
通过关键词采集文章采集api
WordPress采集插件WPRobot_2.12破解版及使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 391 次浏览 • 2021-07-29 01:26
AllRights Reserved Wor dPr ess 采集plugin WPRobot_2.12破解版及教程 Wprobot3.12破解版下载地址: WPRobot3.1-6700-65b0-7834-89e3-7248.rar/ .page WPRobot 一直是WP英语垃圾站必备插件,特别是对于我这种英语不好的人。它是Wordpress博客的采集插件。以上是WPRobot3.12最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您会意识到它有多智能,它从多个来源生成您在 Autopilot 上创建的 Wor dpress 博客。在设计WPRobot时,负责人认为最好将其拆分成模块,让客户可以根据自己的特殊需求定制插件。例如,Amazon 和 Youtube 附加组件允许您添加主目录和注释。该系统的优点是所有模块都可以由选定的模块单独购买。模块智能的产生是为了满足所有用户的需求。
WPRobot 是一个自动博客的超级插件。想想您喜欢的所有主题,它会让您发布目录而不是编写目录。使工作自动更新您的博客,关于您选择的日程安排设置 带有新帖子的热门站点,例如关联目录的抓取可能是获取目录的好地方。 wpRobot是一个自动生成Wordpress Bl og 文章的插件,可以根据关键词采集yahoo ews、yahooanswer、youut ube、f ckr、amazon、ebay、Cl ckbank、Cj等自动设置.文章、视频、图片、产品信息等,配合自动改写插件伪原创,再也不用担心建英文网站了。 WpRobot的特点 创建任何你想要文章发布到你的WordPr ess博客的内容,你只需要设置相关关键词来精确控制文章内容生成,通过关键词搭配创建不同的任务,避免重复文章;版权所有 ags,标签 Wordpress 具有更好的功能之一。访客可以通过一些标签自定义模板。如果对自己的模板不满意,可以修改模板;其实WpRobot绝对连这些功能都没有,只是暂时还没想到。在使用的过程中你会发现它是如此的强大和易用。用它建立英文博客不再是障碍。
以下是WpRobot的基本使用教程。第一步:上传WpRobot插件并在后台激活 第二步:设置关键词进入WP后台,找到WpRobot选项,点击创建活动(创建采集群),采集共有三个@方法,一个是keywor campaign(按关键字),Rss campai gn(blog文章RSS),Br owseNode campai n(亚马逊产品节点)。首先是按关键字采集,点击右侧的Quick setup(快速设置模板),当然也可以选择Random e(随机模板),看看两者有什么区别,填写Nameyour campai gn 你的关键词组名,如I Pad,在keyword ds下方的框中填写关键词,每行一个关键词,并设置类别cat egor es。下面左边设置采集频率,比如一小时,一天等,右边是否自动建立分类(不推荐,因为效果真的很差)。以下是按键模板设置,一共8个(注意点击Quick setup时显示8个)。它们是文章、亚马逊产品、雅虎问答、雅虎新闻、CB、youtube 视频、ebay 和 Flickr。建议不要在这里全部使用。保留你想使用的任何一个,并添加每个模板的采集比例。
如果您不想要,请单击相应模板下的移除模板。后面的设置如下图,基本没有变化,主要是替换关键词,去除关键词,设置翻译等。All Rights Reserved 都设置好了,点击下面的Create Campaign就完成了广告组的创建。第三步:WP Robot Optons选项设置License Optons许可选项,填写您购买正版WpRobot插件的PayPal邮箱,输入破解版邮箱。此选项会自动显示,您正在启用它。 WpRobot 会要求您输入此电子邮件地址。 General Optons常用选项设置Enable Simple Mode,是否允许简单模式,如果允许请打勾; New Post Status,新的文章状态,有发布和草稿三种状态,一般选择发布;重置邮政计数器:文章数计算回零,否或是; Enable Help Tooltips,是否启用帮助工具提示; Enable Old Duplicate Check,是否启用旧版本重复检查;随机发帖时间,随机文章publication时间,还有一些其他的选项这里就不一一解释了,用翻译工具翻译一下就知道是什么意思了。
All Rights Reserved Amazon Optons选项设置Amazon Affiliate D,填写Amazonaffiliate ID号; API Key(Access Key D),填写亚马逊API;申请; Secre AccessKey,申请API后会给你; Search Method、Search method:Exact Match(严格匹配)Broad Match(广泛匹配);跳过产品 f、当Dontskip(生死不跳过)或No description found(无描述)或No缩略图(无缩略图)或No description缩略图(无描述或缩略图)时跳过该产品; Amazon Description Length,描述长度;亚马逊网站,选择;标题中的 Stri 括号,是(默认);发表评论 评论?选择是;帖子模板:pos 模板,默认或修改。烟台SEO http://整理,转载并注明出处。
谢谢。 All Rights Reserved Ar ons文章选项设置文章语言,文章语选英文,Pages,如果勾选,将很长的文章分成几页N个字符;从...中剥离所有链接,删除所有链接。 Cl ckbankOpt ons 设置Clickbank Affiliate D,填写Clickbank Affiliate ID;过滤广告?过滤广告。 eBay 选项设置 版权所有 eBay Affiliate (CampID),eBay 会员 ID;国家,国家选择美国;语言,语言选择英文;排序结果,通过什么排序。 Fl ckrOpt ons 设置 Flickr API Key、Flickr API 应用程序密钥;许可、许可方式;图像大小,图像大小。 Yahoo Answer ons 和Yahoo News Optons 设置为Yahoo Application D。两者具有相同的ID。点击这里申请; All Rights Reserved Yout ube Opt ons 和 RSS Optons 设置看图翻译你就知道怎么设置了。
Tr ansl ons 翻译选项设置 Use Proxies Use proxy, Yes, 随机选择一个translationfails... 如果翻译失败,创建一个未翻译的文章 或跳过文章。版权所有 Twi erOpt ons settings Commi ssi ons settings 如果你有做过CJ的朋友,这些设置应该很容易搞定,如果你没有做过CJ,直接跳过。这里省略了一些设置,这些不常用,默认就OK了,最后按Save Optons保存设置。第四步:修改模板。修改模板也是比较关键的一步。如果对现有模板不满意,可以自行修改。有时会有很好的效果。比如一些很赞的采集ebay信息,把标题改成产品名称+拍卖组合模板效果很明显,加了很多Sal。第五步:发布文章publish 文章是最后一步。添加关键词后,点击WpRobot Select Campaigns中的第一个,就会发现刚才填写的采集关键词都在这里了。将鼠标移动到某个关键字,就会出现一堆链接。点击立即发布,你会惊奇地发现WpRobot开始采集并再次发布文章。版权所有 当然还有更厉害的,你可以同时发布N篇文章。
选择你要采集的群,填写下图中Nuber Posts的帖子数,例如50个帖子,在Backdate?前面打勾,文章post日期从2008-09开始-24,两个帖子文章发布时间相隔1天,然后点击PostNow,WpRobot将启动采集文章,采集达到50个文章,发布日期从2008年开始- 09-24,两次文章间隔一到两天。 WP自动外链插件 在这里,我要推荐WP自动外链插件:Automatic Backlink Creator插件。这个软件我自己用过,效果很好,所以今天推荐到这里,希望可以节省大家做外链的时间和精力! Automatic Backlink Creator主要针对wordpress程序创建的网站。热衷WP的站长朋友,尤其是做外贸的,主要是做谷歌和雅虎搜索引擎SEO的,应该是非常好的消息了!本软件类似于WP插件,是WP网站外链的完美解决方案!你只需要在网站后台轻松安装,就可以用一种对搜索引擎有利的方式,让WP网站自动添加高权重外链。近日,这款软件的官方网站,Automatic Backlink Creator的价格仅为37美元,可以使用信用卡或paypal支付,在国外很受欢迎!购买的同时还赠送了MetaSnatcher插件。这个插件可以自动跟踪谷歌网站Core Key中的顶级竞争对手,并自动返回软件,为关键字分析节省大量时间。
Spin Master Pro 插件。这个插件相当于WP下线伪原创并发布插件。安装此插件后,就可以在电脑上进行内容伪原创并离线发布,节省大量时间。同时,软件提供60天不满意退款保证。点击查看本软件开发者是一群SEO高手,结合谷歌和雅虎的外链算法,综合考虑外链PR、OBL、FLAG等方面的极端情况,开发了这款功能强大、优秀的外链软件。并且通过这个系统,可以产生稳定且不断增加的优质反链,如.edu、.gov等网站外链。下载:最经典的SEO链轮解决方案 查看全部
WordPress采集插件WPRobot_2.12破解版及使用教程
AllRights Reserved Wor dPr ess 采集plugin WPRobot_2.12破解版及教程 Wprobot3.12破解版下载地址: WPRobot3.1-6700-65b0-7834-89e3-7248.rar/ .page WPRobot 一直是WP英语垃圾站必备插件,特别是对于我这种英语不好的人。它是Wordpress博客的采集插件。以上是WPRobot3.12最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您会意识到它有多智能,它从多个来源生成您在 Autopilot 上创建的 Wor dpress 博客。在设计WPRobot时,负责人认为最好将其拆分成模块,让客户可以根据自己的特殊需求定制插件。例如,Amazon 和 Youtube 附加组件允许您添加主目录和注释。该系统的优点是所有模块都可以由选定的模块单独购买。模块智能的产生是为了满足所有用户的需求。
WPRobot 是一个自动博客的超级插件。想想您喜欢的所有主题,它会让您发布目录而不是编写目录。使工作自动更新您的博客,关于您选择的日程安排设置 带有新帖子的热门站点,例如关联目录的抓取可能是获取目录的好地方。 wpRobot是一个自动生成Wordpress Bl og 文章的插件,可以根据关键词采集yahoo ews、yahooanswer、youut ube、f ckr、amazon、ebay、Cl ckbank、Cj等自动设置.文章、视频、图片、产品信息等,配合自动改写插件伪原创,再也不用担心建英文网站了。 WpRobot的特点 创建任何你想要文章发布到你的WordPr ess博客的内容,你只需要设置相关关键词来精确控制文章内容生成,通过关键词搭配创建不同的任务,避免重复文章;版权所有 ags,标签 Wordpress 具有更好的功能之一。访客可以通过一些标签自定义模板。如果对自己的模板不满意,可以修改模板;其实WpRobot绝对连这些功能都没有,只是暂时还没想到。在使用的过程中你会发现它是如此的强大和易用。用它建立英文博客不再是障碍。
以下是WpRobot的基本使用教程。第一步:上传WpRobot插件并在后台激活 第二步:设置关键词进入WP后台,找到WpRobot选项,点击创建活动(创建采集群),采集共有三个@方法,一个是keywor campaign(按关键字),Rss campai gn(blog文章RSS),Br owseNode campai n(亚马逊产品节点)。首先是按关键字采集,点击右侧的Quick setup(快速设置模板),当然也可以选择Random e(随机模板),看看两者有什么区别,填写Nameyour campai gn 你的关键词组名,如I Pad,在keyword ds下方的框中填写关键词,每行一个关键词,并设置类别cat egor es。下面左边设置采集频率,比如一小时,一天等,右边是否自动建立分类(不推荐,因为效果真的很差)。以下是按键模板设置,一共8个(注意点击Quick setup时显示8个)。它们是文章、亚马逊产品、雅虎问答、雅虎新闻、CB、youtube 视频、ebay 和 Flickr。建议不要在这里全部使用。保留你想使用的任何一个,并添加每个模板的采集比例。
如果您不想要,请单击相应模板下的移除模板。后面的设置如下图,基本没有变化,主要是替换关键词,去除关键词,设置翻译等。All Rights Reserved 都设置好了,点击下面的Create Campaign就完成了广告组的创建。第三步:WP Robot Optons选项设置License Optons许可选项,填写您购买正版WpRobot插件的PayPal邮箱,输入破解版邮箱。此选项会自动显示,您正在启用它。 WpRobot 会要求您输入此电子邮件地址。 General Optons常用选项设置Enable Simple Mode,是否允许简单模式,如果允许请打勾; New Post Status,新的文章状态,有发布和草稿三种状态,一般选择发布;重置邮政计数器:文章数计算回零,否或是; Enable Help Tooltips,是否启用帮助工具提示; Enable Old Duplicate Check,是否启用旧版本重复检查;随机发帖时间,随机文章publication时间,还有一些其他的选项这里就不一一解释了,用翻译工具翻译一下就知道是什么意思了。
All Rights Reserved Amazon Optons选项设置Amazon Affiliate D,填写Amazonaffiliate ID号; API Key(Access Key D),填写亚马逊API;申请; Secre AccessKey,申请API后会给你; Search Method、Search method:Exact Match(严格匹配)Broad Match(广泛匹配);跳过产品 f、当Dontskip(生死不跳过)或No description found(无描述)或No缩略图(无缩略图)或No description缩略图(无描述或缩略图)时跳过该产品; Amazon Description Length,描述长度;亚马逊网站,选择;标题中的 Stri 括号,是(默认);发表评论 评论?选择是;帖子模板:pos 模板,默认或修改。烟台SEO http://整理,转载并注明出处。
谢谢。 All Rights Reserved Ar ons文章选项设置文章语言,文章语选英文,Pages,如果勾选,将很长的文章分成几页N个字符;从...中剥离所有链接,删除所有链接。 Cl ckbankOpt ons 设置Clickbank Affiliate D,填写Clickbank Affiliate ID;过滤广告?过滤广告。 eBay 选项设置 版权所有 eBay Affiliate (CampID),eBay 会员 ID;国家,国家选择美国;语言,语言选择英文;排序结果,通过什么排序。 Fl ckrOpt ons 设置 Flickr API Key、Flickr API 应用程序密钥;许可、许可方式;图像大小,图像大小。 Yahoo Answer ons 和Yahoo News Optons 设置为Yahoo Application D。两者具有相同的ID。点击这里申请; All Rights Reserved Yout ube Opt ons 和 RSS Optons 设置看图翻译你就知道怎么设置了。
Tr ansl ons 翻译选项设置 Use Proxies Use proxy, Yes, 随机选择一个translationfails... 如果翻译失败,创建一个未翻译的文章 或跳过文章。版权所有 Twi erOpt ons settings Commi ssi ons settings 如果你有做过CJ的朋友,这些设置应该很容易搞定,如果你没有做过CJ,直接跳过。这里省略了一些设置,这些不常用,默认就OK了,最后按Save Optons保存设置。第四步:修改模板。修改模板也是比较关键的一步。如果对现有模板不满意,可以自行修改。有时会有很好的效果。比如一些很赞的采集ebay信息,把标题改成产品名称+拍卖组合模板效果很明显,加了很多Sal。第五步:发布文章publish 文章是最后一步。添加关键词后,点击WpRobot Select Campaigns中的第一个,就会发现刚才填写的采集关键词都在这里了。将鼠标移动到某个关键字,就会出现一堆链接。点击立即发布,你会惊奇地发现WpRobot开始采集并再次发布文章。版权所有 当然还有更厉害的,你可以同时发布N篇文章。
选择你要采集的群,填写下图中Nuber Posts的帖子数,例如50个帖子,在Backdate?前面打勾,文章post日期从2008-09开始-24,两个帖子文章发布时间相隔1天,然后点击PostNow,WpRobot将启动采集文章,采集达到50个文章,发布日期从2008年开始- 09-24,两次文章间隔一到两天。 WP自动外链插件 在这里,我要推荐WP自动外链插件:Automatic Backlink Creator插件。这个软件我自己用过,效果很好,所以今天推荐到这里,希望可以节省大家做外链的时间和精力! Automatic Backlink Creator主要针对wordpress程序创建的网站。热衷WP的站长朋友,尤其是做外贸的,主要是做谷歌和雅虎搜索引擎SEO的,应该是非常好的消息了!本软件类似于WP插件,是WP网站外链的完美解决方案!你只需要在网站后台轻松安装,就可以用一种对搜索引擎有利的方式,让WP网站自动添加高权重外链。近日,这款软件的官方网站,Automatic Backlink Creator的价格仅为37美元,可以使用信用卡或paypal支付,在国外很受欢迎!购买的同时还赠送了MetaSnatcher插件。这个插件可以自动跟踪谷歌网站Core Key中的顶级竞争对手,并自动返回软件,为关键字分析节省大量时间。
Spin Master Pro 插件。这个插件相当于WP下线伪原创并发布插件。安装此插件后,就可以在电脑上进行内容伪原创并离线发布,节省大量时间。同时,软件提供60天不满意退款保证。点击查看本软件开发者是一群SEO高手,结合谷歌和雅虎的外链算法,综合考虑外链PR、OBL、FLAG等方面的极端情况,开发了这款功能强大、优秀的外链软件。并且通过这个系统,可以产生稳定且不断增加的优质反链,如.edu、.gov等网站外链。下载:最经典的SEO链轮解决方案
通过关键词采集文章采集api接口来写个爬虫吧
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-07-27 20:00
通过关键词采集文章采集api接口实现。来写个爬虫吧!以前一个学生让我写个爬虫,可我连python的get都写不好,还是用的googlechrome浏览器自带的爬虫程序,而且传统的爬虫要不然有多种限制,要不然要有threadstart_user等,安全性等多方面来说不利于个人学习提高,没有啥不利,只是以前不懂api实现更方便。
最近做实验,用一台macwindows笔记本搭建一个小框架,用的是column.js2.5.js,可以解析几乎所有webapi!!!如果你要买正版开发工具,推荐谷歌的开发者工具.下载安装!!接下来,要说的是配置项的node_env!现在是笔记本!本来以为开发用台机就可以了,可要来个电脑开发板电源不稳定,估计最多跑一个小时就开始重启,然后说电脑黑屏黑屏没反应等等!网上各种文章找新机器的电源问题,写测试代码最后用了一个usbftp直接把工作站的笔记本电脑连上,然后服务器上的笔记本电脑跑了一会结果花屏,正常登录时总有断,选中断自动切断!为此我一个简单问题我的各种包都是旧包,要老老实实从头写起,程序运行过程中还要问重复内容,内存等!好像没有什么大不了的,大不了工作站变成服务器!笔记本变成工作站!直到我了解到程序开发板,才知道程序开发板这是在大型软件公司,或开发app也有几乎近百个api。
通过程序开发板,电脑或者服务器开发板连接程序开发板,通过getapi接口可以连接到服务器上的api接口,做一个类似于爬虫的工作,最好是下载api!我才知道,你让我一个学生这么简单的方法只能写出千篇一律的爬虫。经过一段时间的学习,我找到一个程序开发板如下,需要用一台机器连接好,把api连接好,通过电脑连接到服务器做开发,在服务器上用一台电脑ssh到自己的笔记本,此时就能做一个分页一样的工作了。过程中遇到的问题可以百度。还是一句话,先把网页搞定!!!。 查看全部
通过关键词采集文章采集api接口来写个爬虫吧
通过关键词采集文章采集api接口实现。来写个爬虫吧!以前一个学生让我写个爬虫,可我连python的get都写不好,还是用的googlechrome浏览器自带的爬虫程序,而且传统的爬虫要不然有多种限制,要不然要有threadstart_user等,安全性等多方面来说不利于个人学习提高,没有啥不利,只是以前不懂api实现更方便。
最近做实验,用一台macwindows笔记本搭建一个小框架,用的是column.js2.5.js,可以解析几乎所有webapi!!!如果你要买正版开发工具,推荐谷歌的开发者工具.下载安装!!接下来,要说的是配置项的node_env!现在是笔记本!本来以为开发用台机就可以了,可要来个电脑开发板电源不稳定,估计最多跑一个小时就开始重启,然后说电脑黑屏黑屏没反应等等!网上各种文章找新机器的电源问题,写测试代码最后用了一个usbftp直接把工作站的笔记本电脑连上,然后服务器上的笔记本电脑跑了一会结果花屏,正常登录时总有断,选中断自动切断!为此我一个简单问题我的各种包都是旧包,要老老实实从头写起,程序运行过程中还要问重复内容,内存等!好像没有什么大不了的,大不了工作站变成服务器!笔记本变成工作站!直到我了解到程序开发板,才知道程序开发板这是在大型软件公司,或开发app也有几乎近百个api。
通过程序开发板,电脑或者服务器开发板连接程序开发板,通过getapi接口可以连接到服务器上的api接口,做一个类似于爬虫的工作,最好是下载api!我才知道,你让我一个学生这么简单的方法只能写出千篇一律的爬虫。经过一段时间的学习,我找到一个程序开发板如下,需要用一台机器连接好,把api连接好,通过电脑连接到服务器做开发,在服务器上用一台电脑ssh到自己的笔记本,此时就能做一个分页一样的工作了。过程中遇到的问题可以百度。还是一句话,先把网页搞定!!!。
软件设计开发:基于API的微博信息采集系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-24 01:01
ComputerKnowledge (June 2013) Software Design and Development 本专栏主编:谢媛媛,基于API的微博信息采集系统设计与实现(浙江树人大学信息技术学院,杭州310015)Abstract : 微博已经成为网络信息的重要来源,本文分析了微博信息采集的相关方法和技术,提出了一种基于API的信息采集方法,然后设计了一个信息采集系统,可以用于新浪微博博客的相关信息为采集。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;信息采集;C#语言中图分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博数据采集系统基于新浪的API 吴斌杰、徐子伟、于飞-hua(信息科学技术浙江树人大学人类学学院,杭州 310015) 摘要:微博已成为重要的网络信息来源,论文分析了相关方法技术微博信息采集。基于数据采集的选词数据新浪微博。实验证明有效。关键词:新浪微博;应用程序接口;数据采集器;即微博客的缩写,是一个基于用户关系进行信息共享、传播和获取的平台。用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息,实现即时分享。
中国互联网络信息中心第31次中国互联网络发展状况统计报告显示,截至2012年12月末,截至2012年12月末,我国微博用户数为3.09亿元,较2011年底增加5873万,微博用户在网民中的占比较去年底提高6个百分点,达到54.7%。随着微博网络影响力的迅速扩大,政府部门、学校、知名企业、公众人物纷纷开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。研究方法和技术路线 国内微博用户以新浪微博为主,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现目前新浪微博的信息采集方式主要分为两类:一类是“模拟登录”和“网络爬虫”信息结合三种技术采集第二种方法是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API发送微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集在微博上找不到信息。
同时,“网络爬虫”采集到达的网页需要“网页内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。微博信息采集系统基于新浪微博开放平台API文档,主要采用两种研究方法:文档分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现数据@的相关测试开发采集。基于以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1。 研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、 采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。
收稿日期:2013-04-15 基金项目:2012年浙江大学文学系科技创新项目(项目编号:2012R420010)科研成果一)作者简介:吴斌杰(1991-),男,浙江 出生于嘉兴,2010级学生,浙江树人大学信息学院电子商务专业;监事:于飞华。 E-mail: Tel:+86-551-65690963 65690964 ISSN 1009-3044 Computer Knowledge Technology Vol.9, No.17, June 2013.4005 Computer Knowledge (2013年6月) 本栏目主编:谢元元软件设计开发微博接口认证:新浪微博访问大部分API,如发布微博、获取私信等需要注意。用户身份,目前新浪微博开放平台用户身份认证有OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版本的接口也只支持这两种方式。所以系统设计开发的第一步是做一个微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:该功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的账号信息,比如他有多少粉丝,他是谁关注了,他被多少人关注了,这个信息在微博采集上也是很有价值的。 5)采集 其他用户的微博:该功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询来获取采集学校的微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。主要功能实现3.1 微博界面认证功能 新浪微博API访问大部分需要用户认证。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
新浪微博用户 新浪微博用户 新浪微博用户 新浪微博用户 授权服务器 授权服务器 授权服务器 授权服务器 新浪 API AP APIAP 服务器服务器 服务器 认证请求 认证请求 认证请求 认证请求请求授权 授权授权 授权授权 授权授权 授权授权注册rotect ed Res our ce rotect ed Res our ce rotect ed Res our ce Access Access Access Access 基于API 新浪微博 information采集技术路图4006 计算机知识(2013年6月) 软件设计与开发 本专栏责任编辑:谢元元 从图3可以看出,新浪微博界面访问认证需要通过两个流程进行设计:第一步是登录微博用户账号,请求用户对token进行授权;第二步是获取授权令牌。 Access Token,用于调用API,实现接口认证功能的部分代码如下: public OAuth(string appKey, string appSecret, string callbackUrl appKey;this.AppSecret appSecret;this.AccessToken string.Empty;this. CallbackUrl publicAccessToken GetAccessTokenByPassword(字符串护照,字符串密码) returnGetAccessToken(GrantType.Password, new Dictionary {"username",passport},{"password", password} 3.2 微博用户登录功能 微博登录模块的主要功能是输入新浪微博用户账号和密码,调用Oauth类中的GetAccessTokenByPassword()方法,登录成功后可以获得Access Token,然后登录的用户就可以使用系统信息采集功能,登录界面如图4所示。
系统登录界面图3.3 登录用户微博信息和关注用户微博信息采集登录用户信息采集图 登录用户微博信息和关注用户微博信息模块界面如图如图5所示,主要包括三个功能:登录用户信息采集、当前登录用户发布微博、采集登录用户微博信息和登录用户关注的用户微博信息。 3.4其他用户的微博信息采集采集其他用户的微博信息功能界面如图6所示,该功能主要是通过微博用户的昵称来获取采集该用户的用户信息和该用户发布的微博信息. 3.5学校基本信息采集采集学校信息功能模块界面如图7所示。该功能主要是通过学校名称的模糊查询来获取学校微博平台的信息,采集到的该信息主要用于研究学校在微博上的影响力。 4007计算机知识(2013年6月) 本栏目主编:谢媛媛软件设计与开发总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博博客信息采集系统实现了微博基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究是如何设计一个话题模型来优化系统。
参考资料:中国互联网络信息中心。第31次中国互联网发展统计报告[EB/OL]。 (2013-01-15).⁃ wtjbg/201301/t20130115_38508.htm.NickRandolph,David Gardner,Chris Anderson,et al.Professional Visual Studio 2010[M].Wrox,2018.k43 开放平台. 授权机制说明[EB/OL].(2013-01-19).% E6%8E%88%E6%9 D%83%E6%9C%BA% E5%88%B6%E8%AF %B4%E6%98%8E.学校信息采集图4008 查看全部
软件设计开发:基于API的微博信息采集系统设计与实现
ComputerKnowledge (June 2013) Software Design and Development 本专栏主编:谢媛媛,基于API的微博信息采集系统设计与实现(浙江树人大学信息技术学院,杭州310015)Abstract : 微博已经成为网络信息的重要来源,本文分析了微博信息采集的相关方法和技术,提出了一种基于API的信息采集方法,然后设计了一个信息采集系统,可以用于新浪微博博客的相关信息为采集。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;信息采集;C#语言中图分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博数据采集系统基于新浪的API 吴斌杰、徐子伟、于飞-hua(信息科学技术浙江树人大学人类学学院,杭州 310015) 摘要:微博已成为重要的网络信息来源,论文分析了相关方法技术微博信息采集。基于数据采集的选词数据新浪微博。实验证明有效。关键词:新浪微博;应用程序接口;数据采集器;即微博客的缩写,是一个基于用户关系进行信息共享、传播和获取的平台。用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息,实现即时分享。
中国互联网络信息中心第31次中国互联网络发展状况统计报告显示,截至2012年12月末,截至2012年12月末,我国微博用户数为3.09亿元,较2011年底增加5873万,微博用户在网民中的占比较去年底提高6个百分点,达到54.7%。随着微博网络影响力的迅速扩大,政府部门、学校、知名企业、公众人物纷纷开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。研究方法和技术路线 国内微博用户以新浪微博为主,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现目前新浪微博的信息采集方式主要分为两类:一类是“模拟登录”和“网络爬虫”信息结合三种技术采集第二种方法是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API发送微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集在微博上找不到信息。
同时,“网络爬虫”采集到达的网页需要“网页内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。微博信息采集系统基于新浪微博开放平台API文档,主要采用两种研究方法:文档分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现数据@的相关测试开发采集。基于以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1。 研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、 采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。
收稿日期:2013-04-15 基金项目:2012年浙江大学文学系科技创新项目(项目编号:2012R420010)科研成果一)作者简介:吴斌杰(1991-),男,浙江 出生于嘉兴,2010级学生,浙江树人大学信息学院电子商务专业;监事:于飞华。 E-mail: Tel:+86-551-65690963 65690964 ISSN 1009-3044 Computer Knowledge Technology Vol.9, No.17, June 2013.4005 Computer Knowledge (2013年6月) 本栏目主编:谢元元软件设计开发微博接口认证:新浪微博访问大部分API,如发布微博、获取私信等需要注意。用户身份,目前新浪微博开放平台用户身份认证有OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版本的接口也只支持这两种方式。所以系统设计开发的第一步是做一个微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:该功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的账号信息,比如他有多少粉丝,他是谁关注了,他被多少人关注了,这个信息在微博采集上也是很有价值的。 5)采集 其他用户的微博:该功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询来获取采集学校的微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。主要功能实现3.1 微博界面认证功能 新浪微博API访问大部分需要用户认证。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
新浪微博用户 新浪微博用户 新浪微博用户 新浪微博用户 授权服务器 授权服务器 授权服务器 授权服务器 新浪 API AP APIAP 服务器服务器 服务器 认证请求 认证请求 认证请求 认证请求请求授权 授权授权 授权授权 授权授权 授权授权注册rotect ed Res our ce rotect ed Res our ce rotect ed Res our ce Access Access Access Access 基于API 新浪微博 information采集技术路图4006 计算机知识(2013年6月) 软件设计与开发 本专栏责任编辑:谢元元 从图3可以看出,新浪微博界面访问认证需要通过两个流程进行设计:第一步是登录微博用户账号,请求用户对token进行授权;第二步是获取授权令牌。 Access Token,用于调用API,实现接口认证功能的部分代码如下: public OAuth(string appKey, string appSecret, string callbackUrl appKey;this.AppSecret appSecret;this.AccessToken string.Empty;this. CallbackUrl publicAccessToken GetAccessTokenByPassword(字符串护照,字符串密码) returnGetAccessToken(GrantType.Password, new Dictionary {"username",passport},{"password", password} 3.2 微博用户登录功能 微博登录模块的主要功能是输入新浪微博用户账号和密码,调用Oauth类中的GetAccessTokenByPassword()方法,登录成功后可以获得Access Token,然后登录的用户就可以使用系统信息采集功能,登录界面如图4所示。
系统登录界面图3.3 登录用户微博信息和关注用户微博信息采集登录用户信息采集图 登录用户微博信息和关注用户微博信息模块界面如图如图5所示,主要包括三个功能:登录用户信息采集、当前登录用户发布微博、采集登录用户微博信息和登录用户关注的用户微博信息。 3.4其他用户的微博信息采集采集其他用户的微博信息功能界面如图6所示,该功能主要是通过微博用户的昵称来获取采集该用户的用户信息和该用户发布的微博信息. 3.5学校基本信息采集采集学校信息功能模块界面如图7所示。该功能主要是通过学校名称的模糊查询来获取学校微博平台的信息,采集到的该信息主要用于研究学校在微博上的影响力。 4007计算机知识(2013年6月) 本栏目主编:谢媛媛软件设计与开发总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博博客信息采集系统实现了微博基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究是如何设计一个话题模型来优化系统。
参考资料:中国互联网络信息中心。第31次中国互联网发展统计报告[EB/OL]。 (2013-01-15).⁃ wtjbg/201301/t20130115_38508.htm.NickRandolph,David Gardner,Chris Anderson,et al.Professional Visual Studio 2010[M].Wrox,2018.k43 开放平台. 授权机制说明[EB/OL].(2013-01-19).% E6%8E%88%E6%9 D%83%E6%9C%BA% E5%88%B6%E8%AF %B4%E6%98%8E.学校信息采集图4008
python爬取数据的第一步必须分析目标网站的技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-07-22 18:01
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时用python爬虫(结合tkinter开发爬虫应用),用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基础的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略爬取数据,提升性能,提高操作舒适度(结合客户端技术,自定义爬虫接口),根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境! 查看全部
python爬取数据的第一步必须分析目标网站的技术
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时用python爬虫(结合tkinter开发爬虫应用),用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基础的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略爬取数据,提升性能,提高操作舒适度(结合客户端技术,自定义爬虫接口),根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境!
通过关键词采集文章采集api开发框架提供采集,抓取信息供研究使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-22 02:01
通过关键词采集文章采集api开发框架提供采集api,抓取信息供研究使用,所有的数据都可以导出保存于excel文件和csv文件。本框架所有的数据都采集于csv文件,并且数据都已经转换成dataframe结构。采集效率、采集性能1.采集前端请求响应速度:高并发采集/请求速度:秒级page速度:秒级采集时间:秒级抓取效率:秒级请求内容api内容及获取json源数据(json字符串格式包含access_token和arraybuffer,即用户账号和密码,以及airmail|smtp|smtp_ftp_http)2.采集目标pagepageage页面返回方式:querypagepage获取目标页面各元素信息信息是点击鼠标获取相应位置元素的内容,而case_click方法中的add方法采用的是点击获取元素信息,而没有提供目标位置的元素信息。
2.1useruser个人身份信息账号:some_pwd_username密码:some_pass_username2.2terms按钮设置一般返回的是回调函数函数名:user.show_terms,可修改参数返回值:some_pwd_username返回值:some_pass_username返回值:some_array3.爬虫框架实现数据部分:#python3classmy_codespy(object):"""采集爬虫框架"""package_first_importpygame#带引号版本package_first_importpygame.io.browser32.1#c++2014,python,javapackage_first_importpygame.io.browser32#c++1943package_first_importpygame.io.browser32importpygame.httpimportpygame.io.browser32#此为未实现,计划2019实现importpygame.io.browser32importpygame.pygame.io.browser32#此为未实现,计划2019实现importpygame.httpimportpygame.selfimportpygame.self#此为未实现,计划2019实现importpygame.textimportpygame.textimportpygame.text.fieldsimportpygame.text.renderimportpygame.text.string.ascii.utf8importpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.coreimportosimportpygame.io.messageimportpygame.io.synchronizedimportpygame.io.useimportpygame.text.unicodeimportosimportpy。 查看全部
通过关键词采集文章采集api开发框架提供采集,抓取信息供研究使用
通过关键词采集文章采集api开发框架提供采集api,抓取信息供研究使用,所有的数据都可以导出保存于excel文件和csv文件。本框架所有的数据都采集于csv文件,并且数据都已经转换成dataframe结构。采集效率、采集性能1.采集前端请求响应速度:高并发采集/请求速度:秒级page速度:秒级采集时间:秒级抓取效率:秒级请求内容api内容及获取json源数据(json字符串格式包含access_token和arraybuffer,即用户账号和密码,以及airmail|smtp|smtp_ftp_http)2.采集目标pagepageage页面返回方式:querypagepage获取目标页面各元素信息信息是点击鼠标获取相应位置元素的内容,而case_click方法中的add方法采用的是点击获取元素信息,而没有提供目标位置的元素信息。
2.1useruser个人身份信息账号:some_pwd_username密码:some_pass_username2.2terms按钮设置一般返回的是回调函数函数名:user.show_terms,可修改参数返回值:some_pwd_username返回值:some_pass_username返回值:some_array3.爬虫框架实现数据部分:#python3classmy_codespy(object):"""采集爬虫框架"""package_first_importpygame#带引号版本package_first_importpygame.io.browser32.1#c++2014,python,javapackage_first_importpygame.io.browser32#c++1943package_first_importpygame.io.browser32importpygame.httpimportpygame.io.browser32#此为未实现,计划2019实现importpygame.io.browser32importpygame.pygame.io.browser32#此为未实现,计划2019实现importpygame.httpimportpygame.selfimportpygame.self#此为未实现,计划2019实现importpygame.textimportpygame.textimportpygame.text.fieldsimportpygame.text.renderimportpygame.text.string.ascii.utf8importpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.coreimportosimportpygame.io.messageimportpygame.io.synchronizedimportpygame.io.useimportpygame.text.unicodeimportosimportpy。
人人都是大牛采集器-spider-builder/机器人也可以,同步
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-07-15 19:01
通过关键词采集文章采集api接口,满足现在需求比较广泛,基本上覆盖我所需要的都可以采集。除了全网互联,还有类似360浏览器,腾讯手机浏览器都可以采集其他网站。现在需要每天1-2次去采集网页内容,这样才能实现你的采集,一天下来时间就没有了,有想获取相关采集的朋友可以在评论区留言。苹果手机上可以直接注册appstore,安卓的手机可以关注公众号【异步小说】,也可以获取相关的采集api,小程序。
可以上飞速采集网看看,网站有30w条到200w条每天的爬虫采集历史,还有采集器功能,
想爬哪个网站的数据呢?一般爬虫是接口为主,根据网站规定爬取数据。
推荐赛迪网采集器-spider-builder/机器人也可以
,同步专注爬虫数据与开发
别的不知道,是安卓端的,我知道的和微信公众号“生活消费与信息化”互联。
学个爬虫,
我在大鲸鱼分享过一个大鲸鱼采集器还不错,
我觉得你可以考虑下王大噜分享的《人人都是大牛采集器》,
优漫爬虫程序,是一个小巧灵活的使用微信内置浏览器接口的采集器,适用于各种微信公众号和自媒体平台,完全免费分享,支持pc、mac以及安卓平台,可以按需抓取,当需要抓取某一固定公众号或某一平台时,完全可以借助这个采集器,快速的抓取你需要的数据。 查看全部
人人都是大牛采集器-spider-builder/机器人也可以,同步
通过关键词采集文章采集api接口,满足现在需求比较广泛,基本上覆盖我所需要的都可以采集。除了全网互联,还有类似360浏览器,腾讯手机浏览器都可以采集其他网站。现在需要每天1-2次去采集网页内容,这样才能实现你的采集,一天下来时间就没有了,有想获取相关采集的朋友可以在评论区留言。苹果手机上可以直接注册appstore,安卓的手机可以关注公众号【异步小说】,也可以获取相关的采集api,小程序。
可以上飞速采集网看看,网站有30w条到200w条每天的爬虫采集历史,还有采集器功能,
想爬哪个网站的数据呢?一般爬虫是接口为主,根据网站规定爬取数据。
推荐赛迪网采集器-spider-builder/机器人也可以
,同步专注爬虫数据与开发
别的不知道,是安卓端的,我知道的和微信公众号“生活消费与信息化”互联。
学个爬虫,
我在大鲸鱼分享过一个大鲸鱼采集器还不错,
我觉得你可以考虑下王大噜分享的《人人都是大牛采集器》,
优漫爬虫程序,是一个小巧灵活的使用微信内置浏览器接口的采集器,适用于各种微信公众号和自媒体平台,完全免费分享,支持pc、mac以及安卓平台,可以按需抓取,当需要抓取某一固定公众号或某一平台时,完全可以借助这个采集器,快速的抓取你需要的数据。
通过关键词采集文章采集api通过文章匹配技术获取相关
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-09 20:03
通过关键词采集文章采集api通过文章匹配技术获取相关apiweb页面点击该页面获取登录过的用户的身份信息网站数据的变更来自页面更新apichangelog更新采集技术主要分两类:基于代理,服务器本地文件抓取基于采集框架爬虫。基于代理:接收一个网站或者应用服务的响应的form请求,然后判断回应是否是响应,判断响应header,从而判断这个响应是不是响应网站就返回一个post对象,爬虫(采集器)根据这个post对象访问从这个post对象获取到这个网站的header,来确定是哪个网站对应了该header,一般返回有的网站对应header的话,则为采集器成功爬取。
服务器本地文件抓取:在用户浏览器本地上存一个一个html文件,保存的是格式为[xxxx]->tab->下载链接链接(可是一个单独的文件也可以是zip压缩文件),找出这个链接,解析form请求,这里就是进行采集,爬虫去获取该链接要么是一个单独的文件,要么是一个压缩包,然后进行http请求,比如一个json,一个html文件。
服务器本地文件抓取的优势:不用被淘汰的googleapi。taobao有没有共享呢,其实在天猫api上也已经有了,不过天猫用的还是代理服务器自己写的,我们都可以用。基于采集框架爬虫:采集框架虽然省代理和服务器成本,但是同样存在问题,你把他解析出来的请求存在在本地,其他爬虫也很可能拿不到。其实有一种办法就是利用大家共用的服务器,可以存一个采集链接的规则文件,这样其他爬虫就可以通过链接拿到真正的header和路由地址,那么获取下来的数据就更加真实。 查看全部
通过关键词采集文章采集api通过文章匹配技术获取相关
通过关键词采集文章采集api通过文章匹配技术获取相关apiweb页面点击该页面获取登录过的用户的身份信息网站数据的变更来自页面更新apichangelog更新采集技术主要分两类:基于代理,服务器本地文件抓取基于采集框架爬虫。基于代理:接收一个网站或者应用服务的响应的form请求,然后判断回应是否是响应,判断响应header,从而判断这个响应是不是响应网站就返回一个post对象,爬虫(采集器)根据这个post对象访问从这个post对象获取到这个网站的header,来确定是哪个网站对应了该header,一般返回有的网站对应header的话,则为采集器成功爬取。
服务器本地文件抓取:在用户浏览器本地上存一个一个html文件,保存的是格式为[xxxx]->tab->下载链接链接(可是一个单独的文件也可以是zip压缩文件),找出这个链接,解析form请求,这里就是进行采集,爬虫去获取该链接要么是一个单独的文件,要么是一个压缩包,然后进行http请求,比如一个json,一个html文件。
服务器本地文件抓取的优势:不用被淘汰的googleapi。taobao有没有共享呢,其实在天猫api上也已经有了,不过天猫用的还是代理服务器自己写的,我们都可以用。基于采集框架爬虫:采集框架虽然省代理和服务器成本,但是同样存在问题,你把他解析出来的请求存在在本地,其他爬虫也很可能拿不到。其实有一种办法就是利用大家共用的服务器,可以存一个采集链接的规则文件,这样其他爬虫就可以通过链接拿到真正的header和路由地址,那么获取下来的数据就更加真实。
搜索引擎最怕什么?我们可以怎样做到更好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-06-28 06:17
作为一个在SEO工作了13年的老司机,经常会思考SEO的本质是什么?对于大部分SEO优化者来说,大部分人都理解SEO=外链+内容,其实很简单这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。 SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的事业,而不是一无所有。日夜交换链接和伪原创。
搜索引擎是怎么来的?
当互联网首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息更快地被搜索到,一些聪明人编写了一个简单的爬虫程序来检查网络上每台计算机上分布的文件。索引,然后通过一个简单的搜索框,让用户可以快速搜索岛上的信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放入自己的索引中。下次用户搜索时,他们会很满意。走开。
SEO 从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。你觉得它很棒吗?
如果你不能意识到这一点,你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!
我们怎样才能做得更好?
1、拥有最全面准确的行业词库
当我们经营网站或专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。如果用通俗的话说,其实每个行业都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,因此拥有一个行业词库是完全掌握一个行业的必备产品。
例如,围绕财富管理行业的核心词如下:
理财行业核心词下长尾词列表如下:
2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出能够带来最多流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划师PC搜索量、竞价策划师移动搜索量、竞价策划师竞争:
通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。
3.通过API过滤掉搜索引擎中最缺乏的内容关键词
通过上面过滤掉的104635个流量词,我们可以将它们放入百度、360等搜索引擎进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否为内容已经饱和了。
我们可以通过API商城(www 5118 com/apistore)百度PC端TOP 50排名API方便获取JSON格式的排名状态。
下图中,我们以“what is an index fund”这个词为例,得到TOP20搜索结果的排名:
返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息显示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指这个关键词在网上的内容是否已经饱和,还是因为百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以先判断这个关键词是否值得一看。
这是一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级的网站排名结果。如果是这样,我们还有机会占领他们的位置。
还有一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,也就是说搜索结果中的部分内容标题并不完全匹配关键词。
比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放的一个索引,那么我们也可以标记这些位置作为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们将保留这些关键词并进入第四阶段。
4.帮助搜索引擎改进这些内容
我们通过前三步完成性价比最高的SEO关键词筛选后,可以安排编辑写文章或者话题,或者安排技术部做文章的采集,也或安排运营部门指导用户创作内容。
通过这四步分层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:
5.监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不受其他技术运维的影响干扰因素。 .
通过5118PC收录检测功能或百度PC收录API检测制作内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬行都没有意义。如果内容不是收录,也会对内容策略造成打击,所以对收录的监控也很重要。
检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。
2.监控个人关键词排名,评估每个内容制作作品的稳定性,关注细节。
▲ 可以在5118关键词monitoring的帮助下批量添加自己关键词进行监控
▲ 也可以使用 5118关键词ranked采集API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词ranking查询API进行采集排名数据,并集成到现有的管理系统中。
最终总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进实现自我。突破。
通过这个内容制作流程,我们可以逐步优化我们的内容策略,最大限度地发挥内容制作流量的效果。还等什么,赶快使用这些大数据API让你轻松推广。
查看全部
搜索引擎最怕什么?我们可以怎样做到更好?
作为一个在SEO工作了13年的老司机,经常会思考SEO的本质是什么?对于大部分SEO优化者来说,大部分人都理解SEO=外链+内容,其实很简单这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。 SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的事业,而不是一无所有。日夜交换链接和伪原创。
搜索引擎是怎么来的?
当互联网首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息更快地被搜索到,一些聪明人编写了一个简单的爬虫程序来检查网络上每台计算机上分布的文件。索引,然后通过一个简单的搜索框,让用户可以快速搜索岛上的信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放入自己的索引中。下次用户搜索时,他们会很满意。走开。
SEO 从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。你觉得它很棒吗?
如果你不能意识到这一点,你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!

