
文章采集完
内容分享:微信公众号文章批量采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2021-01-07 12:08
目前,有很多方法可以在市场上抓取微信公众号文章,但是其中许多方法不可用,并且无法记录阅读次数和喜欢的次数,并且教程非常复杂并且全部被复制。复制它,该程序是经过许多实际操作总结的可执行程序,并且简单易用。本教程仅讨论干货。
首先安装所需的环境1.node.js + anyproxy安装
1.1node.js安装
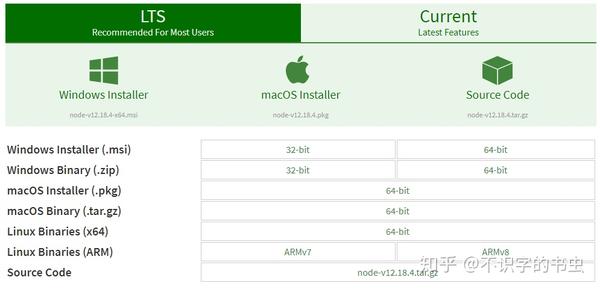
下载Node.js并打开官方网站下载链接:/ en / download /我下载了node-v6.9.2-x64.msi,如下所示:
下载完成后,双击“ node-v6.9.2-x64.msi”开始安装Node.js,只需单击下一步。需要注意的主要事情是Node.js的默认安装目录是“ C:\ Program Files \ nodejs \”。您可以单击更改以修改目录。通常,我将其安装在“ D:\ Program Files \ nodejs \”下。
安装完成后,检查是否在PATH环境变量中配置了Node.js。单击开始=》运行=》输入“ cmd” =>输入命令“路径”,然后查看输出中是否有节点安装目录。
最后,测试节点是否安装成功。
点击开始=>运行=》输入“ cmd” =>输入命令“ node -v”和“ npm -v”,显示如图所示结果,表明安装成功。
1.2 anyproxy安装
点击开始=>运行=》输入“ cmd” =>输入命令“ npm install -g anyproxy”安装完成后,输入命令“ anyproxy -i”以启动anyproxy。
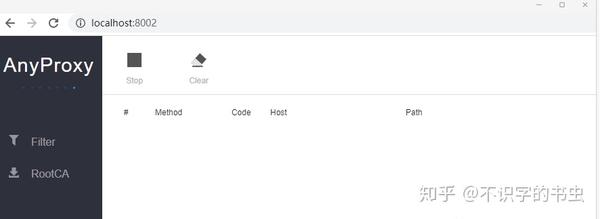
打开浏览器并输入localhost:8002以打开anyproxy界面。
2.安装手机模拟器
我尝试了几种模拟器,我认为MuMu模拟器相对易于使用。它是由网易生产的,具有一定的质量保证。下载地址:/,您可以从官方网站下载并安装。
3.网络配置和证书安装
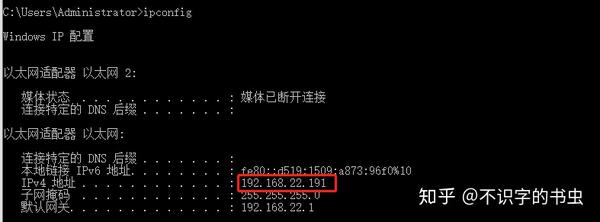
首先检查本地IP,单击Start =》 Run =》输入“ cmd” =>输入命令“ ipconfig”以检查您的IP,如图所示
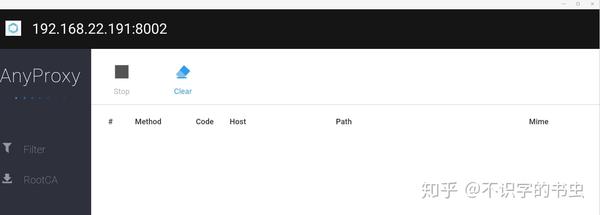
然后在仿真器上打开浏览器,然后输入找到的IP:8002。如图所示:
点击ROOTCA以安装证书
在模拟器上,依次单击“设置”,“ WLAN”,“配置代理”
4.在模拟器上安装微信
通过MuMu模拟器上的应用程序中心安装微信。
在计算机端,打开浏览器,输入localhost:8002,打开仿真器微信,访问任何官方帐户,并检查计算机浏览器,即可看到微信请求的数据包。
准备好环境后,让我们开始分析界面和相关的重要参数。
首先我们要谈一些重要的参数
我们来谈谈几个重要的界面
要获取正式帐户文章,您需要先输入一个条目。许多文章从旧的文章列表条目开始。获取第一页的html,获取第16个脚本标签中msgList变量的值,获取第一页的内容,然后通过该接口请求json数据以获取其他页的数据。除了获取喜欢和观看数据的界面之外,整个过程还需要三个界面。
实际上,可以优化整个爬网过程。我们可以合并第一个和第二个接口。只需要两个接口即可完成正式帐户文章列表,并且可以看到喜欢的次数。爬行。
通过修改偏移量以控制页数来获取列表数据接口,其中计数不能大于10,这意味着一个页面中最多有十个项目。
"/mp/profile_ext?action=getmsg&__biz="+__biz+"&f=json&offset="+offset+"&count=10&appmsg_token="+appmsg_token+"";
要获取喜欢人数的第二个界面,请在手表编号界面中,请注意,这是此界面中的POST请求,
"/mp/getappmsgext?f=json&__biz="+__biz+"&appmsg_token="+appmsg_token+"&fasttmplajax=1";
需要上传请求正文
"mid="+mid+"&sn="+sn+"&idx="+idx+"&is_only_read=1"
通过这两个界面,您可以获取任何正式帐户的全部文章,以及点赞次数和计数等。在此处应注意,列表请求应以2秒分开,并且点赞数量的界面应间隔2秒。 ,否则,微信帐户将被阻止并且无法访问官方帐户,其他功能将不受影响,并且将在24小时内自动解除锁定。
WeChat官方帐户文章批处理采集就是这样。如有任何疑问,可以留言讨论~~ 查看全部
内容分享:微信公众号文章批量采集
目前,有很多方法可以在市场上抓取微信公众号文章,但是其中许多方法不可用,并且无法记录阅读次数和喜欢的次数,并且教程非常复杂并且全部被复制。复制它,该程序是经过许多实际操作总结的可执行程序,并且简单易用。本教程仅讨论干货。
首先安装所需的环境1.node.js + anyproxy安装
1.1node.js安装
下载Node.js并打开官方网站下载链接:/ en / download /我下载了node-v6.9.2-x64.msi,如下所示:
下载完成后,双击“ node-v6.9.2-x64.msi”开始安装Node.js,只需单击下一步。需要注意的主要事情是Node.js的默认安装目录是“ C:\ Program Files \ nodejs \”。您可以单击更改以修改目录。通常,我将其安装在“ D:\ Program Files \ nodejs \”下。
安装完成后,检查是否在PATH环境变量中配置了Node.js。单击开始=》运行=》输入“ cmd” =>输入命令“路径”,然后查看输出中是否有节点安装目录。
最后,测试节点是否安装成功。
点击开始=>运行=》输入“ cmd” =>输入命令“ node -v”和“ npm -v”,显示如图所示结果,表明安装成功。

1.2 anyproxy安装
点击开始=>运行=》输入“ cmd” =>输入命令“ npm install -g anyproxy”安装完成后,输入命令“ anyproxy -i”以启动anyproxy。
打开浏览器并输入localhost:8002以打开anyproxy界面。
2.安装手机模拟器
我尝试了几种模拟器,我认为MuMu模拟器相对易于使用。它是由网易生产的,具有一定的质量保证。下载地址:/,您可以从官方网站下载并安装。
3.网络配置和证书安装
首先检查本地IP,单击Start =》 Run =》输入“ cmd” =>输入命令“ ipconfig”以检查您的IP,如图所示
然后在仿真器上打开浏览器,然后输入找到的IP:8002。如图所示:
点击ROOTCA以安装证书
在模拟器上,依次单击“设置”,“ WLAN”,“配置代理”

4.在模拟器上安装微信
通过MuMu模拟器上的应用程序中心安装微信。
在计算机端,打开浏览器,输入localhost:8002,打开仿真器微信,访问任何官方帐户,并检查计算机浏览器,即可看到微信请求的数据包。
准备好环境后,让我们开始分析界面和相关的重要参数。
首先我们要谈一些重要的参数
我们来谈谈几个重要的界面
要获取正式帐户文章,您需要先输入一个条目。许多文章从旧的文章列表条目开始。获取第一页的html,获取第16个脚本标签中msgList变量的值,获取第一页的内容,然后通过该接口请求json数据以获取其他页的数据。除了获取喜欢和观看数据的界面之外,整个过程还需要三个界面。
实际上,可以优化整个爬网过程。我们可以合并第一个和第二个接口。只需要两个接口即可完成正式帐户文章列表,并且可以看到喜欢的次数。爬行。
通过修改偏移量以控制页数来获取列表数据接口,其中计数不能大于10,这意味着一个页面中最多有十个项目。
"/mp/profile_ext?action=getmsg&__biz="+__biz+"&f=json&offset="+offset+"&count=10&appmsg_token="+appmsg_token+"";
要获取喜欢人数的第二个界面,请在手表编号界面中,请注意,这是此界面中的POST请求,
"/mp/getappmsgext?f=json&__biz="+__biz+"&appmsg_token="+appmsg_token+"&fasttmplajax=1";
需要上传请求正文
"mid="+mid+"&sn="+sn+"&idx="+idx+"&is_only_read=1"
通过这两个界面,您可以获取任何正式帐户的全部文章,以及点赞次数和计数等。在此处应注意,列表请求应以2秒分开,并且点赞数量的界面应间隔2秒。 ,否则,微信帐户将被阻止并且无法访问官方帐户,其他功能将不受影响,并且将在24小时内自动解除锁定。
WeChat官方帐户文章批处理采集就是这样。如有任何疑问,可以留言讨论~~
事实:文章被采集的解决方法是什么呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-12-28 09:12
尽管这可能仍不能阻止另一方出现采集并离开您网站,但毕竟这也是书面交流和建议。有总比没有好,它会产生一定的效果。
三、在文章页面上添加了一些特色内容
1、例如,在文章中添加一些小标签代码,例如H1,H2,强标签,颜色标签等。这些搜索引擎将更加敏感,可以在一定意义上加深它们的配对原创文章判决。
2、主要在文章中,添加一些自己的品牌关键词,例如Shanghai 网站 Construction,Shanghai Internet Company,Shanghai 网站 Optimization,您可能希望添加与此类似的词
3、在文章中添加了一些内部链接,因为喜欢采集的人通常很懒。不排除某些人可能会复制并粘贴该链接样式并将其复制到其中。这是可能的,结果是另一方为自己建立了外部链接。在大型平台上,这种情况也很常见。
4、文章页面加入时间,当判断文章的原创度时,搜索引擎也会参考时间顺序。
四、阻止网页的右键单击功能
我们都知道大多数人采集 文章使用鼠标右键进行复制。如果此功能在技术上被阻止,那么无疑会增加采集的麻烦。方法建议网站可以在重量增加之前执行此操作,最好在起来之后将其删除,因为当网站用户组出现时,并不排除某些用户对此方面感到厌恶,这会影响用户体验。
五、尝试在晚上文章更新
对于采集,最可怕的是对手会发现您的习惯,尤其是在白天充裕的情况下。许多人喜欢在白天定期且定量地更新文章。结果,他们被其他人跟随。 文章被带走,结果搜索引擎无法确定谁是原创的作者。但是晚上却有所不同。很少有人在半夜里等着你网站,据说此时的蜘蛛更加勤奋,更有利于捕捉蜘蛛。
实际上,网站的文章总是会受到采集的网站排名的伤害,这会严重影响文章的稀缺性,因此上面提到的上海网站建筑编辑最好在阅读网站之后将这些方法应用到您的网站。我相信这将使文章被采集的损害最小化。当然,还有更多的方法。有关特定的详细信息,我建议您参考一些排名较高的网站,尤其是那些排名较高的新电台。总结并了解更多,您将逐渐获得更多。
特别声明:上述内容(包括图片或视频,如果有的话)由自媒体平台“网易”的用户上传和发布。该平台仅提供信息存储服务。 查看全部
事实:文章被采集的解决方法是什么呢?
尽管这可能仍不能阻止另一方出现采集并离开您网站,但毕竟这也是书面交流和建议。有总比没有好,它会产生一定的效果。
三、在文章页面上添加了一些特色内容
1、例如,在文章中添加一些小标签代码,例如H1,H2,强标签,颜色标签等。这些搜索引擎将更加敏感,可以在一定意义上加深它们的配对原创文章判决。
2、主要在文章中,添加一些自己的品牌关键词,例如Shanghai 网站 Construction,Shanghai Internet Company,Shanghai 网站 Optimization,您可能希望添加与此类似的词
3、在文章中添加了一些内部链接,因为喜欢采集的人通常很懒。不排除某些人可能会复制并粘贴该链接样式并将其复制到其中。这是可能的,结果是另一方为自己建立了外部链接。在大型平台上,这种情况也很常见。
4、文章页面加入时间,当判断文章的原创度时,搜索引擎也会参考时间顺序。
四、阻止网页的右键单击功能
我们都知道大多数人采集 文章使用鼠标右键进行复制。如果此功能在技术上被阻止,那么无疑会增加采集的麻烦。方法建议网站可以在重量增加之前执行此操作,最好在起来之后将其删除,因为当网站用户组出现时,并不排除某些用户对此方面感到厌恶,这会影响用户体验。
五、尝试在晚上文章更新
对于采集,最可怕的是对手会发现您的习惯,尤其是在白天充裕的情况下。许多人喜欢在白天定期且定量地更新文章。结果,他们被其他人跟随。 文章被带走,结果搜索引擎无法确定谁是原创的作者。但是晚上却有所不同。很少有人在半夜里等着你网站,据说此时的蜘蛛更加勤奋,更有利于捕捉蜘蛛。
实际上,网站的文章总是会受到采集的网站排名的伤害,这会严重影响文章的稀缺性,因此上面提到的上海网站建筑编辑最好在阅读网站之后将这些方法应用到您的网站。我相信这将使文章被采集的损害最小化。当然,还有更多的方法。有关特定的详细信息,我建议您参考一些排名较高的网站,尤其是那些排名较高的新电台。总结并了解更多,您将逐渐获得更多。
特别声明:上述内容(包括图片或视频,如果有的话)由自媒体平台“网易”的用户上传和发布。该平台仅提供信息存储服务。
解读:采集文章及被采集的后果分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-12-25 09:13
每个网站都会定期更新其自身站点的文章,但并不是每个网站都关注原创,所以有人会上网采集文章是很自然的。百度蜘蛛在判断文章是否属于原创时常常不准确,甚至无法判断文章最初来自哪个站点。大型网站上传文章文章后,将有很多网站要复制,有些网站管理员不会对其进行修改,导致蜘蛛在获得收入时会找到很多相同的文章,然后会很困惑,无法分辨原创。因此,我们经常更新的文章也可能会被其他站点复制。如果网站本身的权重不高,则蜘蛛会认为您网站的文章是互联网上的采集,因此不会赢得您的文章。
如果蜘蛛这样对待您的网站,您网站可能会发生什么?让我们看一下:
首先文章页停止收录,然后整个网站不是收录吗?
遇到这种情况很正常。首先,您的文章已被百度列为评估候选人。在此期间,所有文章都不会进入收录。但是,蜘蛛程序将继续检查您上传的文章,直到找不到采集文章。
网站 收录开始减少并且快照停滞了?
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是很收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量是否正常?
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改善后网站 收录仍然异常吗?
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将慢慢恢复。
当网站长时间处于别人采集的情况下时,会出现这一系列现象,因此当您自己的网站中有某些此类现象时,您首先应该找到原因是我每天更新的文章是否正在被其他人采集使用。如果您的网站确实处于这种情况下,则必须找到一种解决方法。当然,其他人想要采集您的文章,您不能强迫说不让其他人参加采集,因此我们可以做的就是对自己进行一些更改。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击,这对收录非常有帮助。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集]。例如,页面不应设计得过于传统或太流行; Url的文字应稍作更改,并且不应作为默认覆盖。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
无论是我们采集的其他人还是我们采集的其他人,我们都必须注意这些问题。对于原创的文章,您必须注意添加超链接,最好在文章中反映您自己的情况,添加图片并指明转载来源,以确保您文章发挥作用。在Internet上获得最大收益,更好地进行网站优化工作。对于经常复制他人文章的网站,我们还必须学习使用一些网络营销软件。最近,发布了“快上通”新群发邮件功能的强大版本。对于网络营销软件的泛滥,我们只做最好,最专业。 查看全部
解读:采集文章及被采集的后果分析
每个网站都会定期更新其自身站点的文章,但并不是每个网站都关注原创,所以有人会上网采集文章是很自然的。百度蜘蛛在判断文章是否属于原创时常常不准确,甚至无法判断文章最初来自哪个站点。大型网站上传文章文章后,将有很多网站要复制,有些网站管理员不会对其进行修改,导致蜘蛛在获得收入时会找到很多相同的文章,然后会很困惑,无法分辨原创。因此,我们经常更新的文章也可能会被其他站点复制。如果网站本身的权重不高,则蜘蛛会认为您网站的文章是互联网上的采集,因此不会赢得您的文章。
如果蜘蛛这样对待您的网站,您网站可能会发生什么?让我们看一下:
首先文章页停止收录,然后整个网站不是收录吗?
遇到这种情况很正常。首先,您的文章已被百度列为评估候选人。在此期间,所有文章都不会进入收录。但是,蜘蛛程序将继续检查您上传的文章,直到找不到采集文章。
网站 收录开始减少并且快照停滞了?
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是很收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量是否正常?
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改善后网站 收录仍然异常吗?
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将慢慢恢复。
当网站长时间处于别人采集的情况下时,会出现这一系列现象,因此当您自己的网站中有某些此类现象时,您首先应该找到原因是我每天更新的文章是否正在被其他人采集使用。如果您的网站确实处于这种情况下,则必须找到一种解决方法。当然,其他人想要采集您的文章,您不能强迫说不让其他人参加采集,因此我们可以做的就是对自己进行一些更改。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击,这对收录非常有帮助。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集]。例如,页面不应设计得过于传统或太流行; Url的文字应稍作更改,并且不应作为默认覆盖。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
无论是我们采集的其他人还是我们采集的其他人,我们都必须注意这些问题。对于原创的文章,您必须注意添加超链接,最好在文章中反映您自己的情况,添加图片并指明转载来源,以确保您文章发挥作用。在Internet上获得最大收益,更好地进行网站优化工作。对于经常复制他人文章的网站,我们还必须学习使用一些网络营销软件。最近,发布了“快上通”新群发邮件功能的强大版本。对于网络营销软件的泛滥,我们只做最好,最专业。
解读:原创文章被采集怎么办?处理网站文章采集的预防措施
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2020-12-09 12:21
的预防措施
许多人讨厌他们的原创文章被他人立即复制。甚至有人用它来发送一些败类链。我特别相信,很多老人都遇到过这种情况。有时候,他们的努力不如财富。我们如何应对这种情况?
首先,在竞争对手采集此文章之前,请尝试让搜索引擎将其包括在内。
1、实时抓取文章,让搜索引擎知道此文章。
2、ping在百度网站管理员本人的文章链接上。这也是百度官员告知我们的一种方式。
二、文章使用作者或版本作为标记。
Youbangyun认为偶然地阻止不了别人窃您的文章,但这也是书面交流和提醒,总比没有好。
三,在文章中添加一些功能。
1、例如,在文章中的标签代码(例如n 1、 n 2、color)中,搜索引擎将对这些内容更加敏感,这将加深原创的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些外部链接,因为喜欢复制文章的人通常很懒,因此某些人可以直接复制和粘贴而不会消除它们。
4、当实时添加文章文章时,搜索引擎将确定文章的原创级别并引用时间元素。
四、选择网页的关键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此效果的影响,无疑会增加采集的麻烦。
五、每晚更新
您最担心的是对手知道您的习惯,尤其是在白天。许多人喜欢在白天更新文章,结果被其他人盯着。 文章被立即窃。
在我们的网站上可以看到并使用这些方法后,我相信这可以增加文章的采集数量。
更多阅读建议:淮南华帝洗碗机维修,盐城伊莱克斯电烤箱维修 查看全部
原创文章是采集怎么办?网站文章 采集
的预防措施
许多人讨厌他们的原创文章被他人立即复制。甚至有人用它来发送一些败类链。我特别相信,很多老人都遇到过这种情况。有时候,他们的努力不如财富。我们如何应对这种情况?
首先,在竞争对手采集此文章之前,请尝试让搜索引擎将其包括在内。
1、实时抓取文章,让搜索引擎知道此文章。
2、ping在百度网站管理员本人的文章链接上。这也是百度官员告知我们的一种方式。
二、文章使用作者或版本作为标记。
Youbangyun认为偶然地阻止不了别人窃您的文章,但这也是书面交流和提醒,总比没有好。
三,在文章中添加一些功能。
1、例如,在文章中的标签代码(例如n 1、 n 2、color)中,搜索引擎将对这些内容更加敏感,这将加深原创的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些外部链接,因为喜欢复制文章的人通常很懒,因此某些人可以直接复制和粘贴而不会消除它们。
4、当实时添加文章文章时,搜索引擎将确定文章的原创级别并引用时间元素。
四、选择网页的关键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此效果的影响,无疑会增加采集的麻烦。
五、每晚更新
您最担心的是对手知道您的习惯,尤其是在白天。许多人喜欢在白天更新文章,结果被其他人盯着。 文章被立即窃。
在我们的网站上可以看到并使用这些方法后,我相信这可以增加文章的采集数量。
更多阅读建议:淮南华帝洗碗机维修,盐城伊莱克斯电烤箱维修
解决方法:文章被长期他人采集的后果及避免方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-11-24 09:10
定期更新站中的文章是几乎每个网站都会做的事,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人的手很久了这种后果,以及避免被别人采集的方法。
BaiduSpider喜欢原创中的内容,但百度蜘蛛对原创来源的判断尚不准确,并且当我们更新文章时,它无法完全自主地判断某文章文章的来源文章并且很快被其他人采集吸引,蜘蛛可能会同时与许多相同的文章接触,那么这将非常混乱,并且不确定到底是原创和已复制。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样查看您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当收录减小并且快照停滞时,我们最关心的是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改进后,网站 收录仍然有异常
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将缓慢恢复。
这一系列现象都在网站长时间处于别人采集的情况下出现,因此当您自己的网站中有某些此类现象时,您应该首先找到原因Is我每天更新的文章还是别人更新的采集。
如果您的网站确实处于这种情况下,则必须找到解决方案,当然其他人希望采集您的文章,您不能强迫说不让其他人离开采集,那又如何?我们可以做的就是改变自己。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击。这对收录非常有用。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集 ]。例如,页面设计不应太过传统和流行。 Url的文字应稍作更改,并且不应使用默认的叠加层和其他设置。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
文章通常是采集,肯定会影响我们,因此我们应该避免使用它,让我们的网站内容在互联网上具有唯一性,并改善百度对我们的待遇网站使我们的优化工作更加顺畅。
本文提到的现象是作者遇到的真实情况网站。 文章由Aidai.com提供,请附上转载的源链接 查看全部
文章长期处于他人采集的后果以及如何避免
定期更新站中的文章是几乎每个网站都会做的事,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人的手很久了这种后果,以及避免被别人采集的方法。
BaiduSpider喜欢原创中的内容,但百度蜘蛛对原创来源的判断尚不准确,并且当我们更新文章时,它无法完全自主地判断某文章文章的来源文章并且很快被其他人采集吸引,蜘蛛可能会同时与许多相同的文章接触,那么这将非常混乱,并且不确定到底是原创和已复制。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样查看您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当收录减小并且快照停滞时,我们最关心的是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改进后,网站 收录仍然有异常
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将缓慢恢复。
这一系列现象都在网站长时间处于别人采集的情况下出现,因此当您自己的网站中有某些此类现象时,您应该首先找到原因Is我每天更新的文章还是别人更新的采集。
如果您的网站确实处于这种情况下,则必须找到解决方案,当然其他人希望采集您的文章,您不能强迫说不让其他人离开采集,那又如何?我们可以做的就是改变自己。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击。这对收录非常有用。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集 ]。例如,页面设计不应太过传统和流行。 Url的文字应稍作更改,并且不应使用默认的叠加层和其他设置。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
文章通常是采集,肯定会影响我们,因此我们应该避免使用它,让我们的网站内容在互联网上具有唯一性,并改善百度对我们的待遇网站使我们的优化工作更加顺畅。
本文提到的现象是作者遇到的真实情况网站。 文章由Aidai.com提供,请附上转载的源链接
解决方法:文章被采集的处理方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-11-23 13:01
许多人讨厌别人瞬间复制他们的原创文章,有些人甚至用它发送一些垃圾链接。我特别相信,很多老年人都遇到过这种情况,有时他们的辛苦不如采集。我们如何处理这种情况?
首先,尝试让搜索引擎将此文章 收录放在对手的采集之前。
1、及时抓取文章,以使搜索引擎知道此文章。
2、Ping百度网站管理员自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章由作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、向文章添加了一些特征内容。
1、例如文章中的标记代码,例如N 1、 N2、颜色等。搜索引擎将对此更加敏感,并可以加深对原创的判断。
2、将自己的品牌词汇添加到文章
3、添加了一些内部链接,因为喜欢窃文章的人通常很懒,因此有些人可以直接复制和粘贴。
4、当在时间上添加文章时,搜索引擎将判断文章的独创性并参考时间因素。
阻止网页的正确按键功能
当大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最怕的是对手知道你的习惯,尤其是在白天。许多人白天喜欢更新文章,而其他人则盯着他们看,然后立即[窃文章。
这些方法可以在我们的网站上看到和应用,我相信这可以减少集合文章。 查看全部
如何处理文章为采集
许多人讨厌别人瞬间复制他们的原创文章,有些人甚至用它发送一些垃圾链接。我特别相信,很多老年人都遇到过这种情况,有时他们的辛苦不如采集。我们如何处理这种情况?
首先,尝试让搜索引擎将此文章 收录放在对手的采集之前。
1、及时抓取文章,以使搜索引擎知道此文章。
2、Ping百度网站管理员自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章由作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、向文章添加了一些特征内容。
1、例如文章中的标记代码,例如N 1、 N2、颜色等。搜索引擎将对此更加敏感,并可以加深对原创的判断。
2、将自己的品牌词汇添加到文章
3、添加了一些内部链接,因为喜欢窃文章的人通常很懒,因此有些人可以直接复制和粘贴。
4、当在时间上添加文章时,搜索引擎将判断文章的独创性并参考时间因素。
阻止网页的正确按键功能
当大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最怕的是对手知道你的习惯,尤其是在白天。许多人白天喜欢更新文章,而其他人则盯着他们看,然后立即[窃文章。
这些方法可以在我们的网站上看到和应用,我相信这可以减少集合文章。
解决方案:dedecms采集文档审核后生成文档以采集时间显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-11-14 13:00
对于网站的每日更新,许多网站管理员会选择使用采集来丰富网站的内容。对于采集,它会占用php虚拟主机的资源,并且“无忧无虑”主机的编辑器强烈建议不要使用采集。尽管采集可以丰富网站的内容,但很容易被检索引擎判断为作弊,并且存在降低功率并停止收录的风险。今天,一个用户问:采集完成采集之后,dedecms生成文档之后的时间是采集的时间,如何解决这个问题?有了这个问题,让我们开始今天的文档共享。审核dedecms采集文档后,生成的文档在采集时间中显示如下:1、首先,单击进入我们的控制面板,然后找到文件管理选项,如图所示:
2、单击进入并找到我们网站的根目录,如图所示:
3、进入此目录后,找到我们程序后端的路径:/dede/archives_do.php,单击edit,如图所示:
4、修改代码操作,如图所示:
查找代码:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set arcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set arcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set arcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
修改为:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$newdate = time();
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set sortrank=$newdatesenddate=$newdatearcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
提醒:此技术解决方案是由无忧主机客户服务提供的处理方法,用于为我们的航天客户解决该问题,以确保可以在无忧主机中完美实现。由于更多的服务和繁忙的客户服务,我们没有足够的精力进行大规模测试,所以无法确保所有虚拟主机都能得到完美处理,请谅解!无忧的主机提供365天*一天24小时,全天,实时在线和零等待的售后技术支持。我们将尽最大努力为您免费使用无忧主机的过程中遇到的所有问题!如果您是无忧主机用户,则可以使用企业QQ [800088151],售后QQ [网站最底端],网旺[风讯企业],免费电话和后台提交工作订购无忧主机的客户服务!如果您不是我们的客户,没问题,请单击页面最右侧的公司QQ在线咨询图标与我们联系并购买,我们将为您提供免费的无缝移动服务,让您享受网站零访问权限延迟迁移到无忧的主机服务!与无忧托管相关的文章推荐阅读: 查看全部
dedecms采集审核文档后,生成的文档将在采集时间显示
对于网站的每日更新,许多网站管理员会选择使用采集来丰富网站的内容。对于采集,它会占用php虚拟主机的资源,并且“无忧无虑”主机的编辑器强烈建议不要使用采集。尽管采集可以丰富网站的内容,但很容易被检索引擎判断为作弊,并且存在降低功率并停止收录的风险。今天,一个用户问:采集完成采集之后,dedecms生成文档之后的时间是采集的时间,如何解决这个问题?有了这个问题,让我们开始今天的文档共享。审核dedecms采集文档后,生成的文档在采集时间中显示如下:1、首先,单击进入我们的控制面板,然后找到文件管理选项,如图所示:
2、单击进入并找到我们网站的根目录,如图所示:
3、进入此目录后,找到我们程序后端的路径:/dede/archives_do.php,单击edit,如图所示:
4、修改代码操作,如图所示:
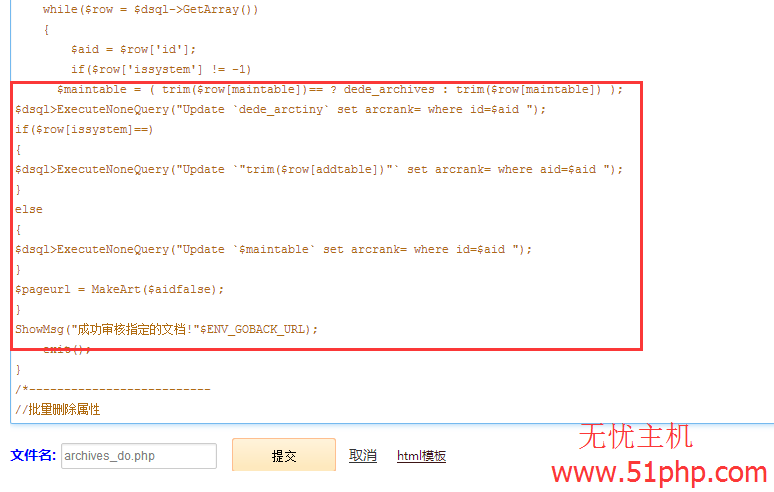
查找代码:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set arcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set arcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set arcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
修改为:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$newdate = time();
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set sortrank=$newdatesenddate=$newdatearcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
提醒:此技术解决方案是由无忧主机客户服务提供的处理方法,用于为我们的航天客户解决该问题,以确保可以在无忧主机中完美实现。由于更多的服务和繁忙的客户服务,我们没有足够的精力进行大规模测试,所以无法确保所有虚拟主机都能得到完美处理,请谅解!无忧的主机提供365天*一天24小时,全天,实时在线和零等待的售后技术支持。我们将尽最大努力为您免费使用无忧主机的过程中遇到的所有问题!如果您是无忧主机用户,则可以使用企业QQ [800088151],售后QQ [网站最底端],网旺[风讯企业],免费电话和后台提交工作订购无忧主机的客户服务!如果您不是我们的客户,没问题,请单击页面最右侧的公司QQ在线咨询图标与我们联系并购买,我们将为您提供免费的无缝移动服务,让您享受网站零访问权限延迟迁移到无忧的主机服务!与无忧托管相关的文章推荐阅读:
干货:爆款文章怎么搜集?看完这篇文章就懂了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 592 次浏览 • 2020-10-26 10:04
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,从而使搜索内容更加准确。
2、广告过滤 查看全部
如何采集热钱文章?阅读此文章之后,您将了解!
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。


