
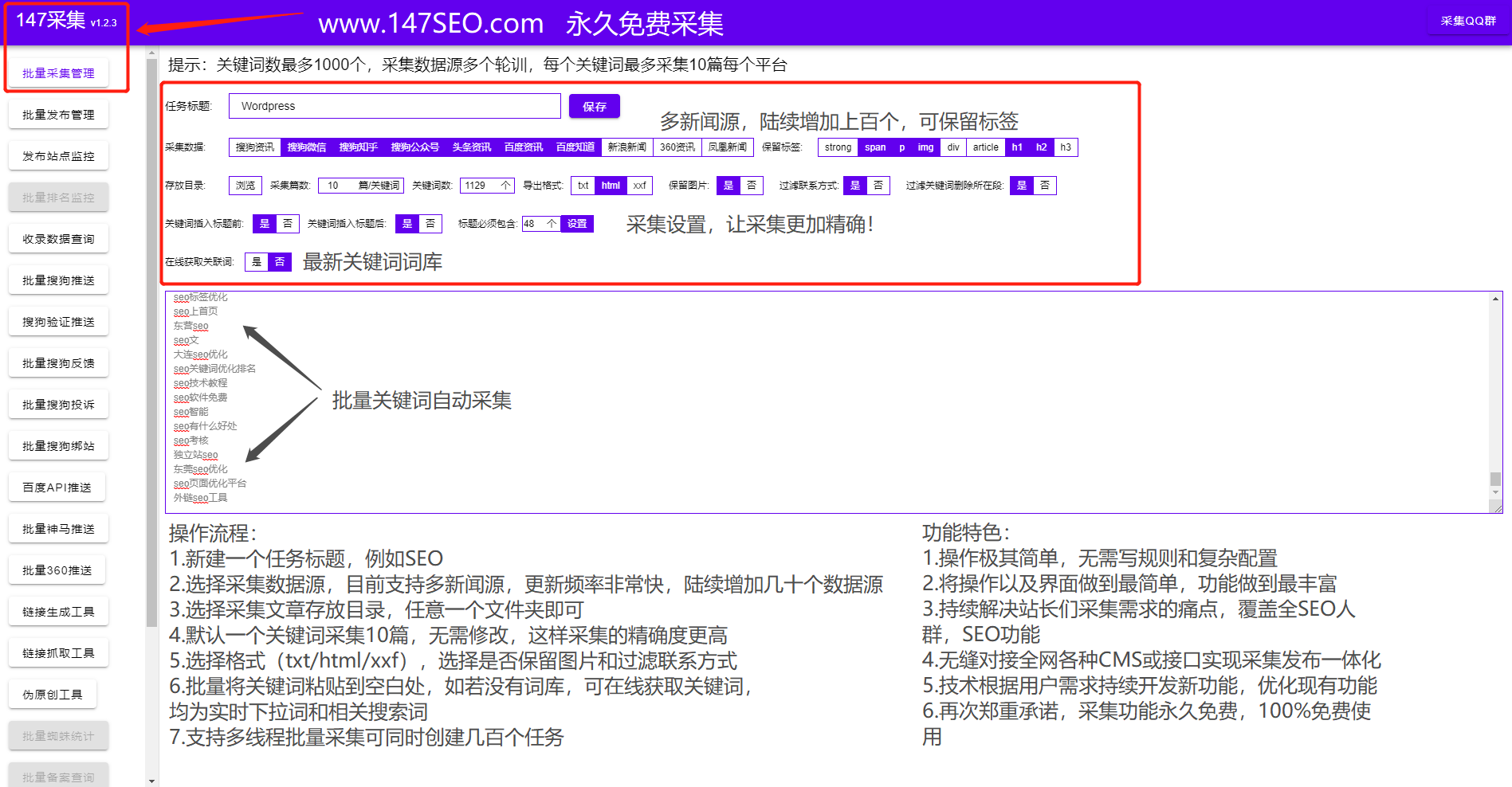
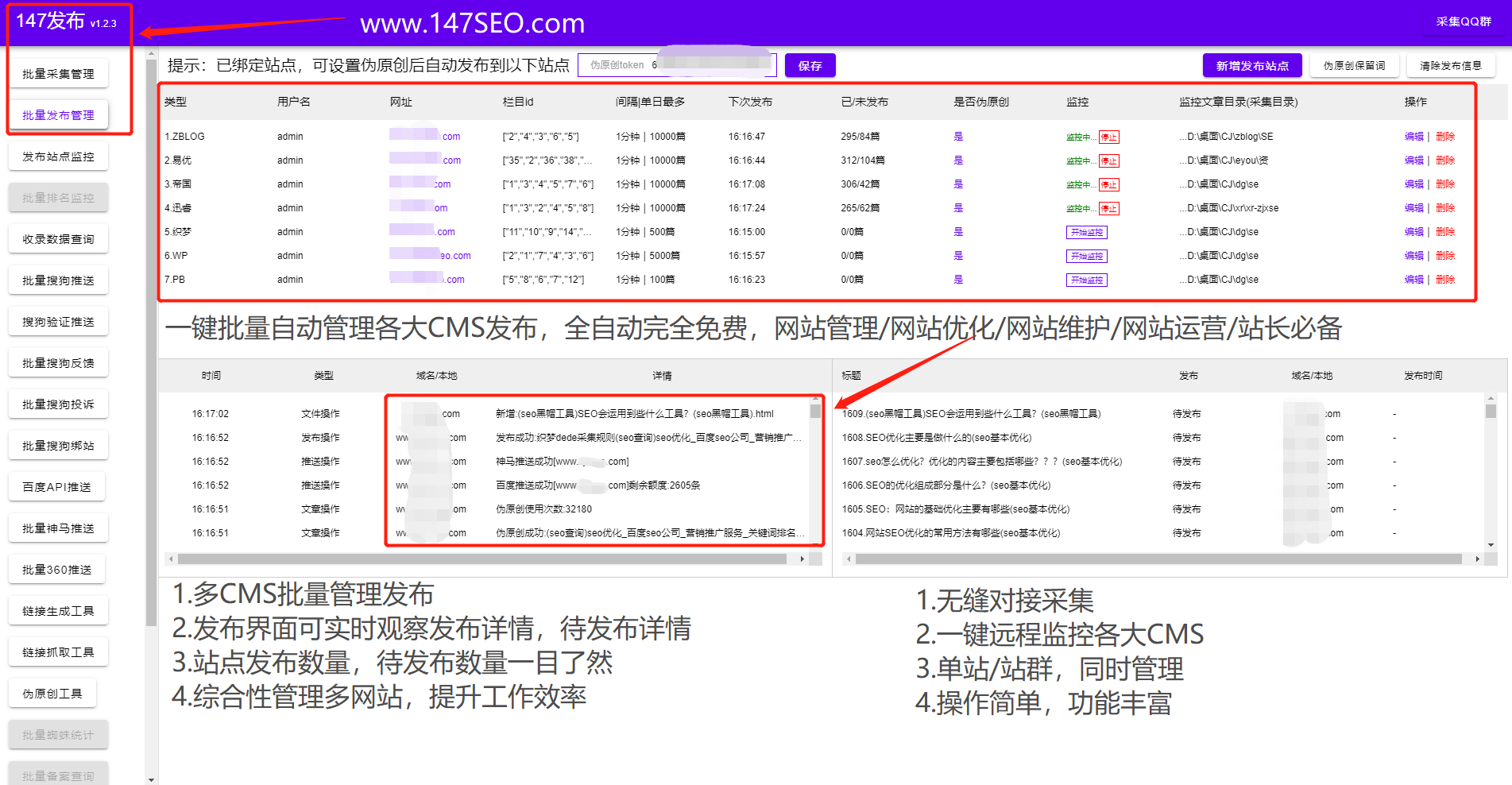
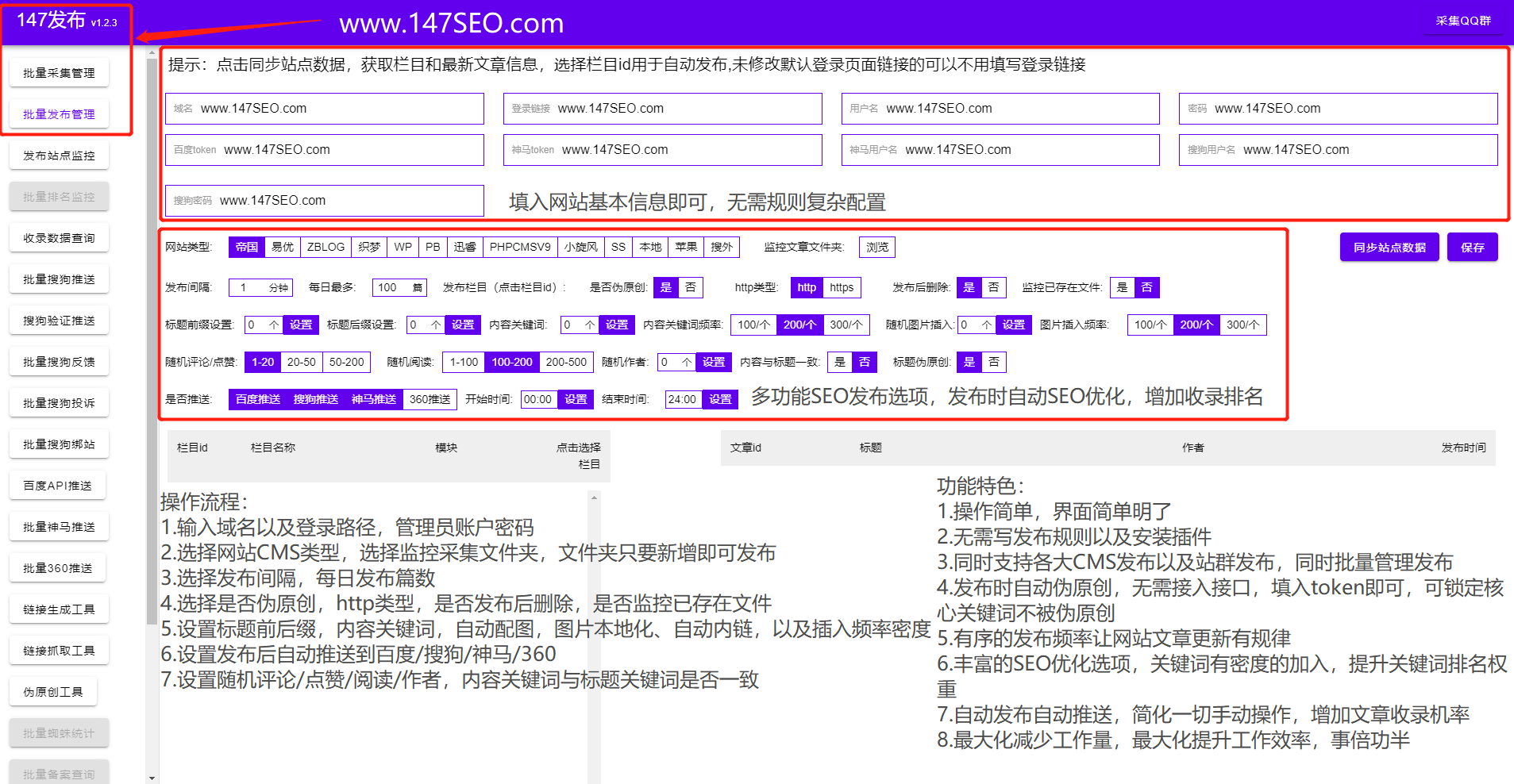
文章实时采集
文章实时采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-24 12:25
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br />import time<br /><br />import scrapy<br />from scrapy import Selector<br /><br />from .. import common<br /><br />class ZbjtaskSpider(scrapy.Spider):<br /> name = 'zbjtask'<br /> allowed_domains = ['zbj.com']<br /> start_urls = ['https://task.zbj.com/?m=1111&so=1&ss=0&fee=1']<br /><br /> def parse(self, response):<br /> #30 item per page<br /> nodes = response.xpath('//div[@class="demand-card"]').getall()<br /> id_nodes = response.xpath('//a[@class="prevent-defalut-link"]/@href').getall()<br /><br /> print(id_nodes)<br /> max_id = 0<br /> for url in id_nodes:<br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori) - 1]<br /> id = int(id_str)<br /> if id > max_id:<br /> max_id = id<br /> print(max_id)<br /><br /> for node in nodes:<br /> date = Selector(text=node).xpath('//span[@class="card-pub-time flt"]/text()').get()<br /> url = "https:" + Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/@href').get()<br /> name = Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/text()').get()<br /> desc = Selector(text=node).xpath('//div[@class="demand-card-desc"]/text()').get()<br /> price = Selector(text=node).xpath('//div[@class="demand-price"]/text()').get()<br /> tag = Selector(text=node).xpath('//span[@class="demand-tags"]/i/text()').get()<br /><br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori)-1]<br /> id = int(id_str)<br /><br /> sended_id = common.read_taskid()<br /> if id > sended_id :<br /> subject = "ZBJ " + id_str + " " + name<br /> # content = price + "\n" + desc + "\n" + url + "\n" + tag + "\n"<br /> content = "%s <p> %s <p> <a href=%s>%s</a> <p> %s" % (price, desc, url, url, tag)<br /> if common.send_mail(subject, content):<br /> print("ZBJ mail: send task sucess " % id)<br /> else:<br /> print("ZBJ mail: send task fail " % id)<br /> else :<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接收率非常有效!
附:猪八戒平台架构图
附:Scrapy思维导图
-------------------------------------------------- -------------------------------------------------- --------------- 查看全部
文章实时采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属)
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br />import time<br /><br />import scrapy<br />from scrapy import Selector<br /><br />from .. import common<br /><br />class ZbjtaskSpider(scrapy.Spider):<br /> name = 'zbjtask'<br /> allowed_domains = ['zbj.com']<br /> start_urls = ['https://task.zbj.com/?m=1111&so=1&ss=0&fee=1']<br /><br /> def parse(self, response):<br /> #30 item per page<br /> nodes = response.xpath('//div[@class="demand-card"]').getall()<br /> id_nodes = response.xpath('//a[@class="prevent-defalut-link"]/@href').getall()<br /><br /> print(id_nodes)<br /> max_id = 0<br /> for url in id_nodes:<br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori) - 1]<br /> id = int(id_str)<br /> if id > max_id:<br /> max_id = id<br /> print(max_id)<br /><br /> for node in nodes:<br /> date = Selector(text=node).xpath('//span[@class="card-pub-time flt"]/text()').get()<br /> url = "https:" + Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/@href').get()<br /> name = Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/text()').get()<br /> desc = Selector(text=node).xpath('//div[@class="demand-card-desc"]/text()').get()<br /> price = Selector(text=node).xpath('//div[@class="demand-price"]/text()').get()<br /> tag = Selector(text=node).xpath('//span[@class="demand-tags"]/i/text()').get()<br /><br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori)-1]<br /> id = int(id_str)<br /><br /> sended_id = common.read_taskid()<br /> if id > sended_id :<br /> subject = "ZBJ " + id_str + " " + name<br /> # content = price + "\n" + desc + "\n" + url + "\n" + tag + "\n"<br /> content = "%s <p> %s <p> <a href=%s>%s</a> <p> %s" % (price, desc, url, url, tag)<br /> if common.send_mail(subject, content):<br /> print("ZBJ mail: send task sucess " % id)<br /> else:<br /> print("ZBJ mail: send task fail " % id)<br /> else :<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接收率非常有效!
附:猪八戒平台架构图

附:Scrapy思维导图
-------------------------------------------------- -------------------------------------------------- ---------------
文章实时采集(怎么用飞飞CMS采集让关键词排名以及网站快速收录?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-24 02:13
如何使用飞飞cms采集让关键词排名和网站快收录,相信很多朋友的网站排名都有经历了天堂和地狱......百度在近端时间波动很大,很多网站排名被PASS直接掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前没有迹象表明百度推出了新算法,但作为SEO优化者,我们还是要根据百度目前的算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家分享一个可以批量管理网站的飞飞cms采集工具。不管你有成百上千个不同的飞飞cms< @网站或其他网站,可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、菲菲cms已发表
1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等主要cms,可批量管理采集伪原创,同时发布和推送工具)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、飞飞cms批量发布设置-覆盖SEO功能
本次飞飞cms版本还配备了很多SEO功能,不仅通过飞飞cms版本实现采集伪原创版本主动推送到搜索引擎,而且还有很多SEO方面的功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题区分更好收录)
2、内容关键词插入(合理增加关键词的密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、飞飞cms采集
1、通过 Feifeicms采集 填充内容,根据 关键词采集文章。(飞飞cms采集插件也配置了关键词采集功能和无关词拦截功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、飞飞cms采集
1、查看采集平台
2、工作中采集
3、有采集
4、采集内容视图
查看5、采集之后的内容
五、飞飞cms伪原创:伪原创的意思是重新处理一个原创的文章,让搜索引擎认为它是一篇文章原创文章,从而增加了网站的权重。飞飞cms伪原创是为搜索引擎开发的伪原创。对于搜索引擎,它是 原创。当我们使用飞飞cms插件维护好网站的时候,接下来面临的就是关键词排名波动的网站自身因素。
1、 网站排名的自然波动
网站关键词排名并不总是一样的。即使每天优化,排名也会有一定的波动。这是正常现象。但是如果关键词的排名一直在上下,那么网站的收视率就比较不稳定,需要对网站的问题进行诊断再调整。
2、 竞争对手
在我们 网站 进行优化的同时,其他节点 网站 也在运行。有多种SEO优化方法。如果别人比我们的网站优化,那么搜索引擎也会把我们同行的网站放在我们的网站排名之上,网站的排名会波动。因此,SEO优化是一个长期且不可阻挡的过程。需要不断学习新的SEO优化技巧和方法来保持网站的竞争力。
3、 具体时间和热点
<p>尤其是飞飞cms网站在某个时间点和一些热点很容易增加流量,所以有时候排名是平的,但是在某个时间段,搜索的人比较多,而 查看全部
文章实时采集(怎么用飞飞CMS采集让关键词排名以及网站快速收录?)
如何使用飞飞cms采集让关键词排名和网站快收录,相信很多朋友的网站排名都有经历了天堂和地狱......百度在近端时间波动很大,很多网站排名被PASS直接掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前没有迹象表明百度推出了新算法,但作为SEO优化者,我们还是要根据百度目前的算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家分享一个可以批量管理网站的飞飞cms采集工具。不管你有成百上千个不同的飞飞cms< @网站或其他网站,可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、菲菲cms已发表

1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等主要cms,可批量管理采集伪原创,同时发布和推送工具)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、飞飞cms批量发布设置-覆盖SEO功能
本次飞飞cms版本还配备了很多SEO功能,不仅通过飞飞cms版本实现采集伪原创版本主动推送到搜索引擎,而且还有很多SEO方面的功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题区分更好收录)
2、内容关键词插入(合理增加关键词的密度)

3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、飞飞cms采集
1、通过 Feifeicms采集 填充内容,根据 关键词采集文章。(飞飞cms采集插件也配置了关键词采集功能和无关词拦截功能)

2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、飞飞cms采集
1、查看采集平台
2、工作中采集

3、有采集
4、采集内容视图
查看5、采集之后的内容
五、飞飞cms伪原创:伪原创的意思是重新处理一个原创的文章,让搜索引擎认为它是一篇文章原创文章,从而增加了网站的权重。飞飞cms伪原创是为搜索引擎开发的伪原创。对于搜索引擎,它是 原创。当我们使用飞飞cms插件维护好网站的时候,接下来面临的就是关键词排名波动的网站自身因素。
1、 网站排名的自然波动
网站关键词排名并不总是一样的。即使每天优化,排名也会有一定的波动。这是正常现象。但是如果关键词的排名一直在上下,那么网站的收视率就比较不稳定,需要对网站的问题进行诊断再调整。
2、 竞争对手
在我们 网站 进行优化的同时,其他节点 网站 也在运行。有多种SEO优化方法。如果别人比我们的网站优化,那么搜索引擎也会把我们同行的网站放在我们的网站排名之上,网站的排名会波动。因此,SEO优化是一个长期且不可阻挡的过程。需要不断学习新的SEO优化技巧和方法来保持网站的竞争力。
3、 具体时间和热点
<p>尤其是飞飞cms网站在某个时间点和一些热点很容易增加流量,所以有时候排名是平的,但是在某个时间段,搜索的人比较多,而
文章实时采集(如何使用文章:牛逼的爬虫爬取工具分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-21 16:03
文章实时采集,分析关键信息这种信息获取的方式,一般是通过文本类型进行收集的,比如你设计的一款产品app,对于用户评论的采集,就是使用词云工具echarts进行数据收集的。如果你想获取特定的用户评论的内容,你可以使用特定的关键词和内容进行匹配,或者是查找与用户最相似的人也是可以的,只要内容有一定的相似性就可以了。
数据分析内容的采集方式主要有指数图表收集、文本分析收集、人物画像分析收集、用户场景可视化分析收集等,都是比较常见的一些收集数据的方式。如何使用excel进行数据分析和可视化分析可以看这个文章:牛逼的爬虫爬取工具httpcrawler分析数据的方式有很多种,excel完全可以满足大部分,就拿网络爬虫来说,主要有下面几种收集数据的方式:1.spider的采集2.蜘蛛的采集3.爬虫的采集4.软件/网站的收集简单来说,前两种主要用于搜索引擎,最后一种则是一些网站对于爬虫的要求。
如何查看招聘网站上的岗位信息,也可以通过抓包工具来查看:edupro/get_job_demos_key_class。
谢邀,excel适合统计分析以及基础数据整理,提升数据处理能力,工作中可以不用学习,而数据分析则需要相应的统计知识。excel一个个字母打出来的单元格内容数字类型很少,很难用来做表格;另外现在it科技发展迅速,很多中小企业已经购买各类数据库,如果你是统计数据,则需要进行关联查询,类似excelcountif函数,excel求和会有一定局限性,excel需要现有自己的特色,这块跟用人单位沟通才有价值,否则就是费时费力。
数据分析简单的说就是利用excel对数据进行数据处理分析的过程,大量的数据需要各种统计方法,但excel提供这样一个集成的解决方案,而且有很多快捷方式,在结合统计软件,如sas,spss,stata等数据分析软件来解决日常工作问题,非常可取,只要熟练掌握就可以熟练操作,是互联网工作者的必备技能之一。 查看全部
文章实时采集(如何使用文章:牛逼的爬虫爬取工具分析)
文章实时采集,分析关键信息这种信息获取的方式,一般是通过文本类型进行收集的,比如你设计的一款产品app,对于用户评论的采集,就是使用词云工具echarts进行数据收集的。如果你想获取特定的用户评论的内容,你可以使用特定的关键词和内容进行匹配,或者是查找与用户最相似的人也是可以的,只要内容有一定的相似性就可以了。
数据分析内容的采集方式主要有指数图表收集、文本分析收集、人物画像分析收集、用户场景可视化分析收集等,都是比较常见的一些收集数据的方式。如何使用excel进行数据分析和可视化分析可以看这个文章:牛逼的爬虫爬取工具httpcrawler分析数据的方式有很多种,excel完全可以满足大部分,就拿网络爬虫来说,主要有下面几种收集数据的方式:1.spider的采集2.蜘蛛的采集3.爬虫的采集4.软件/网站的收集简单来说,前两种主要用于搜索引擎,最后一种则是一些网站对于爬虫的要求。
如何查看招聘网站上的岗位信息,也可以通过抓包工具来查看:edupro/get_job_demos_key_class。
谢邀,excel适合统计分析以及基础数据整理,提升数据处理能力,工作中可以不用学习,而数据分析则需要相应的统计知识。excel一个个字母打出来的单元格内容数字类型很少,很难用来做表格;另外现在it科技发展迅速,很多中小企业已经购买各类数据库,如果你是统计数据,则需要进行关联查询,类似excelcountif函数,excel求和会有一定局限性,excel需要现有自己的特色,这块跟用人单位沟通才有价值,否则就是费时费力。
数据分析简单的说就是利用excel对数据进行数据处理分析的过程,大量的数据需要各种统计方法,但excel提供这样一个集成的解决方案,而且有很多快捷方式,在结合统计软件,如sas,spss,stata等数据分析软件来解决日常工作问题,非常可取,只要熟练掌握就可以熟练操作,是互联网工作者的必备技能之一。
文章实时采集(如何借助Dede采集插件让网站快速收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-20 17:03
我们应该如何使用 Dede采集 插件使 网站 快速收录 和 关键词 排名,然后才能使 网站 快速收录 我们需要了解百度蜘蛛,不同网站的百度蜘蛛抓取规则不同,百度蜘蛛抓取频率对我们的SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。
网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站
更新频率:更新频率越高,百度蜘蛛就会越多。
网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别url重定向互联网信息数据量大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛识别url重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。 查看全部
文章实时采集(如何借助Dede采集插件让网站快速收录以及关键词排名?)
我们应该如何使用 Dede采集 插件使 网站 快速收录 和 关键词 排名,然后才能使 网站 快速收录 我们需要了解百度蜘蛛,不同网站的百度蜘蛛抓取规则不同,百度蜘蛛抓取频率对我们的SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。

网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站
更新频率:更新频率越高,百度蜘蛛就会越多。
网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别url重定向互联网信息数据量大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛识别url重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。

