
文章采集完
文章采集完(文章采集完毕,并保存至服务器,就有样本了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-04 11:12
文章采集完毕,并保存至服务器,请查看。请点击题图上二维码,可获取更多统计结果查看详情,
保存文章网页就有样本了
据我所知:使用python进行数据抓取最重要的是能够明确并传递数据,数据处理以及分析的明确过程给定调用者。官方文档中并未详细介绍相关技术,本文也未提及,但其思想基本已经得到业界认可。它能够大幅提升问题处理速度,更多的从业者接受以规范的形式来交流数据处理。数据聚合策略,包括数据分析过程、可视化、分布式等技术。
同时还有跟其他技术相结合的落地案例,最终落地到服务端。python是爬虫,数据处理,可视化和分布式都会用到的语言,掌握一些基本技术理论、方法还有案例应该是学习使用的最基本要求。如果仅仅学习爬虫(oracle或sql),它在线性结构获取数据方面有点不足。其他诸如分布式分析以及大数据获取仍需要系统学习,难度也较大。
对数据的保存存储也算是开发的一个重要技能,
python后端支持
一门语言不是全部。基础的使用不难,掌握核心的东西才好。另外在学习的过程中需要一些理论,比如面向对象, 查看全部
文章采集完(文章采集完毕,并保存至服务器,就有样本了)
文章采集完毕,并保存至服务器,请查看。请点击题图上二维码,可获取更多统计结果查看详情,
保存文章网页就有样本了
据我所知:使用python进行数据抓取最重要的是能够明确并传递数据,数据处理以及分析的明确过程给定调用者。官方文档中并未详细介绍相关技术,本文也未提及,但其思想基本已经得到业界认可。它能够大幅提升问题处理速度,更多的从业者接受以规范的形式来交流数据处理。数据聚合策略,包括数据分析过程、可视化、分布式等技术。
同时还有跟其他技术相结合的落地案例,最终落地到服务端。python是爬虫,数据处理,可视化和分布式都会用到的语言,掌握一些基本技术理论、方法还有案例应该是学习使用的最基本要求。如果仅仅学习爬虫(oracle或sql),它在线性结构获取数据方面有点不足。其他诸如分布式分析以及大数据获取仍需要系统学习,难度也较大。
对数据的保存存储也算是开发的一个重要技能,
python后端支持
一门语言不是全部。基础的使用不难,掌握核心的东西才好。另外在学习的过程中需要一些理论,比如面向对象,
文章采集完(python数据分析入门指南-知乎专栏(2016.10.21))
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-12-01 03:02
文章采集完之后,还需要制作一个数据分析报告,方便后续统计数据。通常流程如下:今天我们从网站抓取实时热度信息,相当于浏览器的新闻源。选取对口的“大数据自媒体”获取数据源。加载所需要的数据源。利用python的matplotlib绘制数据可视化图形。优点:直观,图形清晰结构简单。缺点:没有提供对应的表格数据,需要后续统计。
python数据分析入门指南-知乎专栏python数据分析入门指南-知乎专栏重要提示:python数据分析入门指南-知乎专栏并不适合新手学习。每一步都会有代码,所以代码不在专栏公布,请自行搜索相关的代码搜索引擎。
谢邀。题主问数据分析和爬虫,还是数据采集和数据处理?建议先明确问题,数据量的大小,采集的方式,还有处理的程度?比如是否是网站外部爬虫采集,是否是直接爬取,还是有专门的数据采集站,比如百度,天天猫,,甚至贴吧等?等等问题。而且因为数据分析和数据采集的技术差异性非常大,
这个问题是我在另一个问题下的回答~本文删除了我认为非常重要的删除设计操作,保留原发布于apollodata的原网址:知乎专栏。感谢新浪微博网友@夏驰dave提供的数据:-food-shop茶の實茶の消光数知害の男女の人数の比年間の検(消光害)(知害の男女人数の比年間):男の人数の45.男の人数の46.加藤井下2人の166.2人の183.2人の216.2人の100.2人の190.2人の190.2人の190.2人の100.2人の190.2人の100.2人の190.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2。 查看全部
文章采集完(python数据分析入门指南-知乎专栏(2016.10.21))
文章采集完之后,还需要制作一个数据分析报告,方便后续统计数据。通常流程如下:今天我们从网站抓取实时热度信息,相当于浏览器的新闻源。选取对口的“大数据自媒体”获取数据源。加载所需要的数据源。利用python的matplotlib绘制数据可视化图形。优点:直观,图形清晰结构简单。缺点:没有提供对应的表格数据,需要后续统计。
python数据分析入门指南-知乎专栏python数据分析入门指南-知乎专栏重要提示:python数据分析入门指南-知乎专栏并不适合新手学习。每一步都会有代码,所以代码不在专栏公布,请自行搜索相关的代码搜索引擎。
谢邀。题主问数据分析和爬虫,还是数据采集和数据处理?建议先明确问题,数据量的大小,采集的方式,还有处理的程度?比如是否是网站外部爬虫采集,是否是直接爬取,还是有专门的数据采集站,比如百度,天天猫,,甚至贴吧等?等等问题。而且因为数据分析和数据采集的技术差异性非常大,
这个问题是我在另一个问题下的回答~本文删除了我认为非常重要的删除设计操作,保留原发布于apollodata的原网址:知乎专栏。感谢新浪微博网友@夏驰dave提供的数据:-food-shop茶の實茶の消光数知害の男女の人数の比年間の検(消光害)(知害の男女人数の比年間):男の人数の45.男の人数の46.加藤井下2人の166.2人の183.2人の216.2人の100.2人の190.2人の190.2人の190.2人の100.2人の190.2人の100.2人の190.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2。
文章采集完( 什么是采集站?现在做网站还能做采集站吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-11-30 07:25
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为互联网的常态网站,所以我想做一个网站或者已经有网站上网的同学一定要清楚了解采集站!小编自己的小说网站和门户网站都是通过采集的方式创建的。目前,全流和全武已将日均IP流量稳定在1万左右。通过这篇文章的文章,和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要用到各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人站点也被一些人使用采集,因为有些情况不想自己更新文章或者大站点需要更新的文章很多而复杂的,比如新闻网站,都用采集。编辑器通常使用147采集来完成所有采集站点的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天新增100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做 采集 网站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。只是看着它很有趣,只是乱搞。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,我明确告诉大家,文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,是用户需要你文章已经有排名机会了。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是< @网站content收录 要快。想要快速制作收录需要大量的蜘蛛来抢你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的是用对的方式去做,而不是因为采集和采集,经过采集一个SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以的。
查看全部
文章采集完(
什么是采集站?现在做网站还能做采集站吗?
)

采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为互联网的常态网站,所以我想做一个网站或者已经有网站上网的同学一定要清楚了解采集站!小编自己的小说网站和门户网站都是通过采集的方式创建的。目前,全流和全武已将日均IP流量稳定在1万左右。通过这篇文章的文章,和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要用到各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人站点也被一些人使用采集,因为有些情况不想自己更新文章或者大站点需要更新的文章很多而复杂的,比如新闻网站,都用采集。编辑器通常使用147采集来完成所有采集站点的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天新增100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做 采集 网站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。只是看着它很有趣,只是乱搞。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,我明确告诉大家,文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,是用户需要你文章已经有排名机会了。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是< @网站content收录 要快。想要快速制作收录需要大量的蜘蛛来抢你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的是用对的方式去做,而不是因为采集和采集,经过采集一个SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以的。

文章采集完(网上最好的优质壁纸,怎么样才能找到你中意的壁纸 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-11-28 15:03
)
也许你之前在百度上搜索壁纸,或者使用一些国内的图片资源站。相信你也被那些复杂的积分系统或者收费方式折磨过,但是在Wallhaven之后,你要做的就是把这个网站采集起来。
Wallhaven 被誉为“互联网上最好的壁纸”。这一点都不谦虚。真是“天生骄傲”。这么大的口气,当然得有什么引以为傲的了。
它有一个简单的界面,没有广告。以上壁纸虽然基本都是用户上传的,但绝对是一流的高画质高清壁纸。
类别过滤器
打开这个网站,你会发现一个幸福的烦恼:海量的优质壁纸,怎么才能找到自己喜欢的壁纸呢?
首先点击首页的这个Toplist,可以看到Wallhaven将壁纸按照General、Anime、People(一般、动漫、人物)分为三种。这只是最基本的分类。
同时,它还提供了三类:SFW、Sketchy和NSFW。这是什么意思?我不会在这里打电话。我直接给你解释。SFW 是 Safe for Work 的缩写。这是两者之间的程度。
这种分类没有任何问题。在家可以在电脑上设置壁纸,但是在办公室里,工作时不适合在电脑屏幕上看到流鼻血,你懂的。不得不说,这种对壁纸图片“分级”的操作,可以让我们更容易的找到自己想要的壁纸图片。
在搜索框下方,有一系列标签,您可以根据自己喜欢的标签进行选择。如果上面提供的标签不够,点击更多标签,会有更丰富的标签,还会显示该标签下的壁纸数量和浏览量。
要知道,在网站的壁纸中,收录的海量壁纸并不少见。真正的难点在于是否有高效的分类检索机制,让你快速锁定自己喜欢的壁纸。
爬行巨蟒领主
接下来想采集页面图片进行采集排序,并在电脑上设置幻灯片壁纸,所以写了一个python代码爬取img,主要是因为一张一张保存漂亮的图片太费力了。
大体思路是先看html的整体结构,看到图片集合固定在链接前面,然后下拉,后面跟着page=x,再看一遍,可以看到所有图片都是在格式中,图片的真实地址就是这个。那会容易些。
使用BeautifulSoup库从HTML文件中提取数据,定义getpages_HTML函数连接wallhaven壁纸页面,定义getURL获取href,定义parseHTML函数,解析html页面中的img src标签,返回.jpg文件下载链接,getDownload函数下载到自己在定义Path下,main函数开始定义Path和url,输入页码,如果第一页没有添加page参数,直接保存第一页的所有图片,否则循环1到页保存图片地址。最后循环下载保存的地址。
import requests
from bs4 import BeautifulSoup
import os
def getpages_HTML(url,info = None):#连接wallhaven随机壁纸页面
try:
r = requests.request('GET',url = url,params = info)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Failed")
def getURL(html,lst):
soup = BeautifulSoup(html,'html.parser')
trs = soup.find_all('a')
for tr in trs:
if tr.get('href') is not None and len(tr.get('href')) == 29:
lst.append(tr.get('href'))#提取href
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
img = soup.find_all('img')#解析html页面里的img src标签
src = img[2].get('src')
return src #返回.jpg文件下载链接
def getDownload(url,path):
try:
r = requests.get(url)
r.raise_for_status()
with open(path,'wb')as f:
f.write(r.content)
except:
return "Failed"
if __name__ == '__main__':
pic_dir = 'C://Users//Administrator//Pictures//wallpapers'
if not os.path.exists(pic_dir):
os.mkdir(pic_dir)
infoDict = {}
lst = []
page_num = int(input('plese input the page number:'))
url = 'https://wallhaven.cc/search?categories=110&purity=100&sorting=favorites&order=desc'
if page_num == 1:#对输入数字进行判断
infoDict['page'] = 1
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
else:
for i in range(1,page_num + 1):
infoDict['page'] = i
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
for i in range(len(lst)):
pic_html = getpages_HTML(lst[i],info = None)
downloader = parseHTML(pic_html)
path = pic_dir + '//' + lst[i][-6:] + '.jpg'
getDownload(downloader,path)
查看全部
文章采集完(网上最好的优质壁纸,怎么样才能找到你中意的壁纸
)
也许你之前在百度上搜索壁纸,或者使用一些国内的图片资源站。相信你也被那些复杂的积分系统或者收费方式折磨过,但是在Wallhaven之后,你要做的就是把这个网站采集起来。
Wallhaven 被誉为“互联网上最好的壁纸”。这一点都不谦虚。真是“天生骄傲”。这么大的口气,当然得有什么引以为傲的了。
它有一个简单的界面,没有广告。以上壁纸虽然基本都是用户上传的,但绝对是一流的高画质高清壁纸。
类别过滤器
打开这个网站,你会发现一个幸福的烦恼:海量的优质壁纸,怎么才能找到自己喜欢的壁纸呢?
首先点击首页的这个Toplist,可以看到Wallhaven将壁纸按照General、Anime、People(一般、动漫、人物)分为三种。这只是最基本的分类。
同时,它还提供了三类:SFW、Sketchy和NSFW。这是什么意思?我不会在这里打电话。我直接给你解释。SFW 是 Safe for Work 的缩写。这是两者之间的程度。
这种分类没有任何问题。在家可以在电脑上设置壁纸,但是在办公室里,工作时不适合在电脑屏幕上看到流鼻血,你懂的。不得不说,这种对壁纸图片“分级”的操作,可以让我们更容易的找到自己想要的壁纸图片。
在搜索框下方,有一系列标签,您可以根据自己喜欢的标签进行选择。如果上面提供的标签不够,点击更多标签,会有更丰富的标签,还会显示该标签下的壁纸数量和浏览量。
要知道,在网站的壁纸中,收录的海量壁纸并不少见。真正的难点在于是否有高效的分类检索机制,让你快速锁定自己喜欢的壁纸。
爬行巨蟒领主
接下来想采集页面图片进行采集排序,并在电脑上设置幻灯片壁纸,所以写了一个python代码爬取img,主要是因为一张一张保存漂亮的图片太费力了。
大体思路是先看html的整体结构,看到图片集合固定在链接前面,然后下拉,后面跟着page=x,再看一遍,可以看到所有图片都是在格式中,图片的真实地址就是这个。那会容易些。
使用BeautifulSoup库从HTML文件中提取数据,定义getpages_HTML函数连接wallhaven壁纸页面,定义getURL获取href,定义parseHTML函数,解析html页面中的img src标签,返回.jpg文件下载链接,getDownload函数下载到自己在定义Path下,main函数开始定义Path和url,输入页码,如果第一页没有添加page参数,直接保存第一页的所有图片,否则循环1到页保存图片地址。最后循环下载保存的地址。
import requests
from bs4 import BeautifulSoup
import os
def getpages_HTML(url,info = None):#连接wallhaven随机壁纸页面
try:
r = requests.request('GET',url = url,params = info)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Failed")
def getURL(html,lst):
soup = BeautifulSoup(html,'html.parser')
trs = soup.find_all('a')
for tr in trs:
if tr.get('href') is not None and len(tr.get('href')) == 29:
lst.append(tr.get('href'))#提取href
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
img = soup.find_all('img')#解析html页面里的img src标签
src = img[2].get('src')
return src #返回.jpg文件下载链接
def getDownload(url,path):
try:
r = requests.get(url)
r.raise_for_status()
with open(path,'wb')as f:
f.write(r.content)
except:
return "Failed"
if __name__ == '__main__':
pic_dir = 'C://Users//Administrator//Pictures//wallpapers'
if not os.path.exists(pic_dir):
os.mkdir(pic_dir)
infoDict = {}
lst = []
page_num = int(input('plese input the page number:'))
url = 'https://wallhaven.cc/search?categories=110&purity=100&sorting=favorites&order=desc'
if page_num == 1:#对输入数字进行判断
infoDict['page'] = 1
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
else:
for i in range(1,page_num + 1):
infoDict['page'] = i
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
for i in range(len(lst)):
pic_html = getpages_HTML(lst[i],info = None)
downloader = parseHTML(pic_html)
path = pic_dir + '//' + lst[i][-6:] + '.jpg'
getDownload(downloader,path)

文章采集完(什么是采集站顾名思义就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-25 00:17
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,距域名历史成立仅1年多。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。
1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、 选择好的采集 来源是重中之重,比如屏蔽百度蜘蛛的新闻来源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章,如果你喜欢这篇文章,不妨采集一下或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
文章采集完(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充

只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,距域名历史成立仅1年多。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。

1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、 选择好的采集 来源是重中之重,比如屏蔽百度蜘蛛的新闻来源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎

这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章,如果你喜欢这篇文章,不妨采集一下或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
文章采集完(这些一键批量采集的工具,你值得拥有!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-24 08:03
文章采集完,总会有人问,是不是已经批量采集数据了呀,现在市面上有批量采集工具,接下来跟大家讲下这些一键批量采集的工具吧。1/金数据金数据是一款线上金融数据采集软件,你想要采集的数据种类基本都会给你包含,无论是批量查房贷利率,还是批量查访客,哪里都采集的到,下载后是单个文件,每个文件都是网页链接,看不懂的看截图可以吗!下载完就是一个专门的demo例子。
2/乐采宝乐采宝是一款全自动快速采集小程序数据工具,里面数据采集种类丰富,只需点击采集小程序,里面就会自动联想到小程序各个数据指标了,批量采集,你值得拥有。3/网飞采集器网飞采集器是一款在线视频数据采集器,通过它在线挖掘影视作品的日播放量和简介等信息,让你可以查看下载完整影视作品。采集网易公开课,可以是观看渠道页面,还可以直接下载电子书。
4/tc获取搜索你想要采集的信息平台,一键获取页面截图;一键获取内容重要性分析,将问题一次性提交给百度、谷歌等搜索引擎,轻松采集公开可见的信息。(二维码自动识别)。
数据掘金,金数据,爬虫-专注于python数据分析及数据采集的开源工具,不需要编程基础,数据采集速度超快,电脑性能要求不高,并且服务端机器配置要求不高,几乎不占用服务器资源。 查看全部
文章采集完(这些一键批量采集的工具,你值得拥有!(组图))
文章采集完,总会有人问,是不是已经批量采集数据了呀,现在市面上有批量采集工具,接下来跟大家讲下这些一键批量采集的工具吧。1/金数据金数据是一款线上金融数据采集软件,你想要采集的数据种类基本都会给你包含,无论是批量查房贷利率,还是批量查访客,哪里都采集的到,下载后是单个文件,每个文件都是网页链接,看不懂的看截图可以吗!下载完就是一个专门的demo例子。
2/乐采宝乐采宝是一款全自动快速采集小程序数据工具,里面数据采集种类丰富,只需点击采集小程序,里面就会自动联想到小程序各个数据指标了,批量采集,你值得拥有。3/网飞采集器网飞采集器是一款在线视频数据采集器,通过它在线挖掘影视作品的日播放量和简介等信息,让你可以查看下载完整影视作品。采集网易公开课,可以是观看渠道页面,还可以直接下载电子书。
4/tc获取搜索你想要采集的信息平台,一键获取页面截图;一键获取内容重要性分析,将问题一次性提交给百度、谷歌等搜索引擎,轻松采集公开可见的信息。(二维码自动识别)。
数据掘金,金数据,爬虫-专注于python数据分析及数据采集的开源工具,不需要编程基础,数据采集速度超快,电脑性能要求不高,并且服务端机器配置要求不高,几乎不占用服务器资源。
文章采集完(网页元素与网页源代码的区别(x4)分析(x4) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2021-11-21 16:09
)
内容
前言
分析 (x0)
分析 (x1)
分析 (x2)
分析 (x3)
分析 (x4)
总结
我有话要说
前言
大家好,我叫山年,这是我的第三篇技术博文。这次是音乐、小说、视频,也许下次是图片。
文章 我是在同一天写的,我自己从来没有做过。
我们要去采集的网站是网页版的DY数据:目标网址
给采集随便选一个博主的视频吧,饿了就找美食博主。
分析 (x0)
在网页元素中,我们可以找到当前视频的跳转链接:
经过我的观察,我发现每个li标签都收录一个短视频信息:
?
