
文章采集系统
9.Spark小型电商项目-离线日志采集流程介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-08-09 11:20
项目一Spark离线处理本项目来源于企业级电商网站的大数据统计剖析平台,该平台以Spark 框架为核心,对电商网站的日志进行离线和实时剖析。该大数据剖析平台对电商网站的各类用户行为(访问行为、购物行为、广告点击行为等)进行剖析,根据平台统计下来的数据,辅助公司中的PM(产品总监)、数据分析师以及管理人员剖析现有产品的情况,并按照用户行为剖析结果持续改进产品的设计,以及调整公司的战略和业务。最终达到用大数据技术来帮助提高公司的业绩、营业额以及市场占有率的目标。本项目使用了Spark 技术生态栈中最常用的三个技术框架,Spark Core、Spark SQL 和Spark Streaming,进行离线估算和实时估算业务模块的开发。实现了包括用户访问session 分析、页面单跳转化率统计、热门商品离线统计、广告流量实时统计4 个业务模块。通过合理的将实际业务模块进行技术整合与改建,该项目几乎完全囊括了Spark Core、Spark SQL 和Spark Streaming 这三个技术框架中大部份的功能点、知识点,学员对于Spark 技术框架的理解将会在本项目中得到很大的提升。项目二Spark实时处理项目简介对于实时性要求高的应用,如用户即时详单查询,业务量监控等,需要应用实时处理构架项目场景对于实时要求高的应用、有对数据进行实时展示和查询需求时项目技术分别使用canal和kafka搭建各自针对业务数据库和用户行为数据的实时数据采集系统,使用SparkStreaming搭建高吞吐的数据实时处理模块,选用ES作为最终的实时数据处理结果的储存位置,并从中获取数据进行展示,进一步增加响应时间。
航测数据采集系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-09 06:26
万方数据
航空测绘数据采集系统的设计与实现引言2系统的功能设计] 20078_2l王海英,“航空测绘数据的采集与编辑过程中,存在很多人工操作和很大的自由度. 数据输入操作不够严格. 因此,出现了以下问题: (1)非常熟悉线型库,并且必须记住每个元素的对应层,颜色和其他值. 在采集过程中,需要手动输入相关参数值并切换相关工具栏. 地球会降低数据生产的效率,并且不能保证数据质量. (2)采集量很大,采集器需要频繁输入标高值,必然导致标高与实际情况不一致,导致标高与标高不一致的逻辑错误. 轮廓. 因此,传统的航测数据采集操作方式不利于后期的GIS数据,已成为航测数据生成的关键. 为了解决这些问题而开发了航空测量数据采集系统. (2)(3)(4)(5)设计数据采集标准是与多比例尺地形图的符号,线,文本和表面相对应的图层,颜色,线型,线. 宽度,比率,角度,字符高度,字符宽度,字体和其他属性值是空间数据数据库构建的数据标准,也是管理内部和外部行业集成元素的基础. 不难看出,数据采集标准不仅为系统服务,而且是通用标准,它将从现场数据到内部编辑再到数据存储的一系列工作流程链接在一起. 由于涉及的工作范围广,影响大,因此数据采集标准的设计必须严格,精心设计,并应满足以下条件: (1)(2)(3)根据上述条件,需要进行编码管理每个元素,并根据“,000”对各种地理元素进行分类和编码,并且应该能够根据需要扩展每种地理要素类型,以满足将来对新元素的需求. 可以找到元素,因此可以区分不同类型的元素.
根据此设计思想,系统选择使用数据库来管理数据采集标准. 1考虑到将来可能会根据实际需要扩展和更改数据采集标准,因此数据库的相关变量(例如数据源名称,表名称和各个字段)都应随系统的变化而变化,因此该系统已建立环境变量. 程序在运行时首先访问环境变量,然后根据环境变量的值定义数据源名称(DSN)(表名)(字段)数据库. 互动关系. 当数据库更改时,只需要更新相应的环境变量值即可完成整个数据库和采集系统的配置. 系统与数据库的交互2Edit2,王海英. 航测数据采集系统的设计与实现文章编号: -中国图书馆分类编号: B. 甘肃省兰州测绘研究院贾林ie,严攀⒅星模贾世华摘要: 在航测数据采集中介绍,利用7⒂,“动态链接库”技术开发航测数据采集系统,该系统主要用于控制数据采集的标准化,提高生产效率和数据质量MicroStationMDL00012王海英,女,助理工程师,主要从事地理信息软件的开发和地理信息数据的生产.
万方数据 查看全部
文档简介:
万方数据
航空测绘数据采集系统的设计与实现引言2系统的功能设计] 20078_2l王海英,“航空测绘数据的采集与编辑过程中,存在很多人工操作和很大的自由度. 数据输入操作不够严格. 因此,出现了以下问题: (1)非常熟悉线型库,并且必须记住每个元素的对应层,颜色和其他值. 在采集过程中,需要手动输入相关参数值并切换相关工具栏. 地球会降低数据生产的效率,并且不能保证数据质量. (2)采集量很大,采集器需要频繁输入标高值,必然导致标高与实际情况不一致,导致标高与标高不一致的逻辑错误. 轮廓. 因此,传统的航测数据采集操作方式不利于后期的GIS数据,已成为航测数据生成的关键. 为了解决这些问题而开发了航空测量数据采集系统. (2)(3)(4)(5)设计数据采集标准是与多比例尺地形图的符号,线,文本和表面相对应的图层,颜色,线型,线. 宽度,比率,角度,字符高度,字符宽度,字体和其他属性值是空间数据数据库构建的数据标准,也是管理内部和外部行业集成元素的基础. 不难看出,数据采集标准不仅为系统服务,而且是通用标准,它将从现场数据到内部编辑再到数据存储的一系列工作流程链接在一起. 由于涉及的工作范围广,影响大,因此数据采集标准的设计必须严格,精心设计,并应满足以下条件: (1)(2)(3)根据上述条件,需要进行编码管理每个元素,并根据“,000”对各种地理元素进行分类和编码,并且应该能够根据需要扩展每种地理要素类型,以满足将来对新元素的需求. 可以找到元素,因此可以区分不同类型的元素.
根据此设计思想,系统选择使用数据库来管理数据采集标准. 1考虑到将来可能会根据实际需要扩展和更改数据采集标准,因此数据库的相关变量(例如数据源名称,表名称和各个字段)都应随系统的变化而变化,因此该系统已建立环境变量. 程序在运行时首先访问环境变量,然后根据环境变量的值定义数据源名称(DSN)(表名)(字段)数据库. 互动关系. 当数据库更改时,只需要更新相应的环境变量值即可完成整个数据库和采集系统的配置. 系统与数据库的交互2Edit2,王海英. 航测数据采集系统的设计与实现文章编号: -中国图书馆分类编号: B. 甘肃省兰州测绘研究院贾林ie,严攀⒅星模贾世华摘要: 在航测数据采集中介绍,利用7⒂,“动态链接库”技术开发航测数据采集系统,该系统主要用于控制数据采集的标准化,提高生产效率和数据质量MicroStationMDL00012王海英,女,助理工程师,主要从事地理信息软件的开发和地理信息数据的生产.
万方数据
08CMS v3.4版本采集系统使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 507 次浏览 • 2020-08-09 06:25
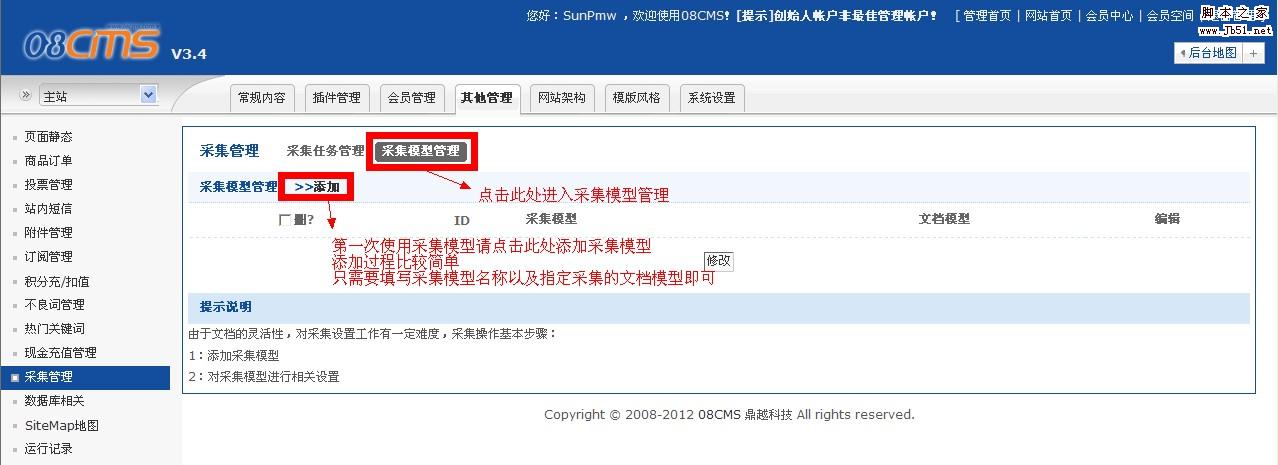
第三步,编辑采集模型
请参见插图:
图1.编辑模型
图二,
模型编辑界面
在这里,采集模型的添加完成
开始在下面添加采集任务
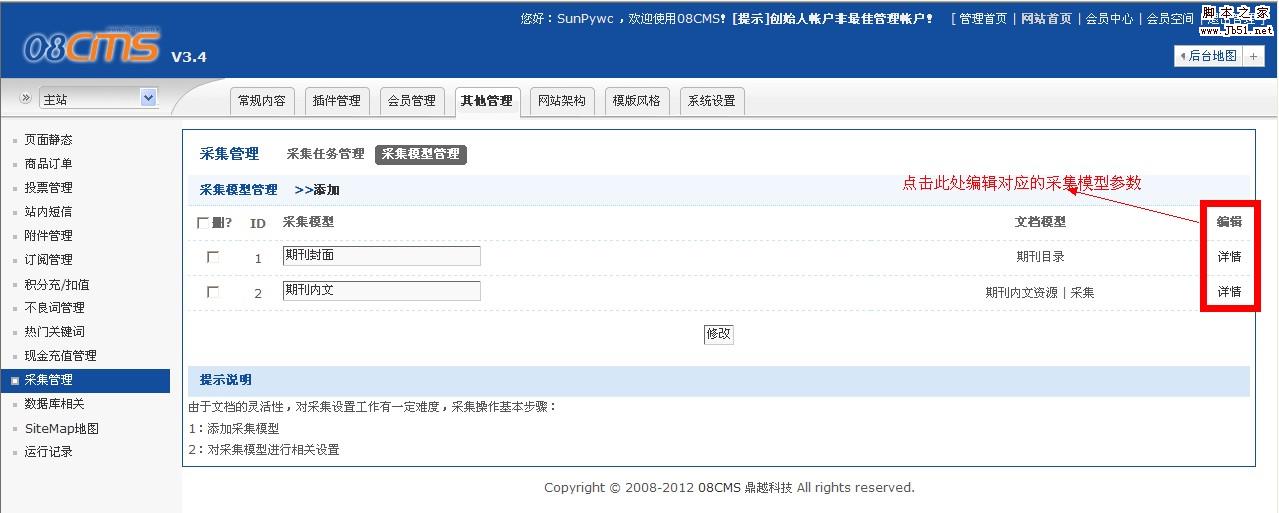
第四步,添加采集任务
以下是采集任务界面的示意图,请仔细阅读图中的注释
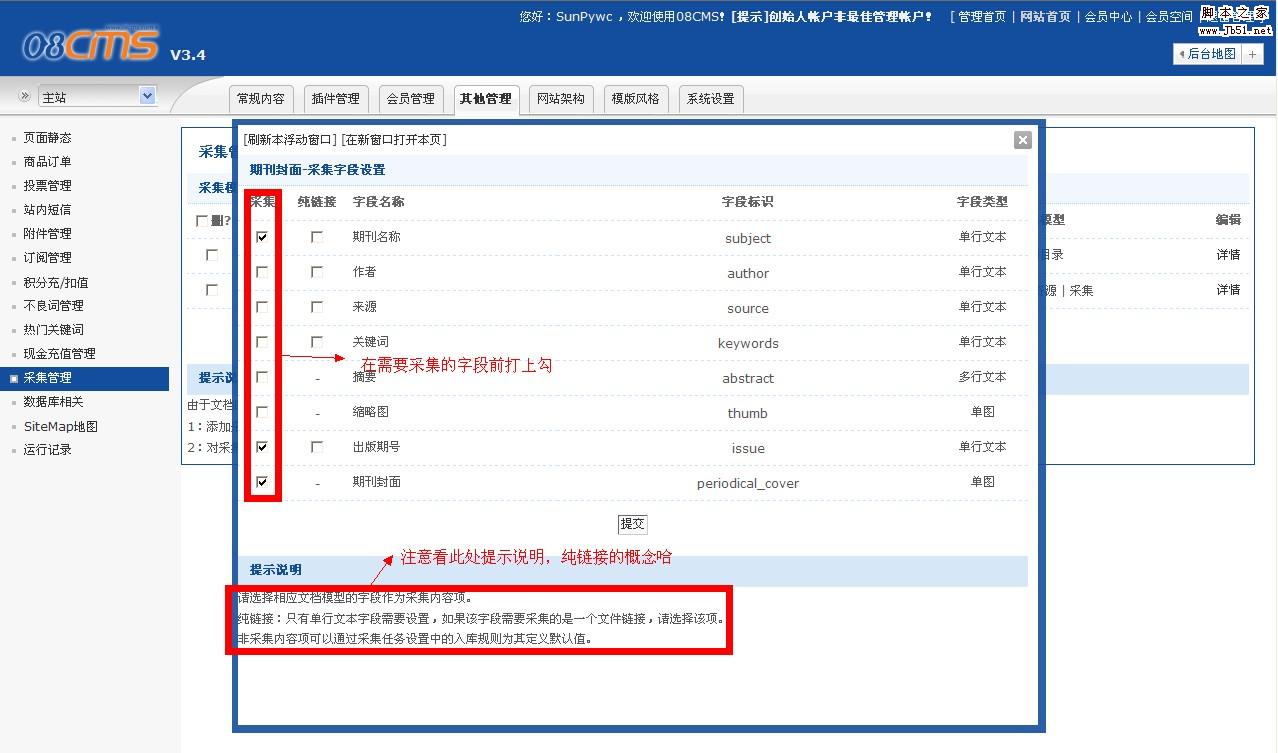
第六步,突出显示,设置采集规则
首先,分析目标页面的代码结构. 以IE为例.
查看采集目标页面,单击IE
页面----查看源文件
很容易看到目标页面的代码结构
采集页面的代码分析主要是查找采集目标的特征
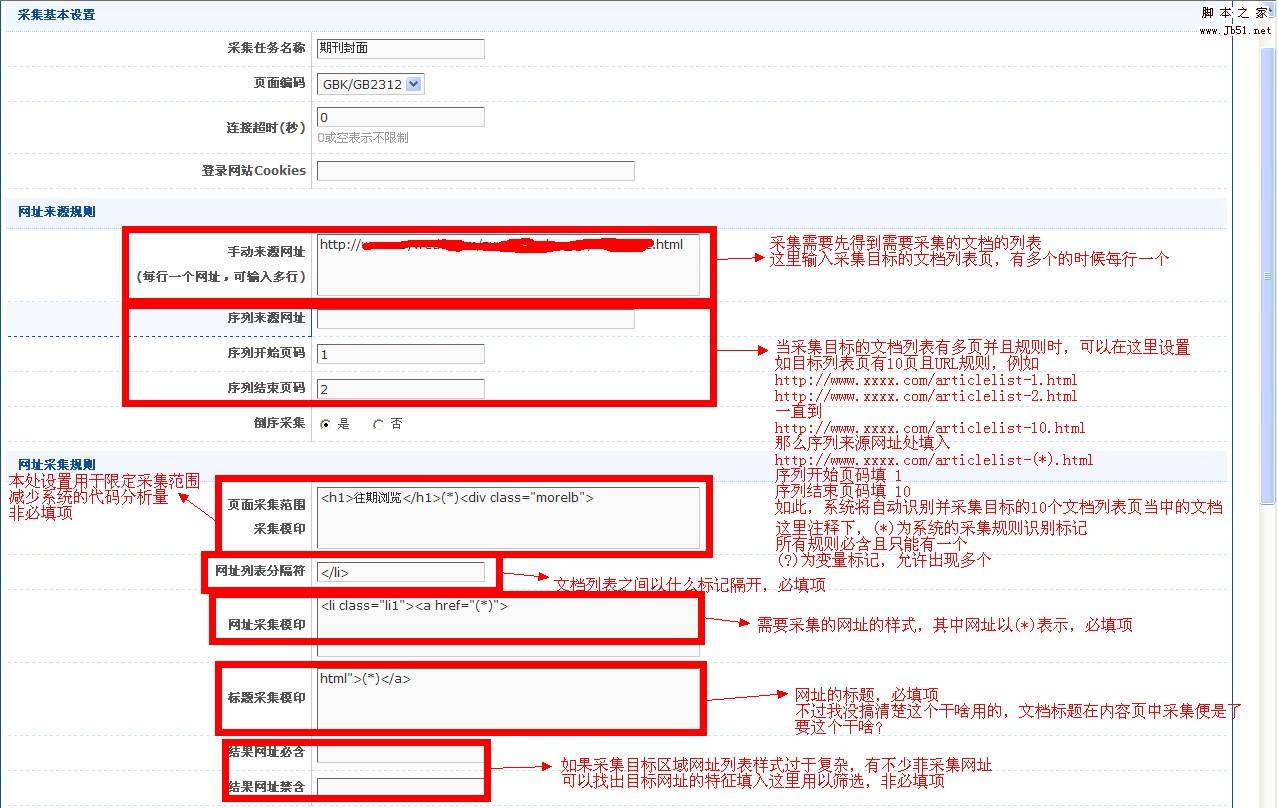
该页面太大,因此在此处很难解析. 上图说明了URL采集界面的相关规则的设置
点击提交将设置保存在此处
我想知道为什么我不直接跳到下一个内容集,而是在提交后返回此页面
此屏幕截图页面下方还有另一部分,称为追溯URL规则
这不是可选项目,通常不是必需的
此外,这只能获取一个URL,而不是URL列表. 我个人感觉有点鸡肋,并附上官方解释.
复古URL: 内容URL的扩展名. 对于某些采集的文档,各个字段的内容不在主要内容页面上,而是在附加页面上,尤其是附件的内容. 可追溯性URL用于采集附加页面的URL. 每个内容URL都可以追溯到另外两个页面,网站2是基于追溯网站1采集的.