例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。
文章实时采集(如何利用人人站CMS采集CMS让网站快速收录关键词排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-19 15:20
)
我们为什么要做 网站 的 收录?网站排名离不开网站收录,同时对于搜索引擎来说,网站收录证明了对网站的信任,它可以让搜索引擎给予更多的权重,有利于网站排名的提升。那么如何利用人人站cms采集来快速网站收录关键词排名。
一、网站内容维护
肯定会有很多人有疑问,网站内容需要每天维护吗?答案是肯定的,只要你在各个方面都比同龄人做得更多,网站就可以比同龄人排名更高。那么我们如何每天创作这么多内容呢?如何快速采集素材库?今天给大家分享一个快速的采集优质文章人人站cms采集。
本人人站cms采集无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在人人站cms对采集进行简单设置,完成后人人站cms采集会根据用户设置的关键词进行内容和图片的高精度匹配。您可以选择在伪原创之后发布,提供方便快捷的内容采集伪原创发布服务!!
相比其他人人站cms采集这个人人站cms采集基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟即可上手,只需输入关键词即可实现采集(人人站cms采集同样配备关键词采集@ > 功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这款人人cms采集发布插件工具还配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创 .
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、服务器维护
网站的服务器很容易出问题,因为它每天承载很多东西,而且它每秒都在运行,所以服务器的硬件和软件都可能出现问题。服务器的维护不是一件容易的事,因为服务器本身比较复杂,所以需要定期检查并设置定时报警,以便在服务器出现问题时及时提醒工作人员。另外,服务器的硬件设施要定期更换,不要一直使用,以节省成本,否则真正出问题后损失更大。
三、网站系统维护
网站系统也需要经常维护。如果系统长期保持不变,那么肯定会有一些懒惰的人或者一些粗俗的文章不符合网站的内容,一些管理者会做不利于自己的事情网站 是为了自己的利益,所以要维护系统。
不要把网站的维护工作放在心上,因为如果维护不好网站,网站的质量会下降,或者登录网站@时会出现消费者> 如果出现问题,会导致大量客户流失,对网站的未来发展极为不利。
如何制作符合SEO框架的网站:
我们知道开发网站的人不一定知道如何成为网站的优秀优化者,所以只有知道如何优化网站的人才能规范网站@的制作> 流程可以标准化,制作出来的网站符合SEO框架,要做出符合SEO框架的网站,首先网站的背景需要一些基本的自定义函数,如文章标题、内联链接、关键词描述、关键词、友情链接等。这些都是基本的优化功能,需要有背景。如果这些功能不可用,我们就不能谈论它们。上面是一个优化的 网站。
二、 处的 URL 规范化
关于如何解决URL规范化的问题,这可能是站长们的重点和核心内容。那么,解决URL规范化问题的方法有很多,比如以下:
①:现在企业和个人站长使用的程序比较多cms,那么你需要判断你使用的cms系统是否只能生成规范化的url,不管有没有静态的,如DEDE、Empirecms等。
②:所有内部链接要统一,指向标准化的URL。例如:以带www和不带www的www为例,确定一个版本为canonical URL后,网站的内部链接必须统一使用这个版本,这样搜索引擎才会明白哪个是网站所有者想要网站 @> 规范化的 URL。从用户体验的角度来看:用户通常会选择以 www 为规范 URL 的版本。
③:301转。这是一种常见且常用的方法。站长可以通过 301 重定向将所有非规范化的 URL 转换为规范化的 URL。
④:规范标签。目前也是站长用的比较多的一个,百度也支持这个标签。
⑤:制作XML地图,在地图中使用规范化的URL,提交给搜索引擎。
虽然方法很多,但是很多方法都有局限性,比如:一些网站因为技术的缺失或者不成熟,301不能实现。再比如:很多cms系统经常是自己无法控制的等等。
三、网站 的代码简化
网站页面优化后如何简化网页代码?简化代码是为了提高网页的质量要求,这在营销类型网站的构建中非常突出,一般的网页制作设计师通常会在制作代码中产生很多冗余,不仅减慢页面下载速度,但也给搜索引擎检索留下不好的印象。下面是一个很好的营销类型网站build,教你精简和优化你的代码。
1、代码尽量简洁
要想提高网页浏览的速度,就需要减小页面文件的大小,简化代码的使用,尽量减少字节数。当我们制作粗体字体时,我们可以使用
B或者strong标签,在同样的前提下,为了加厚网站速度效果,我们一般使用B标签,因为strong比B标签多5个字符。所以使用B标签会减少很多不必要的冗余代码,可以说大大提高了网页的加载速度。
2、CSS 代码是一个不错的选择。CSS 代码中的垃圾,这些都是有意或无意创建的,即便如此,我们也不能忽视 CSS 格式。外部CSS代码大大减少了搜索引擎的索引,减少了页面大小。我们在调整页面格式的时候,不需要修改每个页面,只需要调整css文件即可。
3、避免重复嵌套标签
HTML代码的流行是因为它的可操作性强,嵌套代码很好,但是有一个问题。当我们在 Dreamweaver 编辑器中修改格式时,原来的格式会被删除,这会导致一些问题。这将导致臃肿的代码。
4、放弃 TABLE 的网页设计
列表是流行的网站制作,但是无限嵌套的网页布局使得代码极其臃肿,会影响网站的登录速度,更何况对蜘蛛搜索引擎不友好。当然,这并不意味着要放弃table,TABLE的设计能力非常强大,所以在使用的时候一定要懂得扬长避短。如果你的主机支持gzip压缩,开启gzip会大大压缩网页的大小,从而提高整个网页的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
查看全部
文章实时采集(如何利用人人站CMS采集CMS让网站快速收录关键词排名
)
我们为什么要做 网站 的 收录?网站排名离不开网站收录,同时对于搜索引擎来说,网站收录证明了对网站的信任,它可以让搜索引擎给予更多的权重,有利于网站排名的提升。那么如何利用人人站cms采集来快速网站收录关键词排名。

一、网站内容维护
肯定会有很多人有疑问,网站内容需要每天维护吗?答案是肯定的,只要你在各个方面都比同龄人做得更多,网站就可以比同龄人排名更高。那么我们如何每天创作这么多内容呢?如何快速采集素材库?今天给大家分享一个快速的采集优质文章人人站cms采集。
本人人站cms采集无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在人人站cms对采集进行简单设置,完成后人人站cms采集会根据用户设置的关键词进行内容和图片的高精度匹配。您可以选择在伪原创之后发布,提供方便快捷的内容采集伪原创发布服务!!
相比其他人人站cms采集这个人人站cms采集基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟即可上手,只需输入关键词即可实现采集(人人站cms采集同样配备关键词采集@ > 功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这款人人cms采集发布插件工具还配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创 .

例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、服务器维护
网站的服务器很容易出问题,因为它每天承载很多东西,而且它每秒都在运行,所以服务器的硬件和软件都可能出现问题。服务器的维护不是一件容易的事,因为服务器本身比较复杂,所以需要定期检查并设置定时报警,以便在服务器出现问题时及时提醒工作人员。另外,服务器的硬件设施要定期更换,不要一直使用,以节省成本,否则真正出问题后损失更大。
三、网站系统维护
网站系统也需要经常维护。如果系统长期保持不变,那么肯定会有一些懒惰的人或者一些粗俗的文章不符合网站的内容,一些管理者会做不利于自己的事情网站 是为了自己的利益,所以要维护系统。
不要把网站的维护工作放在心上,因为如果维护不好网站,网站的质量会下降,或者登录网站@时会出现消费者> 如果出现问题,会导致大量客户流失,对网站的未来发展极为不利。
如何制作符合SEO框架的网站:
我们知道开发网站的人不一定知道如何成为网站的优秀优化者,所以只有知道如何优化网站的人才能规范网站@的制作> 流程可以标准化,制作出来的网站符合SEO框架,要做出符合SEO框架的网站,首先网站的背景需要一些基本的自定义函数,如文章标题、内联链接、关键词描述、关键词、友情链接等。这些都是基本的优化功能,需要有背景。如果这些功能不可用,我们就不能谈论它们。上面是一个优化的 网站。
二、 处的 URL 规范化
关于如何解决URL规范化的问题,这可能是站长们的重点和核心内容。那么,解决URL规范化问题的方法有很多,比如以下:
①:现在企业和个人站长使用的程序比较多cms,那么你需要判断你使用的cms系统是否只能生成规范化的url,不管有没有静态的,如DEDE、Empirecms等。
②:所有内部链接要统一,指向标准化的URL。例如:以带www和不带www的www为例,确定一个版本为canonical URL后,网站的内部链接必须统一使用这个版本,这样搜索引擎才会明白哪个是网站所有者想要网站 @> 规范化的 URL。从用户体验的角度来看:用户通常会选择以 www 为规范 URL 的版本。
③:301转。这是一种常见且常用的方法。站长可以通过 301 重定向将所有非规范化的 URL 转换为规范化的 URL。
④:规范标签。目前也是站长用的比较多的一个,百度也支持这个标签。
⑤:制作XML地图,在地图中使用规范化的URL,提交给搜索引擎。
虽然方法很多,但是很多方法都有局限性,比如:一些网站因为技术的缺失或者不成熟,301不能实现。再比如:很多cms系统经常是自己无法控制的等等。
三、网站 的代码简化
网站页面优化后如何简化网页代码?简化代码是为了提高网页的质量要求,这在营销类型网站的构建中非常突出,一般的网页制作设计师通常会在制作代码中产生很多冗余,不仅减慢页面下载速度,但也给搜索引擎检索留下不好的印象。下面是一个很好的营销类型网站build,教你精简和优化你的代码。
1、代码尽量简洁
要想提高网页浏览的速度,就需要减小页面文件的大小,简化代码的使用,尽量减少字节数。当我们制作粗体字体时,我们可以使用
B或者strong标签,在同样的前提下,为了加厚网站速度效果,我们一般使用B标签,因为strong比B标签多5个字符。所以使用B标签会减少很多不必要的冗余代码,可以说大大提高了网页的加载速度。
2、CSS 代码是一个不错的选择。CSS 代码中的垃圾,这些都是有意或无意创建的,即便如此,我们也不能忽视 CSS 格式。外部CSS代码大大减少了搜索引擎的索引,减少了页面大小。我们在调整页面格式的时候,不需要修改每个页面,只需要调整css文件即可。
3、避免重复嵌套标签
HTML代码的流行是因为它的可操作性强,嵌套代码很好,但是有一个问题。当我们在 Dreamweaver 编辑器中修改格式时,原来的格式会被删除,这会导致一些问题。这将导致臃肿的代码。
4、放弃 TABLE 的网页设计
列表是流行的网站制作,但是无限嵌套的网页布局使得代码极其臃肿,会影响网站的登录速度,更何况对蜘蛛搜索引擎不友好。当然,这并不意味着要放弃table,TABLE的设计能力非常强大,所以在使用的时候一定要懂得扬长避短。如果你的主机支持gzip压缩,开启gzip会大大压缩网页的大小,从而提高整个网页的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!

文章实时采集(文章实时采集到的数据特征提取、相似度计算、缩放调整)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-18 15:04
文章实时采集到的数据,通过bloomfilter做特征提取、相似度计算、缩放调整,可以做为待办事项的一部分,对task的执行产生影响,
最近学习im2col,我来说说我的理解。数据特征化:首先要明确确定数据的目的,想用来做什么?分析?聚类?...定义好方向。样本特征:数据特征还可以分为文本特征、图片特征、动物特征、景点特征等等。可以依据数据特征提取或转换获得更有用的特征。数据标注:现在的人工智能领域很大一部分需要依靠的还是对数据标注。
利用计算机来对未标注的文本数据、图片数据等等(数据没有标注就需要extraction,对数据进行extraction然后baseline进行学习训练)进行标注,然后针对标注结果做模型训练和测试。模型效果好了,又可以用训练好的模型来训练新的数据。
常见的大概两类:数据特征化和数据标注。标注就是原始数据有问题,需要人工标注。也有一些基于人工标注而整出的数据模型。其实就是标记输入文字;数据特征化是通过数据描述框架,将标注语言转换成数据描述语言。主要就是某个领域内的固定术语。能标注的就标注一下吧,至少本行能标注出来还是有用的。
最近很火的im2col技术,不仅能将用户数据特征化,还能设计标注好的特征, 查看全部
文章实时采集(文章实时采集到的数据特征提取、相似度计算、缩放调整)
文章实时采集到的数据,通过bloomfilter做特征提取、相似度计算、缩放调整,可以做为待办事项的一部分,对task的执行产生影响,
最近学习im2col,我来说说我的理解。数据特征化:首先要明确确定数据的目的,想用来做什么?分析?聚类?...定义好方向。样本特征:数据特征还可以分为文本特征、图片特征、动物特征、景点特征等等。可以依据数据特征提取或转换获得更有用的特征。数据标注:现在的人工智能领域很大一部分需要依靠的还是对数据标注。
利用计算机来对未标注的文本数据、图片数据等等(数据没有标注就需要extraction,对数据进行extraction然后baseline进行学习训练)进行标注,然后针对标注结果做模型训练和测试。模型效果好了,又可以用训练好的模型来训练新的数据。
常见的大概两类:数据特征化和数据标注。标注就是原始数据有问题,需要人工标注。也有一些基于人工标注而整出的数据模型。其实就是标记输入文字;数据特征化是通过数据描述框架,将标注语言转换成数据描述语言。主要就是某个领域内的固定术语。能标注的就标注一下吧,至少本行能标注出来还是有用的。
最近很火的im2col技术,不仅能将用户数据特征化,还能设计标注好的特征,
文章实时采集(Wordpress采集资料和Wordpress采集相关工具,无需采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-02-16 03:05
Wordpress采集分享给所有站长,如果你想通过本文文章找到关于Wordpress采集和Wordpress采集相关工具的信息,你不需要阅读文章 ,可以直接查看本文图片。【图注1,重点1,快看!】
Wordpress采集是一个全自动的采集插件,可以采集any网站,设置轻而易举,只需设置定位采集 URL,准确无误由 CSS 选择器 采集 识别区域,包括(内容、摘要、TAG、缩略图、自定义字段等)然后自动检测和抓取网页内容,文章删除、更新和发布,这过程全自动,无需人工干预。
安装 Wordpress 后,是时候开始发布 文章 了。由于之前的文章分散在各个平台上,一一复制真的很费时费力。因此,如果你想一劳永逸地解决这个问题,Wordpress采集可以完美解决。【图注2,重点2,快看!】
在短短一分钟内对 网站 的即时更新是完全自动化的,无需人工干预。多线程,多任务同时执行,每个任务互不干扰,提高了近40%的执行速度。只需设置规则即可准确地采集标题、正文和任何其他 HTML 内容。只需设置每个任务,多久执行一次任务时间,然后就可以定时执行采集任务了。完美支持WordPress功能、标签、片段、特色图片、自定义栏目等。支持内容过滤,甚至可以在文章的任意位置添加自定义内容,还可以自定义文章样式。【图注3,重点3,快看!】
一个 Wordpress 插件,用于聚合来自多个博客的内容。适合拥有多个博客的博主,或者资源聚合分享博主,群博主。Wordpress插件主要聚合标题和部分摘要,不收录全文的实际内容,也不将对方的文章导入到自己的数据库中。Wordpress插件只需要在后台设置Rss源和采集的时间,Wordpress插件就会自动执行。甚至可以采集对方网站的附件和图片,符合国内cms制度,无需站长浪费时间和精力。【图注4,关键点4,快看!】
目前,各种版本的 Wordpress 都在完美运行。Wordpress采集是一款优秀的Wordpress文章采集器,是操作站群,让网站自动更新内容的强大工具!您可以轻松获得优质的“原创”文章,增加百度的收录音量和网站权重。您可以采集任何网站内容,采集信息一目了然。通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行。您可以将任务设置为自动或手动运行。主任务列表显示每个采集任务的状态:上一次巡检的时间采集,下一次采集的时间。
Wordpress采集可以满足新建的Wordpress网站,内容较少,希望尽快有更丰富的内容;热点内容自动采集自动发布;定时 采集,手动 采集 发布或保存到草稿;css 样式规则可以更精确地 采集 所需内容。伪原创使用翻译和代理IP进行采集,保存cookie记录;您可以将 采集 内容添加到自定义列。 查看全部
文章实时采集(Wordpress采集资料和Wordpress采集相关工具,无需采集)
Wordpress采集分享给所有站长,如果你想通过本文文章找到关于Wordpress采集和Wordpress采集相关工具的信息,你不需要阅读文章 ,可以直接查看本文图片。【图注1,重点1,快看!】
Wordpress采集是一个全自动的采集插件,可以采集any网站,设置轻而易举,只需设置定位采集 URL,准确无误由 CSS 选择器 采集 识别区域,包括(内容、摘要、TAG、缩略图、自定义字段等)然后自动检测和抓取网页内容,文章删除、更新和发布,这过程全自动,无需人工干预。
安装 Wordpress 后,是时候开始发布 文章 了。由于之前的文章分散在各个平台上,一一复制真的很费时费力。因此,如果你想一劳永逸地解决这个问题,Wordpress采集可以完美解决。【图注2,重点2,快看!】
在短短一分钟内对 网站 的即时更新是完全自动化的,无需人工干预。多线程,多任务同时执行,每个任务互不干扰,提高了近40%的执行速度。只需设置规则即可准确地采集标题、正文和任何其他 HTML 内容。只需设置每个任务,多久执行一次任务时间,然后就可以定时执行采集任务了。完美支持WordPress功能、标签、片段、特色图片、自定义栏目等。支持内容过滤,甚至可以在文章的任意位置添加自定义内容,还可以自定义文章样式。【图注3,重点3,快看!】
一个 Wordpress 插件,用于聚合来自多个博客的内容。适合拥有多个博客的博主,或者资源聚合分享博主,群博主。Wordpress插件主要聚合标题和部分摘要,不收录全文的实际内容,也不将对方的文章导入到自己的数据库中。Wordpress插件只需要在后台设置Rss源和采集的时间,Wordpress插件就会自动执行。甚至可以采集对方网站的附件和图片,符合国内cms制度,无需站长浪费时间和精力。【图注4,关键点4,快看!】
目前,各种版本的 Wordpress 都在完美运行。Wordpress采集是一款优秀的Wordpress文章采集器,是操作站群,让网站自动更新内容的强大工具!您可以轻松获得优质的“原创”文章,增加百度的收录音量和网站权重。您可以采集任何网站内容,采集信息一目了然。通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行。您可以将任务设置为自动或手动运行。主任务列表显示每个采集任务的状态:上一次巡检的时间采集,下一次采集的时间。

Wordpress采集可以满足新建的Wordpress网站,内容较少,希望尽快有更丰富的内容;热点内容自动采集自动发布;定时 采集,手动 采集 发布或保存到草稿;css 样式规则可以更精确地 采集 所需内容。伪原创使用翻译和代理IP进行采集,保存cookie记录;您可以将 采集 内容添加到自定义列。
文章实时采集(这是捕获音视频而后生成avi,再进行264编码的方法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-02-16 01:05
)
转载:0. 前言
前两篇文章中写了DirectShow中采集音视频,生成avi,然后264编码的方法。该方法有一定的局限性,不适合实时应用,例如:视频会议、视频聊天、视频监控等。本文使用的技术适合这种实时应用。对来自采集的每一帧音视频进行处理后,实现实时编码和实时输出。这是我的直播系列申请的一部分。目前的情况是输入端使用DirectShow技术采集音视频,然后用h.264编码视频,用aac编码音频,在输出端生成文件。扩展输入输出,支持文件、桌面输入、RTSP、RTMP、HTTP 和其他流协议输出。html
1. linux简单介绍
首先是捕获,这里使用DirectShow对其进行了一定程度的封装,包括音频和视频。好处是可以直接使用原生的api,可以随意修改。缺点是不能跨平台。采集音视频的应用也需要下放到Linux平台上。有一种跨平台的方式,视频可以使用OpenCV,音频可以使用OpenAL或者PortAudio等等,就这样。网络
编码有很多选择。视频方面有H264、MPEG-4、WebM/VP8、Theora等,音频方面有Speex、AAC、Ogg/Vorbis等,都有相应的开源项目解决方案。我用的是x264做H264编码,libfaac做aac编码,以后是否改变编码方案,具体项目需求再说。这里要提一下WebM,谷歌牵头的一个项目,完全开放免费,采用VP8和Vorbis编码,webm(mkv)封装,很多巨头都支持,目的是替代目前的H264视频编码,号称比后者,我没有测试过实际效果。但是,如果一家商业公司带头,情况就不同了。各种支持都很全面,有时间可以关注一下。api
2. 逻辑和流程
基本思路是实现dshowISampleGrabberCB接口,通过回调保存每个缓冲区。除了接口线程和dshow本身的线程外,我们分别启动了AudioEncoderThread和VideoEncoderThread两个线程,分别从SampleGrabber中提取数据,调用encoder进行编码,编码后的文件可以直接输出。看图:post
程序是用VS2010搭建的,见张项目截图:test
Base 下面是对系统 API 的一些简单封装,主要是线程和锁。这里我简单封装了dshow的抓包过程,包括graph builder的建立,filter的链接等等,directshow是出了名的难用。由于是VS2010,调用了Windows SDK 7.1中的dshow,没有qedit.h文件,官方定义了ISampleGrabberCB。别着急,系统里还有qedit.dll,我们要做的就是从Windows SDK 6.0中拷贝出来,然后将这几行代码添加到stdafx.h中,然后我们将能够ui
1 #pragma include_alias( "dxtrans.h", "qedit.h" )
2 #define __IDxtCompositor_INTERFACE_DEFINED__
3 #define __IDxtAlphaSetter_INTERFACE_DEFINED__
4 #define __IDxtJpeg_INTERFACE_DEFINED__
5 #define __IDxtKey_INTERFACE_DEFINED__
6 #include "qedit.h"
3. 音视频编码
相关文件:水疗
Encoder下面是音视频编码相关的代码。X264Encoder封装调用x264编码器的操作,FAACEncoder封装调用libfaac编码器的操作,VideoEncoderThread和AudioEncoderThread负责主进程。下面我贴出关键代码,大家可以参考。
A. 视频编码线程
主要流程是先初始化x264编码器,然后开始循环调用DSVideoGraph,从SampleGrabber中取出视频帧,调用x264进行编码。过程比较简单,调用的频率就是你想要得到的视频帧率。需要注意的是,x264 编码比较耗时。在计算线程Sleep时间的时候,要计算这个进程消耗的时间,避免采集的视频帧率错误。
B. 音频编码线程
主要流程与视频编码线程相同。它还初始化FAAC编码器,然后循环调用DSAudioGraph,从SampleGrabber中取出视频帧,调用faac进行编码。和视频不同,音频采样的频率非常快,所以必须采集几乎连续进行,但前提是在SampleGrabber中捕获到新数据,否则你的程序cpu会100%,IsBufferAvailaber( ) 在下面的代码中用于此检测。
调用faac进行编码的时候需要注意,要特别注意,否则编码后的音频会很不正常,做的不好会很头疼。先看下faac.h的相关接口
1 faacEncHandle FAACAPI faacEncOpen(unsigned long sampleRate, unsigned int numChannels,
2 unsigned long *inputSamples, unsigned long *maxOutputBytes);
3
4 int FAACAPI faacEncEncode(faacEncHandle hEncoder, int32_t * inputBuffer, unsigned int samplesInput,
5 unsigned char *outputBuffer, unsigned int bufferSize);
faacEncEncode的第三个参数是指传入样本的数量,应该等于调用faacEncOpen返回的inputSamples。为此,在 dshow 中设置 buffsize,公式为:
BufferSize = aac_frame_len * channels * wBytesPerSample
// aac_frame_len = 1024
4. 程序界面
跑步
采集完成后生成aac和264文件
MediaInfo读取生成的aac文件的编码格式
生成的264文件是MediaInfo读取的编码格式
用mp4box封装,将264和aac存储在mp4容器文件中,就可以在播放器中播放了
查看全部
文章实时采集(这是捕获音视频而后生成avi,再进行264编码的方法
)
转载:0. 前言
前两篇文章中写了DirectShow中采集音视频,生成avi,然后264编码的方法。该方法有一定的局限性,不适合实时应用,例如:视频会议、视频聊天、视频监控等。本文使用的技术适合这种实时应用。对来自采集的每一帧音视频进行处理后,实现实时编码和实时输出。这是我的直播系列申请的一部分。目前的情况是输入端使用DirectShow技术采集音视频,然后用h.264编码视频,用aac编码音频,在输出端生成文件。扩展输入输出,支持文件、桌面输入、RTSP、RTMP、HTTP 和其他流协议输出。html
1. linux简单介绍
首先是捕获,这里使用DirectShow对其进行了一定程度的封装,包括音频和视频。好处是可以直接使用原生的api,可以随意修改。缺点是不能跨平台。采集音视频的应用也需要下放到Linux平台上。有一种跨平台的方式,视频可以使用OpenCV,音频可以使用OpenAL或者PortAudio等等,就这样。网络
编码有很多选择。视频方面有H264、MPEG-4、WebM/VP8、Theora等,音频方面有Speex、AAC、Ogg/Vorbis等,都有相应的开源项目解决方案。我用的是x264做H264编码,libfaac做aac编码,以后是否改变编码方案,具体项目需求再说。这里要提一下WebM,谷歌牵头的一个项目,完全开放免费,采用VP8和Vorbis编码,webm(mkv)封装,很多巨头都支持,目的是替代目前的H264视频编码,号称比后者,我没有测试过实际效果。但是,如果一家商业公司带头,情况就不同了。各种支持都很全面,有时间可以关注一下。api
2. 逻辑和流程
基本思路是实现dshowISampleGrabberCB接口,通过回调保存每个缓冲区。除了接口线程和dshow本身的线程外,我们分别启动了AudioEncoderThread和VideoEncoderThread两个线程,分别从SampleGrabber中提取数据,调用encoder进行编码,编码后的文件可以直接输出。看图:post

程序是用VS2010搭建的,见张项目截图:test

Base 下面是对系统 API 的一些简单封装,主要是线程和锁。这里我简单封装了dshow的抓包过程,包括graph builder的建立,filter的链接等等,directshow是出了名的难用。由于是VS2010,调用了Windows SDK 7.1中的dshow,没有qedit.h文件,官方定义了ISampleGrabberCB。别着急,系统里还有qedit.dll,我们要做的就是从Windows SDK 6.0中拷贝出来,然后将这几行代码添加到stdafx.h中,然后我们将能够ui
1 #pragma include_alias( "dxtrans.h", "qedit.h" )
2 #define __IDxtCompositor_INTERFACE_DEFINED__
3 #define __IDxtAlphaSetter_INTERFACE_DEFINED__
4 #define __IDxtJpeg_INTERFACE_DEFINED__
5 #define __IDxtKey_INTERFACE_DEFINED__
6 #include "qedit.h"
3. 音视频编码
相关文件:水疗