我们怎样才能做得更好?
1、拥有最全面准确的行业词库
当我们经营网站或专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。如果用通俗的话说,其实每个行业都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,因此拥有一个行业词库是完全掌握一个行业的必备产品。
例如,围绕财富管理行业的核心词如下:

理财行业核心词下长尾词列表如下:


2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出能够带来最多流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划师PC搜索量、竞价策划师移动搜索量、竞价策划师竞争:

通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。

3.通过API过滤掉搜索引擎中最缺乏的内容关键词
通过上面过滤掉的104635个流量词,我们可以将它们放入百度、360等搜索引擎进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否为内容已经饱和了。
我们可以通过API商城(www 5118 com/apistore)百度PC端TOP 50排名API方便获取JSON格式的排名状态。
下图中,我们以“what is an index fund”这个词为例,得到TOP20搜索结果的排名:

返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息显示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指这个关键词在网上的内容是否已经饱和,还是因为百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以先判断这个关键词是否值得一看。
这是一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级的网站排名结果。如果是这样,我们还有机会占领他们的位置。

还有一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,也就是说搜索结果中的部分内容标题并不完全匹配关键词。

比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放的一个索引,那么我们也可以标记这些位置作为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们将保留这些关键词并进入第四阶段。
4.帮助搜索引擎改进这些内容
我们通过前三步完成性价比最高的SEO关键词筛选后,可以安排编辑写文章或者话题,或者安排技术部做文章的采集,也或安排运营部门指导用户创作内容。
通过这四步分层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:

5.监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不受其他技术运维的影响干扰因素。 .


通过5118PC收录检测功能或百度PC收录API检测制作内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬行都没有意义。如果内容不是收录,也会对内容策略造成打击,所以对收录的监控也很重要。

检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。

2.监控个人关键词排名,评估每个内容制作作品的稳定性,关注细节。
▲ 可以在5118关键词monitoring的帮助下批量添加自己关键词进行监控

▲ 也可以使用 5118关键词ranked采集API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词ranking查询API进行采集排名数据,并集成到现有的管理系统中。

最终总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进实现自我。突破。
通过这个内容制作流程,我们可以逐步优化我们的内容策略,最大限度地发挥内容制作流量的效果。还等什么,赶快使用这些大数据API让你轻松推广。

基于API微博信息采集系统设计与实现(1)_光明网
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-06-28 02:01
基于API微博信息采集系统设计与实现总结:微博已经成为网络信息的重要来源。本文分析了微博Information采集的相关方法和技术,提出了基于API的information采集方法,然后设计了一个信息采集系统,可以采集新浪微博上的相关信息。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文库分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博[1],微博的缩写,是一个分享、传播和获取的平台基于用户关系的信息,用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息实时分享中国互联网络发布的《第31次中国互联网络发展状况统计报告》信息中心显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.090亿,较2011年末增加5873万,微博占比网民用户比去年底增长6个百分点,达到54.7%[2]。公众人物已开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析发现,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ,以及“网页内容分析” [4] 结合三种技术的信息采集方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API来执行微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集无法在微博上找到信息。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博信息采集系统主要采用两种研究方法:文档分析和实验测试。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,以C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据采集。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口。代码类(c#语言),然后来测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或者GET调用API接口,最后返回JOSN数据流,最后解析将此数据流保存为本地文本文件或数据库。详细技术路线如图1所示。 2 研究内容设计 微博信息采集系统功能结构 如图2所示,系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。 1)微博接口认证:访问大部分新浪微博API,如发微博、获取私信、关注等,都需要用户身份。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于调试应用开发者的界面),新版界面仅支持这两种方法[6]。因此,系统设计开发的第一步就是做微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:这个功能主要是输入微博用户的昵称,你可以采集获取昵称用户的账号信息,比如有多少粉丝,关注谁,还有他被多少人抓到了关注,这个信息在微博采集中也是很有价值的。 5)采集 其他用户的微博:此功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询,获取采集学校在微博中的账号ID、学校所在区域、学校类型信息。这就是采集学校在微博影响力的基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核前无法直接测试使用。 3 主要功能实现3.1 微博界面鉴权功能新浪微博API访问大部分需要用户鉴权。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
4 总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博采集的基础信息k15@,在一定程度上解决了微博信息采集的自动化和结果数据采集格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究就是如何设计话题模型来优化系统。参考文献:[1]文锐.微博智智[J].软件工程师,2009( 12):19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展状况统计报告[EB/OL]. (2013-01-15). /hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 编写自己的网络爬虫[ M]. 北京: 清华大学出版社, 2010. [4] 于曼全, 陈铁瑞,徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al. Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。 (2013-01-19). D%83%E6%9C%BA%E5%88%B6%E8 %AF%B4%E6 %98%8E。 查看全部
基于API微博信息采集系统设计与实现(1)_光明网
基于API微博信息采集系统设计与实现总结:微博已经成为网络信息的重要来源。本文分析了微博Information采集的相关方法和技术,提出了基于API的information采集方法,然后设计了一个信息采集系统,可以采集新浪微博上的相关信息。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文库分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博[1],微博的缩写,是一个分享、传播和获取的平台基于用户关系的信息,用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息实时分享中国互联网络发布的《第31次中国互联网络发展状况统计报告》信息中心显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.090亿,较2011年末增加5873万,微博占比网民用户比去年底增长6个百分点,达到54.7%[2]。公众人物已开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析发现,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ,以及“网页内容分析” [4] 结合三种技术的信息采集方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API来执行微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集无法在微博上找到信息。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博信息采集系统主要采用两种研究方法:文档分析和实验测试。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,以C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据采集。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口。代码类(c#语言),然后来测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或者GET调用API接口,最后返回JOSN数据流,最后解析将此数据流保存为本地文本文件或数据库。详细技术路线如图1所示。 2 研究内容设计 微博信息采集系统功能结构 如图2所示,系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。 1)微博接口认证:访问大部分新浪微博API,如发微博、获取私信、关注等,都需要用户身份。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于调试应用开发者的界面),新版界面仅支持这两种方法[6]。因此,系统设计开发的第一步就是做微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:这个功能主要是输入微博用户的昵称,你可以采集获取昵称用户的账号信息,比如有多少粉丝,关注谁,还有他被多少人抓到了关注,这个信息在微博采集中也是很有价值的。 5)采集 其他用户的微博:此功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询,获取采集学校在微博中的账号ID、学校所在区域、学校类型信息。这就是采集学校在微博影响力的基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核前无法直接测试使用。 3 主要功能实现3.1 微博界面鉴权功能新浪微博API访问大部分需要用户鉴权。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
4 总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博采集的基础信息k15@,在一定程度上解决了微博信息采集的自动化和结果数据采集格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究就是如何设计话题模型来优化系统。参考文献:[1]文锐.微博智智[J].软件工程师,2009( 12):19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展状况统计报告[EB/OL]. (2013-01-15). /hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 编写自己的网络爬虫[ M]. 北京: 清华大学出版社, 2010. [4] 于曼全, 陈铁瑞,徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al. Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。 (2013-01-19). D%83%E6%9C%BA%E5%88%B6%E8 %AF%B4%E6 %98%8E。
设计日志的实时分析并可视化,操作步骤开启WebTracking功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-06-28 01:49
当我们有新的内容(比如新功能、新活动、新游戏、新文章)时,作为运营商,我们总是迫不及待想尽快和用户沟通,因为这是第一获取用户的一步,也是最重要的一步。
以游戏发行为例。市场有巨大的游戏推广费用,比如1W的广告。 2000人成功加载广告,约占20%。其中点击了800人,最终下载注册账号试用的往往很少。
可见,能够准确、实时地获取内容推广的效果对业务来说是非常重要的。运营商为了实现整体推广目标,往往会选择多种渠道进行推广。
用户内部留言(Mail)、官网博客(Blog)、首页文案(Banner等)。短信、用户邮箱、传单等新浪微博、钉钉用户群、微信公众号、知乎论坛、今日头条等新媒体
操作步骤 开启网络追踪功能。
在日志服务中创建一个Logstore(例如:myclick)并开启WebTracking功能。
生成网络跟踪标签。对于需要推广的文档(文章=1001),为每个推广渠道添加logo,并生成Web Tracking标签(以Img标签为例)。
可以在from参数后添加更多频道,也可以在URL中添加更多需要采集的参数。
在宣传内容中放置img标签并发布。分析日志。
完成采集的埋葬后,我们可以使用日志服务功能,实时查询分析海量日志数据。除了结果分析的可视化,还支持、、、Tableau等对接方式。
以下是采集目前为止的日志数据,您可以在搜索框中输入关键词进行查询。
查询后还可以输入SQL,实现秒级实时分析和可视化。
设计查询语句。
以下是我们为用户点击/阅读日志的实时分析语句。更多的领域和分析场景可以找到。
将这些实时数据配置到一个实时刷新的Dashboard中,效果如下
描述 当你读完这篇文章时,会有一个隐形的Img标签来记录这次访问。您可以在此页面的源代码中查看此标签。 查看全部
设计日志的实时分析并可视化,操作步骤开启WebTracking功能
当我们有新的内容(比如新功能、新活动、新游戏、新文章)时,作为运营商,我们总是迫不及待想尽快和用户沟通,因为这是第一获取用户的一步,也是最重要的一步。
以游戏发行为例。市场有巨大的游戏推广费用,比如1W的广告。 2000人成功加载广告,约占20%。其中点击了800人,最终下载注册账号试用的往往很少。

可见,能够准确、实时地获取内容推广的效果对业务来说是非常重要的。运营商为了实现整体推广目标,往往会选择多种渠道进行推广。

用户内部留言(Mail)、官网博客(Blog)、首页文案(Banner等)。短信、用户邮箱、传单等新浪微博、钉钉用户群、微信公众号、知乎论坛、今日头条等新媒体
操作步骤 开启网络追踪功能。
在日志服务中创建一个Logstore(例如:myclick)并开启WebTracking功能。
生成网络跟踪标签。对于需要推广的文档(文章=1001),为每个推广渠道添加logo,并生成Web Tracking标签(以Img标签为例)。
可以在from参数后添加更多频道,也可以在URL中添加更多需要采集的参数。
在宣传内容中放置img标签并发布。分析日志。
完成采集的埋葬后,我们可以使用日志服务功能,实时查询分析海量日志数据。除了结果分析的可视化,还支持、、、Tableau等对接方式。
以下是采集目前为止的日志数据,您可以在搜索框中输入关键词进行查询。