([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。


([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,从而使搜索内容更加准确。

2、广告过滤
分享:微信公众号文章采集的入口--历史消息页详解
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-10-20 09:01
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
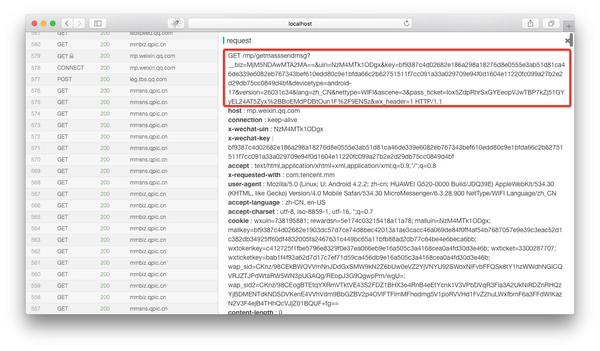
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,即可在浏览器中打开。
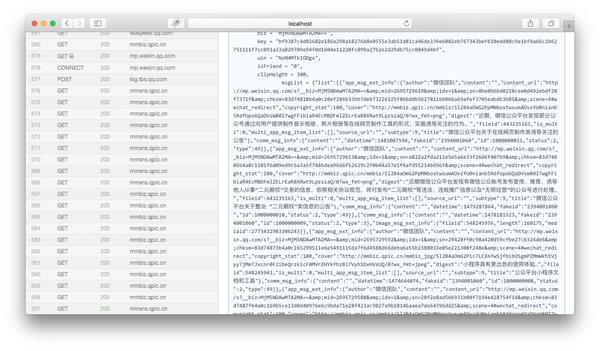
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要一个官方帐户采集的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将介绍如何根据历史新闻中的文章链接地址获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我对自己写的内容不甚了解,或者有不明白的地方,请在下面发表评论。或骚扰微信帐户翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集的进入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,高级使用anyproxy 查看全部
微信公众号文章采集的进入-历史新闻页面的详细说明
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,即可在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要一个官方帐户采集的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将介绍如何根据历史新闻中的文章链接地址获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我对自己写的内容不甚了解,或者有不明白的地方,请在下面发表评论。或骚扰微信帐户翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集的进入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,高级使用anyproxy
解读:文章被采集应该怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-09-14 08:02
了文章该怎么办?
您是否遇到过这种情况。打开其他人的网站,看看自己写的文章。你在生气吗?每次我一个人写作时,您是否觉得自己讨厌他们?我们如何处理这种情况?
一、尝试让搜索引擎在对手的采集
之前收录
这篇文章。
1、及时抓取文章,以使搜索引擎知道它。
2、 Ping百度网站站长自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章按作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、在文章中添加一些特色内容
1、例如,文章中的标签代码(例如N 1、 N 2、 color等),搜索引擎将对此更加敏感,并可以加深对其创意的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些内部链接,因为喜欢like窃文章的人通常很懒,并且不排除某些人可以直接复制和粘贴。
4、将文章添加到时间后,搜索引擎将判断文章的原创性并参考时间因素。
阻止网页的正确按键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器
的麻烦。
5、晚上更新
最可怕的聚会是对手了解你的习惯,尤其是在白天。许多人喜欢在白天更新文章,但是却被其他人盯着看,并且文章被pla窃。
采用上述方法可以防止我辛苦写的文章被采集
。 查看全部
如果采集
了文章该怎么办?
您是否遇到过这种情况。打开其他人的网站,看看自己写的文章。你在生气吗?每次我一个人写作时,您是否觉得自己讨厌他们?我们如何处理这种情况?

一、尝试让搜索引擎在对手的采集
之前收录
这篇文章。
1、及时抓取文章,以使搜索引擎知道它。
2、 Ping百度网站站长自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章按作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、在文章中添加一些特色内容
1、例如,文章中的标签代码(例如N 1、 N 2、 color等),搜索引擎将对此更加敏感,并可以加深对其创意的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些内部链接,因为喜欢like窃文章的人通常很懒,并且不排除某些人可以直接复制和粘贴。
4、将文章添加到时间后,搜索引擎将判断文章的原创性并参考时间因素。
阻止网页的正确按键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器
的麻烦。
5、晚上更新
最可怕的聚会是对手了解你的习惯,尤其是在白天。许多人喜欢在白天更新文章,但是却被其他人盯着看,并且文章被pla窃。
采用上述方法可以防止我辛苦写的文章被采集
。
解决方案:网站文章内容来源是否让你头疼不已?看完文章就能解决!
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-09-05 04:00
1、公司新闻,您可以将公司的近期活动和公告整理到文章中
2、产品使用情况介绍,产品使用情况详细介绍或产品使用后等信息都组织为文章
3、如果咨询量很大,则可以将客户服务和用户之间的对话变成文章
1、寻找一些网站来阻止蜘蛛爬行,然后直接采集他们的网站 文章。
2、打开外来网站,直接打开采集! !
3、 采集国内商品文章,然后将其更改为伪原创!
在互联网上找到作家来写作,如果您无法写作,则SEO将完成
网站的内容是整个网站的核心,内容的质量是搜索引擎判断网站的质量的重要指标。因此,内容的来源限制了整个网站的发展。对于中小企业网站而言,网站内容稀缺性普遍存在。因此,如何获得大量的高质量网站内容已成为这些网站网站站长在构建过程中最头疼的问题。这里的MetInfo可以教您如何获取稳定的高质量网站内容源流。
1:编写自己的原创 文章
原创 文章在搜索引擎中最受欢迎。编写原创 文章的目的是让搜索引擎知道我们的网站具有高质量的内容。不断更新高质量内容的网站将吸引搜索引擎的索引,这也将促进网站内容的更新。
此外,这些高质量的原创内容将由许多网站管理员重新发布,或者由许多文章 采集器进行爬网,这将始终产生许多出色的外部链接,但是您要编写原创的[k8 ] 文章消耗更多时间和精力。您可能会说:怎么有这么多原创内容?一位大师曾经就此问题发表过意见。以下是他关于扩大不受欢迎的产品内容的建议。
(1)从产品的历史和演变开始:该产品是如何发明的,每次更新的过程是什么?发明人和改进者是谁?产品的具体贡献是什么,获得了哪些奖项?如果您的公司发明了此产品,那么还有更多要写的东西;
(2)从产品制造者开始:研发团队的成员,背景,经验以及直接生产工人需要哪些技能;
(3)从原材料开始:产品是用什么原材料制造的,哪里生产的是最好的原材料,为什么?等等;
当然,有很多角度。您可以围绕产品开始描述。只要您开阔思路,任何产品都可以编写很多相关内容。
2:“ 原创”重印内容
“ 原创”的重印内容也称为文章汇编。如果我们看到文章文章,并认为其中的某些要点与我们不一致,则可以从原创文本中提取要点,并发表自己的观点;或者,如果我们认为文章中的点有扩展的余地,您还可以继续按照原创作者的想法来扩展原创文本。但是在这里,请记住一个原则,那就是重新创建的文本信息的内容。尝试获取比摘录更多的信息。
3:鼓励用户贡献内容
实际上,网站的访问者有时也强烈希望进行写作和交流。因此,我们可以不断提高网站的交互功能。最简单的方法之一是打开网站内容的注释功能。让用户参与网站的信息内容构建。当然,如果它是基于内容的网站,则打开网站的提交界面,允许用户通过此接口将其创建的内容提交给网站编辑器。 ?
4:翻译外来原创 文章
国外有许多优秀而有影响力的文章。如果英语足够好,您还可以翻译一些更有影响力的外语文章。对于搜索引擎来说,用不同文本书写的文章是不同的。如果您没有足够的能力写原创 文章,则翻译别人的文章可能不是一个好方法。
5:采集行业信息
现在有许多论坛的权重更高,内容也更好。这些论坛存储了大量高质量的信息。无论是前沿内容还是最新行业趋势,这些论坛都有及时有效的内容,因此您可以搜索整理为文章的这些内容,也可以用作出色的原创 文章。
6:适当的“ 伪原创”
如果网站的内容可以为原创,那是最好的方法。如果不能,也可以尝试适当的伪原创。当我们收到别人的文章文章时,您可以进行以下编辑伪原创
([1) 文章标题修改
排序方法:文章标题顺序可以修改,但其原创含义不能更改,例如:美国主机VS香港主机的优势,我们可以将其更改为香港主机的劣势VS美国主机;
文本减少/添加,替换方法:在原创标题上添加或减少一些文本,例如:选择MetInfo cms系统的新手用户的五个优点可以变为选择MetInfo的新手用户的五个优点建立一个网站;
([2)文本修改
重写内容的第一段:搜索导致蜘蛛重视文章的第一段及其重要性,因此,请尝试自己重写第一段并带来网站 关键词,不要太长,只是超过100个字;
插入链接方法:在文本中插入您自己的网站链接,当其他人采集我们的文章时,等效于为我们网站做一个外部链接;
分割方法:将原创文章内容平均分成几段,然后更改段落顺序以继续伪原创;
<p>标签方法:使用关键词在文章上添加友谊便笺,这样您不仅可以自然地重复关键词,增加关键词的密度,还可以让客户了解更多不熟悉的专业术语; 查看全部
网站 文章内容来源会让您头痛吗?读完文章即可解决!

1、公司新闻,您可以将公司的近期活动和公告整理到文章中
2、产品使用情况介绍,产品使用情况详细介绍或产品使用后等信息都组织为文章
3、如果咨询量很大,则可以将客户服务和用户之间的对话变成文章
1、寻找一些网站来阻止蜘蛛爬行,然后直接采集他们的网站 文章。
2、打开外来网站,直接打开采集! !
3、 采集国内商品文章,然后将其更改为伪原创!
在互联网上找到作家来写作,如果您无法写作,则SEO将完成
网站的内容是整个网站的核心,内容的质量是搜索引擎判断网站的质量的重要指标。因此,内容的来源限制了整个网站的发展。对于中小企业网站而言,网站内容稀缺性普遍存在。因此,如何获得大量的高质量网站内容已成为这些网站网站站长在构建过程中最头疼的问题。这里的MetInfo可以教您如何获取稳定的高质量网站内容源流。
1:编写自己的原创 文章
原创 文章在搜索引擎中最受欢迎。编写原创 文章的目的是让搜索引擎知道我们的网站具有高质量的内容。不断更新高质量内容的网站将吸引搜索引擎的索引,这也将促进网站内容的更新。
此外,这些高质量的原创内容将由许多网站管理员重新发布,或者由许多文章 采集器进行爬网,这将始终产生许多出色的外部链接,但是您要编写原创的[k8 ] 文章消耗更多时间和精力。您可能会说:怎么有这么多原创内容?一位大师曾经就此问题发表过意见。以下是他关于扩大不受欢迎的产品内容的建议。
(1)从产品的历史和演变开始:该产品是如何发明的,每次更新的过程是什么?发明人和改进者是谁?产品的具体贡献是什么,获得了哪些奖项?如果您的公司发明了此产品,那么还有更多要写的东西;
(2)从产品制造者开始:研发团队的成员,背景,经验以及直接生产工人需要哪些技能;
(3)从原材料开始:产品是用什么原材料制造的,哪里生产的是最好的原材料,为什么?等等;
当然,有很多角度。您可以围绕产品开始描述。只要您开阔思路,任何产品都可以编写很多相关内容。
2:“ 原创”重印内容
“ 原创”的重印内容也称为文章汇编。如果我们看到文章文章,并认为其中的某些要点与我们不一致,则可以从原创文本中提取要点,并发表自己的观点;或者,如果我们认为文章中的点有扩展的余地,您还可以继续按照原创作者的想法来扩展原创文本。但是在这里,请记住一个原则,那就是重新创建的文本信息的内容。尝试获取比摘录更多的信息。
3:鼓励用户贡献内容
实际上,网站的访问者有时也强烈希望进行写作和交流。因此,我们可以不断提高网站的交互功能。最简单的方法之一是打开网站内容的注释功能。让用户参与网站的信息内容构建。当然,如果它是基于内容的网站,则打开网站的提交界面,允许用户通过此接口将其创建的内容提交给网站编辑器。 ?
4:翻译外来原创 文章
国外有许多优秀而有影响力的文章。如果英语足够好,您还可以翻译一些更有影响力的外语文章。对于搜索引擎来说,用不同文本书写的文章是不同的。如果您没有足够的能力写原创 文章,则翻译别人的文章可能不是一个好方法。
5:采集行业信息
现在有许多论坛的权重更高,内容也更好。这些论坛存储了大量高质量的信息。无论是前沿内容还是最新行业趋势,这些论坛都有及时有效的内容,因此您可以搜索整理为文章的这些内容,也可以用作出色的原创 文章。
6:适当的“ 伪原创”
如果网站的内容可以为原创,那是最好的方法。如果不能,也可以尝试适当的伪原创。当我们收到别人的文章文章时,您可以进行以下编辑伪原创
([1) 文章标题修改
排序方法:文章标题顺序可以修改,但其原创含义不能更改,例如:美国主机VS香港主机的优势,我们可以将其更改为香港主机的劣势VS美国主机;
文本减少/添加,替换方法:在原创标题上添加或减少一些文本,例如:选择MetInfo cms系统的新手用户的五个优点可以变为选择MetInfo的新手用户的五个优点建立一个网站;
([2)文本修改
重写内容的第一段:搜索导致蜘蛛重视文章的第一段及其重要性,因此,请尝试自己重写第一段并带来网站 关键词,不要太长,只是超过100个字;
插入链接方法:在文本中插入您自己的网站链接,当其他人采集我们的文章时,等效于为我们网站做一个外部链接;
分割方法:将原创文章内容平均分成几段,然后更改段落顺序以继续伪原创;
<p>标签方法:使用关键词在文章上添加友谊便笺,这样您不仅可以自然地重复关键词,增加关键词的密度,还可以让客户了解更多不熟悉的专业术语;
分享:易语言微信公众号文章采集思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-09-03 18:10
由于某些原因,Hong Yu需要采集微信公众号文章。
别胡说八道,只是说说要点。
最初的想法很简单。当时是使用搜狗微信搜索功能来采集,但未执行时我看到了一些注释。
说到搜狗微信,如果采集的文章不完整且采集太多,则会屏蔽IP。
因此,我果断地放弃了,甚至没有研究它,因为洪宇知道此搜索引擎的采集相对简单。如果每个人都是采集,则确实会对服务器造成压力。
Hong Yu开始考虑第二套计划,直接考虑采集官方帐户。
可以在网络上打开官方帐户的文章链接,但不能再在PC端打开官方帐户文章的历史记录。有一个问题,采集官方帐户的文章链接是不可能的。
要打开历史文章,洪宇想到了两种方法。一种是使用模拟器来模拟手机环境并打开链接。另一种是使用网页微信打开官方帐户历史记录链接。
当然,直接在网络上使用微信绝对比使用模拟器更容易。
Hong Yu发现无法打开网页微信。只能安装客户端以在PC上打开微信。幸运的是,仍然可以看到官方帐户文章的历史记录。
这时,问题又来了,我该如何在模拟器或客户端中获取历史记录文章的内容,然后链接采集。
洪宇想到的第一件事是互联网拦截和数据包捕获,现在提琴手越来越流行。
但是您无法直接批量获取和过滤这些数据,因此请考虑直接在Yilang中捕获数据包的方法,捕获的数据包,网络拦截以及已读取过程的方法...
结果,经过长时间的搜索,我找不到一种简单有效的方法。有一个使用模拟器捕获数据包的教程,但是我仍然使用提琴手来捕获数据包...
最后,Hong Yu想从微信客户端的句柄开始。
使用编程助手获取窗口句柄,Hong Yu惊讶地发现原创的官方帐户内容在微信客户端上以内置浏览器的形式显示,包括历史记录文章。
尽管它是Google核心的浏览器,但无法通过填写表单进行操作,但它已经非常好。
我们可以使用鼠标模拟方法制作微信客户端,然后获取内置浏览器的网页源代码。有了源代码,一切都很容易。
剩下的就是过滤有用的信息。
只要采集链接到每个文章文章,就可以了,因为可以在PC浏览器中打开单个文章文章的链接。换句话说,可以直接读取源代码采集至文章。
现在,完成输入。
要组织该过程,我们必须首先注意采集的官方帐户,然后在登录微信的PC客户端中打开历史记录文章页面,获取源代码,然后使用采集至文章软件链接。然后直接读取文章的源代码和采集 文章的内容。
作为个人,这是一种傻瓜式采集方法。它不需要困难的技术,也不需要涉及微信官方账号的开发。唯一的缺点是效率相对较慢。
但是作为个人采集,就足够了。 查看全部
彝语微信公众号文章 采集想法
由于某些原因,Hong Yu需要采集微信公众号文章。
别胡说八道,只是说说要点。
最初的想法很简单。当时是使用搜狗微信搜索功能来采集,但未执行时我看到了一些注释。
说到搜狗微信,如果采集的文章不完整且采集太多,则会屏蔽IP。
因此,我果断地放弃了,甚至没有研究它,因为洪宇知道此搜索引擎的采集相对简单。如果每个人都是采集,则确实会对服务器造成压力。
Hong Yu开始考虑第二套计划,直接考虑采集官方帐户。
可以在网络上打开官方帐户的文章链接,但不能再在PC端打开官方帐户文章的历史记录。有一个问题,采集官方帐户的文章链接是不可能的。
要打开历史文章,洪宇想到了两种方法。一种是使用模拟器来模拟手机环境并打开链接。另一种是使用网页微信打开官方帐户历史记录链接。
当然,直接在网络上使用微信绝对比使用模拟器更容易。
Hong Yu发现无法打开网页微信。只能安装客户端以在PC上打开微信。幸运的是,仍然可以看到官方帐户文章的历史记录。
这时,问题又来了,我该如何在模拟器或客户端中获取历史记录文章的内容,然后链接采集。
洪宇想到的第一件事是互联网拦截和数据包捕获,现在提琴手越来越流行。
但是您无法直接批量获取和过滤这些数据,因此请考虑直接在Yilang中捕获数据包的方法,捕获的数据包,网络拦截以及已读取过程的方法...
结果,经过长时间的搜索,我找不到一种简单有效的方法。有一个使用模拟器捕获数据包的教程,但是我仍然使用提琴手来捕获数据包...
最后,Hong Yu想从微信客户端的句柄开始。
使用编程助手获取窗口句柄,Hong Yu惊讶地发现原创的官方帐户内容在微信客户端上以内置浏览器的形式显示,包括历史记录文章。
尽管它是Google核心的浏览器,但无法通过填写表单进行操作,但它已经非常好。
我们可以使用鼠标模拟方法制作微信客户端,然后获取内置浏览器的网页源代码。有了源代码,一切都很容易。
剩下的就是过滤有用的信息。
只要采集链接到每个文章文章,就可以了,因为可以在PC浏览器中打开单个文章文章的链接。换句话说,可以直接读取源代码采集至文章。
现在,完成输入。
要组织该过程,我们必须首先注意采集的官方帐户,然后在登录微信的PC客户端中打开历史记录文章页面,获取源代码,然后使用采集至文章软件链接。然后直接读取文章的源代码和采集 文章的内容。
作为个人,这是一种傻瓜式采集方法。它不需要困难的技术,也不需要涉及微信官方账号的开发。唯一的缺点是效率相对较慢。
但是作为个人采集,就足够了。
企业建设网站用数据采集功能对网站有哪些影响?
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-27 04:52
在现今无论做哪些都用数据来说话的时代,掌握一定的数据在进行剖析,能够帮助企业更好的去规划与市场定位。那么企业建设的网站真的须要用数据采集功能吗?用数据采集功能以后对网站是好还是不好?上海网站设计松一公司的小编经过和朋友的讨论,再加小编自己的研究和理解给大谈谈数据采集的历史和方法以及对网站有哪些影响。
首先,小编带你们先来了解一下网站数据采集这个功能是如何回事。网站数据采集分为两个阶段:一个阶段就是C2C没有盛行之前,采集网站数据主要是一些小型的搜索引擎公司,像百度、谷歌它们用采集数据功能是通过网路爬虫来实现所须要的信息采集。第二个阶段就是C2C盛行以后,随着互联网的发,企业建设网站或个人建设网站或者机构建站为了快速填充网站上空缺的信息,通过采集其它类似网站上的内容信息使自己的网站丰富。
第二个阶段开始越来越多的企业或个人用网站数据采集功能了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后才能发布的。
其次,网站数据采集方式有二种:一种是传统的采集方式,主要人工采集方式,现在还有一部企业或个人在用,简单来说:“就是把他人网站的信息通过复制、粘贴的形式放在自己的网站上。一种是软件数据采集方式,这个方法就是因为传统的人工复制方法费时又吃力,然后随着软件技术的发展,软件公司为了适应市场开发下来的数据采集功能软件来满足市场需求。
End,介绍完数据采集功能历史方法,相信你们也应当晓得数据采集是哪些个概念了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后就会发布的。
为什么采集功能在如今几乎没有人用了呢!简单来说,搜索引擎不喜欢,对这样的网站不会给权重更不会给排名,搞不好网站还会被百度给拉入黑名单。因搜索引擎如今都喜欢用户去用心原创的高质量内容,如果一个四处去复制信息的网站搜索引擎都能排行挺好的话,那么谁还去花心思去撰写文章呢?在说一个网站上发布的都是从他人那儿复制过来的,一点自己的特色也没有,是不帮企业带来顾客,那么企业建设网站就丧失了意义。 查看全部
企业建设网站用数据采集功能对网站有哪些影响?
在现今无论做哪些都用数据来说话的时代,掌握一定的数据在进行剖析,能够帮助企业更好的去规划与市场定位。那么企业建设的网站真的须要用数据采集功能吗?用数据采集功能以后对网站是好还是不好?上海网站设计松一公司的小编经过和朋友的讨论,再加小编自己的研究和理解给大谈谈数据采集的历史和方法以及对网站有哪些影响。