Encoder下面是音视频编码相关的代码。X264Encoder封装调用x264编码器的操作,FAACEncoder封装调用libfaac编码器的操作,VideoEncoderThread和AudioEncoderThread负责主进程。下面我贴出关键代码,大家可以参考。
A. 视频编码线程
主要流程是先初始化x264编码器,然后开始循环调用DSVideoGraph,从SampleGrabber中取出视频帧,调用x264进行编码。过程比较简单,调用的频率就是你想要得到的视频帧率。需要注意的是,x264 编码比较耗时。在计算线程Sleep时间的时候,要计算这个进程消耗的时间,避免采集的视频帧率错误。

B. 音频编码线程
主要流程与视频编码线程相同。它还初始化FAAC编码器,然后循环调用DSAudioGraph,从SampleGrabber中取出视频帧,调用faac进行编码。和视频不同,音频采样的频率非常快,所以必须采集几乎连续进行,但前提是在SampleGrabber中捕获到新数据,否则你的程序cpu会100%,IsBufferAvailaber( ) 在下面的代码中用于此检测。

调用faac进行编码的时候需要注意,要特别注意,否则编码后的音频会很不正常,做的不好会很头疼。先看下faac.h的相关接口
1 faacEncHandle FAACAPI faacEncOpen(unsigned long sampleRate, unsigned int numChannels,
2 unsigned long *inputSamples, unsigned long *maxOutputBytes);
3
4 int FAACAPI faacEncEncode(faacEncHandle hEncoder, int32_t * inputBuffer, unsigned int samplesInput,
5 unsigned char *outputBuffer, unsigned int bufferSize);
faacEncEncode的第三个参数是指传入样本的数量,应该等于调用faacEncOpen返回的inputSamples。为此,在 dshow 中设置 buffsize,公式为:
BufferSize = aac_frame_len * channels * wBytesPerSample
// aac_frame_len = 1024
4. 程序界面
跑步

采集完成后生成aac和264文件

MediaInfo读取生成的aac文件的编码格式

生成的264文件是MediaInfo读取的编码格式

用mp4box封装,将264和aac存储在mp4容器文件中,就可以在播放器中播放了

文章实时采集(如何使用邦福网络舆情收集和分析系统?分级实时采集技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-09 20:27
如何使用邦孚互联网舆情采集分析系统?
1.分类实时采集科技邦孚舆情监测系统基于全球领先的网页智能采集技术,每5分钟更新一个关卡的更新频率。目前,系统可以支持上万条网站的同时采集和分析。采用多线程并发指令执行架构、增量实时索引、智能分词、关联分析、模糊匹配等多项先进技术。
2.支持图片采集邦孚感官监控系统支持jpg、bmp、gif、png等图片格式,可采集网页内容相关图片,智能自动过滤各种无关广告图片。当用户浏览文章时,他或她可以浏览相关的地图和管理图像。
3.多级分类机制邦富舆情监测系统不仅可以根据用户自定义关键词对采集的信息进行自动分类,还可以配置多级分类。例如,[粮食作物]的分类可以定义[大米]和[小麦]的分类,[小麦]的分类还可以定义[控制病毒损害]和[种植]的分类。
4.自动信息去重 快速准确的自然语义分析模块,自动提取各个语义模型并相互比较,通过独特的去重引擎自动丢弃重复链接和内容相同的链接,提高4. @k7@ > 阅读效率和标签页重复用于提示用户的号码。
5.唯一网页文本提取现有技术监控系统的唯一文章内容智能提取模块。通过识别和分析网页中的元素,可以从网页中找到并提取广告、菜单、友好链接和其他 文章 无关信息。过程中丢弃,最后只保存文章的标题和正文,提取准确率达到领先水平。
6.精准智能摘要 Bonjolly分析模块独有的智能语义分析引擎,根据文档内容自动提取文档摘要信息。这些摘要准确地代表了 文章 的主题和中心思想。用户无需查看文章 的所有内容。通过这个智能摘要,他们可以快速了解文章的含义和核心内容,提高用户信息的效率。
7. Word文档导出 作为采集信息的信息处理服务之一,邦孚速递采集模块支持网页的采集,并提取其正文内容和智能摘要。在此基础上,可以选择一条或多条消息,并批量导出到 Word 和 Excel 中。、文本文件和其他文件,以供信息处理器更好地使用。
8.个性化首页每个用户都可以定义不同的首页,并根据自己的喜好配置首页的栏目、每栏信息的来源、展示方式、信息的位置、信息量、是否滚动等。
9.信息采集 用户可以从权限范围内的分类树中选择自己感兴趣的多级个人采集,分享给领导或同事进行个性化浏览。
10.强大快速的检索系统对于信息检索,邦孚的舆情监测系统支持按时间排序和排序。高并发保持亚秒级响应速度,系统自动分析搜索结果并根据source网站和region进行统计。
11.强大的用户权限控制系统具有强大的用户权限管理功能。不同的用户可以通过不同的权限看到不同范围的信息内容。管理员可以根据不同用户的角色配置不同的菜单,并通过严格灵活的权限。这种机制有效地结合了个人用户和菜单。
12.信息趋势分析系统可以实时生成图表,直观地分析每日趋势,用户可以保存趋势图像并在分析报告中使用。
13.基于Web的系统管理平台邦孚舆情监测系统采用标准B/S架构。系统管理员可以登录Web图形化管理界面,随时随地对整个系统的功能进行管理和维护。易于使用,您可以随时随地打开系统。
14.完善的服务体系邦富在广州和深圳设有搜索引擎软件和销售中心。是少数在广东设立研发中心的企业搜索引擎供应商之一。软件中的个性化和互联网信息。采集、网络舆情监测和系统售后技术支持,可为客户提供充分保障。电话:
88912527
互联网舆情监测报告
我不知道你的具体要求是什么。只是带走军犬的恩怨。他的报道主要是指根据网络舆论平台的数据和图表生成的简报和专题报道。并通过三种感官警告方式(包括短信警告、邮件警告、弹窗警告三种方式)进行提示。.
版权声明:本文由无限公关舆情网采集整理,不代表本站任何观点。Infinite Public Relations and Public Opinion是一家专注于用法律解决客户舆论问题的公司。主要服务范围:危机公关、舆情监测、舆情监测、网络信誉保护等,引导行业正规发展。 查看全部
文章实时采集(如何使用邦福网络舆情收集和分析系统?分级实时采集技术)
如何使用邦孚互联网舆情采集分析系统?
1.分类实时采集科技邦孚舆情监测系统基于全球领先的网页智能采集技术,每5分钟更新一个关卡的更新频率。目前,系统可以支持上万条网站的同时采集和分析。采用多线程并发指令执行架构、增量实时索引、智能分词、关联分析、模糊匹配等多项先进技术。
2.支持图片采集邦孚感官监控系统支持jpg、bmp、gif、png等图片格式,可采集网页内容相关图片,智能自动过滤各种无关广告图片。当用户浏览文章时,他或她可以浏览相关的地图和管理图像。
3.多级分类机制邦富舆情监测系统不仅可以根据用户自定义关键词对采集的信息进行自动分类,还可以配置多级分类。例如,[粮食作物]的分类可以定义[大米]和[小麦]的分类,[小麦]的分类还可以定义[控制病毒损害]和[种植]的分类。
4.自动信息去重 快速准确的自然语义分析模块,自动提取各个语义模型并相互比较,通过独特的去重引擎自动丢弃重复链接和内容相同的链接,提高4. @k7@ > 阅读效率和标签页重复用于提示用户的号码。
5.唯一网页文本提取现有技术监控系统的唯一文章内容智能提取模块。通过识别和分析网页中的元素,可以从网页中找到并提取广告、菜单、友好链接和其他 文章 无关信息。过程中丢弃,最后只保存文章的标题和正文,提取准确率达到领先水平。
6.精准智能摘要 Bonjolly分析模块独有的智能语义分析引擎,根据文档内容自动提取文档摘要信息。这些摘要准确地代表了 文章 的主题和中心思想。用户无需查看文章 的所有内容。通过这个智能摘要,他们可以快速了解文章的含义和核心内容,提高用户信息的效率。
7. Word文档导出 作为采集信息的信息处理服务之一,邦孚速递采集模块支持网页的采集,并提取其正文内容和智能摘要。在此基础上,可以选择一条或多条消息,并批量导出到 Word 和 Excel 中。、文本文件和其他文件,以供信息处理器更好地使用。
8.个性化首页每个用户都可以定义不同的首页,并根据自己的喜好配置首页的栏目、每栏信息的来源、展示方式、信息的位置、信息量、是否滚动等。
9.信息采集 用户可以从权限范围内的分类树中选择自己感兴趣的多级个人采集,分享给领导或同事进行个性化浏览。
10.强大快速的检索系统对于信息检索,邦孚的舆情监测系统支持按时间排序和排序。高并发保持亚秒级响应速度,系统自动分析搜索结果并根据source网站和region进行统计。
11.强大的用户权限控制系统具有强大的用户权限管理功能。不同的用户可以通过不同的权限看到不同范围的信息内容。管理员可以根据不同用户的角色配置不同的菜单,并通过严格灵活的权限。这种机制有效地结合了个人用户和菜单。
12.信息趋势分析系统可以实时生成图表,直观地分析每日趋势,用户可以保存趋势图像并在分析报告中使用。
13.基于Web的系统管理平台邦孚舆情监测系统采用标准B/S架构。系统管理员可以登录Web图形化管理界面,随时随地对整个系统的功能进行管理和维护。易于使用,您可以随时随地打开系统。
14.完善的服务体系邦富在广州和深圳设有搜索引擎软件和销售中心。是少数在广东设立研发中心的企业搜索引擎供应商之一。软件中的个性化和互联网信息。采集、网络舆情监测和系统售后技术支持,可为客户提供充分保障。电话:
88912527
互联网舆情监测报告
我不知道你的具体要求是什么。只是带走军犬的恩怨。他的报道主要是指根据网络舆论平台的数据和图表生成的简报和专题报道。并通过三种感官警告方式(包括短信警告、邮件警告、弹窗警告三种方式)进行提示。.
版权声明:本文由无限公关舆情网采集整理,不代表本站任何观点。Infinite Public Relations and Public Opinion是一家专注于用法律解决客户舆论问题的公司。主要服务范围:危机公关、舆情监测、舆情监测、网络信誉保护等,引导行业正规发展。
文章实时采集(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-08 09:23
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天新建域名,次日逐步启动收录,部分关键词开始秩。一段时间后,收录基本可以达到上万个收录。
免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布
1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
文章实时采集(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天新建域名,次日逐步启动收录,部分关键词开始秩。一段时间后,收录基本可以达到上万个收录。

免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布

1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
文章实时采集(什么是全网采集截流获客系统?全网快手(快手是旗下的产品))
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-02-08 07:02
大家好,我叫希妍。今天给大家介绍一款全网采集拦截获客软件。
什么是全网采集拦截和获客系统?采集拦截流量、获客的平台有哪些?全网采集拦截获客系统有什么用?
在介绍软件之前,先简单总结一下什么是短视频?短视频流行的平台有哪些?
短视频就是短视频。从名字的意思可以知道,它是一个时长比较短的视频。作为一种新型的互联网传播方式,它在互联网上掀起了一股热潮。视频统称为短视频。随着移动终端的普及和互联网的提速,短时间、快节奏、大流量的内容传播逐渐获得各大平台、粉丝和资本的青睐。
随着网红经济的兴起,视频行业逐渐涌现出一批优质的UGC内容生产者。
微博、秒拍、快手、今日头条都进入了短视频行业,招揽了一批优秀的内容制作团队入驻,也带动了越来越多的商家留在短视频平台。
短视频流行的平台有哪些?
1. 快手(快手是它的产品。快手的前身,叫“GIF快手”,诞生于2011年3月。最初是一个用于创建和分享GIF图片的移动应用程序。2012年11月,快手从短视频社区的纯工具应用,用户记录和分享生产生活的平台。后来随着智能手机、平板电脑的普及以及移动流量成本的下降,快手在2015年后迎来了市场)
2. 抖音(抖音,是字节跳动孵化的一款音乐创意短视频社交软件。该软件于2016年9月20日上线,是一款老少皆宜的社交软件。短视频社区平台。也是目前商家人气最高的平台)
3.哔哩哔哩(简称B站)现在是中国年轻一代高度集中的文化社区和视频平台。建站初期是一个ACG(动画、漫画、游戏)内容创作分享视频网站。经过十多年的发展,围绕用户、创作者和内容,我们构建了一个生态系统不断产生高质量的内容。B站已覆盖7000多个多元文化兴趣圈社区,并被QuestMobile研究院选中。在“Z世代偏爱APP”和“Z世代偏爱泛娱乐APP”两项榜单中排名第一,入选《BrandZ》报告2019最具价值中国品牌100强)
4. 西瓜视频(西瓜视频是字节跳动旗下的中文视频平台,以“点亮对生活的好奇”为口号。西瓜视频通过人工智能帮助大家发现自己喜欢的视频,帮助视频创作者轻松分享自己喜欢的视频。视频与世界同行。西瓜视频鼓励多元化创作,帮助人们与世界分享视频作品,创造更大价值。目前平台月活跃创作者超过320万,月活跃用户超过320万。1.8亿,日均播放量超过40亿,用户平均使用时长超过100分钟。)
5.火山小视频(《抖音火山版》是一个15s原创生活小视频社区,今天由今日头条孵化,通过小视频帮助用户快速获取内容、展示自我、获取粉丝,找朋友)
目前这些平台是最受欢迎的,还有很多其他的我就不一一介绍了。让我们继续今天的主题。“全网采集拦截获客系统”
什么是全网采集拦截和获客系统?
简单来说就是通过短视频平台进行宣传,让客户咨询你了解你,然后进行交易转化。就是数字化,即从物理世界,挖掘数据,提炼信息,提炼知识,汇聚智慧,最终提高生产力。
今天就来说说全网采集拦截和获客系统的抖音查询系统。需要通过短视频拓展客源、寻找新客源的渠道,只要行业需要在线获客即可。
它具有以下功能:
1、客户挖掘:获取同行视频评论数据,拦截潜在客户,输出潜在客户表单,帮助企业获客
2、精准定位:多重筛选精准定位潜在客户,提升潜在客户质量,精准锁定潜在客户
3、实时监控:实时监控对端视频数据,同步抓取最新查询信息,保证信息的及时性
4、多种策略:关键词监控、单一视频监控、个人主页监控以及多种获客方式,精准获客
抖音查询系统是用软件捕捉关键词在抖音中你想知道的人气。可以抓取的信息包括抖音博主,抖音@抖音回复咨询信息获取客户信息,还可以监控一个抖音用户正在关注和评论某热门实时视频私信他,也可以监控抖音博主主页,通过主页获取访问者信息,实现流量拦截!
如何把别人的粉丝变成你的精准客户。所以你觉得这个好不好,别人打包的产品,别人的视频,别人花钱宣传,别人作品下面有很多营销不错的潜在客户,直接问尺寸,问价格,留个购买方法等留言等等...这种你直接启动我们的软件私信给他们...我的质量比它好,价格更合理,我们是厂家直销等. 想了解更多,直接加我。直接在精准的客户群中找到您的客户……您认为可以在最大的流量平台上免费做广告,推销我们的产品。有了流量才有曝光,有了曝光,
指定网红账号进行关注,私信推送给指定账号的粉丝,实现精准引流。它可以从帐户粉丝界面或搜索中的用户界面运行。
截流评论区引流可以指定竞争对手视频下方的评论一一进行评论,瞬间将竞争对手的粉丝引流到自己的精准流量中!可以在任何播放界面运行。
借助抖音的流量红利,您可以免费帮我们做广告,在非常精准的行业中找到您的有效客户。互联网实际上是信息的采集和有效分发。要获得用户想要的价值,我们不需要在茫茫人海中找到我们的客户,我们只需要在我们精准的行业中找到我们的客户。
一键回访意向客户,跟进意向客户回复私信。消息转为微信,运行在消息界面
一键私信粉丝对自己的粉丝一一进行二次营销,在自己的粉丝界面上运行
一键取消关注自己取消关注,同时可以选择对关注的用户进行二次营销,在自己的关注界面运行。
我们的市场就是现在流量所在的地方。在自媒体时代,抖音的流量已经超过任何一个自媒体,一马当先,成为最有价值的流量平台。你还在担心行不通吗……如果你愿意接受并尝试这种跟风的新营销方式,我想你已经成功了一半……雷军说试错不高,遗漏成本很高
快手、西瓜、B站也是如此。当然,我们不限于此。毕竟,我们是在做整个网络。还有知乎、今日头条、豆瓣、微视等,想要获得更多客户,请关注回复
大家好,我是希言,我们是专业的全网采集拦截和获客系统。 查看全部
文章实时采集(什么是全网采集截流获客系统?全网快手(快手是旗下的产品))
大家好,我叫希妍。今天给大家介绍一款全网采集拦截获客软件。

什么是全网采集拦截和获客系统?采集拦截流量、获客的平台有哪些?全网采集拦截获客系统有什么用?
在介绍软件之前,先简单总结一下什么是短视频?短视频流行的平台有哪些?

短视频就是短视频。从名字的意思可以知道,它是一个时长比较短的视频。作为一种新型的互联网传播方式,它在互联网上掀起了一股热潮。视频统称为短视频。随着移动终端的普及和互联网的提速,短时间、快节奏、大流量的内容传播逐渐获得各大平台、粉丝和资本的青睐。
随着网红经济的兴起,视频行业逐渐涌现出一批优质的UGC内容生产者。
微博、秒拍、快手、今日头条都进入了短视频行业,招揽了一批优秀的内容制作团队入驻,也带动了越来越多的商家留在短视频平台。
短视频流行的平台有哪些?
1. 快手(快手是它的产品。快手的前身,叫“GIF快手”,诞生于2011年3月。最初是一个用于创建和分享GIF图片的移动应用程序。2012年11月,快手从短视频社区的纯工具应用,用户记录和分享生产生活的平台。后来随着智能手机、平板电脑的普及以及移动流量成本的下降,快手在2015年后迎来了市场)

2. 抖音(抖音,是字节跳动孵化的一款音乐创意短视频社交软件。该软件于2016年9月20日上线,是一款老少皆宜的社交软件。短视频社区平台。也是目前商家人气最高的平台)

3.哔哩哔哩(简称B站)现在是中国年轻一代高度集中的文化社区和视频平台。建站初期是一个ACG(动画、漫画、游戏)内容创作分享视频网站。经过十多年的发展,围绕用户、创作者和内容,我们构建了一个生态系统不断产生高质量的内容。B站已覆盖7000多个多元文化兴趣圈社区,并被QuestMobile研究院选中。在“Z世代偏爱APP”和“Z世代偏爱泛娱乐APP”两项榜单中排名第一,入选《BrandZ》报告2019最具价值中国品牌100强)

4. 西瓜视频(西瓜视频是字节跳动旗下的中文视频平台,以“点亮对生活的好奇”为口号。西瓜视频通过人工智能帮助大家发现自己喜欢的视频,帮助视频创作者轻松分享自己喜欢的视频。视频与世界同行。西瓜视频鼓励多元化创作,帮助人们与世界分享视频作品,创造更大价值。目前平台月活跃创作者超过320万,月活跃用户超过320万。1.8亿,日均播放量超过40亿,用户平均使用时长超过100分钟。)

5.火山小视频(《抖音火山版》是一个15s原创生活小视频社区,今天由今日头条孵化,通过小视频帮助用户快速获取内容、展示自我、获取粉丝,找朋友)

目前这些平台是最受欢迎的,还有很多其他的我就不一一介绍了。让我们继续今天的主题。“全网采集拦截获客系统”
什么是全网采集拦截和获客系统?
简单来说就是通过短视频平台进行宣传,让客户咨询你了解你,然后进行交易转化。就是数字化,即从物理世界,挖掘数据,提炼信息,提炼知识,汇聚智慧,最终提高生产力。
今天就来说说全网采集拦截和获客系统的抖音查询系统。需要通过短视频拓展客源、寻找新客源的渠道,只要行业需要在线获客即可。
它具有以下功能:
1、客户挖掘:获取同行视频评论数据,拦截潜在客户,输出潜在客户表单,帮助企业获客
2、精准定位:多重筛选精准定位潜在客户,提升潜在客户质量,精准锁定潜在客户
3、实时监控:实时监控对端视频数据,同步抓取最新查询信息,保证信息的及时性
4、多种策略:关键词监控、单一视频监控、个人主页监控以及多种获客方式,精准获客
抖音查询系统是用软件捕捉关键词在抖音中你想知道的人气。可以抓取的信息包括抖音博主,抖音@抖音回复咨询信息获取客户信息,还可以监控一个抖音用户正在关注和评论某热门实时视频私信他,也可以监控抖音博主主页,通过主页获取访问者信息,实现流量拦截!
如何把别人的粉丝变成你的精准客户。所以你觉得这个好不好,别人打包的产品,别人的视频,别人花钱宣传,别人作品下面有很多营销不错的潜在客户,直接问尺寸,问价格,留个购买方法等留言等等...这种你直接启动我们的软件私信给他们...我的质量比它好,价格更合理,我们是厂家直销等. 想了解更多,直接加我。直接在精准的客户群中找到您的客户……您认为可以在最大的流量平台上免费做广告,推销我们的产品。有了流量才有曝光,有了曝光,
指定网红账号进行关注,私信推送给指定账号的粉丝,实现精准引流。它可以从帐户粉丝界面或搜索中的用户界面运行。
截流评论区引流可以指定竞争对手视频下方的评论一一进行评论,瞬间将竞争对手的粉丝引流到自己的精准流量中!可以在任何播放界面运行。
借助抖音的流量红利,您可以免费帮我们做广告,在非常精准的行业中找到您的有效客户。互联网实际上是信息的采集和有效分发。要获得用户想要的价值,我们不需要在茫茫人海中找到我们的客户,我们只需要在我们精准的行业中找到我们的客户。
一键回访意向客户,跟进意向客户回复私信。消息转为微信,运行在消息界面
一键私信粉丝对自己的粉丝一一进行二次营销,在自己的粉丝界面上运行
一键取消关注自己取消关注,同时可以选择对关注的用户进行二次营销,在自己的关注界面运行。


