
文章采集完
文章采集完(好消息鱼虾网提供原创文章、伪原创、seo文章代写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-27 01:15
好消息:宇侠网提供原创文章、伪原创、seo文章代写、网站内容文章代更新服务,
另外还提供,文章代,软文代,外链代,有需要的朋友可以联系我们咨询。
鱼虾网seo(),专业的网站建设、seo优化和网络营销团队
答:关于文章的采集和组合,我的想法适合大家:
1.选择最重要的关键词,然后对属于自己的网站的关键词进行分类。别说难,不自己开发,其实就像5118脑图。2. 选择关键词后,即可挖掘出优质内容。你必须先选择最全面的各大电台,包括你选择的关键词。一定要站起来,因为大站很全面。然后,根据你的关键词采集这个大网站的内容。在采集文章的时候,不仅这个大网站,你的关键词也会被百度收录。
例如:一个关键词包括一个主要的网站和一个相关的文章,百度的倒置也包括在前两个文章中。就这样,关键词A采集了3个优质的文章,以此类推。其他关键词的处理方式相同。然后,我们所有的 关键词 集合 文章 都存储在库中。在数据库中,每一个关键词对应三个高质量的文章。然后用软件从数据库中查询标题文章。查询时,是时候合并数据了。
第一次:采集存储,第二次:从数据库查询。经过查询,我们可以替换这三个文章。为什么要编写查询软件?那是因为在编写软件时。你也可以有一个共同的起点和一个共同的终点。这样,在查询过程中,将三个文章和你的万能开头和万能结尾替换后,就是伪原创。
好的,查询之后,文章 看起来更好了,出现了伪文本。其实这样更能满足用户的需求。第三步就是通过以上两步。你有更好的伪造原创文章。那就别停。同理,提取百度知道的文章的关键词,了解问答平台,采集问答知识,然后和你的文章结合,很不爽。然后就是最终替换,删除删除,这些都是批量替换软件。这样,一个文章的优质合集就会发布。 查看全部
文章采集完(好消息鱼虾网提供原创文章、伪原创、seo文章代写)
好消息:宇侠网提供原创文章、伪原创、seo文章代写、网站内容文章代更新服务,
另外还提供,文章代,软文代,外链代,有需要的朋友可以联系我们咨询。
鱼虾网seo(),专业的网站建设、seo优化和网络营销团队
答:关于文章的采集和组合,我的想法适合大家:
1.选择最重要的关键词,然后对属于自己的网站的关键词进行分类。别说难,不自己开发,其实就像5118脑图。2. 选择关键词后,即可挖掘出优质内容。你必须先选择最全面的各大电台,包括你选择的关键词。一定要站起来,因为大站很全面。然后,根据你的关键词采集这个大网站的内容。在采集文章的时候,不仅这个大网站,你的关键词也会被百度收录。
例如:一个关键词包括一个主要的网站和一个相关的文章,百度的倒置也包括在前两个文章中。就这样,关键词A采集了3个优质的文章,以此类推。其他关键词的处理方式相同。然后,我们所有的 关键词 集合 文章 都存储在库中。在数据库中,每一个关键词对应三个高质量的文章。然后用软件从数据库中查询标题文章。查询时,是时候合并数据了。
第一次:采集存储,第二次:从数据库查询。经过查询,我们可以替换这三个文章。为什么要编写查询软件?那是因为在编写软件时。你也可以有一个共同的起点和一个共同的终点。这样,在查询过程中,将三个文章和你的万能开头和万能结尾替换后,就是伪原创。
好的,查询之后,文章 看起来更好了,出现了伪文本。其实这样更能满足用户的需求。第三步就是通过以上两步。你有更好的伪造原创文章。那就别停。同理,提取百度知道的文章的关键词,了解问答平台,采集问答知识,然后和你的文章结合,很不爽。然后就是最终替换,删除删除,这些都是批量替换软件。这样,一个文章的优质合集就会发布。
文章采集完(网站要不要写原创文章这个话题你知道吗?!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-26 23:03
指南:更新文章是每个网站运营商必须做的工作。经常更新网站内部文章,保持网站活跃,帮助吸引蜘蛛爬取网站页面,完善内部链接,增加网站权重。在更新网站文章的时候,很多站长忍不住写原创文章,看到别人网站文章从网上抄来的,我被收录,各种采集,各种抄袭也很聪明,认为只要保持网站的内容更新,你不知道其他人们的网站权重高,搜索引擎之间的信任度非常好。如果您有一个新网站或小型企业网站,如果您这样做,您需要承担多少风险?让' 下面就深度网络和大家聊一聊。网站要不要写?原创文章这个话题。
原创 文章 的值
1、搜索引擎喜欢原创有价值的文章
搜索引擎发展了这么久,现在不注重数量,只注重质量。对于网上重复的内容,搜索引擎会认为没有收录的价值,甚至会影响搜索引擎对网站的判断。. 频繁复制互联网上已经存在的内容会让搜索引擎认为这个网站对用户没有帮助,对搜索引擎也不友好,因为内容互联网已经存在,你要去收录的内容只会增加搜索引擎服务器的负载,让你不再去收录你网站的内容,严重的会导致网站降级并降低 关键词 的排名。
2、用户喜欢原创高质量文章
对于用户来说,他们也喜欢看到新鲜的内容,这增加了用户的吸引力。过时的内容毫无价值。用户看了一次就不会来第二次,导致网站的跳出率很高。写原创文章是为了满足用户需求,解决用户疑惑,提升用户体验,增加用户对网站的粘性。
3、原创文章提升企业形象
经常更新原创和有价值的文章,用户喜欢阅读,不仅经常访问网站,觉得公司写的内容专业,有价值,给用户留下一个好印象中,频繁更新互联网内容,会让用户觉得贵公司不专业,损害企业形象。
4、原创文章对网站的影响
更新原创文章很费力,但是满足了搜索引擎的需求,也满足了用户的需求。尤其是新站期,更新原创对加快搜索引擎速度非常重要 网站审核期提高了搜索引擎对网站的信任度、网站的权重、排名关键词。即使是老站,也要经常更新原创文章,吸引更多潜在客户浏览,保持网站关键词的排名。
5、原创文章长尾福利关键词排名
更新文章时,在文章的内容和标题中添加长尾关键词,使用文章优化长尾关键词,更新一篇文章< @文章,做长尾关键词优化。随着时间的推移,更多的长尾关键词会在搜索引擎中排名,带来更多的潜在客户。
综上所述,更新原创文章对优化和用户都有帮助。站长还是要关注原创文章带来的价值。有的站长说不可能写出高质量的伪原创文章,这样的文章对于搜索引擎来说也是高质量的原创文章,就是诚然,高质量的伪原创文章也是可取的,但是高质量的伪原创文章也对质量有很高的要求,不是简单的用工具做一个伪原创文章,并且你必须遵循高质量的文章写作要求,才能满足最初的要求。当您在新站点上时,您必须更新 原创文章 以与搜索引擎建立良好的信任度。 查看全部
文章采集完(网站要不要写原创文章这个话题你知道吗?!)
指南:更新文章是每个网站运营商必须做的工作。经常更新网站内部文章,保持网站活跃,帮助吸引蜘蛛爬取网站页面,完善内部链接,增加网站权重。在更新网站文章的时候,很多站长忍不住写原创文章,看到别人网站文章从网上抄来的,我被收录,各种采集,各种抄袭也很聪明,认为只要保持网站的内容更新,你不知道其他人们的网站权重高,搜索引擎之间的信任度非常好。如果您有一个新网站或小型企业网站,如果您这样做,您需要承担多少风险?让' 下面就深度网络和大家聊一聊。网站要不要写?原创文章这个话题。

原创 文章 的值
1、搜索引擎喜欢原创有价值的文章
搜索引擎发展了这么久,现在不注重数量,只注重质量。对于网上重复的内容,搜索引擎会认为没有收录的价值,甚至会影响搜索引擎对网站的判断。. 频繁复制互联网上已经存在的内容会让搜索引擎认为这个网站对用户没有帮助,对搜索引擎也不友好,因为内容互联网已经存在,你要去收录的内容只会增加搜索引擎服务器的负载,让你不再去收录你网站的内容,严重的会导致网站降级并降低 关键词 的排名。
2、用户喜欢原创高质量文章
对于用户来说,他们也喜欢看到新鲜的内容,这增加了用户的吸引力。过时的内容毫无价值。用户看了一次就不会来第二次,导致网站的跳出率很高。写原创文章是为了满足用户需求,解决用户疑惑,提升用户体验,增加用户对网站的粘性。
3、原创文章提升企业形象
经常更新原创和有价值的文章,用户喜欢阅读,不仅经常访问网站,觉得公司写的内容专业,有价值,给用户留下一个好印象中,频繁更新互联网内容,会让用户觉得贵公司不专业,损害企业形象。
4、原创文章对网站的影响
更新原创文章很费力,但是满足了搜索引擎的需求,也满足了用户的需求。尤其是新站期,更新原创对加快搜索引擎速度非常重要 网站审核期提高了搜索引擎对网站的信任度、网站的权重、排名关键词。即使是老站,也要经常更新原创文章,吸引更多潜在客户浏览,保持网站关键词的排名。
5、原创文章长尾福利关键词排名
更新文章时,在文章的内容和标题中添加长尾关键词,使用文章优化长尾关键词,更新一篇文章< @文章,做长尾关键词优化。随着时间的推移,更多的长尾关键词会在搜索引擎中排名,带来更多的潜在客户。
综上所述,更新原创文章对优化和用户都有帮助。站长还是要关注原创文章带来的价值。有的站长说不可能写出高质量的伪原创文章,这样的文章对于搜索引擎来说也是高质量的原创文章,就是诚然,高质量的伪原创文章也是可取的,但是高质量的伪原创文章也对质量有很高的要求,不是简单的用工具做一个伪原创文章,并且你必须遵循高质量的文章写作要求,才能满足最初的要求。当您在新站点上时,您必须更新 原创文章 以与搜索引擎建立良好的信任度。
文章采集完(大部分《搜狗seo如何优化》搜狗高收录采集站))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-26 13:10
大多数seoer只关注百度搜索引擎优化,而忽略搜狗、360和神马等搜索引擎优化。对采集的测试发现搜狗搜索收录表现非常好。今天发错博客()带来了《如何优化搜狗seo(搜狗高收录采集站)》。我希望能有所帮助。
一、 搜狗搜索引擎优化
搜狗比百度更容易优化,但搜狗的市场份额较低,这意味着来自搜狗的流量会更少。只要内容偏原创,继续做一段时间,或者是老域名,搜狗收录很快。
二、采集
以前很鄙视采集站,但现在看各种优质大站,哪一个是真正的纯原创?一部分为近期新闻出处采集并注明出处,一部分为网站编辑,另一部分为用户投稿。也就是说,没有 100% 原创 站点。网站合理采集一些相对较新的内容对网站来说并不全是坏事,但合适。
三、搜狗高收录实战
这里只是说说之前错误博客测试的采集文章,观察收录的情况。当时采用了优采云采集规则。采集做好后直接输出excel表格,最后在dedecms批量上传发布。说几个主要规则:
1、标题混词
采集一些很正常的信息网站,标题中混入一些不受欢迎的词(比如小品牌词,比如错博客、错博客seo、错博客优质ip等) ,这将与其他网站的这个文章的标题有很大的不同。在 Internet 上找不到具有相同标题的页面是不可能的。
2、混句
在正文的第一句中混入一些不受欢迎的词。这样冷门的词变成了句子,看起来更像是开句,也就是说开句是原创句,对于收录的好处也有一定的意义。
3、文中混词
多次融入文中文章想优化关键词,从而增加关键词的密度,但没必要过分。
4、文中三图
将三张图片合并到文章文章中,文章有图片更好参与排名,就像说一张图片是必须的,当然也有很多页面没有图片. 非常好的排名,如果是三张图,像搜狗这样搜索会提示文章多图,显然更有利于优化。
5、没有内容
以上四点是错误博客的初步想法。结果是采集规则的使用出了问题,导致几乎没有采集的内容。然后,可能是因为内容少,基本没问题。算是原创,再加上三张图的效果,终于把这些文章都搜到了搜狗收录。
那个时候采集不多,2万左右,都是收录,而且很多也有排名。排名主要是因为这几个词的难度很低。这样做网站估计流量很好看。当然,实际的流量并不多。
以上是《如何优化搜狗seo(搜狗高收录采集站)"带来的错误博客()。感谢您的阅读。更多原创文章 搜索错误博客。 查看全部
文章采集完(大部分《搜狗seo如何优化》搜狗高收录采集站))
大多数seoer只关注百度搜索引擎优化,而忽略搜狗、360和神马等搜索引擎优化。对采集的测试发现搜狗搜索收录表现非常好。今天发错博客()带来了《如何优化搜狗seo(搜狗高收录采集站)》。我希望能有所帮助。

