卓市场。
可以试试爱问和福昕阅读,
如果是采集工作,应该不好办,一般的安卓app都有自己开发的api。php程序员或者ios程序员都可以写爬虫程序。主要用于收集答案,可以用robots协议。spider也有搜集知乎用户的。
好像只能用php对api进行抓取...
可以去专业的平台接入专业的服务,或者使用python+requests+urllib...很多抓取库可以使用比如w3cschool/execl有在线的课程可以下载w3cschool-教你玩转wordprocessor.
只要你需要就能够爬取知乎的内容,app功能齐全,api开放给app开发者。
采集原理:1.appid获取2.scheme获取3.cookie4.selenium获取采集规则及详情参考:如何采集知乎的图片?
前面的回答基本都是正确的。今天我告诉你的是采集可以不用知乎账号登录,你只需要注册账号就可以,通过关键词googlesearch就可以采集所有页面的全部内容。不过会有一些失败,app的api一般会提示你请求超时,需要等待一段时间才能返回。
利用新浪、网易、腾讯、搜狐微博开放平台API,切换任务调度
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-05-24 06:18
多微博平台用户数据采集 .doc多微博平台用户数据采集摘要:本文介绍了使用新浪,网易,腾讯,搜狐微博开放平台API来获取关键人物和关键主题的方法。针对不同的微博平台返回结果的差异,提出了一种情境数据的分发方法,提出了一种数据融合的方法,并提出了接口封装,访问令牌交换,任务调度等技术,以提高效率。微博API调用,以减少系统消耗的目的。 关键词:微博API数据采集令牌交换任务调度中文图书馆分类号:TP39 3. 08文档标识码:A 文章编号:1007-9416(201 3) 11-0141-011概述微博是一个基于用户关系的共享,传播和获取信息的平台,它具有软通信,实时,参与性和交互性[1],网民使用微博传递实时信息,表达个人感受,甚至参与讨论。目前,中国的微博用户超过5亿[2],但是微博正在蓬勃发展,同时也带来了虚假信息的增加,以及辨别真假的困难。 “煽动”行为,破坏社会稳定,仅依靠在线舆论,尽早监测和发现恶意事件迹象,微博信息量巨大,难以满足数据需求采集 要是 使用人工手段。本文的核心内容是使用微博开放平台API来高效获取关键信息和关键信息。主题信息和主题传播趋势等数据。 2使用微博API获取数据2. 1微博API调用过程微博运营商已开放微博API,以吸引第三方应用程序并增加用户体验。
微博API实际上是部署在微博开放平台服务器上的一组动态页面。这些页面可以接受来自第三方应用程序的GET或POST请求,然后返回相应的结果。使用微博API主要包括以下步骤:(1)申请应用程序。微博开放平台为开发人员分配了唯一标识应用程序的“ AppKey”和“ AppSecret”。(2)获得授权。通过OAuth协议令牌[3]。(3)访问API页面。根据所需功能选择要使用的API,并根据RFC3986建议对所需参数进行编码,然后访问该页面。(4)分析结果。从服务器返回的XML或JSON文件中提取数据。JSON格式文件具有较快的解析速度[4],更适合于具有大量数据的情况2. 2多个数据融合处理微博平台应在不同的微博平台上处理。要获得相同类型的数据,一种是选择相应的界面,另一种是统一处理返回的结果。(1)关键人物数据。主要包括“意见领袖”并且经常有意发布或转发虚假信息和不良信息,以试图在微博平台上煽风点火的人们,他们发表的意见可以迅速传播并产生巨大影响。 采集的内容包括用户的个人信息,微博使用信息和已发布的微博。 (2)关键主题数据。指的是包括与国家和地区安全,社会稳定等有关的词。这种类型的微博出版商的思想倾向具有很大的价值。(3)我想知道如何广泛传播微博传播,有必要分析一下微博的传播趋势,以新浪微博为例:调用,可以获得该微博的ID进行转发,然后递归调用此API以获取转发的微博的ID,最后通过数据可视化技术构建传播情况图。
这是一个类似于“遍历遍历”的过程。当确定“遍历的层数”时,可以确定地完成数据采集的工作。 (4)结果分析。API调用结果包括三个部分:微博文本,多媒体信息和用户数据。由于每个微博平台定义的返回格式不同,因此必须有相应的处理方法。可以提取JSON属性字段2. 3API三层封装直接调用该API程序代码是:复杂,参数难以理解,程序代码冗余第一层封装是指基本过程的子集,如连接建立和参数编码,除搜狐微博外,其他微博平台提供的SDK都有已经完成了这一步骤;第二层封装接受了更易理解的参数,并将“获取全部”和“有多少个项目”转换为SDK所需的nto属性参数和翻页参数;第三层封装集成了在调用API之前和之后访问数据库的操作,并统一了函数名。 2. 4令牌交换技术有关API调用次数的信息记录在通过OAuth身份验证获得的访问令牌中。单个访问令牌收录的调用太少,并且必须通过多令牌交换来增加API调用的数量。 (1) 403异常硬开关,适用于新浪微博。继续使用访问令牌,直到服务器返回403异常。捕获到异常之后,切换到下一个访问令牌,然后重新启动采集任务。(2)预切换,适用于网易微博。
提取HTTP头中收录的令牌信息,并决定是否进行切换。 (3)随机切换。每次调用API之前,都会随机选择一个令牌。此方法通用并且具有少量代码,但是可能会发生错误。(4)贪婪的切换,每次调用API之前,始终选择剩余时间最多的令牌。这种方法是通用的,但它需要记录每个令牌的使用情况3当数据量少且令牌丰富时,系统设计和实现就很简单。 API,实际上,当要采集的数据量非常大,令牌和系统资源的数量有限时,我们必须考虑避免盲目性采集,减少突发数据和任务调度3. 1 采集重复数据删除这是一个增量采集问题,我们只想获取“新”数据,而不是“旧”数据。因此 查看全部
利用新浪、网易、腾讯、搜狐微博开放平台API,切换任务调度
多微博平台用户数据采集 .doc多微博平台用户数据采集摘要:本文介绍了使用新浪,网易,腾讯,搜狐微博开放平台API来获取关键人物和关键主题的方法。针对不同的微博平台返回结果的差异,提出了一种情境数据的分发方法,提出了一种数据融合的方法,并提出了接口封装,访问令牌交换,任务调度等技术,以提高效率。微博API调用,以减少系统消耗的目的。 关键词:微博API数据采集令牌交换任务调度中文图书馆分类号:TP39 3. 08文档标识码:A 文章编号:1007-9416(201 3) 11-0141-011概述微博是一个基于用户关系的共享,传播和获取信息的平台,它具有软通信,实时,参与性和交互性[1],网民使用微博传递实时信息,表达个人感受,甚至参与讨论。目前,中国的微博用户超过5亿[2],但是微博正在蓬勃发展,同时也带来了虚假信息的增加,以及辨别真假的困难。 “煽动”行为,破坏社会稳定,仅依靠在线舆论,尽早监测和发现恶意事件迹象,微博信息量巨大,难以满足数据需求采集 要是 使用人工手段。本文的核心内容是使用微博开放平台API来高效获取关键信息和关键信息。主题信息和主题传播趋势等数据。 2使用微博API获取数据2. 1微博API调用过程微博运营商已开放微博API,以吸引第三方应用程序并增加用户体验。
微博API实际上是部署在微博开放平台服务器上的一组动态页面。这些页面可以接受来自第三方应用程序的GET或POST请求,然后返回相应的结果。使用微博API主要包括以下步骤:(1)申请应用程序。微博开放平台为开发人员分配了唯一标识应用程序的“ AppKey”和“ AppSecret”。(2)获得授权。通过OAuth协议令牌[3]。(3)访问API页面。根据所需功能选择要使用的API,并根据RFC3986建议对所需参数进行编码,然后访问该页面。(4)分析结果。从服务器返回的XML或JSON文件中提取数据。JSON格式文件具有较快的解析速度[4],更适合于具有大量数据的情况2. 2多个数据融合处理微博平台应在不同的微博平台上处理。要获得相同类型的数据,一种是选择相应的界面,另一种是统一处理返回的结果。(1)关键人物数据。主要包括“意见领袖”并且经常有意发布或转发虚假信息和不良信息,以试图在微博平台上煽风点火的人们,他们发表的意见可以迅速传播并产生巨大影响。 采集的内容包括用户的个人信息,微博使用信息和已发布的微博。 (2)关键主题数据。指的是包括与国家和地区安全,社会稳定等有关的词。这种类型的微博出版商的思想倾向具有很大的价值。(3)我想知道如何广泛传播微博传播,有必要分析一下微博的传播趋势,以新浪微博为例:调用,可以获得该微博的ID进行转发,然后递归调用此API以获取转发的微博的ID,最后通过数据可视化技术构建传播情况图。
这是一个类似于“遍历遍历”的过程。当确定“遍历的层数”时,可以确定地完成数据采集的工作。 (4)结果分析。API调用结果包括三个部分:微博文本,多媒体信息和用户数据。由于每个微博平台定义的返回格式不同,因此必须有相应的处理方法。可以提取JSON属性字段2. 3API三层封装直接调用该API程序代码是:复杂,参数难以理解,程序代码冗余第一层封装是指基本过程的子集,如连接建立和参数编码,除搜狐微博外,其他微博平台提供的SDK都有已经完成了这一步骤;第二层封装接受了更易理解的参数,并将“获取全部”和“有多少个项目”转换为SDK所需的nto属性参数和翻页参数;第三层封装集成了在调用API之前和之后访问数据库的操作,并统一了函数名。 2. 4令牌交换技术有关API调用次数的信息记录在通过OAuth身份验证获得的访问令牌中。单个访问令牌收录的调用太少,并且必须通过多令牌交换来增加API调用的数量。 (1) 403异常硬开关,适用于新浪微博。继续使用访问令牌,直到服务器返回403异常。捕获到异常之后,切换到下一个访问令牌,然后重新启动采集任务。(2)预切换,适用于网易微博。
提取HTTP头中收录的令牌信息,并决定是否进行切换。 (3)随机切换。每次调用API之前,都会随机选择一个令牌。此方法通用并且具有少量代码,但是可能会发生错误。(4)贪婪的切换,每次调用API之前,始终选择剩余时间最多的令牌。这种方法是通用的,但它需要记录每个令牌的使用情况3当数据量少且令牌丰富时,系统设计和实现就很简单。 API,实际上,当要采集的数据量非常大,令牌和系统资源的数量有限时,我们必须考虑避免盲目性采集,减少突发数据和任务调度3. 1 采集重复数据删除这是一个增量采集问题,我们只想获取“新”数据,而不是“旧”数据。因此
通过关键词采集文章采集api2.js可以做表格统计楼上都没说到要点啊
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-05-21 18:03
通过关键词采集文章采集api2.js可以用wordpress转码为flash3.登录数据可以做表格统计
楼上都没说到要点啊,关键在于找一个开源的js接口程序。
可以用.google+flash接口来提取这些数据.photowrite可以把图片发送到googleimageteam的服务器来进行分析,pastebox可以把图片中的文字添加到googleeditor
用大的seo系统;比如做品牌数据分析的edm,主要是看发文章的浏览量,分析其带来的点击。
请先关注百度云:网页采集方案采集api
adsense也可以啊,他们专门有开发google图片采集接口。如果还嫌贵,只有他们了,但是基本都不是免费的。
找一个免费的api接口,很容易做到,现在不行就过2年看看。
eyesigner可以采集android和ios的图片,你可以自己搜一下,
试试51yuan
formatpill这个接口,对于中国大陆地区来说是免费的,这个可以去百度一下看看,虽然不是所有类型的图片都能够下载,但是一些不合法的图片是可以下载的。感谢,帮我膜拜下大神。
可以采集企业网站的商务性图片。demo地址:-guide.json另外还可以使用filtea接口,网站有api还可以开发。如果你想深入学习采集,可以到我的博客学习一下。 查看全部
通过关键词采集文章采集api2.js可以做表格统计楼上都没说到要点啊
通过关键词采集文章采集api2.js可以用wordpress转码为flash3.登录数据可以做表格统计
楼上都没说到要点啊,关键在于找一个开源的js接口程序。
可以用.google+flash接口来提取这些数据.photowrite可以把图片发送到googleimageteam的服务器来进行分析,pastebox可以把图片中的文字添加到googleeditor
用大的seo系统;比如做品牌数据分析的edm,主要是看发文章的浏览量,分析其带来的点击。
请先关注百度云:网页采集方案采集api
adsense也可以啊,他们专门有开发google图片采集接口。如果还嫌贵,只有他们了,但是基本都不是免费的。
找一个免费的api接口,很容易做到,现在不行就过2年看看。
eyesigner可以采集android和ios的图片,你可以自己搜一下,
试试51yuan
formatpill这个接口,对于中国大陆地区来说是免费的,这个可以去百度一下看看,虽然不是所有类型的图片都能够下载,但是一些不合法的图片是可以下载的。感谢,帮我膜拜下大神。
可以采集企业网站的商务性图片。demo地址:-guide.json另外还可以使用filtea接口,网站有api还可以开发。如果你想深入学习采集,可以到我的博客学习一下。
如何通过关键词采集文章采集api调用就可以咯?