首先,小编带你们先来了解一下网站数据采集这个功能是如何回事。网站数据采集分为两个阶段:一个阶段就是C2C没有盛行之前,采集网站数据主要是一些小型的搜索引擎公司,像百度、谷歌它们用采集数据功能是通过网路爬虫来实现所须要的信息采集。第二个阶段就是C2C盛行以后,随着互联网的发,企业建设网站或个人建设网站或者机构建站为了快速填充网站上空缺的信息,通过采集其它类似网站上的内容信息使自己的网站丰富。
第二个阶段开始越来越多的企业或个人用网站数据采集功能了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后才能发布的。
其次,网站数据采集方式有二种:一种是传统的采集方式,主要人工采集方式,现在还有一部企业或个人在用,简单来说:“就是把他人网站的信息通过复制、粘贴的形式放在自己的网站上。一种是软件数据采集方式,这个方法就是因为传统的人工复制方法费时又吃力,然后随着软件技术的发展,软件公司为了适应市场开发下来的数据采集功能软件来满足市场需求。

End,介绍完数据采集功能历史方法,相信你们也应当晓得数据采集是哪些个概念了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后就会发布的。
为什么采集功能在如今几乎没有人用了呢!简单来说,搜索引擎不喜欢,对这样的网站不会给权重更不会给排名,搞不好网站还会被百度给拉入黑名单。因搜索引擎如今都喜欢用户去用心原创的高质量内容,如果一个四处去复制信息的网站搜索引擎都能排行挺好的话,那么谁还去花心思去撰写文章呢?在说一个网站上发布的都是从他人那儿复制过来的,一点自己的特色也没有,是不帮企业带来顾客,那么企业建设网站就丧失了意义。
采集数据的方式有几种,采集数据的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-27 00:12
在我们进行数据剖析的时侯,都是须要根据既定的步骤进行,谁也不能直接就就能得到想要的剖析结果。一般来说,我们在进行数据剖析的时侯会分为以下几个步骤:
1.前期设计数据剖析方案和内容
2.采集数据
3.处理数据及展示数据
4.进行数据剖析
通过以上四个步骤基本上就才能完成一个完整的数据剖析过程。我们在进行任何一个数据剖析之前的首要任务就是明晰我们的目的是哪些,为什么要做这个数据剖析,我们须要用这个数据剖析结果解决哪些问题。只有明晰了数据剖析的目的,我们才不会偏离我们的方向,不然我们最终得出的数据剖析结果是没有任何指导意义的,甚至可能会导致连锁反应,造成一个错误决策的诞生。
当我们明晰了剖析的目的,接下来就须要将过程拆解开来,找到不同的剖析要点,沿着一条线一步一步的去进行,在这个过程中我们须要确定怎样找数据,用什么剖析方式,需要耗费多长的周期和预算。这样的话我们整个数据剖析过程就得到了保障,得到的结果也是符合我们的剖析目的。
在搜集数据的时侯,一般我们把数据类型分为一手数据和二手数据这两个类型。其中一手数据主要是指我们可以直接得到的数据,二手数据主要是指我们须要通过一定的方法对原创数据进行加工处理最后得到的可以进行使用的数据。而在搜集数据的时侯,一手数据和二手数据的来源是不一样的,所以我们须要从不同的地方去搜集。
一手数据
一手数据的搜集技巧我们通常有三种,分别是问答法、观察法和直接实验法。其中问答法指的是我们直接和被调查者进行交流,通过当面或则电话这类的形式,直接想被调查者提出我们的问题,从而直接获得我们须要的数据,在数据搜集中比较常见。观察法比较具象一点,主要是针对我们的剖析目的,对被调查对象进行观察,从而获得我们所须要的数据,目的性比较强,同时也可重复进行。最后一种直接实验法就是通过在一定条件下的规模实验,通过实验结果得到我们想要的数据。这种方式应用范围比较广泛,在好多社会和科学领域都在使用。
二手数据
二手数据的搜集途径我们通常也分三种,分别是数据库、社会公开出版物、互联网这三个途径。其中数据库你们肯定都有接触,现在基本上任何一家企业就会有自己的数据库,我们在进行数据剖析的时侯可以直接从数据库中调阅企业历年的经营数据。社会公开出版物指的是一些专业性的数据期刊,比如一些统计年鉴和统计报告,我们可以从中得到我们想要的数据。最后一种互联网你们肯定都晓得,我们可以借助搜索引擎得到绝大多数我们想要的数据,在一些门户网站中好多时侯都是可以直接下载相关的数据。
到这儿就基本上给你们介绍完数据剖析中数据的类型以及怎样搜集了。我们在进行数据剖析的时侯一定要首先确定剖析目的,这样的话就能够循序渐进,最后得到我们想要的剖析结果。 查看全部
采集数据的方式有几种,采集数据的方法
在我们进行数据剖析的时侯,都是须要根据既定的步骤进行,谁也不能直接就就能得到想要的剖析结果。一般来说,我们在进行数据剖析的时侯会分为以下几个步骤:
1.前期设计数据剖析方案和内容
2.采集数据
3.处理数据及展示数据
4.进行数据剖析
通过以上四个步骤基本上就才能完成一个完整的数据剖析过程。我们在进行任何一个数据剖析之前的首要任务就是明晰我们的目的是哪些,为什么要做这个数据剖析,我们须要用这个数据剖析结果解决哪些问题。只有明晰了数据剖析的目的,我们才不会偏离我们的方向,不然我们最终得出的数据剖析结果是没有任何指导意义的,甚至可能会导致连锁反应,造成一个错误决策的诞生。
当我们明晰了剖析的目的,接下来就须要将过程拆解开来,找到不同的剖析要点,沿着一条线一步一步的去进行,在这个过程中我们须要确定怎样找数据,用什么剖析方式,需要耗费多长的周期和预算。这样的话我们整个数据剖析过程就得到了保障,得到的结果也是符合我们的剖析目的。
在搜集数据的时侯,一般我们把数据类型分为一手数据和二手数据这两个类型。其中一手数据主要是指我们可以直接得到的数据,二手数据主要是指我们须要通过一定的方法对原创数据进行加工处理最后得到的可以进行使用的数据。而在搜集数据的时侯,一手数据和二手数据的来源是不一样的,所以我们须要从不同的地方去搜集。

一手数据
一手数据的搜集技巧我们通常有三种,分别是问答法、观察法和直接实验法。其中问答法指的是我们直接和被调查者进行交流,通过当面或则电话这类的形式,直接想被调查者提出我们的问题,从而直接获得我们须要的数据,在数据搜集中比较常见。观察法比较具象一点,主要是针对我们的剖析目的,对被调查对象进行观察,从而获得我们所须要的数据,目的性比较强,同时也可重复进行。最后一种直接实验法就是通过在一定条件下的规模实验,通过实验结果得到我们想要的数据。这种方式应用范围比较广泛,在好多社会和科学领域都在使用。
二手数据
二手数据的搜集途径我们通常也分三种,分别是数据库、社会公开出版物、互联网这三个途径。其中数据库你们肯定都有接触,现在基本上任何一家企业就会有自己的数据库,我们在进行数据剖析的时侯可以直接从数据库中调阅企业历年的经营数据。社会公开出版物指的是一些专业性的数据期刊,比如一些统计年鉴和统计报告,我们可以从中得到我们想要的数据。最后一种互联网你们肯定都晓得,我们可以借助搜索引擎得到绝大多数我们想要的数据,在一些门户网站中好多时侯都是可以直接下载相关的数据。
到这儿就基本上给你们介绍完数据剖析中数据的类型以及怎样搜集了。我们在进行数据剖析的时侯一定要首先确定剖析目的,这样的话就能够循序渐进,最后得到我们想要的剖析结果。
站长降低网站内容绝对不能用采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-26 04:14
现在好多站长为了给自己的网站填充内容,都用采集工具给网站增加内容,这样做可以大大降低人力,但是常年这样的做的后果是给你的网站增加了一个不可抹除的失败理由。
给你们谈谈一下几种采集的都是会被搜索辨识下来的,所以请你们不要耍小聪明,因为搜索比你聪明多了:
首先我要给什么如今还在以采集而降低网站内容的同学提个醒了,虽然如今你的网站收录在不断的下降,而且速率很快,但哪天搜索觉得是该处理问题的时侯你的网站收录量会被搜索大大删节,而且权重也会大大的降低。现在没有出现这样的情况只是搜索还在考察你,等考察清楚后对于这样常年采集的网站就会得到上面所说的什么惩罚。
第一种采集方法、最近听到说是采集时只用采集的文章的一部分内容,这样搜索由于没见过这文章,以原创方法来收录的你网站页面,这样收录的太是厉害。这种情况我可以明晰的告诉你的是失败的做法,一段时间后搜索会渐渐的拒绝收录的你网站内的内容,为什么这样呢?一直采集的都是原文的部份内容,这样到了你网站里的内容却是没头没尾的内容了,这样搜索觉得你网站的权威性不够。
第二种采集方法、据了解现今的优采云等著名采集软件都具备同义词替换功能,例如“SEO”自动替换为“优化”这样的替换,虽然一开始只要你的替换单词多,那么一篇文章,可以说就有好多的成语会被替换掉。但是经过那么多的搜索的更新,搜索如今可以完完全全的辨识下来,所以借助这样功能来采集内容的结果是一样的。
第三种采集方法、这样情况更是常见了,就是把多个网站的内容都采集到自己的网站上。其实这样情况是最好理解的,不管你四处采集东西,还是在一个地方认真的采集东西,情况都是一样的,那就是采集,搜索对于采用这样方式的网站都是实施抛弃的动作。
其实那么三种方式都不可行,不是说不能用采集,只是要告诉你们降低网站的内容绝对是不能用采集的,如果你的网站内容有超过百分之五十都是采集过来的内容,那么你的网站危险了,请你们根据现网路上流程的更新原创、伪原创、转载的比列1:2:2来适当的降低网站内容。 查看全部
站长降低网站内容绝对不能用采集
现在好多站长为了给自己的网站填充内容,都用采集工具给网站增加内容,这样做可以大大降低人力,但是常年这样的做的后果是给你的网站增加了一个不可抹除的失败理由。
给你们谈谈一下几种采集的都是会被搜索辨识下来的,所以请你们不要耍小聪明,因为搜索比你聪明多了:
首先我要给什么如今还在以采集而降低网站内容的同学提个醒了,虽然如今你的网站收录在不断的下降,而且速率很快,但哪天搜索觉得是该处理问题的时侯你的网站收录量会被搜索大大删节,而且权重也会大大的降低。现在没有出现这样的情况只是搜索还在考察你,等考察清楚后对于这样常年采集的网站就会得到上面所说的什么惩罚。
第一种采集方法、最近听到说是采集时只用采集的文章的一部分内容,这样搜索由于没见过这文章,以原创方法来收录的你网站页面,这样收录的太是厉害。这种情况我可以明晰的告诉你的是失败的做法,一段时间后搜索会渐渐的拒绝收录的你网站内的内容,为什么这样呢?一直采集的都是原文的部份内容,这样到了你网站里的内容却是没头没尾的内容了,这样搜索觉得你网站的权威性不够。
第二种采集方法、据了解现今的优采云等著名采集软件都具备同义词替换功能,例如“SEO”自动替换为“优化”这样的替换,虽然一开始只要你的替换单词多,那么一篇文章,可以说就有好多的成语会被替换掉。但是经过那么多的搜索的更新,搜索如今可以完完全全的辨识下来,所以借助这样功能来采集内容的结果是一样的。
第三种采集方法、这样情况更是常见了,就是把多个网站的内容都采集到自己的网站上。其实这样情况是最好理解的,不管你四处采集东西,还是在一个地方认真的采集东西,情况都是一样的,那就是采集,搜索对于采用这样方式的网站都是实施抛弃的动作。
其实那么三种方式都不可行,不是说不能用采集,只是要告诉你们降低网站的内容绝对是不能用采集的,如果你的网站内容有超过百分之五十都是采集过来的内容,那么你的网站危险了,请你们根据现网路上流程的更新原创、伪原创、转载的比列1:2:2来适当的降低网站内容。
文章被常年别人采集的后果及防止方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-25 17:34
定期更新站内的文章几乎是每一个网站都会做的事情,当然不是每网站都重视原创,也不是每位网站都乐意花这个时间去做原创的文章,不少人就在用采集的形式在更新自己的网站文章。且不说大量采集他人文章的网站会怎么样,这里按照笔者自己网站的实际情况,说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
BaiduSpider喜欢原创的东西,但是百度蜘蛛对于原创源址的判定目前还难以做到精准的地步,它并不能完全自主的判定某一篇文章它的始发点是那里,当我们更新一篇文章,并且很快的被别人采集的时侯,蜘蛛可能同一时间接触了到好多一摸一样的文章,那么它还会太苦恼,并不清楚究竟那个是原创的,哪些是复制的。
因此,当我们的网站长期处于被采集的状态的时侯,我们网站上更新的文章大部分都在互联网上存在一样的内容,而如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。
当蜘蛛这样的看待你的网站的时侯,你网站可能还会遇到如此几种情况:
先文章页停止收录,然后整个网站不收录
这点是一定会发生的,因为被百度错判为采集站,所以你的文章页一定会被百度列为考察期,在这个期间,文章页是一定会停止收录的。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。笔者的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
网站收录开始降低,快照停滞
正如上面所说,百度会重新对你的网站进行审视,这个时侯,一定会发觉你网站存在着一些页面和互联网当中存在类似,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
排名并未有所波动,流量正常
当出现收录降低,快照停滞的时侯,我们最关心的问题就是排行的问题,担心排行会有所影响。这点到是可以放心,因为文章被采集,导致自己站遭到百度的考评,这个只是影响了百度对网站的信任度,并不会造成网站权重的增长,所以网站的关键词排行并不会遭到影响。
改善以后,网站收录仍然存在异常
假设我们发觉自己网站被采集之后,我们对网站进行了一些改善,成功的防止了网站被采集,那么你的网站还会有一个适应期,整个适应期表现下来的病症为:网站渐渐的开始收录文章页,但是收录的并不是即时更新的文章,有可能是前天的或则大前天更新的。这样的病症大约会存在1周的时间,之后收录会渐渐的趋向正常,快照也会渐渐的恢复。
这一系列的现象都是当网站处于常年被别人采集的情况下会出现的,所以当你自己的网站存在这样的一些现象的时侯,你首先要找的诱因就是自己每晚更新的文章是不是正在被他人采集。
如果你的网站确实是处于这样的情况,肯定是要想办法解决的,当然他人要采集你的文章,你不可能强制性的说不使他人去采集,所以我们能做的就是在自己本头上做一些改动。
1、提升页面权重
提升页面的权重是可以从根本上解决这个问题的,我们都晓得,像A5、Chinaz这样的网站每天还会被他人采集,但是这完全没有影响到A5、Chinaz网站的收录,这就是由于她们的权重足够的高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。所以一定要提高文章页面的权重,多做一些这个页面的外链。
2、Rss合理借助
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而且Rss也能有效降低网站的流量,可以说是一举两得。
3、做一些细节,限制机器的采集
被人工采集还没哪些,要是没人用工具定时、大量的采集你网站的文章,这确实使人太难受,所以我们应当在页面的细节上做一些处理,至少还能避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置。
4、被采集的时侯,更新的文章多与自己网站有关
别人采集我们的文章,是因为她们也须要我们更新的内容,所以假如我们更新的都是与自己网站有关的信息,经常会穿插我们网站的名称,别人在采集的时侯才会认为我们的文章对她们并没有太多的意义,这也是很不错的防止采集的形式。
文章经常被采集,这肯定是会对我们形成影响的,所以我们要尽量的去防止,让自己网站的内容在互联网当中成为唯一性,提升百度对我们网站的信任度,让我们的优化工作愈加顺畅。 查看全部
文章被常年别人采集的后果及防止方式
定期更新站内的文章几乎是每一个网站都会做的事情,当然不是每网站都重视原创,也不是每位网站都乐意花这个时间去做原创的文章,不少人就在用采集的形式在更新自己的网站文章。且不说大量采集他人文章的网站会怎么样,这里按照笔者自己网站的实际情况,说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
BaiduSpider喜欢原创的东西,但是百度蜘蛛对于原创源址的判定目前还难以做到精准的地步,它并不能完全自主的判定某一篇文章它的始发点是那里,当我们更新一篇文章,并且很快的被别人采集的时侯,蜘蛛可能同一时间接触了到好多一摸一样的文章,那么它还会太苦恼,并不清楚究竟那个是原创的,哪些是复制的。
因此,当我们的网站长期处于被采集的状态的时侯,我们网站上更新的文章大部分都在互联网上存在一样的内容,而如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。
当蜘蛛这样的看待你的网站的时侯,你网站可能还会遇到如此几种情况:
先文章页停止收录,然后整个网站不收录
这点是一定会发生的,因为被百度错判为采集站,所以你的文章页一定会被百度列为考察期,在这个期间,文章页是一定会停止收录的。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。笔者的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
网站收录开始降低,快照停滞
正如上面所说,百度会重新对你的网站进行审视,这个时侯,一定会发觉你网站存在着一些页面和互联网当中存在类似,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
排名并未有所波动,流量正常
当出现收录降低,快照停滞的时侯,我们最关心的问题就是排行的问题,担心排行会有所影响。这点到是可以放心,因为文章被采集,导致自己站遭到百度的考评,这个只是影响了百度对网站的信任度,并不会造成网站权重的增长,所以网站的关键词排行并不会遭到影响。
改善以后,网站收录仍然存在异常
假设我们发觉自己网站被采集之后,我们对网站进行了一些改善,成功的防止了网站被采集,那么你的网站还会有一个适应期,整个适应期表现下来的病症为:网站渐渐的开始收录文章页,但是收录的并不是即时更新的文章,有可能是前天的或则大前天更新的。这样的病症大约会存在1周的时间,之后收录会渐渐的趋向正常,快照也会渐渐的恢复。
这一系列的现象都是当网站处于常年被别人采集的情况下会出现的,所以当你自己的网站存在这样的一些现象的时侯,你首先要找的诱因就是自己每晚更新的文章是不是正在被他人采集。
如果你的网站确实是处于这样的情况,肯定是要想办法解决的,当然他人要采集你的文章,你不可能强制性的说不使他人去采集,所以我们能做的就是在自己本头上做一些改动。
1、提升页面权重
提升页面的权重是可以从根本上解决这个问题的,我们都晓得,像A5、Chinaz这样的网站每天还会被他人采集,但是这完全没有影响到A5、Chinaz网站的收录,这就是由于她们的权重足够的高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。所以一定要提高文章页面的权重,多做一些这个页面的外链。
2、Rss合理借助
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而且Rss也能有效降低网站的流量,可以说是一举两得。
3、做一些细节,限制机器的采集
被人工采集还没哪些,要是没人用工具定时、大量的采集你网站的文章,这确实使人太难受,所以我们应当在页面的细节上做一些处理,至少还能避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置。
4、被采集的时侯,更新的文章多与自己网站有关
别人采集我们的文章,是因为她们也须要我们更新的内容,所以假如我们更新的都是与自己网站有关的信息,经常会穿插我们网站的名称,别人在采集的时侯才会认为我们的文章对她们并没有太多的意义,这也是很不错的防止采集的形式。
文章经常被采集,这肯定是会对我们形成影响的,所以我们要尽量的去防止,让自己网站的内容在互联网当中成为唯一性,提升百度对我们网站的信任度,让我们的优化工作愈加顺畅。
z-blog和WordPress提高收录的方式,大量复制采集文章还收录了
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-08-22 15:18
采集复制转载的文章,发布到网站上,哪怕是没有更改一个字。百度也会收录,这时候就有很多人困惑了,那我为何还要坚持原创。
大家要知道一个误区就是,不是说收录了就有排行,哪怕是有排行,也是暂时性的。后面的索引量不断地升高,就证明了你的内容质量不行,非原创,被搜索引擎降权了。
那么影响文章排名的几个诱因就是:
1.一开始搭建网站,是否是原创文章,哪怕是伪原创,也要做得好。只要给了好印象,到旁边排行都会好好多。
2.新老域名,新域名通常有个审核期,你前几个月写的文章一般都是收录困难,哪怕收录了搜索全标题,也没排行。这个时侯别沮丧保持更新就好。
3.不要乱改tdk,建议搭建网站前就要想好,上线后谨记不要更改,不然会影响收录和排行。
4.建议你们写文章字数尽量可以多点,能到600以上字更合适。要说如何辨识你是原创,字数就是最好的证明。标题尽量也别改这么大众化,可以适当地长一点。
5.下载递交插件,发布文章第一时间递交到搜索引擎。一般插件只有百度,其他搜索引擎须要登陆后台和输入验证码才可以递交。百度那儿支持api递交,所以通常都有免费插件可下载。WordPress绝对是有的,上面截图是z-blog插件免费。
6.打开速率,我建议你们使用z-blog,WordPress相对慢一点。如果坚持要使用wp,可以找一款速度快的模板使用,这才是正道。
7.自适应的模板有利于排行,而且模板主题要重视移动端的展示,现在流量都偏向于手机端了。电脑端没哪些必要,不用做太多的更改。
下载文章收录查询插件,观察近来的文章收录情况,虽然是收费的,还是有一点好处。毕竟有时候用站长工具site下来的数据不太确切,相反用插件查询会确切一点。不管怎样,做网站,要考虑3个搜索引擎,神马、搜狗和百度。这些都要做好新站递交,坚持出来,还是有流量的。 查看全部
z-blog和WordPress提高收录的方式,大量复制采集文章还收录了
采集复制转载的文章,发布到网站上,哪怕是没有更改一个字。百度也会收录,这时候就有很多人困惑了,那我为何还要坚持原创。
大家要知道一个误区就是,不是说收录了就有排行,哪怕是有排行,也是暂时性的。后面的索引量不断地升高,就证明了你的内容质量不行,非原创,被搜索引擎降权了。
那么影响文章排名的几个诱因就是:
1.一开始搭建网站,是否是原创文章,哪怕是伪原创,也要做得好。只要给了好印象,到旁边排行都会好好多。
2.新老域名,新域名通常有个审核期,你前几个月写的文章一般都是收录困难,哪怕收录了搜索全标题,也没排行。这个时侯别沮丧保持更新就好。
3.不要乱改tdk,建议搭建网站前就要想好,上线后谨记不要更改,不然会影响收录和排行。
4.建议你们写文章字数尽量可以多点,能到600以上字更合适。要说如何辨识你是原创,字数就是最好的证明。标题尽量也别改这么大众化,可以适当地长一点。
5.下载递交插件,发布文章第一时间递交到搜索引擎。一般插件只有百度,其他搜索引擎须要登陆后台和输入验证码才可以递交。百度那儿支持api递交,所以通常都有免费插件可下载。WordPress绝对是有的,上面截图是z-blog插件免费。
6.打开速率,我建议你们使用z-blog,WordPress相对慢一点。如果坚持要使用wp,可以找一款速度快的模板使用,这才是正道。
7.自适应的模板有利于排行,而且模板主题要重视移动端的展示,现在流量都偏向于手机端了。电脑端没哪些必要,不用做太多的更改。

