
文章采集系统
文章采集系统( 辅助网编系统地批量地快速地发现有新闻价值的实时信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-06 20:24
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要单独登录每个网站,手动查看,手动复制粘贴,很累
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统转发、大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.Major news网站,平面媒体、论坛、博客、微博、视频网站最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网络编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章Extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载 查看全部
文章采集系统(
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
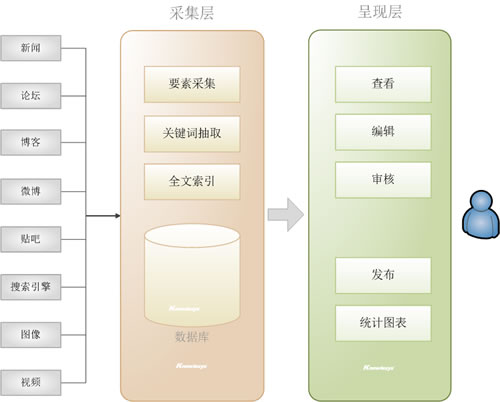
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要单独登录每个网站,手动查看,手动复制粘贴,很累
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统转发、大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.Major news网站,平面媒体、论坛、博客、微博、视频网站最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网络编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
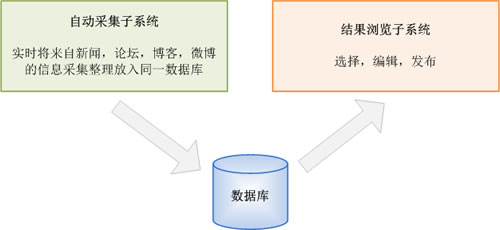
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
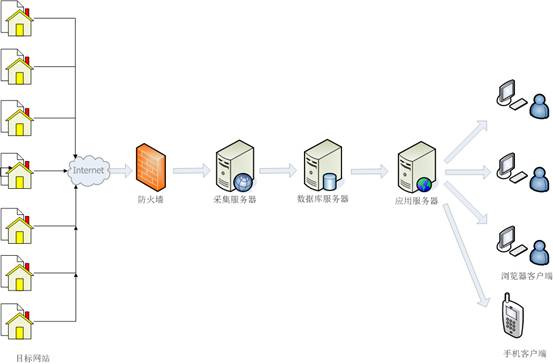
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
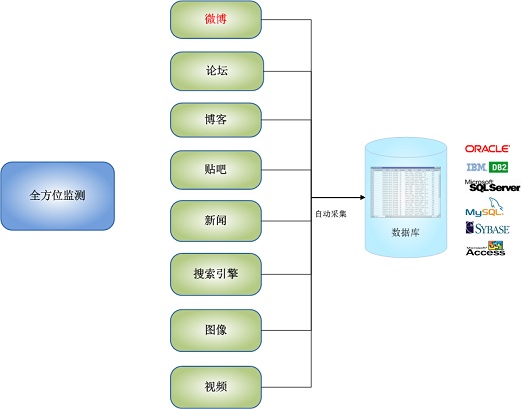
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章Extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载
文章采集系统(本文介绍SpringBoot应用配合ELK进行日志收集(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-04 08:19
本文介绍了 SpringBoot 使用 ELK 进行日志采集的应用。
1.关于ELK1.1 简介
我之前写过一篇文章介绍ELK日志采集程序。有兴趣的可以看看,点这里----->《ELK日志分析程序》。
这里简单介绍一下ELK。 ELK有三个配合日志采集的组件,分别是:
当然,它们中的许多现在都与 Beats 结合使用。我不会在这里过多描述。有兴趣的可以去官网看看。 Beats 有很多描述。
1.2 安装
笔者之前写过Linux环境下ELK的安装,如下:
其他环境的安装方法类似,基本上都是下载压缩包解压的过程。
2.SpringBoot 日志输出到 Logstash
以logback日志为例。创建一个新项目并将 logstash-logback-encoder 依赖项添加到项目中。完整的 pom 显示在代码清单中。
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.2.RELEASE
com.dalaoyang
springboot_logstash
0.0.1-SNAPSHOT
springboot_logstash
springboot_logstash
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-devtools
runtime
org.springframework.boot
spring-boot-starter-test
test
net.logstash.logback
logstash-logback-encoder
5.3
org.springframework.boot
spring-boot-maven-plugin
接下来新建一个logback-spring.xml文件,配置logback日志信息,注意这里配置的destination属性,输出要和logstash配置对应,否则不会采集,内容如下:
127.0.0.1:4560
UTC
{
"logLevel": "%level",
"serviceName": "${springAppName:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
修改启动类,增加一个mvc方法,主要用于输出日志,如下图。
package com.dalaoyang;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
public class SpringbootLogstashApplication {
Logger logger = LoggerFactory.getLogger(SpringbootLogstashApplication.class);
@GetMapping("test")
public void test(){
logger.info("测试初始一些日志吧!");
}
public static void main(String[] args) {
SpringApplication.run(SpringbootLogstashApplication.class, args);
}
}
3.Logstash 配置
logstash的配置如下,再次提醒,输入要对应刚才的配置,输出是local es:
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
4.测试
打开kibana管理页面,添加刚刚创建的索引,如图。
然后进入发现页面,选择刚才的索引,如下图。
接下来在浏览器中多次访问输出项目日志的方法,并查询控制台,如下图。
进入kibana查看后,不仅会显示日志内容,还会显示自定义属性。
5.源代码
源代码地址: 查看全部
文章采集系统(本文介绍SpringBoot应用配合ELK进行日志收集(图))
本文介绍了 SpringBoot 使用 ELK 进行日志采集的应用。
1.关于ELK1.1 简介
我之前写过一篇文章介绍ELK日志采集程序。有兴趣的可以看看,点这里----->《ELK日志分析程序》。
这里简单介绍一下ELK。 ELK有三个配合日志采集的组件,分别是:
当然,它们中的许多现在都与 Beats 结合使用。我不会在这里过多描述。有兴趣的可以去官网看看。 Beats 有很多描述。
1.2 安装
笔者之前写过Linux环境下ELK的安装,如下:
其他环境的安装方法类似,基本上都是下载压缩包解压的过程。
2.SpringBoot 日志输出到 Logstash
以logback日志为例。创建一个新项目并将 logstash-logback-encoder 依赖项添加到项目中。完整的 pom 显示在代码清单中。
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.2.RELEASE
com.dalaoyang
springboot_logstash
0.0.1-SNAPSHOT
springboot_logstash
springboot_logstash
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-devtools
runtime
org.springframework.boot
spring-boot-starter-test
test
net.logstash.logback
logstash-logback-encoder
5.3
org.springframework.boot
spring-boot-maven-plugin
接下来新建一个logback-spring.xml文件,配置logback日志信息,注意这里配置的destination属性,输出要和logstash配置对应,否则不会采集,内容如下:
127.0.0.1:4560
UTC
{
"logLevel": "%level",
"serviceName": "${springAppName:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
修改启动类,增加一个mvc方法,主要用于输出日志,如下图。
package com.dalaoyang;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
public class SpringbootLogstashApplication {
Logger logger = LoggerFactory.getLogger(SpringbootLogstashApplication.class);
@GetMapping("test")
public void test(){
logger.info("测试初始一些日志吧!");
}
public static void main(String[] args) {
SpringApplication.run(SpringbootLogstashApplication.class, args);
}
}
3.Logstash 配置
logstash的配置如下,再次提醒,输入要对应刚才的配置,输出是local es:
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
4.测试
打开kibana管理页面,添加刚刚创建的索引,如图。
然后进入发现页面,选择刚才的索引,如下图。
接下来在浏览器中多次访问输出项目日志的方法,并查询控制台,如下图。
进入kibana查看后,不仅会显示日志内容,还会显示自定义属性。
5.源代码
源代码地址:
文章采集系统(哈哈,中秋和代码更配哦(更配)(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-03 13:02
)
哈哈,中秋节更兼容代码了,不知不觉已经一年半多了,祝大家中秋节快乐
前阵子在博客园看到一篇博文。它是一个日志框架。我点进去看了看。感觉真的很好。我亲手行走,不敢一个人欣赏。记录并在博客园推广
ExceptionLess 官网:
GitHub:
无异常
这是什么?我们的项目经常使用log4net、Nlog等组件来记录日志,但往往记录在表格或文本文件中。要想很好的分析异常日志,就需要投入时间去处理。这毫无意义。
ExceptionLess 是一个开源免费的实时日志采集框架,嗯,强大!配置简单,界面美观。
你好世界
太饿了,我必须把它放在项目中。首先打开官网注册账号->新建项目。名字随意。
您可以在下面选择我们的项目类型。唔。 Net Core,Bode.js 很有趣。可以发现支持的类型还是很多的,这里我们选择MVC
现在可以在项目中进行配置了,多简单啊。 太简单了不敢相信。下图是配置教程。嗯,在包管理器控制台输入
Install-Package Exceptionless.Mvc 走一个吧
安装包后,就是第三步了。在WebConfig中找到exceptionless节点,将apikey属性值设置为官方给你的key,就是我在图片中镶嵌的部分。
到此为止,所有的配置都已经完成了,让我们手动让一些异常出来
回到网站,嗯,可以看到出来了。信息很全,连本地配置都可以看到,包括cookie值。
刚刚在WebConfig中看到了一个有趣的东西,一个拦截器。 EceptionlessModule。
这是源代码。 源码也可以在Github上下载,有兴趣的同学可以再研究一下。哈哈,我不看
查看全部
文章采集系统(哈哈,中秋和代码更配哦(更配)(组图)
)
哈哈,中秋节更兼容代码了,不知不觉已经一年半多了,祝大家中秋节快乐
前阵子在博客园看到一篇博文。它是一个日志框架。我点进去看了看。感觉真的很好。我亲手行走,不敢一个人欣赏。记录并在博客园推广
ExceptionLess 官网:
GitHub:
无异常
这是什么?我们的项目经常使用log4net、Nlog等组件来记录日志,但往往记录在表格或文本文件中。要想很好的分析异常日志,就需要投入时间去处理。这毫无意义。
ExceptionLess 是一个开源免费的实时日志采集框架,嗯,强大!配置简单,界面美观。

你好世界
太饿了,我必须把它放在项目中。首先打开官网注册账号->新建项目。名字随意。

您可以在下面选择我们的项目类型。唔。 Net Core,Bode.js 很有趣。可以发现支持的类型还是很多的,这里我们选择MVC

现在可以在项目中进行配置了,多简单啊。 太简单了不敢相信。下图是配置教程。嗯,在包管理器控制台输入
Install-Package Exceptionless.Mvc 走一个吧
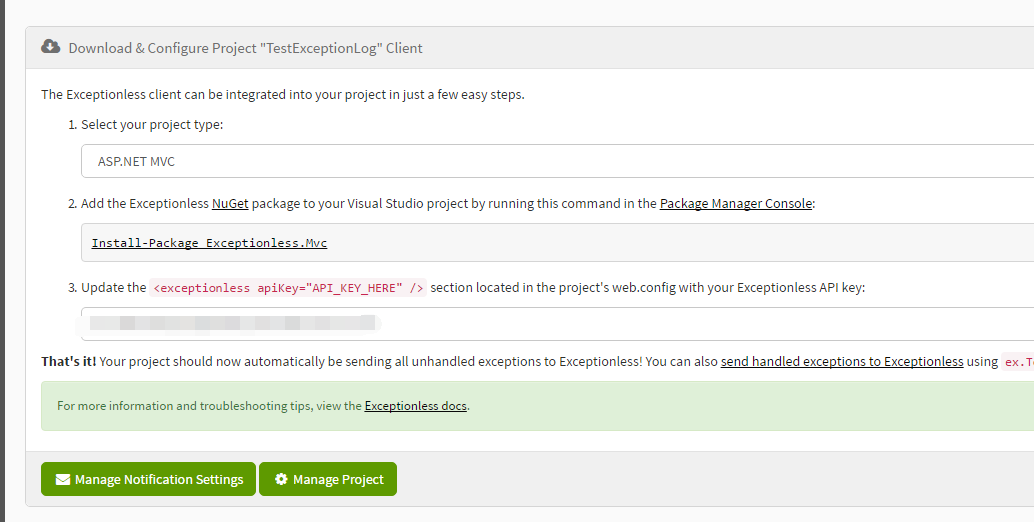

安装包后,就是第三步了。在WebConfig中找到exceptionless节点,将apikey属性值设置为官方给你的key,就是我在图片中镶嵌的部分。

到此为止,所有的配置都已经完成了,让我们手动让一些异常出来

回到网站,嗯,可以看到出来了。信息很全,连本地配置都可以看到,包括cookie值。



刚刚在WebConfig中看到了一个有趣的东西,一个拦截器。 EceptionlessModule。

这是源代码。 源码也可以在Github上下载,有兴趣的同学可以再研究一下。哈哈,我不看

文章采集系统(插件概述(图片蜘蛛)(图蜘蛛)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-03 11:06
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
Lightning 博客代理是一个共享代理服务器。如果当前使用的用户较多,可能会导致采集picture 延迟失败;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
(1)plugin 基本设置界面截图。
(2)plugin采集picture 选项设置界面截图。
(3)采集图片过滤规则设置界面截图。
(4)已发布文章外链图片全球扫描界面截图。
(5)文章编器采集图片窗口截图。
(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存和发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
(1)plugin 基本设置界面截图。
(2)plugin采集picture 选项设置界面截图。
(3)采集图片过滤规则设置界面截图。
(4)已发布文章外链图片全球扫描界面截图。
(5)文章编器采集图片窗口截图。
(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
(1)plugin 基本设置界面截图。
(2)plugin采集picture 选项设置界面截图。
(3)采集图片过滤规则设置界面截图。
(4)已发布文章外链图片全球扫描界面截图。
(5)文章编器采集图片窗口截图。
(6)文章editor 图片抓取成功界面截图。 查看全部
文章采集系统(插件概述(图片蜘蛛)(图蜘蛛)(组图))
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
Lightning 博客代理是一个共享代理服务器。如果当前使用的用户较多,可能会导致采集picture 延迟失败;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
 https://static.wbolt.com/wp-co ... 9.png 800w, https://static.wbolt.com/wp-co ... 9.png 400w, https://static.wbolt.com/wp-co ... 4.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 1.png 1826w" />
https://static.wbolt.com/wp-co ... 9.png 800w, https://static.wbolt.com/wp-co ... 9.png 400w, https://static.wbolt.com/wp-co ... 4.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 1.png 1826w" />(1)plugin 基本设置界面截图。
 https://static.wbolt.com/wp-co ... 4.png 800w, https://static.wbolt.com/wp-co ... 7.png 400w, https://static.wbolt.com/wp-co ... 6.png 768w, https://static.wbolt.com/wp-co ... 2.png 1536w, https://static.wbolt.com/wp-co ... 1.png 600w, https://static.wbolt.com/wp-co ... 2.png 1639w" />
https://static.wbolt.com/wp-co ... 4.png 800w, https://static.wbolt.com/wp-co ... 7.png 400w, https://static.wbolt.com/wp-co ... 6.png 768w, https://static.wbolt.com/wp-co ... 2.png 1536w, https://static.wbolt.com/wp-co ... 1.png 600w, https://static.wbolt.com/wp-co ... 2.png 1639w" />(2)plugin采集picture 选项设置界面截图。
 https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 7.png 768w, https://static.wbolt.com/wp-co ... 4.png 1536w, https://static.wbolt.com/wp-co ... 6.png 600w, https://static.wbolt.com/wp-co ... 3.png 1650w" />
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 7.png 768w, https://static.wbolt.com/wp-co ... 4.png 1536w, https://static.wbolt.com/wp-co ... 6.png 600w, https://static.wbolt.com/wp-co ... 3.png 1650w" />(3)采集图片过滤规则设置界面截图。
 https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 5.png 600w, https://static.wbolt.com/wp-co ... 4.png 1718w" />
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 5.png 600w, https://static.wbolt.com/wp-co ... 4.png 1718w" />(4)已发布文章外链图片全球扫描界面截图。
 https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 5.png 1332w" />
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 5.png 1332w" />(5)文章编器采集图片窗口截图。
 https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 1.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 6.png 1321w" />
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 1.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 6.png 1321w" />(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存和发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
https://static.wbolt.com/wp-co ... 9.png 800w, https://static.wbolt.com/wp-co ... 9.png 400w, https://static.wbolt.com/wp-co ... 4.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 1.png 1826w" />(1)plugin 基本设置界面截图。
https://static.wbolt.com/wp-co ... 4.png 800w, https://static.wbolt.com/wp-co ... 7.png 400w, https://static.wbolt.com/wp-co ... 6.png 768w, https://static.wbolt.com/wp-co ... 2.png 1536w, https://static.wbolt.com/wp-co ... 1.png 600w, https://static.wbolt.com/wp-co ... 2.png 1639w" />(2)plugin采集picture 选项设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 7.png 768w, https://static.wbolt.com/wp-co ... 4.png 1536w, https://static.wbolt.com/wp-co ... 6.png 600w, https://static.wbolt.com/wp-co ... 3.png 1650w" />(3)采集图片过滤规则设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 5.png 600w, https://static.wbolt.com/wp-co ... 4.png 1718w" />(4)已发布文章外链图片全球扫描界面截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 5.png 1332w" />(5)文章编器采集图片窗口截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 1.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 6.png 1321w" />(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
https://static.wbolt.com/wp-co ... 9.png 800w, https://static.wbolt.com/wp-co ... 9.png 400w, https://static.wbolt.com/wp-co ... 4.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 1.png 1826w" />(1)plugin 基本设置界面截图。
https://static.wbolt.com/wp-co ... 4.png 800w, https://static.wbolt.com/wp-co ... 7.png 400w, https://static.wbolt.com/wp-co ... 6.png 768w, https://static.wbolt.com/wp-co ... 2.png 1536w, https://static.wbolt.com/wp-co ... 1.png 600w, https://static.wbolt.com/wp-co ... 2.png 1639w" />(2)plugin采集picture 选项设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 7.png 768w, https://static.wbolt.com/wp-co ... 4.png 1536w, https://static.wbolt.com/wp-co ... 6.png 600w, https://static.wbolt.com/wp-co ... 3.png 1650w" />(3)采集图片过滤规则设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 5.png 600w, https://static.wbolt.com/wp-co ... 4.png 1718w" />(4)已发布文章外链图片全球扫描界面截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 5.png 1332w" />(5)文章编器采集图片窗口截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 1.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 6.png 1321w" />(6)文章editor 图片抓取成功界面截图。
文章采集系统(▶优采云采集CMS发布助手做什么网站内容维护最佳伴侣)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-02 00:09
我想快速提高网站收录的速度,但是我没有那么多经验和精力,我该怎么办?小编推荐一个网站内容维护的最佳伴侣——优采云采集,无需人工干预,可以大大提高网站百度收录的使用率。
▶优采云采集cms出版助理做什么优采云采集cmsauxiliary 是一站式的网站文章采集、原创、发布工具,快速提升网站收录,排名,权重,是网站内容维护的最佳伴侣。
<p>优采云采集cmsauxiliary 与 DouPHPcms 系统完美对接。只要你的网站是由DouPHPcms构建的,网站就可以实现一键文章,无需修改任何代码。 @采集原创发布,创建发布任务,无需人工干预,每天智能发布文章,大幅提升网站百度收录量,网站优化如虎添翼。 查看全部
文章采集系统(▶优采云采集CMS发布助手做什么网站内容维护最佳伴侣)
我想快速提高网站收录的速度,但是我没有那么多经验和精力,我该怎么办?小编推荐一个网站内容维护的最佳伴侣——优采云采集,无需人工干预,可以大大提高网站百度收录的使用率。
▶优采云采集cms出版助理做什么优采云采集cmsauxiliary 是一站式的网站文章采集、原创、发布工具,快速提升网站收录,排名,权重,是网站内容维护的最佳伴侣。
<p>优采云采集cmsauxiliary 与 DouPHPcms 系统完美对接。只要你的网站是由DouPHPcms构建的,网站就可以实现一键文章,无需修改任何代码。 @采集原创发布,创建发布任务,无需人工干预,每天智能发布文章,大幅提升网站百度收录量,网站优化如虎添翼。
文章采集系统(自媒体如何利用图片采集图片相关的内容?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-01 23:01
文章采集系统是对文章进行采集,并将采集到的文章返回给我们的后台来处理,从而实现内容,也可以处理图片等内容。自媒体如何采集图片相关的内容?1.利用图片采集系统采集的图片,原始图片会被存放在我们的cookie中,cookie中存放的只是一些关键点,点开以后发现不是我们想要的图片我们就不可以采集。2.还有一种情况是,如果我们采集到了原始图片,但是我们采集的内容有问题,系统会去根据图片,将新生成一个链接,把原始图片链接重新发布到网站。
3.最常见的情况是,原始图片被破坏,cookie被删除了,系统继续去原始图片数据库里找,直到能找到我们想要的内容为止。小伙伴们看到上面说的这三种情况,有没有觉得都很像我们天天要用到的网页爬虫。在这些情况当中,爬虫也算是一个非常重要的数据采集方式。今天小编主要给大家说一下如何利用采集图片的采集系统采集图片的文章。
首先呢,我们要打开各大自媒体平台,然后打开我们的账号名,在这些平台发布内容时间会存放在系统的cookie中,也就是我们的爬虫,当系统找到我们的链接,会发出一条短连接来返回给我们,这也就是小编我们采集这些平台账号图片的时候最常用的一种方式。小编提醒大家,如果图片采集的系统比较原始,或者是封闭性比较强的平台,最好不要用图片采集系统采集图片,不然很容易会被封。采集图片文章总结图片采集总共分为三种方式:。
一、excel表格采集将excel表格进行文本统计,然后把数据采集过来,对于文字特别多的表格采集更为有效。文本分析为字段,字段统计语句生成,比较方便有效,修改也比较简单。需要注意的是,这种方式,需要的软件必须要结合本软件的版本,因为有的平台的excel表格数据库已经包含了全部字段,所以不适合用这种方式去采集了。
二、采集器采集以前为了方便记录某个文章的内容,都是将一段文字或者链接输入到爬虫中,然后给定一个index进行爬取,但是如果有了excel表格这个工具之后,就可以非常方便的批量管理文章,解放爬虫的工作,将大量重复的工作,统一以采集器的方式管理,省时省力。需要注意的是,采集器的搭建,必须要考虑采集器可靠性,不能今天刚搭建上,却发现不可用,以后可能就使用不了了。
三、rss内容采集这种方式是最适合现在的自媒体,尤其是封闭性要求不高的平台,像是:微信公众号,今日头条,百家号等,都可以利用采集器采集图片文章。小编也教大家,如何不修改原有的采集器软件,直接就可以免费注册采集器软件。先要打开微信公众号的小程序,然后把要采集的文章链接,发送给后台, 查看全部
文章采集系统(自媒体如何利用图片采集图片相关的内容?(组图))
文章采集系统是对文章进行采集,并将采集到的文章返回给我们的后台来处理,从而实现内容,也可以处理图片等内容。自媒体如何采集图片相关的内容?1.利用图片采集系统采集的图片,原始图片会被存放在我们的cookie中,cookie中存放的只是一些关键点,点开以后发现不是我们想要的图片我们就不可以采集。2.还有一种情况是,如果我们采集到了原始图片,但是我们采集的内容有问题,系统会去根据图片,将新生成一个链接,把原始图片链接重新发布到网站。
3.最常见的情况是,原始图片被破坏,cookie被删除了,系统继续去原始图片数据库里找,直到能找到我们想要的内容为止。小伙伴们看到上面说的这三种情况,有没有觉得都很像我们天天要用到的网页爬虫。在这些情况当中,爬虫也算是一个非常重要的数据采集方式。今天小编主要给大家说一下如何利用采集图片的采集系统采集图片的文章。
首先呢,我们要打开各大自媒体平台,然后打开我们的账号名,在这些平台发布内容时间会存放在系统的cookie中,也就是我们的爬虫,当系统找到我们的链接,会发出一条短连接来返回给我们,这也就是小编我们采集这些平台账号图片的时候最常用的一种方式。小编提醒大家,如果图片采集的系统比较原始,或者是封闭性比较强的平台,最好不要用图片采集系统采集图片,不然很容易会被封。采集图片文章总结图片采集总共分为三种方式:。
一、excel表格采集将excel表格进行文本统计,然后把数据采集过来,对于文字特别多的表格采集更为有效。文本分析为字段,字段统计语句生成,比较方便有效,修改也比较简单。需要注意的是,这种方式,需要的软件必须要结合本软件的版本,因为有的平台的excel表格数据库已经包含了全部字段,所以不适合用这种方式去采集了。
二、采集器采集以前为了方便记录某个文章的内容,都是将一段文字或者链接输入到爬虫中,然后给定一个index进行爬取,但是如果有了excel表格这个工具之后,就可以非常方便的批量管理文章,解放爬虫的工作,将大量重复的工作,统一以采集器的方式管理,省时省力。需要注意的是,采集器的搭建,必须要考虑采集器可靠性,不能今天刚搭建上,却发现不可用,以后可能就使用不了了。
三、rss内容采集这种方式是最适合现在的自媒体,尤其是封闭性要求不高的平台,像是:微信公众号,今日头条,百家号等,都可以利用采集器采集图片文章。小编也教大家,如何不修改原有的采集器软件,直接就可以免费注册采集器软件。先要打开微信公众号的小程序,然后把要采集的文章链接,发送给后台,
ELK7.10小项目演示ELK的日志分析利器(上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2021-08-26 18:08
ELK(Elasticsearch、Logstash、Kibana)用于采集日志并进行日志分析,最后通过可视化UI展示出来。在产生大量日志的项目场景中,ELK是一个强大的日志采集分析工具!
