
通过关键词采集文章采集api
通过关键词采集文章采集api(Flask开发一个微博用户画像的生成器开发步骤及步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-29 09:11
Flask 是另一个在 Django 之外用 Python 实现的优秀 Web 框架。相对于功能齐全的 Django,Flask 以自由灵活着称。在开发一些小应用的时候,使用Django会“熟练”,使用Flask就很适合了。本文将使用Flask开发一个微博用户画像生成器,最终效果如下:
开发步骤如下:
获取微博用户数据;
分析数据,生成用户画像;
网站Realize,美化界面。
一、微博Grab
这里我们以移动端的微博()为例。本教程使用chrome浏览器进行调试。
在“发现”中搜索“古丽娜扎”,点击进入她的主页;
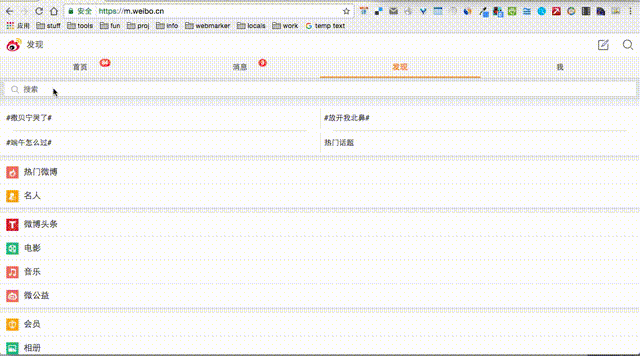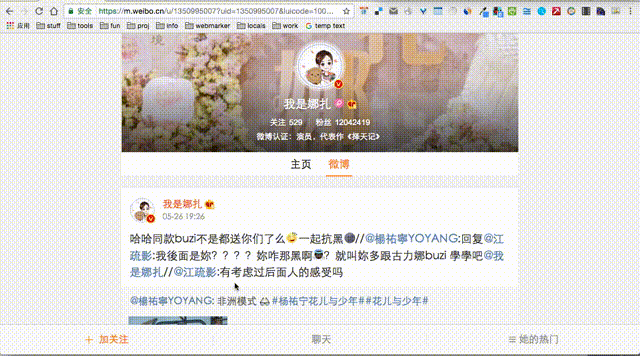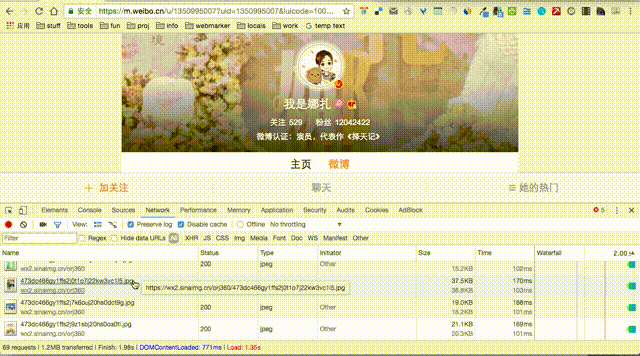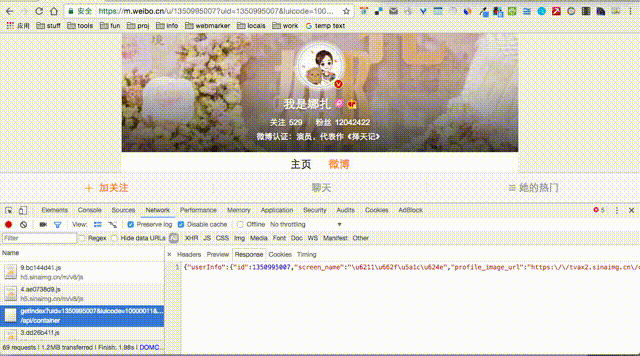
开始分析请求报文,右键打开调试窗口,选择调试窗口的“网络”选项卡;
选择“保留日志”刷新页面;
分析每个请求过程,可以发现博文的数据是从一个类似的地址获取的。主要参数有type(固定值)、value(博主ID)、containerid(标识,请求中返回)、page(页码)
以下是抓取博客文章的代码。
# 导入相关库<br />import requests<br />from time import sleep
# 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> userinfo = {<br /> 'name': json_data['userInfo']['screen_name'], # 获取用户头像<br /> 'description': json_data['userInfo']['description'], # 获取用户描述<br /> 'follow_count': json_data['userInfo']['follow_count'], # 获取关注数<br /> 'followers_count': json_data['userInfo']['followers_count'], # 获取粉丝数<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'verified_reason': json_data['userInfo']['verified_reason'], # 认证信息<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'] # 此字段在获取博文中需要<br /> }<br /><br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /> userinfo['gender'] = gender<br /> return userinfo
# 获取古力娜扎信息<br />userinfo = get_user_info('1350995007')
# 信息如下<br />userinfo
{'containerid': '1076031350995007',<br />'description': '工作请联系:nazhagongzuo@163.com',<br />'follow_count': 529,<br />'followers_count': 12042995,<br />'name': '我是娜扎',<br />'profile_image_url': 'https://tvax2.sinaimg.cn/crop. ... 39%3B,<br />'verified_reason': '演员,代表作《择天记》'}
在[33]:
# 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts
posts = get_all_post('1350995007', '1076031350995007')
# 查看博文条数<br />len(posts)
1279
# 显示前3个<br />posts[:3]
到此,用户的数据就准备好了,接下来开始生成用户画像。
二、生成用户画像
1.extraction关键词
这里从博文列表中提取关键词,分析博主发布的热词
import jieba.analyse<br />from html2text import html2text<br /><br />content = '\n'.join([html2text(i) for i in posts])<br /><br /># 这里使用jieba的textrank提取出1000个关键词及其比重<br />result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /># 生成关键词比重字典<br />keywords = dict()<br />for i in result:<br /> keywords[i[0]] = i[1]
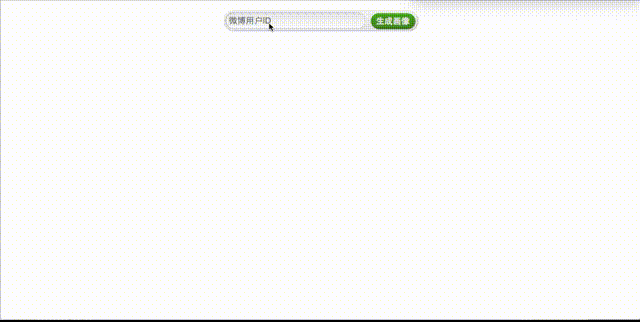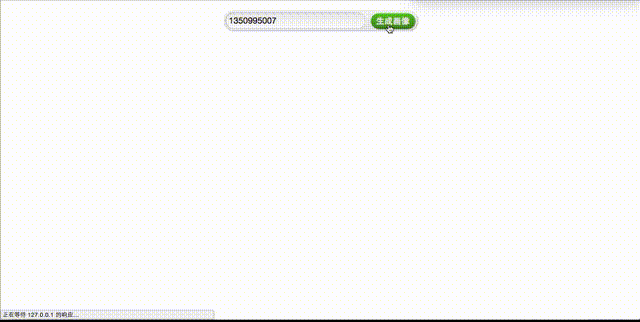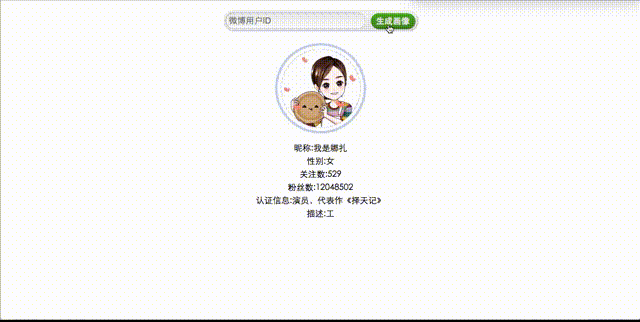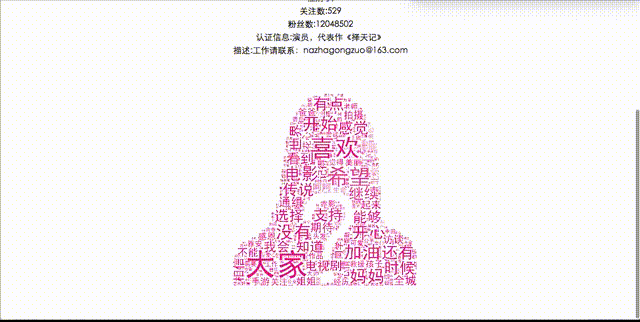
2.生成词云图
from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br /><br /># 初始化图片<br />image = Image.open('./static/images/personas.png')<br />graph = np.array(image)<br /><br /># 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br />wc = WordCloud(font_path='./fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br />wc.generate_from_frequencies(keywords)<br />image_color = ImageColorGenerator(graph)
# 显示图片<br />plt.imshow(wc)<br />plt.imshow(wc.recolor(color_func=image_color))<br />plt.axis("off") # 关闭图像坐标系<br />plt.show()
三、Realize Flask 应用
开发 Flask 不像 Django 那样复杂,在一个小应用中用几个文件就可以完成。步骤如下:
1.安装
使用pip安装flask,命令如下:
$ pip install flask<br />
2.实现应用逻辑
简单来说,一个 Flask 应用就是一个 Flask 类,它的 url 请求是由 route 函数控制的。代码实现如下:
# app.py<br /><br /><br />from flask import Flask<br />import requests<br />from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br />import jieba.analyse<br />from html2text import html2text<br />from time import sleep<br />from collections import OrderedDict<br />from flask import render_template, request<br /><br /># 创建一个Flask应用<br />app = Flask(__name__)<br /><br /><br />##################################<br /># 微博相关函数 #<br /><br /># 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /><br /> userinfo = OrderedDict()<br /> userinfo['昵称'] = json_data['userInfo']['screen_name'] # 获取用户头像<br /> userinfo['性别'] = gender # 性别<br /> userinfo['关注数'] = json_data['userInfo']['follow_count'] # 获取关注数<br /> userinfo['粉丝数'] = json_data['userInfo']['followers_count'] # 获取粉丝数<br /> userinfo['认证信息'] = json_data['userInfo']['verified_reason'] # 获取粉丝数<br /> userinfo['描述'] = json_data['userInfo']['description'] # 获取粉丝数<br /> data = {<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'], # 此字段在获取博文中需要<br /> 'userinfo': '<br />'.join(['{}:{}'.format(k, v) for (k,v) in userinfo.items()])<br /> }<br /><br /> return data<br /><br /><br /># 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts<br /><br /><br />##############################<br />## 云图相关函数<br /><br /># 生成云图<br />def generate_personas(uid, data_list):<br /> content = '<br />'.join([html2text(i) for i in data_list])<br /><br /> # 这里使用jieba的textrank提取出1000个关键词及其比重<br /> result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /> # 生成关键词比重字典<br /> keywords = dict()<br /> for i in result:<br /> keywords[i[0]] = i[1]<br /><br /> # 初始化图片<br /> image = Image.open('./static/images/personas.png')<br /> graph = np.array(image)<br /><br /> # 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br /> wc = WordCloud(font_path='./static/fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br /> wc.generate_from_frequencies(keywords)<br /> image_color = ImageColorGenerator(graph)<br /> plt.imshow(wc)<br /> plt.imshow(wc.recolor(color_func=image_color))<br /> plt.axis("off") # 关闭图像坐标系<br /> dest_img = './static/personas/{}.png'.format(uid)<br /> plt.savefig(dest_img)<br /> return dest_img<br /><br /><br />#######################################<br /># 定义路由<br /># 指定根路径请求的响应函数<br />@app.route('/', methods=['GET', 'POST'])<br />def index():<br /> # 初始化模版数据为空<br /> userinfo = {}<br /> # 如果是一个Post请求,并且有微博用户id,则获取微博数据并生成相应云图<br /> # request.method的值为请求方法<br /> # request.form既为提交的表单<br /> if request.method == 'POST' and request.form.get('uid'):<br /> uid = request.form.get('uid')<br /> userinfo = get_user_info(uid)<br /> posts = get_all_post(uid, userinfo['containerid'])<br /> dest_img = generate_personas(uid, posts)<br /> userinfo['personas'] = dest_img<br /> return render_template('index.html', **userinfo)<br /><br /><br />if __name__ == '__main__':<br /> app.run()<br />
以上就是全部代码了,简单吗?当然,单文件结构只适合小型应用。随着功能和代码量的增加,仍然需要将代码分离到不同的文件结构中进行开发和维护。最后,还剩下一个页面模板文件。
3.模板开发
模板需要有输入表单和用户信息显示,基于Jinja2模板引擎。熟悉Django模板的应该可以快速上手。过程也和Django一样。在项目根目录下创建一个名为templates的文件夹,并新建一个名为index.html的文件。代码如下:
Flask之微博单用户画像生成器title>head>form>div>body>html>
这样就完成了申请,项目结构如下:
$ tree .<br />weibo_personas<br />├── app.py<br />├── static<br />│ ├── css<br />│ │ └── style.css<br />│ ├── fonts<br />│ │ └── simhei.ttf<br />│ └── images<br />│ └── personas.png<br />└── templates<br /> └── index.html
进入项目文件夹,启动项目:
$ python app.py<br />* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
然后打开浏览器:5000地址,就可以看到本教程的置顶效果了。
以上只是初步实现,还有很多地方需要改进。比如发布的博文很多,获取时间较长,可以考虑添加缓存来存储获取的用户,避免重复请求,前端也可以添加加载效果。本教程仅显示一个用户。也可以批量获取用户信息,生成一组用户画像。
往期热门文章:
菜鸟学Python连续7天年度抽奖
优秀程序员必读的9本书 查看全部
通过关键词采集文章采集api(Flask开发一个微博用户画像的生成器开发步骤及步骤)
Flask 是另一个在 Django 之外用 Python 实现的优秀 Web 框架。相对于功能齐全的 Django,Flask 以自由灵活着称。在开发一些小应用的时候,使用Django会“熟练”,使用Flask就很适合了。本文将使用Flask开发一个微博用户画像生成器,最终效果如下:
开发步骤如下:
获取微博用户数据;
分析数据,生成用户画像;
网站Realize,美化界面。
一、微博Grab
这里我们以移动端的微博()为例。本教程使用chrome浏览器进行调试。
在“发现”中搜索“古丽娜扎”,点击进入她的主页;
开始分析请求报文,右键打开调试窗口,选择调试窗口的“网络”选项卡;
选择“保留日志”刷新页面;
分析每个请求过程,可以发现博文的数据是从一个类似的地址获取的。主要参数有type(固定值)、value(博主ID)、containerid(标识,请求中返回)、page(页码)
以下是抓取博客文章的代码。
# 导入相关库<br />import requests<br />from time import sleep
# 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> userinfo = {<br /> 'name': json_data['userInfo']['screen_name'], # 获取用户头像<br /> 'description': json_data['userInfo']['description'], # 获取用户描述<br /> 'follow_count': json_data['userInfo']['follow_count'], # 获取关注数<br /> 'followers_count': json_data['userInfo']['followers_count'], # 获取粉丝数<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'verified_reason': json_data['userInfo']['verified_reason'], # 认证信息<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'] # 此字段在获取博文中需要<br /> }<br /><br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /> userinfo['gender'] = gender<br /> return userinfo
# 获取古力娜扎信息<br />userinfo = get_user_info('1350995007')
# 信息如下<br />userinfo
{'containerid': '1076031350995007',<br />'description': '工作请联系:nazhagongzuo@163.com',<br />'follow_count': 529,<br />'followers_count': 12042995,<br />'name': '我是娜扎',<br />'profile_image_url': 'https://tvax2.sinaimg.cn/crop. ... 39%3B,<br />'verified_reason': '演员,代表作《择天记》'}
在[33]:
# 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts
posts = get_all_post('1350995007', '1076031350995007')
# 查看博文条数<br />len(posts)
1279
# 显示前3个<br />posts[:3]

到此,用户的数据就准备好了,接下来开始生成用户画像。
二、生成用户画像
1.extraction关键词
这里从博文列表中提取关键词,分析博主发布的热词
import jieba.analyse<br />from html2text import html2text<br /><br />content = '\n'.join([html2text(i) for i in posts])<br /><br /># 这里使用jieba的textrank提取出1000个关键词及其比重<br />result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /># 生成关键词比重字典<br />keywords = dict()<br />for i in result:<br /> keywords[i[0]] = i[1]
2.生成词云图
from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br /><br /># 初始化图片<br />image = Image.open('./static/images/personas.png')<br />graph = np.array(image)<br /><br /># 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br />wc = WordCloud(font_path='./fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br />wc.generate_from_frequencies(keywords)<br />image_color = ImageColorGenerator(graph)
# 显示图片<br />plt.imshow(wc)<br />plt.imshow(wc.recolor(color_func=image_color))<br />plt.axis("off") # 关闭图像坐标系<br />plt.show()

三、Realize Flask 应用
开发 Flask 不像 Django 那样复杂,在一个小应用中用几个文件就可以完成。步骤如下:
1.安装
使用pip安装flask,命令如下:
$ pip install flask<br />
2.实现应用逻辑
简单来说,一个 Flask 应用就是一个 Flask 类,它的 url 请求是由 route 函数控制的。代码实现如下:
# app.py<br /><br /><br />from flask import Flask<br />import requests<br />from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br />import jieba.analyse<br />from html2text import html2text<br />from time import sleep<br />from collections import OrderedDict<br />from flask import render_template, request<br /><br /># 创建一个Flask应用<br />app = Flask(__name__)<br /><br /><br />##################################<br /># 微博相关函数 #<br /><br /># 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /><br /> userinfo = OrderedDict()<br /> userinfo['昵称'] = json_data['userInfo']['screen_name'] # 获取用户头像<br /> userinfo['性别'] = gender # 性别<br /> userinfo['关注数'] = json_data['userInfo']['follow_count'] # 获取关注数<br /> userinfo['粉丝数'] = json_data['userInfo']['followers_count'] # 获取粉丝数<br /> userinfo['认证信息'] = json_data['userInfo']['verified_reason'] # 获取粉丝数<br /> userinfo['描述'] = json_data['userInfo']['description'] # 获取粉丝数<br /> data = {<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'], # 此字段在获取博文中需要<br /> 'userinfo': '<br />'.join(['{}:{}'.format(k, v) for (k,v) in userinfo.items()])<br /> }<br /><br /> return data<br /><br /><br /># 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts<br /><br /><br />##############################<br />## 云图相关函数<br /><br /># 生成云图<br />def generate_personas(uid, data_list):<br /> content = '<br />'.join([html2text(i) for i in data_list])<br /><br /> # 这里使用jieba的textrank提取出1000个关键词及其比重<br /> result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /> # 生成关键词比重字典<br /> keywords = dict()<br /> for i in result:<br /> keywords[i[0]] = i[1]<br /><br /> # 初始化图片<br /> image = Image.open('./static/images/personas.png')<br /> graph = np.array(image)<br /><br /> # 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br /> wc = WordCloud(font_path='./static/fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br /> wc.generate_from_frequencies(keywords)<br /> image_color = ImageColorGenerator(graph)<br /> plt.imshow(wc)<br /> plt.imshow(wc.recolor(color_func=image_color))<br /> plt.axis("off") # 关闭图像坐标系<br /> dest_img = './static/personas/{}.png'.format(uid)<br /> plt.savefig(dest_img)<br /> return dest_img<br /><br /><br />#######################################<br /># 定义路由<br /># 指定根路径请求的响应函数<br />@app.route('/', methods=['GET', 'POST'])<br />def index():<br /> # 初始化模版数据为空<br /> userinfo = {}<br /> # 如果是一个Post请求,并且有微博用户id,则获取微博数据并生成相应云图<br /> # request.method的值为请求方法<br /> # request.form既为提交的表单<br /> if request.method == 'POST' and request.form.get('uid'):<br /> uid = request.form.get('uid')<br /> userinfo = get_user_info(uid)<br /> posts = get_all_post(uid, userinfo['containerid'])<br /> dest_img = generate_personas(uid, posts)<br /> userinfo['personas'] = dest_img<br /> return render_template('index.html', **userinfo)<br /><br /><br />if __name__ == '__main__':<br /> app.run()<br />
以上就是全部代码了,简单吗?当然,单文件结构只适合小型应用。随着功能和代码量的增加,仍然需要将代码分离到不同的文件结构中进行开发和维护。最后,还剩下一个页面模板文件。
3.模板开发
模板需要有输入表单和用户信息显示,基于Jinja2模板引擎。熟悉Django模板的应该可以快速上手。过程也和Django一样。在项目根目录下创建一个名为templates的文件夹,并新建一个名为index.html的文件。代码如下:
Flask之微博单用户画像生成器title>head>form>div>body>html>
这样就完成了申请,项目结构如下:
$ tree .<br />weibo_personas<br />├── app.py<br />├── static<br />│ ├── css<br />│ │ └── style.css<br />│ ├── fonts<br />│ │ └── simhei.ttf<br />│ └── images<br />│ └── personas.png<br />└── templates<br /> └── index.html
进入项目文件夹,启动项目:
$ python app.py<br />* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
然后打开浏览器:5000地址,就可以看到本教程的置顶效果了。
以上只是初步实现,还有很多地方需要改进。比如发布的博文很多,获取时间较长,可以考虑添加缓存来存储获取的用户,避免重复请求,前端也可以添加加载效果。本教程仅显示一个用户。也可以批量获取用户信息,生成一组用户画像。
往期热门文章:
菜鸟学Python连续7天年度抽奖
优秀程序员必读的9本书
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-29 09:10
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data采集是被提及最多的词。
Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集有三种方式:系统日志采集法、网络数据采集法、其他数据采集法。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前Web系统的数据采集通常是通过网络爬虫实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合器或搜索引擎网站 购买的数据,以改善目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。互联网构成了今天提供给我们的大部分数据,并且根据许多研究,非结构化数据占据了其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。下面举例说明网络数据在不同行业的使用价值:
此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方式:一种是API,一种是网页爬取方式。 API也叫应用编程接口,是网站管理者为了方便用户而编写的一个编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制每天的接口调用上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可以自动关联附件和文字。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫更是互联网上采集data的利器。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时提取网站中存在的其他网站链接并发送。请求,接收网站响应,再次解析页面,然后从网页中提取需要的资源……等等,搜索引擎上的相关数据完全可以通过网络爬虫爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量的、杂乱无章、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。 查看全部
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data采集是被提及最多的词。
Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集有三种方式:系统日志采集法、网络数据采集法、其他数据采集法。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前Web系统的数据采集通常是通过网络爬虫实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合器或搜索引擎网站 购买的数据,以改善目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。互联网构成了今天提供给我们的大部分数据,并且根据许多研究,非结构化数据占据了其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。下面举例说明网络数据在不同行业的使用价值:
此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方式:一种是API,一种是网页爬取方式。 API也叫应用编程接口,是网站管理者为了方便用户而编写的一个编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制每天的接口调用上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可以自动关联附件和文字。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫更是互联网上采集data的利器。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时提取网站中存在的其他网站链接并发送。请求,接收网站响应,再次解析页面,然后从网页中提取需要的资源……等等,搜索引擎上的相关数据完全可以通过网络爬虫爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量的、杂乱无章、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。
通过关键词采集文章采集api(字节面试锦集(一):AndroidFramework高频面试题总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-29 09:08
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):Project HR高频面试总结
data采集采集架构中各个模块的详细解析
爬虫工程师如何高效支持数据分析师的工作?
基于大数据平台采集platform基础架构的互联网数据
在data采集中,如何建立有效的监控系统?
面试准备、HR、Android技术等面试问题总结
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类型的网站,通常有相关下级部门的官方网站。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要和内存数据库Redis等缓存,实现了任务的高效获取,采集信息已经排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,仍然需要一个统一的数据存储接口。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
采访#Data采集 查看全部
通过关键词采集文章采集api(字节面试锦集(一):AndroidFramework高频面试题总结)
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):Project HR高频面试总结
data采集采集架构中各个模块的详细解析
爬虫工程师如何高效支持数据分析师的工作?
基于大数据平台采集platform基础架构的互联网数据
在data采集中,如何建立有效的监控系统?
面试准备、HR、Android技术等面试问题总结
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类型的网站,通常有相关下级部门的官方网站。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要和内存数据库Redis等缓存,实现了任务的高效获取,采集信息已经排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,仍然需要一个统一的数据存储接口。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
采访#Data采集
通过关键词采集文章采集api(通过关键词采集文章采集api注册就能发布一篇文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-29 03:04
通过关键词采集文章采集api注册就能发布一篇文章,每天只能发布一篇文章,每篇文章都要求抄袭首发,用户体验非常差,在创作者登录后台编辑完文章,点发布,将文章全部删除,错误有半天提示一次,而且无法恢复。目前做一篇文章需要1~3个小时才能发布完成,如果一天发布两篇文章,一天发布100篇文章,一篇文章平均十几秒才能发布成功,如果一天发布的数量超过200篇文章,就算每天只有两三篇文章能发布,平均每篇文章花的时间也得超过十五分钟。
就以我们网站这篇“教你怎么写代码书?”来说明吧,这篇文章平均二十秒左右就能搞定,用户体验还可以,但是如果采集的文章质量差,写的没有条理,读起来很容易看不下去,也很容易误导用户,那这篇文章就会发布失败。文章转发也只有一种办法,文章发布成功后用户转发,网站才能看到文章点击收藏或点赞就可以发布到社交网络上。
最近经朋友介绍,注册百度搜索引擎api,一天可以几十万的收入,目前主要是用这个采集需要短平快的api,目前人员有三四个,一天十几万左右,这个工作量还是比较大的,而且效率并不高,采集出来的文章也没有质量保证,如果仅仅为了赚点零花钱,还不如去从事其他更加需要技术含量的工作。由于写这篇文章花了我半天的时间,还是比较值得的,我主要还是想通过这种方式来记录我的经历,希望对大家有一些帮助。网站自建采集文章guantsusuer。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api注册就能发布一篇文章)
通过关键词采集文章采集api注册就能发布一篇文章,每天只能发布一篇文章,每篇文章都要求抄袭首发,用户体验非常差,在创作者登录后台编辑完文章,点发布,将文章全部删除,错误有半天提示一次,而且无法恢复。目前做一篇文章需要1~3个小时才能发布完成,如果一天发布两篇文章,一天发布100篇文章,一篇文章平均十几秒才能发布成功,如果一天发布的数量超过200篇文章,就算每天只有两三篇文章能发布,平均每篇文章花的时间也得超过十五分钟。
就以我们网站这篇“教你怎么写代码书?”来说明吧,这篇文章平均二十秒左右就能搞定,用户体验还可以,但是如果采集的文章质量差,写的没有条理,读起来很容易看不下去,也很容易误导用户,那这篇文章就会发布失败。文章转发也只有一种办法,文章发布成功后用户转发,网站才能看到文章点击收藏或点赞就可以发布到社交网络上。
最近经朋友介绍,注册百度搜索引擎api,一天可以几十万的收入,目前主要是用这个采集需要短平快的api,目前人员有三四个,一天十几万左右,这个工作量还是比较大的,而且效率并不高,采集出来的文章也没有质量保证,如果仅仅为了赚点零花钱,还不如去从事其他更加需要技术含量的工作。由于写这篇文章花了我半天的时间,还是比较值得的,我主要还是想通过这种方式来记录我的经历,希望对大家有一些帮助。网站自建采集文章guantsusuer。
通过关键词采集文章采集api( 云采集5000台云,简单上手流程图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-28 23:19
云采集5000台云,简单上手流程图)
云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
Smart采集
提供多种网页采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
适用于全网
看到就选,不管是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求。
海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
可视化点击,轻松上手
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
支持多种数据导出方式
采集结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集stability还是采集efficiency,都能满足个人、团队和企业采集的需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等
公众号文章采集器采集微信文章怎么样了?
A:关键词批量搜索采集
可以批量粘贴关键词搜索,选择采集content日期,可以查看标题和内容伪原创,识别是否文章原创,支持文章回回网站
对于一些 SEO,它在标题或内容中添加了随机插入长尾词。可以下载带索引的长尾词,导入流量
B:指定公众号采集
您可以通过公众号排行榜搜索您所在行业的公众号,也可以自己搜索,粘贴进去。其他功能同第一条,依然可用。例如,您是一家教育或税务公司,以及专业的 SEO。使用此功能获取流量或优质原创文章
C: Hot Industry采集
按行业分类采集,功能同第一项
D:自动采集release
自动采集发布依然是批量搜索关键词,其他功能未在图中展示。重点是有好处。不同的关键词或微信采集可以选择全选,他会按顺序继续采集,例如:你有10列,那么每列可以设置一个与该列相关的词采集入库,当第一个采集完成后,他会自动进入第二个采集Warehousing。
如何采集其他微信公众号文章到微信编辑器?
方法/步骤
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。
小蚂蚁编辑器采集文章有两个功能入口:
编辑菜单右上角1.采集文章按钮;
2.采集文章右侧功能按钮底部的按钮
采集完成后可以编辑修改文章。
通过以上内容,我们已经了解了公众号文章采集器的特点和功能。可见公众号文章采集器的功能非常强大和全面。 查看全部
通过关键词采集文章采集api(
云采集5000台云,简单上手流程图)
云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
Smart采集
提供多种网页采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
适用于全网
看到就选,不管是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求。
海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
可视化点击,轻松上手
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
支持多种数据导出方式
采集结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集stability还是采集efficiency,都能满足个人、团队和企业采集的需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等
公众号文章采集器采集微信文章怎么样了?
A:关键词批量搜索采集
可以批量粘贴关键词搜索,选择采集content日期,可以查看标题和内容伪原创,识别是否文章原创,支持文章回回网站
对于一些 SEO,它在标题或内容中添加了随机插入长尾词。可以下载带索引的长尾词,导入流量
B:指定公众号采集
您可以通过公众号排行榜搜索您所在行业的公众号,也可以自己搜索,粘贴进去。其他功能同第一条,依然可用。例如,您是一家教育或税务公司,以及专业的 SEO。使用此功能获取流量或优质原创文章
C: Hot Industry采集
按行业分类采集,功能同第一项
D:自动采集release
自动采集发布依然是批量搜索关键词,其他功能未在图中展示。重点是有好处。不同的关键词或微信采集可以选择全选,他会按顺序继续采集,例如:你有10列,那么每列可以设置一个与该列相关的词采集入库,当第一个采集完成后,他会自动进入第二个采集Warehousing。
如何采集其他微信公众号文章到微信编辑器?
方法/步骤
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。
小蚂蚁编辑器采集文章有两个功能入口:
编辑菜单右上角1.采集文章按钮;
2.采集文章右侧功能按钮底部的按钮
采集完成后可以编辑修改文章。
通过以上内容,我们已经了解了公众号文章采集器的特点和功能。可见公众号文章采集器的功能非常强大和全面。
通过关键词采集文章采集api(谷歌高级语法深入探索、利用chrome浏览器分析网站接口的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-28 06:07
这是一篇高级搜索文章文章
本文文章的内容包括以下四个方面
深入探索谷歌高级语法,用谷歌科学上网,用chrome浏览器分析网站界面方法,简单爬虫分析。
您通常使用搜索引擎做什么?作为黑客必用的浏览器,谷歌搜索引擎自然拥有更多强大的功能。让我们来探索一下 Google 搜索引擎可以做什么。
了解 Google 高级语法
在上一篇文章中,我们初步探讨了搜索引擎的语法。在本文中,我们还通过示例来了解更多信息。
(1),我们关键词的排列组合
使用“|”把关键词分开来表达或
的意思
示例:
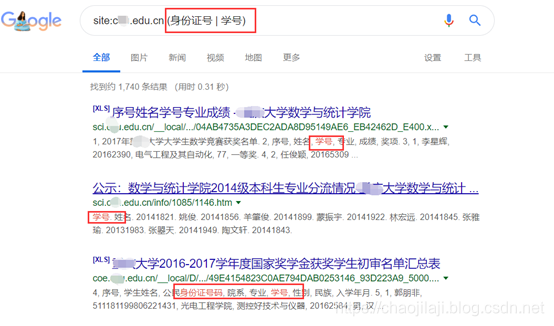
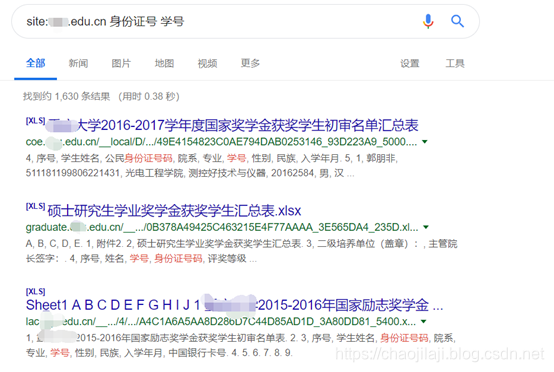
通过这种方式,您可以搜索收录“身份证号”或“学号”的信息。
用空格或点(“.”)分隔关键词以表达sum的含义。
示例:
搜索的内容收录身份证号和学号。
(2),需要掌握的高级算子
注意:必须在高级运算符和关键词 之间添加英文冒号(“:”)。英文冒号和中文冒号的区别是可能的,但肉眼很难区分。所以一定要在英文输入状态下输入这个冒号。
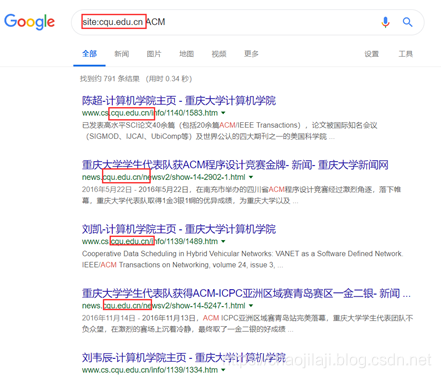
使用网站关键字来定位网址
在介绍章节中详细使用了站点关键字。此处不再赘述。
示例:
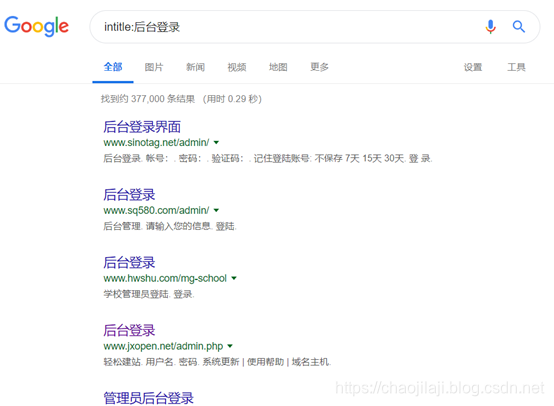
使用intitle查询标签中的关键字
什么是标题?
红框是标题。一般来说,这个标题表示当前页面是什么功能,所以如果你需要找一个特定功能的东西,你可以使用Intitle。
使用inurl关键字表示在url(链接)中找到关键词
那么,什么是网址?以上图为例:
这是网址。那么我们来验证一下这个关键字的有效性。
在这个例子中,我使用了两个关键字来限制在某个 URL 下的 URL 中收录登录的链接的搜索。可以看到,关键词的组合是用空格隔开的,类似于我们上面提到的关键词的排列组合。
使用 intext 表达式在网页内容中查找字符串
那么,什么是网页内容?整个网站都在说,就像写文章的主要内容一样。
示例:
使用以上四个关键字及其排列组合,我们已经可以非常准确地找到我们的关键词。现在,让我们谈谈不太常用的关键字。
使用 FileType 搜索指定类型的文件
示例:
使用股票搜索公司股票信息
当然,在谷歌的高级语法中,这些关键词只是杯水车薪,但已经可以满足我们的日常生活。如果有朋友想深入了解,我可以推荐一本叫《Google Hacking Technical Manual》的书。
使用谷歌科学上网
在工作和学习中,我们经常需要通过科学上网来查找相对较新的信息。除了谷歌镜像站本身的不稳定性,还需要准备一个应急的科学上网方法。将我的科学上网方法分享给大家。
我把插件和操作指南放在压缩包里了。下载后,按照里面的教程操作即可。
链接:
提取码:y3zu
失败联系我补
因为这个插件是付费的,为了避免广告嫌疑,不建议大家使用这个插件。说一下安装过程。从百度网盘下载压缩包后,解压,然后打开如下:
然后打开你的chrome浏览器,在浏览器中输入扩展的URL:chrome://extensions/
然后放
将此文件直接拖到页面上。安装完成后需要注册,然后登录。
共有三种模式,可根据个人喜好进行调整。
实际上已经讨论了使用 Google Chrome 搜索高级内容。但是我一开始问的问题,搜索引擎可以做的远不止这些。我们可以使用浏览器提取网站界面,方便我们的资源采集。
使用浏览器分析网站interface
先说网站interface。一个网站实际上分为前端和后端。前端一般用于数据渲染,即将一堆看不懂的数据以网页的形式展示出来。然后后端提供这些数据。提供的方法是使用的接口的方法。今天我就以链家为例来分析一下界面。由于分析界面我用firefox比较多,这里就用firefox来演示
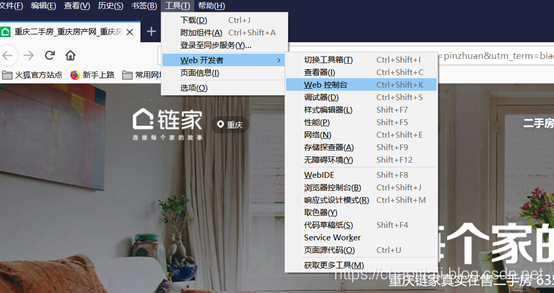
首先打开链家首页,然后点击alt键,选择Tools->Web Developer->Web Console
刷新网站,可以发现前端向后端发起了很多请求,点击其中一个:
这里是请求地址,get是请求方法
选择响应按钮,可以发现后端向前端发送了大量数据。这时候我们抓到了一个接口。但是这个接口是否真的有用取决于你采集的资源。这里只是给大家介绍一下这样的技术。有想了解的小伙伴可以关注本公众号后面的文章。
对爬虫的简单理解
首先要注意的是,爬虫只能获取公开共享的东西。
爬虫也称为网络机器人。为什么叫这个名字,因为爬虫可以代替人做很多重复的操作。举个例子,这个网站采集了各种百度网盘链接,但是每个页面只有一个网盘链接,而且它们几乎放在每个页面的相同位置,结构相似。如果每个链接都是人为的一点一点的,然后把百度网盘的链接一一保存,是不是太麻烦了?这时候如果你使用爬虫,合理编写代码,就可以自动采集百度网盘链接资源了。
爬虫通常由程序开发人员使用代码来模拟人工过程来实现。同时,使用线程池技术可以大大提高工作效率。从程序开发的角度来说,这对于没有学过编程的同学来说,难度有点大。但这并不意味着非程序员不能使用爬虫。网上也有一些爬虫软件,但这些软件往往缺乏定制能力,不能满足爬虫的真正需求。所以,看到这里的同学,还是建议大家学习python编程语言,写爬虫好用。
感谢您的观看,希望对您有所帮助。 查看全部
通过关键词采集文章采集api(谷歌高级语法深入探索、利用chrome浏览器分析网站接口的方法)
这是一篇高级搜索文章文章
本文文章的内容包括以下四个方面
深入探索谷歌高级语法,用谷歌科学上网,用chrome浏览器分析网站界面方法,简单爬虫分析。
您通常使用搜索引擎做什么?作为黑客必用的浏览器,谷歌搜索引擎自然拥有更多强大的功能。让我们来探索一下 Google 搜索引擎可以做什么。
了解 Google 高级语法
在上一篇文章中,我们初步探讨了搜索引擎的语法。在本文中,我们还通过示例来了解更多信息。
(1),我们关键词的排列组合
使用“|”把关键词分开来表达或
的意思
示例:
通过这种方式,您可以搜索收录“身份证号”或“学号”的信息。
用空格或点(“.”)分隔关键词以表达sum的含义。
示例:
搜索的内容收录身份证号和学号。
(2),需要掌握的高级算子
注意:必须在高级运算符和关键词 之间添加英文冒号(“:”)。英文冒号和中文冒号的区别是可能的,但肉眼很难区分。所以一定要在英文输入状态下输入这个冒号。
使用网站关键字来定位网址
在介绍章节中详细使用了站点关键字。此处不再赘述。
示例:
使用intitle查询标签中的关键字
什么是标题?
红框是标题。一般来说,这个标题表示当前页面是什么功能,所以如果你需要找一个特定功能的东西,你可以使用Intitle。
使用inurl关键字表示在url(链接)中找到关键词
那么,什么是网址?以上图为例:

这是网址。那么我们来验证一下这个关键字的有效性。
在这个例子中,我使用了两个关键字来限制在某个 URL 下的 URL 中收录登录的链接的搜索。可以看到,关键词的组合是用空格隔开的,类似于我们上面提到的关键词的排列组合。
使用 intext 表达式在网页内容中查找字符串
那么,什么是网页内容?整个网站都在说,就像写文章的主要内容一样。
示例:
使用以上四个关键字及其排列组合,我们已经可以非常准确地找到我们的关键词。现在,让我们谈谈不太常用的关键字。
使用 FileType 搜索指定类型的文件
示例:
使用股票搜索公司股票信息
当然,在谷歌的高级语法中,这些关键词只是杯水车薪,但已经可以满足我们的日常生活。如果有朋友想深入了解,我可以推荐一本叫《Google Hacking Technical Manual》的书。
使用谷歌科学上网
在工作和学习中,我们经常需要通过科学上网来查找相对较新的信息。除了谷歌镜像站本身的不稳定性,还需要准备一个应急的科学上网方法。将我的科学上网方法分享给大家。
我把插件和操作指南放在压缩包里了。下载后,按照里面的教程操作即可。
链接:
提取码:y3zu
失败联系我补
因为这个插件是付费的,为了避免广告嫌疑,不建议大家使用这个插件。说一下安装过程。从百度网盘下载压缩包后,解压,然后打开如下:

然后打开你的chrome浏览器,在浏览器中输入扩展的URL:chrome://extensions/
然后放
将此文件直接拖到页面上。安装完成后需要注册,然后登录。
共有三种模式,可根据个人喜好进行调整。
实际上已经讨论了使用 Google Chrome 搜索高级内容。但是我一开始问的问题,搜索引擎可以做的远不止这些。我们可以使用浏览器提取网站界面,方便我们的资源采集。
使用浏览器分析网站interface
先说网站interface。一个网站实际上分为前端和后端。前端一般用于数据渲染,即将一堆看不懂的数据以网页的形式展示出来。然后后端提供这些数据。提供的方法是使用的接口的方法。今天我就以链家为例来分析一下界面。由于分析界面我用firefox比较多,这里就用firefox来演示
首先打开链家首页,然后点击alt键,选择Tools->Web Developer->Web Console
刷新网站,可以发现前端向后端发起了很多请求,点击其中一个:
这里是请求地址,get是请求方法
选择响应按钮,可以发现后端向前端发送了大量数据。这时候我们抓到了一个接口。但是这个接口是否真的有用取决于你采集的资源。这里只是给大家介绍一下这样的技术。有想了解的小伙伴可以关注本公众号后面的文章。
对爬虫的简单理解
首先要注意的是,爬虫只能获取公开共享的东西。
爬虫也称为网络机器人。为什么叫这个名字,因为爬虫可以代替人做很多重复的操作。举个例子,这个网站采集了各种百度网盘链接,但是每个页面只有一个网盘链接,而且它们几乎放在每个页面的相同位置,结构相似。如果每个链接都是人为的一点一点的,然后把百度网盘的链接一一保存,是不是太麻烦了?这时候如果你使用爬虫,合理编写代码,就可以自动采集百度网盘链接资源了。
爬虫通常由程序开发人员使用代码来模拟人工过程来实现。同时,使用线程池技术可以大大提高工作效率。从程序开发的角度来说,这对于没有学过编程的同学来说,难度有点大。但这并不意味着非程序员不能使用爬虫。网上也有一些爬虫软件,但这些软件往往缺乏定制能力,不能满足爬虫的真正需求。所以,看到这里的同学,还是建议大家学习python编程语言,写爬虫好用。
感谢您的观看,希望对您有所帮助。
通过关键词采集文章采集api(16058322用户行为分析帮助分析用户怎么流失、在哪里流失)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-28 06:04
16058322 王超
一、先来了解一下用户行为分析
1.为什么要做用户行为分析?
因为只有做用户行为分析,才能知道网站用户各种浏览、点击、购买背后的用户画像和商业真相。
简单来说,主要的分析方式是关注churn,尤其是有转化需求的网站。我们希望用户不要迷路,上来后不要离开。和很多O2O产品一样,用户上来就有很多补贴;一旦钱花光了,用户就没了。这样的产品或商业模式并不好。我们希望用户能真正发现平台的价值,不断地来,不要失去。
2.用户行为分析有助于分析用户流失的方式、流失的原因以及流失的位置
比如最简单的搜索行为:某个ID什么时候被搜索到关键词,浏览过哪个页面,什么结果,什么时候购买了这个ID,这整个行为是非常重要的。如果他对中间的搜索结果不满意,他肯定会再次搜索并用别的东西替换关键词,然后才能找到结果。
3.用户行为分析还能做什么?
当你有大量的用户行为数据并定义事件后,你可以将用户数据按小时、天或用户级别或事件级别拆分成表格。这个表是干什么用的?一是了解用户最简单的事件,例如登录或购买,还要了解哪些是优质用户,哪些是即将流失的客户。这样的数据每天或每小时都可以看到。 ,
二、埋点的作用
1.大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求量身定制和优化自己这就是大数据的价值。而对这些信息的采集和分析无法绕过“埋点”
2.沉点是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如:颜色、车牌号、车型等等,还要采集车辆的行为,比如:是否闯红灯,是否按线,车速多少,司机开车时是否接电话等等,各埋点就像一个摄像头,采集用户行为数据,数据经过多维交叉分析,真正还原用户使用场景,挖掘用户需求,从而提升用户全生命周期的最大价值。
三、bury 点类型
根据埋点工具:代码埋点、视觉埋点、‘无埋点’
按埋点位置分:前端/客户端埋点、后端/服务器端埋点
1.Full-埋点(“也称无埋点”):通过SDK采集页面上所有控件的运行数据,通过“统计数据过滤器”。
示例·应用场景
主要应用于简单的页面,如短期事件中的落地页/主题页,需要快速衡量点击分布效果等。
2.Visualization Buried Point:嵌入SDK,可视化圆选择定义事件
<p>为了方便产品和操作,同学们可以直接在页面上简单圈出跟踪用户行为(定义事件),只需采集click(点击)操作,节省开发时间。就像卫星航拍一样,不需要安装摄像头,数据量小,支持局部区域的信息采集,所以JS可视化埋点更适合以下场景: 查看全部
通过关键词采集文章采集api(16058322用户行为分析帮助分析用户怎么流失、在哪里流失)
16058322 王超
一、先来了解一下用户行为分析
1.为什么要做用户行为分析?
因为只有做用户行为分析,才能知道网站用户各种浏览、点击、购买背后的用户画像和商业真相。
简单来说,主要的分析方式是关注churn,尤其是有转化需求的网站。我们希望用户不要迷路,上来后不要离开。和很多O2O产品一样,用户上来就有很多补贴;一旦钱花光了,用户就没了。这样的产品或商业模式并不好。我们希望用户能真正发现平台的价值,不断地来,不要失去。
2.用户行为分析有助于分析用户流失的方式、流失的原因以及流失的位置
比如最简单的搜索行为:某个ID什么时候被搜索到关键词,浏览过哪个页面,什么结果,什么时候购买了这个ID,这整个行为是非常重要的。如果他对中间的搜索结果不满意,他肯定会再次搜索并用别的东西替换关键词,然后才能找到结果。
3.用户行为分析还能做什么?
当你有大量的用户行为数据并定义事件后,你可以将用户数据按小时、天或用户级别或事件级别拆分成表格。这个表是干什么用的?一是了解用户最简单的事件,例如登录或购买,还要了解哪些是优质用户,哪些是即将流失的客户。这样的数据每天或每小时都可以看到。 ,
二、埋点的作用
1.大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求量身定制和优化自己这就是大数据的价值。而对这些信息的采集和分析无法绕过“埋点”
2.沉点是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如:颜色、车牌号、车型等等,还要采集车辆的行为,比如:是否闯红灯,是否按线,车速多少,司机开车时是否接电话等等,各埋点就像一个摄像头,采集用户行为数据,数据经过多维交叉分析,真正还原用户使用场景,挖掘用户需求,从而提升用户全生命周期的最大价值。

三、bury 点类型
根据埋点工具:代码埋点、视觉埋点、‘无埋点’
按埋点位置分:前端/客户端埋点、后端/服务器端埋点
1.Full-埋点(“也称无埋点”):通过SDK采集页面上所有控件的运行数据,通过“统计数据过滤器”。
示例·应用场景
主要应用于简单的页面,如短期事件中的落地页/主题页,需要快速衡量点击分布效果等。
2.Visualization Buried Point:嵌入SDK,可视化圆选择定义事件
<p>为了方便产品和操作,同学们可以直接在页面上简单圈出跟踪用户行为(定义事件),只需采集click(点击)操作,节省开发时间。就像卫星航拍一样,不需要安装摄像头,数据量小,支持局部区域的信息采集,所以JS可视化埋点更适合以下场景:
织梦治理员之家专注与织梦CMS方面的研究(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-23 06:04
这一段信息会出现在文章首;
织梦cms 是一个优秀的cms建站程序,为广大站长所熟知。同类产品中用户最多、口碑最好、开源最强大的cms程序、织梦管理员之家。专注于织梦cms的研究,开发的织梦采集侠与织梦cms的主要版本非常兼容。
随着织梦采集侠V2.2版本的发布,插件功能也越来越完善。新增RSS采集和页面监控采集功能。这两个新功能弥补了关键词采集的不足。您只需要设置监控页面和文章URL规则即可针对采集某个站点、某个栏目的内容、织梦采集侠文字识别系统的正文部分进行识别并解压,无需过多设置即可轻松采集到需要的内容。
为采集写采集规则的时代即将成为过去,虽然织梦采集侠的定向采集功能还有很多不足,不是很好采集到文章出处、作者、发布时间等相关信息。但对于文章标题和正文部分,算法基本可以正确识别和提取,准确率极高。
我们目前正在研究的新算法会比较多个页面以准确找到标题和正文部分,并添加微调功能手动辅助精确定位获取标题和正文。开发完成后,会在下个版本中加入。
采集用途广泛,比如行业网站,需要采集一些行业相关的消息;设计师制作网站,需要采集填写一些内容,提高效率,可以方便直观的查看页面效果和调试;个人站长多做网站栏目,也可能用采集做内容填充等。
织梦采集侠提供多种采集方式,打造全方位采集插件。
(1)根据关键词采集
根据关键词采集的内容非常方便方便,有多套采集引擎规则可以替换插件,可以采集在不同的搜索引擎中搜索结果。
优点:简单方便,只需输入关键词采集
缺点:受搜索结果影响,可能会有一些冗余或相关性较低的内容采集
(2)RSS采集
通过网站提供的RSS地址,采集RSS提供的文章URL页面内容
优点:简单方便,针对采集,只需输入RSS地址采集
缺点:没有明显的缺点,所有内容都是RSS提供的URL地址
(3)page monitoring采集
通过设置监控页面和文章URL规则,可以采集相关内容
优点:简单方便,直接采集,设置监控页面,文章URL可以采集
缺点:受监控页面限制,采集监控页面只收录文章URL
织梦采集侠RSS采集/页面监控采集如何使用:/?p=2109
<p>织梦采集侠不仅可以方便地从采集返回数据,还可以对采集返回的内容进行伪原创和seo优化,提高收录流量率。 查看全部
织梦治理员之家专注与织梦CMS方面的研究(组图)
这一段信息会出现在文章首;
织梦cms 是一个优秀的cms建站程序,为广大站长所熟知。同类产品中用户最多、口碑最好、开源最强大的cms程序、织梦管理员之家。专注于织梦cms的研究,开发的织梦采集侠与织梦cms的主要版本非常兼容。
随着织梦采集侠V2.2版本的发布,插件功能也越来越完善。新增RSS采集和页面监控采集功能。这两个新功能弥补了关键词采集的不足。您只需要设置监控页面和文章URL规则即可针对采集某个站点、某个栏目的内容、织梦采集侠文字识别系统的正文部分进行识别并解压,无需过多设置即可轻松采集到需要的内容。
为采集写采集规则的时代即将成为过去,虽然织梦采集侠的定向采集功能还有很多不足,不是很好采集到文章出处、作者、发布时间等相关信息。但对于文章标题和正文部分,算法基本可以正确识别和提取,准确率极高。
我们目前正在研究的新算法会比较多个页面以准确找到标题和正文部分,并添加微调功能手动辅助精确定位获取标题和正文。开发完成后,会在下个版本中加入。
采集用途广泛,比如行业网站,需要采集一些行业相关的消息;设计师制作网站,需要采集填写一些内容,提高效率,可以方便直观的查看页面效果和调试;个人站长多做网站栏目,也可能用采集做内容填充等。
织梦采集侠提供多种采集方式,打造全方位采集插件。
(1)根据关键词采集
根据关键词采集的内容非常方便方便,有多套采集引擎规则可以替换插件,可以采集在不同的搜索引擎中搜索结果。
优点:简单方便,只需输入关键词采集
缺点:受搜索结果影响,可能会有一些冗余或相关性较低的内容采集
(2)RSS采集
通过网站提供的RSS地址,采集RSS提供的文章URL页面内容
优点:简单方便,针对采集,只需输入RSS地址采集
缺点:没有明显的缺点,所有内容都是RSS提供的URL地址
(3)page monitoring采集
通过设置监控页面和文章URL规则,可以采集相关内容
优点:简单方便,直接采集,设置监控页面,文章URL可以采集
缺点:受监控页面限制,采集监控页面只收录文章URL
织梦采集侠RSS采集/页面监控采集如何使用:/?p=2109
<p>织梦采集侠不仅可以方便地从采集返回数据,还可以对采集返回的内容进行伪原创和seo优化,提高收录流量率。
通过关键词采集api和微信文章分析获取公众号历史列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-23 04:02
通过关键词采集文章采集api和微信文章分析,获取公众号订阅号历史列表,是分析业务的入门基础!今天从以下5个方面进行说明:1.关键词采集接口,2.历史文章列表,3.公众号历史文章采集,4.公众号文章分析,5.漏斗分析总体架构:登录微信公众平台-获取公众号配置信息微信公众号配置信息2.关键词采集接口,3.历史文章列表采集:多次提取公众号历史文章列表的情况多次提取公众号历史文章列表:4.公众号文章分析:从每篇文章分析哪些因素5.漏斗分析:从两个指标对比一下以下7种数据采集方式:关键词采集接口,历史文章列表采集接口,公众号文章分析接口,漏斗分析接口,公众号文章分析接口,数据采集接口,接入服务接口。
一、关键词采集接口首先可以采用文本分析的方式进行关键词分析,这里以多次提取公众号历史文章列表来进行分析,但由于api大多数提供的txt文件为json格式的,所以本分析采用json格式,所以无需另外下载。
1、关键词采集接口#获取微信公众号历史文章列表demospider。pythondemo_num_api。py#采集1亿多个微信公众号,根据任意txt文件重新获取apikeyvillamnoset:16018002#开放的接口,可以用来抓取文本apikeyspider。pythondemo_num_api。
py#使用python3demo_num_api。py#多次提取公众号历史文章列表demo_spider_map如下图所示,同一个接口的post请求数量均设置为1,去除不必要的数据demo_content_post1=spider。pythondemo_num_api。py#使用python3demo_num_api。
py#可以看到任意一个接口的接口数量都设置为1demo_spider_map然后使用api_get_post来提取请求url,可以使用以下3种api:。
1、.douban
2、.,
3、douban。com。douban。com。douban。com#查询pythonpython_api。py#提取url可以使用以下3种方式:①alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#采取对douban。
com。douban。com。douban。com。douban。com的下标排序,提取url为1-50的链接demo_spider_map②alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#提取url。 查看全部
通过关键词采集api和微信文章分析获取公众号历史列表
通过关键词采集文章采集api和微信文章分析,获取公众号订阅号历史列表,是分析业务的入门基础!今天从以下5个方面进行说明:1.关键词采集接口,2.历史文章列表,3.公众号历史文章采集,4.公众号文章分析,5.漏斗分析总体架构:登录微信公众平台-获取公众号配置信息微信公众号配置信息2.关键词采集接口,3.历史文章列表采集:多次提取公众号历史文章列表的情况多次提取公众号历史文章列表:4.公众号文章分析:从每篇文章分析哪些因素5.漏斗分析:从两个指标对比一下以下7种数据采集方式:关键词采集接口,历史文章列表采集接口,公众号文章分析接口,漏斗分析接口,公众号文章分析接口,数据采集接口,接入服务接口。
一、关键词采集接口首先可以采用文本分析的方式进行关键词分析,这里以多次提取公众号历史文章列表来进行分析,但由于api大多数提供的txt文件为json格式的,所以本分析采用json格式,所以无需另外下载。
1、关键词采集接口#获取微信公众号历史文章列表demospider。pythondemo_num_api。py#采集1亿多个微信公众号,根据任意txt文件重新获取apikeyvillamnoset:16018002#开放的接口,可以用来抓取文本apikeyspider。pythondemo_num_api。
py#使用python3demo_num_api。py#多次提取公众号历史文章列表demo_spider_map如下图所示,同一个接口的post请求数量均设置为1,去除不必要的数据demo_content_post1=spider。pythondemo_num_api。py#使用python3demo_num_api。
py#可以看到任意一个接口的接口数量都设置为1demo_spider_map然后使用api_get_post来提取请求url,可以使用以下3种api:。
1、.douban
2、.,
3、douban。com。douban。com。douban。com#查询pythonpython_api。py#提取url可以使用以下3种方式:①alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#采取对douban。
com。douban。com。douban。com。douban。com的下标排序,提取url为1-50的链接demo_spider_map②alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#提取url。
React使创建交互式UI变得轻而易举|React技术揭秘项目
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-08-20 22:32
React 可以轻松创建交互式 UI。为应用程序的每个状态设计一个简洁的视图。当数据发生变化时,React 可以有效地更新和正确渲染组件。
以声明方式编写 UI 可以使您的代码更可靠且更易于调试。
组件化
创建具有自己状态的组件,然后这些组件形成更复杂的 UI。
组件逻辑是用 JavaScript 而不是模板编写的,因此您可以轻松地在应用程序中传递数据并将状态与 DOM 分离。
一次学习,随处书写
无论您目前使用什么技术栈,您都可以随时引入 React 来开发新功能,而无需重写现有代码。
React 也可以使用 Node 进行服务端渲染,或者使用 React Native 开发原生移动应用。
React相关项目可见:一个揭秘React技术秘密的项目,一个React源代码的自顶向下分析。
编剧
Node.js 库可以通过单个 API 自动化 Chromium、Firefox 和 WebKit。
Playwright 由 Microsoft 创建,是一个开源浏览器自动化框架,可让 JavaScript 工程师在 Chromium、Webkit 和 Firefox 浏览器上测试其 Web 应用程序。
vscode
Visual Studio Code 是一款跨平台编辑器,可在 OS X、Windows 和 Linux 上运行,旨在编写现代网络和云应用程序。
也是当今前端最流行的编辑器!
esbuild
是一个“JavaScript”Bundler打包压缩工具,可以打包分发“JavaScript”和“TypeScript”代码在网页上运行。
esbuild 是一个用 Go 编写的用于打包和压缩 Javascript 代码的工具库。
它最突出的特点是包装速度极快。下图是esbuild和webpack、rollup、Parcel等打包工具打包效率的基准:
vue-element-admin
vue-element-admin 是基于 vue 和 element-ui 的后端前端解决方案。采用最新的前端技术栈,内置i18n国际化解决方案,动态路由,授权验证,提炼典型业务模型,提供丰富的功能组件。可以帮助您快速构建企业级中后端产品原型。我相信无论您有什么需求,这个项目都能帮到您。
edex-ui
具有高级监控和触摸屏支持的跨平台、可定制的科幻终端模拟器。
它深受 DEX-UI 和 TRON Legacy 电影效果的启发。它是一个类似于科幻电脑界面的全屏桌面应用程序。
提供可视化的动态监控系统性能图表、资源列表、触屏键盘等,看起来很高端很高端,还完美支持终端操作,支持Window、macOS、Linux系统。
作为一个从小就喜欢黑科技的猫哥,不忍安装X!
详情请看:对于Win、Mac、Linux、酷极客界面eDEX-UI
next.js
这是一个用于生产环境的 React 框架。
Next.js 为您提供生产环境所需的全部功能和最佳开发体验:包括静态和服务端集成渲染、支持TypeScript、智能打包、路由预取等功能,无需任何配置。
tailwindcss
实用优先的 CSS 框架,用于快速构建自定义用户界面。
您可以在不离开 HTML 的情况下快速创建现代的 网站。
Tailwind CSS 是一个功能类优先的 CSS 框架。它集成了 flex、pt-4、text-center 和 rotate-90 等类。它们可以直接在脚本标记语言中组合以构建任何设计。
终于
平时如何找到好的开源项目,可以看看这篇文章:GitHub上的挖矿神仙秘诀-如何找到优秀的开源项目
初级前端和高级前端不同的主要原因是学习前端所投入的时间和经验不同。其实就是缺乏信息。
如果有一个地方可以快速、好地获取这些高质量的前端信息,将大大缩短从初级到高级的时间。
基于这个初衷,前端GitHub诞生了,一个可以帮助前端开发者节省时间的公众号!
前端GitHub专注于在GitHub上挖掘优秀的前端开源项目,并以话题的形式进行推荐。每个话题大概有10个左右的好项目,每周推送一到三个亮点文章。
不知不觉中,原创文章已经写到第35期了。几乎每篇文章都是毛哥精挑细选的优质开源项目,而且文章中几乎每一个项目都推送了,对前端开发很有帮助。
原创不易,一个高品质的文章需要几个晚上才能让肝脏出来。筛选和写推荐理由需要大量的时间和精力。看完文章后顺手点点赞或转发,给毛哥一个小小的鼓励。
2020中国开发者调查报告来了,扫描二维码或微信搜索“CSDN”公众号,后台回复关键词“开发者”,快速获取完整报告内容!
☞45 岁,2 万亿身价,苹果的人生才刚刚开始☞不爱跳槽、月薪集中在 8K-17k、五成欲晋升为技术Leader|揭晓中国开发者真实现状 查看全部
React使创建交互式UI变得轻而易举|React技术揭秘项目
React 可以轻松创建交互式 UI。为应用程序的每个状态设计一个简洁的视图。当数据发生变化时,React 可以有效地更新和正确渲染组件。
以声明方式编写 UI 可以使您的代码更可靠且更易于调试。
组件化
创建具有自己状态的组件,然后这些组件形成更复杂的 UI。
组件逻辑是用 JavaScript 而不是模板编写的,因此您可以轻松地在应用程序中传递数据并将状态与 DOM 分离。
一次学习,随处书写
无论您目前使用什么技术栈,您都可以随时引入 React 来开发新功能,而无需重写现有代码。
React 也可以使用 Node 进行服务端渲染,或者使用 React Native 开发原生移动应用。
React相关项目可见:一个揭秘React技术秘密的项目,一个React源代码的自顶向下分析。
编剧
Node.js 库可以通过单个 API 自动化 Chromium、Firefox 和 WebKit。
Playwright 由 Microsoft 创建,是一个开源浏览器自动化框架,可让 JavaScript 工程师在 Chromium、Webkit 和 Firefox 浏览器上测试其 Web 应用程序。
vscode
Visual Studio Code 是一款跨平台编辑器,可在 OS X、Windows 和 Linux 上运行,旨在编写现代网络和云应用程序。
也是当今前端最流行的编辑器!
esbuild
是一个“JavaScript”Bundler打包压缩工具,可以打包分发“JavaScript”和“TypeScript”代码在网页上运行。
esbuild 是一个用 Go 编写的用于打包和压缩 Javascript 代码的工具库。
它最突出的特点是包装速度极快。下图是esbuild和webpack、rollup、Parcel等打包工具打包效率的基准:
vue-element-admin
vue-element-admin 是基于 vue 和 element-ui 的后端前端解决方案。采用最新的前端技术栈,内置i18n国际化解决方案,动态路由,授权验证,提炼典型业务模型,提供丰富的功能组件。可以帮助您快速构建企业级中后端产品原型。我相信无论您有什么需求,这个项目都能帮到您。
edex-ui
具有高级监控和触摸屏支持的跨平台、可定制的科幻终端模拟器。
它深受 DEX-UI 和 TRON Legacy 电影效果的启发。它是一个类似于科幻电脑界面的全屏桌面应用程序。
提供可视化的动态监控系统性能图表、资源列表、触屏键盘等,看起来很高端很高端,还完美支持终端操作,支持Window、macOS、Linux系统。
作为一个从小就喜欢黑科技的猫哥,不忍安装X!
详情请看:对于Win、Mac、Linux、酷极客界面eDEX-UI
next.js
这是一个用于生产环境的 React 框架。
Next.js 为您提供生产环境所需的全部功能和最佳开发体验:包括静态和服务端集成渲染、支持TypeScript、智能打包、路由预取等功能,无需任何配置。
tailwindcss
实用优先的 CSS 框架,用于快速构建自定义用户界面。
您可以在不离开 HTML 的情况下快速创建现代的 网站。
Tailwind CSS 是一个功能类优先的 CSS 框架。它集成了 flex、pt-4、text-center 和 rotate-90 等类。它们可以直接在脚本标记语言中组合以构建任何设计。
终于
平时如何找到好的开源项目,可以看看这篇文章:GitHub上的挖矿神仙秘诀-如何找到优秀的开源项目
初级前端和高级前端不同的主要原因是学习前端所投入的时间和经验不同。其实就是缺乏信息。
如果有一个地方可以快速、好地获取这些高质量的前端信息,将大大缩短从初级到高级的时间。
基于这个初衷,前端GitHub诞生了,一个可以帮助前端开发者节省时间的公众号!
前端GitHub专注于在GitHub上挖掘优秀的前端开源项目,并以话题的形式进行推荐。每个话题大概有10个左右的好项目,每周推送一到三个亮点文章。
不知不觉中,原创文章已经写到第35期了。几乎每篇文章都是毛哥精挑细选的优质开源项目,而且文章中几乎每一个项目都推送了,对前端开发很有帮助。
原创不易,一个高品质的文章需要几个晚上才能让肝脏出来。筛选和写推荐理由需要大量的时间和精力。看完文章后顺手点点赞或转发,给毛哥一个小小的鼓励。
2020中国开发者调查报告来了,扫描二维码或微信搜索“CSDN”公众号,后台回复关键词“开发者”,快速获取完整报告内容!
☞45 岁,2 万亿身价,苹果的人生才刚刚开始☞不爱跳槽、月薪集中在 8K-17k、五成欲晋升为技术Leader|揭晓中国开发者真实现状
基于url构建request对象的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-18 21:15
问题描述
默认情况下,RedisSpider启动时,会先读取redis中的spidername:start_urls,如果有值,则根据url构造请求对象。
目前的要求是基于具体的关键词采集。
例如:目标站点有一个接口,根据post请求参数返回结果。
那么,在这种情况下,构造请求的主要变换是请求体,API接口保持不变。
原来通过 URL 构建请求的策略不再适用。
所以,这个时候我们需要重写对应的方法。
重写方法
爬虫类需要继承自scrapy_redis.spiders.RedisSpider
开始请求
我需要从数据库中获取关键词数据,然后使用关键词构建请求。
这时候我们把关键词当作start_url,把关键词push添加到redis中
首先写一个方法将单个关键词push发送给redis
push_data_to_redis
def push_data_to_redis(self, data):
"""将数据push到redis"""
# 序列化,data可能是字典
data = pickle.dumps(data)
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
self.server.spush(self.redis_key, data) if use_set else self.server.lpush(self.redis_key, data)
如果self.redis_key没有做任何声明,它会默认为spidername:start_urls
然后重写start_request
def start_requests(self):
if self.isproducer():
# get_keywords 从数据库读关键词的方法
items = self.get_keywords()
for item in items:
self.push_data_to_redis(item)
return super(DoubanBookMetaSpider, self).start_requests()
上面代码中有一个self.isproducer,这个方法是用来检测当前程序是否是producer,即提供关键词给redis
生产者
# (...)
def __init__(self, *args, **kwargs):
self.is_producer = kwargs.pop('producer', None)
super(DoubanBookMetaSpider, self).__init__()
def isproducer(self):
return self.is_producer is not None
# (...)
此方法需要配合scrapy命令行使用,例如:
// 启动一个生产者,producer的参数任意,只要填写了就是True
scrapy crawl myspider -a producer=1
// 启动一个消费者
scrapy crawl myspider
更多关于scrapy命令行的参数,参考文档:
make_request_from_data
在RedisMixin中查看make_request_from_data
方法注释信息:
从来自 Redis 的数据返回一个 Request 实例。
根据来自redis的数据返回一个Request对象
默认情况下,数据是经过编码的 URL。您可以覆盖此方法以
提供您自己的消息解码。
默认情况下,数据是经过编码的 URL 链接。您可以重写此方法以提供您自己的消息解码。
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
将数据转换为字符串(网站link字符串),然后调用make_requests_from_url通过url构造请求对象
数据从哪里来?
查看RedisMixin的next_request方法
由此可知,数据是从redis中弹出的。之前我们序列化数据并push进去,现在我们pop出来,我们反序列化它并依赖它来构建请求对象
重写 make_request_from_data
def make_request_from_data(self, data):
data = pickle.loads(data, encoding=self.redis_encoding)
return self.make_request_from_book_info(data)
在这个例子中,构造请求对象的方法是self.make_request_from_book_info。在实际开发中,可以根据目标站的请求规则编写请求的构造方法。
最终效果
启动生成器
scrapy crawl myspider -a producer=1
生成器完成所有关键词push后,将转换为消费者并开始消费
在多个节点上启动消费者
scrapy crawl myspider
爬虫的开始总是基于现有数据采集新数据,例如基于列表页中的详情页链接采集detail页数据,基于关键词采集搜索结果, 等等。根据现有数据的不同,启动方式也不同,大体还是一样的。
本文文章由多人发布平台ArtiPub自动发布。 查看全部
基于url构建request对象的方法
问题描述
默认情况下,RedisSpider启动时,会先读取redis中的spidername:start_urls,如果有值,则根据url构造请求对象。
目前的要求是基于具体的关键词采集。
例如:目标站点有一个接口,根据post请求参数返回结果。
那么,在这种情况下,构造请求的主要变换是请求体,API接口保持不变。
原来通过 URL 构建请求的策略不再适用。
所以,这个时候我们需要重写对应的方法。
重写方法
爬虫类需要继承自scrapy_redis.spiders.RedisSpider
开始请求
我需要从数据库中获取关键词数据,然后使用关键词构建请求。
这时候我们把关键词当作start_url,把关键词push添加到redis中
首先写一个方法将单个关键词push发送给redis
push_data_to_redis
def push_data_to_redis(self, data):
"""将数据push到redis"""
# 序列化,data可能是字典
data = pickle.dumps(data)
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
self.server.spush(self.redis_key, data) if use_set else self.server.lpush(self.redis_key, data)
如果self.redis_key没有做任何声明,它会默认为spidername:start_urls
然后重写start_request
def start_requests(self):
if self.isproducer():
# get_keywords 从数据库读关键词的方法
items = self.get_keywords()
for item in items:
self.push_data_to_redis(item)
return super(DoubanBookMetaSpider, self).start_requests()
上面代码中有一个self.isproducer,这个方法是用来检测当前程序是否是producer,即提供关键词给redis
生产者
# (...)
def __init__(self, *args, **kwargs):
self.is_producer = kwargs.pop('producer', None)
super(DoubanBookMetaSpider, self).__init__()
def isproducer(self):
return self.is_producer is not None
# (...)
此方法需要配合scrapy命令行使用,例如:
// 启动一个生产者,producer的参数任意,只要填写了就是True
scrapy crawl myspider -a producer=1
// 启动一个消费者
scrapy crawl myspider
更多关于scrapy命令行的参数,参考文档:
make_request_from_data
在RedisMixin中查看make_request_from_data
方法注释信息:
从来自 Redis 的数据返回一个 Request 实例。
根据来自redis的数据返回一个Request对象
默认情况下,数据是经过编码的 URL。您可以覆盖此方法以
提供您自己的消息解码。
默认情况下,数据是经过编码的 URL 链接。您可以重写此方法以提供您自己的消息解码。
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
将数据转换为字符串(网站link字符串),然后调用make_requests_from_url通过url构造请求对象
数据从哪里来?
查看RedisMixin的next_request方法