回顾性概念的一个例子: 当我们进入下载站点时,我们点击进入的页面通常只是软件信息描述和一个或多个指向下载页面的链接
注意: 这是下载页面的链接,而不是下载地址. 要下载软件时,必须首先打开此下载页面以查看下载地址
这是可追溯性的第一级,因为我们必须再次单击才能进入下载页面. 目前,我们的1级可追溯地址是进入下载页面的链接
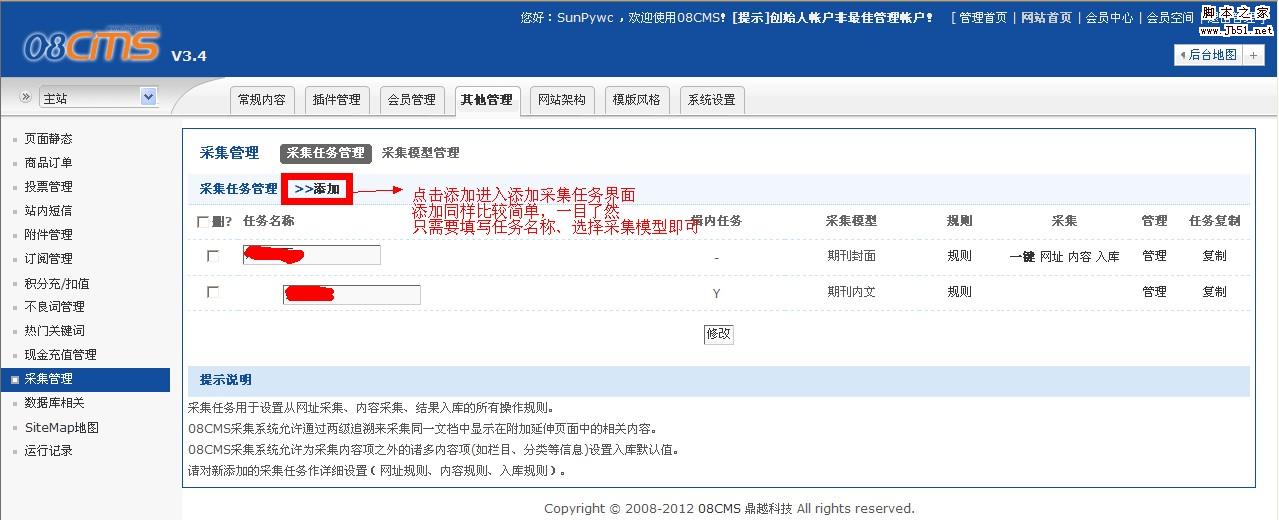
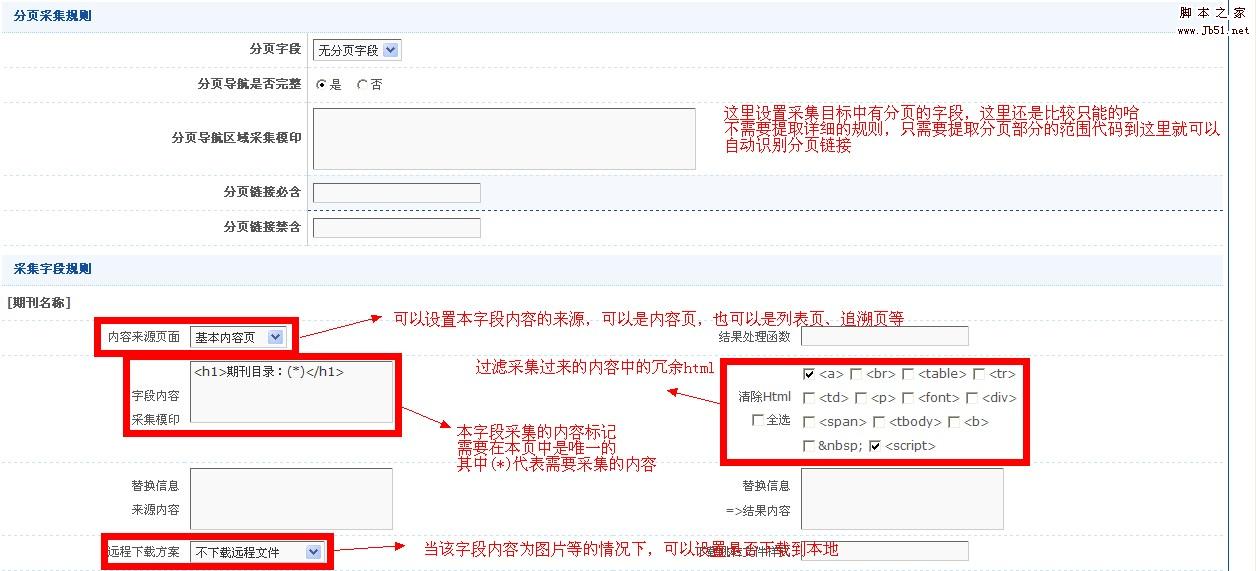
接下来是内容页面的规则
使用同一图形进行分析,这里仅以一个字段规则设置为例,其他字段基本相似.
传入参数设置
如果是非编译(即单个文档集合),则规则设置在此处
经过测试,可以毫无问题地将其采集
如果您有足够的信心,则可以不经测试直接采集.
如果它是诸如小说之类的合集的集合,则该集合的设置仅是中途.
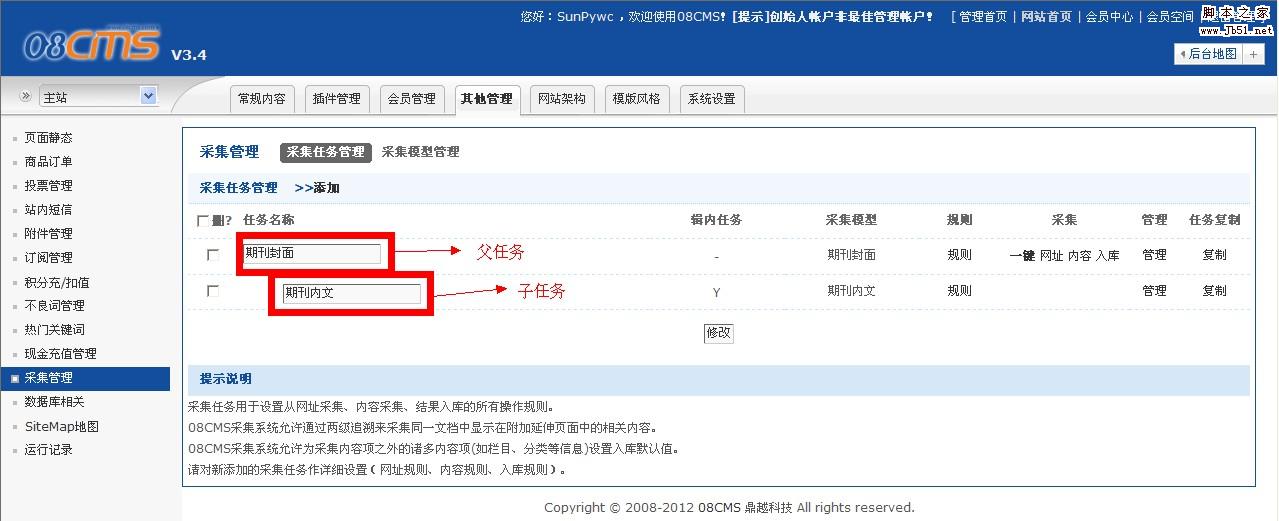
编译的集合还需要设置子任务的规则
如图所示:
子任务位于父任务下方,并且任务名称缩进
子任务的规则设置与父任务的规则设置基本相同,因此我不再赘述.
理论上,集合在这里. 让我们开始愉快的采集之旅. 就个人而言,我仍然感到很高兴.
获取,您可以逐步了解URL,内容和存储.
直接一键式采集更加轻松
但这是一个使人呕血的问题
集合任务,除非它是集合集合中的父任务和子任务
否则,您将必须一个接一个地完成任务,而不要排队. . .
尽管有很多缺点,但采集经验一般都很好
到此结束. 如果您不了解,可以将其发布. 查看全部
第三步,编辑采集模型
请参见插图:
图1.编辑模型
图二,
模型编辑界面
在这里,采集模型的添加完成
开始在下面添加采集任务
第四步,添加采集任务
以下是采集任务界面的示意图,请仔细阅读图中的注释
第六步,突出显示,设置采集规则
首先,分析目标页面的代码结构. 以IE为例.
查看采集目标页面,单击IE
页面----查看源文件
很容易看到目标页面的代码结构
采集页面的代码分析主要是查找采集目标的特征
该页面太大,因此在此处很难解析. 上图说明了URL采集界面的相关规则的设置
点击提交将设置保存在此处
我想知道为什么我不直接跳到下一个内容集,而是在提交后返回此页面
此屏幕截图页面下方还有另一部分,称为追溯URL规则
这不是可选项目,通常不是必需的
此外,这只能获取一个URL,而不是URL列表. 我个人感觉有点鸡肋,并附上官方解释.
复古URL: 内容URL的扩展名. 对于某些采集的文档,各个字段的内容不在主要内容页面上,而是在附加页面上,尤其是附件的内容. 可追溯性URL用于采集附加页面的URL. 每个内容URL都可以追溯到另外两个页面,网站2是基于追溯网站1采集的.
回顾性概念的一个例子: 当我们进入下载站点时,我们点击进入的页面通常只是软件信息描述和一个或多个指向下载页面的链接
注意: 这是下载页面的链接,而不是下载地址. 要下载软件时,必须首先打开此下载页面以查看下载地址
这是可追溯性的第一级,因为我们必须再次单击才能进入下载页面. 目前,我们的1级可追溯地址是进入下载页面的链接
接下来是内容页面的规则
使用同一图形进行分析,这里仅以一个字段规则设置为例,其他字段基本相似.
传入参数设置

如果是非编译(即单个文档集合),则规则设置在此处
经过测试,可以毫无问题地将其采集
如果您有足够的信心,则可以不经测试直接采集.
如果它是诸如小说之类的合集的集合,则该集合的设置仅是中途.
编译的集合还需要设置子任务的规则
如图所示:
子任务位于父任务下方,并且任务名称缩进
子任务的规则设置与父任务的规则设置基本相同,因此我不再赘述.
理论上,集合在这里. 让我们开始愉快的采集之旅. 就个人而言,我仍然感到很高兴.

获取,您可以逐步了解URL,内容和存储.
直接一键式采集更加轻松
但这是一个使人呕血的问题
集合任务,除非它是集合集合中的父任务和子任务
否则,您将必须一个接一个地完成任务,而不要排队. . .
尽管有很多缺点,但采集经验一般都很好
到此结束. 如果您不了解,可以将其发布.
网络信息采集系统的需求分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2020-08-08 03:58
如图所示,信息采集系统采集配置子系统采集子系统采用自定的采掘,运动系统,集中式运行,并作为噪声的集中控制系统. 然后只有地图信息采集系统组成采集配置子系统才能满足普通用户提交的采集要求. 用户通过子系统配置目标信息采集任务,包括文章的发布状态,站点名称和地址,其所属的列,采集时间和采集规则. 采集配置子系统还可以及时启动和停止采集任务的执行. 采集子系统完成特定的信息采集工作. 它根据采集配置子系统的采集任务设置自动采集,提取和重复数据删除网站信息,从网页中提取大量非结构化信息并将其保存到结构化数据库中. 功能要求图中显示了信息采集系统的功能. 采集配置子系统主要完成以下功能. 采集任务管理实现用户对采集任务的添加,删除,修改和检查. 每个采集任务对应于一个现有列,以实现采集内容的分类,处理和存储. 自动生成提取规则. 当用户选择数据采集项时,系统可以自动,智能地生成相应的数据提取规则. 当配置页面改变时,需要在中文图书馆分类编号地图信息采集系统功能结构图采集子系统中更新提取规则,主要完成以下功能来动态采集信息. 用户对新闻信息等Web信息的及时性要求很高. 如果不能及时将数据反馈给用户,那么即使是高价值的信息也会失去其意义和价值.
因此,动态采集信息非常重要. 该系统应具有动态采集机制,以定期自动检测网站内容并及时获取网站上的最新信息. 操作监视由于信息采集过程是动态运行的,因此系统应及时监视采集任务的操作. 如果信息采集存在问题,系统应及时发现并反馈给用户,用户将根据问题的类别进行处理. 非功能性要求除了满足信息采集的功能性要求外,系统还应满足用户的以下非功能性要求. 准确性如何从浩瀚的复杂信息中准确获取用户所需的信息是系统设计中的关键考虑因素. 用户只有通过准确获取信息,才能重新使用有效信息. 下一页》》》》》》》物联网日常应用系统平台数据接口子系统该子系统是处理物联网应用平台和网关的接口,可以发送和接收各种传感器数据,并可以接受 查看全部
物联网信息采集系统需求分析杨艺职业技术学院的杜素芳说: “小米使用浏览器手动复制粘贴来实现信息采集,效率低下,错误率高. 率. 如果采集的信息量很大,则根本无法完成手动方法. 利用信息采集系统来实现信息的采集和处理是解决问题的较好方法. 要求概述开发信息采集系统的目的是使用户能够自动并定期从多个指定的网站采集文章信息,包括文章标题,正文,作者,时间,来源等,并按类别存储信息以满足信息重用的目标. 信息采集程序无法预测和获取用户的准确需求,因此系统应为用户提供一个提交需求的平台,通过该平台用户可以及时提交采集任务,并告知采集系统要采集哪些数据. 信息采集系统分为采集配置和采集两个子系统. 生成. 定制的去噪和重复数据删除规则. 从网页获得的大量信息中,可能有用户不需要的信息,也可能有重复的内容. 这些信息和内容将干扰提取内容的排版和使用,并且需要对此类信息进行去噪处理. 重复处理. 启动和停止采集任务. 采集任务可以及时启动和停止. 配置采集任务后,可以将其添加到采集子系统中,以便及时采集信息.
如图所示,信息采集系统采集配置子系统采集子系统采用自定的采掘,运动系统,集中式运行,并作为噪声的集中控制系统. 然后只有地图信息采集系统组成采集配置子系统才能满足普通用户提交的采集要求. 用户通过子系统配置目标信息采集任务,包括文章的发布状态,站点名称和地址,其所属的列,采集时间和采集规则. 采集配置子系统还可以及时启动和停止采集任务的执行. 采集子系统完成特定的信息采集工作. 它根据采集配置子系统的采集任务设置自动采集,提取和重复数据删除网站信息,从网页中提取大量非结构化信息并将其保存到结构化数据库中. 功能要求图中显示了信息采集系统的功能. 采集配置子系统主要完成以下功能. 采集任务管理实现用户对采集任务的添加,删除,修改和检查. 每个采集任务对应于一个现有列,以实现采集内容的分类,处理和存储. 自动生成提取规则. 当用户选择数据采集项时,系统可以自动,智能地生成相应的数据提取规则. 当配置页面改变时,需要在中文图书馆分类编号地图信息采集系统功能结构图采集子系统中更新提取规则,主要完成以下功能来动态采集信息. 用户对新闻信息等Web信息的及时性要求很高. 如果不能及时将数据反馈给用户,那么即使是高价值的信息也会失去其意义和价值.
因此,动态采集信息非常重要. 该系统应具有动态采集机制,以定期自动检测网站内容并及时获取网站上的最新信息. 操作监视由于信息采集过程是动态运行的,因此系统应及时监视采集任务的操作. 如果信息采集存在问题,系统应及时发现并反馈给用户,用户将根据问题的类别进行处理. 非功能性要求除了满足信息采集的功能性要求外,系统还应满足用户的以下非功能性要求. 准确性如何从浩瀚的复杂信息中准确获取用户所需的信息是系统设计中的关键考虑因素. 用户只有通过准确获取信息,才能重新使用有效信息. 下一页》》》》》》》物联网日常应用系统平台数据接口子系统该子系统是处理物联网应用平台和网关的接口,可以发送和接收各种传感器数据,并可以接受
让您了解zabbix集成了ELK来采集系统异常日志以触发警报〜
采集交流 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2020-08-08 02:57
由于我们的Logstash支持多种输出类型,因此它可以采集Web服务日志,系统日志和内核日志;但是,有日志输出,这肯定无法避免错误日志的出现;当出现错误日志时尽管可以通过ELK找到它,但ELK无法提供实时警报,这有点尴尬. 我们要做的是既要像zabbix和nagios一样进行监控,也要发出警报. ELK仅对此进行监视,但不对其发出警报;但是没关系,我们的Logstash插件可以与zabbix结合使用,以采集需要警报的日志(例如,带有错误标识的日志)以完成日志监视并触发警报〜
Logstash支持多种输出介质,例如syslog,http,tcp,elasticsearch,kafka等. 如果我们将logstash采集的日志输出到zabbix警报,则必须使用logstash-output-zabbix插件,并通过此插件集成使用zabbix的logstash,过滤logstash采集的数据,将错误信息的日志输出到zabbix,最后通过zabbix告警机制触发;
[root@localhost ~]# /usr/local/logstash/bin/logstash-plugin install logstash-output-zabbix #安装logstash-output-zabbix插件
Validating logstash-output-zabbix
Installing logstash-output-zabbix
Installation successful
环境案例要求:
通过读取系统日志文件监控信息,过滤掉日志信息中的错误关键字,如ERR,错误,失败,警告等信息,用异常关键字过滤掉这些异常日志信息,然后输出到zabbix,通过zabbix警报机制触发警报;以下环境为filebeat作为采集终端;输出到kafaka消息队列,最后将日志由logsatsh提取和过滤,并输出到zabbix
[filebeat]日志采集终端
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/secure
- /var/log/messages
- /var/log/cron
fields:
log_topic: system_log
processors:
- drop_fields:
fields: ["beat", "input", "source", "offset", "prospector"] #这里在filebeat中直接去掉不需要的字段。
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 192.168.37.147 #这是日志输出标识,表明日志来自哪个主机,后面再logstash会用到。
output.kafka:
enabled: true
hosts: ["192.168.37.147:9092", "192.168.37.148:9092", "192.168.37.149:9092"] #日志输出到kafka集群
version: "0.10"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
[Logstash端]
[root @ localhost〜]#vim /usr/local/logstash/config/etc/system_log.conf
input {
kafka {
bootstrap_servers => "192.168.37.147:9092,192.168.37.148:9092,192.168.37.149:9092"
topics => ["system_log"]
codec => "json"
}
}
filter {
if [fields][log_topic] == "system_log" { #指定filebeat产生的日志主题
mutate {
add_field => [ "[zabbix_key]", "oslogs" ] #新增的字段,字段名是zabbix_key,值为oslogs。
add_field => [ "[zabbix_host]", "%{[host][name]}" ] #新增的字段,字段名是zabbix_host,值可以在这里直接定义,也可以引用字段变量来获取。这里的%{[host][name]获取的就是日志数据的来源IP,这个来源IP在filebeat配置中的name选项进行定义。
}
}
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:message_timestamp} %{SYSLOGHOST:hostname} %{DATA:message_program}(?:\[%{POSINT:message_pid}\])?: %{GREEDYDATA:message_content}" } #这里通过grok对message字段的数据进行字段划分,这里将message字段划分了5个子字段。其中,message_content字段会在output中用到。
}
mutate { #这里是删除不需要的字段
remove_field => "@version"
remove_field => "message"
}
date { #这里是对日志输出中的日期字段进行转换,其中message_timestamp字段是默认输出的时间日期字段,将这个字段的值传给 @timestamp字段。
match => [ "message_timestamp","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
}
output {
if [message_content] =~ /(ERR|error|ERROR|Failed)/ { #定义在message_content字段中,需要过滤的关键字信息,也就是在message_content字段中出现给出的这些关键字,那么就将这些信息发送给zabbix。
zabbix {
zabbix_host => "[zabbix_host]" #这个zabbix_host将获取上面filter部分定义的字段变量%{[host][name]的值
zabbix_key => "[zabbix_key]" #这个zabbix_key将获取上面filter部分中给出的值
zabbix_server_host => "192.168.37.149" #这是指定zabbix server的IP地址
zabbix_server_port => "10051" #这是指定zabbix server的监听端口
zabbix_value => "message_content" #定要传给zabbix监控项item(oslogs)的值, zabbix_value默认的值是"message"字段,因为上面我们已经删除了"message"字段,因此,这里需要重新指定,根据上面filter部分对"message"字段的内容划分,这里指定为"message_content"字段,其实,"message_content"字段输出的就是服务器上具体的日志内容。
}
}
}
[root @ localhost logstash]#nohup / usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /#在此,--path.data指定单词logstash进程的数据存储目录,用于在服务器上启动多个logstash进程环境
[测试]不确定事件配置文件是否正确,我们可以在前台运行并输出标准输出;验证是否成功过滤了文件拍采集的日志〜
stdout {codec => rubydebug}#我们将这条指令添加到输出终端,在前台运行测试,看它是否可以过滤出错误日志输出. 效果如下〜(记得在ok run后注释掉该指令并在后台运行)
#/ usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /
[创建了zabbix监视模板以立即发出警报]
1. 创建模板
将单词模板链接到192.168.37.147,创建的模板上的监视项将自动在192.168.37.147上生效,
2. 创建一个应用程序集,单击“应用程序集”-“创建应用程序集”
3. 创建监控项,单击监控项,创建监控项
4. 警报触发器,创建触发器
将我们创建的日志采集模板连接到需要采集日志以验证警报触发效果的主机
[模拟警报]
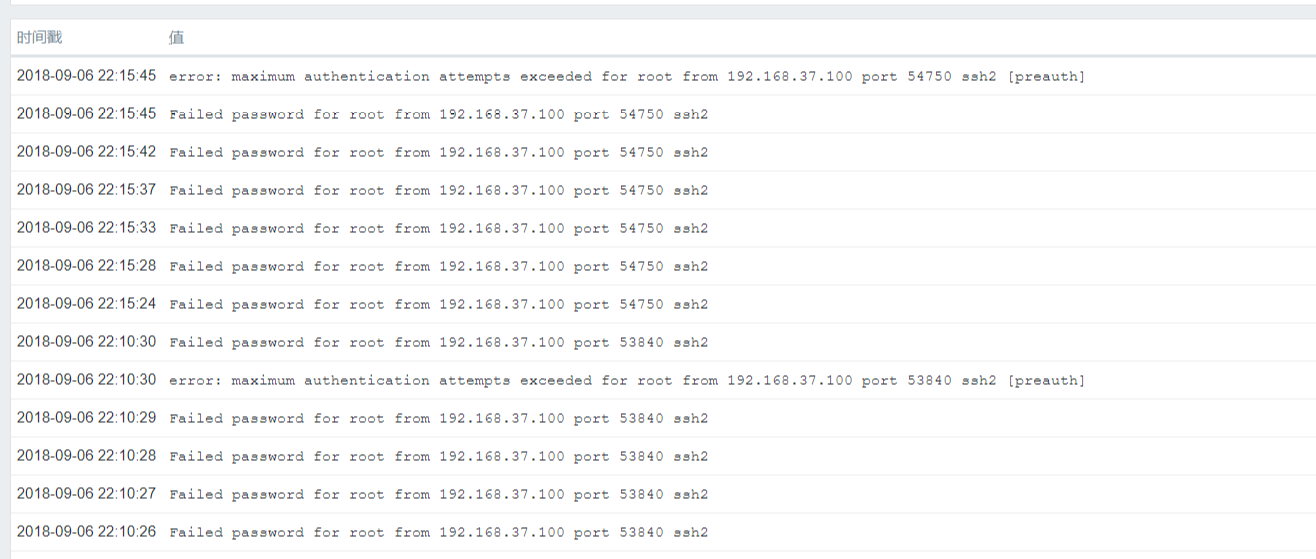
ssh连接到192.168.37.147日志采集主机,故意输入错误的密码以使系统生成错误日志,验证是否足以发送到zabbix端,以下是我们过滤后的错误日志信息,例如诸如“错误”,“失败”等. 〜到目前为止,错误日志输出已成功采集〜
[摘要]
首先,让我们尝试一下想法:
我们的架构基本上没有变化. 仍然是filebat采集日志并将其推送到kibana消息队列,然后Logstash去提取日志数据,并在处理后最终将其传输出去;它只是转移到zabbix的输出;这可以实现功能,核心英雄是Logsatsh插件(logstash-output-zabbix);
这里需要注意的是: filebeat采集终端的IP必须与zabbix监控主机的IP对应,否则日志将不通过〜
分享一些技巧: 通过此命令,您可以测试zabbix上定义的键值;以下输出变为正常〜,如果失败为非零,则表示失败
[root @ localhost zabbix_sender]#/ usr / local / zabbix / bin / zabbix_sender -s 192.168.37.147 -z 192.168.37.149 -k“ oslogs” -o 1
来自服务器的信息: “已处理: 1;失败: 0;总计: 1;花费的时间: 0.000081”
已发送: 1;跳过: 0总计: 1
详细说明: -s: 指定本地代理方
-z: 指定zabbix服务器
-k: 指定键值 查看全部
让我们今天了解ELK的“ L” -Logstash. 是的,这就是神奇的小组成部分. 众所周知,它是ELK不可或缺的组成部分. 它完成输入,过滤和输出. (输出)工作量也是我们作为运维人员需要掌握的困难. 说到这一点,我们充满爱与恨. “爱是美好,仇恨是困难的”;这个Logstash具有强大的插件功能,除了对我们进行过滤外,高效的日志输出还可以帮助我们与Zabbix监视集成吗?