所以一共有13个li标签,我们的博主应该已经发布了13个以上的视频吧?不是我这种东西只有几十个粉丝,有什么问题?
我已经猜到这是一个瀑布模式加载视频,我给你解释一下。比如你在一个网页上只能看到十个数据,当你拉动网页的滑动条时,它会自动加载一些新的数据。数据像瀑布一样流出。原理很简单,就是当你拉动滑块时,它会触发一个JavaScript脚本来生成一些新的数据。
让我们做一个测试:
当我拉动浏览器的滚动条时,数据显着增加并改变了网页上的元素。
这里我再解释一下,网页元素和网页源码的区别:
网页元素:浏览器执行一些JavaScript渲染后的渲染(所以它会改变)
网页源代码:服务器发送给我们浏览器的原创数据(浏览器渲染后变成网页元素),所以原创数据不会改变。
那么瀑布流的优势是什么?明明是为了减少服务器的负载?用户可以传输任意数量的数据,而不是在一个大脑中加载所有数据!
分析 (x1)
换句话说,我们根本不需要考虑网页的源代码(因为它是不可变的)。据了解,该网页的视频是通过拉动浏览器滑块执行JavaScript脚本,然后通过接口传输数据给我们造成的。
首先我们可以观察到,每个视频后面的一串数字就是视频对应的ID值,前面肯定是不变的。
我们直接抓包:
根据瀑布流定律,这个包很容易被抓到,因为每次滑动下拉条,都会生成这样一个新包
确实这个值对应,但是别忘了看上图中圈起来的_signature参数,传说中的DY签名加密。其他值是固定值是一些电脑信息,浏览器版本。只有这个 _signature 是加密的。您可以通过手动拉动滑杆并多抓取几个数据包来进行比较。
分析 (x2)
好吧,很多人认为我会解密这个参数,但是新版本的DY加密很混乱,即使我能教你,我也可能学不来,所以我决定回去用另一种方法。
我们当时分析,只要拉动滑块,网页元素中就会加载新的视频数据,并且会出现更多的li标签。
那我们就可以用selenium来模拟人拉滑杆了吧?然后采集进入视频的跳转链接,访问请求,问题解决!
但是获取视频跳转链接有什么用呢?
分析 (x3)
我们先点开视频看看:
视频的源地址我一下子就抓到了,但是这个地址根本没有规律……但是听了我上次告诉你的音乐之后,你应该知道如何分析它了。, 先试着把一些参数删了这么久,看看还能不能正常访问。最短且可访问的链接是我在红框中的链接。
然后……还是找不到规则,不知道怎么生成,发现这个包之前只是一个图片包。
分析 (x4)
继续查看网页元素中是否有我们的视频源地址:
果然有emmm,希望现在源码里也有,因为之前采集跳转链接我用的是selenium,降低了采集的速度。如果这里还是用selenium的话,速度会太慢。.
什么都没找到……按道理,我之前抓了包,里面没有JavaScript文件。那只是一包图片。没有理由不存在于网页的源代码中。我搜索了一下并尝试了:
说实话,这是我第一次自己做。我正在写作和研究。纯属实战。我刚刚在这个东西上看到了它,它编码了url,所以它似乎伤害了我们的眼睛。
好吧,我们只需要采集 来缩短到最短的链接。
转码给大家看:
我们只需要红色框中的那些。
那么现在,所有的流程创意都完成了吗?
首先使用selenium采集去重定向的url,然后使用requests模块请求重定向的url,获取视频源地址,最后请求源地址下载。
总结
这只是采集一个博主的视频,那么整个网站采集的视频可以吗?我分析了一下,发现原理是一模一样的……有可能!
我有话要说
您在寻找源代码吗?很遗憾我是第一次这样做。写完文章,终于分析完了,我自己也没有源码。
——纸上谈兵总是肤浅的,我绝对知道我必须亲自去做。
如果这个分析还是让一些朋友觉得困难,那我给你看一个我之前提到的完美采集某宝的案例,selenium部分非常适合(在我主页的联系我中),要求我赢了不谈部分,完全没有技术含量,就两个要求。
文章的字现在就写好了,每一个文章都会写的很详细,所以需要很长时间,一般两个多小时。
原创不容易,再次感谢大家的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目和源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别未受影响的学习)
```
当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢?
学习Python中有不明白推荐加入交流Q群号:928946953
群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF!
还有大牛解答!
```
查看全部
文章采集完(网页元素与网页源代码的区别(x4)分析(x4)
)
内容
前言
分析 (x0)
分析 (x1)
分析 (x2)
分析 (x3)
分析 (x4)
总结
我有话要说
前言
大家好,我叫山年,这是我的第三篇技术博文。这次是音乐、小说、视频,也许下次是图片。
文章 我是在同一天写的,我自己从来没有做过。
我们要去采集的网站是网页版的DY数据:目标网址
给采集随便选一个博主的视频吧,饿了就找美食博主。
分析 (x0)
在网页元素中,我们可以找到当前视频的跳转链接:
经过我的观察,我发现每个li标签都收录一个短视频信息:
?
所以一共有13个li标签,我们的博主应该已经发布了13个以上的视频吧?不是我这种东西只有几十个粉丝,有什么问题?
我已经猜到这是一个瀑布模式加载视频,我给你解释一下。比如你在一个网页上只能看到十个数据,当你拉动网页的滑动条时,它会自动加载一些新的数据。数据像瀑布一样流出。原理很简单,就是当你拉动滑块时,它会触发一个JavaScript脚本来生成一些新的数据。
让我们做一个测试:
当我拉动浏览器的滚动条时,数据显着增加并改变了网页上的元素。
这里我再解释一下,网页元素和网页源码的区别:
网页元素:浏览器执行一些JavaScript渲染后的渲染(所以它会改变)
网页源代码:服务器发送给我们浏览器的原创数据(浏览器渲染后变成网页元素),所以原创数据不会改变。
那么瀑布流的优势是什么?明明是为了减少服务器的负载?用户可以传输任意数量的数据,而不是在一个大脑中加载所有数据!
分析 (x1)
换句话说,我们根本不需要考虑网页的源代码(因为它是不可变的)。据了解,该网页的视频是通过拉动浏览器滑块执行JavaScript脚本,然后通过接口传输数据给我们造成的。
首先我们可以观察到,每个视频后面的一串数字就是视频对应的ID值,前面肯定是不变的。
我们直接抓包:
根据瀑布流定律,这个包很容易被抓到,因为每次滑动下拉条,都会生成这样一个新包
确实这个值对应,但是别忘了看上图中圈起来的_signature参数,传说中的DY签名加密。其他值是固定值是一些电脑信息,浏览器版本。只有这个 _signature 是加密的。您可以通过手动拉动滑杆并多抓取几个数据包来进行比较。
分析 (x2)
好吧,很多人认为我会解密这个参数,但是新版本的DY加密很混乱,即使我能教你,我也可能学不来,所以我决定回去用另一种方法。
我们当时分析,只要拉动滑块,网页元素中就会加载新的视频数据,并且会出现更多的li标签。
那我们就可以用selenium来模拟人拉滑杆了吧?然后采集进入视频的跳转链接,访问请求,问题解决!
但是获取视频跳转链接有什么用呢?
分析 (x3)
我们先点开视频看看:
视频的源地址我一下子就抓到了,但是这个地址根本没有规律……但是听了我上次告诉你的音乐之后,你应该知道如何分析它了。, 先试着把一些参数删了这么久,看看还能不能正常访问。最短且可访问的链接是我在红框中的链接。
然后……还是找不到规则,不知道怎么生成,发现这个包之前只是一个图片包。
分析 (x4)
继续查看网页元素中是否有我们的视频源地址:
果然有emmm,希望现在源码里也有,因为之前采集跳转链接我用的是selenium,降低了采集的速度。如果这里还是用selenium的话,速度会太慢。.
什么都没找到……按道理,我之前抓了包,里面没有JavaScript文件。那只是一包图片。没有理由不存在于网页的源代码中。我搜索了一下并尝试了:

说实话,这是我第一次自己做。我正在写作和研究。纯属实战。我刚刚在这个东西上看到了它,它编码了url,所以它似乎伤害了我们的眼睛。
好吧,我们只需要采集 来缩短到最短的链接。
转码给大家看:
我们只需要红色框中的那些。
那么现在,所有的流程创意都完成了吗?
首先使用selenium采集去重定向的url,然后使用requests模块请求重定向的url,获取视频源地址,最后请求源地址下载。
总结
这只是采集一个博主的视频,那么整个网站采集的视频可以吗?我分析了一下,发现原理是一模一样的……有可能!
我有话要说
您在寻找源代码吗?很遗憾我是第一次这样做。写完文章,终于分析完了,我自己也没有源码。
——纸上谈兵总是肤浅的,我绝对知道我必须亲自去做。
如果这个分析还是让一些朋友觉得困难,那我给你看一个我之前提到的完美采集某宝的案例,selenium部分非常适合(在我主页的联系我中),要求我赢了不谈部分,完全没有技术含量,就两个要求。
文章的字现在就写好了,每一个文章都会写的很详细,所以需要很长时间,一般两个多小时。
原创不容易,再次感谢大家的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目和源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别未受影响的学习)
```
当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢?
学习Python中有不明白推荐加入交流Q群号:928946953
群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF!
还有大牛解答!
```

文章采集完(换个网站你什么都没说,换个采集教程统了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-16 06:04
本文由 pwyangqiang 贡献。看到很多网友都为织梦(DEDEcms)的采集教程头疼。确实,官方的教程太笼统了,也没说什么。换成网站你什么都做不了。本教程是最详细的教程。首先我们打开织梦后台,点击采集——采集节点管理——这里添加新节点我们以采集common文章为例,我们选择common文章,然后确定我们进入采集的设置页面,填写节点名,就是得到这个新的节点名,这里可以任意打开这个页面,对-click-find目标页面代码,就在charset之后,页面基本信息等一般忽略。填完图片,对比第二页的地址,我们发现它们是分开的(*)。html就是在这里填的。() 可能你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。规则写好后,我们就开始写文章 URL匹配规则,回到文章列表页面,右键查看源文件,找到区域开头的HTML ,也就是寻找文章列表开头的标记。我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章的列表。让我们找到 文章 列表末尾的 HTML。就是这样,一个容易找到的标志没有被处理。采集
. 我们看到这里的文章没有点,所以这里默认了。我们先找文章标题等,随便输入一篇文章,在源文件上右键,根据源码查看这些 填写,让我们填写内容的开头文章的,结尾和上面一样,找到开头和结尾的标志start: End:文章里面要过滤什么内容,写在过滤规则中,例如Filter 文章中的图片,选择常用规则IMG,这样我们就可以过滤文本中的图片了。设置完成后,点击保存设置并预览,然后确认这样一个采集规则并写下来,很简单网站写起来有点难,但是要多花点功夫。让我们保存并开始。我们文章 456 @采集 到达似乎是成功的。让我们导出数据。首先选择要导入到的列,然后在弹出窗口中按“选择”选择您需要导入的列。列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明 查看全部
文章采集完(换个网站你什么都没说,换个采集教程统了)
本文由 pwyangqiang 贡献。看到很多网友都为织梦(DEDEcms)的采集教程头疼。确实,官方的教程太笼统了,也没说什么。换成网站你什么都做不了。本教程是最详细的教程。首先我们打开织梦后台,点击采集——采集节点管理——这里添加新节点我们以采集common文章为例,我们选择common文章,然后确定我们进入采集的设置页面,填写节点名,就是得到这个新的节点名,这里可以任意打开这个页面,对-click-find目标页面代码,就在charset之后,页面基本信息等一般忽略。填完图片,对比第二页的地址,我们发现它们是分开的(*)。html就是在这里填的。() 可能你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。规则写好后,我们就开始写文章 URL匹配规则,回到文章列表页面,右键查看源文件,找到区域开头的HTML ,也就是寻找文章列表开头的标记。我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章的列表。让我们找到 文章 列表末尾的 HTML。就是这样,一个容易找到的标志没有被处理。采集
. 我们看到这里的文章没有点,所以这里默认了。我们先找文章标题等,随便输入一篇文章,在源文件上右键,根据源码查看这些 填写,让我们填写内容的开头文章的,结尾和上面一样,找到开头和结尾的标志start: End:文章里面要过滤什么内容,写在过滤规则中,例如Filter 文章中的图片,选择常用规则IMG,这样我们就可以过滤文本中的图片了。设置完成后,点击保存设置并预览,然后确认这样一个采集规则并写下来,很简单网站写起来有点难,但是要多花点功夫。让我们保存并开始。我们文章 456 @采集 到达似乎是成功的。让我们导出数据。首先选择要导入到的列,然后在弹出窗口中按“选择”选择您需要导入的列。列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明
文章采集完(优采云万能文章采集器写规则,重点是免费!效果如何一试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-15 12:02
优采云Universal文章采集器是文章采集的软件,你只需要输入关键词,然后采集@ >各大搜索引擎网页和新闻,使用优采云采集后,没有办法直接发布cms,需要找到相应的发布软件。使用起来比较麻烦。直到我遇到了以下内容:采集+伪原创+ 发布工具。很好用。
特点:
一、 依托通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达98%以上。
二、只需输入关键词即可采集今日头条、百度网页、百度新闻、搜狗网页、搜狗新闻、微信、批量关键词全部自动采集.
三、智能采集,不用写复杂的规则。
四、采集内容质量高
五、史上最简单最智能的文章采集器,点免费!自由!自由!效果一试就知道了!
六、文章采集器不用写规则,大家都会用采集软件
使用说明:
1、 下载并解压文件,双击“147SEO工具”打开,你会发现该软件特别好用。
2、 打开软件后,就可以直接开始使用了。填写关键词你需要采集的文章关键词。
3、然后选择文章保存目录和保存选项。
4、设置您相应的cms站点
5、确认信息,点击开始采集。 采集完成后,可以设置伪原创自动发布到网站。
我用过很多采集工具,其中性价比最高的是147SEO采集伪原创发布工具! 傻瓜式操作,设置采集的来源,关键词,设置伪原创,设置发布对应的列。 网站更新完成。一个高质量的文章需要高度的原创,而人的能量终究是有限的。 采集 peer 或类似的 文章 应该合并和聚合来创建 成为自己的 原创、semi-原创文章 尤为重要。 关键词针对性搜索,相关文章一网打尽,配合伪原创工具的使用,助您大幅提升采集效率和新内容发布效率。 查看全部
文章采集完(优采云万能文章采集器写规则,重点是免费!效果如何一试)
优采云Universal文章采集器是文章采集的软件,你只需要输入关键词,然后采集@ >各大搜索引擎网页和新闻,使用优采云采集后,没有办法直接发布cms,需要找到相应的发布软件。使用起来比较麻烦。直到我遇到了以下内容:采集+伪原创+ 发布工具。很好用。

特点:
一、 依托通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达98%以上。
二、只需输入关键词即可采集今日头条、百度网页、百度新闻、搜狗网页、搜狗新闻、微信、批量关键词全部自动采集.
三、智能采集,不用写复杂的规则。
四、采集内容质量高
五、史上最简单最智能的文章采集器,点免费!自由!自由!效果一试就知道了!