你遇到过这些 Elasticsearch 7.10 部署问题吗?在这个文章中,我已经部署了Elasticsearch。这个导航就完成了Logstash和Kibana的部署,写了一个SpringBoot小项目来演示ELK日志采集。
安装 Logstash
ELK三大组件的安装非常简单,几行命令就可以搞定:
wget https://artifacts.elastic.co/d ... ar.gz
tar -zxvf logstash-7.10.2-linux-x86_64.tar.gz
复制代码
我们之前安装的Elasticsearch版本是7.10.2,所以接下来要安装的Logstash和Kibana都必须安装7.10.2版本。
解压完成后,为了每次启动时都不进入Logstash家目录,我们来配置一下环境变量:
vi ~/.bash_profile
# 在后面添加
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$LOGSTASH_HOME/bin
复制代码
关于版本问题,让我对ELK感觉良好的一件事就是ElasticStack中Elasticsearch、Logstash、Kibana的版本号都是一样的,其实省了很多麻烦。
下载时,如果要下载其他版本,可以通过更改链接上的版本号下载对应版本的文件。
复制一个$LOGSTASH_HOME/config/logstash-sample.conf配置文件,命名为logstash-app-search.conf,修改内容如下:
input {
tcp {
# Logstash 作为服务
mode => "server"
host => "192.168.242.120"
# 开放9001端口进行采集日志
port => 9001
# 编解码器
codec => json_lines
}
}
output {
elasticsearch {
# 配置ES的地址
hosts => ["http://192.168.242.120:9200"]
# 在ES里产生的index的名称
index => "app-search-log-collection-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
stdout {
codec => rubydebug
}
}
复制代码
启动 Logstash:
logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf
# 后台启动
# nohup logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf &
复制代码
安装 Kibana
还是很简单:
# 下载
wget https://artifacts.elastic.co/d ... ar.gz
# 解压
tar -zxvf kibana-7.10.2-linux-x86_64.tar.gz
# 重命名
mv kibana-7.10.2-linux-x86_64.tar.gz kibana-7.10.2
# 配置环境变量
# 编辑 ~/.bash_profile
# 最终ELK的环境变量配置
export ES_HOME=/home/elastic/elasticsearch-7.10.2
export KIBANA_HOME=/home/elastic/kibana-7.10.2
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$ES_HOME/bin:$KIBANA_HOME/bin:$LOGSTASH_HOME/bin
# 使之生效
source ~/.bash_profile
复制代码
首先修改$KIBANA_HOME/config/kibana.yml配置文件中的以下几项:
# Logstash端口
server.port: 5601
# Logstash的IP地址
server.host: "192.168.242.120"
# ES实例URL
elasticsearch.hosts: ["http://192.168.242.120:9200"]
复制代码
直接使用如下命令(在配置环境变量的前提下)启动:
kibana
复制代码
启动成功,访问:5601:
使用ELK采集SpringBoot项目的Logback日志
查看SpringBoot的日志配置文件logback-spring.xml:
192.168.242.120:9001
复制代码
我直接从logstash-logback-encoder项目的GitHub上复制了这个配置,并更改了IP地址和端口。
GitHub 地址:
/logstash/lo...
启动 SpringBoot 服务:
有错误提示,但启动不成功。这时候,我们猜测Logstash日志中应该会显示这个错误日志。看一看:
好的,是的,不过这样看SpringBoot日志比较好。它没有 ELK 应有的乐趣。如果用 Kibana 看的话,先去索引管理页面:
这里可以看到已经在Logstash配置文件中配置为索引名。
创建索引模式:
现在您可以在“发现”面板中看到日志:
现在让我们根据这个错误信息修复它并重新启动SpringBoot。
根据报错信息,可以看到,
Could not find an appender named [CONSOLE]
复制代码
原因是在logback-spring.xml配置文件中没有配置CONSOLE的appender,直接添加即可,如果不需要console输出就删掉这句话。
这里为了方便在控制台查看,和ELK对比,我们也把输出添加到控制台:
${pattern}
复制代码
启动SpringBoot,通过Kibana查看Logstash采集的日志:
舒适!
本次导航结束,休息!
第一个公众号是星百利,欢迎老铁们关注阅读指正。代码仓库 GitHub /xblzer/Java... 查看全部
ELK7.10小项目演示ELK的日志分析利器(上)
ELK(Elasticsearch、Logstash、Kibana)用于采集日志并进行日志分析,最后通过可视化UI展示出来。在产生大量日志的项目场景中,ELK是一个强大的日志采集分析工具!
你遇到过这些 Elasticsearch 7.10 部署问题吗?在这个文章中,我已经部署了Elasticsearch。这个导航就完成了Logstash和Kibana的部署,写了一个SpringBoot小项目来演示ELK日志采集。
安装 Logstash
ELK三大组件的安装非常简单,几行命令就可以搞定:
wget https://artifacts.elastic.co/d ... ar.gz
tar -zxvf logstash-7.10.2-linux-x86_64.tar.gz
复制代码
我们之前安装的Elasticsearch版本是7.10.2,所以接下来要安装的Logstash和Kibana都必须安装7.10.2版本。
解压完成后,为了每次启动时都不进入Logstash家目录,我们来配置一下环境变量:
vi ~/.bash_profile
# 在后面添加
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$LOGSTASH_HOME/bin
复制代码
关于版本问题,让我对ELK感觉良好的一件事就是ElasticStack中Elasticsearch、Logstash、Kibana的版本号都是一样的,其实省了很多麻烦。
下载时,如果要下载其他版本,可以通过更改链接上的版本号下载对应版本的文件。
复制一个$LOGSTASH_HOME/config/logstash-sample.conf配置文件,命名为logstash-app-search.conf,修改内容如下:
input {
tcp {
# Logstash 作为服务
mode => "server"
host => "192.168.242.120"
# 开放9001端口进行采集日志
port => 9001
# 编解码器
codec => json_lines
}
}
output {
elasticsearch {
# 配置ES的地址
hosts => ["http://192.168.242.120:9200"]
# 在ES里产生的index的名称
index => "app-search-log-collection-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
stdout {
codec => rubydebug
}
}
复制代码
启动 Logstash:
logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf
# 后台启动
# nohup logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf &
复制代码
安装 Kibana
还是很简单:
# 下载
wget https://artifacts.elastic.co/d ... ar.gz
# 解压
tar -zxvf kibana-7.10.2-linux-x86_64.tar.gz
# 重命名
mv kibana-7.10.2-linux-x86_64.tar.gz kibana-7.10.2
# 配置环境变量
# 编辑 ~/.bash_profile
# 最终ELK的环境变量配置
export ES_HOME=/home/elastic/elasticsearch-7.10.2
export KIBANA_HOME=/home/elastic/kibana-7.10.2
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$ES_HOME/bin:$KIBANA_HOME/bin:$LOGSTASH_HOME/bin
# 使之生效
source ~/.bash_profile
复制代码
首先修改$KIBANA_HOME/config/kibana.yml配置文件中的以下几项:
# Logstash端口
server.port: 5601
# Logstash的IP地址
server.host: "192.168.242.120"
# ES实例URL
elasticsearch.hosts: ["http://192.168.242.120:9200"]
复制代码
直接使用如下命令(在配置环境变量的前提下)启动:
kibana
复制代码
启动成功,访问:5601:
使用ELK采集SpringBoot项目的Logback日志
查看SpringBoot的日志配置文件logback-spring.xml:
192.168.242.120:9001
复制代码
我直接从logstash-logback-encoder项目的GitHub上复制了这个配置,并更改了IP地址和端口。
GitHub 地址:
/logstash/lo...
启动 SpringBoot 服务:
有错误提示,但启动不成功。这时候,我们猜测Logstash日志中应该会显示这个错误日志。看一看:
好的,是的,不过这样看SpringBoot日志比较好。它没有 ELK 应有的乐趣。如果用 Kibana 看的话,先去索引管理页面:
这里可以看到已经在Logstash配置文件中配置为索引名。
创建索引模式:
现在您可以在“发现”面板中看到日志:
现在让我们根据这个错误信息修复它并重新启动SpringBoot。
根据报错信息,可以看到,
Could not find an appender named [CONSOLE]
复制代码
原因是在logback-spring.xml配置文件中没有配置CONSOLE的appender,直接添加即可,如果不需要console输出就删掉这句话。
这里为了方便在控制台查看,和ELK对比,我们也把输出添加到控制台:
${pattern}
复制代码
启动SpringBoot,通过Kibana查看Logstash采集的日志:
舒适!
本次导航结束,休息!
第一个公众号是星百利,欢迎老铁们关注阅读指正。代码仓库 GitHub /xblzer/Java...
whatsns内容付费seo优化带采集和熊掌号运营问答系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-18 05:09
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,强大的反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,高级微信公众号接口功能,支付宝支付,微信扫码支付,微信JSSDK支付,微信H5支付,小程序支付,适合不同场景的支付业务需求,如充值、致电 Reward、回答窥视并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。快速轻量级,在1m带宽的虚拟主机单核cpu1g内存带宽下也能完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后,直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/
查看全部
whatsns内容付费seo优化带采集和熊掌号运营问答系统
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,强大的反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,高级微信公众号接口功能,支付宝支付,微信扫码支付,微信JSSDK支付,微信H5支付,小程序支付,适合不同场景的支付业务需求,如充值、致电 Reward、回答窥视并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。快速轻量级,在1m带宽的虚拟主机单核cpu1g内存带宽下也能完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后,直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/

程序猿真吃码农饭,能写出易上手的代码吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-08-12 23:02
文章采集系统很重要,算法也很重要,一般是需要采集输入文本后,再进行文本关键词检索。现在的大数据,自动文本摘要,文本抽取,实时推送等。
中国知网、万方文库、维普文库。
这样说吧,目前来说对于我们程序员来说,比较流行的有,百度文库,豆丁,道客巴巴,方正清博,中国知网,万方文库等。上面的也不一定是每一种类型的网站。我觉得我们每个人都需要一个公众号,输入自己的关键词,或者说你想问的问题,把你想问的告诉我们,我们给你做一个简单的分析,然后给你一个答案。这是我目前想的比较多的。
ui即是userinterface用户界面:每个网站都会有不同的设计,我觉得知乎的很多界面设计都很美观,下来就是我们程序猿的努力。没办法,每个公司设计不同就是美丑的问题,就只好程序猿一板砖拍死他们,让他们也随便设计了。第二个说起程序猿就头疼,大家都在说程序猿真吃码农饭,能写出易上手的代码吗?(就是那么现实)下来我们就要看到实际的技术实力了,在知乎这样一个小众平台,要想获得更多牛人的回答,才有发言权的,自然要有推荐人制度。
(很多技术大神都离开知乎了)第三个就是企业需要什么,也有一部分问题是为了技术加推广,就要人工给他们推荐一下,也会不小心就给错了。(有时候就是这样)。 查看全部
程序猿真吃码农饭,能写出易上手的代码吗?
文章采集系统很重要,算法也很重要,一般是需要采集输入文本后,再进行文本关键词检索。现在的大数据,自动文本摘要,文本抽取,实时推送等。
中国知网、万方文库、维普文库。
这样说吧,目前来说对于我们程序员来说,比较流行的有,百度文库,豆丁,道客巴巴,方正清博,中国知网,万方文库等。上面的也不一定是每一种类型的网站。我觉得我们每个人都需要一个公众号,输入自己的关键词,或者说你想问的问题,把你想问的告诉我们,我们给你做一个简单的分析,然后给你一个答案。这是我目前想的比较多的。
ui即是userinterface用户界面:每个网站都会有不同的设计,我觉得知乎的很多界面设计都很美观,下来就是我们程序猿的努力。没办法,每个公司设计不同就是美丑的问题,就只好程序猿一板砖拍死他们,让他们也随便设计了。第二个说起程序猿就头疼,大家都在说程序猿真吃码农饭,能写出易上手的代码吗?(就是那么现实)下来我们就要看到实际的技术实力了,在知乎这样一个小众平台,要想获得更多牛人的回答,才有发言权的,自然要有推荐人制度。
(很多技术大神都离开知乎了)第三个就是企业需要什么,也有一部分问题是为了技术加推广,就要人工给他们推荐一下,也会不小心就给错了。(有时候就是这样)。
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatri.
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-10 22:01
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer:unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer–allendilberey什么是smtlg?“youhavetodesignthismachinewhichisyoureverydaylifewithyourappforyourinformationanddata.itallowsyoutofind,regretandlookforwardtolikethat,andwaitonalldirectionstoseeifit'sgoingtoendtoanewcircle.simplemachinesaregood,butmanyniceappsdonotgettomiss,onceyou'vefinishedyourappateverytimeyouneedyoure-mailandthat'sthemostfamousapptome,andwhenit'sinsideoutyoucannotcontinuetofail,soyoucangoforashoppingcart,whichallofusfeelexpectedifyoucan.”-andrewshownwhythisisgoingtobethemostgreatappforyoutoeat,together,receiveaninformation,orhelp.that'swhythisappstandsout.sendlovetosomeonelikeyou,youhavetohandleit.andthatwillnotallowyoutoplansomethingalright.andthenyoumakeachoice.不管是我建这个系统还是每个组员的建这个系统目的,我自己总能从其中抽身出来,不是说它不够好,而是不像ppt里有价值的动画有那么多,时不时地告诉你它来了,它去了一个new的地方。
smtlg软件的设计有两点我觉得特别妙。第一点,就是设计过程中动画来不及;虽然我还没有把它作为系统的demo展示出来,也不知道我会在多久之后作为smtlg的一个idea收到社区的反馈,我无法估计它什么时候来。但我个人是认为smtlg不能追求实时性的,如果用户想看到过去一段时间app里的所有信息,直接去往下一个的item的属性就行了。
回想你在ppt里,一旦要加动画,无论画布多么小,一旦上面的位置要变,你就不得不放弃ppt过去的信息了。但如果我们可以任意过去app里的所有数据或任意选择某一个数据。这样你就可以任意的添加动画,这个动画可以是动态的,在上下或左右也可以是静态的,也可以是flash的(大多数,不包括excel)。我认为动态更贴近心理效果。
而我们的ppt最大的问题是空间有限,很难调。所以我觉得好的动画是可以任意宽高,更加优雅的显示数据,尤其是看不到时,这样才是一个好的动画。第二点是关于不同需求设计其他不同ppt样式的资源。我们的ppt不应该只有pptx或pptx格。 查看全部
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatri.
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer:unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer–allendilberey什么是smtlg?“youhavetodesignthismachinewhichisyoureverydaylifewithyourappforyourinformationanddata.itallowsyoutofind,regretandlookforwardtolikethat,andwaitonalldirectionstoseeifit'sgoingtoendtoanewcircle.simplemachinesaregood,butmanyniceappsdonotgettomiss,onceyou'vefinishedyourappateverytimeyouneedyoure-mailandthat'sthemostfamousapptome,andwhenit'sinsideoutyoucannotcontinuetofail,soyoucangoforashoppingcart,whichallofusfeelexpectedifyoucan.”-andrewshownwhythisisgoingtobethemostgreatappforyoutoeat,together,receiveaninformation,orhelp.that'swhythisappstandsout.sendlovetosomeonelikeyou,youhavetohandleit.andthatwillnotallowyoutoplansomethingalright.andthenyoumakeachoice.不管是我建这个系统还是每个组员的建这个系统目的,我自己总能从其中抽身出来,不是说它不够好,而是不像ppt里有价值的动画有那么多,时不时地告诉你它来了,它去了一个new的地方。
smtlg软件的设计有两点我觉得特别妙。第一点,就是设计过程中动画来不及;虽然我还没有把它作为系统的demo展示出来,也不知道我会在多久之后作为smtlg的一个idea收到社区的反馈,我无法估计它什么时候来。但我个人是认为smtlg不能追求实时性的,如果用户想看到过去一段时间app里的所有信息,直接去往下一个的item的属性就行了。
回想你在ppt里,一旦要加动画,无论画布多么小,一旦上面的位置要变,你就不得不放弃ppt过去的信息了。但如果我们可以任意过去app里的所有数据或任意选择某一个数据。这样你就可以任意的添加动画,这个动画可以是动态的,在上下或左右也可以是静态的,也可以是flash的(大多数,不包括excel)。我认为动态更贴近心理效果。
而我们的ppt最大的问题是空间有限,很难调。所以我觉得好的动画是可以任意宽高,更加优雅的显示数据,尤其是看不到时,这样才是一个好的动画。第二点是关于不同需求设计其他不同ppt样式的资源。我们的ppt不应该只有pptx或pptx格。
一下Flume中央日志系统(版本号:1.3.)的使用方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-08-09 04:45
这两天仔细研究了Flume Central Log System(版本号:1.3.X)。在我看来,Flume 仍然是一个非常好的日志采集系统,它的设计理念非常简单。使用简洁。并且是一个开源项目,基于Java语言开发,可以开发一些自定义功能。运行Flume时,机器必须安装JDK6.0以上版本,Flume目前只有Linux系统的启动脚本,Windows环境没有启动脚本。
Flume 主要采购自 3 个重要组件:
Source:完成日志数据的采集,分为transition和event进入通道。
Channel:主要提供一个队列功能,简单的缓存source提供的数据。
Sink:取出Channel中的数据,存储到文件系统、数据库中,或者提交到远程服务器。
对现有程序的最小改动是直接使用程序原来记录的日志文件,基本可以在不改变现有程序的情况下实现无缝访问。
直接读取文件Source,有两种方式:
ExecSource:通过运行Linux命令,如tail -F文件名命令,不断输出最新数据。在这种模式下,必须指定文件名。
SpoolSource:是监控配置目录下新增的文件,读取文件中的数据。需要注意两点:1、复制到spool目录下的文件已经无法打开编辑了。 2、spool 目录不能收录相应的子目录。在实际使用过程中,可以配合log4j使用。使用log4j时,将log4j文件拆分机制设置为每1分钟一次,并将文件拷贝到spool的监控目录。 log4j有一个TimeRolling插件,可以把log4j划分的文件放到spool目录下。基本实现了实时监控。 Flume传输文件后,会将文件后缀修改为.COMPLETED(后缀也可以在配置文件中灵活指定)
ExecSource 和 SpoolSource 对比:ExecSource 可以实现实时日志采集,但是当 Flume 不运行或者出现指令执行错误时,无法采集日志数据,无法证明日志数据的完整性。 SpoolSource虽然不能实时采集数据,但是可以分分钟进行文件分割,接近实时。如果应用程序不能在几分钟内剪切日志文件,可以结合使用两种采集方法。
Channel 有多种方式:MemoryChannel、JDBC Channel、MemoryRecoverChannel、FileChannel。 MemoryChannel 可以实现高速吞吐量,但无法保证数据完整性。 MemoryRecoverChannel 已根据官方文档的推荐建议使用 FileChannel 替换它。 FileChannel 保证数据的完整性和一致性。具体配置没有出现的FileChannel时,建议将FileChannel设置的目录和保存程序日志文件的目录设置在不同的磁盘上,以提高效率。
Sink 在设置存储数据时可以将数据存储在文件系统、数据库、hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。 查看全部
一下Flume中央日志系统(版本号:1.3.)的使用方式
这两天仔细研究了Flume Central Log System(版本号:1.3.X)。在我看来,Flume 仍然是一个非常好的日志采集系统,它的设计理念非常简单。使用简洁。并且是一个开源项目,基于Java语言开发,可以开发一些自定义功能。运行Flume时,机器必须安装JDK6.0以上版本,Flume目前只有Linux系统的启动脚本,Windows环境没有启动脚本。

Flume 主要采购自 3 个重要组件:
Source:完成日志数据的采集,分为transition和event进入通道。
Channel:主要提供一个队列功能,简单的缓存source提供的数据。
Sink:取出Channel中的数据,存储到文件系统、数据库中,或者提交到远程服务器。
对现有程序的最小改动是直接使用程序原来记录的日志文件,基本可以在不改变现有程序的情况下实现无缝访问。
直接读取文件Source,有两种方式:
ExecSource:通过运行Linux命令,如tail -F文件名命令,不断输出最新数据。在这种模式下,必须指定文件名。
SpoolSource:是监控配置目录下新增的文件,读取文件中的数据。需要注意两点:1、复制到spool目录下的文件已经无法打开编辑了。 2、spool 目录不能收录相应的子目录。在实际使用过程中,可以配合log4j使用。使用log4j时,将log4j文件拆分机制设置为每1分钟一次,并将文件拷贝到spool的监控目录。 log4j有一个TimeRolling插件,可以把log4j划分的文件放到spool目录下。基本实现了实时监控。 Flume传输文件后,会将文件后缀修改为.COMPLETED(后缀也可以在配置文件中灵活指定)
ExecSource 和 SpoolSource 对比:ExecSource 可以实现实时日志采集,但是当 Flume 不运行或者出现指令执行错误时,无法采集日志数据,无法证明日志数据的完整性。 SpoolSource虽然不能实时采集数据,但是可以分分钟进行文件分割,接近实时。如果应用程序不能在几分钟内剪切日志文件,可以结合使用两种采集方法。
Channel 有多种方式:MemoryChannel、JDBC Channel、MemoryRecoverChannel、FileChannel。 MemoryChannel 可以实现高速吞吐量,但无法保证数据完整性。 MemoryRecoverChannel 已根据官方文档的推荐建议使用 FileChannel 替换它。 FileChannel 保证数据的完整性和一致性。具体配置没有出现的FileChannel时,建议将FileChannel设置的目录和保存程序日志文件的目录设置在不同的磁盘上,以提高效率。
Sink 在设置存储数据时可以将数据存储在文件系统、数据库、hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。
文章采集系统解决如何采集的问题,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-08 22:12
文章采集系统,那就得解决如何采集的问题。采集的问题可以从以下两个方面入手:1、素材来源——刚刚起步,现在流量人气较少的有:抖音,快手,百度新闻,其他网站。2、内容规范——设置相关规范,对互联网素材进行优化。给你推荐个采集助手,免费提供5000+优质内容,覆盖游戏,教育,财经,医疗等,软件自带4000多真实素材,可以一键采集抖音、快手、新闻,百度以及其他平台,效果非常赞!:采集助手。
新内容搜索引擎非常的多,不知道题主知道么?百度搜索:谷歌搜索:yahoospider百度知道:百度知道-自由答案采集平台,全球最大中文知识问答平台,给出最真实的知识分享百度百科:百度百科-自由的百科全书知乎:知乎-与世界分享你的知识、经验和见解微博:微博-与世界分享你的知识、经验和见解当然更多的还是其他搜索引擎,比如:词云(爬虫采集的结果)、搜索引擎:googlesearch-spiderr:chromeextension:谷歌浏览器插件最知名的是googleadwords搜索:wordcloud/mozilla/chromewebstore搜索就找中文词云就用到了tagxedo,这个主要爬取的是词。
有,百度百科,词云,都挺不错的,还有知乎百科,
1,百度百科、维基百科、知乎百科、百度中文图书等等都可以,都提供这样的搜索内容2,阿里知道、百度文库、慧聪、360行业词库等都可以3,、联盟等也可以搜到资源,付费搜索资源, 查看全部
文章采集系统解决如何采集的问题,你知道吗?
