08CMS v3.4版本采集系统使用教程
优采云 发布时间: 2020-08-09 06:25
第三步,编辑采集模型
请参见插图:
图1.编辑模型
图二,
模型编辑界面
在这里,采集模型的添加完成
开始在下面添加采集任务
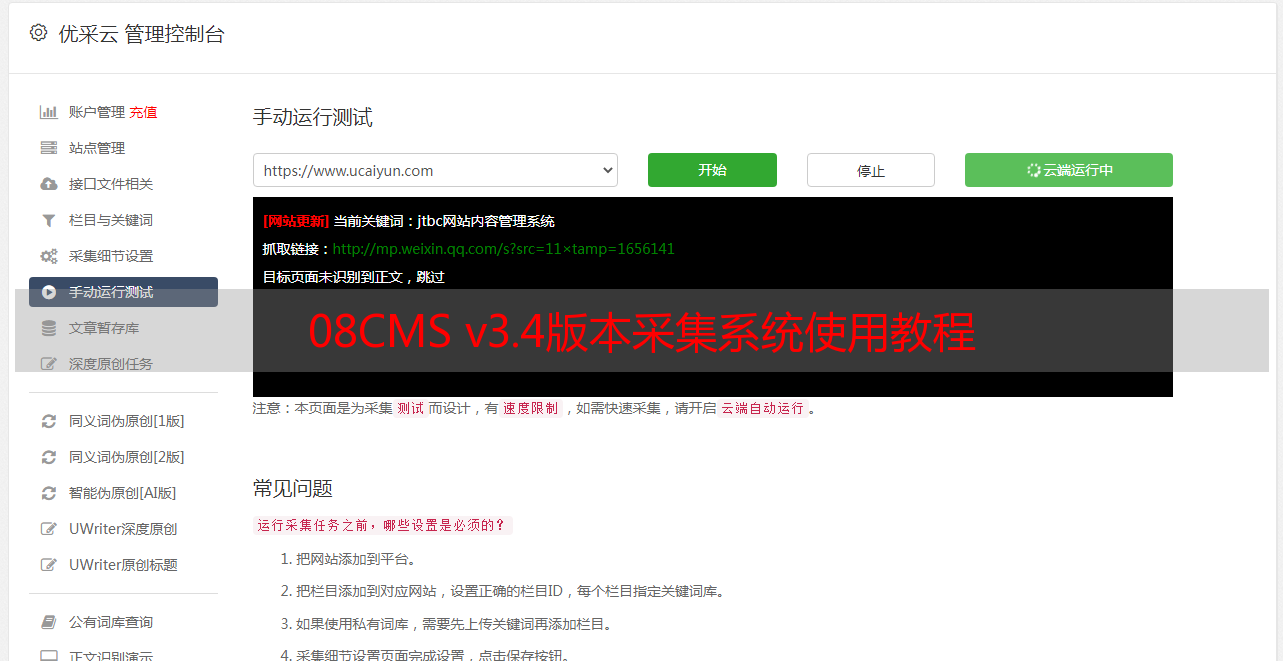
第四步,添加采集任务
以下是采集任务界面的*敏*感*词*,请仔细阅读图中的注释
第六步,突出显示,设置采集规则
首先,分析目标页面的代码结构. 以IE为例.
查看采集目标页面,单击IE
页面----查看源文件
很容易看到目标页面的代码结构
采集页面的代码分析主要是查找采集目标的特征
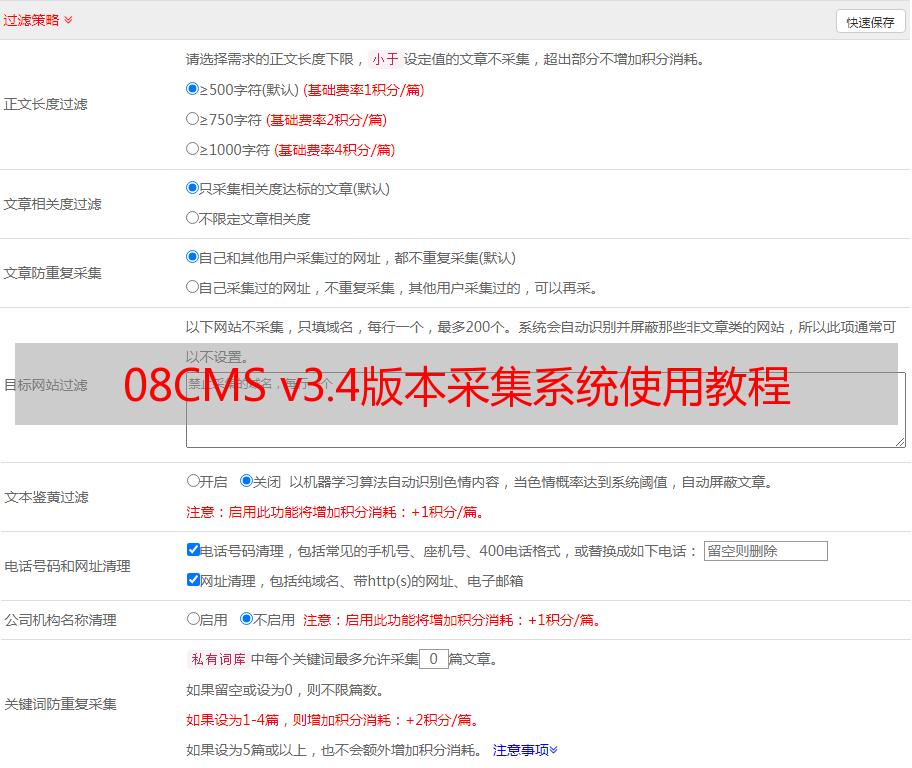
该页面太大,因此在此处很难解析. 上图说明了URL采集界面的相关规则的设置
点击提交将设置保存在此处
我想知道为什么我不直接跳到下一个内容集,而是在提交后返回此页面
此屏幕截图页面下方还有另一部分,称为追溯URL规则
这不是可选项目,通常不是必需的
此外,这只能获取一个URL,而不是URL列表. 我个人感觉有点鸡肋,并附上官方解释.