我们的市场就是现在流量所在的地方。在自媒体时代,抖音的流量已经超过任何一个自媒体,一马当先,成为最有价值的流量平台。你还在担心行不通吗……如果你愿意接受并尝试这种跟风的新营销方式,我想你已经成功了一半……雷军说试错不高,遗漏成本很高
快手、西瓜、B站也是如此。当然,我们不限于此。毕竟,我们是在做整个网络。还有知乎、今日头条、豆瓣、微视等,想要获得更多客户,请关注回复
大家好,我是希言,我们是专业的全网采集拦截和获客系统。
文章实时采集(【之前】项目1本版 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-08 01:12
)
以前的项目 1
此版本采用TCP服务器模式接收数据。数据格式也有一些变化
1.先上图(其实也支持串口,因为暂时不用,被我隐藏了)
简单,无话可说。但是也有网友问了访问操作类,直接贴出来了:
using System;
using System.Data;
using System.Data.OleDb;
namespace SerialCommDemo
{
/**
/// AccessDb 的摘要说明,以下信息请完整保留
/// 请在数据传递完毕后调用Close()方法,关闭数据链接。
///
public class AccessDbClass
{
//变量声明处#region 变量声明处
public OleDbConnection Conn;
public string ConnString;//连接字符串
//构造函数与连接关闭数据库#region 构造函数与连接关闭数据库
/**
/// 构造函数
///
/// ACCESS数据库路径
public AccessDbClass(string Dbpath)
{
//Provider=Microsoft.ACE.OLEDB.12.0;Data Source=C:\myFolder\*.accdb;Persist Security Info=False;
ConnString = "Provider=Microsoft.ACE.OLEDB.12.0;Data Source="+Dbpath+";Persist Security Info=False;";
Conn = new OleDbConnection(ConnString);
Conn.Open();
}
/**
/// 打开数据源链接
///
///
public OleDbConnection DbConn()
{
Conn.Open();
return Conn;
}
/**
/// 请在数据传递完毕后调用该函数,关闭数据链接。
///
public void Close()
{
Conn.Close();
}
// 数据库基本操作#region 数据库基本操作
/**
/// 根据SQL命令返回数据DataTable数据表,
/// 可直接作为dataGridView的数据源
///
///
///
public DataTable SelectToDataTable(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
adapter.Fill(Dt);
return Dt;
}
/**
/// 根据SQL命令返回数据DataSet数据集,其中的表可直接作为dataGridView的数据源。
///
///
/// 在返回的数据集中所添加的表的名称
///
public DataSet SelectToDataSet(string SQL, string subtableName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataSet Ds = new DataSet();
Ds.Tables.Add(subtableName);
adapter.Fill(Ds, subtableName);
return Ds;
}
/**
/// 在指定的数据集中添加带有指定名称的表,由于存在覆盖已有名称表的危险,返回操作之前的数据集。
///
///
/// 添加的表名
/// 被添加的数据集名
///
public DataSet SelectToDataSet (string SQL, string subtableName, DataSet DataSetName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
DataSet Ds = new DataSet();
Ds = DataSetName;
adapter.Fill(DataSetName, subtableName);
return Ds;
}
/**
/// 根据SQL命令返回OleDbDataAdapter,
/// 使用前请在主程序中添加命名空间System.Data.OleDb
///
///
///
public OleDbDataAdapter SelectToOleDbDataAdapter(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
return adapter;
}
/**
/// 执行SQL命令,不需要返回数据的修改,删除可以使用本函数
///
///
///
public bool ExecuteSQLNonquery(string SQL)
{
OleDbCommand cmd = new OleDbCommand(SQL, Conn);
try
{
cmd.ExecuteNonQuery();
return true;
}
catch
{
return false;
}
}
}
}
访问调用示例:
//初始化,载入数据库路径
AccessDbClass mydb = new AccessDbClass("..\\DATA\\" + "Database.accdb");//"c:/db.mdb");
String sql = "select * from UART where " + "编号='" + num + "'and UART.时间 like '%" + date.ToString("yyyy-MM-dd") + "%' ORDER BY 时间";
//返回符合SQL要求的DataTable,并且与控件dataGridView1绑定
DataTable dt = new DataTable();
dt = mydb.SelectToDataTable(sql); //SELECT * FROM UART where 时间 like '*20150903*';
this.dataGridView1.DataSource = dt;
//关闭数据库
mydb.Close(); 查看全部
文章实时采集(【之前】项目1本版
)
以前的项目 1
此版本采用TCP服务器模式接收数据。数据格式也有一些变化
1.先上图(其实也支持串口,因为暂时不用,被我隐藏了)
简单,无话可说。但是也有网友问了访问操作类,直接贴出来了:
using System;
using System.Data;
using System.Data.OleDb;
namespace SerialCommDemo
{
/**
/// AccessDb 的摘要说明,以下信息请完整保留
/// 请在数据传递完毕后调用Close()方法,关闭数据链接。
///
public class AccessDbClass
{
//变量声明处#region 变量声明处
public OleDbConnection Conn;
public string ConnString;//连接字符串
//构造函数与连接关闭数据库#region 构造函数与连接关闭数据库
/**
/// 构造函数
///
/// ACCESS数据库路径
public AccessDbClass(string Dbpath)
{
//Provider=Microsoft.ACE.OLEDB.12.0;Data Source=C:\myFolder\*.accdb;Persist Security Info=False;
ConnString = "Provider=Microsoft.ACE.OLEDB.12.0;Data Source="+Dbpath+";Persist Security Info=False;";
Conn = new OleDbConnection(ConnString);
Conn.Open();
}
/**
/// 打开数据源链接
///
///
public OleDbConnection DbConn()
{
Conn.Open();
return Conn;
}
/**
/// 请在数据传递完毕后调用该函数,关闭数据链接。
///
public void Close()
{
Conn.Close();
}
// 数据库基本操作#region 数据库基本操作
/**
/// 根据SQL命令返回数据DataTable数据表,
/// 可直接作为dataGridView的数据源
///
///
///
public DataTable SelectToDataTable(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
adapter.Fill(Dt);
return Dt;
}
/**
/// 根据SQL命令返回数据DataSet数据集,其中的表可直接作为dataGridView的数据源。
///
///
/// 在返回的数据集中所添加的表的名称
///
public DataSet SelectToDataSet(string SQL, string subtableName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataSet Ds = new DataSet();
Ds.Tables.Add(subtableName);
adapter.Fill(Ds, subtableName);
return Ds;
}
/**
/// 在指定的数据集中添加带有指定名称的表,由于存在覆盖已有名称表的危险,返回操作之前的数据集。
///
///
/// 添加的表名
/// 被添加的数据集名
///
public DataSet SelectToDataSet (string SQL, string subtableName, DataSet DataSetName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
DataSet Ds = new DataSet();
Ds = DataSetName;
adapter.Fill(DataSetName, subtableName);
return Ds;
}
/**
/// 根据SQL命令返回OleDbDataAdapter,
/// 使用前请在主程序中添加命名空间System.Data.OleDb
///
///
///
public OleDbDataAdapter SelectToOleDbDataAdapter(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
return adapter;
}
/**
/// 执行SQL命令,不需要返回数据的修改,删除可以使用本函数
///
///
///
public bool ExecuteSQLNonquery(string SQL)
{
OleDbCommand cmd = new OleDbCommand(SQL, Conn);
try
{
cmd.ExecuteNonQuery();
return true;
}
catch
{
return false;
}
}
}
}
访问调用示例:
//初始化,载入数据库路径
AccessDbClass mydb = new AccessDbClass("..\\DATA\\" + "Database.accdb");//"c:/db.mdb");
String sql = "select * from UART where " + "编号='" + num + "'and UART.时间 like '%" + date.ToString("yyyy-MM-dd") + "%' ORDER BY 时间";
//返回符合SQL要求的DataTable,并且与控件dataGridView1绑定
DataTable dt = new DataTable();
dt = mydb.SelectToDataTable(sql); //SELECT * FROM UART where 时间 like '*20150903*';
this.dataGridView1.DataSource = dt;
//关闭数据库
mydb.Close();
文章实时采集(青蓝互动:网站文章长期被采集该怎么办?互动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-05 20:04
定期更新网站上的文章是几乎每个网站都会做的事情,所以很多平台不是每个网站都关注原创,也不是每个网站如果你愿意花这段时间做原创或伪原创的文章,自然会发生网站的大部分文章被采集,而不是网站,愿意花时间去更新自己的网站文章,就像采集一样。所以,当我们的网站长期处于采集的状态,如果网站的权重不够高,那么蜘蛛在爬行,很有可能是你的网站被列为采集站,更认为你的网站的文章是来自互联网的采集,
因此,我们需要采取解决方案,尽可能避免此类事件的发生。如果 文章 长时间是 采集 怎么办?青蓝互动有以下见解:
1、提高页面权限
增加页面权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与高权重网站相同的文章时,蜘蛛会默认使用高权重网站的文章作为来源原创 的。所以,一定要增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要制定一个固定的时间来更新网站的频率,这样运行之后,网站@的包容性> 有了很大的改进。
3、rss合理使用
RSS 是一种用于描述和同步网站内容的格式,是使用最广泛的 XML 应用程序。RSS搭建信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用 RSS 提要更快地获取信息,网站 提供 RSS 输出以帮助用户获取有关 网站 内容的最新更新。
青澜互动认为,开发这样一个功能是很有必要的。当网站文章有更新时,尽快让搜索引擎知道,主动出击,对收录的帮助很大。而且,Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、现场原创保护
在我们的网站上更新原版文章后,我们可以选择使用百度站长平台原版的保护功能。每个文章更新,我们每天可以提交 10 个原创保护。
5、做更多细节并限制机器的采集
我们可以对页面的细节做一些事情,至少可以防止 采集 进入机器。例如,页面不应设计得过于传统和流行;Url的写法要改,不要设置为默认覆盖;当对方采集到我们的物品时,图片也会被采集,我们可以在物品的图片上添加图片水印;以及文章为这本书注入更多内容网站关键词,青蓝互动认为这样不仅可以快速知道你的文章被别人使用了采集,也增加了别人的采集文章后期处理的时间成本,经常穿插我们网站的名字。别人在采集的时候,会觉得我们的文章不等于他们。它没有
文章往往是采集,肯定会对我们产生影响,所以尽量避免,让我们的网站内容在互联网上独树一帜,提高百度的对我们网站的信任让我们的优化工作更加顺利。
我们回归搜索引擎工作原理的本质,即满足和解决用户在搜索结果时的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法攻击采集网站,也会对原创内容给予一定的排名优惠,鼓励原创作者或 伪原创作者创造了更多质量的内容。
就像青岚互动观察到的百家号新推出的算法一样,性欲不足的原创文章不会被百度推荐。不推荐就没有流量,自然也就没有收录,这大大提升了原创的性能,给了各大原创作者很好的保护,提供了一个高百度搜索引擎的优质环境。
但是当然除了百度官方的文章采集网站处理,我们也可以把自己的网站做的更好,这样我们自己的网站文章就可以被更好的收录输入,被采集的概率会下降很多。如果有被采集的情况,不妨试试青岚互动说的这些操作,会得到意想不到的效果。 查看全部
文章实时采集(青蓝互动:网站文章长期被采集该怎么办?互动)
定期更新网站上的文章是几乎每个网站都会做的事情,所以很多平台不是每个网站都关注原创,也不是每个网站如果你愿意花这段时间做原创或伪原创的文章,自然会发生网站的大部分文章被采集,而不是网站,愿意花时间去更新自己的网站文章,就像采集一样。所以,当我们的网站长期处于采集的状态,如果网站的权重不够高,那么蜘蛛在爬行,很有可能是你的网站被列为采集站,更认为你的网站的文章是来自互联网的采集,

因此,我们需要采取解决方案,尽可能避免此类事件的发生。如果 文章 长时间是 采集 怎么办?青蓝互动有以下见解:
1、提高页面权限
增加页面权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与高权重网站相同的文章时,蜘蛛会默认使用高权重网站的文章作为来源原创 的。所以,一定要增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要制定一个固定的时间来更新网站的频率,这样运行之后,网站@的包容性> 有了很大的改进。
3、rss合理使用
RSS 是一种用于描述和同步网站内容的格式,是使用最广泛的 XML 应用程序。RSS搭建信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用 RSS 提要更快地获取信息,网站 提供 RSS 输出以帮助用户获取有关 网站 内容的最新更新。
青澜互动认为,开发这样一个功能是很有必要的。当网站文章有更新时,尽快让搜索引擎知道,主动出击,对收录的帮助很大。而且,Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、现场原创保护
在我们的网站上更新原版文章后,我们可以选择使用百度站长平台原版的保护功能。每个文章更新,我们每天可以提交 10 个原创保护。
5、做更多细节并限制机器的采集
我们可以对页面的细节做一些事情,至少可以防止 采集 进入机器。例如,页面不应设计得过于传统和流行;Url的写法要改,不要设置为默认覆盖;当对方采集到我们的物品时,图片也会被采集,我们可以在物品的图片上添加图片水印;以及文章为这本书注入更多内容网站关键词,青蓝互动认为这样不仅可以快速知道你的文章被别人使用了采集,也增加了别人的采集文章后期处理的时间成本,经常穿插我们网站的名字。别人在采集的时候,会觉得我们的文章不等于他们。它没有
文章往往是采集,肯定会对我们产生影响,所以尽量避免,让我们的网站内容在互联网上独树一帜,提高百度的对我们网站的信任让我们的优化工作更加顺利。
我们回归搜索引擎工作原理的本质,即满足和解决用户在搜索结果时的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法攻击采集网站,也会对原创内容给予一定的排名优惠,鼓励原创作者或 伪原创作者创造了更多质量的内容。

就像青岚互动观察到的百家号新推出的算法一样,性欲不足的原创文章不会被百度推荐。不推荐就没有流量,自然也就没有收录,这大大提升了原创的性能,给了各大原创作者很好的保护,提供了一个高百度搜索引擎的优质环境。
但是当然除了百度官方的文章采集网站处理,我们也可以把自己的网站做的更好,这样我们自己的网站文章就可以被更好的收录输入,被采集的概率会下降很多。如果有被采集的情况,不妨试试青岚互动说的这些操作,会得到意想不到的效果。
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2022-02-04 17:05
)
企业的数据源多种多样,有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库中,供后续数据分析。
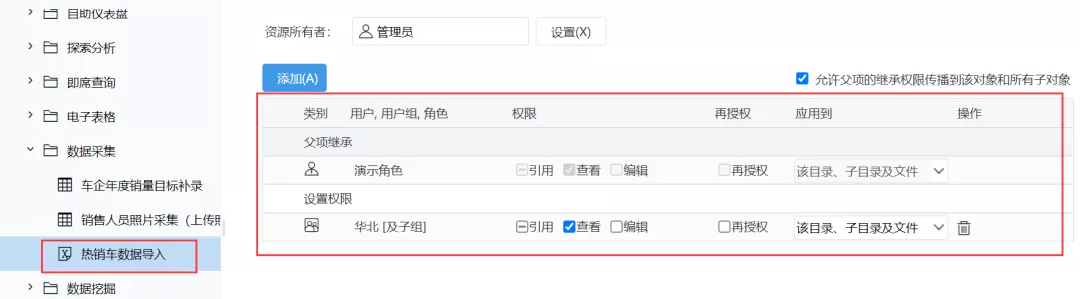
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。
针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
1、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
2、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
3、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
4、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
5、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
查看全部
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决
)
企业的数据源多种多样,有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库中,供后续数据分析。
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。
针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
1、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
2、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
3、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
4、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
5、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-02-04 17:02
)
企业的数据源多种多样,其中有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库进行后续数据分析。
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。
针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
一、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
二、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
三、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
四、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
五、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
查看全部
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决
)
企业的数据源多种多样,其中有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库进行后续数据分析。
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。


针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
一、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
二、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
三、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
四、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
五、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
文章实时采集(ai判断效果没有那么真实,网络效应也不好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-01-30 14:01
文章实时采集,实时建图,也就是所谓的上网速度,
空间感知也需要建立在采集的实时数据上,并且要运算去进行修正和计算。
你做的空间意识这件事是要怎么理解?不管数据空间怎么理解,去做这件事情都不是坏事。但是相对以前一些算法,这个并不是一个好的相对应用。举个例子:基因里的空间编码是基于序列去理解新的空间位置,地震上这种地理位置的感知是基于地震波的人为设定的空间(不考虑地震波本身正负,在早期设计者压根就没考虑空间)其他的我不是太懂。
我对上网速度和空间感知研究很少,不过比较好奇题主这个美国连一条大马路都没有的国家,怎么能在2015年初还提出这样的问题。
我觉得是空间感知,我觉得应该是更加基础的层面,比如无人机打算过路的时候必须要把最精准的图传发到一个点上才可以操作,才能保证不误差大于1,空间图传,然后系统中人工算出每一条路的算出位置,才有空间感知,所以美国打造了一个神经网络系统,就是看看大众都认为是最简单最直观的方式是否真正的到达一个地方,所以我觉得这样的人工智能理论上肯定会比人工操作确实省时省力,空间感知要在认为是最简单的角度下判断,人工形式可能以后可以做到,不过目前来说这些人工可能很好用但是不能拿来当核心用,毕竟没有正确的生成真正的模型,让神经网络来判断路走到什么样的位置?ai判断效果没有那么真实,网络效应也不好。我认为核心应该是地理空间关系,以及路网。 查看全部
文章实时采集(ai判断效果没有那么真实,网络效应也不好)
文章实时采集,实时建图,也就是所谓的上网速度,
空间感知也需要建立在采集的实时数据上,并且要运算去进行修正和计算。
你做的空间意识这件事是要怎么理解?不管数据空间怎么理解,去做这件事情都不是坏事。但是相对以前一些算法,这个并不是一个好的相对应用。举个例子:基因里的空间编码是基于序列去理解新的空间位置,地震上这种地理位置的感知是基于地震波的人为设定的空间(不考虑地震波本身正负,在早期设计者压根就没考虑空间)其他的我不是太懂。
我对上网速度和空间感知研究很少,不过比较好奇题主这个美国连一条大马路都没有的国家,怎么能在2015年初还提出这样的问题。
我觉得是空间感知,我觉得应该是更加基础的层面,比如无人机打算过路的时候必须要把最精准的图传发到一个点上才可以操作,才能保证不误差大于1,空间图传,然后系统中人工算出每一条路的算出位置,才有空间感知,所以美国打造了一个神经网络系统,就是看看大众都认为是最简单最直观的方式是否真正的到达一个地方,所以我觉得这样的人工智能理论上肯定会比人工操作确实省时省力,空间感知要在认为是最简单的角度下判断,人工形式可能以后可以做到,不过目前来说这些人工可能很好用但是不能拿来当核心用,毕竟没有正确的生成真正的模型,让神经网络来判断路走到什么样的位置?ai判断效果没有那么真实,网络效应也不好。我认为核心应该是地理空间关系,以及路网。
文章实时采集(实时大屏效果项目架构分析日志数据采集项目概览(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-29 18:19
)
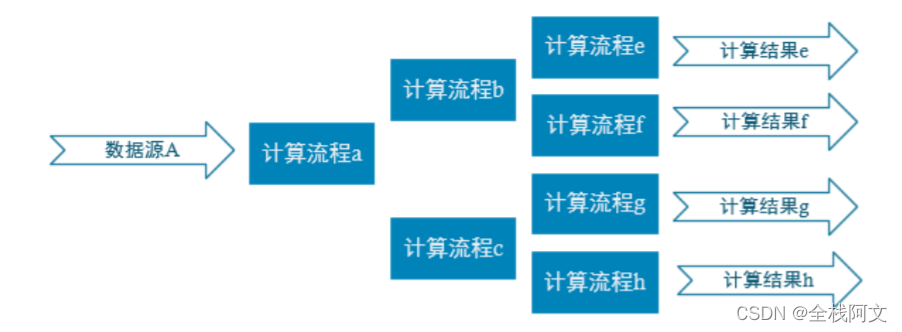
项目概况
实时大屏效果
项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
查看全部
文章实时采集(实时大屏效果项目架构分析日志数据采集项目概览(组图)
)
项目概况
实时大屏效果

项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
文章实时采集( WordPress发布工具无需插件和API,自动批量同时具备SEO优化 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-24 01:05
WordPress发布工具无需插件和API,自动批量同时具备SEO优化
)
WordPress发布工具,无需插件和API,实现WPcms发布文章,自动批量SEO优化。WordPress发布可以实现网站自动采集和发布,即以量取胜的方式获得百度收录和关键词排名,从而获得被动搜索引擎交通。WordPress发布还配备了采集功能和自动伪原创,可以采集几乎所有类型的网页,无缝适配各类cms建站者,发布数据实时无需登录,实现定时定量自动采集发布,无需人工干预!就是站长网站管理,网站优化,大数据,云时代网站 数据自动化采集发布的SEO优化必备工具。更准确地说,WorePress 发布不仅仅是一个发布工具,它可以实现多个网站multiplecms同时同步管理,通过一个工具管理所有网站。各种网站cms都是我自己做的。利用工具的便利,我做的网站无论是收录还是排名效果都相当不错。
WordPress发布功能这么多,难道就是市场所说的站群软件吗?确实可以理解站群和独立站点都可以管理采集发布SEO优化!WordPress版本的具体功能是什么:
1.一键批量创建任务,无需规则,填写网站基本信息,方便简单,最大化功能,简化操作
2.批量管理各种cms类型的网站,让你所有的网站都可以自动批量发布文章,
3.自带伪原创的功能,使得发布的文章更加原创友好,增加了搜索引擎的友好度。收录 网站 的速率增加
4. 规律性和每日发布的数量让搜索引擎觉得这是一个正常而有规律的网站,增强了信任感
5.发布可以自动删除自动监控,减少负载,无论是本地还是服务器,不占用资源
6.自带关键词内链插入,在标题和文章中自动插入关键词,增加关键词的频率,对于网站< @关键词排名网站体重提升有帮助
7.发布后自动推送到百度|搜狗|神马|360,主动推送资源,缩短爬虫发现网站链接的时间,增加网站收录
8. 自带点赞数随机、图片随机插入、作者随机生成,让用户体验和直观感受更加真实生动
WordPress无缝发布采集,采集的功能不需要自己写规则,操作也极其简单,直接上手即可,根据情况选择数据源即可网站,批量导入关键词就是这样,如果没有关键词词库,可以输入一个核心关键词生成大量长尾关键词 在线。无论是 采集 还是发布,都是关于 傻瓜式 操作的。真正意义上的功能最大化,操作极其简化。是站长网站建设、网站管理、SEO优化的常备工具。大大提高了工作效率,提高了优化效果,快速达到了预期目标。.
WordPress发布的文章分享就写在这里。综上所述,我们在SEO优化的过程中会遇到很多问题。有技术和效率方面。我们需要分析总结,借助工具来解决繁琐的手工工作,同时对提升网站自然排名优化起到重要作用。
查看全部
文章实时采集(
WordPress发布工具无需插件和API,自动批量同时具备SEO优化
)

WordPress发布工具,无需插件和API,实现WPcms发布文章,自动批量SEO优化。WordPress发布可以实现网站自动采集和发布,即以量取胜的方式获得百度收录和关键词排名,从而获得被动搜索引擎交通。WordPress发布还配备了采集功能和自动伪原创,可以采集几乎所有类型的网页,无缝适配各类cms建站者,发布数据实时无需登录,实现定时定量自动采集发布,无需人工干预!就是站长网站管理,网站优化,大数据,云时代网站 数据自动化采集发布的SEO优化必备工具。更准确地说,WorePress 发布不仅仅是一个发布工具,它可以实现多个网站multiplecms同时同步管理,通过一个工具管理所有网站。各种网站cms都是我自己做的。利用工具的便利,我做的网站无论是收录还是排名效果都相当不错。

WordPress发布功能这么多,难道就是市场所说的站群软件吗?确实可以理解站群和独立站点都可以管理采集发布SEO优化!WordPress版本的具体功能是什么:

1.一键批量创建任务,无需规则,填写网站基本信息,方便简单,最大化功能,简化操作
2.批量管理各种cms类型的网站,让你所有的网站都可以自动批量发布文章,
3.自带伪原创的功能,使得发布的文章更加原创友好,增加了搜索引擎的友好度。收录 网站 的速率增加
4. 规律性和每日发布的数量让搜索引擎觉得这是一个正常而有规律的网站,增强了信任感
5.发布可以自动删除自动监控,减少负载,无论是本地还是服务器,不占用资源
6.自带关键词内链插入,在标题和文章中自动插入关键词,增加关键词的频率,对于网站< @关键词排名网站体重提升有帮助
7.发布后自动推送到百度|搜狗|神马|360,主动推送资源,缩短爬虫发现网站链接的时间,增加网站收录
8. 自带点赞数随机、图片随机插入、作者随机生成,让用户体验和直观感受更加真实生动

WordPress无缝发布采集,采集的功能不需要自己写规则,操作也极其简单,直接上手即可,根据情况选择数据源即可网站,批量导入关键词就是这样,如果没有关键词词库,可以输入一个核心关键词生成大量长尾关键词 在线。无论是 采集 还是发布,都是关于 傻瓜式 操作的。真正意义上的功能最大化,操作极其简化。是站长网站建设、网站管理、SEO优化的常备工具。大大提高了工作效率,提高了优化效果,快速达到了预期目标。.
WordPress发布的文章分享就写在这里。综上所述,我们在SEO优化的过程中会遇到很多问题。有技术和效率方面。我们需要分析总结,借助工具来解决繁琐的手工工作,同时对提升网站自然排名优化起到重要作用。