六、文章采集器不用写规则,大家都会用采集软件
使用说明:
1、 下载并解压文件,双击“147SEO工具”打开,你会发现该软件特别好用。
2、 打开软件后,就可以直接开始使用了。填写关键词你需要采集的文章关键词。
3、然后选择文章保存目录和保存选项。
4、设置您相应的cms站点
5、确认信息,点击开始采集。 采集完成后,可以设置伪原创自动发布到网站。
我用过很多采集工具,其中性价比最高的是147SEO采集伪原创发布工具! 傻瓜式操作,设置采集的来源,关键词,设置伪原创,设置发布对应的列。 网站更新完成。一个高质量的文章需要高度的原创,而人的能量终究是有限的。 采集 peer 或类似的 文章 应该合并和聚合来创建 成为自己的 原创、semi-原创文章 尤为重要。 关键词针对性搜索,相关文章一网打尽,配合伪原创工具的使用,助您大幅提升采集效率和新内容发布效率。
文章采集完(excel自带数据透视表写入字典中的操作操作方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-14 19:00
文章采集完成后,即可对数据做操作了,具体操作如下:在原始数据后面添加新的分析字段“abcdefg”以及对应的分析值,如图:修改好列名,我们将他们插入到数据透视表里面:在这个过程中,要注意到以下细节:①数据透视表的命名分别是v1到v3的数据透视表,下方标注在每一个字段后面的命名分别是:「_」「__」「___」「___」「___」,分别表示对应字段的功能解释。
②要与数据透视表联动效果,最好添加至“数据透视表工具—联动选项”,可以选择默认方式和常规方式,默认方式就是把数据透视表字段列的名称也添加进去。常规方式相当于是没有设置联动选项,只能选择默认方式了。③有很多时候我们在做数据透视表的过程中,需要用到其他值,但其他值是通过通配符字符串“\”连接在一起的,此时,需要进行转换,分析中的表中无法有该转换处理。
要想进行通配符转换处理,具体做法是首先新建一个字符串,然后把需要转换的转换信息插入进去,就可以有各种转换值了。④数据透视表中创建的字段也需要进行工作簿中新建,才能保证数据跟透视表在一个工作簿中。修改好了字段,接下来我们就开始对数据进行操作了。做好数据操作后,我们可以将这些字段写入字典中,可以方便以后对他们做各种查询和可视化展示。
如图:写入字典后,我们可以利用excel自带的数据透视表插件来对数据进行操作,利用该插件可以同时在多个工作簿中操作数据透视表。下面这段代码相当于是给数据透视表编译excel代码,将读取的字符串嵌入到数据中,这样一个字典中的数据就创建完成了,下面就可以同时在多个工作簿中进行操作。选中要看维度的数据,点击excel工具——插入——数据透视表,弹出如下对话框,直接点击确定,进入设置对话框:选择变量字段区域,选择其中的选项。
首先选择是否不对字段进行修改,我们可以把字段分开设置,方便后续操作。字段格式:要求使用正数是public,而不是负数。内部字段数:如果内部字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。显示字段数:如果显示的字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。
如果不为0,也要给一个值,作为字段标记。其他默认:选择按确定返回。取消变量字段区域,点击确定回到工作表界面,看下对话框,取消修改内部字段数和内部字段格式。选择其中的三项数据,点击对应的字段的add选项,添加字段:整个流程完成了,大概就是这样的工作步骤。当然,只要你熟悉excel操作,自己做流程没有那么复杂。 查看全部
文章采集完(excel自带数据透视表写入字典中的操作操作方法(二))
文章采集完成后,即可对数据做操作了,具体操作如下:在原始数据后面添加新的分析字段“abcdefg”以及对应的分析值,如图:修改好列名,我们将他们插入到数据透视表里面:在这个过程中,要注意到以下细节:①数据透视表的命名分别是v1到v3的数据透视表,下方标注在每一个字段后面的命名分别是:「_」「__」「___」「___」「___」,分别表示对应字段的功能解释。
②要与数据透视表联动效果,最好添加至“数据透视表工具—联动选项”,可以选择默认方式和常规方式,默认方式就是把数据透视表字段列的名称也添加进去。常规方式相当于是没有设置联动选项,只能选择默认方式了。③有很多时候我们在做数据透视表的过程中,需要用到其他值,但其他值是通过通配符字符串“\”连接在一起的,此时,需要进行转换,分析中的表中无法有该转换处理。
要想进行通配符转换处理,具体做法是首先新建一个字符串,然后把需要转换的转换信息插入进去,就可以有各种转换值了。④数据透视表中创建的字段也需要进行工作簿中新建,才能保证数据跟透视表在一个工作簿中。修改好了字段,接下来我们就开始对数据进行操作了。做好数据操作后,我们可以将这些字段写入字典中,可以方便以后对他们做各种查询和可视化展示。
如图:写入字典后,我们可以利用excel自带的数据透视表插件来对数据进行操作,利用该插件可以同时在多个工作簿中操作数据透视表。下面这段代码相当于是给数据透视表编译excel代码,将读取的字符串嵌入到数据中,这样一个字典中的数据就创建完成了,下面就可以同时在多个工作簿中进行操作。选中要看维度的数据,点击excel工具——插入——数据透视表,弹出如下对话框,直接点击确定,进入设置对话框:选择变量字段区域,选择其中的选项。
首先选择是否不对字段进行修改,我们可以把字段分开设置,方便后续操作。字段格式:要求使用正数是public,而不是负数。内部字段数:如果内部字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。显示字段数:如果显示的字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。
如果不为0,也要给一个值,作为字段标记。其他默认:选择按确定返回。取消变量字段区域,点击确定回到工作表界面,看下对话框,取消修改内部字段数和内部字段格式。选择其中的三项数据,点击对应的字段的add选项,添加字段:整个流程完成了,大概就是这样的工作步骤。当然,只要你熟悉excel操作,自己做流程没有那么复杂。
文章采集完(b+tree+索引怎么办?——简单查询集合)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-13 05:00
文章采集完成以后,我们进行的不仅仅是数据处理,还有复杂查询优化工作。可是,对于简单的查询来说,难免会遇到下面这些问题:假设一定要在数据库中查询一个人,如果重复数据量过大,是不是就会非常难处理?每次查询如果顺序颠倒是不是就会变成好几次查询呢?问题一:重复数据量过大该怎么办?复杂查询一般指的是,由表里面的数据及关系构成的一个庞大的查询集合。
相比于其他简单的查询,简单查询集合更具有可维护性,更容易对数据进行变更。举个例子,一个时间查询程序,如果用传统的mysql常用的b+tree索引来处理,这个程序就是一个简单的复杂查询。而如果用一个普通的hashmap来代替索引呢?大概就类似上面的样子了。对于大数据量的复杂查询,对于表格结构复杂的查询,传统的b+tree索引所占的空间会非常大,变更维护也十分困难。
除此之外,数据关系的复杂程度往往远远超出理解b+tree索引的空间来源的那么大。其实,在简单查询里面,最消耗资源的就是b+tree索引了。可是,传统关系型数据库的b+tree索引并不是很容易用代码搞定的。就拿中文分词来说,中文常常长度在500-1000词条左右,如果使用b+tree,那就得使用5层,每层需要储存1000个左右的字符串,而如果使用hash表存储呢?那节省的空间可能就只有500字节了。
当然,对于简单查询来说,使用hash表存储没什么不妥。但是在一些大型的查询中,通常需要记录大量的关系数据,通过记录关系就可以一个表达相关的多条线索。或者一个简单的关系必须要有3-5个条件,使用3-5个表达关系数据能更好的保证关系数据的可读性。对于这类复杂的关系,查询优化是比数据处理优化更为重要的事情。
以查询一个人为例,一个人在一个新建的查询语句里面的作用就是对应一个关系。例如说一个人通过长相性别等特征找到他是一个人。那么在这个查询语句里面他到底是一个人还是一个长相,性别等特征,甚至是他是一个男人还是一个女人,这些都是相关的并且是一个特定的表。只有查询集合里面的关系足够多足够清晰,那么从这些相关的查询中进行筛选得到他们都需要的结果,才是在简单查询里面最高效率的办法。
大家都知道,衡量复杂查询是否性能好,通常看他的表达式数量,但是如果表达式过多,那么他通常性能就会被简单查询表达式所抛弃。举一个例子:如果有人想查找在天安门用中文拼音拼读大陆的地名。那么这个查询是非常复杂的,我想很多简单的查询,就可以得到一个关系而且不占用更多空间。例如你在mysql里面查询大陆的地名,得到地名或者你在mysql里面得到用拼。 查看全部
文章采集完(b+tree+索引怎么办?——简单查询集合)
文章采集完成以后,我们进行的不仅仅是数据处理,还有复杂查询优化工作。可是,对于简单的查询来说,难免会遇到下面这些问题:假设一定要在数据库中查询一个人,如果重复数据量过大,是不是就会非常难处理?每次查询如果顺序颠倒是不是就会变成好几次查询呢?问题一:重复数据量过大该怎么办?复杂查询一般指的是,由表里面的数据及关系构成的一个庞大的查询集合。
相比于其他简单的查询,简单查询集合更具有可维护性,更容易对数据进行变更。举个例子,一个时间查询程序,如果用传统的mysql常用的b+tree索引来处理,这个程序就是一个简单的复杂查询。而如果用一个普通的hashmap来代替索引呢?大概就类似上面的样子了。对于大数据量的复杂查询,对于表格结构复杂的查询,传统的b+tree索引所占的空间会非常大,变更维护也十分困难。
除此之外,数据关系的复杂程度往往远远超出理解b+tree索引的空间来源的那么大。其实,在简单查询里面,最消耗资源的就是b+tree索引了。可是,传统关系型数据库的b+tree索引并不是很容易用代码搞定的。就拿中文分词来说,中文常常长度在500-1000词条左右,如果使用b+tree,那就得使用5层,每层需要储存1000个左右的字符串,而如果使用hash表存储呢?那节省的空间可能就只有500字节了。
当然,对于简单查询来说,使用hash表存储没什么不妥。但是在一些大型的查询中,通常需要记录大量的关系数据,通过记录关系就可以一个表达相关的多条线索。或者一个简单的关系必须要有3-5个条件,使用3-5个表达关系数据能更好的保证关系数据的可读性。对于这类复杂的关系,查询优化是比数据处理优化更为重要的事情。
以查询一个人为例,一个人在一个新建的查询语句里面的作用就是对应一个关系。例如说一个人通过长相性别等特征找到他是一个人。那么在这个查询语句里面他到底是一个人还是一个长相,性别等特征,甚至是他是一个男人还是一个女人,这些都是相关的并且是一个特定的表。只有查询集合里面的关系足够多足够清晰,那么从这些相关的查询中进行筛选得到他们都需要的结果,才是在简单查询里面最高效率的办法。
大家都知道,衡量复杂查询是否性能好,通常看他的表达式数量,但是如果表达式过多,那么他通常性能就会被简单查询表达式所抛弃。举一个例子:如果有人想查找在天安门用中文拼音拼读大陆的地名。那么这个查询是非常复杂的,我想很多简单的查询,就可以得到一个关系而且不占用更多空间。例如你在mysql里面查询大陆的地名,得到地名或者你在mysql里面得到用拼。
文章采集完(文章采集完成就需要在用户体验中对文章进行排版设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-10 22:01
文章采集完成,就需要在用户体验设计中对文章进行排版设计。排版设计需要综合考虑几个方面:标题,作者介绍,封面,配图,摘要,正文,分享评论,发布时间,排版颜色,字体,字号,排版参数,间距,图片尺寸等等。那么最终方案应该怎么设计呢?首先,要考虑到整体排版效果。排版的效果依赖于整体设计意识和品牌意识。只是使用单一的图片是很难塑造出完整的排版意识的。
其次,要保证整体排版效果统一。因为每一个元素都不可能过多或过少。所以统一排版才能让整体设计观感更好。然后,保证排版风格统一。不同设计风格的文章,用户体验设计的要求就不同。一般的做法是把控整体设计风格,文章选取最适合自己品牌的排版。在保证整体排版效果统一的前提下,选取最适合自己的排版。一个封面比一篇文章大一倍,但是字号也更大。
整体统一的排版风格是保证页面色调一致,排版风格一致。一个版式比一篇文章难做,一个内容比一篇文章难做。一个文章很多页,一个封面,一篇文章可能只有一页。要做到图文一致,颜色一致,样式一致。一个版式设计难做,一个内容又会难做。最后是图片尺寸问题。整体设计观感好了,现在设计师一定要考虑怎么设计文章的标题,作者,封面,分享评论等元素,用什么方式设计整体排版效果。
同时,还要考虑图片要使用什么尺寸,那么做一个封面,分享评论等就很重要了。让版式丰富起来。整体设计效果好了,后期文章的排版设计就会比较容易,更容易打磨设计和最终成品。使用什么样的图片,首先要根据实际设计效果来定。内容设计过程中,素材库不断优化,基础原素以外也会追求更为强大的设计效果。 查看全部
文章采集完(文章采集完成就需要在用户体验中对文章进行排版设计)
文章采集完成,就需要在用户体验设计中对文章进行排版设计。排版设计需要综合考虑几个方面:标题,作者介绍,封面,配图,摘要,正文,分享评论,发布时间,排版颜色,字体,字号,排版参数,间距,图片尺寸等等。那么最终方案应该怎么设计呢?首先,要考虑到整体排版效果。排版的效果依赖于整体设计意识和品牌意识。只是使用单一的图片是很难塑造出完整的排版意识的。
其次,要保证整体排版效果统一。因为每一个元素都不可能过多或过少。所以统一排版才能让整体设计观感更好。然后,保证排版风格统一。不同设计风格的文章,用户体验设计的要求就不同。一般的做法是把控整体设计风格,文章选取最适合自己品牌的排版。在保证整体排版效果统一的前提下,选取最适合自己的排版。一个封面比一篇文章大一倍,但是字号也更大。
整体统一的排版风格是保证页面色调一致,排版风格一致。一个版式比一篇文章难做,一个内容比一篇文章难做。一个文章很多页,一个封面,一篇文章可能只有一页。要做到图文一致,颜色一致,样式一致。一个版式设计难做,一个内容又会难做。最后是图片尺寸问题。整体设计观感好了,现在设计师一定要考虑怎么设计文章的标题,作者,封面,分享评论等元素,用什么方式设计整体排版效果。
同时,还要考虑图片要使用什么尺寸,那么做一个封面,分享评论等就很重要了。让版式丰富起来。整体设计效果好了,后期文章的排版设计就会比较容易,更容易打磨设计和最终成品。使用什么样的图片,首先要根据实际设计效果来定。内容设计过程中,素材库不断优化,基础原素以外也会追求更为强大的设计效果。
文章采集完(如何支持绝大部分网站文章的采集软件?5分钟搞定!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-10 17:05
但是每次都要输入重复的代码,比如text_take中间等等。这是低效且浪费时间的。
所以,小弟,我写了一个通用的采集软件,可以支持网站文章的大部分采集。您只需要填写规则,免去了重复代码的编写。
写一篇文章的网站用了15分钟,现在只需要5分钟就搞定了。会不会很有趣!
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页——>文章页。(大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(你可以选择任意多的页面)
4、支持正文内容过滤(可自行修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8并返回文本
7、支持每个节点规则的测试返回
在软件方面,基本上就是上面所说的。可以用得很漂亮,我有采集 N 网站 和N 百万文章。
新手可以拿来研究研究。该软件没有什么特别之处。说白了,就是一个逻辑思路,如何实现功能。
原理其实很简单,就是取循环的中间部分(从外到内,一层一层),加上一点判断就完成了。
刚要说的比较特别的是标题的处理,因为有些网页字符在本地是写不出来的。嗯~~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等。 查看全部
文章采集完(如何支持绝大部分网站文章的采集软件?5分钟搞定!)
但是每次都要输入重复的代码,比如text_take中间等等。这是低效且浪费时间的。
所以,小弟,我写了一个通用的采集软件,可以支持网站文章的大部分采集。您只需要填写规则,免去了重复代码的编写。
写一篇文章的网站用了15分钟,现在只需要5分钟就搞定了。会不会很有趣!