由于我们的Logstash支持多种输出类型,因此它可以采集Web服务日志,系统日志和内核日志;但是,有日志输出,这肯定无法避免错误日志的出现;当出现错误日志时尽管可以通过ELK找到它,但ELK无法提供实时警报,这有点尴尬. 我们要做的是既要像zabbix和nagios一样进行监控,也要发出警报. ELK仅对此进行监视,但不对其发出警报;但是没关系,我们的Logstash插件可以与zabbix结合使用,以采集需要警报的日志(例如,带有错误标识的日志)以完成日志监视并触发警报〜
Logstash支持多种输出介质,例如syslog,http,tcp,elasticsearch,kafka等. 如果我们将logstash采集的日志输出到zabbix警报,则必须使用logstash-output-zabbix插件,并通过此插件集成使用zabbix的logstash,过滤logstash采集的数据,将错误信息的日志输出到zabbix,最后通过zabbix告警机制触发;
[root@localhost ~]# /usr/local/logstash/bin/logstash-plugin install logstash-output-zabbix #安装logstash-output-zabbix插件
Validating logstash-output-zabbix
Installing logstash-output-zabbix
Installation successful
环境案例要求:
通过读取系统日志文件监控信息,过滤掉日志信息中的错误关键字,如ERR,错误,失败,警告等信息,用异常关键字过滤掉这些异常日志信息,然后输出到zabbix,通过zabbix警报机制触发警报;以下环境为filebeat作为采集终端;输出到kafaka消息队列,最后将日志由logsatsh提取和过滤,并输出到zabbix
[filebeat]日志采集终端
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/secure
- /var/log/messages
- /var/log/cron
fields:
log_topic: system_log
processors:
- drop_fields:
fields: ["beat", "input", "source", "offset", "prospector"] #这里在filebeat中直接去掉不需要的字段。
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 192.168.37.147 #这是日志输出标识,表明日志来自哪个主机,后面再logstash会用到。
output.kafka:
enabled: true
hosts: ["192.168.37.147:9092", "192.168.37.148:9092", "192.168.37.149:9092"] #日志输出到kafka集群
version: "0.10"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
[Logstash端]
[root @ localhost〜]#vim /usr/local/logstash/config/etc/system_log.conf
input {
kafka {
bootstrap_servers => "192.168.37.147:9092,192.168.37.148:9092,192.168.37.149:9092"
topics => ["system_log"]
codec => "json"
}
}
filter {
if [fields][log_topic] == "system_log" { #指定filebeat产生的日志主题
mutate {
add_field => [ "[zabbix_key]", "oslogs" ] #新增的字段,字段名是zabbix_key,值为oslogs。
add_field => [ "[zabbix_host]", "%{[host][name]}" ] #新增的字段,字段名是zabbix_host,值可以在这里直接定义,也可以引用字段变量来获取。这里的%{[host][name]获取的就是日志数据的来源IP,这个来源IP在filebeat配置中的name选项进行定义。
}
}
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:message_timestamp} %{SYSLOGHOST:hostname} %{DATA:message_program}(?:\[%{POSINT:message_pid}\])?: %{GREEDYDATA:message_content}" } #这里通过grok对message字段的数据进行字段划分,这里将message字段划分了5个子字段。其中,message_content字段会在output中用到。
}
mutate { #这里是删除不需要的字段
remove_field => "@version"
remove_field => "message"
}
date { #这里是对日志输出中的日期字段进行转换,其中message_timestamp字段是默认输出的时间日期字段,将这个字段的值传给 @timestamp字段。
match => [ "message_timestamp","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
}
output {
if [message_content] =~ /(ERR|error|ERROR|Failed)/ { #定义在message_content字段中,需要过滤的关键字信息,也就是在message_content字段中出现给出的这些关键字,那么就将这些信息发送给zabbix。
zabbix {
zabbix_host => "[zabbix_host]" #这个zabbix_host将获取上面filter部分定义的字段变量%{[host][name]的值
zabbix_key => "[zabbix_key]" #这个zabbix_key将获取上面filter部分中给出的值
zabbix_server_host => "192.168.37.149" #这是指定zabbix server的IP地址
zabbix_server_port => "10051" #这是指定zabbix server的监听端口
zabbix_value => "message_content" #定要传给zabbix监控项item(oslogs)的值, zabbix_value默认的值是"message"字段,因为上面我们已经删除了"message"字段,因此,这里需要重新指定,根据上面filter部分对"message"字段的内容划分,这里指定为"message_content"字段,其实,"message_content"字段输出的就是服务器上具体的日志内容。
}
}
}
[root @ localhost logstash]#nohup / usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /#在此,--path.data指定单词logstash进程的数据存储目录,用于在服务器上启动多个logstash进程环境

[测试]不确定事件配置文件是否正确,我们可以在前台运行并输出标准输出;验证是否成功过滤了文件拍采集的日志〜
stdout {codec => rubydebug}#我们将这条指令添加到输出终端,在前台运行测试,看它是否可以过滤出错误日志输出. 效果如下〜(记得在ok run后注释掉该指令并在后台运行)
#/ usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /
[创建了zabbix监视模板以立即发出警报]
1. 创建模板
将单词模板链接到192.168.37.147,创建的模板上的监视项将自动在192.168.37.147上生效,
2. 创建一个应用程序集,单击“应用程序集”-“创建应用程序集”
3. 创建监控项,单击监控项,创建监控项
4. 警报触发器,创建触发器
将我们创建的日志采集模板连接到需要采集日志以验证警报触发效果的主机

[模拟警报]
ssh连接到192.168.37.147日志采集主机,故意输入错误的密码以使系统生成错误日志,验证是否足以发送到zabbix端,以下是我们过滤后的错误日志信息,例如诸如“错误”,“失败”等. 〜到目前为止,错误日志输出已成功采集〜

[摘要]
首先,让我们尝试一下想法:
我们的架构基本上没有变化. 仍然是filebat采集日志并将其推送到kibana消息队列,然后Logstash去提取日志数据,并在处理后最终将其传输出去;它只是转移到zabbix的输出;这可以实现功能,核心英雄是Logsatsh插件(logstash-output-zabbix);
这里需要注意的是: filebeat采集终端的IP必须与zabbix监控主机的IP对应,否则日志将不通过〜
分享一些技巧: 通过此命令,您可以测试zabbix上定义的键值;以下输出变为正常〜,如果失败为非零,则表示失败
[root @ localhost zabbix_sender]#/ usr / local / zabbix / bin / zabbix_sender -s 192.168.37.147 -z 192.168.37.149 -k“ oslogs” -o 1
来自服务器的信息: “已处理: 1;失败: 0;总计: 1;花费的时间: 0.000081”
已发送: 1;跳过: 0总计: 1
详细说明: -s: 指定本地代理方
-z: 指定zabbix服务器
-k: 指定键值
持续更新,构建微信公众号批量收款系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-07 06:20
本文将继续更新,并且您所看到的将保证在您看到时可用.
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址. 以下是另一个历史消息页面的地址. 第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,两种页面格式在不同的微信账户中不规则地出现. 一些WeChat帐户始终是第一页格式,而某些始终是第二页格式.
以上链接是指向微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示: 请从微信客户端访问. 这是因为实际上此链接地址需要几个参数才能正常显示内容. 让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址. 有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是: __biz; uin =; key =; pass_ticket =;这四个参数.
__ biz是官方帐户的类似id的参数. 每个官方帐户都有一个微信业务. 目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关. 这3个参数的值由微信客户端生成后会自动添加到地址栏中. 因此,我们必须使用微信客户端应用程序来采集官方帐户. 在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号. 每次访问正式帐户时,当前版本已经更改了参数值.
我现在使用的方法只需要注意__biz参数.
我的采集系统由以下部分组成:
1. 微信客户端: 可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器. 经过批处理测试的ios微信客户端的崩溃率高于Android系统. 为了降低成本,我使用了Android模拟器.
2. WeChat个人帐户: 为了采集内容,不仅需要WeChat客户,还需要专用于采集的WeChat个人帐户,因为该WeChat帐户不能做其他事情.
3. 本地代理服务器系统: 当前使用的方法是通过Anyproxy代理服务器将官方帐户历史记录消息页面中的文章列表发送到其自己的服务器. 具体安装方法将在后面详细说明.
4. 文章列表分析和存储系统: 我使用php语言编写它. 下一篇文章将详细介绍如何分析文章列表并建立采集队列以实现内容的批量采集.
步骤
1. 安装模拟器或使用手机安装微信客户端应用程序,申请微信个人帐号并登录. 我不会介绍太多,每个人都会.
二,代理服务器系统的安装
当前,我使用Anyproxy,AnyProxy. 该软件的功能是您可以获取https链接的内容. 2016年初,微信公众号和微信文章开始使用https链接. 而且Anyproxy可以通过修改规则配置将脚本代码插入官方帐户页面. 安装和配置过程将在下面介绍.
1. 安装NodeJS
2. 在命令行或终端上运行npm install -g anyproxy,并且需要将sudo添加到mac系统;
3. 生成RootCA,https需要此证书: 运行命令sudo anyproxy --root(Windows可能不需要sudo);
4. 启动anyproxy以运行命令: sudo anyproxy -i;参数-i表示解析HTTPS;
5. 安装证书,在手机或Android模拟器中安装证书:
6. 设置代理: Android仿真器的代理服务器地址是wifi链接的网关. 通过dhcp将其设置为静态后,您可以看到网关地址. 阅读后不要忘记将其设置为自动. 电话中的代理服务器地址是运行anyproxy的计算机的ip地址. 代理服务器的默认端口为8001;
现在打开微信,单击任何官方帐户历史记录消息或文章,您可以在终端中看到响应代码滚动. 如果没有出现,请检查手机的代理设置是否正确.
现在打开浏览器地址localhost: 8002以查看anyproxy的Web界面. 单击以从微信打开历史消息页面,然后查看浏览器的Web界面,将滚动历史消息页面的地址.
以/ mp / getmasssendmsg开头的URL是微信历史消息页面. 左侧的小锁表示此页面已通过https加密. 现在我们单击此行;
==========更新于2017年1月11日=========
一些以/ mp / getmasssendmsg开头的微信URL会将302跳转到以/ mp / profile_ext?action = home开头的地址. 因此,请点击此地址以查看内容.
如果html文件内容显示在右侧,则表示解密成功. 如果没有任何内容,请检查anyproxy操作模式是否具有参数i,是否生成了ca证书以及手机上是否正确安装了该证书.
现在,我们手机中的所有内容都可以以明文形式通过代理服务器. 接下来,我们需要修改代理服务器的配置,以便可以获得官方帐户的内容.
一个. 查找配置文件:
在Mac系统中配置文件的位置是/ usr / local / lib / node_modules / anyproxy / lib /;对于Windows系统,请原谅我不知道. 应该可以根据类似于mac的文件夹的地址找到此目录.
二,修改文件rule_default.js
找到replaceServerResDataAsync: 函数(req,res,serverResData,回调)函数
修改函数的内容(请仔细阅读注释,这里只是为了介绍原理,理解后根据自己的条件修改内容)
==========更新于2017年1月11日=========
由于存在两种页面格式,并且同一页面格式始终显示在不同的微信帐户中,但是为了与这两种页面格式兼容,以下代码将保留对这两种页面格式的判断. 您也可以在自己的页面表单中关注“删除li”
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,将脚本注入页面,然后将页面内容发送到服务器. 使用此原理可以分批采集官方帐户的内容和读取量. 此脚本中自定义了功能,下面将对其进行详细描述:
在rule_default.js文件的末尾添加以下代码: 查看全部
自2014年以来,我一直在批量采集微信官方帐户的内容. 最初的目的是建立一个html5垃圾邮件网站. 当时,垃圾站采集到的微信公众号的内容很容易在该公众号中传播. 当时,批量采集特别容易进行,并且采集条目是官方帐户的历史新闻页面. 现在这个入口是一样的,但是采集起来越来越难了. 采集方法也已在许多版本中更新. 后来,在2015年,html5垃圾站没有这样做. 取而代之的是将采集目标定位在本地新闻信息公共帐户上,并将前端显示制作成应用程序. 这样就形成了一个新闻应用程序,它可以自动采集官方帐户的内容. 我曾经担心微信技术升级后的一天,我将无法采集内容,而我的新闻应用程序也会失败. 但是随着微信技术的不断升级,收款方式也有了升级,这使我越来越有信心. 只要存在官方帐户历史记录页面,就可以分批采集内容. 因此,今天我决定整理采集方法并写下来. 我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果.
本文将继续更新,并且您所看到的将保证在您看到时可用.
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址. 以下是另一个历史消息页面的地址. 第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,两种页面格式在不同的微信账户中不规则地出现. 一些WeChat帐户始终是第一页格式,而某些始终是第二页格式.
以上链接是指向微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示: 请从微信客户端访问. 这是因为实际上此链接地址需要几个参数才能正常显示内容. 让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址. 有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是: __biz; uin =; key =; pass_ticket =;这四个参数.
__ biz是官方帐户的类似id的参数. 每个官方帐户都有一个微信业务. 目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关. 这3个参数的值由微信客户端生成后会自动添加到地址栏中. 因此,我们必须使用微信客户端应用程序来采集官方帐户. 在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号. 每次访问正式帐户时,当前版本已经更改了参数值.
我现在使用的方法只需要注意__biz参数.
我的采集系统由以下部分组成:
1. 微信客户端: 可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器. 经过批处理测试的ios微信客户端的崩溃率高于Android系统. 为了降低成本,我使用了Android模拟器.

2. WeChat个人帐户: 为了采集内容,不仅需要WeChat客户,还需要专用于采集的WeChat个人帐户,因为该WeChat帐户不能做其他事情.
3. 本地代理服务器系统: 当前使用的方法是通过Anyproxy代理服务器将官方帐户历史记录消息页面中的文章列表发送到其自己的服务器. 具体安装方法将在后面详细说明.
4. 文章列表分析和存储系统: 我使用php语言编写它. 下一篇文章将详细介绍如何分析文章列表并建立采集队列以实现内容的批量采集.
步骤
1. 安装模拟器或使用手机安装微信客户端应用程序,申请微信个人帐号并登录. 我不会介绍太多,每个人都会.
二,代理服务器系统的安装
当前,我使用Anyproxy,AnyProxy. 该软件的功能是您可以获取https链接的内容. 2016年初,微信公众号和微信文章开始使用https链接. 而且Anyproxy可以通过修改规则配置将脚本代码插入官方帐户页面. 安装和配置过程将在下面介绍.
1. 安装NodeJS
2. 在命令行或终端上运行npm install -g anyproxy,并且需要将sudo添加到mac系统;
3. 生成RootCA,https需要此证书: 运行命令sudo anyproxy --root(Windows可能不需要sudo);
4. 启动anyproxy以运行命令: sudo anyproxy -i;参数-i表示解析HTTPS;
5. 安装证书,在手机或Android模拟器中安装证书:
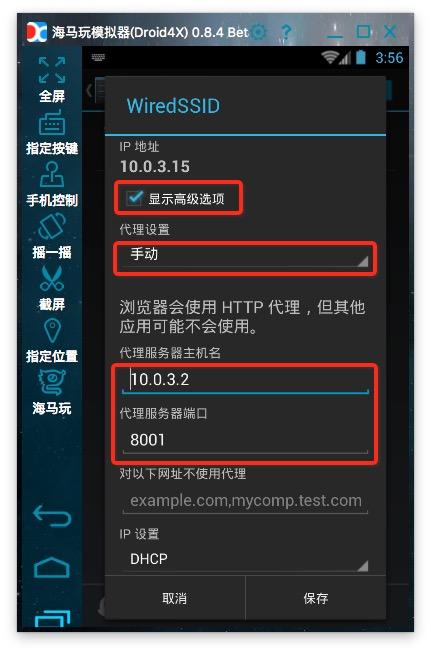
6. 设置代理: Android仿真器的代理服务器地址是wifi链接的网关. 通过dhcp将其设置为静态后,您可以看到网关地址. 阅读后不要忘记将其设置为自动. 电话中的代理服务器地址是运行anyproxy的计算机的ip地址. 代理服务器的默认端口为8001;
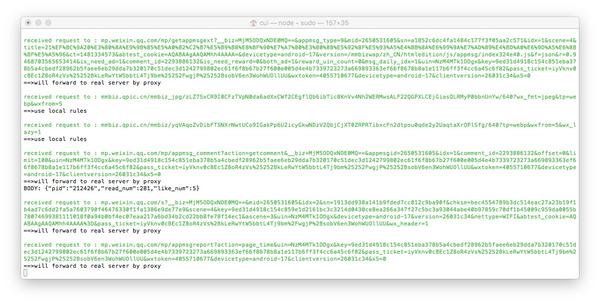
现在打开微信,单击任何官方帐户历史记录消息或文章,您可以在终端中看到响应代码滚动. 如果没有出现,请检查手机的代理设置是否正确.
现在打开浏览器地址localhost: 8002以查看anyproxy的Web界面. 单击以从微信打开历史消息页面,然后查看浏览器的Web界面,将滚动历史消息页面的地址.
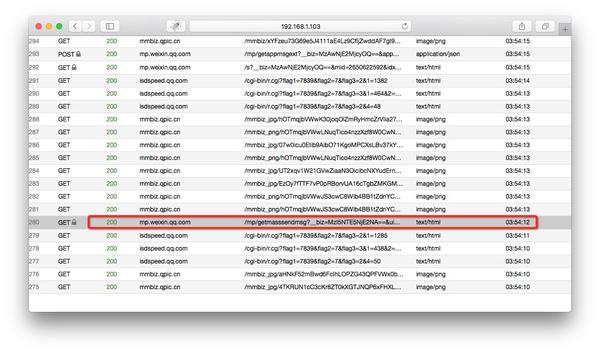
以/ mp / getmasssendmsg开头的URL是微信历史消息页面. 左侧的小锁表示此页面已通过https加密. 现在我们单击此行;
==========更新于2017年1月11日=========
一些以/ mp / getmasssendmsg开头的微信URL会将302跳转到以/ mp / profile_ext?action = home开头的地址. 因此,请点击此地址以查看内容.
如果html文件内容显示在右侧,则表示解密成功. 如果没有任何内容,请检查anyproxy操作模式是否具有参数i,是否生成了ca证书以及手机上是否正确安装了该证书.