下载文章收录查询插件,观察近来的文章收录情况,虽然是收费的,还是有一点好处。毕竟有时候用站长工具site下来的数据不太确切,相反用插件查询会确切一点。不管怎样,做网站,要考虑3个搜索引擎,神马、搜狗和百度。这些都要做好新站递交,坚持出来,还是有流量的。
数据采集-微信公众号文章的完整爬取过程笔记
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-19 06:56
微信公众号文章的完整爬取过程笔记
outline一.基于sougou-api实现文章的爬取二.基于anyproxy和monkeyrunner的文章自动爬取一.基于sougou-api实现文章的爬取
1.可以直接抓陌陌搜狗主页
2.使用已有的软件包 + 代理的方法
调用API,通过微信公众号的ID,获取该帐号的部份文章
这种办法只能获取陌陌文章的临时链接,所以须要把html文本保存到出来
二.基于anyproxy和monkeyrunner的文章自动爬取
假设条件:你有一批微信公众号ID(eg:gh_1380fb0258f6)
硬件条件:一台普通PC(笔者使用windows系统),一台安卓手机(本人使用的是华为荣耀8lite)
尽量不要使用模拟器,笔者在使用模拟器登录陌陌后发觉帐户被封!!!
目标:爬取该批微信公众号的所有历史文章并增量爬取
1.基于anyproxy爬取公众号的所有文章
这一步早已有前辈早已实现,这里直接使用他的代码:wechat_spider 微信爬虫
具体实现过程可参考github,在这一步须要注意选择正确的IP
2.基于monkeyrunner实现爬取的自动化(1) 手机开启开发者模式
目前笔者遇见的手机开启开发者模式的方法是“在系统版本号上点击7,8次”
(2) PC安装安卓开发套件
安卓sdk的下载与安装可以参考AndroidDevTools
安装是否成功的测量方式可参考:入门monkeyrunner1-monkeyrunner的录制以及回放
(3) 自动化爬取的流程S1 使用陌陌的搜索框,通过微信公众号ID搜索到该帐号
image
image
S2 点击步入该帐号,下拉,点击全部文章,进入
image
S3 下拉,点击文章列表的某一篇文章,打开
image 查看全部
数据采集-微信公众号文章的完整爬取过程笔记
微信公众号文章的完整爬取过程笔记
outline一.基于sougou-api实现文章的爬取二.基于anyproxy和monkeyrunner的文章自动爬取一.基于sougou-api实现文章的爬取
1.可以直接抓陌陌搜狗主页
2.使用已有的软件包 + 代理的方法
调用API,通过微信公众号的ID,获取该帐号的部份文章
这种办法只能获取陌陌文章的临时链接,所以须要把html文本保存到出来
二.基于anyproxy和monkeyrunner的文章自动爬取
假设条件:你有一批微信公众号ID(eg:gh_1380fb0258f6)
硬件条件:一台普通PC(笔者使用windows系统),一台安卓手机(本人使用的是华为荣耀8lite)
尽量不要使用模拟器,笔者在使用模拟器登录陌陌后发觉帐户被封!!!
目标:爬取该批微信公众号的所有历史文章并增量爬取
1.基于anyproxy爬取公众号的所有文章
这一步早已有前辈早已实现,这里直接使用他的代码:wechat_spider 微信爬虫
具体实现过程可参考github,在这一步须要注意选择正确的IP
2.基于monkeyrunner实现爬取的自动化(1) 手机开启开发者模式
目前笔者遇见的手机开启开发者模式的方法是“在系统版本号上点击7,8次”
(2) PC安装安卓开发套件
安卓sdk的下载与安装可以参考AndroidDevTools
安装是否成功的测量方式可参考:入门monkeyrunner1-monkeyrunner的录制以及回放
(3) 自动化爬取的流程S1 使用陌陌的搜索框,通过微信公众号ID搜索到该帐号

image

image
S2 点击步入该帐号,下拉,点击全部文章,进入

image
S3 下拉,点击文章列表的某一篇文章,打开

image
一键采集今日头条试用版 9.0.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-08-19 05:13
问题:为什么Discuz峰会必须要安装采集插件?
解答:反过来问你一下,如果不安装采集插件,你自己原创写文章,你能写多少篇??我相信99.9%的人都不会完全原创所有的内容,都会转载其它网站的一些内容,包括一些xx日报,xx电视台,都会或多或少转载一些其它网站的优质内容,你的Discuz峰会安装采集插件,主要是辅助你,运营好自己的网站内容,既然都要手工转载内容,为什么不用效率更高,不会出错,简单易用的采集工具,让自己事半功倍呢??
问题:采集的内容,百度会收录吗??如何做好SEO优化??
解答:当下来一条新闻,你在百度搜索会看见,很多内容重复的文章也同样收录了,其实这些重复的内容,都是转载过来的,所以采集的内容百度同样也会收录,特别是最新的原创类内容,及时采集过来,同步发布出去,这样你的收录和原创的没有哪些区别,为了更好的提升SEO收录优化,除了及时采集最新的原创内容之外,最好能采集一些拒绝百度收录的平台内容,比如:微信公众号文章,另外还可以采集一些须要登陆以后,才能看见的内容,一些用ajax加载的内容,等等,这类内容百度都是抓取不到的,如果你发布这类的内容,SEO的收录会更好,排名会更好!!
问题:采集到的内容,会不会侵权??
解答:一些对社会正常运作,有帮助的内容,这类内容是规定可以转载的,比如:近期新冠脑炎太严重,一些疫情相关的公开报导内容,这些是没有问题的,因为这种疫情防治的信息,越多人晓得,就越好!!对疫情防治就越有帮助,采集这类内容是没有问题的!还有一类内容,就是对某一个企业有负面影响的,某一个企业的公关人员,会通知你,删除那些内容,只要你配合删掉掉内容,就可以了!!只有很少一部分内容,申请了著作权,如果不留神转载了,有可能被著作权所有人胜诉,这是低几率风波,一般不会遇见!!智伍应用的采集插件,支持先审后发,不支持不初审就手动采集发布出去!!确保了采集内容的安全!!因为每一篇文章内容,都是经过你审查过后,再采集发布的。
问题:智伍应用靠谱吗?会不会骗钱?
解答:非常靠谱!!智伍应用的产品上线之前,都会经过严格的测试和初审代码质量,确保安全而且能用和好用,全部都评比通过以后,才会申请上架!!同时源代码开放,任何人都可以查看到原创透明的代码,有技术能力的用户,可以很方便快捷进行二次开发,智伍应用的任何一款产品,都可以免费试用,满意以后再考虑,是否须要升级到即将商用版本,如果安装以后,发现不能使用,可以联系在线客服解决,如果碰到难以解决的问题,这个插件难以使用,会全额退票给你,总体的一个原则,就是使用户安全无风险,准确找到自己的需求,购买自己用得上的插件模块,如果订购以后,发现用不上,智伍应用会给你退票,如果确实有须要,请放心订购智伍应用的各个产品!!!智伍应用仍然都认真听取用户的反馈意见,根据用户的建议不断的升级更新产品,尊重用户的各项权益和合理诉求!!把用户放到最高的位置上,全心全意为用户服务!!
问题:智伍应用的采集插件都有哪些亮点和优势?
解答:多数都使用Chrome扩充采集程序,需要在自己的网页浏览器chrome那儿安装一个扩充程序,因为经过研究发觉,把浏览器弄成采集工具,是最可靠和成熟稳定的采集方式!一些通过程序抓取函数来采集内容的传统采集方式,虽然可以不用安装chrome扩充程序,但时常出问题,遇到采集不到内容的事情常有发生!!
问题:智伍应用开发了什么采集插件?
解答:很多!!我们专注研制采集插件多年,经过多次升级更新,在采集插件研制方面积累了丰富的经验,如果找不到你须要的采集插件,请反馈给智伍应用在线客服。
问题:智伍应用的采集插件那个好用?
解答:内核技术都一样,只是采集规则不一样,智伍应用的采集插件都好用,主要看你须要采集哪个网站,然后就用那种网站相对应的采集插件。
问题:我完全不懂技术,但想用智伍应用的Discuz采集插件,怎么办?
解答:联系智伍应用在线客服,在线帮助你安装和配置,直到插件完全可以使用,没有任何问题!!不需要你懂技术,售后客服会帮你解决所有的问题。
问题:为什么要用chrome扩充采集程序??
解答:因为这些采集方式,是最稳定和成熟的!!网页都是HTML代码经过浏览器渲染才下来的,所以把自己的浏览器弄成采集工具,所见即所采的方法,是最好的。
问题:chrome扩充安全吗??为什么会弹出“请停用以开发者模式运行的扩充程序”
解答:只要安装了chrome扩充程序,不管是哪些chrome扩充程序,都会弹出这样的提醒:“以开发者模式运行的扩充程序可能会损害您的计算机。如果您不是开发者,那么,为安全起见,应停用以开发者模式运行的扩充程序。”,这就似乎在百货商城里提醒你:“遇到火警请打119。”一样,有提醒你打119,并不代表你遇见了起火,这只是一个提醒信息!!智伍应用的chrome扩充程序都是经过人工初审,多方检测和测试,是安全可靠的扩充程序!!
问题:可以无人值守,自动采集内容吗??
解答:不可以!!全手动采集内容并发布,这样采集内容不安全!!智伍应用的采集插件都是先审后发,确保内容的质量和安全!!不能不经过你的同意,就手动发布内容了!!如果你须要短时间内采集发布大量的内容,来填充网站,可以在【待发布】那里,选择【用chrome扩充批量发布内容】 查看全部
一键采集今日头条试用版 9.0.0
问题:为什么Discuz峰会必须要安装采集插件?
解答:反过来问你一下,如果不安装采集插件,你自己原创写文章,你能写多少篇??我相信99.9%的人都不会完全原创所有的内容,都会转载其它网站的一些内容,包括一些xx日报,xx电视台,都会或多或少转载一些其它网站的优质内容,你的Discuz峰会安装采集插件,主要是辅助你,运营好自己的网站内容,既然都要手工转载内容,为什么不用效率更高,不会出错,简单易用的采集工具,让自己事半功倍呢??
问题:采集的内容,百度会收录吗??如何做好SEO优化??
解答:当下来一条新闻,你在百度搜索会看见,很多内容重复的文章也同样收录了,其实这些重复的内容,都是转载过来的,所以采集的内容百度同样也会收录,特别是最新的原创类内容,及时采集过来,同步发布出去,这样你的收录和原创的没有哪些区别,为了更好的提升SEO收录优化,除了及时采集最新的原创内容之外,最好能采集一些拒绝百度收录的平台内容,比如:微信公众号文章,另外还可以采集一些须要登陆以后,才能看见的内容,一些用ajax加载的内容,等等,这类内容百度都是抓取不到的,如果你发布这类的内容,SEO的收录会更好,排名会更好!!
问题:采集到的内容,会不会侵权??
解答:一些对社会正常运作,有帮助的内容,这类内容是规定可以转载的,比如:近期新冠脑炎太严重,一些疫情相关的公开报导内容,这些是没有问题的,因为这种疫情防治的信息,越多人晓得,就越好!!对疫情防治就越有帮助,采集这类内容是没有问题的!还有一类内容,就是对某一个企业有负面影响的,某一个企业的公关人员,会通知你,删除那些内容,只要你配合删掉掉内容,就可以了!!只有很少一部分内容,申请了著作权,如果不留神转载了,有可能被著作权所有人胜诉,这是低几率风波,一般不会遇见!!智伍应用的采集插件,支持先审后发,不支持不初审就手动采集发布出去!!确保了采集内容的安全!!因为每一篇文章内容,都是经过你审查过后,再采集发布的。
问题:智伍应用靠谱吗?会不会骗钱?
解答:非常靠谱!!智伍应用的产品上线之前,都会经过严格的测试和初审代码质量,确保安全而且能用和好用,全部都评比通过以后,才会申请上架!!同时源代码开放,任何人都可以查看到原创透明的代码,有技术能力的用户,可以很方便快捷进行二次开发,智伍应用的任何一款产品,都可以免费试用,满意以后再考虑,是否须要升级到即将商用版本,如果安装以后,发现不能使用,可以联系在线客服解决,如果碰到难以解决的问题,这个插件难以使用,会全额退票给你,总体的一个原则,就是使用户安全无风险,准确找到自己的需求,购买自己用得上的插件模块,如果订购以后,发现用不上,智伍应用会给你退票,如果确实有须要,请放心订购智伍应用的各个产品!!!智伍应用仍然都认真听取用户的反馈意见,根据用户的建议不断的升级更新产品,尊重用户的各项权益和合理诉求!!把用户放到最高的位置上,全心全意为用户服务!!
问题:智伍应用的采集插件都有哪些亮点和优势?
解答:多数都使用Chrome扩充采集程序,需要在自己的网页浏览器chrome那儿安装一个扩充程序,因为经过研究发觉,把浏览器弄成采集工具,是最可靠和成熟稳定的采集方式!一些通过程序抓取函数来采集内容的传统采集方式,虽然可以不用安装chrome扩充程序,但时常出问题,遇到采集不到内容的事情常有发生!!
问题:智伍应用开发了什么采集插件?
解答:很多!!我们专注研制采集插件多年,经过多次升级更新,在采集插件研制方面积累了丰富的经验,如果找不到你须要的采集插件,请反馈给智伍应用在线客服。
问题:智伍应用的采集插件那个好用?
解答:内核技术都一样,只是采集规则不一样,智伍应用的采集插件都好用,主要看你须要采集哪个网站,然后就用那种网站相对应的采集插件。
问题:我完全不懂技术,但想用智伍应用的Discuz采集插件,怎么办?
解答:联系智伍应用在线客服,在线帮助你安装和配置,直到插件完全可以使用,没有任何问题!!不需要你懂技术,售后客服会帮你解决所有的问题。
问题:为什么要用chrome扩充采集程序??
解答:因为这些采集方式,是最稳定和成熟的!!网页都是HTML代码经过浏览器渲染才下来的,所以把自己的浏览器弄成采集工具,所见即所采的方法,是最好的。
问题:chrome扩充安全吗??为什么会弹出“请停用以开发者模式运行的扩充程序”
解答:只要安装了chrome扩充程序,不管是哪些chrome扩充程序,都会弹出这样的提醒:“以开发者模式运行的扩充程序可能会损害您的计算机。如果您不是开发者,那么,为安全起见,应停用以开发者模式运行的扩充程序。”,这就似乎在百货商城里提醒你:“遇到火警请打119。”一样,有提醒你打119,并不代表你遇见了起火,这只是一个提醒信息!!智伍应用的chrome扩充程序都是经过人工初审,多方检测和测试,是安全可靠的扩充程序!!
问题:可以无人值守,自动采集内容吗??
解答:不可以!!全手动采集内容并发布,这样采集内容不安全!!智伍应用的采集插件都是先审后发,确保内容的质量和安全!!不能不经过你的同意,就手动发布内容了!!如果你须要短时间内采集发布大量的内容,来填充网站,可以在【待发布】那里,选择【用chrome扩充批量发布内容】
[c#] 多线程网路编程应用[多线程文章采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-09 15:08
如今的网路越来越发达,分享一个文件是这么的简单。特别是有了电骡、迅雷这样的下载软件就愈加如虎添翼了,想从网上下载一个几个G大小的文件,真是不费吹灰之力。好,废话太多了,直接步入俺们明天的主题吧。
要实现象迅雷一样的多线程下载,核心问题是要将多线程的概念以及如何实现的问题弄清。
当然,本文技术浓度太低,大牛请直接绕路。
多线程是相对单线程来说的,具体可以参考百度百科里的解释:
每个程序运行都有一个最基本的主线程,用于处理界面书法,人机交互,后台处理等过程,因此假如是在单线程程序里操作注视历时的动作,主界面都会太卡,甚至是难以工作。因此不管您是不是喜欢,最好都别用主线程把一切事务夺得,否则很难给用户一个凉爽的顾客体验。
那么在C#里怎么实现多线程呢?
下面使我们实现一个最简单的多线程实例;
为了演示便捷,我们新建一个winform项目,取名为 MultiThreadDemo。
先创建一个足够使你的程序卡住不动的方式函数:
private void Display()
{
while (true)
textBox1.Text = new Random().NextDouble().ToString();
}
然后给button1添加调用,发现确实够卡吧,谁使你把那种死循环的事情交给主线程去做呢,一个人又作图,又要算数,哪还有时间给你答复。
using System.Threading;
接着补充一下button1上面的代码,给他创建一个线程,我们把这线程起名叫“UiThread”用于专门处理显示吧。
View Code
private void button1_Click(object sender, EventArgs e)
{
Thread thread = new Thread(Display);//创建一个线程
thread.Start();
// Display();
}
如果你急着运行,肯定会回过头来骂我了,怎么不行呢,是不是哪些会提示:“线程间操作无效: 从不是创建控件“textBox1”的线程访问它。”。因为主线程和你创建的那种线程是两个互不相干的线程,两个陌生人如何打交道?也就是当你这个UiThread没经过主线程同意就去调用textBox1,别人会使你这么做吗?
因此,为了处理他俩工作不协调的问题,特意强制性取消线程警告.在构造函数里添加一句:
public Form1()
{
InitializeComponent();
Control.CheckForIllegalCrossThreadCalls = false;//加上这句就不会警告了
}
这样一个简单的多线程程序就诞生了。不过有个时侯有很多代码须要用到委托,又不想单独创建一个函数,就可以这样做:
View Code
private void button1_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Display(); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
不过并不推荐如此做,这在线程上是不安全的,有很大的机率会使程序奔溃。
通过前面的练习,我们晓得创建一个线程可以多做一些事,同样,我们多创建几个线程,做的事岂不是更多?这是必须的。
接下来即将走入我们明天的题外话:多线程采集
要想多线程采集,首先要解决单个下载。
using System.Net;
using System.IO;
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕"));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
sw.Write(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
return;
}
}
然后在在button2里调用
View Code
private void button2_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Request(richTextBox1, 158100); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
这样以来单次采集就完成了。
要想象优采云一样采集,自然以目前的水平是做不到的。起码也要把批量采集做下来。无外乎使用多线程。
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕\n"));
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
}
}
private void button2_Click(object sender, EventArgs e)
{
Thread.CurrentThread.Name = "主线程";
Thread[] threads = new Thread[51];
DateTime endTime = DateTime.Now;
DateTime startTime = DateTime.Now;
TimeSpan timeSpan = endTime - startTime;
string span = timeSpan.TotalSeconds.ToString();
startTime = DateTime.Now;
Mutex mt = new Mutex();
mt.WaitOne();
for (int i = 158300; i >158250; i--)
{
threads[158300 - i] = new Thread(new ParameterizedThreadStart(delegate { Request(richTextBox1, i); }));
threads[158300 - i].Name = "线程" + (i).ToString(); ;
threads[158300 - i].Start();
}
mt.ReleaseMutex();
endTime = DateTime.Now;
timeSpan = endTime - startTime;
span = timeSpan.TotalSeconds.ToString();
richTextBox1.AppendText(string.Format("多线程接受的话共花费了{0}秒钟\n", span));
}
多线程采集就完成了。其实本文讲来讲去主要是围绕创建线程这一话题,技术浓度相当低,就当给刚入门的同学练练手吧!
教程每晚还会更新,欢迎继续关注。 查看全部
编程不能死记硬背,要靠多实践操作
如今的网路越来越发达,分享一个文件是这么的简单。特别是有了电骡、迅雷这样的下载软件就愈加如虎添翼了,想从网上下载一个几个G大小的文件,真是不费吹灰之力。好,废话太多了,直接步入俺们明天的主题吧。
要实现象迅雷一样的多线程下载,核心问题是要将多线程的概念以及如何实现的问题弄清。
当然,本文技术浓度太低,大牛请直接绕路。
多线程是相对单线程来说的,具体可以参考百度百科里的解释:
每个程序运行都有一个最基本的主线程,用于处理界面书法,人机交互,后台处理等过程,因此假如是在单线程程序里操作注视历时的动作,主界面都会太卡,甚至是难以工作。因此不管您是不是喜欢,最好都别用主线程把一切事务夺得,否则很难给用户一个凉爽的顾客体验。
那么在C#里怎么实现多线程呢?
下面使我们实现一个最简单的多线程实例;
为了演示便捷,我们新建一个winform项目,取名为 MultiThreadDemo。

先创建一个足够使你的程序卡住不动的方式函数:
private void Display()
{
while (true)
textBox1.Text = new Random().NextDouble().ToString();
}
然后给button1添加调用,发现确实够卡吧,谁使你把那种死循环的事情交给主线程去做呢,一个人又作图,又要算数,哪还有时间给你答复。
using System.Threading;
接着补充一下button1上面的代码,给他创建一个线程,我们把这线程起名叫“UiThread”用于专门处理显示吧。


View Code
private void button1_Click(object sender, EventArgs e)
{
Thread thread = new Thread(Display);//创建一个线程
thread.Start();
// Display();
}
如果你急着运行,肯定会回过头来骂我了,怎么不行呢,是不是哪些会提示:“线程间操作无效: 从不是创建控件“textBox1”的线程访问它。”。因为主线程和你创建的那种线程是两个互不相干的线程,两个陌生人如何打交道?也就是当你这个UiThread没经过主线程同意就去调用textBox1,别人会使你这么做吗?
因此,为了处理他俩工作不协调的问题,特意强制性取消线程警告.在构造函数里添加一句:
public Form1()
{
InitializeComponent();
Control.CheckForIllegalCrossThreadCalls = false;//加上这句就不会警告了
}
这样一个简单的多线程程序就诞生了。不过有个时侯有很多代码须要用到委托,又不想单独创建一个函数,就可以这样做:
View Code
private void button1_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Display(); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
不过并不推荐如此做,这在线程上是不安全的,有很大的机率会使程序奔溃。
通过前面的练习,我们晓得创建一个线程可以多做一些事,同样,我们多创建几个线程,做的事岂不是更多?这是必须的。
接下来即将走入我们明天的题外话:多线程采集
要想多线程采集,首先要解决单个下载。
using System.Net;
using System.IO;
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕"));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
sw.Write(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
return;
}
}
然后在在button2里调用
View Code
private void button2_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Request(richTextBox1, 158100); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
这样以来单次采集就完成了。
要想象优采云一样采集,自然以目前的水平是做不到的。起码也要把批量采集做下来。无外乎使用多线程。
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕\n"));
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
}
}
private void button2_Click(object sender, EventArgs e)
{
Thread.CurrentThread.Name = "主线程";
Thread[] threads = new Thread[51];
DateTime endTime = DateTime.Now;
DateTime startTime = DateTime.Now;
TimeSpan timeSpan = endTime - startTime;
string span = timeSpan.TotalSeconds.ToString();
startTime = DateTime.Now;
Mutex mt = new Mutex();
mt.WaitOne();
for (int i = 158300; i >158250; i--)
{
threads[158300 - i] = new Thread(new ParameterizedThreadStart(delegate { Request(richTextBox1, i); }));
threads[158300 - i].Name = "线程" + (i).ToString(); ;
threads[158300 - i].Start();
}
mt.ReleaseMutex();
endTime = DateTime.Now;
timeSpan = endTime - startTime;
span = timeSpan.TotalSeconds.ToString();
richTextBox1.AppendText(string.Format("多线程接受的话共花费了{0}秒钟\n", span));
}
多线程采集就完成了。其实本文讲来讲去主要是围绕创建线程这一话题,技术浓度相当低,就当给刚入门的同学练练手吧!