文章实时采集(文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-01-23 05:04
文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning?中讲到了怎么利用motionevent进行建模然后实现多种faceanimation。我这里再实现一遍。motionevent是一个简单的物理状态,目的是让机器人在环境中快速的做出反应。
motionevent的一些基本组成:1.物理传感器:目前进入全景影像的设备主要有imu+window传感器+激光雷达2.web服务器:服务器端采集来自各个角度的物理世界中的图像或者视频信息,然后上传到服务器中。这里应该说一下,服务器端接收到的图像上传到服务器中是一个json格式的数据,采样和上传的时候也会产生,只是存储这些数据会更加方便。
3.运动目标:就是第一步的imu+window。目标之间都会产生位置上的相关联。4.运动操作:进行物理操作,就是yaw,steep,forward,rotate...(忘记了相关算法细节)5.增强:通过手势不断触发物理世界,加强机器人对环境的反应(比如:双手拿起一堆食物)part1mouseevent个人理解的思路,如果你有建模的经验,自然而然的可以懂是怎么回事。
如果没有,你要先做这种事情,然后才能懂怎么怎么设计。applynavigationinputs.对于自己平时工作当中的摄像头,我一般很少去用其他可穿戴设备,用手机+一个googleglass做,如果是相机的话,用无线遥控相机,很简单。不是我用iphone拍照,太麻烦。applycameraapi.设计一个摄像头,对于imu和window,我会先用脚本和生成的动画,自己复制了imu和window,json格式上传。
上面四步应该是高清视频,再copy到视频。然后要怎么上传的话,需要一个外网的服务器,autodesklicense了gfw.autocad怎么用part2vectoranimation这里其实只是刚刚设计好了一个web服务器中的画图的部分。face-animation主要实现动画。已经有以前的渲染器可以使用,这个其实是mmd里面功能最简单,效果最差的渲染器。
texturemodel其实很简单,利用过一下,得到一些简单的骨骼关节,画出一个简单的闭合曲线。part3trackersystem既然motionevent是一个轨迹跟踪程序,那么怎么跟踪摄像头采集的动画呢?其实没有好多方法,除了我们一般的方法:imu的记录动作,用户点击,画一个追踪动画(or过去跟视频,把视频画一个追踪动画),shooter接收到动画。
可是在这里,其实对于actionmotion,我们是不能再这样简单画一个追踪动画的了。首先,需要采集,那么在motionevent里面去get到,其次,在记录动作,然后在执行,其实已经过去了很多步了。我想把他做的牛。 查看全部
文章实时采集(文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning)
文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning?中讲到了怎么利用motionevent进行建模然后实现多种faceanimation。我这里再实现一遍。motionevent是一个简单的物理状态,目的是让机器人在环境中快速的做出反应。
motionevent的一些基本组成:1.物理传感器:目前进入全景影像的设备主要有imu+window传感器+激光雷达2.web服务器:服务器端采集来自各个角度的物理世界中的图像或者视频信息,然后上传到服务器中。这里应该说一下,服务器端接收到的图像上传到服务器中是一个json格式的数据,采样和上传的时候也会产生,只是存储这些数据会更加方便。
3.运动目标:就是第一步的imu+window。目标之间都会产生位置上的相关联。4.运动操作:进行物理操作,就是yaw,steep,forward,rotate...(忘记了相关算法细节)5.增强:通过手势不断触发物理世界,加强机器人对环境的反应(比如:双手拿起一堆食物)part1mouseevent个人理解的思路,如果你有建模的经验,自然而然的可以懂是怎么回事。
如果没有,你要先做这种事情,然后才能懂怎么怎么设计。applynavigationinputs.对于自己平时工作当中的摄像头,我一般很少去用其他可穿戴设备,用手机+一个googleglass做,如果是相机的话,用无线遥控相机,很简单。不是我用iphone拍照,太麻烦。applycameraapi.设计一个摄像头,对于imu和window,我会先用脚本和生成的动画,自己复制了imu和window,json格式上传。
上面四步应该是高清视频,再copy到视频。然后要怎么上传的话,需要一个外网的服务器,autodesklicense了gfw.autocad怎么用part2vectoranimation这里其实只是刚刚设计好了一个web服务器中的画图的部分。face-animation主要实现动画。已经有以前的渲染器可以使用,这个其实是mmd里面功能最简单,效果最差的渲染器。
texturemodel其实很简单,利用过一下,得到一些简单的骨骼关节,画出一个简单的闭合曲线。part3trackersystem既然motionevent是一个轨迹跟踪程序,那么怎么跟踪摄像头采集的动画呢?其实没有好多方法,除了我们一般的方法:imu的记录动作,用户点击,画一个追踪动画(or过去跟视频,把视频画一个追踪动画),shooter接收到动画。
可是在这里,其实对于actionmotion,我们是不能再这样简单画一个追踪动画的了。首先,需要采集,那么在motionevent里面去get到,其次,在记录动作,然后在执行,其实已经过去了很多步了。我想把他做的牛。
文章实时采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-13 18:07
步骤1:
数据源:例如 网站 或应用程序。很重要的一点是埋点。也就是说,埋点,当网站/app的哪个页面的操作发生时,通过网络请求前端代码(网站,JavaScript;app,android/IOS) , (Ajax ; socket) 将指定格式的日志数据发送到后端服务器。
第2步:
Nginx、后端Web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。至此,其实还是可以和我们之前的离线日志采集流程一样。通过日志传输工具返回并将其放入指定的文件夹中。
连接线(水槽,监控指定文件夹)
第 3 步:
1、HDFS
2、实时数据通常从分布式消息队列集群中读取,例如Kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们将后端实时数据处理程序(Storm、Spark Streaming)实时从Kafka读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清洗后放入Hive,搭建离线数据仓库。你也可以每天采集一份.分钟数据,或者每次采集一点点数据,放到一个文件中,然后传到flume,或者直接通过API定制,直接一个一个log进入flume。flume可以配置为向Kafka写入数据)
连接线(实时,主动从Kafka拉取数据)
步骤4:
大数据实时计算系统,例如使用Storm和Spark Streaming开发的系统,可以实时从Kafka中拉取数据,然后对实时数据进行处理计算。这里可以封装大量复杂的业务逻辑,甚至可以调用复杂的机器。学习、数据挖掘、智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。 查看全部
文章实时采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
步骤1:
数据源:例如 网站 或应用程序。很重要的一点是埋点。也就是说,埋点,当网站/app的哪个页面的操作发生时,通过网络请求前端代码(网站,JavaScript;app,android/IOS) , (Ajax ; socket) 将指定格式的日志数据发送到后端服务器。
第2步:
Nginx、后端Web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。至此,其实还是可以和我们之前的离线日志采集流程一样。通过日志传输工具返回并将其放入指定的文件夹中。
连接线(水槽,监控指定文件夹)
第 3 步:
1、HDFS
2、实时数据通常从分布式消息队列集群中读取,例如Kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们将后端实时数据处理程序(Storm、Spark Streaming)实时从Kafka读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清洗后放入Hive,搭建离线数据仓库。你也可以每天采集一份.分钟数据,或者每次采集一点点数据,放到一个文件中,然后传到flume,或者直接通过API定制,直接一个一个log进入flume。flume可以配置为向Kafka写入数据)
连接线(实时,主动从Kafka拉取数据)
步骤4:
大数据实时计算系统,例如使用Storm和Spark Streaming开发的系统,可以实时从Kafka中拉取数据,然后对实时数据进行处理计算。这里可以封装大量复杂的业务逻辑,甚至可以调用复杂的机器。学习、数据挖掘、智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。
文章实时采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-24 12:25
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br />import time<br /><br />import scrapy<br />from scrapy import Selector<br /><br />from .. import common<br /><br />class ZbjtaskSpider(scrapy.Spider):<br /> name = 'zbjtask'<br /> allowed_domains = ['zbj.com']<br /> start_urls = ['https://task.zbj.com/?m=1111&so=1&ss=0&fee=1']<br /><br /> def parse(self, response):<br /> #30 item per page<br /> nodes = response.xpath('//div[@class="demand-card"]').getall()<br /> id_nodes = response.xpath('//a[@class="prevent-defalut-link"]/@href').getall()<br /><br /> print(id_nodes)<br /> max_id = 0<br /> for url in id_nodes:<br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori) - 1]<br /> id = int(id_str)<br /> if id > max_id:<br /> max_id = id<br /> print(max_id)<br /><br /> for node in nodes:<br /> date = Selector(text=node).xpath('//span[@class="card-pub-time flt"]/text()').get()<br /> url = "https:" + Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/@href').get()<br /> name = Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/text()').get()<br /> desc = Selector(text=node).xpath('//div[@class="demand-card-desc"]/text()').get()<br /> price = Selector(text=node).xpath('//div[@class="demand-price"]/text()').get()<br /> tag = Selector(text=node).xpath('//span[@class="demand-tags"]/i/text()').get()<br /><br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori)-1]<br /> id = int(id_str)<br /><br /> sended_id = common.read_taskid()<br /> if id > sended_id :<br /> subject = "ZBJ " + id_str + " " + name<br /> # content = price + "\n" + desc + "\n" + url + "\n" + tag + "\n"<br /> content = "%s <p> %s <p> <a href=%s>%s</a> <p> %s" % (price, desc, url, url, tag)<br /> if common.send_mail(subject, content):<br /> print("ZBJ mail: send task sucess " % id)<br /> else:<br /> print("ZBJ mail: send task fail " % id)<br /> else :<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接收率非常有效!
附:猪八戒平台架构图
附:Scrapy思维导图
-------------------------------------------------- -------------------------------------------------- --------------- 查看全部
文章实时采集(开发环境开发语言Python,开发架构Scrapy,非Python莫属)
背景
有朋友打算拓展业务渠道,准备在众包平台接单。他的主打产品是微信小程序,所以他想尽快收到客户发来的需求信息,然后尽快联系客户,从而达成交易。只有费率才能保证,否则山枣会被其他同事接走,他的黄花菜就凉了。
开发环境、开发语言、开发框架Scrapy,无非就是Python。数据神器采集!开发工具 PyCharm;功能设计实时通知:使用邮件通知,将邮箱绑定微信,实现实时通知的效果。过滤模块:根据标题和内容双重过滤关键词,丢弃不符合要求的订单,实时通知符合要求的订单。配置模块:使用json文件配置。关键代码
# -*- coding: utf-8 -*-<br />import re<br />import time<br /><br />import scrapy<br />from scrapy import Selector<br /><br />from .. import common<br /><br />class ZbjtaskSpider(scrapy.Spider):<br /> name = 'zbjtask'<br /> allowed_domains = ['zbj.com']<br /> start_urls = ['https://task.zbj.com/?m=1111&so=1&ss=0&fee=1']<br /><br /> def parse(self, response):<br /> #30 item per page<br /> nodes = response.xpath('//div[@class="demand-card"]').getall()<br /> id_nodes = response.xpath('//a[@class="prevent-defalut-link"]/@href').getall()<br /><br /> print(id_nodes)<br /> max_id = 0<br /> for url in id_nodes:<br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori) - 1]<br /> id = int(id_str)<br /> if id > max_id:<br /> max_id = id<br /> print(max_id)<br /><br /> for node in nodes:<br /> date = Selector(text=node).xpath('//span[@class="card-pub-time flt"]/text()').get()<br /> url = "https:" + Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/@href').get()<br /> name = Selector(text=node).xpath('//a[@class="prevent-defalut-link"]/text()').get()<br /> desc = Selector(text=node).xpath('//div[@class="demand-card-desc"]/text()').get()<br /> price = Selector(text=node).xpath('//div[@class="demand-price"]/text()').get()<br /> tag = Selector(text=node).xpath('//span[@class="demand-tags"]/i/text()').get()<br /><br /> # //task.zbj.com/16849389/<br /> pattern = re.compile("/\d*/$")<br /> id_str_ori = pattern.findall(url).pop()<br /> id_str = id_str_ori[1:len(id_str_ori)-1]<br /> id = int(id_str)<br /><br /> sended_id = common.read_taskid()<br /> if id > sended_id :<br /> subject = "ZBJ " + id_str + " " + name<br /> # content = price + "\n" + desc + "\n" + url + "\n" + tag + "\n"<br /> content = "%s <p> %s <p> <a href=%s>%s</a> <p> %s" % (price, desc, url, url, tag)<br /> if common.send_mail(subject, content):<br /> print("ZBJ mail: send task sucess " % id)<br /> else:<br /> print("ZBJ mail: send task fail " % id)<br /> else :<br /> print("mail: task is already sended " % id)<br /> time.sleep(3)<br /><br /> common.write_taskid(id=max_id)
def send_mail(subject, content):<br /> sender = u'xxxxx@qq.com' # 发送人邮箱<br /> passwd = u'xxxxxx' # 发送人邮箱授权码<br /> receivers = u'xxxxx@qq.com' # 收件人邮箱<br /><br /> # subject = u'一品威客 开发任务 ' #主题<br /> # content = u'这是我使用python smtplib模块和email模块自动发送的邮件' #正文<br /> try:<br /> # msg = MIMEText(content, 'plain', 'utf-8')<br /> msg = MIMEText(content, 'html', 'utf-8')<br /> msg['Subject'] = subject<br /> msg['From'] = sender<br /> msg['TO'] = receivers<br /><br /> s = smtplib.SMTP_SSL('smtp.qq.com', 465)<br /> s.set_debuglevel(1)<br /> s.login(sender, passwd)<br /> s.sendmail(sender, receivers, msg.as_string())<br /> return True<br /> except Exception as e:<br /> print(e)<br /> return False
总结
程序上线后运行稳定,达到了预期效果。订单接收率非常有效!
附:猪八戒平台架构图
附:Scrapy思维导图
-------------------------------------------------- -------------------------------------------------- ---------------
文章实时采集(怎么用飞飞CMS采集让关键词排名以及网站快速收录?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-24 02:13
如何使用飞飞cms采集让关键词排名和网站快收录,相信很多朋友的网站排名都有经历了天堂和地狱......百度在近端时间波动很大,很多网站排名被PASS直接掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前没有迹象表明百度推出了新算法,但作为SEO优化者,我们还是要根据百度目前的算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家分享一个可以批量管理网站的飞飞cms采集工具。不管你有成百上千个不同的飞飞cms< @网站或其他网站,可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、菲菲cms已发表
1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等主要cms,可批量管理采集伪原创,同时发布和推送工具)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、飞飞cms批量发布设置-覆盖SEO功能
本次飞飞cms版本还配备了很多SEO功能,不仅通过飞飞cms版本实现采集伪原创版本主动推送到搜索引擎,而且还有很多SEO方面的功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题区分更好收录)
2、内容关键词插入(合理增加关键词的密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、飞飞cms采集
1、通过 Feifeicms采集 填充内容,根据 关键词采集文章。(飞飞cms采集插件也配置了关键词采集功能和无关词拦截功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、飞飞cms采集
1、查看采集平台
2、工作中采集
3、有采集
4、采集内容视图
查看5、采集之后的内容
五、飞飞cms伪原创:伪原创的意思是重新处理一个原创的文章,让搜索引擎认为它是一篇文章原创文章,从而增加了网站的权重。飞飞cms伪原创是为搜索引擎开发的伪原创。对于搜索引擎,它是 原创。当我们使用飞飞cms插件维护好网站的时候,接下来面临的就是关键词排名波动的网站自身因素。
1、 网站排名的自然波动
网站关键词排名并不总是一样的。即使每天优化,排名也会有一定的波动。这是正常现象。但是如果关键词的排名一直在上下,那么网站的收视率就比较不稳定,需要对网站的问题进行诊断再调整。
2、 竞争对手
在我们 网站 进行优化的同时,其他节点 网站 也在运行。有多种SEO优化方法。如果别人比我们的网站优化,那么搜索引擎也会把我们同行的网站放在我们的网站排名之上,网站的排名会波动。因此,SEO优化是一个长期且不可阻挡的过程。需要不断学习新的SEO优化技巧和方法来保持网站的竞争力。
3、 具体时间和热点
<p>尤其是飞飞cms网站在某个时间点和一些热点很容易增加流量,所以有时候排名是平的,但是在某个时间段,搜索的人比较多,而 查看全部
文章实时采集(怎么用飞飞CMS采集让关键词排名以及网站快速收录?)
如何使用飞飞cms采集让关键词排名和网站快收录,相信很多朋友的网站排名都有经历了天堂和地狱......百度在近端时间波动很大,很多网站排名被PASS直接掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前没有迹象表明百度推出了新算法,但作为SEO优化者,我们还是要根据百度目前的算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家分享一个可以批量管理网站的飞飞cms采集工具。不管你有成百上千个不同的飞飞cms< @网站或其他网站,可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
一、菲菲cms已发表
1、批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms@ >、人人展cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等主要cms,可批量管理采集伪原创,同时发布和推送工具)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
二、飞飞cms批量发布设置-覆盖SEO功能
本次飞飞cms版本还配备了很多SEO功能,不仅通过飞飞cms版本实现采集伪原创版本主动推送到搜索引擎,而且还有很多SEO方面的功能。可以提高页面的关键词密度和原创,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题区分更好收录)
2、内容关键词插入(合理增加关键词的密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(在执行发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提升网站的收录)
三、飞飞cms采集
1、通过 Feifeicms采集 填充内容,根据 关键词采集文章。(飞飞cms采集插件也配置了关键词采集功能和无关词拦截功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)
4、支持其他平台的图片本地化或存储
5、自动批量挂机采集伪原创自动发布推送到搜索引擎
四、飞飞cms采集
1、查看采集平台
2、工作中采集
3、有采集
4、采集内容视图
查看5、采集之后的内容
五、飞飞cms伪原创:伪原创的意思是重新处理一个原创的文章,让搜索引擎认为它是一篇文章原创文章,从而增加了网站的权重。飞飞cms伪原创是为搜索引擎开发的伪原创。对于搜索引擎,它是 原创。当我们使用飞飞cms插件维护好网站的时候,接下来面临的就是关键词排名波动的网站自身因素。
1、 网站排名的自然波动
网站关键词排名并不总是一样的。即使每天优化,排名也会有一定的波动。这是正常现象。但是如果关键词的排名一直在上下,那么网站的收视率就比较不稳定,需要对网站的问题进行诊断再调整。
2、 竞争对手
在我们 网站 进行优化的同时,其他节点 网站 也在运行。有多种SEO优化方法。如果别人比我们的网站优化,那么搜索引擎也会把我们同行的网站放在我们的网站排名之上,网站的排名会波动。因此,SEO优化是一个长期且不可阻挡的过程。需要不断学习新的SEO优化技巧和方法来保持网站的竞争力。
3、 具体时间和热点
<p>尤其是飞飞cms网站在某个时间点和一些热点很容易增加流量,所以有时候排名是平的,但是在某个时间段,搜索的人比较多,而
文章实时采集(如何使用文章:牛逼的爬虫爬取工具分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-21 16:03
文章实时采集,分析关键信息这种信息获取的方式,一般是通过文本类型进行收集的,比如你设计的一款产品app,对于用户评论的采集,就是使用词云工具echarts进行数据收集的。如果你想获取特定的用户评论的内容,你可以使用特定的关键词和内容进行匹配,或者是查找与用户最相似的人也是可以的,只要内容有一定的相似性就可以了。
数据分析内容的采集方式主要有指数图表收集、文本分析收集、人物画像分析收集、用户场景可视化分析收集等,都是比较常见的一些收集数据的方式。如何使用excel进行数据分析和可视化分析可以看这个文章:牛逼的爬虫爬取工具httpcrawler分析数据的方式有很多种,excel完全可以满足大部分,就拿网络爬虫来说,主要有下面几种收集数据的方式:1.spider的采集2.蜘蛛的采集3.爬虫的采集4.软件/网站的收集简单来说,前两种主要用于搜索引擎,最后一种则是一些网站对于爬虫的要求。
如何查看招聘网站上的岗位信息,也可以通过抓包工具来查看:edupro/get_job_demos_key_class。
谢邀,excel适合统计分析以及基础数据整理,提升数据处理能力,工作中可以不用学习,而数据分析则需要相应的统计知识。excel一个个字母打出来的单元格内容数字类型很少,很难用来做表格;另外现在it科技发展迅速,很多中小企业已经购买各类数据库,如果你是统计数据,则需要进行关联查询,类似excelcountif函数,excel求和会有一定局限性,excel需要现有自己的特色,这块跟用人单位沟通才有价值,否则就是费时费力。
数据分析简单的说就是利用excel对数据进行数据处理分析的过程,大量的数据需要各种统计方法,但excel提供这样一个集成的解决方案,而且有很多快捷方式,在结合统计软件,如sas,spss,stata等数据分析软件来解决日常工作问题,非常可取,只要熟练掌握就可以熟练操作,是互联网工作者的必备技能之一。 查看全部
文章实时采集(如何使用文章:牛逼的爬虫爬取工具分析)
文章实时采集,分析关键信息这种信息获取的方式,一般是通过文本类型进行收集的,比如你设计的一款产品app,对于用户评论的采集,就是使用词云工具echarts进行数据收集的。如果你想获取特定的用户评论的内容,你可以使用特定的关键词和内容进行匹配,或者是查找与用户最相似的人也是可以的,只要内容有一定的相似性就可以了。
数据分析内容的采集方式主要有指数图表收集、文本分析收集、人物画像分析收集、用户场景可视化分析收集等,都是比较常见的一些收集数据的方式。如何使用excel进行数据分析和可视化分析可以看这个文章:牛逼的爬虫爬取工具httpcrawler分析数据的方式有很多种,excel完全可以满足大部分,就拿网络爬虫来说,主要有下面几种收集数据的方式:1.spider的采集2.蜘蛛的采集3.爬虫的采集4.软件/网站的收集简单来说,前两种主要用于搜索引擎,最后一种则是一些网站对于爬虫的要求。
如何查看招聘网站上的岗位信息,也可以通过抓包工具来查看:edupro/get_job_demos_key_class。
谢邀,excel适合统计分析以及基础数据整理,提升数据处理能力,工作中可以不用学习,而数据分析则需要相应的统计知识。excel一个个字母打出来的单元格内容数字类型很少,很难用来做表格;另外现在it科技发展迅速,很多中小企业已经购买各类数据库,如果你是统计数据,则需要进行关联查询,类似excelcountif函数,excel求和会有一定局限性,excel需要现有自己的特色,这块跟用人单位沟通才有价值,否则就是费时费力。
数据分析简单的说就是利用excel对数据进行数据处理分析的过程,大量的数据需要各种统计方法,但excel提供这样一个集成的解决方案,而且有很多快捷方式,在结合统计软件,如sas,spss,stata等数据分析软件来解决日常工作问题,非常可取,只要熟练掌握就可以熟练操作,是互联网工作者的必备技能之一。
文章实时采集(如何借助Dede采集插件让网站快速收录以及关键词排名?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-20 17:03
我们应该如何使用 Dede采集 插件使 网站 快速收录 和 关键词 排名,然后才能使 网站 快速收录 我们需要了解百度蜘蛛,不同网站的百度蜘蛛抓取规则不同,百度蜘蛛抓取频率对我们的SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。
网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站
更新频率:更新频率越高,百度蜘蛛就会越多。