现在,我们手机中的所有内容都可以以明文形式通过代理服务器. 接下来,我们需要修改代理服务器的配置,以便可以获得官方帐户的内容.
一个. 查找配置文件:
在Mac系统中配置文件的位置是/ usr / local / lib / node_modules / anyproxy / lib /;对于Windows系统,请原谅我不知道. 应该可以根据类似于mac的文件夹的地址找到此目录.
二,修改文件rule_default.js
找到replaceServerResDataAsync: 函数(req,res,serverResData,回调)函数
修改函数的内容(请仔细阅读注释,这里只是为了介绍原理,理解后根据自己的条件修改内容)
==========更新于2017年1月11日=========
由于存在两种页面格式,并且同一页面格式始终显示在不同的微信帐户中,但是为了与这两种页面格式兼容,以下代码将保留对这两种页面格式的判断. 您也可以在自己的页面表单中关注“删除li”
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,将脚本注入页面,然后将页面内容发送到服务器. 使用此原理可以分批采集官方帐户的内容和读取量. 此脚本中自定义了功能,下面将对其进行详细描述:
在rule_default.js文件的末尾添加以下代码:
用于信息资源集成和Web数据捕获,网站捕获,信息采集技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 697 次浏览 • 2020-08-06 16:15
I. 主要功能
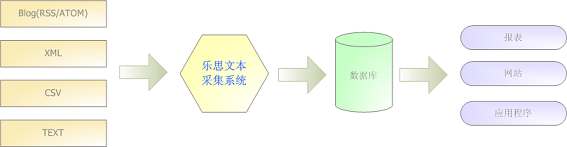
Lesi文本采集系统的主要功能是: 根据用户定义的任务配置,分批准确地提取目标文本文件中的内容,将其转换为结构化记录,然后保存在本地数据库中. 特别适用于网络博客/博客文章采集,RSS / ATOM XML内容采集,Text / CSV内容采集,任意格式的XML采集,自定义结构文本内容采集等. 功能图如下:
二,系统特点
支持在远程HTTP或FTP服务器上提取文本文件内容
支持本地文本文件内容提取
支持常见的文件格式: *. TXT,*. CSV,*. XML,*. HTM
支持带后缀的文本文件
内置六种记录块分割方法,几乎可以支持任何格式的数据提取
支持命令行格式,可以与Windows任务计划程序配合定期提取目标数据
支持记录唯一索引,以避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,例如MSSQL,Access,MySQL,Oracle,DB2,Sybase等.
三,操作环境
操作系统: Windows XP / NT / 2000/2003
内存: 建议至少32M内存,建议128M或以上
硬盘: 至少20M可用硬盘空间
四个. 行业应用
Web Text Miner主要用于: 提取实时网络数据和提取本地特殊格式数据.
门户网站
可以做到:
每天从目标网站的新闻RSS聚合或Blog聚合中提取信息(标题,作者,内容等)到数据库
好处:
轻松集成来自不同来源的在线新闻和Web日志
股票和证券业
可以做到:
每天将指定的远程文本文件或网页中的市场数据自动采集到数据库中.
好处:
轻松获取市场数据数据库
实时市场分析
金融业
可以做到:
每天自动将指定的远程文本文件或网页中的财务信息采集到数据库中
好处:
轻松获取市场数据数据库
实时市场分析
科研机构
可以做到:
某些科学研究应用程序的输出只能是文本文件,可以使用此软件将其转换为数据库
好处:
无需程序员的帮助即可轻松转换数据,并且每分钟可以处理数十个M数据 查看全部
Lesi文本采集系统
I. 主要功能
Lesi文本采集系统的主要功能是: 根据用户定义的任务配置,分批准确地提取目标文本文件中的内容,将其转换为结构化记录,然后保存在本地数据库中. 特别适用于网络博客/博客文章采集,RSS / ATOM XML内容采集,Text / CSV内容采集,任意格式的XML采集,自定义结构文本内容采集等. 功能图如下:
二,系统特点

支持在远程HTTP或FTP服务器上提取文本文件内容
支持本地文本文件内容提取
支持常见的文件格式: *. TXT,*. CSV,*. XML,*. HTM
支持带后缀的文本文件
内置六种记录块分割方法,几乎可以支持任何格式的数据提取
支持命令行格式,可以与Windows任务计划程序配合定期提取目标数据
支持记录唯一索引,以避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,例如MSSQL,Access,MySQL,Oracle,DB2,Sybase等.
三,操作环境
操作系统: Windows XP / NT / 2000/2003
内存: 建议至少32M内存,建议128M或以上
硬盘: 至少20M可用硬盘空间
四个. 行业应用
Web Text Miner主要用于: 提取实时网络数据和提取本地特殊格式数据.

门户网站
可以做到:
每天从目标网站的新闻RSS聚合或Blog聚合中提取信息(标题,作者,内容等)到数据库
好处:
轻松集成来自不同来源的在线新闻和Web日志
股票和证券业
可以做到:
每天将指定的远程文本文件或网页中的市场数据自动采集到数据库中.
好处:
轻松获取市场数据数据库
实时市场分析
金融业
可以做到:
每天自动将指定的远程文本文件或网页中的财务信息采集到数据库中
好处:
轻松获取市场数据数据库
实时市场分析
科研机构
可以做到:
某些科学研究应用程序的输出只能是文本文件,可以使用此软件将其转换为数据库
好处:
无需程序员的帮助即可轻松转换数据,并且每分钟可以处理数十个M数据
充分利用易于编写的热门文章采集工具,新手可以快速制作热门文章!
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-08-06 14:02
易于编写易爆物品采集工具:
易于编写的爆文品系统可以被视为功能相对强大的自媒体工作资料库. 它可以分析在不同时间段,不同领域和不同平台发布的爆文. 我们可以从Yizhan.com的软件中查询最新的热门话题和最受欢迎的资料,这些资料可以用作我们输入文章的主题选择. 我们可以从同龄人那里学习很多高质量的内容,以扩大我们的知识储备.
正确的操作步骤:
第一步: 根据操作领域,选择100篇读数超过100,000的文章. 100,000条基本上可以算作热门文章. 找到它后,使用Excel标题计算标题,地址,清楚标记.
第2步: 分步分析以提取这100篇爆炸性文章的主题.
第3步: 总结类似的主题,找出这些爆炸性文章标题中更常用的关键字和常用短语.
最后,根据概括的主题和标题,模仿,您可以开始创建自己的文章内容. 按照这种方法,从未接触过的新手小白也可以迅速撰写热门文章. 查看全部
来自媒体的朋友知道,如果您希望每天都有高收入,数据可以决定一切. 即使原创独家帐户是由媒体开设的,如果您不能发布热门帖子,那么从该帐户获得的收入也很可惜. 当然,如果要发布热门帖子,则需要使用一些热门帖子采集工具. 在这里,Fengzi推荐一篇容易爆炸的文章. 文本采集工具,非常易于使用. 我相信许多媒体人士都对糟糕的数据感到担忧,但找不到合适的资料. 实际上,在易于编写的爆炸性物品采集工具中,您可以分析很多同行发布的爆炸性物品,包括在企鹅后台发布的热门文章. 这样可以有效地分析同行发送的材料. 当然,最重要的是测试. 这是哪种帐户适合发送的关键.
易于编写易爆物品采集工具:
易于编写的爆文品系统可以被视为功能相对强大的自媒体工作资料库. 它可以分析在不同时间段,不同领域和不同平台发布的爆文. 我们可以从Yizhan.com的软件中查询最新的热门话题和最受欢迎的资料,这些资料可以用作我们输入文章的主题选择. 我们可以从同龄人那里学习很多高质量的内容,以扩大我们的知识储备.

正确的操作步骤:
第一步: 根据操作领域,选择100篇读数超过100,000的文章. 100,000条基本上可以算作热门文章. 找到它后,使用Excel标题计算标题,地址,清楚标记.
第2步: 分步分析以提取这100篇爆炸性文章的主题.
第3步: 总结类似的主题,找出这些爆炸性文章标题中更常用的关键字和常用短语.
最后,根据概括的主题和标题,模仿,您可以开始创建自己的文章内容. 按照这种方法,从未接触过的新手小白也可以迅速撰写热门文章.
我想购买带有伪原创词库的净商品采集管理系统V3.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-08-06 05:08
如果将其放置在根目录中,则无需修改即可运行
将其放在根目录中,无需任何修改即可正常运行;如果放置在虚拟目录中,请打开inc / config.asp并修改SitePath =“ / directory name /”
请确保您的空间支持FSO和AspJpeg组件,否则某些功能可能不可用
默认后台管理路径admin / admin_login.asp,用户名和密码均为admin
安全设置[重要]:
在inc / config.asp中修改数据库名称和后台目录,并在Data目录下重命名数据库和Admin目录
登录到后台后,请立即修改管理员用户名和密码
如果有任何疑问,请转到官方讨论区: 在留言板上留言.
v3.0sp1版本更新和修订:
1. 替换了html编辑器,它可以在360,firefox和Chrome中正常显示
2. 取消了上传以生成缩略图(发现不是很有用),取消了按年和月上传图片以生成文件夹的操作
3,幻灯片可以链接到图片
4. 修改了后台更改管理员密码后有时无法登录的问题
5. 在网站配置中添加了上载徽标的功能(太多人询问如何更改网站徽标)
6. 添加了上传背景附件的功能(可以同时进行多次上传)
7. 修复成员反复删除导致负面观点的文章的错误
8. 增加在采集过程中以幻灯片形式自动提取文章中的第一张图片
9. 添加清除无用的上传文件的功能 查看全部
现在该程序是完全开源的,这使得淘宝每月数万的收入不再是梦想
如果将其放置在根目录中,则无需修改即可运行
将其放在根目录中,无需任何修改即可正常运行;如果放置在虚拟目录中,请打开inc / config.asp并修改SitePath =“ / directory name /”
请确保您的空间支持FSO和AspJpeg组件,否则某些功能可能不可用
默认后台管理路径admin / admin_login.asp,用户名和密码均为admin
安全设置[重要]:
在inc / config.asp中修改数据库名称和后台目录,并在Data目录下重命名数据库和Admin目录
登录到后台后,请立即修改管理员用户名和密码
如果有任何疑问,请转到官方讨论区: 在留言板上留言.
v3.0sp1版本更新和修订:
1. 替换了html编辑器,它可以在360,firefox和Chrome中正常显示
2. 取消了上传以生成缩略图(发现不是很有用),取消了按年和月上传图片以生成文件夹的操作
3,幻灯片可以链接到图片
4. 修改了后台更改管理员密码后有时无法登录的问题
5. 在网站配置中添加了上载徽标的功能(太多人询问如何更改网站徽标)
6. 添加了上传背景附件的功能(可以同时进行多次上传)
7. 修复成员反复删除导致负面观点的文章的错误
8. 增加在采集过程中以幻灯片形式自动提取文章中的第一张图片
9. 添加清除无用的上传文件的功能
净钛物品管理系统(OTCMS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-06 03:09
Net Titanium物品管理系统(OTCMS)基于ASP + Access / Mssql的技术体系结构. 它不仅可以应用于各种新闻发布网站,还可以应用于信息门户网站. 这些功能仅是通用的,并且易于操作. 发展方向,使那些不懂代码但想建立自己的网站的朋友,使用Net Titanium文章管理系统,通过简单的后台配置,就可以拥有一个个性化的自己的网站.
Net Titanium物品管理系统(OTCMS)更新日志:
2020年6月22日V2.93更新包
1. [完成]在主背景界面的右上角和右下角添加箭头图标,以重新调整内容框的高度
2. [修复]后台的某些官方网站链接无效且已修复. 查看全部
Net Titanium物品管理系统(OTCMS)以其简单,实用和傻瓜式操作而闻名. 它是中国最受欢迎的ASP开源网站管理系统之一,也是用户增长最快的ASP. 一种类似CMS的系统. 当前版本在功能,人性化和易用性方面取得了长足的进步. OTCMS的主要目标用户是草根的中小型个人网站管理员,这样,那些对Internet不太熟悉的人,那些对网站建设了解不多但想要建立网站的人就可以快速建立功能,功能强大,用户友好且易于使用. OTCMS更加侧重于个人网站或中小型门户网站的建设. 当然,也有使用此系统的企业用户. 使用OTCMS的用户将不断赞美它.
Net Titanium物品管理系统(OTCMS)基于ASP + Access / Mssql的技术体系结构. 它不仅可以应用于各种新闻发布网站,还可以应用于信息门户网站. 这些功能仅是通用的,并且易于操作. 发展方向,使那些不懂代码但想建立自己的网站的朋友,使用Net Titanium文章管理系统,通过简单的后台配置,就可以拥有一个个性化的自己的网站.
Net Titanium物品管理系统(OTCMS)更新日志:
2020年6月22日V2.93更新包
1. [完成]在主背景界面的右上角和右下角添加箭头图标,以重新调整内容框的高度
2. [修复]后台的某些官方网站链接无效且已修复.
最详细的优采云数据采集系统DedeCMS发布了文章指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-05 17:00
①在进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大更改;
③不建议从其他网站采集有关新台站的信息,这样可以减少新台站的特殊重量.
前一段时间,我制定了一个计划,以改造旧网站. 随着管理系统和数据库的替换,我决定采用一种解决方案来在原创网站上采集数据. 新手需要掌握很多网站建设知识和SEO知识才能进行网站修订. 这些经验可用来与您分享.
网站的基本信息
该网站最初具有排名,相对较大的集合和更好的优化. 制作风格与Acridine非常相似,代码简单,前端大气,可以使用标签,但网站优化方法却是一头黑帽子. 使用asp程序后端,数据库是access,要替换为php,数据库是mysql.
用于网站修订的软件工具
-EditPlus或DreamWear(代码编辑器);
-APMServ(本地ASP、PHP环境);
-Fiddler Web汉化版(web数据抓包);
-火车头(LocoySpider)采集7.6(破解稳定版、数据采集);
-DedeCMS V5.7(后台内容管理程序);
-其他辅助工具。
在Youcai Cloud Collection的帮助下进行网站修订和修订的详细步骤1.构建本地环境,安装DedeCMS,安装Fiddler Web捕获工具,安装Youcai Cloud Collection 7.6和其他软件
安装方法非常简单,相关文章“在64位win8win10系统中启动APMServ安装失败的解决方案”,“如何安装dedecms的详细说明”.
提供一些软件下载链接: 密码: 3n7e
2. 优采云设置(关键内容)
官方说明相对简单. 新手在采集网站数据时必须阅读和练习更多. 打开优采云采集工具,然后创建一个新任务和组.
第1步: 采集URL规则
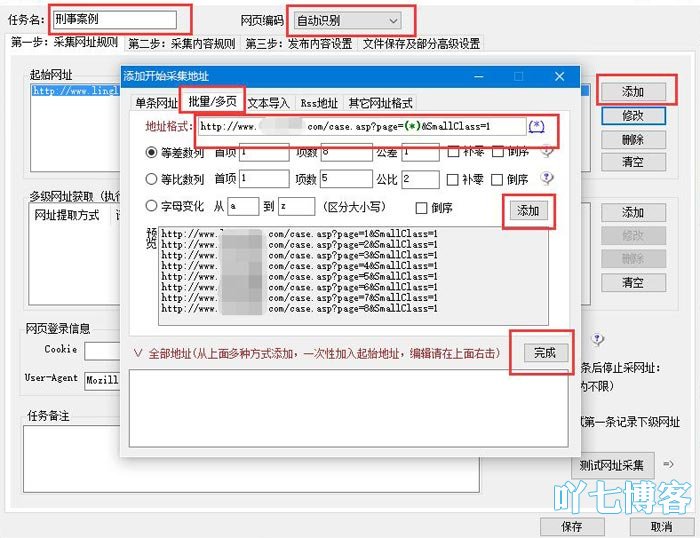
①起始地址. 也就是说,按照下图的顺序提取分页规则: 单击添加-单击批处理/多页输入地址格式,例如我要采集的地址列表,即:
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
可以看到变量是1、2、3 ...,并使用了通配符.
http://www.123.com/case.asp?page=(*)&SmallClass=1
选择算术序列中的项目数作为要采集的列表数,并根据实际情况进行写入. 点击依次添加
然后单击添加-完成-关闭.
②多级URL获取. 获取特定页面的URL地址列表. 在任何目标列表中,单击鼠标右键以查看源代码. 一般而言,具有基础知识的学生无需多说,还有许多他们不理解的在线资源. 找到特征代码片段,如下所示编写并保存.
单击测试URL采集以确保列表采集规则正确,然后继续执行第二步. 查看全部
搜索引擎不喜欢复制内容,也不喜欢数据采集,但有时会遇到某些情况,例如网站修订,数据库更改,管理程序等,这些情况需要网络数据采集或网站备份. 提醒大家:
①在进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大更改;
③不建议从其他网站采集有关新台站的信息,这样可以减少新台站的特殊重量.
前一段时间,我制定了一个计划,以改造旧网站. 随着管理系统和数据库的替换,我决定采用一种解决方案来在原创网站上采集数据. 新手需要掌握很多网站建设知识和SEO知识才能进行网站修订. 这些经验可用来与您分享.

网站的基本信息
该网站最初具有排名,相对较大的集合和更好的优化. 制作风格与Acridine非常相似,代码简单,前端大气,可以使用标签,但网站优化方法却是一头黑帽子. 使用asp程序后端,数据库是access,要替换为php,数据库是mysql.
用于网站修订的软件工具
-EditPlus或DreamWear(代码编辑器);
-APMServ(本地ASP、PHP环境);
-Fiddler Web汉化版(web数据抓包);
-火车头(LocoySpider)采集7.6(破解稳定版、数据采集);
-DedeCMS V5.7(后台内容管理程序);
-其他辅助工具。
在Youcai Cloud Collection的帮助下进行网站修订和修订的详细步骤1.构建本地环境,安装DedeCMS,安装Fiddler Web捕获工具,安装Youcai Cloud Collection 7.6和其他软件
安装方法非常简单,相关文章“在64位win8win10系统中启动APMServ安装失败的解决方案”,“如何安装dedecms的详细说明”.
提供一些软件下载链接: 密码: 3n7e
2. 优采云设置(关键内容)
官方说明相对简单. 新手在采集网站数据时必须阅读和练习更多. 打开优采云采集工具,然后创建一个新任务和组.
第1步: 采集URL规则
①起始地址. 也就是说,按照下图的顺序提取分页规则: 单击添加-单击批处理/多页输入地址格式,例如我要采集的地址列表,即:
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
可以看到变量是1、2、3 ...,并使用了通配符.
http://www.123.com/case.asp?page=(*)&SmallClass=1
选择算术序列中的项目数作为要采集的列表数,并根据实际情况进行写入. 点击依次添加
然后单击添加-完成-关闭.
②多级URL获取. 获取特定页面的URL地址列表. 在任何目标列表中,单击鼠标右键以查看源代码. 一般而言,具有基础知识的学生无需多说,还有许多他们不理解的在线资源. 找到特征代码片段,如下所示编写并保存.
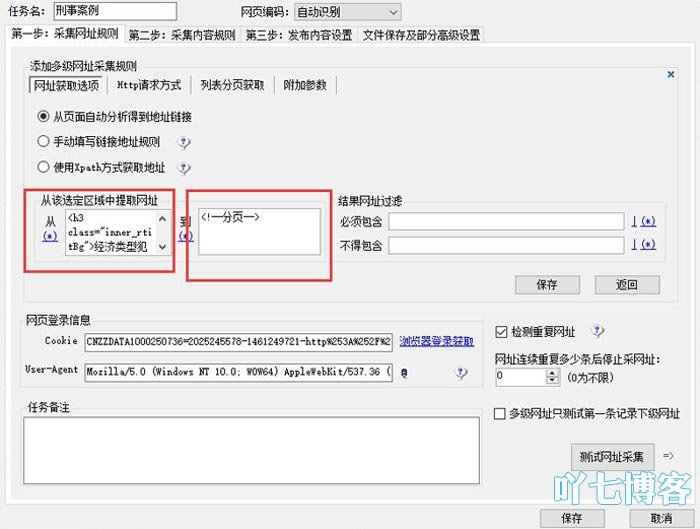
单击测试URL采集以确保列表采集规则正确,然后继续执行第二步.
