
文章采集系统
微信公众号文章采集系统镜像有6个G,用分卷压缩文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-03-23 07:04
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。
系统映像具有6 Gs,文件按子卷压缩,并且记录了一些使用视频并将其放置在其中。
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集解决方案设为开源
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0可以将启动规则开发为模块。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此anyproxy需要打开端口8001才能使所有http请求成功。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作网络服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,用于模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是不能在Windows中完成。虚拟机安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机无法进行二次虚拟化,阿里云Windows服务器无法安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果您认为这对您有用,请随时提供奖励,我没有设置奖励金额
如果在安装和使用过程中遇到任何问题,请将我添加到微信中。 查看全部
微信公众号文章采集系统镜像有6个G,用分卷压缩文件
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。

系统映像具有6 Gs,文件按子卷压缩,并且记录了一些使用视频并将其放置在其中。
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集解决方案设为开源
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0可以将启动规则开发为模块。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此anyproxy需要打开端口8001才能使所有http请求成功。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作网络服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,用于模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是不能在Windows中完成。虚拟机安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机无法进行二次虚拟化,阿里云Windows服务器无法安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果您认为这对您有用,请随时提供奖励,我没有设置奖励金额
如果在安装和使用过程中遇到任何问题,请将我添加到微信中。
云erp工具有赞,有赞云计算工具汇聚了70+个优质的学生
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-03-23 03:04
文章采集系统改版1周后,形成csw三维渲染系统。用多次客户请求告诉我,他们找我做个统计数据,告诉他们孩子的学习成绩,原来在abc也是数据课上成绩好的学生,从而引出他们学校的学习。那分数是怎么决定的呢?a在班级排名第一,b成绩是第四;经计算可知a比b分数多,数据都是值的比较计算,b比a分数多,就值2个。
把课程比例相关按学生重点关注度比较,a成绩第一,b成绩第二,依次类推,直到最后一位数据,可得到“全部学生学习成绩排序”。又因为b最后一位是“5”,与第一位“2”有关,以7为分水岭,如果7,b排在a前面,为第5,依次类推,1234都在1~3之间。即1~5之间,孩子几乎没差别,若6,排在b前面,那就是2~5之间。
排位最后的就是班级倒数第二名的孩子,依次类推。利用了“童年相关”(绘图,计算机或手工)法,可以方便以确定周期内学生学习情况,自动告诉你孩子的排名,进而得出成绩。这个课后反馈系统这么重要,但是使用成本很高。本文推荐使用云erp工具有赞,有赞云计算工具汇聚了70+个优质的云计算厂商,8款主流云计算产品,多数是国外品牌。
分布在103个城市,1.98亿会员,4.26亿活跃用户。用户数、活跃度、借助有赞平台,你可以销售云计算产品,或者获得100+个用户,轻松成为国内最大的精准用户触达平台。做好手里的工作,反馈也就不是问题了。使用有赞必备条件:精准用户触达一定要有,因为再好的软件再好的工具都是有使用成本,到最后反馈结果会很差,你是买卖来用的。有了目标客户,才有今后盈利的可能。 查看全部
云erp工具有赞,有赞云计算工具汇聚了70+个优质的学生
文章采集系统改版1周后,形成csw三维渲染系统。用多次客户请求告诉我,他们找我做个统计数据,告诉他们孩子的学习成绩,原来在abc也是数据课上成绩好的学生,从而引出他们学校的学习。那分数是怎么决定的呢?a在班级排名第一,b成绩是第四;经计算可知a比b分数多,数据都是值的比较计算,b比a分数多,就值2个。
把课程比例相关按学生重点关注度比较,a成绩第一,b成绩第二,依次类推,直到最后一位数据,可得到“全部学生学习成绩排序”。又因为b最后一位是“5”,与第一位“2”有关,以7为分水岭,如果7,b排在a前面,为第5,依次类推,1234都在1~3之间。即1~5之间,孩子几乎没差别,若6,排在b前面,那就是2~5之间。
排位最后的就是班级倒数第二名的孩子,依次类推。利用了“童年相关”(绘图,计算机或手工)法,可以方便以确定周期内学生学习情况,自动告诉你孩子的排名,进而得出成绩。这个课后反馈系统这么重要,但是使用成本很高。本文推荐使用云erp工具有赞,有赞云计算工具汇聚了70+个优质的云计算厂商,8款主流云计算产品,多数是国外品牌。
分布在103个城市,1.98亿会员,4.26亿活跃用户。用户数、活跃度、借助有赞平台,你可以销售云计算产品,或者获得100+个用户,轻松成为国内最大的精准用户触达平台。做好手里的工作,反馈也就不是问题了。使用有赞必备条件:精准用户触达一定要有,因为再好的软件再好的工具都是有使用成本,到最后反馈结果会很差,你是买卖来用的。有了目标客户,才有今后盈利的可能。
深度学习中应用最多的是深度rnn,关键技术是前馈
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-02-22 09:01
文章采集系统通常有三个关键环节:采集-智能分发-数据维护,不同的服务商会有不同侧重点。从推荐产品本身看:主要考虑的是推荐内容的相关性和创新性,以及系统预期的解决方案和可靠性,目标是不断的优化和迭代采集和智能分发的效率,数据维护需要考虑的主要是并发连接的性能,整体架构能否支持大规模的数据处理。
深度学习中应用最多的是深度rnn,关键技术是前馈神经网络和模板匹配技术,这方面中科大和哈工大,人家是王者。
我发现很多企业做深度学习的都是找云厂商购买。
题主是否关注过深度学习可视化?方便做推荐引擎什么的。
如果技术目标是系统的召回概率,那么这些服务商都不错,甚至有一些做商品主动推荐的,选择时看看预测准确度。如果考虑性价比,那就是我觉得fair比较好,搜这方面的项目,机器学习,深度学习应该是未来趋势,这里比较擅长。
deepevolutionofdeeplearningarchitecturesnotarguablyunsupervisedrecurrentneuralnetworksforunsupervisedrecommendationgenerativeadversarialnetworksforunsupervisedrecommendation。
但从客户端推荐来说,以apus为例,是比较普遍存在的通用平台,从客户端和服务端分开的。从产品角度,在工程项目中应该讲究推荐效率,和搜索做类比;前者如果和搜索竞争,对apus的竞争对手是拉勾。对用户来说,是要考虑用户体验的,对服务端来说,是要考虑能否尽快打开业务流量。 查看全部
深度学习中应用最多的是深度rnn,关键技术是前馈
文章采集系统通常有三个关键环节:采集-智能分发-数据维护,不同的服务商会有不同侧重点。从推荐产品本身看:主要考虑的是推荐内容的相关性和创新性,以及系统预期的解决方案和可靠性,目标是不断的优化和迭代采集和智能分发的效率,数据维护需要考虑的主要是并发连接的性能,整体架构能否支持大规模的数据处理。
深度学习中应用最多的是深度rnn,关键技术是前馈神经网络和模板匹配技术,这方面中科大和哈工大,人家是王者。
我发现很多企业做深度学习的都是找云厂商购买。
题主是否关注过深度学习可视化?方便做推荐引擎什么的。
如果技术目标是系统的召回概率,那么这些服务商都不错,甚至有一些做商品主动推荐的,选择时看看预测准确度。如果考虑性价比,那就是我觉得fair比较好,搜这方面的项目,机器学习,深度学习应该是未来趋势,这里比较擅长。
deepevolutionofdeeplearningarchitecturesnotarguablyunsupervisedrecurrentneuralnetworksforunsupervisedrecommendationgenerativeadversarialnetworksforunsupervisedrecommendation。
但从客户端推荐来说,以apus为例,是比较普遍存在的通用平台,从客户端和服务端分开的。从产品角度,在工程项目中应该讲究推荐效率,和搜索做类比;前者如果和搜索竞争,对apus的竞争对手是拉勾。对用户来说,是要考虑用户体验的,对服务端来说,是要考虑能否尽快打开业务流量。
全世界云服务器、大数据、信息系统仿真案例
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-02-14 10:05
文章采集系统仿真案例介绍:本案例将研究一个关于全世界云服务器、大数据、web服务器、文件管理服务器等信息系统的仿真系统。通过本案例,
一、抽象概念。
二、hadoop、hive和spark的相互关系
三、关于socket编程的重要知识。(socket编程几乎涵盖所有的编程中心,极大的拓展了我们在编程中的能力。由于socket被用于方方面面,而java语言本身很难去清楚表述程序逻辑所需要的各个层次的东西,因此hadoop框架的设计初衷就是提供一个方便的lib接口让我们使用,它的核心框架解决了内存管理、消息传递、io等原本应该在编程中必备的技术;)。
四、关于lamp的理解。(其实在之前已经介绍过传统架构和lamp架构的历史了,当时我们提到过apache大部分基于yaml、pmlk等,lamp是用hadoop框架生成的构建模型;lamp架构才是计算分布式架构的基础;apache因为开源建设的不成熟,数据库服务还是直接对接mysql,而新成立的cloudera只有mysql,而hadoop框架本身只支持mysql。所以我们需要继续重新架构spark的基础架构;)。
五、lamp的运行机制和spark的运行机制;(我们从spark概念进行引入:传统的架构是客户端把要操作的数据源地址发给client,由client进行与数据源进行建立tcp连接,从而存储tcp连接状态的变化,然后通过socket通讯进行传输;lamp架构与spark架构最大的不同是云服务器,从spark中对于客户端最主要的一个概念就是客户端是一个包含schema的虚拟机,所以云服务器要求对client实施和虚拟机一样的功能,要给客户端一个好的交互界面,而spark和lamp不同的是它更好的支持对schema之间的http/web访问,从而实现spark的api客户端,而且spark与opentsdb进行了集成,更好的进行了sql类型的转换;这些对hadoop来说相对较难。)。
六、hadoop模式。
七、mysql和sql的关系。
八、hadoop支持的和其他sql数据库集成。本案例中的代码虽然都是通过java语言开发的,但是,在具体编写的时候要掌握driver(可以理解为server,是类型转换工具类)和driverdatasource(是存储服务器,是类型转换工具类)中间的数据流;这样才能写出优美的代码。如果是其他语言编写的web服务器类要注意大量的特征转换,转换和类型转换过程。参考文献:《java编程思想》ggii:hadoop与lamp环境搭建。 查看全部
全世界云服务器、大数据、信息系统仿真案例
文章采集系统仿真案例介绍:本案例将研究一个关于全世界云服务器、大数据、web服务器、文件管理服务器等信息系统的仿真系统。通过本案例,
一、抽象概念。
二、hadoop、hive和spark的相互关系
三、关于socket编程的重要知识。(socket编程几乎涵盖所有的编程中心,极大的拓展了我们在编程中的能力。由于socket被用于方方面面,而java语言本身很难去清楚表述程序逻辑所需要的各个层次的东西,因此hadoop框架的设计初衷就是提供一个方便的lib接口让我们使用,它的核心框架解决了内存管理、消息传递、io等原本应该在编程中必备的技术;)。
四、关于lamp的理解。(其实在之前已经介绍过传统架构和lamp架构的历史了,当时我们提到过apache大部分基于yaml、pmlk等,lamp是用hadoop框架生成的构建模型;lamp架构才是计算分布式架构的基础;apache因为开源建设的不成熟,数据库服务还是直接对接mysql,而新成立的cloudera只有mysql,而hadoop框架本身只支持mysql。所以我们需要继续重新架构spark的基础架构;)。
五、lamp的运行机制和spark的运行机制;(我们从spark概念进行引入:传统的架构是客户端把要操作的数据源地址发给client,由client进行与数据源进行建立tcp连接,从而存储tcp连接状态的变化,然后通过socket通讯进行传输;lamp架构与spark架构最大的不同是云服务器,从spark中对于客户端最主要的一个概念就是客户端是一个包含schema的虚拟机,所以云服务器要求对client实施和虚拟机一样的功能,要给客户端一个好的交互界面,而spark和lamp不同的是它更好的支持对schema之间的http/web访问,从而实现spark的api客户端,而且spark与opentsdb进行了集成,更好的进行了sql类型的转换;这些对hadoop来说相对较难。)。
六、hadoop模式。
七、mysql和sql的关系。
八、hadoop支持的和其他sql数据库集成。本案例中的代码虽然都是通过java语言开发的,但是,在具体编写的时候要掌握driver(可以理解为server,是类型转换工具类)和driverdatasource(是存储服务器,是类型转换工具类)中间的数据流;这样才能写出优美的代码。如果是其他语言编写的web服务器类要注意大量的特征转换,转换和类型转换过程。参考文献:《java编程思想》ggii:hadoop与lamp环境搭建。
解决方案:持续更新,微信公众号文章批量采集系统的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 392 次浏览 • 2020-10-01 13:03
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是它越来越难采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。这样就形成了可以自动采集正式帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定写下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为实际上此链接地址需要几个参数才能正常显示内容。让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址。有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似ID的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。 查看全部
持续更新,建设微信公众号文章批处理采集系统
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是它越来越难采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。这样就形成了可以自动采集正式帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定写下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为实际上此链接地址需要几个参数才能正常显示内容。让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址。有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似ID的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。

<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。
汇总:持续更新,微信公众号文章批量采集系统的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-10-01 11:00
2019年10月28日更新:
录制了YouTube视频以详细说明操作步骤:
youtu.be
<p>=================原创============================ 查看全部
持续更新,建设微信公众号文章批处理采集系统
2019年10月28日更新:
录制了YouTube视频以详细说明操作步骤:
youtu.be
<p>=================原创============================
解决方案:最详细优采云数据采集系统DedeCMS发布文章攻略
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-09-05 15:25
搜索引擎不喜欢复制内容,也不喜欢数据采集,但有时会遇到某些情况。例如,网站需要更改网络数据采集或网站备份。提醒大家:
①进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大修改;
③不建议将采集个其他网站信息用于新站点,这将减少新站点的特殊权重。
前一段时间,我制定了一个旧的网站修订计划。由于更换了管理系统和数据库,因此我决定对原创网站数据采集采用解决方案。对于网站修订,新手需要掌握很多站点建设知识和SEO知识。这些经验用于与您分享。
网站基本情况
本网站最初有一个排名,收录也比较大,优化效果更好,制作风格与mousse seo非常相似,代码简单,最详细优采云数据采集系统Dede cms发布文章前端环境突袭,标签应用还可以,但是网站优化方法却有黑帽子。使用asp程序后端,数据库是access,要替换为php,数据库是mysql。
网站用于修订的软件工具
-EditPlus或DreamWear(代码编辑器); -APMServ(本地ASP、PHP环境); -Fiddler Web汉化版(web数据抓包); -火车头(LocoySpider)采集7.6(破解稳定版、数据采集); -DedeCMS V5.7(后台内容管理程序); -其他辅助工具。
网站借助优采云 采集的详细步骤,以构建1.版本的本地环境,安装Dede cms,安装Fiddler Web捕获工具以及安装诸如优采云之类的软件采集 7. 6
安装方法非常简单,涉及文章“在64位win8win10系统启动失败解决方案中安装APMServ”,“如何安装dede cms 织梦详细说明”。
提供一些软件下载链接:密码:3n7e
2. 优采云设置(关键内容)
官方描述相对简单,必须阅读和练习新手采集 网站数据。打开优采云 采集工具并创建一个新任务和组。
第一步:采集 URL规则
①起始地址。即提取分页规则,请按以下图顺序:单击添加-单击批处理/多页输入地址格式,例如,我希望采集具有地址列表,即:
可以看出变量是1,2,3 ...由通配符写出
在算术序列中选择项目数作为所需的列表数采集,并根据实际情况进行写入。点击依次添加
然后单击添加-完成-关闭。
②多级URL获取。获取特定页面的URL地址列表。在任何目标列表中,单击鼠标右键以查看源代码。一般来说,具有基础知识的学生无需多说,而且有许多他们不理解的在线资源。找到特征代码片段,如下所示编写并保存。
单击测试URL 采集,并确保列表采集的规则正确,然后继续执行第二步。 查看全部
最详细的优采云数据采集系统Dede cms发布文章指南
搜索引擎不喜欢复制内容,也不喜欢数据采集,但有时会遇到某些情况。例如,网站需要更改网络数据采集或网站备份。提醒大家:
①进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大修改;
③不建议将采集个其他网站信息用于新站点,这将减少新站点的特殊权重。
前一段时间,我制定了一个旧的网站修订计划。由于更换了管理系统和数据库,因此我决定对原创网站数据采集采用解决方案。对于网站修订,新手需要掌握很多站点建设知识和SEO知识。这些经验用于与您分享。

网站基本情况
本网站最初有一个排名,收录也比较大,优化效果更好,制作风格与mousse seo非常相似,代码简单,最详细优采云数据采集系统Dede cms发布文章前端环境突袭,标签应用还可以,但是网站优化方法却有黑帽子。使用asp程序后端,数据库是access,要替换为php,数据库是mysql。
网站用于修订的软件工具
-EditPlus或DreamWear(代码编辑器); -APMServ(本地ASP、PHP环境); -Fiddler Web汉化版(web数据抓包); -火车头(LocoySpider)采集7.6(破解稳定版、数据采集); -DedeCMS V5.7(后台内容管理程序); -其他辅助工具。
网站借助优采云 采集的详细步骤,以构建1.版本的本地环境,安装Dede cms,安装Fiddler Web捕获工具以及安装诸如优采云之类的软件采集 7. 6
安装方法非常简单,涉及文章“在64位win8win10系统启动失败解决方案中安装APMServ”,“如何安装dede cms 织梦详细说明”。
提供一些软件下载链接:密码:3n7e
2. 优采云设置(关键内容)
官方描述相对简单,必须阅读和练习新手采集 网站数据。打开优采云 采集工具并创建一个新任务和组。

第一步:采集 URL规则
①起始地址。即提取分页规则,请按以下图顺序:单击添加-单击批处理/多页输入地址格式,例如,我希望采集具有地址列表,即:
可以看出变量是1,2,3 ...由通配符写出
在算术序列中选择项目数作为所需的列表数采集,并根据实际情况进行写入。点击依次添加

然后单击添加-完成-关闭。
②多级URL获取。获取特定页面的URL地址列表。在任何目标列表中,单击鼠标右键以查看源代码。一般来说,具有基础知识的学生无需多说,而且有许多他们不理解的在线资源。找到特征代码片段,如下所示编写并保存。

单击测试URL 采集,并确保列表采集的规则正确,然后继续执行第二步。
分享文章:微信公众号搜索接口采集微信公众号文章采集系统---开箱即用
采集交流 • 优采云 发表了文章 • 0 个评论 • 478 次浏览 • 2020-08-31 07:34
摘要: 本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包到虚拟机中. 您只需要下载并安装虚拟机映像即可使用它. 首先,我要感谢团队负责人饭口勇(Iiguchi)开放他的采集解决方案. 规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php. 从一开始就了解公共帐户的文章采集,到了解实施原理,最后到制作镜像,我在中间遇到了种种困难,既费时又费力. 我咨询了很多人,甚至在吃饭和睡觉时都想过一些细节. 解决方案,解决问题的喜悦以及被问题纠缠的困扰,感谢您在此过程中所提供的帮助.
微信公众号搜索界面采集
本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包为虚拟机. 您只需要下载并安装虚拟机映像即可使用它.
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接: 密码: 7r4d
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源.
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1,anyproxy阿里巴巴的开源代理拦截器(使用4.0版)可以轻松修改响应信息. 我已经在系统中安装了anyproxy,并且安装非常简单. 首先安装nodejs环境,然后使用npm安装anyproxy.
anyproxy 4.0的开始规则可以作为模块开发. 编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可. 此处使用的命令是anproxy --rule weixin.js. 关于anproxy如何设置https证书,请访问官方网站. 我已经在虚拟机中设置了全局代理,因此需要先打开任何代理,然后才能在端口8001上成功访问该请求.
规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php.
2,apache + php + mysql,主要用作Web服务器,处理被anyproxy拦截的请求,处理微信文章数据以及喜欢和阅读的次数.
截取的数据的处理可以在特定的PHP代码中看到,逻辑不是太复杂. 为方便起见,这是phpstudy的集成开发环境.
3. 按钮向导. 按钮向导是一种国产工具,可模拟类似于vb语法的键盘和鼠标. 按钮向导在此处用于模拟单击Windows下的微信客户端.
在处理多个微信公众号时,客户需要点击,所有手动操作均由按钮向导模拟. 当我去检查特定的代码时,我使用了一个小技巧来处理单击历史消息. 事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但找不到. 您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮.
当一个想法不起作用时,请尝试其他想法. 整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推.
4. Windows WeChat客户端,我实际上尝试使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是无法将其安装在虚拟机Android模拟器中,也就是说也就是说,不可能在虚拟机中进行辅助虚拟化. 我已经踩到了这个坑,所以您不需要踩到它. 我记得以前有人问过,阿里云Windows服务器可以配备Android模拟器吗?我认为答案是相同的. 虚拟机无法执行辅助虚拟化. 阿里云窗口服务器无法安装Android模拟器.
因此,当我尝试使用Android模拟器时,我发现原创微信PC客户端(包括mac)的功能已经完善,然后尝试了Windows客户端.
5. Virtualbox虚拟机,这是Oracle生产的虚拟机. 将涉及一些网络配置,例如设置为NAT模式.
现在将虚拟机映像开源,其中所有代码都在虚拟机中,您可以随意对其进行修改.
从了解官方帐户文章采集到了解实施原理,然后到最终镜像,我在中间经历了种种困难,这既费时又费力. 我咨询了很多人,甚至想到了吃饭和睡觉. 对于详细的解决方案而言,解决问题会很高兴,而被问题纠缠也很痛苦. 感谢您在此过程中对人们的帮助.
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012) 查看全部
微信公众号搜索界面采集微信公众号文章采集系统---开箱即用
摘要: 本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包到虚拟机中. 您只需要下载并安装虚拟机映像即可使用它. 首先,我要感谢团队负责人饭口勇(Iiguchi)开放他的采集解决方案. 规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php. 从一开始就了解公共帐户的文章采集,到了解实施原理,最后到制作镜像,我在中间遇到了种种困难,既费时又费力. 我咨询了很多人,甚至在吃饭和睡觉时都想过一些细节. 解决方案,解决问题的喜悦以及被问题纠缠的困扰,感谢您在此过程中所提供的帮助.
微信公众号搜索界面采集