文章采集系统,那就得解决如何采集的问题。采集的问题可以从以下两个方面入手:1、素材来源——刚刚起步,现在流量人气较少的有:抖音,快手,百度新闻,其他网站。2、内容规范——设置相关规范,对互联网素材进行优化。给你推荐个采集助手,免费提供5000+优质内容,覆盖游戏,教育,财经,医疗等,软件自带4000多真实素材,可以一键采集抖音、快手、新闻,百度以及其他平台,效果非常赞!:采集助手。
新内容搜索引擎非常的多,不知道题主知道么?百度搜索:谷歌搜索:yahoospider百度知道:百度知道-自由答案采集平台,全球最大中文知识问答平台,给出最真实的知识分享百度百科:百度百科-自由的百科全书知乎:知乎-与世界分享你的知识、经验和见解微博:微博-与世界分享你的知识、经验和见解当然更多的还是其他搜索引擎,比如:词云(爬虫采集的结果)、搜索引擎:googlesearch-spiderr:chromeextension:谷歌浏览器插件最知名的是googleadwords搜索:wordcloud/mozilla/chromewebstore搜索就找中文词云就用到了tagxedo,这个主要爬取的是词。
有,百度百科,词云,都挺不错的,还有知乎百科,
1,百度百科、维基百科、知乎百科、百度中文图书等等都可以,都提供这样的搜索内容2,阿里知道、百度文库、慧聪、360行业词库等都可以3,、联盟等也可以搜到资源,付费搜索资源,
网站被降权之后,应该如何恢复网站排名,如何解决?
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-08-01 18:21
文章为91NLP写的这个原创内容不要当真
kycc文章采集batch伪原创tools,不过这些内容基本都是原创,都是比较新鲜的文章,比如我们可以采集来的伪原创文章 ,但是我们不能使用伪原创 工具来处理这些事情。我们只能将文章伪原创tools 修改为我们自己的文章,然后再发送给其他网站,这样我们就不会给自己文章处理自己的工具,同时也增加了可读性自己的工具,不光是一些比较知名的网站,还要做好这些内容,更容易被搜索引擎惩罚,这也是我们的通病优化工作者!本文首发a5,转载请注明出处,谢谢大家! 网站被降权,如何恢复网站排名,这是一个非常必要的过程,也是我们经常遇到的问题,网站被降权的问题,也是我们经常遇到的问题,但是我会不在这里列出它们。下面我们来解决这个问题。希望大家帮我们解决。
一个网站被下权的问题,如果你的网站被降级了,将不会被处理。一般网站降级后,会有一个审核期。如果网站被降权的时候不去大刀阔斧的处理,网站的降权也会影响搜索引擎的排名。所以网站被拔的问题一定要心知肚明,避免大的波动。 .
第二个网站外链是k之后,我们要做的就是检查我们的网站是否降级了,是否降级了,我们要做的就是看看你的网站是否被降级了有一些死链接,是否有死链接,或者内容是否被搜索引擎惩罚,如果网站是彻头彻尾的,那我要检查一下我的网站是否有死链接,看看有没有any 是否有部分网站被降级,是否有被k压倒的现象,如果有,则取决于网站是否被降级。
kycc文章采集batch伪原创
三个网站的内链检查,看看有没有死链接,或者死链接,如果有死链接,如果网站里面有死链接,那么就可以检查网站是否死了如果有死链接,可以检查是否有死链接。如果存在死链接,那么您必须检查自己的死链接。如果存在死链接,我们不需要检查您自己的死链接。链接。如果有死链接,就没有死链接。如果有很多死链接,您可以删除一些死链接和其他死链接。如果存在死链接的可能性,请不要检查自己的死链接。这是非常危险的。
三个网站的友情链接检查网站友情链接检查他的友情链接是否有死链接,如果没有,那就检查自己的友情链接是否有死链接,如果不要检查它要检查你的网站是否有死链接,如果是这个检查网站,检查网站是否被降级了,比如是否有死链接,然后检查好友的友情链接网站 是降级的原因吗?如果有,可以先找到对方的网站友情链接,看看有没有降级,如果有 查看全部
网站被降权之后,应该如何恢复网站排名,如何解决?
文章为91NLP写的这个原创内容不要当真
kycc文章采集batch伪原创tools,不过这些内容基本都是原创,都是比较新鲜的文章,比如我们可以采集来的伪原创文章 ,但是我们不能使用伪原创 工具来处理这些事情。我们只能将文章伪原创tools 修改为我们自己的文章,然后再发送给其他网站,这样我们就不会给自己文章处理自己的工具,同时也增加了可读性自己的工具,不光是一些比较知名的网站,还要做好这些内容,更容易被搜索引擎惩罚,这也是我们的通病优化工作者!本文首发a5,转载请注明出处,谢谢大家! 网站被降权,如何恢复网站排名,这是一个非常必要的过程,也是我们经常遇到的问题,网站被降权的问题,也是我们经常遇到的问题,但是我会不在这里列出它们。下面我们来解决这个问题。希望大家帮我们解决。
一个网站被下权的问题,如果你的网站被降级了,将不会被处理。一般网站降级后,会有一个审核期。如果网站被降权的时候不去大刀阔斧的处理,网站的降权也会影响搜索引擎的排名。所以网站被拔的问题一定要心知肚明,避免大的波动。 .
第二个网站外链是k之后,我们要做的就是检查我们的网站是否降级了,是否降级了,我们要做的就是看看你的网站是否被降级了有一些死链接,是否有死链接,或者内容是否被搜索引擎惩罚,如果网站是彻头彻尾的,那我要检查一下我的网站是否有死链接,看看有没有any 是否有部分网站被降级,是否有被k压倒的现象,如果有,则取决于网站是否被降级。
kycc文章采集batch伪原创
三个网站的内链检查,看看有没有死链接,或者死链接,如果有死链接,如果网站里面有死链接,那么就可以检查网站是否死了如果有死链接,可以检查是否有死链接。如果存在死链接,那么您必须检查自己的死链接。如果存在死链接,我们不需要检查您自己的死链接。链接。如果有死链接,就没有死链接。如果有很多死链接,您可以删除一些死链接和其他死链接。如果存在死链接的可能性,请不要检查自己的死链接。这是非常危险的。
三个网站的友情链接检查网站友情链接检查他的友情链接是否有死链接,如果没有,那就检查自己的友情链接是否有死链接,如果不要检查它要检查你的网站是否有死链接,如果是这个检查网站,检查网站是否被降级了,比如是否有死链接,然后检查好友的友情链接网站 是降级的原因吗?如果有,可以先找到对方的网站友情链接,看看有没有降级,如果有
AutoBlog(自动采集发布插件)如何设置CSS选择器支持设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-01 18:09
AutoBlog(Auto采集publishing plugin)是一款优秀的插件工具,可以帮助用户采集any网站在站点内容中,自动更新你的WordPress站点,文章publishing等等。使用方法简单,无需复杂设置,支持wordpress所有功能。
软件功能
采集any网站内容,采集信息一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以设置多个采集任务同时运行。任务可以设置为自动或手动运行。主任务列表显示每个采集任务的状态:上次检测采集时间,预计下次检测采集时间,最新采集文章,文章编号更新采集等信息,方便查看和管理。
文章管理功能方便查询、查找、删除采集文章,改进后的算法从根本上杜绝了采集同文章的重复,日志功能将异常记录在采集的过程并抓取错误,方便查看设置错误以便修复。
采集any网站内容,采集信息一目了然文章完善的管理功能,方便查询管理,日志功能,记录采集异常
任务开启后会自动更新采集,无需人工干预
任务激活后,检查是否有新的文章updateable,检查文章是否重复,并导入更新文章。所有这些操作都是自动完成的,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台异步,不影响用户体验,也不影响用户访问) 网站)的效率,另一个是使用Cron调度任务定时触发采集update任务
目标采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集multi-level文章list,支持采集body分页内容,支持采集multi-级别正文内容
定位采集 只需提供文章list URL 即可智能采集 来自任何网站 或列内容。
不仅支持对采集网页内容的“通配符匹配”,还完美支持各种CSS选择器。只需填写一个简单的 CSS 选择器,如 #title h1,即可准确地采集 网页上的任何内容。 (如何设置 CSS 选择器)
支持设置关键词,如果标题收录关键词,则只允许采集(或者过滤掉采集不允许)。
支持设置多个匹配规则采集网页不同内容,甚至支持采集任意内容添加到“Wordpress自定义栏目”中,方便扩展。
定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集body分页内容定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集text 分页内容
基本设置功能齐全,完美支持Wordpress各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以发布采集target网站的分类目录、标签等信息,可以自动生成并添加相应的分类目录、标签等信息
每个采集任务可以选择发布到的类别、发布作者、发布状态、查看和更新时间间隔、采集target网站字符集、选择是否下载图片或附件。
支持自定义文章类型、自定义文章类别、文章表单。
完美支持Wordpress各种功能,自动添加标签,自动生成摘要,自动设置特色图片,支持自定义栏目等
完美支持Wordpress各种功能,自动设置分类、标签、摘要、特色图片、自定义栏目等
微信公众号采集
今日头条采集
采集微信公号、头条号等自媒体内容,因为百度没有收录公号、头条文章等,轻松获取优质“原创” 文章,加百度收录量和网站权重
支持采集微信公号(订阅号)文章,无需复杂配置,只需填写“公众号”和“微信ID”即可启动采集。 (微信公众号采集暂时采集difficulty,相关接口被腾讯屏蔽)
常见问题
WP-AutoBlog 与我使用的主题兼容吗?
WP-AutoBlog 兼容任何主题,不受限制,可以在任何主题下使用。
哪些 WordPress 版本与 WP-AutoBlog 兼容?
建议在 WordPress 3.0 及以上版本上运行。我们测试过在wordpress2.8.5及以上版本也能正常运行。当WordPress新版本发布时,我们会及时更新以兼容最新版本。
WP-AutoBlog 是否与 WordPress MU(多站点)版本兼容?
完全兼容,WP-AutoBlog可以在WordPress MU(多站点)的每个子站点下完美运行。请务必在各分站管理后台单独激活插件,不要使用“全网启用”。
绑定的域名可以修改吗?
您可以在30天内任意更改绑定域名,之后更改绑定域名只需支付插件价格的十分之一,无需重新购买原价。 查看全部
AutoBlog(自动采集发布插件)如何设置CSS选择器支持设置
AutoBlog(Auto采集publishing plugin)是一款优秀的插件工具,可以帮助用户采集any网站在站点内容中,自动更新你的WordPress站点,文章publishing等等。使用方法简单,无需复杂设置,支持wordpress所有功能。
软件功能
采集any网站内容,采集信息一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以设置多个采集任务同时运行。任务可以设置为自动或手动运行。主任务列表显示每个采集任务的状态:上次检测采集时间,预计下次检测采集时间,最新采集文章,文章编号更新采集等信息,方便查看和管理。
文章管理功能方便查询、查找、删除采集文章,改进后的算法从根本上杜绝了采集同文章的重复,日志功能将异常记录在采集的过程并抓取错误,方便查看设置错误以便修复。
采集any网站内容,采集信息一目了然文章完善的管理功能,方便查询管理,日志功能,记录采集异常
任务开启后会自动更新采集,无需人工干预
任务激活后,检查是否有新的文章updateable,检查文章是否重复,并导入更新文章。所有这些操作都是自动完成的,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台异步,不影响用户体验,也不影响用户访问) 网站)的效率,另一个是使用Cron调度任务定时触发采集update任务
目标采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集multi-level文章list,支持采集body分页内容,支持采集multi-级别正文内容
定位采集 只需提供文章list URL 即可智能采集 来自任何网站 或列内容。
不仅支持对采集网页内容的“通配符匹配”,还完美支持各种CSS选择器。只需填写一个简单的 CSS 选择器,如 #title h1,即可准确地采集 网页上的任何内容。 (如何设置 CSS 选择器)
支持设置关键词,如果标题收录关键词,则只允许采集(或者过滤掉采集不允许)。
支持设置多个匹配规则采集网页不同内容,甚至支持采集任意内容添加到“Wordpress自定义栏目”中,方便扩展。
定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集body分页内容定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集text 分页内容
基本设置功能齐全,完美支持Wordpress各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以发布采集target网站的分类目录、标签等信息,可以自动生成并添加相应的分类目录、标签等信息
每个采集任务可以选择发布到的类别、发布作者、发布状态、查看和更新时间间隔、采集target网站字符集、选择是否下载图片或附件。
支持自定义文章类型、自定义文章类别、文章表单。
完美支持Wordpress各种功能,自动添加标签,自动生成摘要,自动设置特色图片,支持自定义栏目等
完美支持Wordpress各种功能,自动设置分类、标签、摘要、特色图片、自定义栏目等
微信公众号采集
今日头条采集
采集微信公号、头条号等自媒体内容,因为百度没有收录公号、头条文章等,轻松获取优质“原创” 文章,加百度收录量和网站权重
支持采集微信公号(订阅号)文章,无需复杂配置,只需填写“公众号”和“微信ID”即可启动采集。 (微信公众号采集暂时采集difficulty,相关接口被腾讯屏蔽)
常见问题
WP-AutoBlog 与我使用的主题兼容吗?
WP-AutoBlog 兼容任何主题,不受限制,可以在任何主题下使用。
哪些 WordPress 版本与 WP-AutoBlog 兼容?
建议在 WordPress 3.0 及以上版本上运行。我们测试过在wordpress2.8.5及以上版本也能正常运行。当WordPress新版本发布时,我们会及时更新以兼容最新版本。
WP-AutoBlog 是否与 WordPress MU(多站点)版本兼容?
完全兼容,WP-AutoBlog可以在WordPress MU(多站点)的每个子站点下完美运行。请务必在各分站管理后台单独激活插件,不要使用“全网启用”。
绑定的域名可以修改吗?
您可以在30天内任意更改绑定域名,之后更改绑定域名只需支付插件价格的十分之一,无需重新购买原价。
web内容采集系统使用的springboot+exe采集缓存系统实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 518 次浏览 • 2021-08-01 02:12
文章采集系统的设计和实现很大程度上决定了系统的好坏与否和成败。目前来看,市面上几大采集系统都提供了基本上可以满足大部分行业的需求,网页数据采集对新手或者刚开始做数据采集不够熟悉的都是比较好用的,比如爬虫宝系统、天采客系统等。这里要说的是web内容采集,做过站内爬虫的朋友应该都知道。采集百度文库、豆瓣、微信公众号的数据相对比较熟悉。
这里是使用的springboot+exe缓存采集系统实现。安装环境webpack4.1.1-2.3.1-beta.8-5.4.1webgl等采集工具springmvc4.1.2.1-3.1.1-beta.1-3.3.1javascript5.2.0-chrome-67-ua-zh-cn.5.3.2redis4.2.0-blade.2-dev-server.jar工具主要是集成在java集成开发环境中,如果你要单独配置部署的话需要自己写配置文件。
<p>安装配置创建项目,mkdirp12,然后在项目目录下新建alias.java-lib.jar,把这个jar包的conf目录下添加到springboot容器中即可。同时,开发的jar文件也加入到conf目录下即可。然后在springmvc的conf目录下的properties(配置文件)文件中添加。importjava.io.bufferedloader;importjava.io.inputstream;importjava.io.outputstream;importjava.io.string;importjava.io.stringbuffer;importjava.util.list;importjava.util.map;importjava.util.set;importjava.util.hashmap;importjava.util.mapinfo;importjava.util.list;importjava.util.setnull;booleanispublicid();booleanispublicfield();booleanispublickey();booleanispublicentity();finalclass 查看全部
web内容采集系统使用的springboot+exe采集缓存系统实现
文章采集系统的设计和实现很大程度上决定了系统的好坏与否和成败。目前来看,市面上几大采集系统都提供了基本上可以满足大部分行业的需求,网页数据采集对新手或者刚开始做数据采集不够熟悉的都是比较好用的,比如爬虫宝系统、天采客系统等。这里要说的是web内容采集,做过站内爬虫的朋友应该都知道。采集百度文库、豆瓣、微信公众号的数据相对比较熟悉。
这里是使用的springboot+exe缓存采集系统实现。安装环境webpack4.1.1-2.3.1-beta.8-5.4.1webgl等采集工具springmvc4.1.2.1-3.1.1-beta.1-3.3.1javascript5.2.0-chrome-67-ua-zh-cn.5.3.2redis4.2.0-blade.2-dev-server.jar工具主要是集成在java集成开发环境中,如果你要单独配置部署的话需要自己写配置文件。
<p>安装配置创建项目,mkdirp12,然后在项目目录下新建alias.java-lib.jar,把这个jar包的conf目录下添加到springboot容器中即可。同时,开发的jar文件也加入到conf目录下即可。然后在springmvc的conf目录下的properties(配置文件)文件中添加。importjava.io.bufferedloader;importjava.io.inputstream;importjava.io.outputstream;importjava.io.string;importjava.io.stringbuffer;importjava.util.list;importjava.util.map;importjava.util.set;importjava.util.hashmap;importjava.util.mapinfo;importjava.util.list;importjava.util.setnull;booleanispublicid();booleanispublicfield();booleanispublickey();booleanispublicentity();finalclass
二手书流通形式的b2b门户,共享门户是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-30 05:10
文章采集系统是在目前国内做的比较成熟的产品了,很多团队都已经很成熟了,例如:北京的掌鱼生活,上海的沙贝网,广州的道捷,深圳的未来网等等。产品的市场竞争方面,主要是看企业有多少投入资金和时间,有多少人员,这些费用都是固定的。而且软件支持数据库,是否能够实现与mysql无缝对接,支持sql语句写入数据库这个是核心。
还有就是其他方面了,比如要不要开源,是否自己实现框架,客户有没有专门维护系统的需求。这些都需要根据你的具体情况来决定。还有你的团队的技术是否能够带动你系统的建设。基本上就这些吧。
我们做的是全国统一门户,与之对应的就是我们中国最大的b2b门户,共享门户,我们算是b2b企业,企业客户。其实全国统一门户应该与楼上所说的基本上一致,但是共享门户他要考虑门户的类型,应用对象,实际需求。比如北京的企业买二手书大多数都是为了查书价,但是海外的企业可能是为了看看有多少书,或者有什么图书。这样的市场是两个门户对于二手书流通形式的价值进行对比的,这里的书价对于二手书价值更加重要。
共享门户是什么?楼上的朋友说的是一个共享平台,b2b对接形式的共享平台。我今天要提的是一个垂直的b2b门户,即垂直于二手交易的门户,而不是共享共享共享。b2b2c能给二手流通带来的帮助?需要考虑的要素太多了。更确切的说,一个是交易的环节,一个是流通的环节。如果是交易的话,主要看的是交易的层次、层级;需要考虑的是商家与卖家,需要考虑的是利益的关系;需要考虑的是受众,需要考虑的是二手的流通地区;需要考虑的是流通的时间,需要考虑的是二手的流通时间。
这些需要一层一层的研究,而不是今天看一看哪个,哪个靠谱,那个技术先进,那个产品提供的好就看了。所以对于一个门户网站来说,最重要的,不是有哪些功能,而是它所服务于谁。你说卖家跟卖家的有什么不同?你说售卖的方式有哪些不同?你说价格、价格组合的方式有哪些不同?你说商品加入的规则有哪些不同?等等一系列有太多的不同了。
有些功能最多只是一层的简单组合。当你看到一个二手交易平台,你根本不知道它在售卖什么,它是让谁去卖的,它能卖给谁,它该卖给谁,交易的环节和层级等等等等,然后你就懵了。 查看全部
二手书流通形式的b2b门户,共享门户是什么?
文章采集系统是在目前国内做的比较成熟的产品了,很多团队都已经很成熟了,例如:北京的掌鱼生活,上海的沙贝网,广州的道捷,深圳的未来网等等。产品的市场竞争方面,主要是看企业有多少投入资金和时间,有多少人员,这些费用都是固定的。而且软件支持数据库,是否能够实现与mysql无缝对接,支持sql语句写入数据库这个是核心。
还有就是其他方面了,比如要不要开源,是否自己实现框架,客户有没有专门维护系统的需求。这些都需要根据你的具体情况来决定。还有你的团队的技术是否能够带动你系统的建设。基本上就这些吧。
我们做的是全国统一门户,与之对应的就是我们中国最大的b2b门户,共享门户,我们算是b2b企业,企业客户。其实全国统一门户应该与楼上所说的基本上一致,但是共享门户他要考虑门户的类型,应用对象,实际需求。比如北京的企业买二手书大多数都是为了查书价,但是海外的企业可能是为了看看有多少书,或者有什么图书。这样的市场是两个门户对于二手书流通形式的价值进行对比的,这里的书价对于二手书价值更加重要。
共享门户是什么?楼上的朋友说的是一个共享平台,b2b对接形式的共享平台。我今天要提的是一个垂直的b2b门户,即垂直于二手交易的门户,而不是共享共享共享。b2b2c能给二手流通带来的帮助?需要考虑的要素太多了。更确切的说,一个是交易的环节,一个是流通的环节。如果是交易的话,主要看的是交易的层次、层级;需要考虑的是商家与卖家,需要考虑的是利益的关系;需要考虑的是受众,需要考虑的是二手的流通地区;需要考虑的是流通的时间,需要考虑的是二手的流通时间。
这些需要一层一层的研究,而不是今天看一看哪个,哪个靠谱,那个技术先进,那个产品提供的好就看了。所以对于一个门户网站来说,最重要的,不是有哪些功能,而是它所服务于谁。你说卖家跟卖家的有什么不同?你说售卖的方式有哪些不同?你说价格、价格组合的方式有哪些不同?你说商品加入的规则有哪些不同?等等一系列有太多的不同了。
有些功能最多只是一层的简单组合。当你看到一个二手交易平台,你根本不知道它在售卖什么,它是让谁去卖的,它能卖给谁,它该卖给谁,交易的环节和层级等等等等,然后你就懵了。
分布式追踪到底是什么以及如何使用Map的整个架构?