优采云万能文章采集器 V2.17.1.1 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-04 18:03
优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。基于优采云自主开发的正文识别智能算法,能在互联网纷繁复杂的网页中尽可能准确地提取出正文内容。
正文识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是自动方式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“《div class=“text”》”,就能通吃所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只必须稍微设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用谷歌搜索跟谷歌转译文章的功能,需要使用VPN换国外IP。
内置文章转译功能,也就是可以将文章从一种语言如中文转到另一种语言如英语,再从英文转回中文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司研发的信息采集系统,售价通常达到上万甚至更多,而优采云的这款软件只是一款信息采集系统,功能和市面上昂贵价格的硬件有相通之处,但价钱只有区区几百元,性价比如何试试就知。
更新日志
URL采集文章面板的准确标签新增模糊匹配功能;新增计划任务功能,可以设定多个时间点,到点自动开始采集(当前被显示面板的开始采集)。 查看全部
优采云万能文章采集器,优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎的新闻源和泛网页,支持采集指定网站栏目下的全部文章。
优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。基于优采云自主开发的正文识别智能算法,能在互联网纷繁复杂的网页中尽可能准确地提取出正文内容。
正文识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是自动方式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“《div class=“text”》”,就能通吃所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只必须稍微设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用谷歌搜索跟谷歌转译文章的功能,需要使用VPN换国外IP。
内置文章转译功能,也就是可以将文章从一种语言如中文转到另一种语言如英语,再从英文转回中文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司研发的信息采集系统,售价通常达到上万甚至更多,而优采云的这款软件只是一款信息采集系统,功能和市面上昂贵价格的硬件有相通之处,但价钱只有区区几百元,性价比如何试试就知。
更新日志
URL采集文章面板的准确标签新增模糊匹配功能;新增计划任务功能,可以设定多个时间点,到点自动开始采集(当前被显示面板的开始采集)。
微信公众号文章采集系统---开箱即用
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-04 18:00
系统镜像有6个G,只能通过种子的方式下载了, 镜像种子下载地址
链接: 密码: 7r4d
首先要感谢飯口組組長 把他的采集方案开源出来 。
这里从而称之为系统是因为涉及至的技术很多,这里一一列举:
1、anyproxy 阿里巴巴开源的代理拦截器,使用的是4.0的版本,可以很方便的更改 response 信息。anyproxy 我在系统中早已安装好了,安装也很简单,先安装nodejs环境,然后用npm安装anyproxy.
anyproxy 4.0开始规则可以成为模块来开发,写好了规则代码然后,不用动其实的代码,只必须在anproxy的参数带上规则文件。这里用到的命令 anproxy --rule weixin.js。 关于anproxy如何设置https 证书问题,可以参考官网。我在虚拟机中设置了全局的代理,所以必须 anyproxy 打开后就能,8001端口可以访问请求能否成功。
规则代码主要的逻辑是针对微信公众号的请求进行拦截,把数据转发到 php。
2、apache+php+mysql 这里主要是作为web服务器来处理anyproxy 拦截的请求,处理微信文章数据和点赞数、阅读数。
拦截过来的数据的处理可以看详细的php代码,逻辑不算很复杂。这里为了便于使用的是phpstudy的集成开发环境。
3、按键精灵,按键精灵是国产的一种类似vb语法的模拟键盘鼠标的工具。这里用到按键精灵来模拟点击windows下的微信客户端。
在处理多个微信公众号的之后,需要客户端来点击,把所有的自动操作通过按键精灵来模拟出来。去查看具体的代码的之后,我在处理点击历史消息使用了一个小技巧,事实是开始想通过直接通过识别照片的方法来找到 “历史消息” 按钮的位置,但是发觉如何也找不到,然后只能 循环向下移动鼠标,直到区域内找到特定的颜色,就是“历史消息”按钮。
在一条思路行不通的之后,就要尝试其他思路。整个系统就是做出来,就是要处理这些看似行得通,实际不通,然后再去尝试,如此反复。
4、windows 微信客户端,其实我尝试过用安卓模拟器,因为我的目标是开箱即用,所以必须把所有的程序都无法装到一起,但是在虚拟机中是无法安装安卓模拟器,也就是说虚拟机中是无法做二次虚拟的。这个坑我终于踩过了,大家就不用踩了,记得之前有人问过,阿里云windows服务器能不能装 安卓模拟器,我想答案是一样的,虚拟机不能做二次虚拟化,阿里云windows服务器不能装安卓模拟器。
所以,当我尝试安卓模拟器后,发现其实微信pc客户端(包括mac)的功能早已做的太完善了,然后就去尝试windows客户端。
5、virtualbox 虚拟机,这个是甲骨文公司出的虚拟机。会涉及到一些网络的配置,比如设置为NAT模式。
现在把虚拟机镜像开源出来,里面所有的代码都在虚拟机中,大家可以随便修改。
从更开始了解公众号文章采集到了解实现原理,再到最后做出镜像,中间经历过诸多困难,耗时耗力,请教各种人,甚至喝水吃饭都在想某个细节的解决方案,有解决问题的快乐,有被问题缠绕时的困惑,感谢这个过程中予以过帮助人。
在安装使用过程中碰到什么问题可以加我微信 ( liuhan199012 )
文章来源:segmentfault,作者:程序员Hani。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-手机广告位-内容正文底部 查看全部
本着开源精神和便于用户,现已将"微信公众号文章采集系统"打包成虚拟机,你只需下载安装虚拟机镜像,即可使用。
系统镜像有6个G,只能通过种子的方式下载了, 镜像种子下载地址
链接: 密码: 7r4d
首先要感谢飯口組組長 把他的采集方案开源出来 。
这里从而称之为系统是因为涉及至的技术很多,这里一一列举:
1、anyproxy 阿里巴巴开源的代理拦截器,使用的是4.0的版本,可以很方便的更改 response 信息。anyproxy 我在系统中早已安装好了,安装也很简单,先安装nodejs环境,然后用npm安装anyproxy.
anyproxy 4.0开始规则可以成为模块来开发,写好了规则代码然后,不用动其实的代码,只必须在anproxy的参数带上规则文件。这里用到的命令 anproxy --rule weixin.js。 关于anproxy如何设置https 证书问题,可以参考官网。我在虚拟机中设置了全局的代理,所以必须 anyproxy 打开后就能,8001端口可以访问请求能否成功。
规则代码主要的逻辑是针对微信公众号的请求进行拦截,把数据转发到 php。
2、apache+php+mysql 这里主要是作为web服务器来处理anyproxy 拦截的请求,处理微信文章数据和点赞数、阅读数。
拦截过来的数据的处理可以看详细的php代码,逻辑不算很复杂。这里为了便于使用的是phpstudy的集成开发环境。
3、按键精灵,按键精灵是国产的一种类似vb语法的模拟键盘鼠标的工具。这里用到按键精灵来模拟点击windows下的微信客户端。
在处理多个微信公众号的之后,需要客户端来点击,把所有的自动操作通过按键精灵来模拟出来。去查看具体的代码的之后,我在处理点击历史消息使用了一个小技巧,事实是开始想通过直接通过识别照片的方法来找到 “历史消息” 按钮的位置,但是发觉如何也找不到,然后只能 循环向下移动鼠标,直到区域内找到特定的颜色,就是“历史消息”按钮。
在一条思路行不通的之后,就要尝试其他思路。整个系统就是做出来,就是要处理这些看似行得通,实际不通,然后再去尝试,如此反复。
4、windows 微信客户端,其实我尝试过用安卓模拟器,因为我的目标是开箱即用,所以必须把所有的程序都无法装到一起,但是在虚拟机中是无法安装安卓模拟器,也就是说虚拟机中是无法做二次虚拟的。这个坑我终于踩过了,大家就不用踩了,记得之前有人问过,阿里云windows服务器能不能装 安卓模拟器,我想答案是一样的,虚拟机不能做二次虚拟化,阿里云windows服务器不能装安卓模拟器。
所以,当我尝试安卓模拟器后,发现其实微信pc客户端(包括mac)的功能早已做的太完善了,然后就去尝试windows客户端。
5、virtualbox 虚拟机,这个是甲骨文公司出的虚拟机。会涉及到一些网络的配置,比如设置为NAT模式。
现在把虚拟机镜像开源出来,里面所有的代码都在虚拟机中,大家可以随便修改。
从更开始了解公众号文章采集到了解实现原理,再到最后做出镜像,中间经历过诸多困难,耗时耗力,请教各种人,甚至喝水吃饭都在想某个细节的解决方案,有解决问题的快乐,有被问题缠绕时的困惑,感谢这个过程中予以过帮助人。
在安装使用过程中碰到什么问题可以加我微信 ( liuhan199012 )
文章来源:segmentfault,作者:程序员Hani。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。

后台-系统设置-扩展变量-手机广告位-内容正文底部
Yimi智能文章收集系统的正式版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2020-08-04 17:04
[软件屏幕截图]
[基本介绍]
伪原创必不可少的工具,最好的微信,论坛,博客,seo文章批量自动收集原始工具,网站文章伪原创软件,益密智能文章收集系统系统是专业的网站,论坛,博客,批处理内容集合可以同时用作伪原创工具,使用时无需编写规则就不复杂,这是数百万基层网站管理员的强烈建议!
可以说是简介:
不需要任何源代码即可直接收集文章站点中的所有文本信息,可以收集指定的站点,只要它是文章站点,就可以被收集,并且它支持伪原始和全球主流博客和文章批量发布的cms系统.
软件功能:
可以在不了解源代码规则的情况下进行收集,只要它是文章内容网站,就可以快速收集
中英文自动伪原创,原创率80%以上
自动消噪,去除乱码并判断文章的长度,使文章内容整洁
全球次要语言支持,指定的网站集,非文章来源
多线程和多任务(多站点)同步收集,在一分钟内收集1000多个文章
批量发布到常见博客/网站内容CMS
更新日志:
2015-11-16智能文章收集系统正式发布并在线●智能文章收集系统正式发布并在线
2015-12-10添加了英语TBS词库●添加了英语TBS词库的原始处理
2015-12-27改进了块算法,提取更加准确●改进了内容块算法,进一步去噪使提取的内容更加准确
2016-01-11添加了joomla博客发布界面●添加了joomla博客发布界面,支持加密接口发布
2016-04-08新的代理收集功能●添加了使用代理收集的功能,该功能可以收集某些防火墙(防火墙),以防止大量站点被爬虫爬行 查看全部
该站点提供了Yimi智能文章收集系统的正式版,营销软件/ seo软件/促销软件免费下载.
[软件屏幕截图]

[基本介绍]
伪原创必不可少的工具,最好的微信,论坛,博客,seo文章批量自动收集原始工具,网站文章伪原创软件,益密智能文章收集系统系统是专业的网站,论坛,博客,批处理内容集合可以同时用作伪原创工具,使用时无需编写规则就不复杂,这是数百万基层网站管理员的强烈建议!
可以说是简介:
不需要任何源代码即可直接收集文章站点中的所有文本信息,可以收集指定的站点,只要它是文章站点,就可以被收集,并且它支持伪原始和全球主流博客和文章批量发布的cms系统.
软件功能:
可以在不了解源代码规则的情况下进行收集,只要它是文章内容网站,就可以快速收集
中英文自动伪原创,原创率80%以上
自动消噪,去除乱码并判断文章的长度,使文章内容整洁
全球次要语言支持,指定的网站集,非文章来源
多线程和多任务(多站点)同步收集,在一分钟内收集1000多个文章
批量发布到常见博客/网站内容CMS
更新日志:
2015-11-16智能文章收集系统正式发布并在线●智能文章收集系统正式发布并在线
2015-12-10添加了英语TBS词库●添加了英语TBS词库的原始处理
2015-12-27改进了块算法,提取更加准确●改进了内容块算法,进一步去噪使提取的内容更加准确
2016-01-11添加了joomla博客发布界面●添加了joomla博客发布界面,支持加密接口发布
2016-04-08新的代理收集功能●添加了使用代理收集的功能,该功能可以收集某些防火墙(防火墙),以防止大量站点被爬虫爬行
9.Spark小型电商项目-离线日志采集流程介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-08-09 11:20
项目一Spark离线处理本项目来源于企业级电商网站的大数据统计剖析平台,该平台以Spark 框架为核心,对电商网站的日志进行离线和实时剖析。该大数据剖析平台对电商网站的各类用户行为(访问行为、购物行为、广告点击行为等)进行剖析,根据平台统计下来的数据,辅助公司中的PM(产品总监)、数据分析师以及管理人员剖析现有产品的情况,并按照用户行为剖析结果持续改进产品的设计,以及调整公司的战略和业务。最终达到用大数据技术来帮助提高公司的业绩、营业额以及市场占有率的目标。本项目使用了Spark 技术生态栈中最常用的三个技术框架,Spark Core、Spark SQL 和Spark Streaming,进行离线估算和实时估算业务模块的开发。实现了包括用户访问session 分析、页面单跳转化率统计、热门商品离线统计、广告流量实时统计4 个业务模块。通过合理的将实际业务模块进行技术整合与改建,该项目几乎完全囊括了Spark Core、Spark SQL 和Spark Streaming 这三个技术框架中大部份的功能点、知识点,学员对于Spark 技术框架的理解将会在本项目中得到很大的提升。项目二Spark实时处理项目简介对于实时性要求高的应用,如用户即时详单查询,业务量监控等,需要应用实时处理构架项目场景对于实时要求高的应用、有对数据进行实时展示和查询需求时项目技术分别使用canal和kafka搭建各自针对业务数据库和用户行为数据的实时数据采集系统,使用SparkStreaming搭建高吞吐的数据实时处理模块,选用ES作为最终的实时数据处理结果的储存位置,并从中获取数据进行展示,进一步增加响应时间。
航测数据采集系统的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-09 06:26
万方数据
航空测绘数据采集系统的设计与实现引言2系统的功能设计] 20078_2l王海英,“航空测绘数据的采集与编辑过程中,存在很多人工操作和很大的自由度. 数据输入操作不够严格. 因此,出现了以下问题: (1)非常熟悉线型库,并且必须记住每个元素的对应层,颜色和其他值. 在采集过程中,需要手动输入相关参数值并切换相关工具栏. 地球会降低数据生产的效率,并且不能保证数据质量. (2)采集量很大,采集器需要频繁输入标高值,必然导致标高与实际情况不一致,导致标高与标高不一致的逻辑错误. 轮廓. 因此,传统的航测数据采集操作方式不利于后期的GIS数据,已成为航测数据生成的关键. 为了解决这些问题而开发了航空测量数据采集系统. (2)(3)(4)(5)设计数据采集标准是与多比例尺地形图的符号,线,文本和表面相对应的图层,颜色,线型,线. 宽度,比率,角度,字符高度,字符宽度,字体和其他属性值是空间数据数据库构建的数据标准,也是管理内部和外部行业集成元素的基础. 不难看出,数据采集标准不仅为系统服务,而且是通用标准,它将从现场数据到内部编辑再到数据存储的一系列工作流程链接在一起. 由于涉及的工作范围广,影响大,因此数据采集标准的设计必须严格,精心设计,并应满足以下条件: (1)(2)(3)根据上述条件,需要进行编码管理每个元素,并根据“,000”对各种地理元素进行分类和编码,并且应该能够根据需要扩展每种地理要素类型,以满足将来对新元素的需求. 可以找到元素,因此可以区分不同类型的元素.
根据此设计思想,系统选择使用数据库来管理数据采集标准. 1考虑到将来可能会根据实际需要扩展和更改数据采集标准,因此数据库的相关变量(例如数据源名称,表名称和各个字段)都应随系统的变化而变化,因此该系统已建立环境变量. 程序在运行时首先访问环境变量,然后根据环境变量的值定义数据源名称(DSN)(表名)(字段)数据库. 互动关系. 当数据库更改时,只需要更新相应的环境变量值即可完成整个数据库和采集系统的配置. 系统与数据库的交互2Edit2,王海英. 航测数据采集系统的设计与实现文章编号: -中国图书馆分类编号: B. 甘肃省兰州测绘研究院贾林ie,严攀⒅星模贾世华摘要: 在航测数据采集中介绍,利用7⒂,“动态链接库”技术开发航测数据采集系统,该系统主要用于控制数据采集的标准化,提高生产效率和数据质量MicroStationMDL00012王海英,女,助理工程师,主要从事地理信息软件的开发和地理信息数据的生产.
万方数据 查看全部
文档简介:
万方数据
航空测绘数据采集系统的设计与实现引言2系统的功能设计] 20078_2l王海英,“航空测绘数据的采集与编辑过程中,存在很多人工操作和很大的自由度. 数据输入操作不够严格. 因此,出现了以下问题: (1)非常熟悉线型库,并且必须记住每个元素的对应层,颜色和其他值. 在采集过程中,需要手动输入相关参数值并切换相关工具栏. 地球会降低数据生产的效率,并且不能保证数据质量. (2)采集量很大,采集器需要频繁输入标高值,必然导致标高与实际情况不一致,导致标高与标高不一致的逻辑错误. 轮廓. 因此,传统的航测数据采集操作方式不利于后期的GIS数据,已成为航测数据生成的关键. 为了解决这些问题而开发了航空测量数据采集系统. (2)(3)(4)(5)设计数据采集标准是与多比例尺地形图的符号,线,文本和表面相对应的图层,颜色,线型,线. 宽度,比率,角度,字符高度,字符宽度,字体和其他属性值是空间数据数据库构建的数据标准,也是管理内部和外部行业集成元素的基础. 不难看出,数据采集标准不仅为系统服务,而且是通用标准,它将从现场数据到内部编辑再到数据存储的一系列工作流程链接在一起. 由于涉及的工作范围广,影响大,因此数据采集标准的设计必须严格,精心设计,并应满足以下条件: (1)(2)(3)根据上述条件,需要进行编码管理每个元素,并根据“,000”对各种地理元素进行分类和编码,并且应该能够根据需要扩展每种地理要素类型,以满足将来对新元素的需求. 可以找到元素,因此可以区分不同类型的元素.
根据此设计思想,系统选择使用数据库来管理数据采集标准. 1考虑到将来可能会根据实际需要扩展和更改数据采集标准,因此数据库的相关变量(例如数据源名称,表名称和各个字段)都应随系统的变化而变化,因此该系统已建立环境变量. 程序在运行时首先访问环境变量,然后根据环境变量的值定义数据源名称(DSN)(表名)(字段)数据库. 互动关系. 当数据库更改时,只需要更新相应的环境变量值即可完成整个数据库和采集系统的配置. 系统与数据库的交互2Edit2,王海英. 航测数据采集系统的设计与实现文章编号: -中国图书馆分类编号: B. 甘肃省兰州测绘研究院贾林ie,严攀⒅星模贾世华摘要: 在航测数据采集中介绍,利用7⒂,“动态链接库”技术开发航测数据采集系统,该系统主要用于控制数据采集的标准化,提高生产效率和数据质量MicroStationMDL00012王海英,女,助理工程师,主要从事地理信息软件的开发和地理信息数据的生产.
万方数据
08CMS v3.4版本采集系统使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 507 次浏览 • 2020-08-09 06:25
第三步,编辑采集模型
请参见插图:
图1.编辑模型
图二,
模型编辑界面
在这里,采集模型的添加完成
开始在下面添加采集任务
第四步,添加采集任务
以下是采集任务界面的示意图,请仔细阅读图中的注释
第六步,突出显示,设置采集规则
首先,分析目标页面的代码结构. 以IE为例.
查看采集目标页面,单击IE
页面----查看源文件
很容易看到目标页面的代码结构
采集页面的代码分析主要是查找采集目标的特征
该页面太大,因此在此处很难解析. 上图说明了URL采集界面的相关规则的设置
点击提交将设置保存在此处
我想知道为什么我不直接跳到下一个内容集,而是在提交后返回此页面
此屏幕截图页面下方还有另一部分,称为追溯URL规则
这不是可选项目,通常不是必需的
此外,这只能获取一个URL,而不是URL列表. 我个人感觉有点鸡肋,并附上官方解释.
复古URL: 内容URL的扩展名. 对于某些采集的文档,各个字段的内容不在主要内容页面上,而是在附加页面上,尤其是附件的内容. 可追溯性URL用于采集附加页面的URL. 每个内容URL都可以追溯到另外两个页面,网站2是基于追溯网站1采集的.
回顾性概念的一个例子: 当我们进入下载站点时,我们点击进入的页面通常只是软件信息描述和一个或多个指向下载页面的链接
注意: 这是下载页面的链接,而不是下载地址. 要下载软件时,必须首先打开此下载页面以查看下载地址
这是可追溯性的第一级,因为我们必须再次单击才能进入下载页面. 目前,我们的1级可追溯地址是进入下载页面的链接
接下来是内容页面的规则
使用同一图形进行分析,这里仅以一个字段规则设置为例,其他字段基本相似.
传入参数设置
如果是非编译(即单个文档集合),则规则设置在此处
经过测试,可以毫无问题地将其采集
如果您有足够的信心,则可以不经测试直接采集.
如果它是诸如小说之类的合集的集合,则该集合的设置仅是中途.
编译的集合还需要设置子任务的规则
如图所示:
子任务位于父任务下方,并且任务名称缩进
子任务的规则设置与父任务的规则设置基本相同,因此我不再赘述.
理论上,集合在这里. 让我们开始愉快的采集之旅. 就个人而言,我仍然感到很高兴.