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-05-21 02:01
通过关键词采集文章采集api调用就可以咯,加载一个js文件就可以,
可以弄个js就ok了,不过知乎里面有很多认证网站,那些每个按钮都有一个网址,你可以去找找。
chrome会给你自动加载前面的浏览器插件。
你就需要一个开发者工具,开发者工具里面有一个搜索插件就能发现哪个按钮在哪个地方。
文章采集比较简单,我之前弄过一个教程,
web运营的话个人感觉无非引流,不管是软文还是付费推广这个目前是大部分从业者主要的工作。引流主要是指每天通过各种途径和手段在已经有的一些免费流量上优化或者增加收费流量,俗称做收银台广告或者是付费流量;然后如果真的想直接再上一层楼,就要开始精细化运营了,关键字对于广告收益的有效提升以及给企业提供更好的广告形式,是越来越重要。
我可以推荐个我自己弄的脚本,不到两分钟直接告诉你我要采集哪些文章给你。但是一定要有会员积分才能使用。
谢邀,首先要看你做什么,例如你要做手机软件可以去引流,网站是可以通过你的网站转化成客户,你现在可以尝试下banner推广,要有付费意识,要及时退出,要让客户看你推广的时候进来你的网站。
现在还有做手机刷单的?针对一部分不要钱的行业也可以,电商就是这样,先把手头这些资源都整合,变成有价值的手头资源。 查看全部
如何通过关键词采集文章采集api调用就可以咯?
通过关键词采集文章采集api调用就可以咯,加载一个js文件就可以,
可以弄个js就ok了,不过知乎里面有很多认证网站,那些每个按钮都有一个网址,你可以去找找。
chrome会给你自动加载前面的浏览器插件。
你就需要一个开发者工具,开发者工具里面有一个搜索插件就能发现哪个按钮在哪个地方。
文章采集比较简单,我之前弄过一个教程,
web运营的话个人感觉无非引流,不管是软文还是付费推广这个目前是大部分从业者主要的工作。引流主要是指每天通过各种途径和手段在已经有的一些免费流量上优化或者增加收费流量,俗称做收银台广告或者是付费流量;然后如果真的想直接再上一层楼,就要开始精细化运营了,关键字对于广告收益的有效提升以及给企业提供更好的广告形式,是越来越重要。
我可以推荐个我自己弄的脚本,不到两分钟直接告诉你我要采集哪些文章给你。但是一定要有会员积分才能使用。
谢邀,首先要看你做什么,例如你要做手机软件可以去引流,网站是可以通过你的网站转化成客户,你现在可以尝试下banner推广,要有付费意识,要及时退出,要让客户看你推广的时候进来你的网站。
现在还有做手机刷单的?针对一部分不要钱的行业也可以,电商就是这样,先把手头这些资源都整合,变成有价值的手头资源。
通过关键词采集文章采集api,获取采集返回的json数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-05-19 07:03
通过关键词采集文章采集api,文章按照标题的形式进行采集,获取采集返回的json数据关键词选择相关新闻,这里考虑和推荐方法一样,有以下几个因素,1.对应百度新闻采集工具2.只知道该网站会有自己网站的收录情况,意思就是网站搜索会有被收录,可以这样说a网站的新闻里就包含关键词b网站则没有被收录,被采集同理获取到信息分为长短的,长的采集返回str信息,短的采集返回txt信息自己写脚本进行清洗。关键词获取接口获取即可。
最近在学习web前端,有时候接触到一些api可以方便网站开发获取历史新闻,加上最近腾讯也开放了自己的api进行互联网新闻数据的接口,感觉还不错,整理了一篇文章给大家分享一下,原理应该是和爬虫的原理一样,就是操作蜘蛛了,说不定在外人看来web前端这个领域就是个爬虫在炒热,大家可以去看看,也可以看看比如这篇文章[8]。/。
关键词采集api大概叫这个名字(具体还是看字面上理解吧):关键词采集api,英文全称:user-agentsearch或user-agentspy,是用来探索网站api接口以及探索未知api接口的利器,提供了一种简单可靠的方式来探索api接口,分析url结构和网站现有api接口的功能,在这里先补充一下人们所说的“爬虫”:它可以像人一样,自主地搜索各种信息,也可以获取事件信息,事件是指任何发生过事情的信息、实物、主体或环境,那么事件相关的api接口是否也是可以自主探索?api接口的目的是数据的实时传递,也就是“实时”接口,只要是发生过的操作,无论何时何地,对于数据进行抓取的网站都会将数据写入api,这就意味着对于数据抓取的各类网站如果想要实时抓取数据,只能依靠爬虫来做到。
以下内容为最近用手机随便写的几篇文章,并非完整的关键词采集方法,感兴趣的朋友可以了解一下,相信对你有所帮助:黑客小甘:针对目前访问速度较慢的情况,我们可以通过爬虫代理来加速这个过程黑客小甘:使用爬虫代理,抓取b站上的番剧并且分享给大家这篇文章刚刚还写了“运用https协议实现反爬虫”的算法分析,以及反代机制实现的相关算法,具体细节请看这篇:黑客小甘:前端反爬虫常见几种形式、原理和对应算法分析;“user-agentsearch”方法,在近期在w3c上发表的相关定义,具体可以查看这篇:黑客小甘:user-agentsearch用法介绍及实践-w3cplus。 查看全部
通过关键词采集文章采集api,获取采集返回的json数据
通过关键词采集文章采集api,文章按照标题的形式进行采集,获取采集返回的json数据关键词选择相关新闻,这里考虑和推荐方法一样,有以下几个因素,1.对应百度新闻采集工具2.只知道该网站会有自己网站的收录情况,意思就是网站搜索会有被收录,可以这样说a网站的新闻里就包含关键词b网站则没有被收录,被采集同理获取到信息分为长短的,长的采集返回str信息,短的采集返回txt信息自己写脚本进行清洗。关键词获取接口获取即可。
最近在学习web前端,有时候接触到一些api可以方便网站开发获取历史新闻,加上最近腾讯也开放了自己的api进行互联网新闻数据的接口,感觉还不错,整理了一篇文章给大家分享一下,原理应该是和爬虫的原理一样,就是操作蜘蛛了,说不定在外人看来web前端这个领域就是个爬虫在炒热,大家可以去看看,也可以看看比如这篇文章[8]。/。
关键词采集api大概叫这个名字(具体还是看字面上理解吧):关键词采集api,英文全称:user-agentsearch或user-agentspy,是用来探索网站api接口以及探索未知api接口的利器,提供了一种简单可靠的方式来探索api接口,分析url结构和网站现有api接口的功能,在这里先补充一下人们所说的“爬虫”:它可以像人一样,自主地搜索各种信息,也可以获取事件信息,事件是指任何发生过事情的信息、实物、主体或环境,那么事件相关的api接口是否也是可以自主探索?api接口的目的是数据的实时传递,也就是“实时”接口,只要是发生过的操作,无论何时何地,对于数据进行抓取的网站都会将数据写入api,这就意味着对于数据抓取的各类网站如果想要实时抓取数据,只能依靠爬虫来做到。
以下内容为最近用手机随便写的几篇文章,并非完整的关键词采集方法,感兴趣的朋友可以了解一下,相信对你有所帮助:黑客小甘:针对目前访问速度较慢的情况,我们可以通过爬虫代理来加速这个过程黑客小甘:使用爬虫代理,抓取b站上的番剧并且分享给大家这篇文章刚刚还写了“运用https协议实现反爬虫”的算法分析,以及反代机制实现的相关算法,具体细节请看这篇:黑客小甘:前端反爬虫常见几种形式、原理和对应算法分析;“user-agentsearch”方法,在近期在w3c上发表的相关定义,具体可以查看这篇:黑客小甘:user-agentsearch用法介绍及实践-w3cplus。
通过关键词采集文章采集api,然后按需求和质量索取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-18 18:03
通过关键词采集文章采集api,然后按需求和质量索取数据。api访问-京东文档采集接口服务平台有最新的全国各省份的省份信息,每日更新的,比如山东的空气质量地区排名,
qq群,上市公司,有好多公司都招各个部门的人。薪资实习100/天起。
excel最好用
我没看过简历,
招聘,不要去百度搜索,你就看看该公司在市场上的声誉,网络上信息少,好多都是赚黑心钱的,大部分都靠刷点击量推广。实在不行,你去搜索本地当地的社区论坛,
企查查啊,
公司直招各专业各种规模的实习生
企业网站很多都要
看看北京的各行各业的实习。
就说beijingyuan有招聘博客的
传统媒体、电视台报纸的记者也不好找,除非特别优秀。要么你去优秀的校园招聘会学校教务部门那里看看有没有机会。
这类的招聘网站有:
1、工信部或三大运营商的各类招聘信息
2、投行业务部门的招聘信息
3、知名企业的相关培训信息和招聘信息如果你有意向去大企业实习,你还得仔细看看你想去的行业在哪些招聘网站上有招聘信息。比如:咨询业在it桔子上有招聘信息;金融业在厚街上有招聘信息;文化传媒在第一财经网、人大经济论坛上有招聘信息;互联网企业在百度百科、搜狗百科上有招聘信息;现在智联招聘、前程无忧和58同城上有,机会也不小。其实,还有很多招聘信息,关键是你怎么找。 查看全部
通过关键词采集文章采集api,然后按需求和质量索取数据
通过关键词采集文章采集api,然后按需求和质量索取数据。api访问-京东文档采集接口服务平台有最新的全国各省份的省份信息,每日更新的,比如山东的空气质量地区排名,
qq群,上市公司,有好多公司都招各个部门的人。薪资实习100/天起。
excel最好用
我没看过简历,
招聘,不要去百度搜索,你就看看该公司在市场上的声誉,网络上信息少,好多都是赚黑心钱的,大部分都靠刷点击量推广。实在不行,你去搜索本地当地的社区论坛,
企查查啊,
公司直招各专业各种规模的实习生
企业网站很多都要
看看北京的各行各业的实习。
就说beijingyuan有招聘博客的
传统媒体、电视台报纸的记者也不好找,除非特别优秀。要么你去优秀的校园招聘会学校教务部门那里看看有没有机会。
这类的招聘网站有:
1、工信部或三大运营商的各类招聘信息
2、投行业务部门的招聘信息
3、知名企业的相关培训信息和招聘信息如果你有意向去大企业实习,你还得仔细看看你想去的行业在哪些招聘网站上有招聘信息。比如:咨询业在it桔子上有招聘信息;金融业在厚街上有招聘信息;文化传媒在第一财经网、人大经济论坛上有招聘信息;互联网企业在百度百科、搜狗百科上有招聘信息;现在智联招聘、前程无忧和58同城上有,机会也不小。其实,还有很多招聘信息,关键是你怎么找。
通过关键词采集api各种微信公众号文章然后传到我的小站
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-05-18 02:00
通过关键词采集文章采集api各种微信公众号文章然后传到我的小站就可以用了
这是我小站的展示
去百度文库下载免费的资料很多也很方便
下载乐吧,一个专门提供微信公众号上传文章的下载网站,
然后你就可以运营你的专业的公众号啦,像我卖文的,更新啊,写个软文,靠收入养自己啊哈哈哈。
收集公众号文章主要是靠订阅号。现在公众号文章都是在服务号上实现。个人建议你使用订阅号有限文章收集功能。
公众号搜索文章,然后会有出来,选中想要的那篇或者列表,
你可以在搜索一下试试看公众号搜索+#小程序#
自己有时会看,也会分享出来,
不知道找谁,于是乎决定自己动手!找了个网站,有些文章还可以筛选文章,希望对你有用吧。别忘了点赞哦。
公众号推文的话,
没有人说到微信公众号的采集吗??!