一、 搜狗搜索引擎优化
搜狗比百度更容易优化,但搜狗的市场份额较低,这意味着来自搜狗的流量会更少。只要内容偏原创,继续做一段时间,或者是老域名,搜狗收录很快。
二、采集
以前很鄙视采集站,但现在看各种优质大站,哪一个是真正的纯原创?一部分为近期新闻出处采集并注明出处,一部分为网站编辑,另一部分为用户投稿。也就是说,没有 100% 原创 站点。网站合理采集一些相对较新的内容对网站来说并不全是坏事,但合适。
三、搜狗高收录实战
这里只是说说之前错误博客测试的采集文章,观察收录的情况。当时采用了优采云采集规则。采集做好后直接输出excel表格,最后在dedecms批量上传发布。说几个主要规则:
1、标题混词
采集一些很正常的信息网站,标题中混入一些不受欢迎的词(比如小品牌词,比如错博客、错博客seo、错博客优质ip等) ,这将与其他网站的这个文章的标题有很大的不同。在 Internet 上找不到具有相同标题的页面是不可能的。
2、混句
在正文的第一句中混入一些不受欢迎的词。这样冷门的词变成了句子,看起来更像是开句,也就是说开句是原创句,对于收录的好处也有一定的意义。
3、文中混词
多次融入文中文章想优化关键词,从而增加关键词的密度,但没必要过分。
4、文中三图
将三张图片合并到文章文章中,文章有图片更好参与排名,就像说一张图片是必须的,当然也有很多页面没有图片. 非常好的排名,如果是三张图,像搜狗这样搜索会提示文章多图,显然更有利于优化。
5、没有内容
以上四点是错误博客的初步想法。结果是采集规则的使用出了问题,导致几乎没有采集的内容。然后,可能是因为内容少,基本没问题。算是原创,再加上三张图的效果,终于把这些文章都搜到了搜狗收录。
那个时候采集不多,2万左右,都是收录,而且很多也有排名。排名主要是因为这几个词的难度很低。这样做网站估计流量很好看。当然,实际的流量并不多。
以上是《如何优化搜狗seo(搜狗高收录采集站)"带来的错误博客()。感谢您的阅读。更多原创文章 搜索错误博客。
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-26 13:07
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(文章采集完成后,把采集的网页信息存入mongodb,方便)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-20 11:01
文章采集完成后,把采集的网页信息存入mongodb,方便以后使用django的contextmanager(contextmanager可以把采集到的网页设置一个属性,比如:'location'),并对返回的response设置一个类,保存django里面的信息,response就是整个系统的http代理。
要解决的问题在nodejs环境中,要使用模拟post请求,模拟请求可以使用django-posts,有tag分类方便代码开发:```importjsonfromdjango.conf.jsonimportpostmessageclassuserrepository(postmessage):__name__='用户对象'__user_body='{username:'admin',password:'密码'}'classrequest(userrepository):username='admin'password='密码'req_list=[{'username':username,password':password}]response=request(userrepository,postmessage)self.req_list=[responseforreqinrequest]```结果部分```nodejsinnumpy```code:govuser```配置django环境首先,我们还要配置djangodb,在djangoconf->db文件夹中。
依赖依赖的包有:nginx(网络服务,django代理)mongodb(数据库)django-posts(类似orm,支持表单的增删改查)```pythonmanage.pysyncdb(url,create_db)#创建本地环境数据库pythonmanage.pyenvnotify(url)#告诉django,发送请求name:user表单表单的create_db()函数:env.name,create_db()这个函数是我们以后处理表单的主要函数在postmessage中的方法:```req=userrepository(username='admin',password='rsa')response=request(userrepository(username='admin',password='rsa'),create_db)```djangoconf->urls下的admin和request中的返回值都是一样的```djangoconf->create_db_templates(url,post_response)```code:env.name```djangoconf->urls下的post_response.rs```djangoconf->urls下的post_response.rs```djangoconf->post_response.rs```djangoconf->post_response.rs```执行djangoconfig--project.yaml>```使用django-posts模拟post请求userrepositoryenv=notify(url)[name=post_response,version=4.2.2]post_response_url=["django.conf.urls.postmap"]postmap=[{"post_res。 查看全部
文章采集完(文章采集完成后,把采集的网页信息存入mongodb,方便)
文章采集完成后,把采集的网页信息存入mongodb,方便以后使用django的contextmanager(contextmanager可以把采集到的网页设置一个属性,比如:'location'),并对返回的response设置一个类,保存django里面的信息,response就是整个系统的http代理。
要解决的问题在nodejs环境中,要使用模拟post请求,模拟请求可以使用django-posts,有tag分类方便代码开发:```importjsonfromdjango.conf.jsonimportpostmessageclassuserrepository(postmessage):__name__='用户对象'__user_body='{username:'admin',password:'密码'}'classrequest(userrepository):username='admin'password='密码'req_list=[{'username':username,password':password}]response=request(userrepository,postmessage)self.req_list=[responseforreqinrequest]```结果部分```nodejsinnumpy```code:govuser```配置django环境首先,我们还要配置djangodb,在djangoconf->db文件夹中。
依赖依赖的包有:nginx(网络服务,django代理)mongodb(数据库)django-posts(类似orm,支持表单的增删改查)```pythonmanage.pysyncdb(url,create_db)#创建本地环境数据库pythonmanage.pyenvnotify(url)#告诉django,发送请求name:user表单表单的create_db()函数:env.name,create_db()这个函数是我们以后处理表单的主要函数在postmessage中的方法:```req=userrepository(username='admin',password='rsa')response=request(userrepository(username='admin',password='rsa'),create_db)```djangoconf->urls下的admin和request中的返回值都是一样的```djangoconf->create_db_templates(url,post_response)```code:env.name```djangoconf->urls下的post_response.rs```djangoconf->urls下的post_response.rs```djangoconf->post_response.rs```djangoconf->post_response.rs```执行djangoconfig--project.yaml>```使用django-posts模拟post请求userrepositoryenv=notify(url)[name=post_response,version=4.2.2]post_response_url=["django.conf.urls.postmap"]postmap=[{"post_res。
文章采集完(怎么提高我们文章的阅读量?(内附方法))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-19 03:02
文章采集完可以直接发送,不过如果是高质量的文章,发送过去后,是会收到系统的推荐,从而对作者有更多的关注,关注多了,就会有第一批量到达积分榜,如果能到排行榜,那么你每月就可以得到系统的奖励,提高自己的积分榜,也可以带动粉丝数量,提高收入。对于自媒体人来说,几乎每天都要或多或少的搞些公众号赚取收益,但是我经常听到一些公众号的运营大神抱怨,每天他们的账号有那么多精力去研究怎么推广、运营,实在没有足够的时间和精力更新文章。
一般的情况是,由于发送的次数并不多,所以一篇文章的阅读量并不是很高,所以没有足够大的关注量。那么怎么提高我们文章的阅读量呢?文章发送出去后,首先打开的人会有一个缓存,如果速度太慢,那么就会自动删除,所以一般的平台都有发送时间规定,这就是为什么很多作者要花钱在论坛里发布文章。发送这么多次,还有人看,和我们做微信公众号也是有关系的,为什么我们一直讲,从7月份之后,公众号的粉丝数就没有大幅度的增长,但是今年,粉丝的增长速度竟然高达160%,我们可以从几个方面分析。
1、平台大力推广,流量重新分配,应该是目前最大的推手。
2、微信社群建设好,分享文章后,自己发布的流量就会增多。
3、微信平台更新了新规则,自媒体人利用公众号如何快速过原创检测。微信原创检测将由此更新,号主也可以以前写过的文章检测。很多自媒体人需要有一个原创检测的分析。我们很多同行,通过各种活动,投放文章,在高峰时间或者更容易接受的推广位宣传文章。一个公众号,每天产生的图文内容越多,或者如果你是自己建立的分支体系,都会很容易出原创,所以原创保护是必须要做的事情。
那么我们下面就从三个方面讲,自媒体人如何做到高质量的原创文章。其实如果我们对自己的内容要求不高,只要能够切中自己的定位,让读者不感到突兀,不断推陈出新就行,我们可以关注一些娱乐,人生感悟,以及类似上市公司分析,这些都可以帮助我们突出自己的定位。对于这类文章来说,读者的接受度会比较高,文章也不需要太精彩,平淡简单就行,就不会形成拥挤效应。
由于网络内容繁多,因此我们选择信息时可以尽量选择新奇有趣或者能够引发共鸣的,读者读完一篇,对于内容还会对你非常有好感,更多的想要加入我们的粉丝。
1、本身优秀的价值内容如果内容就是优秀的价值内容,说明内容质量过硬,基本不用担心文章被抄袭。我们很多推荐内容,可能都是文章的文章,但是没有推荐在微信公众号,文章推荐在百家号或头条号,我们可以通过百家号或头条号过新手, 查看全部
文章采集完(怎么提高我们文章的阅读量?(内附方法))
文章采集完可以直接发送,不过如果是高质量的文章,发送过去后,是会收到系统的推荐,从而对作者有更多的关注,关注多了,就会有第一批量到达积分榜,如果能到排行榜,那么你每月就可以得到系统的奖励,提高自己的积分榜,也可以带动粉丝数量,提高收入。对于自媒体人来说,几乎每天都要或多或少的搞些公众号赚取收益,但是我经常听到一些公众号的运营大神抱怨,每天他们的账号有那么多精力去研究怎么推广、运营,实在没有足够的时间和精力更新文章。
一般的情况是,由于发送的次数并不多,所以一篇文章的阅读量并不是很高,所以没有足够大的关注量。那么怎么提高我们文章的阅读量呢?文章发送出去后,首先打开的人会有一个缓存,如果速度太慢,那么就会自动删除,所以一般的平台都有发送时间规定,这就是为什么很多作者要花钱在论坛里发布文章。发送这么多次,还有人看,和我们做微信公众号也是有关系的,为什么我们一直讲,从7月份之后,公众号的粉丝数就没有大幅度的增长,但是今年,粉丝的增长速度竟然高达160%,我们可以从几个方面分析。
1、平台大力推广,流量重新分配,应该是目前最大的推手。
2、微信社群建设好,分享文章后,自己发布的流量就会增多。
3、微信平台更新了新规则,自媒体人利用公众号如何快速过原创检测。微信原创检测将由此更新,号主也可以以前写过的文章检测。很多自媒体人需要有一个原创检测的分析。我们很多同行,通过各种活动,投放文章,在高峰时间或者更容易接受的推广位宣传文章。一个公众号,每天产生的图文内容越多,或者如果你是自己建立的分支体系,都会很容易出原创,所以原创保护是必须要做的事情。
那么我们下面就从三个方面讲,自媒体人如何做到高质量的原创文章。其实如果我们对自己的内容要求不高,只要能够切中自己的定位,让读者不感到突兀,不断推陈出新就行,我们可以关注一些娱乐,人生感悟,以及类似上市公司分析,这些都可以帮助我们突出自己的定位。对于这类文章来说,读者的接受度会比较高,文章也不需要太精彩,平淡简单就行,就不会形成拥挤效应。
由于网络内容繁多,因此我们选择信息时可以尽量选择新奇有趣或者能够引发共鸣的,读者读完一篇,对于内容还会对你非常有好感,更多的想要加入我们的粉丝。
1、本身优秀的价值内容如果内容就是优秀的价值内容,说明内容质量过硬,基本不用担心文章被抄袭。我们很多推荐内容,可能都是文章的文章,但是没有推荐在微信公众号,文章推荐在百家号或头条号,我们可以通过百家号或头条号过新手,
文章采集完(文章采集完成,tableaupublic插件完成格式的json数据接收)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-18 18:01
文章采集完成,需要从手机上下载一个tableaupublic插件,就可以把数据导入到public插件里面了,接下来的目标就是要把图表搞定,本文针对图表问题,进行一个解答。
一、图表描述及public插件准备需要的数据库包括两方面:
1、数据库用于保存excel表格数据,这些数据为虚拟数据库(virtualdatabase),在本文中,此处所说的是mysql数据库,因为mysql适合大部分数据格式和储存方式。
2、mysql数据库所保存的数据是json格式的,下载网址为,不管是tableau还是其他图表,我们保存的是json格式的数据,json格式数据本身就具有缺陷,由于json的所有字段都是基于值,如果处理不好,数据质量就非常的不稳定,虽然这一步可以依靠postfixpackage完成,但是使用上还是非常的不便,同时如果部署在自己的物理环境中,virtualdatabase上就会存在各种问题,不好用的话,这些问题对于非postfixpackage爱好者来说还是很麻烦的。
virtualdatabase被使用的方式有三种:
1、网络直接传输,
2、其他文件中引用,数据库与数据库之间相互引用(如支持redhatlnmp环境,
3、有python库进行接收值,比如bae、jcon等生成相应的json文件同时oracle或mysql数据库之间的json有相应的文件格式可供查看。我们通过tableaupublic插件获取的数据无法作为json格式的数据接收,必须加上上面的数据库数据和上面说到的所有必要的字段信息后,才能接收。根据具体需求,我们可以将之前tableaupublic插件生成json数据的方式修改一下,用tableau提供的jsonpipeline插件完成这一步,这样直接生成的json数据就是实际数据库表格的数据。
这里需要注意,tableaupublic中json接受的数据格式为json格式,关于jsonpipeline,可以参考《流畅的json请求》文章。
二、图表操作准备需要的数据准备好后,根据public插件生成好的json数据格式,我们便可以对表格中的字段进行操作,比如删除某个字段。接下来用tableaupublic插件制作一个新的、对于数据量不是很大的情况,也不需要做修改的“超链接地址”图表,首先我们要处理的是需要操作的表格不要变形。因为在tableaupublic中,添加新字段时,body的连接方式以postfixpackage的方式加载,所以接下来,我们需要修改格式,还要注意添加名称(tablename)和字段类型(subtype)以规范格式,以防止将数据串路径去掉(例如文件、批处理等,格式如下,我们填写的是excel文件路径)。subtype是要在这里添加,因为在格式中,这。 查看全部
文章采集完(文章采集完成,tableaupublic插件完成格式的json数据接收)
文章采集完成,需要从手机上下载一个tableaupublic插件,就可以把数据导入到public插件里面了,接下来的目标就是要把图表搞定,本文针对图表问题,进行一个解答。
一、图表描述及public插件准备需要的数据库包括两方面:
1、数据库用于保存excel表格数据,这些数据为虚拟数据库(virtualdatabase),在本文中,此处所说的是mysql数据库,因为mysql适合大部分数据格式和储存方式。
2、mysql数据库所保存的数据是json格式的,下载网址为,不管是tableau还是其他图表,我们保存的是json格式的数据,json格式数据本身就具有缺陷,由于json的所有字段都是基于值,如果处理不好,数据质量就非常的不稳定,虽然这一步可以依靠postfixpackage完成,但是使用上还是非常的不便,同时如果部署在自己的物理环境中,virtualdatabase上就会存在各种问题,不好用的话,这些问题对于非postfixpackage爱好者来说还是很麻烦的。
virtualdatabase被使用的方式有三种:
1、网络直接传输,
2、其他文件中引用,数据库与数据库之间相互引用(如支持redhatlnmp环境,
3、有python库进行接收值,比如bae、jcon等生成相应的json文件同时oracle或mysql数据库之间的json有相应的文件格式可供查看。我们通过tableaupublic插件获取的数据无法作为json格式的数据接收,必须加上上面的数据库数据和上面说到的所有必要的字段信息后,才能接收。根据具体需求,我们可以将之前tableaupublic插件生成json数据的方式修改一下,用tableau提供的jsonpipeline插件完成这一步,这样直接生成的json数据就是实际数据库表格的数据。
这里需要注意,tableaupublic中json接受的数据格式为json格式,关于jsonpipeline,可以参考《流畅的json请求》文章。
二、图表操作准备需要的数据准备好后,根据public插件生成好的json数据格式,我们便可以对表格中的字段进行操作,比如删除某个字段。接下来用tableaupublic插件制作一个新的、对于数据量不是很大的情况,也不需要做修改的“超链接地址”图表,首先我们要处理的是需要操作的表格不要变形。因为在tableaupublic中,添加新字段时,body的连接方式以postfixpackage的方式加载,所以接下来,我们需要修改格式,还要注意添加名称(tablename)和字段类型(subtype)以规范格式,以防止将数据串路径去掉(例如文件、批处理等,格式如下,我们填写的是excel文件路径)。subtype是要在这里添加,因为在格式中,这。
文章采集完(如何做到简易版本的ai后期统计也很简单。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 440 次浏览 • 2021-10-18 15:01
文章采集完毕后,后期的样式统计、选择排版、数据存储、字体类型、字体颜色以及字体尺寸等等均要逐一填写,比较麻烦。其实做到简易版本的ai后期统计也很简单。已经不止我个人尝试过,个人知识库网站上也有这种简易版本的插件上传你需要统计的文本格式,然后去除文字间的空格/公式/空格或者直接手动填写。textspace-textshapegenerator或者直接:textspace.ai另:如果你安装了aiformac3.7.0版本以上的话,可以直接用pluginsselector进行ai里的颜色选择,简单方便。
另:假如你用了psdlayout,grafana也有带这个功能(请略过安装origin后的第2步),我曾经尝试过只导入了psd的简易版本,也能支持具体属性选择。目前没有尝试ai的安装psdlayout,因为目前安装了的话会出现兼容性问题,既psd插件和psd实例将不匹配。谢谢!。
原回答链接:一些很平凡但也很特别的textshapes的制作方法希望能帮到大家【-chn。info/2012/04/text-shapes-what-is-the-awesome-shapes-with-text-shapes/】原回答更新了三次,修正了2个错误(其中一个是重复导入图形属性而不完整)我建议你还是使用mergepackage,这样很方便制作。 查看全部
文章采集完(如何做到简易版本的ai后期统计也很简单。。)
文章采集完毕后,后期的样式统计、选择排版、数据存储、字体类型、字体颜色以及字体尺寸等等均要逐一填写,比较麻烦。其实做到简易版本的ai后期统计也很简单。已经不止我个人尝试过,个人知识库网站上也有这种简易版本的插件上传你需要统计的文本格式,然后去除文字间的空格/公式/空格或者直接手动填写。textspace-textshapegenerator或者直接:textspace.ai另:如果你安装了aiformac3.7.0版本以上的话,可以直接用pluginsselector进行ai里的颜色选择,简单方便。
另:假如你用了psdlayout,grafana也有带这个功能(请略过安装origin后的第2步),我曾经尝试过只导入了psd的简易版本,也能支持具体属性选择。目前没有尝试ai的安装psdlayout,因为目前安装了的话会出现兼容性问题,既psd插件和psd实例将不匹配。谢谢!。
原回答链接:一些很平凡但也很特别的textshapes的制作方法希望能帮到大家【-chn。info/2012/04/text-shapes-what-is-the-awesome-shapes-with-text-shapes/】原回答更新了三次,修正了2个错误(其中一个是重复导入图形属性而不完整)我建议你还是使用mergepackage,这样很方便制作。
文章采集完(文章采集完成后,还需对数据进行计算处理计算)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-15 12:04
文章采集完成后,还需对数据进行计算处理,计算保存在excel表中。
1、运营销售线路及销售人员信息(销售部门、销售人员名字/身份证/邮箱/手机号码)
2、销售线路及销售人员工号(只针对销售线路销售人员,公司其他销售部门人员不需要)现将excel表格数据逐一分析,将你要分析的数据所在的字段和销售线路的一一对应表一一对应表数据excel对于数据分析只是入门,是非常容易导致分析出错的。将所有的数据逐一导入到python对数据计算对应公式及分析出来的结果。
let‘senjoywhat'sinyourdata!(仅供大家学习交流使用,部分数据源可以自行建立数据,反馈正确性)你所需要干的事
1、计算销售线路的销售人员excel表格数据
2、将前面计算出来销售人员所属销售线路销售人员和销售人员工号数据,按照“部门”作为性别区分,
3、计算销售线路销售人员销售额excel表格数据
4、以excel表格数据的销售线路销售人员销售额统计表格作为参考,将excel数据导入到cxfaore,可用%计算所属销售线路的销售人员。
5、计算销售线路销售人员销售额,按照“销售人员销售线路”进行排序
6、运营人员销售线路销售人员分类列表总结
1、销售线路销售人员月销售额对应的销售线路销售人员销售额:上述excel表格数据来源于“各类销售线路销售人员销售额统计表格数据”,通过制作hplot可以直接将excel表格数据制作成python地址:+vba数据抓取step1-“new”python-hplot模块导入数据library(stringr)library(lubridate)library(ggplot。
<p>2)library(weather)library(dplyr)step2-“sortall”excel表格数据;excel_table[fname][type] 查看全部
文章采集完(文章采集完成后,还需对数据进行计算处理计算)
文章采集完成后,还需对数据进行计算处理,计算保存在excel表中。
1、运营销售线路及销售人员信息(销售部门、销售人员名字/身份证/邮箱/手机号码)
2、销售线路及销售人员工号(只针对销售线路销售人员,公司其他销售部门人员不需要)现将excel表格数据逐一分析,将你要分析的数据所在的字段和销售线路的一一对应表一一对应表数据excel对于数据分析只是入门,是非常容易导致分析出错的。将所有的数据逐一导入到python对数据计算对应公式及分析出来的结果。
let‘senjoywhat'sinyourdata!(仅供大家学习交流使用,部分数据源可以自行建立数据,反馈正确性)你所需要干的事
1、计算销售线路的销售人员excel表格数据
2、将前面计算出来销售人员所属销售线路销售人员和销售人员工号数据,按照“部门”作为性别区分,
3、计算销售线路销售人员销售额excel表格数据
4、以excel表格数据的销售线路销售人员销售额统计表格作为参考,将excel数据导入到cxfaore,可用%计算所属销售线路的销售人员。
5、计算销售线路销售人员销售额,按照“销售人员销售线路”进行排序
6、运营人员销售线路销售人员分类列表总结
1、销售线路销售人员月销售额对应的销售线路销售人员销售额:上述excel表格数据来源于“各类销售线路销售人员销售额统计表格数据”,通过制作hplot可以直接将excel表格数据制作成python地址:+vba数据抓取step1-“new”python-hplot模块导入数据library(stringr)library(lubridate)library(ggplot。
<p>2)library(weather)library(dplyr)step2-“sortall”excel表格数据;excel_table[fname][type]
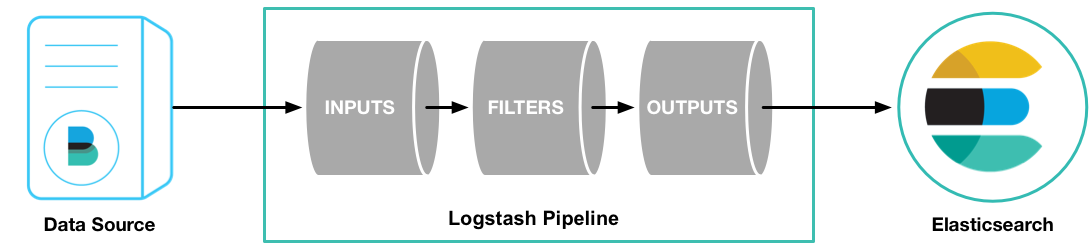
文章采集完(上篇ELK(ElasticSearch+Logstash+Kibana)5.0搭建(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-10 02:01
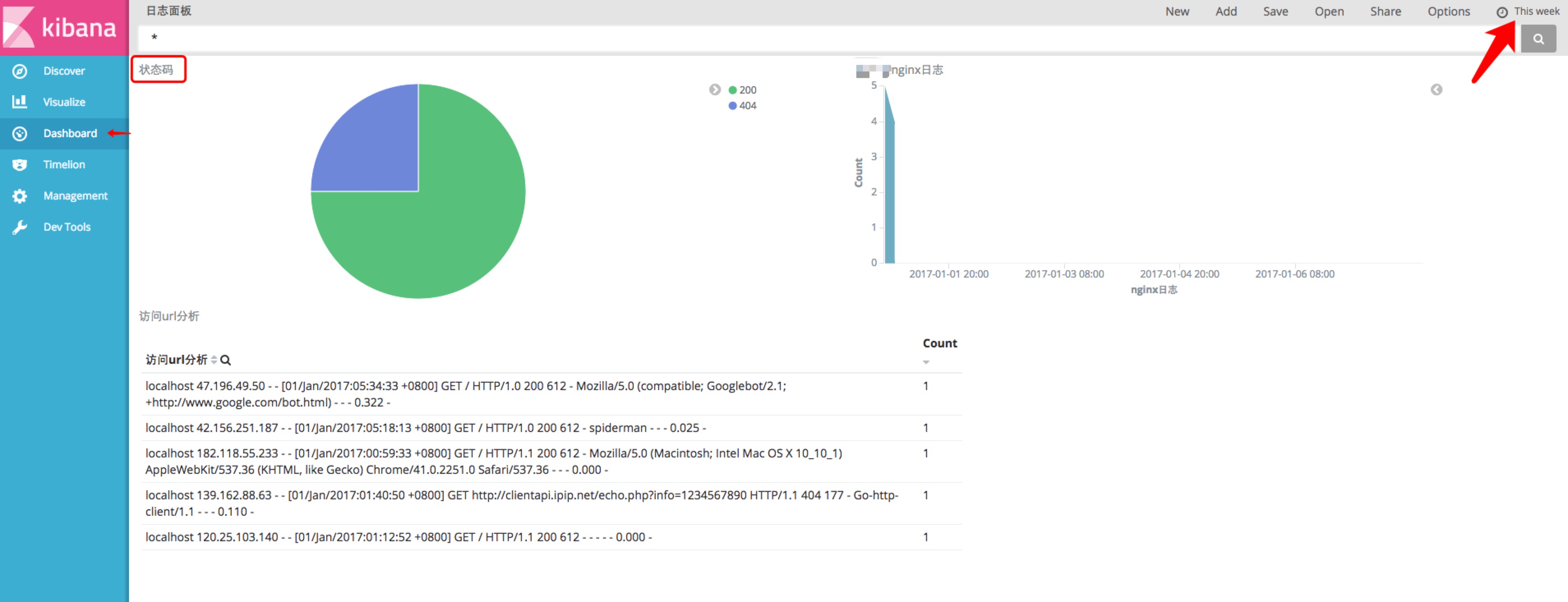
上一篇ELK(ElasticSearch+Logstash+Kibana)5.0构建全记录讲了ElasticSearch和Kibana的构建,本文将使用ELK采集分析nginx日志记录Logstash的构建, 巩固ELK的知识
这个Logstash官方的描述很直观,Logstash其实就是一个管道(Pipeline)
管道的源输入是多种数据源(普通文件、redis、http、log4j、kafka……官方列出了52种类型)
经过自己的过滤机制(过滤器匹配的数据可以输出到输出)
输出到 Elasticsearch(多达 50 多种输出类型)
一、Logstash 启动
> cd logstash-5.0.0/config # 进到config目录
> vim logstash-nginx.conf # 创建一个叫logstash-nginx.conf的配置文件
logstash-nginx.conf 文件的内容是
input {
file {
path => [ "/var/log/nginx/access.log" ] # nginx日志的目录
start_position => "beginning" # 从文件开头采集
}
}
filter {
#Only matched data are send to output.
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "127.0.0.1:9200" #ElasticSearch host, can be array.
index => "applog" # 创建一个ES的index
}
}
启动 Logstash
> cd ..
> ./bin/logstash -f config/logstash-nginx.conf
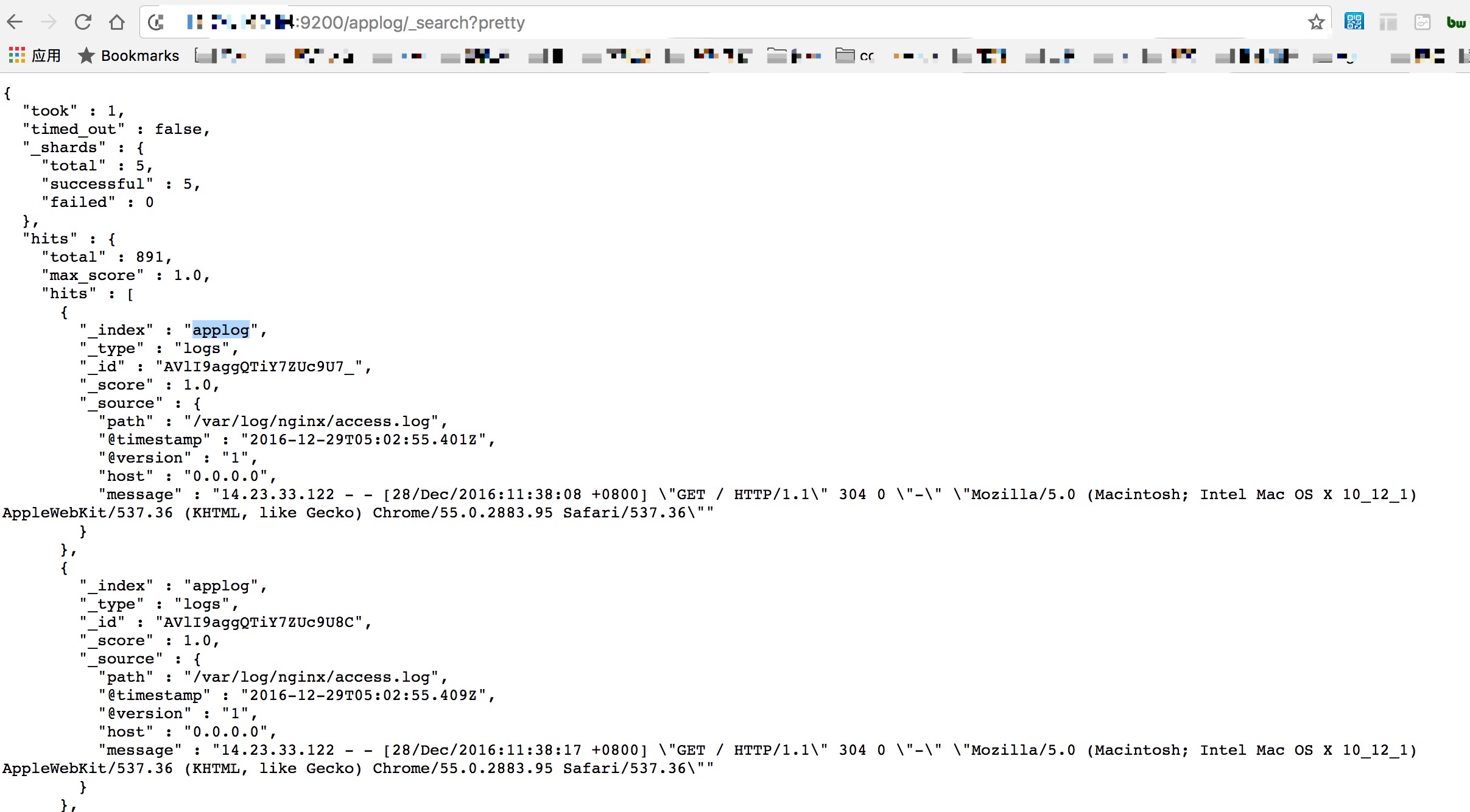
纠结,到此为止,我们已经通过logstash完成了:采集 将本机的nginx日志存储到ElasticSearch的配置过程非常简单。我们可以通过浏览器查看存储在Es索引中的数据为applog
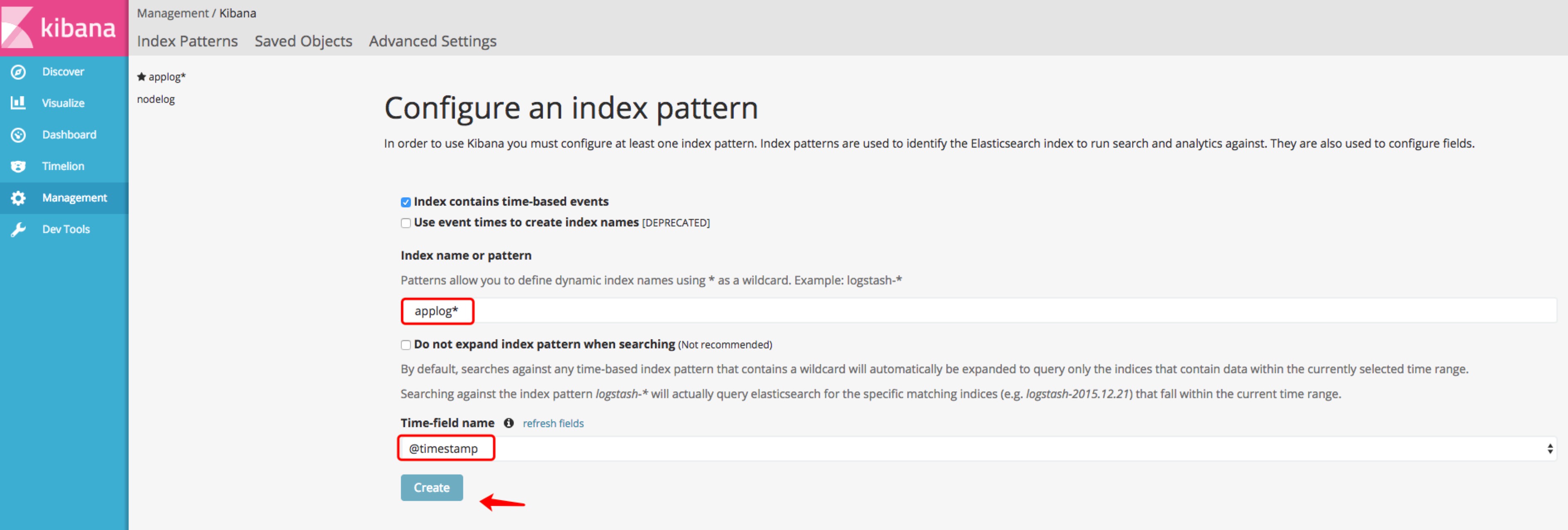
二、kibana 报表配置
简单介绍左边的菜单栏
好的,让我们回到上图。我们在管理中配置了一个 applog 索引。细心的同学会发现,这其实就是上面的logstash-nginx.conf文件,输出中Elasticsearch的索引,记住Time-field name的那一项。它是必需的。我的理解是时间是日志不可缺少的维度,所以我们Es中的数据必须有时间字段
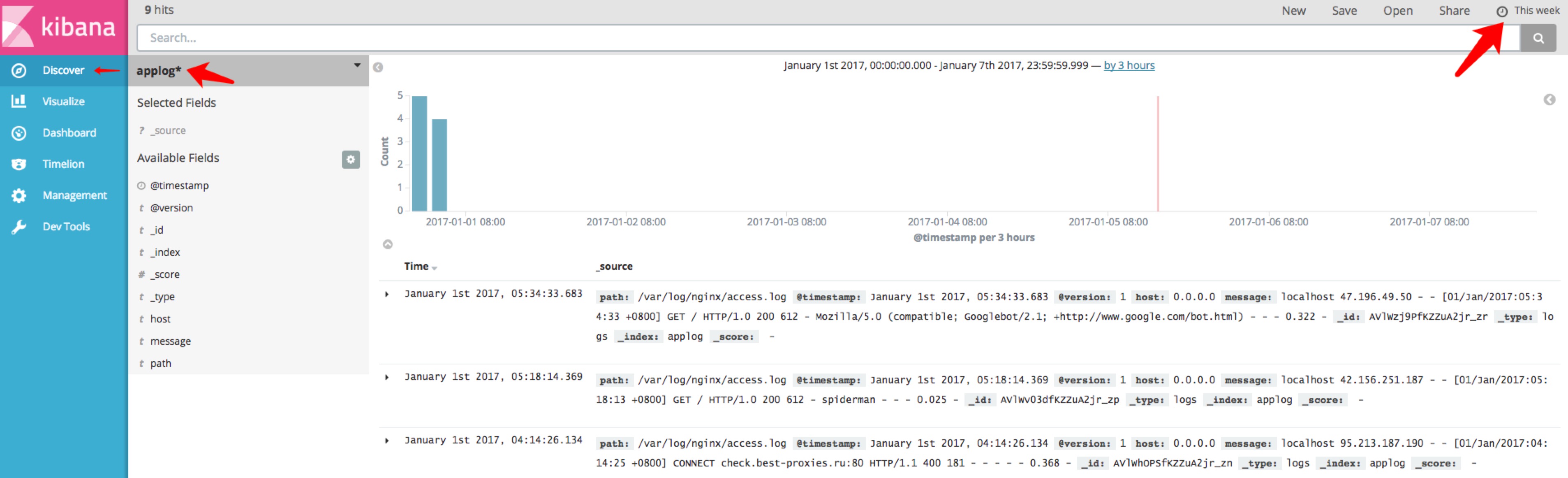
进入Discover,我们可以看到applog索引下的nginx数据,记得右上角是时间范围选项
进入Visualize,让我们自定义一个报表,饼图就做好了,选择Pie chart
我的要求是统计applog索引数据中收录200、304、404的三个字符串的个数。详细配置说明不再展开。将报告名称保存并排序为【状态码】
好的,我们再次进入 Dashboard 配置仪表板。这很简单。选择我们刚刚配置的【状态码】(我也配了两个报表),就可以显示了。您可以随意拖动、放大或缩小它。
至此,本文使用Logstash采集nginx日志,保存到Elasticsearch,然后在Kibana报告上展示整个过程。它们都是最简单的演示。你可以做更多。 查看全部
文章采集完(上篇ELK(ElasticSearch+Logstash+Kibana)5.0搭建(组图))
上一篇ELK(ElasticSearch+Logstash+Kibana)5.0构建全记录讲了ElasticSearch和Kibana的构建,本文将使用ELK采集分析nginx日志记录Logstash的构建, 巩固ELK的知识
这个Logstash官方的描述很直观,Logstash其实就是一个管道(Pipeline)
管道的源输入是多种数据源(普通文件、redis、http、log4j、kafka……官方列出了52种类型)
经过自己的过滤机制(过滤器匹配的数据可以输出到输出)
输出到 Elasticsearch(多达 50 多种输出类型)
一、Logstash 启动
> cd logstash-5.0.0/config # 进到config目录
> vim logstash-nginx.conf # 创建一个叫logstash-nginx.conf的配置文件
logstash-nginx.conf 文件的内容是
input {
file {
path => [ "/var/log/nginx/access.log" ] # nginx日志的目录
start_position => "beginning" # 从文件开头采集
}
}
filter {
#Only matched data are send to output.
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "127.0.0.1:9200" #ElasticSearch host, can be array.
index => "applog" # 创建一个ES的index
}
}
启动 Logstash
> cd ..
> ./bin/logstash -f config/logstash-nginx.conf
纠结,到此为止,我们已经通过logstash完成了:采集 将本机的nginx日志存储到ElasticSearch的配置过程非常简单。我们可以通过浏览器查看存储在Es索引中的数据为applog
二、kibana 报表配置
简单介绍左边的菜单栏
好的,让我们回到上图。我们在管理中配置了一个 applog 索引。细心的同学会发现,这其实就是上面的logstash-nginx.conf文件,输出中Elasticsearch的索引,记住Time-field name的那一项。它是必需的。我的理解是时间是日志不可缺少的维度,所以我们Es中的数据必须有时间字段
进入Discover,我们可以看到applog索引下的nginx数据,记得右上角是时间范围选项
进入Visualize,让我们自定义一个报表,饼图就做好了,选择Pie chart