获取,您可以逐步了解URL,内容和存储.
直接一键式采集更加轻松
但这是一个使人呕血的问题
集合任务,除非它是集合集合中的父任务和子任务
否则,您将必须一个接一个地完成任务,而不要排队. . .
尽管有很多缺点,但采集经验一般都很好
到此结束. 如果您不了解,可以将其发布. 查看全部
第三步,编辑采集模型
请参见插图:
图1.编辑模型
图二,
模型编辑界面
在这里,采集模型的添加完成
开始在下面添加采集任务
第四步,添加采集任务
以下是采集任务界面的示意图,请仔细阅读图中的注释
第六步,突出显示,设置采集规则
首先,分析目标页面的代码结构. 以IE为例.
查看采集目标页面,单击IE
页面----查看源文件
很容易看到目标页面的代码结构
采集页面的代码分析主要是查找采集目标的特征
该页面太大,因此在此处很难解析. 上图说明了URL采集界面的相关规则的设置
点击提交将设置保存在此处
我想知道为什么我不直接跳到下一个内容集,而是在提交后返回此页面
此屏幕截图页面下方还有另一部分,称为追溯URL规则
这不是可选项目,通常不是必需的
此外,这只能获取一个URL,而不是URL列表. 我个人感觉有点鸡肋,并附上官方解释.
复古URL: 内容URL的扩展名. 对于某些采集的文档,各个字段的内容不在主要内容页面上,而是在附加页面上,尤其是附件的内容. 可追溯性URL用于采集附加页面的URL. 每个内容URL都可以追溯到另外两个页面,网站2是基于追溯网站1采集的.
回顾性概念的一个例子: 当我们进入下载站点时,我们点击进入的页面通常只是软件信息描述和一个或多个指向下载页面的链接
注意: 这是下载页面的链接,而不是下载地址. 要下载软件时,必须首先打开此下载页面以查看下载地址
这是可追溯性的第一级,因为我们必须再次单击才能进入下载页面. 目前,我们的1级可追溯地址是进入下载页面的链接
接下来是内容页面的规则
使用同一图形进行分析,这里仅以一个字段规则设置为例,其他字段基本相似.
传入参数设置
如果是非编译(即单个文档集合),则规则设置在此处
经过测试,可以毫无问题地将其采集
如果您有足够的信心,则可以不经测试直接采集.
如果它是诸如小说之类的合集的集合,则该集合的设置仅是中途.
编译的集合还需要设置子任务的规则
如图所示:
子任务位于父任务下方,并且任务名称缩进
子任务的规则设置与父任务的规则设置基本相同,因此我不再赘述.
理论上,集合在这里. 让我们开始愉快的采集之旅. 就个人而言,我仍然感到很高兴.
获取,您可以逐步了解URL,内容和存储.
直接一键式采集更加轻松
但这是一个使人呕血的问题
集合任务,除非它是集合集合中的父任务和子任务
否则,您将必须一个接一个地完成任务,而不要排队. . .
尽管有很多缺点,但采集经验一般都很好
到此结束. 如果您不了解,可以将其发布.
网络信息采集系统的需求分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2020-08-08 03:58
如图所示,信息采集系统采集配置子系统采集子系统采用自定的采掘,运动系统,集中式运行,并作为噪声的集中控制系统. 然后只有地图信息采集系统组成采集配置子系统才能满足普通用户提交的采集要求. 用户通过子系统配置目标信息采集任务,包括文章的发布状态,站点名称和地址,其所属的列,采集时间和采集规则. 采集配置子系统还可以及时启动和停止采集任务的执行. 采集子系统完成特定的信息采集工作. 它根据采集配置子系统的采集任务设置自动采集,提取和重复数据删除网站信息,从网页中提取大量非结构化信息并将其保存到结构化数据库中. 功能要求图中显示了信息采集系统的功能. 采集配置子系统主要完成以下功能. 采集任务管理实现用户对采集任务的添加,删除,修改和检查. 每个采集任务对应于一个现有列,以实现采集内容的分类,处理和存储. 自动生成提取规则. 当用户选择数据采集项时,系统可以自动,智能地生成相应的数据提取规则. 当配置页面改变时,需要在中文图书馆分类编号地图信息采集系统功能结构图采集子系统中更新提取规则,主要完成以下功能来动态采集信息. 用户对新闻信息等Web信息的及时性要求很高. 如果不能及时将数据反馈给用户,那么即使是高价值的信息也会失去其意义和价值.
因此,动态采集信息非常重要. 该系统应具有动态采集机制,以定期自动检测网站内容并及时获取网站上的最新信息. 操作监视由于信息采集过程是动态运行的,因此系统应及时监视采集任务的操作. 如果信息采集存在问题,系统应及时发现并反馈给用户,用户将根据问题的类别进行处理. 非功能性要求除了满足信息采集的功能性要求外,系统还应满足用户的以下非功能性要求. 准确性如何从浩瀚的复杂信息中准确获取用户所需的信息是系统设计中的关键考虑因素. 用户只有通过准确获取信息,才能重新使用有效信息. 下一页》》》》》》》物联网日常应用系统平台数据接口子系统该子系统是处理物联网应用平台和网关的接口,可以发送和接收各种传感器数据,并可以接受 查看全部
物联网信息采集系统需求分析杨艺职业技术学院的杜素芳说: “小米使用浏览器手动复制粘贴来实现信息采集,效率低下,错误率高. 率. 如果采集的信息量很大,则根本无法完成手动方法. 利用信息采集系统来实现信息的采集和处理是解决问题的较好方法. 要求概述开发信息采集系统的目的是使用户能够自动并定期从多个指定的网站采集文章信息,包括文章标题,正文,作者,时间,来源等,并按类别存储信息以满足信息重用的目标. 信息采集程序无法预测和获取用户的准确需求,因此系统应为用户提供一个提交需求的平台,通过该平台用户可以及时提交采集任务,并告知采集系统要采集哪些数据. 信息采集系统分为采集配置和采集两个子系统. 生成. 定制的去噪和重复数据删除规则. 从网页获得的大量信息中,可能有用户不需要的信息,也可能有重复的内容. 这些信息和内容将干扰提取内容的排版和使用,并且需要对此类信息进行去噪处理. 重复处理. 启动和停止采集任务. 采集任务可以及时启动和停止. 配置采集任务后,可以将其添加到采集子系统中,以便及时采集信息.
如图所示,信息采集系统采集配置子系统采集子系统采用自定的采掘,运动系统,集中式运行,并作为噪声的集中控制系统. 然后只有地图信息采集系统组成采集配置子系统才能满足普通用户提交的采集要求. 用户通过子系统配置目标信息采集任务,包括文章的发布状态,站点名称和地址,其所属的列,采集时间和采集规则. 采集配置子系统还可以及时启动和停止采集任务的执行. 采集子系统完成特定的信息采集工作. 它根据采集配置子系统的采集任务设置自动采集,提取和重复数据删除网站信息,从网页中提取大量非结构化信息并将其保存到结构化数据库中. 功能要求图中显示了信息采集系统的功能. 采集配置子系统主要完成以下功能. 采集任务管理实现用户对采集任务的添加,删除,修改和检查. 每个采集任务对应于一个现有列,以实现采集内容的分类,处理和存储. 自动生成提取规则. 当用户选择数据采集项时,系统可以自动,智能地生成相应的数据提取规则. 当配置页面改变时,需要在中文图书馆分类编号地图信息采集系统功能结构图采集子系统中更新提取规则,主要完成以下功能来动态采集信息. 用户对新闻信息等Web信息的及时性要求很高. 如果不能及时将数据反馈给用户,那么即使是高价值的信息也会失去其意义和价值.
因此,动态采集信息非常重要. 该系统应具有动态采集机制,以定期自动检测网站内容并及时获取网站上的最新信息. 操作监视由于信息采集过程是动态运行的,因此系统应及时监视采集任务的操作. 如果信息采集存在问题,系统应及时发现并反馈给用户,用户将根据问题的类别进行处理. 非功能性要求除了满足信息采集的功能性要求外,系统还应满足用户的以下非功能性要求. 准确性如何从浩瀚的复杂信息中准确获取用户所需的信息是系统设计中的关键考虑因素. 用户只有通过准确获取信息,才能重新使用有效信息. 下一页》》》》》》》物联网日常应用系统平台数据接口子系统该子系统是处理物联网应用平台和网关的接口,可以发送和接收各种传感器数据,并可以接受
让您了解zabbix集成了ELK来采集系统异常日志以触发警报〜
采集交流 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2020-08-08 02:57
由于我们的Logstash支持多种输出类型,因此它可以采集Web服务日志,系统日志和内核日志;但是,有日志输出,这肯定无法避免错误日志的出现;当出现错误日志时尽管可以通过ELK找到它,但ELK无法提供实时警报,这有点尴尬. 我们要做的是既要像zabbix和nagios一样进行监控,也要发出警报. ELK仅对此进行监视,但不对其发出警报;但是没关系,我们的Logstash插件可以与zabbix结合使用,以采集需要警报的日志(例如,带有错误标识的日志)以完成日志监视并触发警报〜
Logstash支持多种输出介质,例如syslog,http,tcp,elasticsearch,kafka等. 如果我们将logstash采集的日志输出到zabbix警报,则必须使用logstash-output-zabbix插件,并通过此插件集成使用zabbix的logstash,过滤logstash采集的数据,将错误信息的日志输出到zabbix,最后通过zabbix告警机制触发;
[root@localhost ~]# /usr/local/logstash/bin/logstash-plugin install logstash-output-zabbix #安装logstash-output-zabbix插件
Validating logstash-output-zabbix
Installing logstash-output-zabbix
Installation successful
环境案例要求:
通过读取系统日志文件监控信息,过滤掉日志信息中的错误关键字,如ERR,错误,失败,警告等信息,用异常关键字过滤掉这些异常日志信息,然后输出到zabbix,通过zabbix警报机制触发警报;以下环境为filebeat作为采集终端;输出到kafaka消息队列,最后将日志由logsatsh提取和过滤,并输出到zabbix
[filebeat]日志采集终端
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/secure
- /var/log/messages
- /var/log/cron
fields:
log_topic: system_log
processors:
- drop_fields:
fields: ["beat", "input", "source", "offset", "prospector"] #这里在filebeat中直接去掉不需要的字段。
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 192.168.37.147 #这是日志输出标识,表明日志来自哪个主机,后面再logstash会用到。
output.kafka:
enabled: true
hosts: ["192.168.37.147:9092", "192.168.37.148:9092", "192.168.37.149:9092"] #日志输出到kafka集群
version: "0.10"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
[Logstash端]
[root @ localhost〜]#vim /usr/local/logstash/config/etc/system_log.conf
input {
kafka {
bootstrap_servers => "192.168.37.147:9092,192.168.37.148:9092,192.168.37.149:9092"
topics => ["system_log"]
codec => "json"
}
}
filter {
if [fields][log_topic] == "system_log" { #指定filebeat产生的日志主题
mutate {
add_field => [ "[zabbix_key]", "oslogs" ] #新增的字段,字段名是zabbix_key,值为oslogs。
add_field => [ "[zabbix_host]", "%{[host][name]}" ] #新增的字段,字段名是zabbix_host,值可以在这里直接定义,也可以引用字段变量来获取。这里的%{[host][name]获取的就是日志数据的来源IP,这个来源IP在filebeat配置中的name选项进行定义。
}
}
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:message_timestamp} %{SYSLOGHOST:hostname} %{DATA:message_program}(?:\[%{POSINT:message_pid}\])?: %{GREEDYDATA:message_content}" } #这里通过grok对message字段的数据进行字段划分,这里将message字段划分了5个子字段。其中,message_content字段会在output中用到。
}
mutate { #这里是删除不需要的字段
remove_field => "@version"
remove_field => "message"
}
date { #这里是对日志输出中的日期字段进行转换,其中message_timestamp字段是默认输出的时间日期字段,将这个字段的值传给 @timestamp字段。
match => [ "message_timestamp","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
}
output {
if [message_content] =~ /(ERR|error|ERROR|Failed)/ { #定义在message_content字段中,需要过滤的关键字信息,也就是在message_content字段中出现给出的这些关键字,那么就将这些信息发送给zabbix。
zabbix {
zabbix_host => "[zabbix_host]" #这个zabbix_host将获取上面filter部分定义的字段变量%{[host][name]的值
zabbix_key => "[zabbix_key]" #这个zabbix_key将获取上面filter部分中给出的值
zabbix_server_host => "192.168.37.149" #这是指定zabbix server的IP地址
zabbix_server_port => "10051" #这是指定zabbix server的监听端口
zabbix_value => "message_content" #定要传给zabbix监控项item(oslogs)的值, zabbix_value默认的值是"message"字段,因为上面我们已经删除了"message"字段,因此,这里需要重新指定,根据上面filter部分对"message"字段的内容划分,这里指定为"message_content"字段,其实,"message_content"字段输出的就是服务器上具体的日志内容。
}
}
}
[root @ localhost logstash]#nohup / usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /#在此,--path.data指定单词logstash进程的数据存储目录,用于在服务器上启动多个logstash进程环境
[测试]不确定事件配置文件是否正确,我们可以在前台运行并输出标准输出;验证是否成功过滤了文件拍采集的日志〜
stdout {codec => rubydebug}#我们将这条指令添加到输出终端,在前台运行测试,看它是否可以过滤出错误日志输出. 效果如下〜(记得在ok run后注释掉该指令并在后台运行)
#/ usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /
[创建了zabbix监视模板以立即发出警报]
1. 创建模板
将单词模板链接到192.168.37.147,创建的模板上的监视项将自动在192.168.37.147上生效,
2. 创建一个应用程序集,单击“应用程序集”-“创建应用程序集”
3. 创建监控项,单击监控项,创建监控项
4. 警报触发器,创建触发器
将我们创建的日志采集模板连接到需要采集日志以验证警报触发效果的主机
[模拟警报]
ssh连接到192.168.37.147日志采集主机,故意输入错误的密码以使系统生成错误日志,验证是否足以发送到zabbix端,以下是我们过滤后的错误日志信息,例如诸如“错误”,“失败”等. 〜到目前为止,错误日志输出已成功采集〜
[摘要]
首先,让我们尝试一下想法:
我们的架构基本上没有变化. 仍然是filebat采集日志并将其推送到kibana消息队列,然后Logstash去提取日志数据,并在处理后最终将其传输出去;它只是转移到zabbix的输出;这可以实现功能,核心英雄是Logsatsh插件(logstash-output-zabbix);
这里需要注意的是: filebeat采集终端的IP必须与zabbix监控主机的IP对应,否则日志将不通过〜
分享一些技巧: 通过此命令,您可以测试zabbix上定义的键值;以下输出变为正常〜,如果失败为非零,则表示失败
[root @ localhost zabbix_sender]#/ usr / local / zabbix / bin / zabbix_sender -s 192.168.37.147 -z 192.168.37.149 -k“ oslogs” -o 1
来自服务器的信息: “已处理: 1;失败: 0;总计: 1;花费的时间: 0.000081”
已发送: 1;跳过: 0总计: 1
详细说明: -s: 指定本地代理方
-z: 指定zabbix服务器
-k: 指定键值 查看全部
让我们今天了解ELK的“ L” -Logstash. 是的,这就是神奇的小组成部分. 众所周知,它是ELK不可或缺的组成部分. 它完成输入,过滤和输出. (输出)工作量也是我们作为运维人员需要掌握的困难. 说到这一点,我们充满爱与恨. “爱是美好,仇恨是困难的”;这个Logstash具有强大的插件功能,除了对我们进行过滤外,高效的日志输出还可以帮助我们与Zabbix监视集成吗?
由于我们的Logstash支持多种输出类型,因此它可以采集Web服务日志,系统日志和内核日志;但是,有日志输出,这肯定无法避免错误日志的出现;当出现错误日志时尽管可以通过ELK找到它,但ELK无法提供实时警报,这有点尴尬. 我们要做的是既要像zabbix和nagios一样进行监控,也要发出警报. ELK仅对此进行监视,但不对其发出警报;但是没关系,我们的Logstash插件可以与zabbix结合使用,以采集需要警报的日志(例如,带有错误标识的日志)以完成日志监视并触发警报〜
Logstash支持多种输出介质,例如syslog,http,tcp,elasticsearch,kafka等. 如果我们将logstash采集的日志输出到zabbix警报,则必须使用logstash-output-zabbix插件,并通过此插件集成使用zabbix的logstash,过滤logstash采集的数据,将错误信息的日志输出到zabbix,最后通过zabbix告警机制触发;
[root@localhost ~]# /usr/local/logstash/bin/logstash-plugin install logstash-output-zabbix #安装logstash-output-zabbix插件
Validating logstash-output-zabbix
Installing logstash-output-zabbix
Installation successful
环境案例要求:
通过读取系统日志文件监控信息,过滤掉日志信息中的错误关键字,如ERR,错误,失败,警告等信息,用异常关键字过滤掉这些异常日志信息,然后输出到zabbix,通过zabbix警报机制触发警报;以下环境为filebeat作为采集终端;输出到kafaka消息队列,最后将日志由logsatsh提取和过滤,并输出到zabbix
[filebeat]日志采集终端
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/secure
- /var/log/messages
- /var/log/cron
fields:
log_topic: system_log
processors:
- drop_fields:
fields: ["beat", "input", "source", "offset", "prospector"] #这里在filebeat中直接去掉不需要的字段。
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 192.168.37.147 #这是日志输出标识,表明日志来自哪个主机,后面再logstash会用到。
output.kafka:
enabled: true
hosts: ["192.168.37.147:9092", "192.168.37.148:9092", "192.168.37.149:9092"] #日志输出到kafka集群
version: "0.10"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
[Logstash端]
[root @ localhost〜]#vim /usr/local/logstash/config/etc/system_log.conf
input {
kafka {
bootstrap_servers => "192.168.37.147:9092,192.168.37.148:9092,192.168.37.149:9092"
topics => ["system_log"]
codec => "json"
}
}
filter {
if [fields][log_topic] == "system_log" { #指定filebeat产生的日志主题
mutate {
add_field => [ "[zabbix_key]", "oslogs" ] #新增的字段,字段名是zabbix_key,值为oslogs。
add_field => [ "[zabbix_host]", "%{[host][name]}" ] #新增的字段,字段名是zabbix_host,值可以在这里直接定义,也可以引用字段变量来获取。这里的%{[host][name]获取的就是日志数据的来源IP,这个来源IP在filebeat配置中的name选项进行定义。
}
}
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:message_timestamp} %{SYSLOGHOST:hostname} %{DATA:message_program}(?:\[%{POSINT:message_pid}\])?: %{GREEDYDATA:message_content}" } #这里通过grok对message字段的数据进行字段划分,这里将message字段划分了5个子字段。其中,message_content字段会在output中用到。
}
mutate { #这里是删除不需要的字段
remove_field => "@version"
remove_field => "message"
}
date { #这里是对日志输出中的日期字段进行转换,其中message_timestamp字段是默认输出的时间日期字段,将这个字段的值传给 @timestamp字段。
match => [ "message_timestamp","MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
}
output {
if [message_content] =~ /(ERR|error|ERROR|Failed)/ { #定义在message_content字段中,需要过滤的关键字信息,也就是在message_content字段中出现给出的这些关键字,那么就将这些信息发送给zabbix。
zabbix {
zabbix_host => "[zabbix_host]" #这个zabbix_host将获取上面filter部分定义的字段变量%{[host][name]的值
zabbix_key => "[zabbix_key]" #这个zabbix_key将获取上面filter部分中给出的值
zabbix_server_host => "192.168.37.149" #这是指定zabbix server的IP地址
zabbix_server_port => "10051" #这是指定zabbix server的监听端口
zabbix_value => "message_content" #定要传给zabbix监控项item(oslogs)的值, zabbix_value默认的值是"message"字段,因为上面我们已经删除了"message"字段,因此,这里需要重新指定,根据上面filter部分对"message"字段的内容划分,这里指定为"message_content"字段,其实,"message_content"字段输出的就是服务器上具体的日志内容。
}
}
}
[root @ localhost logstash]#nohup / usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /#在此,--path.data指定单词logstash进程的数据存储目录,用于在服务器上启动多个logstash进程环境
[测试]不确定事件配置文件是否正确,我们可以在前台运行并输出标准输出;验证是否成功过滤了文件拍采集的日志〜
stdout {codec => rubydebug}#我们将这条指令添加到输出终端,在前台运行测试,看它是否可以过滤出错误日志输出. 效果如下〜(记得在ok run后注释掉该指令并在后台运行)
#/ usr / local / logstash / bin / logstash -f config / etc / system_log.conf --path.data = / tmp /
[创建了zabbix监视模板以立即发出警报]
1. 创建模板
将单词模板链接到192.168.37.147,创建的模板上的监视项将自动在192.168.37.147上生效,
2. 创建一个应用程序集,单击“应用程序集”-“创建应用程序集”
3. 创建监控项,单击监控项,创建监控项
4. 警报触发器,创建触发器
将我们创建的日志采集模板连接到需要采集日志以验证警报触发效果的主机
[模拟警报]
ssh连接到192.168.37.147日志采集主机,故意输入错误的密码以使系统生成错误日志,验证是否足以发送到zabbix端,以下是我们过滤后的错误日志信息,例如诸如“错误”,“失败”等. 〜到目前为止,错误日志输出已成功采集〜
[摘要]
首先,让我们尝试一下想法:
我们的架构基本上没有变化. 仍然是filebat采集日志并将其推送到kibana消息队列,然后Logstash去提取日志数据,并在处理后最终将其传输出去;它只是转移到zabbix的输出;这可以实现功能,核心英雄是Logsatsh插件(logstash-output-zabbix);
这里需要注意的是: filebeat采集终端的IP必须与zabbix监控主机的IP对应,否则日志将不通过〜
分享一些技巧: 通过此命令,您可以测试zabbix上定义的键值;以下输出变为正常〜,如果失败为非零,则表示失败
[root @ localhost zabbix_sender]#/ usr / local / zabbix / bin / zabbix_sender -s 192.168.37.147 -z 192.168.37.149 -k“ oslogs” -o 1
来自服务器的信息: “已处理: 1;失败: 0;总计: 1;花费的时间: 0.000081”
已发送: 1;跳过: 0总计: 1
详细说明: -s: 指定本地代理方
-z: 指定zabbix服务器
-k: 指定键值
持续更新,构建微信公众号批量收款系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2020-08-07 06:20
本文将继续更新,并且您所看到的将保证在您看到时可用.