本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包为虚拟机. 您只需要下载并安装虚拟机映像即可使用它.
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接: 密码: 7r4d
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源.
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1,anyproxy阿里巴巴的开源代理拦截器(使用4.0版)可以轻松修改响应信息. 我已经在系统中安装了anyproxy,并且安装非常简单. 首先安装nodejs环境,然后使用npm安装anyproxy.
anyproxy 4.0的开始规则可以作为模块开发. 编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可. 此处使用的命令是anproxy --rule weixin.js. 关于anproxy如何设置https证书,请访问官方网站. 我已经在虚拟机中设置了全局代理,因此需要先打开任何代理,然后才能在端口8001上成功访问该请求.
规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php.
2,apache + php + mysql,主要用作Web服务器,处理被anyproxy拦截的请求,处理微信文章数据以及喜欢和阅读的次数.
截取的数据的处理可以在特定的PHP代码中看到,逻辑不是太复杂. 为方便起见,这是phpstudy的集成开发环境.
3. 按钮向导. 按钮向导是一种国产工具,可模拟类似于vb语法的键盘和鼠标. 按钮向导在此处用于模拟单击Windows下的微信客户端.
在处理多个微信公众号时,客户需要点击,所有手动操作均由按钮向导模拟. 当我去检查特定的代码时,我使用了一个小技巧来处理单击历史消息. 事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但找不到. 您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮.
当一个想法不起作用时,请尝试其他想法. 整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推.
4. Windows WeChat客户端,我实际上尝试使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是无法将其安装在虚拟机Android模拟器中,也就是说也就是说,不可能在虚拟机中进行辅助虚拟化. 我已经踩到了这个坑,所以您不需要踩到它. 我记得以前有人问过,阿里云Windows服务器可以配备Android模拟器吗?我认为答案是相同的. 虚拟机无法执行辅助虚拟化. 阿里云窗口服务器无法安装Android模拟器.
因此,当我尝试使用Android模拟器时,我发现原创微信PC客户端(包括mac)的功能已经完善,然后尝试了Windows客户端.
5. Virtualbox虚拟机,这是Oracle生产的虚拟机. 将涉及一些网络配置,例如设置为NAT模式.
现在将虚拟机映像开源,其中所有代码都在虚拟机中,您可以随意对其进行修改.
从了解官方帐户文章采集到了解实施原理,然后到最终镜像,我在中间经历了种种困难,这既费时又费力. 我咨询了很多人,甚至想到了吃饭和睡觉. 对于详细的解决方案而言,解决问题会很高兴,而被问题纠缠也很痛苦. 感谢您在此过程中对人们的帮助.
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012)
埋点、数仓到中台:数据体系的从0到1
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-28 04:09
前言:有幸深度参与了公司从无数据,到有数据,到开始注重数据,最后才能尊重数据结果,参考数据进行决策的过程。本篇文章是笔者在这个过程中,作为数据产品搭建数据指标体系,如何踩坑、出坑,以及对数据库房建设中的一些总结。
如标题所言,如果贵司早已是B轮过后,数据指标和平台化产品应当早已比较完善,属于数据产品应用阶段。如果贵司处于B轮及B轮之前阶段,大机率上会出现笔者下边所描述的情况。
本文较长,目录如下:
1 混乱期:资源有限,功能为先,忽视数据
1.1 资源永远不够用
1.2 数据产品的困境
2 规范期:他山之石:GrowingIO和神策
2.1 GrowingIO平台实践总结
2.2 神策平台实践总结
2.3 他山之石后的埋点设计及管理
3 平台期:建设数据库房
3.1 数据维护及整治
3.2 数据库房构架设计
4 未来:数据中台?
4.1 我理解的数据中台
4.2 数据中台学习资料推荐
------正文分割线------
1 混乱期:资源有限,功能为先,忽视数据1.1 资源永远不够用
笔者所在的内容服务公司,在搭建指标体系前,已经“裸奔”了3年。对于内容产品来说,最影响用户体验的是内容本身,公司前期借助不错的内容口碑,搭上知识付费的风口,发展迅速,公司资源和业务方向更多是受营运驱动、销售驱动,目标简单而明晰,做哪些心中都有大致预判,轻轻拍拍耳朵,这事儿就定了。后来平台用户数达到第一个1000w,日活步入50w量级后,新人加入,业务线也在拓展,基于主线业务上的优化和探求,不敢再轻易拍脖子了;各业务线也有不同的诉求,如何衡量优先级和协调资源,没有数据,很容易相持不下。
也是在哪个时侯,决定要参考数据来决策了。之前APP偏向于做功能,只在特殊功能点,或活动节点时,会在产品需求文档中,附上埋点需求。彼时猛然想看好多数据,会发觉不仅一些大数据(日活、激活率、付费率等)外,缺少好多细部数据,因为压根没有做埋点上报的需求,从日志中也未能解析出相关数据。
后来在每位版本中,由功能产品总监附上相关功能的埋点需求,大部分开发资源还在具体功能开发上。在功能上线后许久,才会想起来捞数据瞧瞧疗效。初创公司很容易在业务快速扩张中忽略数据的作用,产品开发团队首要解决的是不断新增的业务需求。资源总是不够用的,所以数据埋点处理、数据剖析、复盘等工作仍然处在被忽略的地方。
1.2 数据产品的困境
彼时我转岗到数据产品,常调侃自己是一个取数机器。公司有数据需求的部门共有7个,我负责对接各部门的数据需求,梳理清晰后再递交任务给大数据组,由她们做具体的ETL工作。这中间,常会身陷到以下的汪洋大海中:
与需求方沟通并最后明晰最后的数据需求(比如:活动组提需求想看某活动页分享数据,经沟通以后,其目的是想看新页面的文案上线后,对分享/浏览比的影响,因此明晰了该需求是该页面的uv、pv,以及分享控件点击的人数、次数);
提交明晰需求后,大数据组发觉之前没有埋点,然后须要跟需求方解释,这个数据为何拿不到,从ta的剖析目标再瞧瞧,是否还有其他数据也才能达成这个剖析目标。
那段时间十分繁忙,但总觉得自己是个二传手,最大的收获,就是在对接了N个需求以后,发现我司的数据基础建设情况惨不忍睹:平台埋点不规范、数据指标定义不统一、业务数据库和数据库房标准不统一、数据需求处理周期长…… 我的精力好多耗在沟通需求、管理需求上。后来与公司的数据剖析部门一齐讨论制订了一套新的数据递交流程:每个部门的需求汇总到部门中的一个数据对接人,由ta先行递交到数据剖析组,简单需求,会由数据剖析组通过DBeaver等工具,连接数据库导入,复杂类、工具类需求,则递交给我:
图1:数据需求递交流程
另外,针对每位部门的数据对接人进行了指标定义的说明,以及递交数据需求的规范标准的培训:
图2:培训资料一页:什么是好的数据需求
此时的工作还逗留在偏临时需求的处理上,作为数据产品,却没有作出多少数据产品下来。
2 规范期:他山之石:GrowingIO和神策
在决定搭建数据体系后,我司商讨了几家背部的数据平台,如GIO、ThinkingData、神策等,来补充我司埋点功力薄弱的问题,最后选择了GIO,在使用了一年多以后,因为要做私有化布署,而GIO的私有化布署功能还刚处在开发阶段(写这篇文章的时侯,他们的私有化布署早已做下来了),于是我司又决定换神策平台,重新来一遍POC和SDK接入工作(对,就是如此折腾,o(╥﹏╥)o)。在完整地对接了这两家平台以后,我司数据体系逐渐迈向规范,我也总结了一下两家平台关于指标管理、数据体系搭建的工具特性,以及思路进行了一些总结,如下。
2.1 GrowingIO平台实践总结
在接触了几家平台后,我们最终选择了GIO,该平台的特性特别显著:
拥有无埋点技术,能够实现做功能时,不需要专门针对埋点耗费工时,接入GIO的SDK,在功能上线后,SDK才能采集基础使用信息,同时,针对页面浏览数据,和页面控件点击数据,可以通过“圈选”的形式实现(对于彼时苦于埋点效率低下的现况,这种方案极具诱惑);
公有云布署,接入成本低;
后台操作界面简约,属于营运思路的一款产品,上手较容易;
因为是SaaS服务,线上问题反馈速率比较快。
但后来发觉一些问题:接入SDK后,我们只简单对接了会员状态数据,做了少量的埋点指标,除据悉自动圈选了大量页面指标和控件数据,因为GIO的圈选功能实在很好用了,所见即所得,不必再发版等埋点上线,经过简单操作后就可以自己取数、看数,结合GIO提供的基础剖析工具,如风波剖析、漏斗剖析、留存剖析等功能,人人都能成为一名分析师了。
图3:GIO圈选功能
但到后期,圈选数据的问题日渐曝露,也成为平台要更换GIO平台的导火索。圈选数据的逻辑:是按照页面xpath路径,监听页面浏览风波,和页面上的控件的浏览、点击风波,保留7天,因此圈选完成后,能向前溯源7天的数据。圈选功能的问题主要在于:
耗流量,看下逻辑你应当能理解;
一旦版本迭代,对页面的路径做更改,或者控件位置、文案有更改,原来的圈选数据可能还会出错,需要重新圈选,之前借助圈选指标设定的剖析模型都要替换;
圈选指标难以分辨细部参数,比如:书籍详情页,无法通过圈选数据来分辨是哪一本书;
对web的页面数据处理仍然不好,尤其是涉及到APP的内嵌H5页时,非常苦闷。
图4:版本升级后,某圈选指标数据突降
这似乎也是GIO的业务朋友比较推崇无埋点技术,而我司彼时经验尚不充足踩下的坑,到后半阶段开始补习,开始做客户端和服务端埋点了,埋点开发周期似乎长了点,但是起码才能用得上去。但是由于之前对GIO工具使用上形成的各类不爽,导致前面有了更准确的埋点后,大家用上去也经常怀疑,这数据准不准,能不能用?一旦对数据源形成不信任感,产研团队的解释成本高,数据发挥价值的周期变长,团队屡受指责又看不到成绩,大数据团队本身在数据体系建设的初期存在感就低,如此一来,工作积极性显得更低。
后来受资方等多诱因影响,我们须要做私有化布署,对数据的准确度、智能营运也有更进一步的需求,而彼时GIO还没有成熟的私有化布署功能,因此我们两家后来好聚好散,转而选择了神策。(此处抱着GIO的朋友哭一会儿)
但总体来说,GIO平台还是可圈可点,它的优势在于:
数据响应速度快,圈选功能比较成熟,对于快速迭代活动的场景,圈选功能最为方便;
用户操作界面友好,几大核心剖析功能逻辑结构清晰,学习成本低,能够实现在公司大范围推广使用(你千万别认为这类数据工具是可以轻易上手的,根据我在公司推广GIO和神策的经验,工具使用门槛并不低);
售后团队比较专业,能够从剖析视角,发现我司业务上的问题;并且对平常提及的问题,反馈及时,问题解决程度也比较高。
2.2 神策平台实践总结
后来由于私有化布署的诉求,选择了神策平台的产品。这里解释下,为啥没有选择自己研制数据产品。这显然是一个太经济学的审视。在接入GIO前,我司有自己一套ubt的埋点系统,但是只是基础的数据采集,以及raw data进数据库,从raw data 到数仓,再到提取,把统计类数据以excel方式,或者教会剖析人员使用SSMS或PowerBI来进行取数剖析,中间流程很长,无法做到快速响应及反馈。而找一个团队自研,时间成本和人力成本都很高。
神策、GIO这样的平台,取数功能完整度比较高,而且有一个比较完整的可视化剖析平台,收录了风波剖析、漏斗剖析、留存剖析等基础的剖析功能,也有归因剖析模型、用户画像等功能,这些功能找一个大数据团队和几个算法工程师,一年的成本高了去了。对于B轮左右的公司,建议别折腾,花点钱,除了防止自研成本,还能从这种SaaS平台的服务中,了解到比较成熟的方法论。
神策的剖析全家桶有以下几款产品:
图5:神策产品矩阵
其中,左边【数据基础能力】是基础服务,可以选Pass,也可以选私有化布署,但是节点费、流量费是按照自己的流量来核算。(市政单位,或者对业务数据安全敏感度高的,建议私有化。不是说Pass不安全,像神策、GIO这样专门做数据服务的平台,不至于去窃取顾客数据,一个顾客数据泄漏风波就可以使这类企业直接死掉,这个帐她们拎得清,而且有数据隐私合同)。右边的【数据应用产品】则是可选项了,【神策剖析】收录了风波剖析、漏斗剖析等基础的剖析功能,一般必不可少;【神策用户画像】和【智能营运】是偏向于营运侧的工具,如果自己没有精准营销的产研能力,这两项服务业比较好用。至于【智能推荐】和【神策客景】则依照公司情况,对于内容繁杂,品类繁杂的内容平台、电商平台,还是比较有必要。但我个人觉得,前三项服务玩得转了,再去考虑采购后两项服务不迟。
神策平台的特性是一开始推的是埋点方案,而非无埋点方案;而且最早支持私有化布署的数据服务平台。这一点是使她们才能获得一些金融行业、政企行业的单子的缘由。这也是我们最后评估后,选择她们的缘由。
2.3 我司平台的埋点设计及指标管理
在经过了UBT、GIO和神策三套埋点方案的使用和比较后,对于我司自己的埋点系统也有了比较清晰的方向,最后决定采用常规数据使用后端埋点、关键数据使用服务端埋点、临时活动搭配使用全埋点的方案。
全埋点、前端埋点和服务端埋点的区别
埋点方案
实施方案
优点
缺点
全埋点
部署对应sdk,页面及控件数据全采集,使用时解析
不需要做埋点开发;
需要用的时侯再去圈选使用;
所见即所得,圈选时就可以看见数据;
不需要测试介入,取数周期极短
新圈选时,只能向前溯源7天;
数据不够确切;
发版后会影响之前圈选数据的稳定性。
前端埋点
前端定义的风波触发时,上传对应数据
较为确切;
基本不会受页面改版影响。
有一定开发工作量;
设计新功能时须要考虑对原有埋点的影响,维护指标文档;
会受网路环境等诱因影响,出现数据难以上报或延时上报。
服务端埋点
服务端定义的风波触发时,上传对应数据
最为确切;
不受前台功能改版影响。
开发和测试的工作都较大;
不容易发觉问题。
而我司基本是后端埋点和服务端埋点的组合,其中关于数据指标的设计和管理,采用了右图所展示的数组名,对事实表进行管理和维护。
图6:我司数据指标维护表头
关于数据指标管理,最使我头大的就是怎样保证可读性的前提下,梳理不断新增的数据埋点需求。我的设计思路是:以使用者视角设计,尽可能合并同类型指标,用维度保证扩展性,用备注内容保证可读性。
上面的指标维护表,是要同时给开发人员,和营运人员看的,这里指的使用者,是指营运人员。因为最后埋点设计做完了,也正常上报了,但是营运人员看不懂,用不上去,培训成本高企,是难以充分发挥数据价值的。所以在这里就须要数据产品总监平衡简洁和可用性。
举两个反例:
例子1:平台资源位埋点设计
对于通常互联网产品平台来说,资源位无外乎两种类型,弹出型和轮播型;而具体指标无外乎浏览和点击,因此,将这两种类型的资源位具象成下边4个指标,由维度(资源位位置、轮播位置)来进行分拆。
图7:平台资源位埋点设计
例子2:内容详情页埋点设计
对于内容类、电商类平台来说,内容详情页和商品详情页是最为关键的页面,因此这个页面的浏览数据极为重要。因为详情页是一个通用页面,而且对于一篇文章,或者一个商品来说,可能会在APP出现多个入口,如果对N个入口进行分别埋点,会使指标建设冗余,并且由于网路环境等影响,点击数≠页面加载≠页面加载成功,可能会采到脏数据上来。因此我在这里的设计思路是:以页面加载成功为触发,区分页面本身的数据信息,以及上一个页面的维度信息。
图8:内容详情页埋点设计
这里的挑战来自于去梳理上一个页面的类型和具体参数值,需要与营运组、数据组同学沟通清楚,他们关心的维度,以及下钻的颗粒度。
3 平台期:建设数据库房
建设数据库房是一个必然的选择,在业务体量不大,数据需求不多的情况下,从业务数据库捞数据,甚至解析日志,都是才能满足的。但后期必然会有更多维度、更复杂的分析型、报表型数据需求,全部借助业务数据库其实不现实。现在计算机储存成本不高,数据库房可以看做是一个【用空间换时间】的方案,数据库房是面向剖析、应用的数据库,在构建好标准的ETL流程和更新机制后,分析型、报表型数据需求从数据库房中获取,从而提升效率,也解放业务数据库,让业务库专心处理业务。
特点
面向对象
数据库
处理业务需求,实时性要求高
具体业务
数据库房
ETL后有比较明晰分辨的主题表
可并多个表、多个维度,支持复杂查询
分析型数据
目前有关数据库房的文章非常多,对数据库房应当分几层,也有好多说法。这里须要明晰一点,数据库房的分层是一个理念,其核心是将不同应用层级的数据进行界定。一般来说起码有五级,我司采用的也是五级数仓。
数仓分层
数据来源
特点
ODS
操作型数据、实时数据、日志数据等
近似 = raw data
EDW
ODS层
按明晰主题和维度进行ETL的数据表
DM
ODS层、EDW层
面向明晰应用,ETL获取的数据表
3.1 数据维护及整治
基于Hadoop的成熟体系,搭建完成数仓系框架后,接下来要做的是往数仓中填充数据“血肉”,以及持续进行数据整治的工作了。在用数据赋能业务的链条中:产生数据(埋点)-> 获取数据(ETL) -> 分析数据 -> 发现问题 ->业务决策,似乎并没有数据整治的事情。链条上的四点是可见的过程,而数据本身形成污染后,可能会到获取时、分析时,甚至是决策阶段,才会意识到数据本身可能出现了问题。数据从触发上报-> 发送-> ETL-> 进数仓,中间有任何一个过程出问题,都可能会影响数据的稳定、准确和及时。另外,不断扩充的业务需求,业务数据数组会发生变更,这时错传、漏传了数据进数仓,也会影响数据质量。
总结出来,基于下边三个点,需要持续进行数据维护和整治:
数据进仓链路长,存在出现脏数据的风险;
新业务需求增删改数组,没有及时同步进数仓;
数仓表结构数组设计扩展性不足,新数据须要单独建表,导致冗余。
针对第1点,我司对于数据指标本身的异常波动做了监控的设计。在接入了神策平台以后,该平台提供了一个指标异常波动提醒的功能,还很好用。
图9:神策数据异常监控
针对第2点谈谈我司实践。我司通过搭建【异构数据平台】来解决业务数据同步到数据库房的问题。业务数据在进数据仓的同时,会根据约定的规范,同步传送一份到数据库房;如果有修业务数据的情况,也须要异步地通过该平台,发消息给数据库房,由数仓消费后,更新数仓的数据。
针对第3点,没有哪些好办法,需要数据产品和大数据组、业务产品总监多沟通,对于数仓目前有什么表,哪些数组,功能规划上,未来会新增什么产品线,与当前业务线的关系,有一个大致预判,最大程度降低重复建表的工作。
3.2 数据库房构架设计
基于以上,我司数据库房是基于Hadoop框架,Hive处理离线数据,Flink处理实时数据,实现用户行为数据和业务数据准实时入数仓(有一些延时),并且后端数据产品应用,从数据库房中调插口取数。(目前还没有完全实现所有业务数据都从数据库房走,还在建设中)
图10:数据库房构架设计
4 未来:数据中台?
数据中台概念在19年实在很火了,颇有些12年,到处都在说O2O的情形。对于数据产品来说,将产出的数据产品抽象化、共用化,成为象中台一样的基础服务能力是心之所向。但是否应当盲目上中台项目,谈谈我的理解。
4.1 我所理解的数据中台
我很喜欢【中台】这个词:处于中间,承上启下;成为平台,隔绝上下流动,但自身提供服务上下的能力。对于数据中台,其核心是提炼各业务线的共性需求,将这种需求解决方案封装为标准化、组件化的解决能力,然后以插口的方式提供给前前台业务数据。从而实现尽量少地重复造轮子,尽量多地提升研制的敏捷性。
不是所有公司都须要立即做中台,但按照熵增定律,一家能持续发展的企业,其业务形态一定会不断发展和膨胀,而当新业务线和老业务线有共性诉求,能够通过中台化来提升效率,并且具有能串联多业务线的项目能力,这些问题想清楚,就可以开始做中台项目了。
4.2 资料推荐
在学习数据中台的过程中,整理了一些资料,如下:
数据中台到底是什么?
换个视角看中台的对与错
有赞零售中台建设方式的探求与实践
原文链接:/article/gaBwDw5Jkj 查看全部
埋点、数仓到中台:数据体系的从0到1
前言:有幸深度参与了公司从无数据,到有数据,到开始注重数据,最后才能尊重数据结果,参考数据进行决策的过程。本篇文章是笔者在这个过程中,作为数据产品搭建数据指标体系,如何踩坑、出坑,以及对数据库房建设中的一些总结。
如标题所言,如果贵司早已是B轮过后,数据指标和平台化产品应当早已比较完善,属于数据产品应用阶段。如果贵司处于B轮及B轮之前阶段,大机率上会出现笔者下边所描述的情况。
本文较长,目录如下:
1 混乱期:资源有限,功能为先,忽视数据
1.1 资源永远不够用
1.2 数据产品的困境
2 规范期:他山之石:GrowingIO和神策
2.1 GrowingIO平台实践总结
2.2 神策平台实践总结
2.3 他山之石后的埋点设计及管理
3 平台期:建设数据库房
3.1 数据维护及整治
3.2 数据库房构架设计
4 未来:数据中台?
4.1 我理解的数据中台
4.2 数据中台学习资料推荐
------正文分割线------
1 混乱期:资源有限,功能为先,忽视数据1.1 资源永远不够用
笔者所在的内容服务公司,在搭建指标体系前,已经“裸奔”了3年。对于内容产品来说,最影响用户体验的是内容本身,公司前期借助不错的内容口碑,搭上知识付费的风口,发展迅速,公司资源和业务方向更多是受营运驱动、销售驱动,目标简单而明晰,做哪些心中都有大致预判,轻轻拍拍耳朵,这事儿就定了。后来平台用户数达到第一个1000w,日活步入50w量级后,新人加入,业务线也在拓展,基于主线业务上的优化和探求,不敢再轻易拍脖子了;各业务线也有不同的诉求,如何衡量优先级和协调资源,没有数据,很容易相持不下。
也是在哪个时侯,决定要参考数据来决策了。之前APP偏向于做功能,只在特殊功能点,或活动节点时,会在产品需求文档中,附上埋点需求。彼时猛然想看好多数据,会发觉不仅一些大数据(日活、激活率、付费率等)外,缺少好多细部数据,因为压根没有做埋点上报的需求,从日志中也未能解析出相关数据。
后来在每位版本中,由功能产品总监附上相关功能的埋点需求,大部分开发资源还在具体功能开发上。在功能上线后许久,才会想起来捞数据瞧瞧疗效。初创公司很容易在业务快速扩张中忽略数据的作用,产品开发团队首要解决的是不断新增的业务需求。资源总是不够用的,所以数据埋点处理、数据剖析、复盘等工作仍然处在被忽略的地方。
1.2 数据产品的困境
彼时我转岗到数据产品,常调侃自己是一个取数机器。公司有数据需求的部门共有7个,我负责对接各部门的数据需求,梳理清晰后再递交任务给大数据组,由她们做具体的ETL工作。这中间,常会身陷到以下的汪洋大海中:
与需求方沟通并最后明晰最后的数据需求(比如:活动组提需求想看某活动页分享数据,经沟通以后,其目的是想看新页面的文案上线后,对分享/浏览比的影响,因此明晰了该需求是该页面的uv、pv,以及分享控件点击的人数、次数);
提交明晰需求后,大数据组发觉之前没有埋点,然后须要跟需求方解释,这个数据为何拿不到,从ta的剖析目标再瞧瞧,是否还有其他数据也才能达成这个剖析目标。
那段时间十分繁忙,但总觉得自己是个二传手,最大的收获,就是在对接了N个需求以后,发现我司的数据基础建设情况惨不忍睹:平台埋点不规范、数据指标定义不统一、业务数据库和数据库房标准不统一、数据需求处理周期长…… 我的精力好多耗在沟通需求、管理需求上。后来与公司的数据剖析部门一齐讨论制订了一套新的数据递交流程:每个部门的需求汇总到部门中的一个数据对接人,由ta先行递交到数据剖析组,简单需求,会由数据剖析组通过DBeaver等工具,连接数据库导入,复杂类、工具类需求,则递交给我:
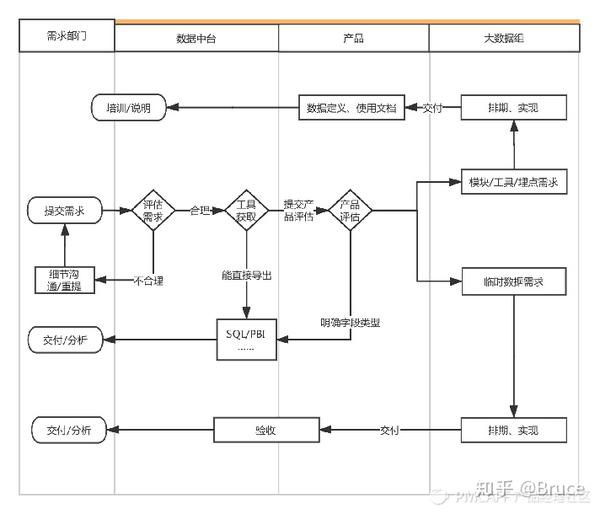
图1:数据需求递交流程
另外,针对每位部门的数据对接人进行了指标定义的说明,以及递交数据需求的规范标准的培训:

图2:培训资料一页:什么是好的数据需求
此时的工作还逗留在偏临时需求的处理上,作为数据产品,却没有作出多少数据产品下来。
2 规范期:他山之石:GrowingIO和神策
在决定搭建数据体系后,我司商讨了几家背部的数据平台,如GIO、ThinkingData、神策等,来补充我司埋点功力薄弱的问题,最后选择了GIO,在使用了一年多以后,因为要做私有化布署,而GIO的私有化布署功能还刚处在开发阶段(写这篇文章的时侯,他们的私有化布署早已做下来了),于是我司又决定换神策平台,重新来一遍POC和SDK接入工作(对,就是如此折腾,o(╥﹏╥)o)。在完整地对接了这两家平台以后,我司数据体系逐渐迈向规范,我也总结了一下两家平台关于指标管理、数据体系搭建的工具特性,以及思路进行了一些总结,如下。
2.1 GrowingIO平台实践总结
在接触了几家平台后,我们最终选择了GIO,该平台的特性特别显著:
拥有无埋点技术,能够实现做功能时,不需要专门针对埋点耗费工时,接入GIO的SDK,在功能上线后,SDK才能采集基础使用信息,同时,针对页面浏览数据,和页面控件点击数据,可以通过“圈选”的形式实现(对于彼时苦于埋点效率低下的现况,这种方案极具诱惑);
公有云布署,接入成本低;
后台操作界面简约,属于营运思路的一款产品,上手较容易;
因为是SaaS服务,线上问题反馈速率比较快。
但后来发觉一些问题:接入SDK后,我们只简单对接了会员状态数据,做了少量的埋点指标,除据悉自动圈选了大量页面指标和控件数据,因为GIO的圈选功能实在很好用了,所见即所得,不必再发版等埋点上线,经过简单操作后就可以自己取数、看数,结合GIO提供的基础剖析工具,如风波剖析、漏斗剖析、留存剖析等功能,人人都能成为一名分析师了。
图3:GIO圈选功能
但到后期,圈选数据的问题日渐曝露,也成为平台要更换GIO平台的导火索。圈选数据的逻辑:是按照页面xpath路径,监听页面浏览风波,和页面上的控件的浏览、点击风波,保留7天,因此圈选完成后,能向前溯源7天的数据。圈选功能的问题主要在于:
耗流量,看下逻辑你应当能理解;
一旦版本迭代,对页面的路径做更改,或者控件位置、文案有更改,原来的圈选数据可能还会出错,需要重新圈选,之前借助圈选指标设定的剖析模型都要替换;
圈选指标难以分辨细部参数,比如:书籍详情页,无法通过圈选数据来分辨是哪一本书;
对web的页面数据处理仍然不好,尤其是涉及到APP的内嵌H5页时,非常苦闷。
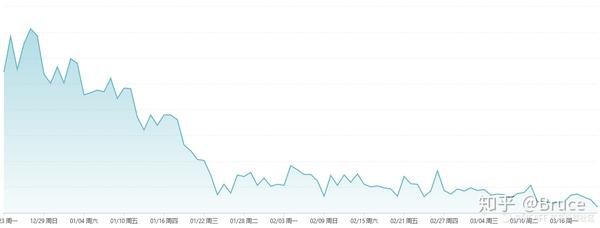
图4:版本升级后,某圈选指标数据突降
这似乎也是GIO的业务朋友比较推崇无埋点技术,而我司彼时经验尚不充足踩下的坑,到后半阶段开始补习,开始做客户端和服务端埋点了,埋点开发周期似乎长了点,但是起码才能用得上去。但是由于之前对GIO工具使用上形成的各类不爽,导致前面有了更准确的埋点后,大家用上去也经常怀疑,这数据准不准,能不能用?一旦对数据源形成不信任感,产研团队的解释成本高,数据发挥价值的周期变长,团队屡受指责又看不到成绩,大数据团队本身在数据体系建设的初期存在感就低,如此一来,工作积极性显得更低。
后来受资方等多诱因影响,我们须要做私有化布署,对数据的准确度、智能营运也有更进一步的需求,而彼时GIO还没有成熟的私有化布署功能,因此我们两家后来好聚好散,转而选择了神策。(此处抱着GIO的朋友哭一会儿)
但总体来说,GIO平台还是可圈可点,它的优势在于:
数据响应速度快,圈选功能比较成熟,对于快速迭代活动的场景,圈选功能最为方便;
用户操作界面友好,几大核心剖析功能逻辑结构清晰,学习成本低,能够实现在公司大范围推广使用(你千万别认为这类数据工具是可以轻易上手的,根据我在公司推广GIO和神策的经验,工具使用门槛并不低);
售后团队比较专业,能够从剖析视角,发现我司业务上的问题;并且对平常提及的问题,反馈及时,问题解决程度也比较高。
2.2 神策平台实践总结
后来由于私有化布署的诉求,选择了神策平台的产品。这里解释下,为啥没有选择自己研制数据产品。这显然是一个太经济学的审视。在接入GIO前,我司有自己一套ubt的埋点系统,但是只是基础的数据采集,以及raw data进数据库,从raw data 到数仓,再到提取,把统计类数据以excel方式,或者教会剖析人员使用SSMS或PowerBI来进行取数剖析,中间流程很长,无法做到快速响应及反馈。而找一个团队自研,时间成本和人力成本都很高。
神策、GIO这样的平台,取数功能完整度比较高,而且有一个比较完整的可视化剖析平台,收录了风波剖析、漏斗剖析、留存剖析等基础的剖析功能,也有归因剖析模型、用户画像等功能,这些功能找一个大数据团队和几个算法工程师,一年的成本高了去了。对于B轮左右的公司,建议别折腾,花点钱,除了防止自研成本,还能从这种SaaS平台的服务中,了解到比较成熟的方法论。
神策的剖析全家桶有以下几款产品:
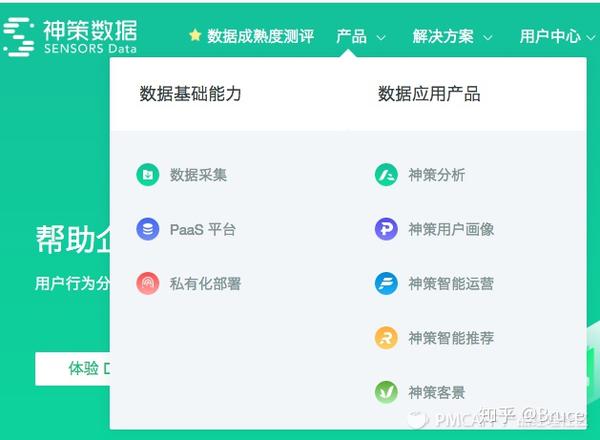
图5:神策产品矩阵
其中,左边【数据基础能力】是基础服务,可以选Pass,也可以选私有化布署,但是节点费、流量费是按照自己的流量来核算。(市政单位,或者对业务数据安全敏感度高的,建议私有化。不是说Pass不安全,像神策、GIO这样专门做数据服务的平台,不至于去窃取顾客数据,一个顾客数据泄漏风波就可以使这类企业直接死掉,这个帐她们拎得清,而且有数据隐私合同)。右边的【数据应用产品】则是可选项了,【神策剖析】收录了风波剖析、漏斗剖析等基础的剖析功能,一般必不可少;【神策用户画像】和【智能营运】是偏向于营运侧的工具,如果自己没有精准营销的产研能力,这两项服务业比较好用。至于【智能推荐】和【神策客景】则依照公司情况,对于内容繁杂,品类繁杂的内容平台、电商平台,还是比较有必要。但我个人觉得,前三项服务玩得转了,再去考虑采购后两项服务不迟。
神策平台的特性是一开始推的是埋点方案,而非无埋点方案;而且最早支持私有化布署的数据服务平台。这一点是使她们才能获得一些金融行业、政企行业的单子的缘由。这也是我们最后评估后,选择她们的缘由。
2.3 我司平台的埋点设计及指标管理
在经过了UBT、GIO和神策三套埋点方案的使用和比较后,对于我司自己的埋点系统也有了比较清晰的方向,最后决定采用常规数据使用后端埋点、关键数据使用服务端埋点、临时活动搭配使用全埋点的方案。
全埋点、前端埋点和服务端埋点的区别
埋点方案
实施方案
优点
缺点
全埋点
部署对应sdk,页面及控件数据全采集,使用时解析
不需要做埋点开发;
需要用的时侯再去圈选使用;
所见即所得,圈选时就可以看见数据;
不需要测试介入,取数周期极短
新圈选时,只能向前溯源7天;
数据不够确切;
发版后会影响之前圈选数据的稳定性。
前端埋点
前端定义的风波触发时,上传对应数据
较为确切;
基本不会受页面改版影响。
有一定开发工作量;
设计新功能时须要考虑对原有埋点的影响,维护指标文档;
会受网路环境等诱因影响,出现数据难以上报或延时上报。
服务端埋点
服务端定义的风波触发时,上传对应数据
最为确切;
不受前台功能改版影响。
开发和测试的工作都较大;
不容易发觉问题。
而我司基本是后端埋点和服务端埋点的组合,其中关于数据指标的设计和管理,采用了右图所展示的数组名,对事实表进行管理和维护。

图6:我司数据指标维护表头
关于数据指标管理,最使我头大的就是怎样保证可读性的前提下,梳理不断新增的数据埋点需求。我的设计思路是:以使用者视角设计,尽可能合并同类型指标,用维度保证扩展性,用备注内容保证可读性。
上面的指标维护表,是要同时给开发人员,和营运人员看的,这里指的使用者,是指营运人员。因为最后埋点设计做完了,也正常上报了,但是营运人员看不懂,用不上去,培训成本高企,是难以充分发挥数据价值的。所以在这里就须要数据产品总监平衡简洁和可用性。
举两个反例:
例子1:平台资源位埋点设计
对于通常互联网产品平台来说,资源位无外乎两种类型,弹出型和轮播型;而具体指标无外乎浏览和点击,因此,将这两种类型的资源位具象成下边4个指标,由维度(资源位位置、轮播位置)来进行分拆。

图7:平台资源位埋点设计
例子2:内容详情页埋点设计
对于内容类、电商类平台来说,内容详情页和商品详情页是最为关键的页面,因此这个页面的浏览数据极为重要。因为详情页是一个通用页面,而且对于一篇文章,或者一个商品来说,可能会在APP出现多个入口,如果对N个入口进行分别埋点,会使指标建设冗余,并且由于网路环境等影响,点击数≠页面加载≠页面加载成功,可能会采到脏数据上来。因此我在这里的设计思路是:以页面加载成功为触发,区分页面本身的数据信息,以及上一个页面的维度信息。
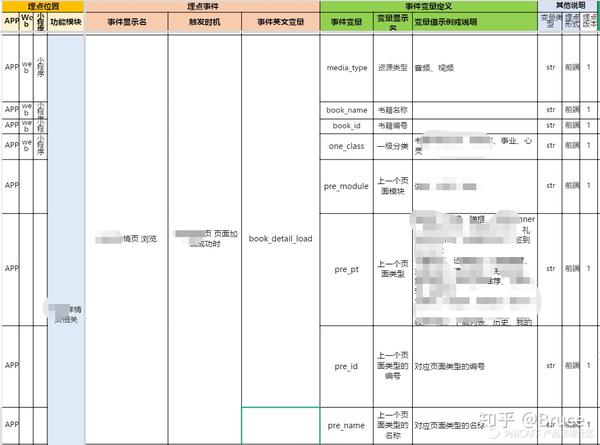
图8:内容详情页埋点设计
这里的挑战来自于去梳理上一个页面的类型和具体参数值,需要与营运组、数据组同学沟通清楚,他们关心的维度,以及下钻的颗粒度。
3 平台期:建设数据库房
建设数据库房是一个必然的选择,在业务体量不大,数据需求不多的情况下,从业务数据库捞数据,甚至解析日志,都是才能满足的。但后期必然会有更多维度、更复杂的分析型、报表型数据需求,全部借助业务数据库其实不现实。现在计算机储存成本不高,数据库房可以看做是一个【用空间换时间】的方案,数据库房是面向剖析、应用的数据库,在构建好标准的ETL流程和更新机制后,分析型、报表型数据需求从数据库房中获取,从而提升效率,也解放业务数据库,让业务库专心处理业务。
特点
面向对象
数据库
处理业务需求,实时性要求高
具体业务
数据库房
ETL后有比较明晰分辨的主题表
可并多个表、多个维度,支持复杂查询
分析型数据
目前有关数据库房的文章非常多,对数据库房应当分几层,也有好多说法。这里须要明晰一点,数据库房的分层是一个理念,其核心是将不同应用层级的数据进行界定。一般来说起码有五级,我司采用的也是五级数仓。
数仓分层
数据来源
特点
ODS
操作型数据、实时数据、日志数据等
近似 = raw data
EDW
ODS层
按明晰主题和维度进行ETL的数据表
DM
ODS层、EDW层
面向明晰应用,ETL获取的数据表
3.1 数据维护及整治
基于Hadoop的成熟体系,搭建完成数仓系框架后,接下来要做的是往数仓中填充数据“血肉”,以及持续进行数据整治的工作了。在用数据赋能业务的链条中:产生数据(埋点)-> 获取数据(ETL) -> 分析数据 -> 发现问题 ->业务决策,似乎并没有数据整治的事情。链条上的四点是可见的过程,而数据本身形成污染后,可能会到获取时、分析时,甚至是决策阶段,才会意识到数据本身可能出现了问题。数据从触发上报-> 发送-> ETL-> 进数仓,中间有任何一个过程出问题,都可能会影响数据的稳定、准确和及时。另外,不断扩充的业务需求,业务数据数组会发生变更,这时错传、漏传了数据进数仓,也会影响数据质量。
总结出来,基于下边三个点,需要持续进行数据维护和整治:
数据进仓链路长,存在出现脏数据的风险;
新业务需求增删改数组,没有及时同步进数仓;
数仓表结构数组设计扩展性不足,新数据须要单独建表,导致冗余。
针对第1点,我司对于数据指标本身的异常波动做了监控的设计。在接入了神策平台以后,该平台提供了一个指标异常波动提醒的功能,还很好用。
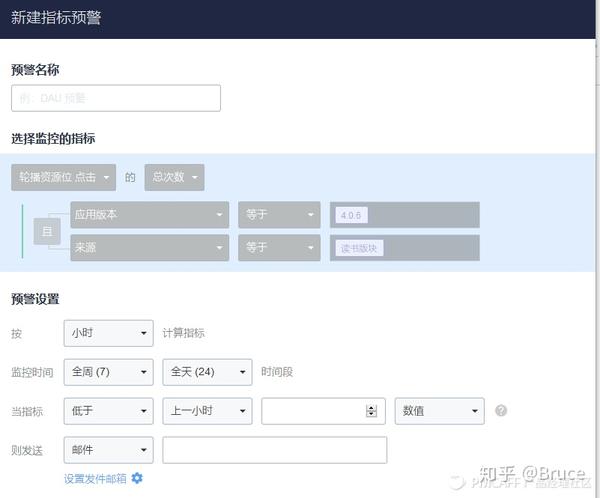
图9:神策数据异常监控
针对第2点谈谈我司实践。我司通过搭建【异构数据平台】来解决业务数据同步到数据库房的问题。业务数据在进数据仓的同时,会根据约定的规范,同步传送一份到数据库房;如果有修业务数据的情况,也须要异步地通过该平台,发消息给数据库房,由数仓消费后,更新数仓的数据。
针对第3点,没有哪些好办法,需要数据产品和大数据组、业务产品总监多沟通,对于数仓目前有什么表,哪些数组,功能规划上,未来会新增什么产品线,与当前业务线的关系,有一个大致预判,最大程度降低重复建表的工作。
3.2 数据库房构架设计
基于以上,我司数据库房是基于Hadoop框架,Hive处理离线数据,Flink处理实时数据,实现用户行为数据和业务数据准实时入数仓(有一些延时),并且后端数据产品应用,从数据库房中调插口取数。(目前还没有完全实现所有业务数据都从数据库房走,还在建设中)
图10:数据库房构架设计
4 未来:数据中台?
数据中台概念在19年实在很火了,颇有些12年,到处都在说O2O的情形。对于数据产品来说,将产出的数据产品抽象化、共用化,成为象中台一样的基础服务能力是心之所向。但是否应当盲目上中台项目,谈谈我的理解。
4.1 我所理解的数据中台
我很喜欢【中台】这个词:处于中间,承上启下;成为平台,隔绝上下流动,但自身提供服务上下的能力。对于数据中台,其核心是提炼各业务线的共性需求,将这种需求解决方案封装为标准化、组件化的解决能力,然后以插口的方式提供给前前台业务数据。从而实现尽量少地重复造轮子,尽量多地提升研制的敏捷性。
不是所有公司都须要立即做中台,但按照熵增定律,一家能持续发展的企业,其业务形态一定会不断发展和膨胀,而当新业务线和老业务线有共性诉求,能够通过中台化来提升效率,并且具有能串联多业务线的项目能力,这些问题想清楚,就可以开始做中台项目了。
4.2 资料推荐
在学习数据中台的过程中,整理了一些资料,如下:
数据中台到底是什么?
换个视角看中台的对与错
有赞零售中台建设方式的探求与实践
原文链接:/article/gaBwDw5Jkj
什么是新闻采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-27 16:27
新闻采集系统是将非结构化的新闻文章从多个新闻来源网页中抽取下来保存到结构化的数据库中的软件。主要功能依据用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为为结构化的记录(标题,作者,内容,采集时间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外部信息的获取。主要技术新闻采集系统核心技术是模式定义和模式匹配。模式属于人工智能的术语,意思为前人积累的经验的具象和升华。简单地说,就是从不断重复出现的风波中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可能存在某种模式。所以要使新闻采集系统才能运行,目标网站必须具备重复出现的特点。目前大多网站都是动态生成的,这样才会使同一模板的页面收录相同的内容,新闻采集系统正是借助这种相同的内容来定位采集数据的。新闻采集系统中的模式大多不是程序手动发觉的,目前几乎所有的新闻采集系统产品都须要通过人工来定义。但模式本身是个很复杂,很具象的内容,所以所有的开发者精力都花在如何使模式定义更简单,更准确,这也是新闻采集系统竞争力的评判标准。现在国外在新闻采集行业,比较领先的是北京的乐思。他们的采集系统可以智能的抓取新闻,也就是说不需要配置。 查看全部
什么是新闻采集?
新闻采集系统是将非结构化的新闻文章从多个新闻来源网页中抽取下来保存到结构化的数据库中的软件。主要功能依据用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为为结构化的记录(标题,作者,内容,采集时间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外部信息的获取。主要技术新闻采集系统核心技术是模式定义和模式匹配。模式属于人工智能的术语,意思为前人积累的经验的具象和升华。简单地说,就是从不断重复出现的风波中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可能存在某种模式。所以要使新闻采集系统才能运行,目标网站必须具备重复出现的特点。目前大多网站都是动态生成的,这样才会使同一模板的页面收录相同的内容,新闻采集系统正是借助这种相同的内容来定位采集数据的。新闻采集系统中的模式大多不是程序手动发觉的,目前几乎所有的新闻采集系统产品都须要通过人工来定义。但模式本身是个很复杂,很具象的内容,所以所有的开发者精力都花在如何使模式定义更简单,更准确,这也是新闻采集系统竞争力的评判标准。现在国外在新闻采集行业,比较领先的是北京的乐思。他们的采集系统可以智能的抓取新闻,也就是说不需要配置。
信息采集系统/网络数据采集案例解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 609 次浏览 • 2020-08-26 14:46
如何把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。随着网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。我们从信息短缺的时代一下子走到了信息极大丰富昨天。在明天,困扰我们的问题不是信息很少,而是太多,多得使你无从区分,无从选择。因此,提供一个才能手动在互联网上抓取挖掘数据,并手动分拣、分析的工具有特别重要的意义。
通用搜索引擎其实帮了我们不少忙,但怎样把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。日前警犬信息采集系统挺好为中国电信完成具以上特征的任务。
第一部分:项目需求:
要求对11市级城市的9大行业(医疗、汽车、餐饮、购物、教育、娱乐休闲、住宿、日常服务、旅游)根据行业的不同,按照不同的数组智能抽取企业网站的相关数组的数据,对所抽取的数据作只能的去重处理,同一个企业的数据做真假分辨,用程序来效验数据,最后构建呼叫中心,人工确认数据的有效性构建呼叫中心,人工确认数据的有效性。
第二部份:数据处理解决方案:
数据分布状态
项目执行流程:
1. 定向抽取结构化数据:从多个平台(阿里巴巴、慧聪网、口碑网、爱帮网、58同城分类等平台)上抽取数据,以最大限度确保数据的数目。
军犬信息采集系统流程图:
2. 定向的结构化信息抽取,针对不同的平台,制定不同的采集规则,以准确地将结构化数据存入对应的数据库中的数组。
3. 信息采集任务保障:
确保采集任务
4. 对于没有的企业结构化数据,通用spider 漫游来访问企业网站,抽取信息正文。
5. 构建词库:在数据抽取后,利用现有的数据构建行业词库和特点词库,并且在剖析其它网页时手动建立词库。
词库的构建与建立
6. 智能提取:采用动词技术,对非结构化数据进行智能抽取。
数据处理及校准 查看全部
信息采集系统/网络数据采集案例解析
如何把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。随着网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。我们从信息短缺的时代一下子走到了信息极大丰富昨天。在明天,困扰我们的问题不是信息很少,而是太多,多得使你无从区分,无从选择。因此,提供一个才能手动在互联网上抓取挖掘数据,并手动分拣、分析的工具有特别重要的意义。
通用搜索引擎其实帮了我们不少忙,但怎样把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。日前警犬信息采集系统挺好为中国电信完成具以上特征的任务。
第一部分:项目需求:
要求对11市级城市的9大行业(医疗、汽车、餐饮、购物、教育、娱乐休闲、住宿、日常服务、旅游)根据行业的不同,按照不同的数组智能抽取企业网站的相关数组的数据,对所抽取的数据作只能的去重处理,同一个企业的数据做真假分辨,用程序来效验数据,最后构建呼叫中心,人工确认数据的有效性构建呼叫中心,人工确认数据的有效性。
第二部份:数据处理解决方案:

数据分布状态
项目执行流程:

1. 定向抽取结构化数据:从多个平台(阿里巴巴、慧聪网、口碑网、爱帮网、58同城分类等平台)上抽取数据,以最大限度确保数据的数目。
军犬信息采集系统流程图:

2. 定向的结构化信息抽取,针对不同的平台,制定不同的采集规则,以准确地将结构化数据存入对应的数据库中的数组。
3. 信息采集任务保障:

确保采集任务
4. 对于没有的企业结构化数据,通用spider 漫游来访问企业网站,抽取信息正文。
5. 构建词库:在数据抽取后,利用现有的数据构建行业词库和特点词库,并且在剖析其它网页时手动建立词库。

词库的构建与建立
6. 智能提取:采用动词技术,对非结构化数据进行智能抽取。

数据处理及校准
中科点击警犬网路信息采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-26 03:02
系统简介
一.“信息采集系统”系统概述:
信息采集是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入的整个过程。
军犬信息采集专家是一款基于人工智能的手动学习技术,功能强悍、简单实用的互联网信息采集与监控软件。
二、互联网信息采集与挖掘:
要求从互联网上对特定目标数据源或不特定目标数据源进行采集与监控,并对信息进行结构化抽取保存为本地结构化数据库,然后按业务流程需求与其它模块结合,导入与应用并服务于到电子行业平台。
互联网数据采集与挖掘技术是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入,并按业务所需,进行数据发布、分析的整个过程。
三、互联网采集系统流程图
第一步:确定采集任务。
第二步:每个采集任务,我们有多个目标数据源可供采集。
第三步:针对不同的目标数据源,进行不同的采集配置,以确保能采集到数据。
第四步:调度采集任务,与目标站点同步更新,增量采集。
第五步:采集到数据结果,完成数据异构到同构的过程。
第六步:通过发布服务器,将数据发布到应用平台。
四、军犬“信息采集系统”8大应用领域:
1、搜索引擎与垂直搜索 2、综合门户与行业门户
3、电子政务与电子商务 4、知识管理与知识共享
5、企业竞争情报系统 6、BI商业智能系统
7、信息咨询与信息增值 8、信息安全和信息监控
五、军犬“信息采集系统”-软件特征
(1)、过滤干净,智能化抽取正文,且图文关联
(2)、数据导入插口丰富,可以将数据导入成各类主流关系型数据结构。
(3)、军犬“信息采集系统”配置简单
对于新闻资讯采集,只需输入待采集目标网站的地址或某个主题页面地址,软件即会手动学习网站的风格,并手动提取网站的资讯,无需配置模板,目标网站风格发生变化,软件手动学习。对于数据采集软件提供了通俗易懂的站点配置向导,维护人员稍加培训即可配置出任何的信息采集。对于复杂的采集过程,通过一张采集卡脚本即可实现信息的手动采集与监控。
(4)、军犬“信息采集系统”所采即所得,所采即可见
(5)、军犬“信息采集系统”增量采集与手动更新
增加采集:对于初次采集目标网站,软件支持完全采集;而对于已采集过的站点支持增量采集。支持手动更新:自动检查站点是否发生更新,并不会遗漏任何一个重要的信息。
(6)、军犬“信息采集系统”采集结果手动排重
不是借助简单的规则判别,而是借助内容的相似性进行排重判别,准确性高,不会由于标题或内容的少许变化而形成漏判,即使把标题进行了改头换面,系统也会正确判断。
(7)、军犬“信息采集系统”内置强悍的信息监控
可以通过一个关键字广域监控互联网上任何一个站点上的相关信息。也可以通过设置监控频道监控任何站点所采集到富含关键字的信息。对于数值数组可以设置监控误差监控数值出现在一定范围内的信息。信息监控达到字段级。您可以对任何一个采集目标网站设置监控属性,监控周期达到了秒级。对于发生变化的信息可以在短时间内采集到本地
强大的站点管理工具可以对所有采集对象进行集中管理和各类操作
(8)、军犬“信息采集系统”支持多种编码
支持多种网站的信息的编码,GBK、BIG5、UNICODE、UTF8,软件会手动转换成GBK码进行统一的处理。软件即会手动辨识网站的组织结构,自动辨识网站的编码。 表单管理,随心所欲自定义表单,方便采集不同的内容,如采集软件用单独的表单,采集图片用图片表单。
(9)、军犬“信息采集系统”信息导出导入随心所欲
提供信息导出导入与其它软件可作无缝联接 ,如CRM OA 软件提供有强悍的信息记录导出导入功能,您可以对任何一个频道、一条记录进行导出与导入。可以导成Excel/Access等,也可以直接导到指定的数据库。与《信息发布服务器》结合使用可以将信息发布到任何一个地方。
(10)、军犬“信息采集系统“支持阅读模板
任何一种信息类型,软件就会手动创建一个阅读模板便捷了您快速阅读;任何信息您可以对任何一种信息表单订制一款漂亮的阅读模板,也可以对任何一个频道设置不同的阅读模板。
(11)、军犬“信息采集系统“多页面内容重组
对于目标数据源的一篇文章在目标网站上分页显示,系统能手动对其重组.软件运行稳定、采集速度快、占用系统资源少。
历经多次改建的软件采集底层模块运行稳定、采集速度快,点用系统资源少。可多线程并发运行,而不占有过多的系统资源。采集速度快到顿时到位。软件完全可以实现7*24小时不间断无人值守的信息采集。更多细节功能有待于您在使用中去体验。
(12)、军犬“信息采集系统”其它特性列表:
1、支持多种语言:支持简体中文、繁体英文、英文、日文、韩文等多国语言
2、支持多种站点类型:包括html与rss
3、支持登入、验证后采集
4、软件支持须要登陆与须要验证码的网站信息采集,采集过程完全仿人工。
5、支持附件采集
包括图片附件采集、多媒体附件采集、音视频附件采集、附件与正文手动映射与关联
6、完全结构化抽取将网页的非结构化数据抽取成特定的结构化信息数据。
网页搜索是以网页为最小单位,基于视觉的网页块剖析是以网页块为最小单位,垂直搜索是以结构化数据为最小单位。然后将这种数据储存到数据库,进行进一步的加工处理,如:去重、分类等,最后动词、索引再以搜索的方法满足用户的需求。
整个过程中,数据由非结构化数据抽取成结构化数据,经过深度加工处理后以非结构化的方法和结构化的形式返回给用户。
7、数据保存到本地,您可以随时查阅信息。 采集到信息手动保存到本地数据库,您可以随时查阅信息。
8、多线层、多任务
9、支持海量数据采集
10、软件实用、易用、功能强悍
11、可移植、可扩充、可定制
六、军犬“信息采集系统”配置要求
要求:WindowsNT4/ Windows 2000 Server 或更新的操作系统。
要求: Microsoft SQL Server 7/ 2000或其它ODBC插口
要求:intel xeon 2G 以上CPU,2G 以上RAM,硬盘空间200GB以上
七、军犬“信息采集系统”性能
l、支持多线程采集。
2、单机在数据采集在G级以上。
3、数据与数据源同步更新大于10秒级。
4、数据同步发布大于10秒级。 查看全部
中科点击警犬网路信息采集系统
系统简介
一.“信息采集系统”系统概述:
信息采集是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入的整个过程。
军犬信息采集专家是一款基于人工智能的手动学习技术,功能强悍、简单实用的互联网信息采集与监控软件。
二、互联网信息采集与挖掘:
要求从互联网上对特定目标数据源或不特定目标数据源进行采集与监控,并对信息进行结构化抽取保存为本地结构化数据库,然后按业务流程需求与其它模块结合,导入与应用并服务于到电子行业平台。
互联网数据采集与挖掘技术是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入,并按业务所需,进行数据发布、分析的整个过程。
三、互联网采集系统流程图

第一步:确定采集任务。
第二步:每个采集任务,我们有多个目标数据源可供采集。
第三步:针对不同的目标数据源,进行不同的采集配置,以确保能采集到数据。
第四步:调度采集任务,与目标站点同步更新,增量采集。
第五步:采集到数据结果,完成数据异构到同构的过程。
第六步:通过发布服务器,将数据发布到应用平台。
四、军犬“信息采集系统”8大应用领域:
1、搜索引擎与垂直搜索 2、综合门户与行业门户
3、电子政务与电子商务 4、知识管理与知识共享
5、企业竞争情报系统 6、BI商业智能系统
7、信息咨询与信息增值 8、信息安全和信息监控
五、军犬“信息采集系统”-软件特征
(1)、过滤干净,智能化抽取正文,且图文关联
(2)、数据导入插口丰富,可以将数据导入成各类主流关系型数据结构。

(3)、军犬“信息采集系统”配置简单
对于新闻资讯采集,只需输入待采集目标网站的地址或某个主题页面地址,软件即会手动学习网站的风格,并手动提取网站的资讯,无需配置模板,目标网站风格发生变化,软件手动学习。对于数据采集软件提供了通俗易懂的站点配置向导,维护人员稍加培训即可配置出任何的信息采集。对于复杂的采集过程,通过一张采集卡脚本即可实现信息的手动采集与监控。
(4)、军犬“信息采集系统”所采即所得,所采即可见
(5)、军犬“信息采集系统”增量采集与手动更新
增加采集:对于初次采集目标网站,软件支持完全采集;而对于已采集过的站点支持增量采集。支持手动更新:自动检查站点是否发生更新,并不会遗漏任何一个重要的信息。
(6)、军犬“信息采集系统”采集结果手动排重
不是借助简单的规则判别,而是借助内容的相似性进行排重判别,准确性高,不会由于标题或内容的少许变化而形成漏判,即使把标题进行了改头换面,系统也会正确判断。
(7)、军犬“信息采集系统”内置强悍的信息监控
可以通过一个关键字广域监控互联网上任何一个站点上的相关信息。也可以通过设置监控频道监控任何站点所采集到富含关键字的信息。对于数值数组可以设置监控误差监控数值出现在一定范围内的信息。信息监控达到字段级。您可以对任何一个采集目标网站设置监控属性,监控周期达到了秒级。对于发生变化的信息可以在短时间内采集到本地
强大的站点管理工具可以对所有采集对象进行集中管理和各类操作
(8)、军犬“信息采集系统”支持多种编码
支持多种网站的信息的编码,GBK、BIG5、UNICODE、UTF8,软件会手动转换成GBK码进行统一的处理。软件即会手动辨识网站的组织结构,自动辨识网站的编码。 表单管理,随心所欲自定义表单,方便采集不同的内容,如采集软件用单独的表单,采集图片用图片表单。
(9)、军犬“信息采集系统”信息导出导入随心所欲
提供信息导出导入与其它软件可作无缝联接 ,如CRM OA 软件提供有强悍的信息记录导出导入功能,您可以对任何一个频道、一条记录进行导出与导入。可以导成Excel/Access等,也可以直接导到指定的数据库。与《信息发布服务器》结合使用可以将信息发布到任何一个地方。
(10)、军犬“信息采集系统“支持阅读模板
任何一种信息类型,软件就会手动创建一个阅读模板便捷了您快速阅读;任何信息您可以对任何一种信息表单订制一款漂亮的阅读模板,也可以对任何一个频道设置不同的阅读模板。
(11)、军犬“信息采集系统“多页面内容重组
对于目标数据源的一篇文章在目标网站上分页显示,系统能手动对其重组.软件运行稳定、采集速度快、占用系统资源少。
历经多次改建的软件采集底层模块运行稳定、采集速度快,点用系统资源少。可多线程并发运行,而不占有过多的系统资源。采集速度快到顿时到位。软件完全可以实现7*24小时不间断无人值守的信息采集。更多细节功能有待于您在使用中去体验。
(12)、军犬“信息采集系统”其它特性列表:
1、支持多种语言:支持简体中文、繁体英文、英文、日文、韩文等多国语言
2、支持多种站点类型:包括html与rss
3、支持登入、验证后采集
4、软件支持须要登陆与须要验证码的网站信息采集,采集过程完全仿人工。
5、支持附件采集
包括图片附件采集、多媒体附件采集、音视频附件采集、附件与正文手动映射与关联
6、完全结构化抽取将网页的非结构化数据抽取成特定的结构化信息数据。
网页搜索是以网页为最小单位,基于视觉的网页块剖析是以网页块为最小单位,垂直搜索是以结构化数据为最小单位。然后将这种数据储存到数据库,进行进一步的加工处理,如:去重、分类等,最后动词、索引再以搜索的方法满足用户的需求。
整个过程中,数据由非结构化数据抽取成结构化数据,经过深度加工处理后以非结构化的方法和结构化的形式返回给用户。
7、数据保存到本地,您可以随时查阅信息。 采集到信息手动保存到本地数据库,您可以随时查阅信息。
8、多线层、多任务
9、支持海量数据采集
10、软件实用、易用、功能强悍
11、可移植、可扩充、可定制
六、军犬“信息采集系统”配置要求
要求:WindowsNT4/ Windows 2000 Server 或更新的操作系统。
要求: Microsoft SQL Server 7/ 2000或其它ODBC插口
要求:intel xeon 2G 以上CPU,2G 以上RAM,硬盘空间200GB以上
七、军犬“信息采集系统”性能
l、支持多线程采集。
2、单机在数据采集在G级以上。
3、数据与数据源同步更新大于10秒级。
4、数据同步发布大于10秒级。
门户网站建设方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-23 22:50
门户网站可以说是一个行业的专业性网站,在这个门户网站中几乎涵盖了一个行业的所有信息,一般来说内容比较丰富和全面,不然的话是不能成为一个门户的,只能叫一个小平台网站。那么门户网站建设如何如何做,方案怎么做。
门户网站建设
建设一个门户网站,我们前期须要做大量的规划和打算,我们须要将这个行业的内容进行整合,规划好地区及分类,网站要针对性地为业内人士提供行业内及行业相关信息服务,强化业内信息的分类,充分彰显本行业特色。
还要将自己的网站品牌塑造下来,形成自己的特色,梳理行业中的权威形象。
门户网站建设方案的特征
1、网站的前瞻性
网站应采用三层url结构、静态网页技术,在选用平台、采用技术上要具有先进性、前瞻性、扩充性,从而保证建成的网站系统具有良好的稳定性、可扩展性和安全性,以便于后期的维护;
2、网站系统的体验度
尽量满足自身业务功能需求,并适应各业务角色的工作特性,该系统做到简单、实用、人性化;便于操作后台的人使用。
3、容错性和可靠性
在建设网站系统时要考虑保证系统的可靠性和安全性,系统设计中,应有适量冗余及其他保护举措,平台和应用软件具有良好的容错性、容灾性等,错误后也能便捷更改。
4、可维护性要强
门户网站的系统设计应标准化、规范化,按照分层设计,软件构件化实现。采用软件构件化的开发方法:一是系统结构分层,业务与实现分离,逻辑与数据分离;二是以统一的服务插口规范为核心,使用开放标准;提炼封装预制构件规范化;拓展性要强便捷后续的人持续开发和拓展。
5、对于网站的规划
提前规划好网站的所有分类,列表,文章发布形式,生成方法,自定义文件,专题页,可下载的资源、是否可评论、是否有采集、防盗链、产品页、购买页、支付方法、广告位预留、数据统计等等,没有内容的,提前预留,以备后期直接调用。
以上就是一个门户网站的建设规则,一个门户网站要设计的东西十分多,需要很多人协作共同完成,才能作出一个比较好的门户网站,长期以优质内容输出,会使网站逐渐产生行业典范,希望此文对你们有所帮助。 查看全部
门户网站建设方案
门户网站可以说是一个行业的专业性网站,在这个门户网站中几乎涵盖了一个行业的所有信息,一般来说内容比较丰富和全面,不然的话是不能成为一个门户的,只能叫一个小平台网站。那么门户网站建设如何如何做,方案怎么做。
门户网站建设
建设一个门户网站,我们前期须要做大量的规划和打算,我们须要将这个行业的内容进行整合,规划好地区及分类,网站要针对性地为业内人士提供行业内及行业相关信息服务,强化业内信息的分类,充分彰显本行业特色。
还要将自己的网站品牌塑造下来,形成自己的特色,梳理行业中的权威形象。

门户网站建设方案的特征
1、网站的前瞻性
网站应采用三层url结构、静态网页技术,在选用平台、采用技术上要具有先进性、前瞻性、扩充性,从而保证建成的网站系统具有良好的稳定性、可扩展性和安全性,以便于后期的维护;
2、网站系统的体验度
尽量满足自身业务功能需求,并适应各业务角色的工作特性,该系统做到简单、实用、人性化;便于操作后台的人使用。
3、容错性和可靠性
在建设网站系统时要考虑保证系统的可靠性和安全性,系统设计中,应有适量冗余及其他保护举措,平台和应用软件具有良好的容错性、容灾性等,错误后也能便捷更改。
4、可维护性要强
门户网站的系统设计应标准化、规范化,按照分层设计,软件构件化实现。采用软件构件化的开发方法:一是系统结构分层,业务与实现分离,逻辑与数据分离;二是以统一的服务插口规范为核心,使用开放标准;提炼封装预制构件规范化;拓展性要强便捷后续的人持续开发和拓展。
5、对于网站的规划
提前规划好网站的所有分类,列表,文章发布形式,生成方法,自定义文件,专题页,可下载的资源、是否可评论、是否有采集、防盗链、产品页、购买页、支付方法、广告位预留、数据统计等等,没有内容的,提前预留,以备后期直接调用。
以上就是一个门户网站的建设规则,一个门户网站要设计的东西十分多,需要很多人协作共同完成,才能作出一个比较好的门户网站,长期以优质内容输出,会使网站逐渐产生行业典范,希望此文对你们有所帮助。
新云文章采集视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-18 18:18
新云文章采集视频教程
网友评分:3
同类人气软件
新云文章采集视频教程软件介绍
我们采集一个网站的文章,其实和我们打开一个网站去浏览他的一篇文章一样,先开打开的文章列表,再人列表中选定一篇文章的标题,点入再找到文章所在的地方!于是,采集也一样,我们先确定他的文章列表,再步入他的文章页面!
而我们怎么一步步的去锁定他的列表,标题,正文等要采集的对象呢?我们可以发觉,我们每写一个代码进去都是有一个开始,有一个结束!这就是拿来确定减少对象范围的,他由系统手动锁定我们写的开始代码到结束代码之间的内容!也就是由于这样,我们的代码不可以有重复!我们就拿教程中的代码来说吧!
下载地址
新云文章采集视频教程下载地址
下载帮助新云文章采集视频教程来自互联网, 如有侵害您的版权, 请与我们来信联系
* 想诠释您的技术风采吗,我们这个大舞台给您机会!有奖投稿方式: 点这儿
* 站内软件和教程仅供技术研究,请于下载后24小时内自行删掉,请勿用于非法用途否则后果自负!
* 站内软件和教程均由网友发布,切莫轻信软件和教程里的广告信息以防上当受骗
* 站内所有软件和教程早已通过本站检查安全,若您仍然发觉存在安全问题,敬请来信通知我们! 查看全部
新云文章采集视频教程
新云文章采集视频教程

网友评分:3
同类人气软件
新云文章采集视频教程软件介绍
我们采集一个网站的文章,其实和我们打开一个网站去浏览他的一篇文章一样,先开打开的文章列表,再人列表中选定一篇文章的标题,点入再找到文章所在的地方!于是,采集也一样,我们先确定他的文章列表,再步入他的文章页面!
而我们怎么一步步的去锁定他的列表,标题,正文等要采集的对象呢?我们可以发觉,我们每写一个代码进去都是有一个开始,有一个结束!这就是拿来确定减少对象范围的,他由系统手动锁定我们写的开始代码到结束代码之间的内容!也就是由于这样,我们的代码不可以有重复!我们就拿教程中的代码来说吧!
下载地址
新云文章采集视频教程下载地址
下载帮助新云文章采集视频教程来自互联网, 如有侵害您的版权, 请与我们来信联系
* 想诠释您的技术风采吗,我们这个大舞台给您机会!有奖投稿方式: 点这儿
* 站内软件和教程仅供技术研究,请于下载后24小时内自行删掉,请勿用于非法用途否则后果自负!
* 站内软件和教程均由网友发布,切莫轻信软件和教程里的广告信息以防上当受骗
* 站内所有软件和教程早已通过本站检查安全,若您仍然发觉存在安全问题,敬请来信通知我们!
ELK之日志搜集系统布署
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-18 11:33
目录
1. EFK 日志搜集系统介绍
在日常维护中,每次线上服务器的Nginx或PHP遇见报错,一般首选方式是开启日志,查看日志内容。我们可能还须要登录到服务器中,利用命令tail -f 查看最新的日志报错,或许还须要利用Linux运维三剑客awk、grep、sed对日志内容过滤、分析等。如果有一套系统能将所有日志搜集在一起,并通过Web界面展示日志内容,或者可以对日志内容进行汇总剖析,以数据表格的方式直观的展示下来,可以为我们节约大量的时间。
由此,社区开发了一套完整的开源的日志采集架构 (ELK Stack)[] ,其中 E 代表 Elasticsearch,L 代表 Logstash,K 代表 Kibana。
社区常用的ELK构架的日志采集方案,在ELK+Filebeat 集中式日志解决方案解读 这篇文章中写得比较详尽了,这里我就不在多余赘言。
为了搭建一个高可用的 ELK 集中式日志解决方案,我们可以对ELK做进一步的改进,可参考从ELK到EFK演化
我们搭建的日志采集系统构架如下图所示:
在ELK的基础之上,我们采用了Filebeat做日志采集端,如果象ELK中的构架,Logstash作为日志采集端,那么每台服务器都须要安装JAVA环境,因为Logstash是基于Java环境,才能正常使用。而我们采用的 Filebeat 不需要任何依赖,直接安装后,修改配置文件,启动服务即可。当采集到日志文件时,在 input 中我们须要在Filebeat中定义一个 fields,定义一个log_topic的数组,将指定路径下的日志文件分为一类。在 Output 中,我们指定 Output 输入至Kafka,并按照 input
Kafka作为一个消息队列,接收来自Filebeat客户端采集上来的所有日志,并按照不同类型的日志(例如nginx、php、system)分类转发。在Kafka中,我们依照 inout中自定义的日志类型,在kafka中创建不同的topic。
Logstash接收来自Kafka消息队列的消息,根据Kafka中不同的topic,将日志分类写入Elasticsearch中;Kibana匹配Elasticsearch中的索引,可以对日志内容剖析、检索、出图展示(当然须要自己设计出图了)。
2.EFK 架构布署之安装 Elasticsearch0x01 环境说明
系统:CentOS 7
软件版本如下图:
软件版本号
Kibana
6.6
Elasticsearch
6.6
Logstash
6.6
Filebeat
6.6
metricbet
6.6
Kafka
kafka_2.11-2.1.0
Kafka-manage
1.3.3.22
Kafka-eagle
kafka-eagle-web-1.3.0
0x02 系统初始化配置
可参考文章:Shell 之CentOS 7 系统初始化
新增配置如下系统参数 (/etc/security/limits.conf):
# 解除文件描述符限制
* soft nofile 65535
* hard nofile 65535
# 操作系统级别对每个用户创建的进程数的限制
* soft nproc 2048
* hard nproc 2048
# 解除对用户内存大小的限制
* soft memlock unlimited
* hard memlock unlimited
重启服务器
0x03 安装 JDK 8
由于Elasticsearch、Logstash、Kafka-eagle、均须要JDK环境,所以需提早安装 java 环境。
可参考官网:
安装包下载地址:Java SE Development Kit 8 Downloads
先选择 Accept License Agreement,再下载对应的安装包, 我这儿使用的是 CentOS 7 的系统,所以选择 rpm 的镜像包,若是 Ubuntu系统的可以选择 .tar.gz 的镜像包
安装步骤可参考:CentOS 7 之安装布署 JDK
rpm 包安装的JDK默认软件安装目录为:/usr/java/jdk1.8.0_201-amd64,需要配置环境变量,后期的好多软件布署均须要这个路径,最后需复查一下 /usr/bin 目录下是否有java的执行文件
[root@efk-master ~]# ll /usr/bin/java
lrwxrwxrwx. 1 root root 22 Mar 4 11:00 /usr/bin/java -> /etc/alternatives/java
最后查看 java 的版本信息:
[root@efk-master ~]# java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
到此为止,JDK环境已然布署完毕
0x04 安装 Elasticsearch
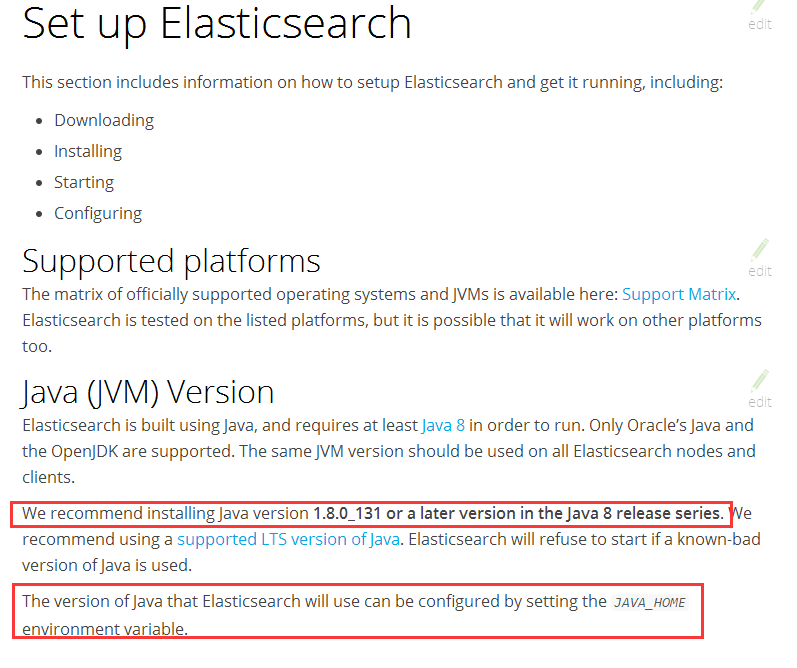
由于 Elasticsearch 是建立于 Java 的基础之上的,所以对 java 的版本有一定的要求,需提早配置好 Java 环境。 Elasticsearch 6.6 版本建议安装java的版本为 Java 8发行版中的 1.8.0_131 之后版本均可。官网更推荐使用提供技术支持(LTS)的 Java 版本。安装完 Java 后建议配置 JAVA_HOME 环境变量。
提示:由于我使用的是CentOS 7 64位的操作系统,后续的安装中均会选择 RPM 包的方式安装,而且我是使用的 root 用户权限布署的。
1.下载安装公共秘钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.手动下载安装安装 RPM 包
# 下载 ES rpm 包
wget https://artifacts.elastic.co/d ... 1.rpm
# 下载 ES 的 sha512 哈希值,保证下载的安装包无数据丢失
wget https://artifacts.elastic.co/d ... ha512
# 验证 哈希值
shasum -a 512 -c elasticsearch-6.6.1.rpm.sha512
# 安装 ES
sudo rpm --install elasticsearch-6.6.1.rpm
3.配置 ES 相关内容,将如下内容添加至主配置文件 /etc/elasticsearch/elasticsearch.yml 中
# 配置 ES 集群的名字,此次没有搭建ES集群,仅为单机部署。但是为了便于后期搭建ES集群,所以需要配置集群名字
cluster.name: efk
# 配置 ES 节点的名字
node.name: es-1
# 是否为主节点
node.master: true
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 允许所有网段访问 9200 端口
network.host: 0.0.0.0
# 开启 http 的 9200 端口
http.port: 9200
# 指定集群中的节点中有几个有 master 资格的节点
discovery.zen.minimum_master_nodes: 1
# 以下配置为 head 插件配置
http.cors.enabled: true
http.cors.allow-origin: "*"
4.配置 ES 内存
vim /etc/elasticsearch/jvm.options
#将如下内容:
-Xms1g
-Xmx1g
#更改为
-Xms32g
-Xmx32g
5.运行 ES
# /bin/systemctl daemon-reload
# /bin/systemctl enable elasticsearch.service
# systemctl start elasticsearch.service
6.检查 ES 是否运行正常
a. 确保ES的默认9200端口开启
b. 确保ES的服务正常启动
# 查看端口
# lsof -i :9200
# 查看服务
# ps -ef | grep elasticsearch| grep -v grep
7.浏览器访问 ES
输入本机IP加端口号
http://ip:9200
8.安装 elasticsearch-head插件(需提早打算好 node.js 环境)
我们先安装布署 node.js 环境
node.js
cd /opt/efk
curl -L -O https://nodejs.org/dist/v10.15 ... ar.xz
tar -xf node-v10.15.3-linux-x64.tar.xz
mv node-v10.15.1-linux-x64 /usr/local
配置 node 的环境变量 (/etc/profile)
# node home
export NODEJS_HOME=/usr/local/node-v10.15.1-linux-x64
export PATH=$PATH:$JAVA_HOME/bin:$NODEJS_HOME/bin
激活环境变量
source /etc/profile
配置软链接
# ln -s /usr/local/node-v10.15.1-linux-x64/bin/node /usr/bin/node
验证是否配置成功
# node --version
v10.15.1
安装 elasticsearch-head
# cd /usr/local
# git clone git://github.com/mobz/elasticsearch-head.git
# cd elasticsearch-head
# npm install
# npm run start
访问地址: :9100
如上图所示:
1.在浏览器中输入:9100(ip为布署环境的本机ip)
2.输入框中输入ES的地址::9200 (端口号9200为ES的主配置文件中配置的 http.port)
3.由于此文档是在整个EFK日志采集系统搭建完毕后,编写的文档,所以,可能会见到 system 的索引,暂时先忽视。我们重点关注es-1;如果不记得的话,可以查看上面配置的ES主配置文件,es-1即为我们上面配置的node.name;这里提醒我们不要小看任何一个配置选项,既然须要配置,必有其用途。
3.EFK 架构布署之安装 Kibana
1.下载 64位安装包,并安装 Kibana
# cd /opt/efk
# wget https://artifacts.elastic.co/d ... ar.gz
# shasum -a 512 kibana-6.6.1-linux-x86_64.tar.gz
# tar -xzf kibana-6.6.1-linux-x86_64.tar.gz
# mv kibana-6.6.1-linux-x86_64/ /usr/local
配置 Kinaba
# kibana 访问端口
server.port: 5601
# kibana 访问 IP 地址
server.host: "192.168.7.3"
# kibana 的服务名
server.name: "efk-master"
# ES 地址
elasticsearch.hosts: ["http://192.168.7.3:9200"]
# kibana 索引
kibana.index: ".kibana"
# ES 登录账号及密码
elasticsearch.username: "admin"
elasticsearch.password: "admin"
# kibana 进程 ID 路径
pid.file: /var/run/kibana.pid
3.启动服务
执行kibana的二进制文件,此命令执行后,进程会在前台运行,后期我们会使用 Supervisord 的形式布署。
# /usr/local/kibana-6.6.0-linux-x86_64/bin/kibana
4.访问kibana 查看全部
ELK之日志搜集系统布署
目录
1. EFK 日志搜集系统介绍
在日常维护中,每次线上服务器的Nginx或PHP遇见报错,一般首选方式是开启日志,查看日志内容。我们可能还须要登录到服务器中,利用命令tail -f 查看最新的日志报错,或许还须要利用Linux运维三剑客awk、grep、sed对日志内容过滤、分析等。如果有一套系统能将所有日志搜集在一起,并通过Web界面展示日志内容,或者可以对日志内容进行汇总剖析,以数据表格的方式直观的展示下来,可以为我们节约大量的时间。
由此,社区开发了一套完整的开源的日志采集架构 (ELK Stack)[] ,其中 E 代表 Elasticsearch,L 代表 Logstash,K 代表 Kibana。
社区常用的ELK构架的日志采集方案,在ELK+Filebeat 集中式日志解决方案解读 这篇文章中写得比较详尽了,这里我就不在多余赘言。
为了搭建一个高可用的 ELK 集中式日志解决方案,我们可以对ELK做进一步的改进,可参考从ELK到EFK演化
我们搭建的日志采集系统构架如下图所示:

在ELK的基础之上,我们采用了Filebeat做日志采集端,如果象ELK中的构架,Logstash作为日志采集端,那么每台服务器都须要安装JAVA环境,因为Logstash是基于Java环境,才能正常使用。而我们采用的 Filebeat 不需要任何依赖,直接安装后,修改配置文件,启动服务即可。当采集到日志文件时,在 input 中我们须要在Filebeat中定义一个 fields,定义一个log_topic的数组,将指定路径下的日志文件分为一类。在 Output 中,我们指定 Output 输入至Kafka,并按照 input
Kafka作为一个消息队列,接收来自Filebeat客户端采集上来的所有日志,并按照不同类型的日志(例如nginx、php、system)分类转发。在Kafka中,我们依照 inout中自定义的日志类型,在kafka中创建不同的topic。
Logstash接收来自Kafka消息队列的消息,根据Kafka中不同的topic,将日志分类写入Elasticsearch中;Kibana匹配Elasticsearch中的索引,可以对日志内容剖析、检索、出图展示(当然须要自己设计出图了)。
2.EFK 架构布署之安装 Elasticsearch0x01 环境说明
系统:CentOS 7
软件版本如下图:
软件版本号
Kibana
6.6
Elasticsearch
6.6
Logstash
6.6
Filebeat
6.6
metricbet
6.6
Kafka
kafka_2.11-2.1.0
Kafka-manage
1.3.3.22
Kafka-eagle
kafka-eagle-web-1.3.0
0x02 系统初始化配置
可参考文章:Shell 之CentOS 7 系统初始化
新增配置如下系统参数 (/etc/security/limits.conf):
# 解除文件描述符限制
* soft nofile 65535
* hard nofile 65535
# 操作系统级别对每个用户创建的进程数的限制
* soft nproc 2048
* hard nproc 2048
# 解除对用户内存大小的限制
* soft memlock unlimited
* hard memlock unlimited
重启服务器
0x03 安装 JDK 8
由于Elasticsearch、Logstash、Kafka-eagle、均须要JDK环境,所以需提早安装 java 环境。
可参考官网:
安装包下载地址:Java SE Development Kit 8 Downloads

先选择 Accept License Agreement,再下载对应的安装包, 我这儿使用的是 CentOS 7 的系统,所以选择 rpm 的镜像包,若是 Ubuntu系统的可以选择 .tar.gz 的镜像包
安装步骤可参考:CentOS 7 之安装布署 JDK
rpm 包安装的JDK默认软件安装目录为:/usr/java/jdk1.8.0_201-amd64,需要配置环境变量,后期的好多软件布署均须要这个路径,最后需复查一下 /usr/bin 目录下是否有java的执行文件
[root@efk-master ~]# ll /usr/bin/java
lrwxrwxrwx. 1 root root 22 Mar 4 11:00 /usr/bin/java -> /etc/alternatives/java
最后查看 java 的版本信息:
[root@efk-master ~]# java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
到此为止,JDK环境已然布署完毕
0x04 安装 Elasticsearch
由于 Elasticsearch 是建立于 Java 的基础之上的,所以对 java 的版本有一定的要求,需提早配置好 Java 环境。 Elasticsearch 6.6 版本建议安装java的版本为 Java 8发行版中的 1.8.0_131 之后版本均可。官网更推荐使用提供技术支持(LTS)的 Java 版本。安装完 Java 后建议配置 JAVA_HOME 环境变量。
提示:由于我使用的是CentOS 7 64位的操作系统,后续的安装中均会选择 RPM 包的方式安装,而且我是使用的 root 用户权限布署的。
1.下载安装公共秘钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.手动下载安装安装 RPM 包
# 下载 ES rpm 包
wget https://artifacts.elastic.co/d ... 1.rpm
# 下载 ES 的 sha512 哈希值,保证下载的安装包无数据丢失
wget https://artifacts.elastic.co/d ... ha512
# 验证 哈希值
shasum -a 512 -c elasticsearch-6.6.1.rpm.sha512
# 安装 ES
sudo rpm --install elasticsearch-6.6.1.rpm
3.配置 ES 相关内容,将如下内容添加至主配置文件 /etc/elasticsearch/elasticsearch.yml 中
# 配置 ES 集群的名字,此次没有搭建ES集群,仅为单机部署。但是为了便于后期搭建ES集群,所以需要配置集群名字
cluster.name: efk
# 配置 ES 节点的名字
node.name: es-1
# 是否为主节点
node.master: true
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 允许所有网段访问 9200 端口
network.host: 0.0.0.0
# 开启 http 的 9200 端口
http.port: 9200
# 指定集群中的节点中有几个有 master 资格的节点
discovery.zen.minimum_master_nodes: 1
# 以下配置为 head 插件配置
http.cors.enabled: true
http.cors.allow-origin: "*"
4.配置 ES 内存
vim /etc/elasticsearch/jvm.options
#将如下内容:
-Xms1g
-Xmx1g
#更改为
-Xms32g
-Xmx32g
5.运行 ES
# /bin/systemctl daemon-reload
# /bin/systemctl enable elasticsearch.service
# systemctl start elasticsearch.service
6.检查 ES 是否运行正常
a. 确保ES的默认9200端口开启
b. 确保ES的服务正常启动
# 查看端口
# lsof -i :9200
# 查看服务
# ps -ef | grep elasticsearch| grep -v grep
7.浏览器访问 ES
输入本机IP加端口号
http://ip:9200
8.安装 elasticsearch-head插件(需提早打算好 node.js 环境)
我们先安装布署 node.js 环境
node.js
cd /opt/efk
curl -L -O https://nodejs.org/dist/v10.15 ... ar.xz
tar -xf node-v10.15.3-linux-x64.tar.xz
mv node-v10.15.1-linux-x64 /usr/local
配置 node 的环境变量 (/etc/profile)
# node home
export NODEJS_HOME=/usr/local/node-v10.15.1-linux-x64
export PATH=$PATH:$JAVA_HOME/bin:$NODEJS_HOME/bin
激活环境变量
source /etc/profile
配置软链接
# ln -s /usr/local/node-v10.15.1-linux-x64/bin/node /usr/bin/node
验证是否配置成功
# node --version
v10.15.1
安装 elasticsearch-head
# cd /usr/local
# git clone git://github.com/mobz/elasticsearch-head.git
# cd elasticsearch-head
# npm install
# npm run start
访问地址: :9100
如上图所示:
1.在浏览器中输入:9100(ip为布署环境的本机ip)
2.输入框中输入ES的地址::9200 (端口号9200为ES的主配置文件中配置的 http.port)
3.由于此文档是在整个EFK日志采集系统搭建完毕后,编写的文档,所以,可能会见到 system 的索引,暂时先忽视。我们重点关注es-1;如果不记得的话,可以查看上面配置的ES主配置文件,es-1即为我们上面配置的node.name;这里提醒我们不要小看任何一个配置选项,既然须要配置,必有其用途。
3.EFK 架构布署之安装 Kibana
1.下载 64位安装包,并安装 Kibana
# cd /opt/efk
# wget https://artifacts.elastic.co/d ... ar.gz
# shasum -a 512 kibana-6.6.1-linux-x86_64.tar.gz
# tar -xzf kibana-6.6.1-linux-x86_64.tar.gz
# mv kibana-6.6.1-linux-x86_64/ /usr/local
配置 Kinaba
# kibana 访问端口
server.port: 5601
# kibana 访问 IP 地址
server.host: "192.168.7.3"
# kibana 的服务名
server.name: "efk-master"
# ES 地址
elasticsearch.hosts: ["http://192.168.7.3:9200"]
# kibana 索引
kibana.index: ".kibana"
# ES 登录账号及密码
elasticsearch.username: "admin"
elasticsearch.password: "admin"
# kibana 进程 ID 路径
pid.file: /var/run/kibana.pid
3.启动服务
执行kibana的二进制文件,此命令执行后,进程会在前台运行,后期我们会使用 Supervisord 的形式布署。
# /usr/local/kibana-6.6.0-linux-x86_64/bin/kibana
4.访问kibana
PHPMaos小说采集系统 3.0 Beta
采集交流 • 优采云 发表了文章 • 0 个评论 • 501 次浏览 • 2020-08-18 07:21
PHPMaos小说采集系统基于PHP+MySQL的技术开发,支持Windows、Linux、Unix等多种服务器平台,从2009年开始发布第一个版本。PHPMaos简单、健壮、灵活几大特征并专注于小说系统,我们会坚持做到国外应用最广泛的php类小说系统。免费版只有三天试用时限。
PHPMaos小说采集系统 3.0 Beta 更新日志:2011-2-27
1、url路径调整:缩减书籍展示url地址过长问题,有利于搜索引擎优化;小说作品html生成地址优化;
2、增加搜索功能,支持精确和模糊搜索作者;
3、增加书柜展示功能;
4、增强书籍展示页的交互功能,用户可自定义背景颜色,字体颜色,字体大小,滚屏间隔,支持保存设置功能;
5、增加后台系统 探针工具 检测系统功能,方便用户直接查看系统状况;
6、增加第六套模板;
PHPMaos 主要功能:
内置模型:连载模块,采集系统,前台模板,友情链接,广告管理,作者模块,会员模块,打包下载,临时书柜,地区分类,类型分类等;
PHPMaos小说采集系统 3.0 功能详尽说明:
1、采用php+mysql构架,可以生成整站html,对搜索引擎收录十分友好;
2、自定义采集功能,目前已支持20个小说站点的采集,所有图片都可本地化处理,支持字符内容替换,自动编码转换和独创的断点续采功能,保证24小不间断采集;
3、作品和分类一对多的关系,解决大多数小说站作品和分类难以多向关联问题;
4、作品和作者多对多的关系,让作者和作品可以多向关联,使读者更便捷的阅读;
5、书架功能:可以为用户开启已阅作品功能;
6、丰富的模板界面,目前已开放4套模板,能满足您各类类型的小说网站界面;
7、智能安装,第一次只须要访问,即可在3步内完成系统安装;
8、丰富的小说排行榜功能,热门排名,top排名,日点击排名,周点击排名,月点击排名,推荐排名,历史排名; 查看全部
PHPMaos小说采集系统 3.0 Beta
PHPMaos小说采集系统基于PHP+MySQL的技术开发,支持Windows、Linux、Unix等多种服务器平台,从2009年开始发布第一个版本。PHPMaos简单、健壮、灵活几大特征并专注于小说系统,我们会坚持做到国外应用最广泛的php类小说系统。免费版只有三天试用时限。
PHPMaos小说采集系统 3.0 Beta 更新日志:2011-2-27
1、url路径调整:缩减书籍展示url地址过长问题,有利于搜索引擎优化;小说作品html生成地址优化;
2、增加搜索功能,支持精确和模糊搜索作者;
3、增加书柜展示功能;
4、增强书籍展示页的交互功能,用户可自定义背景颜色,字体颜色,字体大小,滚屏间隔,支持保存设置功能;
5、增加后台系统 探针工具 检测系统功能,方便用户直接查看系统状况;
6、增加第六套模板;
PHPMaos 主要功能:
内置模型:连载模块,采集系统,前台模板,友情链接,广告管理,作者模块,会员模块,打包下载,临时书柜,地区分类,类型分类等;
PHPMaos小说采集系统 3.0 功能详尽说明:
1、采用php+mysql构架,可以生成整站html,对搜索引擎收录十分友好;
2、自定义采集功能,目前已支持20个小说站点的采集,所有图片都可本地化处理,支持字符内容替换,自动编码转换和独创的断点续采功能,保证24小不间断采集;
3、作品和分类一对多的关系,解决大多数小说站作品和分类难以多向关联问题;
4、作品和作者多对多的关系,让作者和作品可以多向关联,使读者更便捷的阅读;
5、书架功能:可以为用户开启已阅作品功能;
6、丰富的模板界面,目前已开放4套模板,能满足您各类类型的小说网站界面;
7、智能安装,第一次只须要访问,即可在3步内完成系统安装;
8、丰富的小说排行榜功能,热门排名,top排名,日点击排名,周点击排名,月点击排名,推荐排名,历史排名;
数据搜集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-17 22:10
开源比赛火爆报考中,立即报考「赢取亿元奖金」>>>
什么是 Chukwa,简单的说它是一个数据搜集系统,它可以将各种各样类型的数据搜集成适宜 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各类 MapReduce 操作。Chukwa 本身也提供了好多外置的功能,帮助我们进行数据的搜集和整理。
为了愈发简单直观的展示 Chukwa,我们先来看一个假定的场景。假设我们有一个规模很大 ( 牵扯到 Hadoop 的总是很大。。。。) 的网站,网站每天形成数目庞大的日志文件,要搜集,分析这种日志文件可不是件容易的事情,读者可能会想了,做这些事情 Hadoop 挺合适的,很多小型网站都在用,那么问题来了,分散在各个节点的数据如何搜集,采集到的数据假如有重复数据如何处理,如何与 Hadoop 集成。如果自己编撰代码完成这个过程,一来须要耗费不小的精力,二来不可避开的会引入 Bug。这里就是我们 Chukwa 发挥作用的时侯了,Chukwa 是一个开源的软件,有很多聪明的开发者在贡献着自己的智慧。它可以帮助我们在各个节点实时监控日志文件的变化,增量的将文件内容写入 HDFS,同时还可以将数据消除重复,排序等,这时 Hadoop 从 HDFS 中领到的文件早已是 SequenceFile 了。无需任何转换过程,中间纷扰的过程都由 Chukwa 帮我们完成了。是不是太省心呢。这里我们仅仅举了一个应用的事例,它还可以帮我们监控来自 Socket 的数据,甚至定时执行我们指定的命令获取输出数据,等等,具体的可以参看 Chukwa 官方文档。如果这种还不够,我们还可以自己定义自己的适配器来完成愈发中级的功能。 查看全部
数据搜集系统
开源比赛火爆报考中,立即报考「赢取亿元奖金」>>>