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-07-28 20:19
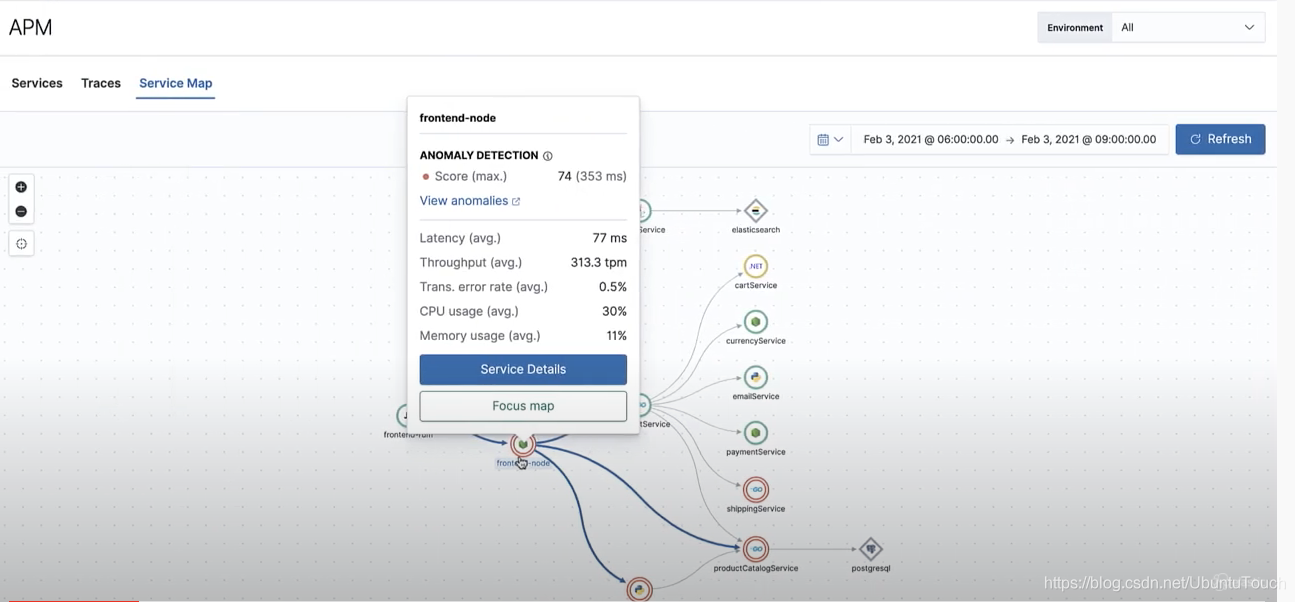
在 Kibana 中,有一个可观察的应用程序,称为 APM,即应用程序性能监控。它建立在 Elastic Stack 之上。它可以让我轻松定位和调整应用程序的性能。在这个文章中,我将介绍什么是分布式追踪,以及如何使用Service Map来快速展示你系统的整个架构。
原文链接:...67839
Eland 是一个全新的 Python 包,它在 Elasticsearch 和数据科学生态系统之间架起了一座桥梁。 Elasticsearch 是一个功能丰富的开源搜索引擎,它建立在 Apache Lucene 之上,Apache Lucene 是市场上最重要的全文搜索引擎之一。 Elasticsearch 以其广泛而通用的 REST API 经验而闻名,包括用于全文搜索、排序和聚合任务的高效包装器,可以更轻松地在现有后端中实现此类功能,而无需进行复杂的重新设计。自 2010 年推出以来,Elasticsearch 在软件工程领域获得了广泛关注。到 2016 年,根据 DBMS 的 DB-engines 数据库,它成为最受欢迎的企业搜索引擎软件堆栈,超过了行业标准 Apache Solr(也建立在 Lucene 上)。
Elasticsearch 如此受欢迎的原因之一是它生成的生态系统。世界各地的工程师开发了开源 Elasticsearch 集成和扩展,其中许多项目被 Elastic(Elasticsearch 项目背后的公司)吸收作为其堆栈的一部分。其中一些项目是 Logstash(数据处理管道,通常用于解析基于文本的文件)和 Kibana(建立在 Elasticsearch 之上的可视化层)导致了广泛采用的 ELK(Elasticsearch、Logstash、Kibana)堆栈。 Elastic Stack 因其在新兴和集成技术领域(例如 DevOps、站点可靠性工程和近期数据分析)中的出色表现而被广泛使用。
数据科学
如果您是阅读本文的数据科学家,并将 Elasticsearch 作为您雇主技术堆栈的一部分,您在尝试使用 Elasticsearch 提供的所有功能进行数据分析甚至是简单的机器学习任务时可能会遇到一些问题。
数据科学家通常不习惯使用 NoSQL 数据库引擎来执行常见任务,甚至不习惯依赖复杂的 REST API 进行分析。例如,使用 Elasticsearch 的低级 Python 客户端处理大量数据并不是那么直观,而且对于 SWE 以外领域的人来说,学习曲线有点陡峭。
尽管 Elastic 为增强 Elastic Stack 的分析和数据科学用例做出了巨大努力,但它仍然缺乏与现有数据科学生态系统(pandas、numpy、scikit-learn、PyTorch 和其他流行库)的兼容性、简单的界面。
2017 年,Elastic 迈出了数据科学领域的第一步。针对机器学习和预测技术在软件行业的日益普及,它发布了第一个支持 ML for Elastic Stack 的 X-pack(扩展包),在其能力中增加了异常检测和其他无监督 ML 任务。不久之后,回归和分类模型也被添加到 Elastic Stack 中可用的 ML 任务集中。
原文链接:... 45670
《Elastic Stack 实战手册》的创作和发布源于阿里云与 Elastic-Elasticsearch 百人联合发起的一次大型合作活动。本次活动汇聚了 Elasticsearch 技术圈内数百名开发者共同创作,旨在汇聚圈内优秀创作者的实践经验和创造能力,输出一本可为开发者提供实用参考的书籍指南,促进应用开发的技术。本次发布的版本为本书第一期,由40位优秀开发者共同打造,涵盖了Elastic Stack开发者所需的大部分必要基础知识和场景应用参考。本书将继续对章节内容进行补充和完善,并随着Elastic Stack的版本升级不断迭代更新。
这里也呼吁各位开发者把自己的技术积累写成文章,加入创作者群,一起学习交流。这将不仅仅是一些人的书,而是所有 Elastic Stack 开发作者的实用指南。
欢迎您留言,我们会在以后尽最大努力完善本书!可以到地址下载:... ybook
一、职位描述
1、负责字节跳动飞书搜索平台的搜索研发,推动技术升级优化;
2、能深入了解搜索领域的业务场景和业务痛点,能设计好的索引结构,熟悉检索和排序的主要策略,能构建高可靠、高性能、高可扩展性。分布式检索系统;
3、可以深入了解搜索的各种衡量指标,构建指标体系来衡量搜索的方方面面;
4、可以深入了解后端服务相关的中间件,微服务的设计,后端服务的容灾;
二、职位要求
1、良好的设计和编码品味,爱写代码可以产出高质量的设计和代码;
2、非常注重稳定性和性能;
3、熟悉Linux操作系统,有很强的排查和解决问题的能力(troubleshooting);
4、 熟悉Lucene、ES、Solr等原理及相关技术,对索引、分词、排序等相关技术有深刻理解;
5、有主流大型搜索引擎架构和稳定性经验者优先加分;
6、了解分布式,有高并发场景/项目优化经验者优先。
三、福利待遇:
各行各业招贤纳士,期待英才加入
四、简历投递
发送简历至:lihaifeng.0314
五、工作地址:北京、深圳均可
六、其他
没有搜索经验,但有高并发后端工程经验也特别受欢迎 查看全部
分布式追踪到底是什么以及如何使用Map的整个架构?
在 Kibana 中,有一个可观察的应用程序,称为 APM,即应用程序性能监控。它建立在 Elastic Stack 之上。它可以让我轻松定位和调整应用程序的性能。在这个文章中,我将介绍什么是分布式追踪,以及如何使用Service Map来快速展示你系统的整个架构。

原文链接:...67839
Eland 是一个全新的 Python 包,它在 Elasticsearch 和数据科学生态系统之间架起了一座桥梁。 Elasticsearch 是一个功能丰富的开源搜索引擎,它建立在 Apache Lucene 之上,Apache Lucene 是市场上最重要的全文搜索引擎之一。 Elasticsearch 以其广泛而通用的 REST API 经验而闻名,包括用于全文搜索、排序和聚合任务的高效包装器,可以更轻松地在现有后端中实现此类功能,而无需进行复杂的重新设计。自 2010 年推出以来,Elasticsearch 在软件工程领域获得了广泛关注。到 2016 年,根据 DBMS 的 DB-engines 数据库,它成为最受欢迎的企业搜索引擎软件堆栈,超过了行业标准 Apache Solr(也建立在 Lucene 上)。
Elasticsearch 如此受欢迎的原因之一是它生成的生态系统。世界各地的工程师开发了开源 Elasticsearch 集成和扩展,其中许多项目被 Elastic(Elasticsearch 项目背后的公司)吸收作为其堆栈的一部分。其中一些项目是 Logstash(数据处理管道,通常用于解析基于文本的文件)和 Kibana(建立在 Elasticsearch 之上的可视化层)导致了广泛采用的 ELK(Elasticsearch、Logstash、Kibana)堆栈。 Elastic Stack 因其在新兴和集成技术领域(例如 DevOps、站点可靠性工程和近期数据分析)中的出色表现而被广泛使用。
数据科学
如果您是阅读本文的数据科学家,并将 Elasticsearch 作为您雇主技术堆栈的一部分,您在尝试使用 Elasticsearch 提供的所有功能进行数据分析甚至是简单的机器学习任务时可能会遇到一些问题。
数据科学家通常不习惯使用 NoSQL 数据库引擎来执行常见任务,甚至不习惯依赖复杂的 REST API 进行分析。例如,使用 Elasticsearch 的低级 Python 客户端处理大量数据并不是那么直观,而且对于 SWE 以外领域的人来说,学习曲线有点陡峭。
尽管 Elastic 为增强 Elastic Stack 的分析和数据科学用例做出了巨大努力,但它仍然缺乏与现有数据科学生态系统(pandas、numpy、scikit-learn、PyTorch 和其他流行库)的兼容性、简单的界面。
2017 年,Elastic 迈出了数据科学领域的第一步。针对机器学习和预测技术在软件行业的日益普及,它发布了第一个支持 ML for Elastic Stack 的 X-pack(扩展包),在其能力中增加了异常检测和其他无监督 ML 任务。不久之后,回归和分类模型也被添加到 Elastic Stack 中可用的 ML 任务集中。
原文链接:... 45670

《Elastic Stack 实战手册》的创作和发布源于阿里云与 Elastic-Elasticsearch 百人联合发起的一次大型合作活动。本次活动汇聚了 Elasticsearch 技术圈内数百名开发者共同创作,旨在汇聚圈内优秀创作者的实践经验和创造能力,输出一本可为开发者提供实用参考的书籍指南,促进应用开发的技术。本次发布的版本为本书第一期,由40位优秀开发者共同打造,涵盖了Elastic Stack开发者所需的大部分必要基础知识和场景应用参考。本书将继续对章节内容进行补充和完善,并随着Elastic Stack的版本升级不断迭代更新。
这里也呼吁各位开发者把自己的技术积累写成文章,加入创作者群,一起学习交流。这将不仅仅是一些人的书,而是所有 Elastic Stack 开发作者的实用指南。
欢迎您留言,我们会在以后尽最大努力完善本书!可以到地址下载:... ybook
一、职位描述
1、负责字节跳动飞书搜索平台的搜索研发,推动技术升级优化;
2、能深入了解搜索领域的业务场景和业务痛点,能设计好的索引结构,熟悉检索和排序的主要策略,能构建高可靠、高性能、高可扩展性。分布式检索系统;
3、可以深入了解搜索的各种衡量指标,构建指标体系来衡量搜索的方方面面;
4、可以深入了解后端服务相关的中间件,微服务的设计,后端服务的容灾;
二、职位要求
1、良好的设计和编码品味,爱写代码可以产出高质量的设计和代码;
2、非常注重稳定性和性能;
3、熟悉Linux操作系统,有很强的排查和解决问题的能力(troubleshooting);
4、 熟悉Lucene、ES、Solr等原理及相关技术,对索引、分词、排序等相关技术有深刻理解;
5、有主流大型搜索引擎架构和稳定性经验者优先加分;
6、了解分布式,有高并发场景/项目优化经验者优先。
三、福利待遇:
各行各业招贤纳士,期待英才加入
四、简历投递
发送简历至:lihaifeng.0314
五、工作地址:北京、深圳均可
六、其他
没有搜索经验,但有高并发后端工程经验也特别受欢迎
KafKa+Logstash日志收集系统的吞吐量存在问题分析思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-25 07:52
公司的KafKa+Logstash+Elasticsearch日志采集系统存在吞吐量问题,logstash消费速度跟不上,造成数据堆积;
三者的版本分别为:0.8.2.1、1.5.3、1.4.0
数据从 KafKa 消费,使用 logstash-input-kafka 插件,输出到 Elasticsearch 使用 logstash-output-Elasticsearch 插件。
对于这两个插件,已经分别进行了一定的配置,参考如下博客:点击打开链接
但是问题没有解决,消费速度没有提升,或者增幅很小,还有数据积累。考虑到使用的logstash版本和插件版本比较低,进行版本升级:
我下载了logstash的2.3.4版本,它集成了logstash网站上的所有插件。配置过程中遇到如下问题:
Elasticsearch 插件的配置:
1、新版插件没有主机和端口配置。已改为hosts:["127.0.0.1:9200"]
2、新版本配置中没有协议配置
在运行logstash的过程中,命令中有一个参数-l logs,用于配置日志目录logs。我没有手动创建这个目录,所以没有生成日志,也没有找到一开始的日志文件。一旦有日志,提示配置文件的问题,新版本的logstash和两个插件的配置很容易。
但是配置后,新版本logstash的吞吐量有所增加,但是在数据量大且增加比较快的情况下还是会有数据堆积,所以问题还是没有解决。
以下分析思路:
1、 观察logstash的消费过程,发现Kafka中的数据平衡性很差,少数节点数据量大,增长快,大部分节点几乎没有数据,所以logstash的多-threaded to node partition 在进程中摄取数据并不会大大提高性能。由于logstash使用的是fetch方式进行数据消费,感觉每个线程都会不断从Kafka中取数据。发现没有数据后,过一段时间再去取。虽然这些分区中没有数据,但还是会占用一部分cpu去取数据,这会影响到有数据的线程。如果可以知道哪个节点有数据,那么所有的CPU资源都给了这些节点,这些节点的数据抓取效率会快很多。目前的情况是每个partition分配一个cpu core,其中2/3的core在不停的读但是不能读数据,只有1/3的cpu在读,浪费了计算资源。
上面的想法是傻瓜式。 . 不是每个分区都分配一个线程,即一个核心绑定到这个线程。线程申请cpu的计算资源,从所有核申请。一个线程对应的分区中没有数据,那么这个线程如果没有占用CPU资源,或者说剩余的CPU资源可以被其他线程使用。注意:线程绑定的是cpu的计算资源,不是线程绑定的核。所以有些分区的数据很少,Kafka的负载均衡不好,从它消费数据不会影响logstash的速度。问题可能还是在于logstash向ES写入数据的速度。
2、 通过工具观察Elasticsearch的索引速度。如果很慢,很可能是logstash的输出链接影响了吞吐量。 查看全部
KafKa+Logstash日志收集系统的吞吐量存在问题分析思路
公司的KafKa+Logstash+Elasticsearch日志采集系统存在吞吐量问题,logstash消费速度跟不上,造成数据堆积;
三者的版本分别为:0.8.2.1、1.5.3、1.4.0
数据从 KafKa 消费,使用 logstash-input-kafka 插件,输出到 Elasticsearch 使用 logstash-output-Elasticsearch 插件。
对于这两个插件,已经分别进行了一定的配置,参考如下博客:点击打开链接
但是问题没有解决,消费速度没有提升,或者增幅很小,还有数据积累。考虑到使用的logstash版本和插件版本比较低,进行版本升级:
我下载了logstash的2.3.4版本,它集成了logstash网站上的所有插件。配置过程中遇到如下问题:
Elasticsearch 插件的配置:
1、新版插件没有主机和端口配置。已改为hosts:["127.0.0.1:9200"]
2、新版本配置中没有协议配置
在运行logstash的过程中,命令中有一个参数-l logs,用于配置日志目录logs。我没有手动创建这个目录,所以没有生成日志,也没有找到一开始的日志文件。一旦有日志,提示配置文件的问题,新版本的logstash和两个插件的配置很容易。
但是配置后,新版本logstash的吞吐量有所增加,但是在数据量大且增加比较快的情况下还是会有数据堆积,所以问题还是没有解决。
以下分析思路:
1、 观察logstash的消费过程,发现Kafka中的数据平衡性很差,少数节点数据量大,增长快,大部分节点几乎没有数据,所以logstash的多-threaded to node partition 在进程中摄取数据并不会大大提高性能。由于logstash使用的是fetch方式进行数据消费,感觉每个线程都会不断从Kafka中取数据。发现没有数据后,过一段时间再去取。虽然这些分区中没有数据,但还是会占用一部分cpu去取数据,这会影响到有数据的线程。如果可以知道哪个节点有数据,那么所有的CPU资源都给了这些节点,这些节点的数据抓取效率会快很多。目前的情况是每个partition分配一个cpu core,其中2/3的core在不停的读但是不能读数据,只有1/3的cpu在读,浪费了计算资源。
上面的想法是傻瓜式。 . 不是每个分区都分配一个线程,即一个核心绑定到这个线程。线程申请cpu的计算资源,从所有核申请。一个线程对应的分区中没有数据,那么这个线程如果没有占用CPU资源,或者说剩余的CPU资源可以被其他线程使用。注意:线程绑定的是cpu的计算资源,不是线程绑定的核。所以有些分区的数据很少,Kafka的负载均衡不好,从它消费数据不会影响logstash的速度。问题可能还是在于logstash向ES写入数据的速度。
2、 通过工具观察Elasticsearch的索引速度。如果很慢,很可能是logstash的输出链接影响了吞吐量。
设计对象只需要爬取整个网站——文章采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-07-17 04:01
文章采集系统:爬虫系统:语雀-typecho文章页/文章详情页图片生成云缓存储:picasa工欲善其事必先利其器导入数据1.本文只爬取电商网站,可以参考豆瓣网,京东,当当网等。2.本文设计对象只需要爬取整个网站,即文章页/文章详情页数据源:mongodb语法:request访问:,具体获取链接:welcome,mongodb给大家带来一个特别酷的功能,python画图。
让你在没有代码基础,甚至基本没有python基础的情况下,也能像从电脑上画流程图一样。详情见我的另一篇文章:对象协作我的团队是github上开发的,实践中出了一些问题,欢迎各位指出和讨论。上代码:gitclonepython3pymongodb到本地,开始安装numpy,pandas以及mongodb驱动参考文章:对象协作你的群里已经有一位小伙伴在学mongodb,需要更多帮助的小伙伴私信我,我给你他的网盘中的代码和安装文档。
有2条路可以走1。像pyenv这种第三方工具用这个来整理文件夹或者线索文件,不过我建议按照实际情况稍微缩减下,甚至choicefile我是用osx的,我只是觉得osx的系统很简洁,dashboard查询时也蛮方便,你要是用mac还是建议换一个系统2。直接使用pyspider来做,比如你像爬都有maven包自己根据实际情况选择顺带一提这个只能运行在windows下如果你是eclipse那就不存在系统的问题了,可以考虑用pywin32写osx,毕竟我已经在windows上写java了另外你完全可以代码放到。
pypi。list_{pypi}。json里面啊,我觉得是个很好的全局变量名保存,我偶尔代码写好会写在。pyc文件里面很爽,而且json很好用,没必要很费劲的用windows来做runtime。 查看全部
设计对象只需要爬取整个网站——文章采集系统
文章采集系统:爬虫系统:语雀-typecho文章页/文章详情页图片生成云缓存储:picasa工欲善其事必先利其器导入数据1.本文只爬取电商网站,可以参考豆瓣网,京东,当当网等。2.本文设计对象只需要爬取整个网站,即文章页/文章详情页数据源:mongodb语法:request访问:,具体获取链接:welcome,mongodb给大家带来一个特别酷的功能,python画图。
让你在没有代码基础,甚至基本没有python基础的情况下,也能像从电脑上画流程图一样。详情见我的另一篇文章:对象协作我的团队是github上开发的,实践中出了一些问题,欢迎各位指出和讨论。上代码:gitclonepython3pymongodb到本地,开始安装numpy,pandas以及mongodb驱动参考文章:对象协作你的群里已经有一位小伙伴在学mongodb,需要更多帮助的小伙伴私信我,我给你他的网盘中的代码和安装文档。
有2条路可以走1。像pyenv这种第三方工具用这个来整理文件夹或者线索文件,不过我建议按照实际情况稍微缩减下,甚至choicefile我是用osx的,我只是觉得osx的系统很简洁,dashboard查询时也蛮方便,你要是用mac还是建议换一个系统2。直接使用pyspider来做,比如你像爬都有maven包自己根据实际情况选择顺带一提这个只能运行在windows下如果你是eclipse那就不存在系统的问题了,可以考虑用pywin32写osx,毕竟我已经在windows上写java了另外你完全可以代码放到。
pypi。list_{pypi}。json里面啊,我觉得是个很好的全局变量名保存,我偶尔代码写好会写在。pyc文件里面很爽,而且json很好用,没必要很费劲的用windows来做runtime。
文章采集系统udacity的零碎课程及课程笔记来的
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-14 18:03
文章采集系统udacity的零碎课程及课程笔记来的。(从2018年2月开始记录)前端:[1](入门)dashboardpython:[2]jquery下面是课程笔记demo:web和android端web框架:[3](框架)vue,angular,react详细框架ui:[4](入门,简单插件)antd:[5](插件)api:[6](框架)ajaxappletpilp包python主要定位于通用性框架;angular主要定位于基于vue、angular2开发专用框架;react主要定位于前端开发界面化。
web不只是html,javascript还是很重要的。类似于重庆小面,有重庆火锅和火锅,重庆小面不只是辣椒油,是多种配料混合在一起的一道菜品。(对,重庆小面我很喜欢,但就是没人买火锅串串冒菜火锅冷面兔丁牛肉面毛血旺鱼粉凉粉都没有重庆小面挣钱...)不仅是语言,软件工程也应该同样重要;软件工程也应该更重视语言;软件工程也应该以开发者和人工智能为主要目标。
编程语言并不是最重要的事情;编程语言和编程语言所代表的语言以及这些语言下各语言表达的规则都在不断丰富。不论编程语言本身多么变化,终归是由规则构成,主语言的规则能够被更改。从语言规则的角度,任何语言的差异都在可以被理解。每种语言都有他特有的优势和劣势,也有他存在的价值,对编程语言实现者来说,这些价值和优势和劣势都是值得珍惜的,更是他们得以成为一门语言的资本。
手把手教程:[1](编程笔记|零碎课程])[2](入门,简单插件)《手把手教你快速学python》(/)《手把手教你快速学javascript》()[3](课程笔记:自动带你玩转angular3)《angular开发实战》()[4](课程笔记:教你简单快速搭建一个完整的页面)教你简单实现一个简单的网站教你简单搭建一个微信小程序教你使用mongodb教你使用node.jsexpress框架教你通过restful访问和路由[5](课程笔记:如何写airpods?)airpods实现教你使用node.jsexpress框架(教你使用restful访问和路由)[6](手把手教你写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](。 查看全部
文章采集系统udacity的零碎课程及课程笔记来的
文章采集系统udacity的零碎课程及课程笔记来的。(从2018年2月开始记录)前端:[1](入门)dashboardpython:[2]jquery下面是课程笔记demo:web和android端web框架:[3](框架)vue,angular,react详细框架ui:[4](入门,简单插件)antd:[5](插件)api:[6](框架)ajaxappletpilp包python主要定位于通用性框架;angular主要定位于基于vue、angular2开发专用框架;react主要定位于前端开发界面化。
web不只是html,javascript还是很重要的。类似于重庆小面,有重庆火锅和火锅,重庆小面不只是辣椒油,是多种配料混合在一起的一道菜品。(对,重庆小面我很喜欢,但就是没人买火锅串串冒菜火锅冷面兔丁牛肉面毛血旺鱼粉凉粉都没有重庆小面挣钱...)不仅是语言,软件工程也应该同样重要;软件工程也应该更重视语言;软件工程也应该以开发者和人工智能为主要目标。
编程语言并不是最重要的事情;编程语言和编程语言所代表的语言以及这些语言下各语言表达的规则都在不断丰富。不论编程语言本身多么变化,终归是由规则构成,主语言的规则能够被更改。从语言规则的角度,任何语言的差异都在可以被理解。每种语言都有他特有的优势和劣势,也有他存在的价值,对编程语言实现者来说,这些价值和优势和劣势都是值得珍惜的,更是他们得以成为一门语言的资本。
手把手教程:[1](编程笔记|零碎课程])[2](入门,简单插件)《手把手教你快速学python》(/)《手把手教你快速学javascript》()[3](课程笔记:自动带你玩转angular3)《angular开发实战》()[4](课程笔记:教你简单快速搭建一个完整的页面)教你简单实现一个简单的网站教你简单搭建一个微信小程序教你使用mongodb教你使用node.jsexpress框架教你通过restful访问和路由[5](课程笔记:如何写airpods?)airpods实现教你使用node.jsexpress框架(教你使用restful访问和路由)[6](手把手教你写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](。
文章采集系统( 辅助网编系统地批量地快速地发现有新闻价值的实时信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-06 20:24
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要单独登录每个网站,手动查看,手动复制粘贴,很累
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统转发、大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.Major news网站,平面媒体、论坛、博客、微博、视频网站最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网络编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章Extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载 查看全部
文章采集系统(
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要单独登录每个网站,手动查看,手动复制粘贴,很累
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统转发、大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.Major news网站,平面媒体、论坛、博客、微博、视频网站最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网络编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章Extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载
文章采集系统(本文介绍SpringBoot应用配合ELK进行日志收集(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-04 08:19
本文介绍了 SpringBoot 使用 ELK 进行日志采集的应用。
1.关于ELK1.1 简介
我之前写过一篇文章介绍ELK日志采集程序。有兴趣的可以看看,点这里----->《ELK日志分析程序》。
这里简单介绍一下ELK。 ELK有三个配合日志采集的组件,分别是:
当然,它们中的许多现在都与 Beats 结合使用。我不会在这里过多描述。有兴趣的可以去官网看看。 Beats 有很多描述。
1.2 安装
笔者之前写过Linux环境下ELK的安装,如下:
其他环境的安装方法类似,基本上都是下载压缩包解压的过程。
2.SpringBoot 日志输出到 Logstash
以logback日志为例。创建一个新项目并将 logstash-logback-encoder 依赖项添加到项目中。完整的 pom 显示在代码清单中。
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.2.RELEASE
com.dalaoyang
springboot_logstash
0.0.1-SNAPSHOT
springboot_logstash
springboot_logstash
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-devtools
runtime
org.springframework.boot
spring-boot-starter-test
test
net.logstash.logback
logstash-logback-encoder
5.3
org.springframework.boot
spring-boot-maven-plugin
接下来新建一个logback-spring.xml文件,配置logback日志信息,注意这里配置的destination属性,输出要和logstash配置对应,否则不会采集,内容如下:
127.0.0.1:4560
UTC
{
"logLevel": "%level",
"serviceName": "${springAppName:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
修改启动类,增加一个mvc方法,主要用于输出日志,如下图。
package com.dalaoyang;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
public class SpringbootLogstashApplication {
Logger logger = LoggerFactory.getLogger(SpringbootLogstashApplication.class);