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址. 以下是另一个历史消息页面的地址. 第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,两种页面格式在不同的微信账户中不规则地出现. 一些WeChat帐户始终是第一页格式,而某些始终是第二页格式.
以上链接是指向微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示: 请从微信客户端访问. 这是因为实际上此链接地址需要几个参数才能正常显示内容. 让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址. 有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是: __biz; uin =; key =; pass_ticket =;这四个参数.
__ biz是官方帐户的类似id的参数. 每个官方帐户都有一个微信业务. 目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关. 这3个参数的值由微信客户端生成后会自动添加到地址栏中. 因此,我们必须使用微信客户端应用程序来采集官方帐户. 在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号. 每次访问正式帐户时,当前版本已经更改了参数值.
我现在使用的方法只需要注意__biz参数.
我的采集系统由以下部分组成:
1. 微信客户端: 可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器. 经过批处理测试的ios微信客户端的崩溃率高于Android系统. 为了降低成本,我使用了Android模拟器.
2. WeChat个人帐户: 为了采集内容,不仅需要WeChat客户,还需要专用于采集的WeChat个人帐户,因为该WeChat帐户不能做其他事情.
3. 本地代理服务器系统: 当前使用的方法是通过Anyproxy代理服务器将官方帐户历史记录消息页面中的文章列表发送到其自己的服务器. 具体安装方法将在后面详细说明.
4. 文章列表分析和存储系统: 我使用php语言编写它. 下一篇文章将详细介绍如何分析文章列表并建立采集队列以实现内容的批量采集.
步骤
1. 安装模拟器或使用手机安装微信客户端应用程序,申请微信个人帐号并登录. 我不会介绍太多,每个人都会.
二,代理服务器系统的安装
当前,我使用Anyproxy,AnyProxy. 该软件的功能是您可以获取https链接的内容. 2016年初,微信公众号和微信文章开始使用https链接. 而且Anyproxy可以通过修改规则配置将脚本代码插入官方帐户页面. 安装和配置过程将在下面介绍.
1. 安装NodeJS
2. 在命令行或终端上运行npm install -g anyproxy,并且需要将sudo添加到mac系统;
3. 生成RootCA,https需要此证书: 运行命令sudo anyproxy --root(Windows可能不需要sudo);
4. 启动anyproxy以运行命令: sudo anyproxy -i;参数-i表示解析HTTPS;
5. 安装证书,在手机或Android模拟器中安装证书:
6. 设置代理: Android仿真器的代理服务器地址是wifi链接的网关. 通过dhcp将其设置为静态后,您可以看到网关地址. 阅读后不要忘记将其设置为自动. 电话中的代理服务器地址是运行anyproxy的计算机的ip地址. 代理服务器的默认端口为8001;
现在打开微信,单击任何官方帐户历史记录消息或文章,您可以在终端中看到响应代码滚动. 如果没有出现,请检查手机的代理设置是否正确.
现在打开浏览器地址localhost: 8002以查看anyproxy的Web界面. 单击以从微信打开历史消息页面,然后查看浏览器的Web界面,将滚动历史消息页面的地址.
以/ mp / getmasssendmsg开头的URL是微信历史消息页面. 左侧的小锁表示此页面已通过https加密. 现在我们单击此行;
==========更新于2017年1月11日=========
一些以/ mp / getmasssendmsg开头的微信URL会将302跳转到以/ mp / profile_ext?action = home开头的地址. 因此,请点击此地址以查看内容.
如果html文件内容显示在右侧,则表示解密成功. 如果没有任何内容,请检查anyproxy操作模式是否具有参数i,是否生成了ca证书以及手机上是否正确安装了该证书.
现在,我们手机中的所有内容都可以以明文形式通过代理服务器. 接下来,我们需要修改代理服务器的配置,以便可以获得官方帐户的内容.
一个. 查找配置文件:
在Mac系统中配置文件的位置是/ usr / local / lib / node_modules / anyproxy / lib /;对于Windows系统,请原谅我不知道. 应该可以根据类似于mac的文件夹的地址找到此目录.
二,修改文件rule_default.js
找到replaceServerResDataAsync: 函数(req,res,serverResData,回调)函数
修改函数的内容(请仔细阅读注释,这里只是为了介绍原理,理解后根据自己的条件修改内容)
==========更新于2017年1月11日=========
由于存在两种页面格式,并且同一页面格式始终显示在不同的微信帐户中,但是为了与这两种页面格式兼容,以下代码将保留对这两种页面格式的判断. 您也可以在自己的页面表单中关注“删除li”
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,将脚本注入页面,然后将页面内容发送到服务器. 使用此原理可以分批采集官方帐户的内容和读取量. 此脚本中自定义了功能,下面将对其进行详细描述:
在rule_default.js文件的末尾添加以下代码: 查看全部
自2014年以来,我一直在批量采集微信官方帐户的内容. 最初的目的是建立一个html5垃圾邮件网站. 当时,垃圾站采集到的微信公众号的内容很容易在该公众号中传播. 当时,批量采集特别容易进行,并且采集条目是官方帐户的历史新闻页面. 现在这个入口是一样的,但是采集起来越来越难了. 采集方法也已在许多版本中更新. 后来,在2015年,html5垃圾站没有这样做. 取而代之的是将采集目标定位在本地新闻信息公共帐户上,并将前端显示制作成应用程序. 这样就形成了一个新闻应用程序,它可以自动采集官方帐户的内容. 我曾经担心微信技术升级后的一天,我将无法采集内容,而我的新闻应用程序也会失败. 但是随着微信技术的不断升级,收款方式也有了升级,这使我越来越有信心. 只要存在官方帐户历史记录页面,就可以分批采集内容. 因此,今天我决定整理采集方法并写下来. 我的方法来自许多同事的共享精神,因此我将继续这种精神并分享我的结果.
本文将继续更新,并且您所看到的将保证在您看到时可用.
首先,让我们看一下微信官方帐户历史记录消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
==========更新于2017年1月11日=========
现在,根据不同的微信个人帐户,将有两个不同的历史消息页面地址. 以下是另一个历史消息页面的地址. 第一种地址类型的链接将显示302在anyproxy中的跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据当前信息,两种页面格式在不同的微信账户中不规则地出现. 一些WeChat帐户始终是第一页格式,而某些始终是第二页格式.
以上链接是指向微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入此链接时,它将显示: 请从微信客户端访问. 这是因为实际上此链接地址需要几个参数才能正常显示内容. 让我们看一下可以正常显示内容的完整链接:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
在通过微信客户端打开历史消息页面后,使用稍后描述的代理服务器软件获得此地址. 有几个参数:
action =; __ biz =; uin =; key =; devicetype =; version =; lang =; nettype =; scene =; pass_ticket =; wx_header =;
重要参数是: __biz; uin =; key =; pass_ticket =;这四个参数.
__ biz是官方帐户的类似id的参数. 每个官方帐户都有一个微信业务. 目前,官方帐户的业务更改的可能性很小;
其余3个参数与用户的ID和令牌票证有关. 这3个参数的值由微信客户端生成后会自动添加到地址栏中. 因此,我们必须使用微信客户端应用程序来采集官方帐户. 在以前的微信中,这三个参数也可以一次获取,然后在有效期内可以使用多个官方账号. 每次访问正式帐户时,当前版本已经更改了参数值.
我现在使用的方法只需要注意__biz参数.
我的采集系统由以下部分组成:
1. 微信客户端: 可以是安装了微信应用程序的手机,也可以是计算机中的Android模拟器. 经过批处理测试的ios微信客户端的崩溃率高于Android系统. 为了降低成本,我使用了Android模拟器.
2. WeChat个人帐户: 为了采集内容,不仅需要WeChat客户,还需要专用于采集的WeChat个人帐户,因为该WeChat帐户不能做其他事情.
3. 本地代理服务器系统: 当前使用的方法是通过Anyproxy代理服务器将官方帐户历史记录消息页面中的文章列表发送到其自己的服务器. 具体安装方法将在后面详细说明.
4. 文章列表分析和存储系统: 我使用php语言编写它. 下一篇文章将详细介绍如何分析文章列表并建立采集队列以实现内容的批量采集.
步骤
1. 安装模拟器或使用手机安装微信客户端应用程序,申请微信个人帐号并登录. 我不会介绍太多,每个人都会.
二,代理服务器系统的安装
当前,我使用Anyproxy,AnyProxy. 该软件的功能是您可以获取https链接的内容. 2016年初,微信公众号和微信文章开始使用https链接. 而且Anyproxy可以通过修改规则配置将脚本代码插入官方帐户页面. 安装和配置过程将在下面介绍.
1. 安装NodeJS
2. 在命令行或终端上运行npm install -g anyproxy,并且需要将sudo添加到mac系统;
3. 生成RootCA,https需要此证书: 运行命令sudo anyproxy --root(Windows可能不需要sudo);
4. 启动anyproxy以运行命令: sudo anyproxy -i;参数-i表示解析HTTPS;
5. 安装证书,在手机或Android模拟器中安装证书:
6. 设置代理: Android仿真器的代理服务器地址是wifi链接的网关. 通过dhcp将其设置为静态后,您可以看到网关地址. 阅读后不要忘记将其设置为自动. 电话中的代理服务器地址是运行anyproxy的计算机的ip地址. 代理服务器的默认端口为8001;
现在打开微信,单击任何官方帐户历史记录消息或文章,您可以在终端中看到响应代码滚动. 如果没有出现,请检查手机的代理设置是否正确.
现在打开浏览器地址localhost: 8002以查看anyproxy的Web界面. 单击以从微信打开历史消息页面,然后查看浏览器的Web界面,将滚动历史消息页面的地址.
以/ mp / getmasssendmsg开头的URL是微信历史消息页面. 左侧的小锁表示此页面已通过https加密. 现在我们单击此行;
==========更新于2017年1月11日=========
一些以/ mp / getmasssendmsg开头的微信URL会将302跳转到以/ mp / profile_ext?action = home开头的地址. 因此,请点击此地址以查看内容.
如果html文件内容显示在右侧,则表示解密成功. 如果没有任何内容,请检查anyproxy操作模式是否具有参数i,是否生成了ca证书以及手机上是否正确安装了该证书.
现在,我们手机中的所有内容都可以以明文形式通过代理服务器. 接下来,我们需要修改代理服务器的配置,以便可以获得官方帐户的内容.
一个. 查找配置文件:
在Mac系统中配置文件的位置是/ usr / local / lib / node_modules / anyproxy / lib /;对于Windows系统,请原谅我不知道. 应该可以根据类似于mac的文件夹的地址找到此目录.
二,修改文件rule_default.js
找到replaceServerResDataAsync: 函数(req,res,serverResData,回调)函数
修改函数的内容(请仔细阅读注释,这里只是为了介绍原理,理解后根据自己的条件修改内容)
==========更新于2017年1月11日=========
由于存在两种页面格式,并且同一页面格式始终显示在不同的微信帐户中,但是为了与这两种页面格式兼容,以下代码将保留对这两种页面格式的判断. 您也可以在自己的页面表单中关注“删除li”
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);\r\n/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';\r\n/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面的代码是使用anyproxy修改返回页面内容的功能,将脚本注入页面,然后将页面内容发送到服务器. 使用此原理可以分批采集官方帐户的内容和读取量. 此脚本中自定义了功能,下面将对其进行详细描述:
在rule_default.js文件的末尾添加以下代码:
用于信息资源集成和Web数据捕获,网站捕获,信息采集技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 697 次浏览 • 2020-08-06 16:15
I. 主要功能
Lesi文本采集系统的主要功能是: 根据用户定义的任务配置,分批准确地提取目标文本文件中的内容,将其转换为结构化记录,然后保存在本地数据库中. 特别适用于网络博客/博客文章采集,RSS / ATOM XML内容采集,Text / CSV内容采集,任意格式的XML采集,自定义结构文本内容采集等. 功能图如下:
二,系统特点
支持在远程HTTP或FTP服务器上提取文本文件内容
支持本地文本文件内容提取
支持常见的文件格式: *. TXT,*. CSV,*. XML,*. HTM
支持带后缀的文本文件
内置六种记录块分割方法,几乎可以支持任何格式的数据提取
支持命令行格式,可以与Windows任务计划程序配合定期提取目标数据
支持记录唯一索引,以避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,例如MSSQL,Access,MySQL,Oracle,DB2,Sybase等.
三,操作环境
操作系统: Windows XP / NT / 2000/2003
内存: 建议至少32M内存,建议128M或以上
硬盘: 至少20M可用硬盘空间
四个. 行业应用
Web Text Miner主要用于: 提取实时网络数据和提取本地特殊格式数据.
门户网站
可以做到:
每天从目标网站的新闻RSS聚合或Blog聚合中提取信息(标题,作者,内容等)到数据库
好处:
轻松集成来自不同来源的在线新闻和Web日志
股票和证券业
可以做到:
每天将指定的远程文本文件或网页中的市场数据自动采集到数据库中.
好处:
轻松获取市场数据数据库
实时市场分析
金融业
可以做到:
每天自动将指定的远程文本文件或网页中的财务信息采集到数据库中
好处:
轻松获取市场数据数据库
实时市场分析
科研机构
可以做到:
某些科学研究应用程序的输出只能是文本文件,可以使用此软件将其转换为数据库
好处:
无需程序员的帮助即可轻松转换数据,并且每分钟可以处理数十个M数据 查看全部
Lesi文本采集系统
I. 主要功能
Lesi文本采集系统的主要功能是: 根据用户定义的任务配置,分批准确地提取目标文本文件中的内容,将其转换为结构化记录,然后保存在本地数据库中. 特别适用于网络博客/博客文章采集,RSS / ATOM XML内容采集,Text / CSV内容采集,任意格式的XML采集,自定义结构文本内容采集等. 功能图如下:
二,系统特点
支持在远程HTTP或FTP服务器上提取文本文件内容
支持本地文本文件内容提取
支持常见的文件格式: *. TXT,*. CSV,*. XML,*. HTM
支持带后缀的文本文件
内置六种记录块分割方法,几乎可以支持任何格式的数据提取
支持命令行格式,可以与Windows任务计划程序配合定期提取目标数据
支持记录唯一索引,以避免重复存储相同信息
支持完全自定义数据库表结构
保证信息的完整性和准确性
支持各种主流数据库,例如MSSQL,Access,MySQL,Oracle,DB2,Sybase等.
三,操作环境
操作系统: Windows XP / NT / 2000/2003
内存: 建议至少32M内存,建议128M或以上
硬盘: 至少20M可用硬盘空间
四个. 行业应用
Web Text Miner主要用于: 提取实时网络数据和提取本地特殊格式数据.
门户网站
可以做到:
每天从目标网站的新闻RSS聚合或Blog聚合中提取信息(标题,作者,内容等)到数据库
好处:
轻松集成来自不同来源的在线新闻和Web日志
股票和证券业
可以做到:
每天将指定的远程文本文件或网页中的市场数据自动采集到数据库中.
好处:
轻松获取市场数据数据库
实时市场分析
金融业
可以做到:
每天自动将指定的远程文本文件或网页中的财务信息采集到数据库中
好处:
轻松获取市场数据数据库
实时市场分析
科研机构
可以做到:
某些科学研究应用程序的输出只能是文本文件,可以使用此软件将其转换为数据库
好处:
无需程序员的帮助即可轻松转换数据,并且每分钟可以处理数十个M数据
充分利用易于编写的热门文章采集工具,新手可以快速制作热门文章!
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-08-06 14:02
易于编写易爆物品采集工具:
易于编写的爆文品系统可以被视为功能相对强大的自媒体工作资料库. 它可以分析在不同时间段,不同领域和不同平台发布的爆文. 我们可以从Yizhan.com的软件中查询最新的热门话题和最受欢迎的资料,这些资料可以用作我们输入文章的主题选择. 我们可以从同龄人那里学习很多高质量的内容,以扩大我们的知识储备.
正确的操作步骤:
第一步: 根据操作领域,选择100篇读数超过100,000的文章. 100,000条基本上可以算作热门文章. 找到它后,使用Excel标题计算标题,地址,清楚标记.
第2步: 分步分析以提取这100篇爆炸性文章的主题.
第3步: 总结类似的主题,找出这些爆炸性文章标题中更常用的关键字和常用短语.
最后,根据概括的主题和标题,模仿,您可以开始创建自己的文章内容. 按照这种方法,从未接触过的新手小白也可以迅速撰写热门文章. 查看全部
来自媒体的朋友知道,如果您希望每天都有高收入,数据可以决定一切. 即使原创独家帐户是由媒体开设的,如果您不能发布热门帖子,那么从该帐户获得的收入也很可惜. 当然,如果要发布热门帖子,则需要使用一些热门帖子采集工具. 在这里,Fengzi推荐一篇容易爆炸的文章. 文本采集工具,非常易于使用. 我相信许多媒体人士都对糟糕的数据感到担忧,但找不到合适的资料. 实际上,在易于编写的爆炸性物品采集工具中,您可以分析很多同行发布的爆炸性物品,包括在企鹅后台发布的热门文章. 这样可以有效地分析同行发送的材料. 当然,最重要的是测试. 这是哪种帐户适合发送的关键.
易于编写易爆物品采集工具:
易于编写的爆文品系统可以被视为功能相对强大的自媒体工作资料库. 它可以分析在不同时间段,不同领域和不同平台发布的爆文. 我们可以从Yizhan.com的软件中查询最新的热门话题和最受欢迎的资料,这些资料可以用作我们输入文章的主题选择. 我们可以从同龄人那里学习很多高质量的内容,以扩大我们的知识储备.
正确的操作步骤:
第一步: 根据操作领域,选择100篇读数超过100,000的文章. 100,000条基本上可以算作热门文章. 找到它后,使用Excel标题计算标题,地址,清楚标记.
第2步: 分步分析以提取这100篇爆炸性文章的主题.
第3步: 总结类似的主题,找出这些爆炸性文章标题中更常用的关键字和常用短语.
最后,根据概括的主题和标题,模仿,您可以开始创建自己的文章内容. 按照这种方法,从未接触过的新手小白也可以迅速撰写热门文章.