什么是 Chukwa,简单的说它是一个数据搜集系统,它可以将各种各样类型的数据搜集成适宜 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各类 MapReduce 操作。Chukwa 本身也提供了好多外置的功能,帮助我们进行数据的搜集和整理。
为了愈发简单直观的展示 Chukwa,我们先来看一个假定的场景。假设我们有一个规模很大 ( 牵扯到 Hadoop 的总是很大。。。。) 的网站,网站每天形成数目庞大的日志文件,要搜集,分析这种日志文件可不是件容易的事情,读者可能会想了,做这些事情 Hadoop 挺合适的,很多小型网站都在用,那么问题来了,分散在各个节点的数据如何搜集,采集到的数据假如有重复数据如何处理,如何与 Hadoop 集成。如果自己编撰代码完成这个过程,一来须要耗费不小的精力,二来不可避开的会引入 Bug。这里就是我们 Chukwa 发挥作用的时侯了,Chukwa 是一个开源的软件,有很多聪明的开发者在贡献着自己的智慧。它可以帮助我们在各个节点实时监控日志文件的变化,增量的将文件内容写入 HDFS,同时还可以将数据消除重复,排序等,这时 Hadoop 从 HDFS 中领到的文件早已是 SequenceFile 了。无需任何转换过程,中间纷扰的过程都由 Chukwa 帮我们完成了。是不是太省心呢。这里我们仅仅举了一个应用的事例,它还可以帮我们监控来自 Socket 的数据,甚至定时执行我们指定的命令获取输出数据,等等,具体的可以参看 Chukwa 官方文档。如果这种还不够,我们还可以自己定义自己的适配器来完成愈发中级的功能。
CmsTop系统文章采集的操作方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-11 17:22
文章采集系统颠覆传统采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需有基础技术知识的人员设置好相关规则。编辑人员无需了解很过细节的技 术规则,只需选中自己想要采集的文章列表,就可以象发布文章一样,轻松地完成采集操作。
a. 方便而简约的采集规则配置
对于须要采集功能的网站来说,简洁而便捷的规则配置是易用性的彰显.技术人员只须要太基本的网页知识就可以随心地去写采集规则.在写规则完成,可以实时地 显示出采集的内容是否正确.通过此功能可以便捷地测试出内容的可用性.
方便而简约的采集规则配置
b. 采集规则可永久性使用
对于早已写好的采集规则,系统会手动添加到规则列表中,以备之后使用。每一规则都可以重复借助,并且可依照需求作出更改。
采集规则可永久性使用
c. 自定义的文章采集数量
根据采集规则的配置参数,可以便捷地在采集控制版选定到所需采集文章的数据量。
d. 高效地采集管理界面
自定配置的所有采集规则就会在采集管理界面呈现下来,并且还能依据采集更新的频度查找出最新文章,系统通过最新,已查看,已采集标示出文章所处的状态。管 理人员可以通过采集管理界面选择性地对须要的文章进行采集。
高效地采集管理界面 查看全部
文章的采集功能是通过程序来远程获取目标网页内容,经过本地规则解析处理后储存到服务器的数据库内。
文章采集系统颠覆传统采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需有基础技术知识的人员设置好相关规则。编辑人员无需了解很过细节的技 术规则,只需选中自己想要采集的文章列表,就可以象发布文章一样,轻松地完成采集操作。
a. 方便而简约的采集规则配置
对于须要采集功能的网站来说,简洁而便捷的规则配置是易用性的彰显.技术人员只须要太基本的网页知识就可以随心地去写采集规则.在写规则完成,可以实时地 显示出采集的内容是否正确.通过此功能可以便捷地测试出内容的可用性.
方便而简约的采集规则配置
b. 采集规则可永久性使用
对于早已写好的采集规则,系统会手动添加到规则列表中,以备之后使用。每一规则都可以重复借助,并且可依照需求作出更改。
采集规则可永久性使用
c. 自定义的文章采集数量
根据采集规则的配置参数,可以便捷地在采集控制版选定到所需采集文章的数据量。
d. 高效地采集管理界面
自定配置的所有采集规则就会在采集管理界面呈现下来,并且还能依据采集更新的频度查找出最新文章,系统通过最新,已查看,已采集标示出文章所处的状态。管 理人员可以通过采集管理界面选择性地对须要的文章进行采集。
高效地采集管理界面
webplus系统文章采集教程[宝典]
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-08-10 16:22
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl在栏目管理中选择该栏目,点击设置采集计划。(如:图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集的基本属性。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉包括执行方法,信息是否手动发布,被采集的栏目类型和页面的编码格式。
(如:图二)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl事先约定好该采集计划的执行方法,自动、定时单次还是定时循环执行。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如仅仅为了采集网页当前的数据,我们可以采用自动和定时单次的形式采集一次即可;假如被采集网页的数据会更新,而我们又要保证信息的同步,即采用定时循环采集的形式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如采集过来的信息不须要更改,可以直接对外网公开,选择手动发布即可。假如采集过来的信息,须要更改,初审等,选择不要手动发布,等采集完成之后,由信息管理人员来进行其他操作。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的网页中只是单纯的一个新闻列表,即是将该页面的新闻采集到指定栏目下,这么选择单栏目即可。如果被采集的页面有多个新闻列表,但是各自提供单独链接进入自己的新闻列表页面,而我们又须要采集所有的新闻信息,这么选择多栏目。另外,假如采集的页面是RSS信息聚合页面,这么设置为相应的RSS单栏目或RSS多栏目。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl因为webplus系统采用的是UTF-8的编码格式,而被采集可能是其他的编码格式,这么为了防止采集过来的信息乱码,这儿须要设置为被采集页面的编码格式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl本文来自笔记本基础知识:系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划的采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目采集计划的设置(如:图三)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl即是被采集页面的访问路径。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置“文章页URL获取规则”webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻列表是以一个iframe方式嵌入在被采集网页中,这么须要设置规则来获取列表iframe接地址,因而来访问新闻列表。
否则不须要拟定该规则。(具体规则形式请参见下边的“采集规则抒发式制订”)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集网页的新闻列表存在分页的情况,这么按照新闻列表分页的方法(链接和表单递交)制订分页的规则,但是须要设置分页开始页脚,间隔页码和采集页数。假如新闻列表不存在分页,即不需要制订该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的页面有多个新闻列表,但是多处新闻列表的url规则类似,而我们只须要采集指定的一处列表,即须要设置限制文章列表的获取规则,这是为了防止采集多余的数据。否则不须要设置该规则。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置文章url的获取规则,为了从采集页面中才能访问具体的新闻页面,因而进行新闻采集。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl具体的新闻页面,假如文章内容是以iframe的方式嵌入在该新闻页面中,这么须要设置规则来获取文章iframe的链接地址,因而来访问新闻内容。否则不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻了内容存在分页的情况,这么依据文章内容分页的形式(链接和表单递交)来制订分页的规则,而且须要设置分页开始页脚,间隔页脚和采集页数。假如文章内容不存在分页,即不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl倘若新闻页面中,不仅新闻内容外,还有其他的附加信息,这么在采集过程中为了更容易找到新闻内容,这儿须要设置限制新闻内容的获取规则。一是为了防止形成垃圾信息,二是为了减少了新闻具体信息获取规则的复杂度。倘若新闻页面比较简单,通常该规则不须要设置。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl新闻属性的设置规则,不仅标题和内容外,其他都是非必须条件,另外新闻的发布时间不设置的话,会采用当前的时间作为发布时间。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划的设置(如:图五)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划不仅须要在“列表页起始URL”下设置列表页URL规则和“文章页URL获取规则”下设置栏目名称的获取规则,其他与单栏目采集计划设置一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目采集计划的设置(如:图四)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目的采集计划不须要设置“文章页URL获取规则”,其他与单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目采集计划的设置(如:图六)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目的采集计划须要在“列表页起始URL”下设置列表页URL获取规则,其他与RSS单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl采集规则表达式制订webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉表达式设置和调整,以及对表达式列表进行测试webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl点击采集页面中某一处“获取规则设置”,步入规则表达式列表页面(如:图七)。在该页面中不仅可以对表达式进行降低,更改,删掉和调整次序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容,对表达式规则列表进行测试。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl表达式类型分为字符串,匹配,匹配替换和公式四种类型。其中匹配和匹配替换须要用到java的正值表达式,这要求采集计划设置人员对表达式有一定的了解。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl字符串:直接输入的字符串常量webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配:从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内容S。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配替换:先从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内中匹配到的内容替换后得到正确的内容。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl公式:只支持[pageIndex],拿来在获取分页地址时代表分页的页脚数。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl图示详情webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉步入栏目管理webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉(图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉在右则栏目列表中选中一个栏目点击设置采集计划。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl自动(须要在栏目列表点击“立即采集”来启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单次(可以设置一个时间,抵达该时间会手动启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目RSS(采集一个RSS地址下的文章)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿多栏目RSS(从一个RSS列表地址开始,采集多个RSS地址下的文章,每位RSS地址产生一个子栏目)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl编码方法为被采集页面的编码webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉设置采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉 查看全部
信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl步骤及详尽webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉现今须要将一个网页的数据(新闻)采集到webplus系统一个指定的栏目下,步骤如下:webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl在栏目管理中选择该栏目,点击设置采集计划。(如:图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集的基本属性。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉包括执行方法,信息是否手动发布,被采集的栏目类型和页面的编码格式。
(如:图二)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl事先约定好该采集计划的执行方法,自动、定时单次还是定时循环执行。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如仅仅为了采集网页当前的数据,我们可以采用自动和定时单次的形式采集一次即可;假如被采集网页的数据会更新,而我们又要保证信息的同步,即采用定时循环采集的形式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如采集过来的信息不须要更改,可以直接对外网公开,选择手动发布即可。假如采集过来的信息,须要更改,初审等,选择不要手动发布,等采集完成之后,由信息管理人员来进行其他操作。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的网页中只是单纯的一个新闻列表,即是将该页面的新闻采集到指定栏目下,这么选择单栏目即可。如果被采集的页面有多个新闻列表,但是各自提供单独链接进入自己的新闻列表页面,而我们又须要采集所有的新闻信息,这么选择多栏目。另外,假如采集的页面是RSS信息聚合页面,这么设置为相应的RSS单栏目或RSS多栏目。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl因为webplus系统采用的是UTF-8的编码格式,而被采集可能是其他的编码格式,这么为了防止采集过来的信息乱码,这儿须要设置为被采集页面的编码格式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl本文来自笔记本基础知识:系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划的采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目采集计划的设置(如:图三)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl即是被采集页面的访问路径。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置“文章页URL获取规则”webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻列表是以一个iframe方式嵌入在被采集网页中,这么须要设置规则来获取列表iframe接地址,因而来访问新闻列表。
否则不须要拟定该规则。(具体规则形式请参见下边的“采集规则抒发式制订”)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集网页的新闻列表存在分页的情况,这么按照新闻列表分页的方法(链接和表单递交)制订分页的规则,但是须要设置分页开始页脚,间隔页码和采集页数。假如新闻列表不存在分页,即不需要制订该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的页面有多个新闻列表,但是多处新闻列表的url规则类似,而我们只须要采集指定的一处列表,即须要设置限制文章列表的获取规则,这是为了防止采集多余的数据。否则不须要设置该规则。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置文章url的获取规则,为了从采集页面中才能访问具体的新闻页面,因而进行新闻采集。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl具体的新闻页面,假如文章内容是以iframe的方式嵌入在该新闻页面中,这么须要设置规则来获取文章iframe的链接地址,因而来访问新闻内容。否则不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻了内容存在分页的情况,这么依据文章内容分页的形式(链接和表单递交)来制订分页的规则,而且须要设置分页开始页脚,间隔页脚和采集页数。假如文章内容不存在分页,即不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl倘若新闻页面中,不仅新闻内容外,还有其他的附加信息,这么在采集过程中为了更容易找到新闻内容,这儿须要设置限制新闻内容的获取规则。一是为了防止形成垃圾信息,二是为了减少了新闻具体信息获取规则的复杂度。倘若新闻页面比较简单,通常该规则不须要设置。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl新闻属性的设置规则,不仅标题和内容外,其他都是非必须条件,另外新闻的发布时间不设置的话,会采用当前的时间作为发布时间。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划的设置(如:图五)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划不仅须要在“列表页起始URL”下设置列表页URL规则和“文章页URL获取规则”下设置栏目名称的获取规则,其他与单栏目采集计划设置一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目采集计划的设置(如:图四)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目的采集计划不须要设置“文章页URL获取规则”,其他与单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目采集计划的设置(如:图六)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目的采集计划须要在“列表页起始URL”下设置列表页URL获取规则,其他与RSS单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl采集规则表达式制订webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉表达式设置和调整,以及对表达式列表进行测试webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl点击采集页面中某一处“获取规则设置”,步入规则表达式列表页面(如:图七)。在该页面中不仅可以对表达式进行降低,更改,删掉和调整次序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容,对表达式规则列表进行测试。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl表达式类型分为字符串,匹配,匹配替换和公式四种类型。其中匹配和匹配替换须要用到java的正值表达式,这要求采集计划设置人员对表达式有一定的了解。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl字符串:直接输入的字符串常量webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配:从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内容S。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配替换:先从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内中匹配到的内容替换后得到正确的内容。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl公式:只支持[pageIndex],拿来在获取分页地址时代表分页的页脚数。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl图示详情webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉步入栏目管理webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉(图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉在右则栏目列表中选中一个栏目点击设置采集计划。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl自动(须要在栏目列表点击“立即采集”来启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单次(可以设置一个时间,抵达该时间会手动启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目RSS(采集一个RSS地址下的文章)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿多栏目RSS(从一个RSS列表地址开始,采集多个RSS地址下的文章,每位RSS地址产生一个子栏目)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl编码方法为被采集页面的编码webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉设置采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉
网钛文章管理系统(OTCMS) 更新日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-10 08:53
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。
网钛文章管理系统(OTCMS) 更新日志:
2020年06月22日 V2.93更新包
1.[完善]后台主界面 右上角 和 右下角 增加箭头图标,可以重新调整内容框高度
2.[修复]后台某些官网链接失效修补下 查看全部
网钛文章管理系统(OTCMS)以简单、实用、傻瓜式操作而著称,是国外 网钛文章管理系统(OTCMS)是最热门ASP开源网站管理系统之一,也是用户增速最快的ASP类CMS系统之一,目前的版本无论在功能,人性化,还是易用性方面,都有了长足的发展,OTCMS的主要目标用户锁定在草根型中小个人站长,让这些对网路不是太熟悉,对网站建设不是太懂又想做网站的人可以很快搭建起一个功能实用又强悍,操作人性又易用。OTCMS更专注于个人网站或中小型门户的建立,当然也不乏有企业用户等在使用本系统,使用过OTCMS的用户就会它好评不断。
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。
网钛文章管理系统(OTCMS) 更新日志:
2020年06月22日 V2.93更新包
1.[完善]后台主界面 右上角 和 右下角 增加箭头图标,可以重新调整内容框高度
2.[修复]后台某些官网链接失效修补下
微信公众号文章采集系统镜像有6个G,用分卷压缩文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-03-23 07:04
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。
系统映像具有6 Gs,文件按子卷压缩,并且记录了一些使用视频并将其放置在其中。
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集解决方案设为开源
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0可以将启动规则开发为模块。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此anyproxy需要打开端口8001才能使所有http请求成功。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作网络服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,用于模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是不能在Windows中完成。虚拟机安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机无法进行二次虚拟化,阿里云Windows服务器无法安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果您认为这对您有用,请随时提供奖励,我没有设置奖励金额
如果在安装和使用过程中遇到任何问题,请将我添加到微信中。 查看全部
微信公众号文章采集系统镜像有6个G,用分卷压缩文件
本着开源和用户方便的精神,“微信公众号文章 采集系统”已打包到虚拟机中。您只需要下载并安装虚拟机映像即可使用它。
系统映像具有6 Gs,文件按子卷压缩,并且记录了一些使用视频并将其放置在其中。
链接:密码:ugcn
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集解决方案设为开源
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1、 anyproxy阿里巴巴的开源代理拦截器,使用的版本为4. 0,可以轻松修改响应信息。我已经在系统中安装了anyproxy,并且安装非常简单。首先安装nodejs环境,然后使用npm安装anyproxy。
anyproxy 4. 0可以将启动规则开发为模块。编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可。此处使用的命令是anproxy --rule weixin.js。关于如何设置https代理证书,请参考官方网站。我在虚拟机中设置了全局代理,因此anyproxy需要打开端口8001才能使所有http请求成功。
规则代码的主要逻辑是拦截微信公众号的请求并将数据转发给php。
2、 apache + php + mysql这主要用作网络服务器,以处理由anyproxy拦截的请求,处理微信文章数据,喜欢和阅读。
截取的数据的处理可以在特定的PHP代码中看到,并且逻辑也不太复杂。为方便起见,这是phpstudy的集成开发环境。
3、按钮向导,按钮向导是国内生产的工具,用于模拟类似于vb语法的键盘和鼠标。按钮向导在此处用于模拟单击Windows下的微信客户端。
在处理多个微信公众号时,客户需要点击,所有的手动操作都通过按钮向导进行模拟。当我去检查特定的代码时,我在处理历史记录消息时使用了一些技巧。事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但发现找不到。您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮。
当一个想法不起作用时,请尝试其他想法。整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推。
4、 windows WeChat客户端,我实际上试图使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是不能在Windows中完成。虚拟机安装Android模拟器,这意味着无法在虚拟机中进行辅助虚拟化。我已经踩到了这个坑,所以您不需要踩到它。我记得以前有人问过,阿里云Windows服务器是否可以配备Android模拟器,我想答案是一样的,虚拟机无法进行二次虚拟化,阿里云Windows服务器无法安装Android模拟器。
因此,当我尝试使用Android模拟器时,我发现原创WeChat pc客户端(包括mac)的功能已经完善,然后尝试了Windows客户端。
5、 virtualbox虚拟机,这是Oracle生产的虚拟机。将涉及一些网络配置,例如设置为NAT模式。
现在将虚拟机映像开源,其中的所有代码都在虚拟机中,您可以随意对其进行修改。
从了解公共帐户文章 采集到了解实现原理,再到最后制作镜像,我在中间经历了种种困难,这既费时又费力密集,询问各种人,甚至考虑饮食和睡眠。对于详细的解决方案而言,解决问题会带来喜悦,而被问题缠住则会带来痛苦。感谢您在此过程中对人们的帮助。
如果您认为这对您有用,请随时提供奖励,我没有设置奖励金额
如果在安装和使用过程中遇到任何问题,请将我添加到微信中。
云erp工具有赞,有赞云计算工具汇聚了70+个优质的学生
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-03-23 03:04
文章采集系统改版1周后,形成csw三维渲染系统。用多次客户请求告诉我,他们找我做个统计数据,告诉他们孩子的学习成绩,原来在abc也是数据课上成绩好的学生,从而引出他们学校的学习。那分数是怎么决定的呢?a在班级排名第一,b成绩是第四;经计算可知a比b分数多,数据都是值的比较计算,b比a分数多,就值2个。
把课程比例相关按学生重点关注度比较,a成绩第一,b成绩第二,依次类推,直到最后一位数据,可得到“全部学生学习成绩排序”。又因为b最后一位是“5”,与第一位“2”有关,以7为分水岭,如果7,b排在a前面,为第5,依次类推,1234都在1~3之间。即1~5之间,孩子几乎没差别,若6,排在b前面,那就是2~5之间。
排位最后的就是班级倒数第二名的孩子,依次类推。利用了“童年相关”(绘图,计算机或手工)法,可以方便以确定周期内学生学习情况,自动告诉你孩子的排名,进而得出成绩。这个课后反馈系统这么重要,但是使用成本很高。本文推荐使用云erp工具有赞,有赞云计算工具汇聚了70+个优质的云计算厂商,8款主流云计算产品,多数是国外品牌。
分布在103个城市,1.98亿会员,4.26亿活跃用户。用户数、活跃度、借助有赞平台,你可以销售云计算产品,或者获得100+个用户,轻松成为国内最大的精准用户触达平台。做好手里的工作,反馈也就不是问题了。使用有赞必备条件:精准用户触达一定要有,因为再好的软件再好的工具都是有使用成本,到最后反馈结果会很差,你是买卖来用的。有了目标客户,才有今后盈利的可能。 查看全部
云erp工具有赞,有赞云计算工具汇聚了70+个优质的学生
文章采集系统改版1周后,形成csw三维渲染系统。用多次客户请求告诉我,他们找我做个统计数据,告诉他们孩子的学习成绩,原来在abc也是数据课上成绩好的学生,从而引出他们学校的学习。那分数是怎么决定的呢?a在班级排名第一,b成绩是第四;经计算可知a比b分数多,数据都是值的比较计算,b比a分数多,就值2个。
把课程比例相关按学生重点关注度比较,a成绩第一,b成绩第二,依次类推,直到最后一位数据,可得到“全部学生学习成绩排序”。又因为b最后一位是“5”,与第一位“2”有关,以7为分水岭,如果7,b排在a前面,为第5,依次类推,1234都在1~3之间。即1~5之间,孩子几乎没差别,若6,排在b前面,那就是2~5之间。
排位最后的就是班级倒数第二名的孩子,依次类推。利用了“童年相关”(绘图,计算机或手工)法,可以方便以确定周期内学生学习情况,自动告诉你孩子的排名,进而得出成绩。这个课后反馈系统这么重要,但是使用成本很高。本文推荐使用云erp工具有赞,有赞云计算工具汇聚了70+个优质的云计算厂商,8款主流云计算产品,多数是国外品牌。
分布在103个城市,1.98亿会员,4.26亿活跃用户。用户数、活跃度、借助有赞平台,你可以销售云计算产品,或者获得100+个用户,轻松成为国内最大的精准用户触达平台。做好手里的工作,反馈也就不是问题了。使用有赞必备条件:精准用户触达一定要有,因为再好的软件再好的工具都是有使用成本,到最后反馈结果会很差,你是买卖来用的。有了目标客户,才有今后盈利的可能。
深度学习中应用最多的是深度rnn,关键技术是前馈
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-02-22 09:01
文章采集系统通常有三个关键环节:采集-智能分发-数据维护,不同的服务商会有不同侧重点。从推荐产品本身看:主要考虑的是推荐内容的相关性和创新性,以及系统预期的解决方案和可靠性,目标是不断的优化和迭代采集和智能分发的效率,数据维护需要考虑的主要是并发连接的性能,整体架构能否支持大规模的数据处理。
深度学习中应用最多的是深度rnn,关键技术是前馈神经网络和模板匹配技术,这方面中科大和哈工大,人家是王者。
我发现很多企业做深度学习的都是找云厂商购买。
题主是否关注过深度学习可视化?方便做推荐引擎什么的。
如果技术目标是系统的召回概率,那么这些服务商都不错,甚至有一些做商品主动推荐的,选择时看看预测准确度。如果考虑性价比,那就是我觉得fair比较好,搜这方面的项目,机器学习,深度学习应该是未来趋势,这里比较擅长。
deepevolutionofdeeplearningarchitecturesnotarguablyunsupervisedrecurrentneuralnetworksforunsupervisedrecommendationgenerativeadversarialnetworksforunsupervisedrecommendation。
但从客户端推荐来说,以apus为例,是比较普遍存在的通用平台,从客户端和服务端分开的。从产品角度,在工程项目中应该讲究推荐效率,和搜索做类比;前者如果和搜索竞争,对apus的竞争对手是拉勾。对用户来说,是要考虑用户体验的,对服务端来说,是要考虑能否尽快打开业务流量。 查看全部
深度学习中应用最多的是深度rnn,关键技术是前馈
文章采集系统通常有三个关键环节:采集-智能分发-数据维护,不同的服务商会有不同侧重点。从推荐产品本身看:主要考虑的是推荐内容的相关性和创新性,以及系统预期的解决方案和可靠性,目标是不断的优化和迭代采集和智能分发的效率,数据维护需要考虑的主要是并发连接的性能,整体架构能否支持大规模的数据处理。
深度学习中应用最多的是深度rnn,关键技术是前馈神经网络和模板匹配技术,这方面中科大和哈工大,人家是王者。
我发现很多企业做深度学习的都是找云厂商购买。
题主是否关注过深度学习可视化?方便做推荐引擎什么的。
如果技术目标是系统的召回概率,那么这些服务商都不错,甚至有一些做商品主动推荐的,选择时看看预测准确度。如果考虑性价比,那就是我觉得fair比较好,搜这方面的项目,机器学习,深度学习应该是未来趋势,这里比较擅长。
deepevolutionofdeeplearningarchitecturesnotarguablyunsupervisedrecurrentneuralnetworksforunsupervisedrecommendationgenerativeadversarialnetworksforunsupervisedrecommendation。
但从客户端推荐来说,以apus为例,是比较普遍存在的通用平台,从客户端和服务端分开的。从产品角度,在工程项目中应该讲究推荐效率,和搜索做类比;前者如果和搜索竞争,对apus的竞争对手是拉勾。对用户来说,是要考虑用户体验的,对服务端来说,是要考虑能否尽快打开业务流量。
全世界云服务器、大数据、信息系统仿真案例
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-02-14 10:05
文章采集系统仿真案例介绍:本案例将研究一个关于全世界云服务器、大数据、web服务器、文件管理服务器等信息系统的仿真系统。通过本案例,
一、抽象概念。
二、hadoop、hive和spark的相互关系
三、关于socket编程的重要知识。(socket编程几乎涵盖所有的编程中心,极大的拓展了我们在编程中的能力。由于socket被用于方方面面,而java语言本身很难去清楚表述程序逻辑所需要的各个层次的东西,因此hadoop框架的设计初衷就是提供一个方便的lib接口让我们使用,它的核心框架解决了内存管理、消息传递、io等原本应该在编程中必备的技术;)。
四、关于lamp的理解。(其实在之前已经介绍过传统架构和lamp架构的历史了,当时我们提到过apache大部分基于yaml、pmlk等,lamp是用hadoop框架生成的构建模型;lamp架构才是计算分布式架构的基础;apache因为开源建设的不成熟,数据库服务还是直接对接mysql,而新成立的cloudera只有mysql,而hadoop框架本身只支持mysql。所以我们需要继续重新架构spark的基础架构;)。
五、lamp的运行机制和spark的运行机制;(我们从spark概念进行引入:传统的架构是客户端把要操作的数据源地址发给client,由client进行与数据源进行建立tcp连接,从而存储tcp连接状态的变化,然后通过socket通讯进行传输;lamp架构与spark架构最大的不同是云服务器,从spark中对于客户端最主要的一个概念就是客户端是一个包含schema的虚拟机,所以云服务器要求对client实施和虚拟机一样的功能,要给客户端一个好的交互界面,而spark和lamp不同的是它更好的支持对schema之间的http/web访问,从而实现spark的api客户端,而且spark与opentsdb进行了集成,更好的进行了sql类型的转换;这些对hadoop来说相对较难。)。
六、hadoop模式。
七、mysql和sql的关系。
八、hadoop支持的和其他sql数据库集成。本案例中的代码虽然都是通过java语言开发的,但是,在具体编写的时候要掌握driver(可以理解为server,是类型转换工具类)和driverdatasource(是存储服务器,是类型转换工具类)中间的数据流;这样才能写出优美的代码。如果是其他语言编写的web服务器类要注意大量的特征转换,转换和类型转换过程。参考文献:《java编程思想》ggii:hadoop与lamp环境搭建。 查看全部
全世界云服务器、大数据、信息系统仿真案例
文章采集系统仿真案例介绍:本案例将研究一个关于全世界云服务器、大数据、web服务器、文件管理服务器等信息系统的仿真系统。通过本案例,
一、抽象概念。
二、hadoop、hive和spark的相互关系
三、关于socket编程的重要知识。(socket编程几乎涵盖所有的编程中心,极大的拓展了我们在编程中的能力。由于socket被用于方方面面,而java语言本身很难去清楚表述程序逻辑所需要的各个层次的东西,因此hadoop框架的设计初衷就是提供一个方便的lib接口让我们使用,它的核心框架解决了内存管理、消息传递、io等原本应该在编程中必备的技术;)。
四、关于lamp的理解。(其实在之前已经介绍过传统架构和lamp架构的历史了,当时我们提到过apache大部分基于yaml、pmlk等,lamp是用hadoop框架生成的构建模型;lamp架构才是计算分布式架构的基础;apache因为开源建设的不成熟,数据库服务还是直接对接mysql,而新成立的cloudera只有mysql,而hadoop框架本身只支持mysql。所以我们需要继续重新架构spark的基础架构;)。
五、lamp的运行机制和spark的运行机制;(我们从spark概念进行引入:传统的架构是客户端把要操作的数据源地址发给client,由client进行与数据源进行建立tcp连接,从而存储tcp连接状态的变化,然后通过socket通讯进行传输;lamp架构与spark架构最大的不同是云服务器,从spark中对于客户端最主要的一个概念就是客户端是一个包含schema的虚拟机,所以云服务器要求对client实施和虚拟机一样的功能,要给客户端一个好的交互界面,而spark和lamp不同的是它更好的支持对schema之间的http/web访问,从而实现spark的api客户端,而且spark与opentsdb进行了集成,更好的进行了sql类型的转换;这些对hadoop来说相对较难。)。
六、hadoop模式。
七、mysql和sql的关系。
八、hadoop支持的和其他sql数据库集成。本案例中的代码虽然都是通过java语言开发的,但是,在具体编写的时候要掌握driver(可以理解为server,是类型转换工具类)和driverdatasource(是存储服务器,是类型转换工具类)中间的数据流;这样才能写出优美的代码。如果是其他语言编写的web服务器类要注意大量的特征转换,转换和类型转换过程。参考文献:《java编程思想》ggii:hadoop与lamp环境搭建。
解决方案:持续更新,微信公众号文章批量采集系统的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 392 次浏览 • 2020-10-01 13:03