复古URL: 内容URL的扩展名. 对于某些采集的文档,各个字段的内容不在主要内容页面上,而是在附加页面上,尤其是附件的内容. 可追溯性URL用于采集附加页面的URL. 每个内容URL都可以追溯到另外两个页面,网站2是基于追溯网站1采集的.
回顾性概念的一个例子: 当我们进入下载站点时,我们点击进入的页面通常只是软件信息描述和一个或多个指向下载页面的链接
注意: 这是下载页面的链接,而不是下载地址. 要下载软件时,必须首先打开此下载页面以查看下载地址
这是可追溯性的第一级,因为我们必须再次单击才能进入下载页面. 目前,我们的1级可追溯地址是进入下载页面的链接
接下来是内容页面的规则
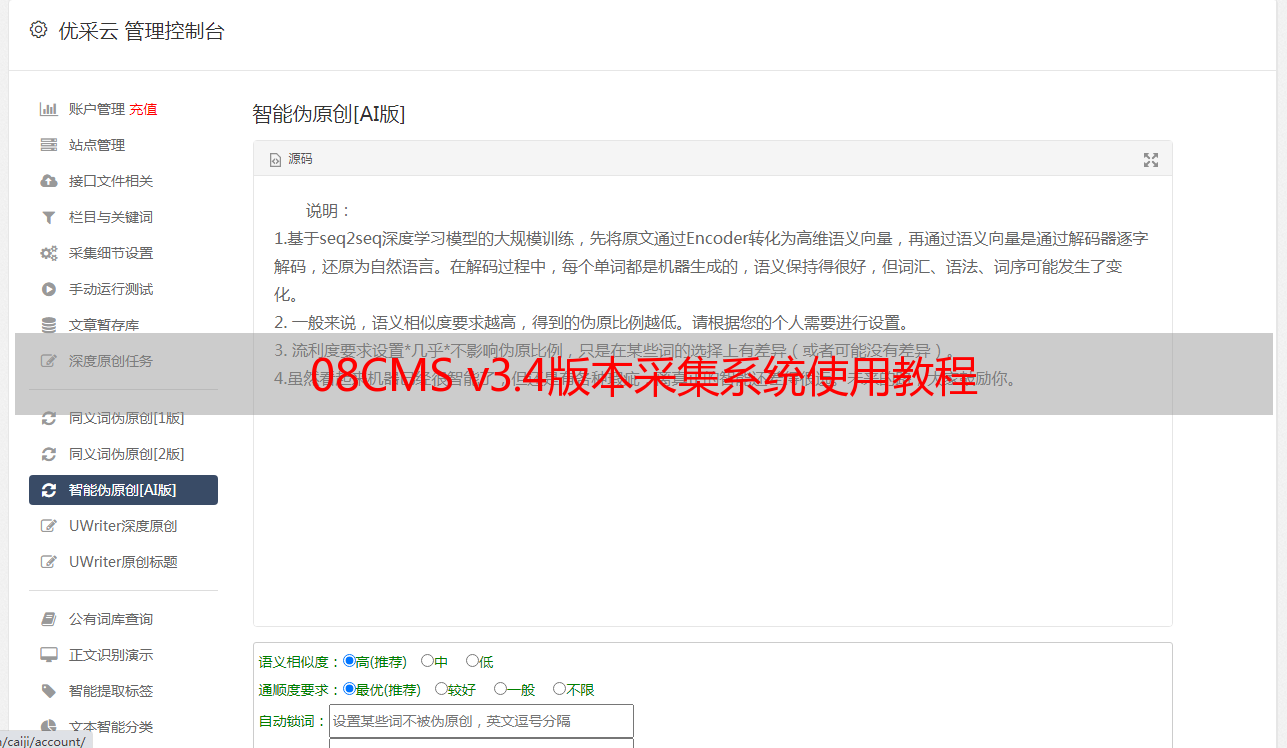
使用同一图形进行分析,这里仅以一个字段规则设置为例,其他字段基本相似.