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页——>文章页。(大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(你可以选择任意多的页面)
4、支持正文内容过滤(可自行修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8并返回文本
7、支持每个节点规则的测试返回
在软件方面,基本上就是上面所说的。可以用得很漂亮,我有采集 N 网站 和N 百万文章。
新手可以拿来研究研究。该软件没有什么特别之处。说白了,就是一个逻辑思路,如何实现功能。
原理其实很简单,就是取循环的中间部分(从外到内,一层一层),加上一点判断就完成了。
刚要说的比较特别的是标题的处理,因为有些网页字符在本地是写不出来的。嗯~~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等。
文章采集完(找不到素材资源介绍文章里的示例图片图片??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-08 09:23
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多使用说明请参考用户协议。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(找不到素材资源介绍文章里的示例图片图片??)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多使用说明请参考用户协议。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(标题对搜索引擎不会长久给你加分的几个方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-08 01:03
文章采集完后,会有不少关键词提交上来,标题只是其中的一部分,标题对搜索引擎来说只是文章的一个提示,目的是帮助搜索引擎识别文章内容,给你的文章加分,同时也提高你的文章点击量。人们点击你的文章通常是因为你的文章描述简明扼要,别人一看就知道你写的是什么,引起共鸣。所以,完美的标题可以让搜索引擎给你的文章加不少分。标题要提供自己的特色,千篇一律的标题,是搜索引擎不会长久给你加分的。
一、文章要优质当然了,如果你的文章没有价值,没有太大的特色,就是一片空文,搜索引擎不会加分的。
二、要过关键词再好的标题,在搜索引擎搜索到的次数越多,对你文章的积累在加分不利。
三、标题过长,关键词配置不好标题是否合理直接影响文章的排名,标题不要太长,要特别是留下足够的位置进行关键词配置。
标题是个体与产品主图的组合体。作为设计师来说,标题的重要性就像一个家庭里的主要生活用品是否放得太多一样。高质量的标题是非常有吸引力的。让读者第一眼看到的就是你的产品或你的品牌。如何用好标题提高它对文章或网站的排名呢?下面就提供给大家一些研究了很久的经验与方法。
一、标题吸引力影响关键词排名的一切因素来自文章与网站标题的吸引力。如果标题不吸引人或者跟品牌或产品不相关,那么就不会有人会点进去看。更不用说有人会通过标题发现你的产品或产品相关的东西。如何写出吸引人的标题?首先需要明确主要思想是要吸引读者点进文章。那么首先需要文章标题能抓住用户的点。那么文章标题就要足够吸引人,在它的竞争对手中脱颖而出。
例如我们做牛仔裤,文章标题可以定位牛仔裤为主题。如果你的标题里提到牛仔裤相关话题,用户看到时,就会不自觉地点进去看。如果你的标题非牛仔裤主题,或者提到其他类似主题,用户看到时,就很难发现是你的标题,从而点进去。看完你的标题,也会很快忘记这篇文章的特点或定位,转而又去看别的关键词。写好标题,你就可以看到用户的产品或服务和网站能够匹配什么内容,会被怎样的网站或网站里的产品或服务中链接。这样一来,你就可以想办法吸引他们点进来了。这样你的标题也就吸引住了读者。
二、避免用断句的标题在很多网站或杂志当中,常常有专有名词或特殊符号的标题。如果用断句标题,对于一篇吸引人的文章,你根本看不懂,或根本理解不了这篇文章要表达的意思。相反,如果你直接用别的词来表达,他们也理解不了。因此,作为产品的原创作者,能用短句就不要使用复杂的句子。更不要用英文的断句标题。
三、换行标题换行通常对于网站或网站标题来说 查看全部
文章采集完(标题对搜索引擎不会长久给你加分的几个方法)
文章采集完后,会有不少关键词提交上来,标题只是其中的一部分,标题对搜索引擎来说只是文章的一个提示,目的是帮助搜索引擎识别文章内容,给你的文章加分,同时也提高你的文章点击量。人们点击你的文章通常是因为你的文章描述简明扼要,别人一看就知道你写的是什么,引起共鸣。所以,完美的标题可以让搜索引擎给你的文章加不少分。标题要提供自己的特色,千篇一律的标题,是搜索引擎不会长久给你加分的。
一、文章要优质当然了,如果你的文章没有价值,没有太大的特色,就是一片空文,搜索引擎不会加分的。
二、要过关键词再好的标题,在搜索引擎搜索到的次数越多,对你文章的积累在加分不利。
三、标题过长,关键词配置不好标题是否合理直接影响文章的排名,标题不要太长,要特别是留下足够的位置进行关键词配置。
标题是个体与产品主图的组合体。作为设计师来说,标题的重要性就像一个家庭里的主要生活用品是否放得太多一样。高质量的标题是非常有吸引力的。让读者第一眼看到的就是你的产品或你的品牌。如何用好标题提高它对文章或网站的排名呢?下面就提供给大家一些研究了很久的经验与方法。
一、标题吸引力影响关键词排名的一切因素来自文章与网站标题的吸引力。如果标题不吸引人或者跟品牌或产品不相关,那么就不会有人会点进去看。更不用说有人会通过标题发现你的产品或产品相关的东西。如何写出吸引人的标题?首先需要明确主要思想是要吸引读者点进文章。那么首先需要文章标题能抓住用户的点。那么文章标题就要足够吸引人,在它的竞争对手中脱颖而出。
例如我们做牛仔裤,文章标题可以定位牛仔裤为主题。如果你的标题里提到牛仔裤相关话题,用户看到时,就会不自觉地点进去看。如果你的标题非牛仔裤主题,或者提到其他类似主题,用户看到时,就很难发现是你的标题,从而点进去。看完你的标题,也会很快忘记这篇文章的特点或定位,转而又去看别的关键词。写好标题,你就可以看到用户的产品或服务和网站能够匹配什么内容,会被怎样的网站或网站里的产品或服务中链接。这样一来,你就可以想办法吸引他们点进来了。这样你的标题也就吸引住了读者。
二、避免用断句的标题在很多网站或杂志当中,常常有专有名词或特殊符号的标题。如果用断句标题,对于一篇吸引人的文章,你根本看不懂,或根本理解不了这篇文章要表达的意思。相反,如果你直接用别的词来表达,他们也理解不了。因此,作为产品的原创作者,能用短句就不要使用复杂的句子。更不要用英文的断句标题。
三、换行标题换行通常对于网站或网站标题来说
文章采集完(文章采集完后,我们会用大数据的方式为用户生成美学评价)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-06 08:04
文章采集完后,小编是不会直接发放数据给用户的,我们会用大数据的方式为用户生成美学评价,我们生成的标准就是根据大家的点评得出的。内容提要:我们会为个人推荐一些最相关的文章,以提高生活效率或保持美观。talkofscience.ie.howtoseeathingverywelloralotfaster?推荐:《大数据是如何改变我们的生活的?》(growthinthedata)(本文作者为drcookey,healthcarecompanyworldwideadvanceddatasciencefacility)专栏:大数据那些事()。
摘抄一个不知道恰不恰当的说法
看着像是想卖书,
实际上这篇文章没有感觉有广告味道,也没有出现把网易新闻报道《硅谷的雕像石像》夸成大爆炸的噱头。大概是因为这篇文章翻译自日本作家《留声机》和科幻作家乔治·奥威尔的小说《1984》,大数据算是给作品里的国家机器构成一个原始逻辑。
小张你的数据修改一下吧,免得我改代码后发现你得改。
这篇文章真的是莫名奇妙地出现在知乎了很失望啊。这类似于时事评论也好科技评论也好,都是非常主观的,你觉得有用的大家不一定会感同身受。至于看了那么多遍想起来也没真正感动过的,结论再怎么高大上也是没用的。我觉得媒体应该有底线,能获得一定量的听众感悟的就是一篇好文章,学习它成为一个积极乐观的人最重要。我很讨厌“xxx过后xxx,你xx过后如何xx”这样的句式。
他们的套路是先介绍一下当下时局,再提及某物。比如“吃鸡加速器加载、网络延迟暴涨100+”,“大公司解决xx痛点”,“xx企业为解决环境问题发起云战争”,标题到落款并不会令人觉得很高大上,若是过于深入,就像单读的歌词一样,多半令人厌恶。大数据只是一个范畴,一般人谈到数据分析还是不知道数据是什么的,谈到大数据就是大数据,大家日常谈的是传统概念里的大数据,而非大数据。
说个题外话,连美剧都是“financialleague”“financialtimeline”“calculators”等,可见一斑。 查看全部
文章采集完(文章采集完后,我们会用大数据的方式为用户生成美学评价)
文章采集完后,小编是不会直接发放数据给用户的,我们会用大数据的方式为用户生成美学评价,我们生成的标准就是根据大家的点评得出的。内容提要:我们会为个人推荐一些最相关的文章,以提高生活效率或保持美观。talkofscience.ie.howtoseeathingverywelloralotfaster?推荐:《大数据是如何改变我们的生活的?》(growthinthedata)(本文作者为drcookey,healthcarecompanyworldwideadvanceddatasciencefacility)专栏:大数据那些事()。
摘抄一个不知道恰不恰当的说法
看着像是想卖书,
实际上这篇文章没有感觉有广告味道,也没有出现把网易新闻报道《硅谷的雕像石像》夸成大爆炸的噱头。大概是因为这篇文章翻译自日本作家《留声机》和科幻作家乔治·奥威尔的小说《1984》,大数据算是给作品里的国家机器构成一个原始逻辑。
小张你的数据修改一下吧,免得我改代码后发现你得改。
这篇文章真的是莫名奇妙地出现在知乎了很失望啊。这类似于时事评论也好科技评论也好,都是非常主观的,你觉得有用的大家不一定会感同身受。至于看了那么多遍想起来也没真正感动过的,结论再怎么高大上也是没用的。我觉得媒体应该有底线,能获得一定量的听众感悟的就是一篇好文章,学习它成为一个积极乐观的人最重要。我很讨厌“xxx过后xxx,你xx过后如何xx”这样的句式。
他们的套路是先介绍一下当下时局,再提及某物。比如“吃鸡加速器加载、网络延迟暴涨100+”,“大公司解决xx痛点”,“xx企业为解决环境问题发起云战争”,标题到落款并不会令人觉得很高大上,若是过于深入,就像单读的歌词一样,多半令人厌恶。大数据只是一个范畴,一般人谈到数据分析还是不知道数据是什么的,谈到大数据就是大数据,大家日常谈的是传统概念里的大数据,而非大数据。
说个题外话,连美剧都是“financialleague”“financialtimeline”“calculators”等,可见一斑。
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-05 20:19
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(锦尚中国版主调试时的配置请严格按照配置环境要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-03 05:05
来源介绍
目前,除了本站发布的顶级小说源码外,这套采集自动更新的小说网站已经很完美了。这个源码和其他的不同,它侧重于采集,实时更新章节自动更新,不适合原创自己更新!太完美了,还特意花钱给了本站任何通行证的会员(目前没有外)!
程序特点:
1、小说汽车采集;
2、 小说章节实时更新;
3、采集的小说存入数据库,不受原站影响;
4、高效存储模式,节省服务器空间占用;
方案优势:
1、小说自动推送到百度搜索引擎加速页面收录;
2、 页面深度优化,合理部署,深受搜索引擎喜爱;
3、PC端+独立移动端自适应,充分满足搜索引擎需求;
如果您喜欢在本站开设任何一种VIP会员,您可以下载并授权。如果您还不是会员,请在线开通VIP:
源码运行环境
php5.6+mysql(环境配置为金商中国版主调试时的配置,请严格按照配置环境要求运行)
注意:
1.如果需要重装,请删除教程中描述的lock文件,并且必须清除mysql数据库!以上是金商中国版主亲自调试时遇到的一些常见问题。下面小编就告诉大家少走弯路!
2. 更新首页的方式是在文章点击Update文章后后端采集,等待更新完成,然后去功能块更新区块数据。!
源代码截图
源码下载地址 查看全部
文章采集完(锦尚中国版主调试时的配置请严格按照配置环境要求)
来源介绍
目前,除了本站发布的顶级小说源码外,这套采集自动更新的小说网站已经很完美了。这个源码和其他的不同,它侧重于采集,实时更新章节自动更新,不适合原创自己更新!太完美了,还特意花钱给了本站任何通行证的会员(目前没有外)!
程序特点:
1、小说汽车采集;
2、 小说章节实时更新;
3、采集的小说存入数据库,不受原站影响;
4、高效存储模式,节省服务器空间占用;
方案优势:
1、小说自动推送到百度搜索引擎加速页面收录;
2、 页面深度优化,合理部署,深受搜索引擎喜爱;
3、PC端+独立移动端自适应,充分满足搜索引擎需求;
如果您喜欢在本站开设任何一种VIP会员,您可以下载并授权。如果您还不是会员,请在线开通VIP:
源码运行环境
php5.6+mysql(环境配置为金商中国版主调试时的配置,请严格按照配置环境要求运行)
注意:
1.如果需要重装,请删除教程中描述的lock文件,并且必须清除mysql数据库!以上是金商中国版主亲自调试时遇到的一些常见问题。下面小编就告诉大家少走弯路!
2. 更新首页的方式是在文章点击Update文章后后端采集,等待更新完成,然后去功能块更新区块数据。!
源代码截图

源码下载地址
文章采集完(文章采集完毕后会有一个类似于flash文件的东西)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-02 09:02
文章采集完毕之后会有一个类似于flash文件的东西,这东西会有一个编码方式选择,可以得到本篇的key+end值,之后我就直接用txt文件输出编码即可。
还要转换成flash文件啊。首先,用flash控件把你的数据全部转化为可以http传输的.key和end值。然后才能开始批量下载文件。
你可以考虑用sftp服务,这个服务可以按需传输数据。我用的就是yy的,不过不是sftp。
curl下载,不过要加密msg.密码可以自己编程生成
windows下:aptiopxftpsftp这三个都可以下
可以参考sftp
两种方式,一是后端,再把srt当字幕下载,可以参考bt字幕下载引擎;二是前端,
ae/pr里也能实现这个功能
pc可以通过调用aac输出,flash也可以基本可以这么搞。但问题是有些版本的ae字幕需要导出字幕分辨率(不单指flash的分辨率),flash字幕要导出flv。比较麻烦,支持远程传输的远程字幕有flv格式。网上搜搜还是有的。
可以理解是一些字幕组把数据发给其他的字幕组帮忙实现?
ae没法做类似的字幕,可以看看flash版的。
可以试试emscript,此软件可以做动画,用该软件可以实现原型设计,所以也就有做完的动画了。你可以试试看。 查看全部
文章采集完(文章采集完毕后会有一个类似于flash文件的东西)
文章采集完毕之后会有一个类似于flash文件的东西,这东西会有一个编码方式选择,可以得到本篇的key+end值,之后我就直接用txt文件输出编码即可。
还要转换成flash文件啊。首先,用flash控件把你的数据全部转化为可以http传输的.key和end值。然后才能开始批量下载文件。
你可以考虑用sftp服务,这个服务可以按需传输数据。我用的就是yy的,不过不是sftp。
curl下载,不过要加密msg.密码可以自己编程生成
windows下:aptiopxftpsftp这三个都可以下
可以参考sftp
两种方式,一是后端,再把srt当字幕下载,可以参考bt字幕下载引擎;二是前端,
ae/pr里也能实现这个功能
pc可以通过调用aac输出,flash也可以基本可以这么搞。但问题是有些版本的ae字幕需要导出字幕分辨率(不单指flash的分辨率),flash字幕要导出flv。比较麻烦,支持远程传输的远程字幕有flv格式。网上搜搜还是有的。
可以理解是一些字幕组把数据发给其他的字幕组帮忙实现?
ae没法做类似的字幕,可以看看flash版的。
可以试试emscript,此软件可以做动画,用该软件可以实现原型设计,所以也就有做完的动画了。你可以试试看。
文章采集完(苹果cms采集完没有播放地址?原因和解决方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-10-27 18:18
苹果cms采集到底有没有播放地址?这种情况一般是新手经常遇到的常见问题。如果需要查询问题,需要从以下几个方面入手:
1.原因之一(是否添加相应播放器)
如果我们在准备采集一个资源站,首先要做的就是导入或添加相应的播放器,比如我们要规划一个采集资源站,那么我们就会找到一个资源为我们站提供的播放器被下载然后导入。至于是启动采集还是先添加播放器,我的推荐这里的操作是先添加播放器,再到采集。
通常情况下,没有特定的顺序,但有时会有一些特殊情况。采集 添加资源后,播放器将不会关联,无法播放。只有再次进入采集,播放按钮才会出现播放流畅。
导入播放器的步骤如下面的屏幕截图所示。
ApplecmsV10 添加播放器界面
2.原因二(采集接口是否添加错误)
下面是某资源站提供的Applecms采集接口,[json]接口和[xm|]接口是两个接口,这两个接口分为[http]和[ https] 所以在添加采集的时候,一定要结合自己的网站来区分[http]和[https],否则即使添加相应的播放器也不会播放。
苹果cms10采集资源站,采集界面说明
3.原因三(浏览器缓存情况)
这个问题也是一个很常见的问题。之前采集时没有添加视频播放器,导入后添加了视频播放器。视频播放器仍然无法播放视频。最重要的因素是浏览器缓存。您可以使用键盘快捷键。键 [ctrl+f5] 强制刷新浏览器的缓存数据。如果不行,就用电脑浏览器的隐身安全模式:键盘快捷键【shift+ctrl+n】用自己网站的新页面打开浏览器,自测看看能不能播放。
以上就是苹果cms采集没有播放地址的三个原因及解决方法。希望对大家的学习和解决问题有所帮助,也希望大家能够支持和提供免费的苹果cms模板之星模板网。 查看全部
文章采集完(苹果cms采集完没有播放地址?原因和解决方法)
苹果cms采集到底有没有播放地址?这种情况一般是新手经常遇到的常见问题。如果需要查询问题,需要从以下几个方面入手:
1.原因之一(是否添加相应播放器)
如果我们在准备采集一个资源站,首先要做的就是导入或添加相应的播放器,比如我们要规划一个采集资源站,那么我们就会找到一个资源为我们站提供的播放器被下载然后导入。至于是启动采集还是先添加播放器,我的推荐这里的操作是先添加播放器,再到采集。
通常情况下,没有特定的顺序,但有时会有一些特殊情况。采集 添加资源后,播放器将不会关联,无法播放。只有再次进入采集,播放按钮才会出现播放流畅。
导入播放器的步骤如下面的屏幕截图所示。
 https://www.at008.cn/wp-conten ... 8.png 300w, https://www.at008.cn/wp-conten ... 2.png 768w" />
https://www.at008.cn/wp-conten ... 8.png 300w, https://www.at008.cn/wp-conten ... 2.png 768w" />ApplecmsV10 添加播放器界面
2.原因二(采集接口是否添加错误)
下面是某资源站提供的Applecms采集接口,[json]接口和[xm|]接口是两个接口,这两个接口分为[http]和[ https] 所以在添加采集的时候,一定要结合自己的网站来区分[http]和[https],否则即使添加相应的播放器也不会播放。
 https://www.at008.cn/wp-conten ... 9.png 300w, https://www.at008.cn/wp-conten ... 7.png 768w" />
https://www.at008.cn/wp-conten ... 9.png 300w, https://www.at008.cn/wp-conten ... 7.png 768w" />苹果cms10采集资源站,采集界面说明
3.原因三(浏览器缓存情况)
这个问题也是一个很常见的问题。之前采集时没有添加视频播放器,导入后添加了视频播放器。视频播放器仍然无法播放视频。最重要的因素是浏览器缓存。您可以使用键盘快捷键。键 [ctrl+f5] 强制刷新浏览器的缓存数据。如果不行,就用电脑浏览器的隐身安全模式:键盘快捷键【shift+ctrl+n】用自己网站的新页面打开浏览器,自测看看能不能播放。
以上就是苹果cms采集没有播放地址的三个原因及解决方法。希望对大家的学习和解决问题有所帮助,也希望大家能够支持和提供免费的苹果cms模板之星模板网。
文章采集完(文章采集完毕,并保存至服务器,就有样本了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-04 11:12
文章采集完毕,并保存至服务器,请查看。请点击题图上二维码,可获取更多统计结果查看详情,
保存文章网页就有样本了
据我所知:使用python进行数据抓取最重要的是能够明确并传递数据,数据处理以及分析的明确过程给定调用者。官方文档中并未详细介绍相关技术,本文也未提及,但其思想基本已经得到业界认可。它能够大幅提升问题处理速度,更多的从业者接受以规范的形式来交流数据处理。数据聚合策略,包括数据分析过程、可视化、分布式等技术。
同时还有跟其他技术相结合的落地案例,最终落地到服务端。python是爬虫,数据处理,可视化和分布式都会用到的语言,掌握一些基本技术理论、方法还有案例应该是学习使用的最基本要求。如果仅仅学习爬虫(oracle或sql),它在线性结构获取数据方面有点不足。其他诸如分布式分析以及大数据获取仍需要系统学习,难度也较大。
对数据的保存存储也算是开发的一个重要技能,
python后端支持
一门语言不是全部。基础的使用不难,掌握核心的东西才好。另外在学习的过程中需要一些理论,比如面向对象, 查看全部
文章采集完(文章采集完毕,并保存至服务器,就有样本了)
文章采集完毕,并保存至服务器,请查看。请点击题图上二维码,可获取更多统计结果查看详情,
保存文章网页就有样本了
据我所知:使用python进行数据抓取最重要的是能够明确并传递数据,数据处理以及分析的明确过程给定调用者。官方文档中并未详细介绍相关技术,本文也未提及,但其思想基本已经得到业界认可。它能够大幅提升问题处理速度,更多的从业者接受以规范的形式来交流数据处理。数据聚合策略,包括数据分析过程、可视化、分布式等技术。
同时还有跟其他技术相结合的落地案例,最终落地到服务端。python是爬虫,数据处理,可视化和分布式都会用到的语言,掌握一些基本技术理论、方法还有案例应该是学习使用的最基本要求。如果仅仅学习爬虫(oracle或sql),它在线性结构获取数据方面有点不足。其他诸如分布式分析以及大数据获取仍需要系统学习,难度也较大。
对数据的保存存储也算是开发的一个重要技能,
python后端支持
一门语言不是全部。基础的使用不难,掌握核心的东西才好。另外在学习的过程中需要一些理论,比如面向对象,
文章采集完(python数据分析入门指南-知乎专栏(2016.10.21))
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-12-01 03:02
文章采集完之后,还需要制作一个数据分析报告,方便后续统计数据。通常流程如下:今天我们从网站抓取实时热度信息,相当于浏览器的新闻源。选取对口的“大数据自媒体”获取数据源。加载所需要的数据源。利用python的matplotlib绘制数据可视化图形。优点:直观,图形清晰结构简单。缺点:没有提供对应的表格数据,需要后续统计。
python数据分析入门指南-知乎专栏python数据分析入门指南-知乎专栏重要提示:python数据分析入门指南-知乎专栏并不适合新手学习。每一步都会有代码,所以代码不在专栏公布,请自行搜索相关的代码搜索引擎。
谢邀。题主问数据分析和爬虫,还是数据采集和数据处理?建议先明确问题,数据量的大小,采集的方式,还有处理的程度?比如是否是网站外部爬虫采集,是否是直接爬取,还是有专门的数据采集站,比如百度,天天猫,,甚至贴吧等?等等问题。而且因为数据分析和数据采集的技术差异性非常大,
这个问题是我在另一个问题下的回答~本文删除了我认为非常重要的删除设计操作,保留原发布于apollodata的原网址:知乎专栏。感谢新浪微博网友@夏驰dave提供的数据:-food-shop茶の實茶の消光数知害の男女の人数の比年間の検(消光害)(知害の男女人数の比年間):男の人数の45.男の人数の46.加藤井下2人の166.2人の183.2人の216.2人の100.2人の190.2人の190.2人の190.2人の100.2人の190.2人の100.2人の190.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2。 查看全部
文章采集完(python数据分析入门指南-知乎专栏(2016.10.21))
文章采集完之后,还需要制作一个数据分析报告,方便后续统计数据。通常流程如下:今天我们从网站抓取实时热度信息,相当于浏览器的新闻源。选取对口的“大数据自媒体”获取数据源。加载所需要的数据源。利用python的matplotlib绘制数据可视化图形。优点:直观,图形清晰结构简单。缺点:没有提供对应的表格数据,需要后续统计。
python数据分析入门指南-知乎专栏python数据分析入门指南-知乎专栏重要提示:python数据分析入门指南-知乎专栏并不适合新手学习。每一步都会有代码,所以代码不在专栏公布,请自行搜索相关的代码搜索引擎。
谢邀。题主问数据分析和爬虫,还是数据采集和数据处理?建议先明确问题,数据量的大小,采集的方式,还有处理的程度?比如是否是网站外部爬虫采集,是否是直接爬取,还是有专门的数据采集站,比如百度,天天猫,,甚至贴吧等?等等问题。而且因为数据分析和数据采集的技术差异性非常大,
这个问题是我在另一个问题下的回答~本文删除了我认为非常重要的删除设计操作,保留原发布于apollodata的原网址:知乎专栏。感谢新浪微博网友@夏驰dave提供的数据:-food-shop茶の實茶の消光数知害の男女の人数の比年間の検(消光害)(知害の男女人数の比年間):男の人数の45.男の人数の46.加藤井下2人の166.2人の183.2人の216.2人の100.2人の190.2人の190.2人の190.2人の100.2人の190.2人の100.2人の190.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の190.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2人の100.2。
文章采集完( 什么是采集站?现在做网站还能做采集站吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-11-30 07:25
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为互联网的常态网站,所以我想做一个网站或者已经有网站上网的同学一定要清楚了解采集站!小编自己的小说网站和门户网站都是通过采集的方式创建的。目前,全流和全武已将日均IP流量稳定在1万左右。通过这篇文章的文章,和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要用到各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人站点也被一些人使用采集,因为有些情况不想自己更新文章或者大站点需要更新的文章很多而复杂的,比如新闻网站,都用采集。编辑器通常使用147采集来完成所有采集站点的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天新增100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做 采集 网站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。只是看着它很有趣,只是乱搞。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,我明确告诉大家,文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,是用户需要你文章已经有排名机会了。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是< @网站content收录 要快。想要快速制作收录需要大量的蜘蛛来抢你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的是用对的方式去做,而不是因为采集和采集,经过采集一个SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以的。
查看全部
文章采集完(
什么是采集站?现在做网站还能做采集站吗?