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是它越来越难采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。这样就形成了可以自动采集正式帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定写下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为实际上此链接地址需要几个参数才能正常显示内容。让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址。有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似ID的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。 查看全部
持续更新,建设微信公众号文章批处理采集系统
自2014年以来,我一直在批量处理微信官方帐户内容采集。最初的目的是创建html5垃圾邮件内容网站。那时,垃圾站采集到达的微信公众号的内容很容易在公众号中传播。当时,采集批处理特别容易,采集的入口是官方帐户的历史新闻页面。现在这个入口是一样的,但是它越来越难采集。 采集的方法也已更新为许多版本。后来,在2015年,html5垃圾站没有这样做,而是转向采集来定位本地新闻和信息公共帐户,并将前端显示制作为应用程序。这样就形成了可以自动采集正式帐户内容的新闻应用程序。我曾经担心微信技术升级后的一天,采集的内容将不可用,我的新闻应用程序将失败。但是随着微信技术的不断升级,采集方法也得到了升级,这使我越来越有信心。只要存在官方帐户历史记录消息页面,就可以将采集批处理到内容。因此,今天我决定写下采集方法。我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果。
这篇文章文章将继续更新,并且您所看到的将保证在您看到时可用。
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,这两种页面格式在不同的微信账户中不规则地出现。一些WeChat帐户始终是第一页格式,而某些始终是第二页格式。
上面的链接是指向微信官方帐户历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示:请从微信客户端访问。这是因为实际上此链接地址需要几个参数才能正常显示内容。让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址。有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是:__biz; uin =; key =; pass_ticket =;这四个参数。
__ biz是官方帐户的类似ID的参数。每个官方帐户都有一个微信业务。目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关。这3个参数的值由微信客户端生成后会自动添加到地址栏中。因此,我们认为采集官方帐户必须通过微信客户端应用程序。在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号。在当前版本中,每次访问正式帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数。
我的采集系统由以下部分组成:
1、微信客户端:它可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器。在批次采集中测试的ios的WeChat客户端的崩溃率高于Android系统。为了降低成本,我使用了Android模拟器。
<p>2、一个微信个人帐户:对于采集的内容,不仅需要一个微信客户端,而且还需要一个专用于采集的微信个人帐户,因为该微信帐户无法执行其他操作。
汇总:持续更新,微信公众号文章批量采集系统的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-10-01 11:00
2019年10月28日更新:
录制了YouTube视频以详细说明操作步骤:
youtu.be
<p>=================原创============================ 查看全部
持续更新,建设微信公众号文章批处理采集系统
2019年10月28日更新:
录制了YouTube视频以详细说明操作步骤:
youtu.be
<p>=================原创============================
解决方案:最详细优采云数据采集系统DedeCMS发布文章攻略
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-09-05 15:25
搜索引擎不喜欢复制内容,也不喜欢数据采集,但有时会遇到某些情况。例如,网站需要更改网络数据采集或网站备份。提醒大家:
①进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大修改;
③不建议将采集个其他网站信息用于新站点,这将减少新站点的特殊权重。
前一段时间,我制定了一个旧的网站修订计划。由于更换了管理系统和数据库,因此我决定对原创网站数据采集采用解决方案。对于网站修订,新手需要掌握很多站点建设知识和SEO知识。这些经验用于与您分享。
网站基本情况
本网站最初有一个排名,收录也比较大,优化效果更好,制作风格与mousse seo非常相似,代码简单,最详细优采云数据采集系统Dede cms发布文章前端环境突袭,标签应用还可以,但是网站优化方法却有黑帽子。使用asp程序后端,数据库是access,要替换为php,数据库是mysql。
网站用于修订的软件工具
-EditPlus或DreamWear(代码编辑器); -APMServ(本地ASP、PHP环境); -Fiddler Web汉化版(web数据抓包); -火车头(LocoySpider)采集7.6(破解稳定版、数据采集); -DedeCMS V5.7(后台内容管理程序); -其他辅助工具。
网站借助优采云 采集的详细步骤,以构建1.版本的本地环境,安装Dede cms,安装Fiddler Web捕获工具以及安装诸如优采云之类的软件采集 7. 6
安装方法非常简单,涉及文章“在64位win8win10系统启动失败解决方案中安装APMServ”,“如何安装dede cms 织梦详细说明”。
提供一些软件下载链接:密码:3n7e
2. 优采云设置(关键内容)
官方描述相对简单,必须阅读和练习新手采集 网站数据。打开优采云 采集工具并创建一个新任务和组。
第一步:采集 URL规则
①起始地址。即提取分页规则,请按以下图顺序:单击添加-单击批处理/多页输入地址格式,例如,我希望采集具有地址列表,即:
可以看出变量是1,2,3 ...由通配符写出
在算术序列中选择项目数作为所需的列表数采集,并根据实际情况进行写入。点击依次添加
然后单击添加-完成-关闭。
②多级URL获取。获取特定页面的URL地址列表。在任何目标列表中,单击鼠标右键以查看源代码。一般来说,具有基础知识的学生无需多说,而且有许多他们不理解的在线资源。找到特征代码片段,如下所示编写并保存。
单击测试URL 采集,并确保列表采集的规则正确,然后继续执行第二步。 查看全部
最详细的优采云数据采集系统Dede cms发布文章指南
搜索引擎不喜欢复制内容,也不喜欢数据采集,但有时会遇到某些情况。例如,网站需要更改网络数据采集或网站备份。提醒大家:
①进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大修改;
③不建议将采集个其他网站信息用于新站点,这将减少新站点的特殊权重。
前一段时间,我制定了一个旧的网站修订计划。由于更换了管理系统和数据库,因此我决定对原创网站数据采集采用解决方案。对于网站修订,新手需要掌握很多站点建设知识和SEO知识。这些经验用于与您分享。
网站基本情况
本网站最初有一个排名,收录也比较大,优化效果更好,制作风格与mousse seo非常相似,代码简单,最详细优采云数据采集系统Dede cms发布文章前端环境突袭,标签应用还可以,但是网站优化方法却有黑帽子。使用asp程序后端,数据库是access,要替换为php,数据库是mysql。
网站用于修订的软件工具
-EditPlus或DreamWear(代码编辑器); -APMServ(本地ASP、PHP环境); -Fiddler Web汉化版(web数据抓包); -火车头(LocoySpider)采集7.6(破解稳定版、数据采集); -DedeCMS V5.7(后台内容管理程序); -其他辅助工具。
网站借助优采云 采集的详细步骤,以构建1.版本的本地环境,安装Dede cms,安装Fiddler Web捕获工具以及安装诸如优采云之类的软件采集 7. 6
安装方法非常简单,涉及文章“在64位win8win10系统启动失败解决方案中安装APMServ”,“如何安装dede cms 织梦详细说明”。
提供一些软件下载链接:密码:3n7e
2. 优采云设置(关键内容)
官方描述相对简单,必须阅读和练习新手采集 网站数据。打开优采云 采集工具并创建一个新任务和组。
第一步:采集 URL规则
①起始地址。即提取分页规则,请按以下图顺序:单击添加-单击批处理/多页输入地址格式,例如,我希望采集具有地址列表,即:
可以看出变量是1,2,3 ...由通配符写出
在算术序列中选择项目数作为所需的列表数采集,并根据实际情况进行写入。点击依次添加
然后单击添加-完成-关闭。
②多级URL获取。获取特定页面的URL地址列表。在任何目标列表中,单击鼠标右键以查看源代码。一般来说,具有基础知识的学生无需多说,而且有许多他们不理解的在线资源。找到特征代码片段,如下所示编写并保存。
单击测试URL 采集,并确保列表采集的规则正确,然后继续执行第二步。
分享文章:微信公众号搜索接口采集微信公众号文章采集系统---开箱即用
采集交流 • 优采云 发表了文章 • 0 个评论 • 478 次浏览 • 2020-08-31 07:34
摘要: 本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包到虚拟机中. 您只需要下载并安装虚拟机映像即可使用它. 首先,我要感谢团队负责人饭口勇(Iiguchi)开放他的采集解决方案. 规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php. 从一开始就了解公共帐户的文章采集,到了解实施原理,最后到制作镜像,我在中间遇到了种种困难,既费时又费力. 我咨询了很多人,甚至在吃饭和睡觉时都想过一些细节. 解决方案,解决问题的喜悦以及被问题纠缠的困扰,感谢您在此过程中所提供的帮助.
微信公众号搜索界面采集
本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包为虚拟机. 您只需要下载并安装虚拟机映像即可使用它.
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接: 密码: 7r4d
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源.
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1,anyproxy阿里巴巴的开源代理拦截器(使用4.0版)可以轻松修改响应信息. 我已经在系统中安装了anyproxy,并且安装非常简单. 首先安装nodejs环境,然后使用npm安装anyproxy.
anyproxy 4.0的开始规则可以作为模块开发. 编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可. 此处使用的命令是anproxy --rule weixin.js. 关于anproxy如何设置https证书,请访问官方网站. 我已经在虚拟机中设置了全局代理,因此需要先打开任何代理,然后才能在端口8001上成功访问该请求.
规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php.
2,apache + php + mysql,主要用作Web服务器,处理被anyproxy拦截的请求,处理微信文章数据以及喜欢和阅读的次数.
截取的数据的处理可以在特定的PHP代码中看到,逻辑不是太复杂. 为方便起见,这是phpstudy的集成开发环境.
3. 按钮向导. 按钮向导是一种国产工具,可模拟类似于vb语法的键盘和鼠标. 按钮向导在此处用于模拟单击Windows下的微信客户端.
在处理多个微信公众号时,客户需要点击,所有手动操作均由按钮向导模拟. 当我去检查特定的代码时,我使用了一个小技巧来处理单击历史消息. 事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但找不到. 您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮.
当一个想法不起作用时,请尝试其他想法. 整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推.
4. Windows WeChat客户端,我实际上尝试使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是无法将其安装在虚拟机Android模拟器中,也就是说也就是说,不可能在虚拟机中进行辅助虚拟化. 我已经踩到了这个坑,所以您不需要踩到它. 我记得以前有人问过,阿里云Windows服务器可以配备Android模拟器吗?我认为答案是相同的. 虚拟机无法执行辅助虚拟化. 阿里云窗口服务器无法安装Android模拟器.
因此,当我尝试使用Android模拟器时,我发现原创微信PC客户端(包括mac)的功能已经完善,然后尝试了Windows客户端.
5. Virtualbox虚拟机,这是Oracle生产的虚拟机. 将涉及一些网络配置,例如设置为NAT模式.
现在将虚拟机映像开源,其中所有代码都在虚拟机中,您可以随意对其进行修改.
从了解官方帐户文章采集到了解实施原理,然后到最终镜像,我在中间经历了种种困难,这既费时又费力. 我咨询了很多人,甚至想到了吃饭和睡觉. 对于详细的解决方案而言,解决问题会很高兴,而被问题纠缠也很痛苦. 感谢您在此过程中对人们的帮助.
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012) 查看全部
微信公众号搜索界面采集微信公众号文章采集系统---开箱即用
摘要: 本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包到虚拟机中. 您只需要下载并安装虚拟机映像即可使用它. 首先,我要感谢团队负责人饭口勇(Iiguchi)开放他的采集解决方案. 规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php. 从一开始就了解公共帐户的文章采集,到了解实施原理,最后到制作镜像,我在中间遇到了种种困难,既费时又费力. 我咨询了很多人,甚至在吃饭和睡觉时都想过一些细节. 解决方案,解决问题的喜悦以及被问题纠缠的困扰,感谢您在此过程中所提供的帮助.
微信公众号搜索界面采集
本着开放源代码和用户方便的精神,“微信公众号文章采集系统”已打包为虚拟机. 您只需要下载并安装虚拟机映像即可使用它.
系统镜像有6 Gs,只能以种子形式下载,镜像种子下载地址
链接: 密码: 7r4d
首先,我要感谢团队负责人饭口勇(Iiguchi)将其采集项目开源.
在这里可以称为系统,因为涉及许多技术,这里是一个接一个的:
1,anyproxy阿里巴巴的开源代理拦截器(使用4.0版)可以轻松修改响应信息. 我已经在系统中安装了anyproxy,并且安装非常简单. 首先安装nodejs环境,然后使用npm安装anyproxy.
anyproxy 4.0的开始规则可以作为模块开发. 编写规则代码后,您无需触摸原创代码,只需将规则文件放在anproxy参数中即可. 此处使用的命令是anproxy --rule weixin.js. 关于anproxy如何设置https证书,请访问官方网站. 我已经在虚拟机中设置了全局代理,因此需要先打开任何代理,然后才能在端口8001上成功访问该请求.
规则代码的主要逻辑是拦截微信公众号请求并将数据转发到php.
2,apache + php + mysql,主要用作Web服务器,处理被anyproxy拦截的请求,处理微信文章数据以及喜欢和阅读的次数.
截取的数据的处理可以在特定的PHP代码中看到,逻辑不是太复杂. 为方便起见,这是phpstudy的集成开发环境.
3. 按钮向导. 按钮向导是一种国产工具,可模拟类似于vb语法的键盘和鼠标. 按钮向导在此处用于模拟单击Windows下的微信客户端.
在处理多个微信公众号时,客户需要点击,所有手动操作均由按钮向导模拟. 当我去检查特定的代码时,我使用了一个小技巧来处理单击历史消息. 事实是,我开始通过直接识别图片来找到“历史记录消息”按钮的位置,但找不到. 您只能循环向下移动鼠标,直到在该区域找到特定的颜色,即“历史记录”按钮.
当一个想法不起作用时,请尝试其他想法. 整个系统完成了,就是要处理这种看似可行但不切实际的问题,然后再试一次,依此类推.
4. Windows WeChat客户端,我实际上尝试使用Android模拟器,因为我的目标是开箱即用,所以我需要将所有程序安装在一起,但是无法将其安装在虚拟机Android模拟器中,也就是说也就是说,不可能在虚拟机中进行辅助虚拟化. 我已经踩到了这个坑,所以您不需要踩到它. 我记得以前有人问过,阿里云Windows服务器可以配备Android模拟器吗?我认为答案是相同的. 虚拟机无法执行辅助虚拟化. 阿里云窗口服务器无法安装Android模拟器.
因此,当我尝试使用Android模拟器时,我发现原创微信PC客户端(包括mac)的功能已经完善,然后尝试了Windows客户端.
5. Virtualbox虚拟机,这是Oracle生产的虚拟机. 将涉及一些网络配置,例如设置为NAT模式.
现在将虚拟机映像开源,其中所有代码都在虚拟机中,您可以随意对其进行修改.
从了解官方帐户文章采集到了解实施原理,然后到最终镜像,我在中间经历了种种困难,这既费时又费力. 我咨询了很多人,甚至想到了吃饭和睡觉. 对于详细的解决方案而言,解决问题会很高兴,而被问题纠缠也很痛苦. 感谢您在此过程中对人们的帮助.
如果在安装和使用过程中遇到任何问题,请将我添加到微信(liuhan199012)
埋点、数仓到中台:数据体系的从0到1
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-28 04:09
前言:有幸深度参与了公司从无数据,到有数据,到开始注重数据,最后才能尊重数据结果,参考数据进行决策的过程。本篇文章是笔者在这个过程中,作为数据产品搭建数据指标体系,如何踩坑、出坑,以及对数据库房建设中的一些总结。
如标题所言,如果贵司早已是B轮过后,数据指标和平台化产品应当早已比较完善,属于数据产品应用阶段。如果贵司处于B轮及B轮之前阶段,大机率上会出现笔者下边所描述的情况。
本文较长,目录如下:
1 混乱期:资源有限,功能为先,忽视数据
1.1 资源永远不够用
1.2 数据产品的困境
2 规范期:他山之石:GrowingIO和神策
2.1 GrowingIO平台实践总结
2.2 神策平台实践总结
2.3 他山之石后的埋点设计及管理
3 平台期:建设数据库房
3.1 数据维护及整治
3.2 数据库房构架设计
4 未来:数据中台?
4.1 我理解的数据中台
4.2 数据中台学习资料推荐
------正文分割线------
1 混乱期:资源有限,功能为先,忽视数据1.1 资源永远不够用
笔者所在的内容服务公司,在搭建指标体系前,已经“裸奔”了3年。对于内容产品来说,最影响用户体验的是内容本身,公司前期借助不错的内容口碑,搭上知识付费的风口,发展迅速,公司资源和业务方向更多是受营运驱动、销售驱动,目标简单而明晰,做哪些心中都有大致预判,轻轻拍拍耳朵,这事儿就定了。后来平台用户数达到第一个1000w,日活步入50w量级后,新人加入,业务线也在拓展,基于主线业务上的优化和探求,不敢再轻易拍脖子了;各业务线也有不同的诉求,如何衡量优先级和协调资源,没有数据,很容易相持不下。
也是在哪个时侯,决定要参考数据来决策了。之前APP偏向于做功能,只在特殊功能点,或活动节点时,会在产品需求文档中,附上埋点需求。彼时猛然想看好多数据,会发觉不仅一些大数据(日活、激活率、付费率等)外,缺少好多细部数据,因为压根没有做埋点上报的需求,从日志中也未能解析出相关数据。
后来在每位版本中,由功能产品总监附上相关功能的埋点需求,大部分开发资源还在具体功能开发上。在功能上线后许久,才会想起来捞数据瞧瞧疗效。初创公司很容易在业务快速扩张中忽略数据的作用,产品开发团队首要解决的是不断新增的业务需求。资源总是不够用的,所以数据埋点处理、数据剖析、复盘等工作仍然处在被忽略的地方。
1.2 数据产品的困境
彼时我转岗到数据产品,常调侃自己是一个取数机器。公司有数据需求的部门共有7个,我负责对接各部门的数据需求,梳理清晰后再递交任务给大数据组,由她们做具体的ETL工作。这中间,常会身陷到以下的汪洋大海中:
与需求方沟通并最后明晰最后的数据需求(比如:活动组提需求想看某活动页分享数据,经沟通以后,其目的是想看新页面的文案上线后,对分享/浏览比的影响,因此明晰了该需求是该页面的uv、pv,以及分享控件点击的人数、次数);
提交明晰需求后,大数据组发觉之前没有埋点,然后须要跟需求方解释,这个数据为何拿不到,从ta的剖析目标再瞧瞧,是否还有其他数据也才能达成这个剖析目标。
那段时间十分繁忙,但总觉得自己是个二传手,最大的收获,就是在对接了N个需求以后,发现我司的数据基础建设情况惨不忍睹:平台埋点不规范、数据指标定义不统一、业务数据库和数据库房标准不统一、数据需求处理周期长…… 我的精力好多耗在沟通需求、管理需求上。后来与公司的数据剖析部门一齐讨论制订了一套新的数据递交流程:每个部门的需求汇总到部门中的一个数据对接人,由ta先行递交到数据剖析组,简单需求,会由数据剖析组通过DBeaver等工具,连接数据库导入,复杂类、工具类需求,则递交给我:
图1:数据需求递交流程
另外,针对每位部门的数据对接人进行了指标定义的说明,以及递交数据需求的规范标准的培训:
图2:培训资料一页:什么是好的数据需求
此时的工作还逗留在偏临时需求的处理上,作为数据产品,却没有作出多少数据产品下来。
2 规范期:他山之石:GrowingIO和神策
在决定搭建数据体系后,我司商讨了几家背部的数据平台,如GIO、ThinkingData、神策等,来补充我司埋点功力薄弱的问题,最后选择了GIO,在使用了一年多以后,因为要做私有化布署,而GIO的私有化布署功能还刚处在开发阶段(写这篇文章的时侯,他们的私有化布署早已做下来了),于是我司又决定换神策平台,重新来一遍POC和SDK接入工作(对,就是如此折腾,o(╥﹏╥)o)。在完整地对接了这两家平台以后,我司数据体系逐渐迈向规范,我也总结了一下两家平台关于指标管理、数据体系搭建的工具特性,以及思路进行了一些总结,如下。
2.1 GrowingIO平台实践总结
在接触了几家平台后,我们最终选择了GIO,该平台的特性特别显著:
拥有无埋点技术,能够实现做功能时,不需要专门针对埋点耗费工时,接入GIO的SDK,在功能上线后,SDK才能采集基础使用信息,同时,针对页面浏览数据,和页面控件点击数据,可以通过“圈选”的形式实现(对于彼时苦于埋点效率低下的现况,这种方案极具诱惑);
公有云布署,接入成本低;
后台操作界面简约,属于营运思路的一款产品,上手较容易;
因为是SaaS服务,线上问题反馈速率比较快。
但后来发觉一些问题:接入SDK后,我们只简单对接了会员状态数据,做了少量的埋点指标,除据悉自动圈选了大量页面指标和控件数据,因为GIO的圈选功能实在很好用了,所见即所得,不必再发版等埋点上线,经过简单操作后就可以自己取数、看数,结合GIO提供的基础剖析工具,如风波剖析、漏斗剖析、留存剖析等功能,人人都能成为一名分析师了。
图3:GIO圈选功能
但到后期,圈选数据的问题日渐曝露,也成为平台要更换GIO平台的导火索。圈选数据的逻辑:是按照页面xpath路径,监听页面浏览风波,和页面上的控件的浏览、点击风波,保留7天,因此圈选完成后,能向前溯源7天的数据。圈选功能的问题主要在于:
耗流量,看下逻辑你应当能理解;
一旦版本迭代,对页面的路径做更改,或者控件位置、文案有更改,原来的圈选数据可能还会出错,需要重新圈选,之前借助圈选指标设定的剖析模型都要替换;
圈选指标难以分辨细部参数,比如:书籍详情页,无法通过圈选数据来分辨是哪一本书;
对web的页面数据处理仍然不好,尤其是涉及到APP的内嵌H5页时,非常苦闷。
图4:版本升级后,某圈选指标数据突降
这似乎也是GIO的业务朋友比较推崇无埋点技术,而我司彼时经验尚不充足踩下的坑,到后半阶段开始补习,开始做客户端和服务端埋点了,埋点开发周期似乎长了点,但是起码才能用得上去。但是由于之前对GIO工具使用上形成的各类不爽,导致前面有了更准确的埋点后,大家用上去也经常怀疑,这数据准不准,能不能用?一旦对数据源形成不信任感,产研团队的解释成本高,数据发挥价值的周期变长,团队屡受指责又看不到成绩,大数据团队本身在数据体系建设的初期存在感就低,如此一来,工作积极性显得更低。
后来受资方等多诱因影响,我们须要做私有化布署,对数据的准确度、智能营运也有更进一步的需求,而彼时GIO还没有成熟的私有化布署功能,因此我们两家后来好聚好散,转而选择了神策。(此处抱着GIO的朋友哭一会儿)
但总体来说,GIO平台还是可圈可点,它的优势在于:
数据响应速度快,圈选功能比较成熟,对于快速迭代活动的场景,圈选功能最为方便;
用户操作界面友好,几大核心剖析功能逻辑结构清晰,学习成本低,能够实现在公司大范围推广使用(你千万别认为这类数据工具是可以轻易上手的,根据我在公司推广GIO和神策的经验,工具使用门槛并不低);
售后团队比较专业,能够从剖析视角,发现我司业务上的问题;并且对平常提及的问题,反馈及时,问题解决程度也比较高。
2.2 神策平台实践总结
后来由于私有化布署的诉求,选择了神策平台的产品。这里解释下,为啥没有选择自己研制数据产品。这显然是一个太经济学的审视。在接入GIO前,我司有自己一套ubt的埋点系统,但是只是基础的数据采集,以及raw data进数据库,从raw data 到数仓,再到提取,把统计类数据以excel方式,或者教会剖析人员使用SSMS或PowerBI来进行取数剖析,中间流程很长,无法做到快速响应及反馈。而找一个团队自研,时间成本和人力成本都很高。
神策、GIO这样的平台,取数功能完整度比较高,而且有一个比较完整的可视化剖析平台,收录了风波剖析、漏斗剖析、留存剖析等基础的剖析功能,也有归因剖析模型、用户画像等功能,这些功能找一个大数据团队和几个算法工程师,一年的成本高了去了。对于B轮左右的公司,建议别折腾,花点钱,除了防止自研成本,还能从这种SaaS平台的服务中,了解到比较成熟的方法论。
神策的剖析全家桶有以下几款产品:
图5:神策产品矩阵
其中,左边【数据基础能力】是基础服务,可以选Pass,也可以选私有化布署,但是节点费、流量费是按照自己的流量来核算。(市政单位,或者对业务数据安全敏感度高的,建议私有化。不是说Pass不安全,像神策、GIO这样专门做数据服务的平台,不至于去窃取顾客数据,一个顾客数据泄漏风波就可以使这类企业直接死掉,这个帐她们拎得清,而且有数据隐私合同)。右边的【数据应用产品】则是可选项了,【神策剖析】收录了风波剖析、漏斗剖析等基础的剖析功能,一般必不可少;【神策用户画像】和【智能营运】是偏向于营运侧的工具,如果自己没有精准营销的产研能力,这两项服务业比较好用。至于【智能推荐】和【神策客景】则依照公司情况,对于内容繁杂,品类繁杂的内容平台、电商平台,还是比较有必要。但我个人觉得,前三项服务玩得转了,再去考虑采购后两项服务不迟。
神策平台的特性是一开始推的是埋点方案,而非无埋点方案;而且最早支持私有化布署的数据服务平台。这一点是使她们才能获得一些金融行业、政企行业的单子的缘由。这也是我们最后评估后,选择她们的缘由。
2.3 我司平台的埋点设计及指标管理
在经过了UBT、GIO和神策三套埋点方案的使用和比较后,对于我司自己的埋点系统也有了比较清晰的方向,最后决定采用常规数据使用后端埋点、关键数据使用服务端埋点、临时活动搭配使用全埋点的方案。
全埋点、前端埋点和服务端埋点的区别
埋点方案
实施方案
优点
缺点
全埋点
部署对应sdk,页面及控件数据全采集,使用时解析
不需要做埋点开发;
需要用的时侯再去圈选使用;
所见即所得,圈选时就可以看见数据;
不需要测试介入,取数周期极短
新圈选时,只能向前溯源7天;
数据不够确切;
发版后会影响之前圈选数据的稳定性。
前端埋点
前端定义的风波触发时,上传对应数据
较为确切;
基本不会受页面改版影响。
有一定开发工作量;
设计新功能时须要考虑对原有埋点的影响,维护指标文档;
会受网路环境等诱因影响,出现数据难以上报或延时上报。
服务端埋点
服务端定义的风波触发时,上传对应数据
最为确切;
不受前台功能改版影响。
开发和测试的工作都较大;
不容易发觉问题。
而我司基本是后端埋点和服务端埋点的组合,其中关于数据指标的设计和管理,采用了右图所展示的数组名,对事实表进行管理和维护。
图6:我司数据指标维护表头
关于数据指标管理,最使我头大的就是怎样保证可读性的前提下,梳理不断新增的数据埋点需求。我的设计思路是:以使用者视角设计,尽可能合并同类型指标,用维度保证扩展性,用备注内容保证可读性。
上面的指标维护表,是要同时给开发人员,和营运人员看的,这里指的使用者,是指营运人员。因为最后埋点设计做完了,也正常上报了,但是营运人员看不懂,用不上去,培训成本高企,是难以充分发挥数据价值的。所以在这里就须要数据产品总监平衡简洁和可用性。
举两个反例:
例子1:平台资源位埋点设计
对于通常互联网产品平台来说,资源位无外乎两种类型,弹出型和轮播型;而具体指标无外乎浏览和点击,因此,将这两种类型的资源位具象成下边4个指标,由维度(资源位位置、轮播位置)来进行分拆。
图7:平台资源位埋点设计
例子2:内容详情页埋点设计
对于内容类、电商类平台来说,内容详情页和商品详情页是最为关键的页面,因此这个页面的浏览数据极为重要。因为详情页是一个通用页面,而且对于一篇文章,或者一个商品来说,可能会在APP出现多个入口,如果对N个入口进行分别埋点,会使指标建设冗余,并且由于网路环境等影响,点击数≠页面加载≠页面加载成功,可能会采到脏数据上来。因此我在这里的设计思路是:以页面加载成功为触发,区分页面本身的数据信息,以及上一个页面的维度信息。
图8:内容详情页埋点设计
这里的挑战来自于去梳理上一个页面的类型和具体参数值,需要与营运组、数据组同学沟通清楚,他们关心的维度,以及下钻的颗粒度。
3 平台期:建设数据库房
建设数据库房是一个必然的选择,在业务体量不大,数据需求不多的情况下,从业务数据库捞数据,甚至解析日志,都是才能满足的。但后期必然会有更多维度、更复杂的分析型、报表型数据需求,全部借助业务数据库其实不现实。现在计算机储存成本不高,数据库房可以看做是一个【用空间换时间】的方案,数据库房是面向剖析、应用的数据库,在构建好标准的ETL流程和更新机制后,分析型、报表型数据需求从数据库房中获取,从而提升效率,也解放业务数据库,让业务库专心处理业务。
特点
面向对象
数据库
处理业务需求,实时性要求高
具体业务
数据库房
ETL后有比较明晰分辨的主题表
可并多个表、多个维度,支持复杂查询
分析型数据
目前有关数据库房的文章非常多,对数据库房应当分几层,也有好多说法。这里须要明晰一点,数据库房的分层是一个理念,其核心是将不同应用层级的数据进行界定。一般来说起码有五级,我司采用的也是五级数仓。
数仓分层
数据来源
特点
ODS
操作型数据、实时数据、日志数据等
近似 = raw data
EDW
ODS层
按明晰主题和维度进行ETL的数据表
DM
ODS层、EDW层
面向明晰应用,ETL获取的数据表
3.1 数据维护及整治
基于Hadoop的成熟体系,搭建完成数仓系框架后,接下来要做的是往数仓中填充数据“血肉”,以及持续进行数据整治的工作了。在用数据赋能业务的链条中:产生数据(埋点)-> 获取数据(ETL) -> 分析数据 -> 发现问题 ->业务决策,似乎并没有数据整治的事情。链条上的四点是可见的过程,而数据本身形成污染后,可能会到获取时、分析时,甚至是决策阶段,才会意识到数据本身可能出现了问题。数据从触发上报-> 发送-> ETL-> 进数仓,中间有任何一个过程出问题,都可能会影响数据的稳定、准确和及时。另外,不断扩充的业务需求,业务数据数组会发生变更,这时错传、漏传了数据进数仓,也会影响数据质量。
总结出来,基于下边三个点,需要持续进行数据维护和整治:
数据进仓链路长,存在出现脏数据的风险;
新业务需求增删改数组,没有及时同步进数仓;
数仓表结构数组设计扩展性不足,新数据须要单独建表,导致冗余。
针对第1点,我司对于数据指标本身的异常波动做了监控的设计。在接入了神策平台以后,该平台提供了一个指标异常波动提醒的功能,还很好用。
图9:神策数据异常监控
针对第2点谈谈我司实践。我司通过搭建【异构数据平台】来解决业务数据同步到数据库房的问题。业务数据在进数据仓的同时,会根据约定的规范,同步传送一份到数据库房;如果有修业务数据的情况,也须要异步地通过该平台,发消息给数据库房,由数仓消费后,更新数仓的数据。
针对第3点,没有哪些好办法,需要数据产品和大数据组、业务产品总监多沟通,对于数仓目前有什么表,哪些数组,功能规划上,未来会新增什么产品线,与当前业务线的关系,有一个大致预判,最大程度降低重复建表的工作。
3.2 数据库房构架设计
基于以上,我司数据库房是基于Hadoop框架,Hive处理离线数据,Flink处理实时数据,实现用户行为数据和业务数据准实时入数仓(有一些延时),并且后端数据产品应用,从数据库房中调插口取数。(目前还没有完全实现所有业务数据都从数据库房走,还在建设中)
图10:数据库房构架设计
4 未来:数据中台?
数据中台概念在19年实在很火了,颇有些12年,到处都在说O2O的情形。对于数据产品来说,将产出的数据产品抽象化、共用化,成为象中台一样的基础服务能力是心之所向。但是否应当盲目上中台项目,谈谈我的理解。
4.1 我所理解的数据中台
我很喜欢【中台】这个词:处于中间,承上启下;成为平台,隔绝上下流动,但自身提供服务上下的能力。对于数据中台,其核心是提炼各业务线的共性需求,将这种需求解决方案封装为标准化、组件化的解决能力,然后以插口的方式提供给前前台业务数据。从而实现尽量少地重复造轮子,尽量多地提升研制的敏捷性。
不是所有公司都须要立即做中台,但按照熵增定律,一家能持续发展的企业,其业务形态一定会不断发展和膨胀,而当新业务线和老业务线有共性诉求,能够通过中台化来提升效率,并且具有能串联多业务线的项目能力,这些问题想清楚,就可以开始做中台项目了。
4.2 资料推荐
在学习数据中台的过程中,整理了一些资料,如下:
数据中台到底是什么?
换个视角看中台的对与错
有赞零售中台建设方式的探求与实践
原文链接:/article/gaBwDw5Jkj 查看全部
埋点、数仓到中台:数据体系的从0到1
前言:有幸深度参与了公司从无数据,到有数据,到开始注重数据,最后才能尊重数据结果,参考数据进行决策的过程。本篇文章是笔者在这个过程中,作为数据产品搭建数据指标体系,如何踩坑、出坑,以及对数据库房建设中的一些总结。
如标题所言,如果贵司早已是B轮过后,数据指标和平台化产品应当早已比较完善,属于数据产品应用阶段。如果贵司处于B轮及B轮之前阶段,大机率上会出现笔者下边所描述的情况。
本文较长,目录如下:
1 混乱期:资源有限,功能为先,忽视数据
1.1 资源永远不够用
1.2 数据产品的困境
2 规范期:他山之石:GrowingIO和神策
2.1 GrowingIO平台实践总结
2.2 神策平台实践总结
2.3 他山之石后的埋点设计及管理
3 平台期:建设数据库房
3.1 数据维护及整治
3.2 数据库房构架设计
4 未来:数据中台?
4.1 我理解的数据中台
4.2 数据中台学习资料推荐
------正文分割线------
1 混乱期:资源有限,功能为先,忽视数据1.1 资源永远不够用
笔者所在的内容服务公司,在搭建指标体系前,已经“裸奔”了3年。对于内容产品来说,最影响用户体验的是内容本身,公司前期借助不错的内容口碑,搭上知识付费的风口,发展迅速,公司资源和业务方向更多是受营运驱动、销售驱动,目标简单而明晰,做哪些心中都有大致预判,轻轻拍拍耳朵,这事儿就定了。后来平台用户数达到第一个1000w,日活步入50w量级后,新人加入,业务线也在拓展,基于主线业务上的优化和探求,不敢再轻易拍脖子了;各业务线也有不同的诉求,如何衡量优先级和协调资源,没有数据,很容易相持不下。
也是在哪个时侯,决定要参考数据来决策了。之前APP偏向于做功能,只在特殊功能点,或活动节点时,会在产品需求文档中,附上埋点需求。彼时猛然想看好多数据,会发觉不仅一些大数据(日活、激活率、付费率等)外,缺少好多细部数据,因为压根没有做埋点上报的需求,从日志中也未能解析出相关数据。
后来在每位版本中,由功能产品总监附上相关功能的埋点需求,大部分开发资源还在具体功能开发上。在功能上线后许久,才会想起来捞数据瞧瞧疗效。初创公司很容易在业务快速扩张中忽略数据的作用,产品开发团队首要解决的是不断新增的业务需求。资源总是不够用的,所以数据埋点处理、数据剖析、复盘等工作仍然处在被忽略的地方。
1.2 数据产品的困境
彼时我转岗到数据产品,常调侃自己是一个取数机器。公司有数据需求的部门共有7个,我负责对接各部门的数据需求,梳理清晰后再递交任务给大数据组,由她们做具体的ETL工作。这中间,常会身陷到以下的汪洋大海中:
与需求方沟通并最后明晰最后的数据需求(比如:活动组提需求想看某活动页分享数据,经沟通以后,其目的是想看新页面的文案上线后,对分享/浏览比的影响,因此明晰了该需求是该页面的uv、pv,以及分享控件点击的人数、次数);
提交明晰需求后,大数据组发觉之前没有埋点,然后须要跟需求方解释,这个数据为何拿不到,从ta的剖析目标再瞧瞧,是否还有其他数据也才能达成这个剖析目标。
那段时间十分繁忙,但总觉得自己是个二传手,最大的收获,就是在对接了N个需求以后,发现我司的数据基础建设情况惨不忍睹:平台埋点不规范、数据指标定义不统一、业务数据库和数据库房标准不统一、数据需求处理周期长…… 我的精力好多耗在沟通需求、管理需求上。后来与公司的数据剖析部门一齐讨论制订了一套新的数据递交流程:每个部门的需求汇总到部门中的一个数据对接人,由ta先行递交到数据剖析组,简单需求,会由数据剖析组通过DBeaver等工具,连接数据库导入,复杂类、工具类需求,则递交给我:
图1:数据需求递交流程
另外,针对每位部门的数据对接人进行了指标定义的说明,以及递交数据需求的规范标准的培训:
图2:培训资料一页:什么是好的数据需求
此时的工作还逗留在偏临时需求的处理上,作为数据产品,却没有作出多少数据产品下来。
2 规范期:他山之石:GrowingIO和神策
在决定搭建数据体系后,我司商讨了几家背部的数据平台,如GIO、ThinkingData、神策等,来补充我司埋点功力薄弱的问题,最后选择了GIO,在使用了一年多以后,因为要做私有化布署,而GIO的私有化布署功能还刚处在开发阶段(写这篇文章的时侯,他们的私有化布署早已做下来了),于是我司又决定换神策平台,重新来一遍POC和SDK接入工作(对,就是如此折腾,o(╥﹏╥)o)。在完整地对接了这两家平台以后,我司数据体系逐渐迈向规范,我也总结了一下两家平台关于指标管理、数据体系搭建的工具特性,以及思路进行了一些总结,如下。
2.1 GrowingIO平台实践总结
在接触了几家平台后,我们最终选择了GIO,该平台的特性特别显著:
拥有无埋点技术,能够实现做功能时,不需要专门针对埋点耗费工时,接入GIO的SDK,在功能上线后,SDK才能采集基础使用信息,同时,针对页面浏览数据,和页面控件点击数据,可以通过“圈选”的形式实现(对于彼时苦于埋点效率低下的现况,这种方案极具诱惑);
公有云布署,接入成本低;
后台操作界面简约,属于营运思路的一款产品,上手较容易;
因为是SaaS服务,线上问题反馈速率比较快。
但后来发觉一些问题:接入SDK后,我们只简单对接了会员状态数据,做了少量的埋点指标,除据悉自动圈选了大量页面指标和控件数据,因为GIO的圈选功能实在很好用了,所见即所得,不必再发版等埋点上线,经过简单操作后就可以自己取数、看数,结合GIO提供的基础剖析工具,如风波剖析、漏斗剖析、留存剖析等功能,人人都能成为一名分析师了。
图3:GIO圈选功能
但到后期,圈选数据的问题日渐曝露,也成为平台要更换GIO平台的导火索。圈选数据的逻辑:是按照页面xpath路径,监听页面浏览风波,和页面上的控件的浏览、点击风波,保留7天,因此圈选完成后,能向前溯源7天的数据。圈选功能的问题主要在于:
耗流量,看下逻辑你应当能理解;
一旦版本迭代,对页面的路径做更改,或者控件位置、文案有更改,原来的圈选数据可能还会出错,需要重新圈选,之前借助圈选指标设定的剖析模型都要替换;
圈选指标难以分辨细部参数,比如:书籍详情页,无法通过圈选数据来分辨是哪一本书;
对web的页面数据处理仍然不好,尤其是涉及到APP的内嵌H5页时,非常苦闷。
图4:版本升级后,某圈选指标数据突降
这似乎也是GIO的业务朋友比较推崇无埋点技术,而我司彼时经验尚不充足踩下的坑,到后半阶段开始补习,开始做客户端和服务端埋点了,埋点开发周期似乎长了点,但是起码才能用得上去。但是由于之前对GIO工具使用上形成的各类不爽,导致前面有了更准确的埋点后,大家用上去也经常怀疑,这数据准不准,能不能用?一旦对数据源形成不信任感,产研团队的解释成本高,数据发挥价值的周期变长,团队屡受指责又看不到成绩,大数据团队本身在数据体系建设的初期存在感就低,如此一来,工作积极性显得更低。
后来受资方等多诱因影响,我们须要做私有化布署,对数据的准确度、智能营运也有更进一步的需求,而彼时GIO还没有成熟的私有化布署功能,因此我们两家后来好聚好散,转而选择了神策。(此处抱着GIO的朋友哭一会儿)
但总体来说,GIO平台还是可圈可点,它的优势在于:
数据响应速度快,圈选功能比较成熟,对于快速迭代活动的场景,圈选功能最为方便;
用户操作界面友好,几大核心剖析功能逻辑结构清晰,学习成本低,能够实现在公司大范围推广使用(你千万别认为这类数据工具是可以轻易上手的,根据我在公司推广GIO和神策的经验,工具使用门槛并不低);
售后团队比较专业,能够从剖析视角,发现我司业务上的问题;并且对平常提及的问题,反馈及时,问题解决程度也比较高。
2.2 神策平台实践总结
后来由于私有化布署的诉求,选择了神策平台的产品。这里解释下,为啥没有选择自己研制数据产品。这显然是一个太经济学的审视。在接入GIO前,我司有自己一套ubt的埋点系统,但是只是基础的数据采集,以及raw data进数据库,从raw data 到数仓,再到提取,把统计类数据以excel方式,或者教会剖析人员使用SSMS或PowerBI来进行取数剖析,中间流程很长,无法做到快速响应及反馈。而找一个团队自研,时间成本和人力成本都很高。
神策、GIO这样的平台,取数功能完整度比较高,而且有一个比较完整的可视化剖析平台,收录了风波剖析、漏斗剖析、留存剖析等基础的剖析功能,也有归因剖析模型、用户画像等功能,这些功能找一个大数据团队和几个算法工程师,一年的成本高了去了。对于B轮左右的公司,建议别折腾,花点钱,除了防止自研成本,还能从这种SaaS平台的服务中,了解到比较成熟的方法论。
神策的剖析全家桶有以下几款产品:
图5:神策产品矩阵
其中,左边【数据基础能力】是基础服务,可以选Pass,也可以选私有化布署,但是节点费、流量费是按照自己的流量来核算。(市政单位,或者对业务数据安全敏感度高的,建议私有化。不是说Pass不安全,像神策、GIO这样专门做数据服务的平台,不至于去窃取顾客数据,一个顾客数据泄漏风波就可以使这类企业直接死掉,这个帐她们拎得清,而且有数据隐私合同)。右边的【数据应用产品】则是可选项了,【神策剖析】收录了风波剖析、漏斗剖析等基础的剖析功能,一般必不可少;【神策用户画像】和【智能营运】是偏向于营运侧的工具,如果自己没有精准营销的产研能力,这两项服务业比较好用。至于【智能推荐】和【神策客景】则依照公司情况,对于内容繁杂,品类繁杂的内容平台、电商平台,还是比较有必要。但我个人觉得,前三项服务玩得转了,再去考虑采购后两项服务不迟。
神策平台的特性是一开始推的是埋点方案,而非无埋点方案;而且最早支持私有化布署的数据服务平台。这一点是使她们才能获得一些金融行业、政企行业的单子的缘由。这也是我们最后评估后,选择她们的缘由。
2.3 我司平台的埋点设计及指标管理
在经过了UBT、GIO和神策三套埋点方案的使用和比较后,对于我司自己的埋点系统也有了比较清晰的方向,最后决定采用常规数据使用后端埋点、关键数据使用服务端埋点、临时活动搭配使用全埋点的方案。
全埋点、前端埋点和服务端埋点的区别
埋点方案
实施方案
优点
缺点
全埋点
部署对应sdk,页面及控件数据全采集,使用时解析