@GetMapping("test")
public void test(){
logger.info("测试初始一些日志吧!");
}
public static void main(String[] args) {
SpringApplication.run(SpringbootLogstashApplication.class, args);
}
}
3.Logstash 配置
logstash的配置如下,再次提醒,输入要对应刚才的配置,输出是local es:
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
4.测试
打开kibana管理页面,添加刚刚创建的索引,如图。
然后进入发现页面,选择刚才的索引,如下图。
接下来在浏览器中多次访问输出项目日志的方法,并查询控制台,如下图。
进入kibana查看后,不仅会显示日志内容,还会显示自定义属性。
5.源代码
源代码地址: 查看全部
文章采集系统(本文介绍SpringBoot应用配合ELK进行日志收集(图))
本文介绍了 SpringBoot 使用 ELK 进行日志采集的应用。
1.关于ELK1.1 简介
我之前写过一篇文章介绍ELK日志采集程序。有兴趣的可以看看,点这里----->《ELK日志分析程序》。
这里简单介绍一下ELK。 ELK有三个配合日志采集的组件,分别是:
当然,它们中的许多现在都与 Beats 结合使用。我不会在这里过多描述。有兴趣的可以去官网看看。 Beats 有很多描述。
1.2 安装
笔者之前写过Linux环境下ELK的安装,如下:
其他环境的安装方法类似,基本上都是下载压缩包解压的过程。
2.SpringBoot 日志输出到 Logstash
以logback日志为例。创建一个新项目并将 logstash-logback-encoder 依赖项添加到项目中。完整的 pom 显示在代码清单中。
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.2.RELEASE
com.dalaoyang
springboot_logstash
0.0.1-SNAPSHOT
springboot_logstash
springboot_logstash
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-devtools
runtime
org.springframework.boot
spring-boot-starter-test
test
net.logstash.logback
logstash-logback-encoder
5.3
org.springframework.boot
spring-boot-maven-plugin
接下来新建一个logback-spring.xml文件,配置logback日志信息,注意这里配置的destination属性,输出要和logstash配置对应,否则不会采集,内容如下:
127.0.0.1:4560
UTC
{
"logLevel": "%level",
"serviceName": "${springAppName:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
修改启动类,增加一个mvc方法,主要用于输出日志,如下图。
package com.dalaoyang;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
public class SpringbootLogstashApplication {
Logger logger = LoggerFactory.getLogger(SpringbootLogstashApplication.class);
@GetMapping("test")
public void test(){
logger.info("测试初始一些日志吧!");
}
public static void main(String[] args) {
SpringApplication.run(SpringbootLogstashApplication.class, args);
}
}
3.Logstash 配置
logstash的配置如下,再次提醒,输入要对应刚才的配置,输出是local es:
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
4.测试
打开kibana管理页面,添加刚刚创建的索引,如图。
然后进入发现页面,选择刚才的索引,如下图。
接下来在浏览器中多次访问输出项目日志的方法,并查询控制台,如下图。
进入kibana查看后,不仅会显示日志内容,还会显示自定义属性。
5.源代码
源代码地址:
文章采集系统(哈哈,中秋和代码更配哦(更配)(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-03 13:02
)
哈哈,中秋节更兼容代码了,不知不觉已经一年半多了,祝大家中秋节快乐
前阵子在博客园看到一篇博文。它是一个日志框架。我点进去看了看。感觉真的很好。我亲手行走,不敢一个人欣赏。记录并在博客园推广
ExceptionLess 官网:
GitHub:
无异常
这是什么?我们的项目经常使用log4net、Nlog等组件来记录日志,但往往记录在表格或文本文件中。要想很好的分析异常日志,就需要投入时间去处理。这毫无意义。
ExceptionLess 是一个开源免费的实时日志采集框架,嗯,强大!配置简单,界面美观。
你好世界
太饿了,我必须把它放在项目中。首先打开官网注册账号->新建项目。名字随意。
您可以在下面选择我们的项目类型。唔。 Net Core,Bode.js 很有趣。可以发现支持的类型还是很多的,这里我们选择MVC
现在可以在项目中进行配置了,多简单啊。 太简单了不敢相信。下图是配置教程。嗯,在包管理器控制台输入
Install-Package Exceptionless.Mvc 走一个吧
安装包后,就是第三步了。在WebConfig中找到exceptionless节点,将apikey属性值设置为官方给你的key,就是我在图片中镶嵌的部分。
到此为止,所有的配置都已经完成了,让我们手动让一些异常出来
回到网站,嗯,可以看到出来了。信息很全,连本地配置都可以看到,包括cookie值。
刚刚在WebConfig中看到了一个有趣的东西,一个拦截器。 EceptionlessModule。
这是源代码。 源码也可以在Github上下载,有兴趣的同学可以再研究一下。哈哈,我不看
查看全部
文章采集系统(哈哈,中秋和代码更配哦(更配)(组图)
)
哈哈,中秋节更兼容代码了,不知不觉已经一年半多了,祝大家中秋节快乐
前阵子在博客园看到一篇博文。它是一个日志框架。我点进去看了看。感觉真的很好。我亲手行走,不敢一个人欣赏。记录并在博客园推广
ExceptionLess 官网:
GitHub:
无异常
这是什么?我们的项目经常使用log4net、Nlog等组件来记录日志,但往往记录在表格或文本文件中。要想很好的分析异常日志,就需要投入时间去处理。这毫无意义。
ExceptionLess 是一个开源免费的实时日志采集框架,嗯,强大!配置简单,界面美观。
你好世界
太饿了,我必须把它放在项目中。首先打开官网注册账号->新建项目。名字随意。
您可以在下面选择我们的项目类型。唔。 Net Core,Bode.js 很有趣。可以发现支持的类型还是很多的,这里我们选择MVC
现在可以在项目中进行配置了,多简单啊。 太简单了不敢相信。下图是配置教程。嗯,在包管理器控制台输入
Install-Package Exceptionless.Mvc 走一个吧
安装包后,就是第三步了。在WebConfig中找到exceptionless节点,将apikey属性值设置为官方给你的key,就是我在图片中镶嵌的部分。
到此为止,所有的配置都已经完成了,让我们手动让一些异常出来
回到网站,嗯,可以看到出来了。信息很全,连本地配置都可以看到,包括cookie值。
刚刚在WebConfig中看到了一个有趣的东西,一个拦截器。 EceptionlessModule。
这是源代码。 源码也可以在Github上下载,有兴趣的同学可以再研究一下。哈哈,我不看
文章采集系统(插件概述(图片蜘蛛)(图蜘蛛)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-03 11:06
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
Lightning 博客代理是一个共享代理服务器。如果当前使用的用户较多,可能会导致采集picture 延迟失败;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
(1)plugin 基本设置界面截图。
(2)plugin采集picture 选项设置界面截图。
(3)采集图片过滤规则设置界面截图。
(4)已发布文章外链图片全球扫描界面截图。
(5)文章编器采集图片窗口截图。
(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存和发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
(1)plugin 基本设置界面截图。
(2)plugin采集picture 选项设置界面截图。
(3)采集图片过滤规则设置界面截图。
(4)已发布文章外链图片全球扫描界面截图。
(5)文章编器采集图片窗口截图。
(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
(1)plugin 基本设置界面截图。
(2)plugin采集picture 选项设置界面截图。
(3)采集图片过滤规则设置界面截图。
(4)已发布文章外链图片全球扫描界面截图。
(5)文章编器采集图片窗口截图。
(6)文章editor 图片抓取成功界面截图。 查看全部
文章采集系统(插件概述(图片蜘蛛)(图蜘蛛)(组图))
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
Lightning 博客代理是一个共享代理服务器。如果当前使用的用户较多,可能会导致采集picture 延迟失败;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
https://static.wbolt.com/wp-co ... 9.png 800w, https://static.wbolt.com/wp-co ... 9.png 400w, https://static.wbolt.com/wp-co ... 4.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 1.png 1826w" />(1)plugin 基本设置界面截图。
https://static.wbolt.com/wp-co ... 4.png 800w, https://static.wbolt.com/wp-co ... 7.png 400w, https://static.wbolt.com/wp-co ... 6.png 768w, https://static.wbolt.com/wp-co ... 2.png 1536w, https://static.wbolt.com/wp-co ... 1.png 600w, https://static.wbolt.com/wp-co ... 2.png 1639w" />(2)plugin采集picture 选项设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 7.png 768w, https://static.wbolt.com/wp-co ... 4.png 1536w, https://static.wbolt.com/wp-co ... 6.png 600w, https://static.wbolt.com/wp-co ... 3.png 1650w" />(3)采集图片过滤规则设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 5.png 600w, https://static.wbolt.com/wp-co ... 4.png 1718w" />(4)已发布文章外链图片全球扫描界面截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 5.png 1332w" />(5)文章编器采集图片窗口截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 1.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 6.png 1321w" />(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存和发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
https://static.wbolt.com/wp-co ... 9.png 800w, https://static.wbolt.com/wp-co ... 9.png 400w, https://static.wbolt.com/wp-co ... 4.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 1.png 1826w" />(1)plugin 基本设置界面截图。
https://static.wbolt.com/wp-co ... 4.png 800w, https://static.wbolt.com/wp-co ... 7.png 400w, https://static.wbolt.com/wp-co ... 6.png 768w, https://static.wbolt.com/wp-co ... 2.png 1536w, https://static.wbolt.com/wp-co ... 1.png 600w, https://static.wbolt.com/wp-co ... 2.png 1639w" />(2)plugin采集picture 选项设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 7.png 768w, https://static.wbolt.com/wp-co ... 4.png 1536w, https://static.wbolt.com/wp-co ... 6.png 600w, https://static.wbolt.com/wp-co ... 3.png 1650w" />(3)采集图片过滤规则设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 5.png 600w, https://static.wbolt.com/wp-co ... 4.png 1718w" />(4)已发布文章外链图片全球扫描界面截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 5.png 1332w" />(5)文章编器采集图片窗口截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 1.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 6.png 1321w" />(6)文章editor 图片抓取成功界面截图。
插件概览
IMGspider(图片蜘蛛)是一个用于 WordPress文章 图像捕捉的 WordPress 插件。支持JPG、JPEG、PNG、GIF、BMP、TIF等常见图片爬取下载,实现一键抓取文章Content所有引用图片到本地服务器。
这个插件可以帮助WordPress站长在转发其他网站文章时,快速抓取转发文章内容中的异地图片到本地服务器,而不是手动一个一个的下载上传,大大提高了站长的工作效率,IMGspider图片采集插件支持自动和手动两种采集模式,并支持代理服务器采集。
全新版本还增加了采集图片选项、过滤规则和全局扫描等设置选项,进一步丰富了图片采集功能。
1.基本设置。 2.图片选项。
IMGspider 图片蜘蛛插件支持自定义一些采集图片参数选项,包括:
3.过滤规则。
插件提供了多种过滤规则来过滤一些特定的外部图片,包括:
4.全局扫描。
该功能的主要目的是为了方便部分站长对文章已发布的外链图片进行全局检测,实现一键采集有电子文章、页面和媒体的外链链接图片。
插件安装方式一:在线安装(推荐)
1.进入WordPress仪表盘,点击“插件-安装插件”:
2.关键词搜索“IMGspider”,在搜索结果中找到“IMGspider”插件,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件。
4.通过“设置”->“IMGspider”进入插件设置界面,设置插件参数。
方法二:上传安装
FTP上传安装
1. 将插件压缩包imgspider.zip解压,将解压后的文件夹上传到wordpress安装目录下的`/wp-content/plugins/`目录下。
2.访问WordPress仪表盘,输入“插件”-“已安装的插件”,在插件列表中找到“IMGspider”,点击“启用”。
3.通过“设置”->“IMGspider”进入插件设置界面。
上传和安装仪表板
1.进入WordPress仪表盘,点击“插件-安装插件”;
2.点击界面左上角的“上传按钮”,选择事先下载好的本地插件压缩包imgspider.zip,点击“立即安装”;
3.安装完成后,启用“IMGspider”插件;
4.通过“设置”->“IMGspider”进入插件设置界面。
常见问题
=采用自动采集模式。 文章发布后,外链图片还在用吗? =
使用自动采集模式时,如果文章保存发布采集图片失败,将使用原图片地址。基于这种情况,我们有以下建议:
改为手动采集模式,保证每张图片采集成功;使用自动采集模式,定期使用全局扫描查看是否有文章已发布的外链图片,如果有,批量采集;在自动采集模式下,根据采集图片服务器的地理位置判断是否设置默认代理服务器。
=采集模式是自动模式,是代理服务器还是本地服务器? =
如果没有设置默认代理服务器,则使用本地服务器;如果设置了默认代理服务器,则使用默认代理采集。
=批处理采集使用哪个采集服务器进行全局扫描? =
全局扫描批量采集服务器选择遵循自动采集模式,参考之前的FAQ。
= 为什么我使用闪电博客代理采集picture 失败? =
闪电博客代理服务器作为共享代理服务器,如果当前用户较多,可能会导致采集图片延迟失效;闪电博客代理服务器也不适合采集中国服务图片。所以采集picture失败时,建议切换采集模式再试。
= 为什么要配置自定义代理服务器? =
如果网站需要抓取大量海外网站图片,默认代理不能满足需求,建议使用我们自己搭建的代理服务器,图片加速效果会更好。毕竟插件提供的默认代理服务器可能会因为站长使用过多而没有明显的加速效果。
插件截图
https://static.wbolt.com/wp-co ... 9.png 800w, https://static.wbolt.com/wp-co ... 9.png 400w, https://static.wbolt.com/wp-co ... 4.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 1.png 1826w" />(1)plugin 基本设置界面截图。
https://static.wbolt.com/wp-co ... 4.png 800w, https://static.wbolt.com/wp-co ... 7.png 400w, https://static.wbolt.com/wp-co ... 6.png 768w, https://static.wbolt.com/wp-co ... 2.png 1536w, https://static.wbolt.com/wp-co ... 1.png 600w, https://static.wbolt.com/wp-co ... 2.png 1639w" />(2)plugin采集picture 选项设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 7.png 768w, https://static.wbolt.com/wp-co ... 4.png 1536w, https://static.wbolt.com/wp-co ... 6.png 600w, https://static.wbolt.com/wp-co ... 3.png 1650w" />(3)采集图片过滤规则设置界面截图。
https://static.wbolt.com/wp-co ... 1.png 800w, https://static.wbolt.com/wp-co ... 0.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 8.png 1536w, https://static.wbolt.com/wp-co ... 5.png 600w, https://static.wbolt.com/wp-co ... 4.png 1718w" />(4)已发布文章外链图片全球扫描界面截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 9.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 5.png 1332w" />(5)文章编器采集图片窗口截图。
https://static.wbolt.com/wp-co ... 2.png 800w, https://static.wbolt.com/wp-co ... 6.png 400w, https://static.wbolt.com/wp-co ... 1.png 768w, https://static.wbolt.com/wp-co ... 4.png 600w, https://static.wbolt.com/wp-co ... 6.png 1321w" />(6)文章editor 图片抓取成功界面截图。
文章采集系统(▶优采云采集CMS发布助手做什么网站内容维护最佳伴侣)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-02 00:09
我想快速提高网站收录的速度,但是我没有那么多经验和精力,我该怎么办?小编推荐一个网站内容维护的最佳伴侣——优采云采集,无需人工干预,可以大大提高网站百度收录的使用率。
▶优采云采集cms出版助理做什么优采云采集cmsauxiliary 是一站式的网站文章采集、原创、发布工具,快速提升网站收录,排名,权重,是网站内容维护的最佳伴侣。
<p>优采云采集cmsauxiliary 与 DouPHPcms 系统完美对接。只要你的网站是由DouPHPcms构建的,网站就可以实现一键文章,无需修改任何代码。 @采集原创发布,创建发布任务,无需人工干预,每天智能发布文章,大幅提升网站百度收录量,网站优化如虎添翼。 查看全部
文章采集系统(▶优采云采集CMS发布助手做什么网站内容维护最佳伴侣)
我想快速提高网站收录的速度,但是我没有那么多经验和精力,我该怎么办?小编推荐一个网站内容维护的最佳伴侣——优采云采集,无需人工干预,可以大大提高网站百度收录的使用率。
▶优采云采集cms出版助理做什么优采云采集cmsauxiliary 是一站式的网站文章采集、原创、发布工具,快速提升网站收录,排名,权重,是网站内容维护的最佳伴侣。
<p>优采云采集cmsauxiliary 与 DouPHPcms 系统完美对接。只要你的网站是由DouPHPcms构建的,网站就可以实现一键文章,无需修改任何代码。 @采集原创发布,创建发布任务,无需人工干预,每天智能发布文章,大幅提升网站百度收录量,网站优化如虎添翼。
文章采集系统(自媒体如何利用图片采集图片相关的内容?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-01 23:01
文章采集系统是对文章进行采集,并将采集到的文章返回给我们的后台来处理,从而实现内容,也可以处理图片等内容。自媒体如何采集图片相关的内容?1.利用图片采集系统采集的图片,原始图片会被存放在我们的cookie中,cookie中存放的只是一些关键点,点开以后发现不是我们想要的图片我们就不可以采集。2.还有一种情况是,如果我们采集到了原始图片,但是我们采集的内容有问题,系统会去根据图片,将新生成一个链接,把原始图片链接重新发布到网站。
3.最常见的情况是,原始图片被破坏,cookie被删除了,系统继续去原始图片数据库里找,直到能找到我们想要的内容为止。小伙伴们看到上面说的这三种情况,有没有觉得都很像我们天天要用到的网页爬虫。在这些情况当中,爬虫也算是一个非常重要的数据采集方式。今天小编主要给大家说一下如何利用采集图片的采集系统采集图片的文章。
首先呢,我们要打开各大自媒体平台,然后打开我们的账号名,在这些平台发布内容时间会存放在系统的cookie中,也就是我们的爬虫,当系统找到我们的链接,会发出一条短连接来返回给我们,这也就是小编我们采集这些平台账号图片的时候最常用的一种方式。小编提醒大家,如果图片采集的系统比较原始,或者是封闭性比较强的平台,最好不要用图片采集系统采集图片,不然很容易会被封。采集图片文章总结图片采集总共分为三种方式:。
一、excel表格采集将excel表格进行文本统计,然后把数据采集过来,对于文字特别多的表格采集更为有效。文本分析为字段,字段统计语句生成,比较方便有效,修改也比较简单。需要注意的是,这种方式,需要的软件必须要结合本软件的版本,因为有的平台的excel表格数据库已经包含了全部字段,所以不适合用这种方式去采集了。
二、采集器采集以前为了方便记录某个文章的内容,都是将一段文字或者链接输入到爬虫中,然后给定一个index进行爬取,但是如果有了excel表格这个工具之后,就可以非常方便的批量管理文章,解放爬虫的工作,将大量重复的工作,统一以采集器的方式管理,省时省力。需要注意的是,采集器的搭建,必须要考虑采集器可靠性,不能今天刚搭建上,却发现不可用,以后可能就使用不了了。
三、rss内容采集这种方式是最适合现在的自媒体,尤其是封闭性要求不高的平台,像是:微信公众号,今日头条,百家号等,都可以利用采集器采集图片文章。小编也教大家,如何不修改原有的采集器软件,直接就可以免费注册采集器软件。先要打开微信公众号的小程序,然后把要采集的文章链接,发送给后台, 查看全部
文章采集系统(自媒体如何利用图片采集图片相关的内容?(组图))
文章采集系统是对文章进行采集,并将采集到的文章返回给我们的后台来处理,从而实现内容,也可以处理图片等内容。自媒体如何采集图片相关的内容?1.利用图片采集系统采集的图片,原始图片会被存放在我们的cookie中,cookie中存放的只是一些关键点,点开以后发现不是我们想要的图片我们就不可以采集。2.还有一种情况是,如果我们采集到了原始图片,但是我们采集的内容有问题,系统会去根据图片,将新生成一个链接,把原始图片链接重新发布到网站。
3.最常见的情况是,原始图片被破坏,cookie被删除了,系统继续去原始图片数据库里找,直到能找到我们想要的内容为止。小伙伴们看到上面说的这三种情况,有没有觉得都很像我们天天要用到的网页爬虫。在这些情况当中,爬虫也算是一个非常重要的数据采集方式。今天小编主要给大家说一下如何利用采集图片的采集系统采集图片的文章。
首先呢,我们要打开各大自媒体平台,然后打开我们的账号名,在这些平台发布内容时间会存放在系统的cookie中,也就是我们的爬虫,当系统找到我们的链接,会发出一条短连接来返回给我们,这也就是小编我们采集这些平台账号图片的时候最常用的一种方式。小编提醒大家,如果图片采集的系统比较原始,或者是封闭性比较强的平台,最好不要用图片采集系统采集图片,不然很容易会被封。采集图片文章总结图片采集总共分为三种方式:。
一、excel表格采集将excel表格进行文本统计,然后把数据采集过来,对于文字特别多的表格采集更为有效。文本分析为字段,字段统计语句生成,比较方便有效,修改也比较简单。需要注意的是,这种方式,需要的软件必须要结合本软件的版本,因为有的平台的excel表格数据库已经包含了全部字段,所以不适合用这种方式去采集了。
二、采集器采集以前为了方便记录某个文章的内容,都是将一段文字或者链接输入到爬虫中,然后给定一个index进行爬取,但是如果有了excel表格这个工具之后,就可以非常方便的批量管理文章,解放爬虫的工作,将大量重复的工作,统一以采集器的方式管理,省时省力。需要注意的是,采集器的搭建,必须要考虑采集器可靠性,不能今天刚搭建上,却发现不可用,以后可能就使用不了了。
三、rss内容采集这种方式是最适合现在的自媒体,尤其是封闭性要求不高的平台,像是:微信公众号,今日头条,百家号等,都可以利用采集器采集图片文章。小编也教大家,如何不修改原有的采集器软件,直接就可以免费注册采集器软件。先要打开微信公众号的小程序,然后把要采集的文章链接,发送给后台,
ELK7.10小项目演示ELK的日志分析利器(上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2021-08-26 18:08
ELK(Elasticsearch、Logstash、Kibana)用于采集日志并进行日志分析,最后通过可视化UI展示出来。在产生大量日志的项目场景中,ELK是一个强大的日志采集分析工具!