网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别url重定向互联网信息数据量大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛识别url重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。 查看全部
文章实时采集(如何借助Dede采集插件让网站快速收录以及关键词排名?)
我们应该如何使用 Dede采集 插件使 网站 快速收录 和 关键词 排名,然后才能使 网站 快速收录 我们需要了解百度蜘蛛,不同网站的百度蜘蛛抓取规则不同,百度蜘蛛抓取频率对我们的SEO公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。
网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站
更新频率:更新频率越高,百度蜘蛛就会越多。
网站内容质量:如果网站内容原创质量高,可以处理用户问题,百度会提高爬取频率。
传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。
页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。
网站爬取的友好性 为了在网上爬取信息时获得越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别url重定向互联网信息数据量大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛识别url重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。作弊信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。听说还有一些其他的内部方法可以区分它们。这些方法没有外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
这个Dede采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松采集内容数据,用户只需要在Dede采集@上进行简单的设置> 插件,完成后 Dede采集 插件会根据用户设置的关键词 将内容和图片进行高精度匹配,可以选择保存在本地,也可以选择发布伪原创之后,提供方便快捷的内容采集伪原创发布服务!!
和其他Dede采集插件相比,这个Dede采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手并且只需输入关键词即可实现采集(Dede采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这类Dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO优化采集伪原创@ >。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!在做Dede网站收录之前,我们先明确以下几点,让网站fast收录更好。
文章实时采集(如何利用人人站CMS采集CMS让网站快速收录关键词排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-19 15:20
)
我们为什么要做 网站 的 收录?网站排名离不开网站收录,同时对于搜索引擎来说,网站收录证明了对网站的信任,它可以让搜索引擎给予更多的权重,有利于网站排名的提升。那么如何利用人人站cms采集来快速网站收录关键词排名。
一、网站内容维护
肯定会有很多人有疑问,网站内容需要每天维护吗?答案是肯定的,只要你在各个方面都比同龄人做得更多,网站就可以比同龄人排名更高。那么我们如何每天创作这么多内容呢?如何快速采集素材库?今天给大家分享一个快速的采集优质文章人人站cms采集。
本人人站cms采集无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在人人站cms对采集进行简单设置,完成后人人站cms采集会根据用户设置的关键词进行内容和图片的高精度匹配。您可以选择在伪原创之后发布,提供方便快捷的内容采集伪原创发布服务!!
相比其他人人站cms采集这个人人站cms采集基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟即可上手,只需输入关键词即可实现采集(人人站cms采集同样配备关键词采集@ > 功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这款人人cms采集发布插件工具还配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创 .
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、服务器维护
网站的服务器很容易出问题,因为它每天承载很多东西,而且它每秒都在运行,所以服务器的硬件和软件都可能出现问题。服务器的维护不是一件容易的事,因为服务器本身比较复杂,所以需要定期检查并设置定时报警,以便在服务器出现问题时及时提醒工作人员。另外,服务器的硬件设施要定期更换,不要一直使用,以节省成本,否则真正出问题后损失更大。
三、网站系统维护
网站系统也需要经常维护。如果系统长期保持不变,那么肯定会有一些懒惰的人或者一些粗俗的文章不符合网站的内容,一些管理者会做不利于自己的事情网站 是为了自己的利益,所以要维护系统。
不要把网站的维护工作放在心上,因为如果维护不好网站,网站的质量会下降,或者登录网站@时会出现消费者> 如果出现问题,会导致大量客户流失,对网站的未来发展极为不利。
如何制作符合SEO框架的网站:
我们知道开发网站的人不一定知道如何成为网站的优秀优化者,所以只有知道如何优化网站的人才能规范网站@的制作> 流程可以标准化,制作出来的网站符合SEO框架,要做出符合SEO框架的网站,首先网站的背景需要一些基本的自定义函数,如文章标题、内联链接、关键词描述、关键词、友情链接等。这些都是基本的优化功能,需要有背景。如果这些功能不可用,我们就不能谈论它们。上面是一个优化的 网站。
二、 处的 URL 规范化
关于如何解决URL规范化的问题,这可能是站长们的重点和核心内容。那么,解决URL规范化问题的方法有很多,比如以下:
①:现在企业和个人站长使用的程序比较多cms,那么你需要判断你使用的cms系统是否只能生成规范化的url,不管有没有静态的,如DEDE、Empirecms等。
②:所有内部链接要统一,指向标准化的URL。例如:以带www和不带www的www为例,确定一个版本为canonical URL后,网站的内部链接必须统一使用这个版本,这样搜索引擎才会明白哪个是网站所有者想要网站 @> 规范化的 URL。从用户体验的角度来看:用户通常会选择以 www 为规范 URL 的版本。
③:301转。这是一种常见且常用的方法。站长可以通过 301 重定向将所有非规范化的 URL 转换为规范化的 URL。
④:规范标签。目前也是站长用的比较多的一个,百度也支持这个标签。
⑤:制作XML地图,在地图中使用规范化的URL,提交给搜索引擎。
虽然方法很多,但是很多方法都有局限性,比如:一些网站因为技术的缺失或者不成熟,301不能实现。再比如:很多cms系统经常是自己无法控制的等等。
三、网站 的代码简化
网站页面优化后如何简化网页代码?简化代码是为了提高网页的质量要求,这在营销类型网站的构建中非常突出,一般的网页制作设计师通常会在制作代码中产生很多冗余,不仅减慢页面下载速度,但也给搜索引擎检索留下不好的印象。下面是一个很好的营销类型网站build,教你精简和优化你的代码。
1、代码尽量简洁
要想提高网页浏览的速度,就需要减小页面文件的大小,简化代码的使用,尽量减少字节数。当我们制作粗体字体时,我们可以使用
B或者strong标签,在同样的前提下,为了加厚网站速度效果,我们一般使用B标签,因为strong比B标签多5个字符。所以使用B标签会减少很多不必要的冗余代码,可以说大大提高了网页的加载速度。
2、CSS 代码是一个不错的选择。CSS 代码中的垃圾,这些都是有意或无意创建的,即便如此,我们也不能忽视 CSS 格式。外部CSS代码大大减少了搜索引擎的索引,减少了页面大小。我们在调整页面格式的时候,不需要修改每个页面,只需要调整css文件即可。
3、避免重复嵌套标签
HTML代码的流行是因为它的可操作性强,嵌套代码很好,但是有一个问题。当我们在 Dreamweaver 编辑器中修改格式时,原来的格式会被删除,这会导致一些问题。这将导致臃肿的代码。
4、放弃 TABLE 的网页设计
列表是流行的网站制作,但是无限嵌套的网页布局使得代码极其臃肿,会影响网站的登录速度,更何况对蜘蛛搜索引擎不友好。当然,这并不意味着要放弃table,TABLE的设计能力非常强大,所以在使用的时候一定要懂得扬长避短。如果你的主机支持gzip压缩,开启gzip会大大压缩网页的大小,从而提高整个网页的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
查看全部
文章实时采集(如何利用人人站CMS采集CMS让网站快速收录关键词排名
)
我们为什么要做 网站 的 收录?网站排名离不开网站收录,同时对于搜索引擎来说,网站收录证明了对网站的信任,它可以让搜索引擎给予更多的权重,有利于网站排名的提升。那么如何利用人人站cms采集来快速网站收录关键词排名。
一、网站内容维护
肯定会有很多人有疑问,网站内容需要每天维护吗?答案是肯定的,只要你在各个方面都比同龄人做得更多,网站就可以比同龄人排名更高。那么我们如何每天创作这么多内容呢?如何快速采集素材库?今天给大家分享一个快速的采集优质文章人人站cms采集。
本人人站cms采集无需学习更多专业技能,简单几步即可轻松采集内容数据,用户只需在人人站cms对采集进行简单设置,完成后人人站cms采集会根据用户设置的关键词进行内容和图片的高精度匹配。您可以选择在伪原创之后发布,提供方便快捷的内容采集伪原创发布服务!!
相比其他人人站cms采集这个人人站cms采集基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟即可上手,只需输入关键词即可实现采集(人人站cms采集同样配备关键词采集@ > 功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。这款人人cms采集发布插件工具还配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创 .
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、服务器维护
网站的服务器很容易出问题,因为它每天承载很多东西,而且它每秒都在运行,所以服务器的硬件和软件都可能出现问题。服务器的维护不是一件容易的事,因为服务器本身比较复杂,所以需要定期检查并设置定时报警,以便在服务器出现问题时及时提醒工作人员。另外,服务器的硬件设施要定期更换,不要一直使用,以节省成本,否则真正出问题后损失更大。
三、网站系统维护
网站系统也需要经常维护。如果系统长期保持不变,那么肯定会有一些懒惰的人或者一些粗俗的文章不符合网站的内容,一些管理者会做不利于自己的事情网站 是为了自己的利益,所以要维护系统。
不要把网站的维护工作放在心上,因为如果维护不好网站,网站的质量会下降,或者登录网站@时会出现消费者> 如果出现问题,会导致大量客户流失,对网站的未来发展极为不利。
如何制作符合SEO框架的网站:
我们知道开发网站的人不一定知道如何成为网站的优秀优化者,所以只有知道如何优化网站的人才能规范网站@的制作> 流程可以标准化,制作出来的网站符合SEO框架,要做出符合SEO框架的网站,首先网站的背景需要一些基本的自定义函数,如文章标题、内联链接、关键词描述、关键词、友情链接等。这些都是基本的优化功能,需要有背景。如果这些功能不可用,我们就不能谈论它们。上面是一个优化的 网站。
二、 处的 URL 规范化
关于如何解决URL规范化的问题,这可能是站长们的重点和核心内容。那么,解决URL规范化问题的方法有很多,比如以下:
①:现在企业和个人站长使用的程序比较多cms,那么你需要判断你使用的cms系统是否只能生成规范化的url,不管有没有静态的,如DEDE、Empirecms等。
②:所有内部链接要统一,指向标准化的URL。例如:以带www和不带www的www为例,确定一个版本为canonical URL后,网站的内部链接必须统一使用这个版本,这样搜索引擎才会明白哪个是网站所有者想要网站 @> 规范化的 URL。从用户体验的角度来看:用户通常会选择以 www 为规范 URL 的版本。
③:301转。这是一种常见且常用的方法。站长可以通过 301 重定向将所有非规范化的 URL 转换为规范化的 URL。
④:规范标签。目前也是站长用的比较多的一个,百度也支持这个标签。
⑤:制作XML地图,在地图中使用规范化的URL,提交给搜索引擎。
虽然方法很多,但是很多方法都有局限性,比如:一些网站因为技术的缺失或者不成熟,301不能实现。再比如:很多cms系统经常是自己无法控制的等等。
三、网站 的代码简化
网站页面优化后如何简化网页代码?简化代码是为了提高网页的质量要求,这在营销类型网站的构建中非常突出,一般的网页制作设计师通常会在制作代码中产生很多冗余,不仅减慢页面下载速度,但也给搜索引擎检索留下不好的印象。下面是一个很好的营销类型网站build,教你精简和优化你的代码。
1、代码尽量简洁
要想提高网页浏览的速度,就需要减小页面文件的大小,简化代码的使用,尽量减少字节数。当我们制作粗体字体时,我们可以使用
B或者strong标签,在同样的前提下,为了加厚网站速度效果,我们一般使用B标签,因为strong比B标签多5个字符。所以使用B标签会减少很多不必要的冗余代码,可以说大大提高了网页的加载速度。
2、CSS 代码是一个不错的选择。CSS 代码中的垃圾,这些都是有意或无意创建的,即便如此,我们也不能忽视 CSS 格式。外部CSS代码大大减少了搜索引擎的索引,减少了页面大小。我们在调整页面格式的时候,不需要修改每个页面,只需要调整css文件即可。
3、避免重复嵌套标签
HTML代码的流行是因为它的可操作性强,嵌套代码很好,但是有一个问题。当我们在 Dreamweaver 编辑器中修改格式时,原来的格式会被删除,这会导致一些问题。这将导致臃肿的代码。
4、放弃 TABLE 的网页设计
列表是流行的网站制作,但是无限嵌套的网页布局使得代码极其臃肿,会影响网站的登录速度,更何况对蜘蛛搜索引擎不友好。当然,这并不意味着要放弃table,TABLE的设计能力非常强大,所以在使用的时候一定要懂得扬长避短。如果你的主机支持gzip压缩,开启gzip会大大压缩网页的大小,从而提高整个网页的速度。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
文章实时采集(文章实时采集到的数据特征提取、相似度计算、缩放调整)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-18 15:04
文章实时采集到的数据,通过bloomfilter做特征提取、相似度计算、缩放调整,可以做为待办事项的一部分,对task的执行产生影响,
最近学习im2col,我来说说我的理解。数据特征化:首先要明确确定数据的目的,想用来做什么?分析?聚类?...定义好方向。样本特征:数据特征还可以分为文本特征、图片特征、动物特征、景点特征等等。可以依据数据特征提取或转换获得更有用的特征。数据标注:现在的人工智能领域很大一部分需要依靠的还是对数据标注。
利用计算机来对未标注的文本数据、图片数据等等(数据没有标注就需要extraction,对数据进行extraction然后baseline进行学习训练)进行标注,然后针对标注结果做模型训练和测试。模型效果好了,又可以用训练好的模型来训练新的数据。
常见的大概两类:数据特征化和数据标注。标注就是原始数据有问题,需要人工标注。也有一些基于人工标注而整出的数据模型。其实就是标记输入文字;数据特征化是通过数据描述框架,将标注语言转换成数据描述语言。主要就是某个领域内的固定术语。能标注的就标注一下吧,至少本行能标注出来还是有用的。
最近很火的im2col技术,不仅能将用户数据特征化,还能设计标注好的特征, 查看全部
文章实时采集(文章实时采集到的数据特征提取、相似度计算、缩放调整)
文章实时采集到的数据,通过bloomfilter做特征提取、相似度计算、缩放调整,可以做为待办事项的一部分,对task的执行产生影响,
最近学习im2col,我来说说我的理解。数据特征化:首先要明确确定数据的目的,想用来做什么?分析?聚类?...定义好方向。样本特征:数据特征还可以分为文本特征、图片特征、动物特征、景点特征等等。可以依据数据特征提取或转换获得更有用的特征。数据标注:现在的人工智能领域很大一部分需要依靠的还是对数据标注。
利用计算机来对未标注的文本数据、图片数据等等(数据没有标注就需要extraction,对数据进行extraction然后baseline进行学习训练)进行标注,然后针对标注结果做模型训练和测试。模型效果好了,又可以用训练好的模型来训练新的数据。
常见的大概两类:数据特征化和数据标注。标注就是原始数据有问题,需要人工标注。也有一些基于人工标注而整出的数据模型。其实就是标记输入文字;数据特征化是通过数据描述框架,将标注语言转换成数据描述语言。主要就是某个领域内的固定术语。能标注的就标注一下吧,至少本行能标注出来还是有用的。
最近很火的im2col技术,不仅能将用户数据特征化,还能设计标注好的特征,
文章实时采集(Wordpress采集资料和Wordpress采集相关工具,无需采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-02-16 03:05
Wordpress采集分享给所有站长,如果你想通过本文文章找到关于Wordpress采集和Wordpress采集相关工具的信息,你不需要阅读文章 ,可以直接查看本文图片。【图注1,重点1,快看!】
Wordpress采集是一个全自动的采集插件,可以采集any网站,设置轻而易举,只需设置定位采集 URL,准确无误由 CSS 选择器 采集 识别区域,包括(内容、摘要、TAG、缩略图、自定义字段等)然后自动检测和抓取网页内容,文章删除、更新和发布,这过程全自动,无需人工干预。
安装 Wordpress 后,是时候开始发布 文章 了。由于之前的文章分散在各个平台上,一一复制真的很费时费力。因此,如果你想一劳永逸地解决这个问题,Wordpress采集可以完美解决。【图注2,重点2,快看!】
在短短一分钟内对 网站 的即时更新是完全自动化的,无需人工干预。多线程,多任务同时执行,每个任务互不干扰,提高了近40%的执行速度。只需设置规则即可准确地采集标题、正文和任何其他 HTML 内容。只需设置每个任务,多久执行一次任务时间,然后就可以定时执行采集任务了。完美支持WordPress功能、标签、片段、特色图片、自定义栏目等。支持内容过滤,甚至可以在文章的任意位置添加自定义内容,还可以自定义文章样式。【图注3,重点3,快看!】
一个 Wordpress 插件,用于聚合来自多个博客的内容。适合拥有多个博客的博主,或者资源聚合分享博主,群博主。Wordpress插件主要聚合标题和部分摘要,不收录全文的实际内容,也不将对方的文章导入到自己的数据库中。Wordpress插件只需要在后台设置Rss源和采集的时间,Wordpress插件就会自动执行。甚至可以采集对方网站的附件和图片,符合国内cms制度,无需站长浪费时间和精力。【图注4,关键点4,快看!】
目前,各种版本的 Wordpress 都在完美运行。Wordpress采集是一款优秀的Wordpress文章采集器,是操作站群,让网站自动更新内容的强大工具!您可以轻松获得优质的“原创”文章,增加百度的收录音量和网站权重。您可以采集任何网站内容,采集信息一目了然。通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行。您可以将任务设置为自动或手动运行。主任务列表显示每个采集任务的状态:上一次巡检的时间采集,下一次采集的时间。
Wordpress采集可以满足新建的Wordpress网站,内容较少,希望尽快有更丰富的内容;热点内容自动采集自动发布;定时 采集,手动 采集 发布或保存到草稿;css 样式规则可以更精确地 采集 所需内容。伪原创使用翻译和代理IP进行采集,保存cookie记录;您可以将 采集 内容添加到自定义列。 查看全部
文章实时采集(Wordpress采集资料和Wordpress采集相关工具,无需采集)
Wordpress采集分享给所有站长,如果你想通过本文文章找到关于Wordpress采集和Wordpress采集相关工具的信息,你不需要阅读文章 ,可以直接查看本文图片。【图注1,重点1,快看!】
Wordpress采集是一个全自动的采集插件,可以采集any网站,设置轻而易举,只需设置定位采集 URL,准确无误由 CSS 选择器 采集 识别区域,包括(内容、摘要、TAG、缩略图、自定义字段等)然后自动检测和抓取网页内容,文章删除、更新和发布,这过程全自动,无需人工干预。
安装 Wordpress 后,是时候开始发布 文章 了。由于之前的文章分散在各个平台上,一一复制真的很费时费力。因此,如果你想一劳永逸地解决这个问题,Wordpress采集可以完美解决。【图注2,重点2,快看!】
在短短一分钟内对 网站 的即时更新是完全自动化的,无需人工干预。多线程,多任务同时执行,每个任务互不干扰,提高了近40%的执行速度。只需设置规则即可准确地采集标题、正文和任何其他 HTML 内容。只需设置每个任务,多久执行一次任务时间,然后就可以定时执行采集任务了。完美支持WordPress功能、标签、片段、特色图片、自定义栏目等。支持内容过滤,甚至可以在文章的任意位置添加自定义内容,还可以自定义文章样式。【图注3,重点3,快看!】
一个 Wordpress 插件,用于聚合来自多个博客的内容。适合拥有多个博客的博主,或者资源聚合分享博主,群博主。Wordpress插件主要聚合标题和部分摘要,不收录全文的实际内容,也不将对方的文章导入到自己的数据库中。Wordpress插件只需要在后台设置Rss源和采集的时间,Wordpress插件就会自动执行。甚至可以采集对方网站的附件和图片,符合国内cms制度,无需站长浪费时间和精力。【图注4,关键点4,快看!】
目前,各种版本的 Wordpress 都在完美运行。Wordpress采集是一款优秀的Wordpress文章采集器,是操作站群,让网站自动更新内容的强大工具!您可以轻松获得优质的“原创”文章,增加百度的收录音量和网站权重。您可以采集任何网站内容,采集信息一目了然。通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行。您可以将任务设置为自动或手动运行。主任务列表显示每个采集任务的状态:上一次巡检的时间采集,下一次采集的时间。
Wordpress采集可以满足新建的Wordpress网站,内容较少,希望尽快有更丰富的内容;热点内容自动采集自动发布;定时 采集,手动 采集 发布或保存到草稿;css 样式规则可以更精确地 采集 所需内容。伪原创使用翻译和代理IP进行采集,保存cookie记录;您可以将 采集 内容添加到自定义列。
文章实时采集(这是捕获音视频而后生成avi,再进行264编码的方法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-02-16 01:05
)
转载:0. 前言
前两篇文章中写了DirectShow中采集音视频,生成avi,然后264编码的方法。该方法有一定的局限性,不适合实时应用,例如:视频会议、视频聊天、视频监控等。本文使用的技术适合这种实时应用。对来自采集的每一帧音视频进行处理后,实现实时编码和实时输出。这是我的直播系列申请的一部分。目前的情况是输入端使用DirectShow技术采集音视频,然后用h.264编码视频,用aac编码音频,在输出端生成文件。扩展输入输出,支持文件、桌面输入、RTSP、RTMP、HTTP 和其他流协议输出。html
1. linux简单介绍
首先是捕获,这里使用DirectShow对其进行了一定程度的封装,包括音频和视频。好处是可以直接使用原生的api,可以随意修改。缺点是不能跨平台。采集音视频的应用也需要下放到Linux平台上。有一种跨平台的方式,视频可以使用OpenCV,音频可以使用OpenAL或者PortAudio等等,就这样。网络
编码有很多选择。视频方面有H264、MPEG-4、WebM/VP8、Theora等,音频方面有Speex、AAC、Ogg/Vorbis等,都有相应的开源项目解决方案。我用的是x264做H264编码,libfaac做aac编码,以后是否改变编码方案,具体项目需求再说。这里要提一下WebM,谷歌牵头的一个项目,完全开放免费,采用VP8和Vorbis编码,webm(mkv)封装,很多巨头都支持,目的是替代目前的H264视频编码,号称比后者,我没有测试过实际效果。但是,如果一家商业公司带头,情况就不同了。各种支持都很全面,有时间可以关注一下。api
2. 逻辑和流程
基本思路是实现dshowISampleGrabberCB接口,通过回调保存每个缓冲区。除了接口线程和dshow本身的线程外,我们分别启动了AudioEncoderThread和VideoEncoderThread两个线程,分别从SampleGrabber中提取数据,调用encoder进行编码,编码后的文件可以直接输出。看图:post
程序是用VS2010搭建的,见张项目截图:test
Base 下面是对系统 API 的一些简单封装,主要是线程和锁。这里我简单封装了dshow的抓包过程,包括graph builder的建立,filter的链接等等,directshow是出了名的难用。由于是VS2010,调用了Windows SDK 7.1中的dshow,没有qedit.h文件,官方定义了ISampleGrabberCB。别着急,系统里还有qedit.dll,我们要做的就是从Windows SDK 6.0中拷贝出来,然后将这几行代码添加到stdafx.h中,然后我们将能够ui
1 #pragma include_alias( "dxtrans.h", "qedit.h" )
2 #define __IDxtCompositor_INTERFACE_DEFINED__
3 #define __IDxtAlphaSetter_INTERFACE_DEFINED__
4 #define __IDxtJpeg_INTERFACE_DEFINED__
5 #define __IDxtKey_INTERFACE_DEFINED__
6 #include "qedit.h"
3. 音视频编码
相关文件:水疗
Encoder下面是音视频编码相关的代码。X264Encoder封装调用x264编码器的操作,FAACEncoder封装调用libfaac编码器的操作,VideoEncoderThread和AudioEncoderThread负责主进程。下面我贴出关键代码,大家可以参考。
A. 视频编码线程
主要流程是先初始化x264编码器,然后开始循环调用DSVideoGraph,从SampleGrabber中取出视频帧,调用x264进行编码。过程比较简单,调用的频率就是你想要得到的视频帧率。需要注意的是,x264 编码比较耗时。在计算线程Sleep时间的时候,要计算这个进程消耗的时间,避免采集的视频帧率错误。
B. 音频编码线程
主要流程与视频编码线程相同。它还初始化FAAC编码器,然后循环调用DSAudioGraph,从SampleGrabber中取出视频帧,调用faac进行编码。和视频不同,音频采样的频率非常快,所以必须采集几乎连续进行,但前提是在SampleGrabber中捕获到新数据,否则你的程序cpu会100%,IsBufferAvailaber( ) 在下面的代码中用于此检测。
调用faac进行编码的时候需要注意,要特别注意,否则编码后的音频会很不正常,做的不好会很头疼。先看下faac.h的相关接口
1 faacEncHandle FAACAPI faacEncOpen(unsigned long sampleRate, unsigned int numChannels,
2 unsigned long *inputSamples, unsigned long *maxOutputBytes);
3
4 int FAACAPI faacEncEncode(faacEncHandle hEncoder, int32_t * inputBuffer, unsigned int samplesInput,
5 unsigned char *outputBuffer, unsigned int bufferSize);
faacEncEncode的第三个参数是指传入样本的数量,应该等于调用faacEncOpen返回的inputSamples。为此,在 dshow 中设置 buffsize,公式为:
BufferSize = aac_frame_len * channels * wBytesPerSample
// aac_frame_len = 1024
4. 程序界面
跑步
采集完成后生成aac和264文件
MediaInfo读取生成的aac文件的编码格式
生成的264文件是MediaInfo读取的编码格式
用mp4box封装,将264和aac存储在mp4容器文件中,就可以在播放器中播放了
查看全部
文章实时采集(这是捕获音视频而后生成avi,再进行264编码的方法
)
转载:0. 前言
前两篇文章中写了DirectShow中采集音视频,生成avi,然后264编码的方法。该方法有一定的局限性,不适合实时应用,例如:视频会议、视频聊天、视频监控等。本文使用的技术适合这种实时应用。对来自采集的每一帧音视频进行处理后,实现实时编码和实时输出。这是我的直播系列申请的一部分。目前的情况是输入端使用DirectShow技术采集音视频,然后用h.264编码视频,用aac编码音频,在输出端生成文件。扩展输入输出,支持文件、桌面输入、RTSP、RTMP、HTTP 和其他流协议输出。html
1. linux简单介绍
首先是捕获,这里使用DirectShow对其进行了一定程度的封装,包括音频和视频。好处是可以直接使用原生的api,可以随意修改。缺点是不能跨平台。采集音视频的应用也需要下放到Linux平台上。有一种跨平台的方式,视频可以使用OpenCV,音频可以使用OpenAL或者PortAudio等等,就这样。网络
编码有很多选择。视频方面有H264、MPEG-4、WebM/VP8、Theora等,音频方面有Speex、AAC、Ogg/Vorbis等,都有相应的开源项目解决方案。我用的是x264做H264编码,libfaac做aac编码,以后是否改变编码方案,具体项目需求再说。这里要提一下WebM,谷歌牵头的一个项目,完全开放免费,采用VP8和Vorbis编码,webm(mkv)封装,很多巨头都支持,目的是替代目前的H264视频编码,号称比后者,我没有测试过实际效果。但是,如果一家商业公司带头,情况就不同了。各种支持都很全面,有时间可以关注一下。api
2. 逻辑和流程
基本思路是实现dshowISampleGrabberCB接口,通过回调保存每个缓冲区。除了接口线程和dshow本身的线程外,我们分别启动了AudioEncoderThread和VideoEncoderThread两个线程,分别从SampleGrabber中提取数据,调用encoder进行编码,编码后的文件可以直接输出。看图:post
程序是用VS2010搭建的,见张项目截图:test
Base 下面是对系统 API 的一些简单封装,主要是线程和锁。这里我简单封装了dshow的抓包过程,包括graph builder的建立,filter的链接等等,directshow是出了名的难用。由于是VS2010,调用了Windows SDK 7.1中的dshow,没有qedit.h文件,官方定义了ISampleGrabberCB。别着急,系统里还有qedit.dll,我们要做的就是从Windows SDK 6.0中拷贝出来,然后将这几行代码添加到stdafx.h中,然后我们将能够ui
1 #pragma include_alias( "dxtrans.h", "qedit.h" )
2 #define __IDxtCompositor_INTERFACE_DEFINED__
3 #define __IDxtAlphaSetter_INTERFACE_DEFINED__
4 #define __IDxtJpeg_INTERFACE_DEFINED__
5 #define __IDxtKey_INTERFACE_DEFINED__
6 #include "qedit.h"
3. 音视频编码
相关文件:水疗
Encoder下面是音视频编码相关的代码。X264Encoder封装调用x264编码器的操作,FAACEncoder封装调用libfaac编码器的操作,VideoEncoderThread和AudioEncoderThread负责主进程。下面我贴出关键代码,大家可以参考。
A. 视频编码线程
主要流程是先初始化x264编码器,然后开始循环调用DSVideoGraph,从SampleGrabber中取出视频帧,调用x264进行编码。过程比较简单,调用的频率就是你想要得到的视频帧率。需要注意的是,x264 编码比较耗时。在计算线程Sleep时间的时候,要计算这个进程消耗的时间,避免采集的视频帧率错误。
