
文章采集完
wordpress怎么一次性消除标题重复文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-09 12:43
以下是二种一次性消除标题重复文章的方式:
去除重复文章,只保留一篇
CREATE TABLE my_tmp AS SELECT MIN(ID) AS col1 FROM wp_posts GROUP BY post_title;<br />
DELETE FROM wp_posts WHERE ID NOT IN (SELECT col1 FROM my_tmp);<br />
DROP TABLE my_tmp;
去除重复文章,一片都不保留
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);<br />
DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); <br />
DROP TABLE my_tmp;
另一种清除所有重复文章的方式
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); DROP TABLE my_tmp;
操作方法很简单,只需将里面的SQL句子,放到自己网站数据库的 SQL框里,然后执行就可以了。(注意:操作之前,请先进行网站备份) 查看全部
有些站长同学使用wordpress做采集站,不断的云采集各类文章自动发布到自己的网站上。但采集站最大的问题就是会采集到好多重复文章。这时,我们需将采集过来的重复文章进行去重处理。(相关教程:wordpress怎样实现手动采集)
以下是二种一次性消除标题重复文章的方式:
去除重复文章,只保留一篇
CREATE TABLE my_tmp AS SELECT MIN(ID) AS col1 FROM wp_posts GROUP BY post_title;<br />
DELETE FROM wp_posts WHERE ID NOT IN (SELECT col1 FROM my_tmp);<br />
DROP TABLE my_tmp;
去除重复文章,一片都不保留
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);<br />
DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); <br />
DROP TABLE my_tmp;
另一种清除所有重复文章的方式
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); DROP TABLE my_tmp;
操作方法很简单,只需将里面的SQL句子,放到自己网站数据库的 SQL框里,然后执行就可以了。(注意:操作之前,请先进行网站备份)
10分钟学会数据信息采集:工具安装、知乎为例介绍采集流程。
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-08-09 08:38
Web scraper是google强悍插件库中十分强悍的一款数据采集插件,有强悍的反爬虫能力,只须要在插件上简单地设置好,可以快速抓取知乎、简书、豆瓣、大众、58等小型、中型、小型的80%以上的网站,包括文字、图片、表格等内容,最后快速导入csv格式文件。Google官方对web scraper给出的说明是:
使用我们的扩充,您可以创建一个计划(sitemap),一个web站点应当怎样遍历,以及应当提取哪些。使用这种sitemaps,Web铲刀将相应地导航站点并提取所有数据。稍后可以将剪贴数据导入为CSV。
本系列是关于web scraper的系类介绍,将会完整介绍流程介绍,用知乎、简书等网站为例介绍怎么采集文字、表格、多元素抓取、不规律分页抓取、二级页抓取、动态网站抓取,以及一些反爬虫技术等全部内容。
Ok,今天就介绍web scraper的安装以及完整的抓取流程。
一、web scraper的安装
Web scraper是google浏览器的拓展插件,只须要在google浏览器上安装就可以了,介绍2种安装方式:
1、打开google浏览器更多工具下的拓展程序——进入到chrome 网上应用点——搜索web scraper——然后点击安装就可以了,如下图所示。
但是以上的安装方式须要翻墙到美国的网站上,所以须要用到vpn,如果有vpn的就可以用这些方式,如果没有就可以用下边的第二种方式:
2、通过链接:/s/1skXkVN3,密码:m672,下载web scraper安装程序,然后直接将安装程序推入到chrome中的拓展程序就可以完成安装了。
二、以知乎为例介绍web scraper完整抓取流程
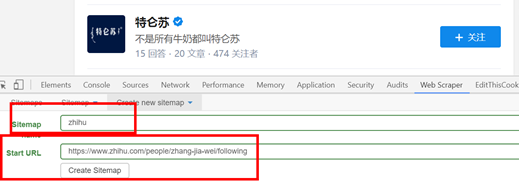
1、打开目标网站,这里以采集知乎第一大v张佳玮的关注对象为例,需要爬取的是关注对象的知乎名子、回答数目、发表文章数量、关注着数目。
2、在网页上右击滑鼠,选择检测选项,或者用快捷键Ctrl + Shift + I / F12 都打开 Web Scraper。
3、打开后点击create sitemap选择create sitemap创建一个站点地图。
点击create sitemap后就得到如图页面,需要填写sitemap name,就是站点名子,这点可以随意写,自己看得懂就好;还须要填写start
url,就是要抓取页面的链接。填写完就点击create sitemap,就完成创建站点地图了。
具体如下图:
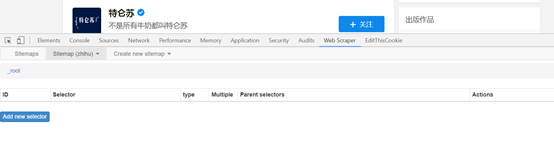
4、设置一级选择器:选定采集范围
接下来就是重中之重了。这里先介绍一下web scraper的抓取逻辑:需要设置一个一级选择器(selector),设定须要抓取的范围;在一级选择器下构建一个二级选择器(selector),设置须要抓取的元素和内容。
以抓取张佳玮关注对象为例,我们的范围就是张佳玮关注的对象,那就须要为这个范围创建一个选择器;而张佳玮关注的对象的粉丝数、文章数量等内容就是二级选择器的内容。
具体步骤如下:
(1) Add new selector 创建一级选择器Selector:
点击后就可以得到右图页面,所须要抓取的内容就在这个页面设置。
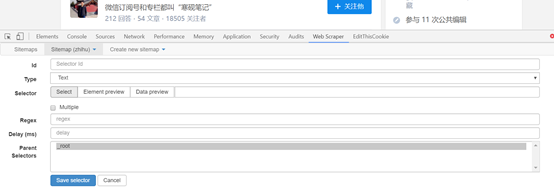
l id:就是对这个选择器命名,同理,自己看得懂就好,这里就叫jiawei-scrap。
l Type:就是要抓取的内容的类型,比如元素element/文本text/链接link/图片image/动态加载内Element Scroll Down等,这里是多个元素就选择element。
l Selector:指的就是选择所要抓取的内容,点击select就可以在页面上选择内容,这个部份在下边具体介绍。
l 勾选Multiple:勾选 Multiple 前面的小框,因为要选的是多个元素而不是单个元素,当勾选的时侯,爬虫插件会辨识页面下具有相同属性的内容;
(2)这一步就须要设置选择的内容了,点击select选项下的select 得到右图:
之后将键盘联通到须要选择的内容上,这时候须要的内容都会弄成红色就表示选取了,这里须要提示一下,如果是所须要的内容是多元素的,就须要将元素都选择,例如下图所示,绿色就表示选择的内容在红色范围内。
选择内容范围后,点击滑鼠,选定的内容范围都会弄成如下图的蓝色:
当一个内容变红后,我们就可以选择接下来的第二个内容,点击后,web scraper都会手动辨识你所要的内容,具有相同元素的内容就就会弄成绿色的。如下图所示:
检查这个页面我们须要的内容全部弄成白色以后,就可以点击 Done selecting选项了,就可以得到如下图所示:
点击save selector,保存设置。到这儿后,一级选择器就创建完成了。
5、设置二级选择器:选择须要采集的元素内容。
(1)点击右图中红框内容,就步入一级选择器jiawei-scrap下:
(2)点击add new selector创建二级选择器,来选择具体内容。
得到右图,这跟一级选择器的内容是相同的,但是设置是有区别的。
id:代表抓取的是那个数组,可以取该数组的英语,比如要选「作者」,就写「writer」;
Type:这里选Text选项,因为要抓取的是文本内容;
Multiple:不要勾选 Multiple 前面的小框,因为在这里要抓取的是单个元素;
保留设置:其余未提到部份保留默认设置。
(3)点击select选项后,将键盘移到具体的元素上,元素都会弄成红色,如下图所示:
在具体元素上点击后,元素都会弄成黑色的,就代表选取该内容了。
(4)点击Done selecting后完成选择,再点击save selector后就可以完成关注对象知乎名子的选定了。
重复以上操作,直到选完你想爬的数组。
(5)点击红框部份可以看见采集的内容。
Data preview可以看见采集内容,edit可以对设置的内容做更改。
6、爬取数据
(1)只须要设置完所有的 Selector,就可以开始爬数据了,点击 Scrape map,
选泽scrape;:
(2)点击后才会跳到时间设置页面,如下图,由于采集的数目不大,保存默认就可以,点击
start scraping,就会跳出一个窗口,就开始即将采集了。
(3)稍等一会就可以得到采集效果,如下图:
(4)选择sitemap下的export data as csv选项就可以将采集的结果以表格的方式导入。
表格疗效:
上面是单页面采集,那假如要设置多个页面呢?需要如何设置呢?会在上篇文章中具体写下来。有疑问的同学可以咨询陌陌zds369466004. 查看全部
就目前而言,最为理想的爬虫工具就是自己编程的爬虫代码,几乎好多代码都可以写出很漂亮的爬虫代码,个人最为理想的就是python了,它可以用极少的简约的代码就可以写出高效的代码,当然象java、c、ruby、php等语言都可以写出爬虫,但是把握的成本要比python高好多;其次就是一些爬虫软件,例如优采云、优采云,以及要介绍的google插件——web scraper。