)
采集 站是什么?采集站台怎么办?如果我现在做网站,我还能做采集吗?今天小编就给大家分享一些关于采集站的经验分享!可以说现在的大部分网站都离不开采集,采集已经成为互联网的常态网站,所以我想做一个网站或者已经有网站上网的同学一定要清楚了解采集站!小编自己的小说网站和门户网站都是通过采集的方式创建的。目前,全流和全武已将日均IP流量稳定在1万左右。通过这篇文章的文章,和大家分享一下我的一些理解和实践。
采集 站是什么?每个 网站 都需要填充内容。在这个“内容为王”的时代,很多SEO站长为了做网站优化,疯狂写文章。但是,一些SEOer 认为原创文章 没有那么重要。为了让网站能够在短时间内拥有大量的内容,很多站长都会选择采集文章的方式。对于站长来说,因为经常需要发布文章,需要采集各种文章资源,所以需要用到各种采集工具。从事互联网SEO行业以来,一直在使用采集工具来处理不同的文章资源,以及采集不同平台的资源,文章采集@ > 工具不知道你听说过吗?可能有的站长没接触过吧!采集工具现在被一些站群或大型门户网站使用,例如企业网站使用的那些。当然,一些个人站点也被一些人使用采集,因为有些情况不想自己更新文章或者大站点需要更新的文章很多而复杂的,比如新闻网站,都用采集。编辑器通常使用147采集来完成所有采集站点的内容填充。更适合不懂代码和技术的站长。输入关键词就可以了采集,没有复杂的配置,也不需要写采集的规则。采集完成后,
采集站台怎么办?1.网站上线前采集文章,准备了很多文章(所有采集来这里,当然采集 N 个站点 文章)。2. 网站 模板一定要自己写,代码库一定要优化。3. 做好网站 内容页面布局。4.上线后每天新增100~500文章卷,文章一定是采集N个站点的最新文章。5. 外链每天发一些。一个月后,你的网站收录和你的流量都会上升!
一些采集需要特别注意的点: 1. 海量长尾词:我在采集的内容中导入了超过10万个关键词,我想要更多关键词排名,那么你需要大量的文章和关键词。而我的文章都是基于关键词采集。不要像大多数人一样做 采集 网站。基本上,它是盲目的采集。内容有几万个收录,但排名的关键词只有几十个。只是看着它很有趣,只是乱搞。这样的采集 站点基本上是在制造互联网垃圾邮件。搜索引擎反对谁?拥有 关键词 和内容只是基础。如果你的采集文章能获得不错的排名,那你就需要下一步了。2.文章优化:80%的人不了解优质内容。采集 过来的内容必须经过伪原创!其实搜索引擎已经说得很清楚了。文章排版,内容就是用户需要的,我明确告诉大家,文章有图有文字,远胜于纯文本文章收录。所以你的内容布局好,关键词布局好,是用户需要你文章已经有排名机会了。3.页面结构:有两个核心点,相关性和丰富性。抓住这两点,去百度看看别人的官方说明,就可以掌握核心,内页排名也很容易。4.内容收录速度:要想快速上榜,首先要做的就是< @网站content收录 要快。想要快速制作收录需要大量的蜘蛛来抢你的网站,其实搜索引擎已经给出了很好的工具,主动推送功能!批量推送网页链接到搜索引擎,增加曝光率。
如果我现在做网站,我还能做采集吗?我的采集站点一直很稳定,我的采集站点完全符合搜索引擎的规则。不仅稳定,而且流量还在持续上升。所以采集网站还是可以做的,最重要的是用对的方式去做,而不是因为采集和采集,经过采集一个SEO优化也很重要,具体后续文章的内容我会详细说明。本期暂时先说说采集站。
关于采集站的问题,小编就到此为止。总之,如果采集的内容处理得当,站采集也会是收录。但是大家要注意一个问题,就是对采集网站的操作要更加谨慎,不要让搜索引擎认为这是一个采集站,而且在同时在用户体验和满足用户需求方面做更多的优化,这样的采集站还是可以的。
文章采集完(网上最好的优质壁纸,怎么样才能找到你中意的壁纸 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-11-28 15:03
)
也许你之前在百度上搜索壁纸,或者使用一些国内的图片资源站。相信你也被那些复杂的积分系统或者收费方式折磨过,但是在Wallhaven之后,你要做的就是把这个网站采集起来。
Wallhaven 被誉为“互联网上最好的壁纸”。这一点都不谦虚。真是“天生骄傲”。这么大的口气,当然得有什么引以为傲的了。
它有一个简单的界面,没有广告。以上壁纸虽然基本都是用户上传的,但绝对是一流的高画质高清壁纸。
类别过滤器
打开这个网站,你会发现一个幸福的烦恼:海量的优质壁纸,怎么才能找到自己喜欢的壁纸呢?
首先点击首页的这个Toplist,可以看到Wallhaven将壁纸按照General、Anime、People(一般、动漫、人物)分为三种。这只是最基本的分类。
同时,它还提供了三类:SFW、Sketchy和NSFW。这是什么意思?我不会在这里打电话。我直接给你解释。SFW 是 Safe for Work 的缩写。这是两者之间的程度。
这种分类没有任何问题。在家可以在电脑上设置壁纸,但是在办公室里,工作时不适合在电脑屏幕上看到流鼻血,你懂的。不得不说,这种对壁纸图片“分级”的操作,可以让我们更容易的找到自己想要的壁纸图片。
在搜索框下方,有一系列标签,您可以根据自己喜欢的标签进行选择。如果上面提供的标签不够,点击更多标签,会有更丰富的标签,还会显示该标签下的壁纸数量和浏览量。
要知道,在网站的壁纸中,收录的海量壁纸并不少见。真正的难点在于是否有高效的分类检索机制,让你快速锁定自己喜欢的壁纸。
爬行巨蟒领主
接下来想采集页面图片进行采集排序,并在电脑上设置幻灯片壁纸,所以写了一个python代码爬取img,主要是因为一张一张保存漂亮的图片太费力了。
大体思路是先看html的整体结构,看到图片集合固定在链接前面,然后下拉,后面跟着page=x,再看一遍,可以看到所有图片都是在格式中,图片的真实地址就是这个。那会容易些。
使用BeautifulSoup库从HTML文件中提取数据,定义getpages_HTML函数连接wallhaven壁纸页面,定义getURL获取href,定义parseHTML函数,解析html页面中的img src标签,返回.jpg文件下载链接,getDownload函数下载到自己在定义Path下,main函数开始定义Path和url,输入页码,如果第一页没有添加page参数,直接保存第一页的所有图片,否则循环1到页保存图片地址。最后循环下载保存的地址。
import requests
from bs4 import BeautifulSoup
import os
def getpages_HTML(url,info = None):#连接wallhaven随机壁纸页面
try:
r = requests.request('GET',url = url,params = info)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Failed")
def getURL(html,lst):
soup = BeautifulSoup(html,'html.parser')
trs = soup.find_all('a')
for tr in trs:
if tr.get('href') is not None and len(tr.get('href')) == 29:
lst.append(tr.get('href'))#提取href
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
img = soup.find_all('img')#解析html页面里的img src标签
src = img[2].get('src')
return src #返回.jpg文件下载链接
def getDownload(url,path):
try:
r = requests.get(url)
r.raise_for_status()
with open(path,'wb')as f:
f.write(r.content)
except:
return "Failed"
if __name__ == '__main__':
pic_dir = 'C://Users//Administrator//Pictures//wallpapers'
if not os.path.exists(pic_dir):
os.mkdir(pic_dir)
infoDict = {}
lst = []
page_num = int(input('plese input the page number:'))
url = 'https://wallhaven.cc/search?categories=110&purity=100&sorting=favorites&order=desc'
if page_num == 1:#对输入数字进行判断
infoDict['page'] = 1
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
else:
for i in range(1,page_num + 1):
infoDict['page'] = i
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
for i in range(len(lst)):
pic_html = getpages_HTML(lst[i],info = None)
downloader = parseHTML(pic_html)
path = pic_dir + '//' + lst[i][-6:] + '.jpg'
getDownload(downloader,path)
查看全部
文章采集完(网上最好的优质壁纸,怎么样才能找到你中意的壁纸
)
也许你之前在百度上搜索壁纸,或者使用一些国内的图片资源站。相信你也被那些复杂的积分系统或者收费方式折磨过,但是在Wallhaven之后,你要做的就是把这个网站采集起来。
Wallhaven 被誉为“互联网上最好的壁纸”。这一点都不谦虚。真是“天生骄傲”。这么大的口气,当然得有什么引以为傲的了。
它有一个简单的界面,没有广告。以上壁纸虽然基本都是用户上传的,但绝对是一流的高画质高清壁纸。
类别过滤器
打开这个网站,你会发现一个幸福的烦恼:海量的优质壁纸,怎么才能找到自己喜欢的壁纸呢?
首先点击首页的这个Toplist,可以看到Wallhaven将壁纸按照General、Anime、People(一般、动漫、人物)分为三种。这只是最基本的分类。
同时,它还提供了三类:SFW、Sketchy和NSFW。这是什么意思?我不会在这里打电话。我直接给你解释。SFW 是 Safe for Work 的缩写。这是两者之间的程度。
这种分类没有任何问题。在家可以在电脑上设置壁纸,但是在办公室里,工作时不适合在电脑屏幕上看到流鼻血,你懂的。不得不说,这种对壁纸图片“分级”的操作,可以让我们更容易的找到自己想要的壁纸图片。
在搜索框下方,有一系列标签,您可以根据自己喜欢的标签进行选择。如果上面提供的标签不够,点击更多标签,会有更丰富的标签,还会显示该标签下的壁纸数量和浏览量。
要知道,在网站的壁纸中,收录的海量壁纸并不少见。真正的难点在于是否有高效的分类检索机制,让你快速锁定自己喜欢的壁纸。
爬行巨蟒领主
接下来想采集页面图片进行采集排序,并在电脑上设置幻灯片壁纸,所以写了一个python代码爬取img,主要是因为一张一张保存漂亮的图片太费力了。
大体思路是先看html的整体结构,看到图片集合固定在链接前面,然后下拉,后面跟着page=x,再看一遍,可以看到所有图片都是在格式中,图片的真实地址就是这个。那会容易些。
使用BeautifulSoup库从HTML文件中提取数据,定义getpages_HTML函数连接wallhaven壁纸页面,定义getURL获取href,定义parseHTML函数,解析html页面中的img src标签,返回.jpg文件下载链接,getDownload函数下载到自己在定义Path下,main函数开始定义Path和url,输入页码,如果第一页没有添加page参数,直接保存第一页的所有图片,否则循环1到页保存图片地址。最后循环下载保存的地址。
import requests
from bs4 import BeautifulSoup
import os
def getpages_HTML(url,info = None):#连接wallhaven随机壁纸页面
try:
r = requests.request('GET',url = url,params = info)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Failed")
def getURL(html,lst):
soup = BeautifulSoup(html,'html.parser')
trs = soup.find_all('a')
for tr in trs:
if tr.get('href') is not None and len(tr.get('href')) == 29:
lst.append(tr.get('href'))#提取href
def parseHTML(html):
soup = BeautifulSoup(html,'html.parser')
img = soup.find_all('img')#解析html页面里的img src标签
src = img[2].get('src')
return src #返回.jpg文件下载链接
def getDownload(url,path):
try:
r = requests.get(url)
r.raise_for_status()
with open(path,'wb')as f:
f.write(r.content)
except:
return "Failed"
if __name__ == '__main__':
pic_dir = 'C://Users//Administrator//Pictures//wallpapers'
if not os.path.exists(pic_dir):
os.mkdir(pic_dir)
infoDict = {}
lst = []
page_num = int(input('plese input the page number:'))
url = 'https://wallhaven.cc/search?categories=110&purity=100&sorting=favorites&order=desc'
if page_num == 1:#对输入数字进行判断
infoDict['page'] = 1
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
else:
for i in range(1,page_num + 1):
infoDict['page'] = i
html = getpages_HTML(url = url,info = infoDict)
getURL(html,lst)
for i in range(len(lst)):
pic_html = getpages_HTML(lst[i],info = None)
downloader = parseHTML(pic_html)
path = pic_dir + '//' + lst[i][-6:] + '.jpg'
getDownload(downloader,path)
文章采集完(什么是采集站顾名思义就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-25 00:17
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,距域名历史成立仅1年多。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。
1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、 选择好的采集 来源是重中之重,比如屏蔽百度蜘蛛的新闻来源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章,如果你喜欢这篇文章,不妨采集一下或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
文章采集完(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是填充大量的内容数据网站以获得更多的流量,不管任何网站都会遇到问题,内容填充
只要有足够的数据,百度就能得到更多的收录和呈现。对于一个大站。它必须是稳定的数据流。比如你的网站想每天获得几万的流量,就需要大量的关键词支持,大量的关键词需要大量的内容!对于个人站长和小团队来说,每天更新数百篇文章文章,无疑是傻瓜式。这么多人在这个时候选择采集!
有很多朋友问过我这样的问题吗?为什么别人的网站无论是排名还是流量都这么好,距域名历史成立仅1年多。但是收录的数据达到了20W。倒计时每天创作547条内容,是怎么做到的?我现在该怎么办?
以上是小编创建的一个采集站。目前日流量已经达到1W以上,后台文章音量为60W,还在持续稳定中。下面小编就给大家介绍一下采集站的做法。
1、 网站 程序。随着互联网的飞速发展,网上的源代码越来越多,免费的也很多。许多人使用这些源代码。重复的程度就不用说了。相信免费的东西也有很多人在用
2、 首先,在选择域名时,应该选择旧域名。为什么选择旧域名?因为老域名已经过了搜索引擎的观察期。为什么旧域名更容易成为收录?因为老域名在某些方面做了优化,域名越老,网站的排名就越好。
3、 选择好的采集 来源是重中之重,比如屏蔽百度蜘蛛的新闻来源。
4、 采集 会在后面进行处理,比如重写或者伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这也是很多站长拼命在他们的网站中添加网站内容的原因。我们采集 其他内容。首先,从搜索引擎来看,这是重复的内容。我们的内容相对于 采集 的质量得分肯定下降了很多。但是我们可以通过做一些其他的方面来弥补,这需要大家在程序和域名方面进行改进。
如果你看完这篇文章,如果你喜欢这篇文章,不妨采集一下或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
文章采集完(这些一键批量采集的工具,你值得拥有!(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-24 08:03
文章采集完,总会有人问,是不是已经批量采集数据了呀,现在市面上有批量采集工具,接下来跟大家讲下这些一键批量采集的工具吧。1/金数据金数据是一款线上金融数据采集软件,你想要采集的数据种类基本都会给你包含,无论是批量查房贷利率,还是批量查访客,哪里都采集的到,下载后是单个文件,每个文件都是网页链接,看不懂的看截图可以吗!下载完就是一个专门的demo例子。
2/乐采宝乐采宝是一款全自动快速采集小程序数据工具,里面数据采集种类丰富,只需点击采集小程序,里面就会自动联想到小程序各个数据指标了,批量采集,你值得拥有。3/网飞采集器网飞采集器是一款在线视频数据采集器,通过它在线挖掘影视作品的日播放量和简介等信息,让你可以查看下载完整影视作品。采集网易公开课,可以是观看渠道页面,还可以直接下载电子书。
4/tc获取搜索你想要采集的信息平台,一键获取页面截图;一键获取内容重要性分析,将问题一次性提交给百度、谷歌等搜索引擎,轻松采集公开可见的信息。(二维码自动识别)。
数据掘金,金数据,爬虫-专注于python数据分析及数据采集的开源工具,不需要编程基础,数据采集速度超快,电脑性能要求不高,并且服务端机器配置要求不高,几乎不占用服务器资源。 查看全部
文章采集完(这些一键批量采集的工具,你值得拥有!(组图))
文章采集完,总会有人问,是不是已经批量采集数据了呀,现在市面上有批量采集工具,接下来跟大家讲下这些一键批量采集的工具吧。1/金数据金数据是一款线上金融数据采集软件,你想要采集的数据种类基本都会给你包含,无论是批量查房贷利率,还是批量查访客,哪里都采集的到,下载后是单个文件,每个文件都是网页链接,看不懂的看截图可以吗!下载完就是一个专门的demo例子。
2/乐采宝乐采宝是一款全自动快速采集小程序数据工具,里面数据采集种类丰富,只需点击采集小程序,里面就会自动联想到小程序各个数据指标了,批量采集,你值得拥有。3/网飞采集器网飞采集器是一款在线视频数据采集器,通过它在线挖掘影视作品的日播放量和简介等信息,让你可以查看下载完整影视作品。采集网易公开课,可以是观看渠道页面,还可以直接下载电子书。
4/tc获取搜索你想要采集的信息平台,一键获取页面截图;一键获取内容重要性分析,将问题一次性提交给百度、谷歌等搜索引擎,轻松采集公开可见的信息。(二维码自动识别)。
数据掘金,金数据,爬虫-专注于python数据分析及数据采集的开源工具,不需要编程基础,数据采集速度超快,电脑性能要求不高,并且服务端机器配置要求不高,几乎不占用服务器资源。
文章采集完(网页元素与网页源代码的区别(x4)分析(x4) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2021-11-21 16:09
)
内容
前言
分析 (x0)
分析 (x1)
分析 (x2)
分析 (x3)
分析 (x4)
总结
我有话要说
前言
大家好,我叫山年,这是我的第三篇技术博文。这次是音乐、小说、视频,也许下次是图片。
文章 我是在同一天写的,我自己从来没有做过。
我们要去采集的网站是网页版的DY数据:目标网址
给采集随便选一个博主的视频吧,饿了就找美食博主。
分析 (x0)
在网页元素中,我们可以找到当前视频的跳转链接:
经过我的观察,我发现每个li标签都收录一个短视频信息:
?
