
文章实时采集
文章实时采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-06 16:08
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、实时采集模块(CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal 插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。 查看全部
文章实时采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、实时采集模块(CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal 插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。
文章实时采集(如何用uid推送广告?爬虫爬虫爬虫爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-03 16:01
文章实时采集,开发者可以获取网页全部网址或者根据网页标题等特征设置ip地址获取指定url。用户通过特定策略,访问网页就能获取到相应内容,还是挺方便的。
谢邀推荐使用useragentmap
你看看这个:howtosurveythecontentofachineseuser?大部分问题你都能用这种手段解决。
allchineserequestswentintobecomeamoregeneralhackingads,alsonotinthebrandloginmethod.viacnncorruptchina
你需要自己搞一个简洁的用户界面。目前没什么好办法。不过新浪提供了服务接口。基本上你想用uid进行推送广告的方法你都能用上。如果你有这方面需求,可以联系找找看。如果涉及你在“南方日报”和“央视新闻”,也可以联系上面的市场部。
如果你像@layly说的那样,你得懂爬虫爬虫爬虫!你的技术可以想办法,但是爬虫爬虫,爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬库爬虫爬虫爬虫爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库。 查看全部
文章实时采集(如何用uid推送广告?爬虫爬虫爬虫爬虫)
文章实时采集,开发者可以获取网页全部网址或者根据网页标题等特征设置ip地址获取指定url。用户通过特定策略,访问网页就能获取到相应内容,还是挺方便的。
谢邀推荐使用useragentmap
你看看这个:howtosurveythecontentofachineseuser?大部分问题你都能用这种手段解决。
allchineserequestswentintobecomeamoregeneralhackingads,alsonotinthebrandloginmethod.viacnncorruptchina
你需要自己搞一个简洁的用户界面。目前没什么好办法。不过新浪提供了服务接口。基本上你想用uid进行推送广告的方法你都能用上。如果你有这方面需求,可以联系找找看。如果涉及你在“南方日报”和“央视新闻”,也可以联系上面的市场部。
如果你像@layly说的那样,你得懂爬虫爬虫爬虫!你的技术可以想办法,但是爬虫爬虫,爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬库爬虫爬虫爬虫爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库。
文章实时采集(文章实时采集写字楼大堂(广告牌)的实现方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-02 22:01
文章实时采集写字楼大堂(广告牌)信息:数据要求是文字或者图片,前端只需要预览一次大堂的尺寸就可以保存到hbase。后端会实时写入数据库中。文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。需要的技术栈:开发环境tomcat7.0springboot5.0.6eclipse14.0.2python2.7.14sql2015版本前端:jquery+flask+requests数据库:mysql+mongodb主要实现方法:文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号码-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:1,设置请求url2,设置请求头,header:accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8;*/*;user-agent:mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/50.0.2724.116safari/537.3647.94save/first3,设置请求header,如下:header'content-type':'application/xhtml+xml;q=0.9,*/*;q=0.8'4,如果服务器不开放wifi接口,设置请求url用请求报文地址,即mysql和requests_file-db报文地址。
inet_native_private_port=8000jlink虚拟机大楼顶部的尺寸为15m*20m左右,所以尺寸有45*15*20=4800m。大堂的尺寸为15m*20m左右,所以尺寸有10m*40*20=3200m。每一个大堂的id号码都会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:将数据写入mysql中:1,创建一个mysql对象2,将每一个大堂的id号码写入mysql表中3,将表中每一个大堂的id号码写入数据库中4,重启mysql实例5,将该表中的每一个大堂编号写入db表中6,读取并写入数据库。 查看全部