Web scraper是google强悍插件库中十分强悍的一款数据采集插件,有强悍的反爬虫能力,只须要在插件上简单地设置好,可以快速抓取知乎、简书、豆瓣、大众、58等小型、中型、小型的80%以上的网站,包括文字、图片、表格等内容,最后快速导入csv格式文件。Google官方对web scraper给出的说明是:
使用我们的扩充,您可以创建一个计划(sitemap),一个web站点应当怎样遍历,以及应当提取哪些。使用这种sitemaps,Web铲刀将相应地导航站点并提取所有数据。稍后可以将剪贴数据导入为CSV。
本系列是关于web scraper的系类介绍,将会完整介绍流程介绍,用知乎、简书等网站为例介绍怎么采集文字、表格、多元素抓取、不规律分页抓取、二级页抓取、动态网站抓取,以及一些反爬虫技术等全部内容。
Ok,今天就介绍web scraper的安装以及完整的抓取流程。
一、web scraper的安装
Web scraper是google浏览器的拓展插件,只须要在google浏览器上安装就可以了,介绍2种安装方式:
1、打开google浏览器更多工具下的拓展程序——进入到chrome 网上应用点——搜索web scraper——然后点击安装就可以了,如下图所示。
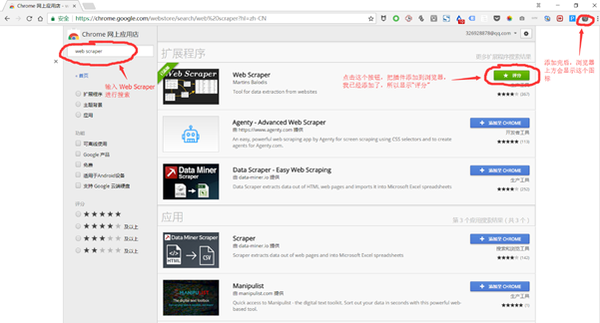
但是以上的安装方式须要翻墙到美国的网站上,所以须要用到vpn,如果有vpn的就可以用这些方式,如果没有就可以用下边的第二种方式:
2、通过链接:/s/1skXkVN3,密码:m672,下载web scraper安装程序,然后直接将安装程序推入到chrome中的拓展程序就可以完成安装了。
二、以知乎为例介绍web scraper完整抓取流程
1、打开目标网站,这里以采集知乎第一大v张佳玮的关注对象为例,需要爬取的是关注对象的知乎名子、回答数目、发表文章数量、关注着数目。
2、在网页上右击滑鼠,选择检测选项,或者用快捷键Ctrl + Shift + I / F12 都打开 Web Scraper。
3、打开后点击create sitemap选择create sitemap创建一个站点地图。

点击create sitemap后就得到如图页面,需要填写sitemap name,就是站点名子,这点可以随意写,自己看得懂就好;还须要填写start
url,就是要抓取页面的链接。填写完就点击create sitemap,就完成创建站点地图了。
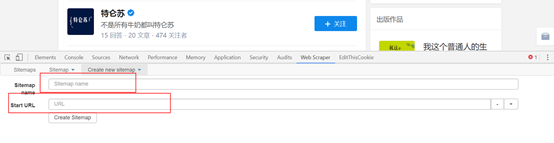
具体如下图:
4、设置一级选择器:选定采集范围
接下来就是重中之重了。这里先介绍一下web scraper的抓取逻辑:需要设置一个一级选择器(selector),设定须要抓取的范围;在一级选择器下构建一个二级选择器(selector),设置须要抓取的元素和内容。
以抓取张佳玮关注对象为例,我们的范围就是张佳玮关注的对象,那就须要为这个范围创建一个选择器;而张佳玮关注的对象的粉丝数、文章数量等内容就是二级选择器的内容。
具体步骤如下:
(1) Add new selector 创建一级选择器Selector:
点击后就可以得到右图页面,所须要抓取的内容就在这个页面设置。
l id:就是对这个选择器命名,同理,自己看得懂就好,这里就叫jiawei-scrap。
l Type:就是要抓取的内容的类型,比如元素element/文本text/链接link/图片image/动态加载内Element Scroll Down等,这里是多个元素就选择element。
l Selector:指的就是选择所要抓取的内容,点击select就可以在页面上选择内容,这个部份在下边具体介绍。
l 勾选Multiple:勾选 Multiple 前面的小框,因为要选的是多个元素而不是单个元素,当勾选的时侯,爬虫插件会辨识页面下具有相同属性的内容;
(2)这一步就须要设置选择的内容了,点击select选项下的select 得到右图:
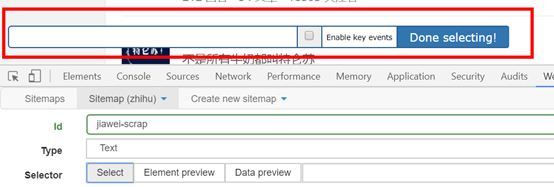
之后将键盘联通到须要选择的内容上,这时候须要的内容都会弄成红色就表示选取了,这里须要提示一下,如果是所须要的内容是多元素的,就须要将元素都选择,例如下图所示,绿色就表示选择的内容在红色范围内。
选择内容范围后,点击滑鼠,选定的内容范围都会弄成如下图的蓝色:
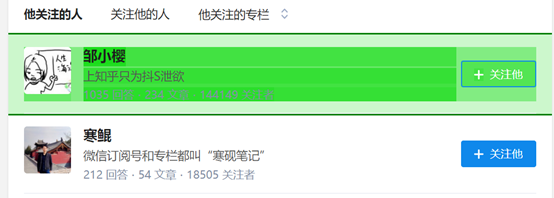
当一个内容变红后,我们就可以选择接下来的第二个内容,点击后,web scraper都会手动辨识你所要的内容,具有相同元素的内容就就会弄成绿色的。如下图所示:
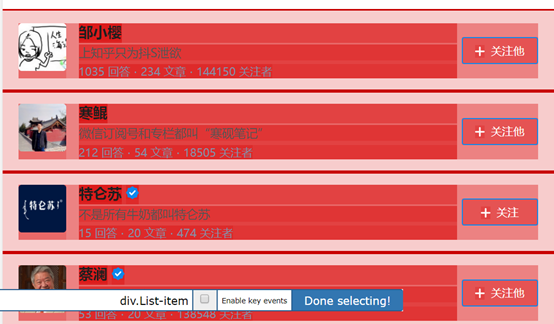
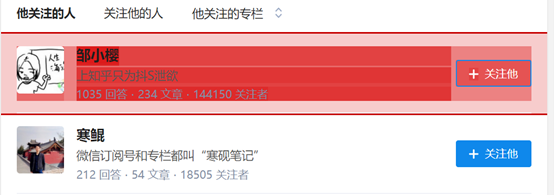
检查这个页面我们须要的内容全部弄成白色以后,就可以点击 Done selecting选项了,就可以得到如下图所示:
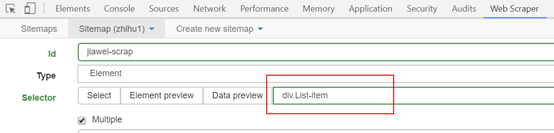
点击save selector,保存设置。到这儿后,一级选择器就创建完成了。

5、设置二级选择器:选择须要采集的元素内容。
(1)点击右图中红框内容,就步入一级选择器jiawei-scrap下:
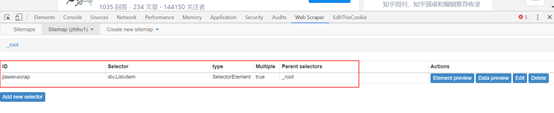
(2)点击add new selector创建二级选择器,来选择具体内容。
得到右图,这跟一级选择器的内容是相同的,但是设置是有区别的。
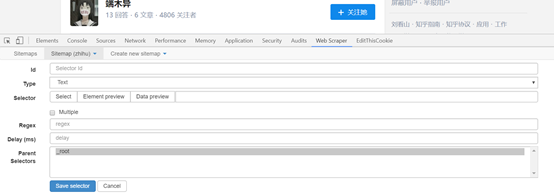
id:代表抓取的是那个数组,可以取该数组的英语,比如要选「作者」,就写「writer」;
Type:这里选Text选项,因为要抓取的是文本内容;
Multiple:不要勾选 Multiple 前面的小框,因为在这里要抓取的是单个元素;
保留设置:其余未提到部份保留默认设置。
(3)点击select选项后,将键盘移到具体的元素上,元素都会弄成红色,如下图所示:
在具体元素上点击后,元素都会弄成黑色的,就代表选取该内容了。
(4)点击Done selecting后完成选择,再点击save selector后就可以完成关注对象知乎名子的选定了。

重复以上操作,直到选完你想爬的数组。
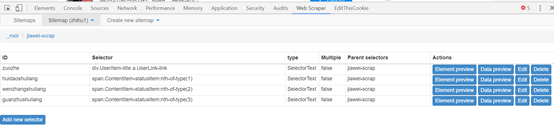
(5)点击红框部份可以看见采集的内容。
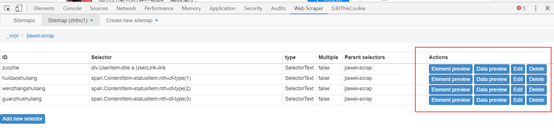
Data preview可以看见采集内容,edit可以对设置的内容做更改。
6、爬取数据
(1)只须要设置完所有的 Selector,就可以开始爬数据了,点击 Scrape map,
选泽scrape;:
(2)点击后才会跳到时间设置页面,如下图,由于采集的数目不大,保存默认就可以,点击
start scraping,就会跳出一个窗口,就开始即将采集了。
(3)稍等一会就可以得到采集效果,如下图:
(4)选择sitemap下的export data as csv选项就可以将采集的结果以表格的方式导入。
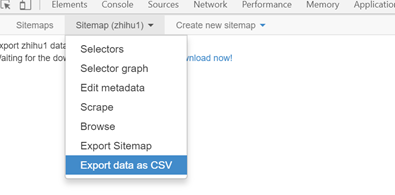
表格疗效:
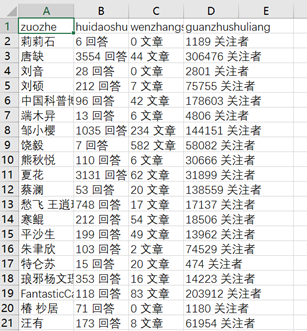
上面是单页面采集,那假如要设置多个页面呢?需要如何设置呢?会在上篇文章中具体写下来。有疑问的同学可以咨询陌陌zds369466004.
可以采集百度尚未收录的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-08-08 14:01
问题: 采集百度尚未收录的文章好吗?
问题的补充: 百度对内容有严格的限制,但是网站内容的建设存在困难,因此我想采集百度尚未包括的那些问题,以便达到原创文章的目的. 这种方法行不通?
答案: 从理论上讲,采集百度尚未收录的文章是可行的. 当然,这里必须考虑两个方面:
1. 所采集的文章必须具有相关性
尽管原创文章对于网站seo优化非常重要,但前提条件之一就是相关专栏. 如果文章的内容不相关,则没有什么用. 因此,在决定采集之前,您应该分析这些文章是否与您的网站有关,并果断地放弃那些无关紧要的内容.
2,确保确实不收录该文章
有时,我们只会看到百度未收录该文章的URL链接. 实际上,文章的内容已经收录了很多. 我们看到的文章也有可能被采集了,因此百度未将其收录.
因此,我们必须检查文章的内容,以查看百度的数据库中是否确实没有信息. 例如,我们可以复制文章中的一些段落或句子,然后转到百度搜索. 如果有大量红色内容,则表示该内容已被淹没. 如果没有这样的东西,那就意味着百度确实不包括这些. 内容.
采集百度尚未收录的文章是否很好?我只是说了很多. 总而言之,如果这些文章未被百度索引,并且这些文章是相关的高质量文章,那么采集它们是可行的. 但是,如果这些文章只是未收录在网站的页面URL中,而文章本身已收录在其中,那么采集它们的意义就不是很大.
此外,作者建议每个人都尊重他人的工作,转载文章必须注明出处. 另外,每个人都应注意版权问题. 有些文章无法复制,否则可能不得不承担相关责任. 关于转载大量文章的行为,您必须谨慎. 查看全部
可以采集百度尚未收录的文章
问题: 采集百度尚未收录的文章好吗?
问题的补充: 百度对内容有严格的限制,但是网站内容的建设存在困难,因此我想采集百度尚未包括的那些问题,以便达到原创文章的目的. 这种方法行不通?
答案: 从理论上讲,采集百度尚未收录的文章是可行的. 当然,这里必须考虑两个方面:
1. 所采集的文章必须具有相关性
尽管原创文章对于网站seo优化非常重要,但前提条件之一就是相关专栏. 如果文章的内容不相关,则没有什么用. 因此,在决定采集之前,您应该分析这些文章是否与您的网站有关,并果断地放弃那些无关紧要的内容.
2,确保确实不收录该文章
有时,我们只会看到百度未收录该文章的URL链接. 实际上,文章的内容已经收录了很多. 我们看到的文章也有可能被采集了,因此百度未将其收录.
因此,我们必须检查文章的内容,以查看百度的数据库中是否确实没有信息. 例如,我们可以复制文章中的一些段落或句子,然后转到百度搜索. 如果有大量红色内容,则表示该内容已被淹没. 如果没有这样的东西,那就意味着百度确实不包括这些. 内容.