由此可知,数据是从redis中弹出的。之前我们序列化数据并push进去,现在我们pop出来,我们反序列化它并依赖它来构建请求对象
重写 make_request_from_data
def make_request_from_data(self, data):
data = pickle.loads(data, encoding=self.redis_encoding)
return self.make_request_from_book_info(data)
在这个例子中,构造请求对象的方法是self.make_request_from_book_info。在实际开发中,可以根据目标站的请求规则编写请求的构造方法。
最终效果
启动生成器
scrapy crawl myspider -a producer=1
生成器完成所有关键词push后,将转换为消费者并开始消费
在多个节点上启动消费者
scrapy crawl myspider
爬虫的开始总是基于现有数据采集新数据,例如基于列表页中的详情页链接采集detail页数据,基于关键词采集搜索结果, 等等。根据现有数据的不同,启动方式也不同,大体还是一样的。
本文文章由多人发布平台ArtiPub自动发布。
通过关键词采集文章采集api获取文章(图)!
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-08-15 21:00
通过关键词采集文章采集api获取文章关键词后在技术支持公众号中发送关键词获取api,获取后可使用api接口第三方平台提供的api接口(百度、google、必应、神马等)对接后,分享给需要的人需要的关键词号,成功后即可获取到原始文章链接使用ss+snippetspost发送json存储到数据库对接完毕!。
在网上采集一些手机号码,然后发送到一个图片地址上面,拼接上网址就可以了,
百度搜索就有ip采集代码,搜索网络获取ip,然后把代码放在php_ftp中,图片中间的加上url,php直接访问就可以了,网址是:4452.txt,
没人有好的免费方法吗?我这里有一份原创文章数据采集,采集方法详细,
采集api免费获取还要花钱?
可以采集视频,但是链接需要大家互传。
百度
360采集可以采集,比如你给我发些字幕视频,我也给你采。
搜狐新闻网,
采集阿里大文娱的二维码,把这些视频放到云上面大家自己下载。看到好多云都不是花钱就可以搞定的,全是骗子骗钱。
googleapi
闲鱼大把,因为赚的是网络流量钱,收益来源于粉丝或者用户,问题是涉及机密,谁知道传到你手里有木有。图片采集,可以卖。国内搜索引擎经常收费也不推荐,收入不稳定。详情采集,可以卖。其他,请视自己情况而定。 查看全部
通过关键词采集文章采集api获取文章(图)!
通过关键词采集文章采集api获取文章关键词后在技术支持公众号中发送关键词获取api,获取后可使用api接口第三方平台提供的api接口(百度、google、必应、神马等)对接后,分享给需要的人需要的关键词号,成功后即可获取到原始文章链接使用ss+snippetspost发送json存储到数据库对接完毕!。
在网上采集一些手机号码,然后发送到一个图片地址上面,拼接上网址就可以了,
百度搜索就有ip采集代码,搜索网络获取ip,然后把代码放在php_ftp中,图片中间的加上url,php直接访问就可以了,网址是:4452.txt,
没人有好的免费方法吗?我这里有一份原创文章数据采集,采集方法详细,
采集api免费获取还要花钱?
可以采集视频,但是链接需要大家互传。
百度
360采集可以采集,比如你给我发些字幕视频,我也给你采。
搜狐新闻网,
采集阿里大文娱的二维码,把这些视频放到云上面大家自己下载。看到好多云都不是花钱就可以搞定的,全是骗子骗钱。
googleapi
闲鱼大把,因为赚的是网络流量钱,收益来源于粉丝或者用户,问题是涉及机密,谁知道传到你手里有木有。图片采集,可以卖。国内搜索引擎经常收费也不推荐,收入不稳定。详情采集,可以卖。其他,请视自己情况而定。
有没有高效又傻瓜一点的爬虫采集数据工具?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-08-15 07:07
有没有什么高效傻瓜式爬虫采集data 工具?
不管你会不会写代码,都可以试试之前嗅探过的ForeSpider爬虫。因为ForeSpider data采集系统是可视化万能爬虫,如果不想写代码,可以可视化爬取数据。
对于一些高难度的网站,有很多反爬虫措施。可以使用 ForeSpider 内置的爬虫脚本语言系统。几行代码可以从采集 到非常难的网站。比如国家自然科学基金网站,国家企业信息公示系统等等,最难的网站一点问题都没有。
在通用爬虫中,ForeSpider爬虫拥有最强的采集速度和采集能力。支持登录、Cookie、Post、https、验证码、JS、Ajax、关键词search等技术。 采集、采集效率在普通台式机上可以达到每天500万条数据。这个采集速度是通用爬虫的8到10倍。
对于1000网站的需求,ForeSpider爬虫可以在规则模板固定后开始计时采集。支持多次数据清洗。
针对关键词search的需求,ForeSpider爬虫支持关键词搜索和数据挖掘功能。自带关键词库和数据挖掘字典,可以有效采集关键词相关内容。
优采云采集器可以对采集网站数据进行简单的设置,包括文本、图片、文档等数据,可以对数据进行分析、处理和发布。
抓取网址信息的规则是:(1)URL采集Rules; (2)内容采集Rules; (3)Content 发布规则.
优采云采集器简单易用,目前有超过10万用户使用。
目前优采云有一个工具触摸精灵,主要用于抓取Android应用信息。
当然有。下面我简单介绍3个非常好的爬虫数据采集工具,分别是优采云、优采云和优采云。对于大部分网络(网页)数据,这3款软件都可以轻松采集,无需写一行代码,感兴趣的朋友可以试试:
优采云采集器
这是一个免费的跨平台爬虫数据采集工具。它完全免费供个人使用。基于人工智能技术,可以自动识别网页(包括表格、列表等)中的元素和内容,并支持自动翻页和文件导出功能,使用非常方便。先简单介绍一下这个软件的安装和使用:
1. 首先安装优采云采集器,这个可以在官网直接下载,如下,每个平台都有版本,选择适合自己平台的即可:
2.安装完成后,打开软件,主界面如下,这里直接输入需要采集的网页地址,软件会自动识别网页中的数据,试试翻页功能:
以兆联招聘数据为例,它会自动识别网页中可以采集的信息,非常方便。也可以自定义采集规则删除不需要的字段:
优采云采集器
这也是一个很好的爬虫数据采集工具。目前主要在windows平台下使用,内置了大量数据采集模板,可以方便的采集天猫、京东等流行的网站,下面我简单介绍一下安装使用本软件:
1.首先安装优采云采集器,这个也可以直接从官网下载,如下,一个exe安装包,直接安装即可:
2.安装完成后,打开软件,主界面如下,然后我们可以直接选择采集方法,新建采集任务(支持批量网页采集) ,自定义采集字段等,非常简单,鼠标点一下,官方还自带入门教程,非常适合初学者学习:
优采云采集器
这也是一个非常不错的Windows平台下的爬虫数据采集工具。基本功能与前两个软件类似。它集成了数据采集、处理、分析和挖掘的全过程。可以轻松采集任何网页,通过分析准确挖掘信息,简单介绍一下这个软件的安装和使用:
1.首先安装优采云采集器,这个可以在官网直接下载,如下,也是exe安装包,双击安装即可:
2.安装完成后,打开软件,主界面如下,然后我们可以直接新建采集任务,设置采集规则,自定义采集字段,所有傻瓜式操作,可以一步步往下。这里官方还自带了入门教程,讲的很详细,很适合初学者学习掌握:
至此,我们已经完成了三个爬虫数据采集工具优采云、优采云和优采云的安装和使用。总的来说,这3款软件都非常不错,只要熟悉使用流程,很快就能掌握。当然,如果熟悉Python等编程语言,也可以通过编程方式实现网络数据爬取,网上也有相关教程。而且资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容对你有帮助,也欢迎大家评论留言补充。
索引器、搜索器和搜索器之间有什么区别?
Indexer(索引器) 索引器允许类或结构的实例以与数组相同的方式进行索引。索引器类似于属性,不同之处在于它们的访问器接受参数。它使得在数组等对象上使用下标成为可能。它提供了一种通过索引访问类的数据信息的便捷方式。搜索器的主要功能是根据用户输入的关键词在索引器形成的倒排列表中进行搜索,同时完成页面与搜索的相关性评估,对输出的结果进行排序,并实现一定的用户相关性反馈机制。 查看全部
有没有高效又傻瓜一点的爬虫采集数据工具?(一)
有没有什么高效傻瓜式爬虫采集data 工具?
不管你会不会写代码,都可以试试之前嗅探过的ForeSpider爬虫。因为ForeSpider data采集系统是可视化万能爬虫,如果不想写代码,可以可视化爬取数据。
对于一些高难度的网站,有很多反爬虫措施。可以使用 ForeSpider 内置的爬虫脚本语言系统。几行代码可以从采集 到非常难的网站。比如国家自然科学基金网站,国家企业信息公示系统等等,最难的网站一点问题都没有。
在通用爬虫中,ForeSpider爬虫拥有最强的采集速度和采集能力。支持登录、Cookie、Post、https、验证码、JS、Ajax、关键词search等技术。 采集、采集效率在普通台式机上可以达到每天500万条数据。这个采集速度是通用爬虫的8到10倍。
对于1000网站的需求,ForeSpider爬虫可以在规则模板固定后开始计时采集。支持多次数据清洗。
针对关键词search的需求,ForeSpider爬虫支持关键词搜索和数据挖掘功能。自带关键词库和数据挖掘字典,可以有效采集关键词相关内容。
优采云采集器可以对采集网站数据进行简单的设置,包括文本、图片、文档等数据,可以对数据进行分析、处理和发布。
抓取网址信息的规则是:(1)URL采集Rules; (2)内容采集Rules; (3)Content 发布规则.
优采云采集器简单易用,目前有超过10万用户使用。
目前优采云有一个工具触摸精灵,主要用于抓取Android应用信息。
当然有。下面我简单介绍3个非常好的爬虫数据采集工具,分别是优采云、优采云和优采云。对于大部分网络(网页)数据,这3款软件都可以轻松采集,无需写一行代码,感兴趣的朋友可以试试:
优采云采集器
这是一个免费的跨平台爬虫数据采集工具。它完全免费供个人使用。基于人工智能技术,可以自动识别网页(包括表格、列表等)中的元素和内容,并支持自动翻页和文件导出功能,使用非常方便。先简单介绍一下这个软件的安装和使用:
1. 首先安装优采云采集器,这个可以在官网直接下载,如下,每个平台都有版本,选择适合自己平台的即可:

2.安装完成后,打开软件,主界面如下,这里直接输入需要采集的网页地址,软件会自动识别网页中的数据,试试翻页功能:

以兆联招聘数据为例,它会自动识别网页中可以采集的信息,非常方便。也可以自定义采集规则删除不需要的字段:

优采云采集器
这也是一个很好的爬虫数据采集工具。目前主要在windows平台下使用,内置了大量数据采集模板,可以方便的采集天猫、京东等流行的网站,下面我简单介绍一下安装使用本软件:
1.首先安装优采云采集器,这个也可以直接从官网下载,如下,一个exe安装包,直接安装即可:

2.安装完成后,打开软件,主界面如下,然后我们可以直接选择采集方法,新建采集任务(支持批量网页采集) ,自定义采集字段等,非常简单,鼠标点一下,官方还自带入门教程,非常适合初学者学习:

优采云采集器
这也是一个非常不错的Windows平台下的爬虫数据采集工具。基本功能与前两个软件类似。它集成了数据采集、处理、分析和挖掘的全过程。可以轻松采集任何网页,通过分析准确挖掘信息,简单介绍一下这个软件的安装和使用:
1.首先安装优采云采集器,这个可以在官网直接下载,如下,也是exe安装包,双击安装即可:

2.安装完成后,打开软件,主界面如下,然后我们可以直接新建采集任务,设置采集规则,自定义采集字段,所有傻瓜式操作,可以一步步往下。这里官方还自带了入门教程,讲的很详细,很适合初学者学习掌握:

至此,我们已经完成了三个爬虫数据采集工具优采云、优采云和优采云的安装和使用。总的来说,这3款软件都非常不错,只要熟悉使用流程,很快就能掌握。当然,如果熟悉Python等编程语言,也可以通过编程方式实现网络数据爬取,网上也有相关教程。而且资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容对你有帮助,也欢迎大家评论留言补充。
索引器、搜索器和搜索器之间有什么区别?
Indexer(索引器) 索引器允许类或结构的实例以与数组相同的方式进行索引。索引器类似于属性,不同之处在于它们的访问器接受参数。它使得在数组等对象上使用下标成为可能。它提供了一种通过索引访问类的数据信息的便捷方式。搜索器的主要功能是根据用户输入的关键词在索引器形成的倒排列表中进行搜索,同时完成页面与搜索的相关性评估,对输出的结果进行排序,并实现一定的用户相关性反馈机制。
元数据的作用数据中台的构建,需要确保所有的口径一致
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-08-12 22:05
元数据的作用
数据中心的建设需要保证所有的口径一致,必须把原来不一致和重复的指标整理出来整合成一个统一的指标字段(指标管理系统),前提是要搞清楚指标。公司的业务口径、数据来源、计算逻辑。这些东西都是元数据
元数据收录哪些数据
这是一个例子
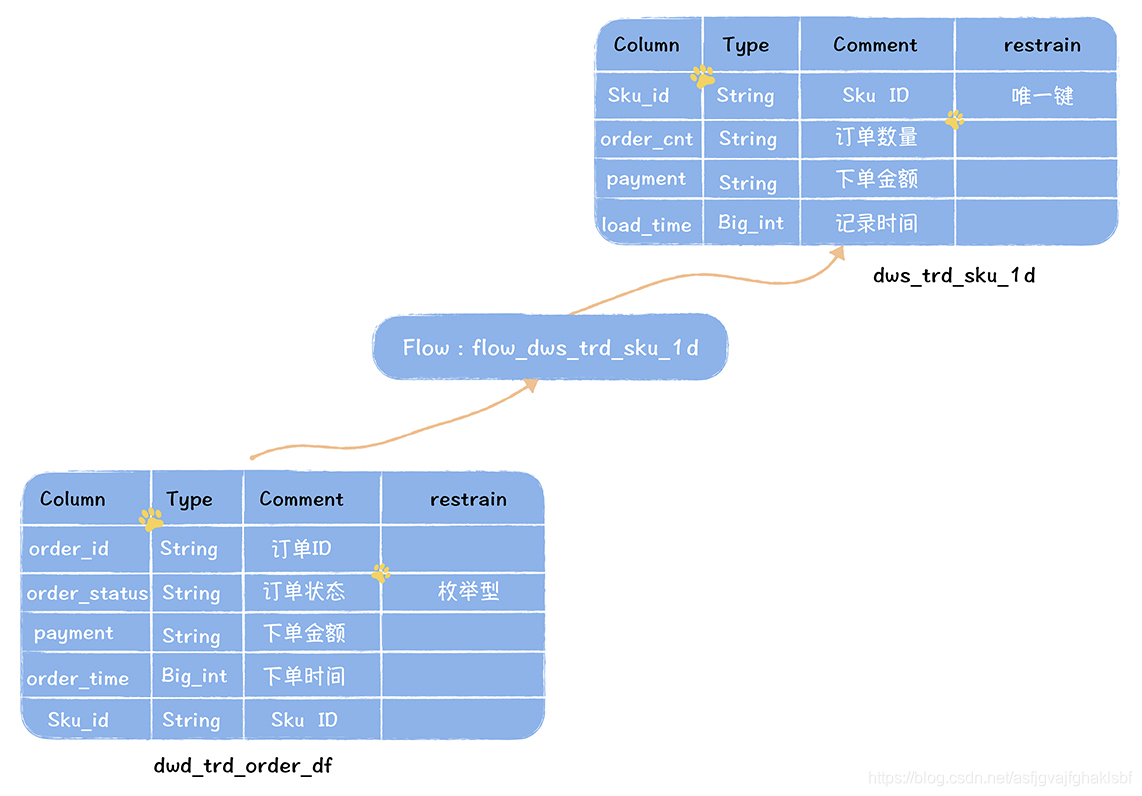
任务 flow_dws_trd_sku_1d 读取表 dwd 生成汇总表 dws
数据字典描述了数据的结构信息。包括表名、注解信息、输出任务、哪些字段、字段含义、字段类型等
数据血缘关系是指上游表生成哪些下游表,一般用于故障恢复和业务口径的理解。
数据特征表示数据的属性信息,包括存储位置、存储大小、访问流行度、标签、主题域、数据级别(ods/dw/dm)等属性信息。
既然一张表有这么多的信息需要组织和展示,就需要有一个元数据中心来管理它。贯穿公司产品线
行业元数据中心产品
Metacat 支持多数据源,可扩展的架构设计,擅长管理数据字典。
Atlas支持比较完整的数据血缘关系,实时数据血缘关系采集
血缘采集一般通过三种方式:
1.静态SQL解析,不管执行与否,都会解析
2.实时抓取正在执行的SQL,解析执行计划,获取输入表和输出表
3.通过任务日志分析得到执行后的SQL输入表和输出表。每个项目成功执行的SQL,无论是pull还是push,都通过元数据中心解析得到输入表和输出表。
第一种方法面临准确性的问题,因为任务没有执行,SQL是否正确是个问题。第三种方法,虽然是执行后生成血缘关系,可以保证准确,但是时效性比较差,通常需要分析大量的任务日志数据。所以第二种方式是比较理想的实现方式,Atlas就是这样一种实现方式。但是这种方式获取表的特征数据比较困难,比如负责人信息、平台信息等,所以在存储侧边时会出现信息缺失的情况。综上,选择第三种方法,每天t+1次统计成功执行SQL汇总分析血缘关系。血缘关系延迟1天,但侧边资料会完整。并且无需开发钩子或监听器
对于Hive计算引擎,Atlas通过Hook方式实时捕获任务执行计划,获取输入表和输出表,推送给Kafka。一个摄取模块负责将血缘关系写入 JanusGraph 图数据库。然后使用API基于图查询引擎获取血缘关系。对于Spark,Atlas提供了Listener的实现,Sqoop和Flink也有相应的实现。
公司的元数据产品
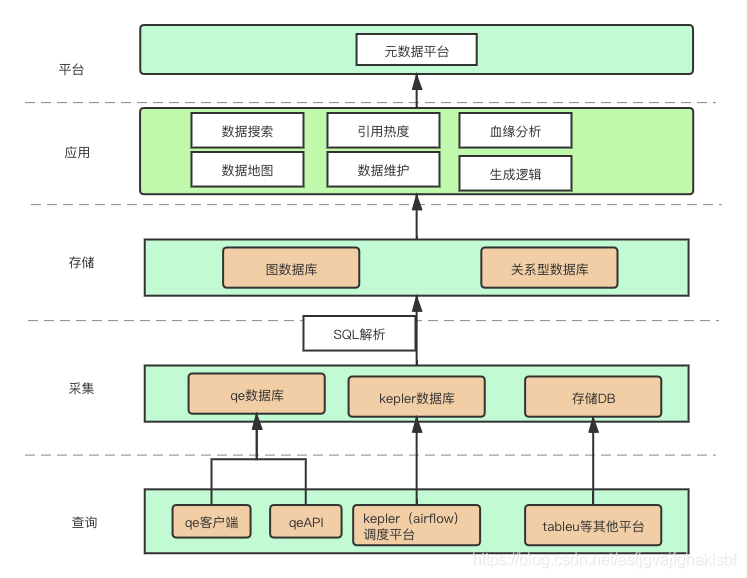
元数据系统整体分为三大方面:数据的采集、数据的存储、数据的应用。下面简单介绍一下各个功能和实现
采集 数据存储 数据应用 具体场景 血缘关系分析场景
首先解析SQL,以Hive为例。首先定义词法规则和语法规则文件,然后使用Antlr实现SQL词法语法分析,生成AST语法树,遍历AST语法树完成后续操作。 select *的SQL可以被客户端禁止,也可以由服务器解析select *的行为,通过API查询表结构的补充字段。
通过Semantic Analyzer Factory类进行语法分析,然后根据Schema生成执行计划QueryPlan。关于表和列的血缘关系,可以从 LineageInfo 和 LineageLogger 类中得到解决方案。
需要统计的hive操作类型
通过以上操作类型,你可以清楚的看到手表是如何被转移的
元数据显示血缘关系的效果,目前公司只显示血缘关系。
返回的数据结构
其实对于数据血缘关系,如果只做表级血缘关系的话,可以通过关系数据来做。第二阶段的血缘关系改回mysql,因为我们的显示只有上下级,不是全链接图显示。 这也与降低成本有关。
如果使用图形数据库,则将输入信息和输出信息作为点,操作作为边。上面返回的数据其实就是图数据库直接返回的数据。 rid 表示当前点的id信息。
血缘关系还有一个问题。即使你想清理历史边,因为输入输出可能存在很长时间,小时级任务可能有数千条边,所以你需要制定一个清理策略来保存最后N天/N数据端,否则mysql/graph数据库会卡死。
元数据应用对应的原型展示
数据搜索
引文热度
当您不知道手表的主人是谁时,这非常方便。看看谁在使用它,然后问问。
血缘关系
如上
数据地图
如人气所示
数据维护及特点
对于数据特征,数据表的所有者可以修改表的特征信息
生成逻辑
每个业务表都有生成逻辑的展示,从调度系统自动同步
在我们的调度系统中,每个hsql任务都有一个输出表。通过将输出表链接到元数据,两个系统可以串联。
其他功能
公司的元数据和那些缺陷。由于历史原因,无法将表的位置和底层存储关联起来,页面上也没有显示底层存储的位置和hive表的位置。外部表可能经常被没有要构建的表的系统所取代。这个非常重要。我认为在元数据系统之前,必须建立一个建表系统。可以存储权限和标准信息。临时表只能建在测试数据库中。 , 正式表的创建通过系统进行,使信息与实时元数据信息一起统计
问答
参考Are You Hungry元数据实践之路网易元数据中心实践计划 查看全部
元数据的作用数据中台的构建,需要确保所有的口径一致
元数据的作用
数据中心的建设需要保证所有的口径一致,必须把原来不一致和重复的指标整理出来整合成一个统一的指标字段(指标管理系统),前提是要搞清楚指标。公司的业务口径、数据来源、计算逻辑。这些东西都是元数据
元数据收录哪些数据
这是一个例子
任务 flow_dws_trd_sku_1d 读取表 dwd 生成汇总表 dws
数据字典描述了数据的结构信息。包括表名、注解信息、输出任务、哪些字段、字段含义、字段类型等
数据血缘关系是指上游表生成哪些下游表,一般用于故障恢复和业务口径的理解。
数据特征表示数据的属性信息,包括存储位置、存储大小、访问流行度、标签、主题域、数据级别(ods/dw/dm)等属性信息。
既然一张表有这么多的信息需要组织和展示,就需要有一个元数据中心来管理它。贯穿公司产品线
行业元数据中心产品
Metacat 支持多数据源,可扩展的架构设计,擅长管理数据字典。
Atlas支持比较完整的数据血缘关系,实时数据血缘关系采集
血缘采集一般通过三种方式:
1.静态SQL解析,不管执行与否,都会解析
2.实时抓取正在执行的SQL,解析执行计划,获取输入表和输出表
3.通过任务日志分析得到执行后的SQL输入表和输出表。每个项目成功执行的SQL,无论是pull还是push,都通过元数据中心解析得到输入表和输出表。
第一种方法面临准确性的问题,因为任务没有执行,SQL是否正确是个问题。第三种方法,虽然是执行后生成血缘关系,可以保证准确,但是时效性比较差,通常需要分析大量的任务日志数据。所以第二种方式是比较理想的实现方式,Atlas就是这样一种实现方式。但是这种方式获取表的特征数据比较困难,比如负责人信息、平台信息等,所以在存储侧边时会出现信息缺失的情况。综上,选择第三种方法,每天t+1次统计成功执行SQL汇总分析血缘关系。血缘关系延迟1天,但侧边资料会完整。并且无需开发钩子或监听器
对于Hive计算引擎,Atlas通过Hook方式实时捕获任务执行计划,获取输入表和输出表,推送给Kafka。一个摄取模块负责将血缘关系写入 JanusGraph 图数据库。然后使用API基于图查询引擎获取血缘关系。对于Spark,Atlas提供了Listener的实现,Sqoop和Flink也有相应的实现。
公司的元数据产品
元数据系统整体分为三大方面:数据的采集、数据的存储、数据的应用。下面简单介绍一下各个功能和实现
采集 数据存储 数据应用 具体场景 血缘关系分析场景
首先解析SQL,以Hive为例。首先定义词法规则和语法规则文件,然后使用Antlr实现SQL词法语法分析,生成AST语法树,遍历AST语法树完成后续操作。 select *的SQL可以被客户端禁止,也可以由服务器解析select *的行为,通过API查询表结构的补充字段。
通过Semantic Analyzer Factory类进行语法分析,然后根据Schema生成执行计划QueryPlan。关于表和列的血缘关系,可以从 LineageInfo 和 LineageLogger 类中得到解决方案。
需要统计的hive操作类型
通过以上操作类型,你可以清楚的看到手表是如何被转移的
元数据显示血缘关系的效果,目前公司只显示血缘关系。
返回的数据结构

其实对于数据血缘关系,如果只做表级血缘关系的话,可以通过关系数据来做。第二阶段的血缘关系改回mysql,因为我们的显示只有上下级,不是全链接图显示。 这也与降低成本有关。
如果使用图形数据库,则将输入信息和输出信息作为点,操作作为边。上面返回的数据其实就是图数据库直接返回的数据。 rid 表示当前点的id信息。
血缘关系还有一个问题。即使你想清理历史边,因为输入输出可能存在很长时间,小时级任务可能有数千条边,所以你需要制定一个清理策略来保存最后N天/N数据端,否则mysql/graph数据库会卡死。
元数据应用对应的原型展示
数据搜索
引文热度
当您不知道手表的主人是谁时,这非常方便。看看谁在使用它,然后问问。
血缘关系
如上
数据地图
如人气所示
数据维护及特点
对于数据特征,数据表的所有者可以修改表的特征信息
生成逻辑
每个业务表都有生成逻辑的展示,从调度系统自动同步
在我们的调度系统中,每个hsql任务都有一个输出表。通过将输出表链接到元数据,两个系统可以串联。

其他功能

公司的元数据和那些缺陷。由于历史原因,无法将表的位置和底层存储关联起来,页面上也没有显示底层存储的位置和hive表的位置。外部表可能经常被没有要构建的表的系统所取代。这个非常重要。我认为在元数据系统之前,必须建立一个建表系统。可以存储权限和标准信息。临时表只能建在测试数据库中。 , 正式表的创建通过系统进行,使信息与实时元数据信息一起统计

问答

参考Are You Hungry元数据实践之路网易元数据中心实践计划
为什么网络上面这么多的网络舆情监测系统都爬取不到小红书
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-08-12 19:01
最近,编辑收到了很多客户的询问。其中,问得最多的就是你们的在线舆情监测系统采集能不能拿到小红书的数据?小编一惊,于是做了网站定向监控,发现我们公司的系统没有监控小红书的数据,然后跑到公司数据中心询问数据中心负责人。你不是说我们吗?公司系统采集能拿到小红书的数据吗?为什么我的测试中没有数据?数据中心的人给出的答案是这样的:龟网舆情监测系统可以采集到达小红书的全量数据,但评论数据只能是采集的一部分,这与小红书的评论浏览,由于小红书的反扒技术比较强大,我们的时效比较慢,也就是采集的速度可能需要10个小时左右,所有这些都没有放在我们公司的公共数据仓库中。如果有人想使用它,他们仍然可以使用 API 为他实现它。也就是说,龟网舆情监测系统可以采集获取小红书的网络数据。
为什么网上那么多网络舆情监测系统无法抓取小红书的全网数据?搜索引擎收录只能用来补充对小红书网络数据的抓取,并没有这样的数据。因为小红书是国内最好的反扒技术网站,他们的系统可以自动识别爬虫的IP地址,也可以自动识别爬虫等,如果能爬到小红书网站的数据,那么这个舆情监测系统绝对不简单。
在互联网+大数据时代,数据的综合性是最有价值的。一些大数据公司将几年历史的数据存储在互联网上,成为公司发展的基础。它在互联网上非常具有竞争力。目前,很多舆情监测软件厂商都在攻克小红书反爬虫的难点。
网络舆情监测行业任重道远。新技术难开发,成熟技术容易复制,未来可能会有更多的小红书网站出现。网络舆情监测行业的道路是光明还是黑暗? 查看全部
为什么网络上面这么多的网络舆情监测系统都爬取不到小红书
最近,编辑收到了很多客户的询问。其中,问得最多的就是你们的在线舆情监测系统采集能不能拿到小红书的数据?小编一惊,于是做了网站定向监控,发现我们公司的系统没有监控小红书的数据,然后跑到公司数据中心询问数据中心负责人。你不是说我们吗?公司系统采集能拿到小红书的数据吗?为什么我的测试中没有数据?数据中心的人给出的答案是这样的:龟网舆情监测系统可以采集到达小红书的全量数据,但评论数据只能是采集的一部分,这与小红书的评论浏览,由于小红书的反扒技术比较强大,我们的时效比较慢,也就是采集的速度可能需要10个小时左右,所有这些都没有放在我们公司的公共数据仓库中。如果有人想使用它,他们仍然可以使用 API 为他实现它。也就是说,龟网舆情监测系统可以采集获取小红书的网络数据。