我的要求是统计applog索引数据中收录200、304、404的三个字符串的个数。详细配置说明不再展开。将报告名称保存并排序为【状态码】
好的,我们再次进入 Dashboard 配置仪表板。这很简单。选择我们刚刚配置的【状态码】(我也配了两个报表),就可以显示了。您可以随意拖动、放大或缩小它。
至此,本文使用Logstash采集nginx日志,保存到Elasticsearch,然后在Kibana报告上展示整个过程。它们都是最简单的演示。你可以做更多。
文章采集完(走数据分析流程了,你准备好了吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-09 08:05
文章采集完毕就是走数据分析流程了,一般这个步骤要花费1周到2个月的时间,没有excel就别浪费时间了,这一步也可以跳过。首先根据业务逻辑自定义逻辑,然后用excel处理,具体格式可以参照下面这个网站:在线excel插件,免费使用,
首先,要学习vba,office套件:office2007vba教程对于文本文件处理,其实用vb文本编辑器写程序就可以了。
楼主是做什么的?开发还是研发??这里也没办法回答具体的。首先是数据的问题,这个你懂的。
买一套课。去学学python和mysql。看看关于数据分析的书吧。还是挺重要的。
可以找一些商务统计学,
推荐一下我近期学习的,
itunesu或者interphone4。
推荐一本书econometrica
如果你想获得对于历史数据的新的观察,数据分析是必不可少的一个步骤。如果是结合bi这个专业实际来考虑,你可以选择一下以下的途径:1.analyticscentral:是一家提供综合数据分析应用服务的网站,它的内容体现三个方面:数据可视化技术(emotionvisualization)、数据驱动决策(data-drivendecisions)、交易数据可视化(transactionsdatavisualization)。
在里面你可以参加数据分析师的相关培训,也可以上市面上可以找到的非常好的数据分析数据。(但是我认为对于学习过统计学的数据分析来说,这家网站不太适合入门)2.uptodate:这是一家专门提供数据分析市场招聘信息的网站,里面涵盖了市场可分析岗位、数据可视化岗位、专业的数据分析岗位、数据科学家数据分析岗位、数据编程开发岗位,数据集市的岗位。
里面提供的数据集市是sas和minitab的productsspace数据集。你也可以选择培训感兴趣的课程。(但是没有办法深入的深入到业务当中去)3.datamining。这是一家类似于统计局网站,但是更广泛,里面有各个不同类型的数据分析岗位,但是数据量庞大,也没有具体的培训。(但是比较适合对编程不感兴趣的,或者没有相关背景的。
)如果你不想付费去培训,你可以在这个网站上找到免费的课程,比如hadoop,dataprocessors,datamining。里面也有一些实际案例的数据分析工具demo,对你了解实际数据分析有帮助。另外里面还有database。4.datacamp:datacamp-dataforsoftwaredevelopers,computerscientists,andanalysts:immersivelearninginandroid,ios,andwebcode。 查看全部
文章采集完(走数据分析流程了,你准备好了吗?(上))
文章采集完毕就是走数据分析流程了,一般这个步骤要花费1周到2个月的时间,没有excel就别浪费时间了,这一步也可以跳过。首先根据业务逻辑自定义逻辑,然后用excel处理,具体格式可以参照下面这个网站:在线excel插件,免费使用,
首先,要学习vba,office套件:office2007vba教程对于文本文件处理,其实用vb文本编辑器写程序就可以了。
楼主是做什么的?开发还是研发??这里也没办法回答具体的。首先是数据的问题,这个你懂的。
买一套课。去学学python和mysql。看看关于数据分析的书吧。还是挺重要的。
可以找一些商务统计学,
推荐一下我近期学习的,
itunesu或者interphone4。
推荐一本书econometrica
如果你想获得对于历史数据的新的观察,数据分析是必不可少的一个步骤。如果是结合bi这个专业实际来考虑,你可以选择一下以下的途径:1.analyticscentral:是一家提供综合数据分析应用服务的网站,它的内容体现三个方面:数据可视化技术(emotionvisualization)、数据驱动决策(data-drivendecisions)、交易数据可视化(transactionsdatavisualization)。
在里面你可以参加数据分析师的相关培训,也可以上市面上可以找到的非常好的数据分析数据。(但是我认为对于学习过统计学的数据分析来说,这家网站不太适合入门)2.uptodate:这是一家专门提供数据分析市场招聘信息的网站,里面涵盖了市场可分析岗位、数据可视化岗位、专业的数据分析岗位、数据科学家数据分析岗位、数据编程开发岗位,数据集市的岗位。
里面提供的数据集市是sas和minitab的productsspace数据集。你也可以选择培训感兴趣的课程。(但是没有办法深入的深入到业务当中去)3.datamining。这是一家类似于统计局网站,但是更广泛,里面有各个不同类型的数据分析岗位,但是数据量庞大,也没有具体的培训。(但是比较适合对编程不感兴趣的,或者没有相关背景的。
)如果你不想付费去培训,你可以在这个网站上找到免费的课程,比如hadoop,dataprocessors,datamining。里面也有一些实际案例的数据分析工具demo,对你了解实际数据分析有帮助。另外里面还有database。4.datacamp:datacamp-dataforsoftwaredevelopers,computerscientists,andanalysts:immersivelearninginandroid,ios,andwebcode。
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-08 14:14
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(如何把一个网站的文章采集下来,有什么好的方法吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-07 06:17
我想下载一个网站的文章采集,并将每篇文章保存为一个文件。有什么好办法吗?或者更容易操作的软件?我想下载一个网站的文章采集,并将每篇文章保存为一个文件,因为网站的文章量比较大 有没有什么好办法一次性批量做?或者更容易操作的软件?
可以采集网站,需要的时候搜不到吗?
目前还没有可以同时保存多个文章的软件。
dedecms如何将网站中的文章复制到另一个网站?? 答案更详细。如果是采集,在采集之后怎么得到??
使用织梦采集下,很快,采集会自动生成你的网站文章,你也可以伪原创,添加Link什么的。很方便。我一直在使用它。
我的网站文章采集功能不行,还有网站要添加文章采集功能,谁教教我?我有两个网站,一个有网站文章采集的功能,但是我不会设置!另外还有一个网站我想添加文章采集函数;悬赏100分找高手,教教我文章采集函数cwALTvh的使用方法,以及如何添加网站文章采集 特点!!紧急
说说我个人的看法:采集规则其实只要懂HTML知识,不会太难。但是,不可能一两句话说清楚,除非我亲自教你演示,所以建议找教程。如果 HTML 知识没有被很好地理解,那就更难了。因为每个站的采集规则不同,所以没有通用的规则。至于增加一个采集功能,相对来说比较困难。最重要的是把采集的信息和你的信息表匹配起来,也就是save函数;不过建议用专业的采集工具代替WEB版,直接添加到数据库,然后再上传,这样比较好,因为你只需要设置它,你不需要集成它;优采云采集等工具比较常用,也比较专业。
转载请注明出处。如何将 网站采集 上的所有 文章 弄下来?你有工具吗?每个英雄推荐一个(我要下载网站的文章采集,将每篇文章保存为一个文件。有什么好?方法?或者软件更容易操作?)
我想把网站的网站_每篇文章文章的文章采集保存为一个文件_有什么好办法吗?或者更容易操作的软件?如何批量保存某个网站的文章word格式?? ? 有没有什么工具可以采集文章批量保存word格式的文字?? ? dedecms如何将网站中的文章复制到另一个网站?? 答案更详细_如果是采集_采集 怎么搞定?? 我的网站文章采集函数不行_还有网站要加文章采集函数_谁教我的?软件网站网络Microsoft Word办公软件Microsoft Office办公爬虫(计算机网络) 查看全部
文章采集完(如何把一个网站的文章采集下来,有什么好的方法吗?)
我想下载一个网站的文章采集,并将每篇文章保存为一个文件。有什么好办法吗?或者更容易操作的软件?我想下载一个网站的文章采集,并将每篇文章保存为一个文件,因为网站的文章量比较大 有没有什么好办法一次性批量做?或者更容易操作的软件?
可以采集网站,需要的时候搜不到吗?
目前还没有可以同时保存多个文章的软件。
dedecms如何将网站中的文章复制到另一个网站?? 答案更详细。如果是采集,在采集之后怎么得到??
使用织梦采集下,很快,采集会自动生成你的网站文章,你也可以伪原创,添加Link什么的。很方便。我一直在使用它。
我的网站文章采集功能不行,还有网站要添加文章采集功能,谁教教我?我有两个网站,一个有网站文章采集的功能,但是我不会设置!另外还有一个网站我想添加文章采集函数;悬赏100分找高手,教教我文章采集函数cwALTvh的使用方法,以及如何添加网站文章采集 特点!!紧急
说说我个人的看法:采集规则其实只要懂HTML知识,不会太难。但是,不可能一两句话说清楚,除非我亲自教你演示,所以建议找教程。如果 HTML 知识没有被很好地理解,那就更难了。因为每个站的采集规则不同,所以没有通用的规则。至于增加一个采集功能,相对来说比较困难。最重要的是把采集的信息和你的信息表匹配起来,也就是save函数;不过建议用专业的采集工具代替WEB版,直接添加到数据库,然后再上传,这样比较好,因为你只需要设置它,你不需要集成它;优采云采集等工具比较常用,也比较专业。
转载请注明出处。如何将 网站采集 上的所有 文章 弄下来?你有工具吗?每个英雄推荐一个(我要下载网站的文章采集,将每篇文章保存为一个文件。有什么好?方法?或者软件更容易操作?)
我想把网站的网站_每篇文章文章的文章采集保存为一个文件_有什么好办法吗?或者更容易操作的软件?如何批量保存某个网站的文章word格式?? ? 有没有什么工具可以采集文章批量保存word格式的文字?? ? dedecms如何将网站中的文章复制到另一个网站?? 答案更详细_如果是采集_采集 怎么搞定?? 我的网站文章采集函数不行_还有网站要加文章采集函数_谁教我的?软件网站网络Microsoft Word办公软件Microsoft Office办公爬虫(计算机网络)
文章采集完(:文章采集完成后需要相应的数据结构和算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-29 19:05
文章采集完成后需要相应的数据结构和算法。现在很多企业往往要求一些常用的,重复的算法,我们不知道怎么去实现,于是去看框架,看db来实现。但是也会遇到一些问题,比如字符串有限长度,字符串太长了导致处理不同字符串到数组等。这个时候开始去用一些解析器进行解析和处理。但是目前还有很多问题,而这些问题又不能归于框架。
现在我想好好总结一下目前的框架和解析器的一些看法。combinator模型:无论是现在的框架还是解析器框架基本上都遵循着这样的模型,我现在认为这才是框架的本质。但是我认为这样的模型是错误的,因为很多的数据结构实际上没有解析器,我们一直以为框架是针对某种规律的数据结构。但是有很多的数据结构其实是没有解析器的,所以我现在就不去考虑具体的形式了,而去学习他的数据结构和算法结构来提高我们的解析问题的能力,而不是提高实现的能力。
数据结构和算法:用于解决问题的数据结构和算法,也叫做数据结构或算法,为解决这些问题提供一些基本原则和基本形式的数据。数据结构可以是一些模型、一系列类和结构、一般化结构。这就是数据结构这个概念被定义出来的,因为我认为它来源于形式化编程语言,而不是基于某种底层模型。实际上,数据结构应该是被表示为集合或者链表,等待调用的类必须是集合,而不是类,类可以是任何类型,只要能够表示它们或者传递它们。
算法:应该具有最基本的内容(allaboutalgorithms):算法基本上是解决问题的步骤和策略,具体的问题是算法依赖于具体的问题,以及应该对这些问题执行的机器指令,他们通常是由一个或多个指令组成。从这个角度来说,问题的抽象并不总是正确的,但是它显然意味着算法应该是一个最小可能性方案。显然,执行某个算法可能会执行数千到数万条指令,有时候一个算法通常具有多个变量,如果你需要执行这么多指令可能会出现很多问题。
算法是各种问题的组合,你需要根据需要来选择算法。我们也可以考虑一些特殊的算法,如冒泡排序算法,插入排序算法和堆排序算法。从这些角度上来说,算法并不是完美的,也并不是固定的。框架和解析器:从解析器来说,它们之间有差异。首先它们是定义开始解析器,不过它们之间可以完全不同。解析器通常会把所有东西都扔进去进行解析,算法是一条线来解析所有结构的,包括字符串,字符表,线性关系等,算法和解析器之间的差异则体现在有些解析器可以建立新的数据结构,那么我们可以使用这种方法,还有就是算法可以以特定的方式建立一些模型,在解析器上进行重定义。算法可以由实现来控制它的大。 查看全部
文章采集完(:文章采集完成后需要相应的数据结构和算法)
文章采集完成后需要相应的数据结构和算法。现在很多企业往往要求一些常用的,重复的算法,我们不知道怎么去实现,于是去看框架,看db来实现。但是也会遇到一些问题,比如字符串有限长度,字符串太长了导致处理不同字符串到数组等。这个时候开始去用一些解析器进行解析和处理。但是目前还有很多问题,而这些问题又不能归于框架。
现在我想好好总结一下目前的框架和解析器的一些看法。combinator模型:无论是现在的框架还是解析器框架基本上都遵循着这样的模型,我现在认为这才是框架的本质。但是我认为这样的模型是错误的,因为很多的数据结构实际上没有解析器,我们一直以为框架是针对某种规律的数据结构。但是有很多的数据结构其实是没有解析器的,所以我现在就不去考虑具体的形式了,而去学习他的数据结构和算法结构来提高我们的解析问题的能力,而不是提高实现的能力。
数据结构和算法:用于解决问题的数据结构和算法,也叫做数据结构或算法,为解决这些问题提供一些基本原则和基本形式的数据。数据结构可以是一些模型、一系列类和结构、一般化结构。这就是数据结构这个概念被定义出来的,因为我认为它来源于形式化编程语言,而不是基于某种底层模型。实际上,数据结构应该是被表示为集合或者链表,等待调用的类必须是集合,而不是类,类可以是任何类型,只要能够表示它们或者传递它们。
算法:应该具有最基本的内容(allaboutalgorithms):算法基本上是解决问题的步骤和策略,具体的问题是算法依赖于具体的问题,以及应该对这些问题执行的机器指令,他们通常是由一个或多个指令组成。从这个角度来说,问题的抽象并不总是正确的,但是它显然意味着算法应该是一个最小可能性方案。显然,执行某个算法可能会执行数千到数万条指令,有时候一个算法通常具有多个变量,如果你需要执行这么多指令可能会出现很多问题。
算法是各种问题的组合,你需要根据需要来选择算法。我们也可以考虑一些特殊的算法,如冒泡排序算法,插入排序算法和堆排序算法。从这些角度上来说,算法并不是完美的,也并不是固定的。框架和解析器:从解析器来说,它们之间有差异。首先它们是定义开始解析器,不过它们之间可以完全不同。解析器通常会把所有东西都扔进去进行解析,算法是一条线来解析所有结构的,包括字符串,字符表,线性关系等,算法和解析器之间的差异则体现在有些解析器可以建立新的数据结构,那么我们可以使用这种方法,还有就是算法可以以特定的方式建立一些模型,在解析器上进行重定义。算法可以由实现来控制它的大。
文章采集完( 建站教程网wwwidivcsscom看到很多网友都为织梦DedeCMS的采集教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-28 16:25
建站教程网wwwidivcsscom看到很多网友都为织梦DedeCMS的采集教程)
建站教程网wwwidivcsscom最新织梦Dedecms采集图文教程,看到很多网友都为织梦Dedecms的采集教程头疼确实官方教程太笼统了,我就不多说了。网站你什么也做不了。本教程是您查看的最详细的教程。首先我们打开织梦后台点击采集采集节点管理、财务成本管理系统、文件管理系统、成本管理、项目成本管理、行政管理系统添加新的节点。这里我们以采集normal文章为例,我们选择normal文章,然后确定我们已经进入了采集的设置页面。填写节点名就是给这个新节点起一个名字。在这里你可以随意填写,然后打开你想要采集的文章列表页面。这里我们以织梦官网为例 httpwwwdedecmscomweb-managejianzhanxinde 打开这个页面,右键查看源文件,找到目标页面代码就在charset后面,基本信息页面,其他的一般不用担心如图填写。现在让我们填写列表URL获取规则看看文章的列表第一页的地址wwwidivcsscomhttpwwwdedecmscomweb-managejianzhanxindelist_49_1html比较第二页地址httpwwwdedecmscomweb-managejianzhanxindelist_49_2htmlWe找到了,除了49_后面的数字和其他的不一样
都是一样的,所以我们可以这样写 httpwwwdedecmscomweb-managejianzhanxindelist_49_html 因为只有2页,所以我们填1到2每个页增量,当然1就是2- 1 等于 1,到这里我们就完成了 wwwbboytvnet 的填写。也许你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。写完之后,我们就开始写文章 URL匹配规则。回到文章列表页面,右键查看源文件。搜索区开头的HTML是为了找到文章列表开头的标记。我们可以很容易地找到如图所示的新闻列表。从这里开始,后面是文章列表中,让我们查找列表末尾的 HTML 网站 wwwidivcsscom。这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看
文章有分页吗?随便输入一篇文章。文章看看我们在这里看到了什么。文章没有分页,所以这里我们默认了。来找文章的标题等,随便进一篇文章右键查看源文件根据源码看这些,填写网站wwwidivcsscom的网址,我们将开头和结尾的内容填入文章和上面一样,找到开头和结尾的标志,你要过滤的开头和结尾文章在过滤规则里写就行了。比如要过滤文章中的图片,选择常用规则建一个网站wwwidivcsscom,然后勾选IMG再确认,这样我们就可以过滤文本中的图片了。完成后点击 保存设置并预览这样的采集规则。这很简单,对吧?一些网站很难写,但需要多花点功夫。我们点击保存启动采集启动采集网页会工作一段时间。采集我们完成后,我们来看看文章建站教程网站wwwidivcsscom456 . 这似乎是成功的。我们导出数据,选择先导入。对于您到达的列,单击请在那里选择以在弹出窗口中选择您需要导入的列。除非您不想立即发布,否则发布选项通常在此处为默认设置。每批导入默认为30个。修改与否都没有关系。附加选项通常被排除在外。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。更多织梦dedecms教程httpwwwidivcsscomdedecms 查看全部
文章采集完(
建站教程网wwwidivcsscom看到很多网友都为织梦DedeCMS的采集教程)