不需要做埋点开发;
需要用的时侯再去圈选使用;
所见即所得,圈选时就可以看见数据;
不需要测试介入,取数周期极短
新圈选时,只能向前溯源7天;
数据不够确切;
发版后会影响之前圈选数据的稳定性。
前端埋点
前端定义的风波触发时,上传对应数据
较为确切;
基本不会受页面改版影响。
有一定开发工作量;
设计新功能时须要考虑对原有埋点的影响,维护指标文档;
会受网路环境等诱因影响,出现数据难以上报或延时上报。
服务端埋点
服务端定义的风波触发时,上传对应数据
最为确切;
不受前台功能改版影响。
开发和测试的工作都较大;
不容易发觉问题。
而我司基本是后端埋点和服务端埋点的组合,其中关于数据指标的设计和管理,采用了右图所展示的数组名,对事实表进行管理和维护。
图6:我司数据指标维护表头
关于数据指标管理,最使我头大的就是怎样保证可读性的前提下,梳理不断新增的数据埋点需求。我的设计思路是:以使用者视角设计,尽可能合并同类型指标,用维度保证扩展性,用备注内容保证可读性。
上面的指标维护表,是要同时给开发人员,和营运人员看的,这里指的使用者,是指营运人员。因为最后埋点设计做完了,也正常上报了,但是营运人员看不懂,用不上去,培训成本高企,是难以充分发挥数据价值的。所以在这里就须要数据产品总监平衡简洁和可用性。
举两个反例:
例子1:平台资源位埋点设计
对于通常互联网产品平台来说,资源位无外乎两种类型,弹出型和轮播型;而具体指标无外乎浏览和点击,因此,将这两种类型的资源位具象成下边4个指标,由维度(资源位位置、轮播位置)来进行分拆。
图7:平台资源位埋点设计
例子2:内容详情页埋点设计
对于内容类、电商类平台来说,内容详情页和商品详情页是最为关键的页面,因此这个页面的浏览数据极为重要。因为详情页是一个通用页面,而且对于一篇文章,或者一个商品来说,可能会在APP出现多个入口,如果对N个入口进行分别埋点,会使指标建设冗余,并且由于网路环境等影响,点击数≠页面加载≠页面加载成功,可能会采到脏数据上来。因此我在这里的设计思路是:以页面加载成功为触发,区分页面本身的数据信息,以及上一个页面的维度信息。
图8:内容详情页埋点设计
这里的挑战来自于去梳理上一个页面的类型和具体参数值,需要与营运组、数据组同学沟通清楚,他们关心的维度,以及下钻的颗粒度。
3 平台期:建设数据库房
建设数据库房是一个必然的选择,在业务体量不大,数据需求不多的情况下,从业务数据库捞数据,甚至解析日志,都是才能满足的。但后期必然会有更多维度、更复杂的分析型、报表型数据需求,全部借助业务数据库其实不现实。现在计算机储存成本不高,数据库房可以看做是一个【用空间换时间】的方案,数据库房是面向剖析、应用的数据库,在构建好标准的ETL流程和更新机制后,分析型、报表型数据需求从数据库房中获取,从而提升效率,也解放业务数据库,让业务库专心处理业务。
特点
面向对象
数据库
处理业务需求,实时性要求高
具体业务
数据库房
ETL后有比较明晰分辨的主题表
可并多个表、多个维度,支持复杂查询
分析型数据
目前有关数据库房的文章非常多,对数据库房应当分几层,也有好多说法。这里须要明晰一点,数据库房的分层是一个理念,其核心是将不同应用层级的数据进行界定。一般来说起码有五级,我司采用的也是五级数仓。
数仓分层
数据来源
特点
ODS
操作型数据、实时数据、日志数据等
近似 = raw data
EDW
ODS层
按明晰主题和维度进行ETL的数据表
DM
ODS层、EDW层
面向明晰应用,ETL获取的数据表
3.1 数据维护及整治
基于Hadoop的成熟体系,搭建完成数仓系框架后,接下来要做的是往数仓中填充数据“血肉”,以及持续进行数据整治的工作了。在用数据赋能业务的链条中:产生数据(埋点)-> 获取数据(ETL) -> 分析数据 -> 发现问题 ->业务决策,似乎并没有数据整治的事情。链条上的四点是可见的过程,而数据本身形成污染后,可能会到获取时、分析时,甚至是决策阶段,才会意识到数据本身可能出现了问题。数据从触发上报-> 发送-> ETL-> 进数仓,中间有任何一个过程出问题,都可能会影响数据的稳定、准确和及时。另外,不断扩充的业务需求,业务数据数组会发生变更,这时错传、漏传了数据进数仓,也会影响数据质量。
总结出来,基于下边三个点,需要持续进行数据维护和整治:
数据进仓链路长,存在出现脏数据的风险;
新业务需求增删改数组,没有及时同步进数仓;
数仓表结构数组设计扩展性不足,新数据须要单独建表,导致冗余。
针对第1点,我司对于数据指标本身的异常波动做了监控的设计。在接入了神策平台以后,该平台提供了一个指标异常波动提醒的功能,还很好用。
图9:神策数据异常监控
针对第2点谈谈我司实践。我司通过搭建【异构数据平台】来解决业务数据同步到数据库房的问题。业务数据在进数据仓的同时,会根据约定的规范,同步传送一份到数据库房;如果有修业务数据的情况,也须要异步地通过该平台,发消息给数据库房,由数仓消费后,更新数仓的数据。
针对第3点,没有哪些好办法,需要数据产品和大数据组、业务产品总监多沟通,对于数仓目前有什么表,哪些数组,功能规划上,未来会新增什么产品线,与当前业务线的关系,有一个大致预判,最大程度降低重复建表的工作。
3.2 数据库房构架设计
基于以上,我司数据库房是基于Hadoop框架,Hive处理离线数据,Flink处理实时数据,实现用户行为数据和业务数据准实时入数仓(有一些延时),并且后端数据产品应用,从数据库房中调插口取数。(目前还没有完全实现所有业务数据都从数据库房走,还在建设中)
图10:数据库房构架设计
4 未来:数据中台?
数据中台概念在19年实在很火了,颇有些12年,到处都在说O2O的情形。对于数据产品来说,将产出的数据产品抽象化、共用化,成为象中台一样的基础服务能力是心之所向。但是否应当盲目上中台项目,谈谈我的理解。
4.1 我所理解的数据中台
我很喜欢【中台】这个词:处于中间,承上启下;成为平台,隔绝上下流动,但自身提供服务上下的能力。对于数据中台,其核心是提炼各业务线的共性需求,将这种需求解决方案封装为标准化、组件化的解决能力,然后以插口的方式提供给前前台业务数据。从而实现尽量少地重复造轮子,尽量多地提升研制的敏捷性。
不是所有公司都须要立即做中台,但按照熵增定律,一家能持续发展的企业,其业务形态一定会不断发展和膨胀,而当新业务线和老业务线有共性诉求,能够通过中台化来提升效率,并且具有能串联多业务线的项目能力,这些问题想清楚,就可以开始做中台项目了。
4.2 资料推荐
在学习数据中台的过程中,整理了一些资料,如下:
数据中台到底是什么?
换个视角看中台的对与错
有赞零售中台建设方式的探求与实践
原文链接:/article/gaBwDw5Jkj
什么是新闻采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-27 16:27
新闻采集系统是将非结构化的新闻文章从多个新闻来源网页中抽取下来保存到结构化的数据库中的软件。主要功能依据用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为为结构化的记录(标题,作者,内容,采集时间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外部信息的获取。主要技术新闻采集系统核心技术是模式定义和模式匹配。模式属于人工智能的术语,意思为前人积累的经验的具象和升华。简单地说,就是从不断重复出现的风波中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可能存在某种模式。所以要使新闻采集系统才能运行,目标网站必须具备重复出现的特点。目前大多网站都是动态生成的,这样才会使同一模板的页面收录相同的内容,新闻采集系统正是借助这种相同的内容来定位采集数据的。新闻采集系统中的模式大多不是程序手动发觉的,目前几乎所有的新闻采集系统产品都须要通过人工来定义。但模式本身是个很复杂,很具象的内容,所以所有的开发者精力都花在如何使模式定义更简单,更准确,这也是新闻采集系统竞争力的评判标准。现在国外在新闻采集行业,比较领先的是北京的乐思。他们的采集系统可以智能的抓取新闻,也就是说不需要配置。 查看全部
什么是新闻采集?
新闻采集系统是将非结构化的新闻文章从多个新闻来源网页中抽取下来保存到结构化的数据库中的软件。主要功能依据用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为为结构化的记录(标题,作者,内容,采集时间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外部信息的获取。主要技术新闻采集系统核心技术是模式定义和模式匹配。模式属于人工智能的术语,意思为前人积累的经验的具象和升华。简单地说,就是从不断重复出现的风波中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可能存在某种模式。所以要使新闻采集系统才能运行,目标网站必须具备重复出现的特点。目前大多网站都是动态生成的,这样才会使同一模板的页面收录相同的内容,新闻采集系统正是借助这种相同的内容来定位采集数据的。新闻采集系统中的模式大多不是程序手动发觉的,目前几乎所有的新闻采集系统产品都须要通过人工来定义。但模式本身是个很复杂,很具象的内容,所以所有的开发者精力都花在如何使模式定义更简单,更准确,这也是新闻采集系统竞争力的评判标准。现在国外在新闻采集行业,比较领先的是北京的乐思。他们的采集系统可以智能的抓取新闻,也就是说不需要配置。
信息采集系统/网络数据采集案例解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 609 次浏览 • 2020-08-26 14:46
如何把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。随着网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。我们从信息短缺的时代一下子走到了信息极大丰富昨天。在明天,困扰我们的问题不是信息很少,而是太多,多得使你无从区分,无从选择。因此,提供一个才能手动在互联网上抓取挖掘数据,并手动分拣、分析的工具有特别重要的意义。
通用搜索引擎其实帮了我们不少忙,但怎样把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。日前警犬信息采集系统挺好为中国电信完成具以上特征的任务。
第一部分:项目需求:
要求对11市级城市的9大行业(医疗、汽车、餐饮、购物、教育、娱乐休闲、住宿、日常服务、旅游)根据行业的不同,按照不同的数组智能抽取企业网站的相关数组的数据,对所抽取的数据作只能的去重处理,同一个企业的数据做真假分辨,用程序来效验数据,最后构建呼叫中心,人工确认数据的有效性构建呼叫中心,人工确认数据的有效性。
第二部份:数据处理解决方案:
数据分布状态
项目执行流程:
1. 定向抽取结构化数据:从多个平台(阿里巴巴、慧聪网、口碑网、爱帮网、58同城分类等平台)上抽取数据,以最大限度确保数据的数目。
军犬信息采集系统流程图:
2. 定向的结构化信息抽取,针对不同的平台,制定不同的采集规则,以准确地将结构化数据存入对应的数据库中的数组。
3. 信息采集任务保障:
确保采集任务
4. 对于没有的企业结构化数据,通用spider 漫游来访问企业网站,抽取信息正文。
5. 构建词库:在数据抽取后,利用现有的数据构建行业词库和特点词库,并且在剖析其它网页时手动建立词库。
词库的构建与建立
6. 智能提取:采用动词技术,对非结构化数据进行智能抽取。
数据处理及校准 查看全部
信息采集系统/网络数据采集案例解析
如何把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。随着网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。我们从信息短缺的时代一下子走到了信息极大丰富昨天。在明天,困扰我们的问题不是信息很少,而是太多,多得使你无从区分,无从选择。因此,提供一个才能手动在互联网上抓取挖掘数据,并手动分拣、分析的工具有特别重要的意义。
通用搜索引擎其实帮了我们不少忙,但怎样把搜索引擎的数据储存以及再加工再利用、如何根据我须要的数组给抽取下来、如何不局限百度微软上面的数据。如何自定义收录网站更新频度。日前警犬信息采集系统挺好为中国电信完成具以上特征的任务。
第一部分:项目需求:
要求对11市级城市的9大行业(医疗、汽车、餐饮、购物、教育、娱乐休闲、住宿、日常服务、旅游)根据行业的不同,按照不同的数组智能抽取企业网站的相关数组的数据,对所抽取的数据作只能的去重处理,同一个企业的数据做真假分辨,用程序来效验数据,最后构建呼叫中心,人工确认数据的有效性构建呼叫中心,人工确认数据的有效性。
第二部份:数据处理解决方案:
数据分布状态
项目执行流程:
1. 定向抽取结构化数据:从多个平台(阿里巴巴、慧聪网、口碑网、爱帮网、58同城分类等平台)上抽取数据,以最大限度确保数据的数目。
军犬信息采集系统流程图:
2. 定向的结构化信息抽取,针对不同的平台,制定不同的采集规则,以准确地将结构化数据存入对应的数据库中的数组。
3. 信息采集任务保障:
确保采集任务
4. 对于没有的企业结构化数据,通用spider 漫游来访问企业网站,抽取信息正文。
5. 构建词库:在数据抽取后,利用现有的数据构建行业词库和特点词库,并且在剖析其它网页时手动建立词库。
词库的构建与建立
6. 智能提取:采用动词技术,对非结构化数据进行智能抽取。
数据处理及校准
中科点击警犬网路信息采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-26 03:02
系统简介
一.“信息采集系统”系统概述:
信息采集是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入的整个过程。
军犬信息采集专家是一款基于人工智能的手动学习技术,功能强悍、简单实用的互联网信息采集与监控软件。
二、互联网信息采集与挖掘:
要求从互联网上对特定目标数据源或不特定目标数据源进行采集与监控,并对信息进行结构化抽取保存为本地结构化数据库,然后按业务流程需求与其它模块结合,导入与应用并服务于到电子行业平台。
互联网数据采集与挖掘技术是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入,并按业务所需,进行数据发布、分析的整个过程。
三、互联网采集系统流程图
第一步:确定采集任务。
第二步:每个采集任务,我们有多个目标数据源可供采集。
第三步:针对不同的目标数据源,进行不同的采集配置,以确保能采集到数据。
第四步:调度采集任务,与目标站点同步更新,增量采集。
第五步:采集到数据结果,完成数据异构到同构的过程。
第六步:通过发布服务器,将数据发布到应用平台。
四、军犬“信息采集系统”8大应用领域:
1、搜索引擎与垂直搜索 2、综合门户与行业门户
3、电子政务与电子商务 4、知识管理与知识共享
5、企业竞争情报系统 6、BI商业智能系统
7、信息咨询与信息增值 8、信息安全和信息监控
五、军犬“信息采集系统”-软件特征
(1)、过滤干净,智能化抽取正文,且图文关联
(2)、数据导入插口丰富,可以将数据导入成各类主流关系型数据结构。
(3)、军犬“信息采集系统”配置简单
对于新闻资讯采集,只需输入待采集目标网站的地址或某个主题页面地址,软件即会手动学习网站的风格,并手动提取网站的资讯,无需配置模板,目标网站风格发生变化,软件手动学习。对于数据采集软件提供了通俗易懂的站点配置向导,维护人员稍加培训即可配置出任何的信息采集。对于复杂的采集过程,通过一张采集卡脚本即可实现信息的手动采集与监控。
(4)、军犬“信息采集系统”所采即所得,所采即可见
(5)、军犬“信息采集系统”增量采集与手动更新
增加采集:对于初次采集目标网站,软件支持完全采集;而对于已采集过的站点支持增量采集。支持手动更新:自动检查站点是否发生更新,并不会遗漏任何一个重要的信息。
(6)、军犬“信息采集系统”采集结果手动排重
不是借助简单的规则判别,而是借助内容的相似性进行排重判别,准确性高,不会由于标题或内容的少许变化而形成漏判,即使把标题进行了改头换面,系统也会正确判断。
(7)、军犬“信息采集系统”内置强悍的信息监控
可以通过一个关键字广域监控互联网上任何一个站点上的相关信息。也可以通过设置监控频道监控任何站点所采集到富含关键字的信息。对于数值数组可以设置监控误差监控数值出现在一定范围内的信息。信息监控达到字段级。您可以对任何一个采集目标网站设置监控属性,监控周期达到了秒级。对于发生变化的信息可以在短时间内采集到本地
强大的站点管理工具可以对所有采集对象进行集中管理和各类操作
(8)、军犬“信息采集系统”支持多种编码
支持多种网站的信息的编码,GBK、BIG5、UNICODE、UTF8,软件会手动转换成GBK码进行统一的处理。软件即会手动辨识网站的组织结构,自动辨识网站的编码。 表单管理,随心所欲自定义表单,方便采集不同的内容,如采集软件用单独的表单,采集图片用图片表单。
(9)、军犬“信息采集系统”信息导出导入随心所欲
提供信息导出导入与其它软件可作无缝联接 ,如CRM OA 软件提供有强悍的信息记录导出导入功能,您可以对任何一个频道、一条记录进行导出与导入。可以导成Excel/Access等,也可以直接导到指定的数据库。与《信息发布服务器》结合使用可以将信息发布到任何一个地方。
(10)、军犬“信息采集系统“支持阅读模板
任何一种信息类型,软件就会手动创建一个阅读模板便捷了您快速阅读;任何信息您可以对任何一种信息表单订制一款漂亮的阅读模板,也可以对任何一个频道设置不同的阅读模板。
(11)、军犬“信息采集系统“多页面内容重组
对于目标数据源的一篇文章在目标网站上分页显示,系统能手动对其重组.软件运行稳定、采集速度快、占用系统资源少。
历经多次改建的软件采集底层模块运行稳定、采集速度快,点用系统资源少。可多线程并发运行,而不占有过多的系统资源。采集速度快到顿时到位。软件完全可以实现7*24小时不间断无人值守的信息采集。更多细节功能有待于您在使用中去体验。
(12)、军犬“信息采集系统”其它特性列表:
1、支持多种语言:支持简体中文、繁体英文、英文、日文、韩文等多国语言
2、支持多种站点类型:包括html与rss
3、支持登入、验证后采集
4、软件支持须要登陆与须要验证码的网站信息采集,采集过程完全仿人工。
5、支持附件采集
包括图片附件采集、多媒体附件采集、音视频附件采集、附件与正文手动映射与关联
6、完全结构化抽取将网页的非结构化数据抽取成特定的结构化信息数据。
网页搜索是以网页为最小单位,基于视觉的网页块剖析是以网页块为最小单位,垂直搜索是以结构化数据为最小单位。然后将这种数据储存到数据库,进行进一步的加工处理,如:去重、分类等,最后动词、索引再以搜索的方法满足用户的需求。
整个过程中,数据由非结构化数据抽取成结构化数据,经过深度加工处理后以非结构化的方法和结构化的形式返回给用户。
7、数据保存到本地,您可以随时查阅信息。 采集到信息手动保存到本地数据库,您可以随时查阅信息。
8、多线层、多任务
9、支持海量数据采集
10、软件实用、易用、功能强悍
11、可移植、可扩充、可定制
六、军犬“信息采集系统”配置要求
要求:WindowsNT4/ Windows 2000 Server 或更新的操作系统。
要求: Microsoft SQL Server 7/ 2000或其它ODBC插口
要求:intel xeon 2G 以上CPU,2G 以上RAM,硬盘空间200GB以上
七、军犬“信息采集系统”性能
l、支持多线程采集。
2、单机在数据采集在G级以上。
3、数据与数据源同步更新大于10秒级。
4、数据同步发布大于10秒级。 查看全部
中科点击警犬网路信息采集系统
系统简介
一.“信息采集系统”系统概述:
信息采集是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入的整个过程。
军犬信息采集专家是一款基于人工智能的手动学习技术,功能强悍、简单实用的互联网信息采集与监控软件。
二、互联网信息采集与挖掘:
要求从互联网上对特定目标数据源或不特定目标数据源进行采集与监控,并对信息进行结构化抽取保存为本地结构化数据库,然后按业务流程需求与其它模块结合,导入与应用并服务于到电子行业平台。
互联网数据采集与挖掘技术是指借助计算机软件技术,针对订制的目标数据源,实时进行信息采集、抽取、挖掘、处理,从而为各类信息服务系统提供数据输入,并按业务所需,进行数据发布、分析的整个过程。
三、互联网采集系统流程图
第一步:确定采集任务。
第二步:每个采集任务,我们有多个目标数据源可供采集。
第三步:针对不同的目标数据源,进行不同的采集配置,以确保能采集到数据。
第四步:调度采集任务,与目标站点同步更新,增量采集。
第五步:采集到数据结果,完成数据异构到同构的过程。
第六步:通过发布服务器,将数据发布到应用平台。
四、军犬“信息采集系统”8大应用领域:
1、搜索引擎与垂直搜索 2、综合门户与行业门户
3、电子政务与电子商务 4、知识管理与知识共享
5、企业竞争情报系统 6、BI商业智能系统
7、信息咨询与信息增值 8、信息安全和信息监控
五、军犬“信息采集系统”-软件特征
(1)、过滤干净,智能化抽取正文,且图文关联
(2)、数据导入插口丰富,可以将数据导入成各类主流关系型数据结构。
(3)、军犬“信息采集系统”配置简单
对于新闻资讯采集,只需输入待采集目标网站的地址或某个主题页面地址,软件即会手动学习网站的风格,并手动提取网站的资讯,无需配置模板,目标网站风格发生变化,软件手动学习。对于数据采集软件提供了通俗易懂的站点配置向导,维护人员稍加培训即可配置出任何的信息采集。对于复杂的采集过程,通过一张采集卡脚本即可实现信息的手动采集与监控。
(4)、军犬“信息采集系统”所采即所得,所采即可见
(5)、军犬“信息采集系统”增量采集与手动更新
增加采集:对于初次采集目标网站,软件支持完全采集;而对于已采集过的站点支持增量采集。支持手动更新:自动检查站点是否发生更新,并不会遗漏任何一个重要的信息。
(6)、军犬“信息采集系统”采集结果手动排重
不是借助简单的规则判别,而是借助内容的相似性进行排重判别,准确性高,不会由于标题或内容的少许变化而形成漏判,即使把标题进行了改头换面,系统也会正确判断。
(7)、军犬“信息采集系统”内置强悍的信息监控
可以通过一个关键字广域监控互联网上任何一个站点上的相关信息。也可以通过设置监控频道监控任何站点所采集到富含关键字的信息。对于数值数组可以设置监控误差监控数值出现在一定范围内的信息。信息监控达到字段级。您可以对任何一个采集目标网站设置监控属性,监控周期达到了秒级。对于发生变化的信息可以在短时间内采集到本地
强大的站点管理工具可以对所有采集对象进行集中管理和各类操作
(8)、军犬“信息采集系统”支持多种编码
支持多种网站的信息的编码,GBK、BIG5、UNICODE、UTF8,软件会手动转换成GBK码进行统一的处理。软件即会手动辨识网站的组织结构,自动辨识网站的编码。 表单管理,随心所欲自定义表单,方便采集不同的内容,如采集软件用单独的表单,采集图片用图片表单。
(9)、军犬“信息采集系统”信息导出导入随心所欲
提供信息导出导入与其它软件可作无缝联接 ,如CRM OA 软件提供有强悍的信息记录导出导入功能,您可以对任何一个频道、一条记录进行导出与导入。可以导成Excel/Access等,也可以直接导到指定的数据库。与《信息发布服务器》结合使用可以将信息发布到任何一个地方。
(10)、军犬“信息采集系统“支持阅读模板
任何一种信息类型,软件就会手动创建一个阅读模板便捷了您快速阅读;任何信息您可以对任何一种信息表单订制一款漂亮的阅读模板,也可以对任何一个频道设置不同的阅读模板。
(11)、军犬“信息采集系统“多页面内容重组
对于目标数据源的一篇文章在目标网站上分页显示,系统能手动对其重组.软件运行稳定、采集速度快、占用系统资源少。
历经多次改建的软件采集底层模块运行稳定、采集速度快,点用系统资源少。可多线程并发运行,而不占有过多的系统资源。采集速度快到顿时到位。软件完全可以实现7*24小时不间断无人值守的信息采集。更多细节功能有待于您在使用中去体验。
(12)、军犬“信息采集系统”其它特性列表:
1、支持多种语言:支持简体中文、繁体英文、英文、日文、韩文等多国语言
2、支持多种站点类型:包括html与rss
3、支持登入、验证后采集
4、软件支持须要登陆与须要验证码的网站信息采集,采集过程完全仿人工。
5、支持附件采集
包括图片附件采集、多媒体附件采集、音视频附件采集、附件与正文手动映射与关联
6、完全结构化抽取将网页的非结构化数据抽取成特定的结构化信息数据。
网页搜索是以网页为最小单位,基于视觉的网页块剖析是以网页块为最小单位,垂直搜索是以结构化数据为最小单位。然后将这种数据储存到数据库,进行进一步的加工处理,如:去重、分类等,最后动词、索引再以搜索的方法满足用户的需求。
整个过程中,数据由非结构化数据抽取成结构化数据,经过深度加工处理后以非结构化的方法和结构化的形式返回给用户。
7、数据保存到本地,您可以随时查阅信息。 采集到信息手动保存到本地数据库,您可以随时查阅信息。
8、多线层、多任务
9、支持海量数据采集
10、软件实用、易用、功能强悍
11、可移植、可扩充、可定制
六、军犬“信息采集系统”配置要求
要求:WindowsNT4/ Windows 2000 Server 或更新的操作系统。
要求: Microsoft SQL Server 7/ 2000或其它ODBC插口
要求:intel xeon 2G 以上CPU,2G 以上RAM,硬盘空间200GB以上
七、军犬“信息采集系统”性能
l、支持多线程采集。
2、单机在数据采集在G级以上。
3、数据与数据源同步更新大于10秒级。
4、数据同步发布大于10秒级。
门户网站建设方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-23 22:50
门户网站可以说是一个行业的专业性网站,在这个门户网站中几乎涵盖了一个行业的所有信息,一般来说内容比较丰富和全面,不然的话是不能成为一个门户的,只能叫一个小平台网站。那么门户网站建设如何如何做,方案怎么做。
门户网站建设
建设一个门户网站,我们前期须要做大量的规划和打算,我们须要将这个行业的内容进行整合,规划好地区及分类,网站要针对性地为业内人士提供行业内及行业相关信息服务,强化业内信息的分类,充分彰显本行业特色。
还要将自己的网站品牌塑造下来,形成自己的特色,梳理行业中的权威形象。
门户网站建设方案的特征
1、网站的前瞻性
网站应采用三层url结构、静态网页技术,在选用平台、采用技术上要具有先进性、前瞻性、扩充性,从而保证建成的网站系统具有良好的稳定性、可扩展性和安全性,以便于后期的维护;
2、网站系统的体验度
尽量满足自身业务功能需求,并适应各业务角色的工作特性,该系统做到简单、实用、人性化;便于操作后台的人使用。
3、容错性和可靠性
在建设网站系统时要考虑保证系统的可靠性和安全性,系统设计中,应有适量冗余及其他保护举措,平台和应用软件具有良好的容错性、容灾性等,错误后也能便捷更改。
4、可维护性要强
门户网站的系统设计应标准化、规范化,按照分层设计,软件构件化实现。采用软件构件化的开发方法:一是系统结构分层,业务与实现分离,逻辑与数据分离;二是以统一的服务插口规范为核心,使用开放标准;提炼封装预制构件规范化;拓展性要强便捷后续的人持续开发和拓展。
5、对于网站的规划
提前规划好网站的所有分类,列表,文章发布形式,生成方法,自定义文件,专题页,可下载的资源、是否可评论、是否有采集、防盗链、产品页、购买页、支付方法、广告位预留、数据统计等等,没有内容的,提前预留,以备后期直接调用。
以上就是一个门户网站的建设规则,一个门户网站要设计的东西十分多,需要很多人协作共同完成,才能作出一个比较好的门户网站,长期以优质内容输出,会使网站逐渐产生行业典范,希望此文对你们有所帮助。 查看全部
门户网站建设方案
门户网站可以说是一个行业的专业性网站,在这个门户网站中几乎涵盖了一个行业的所有信息,一般来说内容比较丰富和全面,不然的话是不能成为一个门户的,只能叫一个小平台网站。那么门户网站建设如何如何做,方案怎么做。
门户网站建设
建设一个门户网站,我们前期须要做大量的规划和打算,我们须要将这个行业的内容进行整合,规划好地区及分类,网站要针对性地为业内人士提供行业内及行业相关信息服务,强化业内信息的分类,充分彰显本行业特色。
还要将自己的网站品牌塑造下来,形成自己的特色,梳理行业中的权威形象。
门户网站建设方案的特征
1、网站的前瞻性
网站应采用三层url结构、静态网页技术,在选用平台、采用技术上要具有先进性、前瞻性、扩充性,从而保证建成的网站系统具有良好的稳定性、可扩展性和安全性,以便于后期的维护;
2、网站系统的体验度
尽量满足自身业务功能需求,并适应各业务角色的工作特性,该系统做到简单、实用、人性化;便于操作后台的人使用。
3、容错性和可靠性
在建设网站系统时要考虑保证系统的可靠性和安全性,系统设计中,应有适量冗余及其他保护举措,平台和应用软件具有良好的容错性、容灾性等,错误后也能便捷更改。
4、可维护性要强
门户网站的系统设计应标准化、规范化,按照分层设计,软件构件化实现。采用软件构件化的开发方法:一是系统结构分层,业务与实现分离,逻辑与数据分离;二是以统一的服务插口规范为核心,使用开放标准;提炼封装预制构件规范化;拓展性要强便捷后续的人持续开发和拓展。
5、对于网站的规划
提前规划好网站的所有分类,列表,文章发布形式,生成方法,自定义文件,专题页,可下载的资源、是否可评论、是否有采集、防盗链、产品页、购买页、支付方法、广告位预留、数据统计等等,没有内容的,提前预留,以备后期直接调用。
以上就是一个门户网站的建设规则,一个门户网站要设计的东西十分多,需要很多人协作共同完成,才能作出一个比较好的门户网站,长期以优质内容输出,会使网站逐渐产生行业典范,希望此文对你们有所帮助。
新云文章采集视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-18 18:18
新云文章采集视频教程
网友评分:3
同类人气软件
新云文章采集视频教程软件介绍
我们采集一个网站的文章,其实和我们打开一个网站去浏览他的一篇文章一样,先开打开的文章列表,再人列表中选定一篇文章的标题,点入再找到文章所在的地方!于是,采集也一样,我们先确定他的文章列表,再步入他的文章页面!
而我们怎么一步步的去锁定他的列表,标题,正文等要采集的对象呢?我们可以发觉,我们每写一个代码进去都是有一个开始,有一个结束!这就是拿来确定减少对象范围的,他由系统手动锁定我们写的开始代码到结束代码之间的内容!也就是由于这样,我们的代码不可以有重复!我们就拿教程中的代码来说吧!
下载地址
新云文章采集视频教程下载地址
下载帮助新云文章采集视频教程来自互联网, 如有侵害您的版权, 请与我们来信联系
* 想诠释您的技术风采吗,我们这个大舞台给您机会!有奖投稿方式: 点这儿
* 站内软件和教程仅供技术研究,请于下载后24小时内自行删掉,请勿用于非法用途否则后果自负!
* 站内软件和教程均由网友发布,切莫轻信软件和教程里的广告信息以防上当受骗
* 站内所有软件和教程早已通过本站检查安全,若您仍然发觉存在安全问题,敬请来信通知我们! 查看全部
新云文章采集视频教程
新云文章采集视频教程
网友评分:3
同类人气软件
新云文章采集视频教程软件介绍
我们采集一个网站的文章,其实和我们打开一个网站去浏览他的一篇文章一样,先开打开的文章列表,再人列表中选定一篇文章的标题,点入再找到文章所在的地方!于是,采集也一样,我们先确定他的文章列表,再步入他的文章页面!
而我们怎么一步步的去锁定他的列表,标题,正文等要采集的对象呢?我们可以发觉,我们每写一个代码进去都是有一个开始,有一个结束!这就是拿来确定减少对象范围的,他由系统手动锁定我们写的开始代码到结束代码之间的内容!也就是由于这样,我们的代码不可以有重复!我们就拿教程中的代码来说吧!
下载地址
新云文章采集视频教程下载地址
下载帮助新云文章采集视频教程来自互联网, 如有侵害您的版权, 请与我们来信联系
* 想诠释您的技术风采吗,我们这个大舞台给您机会!有奖投稿方式: 点这儿
* 站内软件和教程仅供技术研究,请于下载后24小时内自行删掉,请勿用于非法用途否则后果自负!
* 站内软件和教程均由网友发布,切莫轻信软件和教程里的广告信息以防上当受骗
* 站内所有软件和教程早已通过本站检查安全,若您仍然发觉存在安全问题,敬请来信通知我们!
ELK之日志搜集系统布署
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-18 11:33
目录
1. EFK 日志搜集系统介绍
在日常维护中,每次线上服务器的Nginx或PHP遇见报错,一般首选方式是开启日志,查看日志内容。我们可能还须要登录到服务器中,利用命令tail -f 查看最新的日志报错,或许还须要利用Linux运维三剑客awk、grep、sed对日志内容过滤、分析等。如果有一套系统能将所有日志搜集在一起,并通过Web界面展示日志内容,或者可以对日志内容进行汇总剖析,以数据表格的方式直观的展示下来,可以为我们节约大量的时间。
由此,社区开发了一套完整的开源的日志采集架构 (ELK Stack)[] ,其中 E 代表 Elasticsearch,L 代表 Logstash,K 代表 Kibana。
社区常用的ELK构架的日志采集方案,在ELK+Filebeat 集中式日志解决方案解读 这篇文章中写得比较详尽了,这里我就不在多余赘言。
为了搭建一个高可用的 ELK 集中式日志解决方案,我们可以对ELK做进一步的改进,可参考从ELK到EFK演化
我们搭建的日志采集系统构架如下图所示:
在ELK的基础之上,我们采用了Filebeat做日志采集端,如果象ELK中的构架,Logstash作为日志采集端,那么每台服务器都须要安装JAVA环境,因为Logstash是基于Java环境,才能正常使用。而我们采用的 Filebeat 不需要任何依赖,直接安装后,修改配置文件,启动服务即可。当采集到日志文件时,在 input 中我们须要在Filebeat中定义一个 fields,定义一个log_topic的数组,将指定路径下的日志文件分为一类。在 Output 中,我们指定 Output 输入至Kafka,并按照 input
Kafka作为一个消息队列,接收来自Filebeat客户端采集上来的所有日志,并按照不同类型的日志(例如nginx、php、system)分类转发。在Kafka中,我们依照 inout中自定义的日志类型,在kafka中创建不同的topic。
Logstash接收来自Kafka消息队列的消息,根据Kafka中不同的topic,将日志分类写入Elasticsearch中;Kibana匹配Elasticsearch中的索引,可以对日志内容剖析、检索、出图展示(当然须要自己设计出图了)。
2.EFK 架构布署之安装 Elasticsearch0x01 环境说明
系统:CentOS 7
软件版本如下图:
软件版本号
Kibana
6.6
Elasticsearch
6.6
Logstash
6.6
Filebeat
6.6
metricbet
6.6
Kafka
kafka_2.11-2.1.0
Kafka-manage
1.3.3.22
Kafka-eagle
kafka-eagle-web-1.3.0
0x02 系统初始化配置
可参考文章:Shell 之CentOS 7 系统初始化
新增配置如下系统参数 (/etc/security/limits.conf):
# 解除文件描述符限制
* soft nofile 65535
* hard nofile 65535
# 操作系统级别对每个用户创建的进程数的限制
* soft nproc 2048
* hard nproc 2048
# 解除对用户内存大小的限制
* soft memlock unlimited
* hard memlock unlimited
重启服务器
0x03 安装 JDK 8
由于Elasticsearch、Logstash、Kafka-eagle、均须要JDK环境,所以需提早安装 java 环境。
可参考官网:
安装包下载地址:Java SE Development Kit 8 Downloads
先选择 Accept License Agreement,再下载对应的安装包, 我这儿使用的是 CentOS 7 的系统,所以选择 rpm 的镜像包,若是 Ubuntu系统的可以选择 .tar.gz 的镜像包
安装步骤可参考:CentOS 7 之安装布署 JDK
rpm 包安装的JDK默认软件安装目录为:/usr/java/jdk1.8.0_201-amd64,需要配置环境变量,后期的好多软件布署均须要这个路径,最后需复查一下 /usr/bin 目录下是否有java的执行文件
[root@efk-master ~]# ll /usr/bin/java
lrwxrwxrwx. 1 root root 22 Mar 4 11:00 /usr/bin/java -> /etc/alternatives/java
最后查看 java 的版本信息:
[root@efk-master ~]# java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
到此为止,JDK环境已然布署完毕
0x04 安装 Elasticsearch
由于 Elasticsearch 是建立于 Java 的基础之上的,所以对 java 的版本有一定的要求,需提早配置好 Java 环境。 Elasticsearch 6.6 版本建议安装java的版本为 Java 8发行版中的 1.8.0_131 之后版本均可。官网更推荐使用提供技术支持(LTS)的 Java 版本。安装完 Java 后建议配置 JAVA_HOME 环境变量。
提示:由于我使用的是CentOS 7 64位的操作系统,后续的安装中均会选择 RPM 包的方式安装,而且我是使用的 root 用户权限布署的。
1.下载安装公共秘钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.手动下载安装安装 RPM 包
# 下载 ES rpm 包
wget https://artifacts.elastic.co/d ... 1.rpm
# 下载 ES 的 sha512 哈希值,保证下载的安装包无数据丢失
wget https://artifacts.elastic.co/d ... ha512
# 验证 哈希值
shasum -a 512 -c elasticsearch-6.6.1.rpm.sha512
# 安装 ES
sudo rpm --install elasticsearch-6.6.1.rpm
3.配置 ES 相关内容,将如下内容添加至主配置文件 /etc/elasticsearch/elasticsearch.yml 中
# 配置 ES 集群的名字,此次没有搭建ES集群,仅为单机部署。但是为了便于后期搭建ES集群,所以需要配置集群名字
cluster.name: efk
# 配置 ES 节点的名字
node.name: es-1
# 是否为主节点
node.master: true
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 允许所有网段访问 9200 端口
network.host: 0.0.0.0
# 开启 http 的 9200 端口
http.port: 9200
# 指定集群中的节点中有几个有 master 资格的节点
discovery.zen.minimum_master_nodes: 1
# 以下配置为 head 插件配置
http.cors.enabled: true
http.cors.allow-origin: "*"
4.配置 ES 内存
vim /etc/elasticsearch/jvm.options
#将如下内容:
-Xms1g
-Xmx1g
#更改为
-Xms32g
-Xmx32g
5.运行 ES
# /bin/systemctl daemon-reload
# /bin/systemctl enable elasticsearch.service
# systemctl start elasticsearch.service
6.检查 ES 是否运行正常
a. 确保ES的默认9200端口开启
b. 确保ES的服务正常启动
# 查看端口
# lsof -i :9200
# 查看服务
# ps -ef | grep elasticsearch| grep -v grep
7.浏览器访问 ES
输入本机IP加端口号
http://ip:9200
8.安装 elasticsearch-head插件(需提早打算好 node.js 环境)
我们先安装布署 node.js 环境
node.js
cd /opt/efk
curl -L -O https://nodejs.org/dist/v10.15 ... ar.xz
tar -xf node-v10.15.3-linux-x64.tar.xz
mv node-v10.15.1-linux-x64 /usr/local
配置 node 的环境变量 (/etc/profile)
# node home
export NODEJS_HOME=/usr/local/node-v10.15.1-linux-x64
export PATH=$PATH:$JAVA_HOME/bin:$NODEJS_HOME/bin
激活环境变量
source /etc/profile
配置软链接
# ln -s /usr/local/node-v10.15.1-linux-x64/bin/node /usr/bin/node
验证是否配置成功
# node --version
v10.15.1
安装 elasticsearch-head
# cd /usr/local
# git clone git://github.com/mobz/elasticsearch-head.git
# cd elasticsearch-head
# npm install
# npm run start
访问地址: :9100
如上图所示:
1.在浏览器中输入:9100(ip为布署环境的本机ip)
2.输入框中输入ES的地址::9200 (端口号9200为ES的主配置文件中配置的 http.port)
3.由于此文档是在整个EFK日志采集系统搭建完毕后,编写的文档,所以,可能会见到 system 的索引,暂时先忽视。我们重点关注es-1;如果不记得的话,可以查看上面配置的ES主配置文件,es-1即为我们上面配置的node.name;这里提醒我们不要小看任何一个配置选项,既然须要配置,必有其用途。
3.EFK 架构布署之安装 Kibana
1.下载 64位安装包,并安装 Kibana
# cd /opt/efk
# wget https://artifacts.elastic.co/d ... ar.gz
# shasum -a 512 kibana-6.6.1-linux-x86_64.tar.gz
# tar -xzf kibana-6.6.1-linux-x86_64.tar.gz
# mv kibana-6.6.1-linux-x86_64/ /usr/local
配置 Kinaba
# kibana 访问端口
server.port: 5601
# kibana 访问 IP 地址
server.host: "192.168.7.3"
# kibana 的服务名
server.name: "efk-master"
# ES 地址
elasticsearch.hosts: ["http://192.168.7.3:9200"]
# kibana 索引
kibana.index: ".kibana"
# ES 登录账号及密码
elasticsearch.username: "admin"
elasticsearch.password: "admin"
# kibana 进程 ID 路径
pid.file: /var/run/kibana.pid
3.启动服务
执行kibana的二进制文件,此命令执行后,进程会在前台运行,后期我们会使用 Supervisord 的形式布署。
# /usr/local/kibana-6.6.0-linux-x86_64/bin/kibana
4.访问kibana 查看全部
ELK之日志搜集系统布署
目录
1. EFK 日志搜集系统介绍
在日常维护中,每次线上服务器的Nginx或PHP遇见报错,一般首选方式是开启日志,查看日志内容。我们可能还须要登录到服务器中,利用命令tail -f 查看最新的日志报错,或许还须要利用Linux运维三剑客awk、grep、sed对日志内容过滤、分析等。如果有一套系统能将所有日志搜集在一起,并通过Web界面展示日志内容,或者可以对日志内容进行汇总剖析,以数据表格的方式直观的展示下来,可以为我们节约大量的时间。