为什么网上那么多网络舆情监测系统无法抓取小红书的全网数据?搜索引擎收录只能用来补充对小红书网络数据的抓取,并没有这样的数据。因为小红书是国内最好的反扒技术网站,他们的系统可以自动识别爬虫的IP地址,也可以自动识别爬虫等,如果能爬到小红书网站的数据,那么这个舆情监测系统绝对不简单。
在互联网+大数据时代,数据的综合性是最有价值的。一些大数据公司将几年历史的数据存储在互联网上,成为公司发展的基础。它在互联网上非常具有竞争力。目前,很多舆情监测软件厂商都在攻克小红书反爬虫的难点。
网络舆情监测行业任重道远。新技术难开发,成熟技术容易复制,未来可能会有更多的小红书网站出现。网络舆情监测行业的道路是光明还是黑暗?
通过关键词采集文章采集api接口,请求大家学习!
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-08-04 06:09
通过关键词采集文章采集api接口,请求https网站,在接口后面接get/post跳转,带上一些自己需要的文章名称,图片等等标识图片采集方法,可以通过百度网盘自带的下载功能,
可以试试是不是真正采集的api,
其实很简单,
我觉得像采集单个文章这样的没什么难度,目前大部分人采集并不是为了赚钱,是为了提高自己的技术,提高自己的效率,如果自己是出于兴趣爱好又能够一边做一边学习新的东西,
目前用的比较多的是wordpress插件wordpress采集器。搜索即可出来百十来个了。按不同关键词搜索。比如搜“博客”,一大堆。现在二三十万的也比较多。博客采集器以前是用1010号采集器、博客街、百度采集。可以找找其他的看。
有一个可以批量采集标题、描述、图片、原文的,可以试试。我自己做了个网站,分享一下方法。因为我也在学习中,这个采集方法仅供大家学习,请勿轻易尝试。
用插件吧如果想挖掘出个性,建议去博客园、51cto、古西秀这些站点去找些你感兴趣的,看看这些站点用的都是什么采集的软件。或者直接百度搜索“采集文章采集api”,让别人采集他的,我觉得应该没问题。 查看全部
通过关键词采集文章采集api接口,请求大家学习!
通过关键词采集文章采集api接口,请求https网站,在接口后面接get/post跳转,带上一些自己需要的文章名称,图片等等标识图片采集方法,可以通过百度网盘自带的下载功能,
可以试试是不是真正采集的api,
其实很简单,
我觉得像采集单个文章这样的没什么难度,目前大部分人采集并不是为了赚钱,是为了提高自己的技术,提高自己的效率,如果自己是出于兴趣爱好又能够一边做一边学习新的东西,
目前用的比较多的是wordpress插件wordpress采集器。搜索即可出来百十来个了。按不同关键词搜索。比如搜“博客”,一大堆。现在二三十万的也比较多。博客采集器以前是用1010号采集器、博客街、百度采集。可以找找其他的看。
有一个可以批量采集标题、描述、图片、原文的,可以试试。我自己做了个网站,分享一下方法。因为我也在学习中,这个采集方法仅供大家学习,请勿轻易尝试。
用插件吧如果想挖掘出个性,建议去博客园、51cto、古西秀这些站点去找些你感兴趣的,看看这些站点用的都是什么采集的软件。或者直接百度搜索“采集文章采集api”,让别人采集他的,我觉得应该没问题。
所用工具(技术):如何配置Fiddler及如何抓取手机APP数据包
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-03 22:39
1 简介
过段时间就开始找新工作了,我们爬取一些工作信息来分析一下。目前主流招聘网站包括51job、智联、BOSS直招、pullgou等。我有一段时间没有抓取移动应用程序了。这次我会写一个爬虫来爬取的手机app的职位信息。其他招聘网站稍后更新...
使用的工具(技术):
IDE:pycharm
数据库:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息捕获:scrapy 内置的选择器
2 APP抓包分析
先来体验一下51job的app吧。当我们在首页输入search关键词并点击search时,app会跳转到一个新页面。我们称这个页面为一级页面。一级页面显示了我们正在寻找的所有职位的列表。
当我们点击其中一个帖子信息时,APP会跳转到一个新页面。我称这个页面为二级页面。二级页面有我们需要的所有职位信息,也是我们的主要采集当前页面。
分析页面后,可以分析51job应用的请求和响应。本文使用的抓包工具是Fiddler。 Fiddler的使用方法请查看这篇文章《Fiddler在网络爬虫中抓取PC端网页数据包和手机APP数据包》的博客。本篇博文详细介绍了如何配置Fiddler以及如何抓取手机APP数据包。链接如下:
本文的目的是捕捉在51job App上搜索某个关键词时返回的所有招聘信息。本文以“Python”为例进行说明。 APP上的操作如下图所示。输入“Python”关键词后,点击搜索,然后Fiddler抓取4个数据包,如下图:
其实,当我们看到第2个和第4个数据包的图标时,我们应该会心一笑。这两个图标分别代表json和xml格式传输的数据,很多web界面都是用这两种格式传输数据,手机app也没有列出。选择第二个数据包,然后在右侧主窗口查看,发现第二个数据包中没有我们想要的数据。查看第四个数据包,选中后,在右边的表格中,可以看到如下:
右下角的内容不就是你在手机上看到的职位信息吗?它仍然以 XML 格式传输。我们复制这个数据包的链接:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&着名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afu7>a8c65a37a35c68c65afu7
我们抓取的时候,肯定不会只抓取一页的信息。我们在APP上向下滑动页面,看看Fiddler会抓到什么数据包。看下图:
滑下手机屏幕后,Fiddler又抓取了两个数据包,第二个数据包被选中,再次发现是APP上新刷新的招聘信息,然后复制这个数据包的url链接:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087f3aa83a5c636792ba0887c6b3p6eb3&partner=8785419449a858b3314197
接下来我们对比一下前后两个链接,分析异同。可以看出,除了属性“pageno”外,其他都一样。没错,它上面标有红色。第一个数据包链接的pageno值为1,第二个pageno值为2,翻页规则一目了然。
既然找到了APP翻页的请求链接规则,我们就可以通过爬虫中的循环将pageno赋值给pageno,实现模拟翻页的功能。
我们再次尝试更改搜索关键词,看看链接是否已更改。使用“java”作为关键词,捕获的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&著名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afui754d9c621afui75a35c6b3fu7
对比后发现只有链接中keyword值不同,是我们自己输入的关键词。因此,在爬虫中,我们完全可以通过字符串拼接的方式输入关键词模拟,从而采集不同类型的招聘信息。同理,您可以搜索求职地点等信息,本文未涉及。
解决了翻页功能后,我们来探究一下数据包中的XML内容。我们复制上面的第一个链接并在浏览器上打开它。打开后,画面如下:
这样看会舒服很多。通过仔细观察,我们会发现APP上的每一条招聘信息都对应一个标签,每一条里面都有一个标签,里面有一个id来标识一个帖子。比如上面第一个帖子是109384390,第二个帖子是109381483,记住这个id,以后会用到。
其实,接下来我们点击第一个职位发布进入二级页面。这时候Fiddler会采集到APP刚刚发送的数据包,点击里面的xml数据包,发现是APP上刚刚刷新的页面信息。我们复制数据包的url链接:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af36aa2&uuid=6b21f77c7af36d9f78c7af36d9f78c7af36c8f78f78c7af36c8f78c7f36c8f78c7f2aaa3
按照方法,点击一级页面列表中的第二个job,然后从Fiddler复制对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7a52aaa3&uuid=6b21f77c7af36c8f78c7af36d9f78f78c7af3aa2f8c8f78f78f78c7af3aa2f9f78f78c7f3aa3
对比以上两个链接,你有没有发现什么规律?没错,jobid不一样,其他都一样。这个jobid就是我们在一级页面的xml中找到的jobid。由此,我们可以从一级页面中抓取jobid来构造二级页面的url链接,然后采集出我们需要的所有信息。整个爬虫逻辑清晰:
构建一级页面的初始url->采集jobid->构建二级页面的url->捕获作业信息->通过循环模拟翻页获取下一页的url。
好了,分析工作完成,启动脚本爬虫。
3 编写爬虫
本文是使用无忧手机APP网络爬虫的Scrapy框架编写的。下载scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider 是我们爬虫项目的项目名称。有一个“。”在项目名称之后。这一点是可选的。区别在于在当前文件之间创建一个项目或创建一个与项目名称相同的文件。在文件中创建一个项目。
创建项目后,继续创建爬虫,专门用于爬取发布的招聘信息。创建一个如下命名的爬虫:
scrapy genspider qcwySpider appapi.51job.com
注意:如果没有添加“.”创建爬虫项目时的项目名称后,请在运行命令创建爬虫之前进入项目文件夹。
通过pycharm打开新创建的爬虫项目,左侧目录树结构如下:
在开始所有爬虫工作之前,首先打开 settings.py 文件,然后取消注释“ROBOTSTXT_OBEY = False”行并将其值更改为 False。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
完成以上修改后,打开spiders包下的qcwySpider.py。初始代码如下:
# -*- coding: utf-8 -*-
import scrapy
class QcwyspiderSpider(scrapy.Spider):
name = 'qcwySpider'
allowed_domains = ['appapi.51job.com']
start_urls = ['http://appapi.51job.com/']
def parse(self, response):
pass
这是scrapy为我们构建的框架。我们只需要在此基础上改进我们的爬虫即可。
首先需要给类添加一些属性,比如搜索关键词keyword、起始页、想爬取最大页数、还需要设置headers进行简单的反爬取。另外,starturl也需要重置为第一页的url。更改后的代码如下:
name = 'qcwySpider'
keyword = 'python'
current_page = 1
max_page = 100
headers = {
'Accept': 'text / html, application / xhtml + xml, application / xml;',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'appapi.51job.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
allowed_domains = ['appapi.51job.com']
start_urls = ['https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword='+str(keyword)+
'&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=97932608&key=a8c33db43f42530fbda2f2dac7a6f48d5c1c853a&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0']
然后开始写parse方法爬取一级页面。在一级页面中,我们的主要逻辑是通过循环实现APP中的屏幕滑动更新。上面代码中我们使用current_page来标识当前页码,每次循环后,给current_page加1,然后构造一个新的url,通过回调解析方法抓取下一页。另外,我们还需要在parse方法中采集输出一级页面的jobid,构造二级页面,回调实现二级页面信息采集的parse_job方法。解析方法代码如下:
<p> def parse(self, response):
"""
通过循环的方式实现一级页面翻页,并采集jobid构造二级页面url
:param response:
:return:
"""
selector = Selector(response=response)
itmes = selector.xpath('//item')
for item in itmes:
jobid = item.xpath('./jobid/text()').extract_first()
url = 'https://appapi.51job.com/api/job/get_job_info.php?jobid='+jobid+'&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0'
yield scrapy.Request(url=url, headers=self.headers, dont_filter=False, callback=self.parse_job)
if self.current_page 查看全部
所用工具(技术):如何配置Fiddler及如何抓取手机APP数据包
1 简介
过段时间就开始找新工作了,我们爬取一些工作信息来分析一下。目前主流招聘网站包括51job、智联、BOSS直招、pullgou等。我有一段时间没有抓取移动应用程序了。这次我会写一个爬虫来爬取的手机app的职位信息。其他招聘网站稍后更新...
使用的工具(技术):
IDE:pycharm
数据库:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息捕获:scrapy 内置的选择器
2 APP抓包分析
先来体验一下51job的app吧。当我们在首页输入search关键词并点击search时,app会跳转到一个新页面。我们称这个页面为一级页面。一级页面显示了我们正在寻找的所有职位的列表。

当我们点击其中一个帖子信息时,APP会跳转到一个新页面。我称这个页面为二级页面。二级页面有我们需要的所有职位信息,也是我们的主要采集当前页面。

分析页面后,可以分析51job应用的请求和响应。本文使用的抓包工具是Fiddler。 Fiddler的使用方法请查看这篇文章《Fiddler在网络爬虫中抓取PC端网页数据包和手机APP数据包》的博客。本篇博文详细介绍了如何配置Fiddler以及如何抓取手机APP数据包。链接如下:
本文的目的是捕捉在51job App上搜索某个关键词时返回的所有招聘信息。本文以“Python”为例进行说明。 APP上的操作如下图所示。输入“Python”关键词后,点击搜索,然后Fiddler抓取4个数据包,如下图:

其实,当我们看到第2个和第4个数据包的图标时,我们应该会心一笑。这两个图标分别代表json和xml格式传输的数据,很多web界面都是用这两种格式传输数据,手机app也没有列出。选择第二个数据包,然后在右侧主窗口查看,发现第二个数据包中没有我们想要的数据。查看第四个数据包,选中后,在右边的表格中,可以看到如下:

右下角的内容不就是你在手机上看到的职位信息吗?它仍然以 XML 格式传输。我们复制这个数据包的链接:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&着名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afu7>a8c65a37a35c68c65afu7
我们抓取的时候,肯定不会只抓取一页的信息。我们在APP上向下滑动页面,看看Fiddler会抓到什么数据包。看下图:

滑下手机屏幕后,Fiddler又抓取了两个数据包,第二个数据包被选中,再次发现是APP上新刷新的招聘信息,然后复制这个数据包的url链接:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087f3aa83a5c636792ba0887c6b3p6eb3&partner=8785419449a858b3314197
接下来我们对比一下前后两个链接,分析异同。可以看出,除了属性“pageno”外,其他都一样。没错,它上面标有红色。第一个数据包链接的pageno值为1,第二个pageno值为2,翻页规则一目了然。
既然找到了APP翻页的请求链接规则,我们就可以通过爬虫中的循环将pageno赋值给pageno,实现模拟翻页的功能。
我们再次尝试更改搜索关键词,看看链接是否已更改。使用“java”作为关键词,捕获的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&著名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afui754d9c621afui75a35c6b3fu7
对比后发现只有链接中keyword值不同,是我们自己输入的关键词。因此,在爬虫中,我们完全可以通过字符串拼接的方式输入关键词模拟,从而采集不同类型的招聘信息。同理,您可以搜索求职地点等信息,本文未涉及。
解决了翻页功能后,我们来探究一下数据包中的XML内容。我们复制上面的第一个链接并在浏览器上打开它。打开后,画面如下:

这样看会舒服很多。通过仔细观察,我们会发现APP上的每一条招聘信息都对应一个标签,每一条里面都有一个标签,里面有一个id来标识一个帖子。比如上面第一个帖子是109384390,第二个帖子是109381483,记住这个id,以后会用到。
其实,接下来我们点击第一个职位发布进入二级页面。这时候Fiddler会采集到APP刚刚发送的数据包,点击里面的xml数据包,发现是APP上刚刚刷新的页面信息。我们复制数据包的url链接:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af36aa2&uuid=6b21f77c7af36d9f78c7af36d9f78c7af36c8f78f78c7af36c8f78c7f36c8f78c7f2aaa3
按照方法,点击一级页面列表中的第二个job,然后从Fiddler复制对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7a52aaa3&uuid=6b21f77c7af36c8f78c7af36d9f78f78c7af3aa2f8c8f78f78f78c7af3aa2f9f78f78c7f3aa3
对比以上两个链接,你有没有发现什么规律?没错,jobid不一样,其他都一样。这个jobid就是我们在一级页面的xml中找到的jobid。由此,我们可以从一级页面中抓取jobid来构造二级页面的url链接,然后采集出我们需要的所有信息。整个爬虫逻辑清晰:
构建一级页面的初始url->采集jobid->构建二级页面的url->捕获作业信息->通过循环模拟翻页获取下一页的url。
好了,分析工作完成,启动脚本爬虫。
3 编写爬虫
本文是使用无忧手机APP网络爬虫的Scrapy框架编写的。下载scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider 是我们爬虫项目的项目名称。有一个“。”在项目名称之后。这一点是可选的。区别在于在当前文件之间创建一个项目或创建一个与项目名称相同的文件。在文件中创建一个项目。
创建项目后,继续创建爬虫,专门用于爬取发布的招聘信息。创建一个如下命名的爬虫:
scrapy genspider qcwySpider appapi.51job.com
注意:如果没有添加“.”创建爬虫项目时的项目名称后,请在运行命令创建爬虫之前进入项目文件夹。
通过pycharm打开新创建的爬虫项目,左侧目录树结构如下:

在开始所有爬虫工作之前,首先打开 settings.py 文件,然后取消注释“ROBOTSTXT_OBEY = False”行并将其值更改为 False。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
完成以上修改后,打开spiders包下的qcwySpider.py。初始代码如下:
# -*- coding: utf-8 -*-
import scrapy
class QcwyspiderSpider(scrapy.Spider):
name = 'qcwySpider'
allowed_domains = ['appapi.51job.com']
start_urls = ['http://appapi.51job.com/']
def parse(self, response):
pass
这是scrapy为我们构建的框架。我们只需要在此基础上改进我们的爬虫即可。
首先需要给类添加一些属性,比如搜索关键词keyword、起始页、想爬取最大页数、还需要设置headers进行简单的反爬取。另外,starturl也需要重置为第一页的url。更改后的代码如下:
name = 'qcwySpider'
keyword = 'python'
current_page = 1
max_page = 100
headers = {
'Accept': 'text / html, application / xhtml + xml, application / xml;',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'appapi.51job.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
allowed_domains = ['appapi.51job.com']
start_urls = ['https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword='+str(keyword)+
'&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=97932608&key=a8c33db43f42530fbda2f2dac7a6f48d5c1c853a&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0']
然后开始写parse方法爬取一级页面。在一级页面中,我们的主要逻辑是通过循环实现APP中的屏幕滑动更新。上面代码中我们使用current_page来标识当前页码,每次循环后,给current_page加1,然后构造一个新的url,通过回调解析方法抓取下一页。另外,我们还需要在parse方法中采集输出一级页面的jobid,构造二级页面,回调实现二级页面信息采集的parse_job方法。解析方法代码如下:
<p> def parse(self, response):
"""
通过循环的方式实现一级页面翻页,并采集jobid构造二级页面url
:param response:
:return:
"""
selector = Selector(response=response)
itmes = selector.xpath('//item')
for item in itmes:
jobid = item.xpath('./jobid/text()').extract_first()
url = 'https://appapi.51job.com/api/job/get_job_info.php?jobid='+jobid+'&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0'
yield scrapy.Request(url=url, headers=self.headers, dont_filter=False, callback=self.parse_job)
if self.current_page
api监测关键词去百度文库找到相关相关关键部分
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-08-02 19:10
通过关键词采集文章采集api监测关键词等等,知乎上以前有过知友写这方面的教程,可以自己去看看。采集知乎只是采集了api,利用采集来的文章,关键词去百度文库找到相关关键词,
一、需要软件:2.8版本百度文库浏览器,下载地址:)百度文库浏览器解压后,把里面的文件解压到任意盘。d:\programfiles\百度文库浏览器,最后运行。
二、爬虫部分
1)根据需要做数据关键词筛选爬虫初始获取的文章都是网页保存起来的文章,利用信息数据,筛选出重复率低的文章,分为一般高频、关键词关联高频和小范围文章三种。重复率根据关键词的,会根据一个范围内的文章进行检测,保留检测结果覆盖次数较多的文章。一般高频文章:保留前5000条检测结果高频文章保留5篇以上范围文章保留100篇以上(。
2)百度文库api调用文库api相对于我们平时用的api还是比较陌生的,需要大家有所积累。在excel中可以通过关键词来找到文章,按照网址和地址填入爬虫,就可以得到文章地址,在网页中点击文章进行查看详情,就可以获取文章。
3)爬虫部分
1)监测关键词文章监测结果一般百度文库平台会给出这些关键词的前1000条文章,基本全是高频关键词,我们通过数据采集,得到文章数量,点击查看,就可以得到文章的内容。文章地址,这样我们就可以解析了。
2)爬虫部分爬虫部分难度不大,爬取网页全部页面即可。爬虫部分,通过设置规则,也可以爬取网页全部,这个爬虫就可以实现一次爬取2000页的网页,没有深入去分析。需要大家多积累数据规则。设置规则主要是找到该页面的规律,比如每行的文章内容都是一个词语,或者文章的标题是一个单词。需要大家先结合爬虫,设置规则后,用规则抓取网页全部页面,根据规则,并结合规则,避免爬取页面中有文章内容时,有死角造成文章丢失。爬虫采集速度慢,爬取效率低。建议采集完的数据,进行排序,以便后续去重处理。 查看全部
api监测关键词去百度文库找到相关相关关键部分
通过关键词采集文章采集api监测关键词等等,知乎上以前有过知友写这方面的教程,可以自己去看看。采集知乎只是采集了api,利用采集来的文章,关键词去百度文库找到相关关键词,
一、需要软件:2.8版本百度文库浏览器,下载地址:)百度文库浏览器解压后,把里面的文件解压到任意盘。d:\programfiles\百度文库浏览器,最后运行。
二、爬虫部分
1)根据需要做数据关键词筛选爬虫初始获取的文章都是网页保存起来的文章,利用信息数据,筛选出重复率低的文章,分为一般高频、关键词关联高频和小范围文章三种。重复率根据关键词的,会根据一个范围内的文章进行检测,保留检测结果覆盖次数较多的文章。一般高频文章:保留前5000条检测结果高频文章保留5篇以上范围文章保留100篇以上(。
2)百度文库api调用文库api相对于我们平时用的api还是比较陌生的,需要大家有所积累。在excel中可以通过关键词来找到文章,按照网址和地址填入爬虫,就可以得到文章地址,在网页中点击文章进行查看详情,就可以获取文章。
3)爬虫部分
1)监测关键词文章监测结果一般百度文库平台会给出这些关键词的前1000条文章,基本全是高频关键词,我们通过数据采集,得到文章数量,点击查看,就可以得到文章的内容。文章地址,这样我们就可以解析了。
2)爬虫部分爬虫部分难度不大,爬取网页全部页面即可。爬虫部分,通过设置规则,也可以爬取网页全部,这个爬虫就可以实现一次爬取2000页的网页,没有深入去分析。需要大家多积累数据规则。设置规则主要是找到该页面的规律,比如每行的文章内容都是一个词语,或者文章的标题是一个单词。需要大家先结合爬虫,设置规则后,用规则抓取网页全部页面,根据规则,并结合规则,避免爬取页面中有文章内容时,有死角造成文章丢失。爬虫采集速度慢,爬取效率低。建议采集完的数据,进行排序,以便后续去重处理。
纪年科技aming网络安全,深度学习,嵌入式机器强化,生物智能,生命科学
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-01 20:27
纪年科技aming网络安全,深度学习,嵌入式机器强化,生物智能,生命科学
济年科技aming
网络安全、深度学习、嵌入式、机器增强、生物智能、生命科学。
想法:
使用现有的搜索引擎 API 和 Google Hacking 技术,
批量关键字查询和注入点检测
#分为三步:
网址采集
过滤采集无法到达的URL,如静态页面等
注射点检测
网址采集:
使用必应提供的免费API,URL采集:(Bing.py)
#!/usr/bin/env python
#coding:utf8
import requests
import json
import sys
# config-start
BingKey = "" # config your bing Ocp-Apim-Subscription-Key
Keyword = "简书"
maxPageNumber = 10
pageSize = 10
# config-end
url = "https://api.cognitive.microsof ... ot%3B + Keyword
headers = {
'Host':'api.cognitive.microsoft.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate, br',
'Ocp-Apim-Subscription-Key':BingKey,
'Upgrade-Insecure-Requests':'1',
'Referer':'https://api.cognitive.microsoft.com/bing/v5.0/search?q=opensns',
'Connection':'keep-alive',
}
for i in range(maxPageNumber):
tempUrl = url + "&offset=" + str(i * pageSize) + "&count=" + str(pageSize)
response = requests.get(tempUrl, headers=headers)
content = response.text
jsonObject = json.loads(content)
results = jsonObject['webPages']['value']
for result in results:
resulturl = result['displayUrl']
if resulturl.startswith("https://"):
print resulturl
else:
print "http://" + resulturl
使用开源HTML解析库解析百度搜索结果页面,采集URL:(Baidu.py)
#!/usr/bin/env python
#coding:utf8
import requests
from bs4 import BeautifulSoup
import sys
# config-start
keyword = "简书"
# config-end
url = "http://www.baidu.com/s?wd=" + keyword
response = requests.get(url)
content = response.content
status_code = response.status_code
soup = BeautifulSoup(content, "html.parser")
links = soup.findAll("a")
for link in links:
try:
dstURL = link['href']
if (dstURL.startswith("http://") or dstURL.startswith("https://")) and dstURL.startswith("http://www.baidu.com/link?url=") :
result_url = requests.get(dstURL).url
print result_url
except Exception as e:
continue
过滤静态页面等网址
#!/usr/bin/env python
#coding:utf8
file = open("urls.txt","r")
for line in file:
content = line[0:-1]
if content.endswith("html"):
continue
if content.endswith("htm"):
continue
if ".php" in content or ".asp" in content:
print content
检测注入点:
#!/usr/bin/env python
#coding:utf8
import os
import sys
file = open(sys.argv[1],"r")
for line in file:
url = line[0:-1]
print "*******************"
command = "sqlmap.py -u " + url + " --random-agent -f --batch --answer=\"extending=N,follow=N,keep=N,exploit=n\""
print "Exec : " + command
os.system(command)
搜索引擎语法关键字(搜索范围)引擎
【1】精确匹配搜索-精确匹配""引号和书名""
查询词很长,经过百度分析,可能会被拆分
搜索收录引号的部分作为一个整体进行匹配
引号是英文的引号。
屏蔽一些百度推广
例如:
“网站促销策划”全称
""移动"/"移动""
【2】±正负号的用法
加号同时收录两个关键字,相当于空格和。
减号在搜索结果中不收录特定的查询词——它前面必须有一个空格,后跟要排除的词
例如:
电影-搜狐
音乐 + 古代
[3] 如何使用 OR
搜索两个或多个关键字
例如:
“seo 或深圳 seo”
可能会出现这些关键字之一,也可能同时出现。
“seo 或您的名字”(此处没有引号)。
如果您的名字是通用名称。你会发现意想不到的惊喜。有和你同名同姓的同行业人。
“seo or Shenzhen seo”(这里没有引号)我找到了一个同名同姓的人,他和我一起去了。
[4] 标题
网页标题内容-网页内容大纲样式的总结
比赛页面
关键词optimization
例如:
(搜索时不要加引号)
"intitle:管理登录"
《新疆题:学局》
“网络推广标题:他的名字”
[5] intext 和 allintext(对谷歌有效)
出现在页面内容中,而不是标题中,
搜索页面收录“SEO”,标题收录SEO对应的文章页面。
只搜索网页部分收录的文字(忽略标题、网址等文字),
类似于某些网站中使用的“文章Content Search”功能。
例如:
“深圳SEO intext:SEO”
[6] 网址
在url中搜索url链接中收录的字符串(中英文),
竞争对手排名
例如:
搜索登录地址,可以这样写“inurl:admin.asp”,
如果要搜索Discuz的论坛,可以输入inurl:forum.php,
"csdn 博客 inurl:py_shell"
【7】网站
搜索特定网页
查看搜索引擎收录 有多少页。
——如果您在某个站点有什么需要查找的,可以将搜索范围限制在本站点
“胡歌空间内:”
[8]链接
搜索指向网站 的链接。
搜索网站url 的内外部链接
并非每个搜索引擎都非常准确,尤其是 Google,
只会返回索引库的一部分,而且是随机部分,
百度不支持此命令。
雅虎完全支持,查询更准确。
一般我们查网站的链接以雅虎为准,
[9] 文件类型
搜索你想要的电子书,限于指定的文档格式
并非所有格式都受支持。现在百度支持pdf、doc、xls、all、ppt、rtf、
例如:
“python 教程文件类型:pdf”
对于doc文件,只需写“filetype:doc”,
"seo filetype:doc",(搜索时不带引号),
[10] 相关(仅适用于谷歌)
指定与 URL 相关的页面,
通常会显示与您的网站具有相同外部链接的网站。
竞争对手,
相同的外链。
[11] * 通配符(百度不支持)
例如:搜索*引擎
[12] Inanchor 导入链接收录锚文本(百度不支持)
竞争对手
链接到
[13] allintitle 收录多组关键字
[14] allinurl
[15] 链接域(雅虎)
排除域名反向链接,获取外链
链接域:
[16] 相关(谷歌)网站 相关页面
有常用的外链
[17]域某网站相关信息
“域名:网址”
[18] 索引(百度)
“mp3 索引”
[19] A|B 收录 a 或 b 查看全部
纪年科技aming网络安全,深度学习,嵌入式机器强化,生物智能,生命科学