可以利用一些插件的,直接在网站上采集,或者说你可以在某宝上看看,有没有出售此类的插件,
我也想知道
通过公众号转发可以找到。
直接百度搜,等于是增加了几步。
你要做的是找合适的工具,然后更改代码。没有合适的工具就自己写。实在想象不出来了,就自己找,
采集公众号文章怎么还要要数据库?求交流,不知道该怎么去找数据库怎么办了。 查看全部
通过关键词采集api各种微信公众号文章然后传到我的小站
通过关键词采集文章采集api各种微信公众号文章然后传到我的小站就可以用了
这是我小站的展示
去百度文库下载免费的资料很多也很方便
下载乐吧,一个专门提供微信公众号上传文章的下载网站,
然后你就可以运营你的专业的公众号啦,像我卖文的,更新啊,写个软文,靠收入养自己啊哈哈哈。
收集公众号文章主要是靠订阅号。现在公众号文章都是在服务号上实现。个人建议你使用订阅号有限文章收集功能。
公众号搜索文章,然后会有出来,选中想要的那篇或者列表,
你可以在搜索一下试试看公众号搜索+#小程序#
自己有时会看,也会分享出来,
不知道找谁,于是乎决定自己动手!找了个网站,有些文章还可以筛选文章,希望对你有用吧。别忘了点赞哦。
公众号推文的话,
没有人说到微信公众号的采集吗??!
可以利用一些插件的,直接在网站上采集,或者说你可以在某宝上看看,有没有出售此类的插件,
我也想知道
通过公众号转发可以找到。
直接百度搜,等于是增加了几步。
你要做的是找合适的工具,然后更改代码。没有合适的工具就自己写。实在想象不出来了,就自己找,
采集公众号文章怎么还要要数据库?求交流,不知道该怎么去找数据库怎么办了。
通过关键词采集文章采集api接口,网上还是很多的
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-05-13 03:04
通过关键词采集文章采集api接口,网上还是很多的;抓取视频网站上的视频,可以通过抓包工具抓取,或者是购买视频的地址转换swf格式,然后再解析链接就可以转化成功。网络分析类api接口,之前在做一个网站数据分析项目时,刚好用到了api。我把抓取地址留在github上了,
现在有很多第三方通过openinstall抓取好网页的
大多是需要付费的,只能通过google或者是你觉得可以的人翻墙去用,另外也可以去,一些比较大的b2c平台,基本他们是允许用户免费用的。网上有大量的文章,用来教你怎么去做的。
谢邀。因为我也是个新手...平时喜欢捣鼓网站和爬虫,所以根据自己的经验讲一点。1、类似于这样的购物平台有不少是付费的,但其实很多都是很便宜的在发布。(只要你有时间有耐心肯定能找到免费的)2、还有一些,通过翻墙就能爬取到。当然最好的方法还是自己抓下来。总之免费的东西大多不靠谱,抓完不给钱给差评(实在对不起,我)。
1.进入2.进入商品页面3.选中或是复制地址页(不同推广的域名都不一样,百度搜即可找到对应那一个搜索,)4.点击右上角的页面管理,创建新的推广,并选择推广品类5.创建推广推广:页面转到下一页,点击推广“创建推广”5.打开浏览页面,进行收货地址填写,推广人为你自己,推广主地址为,推广时间设定为你将来上架的时间段(1-3个月)或者是你确定好的日期(3-6个月)。
推广“投放计划”6.设置你推广的时间、设定你的出单量(包括配合各个应用的活动推广),选择推广计划下方的投放方式7.根据你的意图,将你的投放方式点击确定8.输入推广商品的关键词和属性9.然后输入推广链接,等待审核。10.审核通过后,返回上面的页面,你可以推广收货地址填写在推广计划的地址栏,也可以输入推广链接,等待商品推荐11.返回新的推广计划页面,重复步骤1~6,你会得到一个推广计划。
12.推广商品推荐打开“推广助手”13.进入到推广管理页面,选择你所有想推广的商品,选择商品时一定要对这个商品名进行一些设置,这样可以节省后期的审核时间。输入你所想推广的商品的关键词,计划名、推广区域(选择你想推广的一个区域,根据你的资金水平设置推广区域,建议选择中间的),点击下一步即可!14.是否返回整个计划推广返回上一步页面,在你确定好商品推广后,计划分配给哪个计划,你就选择哪个计划推广。如果审核没有通过,可以看看哪个计划没有计划推广,再返回到上一步15.商品推广返回上一步页面,选择。 查看全部
通过关键词采集文章采集api接口,网上还是很多的
通过关键词采集文章采集api接口,网上还是很多的;抓取视频网站上的视频,可以通过抓包工具抓取,或者是购买视频的地址转换swf格式,然后再解析链接就可以转化成功。网络分析类api接口,之前在做一个网站数据分析项目时,刚好用到了api。我把抓取地址留在github上了,
现在有很多第三方通过openinstall抓取好网页的
大多是需要付费的,只能通过google或者是你觉得可以的人翻墙去用,另外也可以去,一些比较大的b2c平台,基本他们是允许用户免费用的。网上有大量的文章,用来教你怎么去做的。
谢邀。因为我也是个新手...平时喜欢捣鼓网站和爬虫,所以根据自己的经验讲一点。1、类似于这样的购物平台有不少是付费的,但其实很多都是很便宜的在发布。(只要你有时间有耐心肯定能找到免费的)2、还有一些,通过翻墙就能爬取到。当然最好的方法还是自己抓下来。总之免费的东西大多不靠谱,抓完不给钱给差评(实在对不起,我)。
1.进入2.进入商品页面3.选中或是复制地址页(不同推广的域名都不一样,百度搜即可找到对应那一个搜索,)4.点击右上角的页面管理,创建新的推广,并选择推广品类5.创建推广推广:页面转到下一页,点击推广“创建推广”5.打开浏览页面,进行收货地址填写,推广人为你自己,推广主地址为,推广时间设定为你将来上架的时间段(1-3个月)或者是你确定好的日期(3-6个月)。
推广“投放计划”6.设置你推广的时间、设定你的出单量(包括配合各个应用的活动推广),选择推广计划下方的投放方式7.根据你的意图,将你的投放方式点击确定8.输入推广商品的关键词和属性9.然后输入推广链接,等待审核。10.审核通过后,返回上面的页面,你可以推广收货地址填写在推广计划的地址栏,也可以输入推广链接,等待商品推荐11.返回新的推广计划页面,重复步骤1~6,你会得到一个推广计划。
12.推广商品推荐打开“推广助手”13.进入到推广管理页面,选择你所有想推广的商品,选择商品时一定要对这个商品名进行一些设置,这样可以节省后期的审核时间。输入你所想推广的商品的关键词,计划名、推广区域(选择你想推广的一个区域,根据你的资金水平设置推广区域,建议选择中间的),点击下一步即可!14.是否返回整个计划推广返回上一步页面,在你确定好商品推广后,计划分配给哪个计划,你就选择哪个计划推广。如果审核没有通过,可以看看哪个计划没有计划推广,再返回到上一步15.商品推广返回上一步页面,选择。
社招进腾讯阿里的面试呗,你值得拥有!
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-05-02 07:13
内容
前言
几天前,我接受了阿里外籍人士的采访。作为一个自信和自大的人,尽管我是外籍人士,但我仍然对阿里充满钦佩之情,就像我要进入清华北大参加高考,而我想进入腾讯上班一样,阿里也是一样。当然,除了可以招募阿里的学校招募985/211之外,想要通过社会招募阿里的其他人更加困难。至少他们是某个领域的专家。因此,如果您有机会,请尝试阿里的采访。
一、面试内容1、电话面试和项目实践问题
首先,这是电话采访:这通常不是问题。仔细阅读并阅读更多书籍,少吃零食,多睡些……这肯定可以回答。
接下来是一个手写的演示主题,如下所示
文档链接:
在左侧的文档树中爬网所有文档列表
在查询页面上输入关键词或描述性语言,并给出3个最匹配的文档(从高到低排序)。
提供:
1.代码
2.匹配提示
奖励项目:如何提供描述性语言的推荐文档。例如,用户输入:我的日志采集不可用
大多数人在听到编写演示的消息时都会感到恐慌,不要害怕,我不是在这里与您分享经验和代码示例,因此在阅读本内容文章之后,我应该没问题了无论如何,一切都结束了。
2、动手主题:文档爬网和搜索
3、研究主题
首先,让我们看一下链接。让我们看看它是什么。原来是阿里云的帮助文档。看来,这个简单的演示实际上是在根据用户输入关键词一个小项目搜索相应的解决方案的。
第一步,抓取内容应该不难。不管您使用Java还是Python,困难都是第一位的,但是Python可能会更简单,并且用Java编写的代码会更多,当然也会更少。目前,编辑器仍然想首先学习Java,因此演示是通过Java代码完成的。对于Python,首先要学习学习一种语言,然后再扩展另一种语言,以便更好地为您提供帮助。
困难在于第二个小步骤,“在查询页面上输入关键词或描述性语言,并给出最匹配的3个文档(从高到低排序)”,
我们不要先进行爬网,因为我们必须封装所需的爬网格式。当我们不打算查询关键词此功能时,我们应该先保留它。
①查询输入关键词,给出最佳匹配解决方案主意
当然,您可以编写自己的算法和匹配项,但是在这种情况下,匹配项肯定不是非常准确,并且几乎不可能在一天内编写它。因此,让我们看看前辈是否有这种类型的更好的解决方案,而站在巨人的肩膀上,将事半功倍。
实际上,有很多方法可以实现相似的功能,
例如,搜索分词器:捷巴分词,Ansj分词...有关其他特定的分词效果,您可以单击此处:了解11种开源中文分词器
或类似于搜索引擎服务器的开源框架:Elasticsearch,Lucene ...对于其他特定的搜索引擎服务,您可以单击此处:了解13个开源搜索引擎
这里展示的编辑器是一个演示项目,用于使用solr搜索引擎进行爬网和搜索
二、开始学习
Solr下载地址:最好下载较低的版本,较高的版本需要较高的jdk版本,我的jdk是1. 7,而下载的solr版本是4. 7. 0,或者下载时在本文结尾处进行的演示中,我还将在其中使用的所有内容都放入其中。
1、配置步骤
①下载后,解压缩
②cmd进入此目录:xxxxx / solr- 4. 7. 0 / example
③执行命令:java -jar start.jar
④访问是否成功启动,请在浏览器中输入:8983 / solr进行访问,表明启动成功。
2、 Solr界面说明和使用
我不会详细介绍特定solr的其他功能。您可以参考在线资料,以进一步加深对solr的理解和使用
三、开始抓取
首先将solr的maven包引入项目中
org.apache.solr
solr-solrj
4.7.0
抓取非常简单,只需模拟浏览器即可访问内容,我们可以看到要抓取的网站左侧的所有文本内容都在其中
内部
这很简单,因此,在对抓取的数据进行常规匹配之后,我们可以获得所需的所有文本标题信息。
代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField()方法和addIndex()方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet()方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/"); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/"); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上就完成了爬网功能,我们可以看到我们要爬网的就是我们想要的信息
四、通过关键词搜索
检索更加简单,因为使用了solr搜索引擎的服务,因此只要根据solr api传递数据,就可以对其进行检索,它将自动过滤单词分割并返回数据根据匹配程度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex()方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、主页页面
最后一页是前台页面。它不是很好,因为它很着急,只给一天时间,而且您白天必须上班,晚上只能花几个小时学习背景代码,前台会留下来独自的。如果有时间,就可以美化它
前景代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行效果图
基本上可以,并且只需完成即可。它仍然与我的预期有所不同。但是,为了赶快,我迅速发送了它。我是在晚上22:21左右发送的。我以为面试官明天必须给出结果,但是阿里成为如此出色的公司并不无道理。面试官当场回答我,说我通过了,有那么多敬业的程序员。您的公司会失败吗?