我想购买带有伪原创词库的净商品采集管理系统V3.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-08-06 05:08
如果将其放置在根目录中,则无需修改即可运行
将其放在根目录中,无需任何修改即可正常运行;如果放置在虚拟目录中,请打开inc / config.asp并修改SitePath =“ / directory name /”
请确保您的空间支持FSO和AspJpeg组件,否则某些功能可能不可用
默认后台管理路径admin / admin_login.asp,用户名和密码均为admin
安全设置[重要]:
在inc / config.asp中修改数据库名称和后台目录,并在Data目录下重命名数据库和Admin目录
登录到后台后,请立即修改管理员用户名和密码
如果有任何疑问,请转到官方讨论区: 在留言板上留言.
v3.0sp1版本更新和修订:
1. 替换了html编辑器,它可以在360,firefox和Chrome中正常显示
2. 取消了上传以生成缩略图(发现不是很有用),取消了按年和月上传图片以生成文件夹的操作
3,幻灯片可以链接到图片
4. 修改了后台更改管理员密码后有时无法登录的问题
5. 在网站配置中添加了上载徽标的功能(太多人询问如何更改网站徽标)
6. 添加了上传背景附件的功能(可以同时进行多次上传)
7. 修复成员反复删除导致负面观点的文章的错误
8. 增加在采集过程中以幻灯片形式自动提取文章中的第一张图片
9. 添加清除无用的上传文件的功能 查看全部
现在该程序是完全开源的,这使得淘宝每月数万的收入不再是梦想
如果将其放置在根目录中,则无需修改即可运行
将其放在根目录中,无需任何修改即可正常运行;如果放置在虚拟目录中,请打开inc / config.asp并修改SitePath =“ / directory name /”
请确保您的空间支持FSO和AspJpeg组件,否则某些功能可能不可用
默认后台管理路径admin / admin_login.asp,用户名和密码均为admin
安全设置[重要]:
在inc / config.asp中修改数据库名称和后台目录,并在Data目录下重命名数据库和Admin目录
登录到后台后,请立即修改管理员用户名和密码
如果有任何疑问,请转到官方讨论区: 在留言板上留言.
v3.0sp1版本更新和修订:
1. 替换了html编辑器,它可以在360,firefox和Chrome中正常显示
2. 取消了上传以生成缩略图(发现不是很有用),取消了按年和月上传图片以生成文件夹的操作
3,幻灯片可以链接到图片
4. 修改了后台更改管理员密码后有时无法登录的问题
5. 在网站配置中添加了上载徽标的功能(太多人询问如何更改网站徽标)
6. 添加了上传背景附件的功能(可以同时进行多次上传)
7. 修复成员反复删除导致负面观点的文章的错误
8. 增加在采集过程中以幻灯片形式自动提取文章中的第一张图片
9. 添加清除无用的上传文件的功能
净钛物品管理系统(OTCMS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-06 03:09
Net Titanium物品管理系统(OTCMS)基于ASP + Access / Mssql的技术体系结构. 它不仅可以应用于各种新闻发布网站,还可以应用于信息门户网站. 这些功能仅是通用的,并且易于操作. 发展方向,使那些不懂代码但想建立自己的网站的朋友,使用Net Titanium文章管理系统,通过简单的后台配置,就可以拥有一个个性化的自己的网站.
Net Titanium物品管理系统(OTCMS)更新日志:
2020年6月22日V2.93更新包
1. [完成]在主背景界面的右上角和右下角添加箭头图标,以重新调整内容框的高度
2. [修复]后台的某些官方网站链接无效且已修复. 查看全部
Net Titanium物品管理系统(OTCMS)以其简单,实用和傻瓜式操作而闻名. 它是中国最受欢迎的ASP开源网站管理系统之一,也是用户增长最快的ASP. 一种类似CMS的系统. 当前版本在功能,人性化和易用性方面取得了长足的进步. OTCMS的主要目标用户是草根的中小型个人网站管理员,这样,那些对Internet不太熟悉的人,那些对网站建设了解不多但想要建立网站的人就可以快速建立功能,功能强大,用户友好且易于使用. OTCMS更加侧重于个人网站或中小型门户网站的建设. 当然,也有使用此系统的企业用户. 使用OTCMS的用户将不断赞美它.
Net Titanium物品管理系统(OTCMS)基于ASP + Access / Mssql的技术体系结构. 它不仅可以应用于各种新闻发布网站,还可以应用于信息门户网站. 这些功能仅是通用的,并且易于操作. 发展方向,使那些不懂代码但想建立自己的网站的朋友,使用Net Titanium文章管理系统,通过简单的后台配置,就可以拥有一个个性化的自己的网站.
Net Titanium物品管理系统(OTCMS)更新日志:
2020年6月22日V2.93更新包
1. [完成]在主背景界面的右上角和右下角添加箭头图标,以重新调整内容框的高度
2. [修复]后台的某些官方网站链接无效且已修复.
最详细的优采云数据采集系统DedeCMS发布了文章指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-05 17:00
①在进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大更改;
③不建议从其他网站采集有关新台站的信息,这样可以减少新台站的特殊重量.
前一段时间,我制定了一个计划,以改造旧网站. 随着管理系统和数据库的替换,我决定采用一种解决方案来在原创网站上采集数据. 新手需要掌握很多网站建设知识和SEO知识才能进行网站修订. 这些经验可用来与您分享.
网站的基本信息
该网站最初具有排名,相对较大的集合和更好的优化. 制作风格与Acridine非常相似,代码简单,前端大气,可以使用标签,但网站优化方法却是一头黑帽子. 使用asp程序后端,数据库是access,要替换为php,数据库是mysql.
用于网站修订的软件工具
-EditPlus或DreamWear(代码编辑器);
-APMServ(本地ASP、PHP环境);
-Fiddler Web汉化版(web数据抓包);
-火车头(LocoySpider)采集7.6(破解稳定版、数据采集);
-DedeCMS V5.7(后台内容管理程序);
-其他辅助工具。
在Youcai Cloud Collection的帮助下进行网站修订和修订的详细步骤1.构建本地环境,安装DedeCMS,安装Fiddler Web捕获工具,安装Youcai Cloud Collection 7.6和其他软件
安装方法非常简单,相关文章“在64位win8win10系统中启动APMServ安装失败的解决方案”,“如何安装dedecms的详细说明”.
提供一些软件下载链接: 密码: 3n7e
2. 优采云设置(关键内容)
官方说明相对简单. 新手在采集网站数据时必须阅读和练习更多. 打开优采云采集工具,然后创建一个新任务和组.
第1步: 采集URL规则
①起始地址. 也就是说,按照下图的顺序提取分页规则: 单击添加-单击批处理/多页输入地址格式,例如我要采集的地址列表,即:
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
可以看到变量是1、2、3 ...,并使用了通配符.
http://www.123.com/case.asp?page=(*)&SmallClass=1
选择算术序列中的项目数作为要采集的列表数,并根据实际情况进行写入. 点击依次添加
然后单击添加-完成-关闭.
②多级URL获取. 获取特定页面的URL地址列表. 在任何目标列表中,单击鼠标右键以查看源代码. 一般而言,具有基础知识的学生无需多说,还有许多他们不理解的在线资源. 找到特征代码片段,如下所示编写并保存.
单击测试URL采集以确保列表采集规则正确,然后继续执行第二步. 查看全部
搜索引擎不喜欢复制内容,也不喜欢数据采集,但有时会遇到某些情况,例如网站修订,数据库更改,管理程序等,这些情况需要网络数据采集或网站备份. 提醒大家:
①在进行任何操作之前,必须备份数据库并打包原创站点;
②对于排名较高的网站,不建议对网站管理系统进行重大更改;
③不建议从其他网站采集有关新台站的信息,这样可以减少新台站的特殊重量.
前一段时间,我制定了一个计划,以改造旧网站. 随着管理系统和数据库的替换,我决定采用一种解决方案来在原创网站上采集数据. 新手需要掌握很多网站建设知识和SEO知识才能进行网站修订. 这些经验可用来与您分享.
网站的基本信息
该网站最初具有排名,相对较大的集合和更好的优化. 制作风格与Acridine非常相似,代码简单,前端大气,可以使用标签,但网站优化方法却是一头黑帽子. 使用asp程序后端,数据库是access,要替换为php,数据库是mysql.
用于网站修订的软件工具
-EditPlus或DreamWear(代码编辑器);
-APMServ(本地ASP、PHP环境);
-Fiddler Web汉化版(web数据抓包);
-火车头(LocoySpider)采集7.6(破解稳定版、数据采集);
-DedeCMS V5.7(后台内容管理程序);
-其他辅助工具。
在Youcai Cloud Collection的帮助下进行网站修订和修订的详细步骤1.构建本地环境,安装DedeCMS,安装Fiddler Web捕获工具,安装Youcai Cloud Collection 7.6和其他软件
安装方法非常简单,相关文章“在64位win8win10系统中启动APMServ安装失败的解决方案”,“如何安装dedecms的详细说明”.
提供一些软件下载链接: 密码: 3n7e
2. 优采云设置(关键内容)
官方说明相对简单. 新手在采集网站数据时必须阅读和练习更多. 打开优采云采集工具,然后创建一个新任务和组.
第1步: 采集URL规则
①起始地址. 也就是说,按照下图的顺序提取分页规则: 单击添加-单击批处理/多页输入地址格式,例如我要采集的地址列表,即:
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
http://www.123.com/case.asp%3F ... s%3D1
可以看到变量是1、2、3 ...,并使用了通配符.
http://www.123.com/case.asp?page=(*)&SmallClass=1
选择算术序列中的项目数作为要采集的列表数,并根据实际情况进行写入. 点击依次添加
然后单击添加-完成-关闭.
②多级URL获取. 获取特定页面的URL地址列表. 在任何目标列表中,单击鼠标右键以查看源代码. 一般而言,具有基础知识的学生无需多说,还有许多他们不理解的在线资源. 找到特征代码片段,如下所示编写并保存.
单击测试URL采集以确保列表采集规则正确,然后继续执行第二步.
优采云万能文章采集器 V2.17.1.1 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-04 18:03
优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。基于优采云自主开发的正文识别智能算法,能在互联网纷繁复杂的网页中尽可能准确地提取出正文内容。
正文识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是自动方式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“《div class=“text”》”,就能通吃所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只必须稍微设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用谷歌搜索跟谷歌转译文章的功能,需要使用VPN换国外IP。
内置文章转译功能,也就是可以将文章从一种语言如中文转到另一种语言如英语,再从英文转回中文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司研发的信息采集系统,售价通常达到上万甚至更多,而优采云的这款软件只是一款信息采集系统,功能和市面上昂贵价格的硬件有相通之处,但价钱只有区区几百元,性价比如何试试就知。
更新日志
URL采集文章面板的准确标签新增模糊匹配功能;新增计划任务功能,可以设定多个时间点,到点自动开始采集(当前被显示面板的开始采集)。 查看全部
优采云万能文章采集器,优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎的新闻源和泛网页,支持采集指定网站栏目下的全部文章。
优采云软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。基于优采云自主开发的正文识别智能算法,能在互联网纷繁复杂的网页中尽可能准确地提取出正文内容。
正文识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是自动方式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“《div class=“text”》”,就能通吃所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只必须稍微设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用谷歌搜索跟谷歌转译文章的功能,需要使用VPN换国外IP。
内置文章转译功能,也就是可以将文章从一种语言如中文转到另一种语言如英语,再从英文转回中文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司研发的信息采集系统,售价通常达到上万甚至更多,而优采云的这款软件只是一款信息采集系统,功能和市面上昂贵价格的硬件有相通之处,但价钱只有区区几百元,性价比如何试试就知。
更新日志
URL采集文章面板的准确标签新增模糊匹配功能;新增计划任务功能,可以设定多个时间点,到点自动开始采集(当前被显示面板的开始采集)。
微信公众号文章采集系统---开箱即用
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-04 18:00
系统镜像有6个G,只能通过种子的方式下载了, 镜像种子下载地址
链接: 密码: 7r4d
首先要感谢飯口組組長 把他的采集方案开源出来 。
这里从而称之为系统是因为涉及至的技术很多,这里一一列举:
1、anyproxy 阿里巴巴开源的代理拦截器,使用的是4.0的版本,可以很方便的更改 response 信息。anyproxy 我在系统中早已安装好了,安装也很简单,先安装nodejs环境,然后用npm安装anyproxy.
anyproxy 4.0开始规则可以成为模块来开发,写好了规则代码然后,不用动其实的代码,只必须在anproxy的参数带上规则文件。这里用到的命令 anproxy --rule weixin.js。 关于anproxy如何设置https 证书问题,可以参考官网。我在虚拟机中设置了全局的代理,所以必须 anyproxy 打开后就能,8001端口可以访问请求能否成功。
规则代码主要的逻辑是针对微信公众号的请求进行拦截,把数据转发到 php。
2、apache+php+mysql 这里主要是作为web服务器来处理anyproxy 拦截的请求,处理微信文章数据和点赞数、阅读数。
拦截过来的数据的处理可以看详细的php代码,逻辑不算很复杂。这里为了便于使用的是phpstudy的集成开发环境。
3、按键精灵,按键精灵是国产的一种类似vb语法的模拟键盘鼠标的工具。这里用到按键精灵来模拟点击windows下的微信客户端。
在处理多个微信公众号的之后,需要客户端来点击,把所有的自动操作通过按键精灵来模拟出来。去查看具体的代码的之后,我在处理点击历史消息使用了一个小技巧,事实是开始想通过直接通过识别照片的方法来找到 “历史消息” 按钮的位置,但是发觉如何也找不到,然后只能 循环向下移动鼠标,直到区域内找到特定的颜色,就是“历史消息”按钮。
在一条思路行不通的之后,就要尝试其他思路。整个系统就是做出来,就是要处理这些看似行得通,实际不通,然后再去尝试,如此反复。
4、windows 微信客户端,其实我尝试过用安卓模拟器,因为我的目标是开箱即用,所以必须把所有的程序都无法装到一起,但是在虚拟机中是无法安装安卓模拟器,也就是说虚拟机中是无法做二次虚拟的。这个坑我终于踩过了,大家就不用踩了,记得之前有人问过,阿里云windows服务器能不能装 安卓模拟器,我想答案是一样的,虚拟机不能做二次虚拟化,阿里云windows服务器不能装安卓模拟器。
所以,当我尝试安卓模拟器后,发现其实微信pc客户端(包括mac)的功能早已做的太完善了,然后就去尝试windows客户端。
5、virtualbox 虚拟机,这个是甲骨文公司出的虚拟机。会涉及到一些网络的配置,比如设置为NAT模式。
现在把虚拟机镜像开源出来,里面所有的代码都在虚拟机中,大家可以随便修改。
从更开始了解公众号文章采集到了解实现原理,再到最后做出镜像,中间经历过诸多困难,耗时耗力,请教各种人,甚至喝水吃饭都在想某个细节的解决方案,有解决问题的快乐,有被问题缠绕时的困惑,感谢这个过程中予以过帮助人。
在安装使用过程中碰到什么问题可以加我微信 ( liuhan199012 )
文章来源:segmentfault,作者:程序员Hani。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-手机广告位-内容正文底部 查看全部
本着开源精神和便于用户,现已将"微信公众号文章采集系统"打包成虚拟机,你只需下载安装虚拟机镜像,即可使用。
系统镜像有6个G,只能通过种子的方式下载了, 镜像种子下载地址
链接: 密码: 7r4d
首先要感谢飯口組組長 把他的采集方案开源出来 。
这里从而称之为系统是因为涉及至的技术很多,这里一一列举:
1、anyproxy 阿里巴巴开源的代理拦截器,使用的是4.0的版本,可以很方便的更改 response 信息。anyproxy 我在系统中早已安装好了,安装也很简单,先安装nodejs环境,然后用npm安装anyproxy.
anyproxy 4.0开始规则可以成为模块来开发,写好了规则代码然后,不用动其实的代码,只必须在anproxy的参数带上规则文件。这里用到的命令 anproxy --rule weixin.js。 关于anproxy如何设置https 证书问题,可以参考官网。我在虚拟机中设置了全局的代理,所以必须 anyproxy 打开后就能,8001端口可以访问请求能否成功。
规则代码主要的逻辑是针对微信公众号的请求进行拦截,把数据转发到 php。
2、apache+php+mysql 这里主要是作为web服务器来处理anyproxy 拦截的请求,处理微信文章数据和点赞数、阅读数。
拦截过来的数据的处理可以看详细的php代码,逻辑不算很复杂。这里为了便于使用的是phpstudy的集成开发环境。
3、按键精灵,按键精灵是国产的一种类似vb语法的模拟键盘鼠标的工具。这里用到按键精灵来模拟点击windows下的微信客户端。
在处理多个微信公众号的之后,需要客户端来点击,把所有的自动操作通过按键精灵来模拟出来。去查看具体的代码的之后,我在处理点击历史消息使用了一个小技巧,事实是开始想通过直接通过识别照片的方法来找到 “历史消息” 按钮的位置,但是发觉如何也找不到,然后只能 循环向下移动鼠标,直到区域内找到特定的颜色,就是“历史消息”按钮。
在一条思路行不通的之后,就要尝试其他思路。整个系统就是做出来,就是要处理这些看似行得通,实际不通,然后再去尝试,如此反复。
4、windows 微信客户端,其实我尝试过用安卓模拟器,因为我的目标是开箱即用,所以必须把所有的程序都无法装到一起,但是在虚拟机中是无法安装安卓模拟器,也就是说虚拟机中是无法做二次虚拟的。这个坑我终于踩过了,大家就不用踩了,记得之前有人问过,阿里云windows服务器能不能装 安卓模拟器,我想答案是一样的,虚拟机不能做二次虚拟化,阿里云windows服务器不能装安卓模拟器。
所以,当我尝试安卓模拟器后,发现其实微信pc客户端(包括mac)的功能早已做的太完善了,然后就去尝试windows客户端。
5、virtualbox 虚拟机,这个是甲骨文公司出的虚拟机。会涉及到一些网络的配置,比如设置为NAT模式。
现在把虚拟机镜像开源出来,里面所有的代码都在虚拟机中,大家可以随便修改。
从更开始了解公众号文章采集到了解实现原理,再到最后做出镜像,中间经历过诸多困难,耗时耗力,请教各种人,甚至喝水吃饭都在想某个细节的解决方案,有解决问题的快乐,有被问题缠绕时的困惑,感谢这个过程中予以过帮助人。
在安装使用过程中碰到什么问题可以加我微信 ( liuhan199012 )
文章来源:segmentfault,作者:程序员Hani。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:william.shi#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-手机广告位-内容正文底部
Yimi智能文章收集系统的正式版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2020-08-04 17:04
[软件屏幕截图]
[基本介绍]
伪原创必不可少的工具,最好的微信,论坛,博客,seo文章批量自动收集原始工具,网站文章伪原创软件,益密智能文章收集系统系统是专业的网站,论坛,博客,批处理内容集合可以同时用作伪原创工具,使用时无需编写规则就不复杂,这是数百万基层网站管理员的强烈建议!
可以说是简介:
不需要任何源代码即可直接收集文章站点中的所有文本信息,可以收集指定的站点,只要它是文章站点,就可以被收集,并且它支持伪原始和全球主流博客和文章批量发布的cms系统.
软件功能:
可以在不了解源代码规则的情况下进行收集,只要它是文章内容网站,就可以快速收集
中英文自动伪原创,原创率80%以上
自动消噪,去除乱码并判断文章的长度,使文章内容整洁
全球次要语言支持,指定的网站集,非文章来源
多线程和多任务(多站点)同步收集,在一分钟内收集1000多个文章
批量发布到常见博客/网站内容CMS
更新日志:
2015-11-16智能文章收集系统正式发布并在线●智能文章收集系统正式发布并在线
2015-12-10添加了英语TBS词库●添加了英语TBS词库的原始处理
2015-12-27改进了块算法,提取更加准确●改进了内容块算法,进一步去噪使提取的内容更加准确
2016-01-11添加了joomla博客发布界面●添加了joomla博客发布界面,支持加密接口发布
2016-04-08新的代理收集功能●添加了使用代理收集的功能,该功能可以收集某些防火墙(防火墙),以防止大量站点被爬虫爬行 查看全部
该站点提供了Yimi智能文章收集系统的正式版,营销软件/ seo软件/促销软件免费下载.
[软件屏幕截图]
[基本介绍]
伪原创必不可少的工具,最好的微信,论坛,博客,seo文章批量自动收集原始工具,网站文章伪原创软件,益密智能文章收集系统系统是专业的网站,论坛,博客,批处理内容集合可以同时用作伪原创工具,使用时无需编写规则就不复杂,这是数百万基层网站管理员的强烈建议!
可以说是简介:
不需要任何源代码即可直接收集文章站点中的所有文本信息,可以收集指定的站点,只要它是文章站点,就可以被收集,并且它支持伪原始和全球主流博客和文章批量发布的cms系统.
软件功能:
可以在不了解源代码规则的情况下进行收集,只要它是文章内容网站,就可以快速收集
中英文自动伪原创,原创率80%以上
自动消噪,去除乱码并判断文章的长度,使文章内容整洁
全球次要语言支持,指定的网站集,非文章来源
多线程和多任务(多站点)同步收集,在一分钟内收集1000多个文章
批量发布到常见博客/网站内容CMS
更新日志:
2015-11-16智能文章收集系统正式发布并在线●智能文章收集系统正式发布并在线
2015-12-10添加了英语TBS词库●添加了英语TBS词库的原始处理
2015-12-27改进了块算法,提取更加准确●改进了内容块算法,进一步去噪使提取的内容更加准确
2016-01-11添加了joomla博客发布界面●添加了joomla博客发布界面,支持加密接口发布
2016-04-08新的代理收集功能●添加了使用代理收集的功能,该功能可以收集某些防火墙(防火墙),以防止大量站点被爬虫爬行