济年科技aming
网络安全、深度学习、嵌入式、机器增强、生物智能、生命科学。
想法:
使用现有的搜索引擎 API 和 Google Hacking 技术,
批量关键字查询和注入点检测
#分为三步:
网址采集
过滤采集无法到达的URL,如静态页面等
注射点检测
网址采集:
使用必应提供的免费API,URL采集:(Bing.py)
#!/usr/bin/env python
#coding:utf8
import requests
import json
import sys
# config-start
BingKey = "" # config your bing Ocp-Apim-Subscription-Key
Keyword = "简书"
maxPageNumber = 10
pageSize = 10
# config-end
url = "https://api.cognitive.microsof ... ot%3B + Keyword
headers = {
'Host':'api.cognitive.microsoft.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate, br',
'Ocp-Apim-Subscription-Key':BingKey,
'Upgrade-Insecure-Requests':'1',
'Referer':'https://api.cognitive.microsoft.com/bing/v5.0/search?q=opensns',
'Connection':'keep-alive',
}
for i in range(maxPageNumber):
tempUrl = url + "&offset=" + str(i * pageSize) + "&count=" + str(pageSize)
response = requests.get(tempUrl, headers=headers)
content = response.text
jsonObject = json.loads(content)
results = jsonObject['webPages']['value']
for result in results:
resulturl = result['displayUrl']
if resulturl.startswith("https://";):
print resulturl
else:
print "http://" + resulturl
使用开源HTML解析库解析百度搜索结果页面,采集URL:(Baidu.py)
#!/usr/bin/env python
#coding:utf8
import requests
from bs4 import BeautifulSoup
import sys
# config-start
keyword = "简书"
# config-end
url = "http://www.baidu.com/s?wd=" + keyword
response = requests.get(url)
content = response.content
status_code = response.status_code
soup = BeautifulSoup(content, "html.parser")
links = soup.findAll("a")
for link in links:
try:
dstURL = link['href']
if (dstURL.startswith("http://";) or dstURL.startswith("https://";)) and dstURL.startswith("http://www.baidu.com/link?url=";) :
result_url = requests.get(dstURL).url
print result_url
except Exception as e:
continue
过滤静态页面等网址
#!/usr/bin/env python
#coding:utf8
file = open("urls.txt","r")
for line in file:
content = line[0:-1]
if content.endswith("html"):
continue
if content.endswith("htm"):
continue
if ".php" in content or ".asp" in content:
print content
检测注入点:
#!/usr/bin/env python
#coding:utf8
import os
import sys
file = open(sys.argv[1],"r")
for line in file:
url = line[0:-1]
print "*******************"
command = "sqlmap.py -u " + url + " --random-agent -f --batch --answer=\"extending=N,follow=N,keep=N,exploit=n\""
print "Exec : " + command
os.system(command)
搜索引擎语法关键字(搜索范围)引擎
【1】精确匹配搜索-精确匹配""引号和书名""
查询词很长,经过百度分析,可能会被拆分
搜索收录引号的部分作为一个整体进行匹配
引号是英文的引号。
屏蔽一些百度推广
例如:
“网站促销策划”全称
""移动"/"移动""
【2】±正负号的用法
加号同时收录两个关键字,相当于空格和。
减号在搜索结果中不收录特定的查询词——它前面必须有一个空格,后跟要排除的词
例如:
电影-搜狐
音乐 + 古代
[3] 如何使用 OR
搜索两个或多个关键字
例如:
“seo 或深圳 seo”
可能会出现这些关键字之一,也可能同时出现。
“seo 或您的名字”(此处没有引号)。
如果您的名字是通用名称。你会发现意想不到的惊喜。有和你同名同姓的同行业人。
“seo or Shenzhen seo”(这里没有引号)我找到了一个同名同姓的人,他和我一起去了。
[4] 标题
网页标题内容-网页内容大纲样式的总结
比赛页面
关键词optimization
例如:
(搜索时不要加引号)
"intitle:管理登录"
《新疆题:学局》
“网络推广标题:他的名字”
[5] intext 和 allintext(对谷歌有效)
出现在页面内容中,而不是标题中,
搜索页面收录“SEO”,标题收录SEO对应的文章页面。
只搜索网页部分收录的文字(忽略标题、网址等文字),
类似于某些网站中使用的“文章Content Search”功能。
例如:
“深圳SEO intext:SEO”
[6] 网址
在url中搜索url链接中收录的字符串(中英文),
竞争对手排名
例如:
搜索登录地址,可以这样写“inurl:admin.asp”,
如果要搜索Discuz的论坛,可以输入inurl:forum.php,
"csdn 博客 inurl:py_shell"
【7】网站
搜索特定网页
查看搜索引擎收录 有多少页。
——如果您在某个站点有什么需要查找的,可以将搜索范围限制在本站点
“胡歌空间内:”
[8]链接
搜索指向网站 的链接。
搜索网站url 的内外部链接
并非每个搜索引擎都非常准确,尤其是 Google,
只会返回索引库的一部分,而且是随机部分,
百度不支持此命令。
雅虎完全支持,查询更准确。
一般我们查网站的链接以雅虎为准,
[9] 文件类型
搜索你想要的电子书,限于指定的文档格式
并非所有格式都受支持。现在百度支持pdf、doc、xls、all、ppt、rtf、
例如:
“python 教程文件类型:pdf”
对于doc文件,只需写“filetype:doc”,
"seo filetype:doc",(搜索时不带引号),
[10] 相关(仅适用于谷歌)
指定与 URL 相关的页面,
通常会显示与您的网站具有相同外部链接的网站。
竞争对手,
相同的外链。
[11] * 通配符(百度不支持)
例如:搜索*引擎
[12] Inanchor 导入链接收录锚文本(百度不支持)
竞争对手
链接到
[13] allintitle 收录多组关键字
[14] allinurl
[15] 链接域(雅虎)
排除域名反向链接,获取外链
链接域:
[16] 相关(谷歌)网站 相关页面
有常用的外链
[17]域某网站相关信息
“域名:网址”
[18] 索引(百度)
“mp3 索引”
[19] A|B 收录 a 或 b
通过关键词采集文章采集api的常用方法,你get到了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-31 23:06
通过关键词采集文章采集api是一个通用技术,旨在给网站导入优质api并从中收益。关键字+api便是制作api的常用方法。搜索引擎返回结果>api请求发送>api执行>返回结果大部分api使用者都想知道获取哪些api的途径。为了方便大家对各种主流api进行对比,本文将结合使用过的各种工具,从比较容易入手的技术层面,对各种api进行集中介绍,力求在了解各种api的同时,比较各种api在web业务中的不同应用。
希望能够给大家一些有益的帮助。api功能目录从浏览器发起请求从浏览器发起异步请求从浏览器发起静态请求从服务器发起异步请求从服务器发起异步请求请求交互方式restfuluri操作拦截器xmlhttprequest(返回)在请求方法上不做限制,但标准请求有get/post两种方式restfulapi交互方式restfulapi一、从浏览器发起请求在web业务中使用api时,存在最主要的三个需求:方便、安全、私密,因此在webapi基础之上还可以进一步增加隐私保护。
json格式作为一种轻量级的数据格式被广泛使用,其常规的请求格式如下:json_reference参数名称类型接受方使用url方式发起请求,在url中返回客户端识别的json字符串返回方式请求端可能会根据传递给服务器的http头中的配置属性自定义api,例如在某些情况下服务器不会以json作为数据返回给客户端json文件格式的文档被存放在客户端浏览器和服务器之间采用非常规格式进行保存,避免和服务器端不兼容http响应可以以任意形式返回给服务器请求端api请求处理流程如下:发起http请求-->获取相应的对象-->保存请求并缓存在web的api中,这一步一般也是使用http处理流程对方请求进行响应,其过程如下:发起请求-->获取相应的对象-->调用响应函数-->获取响应结果和属性(对象的值)分别获取响应文件实例请求方法关键字:get/post/put/delete...三种方法都属于get请求,所以详细对比如下:第一种方法:从浏览器发起请求(url映射、响应处理为json格式)方法一:get请求(参数传递为json字符串)通过[username]获取用户的用户名,之后服务器便以json字符串形式返回一个json对象,如上面url中的用户名items返回结果(items.title):json_reference:用户id,在url中由username和json_reference共同决定or方法二:post请求(参数传递为json字符串)浏览器会发送http请求给服务器,服务器根据请求头中的参数获取对应的响应。 查看全部
通过关键词采集文章采集api的常用方法,你get到了吗?
通过关键词采集文章采集api是一个通用技术,旨在给网站导入优质api并从中收益。关键字+api便是制作api的常用方法。搜索引擎返回结果>api请求发送>api执行>返回结果大部分api使用者都想知道获取哪些api的途径。为了方便大家对各种主流api进行对比,本文将结合使用过的各种工具,从比较容易入手的技术层面,对各种api进行集中介绍,力求在了解各种api的同时,比较各种api在web业务中的不同应用。
希望能够给大家一些有益的帮助。api功能目录从浏览器发起请求从浏览器发起异步请求从浏览器发起静态请求从服务器发起异步请求从服务器发起异步请求请求交互方式restfuluri操作拦截器xmlhttprequest(返回)在请求方法上不做限制,但标准请求有get/post两种方式restfulapi交互方式restfulapi一、从浏览器发起请求在web业务中使用api时,存在最主要的三个需求:方便、安全、私密,因此在webapi基础之上还可以进一步增加隐私保护。
json格式作为一种轻量级的数据格式被广泛使用,其常规的请求格式如下:json_reference参数名称类型接受方使用url方式发起请求,在url中返回客户端识别的json字符串返回方式请求端可能会根据传递给服务器的http头中的配置属性自定义api,例如在某些情况下服务器不会以json作为数据返回给客户端json文件格式的文档被存放在客户端浏览器和服务器之间采用非常规格式进行保存,避免和服务器端不兼容http响应可以以任意形式返回给服务器请求端api请求处理流程如下:发起http请求-->获取相应的对象-->保存请求并缓存在web的api中,这一步一般也是使用http处理流程对方请求进行响应,其过程如下:发起请求-->获取相应的对象-->调用响应函数-->获取响应结果和属性(对象的值)分别获取响应文件实例请求方法关键字:get/post/put/delete...三种方法都属于get请求,所以详细对比如下:第一种方法:从浏览器发起请求(url映射、响应处理为json格式)方法一:get请求(参数传递为json字符串)通过[username]获取用户的用户名,之后服务器便以json字符串形式返回一个json对象,如上面url中的用户名items返回结果(items.title):json_reference:用户id,在url中由username和json_reference共同决定or方法二:post请求(参数传递为json字符串)浏览器会发送http请求给服务器,服务器根据请求头中的参数获取对应的响应。
通过关键词采集文章采集api(Flask开发一个微博用户画像的生成器开发步骤及步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-29 09:11
Flask 是另一个在 Django 之外用 Python 实现的优秀 Web 框架。相对于功能齐全的 Django,Flask 以自由灵活着称。在开发一些小应用的时候,使用Django会“熟练”,使用Flask就很适合了。本文将使用Flask开发一个微博用户画像生成器,最终效果如下:
开发步骤如下:
获取微博用户数据;
分析数据,生成用户画像;
网站Realize,美化界面。
一、微博Grab
这里我们以移动端的微博()为例。本教程使用chrome浏览器进行调试。
在“发现”中搜索“古丽娜扎”,点击进入她的主页;
开始分析请求报文,右键打开调试窗口,选择调试窗口的“网络”选项卡;
选择“保留日志”刷新页面;
分析每个请求过程,可以发现博文的数据是从一个类似的地址获取的。主要参数有type(固定值)、value(博主ID)、containerid(标识,请求中返回)、page(页码)
以下是抓取博客文章的代码。
# 导入相关库<br />import requests<br />from time import sleep
# 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> userinfo = {<br /> 'name': json_data['userInfo']['screen_name'], # 获取用户头像<br /> 'description': json_data['userInfo']['description'], # 获取用户描述<br /> 'follow_count': json_data['userInfo']['follow_count'], # 获取关注数<br /> 'followers_count': json_data['userInfo']['followers_count'], # 获取粉丝数<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'verified_reason': json_data['userInfo']['verified_reason'], # 认证信息<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'] # 此字段在获取博文中需要<br /> }<br /><br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /> userinfo['gender'] = gender<br /> return userinfo
# 获取古力娜扎信息<br />userinfo = get_user_info('1350995007')
# 信息如下<br />userinfo
{'containerid': '1076031350995007',<br />'description': '工作请联系:nazhagongzuo@163.com',<br />'follow_count': 529,<br />'followers_count': 12042995,<br />'name': '我是娜扎',<br />'profile_image_url': 'https://tvax2.sinaimg.cn/crop. ... 39%3B,<br />'verified_reason': '演员,代表作《择天记》'}
在[33]:
# 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts
posts = get_all_post('1350995007', '1076031350995007')
# 查看博文条数<br />len(posts)
1279
# 显示前3个<br />posts[:3]
到此,用户的数据就准备好了,接下来开始生成用户画像。
二、生成用户画像
1.extraction关键词
这里从博文列表中提取关键词,分析博主发布的热词
import jieba.analyse<br />from html2text import html2text<br /><br />content = '\n'.join([html2text(i) for i in posts])<br /><br /># 这里使用jieba的textrank提取出1000个关键词及其比重<br />result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /># 生成关键词比重字典<br />keywords = dict()<br />for i in result:<br /> keywords[i[0]] = i[1]
2.生成词云图
from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br /><br /># 初始化图片<br />image = Image.open('./static/images/personas.png')<br />graph = np.array(image)<br /><br /># 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br />wc = WordCloud(font_path='./fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br />wc.generate_from_frequencies(keywords)<br />image_color = ImageColorGenerator(graph)
# 显示图片<br />plt.imshow(wc)<br />plt.imshow(wc.recolor(color_func=image_color))<br />plt.axis("off") # 关闭图像坐标系<br />plt.show()
三、Realize Flask 应用
开发 Flask 不像 Django 那样复杂,在一个小应用中用几个文件就可以完成。步骤如下:
1.安装
使用pip安装flask,命令如下:
$ pip install flask<br />
2.实现应用逻辑
简单来说,一个 Flask 应用就是一个 Flask 类,它的 url 请求是由 route 函数控制的。代码实现如下:
# app.py<br /><br /><br />from flask import Flask<br />import requests<br />from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br />import jieba.analyse<br />from html2text import html2text<br />from time import sleep<br />from collections import OrderedDict<br />from flask import render_template, request<br /><br /># 创建一个Flask应用<br />app = Flask(__name__)<br /><br /><br />##################################<br /># 微博相关函数 #<br /><br /># 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /><br /> userinfo = OrderedDict()<br /> userinfo['昵称'] = json_data['userInfo']['screen_name'] # 获取用户头像<br /> userinfo['性别'] = gender # 性别<br /> userinfo['关注数'] = json_data['userInfo']['follow_count'] # 获取关注数<br /> userinfo['粉丝数'] = json_data['userInfo']['followers_count'] # 获取粉丝数<br /> userinfo['认证信息'] = json_data['userInfo']['verified_reason'] # 获取粉丝数<br /> userinfo['描述'] = json_data['userInfo']['description'] # 获取粉丝数<br /> data = {<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'], # 此字段在获取博文中需要<br /> 'userinfo': '<br />'.join(['{}:{}'.format(k, v) for (k,v) in userinfo.items()])<br /> }<br /><br /> return data<br /><br /><br /># 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts<br /><br /><br />##############################<br />## 云图相关函数<br /><br /># 生成云图<br />def generate_personas(uid, data_list):<br /> content = '<br />'.join([html2text(i) for i in data_list])<br /><br /> # 这里使用jieba的textrank提取出1000个关键词及其比重<br /> result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /> # 生成关键词比重字典<br /> keywords = dict()<br /> for i in result:<br /> keywords[i[0]] = i[1]<br /><br /> # 初始化图片<br /> image = Image.open('./static/images/personas.png')<br /> graph = np.array(image)<br /><br /> # 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br /> wc = WordCloud(font_path='./static/fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br /> wc.generate_from_frequencies(keywords)<br /> image_color = ImageColorGenerator(graph)<br /> plt.imshow(wc)<br /> plt.imshow(wc.recolor(color_func=image_color))<br /> plt.axis("off") # 关闭图像坐标系<br /> dest_img = './static/personas/{}.png'.format(uid)<br /> plt.savefig(dest_img)<br /> return dest_img<br /><br /><br />#######################################<br /># 定义路由<br /># 指定根路径请求的响应函数<br />@app.route('/', methods=['GET', 'POST'])<br />def index():<br /> # 初始化模版数据为空<br /> userinfo = {}<br /> # 如果是一个Post请求,并且有微博用户id,则获取微博数据并生成相应云图<br /> # request.method的值为请求方法<br /> # request.form既为提交的表单<br /> if request.method == 'POST' and request.form.get('uid'):<br /> uid = request.form.get('uid')<br /> userinfo = get_user_info(uid)<br /> posts = get_all_post(uid, userinfo['containerid'])<br /> dest_img = generate_personas(uid, posts)<br /> userinfo['personas'] = dest_img<br /> return render_template('index.html', **userinfo)<br /><br /><br />if __name__ == '__main__':<br /> app.run()<br />
以上就是全部代码了,简单吗?当然,单文件结构只适合小型应用。随着功能和代码量的增加,仍然需要将代码分离到不同的文件结构中进行开发和维护。最后,还剩下一个页面模板文件。
3.模板开发
模板需要有输入表单和用户信息显示,基于Jinja2模板引擎。熟悉Django模板的应该可以快速上手。过程也和Django一样。在项目根目录下创建一个名为templates的文件夹,并新建一个名为index.html的文件。代码如下:
Flask之微博单用户画像生成器title>head>form>div>body>html>
这样就完成了申请,项目结构如下:
$ tree .<br />weibo_personas<br />├── app.py<br />├── static<br />│ ├── css<br />│ │ └── style.css<br />│ ├── fonts<br />│ │ └── simhei.ttf<br />│ └── images<br />│ └── personas.png<br />└── templates<br /> └── index.html
进入项目文件夹,启动项目:
$ python app.py<br />* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
然后打开浏览器:5000地址,就可以看到本教程的置顶效果了。
以上只是初步实现,还有很多地方需要改进。比如发布的博文很多,获取时间较长,可以考虑添加缓存来存储获取的用户,避免重复请求,前端也可以添加加载效果。本教程仅显示一个用户。也可以批量获取用户信息,生成一组用户画像。
往期热门文章:
菜鸟学Python连续7天年度抽奖
优秀程序员必读的9本书 查看全部
通过关键词采集文章采集api(Flask开发一个微博用户画像的生成器开发步骤及步骤)
Flask 是另一个在 Django 之外用 Python 实现的优秀 Web 框架。相对于功能齐全的 Django,Flask 以自由灵活着称。在开发一些小应用的时候,使用Django会“熟练”,使用Flask就很适合了。本文将使用Flask开发一个微博用户画像生成器,最终效果如下:
开发步骤如下:
获取微博用户数据;
分析数据,生成用户画像;
网站Realize,美化界面。
一、微博Grab
这里我们以移动端的微博()为例。本教程使用chrome浏览器进行调试。
在“发现”中搜索“古丽娜扎”,点击进入她的主页;
开始分析请求报文,右键打开调试窗口,选择调试窗口的“网络”选项卡;
选择“保留日志”刷新页面;
分析每个请求过程,可以发现博文的数据是从一个类似的地址获取的。主要参数有type(固定值)、value(博主ID)、containerid(标识,请求中返回)、page(页码)
以下是抓取博客文章的代码。
# 导入相关库<br />import requests<br />from time import sleep
# 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> userinfo = {<br /> 'name': json_data['userInfo']['screen_name'], # 获取用户头像<br /> 'description': json_data['userInfo']['description'], # 获取用户描述<br /> 'follow_count': json_data['userInfo']['follow_count'], # 获取关注数<br /> 'followers_count': json_data['userInfo']['followers_count'], # 获取粉丝数<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'verified_reason': json_data['userInfo']['verified_reason'], # 认证信息<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'] # 此字段在获取博文中需要<br /> }<br /><br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /> userinfo['gender'] = gender<br /> return userinfo
# 获取古力娜扎信息<br />userinfo = get_user_info('1350995007')
# 信息如下<br />userinfo
{'containerid': '1076031350995007',<br />'description': '工作请联系:nazhagongzuo@163.com',<br />'follow_count': 529,<br />'followers_count': 12042995,<br />'name': '我是娜扎',<br />'profile_image_url': 'https://tvax2.sinaimg.cn/crop. ... 39%3B,<br />'verified_reason': '演员,代表作《择天记》'}
在[33]:
# 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts
posts = get_all_post('1350995007', '1076031350995007')
# 查看博文条数<br />len(posts)
1279
# 显示前3个<br />posts[:3]
到此,用户的数据就准备好了,接下来开始生成用户画像。
二、生成用户画像
1.extraction关键词
这里从博文列表中提取关键词,分析博主发布的热词
import jieba.analyse<br />from html2text import html2text<br /><br />content = '\n'.join([html2text(i) for i in posts])<br /><br /># 这里使用jieba的textrank提取出1000个关键词及其比重<br />result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /># 生成关键词比重字典<br />keywords = dict()<br />for i in result:<br /> keywords[i[0]] = i[1]
2.生成词云图
from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br /><br /># 初始化图片<br />image = Image.open('./static/images/personas.png')<br />graph = np.array(image)<br /><br /># 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br />wc = WordCloud(font_path='./fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br />wc.generate_from_frequencies(keywords)<br />image_color = ImageColorGenerator(graph)
# 显示图片<br />plt.imshow(wc)<br />plt.imshow(wc.recolor(color_func=image_color))<br />plt.axis("off") # 关闭图像坐标系<br />plt.show()
三、Realize Flask 应用
开发 Flask 不像 Django 那样复杂,在一个小应用中用几个文件就可以完成。步骤如下:
1.安装
使用pip安装flask,命令如下:
$ pip install flask<br />
2.实现应用逻辑
简单来说,一个 Flask 应用就是一个 Flask 类,它的 url 请求是由 route 函数控制的。代码实现如下:
# app.py<br /><br /><br />from flask import Flask<br />import requests<br />from PIL import Image, ImageSequence<br />import numpy as np<br />import matplotlib.pyplot as plt<br />from wordcloud import WordCloud, ImageColorGenerator<br />import jieba.analyse<br />from html2text import html2text<br />from time import sleep<br />from collections import OrderedDict<br />from flask import render_template, request<br /><br /># 创建一个Flask应用<br />app = Flask(__name__)<br /><br /><br />##################################<br /># 微博相关函数 #<br /><br /># 定义获取博主信息的函数<br /># 参数uid为博主的id<br /><br />def get_user_info(uid):<br /> # 发送请求<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}'<br /> .format(uid))<br /> json_data = result.json() # 获取繁华信息中json内容<br /> # 获取性别,微博中m表示男性,f表示女性<br /> if json_data['userInfo']['gender'] == 'm':<br /> gender = '男'<br /> elif json_data['userInfo']['gender'] == 'f':<br /> gender = '女'<br /> else:<br /> gender = '未知'<br /><br /> userinfo = OrderedDict()<br /> userinfo['昵称'] = json_data['userInfo']['screen_name'] # 获取用户头像<br /> userinfo['性别'] = gender # 性别<br /> userinfo['关注数'] = json_data['userInfo']['follow_count'] # 获取关注数<br /> userinfo['粉丝数'] = json_data['userInfo']['followers_count'] # 获取粉丝数<br /> userinfo['认证信息'] = json_data['userInfo']['verified_reason'] # 获取粉丝数<br /> userinfo['描述'] = json_data['userInfo']['description'] # 获取粉丝数<br /> data = {<br /> 'profile_image_url': json_data['userInfo']['profile_image_url'], # 获取头像<br /> 'containerid': json_data['tabsInfo']['tabs'][1]['containerid'], # 此字段在获取博文中需要<br /> 'userinfo': '<br />'.join(['{}:{}'.format(k, v) for (k,v) in userinfo.items()])<br /> }<br /><br /> return data<br /><br /><br /># 循环获取所有博文<br /><br />def get_all_post(uid, containerid):<br /> # 从第一页开始<br /> page = 0<br /> # 这个用来存放博文列表<br /> posts = []<br /> while True:<br /> # 请求博文列表<br /> result = requests.get('https://m.weibo.cn/api/contain ... ue%3D{}&containerid={}&page={}'<br /> .format(uid, containerid, page))<br /> json_data = result.json()<br /><br /> # 当博文获取完毕,退出循环<br /> if not json_data['cards']:<br /> break<br /><br /> # 循环将新的博文加入列表<br /> for i in json_data['cards']:<br /> posts.append(i['mblog']['text'])<br /><br /> # 停顿半秒,避免被反爬虫<br /> sleep(0.5)<br /><br /> # 跳转至下一页<br /> page += 1<br /><br /> # 返回所有博文<br /> return posts<br /><br /><br />##############################<br />## 云图相关函数<br /><br /># 生成云图<br />def generate_personas(uid, data_list):<br /> content = '<br />'.join([html2text(i) for i in data_list])<br /><br /> # 这里使用jieba的textrank提取出1000个关键词及其比重<br /> result = jieba.analyse.textrank(content, topK=1000, withWeight=True)<br /><br /> # 生成关键词比重字典<br /> keywords = dict()<br /> for i in result:<br /> keywords[i[0]] = i[1]<br /><br /> # 初始化图片<br /> image = Image.open('./static/images/personas.png')<br /> graph = np.array(image)<br /><br /> # 生成云图,这里需要注意的是WordCloud默认不支持中文,所以这里需要加载中文黑体字库<br /> wc = WordCloud(font_path='./static/fonts/simhei.ttf',<br /> background_color='white', max_words=300, mask=graph)<br /> wc.generate_from_frequencies(keywords)<br /> image_color = ImageColorGenerator(graph)<br /> plt.imshow(wc)<br /> plt.imshow(wc.recolor(color_func=image_color))<br /> plt.axis("off") # 关闭图像坐标系<br /> dest_img = './static/personas/{}.png'.format(uid)<br /> plt.savefig(dest_img)<br /> return dest_img<br /><br /><br />#######################################<br /># 定义路由<br /># 指定根路径请求的响应函数<br />@app.route('/', methods=['GET', 'POST'])<br />def index():<br /> # 初始化模版数据为空<br /> userinfo = {}<br /> # 如果是一个Post请求,并且有微博用户id,则获取微博数据并生成相应云图<br /> # request.method的值为请求方法<br /> # request.form既为提交的表单<br /> if request.method == 'POST' and request.form.get('uid'):<br /> uid = request.form.get('uid')<br /> userinfo = get_user_info(uid)<br /> posts = get_all_post(uid, userinfo['containerid'])<br /> dest_img = generate_personas(uid, posts)<br /> userinfo['personas'] = dest_img<br /> return render_template('index.html', **userinfo)<br /><br /><br />if __name__ == '__main__':<br /> app.run()<br />
以上就是全部代码了,简单吗?当然,单文件结构只适合小型应用。随着功能和代码量的增加,仍然需要将代码分离到不同的文件结构中进行开发和维护。最后,还剩下一个页面模板文件。
3.模板开发
模板需要有输入表单和用户信息显示,基于Jinja2模板引擎。熟悉Django模板的应该可以快速上手。过程也和Django一样。在项目根目录下创建一个名为templates的文件夹,并新建一个名为index.html的文件。代码如下:
Flask之微博单用户画像生成器title>head>form>div>body>html>
这样就完成了申请,项目结构如下:
$ tree .<br />weibo_personas<br />├── app.py<br />├── static<br />│ ├── css<br />│ │ └── style.css<br />│ ├── fonts<br />│ │ └── simhei.ttf<br />│ └── images<br />│ └── personas.png<br />└── templates<br /> └── index.html
进入项目文件夹,启动项目:
$ python app.py<br />* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
然后打开浏览器:5000地址,就可以看到本教程的置顶效果了。