教程每晚还会更新,欢迎继续关注。
内容分享:微信公众号文章批量采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2021-01-07 12:08
目前,有很多方法可以在市场上抓取微信公众号文章,但是其中许多方法不可用,并且无法记录阅读次数和喜欢的次数,并且教程非常复杂并且全部被复制。复制它,该程序是经过许多实际操作总结的可执行程序,并且简单易用。本教程仅讨论干货。
首先安装所需的环境1.node.js + anyproxy安装
1.1node.js安装
下载Node.js并打开官方网站下载链接:/ en / download /我下载了node-v6.9.2-x64.msi,如下所示:
下载完成后,双击“ node-v6.9.2-x64.msi”开始安装Node.js,只需单击下一步。需要注意的主要事情是Node.js的默认安装目录是“ C:\ Program Files \ nodejs \”。您可以单击更改以修改目录。通常,我将其安装在“ D:\ Program Files \ nodejs \”下。
安装完成后,检查是否在PATH环境变量中配置了Node.js。单击开始=》运行=》输入“ cmd” =>输入命令“路径”,然后查看输出中是否有节点安装目录。
最后,测试节点是否安装成功。
点击开始=>运行=》输入“ cmd” =>输入命令“ node -v”和“ npm -v”,显示如图所示结果,表明安装成功。
1.2 anyproxy安装
点击开始=>运行=》输入“ cmd” =>输入命令“ npm install -g anyproxy”安装完成后,输入命令“ anyproxy -i”以启动anyproxy。
打开浏览器并输入localhost:8002以打开anyproxy界面。
2.安装手机模拟器
我尝试了几种模拟器,我认为MuMu模拟器相对易于使用。它是由网易生产的,具有一定的质量保证。下载地址:/,您可以从官方网站下载并安装。
3.网络配置和证书安装
首先检查本地IP,单击Start =》 Run =》输入“ cmd” =>输入命令“ ipconfig”以检查您的IP,如图所示
然后在仿真器上打开浏览器,然后输入找到的IP:8002。如图所示:
点击ROOTCA以安装证书
在模拟器上,依次单击“设置”,“ WLAN”,“配置代理”
4.在模拟器上安装微信
通过MuMu模拟器上的应用程序中心安装微信。
在计算机端,打开浏览器,输入localhost:8002,打开仿真器微信,访问任何官方帐户,并检查计算机浏览器,即可看到微信请求的数据包。
准备好环境后,让我们开始分析界面和相关的重要参数。
首先我们要谈一些重要的参数
我们来谈谈几个重要的界面
要获取正式帐户文章,您需要先输入一个条目。许多文章从旧的文章列表条目开始。获取第一页的html,获取第16个脚本标签中msgList变量的值,获取第一页的内容,然后通过该接口请求json数据以获取其他页的数据。除了获取喜欢和观看数据的界面之外,整个过程还需要三个界面。
实际上,可以优化整个爬网过程。我们可以合并第一个和第二个接口。只需要两个接口即可完成正式帐户文章列表,并且可以看到喜欢的次数。爬行。
通过修改偏移量以控制页数来获取列表数据接口,其中计数不能大于10,这意味着一个页面中最多有十个项目。
"/mp/profile_ext?action=getmsg&__biz="+__biz+"&f=json&offset="+offset+"&count=10&appmsg_token="+appmsg_token+"";
要获取喜欢人数的第二个界面,请在手表编号界面中,请注意,这是此界面中的POST请求,
"/mp/getappmsgext?f=json&__biz="+__biz+"&appmsg_token="+appmsg_token+"&fasttmplajax=1";
需要上传请求正文
"mid="+mid+"&sn="+sn+"&idx="+idx+"&is_only_read=1"
通过这两个界面,您可以获取任何正式帐户的全部文章,以及点赞次数和计数等。在此处应注意,列表请求应以2秒分开,并且点赞数量的界面应间隔2秒。 ,否则,微信帐户将被阻止并且无法访问官方帐户,其他功能将不受影响,并且将在24小时内自动解除锁定。
WeChat官方帐户文章批处理采集就是这样。如有任何疑问,可以留言讨论~~ 查看全部
内容分享:微信公众号文章批量采集
目前,有很多方法可以在市场上抓取微信公众号文章,但是其中许多方法不可用,并且无法记录阅读次数和喜欢的次数,并且教程非常复杂并且全部被复制。复制它,该程序是经过许多实际操作总结的可执行程序,并且简单易用。本教程仅讨论干货。
首先安装所需的环境1.node.js + anyproxy安装
1.1node.js安装
下载Node.js并打开官方网站下载链接:/ en / download /我下载了node-v6.9.2-x64.msi,如下所示:
下载完成后,双击“ node-v6.9.2-x64.msi”开始安装Node.js,只需单击下一步。需要注意的主要事情是Node.js的默认安装目录是“ C:\ Program Files \ nodejs \”。您可以单击更改以修改目录。通常,我将其安装在“ D:\ Program Files \ nodejs \”下。
安装完成后,检查是否在PATH环境变量中配置了Node.js。单击开始=》运行=》输入“ cmd” =>输入命令“路径”,然后查看输出中是否有节点安装目录。
最后,测试节点是否安装成功。
点击开始=>运行=》输入“ cmd” =>输入命令“ node -v”和“ npm -v”,显示如图所示结果,表明安装成功。
1.2 anyproxy安装
点击开始=>运行=》输入“ cmd” =>输入命令“ npm install -g anyproxy”安装完成后,输入命令“ anyproxy -i”以启动anyproxy。
打开浏览器并输入localhost:8002以打开anyproxy界面。
2.安装手机模拟器
我尝试了几种模拟器,我认为MuMu模拟器相对易于使用。它是由网易生产的,具有一定的质量保证。下载地址:/,您可以从官方网站下载并安装。
3.网络配置和证书安装
首先检查本地IP,单击Start =》 Run =》输入“ cmd” =>输入命令“ ipconfig”以检查您的IP,如图所示
然后在仿真器上打开浏览器,然后输入找到的IP:8002。如图所示:
点击ROOTCA以安装证书
在模拟器上,依次单击“设置”,“ WLAN”,“配置代理”
4.在模拟器上安装微信
通过MuMu模拟器上的应用程序中心安装微信。
在计算机端,打开浏览器,输入localhost:8002,打开仿真器微信,访问任何官方帐户,并检查计算机浏览器,即可看到微信请求的数据包。
准备好环境后,让我们开始分析界面和相关的重要参数。
首先我们要谈一些重要的参数
我们来谈谈几个重要的界面
要获取正式帐户文章,您需要先输入一个条目。许多文章从旧的文章列表条目开始。获取第一页的html,获取第16个脚本标签中msgList变量的值,获取第一页的内容,然后通过该接口请求json数据以获取其他页的数据。除了获取喜欢和观看数据的界面之外,整个过程还需要三个界面。
实际上,可以优化整个爬网过程。我们可以合并第一个和第二个接口。只需要两个接口即可完成正式帐户文章列表,并且可以看到喜欢的次数。爬行。
通过修改偏移量以控制页数来获取列表数据接口,其中计数不能大于10,这意味着一个页面中最多有十个项目。
"/mp/profile_ext?action=getmsg&__biz="+__biz+"&f=json&offset="+offset+"&count=10&appmsg_token="+appmsg_token+"";
要获取喜欢人数的第二个界面,请在手表编号界面中,请注意,这是此界面中的POST请求,
"/mp/getappmsgext?f=json&__biz="+__biz+"&appmsg_token="+appmsg_token+"&fasttmplajax=1";
需要上传请求正文
"mid="+mid+"&sn="+sn+"&idx="+idx+"&is_only_read=1"
通过这两个界面,您可以获取任何正式帐户的全部文章,以及点赞次数和计数等。在此处应注意,列表请求应以2秒分开,并且点赞数量的界面应间隔2秒。 ,否则,微信帐户将被阻止并且无法访问官方帐户,其他功能将不受影响,并且将在24小时内自动解除锁定。
WeChat官方帐户文章批处理采集就是这样。如有任何疑问,可以留言讨论~~
事实:文章被采集的解决方法是什么呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-12-28 09:12
尽管这可能仍不能阻止另一方出现采集并离开您网站,但毕竟这也是书面交流和建议。有总比没有好,它会产生一定的效果。
三、在文章页面上添加了一些特色内容
1、例如,在文章中添加一些小标签代码,例如H1,H2,强标签,颜色标签等。这些搜索引擎将更加敏感,可以在一定意义上加深它们的配对原创文章判决。
2、主要在文章中,添加一些自己的品牌关键词,例如Shanghai 网站 Construction,Shanghai Internet Company,Shanghai 网站 Optimization,您可能希望添加与此类似的词
3、在文章中添加了一些内部链接,因为喜欢采集的人通常很懒。不排除某些人可能会复制并粘贴该链接样式并将其复制到其中。这是可能的,结果是另一方为自己建立了外部链接。在大型平台上,这种情况也很常见。
4、文章页面加入时间,当判断文章的原创度时,搜索引擎也会参考时间顺序。
四、阻止网页的右键单击功能
我们都知道大多数人采集 文章使用鼠标右键进行复制。如果此功能在技术上被阻止,那么无疑会增加采集的麻烦。方法建议网站可以在重量增加之前执行此操作,最好在起来之后将其删除,因为当网站用户组出现时,并不排除某些用户对此方面感到厌恶,这会影响用户体验。
五、尝试在晚上文章更新
对于采集,最可怕的是对手会发现您的习惯,尤其是在白天充裕的情况下。许多人喜欢在白天定期且定量地更新文章。结果,他们被其他人跟随。 文章被带走,结果搜索引擎无法确定谁是原创的作者。但是晚上却有所不同。很少有人在半夜里等着你网站,据说此时的蜘蛛更加勤奋,更有利于捕捉蜘蛛。
实际上,网站的文章总是会受到采集的网站排名的伤害,这会严重影响文章的稀缺性,因此上面提到的上海网站建筑编辑最好在阅读网站之后将这些方法应用到您的网站。我相信这将使文章被采集的损害最小化。当然,还有更多的方法。有关特定的详细信息,我建议您参考一些排名较高的网站,尤其是那些排名较高的新电台。总结并了解更多,您将逐渐获得更多。
特别声明:上述内容(包括图片或视频,如果有的话)由自媒体平台“网易”的用户上传和发布。该平台仅提供信息存储服务。 查看全部
事实:文章被采集的解决方法是什么呢?
尽管这可能仍不能阻止另一方出现采集并离开您网站,但毕竟这也是书面交流和建议。有总比没有好,它会产生一定的效果。
三、在文章页面上添加了一些特色内容
1、例如,在文章中添加一些小标签代码,例如H1,H2,强标签,颜色标签等。这些搜索引擎将更加敏感,可以在一定意义上加深它们的配对原创文章判决。
2、主要在文章中,添加一些自己的品牌关键词,例如Shanghai 网站 Construction,Shanghai Internet Company,Shanghai 网站 Optimization,您可能希望添加与此类似的词
3、在文章中添加了一些内部链接,因为喜欢采集的人通常很懒。不排除某些人可能会复制并粘贴该链接样式并将其复制到其中。这是可能的,结果是另一方为自己建立了外部链接。在大型平台上,这种情况也很常见。
4、文章页面加入时间,当判断文章的原创度时,搜索引擎也会参考时间顺序。
四、阻止网页的右键单击功能
我们都知道大多数人采集 文章使用鼠标右键进行复制。如果此功能在技术上被阻止,那么无疑会增加采集的麻烦。方法建议网站可以在重量增加之前执行此操作,最好在起来之后将其删除,因为当网站用户组出现时,并不排除某些用户对此方面感到厌恶,这会影响用户体验。
五、尝试在晚上文章更新
对于采集,最可怕的是对手会发现您的习惯,尤其是在白天充裕的情况下。许多人喜欢在白天定期且定量地更新文章。结果,他们被其他人跟随。 文章被带走,结果搜索引擎无法确定谁是原创的作者。但是晚上却有所不同。很少有人在半夜里等着你网站,据说此时的蜘蛛更加勤奋,更有利于捕捉蜘蛛。
实际上,网站的文章总是会受到采集的网站排名的伤害,这会严重影响文章的稀缺性,因此上面提到的上海网站建筑编辑最好在阅读网站之后将这些方法应用到您的网站。我相信这将使文章被采集的损害最小化。当然,还有更多的方法。有关特定的详细信息,我建议您参考一些排名较高的网站,尤其是那些排名较高的新电台。总结并了解更多,您将逐渐获得更多。
特别声明:上述内容(包括图片或视频,如果有的话)由自媒体平台“网易”的用户上传和发布。该平台仅提供信息存储服务。
解读:采集文章及被采集的后果分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-12-25 09:13
每个网站都会定期更新其自身站点的文章,但并不是每个网站都关注原创,所以有人会上网采集文章是很自然的。百度蜘蛛在判断文章是否属于原创时常常不准确,甚至无法判断文章最初来自哪个站点。大型网站上传文章文章后,将有很多网站要复制,有些网站管理员不会对其进行修改,导致蜘蛛在获得收入时会找到很多相同的文章,然后会很困惑,无法分辨原创。因此,我们经常更新的文章也可能会被其他站点复制。如果网站本身的权重不高,则蜘蛛会认为您网站的文章是互联网上的采集,因此不会赢得您的文章。
如果蜘蛛这样对待您的网站,您网站可能会发生什么?让我们看一下:
首先文章页停止收录,然后整个网站不是收录吗?
遇到这种情况很正常。首先,您的文章已被百度列为评估候选人。在此期间,所有文章都不会进入收录。但是,蜘蛛程序将继续检查您上传的文章,直到找不到采集文章。
网站 收录开始减少并且快照停滞了?
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是很收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量是否正常?
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改善后网站 收录仍然异常吗?
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将慢慢恢复。
当网站长时间处于别人采集的情况下时,会出现这一系列现象,因此当您自己的网站中有某些此类现象时,您首先应该找到原因是我每天更新的文章是否正在被其他人采集使用。如果您的网站确实处于这种情况下,则必须找到一种解决方法。当然,其他人想要采集您的文章,您不能强迫说不让其他人参加采集,因此我们可以做的就是对自己进行一些更改。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击,这对收录非常有帮助。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集]。例如,页面不应设计得过于传统或太流行; Url的文字应稍作更改,并且不应作为默认覆盖。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
无论是我们采集的其他人还是我们采集的其他人,我们都必须注意这些问题。对于原创的文章,您必须注意添加超链接,最好在文章中反映您自己的情况,添加图片并指明转载来源,以确保您文章发挥作用。在Internet上获得最大收益,更好地进行网站优化工作。对于经常复制他人文章的网站,我们还必须学习使用一些网络营销软件。最近,发布了“快上通”新群发邮件功能的强大版本。对于网络营销软件的泛滥,我们只做最好,最专业。 查看全部
解读:采集文章及被采集的后果分析
每个网站都会定期更新其自身站点的文章,但并不是每个网站都关注原创,所以有人会上网采集文章是很自然的。百度蜘蛛在判断文章是否属于原创时常常不准确,甚至无法判断文章最初来自哪个站点。大型网站上传文章文章后,将有很多网站要复制,有些网站管理员不会对其进行修改,导致蜘蛛在获得收入时会找到很多相同的文章,然后会很困惑,无法分辨原创。因此,我们经常更新的文章也可能会被其他站点复制。如果网站本身的权重不高,则蜘蛛会认为您网站的文章是互联网上的采集,因此不会赢得您的文章。
如果蜘蛛这样对待您的网站,您网站可能会发生什么?让我们看一下:
首先文章页停止收录,然后整个网站不是收录吗?
遇到这种情况很正常。首先,您的文章已被百度列为评估候选人。在此期间,所有文章都不会进入收录。但是,蜘蛛程序将继续检查您上传的文章,直到找不到采集文章。
网站 收录开始减少并且快照停滞了?
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是很收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量是否正常?
当减少收录且快照停滞时,我们最大的担忧是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改善后网站 收录仍然异常吗?
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将慢慢恢复。
当网站长时间处于别人采集的情况下时,会出现这一系列现象,因此当您自己的网站中有某些此类现象时,您首先应该找到原因是我每天更新的文章是否正在被其他人采集使用。如果您的网站确实处于这种情况下,则必须找到一种解决方法。当然,其他人想要采集您的文章,您不能强迫说不让其他人参加采集,因此我们可以做的就是对自己进行一些更改。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击,这对收录非常有帮助。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集]。例如,页面不应设计得过于传统或太流行; Url的文字应稍作更改,并且不应作为默认覆盖。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
无论是我们采集的其他人还是我们采集的其他人,我们都必须注意这些问题。对于原创的文章,您必须注意添加超链接,最好在文章中反映您自己的情况,添加图片并指明转载来源,以确保您文章发挥作用。在Internet上获得最大收益,更好地进行网站优化工作。对于经常复制他人文章的网站,我们还必须学习使用一些网络营销软件。最近,发布了“快上通”新群发邮件功能的强大版本。对于网络营销软件的泛滥,我们只做最好,最专业。
解读:原创文章被采集怎么办?处理网站文章采集的预防措施
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2020-12-09 12:21
的预防措施
许多人讨厌他们的原创文章被他人立即复制。甚至有人用它来发送一些败类链。我特别相信,很多老人都遇到过这种情况。有时候,他们的努力不如财富。我们如何应对这种情况?
首先,在竞争对手采集此文章之前,请尝试让搜索引擎将其包括在内。
1、实时抓取文章,让搜索引擎知道此文章。
2、ping在百度网站管理员本人的文章链接上。这也是百度官员告知我们的一种方式。
二、文章使用作者或版本作为标记。
Youbangyun认为偶然地阻止不了别人窃您的文章,但这也是书面交流和提醒,总比没有好。
三,在文章中添加一些功能。
1、例如,在文章中的标签代码(例如n 1、 n 2、color)中,搜索引擎将对这些内容更加敏感,这将加深原创的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些外部链接,因为喜欢复制文章的人通常很懒,因此某些人可以直接复制和粘贴而不会消除它们。
4、当实时添加文章文章时,搜索引擎将确定文章的原创级别并引用时间元素。
四、选择网页的关键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此效果的影响,无疑会增加采集的麻烦。
五、每晚更新
您最担心的是对手知道您的习惯,尤其是在白天。许多人喜欢在白天更新文章,结果被其他人盯着。 文章被立即窃。
在我们的网站上可以看到并使用这些方法后,我相信这可以增加文章的采集数量。
更多阅读建议:淮南华帝洗碗机维修,盐城伊莱克斯电烤箱维修 查看全部
原创文章是采集怎么办?网站文章 采集
的预防措施
许多人讨厌他们的原创文章被他人立即复制。甚至有人用它来发送一些败类链。我特别相信,很多老人都遇到过这种情况。有时候,他们的努力不如财富。我们如何应对这种情况?
首先,在竞争对手采集此文章之前,请尝试让搜索引擎将其包括在内。
1、实时抓取文章,让搜索引擎知道此文章。
2、ping在百度网站管理员本人的文章链接上。这也是百度官员告知我们的一种方式。
二、文章使用作者或版本作为标记。
Youbangyun认为偶然地阻止不了别人窃您的文章,但这也是书面交流和提醒,总比没有好。
三,在文章中添加一些功能。
1、例如,在文章中的标签代码(例如n 1、 n 2、color)中,搜索引擎将对这些内容更加敏感,这将加深原创的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些外部链接,因为喜欢复制文章的人通常很懒,因此某些人可以直接复制和粘贴而不会消除它们。
4、当实时添加文章文章时,搜索引擎将确定文章的原创级别并引用时间元素。
四、选择网页的关键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此效果的影响,无疑会增加采集的麻烦。
五、每晚更新
您最担心的是对手知道您的习惯,尤其是在白天。许多人喜欢在白天更新文章,结果被其他人盯着。 文章被立即窃。
在我们的网站上可以看到并使用这些方法后,我相信这可以增加文章的采集数量。
更多阅读建议:淮南华帝洗碗机维修,盐城伊莱克斯电烤箱维修
解决方法:文章被长期他人采集的后果及避免方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-11-24 09:10
定期更新站中的文章是几乎每个网站都会做的事,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人的手很久了这种后果,以及避免被别人采集的方法。
BaiduSpider喜欢原创中的内容,但百度蜘蛛对原创来源的判断尚不准确,并且当我们更新文章时,它无法完全自主地判断某文章文章的来源文章并且很快被其他人采集吸引,蜘蛛可能会同时与许多相同的文章接触,那么这将非常混乱,并且不确定到底是原创和已复制。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样查看您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当收录减小并且快照停滞时,我们最关心的是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改进后,网站 收录仍然有异常
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将缓慢恢复。
这一系列现象都在网站长时间处于别人采集的情况下出现,因此当您自己的网站中有某些此类现象时,您应该首先找到原因Is我每天更新的文章还是别人更新的采集。
如果您的网站确实处于这种情况下,则必须找到解决方案,当然其他人希望采集您的文章,您不能强迫说不让其他人离开采集,那又如何?我们可以做的就是改变自己。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击。这对收录非常有用。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集 ]。例如,页面设计不应太过传统和流行。 Url的文字应稍作更改,并且不应使用默认的叠加层和其他设置。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
文章通常是采集,肯定会影响我们,因此我们应该避免使用它,让我们的网站内容在互联网上具有唯一性,并改善百度对我们的待遇网站使我们的优化工作更加顺畅。
本文提到的现象是作者遇到的真实情况网站。 文章由Aidai.com提供,请附上转载的源链接 查看全部
文章长期处于他人采集的后果以及如何避免
定期更新站中的文章是几乎每个网站都会做的事,当然不是每个网站都关注原创,也不是每个网站都愿意花这个时间做文章的[k17 文章,很多人正在使用采集更新他们的网站 文章。更不用说大量采集其他文章的网站,在此根据作者自己的网站实际情况,让我们谈谈采集 文章的网站将会发生什么。 ]谁已经在别人的手很久了这种后果,以及避免被别人采集的方法。
BaiduSpider喜欢原创中的内容,但百度蜘蛛对原创来源的判断尚不准确,并且当我们更新文章时,它无法完全自主地判断某文章文章的来源文章并且很快被其他人采集吸引,蜘蛛可能会同时与许多相同的文章接触,那么这将非常混乱,并且不确定到底是原创和已复制。
因此,当我们的网站长时间处于采集的状态时,我们网站上更新的文章的大部分内容在互联网上都具有相同的内容,并且如果[如果仍然不够高,则蜘蛛可能会将您的网站列为采集电台,并且它认为您的网站的文章是互联网上的采集,而不是互联网上的其他电台是采集是您的文章。
当蜘蛛这样查看您的网站时,您网站可能会遇到几种情况:
首先文章页停止收录,然后整个网站则不收录
这肯定会发生,因为百度将其错误地视为采集网站,因此您的文章页面肯定会被百度列为审核期。在此期间,文章页面肯定会停止收录。当然,此停止收录不仅会影响您的文章页面,还会使百度重新查看您的整个网站,因此其他页面将不会收录逐渐开始。作者的网站在收录中没有页面了半个月,原因是因为这个。
网站 收录开始减少,快照停滞
如前所述,百度将重新考虑您的网站。目前,您肯定会发现网站的某些页面与Internet上的页面相似。百度会在不考虑您的情况下减少这些页面。 收录,所以很多人发现网站停止收录并缓慢地导致网站在整个收录中减小。这就是原因。该页面不是收录,百度对网站的信任度下降了,最终快照将停滞了一段时间。
排名没有波动,访问量正常
当收录减小并且快照停滞时,我们最关心的是排名问题,并且我们担心排名会受到影响。可以肯定这一点,因为文章是采集,这导致了百度对其网站的评估。这仅影响了百度对网站的信任,并没有导致网站的权重降低,因此[[k14的关键词排名]不会受到影响。
改进后,网站 收录仍然有异常
假设我们发现网站为采集之后,我们对网站进行了一些改进并成功避免了网站为采集,那么您的网站将有一个适应期,整个过程中所显示的症状适应期为:网站逐渐开始收录 文章页,但是收录不会立即更新文章,它可能会在前一天或前天进行更新。这些症状将持续大约一周,然后收录逐渐恢复正常,快照将缓慢恢复。
这一系列现象都在网站长时间处于别人采集的情况下出现,因此当您自己的网站中有某些此类现象时,您应该首先找到原因Is我每天更新的文章还是别人更新的采集。
如果您的网站确实处于这种情况下,则必须找到解决方案,当然其他人希望采集您的文章,您不能强迫说不让其他人离开采集,那又如何?我们可以做的就是改变自己。
1、提高页面权重
提高页面的重量可以从根本上解决此问题。我们都知道,像A5、Chinaz一样的网站每天都会被采集别人对待,但这并不影响A5、Chinaz 网站的收录,这是因为他们的体重足够高,当其他人网站与他们的文章看起来相同时,蜘蛛会默认使用他们的文章作为原创的来源。因此,我们必须增加文章页的权重,并为此页做更多的外部链接。
2、Rss合理使用
也有必要开发这种功能。更新网站 文章后,请尽快让搜索引擎知道并主动进行攻击。这对收录非常有用。而且Rss还可以有效地增加网站的流量,可以说用一块石头杀死了两只鸟。
3、做一些细节并限制机器的采集
手动采集没什么。如果没有人使用工具来计时并且大量采集您的网站 文章,这确实令人头疼,所以我们应该对页面的详细信息进行一些处理,至少可以防止机器采集 ]。例如,页面设计不应太过传统和流行。 Url的文字应稍作更改,并且不应使用默认的叠加层和其他设置。
当4、为采集时,更新的文章主要与他的网站相关
其他采集和我们的文章是因为它们也需要我们更新内容,因此,如果我们更新与自己网站相关的信息,我们经常会在采集中插入我们的网站名称,其他名称,我们认为文章对他们没有太大的意义,这也是避免采集的一种很好的方法。
文章通常是采集,肯定会影响我们,因此我们应该避免使用它,让我们的网站内容在互联网上具有唯一性,并改善百度对我们的待遇网站使我们的优化工作更加顺畅。
本文提到的现象是作者遇到的真实情况网站。 文章由Aidai.com提供,请附上转载的源链接
解决方法:文章被采集的处理方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-11-23 13:01