查询后还可以输入SQL,实现秒级实时分析和可视化。

设计查询语句。
以下是我们为用户点击/阅读日志的实时分析语句。更多的领域和分析场景可以找到。
将这些实时数据配置到一个实时刷新的Dashboard中,效果如下

描述 当你读完这篇文章时,会有一个隐形的Img标签来记录这次访问。您可以在此页面的源代码中查看此标签。
网站该如何申请成为百度新闻源的具体操作步骤?
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-27 19:04
百度新闻源,其实就是指百度的新闻源,一个百度蜘蛛经常光顾的地方,会采集新闻和相关信息。对于网站站长来说,如果他们的网站能够成功申请加入百度动态消息,那么无论是网站的推广还是网站内部的信息传播,都会起到很好的效果。成为百度新闻源后,网站可以向百度提交自己的符合互联网新闻开放协议标准的XML网页。这样网站就可以在之前的内容发布后被动等待百度收录主动提交内容给百度。这不仅会大大提高收录内容的速度,还会为网站引入更多的流量,给网站带来更好的权重。为了网站的整体发展,申请成为百度新闻源是非常有必要的。成为百度新闻源后,无论是增加网站权重,还是增加网站品牌度,都能得到更好的帮助。尤其值得一提的是,如果你的网站内容能在百度新闻频道被推荐,将为你的网站带来无限流量。虽然网站申请成为百度新闻源可以带来这么多好处,但仍有大部分网站站长不知道如何申请成为百度新闻源。下面我就带大家了解一下网站申请成为百度新闻源的具体步骤,以及成为百度新闻源后需要注意的一些事项。
方法/步骤
1
网站成为百度新闻源的基本条件
要成功申请成为百度新闻源,首先需要了解您的网站是否具备成为百度新闻源的条件。另一方面,站长首先要了解百度新闻源申请网站的最基本要求是什么:
1:网站需要安全可靠
网站要成为百度新闻源,网站首先要有明确的责任人。商业网站需要有公司营业执照,非商业网站需要负责人备案网站。另外网站的服务器一定要稳定,访问速度要好。只有安全可靠的网站才能随时响应百度蜘蛛的抓取和内容抓取。
2:网站需要高质量的新闻内容
大家需要明白的是,并不是所有网站的内容都能被百度新闻收录。百度新闻对网站的内容质量也有着极高的要求。 网站内容需要基于原创或优质伪原创,并且这些内容可以定期维护和更新。搜索引擎看重网站,每天24小时不断更新,尤其是新闻来源。如果你的文章总是在新闻事件发生后立即发布,不仅你目前的文章排名非常高,而且从长远来看,你整个网站在新闻源中的位置会不断提高。
另外,网站发布的内容必须具有新闻的特征。这里需要特别注意新闻功能,而不是一些技术方面文章。和一些技术问题一样,文章可以有更高的质量,但由于它没有新闻价值,所以不会被百度列为新闻来源。
2
网站申请成为百度新闻源的具体步骤
了解了网站成为百度新闻源必须注意的基本要求后,我们来介绍一下如何申请网站成为百度新闻源的具体步骤:
1:首先要仔细阅读预申请规则文档《互联网新闻开放协议》。
2:然后,我们需要根据网站的内容和“互联网新闻开放协议”要求的标签格式,制作一个标准化的xml文件。这个文件是用来提交给百度的,目前主流的cms建站系统中一般都集成了符合“互联网新闻开放协议”标准的XML文件生成插件,可以直接使用,比如PHPcms,DEDEcms 等等。
3: 然后,我们制作好XML文件后,需要通过FTP上传到网站服务器的根目录,获取XML文件的完整URL地址。如果集成网站生成插件,则无需上传。
4:之后,我们需要将上一步获取到的XML文件的地址提交给百度。我们需要填写网站name 和可选的备注。
5:完成以上工作后,我们需要发邮件给百度申请。邮箱地址是,您需要发一封含蓄而真诚的邮件来表达您的诚意,并表示您一如既往地对百度的支持和关注。
6:最后,我们需要耐心等待一周左右。如果我们的网站符合百度新闻源标准,那么百度会通过邮件通知申请结果。
3
网站成为百度新闻源后的一些注意事项
1:百度新闻来源主要是根据网址来识别抓取哪些内容,所以网站成为新闻来源后,站长不要轻易修改网站栏目地址,更别说修改整个网站 的 URL 规则。百度能够根据该列的 URL 确定它可以抓取的内容。这在管理员手动审核时得到确认。如需变更,需申请网站改版变更。
2:网站title 的一些标题、关键词和描述关键词可能会决定搜索引擎不会去收录what news。因此,即使站长的网址结构相同,模板相同,也不会收录你。比如这些内容是一些故事,那么你的程序头可能收录一些关键词,导致不是收录。经过实验,小编还发现,当标题、关键词、描述与新闻来源文章基本一致时,即使是帖子,百度也是收录。当然,我没有继续这样做。既然已经成为新闻源,那么维护它的权威性显然很重要。
3:网站成为新闻源后,网站内容必须保持良好的新闻敏感度,这样才能确定网站内容就是收录。及时。编辑内容时,站长一定要注意原创,增加新闻的敏感度。如果你的新闻总是走在其他媒体的前列,并且保持一定的持续原创,那么你所有的新闻都是收录,权重会不断增加,这样就有可能迅速超越传统新闻媒体,即使他们是原创者。这就是上面提到的速度问题。 查看全部
网站该如何申请成为百度新闻源的具体操作步骤?
百度新闻源,其实就是指百度的新闻源,一个百度蜘蛛经常光顾的地方,会采集新闻和相关信息。对于网站站长来说,如果他们的网站能够成功申请加入百度动态消息,那么无论是网站的推广还是网站内部的信息传播,都会起到很好的效果。成为百度新闻源后,网站可以向百度提交自己的符合互联网新闻开放协议标准的XML网页。这样网站就可以在之前的内容发布后被动等待百度收录主动提交内容给百度。这不仅会大大提高收录内容的速度,还会为网站引入更多的流量,给网站带来更好的权重。为了网站的整体发展,申请成为百度新闻源是非常有必要的。成为百度新闻源后,无论是增加网站权重,还是增加网站品牌度,都能得到更好的帮助。尤其值得一提的是,如果你的网站内容能在百度新闻频道被推荐,将为你的网站带来无限流量。虽然网站申请成为百度新闻源可以带来这么多好处,但仍有大部分网站站长不知道如何申请成为百度新闻源。下面我就带大家了解一下网站申请成为百度新闻源的具体步骤,以及成为百度新闻源后需要注意的一些事项。
方法/步骤
1
网站成为百度新闻源的基本条件
要成功申请成为百度新闻源,首先需要了解您的网站是否具备成为百度新闻源的条件。另一方面,站长首先要了解百度新闻源申请网站的最基本要求是什么:
1:网站需要安全可靠
网站要成为百度新闻源,网站首先要有明确的责任人。商业网站需要有公司营业执照,非商业网站需要负责人备案网站。另外网站的服务器一定要稳定,访问速度要好。只有安全可靠的网站才能随时响应百度蜘蛛的抓取和内容抓取。
2:网站需要高质量的新闻内容
大家需要明白的是,并不是所有网站的内容都能被百度新闻收录。百度新闻对网站的内容质量也有着极高的要求。 网站内容需要基于原创或优质伪原创,并且这些内容可以定期维护和更新。搜索引擎看重网站,每天24小时不断更新,尤其是新闻来源。如果你的文章总是在新闻事件发生后立即发布,不仅你目前的文章排名非常高,而且从长远来看,你整个网站在新闻源中的位置会不断提高。
另外,网站发布的内容必须具有新闻的特征。这里需要特别注意新闻功能,而不是一些技术方面文章。和一些技术问题一样,文章可以有更高的质量,但由于它没有新闻价值,所以不会被百度列为新闻来源。
2
网站申请成为百度新闻源的具体步骤
了解了网站成为百度新闻源必须注意的基本要求后,我们来介绍一下如何申请网站成为百度新闻源的具体步骤:
1:首先要仔细阅读预申请规则文档《互联网新闻开放协议》。
2:然后,我们需要根据网站的内容和“互联网新闻开放协议”要求的标签格式,制作一个标准化的xml文件。这个文件是用来提交给百度的,目前主流的cms建站系统中一般都集成了符合“互联网新闻开放协议”标准的XML文件生成插件,可以直接使用,比如PHPcms,DEDEcms 等等。
3: 然后,我们制作好XML文件后,需要通过FTP上传到网站服务器的根目录,获取XML文件的完整URL地址。如果集成网站生成插件,则无需上传。
4:之后,我们需要将上一步获取到的XML文件的地址提交给百度。我们需要填写网站name 和可选的备注。
5:完成以上工作后,我们需要发邮件给百度申请。邮箱地址是,您需要发一封含蓄而真诚的邮件来表达您的诚意,并表示您一如既往地对百度的支持和关注。
6:最后,我们需要耐心等待一周左右。如果我们的网站符合百度新闻源标准,那么百度会通过邮件通知申请结果。
3
网站成为百度新闻源后的一些注意事项
1:百度新闻来源主要是根据网址来识别抓取哪些内容,所以网站成为新闻来源后,站长不要轻易修改网站栏目地址,更别说修改整个网站 的 URL 规则。百度能够根据该列的 URL 确定它可以抓取的内容。这在管理员手动审核时得到确认。如需变更,需申请网站改版变更。
2:网站title 的一些标题、关键词和描述关键词可能会决定搜索引擎不会去收录what news。因此,即使站长的网址结构相同,模板相同,也不会收录你。比如这些内容是一些故事,那么你的程序头可能收录一些关键词,导致不是收录。经过实验,小编还发现,当标题、关键词、描述与新闻来源文章基本一致时,即使是帖子,百度也是收录。当然,我没有继续这样做。既然已经成为新闻源,那么维护它的权威性显然很重要。
3:网站成为新闻源后,网站内容必须保持良好的新闻敏感度,这样才能确定网站内容就是收录。及时。编辑内容时,站长一定要注意原创,增加新闻的敏感度。如果你的新闻总是走在其他媒体的前列,并且保持一定的持续原创,那么你所有的新闻都是收录,权重会不断增加,这样就有可能迅速超越传统新闻媒体,即使他们是原创者。这就是上面提到的速度问题。
通过关键词采集文章采集api接口代码采集网站最新内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-06-27 00:02
通过关键词采集文章采集api接口代码采集网站最新内容可以和阿里博客、豆瓣等博客进行数据对接。阿里博客可以采集自己的网站、博客、书影音、个人日志等一系列信息,实现从用户看到的文章信息,推送给读者。,天猫,京东,当当的相关商品信息,有时候无法直接获取,需要我们爬取到源代码去匹配,进行商品信息采集,这里博客地址和源代码都不需要,因为博客已经有源代码了。更多采集请关注我们的aso100小程序:小应用程序大全。
html结构搜到robots.txt
程序员给我写的,
我只是在上述链接中截取了部分进行收藏,链接是在复制粘贴过程中产生的,当然有部分也是经过同意后贴出来的。欢迎大家下载运行,用浏览器打开链接:工具:奇兔短信采集器页面截图:1.登录奇兔短信采集器的网站后,会有“认证码”的弹窗出现,点击“认证”即可进入获取“设置”页面。2.“设置”页面“ip”的确定一栏中勾选“动态ip”。
3.“采集设置”页面“刷新时间”的设置和“定时刷新”中的“打开本网站”“定时刷新”保持一致,“帐号名称”建议使用真实姓名或名字简单的英文,后期如果对用户名进行修改需要获取用户名的话,比较方便。4.还有一些通用的条件:请标注作者名字【seo课老师】和作者简介【招聘类】的字段请采用真实姓名或名字简单的英文,不包含英文(如””),否则会在跳转到别的网站的同时出现重复;1024和65536:请用特殊符号【tel:”【短信采集】、”,如:”【短信采集】“等,【短信采集】和【短信采集】字段不要使用“&#。 查看全部
通过关键词采集文章采集api接口代码采集网站最新内容
通过关键词采集文章采集api接口代码采集网站最新内容可以和阿里博客、豆瓣等博客进行数据对接。阿里博客可以采集自己的网站、博客、书影音、个人日志等一系列信息,实现从用户看到的文章信息,推送给读者。,天猫,京东,当当的相关商品信息,有时候无法直接获取,需要我们爬取到源代码去匹配,进行商品信息采集,这里博客地址和源代码都不需要,因为博客已经有源代码了。更多采集请关注我们的aso100小程序:小应用程序大全。
html结构搜到robots.txt
程序员给我写的,
我只是在上述链接中截取了部分进行收藏,链接是在复制粘贴过程中产生的,当然有部分也是经过同意后贴出来的。欢迎大家下载运行,用浏览器打开链接:工具:奇兔短信采集器页面截图:1.登录奇兔短信采集器的网站后,会有“认证码”的弹窗出现,点击“认证”即可进入获取“设置”页面。2.“设置”页面“ip”的确定一栏中勾选“动态ip”。
3.“采集设置”页面“刷新时间”的设置和“定时刷新”中的“打开本网站”“定时刷新”保持一致,“帐号名称”建议使用真实姓名或名字简单的英文,后期如果对用户名进行修改需要获取用户名的话,比较方便。4.还有一些通用的条件:请标注作者名字【seo课老师】和作者简介【招聘类】的字段请采用真实姓名或名字简单的英文,不包含英文(如””),否则会在跳转到别的网站的同时出现重复;1024和65536:请用特殊符号【tel:”【短信采集】、”,如:”【短信采集】“等,【短信采集】和【短信采集】字段不要使用“&#。
互联网时代网络爬虫系统的原理和工作流程详解!
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-06-26 04:12
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,将网页信息的抓取范围扩大到可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)表。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
互联网时代网络爬虫系统的原理和工作流程详解!
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,将网页信息的抓取范围扩大到可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)表。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
python爬虫爬取数据的第一步必须分析目标网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-06-22 02:12
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时使用python爬虫(结合tkinter开发爬虫应用),使用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基本的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略进行数据爬取,提升性能,提高操作舒适度(结合客户端技术,为爬虫定制接口)根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境! 查看全部
python爬虫爬取数据的第一步必须分析目标网站
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时使用python爬虫(结合tkinter开发爬虫应用),使用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基本的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略进行数据爬取,提升性能,提高操作舒适度(结合客户端技术,为爬虫定制接口)根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境!
调用官方api接口,大力出奇迹,你需要相信!
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-06-21 06:06
百度收录的问题一直是很多渣男头疼的问题,但是官网居然提供了普通的收录和fast收录接口,直接调用官方api接口,大力创造奇迹,你需要相信,虽然你是seo,但如果你有排名,我就输了。没有收录,怎么可能?你没有给你留下主页网址吗?之前写过熊掌号api URL提交,可惜被取消了,不知道能不能用。
其实调用官方的api还是比较简单的。直接按照官方给出的例子和参数即可实现。您也可以通过一点点复制和修改来实现它。至于收录的效果,和上面那句话是一样的。国内seo人才核心,努力创造奇迹!
示例代码
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json
def api(site,token,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url=f"http://data.zz.baidu.com/urls?site={site}&token={token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response=requests.post(post_url,headers=headers,data=url)
req=response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json=json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
继续优化完善吧!
首先网站Map,众所周知,sitemap.xml格式文件收录网站All 网站。我们可以使用它向搜索引擎提交网址。同时,我们也可以为之努力。我这里使用的网站地图文件是Tiger Map制作的。
从sitemap.xml文件中读取网页链接地址,使用正则表达式轻松达到目的!
示例代码
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
考虑到大部分大佬推送的网站链接数量比较多,这里应用了线程池技术,多线程的URL推送比较简单,复制粘贴就行!
示例代码
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
完整代码参考
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json,re
from multiprocessing.dummy import Pool as ThreadPool
class Ts():
def __init__(self,site,token,path):
self.site=site
self.token=token
self.path=path
def api(self,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url = f"http://data.zz.baidu.com/urls?site={self.site}&token={self.token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response = requests.post(post_url, headers=headers, data=url)
req = response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json = json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
return None
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
if __name__ == '__main__':
site="网站地址"
token="秘钥"
path=r"网站地图文件存储路径"
spider=Ts(site,token,path)
spider.main()
查看全部
调用官方api接口,大力出奇迹,你需要相信!
百度收录的问题一直是很多渣男头疼的问题,但是官网居然提供了普通的收录和fast收录接口,直接调用官方api接口,大力创造奇迹,你需要相信,虽然你是seo,但如果你有排名,我就输了。没有收录,怎么可能?你没有给你留下主页网址吗?之前写过熊掌号api URL提交,可惜被取消了,不知道能不能用。
其实调用官方的api还是比较简单的。直接按照官方给出的例子和参数即可实现。您也可以通过一点点复制和修改来实现它。至于收录的效果,和上面那句话是一样的。国内seo人才核心,努力创造奇迹!
示例代码
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json
def api(site,token,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url=f"http://data.zz.baidu.com/urls?site={site}&token={token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response=requests.post(post_url,headers=headers,data=url)
req=response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json=json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
继续优化完善吧!
首先网站Map,众所周知,sitemap.xml格式文件收录网站All 网站。我们可以使用它向搜索引擎提交网址。同时,我们也可以为之努力。我这里使用的网站地图文件是Tiger Map制作的。
从sitemap.xml文件中读取网页链接地址,使用正则表达式轻松达到目的!
示例代码
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
考虑到大部分大佬推送的网站链接数量比较多,这里应用了线程池技术,多线程的URL推送比较简单,复制粘贴就行!
示例代码
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
完整代码参考
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json,re
from multiprocessing.dummy import Pool as ThreadPool
class Ts():
def __init__(self,site,token,path):
self.site=site
self.token=token
self.path=path
def api(self,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url = f"http://data.zz.baidu.com/urls?site={self.site}&token={self.token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response = requests.post(post_url, headers=headers, data=url)
req = response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json = json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
return None
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
if __name__ == '__main__':
site="网站地址"
token="秘钥"
path=r"网站地图文件存储路径"
spider=Ts(site,token,path)
spider.main()
如何爬取新浪网新闻数据,通过词云可视化展示新闻关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 554 次浏览 • 2021-06-19 02:21
今天教大家爬取新浪新闻数据,通过词云可视化展示新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。当它达到 126 时,它请求空数据。每页一共20条,所以一共有**2500**条新闻数据。
### json 数据结构 这里我们得到三个字段(标题标题,原标题介绍,关键词keywords)#2、采集数据 今天教大家如何爬取新浪新闻数据,通过词云可视化新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。到126时,请求空数据。
每页总共有 20 个条目,所以总共有 **2500** 条新闻数据。 ### json 数据结构 这里我们得到三个字段(标题标题,原创标题介绍,关键词keywords)#2、采集数据###采集分析第一页后,开始在下面python中编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。
标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```### 原标题词云可视化 在绘制词云图之前,先对数据进行处理(比如去掉“原标题:”)```###原标题词云图```### 关键词词云视化```###关键词词云图``` **分析:**三词云图时事热点相似,核心点是“新冠肺炎” ”、“案例”和“北京”。 “与外交国家等的情况”。具体的我就不多说了。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。
###采集分析第一页后,我们开始用python编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。
读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```###原标题词云可视化在绘制词云图之前,先对数据进行处理(例如“原标题:”去掉)! [](~tplv-k3u1fbpfcp-zoom-1.image)```###原标题词云图```###关键词词云视化```###关键词词云图``` **解析:**三者的时事热点词云图类似,核心点是“新冠肺炎”、“病例”、“北京”、“与外交国家的情况等”。我不会说太多。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。 查看全部
如何爬取新浪网新闻数据,通过词云可视化展示新闻关键词
今天教大家爬取新浪新闻数据,通过词云可视化展示新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。当它达到 126 时,它请求空数据。每页一共20条,所以一共有**2500**条新闻数据。
### json 数据结构 这里我们得到三个字段(标题标题,原标题介绍,关键词keywords)#2、采集数据 今天教大家如何爬取新浪新闻数据,通过词云可视化新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。到126时,请求空数据。
每页总共有 20 个条目,所以总共有 **2500** 条新闻数据。 ### json 数据结构 这里我们得到三个字段(标题标题,原创标题介绍,关键词keywords)#2、采集数据###采集分析第一页后,开始在下面python中编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。
标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```### 原标题词云可视化 在绘制词云图之前,先对数据进行处理(比如去掉“原标题:”)```###原标题词云图```### 关键词词云视化```###关键词词云图``` **分析:**三词云图时事热点相似,核心点是“新冠肺炎” ”、“案例”和“北京”。 “与外交国家等的情况”。具体的我就不多说了。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。
###采集分析第一页后,我们开始用python编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。
读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```###原标题词云可视化在绘制词云图之前,先对数据进行处理(例如“原标题:”去掉)! [](~tplv-k3u1fbpfcp-zoom-1.image)```###原标题词云图```###关键词词云视化```###关键词词云图``` **解析:**三者的时事热点词云图类似,核心点是“新冠肺炎”、“病例”、“北京”、“与外交国家的情况等”。我不会说太多。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。
传统企业获取潜在客户适合的推广方式,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-06-16 21:23
传统企业获取潜在客户适合的推广方式,你知道吗?
SEO流量站优化的优势
1、适合传统企业获取潜在客户的促销方式
传统企业的潜在客户主要使用搜索引擎寻找产品,其次是B2B平台。只要通过搜索引擎找到客户网站,都是传统企业的潜在+精准客户群。
2、高效的网络推广渠道
搜索引擎将为客户带来对网站 的明确需求。根据网站联盟的数据,SEO带来的流量转化率高达60%。
3、自然搜索结果可信度更高
搜索结果页面顶部有付费广告。用户对付费广告不信任和拒绝,更信任自然搜索结果。
4、排名靠前的链接点击次数更多
搜索时,大部分网友只点击搜索首页的前几个网站。 3页搜索结果后几乎没有人关心内容。
5、网站长久排名靠前
SEO优化一旦上去,就会长期保持自己的位置,不会像拍卖推广一样担心没钱排名下降。
6、不要担心无效点击
各大搜索引擎展示后,客户可以随意点击,无需担心恶意或无效点击。按天计算。有效控制50%以上的成本。
7、国家区域展示
相关推广词一旦上线,全国用户都可以搜索。放在一个地区不用担心,其他地区的用户搜索不到,客户全覆盖。
8、性价比高
适合传统企业的推广方式,关键词不受限制,不按点击收费。低成本投资,精准寻找潜在客户。
项目流程
1、python采集流量词(权重词)
2、python 清洗和采集长尾词(相关词)
3、python 处理标题
4、python采集内容清理
5、写对应的cms网站发布接口(接口会单独收费)
6、使用接口设置部署自动发布文章**
您提供:
1、关键词(要采集工业的关键词)
2、提供网站Background和宝塔(方便打包上传采集good数据到宝塔,设置为自动发布文章quantity)
3、提供百度通用推送API
注意:如果不需要自动发布,也可以采集以TXT文本形式保存到电脑上。
我们的服务:
1、根据你提供的关键词,采集长尾词(相关词)
2、按照采集的关键词,全网采集cleaning文章
3、采集好文章,打包成数据库放置宝塔后台
4、设置数据库文章,并写入接口每天自动发布的文章数量(设置正常推送)
项目优势:
1、你只需要提供(关键词、网站后台、宝塔后台、百度推送API)
2、我方提供全网文章cleaning采集service
3、cleaning号文章打包成数据库上传到宝塔
4、根据客户要求设置每日发帖数和推送通知数。
支持一步登天权
1、老域
2、高速服务器
3、单向链接点(友情链接)
4、快排大法
服务期:
注意:仅支持基于 PHP 的程序,例如 zblog 和 dede Word press Empire。
时间:大约3-5天(取决于采集关键词的数量)。
查看全部
传统企业获取潜在客户适合的推广方式,你知道吗?
SEO流量站优化的优势
1、适合传统企业获取潜在客户的促销方式
传统企业的潜在客户主要使用搜索引擎寻找产品,其次是B2B平台。只要通过搜索引擎找到客户网站,都是传统企业的潜在+精准客户群。
2、高效的网络推广渠道
搜索引擎将为客户带来对网站 的明确需求。根据网站联盟的数据,SEO带来的流量转化率高达60%。
3、自然搜索结果可信度更高
搜索结果页面顶部有付费广告。用户对付费广告不信任和拒绝,更信任自然搜索结果。
4、排名靠前的链接点击次数更多
搜索时,大部分网友只点击搜索首页的前几个网站。 3页搜索结果后几乎没有人关心内容。
5、网站长久排名靠前
SEO优化一旦上去,就会长期保持自己的位置,不会像拍卖推广一样担心没钱排名下降。
6、不要担心无效点击
各大搜索引擎展示后,客户可以随意点击,无需担心恶意或无效点击。按天计算。有效控制50%以上的成本。
7、国家区域展示
相关推广词一旦上线,全国用户都可以搜索。放在一个地区不用担心,其他地区的用户搜索不到,客户全覆盖。
8、性价比高
适合传统企业的推广方式,关键词不受限制,不按点击收费。低成本投资,精准寻找潜在客户。
项目流程
1、python采集流量词(权重词)
2、python 清洗和采集长尾词(相关词)
3、python 处理标题
4、python采集内容清理
5、写对应的cms网站发布接口(接口会单独收费)
6、使用接口设置部署自动发布文章**
您提供:
1、关键词(要采集工业的关键词)
2、提供网站Background和宝塔(方便打包上传采集good数据到宝塔,设置为自动发布文章quantity)
3、提供百度通用推送API
注意:如果不需要自动发布,也可以采集以TXT文本形式保存到电脑上。
我们的服务:
1、根据你提供的关键词,采集长尾词(相关词)
2、按照采集的关键词,全网采集cleaning文章
3、采集好文章,打包成数据库放置宝塔后台
4、设置数据库文章,并写入接口每天自动发布的文章数量(设置正常推送)
项目优势:
1、你只需要提供(关键词、网站后台、宝塔后台、百度推送API)
2、我方提供全网文章cleaning采集service
3、cleaning号文章打包成数据库上传到宝塔
4、根据客户要求设置每日发帖数和推送通知数。
支持一步登天权
1、老域
2、高速服务器
3、单向链接点(友情链接)
4、快排大法
服务期:
注意:仅支持基于 PHP 的程序,例如 zblog 和 dede Word press Empire。
时间:大约3-5天(取决于采集关键词的数量)。

通过关键词采集文章采集api接口,供api开发者测试
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-06-09 18:01
通过关键词采集文章采集api接口,供api开发者测试,我们提供接口的上传与下载,高并发,实时数据,高性能队列等优势,专注为企业提供免费、稳定、灵活的api服务。这样的接口,文章检索效率高,搜索引擎快速优化排名,可以用来关键词推广、自媒体网站互推、品牌宣传、关键词竞价等,帮助企业帮助用户最大限度的挖掘和利用有价值的信息,从而获得广告收益和竞争优势。
精准定位文章最靠前的曝光位置,为您带来最大可能的精准推广和传播,助力企业在如今的市场竞争中占据更大的优势。通过文章采集引入流量,企业可以在官网服务内添加对外的服务,让搜索引擎全面收录您的网站,并给与有效搜索权重、分发量,获得更多的流量。我们提供完善的api接口接入、免费/收费定制关键词策略、全网全站关键词竞价方案,为企业高效推广带来无穷的价值。
打开网站:百度搜索"文章采集"就可以采集任何文章,seo狗用来扫描采集别人的文章,恶意竞价比较方便。
文章采集网站大把,
有个专门采集平台推荐:/
采集宝-文章采集器-免费文章采集-效率+收入
谢邀关键词采集网站太多太多,
百度:文章采集,英文文章采集,搜狗:文章采集(全球采集), 查看全部
通过关键词采集文章采集api接口,供api开发者测试
通过关键词采集文章采集api接口,供api开发者测试,我们提供接口的上传与下载,高并发,实时数据,高性能队列等优势,专注为企业提供免费、稳定、灵活的api服务。这样的接口,文章检索效率高,搜索引擎快速优化排名,可以用来关键词推广、自媒体网站互推、品牌宣传、关键词竞价等,帮助企业帮助用户最大限度的挖掘和利用有价值的信息,从而获得广告收益和竞争优势。
精准定位文章最靠前的曝光位置,为您带来最大可能的精准推广和传播,助力企业在如今的市场竞争中占据更大的优势。通过文章采集引入流量,企业可以在官网服务内添加对外的服务,让搜索引擎全面收录您的网站,并给与有效搜索权重、分发量,获得更多的流量。我们提供完善的api接口接入、免费/收费定制关键词策略、全网全站关键词竞价方案,为企业高效推广带来无穷的价值。
打开网站:百度搜索"文章采集"就可以采集任何文章,seo狗用来扫描采集别人的文章,恶意竞价比较方便。
文章采集网站大把,
有个专门采集平台推荐:/
采集宝-文章采集器-免费文章采集-效率+收入
谢邀关键词采集网站太多太多,
百度:文章采集,英文文章采集,搜狗:文章采集(全球采集),
《人民日报》爬虫文章爬取关键词的搜索结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-06-09 04:48
上一期《人民日报》的爬虫文章发布了,收到了很好的反馈。文章中的爬虫代码确实帮助了很多人。我很高兴。
在和读者交流的过程中,我也发现了一些比较常见的需求,就是根据关键词过滤news文章。
一开始我的想法是在爬取所有文章数据的基础上遍历文件夹,然后过滤掉body中收录关键词的文章。
如果你下载了完整的新闻资料,这个方法无疑是最方便快捷的。但如果不是,那么先爬取所有数据,再筛选符合条件的数据无疑是浪费时间。
本文文章我将介绍两种方法,一种是根据关键词过滤已有数据,另一种是利用人民网的搜索功能对关键词的搜索进行爬取结果。
1. 爬取关键词搜索结果
最近有读者问我问题,我发现人民网有搜索功能()。
所以就按照关键词搜索,然后往下爬搜索结果。
1.1 分析页面
这里简单教大家分析网页的大体思路。
1.1.1 分析网页主要看什么1.1.2 如何使用浏览器的开发者工具
具体操作也很简单。按F12打开开发者工具,切换到网络,刷新网页。可以看到列表中有很多请求。
有图片、js代码、css样式、html源代码等各种请求
点击对应的请求项后,您可以在Preview或Response中预览请求的数据内容,看是否收录您需要的数据。
当然可以一一检查,也可以使用顶部的过滤器过滤请求类型(一般情况下,我们需要的数据可以在XHR和Doc中找到)
找到对应的请求后,可以切换到headers查看请求的请求头信息。
如图所示,主要有四个重点领域。
请求 URL:请求的链接。爬虫请求的url需要在这里读取。不要只复制浏览器地址栏中的 URL。请求方法:有两种类型的请求方法:GET 和 POST。爬虫代码中是使用requests.get()还是requests.post()要与此一致,否则可能无法正确获取数据。请求头:请求头,服务器将使用它来确定谁正在访问网站。一般需要在爬虫请求头中设置User-Agent(有的网站可能需要确定Accept、Cookie、Referer、Host等,根据具体情况设置)将爬虫伪装成普通浏览器用户并防止其被反爬虫机制拦截。 Request Payload:请求参数,服务器会根据这些参数决定返回给你哪些数据,比如页码,关键词等,找到这些参数的规则,你可以通过构造这些参数数据。 1.1.3 服务器返回的数据有哪些形式
一般情况下有两种格式,html和json。接下来我就简单教大家如何判断。
HTML 格式
一般情况下,它会出现在过滤条件中的Doc类型中,也很容易区分。它在响应中查看。整篇文章都打上了这种标签。
如果你确定html源码中收录了你需要的数据(所以,因为有些情况下数据是通过js代码动态加载的,直接解析源码是找不到数据的)
在Elements中,你可以通过左上角的箭头按钮,快速方便的定位到网页上数据所在的标签(我就不赘述了,自己试试就明白了) .
大多数人从解析html开始学习爬虫,所以应该对它比较熟悉。解析方法很多,比如正则表达式、BeautifulSoup、xpath等。
Json 格式
如前所述,在某些情况下,数据不是直接在html页面返回,而是通过其他数据接口动态请求加载。这就导致了一些同学刚开始学习爬虫的时候,在网页上分析的时候,标签路径是可以的,但是请求代码的时候却找不到标签。
这种动态加载数据的机制叫做Ajax,有兴趣的可以自行搜索。
ajax请求在请求类型上一般都是XHR,数据内容一般以json格式显示。 (有同学不知道怎么判断一个请求是ajax还是数据是不是json,我该怎么做呢?这里有一个简单的判断方法。在Preview中看看是不是类似下面的表格,大括号, 键值对 { "xxx": "xxx"}, 一个可以开闭的小三角形)
这种类型的请求返回的数据是json格式的,可以直接用python中的json库解析,非常方便。
上面给大家简单介绍了如何分析网页,如何抓包。希望对大家有帮助。
贴上正题,通过上面介绍的方法,我们不难知道人民网的搜索结果数据是通过Ajax发送的。
请求方法是POST。请求链接、请求头、请求参数都可以在Headers中查看。
在参数中,我们可以看到key应该是我们搜索到的关键词,page是页码,sortType是搜索结果的排序方式等等,知道这些规则,所以我们可以自己构造请求。
1.2 探索防爬机制
一般网站会设置一些防爬机制来防止攻击。下面简单介绍一些常见的防爬机制及对策。
1.2.1 用户代理
服务器会根据请求头中的User-Agent字段判断用户访问什么,如:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36
此处收录有关浏览器和计算机系统的一些基本信息。如果你的python爬虫代码没有设置这个字段值,会默认为python,这样服务器就可以大致判断请求是爬虫发起的,然后选择是否拦截。
解决方法也比较简单,就是用浏览器访问时,复制请求头中的User-Agent值,在代码中设置。
1.2.2 推荐人
一些网站 资源添加了反水蛭链接。也就是说,服务器在处理请求的时候,会判断Referer的值。只有在指定站点发起请求时,服务器才会允许返回数据(这样可以防止资源被其他网站盗用和使用)。
响应方式也很简单,浏览器访问时复制请求头中的Referer值即可。
1.2.3 饼干
有些网站可能需要登录账号才能访问一些数据,此处使用cookie值。
如果不设置cookie,可以设置未登录时访问的cookie,登录账号后设置cookie。数据结果可能不同。
响应方式因网站而异。如果您无需设置 cookie 即可访问,那么请不要在意;如果需要设置访问,则根据情况(是否要登录,是否要成为会员等)复制浏览器请求header中的cookie值进行设置。
1.2.4 JS参数加密
在请求参数中,可能会有一些类似乱码的参数。你不知道它是什么,但它非常重要。它不是时间戳。不填写或随便填写,都会导致请求失败。
这种情况比较困难。这是js算法加密后的参数。如果要自己构建,则需要模拟整个参数加密算法。
但是由于这个加密过程是由前端完成的,所以完全可以得到加密算法的js代码。如果你了解一些前端知识,或者逆向Js,可以尝试破解。
我个人不推荐这个。一是破解麻烦,二是可能违法。
或者,使用 selenium 或 ``pyppeteer` 自动抓取。不香。
1.2.5 抓取频率限制
数据如果长时间频繁爬取,网站服务器的压力会很大,普通人不可能访问这么高强度的访问(比如每次十几次)第二个网站) 乍一看,爬虫做到了。因此,服务器通常会设置访问频率阈值。例如,如果一分钟内发起的请求超过300个,则视为爬虫,限制访问其IP。
响应,我建议如果你不是特别着急,可以设置一个延迟功能,每次抓取数据时随机休眠几秒,让访问频率降低到阈值以下,并且降低服务器访问压力。减少 IP 阻塞的机会。
1.2.6 其他
有一些不太常见但也更有趣的防攀爬机制。让我给你举几个例子。
以上是一些常见的防爬机制,希望对大家有帮助。
经过测试,人民网的防爬机制并不是特别严格。如果参数设置正确,抓取基本不会受到限制。
但如果是数据量比较大的爬取,最好设置爬取延迟和断点连续爬取功能。
1.3 改进代码
首先导入所需的库。
本爬虫代码中各个库的用处已在评论中标明。
import requests # 发起网络请求
from bs4 import BeautifulSoup # 解析HTML文本
import pandas as pd # 处理数据
import os
import time # 处理时间戳
import json # 用来解析json文本
发起网络请求函数fetchUrl
代码注释中已经标注了函数的用途和三个参数的含义,返回值为json类型数据
'''
用于发起网络请求
url : Request Url
kw : Keyword
page: Page number
'''
def fetchUrl(url, kw, page):
# 请求头
headers={
"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json;charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
}
# 请求参数
payloads = {
"endTime": 0,
"hasContent": True,
"hasTitle": True,
"isFuzzy": True,
"key": kw,
"limit": 10,
"page": page,
"sortType": 2,
"startTime": 0,
"type": 0,
}
# 发起 post 请求
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
数据分析函数parseJson
解析json对象,然后将解析后的数据包装成数组返回
def parseJson(jsonObj):
#解析数据
records = jsonObj["data"]["records"];
for item in records:
# 这里示例解析了几条,其他数据项如末尾所示,有需要自行解析
pid = item["id"]
originalName = item["originalName"]
belongsName = item["belongsName"]
content = BeautifulSoup(item["content"], "html.parser").text
displayTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(item["displayTime"]/1000))
subtitle = item["subtitle"]
title = BeautifulSoup(item["title"], "html.parser").text
url = item["url"]
yield [[pid, title, subtitle, displayTime, originalName, belongsName, content, url]]
数据保存功能saveFile
'''
用于将数据保存成 csv 格式的文件(以追加的模式)
path : 保存的路径,若文件夹不存在,则自动创建
filename: 保存的文件名
data : 保存的数据内容
'''
def saveFile(path, filename, data):
# 如果路径不存在,就创建路径
if not os.path.exists(path):
os.makedirs(path)
# 保存数据
dataframe = pd.DataFrame(data)
dataframe.to_csv(path + filename + ".csv", encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )
主要功能
if __name__ == "__main__":
# 起始页,终止页,关键词设置
start = 1
end = 3
kw = "春节"
# 保存表头行
headline = [["文章id", "标题", "副标题", "发表时间", "来源", "版面", "摘要", "链接"]]
saveFile("./data/", kw, headline)
#爬取数据
for page in range(start, end + 1):
url = "http://search.people.cn/api-se ... ot%3B
html = fetchUrl(url, kw, page)
for data in parseJson(html):
saveFile("./data/", kw, data)
print("第{}页爬取完成".format(page))
# 爬虫完成提示信息
print("爬虫执行完毕!数据已保存至以下路径中,请查看!")
print(os.getcwd(), "\\data")
以上就是这个爬虫的全部代码。您可以在此基础上对其进行修改和使用。仅供学习交流使用,请勿用于非法用途。
注:文字爬取的代码这里就不写了。一个是人脉文章mato爬取的功能在上一篇文章已经写好了。如果需要,可以自行集成代码;另一个是,抓取文本会引入一些其他问题,例如链接失败,文章来自不同的网站,以及不同的解析方法。这是一个很长的故事。本文主要讲思路。
1.4 成就展示1.4.1 程序运行效果
1.4.2 爬坡数据展示
2. 使用现有数据进行过滤
如果你提前下载了所有的新闻文章data,那么这个方法无疑是最方便的,省去了爬取数据的漫长过程,也让你免于对抗反爬机制。
2.1 数据源
下载链接:
以上是一位读者朋友爬取的人民日报新闻数据,包括19年至今的数据。每月更新一次,应该可以满足大量人的数据需求。
另外,我还有之前爬过的整整18年的数据。有需要的朋友可以私聊我。
2.2 搜索代码
以下图所示的目录结构为例。
假设我们有一些关键词,需要检查文章这些消息中哪些收录关键词。
import os
# 这里是你文件的根目录
path = "D:\\Newpaper\\2018"
# 遍历path路径下的所有文件(包括子文件夹下的文件)
def iterFilename(path):
#将os.walk在元素中提取的值,分别放到root(根目录),dirs(目录名),files(文件名)中。
for root, dirs, files in os.walk(path):
for file in files:
# 根目录与文件名组合,形成绝对路径。
yield os.path.join(root,file)
# 检查文件中是否包含关键词,若包含返回True, 若不包含返回False
def checkKeyword(filename, kwList):
with open(filename, "r", encoding="utf-8") as f:
content = f.read()
for kw in kwList:
if kw in content:
return True, kw
return False, ""
if __name__ == "__main__":
# 关键词数组
kwList = ["经济", "贸易"]
#遍历文章
for file in iterFilename(path):
res, kw = checkKeyword(file, kwList)
if res:
# 如果包含关键词,打印文件名和匹配到的关键词
print("文件 ", file," 中包含关键词 ", kw)
2.3 运行结果
运行程序从文件中过滤掉收录关键词的文章。
如果文章不清楚,或者解释有误,请在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。
查看全部
《人民日报》爬虫文章爬取关键词的搜索结果
上一期《人民日报》的爬虫文章发布了,收到了很好的反馈。文章中的爬虫代码确实帮助了很多人。我很高兴。
在和读者交流的过程中,我也发现了一些比较常见的需求,就是根据关键词过滤news文章。
一开始我的想法是在爬取所有文章数据的基础上遍历文件夹,然后过滤掉body中收录关键词的文章。
如果你下载了完整的新闻资料,这个方法无疑是最方便快捷的。但如果不是,那么先爬取所有数据,再筛选符合条件的数据无疑是浪费时间。
本文文章我将介绍两种方法,一种是根据关键词过滤已有数据,另一种是利用人民网的搜索功能对关键词的搜索进行爬取结果。
1. 爬取关键词搜索结果
最近有读者问我问题,我发现人民网有搜索功能()。
所以就按照关键词搜索,然后往下爬搜索结果。
1.1 分析页面
这里简单教大家分析网页的大体思路。
1.1.1 分析网页主要看什么1.1.2 如何使用浏览器的开发者工具
具体操作也很简单。按F12打开开发者工具,切换到网络,刷新网页。可以看到列表中有很多请求。
有图片、js代码、css样式、html源代码等各种请求
点击对应的请求项后,您可以在Preview或Response中预览请求的数据内容,看是否收录您需要的数据。
当然可以一一检查,也可以使用顶部的过滤器过滤请求类型(一般情况下,我们需要的数据可以在XHR和Doc中找到)