七、摘要:(使用代码下载)
1.必须首先开始solr
解压缩,在xxxxx / solr- 4. 7. 0 / example cmd目录中
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先单击“抓取”,稍等片刻,等待页面上出现“成功抓取”一词,然后您就可以进行查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原创作者的分享,以便技术人员可以更快地解决问题 查看全部
社招进腾讯阿里的面试呗,你值得拥有!
内容
前言
几天前,我接受了阿里外籍人士的采访。作为一个自信和自大的人,尽管我是外籍人士,但我仍然对阿里充满钦佩之情,就像我要进入清华北大参加高考,而我想进入腾讯上班一样,阿里也是一样。当然,除了可以招募阿里的学校招募985/211之外,想要通过社会招募阿里的其他人更加困难。至少他们是某个领域的专家。因此,如果您有机会,请尝试阿里的采访。
一、面试内容1、电话面试和项目实践问题
首先,这是电话采访:这通常不是问题。仔细阅读并阅读更多书籍,少吃零食,多睡些……这肯定可以回答。
接下来是一个手写的演示主题,如下所示
文档链接:
在左侧的文档树中爬网所有文档列表
在查询页面上输入关键词或描述性语言,并给出3个最匹配的文档(从高到低排序)。
提供:
1.代码
2.匹配提示
奖励项目:如何提供描述性语言的推荐文档。例如,用户输入:我的日志采集不可用
大多数人在听到编写演示的消息时都会感到恐慌,不要害怕,我不是在这里与您分享经验和代码示例,因此在阅读本内容文章之后,我应该没问题了无论如何,一切都结束了。
2、动手主题:文档爬网和搜索
3、研究主题
首先,让我们看一下链接。让我们看看它是什么。原来是阿里云的帮助文档。看来,这个简单的演示实际上是在根据用户输入关键词一个小项目搜索相应的解决方案的。
第一步,抓取内容应该不难。不管您使用Java还是Python,困难都是第一位的,但是Python可能会更简单,并且用Java编写的代码会更多,当然也会更少。目前,编辑器仍然想首先学习Java,因此演示是通过Java代码完成的。对于Python,首先要学习学习一种语言,然后再扩展另一种语言,以便更好地为您提供帮助。
困难在于第二个小步骤,“在查询页面上输入关键词或描述性语言,并给出最匹配的3个文档(从高到低排序)”,
我们不要先进行爬网,因为我们必须封装所需的爬网格式。当我们不打算查询关键词此功能时,我们应该先保留它。
①查询输入关键词,给出最佳匹配解决方案主意
当然,您可以编写自己的算法和匹配项,但是在这种情况下,匹配项肯定不是非常准确,并且几乎不可能在一天内编写它。因此,让我们看看前辈是否有这种类型的更好的解决方案,而站在巨人的肩膀上,将事半功倍。
实际上,有很多方法可以实现相似的功能,
例如,搜索分词器:捷巴分词,Ansj分词...有关其他特定的分词效果,您可以单击此处:了解11种开源中文分词器
或类似于搜索引擎服务器的开源框架:Elasticsearch,Lucene ...对于其他特定的搜索引擎服务,您可以单击此处:了解13个开源搜索引擎
这里展示的编辑器是一个演示项目,用于使用solr搜索引擎进行爬网和搜索
二、开始学习
Solr下载地址:最好下载较低的版本,较高的版本需要较高的jdk版本,我的jdk是1. 7,而下载的solr版本是4. 7. 0,或者下载时在本文结尾处进行的演示中,我还将在其中使用的所有内容都放入其中。
1、配置步骤
①下载后,解压缩
②cmd进入此目录:xxxxx / solr- 4. 7. 0 / example
③执行命令:java -jar start.jar
④访问是否成功启动,请在浏览器中输入:8983 / solr进行访问,表明启动成功。
2、 Solr界面说明和使用
我不会详细介绍特定solr的其他功能。您可以参考在线资料,以进一步加深对solr的理解和使用
三、开始抓取
首先将solr的maven包引入项目中
org.apache.solr
solr-solrj
4.7.0
抓取非常简单,只需模拟浏览器即可访问内容,我们可以看到要抓取的网站左侧的所有文本内容都在其中
内部
这很简单,因此,在对抓取的数据进行常规匹配之后,我们可以获得所需的所有文本标题信息。
代码示例:
/**
* 爬取数据
* @return
*/
@ResponseBody
@RequestMapping("/getDocs")
public String getDocs() {
Map mapReturn = new HashMap(); //返回结果
try {
//爬取前先在solr上建林索引属性
alibabaService.addDefaultField();
//开始爬取指定url的数据
String htmlResult = GetAliApi.sendGet("https://help.aliyun.com/docume ... ot%3B, "");
//获取到 树文档的内容
String[] mainMenuListContainer = htmlResult.split("")[1].split("");
//log.debug(mainMenuListContainer[0]);
//log.debug("------------------------------");
//进行正则获取数据
String searchReg = "(.*?)";
Pattern pattern = Pattern.compile(searchReg); // 讲编译的正则表达式对象赋给pattern
Matcher matcher = pattern.matcher(mainMenuListContainer[0]);
int i = 0;
String pre = "A";
while (matcher.find()) {
i++;
String title = matcher.group(1);
log.debug(title);
//将数据放到solr里,添加索引
Alidocs alidocs = new Alidocs();
alidocs.setId(pre+i);
alidocs.setTitle(title);
alibabaService.addIndex(alidocs);
}
mapReturn.put("returnCode","00");
mapReturn.put("content","爬取成功");
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","爬取失败,请重试");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
addDefaultField()方法和addIndex()方法:
// 添加默认索引属性
public void addDefaultField() throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "默认情况下必须添加的字段,用来区分文档的唯一标识");
doc.addField("title", "默认的名称属性字段");
solr.add(doc);
solr.commit();
}
// 添加索引
public void addIndex(Alidocs alidocs) throws SolrServerException, IOException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
solr.addBean(alidocs);
solr.commit();
}
sendGet()方法:
public static String sendGet(String url, String param) {
String result = "";
String urlName = url + "?" + param;
try {
URL realURL = new URL(urlName);
URLConnection conn = realURL.openConnection();
//伪造ip访问
String ip = randIP();
System.out.println("目前伪造的ip:"+ip);
conn.setRequestProperty("X-Forwarded-For", ip);
conn.setRequestProperty("HTTP_X_FORWARDED_FOR", ip);
conn.setRequestProperty("HTTP_CLIENT_IP", ip);
conn.setRequestProperty("REMOTE_ADDR", ip);
conn.setRequestProperty("Host", "help.aliyun.com/");
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
conn.setRequestProperty("Referer","https://help.aliyun.com/";); //伪造访问来源
conn.setRequestProperty("Origin", "https://help.aliyun.com/";); //伪造访问域名
conn.connect();
Map map = conn.getHeaderFields();
for (String s : map.keySet()) {
System.out.println(s + "-->" + map.get(s));
}
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "utf-8"));
String line;
while ((line = in.readLine()) != null) {
result += "\n" + line;
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
这样,基本上就完成了爬网功能,我们可以看到我们要爬网的就是我们想要的信息
四、通过关键词搜索
检索更加简单,因为使用了solr搜索引擎的服务,因此只要根据solr api传递数据,就可以对其进行检索,它将自动过滤单词分割并返回数据根据匹配程度。
代码示例:
/**
* 通过关键词获取数据
* @param title
* @return
*/
@ResponseBody
@RequestMapping("/findDocs")
public String findDocs(String title) {
Map mapReturn = new HashMap(); //返回结果
try {
String result = alibabaService.findIndex(title);
mapReturn.put("returnCode","00");
mapReturn.put("content",result);
}catch (Exception e){
e.printStackTrace();
mapReturn.put("returnCode","-1");
mapReturn.put("content","查询异常");
}
String mapStr = JSONObject.toJSONString(mapReturn);
return mapStr;
}
findIndex()方法:
// 查找索引
public String findIndex(String titleInput) throws SolrServerException {
// 声明要连接solr服务器的地址
String url = "http://localhost:8983/solr";
SolrServer solr = new HttpSolrServer(url);
// 查询条件
SolrQuery solrParams = new SolrQuery();
solrParams.setStart(0);
solrParams.setRows(10);
solrParams.setQuery("title:"+titleInput);
// 开启高亮
solrParams.setHighlight(true);
solrParams.setHighlightSimplePre("");
solrParams.setHighlightSimplePost("");
// 设置高亮的字段
solrParams.setParam("hl.fl", "title");
// SolrParams是SolrQuery的子类
QueryResponse queryResponse = solr.query(solrParams);
// (一)获取查询的结果集合
SolrDocumentList solrDocumentList = queryResponse.getResults();
List contentList = new LinkedList();
for (SolrDocument solrDocument : solrDocumentList) {
Map map = new HashMap();
map.put("id",solrDocument.get("id"));
map.put("title",solrDocument.get("title"));
contentList.add(map);
}
return contentList.toString();
}
五、主页页面
最后一页是前台页面。它不是很好,因为它很着急,只给一天时间,而且您白天必须上班,晚上只能花几个小时学习背景代码,前台会留下来独自的。如果有时间,就可以美化它
前景代码示例:
阿里测试题
1、先爬取文档数据
<a class="weui-btn weui-btn_mini weui-btn_primary" id="getDocs">开始爬取</a>
搜索关键词
<a class="weui-btn weui-btn_mini weui-btn_primary" id="findDocs">查询</a>
$('#getDocs').click(function () {
ajaxLoading('爬取中,请稍后...');
$.ajax({
url: "/ali/getDocs",
data: {},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
$.MsgBox.Alert("提示",data.content,"确定");
},
error: function () {
$.MsgBox.Alert("异常","爬取发生异常,请联系管理员!","确定");
}
})
})
$('#findDocs').click(function () {
var keytitle = $('.keytitle').val();
if(keytitle==""){
$.MsgBox.Alert("提示","淘气!请输入内容","确定");
return
}
ajaxLoading('查询中...');
$.ajax({
url: "/ali/findDocs",
data: {"title":keytitle},
type: 'post',
dataType: 'json',
success: function (data) {
ajaxLoadEnd();
if (data.returnCode=="00"){
$.MsgBox.Alert("提示",data.content,"确定");
}else {
$.MsgBox.Alert("提示",data.content,"确定");
}
},
error: function () {
$.MsgBox.Alert("异常","查询发生异常,请联系管理员!","确定");
}
})
})
function ajaxLoading(text){
$("").css({display:"block",width:"100%",height:$(window).height()}).appendTo("body");
$("").html(text).appendTo("body").css({display:"block",left:($(document.body).outerWidth(true) - 190) / 2,top:($(window).height() - 45) / 2});
}
function ajaxLoadEnd(){
$(".datagrid-mask").remove();
$(".datagrid-mask-msg").remove();
}
六、运行效果图
基本上可以,并且只需完成即可。它仍然与我的预期有所不同。但是,为了赶快,我迅速发送了它。我是在晚上22:21左右发送的。我以为面试官明天必须给出结果,但是阿里成为如此出色的公司并不无道理。面试官当场回答我,说我通过了,有那么多敬业的程序员。您的公司会失败吗?