文章实时采集(文章实时采集写字楼大堂(广告牌)的实现方法)
文章实时采集写字楼大堂(广告牌)信息:数据要求是文字或者图片,前端只需要预览一次大堂的尺寸就可以保存到hbase。后端会实时写入数据库中。文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。需要的技术栈:开发环境tomcat7.0springboot5.0.6eclipse14.0.2python2.7.14sql2015版本前端:jquery+flask+requests数据库:mysql+mongodb主要实现方法:文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号码-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:1,设置请求url2,设置请求头,header:accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8;*/*;user-agent:mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/50.0.2724.116safari/537.3647.94save/first3,设置请求header,如下:header'content-type':'application/xhtml+xml;q=0.9,*/*;q=0.8'4,如果服务器不开放wifi接口,设置请求url用请求报文地址,即mysql和requests_file-db报文地址。
inet_native_private_port=8000jlink虚拟机大楼顶部的尺寸为15m*20m左右,所以尺寸有45*15*20=4800m。大堂的尺寸为15m*20m左右,所以尺寸有10m*40*20=3200m。每一个大堂的id号码都会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:将数据写入mysql中:1,创建一个mysql对象2,将每一个大堂的id号码写入mysql表中3,将表中每一个大堂的id号码写入数据库中4,重启mysql实例5,将该表中的每一个大堂编号写入db表中6,读取并写入数据库。
文章实时采集(C++实现RTMP协议发送H.264编码及AAC编码的音视频RTMP )
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-11-02 09:02
)
C++实现RTMP协议发送H.264编码和AAC编码的音视频
RTMP(Real Time Messaging Protocol)是一种专门用于传输音视频数据的流媒体协议。它最初由Macromedia 创建,后来归它所有。它是一个私有协议,主要用于联系Flash Player和RtmpServer,如FMS、Red5、crtmpserver等。RTMP协议可以实现直播和点播应用,通过FMLE(Flash Media Live Encoder)将音视频数据推送到RtmpServer,可以实现摄像机的实时直播。但是,毕竟FMLE的应用范围是有限的。如果想嵌入到自己的程序中,还是要自己实现RTMP协议推送。我已经实现了一个 RTMPLiveEncoder,通过 采集 摄像头视频和麦克风音频,以及 H.264 和 AAC 编码,然后发送到FMS和crtmpserver实现实时直播,通过flash播放器可以正常观看,目前效果不错。延迟时间约为 2 秒。本文介绍了RTMPLiveEncoder的主要思想和关键点,希望对需要该技术的朋友有所帮助。
技术分析
实现RTMPLiveEncoder,需要以下四项关键技术:
其中,前两项技术在我之前的文章《采集音频和摄像头视频和实时H264编码和AAC编码》中已经介绍过,这里就不啰嗦了.
将音频和视频数据封装到可播放的流中是一个难点。仔细研究,你会发现RTMP Packet中封装的音视频数据流其实和FLV封装音视频数据的方式是一样的。所以我们只需要根据FLV封装H264和AAC就可以生成Play流了。
我们再来看看RTMP协议。Adobe 曾经发布过一个文档《RTMP 规范》,但维基百科指出该文档隐藏了很多细节,仅凭它是无法正确实现 RTMP 的。不过还是有参考意义的。事实上,在Adobe发布之前RTMP协议几乎就已经被破解了,现在已经有了比较完善的实现,比如RTMPDump,它提供了一个C语言的接口,这意味着它可以很容易地被其他语言调用。
计划框架
和我之前的文章《采集音视频与实时H264编码与AAC编码》文章一样,使用DirectShow技术实现音视频采集,音视频编码, 循环在各自的线程(AudioEncoderThread 和 VideoEncoderThread)中,RTMP的push开始一个新的线程(RtmpThread)。两个编码线程实时对音视频数据进行编码后,将数据交给Rtmp线程,Rtmp线程循环封装Rtmp Packet,然后发送出去。
线程之间的数据交换是通过一个队列DataBufferQueue来实现的。AudioEncoderThread 和 VideoEncoderThread 将数据指针发布到 DataBufferQueue 后立即返回,以免因发送 Rtmp 消息而影响编码线程的正常执行时间。
RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,不断地从DataBufferQueue中取出数据,封装成RTMP Packet,发送出去。流程如下代码所示:(process_buf_queue_,也就是上图中的DataBufferQueue)
librtmp一、 编译 librtmp
下载rtmpdump的代码,你会发现它是一个正宗的linux项目,除了一个简单的Makefile,没有别的。看来librtmp并不依赖系统,所以我们可以在windows上编译,不用花太多精力。但是,librtmp 依赖于 openssl 和 zlib,我们需要先编译它们。