你遇到过这些 Elasticsearch 7.10 部署问题吗?在这个文章中,我已经部署了Elasticsearch。这个导航就完成了Logstash和Kibana的部署,写了一个SpringBoot小项目来演示ELK日志采集。
安装 Logstash
ELK三大组件的安装非常简单,几行命令就可以搞定:
wget https://artifacts.elastic.co/d ... ar.gz
tar -zxvf logstash-7.10.2-linux-x86_64.tar.gz
复制代码
我们之前安装的Elasticsearch版本是7.10.2,所以接下来要安装的Logstash和Kibana都必须安装7.10.2版本。
解压完成后,为了每次启动时都不进入Logstash家目录,我们来配置一下环境变量:
vi ~/.bash_profile
# 在后面添加
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$LOGSTASH_HOME/bin
复制代码
关于版本问题,让我对ELK感觉良好的一件事就是ElasticStack中Elasticsearch、Logstash、Kibana的版本号都是一样的,其实省了很多麻烦。
下载时,如果要下载其他版本,可以通过更改链接上的版本号下载对应版本的文件。
复制一个$LOGSTASH_HOME/config/logstash-sample.conf配置文件,命名为logstash-app-search.conf,修改内容如下:
input {
tcp {
# Logstash 作为服务
mode => "server"
host => "192.168.242.120"
# 开放9001端口进行采集日志
port => 9001
# 编解码器
codec => json_lines
}
}
output {
elasticsearch {
# 配置ES的地址
hosts => ["http://192.168.242.120:9200"]
# 在ES里产生的index的名称
index => "app-search-log-collection-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
stdout {
codec => rubydebug
}
}
复制代码
启动 Logstash:
logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf
# 后台启动
# nohup logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf &
复制代码
安装 Kibana
还是很简单:
# 下载
wget https://artifacts.elastic.co/d ... ar.gz
# 解压
tar -zxvf kibana-7.10.2-linux-x86_64.tar.gz
# 重命名
mv kibana-7.10.2-linux-x86_64.tar.gz kibana-7.10.2
# 配置环境变量
# 编辑 ~/.bash_profile
# 最终ELK的环境变量配置
export ES_HOME=/home/elastic/elasticsearch-7.10.2
export KIBANA_HOME=/home/elastic/kibana-7.10.2
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$ES_HOME/bin:$KIBANA_HOME/bin:$LOGSTASH_HOME/bin
# 使之生效
source ~/.bash_profile
复制代码
首先修改$KIBANA_HOME/config/kibana.yml配置文件中的以下几项:
# Logstash端口
server.port: 5601
# Logstash的IP地址
server.host: "192.168.242.120"
# ES实例URL
elasticsearch.hosts: ["http://192.168.242.120:9200"]
复制代码
直接使用如下命令(在配置环境变量的前提下)启动:
kibana
复制代码
启动成功,访问:5601:
使用ELK采集SpringBoot项目的Logback日志
查看SpringBoot的日志配置文件logback-spring.xml:
192.168.242.120:9001
复制代码
我直接从logstash-logback-encoder项目的GitHub上复制了这个配置,并更改了IP地址和端口。
GitHub 地址:
/logstash/lo...
启动 SpringBoot 服务:
有错误提示,但启动不成功。这时候,我们猜测Logstash日志中应该会显示这个错误日志。看一看:
好的,是的,不过这样看SpringBoot日志比较好。它没有 ELK 应有的乐趣。如果用 Kibana 看的话,先去索引管理页面:
这里可以看到已经在Logstash配置文件中配置为索引名。
创建索引模式:
现在您可以在“发现”面板中看到日志:
现在让我们根据这个错误信息修复它并重新启动SpringBoot。
根据报错信息,可以看到,
Could not find an appender named [CONSOLE]
复制代码
原因是在logback-spring.xml配置文件中没有配置CONSOLE的appender,直接添加即可,如果不需要console输出就删掉这句话。
这里为了方便在控制台查看,和ELK对比,我们也把输出添加到控制台:
${pattern}
复制代码
启动SpringBoot,通过Kibana查看Logstash采集的日志:
舒适!
本次导航结束,休息!
第一个公众号是星百利,欢迎老铁们关注阅读指正。代码仓库 GitHub /xblzer/Java... 查看全部
ELK7.10小项目演示ELK的日志分析利器(上)
ELK(Elasticsearch、Logstash、Kibana)用于采集日志并进行日志分析,最后通过可视化UI展示出来。在产生大量日志的项目场景中,ELK是一个强大的日志采集分析工具!
你遇到过这些 Elasticsearch 7.10 部署问题吗?在这个文章中,我已经部署了Elasticsearch。这个导航就完成了Logstash和Kibana的部署,写了一个SpringBoot小项目来演示ELK日志采集。
安装 Logstash
ELK三大组件的安装非常简单,几行命令就可以搞定:
wget https://artifacts.elastic.co/d ... ar.gz
tar -zxvf logstash-7.10.2-linux-x86_64.tar.gz
复制代码
我们之前安装的Elasticsearch版本是7.10.2,所以接下来要安装的Logstash和Kibana都必须安装7.10.2版本。
解压完成后,为了每次启动时都不进入Logstash家目录,我们来配置一下环境变量:
vi ~/.bash_profile
# 在后面添加
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$LOGSTASH_HOME/bin
复制代码
关于版本问题,让我对ELK感觉良好的一件事就是ElasticStack中Elasticsearch、Logstash、Kibana的版本号都是一样的,其实省了很多麻烦。
下载时,如果要下载其他版本,可以通过更改链接上的版本号下载对应版本的文件。
复制一个$LOGSTASH_HOME/config/logstash-sample.conf配置文件,命名为logstash-app-search.conf,修改内容如下:
input {
tcp {
# Logstash 作为服务
mode => "server"
host => "192.168.242.120"
# 开放9001端口进行采集日志
port => 9001
# 编解码器
codec => json_lines
}
}
output {
elasticsearch {
# 配置ES的地址
hosts => ["http://192.168.242.120:9200"]
# 在ES里产生的index的名称
index => "app-search-log-collection-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
stdout {
codec => rubydebug
}
}
复制代码
启动 Logstash:
logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf
# 后台启动
# nohup logstash -f $LOGSTASH_HOME/config/logstash-app-search.conf &
复制代码
安装 Kibana
还是很简单:
# 下载
wget https://artifacts.elastic.co/d ... ar.gz
# 解压
tar -zxvf kibana-7.10.2-linux-x86_64.tar.gz
# 重命名
mv kibana-7.10.2-linux-x86_64.tar.gz kibana-7.10.2
# 配置环境变量
# 编辑 ~/.bash_profile
# 最终ELK的环境变量配置
export ES_HOME=/home/elastic/elasticsearch-7.10.2
export KIBANA_HOME=/home/elastic/kibana-7.10.2
export LOGSTASH_HOME=/home/elastic/logstash-7.10.2
export PATH=$PATH:$ES_HOME/bin:$KIBANA_HOME/bin:$LOGSTASH_HOME/bin
# 使之生效
source ~/.bash_profile
复制代码
首先修改$KIBANA_HOME/config/kibana.yml配置文件中的以下几项:
# Logstash端口
server.port: 5601
# Logstash的IP地址
server.host: "192.168.242.120"
# ES实例URL
elasticsearch.hosts: ["http://192.168.242.120:9200"]
复制代码
直接使用如下命令(在配置环境变量的前提下)启动:
kibana
复制代码
启动成功,访问:5601:
使用ELK采集SpringBoot项目的Logback日志
查看SpringBoot的日志配置文件logback-spring.xml:
192.168.242.120:9001
复制代码
我直接从logstash-logback-encoder项目的GitHub上复制了这个配置,并更改了IP地址和端口。
GitHub 地址:
/logstash/lo...
启动 SpringBoot 服务:
有错误提示,但启动不成功。这时候,我们猜测Logstash日志中应该会显示这个错误日志。看一看:
好的,是的,不过这样看SpringBoot日志比较好。它没有 ELK 应有的乐趣。如果用 Kibana 看的话,先去索引管理页面:
这里可以看到已经在Logstash配置文件中配置为索引名。
创建索引模式:
现在您可以在“发现”面板中看到日志:
现在让我们根据这个错误信息修复它并重新启动SpringBoot。
根据报错信息,可以看到,
Could not find an appender named [CONSOLE]
复制代码
原因是在logback-spring.xml配置文件中没有配置CONSOLE的appender,直接添加即可,如果不需要console输出就删掉这句话。
这里为了方便在控制台查看,和ELK对比,我们也把输出添加到控制台:
${pattern}
复制代码
启动SpringBoot,通过Kibana查看Logstash采集的日志:
舒适!
本次导航结束,休息!
第一个公众号是星百利,欢迎老铁们关注阅读指正。代码仓库 GitHub /xblzer/Java...
whatsns内容付费seo优化带采集和熊掌号运营问答系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-08-18 05:09
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,强大的反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,高级微信公众号接口功能,支付宝支付,微信扫码支付,微信JSSDK支付,微信H5支付,小程序支付,适合不同场景的支付业务需求,如充值、致电 Reward、回答窥视并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。快速轻量级,在1m带宽的虚拟主机单核cpu1g内存带宽下也能完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后,直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/
查看全部
whatsns内容付费seo优化带采集和熊掌号运营问答系统
Whatsns内容付费seo优化带采集和熊掌号运营问答系统项目介绍
Whatsns问答系统是一个PHP开源问答系统,可以根据自身业务需求快速搭建垂直领域。内置强大的采集功能,支持云存储、图片水印设置、全文检索、站点行为监控、短信注册和通知、伪静态URL自定义、熊掌号功能、百度结构化地图(标签、题,文章,分类,用户空间),PC和Wap模板分离,内置多套pc和wap模板,站长免费同时后台支持模板管理,模板在线编辑修改,强大的反灌拦截过滤配置等数百项功能,深度SEO优化,适合需要SEO的站长。商业版还支持优采云采集,高级微信公众号接口功能,支付宝支付,微信扫码支付,微信JSSDK支付,微信H5支付,小程序支付,适合不同场景的支付业务需求,如充值、致电 Reward、回答窥视并咨询付费专家。
特别提示
V4免费版用户已安装,如需更新请移动V4更新地址
软件架构
基于php的CodeIgniter3.1.6开发的优雅CI框架,是国内php开发者最喜欢的MVC框架。快速轻量级,在1m带宽的虚拟主机单核cpu1g内存带宽下也能完美流畅。运行,更多框架信息可以参考CI官网
安装教程
直接把程序上传到问答的根目录即可,安装方法,上传程序后,直接输入你的域名/install/
如果是二级目录安装:安装在某个域名网站下的用户,请定位到你问答的安装地址,输入你的域名/二级目录/install/
程序猿真吃码农饭,能写出易上手的代码吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-08-12 23:02
文章采集系统很重要,算法也很重要,一般是需要采集输入文本后,再进行文本关键词检索。现在的大数据,自动文本摘要,文本抽取,实时推送等。
中国知网、万方文库、维普文库。
这样说吧,目前来说对于我们程序员来说,比较流行的有,百度文库,豆丁,道客巴巴,方正清博,中国知网,万方文库等。上面的也不一定是每一种类型的网站。我觉得我们每个人都需要一个公众号,输入自己的关键词,或者说你想问的问题,把你想问的告诉我们,我们给你做一个简单的分析,然后给你一个答案。这是我目前想的比较多的。
ui即是userinterface用户界面:每个网站都会有不同的设计,我觉得知乎的很多界面设计都很美观,下来就是我们程序猿的努力。没办法,每个公司设计不同就是美丑的问题,就只好程序猿一板砖拍死他们,让他们也随便设计了。第二个说起程序猿就头疼,大家都在说程序猿真吃码农饭,能写出易上手的代码吗?(就是那么现实)下来我们就要看到实际的技术实力了,在知乎这样一个小众平台,要想获得更多牛人的回答,才有发言权的,自然要有推荐人制度。
(很多技术大神都离开知乎了)第三个就是企业需要什么,也有一部分问题是为了技术加推广,就要人工给他们推荐一下,也会不小心就给错了。(有时候就是这样)。 查看全部
程序猿真吃码农饭,能写出易上手的代码吗?
文章采集系统很重要,算法也很重要,一般是需要采集输入文本后,再进行文本关键词检索。现在的大数据,自动文本摘要,文本抽取,实时推送等。
中国知网、万方文库、维普文库。
这样说吧,目前来说对于我们程序员来说,比较流行的有,百度文库,豆丁,道客巴巴,方正清博,中国知网,万方文库等。上面的也不一定是每一种类型的网站。我觉得我们每个人都需要一个公众号,输入自己的关键词,或者说你想问的问题,把你想问的告诉我们,我们给你做一个简单的分析,然后给你一个答案。这是我目前想的比较多的。
ui即是userinterface用户界面:每个网站都会有不同的设计,我觉得知乎的很多界面设计都很美观,下来就是我们程序猿的努力。没办法,每个公司设计不同就是美丑的问题,就只好程序猿一板砖拍死他们,让他们也随便设计了。第二个说起程序猿就头疼,大家都在说程序猿真吃码农饭,能写出易上手的代码吗?(就是那么现实)下来我们就要看到实际的技术实力了,在知乎这样一个小众平台,要想获得更多牛人的回答,才有发言权的,自然要有推荐人制度。
(很多技术大神都离开知乎了)第三个就是企业需要什么,也有一部分问题是为了技术加推广,就要人工给他们推荐一下,也会不小心就给错了。(有时候就是这样)。
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatri.
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-10 22:01
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer:unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer–allendilberey什么是smtlg?“youhavetodesignthismachinewhichisyoureverydaylifewithyourappforyourinformationanddata.itallowsyoutofind,regretandlookforwardtolikethat,andwaitonalldirectionstoseeifit'sgoingtoendtoanewcircle.simplemachinesaregood,butmanyniceappsdonotgettomiss,onceyou'vefinishedyourappateverytimeyouneedyoure-mailandthat'sthemostfamousapptome,andwhenit'sinsideoutyoucannotcontinuetofail,soyoucangoforashoppingcart,whichallofusfeelexpectedifyoucan.”-andrewshownwhythisisgoingtobethemostgreatappforyoutoeat,together,receiveaninformation,orhelp.that'swhythisappstandsout.sendlovetosomeonelikeyou,youhavetohandleit.andthatwillnotallowyoutoplansomethingalright.andthenyoumakeachoice.不管是我建这个系统还是每个组员的建这个系统目的,我自己总能从其中抽身出来,不是说它不够好,而是不像ppt里有价值的动画有那么多,时不时地告诉你它来了,它去了一个new的地方。
smtlg软件的设计有两点我觉得特别妙。第一点,就是设计过程中动画来不及;虽然我还没有把它作为系统的demo展示出来,也不知道我会在多久之后作为smtlg的一个idea收到社区的反馈,我无法估计它什么时候来。但我个人是认为smtlg不能追求实时性的,如果用户想看到过去一段时间app里的所有信息,直接去往下一个的item的属性就行了。
回想你在ppt里,一旦要加动画,无论画布多么小,一旦上面的位置要变,你就不得不放弃ppt过去的信息了。但如果我们可以任意过去app里的所有数据或任意选择某一个数据。这样你就可以任意的添加动画,这个动画可以是动态的,在上下或左右也可以是静态的,也可以是flash的(大多数,不包括excel)。我认为动态更贴近心理效果。
而我们的ppt最大的问题是空间有限,很难调。所以我觉得好的动画是可以任意宽高,更加优雅的显示数据,尤其是看不到时,这样才是一个好的动画。第二点是关于不同需求设计其他不同ppt样式的资源。我们的ppt不应该只有pptx或pptx格。 查看全部
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatri.
文章采集系统设计者allendilberey自创unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer:unifiedjoy.contenttrackingandstochasticmatrixdesigngameexplorer–allendilberey什么是smtlg?“youhavetodesignthismachinewhichisyoureverydaylifewithyourappforyourinformationanddata.itallowsyoutofind,regretandlookforwardtolikethat,andwaitonalldirectionstoseeifit'sgoingtoendtoanewcircle.simplemachinesaregood,butmanyniceappsdonotgettomiss,onceyou'vefinishedyourappateverytimeyouneedyoure-mailandthat'sthemostfamousapptome,andwhenit'sinsideoutyoucannotcontinuetofail,soyoucangoforashoppingcart,whichallofusfeelexpectedifyoucan.”-andrewshownwhythisisgoingtobethemostgreatappforyoutoeat,together,receiveaninformation,orhelp.that'swhythisappstandsout.sendlovetosomeonelikeyou,youhavetohandleit.andthatwillnotallowyoutoplansomethingalright.andthenyoumakeachoice.不管是我建这个系统还是每个组员的建这个系统目的,我自己总能从其中抽身出来,不是说它不够好,而是不像ppt里有价值的动画有那么多,时不时地告诉你它来了,它去了一个new的地方。
smtlg软件的设计有两点我觉得特别妙。第一点,就是设计过程中动画来不及;虽然我还没有把它作为系统的demo展示出来,也不知道我会在多久之后作为smtlg的一个idea收到社区的反馈,我无法估计它什么时候来。但我个人是认为smtlg不能追求实时性的,如果用户想看到过去一段时间app里的所有信息,直接去往下一个的item的属性就行了。
回想你在ppt里,一旦要加动画,无论画布多么小,一旦上面的位置要变,你就不得不放弃ppt过去的信息了。但如果我们可以任意过去app里的所有数据或任意选择某一个数据。这样你就可以任意的添加动画,这个动画可以是动态的,在上下或左右也可以是静态的,也可以是flash的(大多数,不包括excel)。我认为动态更贴近心理效果。
而我们的ppt最大的问题是空间有限,很难调。所以我觉得好的动画是可以任意宽高,更加优雅的显示数据,尤其是看不到时,这样才是一个好的动画。第二点是关于不同需求设计其他不同ppt样式的资源。我们的ppt不应该只有pptx或pptx格。
一下Flume中央日志系统(版本号:1.3.)的使用方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-08-09 04:45
这两天仔细研究了Flume Central Log System(版本号:1.3.X)。在我看来,Flume 仍然是一个非常好的日志采集系统,它的设计理念非常简单。使用简洁。并且是一个开源项目,基于Java语言开发,可以开发一些自定义功能。运行Flume时,机器必须安装JDK6.0以上版本,Flume目前只有Linux系统的启动脚本,Windows环境没有启动脚本。
Flume 主要采购自 3 个重要组件:
Source:完成日志数据的采集,分为transition和event进入通道。
Channel:主要提供一个队列功能,简单的缓存source提供的数据。
Sink:取出Channel中的数据,存储到文件系统、数据库中,或者提交到远程服务器。
对现有程序的最小改动是直接使用程序原来记录的日志文件,基本可以在不改变现有程序的情况下实现无缝访问。
直接读取文件Source,有两种方式:
ExecSource:通过运行Linux命令,如tail -F文件名命令,不断输出最新数据。在这种模式下,必须指定文件名。
SpoolSource:是监控配置目录下新增的文件,读取文件中的数据。需要注意两点:1、复制到spool目录下的文件已经无法打开编辑了。 2、spool 目录不能收录相应的子目录。在实际使用过程中,可以配合log4j使用。使用log4j时,将log4j文件拆分机制设置为每1分钟一次,并将文件拷贝到spool的监控目录。 log4j有一个TimeRolling插件,可以把log4j划分的文件放到spool目录下。基本实现了实时监控。 Flume传输文件后,会将文件后缀修改为.COMPLETED(后缀也可以在配置文件中灵活指定)
ExecSource 和 SpoolSource 对比:ExecSource 可以实现实时日志采集,但是当 Flume 不运行或者出现指令执行错误时,无法采集日志数据,无法证明日志数据的完整性。 SpoolSource虽然不能实时采集数据,但是可以分分钟进行文件分割,接近实时。如果应用程序不能在几分钟内剪切日志文件,可以结合使用两种采集方法。
Channel 有多种方式:MemoryChannel、JDBC Channel、MemoryRecoverChannel、FileChannel。 MemoryChannel 可以实现高速吞吐量,但无法保证数据完整性。 MemoryRecoverChannel 已根据官方文档的推荐建议使用 FileChannel 替换它。 FileChannel 保证数据的完整性和一致性。具体配置没有出现的FileChannel时,建议将FileChannel设置的目录和保存程序日志文件的目录设置在不同的磁盘上,以提高效率。
Sink 在设置存储数据时可以将数据存储在文件系统、数据库、hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。 查看全部
一下Flume中央日志系统(版本号:1.3.)的使用方式
这两天仔细研究了Flume Central Log System(版本号:1.3.X)。在我看来,Flume 仍然是一个非常好的日志采集系统,它的设计理念非常简单。使用简洁。并且是一个开源项目,基于Java语言开发,可以开发一些自定义功能。运行Flume时,机器必须安装JDK6.0以上版本,Flume目前只有Linux系统的启动脚本,Windows环境没有启动脚本。
Flume 主要采购自 3 个重要组件:
Source:完成日志数据的采集,分为transition和event进入通道。
Channel:主要提供一个队列功能,简单的缓存source提供的数据。
Sink:取出Channel中的数据,存储到文件系统、数据库中,或者提交到远程服务器。
对现有程序的最小改动是直接使用程序原来记录的日志文件,基本可以在不改变现有程序的情况下实现无缝访问。
直接读取文件Source,有两种方式:
ExecSource:通过运行Linux命令,如tail -F文件名命令,不断输出最新数据。在这种模式下,必须指定文件名。
SpoolSource:是监控配置目录下新增的文件,读取文件中的数据。需要注意两点:1、复制到spool目录下的文件已经无法打开编辑了。 2、spool 目录不能收录相应的子目录。在实际使用过程中,可以配合log4j使用。使用log4j时,将log4j文件拆分机制设置为每1分钟一次,并将文件拷贝到spool的监控目录。 log4j有一个TimeRolling插件,可以把log4j划分的文件放到spool目录下。基本实现了实时监控。 Flume传输文件后,会将文件后缀修改为.COMPLETED(后缀也可以在配置文件中灵活指定)
ExecSource 和 SpoolSource 对比:ExecSource 可以实现实时日志采集,但是当 Flume 不运行或者出现指令执行错误时,无法采集日志数据,无法证明日志数据的完整性。 SpoolSource虽然不能实时采集数据,但是可以分分钟进行文件分割,接近实时。如果应用程序不能在几分钟内剪切日志文件,可以结合使用两种采集方法。
Channel 有多种方式:MemoryChannel、JDBC Channel、MemoryRecoverChannel、FileChannel。 MemoryChannel 可以实现高速吞吐量,但无法保证数据完整性。 MemoryRecoverChannel 已根据官方文档的推荐建议使用 FileChannel 替换它。 FileChannel 保证数据的完整性和一致性。具体配置没有出现的FileChannel时,建议将FileChannel设置的目录和保存程序日志文件的目录设置在不同的磁盘上,以提高效率。
Sink 在设置存储数据时可以将数据存储在文件系统、数据库、hadoop 中。当日志数据较小时,可以将数据存储在文件系统中,并设置一定的时间间隔来保存数据。当日志数据较多时,可以将相应的日志数据存储在Hadoop中,方便日后进行相应的数据分析。
文章采集系统解决如何采集的问题,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-08 22:12
文章采集系统,那就得解决如何采集的问题。采集的问题可以从以下两个方面入手:1、素材来源——刚刚起步,现在流量人气较少的有:抖音,快手,百度新闻,其他网站。2、内容规范——设置相关规范,对互联网素材进行优化。给你推荐个采集助手,免费提供5000+优质内容,覆盖游戏,教育,财经,医疗等,软件自带4000多真实素材,可以一键采集抖音、快手、新闻,百度以及其他平台,效果非常赞!:采集助手。
新内容搜索引擎非常的多,不知道题主知道么?百度搜索:谷歌搜索:yahoospider百度知道:百度知道-自由答案采集平台,全球最大中文知识问答平台,给出最真实的知识分享百度百科:百度百科-自由的百科全书知乎:知乎-与世界分享你的知识、经验和见解微博:微博-与世界分享你的知识、经验和见解当然更多的还是其他搜索引擎,比如:词云(爬虫采集的结果)、搜索引擎:googlesearch-spiderr:chromeextension:谷歌浏览器插件最知名的是googleadwords搜索:wordcloud/mozilla/chromewebstore搜索就找中文词云就用到了tagxedo,这个主要爬取的是词。
有,百度百科,词云,都挺不错的,还有知乎百科,
1,百度百科、维基百科、知乎百科、百度中文图书等等都可以,都提供这样的搜索内容2,阿里知道、百度文库、慧聪、360行业词库等都可以3,、联盟等也可以搜到资源,付费搜索资源, 查看全部
文章采集系统解决如何采集的问题,你知道吗?