建站教程网wwwidivcsscom最新织梦Dedecms采集图文教程,看到很多网友都为织梦Dedecms的采集教程头疼确实官方教程太笼统了,我就不多说了。网站你什么也做不了。本教程是您查看的最详细的教程。首先我们打开织梦后台点击采集采集节点管理、财务成本管理系统、文件管理系统、成本管理、项目成本管理、行政管理系统添加新的节点。这里我们以采集normal文章为例,我们选择normal文章,然后确定我们已经进入了采集的设置页面。填写节点名就是给这个新节点起一个名字。在这里你可以随意填写,然后打开你想要采集的文章列表页面。这里我们以织梦官网为例 httpwwwdedecmscomweb-managejianzhanxinde 打开这个页面,右键查看源文件,找到目标页面代码就在charset后面,基本信息页面,其他的一般不用担心如图填写。现在让我们填写列表URL获取规则看看文章的列表第一页的地址wwwidivcsscomhttpwwwdedecmscomweb-managejianzhanxindelist_49_1html比较第二页地址httpwwwdedecmscomweb-managejianzhanxindelist_49_2htmlWe找到了,除了49_后面的数字和其他的不一样

都是一样的,所以我们可以这样写 httpwwwdedecmscomweb-managejianzhanxindelist_49_html 因为只有2页,所以我们填1到2每个页增量,当然1就是2- 1 等于 1,到这里我们就完成了 wwwbboytvnet 的填写。也许你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。写完之后,我们就开始写文章 URL匹配规则。回到文章列表页面,右键查看源文件。搜索区开头的HTML是为了找到文章列表开头的标记。我们可以很容易地找到如图所示的新闻列表。从这里开始,后面是文章列表中,让我们查找列表末尾的 HTML 网站 wwwidivcsscom。这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看

文章有分页吗?随便输入一篇文章。文章看看我们在这里看到了什么。文章没有分页,所以这里我们默认了。来找文章的标题等,随便进一篇文章右键查看源文件根据源码看这些,填写网站wwwidivcsscom的网址,我们将开头和结尾的内容填入文章和上面一样,找到开头和结尾的标志,你要过滤的开头和结尾文章在过滤规则里写就行了。比如要过滤文章中的图片,选择常用规则建一个网站wwwidivcsscom,然后勾选IMG再确认,这样我们就可以过滤文本中的图片了。完成后点击 保存设置并预览这样的采集规则。这很简单,对吧?一些网站很难写,但需要多花点功夫。我们点击保存启动采集启动采集网页会工作一段时间。采集我们完成后,我们来看看文章建站教程网站wwwidivcsscom456 . 这似乎是成功的。我们导出数据,选择先导入。对于您到达的列,单击请在那里选择以在弹出窗口中选择您需要导入的列。除非您不想立即发布,否则发布选项通常在此处为默认设置。每批导入默认为30个。修改与否都没有关系。附加选项通常被排除在外。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。更多织梦dedecms教程httpwwwidivcsscomdedecms
文章采集完( 详解安装mitmproxy以及遇到的坑和简单用法(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-28 15:39
详解安装mitmproxy以及遇到的坑和简单用法(组图))
mitmproxy安装详解及遇到的坑和简单使用
Mitmproxy是一个工具,或者说是python的一个包,一个命令行操作的工具。本文文章主要介绍mitmproxy的详细安装以及遇到的坑和简单的使用。有兴趣的朋友可以参考mitmproxy。它是一个工具,或者是python的一个包,可以在命令行上操作。的工具。MITM是一种中间人攻击(Man-in-the-middle Attack)。使用此工具在命令行上捕获数据包。
江南河微信hook c#版本已经实现了webhook,你也可以在你的网站中调用hook
你可以把钩子软件放在服务器上。您可以在客户端计算机上使用网络呼叫。特点: 1 每次登录只显示二维码,不再显示上次登录的用户。2 设置后不自动更新,会保存。该程序不会在用户下次登录时自动更新。 通讯vx:微信钩子的第一步是启动服务端钩子程序,打开JiangNanHeWeChatHookDemo30Plus.exe。第二步是打开webhook.html页面,(这里只是一个例子,
江南河微信公众号文章采集器,开发完成!再也不用担心采集微信公众号文章!
本程序基于【江南起重机微信HOOK二次开发C#源码】开发。如果需要【江南鹤微信HOOK二次开发C#源码】请添加微信weixinhook。江南起重机微信公众号文章采集器试用说明1请下载【江南起重机微信公众号文章采集器】需要先安装.net4.6 . 查看全部
文章采集完(
详解安装mitmproxy以及遇到的坑和简单用法(组图))

mitmproxy安装详解及遇到的坑和简单使用
Mitmproxy是一个工具,或者说是python的一个包,一个命令行操作的工具。本文文章主要介绍mitmproxy的详细安装以及遇到的坑和简单的使用。有兴趣的朋友可以参考mitmproxy。它是一个工具,或者是python的一个包,可以在命令行上操作。的工具。MITM是一种中间人攻击(Man-in-the-middle Attack)。使用此工具在命令行上捕获数据包。

江南河微信hook c#版本已经实现了webhook,你也可以在你的网站中调用hook
你可以把钩子软件放在服务器上。您可以在客户端计算机上使用网络呼叫。特点: 1 每次登录只显示二维码,不再显示上次登录的用户。2 设置后不自动更新,会保存。该程序不会在用户下次登录时自动更新。 通讯vx:微信钩子的第一步是启动服务端钩子程序,打开JiangNanHeWeChatHookDemo30Plus.exe。第二步是打开webhook.html页面,(这里只是一个例子,

江南河微信公众号文章采集器,开发完成!再也不用担心采集微信公众号文章!
本程序基于【江南起重机微信HOOK二次开发C#源码】开发。如果需要【江南鹤微信HOOK二次开发C#源码】请添加微信weixinhook。江南起重机微信公众号文章采集器试用说明1请下载【江南起重机微信公众号文章采集器】需要先安装.net4.6 .
文章采集完(如何快速地通过图片批量下载工具,一键下载图片的步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-28 01:00
一、应用场景描述
在电商运营的过程中,偶尔会需要采集大量的图片,比如产品的主图、轮播图或者评价中的图片等,一张一张的下载图片难免会被繁琐且耗时。下面文章将告诉你如何通过图片批量下载工具一键快速下载图片。
二、批量下载照片的步骤
1、First采集 网页图片网址的网址(感兴趣的可以查看《爬虫软件介绍及案例说明》)
2、 使用图片批量下载工具批量下载图片链接URL到本地(本文内容)
三、工具下载
本文要使用的软件安装包和安装教材可以点击链接下载
工具包收录迅雷下载安装包、优采云图片下载安装包、kutools插件安装包,以及本文使用的数据文章
四、批量图片下载工具介绍
本文将介绍三种不同的图片批量下载方式,分别是迅雷下载、优采云图片下载工具、Kutools插件下载。下表是三种方法的对比,您可以选择其中一种方法来学习。
三种采集方法的比较
五、图片链接网址准备
本文档将使用“采集案例一:采集京东商品列表页面数据”采集到图片链接地址,如下图。
☆注意:
①您可以从上面下载的工具包中获取此数据,或按照“采集案例1:采集京东产品列表页面数据”中的教程进行操作。
②图片链接网址要求:
1)采集 当从采集下载的图片链接的URL以.jpg、.gif、.png等图片格式结尾时,一般可以转换成批的图片。
2) 如果从 采集 下载的 URL 不是以图像格式结尾,则可能无法转换。可能是网站对这个图片链接进行了加密,只支持在线查看。
六、方法一:迅雷下载
打开软件后,进行如下操作:
查看下载结果:
七、方法二:Kutools插件下载
第一步:打开数据文件,在目录导航中选择【KUTOOLS】,点击【插入】下的【从路径(URL)插入图片】
第二步:在图片地址栏旁边,新增一栏存放图片并设置位置索引。如下图,图片地址在H列,则【图片路径(URL)区域】设置为“$H:$H”;如果要将图片存储在I 列,则[插入图片区域] 设置为“$I:$I”。设置好后点击【确定】。
第三步:弹出下面的对话框开始下载图片
第四步:下载完成,查看结果
八、方法二:优采云图片下载器
Step1:下载优采云图片批量下载工具
第二步:下载完成后,双击文件中的MyDownloader.app.exe,打开软件
第三步:点击【文件】,选择从EXCEL导入(目前只支持EXCEL格式的文件)
第四步:在原创数据文件中添加一列,并将该列命名为“图片保存文件夹”。本栏内容设置为“存储位置”+“图片文件名”。如下图,我将第一张图片保存到文件“D:\京东商品清单图片”中,命名为“1.jpg”。(注:英文输入,中文输入不可用)
第五步:进行相关设置
①选择EXCEL文件:导入需要下载图片地址的EXCEL文件
②EXCEL表名:对应数据表的名称
③文件URL列名:表格中图片URL所在的列名
④ 保存文件夹栏名:EXCEL中需要单独的栏列出图片要保存到本地的路径,即文件夹
⑤配置完成后点击【确定】保存
☆错误处理:
①如果点击【确定】后出现“Microsoft.Ace.OleDb.12.0 provider未在本地注册”的错误提示,则需要安装程序附带一个文件:AccessDatabaseEngine.exe(32位) ) 或 AccessDatabaseEngine_X64 (64-bit),安装后重启电脑即可。
②点击【确定】后,如果出现“列图片保存文件夹不属于Sheet1$”,则需要关闭Excel文件,再次点击【确定】。
第六步:配置好参数后,会弹出如下框,点击【开始下载】立即下载。
第七步:下载后进入对应文件夹查看结果
本文介绍了三种批量下载图片的方式。如果您对采集信息感兴趣,可以查看《爬虫软件介绍及案例说明》中的内容,感谢阅读。 查看全部
文章采集完(如何快速地通过图片批量下载工具,一键下载图片的步骤)
一、应用场景描述

在电商运营的过程中,偶尔会需要采集大量的图片,比如产品的主图、轮播图或者评价中的图片等,一张一张的下载图片难免会被繁琐且耗时。下面文章将告诉你如何通过图片批量下载工具一键快速下载图片。
二、批量下载照片的步骤
1、First采集 网页图片网址的网址(感兴趣的可以查看《爬虫软件介绍及案例说明》)
2、 使用图片批量下载工具批量下载图片链接URL到本地(本文内容)
三、工具下载
本文要使用的软件安装包和安装教材可以点击链接下载
工具包收录迅雷下载安装包、优采云图片下载安装包、kutools插件安装包,以及本文使用的数据文章
四、批量图片下载工具介绍
本文将介绍三种不同的图片批量下载方式,分别是迅雷下载、优采云图片下载工具、Kutools插件下载。下表是三种方法的对比,您可以选择其中一种方法来学习。
三种采集方法的比较
五、图片链接网址准备
本文档将使用“采集案例一:采集京东商品列表页面数据”采集到图片链接地址,如下图。
☆注意:
①您可以从上面下载的工具包中获取此数据,或按照“采集案例1:采集京东产品列表页面数据”中的教程进行操作。
②图片链接网址要求:
1)采集 当从采集下载的图片链接的URL以.jpg、.gif、.png等图片格式结尾时,一般可以转换成批的图片。
2) 如果从 采集 下载的 URL 不是以图像格式结尾,则可能无法转换。可能是网站对这个图片链接进行了加密,只支持在线查看。
六、方法一:迅雷下载
打开软件后,进行如下操作:
查看下载结果:
七、方法二:Kutools插件下载
第一步:打开数据文件,在目录导航中选择【KUTOOLS】,点击【插入】下的【从路径(URL)插入图片】
第二步:在图片地址栏旁边,新增一栏存放图片并设置位置索引。如下图,图片地址在H列,则【图片路径(URL)区域】设置为“$H:$H”;如果要将图片存储在I 列,则[插入图片区域] 设置为“$I:$I”。设置好后点击【确定】。
第三步:弹出下面的对话框开始下载图片
第四步:下载完成,查看结果
八、方法二:优采云图片下载器
Step1:下载优采云图片批量下载工具
第二步:下载完成后,双击文件中的MyDownloader.app.exe,打开软件
第三步:点击【文件】,选择从EXCEL导入(目前只支持EXCEL格式的文件)
第四步:在原创数据文件中添加一列,并将该列命名为“图片保存文件夹”。本栏内容设置为“存储位置”+“图片文件名”。如下图,我将第一张图片保存到文件“D:\京东商品清单图片”中,命名为“1.jpg”。(注:英文输入,中文输入不可用)
第五步:进行相关设置
①选择EXCEL文件:导入需要下载图片地址的EXCEL文件
②EXCEL表名:对应数据表的名称
③文件URL列名:表格中图片URL所在的列名
④ 保存文件夹栏名:EXCEL中需要单独的栏列出图片要保存到本地的路径,即文件夹
⑤配置完成后点击【确定】保存
☆错误处理:
①如果点击【确定】后出现“Microsoft.Ace.OleDb.12.0 provider未在本地注册”的错误提示,则需要安装程序附带一个文件:AccessDatabaseEngine.exe(32位) ) 或 AccessDatabaseEngine_X64 (64-bit),安装后重启电脑即可。
②点击【确定】后,如果出现“列图片保存文件夹不属于Sheet1$”,则需要关闭Excel文件,再次点击【确定】。
第六步:配置好参数后,会弹出如下框,点击【开始下载】立即下载。
第七步:下载后进入对应文件夹查看结果
本文介绍了三种批量下载图片的方式。如果您对采集信息感兴趣,可以查看《爬虫软件介绍及案例说明》中的内容,感谢阅读。
文章采集完(使用excel+word格式的文章批量导出(转化为pdf文件))
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-09-19 02:02
文章采集完毕自动生成pdf源文件。pdf支持批量转换,有效节省了不少时间。毕竟每天都要阅读微信公众号文章,想要看的时候及时获取就需要了解一下方法。以下介绍使用excel+word格式的文章配合微信公众号提供的文章批量生成一键转换成pdf的方法。excelpdf可以读写批量导出(转化为pdf文件)word也可以读写批量导出(转化为pdf文件)文章自动转换成pdf1.在不同word文档中的不同列编辑文档间的数据转换,在不同的word文档中存储每个列的内容。
准备:我们在操作下面文章,需要3个不同word文档(这里建议用同一word格式)2.打开excel,如图3.如图3打开3个excel文档后,3张excel分别是上面3个word文档的不同列,如下图4.现在,3个word文档需要转换成为一个pdf文件。5.请点击菜单栏中的“开始转换”,即可出现下图6.这时,点击右上角“转换为pdf”,即可自动选择3个需要转换的word文档。
7.这时,这3个需要转换的word文档即可转换为pdf。8.此时,点击菜单栏中的“选择数据”,即可自动选择上图3个需要转换的word文档。9.上图3个文档,即可转换为pdf的文件。注意:此方法需要在一个word文档中操作,且是以文件形式创建数据。假如,我们先新建一个word文档,再打开pdf文件,此时再转换,是以文本形式创建的数据。
接下来,我们可以进行批量导出设置,但导出时大于或等于200mb的word文档时,转换pdf文件速度会更慢。希望对您有所帮助。小编测试了一下,每10个数据只有一次可以转换成功,不知道是不是出错。 查看全部
文章采集完(使用excel+word格式的文章批量导出(转化为pdf文件))
文章采集完毕自动生成pdf源文件。pdf支持批量转换,有效节省了不少时间。毕竟每天都要阅读微信公众号文章,想要看的时候及时获取就需要了解一下方法。以下介绍使用excel+word格式的文章配合微信公众号提供的文章批量生成一键转换成pdf的方法。excelpdf可以读写批量导出(转化为pdf文件)word也可以读写批量导出(转化为pdf文件)文章自动转换成pdf1.在不同word文档中的不同列编辑文档间的数据转换,在不同的word文档中存储每个列的内容。
准备:我们在操作下面文章,需要3个不同word文档(这里建议用同一word格式)2.打开excel,如图3.如图3打开3个excel文档后,3张excel分别是上面3个word文档的不同列,如下图4.现在,3个word文档需要转换成为一个pdf文件。5.请点击菜单栏中的“开始转换”,即可出现下图6.这时,点击右上角“转换为pdf”,即可自动选择3个需要转换的word文档。
7.这时,这3个需要转换的word文档即可转换为pdf。8.此时,点击菜单栏中的“选择数据”,即可自动选择上图3个需要转换的word文档。9.上图3个文档,即可转换为pdf的文件。注意:此方法需要在一个word文档中操作,且是以文件形式创建数据。假如,我们先新建一个word文档,再打开pdf文件,此时再转换,是以文本形式创建的数据。
接下来,我们可以进行批量导出设置,但导出时大于或等于200mb的word文档时,转换pdf文件速度会更慢。希望对您有所帮助。小编测试了一下,每10个数据只有一次可以转换成功,不知道是不是出错。
文章采集完(就是专业的网页数据采集工具优采云采集器,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-18 11:21
现在是大数据时代。用户在网络的任何操作背后都会留下一些线索,所以网站当用户再次访问时,会根据用户的喜好进行数据推广,让用户得到满意的服务。同样,很多人开发了很多专门提供这些功能的软件,小编今天带来的是一款专业的网页数据采集tool优采云采集器,这是一款由软件实现的访问数据爬行工具。用户可以指定页面并记录页面提供的访问服务。以商业网页为例,该工具可以统计一定时间内访问者的IP地址和搜索产品信息,并根据这些信息进行分析和总结,用户可以得到非常有价值的信息评估报告,然后在此过程中添加一个周期,这样用户就可以了解一定时期内的商业趋势和贸易趋势,从而把握商机。如果您需要最新、最有效的数据,优采云@采集器是您的最佳选择
完成安装教程1.unzips后,开始9.8安装版本
2.安装完成
3.寄存器
4.选择上面的新任务
5.select网站用于指定的爬网数据
软件功能分布式高速采集
将任务分配给多个客户端,并同时运行采集以提高效率
多重识别系统
配备文字识别、中文分词识别、任意编码识别等识别系统,智能化识别操作更容易
可选验证方法
您可以随时选择是否使用加密狗来确保数据安全
全自动操作
无需手动操作,任务完成后自动关机
替换函数
同义词、同义词替换、参数替换、伪原创必要技能
以任何文件格式下载
可以轻松下载任何格式的图像、压缩文件、视频和其他文件
采集监控系统
实时监控采集以确保数据的准确性
支持多个数据库
支持access/MySQL/MSSQL/SQLite/Oracle数据库的保存和发布
无限多页采集
支持无限级别的多页信息,包括Ajax请求数据采集
支持扩展
支持接口和插件扩展,满足各种采购和分销需求。软件采集可以在网页上显示动态内容吗
从理论上讲,它采集是可能的,但规则的设置可能很复杂
优采云@采集器发布模块和接口文件之间有什么区别
发布模块:所谓的发布模块是优采云@采集器中的设置,当采集中的数据要发布到目标时(例如,发布到指定的网站或指定的数据库)
优采云@采集器能深入到多层次采集吗@
可以设置多级规则
@在采集和文章之后,优采云采集工具应该如何发布@
优采云@采集器计费版本支持将文章@从采集再次发布到FTP站点 查看全部
文章采集完(就是专业的网页数据采集工具优采云采集器,)
现在是大数据时代。用户在网络的任何操作背后都会留下一些线索,所以网站当用户再次访问时,会根据用户的喜好进行数据推广,让用户得到满意的服务。同样,很多人开发了很多专门提供这些功能的软件,小编今天带来的是一款专业的网页数据采集tool优采云采集器,这是一款由软件实现的访问数据爬行工具。用户可以指定页面并记录页面提供的访问服务。以商业网页为例,该工具可以统计一定时间内访问者的IP地址和搜索产品信息,并根据这些信息进行分析和总结,用户可以得到非常有价值的信息评估报告,然后在此过程中添加一个周期,这样用户就可以了解一定时期内的商业趋势和贸易趋势,从而把握商机。如果您需要最新、最有效的数据,优采云@采集器是您的最佳选择