许多人讨厌别人瞬间复制他们的原创文章,有些人甚至用它发送一些垃圾链接。我特别相信,很多老年人都遇到过这种情况,有时他们的辛苦不如采集。我们如何处理这种情况?
首先,尝试让搜索引擎将此文章 收录放在对手的采集之前。
1、及时抓取文章,以使搜索引擎知道此文章。
2、Ping百度网站管理员自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章由作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、向文章添加了一些特征内容。
1、例如文章中的标记代码,例如N 1、 N2、颜色等。搜索引擎将对此更加敏感,并可以加深对原创的判断。
2、将自己的品牌词汇添加到文章
3、添加了一些内部链接,因为喜欢窃文章的人通常很懒,因此有些人可以直接复制和粘贴。
4、当在时间上添加文章时,搜索引擎将判断文章的独创性并参考时间因素。
阻止网页的正确按键功能
当大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最怕的是对手知道你的习惯,尤其是在白天。许多人白天喜欢更新文章,而其他人则盯着他们看,然后立即[窃文章。
这些方法可以在我们的网站上看到和应用,我相信这可以减少集合文章。 查看全部
如何处理文章为采集
许多人讨厌别人瞬间复制他们的原创文章,有些人甚至用它发送一些垃圾链接。我特别相信,很多老年人都遇到过这种情况,有时他们的辛苦不如采集。我们如何处理这种情况?
首先,尝试让搜索引擎将此文章 收录放在对手的采集之前。
1、及时抓取文章,以使搜索引擎知道此文章。
2、Ping百度网站管理员自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章由作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、向文章添加了一些特征内容。
1、例如文章中的标记代码,例如N 1、 N2、颜色等。搜索引擎将对此更加敏感,并可以加深对原创的判断。
2、将自己的品牌词汇添加到文章
3、添加了一些内部链接,因为喜欢窃文章的人通常很懒,因此有些人可以直接复制和粘贴。
4、当在时间上添加文章时,搜索引擎将判断文章的独创性并参考时间因素。
阻止网页的正确按键功能
当大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器的麻烦。
5、晚上更新
采集最怕的是对手知道你的习惯,尤其是在白天。许多人白天喜欢更新文章,而其他人则盯着他们看,然后立即[窃文章。
这些方法可以在我们的网站上看到和应用,我相信这可以减少集合文章。
解决方案:dedecms采集文档审核后生成文档以采集时间显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-11-14 13:00
对于网站的每日更新,许多网站管理员会选择使用采集来丰富网站的内容。对于采集,它会占用php虚拟主机的资源,并且“无忧无虑”主机的编辑器强烈建议不要使用采集。尽管采集可以丰富网站的内容,但很容易被检索引擎判断为作弊,并且存在降低功率并停止收录的风险。今天,一个用户问:采集完成采集之后,dedecms生成文档之后的时间是采集的时间,如何解决这个问题?有了这个问题,让我们开始今天的文档共享。审核dedecms采集文档后,生成的文档在采集时间中显示如下:1、首先,单击进入我们的控制面板,然后找到文件管理选项,如图所示:
2、单击进入并找到我们网站的根目录,如图所示:
3、进入此目录后,找到我们程序后端的路径:/dede/archives_do.php,单击edit,如图所示:
4、修改代码操作,如图所示:
查找代码:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set arcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set arcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set arcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
修改为:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$newdate = time();
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set sortrank=$newdatesenddate=$newdatearcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
提醒:此技术解决方案是由无忧主机客户服务提供的处理方法,用于为我们的航天客户解决该问题,以确保可以在无忧主机中完美实现。由于更多的服务和繁忙的客户服务,我们没有足够的精力进行大规模测试,所以无法确保所有虚拟主机都能得到完美处理,请谅解!无忧的主机提供365天*一天24小时,全天,实时在线和零等待的售后技术支持。我们将尽最大努力为您免费使用无忧主机的过程中遇到的所有问题!如果您是无忧主机用户,则可以使用企业QQ [800088151],售后QQ [网站最底端],网旺[风讯企业],免费电话和后台提交工作订购无忧主机的客户服务!如果您不是我们的客户,没问题,请单击页面最右侧的公司QQ在线咨询图标与我们联系并购买,我们将为您提供免费的无缝移动服务,让您享受网站零访问权限延迟迁移到无忧的主机服务!与无忧托管相关的文章推荐阅读: 查看全部
dedecms采集审核文档后,生成的文档将在采集时间显示
对于网站的每日更新,许多网站管理员会选择使用采集来丰富网站的内容。对于采集,它会占用php虚拟主机的资源,并且“无忧无虑”主机的编辑器强烈建议不要使用采集。尽管采集可以丰富网站的内容,但很容易被检索引擎判断为作弊,并且存在降低功率并停止收录的风险。今天,一个用户问:采集完成采集之后,dedecms生成文档之后的时间是采集的时间,如何解决这个问题?有了这个问题,让我们开始今天的文档共享。审核dedecms采集文档后,生成的文档在采集时间中显示如下:1、首先,单击进入我们的控制面板,然后找到文件管理选项,如图所示:
2、单击进入并找到我们网站的根目录,如图所示:
3、进入此目录后,找到我们程序后端的路径:/dede/archives_do.php,单击edit,如图所示:
4、修改代码操作,如图所示:
查找代码:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set arcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set arcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set arcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
修改为:
$maintable = ( trim($row[maintable])== ? dede_archives : trim($row[maintable]) );
$newdate = time();
$dsql>ExecuteNoneQuery("Update `dede_arctiny` set sortrank=$newdatesenddate=$newdatearcrank= where id=$aid ");
if($row[issystem]==)
{
$dsql>ExecuteNoneQuery("Update `"trim($row[addtable])"` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where aid=$aid ");
}
else
{
$dsql>ExecuteNoneQuery("Update `$maintable` set sortrank=$newdatepubdate=$newdatesenddate=$newdatearcrank= where id=$aid ");
}
$pageurl = MakeArt($aidfalse);
}
ShowMsg("成功审核指定的文档!"$ENV_GOBACK_URL);
提醒:此技术解决方案是由无忧主机客户服务提供的处理方法,用于为我们的航天客户解决该问题,以确保可以在无忧主机中完美实现。由于更多的服务和繁忙的客户服务,我们没有足够的精力进行大规模测试,所以无法确保所有虚拟主机都能得到完美处理,请谅解!无忧的主机提供365天*一天24小时,全天,实时在线和零等待的售后技术支持。我们将尽最大努力为您免费使用无忧主机的过程中遇到的所有问题!如果您是无忧主机用户,则可以使用企业QQ [800088151],售后QQ [网站最底端],网旺[风讯企业],免费电话和后台提交工作订购无忧主机的客户服务!如果您不是我们的客户,没问题,请单击页面最右侧的公司QQ在线咨询图标与我们联系并购买,我们将为您提供免费的无缝移动服务,让您享受网站零访问权限延迟迁移到无忧的主机服务!与无忧托管相关的文章推荐阅读:
干货:爆款文章怎么搜集?看完这篇文章就懂了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 592 次浏览 • 2020-10-26 10:04
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,从而使搜索内容更加准确。
2、广告过滤 查看全部
如何采集热钱文章?阅读此文章之后,您将了解!
在流行期间,许多公司不得不选择远程在线办公室。互联网是受流行病影响较小的行业之一。但是,远程办公室的效率仍然不如面对面的工作。因此,优采云采集特别推出了智能采集工具。
我相信许多操作员已经接触过采集工具。市场上有很多采集工具。许多人认为采集工具仅用作文章热门/节日主题和其他信息采集的辅助工具,实际上,不仅如此。成熟的采集工具不仅可以帮助操作采集信息,而且可以准确地分析数据趋势,从而有助于增加收入
1、什么是优采云采集?
优采云采集是用于自媒体素材搜索,文章 原创一键式发布的操作工具,可有效提高新媒体运营的效率并降低公司成本。
2、如何用优采云采集搜索?
([1)输入关键词
优采云采集根据用户输入的关键词,搜索引擎会通过程序自动输入主流自媒体数据源进行搜索。
优采云采集基于高级算法匹配更准确的内容,以提高搜索内容的准确性。
例如:
用户需要采集与流行病有关的资料,并在主页上输入关键词“流行病”。 优采云采集会将搜索结果合并到一个列表中。
([2)保存搜索材料
优采云采集具有批量保存搜索资料的功能。
单击[在当前页上全部选择]功能,然后选中所需的文章,文章将添加到操作面板中,方便用户批量保存。
([3)精确过滤
1、搜索过滤器
优采云采集支持根据标题,内容,时间,平台,是否为原创等参数进行过滤,从而使搜索内容更加准确。
2、广告过滤
分享:微信公众号文章采集的入口--历史消息页详解
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-10-20 09:01
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,即可在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要一个官方帐户采集的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将介绍如何根据历史新闻中的文章链接地址获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我对自己写的内容不甚了解,或者有不明白的地方,请在下面发表评论。或骚扰微信帐户翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集的进入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,高级使用anyproxy 查看全部
微信公众号文章采集的进入-历史新闻页面的详细说明
采集 WeChat文章和采集 网站具有相同的内容,都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如前一篇文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有官方帐户中唯一的帐户。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址过期之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果我们想自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到以getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,即可在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍一些重要信息,而其他信息则省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的消息内容历史记录,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy匹配msgList变量值并将其异步提交到服务器,然后使用php的json_decode将json解析为服务器。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要一个官方帐户采集的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将介绍如何根据历史新闻中的文章链接地址获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我对自己写的内容不甚了解,或者有不明白的地方,请在下面发表评论。或骚扰微信帐户翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集的进入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,高级使用anyproxy
解读:文章被采集应该怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-09-14 08:02
了文章该怎么办?
您是否遇到过这种情况。打开其他人的网站,看看自己写的文章。你在生气吗?每次我一个人写作时,您是否觉得自己讨厌他们?我们如何处理这种情况?
一、尝试让搜索引擎在对手的采集
之前收录
这篇文章。
1、及时抓取文章,以使搜索引擎知道它。
2、 Ping百度网站站长自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章按作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、在文章中添加一些特色内容
1、例如,文章中的标签代码(例如N 1、 N 2、 color等),搜索引擎将对此更加敏感,并可以加深对其创意的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些内部链接,因为喜欢like窃文章的人通常很懒,并且不排除某些人可以直接复制和粘贴。
4、将文章添加到时间后,搜索引擎将判断文章的原创性并参考时间因素。
阻止网页的正确按键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器
的麻烦。
5、晚上更新
最可怕的聚会是对手了解你的习惯,尤其是在白天。许多人喜欢在白天更新文章,但是却被其他人盯着看,并且文章被pla窃。
采用上述方法可以防止我辛苦写的文章被采集
。 查看全部
如果采集
了文章该怎么办?
您是否遇到过这种情况。打开其他人的网站,看看自己写的文章。你在生气吗?每次我一个人写作时,您是否觉得自己讨厌他们?我们如何处理这种情况?
一、尝试让搜索引擎在对手的采集
之前收录
这篇文章。
1、及时抓取文章,以使搜索引擎知道它。
2、 Ping百度网站站长自己的文章链接,这也是百度正式告诉我们的一种方式。
二、文章按作者或版本标记
尽管有时无法阻止他人复制您的文章,但这也是书面交流和建议,总比没有好。
三、在文章中添加一些特色内容
1、例如,文章中的标签代码(例如N 1、 N 2、 color等),搜索引擎将对此更加敏感,并可以加深对其创意的判断。
2、在文章中添加您自己的品牌词汇
3、添加了一些内部链接,因为喜欢like窃文章的人通常很懒,并且不排除某些人可以直接复制和粘贴。
4、将文章添加到时间后,搜索引擎将判断文章的原创性并参考时间因素。
阻止网页的正确按键功能
大多数人使用鼠标右键复制文章时,如果该技术不受此功能的影响,无疑会增加采集器
的麻烦。
5、晚上更新
最可怕的聚会是对手了解你的习惯,尤其是在白天。许多人喜欢在白天更新文章,但是却被其他人盯着看,并且文章被pla窃。
采用上述方法可以防止我辛苦写的文章被采集
。
解决方案:网站文章内容来源是否让你头疼不已?看完文章就能解决!
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-09-05 04:00
1、公司新闻,您可以将公司的近期活动和公告整理到文章中
2、产品使用情况介绍,产品使用情况详细介绍或产品使用后等信息都组织为文章
3、如果咨询量很大,则可以将客户服务和用户之间的对话变成文章
1、寻找一些网站来阻止蜘蛛爬行,然后直接采集他们的网站 文章。
2、打开外来网站,直接打开采集! !
3、 采集国内商品文章,然后将其更改为伪原创!
在互联网上找到作家来写作,如果您无法写作,则SEO将完成
网站的内容是整个网站的核心,内容的质量是搜索引擎判断网站的质量的重要指标。因此,内容的来源限制了整个网站的发展。对于中小企业网站而言,网站内容稀缺性普遍存在。因此,如何获得大量的高质量网站内容已成为这些网站网站站长在构建过程中最头疼的问题。这里的MetInfo可以教您如何获取稳定的高质量网站内容源流。
1:编写自己的原创 文章
原创 文章在搜索引擎中最受欢迎。编写原创 文章的目的是让搜索引擎知道我们的网站具有高质量的内容。不断更新高质量内容的网站将吸引搜索引擎的索引,这也将促进网站内容的更新。
此外,这些高质量的原创内容将由许多网站管理员重新发布,或者由许多文章 采集器进行爬网,这将始终产生许多出色的外部链接,但是您要编写原创的[k8 ] 文章消耗更多时间和精力。您可能会说:怎么有这么多原创内容?一位大师曾经就此问题发表过意见。以下是他关于扩大不受欢迎的产品内容的建议。
(1)从产品的历史和演变开始:该产品是如何发明的,每次更新的过程是什么?发明人和改进者是谁?产品的具体贡献是什么,获得了哪些奖项?如果您的公司发明了此产品,那么还有更多要写的东西;
(2)从产品制造者开始:研发团队的成员,背景,经验以及直接生产工人需要哪些技能;
(3)从原材料开始:产品是用什么原材料制造的,哪里生产的是最好的原材料,为什么?等等;
当然,有很多角度。您可以围绕产品开始描述。只要您开阔思路,任何产品都可以编写很多相关内容。
2:“ 原创”重印内容
“ 原创”的重印内容也称为文章汇编。如果我们看到文章文章,并认为其中的某些要点与我们不一致,则可以从原创文本中提取要点,并发表自己的观点;或者,如果我们认为文章中的点有扩展的余地,您还可以继续按照原创作者的想法来扩展原创文本。但是在这里,请记住一个原则,那就是重新创建的文本信息的内容。尝试获取比摘录更多的信息。
3:鼓励用户贡献内容
实际上,网站的访问者有时也强烈希望进行写作和交流。因此,我们可以不断提高网站的交互功能。最简单的方法之一是打开网站内容的注释功能。让用户参与网站的信息内容构建。当然,如果它是基于内容的网站,则打开网站的提交界面,允许用户通过此接口将其创建的内容提交给网站编辑器。 ?
4:翻译外来原创 文章
国外有许多优秀而有影响力的文章。如果英语足够好,您还可以翻译一些更有影响力的外语文章。对于搜索引擎来说,用不同文本书写的文章是不同的。如果您没有足够的能力写原创 文章,则翻译别人的文章可能不是一个好方法。
5:采集行业信息
现在有许多论坛的权重更高,内容也更好。这些论坛存储了大量高质量的信息。无论是前沿内容还是最新行业趋势,这些论坛都有及时有效的内容,因此您可以搜索整理为文章的这些内容,也可以用作出色的原创 文章。
6:适当的“ 伪原创”
如果网站的内容可以为原创,那是最好的方法。如果不能,也可以尝试适当的伪原创。当我们收到别人的文章文章时,您可以进行以下编辑伪原创
([1) 文章标题修改
排序方法:文章标题顺序可以修改,但其原创含义不能更改,例如:美国主机VS香港主机的优势,我们可以将其更改为香港主机的劣势VS美国主机;
文本减少/添加,替换方法:在原创标题上添加或减少一些文本,例如:选择MetInfo cms系统的新手用户的五个优点可以变为选择MetInfo的新手用户的五个优点建立一个网站;
([2)文本修改
重写内容的第一段:搜索导致蜘蛛重视文章的第一段及其重要性,因此,请尝试自己重写第一段并带来网站 关键词,不要太长,只是超过100个字;
插入链接方法:在文本中插入您自己的网站链接,当其他人采集我们的文章时,等效于为我们网站做一个外部链接;
分割方法:将原创文章内容平均分成几段,然后更改段落顺序以继续伪原创;
<p>标签方法:使用关键词在文章上添加友谊便笺,这样您不仅可以自然地重复关键词,增加关键词的密度,还可以让客户了解更多不熟悉的专业术语; 查看全部
网站 文章内容来源会让您头痛吗?读完文章即可解决!
1、公司新闻,您可以将公司的近期活动和公告整理到文章中
2、产品使用情况介绍,产品使用情况详细介绍或产品使用后等信息都组织为文章
3、如果咨询量很大,则可以将客户服务和用户之间的对话变成文章
1、寻找一些网站来阻止蜘蛛爬行,然后直接采集他们的网站 文章。
2、打开外来网站,直接打开采集! !
3、 采集国内商品文章,然后将其更改为伪原创!
在互联网上找到作家来写作,如果您无法写作,则SEO将完成
网站的内容是整个网站的核心,内容的质量是搜索引擎判断网站的质量的重要指标。因此,内容的来源限制了整个网站的发展。对于中小企业网站而言,网站内容稀缺性普遍存在。因此,如何获得大量的高质量网站内容已成为这些网站网站站长在构建过程中最头疼的问题。这里的MetInfo可以教您如何获取稳定的高质量网站内容源流。
1:编写自己的原创 文章
原创 文章在搜索引擎中最受欢迎。编写原创 文章的目的是让搜索引擎知道我们的网站具有高质量的内容。不断更新高质量内容的网站将吸引搜索引擎的索引,这也将促进网站内容的更新。
此外,这些高质量的原创内容将由许多网站管理员重新发布,或者由许多文章 采集器进行爬网,这将始终产生许多出色的外部链接,但是您要编写原创的[k8 ] 文章消耗更多时间和精力。您可能会说:怎么有这么多原创内容?一位大师曾经就此问题发表过意见。以下是他关于扩大不受欢迎的产品内容的建议。
(1)从产品的历史和演变开始:该产品是如何发明的,每次更新的过程是什么?发明人和改进者是谁?产品的具体贡献是什么,获得了哪些奖项?如果您的公司发明了此产品,那么还有更多要写的东西;
(2)从产品制造者开始:研发团队的成员,背景,经验以及直接生产工人需要哪些技能;
(3)从原材料开始:产品是用什么原材料制造的,哪里生产的是最好的原材料,为什么?等等;
当然,有很多角度。您可以围绕产品开始描述。只要您开阔思路,任何产品都可以编写很多相关内容。
2:“ 原创”重印内容
“ 原创”的重印内容也称为文章汇编。如果我们看到文章文章,并认为其中的某些要点与我们不一致,则可以从原创文本中提取要点,并发表自己的观点;或者,如果我们认为文章中的点有扩展的余地,您还可以继续按照原创作者的想法来扩展原创文本。但是在这里,请记住一个原则,那就是重新创建的文本信息的内容。尝试获取比摘录更多的信息。
3:鼓励用户贡献内容
实际上,网站的访问者有时也强烈希望进行写作和交流。因此,我们可以不断提高网站的交互功能。最简单的方法之一是打开网站内容的注释功能。让用户参与网站的信息内容构建。当然,如果它是基于内容的网站,则打开网站的提交界面,允许用户通过此接口将其创建的内容提交给网站编辑器。 ?
4:翻译外来原创 文章
国外有许多优秀而有影响力的文章。如果英语足够好,您还可以翻译一些更有影响力的外语文章。对于搜索引擎来说,用不同文本书写的文章是不同的。如果您没有足够的能力写原创 文章,则翻译别人的文章可能不是一个好方法。
5:采集行业信息
现在有许多论坛的权重更高,内容也更好。这些论坛存储了大量高质量的信息。无论是前沿内容还是最新行业趋势,这些论坛都有及时有效的内容,因此您可以搜索整理为文章的这些内容,也可以用作出色的原创 文章。
6:适当的“ 伪原创”
如果网站的内容可以为原创,那是最好的方法。如果不能,也可以尝试适当的伪原创。当我们收到别人的文章文章时,您可以进行以下编辑伪原创
([1) 文章标题修改
排序方法:文章标题顺序可以修改,但其原创含义不能更改,例如:美国主机VS香港主机的优势,我们可以将其更改为香港主机的劣势VS美国主机;
文本减少/添加,替换方法:在原创标题上添加或减少一些文本,例如:选择MetInfo cms系统的新手用户的五个优点可以变为选择MetInfo的新手用户的五个优点建立一个网站;
([2)文本修改
重写内容的第一段:搜索导致蜘蛛重视文章的第一段及其重要性,因此,请尝试自己重写第一段并带来网站 关键词,不要太长,只是超过100个字;
插入链接方法:在文本中插入您自己的网站链接,当其他人采集我们的文章时,等效于为我们网站做一个外部链接;
分割方法:将原创文章内容平均分成几段,然后更改段落顺序以继续伪原创;
<p>标签方法:使用关键词在文章上添加友谊便笺,这样您不仅可以自然地重复关键词,增加关键词的密度,还可以让客户了解更多不熟悉的专业术语;
分享:易语言微信公众号文章采集思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-09-03 18:10
由于某些原因,Hong Yu需要采集微信公众号文章。
别胡说八道,只是说说要点。
最初的想法很简单。当时是使用搜狗微信搜索功能来采集,但未执行时我看到了一些注释。
说到搜狗微信,如果采集的文章不完整且采集太多,则会屏蔽IP。
因此,我果断地放弃了,甚至没有研究它,因为洪宇知道此搜索引擎的采集相对简单。如果每个人都是采集,则确实会对服务器造成压力。
Hong Yu开始考虑第二套计划,直接考虑采集官方帐户。
可以在网络上打开官方帐户的文章链接,但不能再在PC端打开官方帐户文章的历史记录。有一个问题,采集官方帐户的文章链接是不可能的。
要打开历史文章,洪宇想到了两种方法。一种是使用模拟器来模拟手机环境并打开链接。另一种是使用网页微信打开官方帐户历史记录链接。
当然,直接在网络上使用微信绝对比使用模拟器更容易。
Hong Yu发现无法打开网页微信。只能安装客户端以在PC上打开微信。幸运的是,仍然可以看到官方帐户文章的历史记录。
这时,问题又来了,我该如何在模拟器或客户端中获取历史记录文章的内容,然后链接采集。
洪宇想到的第一件事是互联网拦截和数据包捕获,现在提琴手越来越流行。
但是您无法直接批量获取和过滤这些数据,因此请考虑直接在Yilang中捕获数据包的方法,捕获的数据包,网络拦截以及已读取过程的方法...
结果,经过长时间的搜索,我找不到一种简单有效的方法。有一个使用模拟器捕获数据包的教程,但是我仍然使用提琴手来捕获数据包...
最后,Hong Yu想从微信客户端的句柄开始。
使用编程助手获取窗口句柄,Hong Yu惊讶地发现原创的官方帐户内容在微信客户端上以内置浏览器的形式显示,包括历史记录文章。
尽管它是Google核心的浏览器,但无法通过填写表单进行操作,但它已经非常好。
我们可以使用鼠标模拟方法制作微信客户端,然后获取内置浏览器的网页源代码。有了源代码,一切都很容易。
剩下的就是过滤有用的信息。
只要采集链接到每个文章文章,就可以了,因为可以在PC浏览器中打开单个文章文章的链接。换句话说,可以直接读取源代码采集至文章。
现在,完成输入。
要组织该过程,我们必须首先注意采集的官方帐户,然后在登录微信的PC客户端中打开历史记录文章页面,获取源代码,然后使用采集至文章软件链接。然后直接读取文章的源代码和采集 文章的内容。
作为个人,这是一种傻瓜式采集方法。它不需要困难的技术,也不需要涉及微信官方账号的开发。唯一的缺点是效率相对较慢。
但是作为个人采集,就足够了。 查看全部
彝语微信公众号文章 采集想法
由于某些原因,Hong Yu需要采集微信公众号文章。
别胡说八道,只是说说要点。
最初的想法很简单。当时是使用搜狗微信搜索功能来采集,但未执行时我看到了一些注释。
说到搜狗微信,如果采集的文章不完整且采集太多,则会屏蔽IP。
因此,我果断地放弃了,甚至没有研究它,因为洪宇知道此搜索引擎的采集相对简单。如果每个人都是采集,则确实会对服务器造成压力。