七、摘要:(使用代码下载)
1.必须首先开始solr
解压缩,在xxxxx / solr- 4. 7. 0 / example cmd目录中
执行命令:java -jar start.jar
2、启动项目aliTestProject
然后先单击“抓取”,稍等片刻,等待页面上出现“成功抓取”一词,然后您就可以进行查询
3、查询效果图
整个项目代码下载链接:
参考文章:
感谢原创作者的分享,以便技术人员可以更快地解决问题
基于API的微博信息采集系统设计与实现(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2021-05-02 03:04
基于API的微博信息采集系统设计与实现摘要:微博已成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API 采集方法的信息,然后设计了可以在新浪微博相关信息上执行采集的信息采集系统。实验测试表明,信息采集系统可以快速有效地[新浪微博]信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文图书馆分类号:TP315文档标识号:A 文章编号:1009-3044(201 3) 17-Weibo [1]是微博客的缩写,是基于信息的共享,传播和获取信息的平台根据用户关系,用户可以通过WEB,WAP和各种客户端组件个人社区更新约140个字符的信息,并实现即时共享。 ,截至2012年12月底,截至2012年12月,中国微博用户数为3. 9亿,较2011年底增加了5873。与去年年底相比增长了6个百分点,达到5 4. 7%[2]。随着微博网络,政府部门,学校,知名企业和公众的影响力迅速扩大cters已打开微博。
在公众的参与下,微博已成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用它采集微博信息已经成为具有重要应用价值的研究。 1研究方法和技术路线国内微博用户主要是新浪微博,因此本文以新浪微博为例来设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现新浪微博采集目前的信息主要有两种:一种是“模拟登录”,“网络爬虫” [3],“网站内容分析” [4]结合了这三种技术的信息采集方法。第二个是基于新浪微博开放平台的API文档。开发人员编写自己的程序来调用微博API来处理微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”步骤。有必要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的更改将导致“网络爬虫”。 “最终导致采集无法找到微博信息的失败。同时,“网络爬虫” 采集访问的网页需要进行“页面内容分析”,并且存在明显的差距与基于API的数据采集相比,效率和性能之间存在差异,本文打算采用第二种方法进行研究,基于新浪微博开放平台API文档的微博信息采集系统主要采用两项研究方法:文献分析法和实验测试法。
文档分析方法:请参见新浪微博开放平台的API文档,并将这些API描述文档作为单独的接口文件编写。实验测试方法:关于VS。 NET2010平台[5],以C / S模式开发程序以调用接口类,采集微博返回的JOSN数据流,并实现数据的相关测试和开发采集。基于以上两种研究方法,设计了本研究的技术路线:首先,申请新浪微博开放平台的App Key和App Secret。通过审核后,阅读并理解API文档,并将API文档描述写入API接口代码类(c#语言),然后测试OAuth 2. 0身份验证。通过身份验证后,可以获得访问令牌,因此您有权调用API的各种功能接口,然后通过POST或GET调用API接口,最后返回JOSN数据流,最后解析该数据流即可保存为本地文本文件或数据库。详细的技术路线如图1所示。2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证,微博用户登录,发送微博登录用户,采集当前登录用户信息,采集他人的用户信息,采集他人的用户微薄,采集学校信息,采集微博信息内容。
1)微博界面身份验证:要访问大多数新浪微博API,例如发布微博,获取私人消息以及进行后续操作,都需要用户身份。目前,新浪微博开放平台上的用户身份认证包括OAuth 2. 0和Basic。 Auth(仅用于属于该应用程序的开发人员的调试接口),该接口的新版本也仅支持这两种方法[6]。因此,系统设计与开发的第一步是实现微博界面认证功能。 2)微博用户登录:通过身份验证后,所有在新浪微博上注册的用户都可以登录该系统,并可以通过该系统发布微博。 3) 采集登录用户信息:用户登录后,可以通过该系统查看自己的账户信息,自己的微博信息以及关注者的微博信息。 4) 采集其他用户信息:此功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的帐户信息,例如他拥有多少粉丝,他关注谁,还有多少人关注他,这个信息在微博采集中也非常有价值。 5) 采集其他用户的微博:此功能还使用微博用户的昵称来采集更改该用户发送的所有微博信息。此功能的目的是将来扩展到其他每个时间段。 ,自动将目标中的多个微博用户的微博信息设置为本地的微博信息,以进行数据内容分析。 6) 采集学校信息:此功能使用学校名称的模糊查询,以采集学校在微博中的帐户ID,学校所在的地区以及学校信息的类型。这是采集学校对微博的影响力的基本数据。
7) 采集微博信息内容:您可以单击微博内容的关键词进行查询,采集此微博信息收录此关键词。但是,由于此API接口调用需要高级权限,因此无法在系统完全发布之前和对新浪微博开放平台进行审查之前直接对其进行测试和使用。 3主要功能的实现3. 1微博界面身份验证功能大多数新浪微博API访问都需要用户身份验证。本系统采用OAuth 2. 0方法设计微博界面认证功能。新浪微博的身份验证过程如图3所示。 4小结本文主要对微博信息采集的方法和技术进行了一系列研究,然后设计并开发了一个基于API的新浪微博信息采集系统,该系统实现了微博采集的基本信息,在一定程度上解决了微博信息采集的自动化和结果数据格式采集的标准化。但是,该系统当前的微博信息采集方法只能通过输入单个“ 关键词” 采集进行唯一匹配,并且批次采集中没有多个“搜索词”,也没有具有“主题类型”。 “微博信息采集起作用,因此下一步的研究是如何设计主题模型来优化系统。参考文献:[1]温睿。微博的知识[J]。软件工程师,2009(1 2) :19-2 0. [2]中国互联网络信息中心。第31届中国互联网络发展状况统计报告[EB / OL]。(2013-01-1 5)。http:// www。。 cn / hlwfzyj / hlwxzbg / hlwtjbg / 201301 / t20130115_3850 8. htm。[3]罗刚,王振东。自己编写手写网络爬虫[M]。北京:清华大学出版社,201 0. [4]余曼泉,陈铁瑞,徐洪波。基于块的网页信息解析器的研究与设计[J]。计算机应用,2005,25(4):974-97 6. [5]尼克·兰道夫,大卫·加德纳,克里斯·安德森,et al。Professional Visual Studio 2010 [M]。Wrox,201 0. [6]新浪微博开放平台。授权机制的说明[EB / OL]。(2013-01-19)。http:// open 。weibo。com / wiki /%E6%8E%88%E6%9 D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E。 查看全部
基于API的微博信息采集系统设计与实现(组图)
基于API的微博信息采集系统设计与实现摘要:微博已成为网络信息的重要来源。本文分析了微博信息采集的相关方法和技术,提出了基于API 采集方法的信息,然后设计了可以在新浪微博相关信息上执行采集的信息采集系统。实验测试表明,信息采集系统可以快速有效地[新浪微博]信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文图书馆分类号:TP315文档标识号:A 文章编号:1009-3044(201 3) 17-Weibo [1]是微博客的缩写,是基于信息的共享,传播和获取信息的平台根据用户关系,用户可以通过WEB,WAP和各种客户端组件个人社区更新约140个字符的信息,并实现即时共享。 ,截至2012年12月底,截至2012年12月,中国微博用户数为3. 9亿,较2011年底增加了5873。与去年年底相比增长了6个百分点,达到5 4. 7%[2]。随着微博网络,政府部门,学校,知名企业和公众的影响力迅速扩大cters已打开微博。
在公众的参与下,微博已成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用它采集微博信息已经成为具有重要应用价值的研究。 1研究方法和技术路线国内微博用户主要是新浪微博,因此本文以新浪微博为例来设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现新浪微博采集目前的信息主要有两种:一种是“模拟登录”,“网络爬虫” [3],“网站内容分析” [4]结合了这三种技术的信息采集方法。第二个是基于新浪微博开放平台的API文档。开发人员编写自己的程序来调用微博API来处理微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”步骤。有必要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的更改将导致“网络爬虫”。 “最终导致采集无法找到微博信息的失败。同时,“网络爬虫” 采集访问的网页需要进行“页面内容分析”,并且存在明显的差距与基于API的数据采集相比,效率和性能之间存在差异,本文打算采用第二种方法进行研究,基于新浪微博开放平台API文档的微博信息采集系统主要采用两项研究方法:文献分析法和实验测试法。
文档分析方法:请参见新浪微博开放平台的API文档,并将这些API描述文档作为单独的接口文件编写。实验测试方法:关于VS。 NET2010平台[5],以C / S模式开发程序以调用接口类,采集微博返回的JOSN数据流,并实现数据的相关测试和开发采集。基于以上两种研究方法,设计了本研究的技术路线:首先,申请新浪微博开放平台的App Key和App Secret。通过审核后,阅读并理解API文档,并将API文档描述写入API接口代码类(c#语言),然后测试OAuth 2. 0身份验证。通过身份验证后,可以获得访问令牌,因此您有权调用API的各种功能接口,然后通过POST或GET调用API接口,最后返回JOSN数据流,最后解析该数据流即可保存为本地文本文件或数据库。详细的技术路线如图1所示。2研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证,微博用户登录,发送微博登录用户,采集当前登录用户信息,采集他人的用户信息,采集他人的用户微薄,采集学校信息,采集微博信息内容。
1)微博界面身份验证:要访问大多数新浪微博API,例如发布微博,获取私人消息以及进行后续操作,都需要用户身份。目前,新浪微博开放平台上的用户身份认证包括OAuth 2. 0和Basic。 Auth(仅用于属于该应用程序的开发人员的调试接口),该接口的新版本也仅支持这两种方法[6]。因此,系统设计与开发的第一步是实现微博界面认证功能。 2)微博用户登录:通过身份验证后,所有在新浪微博上注册的用户都可以登录该系统,并可以通过该系统发布微博。 3) 采集登录用户信息:用户登录后,可以通过该系统查看自己的账户信息,自己的微博信息以及关注者的微博信息。 4) 采集其他用户信息:此功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的帐户信息,例如他拥有多少粉丝,他关注谁,还有多少人关注他,这个信息在微博采集中也非常有价值。 5) 采集其他用户的微博:此功能还使用微博用户的昵称来采集更改该用户发送的所有微博信息。此功能的目的是将来扩展到其他每个时间段。 ,自动将目标中的多个微博用户的微博信息设置为本地的微博信息,以进行数据内容分析。 6) 采集学校信息:此功能使用学校名称的模糊查询,以采集学校在微博中的帐户ID,学校所在的地区以及学校信息的类型。这是采集学校对微博的影响力的基本数据。
7) 采集微博信息内容:您可以单击微博内容的关键词进行查询,采集此微博信息收录此关键词。但是,由于此API接口调用需要高级权限,因此无法在系统完全发布之前和对新浪微博开放平台进行审查之前直接对其进行测试和使用。 3主要功能的实现3. 1微博界面身份验证功能大多数新浪微博API访问都需要用户身份验证。本系统采用OAuth 2. 0方法设计微博界面认证功能。新浪微博的身份验证过程如图3所示。 4小结本文主要对微博信息采集的方法和技术进行了一系列研究,然后设计并开发了一个基于API的新浪微博信息采集系统,该系统实现了微博采集的基本信息,在一定程度上解决了微博信息采集的自动化和结果数据格式采集的标准化。但是,该系统当前的微博信息采集方法只能通过输入单个“ 关键词” 采集进行唯一匹配,并且批次采集中没有多个“搜索词”,也没有具有“主题类型”。 “微博信息采集起作用,因此下一步的研究是如何设计主题模型来优化系统。参考文献:[1]温睿。微博的知识[J]。软件工程师,2009(1 2) :19-2 0. [2]中国互联网络信息中心。第31届中国互联网络发展状况统计报告[EB / OL]。(2013-01-1 5)。http:// www。。 cn / hlwfzyj / hlwxzbg / hlwtjbg / 201301 / t20130115_3850 8. htm。[3]罗刚,王振东。自己编写手写网络爬虫[M]。北京:清华大学出版社,201 0. [4]余曼泉,陈铁瑞,徐洪波。基于块的网页信息解析器的研究与设计[J]。计算机应用,2005,25(4):974-97 6. [5]尼克·兰道夫,大卫·加德纳,克里斯·安德森,et al。Professional Visual Studio 2010 [M]。Wrox,201 0. [6]新浪微博开放平台。授权机制的说明[EB / OL]。(2013-01-19)。http:// open 。weibo。com / wiki /%E6%8E%88%E6%9 D%83%E6%9C%BA%E5%88%B6%E8%AF%B4%E6%98%8E。
ai模型大全数据从哪来的?百度云?使用各种爬虫爬取分析获取!