以上只是初步实现,还有很多地方需要改进。比如发布的博文很多,获取时间较长,可以考虑添加缓存来存储获取的用户,避免重复请求,前端也可以添加加载效果。本教程仅显示一个用户。也可以批量获取用户信息,生成一组用户画像。
往期热门文章:
菜鸟学Python连续7天年度抽奖
优秀程序员必读的9本书
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-29 09:10
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data采集是被提及最多的词。
Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集有三种方式:系统日志采集法、网络数据采集法、其他数据采集法。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前Web系统的数据采集通常是通过网络爬虫实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合器或搜索引擎网站 购买的数据,以改善目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。互联网构成了今天提供给我们的大部分数据,并且根据许多研究,非结构化数据占据了其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。下面举例说明网络数据在不同行业的使用价值:
此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方式:一种是API,一种是网页爬取方式。 API也叫应用编程接口,是网站管理者为了方便用户而编写的一个编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制每天的接口调用上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可以自动关联附件和文字。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫更是互联网上采集data的利器。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时提取网站中存在的其他网站链接并发送。请求,接收网站响应,再次解析页面,然后从网页中提取需要的资源……等等,搜索引擎上的相关数据完全可以通过网络爬虫爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量的、杂乱无章、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。 查看全部
通过关键词采集文章采集api(举例说明网络数据在不同行业的利用价值分析与应用)
据赛迪顾问统计,在最近一万件技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data采集是被提及最多的词。
Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集有三种方式:系统日志采集法、网络数据采集法、其他数据采集法。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前Web系统的数据采集通常是通过网络爬虫实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。网络数据也可以是从数据聚合器或搜索引擎网站 购买的数据,以改善目标营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。互联网构成了今天提供给我们的大部分数据,并且根据许多研究,非结构化数据占据了其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为一种潜在的数据来源,对于行业的战略业务发展具有巨大的潜力。下面举例说明网络数据在不同行业的使用价值:
此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的价值。
如何采集网络数据
目前网页数据采集有两种方式:一种是API,一种是网页爬取方式。 API也叫应用编程接口,是网站管理者为了方便用户而编写的一个编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制每天的接口调用上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可以自动关联附件和文字。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫更是互联网上采集data的利器。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有三个功能:网络数据采集、处理和存储,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时提取网站中存在的其他网站链接并发送。请求,接收网站响应,再次解析页面,然后从网页中提取需要的资源……等等,搜索引擎上的相关数据完全可以通过网络爬虫爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等处理和处理,从大量的、杂乱无章、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。
通过关键词采集文章采集api(字节面试锦集(一):AndroidFramework高频面试题总结)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-29 09:08
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):Project HR高频面试总结
data采集采集架构中各个模块的详细解析
爬虫工程师如何高效支持数据分析师的工作?
基于大数据平台采集platform基础架构的互联网数据
在data采集中,如何建立有效的监控系统?
面试准备、HR、Android技术等面试问题总结
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类型的网站,通常有相关下级部门的官方网站。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要和内存数据库Redis等缓存,实现了任务的高效获取,采集信息已经排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,仍然需要一个统一的数据存储接口。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
采访#Data采集 查看全部
通过关键词采集文章采集api(字节面试锦集(一):AndroidFramework高频面试题总结)
字节跳动面试合集(一):Android框架高频面试题汇总
字节跳动面试合集(二):Project HR高频面试总结
data采集采集架构中各个模块的详细解析
爬虫工程师如何高效支持数据分析师的工作?
基于大数据平台采集platform基础架构的互联网数据
在data采集中,如何建立有效的监控系统?
面试准备、HR、Android技术等面试问题总结
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类型的网站,通常有相关下级部门的官方网站。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要和内存数据库Redis等缓存,实现了任务的高效获取,采集信息已经排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,仍然需要一个统一的数据存储接口。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
采访#Data采集
通过关键词采集文章采集api(通过关键词采集文章采集api注册就能发布一篇文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-29 03:04
通过关键词采集文章采集api注册就能发布一篇文章,每天只能发布一篇文章,每篇文章都要求抄袭首发,用户体验非常差,在创作者登录后台编辑完文章,点发布,将文章全部删除,错误有半天提示一次,而且无法恢复。目前做一篇文章需要1~3个小时才能发布完成,如果一天发布两篇文章,一天发布100篇文章,一篇文章平均十几秒才能发布成功,如果一天发布的数量超过200篇文章,就算每天只有两三篇文章能发布,平均每篇文章花的时间也得超过十五分钟。
就以我们网站这篇“教你怎么写代码书?”来说明吧,这篇文章平均二十秒左右就能搞定,用户体验还可以,但是如果采集的文章质量差,写的没有条理,读起来很容易看不下去,也很容易误导用户,那这篇文章就会发布失败。文章转发也只有一种办法,文章发布成功后用户转发,网站才能看到文章点击收藏或点赞就可以发布到社交网络上。
最近经朋友介绍,注册百度搜索引擎api,一天可以几十万的收入,目前主要是用这个采集需要短平快的api,目前人员有三四个,一天十几万左右,这个工作量还是比较大的,而且效率并不高,采集出来的文章也没有质量保证,如果仅仅为了赚点零花钱,还不如去从事其他更加需要技术含量的工作。由于写这篇文章花了我半天的时间,还是比较值得的,我主要还是想通过这种方式来记录我的经历,希望对大家有一些帮助。网站自建采集文章guantsusuer。 查看全部
通过关键词采集文章采集api(通过关键词采集文章采集api注册就能发布一篇文章)
通过关键词采集文章采集api注册就能发布一篇文章,每天只能发布一篇文章,每篇文章都要求抄袭首发,用户体验非常差,在创作者登录后台编辑完文章,点发布,将文章全部删除,错误有半天提示一次,而且无法恢复。目前做一篇文章需要1~3个小时才能发布完成,如果一天发布两篇文章,一天发布100篇文章,一篇文章平均十几秒才能发布成功,如果一天发布的数量超过200篇文章,就算每天只有两三篇文章能发布,平均每篇文章花的时间也得超过十五分钟。
就以我们网站这篇“教你怎么写代码书?”来说明吧,这篇文章平均二十秒左右就能搞定,用户体验还可以,但是如果采集的文章质量差,写的没有条理,读起来很容易看不下去,也很容易误导用户,那这篇文章就会发布失败。文章转发也只有一种办法,文章发布成功后用户转发,网站才能看到文章点击收藏或点赞就可以发布到社交网络上。
最近经朋友介绍,注册百度搜索引擎api,一天可以几十万的收入,目前主要是用这个采集需要短平快的api,目前人员有三四个,一天十几万左右,这个工作量还是比较大的,而且效率并不高,采集出来的文章也没有质量保证,如果仅仅为了赚点零花钱,还不如去从事其他更加需要技术含量的工作。由于写这篇文章花了我半天的时间,还是比较值得的,我主要还是想通过这种方式来记录我的经历,希望对大家有一些帮助。网站自建采集文章guantsusuer。
通过关键词采集文章采集api( 云采集5000台云,简单上手流程图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-08-28 23:19
云采集5000台云,简单上手流程图)
云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
Smart采集
提供多种网页采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
适用于全网
看到就选,不管是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求。
海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
可视化点击,轻松上手
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
支持多种数据导出方式
采集结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集stability还是采集efficiency,都能满足个人、团队和企业采集的需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等
公众号文章采集器采集微信文章怎么样了?
A:关键词批量搜索采集
可以批量粘贴关键词搜索,选择采集content日期,可以查看标题和内容伪原创,识别是否文章原创,支持文章回回网站
对于一些 SEO,它在标题或内容中添加了随机插入长尾词。可以下载带索引的长尾词,导入流量
B:指定公众号采集
您可以通过公众号排行榜搜索您所在行业的公众号,也可以自己搜索,粘贴进去。其他功能同第一条,依然可用。例如,您是一家教育或税务公司,以及专业的 SEO。使用此功能获取流量或优质原创文章
C: Hot Industry采集
按行业分类采集,功能同第一项
D:自动采集release
自动采集发布依然是批量搜索关键词,其他功能未在图中展示。重点是有好处。不同的关键词或微信采集可以选择全选,他会按顺序继续采集,例如:你有10列,那么每列可以设置一个与该列相关的词采集入库,当第一个采集完成后,他会自动进入第二个采集Warehousing。
如何采集其他微信公众号文章到微信编辑器?
方法/步骤
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。
小蚂蚁编辑器采集文章有两个功能入口:
编辑菜单右上角1.采集文章按钮;
2.采集文章右侧功能按钮底部的按钮
采集完成后可以编辑修改文章。
通过以上内容,我们已经了解了公众号文章采集器的特点和功能。可见公众号文章采集器的功能非常强大和全面。 查看全部
通过关键词采集文章采集api(
云采集5000台云,简单上手流程图)
云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步数据。
Smart采集
提供多种网页采集策略和配套资源,帮助采集整个流程实现数据的完整性和稳定性。
适用于全网
看到就选,不管是文字图片还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求。
海量模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
简单易用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库。
稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可以灵活调度任务,平滑抓取海量数据。
可视化点击,轻松上手
流程图模式:只需根据软件提示点击页面,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
支持多种数据导出方式
采集结果可以本地导出,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
功能强大,提供企业级服务
优采云采集器提供了丰富的采集功能,无论是采集stability还是采集efficiency,都能满足个人、团队和企业采集的需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、SKU智能识别、电商大图等
公众号文章采集器采集微信文章怎么样了?
A:关键词批量搜索采集
可以批量粘贴关键词搜索,选择采集content日期,可以查看标题和内容伪原创,识别是否文章原创,支持文章回回网站
对于一些 SEO,它在标题或内容中添加了随机插入长尾词。可以下载带索引的长尾词,导入流量
B:指定公众号采集
您可以通过公众号排行榜搜索您所在行业的公众号,也可以自己搜索,粘贴进去。其他功能同第一条,依然可用。例如,您是一家教育或税务公司,以及专业的 SEO。使用此功能获取流量或优质原创文章
C: Hot Industry采集
按行业分类采集,功能同第一项
D:自动采集release
自动采集发布依然是批量搜索关键词,其他功能未在图中展示。重点是有好处。不同的关键词或微信采集可以选择全选,他会按顺序继续采集,例如:你有10列,那么每列可以设置一个与该列相关的词采集入库,当第一个采集完成后,他会自动进入第二个采集Warehousing。
如何采集其他微信公众号文章到微信编辑器?
方法/步骤
电脑用户可以直接在浏览器地址栏中选择并复制文章链接。
小蚂蚁编辑器采集文章有两个功能入口:
编辑菜单右上角1.采集文章按钮;
2.采集文章右侧功能按钮底部的按钮
采集完成后可以编辑修改文章。
通过以上内容,我们已经了解了公众号文章采集器的特点和功能。可见公众号文章采集器的功能非常强大和全面。
通过关键词采集文章采集api(谷歌高级语法深入探索、利用chrome浏览器分析网站接口的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-28 06:07
这是一篇高级搜索文章文章
本文文章的内容包括以下四个方面
深入探索谷歌高级语法,用谷歌科学上网,用chrome浏览器分析网站界面方法,简单爬虫分析。
您通常使用搜索引擎做什么?作为黑客必用的浏览器,谷歌搜索引擎自然拥有更多强大的功能。让我们来探索一下 Google 搜索引擎可以做什么。
了解 Google 高级语法
在上一篇文章中,我们初步探讨了搜索引擎的语法。在本文中,我们还通过示例来了解更多信息。
(1),我们关键词的排列组合
使用“|”把关键词分开来表达或
的意思
示例:
通过这种方式,您可以搜索收录“身份证号”或“学号”的信息。
用空格或点(“.”)分隔关键词以表达sum的含义。
示例:
搜索的内容收录身份证号和学号。
(2),需要掌握的高级算子
注意:必须在高级运算符和关键词 之间添加英文冒号(“:”)。英文冒号和中文冒号的区别是可能的,但肉眼很难区分。所以一定要在英文输入状态下输入这个冒号。
使用网站关键字来定位网址
在介绍章节中详细使用了站点关键字。此处不再赘述。
示例:
使用intitle查询标签中的关键字
什么是标题?
红框是标题。一般来说,这个标题表示当前页面是什么功能,所以如果你需要找一个特定功能的东西,你可以使用Intitle。
使用inurl关键字表示在url(链接)中找到关键词
那么,什么是网址?以上图为例:
这是网址。那么我们来验证一下这个关键字的有效性。
在这个例子中,我使用了两个关键字来限制在某个 URL 下的 URL 中收录登录的链接的搜索。可以看到,关键词的组合是用空格隔开的,类似于我们上面提到的关键词的排列组合。
使用 intext 表达式在网页内容中查找字符串
那么,什么是网页内容?整个网站都在说,就像写文章的主要内容一样。
示例:
使用以上四个关键字及其排列组合,我们已经可以非常准确地找到我们的关键词。现在,让我们谈谈不太常用的关键字。
使用 FileType 搜索指定类型的文件
示例:
使用股票搜索公司股票信息
当然,在谷歌的高级语法中,这些关键词只是杯水车薪,但已经可以满足我们的日常生活。如果有朋友想深入了解,我可以推荐一本叫《Google Hacking Technical Manual》的书。
使用谷歌科学上网
在工作和学习中,我们经常需要通过科学上网来查找相对较新的信息。除了谷歌镜像站本身的不稳定性,还需要准备一个应急的科学上网方法。将我的科学上网方法分享给大家。
我把插件和操作指南放在压缩包里了。下载后,按照里面的教程操作即可。
链接:
提取码:y3zu
失败联系我补
因为这个插件是付费的,为了避免广告嫌疑,不建议大家使用这个插件。说一下安装过程。从百度网盘下载压缩包后,解压,然后打开如下:
然后打开你的chrome浏览器,在浏览器中输入扩展的URL:chrome://extensions/
然后放
将此文件直接拖到页面上。安装完成后需要注册,然后登录。
共有三种模式,可根据个人喜好进行调整。
实际上已经讨论了使用 Google Chrome 搜索高级内容。但是我一开始问的问题,搜索引擎可以做的远不止这些。我们可以使用浏览器提取网站界面,方便我们的资源采集。
使用浏览器分析网站interface
先说网站interface。一个网站实际上分为前端和后端。前端一般用于数据渲染,即将一堆看不懂的数据以网页的形式展示出来。然后后端提供这些数据。提供的方法是使用的接口的方法。今天我就以链家为例来分析一下界面。由于分析界面我用firefox比较多,这里就用firefox来演示
首先打开链家首页,然后点击alt键,选择Tools->Web Developer->Web Console
刷新网站,可以发现前端向后端发起了很多请求,点击其中一个:
这里是请求地址,get是请求方法
选择响应按钮,可以发现后端向前端发送了大量数据。这时候我们抓到了一个接口。但是这个接口是否真的有用取决于你采集的资源。这里只是给大家介绍一下这样的技术。有想了解的小伙伴可以关注本公众号后面的文章。
对爬虫的简单理解
首先要注意的是,爬虫只能获取公开共享的东西。
爬虫也称为网络机器人。为什么叫这个名字,因为爬虫可以代替人做很多重复的操作。举个例子,这个网站采集了各种百度网盘链接,但是每个页面只有一个网盘链接,而且它们几乎放在每个页面的相同位置,结构相似。如果每个链接都是人为的一点一点的,然后把百度网盘的链接一一保存,是不是太麻烦了?这时候如果你使用爬虫,合理编写代码,就可以自动采集百度网盘链接资源了。
爬虫通常由程序开发人员使用代码来模拟人工过程来实现。同时,使用线程池技术可以大大提高工作效率。从程序开发的角度来说,这对于没有学过编程的同学来说,难度有点大。但这并不意味着非程序员不能使用爬虫。网上也有一些爬虫软件,但这些软件往往缺乏定制能力,不能满足爬虫的真正需求。所以,看到这里的同学,还是建议大家学习python编程语言,写爬虫好用。
感谢您的观看,希望对您有所帮助。 查看全部
通过关键词采集文章采集api(谷歌高级语法深入探索、利用chrome浏览器分析网站接口的方法)
这是一篇高级搜索文章文章
本文文章的内容包括以下四个方面
深入探索谷歌高级语法,用谷歌科学上网,用chrome浏览器分析网站界面方法,简单爬虫分析。
您通常使用搜索引擎做什么?作为黑客必用的浏览器,谷歌搜索引擎自然拥有更多强大的功能。让我们来探索一下 Google 搜索引擎可以做什么。
了解 Google 高级语法
在上一篇文章中,我们初步探讨了搜索引擎的语法。在本文中,我们还通过示例来了解更多信息。
(1),我们关键词的排列组合
使用“|”把关键词分开来表达或
的意思
示例:
通过这种方式,您可以搜索收录“身份证号”或“学号”的信息。
用空格或点(“.”)分隔关键词以表达sum的含义。
示例:
搜索的内容收录身份证号和学号。
(2),需要掌握的高级算子
注意:必须在高级运算符和关键词 之间添加英文冒号(“:”)。英文冒号和中文冒号的区别是可能的,但肉眼很难区分。所以一定要在英文输入状态下输入这个冒号。
使用网站关键字来定位网址
在介绍章节中详细使用了站点关键字。此处不再赘述。
示例:
使用intitle查询标签中的关键字
什么是标题?
红框是标题。一般来说,这个标题表示当前页面是什么功能,所以如果你需要找一个特定功能的东西,你可以使用Intitle。
使用inurl关键字表示在url(链接)中找到关键词
那么,什么是网址?以上图为例:
这是网址。那么我们来验证一下这个关键字的有效性。
在这个例子中,我使用了两个关键字来限制在某个 URL 下的 URL 中收录登录的链接的搜索。可以看到,关键词的组合是用空格隔开的,类似于我们上面提到的关键词的排列组合。
使用 intext 表达式在网页内容中查找字符串
那么,什么是网页内容?整个网站都在说,就像写文章的主要内容一样。
示例:
使用以上四个关键字及其排列组合,我们已经可以非常准确地找到我们的关键词。现在,让我们谈谈不太常用的关键字。
使用 FileType 搜索指定类型的文件
示例:
使用股票搜索公司股票信息
当然,在谷歌的高级语法中,这些关键词只是杯水车薪,但已经可以满足我们的日常生活。如果有朋友想深入了解,我可以推荐一本叫《Google Hacking Technical Manual》的书。
使用谷歌科学上网
在工作和学习中,我们经常需要通过科学上网来查找相对较新的信息。除了谷歌镜像站本身的不稳定性,还需要准备一个应急的科学上网方法。将我的科学上网方法分享给大家。
我把插件和操作指南放在压缩包里了。下载后,按照里面的教程操作即可。
链接:
提取码:y3zu
失败联系我补
因为这个插件是付费的,为了避免广告嫌疑,不建议大家使用这个插件。说一下安装过程。从百度网盘下载压缩包后,解压,然后打开如下:
然后打开你的chrome浏览器,在浏览器中输入扩展的URL:chrome://extensions/
然后放
将此文件直接拖到页面上。安装完成后需要注册,然后登录。
共有三种模式,可根据个人喜好进行调整。
实际上已经讨论了使用 Google Chrome 搜索高级内容。但是我一开始问的问题,搜索引擎可以做的远不止这些。我们可以使用浏览器提取网站界面,方便我们的资源采集。
使用浏览器分析网站interface
先说网站interface。一个网站实际上分为前端和后端。前端一般用于数据渲染,即将一堆看不懂的数据以网页的形式展示出来。然后后端提供这些数据。提供的方法是使用的接口的方法。今天我就以链家为例来分析一下界面。由于分析界面我用firefox比较多,这里就用firefox来演示
首先打开链家首页,然后点击alt键,选择Tools->Web Developer->Web Console
刷新网站,可以发现前端向后端发起了很多请求,点击其中一个:
这里是请求地址,get是请求方法
选择响应按钮,可以发现后端向前端发送了大量数据。这时候我们抓到了一个接口。但是这个接口是否真的有用取决于你采集的资源。这里只是给大家介绍一下这样的技术。有想了解的小伙伴可以关注本公众号后面的文章。
对爬虫的简单理解
首先要注意的是,爬虫只能获取公开共享的东西。
爬虫也称为网络机器人。为什么叫这个名字,因为爬虫可以代替人做很多重复的操作。举个例子,这个网站采集了各种百度网盘链接,但是每个页面只有一个网盘链接,而且它们几乎放在每个页面的相同位置,结构相似。如果每个链接都是人为的一点一点的,然后把百度网盘的链接一一保存,是不是太麻烦了?这时候如果你使用爬虫,合理编写代码,就可以自动采集百度网盘链接资源了。
爬虫通常由程序开发人员使用代码来模拟人工过程来实现。同时,使用线程池技术可以大大提高工作效率。从程序开发的角度来说,这对于没有学过编程的同学来说,难度有点大。但这并不意味着非程序员不能使用爬虫。网上也有一些爬虫软件,但这些软件往往缺乏定制能力,不能满足爬虫的真正需求。所以,看到这里的同学,还是建议大家学习python编程语言,写爬虫好用。
感谢您的观看,希望对您有所帮助。
通过关键词采集文章采集api(16058322用户行为分析帮助分析用户怎么流失、在哪里流失)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-08-28 06:04
16058322 王超
一、先来了解一下用户行为分析
1.为什么要做用户行为分析?
因为只有做用户行为分析,才能知道网站用户各种浏览、点击、购买背后的用户画像和商业真相。
简单来说,主要的分析方式是关注churn,尤其是有转化需求的网站。我们希望用户不要迷路,上来后不要离开。和很多O2O产品一样,用户上来就有很多补贴;一旦钱花光了,用户就没了。这样的产品或商业模式并不好。我们希望用户能真正发现平台的价值,不断地来,不要失去。
2.用户行为分析有助于分析用户流失的方式、流失的原因以及流失的位置
比如最简单的搜索行为:某个ID什么时候被搜索到关键词,浏览过哪个页面,什么结果,什么时候购买了这个ID,这整个行为是非常重要的。如果他对中间的搜索结果不满意,他肯定会再次搜索并用别的东西替换关键词,然后才能找到结果。
3.用户行为分析还能做什么?
当你有大量的用户行为数据并定义事件后,你可以将用户数据按小时、天或用户级别或事件级别拆分成表格。这个表是干什么用的?一是了解用户最简单的事件,例如登录或购买,还要了解哪些是优质用户,哪些是即将流失的客户。这样的数据每天或每小时都可以看到。 ,
二、埋点的作用
1.大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求量身定制和优化自己这就是大数据的价值。而对这些信息的采集和分析无法绕过“埋点”
2.沉点是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如:颜色、车牌号、车型等等,还要采集车辆的行为,比如:是否闯红灯,是否按线,车速多少,司机开车时是否接电话等等,各埋点就像一个摄像头,采集用户行为数据,数据经过多维交叉分析,真正还原用户使用场景,挖掘用户需求,从而提升用户全生命周期的最大价值。
三、bury 点类型
根据埋点工具:代码埋点、视觉埋点、‘无埋点’
按埋点位置分:前端/客户端埋点、后端/服务器端埋点
1.Full-埋点(“也称无埋点”):通过SDK采集页面上所有控件的运行数据,通过“统计数据过滤器”。
示例·应用场景
主要应用于简单的页面,如短期事件中的落地页/主题页,需要快速衡量点击分布效果等。
2.Visualization Buried Point:嵌入SDK,可视化圆选择定义事件
<p>为了方便产品和操作,同学们可以直接在页面上简单圈出跟踪用户行为(定义事件),只需采集click(点击)操作,节省开发时间。就像卫星航拍一样,不需要安装摄像头,数据量小,支持局部区域的信息采集,所以JS可视化埋点更适合以下场景: 查看全部
通过关键词采集文章采集api(16058322用户行为分析帮助分析用户怎么流失、在哪里流失)
16058322 王超
一、先来了解一下用户行为分析
1.为什么要做用户行为分析?
因为只有做用户行为分析,才能知道网站用户各种浏览、点击、购买背后的用户画像和商业真相。
简单来说,主要的分析方式是关注churn,尤其是有转化需求的网站。我们希望用户不要迷路,上来后不要离开。和很多O2O产品一样,用户上来就有很多补贴;一旦钱花光了,用户就没了。这样的产品或商业模式并不好。我们希望用户能真正发现平台的价值,不断地来,不要失去。
2.用户行为分析有助于分析用户流失的方式、流失的原因以及流失的位置
比如最简单的搜索行为:某个ID什么时候被搜索到关键词,浏览过哪个页面,什么结果,什么时候购买了这个ID,这整个行为是非常重要的。如果他对中间的搜索结果不满意,他肯定会再次搜索并用别的东西替换关键词,然后才能找到结果。
3.用户行为分析还能做什么?
当你有大量的用户行为数据并定义事件后,你可以将用户数据按小时、天或用户级别或事件级别拆分成表格。这个表是干什么用的?一是了解用户最简单的事件,例如登录或购买,还要了解哪些是优质用户,哪些是即将流失的客户。这样的数据每天或每小时都可以看到。 ,
二、埋点的作用
1.大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求量身定制和优化自己这就是大数据的价值。而对这些信息的采集和分析无法绕过“埋点”
2.沉点是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如:颜色、车牌号、车型等等,还要采集车辆的行为,比如:是否闯红灯,是否按线,车速多少,司机开车时是否接电话等等,各埋点就像一个摄像头,采集用户行为数据,数据经过多维交叉分析,真正还原用户使用场景,挖掘用户需求,从而提升用户全生命周期的最大价值。
三、bury 点类型
根据埋点工具:代码埋点、视觉埋点、‘无埋点’
按埋点位置分:前端/客户端埋点、后端/服务器端埋点
1.Full-埋点(“也称无埋点”):通过SDK采集页面上所有控件的运行数据,通过“统计数据过滤器”。
示例·应用场景
主要应用于简单的页面,如短期事件中的落地页/主题页,需要快速衡量点击分布效果等。
2.Visualization Buried Point:嵌入SDK,可视化圆选择定义事件
<p>为了方便产品和操作,同学们可以直接在页面上简单圈出跟踪用户行为(定义事件),只需采集click(点击)操作,节省开发时间。就像卫星航拍一样,不需要安装摄像头,数据量小,支持局部区域的信息采集,所以JS可视化埋点更适合以下场景:
织梦治理员之家专注与织梦CMS方面的研究(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-23 06:04
这一段信息会出现在文章首;
织梦cms 是一个优秀的cms建站程序,为广大站长所熟知。同类产品中用户最多、口碑最好、开源最强大的cms程序、织梦管理员之家。专注于织梦cms的研究,开发的织梦采集侠与织梦cms的主要版本非常兼容。
随着织梦采集侠V2.2版本的发布,插件功能也越来越完善。新增RSS采集和页面监控采集功能。这两个新功能弥补了关键词采集的不足。您只需要设置监控页面和文章URL规则即可针对采集某个站点、某个栏目的内容、织梦采集侠文字识别系统的正文部分进行识别并解压,无需过多设置即可轻松采集到需要的内容。
为采集写采集规则的时代即将成为过去,虽然织梦采集侠的定向采集功能还有很多不足,不是很好采集到文章出处、作者、发布时间等相关信息。但对于文章标题和正文部分,算法基本可以正确识别和提取,准确率极高。
我们目前正在研究的新算法会比较多个页面以准确找到标题和正文部分,并添加微调功能手动辅助精确定位获取标题和正文。开发完成后,会在下个版本中加入。
采集用途广泛,比如行业网站,需要采集一些行业相关的消息;设计师制作网站,需要采集填写一些内容,提高效率,可以方便直观的查看页面效果和调试;个人站长多做网站栏目,也可能用采集做内容填充等。
织梦采集侠提供多种采集方式,打造全方位采集插件。
(1)根据关键词采集
根据关键词采集的内容非常方便方便,有多套采集引擎规则可以替换插件,可以采集在不同的搜索引擎中搜索结果。
优点:简单方便,只需输入关键词采集
缺点:受搜索结果影响,可能会有一些冗余或相关性较低的内容采集
(2)RSS采集
通过网站提供的RSS地址,采集RSS提供的文章URL页面内容
优点:简单方便,针对采集,只需输入RSS地址采集
缺点:没有明显的缺点,所有内容都是RSS提供的URL地址
(3)page monitoring采集
通过设置监控页面和文章URL规则,可以采集相关内容
优点:简单方便,直接采集,设置监控页面,文章URL可以采集
缺点:受监控页面限制,采集监控页面只收录文章URL
织梦采集侠RSS采集/页面监控采集如何使用:/?p=2109
<p>织梦采集侠不仅可以方便地从采集返回数据,还可以对采集返回的内容进行伪原创和seo优化,提高收录流量率。 查看全部
织梦治理员之家专注与织梦CMS方面的研究(组图)
这一段信息会出现在文章首;
织梦cms 是一个优秀的cms建站程序,为广大站长所熟知。同类产品中用户最多、口碑最好、开源最强大的cms程序、织梦管理员之家。专注于织梦cms的研究,开发的织梦采集侠与织梦cms的主要版本非常兼容。
随着织梦采集侠V2.2版本的发布,插件功能也越来越完善。新增RSS采集和页面监控采集功能。这两个新功能弥补了关键词采集的不足。您只需要设置监控页面和文章URL规则即可针对采集某个站点、某个栏目的内容、织梦采集侠文字识别系统的正文部分进行识别并解压,无需过多设置即可轻松采集到需要的内容。
为采集写采集规则的时代即将成为过去,虽然织梦采集侠的定向采集功能还有很多不足,不是很好采集到文章出处、作者、发布时间等相关信息。但对于文章标题和正文部分,算法基本可以正确识别和提取,准确率极高。
我们目前正在研究的新算法会比较多个页面以准确找到标题和正文部分,并添加微调功能手动辅助精确定位获取标题和正文。开发完成后,会在下个版本中加入。
采集用途广泛,比如行业网站,需要采集一些行业相关的消息;设计师制作网站,需要采集填写一些内容,提高效率,可以方便直观的查看页面效果和调试;个人站长多做网站栏目,也可能用采集做内容填充等。
织梦采集侠提供多种采集方式,打造全方位采集插件。
(1)根据关键词采集
根据关键词采集的内容非常方便方便,有多套采集引擎规则可以替换插件,可以采集在不同的搜索引擎中搜索结果。
优点:简单方便,只需输入关键词采集
缺点:受搜索结果影响,可能会有一些冗余或相关性较低的内容采集
(2)RSS采集
通过网站提供的RSS地址,采集RSS提供的文章URL页面内容
优点:简单方便,针对采集,只需输入RSS地址采集
缺点:没有明显的缺点,所有内容都是RSS提供的URL地址
(3)page monitoring采集
通过设置监控页面和文章URL规则,可以采集相关内容
优点:简单方便,直接采集,设置监控页面,文章URL可以采集
缺点:受监控页面限制,采集监控页面只收录文章URL
织梦采集侠RSS采集/页面监控采集如何使用:/?p=2109
<p>织梦采集侠不仅可以方便地从采集返回数据,还可以对采集返回的内容进行伪原创和seo优化,提高收录流量率。
通过关键词采集api和微信文章分析获取公众号历史列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-23 04:02
通过关键词采集文章采集api和微信文章分析,获取公众号订阅号历史列表,是分析业务的入门基础!今天从以下5个方面进行说明:1.关键词采集接口,2.历史文章列表,3.公众号历史文章采集,4.公众号文章分析,5.漏斗分析总体架构:登录微信公众平台-获取公众号配置信息微信公众号配置信息2.关键词采集接口,3.历史文章列表采集:多次提取公众号历史文章列表的情况多次提取公众号历史文章列表:4.公众号文章分析:从每篇文章分析哪些因素5.漏斗分析:从两个指标对比一下以下7种数据采集方式:关键词采集接口,历史文章列表采集接口,公众号文章分析接口,漏斗分析接口,公众号文章分析接口,数据采集接口,接入服务接口。
一、关键词采集接口首先可以采用文本分析的方式进行关键词分析,这里以多次提取公众号历史文章列表来进行分析,但由于api大多数提供的txt文件为json格式的,所以本分析采用json格式,所以无需另外下载。
1、关键词采集接口#获取微信公众号历史文章列表demospider。pythondemo_num_api。py#采集1亿多个微信公众号,根据任意txt文件重新获取apikeyvillamnoset:16018002#开放的接口,可以用来抓取文本apikeyspider。pythondemo_num_api。
py#使用python3demo_num_api。py#多次提取公众号历史文章列表demo_spider_map如下图所示,同一个接口的post请求数量均设置为1,去除不必要的数据demo_content_post1=spider。pythondemo_num_api。py#使用python3demo_num_api。
py#可以看到任意一个接口的接口数量都设置为1demo_spider_map然后使用api_get_post来提取请求url,可以使用以下3种api:。
1、.douban
2、.,
3、douban。com。douban。com。douban。com#查询pythonpython_api。py#提取url可以使用以下3种方式:①alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#采取对douban。
com。douban。com。douban。com。douban。com的下标排序,提取url为1-50的链接demo_spider_map②alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#提取url。 查看全部
通过关键词采集api和微信文章分析获取公众号历史列表
通过关键词采集文章采集api和微信文章分析,获取公众号订阅号历史列表,是分析业务的入门基础!今天从以下5个方面进行说明:1.关键词采集接口,2.历史文章列表,3.公众号历史文章采集,4.公众号文章分析,5.漏斗分析总体架构:登录微信公众平台-获取公众号配置信息微信公众号配置信息2.关键词采集接口,3.历史文章列表采集:多次提取公众号历史文章列表的情况多次提取公众号历史文章列表:4.公众号文章分析:从每篇文章分析哪些因素5.漏斗分析:从两个指标对比一下以下7种数据采集方式:关键词采集接口,历史文章列表采集接口,公众号文章分析接口,漏斗分析接口,公众号文章分析接口,数据采集接口,接入服务接口。
一、关键词采集接口首先可以采用文本分析的方式进行关键词分析,这里以多次提取公众号历史文章列表来进行分析,但由于api大多数提供的txt文件为json格式的,所以本分析采用json格式,所以无需另外下载。
1、关键词采集接口#获取微信公众号历史文章列表demospider。pythondemo_num_api。py#采集1亿多个微信公众号,根据任意txt文件重新获取apikeyvillamnoset:16018002#开放的接口,可以用来抓取文本apikeyspider。pythondemo_num_api。
py#使用python3demo_num_api。py#多次提取公众号历史文章列表demo_spider_map如下图所示,同一个接口的post请求数量均设置为1,去除不必要的数据demo_content_post1=spider。pythondemo_num_api。py#使用python3demo_num_api。
py#可以看到任意一个接口的接口数量都设置为1demo_spider_map然后使用api_get_post来提取请求url,可以使用以下3种api:。
1、.douban
2、.,
3、douban。com。douban。com。douban。com#查询pythonpython_api。py#提取url可以使用以下3种方式:①alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#采取对douban。
com。douban。com。douban。com。douban。com的下标排序,提取url为1-50的链接demo_spider_map②alias=get_urls_and_requests,如果想从get方法返回的对象中提取url或request对象内部的数据的话,需要在代码中指定urlvillamnoset:16018002#提取url。
React使创建交互式UI变得轻而易举|React技术揭秘项目
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-08-20 22:32
React 可以轻松创建交互式 UI。为应用程序的每个状态设计一个简洁的视图。当数据发生变化时,React 可以有效地更新和正确渲染组件。
以声明方式编写 UI 可以使您的代码更可靠且更易于调试。
组件化
创建具有自己状态的组件,然后这些组件形成更复杂的 UI。
组件逻辑是用 JavaScript 而不是模板编写的,因此您可以轻松地在应用程序中传递数据并将状态与 DOM 分离。
一次学习,随处书写
无论您目前使用什么技术栈,您都可以随时引入 React 来开发新功能,而无需重写现有代码。
React 也可以使用 Node 进行服务端渲染,或者使用 React Native 开发原生移动应用。
React相关项目可见:一个揭秘React技术秘密的项目,一个React源代码的自顶向下分析。
编剧
Node.js 库可以通过单个 API 自动化 Chromium、Firefox 和 WebKit。
Playwright 由 Microsoft 创建,是一个开源浏览器自动化框架,可让 JavaScript 工程师在 Chromium、Webkit 和 Firefox 浏览器上测试其 Web 应用程序。
vscode
Visual Studio Code 是一款跨平台编辑器,可在 OS X、Windows 和 Linux 上运行,旨在编写现代网络和云应用程序。
也是当今前端最流行的编辑器!
esbuild
是一个“JavaScript”Bundler打包压缩工具,可以打包分发“JavaScript”和“TypeScript”代码在网页上运行。
esbuild 是一个用 Go 编写的用于打包和压缩 Javascript 代码的工具库。
它最突出的特点是包装速度极快。下图是esbuild和webpack、rollup、Parcel等打包工具打包效率的基准:
vue-element-admin
vue-element-admin 是基于 vue 和 element-ui 的后端前端解决方案。采用最新的前端技术栈,内置i18n国际化解决方案,动态路由,授权验证,提炼典型业务模型,提供丰富的功能组件。可以帮助您快速构建企业级中后端产品原型。我相信无论您有什么需求,这个项目都能帮到您。
edex-ui
具有高级监控和触摸屏支持的跨平台、可定制的科幻终端模拟器。
它深受 DEX-UI 和 TRON Legacy 电影效果的启发。它是一个类似于科幻电脑界面的全屏桌面应用程序。
提供可视化的动态监控系统性能图表、资源列表、触屏键盘等,看起来很高端很高端,还完美支持终端操作,支持Window、macOS、Linux系统。
作为一个从小就喜欢黑科技的猫哥,不忍安装X!
详情请看:对于Win、Mac、Linux、酷极客界面eDEX-UI
next.js
这是一个用于生产环境的 React 框架。
Next.js 为您提供生产环境所需的全部功能和最佳开发体验:包括静态和服务端集成渲染、支持TypeScript、智能打包、路由预取等功能,无需任何配置。
tailwindcss
实用优先的 CSS 框架,用于快速构建自定义用户界面。
您可以在不离开 HTML 的情况下快速创建现代的 网站。
Tailwind CSS 是一个功能类优先的 CSS 框架。它集成了 flex、pt-4、text-center 和 rotate-90 等类。它们可以直接在脚本标记语言中组合以构建任何设计。
终于
平时如何找到好的开源项目,可以看看这篇文章:GitHub上的挖矿神仙秘诀-如何找到优秀的开源项目
初级前端和高级前端不同的主要原因是学习前端所投入的时间和经验不同。其实就是缺乏信息。