文章采集系统,那就得解决如何采集的问题。采集的问题可以从以下两个方面入手:1、素材来源——刚刚起步,现在流量人气较少的有:抖音,快手,百度新闻,其他网站。2、内容规范——设置相关规范,对互联网素材进行优化。给你推荐个采集助手,免费提供5000+优质内容,覆盖游戏,教育,财经,医疗等,软件自带4000多真实素材,可以一键采集抖音、快手、新闻,百度以及其他平台,效果非常赞!:采集助手。
新内容搜索引擎非常的多,不知道题主知道么?百度搜索:谷歌搜索:yahoospider百度知道:百度知道-自由答案采集平台,全球最大中文知识问答平台,给出最真实的知识分享百度百科:百度百科-自由的百科全书知乎:知乎-与世界分享你的知识、经验和见解微博:微博-与世界分享你的知识、经验和见解当然更多的还是其他搜索引擎,比如:词云(爬虫采集的结果)、搜索引擎:googlesearch-spiderr:chromeextension:谷歌浏览器插件最知名的是googleadwords搜索:wordcloud/mozilla/chromewebstore搜索就找中文词云就用到了tagxedo,这个主要爬取的是词。
有,百度百科,词云,都挺不错的,还有知乎百科,
1,百度百科、维基百科、知乎百科、百度中文图书等等都可以,都提供这样的搜索内容2,阿里知道、百度文库、慧聪、360行业词库等都可以3,、联盟等也可以搜到资源,付费搜索资源,
网站被降权之后,应该如何恢复网站排名,如何解决?
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-08-01 18:21
文章为91NLP写的这个原创内容不要当真
kycc文章采集batch伪原创tools,不过这些内容基本都是原创,都是比较新鲜的文章,比如我们可以采集来的伪原创文章 ,但是我们不能使用伪原创 工具来处理这些事情。我们只能将文章伪原创tools 修改为我们自己的文章,然后再发送给其他网站,这样我们就不会给自己文章处理自己的工具,同时也增加了可读性自己的工具,不光是一些比较知名的网站,还要做好这些内容,更容易被搜索引擎惩罚,这也是我们的通病优化工作者!本文首发a5,转载请注明出处,谢谢大家! 网站被降权,如何恢复网站排名,这是一个非常必要的过程,也是我们经常遇到的问题,网站被降权的问题,也是我们经常遇到的问题,但是我会不在这里列出它们。下面我们来解决这个问题。希望大家帮我们解决。
一个网站被下权的问题,如果你的网站被降级了,将不会被处理。一般网站降级后,会有一个审核期。如果网站被降权的时候不去大刀阔斧的处理,网站的降权也会影响搜索引擎的排名。所以网站被拔的问题一定要心知肚明,避免大的波动。 .
第二个网站外链是k之后,我们要做的就是检查我们的网站是否降级了,是否降级了,我们要做的就是看看你的网站是否被降级了有一些死链接,是否有死链接,或者内容是否被搜索引擎惩罚,如果网站是彻头彻尾的,那我要检查一下我的网站是否有死链接,看看有没有any 是否有部分网站被降级,是否有被k压倒的现象,如果有,则取决于网站是否被降级。
kycc文章采集batch伪原创
三个网站的内链检查,看看有没有死链接,或者死链接,如果有死链接,如果网站里面有死链接,那么就可以检查网站是否死了如果有死链接,可以检查是否有死链接。如果存在死链接,那么您必须检查自己的死链接。如果存在死链接,我们不需要检查您自己的死链接。链接。如果有死链接,就没有死链接。如果有很多死链接,您可以删除一些死链接和其他死链接。如果存在死链接的可能性,请不要检查自己的死链接。这是非常危险的。
三个网站的友情链接检查网站友情链接检查他的友情链接是否有死链接,如果没有,那就检查自己的友情链接是否有死链接,如果不要检查它要检查你的网站是否有死链接,如果是这个检查网站,检查网站是否被降级了,比如是否有死链接,然后检查好友的友情链接网站 是降级的原因吗?如果有,可以先找到对方的网站友情链接,看看有没有降级,如果有 查看全部
网站被降权之后,应该如何恢复网站排名,如何解决?
文章为91NLP写的这个原创内容不要当真
kycc文章采集batch伪原创tools,不过这些内容基本都是原创,都是比较新鲜的文章,比如我们可以采集来的伪原创文章 ,但是我们不能使用伪原创 工具来处理这些事情。我们只能将文章伪原创tools 修改为我们自己的文章,然后再发送给其他网站,这样我们就不会给自己文章处理自己的工具,同时也增加了可读性自己的工具,不光是一些比较知名的网站,还要做好这些内容,更容易被搜索引擎惩罚,这也是我们的通病优化工作者!本文首发a5,转载请注明出处,谢谢大家! 网站被降权,如何恢复网站排名,这是一个非常必要的过程,也是我们经常遇到的问题,网站被降权的问题,也是我们经常遇到的问题,但是我会不在这里列出它们。下面我们来解决这个问题。希望大家帮我们解决。
一个网站被下权的问题,如果你的网站被降级了,将不会被处理。一般网站降级后,会有一个审核期。如果网站被降权的时候不去大刀阔斧的处理,网站的降权也会影响搜索引擎的排名。所以网站被拔的问题一定要心知肚明,避免大的波动。 .
第二个网站外链是k之后,我们要做的就是检查我们的网站是否降级了,是否降级了,我们要做的就是看看你的网站是否被降级了有一些死链接,是否有死链接,或者内容是否被搜索引擎惩罚,如果网站是彻头彻尾的,那我要检查一下我的网站是否有死链接,看看有没有any 是否有部分网站被降级,是否有被k压倒的现象,如果有,则取决于网站是否被降级。
kycc文章采集batch伪原创
三个网站的内链检查,看看有没有死链接,或者死链接,如果有死链接,如果网站里面有死链接,那么就可以检查网站是否死了如果有死链接,可以检查是否有死链接。如果存在死链接,那么您必须检查自己的死链接。如果存在死链接,我们不需要检查您自己的死链接。链接。如果有死链接,就没有死链接。如果有很多死链接,您可以删除一些死链接和其他死链接。如果存在死链接的可能性,请不要检查自己的死链接。这是非常危险的。
三个网站的友情链接检查网站友情链接检查他的友情链接是否有死链接,如果没有,那就检查自己的友情链接是否有死链接,如果不要检查它要检查你的网站是否有死链接,如果是这个检查网站,检查网站是否被降级了,比如是否有死链接,然后检查好友的友情链接网站 是降级的原因吗?如果有,可以先找到对方的网站友情链接,看看有没有降级,如果有
AutoBlog(自动采集发布插件)如何设置CSS选择器支持设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-01 18:09
AutoBlog(Auto采集publishing plugin)是一款优秀的插件工具,可以帮助用户采集any网站在站点内容中,自动更新你的WordPress站点,文章publishing等等。使用方法简单,无需复杂设置,支持wordpress所有功能。
软件功能
采集any网站内容,采集信息一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以设置多个采集任务同时运行。任务可以设置为自动或手动运行。主任务列表显示每个采集任务的状态:上次检测采集时间,预计下次检测采集时间,最新采集文章,文章编号更新采集等信息,方便查看和管理。
文章管理功能方便查询、查找、删除采集文章,改进后的算法从根本上杜绝了采集同文章的重复,日志功能将异常记录在采集的过程并抓取错误,方便查看设置错误以便修复。
采集any网站内容,采集信息一目了然文章完善的管理功能,方便查询管理,日志功能,记录采集异常
任务开启后会自动更新采集,无需人工干预
任务激活后,检查是否有新的文章updateable,检查文章是否重复,并导入更新文章。所有这些操作都是自动完成的,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台异步,不影响用户体验,也不影响用户访问) 网站)的效率,另一个是使用Cron调度任务定时触发采集update任务
目标采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集multi-level文章list,支持采集body分页内容,支持采集multi-级别正文内容
定位采集 只需提供文章list URL 即可智能采集 来自任何网站 或列内容。
不仅支持对采集网页内容的“通配符匹配”,还完美支持各种CSS选择器。只需填写一个简单的 CSS 选择器,如 #title h1,即可准确地采集 网页上的任何内容。 (如何设置 CSS 选择器)
支持设置关键词,如果标题收录关键词,则只允许采集(或者过滤掉采集不允许)。
支持设置多个匹配规则采集网页不同内容,甚至支持采集任意内容添加到“Wordpress自定义栏目”中,方便扩展。
定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集body分页内容定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集text 分页内容
基本设置功能齐全,完美支持Wordpress各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以发布采集target网站的分类目录、标签等信息,可以自动生成并添加相应的分类目录、标签等信息
每个采集任务可以选择发布到的类别、发布作者、发布状态、查看和更新时间间隔、采集target网站字符集、选择是否下载图片或附件。
支持自定义文章类型、自定义文章类别、文章表单。
完美支持Wordpress各种功能,自动添加标签,自动生成摘要,自动设置特色图片,支持自定义栏目等
完美支持Wordpress各种功能,自动设置分类、标签、摘要、特色图片、自定义栏目等
微信公众号采集
今日头条采集
采集微信公号、头条号等自媒体内容,因为百度没有收录公号、头条文章等,轻松获取优质“原创” 文章,加百度收录量和网站权重
支持采集微信公号(订阅号)文章,无需复杂配置,只需填写“公众号”和“微信ID”即可启动采集。 (微信公众号采集暂时采集difficulty,相关接口被腾讯屏蔽)
常见问题
WP-AutoBlog 与我使用的主题兼容吗?
WP-AutoBlog 兼容任何主题,不受限制,可以在任何主题下使用。
哪些 WordPress 版本与 WP-AutoBlog 兼容?
建议在 WordPress 3.0 及以上版本上运行。我们测试过在wordpress2.8.5及以上版本也能正常运行。当WordPress新版本发布时,我们会及时更新以兼容最新版本。
WP-AutoBlog 是否与 WordPress MU(多站点)版本兼容?
完全兼容,WP-AutoBlog可以在WordPress MU(多站点)的每个子站点下完美运行。请务必在各分站管理后台单独激活插件,不要使用“全网启用”。
绑定的域名可以修改吗?
您可以在30天内任意更改绑定域名,之后更改绑定域名只需支付插件价格的十分之一,无需重新购买原价。 查看全部
AutoBlog(自动采集发布插件)如何设置CSS选择器支持设置
AutoBlog(Auto采集publishing plugin)是一款优秀的插件工具,可以帮助用户采集any网站在站点内容中,自动更新你的WordPress站点,文章publishing等等。使用方法简单,无需复杂设置,支持wordpress所有功能。
软件功能
采集any网站内容,采集信息一目了然
通过简单的设置,采集可以来自任何网站内容,并且可以设置多个采集任务同时运行。任务可以设置为自动或手动运行。主任务列表显示每个采集任务的状态:上次检测采集时间,预计下次检测采集时间,最新采集文章,文章编号更新采集等信息,方便查看和管理。
文章管理功能方便查询、查找、删除采集文章,改进后的算法从根本上杜绝了采集同文章的重复,日志功能将异常记录在采集的过程并抓取错误,方便查看设置错误以便修复。
采集any网站内容,采集信息一目了然文章完善的管理功能,方便查询管理,日志功能,记录采集异常
任务开启后会自动更新采集,无需人工干预
任务激活后,检查是否有新的文章updateable,检查文章是否重复,并导入更新文章。所有这些操作都是自动完成的,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台异步,不影响用户体验,也不影响用户访问) 网站)的效率,另一个是使用Cron调度任务定时触发采集update任务
目标采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集multi-level文章list,支持采集body分页内容,支持采集multi-级别正文内容
定位采集 只需提供文章list URL 即可智能采集 来自任何网站 或列内容。
不仅支持对采集网页内容的“通配符匹配”,还完美支持各种CSS选择器。只需填写一个简单的 CSS 选择器,如 #title h1,即可准确地采集 网页上的任何内容。 (如何设置 CSS 选择器)
支持设置关键词,如果标题收录关键词,则只允许采集(或者过滤掉采集不允许)。
支持设置多个匹配规则采集网页不同内容,甚至支持采集任意内容添加到“Wordpress自定义栏目”中,方便扩展。
定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集body分页内容定位采集,支持通配符匹配,或者CSS选择器精确采集any内容,支持采集text 分页内容
基本设置功能齐全,完美支持Wordpress各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以发布采集target网站的分类目录、标签等信息,可以自动生成并添加相应的分类目录、标签等信息
每个采集任务可以选择发布到的类别、发布作者、发布状态、查看和更新时间间隔、采集target网站字符集、选择是否下载图片或附件。
支持自定义文章类型、自定义文章类别、文章表单。
完美支持Wordpress各种功能,自动添加标签,自动生成摘要,自动设置特色图片,支持自定义栏目等
完美支持Wordpress各种功能,自动设置分类、标签、摘要、特色图片、自定义栏目等
微信公众号采集
今日头条采集
采集微信公号、头条号等自媒体内容,因为百度没有收录公号、头条文章等,轻松获取优质“原创” 文章,加百度收录量和网站权重
支持采集微信公号(订阅号)文章,无需复杂配置,只需填写“公众号”和“微信ID”即可启动采集。 (微信公众号采集暂时采集difficulty,相关接口被腾讯屏蔽)
常见问题
WP-AutoBlog 与我使用的主题兼容吗?
WP-AutoBlog 兼容任何主题,不受限制,可以在任何主题下使用。
哪些 WordPress 版本与 WP-AutoBlog 兼容?
建议在 WordPress 3.0 及以上版本上运行。我们测试过在wordpress2.8.5及以上版本也能正常运行。当WordPress新版本发布时,我们会及时更新以兼容最新版本。
WP-AutoBlog 是否与 WordPress MU(多站点)版本兼容?
完全兼容,WP-AutoBlog可以在WordPress MU(多站点)的每个子站点下完美运行。请务必在各分站管理后台单独激活插件,不要使用“全网启用”。
绑定的域名可以修改吗?
您可以在30天内任意更改绑定域名,之后更改绑定域名只需支付插件价格的十分之一,无需重新购买原价。
web内容采集系统使用的springboot+exe采集缓存系统实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 518 次浏览 • 2021-08-01 02:12
文章采集系统的设计和实现很大程度上决定了系统的好坏与否和成败。目前来看,市面上几大采集系统都提供了基本上可以满足大部分行业的需求,网页数据采集对新手或者刚开始做数据采集不够熟悉的都是比较好用的,比如爬虫宝系统、天采客系统等。这里要说的是web内容采集,做过站内爬虫的朋友应该都知道。采集百度文库、豆瓣、微信公众号的数据相对比较熟悉。
这里是使用的springboot+exe缓存采集系统实现。安装环境webpack4.1.1-2.3.1-beta.8-5.4.1webgl等采集工具springmvc4.1.2.1-3.1.1-beta.1-3.3.1javascript5.2.0-chrome-67-ua-zh-cn.5.3.2redis4.2.0-blade.2-dev-server.jar工具主要是集成在java集成开发环境中,如果你要单独配置部署的话需要自己写配置文件。
<p>安装配置创建项目,mkdirp12,然后在项目目录下新建alias.java-lib.jar,把这个jar包的conf目录下添加到springboot容器中即可。同时,开发的jar文件也加入到conf目录下即可。然后在springmvc的conf目录下的properties(配置文件)文件中添加。importjava.io.bufferedloader;importjava.io.inputstream;importjava.io.outputstream;importjava.io.string;importjava.io.stringbuffer;importjava.util.list;importjava.util.map;importjava.util.set;importjava.util.hashmap;importjava.util.mapinfo;importjava.util.list;importjava.util.setnull;booleanispublicid();booleanispublicfield();booleanispublickey();booleanispublicentity();finalclass 查看全部
web内容采集系统使用的springboot+exe采集缓存系统实现
文章采集系统的设计和实现很大程度上决定了系统的好坏与否和成败。目前来看,市面上几大采集系统都提供了基本上可以满足大部分行业的需求,网页数据采集对新手或者刚开始做数据采集不够熟悉的都是比较好用的,比如爬虫宝系统、天采客系统等。这里要说的是web内容采集,做过站内爬虫的朋友应该都知道。采集百度文库、豆瓣、微信公众号的数据相对比较熟悉。
这里是使用的springboot+exe缓存采集系统实现。安装环境webpack4.1.1-2.3.1-beta.8-5.4.1webgl等采集工具springmvc4.1.2.1-3.1.1-beta.1-3.3.1javascript5.2.0-chrome-67-ua-zh-cn.5.3.2redis4.2.0-blade.2-dev-server.jar工具主要是集成在java集成开发环境中,如果你要单独配置部署的话需要自己写配置文件。
<p>安装配置创建项目,mkdirp12,然后在项目目录下新建alias.java-lib.jar,把这个jar包的conf目录下添加到springboot容器中即可。同时,开发的jar文件也加入到conf目录下即可。然后在springmvc的conf目录下的properties(配置文件)文件中添加。importjava.io.bufferedloader;importjava.io.inputstream;importjava.io.outputstream;importjava.io.string;importjava.io.stringbuffer;importjava.util.list;importjava.util.map;importjava.util.set;importjava.util.hashmap;importjava.util.mapinfo;importjava.util.list;importjava.util.setnull;booleanispublicid();booleanispublicfield();booleanispublickey();booleanispublicentity();finalclass
二手书流通形式的b2b门户,共享门户是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-30 05:10
文章采集系统是在目前国内做的比较成熟的产品了,很多团队都已经很成熟了,例如:北京的掌鱼生活,上海的沙贝网,广州的道捷,深圳的未来网等等。产品的市场竞争方面,主要是看企业有多少投入资金和时间,有多少人员,这些费用都是固定的。而且软件支持数据库,是否能够实现与mysql无缝对接,支持sql语句写入数据库这个是核心。
还有就是其他方面了,比如要不要开源,是否自己实现框架,客户有没有专门维护系统的需求。这些都需要根据你的具体情况来决定。还有你的团队的技术是否能够带动你系统的建设。基本上就这些吧。
我们做的是全国统一门户,与之对应的就是我们中国最大的b2b门户,共享门户,我们算是b2b企业,企业客户。其实全国统一门户应该与楼上所说的基本上一致,但是共享门户他要考虑门户的类型,应用对象,实际需求。比如北京的企业买二手书大多数都是为了查书价,但是海外的企业可能是为了看看有多少书,或者有什么图书。这样的市场是两个门户对于二手书流通形式的价值进行对比的,这里的书价对于二手书价值更加重要。
共享门户是什么?楼上的朋友说的是一个共享平台,b2b对接形式的共享平台。我今天要提的是一个垂直的b2b门户,即垂直于二手交易的门户,而不是共享共享共享。b2b2c能给二手流通带来的帮助?需要考虑的要素太多了。更确切的说,一个是交易的环节,一个是流通的环节。如果是交易的话,主要看的是交易的层次、层级;需要考虑的是商家与卖家,需要考虑的是利益的关系;需要考虑的是受众,需要考虑的是二手的流通地区;需要考虑的是流通的时间,需要考虑的是二手的流通时间。
这些需要一层一层的研究,而不是今天看一看哪个,哪个靠谱,那个技术先进,那个产品提供的好就看了。所以对于一个门户网站来说,最重要的,不是有哪些功能,而是它所服务于谁。你说卖家跟卖家的有什么不同?你说售卖的方式有哪些不同?你说价格、价格组合的方式有哪些不同?你说商品加入的规则有哪些不同?等等一系列有太多的不同了。
有些功能最多只是一层的简单组合。当你看到一个二手交易平台,你根本不知道它在售卖什么,它是让谁去卖的,它能卖给谁,它该卖给谁,交易的环节和层级等等等等,然后你就懵了。 查看全部
二手书流通形式的b2b门户,共享门户是什么?
文章采集系统是在目前国内做的比较成熟的产品了,很多团队都已经很成熟了,例如:北京的掌鱼生活,上海的沙贝网,广州的道捷,深圳的未来网等等。产品的市场竞争方面,主要是看企业有多少投入资金和时间,有多少人员,这些费用都是固定的。而且软件支持数据库,是否能够实现与mysql无缝对接,支持sql语句写入数据库这个是核心。
还有就是其他方面了,比如要不要开源,是否自己实现框架,客户有没有专门维护系统的需求。这些都需要根据你的具体情况来决定。还有你的团队的技术是否能够带动你系统的建设。基本上就这些吧。
我们做的是全国统一门户,与之对应的就是我们中国最大的b2b门户,共享门户,我们算是b2b企业,企业客户。其实全国统一门户应该与楼上所说的基本上一致,但是共享门户他要考虑门户的类型,应用对象,实际需求。比如北京的企业买二手书大多数都是为了查书价,但是海外的企业可能是为了看看有多少书,或者有什么图书。这样的市场是两个门户对于二手书流通形式的价值进行对比的,这里的书价对于二手书价值更加重要。
共享门户是什么?楼上的朋友说的是一个共享平台,b2b对接形式的共享平台。我今天要提的是一个垂直的b2b门户,即垂直于二手交易的门户,而不是共享共享共享。b2b2c能给二手流通带来的帮助?需要考虑的要素太多了。更确切的说,一个是交易的环节,一个是流通的环节。如果是交易的话,主要看的是交易的层次、层级;需要考虑的是商家与卖家,需要考虑的是利益的关系;需要考虑的是受众,需要考虑的是二手的流通地区;需要考虑的是流通的时间,需要考虑的是二手的流通时间。
这些需要一层一层的研究,而不是今天看一看哪个,哪个靠谱,那个技术先进,那个产品提供的好就看了。所以对于一个门户网站来说,最重要的,不是有哪些功能,而是它所服务于谁。你说卖家跟卖家的有什么不同?你说售卖的方式有哪些不同?你说价格、价格组合的方式有哪些不同?你说商品加入的规则有哪些不同?等等一系列有太多的不同了。
有些功能最多只是一层的简单组合。当你看到一个二手交易平台,你根本不知道它在售卖什么,它是让谁去卖的,它能卖给谁,它该卖给谁,交易的环节和层级等等等等,然后你就懵了。
分布式追踪到底是什么以及如何使用Map的整个架构?