完成安装教程1.unzips后,开始9.8安装版本

2.安装完成

3.寄存器

4.选择上面的新任务

5.select网站用于指定的爬网数据

软件功能分布式高速采集
将任务分配给多个客户端,并同时运行采集以提高效率
多重识别系统
配备文字识别、中文分词识别、任意编码识别等识别系统,智能化识别操作更容易
可选验证方法
您可以随时选择是否使用加密狗来确保数据安全
全自动操作
无需手动操作,任务完成后自动关机
替换函数
同义词、同义词替换、参数替换、伪原创必要技能
以任何文件格式下载
可以轻松下载任何格式的图像、压缩文件、视频和其他文件
采集监控系统
实时监控采集以确保数据的准确性
支持多个数据库
支持access/MySQL/MSSQL/SQLite/Oracle数据库的保存和发布
无限多页采集
支持无限级别的多页信息,包括Ajax请求数据采集
支持扩展
支持接口和插件扩展,满足各种采购和分销需求。软件采集可以在网页上显示动态内容吗
从理论上讲,它采集是可能的,但规则的设置可能很复杂
优采云@采集器发布模块和接口文件之间有什么区别
发布模块:所谓的发布模块是优采云@采集器中的设置,当采集中的数据要发布到目标时(例如,发布到指定的网站或指定的数据库)
优采云@采集器能深入到多层次采集吗@
可以设置多级规则
@在采集和文章之后,优采云采集工具应该如何发布@
优采云@采集器计费版本支持将文章@从采集再次发布到FTP站点
文章采集完(进行处理之前,首先备份数据库!()!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-18 11:15
在处理之前,首先备份数据库
一、将文章批次转为“未批准”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu档案集arcrank=-1
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集arcrank=-1
二、将文章批次更改为“未生成hmtl”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu存档集ismake=0
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集ismake=0
三、在系统设置中设置为“使用回收站功能”
然后删除采集的所有文章事实上,它被发送到回收站,然后批量恢复回收站的所有文章。哈哈,在所有文章列表中选中一个文章来试试。祝你好运,完毕
中弘中国
{dede:global.cfg_webname/}
{dede:global.cfg_admineal/}
{dede:arclist row='60'col='1'titlelen='100'orderby='pubdate'}
[字段:arcurl/]
[字段:writer/]
[字段:typename/]
[字段:pubdate函数='strftime(“%a,%d%b%Y%H:%M:%S+0800,@me)”/]
[字段:arcurl/]
文章classification:[字段:typename/]
]]&燃气轮机
织梦好的,好的织梦
{/dede:arclist}
如果您使用自己的网站,请将网址替换为您的网址。将文件保存在与index.htm主页模板相同的目录中,登录到管理后台,清理缓存并更新HTML
---------------------------------------------
以上是动态输入。如果要将其更改为静态输出,必须执行以下操作
--------------------------------------
步骤1:打开渠道模型下的单页单据管理
单击以添加页面
根据上图构建这样一个单页文件是可以的,但名称不能是“整个站点的RSS静态输出”。最好用英文名字。你可以随意开始。单击以保存其他人,而不关心它
最后,更新缓存。最好在整个站点中更新它
对于RSS订阅,我在Dede中重做原创文件rssmap.html,然后覆盖原创文件。原创文件位于数据文件夹中
以下是一些流行的RSS订阅代码供您参考
织梦内容管理系统
本文来自织梦
这篇文章来自博客“玩Linux…做操作和维护…什么都没有…”。请保留此来源
方法1:
找到:includeinc_uarcpart_uuview.php文件,找到函数parsetemplet();在这个函数中
〔2〕
$this->dtp->Assign($tagid
$this->GetArcList($typeid,$ctag->GetAtt(“行”),$ctag->GetAtt(“列”)
$titlelen、$infolen、$ctag->GetAtt(“imgwidth”)、$ctag->GetAtt(“imgheight”)
$ctag->GetAtt(“type”),$orderby,$ctag->GetAtt(“关键字”),$innertext
$ctag->GetAtt(“表格宽度”)、0、$channelid、$ctag->GetAtt(“限制”)、$ctag->GetAtt(“附件”)
$ctag->GetAtt(“订单方式”),$ctag->GetAtt(“子日”),$autopartid,$ctag->GetAtt(“ismember”)
)
]
将红色0更改为$CTAG->getatt('arcid'),然后在includeinc\u fun\u spgetarclist.php文件中找到它
〔如果($arcid!=0)$orwhere.=“和arc.ID'$arcid'”)
将这句话改为:if($arcid!=0)$where.=”和arc.Id='$arcid''
如果($arcid==0)$orwhere.=“和arc.ID'$arcid'”
将上述声明替换为
然后你可以调用它:如果你调用主页上ID号为145的文章内容
{dede:arclist arcid='145'行='5'列='1'标题栏='24'}
[字段:title/]
[字段:info/]
{/dede:arclist}
这样,将只调用一个ID为145的文章,也就是说,将初始行设置为5是无用的,因为数据库中只建议了一条记录
但是,HTML语法还无法解析。文章建议的格式没有格式。下次将对其进行改进
方法2:
一开始,我没有仔细阅读论坛,所以我自己写了这个方法。事实上,我不必遵循上面的方法。我可以使用强大的循环来实现这个需求。现在我在下面写我的个人方法,希望能帮助那些需要帮助的人 查看全部
文章采集完(进行处理之前,首先备份数据库!()!)
在处理之前,首先备份数据库
一、将文章批次转为“未批准”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu档案集arcrank=-1
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集arcrank=-1
二、将文章批次更改为“未生成hmtl”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu存档集ismake=0
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集ismake=0
三、在系统设置中设置为“使用回收站功能”
然后删除采集的所有文章事实上,它被发送到回收站,然后批量恢复回收站的所有文章。哈哈,在所有文章列表中选中一个文章来试试。祝你好运,完毕
中弘中国
{dede:global.cfg_webname/}
{dede:global.cfg_admineal/}
{dede:arclist row='60'col='1'titlelen='100'orderby='pubdate'}
[字段:arcurl/]
[字段:writer/]
[字段:typename/]
[字段:pubdate函数='strftime(“%a,%d%b%Y%H:%M:%S+0800,@me)”/]
[字段:arcurl/]
文章classification:[字段:typename/]
]]&燃气轮机
织梦好的,好的织梦
{/dede:arclist}
如果您使用自己的网站,请将网址替换为您的网址。将文件保存在与index.htm主页模板相同的目录中,登录到管理后台,清理缓存并更新HTML
---------------------------------------------
以上是动态输入。如果要将其更改为静态输出,必须执行以下操作
--------------------------------------
步骤1:打开渠道模型下的单页单据管理
单击以添加页面

根据上图构建这样一个单页文件是可以的,但名称不能是“整个站点的RSS静态输出”。最好用英文名字。你可以随意开始。单击以保存其他人,而不关心它
最后,更新缓存。最好在整个站点中更新它
对于RSS订阅,我在Dede中重做原创文件rssmap.html,然后覆盖原创文件。原创文件位于数据文件夹中
以下是一些流行的RSS订阅代码供您参考