采集百度尚未收录的文章是否很好?我只是说了很多. 总而言之,如果这些文章未被百度索引,并且这些文章是相关的高质量文章,那么采集它们是可行的. 但是,如果这些文章只是未收录在网站的页面URL中,而文章本身已收录在其中,那么采集它们的意义就不是很大.
此外,作者建议每个人都尊重他人的工作,转载文章必须注明出处. 另外,每个人都应注意版权问题. 有些文章无法复制,否则可能不得不承担相关责任. 关于转载大量文章的行为,您必须谨慎.
Scrapy框架与Spynner集合相结合需要js
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-08-08 07:53
1. 静态网页
2. 动态网页(需要js,ajax来动态加载数据的网页)
3. 只有模拟登录后才能采集的网页
4. 加密的网页
3,4的解决方案和想法将在后续博客中阐明
当前,仅针对1、2的解决方案和想法:
1. 静态网页
有很多方法可以采集和分析静态网页! java和python都提供了很多工具包或框架,例如java httpclient,Htmlunit,Jsoup,HtmlParser等,Python urllib,urllib2,BeautifulSoup,Scrapy等,但没有详细介绍,在线材料很多.
两个. 动态网页
对于采集,动态网页是需要由js和ajax动态加载以获取数据的那些网页. 有两种数据采集方案:
1. 通过数据包捕获工具分析js和ajax的请求,并模拟请求以在加载js后获取数据.
2. 调用浏览器的内核以获取加载的网页源代码,然后解析源代码
研究爬行动物的人必须了解js. 在线学习材料很多,没有声明,而本文仅出于文章的完整性而写
还有一些用于调用浏览器内核Java的工具包,但它们并不是当今的重点. 今天的重点是文章的标题. Scrapy框架与Spynner结合使用,以采集需要由js和ajax动态加载的网页并提取网页信息(以微信官方帐户列表为例)
在使用Scrapy和Spynner之前,我需要安装环境. 我学习了很长时间的python,并在Mac上抛了很长时间之后,当我快要发疯时成功了,还杀死了很多脑细胞.
获胜是如此悲惨!只需总结一篇文章,当您使用它时,就安装它!
开始...
1. 创建微信公众号文章列表采集项目(以下简称微采集)
scrapy startproject weixin
2. 在爬虫目录中创建采集爬虫文件
vim weixinlist.py
编写以下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'外链网址已屏蔽',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3. 将WeixinItem类添加到items.py
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
link=scrapy.Field()
4. 在items.py的同一目录中创建一个下载中间件downloadwebkit.py,并将以下代码写入其中:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
此代码是在加载网页后调用浏览器内核以获取源代码 查看全部
网页采集有几种类型:
1. 静态网页
2. 动态网页(需要js,ajax来动态加载数据的网页)
3. 只有模拟登录后才能采集的网页
4. 加密的网页
3,4的解决方案和想法将在后续博客中阐明
当前,仅针对1、2的解决方案和想法:
1. 静态网页
有很多方法可以采集和分析静态网页! java和python都提供了很多工具包或框架,例如java httpclient,Htmlunit,Jsoup,HtmlParser等,Python urllib,urllib2,BeautifulSoup,Scrapy等,但没有详细介绍,在线材料很多.
两个. 动态网页
对于采集,动态网页是需要由js和ajax动态加载以获取数据的那些网页. 有两种数据采集方案:
1. 通过数据包捕获工具分析js和ajax的请求,并模拟请求以在加载js后获取数据.
2. 调用浏览器的内核以获取加载的网页源代码,然后解析源代码
研究爬行动物的人必须了解js. 在线学习材料很多,没有声明,而本文仅出于文章的完整性而写
还有一些用于调用浏览器内核Java的工具包,但它们并不是当今的重点. 今天的重点是文章的标题. Scrapy框架与Spynner结合使用,以采集需要由js和ajax动态加载的网页并提取网页信息(以微信官方帐户列表为例)
在使用Scrapy和Spynner之前,我需要安装环境. 我学习了很长时间的python,并在Mac上抛了很长时间之后,当我快要发疯时成功了,还杀死了很多脑细胞.

获胜是如此悲惨!只需总结一篇文章,当您使用它时,就安装它!
开始...
1. 创建微信公众号文章列表采集项目(以下简称微采集)
scrapy startproject weixin
2. 在爬虫目录中创建采集爬虫文件
vim weixinlist.py
编写以下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'外链网址已屏蔽',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3. 将WeixinItem类添加到items.py
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
link=scrapy.Field()
4. 在items.py的同一目录中创建一个下载中间件downloadwebkit.py,并将以下代码写入其中:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
此代码是在加载网页后调用浏览器内核以获取源代码
如何采集热门文章?阅读本文后,您将理解!
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-07 22:24
我相信许多运营商已经开始使用采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作采集诸如热门文章/节日主题之类的信息的辅助工具. 实际上,不仅如此. 成熟的采集工具不仅可以采集运营信息,还可以准确分析数据趋势以帮助增加收入.
什么是最好的云采集?
优采云 采集是用于自媒体资料搜索,原创文章和一键式发布的操作工具,可有效提高新媒体运营的效率并降低企业成本.
如何使用优采云 采集搜索?
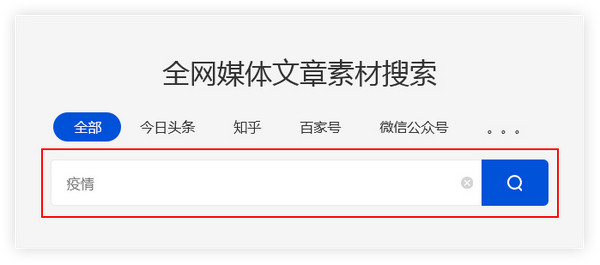
输入关键字
优采云采集用户输入的关键字,并通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集根据高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
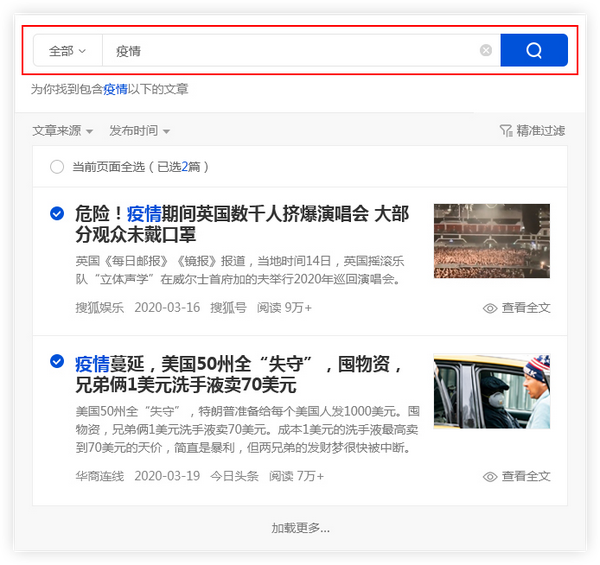
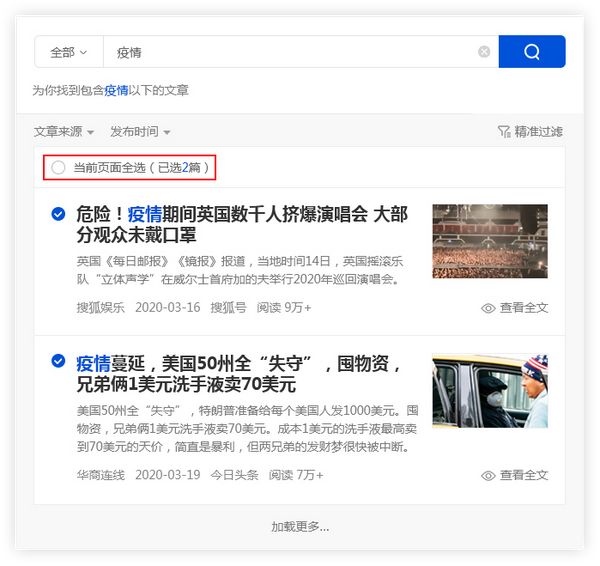
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集会将搜索结果整合到一个列表中.
保存搜索材料
优采云 采集具有批量保存搜索资料的功能.
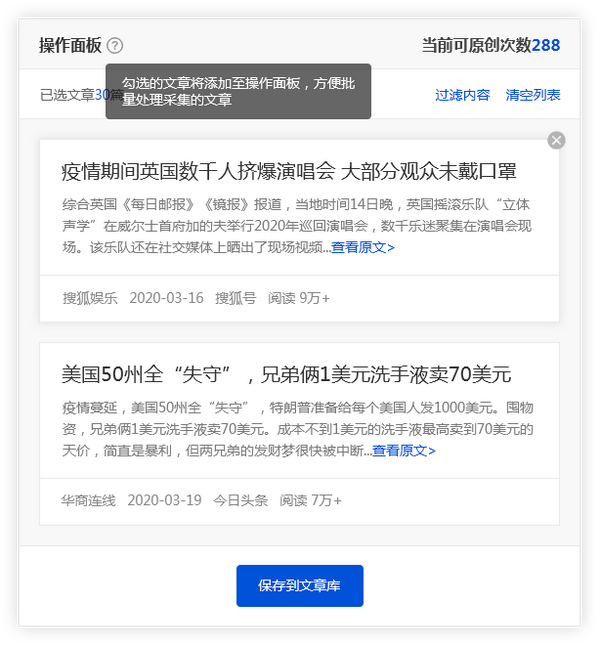
单击[在当前页面上全部选择]功能,然后检查所需的文章,这些文章将被添加到操作面板中,方便用户批量保存.
精确过滤
搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,原创性等参数进行过滤,从而使搜索内容更加准确.
广告过滤 查看全部
在流行期间,许多公司不得不选择远程在线办公室. 互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作. 因此,优采云 采集启动了智能采集工具.
我相信许多运营商已经开始使用采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作采集诸如热门文章/节日主题之类的信息的辅助工具. 实际上,不仅如此. 成熟的采集工具不仅可以采集运营信息,还可以准确分析数据趋势以帮助增加收入.
什么是最好的云采集?
优采云 采集是用于自媒体资料搜索,原创文章和一键式发布的操作工具,可有效提高新媒体运营的效率并降低企业成本.
如何使用优采云 采集搜索?
输入关键字
优采云采集用户输入的关键字,并通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集根据高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集会将搜索结果整合到一个列表中.
保存搜索材料
优采云 采集具有批量保存搜索资料的功能.
单击[在当前页面上全部选择]功能,然后检查所需的文章,这些文章将被添加到操作面板中,方便用户批量保存.