Hong Yu开始考虑第二套计划,直接考虑采集官方帐户。
可以在网络上打开官方帐户的文章链接,但不能再在PC端打开官方帐户文章的历史记录。有一个问题,采集官方帐户的文章链接是不可能的。
要打开历史文章,洪宇想到了两种方法。一种是使用模拟器来模拟手机环境并打开链接。另一种是使用网页微信打开官方帐户历史记录链接。
当然,直接在网络上使用微信绝对比使用模拟器更容易。
Hong Yu发现无法打开网页微信。只能安装客户端以在PC上打开微信。幸运的是,仍然可以看到官方帐户文章的历史记录。
这时,问题又来了,我该如何在模拟器或客户端中获取历史记录文章的内容,然后链接采集。
洪宇想到的第一件事是互联网拦截和数据包捕获,现在提琴手越来越流行。
但是您无法直接批量获取和过滤这些数据,因此请考虑直接在Yilang中捕获数据包的方法,捕获的数据包,网络拦截以及已读取过程的方法...
结果,经过长时间的搜索,我找不到一种简单有效的方法。有一个使用模拟器捕获数据包的教程,但是我仍然使用提琴手来捕获数据包...
最后,Hong Yu想从微信客户端的句柄开始。
使用编程助手获取窗口句柄,Hong Yu惊讶地发现原创的官方帐户内容在微信客户端上以内置浏览器的形式显示,包括历史记录文章。
尽管它是Google核心的浏览器,但无法通过填写表单进行操作,但它已经非常好。
我们可以使用鼠标模拟方法制作微信客户端,然后获取内置浏览器的网页源代码。有了源代码,一切都很容易。
剩下的就是过滤有用的信息。
只要采集链接到每个文章文章,就可以了,因为可以在PC浏览器中打开单个文章文章的链接。换句话说,可以直接读取源代码采集至文章。
现在,完成输入。
要组织该过程,我们必须首先注意采集的官方帐户,然后在登录微信的PC客户端中打开历史记录文章页面,获取源代码,然后使用采集至文章软件链接。然后直接读取文章的源代码和采集 文章的内容。
作为个人,这是一种傻瓜式采集方法。它不需要困难的技术,也不需要涉及微信官方账号的开发。唯一的缺点是效率相对较慢。
但是作为个人采集,就足够了。
企业建设网站用数据采集功能对网站有哪些影响?
采集交流 • 优采云 发表了文章 • 0 个评论 • 336 次浏览 • 2020-08-27 04:52
在现今无论做哪些都用数据来说话的时代,掌握一定的数据在进行剖析,能够帮助企业更好的去规划与市场定位。那么企业建设的网站真的须要用数据采集功能吗?用数据采集功能以后对网站是好还是不好?上海网站设计松一公司的小编经过和朋友的讨论,再加小编自己的研究和理解给大谈谈数据采集的历史和方法以及对网站有哪些影响。
首先,小编带你们先来了解一下网站数据采集这个功能是如何回事。网站数据采集分为两个阶段:一个阶段就是C2C没有盛行之前,采集网站数据主要是一些小型的搜索引擎公司,像百度、谷歌它们用采集数据功能是通过网路爬虫来实现所须要的信息采集。第二个阶段就是C2C盛行以后,随着互联网的发,企业建设网站或个人建设网站或者机构建站为了快速填充网站上空缺的信息,通过采集其它类似网站上的内容信息使自己的网站丰富。
第二个阶段开始越来越多的企业或个人用网站数据采集功能了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后才能发布的。
其次,网站数据采集方式有二种:一种是传统的采集方式,主要人工采集方式,现在还有一部企业或个人在用,简单来说:“就是把他人网站的信息通过复制、粘贴的形式放在自己的网站上。一种是软件数据采集方式,这个方法就是因为传统的人工复制方法费时又吃力,然后随着软件技术的发展,软件公司为了适应市场开发下来的数据采集功能软件来满足市场需求。
End,介绍完数据采集功能历史方法,相信你们也应当晓得数据采集是哪些个概念了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后就会发布的。
为什么采集功能在如今几乎没有人用了呢!简单来说,搜索引擎不喜欢,对这样的网站不会给权重更不会给排名,搞不好网站还会被百度给拉入黑名单。因搜索引擎如今都喜欢用户去用心原创的高质量内容,如果一个四处去复制信息的网站搜索引擎都能排行挺好的话,那么谁还去花心思去撰写文章呢?在说一个网站上发布的都是从他人那儿复制过来的,一点自己的特色也没有,是不帮企业带来顾客,那么企业建设网站就丧失了意义。 查看全部
企业建设网站用数据采集功能对网站有哪些影响?
在现今无论做哪些都用数据来说话的时代,掌握一定的数据在进行剖析,能够帮助企业更好的去规划与市场定位。那么企业建设的网站真的须要用数据采集功能吗?用数据采集功能以后对网站是好还是不好?上海网站设计松一公司的小编经过和朋友的讨论,再加小编自己的研究和理解给大谈谈数据采集的历史和方法以及对网站有哪些影响。
首先,小编带你们先来了解一下网站数据采集这个功能是如何回事。网站数据采集分为两个阶段:一个阶段就是C2C没有盛行之前,采集网站数据主要是一些小型的搜索引擎公司,像百度、谷歌它们用采集数据功能是通过网路爬虫来实现所须要的信息采集。第二个阶段就是C2C盛行以后,随着互联网的发,企业建设网站或个人建设网站或者机构建站为了快速填充网站上空缺的信息,通过采集其它类似网站上的内容信息使自己的网站丰富。
第二个阶段开始越来越多的企业或个人用网站数据采集功能了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后才能发布的。
其次,网站数据采集方式有二种:一种是传统的采集方式,主要人工采集方式,现在还有一部企业或个人在用,简单来说:“就是把他人网站的信息通过复制、粘贴的形式放在自己的网站上。一种是软件数据采集方式,这个方法就是因为传统的人工复制方法费时又吃力,然后随着软件技术的发展,软件公司为了适应市场开发下来的数据采集功能软件来满足市场需求。
End,介绍完数据采集功能历史方法,相信你们也应当晓得数据采集是哪些个概念了。根据互联网技术发展示和互联网对信息内容要求丰富多彩,似乎越来越少的人用数据采集信息了,就算是现今很大的信息平台也不用数据采集信息了,也都是人工进行编辑后就会发布的。
为什么采集功能在如今几乎没有人用了呢!简单来说,搜索引擎不喜欢,对这样的网站不会给权重更不会给排名,搞不好网站还会被百度给拉入黑名单。因搜索引擎如今都喜欢用户去用心原创的高质量内容,如果一个四处去复制信息的网站搜索引擎都能排行挺好的话,那么谁还去花心思去撰写文章呢?在说一个网站上发布的都是从他人那儿复制过来的,一点自己的特色也没有,是不帮企业带来顾客,那么企业建设网站就丧失了意义。
采集数据的方式有几种,采集数据的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2020-08-27 00:12
在我们进行数据剖析的时侯,都是须要根据既定的步骤进行,谁也不能直接就就能得到想要的剖析结果。一般来说,我们在进行数据剖析的时侯会分为以下几个步骤:
1.前期设计数据剖析方案和内容
2.采集数据
3.处理数据及展示数据
4.进行数据剖析
通过以上四个步骤基本上就才能完成一个完整的数据剖析过程。我们在进行任何一个数据剖析之前的首要任务就是明晰我们的目的是哪些,为什么要做这个数据剖析,我们须要用这个数据剖析结果解决哪些问题。只有明晰了数据剖析的目的,我们才不会偏离我们的方向,不然我们最终得出的数据剖析结果是没有任何指导意义的,甚至可能会导致连锁反应,造成一个错误决策的诞生。
当我们明晰了剖析的目的,接下来就须要将过程拆解开来,找到不同的剖析要点,沿着一条线一步一步的去进行,在这个过程中我们须要确定怎样找数据,用什么剖析方式,需要耗费多长的周期和预算。这样的话我们整个数据剖析过程就得到了保障,得到的结果也是符合我们的剖析目的。
在搜集数据的时侯,一般我们把数据类型分为一手数据和二手数据这两个类型。其中一手数据主要是指我们可以直接得到的数据,二手数据主要是指我们须要通过一定的方法对原创数据进行加工处理最后得到的可以进行使用的数据。而在搜集数据的时侯,一手数据和二手数据的来源是不一样的,所以我们须要从不同的地方去搜集。
一手数据
一手数据的搜集技巧我们通常有三种,分别是问答法、观察法和直接实验法。其中问答法指的是我们直接和被调查者进行交流,通过当面或则电话这类的形式,直接想被调查者提出我们的问题,从而直接获得我们须要的数据,在数据搜集中比较常见。观察法比较具象一点,主要是针对我们的剖析目的,对被调查对象进行观察,从而获得我们所须要的数据,目的性比较强,同时也可重复进行。最后一种直接实验法就是通过在一定条件下的规模实验,通过实验结果得到我们想要的数据。这种方式应用范围比较广泛,在好多社会和科学领域都在使用。
二手数据
二手数据的搜集途径我们通常也分三种,分别是数据库、社会公开出版物、互联网这三个途径。其中数据库你们肯定都有接触,现在基本上任何一家企业就会有自己的数据库,我们在进行数据剖析的时侯可以直接从数据库中调阅企业历年的经营数据。社会公开出版物指的是一些专业性的数据期刊,比如一些统计年鉴和统计报告,我们可以从中得到我们想要的数据。最后一种互联网你们肯定都晓得,我们可以借助搜索引擎得到绝大多数我们想要的数据,在一些门户网站中好多时侯都是可以直接下载相关的数据。
到这儿就基本上给你们介绍完数据剖析中数据的类型以及怎样搜集了。我们在进行数据剖析的时侯一定要首先确定剖析目的,这样的话就能够循序渐进,最后得到我们想要的剖析结果。 查看全部
采集数据的方式有几种,采集数据的方法
在我们进行数据剖析的时侯,都是须要根据既定的步骤进行,谁也不能直接就就能得到想要的剖析结果。一般来说,我们在进行数据剖析的时侯会分为以下几个步骤:
1.前期设计数据剖析方案和内容
2.采集数据
3.处理数据及展示数据
4.进行数据剖析
通过以上四个步骤基本上就才能完成一个完整的数据剖析过程。我们在进行任何一个数据剖析之前的首要任务就是明晰我们的目的是哪些,为什么要做这个数据剖析,我们须要用这个数据剖析结果解决哪些问题。只有明晰了数据剖析的目的,我们才不会偏离我们的方向,不然我们最终得出的数据剖析结果是没有任何指导意义的,甚至可能会导致连锁反应,造成一个错误决策的诞生。
当我们明晰了剖析的目的,接下来就须要将过程拆解开来,找到不同的剖析要点,沿着一条线一步一步的去进行,在这个过程中我们须要确定怎样找数据,用什么剖析方式,需要耗费多长的周期和预算。这样的话我们整个数据剖析过程就得到了保障,得到的结果也是符合我们的剖析目的。
在搜集数据的时侯,一般我们把数据类型分为一手数据和二手数据这两个类型。其中一手数据主要是指我们可以直接得到的数据,二手数据主要是指我们须要通过一定的方法对原创数据进行加工处理最后得到的可以进行使用的数据。而在搜集数据的时侯,一手数据和二手数据的来源是不一样的,所以我们须要从不同的地方去搜集。
一手数据
一手数据的搜集技巧我们通常有三种,分别是问答法、观察法和直接实验法。其中问答法指的是我们直接和被调查者进行交流,通过当面或则电话这类的形式,直接想被调查者提出我们的问题,从而直接获得我们须要的数据,在数据搜集中比较常见。观察法比较具象一点,主要是针对我们的剖析目的,对被调查对象进行观察,从而获得我们所须要的数据,目的性比较强,同时也可重复进行。最后一种直接实验法就是通过在一定条件下的规模实验,通过实验结果得到我们想要的数据。这种方式应用范围比较广泛,在好多社会和科学领域都在使用。
二手数据
二手数据的搜集途径我们通常也分三种,分别是数据库、社会公开出版物、互联网这三个途径。其中数据库你们肯定都有接触,现在基本上任何一家企业就会有自己的数据库,我们在进行数据剖析的时侯可以直接从数据库中调阅企业历年的经营数据。社会公开出版物指的是一些专业性的数据期刊,比如一些统计年鉴和统计报告,我们可以从中得到我们想要的数据。最后一种互联网你们肯定都晓得,我们可以借助搜索引擎得到绝大多数我们想要的数据,在一些门户网站中好多时侯都是可以直接下载相关的数据。
到这儿就基本上给你们介绍完数据剖析中数据的类型以及怎样搜集了。我们在进行数据剖析的时侯一定要首先确定剖析目的,这样的话就能够循序渐进,最后得到我们想要的剖析结果。
站长降低网站内容绝对不能用采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-08-26 04:14
现在好多站长为了给自己的网站填充内容,都用采集工具给网站增加内容,这样做可以大大降低人力,但是常年这样的做的后果是给你的网站增加了一个不可抹除的失败理由。
给你们谈谈一下几种采集的都是会被搜索辨识下来的,所以请你们不要耍小聪明,因为搜索比你聪明多了:
首先我要给什么如今还在以采集而降低网站内容的同学提个醒了,虽然如今你的网站收录在不断的下降,而且速率很快,但哪天搜索觉得是该处理问题的时侯你的网站收录量会被搜索大大删节,而且权重也会大大的降低。现在没有出现这样的情况只是搜索还在考察你,等考察清楚后对于这样常年采集的网站就会得到上面所说的什么惩罚。
第一种采集方法、最近听到说是采集时只用采集的文章的一部分内容,这样搜索由于没见过这文章,以原创方法来收录的你网站页面,这样收录的太是厉害。这种情况我可以明晰的告诉你的是失败的做法,一段时间后搜索会渐渐的拒绝收录的你网站内的内容,为什么这样呢?一直采集的都是原文的部份内容,这样到了你网站里的内容却是没头没尾的内容了,这样搜索觉得你网站的权威性不够。
第二种采集方法、据了解现今的优采云等著名采集软件都具备同义词替换功能,例如“SEO”自动替换为“优化”这样的替换,虽然一开始只要你的替换单词多,那么一篇文章,可以说就有好多的成语会被替换掉。但是经过那么多的搜索的更新,搜索如今可以完完全全的辨识下来,所以借助这样功能来采集内容的结果是一样的。
第三种采集方法、这样情况更是常见了,就是把多个网站的内容都采集到自己的网站上。其实这样情况是最好理解的,不管你四处采集东西,还是在一个地方认真的采集东西,情况都是一样的,那就是采集,搜索对于采用这样方式的网站都是实施抛弃的动作。
其实那么三种方式都不可行,不是说不能用采集,只是要告诉你们降低网站的内容绝对是不能用采集的,如果你的网站内容有超过百分之五十都是采集过来的内容,那么你的网站危险了,请你们根据现网路上流程的更新原创、伪原创、转载的比列1:2:2来适当的降低网站内容。 查看全部
站长降低网站内容绝对不能用采集
现在好多站长为了给自己的网站填充内容,都用采集工具给网站增加内容,这样做可以大大降低人力,但是常年这样的做的后果是给你的网站增加了一个不可抹除的失败理由。
给你们谈谈一下几种采集的都是会被搜索辨识下来的,所以请你们不要耍小聪明,因为搜索比你聪明多了:
首先我要给什么如今还在以采集而降低网站内容的同学提个醒了,虽然如今你的网站收录在不断的下降,而且速率很快,但哪天搜索觉得是该处理问题的时侯你的网站收录量会被搜索大大删节,而且权重也会大大的降低。现在没有出现这样的情况只是搜索还在考察你,等考察清楚后对于这样常年采集的网站就会得到上面所说的什么惩罚。
第一种采集方法、最近听到说是采集时只用采集的文章的一部分内容,这样搜索由于没见过这文章,以原创方法来收录的你网站页面,这样收录的太是厉害。这种情况我可以明晰的告诉你的是失败的做法,一段时间后搜索会渐渐的拒绝收录的你网站内的内容,为什么这样呢?一直采集的都是原文的部份内容,这样到了你网站里的内容却是没头没尾的内容了,这样搜索觉得你网站的权威性不够。
第二种采集方法、据了解现今的优采云等著名采集软件都具备同义词替换功能,例如“SEO”自动替换为“优化”这样的替换,虽然一开始只要你的替换单词多,那么一篇文章,可以说就有好多的成语会被替换掉。但是经过那么多的搜索的更新,搜索如今可以完完全全的辨识下来,所以借助这样功能来采集内容的结果是一样的。
第三种采集方法、这样情况更是常见了,就是把多个网站的内容都采集到自己的网站上。其实这样情况是最好理解的,不管你四处采集东西,还是在一个地方认真的采集东西,情况都是一样的,那就是采集,搜索对于采用这样方式的网站都是实施抛弃的动作。
其实那么三种方式都不可行,不是说不能用采集,只是要告诉你们降低网站的内容绝对是不能用采集的,如果你的网站内容有超过百分之五十都是采集过来的内容,那么你的网站危险了,请你们根据现网路上流程的更新原创、伪原创、转载的比列1:2:2来适当的降低网站内容。
文章被常年别人采集的后果及防止方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-25 17:34
定期更新站内的文章几乎是每一个网站都会做的事情,当然不是每网站都重视原创,也不是每位网站都乐意花这个时间去做原创的文章,不少人就在用采集的形式在更新自己的网站文章。且不说大量采集他人文章的网站会怎么样,这里按照笔者自己网站的实际情况,说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
BaiduSpider喜欢原创的东西,但是百度蜘蛛对于原创源址的判定目前还难以做到精准的地步,它并不能完全自主的判定某一篇文章它的始发点是那里,当我们更新一篇文章,并且很快的被别人采集的时侯,蜘蛛可能同一时间接触了到好多一摸一样的文章,那么它还会太苦恼,并不清楚究竟那个是原创的,哪些是复制的。
因此,当我们的网站长期处于被采集的状态的时侯,我们网站上更新的文章大部分都在互联网上存在一样的内容,而如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。
当蜘蛛这样的看待你的网站的时侯,你网站可能还会遇到如此几种情况:
先文章页停止收录,然后整个网站不收录
这点是一定会发生的,因为被百度错判为采集站,所以你的文章页一定会被百度列为考察期,在这个期间,文章页是一定会停止收录的。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。笔者的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
网站收录开始降低,快照停滞
正如上面所说,百度会重新对你的网站进行审视,这个时侯,一定会发觉你网站存在着一些页面和互联网当中存在类似,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
排名并未有所波动,流量正常
当出现收录降低,快照停滞的时侯,我们最关心的问题就是排行的问题,担心排行会有所影响。这点到是可以放心,因为文章被采集,导致自己站遭到百度的考评,这个只是影响了百度对网站的信任度,并不会造成网站权重的增长,所以网站的关键词排行并不会遭到影响。
改善以后,网站收录仍然存在异常
假设我们发觉自己网站被采集之后,我们对网站进行了一些改善,成功的防止了网站被采集,那么你的网站还会有一个适应期,整个适应期表现下来的病症为:网站渐渐的开始收录文章页,但是收录的并不是即时更新的文章,有可能是前天的或则大前天更新的。这样的病症大约会存在1周的时间,之后收录会渐渐的趋向正常,快照也会渐渐的恢复。
这一系列的现象都是当网站处于常年被别人采集的情况下会出现的,所以当你自己的网站存在这样的一些现象的时侯,你首先要找的诱因就是自己每晚更新的文章是不是正在被他人采集。
如果你的网站确实是处于这样的情况,肯定是要想办法解决的,当然他人要采集你的文章,你不可能强制性的说不使他人去采集,所以我们能做的就是在自己本头上做一些改动。
1、提升页面权重
提升页面的权重是可以从根本上解决这个问题的,我们都晓得,像A5、Chinaz这样的网站每天还会被他人采集,但是这完全没有影响到A5、Chinaz网站的收录,这就是由于她们的权重足够的高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。所以一定要提高文章页面的权重,多做一些这个页面的外链。
2、Rss合理借助
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而且Rss也能有效降低网站的流量,可以说是一举两得。
3、做一些细节,限制机器的采集
被人工采集还没哪些,要是没人用工具定时、大量的采集你网站的文章,这确实使人太难受,所以我们应当在页面的细节上做一些处理,至少还能避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置。
4、被采集的时侯,更新的文章多与自己网站有关
别人采集我们的文章,是因为她们也须要我们更新的内容,所以假如我们更新的都是与自己网站有关的信息,经常会穿插我们网站的名称,别人在采集的时侯才会认为我们的文章对她们并没有太多的意义,这也是很不错的防止采集的形式。
文章经常被采集,这肯定是会对我们形成影响的,所以我们要尽量的去防止,让自己网站的内容在互联网当中成为唯一性,提升百度对我们网站的信任度,让我们的优化工作愈加顺畅。 查看全部
文章被常年别人采集的后果及防止方式
定期更新站内的文章几乎是每一个网站都会做的事情,当然不是每网站都重视原创,也不是每位网站都乐意花这个时间去做原创的文章,不少人就在用采集的形式在更新自己的网站文章。且不说大量采集他人文章的网站会怎么样,这里按照笔者自己网站的实际情况,说一说常年处于被别人采集文章的网站会有什么样的后果,以及要避开被别人采集的方式。
BaiduSpider喜欢原创的东西,但是百度蜘蛛对于原创源址的判定目前还难以做到精准的地步,它并不能完全自主的判定某一篇文章它的始发点是那里,当我们更新一篇文章,并且很快的被别人采集的时侯,蜘蛛可能同一时间接触了到好多一摸一样的文章,那么它还会太苦恼,并不清楚究竟那个是原创的,哪些是复制的。
因此,当我们的网站长期处于被采集的状态的时侯,我们网站上更新的文章大部分都在互联网上存在一样的内容,而如果网站权重又不够高,那么蜘蛛就太可能将你的网站列为采集站,它更相信你网站的文章是采集自互联网的,而不是互联网当中其他的站是采集你的文章。
当蜘蛛这样的看待你的网站的时侯,你网站可能还会遇到如此几种情况:
先文章页停止收录,然后整个网站不收录
这点是一定会发生的,因为被百度错判为采集站,所以你的文章页一定会被百度列为考察期,在这个期间,文章页是一定会停止收录的。当然这个停止收录不会只是影响你的文章页,它也会使那种百度重新初审你整个网站,所以其他的页面也会慢慢的开始不收录。笔者的网站曾有半个月没有收录过一个页面,原因就是由于这个引起的。
网站收录开始降低,快照停滞
正如上面所说,百度会重新对你的网站进行审视,这个时侯,一定会发觉你网站存在着一些页面和互联网当中存在类似,百度会毫不考虑的降低你那些页面的收录,所以很多人发觉网站停止收录以后,慢慢的导致了网站整个收录的降低,就是这个缘由。页面不怎样收录,百度对网站的信任度增长,最终,快照也会停滞一段时间。
排名并未有所波动,流量正常
当出现收录降低,快照停滞的时侯,我们最关心的问题就是排行的问题,担心排行会有所影响。这点到是可以放心,因为文章被采集,导致自己站遭到百度的考评,这个只是影响了百度对网站的信任度,并不会造成网站权重的增长,所以网站的关键词排行并不会遭到影响。
改善以后,网站收录仍然存在异常
假设我们发觉自己网站被采集之后,我们对网站进行了一些改善,成功的防止了网站被采集,那么你的网站还会有一个适应期,整个适应期表现下来的病症为:网站渐渐的开始收录文章页,但是收录的并不是即时更新的文章,有可能是前天的或则大前天更新的。这样的病症大约会存在1周的时间,之后收录会渐渐的趋向正常,快照也会渐渐的恢复。
这一系列的现象都是当网站处于常年被别人采集的情况下会出现的,所以当你自己的网站存在这样的一些现象的时侯,你首先要找的诱因就是自己每晚更新的文章是不是正在被他人采集。
如果你的网站确实是处于这样的情况,肯定是要想办法解决的,当然他人要采集你的文章,你不可能强制性的说不使他人去采集,所以我们能做的就是在自己本头上做一些改动。
1、提升页面权重
提升页面的权重是可以从根本上解决这个问题的,我们都晓得,像A5、Chinaz这样的网站每天还会被他人采集,但是这完全没有影响到A5、Chinaz网站的收录,这就是由于她们的权重足够的高,当他人网站出现和她们一样的文章的时侯,蜘蛛会默认的把她们的文章作为原创源。所以一定要提高文章页面的权重,多做一些这个页面的外链。
2、Rss合理借助
开发一个这样的功能也是有必要的,在网站文章有更新的时侯,第一时间就让搜索引擎晓得,主动出击,这样会太有助于收录的。而且Rss也能有效降低网站的流量,可以说是一举两得。
3、做一些细节,限制机器的采集
被人工采集还没哪些,要是没人用工具定时、大量的采集你网站的文章,这确实使人太难受,所以我们应当在页面的细节上做一些处理,至少还能避免机器的采集。比如页面不要设计的很传统、大众化;Url的写法要多变一些,不要成为默认叠加等设置。
4、被采集的时侯,更新的文章多与自己网站有关
别人采集我们的文章,是因为她们也须要我们更新的内容,所以假如我们更新的都是与自己网站有关的信息,经常会穿插我们网站的名称,别人在采集的时侯才会认为我们的文章对她们并没有太多的意义,这也是很不错的防止采集的形式。
文章经常被采集,这肯定是会对我们形成影响的,所以我们要尽量的去防止,让自己网站的内容在互联网当中成为唯一性,提升百度对我们网站的信任度,让我们的优化工作愈加顺畅。
z-blog和WordPress提高收录的方式,大量复制采集文章还收录了
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-08-22 15:18
采集复制转载的文章,发布到网站上,哪怕是没有更改一个字。百度也会收录,这时候就有很多人困惑了,那我为何还要坚持原创。
大家要知道一个误区就是,不是说收录了就有排行,哪怕是有排行,也是暂时性的。后面的索引量不断地升高,就证明了你的内容质量不行,非原创,被搜索引擎降权了。
那么影响文章排名的几个诱因就是:
1.一开始搭建网站,是否是原创文章,哪怕是伪原创,也要做得好。只要给了好印象,到旁边排行都会好好多。
2.新老域名,新域名通常有个审核期,你前几个月写的文章一般都是收录困难,哪怕收录了搜索全标题,也没排行。这个时侯别沮丧保持更新就好。
3.不要乱改tdk,建议搭建网站前就要想好,上线后谨记不要更改,不然会影响收录和排行。
4.建议你们写文章字数尽量可以多点,能到600以上字更合适。要说如何辨识你是原创,字数就是最好的证明。标题尽量也别改这么大众化,可以适当地长一点。
5.下载递交插件,发布文章第一时间递交到搜索引擎。一般插件只有百度,其他搜索引擎须要登陆后台和输入验证码才可以递交。百度那儿支持api递交,所以通常都有免费插件可下载。WordPress绝对是有的,上面截图是z-blog插件免费。
6.打开速率,我建议你们使用z-blog,WordPress相对慢一点。如果坚持要使用wp,可以找一款速度快的模板使用,这才是正道。
7.自适应的模板有利于排行,而且模板主题要重视移动端的展示,现在流量都偏向于手机端了。电脑端没哪些必要,不用做太多的更改。
下载文章收录查询插件,观察近来的文章收录情况,虽然是收费的,还是有一点好处。毕竟有时候用站长工具site下来的数据不太确切,相反用插件查询会确切一点。不管怎样,做网站,要考虑3个搜索引擎,神马、搜狗和百度。这些都要做好新站递交,坚持出来,还是有流量的。 查看全部
z-blog和WordPress提高收录的方式,大量复制采集文章还收录了
采集复制转载的文章,发布到网站上,哪怕是没有更改一个字。百度也会收录,这时候就有很多人困惑了,那我为何还要坚持原创。
大家要知道一个误区就是,不是说收录了就有排行,哪怕是有排行,也是暂时性的。后面的索引量不断地升高,就证明了你的内容质量不行,非原创,被搜索引擎降权了。
那么影响文章排名的几个诱因就是:
1.一开始搭建网站,是否是原创文章,哪怕是伪原创,也要做得好。只要给了好印象,到旁边排行都会好好多。
2.新老域名,新域名通常有个审核期,你前几个月写的文章一般都是收录困难,哪怕收录了搜索全标题,也没排行。这个时侯别沮丧保持更新就好。
3.不要乱改tdk,建议搭建网站前就要想好,上线后谨记不要更改,不然会影响收录和排行。
4.建议你们写文章字数尽量可以多点,能到600以上字更合适。要说如何辨识你是原创,字数就是最好的证明。标题尽量也别改这么大众化,可以适当地长一点。
5.下载递交插件,发布文章第一时间递交到搜索引擎。一般插件只有百度,其他搜索引擎须要登陆后台和输入验证码才可以递交。百度那儿支持api递交,所以通常都有免费插件可下载。WordPress绝对是有的,上面截图是z-blog插件免费。
6.打开速率,我建议你们使用z-blog,WordPress相对慢一点。如果坚持要使用wp,可以找一款速度快的模板使用,这才是正道。
7.自适应的模板有利于排行,而且模板主题要重视移动端的展示,现在流量都偏向于手机端了。电脑端没哪些必要,不用做太多的更改。
下载文章收录查询插件,观察近来的文章收录情况,虽然是收费的,还是有一点好处。毕竟有时候用站长工具site下来的数据不太确切,相反用插件查询会确切一点。不管怎样,做网站,要考虑3个搜索引擎,神马、搜狗和百度。这些都要做好新站递交,坚持出来,还是有流量的。
数据采集-微信公众号文章的完整爬取过程笔记
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-08-19 06:56
微信公众号文章的完整爬取过程笔记
outline一.基于sougou-api实现文章的爬取二.基于anyproxy和monkeyrunner的文章自动爬取一.基于sougou-api实现文章的爬取