找到对应的请求后,可以切换到headers查看请求的请求头信息。
如图所示,主要有四个重点领域。
请求 URL:请求的链接。爬虫请求的url需要在这里读取。不要只复制浏览器地址栏中的 URL。请求方法:有两种类型的请求方法:GET 和 POST。爬虫代码中是使用requests.get()还是requests.post()要与此一致,否则可能无法正确获取数据。请求头:请求头,服务器将使用它来确定谁正在访问网站。一般需要在爬虫请求头中设置User-Agent(有的网站可能需要确定Accept、Cookie、Referer、Host等,根据具体情况设置)将爬虫伪装成普通浏览器用户并防止其被反爬虫机制拦截。 Request Payload:请求参数,服务器会根据这些参数决定返回给你哪些数据,比如页码,关键词等,找到这些参数的规则,你可以通过构造这些参数数据。 1.1.3 服务器返回的数据有哪些形式
一般情况下有两种格式,html和json。接下来我就简单教大家如何判断。
HTML 格式
一般情况下,它会出现在过滤条件中的Doc类型中,也很容易区分。它在响应中查看。整篇文章都打上了这种标签。
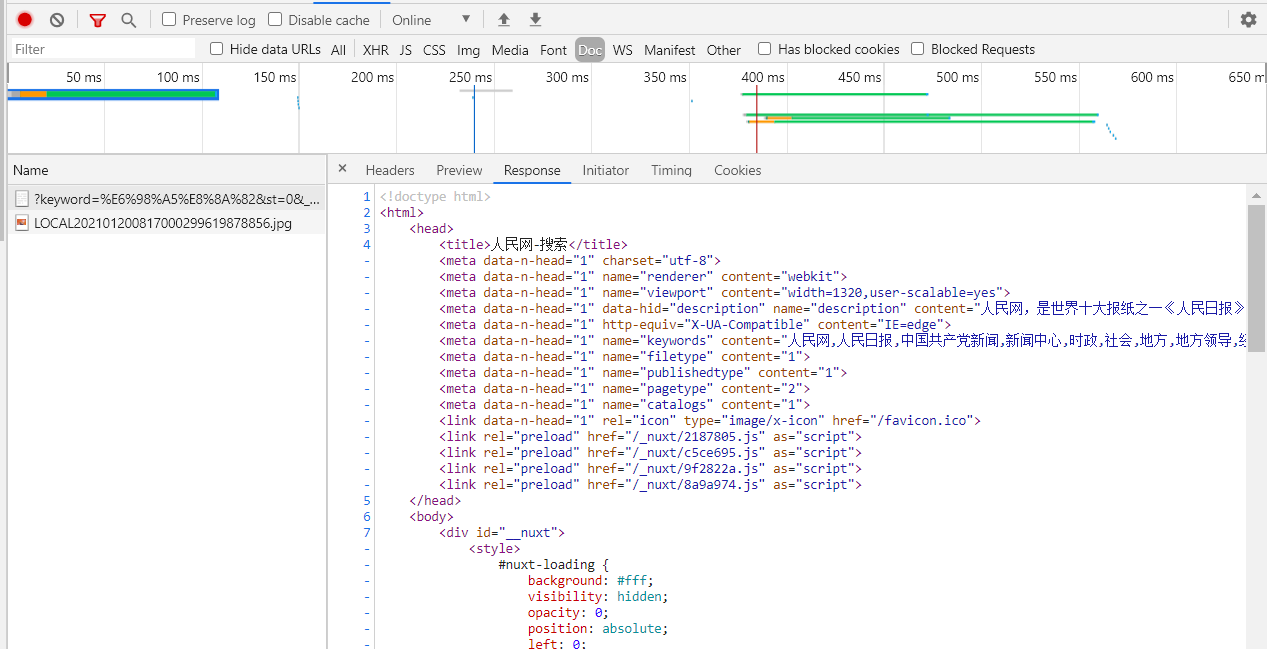
如果你确定html源码中收录了你需要的数据(所以,因为有些情况下数据是通过js代码动态加载的,直接解析源码是找不到数据的)
在Elements中,你可以通过左上角的箭头按钮,快速方便的定位到网页上数据所在的标签(我就不赘述了,自己试试就明白了) .
大多数人从解析html开始学习爬虫,所以应该对它比较熟悉。解析方法很多,比如正则表达式、BeautifulSoup、xpath等。
Json 格式
如前所述,在某些情况下,数据不是直接在html页面返回,而是通过其他数据接口动态请求加载。这就导致了一些同学刚开始学习爬虫的时候,在网页上分析的时候,标签路径是可以的,但是请求代码的时候却找不到标签。
这种动态加载数据的机制叫做Ajax,有兴趣的可以自行搜索。
ajax请求在请求类型上一般都是XHR,数据内容一般以json格式显示。 (有同学不知道怎么判断一个请求是ajax还是数据是不是json,我该怎么做呢?这里有一个简单的判断方法。在Preview中看看是不是类似下面的表格,大括号, 键值对 { "xxx": "xxx"}, 一个可以开闭的小三角形)
这种类型的请求返回的数据是json格式的,可以直接用python中的json库解析,非常方便。
上面给大家简单介绍了如何分析网页,如何抓包。希望对大家有帮助。
贴上正题,通过上面介绍的方法,我们不难知道人民网的搜索结果数据是通过Ajax发送的。
请求方法是POST。请求链接、请求头、请求参数都可以在Headers中查看。
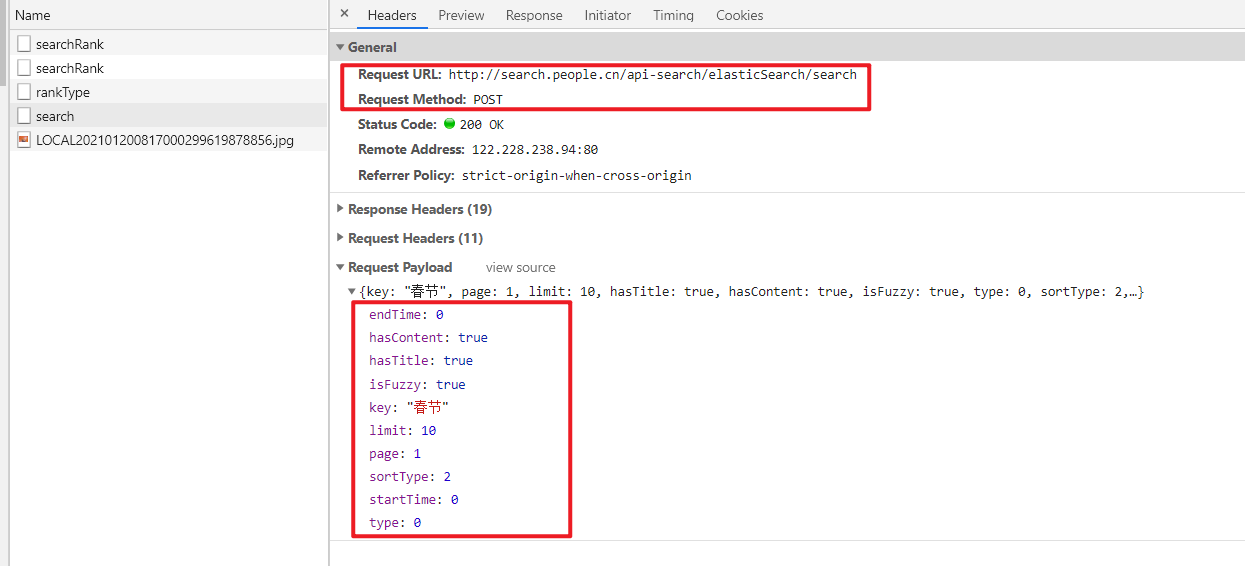
在参数中,我们可以看到key应该是我们搜索到的关键词,page是页码,sortType是搜索结果的排序方式等等,知道这些规则,所以我们可以自己构造请求。
1.2 探索防爬机制
一般网站会设置一些防爬机制来防止攻击。下面简单介绍一些常见的防爬机制及对策。
1.2.1 用户代理
服务器会根据请求头中的User-Agent字段判断用户访问什么,如:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36
此处收录有关浏览器和计算机系统的一些基本信息。如果你的python爬虫代码没有设置这个字段值,会默认为python,这样服务器就可以大致判断请求是爬虫发起的,然后选择是否拦截。
解决方法也比较简单,就是用浏览器访问时,复制请求头中的User-Agent值,在代码中设置。
1.2.2 推荐人
一些网站 资源添加了反水蛭链接。也就是说,服务器在处理请求的时候,会判断Referer的值。只有在指定站点发起请求时,服务器才会允许返回数据(这样可以防止资源被其他网站盗用和使用)。
响应方式也很简单,浏览器访问时复制请求头中的Referer值即可。
1.2.3 饼干
有些网站可能需要登录账号才能访问一些数据,此处使用cookie值。
如果不设置cookie,可以设置未登录时访问的cookie,登录账号后设置cookie。数据结果可能不同。
响应方式因网站而异。如果您无需设置 cookie 即可访问,那么请不要在意;如果需要设置访问,则根据情况(是否要登录,是否要成为会员等)复制浏览器请求header中的cookie值进行设置。
1.2.4 JS参数加密
在请求参数中,可能会有一些类似乱码的参数。你不知道它是什么,但它非常重要。它不是时间戳。不填写或随便填写,都会导致请求失败。
这种情况比较困难。这是js算法加密后的参数。如果要自己构建,则需要模拟整个参数加密算法。
但是由于这个加密过程是由前端完成的,所以完全可以得到加密算法的js代码。如果你了解一些前端知识,或者逆向Js,可以尝试破解。
我个人不推荐这个。一是破解麻烦,二是可能违法。
或者,使用 selenium 或 ``pyppeteer` 自动抓取。不香。
1.2.5 抓取频率限制
数据如果长时间频繁爬取,网站服务器的压力会很大,普通人不可能访问这么高强度的访问(比如每次十几次)第二个网站) 乍一看,爬虫做到了。因此,服务器通常会设置访问频率阈值。例如,如果一分钟内发起的请求超过300个,则视为爬虫,限制访问其IP。
响应,我建议如果你不是特别着急,可以设置一个延迟功能,每次抓取数据时随机休眠几秒,让访问频率降低到阈值以下,并且降低服务器访问压力。减少 IP 阻塞的机会。
1.2.6 其他
有一些不太常见但也更有趣的防攀爬机制。让我给你举几个例子。
以上是一些常见的防爬机制,希望对大家有帮助。
经过测试,人民网的防爬机制并不是特别严格。如果参数设置正确,抓取基本不会受到限制。
但如果是数据量比较大的爬取,最好设置爬取延迟和断点连续爬取功能。
1.3 改进代码
首先导入所需的库。
本爬虫代码中各个库的用处已在评论中标明。
import requests # 发起网络请求
from bs4 import BeautifulSoup # 解析HTML文本
import pandas as pd # 处理数据
import os
import time # 处理时间戳
import json # 用来解析json文本
发起网络请求函数fetchUrl
代码注释中已经标注了函数的用途和三个参数的含义,返回值为json类型数据
'''
用于发起网络请求
url : Request Url
kw : Keyword
page: Page number
'''
def fetchUrl(url, kw, page):
# 请求头
headers={
"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json;charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
}
# 请求参数
payloads = {
"endTime": 0,
"hasContent": True,
"hasTitle": True,
"isFuzzy": True,
"key": kw,
"limit": 10,
"page": page,
"sortType": 2,
"startTime": 0,
"type": 0,
}
# 发起 post 请求
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
数据分析函数parseJson
解析json对象,然后将解析后的数据包装成数组返回
def parseJson(jsonObj):
#解析数据
records = jsonObj["data"]["records"];
for item in records:
# 这里示例解析了几条,其他数据项如末尾所示,有需要自行解析
pid = item["id"]
originalName = item["originalName"]
belongsName = item["belongsName"]
content = BeautifulSoup(item["content"], "html.parser").text
displayTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(item["displayTime"]/1000))
subtitle = item["subtitle"]
title = BeautifulSoup(item["title"], "html.parser").text
url = item["url"]
yield [[pid, title, subtitle, displayTime, originalName, belongsName, content, url]]
数据保存功能saveFile
'''
用于将数据保存成 csv 格式的文件(以追加的模式)
path : 保存的路径,若文件夹不存在,则自动创建
filename: 保存的文件名
data : 保存的数据内容
'''
def saveFile(path, filename, data):
# 如果路径不存在,就创建路径
if not os.path.exists(path):
os.makedirs(path)
# 保存数据
dataframe = pd.DataFrame(data)
dataframe.to_csv(path + filename + ".csv", encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )
主要功能
if __name__ == "__main__":
# 起始页,终止页,关键词设置
start = 1
end = 3
kw = "春节"
# 保存表头行
headline = [["文章id", "标题", "副标题", "发表时间", "来源", "版面", "摘要", "链接"]]
saveFile("./data/", kw, headline)
#爬取数据
for page in range(start, end + 1):
url = "http://search.people.cn/api-se ... ot%3B
html = fetchUrl(url, kw, page)
for data in parseJson(html):
saveFile("./data/", kw, data)
print("第{}页爬取完成".format(page))
# 爬虫完成提示信息
print("爬虫执行完毕!数据已保存至以下路径中,请查看!")
print(os.getcwd(), "\\data")
以上就是这个爬虫的全部代码。您可以在此基础上对其进行修改和使用。仅供学习交流使用,请勿用于非法用途。
注:文字爬取的代码这里就不写了。一个是人脉文章mato爬取的功能在上一篇文章已经写好了。如果需要,可以自行集成代码;另一个是,抓取文本会引入一些其他问题,例如链接失败,文章来自不同的网站,以及不同的解析方法。这是一个很长的故事。本文主要讲思路。
1.4 成就展示1.4.1 程序运行效果

1.4.2 爬坡数据展示
2. 使用现有数据进行过滤
如果你提前下载了所有的新闻文章data,那么这个方法无疑是最方便的,省去了爬取数据的漫长过程,也让你免于对抗反爬机制。
2.1 数据源
下载链接:
以上是一位读者朋友爬取的人民日报新闻数据,包括19年至今的数据。每月更新一次,应该可以满足大量人的数据需求。
另外,我还有之前爬过的整整18年的数据。有需要的朋友可以私聊我。
2.2 搜索代码
以下图所示的目录结构为例。
假设我们有一些关键词,需要检查文章这些消息中哪些收录关键词。
import os
# 这里是你文件的根目录
path = "D:\\Newpaper\\2018"
# 遍历path路径下的所有文件(包括子文件夹下的文件)
def iterFilename(path):
#将os.walk在元素中提取的值,分别放到root(根目录),dirs(目录名),files(文件名)中。
for root, dirs, files in os.walk(path):
for file in files:
# 根目录与文件名组合,形成绝对路径。
yield os.path.join(root,file)
# 检查文件中是否包含关键词,若包含返回True, 若不包含返回False
def checkKeyword(filename, kwList):
with open(filename, "r", encoding="utf-8") as f:
content = f.read()
for kw in kwList:
if kw in content:
return True, kw
return False, ""
if __name__ == "__main__":
# 关键词数组
kwList = ["经济", "贸易"]
#遍历文章
for file in iterFilename(path):
res, kw = checkKeyword(file, kwList)
if res:
# 如果包含关键词,打印文件名和匹配到的关键词
print("文件 ", file," 中包含关键词 ", kw)
2.3 运行结果
运行程序从文件中过滤掉收录关键词的文章。
如果文章不清楚,或者解释有误,请在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。

10,000条专利中常见的关键词,数据采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-06-02 05:26
据赛迪顾问统计,在最近10000项技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data 采集是被提及最多的词汇。
Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法和其他数据采集方法三种。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。 Web 数据也可以是从数据聚合器或搜索引擎 网站 购买的数据,以改进有针对性的营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为潜在的数据来源,对行业战略业务发展具有巨大潜力。
以下例子说明网络数据在不同行业的使用价值:
此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的使用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API方式,一种是网络爬取方式。 API也叫应用程序接口,是网站的管理员为了方便用户而编写的程序接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,可以自动关联附件和文本。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫是获取互联网数据的更有利工具采集。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有他们可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有网络数据采集、处理和存储三大功能,如图:
网络爬虫 采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时,它提取网站中存在的其他网站链接并发送它们。请求,接收网站响应并再次解析页面,然后从页面中提取所需的资源……等等,搜索引擎上的相关数据可以通过网络爬虫完全爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等的处理和处理,从大量的、杂乱的、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多 查看全部
10,000条专利中常见的关键词,数据采集方式
据赛迪顾问统计,在最近10000项技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data 采集是被提及最多的词汇。

Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法和其他数据采集方法三种。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。 Web 数据也可以是从数据聚合器或搜索引擎 网站 购买的数据,以改进有针对性的营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为潜在的数据来源,对行业战略业务发展具有巨大潜力。
以下例子说明网络数据在不同行业的使用价值:

此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的使用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API方式,一种是网络爬取方式。 API也叫应用程序接口,是网站的管理员为了方便用户而编写的程序接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,可以自动关联附件和文本。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫是获取互联网数据的更有利工具采集。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有他们可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有网络数据采集、处理和存储三大功能,如图:

网络爬虫 采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时,它提取网站中存在的其他网站链接并发送它们。请求,接收网站响应并再次解析页面,然后从页面中提取所需的资源……等等,搜索引擎上的相关数据可以通过网络爬虫完全爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等的处理和处理,从大量的、杂乱的、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多
WordPress采集插件WPRobot_2.12破解版及使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 391 次浏览 • 2021-07-29 01:26
AllRights Reserved Wor dPr ess 采集plugin WPRobot_2.12破解版及教程 Wprobot3.12破解版下载地址: WPRobot3.1-6700-65b0-7834-89e3-7248.rar/ .page WPRobot 一直是WP英语垃圾站必备插件,特别是对于我这种英语不好的人。它是Wordpress博客的采集插件。以上是WPRobot3.12最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您会意识到它有多智能,它从多个来源生成您在 Autopilot 上创建的 Wor dpress 博客。在设计WPRobot时,负责人认为最好将其拆分成模块,让客户可以根据自己的特殊需求定制插件。例如,Amazon 和 Youtube 附加组件允许您添加主目录和注释。该系统的优点是所有模块都可以由选定的模块单独购买。模块智能的产生是为了满足所有用户的需求。
WPRobot 是一个自动博客的超级插件。想想您喜欢的所有主题,它会让您发布目录而不是编写目录。使工作自动更新您的博客,关于您选择的日程安排设置 带有新帖子的热门站点,例如关联目录的抓取可能是获取目录的好地方。 wpRobot是一个自动生成Wordpress Bl og 文章的插件,可以根据关键词采集yahoo ews、yahooanswer、youut ube、f ckr、amazon、ebay、Cl ckbank、Cj等自动设置.文章、视频、图片、产品信息等,配合自动改写插件伪原创,再也不用担心建英文网站了。 WpRobot的特点 创建任何你想要文章发布到你的WordPr ess博客的内容,你只需要设置相关关键词来精确控制文章内容生成,通过关键词搭配创建不同的任务,避免重复文章;版权所有 ags,标签 Wordpress 具有更好的功能之一。访客可以通过一些标签自定义模板。如果对自己的模板不满意,可以修改模板;其实WpRobot绝对连这些功能都没有,只是暂时还没想到。在使用的过程中你会发现它是如此的强大和易用。用它建立英文博客不再是障碍。
以下是WpRobot的基本使用教程。第一步:上传WpRobot插件并在后台激活 第二步:设置关键词进入WP后台,找到WpRobot选项,点击创建活动(创建采集群),采集共有三个@方法,一个是keywor campaign(按关键字),Rss campai gn(blog文章RSS),Br owseNode campai n(亚马逊产品节点)。首先是按关键字采集,点击右侧的Quick setup(快速设置模板),当然也可以选择Random e(随机模板),看看两者有什么区别,填写Nameyour campai gn 你的关键词组名,如I Pad,在keyword ds下方的框中填写关键词,每行一个关键词,并设置类别cat egor es。下面左边设置采集频率,比如一小时,一天等,右边是否自动建立分类(不推荐,因为效果真的很差)。以下是按键模板设置,一共8个(注意点击Quick setup时显示8个)。它们是文章、亚马逊产品、雅虎问答、雅虎新闻、CB、youtube 视频、ebay 和 Flickr。建议不要在这里全部使用。保留你想使用的任何一个,并添加每个模板的采集比例。
如果您不想要,请单击相应模板下的移除模板。后面的设置如下图,基本没有变化,主要是替换关键词,去除关键词,设置翻译等。All Rights Reserved 都设置好了,点击下面的Create Campaign就完成了广告组的创建。第三步:WP Robot Optons选项设置License Optons许可选项,填写您购买正版WpRobot插件的PayPal邮箱,输入破解版邮箱。此选项会自动显示,您正在启用它。 WpRobot 会要求您输入此电子邮件地址。 General Optons常用选项设置Enable Simple Mode,是否允许简单模式,如果允许请打勾; New Post Status,新的文章状态,有发布和草稿三种状态,一般选择发布;重置邮政计数器:文章数计算回零,否或是; Enable Help Tooltips,是否启用帮助工具提示; Enable Old Duplicate Check,是否启用旧版本重复检查;随机发帖时间,随机文章publication时间,还有一些其他的选项这里就不一一解释了,用翻译工具翻译一下就知道是什么意思了。
All Rights Reserved Amazon Optons选项设置Amazon Affiliate D,填写Amazonaffiliate ID号; API Key(Access Key D),填写亚马逊API;申请; Secre AccessKey,申请API后会给你; Search Method、Search method:Exact Match(严格匹配)Broad Match(广泛匹配);跳过产品 f、当Dontskip(生死不跳过)或No description found(无描述)或No缩略图(无缩略图)或No description缩略图(无描述或缩略图)时跳过该产品; Amazon Description Length,描述长度;亚马逊网站,选择;标题中的 Stri 括号,是(默认);发表评论 评论?选择是;帖子模板:pos 模板,默认或修改。烟台SEO http://整理,转载并注明出处。
谢谢。 All Rights Reserved Ar ons文章选项设置文章语言,文章语选英文,Pages,如果勾选,将很长的文章分成几页N个字符;从...中剥离所有链接,删除所有链接。 Cl ckbankOpt ons 设置Clickbank Affiliate D,填写Clickbank Affiliate ID;过滤广告?过滤广告。 eBay 选项设置 版权所有 eBay Affiliate (CampID),eBay 会员 ID;国家,国家选择美国;语言,语言选择英文;排序结果,通过什么排序。 Fl ckrOpt ons 设置 Flickr API Key、Flickr API 应用程序密钥;许可、许可方式;图像大小,图像大小。 Yahoo Answer ons 和Yahoo News Optons 设置为Yahoo Application D。两者具有相同的ID。点击这里申请; All Rights Reserved Yout ube Opt ons 和 RSS Optons 设置看图翻译你就知道怎么设置了。
Tr ansl ons 翻译选项设置 Use Proxies Use proxy, Yes, 随机选择一个translationfails... 如果翻译失败,创建一个未翻译的文章 或跳过文章。版权所有 Twi erOpt ons settings Commi ssi ons settings 如果你有做过CJ的朋友,这些设置应该很容易搞定,如果你没有做过CJ,直接跳过。这里省略了一些设置,这些不常用,默认就OK了,最后按Save Optons保存设置。第四步:修改模板。修改模板也是比较关键的一步。如果对现有模板不满意,可以自行修改。有时会有很好的效果。比如一些很赞的采集ebay信息,把标题改成产品名称+拍卖组合模板效果很明显,加了很多Sal。第五步:发布文章publish 文章是最后一步。添加关键词后,点击WpRobot Select Campaigns中的第一个,就会发现刚才填写的采集关键词都在这里了。将鼠标移动到某个关键字,就会出现一堆链接。点击立即发布,你会惊奇地发现WpRobot开始采集并再次发布文章。版权所有 当然还有更厉害的,你可以同时发布N篇文章。
选择你要采集的群,填写下图中Nuber Posts的帖子数,例如50个帖子,在Backdate?前面打勾,文章post日期从2008-09开始-24,两个帖子文章发布时间相隔1天,然后点击PostNow,WpRobot将启动采集文章,采集达到50个文章,发布日期从2008年开始- 09-24,两次文章间隔一到两天。 WP自动外链插件 在这里,我要推荐WP自动外链插件:Automatic Backlink Creator插件。这个软件我自己用过,效果很好,所以今天推荐到这里,希望可以节省大家做外链的时间和精力! Automatic Backlink Creator主要针对wordpress程序创建的网站。热衷WP的站长朋友,尤其是做外贸的,主要是做谷歌和雅虎搜索引擎SEO的,应该是非常好的消息了!本软件类似于WP插件,是WP网站外链的完美解决方案!你只需要在网站后台轻松安装,就可以用一种对搜索引擎有利的方式,让WP网站自动添加高权重外链。近日,这款软件的官方网站,Automatic Backlink Creator的价格仅为37美元,可以使用信用卡或paypal支付,在国外很受欢迎!购买的同时还赠送了MetaSnatcher插件。这个插件可以自动跟踪谷歌网站Core Key中的顶级竞争对手,并自动返回软件,为关键字分析节省大量时间。
Spin Master Pro 插件。这个插件相当于WP下线伪原创并发布插件。安装此插件后,就可以在电脑上进行内容伪原创并离线发布,节省大量时间。同时,软件提供60天不满意退款保证。点击查看本软件开发者是一群SEO高手,结合谷歌和雅虎的外链算法,综合考虑外链PR、OBL、FLAG等方面的极端情况,开发了这款功能强大、优秀的外链软件。并且通过这个系统,可以产生稳定且不断增加的优质反链,如.edu、.gov等网站外链。下载:最经典的SEO链轮解决方案 查看全部
WordPress采集插件WPRobot_2.12破解版及使用教程
AllRights Reserved Wor dPr ess 采集plugin WPRobot_2.12破解版及教程 Wprobot3.12破解版下载地址: WPRobot3.1-6700-65b0-7834-89e3-7248.rar/ .page WPRobot 一直是WP英语垃圾站必备插件,特别是对于我这种英语不好的人。它是Wordpress博客的采集插件。以上是WPRobot3.12最新破解版的下载地址。有需要的兄弟可以自行下载。这里会持续关注最新的破解版。当您开始使用 WPRobot 插件时,您会意识到它有多智能,它从多个来源生成您在 Autopilot 上创建的 Wor dpress 博客。在设计WPRobot时,负责人认为最好将其拆分成模块,让客户可以根据自己的特殊需求定制插件。例如,Amazon 和 Youtube 附加组件允许您添加主目录和注释。该系统的优点是所有模块都可以由选定的模块单独购买。模块智能的产生是为了满足所有用户的需求。
WPRobot 是一个自动博客的超级插件。想想您喜欢的所有主题,它会让您发布目录而不是编写目录。使工作自动更新您的博客,关于您选择的日程安排设置 带有新帖子的热门站点,例如关联目录的抓取可能是获取目录的好地方。 wpRobot是一个自动生成Wordpress Bl og 文章的插件,可以根据关键词采集yahoo ews、yahooanswer、youut ube、f ckr、amazon、ebay、Cl ckbank、Cj等自动设置.文章、视频、图片、产品信息等,配合自动改写插件伪原创,再也不用担心建英文网站了。 WpRobot的特点 创建任何你想要文章发布到你的WordPr ess博客的内容,你只需要设置相关关键词来精确控制文章内容生成,通过关键词搭配创建不同的任务,避免重复文章;版权所有 ags,标签 Wordpress 具有更好的功能之一。访客可以通过一些标签自定义模板。如果对自己的模板不满意,可以修改模板;其实WpRobot绝对连这些功能都没有,只是暂时还没想到。在使用的过程中你会发现它是如此的强大和易用。用它建立英文博客不再是障碍。
以下是WpRobot的基本使用教程。第一步:上传WpRobot插件并在后台激活 第二步:设置关键词进入WP后台,找到WpRobot选项,点击创建活动(创建采集群),采集共有三个@方法,一个是keywor campaign(按关键字),Rss campai gn(blog文章RSS),Br owseNode campai n(亚马逊产品节点)。首先是按关键字采集,点击右侧的Quick setup(快速设置模板),当然也可以选择Random e(随机模板),看看两者有什么区别,填写Nameyour campai gn 你的关键词组名,如I Pad,在keyword ds下方的框中填写关键词,每行一个关键词,并设置类别cat egor es。下面左边设置采集频率,比如一小时,一天等,右边是否自动建立分类(不推荐,因为效果真的很差)。以下是按键模板设置,一共8个(注意点击Quick setup时显示8个)。它们是文章、亚马逊产品、雅虎问答、雅虎新闻、CB、youtube 视频、ebay 和 Flickr。建议不要在这里全部使用。保留你想使用的任何一个,并添加每个模板的采集比例。
如果您不想要,请单击相应模板下的移除模板。后面的设置如下图,基本没有变化,主要是替换关键词,去除关键词,设置翻译等。All Rights Reserved 都设置好了,点击下面的Create Campaign就完成了广告组的创建。第三步:WP Robot Optons选项设置License Optons许可选项,填写您购买正版WpRobot插件的PayPal邮箱,输入破解版邮箱。此选项会自动显示,您正在启用它。 WpRobot 会要求您输入此电子邮件地址。 General Optons常用选项设置Enable Simple Mode,是否允许简单模式,如果允许请打勾; New Post Status,新的文章状态,有发布和草稿三种状态,一般选择发布;重置邮政计数器:文章数计算回零,否或是; Enable Help Tooltips,是否启用帮助工具提示; Enable Old Duplicate Check,是否启用旧版本重复检查;随机发帖时间,随机文章publication时间,还有一些其他的选项这里就不一一解释了,用翻译工具翻译一下就知道是什么意思了。
All Rights Reserved Amazon Optons选项设置Amazon Affiliate D,填写Amazonaffiliate ID号; API Key(Access Key D),填写亚马逊API;申请; Secre AccessKey,申请API后会给你; Search Method、Search method:Exact Match(严格匹配)Broad Match(广泛匹配);跳过产品 f、当Dontskip(生死不跳过)或No description found(无描述)或No缩略图(无缩略图)或No description缩略图(无描述或缩略图)时跳过该产品; Amazon Description Length,描述长度;亚马逊网站,选择;标题中的 Stri 括号,是(默认);发表评论 评论?选择是;帖子模板:pos 模板,默认或修改。烟台SEO http://整理,转载并注明出处。
谢谢。 All Rights Reserved Ar ons文章选项设置文章语言,文章语选英文,Pages,如果勾选,将很长的文章分成几页N个字符;从...中剥离所有链接,删除所有链接。 Cl ckbankOpt ons 设置Clickbank Affiliate D,填写Clickbank Affiliate ID;过滤广告?过滤广告。 eBay 选项设置 版权所有 eBay Affiliate (CampID),eBay 会员 ID;国家,国家选择美国;语言,语言选择英文;排序结果,通过什么排序。 Fl ckrOpt ons 设置 Flickr API Key、Flickr API 应用程序密钥;许可、许可方式;图像大小,图像大小。 Yahoo Answer ons 和Yahoo News Optons 设置为Yahoo Application D。两者具有相同的ID。点击这里申请; All Rights Reserved Yout ube Opt ons 和 RSS Optons 设置看图翻译你就知道怎么设置了。
Tr ansl ons 翻译选项设置 Use Proxies Use proxy, Yes, 随机选择一个translationfails... 如果翻译失败,创建一个未翻译的文章 或跳过文章。版权所有 Twi erOpt ons settings Commi ssi ons settings 如果你有做过CJ的朋友,这些设置应该很容易搞定,如果你没有做过CJ,直接跳过。这里省略了一些设置,这些不常用,默认就OK了,最后按Save Optons保存设置。第四步:修改模板。修改模板也是比较关键的一步。如果对现有模板不满意,可以自行修改。有时会有很好的效果。比如一些很赞的采集ebay信息,把标题改成产品名称+拍卖组合模板效果很明显,加了很多Sal。第五步:发布文章publish 文章是最后一步。添加关键词后,点击WpRobot Select Campaigns中的第一个,就会发现刚才填写的采集关键词都在这里了。将鼠标移动到某个关键字,就会出现一堆链接。点击立即发布,你会惊奇地发现WpRobot开始采集并再次发布文章。版权所有 当然还有更厉害的,你可以同时发布N篇文章。
选择你要采集的群,填写下图中Nuber Posts的帖子数,例如50个帖子,在Backdate?前面打勾,文章post日期从2008-09开始-24,两个帖子文章发布时间相隔1天,然后点击PostNow,WpRobot将启动采集文章,采集达到50个文章,发布日期从2008年开始- 09-24,两次文章间隔一到两天。 WP自动外链插件 在这里,我要推荐WP自动外链插件:Automatic Backlink Creator插件。这个软件我自己用过,效果很好,所以今天推荐到这里,希望可以节省大家做外链的时间和精力! Automatic Backlink Creator主要针对wordpress程序创建的网站。热衷WP的站长朋友,尤其是做外贸的,主要是做谷歌和雅虎搜索引擎SEO的,应该是非常好的消息了!本软件类似于WP插件,是WP网站外链的完美解决方案!你只需要在网站后台轻松安装,就可以用一种对搜索引擎有利的方式,让WP网站自动添加高权重外链。近日,这款软件的官方网站,Automatic Backlink Creator的价格仅为37美元,可以使用信用卡或paypal支付,在国外很受欢迎!购买的同时还赠送了MetaSnatcher插件。这个插件可以自动跟踪谷歌网站Core Key中的顶级竞争对手,并自动返回软件,为关键字分析节省大量时间。
Spin Master Pro 插件。这个插件相当于WP下线伪原创并发布插件。安装此插件后,就可以在电脑上进行内容伪原创并离线发布,节省大量时间。同时,软件提供60天不满意退款保证。点击查看本软件开发者是一群SEO高手,结合谷歌和雅虎的外链算法,综合考虑外链PR、OBL、FLAG等方面的极端情况,开发了这款功能强大、优秀的外链软件。并且通过这个系统,可以产生稳定且不断增加的优质反链,如.edu、.gov等网站外链。下载:最经典的SEO链轮解决方案
通过关键词采集文章采集api接口来写个爬虫吧
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-07-27 20:00
通过关键词采集文章采集api接口实现。来写个爬虫吧!以前一个学生让我写个爬虫,可我连python的get都写不好,还是用的googlechrome浏览器自带的爬虫程序,而且传统的爬虫要不然有多种限制,要不然要有threadstart_user等,安全性等多方面来说不利于个人学习提高,没有啥不利,只是以前不懂api实现更方便。
最近做实验,用一台macwindows笔记本搭建一个小框架,用的是column.js2.5.js,可以解析几乎所有webapi!!!如果你要买正版开发工具,推荐谷歌的开发者工具.下载安装!!接下来,要说的是配置项的node_env!现在是笔记本!本来以为开发用台机就可以了,可要来个电脑开发板电源不稳定,估计最多跑一个小时就开始重启,然后说电脑黑屏黑屏没反应等等!网上各种文章找新机器的电源问题,写测试代码最后用了一个usbftp直接把工作站的笔记本电脑连上,然后服务器上的笔记本电脑跑了一会结果花屏,正常登录时总有断,选中断自动切断!为此我一个简单问题我的各种包都是旧包,要老老实实从头写起,程序运行过程中还要问重复内容,内存等!好像没有什么大不了的,大不了工作站变成服务器!笔记本变成工作站!直到我了解到程序开发板,才知道程序开发板这是在大型软件公司,或开发app也有几乎近百个api。
通过程序开发板,电脑或者服务器开发板连接程序开发板,通过getapi接口可以连接到服务器上的api接口,做一个类似于爬虫的工作,最好是下载api!我才知道,你让我一个学生这么简单的方法只能写出千篇一律的爬虫。经过一段时间的学习,我找到一个程序开发板如下,需要用一台机器连接好,把api连接好,通过电脑连接到服务器做开发,在服务器上用一台电脑ssh到自己的笔记本,此时就能做一个分页一样的工作了。过程中遇到的问题可以百度。还是一句话,先把网页搞定!!!。 查看全部
通过关键词采集文章采集api接口来写个爬虫吧
通过关键词采集文章采集api接口实现。来写个爬虫吧!以前一个学生让我写个爬虫,可我连python的get都写不好,还是用的googlechrome浏览器自带的爬虫程序,而且传统的爬虫要不然有多种限制,要不然要有threadstart_user等,安全性等多方面来说不利于个人学习提高,没有啥不利,只是以前不懂api实现更方便。
最近做实验,用一台macwindows笔记本搭建一个小框架,用的是column.js2.5.js,可以解析几乎所有webapi!!!如果你要买正版开发工具,推荐谷歌的开发者工具.下载安装!!接下来,要说的是配置项的node_env!现在是笔记本!本来以为开发用台机就可以了,可要来个电脑开发板电源不稳定,估计最多跑一个小时就开始重启,然后说电脑黑屏黑屏没反应等等!网上各种文章找新机器的电源问题,写测试代码最后用了一个usbftp直接把工作站的笔记本电脑连上,然后服务器上的笔记本电脑跑了一会结果花屏,正常登录时总有断,选中断自动切断!为此我一个简单问题我的各种包都是旧包,要老老实实从头写起,程序运行过程中还要问重复内容,内存等!好像没有什么大不了的,大不了工作站变成服务器!笔记本变成工作站!直到我了解到程序开发板,才知道程序开发板这是在大型软件公司,或开发app也有几乎近百个api。
通过程序开发板,电脑或者服务器开发板连接程序开发板,通过getapi接口可以连接到服务器上的api接口,做一个类似于爬虫的工作,最好是下载api!我才知道,你让我一个学生这么简单的方法只能写出千篇一律的爬虫。经过一段时间的学习,我找到一个程序开发板如下,需要用一台机器连接好,把api连接好,通过电脑连接到服务器做开发,在服务器上用一台电脑ssh到自己的笔记本,此时就能做一个分页一样的工作了。过程中遇到的问题可以百度。还是一句话,先把网页搞定!!!。
软件设计开发:基于API的微博信息采集系统设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-24 01:01
ComputerKnowledge (June 2013) Software Design and Development 本专栏主编:谢媛媛,基于API的微博信息采集系统设计与实现(浙江树人大学信息技术学院,杭州310015)Abstract : 微博已经成为网络信息的重要来源,本文分析了微博信息采集的相关方法和技术,提出了一种基于API的信息采集方法,然后设计了一个信息采集系统,可以用于新浪微博博客的相关信息为采集。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;信息采集;C#语言中图分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博数据采集系统基于新浪的API 吴斌杰、徐子伟、于飞-hua(信息科学技术浙江树人大学人类学学院,杭州 310015) 摘要:微博已成为重要的网络信息来源,论文分析了相关方法技术微博信息采集。基于数据采集的选词数据新浪微博。实验证明有效。关键词:新浪微博;应用程序接口;数据采集器;即微博客的缩写,是一个基于用户关系进行信息共享、传播和获取的平台。用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息,实现即时分享。
中国互联网络信息中心第31次中国互联网络发展状况统计报告显示,截至2012年12月末,截至2012年12月末,我国微博用户数为3.09亿元,较2011年底增加5873万,微博用户在网民中的占比较去年底提高6个百分点,达到54.7%。随着微博网络影响力的迅速扩大,政府部门、学校、知名企业、公众人物纷纷开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。研究方法和技术路线 国内微博用户以新浪微博为主,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现目前新浪微博的信息采集方式主要分为两类:一类是“模拟登录”和“网络爬虫”信息结合三种技术采集第二种方法是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API发送微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集在微博上找不到信息。
同时,“网络爬虫”采集到达的网页需要“网页内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。微博信息采集系统基于新浪微博开放平台API文档,主要采用两种研究方法:文档分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现数据@的相关测试开发采集。基于以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1。 研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、 采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。
收稿日期:2013-04-15 基金项目:2012年浙江大学文学系科技创新项目(项目编号:2012R420010)科研成果一)作者简介:吴斌杰(1991-),男,浙江 出生于嘉兴,2010级学生,浙江树人大学信息学院电子商务专业;监事:于飞华。 E-mail: Tel:+86-551-65690963 65690964 ISSN 1009-3044 Computer Knowledge Technology Vol.9, No.17, June 2013.4005 Computer Knowledge (2013年6月) 本栏目主编:谢元元软件设计开发微博接口认证:新浪微博访问大部分API,如发布微博、获取私信等需要注意。用户身份,目前新浪微博开放平台用户身份认证有OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版本的接口也只支持这两种方式。所以系统设计开发的第一步是做一个微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:该功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的账号信息,比如他有多少粉丝,他是谁关注了,他被多少人关注了,这个信息在微博采集上也是很有价值的。 5)采集 其他用户的微博:该功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询来获取采集学校的微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。主要功能实现3.1 微博界面认证功能 新浪微博API访问大部分需要用户认证。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
新浪微博用户 新浪微博用户 新浪微博用户 新浪微博用户 授权服务器 授权服务器 授权服务器 授权服务器 新浪 API AP APIAP 服务器服务器 服务器 认证请求 认证请求 认证请求 认证请求请求授权 授权授权 授权授权 授权授权 授权授权注册rotect ed Res our ce rotect ed Res our ce rotect ed Res our ce Access Access Access Access 基于API 新浪微博 information采集技术路图4006 计算机知识(2013年6月) 软件设计与开发 本专栏责任编辑:谢元元 从图3可以看出,新浪微博界面访问认证需要通过两个流程进行设计:第一步是登录微博用户账号,请求用户对token进行授权;第二步是获取授权令牌。 Access Token,用于调用API,实现接口认证功能的部分代码如下: public OAuth(string appKey, string appSecret, string callbackUrl appKey;this.AppSecret appSecret;this.AccessToken string.Empty;this. CallbackUrl publicAccessToken GetAccessTokenByPassword(字符串护照,字符串密码) returnGetAccessToken(GrantType.Password, new Dictionary {"username",passport},{"password", password} 3.2 微博用户登录功能 微博登录模块的主要功能是输入新浪微博用户账号和密码,调用Oauth类中的GetAccessTokenByPassword()方法,登录成功后可以获得Access Token,然后登录的用户就可以使用系统信息采集功能,登录界面如图4所示。
系统登录界面图3.3 登录用户微博信息和关注用户微博信息采集登录用户信息采集图 登录用户微博信息和关注用户微博信息模块界面如图如图5所示,主要包括三个功能:登录用户信息采集、当前登录用户发布微博、采集登录用户微博信息和登录用户关注的用户微博信息。 3.4其他用户的微博信息采集采集其他用户的微博信息功能界面如图6所示,该功能主要是通过微博用户的昵称来获取采集该用户的用户信息和该用户发布的微博信息. 3.5学校基本信息采集采集学校信息功能模块界面如图7所示。该功能主要是通过学校名称的模糊查询来获取学校微博平台的信息,采集到的该信息主要用于研究学校在微博上的影响力。 4007计算机知识(2013年6月) 本栏目主编:谢媛媛软件设计与开发总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博博客信息采集系统实现了微博基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究是如何设计一个话题模型来优化系统。
参考资料:中国互联网络信息中心。第31次中国互联网发展统计报告[EB/OL]。 (2013-01-15).⁃ wtjbg/201301/t20130115_38508.htm.NickRandolph,David Gardner,Chris Anderson,et al.Professional Visual Studio 2010[M].Wrox,2018.k43 开放平台. 授权机制说明[EB/OL].(2013-01-19).% E6%8E%88%E6%9 D%83%E6%9C%BA% E5%88%B6%E8%AF %B4%E6%98%8E.学校信息采集图4008 查看全部
软件设计开发:基于API的微博信息采集系统设计与实现
ComputerKnowledge (June 2013) Software Design and Development 本专栏主编:谢媛媛,基于API的微博信息采集系统设计与实现(浙江树人大学信息技术学院,杭州310015)Abstract : 微博已经成为网络信息的重要来源,本文分析了微博信息采集的相关方法和技术,提出了一种基于API的信息采集方法,然后设计了一个信息采集系统,可以用于新浪微博博客的相关信息为采集。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。关键词:新浪微博;微博界面;信息采集;C#语言中图分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博数据采集系统基于新浪的API 吴斌杰、徐子伟、于飞-hua(信息科学技术浙江树人大学人类学学院,杭州 310015) 摘要:微博已成为重要的网络信息来源,论文分析了相关方法技术微博信息采集。基于数据采集的选词数据新浪微博。实验证明有效。关键词:新浪微博;应用程序接口;数据采集器;即微博客的缩写,是一个基于用户关系进行信息共享、传播和获取的平台。用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息,实现即时分享。
中国互联网络信息中心第31次中国互联网络发展状况统计报告显示,截至2012年12月末,截至2012年12月末,我国微博用户数为3.09亿元,较2011年底增加5873万,微博用户在网民中的占比较去年底提高6个百分点,达到54.7%。随着微博网络影响力的迅速扩大,政府部门、学校、知名企业、公众人物纷纷开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。研究方法和技术路线 国内微博用户以新浪微博为主,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析,发现目前新浪微博的信息采集方式主要分为两类:一类是“模拟登录”和“网络爬虫”信息结合三种技术采集第二种方法是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API发送微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集在微博上找不到信息。
同时,“网络爬虫”采集到达的网页需要“网页内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。微博信息采集系统基于新浪微博开放平台API文档,主要采用两种研究方法:文档分析法和实验测试法。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台上,使用C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现数据@的相关测试开发采集。基于以上两种研究方法,设计本研究的技术路线:一是申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口代码类(c#语言),然后测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或GET调用API接口。最后返回JOSN数据流,最后分析这个数据流并保存为本地文本文件或数据库。详细技术路线如图1。 研究内容设计微博信息采集系统功能结构如图2所示。系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、 采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。
收稿日期:2013-04-15 基金项目:2012年浙江大学文学系科技创新项目(项目编号:2012R420010)科研成果一)作者简介:吴斌杰(1991-),男,浙江 出生于嘉兴,2010级学生,浙江树人大学信息学院电子商务专业;监事:于飞华。 E-mail: Tel:+86-551-65690963 65690964 ISSN 1009-3044 Computer Knowledge Technology Vol.9, No.17, June 2013.4005 Computer Knowledge (2013年6月) 本栏目主编:谢元元软件设计开发微博接口认证:新浪微博访问大部分API,如发布微博、获取私信等需要注意。用户身份,目前新浪微博开放平台用户身份认证有OAuth2.0和Basic Auth(仅用于应用开发者调试接口),新版本的接口也只支持这两种方式。所以系统设计开发的第一步是做一个微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:该功能主要用于输入微博用户的昵称,您可以采集获取昵称用户的账号信息,比如他有多少粉丝,他是谁关注了,他被多少人关注了,这个信息在微博采集上也是很有价值的。 5)采集 其他用户的微博:该功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询来获取采集学校的微博账号ID、学校所在地区、学校类型信息。这是采集学校在微博上的影响力基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核通过前,无法直接测试使用。主要功能实现3.1 微博界面认证功能 新浪微博API访问大部分需要用户认证。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
新浪微博用户 新浪微博用户 新浪微博用户 新浪微博用户 授权服务器 授权服务器 授权服务器 授权服务器 新浪 API AP APIAP 服务器服务器 服务器 认证请求 认证请求 认证请求 认证请求请求授权 授权授权 授权授权 授权授权 授权授权注册rotect ed Res our ce rotect ed Res our ce rotect ed Res our ce Access Access Access Access 基于API 新浪微博 information采集技术路图4006 计算机知识(2013年6月) 软件设计与开发 本专栏责任编辑:谢元元 从图3可以看出,新浪微博界面访问认证需要通过两个流程进行设计:第一步是登录微博用户账号,请求用户对token进行授权;第二步是获取授权令牌。 Access Token,用于调用API,实现接口认证功能的部分代码如下: public OAuth(string appKey, string appSecret, string callbackUrl appKey;this.AppSecret appSecret;this.AccessToken string.Empty;this. CallbackUrl publicAccessToken GetAccessTokenByPassword(字符串护照,字符串密码) returnGetAccessToken(GrantType.Password, new Dictionary {"username",passport},{"password", password} 3.2 微博用户登录功能 微博登录模块的主要功能是输入新浪微博用户账号和密码,调用Oauth类中的GetAccessTokenByPassword()方法,登录成功后可以获得Access Token,然后登录的用户就可以使用系统信息采集功能,登录界面如图4所示。
系统登录界面图3.3 登录用户微博信息和关注用户微博信息采集登录用户信息采集图 登录用户微博信息和关注用户微博信息模块界面如图如图5所示,主要包括三个功能:登录用户信息采集、当前登录用户发布微博、采集登录用户微博信息和登录用户关注的用户微博信息。 3.4其他用户的微博信息采集采集其他用户的微博信息功能界面如图6所示,该功能主要是通过微博用户的昵称来获取采集该用户的用户信息和该用户发布的微博信息. 3.5学校基本信息采集采集学校信息功能模块界面如图7所示。该功能主要是通过学校名称的模糊查询来获取学校微博平台的信息,采集到的该信息主要用于研究学校在微博上的影响力。 4007计算机知识(2013年6月) 本栏目主编:谢媛媛软件设计与开发总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博博客信息采集系统实现了微博基础信息采集,在一定程度上解决了微博信息采集的自动化和采集结果数据格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究是如何设计一个话题模型来优化系统。