1. 编译 openssl1.0.0e
a) 下载并安装 ActivePerl
b) 下载并安装 nasm()
c) 解压openssl压缩包
d) 运行cmd命令行,切换到openssl目录,分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir
>ms\do_nasm
e) 运行Visual Studio Command Prompt(2010),切入openssl目录,分别执行以下命令。
>nmake -f ms\nt.mak
>nmake -f ms\nt.mak install
f) 编译完成后,可以在第一条命令指定的目录中找到编译好的SDK。
2. 编译 zlib
a) 解压zlib压缩包
b) 运行Visual Studio Command Prompt(2010),切到openssl目录,分别执行以下命令
>cd contrib\masmx86
>bld_ml32.bat
c) 回到zlib目录,进入contrib\vstudio\vc10目录,打开vs2010解决方案文件,
在zlibstat项目属性中,去掉预编译宏ZLIB_WINAPI
d) 选择 debug 或 release 编译
3. 编译 librtmp
a) 首先打开visual studio 2010,新建一个win32控制台项目,指定为静态链接库
b) 将librtmp代码导入工程中,将openssl、zlib和librtmp的头文件放在一起,将编译好的openssl和zlib的静态库放在一起
c) 在项目设置中,添加之前编译好的openssl和zlib库,然后编译。
二、librtmp 的使用
首先初始化RTMP结构
启动后需要向RTMP Server发起握手连接消息
如果连接成功,就可以开始循环发送消息了。在这里您需要指定时间戳和数据类型(音频、视频、元数据)。这里需要注意的一点是,在调用Send之前,buf中的数据必须是封装好的H264或者AAC数据流。
关闭
终于发布了
H264 和 AAC 数据流
如本文所述,RTMP推送的音视频流的封装类似于FLV格式。可以看出,要将H264和AAC直播流推送到FMS,需要先发送“AVC序列头”和“AAC序列头”。数据收录重要的编码信息,没有它们,解码器将无法解码。
AVC 序列头是 AVCDecoderConfigurationRecord 结构,在标准文档“ISO-14496-15 AVC 文件格式”中有详细描述。
AAC 序列头存储 AudioSpecificConfig 结构,在“ISO-14496-3 Audio”中有描述。AudioSpecificConfig 结构体的描述非常复杂。在这里,我将简化它。预先设置要编码的音频格式。其中,音频编码选择“AAC-LC”,音频采样率为44100,因此AudioSpecificConfig简化为下表:
这样就可以基本确定AVC序列头和AAC序列头的内容了。更详细的信息,您可以查看相关文档。
运行结果
RtmpLiveEncoder 开始运行
用 FMS 自带的 flash 播放器玩
++++++++++++++++++++++++++++++++++++++++++++++++++ ++ +++++++++++++
查看全部
文章实时采集(C++实现RTMP协议发送H.264编码及AAC编码的音视频RTMP
)
C++实现RTMP协议发送H.264编码和AAC编码的音视频
RTMP(Real Time Messaging Protocol)是一种专门用于传输音视频数据的流媒体协议。它最初由Macromedia 创建,后来归它所有。它是一个私有协议,主要用于联系Flash Player和RtmpServer,如FMS、Red5、crtmpserver等。RTMP协议可以实现直播和点播应用,通过FMLE(Flash Media Live Encoder)将音视频数据推送到RtmpServer,可以实现摄像机的实时直播。但是,毕竟FMLE的应用范围是有限的。如果想嵌入到自己的程序中,还是要自己实现RTMP协议推送。我已经实现了一个 RTMPLiveEncoder,通过 采集 摄像头视频和麦克风音频,以及 H.264 和 AAC 编码,然后发送到FMS和crtmpserver实现实时直播,通过flash播放器可以正常观看,目前效果不错。延迟时间约为 2 秒。本文介绍了RTMPLiveEncoder的主要思想和关键点,希望对需要该技术的朋友有所帮助。
技术分析
实现RTMPLiveEncoder,需要以下四项关键技术:
其中,前两项技术在我之前的文章《采集音频和摄像头视频和实时H264编码和AAC编码》中已经介绍过,这里就不啰嗦了.
将音频和视频数据封装到可播放的流中是一个难点。仔细研究,你会发现RTMP Packet中封装的音视频数据流其实和FLV封装音视频数据的方式是一样的。所以我们只需要根据FLV封装H264和AAC就可以生成Play流了。
我们再来看看RTMP协议。Adobe 曾经发布过一个文档《RTMP 规范》,但维基百科指出该文档隐藏了很多细节,仅凭它是无法正确实现 RTMP 的。不过还是有参考意义的。事实上,在Adobe发布之前RTMP协议几乎就已经被破解了,现在已经有了比较完善的实现,比如RTMPDump,它提供了一个C语言的接口,这意味着它可以很容易地被其他语言调用。
计划框架
和我之前的文章《采集音视频与实时H264编码与AAC编码》文章一样,使用DirectShow技术实现音视频采集,音视频编码, 循环在各自的线程(AudioEncoderThread 和 VideoEncoderThread)中,RTMP的push开始一个新的线程(RtmpThread)。两个编码线程实时对音视频数据进行编码后,将数据交给Rtmp线程,Rtmp线程循环封装Rtmp Packet,然后发送出去。
线程之间的数据交换是通过一个队列DataBufferQueue来实现的。AudioEncoderThread 和 VideoEncoderThread 将数据指针发布到 DataBufferQueue 后立即返回,以免因发送 Rtmp 消息而影响编码线程的正常执行时间。

RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,不断地从DataBufferQueue中取出数据,封装成RTMP Packet,发送出去。流程如下代码所示:(process_buf_queue_,也就是上图中的DataBufferQueue)

librtmp一、 编译 librtmp
下载rtmpdump的代码,你会发现它是一个正宗的linux项目,除了一个简单的Makefile,没有别的。看来librtmp并不依赖系统,所以我们可以在windows上编译,不用花太多精力。但是,librtmp 依赖于 openssl 和 zlib,我们需要先编译它们。
1. 编译 openssl1.0.0e
a) 下载并安装 ActivePerl
b) 下载并安装 nasm()
c) 解压openssl压缩包
d) 运行cmd命令行,切换到openssl目录,分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir
>ms\do_nasm
e) 运行Visual Studio Command Prompt(2010),切入openssl目录,分别执行以下命令。
>nmake -f ms\nt.mak
>nmake -f ms\nt.mak install
f) 编译完成后,可以在第一条命令指定的目录中找到编译好的SDK。
2. 编译 zlib
a) 解压zlib压缩包
b) 运行Visual Studio Command Prompt(2010),切到openssl目录,分别执行以下命令
>cd contrib\masmx86
>bld_ml32.bat
c) 回到zlib目录,进入contrib\vstudio\vc10目录,打开vs2010解决方案文件,
在zlibstat项目属性中,去掉预编译宏ZLIB_WINAPI
d) 选择 debug 或 release 编译
3. 编译 librtmp
a) 首先打开visual studio 2010,新建一个win32控制台项目,指定为静态链接库
b) 将librtmp代码导入工程中,将openssl、zlib和librtmp的头文件放在一起,将编译好的openssl和zlib的静态库放在一起