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-04-21 04:02
通过关键词采集文章采集api,采集文章方便分类采集文章,api可以参考链接:超级粉丝|机器人采集器设置教程|一键采集器|朋友圈采集站工具机器人采集器启动后就可以开始采集任务了,在任务列表中,手动选择需要抓取的文章,点击保存,选择要抓取的文章,点击采集,就完成文章采集啦!效果如下抓取效果抓取效果抓取效果如果想查看机器人采集页面,点击主页中的详情页,就会跳转到机器人设置的页面啦~详情页的数据其实是伪数据哦!可以进行修改,删除或者修改操作哦!设置页设置页。
这家网站我已经扒了,基本都是利用爬虫软件采集的。可以了解下网址:,可以自己练练。相比ai的api在抓取效率上比较差一点。
ai模型大全
数据从哪来的?百度云?使用各种爬虫爬取分析获取!
作为一个计算机毕业生,好像没有接触过爬虫方面的技术,工作这么多年来,爬虫其实就只是变换一个实现业务流程以达到一个目的。我记得三年前在做用户行为分析的时候用python,都需要输入数据手动去计算,而且能计算一定数量的分布。后来就基本用scrapy这个框架来构建web界面,然后单纯记录爬取的url就行了。
再后来,django出来以后,我又用了几次,感觉下来还是scrapy比较好用,然后就学会了用框架,走上了每天都在写scrapy框架源码的不归路。之前的经验我是总结为框架和scrapy,但是后来想想scrapy其实是核心开发语言就是python。因为框架就是搞定了一些其实也不难的基础功能,然后交给模块去运行,模块本身实现业务功能,scrapy就这么开始了可怕的功能扩展!!!重要说一下,scrapy能爬取的数据非常非常丰富,有广泛的分布式,内容搜索,社区,数据挖掘方面的深入应用。
爬虫只是一小部分其实python是一门解释型语言,作为一个老菜鸟,每天还得做核心的内容搜索,数据处理,感觉大腿都拧不过来啊,之前学习网络搜索方面的,但是三年下来,感觉还是更喜欢动手学东西。一言以蔽之,scrapy基本上包含了我们工作中所有必须的知识点,一言不合就上车。附带一句大神语录,爬虫过程就是保密的!。 查看全部
ai模型大全数据从哪来的?百度云?使用各种爬虫爬取分析获取!
通过关键词采集文章采集api,采集文章方便分类采集文章,api可以参考链接:超级粉丝|机器人采集器设置教程|一键采集器|朋友圈采集站工具机器人采集器启动后就可以开始采集任务了,在任务列表中,手动选择需要抓取的文章,点击保存,选择要抓取的文章,点击采集,就完成文章采集啦!效果如下抓取效果抓取效果抓取效果如果想查看机器人采集页面,点击主页中的详情页,就会跳转到机器人设置的页面啦~详情页的数据其实是伪数据哦!可以进行修改,删除或者修改操作哦!设置页设置页。
这家网站我已经扒了,基本都是利用爬虫软件采集的。可以了解下网址:,可以自己练练。相比ai的api在抓取效率上比较差一点。
ai模型大全
数据从哪来的?百度云?使用各种爬虫爬取分析获取!
作为一个计算机毕业生,好像没有接触过爬虫方面的技术,工作这么多年来,爬虫其实就只是变换一个实现业务流程以达到一个目的。我记得三年前在做用户行为分析的时候用python,都需要输入数据手动去计算,而且能计算一定数量的分布。后来就基本用scrapy这个框架来构建web界面,然后单纯记录爬取的url就行了。
再后来,django出来以后,我又用了几次,感觉下来还是scrapy比较好用,然后就学会了用框架,走上了每天都在写scrapy框架源码的不归路。之前的经验我是总结为框架和scrapy,但是后来想想scrapy其实是核心开发语言就是python。因为框架就是搞定了一些其实也不难的基础功能,然后交给模块去运行,模块本身实现业务功能,scrapy就这么开始了可怕的功能扩展!!!重要说一下,scrapy能爬取的数据非常非常丰富,有广泛的分布式,内容搜索,社区,数据挖掘方面的深入应用。
爬虫只是一小部分其实python是一门解释型语言,作为一个老菜鸟,每天还得做核心的内容搜索,数据处理,感觉大腿都拧不过来啊,之前学习网络搜索方面的,但是三年下来,感觉还是更喜欢动手学东西。一言以蔽之,scrapy基本上包含了我们工作中所有必须的知识点,一言不合就上车。附带一句大神语录,爬虫过程就是保密的!。
通过关键词采集文章采集api二手物品销售apigithub地址/
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-04-12 07:06
通过关键词采集文章采集api二手物品销售apigithub地址/,不过因为国内访问极慢,推荐采用代理方式进行学习。目前来看做采集的同学很多,所以想提醒广大采集者谨慎!并不是你采集一个样本,他就一定会被采纳!不合规的采集手段都会被封闭!1.采集引擎常用的都是按文章数据来收取,使用的简单对文章按定制关键词特征来提取,然后通过库存量以文章级别来收取,这个方式好处也是比较明显的!缺点也是比较明显的,效率不高2.爬虫框架这个好处是效率非常高,不管是什么样的文章类型,都能爬到!缺点是对采集软件的稳定性要求高,如果您用python,pywin32这些框架的话,稳定性还行,你要用别的可能很容易崩溃而导致得不到任何数据!3.抓取工具一般情况下网站上会有你想要的各种文章,但是也会有一些比较独特的图片,各种加密数据等,这类数据采集,一般我们需要用特殊格式的文件,这样不仅有利于你爬取更精准数据,还能节省数据工作量!至于怎么得到这个格式的文件,我们一般都是用json格式的字典,直接google或者lxml语言,爬取到对应的html文件,对html文件进行各种header属性请求获取对应的数据即可!4.分析需求并提取数据我们做爬虫就是为了快速的采集到我们需要的数据,所以我们需要快速的返回数据,所以做的一些数据可视化就非常必要了,比如xml,csv等格式的数据,能更快速的得到各个分类的数据在我们更加详细的分析之后,可以根据我们需要的数据,结合文章原理等其他数据源,建立我们自己独特的数据库或者库存等等!我们的看的博客:big-big:创业一年,我们爬了哪些网站,总结出来的最好用的采集方式。 查看全部
通过关键词采集文章采集api二手物品销售apigithub地址/
通过关键词采集文章采集api二手物品销售apigithub地址/,不过因为国内访问极慢,推荐采用代理方式进行学习。目前来看做采集的同学很多,所以想提醒广大采集者谨慎!并不是你采集一个样本,他就一定会被采纳!不合规的采集手段都会被封闭!1.采集引擎常用的都是按文章数据来收取,使用的简单对文章按定制关键词特征来提取,然后通过库存量以文章级别来收取,这个方式好处也是比较明显的!缺点也是比较明显的,效率不高2.爬虫框架这个好处是效率非常高,不管是什么样的文章类型,都能爬到!缺点是对采集软件的稳定性要求高,如果您用python,pywin32这些框架的话,稳定性还行,你要用别的可能很容易崩溃而导致得不到任何数据!3.抓取工具一般情况下网站上会有你想要的各种文章,但是也会有一些比较独特的图片,各种加密数据等,这类数据采集,一般我们需要用特殊格式的文件,这样不仅有利于你爬取更精准数据,还能节省数据工作量!至于怎么得到这个格式的文件,我们一般都是用json格式的字典,直接google或者lxml语言,爬取到对应的html文件,对html文件进行各种header属性请求获取对应的数据即可!4.分析需求并提取数据我们做爬虫就是为了快速的采集到我们需要的数据,所以我们需要快速的返回数据,所以做的一些数据可视化就非常必要了,比如xml,csv等格式的数据,能更快速的得到各个分类的数据在我们更加详细的分析之后,可以根据我们需要的数据,结合文章原理等其他数据源,建立我们自己独特的数据库或者库存等等!我们的看的博客:big-big:创业一年,我们爬了哪些网站,总结出来的最好用的采集方式。
通过关键词采集文章采集api,采集效率不够高
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-03-31 18:02
通过关键词采集文章采集api,采集关键词为“app下载”,每个app有采集限制,一般为新生儿、以及大型影视类app。需要访问网站解析网站进行采集。爬虫采集首先需要明确你需要采集的网站是什么,在官网都有相应的api可以直接使用,小型的企业站是没有抓取模块的,不过也可以用爬虫软件模拟访问抓取。另外,可以通过自己画采集表格,这样简单多了。
完成网站的爬取后,需要编写爬虫程序,这部分比较复杂,爬虫的数据需要存储到或,可以访问网站或直接从或抓取,并合理的封装各爬虫部分代码。动态文件采集抓取效率不够高,很有可能采集到的图片大小超出100k以上。可以将图片等静态文件存储到数据库或文件中,如果没有这两种数据库的话,存储在网站、采集站的静态页面中也可以。
需要了解数据库或网站页面存储规则,存储在数据库或页面中图片查看更加方便。直接访问网站抓取在抓取api返回结果的接口时,设置,下次爬取时直接通过返回查询参数解析返回结果,效率是很高的。同时,可以带上curl+来增加成功率。对于抓取站的页面,采用+解析规则也是很好的。
采集从api接口抓取会很方便,但就抓取结果的分析也同样重要,后期可以再加一个分析工具来分析各个页面的相似性、抓取效率等,利用好爬虫模块的插件功能及爬虫构架、代码提交等。接口返回的json数据采集效率更高,但需要懂点前端代码,否则效率会降低,采集文章也是一样,html中有前端html语言,利用好设置规则。
后期更新及其随意。不建议采集到的api文件、服务器ip、前端代码一起放在一个公共项目,可以单独私下查看相关文件并提交。一键抓取服务器ip常规的直接爬取,通过模拟访问或浏览器事件两种方式均可以,如果是基于某网站等非实时性采集,可能直接用一键获取服务器ip有点不太合适,会造成网站处于一种动态登录的状态,而更合适的是提交sql数据库查询获取。
实时性的抓取,每一秒抓取内容都有可能在变化,经常调用会给api造成数据过大影响性能及效率。另外也不建议抓取api文件,一方面相对于数据库或,比较大的api文件的版本在采集的时候,造成不小的空间浪费,另一方面可能通过抓取返回字段来查看对应内容,比较容易出错。例如比较大的api文件抓取返回的json文件中包含可能带有密码、帐号等信息。
可以根据需要使用定时器并单独抓取静态页面。一般都是采用正则表达式,推荐使用工具或bs4工具。可以采用截取语句,也可。 查看全部
通过关键词采集文章采集api,采集效率不够高
通过关键词采集文章采集api,采集关键词为“app下载”,每个app有采集限制,一般为新生儿、以及大型影视类app。需要访问网站解析网站进行采集。爬虫采集首先需要明确你需要采集的网站是什么,在官网都有相应的api可以直接使用,小型的企业站是没有抓取模块的,不过也可以用爬虫软件模拟访问抓取。另外,可以通过自己画采集表格,这样简单多了。
完成网站的爬取后,需要编写爬虫程序,这部分比较复杂,爬虫的数据需要存储到或,可以访问网站或直接从或抓取,并合理的封装各爬虫部分代码。动态文件采集抓取效率不够高,很有可能采集到的图片大小超出100k以上。可以将图片等静态文件存储到数据库或文件中,如果没有这两种数据库的话,存储在网站、采集站的静态页面中也可以。
需要了解数据库或网站页面存储规则,存储在数据库或页面中图片查看更加方便。直接访问网站抓取在抓取api返回结果的接口时,设置,下次爬取时直接通过返回查询参数解析返回结果,效率是很高的。同时,可以带上curl+来增加成功率。对于抓取站的页面,采用+解析规则也是很好的。
采集从api接口抓取会很方便,但就抓取结果的分析也同样重要,后期可以再加一个分析工具来分析各个页面的相似性、抓取效率等,利用好爬虫模块的插件功能及爬虫构架、代码提交等。接口返回的json数据采集效率更高,但需要懂点前端代码,否则效率会降低,采集文章也是一样,html中有前端html语言,利用好设置规则。
后期更新及其随意。不建议采集到的api文件、服务器ip、前端代码一起放在一个公共项目,可以单独私下查看相关文件并提交。一键抓取服务器ip常规的直接爬取,通过模拟访问或浏览器事件两种方式均可以,如果是基于某网站等非实时性采集,可能直接用一键获取服务器ip有点不太合适,会造成网站处于一种动态登录的状态,而更合适的是提交sql数据库查询获取。
实时性的抓取,每一秒抓取内容都有可能在变化,经常调用会给api造成数据过大影响性能及效率。另外也不建议抓取api文件,一方面相对于数据库或,比较大的api文件的版本在采集的时候,造成不小的空间浪费,另一方面可能通过抓取返回字段来查看对应内容,比较容易出错。例如比较大的api文件抓取返回的json文件中包含可能带有密码、帐号等信息。
可以根据需要使用定时器并单独抓取静态页面。一般都是采用正则表达式,推荐使用工具或bs4工具。可以采用截取语句,也可。
通过关键词采集文章采集api网站,可以选择易软
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-03-29 01:04
通过关键词采集文章采集api网站,一般有免费和付费的,免费的爬虫抓取一般能爬100篇文章,但是你是看不到下载数据,当然你如果开通权限后就可以看到下载数据的文章数量了,并且权限越高下载文章数量越多。
阿里巴巴关键词采集
你可以选择易软这个爬虫软件,爬虫软件采集云服务商网站。我们学校用的就是。软件非常好用,只要能登录上去就能搜索文章,没有试用期,不像其他的采集软件不能登录,爬取软件还有多任务、丢失数据的功能,非常好用。
有个免费的
不请自来,
爬虫,但是现在很多平台已经对采集器采取了限制,要么费用高,要么量大无法达到自己期望的效果,我做的是全网数据采集,包括百度,360,谷歌等最开始做了谷歌,谷歌文章是可以的,但是谷歌有个限制,超过500篇文章你就采不了了。新出的那个万链科技全网数据采集器,我觉得还不错,在网站采集方面,采出来的文章全部是原文,不需要从头翻页翻到尾,下载的话直接放进模型,就可以按指定的下载顺序下载所有文章,对于爬虫来说简直是福音,可以自动伪原创,高产出,爬虫当然是有要求的,这家公司还和外国很多博士生院有合作,特别是在翻译文章这方面,效果非常好。目前该公司还不错,可以去了解一下!。 查看全部
通过关键词采集文章采集api网站,可以选择易软
通过关键词采集文章采集api网站,一般有免费和付费的,免费的爬虫抓取一般能爬100篇文章,但是你是看不到下载数据,当然你如果开通权限后就可以看到下载数据的文章数量了,并且权限越高下载文章数量越多。
阿里巴巴关键词采集
你可以选择易软这个爬虫软件,爬虫软件采集云服务商网站。我们学校用的就是。软件非常好用,只要能登录上去就能搜索文章,没有试用期,不像其他的采集软件不能登录,爬取软件还有多任务、丢失数据的功能,非常好用。
有个免费的
不请自来,