精确过滤
搜索过滤器
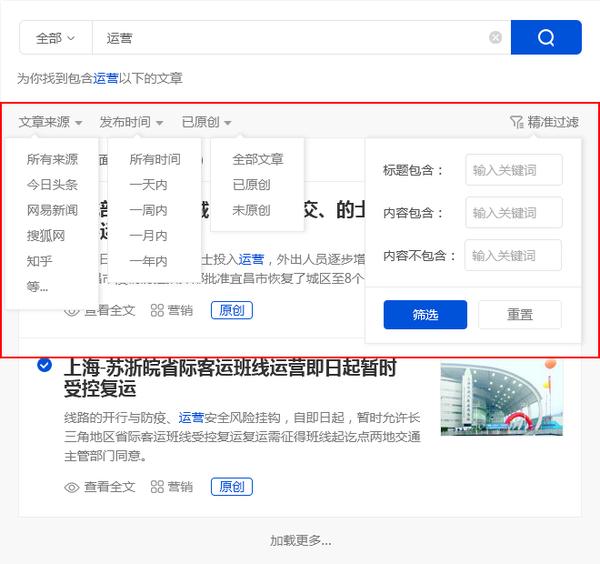
优采云 采集支持根据标题,内容,时间,平台,原创性等参数进行过滤,从而使搜索内容更加准确.
广告过滤
谈论百度的采集和文章采集经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-08-06 19:25
大家好,我叫富云我三天前向新手网站管理员发布了网站建设经验和建议. 有关详细信息,请参见: .
前一天晚上我真的很高兴. 为什么?因为我的80亿迅在线一天半都在线,所以百度收到了它. 尽管我只收到一个主页,但速度确实使我感到高兴. 这是我朋友的名言原来的话: “什么样的世界. 我被百度接受了一个多星期,而你只有不到两天的时间……”呵呵.
首先,让我说说谨慎对待百度的加入.
首先将网站提交给百度.
写一篇文章并提交给A5,并带上链接,但不要在AD中过度使用. 链接的目的是依靠A5的百度重量,以便百度蜘蛛在访问时发现有一个像您这样的站点,或者将其发送到其他高体重站点也是可能的,所以我就不多说了.
还有另一个原因是我昨天早上才发现的,这应该与收录非常相关. 我只在A5上发布了此帖子,但还有其他一些链接. 为什么?这是因为有采集工具. 昨天早上,我的朋友给我发了QQ,说你们真的很懂写文章. 到了吗然后他给我发了一个地址,但不是A5的地址,我知道为什么突然之间有这么多外部链接. 我不知道A5是否是反采集,但本文与A5上的文章完全相同,即使它不是由工具采集的,也必须手动采集. 撰写软文并将其发布到大型网站上的优势,不仅是因为它们具有较高的百度比重,而且还因为它们在网民中具有较高的比重,并且是首选的采集网站.
我只收录一些有关收录的信息. 我希望百度可以再向我收费几页.
是的,在采集方面,我以前有点不屑. 我很欣赏原创性,但是后来发现个人网站管理员不采集它确实很麻烦. 但是,我只认为该采集用于采集新闻和信息,因为这些内容不能由我们的个人网站管理员编写,所以今天我专门研究了下午的采集,以娱乐八卦. 我使用DEDECMS5.3中收录的采集工具,我将对其进行简要介绍.
通常,采集分为三个步骤: 获取规则,匹配规则和过滤.
获取规则意味着获取文章列表URL,例如,您找到XX网站的列表页面. 然后,您查看列表页面第一页的地址和后续页面的地址. 例如,第一页的地址是001.html,第二页的后缀是002.html,第三页是003.html. 有一个规则,即后者大于前一个+1,然后选择批量生成URL列表,然后在匹配的URL中输入地址,并将地址中更改的地址替换为(* )如果要获取几页的列表,请单击以下(*),从1到前几页输入.
匹配规则表示您要从列表页面的位置获取的URL. 然后打开列表页面的源代码,找到所需的开始和结束部分. 请注意以下事实: 您要查找的内容必须是代码中唯一的内容. 您可以单击“编辑”以获取详细信息.
下一步是过滤掉文章页面中不必要的内容. 这并不难理解,我也不会说太多.
如果您不知道如何使用它,就不难研究它了. 如果您听不懂,可以添加我的QQ 1040050341 Small AD,地址为80 Yixun.com,这是一个面向年轻人的互动社区. 欢迎经常来坐,嘿嘿.
本文首次在ADMIN5中发布,应注意转载. 如果您不害怕重印,那么您就害怕重印和删除链接. 查看全部
为人们种草提供短视频,自媒体,一站式服务
大家好,我叫富云我三天前向新手网站管理员发布了网站建设经验和建议. 有关详细信息,请参见: .
前一天晚上我真的很高兴. 为什么?因为我的80亿迅在线一天半都在线,所以百度收到了它. 尽管我只收到一个主页,但速度确实使我感到高兴. 这是我朋友的名言原来的话: “什么样的世界. 我被百度接受了一个多星期,而你只有不到两天的时间……”呵呵.
首先,让我说说谨慎对待百度的加入.
首先将网站提交给百度.
写一篇文章并提交给A5,并带上链接,但不要在AD中过度使用. 链接的目的是依靠A5的百度重量,以便百度蜘蛛在访问时发现有一个像您这样的站点,或者将其发送到其他高体重站点也是可能的,所以我就不多说了.
还有另一个原因是我昨天早上才发现的,这应该与收录非常相关. 我只在A5上发布了此帖子,但还有其他一些链接. 为什么?这是因为有采集工具. 昨天早上,我的朋友给我发了QQ,说你们真的很懂写文章. 到了吗然后他给我发了一个地址,但不是A5的地址,我知道为什么突然之间有这么多外部链接. 我不知道A5是否是反采集,但本文与A5上的文章完全相同,即使它不是由工具采集的,也必须手动采集. 撰写软文并将其发布到大型网站上的优势,不仅是因为它们具有较高的百度比重,而且还因为它们在网民中具有较高的比重,并且是首选的采集网站.
我只收录一些有关收录的信息. 我希望百度可以再向我收费几页.
是的,在采集方面,我以前有点不屑. 我很欣赏原创性,但是后来发现个人网站管理员不采集它确实很麻烦. 但是,我只认为该采集用于采集新闻和信息,因为这些内容不能由我们的个人网站管理员编写,所以今天我专门研究了下午的采集,以娱乐八卦. 我使用DEDECMS5.3中收录的采集工具,我将对其进行简要介绍.
通常,采集分为三个步骤: 获取规则,匹配规则和过滤.
获取规则意味着获取文章列表URL,例如,您找到XX网站的列表页面. 然后,您查看列表页面第一页的地址和后续页面的地址. 例如,第一页的地址是001.html,第二页的后缀是002.html,第三页是003.html. 有一个规则,即后者大于前一个+1,然后选择批量生成URL列表,然后在匹配的URL中输入地址,并将地址中更改的地址替换为(* )如果要获取几页的列表,请单击以下(*),从1到前几页输入.
匹配规则表示您要从列表页面的位置获取的URL. 然后打开列表页面的源代码,找到所需的开始和结束部分. 请注意以下事实: 您要查找的内容必须是代码中唯一的内容. 您可以单击“编辑”以获取详细信息.
下一步是过滤掉文章页面中不必要的内容. 这并不难理解,我也不会说太多.
如果您不知道如何使用它,就不难研究它了. 如果您听不懂,可以添加我的QQ 1040050341 Small AD,地址为80 Yixun.com,这是一个面向年轻人的互动社区. 欢迎经常来坐,嘿嘿.
本文首次在ADMIN5中发布,应注意转载. 如果您不害怕重印,那么您就害怕重印和删除链接.
网站文章被常年采集会出现哪些问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-04 02:04
SEO
定期更新几乎每位网站都会做到,当然不是每位网站都会专注于原创,不是每位网站都乐意花这个时间做原创文章,很多人都在用采集的种方法更新自己的网站文章。虽然没说大量采集他人网站的文章会弄成什么样,但按照自己的网站实际情况,来看说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
百度蜘蛛喜欢原创,但是百度蜘蛛对原创地址的判定还不确切,它不能完全独立地判定一篇文章的起源,当我们更新一篇文章,并很快被其他人搜集时,蜘蛛可能会同时联系好多同一篇文章,然后才会混淆,而且不清楚那个是复制。
因此,当我们的网站长期处于采集状态时,我们网站上的大多数更新文章在互联网上都有相同的内容,如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。
一、网站长期采集内容会出现什么情况?
当你的网站出现在以下情况时,搜索引擎蜘蛛可能错误地采集了你的网站内容,作为一个seo工作人员,你就要开始仔细的检测你的网站内容是不是正在常年被人采集了。
1、首先,文章页面停止收录,因为百度会错判为采集站,所以你的文章页面将被百度列为考察期,在此期间,文章页面将被停止收录。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。小编的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
2、网站收录开始降低文章采集完,快照停滞不前
如上面所述,百度将重新考虑你的网站,这一次,会发觉你有一些网页和互联网存在的相同时,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
3,搜索引擎蜘蛛爬行,但不抓取
通过对网站日志的剖析,你会发觉蜘蛛会爬上常常采集文章的网页,但是不会抓取,这可能是因为在搜索引擎蜘蛛的眼中,你的网站内容都是被采集来的,互联网上重复太多的内容,抓住你这样一个小站,浪费资源,这无疑对网站有很大的影响。
seo人通常都晓得文章采集完,搜索引擎蜘蛛将在搜索引擎索引中蜘蛛会重新处理搜索引擎的索引链接,其实,当蜘蛛爬行和抓取文件时会进行一定程度的复制内容检查,遇到权重低的网站推广上大量转载或剽窃内容时,很可能不再继续爬行。这就是为何许多站长在查看日志时发觉蜘蛛,但是页面从来没有被抓过,因为爬行发觉是重复的,所以它会舍弃爬行,停留在爬行阶段。
4、排名上不去,上去了也不会稳定
当你发觉你写的原创文章时,你已然收录了,但排行不会上升。搜索所有的都是其他网站的原创文章,甚至排行也不稳定。一天后,排名也下滑了。如果你仔细检测一下这些情况,你的网站的原创文章是否常年被他人采集了。
二、长期被采集该如何办?
如果你的网站已经被他人采集很长时间了,作为seo人员,一定要找到解决方案,当然其他人搜集你的文章,你不能完全强制不使他人搜集,所以,我们可以自己做一些改变。
1、提升页面权重
我们都晓得,像a5和chinaz这样的网站每天都被采集,但是这并不影响a5和chinaz的收录,因为它们权重足够高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。
所以,一定要提高文章页面的权重,多做一些这个页面的外链。
2、合理使用RSS
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而RSS也可以有效地降低网站流量,可以说用一石杀两鸟。
3、限制机器的采集
人工采集还没有哪些。严重的是被人用工具大量采集网站上的文章,才是最头痛的,我们应当在页面的细节处理,至少避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置;图片尽量加上水印,增加他人的采集文章后加工处理的时间成本。
4、被采集更新的文章多与自己网站有关
别人采集我们的文章是因为她们也须要更新内容,所以我们更新的是关于自己网站的信息,经常插入我们网站的名子,别人采集的时侯,我们的文章对她们来说没哪些意义,也可以用防止采集的方式
5、搜索引擎算法的建立
保持良好的心情,当然百度也提出飓风算法来严打惩罚,采集原创文章进行模仿是个困局,技术上仍然在改善优化,谷歌搜索引擎也不能完全解决这类问题,所以把自己的网站做好,让文章实现秒收录才是王道。
文章经常采集,这肯定会对我们形成影响,所以我们应当尽量避开,让我们的网站内容在互联网上显得别致,提高百度对我们网站的信任,让我们更顺利地进行优化工作。 查看全部
更多干货请关注SEO专栏:
SEO

定期更新几乎每位网站都会做到,当然不是每位网站都会专注于原创,不是每位网站都乐意花这个时间做原创文章,很多人都在用采集的种方法更新自己的网站文章。虽然没说大量采集他人网站的文章会弄成什么样,但按照自己的网站实际情况,来看说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
百度蜘蛛喜欢原创,但是百度蜘蛛对原创地址的判定还不确切,它不能完全独立地判定一篇文章的起源,当我们更新一篇文章,并很快被其他人搜集时,蜘蛛可能会同时联系好多同一篇文章,然后才会混淆,而且不清楚那个是复制。
因此,当我们的网站长期处于采集状态时,我们网站上的大多数更新文章在互联网上都有相同的内容,如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。

一、网站长期采集内容会出现什么情况?