织梦内容管理系统



本文来自织梦

这篇文章来自博客“玩Linux…做操作和维护…什么都没有…”。请保留此来源
方法1:
找到:includeinc_uarcpart_uuview.php文件,找到函数parsetemplet();在这个函数中
〔2〕
$this->dtp->Assign($tagid
$this->GetArcList($typeid,$ctag->GetAtt(“行”),$ctag->GetAtt(“列”)
$titlelen、$infolen、$ctag->GetAtt(“imgwidth”)、$ctag->GetAtt(“imgheight”)
$ctag->GetAtt(“type”),$orderby,$ctag->GetAtt(“关键字”),$innertext
$ctag->GetAtt(“表格宽度”)、0、$channelid、$ctag->GetAtt(“限制”)、$ctag->GetAtt(“附件”)
$ctag->GetAtt(“订单方式”),$ctag->GetAtt(“子日”),$autopartid,$ctag->GetAtt(“ismember”)
)
]
将红色0更改为$CTAG->getatt('arcid'),然后在includeinc\u fun\u spgetarclist.php文件中找到它
〔如果($arcid!=0)$orwhere.=“和arc.ID'$arcid'”)
将这句话改为:if($arcid!=0)$where.=”和arc.Id='$arcid''
如果($arcid==0)$orwhere.=“和arc.ID'$arcid'”
将上述声明替换为
然后你可以调用它:如果你调用主页上ID号为145的文章内容
{dede:arclist arcid='145'行='5'列='1'标题栏='24'}
[字段:title/]
[字段:info/]
{/dede:arclist}
这样,将只调用一个ID为145的文章,也就是说,将初始行设置为5是无用的,因为数据库中只建议了一条记录
但是,HTML语法还无法解析。文章建议的格式没有格式。下次将对其进行改进
方法2:
一开始,我没有仔细阅读论坛,所以我自己写了这个方法。事实上,我不必遵循上面的方法。我可以使用强大的循环来实现这个需求。现在我在下面写我的个人方法,希望能帮助那些需要帮助的人
文章采集完(好消息鱼虾网提供原创文章、伪原创、seo文章代写)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-27 01:15
好消息:宇侠网提供原创文章、伪原创、seo文章代写、网站内容文章代更新服务,
另外还提供,文章代,软文代,外链代,有需要的朋友可以联系我们咨询。
鱼虾网seo(),专业的网站建设、seo优化和网络营销团队
答:关于文章的采集和组合,我的想法适合大家:
1.选择最重要的关键词,然后对属于自己的网站的关键词进行分类。别说难,不自己开发,其实就像5118脑图。2. 选择关键词后,即可挖掘出优质内容。你必须先选择最全面的各大电台,包括你选择的关键词。一定要站起来,因为大站很全面。然后,根据你的关键词采集这个大网站的内容。在采集文章的时候,不仅这个大网站,你的关键词也会被百度收录。
例如:一个关键词包括一个主要的网站和一个相关的文章,百度的倒置也包括在前两个文章中。就这样,关键词A采集了3个优质的文章,以此类推。其他关键词的处理方式相同。然后,我们所有的 关键词 集合 文章 都存储在库中。在数据库中,每一个关键词对应三个高质量的文章。然后用软件从数据库中查询标题文章。查询时,是时候合并数据了。
第一次:采集存储,第二次:从数据库查询。经过查询,我们可以替换这三个文章。为什么要编写查询软件?那是因为在编写软件时。你也可以有一个共同的起点和一个共同的终点。这样,在查询过程中,将三个文章和你的万能开头和万能结尾替换后,就是伪原创。
好的,查询之后,文章 看起来更好了,出现了伪文本。其实这样更能满足用户的需求。第三步就是通过以上两步。你有更好的伪造原创文章。那就别停。同理,提取百度知道的文章的关键词,了解问答平台,采集问答知识,然后和你的文章结合,很不爽。然后就是最终替换,删除删除,这些都是批量替换软件。这样,一个文章的优质合集就会发布。 查看全部
文章采集完(好消息鱼虾网提供原创文章、伪原创、seo文章代写)
好消息:宇侠网提供原创文章、伪原创、seo文章代写、网站内容文章代更新服务,
另外还提供,文章代,软文代,外链代,有需要的朋友可以联系我们咨询。
鱼虾网seo(),专业的网站建设、seo优化和网络营销团队
答:关于文章的采集和组合,我的想法适合大家:
1.选择最重要的关键词,然后对属于自己的网站的关键词进行分类。别说难,不自己开发,其实就像5118脑图。2. 选择关键词后,即可挖掘出优质内容。你必须先选择最全面的各大电台,包括你选择的关键词。一定要站起来,因为大站很全面。然后,根据你的关键词采集这个大网站的内容。在采集文章的时候,不仅这个大网站,你的关键词也会被百度收录。
例如:一个关键词包括一个主要的网站和一个相关的文章,百度的倒置也包括在前两个文章中。就这样,关键词A采集了3个优质的文章,以此类推。其他关键词的处理方式相同。然后,我们所有的 关键词 集合 文章 都存储在库中。在数据库中,每一个关键词对应三个高质量的文章。然后用软件从数据库中查询标题文章。查询时,是时候合并数据了。
第一次:采集存储,第二次:从数据库查询。经过查询,我们可以替换这三个文章。为什么要编写查询软件?那是因为在编写软件时。你也可以有一个共同的起点和一个共同的终点。这样,在查询过程中,将三个文章和你的万能开头和万能结尾替换后,就是伪原创。
好的,查询之后,文章 看起来更好了,出现了伪文本。其实这样更能满足用户的需求。第三步就是通过以上两步。你有更好的伪造原创文章。那就别停。同理,提取百度知道的文章的关键词,了解问答平台,采集问答知识,然后和你的文章结合,很不爽。然后就是最终替换,删除删除,这些都是批量替换软件。这样,一个文章的优质合集就会发布。
文章采集完(网站要不要写原创文章这个话题你知道吗?!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-26 23:03
指南:更新文章是每个网站运营商必须做的工作。经常更新网站内部文章,保持网站活跃,帮助吸引蜘蛛爬取网站页面,完善内部链接,增加网站权重。在更新网站文章的时候,很多站长忍不住写原创文章,看到别人网站文章从网上抄来的,我被收录,各种采集,各种抄袭也很聪明,认为只要保持网站的内容更新,你不知道其他人们的网站权重高,搜索引擎之间的信任度非常好。如果您有一个新网站或小型企业网站,如果您这样做,您需要承担多少风险?让' 下面就深度网络和大家聊一聊。网站要不要写?原创文章这个话题。
原创 文章 的值
1、搜索引擎喜欢原创有价值的文章
搜索引擎发展了这么久,现在不注重数量,只注重质量。对于网上重复的内容,搜索引擎会认为没有收录的价值,甚至会影响搜索引擎对网站的判断。. 频繁复制互联网上已经存在的内容会让搜索引擎认为这个网站对用户没有帮助,对搜索引擎也不友好,因为内容互联网已经存在,你要去收录的内容只会增加搜索引擎服务器的负载,让你不再去收录你网站的内容,严重的会导致网站降级并降低 关键词 的排名。
2、用户喜欢原创高质量文章
对于用户来说,他们也喜欢看到新鲜的内容,这增加了用户的吸引力。过时的内容毫无价值。用户看了一次就不会来第二次,导致网站的跳出率很高。写原创文章是为了满足用户需求,解决用户疑惑,提升用户体验,增加用户对网站的粘性。
3、原创文章提升企业形象
经常更新原创和有价值的文章,用户喜欢阅读,不仅经常访问网站,觉得公司写的内容专业,有价值,给用户留下一个好印象中,频繁更新互联网内容,会让用户觉得贵公司不专业,损害企业形象。
4、原创文章对网站的影响
更新原创文章很费力,但是满足了搜索引擎的需求,也满足了用户的需求。尤其是新站期,更新原创对加快搜索引擎速度非常重要 网站审核期提高了搜索引擎对网站的信任度、网站的权重、排名关键词。即使是老站,也要经常更新原创文章,吸引更多潜在客户浏览,保持网站关键词的排名。
5、原创文章长尾福利关键词排名
更新文章时,在文章的内容和标题中添加长尾关键词,使用文章优化长尾关键词,更新一篇文章< @文章,做长尾关键词优化。随着时间的推移,更多的长尾关键词会在搜索引擎中排名,带来更多的潜在客户。
综上所述,更新原创文章对优化和用户都有帮助。站长还是要关注原创文章带来的价值。有的站长说不可能写出高质量的伪原创文章,这样的文章对于搜索引擎来说也是高质量的原创文章,就是诚然,高质量的伪原创文章也是可取的,但是高质量的伪原创文章也对质量有很高的要求,不是简单的用工具做一个伪原创文章,并且你必须遵循高质量的文章写作要求,才能满足最初的要求。当您在新站点上时,您必须更新 原创文章 以与搜索引擎建立良好的信任度。 查看全部
文章采集完(网站要不要写原创文章这个话题你知道吗?!)
指南:更新文章是每个网站运营商必须做的工作。经常更新网站内部文章,保持网站活跃,帮助吸引蜘蛛爬取网站页面,完善内部链接,增加网站权重。在更新网站文章的时候,很多站长忍不住写原创文章,看到别人网站文章从网上抄来的,我被收录,各种采集,各种抄袭也很聪明,认为只要保持网站的内容更新,你不知道其他人们的网站权重高,搜索引擎之间的信任度非常好。如果您有一个新网站或小型企业网站,如果您这样做,您需要承担多少风险?让' 下面就深度网络和大家聊一聊。网站要不要写?原创文章这个话题。
原创 文章 的值
1、搜索引擎喜欢原创有价值的文章
搜索引擎发展了这么久,现在不注重数量,只注重质量。对于网上重复的内容,搜索引擎会认为没有收录的价值,甚至会影响搜索引擎对网站的判断。. 频繁复制互联网上已经存在的内容会让搜索引擎认为这个网站对用户没有帮助,对搜索引擎也不友好,因为内容互联网已经存在,你要去收录的内容只会增加搜索引擎服务器的负载,让你不再去收录你网站的内容,严重的会导致网站降级并降低 关键词 的排名。
2、用户喜欢原创高质量文章
对于用户来说,他们也喜欢看到新鲜的内容,这增加了用户的吸引力。过时的内容毫无价值。用户看了一次就不会来第二次,导致网站的跳出率很高。写原创文章是为了满足用户需求,解决用户疑惑,提升用户体验,增加用户对网站的粘性。
3、原创文章提升企业形象
经常更新原创和有价值的文章,用户喜欢阅读,不仅经常访问网站,觉得公司写的内容专业,有价值,给用户留下一个好印象中,频繁更新互联网内容,会让用户觉得贵公司不专业,损害企业形象。
4、原创文章对网站的影响
更新原创文章很费力,但是满足了搜索引擎的需求,也满足了用户的需求。尤其是新站期,更新原创对加快搜索引擎速度非常重要 网站审核期提高了搜索引擎对网站的信任度、网站的权重、排名关键词。即使是老站,也要经常更新原创文章,吸引更多潜在客户浏览,保持网站关键词的排名。
5、原创文章长尾福利关键词排名
更新文章时,在文章的内容和标题中添加长尾关键词,使用文章优化长尾关键词,更新一篇文章< @文章,做长尾关键词优化。随着时间的推移,更多的长尾关键词会在搜索引擎中排名,带来更多的潜在客户。
综上所述,更新原创文章对优化和用户都有帮助。站长还是要关注原创文章带来的价值。有的站长说不可能写出高质量的伪原创文章,这样的文章对于搜索引擎来说也是高质量的原创文章,就是诚然,高质量的伪原创文章也是可取的,但是高质量的伪原创文章也对质量有很高的要求,不是简单的用工具做一个伪原创文章,并且你必须遵循高质量的文章写作要求,才能满足最初的要求。当您在新站点上时,您必须更新 原创文章 以与搜索引擎建立良好的信任度。
文章采集完(大部分《搜狗seo如何优化》搜狗高收录采集站))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-26 13:10
大多数seoer只关注百度搜索引擎优化,而忽略搜狗、360和神马等搜索引擎优化。对采集的测试发现搜狗搜索收录表现非常好。今天发错博客()带来了《如何优化搜狗seo(搜狗高收录采集站)》。我希望能有所帮助。
一、 搜狗搜索引擎优化
搜狗比百度更容易优化,但搜狗的市场份额较低,这意味着来自搜狗的流量会更少。只要内容偏原创,继续做一段时间,或者是老域名,搜狗收录很快。
二、采集
以前很鄙视采集站,但现在看各种优质大站,哪一个是真正的纯原创?一部分为近期新闻出处采集并注明出处,一部分为网站编辑,另一部分为用户投稿。也就是说,没有 100% 原创 站点。网站合理采集一些相对较新的内容对网站来说并不全是坏事,但合适。
三、搜狗高收录实战
这里只是说说之前错误博客测试的采集文章,观察收录的情况。当时采用了优采云采集规则。采集做好后直接输出excel表格,最后在dedecms批量上传发布。说几个主要规则:
1、标题混词
采集一些很正常的信息网站,标题中混入一些不受欢迎的词(比如小品牌词,比如错博客、错博客seo、错博客优质ip等) ,这将与其他网站的这个文章的标题有很大的不同。在 Internet 上找不到具有相同标题的页面是不可能的。
2、混句
在正文的第一句中混入一些不受欢迎的词。这样冷门的词变成了句子,看起来更像是开句,也就是说开句是原创句,对于收录的好处也有一定的意义。
3、文中混词
多次融入文中文章想优化关键词,从而增加关键词的密度,但没必要过分。
4、文中三图
将三张图片合并到文章文章中,文章有图片更好参与排名,就像说一张图片是必须的,当然也有很多页面没有图片. 非常好的排名,如果是三张图,像搜狗这样搜索会提示文章多图,显然更有利于优化。
5、没有内容
以上四点是错误博客的初步想法。结果是采集规则的使用出了问题,导致几乎没有采集的内容。然后,可能是因为内容少,基本没问题。算是原创,再加上三张图的效果,终于把这些文章都搜到了搜狗收录。
那个时候采集不多,2万左右,都是收录,而且很多也有排名。排名主要是因为这几个词的难度很低。这样做网站估计流量很好看。当然,实际的流量并不多。
以上是《如何优化搜狗seo(搜狗高收录采集站)"带来的错误博客()。感谢您的阅读。更多原创文章 搜索错误博客。 查看全部
文章采集完(大部分《搜狗seo如何优化》搜狗高收录采集站))
大多数seoer只关注百度搜索引擎优化,而忽略搜狗、360和神马等搜索引擎优化。对采集的测试发现搜狗搜索收录表现非常好。今天发错博客()带来了《如何优化搜狗seo(搜狗高收录采集站)》。我希望能有所帮助。
一、 搜狗搜索引擎优化
搜狗比百度更容易优化,但搜狗的市场份额较低,这意味着来自搜狗的流量会更少。只要内容偏原创,继续做一段时间,或者是老域名,搜狗收录很快。
二、采集
以前很鄙视采集站,但现在看各种优质大站,哪一个是真正的纯原创?一部分为近期新闻出处采集并注明出处,一部分为网站编辑,另一部分为用户投稿。也就是说,没有 100% 原创 站点。网站合理采集一些相对较新的内容对网站来说并不全是坏事,但合适。
三、搜狗高收录实战
这里只是说说之前错误博客测试的采集文章,观察收录的情况。当时采用了优采云采集规则。采集做好后直接输出excel表格,最后在dedecms批量上传发布。说几个主要规则:
1、标题混词
采集一些很正常的信息网站,标题中混入一些不受欢迎的词(比如小品牌词,比如错博客、错博客seo、错博客优质ip等) ,这将与其他网站的这个文章的标题有很大的不同。在 Internet 上找不到具有相同标题的页面是不可能的。
2、混句
在正文的第一句中混入一些不受欢迎的词。这样冷门的词变成了句子,看起来更像是开句,也就是说开句是原创句,对于收录的好处也有一定的意义。
3、文中混词
多次融入文中文章想优化关键词,从而增加关键词的密度,但没必要过分。
4、文中三图
将三张图片合并到文章文章中,文章有图片更好参与排名,就像说一张图片是必须的,当然也有很多页面没有图片. 非常好的排名,如果是三张图,像搜狗这样搜索会提示文章多图,显然更有利于优化。
5、没有内容
以上四点是错误博客的初步想法。结果是采集规则的使用出了问题,导致几乎没有采集的内容。然后,可能是因为内容少,基本没问题。算是原创,再加上三张图的效果,终于把这些文章都搜到了搜狗收录。
那个时候采集不多,2万左右,都是收录,而且很多也有排名。排名主要是因为这几个词的难度很低。这样做网站估计流量很好看。当然,实际的流量并不多。
以上是《如何优化搜狗seo(搜狗高收录采集站)"带来的错误博客()。感谢您的阅读。更多原创文章 搜索错误博客。
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-26 13:07
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(文章采集完成后,把采集的网页信息存入mongodb,方便)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-20 11:01
文章采集完成后,把采集的网页信息存入mongodb,方便以后使用django的contextmanager(contextmanager可以把采集到的网页设置一个属性,比如:'location'),并对返回的response设置一个类,保存django里面的信息,response就是整个系统的http代理。
要解决的问题在nodejs环境中,要使用模拟post请求,模拟请求可以使用django-posts,有tag分类方便代码开发:```importjsonfromdjango.conf.jsonimportpostmessageclassuserrepository(postmessage):__name__='用户对象'__user_body='{username:'admin',password:'密码'}'classrequest(userrepository):username='admin'password='密码'req_list=[{'username':username,password':password}]response=request(userrepository,postmessage)self.req_list=[responseforreqinrequest]```结果部分```nodejsinnumpy```code:govuser```配置django环境首先,我们还要配置djangodb,在djangoconf->db文件夹中。
依赖依赖的包有:nginx(网络服务,django代理)mongodb(数据库)django-posts(类似orm,支持表单的增删改查)```pythonmanage.pysyncdb(url,create_db)#创建本地环境数据库pythonmanage.pyenvnotify(url)#告诉django,发送请求name:user表单表单的create_db()函数:env.name,create_db()这个函数是我们以后处理表单的主要函数在postmessage中的方法:```req=userrepository(username='admin',password='rsa')response=request(userrepository(username='admin',password='rsa'),create_db)```djangoconf->urls下的admin和request中的返回值都是一样的```djangoconf->create_db_templates(url,post_response)```code:env.name```djangoconf->urls下的post_response.rs```djangoconf->urls下的post_response.rs```djangoconf->post_response.rs```djangoconf->post_response.rs```执行djangoconfig--project.yaml>```使用django-posts模拟post请求userrepositoryenv=notify(url)[name=post_response,version=4.2.2]post_response_url=["django.conf.urls.postmap"]postmap=[{"post_res。 查看全部
文章采集完(文章采集完成后,把采集的网页信息存入mongodb,方便)
文章采集完成后,把采集的网页信息存入mongodb,方便以后使用django的contextmanager(contextmanager可以把采集到的网页设置一个属性,比如:'location'),并对返回的response设置一个类,保存django里面的信息,response就是整个系统的http代理。
要解决的问题在nodejs环境中,要使用模拟post请求,模拟请求可以使用django-posts,有tag分类方便代码开发:```importjsonfromdjango.conf.jsonimportpostmessageclassuserrepository(postmessage):__name__='用户对象'__user_body='{username:'admin',password:'密码'}'classrequest(userrepository):username='admin'password='密码'req_list=[{'username':username,password':password}]response=request(userrepository,postmessage)self.req_list=[responseforreqinrequest]```结果部分```nodejsinnumpy```code:govuser```配置django环境首先,我们还要配置djangodb,在djangoconf->db文件夹中。
依赖依赖的包有:nginx(网络服务,django代理)mongodb(数据库)django-posts(类似orm,支持表单的增删改查)```pythonmanage.pysyncdb(url,create_db)#创建本地环境数据库pythonmanage.pyenvnotify(url)#告诉django,发送请求name:user表单表单的create_db()函数:env.name,create_db()这个函数是我们以后处理表单的主要函数在postmessage中的方法:```req=userrepository(username='admin',password='rsa')response=request(userrepository(username='admin',password='rsa'),create_db)```djangoconf->urls下的admin和request中的返回值都是一样的```djangoconf->create_db_templates(url,post_response)```code:env.name```djangoconf->urls下的post_response.rs```djangoconf->urls下的post_response.rs```djangoconf->post_response.rs```djangoconf->post_response.rs```执行djangoconfig--project.yaml>```使用django-posts模拟post请求userrepositoryenv=notify(url)[name=post_response,version=4.2.2]post_response_url=["django.conf.urls.postmap"]postmap=[{"post_res。
文章采集完(怎么提高我们文章的阅读量?(内附方法))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-19 03:02
文章采集完可以直接发送,不过如果是高质量的文章,发送过去后,是会收到系统的推荐,从而对作者有更多的关注,关注多了,就会有第一批量到达积分榜,如果能到排行榜,那么你每月就可以得到系统的奖励,提高自己的积分榜,也可以带动粉丝数量,提高收入。对于自媒体人来说,几乎每天都要或多或少的搞些公众号赚取收益,但是我经常听到一些公众号的运营大神抱怨,每天他们的账号有那么多精力去研究怎么推广、运营,实在没有足够的时间和精力更新文章。
一般的情况是,由于发送的次数并不多,所以一篇文章的阅读量并不是很高,所以没有足够大的关注量。那么怎么提高我们文章的阅读量呢?文章发送出去后,首先打开的人会有一个缓存,如果速度太慢,那么就会自动删除,所以一般的平台都有发送时间规定,这就是为什么很多作者要花钱在论坛里发布文章。发送这么多次,还有人看,和我们做微信公众号也是有关系的,为什么我们一直讲,从7月份之后,公众号的粉丝数就没有大幅度的增长,但是今年,粉丝的增长速度竟然高达160%,我们可以从几个方面分析。
1、平台大力推广,流量重新分配,应该是目前最大的推手。
2、微信社群建设好,分享文章后,自己发布的流量就会增多。
3、微信平台更新了新规则,自媒体人利用公众号如何快速过原创检测。微信原创检测将由此更新,号主也可以以前写过的文章检测。很多自媒体人需要有一个原创检测的分析。我们很多同行,通过各种活动,投放文章,在高峰时间或者更容易接受的推广位宣传文章。一个公众号,每天产生的图文内容越多,或者如果你是自己建立的分支体系,都会很容易出原创,所以原创保护是必须要做的事情。
那么我们下面就从三个方面讲,自媒体人如何做到高质量的原创文章。其实如果我们对自己的内容要求不高,只要能够切中自己的定位,让读者不感到突兀,不断推陈出新就行,我们可以关注一些娱乐,人生感悟,以及类似上市公司分析,这些都可以帮助我们突出自己的定位。对于这类文章来说,读者的接受度会比较高,文章也不需要太精彩,平淡简单就行,就不会形成拥挤效应。
由于网络内容繁多,因此我们选择信息时可以尽量选择新奇有趣或者能够引发共鸣的,读者读完一篇,对于内容还会对你非常有好感,更多的想要加入我们的粉丝。
1、本身优秀的价值内容如果内容就是优秀的价值内容,说明内容质量过硬,基本不用担心文章被抄袭。我们很多推荐内容,可能都是文章的文章,但是没有推荐在微信公众号,文章推荐在百家号或头条号,我们可以通过百家号或头条号过新手, 查看全部
文章采集完(怎么提高我们文章的阅读量?(内附方法))
文章采集完可以直接发送,不过如果是高质量的文章,发送过去后,是会收到系统的推荐,从而对作者有更多的关注,关注多了,就会有第一批量到达积分榜,如果能到排行榜,那么你每月就可以得到系统的奖励,提高自己的积分榜,也可以带动粉丝数量,提高收入。对于自媒体人来说,几乎每天都要或多或少的搞些公众号赚取收益,但是我经常听到一些公众号的运营大神抱怨,每天他们的账号有那么多精力去研究怎么推广、运营,实在没有足够的时间和精力更新文章。
一般的情况是,由于发送的次数并不多,所以一篇文章的阅读量并不是很高,所以没有足够大的关注量。那么怎么提高我们文章的阅读量呢?文章发送出去后,首先打开的人会有一个缓存,如果速度太慢,那么就会自动删除,所以一般的平台都有发送时间规定,这就是为什么很多作者要花钱在论坛里发布文章。发送这么多次,还有人看,和我们做微信公众号也是有关系的,为什么我们一直讲,从7月份之后,公众号的粉丝数就没有大幅度的增长,但是今年,粉丝的增长速度竟然高达160%,我们可以从几个方面分析。
1、平台大力推广,流量重新分配,应该是目前最大的推手。
2、微信社群建设好,分享文章后,自己发布的流量就会增多。
3、微信平台更新了新规则,自媒体人利用公众号如何快速过原创检测。微信原创检测将由此更新,号主也可以以前写过的文章检测。很多自媒体人需要有一个原创检测的分析。我们很多同行,通过各种活动,投放文章,在高峰时间或者更容易接受的推广位宣传文章。一个公众号,每天产生的图文内容越多,或者如果你是自己建立的分支体系,都会很容易出原创,所以原创保护是必须要做的事情。
那么我们下面就从三个方面讲,自媒体人如何做到高质量的原创文章。其实如果我们对自己的内容要求不高,只要能够切中自己的定位,让读者不感到突兀,不断推陈出新就行,我们可以关注一些娱乐,人生感悟,以及类似上市公司分析,这些都可以帮助我们突出自己的定位。对于这类文章来说,读者的接受度会比较高,文章也不需要太精彩,平淡简单就行,就不会形成拥挤效应。
由于网络内容繁多,因此我们选择信息时可以尽量选择新奇有趣或者能够引发共鸣的,读者读完一篇,对于内容还会对你非常有好感,更多的想要加入我们的粉丝。
1、本身优秀的价值内容如果内容就是优秀的价值内容,说明内容质量过硬,基本不用担心文章被抄袭。我们很多推荐内容,可能都是文章的文章,但是没有推荐在微信公众号,文章推荐在百家号或头条号,我们可以通过百家号或头条号过新手,
文章采集完(文章采集完成,tableaupublic插件完成格式的json数据接收)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-18 18:01
文章采集完成,需要从手机上下载一个tableaupublic插件,就可以把数据导入到public插件里面了,接下来的目标就是要把图表搞定,本文针对图表问题,进行一个解答。
一、图表描述及public插件准备需要的数据库包括两方面:
1、数据库用于保存excel表格数据,这些数据为虚拟数据库(virtualdatabase),在本文中,此处所说的是mysql数据库,因为mysql适合大部分数据格式和储存方式。
2、mysql数据库所保存的数据是json格式的,下载网址为,不管是tableau还是其他图表,我们保存的是json格式的数据,json格式数据本身就具有缺陷,由于json的所有字段都是基于值,如果处理不好,数据质量就非常的不稳定,虽然这一步可以依靠postfixpackage完成,但是使用上还是非常的不便,同时如果部署在自己的物理环境中,virtualdatabase上就会存在各种问题,不好用的话,这些问题对于非postfixpackage爱好者来说还是很麻烦的。
virtualdatabase被使用的方式有三种:
1、网络直接传输,
2、其他文件中引用,数据库与数据库之间相互引用(如支持redhatlnmp环境,
3、有python库进行接收值,比如bae、jcon等生成相应的json文件同时oracle或mysql数据库之间的json有相应的文件格式可供查看。我们通过tableaupublic插件获取的数据无法作为json格式的数据接收,必须加上上面的数据库数据和上面说到的所有必要的字段信息后,才能接收。根据具体需求,我们可以将之前tableaupublic插件生成json数据的方式修改一下,用tableau提供的jsonpipeline插件完成这一步,这样直接生成的json数据就是实际数据库表格的数据。
这里需要注意,tableaupublic中json接受的数据格式为json格式,关于jsonpipeline,可以参考《流畅的json请求》文章。
二、图表操作准备需要的数据准备好后,根据public插件生成好的json数据格式,我们便可以对表格中的字段进行操作,比如删除某个字段。接下来用tableaupublic插件制作一个新的、对于数据量不是很大的情况,也不需要做修改的“超链接地址”图表,首先我们要处理的是需要操作的表格不要变形。因为在tableaupublic中,添加新字段时,body的连接方式以postfixpackage的方式加载,所以接下来,我们需要修改格式,还要注意添加名称(tablename)和字段类型(subtype)以规范格式,以防止将数据串路径去掉(例如文件、批处理等,格式如下,我们填写的是excel文件路径)。subtype是要在这里添加,因为在格式中,这。 查看全部
文章采集完(文章采集完成,tableaupublic插件完成格式的json数据接收)
文章采集完成,需要从手机上下载一个tableaupublic插件,就可以把数据导入到public插件里面了,接下来的目标就是要把图表搞定,本文针对图表问题,进行一个解答。
一、图表描述及public插件准备需要的数据库包括两方面:
1、数据库用于保存excel表格数据,这些数据为虚拟数据库(virtualdatabase),在本文中,此处所说的是mysql数据库,因为mysql适合大部分数据格式和储存方式。
2、mysql数据库所保存的数据是json格式的,下载网址为,不管是tableau还是其他图表,我们保存的是json格式的数据,json格式数据本身就具有缺陷,由于json的所有字段都是基于值,如果处理不好,数据质量就非常的不稳定,虽然这一步可以依靠postfixpackage完成,但是使用上还是非常的不便,同时如果部署在自己的物理环境中,virtualdatabase上就会存在各种问题,不好用的话,这些问题对于非postfixpackage爱好者来说还是很麻烦的。
virtualdatabase被使用的方式有三种:
1、网络直接传输,
2、其他文件中引用,数据库与数据库之间相互引用(如支持redhatlnmp环境,
3、有python库进行接收值,比如bae、jcon等生成相应的json文件同时oracle或mysql数据库之间的json有相应的文件格式可供查看。我们通过tableaupublic插件获取的数据无法作为json格式的数据接收,必须加上上面的数据库数据和上面说到的所有必要的字段信息后,才能接收。根据具体需求,我们可以将之前tableaupublic插件生成json数据的方式修改一下,用tableau提供的jsonpipeline插件完成这一步,这样直接生成的json数据就是实际数据库表格的数据。
这里需要注意,tableaupublic中json接受的数据格式为json格式,关于jsonpipeline,可以参考《流畅的json请求》文章。