如果有一个地方可以快速、好地获取这些高质量的前端信息,将大大缩短从初级到高级的时间。
基于这个初衷,前端GitHub诞生了,一个可以帮助前端开发者节省时间的公众号!
前端GitHub专注于在GitHub上挖掘优秀的前端开源项目,并以话题的形式进行推荐。每个话题大概有10个左右的好项目,每周推送一到三个亮点文章。
不知不觉中,原创文章已经写到第35期了。几乎每篇文章都是毛哥精挑细选的优质开源项目,而且文章中几乎每一个项目都推送了,对前端开发很有帮助。
原创不易,一个高品质的文章需要几个晚上才能让肝脏出来。筛选和写推荐理由需要大量的时间和精力。看完文章后顺手点点赞或转发,给毛哥一个小小的鼓励。
2020中国开发者调查报告来了,扫描二维码或微信搜索“CSDN”公众号,后台回复关键词“开发者”,快速获取完整报告内容!
☞45 岁,2 万亿身价,苹果的人生才刚刚开始☞不爱跳槽、月薪集中在 8K-17k、五成欲晋升为技术Leader|揭晓中国开发者真实现状 查看全部
React使创建交互式UI变得轻而易举|React技术揭秘项目
React 可以轻松创建交互式 UI。为应用程序的每个状态设计一个简洁的视图。当数据发生变化时,React 可以有效地更新和正确渲染组件。
以声明方式编写 UI 可以使您的代码更可靠且更易于调试。
组件化
创建具有自己状态的组件,然后这些组件形成更复杂的 UI。
组件逻辑是用 JavaScript 而不是模板编写的,因此您可以轻松地在应用程序中传递数据并将状态与 DOM 分离。
一次学习,随处书写
无论您目前使用什么技术栈,您都可以随时引入 React 来开发新功能,而无需重写现有代码。
React 也可以使用 Node 进行服务端渲染,或者使用 React Native 开发原生移动应用。
React相关项目可见:一个揭秘React技术秘密的项目,一个React源代码的自顶向下分析。
编剧
Node.js 库可以通过单个 API 自动化 Chromium、Firefox 和 WebKit。
Playwright 由 Microsoft 创建,是一个开源浏览器自动化框架,可让 JavaScript 工程师在 Chromium、Webkit 和 Firefox 浏览器上测试其 Web 应用程序。
vscode
Visual Studio Code 是一款跨平台编辑器,可在 OS X、Windows 和 Linux 上运行,旨在编写现代网络和云应用程序。
也是当今前端最流行的编辑器!
esbuild
是一个“JavaScript”Bundler打包压缩工具,可以打包分发“JavaScript”和“TypeScript”代码在网页上运行。
esbuild 是一个用 Go 编写的用于打包和压缩 Javascript 代码的工具库。
它最突出的特点是包装速度极快。下图是esbuild和webpack、rollup、Parcel等打包工具打包效率的基准:
vue-element-admin
vue-element-admin 是基于 vue 和 element-ui 的后端前端解决方案。采用最新的前端技术栈,内置i18n国际化解决方案,动态路由,授权验证,提炼典型业务模型,提供丰富的功能组件。可以帮助您快速构建企业级中后端产品原型。我相信无论您有什么需求,这个项目都能帮到您。
edex-ui
具有高级监控和触摸屏支持的跨平台、可定制的科幻终端模拟器。
它深受 DEX-UI 和 TRON Legacy 电影效果的启发。它是一个类似于科幻电脑界面的全屏桌面应用程序。
提供可视化的动态监控系统性能图表、资源列表、触屏键盘等,看起来很高端很高端,还完美支持终端操作,支持Window、macOS、Linux系统。
作为一个从小就喜欢黑科技的猫哥,不忍安装X!
详情请看:对于Win、Mac、Linux、酷极客界面eDEX-UI
next.js
这是一个用于生产环境的 React 框架。
Next.js 为您提供生产环境所需的全部功能和最佳开发体验:包括静态和服务端集成渲染、支持TypeScript、智能打包、路由预取等功能,无需任何配置。
tailwindcss
实用优先的 CSS 框架,用于快速构建自定义用户界面。
您可以在不离开 HTML 的情况下快速创建现代的 网站。
Tailwind CSS 是一个功能类优先的 CSS 框架。它集成了 flex、pt-4、text-center 和 rotate-90 等类。它们可以直接在脚本标记语言中组合以构建任何设计。
终于
平时如何找到好的开源项目,可以看看这篇文章:GitHub上的挖矿神仙秘诀-如何找到优秀的开源项目
初级前端和高级前端不同的主要原因是学习前端所投入的时间和经验不同。其实就是缺乏信息。
如果有一个地方可以快速、好地获取这些高质量的前端信息,将大大缩短从初级到高级的时间。
基于这个初衷,前端GitHub诞生了,一个可以帮助前端开发者节省时间的公众号!
前端GitHub专注于在GitHub上挖掘优秀的前端开源项目,并以话题的形式进行推荐。每个话题大概有10个左右的好项目,每周推送一到三个亮点文章。
不知不觉中,原创文章已经写到第35期了。几乎每篇文章都是毛哥精挑细选的优质开源项目,而且文章中几乎每一个项目都推送了,对前端开发很有帮助。
原创不易,一个高品质的文章需要几个晚上才能让肝脏出来。筛选和写推荐理由需要大量的时间和精力。看完文章后顺手点点赞或转发,给毛哥一个小小的鼓励。
2020中国开发者调查报告来了,扫描二维码或微信搜索“CSDN”公众号,后台回复关键词“开发者”,快速获取完整报告内容!
☞45 岁,2 万亿身价,苹果的人生才刚刚开始☞不爱跳槽、月薪集中在 8K-17k、五成欲晋升为技术Leader|揭晓中国开发者真实现状
基于url构建request对象的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-18 21:15
问题描述
默认情况下,RedisSpider启动时,会先读取redis中的spidername:start_urls,如果有值,则根据url构造请求对象。
目前的要求是基于具体的关键词采集。
例如:目标站点有一个接口,根据post请求参数返回结果。
那么,在这种情况下,构造请求的主要变换是请求体,API接口保持不变。
原来通过 URL 构建请求的策略不再适用。
所以,这个时候我们需要重写对应的方法。
重写方法
爬虫类需要继承自scrapy_redis.spiders.RedisSpider
开始请求
我需要从数据库中获取关键词数据,然后使用关键词构建请求。
这时候我们把关键词当作start_url,把关键词push添加到redis中
首先写一个方法将单个关键词push发送给redis
push_data_to_redis
def push_data_to_redis(self, data):
"""将数据push到redis"""
# 序列化,data可能是字典
data = pickle.dumps(data)
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
self.server.spush(self.redis_key, data) if use_set else self.server.lpush(self.redis_key, data)
如果self.redis_key没有做任何声明,它会默认为spidername:start_urls
然后重写start_request
def start_requests(self):
if self.isproducer():
# get_keywords 从数据库读关键词的方法
items = self.get_keywords()
for item in items:
self.push_data_to_redis(item)
return super(DoubanBookMetaSpider, self).start_requests()
上面代码中有一个self.isproducer,这个方法是用来检测当前程序是否是producer,即提供关键词给redis
生产者
# (...)
def __init__(self, *args, **kwargs):
self.is_producer = kwargs.pop('producer', None)
super(DoubanBookMetaSpider, self).__init__()
def isproducer(self):
return self.is_producer is not None
# (...)
此方法需要配合scrapy命令行使用,例如:
// 启动一个生产者,producer的参数任意,只要填写了就是True
scrapy crawl myspider -a producer=1
// 启动一个消费者
scrapy crawl myspider
更多关于scrapy命令行的参数,参考文档:
make_request_from_data
在RedisMixin中查看make_request_from_data
方法注释信息:
从来自 Redis 的数据返回一个 Request 实例。
根据来自redis的数据返回一个Request对象
默认情况下,数据是经过编码的 URL。您可以覆盖此方法以
提供您自己的消息解码。
默认情况下,数据是经过编码的 URL 链接。您可以重写此方法以提供您自己的消息解码。
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
将数据转换为字符串(网站link字符串),然后调用make_requests_from_url通过url构造请求对象
数据从哪里来?
查看RedisMixin的next_request方法
由此可知,数据是从redis中弹出的。之前我们序列化数据并push进去,现在我们pop出来,我们反序列化它并依赖它来构建请求对象
重写 make_request_from_data
def make_request_from_data(self, data):
data = pickle.loads(data, encoding=self.redis_encoding)
return self.make_request_from_book_info(data)
在这个例子中,构造请求对象的方法是self.make_request_from_book_info。在实际开发中,可以根据目标站的请求规则编写请求的构造方法。
最终效果
启动生成器
scrapy crawl myspider -a producer=1
生成器完成所有关键词push后,将转换为消费者并开始消费
在多个节点上启动消费者
scrapy crawl myspider
爬虫的开始总是基于现有数据采集新数据,例如基于列表页中的详情页链接采集detail页数据,基于关键词采集搜索结果, 等等。根据现有数据的不同,启动方式也不同,大体还是一样的。
本文文章由多人发布平台ArtiPub自动发布。 查看全部
基于url构建request对象的方法
问题描述
默认情况下,RedisSpider启动时,会先读取redis中的spidername:start_urls,如果有值,则根据url构造请求对象。
目前的要求是基于具体的关键词采集。
例如:目标站点有一个接口,根据post请求参数返回结果。
那么,在这种情况下,构造请求的主要变换是请求体,API接口保持不变。
原来通过 URL 构建请求的策略不再适用。
所以,这个时候我们需要重写对应的方法。
重写方法
爬虫类需要继承自scrapy_redis.spiders.RedisSpider
开始请求
我需要从数据库中获取关键词数据,然后使用关键词构建请求。
这时候我们把关键词当作start_url,把关键词push添加到redis中
首先写一个方法将单个关键词push发送给redis
push_data_to_redis
def push_data_to_redis(self, data):
"""将数据push到redis"""
# 序列化,data可能是字典
data = pickle.dumps(data)
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
self.server.spush(self.redis_key, data) if use_set else self.server.lpush(self.redis_key, data)
如果self.redis_key没有做任何声明,它会默认为spidername:start_urls
然后重写start_request
def start_requests(self):
if self.isproducer():
# get_keywords 从数据库读关键词的方法
items = self.get_keywords()
for item in items:
self.push_data_to_redis(item)
return super(DoubanBookMetaSpider, self).start_requests()
上面代码中有一个self.isproducer,这个方法是用来检测当前程序是否是producer,即提供关键词给redis
生产者
# (...)
def __init__(self, *args, **kwargs):
self.is_producer = kwargs.pop('producer', None)
super(DoubanBookMetaSpider, self).__init__()
def isproducer(self):
return self.is_producer is not None
# (...)
此方法需要配合scrapy命令行使用,例如:
// 启动一个生产者,producer的参数任意,只要填写了就是True
scrapy crawl myspider -a producer=1
// 启动一个消费者
scrapy crawl myspider
更多关于scrapy命令行的参数,参考文档:
make_request_from_data
在RedisMixin中查看make_request_from_data
方法注释信息:
从来自 Redis 的数据返回一个 Request 实例。
根据来自redis的数据返回一个Request对象
默认情况下,数据是经过编码的 URL。您可以覆盖此方法以
提供您自己的消息解码。
默认情况下,数据是经过编码的 URL 链接。您可以重写此方法以提供您自己的消息解码。
def make_request_from_data(self, data):
url = bytes_to_str(data, self.redis_encoding)
return self.make_requests_from_url(url)
将数据转换为字符串(网站link字符串),然后调用make_requests_from_url通过url构造请求对象
数据从哪里来?
查看RedisMixin的next_request方法
由此可知,数据是从redis中弹出的。之前我们序列化数据并push进去,现在我们pop出来,我们反序列化它并依赖它来构建请求对象
重写 make_request_from_data
def make_request_from_data(self, data):
data = pickle.loads(data, encoding=self.redis_encoding)
return self.make_request_from_book_info(data)
在这个例子中,构造请求对象的方法是self.make_request_from_book_info。在实际开发中,可以根据目标站的请求规则编写请求的构造方法。
最终效果
启动生成器
scrapy crawl myspider -a producer=1
生成器完成所有关键词push后,将转换为消费者并开始消费
在多个节点上启动消费者
scrapy crawl myspider
爬虫的开始总是基于现有数据采集新数据,例如基于列表页中的详情页链接采集detail页数据,基于关键词采集搜索结果, 等等。根据现有数据的不同,启动方式也不同,大体还是一样的。
本文文章由多人发布平台ArtiPub自动发布。
通过关键词采集文章采集api获取文章(图)!
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-08-15 21:00
通过关键词采集文章采集api获取文章关键词后在技术支持公众号中发送关键词获取api,获取后可使用api接口第三方平台提供的api接口(百度、google、必应、神马等)对接后,分享给需要的人需要的关键词号,成功后即可获取到原始文章链接使用ss+snippetspost发送json存储到数据库对接完毕!。
在网上采集一些手机号码,然后发送到一个图片地址上面,拼接上网址就可以了,
百度搜索就有ip采集代码,搜索网络获取ip,然后把代码放在php_ftp中,图片中间的加上url,php直接访问就可以了,网址是:4452.txt,
没人有好的免费方法吗?我这里有一份原创文章数据采集,采集方法详细,
采集api免费获取还要花钱?
可以采集视频,但是链接需要大家互传。
百度
360采集可以采集,比如你给我发些字幕视频,我也给你采。
搜狐新闻网,
采集阿里大文娱的二维码,把这些视频放到云上面大家自己下载。看到好多云都不是花钱就可以搞定的,全是骗子骗钱。
googleapi
闲鱼大把,因为赚的是网络流量钱,收益来源于粉丝或者用户,问题是涉及机密,谁知道传到你手里有木有。图片采集,可以卖。国内搜索引擎经常收费也不推荐,收入不稳定。详情采集,可以卖。其他,请视自己情况而定。 查看全部
通过关键词采集文章采集api获取文章(图)!
通过关键词采集文章采集api获取文章关键词后在技术支持公众号中发送关键词获取api,获取后可使用api接口第三方平台提供的api接口(百度、google、必应、神马等)对接后,分享给需要的人需要的关键词号,成功后即可获取到原始文章链接使用ss+snippetspost发送json存储到数据库对接完毕!。
在网上采集一些手机号码,然后发送到一个图片地址上面,拼接上网址就可以了,
百度搜索就有ip采集代码,搜索网络获取ip,然后把代码放在php_ftp中,图片中间的加上url,php直接访问就可以了,网址是:4452.txt,
没人有好的免费方法吗?我这里有一份原创文章数据采集,采集方法详细,
采集api免费获取还要花钱?
可以采集视频,但是链接需要大家互传。
百度
360采集可以采集,比如你给我发些字幕视频,我也给你采。
搜狐新闻网,
采集阿里大文娱的二维码,把这些视频放到云上面大家自己下载。看到好多云都不是花钱就可以搞定的,全是骗子骗钱。
googleapi
闲鱼大把,因为赚的是网络流量钱,收益来源于粉丝或者用户,问题是涉及机密,谁知道传到你手里有木有。图片采集,可以卖。国内搜索引擎经常收费也不推荐,收入不稳定。详情采集,可以卖。其他,请视自己情况而定。
有没有高效又傻瓜一点的爬虫采集数据工具?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-08-15 07:07
有没有什么高效傻瓜式爬虫采集data 工具?
不管你会不会写代码,都可以试试之前嗅探过的ForeSpider爬虫。因为ForeSpider data采集系统是可视化万能爬虫,如果不想写代码,可以可视化爬取数据。
对于一些高难度的网站,有很多反爬虫措施。可以使用 ForeSpider 内置的爬虫脚本语言系统。几行代码可以从采集 到非常难的网站。比如国家自然科学基金网站,国家企业信息公示系统等等,最难的网站一点问题都没有。
在通用爬虫中,ForeSpider爬虫拥有最强的采集速度和采集能力。支持登录、Cookie、Post、https、验证码、JS、Ajax、关键词search等技术。 采集、采集效率在普通台式机上可以达到每天500万条数据。这个采集速度是通用爬虫的8到10倍。
对于1000网站的需求,ForeSpider爬虫可以在规则模板固定后开始计时采集。支持多次数据清洗。
针对关键词search的需求,ForeSpider爬虫支持关键词搜索和数据挖掘功能。自带关键词库和数据挖掘字典,可以有效采集关键词相关内容。
优采云采集器可以对采集网站数据进行简单的设置,包括文本、图片、文档等数据,可以对数据进行分析、处理和发布。
抓取网址信息的规则是:(1)URL采集Rules; (2)内容采集Rules; (3)Content 发布规则.
优采云采集器简单易用,目前有超过10万用户使用。
目前优采云有一个工具触摸精灵,主要用于抓取Android应用信息。
当然有。下面我简单介绍3个非常好的爬虫数据采集工具,分别是优采云、优采云和优采云。对于大部分网络(网页)数据,这3款软件都可以轻松采集,无需写一行代码,感兴趣的朋友可以试试:
优采云采集器
这是一个免费的跨平台爬虫数据采集工具。它完全免费供个人使用。基于人工智能技术,可以自动识别网页(包括表格、列表等)中的元素和内容,并支持自动翻页和文件导出功能,使用非常方便。先简单介绍一下这个软件的安装和使用:
1. 首先安装优采云采集器,这个可以在官网直接下载,如下,每个平台都有版本,选择适合自己平台的即可:
2.安装完成后,打开软件,主界面如下,这里直接输入需要采集的网页地址,软件会自动识别网页中的数据,试试翻页功能:
以兆联招聘数据为例,它会自动识别网页中可以采集的信息,非常方便。也可以自定义采集规则删除不需要的字段:
优采云采集器
这也是一个很好的爬虫数据采集工具。目前主要在windows平台下使用,内置了大量数据采集模板,可以方便的采集天猫、京东等流行的网站,下面我简单介绍一下安装使用本软件:
1.首先安装优采云采集器,这个也可以直接从官网下载,如下,一个exe安装包,直接安装即可:
2.安装完成后,打开软件,主界面如下,然后我们可以直接选择采集方法,新建采集任务(支持批量网页采集) ,自定义采集字段等,非常简单,鼠标点一下,官方还自带入门教程,非常适合初学者学习:
优采云采集器
这也是一个非常不错的Windows平台下的爬虫数据采集工具。基本功能与前两个软件类似。它集成了数据采集、处理、分析和挖掘的全过程。可以轻松采集任何网页,通过分析准确挖掘信息,简单介绍一下这个软件的安装和使用:
1.首先安装优采云采集器,这个可以在官网直接下载,如下,也是exe安装包,双击安装即可:
2.安装完成后,打开软件,主界面如下,然后我们可以直接新建采集任务,设置采集规则,自定义采集字段,所有傻瓜式操作,可以一步步往下。这里官方还自带了入门教程,讲的很详细,很适合初学者学习掌握:
至此,我们已经完成了三个爬虫数据采集工具优采云、优采云和优采云的安装和使用。总的来说,这3款软件都非常不错,只要熟悉使用流程,很快就能掌握。当然,如果熟悉Python等编程语言,也可以通过编程方式实现网络数据爬取,网上也有相关教程。而且资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容对你有帮助,也欢迎大家评论留言补充。
索引器、搜索器和搜索器之间有什么区别?
Indexer(索引器) 索引器允许类或结构的实例以与数组相同的方式进行索引。索引器类似于属性,不同之处在于它们的访问器接受参数。它使得在数组等对象上使用下标成为可能。它提供了一种通过索引访问类的数据信息的便捷方式。搜索器的主要功能是根据用户输入的关键词在索引器形成的倒排列表中进行搜索,同时完成页面与搜索的相关性评估,对输出的结果进行排序,并实现一定的用户相关性反馈机制。 查看全部
有没有高效又傻瓜一点的爬虫采集数据工具?(一)
有没有什么高效傻瓜式爬虫采集data 工具?
不管你会不会写代码,都可以试试之前嗅探过的ForeSpider爬虫。因为ForeSpider data采集系统是可视化万能爬虫,如果不想写代码,可以可视化爬取数据。
对于一些高难度的网站,有很多反爬虫措施。可以使用 ForeSpider 内置的爬虫脚本语言系统。几行代码可以从采集 到非常难的网站。比如国家自然科学基金网站,国家企业信息公示系统等等,最难的网站一点问题都没有。
在通用爬虫中,ForeSpider爬虫拥有最强的采集速度和采集能力。支持登录、Cookie、Post、https、验证码、JS、Ajax、关键词search等技术。 采集、采集效率在普通台式机上可以达到每天500万条数据。这个采集速度是通用爬虫的8到10倍。
对于1000网站的需求,ForeSpider爬虫可以在规则模板固定后开始计时采集。支持多次数据清洗。
针对关键词search的需求,ForeSpider爬虫支持关键词搜索和数据挖掘功能。自带关键词库和数据挖掘字典,可以有效采集关键词相关内容。
优采云采集器可以对采集网站数据进行简单的设置,包括文本、图片、文档等数据,可以对数据进行分析、处理和发布。
抓取网址信息的规则是:(1)URL采集Rules; (2)内容采集Rules; (3)Content 发布规则.
优采云采集器简单易用,目前有超过10万用户使用。
目前优采云有一个工具触摸精灵,主要用于抓取Android应用信息。
当然有。下面我简单介绍3个非常好的爬虫数据采集工具,分别是优采云、优采云和优采云。对于大部分网络(网页)数据,这3款软件都可以轻松采集,无需写一行代码,感兴趣的朋友可以试试:
优采云采集器
这是一个免费的跨平台爬虫数据采集工具。它完全免费供个人使用。基于人工智能技术,可以自动识别网页(包括表格、列表等)中的元素和内容,并支持自动翻页和文件导出功能,使用非常方便。先简单介绍一下这个软件的安装和使用:
1. 首先安装优采云采集器,这个可以在官网直接下载,如下,每个平台都有版本,选择适合自己平台的即可:
2.安装完成后,打开软件,主界面如下,这里直接输入需要采集的网页地址,软件会自动识别网页中的数据,试试翻页功能:
以兆联招聘数据为例,它会自动识别网页中可以采集的信息,非常方便。也可以自定义采集规则删除不需要的字段:
优采云采集器
这也是一个很好的爬虫数据采集工具。目前主要在windows平台下使用,内置了大量数据采集模板,可以方便的采集天猫、京东等流行的网站,下面我简单介绍一下安装使用本软件:
1.首先安装优采云采集器,这个也可以直接从官网下载,如下,一个exe安装包,直接安装即可:
2.安装完成后,打开软件,主界面如下,然后我们可以直接选择采集方法,新建采集任务(支持批量网页采集) ,自定义采集字段等,非常简单,鼠标点一下,官方还自带入门教程,非常适合初学者学习:
优采云采集器
这也是一个非常不错的Windows平台下的爬虫数据采集工具。基本功能与前两个软件类似。它集成了数据采集、处理、分析和挖掘的全过程。可以轻松采集任何网页,通过分析准确挖掘信息,简单介绍一下这个软件的安装和使用:
1.首先安装优采云采集器,这个可以在官网直接下载,如下,也是exe安装包,双击安装即可:
2.安装完成后,打开软件,主界面如下,然后我们可以直接新建采集任务,设置采集规则,自定义采集字段,所有傻瓜式操作,可以一步步往下。这里官方还自带了入门教程,讲的很详细,很适合初学者学习掌握:
至此,我们已经完成了三个爬虫数据采集工具优采云、优采云和优采云的安装和使用。总的来说,这3款软件都非常不错,只要熟悉使用流程,很快就能掌握。当然,如果熟悉Python等编程语言,也可以通过编程方式实现网络数据爬取,网上也有相关教程。而且资料,介绍的很详细,有兴趣的可以搜索一下,希望上面分享的内容对你有帮助,也欢迎大家评论留言补充。
索引器、搜索器和搜索器之间有什么区别?
Indexer(索引器) 索引器允许类或结构的实例以与数组相同的方式进行索引。索引器类似于属性,不同之处在于它们的访问器接受参数。它使得在数组等对象上使用下标成为可能。它提供了一种通过索引访问类的数据信息的便捷方式。搜索器的主要功能是根据用户输入的关键词在索引器形成的倒排列表中进行搜索,同时完成页面与搜索的相关性评估,对输出的结果进行排序,并实现一定的用户相关性反馈机制。
元数据的作用数据中台的构建,需要确保所有的口径一致
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-08-12 22:05
元数据的作用
数据中心的建设需要保证所有的口径一致,必须把原来不一致和重复的指标整理出来整合成一个统一的指标字段(指标管理系统),前提是要搞清楚指标。公司的业务口径、数据来源、计算逻辑。这些东西都是元数据
元数据收录哪些数据
这是一个例子
任务 flow_dws_trd_sku_1d 读取表 dwd 生成汇总表 dws
数据字典描述了数据的结构信息。包括表名、注解信息、输出任务、哪些字段、字段含义、字段类型等
数据血缘关系是指上游表生成哪些下游表,一般用于故障恢复和业务口径的理解。
数据特征表示数据的属性信息,包括存储位置、存储大小、访问流行度、标签、主题域、数据级别(ods/dw/dm)等属性信息。
既然一张表有这么多的信息需要组织和展示,就需要有一个元数据中心来管理它。贯穿公司产品线
行业元数据中心产品
Metacat 支持多数据源,可扩展的架构设计,擅长管理数据字典。
Atlas支持比较完整的数据血缘关系,实时数据血缘关系采集
血缘采集一般通过三种方式:
1.静态SQL解析,不管执行与否,都会解析
2.实时抓取正在执行的SQL,解析执行计划,获取输入表和输出表
3.通过任务日志分析得到执行后的SQL输入表和输出表。每个项目成功执行的SQL,无论是pull还是push,都通过元数据中心解析得到输入表和输出表。
第一种方法面临准确性的问题,因为任务没有执行,SQL是否正确是个问题。第三种方法,虽然是执行后生成血缘关系,可以保证准确,但是时效性比较差,通常需要分析大量的任务日志数据。所以第二种方式是比较理想的实现方式,Atlas就是这样一种实现方式。但是这种方式获取表的特征数据比较困难,比如负责人信息、平台信息等,所以在存储侧边时会出现信息缺失的情况。综上,选择第三种方法,每天t+1次统计成功执行SQL汇总分析血缘关系。血缘关系延迟1天,但侧边资料会完整。并且无需开发钩子或监听器
对于Hive计算引擎,Atlas通过Hook方式实时捕获任务执行计划,获取输入表和输出表,推送给Kafka。一个摄取模块负责将血缘关系写入 JanusGraph 图数据库。然后使用API基于图查询引擎获取血缘关系。对于Spark,Atlas提供了Listener的实现,Sqoop和Flink也有相应的实现。
公司的元数据产品
元数据系统整体分为三大方面:数据的采集、数据的存储、数据的应用。下面简单介绍一下各个功能和实现
采集 数据存储 数据应用 具体场景 血缘关系分析场景
首先解析SQL,以Hive为例。首先定义词法规则和语法规则文件,然后使用Antlr实现SQL词法语法分析,生成AST语法树,遍历AST语法树完成后续操作。 select *的SQL可以被客户端禁止,也可以由服务器解析select *的行为,通过API查询表结构的补充字段。
通过Semantic Analyzer Factory类进行语法分析,然后根据Schema生成执行计划QueryPlan。关于表和列的血缘关系,可以从 LineageInfo 和 LineageLogger 类中得到解决方案。
需要统计的hive操作类型
通过以上操作类型,你可以清楚的看到手表是如何被转移的
元数据显示血缘关系的效果,目前公司只显示血缘关系。
返回的数据结构
其实对于数据血缘关系,如果只做表级血缘关系的话,可以通过关系数据来做。第二阶段的血缘关系改回mysql,因为我们的显示只有上下级,不是全链接图显示。 这也与降低成本有关。
如果使用图形数据库,则将输入信息和输出信息作为点,操作作为边。上面返回的数据其实就是图数据库直接返回的数据。 rid 表示当前点的id信息。
血缘关系还有一个问题。即使你想清理历史边,因为输入输出可能存在很长时间,小时级任务可能有数千条边,所以你需要制定一个清理策略来保存最后N天/N数据端,否则mysql/graph数据库会卡死。
元数据应用对应的原型展示
数据搜索
引文热度
当您不知道手表的主人是谁时,这非常方便。看看谁在使用它,然后问问。
血缘关系
如上
数据地图
如人气所示
数据维护及特点
对于数据特征,数据表的所有者可以修改表的特征信息
生成逻辑
每个业务表都有生成逻辑的展示,从调度系统自动同步
在我们的调度系统中,每个hsql任务都有一个输出表。通过将输出表链接到元数据,两个系统可以串联。
其他功能
公司的元数据和那些缺陷。由于历史原因,无法将表的位置和底层存储关联起来,页面上也没有显示底层存储的位置和hive表的位置。外部表可能经常被没有要构建的表的系统所取代。这个非常重要。我认为在元数据系统之前,必须建立一个建表系统。可以存储权限和标准信息。临时表只能建在测试数据库中。 , 正式表的创建通过系统进行,使信息与实时元数据信息一起统计
问答
参考Are You Hungry元数据实践之路网易元数据中心实践计划 查看全部
元数据的作用数据中台的构建,需要确保所有的口径一致
元数据的作用
数据中心的建设需要保证所有的口径一致,必须把原来不一致和重复的指标整理出来整合成一个统一的指标字段(指标管理系统),前提是要搞清楚指标。公司的业务口径、数据来源、计算逻辑。这些东西都是元数据
元数据收录哪些数据
这是一个例子
任务 flow_dws_trd_sku_1d 读取表 dwd 生成汇总表 dws
数据字典描述了数据的结构信息。包括表名、注解信息、输出任务、哪些字段、字段含义、字段类型等
数据血缘关系是指上游表生成哪些下游表,一般用于故障恢复和业务口径的理解。
数据特征表示数据的属性信息,包括存储位置、存储大小、访问流行度、标签、主题域、数据级别(ods/dw/dm)等属性信息。
既然一张表有这么多的信息需要组织和展示,就需要有一个元数据中心来管理它。贯穿公司产品线
行业元数据中心产品
Metacat 支持多数据源,可扩展的架构设计,擅长管理数据字典。
Atlas支持比较完整的数据血缘关系,实时数据血缘关系采集
血缘采集一般通过三种方式:
1.静态SQL解析,不管执行与否,都会解析
2.实时抓取正在执行的SQL,解析执行计划,获取输入表和输出表
3.通过任务日志分析得到执行后的SQL输入表和输出表。每个项目成功执行的SQL,无论是pull还是push,都通过元数据中心解析得到输入表和输出表。
第一种方法面临准确性的问题,因为任务没有执行,SQL是否正确是个问题。第三种方法,虽然是执行后生成血缘关系,可以保证准确,但是时效性比较差,通常需要分析大量的任务日志数据。所以第二种方式是比较理想的实现方式,Atlas就是这样一种实现方式。但是这种方式获取表的特征数据比较困难,比如负责人信息、平台信息等,所以在存储侧边时会出现信息缺失的情况。综上,选择第三种方法,每天t+1次统计成功执行SQL汇总分析血缘关系。血缘关系延迟1天,但侧边资料会完整。并且无需开发钩子或监听器
对于Hive计算引擎,Atlas通过Hook方式实时捕获任务执行计划,获取输入表和输出表,推送给Kafka。一个摄取模块负责将血缘关系写入 JanusGraph 图数据库。然后使用API基于图查询引擎获取血缘关系。对于Spark,Atlas提供了Listener的实现,Sqoop和Flink也有相应的实现。
公司的元数据产品
元数据系统整体分为三大方面:数据的采集、数据的存储、数据的应用。下面简单介绍一下各个功能和实现
采集 数据存储 数据应用 具体场景 血缘关系分析场景
首先解析SQL,以Hive为例。首先定义词法规则和语法规则文件,然后使用Antlr实现SQL词法语法分析,生成AST语法树,遍历AST语法树完成后续操作。 select *的SQL可以被客户端禁止,也可以由服务器解析select *的行为,通过API查询表结构的补充字段。
通过Semantic Analyzer Factory类进行语法分析,然后根据Schema生成执行计划QueryPlan。关于表和列的血缘关系,可以从 LineageInfo 和 LineageLogger 类中得到解决方案。
需要统计的hive操作类型
通过以上操作类型,你可以清楚的看到手表是如何被转移的
元数据显示血缘关系的效果,目前公司只显示血缘关系。
返回的数据结构
其实对于数据血缘关系,如果只做表级血缘关系的话,可以通过关系数据来做。第二阶段的血缘关系改回mysql,因为我们的显示只有上下级,不是全链接图显示。 这也与降低成本有关。
如果使用图形数据库,则将输入信息和输出信息作为点,操作作为边。上面返回的数据其实就是图数据库直接返回的数据。 rid 表示当前点的id信息。
血缘关系还有一个问题。即使你想清理历史边,因为输入输出可能存在很长时间,小时级任务可能有数千条边,所以你需要制定一个清理策略来保存最后N天/N数据端,否则mysql/graph数据库会卡死。
元数据应用对应的原型展示
数据搜索
引文热度
当您不知道手表的主人是谁时,这非常方便。看看谁在使用它,然后问问。
血缘关系
如上
数据地图
如人气所示
数据维护及特点
对于数据特征,数据表的所有者可以修改表的特征信息
生成逻辑
每个业务表都有生成逻辑的展示,从调度系统自动同步
在我们的调度系统中,每个hsql任务都有一个输出表。通过将输出表链接到元数据,两个系统可以串联。
其他功能
公司的元数据和那些缺陷。由于历史原因,无法将表的位置和底层存储关联起来,页面上也没有显示底层存储的位置和hive表的位置。外部表可能经常被没有要构建的表的系统所取代。这个非常重要。我认为在元数据系统之前,必须建立一个建表系统。可以存储权限和标准信息。临时表只能建在测试数据库中。 , 正式表的创建通过系统进行,使信息与实时元数据信息一起统计
问答
参考Are You Hungry元数据实践之路网易元数据中心实践计划
为什么网络上面这么多的网络舆情监测系统都爬取不到小红书
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-08-12 19:01
最近,编辑收到了很多客户的询问。其中,问得最多的就是你们的在线舆情监测系统采集能不能拿到小红书的数据?小编一惊,于是做了网站定向监控,发现我们公司的系统没有监控小红书的数据,然后跑到公司数据中心询问数据中心负责人。你不是说我们吗?公司系统采集能拿到小红书的数据吗?为什么我的测试中没有数据?数据中心的人给出的答案是这样的:龟网舆情监测系统可以采集到达小红书的全量数据,但评论数据只能是采集的一部分,这与小红书的评论浏览,由于小红书的反扒技术比较强大,我们的时效比较慢,也就是采集的速度可能需要10个小时左右,所有这些都没有放在我们公司的公共数据仓库中。如果有人想使用它,他们仍然可以使用 API 为他实现它。也就是说,龟网舆情监测系统可以采集获取小红书的网络数据。
为什么网上那么多网络舆情监测系统无法抓取小红书的全网数据?搜索引擎收录只能用来补充对小红书网络数据的抓取,并没有这样的数据。因为小红书是国内最好的反扒技术网站,他们的系统可以自动识别爬虫的IP地址,也可以自动识别爬虫等,如果能爬到小红书网站的数据,那么这个舆情监测系统绝对不简单。
在互联网+大数据时代,数据的综合性是最有价值的。一些大数据公司将几年历史的数据存储在互联网上,成为公司发展的基础。它在互联网上非常具有竞争力。目前,很多舆情监测软件厂商都在攻克小红书反爬虫的难点。
网络舆情监测行业任重道远。新技术难开发,成熟技术容易复制,未来可能会有更多的小红书网站出现。网络舆情监测行业的道路是光明还是黑暗? 查看全部
为什么网络上面这么多的网络舆情监测系统都爬取不到小红书
最近,编辑收到了很多客户的询问。其中,问得最多的就是你们的在线舆情监测系统采集能不能拿到小红书的数据?小编一惊,于是做了网站定向监控,发现我们公司的系统没有监控小红书的数据,然后跑到公司数据中心询问数据中心负责人。你不是说我们吗?公司系统采集能拿到小红书的数据吗?为什么我的测试中没有数据?数据中心的人给出的答案是这样的:龟网舆情监测系统可以采集到达小红书的全量数据,但评论数据只能是采集的一部分,这与小红书的评论浏览,由于小红书的反扒技术比较强大,我们的时效比较慢,也就是采集的速度可能需要10个小时左右,所有这些都没有放在我们公司的公共数据仓库中。如果有人想使用它,他们仍然可以使用 API 为他实现它。也就是说,龟网舆情监测系统可以采集获取小红书的网络数据。
为什么网上那么多网络舆情监测系统无法抓取小红书的全网数据?搜索引擎收录只能用来补充对小红书网络数据的抓取,并没有这样的数据。因为小红书是国内最好的反扒技术网站,他们的系统可以自动识别爬虫的IP地址,也可以自动识别爬虫等,如果能爬到小红书网站的数据,那么这个舆情监测系统绝对不简单。
在互联网+大数据时代,数据的综合性是最有价值的。一些大数据公司将几年历史的数据存储在互联网上,成为公司发展的基础。它在互联网上非常具有竞争力。目前,很多舆情监测软件厂商都在攻克小红书反爬虫的难点。
网络舆情监测行业任重道远。新技术难开发,成熟技术容易复制,未来可能会有更多的小红书网站出现。网络舆情监测行业的道路是光明还是黑暗?
通过关键词采集文章采集api接口,请求大家学习!
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-08-04 06:09
通过关键词采集文章采集api接口,请求https网站,在接口后面接get/post跳转,带上一些自己需要的文章名称,图片等等标识图片采集方法,可以通过百度网盘自带的下载功能,
可以试试是不是真正采集的api,
其实很简单,
我觉得像采集单个文章这样的没什么难度,目前大部分人采集并不是为了赚钱,是为了提高自己的技术,提高自己的效率,如果自己是出于兴趣爱好又能够一边做一边学习新的东西,
目前用的比较多的是wordpress插件wordpress采集器。搜索即可出来百十来个了。按不同关键词搜索。比如搜“博客”,一大堆。现在二三十万的也比较多。博客采集器以前是用1010号采集器、博客街、百度采集。可以找找其他的看。
有一个可以批量采集标题、描述、图片、原文的,可以试试。我自己做了个网站,分享一下方法。因为我也在学习中,这个采集方法仅供大家学习,请勿轻易尝试。
用插件吧如果想挖掘出个性,建议去博客园、51cto、古西秀这些站点去找些你感兴趣的,看看这些站点用的都是什么采集的软件。或者直接百度搜索“采集文章采集api”,让别人采集他的,我觉得应该没问题。 查看全部
通过关键词采集文章采集api接口,请求大家学习!
通过关键词采集文章采集api接口,请求https网站,在接口后面接get/post跳转,带上一些自己需要的文章名称,图片等等标识图片采集方法,可以通过百度网盘自带的下载功能,
可以试试是不是真正采集的api,
其实很简单,
我觉得像采集单个文章这样的没什么难度,目前大部分人采集并不是为了赚钱,是为了提高自己的技术,提高自己的效率,如果自己是出于兴趣爱好又能够一边做一边学习新的东西,
目前用的比较多的是wordpress插件wordpress采集器。搜索即可出来百十来个了。按不同关键词搜索。比如搜“博客”,一大堆。现在二三十万的也比较多。博客采集器以前是用1010号采集器、博客街、百度采集。可以找找其他的看。
有一个可以批量采集标题、描述、图片、原文的,可以试试。我自己做了个网站,分享一下方法。因为我也在学习中,这个采集方法仅供大家学习,请勿轻易尝试。
用插件吧如果想挖掘出个性,建议去博客园、51cto、古西秀这些站点去找些你感兴趣的,看看这些站点用的都是什么采集的软件。或者直接百度搜索“采集文章采集api”,让别人采集他的,我觉得应该没问题。
所用工具(技术):如何配置Fiddler及如何抓取手机APP数据包
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-08-03 22:39
1 简介
过段时间就开始找新工作了,我们爬取一些工作信息来分析一下。目前主流招聘网站包括51job、智联、BOSS直招、pullgou等。我有一段时间没有抓取移动应用程序了。这次我会写一个爬虫来爬取的手机app的职位信息。其他招聘网站稍后更新...
使用的工具(技术):
IDE:pycharm
数据库:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息捕获:scrapy 内置的选择器
2 APP抓包分析
先来体验一下51job的app吧。当我们在首页输入search关键词并点击search时,app会跳转到一个新页面。我们称这个页面为一级页面。一级页面显示了我们正在寻找的所有职位的列表。
当我们点击其中一个帖子信息时,APP会跳转到一个新页面。我称这个页面为二级页面。二级页面有我们需要的所有职位信息,也是我们的主要采集当前页面。
分析页面后,可以分析51job应用的请求和响应。本文使用的抓包工具是Fiddler。 Fiddler的使用方法请查看这篇文章《Fiddler在网络爬虫中抓取PC端网页数据包和手机APP数据包》的博客。本篇博文详细介绍了如何配置Fiddler以及如何抓取手机APP数据包。链接如下:
本文的目的是捕捉在51job App上搜索某个关键词时返回的所有招聘信息。本文以“Python”为例进行说明。 APP上的操作如下图所示。输入“Python”关键词后,点击搜索,然后Fiddler抓取4个数据包,如下图:
其实,当我们看到第2个和第4个数据包的图标时,我们应该会心一笑。这两个图标分别代表json和xml格式传输的数据,很多web界面都是用这两种格式传输数据,手机app也没有列出。选择第二个数据包,然后在右侧主窗口查看,发现第二个数据包中没有我们想要的数据。查看第四个数据包,选中后,在右边的表格中,可以看到如下:
右下角的内容不就是你在手机上看到的职位信息吗?它仍然以 XML 格式传输。我们复制这个数据包的链接:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&着名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afu7>a8c65a37a35c68c65afu7
我们抓取的时候,肯定不会只抓取一页的信息。我们在APP上向下滑动页面,看看Fiddler会抓到什么数据包。看下图:
滑下手机屏幕后,Fiddler又抓取了两个数据包,第二个数据包被选中,再次发现是APP上新刷新的招聘信息,然后复制这个数据包的url链接:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087f3aa83a5c636792ba0887c6b3p6eb3&partner=8785419449a858b3314197