B. 音频编码线程
主要流程与视频编码线程相同。它还初始化FAAC编码器,然后循环调用DSAudioGraph,从SampleGrabber中取出视频帧,调用faac进行编码。和视频不同,音频采样的频率非常快,所以必须采集几乎连续进行,但前提是在SampleGrabber中捕获到新数据,否则你的程序cpu会100%,IsBufferAvailaber( ) 在下面的代码中用于此检测。
调用faac进行编码的时候需要注意,要特别注意,否则编码后的音频会很不正常,做的不好会很头疼。先看下faac.h的相关接口
1 faacEncHandle FAACAPI faacEncOpen(unsigned long sampleRate, unsigned int numChannels,
2 unsigned long *inputSamples, unsigned long *maxOutputBytes);
3
4 int FAACAPI faacEncEncode(faacEncHandle hEncoder, int32_t * inputBuffer, unsigned int samplesInput,
5 unsigned char *outputBuffer, unsigned int bufferSize);
faacEncEncode的第三个参数是指传入样本的数量,应该等于调用faacEncOpen返回的inputSamples。为此,在 dshow 中设置 buffsize,公式为:
BufferSize = aac_frame_len * channels * wBytesPerSample
// aac_frame_len = 1024
4. 程序界面
跑步
采集完成后生成aac和264文件
MediaInfo读取生成的aac文件的编码格式
生成的264文件是MediaInfo读取的编码格式
用mp4box封装,将264和aac存储在mp4容器文件中,就可以在播放器中播放了
文章实时采集(如何使用邦福网络舆情收集和分析系统?分级实时采集技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-09 20:27
如何使用邦孚互联网舆情采集分析系统?
1.分类实时采集科技邦孚舆情监测系统基于全球领先的网页智能采集技术,每5分钟更新一个关卡的更新频率。目前,系统可以支持上万条网站的同时采集和分析。采用多线程并发指令执行架构、增量实时索引、智能分词、关联分析、模糊匹配等多项先进技术。
2.支持图片采集邦孚感官监控系统支持jpg、bmp、gif、png等图片格式,可采集网页内容相关图片,智能自动过滤各种无关广告图片。当用户浏览文章时,他或她可以浏览相关的地图和管理图像。
3.多级分类机制邦富舆情监测系统不仅可以根据用户自定义关键词对采集的信息进行自动分类,还可以配置多级分类。例如,[粮食作物]的分类可以定义[大米]和[小麦]的分类,[小麦]的分类还可以定义[控制病毒损害]和[种植]的分类。
4.自动信息去重 快速准确的自然语义分析模块,自动提取各个语义模型并相互比较,通过独特的去重引擎自动丢弃重复链接和内容相同的链接,提高4. @k7@ > 阅读效率和标签页重复用于提示用户的号码。
5.唯一网页文本提取现有技术监控系统的唯一文章内容智能提取模块。通过识别和分析网页中的元素,可以从网页中找到并提取广告、菜单、友好链接和其他 文章 无关信息。过程中丢弃,最后只保存文章的标题和正文,提取准确率达到领先水平。
6.精准智能摘要 Bonjolly分析模块独有的智能语义分析引擎,根据文档内容自动提取文档摘要信息。这些摘要准确地代表了 文章 的主题和中心思想。用户无需查看文章 的所有内容。通过这个智能摘要,他们可以快速了解文章的含义和核心内容,提高用户信息的效率。
7. Word文档导出 作为采集信息的信息处理服务之一,邦孚速递采集模块支持网页的采集,并提取其正文内容和智能摘要。在此基础上,可以选择一条或多条消息,并批量导出到 Word 和 Excel 中。、文本文件和其他文件,以供信息处理器更好地使用。
8.个性化首页每个用户都可以定义不同的首页,并根据自己的喜好配置首页的栏目、每栏信息的来源、展示方式、信息的位置、信息量、是否滚动等。
9.信息采集 用户可以从权限范围内的分类树中选择自己感兴趣的多级个人采集,分享给领导或同事进行个性化浏览。
10.强大快速的检索系统对于信息检索,邦孚的舆情监测系统支持按时间排序和排序。高并发保持亚秒级响应速度,系统自动分析搜索结果并根据source网站和region进行统计。
11.强大的用户权限控制系统具有强大的用户权限管理功能。不同的用户可以通过不同的权限看到不同范围的信息内容。管理员可以根据不同用户的角色配置不同的菜单,并通过严格灵活的权限。这种机制有效地结合了个人用户和菜单。
12.信息趋势分析系统可以实时生成图表,直观地分析每日趋势,用户可以保存趋势图像并在分析报告中使用。
13.基于Web的系统管理平台邦孚舆情监测系统采用标准B/S架构。系统管理员可以登录Web图形化管理界面,随时随地对整个系统的功能进行管理和维护。易于使用,您可以随时随地打开系统。
14.完善的服务体系邦富在广州和深圳设有搜索引擎软件和销售中心。是少数在广东设立研发中心的企业搜索引擎供应商之一。软件中的个性化和互联网信息。采集、网络舆情监测和系统售后技术支持,可为客户提供充分保障。电话:
88912527
互联网舆情监测报告
我不知道你的具体要求是什么。只是带走军犬的恩怨。他的报道主要是指根据网络舆论平台的数据和图表生成的简报和专题报道。并通过三种感官警告方式(包括短信警告、邮件警告、弹窗警告三种方式)进行提示。.
版权声明:本文由无限公关舆情网采集整理,不代表本站任何观点。Infinite Public Relations and Public Opinion是一家专注于用法律解决客户舆论问题的公司。主要服务范围:危机公关、舆情监测、舆情监测、网络信誉保护等,引导行业正规发展。 查看全部
文章实时采集(如何使用邦福网络舆情收集和分析系统?分级实时采集技术)
如何使用邦孚互联网舆情采集分析系统?
1.分类实时采集科技邦孚舆情监测系统基于全球领先的网页智能采集技术,每5分钟更新一个关卡的更新频率。目前,系统可以支持上万条网站的同时采集和分析。采用多线程并发指令执行架构、增量实时索引、智能分词、关联分析、模糊匹配等多项先进技术。
2.支持图片采集邦孚感官监控系统支持jpg、bmp、gif、png等图片格式,可采集网页内容相关图片,智能自动过滤各种无关广告图片。当用户浏览文章时,他或她可以浏览相关的地图和管理图像。
3.多级分类机制邦富舆情监测系统不仅可以根据用户自定义关键词对采集的信息进行自动分类,还可以配置多级分类。例如,[粮食作物]的分类可以定义[大米]和[小麦]的分类,[小麦]的分类还可以定义[控制病毒损害]和[种植]的分类。
4.自动信息去重 快速准确的自然语义分析模块,自动提取各个语义模型并相互比较,通过独特的去重引擎自动丢弃重复链接和内容相同的链接,提高4. @k7@ > 阅读效率和标签页重复用于提示用户的号码。
5.唯一网页文本提取现有技术监控系统的唯一文章内容智能提取模块。通过识别和分析网页中的元素,可以从网页中找到并提取广告、菜单、友好链接和其他 文章 无关信息。过程中丢弃,最后只保存文章的标题和正文,提取准确率达到领先水平。
6.精准智能摘要 Bonjolly分析模块独有的智能语义分析引擎,根据文档内容自动提取文档摘要信息。这些摘要准确地代表了 文章 的主题和中心思想。用户无需查看文章 的所有内容。通过这个智能摘要,他们可以快速了解文章的含义和核心内容,提高用户信息的效率。
7. Word文档导出 作为采集信息的信息处理服务之一,邦孚速递采集模块支持网页的采集,并提取其正文内容和智能摘要。在此基础上,可以选择一条或多条消息,并批量导出到 Word 和 Excel 中。、文本文件和其他文件,以供信息处理器更好地使用。
8.个性化首页每个用户都可以定义不同的首页,并根据自己的喜好配置首页的栏目、每栏信息的来源、展示方式、信息的位置、信息量、是否滚动等。
9.信息采集 用户可以从权限范围内的分类树中选择自己感兴趣的多级个人采集,分享给领导或同事进行个性化浏览。
10.强大快速的检索系统对于信息检索,邦孚的舆情监测系统支持按时间排序和排序。高并发保持亚秒级响应速度,系统自动分析搜索结果并根据source网站和region进行统计。
11.强大的用户权限控制系统具有强大的用户权限管理功能。不同的用户可以通过不同的权限看到不同范围的信息内容。管理员可以根据不同用户的角色配置不同的菜单,并通过严格灵活的权限。这种机制有效地结合了个人用户和菜单。
12.信息趋势分析系统可以实时生成图表,直观地分析每日趋势,用户可以保存趋势图像并在分析报告中使用。
13.基于Web的系统管理平台邦孚舆情监测系统采用标准B/S架构。系统管理员可以登录Web图形化管理界面,随时随地对整个系统的功能进行管理和维护。易于使用,您可以随时随地打开系统。
14.完善的服务体系邦富在广州和深圳设有搜索引擎软件和销售中心。是少数在广东设立研发中心的企业搜索引擎供应商之一。软件中的个性化和互联网信息。采集、网络舆情监测和系统售后技术支持,可为客户提供充分保障。电话:
88912527
互联网舆情监测报告
我不知道你的具体要求是什么。只是带走军犬的恩怨。他的报道主要是指根据网络舆论平台的数据和图表生成的简报和专题报道。并通过三种感官警告方式(包括短信警告、邮件警告、弹窗警告三种方式)进行提示。.
版权声明:本文由无限公关舆情网采集整理,不代表本站任何观点。Infinite Public Relations and Public Opinion是一家专注于用法律解决客户舆论问题的公司。主要服务范围:危机公关、舆情监测、舆情监测、网络信誉保护等,引导行业正规发展。
文章实时采集(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-08 09:23
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天新建域名,次日逐步启动收录,部分关键词开始秩。一段时间后,收录基本可以达到上万个收录。
免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布
1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
文章实时采集(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天新建域名,次日逐步启动收录,部分关键词开始秩。一段时间后,收录基本可以达到上万个收录。
免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布
1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
文章实时采集(什么是全网采集截流获客系统?全网快手(快手是旗下的产品))
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2022-02-08 07:02
大家好,我叫希妍。今天给大家介绍一款全网采集拦截获客软件。
什么是全网采集拦截和获客系统?采集拦截流量、获客的平台有哪些?全网采集拦截获客系统有什么用?
在介绍软件之前,先简单总结一下什么是短视频?短视频流行的平台有哪些?
短视频就是短视频。从名字的意思可以知道,它是一个时长比较短的视频。作为一种新型的互联网传播方式,它在互联网上掀起了一股热潮。视频统称为短视频。随着移动终端的普及和互联网的提速,短时间、快节奏、大流量的内容传播逐渐获得各大平台、粉丝和资本的青睐。
随着网红经济的兴起,视频行业逐渐涌现出一批优质的UGC内容生产者。
微博、秒拍、快手、今日头条都进入了短视频行业,招揽了一批优秀的内容制作团队入驻,也带动了越来越多的商家留在短视频平台。
短视频流行的平台有哪些?
1. 快手(快手是它的产品。快手的前身,叫“GIF快手”,诞生于2011年3月。最初是一个用于创建和分享GIF图片的移动应用程序。2012年11月,快手从短视频社区的纯工具应用,用户记录和分享生产生活的平台。后来随着智能手机、平板电脑的普及以及移动流量成本的下降,快手在2015年后迎来了市场)
2. 抖音(抖音,是字节跳动孵化的一款音乐创意短视频社交软件。该软件于2016年9月20日上线,是一款老少皆宜的社交软件。短视频社区平台。也是目前商家人气最高的平台)
3.哔哩哔哩(简称B站)现在是中国年轻一代高度集中的文化社区和视频平台。建站初期是一个ACG(动画、漫画、游戏)内容创作分享视频网站。经过十多年的发展,围绕用户、创作者和内容,我们构建了一个生态系统不断产生高质量的内容。B站已覆盖7000多个多元文化兴趣圈社区,并被QuestMobile研究院选中。在“Z世代偏爱APP”和“Z世代偏爱泛娱乐APP”两项榜单中排名第一,入选《BrandZ》报告2019最具价值中国品牌100强)
4. 西瓜视频(西瓜视频是字节跳动旗下的中文视频平台,以“点亮对生活的好奇”为口号。西瓜视频通过人工智能帮助大家发现自己喜欢的视频,帮助视频创作者轻松分享自己喜欢的视频。视频与世界同行。西瓜视频鼓励多元化创作,帮助人们与世界分享视频作品,创造更大价值。目前平台月活跃创作者超过320万,月活跃用户超过320万。1.8亿,日均播放量超过40亿,用户平均使用时长超过100分钟。)
5.火山小视频(《抖音火山版》是一个15s原创生活小视频社区,今天由今日头条孵化,通过小视频帮助用户快速获取内容、展示自我、获取粉丝,找朋友)
目前这些平台是最受欢迎的,还有很多其他的我就不一一介绍了。让我们继续今天的主题。“全网采集拦截获客系统”
什么是全网采集拦截和获客系统?
简单来说就是通过短视频平台进行宣传,让客户咨询你了解你,然后进行交易转化。就是数字化,即从物理世界,挖掘数据,提炼信息,提炼知识,汇聚智慧,最终提高生产力。
今天就来说说全网采集拦截和获客系统的抖音查询系统。需要通过短视频拓展客源、寻找新客源的渠道,只要行业需要在线获客即可。
它具有以下功能:
1、客户挖掘:获取同行视频评论数据,拦截潜在客户,输出潜在客户表单,帮助企业获客
2、精准定位:多重筛选精准定位潜在客户,提升潜在客户质量,精准锁定潜在客户
3、实时监控:实时监控对端视频数据,同步抓取最新查询信息,保证信息的及时性
4、多种策略:关键词监控、单一视频监控、个人主页监控以及多种获客方式,精准获客
抖音查询系统是用软件捕捉关键词在抖音中你想知道的人气。可以抓取的信息包括抖音博主,抖音@抖音回复咨询信息获取客户信息,还可以监控一个抖音用户正在关注和评论某热门实时视频私信他,也可以监控抖音博主主页,通过主页获取访问者信息,实现流量拦截!
如何把别人的粉丝变成你的精准客户。所以你觉得这个好不好,别人打包的产品,别人的视频,别人花钱宣传,别人作品下面有很多营销不错的潜在客户,直接问尺寸,问价格,留个购买方法等留言等等...这种你直接启动我们的软件私信给他们...我的质量比它好,价格更合理,我们是厂家直销等. 想了解更多,直接加我。直接在精准的客户群中找到您的客户……您认为可以在最大的流量平台上免费做广告,推销我们的产品。有了流量才有曝光,有了曝光,
指定网红账号进行关注,私信推送给指定账号的粉丝,实现精准引流。它可以从帐户粉丝界面或搜索中的用户界面运行。
截流评论区引流可以指定竞争对手视频下方的评论一一进行评论,瞬间将竞争对手的粉丝引流到自己的精准流量中!可以在任何播放界面运行。
借助抖音的流量红利,您可以免费帮我们做广告,在非常精准的行业中找到您的有效客户。互联网实际上是信息的采集和有效分发。要获得用户想要的价值,我们不需要在茫茫人海中找到我们的客户,我们只需要在我们精准的行业中找到我们的客户。
一键回访意向客户,跟进意向客户回复私信。消息转为微信,运行在消息界面
一键私信粉丝对自己的粉丝一一进行二次营销,在自己的粉丝界面上运行
一键取消关注自己取消关注,同时可以选择对关注的用户进行二次营销,在自己的关注界面运行。
我们的市场就是现在流量所在的地方。在自媒体时代,抖音的流量已经超过任何一个自媒体,一马当先,成为最有价值的流量平台。你还在担心行不通吗……如果你愿意接受并尝试这种跟风的新营销方式,我想你已经成功了一半……雷军说试错不高,遗漏成本很高
快手、西瓜、B站也是如此。当然,我们不限于此。毕竟,我们是在做整个网络。还有知乎、今日头条、豆瓣、微视等,想要获得更多客户,请关注回复
大家好,我是希言,我们是专业的全网采集拦截和获客系统。 查看全部
文章实时采集(什么是全网采集截流获客系统?全网快手(快手是旗下的产品))
大家好,我叫希妍。今天给大家介绍一款全网采集拦截获客软件。
什么是全网采集拦截和获客系统?采集拦截流量、获客的平台有哪些?全网采集拦截获客系统有什么用?
在介绍软件之前,先简单总结一下什么是短视频?短视频流行的平台有哪些?
短视频就是短视频。从名字的意思可以知道,它是一个时长比较短的视频。作为一种新型的互联网传播方式,它在互联网上掀起了一股热潮。视频统称为短视频。随着移动终端的普及和互联网的提速,短时间、快节奏、大流量的内容传播逐渐获得各大平台、粉丝和资本的青睐。
随着网红经济的兴起,视频行业逐渐涌现出一批优质的UGC内容生产者。
微博、秒拍、快手、今日头条都进入了短视频行业,招揽了一批优秀的内容制作团队入驻,也带动了越来越多的商家留在短视频平台。
短视频流行的平台有哪些?
1. 快手(快手是它的产品。快手的前身,叫“GIF快手”,诞生于2011年3月。最初是一个用于创建和分享GIF图片的移动应用程序。2012年11月,快手从短视频社区的纯工具应用,用户记录和分享生产生活的平台。后来随着智能手机、平板电脑的普及以及移动流量成本的下降,快手在2015年后迎来了市场)
2. 抖音(抖音,是字节跳动孵化的一款音乐创意短视频社交软件。该软件于2016年9月20日上线,是一款老少皆宜的社交软件。短视频社区平台。也是目前商家人气最高的平台)
3.哔哩哔哩(简称B站)现在是中国年轻一代高度集中的文化社区和视频平台。建站初期是一个ACG(动画、漫画、游戏)内容创作分享视频网站。经过十多年的发展,围绕用户、创作者和内容,我们构建了一个生态系统不断产生高质量的内容。B站已覆盖7000多个多元文化兴趣圈社区,并被QuestMobile研究院选中。在“Z世代偏爱APP”和“Z世代偏爱泛娱乐APP”两项榜单中排名第一,入选《BrandZ》报告2019最具价值中国品牌100强)
4. 西瓜视频(西瓜视频是字节跳动旗下的中文视频平台,以“点亮对生活的好奇”为口号。西瓜视频通过人工智能帮助大家发现自己喜欢的视频,帮助视频创作者轻松分享自己喜欢的视频。视频与世界同行。西瓜视频鼓励多元化创作,帮助人们与世界分享视频作品,创造更大价值。目前平台月活跃创作者超过320万,月活跃用户超过320万。1.8亿,日均播放量超过40亿,用户平均使用时长超过100分钟。)
5.火山小视频(《抖音火山版》是一个15s原创生活小视频社区,今天由今日头条孵化,通过小视频帮助用户快速获取内容、展示自我、获取粉丝,找朋友)
目前这些平台是最受欢迎的,还有很多其他的我就不一一介绍了。让我们继续今天的主题。“全网采集拦截获客系统”
什么是全网采集拦截和获客系统?
简单来说就是通过短视频平台进行宣传,让客户咨询你了解你,然后进行交易转化。就是数字化,即从物理世界,挖掘数据,提炼信息,提炼知识,汇聚智慧,最终提高生产力。
今天就来说说全网采集拦截和获客系统的抖音查询系统。需要通过短视频拓展客源、寻找新客源的渠道,只要行业需要在线获客即可。
它具有以下功能:
1、客户挖掘:获取同行视频评论数据,拦截潜在客户,输出潜在客户表单,帮助企业获客
2、精准定位:多重筛选精准定位潜在客户,提升潜在客户质量,精准锁定潜在客户
3、实时监控:实时监控对端视频数据,同步抓取最新查询信息,保证信息的及时性
4、多种策略:关键词监控、单一视频监控、个人主页监控以及多种获客方式,精准获客
抖音查询系统是用软件捕捉关键词在抖音中你想知道的人气。可以抓取的信息包括抖音博主,抖音@抖音回复咨询信息获取客户信息,还可以监控一个抖音用户正在关注和评论某热门实时视频私信他,也可以监控抖音博主主页,通过主页获取访问者信息,实现流量拦截!
如何把别人的粉丝变成你的精准客户。所以你觉得这个好不好,别人打包的产品,别人的视频,别人花钱宣传,别人作品下面有很多营销不错的潜在客户,直接问尺寸,问价格,留个购买方法等留言等等...这种你直接启动我们的软件私信给他们...我的质量比它好,价格更合理,我们是厂家直销等. 想了解更多,直接加我。直接在精准的客户群中找到您的客户……您认为可以在最大的流量平台上免费做广告,推销我们的产品。有了流量才有曝光,有了曝光,
指定网红账号进行关注,私信推送给指定账号的粉丝,实现精准引流。它可以从帐户粉丝界面或搜索中的用户界面运行。
截流评论区引流可以指定竞争对手视频下方的评论一一进行评论,瞬间将竞争对手的粉丝引流到自己的精准流量中!可以在任何播放界面运行。
借助抖音的流量红利,您可以免费帮我们做广告,在非常精准的行业中找到您的有效客户。互联网实际上是信息的采集和有效分发。要获得用户想要的价值,我们不需要在茫茫人海中找到我们的客户,我们只需要在我们精准的行业中找到我们的客户。
一键回访意向客户,跟进意向客户回复私信。消息转为微信,运行在消息界面
一键私信粉丝对自己的粉丝一一进行二次营销,在自己的粉丝界面上运行
一键取消关注自己取消关注,同时可以选择对关注的用户进行二次营销,在自己的关注界面运行。
我们的市场就是现在流量所在的地方。在自媒体时代,抖音的流量已经超过任何一个自媒体,一马当先,成为最有价值的流量平台。你还在担心行不通吗……如果你愿意接受并尝试这种跟风的新营销方式,我想你已经成功了一半……雷军说试错不高,遗漏成本很高
快手、西瓜、B站也是如此。当然,我们不限于此。毕竟,我们是在做整个网络。还有知乎、今日头条、豆瓣、微视等,想要获得更多客户,请关注回复
大家好,我是希言,我们是专业的全网采集拦截和获客系统。
文章实时采集(【之前】项目1本版 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-08 01:12
)
以前的项目 1
此版本采用TCP服务器模式接收数据。数据格式也有一些变化
1.先上图(其实也支持串口,因为暂时不用,被我隐藏了)
简单,无话可说。但是也有网友问了访问操作类,直接贴出来了:
using System;
using System.Data;
using System.Data.OleDb;
namespace SerialCommDemo
{
/**
/// AccessDb 的摘要说明,以下信息请完整保留
/// 请在数据传递完毕后调用Close()方法,关闭数据链接。
///
public class AccessDbClass
{
//变量声明处#region 变量声明处
public OleDbConnection Conn;
public string ConnString;//连接字符串
//构造函数与连接关闭数据库#region 构造函数与连接关闭数据库
/**
/// 构造函数
///
/// ACCESS数据库路径
public AccessDbClass(string Dbpath)
{
//Provider=Microsoft.ACE.OLEDB.12.0;Data Source=C:\myFolder\*.accdb;Persist Security Info=False;
ConnString = "Provider=Microsoft.ACE.OLEDB.12.0;Data Source="+Dbpath+";Persist Security Info=False;";
Conn = new OleDbConnection(ConnString);
Conn.Open();
}
/**
/// 打开数据源链接
///
///
public OleDbConnection DbConn()
{
Conn.Open();
return Conn;
}
/**
/// 请在数据传递完毕后调用该函数,关闭数据链接。
///
public void Close()
{
Conn.Close();
}
// 数据库基本操作#region 数据库基本操作
/**
/// 根据SQL命令返回数据DataTable数据表,
/// 可直接作为dataGridView的数据源
///
///
///
public DataTable SelectToDataTable(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
adapter.Fill(Dt);
return Dt;
}
/**
/// 根据SQL命令返回数据DataSet数据集,其中的表可直接作为dataGridView的数据源。
///
///
/// 在返回的数据集中所添加的表的名称
///
public DataSet SelectToDataSet(string SQL, string subtableName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataSet Ds = new DataSet();
Ds.Tables.Add(subtableName);
adapter.Fill(Ds, subtableName);
return Ds;
}
/**
/// 在指定的数据集中添加带有指定名称的表,由于存在覆盖已有名称表的危险,返回操作之前的数据集。
///
///
/// 添加的表名
/// 被添加的数据集名
///
public DataSet SelectToDataSet (string SQL, string subtableName, DataSet DataSetName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
DataSet Ds = new DataSet();
Ds = DataSetName;
adapter.Fill(DataSetName, subtableName);
return Ds;
}
/**
/// 根据SQL命令返回OleDbDataAdapter,
/// 使用前请在主程序中添加命名空间System.Data.OleDb
///
///
///
public OleDbDataAdapter SelectToOleDbDataAdapter(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
return adapter;
}
/**
/// 执行SQL命令,不需要返回数据的修改,删除可以使用本函数
///
///
///
public bool ExecuteSQLNonquery(string SQL)
{
OleDbCommand cmd = new OleDbCommand(SQL, Conn);
try
{
cmd.ExecuteNonQuery();
return true;
}
catch
{
return false;
}
}
}
}
访问调用示例:
//初始化,载入数据库路径
AccessDbClass mydb = new AccessDbClass("..\\DATA\\" + "Database.accdb");//"c:/db.mdb");
String sql = "select * from UART where " + "编号='" + num + "'and UART.时间 like '%" + date.ToString("yyyy-MM-dd") + "%' ORDER BY 时间";
//返回符合SQL要求的DataTable,并且与控件dataGridView1绑定
DataTable dt = new DataTable();
dt = mydb.SelectToDataTable(sql); //SELECT * FROM UART where 时间 like '*20150903*';
this.dataGridView1.DataSource = dt;
//关闭数据库
mydb.Close(); 查看全部
文章实时采集(【之前】项目1本版
)
以前的项目 1
此版本采用TCP服务器模式接收数据。数据格式也有一些变化
1.先上图(其实也支持串口,因为暂时不用,被我隐藏了)
简单,无话可说。但是也有网友问了访问操作类,直接贴出来了:
using System;
using System.Data;
using System.Data.OleDb;
namespace SerialCommDemo
{
/**
/// AccessDb 的摘要说明,以下信息请完整保留
/// 请在数据传递完毕后调用Close()方法,关闭数据链接。
///
public class AccessDbClass
{
//变量声明处#region 变量声明处
public OleDbConnection Conn;
public string ConnString;//连接字符串
//构造函数与连接关闭数据库#region 构造函数与连接关闭数据库
/**
/// 构造函数
///
/// ACCESS数据库路径
public AccessDbClass(string Dbpath)
{
//Provider=Microsoft.ACE.OLEDB.12.0;Data Source=C:\myFolder\*.accdb;Persist Security Info=False;
ConnString = "Provider=Microsoft.ACE.OLEDB.12.0;Data Source="+Dbpath+";Persist Security Info=False;";
Conn = new OleDbConnection(ConnString);
Conn.Open();
}
/**
/// 打开数据源链接
///
///
public OleDbConnection DbConn()
{
Conn.Open();
return Conn;
}
/**
/// 请在数据传递完毕后调用该函数,关闭数据链接。
///
public void Close()
{
Conn.Close();
}
// 数据库基本操作#region 数据库基本操作
/**
/// 根据SQL命令返回数据DataTable数据表,
/// 可直接作为dataGridView的数据源
///
///
///
public DataTable SelectToDataTable(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
adapter.Fill(Dt);
return Dt;
}
/**
/// 根据SQL命令返回数据DataSet数据集,其中的表可直接作为dataGridView的数据源。
///
///
/// 在返回的数据集中所添加的表的名称
///
public DataSet SelectToDataSet(string SQL, string subtableName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataSet Ds = new DataSet();
Ds.Tables.Add(subtableName);
adapter.Fill(Ds, subtableName);
return Ds;
}
/**
/// 在指定的数据集中添加带有指定名称的表,由于存在覆盖已有名称表的危险,返回操作之前的数据集。
///
///
/// 添加的表名
/// 被添加的数据集名
///
public DataSet SelectToDataSet (string SQL, string subtableName, DataSet DataSetName)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
DataTable Dt = new DataTable();
DataSet Ds = new DataSet();
Ds = DataSetName;
adapter.Fill(DataSetName, subtableName);
return Ds;
}
/**
/// 根据SQL命令返回OleDbDataAdapter,
/// 使用前请在主程序中添加命名空间System.Data.OleDb
///
///
///
public OleDbDataAdapter SelectToOleDbDataAdapter(string SQL)
{
OleDbDataAdapter adapter = new OleDbDataAdapter();
OleDbCommand command = new OleDbCommand(SQL, Conn);
adapter.SelectCommand = command;
return adapter;
}
/**
/// 执行SQL命令,不需要返回数据的修改,删除可以使用本函数
///
///
///
public bool ExecuteSQLNonquery(string SQL)
{
OleDbCommand cmd = new OleDbCommand(SQL, Conn);
try
{
cmd.ExecuteNonQuery();
return true;
}
catch
{
return false;
}
}
}
}
访问调用示例:
//初始化,载入数据库路径
AccessDbClass mydb = new AccessDbClass("..\\DATA\\" + "Database.accdb");//"c:/db.mdb");