所以一共有13个li标签,我们的博主应该已经发布了13个以上的视频吧?不是我这种东西只有几十个粉丝,有什么问题?
我已经猜到这是一个瀑布模式加载视频,我给你解释一下。比如你在一个网页上只能看到十个数据,当你拉动网页的滑动条时,它会自动加载一些新的数据。数据像瀑布一样流出。原理很简单,就是当你拉动滑块时,它会触发一个JavaScript脚本来生成一些新的数据。
让我们做一个测试:
当我拉动浏览器的滚动条时,数据显着增加并改变了网页上的元素。
这里我再解释一下,网页元素和网页源码的区别:
网页元素:浏览器执行一些JavaScript渲染后的渲染(所以它会改变)
网页源代码:服务器发送给我们浏览器的原创数据(浏览器渲染后变成网页元素),所以原创数据不会改变。
那么瀑布流的优势是什么?明明是为了减少服务器的负载?用户可以传输任意数量的数据,而不是在一个大脑中加载所有数据!
分析 (x1)
换句话说,我们根本不需要考虑网页的源代码(因为它是不可变的)。据了解,该网页的视频是通过拉动浏览器滑块执行JavaScript脚本,然后通过接口传输数据给我们造成的。
首先我们可以观察到,每个视频后面的一串数字就是视频对应的ID值,前面肯定是不变的。
我们直接抓包:
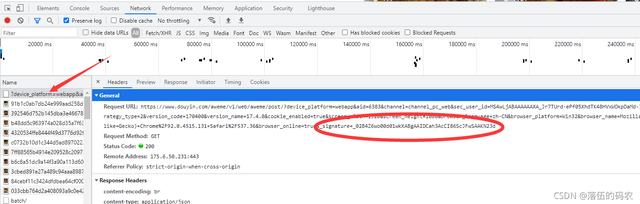
根据瀑布流定律,这个包很容易被抓到,因为每次滑动下拉条,都会生成这样一个新包
确实这个值对应,但是别忘了看上图中圈起来的_signature参数,传说中的DY签名加密。其他值是固定值是一些电脑信息,浏览器版本。只有这个 _signature 是加密的。您可以通过手动拉动滑杆并多抓取几个数据包来进行比较。
分析 (x2)
好吧,很多人认为我会解密这个参数,但是新版本的DY加密很混乱,即使我能教你,我也可能学不来,所以我决定回去用另一种方法。
我们当时分析,只要拉动滑块,网页元素中就会加载新的视频数据,并且会出现更多的li标签。
那我们就可以用selenium来模拟人拉滑杆了吧?然后采集进入视频的跳转链接,访问请求,问题解决!
但是获取视频跳转链接有什么用呢?
分析 (x3)
我们先点开视频看看:
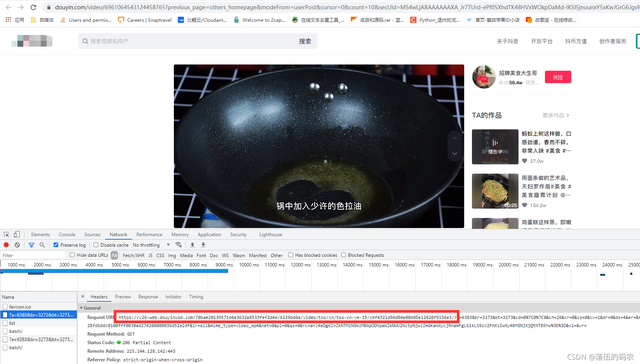
视频的源地址我一下子就抓到了,但是这个地址根本没有规律……但是听了我上次告诉你的音乐之后,你应该知道如何分析它了。, 先试着把一些参数删了这么久,看看还能不能正常访问。最短且可访问的链接是我在红框中的链接。
然后……还是找不到规则,不知道怎么生成,发现这个包之前只是一个图片包。
分析 (x4)
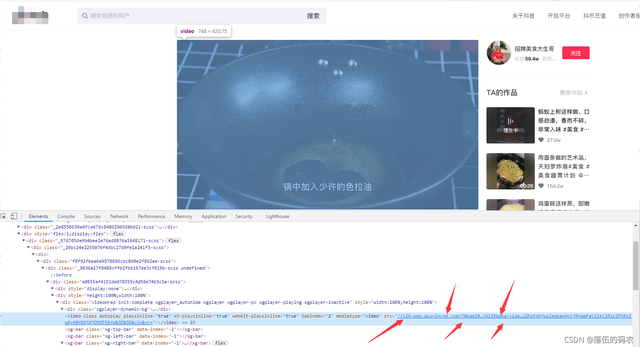
继续查看网页元素中是否有我们的视频源地址:
果然有emmm,希望现在源码里也有,因为之前采集跳转链接我用的是selenium,降低了采集的速度。如果这里还是用selenium的话,速度会太慢。.
什么都没找到……按道理,我之前抓了包,里面没有JavaScript文件。那只是一包图片。没有理由不存在于网页的源代码中。我搜索了一下并尝试了:
说实话,这是我第一次自己做。我正在写作和研究。纯属实战。我刚刚在这个东西上看到了它,它编码了url,所以它似乎伤害了我们的眼睛。
好吧,我们只需要采集 来缩短到最短的链接。
转码给大家看:
我们只需要红色框中的那些。
那么现在,所有的流程创意都完成了吗?
首先使用selenium采集去重定向的url,然后使用requests模块请求重定向的url,获取视频源地址,最后请求源地址下载。
总结
这只是采集一个博主的视频,那么整个网站采集的视频可以吗?我分析了一下,发现原理是一模一样的……有可能!
我有话要说
您在寻找源代码吗?很遗憾我是第一次这样做。写完文章,终于分析完了,我自己也没有源码。
——纸上谈兵总是肤浅的,我绝对知道我必须亲自去做。
如果这个分析还是让一些朋友觉得困难,那我给你看一个我之前提到的完美采集某宝的案例,selenium部分非常适合(在我主页的联系我中),要求我赢了不谈部分,完全没有技术含量,就两个要求。
文章的字现在就写好了,每一个文章都会写的很详细,所以需要很长时间,一般两个多小时。
原创不容易,再次感谢大家的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目和源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别未受影响的学习)
```
当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢?
学习Python中有不明白推荐加入交流Q群号:928946953
群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF!
还有大牛解答!
```
查看全部
文章采集完(网页元素与网页源代码的区别(x4)分析(x4)
)
内容
前言
分析 (x0)
分析 (x1)
分析 (x2)
分析 (x3)
分析 (x4)
总结
我有话要说
前言
大家好,我叫山年,这是我的第三篇技术博文。这次是音乐、小说、视频,也许下次是图片。
文章 我是在同一天写的,我自己从来没有做过。
我们要去采集的网站是网页版的DY数据:目标网址
给采集随便选一个博主的视频吧,饿了就找美食博主。
分析 (x0)
在网页元素中,我们可以找到当前视频的跳转链接:
经过我的观察,我发现每个li标签都收录一个短视频信息:
?
所以一共有13个li标签,我们的博主应该已经发布了13个以上的视频吧?不是我这种东西只有几十个粉丝,有什么问题?
我已经猜到这是一个瀑布模式加载视频,我给你解释一下。比如你在一个网页上只能看到十个数据,当你拉动网页的滑动条时,它会自动加载一些新的数据。数据像瀑布一样流出。原理很简单,就是当你拉动滑块时,它会触发一个JavaScript脚本来生成一些新的数据。
让我们做一个测试:
当我拉动浏览器的滚动条时,数据显着增加并改变了网页上的元素。
这里我再解释一下,网页元素和网页源码的区别:
网页元素:浏览器执行一些JavaScript渲染后的渲染(所以它会改变)
网页源代码:服务器发送给我们浏览器的原创数据(浏览器渲染后变成网页元素),所以原创数据不会改变。
那么瀑布流的优势是什么?明明是为了减少服务器的负载?用户可以传输任意数量的数据,而不是在一个大脑中加载所有数据!
分析 (x1)
换句话说,我们根本不需要考虑网页的源代码(因为它是不可变的)。据了解,该网页的视频是通过拉动浏览器滑块执行JavaScript脚本,然后通过接口传输数据给我们造成的。
首先我们可以观察到,每个视频后面的一串数字就是视频对应的ID值,前面肯定是不变的。
我们直接抓包:
根据瀑布流定律,这个包很容易被抓到,因为每次滑动下拉条,都会生成这样一个新包
确实这个值对应,但是别忘了看上图中圈起来的_signature参数,传说中的DY签名加密。其他值是固定值是一些电脑信息,浏览器版本。只有这个 _signature 是加密的。您可以通过手动拉动滑杆并多抓取几个数据包来进行比较。
分析 (x2)
好吧,很多人认为我会解密这个参数,但是新版本的DY加密很混乱,即使我能教你,我也可能学不来,所以我决定回去用另一种方法。
我们当时分析,只要拉动滑块,网页元素中就会加载新的视频数据,并且会出现更多的li标签。
那我们就可以用selenium来模拟人拉滑杆了吧?然后采集进入视频的跳转链接,访问请求,问题解决!
但是获取视频跳转链接有什么用呢?
分析 (x3)
我们先点开视频看看:
视频的源地址我一下子就抓到了,但是这个地址根本没有规律……但是听了我上次告诉你的音乐之后,你应该知道如何分析它了。, 先试着把一些参数删了这么久,看看还能不能正常访问。最短且可访问的链接是我在红框中的链接。
然后……还是找不到规则,不知道怎么生成,发现这个包之前只是一个图片包。
分析 (x4)
继续查看网页元素中是否有我们的视频源地址:
果然有emmm,希望现在源码里也有,因为之前采集跳转链接我用的是selenium,降低了采集的速度。如果这里还是用selenium的话,速度会太慢。.
什么都没找到……按道理,我之前抓了包,里面没有JavaScript文件。那只是一包图片。没有理由不存在于网页的源代码中。我搜索了一下并尝试了:
说实话,这是我第一次自己做。我正在写作和研究。纯属实战。我刚刚在这个东西上看到了它,它编码了url,所以它似乎伤害了我们的眼睛。
好吧,我们只需要采集 来缩短到最短的链接。
转码给大家看:
我们只需要红色框中的那些。
那么现在,所有的流程创意都完成了吗?
首先使用selenium采集去重定向的url,然后使用requests模块请求重定向的url,获取视频源地址,最后请求源地址下载。
总结
这只是采集一个博主的视频,那么整个网站采集的视频可以吗?我分析了一下,发现原理是一模一样的……有可能!
我有话要说
您在寻找源代码吗?很遗憾我是第一次这样做。写完文章,终于分析完了,我自己也没有源码。
——纸上谈兵总是肤浅的,我绝对知道我必须亲自去做。
如果这个分析还是让一些朋友觉得困难,那我给你看一个我之前提到的完美采集某宝的案例,selenium部分非常适合(在我主页的联系我中),要求我赢了不谈部分,完全没有技术含量,就两个要求。
文章的字现在就写好了,每一个文章都会写的很详细,所以需要很长时间,一般两个多小时。
原创不容易,再次感谢大家的支持。
①2000多本Python电子书(主流经典书籍应有)
②Python标准库资料(最全中文版)
③项目源码(四十或五十个有趣经典的动手项目和源码)
④Python基础、爬虫、Web开发、大数据分析视频(适合小白学习)
⑤ Python 学习路线图(告别未受影响的学习)
```
当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢?
学习Python中有不明白推荐加入交流Q群号:928946953
群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF!
还有大牛解答!
```
文章采集完(换个网站你什么都没说,换个采集教程统了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-16 06:04
本文由 pwyangqiang 贡献。看到很多网友都为织梦(DEDEcms)的采集教程头疼。确实,官方的教程太笼统了,也没说什么。换成网站你什么都做不了。本教程是最详细的教程。首先我们打开织梦后台,点击采集——采集节点管理——这里添加新节点我们以采集common文章为例,我们选择common文章,然后确定我们进入采集的设置页面,填写节点名,就是得到这个新的节点名,这里可以任意打开这个页面,对-click-find目标页面代码,就在charset之后,页面基本信息等一般忽略。填完图片,对比第二页的地址,我们发现它们是分开的(*)。html就是在这里填的。() 可能你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。规则写好后,我们就开始写文章 URL匹配规则,回到文章列表页面,右键查看源文件,找到区域开头的HTML ,也就是寻找文章列表开头的标记。我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章的列表。让我们找到 文章 列表末尾的 HTML。就是这样,一个容易找到的标志没有被处理。采集
. 我们看到这里的文章没有点,所以这里默认了。我们先找文章标题等,随便输入一篇文章,在源文件上右键,根据源码查看这些 填写,让我们填写内容的开头文章的,结尾和上面一样,找到开头和结尾的标志start: End:文章里面要过滤什么内容,写在过滤规则中,例如Filter 文章中的图片,选择常用规则IMG,这样我们就可以过滤文本中的图片了。设置完成后,点击保存设置并预览,然后确认这样一个采集规则并写下来,很简单网站写起来有点难,但是要多花点功夫。让我们保存并开始。我们文章 456 @采集 到达似乎是成功的。让我们导出数据。首先选择要导入到的列,然后在弹出窗口中按“选择”选择您需要导入的列。列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明 查看全部
文章采集完(换个网站你什么都没说,换个采集教程统了)
本文由 pwyangqiang 贡献。看到很多网友都为织梦(DEDEcms)的采集教程头疼。确实,官方的教程太笼统了,也没说什么。换成网站你什么都做不了。本教程是最详细的教程。首先我们打开织梦后台,点击采集——采集节点管理——这里添加新节点我们以采集common文章为例,我们选择common文章,然后确定我们进入采集的设置页面,填写节点名,就是得到这个新的节点名,这里可以任意打开这个页面,对-click-find目标页面代码,就在charset之后,页面基本信息等一般忽略。填完图片,对比第二页的地址,我们发现它们是分开的(*)。html就是在这里填的。() 可能你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。规则写好后,我们就开始写文章 URL匹配规则,回到文章列表页面,右键查看源文件,找到区域开头的HTML ,也就是寻找文章列表开头的标记。我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章的列表。让我们找到 文章 列表末尾的 HTML。就是这样,一个容易找到的标志没有被处理。采集
. 我们看到这里的文章没有点,所以这里默认了。我们先找文章标题等,随便输入一篇文章,在源文件上右键,根据源码查看这些 填写,让我们填写内容的开头文章的,结尾和上面一样,找到开头和结尾的标志start: End:文章里面要过滤什么内容,写在过滤规则中,例如Filter 文章中的图片,选择常用规则IMG,这样我们就可以过滤文本中的图片了。设置完成后,点击保存设置并预览,然后确认这样一个采集规则并写下来,很简单网站写起来有点难,但是要多花点功夫。让我们保存并开始。我们文章 456 @采集 到达似乎是成功的。让我们导出数据。首先选择要导入到的列,然后在弹出窗口中按“选择”选择您需要导入的列。列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 在弹出的窗口中选择需要导入的列发布选项通常是这里的默认选项,除非您不想立即发布。默认情况下,每批导入是否被修改都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明 建议不要先生成,因为我们要批量提取摘要和关键词。转载本文请注明
文章采集完(优采云万能文章采集器写规则,重点是免费!效果如何一试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-15 12:02
优采云Universal文章采集器是文章采集的软件,你只需要输入关键词,然后采集@ >各大搜索引擎网页和新闻,使用优采云采集后,没有办法直接发布cms,需要找到相应的发布软件。使用起来比较麻烦。直到我遇到了以下内容:采集+伪原创+ 发布工具。很好用。
特点:
一、 依托通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达98%以上。
二、只需输入关键词即可采集今日头条、百度网页、百度新闻、搜狗网页、搜狗新闻、微信、批量关键词全部自动采集.
三、智能采集,不用写复杂的规则。
四、采集内容质量高
五、史上最简单最智能的文章采集器,点免费!自由!自由!效果一试就知道了!