传入参数设置
如果是非编译(即单个文档集合),则规则设置在此处
经过测试,可以毫无问题地将其采集
如果您有足够的信心,则可以不经测试直接采集.
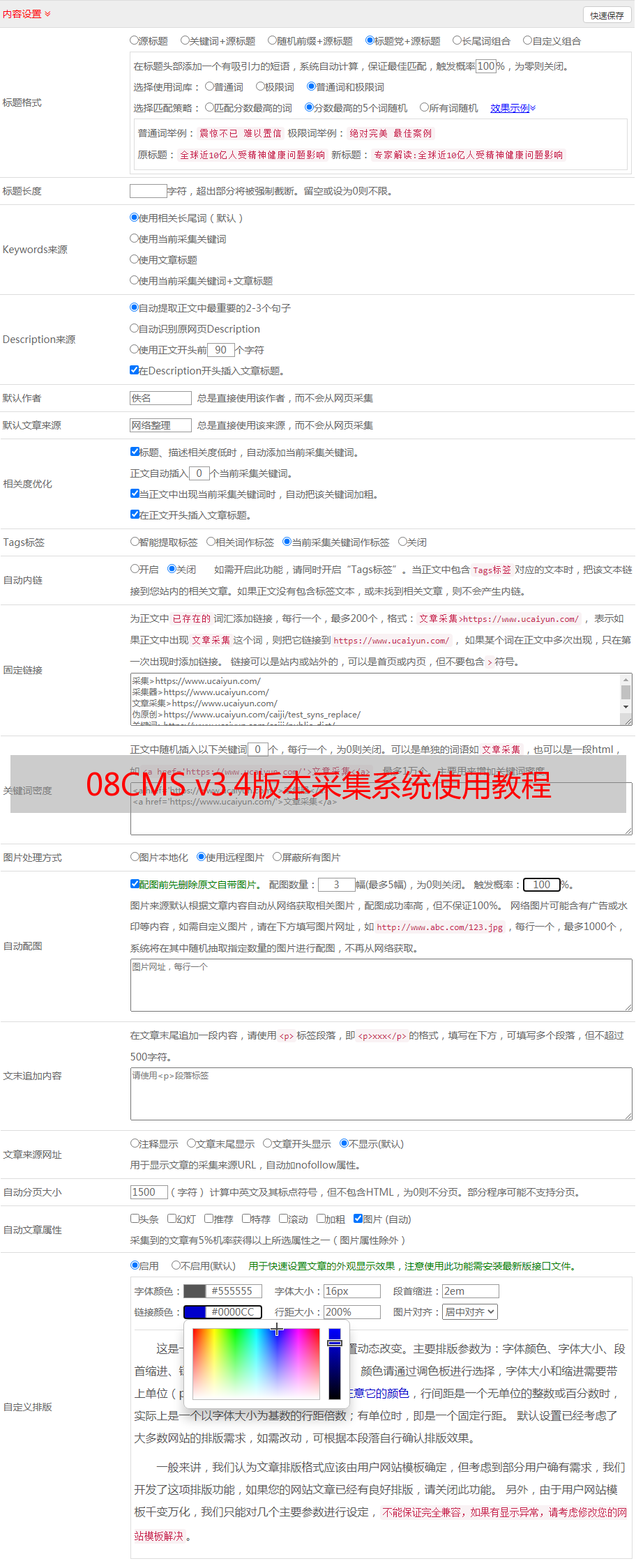
如果它是诸如小说之类的合集的集合,则该集合的设置仅是中途.
编译的集合还需要设置子任务的规则
如图所示:
子任务位于父任务下方,并且任务名称缩进
子任务的规则设置与父任务的规则设置基本相同,因此我不再赘述.
理论上,集合在这里. 让我们开始愉快的采集之旅. 就个人而言,我仍然感到很高兴.
获取,您可以逐步了解URL,内容和存储.
直接一键式采集更加轻松
但这是一个使人呕血的问题
集合任务,除非它是集合集合中的父任务和子任务
否则,您将必须一个接一个地完成任务,而不要排队. . .
尽管有很多缺点,但采集经验一般都很好
到此结束. 如果您不了解,可以将其发布.