二、图表操作准备需要的数据准备好后,根据public插件生成好的json数据格式,我们便可以对表格中的字段进行操作,比如删除某个字段。接下来用tableaupublic插件制作一个新的、对于数据量不是很大的情况,也不需要做修改的“超链接地址”图表,首先我们要处理的是需要操作的表格不要变形。因为在tableaupublic中,添加新字段时,body的连接方式以postfixpackage的方式加载,所以接下来,我们需要修改格式,还要注意添加名称(tablename)和字段类型(subtype)以规范格式,以防止将数据串路径去掉(例如文件、批处理等,格式如下,我们填写的是excel文件路径)。subtype是要在这里添加,因为在格式中,这。
文章采集完(如何做到简易版本的ai后期统计也很简单。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 440 次浏览 • 2021-10-18 15:01
文章采集完毕后,后期的样式统计、选择排版、数据存储、字体类型、字体颜色以及字体尺寸等等均要逐一填写,比较麻烦。其实做到简易版本的ai后期统计也很简单。已经不止我个人尝试过,个人知识库网站上也有这种简易版本的插件上传你需要统计的文本格式,然后去除文字间的空格/公式/空格或者直接手动填写。textspace-textshapegenerator或者直接:textspace.ai另:如果你安装了aiformac3.7.0版本以上的话,可以直接用pluginsselector进行ai里的颜色选择,简单方便。
另:假如你用了psdlayout,grafana也有带这个功能(请略过安装origin后的第2步),我曾经尝试过只导入了psd的简易版本,也能支持具体属性选择。目前没有尝试ai的安装psdlayout,因为目前安装了的话会出现兼容性问题,既psd插件和psd实例将不匹配。谢谢!。
原回答链接:一些很平凡但也很特别的textshapes的制作方法希望能帮到大家【-chn。info/2012/04/text-shapes-what-is-the-awesome-shapes-with-text-shapes/】原回答更新了三次,修正了2个错误(其中一个是重复导入图形属性而不完整)我建议你还是使用mergepackage,这样很方便制作。 查看全部
文章采集完(如何做到简易版本的ai后期统计也很简单。。)
文章采集完毕后,后期的样式统计、选择排版、数据存储、字体类型、字体颜色以及字体尺寸等等均要逐一填写,比较麻烦。其实做到简易版本的ai后期统计也很简单。已经不止我个人尝试过,个人知识库网站上也有这种简易版本的插件上传你需要统计的文本格式,然后去除文字间的空格/公式/空格或者直接手动填写。textspace-textshapegenerator或者直接:textspace.ai另:如果你安装了aiformac3.7.0版本以上的话,可以直接用pluginsselector进行ai里的颜色选择,简单方便。
另:假如你用了psdlayout,grafana也有带这个功能(请略过安装origin后的第2步),我曾经尝试过只导入了psd的简易版本,也能支持具体属性选择。目前没有尝试ai的安装psdlayout,因为目前安装了的话会出现兼容性问题,既psd插件和psd实例将不匹配。谢谢!。
原回答链接:一些很平凡但也很特别的textshapes的制作方法希望能帮到大家【-chn。info/2012/04/text-shapes-what-is-the-awesome-shapes-with-text-shapes/】原回答更新了三次,修正了2个错误(其中一个是重复导入图形属性而不完整)我建议你还是使用mergepackage,这样很方便制作。
文章采集完(文章采集完成后,还需对数据进行计算处理计算)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-15 12:04
文章采集完成后,还需对数据进行计算处理,计算保存在excel表中。
1、运营销售线路及销售人员信息(销售部门、销售人员名字/身份证/邮箱/手机号码)
2、销售线路及销售人员工号(只针对销售线路销售人员,公司其他销售部门人员不需要)现将excel表格数据逐一分析,将你要分析的数据所在的字段和销售线路的一一对应表一一对应表数据excel对于数据分析只是入门,是非常容易导致分析出错的。将所有的数据逐一导入到python对数据计算对应公式及分析出来的结果。
let‘senjoywhat'sinyourdata!(仅供大家学习交流使用,部分数据源可以自行建立数据,反馈正确性)你所需要干的事
1、计算销售线路的销售人员excel表格数据
2、将前面计算出来销售人员所属销售线路销售人员和销售人员工号数据,按照“部门”作为性别区分,
3、计算销售线路销售人员销售额excel表格数据
4、以excel表格数据的销售线路销售人员销售额统计表格作为参考,将excel数据导入到cxfaore,可用%计算所属销售线路的销售人员。
5、计算销售线路销售人员销售额,按照“销售人员销售线路”进行排序
6、运营人员销售线路销售人员分类列表总结
1、销售线路销售人员月销售额对应的销售线路销售人员销售额:上述excel表格数据来源于“各类销售线路销售人员销售额统计表格数据”,通过制作hplot可以直接将excel表格数据制作成python地址:+vba数据抓取step1-“new”python-hplot模块导入数据library(stringr)library(lubridate)library(ggplot。
<p>2)library(weather)library(dplyr)step2-“sortall”excel表格数据;excel_table[fname][type] 查看全部
文章采集完(文章采集完成后,还需对数据进行计算处理计算)
文章采集完成后,还需对数据进行计算处理,计算保存在excel表中。
1、运营销售线路及销售人员信息(销售部门、销售人员名字/身份证/邮箱/手机号码)
2、销售线路及销售人员工号(只针对销售线路销售人员,公司其他销售部门人员不需要)现将excel表格数据逐一分析,将你要分析的数据所在的字段和销售线路的一一对应表一一对应表数据excel对于数据分析只是入门,是非常容易导致分析出错的。将所有的数据逐一导入到python对数据计算对应公式及分析出来的结果。
let‘senjoywhat'sinyourdata!(仅供大家学习交流使用,部分数据源可以自行建立数据,反馈正确性)你所需要干的事
1、计算销售线路的销售人员excel表格数据
2、将前面计算出来销售人员所属销售线路销售人员和销售人员工号数据,按照“部门”作为性别区分,
3、计算销售线路销售人员销售额excel表格数据
4、以excel表格数据的销售线路销售人员销售额统计表格作为参考,将excel数据导入到cxfaore,可用%计算所属销售线路的销售人员。
5、计算销售线路销售人员销售额,按照“销售人员销售线路”进行排序
6、运营人员销售线路销售人员分类列表总结
1、销售线路销售人员月销售额对应的销售线路销售人员销售额:上述excel表格数据来源于“各类销售线路销售人员销售额统计表格数据”,通过制作hplot可以直接将excel表格数据制作成python地址:+vba数据抓取step1-“new”python-hplot模块导入数据library(stringr)library(lubridate)library(ggplot。
<p>2)library(weather)library(dplyr)step2-“sortall”excel表格数据;excel_table[fname][type]
文章采集完(上篇ELK(ElasticSearch+Logstash+Kibana)5.0搭建(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-10 02:01
上一篇ELK(ElasticSearch+Logstash+Kibana)5.0构建全记录讲了ElasticSearch和Kibana的构建,本文将使用ELK采集分析nginx日志记录Logstash的构建, 巩固ELK的知识
这个Logstash官方的描述很直观,Logstash其实就是一个管道(Pipeline)
管道的源输入是多种数据源(普通文件、redis、http、log4j、kafka……官方列出了52种类型)
经过自己的过滤机制(过滤器匹配的数据可以输出到输出)
输出到 Elasticsearch(多达 50 多种输出类型)
一、Logstash 启动
> cd logstash-5.0.0/config # 进到config目录
> vim logstash-nginx.conf # 创建一个叫logstash-nginx.conf的配置文件
logstash-nginx.conf 文件的内容是
input {
file {
path => [ "/var/log/nginx/access.log" ] # nginx日志的目录
start_position => "beginning" # 从文件开头采集
}
}
filter {
#Only matched data are send to output.
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "127.0.0.1:9200" #ElasticSearch host, can be array.
index => "applog" # 创建一个ES的index
}
}
启动 Logstash
> cd ..
> ./bin/logstash -f config/logstash-nginx.conf
纠结,到此为止,我们已经通过logstash完成了:采集 将本机的nginx日志存储到ElasticSearch的配置过程非常简单。我们可以通过浏览器查看存储在Es索引中的数据为applog
二、kibana 报表配置
简单介绍左边的菜单栏
好的,让我们回到上图。我们在管理中配置了一个 applog 索引。细心的同学会发现,这其实就是上面的logstash-nginx.conf文件,输出中Elasticsearch的索引,记住Time-field name的那一项。它是必需的。我的理解是时间是日志不可缺少的维度,所以我们Es中的数据必须有时间字段
进入Discover,我们可以看到applog索引下的nginx数据,记得右上角是时间范围选项
进入Visualize,让我们自定义一个报表,饼图就做好了,选择Pie chart
我的要求是统计applog索引数据中收录200、304、404的三个字符串的个数。详细配置说明不再展开。将报告名称保存并排序为【状态码】
好的,我们再次进入 Dashboard 配置仪表板。这很简单。选择我们刚刚配置的【状态码】(我也配了两个报表),就可以显示了。您可以随意拖动、放大或缩小它。
至此,本文使用Logstash采集nginx日志,保存到Elasticsearch,然后在Kibana报告上展示整个过程。它们都是最简单的演示。你可以做更多。 查看全部
文章采集完(上篇ELK(ElasticSearch+Logstash+Kibana)5.0搭建(组图))
上一篇ELK(ElasticSearch+Logstash+Kibana)5.0构建全记录讲了ElasticSearch和Kibana的构建,本文将使用ELK采集分析nginx日志记录Logstash的构建, 巩固ELK的知识
这个Logstash官方的描述很直观,Logstash其实就是一个管道(Pipeline)
管道的源输入是多种数据源(普通文件、redis、http、log4j、kafka……官方列出了52种类型)
经过自己的过滤机制(过滤器匹配的数据可以输出到输出)
输出到 Elasticsearch(多达 50 多种输出类型)
一、Logstash 启动
> cd logstash-5.0.0/config # 进到config目录
> vim logstash-nginx.conf # 创建一个叫logstash-nginx.conf的配置文件
logstash-nginx.conf 文件的内容是
input {
file {
path => [ "/var/log/nginx/access.log" ] # nginx日志的目录
start_position => "beginning" # 从文件开头采集
}
}
filter {
#Only matched data are send to output.
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "127.0.0.1:9200" #ElasticSearch host, can be array.
index => "applog" # 创建一个ES的index
}
}
启动 Logstash
> cd ..
> ./bin/logstash -f config/logstash-nginx.conf
纠结,到此为止,我们已经通过logstash完成了:采集 将本机的nginx日志存储到ElasticSearch的配置过程非常简单。我们可以通过浏览器查看存储在Es索引中的数据为applog
二、kibana 报表配置
简单介绍左边的菜单栏
好的,让我们回到上图。我们在管理中配置了一个 applog 索引。细心的同学会发现,这其实就是上面的logstash-nginx.conf文件,输出中Elasticsearch的索引,记住Time-field name的那一项。它是必需的。我的理解是时间是日志不可缺少的维度,所以我们Es中的数据必须有时间字段
进入Discover,我们可以看到applog索引下的nginx数据,记得右上角是时间范围选项
进入Visualize,让我们自定义一个报表,饼图就做好了,选择Pie chart
我的要求是统计applog索引数据中收录200、304、404的三个字符串的个数。详细配置说明不再展开。将报告名称保存并排序为【状态码】
好的,我们再次进入 Dashboard 配置仪表板。这很简单。选择我们刚刚配置的【状态码】(我也配了两个报表),就可以显示了。您可以随意拖动、放大或缩小它。
至此,本文使用Logstash采集nginx日志,保存到Elasticsearch,然后在Kibana报告上展示整个过程。它们都是最简单的演示。你可以做更多。
文章采集完(走数据分析流程了,你准备好了吗?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-09 08:05
文章采集完毕就是走数据分析流程了,一般这个步骤要花费1周到2个月的时间,没有excel就别浪费时间了,这一步也可以跳过。首先根据业务逻辑自定义逻辑,然后用excel处理,具体格式可以参照下面这个网站:在线excel插件,免费使用,
首先,要学习vba,office套件:office2007vba教程对于文本文件处理,其实用vb文本编辑器写程序就可以了。
楼主是做什么的?开发还是研发??这里也没办法回答具体的。首先是数据的问题,这个你懂的。
买一套课。去学学python和mysql。看看关于数据分析的书吧。还是挺重要的。
可以找一些商务统计学,
推荐一下我近期学习的,
itunesu或者interphone4。
推荐一本书econometrica
如果你想获得对于历史数据的新的观察,数据分析是必不可少的一个步骤。如果是结合bi这个专业实际来考虑,你可以选择一下以下的途径:1.analyticscentral:是一家提供综合数据分析应用服务的网站,它的内容体现三个方面:数据可视化技术(emotionvisualization)、数据驱动决策(data-drivendecisions)、交易数据可视化(transactionsdatavisualization)。
在里面你可以参加数据分析师的相关培训,也可以上市面上可以找到的非常好的数据分析数据。(但是我认为对于学习过统计学的数据分析来说,这家网站不太适合入门)2.uptodate:这是一家专门提供数据分析市场招聘信息的网站,里面涵盖了市场可分析岗位、数据可视化岗位、专业的数据分析岗位、数据科学家数据分析岗位、数据编程开发岗位,数据集市的岗位。
里面提供的数据集市是sas和minitab的productsspace数据集。你也可以选择培训感兴趣的课程。(但是没有办法深入的深入到业务当中去)3.datamining。这是一家类似于统计局网站,但是更广泛,里面有各个不同类型的数据分析岗位,但是数据量庞大,也没有具体的培训。(但是比较适合对编程不感兴趣的,或者没有相关背景的。
)如果你不想付费去培训,你可以在这个网站上找到免费的课程,比如hadoop,dataprocessors,datamining。里面也有一些实际案例的数据分析工具demo,对你了解实际数据分析有帮助。另外里面还有database。4.datacamp:datacamp-dataforsoftwaredevelopers,computerscientists,andanalysts:immersivelearninginandroid,ios,andwebcode。 查看全部
文章采集完(走数据分析流程了,你准备好了吗?(上))
文章采集完毕就是走数据分析流程了,一般这个步骤要花费1周到2个月的时间,没有excel就别浪费时间了,这一步也可以跳过。首先根据业务逻辑自定义逻辑,然后用excel处理,具体格式可以参照下面这个网站:在线excel插件,免费使用,
首先,要学习vba,office套件:office2007vba教程对于文本文件处理,其实用vb文本编辑器写程序就可以了。
楼主是做什么的?开发还是研发??这里也没办法回答具体的。首先是数据的问题,这个你懂的。
买一套课。去学学python和mysql。看看关于数据分析的书吧。还是挺重要的。
可以找一些商务统计学,
推荐一下我近期学习的,
itunesu或者interphone4。
推荐一本书econometrica
如果你想获得对于历史数据的新的观察,数据分析是必不可少的一个步骤。如果是结合bi这个专业实际来考虑,你可以选择一下以下的途径:1.analyticscentral:是一家提供综合数据分析应用服务的网站,它的内容体现三个方面:数据可视化技术(emotionvisualization)、数据驱动决策(data-drivendecisions)、交易数据可视化(transactionsdatavisualization)。
在里面你可以参加数据分析师的相关培训,也可以上市面上可以找到的非常好的数据分析数据。(但是我认为对于学习过统计学的数据分析来说,这家网站不太适合入门)2.uptodate:这是一家专门提供数据分析市场招聘信息的网站,里面涵盖了市场可分析岗位、数据可视化岗位、专业的数据分析岗位、数据科学家数据分析岗位、数据编程开发岗位,数据集市的岗位。
里面提供的数据集市是sas和minitab的productsspace数据集。你也可以选择培训感兴趣的课程。(但是没有办法深入的深入到业务当中去)3.datamining。这是一家类似于统计局网站,但是更广泛,里面有各个不同类型的数据分析岗位,但是数据量庞大,也没有具体的培训。(但是比较适合对编程不感兴趣的,或者没有相关背景的。
)如果你不想付费去培训,你可以在这个网站上找到免费的课程,比如hadoop,dataprocessors,datamining。里面也有一些实际案例的数据分析工具demo,对你了解实际数据分析有帮助。另外里面还有database。4.datacamp:datacamp-dataforsoftwaredevelopers,computerscientists,andanalysts:immersivelearninginandroid,ios,andwebcode。
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-08 14:14
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
文章采集完(免费下载或者VIP会员资源能否直接商用?浏览器下载)
VIP会员资源是免费下载还是可以直接商业化?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:你可以对比下载后压缩包的容量和网盘的容量,如果小于网盘标示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员专属的素材、全站源码、程序插件、网站模板、网页模板等,文章中用于介绍的图片通常不收录在对应的可下载素材包。这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
文章采集完(如何把一个网站的文章采集下来,有什么好的方法吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-07 06:17
我想下载一个网站的文章采集,并将每篇文章保存为一个文件。有什么好办法吗?或者更容易操作的软件?我想下载一个网站的文章采集,并将每篇文章保存为一个文件,因为网站的文章量比较大 有没有什么好办法一次性批量做?或者更容易操作的软件?
可以采集网站,需要的时候搜不到吗?
目前还没有可以同时保存多个文章的软件。
dedecms如何将网站中的文章复制到另一个网站?? 答案更详细。如果是采集,在采集之后怎么得到??
使用织梦采集下,很快,采集会自动生成你的网站文章,你也可以伪原创,添加Link什么的。很方便。我一直在使用它。
我的网站文章采集功能不行,还有网站要添加文章采集功能,谁教教我?我有两个网站,一个有网站文章采集的功能,但是我不会设置!另外还有一个网站我想添加文章采集函数;悬赏100分找高手,教教我文章采集函数cwALTvh的使用方法,以及如何添加网站文章采集 特点!!紧急
说说我个人的看法:采集规则其实只要懂HTML知识,不会太难。但是,不可能一两句话说清楚,除非我亲自教你演示,所以建议找教程。如果 HTML 知识没有被很好地理解,那就更难了。因为每个站的采集规则不同,所以没有通用的规则。至于增加一个采集功能,相对来说比较困难。最重要的是把采集的信息和你的信息表匹配起来,也就是save函数;不过建议用专业的采集工具代替WEB版,直接添加到数据库,然后再上传,这样比较好,因为你只需要设置它,你不需要集成它;优采云采集等工具比较常用,也比较专业。
转载请注明出处。如何将 网站采集 上的所有 文章 弄下来?你有工具吗?每个英雄推荐一个(我要下载网站的文章采集,将每篇文章保存为一个文件。有什么好?方法?或者软件更容易操作?)
我想把网站的网站_每篇文章文章的文章采集保存为一个文件_有什么好办法吗?或者更容易操作的软件?如何批量保存某个网站的文章word格式?? ? 有没有什么工具可以采集文章批量保存word格式的文字?? ? dedecms如何将网站中的文章复制到另一个网站?? 答案更详细_如果是采集_采集 怎么搞定?? 我的网站文章采集函数不行_还有网站要加文章采集函数_谁教我的?软件网站网络Microsoft Word办公软件Microsoft Office办公爬虫(计算机网络) 查看全部
文章采集完(如何把一个网站的文章采集下来,有什么好的方法吗?)
我想下载一个网站的文章采集,并将每篇文章保存为一个文件。有什么好办法吗?或者更容易操作的软件?我想下载一个网站的文章采集,并将每篇文章保存为一个文件,因为网站的文章量比较大 有没有什么好办法一次性批量做?或者更容易操作的软件?
可以采集网站,需要的时候搜不到吗?
目前还没有可以同时保存多个文章的软件。
dedecms如何将网站中的文章复制到另一个网站?? 答案更详细。如果是采集,在采集之后怎么得到??
使用织梦采集下,很快,采集会自动生成你的网站文章,你也可以伪原创,添加Link什么的。很方便。我一直在使用它。
我的网站文章采集功能不行,还有网站要添加文章采集功能,谁教教我?我有两个网站,一个有网站文章采集的功能,但是我不会设置!另外还有一个网站我想添加文章采集函数;悬赏100分找高手,教教我文章采集函数cwALTvh的使用方法,以及如何添加网站文章采集 特点!!紧急
说说我个人的看法:采集规则其实只要懂HTML知识,不会太难。但是,不可能一两句话说清楚,除非我亲自教你演示,所以建议找教程。如果 HTML 知识没有被很好地理解,那就更难了。因为每个站的采集规则不同,所以没有通用的规则。至于增加一个采集功能,相对来说比较困难。最重要的是把采集的信息和你的信息表匹配起来,也就是save函数;不过建议用专业的采集工具代替WEB版,直接添加到数据库,然后再上传,这样比较好,因为你只需要设置它,你不需要集成它;优采云采集等工具比较常用,也比较专业。
转载请注明出处。如何将 网站采集 上的所有 文章 弄下来?你有工具吗?每个英雄推荐一个(我要下载网站的文章采集,将每篇文章保存为一个文件。有什么好?方法?或者软件更容易操作?)
我想把网站的网站_每篇文章文章的文章采集保存为一个文件_有什么好办法吗?或者更容易操作的软件?如何批量保存某个网站的文章word格式?? ? 有没有什么工具可以采集文章批量保存word格式的文字?? ? dedecms如何将网站中的文章复制到另一个网站?? 答案更详细_如果是采集_采集 怎么搞定?? 我的网站文章采集函数不行_还有网站要加文章采集函数_谁教我的?软件网站网络Microsoft Word办公软件Microsoft Office办公爬虫(计算机网络)
文章采集完(:文章采集完成后需要相应的数据结构和算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-29 19:05
文章采集完成后需要相应的数据结构和算法。现在很多企业往往要求一些常用的,重复的算法,我们不知道怎么去实现,于是去看框架,看db来实现。但是也会遇到一些问题,比如字符串有限长度,字符串太长了导致处理不同字符串到数组等。这个时候开始去用一些解析器进行解析和处理。但是目前还有很多问题,而这些问题又不能归于框架。
现在我想好好总结一下目前的框架和解析器的一些看法。combinator模型:无论是现在的框架还是解析器框架基本上都遵循着这样的模型,我现在认为这才是框架的本质。但是我认为这样的模型是错误的,因为很多的数据结构实际上没有解析器,我们一直以为框架是针对某种规律的数据结构。但是有很多的数据结构其实是没有解析器的,所以我现在就不去考虑具体的形式了,而去学习他的数据结构和算法结构来提高我们的解析问题的能力,而不是提高实现的能力。
数据结构和算法:用于解决问题的数据结构和算法,也叫做数据结构或算法,为解决这些问题提供一些基本原则和基本形式的数据。数据结构可以是一些模型、一系列类和结构、一般化结构。这就是数据结构这个概念被定义出来的,因为我认为它来源于形式化编程语言,而不是基于某种底层模型。实际上,数据结构应该是被表示为集合或者链表,等待调用的类必须是集合,而不是类,类可以是任何类型,只要能够表示它们或者传递它们。
算法:应该具有最基本的内容(allaboutalgorithms):算法基本上是解决问题的步骤和策略,具体的问题是算法依赖于具体的问题,以及应该对这些问题执行的机器指令,他们通常是由一个或多个指令组成。从这个角度来说,问题的抽象并不总是正确的,但是它显然意味着算法应该是一个最小可能性方案。显然,执行某个算法可能会执行数千到数万条指令,有时候一个算法通常具有多个变量,如果你需要执行这么多指令可能会出现很多问题。
算法是各种问题的组合,你需要根据需要来选择算法。我们也可以考虑一些特殊的算法,如冒泡排序算法,插入排序算法和堆排序算法。从这些角度上来说,算法并不是完美的,也并不是固定的。框架和解析器:从解析器来说,它们之间有差异。首先它们是定义开始解析器,不过它们之间可以完全不同。解析器通常会把所有东西都扔进去进行解析,算法是一条线来解析所有结构的,包括字符串,字符表,线性关系等,算法和解析器之间的差异则体现在有些解析器可以建立新的数据结构,那么我们可以使用这种方法,还有就是算法可以以特定的方式建立一些模型,在解析器上进行重定义。算法可以由实现来控制它的大。 查看全部
文章采集完(:文章采集完成后需要相应的数据结构和算法)
文章采集完成后需要相应的数据结构和算法。现在很多企业往往要求一些常用的,重复的算法,我们不知道怎么去实现,于是去看框架,看db来实现。但是也会遇到一些问题,比如字符串有限长度,字符串太长了导致处理不同字符串到数组等。这个时候开始去用一些解析器进行解析和处理。但是目前还有很多问题,而这些问题又不能归于框架。
现在我想好好总结一下目前的框架和解析器的一些看法。combinator模型:无论是现在的框架还是解析器框架基本上都遵循着这样的模型,我现在认为这才是框架的本质。但是我认为这样的模型是错误的,因为很多的数据结构实际上没有解析器,我们一直以为框架是针对某种规律的数据结构。但是有很多的数据结构其实是没有解析器的,所以我现在就不去考虑具体的形式了,而去学习他的数据结构和算法结构来提高我们的解析问题的能力,而不是提高实现的能力。
数据结构和算法:用于解决问题的数据结构和算法,也叫做数据结构或算法,为解决这些问题提供一些基本原则和基本形式的数据。数据结构可以是一些模型、一系列类和结构、一般化结构。这就是数据结构这个概念被定义出来的,因为我认为它来源于形式化编程语言,而不是基于某种底层模型。实际上,数据结构应该是被表示为集合或者链表,等待调用的类必须是集合,而不是类,类可以是任何类型,只要能够表示它们或者传递它们。
算法:应该具有最基本的内容(allaboutalgorithms):算法基本上是解决问题的步骤和策略,具体的问题是算法依赖于具体的问题,以及应该对这些问题执行的机器指令,他们通常是由一个或多个指令组成。从这个角度来说,问题的抽象并不总是正确的,但是它显然意味着算法应该是一个最小可能性方案。显然,执行某个算法可能会执行数千到数万条指令,有时候一个算法通常具有多个变量,如果你需要执行这么多指令可能会出现很多问题。
算法是各种问题的组合,你需要根据需要来选择算法。我们也可以考虑一些特殊的算法,如冒泡排序算法,插入排序算法和堆排序算法。从这些角度上来说,算法并不是完美的,也并不是固定的。框架和解析器:从解析器来说,它们之间有差异。首先它们是定义开始解析器,不过它们之间可以完全不同。解析器通常会把所有东西都扔进去进行解析,算法是一条线来解析所有结构的,包括字符串,字符表,线性关系等,算法和解析器之间的差异则体现在有些解析器可以建立新的数据结构,那么我们可以使用这种方法,还有就是算法可以以特定的方式建立一些模型,在解析器上进行重定义。算法可以由实现来控制它的大。
文章采集完( 建站教程网wwwidivcsscom看到很多网友都为织梦DedeCMS的采集教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-28 16:25
建站教程网wwwidivcsscom看到很多网友都为织梦DedeCMS的采集教程)
建站教程网wwwidivcsscom最新织梦Dedecms采集图文教程,看到很多网友都为织梦Dedecms的采集教程头疼确实官方教程太笼统了,我就不多说了。网站你什么也做不了。本教程是您查看的最详细的教程。首先我们打开织梦后台点击采集采集节点管理、财务成本管理系统、文件管理系统、成本管理、项目成本管理、行政管理系统添加新的节点。这里我们以采集normal文章为例,我们选择normal文章,然后确定我们已经进入了采集的设置页面。填写节点名就是给这个新节点起一个名字。在这里你可以随意填写,然后打开你想要采集的文章列表页面。这里我们以织梦官网为例 httpwwwdedecmscomweb-managejianzhanxinde 打开这个页面,右键查看源文件,找到目标页面代码就在charset后面,基本信息页面,其他的一般不用担心如图填写。现在让我们填写列表URL获取规则看看文章的列表第一页的地址wwwidivcsscomhttpwwwdedecmscomweb-managejianzhanxindelist_49_1html比较第二页地址httpwwwdedecmscomweb-managejianzhanxindelist_49_2htmlWe找到了,除了49_后面的数字和其他的不一样
都是一样的,所以我们可以这样写 httpwwwdedecmscomweb-managejianzhanxindelist_49_html 因为只有2页,所以我们填1到2每个页增量,当然1就是2- 1 等于 1,到这里我们就完成了 wwwbboytvnet 的填写。也许你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。写完之后,我们就开始写文章 URL匹配规则。回到文章列表页面,右键查看源文件。搜索区开头的HTML是为了找到文章列表开头的标记。我们可以很容易地找到如图所示的新闻列表。从这里开始,后面是文章列表中,让我们查找列表末尾的 HTML 网站 wwwidivcsscom。这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看