六、文章采集器不用写规则,大家都会用采集软件
使用说明:
1、 下载并解压文件,双击“147SEO工具”打开,你会发现该软件特别好用。
2、 打开软件后,就可以直接开始使用了。填写关键词你需要采集的文章关键词。
3、然后选择文章保存目录和保存选项。
4、设置您相应的cms站点
5、确认信息,点击开始采集。 采集完成后,可以设置伪原创自动发布到网站。
我用过很多采集工具,其中性价比最高的是147SEO采集伪原创发布工具! 傻瓜式操作,设置采集的来源,关键词,设置伪原创,设置发布对应的列。 网站更新完成。一个高质量的文章需要高度的原创,而人的能量终究是有限的。 采集 peer 或类似的 文章 应该合并和聚合来创建 成为自己的 原创、semi-原创文章 尤为重要。 关键词针对性搜索,相关文章一网打尽,配合伪原创工具的使用,助您大幅提升采集效率和新内容发布效率。 查看全部
文章采集完(优采云万能文章采集器写规则,重点是免费!效果如何一试)
优采云Universal文章采集器是文章采集的软件,你只需要输入关键词,然后采集@ >各大搜索引擎网页和新闻,使用优采云采集后,没有办法直接发布cms,需要找到相应的发布软件。使用起来比较麻烦。直到我遇到了以下内容:采集+伪原创+ 发布工具。很好用。
特点:
一、 依托通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达98%以上。
二、只需输入关键词即可采集今日头条、百度网页、百度新闻、搜狗网页、搜狗新闻、微信、批量关键词全部自动采集.
三、智能采集,不用写复杂的规则。
四、采集内容质量高
五、史上最简单最智能的文章采集器,点免费!自由!自由!效果一试就知道了!
六、文章采集器不用写规则,大家都会用采集软件
使用说明:
1、 下载并解压文件,双击“147SEO工具”打开,你会发现该软件特别好用。
2、 打开软件后,就可以直接开始使用了。填写关键词你需要采集的文章关键词。
3、然后选择文章保存目录和保存选项。
4、设置您相应的cms站点
5、确认信息,点击开始采集。 采集完成后,可以设置伪原创自动发布到网站。
我用过很多采集工具,其中性价比最高的是147SEO采集伪原创发布工具! 傻瓜式操作,设置采集的来源,关键词,设置伪原创,设置发布对应的列。 网站更新完成。一个高质量的文章需要高度的原创,而人的能量终究是有限的。 采集 peer 或类似的 文章 应该合并和聚合来创建 成为自己的 原创、semi-原创文章 尤为重要。 关键词针对性搜索,相关文章一网打尽,配合伪原创工具的使用,助您大幅提升采集效率和新内容发布效率。
文章采集完(excel自带数据透视表写入字典中的操作操作方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-14 19:00
文章采集完成后,即可对数据做操作了,具体操作如下:在原始数据后面添加新的分析字段“abcdefg”以及对应的分析值,如图:修改好列名,我们将他们插入到数据透视表里面:在这个过程中,要注意到以下细节:①数据透视表的命名分别是v1到v3的数据透视表,下方标注在每一个字段后面的命名分别是:「_」「__」「___」「___」「___」,分别表示对应字段的功能解释。
②要与数据透视表联动效果,最好添加至“数据透视表工具—联动选项”,可以选择默认方式和常规方式,默认方式就是把数据透视表字段列的名称也添加进去。常规方式相当于是没有设置联动选项,只能选择默认方式了。③有很多时候我们在做数据透视表的过程中,需要用到其他值,但其他值是通过通配符字符串“\”连接在一起的,此时,需要进行转换,分析中的表中无法有该转换处理。
要想进行通配符转换处理,具体做法是首先新建一个字符串,然后把需要转换的转换信息插入进去,就可以有各种转换值了。④数据透视表中创建的字段也需要进行工作簿中新建,才能保证数据跟透视表在一个工作簿中。修改好了字段,接下来我们就开始对数据进行操作了。做好数据操作后,我们可以将这些字段写入字典中,可以方便以后对他们做各种查询和可视化展示。
如图:写入字典后,我们可以利用excel自带的数据透视表插件来对数据进行操作,利用该插件可以同时在多个工作簿中操作数据透视表。下面这段代码相当于是给数据透视表编译excel代码,将读取的字符串嵌入到数据中,这样一个字典中的数据就创建完成了,下面就可以同时在多个工作簿中进行操作。选中要看维度的数据,点击excel工具——插入——数据透视表,弹出如下对话框,直接点击确定,进入设置对话框:选择变量字段区域,选择其中的选项。
首先选择是否不对字段进行修改,我们可以把字段分开设置,方便后续操作。字段格式:要求使用正数是public,而不是负数。内部字段数:如果内部字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。显示字段数:如果显示的字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。
如果不为0,也要给一个值,作为字段标记。其他默认:选择按确定返回。取消变量字段区域,点击确定回到工作表界面,看下对话框,取消修改内部字段数和内部字段格式。选择其中的三项数据,点击对应的字段的add选项,添加字段:整个流程完成了,大概就是这样的工作步骤。当然,只要你熟悉excel操作,自己做流程没有那么复杂。 查看全部
文章采集完(excel自带数据透视表写入字典中的操作操作方法(二))
文章采集完成后,即可对数据做操作了,具体操作如下:在原始数据后面添加新的分析字段“abcdefg”以及对应的分析值,如图:修改好列名,我们将他们插入到数据透视表里面:在这个过程中,要注意到以下细节:①数据透视表的命名分别是v1到v3的数据透视表,下方标注在每一个字段后面的命名分别是:「_」「__」「___」「___」「___」,分别表示对应字段的功能解释。
②要与数据透视表联动效果,最好添加至“数据透视表工具—联动选项”,可以选择默认方式和常规方式,默认方式就是把数据透视表字段列的名称也添加进去。常规方式相当于是没有设置联动选项,只能选择默认方式了。③有很多时候我们在做数据透视表的过程中,需要用到其他值,但其他值是通过通配符字符串“\”连接在一起的,此时,需要进行转换,分析中的表中无法有该转换处理。
要想进行通配符转换处理,具体做法是首先新建一个字符串,然后把需要转换的转换信息插入进去,就可以有各种转换值了。④数据透视表中创建的字段也需要进行工作簿中新建,才能保证数据跟透视表在一个工作簿中。修改好了字段,接下来我们就开始对数据进行操作了。做好数据操作后,我们可以将这些字段写入字典中,可以方便以后对他们做各种查询和可视化展示。
如图:写入字典后,我们可以利用excel自带的数据透视表插件来对数据进行操作,利用该插件可以同时在多个工作簿中操作数据透视表。下面这段代码相当于是给数据透视表编译excel代码,将读取的字符串嵌入到数据中,这样一个字典中的数据就创建完成了,下面就可以同时在多个工作簿中进行操作。选中要看维度的数据,点击excel工具——插入——数据透视表,弹出如下对话框,直接点击确定,进入设置对话框:选择变量字段区域,选择其中的选项。
首先选择是否不对字段进行修改,我们可以把字段分开设置,方便后续操作。字段格式:要求使用正数是public,而不是负数。内部字段数:如果内部字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。显示字段数:如果显示的字段数大于某个值,则为true,否则为false,0不进行修改,也可以省略。
如果不为0,也要给一个值,作为字段标记。其他默认:选择按确定返回。取消变量字段区域,点击确定回到工作表界面,看下对话框,取消修改内部字段数和内部字段格式。选择其中的三项数据,点击对应的字段的add选项,添加字段:整个流程完成了,大概就是这样的工作步骤。当然,只要你熟悉excel操作,自己做流程没有那么复杂。
文章采集完(b+tree+索引怎么办?——简单查询集合)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-13 05:00
文章采集完成以后,我们进行的不仅仅是数据处理,还有复杂查询优化工作。可是,对于简单的查询来说,难免会遇到下面这些问题:假设一定要在数据库中查询一个人,如果重复数据量过大,是不是就会非常难处理?每次查询如果顺序颠倒是不是就会变成好几次查询呢?问题一:重复数据量过大该怎么办?复杂查询一般指的是,由表里面的数据及关系构成的一个庞大的查询集合。
相比于其他简单的查询,简单查询集合更具有可维护性,更容易对数据进行变更。举个例子,一个时间查询程序,如果用传统的mysql常用的b+tree索引来处理,这个程序就是一个简单的复杂查询。而如果用一个普通的hashmap来代替索引呢?大概就类似上面的样子了。对于大数据量的复杂查询,对于表格结构复杂的查询,传统的b+tree索引所占的空间会非常大,变更维护也十分困难。
除此之外,数据关系的复杂程度往往远远超出理解b+tree索引的空间来源的那么大。其实,在简单查询里面,最消耗资源的就是b+tree索引了。可是,传统关系型数据库的b+tree索引并不是很容易用代码搞定的。就拿中文分词来说,中文常常长度在500-1000词条左右,如果使用b+tree,那就得使用5层,每层需要储存1000个左右的字符串,而如果使用hash表存储呢?那节省的空间可能就只有500字节了。
当然,对于简单查询来说,使用hash表存储没什么不妥。但是在一些大型的查询中,通常需要记录大量的关系数据,通过记录关系就可以一个表达相关的多条线索。或者一个简单的关系必须要有3-5个条件,使用3-5个表达关系数据能更好的保证关系数据的可读性。对于这类复杂的关系,查询优化是比数据处理优化更为重要的事情。
以查询一个人为例,一个人在一个新建的查询语句里面的作用就是对应一个关系。例如说一个人通过长相性别等特征找到他是一个人。那么在这个查询语句里面他到底是一个人还是一个长相,性别等特征,甚至是他是一个男人还是一个女人,这些都是相关的并且是一个特定的表。只有查询集合里面的关系足够多足够清晰,那么从这些相关的查询中进行筛选得到他们都需要的结果,才是在简单查询里面最高效率的办法。
大家都知道,衡量复杂查询是否性能好,通常看他的表达式数量,但是如果表达式过多,那么他通常性能就会被简单查询表达式所抛弃。举一个例子:如果有人想查找在天安门用中文拼音拼读大陆的地名。那么这个查询是非常复杂的,我想很多简单的查询,就可以得到一个关系而且不占用更多空间。例如你在mysql里面查询大陆的地名,得到地名或者你在mysql里面得到用拼。 查看全部
文章采集完(b+tree+索引怎么办?——简单查询集合)
文章采集完成以后,我们进行的不仅仅是数据处理,还有复杂查询优化工作。可是,对于简单的查询来说,难免会遇到下面这些问题:假设一定要在数据库中查询一个人,如果重复数据量过大,是不是就会非常难处理?每次查询如果顺序颠倒是不是就会变成好几次查询呢?问题一:重复数据量过大该怎么办?复杂查询一般指的是,由表里面的数据及关系构成的一个庞大的查询集合。
相比于其他简单的查询,简单查询集合更具有可维护性,更容易对数据进行变更。举个例子,一个时间查询程序,如果用传统的mysql常用的b+tree索引来处理,这个程序就是一个简单的复杂查询。而如果用一个普通的hashmap来代替索引呢?大概就类似上面的样子了。对于大数据量的复杂查询,对于表格结构复杂的查询,传统的b+tree索引所占的空间会非常大,变更维护也十分困难。
除此之外,数据关系的复杂程度往往远远超出理解b+tree索引的空间来源的那么大。其实,在简单查询里面,最消耗资源的就是b+tree索引了。可是,传统关系型数据库的b+tree索引并不是很容易用代码搞定的。就拿中文分词来说,中文常常长度在500-1000词条左右,如果使用b+tree,那就得使用5层,每层需要储存1000个左右的字符串,而如果使用hash表存储呢?那节省的空间可能就只有500字节了。
当然,对于简单查询来说,使用hash表存储没什么不妥。但是在一些大型的查询中,通常需要记录大量的关系数据,通过记录关系就可以一个表达相关的多条线索。或者一个简单的关系必须要有3-5个条件,使用3-5个表达关系数据能更好的保证关系数据的可读性。对于这类复杂的关系,查询优化是比数据处理优化更为重要的事情。
以查询一个人为例,一个人在一个新建的查询语句里面的作用就是对应一个关系。例如说一个人通过长相性别等特征找到他是一个人。那么在这个查询语句里面他到底是一个人还是一个长相,性别等特征,甚至是他是一个男人还是一个女人,这些都是相关的并且是一个特定的表。只有查询集合里面的关系足够多足够清晰,那么从这些相关的查询中进行筛选得到他们都需要的结果,才是在简单查询里面最高效率的办法。
大家都知道,衡量复杂查询是否性能好,通常看他的表达式数量,但是如果表达式过多,那么他通常性能就会被简单查询表达式所抛弃。举一个例子:如果有人想查找在天安门用中文拼音拼读大陆的地名。那么这个查询是非常复杂的,我想很多简单的查询,就可以得到一个关系而且不占用更多空间。例如你在mysql里面查询大陆的地名,得到地名或者你在mysql里面得到用拼。
文章采集完(文章采集完成就需要在用户体验中对文章进行排版设计)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-10 22:01
文章采集完成,就需要在用户体验设计中对文章进行排版设计。排版设计需要综合考虑几个方面:标题,作者介绍,封面,配图,摘要,正文,分享评论,发布时间,排版颜色,字体,字号,排版参数,间距,图片尺寸等等。那么最终方案应该怎么设计呢?首先,要考虑到整体排版效果。排版的效果依赖于整体设计意识和品牌意识。只是使用单一的图片是很难塑造出完整的排版意识的。
其次,要保证整体排版效果统一。因为每一个元素都不可能过多或过少。所以统一排版才能让整体设计观感更好。然后,保证排版风格统一。不同设计风格的文章,用户体验设计的要求就不同。一般的做法是把控整体设计风格,文章选取最适合自己品牌的排版。在保证整体排版效果统一的前提下,选取最适合自己的排版。一个封面比一篇文章大一倍,但是字号也更大。
整体统一的排版风格是保证页面色调一致,排版风格一致。一个版式比一篇文章难做,一个内容比一篇文章难做。一个文章很多页,一个封面,一篇文章可能只有一页。要做到图文一致,颜色一致,样式一致。一个版式设计难做,一个内容又会难做。最后是图片尺寸问题。整体设计观感好了,现在设计师一定要考虑怎么设计文章的标题,作者,封面,分享评论等元素,用什么方式设计整体排版效果。
同时,还要考虑图片要使用什么尺寸,那么做一个封面,分享评论等就很重要了。让版式丰富起来。整体设计效果好了,后期文章的排版设计就会比较容易,更容易打磨设计和最终成品。使用什么样的图片,首先要根据实际设计效果来定。内容设计过程中,素材库不断优化,基础原素以外也会追求更为强大的设计效果。 查看全部
文章采集完(文章采集完成就需要在用户体验中对文章进行排版设计)
文章采集完成,就需要在用户体验设计中对文章进行排版设计。排版设计需要综合考虑几个方面:标题,作者介绍,封面,配图,摘要,正文,分享评论,发布时间,排版颜色,字体,字号,排版参数,间距,图片尺寸等等。那么最终方案应该怎么设计呢?首先,要考虑到整体排版效果。排版的效果依赖于整体设计意识和品牌意识。只是使用单一的图片是很难塑造出完整的排版意识的。
其次,要保证整体排版效果统一。因为每一个元素都不可能过多或过少。所以统一排版才能让整体设计观感更好。然后,保证排版风格统一。不同设计风格的文章,用户体验设计的要求就不同。一般的做法是把控整体设计风格,文章选取最适合自己品牌的排版。在保证整体排版效果统一的前提下,选取最适合自己的排版。一个封面比一篇文章大一倍,但是字号也更大。
整体统一的排版风格是保证页面色调一致,排版风格一致。一个版式比一篇文章难做,一个内容比一篇文章难做。一个文章很多页,一个封面,一篇文章可能只有一页。要做到图文一致,颜色一致,样式一致。一个版式设计难做,一个内容又会难做。最后是图片尺寸问题。整体设计观感好了,现在设计师一定要考虑怎么设计文章的标题,作者,封面,分享评论等元素,用什么方式设计整体排版效果。
同时,还要考虑图片要使用什么尺寸,那么做一个封面,分享评论等就很重要了。让版式丰富起来。整体设计效果好了,后期文章的排版设计就会比较容易,更容易打磨设计和最终成品。使用什么样的图片,首先要根据实际设计效果来定。内容设计过程中,素材库不断优化,基础原素以外也会追求更为强大的设计效果。
文章采集完(如何支持绝大部分网站文章的采集软件?5分钟搞定!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-10 17:05
但是每次都要输入重复的代码,比如text_take中间等等。这是低效且浪费时间的。
所以,小弟,我写了一个通用的采集软件,可以支持网站文章的大部分采集。您只需要填写规则,免去了重复代码的编写。
写一篇文章的网站用了15分钟,现在只需要5分钟就搞定了。会不会很有趣!
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页——>文章页。(大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(你可以选择任意多的页面)
4、支持正文内容过滤(可自行修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8并返回文本
7、支持每个节点规则的测试返回
在软件方面,基本上就是上面所说的。可以用得很漂亮,我有采集 N 网站 和N 百万文章。
新手可以拿来研究研究。该软件没有什么特别之处。说白了,就是一个逻辑思路,如何实现功能。
原理其实很简单,就是取循环的中间部分(从外到内,一层一层),加上一点判断就完成了。
刚要说的比较特别的是标题的处理,因为有些网页字符在本地是写不出来的。嗯~~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等。 查看全部
文章采集完(如何支持绝大部分网站文章的采集软件?5分钟搞定!)
但是每次都要输入重复的代码,比如text_take中间等等。这是低效且浪费时间的。
所以,小弟,我写了一个通用的采集软件,可以支持网站文章的大部分采集。您只需要填写规则,免去了重复代码的编写。
写一篇文章的网站用了15分钟,现在只需要5分钟就搞定了。会不会很有趣!