1.可以直接抓陌陌搜狗主页
2.使用已有的软件包 + 代理的方法
调用API,通过微信公众号的ID,获取该帐号的部份文章
这种办法只能获取陌陌文章的临时链接,所以须要把html文本保存到出来
二.基于anyproxy和monkeyrunner的文章自动爬取
假设条件:你有一批微信公众号ID(eg:gh_1380fb0258f6)
硬件条件:一台普通PC(笔者使用windows系统),一台安卓手机(本人使用的是华为荣耀8lite)
尽量不要使用模拟器,笔者在使用模拟器登录陌陌后发觉帐户被封!!!
目标:爬取该批微信公众号的所有历史文章并增量爬取
1.基于anyproxy爬取公众号的所有文章
这一步早已有前辈早已实现,这里直接使用他的代码:wechat_spider 微信爬虫
具体实现过程可参考github,在这一步须要注意选择正确的IP
2.基于monkeyrunner实现爬取的自动化(1) 手机开启开发者模式
目前笔者遇见的手机开启开发者模式的方法是“在系统版本号上点击7,8次”
(2) PC安装安卓开发套件
安卓sdk的下载与安装可以参考AndroidDevTools
安装是否成功的测量方式可参考:入门monkeyrunner1-monkeyrunner的录制以及回放
(3) 自动化爬取的流程S1 使用陌陌的搜索框,通过微信公众号ID搜索到该帐号
image
image
S2 点击步入该帐号,下拉,点击全部文章,进入
image
S3 下拉,点击文章列表的某一篇文章,打开
image 查看全部
数据采集-微信公众号文章的完整爬取过程笔记
微信公众号文章的完整爬取过程笔记
outline一.基于sougou-api实现文章的爬取二.基于anyproxy和monkeyrunner的文章自动爬取一.基于sougou-api实现文章的爬取
1.可以直接抓陌陌搜狗主页
2.使用已有的软件包 + 代理的方法
调用API,通过微信公众号的ID,获取该帐号的部份文章
这种办法只能获取陌陌文章的临时链接,所以须要把html文本保存到出来
二.基于anyproxy和monkeyrunner的文章自动爬取
假设条件:你有一批微信公众号ID(eg:gh_1380fb0258f6)
硬件条件:一台普通PC(笔者使用windows系统),一台安卓手机(本人使用的是华为荣耀8lite)
尽量不要使用模拟器,笔者在使用模拟器登录陌陌后发觉帐户被封!!!
目标:爬取该批微信公众号的所有历史文章并增量爬取
1.基于anyproxy爬取公众号的所有文章
这一步早已有前辈早已实现,这里直接使用他的代码:wechat_spider 微信爬虫
具体实现过程可参考github,在这一步须要注意选择正确的IP
2.基于monkeyrunner实现爬取的自动化(1) 手机开启开发者模式
目前笔者遇见的手机开启开发者模式的方法是“在系统版本号上点击7,8次”
(2) PC安装安卓开发套件
安卓sdk的下载与安装可以参考AndroidDevTools
安装是否成功的测量方式可参考:入门monkeyrunner1-monkeyrunner的录制以及回放
(3) 自动化爬取的流程S1 使用陌陌的搜索框,通过微信公众号ID搜索到该帐号
image
image
S2 点击步入该帐号,下拉,点击全部文章,进入
image
S3 下拉,点击文章列表的某一篇文章,打开
image
一键采集今日头条试用版 9.0.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-08-19 05:13
问题:为什么Discuz峰会必须要安装采集插件?
解答:反过来问你一下,如果不安装采集插件,你自己原创写文章,你能写多少篇??我相信99.9%的人都不会完全原创所有的内容,都会转载其它网站的一些内容,包括一些xx日报,xx电视台,都会或多或少转载一些其它网站的优质内容,你的Discuz峰会安装采集插件,主要是辅助你,运营好自己的网站内容,既然都要手工转载内容,为什么不用效率更高,不会出错,简单易用的采集工具,让自己事半功倍呢??
问题:采集的内容,百度会收录吗??如何做好SEO优化??
解答:当下来一条新闻,你在百度搜索会看见,很多内容重复的文章也同样收录了,其实这些重复的内容,都是转载过来的,所以采集的内容百度同样也会收录,特别是最新的原创类内容,及时采集过来,同步发布出去,这样你的收录和原创的没有哪些区别,为了更好的提升SEO收录优化,除了及时采集最新的原创内容之外,最好能采集一些拒绝百度收录的平台内容,比如:微信公众号文章,另外还可以采集一些须要登陆以后,才能看见的内容,一些用ajax加载的内容,等等,这类内容百度都是抓取不到的,如果你发布这类的内容,SEO的收录会更好,排名会更好!!
问题:采集到的内容,会不会侵权??
解答:一些对社会正常运作,有帮助的内容,这类内容是规定可以转载的,比如:近期新冠脑炎太严重,一些疫情相关的公开报导内容,这些是没有问题的,因为这种疫情防治的信息,越多人晓得,就越好!!对疫情防治就越有帮助,采集这类内容是没有问题的!还有一类内容,就是对某一个企业有负面影响的,某一个企业的公关人员,会通知你,删除那些内容,只要你配合删掉掉内容,就可以了!!只有很少一部分内容,申请了著作权,如果不留神转载了,有可能被著作权所有人胜诉,这是低几率风波,一般不会遇见!!智伍应用的采集插件,支持先审后发,不支持不初审就手动采集发布出去!!确保了采集内容的安全!!因为每一篇文章内容,都是经过你审查过后,再采集发布的。
问题:智伍应用靠谱吗?会不会骗钱?
解答:非常靠谱!!智伍应用的产品上线之前,都会经过严格的测试和初审代码质量,确保安全而且能用和好用,全部都评比通过以后,才会申请上架!!同时源代码开放,任何人都可以查看到原创透明的代码,有技术能力的用户,可以很方便快捷进行二次开发,智伍应用的任何一款产品,都可以免费试用,满意以后再考虑,是否须要升级到即将商用版本,如果安装以后,发现不能使用,可以联系在线客服解决,如果碰到难以解决的问题,这个插件难以使用,会全额退票给你,总体的一个原则,就是使用户安全无风险,准确找到自己的需求,购买自己用得上的插件模块,如果订购以后,发现用不上,智伍应用会给你退票,如果确实有须要,请放心订购智伍应用的各个产品!!!智伍应用仍然都认真听取用户的反馈意见,根据用户的建议不断的升级更新产品,尊重用户的各项权益和合理诉求!!把用户放到最高的位置上,全心全意为用户服务!!
问题:智伍应用的采集插件都有哪些亮点和优势?
解答:多数都使用Chrome扩充采集程序,需要在自己的网页浏览器chrome那儿安装一个扩充程序,因为经过研究发觉,把浏览器弄成采集工具,是最可靠和成熟稳定的采集方式!一些通过程序抓取函数来采集内容的传统采集方式,虽然可以不用安装chrome扩充程序,但时常出问题,遇到采集不到内容的事情常有发生!!
问题:智伍应用开发了什么采集插件?
解答:很多!!我们专注研制采集插件多年,经过多次升级更新,在采集插件研制方面积累了丰富的经验,如果找不到你须要的采集插件,请反馈给智伍应用在线客服。
问题:智伍应用的采集插件那个好用?
解答:内核技术都一样,只是采集规则不一样,智伍应用的采集插件都好用,主要看你须要采集哪个网站,然后就用那种网站相对应的采集插件。
问题:我完全不懂技术,但想用智伍应用的Discuz采集插件,怎么办?
解答:联系智伍应用在线客服,在线帮助你安装和配置,直到插件完全可以使用,没有任何问题!!不需要你懂技术,售后客服会帮你解决所有的问题。
问题:为什么要用chrome扩充采集程序??
解答:因为这些采集方式,是最稳定和成熟的!!网页都是HTML代码经过浏览器渲染才下来的,所以把自己的浏览器弄成采集工具,所见即所采的方法,是最好的。
问题:chrome扩充安全吗??为什么会弹出“请停用以开发者模式运行的扩充程序”
解答:只要安装了chrome扩充程序,不管是哪些chrome扩充程序,都会弹出这样的提醒:“以开发者模式运行的扩充程序可能会损害您的计算机。如果您不是开发者,那么,为安全起见,应停用以开发者模式运行的扩充程序。”,这就似乎在百货商城里提醒你:“遇到火警请打119。”一样,有提醒你打119,并不代表你遇见了起火,这只是一个提醒信息!!智伍应用的chrome扩充程序都是经过人工初审,多方检测和测试,是安全可靠的扩充程序!!
问题:可以无人值守,自动采集内容吗??
解答:不可以!!全手动采集内容并发布,这样采集内容不安全!!智伍应用的采集插件都是先审后发,确保内容的质量和安全!!不能不经过你的同意,就手动发布内容了!!如果你须要短时间内采集发布大量的内容,来填充网站,可以在【待发布】那里,选择【用chrome扩充批量发布内容】 查看全部
一键采集今日头条试用版 9.0.0
问题:为什么Discuz峰会必须要安装采集插件?
解答:反过来问你一下,如果不安装采集插件,你自己原创写文章,你能写多少篇??我相信99.9%的人都不会完全原创所有的内容,都会转载其它网站的一些内容,包括一些xx日报,xx电视台,都会或多或少转载一些其它网站的优质内容,你的Discuz峰会安装采集插件,主要是辅助你,运营好自己的网站内容,既然都要手工转载内容,为什么不用效率更高,不会出错,简单易用的采集工具,让自己事半功倍呢??
问题:采集的内容,百度会收录吗??如何做好SEO优化??
解答:当下来一条新闻,你在百度搜索会看见,很多内容重复的文章也同样收录了,其实这些重复的内容,都是转载过来的,所以采集的内容百度同样也会收录,特别是最新的原创类内容,及时采集过来,同步发布出去,这样你的收录和原创的没有哪些区别,为了更好的提升SEO收录优化,除了及时采集最新的原创内容之外,最好能采集一些拒绝百度收录的平台内容,比如:微信公众号文章,另外还可以采集一些须要登陆以后,才能看见的内容,一些用ajax加载的内容,等等,这类内容百度都是抓取不到的,如果你发布这类的内容,SEO的收录会更好,排名会更好!!
问题:采集到的内容,会不会侵权??
解答:一些对社会正常运作,有帮助的内容,这类内容是规定可以转载的,比如:近期新冠脑炎太严重,一些疫情相关的公开报导内容,这些是没有问题的,因为这种疫情防治的信息,越多人晓得,就越好!!对疫情防治就越有帮助,采集这类内容是没有问题的!还有一类内容,就是对某一个企业有负面影响的,某一个企业的公关人员,会通知你,删除那些内容,只要你配合删掉掉内容,就可以了!!只有很少一部分内容,申请了著作权,如果不留神转载了,有可能被著作权所有人胜诉,这是低几率风波,一般不会遇见!!智伍应用的采集插件,支持先审后发,不支持不初审就手动采集发布出去!!确保了采集内容的安全!!因为每一篇文章内容,都是经过你审查过后,再采集发布的。
问题:智伍应用靠谱吗?会不会骗钱?
解答:非常靠谱!!智伍应用的产品上线之前,都会经过严格的测试和初审代码质量,确保安全而且能用和好用,全部都评比通过以后,才会申请上架!!同时源代码开放,任何人都可以查看到原创透明的代码,有技术能力的用户,可以很方便快捷进行二次开发,智伍应用的任何一款产品,都可以免费试用,满意以后再考虑,是否须要升级到即将商用版本,如果安装以后,发现不能使用,可以联系在线客服解决,如果碰到难以解决的问题,这个插件难以使用,会全额退票给你,总体的一个原则,就是使用户安全无风险,准确找到自己的需求,购买自己用得上的插件模块,如果订购以后,发现用不上,智伍应用会给你退票,如果确实有须要,请放心订购智伍应用的各个产品!!!智伍应用仍然都认真听取用户的反馈意见,根据用户的建议不断的升级更新产品,尊重用户的各项权益和合理诉求!!把用户放到最高的位置上,全心全意为用户服务!!
问题:智伍应用的采集插件都有哪些亮点和优势?
解答:多数都使用Chrome扩充采集程序,需要在自己的网页浏览器chrome那儿安装一个扩充程序,因为经过研究发觉,把浏览器弄成采集工具,是最可靠和成熟稳定的采集方式!一些通过程序抓取函数来采集内容的传统采集方式,虽然可以不用安装chrome扩充程序,但时常出问题,遇到采集不到内容的事情常有发生!!
问题:智伍应用开发了什么采集插件?
解答:很多!!我们专注研制采集插件多年,经过多次升级更新,在采集插件研制方面积累了丰富的经验,如果找不到你须要的采集插件,请反馈给智伍应用在线客服。
问题:智伍应用的采集插件那个好用?
解答:内核技术都一样,只是采集规则不一样,智伍应用的采集插件都好用,主要看你须要采集哪个网站,然后就用那种网站相对应的采集插件。
问题:我完全不懂技术,但想用智伍应用的Discuz采集插件,怎么办?
解答:联系智伍应用在线客服,在线帮助你安装和配置,直到插件完全可以使用,没有任何问题!!不需要你懂技术,售后客服会帮你解决所有的问题。
问题:为什么要用chrome扩充采集程序??
解答:因为这些采集方式,是最稳定和成熟的!!网页都是HTML代码经过浏览器渲染才下来的,所以把自己的浏览器弄成采集工具,所见即所采的方法,是最好的。
问题:chrome扩充安全吗??为什么会弹出“请停用以开发者模式运行的扩充程序”
解答:只要安装了chrome扩充程序,不管是哪些chrome扩充程序,都会弹出这样的提醒:“以开发者模式运行的扩充程序可能会损害您的计算机。如果您不是开发者,那么,为安全起见,应停用以开发者模式运行的扩充程序。”,这就似乎在百货商城里提醒你:“遇到火警请打119。”一样,有提醒你打119,并不代表你遇见了起火,这只是一个提醒信息!!智伍应用的chrome扩充程序都是经过人工初审,多方检测和测试,是安全可靠的扩充程序!!
问题:可以无人值守,自动采集内容吗??
解答:不可以!!全手动采集内容并发布,这样采集内容不安全!!智伍应用的采集插件都是先审后发,确保内容的质量和安全!!不能不经过你的同意,就手动发布内容了!!如果你须要短时间内采集发布大量的内容,来填充网站,可以在【待发布】那里,选择【用chrome扩充批量发布内容】
[c#] 多线程网路编程应用[多线程文章采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-08-09 15:08
如今的网路越来越发达,分享一个文件是这么的简单。特别是有了电骡、迅雷这样的下载软件就愈加如虎添翼了,想从网上下载一个几个G大小的文件,真是不费吹灰之力。好,废话太多了,直接步入俺们明天的主题吧。
要实现象迅雷一样的多线程下载,核心问题是要将多线程的概念以及如何实现的问题弄清。
当然,本文技术浓度太低,大牛请直接绕路。
多线程是相对单线程来说的,具体可以参考百度百科里的解释:
每个程序运行都有一个最基本的主线程,用于处理界面书法,人机交互,后台处理等过程,因此假如是在单线程程序里操作注视历时的动作,主界面都会太卡,甚至是难以工作。因此不管您是不是喜欢,最好都别用主线程把一切事务夺得,否则很难给用户一个凉爽的顾客体验。
那么在C#里怎么实现多线程呢?
下面使我们实现一个最简单的多线程实例;
为了演示便捷,我们新建一个winform项目,取名为 MultiThreadDemo。
先创建一个足够使你的程序卡住不动的方式函数:
private void Display()
{
while (true)
textBox1.Text = new Random().NextDouble().ToString();
}
然后给button1添加调用,发现确实够卡吧,谁使你把那种死循环的事情交给主线程去做呢,一个人又作图,又要算数,哪还有时间给你答复。
using System.Threading;
接着补充一下button1上面的代码,给他创建一个线程,我们把这线程起名叫“UiThread”用于专门处理显示吧。
View Code
private void button1_Click(object sender, EventArgs e)
{
Thread thread = new Thread(Display);//创建一个线程
thread.Start();
// Display();
}
如果你急着运行,肯定会回过头来骂我了,怎么不行呢,是不是哪些会提示:“线程间操作无效: 从不是创建控件“textBox1”的线程访问它。”。因为主线程和你创建的那种线程是两个互不相干的线程,两个陌生人如何打交道?也就是当你这个UiThread没经过主线程同意就去调用textBox1,别人会使你这么做吗?
因此,为了处理他俩工作不协调的问题,特意强制性取消线程警告.在构造函数里添加一句:
public Form1()
{
InitializeComponent();
Control.CheckForIllegalCrossThreadCalls = false;//加上这句就不会警告了
}
这样一个简单的多线程程序就诞生了。不过有个时侯有很多代码须要用到委托,又不想单独创建一个函数,就可以这样做:
View Code
private void button1_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Display(); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
不过并不推荐如此做,这在线程上是不安全的,有很大的机率会使程序奔溃。
通过前面的练习,我们晓得创建一个线程可以多做一些事,同样,我们多创建几个线程,做的事岂不是更多?这是必须的。
接下来即将走入我们明天的题外话:多线程采集
要想多线程采集,首先要解决单个下载。
using System.Net;
using System.IO;
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕"));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
sw.Write(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
return;
}
}
然后在在button2里调用
View Code
private void button2_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Request(richTextBox1, 158100); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
这样以来单次采集就完成了。
要想象优采云一样采集,自然以目前的水平是做不到的。起码也要把批量采集做下来。无外乎使用多线程。
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕\n"));
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
}
}
private void button2_Click(object sender, EventArgs e)
{
Thread.CurrentThread.Name = "主线程";
Thread[] threads = new Thread[51];
DateTime endTime = DateTime.Now;
DateTime startTime = DateTime.Now;
TimeSpan timeSpan = endTime - startTime;
string span = timeSpan.TotalSeconds.ToString();
startTime = DateTime.Now;
Mutex mt = new Mutex();
mt.WaitOne();
for (int i = 158300; i >158250; i--)
{
threads[158300 - i] = new Thread(new ParameterizedThreadStart(delegate { Request(richTextBox1, i); }));
threads[158300 - i].Name = "线程" + (i).ToString(); ;
threads[158300 - i].Start();
}
mt.ReleaseMutex();
endTime = DateTime.Now;
timeSpan = endTime - startTime;
span = timeSpan.TotalSeconds.ToString();
richTextBox1.AppendText(string.Format("多线程接受的话共花费了{0}秒钟\n", span));
}
多线程采集就完成了。其实本文讲来讲去主要是围绕创建线程这一话题,技术浓度相当低,就当给刚入门的同学练练手吧!
教程每晚还会更新,欢迎继续关注。 查看全部
编程不能死记硬背,要靠多实践操作
如今的网路越来越发达,分享一个文件是这么的简单。特别是有了电骡、迅雷这样的下载软件就愈加如虎添翼了,想从网上下载一个几个G大小的文件,真是不费吹灰之力。好,废话太多了,直接步入俺们明天的主题吧。
要实现象迅雷一样的多线程下载,核心问题是要将多线程的概念以及如何实现的问题弄清。
当然,本文技术浓度太低,大牛请直接绕路。
多线程是相对单线程来说的,具体可以参考百度百科里的解释:
每个程序运行都有一个最基本的主线程,用于处理界面书法,人机交互,后台处理等过程,因此假如是在单线程程序里操作注视历时的动作,主界面都会太卡,甚至是难以工作。因此不管您是不是喜欢,最好都别用主线程把一切事务夺得,否则很难给用户一个凉爽的顾客体验。
那么在C#里怎么实现多线程呢?
下面使我们实现一个最简单的多线程实例;
为了演示便捷,我们新建一个winform项目,取名为 MultiThreadDemo。
先创建一个足够使你的程序卡住不动的方式函数:
private void Display()
{
while (true)
textBox1.Text = new Random().NextDouble().ToString();
}
然后给button1添加调用,发现确实够卡吧,谁使你把那种死循环的事情交给主线程去做呢,一个人又作图,又要算数,哪还有时间给你答复。
using System.Threading;
接着补充一下button1上面的代码,给他创建一个线程,我们把这线程起名叫“UiThread”用于专门处理显示吧。
View Code
private void button1_Click(object sender, EventArgs e)
{
Thread thread = new Thread(Display);//创建一个线程
thread.Start();
// Display();
}
如果你急着运行,肯定会回过头来骂我了,怎么不行呢,是不是哪些会提示:“线程间操作无效: 从不是创建控件“textBox1”的线程访问它。”。因为主线程和你创建的那种线程是两个互不相干的线程,两个陌生人如何打交道?也就是当你这个UiThread没经过主线程同意就去调用textBox1,别人会使你这么做吗?
因此,为了处理他俩工作不协调的问题,特意强制性取消线程警告.在构造函数里添加一句:
public Form1()
{
InitializeComponent();
Control.CheckForIllegalCrossThreadCalls = false;//加上这句就不会警告了
}
这样一个简单的多线程程序就诞生了。不过有个时侯有很多代码须要用到委托,又不想单独创建一个函数,就可以这样做:
View Code
private void button1_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Display(); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
不过并不推荐如此做,这在线程上是不安全的,有很大的机率会使程序奔溃。
通过前面的练习,我们晓得创建一个线程可以多做一些事,同样,我们多创建几个线程,做的事岂不是更多?这是必须的。
接下来即将走入我们明天的题外话:多线程采集
要想多线程采集,首先要解决单个下载。
using System.Net;
using System.IO;
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕"));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
sw.Write(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
return;
}
}
然后在在button2里调用
View Code
private void button2_Click(object sender, EventArgs e)
{
ThreadStart threadStart = new ThreadStart(delegate { Request(richTextBox1, 158100); });//创建一个委托,这样可以调用任意参数的函数了,甚至是零星的代码都可以
Thread thread = new Thread(threadStart);
thread.Start();
}
这样以来单次采集就完成了。
要想象优采云一样采集,自然以目前的水平是做不到的。起码也要把批量采集做下来。无外乎使用多线程。
View Code
///
/// 转载请加上本人博客链接
///
///
///
static void Request(RichTextBox richtextBox,int i)
{
richtextBox.AppendText(string.Format("线程{0}开始接收\n", Thread.CurrentThread.Name));
ServicePointManager.DefaultConnectionLimit = 1000;
HttpWebRequest httpWebRequest = (HttpWebRequest)HttpWebRequest.Create(string.Format("http://news.cnblogs.com/n/{0}/", (int)i));//这里的i最嗨是158100到158999,符合博客园url规则才能采集到
try
{
HttpWebResponse httpWebResponse = (HttpWebResponse)httpWebRequest.GetResponse();
Stream stream = httpWebResponse.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string html = sr.ReadToEnd();
richtextBox.AppendText(string.Format(Thread.CurrentThread.Name + "接收完毕\n"));
StreamWriter sw = File.CreateText(string.Format(Environment.CurrentDirectory + "\\{0}.htm", i));
sw.Write(html);
sw.Close();
}
catch
{
richtextBox.AppendText(string.Format("线程{0}不存在此地址,跳过\n", Thread.CurrentThread.Name));
}
}
private void button2_Click(object sender, EventArgs e)
{
Thread.CurrentThread.Name = "主线程";
Thread[] threads = new Thread[51];
DateTime endTime = DateTime.Now;
DateTime startTime = DateTime.Now;
TimeSpan timeSpan = endTime - startTime;
string span = timeSpan.TotalSeconds.ToString();
startTime = DateTime.Now;
Mutex mt = new Mutex();
mt.WaitOne();
for (int i = 158300; i >158250; i--)
{
threads[158300 - i] = new Thread(new ParameterizedThreadStart(delegate { Request(richTextBox1, i); }));
threads[158300 - i].Name = "线程" + (i).ToString(); ;
threads[158300 - i].Start();
}
mt.ReleaseMutex();
endTime = DateTime.Now;
timeSpan = endTime - startTime;
span = timeSpan.TotalSeconds.ToString();
richTextBox1.AppendText(string.Format("多线程接受的话共花费了{0}秒钟\n", span));
}
多线程采集就完成了。其实本文讲来讲去主要是围绕创建线程这一话题,技术浓度相当低,就当给刚入门的同学练练手吧!
教程每晚还会更新,欢迎继续关注。