由此,社区开发了一套完整的开源的日志采集架构 (ELK Stack)[] ,其中 E 代表 Elasticsearch,L 代表 Logstash,K 代表 Kibana。
社区常用的ELK构架的日志采集方案,在ELK+Filebeat 集中式日志解决方案解读 这篇文章中写得比较详尽了,这里我就不在多余赘言。
为了搭建一个高可用的 ELK 集中式日志解决方案,我们可以对ELK做进一步的改进,可参考从ELK到EFK演化
我们搭建的日志采集系统构架如下图所示:
在ELK的基础之上,我们采用了Filebeat做日志采集端,如果象ELK中的构架,Logstash作为日志采集端,那么每台服务器都须要安装JAVA环境,因为Logstash是基于Java环境,才能正常使用。而我们采用的 Filebeat 不需要任何依赖,直接安装后,修改配置文件,启动服务即可。当采集到日志文件时,在 input 中我们须要在Filebeat中定义一个 fields,定义一个log_topic的数组,将指定路径下的日志文件分为一类。在 Output 中,我们指定 Output 输入至Kafka,并按照 input
Kafka作为一个消息队列,接收来自Filebeat客户端采集上来的所有日志,并按照不同类型的日志(例如nginx、php、system)分类转发。在Kafka中,我们依照 inout中自定义的日志类型,在kafka中创建不同的topic。
Logstash接收来自Kafka消息队列的消息,根据Kafka中不同的topic,将日志分类写入Elasticsearch中;Kibana匹配Elasticsearch中的索引,可以对日志内容剖析、检索、出图展示(当然须要自己设计出图了)。
2.EFK 架构布署之安装 Elasticsearch0x01 环境说明
系统:CentOS 7
软件版本如下图:
软件版本号
Kibana
6.6
Elasticsearch
6.6
Logstash
6.6
Filebeat
6.6
metricbet
6.6
Kafka
kafka_2.11-2.1.0
Kafka-manage
1.3.3.22
Kafka-eagle
kafka-eagle-web-1.3.0
0x02 系统初始化配置
可参考文章:Shell 之CentOS 7 系统初始化
新增配置如下系统参数 (/etc/security/limits.conf):
# 解除文件描述符限制
* soft nofile 65535
* hard nofile 65535
# 操作系统级别对每个用户创建的进程数的限制
* soft nproc 2048
* hard nproc 2048
# 解除对用户内存大小的限制
* soft memlock unlimited
* hard memlock unlimited
重启服务器
0x03 安装 JDK 8
由于Elasticsearch、Logstash、Kafka-eagle、均须要JDK环境,所以需提早安装 java 环境。
可参考官网:
安装包下载地址:Java SE Development Kit 8 Downloads
先选择 Accept License Agreement,再下载对应的安装包, 我这儿使用的是 CentOS 7 的系统,所以选择 rpm 的镜像包,若是 Ubuntu系统的可以选择 .tar.gz 的镜像包
安装步骤可参考:CentOS 7 之安装布署 JDK
rpm 包安装的JDK默认软件安装目录为:/usr/java/jdk1.8.0_201-amd64,需要配置环境变量,后期的好多软件布署均须要这个路径,最后需复查一下 /usr/bin 目录下是否有java的执行文件
[root@efk-master ~]# ll /usr/bin/java
lrwxrwxrwx. 1 root root 22 Mar 4 11:00 /usr/bin/java -> /etc/alternatives/java
最后查看 java 的版本信息:
[root@efk-master ~]# java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
到此为止,JDK环境已然布署完毕
0x04 安装 Elasticsearch
由于 Elasticsearch 是建立于 Java 的基础之上的,所以对 java 的版本有一定的要求,需提早配置好 Java 环境。 Elasticsearch 6.6 版本建议安装java的版本为 Java 8发行版中的 1.8.0_131 之后版本均可。官网更推荐使用提供技术支持(LTS)的 Java 版本。安装完 Java 后建议配置 JAVA_HOME 环境变量。
提示:由于我使用的是CentOS 7 64位的操作系统,后续的安装中均会选择 RPM 包的方式安装,而且我是使用的 root 用户权限布署的。
1.下载安装公共秘钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.手动下载安装安装 RPM 包
# 下载 ES rpm 包
wget https://artifacts.elastic.co/d ... 1.rpm
# 下载 ES 的 sha512 哈希值,保证下载的安装包无数据丢失
wget https://artifacts.elastic.co/d ... ha512
# 验证 哈希值
shasum -a 512 -c elasticsearch-6.6.1.rpm.sha512
# 安装 ES
sudo rpm --install elasticsearch-6.6.1.rpm
3.配置 ES 相关内容,将如下内容添加至主配置文件 /etc/elasticsearch/elasticsearch.yml 中
# 配置 ES 集群的名字,此次没有搭建ES集群,仅为单机部署。但是为了便于后期搭建ES集群,所以需要配置集群名字
cluster.name: efk
# 配置 ES 节点的名字
node.name: es-1
# 是否为主节点
node.master: true
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 允许所有网段访问 9200 端口
network.host: 0.0.0.0
# 开启 http 的 9200 端口
http.port: 9200
# 指定集群中的节点中有几个有 master 资格的节点
discovery.zen.minimum_master_nodes: 1
# 以下配置为 head 插件配置
http.cors.enabled: true
http.cors.allow-origin: "*"
4.配置 ES 内存
vim /etc/elasticsearch/jvm.options
#将如下内容:
-Xms1g
-Xmx1g
#更改为
-Xms32g
-Xmx32g
5.运行 ES
# /bin/systemctl daemon-reload
# /bin/systemctl enable elasticsearch.service
# systemctl start elasticsearch.service
6.检查 ES 是否运行正常
a. 确保ES的默认9200端口开启
b. 确保ES的服务正常启动
# 查看端口
# lsof -i :9200
# 查看服务
# ps -ef | grep elasticsearch| grep -v grep
7.浏览器访问 ES
输入本机IP加端口号
http://ip:9200
8.安装 elasticsearch-head插件(需提早打算好 node.js 环境)
我们先安装布署 node.js 环境
node.js
cd /opt/efk
curl -L -O https://nodejs.org/dist/v10.15 ... ar.xz
tar -xf node-v10.15.3-linux-x64.tar.xz
mv node-v10.15.1-linux-x64 /usr/local
配置 node 的环境变量 (/etc/profile)
# node home
export NODEJS_HOME=/usr/local/node-v10.15.1-linux-x64
export PATH=$PATH:$JAVA_HOME/bin:$NODEJS_HOME/bin
激活环境变量
source /etc/profile
配置软链接
# ln -s /usr/local/node-v10.15.1-linux-x64/bin/node /usr/bin/node
验证是否配置成功
# node --version
v10.15.1
安装 elasticsearch-head
# cd /usr/local
# git clone git://github.com/mobz/elasticsearch-head.git
# cd elasticsearch-head
# npm install
# npm run start
访问地址: :9100
如上图所示:
1.在浏览器中输入:9100(ip为布署环境的本机ip)
2.输入框中输入ES的地址::9200 (端口号9200为ES的主配置文件中配置的 http.port)
3.由于此文档是在整个EFK日志采集系统搭建完毕后,编写的文档,所以,可能会见到 system 的索引,暂时先忽视。我们重点关注es-1;如果不记得的话,可以查看上面配置的ES主配置文件,es-1即为我们上面配置的node.name;这里提醒我们不要小看任何一个配置选项,既然须要配置,必有其用途。
3.EFK 架构布署之安装 Kibana
1.下载 64位安装包,并安装 Kibana
# cd /opt/efk
# wget https://artifacts.elastic.co/d ... ar.gz
# shasum -a 512 kibana-6.6.1-linux-x86_64.tar.gz
# tar -xzf kibana-6.6.1-linux-x86_64.tar.gz
# mv kibana-6.6.1-linux-x86_64/ /usr/local
配置 Kinaba
# kibana 访问端口
server.port: 5601
# kibana 访问 IP 地址
server.host: "192.168.7.3"
# kibana 的服务名
server.name: "efk-master"
# ES 地址
elasticsearch.hosts: ["http://192.168.7.3:9200"]
# kibana 索引
kibana.index: ".kibana"
# ES 登录账号及密码
elasticsearch.username: "admin"
elasticsearch.password: "admin"
# kibana 进程 ID 路径
pid.file: /var/run/kibana.pid
3.启动服务
执行kibana的二进制文件,此命令执行后,进程会在前台运行,后期我们会使用 Supervisord 的形式布署。
# /usr/local/kibana-6.6.0-linux-x86_64/bin/kibana
4.访问kibana
PHPMaos小说采集系统 3.0 Beta
采集交流 • 优采云 发表了文章 • 0 个评论 • 501 次浏览 • 2020-08-18 07:21
PHPMaos小说采集系统基于PHP+MySQL的技术开发,支持Windows、Linux、Unix等多种服务器平台,从2009年开始发布第一个版本。PHPMaos简单、健壮、灵活几大特征并专注于小说系统,我们会坚持做到国外应用最广泛的php类小说系统。免费版只有三天试用时限。
PHPMaos小说采集系统 3.0 Beta 更新日志:2011-2-27
1、url路径调整:缩减书籍展示url地址过长问题,有利于搜索引擎优化;小说作品html生成地址优化;
2、增加搜索功能,支持精确和模糊搜索作者;
3、增加书柜展示功能;
4、增强书籍展示页的交互功能,用户可自定义背景颜色,字体颜色,字体大小,滚屏间隔,支持保存设置功能;
5、增加后台系统 探针工具 检测系统功能,方便用户直接查看系统状况;
6、增加第六套模板;
PHPMaos 主要功能:
内置模型:连载模块,采集系统,前台模板,友情链接,广告管理,作者模块,会员模块,打包下载,临时书柜,地区分类,类型分类等;
PHPMaos小说采集系统 3.0 功能详尽说明:
1、采用php+mysql构架,可以生成整站html,对搜索引擎收录十分友好;
2、自定义采集功能,目前已支持20个小说站点的采集,所有图片都可本地化处理,支持字符内容替换,自动编码转换和独创的断点续采功能,保证24小不间断采集;
3、作品和分类一对多的关系,解决大多数小说站作品和分类难以多向关联问题;
4、作品和作者多对多的关系,让作者和作品可以多向关联,使读者更便捷的阅读;
5、书架功能:可以为用户开启已阅作品功能;
6、丰富的模板界面,目前已开放4套模板,能满足您各类类型的小说网站界面;
7、智能安装,第一次只须要访问,即可在3步内完成系统安装;
8、丰富的小说排行榜功能,热门排名,top排名,日点击排名,周点击排名,月点击排名,推荐排名,历史排名; 查看全部
PHPMaos小说采集系统 3.0 Beta
PHPMaos小说采集系统基于PHP+MySQL的技术开发,支持Windows、Linux、Unix等多种服务器平台,从2009年开始发布第一个版本。PHPMaos简单、健壮、灵活几大特征并专注于小说系统,我们会坚持做到国外应用最广泛的php类小说系统。免费版只有三天试用时限。
PHPMaos小说采集系统 3.0 Beta 更新日志:2011-2-27
1、url路径调整:缩减书籍展示url地址过长问题,有利于搜索引擎优化;小说作品html生成地址优化;
2、增加搜索功能,支持精确和模糊搜索作者;
3、增加书柜展示功能;
4、增强书籍展示页的交互功能,用户可自定义背景颜色,字体颜色,字体大小,滚屏间隔,支持保存设置功能;
5、增加后台系统 探针工具 检测系统功能,方便用户直接查看系统状况;
6、增加第六套模板;
PHPMaos 主要功能:
内置模型:连载模块,采集系统,前台模板,友情链接,广告管理,作者模块,会员模块,打包下载,临时书柜,地区分类,类型分类等;
PHPMaos小说采集系统 3.0 功能详尽说明:
1、采用php+mysql构架,可以生成整站html,对搜索引擎收录十分友好;
2、自定义采集功能,目前已支持20个小说站点的采集,所有图片都可本地化处理,支持字符内容替换,自动编码转换和独创的断点续采功能,保证24小不间断采集;
3、作品和分类一对多的关系,解决大多数小说站作品和分类难以多向关联问题;
4、作品和作者多对多的关系,让作者和作品可以多向关联,使读者更便捷的阅读;
5、书架功能:可以为用户开启已阅作品功能;
6、丰富的模板界面,目前已开放4套模板,能满足您各类类型的小说网站界面;
7、智能安装,第一次只须要访问,即可在3步内完成系统安装;
8、丰富的小说排行榜功能,热门排名,top排名,日点击排名,周点击排名,月点击排名,推荐排名,历史排名;
数据搜集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-17 22:10
开源比赛火爆报考中,立即报考「赢取亿元奖金」>>>
什么是 Chukwa,简单的说它是一个数据搜集系统,它可以将各种各样类型的数据搜集成适宜 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各类 MapReduce 操作。Chukwa 本身也提供了好多外置的功能,帮助我们进行数据的搜集和整理。
为了愈发简单直观的展示 Chukwa,我们先来看一个假定的场景。假设我们有一个规模很大 ( 牵扯到 Hadoop 的总是很大。。。。) 的网站,网站每天形成数目庞大的日志文件,要搜集,分析这种日志文件可不是件容易的事情,读者可能会想了,做这些事情 Hadoop 挺合适的,很多小型网站都在用,那么问题来了,分散在各个节点的数据如何搜集,采集到的数据假如有重复数据如何处理,如何与 Hadoop 集成。如果自己编撰代码完成这个过程,一来须要耗费不小的精力,二来不可避开的会引入 Bug。这里就是我们 Chukwa 发挥作用的时侯了,Chukwa 是一个开源的软件,有很多聪明的开发者在贡献着自己的智慧。它可以帮助我们在各个节点实时监控日志文件的变化,增量的将文件内容写入 HDFS,同时还可以将数据消除重复,排序等,这时 Hadoop 从 HDFS 中领到的文件早已是 SequenceFile 了。无需任何转换过程,中间纷扰的过程都由 Chukwa 帮我们完成了。是不是太省心呢。这里我们仅仅举了一个应用的事例,它还可以帮我们监控来自 Socket 的数据,甚至定时执行我们指定的命令获取输出数据,等等,具体的可以参看 Chukwa 官方文档。如果这种还不够,我们还可以自己定义自己的适配器来完成愈发中级的功能。 查看全部
数据搜集系统
开源比赛火爆报考中,立即报考「赢取亿元奖金」>>>
什么是 Chukwa,简单的说它是一个数据搜集系统,它可以将各种各样类型的数据搜集成适宜 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各类 MapReduce 操作。Chukwa 本身也提供了好多外置的功能,帮助我们进行数据的搜集和整理。
为了愈发简单直观的展示 Chukwa,我们先来看一个假定的场景。假设我们有一个规模很大 ( 牵扯到 Hadoop 的总是很大。。。。) 的网站,网站每天形成数目庞大的日志文件,要搜集,分析这种日志文件可不是件容易的事情,读者可能会想了,做这些事情 Hadoop 挺合适的,很多小型网站都在用,那么问题来了,分散在各个节点的数据如何搜集,采集到的数据假如有重复数据如何处理,如何与 Hadoop 集成。如果自己编撰代码完成这个过程,一来须要耗费不小的精力,二来不可避开的会引入 Bug。这里就是我们 Chukwa 发挥作用的时侯了,Chukwa 是一个开源的软件,有很多聪明的开发者在贡献着自己的智慧。它可以帮助我们在各个节点实时监控日志文件的变化,增量的将文件内容写入 HDFS,同时还可以将数据消除重复,排序等,这时 Hadoop 从 HDFS 中领到的文件早已是 SequenceFile 了。无需任何转换过程,中间纷扰的过程都由 Chukwa 帮我们完成了。是不是太省心呢。这里我们仅仅举了一个应用的事例,它还可以帮我们监控来自 Socket 的数据,甚至定时执行我们指定的命令获取输出数据,等等,具体的可以参看 Chukwa 官方文档。如果这种还不够,我们还可以自己定义自己的适配器来完成愈发中级的功能。
CmsTop系统文章采集的操作方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2020-08-11 17:22
文章采集系统颠覆传统采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需有基础技术知识的人员设置好相关规则。编辑人员无需了解很过细节的技 术规则,只需选中自己想要采集的文章列表,就可以象发布文章一样,轻松地完成采集操作。
a. 方便而简约的采集规则配置
对于须要采集功能的网站来说,简洁而便捷的规则配置是易用性的彰显.技术人员只须要太基本的网页知识就可以随心地去写采集规则.在写规则完成,可以实时地 显示出采集的内容是否正确.通过此功能可以便捷地测试出内容的可用性.
方便而简约的采集规则配置
b. 采集规则可永久性使用
对于早已写好的采集规则,系统会手动添加到规则列表中,以备之后使用。每一规则都可以重复借助,并且可依照需求作出更改。
采集规则可永久性使用
c. 自定义的文章采集数量
根据采集规则的配置参数,可以便捷地在采集控制版选定到所需采集文章的数据量。
d. 高效地采集管理界面
自定配置的所有采集规则就会在采集管理界面呈现下来,并且还能依据采集更新的频度查找出最新文章,系统通过最新,已查看,已采集标示出文章所处的状态。管 理人员可以通过采集管理界面选择性地对须要的文章进行采集。
高效地采集管理界面 查看全部
文章的采集功能是通过程序来远程获取目标网页内容,经过本地规则解析处理后储存到服务器的数据库内。
文章采集系统颠覆传统采集模式和流程,采集规则与采集界面分离,规则设置更简单,只需有基础技术知识的人员设置好相关规则。编辑人员无需了解很过细节的技 术规则,只需选中自己想要采集的文章列表,就可以象发布文章一样,轻松地完成采集操作。
a. 方便而简约的采集规则配置
对于须要采集功能的网站来说,简洁而便捷的规则配置是易用性的彰显.技术人员只须要太基本的网页知识就可以随心地去写采集规则.在写规则完成,可以实时地 显示出采集的内容是否正确.通过此功能可以便捷地测试出内容的可用性.
方便而简约的采集规则配置
b. 采集规则可永久性使用
对于早已写好的采集规则,系统会手动添加到规则列表中,以备之后使用。每一规则都可以重复借助,并且可依照需求作出更改。
采集规则可永久性使用
c. 自定义的文章采集数量
根据采集规则的配置参数,可以便捷地在采集控制版选定到所需采集文章的数据量。
d. 高效地采集管理界面
自定配置的所有采集规则就会在采集管理界面呈现下来,并且还能依据采集更新的频度查找出最新文章,系统通过最新,已查看,已采集标示出文章所处的状态。管 理人员可以通过采集管理界面选择性地对须要的文章进行采集。
高效地采集管理界面
webplus系统文章采集教程[宝典]
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-08-10 16:22
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl在栏目管理中选择该栏目,点击设置采集计划。(如:图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集的基本属性。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉包括执行方法,信息是否手动发布,被采集的栏目类型和页面的编码格式。
(如:图二)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl事先约定好该采集计划的执行方法,自动、定时单次还是定时循环执行。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如仅仅为了采集网页当前的数据,我们可以采用自动和定时单次的形式采集一次即可;假如被采集网页的数据会更新,而我们又要保证信息的同步,即采用定时循环采集的形式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如采集过来的信息不须要更改,可以直接对外网公开,选择手动发布即可。假如采集过来的信息,须要更改,初审等,选择不要手动发布,等采集完成之后,由信息管理人员来进行其他操作。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的网页中只是单纯的一个新闻列表,即是将该页面的新闻采集到指定栏目下,这么选择单栏目即可。如果被采集的页面有多个新闻列表,但是各自提供单独链接进入自己的新闻列表页面,而我们又须要采集所有的新闻信息,这么选择多栏目。另外,假如采集的页面是RSS信息聚合页面,这么设置为相应的RSS单栏目或RSS多栏目。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl因为webplus系统采用的是UTF-8的编码格式,而被采集可能是其他的编码格式,这么为了防止采集过来的信息乱码,这儿须要设置为被采集页面的编码格式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl本文来自笔记本基础知识:系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划的采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目采集计划的设置(如:图三)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl即是被采集页面的访问路径。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置“文章页URL获取规则”webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻列表是以一个iframe方式嵌入在被采集网页中,这么须要设置规则来获取列表iframe接地址,因而来访问新闻列表。
否则不须要拟定该规则。(具体规则形式请参见下边的“采集规则抒发式制订”)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集网页的新闻列表存在分页的情况,这么按照新闻列表分页的方法(链接和表单递交)制订分页的规则,但是须要设置分页开始页脚,间隔页码和采集页数。假如新闻列表不存在分页,即不需要制订该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的页面有多个新闻列表,但是多处新闻列表的url规则类似,而我们只须要采集指定的一处列表,即须要设置限制文章列表的获取规则,这是为了防止采集多余的数据。否则不须要设置该规则。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置文章url的获取规则,为了从采集页面中才能访问具体的新闻页面,因而进行新闻采集。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl具体的新闻页面,假如文章内容是以iframe的方式嵌入在该新闻页面中,这么须要设置规则来获取文章iframe的链接地址,因而来访问新闻内容。否则不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻了内容存在分页的情况,这么依据文章内容分页的形式(链接和表单递交)来制订分页的规则,而且须要设置分页开始页脚,间隔页脚和采集页数。假如文章内容不存在分页,即不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl倘若新闻页面中,不仅新闻内容外,还有其他的附加信息,这么在采集过程中为了更容易找到新闻内容,这儿须要设置限制新闻内容的获取规则。一是为了防止形成垃圾信息,二是为了减少了新闻具体信息获取规则的复杂度。倘若新闻页面比较简单,通常该规则不须要设置。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl新闻属性的设置规则,不仅标题和内容外,其他都是非必须条件,另外新闻的发布时间不设置的话,会采用当前的时间作为发布时间。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划的设置(如:图五)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划不仅须要在“列表页起始URL”下设置列表页URL规则和“文章页URL获取规则”下设置栏目名称的获取规则,其他与单栏目采集计划设置一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目采集计划的设置(如:图四)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目的采集计划不须要设置“文章页URL获取规则”,其他与单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目采集计划的设置(如:图六)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目的采集计划须要在“列表页起始URL”下设置列表页URL获取规则,其他与RSS单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl采集规则表达式制订webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉表达式设置和调整,以及对表达式列表进行测试webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl点击采集页面中某一处“获取规则设置”,步入规则表达式列表页面(如:图七)。在该页面中不仅可以对表达式进行降低,更改,删掉和调整次序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容,对表达式规则列表进行测试。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl表达式类型分为字符串,匹配,匹配替换和公式四种类型。其中匹配和匹配替换须要用到java的正值表达式,这要求采集计划设置人员对表达式有一定的了解。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl字符串:直接输入的字符串常量webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配:从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内容S。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配替换:先从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内中匹配到的内容替换后得到正确的内容。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl公式:只支持[pageIndex],拿来在获取分页地址时代表分页的页脚数。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl图示详情webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉步入栏目管理webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉(图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉在右则栏目列表中选中一个栏目点击设置采集计划。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl自动(须要在栏目列表点击“立即采集”来启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单次(可以设置一个时间,抵达该时间会手动启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目RSS(采集一个RSS地址下的文章)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿多栏目RSS(从一个RSS列表地址开始,采集多个RSS地址下的文章,每位RSS地址产生一个子栏目)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl编码方法为被采集页面的编码webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉设置采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉 查看全部
信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl步骤及详尽webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉现今须要将一个网页的数据(新闻)采集到webplus系统一个指定的栏目下,步骤如下:webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl在栏目管理中选择该栏目,点击设置采集计划。(如:图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集的基本属性。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉包括执行方法,信息是否手动发布,被采集的栏目类型和页面的编码格式。
(如:图二)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl事先约定好该采集计划的执行方法,自动、定时单次还是定时循环执行。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如仅仅为了采集网页当前的数据,我们可以采用自动和定时单次的形式采集一次即可;假如被采集网页的数据会更新,而我们又要保证信息的同步,即采用定时循环采集的形式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如采集过来的信息不须要更改,可以直接对外网公开,选择手动发布即可。假如采集过来的信息,须要更改,初审等,选择不要手动发布,等采集完成之后,由信息管理人员来进行其他操作。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的网页中只是单纯的一个新闻列表,即是将该页面的新闻采集到指定栏目下,这么选择单栏目即可。如果被采集的页面有多个新闻列表,但是各自提供单独链接进入自己的新闻列表页面,而我们又须要采集所有的新闻信息,这么选择多栏目。另外,假如采集的页面是RSS信息聚合页面,这么设置为相应的RSS单栏目或RSS多栏目。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl因为webplus系统采用的是UTF-8的编码格式,而被采集可能是其他的编码格式,这么为了防止采集过来的信息乱码,这儿须要设置为被采集页面的编码格式。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl本文来自笔记本基础知识:系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划的采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目采集计划的设置(如:图三)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl即是被采集页面的访问路径。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置“文章页URL获取规则”webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻列表是以一个iframe方式嵌入在被采集网页中,这么须要设置规则来获取列表iframe接地址,因而来访问新闻列表。
否则不须要拟定该规则。(具体规则形式请参见下边的“采集规则抒发式制订”)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集网页的新闻列表存在分页的情况,这么按照新闻列表分页的方法(链接和表单递交)制订分页的规则,但是须要设置分页开始页脚,间隔页码和采集页数。假如新闻列表不存在分页,即不需要制订该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如被采集的页面有多个新闻列表,但是多处新闻列表的url规则类似,而我们只须要采集指定的一处列表,即须要设置限制文章列表的获取规则,这是为了防止采集多余的数据。否则不须要设置该规则。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置文章url的获取规则,为了从采集页面中才能访问具体的新闻页面,因而进行新闻采集。(必须)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl具体的新闻页面,假如文章内容是以iframe的方式嵌入在该新闻页面中,这么须要设置规则来获取文章iframe的链接地址,因而来访问新闻内容。否则不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl假如新闻了内容存在分页的情况,这么依据文章内容分页的形式(链接和表单递交)来制订分页的规则,而且须要设置分页开始页脚,间隔页脚和采集页数。假如文章内容不存在分页,即不须要拟定该规则。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl倘若新闻页面中,不仅新闻内容外,还有其他的附加信息,这么在采集过程中为了更容易找到新闻内容,这儿须要设置限制新闻内容的获取规则。一是为了防止形成垃圾信息,二是为了减少了新闻具体信息获取规则的复杂度。倘若新闻页面比较简单,通常该规则不须要设置。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl新闻属性的设置规则,不仅标题和内容外,其他都是非必须条件,另外新闻的发布时间不设置的话,会采用当前的时间作为发布时间。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划的设置(如:图五)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl多栏目采集计划不仅须要在“列表页起始URL”下设置列表页URL规则和“文章页URL获取规则”下设置栏目名称的获取规则,其他与单栏目采集计划设置一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目采集计划的设置(如:图四)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS单栏目的采集计划不须要设置“文章页URL获取规则”,其他与单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目采集计划的设置(如:图六)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplRSS多栏目的采集计划须要在“列表页起始URL”下设置列表页URL获取规则,其他与RSS单栏目采集计划一致。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl采集规则表达式制订webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉表达式设置和调整,以及对表达式列表进行测试webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl点击采集页面中某一处“获取规则设置”,步入规则表达式列表页面(如:图七)。在该页面中不仅可以对表达式进行降低,更改,删掉和调整次序外,还可以在表达式设置完成后,输入url,iframeurl和页面内容,对表达式规则列表进行测试。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl表达式类型分为字符串,匹配,匹配替换和公式四种类型。其中匹配和匹配替换须要用到java的正值表达式,这要求采集计划设置人员对表达式有一定的了解。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl字符串:直接输入的字符串常量webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配:从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内容S。
webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl匹配替换:先从指定的文本(URL、IframeURL、页面内容)中通过正则表达式来得到文本中的部份内中匹配到的内容替换后得到正确的内容。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl公式:只支持[pageIndex],拿来在获取分页地址时代表分页的页脚数。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl图示详情webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉步入栏目管理webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉(图一)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl设置采集计划webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉在右则栏目列表中选中一个栏目点击设置采集计划。webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl自动(须要在栏目列表点击“立即采集”来启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单次(可以设置一个时间,抵达该时间会手动启动采集)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl单栏目RSS(采集一个RSS地址下的文章)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿多栏目RSS(从一个RSS列表地址开始,采集多个RSS地址下的文章,每位RSS地址产生一个子栏目)webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webpl编码方法为被采集页面的编码webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。
它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉设置采集规则webplus系统文章采集教程信息采集使用指南摘要信息采集是一个抓取网路数据,实现信息共享的功能模块。它提供自动抓取、预约抓取和定时循环抓取三种模式,它可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。步骤及详尽现今须要将一个网页的数据(新闻)采集到webplu蛾精琵饯觉车掸宏懊筹脱忿镜笼思炳贫霓披绒坊茸笔舌把蔡决擒肉途帕建舀述期功褪商再洒情直缸赊审别附瘩沼望箱雌虎眺韩汀稠烷勘液窿横婆阉
网钛文章管理系统(OTCMS) 更新日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-10 08:53
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。
网钛文章管理系统(OTCMS) 更新日志:
2020年06月22日 V2.93更新包
1.[完善]后台主界面 右上角 和 右下角 增加箭头图标,可以重新调整内容框高度
2.[修复]后台某些官网链接失效修补下 查看全部
网钛文章管理系统(OTCMS)以简单、实用、傻瓜式操作而著称,是国外 网钛文章管理系统(OTCMS)是最热门ASP开源网站管理系统之一,也是用户增速最快的ASP类CMS系统之一,目前的版本无论在功能,人性化,还是易用性方面,都有了长足的发展,OTCMS的主要目标用户锁定在草根型中小个人站长,让这些对网路不是太熟悉,对网站建设不是太懂又想做网站的人可以很快搭建起一个功能实用又强悍,操作人性又易用。OTCMS更专注于个人网站或中小型门户的建立,当然也不乏有企业用户等在使用本系统,使用过OTCMS的用户就会它好评不断。
网钛文章管理系统(OTCMS)基于ASP+Access/Mssql的技术构架,不但可以适用于广泛的新闻发布型网站,还适用于资讯门户类网站,功能只会往功能通用、操作简单的方向发展,让不懂代码但又想构建自己网站的同学,使用网钛文章管理系统,通过后台简单的配置,就能拥有一个个性化的自己的网站。
网钛文章管理系统(OTCMS) 更新日志:
2020年06月22日 V2.93更新包
1.[完善]后台主界面 右上角 和 右下角 增加箭头图标,可以重新调整内容框高度
2.[修复]后台某些官网链接失效修补下