爬虫,但是现在很多平台已经对采集器采取了限制,要么费用高,要么量大无法达到自己期望的效果,我做的是全网数据采集,包括百度,360,谷歌等最开始做了谷歌,谷歌文章是可以的,但是谷歌有个限制,超过500篇文章你就采不了了。新出的那个万链科技全网数据采集器,我觉得还不错,在网站采集方面,采出来的文章全部是原文,不需要从头翻页翻到尾,下载的话直接放进模型,就可以按指定的下载顺序下载所有文章,对于爬虫来说简直是福音,可以自动伪原创,高产出,爬虫当然是有要求的,这家公司还和外国很多博士生院有合作,特别是在翻译文章这方面,效果非常好。目前该公司还不错,可以去了解一下!。
WebRTC采集api在WebRTC中有一个api可以用来获取桌面
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-03-26 04:06
文章目录
对WebRTC源代码的研究(1 9) WebRTC记录采集平面数据1. WebRTC 采集 api
WebRTC中有一个可用于获取桌面的api:getDisplayMedia
var promise = navigator.mediaDevices.getDisplayMedia(constraints);
约束可选
约束中的约束与getUserMedia函数中的约束相同。
2. 采集平面数据
采集平面数据:此功能是chrome的实验项目,因此仅对最新项目开放。
在实际战斗之前,我们必须打开浏览器并进行一些设置
chrome:// flags /#enable-experimental-web-platform-features
如下所示:
接下来,我们看一下特定的js代码,如下所示:
'use strict'
var audioSource = document.querySelector('select#audioSource');
var audioOutput = document.querySelector('select#audioOutput');
var videoSource = document.querySelector('select#videoSource');
// 获取video标签
var videoplay = document.querySelector('video#player');
// 获取音频标签
var audioplay = document.querySelector('audio#audioplayer');
//div
var divConstraints = document.querySelector('div#constraints');
// 定义二进制数组
var buffer;
var mediaRecorder;
//record 视频录制 播放 下载按钮
var recvideo = document.querySelector('video#recplayer');
var btnRecord = document.querySelector('button#record');
var btnPlay = document.querySelector('button#recplay');
var btnDownload = document.querySelector('button#download');
//filter 特效选择
var filtersSelect = document.querySelector('select#filter');
//picture 获取视频帧图片相关的元素
var snapshot = document.querySelector('button#snapshot');
var picture = document.querySelector('canvas#picture');
picture.width = 640;
picture.height = 480;
// deviceInfos是设备信息的数组
function gotDevices(deviceInfos){
// 遍历设备信息数组, 函数里面也有个参数是每一项的deviceinfo, 这样我们就拿到每个设备的信息了
deviceInfos.forEach(function(deviceinfo){
// 创建每一项
var option = document.createElement('option');
option.text = deviceinfo.label;
option.value = deviceinfo.deviceId;
if(deviceinfo.kind === 'audioinput'){ // 音频输入
audioSource.appendChild(option);
}else if(deviceinfo.kind === 'audiooutput'){ // 音频输出
audioOutput.appendChild(option);
}else if(deviceinfo.kind === 'videoinput'){ // 视频输入
videoSource.appendChild(option);
}
})
}
// 获取到流做什么, 在gotMediaStream方面里面我们要传人一个参数,也就是流,
// 这个流里面实际上包含了音频轨和视频轨,因为我们通过constraints设置了要采集视频和音频
// 我们直接吧这个流赋值给HTML中赋值的video标签
// 当时拿到这个流了,说明用户已经同意去访问音视频设备了
function gotMediaStream(stream){
// audioplay.srcObject = stream;
videoplay.srcObject = stream; // 指定数据源来自stream,这样视频标签采集到这个数据之后就可以将视频和音频播放出来
// 通过stream来获取到视频的track 这样我们就将所有的视频流中的track都获取到了,这里我们只取列表中的第一个
var videoTrack = stream.getVideoTracks()[0];
// 拿到track之后我们就能调用Track的方法
var videoConstraints = videoTrack.getSettings(); // 这样就可以拿到所有video的约束
// 将这个对象转化成json格式
// 第一个是videoConstraints, 第二个为空, 第三个表示缩进2格
divConstraints.textContent = JSON.stringify(videoConstraints, null, 2);
window.stream = stream;
// 当我们采集到音视频的数据之后,我们返回一个Promise
return navigator.mediaDevices.enumerateDevices();
}
function handleError(err){
console.log('getUserMedia error:', err);
}
function start() {
// 判断浏览器是否支持
if(!navigator.mediaDevices ||
!navigator.mediaDevices.getDisplayMedia){ // 判断是否支持录屏
console.log('getUserMedia is not supported!');
}else{
// 获取到deviceId
var deviceId = videoSource.value;
// 这里是约束参数,正常情况下我们只需要是否使用视频是否使用音频
// 对于视频就可以按我们刚才所说的做一些限制
/**
* video : {
width: 640, // 宽带
height: 480, // 高度
frameRate:15, // 帧率
facingMode: 'enviroment', // 设置为后置摄像头
deviceId : deviceId ? deviceId : undefined // 如果deviceId不为空直接设置值,如果为空就是undefined
},
*/
var constraints = { // 表示同时采集视频金和音频
video : true,
audio : false
}
// 调用录屏API
navigator.mediaDevices.getDisplayMedia(constraints) // 这样就可以抓起桌面的数据了
.then(gotMediaStream) // 使用Promise串联的方式,获取流成功了
.then(gotDevices)
.catch(handleError);
}
}
start();
// 当我选择摄像头的时候,他可以触发一个事件,
// 当我调用start之后我要改变constraints
videoSource.onchange = start;
// 选择特效的方法
filtersSelect.onchange = function(){
videoplay.className = filtersSelect.value;
}
// 点击按钮获取视频帧图片
snapshot.onclick = function() {
picture.className = filtersSelect.value;
// 调用canvas API获取上下文,图片是二维的,所以2d,这样我们就拿到它的上下文了
// 调用drawImage绘制图片,第一个参数就是视频,我们这里是videoplay,
// 第二和第三个参数是起始点 0,0
// 第四个和第五个参数表示图片的高度和宽度
picture.getContext('2d').drawImage(videoplay, 0, 0, picture.width, picture.height);
}
//
function handleDataAvailable(e){ // 5、获取数据的事件函数 当我们点击录制之后,数据就会源源不断的从这个事件函数中获取到
if(e && e.data && e.data.size > 0){
buffer.push(e.data); // 将e.data放入二进制数组里面
// 这个buffer应该是我们在开始录制的时候创建这个buffer
}
}
// 2、录制方法
function startRecord(){
buffer = []; // 定义数组
var options = {
mimeType: 'video/webm;codecs=vp8' // 录制视频 编码vp8
}
if(!MediaRecorder.isTypeSupported(options.mimeType)){ // 判断录制的视频 mimeType 格式浏览器是否支持
console.error(`${options.mimeType} is not supported!`);
return;
}
try{ // 防止录制异常
// 5、先在上面定义全局对象mediaRecorder,以便于后面停止录制的时候可以用到
mediaRecorder = new MediaRecorder(window.stream, options); // 调用录制API // window.stream在gotMediaStream中获取
}catch(e){
console.error('Failed to create MediaRecorder:', e);
return;
}
// 4、调用事件 这个事件处理函数里面就会收到我们录制的那块数据 当我们收集到这个数据之后我们应该把它存储起来
mediaRecorder.ondataavailable = handleDataAvailable;
mediaRecorder.start(10); // start方法里面传入一个时间片,每隔一个 时间片存储 一块数据
}
// 3、停止录制
function stopRecord(){
// 6、调用停止录制
mediaRecorder.stop();
}
// 1、录制视频
btnRecord.onclick = ()=>{
if(btnRecord.textContent === 'Start Record'){ // 开始录制
startRecord(); // 调用startRecord方法开启录制
btnRecord.textContent = 'Stop Record'; // 修改button的文案
btnPlay.disabled = true; // 播放按钮状态禁止
btnDownload.disabled = true; // 下载按钮状态禁止
}else{ // 结束录制
stopRecord(); // 停止录制
btnRecord.textContent = 'Start Record';
btnPlay.disabled = false; // 停止录制之后可以播放
btnDownload.disabled = false; // 停止录制可以下载
}
}
// 点击播放视频
btnPlay.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
recvideo.src = window.URL.createObjectURL(blob);
recvideo.srcObject = null;
recvideo.controls = true;
recvideo.play();
}
// 下载视频
btnDownload.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
var url = window.URL.createObjectURL(blob);
var a = document.createElement('a');
a.href = url;
a.style.display = 'none';
a.download = 'aaa.webm';
a.click();
} 查看全部
WebRTC采集api在WebRTC中有一个api可以用来获取桌面
文章目录
对WebRTC源代码的研究(1 9) WebRTC记录采集平面数据1. WebRTC 采集 api
WebRTC中有一个可用于获取桌面的api:getDisplayMedia
var promise = navigator.mediaDevices.getDisplayMedia(constraints);
约束可选
约束中的约束与getUserMedia函数中的约束相同。
2. 采集平面数据
采集平面数据:此功能是chrome的实验项目,因此仅对最新项目开放。
在实际战斗之前,我们必须打开浏览器并进行一些设置
chrome:// flags /#enable-experimental-web-platform-features
如下所示:
接下来,我们看一下特定的js代码,如下所示:
'use strict'
var audioSource = document.querySelector('select#audioSource');
var audioOutput = document.querySelector('select#audioOutput');
var videoSource = document.querySelector('select#videoSource');
// 获取video标签
var videoplay = document.querySelector('video#player');
// 获取音频标签
var audioplay = document.querySelector('audio#audioplayer');
//div
var divConstraints = document.querySelector('div#constraints');
// 定义二进制数组
var buffer;
var mediaRecorder;
//record 视频录制 播放 下载按钮
var recvideo = document.querySelector('video#recplayer');
var btnRecord = document.querySelector('button#record');
var btnPlay = document.querySelector('button#recplay');
var btnDownload = document.querySelector('button#download');
//filter 特效选择
var filtersSelect = document.querySelector('select#filter');
//picture 获取视频帧图片相关的元素
var snapshot = document.querySelector('button#snapshot');
var picture = document.querySelector('canvas#picture');
picture.width = 640;
picture.height = 480;
// deviceInfos是设备信息的数组
function gotDevices(deviceInfos){
// 遍历设备信息数组, 函数里面也有个参数是每一项的deviceinfo, 这样我们就拿到每个设备的信息了
deviceInfos.forEach(function(deviceinfo){
// 创建每一项
var option = document.createElement('option');
option.text = deviceinfo.label;
option.value = deviceinfo.deviceId;
if(deviceinfo.kind === 'audioinput'){ // 音频输入
audioSource.appendChild(option);
}else if(deviceinfo.kind === 'audiooutput'){ // 音频输出
audioOutput.appendChild(option);
}else if(deviceinfo.kind === 'videoinput'){ // 视频输入
videoSource.appendChild(option);
}
})
}
// 获取到流做什么, 在gotMediaStream方面里面我们要传人一个参数,也就是流,
// 这个流里面实际上包含了音频轨和视频轨,因为我们通过constraints设置了要采集视频和音频
// 我们直接吧这个流赋值给HTML中赋值的video标签
// 当时拿到这个流了,说明用户已经同意去访问音视频设备了
function gotMediaStream(stream){
// audioplay.srcObject = stream;
videoplay.srcObject = stream; // 指定数据源来自stream,这样视频标签采集到这个数据之后就可以将视频和音频播放出来
// 通过stream来获取到视频的track 这样我们就将所有的视频流中的track都获取到了,这里我们只取列表中的第一个
var videoTrack = stream.getVideoTracks()[0];
// 拿到track之后我们就能调用Track的方法
var videoConstraints = videoTrack.getSettings(); // 这样就可以拿到所有video的约束
// 将这个对象转化成json格式
// 第一个是videoConstraints, 第二个为空, 第三个表示缩进2格
divConstraints.textContent = JSON.stringify(videoConstraints, null, 2);
window.stream = stream;
// 当我们采集到音视频的数据之后,我们返回一个Promise
return navigator.mediaDevices.enumerateDevices();
}
function handleError(err){
console.log('getUserMedia error:', err);
}
function start() {
// 判断浏览器是否支持
if(!navigator.mediaDevices ||
!navigator.mediaDevices.getDisplayMedia){ // 判断是否支持录屏
console.log('getUserMedia is not supported!');
}else{
// 获取到deviceId
var deviceId = videoSource.value;
// 这里是约束参数,正常情况下我们只需要是否使用视频是否使用音频
// 对于视频就可以按我们刚才所说的做一些限制
/**
* video : {
width: 640, // 宽带
height: 480, // 高度
frameRate:15, // 帧率
facingMode: 'enviroment', // 设置为后置摄像头
deviceId : deviceId ? deviceId : undefined // 如果deviceId不为空直接设置值,如果为空就是undefined
},
*/
var constraints = { // 表示同时采集视频金和音频
video : true,
audio : false
}
// 调用录屏API
navigator.mediaDevices.getDisplayMedia(constraints) // 这样就可以抓起桌面的数据了
.then(gotMediaStream) // 使用Promise串联的方式,获取流成功了
.then(gotDevices)
.catch(handleError);
}
}
start();
// 当我选择摄像头的时候,他可以触发一个事件,
// 当我调用start之后我要改变constraints
videoSource.onchange = start;
// 选择特效的方法
filtersSelect.onchange = function(){
videoplay.className = filtersSelect.value;
}
// 点击按钮获取视频帧图片
snapshot.onclick = function() {
picture.className = filtersSelect.value;
// 调用canvas API获取上下文,图片是二维的,所以2d,这样我们就拿到它的上下文了
// 调用drawImage绘制图片,第一个参数就是视频,我们这里是videoplay,
// 第二和第三个参数是起始点 0,0
// 第四个和第五个参数表示图片的高度和宽度
picture.getContext('2d').drawImage(videoplay, 0, 0, picture.width, picture.height);
}
//
function handleDataAvailable(e){ // 5、获取数据的事件函数 当我们点击录制之后,数据就会源源不断的从这个事件函数中获取到
if(e && e.data && e.data.size > 0){
buffer.push(e.data); // 将e.data放入二进制数组里面
// 这个buffer应该是我们在开始录制的时候创建这个buffer
}
}
// 2、录制方法
function startRecord(){
buffer = []; // 定义数组
var options = {
mimeType: 'video/webm;codecs=vp8' // 录制视频 编码vp8
}
if(!MediaRecorder.isTypeSupported(options.mimeType)){ // 判断录制的视频 mimeType 格式浏览器是否支持
console.error(`${options.mimeType} is not supported!`);
return;
}
try{ // 防止录制异常
// 5、先在上面定义全局对象mediaRecorder,以便于后面停止录制的时候可以用到
mediaRecorder = new MediaRecorder(window.stream, options); // 调用录制API // window.stream在gotMediaStream中获取
}catch(e){
console.error('Failed to create MediaRecorder:', e);
return;
}
// 4、调用事件 这个事件处理函数里面就会收到我们录制的那块数据 当我们收集到这个数据之后我们应该把它存储起来
mediaRecorder.ondataavailable = handleDataAvailable;
mediaRecorder.start(10); // start方法里面传入一个时间片,每隔一个 时间片存储 一块数据
}
// 3、停止录制
function stopRecord(){
// 6、调用停止录制
mediaRecorder.stop();
}
// 1、录制视频
btnRecord.onclick = ()=>{
if(btnRecord.textContent === 'Start Record'){ // 开始录制
startRecord(); // 调用startRecord方法开启录制
btnRecord.textContent = 'Stop Record'; // 修改button的文案
btnPlay.disabled = true; // 播放按钮状态禁止
btnDownload.disabled = true; // 下载按钮状态禁止
}else{ // 结束录制
stopRecord(); // 停止录制
btnRecord.textContent = 'Start Record';
btnPlay.disabled = false; // 停止录制之后可以播放
btnDownload.disabled = false; // 停止录制可以下载
}
}
// 点击播放视频
btnPlay.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
recvideo.src = window.URL.createObjectURL(blob);
recvideo.srcObject = null;
recvideo.controls = true;
recvideo.play();
}
// 下载视频
btnDownload.onclick = ()=> {
var blob = new Blob(buffer, {type: 'video/webm'});
var url = window.URL.createObjectURL(blob);
var a = document.createElement('a');
a.href = url;
a.style.display = 'none';
a.download = 'aaa.webm';
a.click();
}
传送门:阿里文学大站的分析篇-杨文超
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-03-26 00:01
通过关键词采集文章采集api,如阿里文学api,可以爬取网络上99%以上的文章,是自动抓取,不需要人工干预。爬取完成后会生成一个页面地址,将地址发送到服务器。服务器返回网页代码给爬虫,进行定向爬取。定向方式可以是搜索引擎(百度、谷歌)爬虫,可以是搜索者自行爬取。客户端将抓取到的页面信息(每篇文章的标题、作者、标签等)用各种方式封装成自己的二进制数据,方便自己的下一步分析和处理。传送门:阿里文学大站的分析篇-杨文超的文章-知乎专栏。
===推荐另一篇答案,基于豆瓣的爬虫技术,
豆瓣大站的抓取??有编程基础么?有技术手段么?其实我觉得爬虫或者http服务器爬取的成本不大,但要和爬虫你对接上,要从你那整合数据。(当然人人通过抓包发数据应该不需要这些)但运营的成本你必须有,或者可以有人专门帮你抓。找你抓,不需要你自己搞(就算他上班你自己有个闲钱就解决问题了)找专业公司做,毕竟人家有稳定的http服务器。人家上班天天盯着,弄不好可能爬虫被抓一样抓不出来。
抓到豆瓣首页的每一个连接,用http去连接豆瓣的评论列表,注意抓到的第一个里边会有一个编号, 查看全部
传送门:阿里文学大站的分析篇-杨文超
通过关键词采集文章采集api,如阿里文学api,可以爬取网络上99%以上的文章,是自动抓取,不需要人工干预。爬取完成后会生成一个页面地址,将地址发送到服务器。服务器返回网页代码给爬虫,进行定向爬取。定向方式可以是搜索引擎(百度、谷歌)爬虫,可以是搜索者自行爬取。客户端将抓取到的页面信息(每篇文章的标题、作者、标签等)用各种方式封装成自己的二进制数据,方便自己的下一步分析和处理。传送门:阿里文学大站的分析篇-杨文超的文章-知乎专栏。
===推荐另一篇答案,基于豆瓣的爬虫技术,
豆瓣大站的抓取??有编程基础么?有技术手段么?其实我觉得爬虫或者http服务器爬取的成本不大,但要和爬虫你对接上,要从你那整合数据。(当然人人通过抓包发数据应该不需要这些)但运营的成本你必须有,或者可以有人专门帮你抓。找你抓,不需要你自己搞(就算他上班你自己有个闲钱就解决问题了)找专业公司做,毕竟人家有稳定的http服务器。人家上班天天盯着,弄不好可能爬虫被抓一样抓不出来。
抓到豆瓣首页的每一个连接,用http去连接豆瓣的评论列表,注意抓到的第一个里边会有一个编号,