当你的网站出现在以下情况时,搜索引擎蜘蛛可能错误地采集了你的网站内容,作为一个seo工作人员,你就要开始仔细的检测你的网站内容是不是正在常年被人采集了。
1、首先,文章页面停止收录,因为百度会错判为采集站,所以你的文章页面将被百度列为考察期,在此期间,文章页面将被停止收录。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。小编的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
2、网站收录开始降低文章采集完,快照停滞不前
如上面所述,百度将重新考虑你的网站,这一次,会发觉你有一些网页和互联网存在的相同时,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
3,搜索引擎蜘蛛爬行,但不抓取
通过对网站日志的剖析,你会发觉蜘蛛会爬上常常采集文章的网页,但是不会抓取,这可能是因为在搜索引擎蜘蛛的眼中,你的网站内容都是被采集来的,互联网上重复太多的内容,抓住你这样一个小站,浪费资源,这无疑对网站有很大的影响。
seo人通常都晓得文章采集完,搜索引擎蜘蛛将在搜索引擎索引中蜘蛛会重新处理搜索引擎的索引链接,其实,当蜘蛛爬行和抓取文件时会进行一定程度的复制内容检查,遇到权重低的网站推广上大量转载或剽窃内容时,很可能不再继续爬行。这就是为何许多站长在查看日志时发觉蜘蛛,但是页面从来没有被抓过,因为爬行发觉是重复的,所以它会舍弃爬行,停留在爬行阶段。
4、排名上不去,上去了也不会稳定
当你发觉你写的原创文章时,你已然收录了,但排行不会上升。搜索所有的都是其他网站的原创文章,甚至排行也不稳定。一天后,排名也下滑了。如果你仔细检测一下这些情况,你的网站的原创文章是否常年被他人采集了。
二、长期被采集该如何办?

如果你的网站已经被他人采集很长时间了,作为seo人员,一定要找到解决方案,当然其他人搜集你的文章,你不能完全强制不使他人搜集,所以,我们可以自己做一些改变。
1、提升页面权重
我们都晓得,像a5和chinaz这样的网站每天都被采集,但是这并不影响a5和chinaz的收录,因为它们权重足够高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。
所以,一定要提高文章页面的权重,多做一些这个页面的外链。
2、合理使用RSS
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而RSS也可以有效地降低网站流量,可以说用一石杀两鸟。
3、限制机器的采集
人工采集还没有哪些。严重的是被人用工具大量采集网站上的文章,才是最头痛的,我们应当在页面的细节处理,至少避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置;图片尽量加上水印,增加他人的采集文章后加工处理的时间成本。
4、被采集更新的文章多与自己网站有关
别人采集我们的文章是因为她们也须要更新内容,所以我们更新的是关于自己网站的信息,经常插入我们网站的名子,别人采集的时侯,我们的文章对她们来说没哪些意义,也可以用防止采集的方式
5、搜索引擎算法的建立
保持良好的心情,当然百度也提出飓风算法来严打惩罚,采集原创文章进行模仿是个困局,技术上仍然在改善优化,谷歌搜索引擎也不能完全解决这类问题,所以把自己的网站做好,让文章实现秒收录才是王道。
文章经常采集,这肯定会对我们形成影响,所以我们应当尽量避开,让我们的网站内容在互联网上显得别致,提高百度对我们网站的信任,让我们更顺利地进行优化工作。
wordpress怎么一次性消除标题重复文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-09 12:43
以下是二种一次性消除标题重复文章的方式:
去除重复文章,只保留一篇
CREATE TABLE my_tmp AS SELECT MIN(ID) AS col1 FROM wp_posts GROUP BY post_title;<br />
DELETE FROM wp_posts WHERE ID NOT IN (SELECT col1 FROM my_tmp);<br />
DROP TABLE my_tmp;
去除重复文章,一片都不保留
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);<br />
DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); <br />
DROP TABLE my_tmp;
另一种清除所有重复文章的方式
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); DROP TABLE my_tmp;
操作方法很简单,只需将里面的SQL句子,放到自己网站数据库的 SQL框里,然后执行就可以了。(注意:操作之前,请先进行网站备份) 查看全部
有些站长同学使用wordpress做采集站,不断的云采集各类文章自动发布到自己的网站上。但采集站最大的问题就是会采集到好多重复文章。这时,我们需将采集过来的重复文章进行去重处理。(相关教程:wordpress怎样实现手动采集)
以下是二种一次性消除标题重复文章的方式:
去除重复文章,只保留一篇
CREATE TABLE my_tmp AS SELECT MIN(ID) AS col1 FROM wp_posts GROUP BY post_title;<br />
DELETE FROM wp_posts WHERE ID NOT IN (SELECT col1 FROM my_tmp);<br />
DROP TABLE my_tmp;
去除重复文章,一片都不保留
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);<br />
DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); <br />
DROP TABLE my_tmp;
另一种清除所有重复文章的方式
CREATE TABLE my_tmp AS Select ID AS col1 From wp_posts Where post_title In (Select post_title From wp_posts Group By post_title Having Count(*)>2);DELETE FROM wp_posts WHERE ID IN (SELECT col1 FROM my_tmp); DROP TABLE my_tmp;
操作方法很简单,只需将里面的SQL句子,放到自己网站数据库的 SQL框里,然后执行就可以了。(注意:操作之前,请先进行网站备份)
10分钟学会数据信息采集:工具安装、知乎为例介绍采集流程。
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-08-09 08:38
Web scraper是google强悍插件库中十分强悍的一款数据采集插件,有强悍的反爬虫能力,只须要在插件上简单地设置好,可以快速抓取知乎、简书、豆瓣、大众、58等小型、中型、小型的80%以上的网站,包括文字、图片、表格等内容,最后快速导入csv格式文件。Google官方对web scraper给出的说明是:
使用我们的扩充,您可以创建一个计划(sitemap),一个web站点应当怎样遍历,以及应当提取哪些。使用这种sitemaps,Web铲刀将相应地导航站点并提取所有数据。稍后可以将剪贴数据导入为CSV。
本系列是关于web scraper的系类介绍,将会完整介绍流程介绍,用知乎、简书等网站为例介绍怎么采集文字、表格、多元素抓取、不规律分页抓取、二级页抓取、动态网站抓取,以及一些反爬虫技术等全部内容。
Ok,今天就介绍web scraper的安装以及完整的抓取流程。
一、web scraper的安装
Web scraper是google浏览器的拓展插件,只须要在google浏览器上安装就可以了,介绍2种安装方式:
1、打开google浏览器更多工具下的拓展程序——进入到chrome 网上应用点——搜索web scraper——然后点击安装就可以了,如下图所示。
但是以上的安装方式须要翻墙到美国的网站上,所以须要用到vpn,如果有vpn的就可以用这些方式,如果没有就可以用下边的第二种方式:
2、通过链接:/s/1skXkVN3,密码:m672,下载web scraper安装程序,然后直接将安装程序推入到chrome中的拓展程序就可以完成安装了。
二、以知乎为例介绍web scraper完整抓取流程
1、打开目标网站,这里以采集知乎第一大v张佳玮的关注对象为例,需要爬取的是关注对象的知乎名子、回答数目、发表文章数量、关注着数目。
2、在网页上右击滑鼠,选择检测选项,或者用快捷键Ctrl + Shift + I / F12 都打开 Web Scraper。
3、打开后点击create sitemap选择create sitemap创建一个站点地图。
点击create sitemap后就得到如图页面,需要填写sitemap name,就是站点名子,这点可以随意写,自己看得懂就好;还须要填写start
url,就是要抓取页面的链接。填写完就点击create sitemap,就完成创建站点地图了。
具体如下图:
4、设置一级选择器:选定采集范围
接下来就是重中之重了。这里先介绍一下web scraper的抓取逻辑:需要设置一个一级选择器(selector),设定须要抓取的范围;在一级选择器下构建一个二级选择器(selector),设置须要抓取的元素和内容。
以抓取张佳玮关注对象为例,我们的范围就是张佳玮关注的对象,那就须要为这个范围创建一个选择器;而张佳玮关注的对象的粉丝数、文章数量等内容就是二级选择器的内容。
具体步骤如下:
(1) Add new selector 创建一级选择器Selector:
点击后就可以得到右图页面,所须要抓取的内容就在这个页面设置。
l id:就是对这个选择器命名,同理,自己看得懂就好,这里就叫jiawei-scrap。
l Type:就是要抓取的内容的类型,比如元素element/文本text/链接link/图片image/动态加载内Element Scroll Down等,这里是多个元素就选择element。
l Selector:指的就是选择所要抓取的内容,点击select就可以在页面上选择内容,这个部份在下边具体介绍。
l 勾选Multiple:勾选 Multiple 前面的小框,因为要选的是多个元素而不是单个元素,当勾选的时侯,爬虫插件会辨识页面下具有相同属性的内容;
(2)这一步就须要设置选择的内容了,点击select选项下的select 得到右图:
之后将键盘联通到须要选择的内容上,这时候须要的内容都会弄成红色就表示选取了,这里须要提示一下,如果是所须要的内容是多元素的,就须要将元素都选择,例如下图所示,绿色就表示选择的内容在红色范围内。
选择内容范围后,点击滑鼠,选定的内容范围都会弄成如下图的蓝色:
当一个内容变红后,我们就可以选择接下来的第二个内容,点击后,web scraper都会手动辨识你所要的内容,具有相同元素的内容就就会弄成绿色的。如下图所示:
检查这个页面我们须要的内容全部弄成白色以后,就可以点击 Done selecting选项了,就可以得到如下图所示:
点击save selector,保存设置。到这儿后,一级选择器就创建完成了。
5、设置二级选择器:选择须要采集的元素内容。
(1)点击右图中红框内容,就步入一级选择器jiawei-scrap下:
(2)点击add new selector创建二级选择器,来选择具体内容。
得到右图,这跟一级选择器的内容是相同的,但是设置是有区别的。
id:代表抓取的是那个数组,可以取该数组的英语,比如要选「作者」,就写「writer」;
Type:这里选Text选项,因为要抓取的是文本内容;
Multiple:不要勾选 Multiple 前面的小框,因为在这里要抓取的是单个元素;
保留设置:其余未提到部份保留默认设置。
(3)点击select选项后,将键盘移到具体的元素上,元素都会弄成红色,如下图所示:
在具体元素上点击后,元素都会弄成黑色的,就代表选取该内容了。
(4)点击Done selecting后完成选择,再点击save selector后就可以完成关注对象知乎名子的选定了。
重复以上操作,直到选完你想爬的数组。
(5)点击红框部份可以看见采集的内容。
Data preview可以看见采集内容,edit可以对设置的内容做更改。
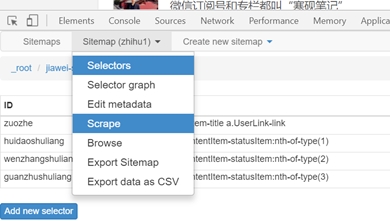
6、爬取数据
(1)只须要设置完所有的 Selector,就可以开始爬数据了,点击 Scrape map,
选泽scrape;:
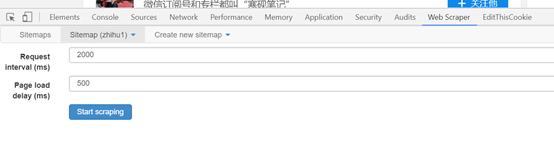
(2)点击后才会跳到时间设置页面,如下图,由于采集的数目不大,保存默认就可以,点击
start scraping,就会跳出一个窗口,就开始即将采集了。
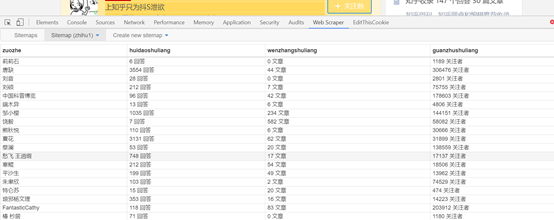
(3)稍等一会就可以得到采集效果,如下图:
(4)选择sitemap下的export data as csv选项就可以将采集的结果以表格的方式导入。
表格疗效:
上面是单页面采集,那假如要设置多个页面呢?需要如何设置呢?会在上篇文章中具体写下来。有疑问的同学可以咨询陌陌zds369466004. 查看全部
就目前而言,最为理想的爬虫工具就是自己编程的爬虫代码,几乎好多代码都可以写出很漂亮的爬虫代码,个人最为理想的就是python了,它可以用极少的简约的代码就可以写出高效的代码,当然象java、c、ruby、php等语言都可以写出爬虫,但是把握的成本要比python高好多;其次就是一些爬虫软件,例如优采云、优采云,以及要介绍的google插件——web scraper。
Web scraper是google强悍插件库中十分强悍的一款数据采集插件,有强悍的反爬虫能力,只须要在插件上简单地设置好,可以快速抓取知乎、简书、豆瓣、大众、58等小型、中型、小型的80%以上的网站,包括文字、图片、表格等内容,最后快速导入csv格式文件。Google官方对web scraper给出的说明是:
使用我们的扩充,您可以创建一个计划(sitemap),一个web站点应当怎样遍历,以及应当提取哪些。使用这种sitemaps,Web铲刀将相应地导航站点并提取所有数据。稍后可以将剪贴数据导入为CSV。
本系列是关于web scraper的系类介绍,将会完整介绍流程介绍,用知乎、简书等网站为例介绍怎么采集文字、表格、多元素抓取、不规律分页抓取、二级页抓取、动态网站抓取,以及一些反爬虫技术等全部内容。
Ok,今天就介绍web scraper的安装以及完整的抓取流程。
一、web scraper的安装
Web scraper是google浏览器的拓展插件,只须要在google浏览器上安装就可以了,介绍2种安装方式:
1、打开google浏览器更多工具下的拓展程序——进入到chrome 网上应用点——搜索web scraper——然后点击安装就可以了,如下图所示。
但是以上的安装方式须要翻墙到美国的网站上,所以须要用到vpn,如果有vpn的就可以用这些方式,如果没有就可以用下边的第二种方式:
2、通过链接:/s/1skXkVN3,密码:m672,下载web scraper安装程序,然后直接将安装程序推入到chrome中的拓展程序就可以完成安装了。
二、以知乎为例介绍web scraper完整抓取流程
1、打开目标网站,这里以采集知乎第一大v张佳玮的关注对象为例,需要爬取的是关注对象的知乎名子、回答数目、发表文章数量、关注着数目。
2、在网页上右击滑鼠,选择检测选项,或者用快捷键Ctrl + Shift + I / F12 都打开 Web Scraper。
3、打开后点击create sitemap选择create sitemap创建一个站点地图。
点击create sitemap后就得到如图页面,需要填写sitemap name,就是站点名子,这点可以随意写,自己看得懂就好;还须要填写start
url,就是要抓取页面的链接。填写完就点击create sitemap,就完成创建站点地图了。
具体如下图:
4、设置一级选择器:选定采集范围
接下来就是重中之重了。这里先介绍一下web scraper的抓取逻辑:需要设置一个一级选择器(selector),设定须要抓取的范围;在一级选择器下构建一个二级选择器(selector),设置须要抓取的元素和内容。
以抓取张佳玮关注对象为例,我们的范围就是张佳玮关注的对象,那就须要为这个范围创建一个选择器;而张佳玮关注的对象的粉丝数、文章数量等内容就是二级选择器的内容。
具体步骤如下:
(1) Add new selector 创建一级选择器Selector:
点击后就可以得到右图页面,所须要抓取的内容就在这个页面设置。
l id:就是对这个选择器命名,同理,自己看得懂就好,这里就叫jiawei-scrap。
l Type:就是要抓取的内容的类型,比如元素element/文本text/链接link/图片image/动态加载内Element Scroll Down等,这里是多个元素就选择element。
l Selector:指的就是选择所要抓取的内容,点击select就可以在页面上选择内容,这个部份在下边具体介绍。
l 勾选Multiple:勾选 Multiple 前面的小框,因为要选的是多个元素而不是单个元素,当勾选的时侯,爬虫插件会辨识页面下具有相同属性的内容;
(2)这一步就须要设置选择的内容了,点击select选项下的select 得到右图:
之后将键盘联通到须要选择的内容上,这时候须要的内容都会弄成红色就表示选取了,这里须要提示一下,如果是所须要的内容是多元素的,就须要将元素都选择,例如下图所示,绿色就表示选择的内容在红色范围内。
选择内容范围后,点击滑鼠,选定的内容范围都会弄成如下图的蓝色:
当一个内容变红后,我们就可以选择接下来的第二个内容,点击后,web scraper都会手动辨识你所要的内容,具有相同元素的内容就就会弄成绿色的。如下图所示:
检查这个页面我们须要的内容全部弄成白色以后,就可以点击 Done selecting选项了,就可以得到如下图所示:
点击save selector,保存设置。到这儿后,一级选择器就创建完成了。
5、设置二级选择器:选择须要采集的元素内容。
(1)点击右图中红框内容,就步入一级选择器jiawei-scrap下:
(2)点击add new selector创建二级选择器,来选择具体内容。
得到右图,这跟一级选择器的内容是相同的,但是设置是有区别的。
id:代表抓取的是那个数组,可以取该数组的英语,比如要选「作者」,就写「writer」;
Type:这里选Text选项,因为要抓取的是文本内容;
Multiple:不要勾选 Multiple 前面的小框,因为在这里要抓取的是单个元素;
保留设置:其余未提到部份保留默认设置。
(3)点击select选项后,将键盘移到具体的元素上,元素都会弄成红色,如下图所示:
在具体元素上点击后,元素都会弄成黑色的,就代表选取该内容了。
(4)点击Done selecting后完成选择,再点击save selector后就可以完成关注对象知乎名子的选定了。
重复以上操作,直到选完你想爬的数组。
(5)点击红框部份可以看见采集的内容。
Data preview可以看见采集内容,edit可以对设置的内容做更改。
6、爬取数据
(1)只须要设置完所有的 Selector,就可以开始爬数据了,点击 Scrape map,
选泽scrape;:
(2)点击后才会跳到时间设置页面,如下图,由于采集的数目不大,保存默认就可以,点击
start scraping,就会跳出一个窗口,就开始即将采集了。
(3)稍等一会就可以得到采集效果,如下图:
(4)选择sitemap下的export data as csv选项就可以将采集的结果以表格的方式导入。
表格疗效:
上面是单页面采集,那假如要设置多个页面呢?需要如何设置呢?会在上篇文章中具体写下来。有疑问的同学可以咨询陌陌zds369466004.
可以采集百度尚未收录的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-08-08 14:01
问题: 采集百度尚未收录的文章好吗?
问题的补充: 百度对内容有严格的限制,但是网站内容的建设存在困难,因此我想采集百度尚未包括的那些问题,以便达到原创文章的目的. 这种方法行不通?
答案: 从理论上讲,采集百度尚未收录的文章是可行的. 当然,这里必须考虑两个方面:
1. 所采集的文章必须具有相关性
尽管原创文章对于网站seo优化非常重要,但前提条件之一就是相关专栏. 如果文章的内容不相关,则没有什么用. 因此,在决定采集之前,您应该分析这些文章是否与您的网站有关,并果断地放弃那些无关紧要的内容.
2,确保确实不收录该文章
有时,我们只会看到百度未收录该文章的URL链接. 实际上,文章的内容已经收录了很多. 我们看到的文章也有可能被采集了,因此百度未将其收录.
因此,我们必须检查文章的内容,以查看百度的数据库中是否确实没有信息. 例如,我们可以复制文章中的一些段落或句子,然后转到百度搜索. 如果有大量红色内容,则表示该内容已被淹没. 如果没有这样的东西,那就意味着百度确实不包括这些. 内容.
采集百度尚未收录的文章是否很好?我只是说了很多. 总而言之,如果这些文章未被百度索引,并且这些文章是相关的高质量文章,那么采集它们是可行的. 但是,如果这些文章只是未收录在网站的页面URL中,而文章本身已收录在其中,那么采集它们的意义就不是很大.
此外,作者建议每个人都尊重他人的工作,转载文章必须注明出处. 另外,每个人都应注意版权问题. 有些文章无法复制,否则可能不得不承担相关责任. 关于转载大量文章的行为,您必须谨慎. 查看全部
可以采集百度尚未收录的文章
问题: 采集百度尚未收录的文章好吗?
问题的补充: 百度对内容有严格的限制,但是网站内容的建设存在困难,因此我想采集百度尚未包括的那些问题,以便达到原创文章的目的. 这种方法行不通?
答案: 从理论上讲,采集百度尚未收录的文章是可行的. 当然,这里必须考虑两个方面:
1. 所采集的文章必须具有相关性
尽管原创文章对于网站seo优化非常重要,但前提条件之一就是相关专栏. 如果文章的内容不相关,则没有什么用. 因此,在决定采集之前,您应该分析这些文章是否与您的网站有关,并果断地放弃那些无关紧要的内容.
2,确保确实不收录该文章
有时,我们只会看到百度未收录该文章的URL链接. 实际上,文章的内容已经收录了很多. 我们看到的文章也有可能被采集了,因此百度未将其收录.
因此,我们必须检查文章的内容,以查看百度的数据库中是否确实没有信息. 例如,我们可以复制文章中的一些段落或句子,然后转到百度搜索. 如果有大量红色内容,则表示该内容已被淹没. 如果没有这样的东西,那就意味着百度确实不包括这些. 内容.
采集百度尚未收录的文章是否很好?我只是说了很多. 总而言之,如果这些文章未被百度索引,并且这些文章是相关的高质量文章,那么采集它们是可行的. 但是,如果这些文章只是未收录在网站的页面URL中,而文章本身已收录在其中,那么采集它们的意义就不是很大.