文章有分页吗?随便输入一篇文章。文章看看我们在这里看到了什么。文章没有分页,所以这里我们默认了。来找文章的标题等,随便进一篇文章右键查看源文件根据源码看这些,填写网站wwwidivcsscom的网址,我们将开头和结尾的内容填入文章和上面一样,找到开头和结尾的标志,你要过滤的开头和结尾文章在过滤规则里写就行了。比如要过滤文章中的图片,选择常用规则建一个网站wwwidivcsscom,然后勾选IMG再确认,这样我们就可以过滤文本中的图片了。完成后点击 保存设置并预览这样的采集规则。这很简单,对吧?一些网站很难写,但需要多花点功夫。我们点击保存启动采集启动采集网页会工作一段时间。采集我们完成后,我们来看看文章建站教程网站wwwidivcsscom456 . 这似乎是成功的。我们导出数据,选择先导入。对于您到达的列,单击请在那里选择以在弹出窗口中选择您需要导入的列。除非您不想立即发布,否则发布选项通常在此处为默认设置。每批导入默认为30个。修改与否都没有关系。附加选项通常被排除在外。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。更多织梦dedecms教程httpwwwidivcsscomdedecms 查看全部
文章采集完(
建站教程网wwwidivcsscom看到很多网友都为织梦DedeCMS的采集教程)
建站教程网wwwidivcsscom最新织梦Dedecms采集图文教程,看到很多网友都为织梦Dedecms的采集教程头疼确实官方教程太笼统了,我就不多说了。网站你什么也做不了。本教程是您查看的最详细的教程。首先我们打开织梦后台点击采集采集节点管理、财务成本管理系统、文件管理系统、成本管理、项目成本管理、行政管理系统添加新的节点。这里我们以采集normal文章为例,我们选择normal文章,然后确定我们已经进入了采集的设置页面。填写节点名就是给这个新节点起一个名字。在这里你可以随意填写,然后打开你想要采集的文章列表页面。这里我们以织梦官网为例 httpwwwdedecmscomweb-managejianzhanxinde 打开这个页面,右键查看源文件,找到目标页面代码就在charset后面,基本信息页面,其他的一般不用担心如图填写。现在让我们填写列表URL获取规则看看文章的列表第一页的地址wwwidivcsscomhttpwwwdedecmscomweb-managejianzhanxindelist_49_1html比较第二页地址httpwwwdedecmscomweb-managejianzhanxindelist_49_2htmlWe找到了,除了49_后面的数字和其他的不一样
都是一样的,所以我们可以这样写 httpwwwdedecmscomweb-managejianzhanxindelist_49_html 因为只有2页,所以我们填1到2每个页增量,当然1就是2- 1 等于 1,到这里我们就完成了 wwwbboytvnet 的填写。也许你的一些 采集 列表没有规则,所以你只需要手动指定列表 URL。如图,每行写一个页地址列表。写完之后,我们就开始写文章 URL匹配规则。回到文章列表页面,右键查看源文件。搜索区开头的HTML是为了找到文章列表开头的标记。我们可以很容易地找到如图所示的新闻列表。从这里开始,后面是文章列表中,让我们查找列表末尾的 HTML 网站 wwwidivcsscom。这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 这是一个很容易找到的标志。如果链接收录图片,请不要处理。采集 是这里的缩略图。区域 URL 再次被过滤。必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 必须收录正则表达式。优先级高于后者。它不能收录开源文件。我们可以清楚的看到文章链接是以html结尾的,所以一定要收录之后再填html。如果遇到一些比较麻烦的列表,也可以把不能收录的填写进去。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看 不能收录的也可以填写。我们点击保存设置进入下一步,可以看到我们获取到的文章 URL。如果您看到这些都正确,我们保存信息并进入下一步设置内容字段获取规则。让我们来看看
文章有分页吗?随便输入一篇文章。文章看看我们在这里看到了什么。文章没有分页,所以这里我们默认了。来找文章的标题等,随便进一篇文章右键查看源文件根据源码看这些,填写网站wwwidivcsscom的网址,我们将开头和结尾的内容填入文章和上面一样,找到开头和结尾的标志,你要过滤的开头和结尾文章在过滤规则里写就行了。比如要过滤文章中的图片,选择常用规则建一个网站wwwidivcsscom,然后勾选IMG再确认,这样我们就可以过滤文本中的图片了。完成后点击 保存设置并预览这样的采集规则。这很简单,对吧?一些网站很难写,但需要多花点功夫。我们点击保存启动采集启动采集网页会工作一段时间。采集我们完成后,我们来看看文章建站教程网站wwwidivcsscom456 . 这似乎是成功的。我们导出数据,选择先导入。对于您到达的列,单击请在那里选择以在弹出窗口中选择您需要导入的列。除非您不想立即发布,否则发布选项通常在此处为默认设置。每批导入默认为30个。修改与否都没有关系。附加选项通常被排除在外。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。更多织梦dedecms教程httpwwwidivcsscomdedecms
文章采集完( 详解安装mitmproxy以及遇到的坑和简单用法(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-28 15:39
详解安装mitmproxy以及遇到的坑和简单用法(组图))
mitmproxy安装详解及遇到的坑和简单使用
Mitmproxy是一个工具,或者说是python的一个包,一个命令行操作的工具。本文文章主要介绍mitmproxy的详细安装以及遇到的坑和简单的使用。有兴趣的朋友可以参考mitmproxy。它是一个工具,或者是python的一个包,可以在命令行上操作。的工具。MITM是一种中间人攻击(Man-in-the-middle Attack)。使用此工具在命令行上捕获数据包。
江南河微信hook c#版本已经实现了webhook,你也可以在你的网站中调用hook
你可以把钩子软件放在服务器上。您可以在客户端计算机上使用网络呼叫。特点: 1 每次登录只显示二维码,不再显示上次登录的用户。2 设置后不自动更新,会保存。该程序不会在用户下次登录时自动更新。 通讯vx:微信钩子的第一步是启动服务端钩子程序,打开JiangNanHeWeChatHookDemo30Plus.exe。第二步是打开webhook.html页面,(这里只是一个例子,
江南河微信公众号文章采集器,开发完成!再也不用担心采集微信公众号文章!
本程序基于【江南起重机微信HOOK二次开发C#源码】开发。如果需要【江南鹤微信HOOK二次开发C#源码】请添加微信weixinhook。江南起重机微信公众号文章采集器试用说明1请下载【江南起重机微信公众号文章采集器】需要先安装.net4.6 . 查看全部
文章采集完(
详解安装mitmproxy以及遇到的坑和简单用法(组图))
mitmproxy安装详解及遇到的坑和简单使用
Mitmproxy是一个工具,或者说是python的一个包,一个命令行操作的工具。本文文章主要介绍mitmproxy的详细安装以及遇到的坑和简单的使用。有兴趣的朋友可以参考mitmproxy。它是一个工具,或者是python的一个包,可以在命令行上操作。的工具。MITM是一种中间人攻击(Man-in-the-middle Attack)。使用此工具在命令行上捕获数据包。
江南河微信hook c#版本已经实现了webhook,你也可以在你的网站中调用hook
你可以把钩子软件放在服务器上。您可以在客户端计算机上使用网络呼叫。特点: 1 每次登录只显示二维码,不再显示上次登录的用户。2 设置后不自动更新,会保存。该程序不会在用户下次登录时自动更新。 通讯vx:微信钩子的第一步是启动服务端钩子程序,打开JiangNanHeWeChatHookDemo30Plus.exe。第二步是打开webhook.html页面,(这里只是一个例子,
江南河微信公众号文章采集器,开发完成!再也不用担心采集微信公众号文章!
本程序基于【江南起重机微信HOOK二次开发C#源码】开发。如果需要【江南鹤微信HOOK二次开发C#源码】请添加微信weixinhook。江南起重机微信公众号文章采集器试用说明1请下载【江南起重机微信公众号文章采集器】需要先安装.net4.6 .
文章采集完(如何快速地通过图片批量下载工具,一键下载图片的步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-28 01:00
一、应用场景描述
在电商运营的过程中,偶尔会需要采集大量的图片,比如产品的主图、轮播图或者评价中的图片等,一张一张的下载图片难免会被繁琐且耗时。下面文章将告诉你如何通过图片批量下载工具一键快速下载图片。
二、批量下载照片的步骤
1、First采集 网页图片网址的网址(感兴趣的可以查看《爬虫软件介绍及案例说明》)
2、 使用图片批量下载工具批量下载图片链接URL到本地(本文内容)
三、工具下载
本文要使用的软件安装包和安装教材可以点击链接下载
工具包收录迅雷下载安装包、优采云图片下载安装包、kutools插件安装包,以及本文使用的数据文章
四、批量图片下载工具介绍
本文将介绍三种不同的图片批量下载方式,分别是迅雷下载、优采云图片下载工具、Kutools插件下载。下表是三种方法的对比,您可以选择其中一种方法来学习。
三种采集方法的比较
五、图片链接网址准备
本文档将使用“采集案例一:采集京东商品列表页面数据”采集到图片链接地址,如下图。
☆注意:
①您可以从上面下载的工具包中获取此数据,或按照“采集案例1:采集京东产品列表页面数据”中的教程进行操作。
②图片链接网址要求:
1)采集 当从采集下载的图片链接的URL以.jpg、.gif、.png等图片格式结尾时,一般可以转换成批的图片。
2) 如果从 采集 下载的 URL 不是以图像格式结尾,则可能无法转换。可能是网站对这个图片链接进行了加密,只支持在线查看。
六、方法一:迅雷下载
打开软件后,进行如下操作:
查看下载结果:
七、方法二:Kutools插件下载
第一步:打开数据文件,在目录导航中选择【KUTOOLS】,点击【插入】下的【从路径(URL)插入图片】
第二步:在图片地址栏旁边,新增一栏存放图片并设置位置索引。如下图,图片地址在H列,则【图片路径(URL)区域】设置为“$H:$H”;如果要将图片存储在I 列,则[插入图片区域] 设置为“$I:$I”。设置好后点击【确定】。
第三步:弹出下面的对话框开始下载图片
第四步:下载完成,查看结果
八、方法二:优采云图片下载器
Step1:下载优采云图片批量下载工具
第二步:下载完成后,双击文件中的MyDownloader.app.exe,打开软件
第三步:点击【文件】,选择从EXCEL导入(目前只支持EXCEL格式的文件)
第四步:在原创数据文件中添加一列,并将该列命名为“图片保存文件夹”。本栏内容设置为“存储位置”+“图片文件名”。如下图,我将第一张图片保存到文件“D:\京东商品清单图片”中,命名为“1.jpg”。(注:英文输入,中文输入不可用)
第五步:进行相关设置
①选择EXCEL文件:导入需要下载图片地址的EXCEL文件
②EXCEL表名:对应数据表的名称
③文件URL列名:表格中图片URL所在的列名
④ 保存文件夹栏名:EXCEL中需要单独的栏列出图片要保存到本地的路径,即文件夹
⑤配置完成后点击【确定】保存
☆错误处理:
①如果点击【确定】后出现“Microsoft.Ace.OleDb.12.0 provider未在本地注册”的错误提示,则需要安装程序附带一个文件:AccessDatabaseEngine.exe(32位) ) 或 AccessDatabaseEngine_X64 (64-bit),安装后重启电脑即可。
②点击【确定】后,如果出现“列图片保存文件夹不属于Sheet1$”,则需要关闭Excel文件,再次点击【确定】。
第六步:配置好参数后,会弹出如下框,点击【开始下载】立即下载。
第七步:下载后进入对应文件夹查看结果
本文介绍了三种批量下载图片的方式。如果您对采集信息感兴趣,可以查看《爬虫软件介绍及案例说明》中的内容,感谢阅读。 查看全部
文章采集完(如何快速地通过图片批量下载工具,一键下载图片的步骤)
一、应用场景描述
在电商运营的过程中,偶尔会需要采集大量的图片,比如产品的主图、轮播图或者评价中的图片等,一张一张的下载图片难免会被繁琐且耗时。下面文章将告诉你如何通过图片批量下载工具一键快速下载图片。
二、批量下载照片的步骤
1、First采集 网页图片网址的网址(感兴趣的可以查看《爬虫软件介绍及案例说明》)
2、 使用图片批量下载工具批量下载图片链接URL到本地(本文内容)
三、工具下载
本文要使用的软件安装包和安装教材可以点击链接下载
工具包收录迅雷下载安装包、优采云图片下载安装包、kutools插件安装包,以及本文使用的数据文章
四、批量图片下载工具介绍
本文将介绍三种不同的图片批量下载方式,分别是迅雷下载、优采云图片下载工具、Kutools插件下载。下表是三种方法的对比,您可以选择其中一种方法来学习。
三种采集方法的比较
五、图片链接网址准备
本文档将使用“采集案例一:采集京东商品列表页面数据”采集到图片链接地址,如下图。
☆注意:
①您可以从上面下载的工具包中获取此数据,或按照“采集案例1:采集京东产品列表页面数据”中的教程进行操作。
②图片链接网址要求:
1)采集 当从采集下载的图片链接的URL以.jpg、.gif、.png等图片格式结尾时,一般可以转换成批的图片。
2) 如果从 采集 下载的 URL 不是以图像格式结尾,则可能无法转换。可能是网站对这个图片链接进行了加密,只支持在线查看。
六、方法一:迅雷下载
打开软件后,进行如下操作:
查看下载结果:
七、方法二:Kutools插件下载
第一步:打开数据文件,在目录导航中选择【KUTOOLS】,点击【插入】下的【从路径(URL)插入图片】
第二步:在图片地址栏旁边,新增一栏存放图片并设置位置索引。如下图,图片地址在H列,则【图片路径(URL)区域】设置为“$H:$H”;如果要将图片存储在I 列,则[插入图片区域] 设置为“$I:$I”。设置好后点击【确定】。
第三步:弹出下面的对话框开始下载图片
第四步:下载完成,查看结果
八、方法二:优采云图片下载器
Step1:下载优采云图片批量下载工具
第二步:下载完成后,双击文件中的MyDownloader.app.exe,打开软件
第三步:点击【文件】,选择从EXCEL导入(目前只支持EXCEL格式的文件)
第四步:在原创数据文件中添加一列,并将该列命名为“图片保存文件夹”。本栏内容设置为“存储位置”+“图片文件名”。如下图,我将第一张图片保存到文件“D:\京东商品清单图片”中,命名为“1.jpg”。(注:英文输入,中文输入不可用)
第五步:进行相关设置
①选择EXCEL文件:导入需要下载图片地址的EXCEL文件
②EXCEL表名:对应数据表的名称
③文件URL列名:表格中图片URL所在的列名
④ 保存文件夹栏名:EXCEL中需要单独的栏列出图片要保存到本地的路径,即文件夹
⑤配置完成后点击【确定】保存
☆错误处理:
①如果点击【确定】后出现“Microsoft.Ace.OleDb.12.0 provider未在本地注册”的错误提示,则需要安装程序附带一个文件:AccessDatabaseEngine.exe(32位) ) 或 AccessDatabaseEngine_X64 (64-bit),安装后重启电脑即可。
②点击【确定】后,如果出现“列图片保存文件夹不属于Sheet1$”,则需要关闭Excel文件,再次点击【确定】。
第六步:配置好参数后,会弹出如下框,点击【开始下载】立即下载。
第七步:下载后进入对应文件夹查看结果
本文介绍了三种批量下载图片的方式。如果您对采集信息感兴趣,可以查看《爬虫软件介绍及案例说明》中的内容,感谢阅读。
文章采集完(使用excel+word格式的文章批量导出(转化为pdf文件))
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-09-19 02:02
文章采集完毕自动生成pdf源文件。pdf支持批量转换,有效节省了不少时间。毕竟每天都要阅读微信公众号文章,想要看的时候及时获取就需要了解一下方法。以下介绍使用excel+word格式的文章配合微信公众号提供的文章批量生成一键转换成pdf的方法。excelpdf可以读写批量导出(转化为pdf文件)word也可以读写批量导出(转化为pdf文件)文章自动转换成pdf1.在不同word文档中的不同列编辑文档间的数据转换,在不同的word文档中存储每个列的内容。
准备:我们在操作下面文章,需要3个不同word文档(这里建议用同一word格式)2.打开excel,如图3.如图3打开3个excel文档后,3张excel分别是上面3个word文档的不同列,如下图4.现在,3个word文档需要转换成为一个pdf文件。5.请点击菜单栏中的“开始转换”,即可出现下图6.这时,点击右上角“转换为pdf”,即可自动选择3个需要转换的word文档。
7.这时,这3个需要转换的word文档即可转换为pdf。8.此时,点击菜单栏中的“选择数据”,即可自动选择上图3个需要转换的word文档。9.上图3个文档,即可转换为pdf的文件。注意:此方法需要在一个word文档中操作,且是以文件形式创建数据。假如,我们先新建一个word文档,再打开pdf文件,此时再转换,是以文本形式创建的数据。
接下来,我们可以进行批量导出设置,但导出时大于或等于200mb的word文档时,转换pdf文件速度会更慢。希望对您有所帮助。小编测试了一下,每10个数据只有一次可以转换成功,不知道是不是出错。 查看全部
文章采集完(使用excel+word格式的文章批量导出(转化为pdf文件))
文章采集完毕自动生成pdf源文件。pdf支持批量转换,有效节省了不少时间。毕竟每天都要阅读微信公众号文章,想要看的时候及时获取就需要了解一下方法。以下介绍使用excel+word格式的文章配合微信公众号提供的文章批量生成一键转换成pdf的方法。excelpdf可以读写批量导出(转化为pdf文件)word也可以读写批量导出(转化为pdf文件)文章自动转换成pdf1.在不同word文档中的不同列编辑文档间的数据转换,在不同的word文档中存储每个列的内容。
准备:我们在操作下面文章,需要3个不同word文档(这里建议用同一word格式)2.打开excel,如图3.如图3打开3个excel文档后,3张excel分别是上面3个word文档的不同列,如下图4.现在,3个word文档需要转换成为一个pdf文件。5.请点击菜单栏中的“开始转换”,即可出现下图6.这时,点击右上角“转换为pdf”,即可自动选择3个需要转换的word文档。
7.这时,这3个需要转换的word文档即可转换为pdf。8.此时,点击菜单栏中的“选择数据”,即可自动选择上图3个需要转换的word文档。9.上图3个文档,即可转换为pdf的文件。注意:此方法需要在一个word文档中操作,且是以文件形式创建数据。假如,我们先新建一个word文档,再打开pdf文件,此时再转换,是以文本形式创建的数据。
接下来,我们可以进行批量导出设置,但导出时大于或等于200mb的word文档时,转换pdf文件速度会更慢。希望对您有所帮助。小编测试了一下,每10个数据只有一次可以转换成功,不知道是不是出错。
文章采集完(就是专业的网页数据采集工具优采云采集器,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-18 11:21
现在是大数据时代。用户在网络的任何操作背后都会留下一些线索,所以网站当用户再次访问时,会根据用户的喜好进行数据推广,让用户得到满意的服务。同样,很多人开发了很多专门提供这些功能的软件,小编今天带来的是一款专业的网页数据采集tool优采云采集器,这是一款由软件实现的访问数据爬行工具。用户可以指定页面并记录页面提供的访问服务。以商业网页为例,该工具可以统计一定时间内访问者的IP地址和搜索产品信息,并根据这些信息进行分析和总结,用户可以得到非常有价值的信息评估报告,然后在此过程中添加一个周期,这样用户就可以了解一定时期内的商业趋势和贸易趋势,从而把握商机。如果您需要最新、最有效的数据,优采云@采集器是您的最佳选择
完成安装教程1.unzips后,开始9.8安装版本
2.安装完成
3.寄存器
4.选择上面的新任务
5.select网站用于指定的爬网数据
软件功能分布式高速采集
将任务分配给多个客户端,并同时运行采集以提高效率
多重识别系统
配备文字识别、中文分词识别、任意编码识别等识别系统,智能化识别操作更容易
可选验证方法
您可以随时选择是否使用加密狗来确保数据安全
全自动操作
无需手动操作,任务完成后自动关机
替换函数
同义词、同义词替换、参数替换、伪原创必要技能
以任何文件格式下载
可以轻松下载任何格式的图像、压缩文件、视频和其他文件
采集监控系统
实时监控采集以确保数据的准确性
支持多个数据库
支持access/MySQL/MSSQL/SQLite/Oracle数据库的保存和发布
无限多页采集
支持无限级别的多页信息,包括Ajax请求数据采集
支持扩展
支持接口和插件扩展,满足各种采购和分销需求。软件采集可以在网页上显示动态内容吗
从理论上讲,它采集是可能的,但规则的设置可能很复杂
优采云@采集器发布模块和接口文件之间有什么区别
发布模块:所谓的发布模块是优采云@采集器中的设置,当采集中的数据要发布到目标时(例如,发布到指定的网站或指定的数据库)
优采云@采集器能深入到多层次采集吗@
可以设置多级规则
@在采集和文章之后,优采云采集工具应该如何发布@
优采云@采集器计费版本支持将文章@从采集再次发布到FTP站点 查看全部
文章采集完(就是专业的网页数据采集工具优采云采集器,)
现在是大数据时代。用户在网络的任何操作背后都会留下一些线索,所以网站当用户再次访问时,会根据用户的喜好进行数据推广,让用户得到满意的服务。同样,很多人开发了很多专门提供这些功能的软件,小编今天带来的是一款专业的网页数据采集tool优采云采集器,这是一款由软件实现的访问数据爬行工具。用户可以指定页面并记录页面提供的访问服务。以商业网页为例,该工具可以统计一定时间内访问者的IP地址和搜索产品信息,并根据这些信息进行分析和总结,用户可以得到非常有价值的信息评估报告,然后在此过程中添加一个周期,这样用户就可以了解一定时期内的商业趋势和贸易趋势,从而把握商机。如果您需要最新、最有效的数据,优采云@采集器是您的最佳选择
完成安装教程1.unzips后,开始9.8安装版本
2.安装完成
3.寄存器
4.选择上面的新任务
5.select网站用于指定的爬网数据
软件功能分布式高速采集
将任务分配给多个客户端,并同时运行采集以提高效率
多重识别系统
配备文字识别、中文分词识别、任意编码识别等识别系统,智能化识别操作更容易
可选验证方法
您可以随时选择是否使用加密狗来确保数据安全
全自动操作
无需手动操作,任务完成后自动关机
替换函数
同义词、同义词替换、参数替换、伪原创必要技能
以任何文件格式下载
可以轻松下载任何格式的图像、压缩文件、视频和其他文件
采集监控系统
实时监控采集以确保数据的准确性
支持多个数据库
支持access/MySQL/MSSQL/SQLite/Oracle数据库的保存和发布
无限多页采集
支持无限级别的多页信息,包括Ajax请求数据采集
支持扩展
支持接口和插件扩展,满足各种采购和分销需求。软件采集可以在网页上显示动态内容吗
从理论上讲,它采集是可能的,但规则的设置可能很复杂
优采云@采集器发布模块和接口文件之间有什么区别
发布模块:所谓的发布模块是优采云@采集器中的设置,当采集中的数据要发布到目标时(例如,发布到指定的网站或指定的数据库)
优采云@采集器能深入到多层次采集吗@
可以设置多级规则
@在采集和文章之后,优采云采集工具应该如何发布@
优采云@采集器计费版本支持将文章@从采集再次发布到FTP站点
文章采集完(进行处理之前,首先备份数据库!()!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-18 11:15
在处理之前,首先备份数据库
一、将文章批次转为“未批准”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu档案集arcrank=-1
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集arcrank=-1
二、将文章批次更改为“未生成hmtl”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu存档集ismake=0
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集ismake=0
三、在系统设置中设置为“使用回收站功能”
然后删除采集的所有文章事实上,它被发送到回收站,然后批量恢复回收站的所有文章。哈哈,在所有文章列表中选中一个文章来试试。祝你好运,完毕
中弘中国
{dede:global.cfg_webname/}
{dede:global.cfg_admineal/}
{dede:arclist row='60'col='1'titlelen='100'orderby='pubdate'}
[字段:arcurl/]
[字段:writer/]
[字段:typename/]
[字段:pubdate函数='strftime(“%a,%d%b%Y%H:%M:%S+0800,@me)”/]
[字段:arcurl/]
文章classification:[字段:typename/]
]]&燃气轮机
织梦好的,好的织梦
{/dede:arclist}
如果您使用自己的网站,请将网址替换为您的网址。将文件保存在与index.htm主页模板相同的目录中,登录到管理后台,清理缓存并更新HTML
---------------------------------------------
以上是动态输入。如果要将其更改为静态输出,必须执行以下操作
--------------------------------------
步骤1:打开渠道模型下的单页单据管理
单击以添加页面
根据上图构建这样一个单页文件是可以的,但名称不能是“整个站点的RSS静态输出”。最好用英文名字。你可以随意开始。单击以保存其他人,而不关心它
最后,更新缓存。最好在整个站点中更新它
对于RSS订阅,我在Dede中重做原创文件rssmap.html,然后覆盖原创文件。原创文件位于数据文件夹中
以下是一些流行的RSS订阅代码供您参考
织梦内容管理系统
本文来自织梦
这篇文章来自博客“玩Linux…做操作和维护…什么都没有…”。请保留此来源
方法1:
找到:includeinc_uarcpart_uuview.php文件,找到函数parsetemplet();在这个函数中
〔2〕
$this->dtp->Assign($tagid
$this->GetArcList($typeid,$ctag->GetAtt(“行”),$ctag->GetAtt(“列”)
$titlelen、$infolen、$ctag->GetAtt(“imgwidth”)、$ctag->GetAtt(“imgheight”)
$ctag->GetAtt(“type”),$orderby,$ctag->GetAtt(“关键字”),$innertext
$ctag->GetAtt(“表格宽度”)、0、$channelid、$ctag->GetAtt(“限制”)、$ctag->GetAtt(“附件”)
$ctag->GetAtt(“订单方式”),$ctag->GetAtt(“子日”),$autopartid,$ctag->GetAtt(“ismember”)
)
]
将红色0更改为$CTAG->getatt('arcid'),然后在includeinc\u fun\u spgetarclist.php文件中找到它
〔如果($arcid!=0)$orwhere.=“和arc.ID'$arcid'”)
将这句话改为:if($arcid!=0)$where.=”和arc.Id='$arcid''
如果($arcid==0)$orwhere.=“和arc.ID'$arcid'”
将上述声明替换为
然后你可以调用它:如果你调用主页上ID号为145的文章内容
{dede:arclist arcid='145'行='5'列='1'标题栏='24'}
[字段:title/]
[字段:info/]
{/dede:arclist}
这样,将只调用一个ID为145的文章,也就是说,将初始行设置为5是无用的,因为数据库中只建议了一条记录
但是,HTML语法还无法解析。文章建议的格式没有格式。下次将对其进行改进
方法2:
一开始,我没有仔细阅读论坛,所以我自己写了这个方法。事实上,我不必遵循上面的方法。我可以使用强大的循环来实现这个需求。现在我在下面写我的个人方法,希望能帮助那些需要帮助的人 查看全部
文章采集完(进行处理之前,首先备份数据库!()!)
在处理之前,首先备份数据库
一、将文章批次转为“未批准”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu档案集arcrank=-1
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集arcrank=-1
二、将文章批次更改为“未生成hmtl”
转到系统设置,运行SQL命令,然后输入:
更新dede_uu存档集ismake=0
如果已安装数据库,则dede\如果更改的前缀,请将其替换为您的前缀
更新****u档案集ismake=0
三、在系统设置中设置为“使用回收站功能”
然后删除采集的所有文章事实上,它被发送到回收站,然后批量恢复回收站的所有文章。哈哈,在所有文章列表中选中一个文章来试试。祝你好运,完毕
中弘中国
{dede:global.cfg_webname/}
{dede:global.cfg_admineal/}
{dede:arclist row='60'col='1'titlelen='100'orderby='pubdate'}
[字段:arcurl/]
[字段:writer/]
[字段:typename/]
[字段:pubdate函数='strftime(“%a,%d%b%Y%H:%M:%S+0800,@me)”/]
[字段:arcurl/]
文章classification:[字段:typename/]
]]&燃气轮机
织梦好的,好的织梦
{/dede:arclist}
如果您使用自己的网站,请将网址替换为您的网址。将文件保存在与index.htm主页模板相同的目录中,登录到管理后台,清理缓存并更新HTML
---------------------------------------------
以上是动态输入。如果要将其更改为静态输出,必须执行以下操作
--------------------------------------
步骤1:打开渠道模型下的单页单据管理
单击以添加页面
根据上图构建这样一个单页文件是可以的,但名称不能是“整个站点的RSS静态输出”。最好用英文名字。你可以随意开始。单击以保存其他人,而不关心它
最后,更新缓存。最好在整个站点中更新它
对于RSS订阅,我在Dede中重做原创文件rssmap.html,然后覆盖原创文件。原创文件位于数据文件夹中
以下是一些流行的RSS订阅代码供您参考
织梦内容管理系统
本文来自织梦
这篇文章来自博客“玩Linux…做操作和维护…什么都没有…”。请保留此来源
方法1:
找到:includeinc_uarcpart_uuview.php文件,找到函数parsetemplet();在这个函数中
〔2〕
$this->dtp->Assign($tagid
$this->GetArcList($typeid,$ctag->GetAtt(“行”),$ctag->GetAtt(“列”)
$titlelen、$infolen、$ctag->GetAtt(“imgwidth”)、$ctag->GetAtt(“imgheight”)
$ctag->GetAtt(“type”),$orderby,$ctag->GetAtt(“关键字”),$innertext
$ctag->GetAtt(“表格宽度”)、0、$channelid、$ctag->GetAtt(“限制”)、$ctag->GetAtt(“附件”)
$ctag->GetAtt(“订单方式”),$ctag->GetAtt(“子日”),$autopartid,$ctag->GetAtt(“ismember”)
)
]
将红色0更改为$CTAG->getatt('arcid'),然后在includeinc\u fun\u spgetarclist.php文件中找到它
〔如果($arcid!=0)$orwhere.=“和arc.ID'$arcid'”)
将这句话改为:if($arcid!=0)$where.=”和arc.Id='$arcid''
如果($arcid==0)$orwhere.=“和arc.ID'$arcid'”
将上述声明替换为
然后你可以调用它:如果你调用主页上ID号为145的文章内容
{dede:arclist arcid='145'行='5'列='1'标题栏='24'}
[字段:title/]
[字段:info/]
{/dede:arclist}
这样,将只调用一个ID为145的文章,也就是说,将初始行设置为5是无用的,因为数据库中只建议了一条记录
但是,HTML语法还无法解析。文章建议的格式没有格式。下次将对其进行改进
方法2:
一开始,我没有仔细阅读论坛,所以我自己写了这个方法。事实上,我不必遵循上面的方法。我可以使用强大的循环来实现这个需求。现在我在下面写我的个人方法,希望能帮助那些需要帮助的人