String sql = "select * from UART where " + "编号='" + num + "'and UART.时间 like '%" + date.ToString("yyyy-MM-dd") + "%' ORDER BY 时间";
//返回符合SQL要求的DataTable,并且与控件dataGridView1绑定
DataTable dt = new DataTable();
dt = mydb.SelectToDataTable(sql); //SELECT * FROM UART where 时间 like '*20150903*';
this.dataGridView1.DataSource = dt;
//关闭数据库
mydb.Close();
文章实时采集(青蓝互动:网站文章长期被采集该怎么办?互动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-05 20:04
定期更新网站上的文章是几乎每个网站都会做的事情,所以很多平台不是每个网站都关注原创,也不是每个网站如果你愿意花这段时间做原创或伪原创的文章,自然会发生网站的大部分文章被采集,而不是网站,愿意花时间去更新自己的网站文章,就像采集一样。所以,当我们的网站长期处于采集的状态,如果网站的权重不够高,那么蜘蛛在爬行,很有可能是你的网站被列为采集站,更认为你的网站的文章是来自互联网的采集,
因此,我们需要采取解决方案,尽可能避免此类事件的发生。如果 文章 长时间是 采集 怎么办?青蓝互动有以下见解:
1、提高页面权限
增加页面权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与高权重网站相同的文章时,蜘蛛会默认使用高权重网站的文章作为来源原创 的。所以,一定要增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要制定一个固定的时间来更新网站的频率,这样运行之后,网站@的包容性> 有了很大的改进。
3、rss合理使用
RSS 是一种用于描述和同步网站内容的格式,是使用最广泛的 XML 应用程序。RSS搭建信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用 RSS 提要更快地获取信息,网站 提供 RSS 输出以帮助用户获取有关 网站 内容的最新更新。
青澜互动认为,开发这样一个功能是很有必要的。当网站文章有更新时,尽快让搜索引擎知道,主动出击,对收录的帮助很大。而且,Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、现场原创保护
在我们的网站上更新原版文章后,我们可以选择使用百度站长平台原版的保护功能。每个文章更新,我们每天可以提交 10 个原创保护。
5、做更多细节并限制机器的采集
我们可以对页面的细节做一些事情,至少可以防止 采集 进入机器。例如,页面不应设计得过于传统和流行;Url的写法要改,不要设置为默认覆盖;当对方采集到我们的物品时,图片也会被采集,我们可以在物品的图片上添加图片水印;以及文章为这本书注入更多内容网站关键词,青蓝互动认为这样不仅可以快速知道你的文章被别人使用了采集,也增加了别人的采集文章后期处理的时间成本,经常穿插我们网站的名字。别人在采集的时候,会觉得我们的文章不等于他们。它没有
文章往往是采集,肯定会对我们产生影响,所以尽量避免,让我们的网站内容在互联网上独树一帜,提高百度的对我们网站的信任让我们的优化工作更加顺利。
我们回归搜索引擎工作原理的本质,即满足和解决用户在搜索结果时的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法攻击采集网站,也会对原创内容给予一定的排名优惠,鼓励原创作者或 伪原创作者创造了更多质量的内容。
就像青岚互动观察到的百家号新推出的算法一样,性欲不足的原创文章不会被百度推荐。不推荐就没有流量,自然也就没有收录,这大大提升了原创的性能,给了各大原创作者很好的保护,提供了一个高百度搜索引擎的优质环境。
但是当然除了百度官方的文章采集网站处理,我们也可以把自己的网站做的更好,这样我们自己的网站文章就可以被更好的收录输入,被采集的概率会下降很多。如果有被采集的情况,不妨试试青岚互动说的这些操作,会得到意想不到的效果。 查看全部
文章实时采集(青蓝互动:网站文章长期被采集该怎么办?互动)
定期更新网站上的文章是几乎每个网站都会做的事情,所以很多平台不是每个网站都关注原创,也不是每个网站如果你愿意花这段时间做原创或伪原创的文章,自然会发生网站的大部分文章被采集,而不是网站,愿意花时间去更新自己的网站文章,就像采集一样。所以,当我们的网站长期处于采集的状态,如果网站的权重不够高,那么蜘蛛在爬行,很有可能是你的网站被列为采集站,更认为你的网站的文章是来自互联网的采集,
因此,我们需要采取解决方案,尽可能避免此类事件的发生。如果 文章 长时间是 采集 怎么办?青蓝互动有以下见解:
1、提高页面权限
增加页面权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与高权重网站相同的文章时,蜘蛛会默认使用高权重网站的文章作为来源原创 的。所以,一定要增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要制定一个固定的时间来更新网站的频率,这样运行之后,网站@的包容性> 有了很大的改进。
3、rss合理使用
RSS 是一种用于描述和同步网站内容的格式,是使用最广泛的 XML 应用程序。RSS搭建信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用 RSS 提要更快地获取信息,网站 提供 RSS 输出以帮助用户获取有关 网站 内容的最新更新。
青澜互动认为,开发这样一个功能是很有必要的。当网站文章有更新时,尽快让搜索引擎知道,主动出击,对收录的帮助很大。而且,Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、现场原创保护
在我们的网站上更新原版文章后,我们可以选择使用百度站长平台原版的保护功能。每个文章更新,我们每天可以提交 10 个原创保护。
5、做更多细节并限制机器的采集
我们可以对页面的细节做一些事情,至少可以防止 采集 进入机器。例如,页面不应设计得过于传统和流行;Url的写法要改,不要设置为默认覆盖;当对方采集到我们的物品时,图片也会被采集,我们可以在物品的图片上添加图片水印;以及文章为这本书注入更多内容网站关键词,青蓝互动认为这样不仅可以快速知道你的文章被别人使用了采集,也增加了别人的采集文章后期处理的时间成本,经常穿插我们网站的名字。别人在采集的时候,会觉得我们的文章不等于他们。它没有
文章往往是采集,肯定会对我们产生影响,所以尽量避免,让我们的网站内容在互联网上独树一帜,提高百度的对我们网站的信任让我们的优化工作更加顺利。
我们回归搜索引擎工作原理的本质,即满足和解决用户在搜索结果时的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法攻击采集网站,也会对原创内容给予一定的排名优惠,鼓励原创作者或 伪原创作者创造了更多质量的内容。
就像青岚互动观察到的百家号新推出的算法一样,性欲不足的原创文章不会被百度推荐。不推荐就没有流量,自然也就没有收录,这大大提升了原创的性能,给了各大原创作者很好的保护,提供了一个高百度搜索引擎的优质环境。
但是当然除了百度官方的文章采集网站处理,我们也可以把自己的网站做的更好,这样我们自己的网站文章就可以被更好的收录输入,被采集的概率会下降很多。如果有被采集的情况,不妨试试青岚互动说的这些操作,会得到意想不到的效果。
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2022-02-04 17:05
)
企业的数据源多种多样,有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库中,供后续数据分析。
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。
针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
1、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
2、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
3、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
4、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
5、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
查看全部
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决
)
企业的数据源多种多样,有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库中,供后续数据分析。
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。
针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
1、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
2、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
3、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
4、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
5、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-02-04 17:02
)
企业的数据源多种多样,其中有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库进行后续数据分析。
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。
针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
一、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
二、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
三、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
四、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
五、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
查看全部
文章实时采集(批量数据采集功能——Excel模板导入来帮你解决
)
企业的数据源多种多样,其中有的需要一线员工采集实时存储在Excel文件中,然后由技术人员通过批量补充记录上传到业务数据库进行后续数据分析。
比如某行的业务员采集时不时填写客户的公司名称、客户代码、地区、内部交易等基本客户信息,然后依靠IT人员填写上传到业务数据库。这些采集对补充记录和补充记录的要求并不复杂,但在实际操作中可能会遇到补充记录不及时、数据不完整等问题,给相关数据采集人员带来麻烦,技术人员及其数据分析师。
针对以上问题,Smartbi提供批量数据采集功能——Excel模板导入帮你解决!允许数据采集补充人员通过统一模板配置一键批量导入Excel文件中的数据,并补充记录到数据库中。既减轻了开发者的工作量,又满足了业务人员对数据采集的需求,让批量导入Excel数据变得简单高效。
我们来看看这个功能是如何满足用户需求的:
一、模板配置
Excel模板导入支持统一模板化配置。技术人员首先通过可视化操作实现Excel模板与数据库表的映射关系,支持绑定列、验证规则设置、数据插入和更新选择等,并上传采集Excel模板文件进行补充数据,让业务人员可以下载并填写数据。
二、支持绑定形式
Excel 导入模板支持绑定到电子表格。通过绑定表格,可以导入报表数据,可以导入固定值、系统值、参数值等,还可以实现动态数据更新导入。
例如,用户要下载的补充记录模板已经收录了一些填写好的数据(如公司代码、公司名称、客户代码、业务分类等),这部分现有数据可能会动态变化。如果切换不同的业务分类参数,下载的数据是不同的。实际上,用户只需要根据已有数据填写“线路类型”和“是否交易”字段的数据即可。
这时候我们可以在配置模板的时候选择创建一个电子表格作为Excel模板,这样在下载模板的时候就可以选择报表的参数,下载不同的数据模板。
三、统一管理
管理员统一配置和管理Excel模板,并可以通过资源授权将导入模板授权给相关用户。只有有权限的用户才能进行导入操作,方便用户填写导入。
四、一键导入
技术人员配置模板并授权给填充人员后,填充人员可以下载模板和采集数据。当数据采集完成后,可以点击上传,完成数据补录操作。简单的。
导入成功或失败都有明确的提示。如果导入失败,用户可以下载异常数据,查看具体数据和导入失败的原因。
五、很好的扩展
Smartbi的Excel模板导入功能支持扩展接口,可以帮助用户通过Java类实现自定义数据处理需求或规则验证需求。
在实际的补录操作中,客户也可能有定制化的数据处理或规则验证需求,比如判断两个指标的值是否相等。如果指标不相等,则验证失败,如果有相关提示信息,可以通过自定义规则验证类来实现这个需求。
文章实时采集(ai判断效果没有那么真实,网络效应也不好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-01-30 14:01
文章实时采集,实时建图,也就是所谓的上网速度,
空间感知也需要建立在采集的实时数据上,并且要运算去进行修正和计算。
你做的空间意识这件事是要怎么理解?不管数据空间怎么理解,去做这件事情都不是坏事。但是相对以前一些算法,这个并不是一个好的相对应用。举个例子:基因里的空间编码是基于序列去理解新的空间位置,地震上这种地理位置的感知是基于地震波的人为设定的空间(不考虑地震波本身正负,在早期设计者压根就没考虑空间)其他的我不是太懂。
我对上网速度和空间感知研究很少,不过比较好奇题主这个美国连一条大马路都没有的国家,怎么能在2015年初还提出这样的问题。
我觉得是空间感知,我觉得应该是更加基础的层面,比如无人机打算过路的时候必须要把最精准的图传发到一个点上才可以操作,才能保证不误差大于1,空间图传,然后系统中人工算出每一条路的算出位置,才有空间感知,所以美国打造了一个神经网络系统,就是看看大众都认为是最简单最直观的方式是否真正的到达一个地方,所以我觉得这样的人工智能理论上肯定会比人工操作确实省时省力,空间感知要在认为是最简单的角度下判断,人工形式可能以后可以做到,不过目前来说这些人工可能很好用但是不能拿来当核心用,毕竟没有正确的生成真正的模型,让神经网络来判断路走到什么样的位置?ai判断效果没有那么真实,网络效应也不好。我认为核心应该是地理空间关系,以及路网。 查看全部
文章实时采集(ai判断效果没有那么真实,网络效应也不好)
文章实时采集,实时建图,也就是所谓的上网速度,
空间感知也需要建立在采集的实时数据上,并且要运算去进行修正和计算。
你做的空间意识这件事是要怎么理解?不管数据空间怎么理解,去做这件事情都不是坏事。但是相对以前一些算法,这个并不是一个好的相对应用。举个例子:基因里的空间编码是基于序列去理解新的空间位置,地震上这种地理位置的感知是基于地震波的人为设定的空间(不考虑地震波本身正负,在早期设计者压根就没考虑空间)其他的我不是太懂。
我对上网速度和空间感知研究很少,不过比较好奇题主这个美国连一条大马路都没有的国家,怎么能在2015年初还提出这样的问题。
我觉得是空间感知,我觉得应该是更加基础的层面,比如无人机打算过路的时候必须要把最精准的图传发到一个点上才可以操作,才能保证不误差大于1,空间图传,然后系统中人工算出每一条路的算出位置,才有空间感知,所以美国打造了一个神经网络系统,就是看看大众都认为是最简单最直观的方式是否真正的到达一个地方,所以我觉得这样的人工智能理论上肯定会比人工操作确实省时省力,空间感知要在认为是最简单的角度下判断,人工形式可能以后可以做到,不过目前来说这些人工可能很好用但是不能拿来当核心用,毕竟没有正确的生成真正的模型,让神经网络来判断路走到什么样的位置?ai判断效果没有那么真实,网络效应也不好。我认为核心应该是地理空间关系,以及路网。
文章实时采集(实时大屏效果项目架构分析日志数据采集项目概览(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-29 18:19
)
项目概况
实时大屏效果
项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
查看全部
文章实时采集(实时大屏效果项目架构分析日志数据采集项目概览(组图)
)
项目概况
实时大屏效果
项目主要通过实时数仓的搭建完成对Flink的进一步掌握和学习。Flink代码是用Java编写的,会涉及到Flink的很多知识点,FlinkCDC,FlinkSQL,航海,丰富的功能等等,习惯了学习Flink,顺便传个仓库还是很不错的。从 FlinkForward2021 的一些进展来看,Flink SQLization 已经势不可挡,流式数据仓库 StreamHouse 也开始缓慢推进。
这里的实时数仓主要是为了提高数据的复用性。见下图,当有大量中间结果时
使用时充分体现了实时数仓的必要性,省去了很多重复计算,提交了实时计算的时效性。
说到数据仓库,数据仓库的分层是分不开的。基于电子商务的实时数仓分层如下:
ods:原创数据,存储业务数据和日志数据
dwd:按数据对象划分,如订单、页面访问量
dim:维度数据
dwm:进一步处理一些数据对象,将其与维度表关联,形成宽表,例如独立访问和跳出行为
dws:根据一个主题轻轻聚合多个事实数据,形成主题宽表
ads:基于数据的可视化过滤器聚合
实时需求
主要分为:每日统计报表或分析图表模块、实时数据监控大屏、数据预警或提示、实时推荐系统。
项目架构分析
记录数据采集
文章实时采集( WordPress发布工具无需插件和API,自动批量同时具备SEO优化 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-24 01:05
WordPress发布工具无需插件和API,自动批量同时具备SEO优化
)
WordPress发布工具,无需插件和API,实现WPcms发布文章,自动批量SEO优化。WordPress发布可以实现网站自动采集和发布,即以量取胜的方式获得百度收录和关键词排名,从而获得被动搜索引擎交通。WordPress发布还配备了采集功能和自动伪原创,可以采集几乎所有类型的网页,无缝适配各类cms建站者,发布数据实时无需登录,实现定时定量自动采集发布,无需人工干预!就是站长网站管理,网站优化,大数据,云时代网站 数据自动化采集发布的SEO优化必备工具。更准确地说,WorePress 发布不仅仅是一个发布工具,它可以实现多个网站multiplecms同时同步管理,通过一个工具管理所有网站。各种网站cms都是我自己做的。利用工具的便利,我做的网站无论是收录还是排名效果都相当不错。
WordPress发布功能这么多,难道就是市场所说的站群软件吗?确实可以理解站群和独立站点都可以管理采集发布SEO优化!WordPress版本的具体功能是什么:
1.一键批量创建任务,无需规则,填写网站基本信息,方便简单,最大化功能,简化操作
2.批量管理各种cms类型的网站,让你所有的网站都可以自动批量发布文章,
3.自带伪原创的功能,使得发布的文章更加原创友好,增加了搜索引擎的友好度。收录 网站 的速率增加
4. 规律性和每日发布的数量让搜索引擎觉得这是一个正常而有规律的网站,增强了信任感
5.发布可以自动删除自动监控,减少负载,无论是本地还是服务器,不占用资源
6.自带关键词内链插入,在标题和文章中自动插入关键词,增加关键词的频率,对于网站< @关键词排名网站体重提升有帮助
7.发布后自动推送到百度|搜狗|神马|360,主动推送资源,缩短爬虫发现网站链接的时间,增加网站收录
8. 自带点赞数随机、图片随机插入、作者随机生成,让用户体验和直观感受更加真实生动
WordPress无缝发布采集,采集的功能不需要自己写规则,操作也极其简单,直接上手即可,根据情况选择数据源即可网站,批量导入关键词就是这样,如果没有关键词词库,可以输入一个核心关键词生成大量长尾关键词 在线。无论是 采集 还是发布,都是关于 傻瓜式 操作的。真正意义上的功能最大化,操作极其简化。是站长网站建设、网站管理、SEO优化的常备工具。大大提高了工作效率,提高了优化效果,快速达到了预期目标。.
WordPress发布的文章分享就写在这里。综上所述,我们在SEO优化的过程中会遇到很多问题。有技术和效率方面。我们需要分析总结,借助工具来解决繁琐的手工工作,同时对提升网站自然排名优化起到重要作用。
查看全部
文章实时采集(
WordPress发布工具无需插件和API,自动批量同时具备SEO优化
)
WordPress发布工具,无需插件和API,实现WPcms发布文章,自动批量SEO优化。WordPress发布可以实现网站自动采集和发布,即以量取胜的方式获得百度收录和关键词排名,从而获得被动搜索引擎交通。WordPress发布还配备了采集功能和自动伪原创,可以采集几乎所有类型的网页,无缝适配各类cms建站者,发布数据实时无需登录,实现定时定量自动采集发布,无需人工干预!就是站长网站管理,网站优化,大数据,云时代网站 数据自动化采集发布的SEO优化必备工具。更准确地说,WorePress 发布不仅仅是一个发布工具,它可以实现多个网站multiplecms同时同步管理,通过一个工具管理所有网站。各种网站cms都是我自己做的。利用工具的便利,我做的网站无论是收录还是排名效果都相当不错。
WordPress发布功能这么多,难道就是市场所说的站群软件吗?确实可以理解站群和独立站点都可以管理采集发布SEO优化!WordPress版本的具体功能是什么:
1.一键批量创建任务,无需规则,填写网站基本信息,方便简单,最大化功能,简化操作
2.批量管理各种cms类型的网站,让你所有的网站都可以自动批量发布文章,
3.自带伪原创的功能,使得发布的文章更加原创友好,增加了搜索引擎的友好度。收录 网站 的速率增加
4. 规律性和每日发布的数量让搜索引擎觉得这是一个正常而有规律的网站,增强了信任感
5.发布可以自动删除自动监控,减少负载,无论是本地还是服务器,不占用资源
6.自带关键词内链插入,在标题和文章中自动插入关键词,增加关键词的频率,对于网站< @关键词排名网站体重提升有帮助
7.发布后自动推送到百度|搜狗|神马|360,主动推送资源,缩短爬虫发现网站链接的时间,增加网站收录
8. 自带点赞数随机、图片随机插入、作者随机生成,让用户体验和直观感受更加真实生动
WordPress无缝发布采集,采集的功能不需要自己写规则,操作也极其简单,直接上手即可,根据情况选择数据源即可网站,批量导入关键词就是这样,如果没有关键词词库,可以输入一个核心关键词生成大量长尾关键词 在线。无论是 采集 还是发布,都是关于 傻瓜式 操作的。真正意义上的功能最大化,操作极其简化。是站长网站建设、网站管理、SEO优化的常备工具。大大提高了工作效率,提高了优化效果,快速达到了预期目标。.
WordPress发布的文章分享就写在这里。综上所述,我们在SEO优化的过程中会遇到很多问题。有技术和效率方面。我们需要分析总结,借助工具来解决繁琐的手工工作,同时对提升网站自然排名优化起到重要作用。
文章实时采集(文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-01-23 05:04
文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning?中讲到了怎么利用motionevent进行建模然后实现多种faceanimation。我这里再实现一遍。motionevent是一个简单的物理状态,目的是让机器人在环境中快速的做出反应。
motionevent的一些基本组成:1.物理传感器:目前进入全景影像的设备主要有imu+window传感器+激光雷达2.web服务器:服务器端采集来自各个角度的物理世界中的图像或者视频信息,然后上传到服务器中。这里应该说一下,服务器端接收到的图像上传到服务器中是一个json格式的数据,采样和上传的时候也会产生,只是存储这些数据会更加方便。
3.运动目标:就是第一步的imu+window。目标之间都会产生位置上的相关联。4.运动操作:进行物理操作,就是yaw,steep,forward,rotate...(忘记了相关算法细节)5.增强:通过手势不断触发物理世界,加强机器人对环境的反应(比如:双手拿起一堆食物)part1mouseevent个人理解的思路,如果你有建模的经验,自然而然的可以懂是怎么回事。
如果没有,你要先做这种事情,然后才能懂怎么怎么设计。applynavigationinputs.对于自己平时工作当中的摄像头,我一般很少去用其他可穿戴设备,用手机+一个googleglass做,如果是相机的话,用无线遥控相机,很简单。不是我用iphone拍照,太麻烦。applycameraapi.设计一个摄像头,对于imu和window,我会先用脚本和生成的动画,自己复制了imu和window,json格式上传。
上面四步应该是高清视频,再copy到视频。然后要怎么上传的话,需要一个外网的服务器,autodesklicense了gfw.autocad怎么用part2vectoranimation这里其实只是刚刚设计好了一个web服务器中的画图的部分。face-animation主要实现动画。已经有以前的渲染器可以使用,这个其实是mmd里面功能最简单,效果最差的渲染器。
texturemodel其实很简单,利用过一下,得到一些简单的骨骼关节,画出一个简单的闭合曲线。part3trackersystem既然motionevent是一个轨迹跟踪程序,那么怎么跟踪摄像头采集的动画呢?其实没有好多方法,除了我们一般的方法:imu的记录动作,用户点击,画一个追踪动画(or过去跟视频,把视频画一个追踪动画),shooter接收到动画。
可是在这里,其实对于actionmotion,我们是不能再这样简单画一个追踪动画的了。首先,需要采集,那么在motionevent里面去get到,其次,在记录动作,然后在执行,其实已经过去了很多步了。我想把他做的牛。 查看全部
文章实时采集(文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning)
文章实时采集代码coursera上的一个免费视频:whatmachinesgesturesareyouplayingbutnotwhattheyarespinning?中讲到了怎么利用motionevent进行建模然后实现多种faceanimation。我这里再实现一遍。motionevent是一个简单的物理状态,目的是让机器人在环境中快速的做出反应。
motionevent的一些基本组成:1.物理传感器:目前进入全景影像的设备主要有imu+window传感器+激光雷达2.web服务器:服务器端采集来自各个角度的物理世界中的图像或者视频信息,然后上传到服务器中。这里应该说一下,服务器端接收到的图像上传到服务器中是一个json格式的数据,采样和上传的时候也会产生,只是存储这些数据会更加方便。
3.运动目标:就是第一步的imu+window。目标之间都会产生位置上的相关联。4.运动操作:进行物理操作,就是yaw,steep,forward,rotate...(忘记了相关算法细节)5.增强:通过手势不断触发物理世界,加强机器人对环境的反应(比如:双手拿起一堆食物)part1mouseevent个人理解的思路,如果你有建模的经验,自然而然的可以懂是怎么回事。
如果没有,你要先做这种事情,然后才能懂怎么怎么设计。applynavigationinputs.对于自己平时工作当中的摄像头,我一般很少去用其他可穿戴设备,用手机+一个googleglass做,如果是相机的话,用无线遥控相机,很简单。不是我用iphone拍照,太麻烦。applycameraapi.设计一个摄像头,对于imu和window,我会先用脚本和生成的动画,自己复制了imu和window,json格式上传。
上面四步应该是高清视频,再copy到视频。然后要怎么上传的话,需要一个外网的服务器,autodesklicense了gfw.autocad怎么用part2vectoranimation这里其实只是刚刚设计好了一个web服务器中的画图的部分。face-animation主要实现动画。已经有以前的渲染器可以使用,这个其实是mmd里面功能最简单,效果最差的渲染器。
texturemodel其实很简单,利用过一下,得到一些简单的骨骼关节,画出一个简单的闭合曲线。part3trackersystem既然motionevent是一个轨迹跟踪程序,那么怎么跟踪摄像头采集的动画呢?其实没有好多方法,除了我们一般的方法:imu的记录动作,用户点击,画一个追踪动画(or过去跟视频,把视频画一个追踪动画),shooter接收到动画。
可是在这里,其实对于actionmotion,我们是不能再这样简单画一个追踪动画的了。首先,需要采集,那么在motionevent里面去get到,其次,在记录动作,然后在执行,其实已经过去了很多步了。我想把他做的牛。
文章实时采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-13 18:07
步骤1:
数据源:例如 网站 或应用程序。很重要的一点是埋点。也就是说,埋点,当网站/app的哪个页面的操作发生时,通过网络请求前端代码(网站,JavaScript;app,android/IOS) , (Ajax ; socket) 将指定格式的日志数据发送到后端服务器。
第2步:
Nginx、后端Web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。至此,其实还是可以和我们之前的离线日志采集流程一样。通过日志传输工具返回并将其放入指定的文件夹中。
连接线(水槽,监控指定文件夹)
第 3 步:
1、HDFS
2、实时数据通常从分布式消息队列集群中读取,例如Kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们将后端实时数据处理程序(Storm、Spark Streaming)实时从Kafka读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清洗后放入Hive,搭建离线数据仓库。你也可以每天采集一份.分钟数据,或者每次采集一点点数据,放到一个文件中,然后传到flume,或者直接通过API定制,直接一个一个log进入flume。flume可以配置为向Kafka写入数据)
连接线(实时,主动从Kafka拉取数据)
步骤4:
大数据实时计算系统,例如使用Storm和Spark Streaming开发的系统,可以实时从Kafka中拉取数据,然后对实时数据进行处理计算。这里可以封装大量复杂的业务逻辑,甚至可以调用复杂的机器。学习、数据挖掘、智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。 查看全部
文章实时采集(网站/app的哪个页面的哪些操作发生时,可以跟我们之前的离线日志收集流程)
步骤1:
数据源:例如 网站 或应用程序。很重要的一点是埋点。也就是说,埋点,当网站/app的哪个页面的操作发生时,通过网络请求前端代码(网站,JavaScript;app,android/IOS) , (Ajax ; socket) 将指定格式的日志数据发送到后端服务器。
第2步:
Nginx、后端Web服务器(Tomcat、Jetty等)、后端系统(J2EE、PHP)。至此,其实还是可以和我们之前的离线日志采集流程一样。通过日志传输工具返回并将其放入指定的文件夹中。
连接线(水槽,监控指定文件夹)
第 3 步:
1、HDFS
2、实时数据通常从分布式消息队列集群中读取,例如Kafka;实时数据,实时日志,实时写入消息队列,如Kafka;然后,我们将后端实时数据处理程序(Storm、Spark Streaming)实时从Kafka读取数据并记录日志。然后进行实时计算和处理。卡夫卡
(Kafka,我们的日志数据怎么处理就看你了。你可以每天采集一份,放到flume中,转入HDFS,清洗后放入Hive,搭建离线数据仓库。你也可以每天采集一份.分钟数据,或者每次采集一点点数据,放到一个文件中,然后传到flume,或者直接通过API定制,直接一个一个log进入flume。flume可以配置为向Kafka写入数据)
连接线(实时,主动从Kafka拉取数据)
步骤4:
大数据实时计算系统,例如使用Storm和Spark Streaming开发的系统,可以实时从Kafka中拉取数据,然后对实时数据进行处理计算。这里可以封装大量复杂的业务逻辑,甚至可以调用复杂的机器。学习、数据挖掘、智能推荐算法,进而实现车辆实时调度、实时推荐、广告流量实时统计。