参考资料:中国互联网络信息中心。第31次中国互联网发展统计报告[EB/OL]。 (2013-01-15).⁃ wtjbg/201301/t20130115_38508.htm.NickRandolph,David Gardner,Chris Anderson,et al.Professional Visual Studio 2010[M].Wrox,2018.k43 开放平台. 授权机制说明[EB/OL].(2013-01-19).% E6%8E%88%E6%9 D%83%E6%9C%BA% E5%88%B6%E8%AF %B4%E6%98%8E.学校信息采集图4008
python爬取数据的第一步必须分析目标网站的技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-07-22 18:01
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时用python爬虫(结合tkinter开发爬虫应用),用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基础的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略爬取数据,提升性能,提高操作舒适度(结合客户端技术,自定义爬虫接口),根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境! 查看全部
python爬取数据的第一步必须分析目标网站的技术
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时用python爬虫(结合tkinter开发爬虫应用),用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基础的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略爬取数据,提升性能,提高操作舒适度(结合客户端技术,自定义爬虫接口),根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境!
通过关键词采集文章采集api开发框架提供采集,抓取信息供研究使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-22 02:01
通过关键词采集文章采集api开发框架提供采集api,抓取信息供研究使用,所有的数据都可以导出保存于excel文件和csv文件。本框架所有的数据都采集于csv文件,并且数据都已经转换成dataframe结构。采集效率、采集性能1.采集前端请求响应速度:高并发采集/请求速度:秒级page速度:秒级采集时间:秒级抓取效率:秒级请求内容api内容及获取json源数据(json字符串格式包含access_token和arraybuffer,即用户账号和密码,以及airmail|smtp|smtp_ftp_http)2.采集目标pagepageage页面返回方式:querypagepage获取目标页面各元素信息信息是点击鼠标获取相应位置元素的内容,而case_click方法中的add方法采用的是点击获取元素信息,而没有提供目标位置的元素信息。
2.1useruser个人身份信息账号:some_pwd_username密码:some_pass_username2.2terms按钮设置一般返回的是回调函数函数名:user.show_terms,可修改参数返回值:some_pwd_username返回值:some_pass_username返回值:some_array3.爬虫框架实现数据部分:#python3classmy_codespy(object):"""采集爬虫框架"""package_first_importpygame#带引号版本package_first_importpygame.io.browser32.1#c++2014,python,javapackage_first_importpygame.io.browser32#c++1943package_first_importpygame.io.browser32importpygame.httpimportpygame.io.browser32#此为未实现,计划2019实现importpygame.io.browser32importpygame.pygame.io.browser32#此为未实现,计划2019实现importpygame.httpimportpygame.selfimportpygame.self#此为未实现,计划2019实现importpygame.textimportpygame.textimportpygame.text.fieldsimportpygame.text.renderimportpygame.text.string.ascii.utf8importpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.coreimportosimportpygame.io.messageimportpygame.io.synchronizedimportpygame.io.useimportpygame.text.unicodeimportosimportpy。 查看全部
通过关键词采集文章采集api开发框架提供采集,抓取信息供研究使用
通过关键词采集文章采集api开发框架提供采集api,抓取信息供研究使用,所有的数据都可以导出保存于excel文件和csv文件。本框架所有的数据都采集于csv文件,并且数据都已经转换成dataframe结构。采集效率、采集性能1.采集前端请求响应速度:高并发采集/请求速度:秒级page速度:秒级采集时间:秒级抓取效率:秒级请求内容api内容及获取json源数据(json字符串格式包含access_token和arraybuffer,即用户账号和密码,以及airmail|smtp|smtp_ftp_http)2.采集目标pagepageage页面返回方式:querypagepage获取目标页面各元素信息信息是点击鼠标获取相应位置元素的内容,而case_click方法中的add方法采用的是点击获取元素信息,而没有提供目标位置的元素信息。
2.1useruser个人身份信息账号:some_pwd_username密码:some_pass_username2.2terms按钮设置一般返回的是回调函数函数名:user.show_terms,可修改参数返回值:some_pwd_username返回值:some_pass_username返回值:some_array3.爬虫框架实现数据部分:#python3classmy_codespy(object):"""采集爬虫框架"""package_first_importpygame#带引号版本package_first_importpygame.io.browser32.1#c++2014,python,javapackage_first_importpygame.io.browser32#c++1943package_first_importpygame.io.browser32importpygame.httpimportpygame.io.browser32#此为未实现,计划2019实现importpygame.io.browser32importpygame.pygame.io.browser32#此为未实现,计划2019实现importpygame.httpimportpygame.selfimportpygame.self#此为未实现,计划2019实现importpygame.textimportpygame.textimportpygame.text.fieldsimportpygame.text.renderimportpygame.text.string.ascii.utf8importpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.stringimportpygame.text.coreimportosimportpygame.io.messageimportpygame.io.synchronizedimportpygame.io.useimportpygame.text.unicodeimportosimportpy。
人人都是大牛采集器-spider-builder/机器人也可以,同步
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2021-07-15 19:01
通过关键词采集文章采集api接口,满足现在需求比较广泛,基本上覆盖我所需要的都可以采集。除了全网互联,还有类似360浏览器,腾讯手机浏览器都可以采集其他网站。现在需要每天1-2次去采集网页内容,这样才能实现你的采集,一天下来时间就没有了,有想获取相关采集的朋友可以在评论区留言。苹果手机上可以直接注册appstore,安卓的手机可以关注公众号【异步小说】,也可以获取相关的采集api,小程序。
可以上飞速采集网看看,网站有30w条到200w条每天的爬虫采集历史,还有采集器功能,
想爬哪个网站的数据呢?一般爬虫是接口为主,根据网站规定爬取数据。
推荐赛迪网采集器-spider-builder/机器人也可以
,同步专注爬虫数据与开发
别的不知道,是安卓端的,我知道的和微信公众号“生活消费与信息化”互联。
学个爬虫,
我在大鲸鱼分享过一个大鲸鱼采集器还不错,
我觉得你可以考虑下王大噜分享的《人人都是大牛采集器》,
优漫爬虫程序,是一个小巧灵活的使用微信内置浏览器接口的采集器,适用于各种微信公众号和自媒体平台,完全免费分享,支持pc、mac以及安卓平台,可以按需抓取,当需要抓取某一固定公众号或某一平台时,完全可以借助这个采集器,快速的抓取你需要的数据。 查看全部
人人都是大牛采集器-spider-builder/机器人也可以,同步
通过关键词采集文章采集api接口,满足现在需求比较广泛,基本上覆盖我所需要的都可以采集。除了全网互联,还有类似360浏览器,腾讯手机浏览器都可以采集其他网站。现在需要每天1-2次去采集网页内容,这样才能实现你的采集,一天下来时间就没有了,有想获取相关采集的朋友可以在评论区留言。苹果手机上可以直接注册appstore,安卓的手机可以关注公众号【异步小说】,也可以获取相关的采集api,小程序。
可以上飞速采集网看看,网站有30w条到200w条每天的爬虫采集历史,还有采集器功能,
想爬哪个网站的数据呢?一般爬虫是接口为主,根据网站规定爬取数据。
推荐赛迪网采集器-spider-builder/机器人也可以
,同步专注爬虫数据与开发
别的不知道,是安卓端的,我知道的和微信公众号“生活消费与信息化”互联。
学个爬虫,
我在大鲸鱼分享过一个大鲸鱼采集器还不错,
我觉得你可以考虑下王大噜分享的《人人都是大牛采集器》,
优漫爬虫程序,是一个小巧灵活的使用微信内置浏览器接口的采集器,适用于各种微信公众号和自媒体平台,完全免费分享,支持pc、mac以及安卓平台,可以按需抓取,当需要抓取某一固定公众号或某一平台时,完全可以借助这个采集器,快速的抓取你需要的数据。
通过关键词采集文章采集api通过文章匹配技术获取相关
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-09 20:03
通过关键词采集文章采集api通过文章匹配技术获取相关apiweb页面点击该页面获取登录过的用户的身份信息网站数据的变更来自页面更新apichangelog更新采集技术主要分两类:基于代理,服务器本地文件抓取基于采集框架爬虫。基于代理:接收一个网站或者应用服务的响应的form请求,然后判断回应是否是响应,判断响应header,从而判断这个响应是不是响应网站就返回一个post对象,爬虫(采集器)根据这个post对象访问从这个post对象获取到这个网站的header,来确定是哪个网站对应了该header,一般返回有的网站对应header的话,则为采集器成功爬取。
服务器本地文件抓取:在用户浏览器本地上存一个一个html文件,保存的是格式为[xxxx]->tab->下载链接链接(可是一个单独的文件也可以是zip压缩文件),找出这个链接,解析form请求,这里就是进行采集,爬虫去获取该链接要么是一个单独的文件,要么是一个压缩包,然后进行http请求,比如一个json,一个html文件。
服务器本地文件抓取的优势:不用被淘汰的googleapi。taobao有没有共享呢,其实在天猫api上也已经有了,不过天猫用的还是代理服务器自己写的,我们都可以用。基于采集框架爬虫:采集框架虽然省代理和服务器成本,但是同样存在问题,你把他解析出来的请求存在在本地,其他爬虫也很可能拿不到。其实有一种办法就是利用大家共用的服务器,可以存一个采集链接的规则文件,这样其他爬虫就可以通过链接拿到真正的header和路由地址,那么获取下来的数据就更加真实。 查看全部
通过关键词采集文章采集api通过文章匹配技术获取相关
通过关键词采集文章采集api通过文章匹配技术获取相关apiweb页面点击该页面获取登录过的用户的身份信息网站数据的变更来自页面更新apichangelog更新采集技术主要分两类:基于代理,服务器本地文件抓取基于采集框架爬虫。基于代理:接收一个网站或者应用服务的响应的form请求,然后判断回应是否是响应,判断响应header,从而判断这个响应是不是响应网站就返回一个post对象,爬虫(采集器)根据这个post对象访问从这个post对象获取到这个网站的header,来确定是哪个网站对应了该header,一般返回有的网站对应header的话,则为采集器成功爬取。
服务器本地文件抓取:在用户浏览器本地上存一个一个html文件,保存的是格式为[xxxx]->tab->下载链接链接(可是一个单独的文件也可以是zip压缩文件),找出这个链接,解析form请求,这里就是进行采集,爬虫去获取该链接要么是一个单独的文件,要么是一个压缩包,然后进行http请求,比如一个json,一个html文件。
服务器本地文件抓取的优势:不用被淘汰的googleapi。taobao有没有共享呢,其实在天猫api上也已经有了,不过天猫用的还是代理服务器自己写的,我们都可以用。基于采集框架爬虫:采集框架虽然省代理和服务器成本,但是同样存在问题,你把他解析出来的请求存在在本地,其他爬虫也很可能拿不到。其实有一种办法就是利用大家共用的服务器,可以存一个采集链接的规则文件,这样其他爬虫就可以通过链接拿到真正的header和路由地址,那么获取下来的数据就更加真实。
搜索引擎最怕什么?我们可以怎样做到更好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-06-28 06:17
作为一个在SEO工作了13年的老司机,经常会思考SEO的本质是什么?对于大部分SEO优化者来说,大部分人都理解SEO=外链+内容,其实很简单这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。 SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的事业,而不是一无所有。日夜交换链接和伪原创。
搜索引擎是怎么来的?
当互联网首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息更快地被搜索到,一些聪明人编写了一个简单的爬虫程序来检查网络上每台计算机上分布的文件。索引,然后通过一个简单的搜索框,让用户可以快速搜索岛上的信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放入自己的索引中。下次用户搜索时,他们会很满意。走开。
SEO 从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。你觉得它很棒吗?
如果你不能意识到这一点,你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!
我们怎样才能做得更好?
1、拥有最全面准确的行业词库
当我们经营网站或专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。如果用通俗的话说,其实每个行业都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,因此拥有一个行业词库是完全掌握一个行业的必备产品。
例如,围绕财富管理行业的核心词如下:
理财行业核心词下长尾词列表如下:
2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出能够带来最多流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划师PC搜索量、竞价策划师移动搜索量、竞价策划师竞争:
通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。
3.通过API过滤掉搜索引擎中最缺乏的内容关键词
通过上面过滤掉的104635个流量词,我们可以将它们放入百度、360等搜索引擎进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否为内容已经饱和了。
我们可以通过API商城(www 5118 com/apistore)百度PC端TOP 50排名API方便获取JSON格式的排名状态。
下图中,我们以“what is an index fund”这个词为例,得到TOP20搜索结果的排名:
返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息显示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指这个关键词在网上的内容是否已经饱和,还是因为百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以先判断这个关键词是否值得一看。
这是一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级的网站排名结果。如果是这样,我们还有机会占领他们的位置。
还有一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,也就是说搜索结果中的部分内容标题并不完全匹配关键词。
比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放的一个索引,那么我们也可以标记这些位置作为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们将保留这些关键词并进入第四阶段。
4.帮助搜索引擎改进这些内容
我们通过前三步完成性价比最高的SEO关键词筛选后,可以安排编辑写文章或者话题,或者安排技术部做文章的采集,也或安排运营部门指导用户创作内容。
通过这四步分层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:
5.监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不受其他技术运维的影响干扰因素。 .
通过5118PC收录检测功能或百度PC收录API检测制作内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬行都没有意义。如果内容不是收录,也会对内容策略造成打击,所以对收录的监控也很重要。
检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。
2.监控个人关键词排名,评估每个内容制作作品的稳定性,关注细节。
▲ 可以在5118关键词monitoring的帮助下批量添加自己关键词进行监控
▲ 也可以使用 5118关键词ranked采集API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词ranking查询API进行采集排名数据,并集成到现有的管理系统中。
最终总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进实现自我。突破。
通过这个内容制作流程,我们可以逐步优化我们的内容策略,最大限度地发挥内容制作流量的效果。还等什么,赶快使用这些大数据API让你轻松推广。
查看全部
搜索引擎最怕什么?我们可以怎样做到更好?
作为一个在SEO工作了13年的老司机,经常会思考SEO的本质是什么?对于大部分SEO优化者来说,大部分人都理解SEO=外链+内容,其实很简单这是从一个非常低的角度来看SEO工作。
SEO的全称是Search Engine Optimization,帮助搜索引擎优化。 SEO 正在帮助百度、谷歌和 360 改进他们的内容。从这个角度思考,你会发现SEO实际上是在做一个伟大的事业,而不是一无所有。日夜交换链接和伪原创。
搜索引擎是怎么来的?
当互联网首次出现时,每台计算机都是一个信息孤岛。为了让这些岛屿上的信息更快地被搜索到,一些聪明人编写了一个简单的爬虫程序来检查网络上每台计算机上分布的文件。索引,然后通过一个简单的搜索框,让用户可以快速搜索岛上的信息,造福人类。
搜索引擎最怕什么?
我最怕我的用户找不到他们想要的结果。希望从各个信息孤岛中,尽可能多地找到用户可能感兴趣的内容,并继续放入自己的索引中。下次用户搜索时,他们会很满意。走开。
SEO 从业者是帮助搜索引擎优化的人。这并不意味着每天都会生成无数的垃圾邮件,或者它们在提供帮助。不是每天建立无数的友情链接来帮助它,而是帮助搜索引擎解决他们的实际问题。你觉得它很棒吗?
如果你不能意识到这一点,你可能无法适应SEO优化领域。这不是鲁莽的早期时代。如果一直依赖链接和伪原创,只会觉得SEO真的很可笑!
我们怎样才能做得更好?
1、拥有最全面准确的行业词库
当我们经营网站或专栏时,我们往往是垂直于一个行业。每个行业都有自己的范围。如果用通俗的话说,其实每个行业都有自己的一批核心关键词+长尾词。这些词定义了一个行业的范围,因此拥有一个行业词库是完全掌握一个行业的必备产品。
例如,围绕财富管理行业的核心词如下:
理财行业核心词下长尾词列表如下:
2.用词库找出搜索引擎最需要什么
当我们掌握了一个行业的所有词汇,才能真正了解这个行业,了解这个行业用户的需求。
接下来,我们要在这近百万的金融词汇中找出能够带来最多流量的词。这里我们使用百度PC指数、360指数、百度移动指数、竞价策划师PC搜索量、竞价策划师移动搜索量、竞价策划师竞争:
通过上面的公式,我们可以筛选出一批业内最能带来流量的词,从百万词库中筛选出104635个流量词。
3.通过API过滤掉搜索引擎中最缺乏的内容关键词
通过上面过滤掉的104635个流量词,我们可以将它们放入百度、360等搜索引擎进行模拟查询,了解前20个网页的URL级别和标题,了解搜索引擎是否为内容已经饱和了。
我们可以通过API商城(www 5118 com/apistore)百度PC端TOP 50排名API方便获取JSON格式的排名状态。
下图中,我们以“what is an index fund”这个词为例,得到TOP20搜索结果的排名:
返回的排名信息中还有两个比较重要的信息,域名权重信息和Title信息。
域名权重信息显示前50个域名是否都是权重相对较低的域名,让您有机会挤进去。
对Title信息的分析,是指这个关键词在网上的内容是否已经饱和,还是因为百度为了填充信息,选择了一些补充信息来填充搜索结果。
通过分析这两条信息,我们可以先判断这个关键词是否值得一看。
这是一个假设。如果我的网站5118的权重是A,那么我们要找出TOP20排名结果中是否有很多5118权重B级甚至C级的网站排名结果。如果是这样,我们还有机会占领他们的位置。
还有一种情况。如果不能通过域名找到机会,还有另一个机会。事实上,这些高权重域名的内容并不完全符合搜索要求,也就是说搜索结果中的部分内容标题并不完全匹配关键词。
比如上图中的Title并没有完全收录“什么是指数基金”这个词,只是搜索引擎为了补充结果而放的一个索引,那么我们也可以标记这些位置作为机会。
通过类似上面的算法,我们可以得到每个词的机会分数。我们可以设置一个筛选阈值,比如设置为8。如果TOP 20结果中有超过8个机会位置,我们将保留这些关键词并进入第四阶段。
4.帮助搜索引擎改进这些内容
我们通过前三步完成性价比最高的SEO关键词筛选后,可以安排编辑写文章或者话题,或者安排技术部做文章的采集,也或安排运营部门指导用户创作内容。
通过这四步分层过滤,我们的内容运营工作就会很有针对性。虽然上面写了这么多字,但其实是以下三个目的:
5.监控 SEO 效果
随着内容的不断完善,我们需要对上面确定的内容策略的有效性进行整体评估,可能需要对一些参数、阈值甚至算法进行微调:
借助百度站长后台(),了解爬虫的爬取次数和爬取时间,了解爬虫遇到的异常次数。
因为只有监控这些参数才能知道百度爬虫在你的内容制作完成后是否如期到达,没有遇到任何障碍,从而保证你的内容策略不受其他技术运维的影响干扰因素。 .
通过5118PC收录检测功能或百度PC收录API检测制作内容是否为收录。
收录 是排名的先决条件。如果内容不能是收录,那么再多的爬行都没有意义。如果内容不是收录,也会对内容策略造成打击,所以对收录的监控也很重要。
检查排名是否按预期增长
随着内容和收录的不断增加,我们SEO的最终目标是获得好的排名。
跟踪整体趋势,确保整体内容策略正确。
2.监控个人关键词排名,评估每个内容制作作品的稳定性,关注细节。
▲ 可以在5118关键词monitoring的帮助下批量添加自己关键词进行监控
▲ 也可以使用 5118关键词ranked采集API 来监控
如果公司有开发能力,可以直接使用5118提供的关键词ranking查询API进行采集排名数据,并集成到现有的管理系统中。
最终总结:
现代人类文明的发展是一个追求极致自动化的过程。无人工厂、无人超市、无人机,作为大数据时代的SEO管理者,也需要追求SEO自动化,与时俱进实现自我。突破。
通过这个内容制作流程,我们可以逐步优化我们的内容策略,最大限度地发挥内容制作流量的效果。还等什么,赶快使用这些大数据API让你轻松推广。
基于API微博信息采集系统设计与实现(1)_光明网
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-06-28 02:01
基于API微博信息采集系统设计与实现总结:微博已经成为网络信息的重要来源。本文分析了微博Information采集的相关方法和技术,提出了基于API的information采集方法,然后设计了一个信息采集系统,可以采集新浪微博上的相关信息。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文库分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博[1],微博的缩写,是一个分享、传播和获取的平台基于用户关系的信息,用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息实时分享中国互联网络发布的《第31次中国互联网络发展状况统计报告》信息中心显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.090亿,较2011年末增加5873万,微博占比网民用户比去年底增长6个百分点,达到54.7%[2]。公众人物已开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析发现,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ,以及“网页内容分析” [4] 结合三种技术的信息采集方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API来执行微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集无法在微博上找到信息。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博信息采集系统主要采用两种研究方法:文档分析和实验测试。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,以C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据采集。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口。代码类(c#语言),然后来测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或者GET调用API接口,最后返回JOSN数据流,最后解析将此数据流保存为本地文本文件或数据库。详细技术路线如图1所示。 2 研究内容设计 微博信息采集系统功能结构 如图2所示,系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。 1)微博接口认证:访问大部分新浪微博API,如发微博、获取私信、关注等,都需要用户身份。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于调试应用开发者的界面),新版界面仅支持这两种方法[6]。因此,系统设计开发的第一步就是做微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:这个功能主要是输入微博用户的昵称,你可以采集获取昵称用户的账号信息,比如有多少粉丝,关注谁,还有他被多少人抓到了关注,这个信息在微博采集中也是很有价值的。 5)采集 其他用户的微博:此功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询,获取采集学校在微博中的账号ID、学校所在区域、学校类型信息。这就是采集学校在微博影响力的基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核前无法直接测试使用。 3 主要功能实现3.1 微博界面鉴权功能新浪微博API访问大部分需要用户鉴权。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
4 总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博采集的基础信息k15@,在一定程度上解决了微博信息采集的自动化和结果数据采集格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究就是如何设计话题模型来优化系统。参考文献:[1]文锐.微博智智[J].软件工程师,2009( 12):19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展状况统计报告[EB/OL]. (2013-01-15). /hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 编写自己的网络爬虫[ M]. 北京: 清华大学出版社, 2010. [4] 于曼全, 陈铁瑞,徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al. Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。 (2013-01-19). D%83%E6%9C%BA%E5%88%B6%E8 %AF%B4%E6 %98%8E。 查看全部
基于API微博信息采集系统设计与实现(1)_光明网
基于API微博信息采集系统设计与实现总结:微博已经成为网络信息的重要来源。本文分析了微博Information采集的相关方法和技术,提出了基于API的information采集方法,然后设计了一个信息采集系统,可以采集新浪微博上的相关信息。实验测试表明信息采集系统可以快速有效地采集新浪微博信息。 关键词:新浪微博;微博界面;信息采集; C#语言中文库分类号:TP315 文档识别码:A文章编号:1009-3044(2013)17-4005-04 微博[1],微博的缩写,是一个分享、传播和获取的平台基于用户关系的信息,用户可以通过WEB、WAP、各种客户端组件个人社区更新140字左右的信息实时分享中国互联网络发布的《第31次中国互联网络发展状况统计报告》信息中心显示,截至2012年12月末,截至2012年12月末,中国微博用户数为3.090亿,较2011年末增加5873万,微博占比网民用户比去年底增长6个百分点,达到54.7%[2]。公众人物已开通微博。在公众的参与下,微博已经成为一个强大的虚拟社会。微博已成为网络信息的重要来源。如何快速有效地使用采集微博信息已成为一项具有重要应用价值的研究。
1 研究方法和技术路线 国内微博用户主要是新浪微博,因此本文拟以新浪微博为例,设计研究方法和技术路线。通过对国内外科技文献和实际应用案例的分析发现,目前新浪微博的信息采集方法主要分为两类:一类是“模拟登录”、“网络爬虫”[3] ,以及“网页内容分析” [4] 结合三种技术的信息采集方法。二是基于新浪微博开放平台的API文档。开发者自己编写程序调用微博API来执行微博信息采集。对于第一种方法,难度较高,研究技术复杂,尤其是“模拟登录”这一步。需要随时跟踪新浪微博的登录加密算法。新浪微博登录加密算法的变化会导致“网络爬虫”。 “”的失败最终导致采集无法在微博上找到信息。同时,“网络爬虫”采集到达的网页需要进行“页面内容分析”,与基于API的数据采集相比,在效率和性能上存在明显差距。基于以上因素,本文拟采用第二种方法进行研究。基于新浪微博开放平台API???文件,微博信息采集系统主要采用两种研究方法:文档分析和实验测试。文档分析方法:参考新浪微博开放平台的API文档,将这些API描述文档写成单独的接口文件。实验测试方法:在VS.NET2010平台[5]上,以C/S模式开发程序调用接口类,采集微博返回的JOSN数据流,实现相关测试开发数据采集。
根据以上两种研究方法,设计本研究的技术路线:首先,申请新浪微博开放平台App Key和App Secret。审核通过后,阅读理解API文档,将API文档描述写入API接口。代码类(c#语言),然后来测试OAuth2.0的认证。认证通过后,可以获得Access Token,从而有权限调用API的各种功能接口,然后通过POST或者GET调用API接口,最后返回JOSN数据流,最后解析将此数据流保存为本地文本文件或数据库。详细技术路线如图1所示。 2 研究内容设计 微博信息采集系统功能结构 如图2所示,系统分为七个部分,分别是:微博界面认证、微博用户登录、登录用户发送微博、采集当前登录用户信息、采集其他用户信息、采集其他用户微博、采集学校信息、采集微博信息内容。 1)微博接口认证:访问大部分新浪微博API,如发微博、获取私信、关注等,都需要用户身份。目前新浪微博开放平台上的用户身份认证包括OAuth2.0和Basic Auth(仅用于调试应用开发者的界面),新版界面仅支持这两种方法[6]。因此,系统设计开发的第一步就是做微博界面认证功能。 2)微博用户登录:认证通过后,所有在新浪微博上注册的用户都可以登录本系统,并可以通过本系统发布微博。
3)采集Login 用户信息:用户登录后,可以通过本系统查看自己的账号信息、自己的微博信息以及关注者的微博信息。 4)采集其他用户信息:这个功能主要是输入微博用户的昵称,你可以采集获取昵称用户的账号信息,比如有多少粉丝,关注谁,还有他被多少人抓到了关注,这个信息在微博采集中也是很有价值的。 5)采集 其他用户的微博:此功能也使用微博用户的昵称来更改用户采集发送的所有微博信息。此功能的目的是扩展到未来每隔一个时间段。 ,采集目标集合中多个微博用户的微博信息自动发送到本地进行数据内容分析。 6)采集学校信息:该函数通过学校名称的模糊查询,获取采集学校在微博中的账号ID、学校所在区域、学校类型信息。这就是采集学校在微博影响力的基本数据。 7)采集微博信息内容:您可以在微博内容中按关键词进行查询,采集这里收录关键词微博信息。但由于本次API接口调用需要高级权限,在系统完全发布前和新浪微博开放平台审核前无法直接测试使用。 3 主要功能实现3.1 微博界面鉴权功能新浪微博API访问大部分需要用户鉴权。本系统采用OAuth2.0设计微博界面认证功能。新浪微博认证流程如图3所示。
4 总结 本文主要对微博信息采集的方法和技术进行了一系列的研究,然后设计开发了一个基于API的新浪微博信息采集系统,实现了微博采集的基础信息k15@,在一定程度上解决了微博信息采集的自动化和结果数据采集格式的标准化。但是,目前本系统的微博信息采集方法只能通过输入单个“关键词”采集进行唯一匹配,并且没有多个“搜索词”批次采集,也没有一个“话题类型”“微博信息采集”的功能,所以下一步的研究就是如何设计话题模型来优化系统。参考文献:[1]文锐.微博智智[J].软件工程师,2009( 12):19-20. [2] 中国互联网络信息中心. 第31次中国互联网络发展状况统计报告[EB/OL]. (2013-01-15). /hlwxzbg/hlwtjbg/201301/38508.htm. [3] 罗刚, 王振东. 编写自己的网络爬虫[ M]. 北京: 清华大学出版社, 2010. [4] 于曼全, 陈铁瑞,徐洪波. 基于块的网页信息解析器的研究与设计[J]. 计算机应用, 2005, 25 (4):974-976. [5] Nick Randolph, David Gardner, Chris Anderson, et al. Professional Visual Studio 2010[M].Wrox, 2010. [6] 新浪微博开放平台。授权机制说明[EB/OL]。 (2013-01-19). D%83%E6%9C%BA%E5%88%B6%E8 %AF%B4%E6 %98%8E。
设计日志的实时分析并可视化,操作步骤开启WebTracking功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-06-28 01:49
当我们有新的内容(比如新功能、新活动、新游戏、新文章)时,作为运营商,我们总是迫不及待想尽快和用户沟通,因为这是第一获取用户的一步,也是最重要的一步。
以游戏发行为例。市场有巨大的游戏推广费用,比如1W的广告。 2000人成功加载广告,约占20%。其中点击了800人,最终下载注册账号试用的往往很少。
可见,能够准确、实时地获取内容推广的效果对业务来说是非常重要的。运营商为了实现整体推广目标,往往会选择多种渠道进行推广。
用户内部留言(Mail)、官网博客(Blog)、首页文案(Banner等)。短信、用户邮箱、传单等新浪微博、钉钉用户群、微信公众号、知乎论坛、今日头条等新媒体
操作步骤 开启网络追踪功能。
在日志服务中创建一个Logstore(例如:myclick)并开启WebTracking功能。
生成网络跟踪标签。对于需要推广的文档(文章=1001),为每个推广渠道添加logo,并生成Web Tracking标签(以Img标签为例)。
可以在from参数后添加更多频道,也可以在URL中添加更多需要采集的参数。
在宣传内容中放置img标签并发布。分析日志。
完成采集的埋葬后,我们可以使用日志服务功能,实时查询分析海量日志数据。除了结果分析的可视化,还支持、、、Tableau等对接方式。
以下是采集目前为止的日志数据,您可以在搜索框中输入关键词进行查询。
查询后还可以输入SQL,实现秒级实时分析和可视化。
设计查询语句。
以下是我们为用户点击/阅读日志的实时分析语句。更多的领域和分析场景可以找到。
将这些实时数据配置到一个实时刷新的Dashboard中,效果如下
描述 当你读完这篇文章时,会有一个隐形的Img标签来记录这次访问。您可以在此页面的源代码中查看此标签。 查看全部
设计日志的实时分析并可视化,操作步骤开启WebTracking功能
当我们有新的内容(比如新功能、新活动、新游戏、新文章)时,作为运营商,我们总是迫不及待想尽快和用户沟通,因为这是第一获取用户的一步,也是最重要的一步。
以游戏发行为例。市场有巨大的游戏推广费用,比如1W的广告。 2000人成功加载广告,约占20%。其中点击了800人,最终下载注册账号试用的往往很少。
可见,能够准确、实时地获取内容推广的效果对业务来说是非常重要的。运营商为了实现整体推广目标,往往会选择多种渠道进行推广。
用户内部留言(Mail)、官网博客(Blog)、首页文案(Banner等)。短信、用户邮箱、传单等新浪微博、钉钉用户群、微信公众号、知乎论坛、今日头条等新媒体
操作步骤 开启网络追踪功能。
在日志服务中创建一个Logstore(例如:myclick)并开启WebTracking功能。
生成网络跟踪标签。对于需要推广的文档(文章=1001),为每个推广渠道添加logo,并生成Web Tracking标签(以Img标签为例)。
可以在from参数后添加更多频道,也可以在URL中添加更多需要采集的参数。
在宣传内容中放置img标签并发布。分析日志。
完成采集的埋葬后,我们可以使用日志服务功能,实时查询分析海量日志数据。除了结果分析的可视化,还支持、、、Tableau等对接方式。