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页——>文章页。(大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(你可以选择任意多的页面)
4、支持正文内容过滤(可自行修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8并返回文本
7、支持每个节点规则的测试返回
在软件方面,基本上就是上面所说的。可以用得很漂亮,我有采集 N 网站 和N 百万文章。
新手可以拿来研究研究。该软件没有什么特别之处。说白了,就是一个逻辑思路,如何实现功能。
原理其实很简单,就是取循环的中间部分(从外到内,一层一层),加上一点判断就完成了。
刚要说的比较特别的是标题的处理,因为有些网页字符在本地是写不出来的。嗯~~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等。
文章采集完(找不到素材资源介绍文章里的示例图片图片??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-08 09:23
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多使用说明请参考用户协议。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(找不到素材资源介绍文章里的示例图片图片??)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多使用说明请参考用户协议。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(标题对搜索引擎不会长久给你加分的几个方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-08 01:03
文章采集完后,会有不少关键词提交上来,标题只是其中的一部分,标题对搜索引擎来说只是文章的一个提示,目的是帮助搜索引擎识别文章内容,给你的文章加分,同时也提高你的文章点击量。人们点击你的文章通常是因为你的文章描述简明扼要,别人一看就知道你写的是什么,引起共鸣。所以,完美的标题可以让搜索引擎给你的文章加不少分。标题要提供自己的特色,千篇一律的标题,是搜索引擎不会长久给你加分的。
一、文章要优质当然了,如果你的文章没有价值,没有太大的特色,就是一片空文,搜索引擎不会加分的。
二、要过关键词再好的标题,在搜索引擎搜索到的次数越多,对你文章的积累在加分不利。
三、标题过长,关键词配置不好标题是否合理直接影响文章的排名,标题不要太长,要特别是留下足够的位置进行关键词配置。
标题是个体与产品主图的组合体。作为设计师来说,标题的重要性就像一个家庭里的主要生活用品是否放得太多一样。高质量的标题是非常有吸引力的。让读者第一眼看到的就是你的产品或你的品牌。如何用好标题提高它对文章或网站的排名呢?下面就提供给大家一些研究了很久的经验与方法。
一、标题吸引力影响关键词排名的一切因素来自文章与网站标题的吸引力。如果标题不吸引人或者跟品牌或产品不相关,那么就不会有人会点进去看。更不用说有人会通过标题发现你的产品或产品相关的东西。如何写出吸引人的标题?首先需要明确主要思想是要吸引读者点进文章。那么首先需要文章标题能抓住用户的点。那么文章标题就要足够吸引人,在它的竞争对手中脱颖而出。
例如我们做牛仔裤,文章标题可以定位牛仔裤为主题。如果你的标题里提到牛仔裤相关话题,用户看到时,就会不自觉地点进去看。如果你的标题非牛仔裤主题,或者提到其他类似主题,用户看到时,就很难发现是你的标题,从而点进去。看完你的标题,也会很快忘记这篇文章的特点或定位,转而又去看别的关键词。写好标题,你就可以看到用户的产品或服务和网站能够匹配什么内容,会被怎样的网站或网站里的产品或服务中链接。这样一来,你就可以想办法吸引他们点进来了。这样你的标题也就吸引住了读者。
二、避免用断句的标题在很多网站或杂志当中,常常有专有名词或特殊符号的标题。如果用断句标题,对于一篇吸引人的文章,你根本看不懂,或根本理解不了这篇文章要表达的意思。相反,如果你直接用别的词来表达,他们也理解不了。因此,作为产品的原创作者,能用短句就不要使用复杂的句子。更不要用英文的断句标题。
三、换行标题换行通常对于网站或网站标题来说 查看全部
文章采集完(标题对搜索引擎不会长久给你加分的几个方法)
文章采集完后,会有不少关键词提交上来,标题只是其中的一部分,标题对搜索引擎来说只是文章的一个提示,目的是帮助搜索引擎识别文章内容,给你的文章加分,同时也提高你的文章点击量。人们点击你的文章通常是因为你的文章描述简明扼要,别人一看就知道你写的是什么,引起共鸣。所以,完美的标题可以让搜索引擎给你的文章加不少分。标题要提供自己的特色,千篇一律的标题,是搜索引擎不会长久给你加分的。
一、文章要优质当然了,如果你的文章没有价值,没有太大的特色,就是一片空文,搜索引擎不会加分的。
二、要过关键词再好的标题,在搜索引擎搜索到的次数越多,对你文章的积累在加分不利。
三、标题过长,关键词配置不好标题是否合理直接影响文章的排名,标题不要太长,要特别是留下足够的位置进行关键词配置。
标题是个体与产品主图的组合体。作为设计师来说,标题的重要性就像一个家庭里的主要生活用品是否放得太多一样。高质量的标题是非常有吸引力的。让读者第一眼看到的就是你的产品或你的品牌。如何用好标题提高它对文章或网站的排名呢?下面就提供给大家一些研究了很久的经验与方法。
一、标题吸引力影响关键词排名的一切因素来自文章与网站标题的吸引力。如果标题不吸引人或者跟品牌或产品不相关,那么就不会有人会点进去看。更不用说有人会通过标题发现你的产品或产品相关的东西。如何写出吸引人的标题?首先需要明确主要思想是要吸引读者点进文章。那么首先需要文章标题能抓住用户的点。那么文章标题就要足够吸引人,在它的竞争对手中脱颖而出。
例如我们做牛仔裤,文章标题可以定位牛仔裤为主题。如果你的标题里提到牛仔裤相关话题,用户看到时,就会不自觉地点进去看。如果你的标题非牛仔裤主题,或者提到其他类似主题,用户看到时,就很难发现是你的标题,从而点进去。看完你的标题,也会很快忘记这篇文章的特点或定位,转而又去看别的关键词。写好标题,你就可以看到用户的产品或服务和网站能够匹配什么内容,会被怎样的网站或网站里的产品或服务中链接。这样一来,你就可以想办法吸引他们点进来了。这样你的标题也就吸引住了读者。
二、避免用断句的标题在很多网站或杂志当中,常常有专有名词或特殊符号的标题。如果用断句标题,对于一篇吸引人的文章,你根本看不懂,或根本理解不了这篇文章要表达的意思。相反,如果你直接用别的词来表达,他们也理解不了。因此,作为产品的原创作者,能用短句就不要使用复杂的句子。更不要用英文的断句标题。
三、换行标题换行通常对于网站或网站标题来说
文章采集完(文章采集完后,我们会用大数据的方式为用户生成美学评价)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-06 08:04
文章采集完后,小编是不会直接发放数据给用户的,我们会用大数据的方式为用户生成美学评价,我们生成的标准就是根据大家的点评得出的。内容提要:我们会为个人推荐一些最相关的文章,以提高生活效率或保持美观。talkofscience.ie.howtoseeathingverywelloralotfaster?推荐:《大数据是如何改变我们的生活的?》(growthinthedata)(本文作者为drcookey,healthcarecompanyworldwideadvanceddatasciencefacility)专栏:大数据那些事()。
摘抄一个不知道恰不恰当的说法
看着像是想卖书,
实际上这篇文章没有感觉有广告味道,也没有出现把网易新闻报道《硅谷的雕像石像》夸成大爆炸的噱头。大概是因为这篇文章翻译自日本作家《留声机》和科幻作家乔治·奥威尔的小说《1984》,大数据算是给作品里的国家机器构成一个原始逻辑。
小张你的数据修改一下吧,免得我改代码后发现你得改。
这篇文章真的是莫名奇妙地出现在知乎了很失望啊。这类似于时事评论也好科技评论也好,都是非常主观的,你觉得有用的大家不一定会感同身受。至于看了那么多遍想起来也没真正感动过的,结论再怎么高大上也是没用的。我觉得媒体应该有底线,能获得一定量的听众感悟的就是一篇好文章,学习它成为一个积极乐观的人最重要。我很讨厌“xxx过后xxx,你xx过后如何xx”这样的句式。
他们的套路是先介绍一下当下时局,再提及某物。比如“吃鸡加速器加载、网络延迟暴涨100+”,“大公司解决xx痛点”,“xx企业为解决环境问题发起云战争”,标题到落款并不会令人觉得很高大上,若是过于深入,就像单读的歌词一样,多半令人厌恶。大数据只是一个范畴,一般人谈到数据分析还是不知道数据是什么的,谈到大数据就是大数据,大家日常谈的是传统概念里的大数据,而非大数据。
说个题外话,连美剧都是“financialleague”“financialtimeline”“calculators”等,可见一斑。 查看全部
文章采集完(文章采集完后,我们会用大数据的方式为用户生成美学评价)
文章采集完后,小编是不会直接发放数据给用户的,我们会用大数据的方式为用户生成美学评价,我们生成的标准就是根据大家的点评得出的。内容提要:我们会为个人推荐一些最相关的文章,以提高生活效率或保持美观。talkofscience.ie.howtoseeathingverywelloralotfaster?推荐:《大数据是如何改变我们的生活的?》(growthinthedata)(本文作者为drcookey,healthcarecompanyworldwideadvanceddatasciencefacility)专栏:大数据那些事()。
摘抄一个不知道恰不恰当的说法
看着像是想卖书,
实际上这篇文章没有感觉有广告味道,也没有出现把网易新闻报道《硅谷的雕像石像》夸成大爆炸的噱头。大概是因为这篇文章翻译自日本作家《留声机》和科幻作家乔治·奥威尔的小说《1984》,大数据算是给作品里的国家机器构成一个原始逻辑。
小张你的数据修改一下吧,免得我改代码后发现你得改。
这篇文章真的是莫名奇妙地出现在知乎了很失望啊。这类似于时事评论也好科技评论也好,都是非常主观的,你觉得有用的大家不一定会感同身受。至于看了那么多遍想起来也没真正感动过的,结论再怎么高大上也是没用的。我觉得媒体应该有底线,能获得一定量的听众感悟的就是一篇好文章,学习它成为一个积极乐观的人最重要。我很讨厌“xxx过后xxx,你xx过后如何xx”这样的句式。
他们的套路是先介绍一下当下时局,再提及某物。比如“吃鸡加速器加载、网络延迟暴涨100+”,“大公司解决xx痛点”,“xx企业为解决环境问题发起云战争”,标题到落款并不会令人觉得很高大上,若是过于深入,就像单读的歌词一样,多半令人厌恶。大数据只是一个范畴,一般人谈到数据分析还是不知道数据是什么的,谈到大数据就是大数据,大家日常谈的是传统概念里的大数据,而非大数据。
说个题外话,连美剧都是“financialleague”“financialtimeline”“calculators”等,可见一斑。
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-05 20:19
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专享、全站源码、程序插件、网站模板、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的下载中材料包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟产品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(锦尚中国版主调试时的配置请严格按照配置环境要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-03 05:05
来源介绍
目前,除了本站发布的顶级小说源码外,这套采集自动更新的小说网站已经很完美了。这个源码和其他的不同,它侧重于采集,实时更新章节自动更新,不适合原创自己更新!太完美了,还特意花钱给了本站任何通行证的会员(目前没有外)!
程序特点:
1、小说汽车采集;
2、 小说章节实时更新;
3、采集的小说存入数据库,不受原站影响;
4、高效存储模式,节省服务器空间占用;
方案优势:
1、小说自动推送到百度搜索引擎加速页面收录;
2、 页面深度优化,合理部署,深受搜索引擎喜爱;
3、PC端+独立移动端自适应,充分满足搜索引擎需求;
如果您喜欢在本站开设任何一种VIP会员,您可以下载并授权。如果您还不是会员,请在线开通VIP:
源码运行环境
php5.6+mysql(环境配置为金商中国版主调试时的配置,请严格按照配置环境要求运行)
注意:
1.如果需要重装,请删除教程中描述的lock文件,并且必须清除mysql数据库!以上是金商中国版主亲自调试时遇到的一些常见问题。下面小编就告诉大家少走弯路!
2. 更新首页的方式是在文章点击Update文章后后端采集,等待更新完成,然后去功能块更新区块数据。!
源代码截图
源码下载地址 查看全部
文章采集完(锦尚中国版主调试时的配置请严格按照配置环境要求)
来源介绍
目前,除了本站发布的顶级小说源码外,这套采集自动更新的小说网站已经很完美了。这个源码和其他的不同,它侧重于采集,实时更新章节自动更新,不适合原创自己更新!太完美了,还特意花钱给了本站任何通行证的会员(目前没有外)!
程序特点:
1、小说汽车采集;
2、 小说章节实时更新;
3、采集的小说存入数据库,不受原站影响;
4、高效存储模式,节省服务器空间占用;
方案优势:
1、小说自动推送到百度搜索引擎加速页面收录;
2、 页面深度优化,合理部署,深受搜索引擎喜爱;
3、PC端+独立移动端自适应,充分满足搜索引擎需求;
如果您喜欢在本站开设任何一种VIP会员,您可以下载并授权。如果您还不是会员,请在线开通VIP:
源码运行环境
php5.6+mysql(环境配置为金商中国版主调试时的配置,请严格按照配置环境要求运行)
注意:
1.如果需要重装,请删除教程中描述的lock文件,并且必须清除mysql数据库!以上是金商中国版主亲自调试时遇到的一些常见问题。下面小编就告诉大家少走弯路!
2. 更新首页的方式是在文章点击Update文章后后端采集,等待更新完成,然后去功能块更新区块数据。!
源代码截图
源码下载地址
文章采集完(文章采集完毕后会有一个类似于flash文件的东西)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-02 09:02
文章采集完毕之后会有一个类似于flash文件的东西,这东西会有一个编码方式选择,可以得到本篇的key+end值,之后我就直接用txt文件输出编码即可。
还要转换成flash文件啊。首先,用flash控件把你的数据全部转化为可以http传输的.key和end值。然后才能开始批量下载文件。
你可以考虑用sftp服务,这个服务可以按需传输数据。我用的就是yy的,不过不是sftp。
curl下载,不过要加密msg.密码可以自己编程生成
windows下:aptiopxftpsftp这三个都可以下
可以参考sftp
两种方式,一是后端,再把srt当字幕下载,可以参考bt字幕下载引擎;二是前端,
ae/pr里也能实现这个功能
pc可以通过调用aac输出,flash也可以基本可以这么搞。但问题是有些版本的ae字幕需要导出字幕分辨率(不单指flash的分辨率),flash字幕要导出flv。比较麻烦,支持远程传输的远程字幕有flv格式。网上搜搜还是有的。
可以理解是一些字幕组把数据发给其他的字幕组帮忙实现?
ae没法做类似的字幕,可以看看flash版的。
可以试试emscript,此软件可以做动画,用该软件可以实现原型设计,所以也就有做完的动画了。你可以试试看。 查看全部
文章采集完(文章采集完毕后会有一个类似于flash文件的东西)
文章采集完毕之后会有一个类似于flash文件的东西,这东西会有一个编码方式选择,可以得到本篇的key+end值,之后我就直接用txt文件输出编码即可。
还要转换成flash文件啊。首先,用flash控件把你的数据全部转化为可以http传输的.key和end值。然后才能开始批量下载文件。
你可以考虑用sftp服务,这个服务可以按需传输数据。我用的就是yy的,不过不是sftp。
curl下载,不过要加密msg.密码可以自己编程生成
windows下:aptiopxftpsftp这三个都可以下
可以参考sftp
两种方式,一是后端,再把srt当字幕下载,可以参考bt字幕下载引擎;二是前端,
ae/pr里也能实现这个功能
pc可以通过调用aac输出,flash也可以基本可以这么搞。但问题是有些版本的ae字幕需要导出字幕分辨率(不单指flash的分辨率),flash字幕要导出flv。比较麻烦,支持远程传输的远程字幕有flv格式。网上搜搜还是有的。
可以理解是一些字幕组把数据发给其他的字幕组帮忙实现?
ae没法做类似的字幕,可以看看flash版的。
可以试试emscript,此软件可以做动画,用该软件可以实现原型设计,所以也就有做完的动画了。你可以试试看。
文章采集完(苹果cms采集完没有播放地址?原因和解决方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-10-27 18:18
苹果cms采集到底有没有播放地址?这种情况一般是新手经常遇到的常见问题。如果需要查询问题,需要从以下几个方面入手:
1.原因之一(是否添加相应播放器)
如果我们在准备采集一个资源站,首先要做的就是导入或添加相应的播放器,比如我们要规划一个采集资源站,那么我们就会找到一个资源为我们站提供的播放器被下载然后导入。至于是启动采集还是先添加播放器,我的推荐这里的操作是先添加播放器,再到采集。
通常情况下,没有特定的顺序,但有时会有一些特殊情况。采集 添加资源后,播放器将不会关联,无法播放。只有再次进入采集,播放按钮才会出现播放流畅。
导入播放器的步骤如下面的屏幕截图所示。
ApplecmsV10 添加播放器界面
2.原因二(采集接口是否添加错误)
下面是某资源站提供的Applecms采集接口,[json]接口和[xm|]接口是两个接口,这两个接口分为[http]和[ https] 所以在添加采集的时候,一定要结合自己的网站来区分[http]和[https],否则即使添加相应的播放器也不会播放。
苹果cms10采集资源站,采集界面说明
3.原因三(浏览器缓存情况)
这个问题也是一个很常见的问题。之前采集时没有添加视频播放器,导入后添加了视频播放器。视频播放器仍然无法播放视频。最重要的因素是浏览器缓存。您可以使用键盘快捷键。键 [ctrl+f5] 强制刷新浏览器的缓存数据。如果不行,就用电脑浏览器的隐身安全模式:键盘快捷键【shift+ctrl+n】用自己网站的新页面打开浏览器,自测看看能不能播放。
以上就是苹果cms采集没有播放地址的三个原因及解决方法。希望对大家的学习和解决问题有所帮助,也希望大家能够支持和提供免费的苹果cms模板之星模板网。 查看全部
文章采集完(苹果cms采集完没有播放地址?原因和解决方法)
苹果cms采集到底有没有播放地址?这种情况一般是新手经常遇到的常见问题。如果需要查询问题,需要从以下几个方面入手:
1.原因之一(是否添加相应播放器)
如果我们在准备采集一个资源站,首先要做的就是导入或添加相应的播放器,比如我们要规划一个采集资源站,那么我们就会找到一个资源为我们站提供的播放器被下载然后导入。至于是启动采集还是先添加播放器,我的推荐这里的操作是先添加播放器,再到采集。
通常情况下,没有特定的顺序,但有时会有一些特殊情况。采集 添加资源后,播放器将不会关联,无法播放。只有再次进入采集,播放按钮才会出现播放流畅。
导入播放器的步骤如下面的屏幕截图所示。
https://www.at008.cn/wp-conten ... 8.png 300w, https://www.at008.cn/wp-conten ... 2.png 768w" />ApplecmsV10 添加播放器界面
2.原因二(采集接口是否添加错误)
下面是某资源站提供的Applecms采集接口,[json]接口和[xm|]接口是两个接口,这两个接口分为[http]和[ https] 所以在添加采集的时候,一定要结合自己的网站来区分[http]和[https],否则即使添加相应的播放器也不会播放。
https://www.at008.cn/wp-conten ... 9.png 300w, https://www.at008.cn/wp-conten ... 7.png 768w" />苹果cms10采集资源站,采集界面说明
3.原因三(浏览器缓存情况)
这个问题也是一个很常见的问题。之前采集时没有添加视频播放器,导入后添加了视频播放器。视频播放器仍然无法播放视频。最重要的因素是浏览器缓存。您可以使用键盘快捷键。键 [ctrl+f5] 强制刷新浏览器的缓存数据。如果不行,就用电脑浏览器的隐身安全模式:键盘快捷键【shift+ctrl+n】用自己网站的新页面打开浏览器,自测看看能不能播放。
以上就是苹果cms采集没有播放地址的三个原因及解决方法。希望对大家的学习和解决问题有所帮助,也希望大家能够支持和提供免费的苹果cms模板之星模板网。