接下来我们对比一下前后两个链接,分析异同。可以看出,除了属性“pageno”外,其他都一样。没错,它上面标有红色。第一个数据包链接的pageno值为1,第二个pageno值为2,翻页规则一目了然。
既然找到了APP翻页的请求链接规则,我们就可以通过爬虫中的循环将pageno赋值给pageno,实现模拟翻页的功能。
我们再次尝试更改搜索关键词,看看链接是否已更改。使用“java”作为关键词,捕获的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&著名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afui754d9c621afui75a35c6b3fu7
对比后发现只有链接中keyword值不同,是我们自己输入的关键词。因此,在爬虫中,我们完全可以通过字符串拼接的方式输入关键词模拟,从而采集不同类型的招聘信息。同理,您可以搜索求职地点等信息,本文未涉及。
解决了翻页功能后,我们来探究一下数据包中的XML内容。我们复制上面的第一个链接并在浏览器上打开它。打开后,画面如下:
这样看会舒服很多。通过仔细观察,我们会发现APP上的每一条招聘信息都对应一个标签,每一条里面都有一个标签,里面有一个id来标识一个帖子。比如上面第一个帖子是109384390,第二个帖子是109381483,记住这个id,以后会用到。
其实,接下来我们点击第一个职位发布进入二级页面。这时候Fiddler会采集到APP刚刚发送的数据包,点击里面的xml数据包,发现是APP上刚刚刷新的页面信息。我们复制数据包的url链接:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af36aa2&uuid=6b21f77c7af36d9f78c7af36d9f78c7af36c8f78f78c7af36c8f78c7f36c8f78c7f2aaa3
按照方法,点击一级页面列表中的第二个job,然后从Fiddler复制对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7a52aaa3&uuid=6b21f77c7af36c8f78c7af36d9f78f78c7af3aa2f8c8f78f78f78c7af3aa2f9f78f78c7f3aa3
对比以上两个链接,你有没有发现什么规律?没错,jobid不一样,其他都一样。这个jobid就是我们在一级页面的xml中找到的jobid。由此,我们可以从一级页面中抓取jobid来构造二级页面的url链接,然后采集出我们需要的所有信息。整个爬虫逻辑清晰:
构建一级页面的初始url->采集jobid->构建二级页面的url->捕获作业信息->通过循环模拟翻页获取下一页的url。
好了,分析工作完成,启动脚本爬虫。
3 编写爬虫
本文是使用无忧手机APP网络爬虫的Scrapy框架编写的。下载scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider 是我们爬虫项目的项目名称。有一个“。”在项目名称之后。这一点是可选的。区别在于在当前文件之间创建一个项目或创建一个与项目名称相同的文件。在文件中创建一个项目。
创建项目后,继续创建爬虫,专门用于爬取发布的招聘信息。创建一个如下命名的爬虫:
scrapy genspider qcwySpider appapi.51job.com
注意:如果没有添加“.”创建爬虫项目时的项目名称后,请在运行命令创建爬虫之前进入项目文件夹。
通过pycharm打开新创建的爬虫项目,左侧目录树结构如下:
在开始所有爬虫工作之前,首先打开 settings.py 文件,然后取消注释“ROBOTSTXT_OBEY = False”行并将其值更改为 False。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
完成以上修改后,打开spiders包下的qcwySpider.py。初始代码如下:
# -*- coding: utf-8 -*-
import scrapy
class QcwyspiderSpider(scrapy.Spider):
name = 'qcwySpider'
allowed_domains = ['appapi.51job.com']
start_urls = ['http://appapi.51job.com/']
def parse(self, response):
pass
这是scrapy为我们构建的框架。我们只需要在此基础上改进我们的爬虫即可。
首先需要给类添加一些属性,比如搜索关键词keyword、起始页、想爬取最大页数、还需要设置headers进行简单的反爬取。另外,starturl也需要重置为第一页的url。更改后的代码如下:
name = 'qcwySpider'
keyword = 'python'
current_page = 1
max_page = 100
headers = {
'Accept': 'text / html, application / xhtml + xml, application / xml;',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'appapi.51job.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
allowed_domains = ['appapi.51job.com']
start_urls = ['https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword='+str(keyword)+
'&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=97932608&key=a8c33db43f42530fbda2f2dac7a6f48d5c1c853a&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0']
然后开始写parse方法爬取一级页面。在一级页面中,我们的主要逻辑是通过循环实现APP中的屏幕滑动更新。上面代码中我们使用current_page来标识当前页码,每次循环后,给current_page加1,然后构造一个新的url,通过回调解析方法抓取下一页。另外,我们还需要在parse方法中采集输出一级页面的jobid,构造二级页面,回调实现二级页面信息采集的parse_job方法。解析方法代码如下:
<p> def parse(self, response):
"""
通过循环的方式实现一级页面翻页,并采集jobid构造二级页面url
:param response:
:return:
"""
selector = Selector(response=response)
itmes = selector.xpath('//item')
for item in itmes:
jobid = item.xpath('./jobid/text()').extract_first()
url = 'https://appapi.51job.com/api/job/get_job_info.php?jobid='+jobid+'&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0'
yield scrapy.Request(url=url, headers=self.headers, dont_filter=False, callback=self.parse_job)
if self.current_page 查看全部
所用工具(技术):如何配置Fiddler及如何抓取手机APP数据包
1 简介
过段时间就开始找新工作了,我们爬取一些工作信息来分析一下。目前主流招聘网站包括51job、智联、BOSS直招、pullgou等。我有一段时间没有抓取移动应用程序了。这次我会写一个爬虫来爬取的手机app的职位信息。其他招聘网站稍后更新...
使用的工具(技术):
IDE:pycharm
数据库:MySQL
抓包工具:Fiddler
爬虫框架:scrapy==1.5.0
信息捕获:scrapy 内置的选择器
2 APP抓包分析
先来体验一下51job的app吧。当我们在首页输入search关键词并点击search时,app会跳转到一个新页面。我们称这个页面为一级页面。一级页面显示了我们正在寻找的所有职位的列表。
当我们点击其中一个帖子信息时,APP会跳转到一个新页面。我称这个页面为二级页面。二级页面有我们需要的所有职位信息,也是我们的主要采集当前页面。
分析页面后,可以分析51job应用的请求和响应。本文使用的抓包工具是Fiddler。 Fiddler的使用方法请查看这篇文章《Fiddler在网络爬虫中抓取PC端网页数据包和手机APP数据包》的博客。本篇博文详细介绍了如何配置Fiddler以及如何抓取手机APP数据包。链接如下:
本文的目的是捕捉在51job App上搜索某个关键词时返回的所有招聘信息。本文以“Python”为例进行说明。 APP上的操作如下图所示。输入“Python”关键词后,点击搜索,然后Fiddler抓取4个数据包,如下图:
其实,当我们看到第2个和第4个数据包的图标时,我们应该会心一笑。这两个图标分别代表json和xml格式传输的数据,很多web界面都是用这两种格式传输数据,手机app也没有列出。选择第二个数据包,然后在右侧主窗口查看,发现第二个数据包中没有我们想要的数据。查看第四个数据包,选中后,在右边的表格中,可以看到如下:
右下角的内容不就是你在手机上看到的职位信息吗?它仍然以 XML 格式传输。我们复制这个数据包的链接:
keyword=Python&keywordtype=2&jobarea=000000&searchid=&着名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afu7>a8c65a37a35c68c65afu7
我们抓取的时候,肯定不会只抓取一页的信息。我们在APP上向下滑动页面,看看Fiddler会抓到什么数据包。看下图:
滑下手机屏幕后,Fiddler又抓取了两个数据包,第二个数据包被选中,再次发现是APP上新刷新的招聘信息,然后复制这个数据包的url链接:
pageno=2&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087f3aa83a5c636792ba0887c6b3p6eb3&partner=8785419449a858b3314197
接下来我们对比一下前后两个链接,分析异同。可以看出,除了属性“pageno”外,其他都一样。没错,它上面标有红色。第一个数据包链接的pageno值为1,第二个pageno值为2,翻页规则一目了然。
既然找到了APP翻页的请求链接规则,我们就可以通过爬虫中的循环将pageno赋值给pageno,实现模拟翻页的功能。
我们再次尝试更改搜索关键词,看看链接是否已更改。使用“java”作为关键词,捕获的数据包为:
keyword=java&keywordtype=2&jobarea=000000&searchid=&著名类型=&pageno=1&pagesize=30&accountid=&key=&productname=51job&partner=8785419449a858b3314197b60d54d9c621afui754d9c621afui75a35c6b3fu7
对比后发现只有链接中keyword值不同,是我们自己输入的关键词。因此,在爬虫中,我们完全可以通过字符串拼接的方式输入关键词模拟,从而采集不同类型的招聘信息。同理,您可以搜索求职地点等信息,本文未涉及。
解决了翻页功能后,我们来探究一下数据包中的XML内容。我们复制上面的第一个链接并在浏览器上打开它。打开后,画面如下:
这样看会舒服很多。通过仔细观察,我们会发现APP上的每一条招聘信息都对应一个标签,每一条里面都有一个标签,里面有一个id来标识一个帖子。比如上面第一个帖子是109384390,第二个帖子是109381483,记住这个id,以后会用到。
其实,接下来我们点击第一个职位发布进入二级页面。这时候Fiddler会采集到APP刚刚发送的数据包,点击里面的xml数据包,发现是APP上刚刚刷新的页面信息。我们复制数据包的url链接:
jobid=109384390&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af36aa2&uuid=6b21f77c7af36d9f78c7af36d9f78c7af36c8f78f78c7af36c8f78c7f36c8f78c7f2aaa3
按照方法,点击一级页面列表中的第二个job,然后从Fiddler复制对应数据包的url链接:
jobid=109381483&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7a52aaa3&uuid=6b21f77c7af36c8f78c7af36d9f78f78c7af3aa2f8c8f78f78f78c7af3aa2f9f78f78c7f3aa3
对比以上两个链接,你有没有发现什么规律?没错,jobid不一样,其他都一样。这个jobid就是我们在一级页面的xml中找到的jobid。由此,我们可以从一级页面中抓取jobid来构造二级页面的url链接,然后采集出我们需要的所有信息。整个爬虫逻辑清晰:
构建一级页面的初始url->采集jobid->构建二级页面的url->捕获作业信息->通过循环模拟翻页获取下一页的url。
好了,分析工作完成,启动脚本爬虫。
3 编写爬虫
本文是使用无忧手机APP网络爬虫的Scrapy框架编写的。下载scrapy第三方包后,通过命令行创建爬虫项目:
scrapy startproject job_spider .
job_spider 是我们爬虫项目的项目名称。有一个“。”在项目名称之后。这一点是可选的。区别在于在当前文件之间创建一个项目或创建一个与项目名称相同的文件。在文件中创建一个项目。
创建项目后,继续创建爬虫,专门用于爬取发布的招聘信息。创建一个如下命名的爬虫:
scrapy genspider qcwySpider appapi.51job.com
注意:如果没有添加“.”创建爬虫项目时的项目名称后,请在运行命令创建爬虫之前进入项目文件夹。
通过pycharm打开新创建的爬虫项目,左侧目录树结构如下:
在开始所有爬虫工作之前,首先打开 settings.py 文件,然后取消注释“ROBOTSTXT_OBEY = False”行并将其值更改为 False。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
完成以上修改后,打开spiders包下的qcwySpider.py。初始代码如下:
# -*- coding: utf-8 -*-
import scrapy
class QcwyspiderSpider(scrapy.Spider):
name = 'qcwySpider'
allowed_domains = ['appapi.51job.com']
start_urls = ['http://appapi.51job.com/']
def parse(self, response):
pass
这是scrapy为我们构建的框架。我们只需要在此基础上改进我们的爬虫即可。
首先需要给类添加一些属性,比如搜索关键词keyword、起始页、想爬取最大页数、还需要设置headers进行简单的反爬取。另外,starturl也需要重置为第一页的url。更改后的代码如下:
name = 'qcwySpider'
keyword = 'python'
current_page = 1
max_page = 100
headers = {
'Accept': 'text / html, application / xhtml + xml, application / xml;',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'appapi.51job.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
allowed_domains = ['appapi.51job.com']
start_urls = ['https://appapi.51job.com/api/job/search_job_list.php?postchannel=0000&&keyword='+str(keyword)+
'&keywordtype=2&jobarea=000000&searchid=&famoustype=&pageno=1&pagesize=30&accountid=97932608&key=a8c33db43f42530fbda2f2dac7a6f48d5c1c853a&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0']
然后开始写parse方法爬取一级页面。在一级页面中,我们的主要逻辑是通过循环实现APP中的屏幕滑动更新。上面代码中我们使用current_page来标识当前页码,每次循环后,给current_page加1,然后构造一个新的url,通过回调解析方法抓取下一页。另外,我们还需要在parse方法中采集输出一级页面的jobid,构造二级页面,回调实现二级页面信息采集的parse_job方法。解析方法代码如下:
<p> def parse(self, response):
"""
通过循环的方式实现一级页面翻页,并采集jobid构造二级页面url
:param response:
:return:
"""
selector = Selector(response=response)
itmes = selector.xpath('//item')
for item in itmes:
jobid = item.xpath('./jobid/text()').extract_first()
url = 'https://appapi.51job.com/api/job/get_job_info.php?jobid='+jobid+'&accountid=&key=&from=searchjoblist&jobtype=0100&productname=51job&partner=8785419449a858b3314197b60d54d9c6&uuid=6b21f77c7af3aa83a5c636792ba087c2&version=845&guid=bbb37e8f266b9de9e2a9fbe3bb81c3d0'
yield scrapy.Request(url=url, headers=self.headers, dont_filter=False, callback=self.parse_job)
if self.current_page
api监测关键词去百度文库找到相关相关关键部分
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-08-02 19:10
通过关键词采集文章采集api监测关键词等等,知乎上以前有过知友写这方面的教程,可以自己去看看。采集知乎只是采集了api,利用采集来的文章,关键词去百度文库找到相关关键词,
一、需要软件:2.8版本百度文库浏览器,下载地址:)百度文库浏览器解压后,把里面的文件解压到任意盘。d:\programfiles\百度文库浏览器,最后运行。
二、爬虫部分
1)根据需要做数据关键词筛选爬虫初始获取的文章都是网页保存起来的文章,利用信息数据,筛选出重复率低的文章,分为一般高频、关键词关联高频和小范围文章三种。重复率根据关键词的,会根据一个范围内的文章进行检测,保留检测结果覆盖次数较多的文章。一般高频文章:保留前5000条检测结果高频文章保留5篇以上范围文章保留100篇以上(。
2)百度文库api调用文库api相对于我们平时用的api还是比较陌生的,需要大家有所积累。在excel中可以通过关键词来找到文章,按照网址和地址填入爬虫,就可以得到文章地址,在网页中点击文章进行查看详情,就可以获取文章。
3)爬虫部分
1)监测关键词文章监测结果一般百度文库平台会给出这些关键词的前1000条文章,基本全是高频关键词,我们通过数据采集,得到文章数量,点击查看,就可以得到文章的内容。文章地址,这样我们就可以解析了。
2)爬虫部分爬虫部分难度不大,爬取网页全部页面即可。爬虫部分,通过设置规则,也可以爬取网页全部,这个爬虫就可以实现一次爬取2000页的网页,没有深入去分析。需要大家多积累数据规则。设置规则主要是找到该页面的规律,比如每行的文章内容都是一个词语,或者文章的标题是一个单词。需要大家先结合爬虫,设置规则后,用规则抓取网页全部页面,根据规则,并结合规则,避免爬取页面中有文章内容时,有死角造成文章丢失。爬虫采集速度慢,爬取效率低。建议采集完的数据,进行排序,以便后续去重处理。 查看全部
api监测关键词去百度文库找到相关相关关键部分
通过关键词采集文章采集api监测关键词等等,知乎上以前有过知友写这方面的教程,可以自己去看看。采集知乎只是采集了api,利用采集来的文章,关键词去百度文库找到相关关键词,
一、需要软件:2.8版本百度文库浏览器,下载地址:)百度文库浏览器解压后,把里面的文件解压到任意盘。d:\programfiles\百度文库浏览器,最后运行。
二、爬虫部分
1)根据需要做数据关键词筛选爬虫初始获取的文章都是网页保存起来的文章,利用信息数据,筛选出重复率低的文章,分为一般高频、关键词关联高频和小范围文章三种。重复率根据关键词的,会根据一个范围内的文章进行检测,保留检测结果覆盖次数较多的文章。一般高频文章:保留前5000条检测结果高频文章保留5篇以上范围文章保留100篇以上(。
2)百度文库api调用文库api相对于我们平时用的api还是比较陌生的,需要大家有所积累。在excel中可以通过关键词来找到文章,按照网址和地址填入爬虫,就可以得到文章地址,在网页中点击文章进行查看详情,就可以获取文章。
3)爬虫部分
1)监测关键词文章监测结果一般百度文库平台会给出这些关键词的前1000条文章,基本全是高频关键词,我们通过数据采集,得到文章数量,点击查看,就可以得到文章的内容。文章地址,这样我们就可以解析了。
2)爬虫部分爬虫部分难度不大,爬取网页全部页面即可。爬虫部分,通过设置规则,也可以爬取网页全部,这个爬虫就可以实现一次爬取2000页的网页,没有深入去分析。需要大家多积累数据规则。设置规则主要是找到该页面的规律,比如每行的文章内容都是一个词语,或者文章的标题是一个单词。需要大家先结合爬虫,设置规则后,用规则抓取网页全部页面,根据规则,并结合规则,避免爬取页面中有文章内容时,有死角造成文章丢失。爬虫采集速度慢,爬取效率低。建议采集完的数据,进行排序,以便后续去重处理。
纪年科技aming网络安全,深度学习,嵌入式机器强化,生物智能,生命科学
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-01 20:27
纪年科技aming网络安全,深度学习,嵌入式机器强化,生物智能,生命科学
济年科技aming
网络安全、深度学习、嵌入式、机器增强、生物智能、生命科学。
想法:
使用现有的搜索引擎 API 和 Google Hacking 技术,
批量关键字查询和注入点检测
#分为三步:
网址采集
过滤采集无法到达的URL,如静态页面等
注射点检测
网址采集:
使用必应提供的免费API,URL采集:(Bing.py)
#!/usr/bin/env python
#coding:utf8
import requests
import json
import sys
# config-start
BingKey = "" # config your bing Ocp-Apim-Subscription-Key
Keyword = "简书"
maxPageNumber = 10
pageSize = 10
# config-end
url = "https://api.cognitive.microsof ... ot%3B + Keyword
headers = {
'Host':'api.cognitive.microsoft.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate, br',
'Ocp-Apim-Subscription-Key':BingKey,
'Upgrade-Insecure-Requests':'1',
'Referer':'https://api.cognitive.microsoft.com/bing/v5.0/search?q=opensns',
'Connection':'keep-alive',
}
for i in range(maxPageNumber):
tempUrl = url + "&offset=" + str(i * pageSize) + "&count=" + str(pageSize)
response = requests.get(tempUrl, headers=headers)
content = response.text
jsonObject = json.loads(content)
results = jsonObject['webPages']['value']
for result in results:
resulturl = result['displayUrl']
if resulturl.startswith("https://"):
print resulturl
else:
print "http://" + resulturl
使用开源HTML解析库解析百度搜索结果页面,采集URL:(Baidu.py)
#!/usr/bin/env python
#coding:utf8
import requests
from bs4 import BeautifulSoup
import sys
# config-start
keyword = "简书"
# config-end
url = "http://www.baidu.com/s?wd=" + keyword
response = requests.get(url)
content = response.content
status_code = response.status_code
soup = BeautifulSoup(content, "html.parser")
links = soup.findAll("a")
for link in links:
try:
dstURL = link['href']
if (dstURL.startswith("http://") or dstURL.startswith("https://")) and dstURL.startswith("http://www.baidu.com/link?url=") :
result_url = requests.get(dstURL).url
print result_url
except Exception as e:
continue
过滤静态页面等网址
#!/usr/bin/env python
#coding:utf8
file = open("urls.txt","r")
for line in file:
content = line[0:-1]
if content.endswith("html"):
continue
if content.endswith("htm"):
continue
if ".php" in content or ".asp" in content:
print content
检测注入点:
#!/usr/bin/env python
#coding:utf8
import os
import sys
file = open(sys.argv[1],"r")
for line in file:
url = line[0:-1]
print "*******************"
command = "sqlmap.py -u " + url + " --random-agent -f --batch --answer=\"extending=N,follow=N,keep=N,exploit=n\""
print "Exec : " + command
os.system(command)
搜索引擎语法关键字(搜索范围)引擎
【1】精确匹配搜索-精确匹配""引号和书名""
查询词很长,经过百度分析,可能会被拆分
搜索收录引号的部分作为一个整体进行匹配
引号是英文的引号。
屏蔽一些百度推广
例如:
“网站促销策划”全称
""移动"/"移动""
【2】±正负号的用法
加号同时收录两个关键字,相当于空格和。
减号在搜索结果中不收录特定的查询词——它前面必须有一个空格,后跟要排除的词
例如:
电影-搜狐
音乐 + 古代
[3] 如何使用 OR
搜索两个或多个关键字
例如:
“seo 或深圳 seo”
可能会出现这些关键字之一,也可能同时出现。
“seo 或您的名字”(此处没有引号)。
如果您的名字是通用名称。你会发现意想不到的惊喜。有和你同名同姓的同行业人。
“seo or Shenzhen seo”(这里没有引号)我找到了一个同名同姓的人,他和我一起去了。
[4] 标题
网页标题内容-网页内容大纲样式的总结
比赛页面
关键词optimization
例如:
(搜索时不要加引号)
"intitle:管理登录"
《新疆题:学局》
“网络推广标题:他的名字”
[5] intext 和 allintext(对谷歌有效)
出现在页面内容中,而不是标题中,
搜索页面收录“SEO”,标题收录SEO对应的文章页面。
只搜索网页部分收录的文字(忽略标题、网址等文字),
类似于某些网站中使用的“文章Content Search”功能。
例如:
“深圳SEO intext:SEO”
[6] 网址
在url中搜索url链接中收录的字符串(中英文),
竞争对手排名
例如:
搜索登录地址,可以这样写“inurl:admin.asp”,
如果要搜索Discuz的论坛,可以输入inurl:forum.php,
"csdn 博客 inurl:py_shell"
【7】网站
搜索特定网页
查看搜索引擎收录 有多少页。
——如果您在某个站点有什么需要查找的,可以将搜索范围限制在本站点
“胡歌空间内:”
[8]链接
搜索指向网站 的链接。
搜索网站url 的内外部链接
并非每个搜索引擎都非常准确,尤其是 Google,
只会返回索引库的一部分,而且是随机部分,
百度不支持此命令。
雅虎完全支持,查询更准确。
一般我们查网站的链接以雅虎为准,
[9] 文件类型
搜索你想要的电子书,限于指定的文档格式
并非所有格式都受支持。现在百度支持pdf、doc、xls、all、ppt、rtf、
例如:
“python 教程文件类型:pdf”
对于doc文件,只需写“filetype:doc”,
"seo filetype:doc",(搜索时不带引号),
[10] 相关(仅适用于谷歌)
指定与 URL 相关的页面,
通常会显示与您的网站具有相同外部链接的网站。
竞争对手,
相同的外链。
[11] * 通配符(百度不支持)
例如:搜索*引擎
[12] Inanchor 导入链接收录锚文本(百度不支持)
竞争对手
链接到
[13] allintitle 收录多组关键字
[14] allinurl
[15] 链接域(雅虎)
排除域名反向链接,获取外链
链接域:
[16] 相关(谷歌)网站 相关页面
有常用的外链
[17]域某网站相关信息
“域名:网址”
[18] 索引(百度)
“mp3 索引”
[19] A|B 收录 a 或 b 查看全部
纪年科技aming网络安全,深度学习,嵌入式机器强化,生物智能,生命科学
济年科技aming
网络安全、深度学习、嵌入式、机器增强、生物智能、生命科学。
想法:
使用现有的搜索引擎 API 和 Google Hacking 技术,
批量关键字查询和注入点检测
#分为三步:
网址采集
过滤采集无法到达的URL,如静态页面等
注射点检测
网址采集:
使用必应提供的免费API,URL采集:(Bing.py)
#!/usr/bin/env python
#coding:utf8
import requests
import json
import sys
# config-start
BingKey = "" # config your bing Ocp-Apim-Subscription-Key
Keyword = "简书"
maxPageNumber = 10
pageSize = 10
# config-end
url = "https://api.cognitive.microsof ... ot%3B + Keyword
headers = {
'Host':'api.cognitive.microsoft.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate, br',
'Ocp-Apim-Subscription-Key':BingKey,
'Upgrade-Insecure-Requests':'1',
'Referer':'https://api.cognitive.microsoft.com/bing/v5.0/search?q=opensns',
'Connection':'keep-alive',
}
for i in range(maxPageNumber):
tempUrl = url + "&offset=" + str(i * pageSize) + "&count=" + str(pageSize)
response = requests.get(tempUrl, headers=headers)
content = response.text
jsonObject = json.loads(content)
results = jsonObject['webPages']['value']
for result in results:
resulturl = result['displayUrl']
if resulturl.startswith("https://";):
print resulturl
else:
print "http://" + resulturl
使用开源HTML解析库解析百度搜索结果页面,采集URL:(Baidu.py)
#!/usr/bin/env python
#coding:utf8
import requests
from bs4 import BeautifulSoup
import sys
# config-start
keyword = "简书"
# config-end
url = "http://www.baidu.com/s?wd=" + keyword
response = requests.get(url)
content = response.content
status_code = response.status_code
soup = BeautifulSoup(content, "html.parser")
links = soup.findAll("a")
for link in links:
try:
dstURL = link['href']
if (dstURL.startswith("http://";) or dstURL.startswith("https://";)) and dstURL.startswith("http://www.baidu.com/link?url=";) :
result_url = requests.get(dstURL).url
print result_url
except Exception as e:
continue
过滤静态页面等网址
#!/usr/bin/env python
#coding:utf8
file = open("urls.txt","r")
for line in file:
content = line[0:-1]
if content.endswith("html"):
continue
if content.endswith("htm"):
continue
if ".php" in content or ".asp" in content:
print content
检测注入点:
#!/usr/bin/env python
#coding:utf8
import os
import sys
file = open(sys.argv[1],"r")
for line in file:
url = line[0:-1]
print "*******************"
command = "sqlmap.py -u " + url + " --random-agent -f --batch --answer=\"extending=N,follow=N,keep=N,exploit=n\""
print "Exec : " + command
os.system(command)
搜索引擎语法关键字(搜索范围)引擎
【1】精确匹配搜索-精确匹配""引号和书名""
查询词很长,经过百度分析,可能会被拆分
搜索收录引号的部分作为一个整体进行匹配
引号是英文的引号。
屏蔽一些百度推广
例如:
“网站促销策划”全称
""移动"/"移动""
【2】±正负号的用法
加号同时收录两个关键字,相当于空格和。
减号在搜索结果中不收录特定的查询词——它前面必须有一个空格,后跟要排除的词
例如:
电影-搜狐
音乐 + 古代
[3] 如何使用 OR
搜索两个或多个关键字
例如:
“seo 或深圳 seo”
可能会出现这些关键字之一,也可能同时出现。
“seo 或您的名字”(此处没有引号)。
如果您的名字是通用名称。你会发现意想不到的惊喜。有和你同名同姓的同行业人。
“seo or Shenzhen seo”(这里没有引号)我找到了一个同名同姓的人,他和我一起去了。
[4] 标题
网页标题内容-网页内容大纲样式的总结
比赛页面
关键词optimization
例如:
(搜索时不要加引号)
"intitle:管理登录"
《新疆题:学局》
“网络推广标题:他的名字”
[5] intext 和 allintext(对谷歌有效)
出现在页面内容中,而不是标题中,
搜索页面收录“SEO”,标题收录SEO对应的文章页面。
只搜索网页部分收录的文字(忽略标题、网址等文字),
类似于某些网站中使用的“文章Content Search”功能。
例如:
“深圳SEO intext:SEO”
[6] 网址
在url中搜索url链接中收录的字符串(中英文),
竞争对手排名
例如:
搜索登录地址,可以这样写“inurl:admin.asp”,
如果要搜索Discuz的论坛,可以输入inurl:forum.php,
"csdn 博客 inurl:py_shell"
【7】网站
搜索特定网页
查看搜索引擎收录 有多少页。
——如果您在某个站点有什么需要查找的,可以将搜索范围限制在本站点
“胡歌空间内:”
[8]链接
搜索指向网站 的链接。
搜索网站url 的内外部链接
并非每个搜索引擎都非常准确,尤其是 Google,
只会返回索引库的一部分,而且是随机部分,
百度不支持此命令。
雅虎完全支持,查询更准确。
一般我们查网站的链接以雅虎为准,
[9] 文件类型
搜索你想要的电子书,限于指定的文档格式
并非所有格式都受支持。现在百度支持pdf、doc、xls、all、ppt、rtf、
例如:
“python 教程文件类型:pdf”
对于doc文件,只需写“filetype:doc”,
"seo filetype:doc",(搜索时不带引号),
[10] 相关(仅适用于谷歌)
指定与 URL 相关的页面,
通常会显示与您的网站具有相同外部链接的网站。
竞争对手,
相同的外链。
[11] * 通配符(百度不支持)
例如:搜索*引擎
[12] Inanchor 导入链接收录锚文本(百度不支持)
竞争对手
链接到
[13] allintitle 收录多组关键字
[14] allinurl
[15] 链接域(雅虎)
排除域名反向链接,获取外链
链接域:
[16] 相关(谷歌)网站 相关页面
有常用的外链
[17]域某网站相关信息
“域名:网址”
[18] 索引(百度)
“mp3 索引”
[19] A|B 收录 a 或 b
通过关键词采集文章采集api的常用方法,你get到了吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-31 23:06
通过关键词采集文章采集api是一个通用技术,旨在给网站导入优质api并从中收益。关键字+api便是制作api的常用方法。搜索引擎返回结果>api请求发送>api执行>返回结果大部分api使用者都想知道获取哪些api的途径。为了方便大家对各种主流api进行对比,本文将结合使用过的各种工具,从比较容易入手的技术层面,对各种api进行集中介绍,力求在了解各种api的同时,比较各种api在web业务中的不同应用。
希望能够给大家一些有益的帮助。api功能目录从浏览器发起请求从浏览器发起异步请求从浏览器发起静态请求从服务器发起异步请求从服务器发起异步请求请求交互方式restfuluri操作拦截器xmlhttprequest(返回)在请求方法上不做限制,但标准请求有get/post两种方式restfulapi交互方式restfulapi一、从浏览器发起请求在web业务中使用api时,存在最主要的三个需求:方便、安全、私密,因此在webapi基础之上还可以进一步增加隐私保护。
json格式作为一种轻量级的数据格式被广泛使用,其常规的请求格式如下:json_reference参数名称类型接受方使用url方式发起请求,在url中返回客户端识别的json字符串返回方式请求端可能会根据传递给服务器的http头中的配置属性自定义api,例如在某些情况下服务器不会以json作为数据返回给客户端json文件格式的文档被存放在客户端浏览器和服务器之间采用非常规格式进行保存,避免和服务器端不兼容http响应可以以任意形式返回给服务器请求端api请求处理流程如下:发起http请求-->获取相应的对象-->保存请求并缓存在web的api中,这一步一般也是使用http处理流程对方请求进行响应,其过程如下:发起请求-->获取相应的对象-->调用响应函数-->获取响应结果和属性(对象的值)分别获取响应文件实例请求方法关键字:get/post/put/delete...三种方法都属于get请求,所以详细对比如下:第一种方法:从浏览器发起请求(url映射、响应处理为json格式)方法一:get请求(参数传递为json字符串)通过[username]获取用户的用户名,之后服务器便以json字符串形式返回一个json对象,如上面url中的用户名items返回结果(items.title):json_reference:用户id,在url中由username和json_reference共同决定or方法二:post请求(参数传递为json字符串)浏览器会发送http请求给服务器,服务器根据请求头中的参数获取对应的响应。 查看全部
通过关键词采集文章采集api的常用方法,你get到了吗?
通过关键词采集文章采集api是一个通用技术,旨在给网站导入优质api并从中收益。关键字+api便是制作api的常用方法。搜索引擎返回结果>api请求发送>api执行>返回结果大部分api使用者都想知道获取哪些api的途径。为了方便大家对各种主流api进行对比,本文将结合使用过的各种工具,从比较容易入手的技术层面,对各种api进行集中介绍,力求在了解各种api的同时,比较各种api在web业务中的不同应用。
希望能够给大家一些有益的帮助。api功能目录从浏览器发起请求从浏览器发起异步请求从浏览器发起静态请求从服务器发起异步请求从服务器发起异步请求请求交互方式restfuluri操作拦截器xmlhttprequest(返回)在请求方法上不做限制,但标准请求有get/post两种方式restfulapi交互方式restfulapi一、从浏览器发起请求在web业务中使用api时,存在最主要的三个需求:方便、安全、私密,因此在webapi基础之上还可以进一步增加隐私保护。
json格式作为一种轻量级的数据格式被广泛使用,其常规的请求格式如下:json_reference参数名称类型接受方使用url方式发起请求,在url中返回客户端识别的json字符串返回方式请求端可能会根据传递给服务器的http头中的配置属性自定义api,例如在某些情况下服务器不会以json作为数据返回给客户端json文件格式的文档被存放在客户端浏览器和服务器之间采用非常规格式进行保存,避免和服务器端不兼容http响应可以以任意形式返回给服务器请求端api请求处理流程如下:发起http请求-->获取相应的对象-->保存请求并缓存在web的api中,这一步一般也是使用http处理流程对方请求进行响应,其过程如下:发起请求-->获取相应的对象-->调用响应函数-->获取响应结果和属性(对象的值)分别获取响应文件实例请求方法关键字:get/post/put/delete...三种方法都属于get请求,所以详细对比如下:第一种方法:从浏览器发起请求(url映射、响应处理为json格式)方法一:get请求(参数传递为json字符串)通过[username]获取用户的用户名,之后服务器便以json字符串形式返回一个json对象,如上面url中的用户名items返回结果(items.title):json_reference:用户id,在url中由username和json_reference共同决定or方法二:post请求(参数传递为json字符串)浏览器会发送http请求给服务器,服务器根据请求头中的参数获取对应的响应。