以下是采集目前为止的日志数据,您可以在搜索框中输入关键词进行查询。
查询后还可以输入SQL,实现秒级实时分析和可视化。
设计查询语句。
以下是我们为用户点击/阅读日志的实时分析语句。更多的领域和分析场景可以找到。
将这些实时数据配置到一个实时刷新的Dashboard中,效果如下
描述 当你读完这篇文章时,会有一个隐形的Img标签来记录这次访问。您可以在此页面的源代码中查看此标签。
网站该如何申请成为百度新闻源的具体操作步骤?
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-06-27 19:04
百度新闻源,其实就是指百度的新闻源,一个百度蜘蛛经常光顾的地方,会采集新闻和相关信息。对于网站站长来说,如果他们的网站能够成功申请加入百度动态消息,那么无论是网站的推广还是网站内部的信息传播,都会起到很好的效果。成为百度新闻源后,网站可以向百度提交自己的符合互联网新闻开放协议标准的XML网页。这样网站就可以在之前的内容发布后被动等待百度收录主动提交内容给百度。这不仅会大大提高收录内容的速度,还会为网站引入更多的流量,给网站带来更好的权重。为了网站的整体发展,申请成为百度新闻源是非常有必要的。成为百度新闻源后,无论是增加网站权重,还是增加网站品牌度,都能得到更好的帮助。尤其值得一提的是,如果你的网站内容能在百度新闻频道被推荐,将为你的网站带来无限流量。虽然网站申请成为百度新闻源可以带来这么多好处,但仍有大部分网站站长不知道如何申请成为百度新闻源。下面我就带大家了解一下网站申请成为百度新闻源的具体步骤,以及成为百度新闻源后需要注意的一些事项。
方法/步骤
1
网站成为百度新闻源的基本条件
要成功申请成为百度新闻源,首先需要了解您的网站是否具备成为百度新闻源的条件。另一方面,站长首先要了解百度新闻源申请网站的最基本要求是什么:
1:网站需要安全可靠
网站要成为百度新闻源,网站首先要有明确的责任人。商业网站需要有公司营业执照,非商业网站需要负责人备案网站。另外网站的服务器一定要稳定,访问速度要好。只有安全可靠的网站才能随时响应百度蜘蛛的抓取和内容抓取。
2:网站需要高质量的新闻内容
大家需要明白的是,并不是所有网站的内容都能被百度新闻收录。百度新闻对网站的内容质量也有着极高的要求。 网站内容需要基于原创或优质伪原创,并且这些内容可以定期维护和更新。搜索引擎看重网站,每天24小时不断更新,尤其是新闻来源。如果你的文章总是在新闻事件发生后立即发布,不仅你目前的文章排名非常高,而且从长远来看,你整个网站在新闻源中的位置会不断提高。
另外,网站发布的内容必须具有新闻的特征。这里需要特别注意新闻功能,而不是一些技术方面文章。和一些技术问题一样,文章可以有更高的质量,但由于它没有新闻价值,所以不会被百度列为新闻来源。
2
网站申请成为百度新闻源的具体步骤
了解了网站成为百度新闻源必须注意的基本要求后,我们来介绍一下如何申请网站成为百度新闻源的具体步骤:
1:首先要仔细阅读预申请规则文档《互联网新闻开放协议》。
2:然后,我们需要根据网站的内容和“互联网新闻开放协议”要求的标签格式,制作一个标准化的xml文件。这个文件是用来提交给百度的,目前主流的cms建站系统中一般都集成了符合“互联网新闻开放协议”标准的XML文件生成插件,可以直接使用,比如PHPcms,DEDEcms 等等。
3: 然后,我们制作好XML文件后,需要通过FTP上传到网站服务器的根目录,获取XML文件的完整URL地址。如果集成网站生成插件,则无需上传。
4:之后,我们需要将上一步获取到的XML文件的地址提交给百度。我们需要填写网站name 和可选的备注。
5:完成以上工作后,我们需要发邮件给百度申请。邮箱地址是,您需要发一封含蓄而真诚的邮件来表达您的诚意,并表示您一如既往地对百度的支持和关注。
6:最后,我们需要耐心等待一周左右。如果我们的网站符合百度新闻源标准,那么百度会通过邮件通知申请结果。
3
网站成为百度新闻源后的一些注意事项
1:百度新闻来源主要是根据网址来识别抓取哪些内容,所以网站成为新闻来源后,站长不要轻易修改网站栏目地址,更别说修改整个网站 的 URL 规则。百度能够根据该列的 URL 确定它可以抓取的内容。这在管理员手动审核时得到确认。如需变更,需申请网站改版变更。
2:网站title 的一些标题、关键词和描述关键词可能会决定搜索引擎不会去收录what news。因此,即使站长的网址结构相同,模板相同,也不会收录你。比如这些内容是一些故事,那么你的程序头可能收录一些关键词,导致不是收录。经过实验,小编还发现,当标题、关键词、描述与新闻来源文章基本一致时,即使是帖子,百度也是收录。当然,我没有继续这样做。既然已经成为新闻源,那么维护它的权威性显然很重要。
3:网站成为新闻源后,网站内容必须保持良好的新闻敏感度,这样才能确定网站内容就是收录。及时。编辑内容时,站长一定要注意原创,增加新闻的敏感度。如果你的新闻总是走在其他媒体的前列,并且保持一定的持续原创,那么你所有的新闻都是收录,权重会不断增加,这样就有可能迅速超越传统新闻媒体,即使他们是原创者。这就是上面提到的速度问题。 查看全部
网站该如何申请成为百度新闻源的具体操作步骤?
百度新闻源,其实就是指百度的新闻源,一个百度蜘蛛经常光顾的地方,会采集新闻和相关信息。对于网站站长来说,如果他们的网站能够成功申请加入百度动态消息,那么无论是网站的推广还是网站内部的信息传播,都会起到很好的效果。成为百度新闻源后,网站可以向百度提交自己的符合互联网新闻开放协议标准的XML网页。这样网站就可以在之前的内容发布后被动等待百度收录主动提交内容给百度。这不仅会大大提高收录内容的速度,还会为网站引入更多的流量,给网站带来更好的权重。为了网站的整体发展,申请成为百度新闻源是非常有必要的。成为百度新闻源后,无论是增加网站权重,还是增加网站品牌度,都能得到更好的帮助。尤其值得一提的是,如果你的网站内容能在百度新闻频道被推荐,将为你的网站带来无限流量。虽然网站申请成为百度新闻源可以带来这么多好处,但仍有大部分网站站长不知道如何申请成为百度新闻源。下面我就带大家了解一下网站申请成为百度新闻源的具体步骤,以及成为百度新闻源后需要注意的一些事项。
方法/步骤
1
网站成为百度新闻源的基本条件
要成功申请成为百度新闻源,首先需要了解您的网站是否具备成为百度新闻源的条件。另一方面,站长首先要了解百度新闻源申请网站的最基本要求是什么:
1:网站需要安全可靠
网站要成为百度新闻源,网站首先要有明确的责任人。商业网站需要有公司营业执照,非商业网站需要负责人备案网站。另外网站的服务器一定要稳定,访问速度要好。只有安全可靠的网站才能随时响应百度蜘蛛的抓取和内容抓取。
2:网站需要高质量的新闻内容
大家需要明白的是,并不是所有网站的内容都能被百度新闻收录。百度新闻对网站的内容质量也有着极高的要求。 网站内容需要基于原创或优质伪原创,并且这些内容可以定期维护和更新。搜索引擎看重网站,每天24小时不断更新,尤其是新闻来源。如果你的文章总是在新闻事件发生后立即发布,不仅你目前的文章排名非常高,而且从长远来看,你整个网站在新闻源中的位置会不断提高。
另外,网站发布的内容必须具有新闻的特征。这里需要特别注意新闻功能,而不是一些技术方面文章。和一些技术问题一样,文章可以有更高的质量,但由于它没有新闻价值,所以不会被百度列为新闻来源。
2
网站申请成为百度新闻源的具体步骤
了解了网站成为百度新闻源必须注意的基本要求后,我们来介绍一下如何申请网站成为百度新闻源的具体步骤:
1:首先要仔细阅读预申请规则文档《互联网新闻开放协议》。
2:然后,我们需要根据网站的内容和“互联网新闻开放协议”要求的标签格式,制作一个标准化的xml文件。这个文件是用来提交给百度的,目前主流的cms建站系统中一般都集成了符合“互联网新闻开放协议”标准的XML文件生成插件,可以直接使用,比如PHPcms,DEDEcms 等等。
3: 然后,我们制作好XML文件后,需要通过FTP上传到网站服务器的根目录,获取XML文件的完整URL地址。如果集成网站生成插件,则无需上传。
4:之后,我们需要将上一步获取到的XML文件的地址提交给百度。我们需要填写网站name 和可选的备注。
5:完成以上工作后,我们需要发邮件给百度申请。邮箱地址是,您需要发一封含蓄而真诚的邮件来表达您的诚意,并表示您一如既往地对百度的支持和关注。
6:最后,我们需要耐心等待一周左右。如果我们的网站符合百度新闻源标准,那么百度会通过邮件通知申请结果。
3
网站成为百度新闻源后的一些注意事项
1:百度新闻来源主要是根据网址来识别抓取哪些内容,所以网站成为新闻来源后,站长不要轻易修改网站栏目地址,更别说修改整个网站 的 URL 规则。百度能够根据该列的 URL 确定它可以抓取的内容。这在管理员手动审核时得到确认。如需变更,需申请网站改版变更。
2:网站title 的一些标题、关键词和描述关键词可能会决定搜索引擎不会去收录what news。因此,即使站长的网址结构相同,模板相同,也不会收录你。比如这些内容是一些故事,那么你的程序头可能收录一些关键词,导致不是收录。经过实验,小编还发现,当标题、关键词、描述与新闻来源文章基本一致时,即使是帖子,百度也是收录。当然,我没有继续这样做。既然已经成为新闻源,那么维护它的权威性显然很重要。
3:网站成为新闻源后,网站内容必须保持良好的新闻敏感度,这样才能确定网站内容就是收录。及时。编辑内容时,站长一定要注意原创,增加新闻的敏感度。如果你的新闻总是走在其他媒体的前列,并且保持一定的持续原创,那么你所有的新闻都是收录,权重会不断增加,这样就有可能迅速超越传统新闻媒体,即使他们是原创者。这就是上面提到的速度问题。
通过关键词采集文章采集api接口代码采集网站最新内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-06-27 00:02
通过关键词采集文章采集api接口代码采集网站最新内容可以和阿里博客、豆瓣等博客进行数据对接。阿里博客可以采集自己的网站、博客、书影音、个人日志等一系列信息,实现从用户看到的文章信息,推送给读者。,天猫,京东,当当的相关商品信息,有时候无法直接获取,需要我们爬取到源代码去匹配,进行商品信息采集,这里博客地址和源代码都不需要,因为博客已经有源代码了。更多采集请关注我们的aso100小程序:小应用程序大全。
html结构搜到robots.txt
程序员给我写的,
我只是在上述链接中截取了部分进行收藏,链接是在复制粘贴过程中产生的,当然有部分也是经过同意后贴出来的。欢迎大家下载运行,用浏览器打开链接:工具:奇兔短信采集器页面截图:1.登录奇兔短信采集器的网站后,会有“认证码”的弹窗出现,点击“认证”即可进入获取“设置”页面。2.“设置”页面“ip”的确定一栏中勾选“动态ip”。
3.“采集设置”页面“刷新时间”的设置和“定时刷新”中的“打开本网站”“定时刷新”保持一致,“帐号名称”建议使用真实姓名或名字简单的英文,后期如果对用户名进行修改需要获取用户名的话,比较方便。4.还有一些通用的条件:请标注作者名字【seo课老师】和作者简介【招聘类】的字段请采用真实姓名或名字简单的英文,不包含英文(如””),否则会在跳转到别的网站的同时出现重复;1024和65536:请用特殊符号【tel:”【短信采集】、”,如:”【短信采集】“等,【短信采集】和【短信采集】字段不要使用“&#。 查看全部
通过关键词采集文章采集api接口代码采集网站最新内容
通过关键词采集文章采集api接口代码采集网站最新内容可以和阿里博客、豆瓣等博客进行数据对接。阿里博客可以采集自己的网站、博客、书影音、个人日志等一系列信息,实现从用户看到的文章信息,推送给读者。,天猫,京东,当当的相关商品信息,有时候无法直接获取,需要我们爬取到源代码去匹配,进行商品信息采集,这里博客地址和源代码都不需要,因为博客已经有源代码了。更多采集请关注我们的aso100小程序:小应用程序大全。
html结构搜到robots.txt
程序员给我写的,
我只是在上述链接中截取了部分进行收藏,链接是在复制粘贴过程中产生的,当然有部分也是经过同意后贴出来的。欢迎大家下载运行,用浏览器打开链接:工具:奇兔短信采集器页面截图:1.登录奇兔短信采集器的网站后,会有“认证码”的弹窗出现,点击“认证”即可进入获取“设置”页面。2.“设置”页面“ip”的确定一栏中勾选“动态ip”。
3.“采集设置”页面“刷新时间”的设置和“定时刷新”中的“打开本网站”“定时刷新”保持一致,“帐号名称”建议使用真实姓名或名字简单的英文,后期如果对用户名进行修改需要获取用户名的话,比较方便。4.还有一些通用的条件:请标注作者名字【seo课老师】和作者简介【招聘类】的字段请采用真实姓名或名字简单的英文,不包含英文(如””),否则会在跳转到别的网站的同时出现重复;1024和65536:请用特殊符号【tel:”【短信采集】、”,如:”【短信采集】“等,【短信采集】和【短信采集】字段不要使用“&#。
互联网时代网络爬虫系统的原理和工作流程详解!
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-06-26 04:12
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,将网页信息的抓取范围扩大到可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)表。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
互联网时代网络爬虫系统的原理和工作流程详解!
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些比较重要的网站 URL,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页呢?如果您对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流群:458号345号782获取学习资源,将网页信息的抓取范围扩大到可能,这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性来确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到它引用的两个页面上,每个页面得到 50。同样,PageRank 值为 9 的网页引用它为 3 个页面中的每个页面传递的值是 3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
,
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略、PageRank 优先策略等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)表。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
python爬虫爬取数据的第一步必须分析目标网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-06-22 02:12
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时使用python爬虫(结合tkinter开发爬虫应用),使用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基本的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略进行数据爬取,提升性能,提高操作舒适度(结合客户端技术,为爬虫定制接口)根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境! 查看全部
python爬虫爬取数据的第一步必须分析目标网站
这几年python的火爆异常火爆!在大学期间,我也做了很多深入的学习。毕业后,我尝试使用python作为我的职业方向。虽然我没有如愿成为一名python工程师,但我对python的掌握也让我现在的工作发展和职业发展更加出色。便利。这个文章主要跟大家分享一下我对python爬虫的收获和感悟。
python爬虫是python应用最熟悉的方式,因为python有丰富的第三方开发库,所以可以做很多工作:比如web开发(django)、应用开发(tkinter、wxpython、qt )、数据统计与计算(numpy)、图形图像处理、深度学习、人工智能等。我平时使用python爬虫(结合tkinter开发爬虫应用),使用django开发一些小人网站。 django框架可以根据实体类自动生成管理终端,大大提高了系统的开发效率。有兴趣的朋友可以试试。
一个成功的爬虫需要对应一个标准化的网站。爬虫主要是为了方便我们获取数据。如果目标系统开发不规范,没有规则,很难用爬虫自定义一套规则来爬取,而爬虫是基本的,是定制的,需要针对不同的系统进行调整。
爬虫爬取数据的第一步必须分析目标网站的技术和网站数据结构(通过前端源码)。您可以使用 chrome 浏览器。目前python爬虫主要会面对三种网站:
1.前后端分离网站
前端通过参数访问接口,后端返回json数据。对于这种网站,python可以模拟浏览器前端,发送参数然后接收数据,完成爬虫数据目标
2.static网站
通过python的第三方库(requests、urllib),下载源码,通过xpath和regular进行数据匹配
3.动态网站
如果采用第二种方式,下载的源代码只是简单的html,源代码中没有数据,因为这样的动态网站需要通过js加载,源代码中才会有数据对于这样的网站,可以使用自动化测试工具selenium
爬虫步骤:
分析网站技术和目标数据的结构。根据第一步,分析结构,选择相应的技术策略进行数据爬取,提升性能,提高操作舒适度(结合客户端技术,为爬虫定制接口)根据需求执行数据清理数据存储,存储到数据库、文档等
反拼写机制:
1.当系统判断属于同一个ip的客户端有多次访问而没有中断时,会拒绝访问这个ip
解决方案:动态代理,不断改变ip访问目标系统,或者从免费ip代理网站爬取ip创建ip池。如果目标数据量不大,可以降低访问速度,避免反扒
2.目标系统需要注册登录才能访问
解决方法:使用python的第三方库(Faker)生成假登录名、密码、个人资料,用于自动注册登录
3.目标系统的目标数据页的链接需要处理后才能进入目标数据页进行访问
解决方法:无法正常访问目标网站的目标数据页面链接。需要研究页面中的js脚本,对链接进行处理。我个人通过搜狗浏览器爬取了微信账号文章。我遇到过这个问题。爬取到的文章链接需要通过js脚本拼接才能得到正确的链接地址
获取目标数据的位置:
通过xpath获取数据的位置,可以使用chrome浏览器调试功能通过正则匹配获取对应数据的xpath路径
Python爬虫第三方常用库:
urllib/requests 请求库
Faker 生成假数据
UserAgent 生成假数据头
etree、beautsoup 匹配数据
json 处理json数据
re 正则库
selenium 自动化测试库
sqlite3 数据库 python3自带
抓取静态网页数据:
import requests
from fake_useragent import UserAgent #提供假的请求头
from lxml import etree # 匹配数据
#爬取目标页面的url
url='http://***ip****:8085/pricePublic/house/public/index'
headers= {'User-Agent':str(UserAgent().random)}
response=requests.get(url,headers=headers)
# 获得网页源码
content=response.text
html=etree.HTML(content)
#使用xpath查找对应标签处的元素值,pageNum此处爬取对应页面的页码
pageNum=html.xpath('//*[@id="dec"]/div[2]/div/span[1]/text()')
爬取前后端分离系统的数据:
import json
import requests
#获取返回的response
url='http://***ip***/FindById/22'
response=requests.get(url)
#通过json库解析json,获得返回的数据
DataNode = json.loads(response.text).get('returndata').get('data')[0]
抓取动态数据:
以下代码示例使用 Google 浏览器,使用 selenium 库,并将浏览器设置为无头模式。爬虫会配合浏览器在后台模拟人工操作。爬虫会根据代码中定义的xpath地址,在浏览器中找到对应的位置进行操作。使用selenium抓取数据时,需要安装相应版本的浏览器驱动
import requests
from faker import Faker
from fake_useragent import UserAgent
from lxml import etree
url='http://***ip***/FindById/22'
#通过faker库获得假email和电话号码
fake=Fakeer('zh_CN')
email=fake.email()
tel=fake.phone_number()
data={
"email":email
}
#使用requests库发送post请求
response=requests.post(url,data,headers=headers)
code=response.status_code
content=response.text
#获得返回的cookies并转换为字典形式
cookies = requests.utils.dict_from_cookiejar(response.cookies)
#请求的时候带上cookies
response=requests.get(url,headers=headers,cookies=cookies)
作为合法公民,爬行只是一种技术。当我们使用它来抓取目标数据时,我们必须遵守一定的规则。每个网站的根目录下都会有robots.txt(爬虫协议)文件规定可以访问哪些网页。抓取公共信息和数据时,不得对目标系统造成严重破坏。因此,我们呼吁大家在使用各种技术开展工作的过程中要遵守各种技术。技术法规和制度规范,共同为你我他创造文明的网络环境!
调用官方api接口,大力出奇迹,你需要相信!
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-06-21 06:06
百度收录的问题一直是很多渣男头疼的问题,但是官网居然提供了普通的收录和fast收录接口,直接调用官方api接口,大力创造奇迹,你需要相信,虽然你是seo,但如果你有排名,我就输了。没有收录,怎么可能?你没有给你留下主页网址吗?之前写过熊掌号api URL提交,可惜被取消了,不知道能不能用。
其实调用官方的api还是比较简单的。直接按照官方给出的例子和参数即可实现。您也可以通过一点点复制和修改来实现它。至于收录的效果,和上面那句话是一样的。国内seo人才核心,努力创造奇迹!
示例代码
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json
def api(site,token,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url=f"http://data.zz.baidu.com/urls?site={site}&token={token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response=requests.post(post_url,headers=headers,data=url)
req=response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json=json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
继续优化完善吧!
首先网站Map,众所周知,sitemap.xml格式文件收录网站All 网站。我们可以使用它向搜索引擎提交网址。同时,我们也可以为之努力。我这里使用的网站地图文件是Tiger Map制作的。
从sitemap.xml文件中读取网页链接地址,使用正则表达式轻松达到目的!
示例代码
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
考虑到大部分大佬推送的网站链接数量比较多,这里应用了线程池技术,多线程的URL推送比较简单,复制粘贴就行!
示例代码
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
完整代码参考
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json,re
from multiprocessing.dummy import Pool as ThreadPool
class Ts():
def __init__(self,site,token,path):
self.site=site
self.token=token
self.path=path
def api(self,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url = f"http://data.zz.baidu.com/urls?site={self.site}&token={self.token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response = requests.post(post_url, headers=headers, data=url)
req = response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json = json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
return None
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
if __name__ == '__main__':
site="网站地址"
token="秘钥"
path=r"网站地图文件存储路径"
spider=Ts(site,token,path)
spider.main()
查看全部
调用官方api接口,大力出奇迹,你需要相信!
百度收录的问题一直是很多渣男头疼的问题,但是官网居然提供了普通的收录和fast收录接口,直接调用官方api接口,大力创造奇迹,你需要相信,虽然你是seo,但如果你有排名,我就输了。没有收录,怎么可能?你没有给你留下主页网址吗?之前写过熊掌号api URL提交,可惜被取消了,不知道能不能用。
其实调用官方的api还是比较简单的。直接按照官方给出的例子和参数即可实现。您也可以通过一点点复制和修改来实现它。至于收录的效果,和上面那句话是一样的。国内seo人才核心,努力创造奇迹!
示例代码
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json
def api(site,token,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url=f"http://data.zz.baidu.com/urls?site={site}&token={token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response=requests.post(post_url,headers=headers,data=url)
req=response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json=json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
继续优化完善吧!
首先网站Map,众所周知,sitemap.xml格式文件收录网站All 网站。我们可以使用它向搜索引擎提交网址。同时,我们也可以为之努力。我这里使用的网站地图文件是Tiger Map制作的。
从sitemap.xml文件中读取网页链接地址,使用正则表达式轻松达到目的!
示例代码
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
考虑到大部分大佬推送的网站链接数量比较多,这里应用了线程池技术,多线程的URL推送比较简单,复制粘贴就行!
示例代码
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
完整代码参考
#百度普通收录 资源提交 API提交
#微信:huguo00289
# -*- coding: UTF-8 -*-
import requests
import json,re
from multiprocessing.dummy import Pool as ThreadPool
class Ts():
def __init__(self,site,token,path):
self.site=site
self.token=token
self.path=path
def api(self,url):
print(f">>> 正在向百度推送链接-- {url} ..")
post_url = f"http://data.zz.baidu.com/urls?site={self.site}&token={self.token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': '83',
}
response = requests.post(post_url, headers=headers, data=url)
req = response.text
if "success" in req:
print(f"恭喜,{url} -- 百度推送成功!")
req_json = json.loads(req)
print(f'当天剩余的可推送url条数: {req_json["remain"]}')
else:
print(f"{url} -- 百度推送失败!")
return None
def get_url(self):
with open(self.path,'r',encoding='utf-8') as f:
xml_data=f.read()
print(">>> 读取网站地图文件成功!")
urls=re.findall(r'(.+?)',xml_data,re.S)
print(urls)
print(f">>> 共有网页链接数 :{len(urls)} 条!")
return urls
def main(self):
urls=self.get_url()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(self.api,urls)
pool.close()
pool.join()
print(">> 采集所有链接百度推送完成!")
except Exception as e:
print(f'错误代码:{e}')
print("Error: unable to start thread")
if __name__ == '__main__':
site="网站地址"
token="秘钥"
path=r"网站地图文件存储路径"
spider=Ts(site,token,path)
spider.main()
如何爬取新浪网新闻数据,通过词云可视化展示新闻关键词
采集交流 • 优采云 发表了文章 • 0 个评论 • 554 次浏览 • 2021-06-19 02:21
今天教大家爬取新浪新闻数据,通过词云可视化展示新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。当它达到 126 时,它请求空数据。每页一共20条,所以一共有**2500**条新闻数据。
### json 数据结构 这里我们得到三个字段(标题标题,原标题介绍,关键词keywords)#2、采集数据 今天教大家如何爬取新浪新闻数据,通过词云可视化新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。到126时,请求空数据。
每页总共有 20 个条目,所以总共有 **2500** 条新闻数据。 ### json 数据结构 这里我们得到三个字段(标题标题,原创标题介绍,关键词keywords)#2、采集数据###采集分析第一页后,开始在下面python中编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。
标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```### 原标题词云可视化 在绘制词云图之前,先对数据进行处理(比如去掉“原标题:”)```###原标题词云图```### 关键词词云视化```###关键词词云图``` **分析:**三词云图时事热点相似,核心点是“新冠肺炎” ”、“案例”和“北京”。 “与外交国家等的情况”。具体的我就不多说了。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。
###采集分析第一页后,我们开始用python编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。
读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```###原标题词云可视化在绘制词云图之前,先对数据进行处理(例如“原标题:”去掉)! [](~tplv-k3u1fbpfcp-zoom-1.image)```###原标题词云图```###关键词词云视化```###关键词词云图``` **解析:**三者的时事热点词云图类似,核心点是“新冠肺炎”、“病例”、“北京”、“与外交国家的情况等”。我不会说太多。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。 查看全部
如何爬取新浪网新闻数据,通过词云可视化展示新闻关键词
今天教大家爬取新浪新闻数据,通过词云可视化展示新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。当它达到 126 时,它请求空数据。每页一共20条,所以一共有**2500**条新闻数据。
### json 数据结构 这里我们得到三个字段(标题标题,原标题介绍,关键词keywords)#2、采集数据 今天教大家如何爬取新浪新闻数据,通过词云可视化新闻关键词,快速了解最新的新闻热点。这里抓取**2500**条新闻数据进行演示。  PS:这里采集主要是国内最新的新闻数据。先来看看数据:#1、网站分析新闻数据源(新浪网)采集````` ` ###下一页分析我们要采集多条数据,所以需要找到下一页的模式 当我点击第二页时,发现网页链接没有变化。这里的数据是异步加载的,所以查了一下网络,找到了目标异步链接:``````但是发现callback=feedCardJsonpCallback&_= 54,可以去掉,所以最后的链接如下:``` ```参数page为页数。经测试,页面范围为1~125。到126时,请求空数据。
每页总共有 20 个条目,所以总共有 **2500** 条新闻数据。 ### json 数据结构 这里我们得到三个字段(标题标题,原创标题介绍,关键词keywords)#2、采集数据###采集分析第一页后,开始在下面python中编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。
标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```### 原标题词云可视化 在绘制词云图之前,先对数据进行处理(比如去掉“原标题:”)```###原标题词云图```### 关键词词云视化```###关键词词云图``` **分析:**三词云图时事热点相似,核心点是“新冠肺炎” ”、“案例”和“北京”。 “与外交国家等的情况”。具体的我就不多说了。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。
###采集分析第一页后,我们开始用python编程采集data。 ```url=";lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"``` 这是第一个页面数据已经可以成功采集,只需将页面值更改为采集下一页数据即可。然后开始在excel中存储采集数据。 ###保存数据这里使用openxl库保存excel中的数据,先定义头```outwb = openpyxl.Workbook()```然后写入excel ```count = 2`` `! [](~tplv-k3u1fbpfcp-zoom-1.image)#3、词云可视化这里我们主要绘制三个词云可视化(有标题,原标题和关键词分布作为数据画图)。标题是原标题的精简版,关键词是这个文章关键词的核心,通过绘制这三个词云图,然后进行对比分析。
读取数据```datafile = u'news data-Li Yunchen.xls'```###标题词云可视化```###标题词云图```###原标题词云可视化在绘制词云图之前,先对数据进行处理(例如“原标题:”去掉)! [](~tplv-k3u1fbpfcp-zoom-1.image)```###原标题词云图```###关键词词云视化```###关键词词云图``` **解析:**三者的时事热点词云图类似,核心点是“新冠肺炎”、“病例”、“北京”、“与外交国家的情况等”。我不会说太多。通过词云图可以一目了然地了解当前国内的核心热点关键词。 #4、小结 为方便大家,陈哥上传了本文**完整源码**,需要同名公众回复:**新闻** 这篇文章解释了采集的获取方式芭网新闻数据及画词云图展示分析。
传统企业获取潜在客户适合的推广方式,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-06-16 21:23
传统企业获取潜在客户适合的推广方式,你知道吗?
SEO流量站优化的优势
1、适合传统企业获取潜在客户的促销方式
传统企业的潜在客户主要使用搜索引擎寻找产品,其次是B2B平台。只要通过搜索引擎找到客户网站,都是传统企业的潜在+精准客户群。
2、高效的网络推广渠道
搜索引擎将为客户带来对网站 的明确需求。根据网站联盟的数据,SEO带来的流量转化率高达60%。
3、自然搜索结果可信度更高
搜索结果页面顶部有付费广告。用户对付费广告不信任和拒绝,更信任自然搜索结果。
4、排名靠前的链接点击次数更多
搜索时,大部分网友只点击搜索首页的前几个网站。 3页搜索结果后几乎没有人关心内容。
5、网站长久排名靠前
SEO优化一旦上去,就会长期保持自己的位置,不会像拍卖推广一样担心没钱排名下降。
6、不要担心无效点击
各大搜索引擎展示后,客户可以随意点击,无需担心恶意或无效点击。按天计算。有效控制50%以上的成本。
7、国家区域展示
相关推广词一旦上线,全国用户都可以搜索。放在一个地区不用担心,其他地区的用户搜索不到,客户全覆盖。
8、性价比高
适合传统企业的推广方式,关键词不受限制,不按点击收费。低成本投资,精准寻找潜在客户。
项目流程
1、python采集流量词(权重词)
2、python 清洗和采集长尾词(相关词)
3、python 处理标题
4、python采集内容清理
5、写对应的cms网站发布接口(接口会单独收费)
6、使用接口设置部署自动发布文章**
您提供:
1、关键词(要采集工业的关键词)
2、提供网站Background和宝塔(方便打包上传采集good数据到宝塔,设置为自动发布文章quantity)
3、提供百度通用推送API
注意:如果不需要自动发布,也可以采集以TXT文本形式保存到电脑上。
我们的服务:
1、根据你提供的关键词,采集长尾词(相关词)
2、按照采集的关键词,全网采集cleaning文章
3、采集好文章,打包成数据库放置宝塔后台
4、设置数据库文章,并写入接口每天自动发布的文章数量(设置正常推送)
项目优势:
1、你只需要提供(关键词、网站后台、宝塔后台、百度推送API)
2、我方提供全网文章cleaning采集service
3、cleaning号文章打包成数据库上传到宝塔
4、根据客户要求设置每日发帖数和推送通知数。
支持一步登天权
1、老域
2、高速服务器
3、单向链接点(友情链接)
4、快排大法
服务期:
注意:仅支持基于 PHP 的程序,例如 zblog 和 dede Word press Empire。
时间:大约3-5天(取决于采集关键词的数量)。
查看全部
传统企业获取潜在客户适合的推广方式,你知道吗?
SEO流量站优化的优势
1、适合传统企业获取潜在客户的促销方式