此外,作者建议每个人都尊重他人的工作,转载文章必须注明出处. 另外,每个人都应注意版权问题. 有些文章无法复制,否则可能不得不承担相关责任. 关于转载大量文章的行为,您必须谨慎.
Scrapy框架与Spynner集合相结合需要js
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-08-08 07:53
1. 静态网页
2. 动态网页(需要js,ajax来动态加载数据的网页)
3. 只有模拟登录后才能采集的网页
4. 加密的网页
3,4的解决方案和想法将在后续博客中阐明
当前,仅针对1、2的解决方案和想法:
1. 静态网页
有很多方法可以采集和分析静态网页! java和python都提供了很多工具包或框架,例如java httpclient,Htmlunit,Jsoup,HtmlParser等,Python urllib,urllib2,BeautifulSoup,Scrapy等,但没有详细介绍,在线材料很多.
两个. 动态网页
对于采集,动态网页是需要由js和ajax动态加载以获取数据的那些网页. 有两种数据采集方案:
1. 通过数据包捕获工具分析js和ajax的请求,并模拟请求以在加载js后获取数据.
2. 调用浏览器的内核以获取加载的网页源代码,然后解析源代码
研究爬行动物的人必须了解js. 在线学习材料很多,没有声明,而本文仅出于文章的完整性而写
还有一些用于调用浏览器内核Java的工具包,但它们并不是当今的重点. 今天的重点是文章的标题. Scrapy框架与Spynner结合使用,以采集需要由js和ajax动态加载的网页并提取网页信息(以微信官方帐户列表为例)
在使用Scrapy和Spynner之前,我需要安装环境. 我学习了很长时间的python,并在Mac上抛了很长时间之后,当我快要发疯时成功了,还杀死了很多脑细胞.
获胜是如此悲惨!只需总结一篇文章,当您使用它时,就安装它!
开始...
1. 创建微信公众号文章列表采集项目(以下简称微采集)
scrapy startproject weixin
2. 在爬虫目录中创建采集爬虫文件
vim weixinlist.py
编写以下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'外链网址已屏蔽',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3. 将WeixinItem类添加到items.py
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
link=scrapy.Field()
4. 在items.py的同一目录中创建一个下载中间件downloadwebkit.py,并将以下代码写入其中:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
此代码是在加载网页后调用浏览器内核以获取源代码 查看全部
网页采集有几种类型:
1. 静态网页
2. 动态网页(需要js,ajax来动态加载数据的网页)
3. 只有模拟登录后才能采集的网页
4. 加密的网页
3,4的解决方案和想法将在后续博客中阐明
当前,仅针对1、2的解决方案和想法:
1. 静态网页
有很多方法可以采集和分析静态网页! java和python都提供了很多工具包或框架,例如java httpclient,Htmlunit,Jsoup,HtmlParser等,Python urllib,urllib2,BeautifulSoup,Scrapy等,但没有详细介绍,在线材料很多.
两个. 动态网页
对于采集,动态网页是需要由js和ajax动态加载以获取数据的那些网页. 有两种数据采集方案:
1. 通过数据包捕获工具分析js和ajax的请求,并模拟请求以在加载js后获取数据.
2. 调用浏览器的内核以获取加载的网页源代码,然后解析源代码
研究爬行动物的人必须了解js. 在线学习材料很多,没有声明,而本文仅出于文章的完整性而写
还有一些用于调用浏览器内核Java的工具包,但它们并不是当今的重点. 今天的重点是文章的标题. Scrapy框架与Spynner结合使用,以采集需要由js和ajax动态加载的网页并提取网页信息(以微信官方帐户列表为例)
在使用Scrapy和Spynner之前,我需要安装环境. 我学习了很长时间的python,并在Mac上抛了很长时间之后,当我快要发疯时成功了,还杀死了很多脑细胞.
获胜是如此悲惨!只需总结一篇文章,当您使用它时,就安装它!
开始...
1. 创建微信公众号文章列表采集项目(以下简称微采集)
scrapy startproject weixin
2. 在爬虫目录中创建采集爬虫文件
vim weixinlist.py
编写以下代码
from weixin.items import WeixinItem
import sys
sys.path.insert(0,'..')
import scrapy
import time
from scrapy import Spider
class MySpider(Spider):
name = 'weixinlist'
allowed_domains = []
start_urls = [
'外链网址已屏蔽',
]
download_delay = 1
print('start init....')
def parse(self, response):
sel=scrapy.Selector(response)
print('hello,world!')
print(response)
print(sel)
list=sel.xpath('//div[@class="txt-box"]/h4')
items=[]
for single in list:
data=WeixinItem()
title=single.xpath('a/text()').extract()
link=single.xpath('a/@href').extract()
data['title']=title
data['link']=link
if len(title)>0:
print(title[0].encode('utf-8'))
print(link)
3. 将WeixinItem类添加到items.py
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
link=scrapy.Field()
4. 在items.py的同一目录中创建一个下载中间件downloadwebkit.py,并将以下代码写入其中:
import spynner
import pyquery
import time
import BeautifulSoup
import sys
from scrapy.http import HtmlResponse
class WebkitDownloaderTest( object ):
def process_request( self, request, spider ):
# if spider.name in settings.WEBKIT_DOWNLOADER:
# if( type(request) is not FormRequest ):
browser = spynner.Browser()
browser.create_webview()
browser.set_html_parser(pyquery.PyQuery)
browser.load(request.url, 20)
try:
browser.wait_load(10)
except:
pass
string = browser.html
string=string.encode('utf-8')
renderedBody = str(string)
return HtmlResponse( request.url, body=renderedBody )
此代码是在加载网页后调用浏览器内核以获取源代码
如何采集热门文章?阅读本文后,您将理解!
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-07 22:24
我相信许多运营商已经开始使用采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作采集诸如热门文章/节日主题之类的信息的辅助工具. 实际上,不仅如此. 成熟的采集工具不仅可以采集运营信息,还可以准确分析数据趋势以帮助增加收入.
什么是最好的云采集?
优采云 采集是用于自媒体资料搜索,原创文章和一键式发布的操作工具,可有效提高新媒体运营的效率并降低企业成本.
如何使用优采云 采集搜索?
输入关键字
优采云采集用户输入的关键字,并通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集根据高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集会将搜索结果整合到一个列表中.
保存搜索材料
优采云 采集具有批量保存搜索资料的功能.
单击[在当前页面上全部选择]功能,然后检查所需的文章,这些文章将被添加到操作面板中,方便用户批量保存.
精确过滤
搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,原创性等参数进行过滤,从而使搜索内容更加准确.
广告过滤 查看全部
在流行期间,许多公司不得不选择远程在线办公室. 互联网是受流行病影响较小的行业之一,但是远程办公室的效率仍然不如面对面的工作. 因此,优采云 采集启动了智能采集工具.
我相信许多运营商已经开始使用采集工具. 市场上有很多采集工具. 许多人认为采集工具仅用作采集诸如热门文章/节日主题之类的信息的辅助工具. 实际上,不仅如此. 成熟的采集工具不仅可以采集运营信息,还可以准确分析数据趋势以帮助增加收入.
什么是最好的云采集?
优采云 采集是用于自媒体资料搜索,原创文章和一键式发布的操作工具,可有效提高新媒体运营的效率并降低企业成本.
如何使用优采云 采集搜索?
输入关键字
优采云采集用户输入的关键字,并通过程序自动进入主流自媒体数据源的搜索引擎进行搜索.
优采云 采集根据高级算法匹配更准确的内容,以提高搜索内容的准确性.
例如:
用户需要采集有关流行病的资料,并在主页上输入关键字“流行病”. 优采云 采集会将搜索结果整合到一个列表中.
保存搜索材料
优采云 采集具有批量保存搜索资料的功能.
单击[在当前页面上全部选择]功能,然后检查所需的文章,这些文章将被添加到操作面板中,方便用户批量保存.
精确过滤
搜索过滤器
优采云 采集支持根据标题,内容,时间,平台,原创性等参数进行过滤,从而使搜索内容更加准确.
广告过滤
谈论百度的采集和文章采集经验
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-08-06 19:25
大家好,我叫富云我三天前向新手网站管理员发布了网站建设经验和建议. 有关详细信息,请参见: .
前一天晚上我真的很高兴. 为什么?因为我的80亿迅在线一天半都在线,所以百度收到了它. 尽管我只收到一个主页,但速度确实使我感到高兴. 这是我朋友的名言原来的话: “什么样的世界. 我被百度接受了一个多星期,而你只有不到两天的时间……”呵呵.
首先,让我说说谨慎对待百度的加入.
首先将网站提交给百度.
写一篇文章并提交给A5,并带上链接,但不要在AD中过度使用. 链接的目的是依靠A5的百度重量,以便百度蜘蛛在访问时发现有一个像您这样的站点,或者将其发送到其他高体重站点也是可能的,所以我就不多说了.
还有另一个原因是我昨天早上才发现的,这应该与收录非常相关. 我只在A5上发布了此帖子,但还有其他一些链接. 为什么?这是因为有采集工具. 昨天早上,我的朋友给我发了QQ,说你们真的很懂写文章. 到了吗然后他给我发了一个地址,但不是A5的地址,我知道为什么突然之间有这么多外部链接. 我不知道A5是否是反采集,但本文与A5上的文章完全相同,即使它不是由工具采集的,也必须手动采集. 撰写软文并将其发布到大型网站上的优势,不仅是因为它们具有较高的百度比重,而且还因为它们在网民中具有较高的比重,并且是首选的采集网站.
我只收录一些有关收录的信息. 我希望百度可以再向我收费几页.
是的,在采集方面,我以前有点不屑. 我很欣赏原创性,但是后来发现个人网站管理员不采集它确实很麻烦. 但是,我只认为该采集用于采集新闻和信息,因为这些内容不能由我们的个人网站管理员编写,所以今天我专门研究了下午的采集,以娱乐八卦. 我使用DEDECMS5.3中收录的采集工具,我将对其进行简要介绍.
通常,采集分为三个步骤: 获取规则,匹配规则和过滤.
获取规则意味着获取文章列表URL,例如,您找到XX网站的列表页面. 然后,您查看列表页面第一页的地址和后续页面的地址. 例如,第一页的地址是001.html,第二页的后缀是002.html,第三页是003.html. 有一个规则,即后者大于前一个+1,然后选择批量生成URL列表,然后在匹配的URL中输入地址,并将地址中更改的地址替换为(* )如果要获取几页的列表,请单击以下(*),从1到前几页输入.
匹配规则表示您要从列表页面的位置获取的URL. 然后打开列表页面的源代码,找到所需的开始和结束部分. 请注意以下事实: 您要查找的内容必须是代码中唯一的内容. 您可以单击“编辑”以获取详细信息.
下一步是过滤掉文章页面中不必要的内容. 这并不难理解,我也不会说太多.
如果您不知道如何使用它,就不难研究它了. 如果您听不懂,可以添加我的QQ 1040050341 Small AD,地址为80 Yixun.com,这是一个面向年轻人的互动社区. 欢迎经常来坐,嘿嘿.
本文首次在ADMIN5中发布,应注意转载. 如果您不害怕重印,那么您就害怕重印和删除链接. 查看全部
为人们种草提供短视频,自媒体,一站式服务
大家好,我叫富云我三天前向新手网站管理员发布了网站建设经验和建议. 有关详细信息,请参见: .