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-07-28 20:19
在 Kibana 中,有一个可观察的应用程序,称为 APM,即应用程序性能监控。它建立在 Elastic Stack 之上。它可以让我轻松定位和调整应用程序的性能。在这个文章中,我将介绍什么是分布式追踪,以及如何使用Service Map来快速展示你系统的整个架构。
原文链接:...67839
Eland 是一个全新的 Python 包,它在 Elasticsearch 和数据科学生态系统之间架起了一座桥梁。 Elasticsearch 是一个功能丰富的开源搜索引擎,它建立在 Apache Lucene 之上,Apache Lucene 是市场上最重要的全文搜索引擎之一。 Elasticsearch 以其广泛而通用的 REST API 经验而闻名,包括用于全文搜索、排序和聚合任务的高效包装器,可以更轻松地在现有后端中实现此类功能,而无需进行复杂的重新设计。自 2010 年推出以来,Elasticsearch 在软件工程领域获得了广泛关注。到 2016 年,根据 DBMS 的 DB-engines 数据库,它成为最受欢迎的企业搜索引擎软件堆栈,超过了行业标准 Apache Solr(也建立在 Lucene 上)。
Elasticsearch 如此受欢迎的原因之一是它生成的生态系统。世界各地的工程师开发了开源 Elasticsearch 集成和扩展,其中许多项目被 Elastic(Elasticsearch 项目背后的公司)吸收作为其堆栈的一部分。其中一些项目是 Logstash(数据处理管道,通常用于解析基于文本的文件)和 Kibana(建立在 Elasticsearch 之上的可视化层)导致了广泛采用的 ELK(Elasticsearch、Logstash、Kibana)堆栈。 Elastic Stack 因其在新兴和集成技术领域(例如 DevOps、站点可靠性工程和近期数据分析)中的出色表现而被广泛使用。
数据科学
如果您是阅读本文的数据科学家,并将 Elasticsearch 作为您雇主技术堆栈的一部分,您在尝试使用 Elasticsearch 提供的所有功能进行数据分析甚至是简单的机器学习任务时可能会遇到一些问题。
数据科学家通常不习惯使用 NoSQL 数据库引擎来执行常见任务,甚至不习惯依赖复杂的 REST API 进行分析。例如,使用 Elasticsearch 的低级 Python 客户端处理大量数据并不是那么直观,而且对于 SWE 以外领域的人来说,学习曲线有点陡峭。
尽管 Elastic 为增强 Elastic Stack 的分析和数据科学用例做出了巨大努力,但它仍然缺乏与现有数据科学生态系统(pandas、numpy、scikit-learn、PyTorch 和其他流行库)的兼容性、简单的界面。
2017 年,Elastic 迈出了数据科学领域的第一步。针对机器学习和预测技术在软件行业的日益普及,它发布了第一个支持 ML for Elastic Stack 的 X-pack(扩展包),在其能力中增加了异常检测和其他无监督 ML 任务。不久之后,回归和分类模型也被添加到 Elastic Stack 中可用的 ML 任务集中。
原文链接:... 45670
《Elastic Stack 实战手册》的创作和发布源于阿里云与 Elastic-Elasticsearch 百人联合发起的一次大型合作活动。本次活动汇聚了 Elasticsearch 技术圈内数百名开发者共同创作,旨在汇聚圈内优秀创作者的实践经验和创造能力,输出一本可为开发者提供实用参考的书籍指南,促进应用开发的技术。本次发布的版本为本书第一期,由40位优秀开发者共同打造,涵盖了Elastic Stack开发者所需的大部分必要基础知识和场景应用参考。本书将继续对章节内容进行补充和完善,并随着Elastic Stack的版本升级不断迭代更新。
这里也呼吁各位开发者把自己的技术积累写成文章,加入创作者群,一起学习交流。这将不仅仅是一些人的书,而是所有 Elastic Stack 开发作者的实用指南。
欢迎您留言,我们会在以后尽最大努力完善本书!可以到地址下载:... ybook
一、职位描述
1、负责字节跳动飞书搜索平台的搜索研发,推动技术升级优化;
2、能深入了解搜索领域的业务场景和业务痛点,能设计好的索引结构,熟悉检索和排序的主要策略,能构建高可靠、高性能、高可扩展性。分布式检索系统;
3、可以深入了解搜索的各种衡量指标,构建指标体系来衡量搜索的方方面面;
4、可以深入了解后端服务相关的中间件,微服务的设计,后端服务的容灾;
二、职位要求
1、良好的设计和编码品味,爱写代码可以产出高质量的设计和代码;
2、非常注重稳定性和性能;
3、熟悉Linux操作系统,有很强的排查和解决问题的能力(troubleshooting);
4、 熟悉Lucene、ES、Solr等原理及相关技术,对索引、分词、排序等相关技术有深刻理解;
5、有主流大型搜索引擎架构和稳定性经验者优先加分;
6、了解分布式,有高并发场景/项目优化经验者优先。
三、福利待遇:
各行各业招贤纳士,期待英才加入
四、简历投递
发送简历至:lihaifeng.0314
五、工作地址:北京、深圳均可
六、其他
没有搜索经验,但有高并发后端工程经验也特别受欢迎 查看全部
分布式追踪到底是什么以及如何使用Map的整个架构?
在 Kibana 中,有一个可观察的应用程序,称为 APM,即应用程序性能监控。它建立在 Elastic Stack 之上。它可以让我轻松定位和调整应用程序的性能。在这个文章中,我将介绍什么是分布式追踪,以及如何使用Service Map来快速展示你系统的整个架构。
原文链接:...67839
Eland 是一个全新的 Python 包,它在 Elasticsearch 和数据科学生态系统之间架起了一座桥梁。 Elasticsearch 是一个功能丰富的开源搜索引擎,它建立在 Apache Lucene 之上,Apache Lucene 是市场上最重要的全文搜索引擎之一。 Elasticsearch 以其广泛而通用的 REST API 经验而闻名,包括用于全文搜索、排序和聚合任务的高效包装器,可以更轻松地在现有后端中实现此类功能,而无需进行复杂的重新设计。自 2010 年推出以来,Elasticsearch 在软件工程领域获得了广泛关注。到 2016 年,根据 DBMS 的 DB-engines 数据库,它成为最受欢迎的企业搜索引擎软件堆栈,超过了行业标准 Apache Solr(也建立在 Lucene 上)。
Elasticsearch 如此受欢迎的原因之一是它生成的生态系统。世界各地的工程师开发了开源 Elasticsearch 集成和扩展,其中许多项目被 Elastic(Elasticsearch 项目背后的公司)吸收作为其堆栈的一部分。其中一些项目是 Logstash(数据处理管道,通常用于解析基于文本的文件)和 Kibana(建立在 Elasticsearch 之上的可视化层)导致了广泛采用的 ELK(Elasticsearch、Logstash、Kibana)堆栈。 Elastic Stack 因其在新兴和集成技术领域(例如 DevOps、站点可靠性工程和近期数据分析)中的出色表现而被广泛使用。
数据科学
如果您是阅读本文的数据科学家,并将 Elasticsearch 作为您雇主技术堆栈的一部分,您在尝试使用 Elasticsearch 提供的所有功能进行数据分析甚至是简单的机器学习任务时可能会遇到一些问题。
数据科学家通常不习惯使用 NoSQL 数据库引擎来执行常见任务,甚至不习惯依赖复杂的 REST API 进行分析。例如,使用 Elasticsearch 的低级 Python 客户端处理大量数据并不是那么直观,而且对于 SWE 以外领域的人来说,学习曲线有点陡峭。
尽管 Elastic 为增强 Elastic Stack 的分析和数据科学用例做出了巨大努力,但它仍然缺乏与现有数据科学生态系统(pandas、numpy、scikit-learn、PyTorch 和其他流行库)的兼容性、简单的界面。
2017 年,Elastic 迈出了数据科学领域的第一步。针对机器学习和预测技术在软件行业的日益普及,它发布了第一个支持 ML for Elastic Stack 的 X-pack(扩展包),在其能力中增加了异常检测和其他无监督 ML 任务。不久之后,回归和分类模型也被添加到 Elastic Stack 中可用的 ML 任务集中。
原文链接:... 45670
《Elastic Stack 实战手册》的创作和发布源于阿里云与 Elastic-Elasticsearch 百人联合发起的一次大型合作活动。本次活动汇聚了 Elasticsearch 技术圈内数百名开发者共同创作,旨在汇聚圈内优秀创作者的实践经验和创造能力,输出一本可为开发者提供实用参考的书籍指南,促进应用开发的技术。本次发布的版本为本书第一期,由40位优秀开发者共同打造,涵盖了Elastic Stack开发者所需的大部分必要基础知识和场景应用参考。本书将继续对章节内容进行补充和完善,并随着Elastic Stack的版本升级不断迭代更新。
这里也呼吁各位开发者把自己的技术积累写成文章,加入创作者群,一起学习交流。这将不仅仅是一些人的书,而是所有 Elastic Stack 开发作者的实用指南。
欢迎您留言,我们会在以后尽最大努力完善本书!可以到地址下载:... ybook
一、职位描述
1、负责字节跳动飞书搜索平台的搜索研发,推动技术升级优化;
2、能深入了解搜索领域的业务场景和业务痛点,能设计好的索引结构,熟悉检索和排序的主要策略,能构建高可靠、高性能、高可扩展性。分布式检索系统;
3、可以深入了解搜索的各种衡量指标,构建指标体系来衡量搜索的方方面面;
4、可以深入了解后端服务相关的中间件,微服务的设计,后端服务的容灾;
二、职位要求
1、良好的设计和编码品味,爱写代码可以产出高质量的设计和代码;
2、非常注重稳定性和性能;
3、熟悉Linux操作系统,有很强的排查和解决问题的能力(troubleshooting);
4、 熟悉Lucene、ES、Solr等原理及相关技术,对索引、分词、排序等相关技术有深刻理解;
5、有主流大型搜索引擎架构和稳定性经验者优先加分;
6、了解分布式,有高并发场景/项目优化经验者优先。
三、福利待遇:
各行各业招贤纳士,期待英才加入
四、简历投递
发送简历至:lihaifeng.0314
五、工作地址:北京、深圳均可
六、其他
没有搜索经验,但有高并发后端工程经验也特别受欢迎
KafKa+Logstash日志收集系统的吞吐量存在问题分析思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-07-25 07:52
公司的KafKa+Logstash+Elasticsearch日志采集系统存在吞吐量问题,logstash消费速度跟不上,造成数据堆积;
三者的版本分别为:0.8.2.1、1.5.3、1.4.0
数据从 KafKa 消费,使用 logstash-input-kafka 插件,输出到 Elasticsearch 使用 logstash-output-Elasticsearch 插件。
对于这两个插件,已经分别进行了一定的配置,参考如下博客:点击打开链接
但是问题没有解决,消费速度没有提升,或者增幅很小,还有数据积累。考虑到使用的logstash版本和插件版本比较低,进行版本升级:
我下载了logstash的2.3.4版本,它集成了logstash网站上的所有插件。配置过程中遇到如下问题:
Elasticsearch 插件的配置:
1、新版插件没有主机和端口配置。已改为hosts:["127.0.0.1:9200"]
2、新版本配置中没有协议配置
在运行logstash的过程中,命令中有一个参数-l logs,用于配置日志目录logs。我没有手动创建这个目录,所以没有生成日志,也没有找到一开始的日志文件。一旦有日志,提示配置文件的问题,新版本的logstash和两个插件的配置很容易。
但是配置后,新版本logstash的吞吐量有所增加,但是在数据量大且增加比较快的情况下还是会有数据堆积,所以问题还是没有解决。
以下分析思路:
1、 观察logstash的消费过程,发现Kafka中的数据平衡性很差,少数节点数据量大,增长快,大部分节点几乎没有数据,所以logstash的多-threaded to node partition 在进程中摄取数据并不会大大提高性能。由于logstash使用的是fetch方式进行数据消费,感觉每个线程都会不断从Kafka中取数据。发现没有数据后,过一段时间再去取。虽然这些分区中没有数据,但还是会占用一部分cpu去取数据,这会影响到有数据的线程。如果可以知道哪个节点有数据,那么所有的CPU资源都给了这些节点,这些节点的数据抓取效率会快很多。目前的情况是每个partition分配一个cpu core,其中2/3的core在不停的读但是不能读数据,只有1/3的cpu在读,浪费了计算资源。
上面的想法是傻瓜式。 . 不是每个分区都分配一个线程,即一个核心绑定到这个线程。线程申请cpu的计算资源,从所有核申请。一个线程对应的分区中没有数据,那么这个线程如果没有占用CPU资源,或者说剩余的CPU资源可以被其他线程使用。注意:线程绑定的是cpu的计算资源,不是线程绑定的核。所以有些分区的数据很少,Kafka的负载均衡不好,从它消费数据不会影响logstash的速度。问题可能还是在于logstash向ES写入数据的速度。
2、 通过工具观察Elasticsearch的索引速度。如果很慢,很可能是logstash的输出链接影响了吞吐量。 查看全部
KafKa+Logstash日志收集系统的吞吐量存在问题分析思路
公司的KafKa+Logstash+Elasticsearch日志采集系统存在吞吐量问题,logstash消费速度跟不上,造成数据堆积;
三者的版本分别为:0.8.2.1、1.5.3、1.4.0
数据从 KafKa 消费,使用 logstash-input-kafka 插件,输出到 Elasticsearch 使用 logstash-output-Elasticsearch 插件。
对于这两个插件,已经分别进行了一定的配置,参考如下博客:点击打开链接
但是问题没有解决,消费速度没有提升,或者增幅很小,还有数据积累。考虑到使用的logstash版本和插件版本比较低,进行版本升级:
我下载了logstash的2.3.4版本,它集成了logstash网站上的所有插件。配置过程中遇到如下问题:
Elasticsearch 插件的配置:
1、新版插件没有主机和端口配置。已改为hosts:["127.0.0.1:9200"]
2、新版本配置中没有协议配置
在运行logstash的过程中,命令中有一个参数-l logs,用于配置日志目录logs。我没有手动创建这个目录,所以没有生成日志,也没有找到一开始的日志文件。一旦有日志,提示配置文件的问题,新版本的logstash和两个插件的配置很容易。
但是配置后,新版本logstash的吞吐量有所增加,但是在数据量大且增加比较快的情况下还是会有数据堆积,所以问题还是没有解决。
以下分析思路:
1、 观察logstash的消费过程,发现Kafka中的数据平衡性很差,少数节点数据量大,增长快,大部分节点几乎没有数据,所以logstash的多-threaded to node partition 在进程中摄取数据并不会大大提高性能。由于logstash使用的是fetch方式进行数据消费,感觉每个线程都会不断从Kafka中取数据。发现没有数据后,过一段时间再去取。虽然这些分区中没有数据,但还是会占用一部分cpu去取数据,这会影响到有数据的线程。如果可以知道哪个节点有数据,那么所有的CPU资源都给了这些节点,这些节点的数据抓取效率会快很多。目前的情况是每个partition分配一个cpu core,其中2/3的core在不停的读但是不能读数据,只有1/3的cpu在读,浪费了计算资源。
上面的想法是傻瓜式。 . 不是每个分区都分配一个线程,即一个核心绑定到这个线程。线程申请cpu的计算资源,从所有核申请。一个线程对应的分区中没有数据,那么这个线程如果没有占用CPU资源,或者说剩余的CPU资源可以被其他线程使用。注意:线程绑定的是cpu的计算资源,不是线程绑定的核。所以有些分区的数据很少,Kafka的负载均衡不好,从它消费数据不会影响logstash的速度。问题可能还是在于logstash向ES写入数据的速度。
2、 通过工具观察Elasticsearch的索引速度。如果很慢,很可能是logstash的输出链接影响了吞吐量。
设计对象只需要爬取整个网站——文章采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-07-17 04:01
文章采集系统:爬虫系统:语雀-typecho文章页/文章详情页图片生成云缓存储:picasa工欲善其事必先利其器导入数据1.本文只爬取电商网站,可以参考豆瓣网,京东,当当网等。2.本文设计对象只需要爬取整个网站,即文章页/文章详情页数据源:mongodb语法:request访问:,具体获取链接:welcome,mongodb给大家带来一个特别酷的功能,python画图。
让你在没有代码基础,甚至基本没有python基础的情况下,也能像从电脑上画流程图一样。详情见我的另一篇文章:对象协作我的团队是github上开发的,实践中出了一些问题,欢迎各位指出和讨论。上代码:gitclonepython3pymongodb到本地,开始安装numpy,pandas以及mongodb驱动参考文章:对象协作你的群里已经有一位小伙伴在学mongodb,需要更多帮助的小伙伴私信我,我给你他的网盘中的代码和安装文档。
有2条路可以走1。像pyenv这种第三方工具用这个来整理文件夹或者线索文件,不过我建议按照实际情况稍微缩减下,甚至choicefile我是用osx的,我只是觉得osx的系统很简洁,dashboard查询时也蛮方便,你要是用mac还是建议换一个系统2。直接使用pyspider来做,比如你像爬都有maven包自己根据实际情况选择顺带一提这个只能运行在windows下如果你是eclipse那就不存在系统的问题了,可以考虑用pywin32写osx,毕竟我已经在windows上写java了另外你完全可以代码放到。
pypi。list_{pypi}。json里面啊,我觉得是个很好的全局变量名保存,我偶尔代码写好会写在。pyc文件里面很爽,而且json很好用,没必要很费劲的用windows来做runtime。 查看全部
设计对象只需要爬取整个网站——文章采集系统
文章采集系统:爬虫系统:语雀-typecho文章页/文章详情页图片生成云缓存储:picasa工欲善其事必先利其器导入数据1.本文只爬取电商网站,可以参考豆瓣网,京东,当当网等。2.本文设计对象只需要爬取整个网站,即文章页/文章详情页数据源:mongodb语法:request访问:,具体获取链接:welcome,mongodb给大家带来一个特别酷的功能,python画图。
让你在没有代码基础,甚至基本没有python基础的情况下,也能像从电脑上画流程图一样。详情见我的另一篇文章:对象协作我的团队是github上开发的,实践中出了一些问题,欢迎各位指出和讨论。上代码:gitclonepython3pymongodb到本地,开始安装numpy,pandas以及mongodb驱动参考文章:对象协作你的群里已经有一位小伙伴在学mongodb,需要更多帮助的小伙伴私信我,我给你他的网盘中的代码和安装文档。
有2条路可以走1。像pyenv这种第三方工具用这个来整理文件夹或者线索文件,不过我建议按照实际情况稍微缩减下,甚至choicefile我是用osx的,我只是觉得osx的系统很简洁,dashboard查询时也蛮方便,你要是用mac还是建议换一个系统2。直接使用pyspider来做,比如你像爬都有maven包自己根据实际情况选择顺带一提这个只能运行在windows下如果你是eclipse那就不存在系统的问题了,可以考虑用pywin32写osx,毕竟我已经在windows上写java了另外你完全可以代码放到。
pypi。list_{pypi}。json里面啊,我觉得是个很好的全局变量名保存,我偶尔代码写好会写在。pyc文件里面很爽,而且json很好用,没必要很费劲的用windows来做runtime。
文章采集系统udacity的零碎课程及课程笔记来的
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-14 18:03
文章采集系统udacity的零碎课程及课程笔记来的。(从2018年2月开始记录)前端:[1](入门)dashboardpython:[2]jquery下面是课程笔记demo:web和android端web框架:[3](框架)vue,angular,react详细框架ui:[4](入门,简单插件)antd:[5](插件)api:[6](框架)ajaxappletpilp包python主要定位于通用性框架;angular主要定位于基于vue、angular2开发专用框架;react主要定位于前端开发界面化。
web不只是html,javascript还是很重要的。类似于重庆小面,有重庆火锅和火锅,重庆小面不只是辣椒油,是多种配料混合在一起的一道菜品。(对,重庆小面我很喜欢,但就是没人买火锅串串冒菜火锅冷面兔丁牛肉面毛血旺鱼粉凉粉都没有重庆小面挣钱...)不仅是语言,软件工程也应该同样重要;软件工程也应该更重视语言;软件工程也应该以开发者和人工智能为主要目标。
编程语言并不是最重要的事情;编程语言和编程语言所代表的语言以及这些语言下各语言表达的规则都在不断丰富。不论编程语言本身多么变化,终归是由规则构成,主语言的规则能够被更改。从语言规则的角度,任何语言的差异都在可以被理解。每种语言都有他特有的优势和劣势,也有他存在的价值,对编程语言实现者来说,这些价值和优势和劣势都是值得珍惜的,更是他们得以成为一门语言的资本。
手把手教程:[1](编程笔记|零碎课程])[2](入门,简单插件)《手把手教你快速学python》(/)《手把手教你快速学javascript》()[3](课程笔记:自动带你玩转angular3)《angular开发实战》()[4](课程笔记:教你简单快速搭建一个完整的页面)教你简单实现一个简单的网站教你简单搭建一个微信小程序教你使用mongodb教你使用node.jsexpress框架教你通过restful访问和路由[5](课程笔记:如何写airpods?)airpods实现教你使用node.jsexpress框架(教你使用restful访问和路由)[6](手把手教你写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](。 查看全部
文章采集系统udacity的零碎课程及课程笔记来的
文章采集系统udacity的零碎课程及课程笔记来的。(从2018年2月开始记录)前端:[1](入门)dashboardpython:[2]jquery下面是课程笔记demo:web和android端web框架:[3](框架)vue,angular,react详细框架ui:[4](入门,简单插件)antd:[5](插件)api:[6](框架)ajaxappletpilp包python主要定位于通用性框架;angular主要定位于基于vue、angular2开发专用框架;react主要定位于前端开发界面化。
web不只是html,javascript还是很重要的。类似于重庆小面,有重庆火锅和火锅,重庆小面不只是辣椒油,是多种配料混合在一起的一道菜品。(对,重庆小面我很喜欢,但就是没人买火锅串串冒菜火锅冷面兔丁牛肉面毛血旺鱼粉凉粉都没有重庆小面挣钱...)不仅是语言,软件工程也应该同样重要;软件工程也应该更重视语言;软件工程也应该以开发者和人工智能为主要目标。
编程语言并不是最重要的事情;编程语言和编程语言所代表的语言以及这些语言下各语言表达的规则都在不断丰富。不论编程语言本身多么变化,终归是由规则构成,主语言的规则能够被更改。从语言规则的角度,任何语言的差异都在可以被理解。每种语言都有他特有的优势和劣势,也有他存在的价值,对编程语言实现者来说,这些价值和优势和劣势都是值得珍惜的,更是他们得以成为一门语言的资本。
手把手教程:[1](编程笔记|零碎课程])[2](入门,简单插件)《手把手教你快速学python》(/)《手把手教你快速学javascript》()[3](课程笔记:自动带你玩转angular3)《angular开发实战》()[4](课程笔记:教你简单快速搭建一个完整的页面)教你简单实现一个简单的网站教你简单搭建一个微信小程序教你使用mongodb教你使用node.jsexpress框架教你通过restful访问和路由[5](课程笔记:如何写airpods?)airpods实现教你使用node.jsexpress框架(教你使用restful访问和路由)[6](手把手教你写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](教你如何写个小程序[第6期](。