传统企业的潜在客户主要使用搜索引擎寻找产品,其次是B2B平台。只要通过搜索引擎找到客户网站,都是传统企业的潜在+精准客户群。
2、高效的网络推广渠道
搜索引擎将为客户带来对网站 的明确需求。根据网站联盟的数据,SEO带来的流量转化率高达60%。
3、自然搜索结果可信度更高
搜索结果页面顶部有付费广告。用户对付费广告不信任和拒绝,更信任自然搜索结果。
4、排名靠前的链接点击次数更多
搜索时,大部分网友只点击搜索首页的前几个网站。 3页搜索结果后几乎没有人关心内容。
5、网站长久排名靠前
SEO优化一旦上去,就会长期保持自己的位置,不会像拍卖推广一样担心没钱排名下降。
6、不要担心无效点击
各大搜索引擎展示后,客户可以随意点击,无需担心恶意或无效点击。按天计算。有效控制50%以上的成本。
7、国家区域展示
相关推广词一旦上线,全国用户都可以搜索。放在一个地区不用担心,其他地区的用户搜索不到,客户全覆盖。
8、性价比高
适合传统企业的推广方式,关键词不受限制,不按点击收费。低成本投资,精准寻找潜在客户。
项目流程
1、python采集流量词(权重词)
2、python 清洗和采集长尾词(相关词)
3、python 处理标题
4、python采集内容清理
5、写对应的cms网站发布接口(接口会单独收费)
6、使用接口设置部署自动发布文章**
您提供:
1、关键词(要采集工业的关键词)
2、提供网站Background和宝塔(方便打包上传采集good数据到宝塔,设置为自动发布文章quantity)
3、提供百度通用推送API
注意:如果不需要自动发布,也可以采集以TXT文本形式保存到电脑上。
我们的服务:
1、根据你提供的关键词,采集长尾词(相关词)
2、按照采集的关键词,全网采集cleaning文章
3、采集好文章,打包成数据库放置宝塔后台
4、设置数据库文章,并写入接口每天自动发布的文章数量(设置正常推送)
项目优势:
1、你只需要提供(关键词、网站后台、宝塔后台、百度推送API)
2、我方提供全网文章cleaning采集service
3、cleaning号文章打包成数据库上传到宝塔
4、根据客户要求设置每日发帖数和推送通知数。
支持一步登天权
1、老域
2、高速服务器
3、单向链接点(友情链接)
4、快排大法
服务期:
注意:仅支持基于 PHP 的程序,例如 zblog 和 dede Word press Empire。
时间:大约3-5天(取决于采集关键词的数量)。
通过关键词采集文章采集api接口,供api开发者测试
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-06-09 18:01
通过关键词采集文章采集api接口,供api开发者测试,我们提供接口的上传与下载,高并发,实时数据,高性能队列等优势,专注为企业提供免费、稳定、灵活的api服务。这样的接口,文章检索效率高,搜索引擎快速优化排名,可以用来关键词推广、自媒体网站互推、品牌宣传、关键词竞价等,帮助企业帮助用户最大限度的挖掘和利用有价值的信息,从而获得广告收益和竞争优势。
精准定位文章最靠前的曝光位置,为您带来最大可能的精准推广和传播,助力企业在如今的市场竞争中占据更大的优势。通过文章采集引入流量,企业可以在官网服务内添加对外的服务,让搜索引擎全面收录您的网站,并给与有效搜索权重、分发量,获得更多的流量。我们提供完善的api接口接入、免费/收费定制关键词策略、全网全站关键词竞价方案,为企业高效推广带来无穷的价值。
打开网站:百度搜索"文章采集"就可以采集任何文章,seo狗用来扫描采集别人的文章,恶意竞价比较方便。
文章采集网站大把,
有个专门采集平台推荐:/
采集宝-文章采集器-免费文章采集-效率+收入
谢邀关键词采集网站太多太多,
百度:文章采集,英文文章采集,搜狗:文章采集(全球采集), 查看全部
通过关键词采集文章采集api接口,供api开发者测试
通过关键词采集文章采集api接口,供api开发者测试,我们提供接口的上传与下载,高并发,实时数据,高性能队列等优势,专注为企业提供免费、稳定、灵活的api服务。这样的接口,文章检索效率高,搜索引擎快速优化排名,可以用来关键词推广、自媒体网站互推、品牌宣传、关键词竞价等,帮助企业帮助用户最大限度的挖掘和利用有价值的信息,从而获得广告收益和竞争优势。
精准定位文章最靠前的曝光位置,为您带来最大可能的精准推广和传播,助力企业在如今的市场竞争中占据更大的优势。通过文章采集引入流量,企业可以在官网服务内添加对外的服务,让搜索引擎全面收录您的网站,并给与有效搜索权重、分发量,获得更多的流量。我们提供完善的api接口接入、免费/收费定制关键词策略、全网全站关键词竞价方案,为企业高效推广带来无穷的价值。
打开网站:百度搜索"文章采集"就可以采集任何文章,seo狗用来扫描采集别人的文章,恶意竞价比较方便。
文章采集网站大把,
有个专门采集平台推荐:/
采集宝-文章采集器-免费文章采集-效率+收入
谢邀关键词采集网站太多太多,
百度:文章采集,英文文章采集,搜狗:文章采集(全球采集),
《人民日报》爬虫文章爬取关键词的搜索结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-06-09 04:48
上一期《人民日报》的爬虫文章发布了,收到了很好的反馈。文章中的爬虫代码确实帮助了很多人。我很高兴。
在和读者交流的过程中,我也发现了一些比较常见的需求,就是根据关键词过滤news文章。
一开始我的想法是在爬取所有文章数据的基础上遍历文件夹,然后过滤掉body中收录关键词的文章。
如果你下载了完整的新闻资料,这个方法无疑是最方便快捷的。但如果不是,那么先爬取所有数据,再筛选符合条件的数据无疑是浪费时间。
本文文章我将介绍两种方法,一种是根据关键词过滤已有数据,另一种是利用人民网的搜索功能对关键词的搜索进行爬取结果。
1. 爬取关键词搜索结果
最近有读者问我问题,我发现人民网有搜索功能()。
所以就按照关键词搜索,然后往下爬搜索结果。
1.1 分析页面
这里简单教大家分析网页的大体思路。
1.1.1 分析网页主要看什么1.1.2 如何使用浏览器的开发者工具
具体操作也很简单。按F12打开开发者工具,切换到网络,刷新网页。可以看到列表中有很多请求。
有图片、js代码、css样式、html源代码等各种请求
点击对应的请求项后,您可以在Preview或Response中预览请求的数据内容,看是否收录您需要的数据。
当然可以一一检查,也可以使用顶部的过滤器过滤请求类型(一般情况下,我们需要的数据可以在XHR和Doc中找到)
找到对应的请求后,可以切换到headers查看请求的请求头信息。
如图所示,主要有四个重点领域。
请求 URL:请求的链接。爬虫请求的url需要在这里读取。不要只复制浏览器地址栏中的 URL。请求方法:有两种类型的请求方法:GET 和 POST。爬虫代码中是使用requests.get()还是requests.post()要与此一致,否则可能无法正确获取数据。请求头:请求头,服务器将使用它来确定谁正在访问网站。一般需要在爬虫请求头中设置User-Agent(有的网站可能需要确定Accept、Cookie、Referer、Host等,根据具体情况设置)将爬虫伪装成普通浏览器用户并防止其被反爬虫机制拦截。 Request Payload:请求参数,服务器会根据这些参数决定返回给你哪些数据,比如页码,关键词等,找到这些参数的规则,你可以通过构造这些参数数据。 1.1.3 服务器返回的数据有哪些形式
一般情况下有两种格式,html和json。接下来我就简单教大家如何判断。
HTML 格式
一般情况下,它会出现在过滤条件中的Doc类型中,也很容易区分。它在响应中查看。整篇文章都打上了这种标签。
如果你确定html源码中收录了你需要的数据(所以,因为有些情况下数据是通过js代码动态加载的,直接解析源码是找不到数据的)
在Elements中,你可以通过左上角的箭头按钮,快速方便的定位到网页上数据所在的标签(我就不赘述了,自己试试就明白了) .
大多数人从解析html开始学习爬虫,所以应该对它比较熟悉。解析方法很多,比如正则表达式、BeautifulSoup、xpath等。
Json 格式
如前所述,在某些情况下,数据不是直接在html页面返回,而是通过其他数据接口动态请求加载。这就导致了一些同学刚开始学习爬虫的时候,在网页上分析的时候,标签路径是可以的,但是请求代码的时候却找不到标签。
这种动态加载数据的机制叫做Ajax,有兴趣的可以自行搜索。
ajax请求在请求类型上一般都是XHR,数据内容一般以json格式显示。 (有同学不知道怎么判断一个请求是ajax还是数据是不是json,我该怎么做呢?这里有一个简单的判断方法。在Preview中看看是不是类似下面的表格,大括号, 键值对 { "xxx": "xxx"}, 一个可以开闭的小三角形)
这种类型的请求返回的数据是json格式的,可以直接用python中的json库解析,非常方便。
上面给大家简单介绍了如何分析网页,如何抓包。希望对大家有帮助。
贴上正题,通过上面介绍的方法,我们不难知道人民网的搜索结果数据是通过Ajax发送的。
请求方法是POST。请求链接、请求头、请求参数都可以在Headers中查看。
在参数中,我们可以看到key应该是我们搜索到的关键词,page是页码,sortType是搜索结果的排序方式等等,知道这些规则,所以我们可以自己构造请求。
1.2 探索防爬机制
一般网站会设置一些防爬机制来防止攻击。下面简单介绍一些常见的防爬机制及对策。
1.2.1 用户代理
服务器会根据请求头中的User-Agent字段判断用户访问什么,如:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36
此处收录有关浏览器和计算机系统的一些基本信息。如果你的python爬虫代码没有设置这个字段值,会默认为python,这样服务器就可以大致判断请求是爬虫发起的,然后选择是否拦截。
解决方法也比较简单,就是用浏览器访问时,复制请求头中的User-Agent值,在代码中设置。
1.2.2 推荐人
一些网站 资源添加了反水蛭链接。也就是说,服务器在处理请求的时候,会判断Referer的值。只有在指定站点发起请求时,服务器才会允许返回数据(这样可以防止资源被其他网站盗用和使用)。
响应方式也很简单,浏览器访问时复制请求头中的Referer值即可。
1.2.3 饼干
有些网站可能需要登录账号才能访问一些数据,此处使用cookie值。
如果不设置cookie,可以设置未登录时访问的cookie,登录账号后设置cookie。数据结果可能不同。
响应方式因网站而异。如果您无需设置 cookie 即可访问,那么请不要在意;如果需要设置访问,则根据情况(是否要登录,是否要成为会员等)复制浏览器请求header中的cookie值进行设置。
1.2.4 JS参数加密
在请求参数中,可能会有一些类似乱码的参数。你不知道它是什么,但它非常重要。它不是时间戳。不填写或随便填写,都会导致请求失败。
这种情况比较困难。这是js算法加密后的参数。如果要自己构建,则需要模拟整个参数加密算法。
但是由于这个加密过程是由前端完成的,所以完全可以得到加密算法的js代码。如果你了解一些前端知识,或者逆向Js,可以尝试破解。
我个人不推荐这个。一是破解麻烦,二是可能违法。
或者,使用 selenium 或 ``pyppeteer` 自动抓取。不香。
1.2.5 抓取频率限制
数据如果长时间频繁爬取,网站服务器的压力会很大,普通人不可能访问这么高强度的访问(比如每次十几次)第二个网站) 乍一看,爬虫做到了。因此,服务器通常会设置访问频率阈值。例如,如果一分钟内发起的请求超过300个,则视为爬虫,限制访问其IP。
响应,我建议如果你不是特别着急,可以设置一个延迟功能,每次抓取数据时随机休眠几秒,让访问频率降低到阈值以下,并且降低服务器访问压力。减少 IP 阻塞的机会。
1.2.6 其他
有一些不太常见但也更有趣的防攀爬机制。让我给你举几个例子。
以上是一些常见的防爬机制,希望对大家有帮助。
经过测试,人民网的防爬机制并不是特别严格。如果参数设置正确,抓取基本不会受到限制。
但如果是数据量比较大的爬取,最好设置爬取延迟和断点连续爬取功能。
1.3 改进代码
首先导入所需的库。
本爬虫代码中各个库的用处已在评论中标明。
import requests # 发起网络请求
from bs4 import BeautifulSoup # 解析HTML文本
import pandas as pd # 处理数据
import os
import time # 处理时间戳
import json # 用来解析json文本
发起网络请求函数fetchUrl
代码注释中已经标注了函数的用途和三个参数的含义,返回值为json类型数据
'''
用于发起网络请求
url : Request Url
kw : Keyword
page: Page number
'''
def fetchUrl(url, kw, page):
# 请求头
headers={
"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json;charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
}
# 请求参数
payloads = {
"endTime": 0,
"hasContent": True,
"hasTitle": True,
"isFuzzy": True,
"key": kw,
"limit": 10,
"page": page,
"sortType": 2,
"startTime": 0,
"type": 0,
}
# 发起 post 请求
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
数据分析函数parseJson
解析json对象,然后将解析后的数据包装成数组返回
def parseJson(jsonObj):
#解析数据
records = jsonObj["data"]["records"];
for item in records:
# 这里示例解析了几条,其他数据项如末尾所示,有需要自行解析
pid = item["id"]
originalName = item["originalName"]
belongsName = item["belongsName"]
content = BeautifulSoup(item["content"], "html.parser").text
displayTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(item["displayTime"]/1000))
subtitle = item["subtitle"]
title = BeautifulSoup(item["title"], "html.parser").text
url = item["url"]
yield [[pid, title, subtitle, displayTime, originalName, belongsName, content, url]]
数据保存功能saveFile
'''
用于将数据保存成 csv 格式的文件(以追加的模式)
path : 保存的路径,若文件夹不存在,则自动创建
filename: 保存的文件名
data : 保存的数据内容
'''
def saveFile(path, filename, data):
# 如果路径不存在,就创建路径
if not os.path.exists(path):
os.makedirs(path)
# 保存数据
dataframe = pd.DataFrame(data)
dataframe.to_csv(path + filename + ".csv", encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )
主要功能
if __name__ == "__main__":
# 起始页,终止页,关键词设置
start = 1
end = 3
kw = "春节"
# 保存表头行
headline = [["文章id", "标题", "副标题", "发表时间", "来源", "版面", "摘要", "链接"]]
saveFile("./data/", kw, headline)
#爬取数据
for page in range(start, end + 1):
url = "http://search.people.cn/api-se ... ot%3B
html = fetchUrl(url, kw, page)
for data in parseJson(html):
saveFile("./data/", kw, data)
print("第{}页爬取完成".format(page))
# 爬虫完成提示信息
print("爬虫执行完毕!数据已保存至以下路径中,请查看!")
print(os.getcwd(), "\\data")
以上就是这个爬虫的全部代码。您可以在此基础上对其进行修改和使用。仅供学习交流使用,请勿用于非法用途。
注:文字爬取的代码这里就不写了。一个是人脉文章mato爬取的功能在上一篇文章已经写好了。如果需要,可以自行集成代码;另一个是,抓取文本会引入一些其他问题,例如链接失败,文章来自不同的网站,以及不同的解析方法。这是一个很长的故事。本文主要讲思路。
1.4 成就展示1.4.1 程序运行效果
1.4.2 爬坡数据展示
2. 使用现有数据进行过滤
如果你提前下载了所有的新闻文章data,那么这个方法无疑是最方便的,省去了爬取数据的漫长过程,也让你免于对抗反爬机制。
2.1 数据源
下载链接:
以上是一位读者朋友爬取的人民日报新闻数据,包括19年至今的数据。每月更新一次,应该可以满足大量人的数据需求。
另外,我还有之前爬过的整整18年的数据。有需要的朋友可以私聊我。
2.2 搜索代码
以下图所示的目录结构为例。
假设我们有一些关键词,需要检查文章这些消息中哪些收录关键词。
import os
# 这里是你文件的根目录
path = "D:\\Newpaper\\2018"
# 遍历path路径下的所有文件(包括子文件夹下的文件)
def iterFilename(path):
#将os.walk在元素中提取的值,分别放到root(根目录),dirs(目录名),files(文件名)中。
for root, dirs, files in os.walk(path):
for file in files:
# 根目录与文件名组合,形成绝对路径。
yield os.path.join(root,file)
# 检查文件中是否包含关键词,若包含返回True, 若不包含返回False
def checkKeyword(filename, kwList):
with open(filename, "r", encoding="utf-8") as f:
content = f.read()
for kw in kwList:
if kw in content:
return True, kw
return False, ""
if __name__ == "__main__":
# 关键词数组
kwList = ["经济", "贸易"]
#遍历文章
for file in iterFilename(path):
res, kw = checkKeyword(file, kwList)
if res:
# 如果包含关键词,打印文件名和匹配到的关键词
print("文件 ", file," 中包含关键词 ", kw)
2.3 运行结果
运行程序从文件中过滤掉收录关键词的文章。
如果文章不清楚,或者解释有误,请在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。
查看全部
《人民日报》爬虫文章爬取关键词的搜索结果
上一期《人民日报》的爬虫文章发布了,收到了很好的反馈。文章中的爬虫代码确实帮助了很多人。我很高兴。
在和读者交流的过程中,我也发现了一些比较常见的需求,就是根据关键词过滤news文章。
一开始我的想法是在爬取所有文章数据的基础上遍历文件夹,然后过滤掉body中收录关键词的文章。
如果你下载了完整的新闻资料,这个方法无疑是最方便快捷的。但如果不是,那么先爬取所有数据,再筛选符合条件的数据无疑是浪费时间。
本文文章我将介绍两种方法,一种是根据关键词过滤已有数据,另一种是利用人民网的搜索功能对关键词的搜索进行爬取结果。
1. 爬取关键词搜索结果
最近有读者问我问题,我发现人民网有搜索功能()。
所以就按照关键词搜索,然后往下爬搜索结果。
1.1 分析页面
这里简单教大家分析网页的大体思路。
1.1.1 分析网页主要看什么1.1.2 如何使用浏览器的开发者工具
具体操作也很简单。按F12打开开发者工具,切换到网络,刷新网页。可以看到列表中有很多请求。
有图片、js代码、css样式、html源代码等各种请求
点击对应的请求项后,您可以在Preview或Response中预览请求的数据内容,看是否收录您需要的数据。
当然可以一一检查,也可以使用顶部的过滤器过滤请求类型(一般情况下,我们需要的数据可以在XHR和Doc中找到)
找到对应的请求后,可以切换到headers查看请求的请求头信息。
如图所示,主要有四个重点领域。
请求 URL:请求的链接。爬虫请求的url需要在这里读取。不要只复制浏览器地址栏中的 URL。请求方法:有两种类型的请求方法:GET 和 POST。爬虫代码中是使用requests.get()还是requests.post()要与此一致,否则可能无法正确获取数据。请求头:请求头,服务器将使用它来确定谁正在访问网站。一般需要在爬虫请求头中设置User-Agent(有的网站可能需要确定Accept、Cookie、Referer、Host等,根据具体情况设置)将爬虫伪装成普通浏览器用户并防止其被反爬虫机制拦截。 Request Payload:请求参数,服务器会根据这些参数决定返回给你哪些数据,比如页码,关键词等,找到这些参数的规则,你可以通过构造这些参数数据。 1.1.3 服务器返回的数据有哪些形式
一般情况下有两种格式,html和json。接下来我就简单教大家如何判断。
HTML 格式
一般情况下,它会出现在过滤条件中的Doc类型中,也很容易区分。它在响应中查看。整篇文章都打上了这种标签。
如果你确定html源码中收录了你需要的数据(所以,因为有些情况下数据是通过js代码动态加载的,直接解析源码是找不到数据的)
在Elements中,你可以通过左上角的箭头按钮,快速方便的定位到网页上数据所在的标签(我就不赘述了,自己试试就明白了) .
大多数人从解析html开始学习爬虫,所以应该对它比较熟悉。解析方法很多,比如正则表达式、BeautifulSoup、xpath等。
Json 格式
如前所述,在某些情况下,数据不是直接在html页面返回,而是通过其他数据接口动态请求加载。这就导致了一些同学刚开始学习爬虫的时候,在网页上分析的时候,标签路径是可以的,但是请求代码的时候却找不到标签。
这种动态加载数据的机制叫做Ajax,有兴趣的可以自行搜索。
ajax请求在请求类型上一般都是XHR,数据内容一般以json格式显示。 (有同学不知道怎么判断一个请求是ajax还是数据是不是json,我该怎么做呢?这里有一个简单的判断方法。在Preview中看看是不是类似下面的表格,大括号, 键值对 { "xxx": "xxx"}, 一个可以开闭的小三角形)
这种类型的请求返回的数据是json格式的,可以直接用python中的json库解析,非常方便。
上面给大家简单介绍了如何分析网页,如何抓包。希望对大家有帮助。
贴上正题,通过上面介绍的方法,我们不难知道人民网的搜索结果数据是通过Ajax发送的。
请求方法是POST。请求链接、请求头、请求参数都可以在Headers中查看。
在参数中,我们可以看到key应该是我们搜索到的关键词,page是页码,sortType是搜索结果的排序方式等等,知道这些规则,所以我们可以自己构造请求。
1.2 探索防爬机制
一般网站会设置一些防爬机制来防止攻击。下面简单介绍一些常见的防爬机制及对策。
1.2.1 用户代理
服务器会根据请求头中的User-Agent字段判断用户访问什么,如:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36
此处收录有关浏览器和计算机系统的一些基本信息。如果你的python爬虫代码没有设置这个字段值,会默认为python,这样服务器就可以大致判断请求是爬虫发起的,然后选择是否拦截。
解决方法也比较简单,就是用浏览器访问时,复制请求头中的User-Agent值,在代码中设置。
1.2.2 推荐人
一些网站 资源添加了反水蛭链接。也就是说,服务器在处理请求的时候,会判断Referer的值。只有在指定站点发起请求时,服务器才会允许返回数据(这样可以防止资源被其他网站盗用和使用)。
响应方式也很简单,浏览器访问时复制请求头中的Referer值即可。
1.2.3 饼干
有些网站可能需要登录账号才能访问一些数据,此处使用cookie值。
如果不设置cookie,可以设置未登录时访问的cookie,登录账号后设置cookie。数据结果可能不同。
响应方式因网站而异。如果您无需设置 cookie 即可访问,那么请不要在意;如果需要设置访问,则根据情况(是否要登录,是否要成为会员等)复制浏览器请求header中的cookie值进行设置。
1.2.4 JS参数加密
在请求参数中,可能会有一些类似乱码的参数。你不知道它是什么,但它非常重要。它不是时间戳。不填写或随便填写,都会导致请求失败。
这种情况比较困难。这是js算法加密后的参数。如果要自己构建,则需要模拟整个参数加密算法。
但是由于这个加密过程是由前端完成的,所以完全可以得到加密算法的js代码。如果你了解一些前端知识,或者逆向Js,可以尝试破解。
我个人不推荐这个。一是破解麻烦,二是可能违法。
或者,使用 selenium 或 ``pyppeteer` 自动抓取。不香。
1.2.5 抓取频率限制
数据如果长时间频繁爬取,网站服务器的压力会很大,普通人不可能访问这么高强度的访问(比如每次十几次)第二个网站) 乍一看,爬虫做到了。因此,服务器通常会设置访问频率阈值。例如,如果一分钟内发起的请求超过300个,则视为爬虫,限制访问其IP。
响应,我建议如果你不是特别着急,可以设置一个延迟功能,每次抓取数据时随机休眠几秒,让访问频率降低到阈值以下,并且降低服务器访问压力。减少 IP 阻塞的机会。
1.2.6 其他
有一些不太常见但也更有趣的防攀爬机制。让我给你举几个例子。
以上是一些常见的防爬机制,希望对大家有帮助。
经过测试,人民网的防爬机制并不是特别严格。如果参数设置正确,抓取基本不会受到限制。
但如果是数据量比较大的爬取,最好设置爬取延迟和断点连续爬取功能。
1.3 改进代码
首先导入所需的库。
本爬虫代码中各个库的用处已在评论中标明。
import requests # 发起网络请求
from bs4 import BeautifulSoup # 解析HTML文本
import pandas as pd # 处理数据
import os
import time # 处理时间戳
import json # 用来解析json文本
发起网络请求函数fetchUrl
代码注释中已经标注了函数的用途和三个参数的含义,返回值为json类型数据
'''
用于发起网络请求
url : Request Url
kw : Keyword
page: Page number
'''
def fetchUrl(url, kw, page):
# 请求头
headers={
"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json;charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
}
# 请求参数
payloads = {
"endTime": 0,
"hasContent": True,
"hasTitle": True,
"isFuzzy": True,
"key": kw,
"limit": 10,
"page": page,
"sortType": 2,
"startTime": 0,
"type": 0,
}
# 发起 post 请求
r = requests.post(url, headers=headers, data=json.dumps(payloads))
return r.json()
数据分析函数parseJson
解析json对象,然后将解析后的数据包装成数组返回
def parseJson(jsonObj):
#解析数据
records = jsonObj["data"]["records"];
for item in records:
# 这里示例解析了几条,其他数据项如末尾所示,有需要自行解析
pid = item["id"]
originalName = item["originalName"]
belongsName = item["belongsName"]
content = BeautifulSoup(item["content"], "html.parser").text
displayTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(item["displayTime"]/1000))
subtitle = item["subtitle"]
title = BeautifulSoup(item["title"], "html.parser").text
url = item["url"]
yield [[pid, title, subtitle, displayTime, originalName, belongsName, content, url]]
数据保存功能saveFile
'''
用于将数据保存成 csv 格式的文件(以追加的模式)
path : 保存的路径,若文件夹不存在,则自动创建
filename: 保存的文件名
data : 保存的数据内容
'''
def saveFile(path, filename, data):
# 如果路径不存在,就创建路径
if not os.path.exists(path):
os.makedirs(path)
# 保存数据
dataframe = pd.DataFrame(data)
dataframe.to_csv(path + filename + ".csv", encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )
主要功能
if __name__ == "__main__":
# 起始页,终止页,关键词设置
start = 1
end = 3
kw = "春节"
# 保存表头行
headline = [["文章id", "标题", "副标题", "发表时间", "来源", "版面", "摘要", "链接"]]
saveFile("./data/", kw, headline)
#爬取数据
for page in range(start, end + 1):
url = "http://search.people.cn/api-se ... ot%3B
html = fetchUrl(url, kw, page)
for data in parseJson(html):
saveFile("./data/", kw, data)
print("第{}页爬取完成".format(page))
# 爬虫完成提示信息
print("爬虫执行完毕!数据已保存至以下路径中,请查看!")
print(os.getcwd(), "\\data")
以上就是这个爬虫的全部代码。您可以在此基础上对其进行修改和使用。仅供学习交流使用,请勿用于非法用途。
注:文字爬取的代码这里就不写了。一个是人脉文章mato爬取的功能在上一篇文章已经写好了。如果需要,可以自行集成代码;另一个是,抓取文本会引入一些其他问题,例如链接失败,文章来自不同的网站,以及不同的解析方法。这是一个很长的故事。本文主要讲思路。
1.4 成就展示1.4.1 程序运行效果
1.4.2 爬坡数据展示
2. 使用现有数据进行过滤
如果你提前下载了所有的新闻文章data,那么这个方法无疑是最方便的,省去了爬取数据的漫长过程,也让你免于对抗反爬机制。
2.1 数据源
下载链接:
以上是一位读者朋友爬取的人民日报新闻数据,包括19年至今的数据。每月更新一次,应该可以满足大量人的数据需求。
另外,我还有之前爬过的整整18年的数据。有需要的朋友可以私聊我。
2.2 搜索代码
以下图所示的目录结构为例。
假设我们有一些关键词,需要检查文章这些消息中哪些收录关键词。
import os
# 这里是你文件的根目录
path = "D:\\Newpaper\\2018"
# 遍历path路径下的所有文件(包括子文件夹下的文件)
def iterFilename(path):
#将os.walk在元素中提取的值,分别放到root(根目录),dirs(目录名),files(文件名)中。
for root, dirs, files in os.walk(path):
for file in files:
# 根目录与文件名组合,形成绝对路径。
yield os.path.join(root,file)
# 检查文件中是否包含关键词,若包含返回True, 若不包含返回False
def checkKeyword(filename, kwList):
with open(filename, "r", encoding="utf-8") as f:
content = f.read()
for kw in kwList:
if kw in content:
return True, kw
return False, ""
if __name__ == "__main__":
# 关键词数组
kwList = ["经济", "贸易"]
#遍历文章
for file in iterFilename(path):
res, kw = checkKeyword(file, kwList)
if res:
# 如果包含关键词,打印文件名和匹配到的关键词
print("文件 ", file," 中包含关键词 ", kw)
2.3 运行结果
运行程序从文件中过滤掉收录关键词的文章。
如果文章不清楚,或者解释有误,请在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。
10,000条专利中常见的关键词,数据采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-06-02 05:26
据赛迪顾问统计,在最近10000项技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data 采集是被提及最多的词汇。
Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法和其他数据采集方法三种。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。 Web 数据也可以是从数据聚合器或搜索引擎 网站 购买的数据,以改进有针对性的营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为潜在的数据来源,对行业战略业务发展具有巨大潜力。
以下例子说明网络数据在不同行业的使用价值:
此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的使用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API方式,一种是网络爬取方式。 API也叫应用程序接口,是网站的管理员为了方便用户而编写的程序接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,可以自动关联附件和文本。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫是获取互联网数据的更有利工具采集。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有他们可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有网络数据采集、处理和存储三大功能,如图:
网络爬虫 采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时,它提取网站中存在的其他网站链接并发送它们。请求,接收网站响应并再次解析页面,然后从页面中提取所需的资源……等等,搜索引擎上的相关数据可以通过网络爬虫完全爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等的处理和处理,从大量的、杂乱的、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多 查看全部
10,000条专利中常见的关键词,数据采集方式
据赛迪顾问统计,在最近10000项技术领域专利中最常见的关键词中,数据采集、存储介质、海量数据、分布式成为技术领域最热的词。其中,data 采集是被提及最多的词汇。
Data采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。数据采集方法分为系统日志采集方法、网络数据采集方法和其他数据采集方法三种。随着Web2.0的发展,整个Web系统涵盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将系统地描述网络数据和网络爬虫。
什么是网络数据
网络数据是指非传统数据源,例如通过搜索引擎爬取获得的不同形式的数据。 Web 数据也可以是从数据聚合器或搜索引擎 网站 购买的数据,以改进有针对性的营销。这种类型的数据可以是结构化的,也可以是非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
互联网构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据较早被忽略,但竞争加剧和对更多数据的需求需要使用尽可能多的数据源。
网络数据有什么用?
互联网拥有数十亿页的数据。网络数据作为潜在的数据来源,对行业战略业务发展具有巨大潜力。
以下例子说明网络数据在不同行业的使用价值:
此外,在“How Web Scraping is Transforming the World with its Applications”文章中,详细列出了网络数据在制造、金融研究、风险管理等领域的使用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API方式,一种是网络爬取方式。 API也叫应用程序接口,是网站的管理员为了方便用户而编写的程序接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关demo可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方法——网络爬虫。
使用爬虫技术采集网络数据
网络爬虫是指按照一定的规则自动抓取万维网上信息的程序或脚本。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,可以自动关联附件和文本。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。大数据时代,网络爬虫是获取互联网数据的更有利工具采集。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有他们可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有网络数据采集、处理和存储三大功能,如图:
网络爬虫 采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。爬虫从网页中提取并保存需要提取的资源。同时,它提取网站中存在的其他网站链接并发送它们。请求,接收网站响应并再次解析页面,然后从页面中提取所需的资源……等等,搜索引擎上的相关数据可以通过网络爬虫完全爬出来。
数据处理
数据处理是分析和处理数据(包括数值和非数值)的技术过程。网络爬虫抓取的初始数据需要“清洗”。在数据处理环节,对各种原创数据进行分析、整理、计算、编辑等的处理和处理,从大量的、杂乱的、难以理解的数据中提取并推导出有价值、有意义的数据。
数据中心
所谓数据中心,也就是数据存储,是指在获取到需要的数据并分解成有用的组件后,通过可扩展的方式将所有提取和解析出来的数据存储在一个数据库或集群中。然后创建一个函数,让用户可以找到相关数据集或及时提取。
网络爬虫工作流程
如下图所示,一个网络爬虫的基本工作流程如下。首先选择种子网址的一部分。
总结
当前,网络大数据规模和复杂度的快速增长,对现有IT架构的处理和计算能力提出了挑战。根据IDC发布的研究报告,预计到2020年,网络大数据总量将达到35ZB,网络大数据将成为行业数字化、信息化的重要推动者。返回搜狐查看更多