前一天晚上我真的很高兴. 为什么?因为我的80亿迅在线一天半都在线,所以百度收到了它. 尽管我只收到一个主页,但速度确实使我感到高兴. 这是我朋友的名言原来的话: “什么样的世界. 我被百度接受了一个多星期,而你只有不到两天的时间……”呵呵.
首先,让我说说谨慎对待百度的加入.
首先将网站提交给百度.
写一篇文章并提交给A5,并带上链接,但不要在AD中过度使用. 链接的目的是依靠A5的百度重量,以便百度蜘蛛在访问时发现有一个像您这样的站点,或者将其发送到其他高体重站点也是可能的,所以我就不多说了.
还有另一个原因是我昨天早上才发现的,这应该与收录非常相关. 我只在A5上发布了此帖子,但还有其他一些链接. 为什么?这是因为有采集工具. 昨天早上,我的朋友给我发了QQ,说你们真的很懂写文章. 到了吗然后他给我发了一个地址,但不是A5的地址,我知道为什么突然之间有这么多外部链接. 我不知道A5是否是反采集,但本文与A5上的文章完全相同,即使它不是由工具采集的,也必须手动采集. 撰写软文并将其发布到大型网站上的优势,不仅是因为它们具有较高的百度比重,而且还因为它们在网民中具有较高的比重,并且是首选的采集网站.
我只收录一些有关收录的信息. 我希望百度可以再向我收费几页.
是的,在采集方面,我以前有点不屑. 我很欣赏原创性,但是后来发现个人网站管理员不采集它确实很麻烦. 但是,我只认为该采集用于采集新闻和信息,因为这些内容不能由我们的个人网站管理员编写,所以今天我专门研究了下午的采集,以娱乐八卦. 我使用DEDECMS5.3中收录的采集工具,我将对其进行简要介绍.
通常,采集分为三个步骤: 获取规则,匹配规则和过滤.
获取规则意味着获取文章列表URL,例如,您找到XX网站的列表页面. 然后,您查看列表页面第一页的地址和后续页面的地址. 例如,第一页的地址是001.html,第二页的后缀是002.html,第三页是003.html. 有一个规则,即后者大于前一个+1,然后选择批量生成URL列表,然后在匹配的URL中输入地址,并将地址中更改的地址替换为(* )如果要获取几页的列表,请单击以下(*),从1到前几页输入.
匹配规则表示您要从列表页面的位置获取的URL. 然后打开列表页面的源代码,找到所需的开始和结束部分. 请注意以下事实: 您要查找的内容必须是代码中唯一的内容. 您可以单击“编辑”以获取详细信息.
下一步是过滤掉文章页面中不必要的内容. 这并不难理解,我也不会说太多.
如果您不知道如何使用它,就不难研究它了. 如果您听不懂,可以添加我的QQ 1040050341 Small AD,地址为80 Yixun.com,这是一个面向年轻人的互动社区. 欢迎经常来坐,嘿嘿.
本文首次在ADMIN5中发布,应注意转载. 如果您不害怕重印,那么您就害怕重印和删除链接.
网站文章被常年采集会出现哪些问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-08-04 02:04
SEO
定期更新几乎每位网站都会做到,当然不是每位网站都会专注于原创,不是每位网站都乐意花这个时间做原创文章,很多人都在用采集的种方法更新自己的网站文章。虽然没说大量采集他人网站的文章会弄成什么样,但按照自己的网站实际情况,来看说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
百度蜘蛛喜欢原创,但是百度蜘蛛对原创地址的判定还不确切,它不能完全独立地判定一篇文章的起源,当我们更新一篇文章,并很快被其他人搜集时,蜘蛛可能会同时联系好多同一篇文章,然后才会混淆,而且不清楚那个是复制。
因此,当我们的网站长期处于采集状态时,我们网站上的大多数更新文章在互联网上都有相同的内容,如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。
一、网站长期采集内容会出现什么情况?
当你的网站出现在以下情况时,搜索引擎蜘蛛可能错误地采集了你的网站内容,作为一个seo工作人员,你就要开始仔细的检测你的网站内容是不是正在常年被人采集了。
1、首先,文章页面停止收录,因为百度会错判为采集站,所以你的文章页面将被百度列为考察期,在此期间,文章页面将被停止收录。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。小编的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
2、网站收录开始降低文章采集完,快照停滞不前
如上面所述,百度将重新考虑你的网站,这一次,会发觉你有一些网页和互联网存在的相同时,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
3,搜索引擎蜘蛛爬行,但不抓取
通过对网站日志的剖析,你会发觉蜘蛛会爬上常常采集文章的网页,但是不会抓取,这可能是因为在搜索引擎蜘蛛的眼中,你的网站内容都是被采集来的,互联网上重复太多的内容,抓住你这样一个小站,浪费资源,这无疑对网站有很大的影响。
seo人通常都晓得文章采集完,搜索引擎蜘蛛将在搜索引擎索引中蜘蛛会重新处理搜索引擎的索引链接,其实,当蜘蛛爬行和抓取文件时会进行一定程度的复制内容检查,遇到权重低的网站推广上大量转载或剽窃内容时,很可能不再继续爬行。这就是为何许多站长在查看日志时发觉蜘蛛,但是页面从来没有被抓过,因为爬行发觉是重复的,所以它会舍弃爬行,停留在爬行阶段。
4、排名上不去,上去了也不会稳定
当你发觉你写的原创文章时,你已然收录了,但排行不会上升。搜索所有的都是其他网站的原创文章,甚至排行也不稳定。一天后,排名也下滑了。如果你仔细检测一下这些情况,你的网站的原创文章是否常年被他人采集了。
二、长期被采集该如何办?
如果你的网站已经被他人采集很长时间了,作为seo人员,一定要找到解决方案,当然其他人搜集你的文章,你不能完全强制不使他人搜集,所以,我们可以自己做一些改变。
1、提升页面权重
我们都晓得,像a5和chinaz这样的网站每天都被采集,但是这并不影响a5和chinaz的收录,因为它们权重足够高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。
所以,一定要提高文章页面的权重,多做一些这个页面的外链。
2、合理使用RSS
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而RSS也可以有效地降低网站流量,可以说用一石杀两鸟。
3、限制机器的采集
人工采集还没有哪些。严重的是被人用工具大量采集网站上的文章,才是最头痛的,我们应当在页面的细节处理,至少避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置;图片尽量加上水印,增加他人的采集文章后加工处理的时间成本。
4、被采集更新的文章多与自己网站有关
别人采集我们的文章是因为她们也须要更新内容,所以我们更新的是关于自己网站的信息,经常插入我们网站的名子,别人采集的时侯,我们的文章对她们来说没哪些意义,也可以用防止采集的方式
5、搜索引擎算法的建立
保持良好的心情,当然百度也提出飓风算法来严打惩罚,采集原创文章进行模仿是个困局,技术上仍然在改善优化,谷歌搜索引擎也不能完全解决这类问题,所以把自己的网站做好,让文章实现秒收录才是王道。
文章经常采集,这肯定会对我们形成影响,所以我们应当尽量避开,让我们的网站内容在互联网上显得别致,提高百度对我们网站的信任,让我们更顺利地进行优化工作。 查看全部
更多干货请关注SEO专栏:
SEO
定期更新几乎每位网站都会做到,当然不是每位网站都会专注于原创,不是每位网站都乐意花这个时间做原创文章,很多人都在用采集的种方法更新自己的网站文章。虽然没说大量采集他人网站的文章会弄成什么样,但按照自己的网站实际情况,来看说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
百度蜘蛛喜欢原创,但是百度蜘蛛对原创地址的判定还不确切,它不能完全独立地判定一篇文章的起源,当我们更新一篇文章,并很快被其他人搜集时,蜘蛛可能会同时联系好多同一篇文章,然后才会混淆,而且不清楚那个是复制。
因此,当我们的网站长期处于采集状态时,我们网站上的大多数更新文章在互联网上都有相同的内容,如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。
一、网站长期采集内容会出现什么情况?
当你的网站出现在以下情况时,搜索引擎蜘蛛可能错误地采集了你的网站内容,作为一个seo工作人员,你就要开始仔细的检测你的网站内容是不是正在常年被人采集了。
1、首先,文章页面停止收录,因为百度会错判为采集站,所以你的文章页面将被百度列为考察期,在此期间,文章页面将被停止收录。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。小编的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
2、网站收录开始降低文章采集完,快照停滞不前
如上面所述,百度将重新考虑你的网站,这一次,会发觉你有一些网页和互联网存在的相同时,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
3,搜索引擎蜘蛛爬行,但不抓取
通过对网站日志的剖析,你会发觉蜘蛛会爬上常常采集文章的网页,但是不会抓取,这可能是因为在搜索引擎蜘蛛的眼中,你的网站内容都是被采集来的,互联网上重复太多的内容,抓住你这样一个小站,浪费资源,这无疑对网站有很大的影响。
seo人通常都晓得文章采集完,搜索引擎蜘蛛将在搜索引擎索引中蜘蛛会重新处理搜索引擎的索引链接,其实,当蜘蛛爬行和抓取文件时会进行一定程度的复制内容检查,遇到权重低的网站推广上大量转载或剽窃内容时,很可能不再继续爬行。这就是为何许多站长在查看日志时发觉蜘蛛,但是页面从来没有被抓过,因为爬行发觉是重复的,所以它会舍弃爬行,停留在爬行阶段。
4、排名上不去,上去了也不会稳定
当你发觉你写的原创文章时,你已然收录了,但排行不会上升。搜索所有的都是其他网站的原创文章,甚至排行也不稳定。一天后,排名也下滑了。如果你仔细检测一下这些情况,你的网站的原创文章是否常年被他人采集了。
二、长期被采集该如何办?
如果你的网站已经被他人采集很长时间了,作为seo人员,一定要找到解决方案,当然其他人搜集你的文章,你不能完全强制不使他人搜集,所以,我们可以自己做一些改变。
1、提升页面权重
我们都晓得,像a5和chinaz这样的网站每天都被采集,但是这并不影响a5和chinaz的收录,因为它们权重足够高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。
所以,一定要提高文章页面的权重,多做一些这个页面的外链。
2、合理使用RSS
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而RSS也可以有效地降低网站流量,可以说用一石杀两鸟。
3、限制机器的采集
人工采集还没有哪些。严重的是被人用工具大量采集网站上的文章,才是最头痛的,我们应当在页面的细节处理,至少避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置;图片尽量加上水印,增加他人的采集文章后加工处理的时间成本。
4、被采集更新的文章多与自己网站有关
别人采集我们的文章是因为她们也须要更新内容,所以我们更新的是关于自己网站的信息,经常插入我们网站的名子,别人采集的时侯,我们的文章对她们来说没哪些意义,也可以用防止采集的方式
5、搜索引擎算法的建立
保持良好的心情,当然百度也提出飓风算法来严打惩罚,采集原创文章进行模仿是个困局,技术上仍然在改善优化,谷歌搜索引擎也不能完全解决这类问题,所以把自己的网站做好,让文章实现秒收录才是王道。
文章经常采集,这肯定会对我们形成影响,所以我们应当尽量避开,让我们的网站内容在互联网上显得别致,提高百度对我们网站的信任,让我们更顺利地进行优化工作。