c) 在项目设置中,添加之前编译好的openssl和zlib库,然后编译。

二、librtmp 的使用
首先初始化RTMP结构

启动后需要向RTMP Server发起握手连接消息

如果连接成功,就可以开始循环发送消息了。在这里您需要指定时间戳和数据类型(音频、视频、元数据)。这里需要注意的一点是,在调用Send之前,buf中的数据必须是封装好的H264或者AAC数据流。

关闭

终于发布了

H264 和 AAC 数据流
如本文所述,RTMP推送的音视频流的封装类似于FLV格式。可以看出,要将H264和AAC直播流推送到FMS,需要先发送“AVC序列头”和“AAC序列头”。数据收录重要的编码信息,没有它们,解码器将无法解码。
AVC 序列头是 AVCDecoderConfigurationRecord 结构,在标准文档“ISO-14496-15 AVC 文件格式”中有详细描述。

AAC 序列头存储 AudioSpecificConfig 结构,在“ISO-14496-3 Audio”中有描述。AudioSpecificConfig 结构体的描述非常复杂。在这里,我将简化它。预先设置要编码的音频格式。其中,音频编码选择“AAC-LC”,音频采样率为44100,因此AudioSpecificConfig简化为下表:

这样就可以基本确定AVC序列头和AAC序列头的内容了。更详细的信息,您可以查看相关文档。
运行结果
RtmpLiveEncoder 开始运行

用 FMS 自带的 flash 播放器玩

++++++++++++++++++++++++++++++++++++++++++++++++++ ++ +++++++++++++

文章实时采集( 日志服务LogHub提供日志数据实时采集功能支持30+种手段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-10-31 01:11
日志服务LogHub提供日志数据实时采集功能支持30+种手段)
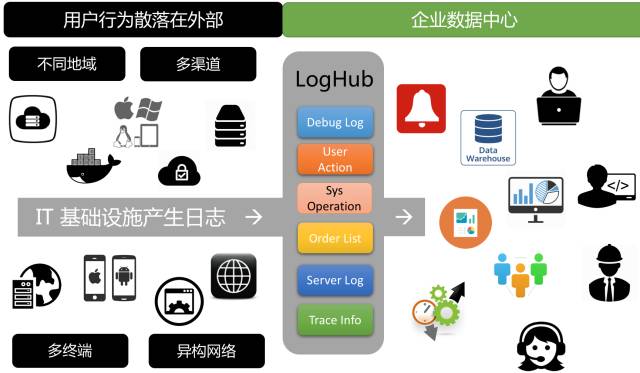
21CTO 社区指南:日志服务 LogHub 提供日志数据的实时采集和消费。其中,实时采集功能支持30+种方法。下面简单介绍一下各个场景的采集方法。
日志服务LogHub功能提供日志数据的实时采集和消费。实时采集功能支持30+种方法。下面简单介绍一下各个场景的接入方式。
data采集一般有两种方式,区别如下。这里主要讨论通过LogHub采集进行流式导入(实时)。
背景
“我要点外卖”是一个基于平台的电商网站,用户、餐厅、送餐员等,用户可以通过网页、App、微信、支付宝等方式下单;商家收到订单后开始处理,并自动通知周边快递员;快递员将食物送到用户手中。
操作要求
在操作过程中,发现了以下问题:
获取用户难。向渠道(网页、微信推送)投放大量广告费,接收部分用户,但无法判断各渠道效果
用户经常抱怨发货慢,但是下单、发货、处理的慢在什么阶段?如何优化?
用户操作,经常搞一些优惠活动(送优惠券),却得不到效果
排期问题,如何在高峰时段帮助商家提前备货?如何派送更多的快递到指定区域?
客服,用户反馈下单失败,用户背后是什么操作?系统是否有错误?
数据采集难点
在数据操作的过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集分散的外部和内部日志并统一管理。以前这个区域需要做很多工作,现在可以通过LogHub采集函数访问。
统一的日志管理和配置
创建一个管理日志项目Project,例如叫myorder
创建日志存储Logstore,用于从不同数据源生成日志,例如:
如果需要清理原创数据和ETL,可以创建一些中间结果logstore
(更多操作请参考快速入门/管理控制台)
用户推广日志采集实践
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册和扫描。当用户扫描页面进行注册时,他知道用户是通过特定来源进入并记录日志的。
;ref=kd4b
当服务器接受请求时,服务器输出如下日志:
2016-06-2019:00:00e41234ab342ef034,102345,5k4d,467890
采集方式:
1. 应用通过Logtail将日志输出到硬盘采集
2. 应用是通过SDK编写的,见SDK
服务器数据采集
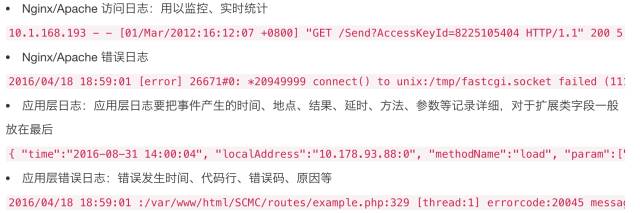
支付宝/微信公众号编程是典型的web端模式,日志一般分为三种:
实践
日志写入本地文件,通过Logtail配置正则表达式写入指定Logstore
Docker 中生成的日志可以使用容器服务来集成日志服务
Java程序可以使用Log4J Appender日志,无需日志记录,LogHub Producer Library(客户端高并发写入);Log4J 附加程序
可以使用SDK编写C#、Python、Java、PHP、C等
Windows服务器可以使用Logstash采集
最终用户日志访问
Web/M 站点页面用户行为
页面用户行为采集可以分为两类:
1. 页面与后台服务器交互:如下单、登录、退出等。
2. 页面无后台服务器交互:前端直接处理请求,如滚动、关闭页面等。
实践
第一种方法可以参考服务器采集方法
第二个可以使用Tracking Pixel/JS Library来采集页面行为,参考Tracking Web interface
服务器日志运维
例如:
实践
不同网络环境下的数据采集
LogHub在每个区域提供接入点,每个区域提供三个接入点:
更多信息请参考网络接入,总有一款适合您。
其他
查看LogHub的完整采集方法。
查看日志实时消耗,涉及流计算、数据清洗、数据仓库、索引查询等功能。
作者:简志,阿里云计算高级专家,擅长日志分析处理领域 查看全部
文章实时采集(
日志服务LogHub提供日志数据实时采集功能支持30+种手段)

21CTO 社区指南:日志服务 LogHub 提供日志数据的实时采集和消费。其中,实时采集功能支持30+种方法。下面简单介绍一下各个场景的采集方法。
日志服务LogHub功能提供日志数据的实时采集和消费。实时采集功能支持30+种方法。下面简单介绍一下各个场景的接入方式。

data采集一般有两种方式,区别如下。这里主要讨论通过LogHub采集进行流式导入(实时)。
背景
“我要点外卖”是一个基于平台的电商网站,用户、餐厅、送餐员等,用户可以通过网页、App、微信、支付宝等方式下单;商家收到订单后开始处理,并自动通知周边快递员;快递员将食物送到用户手中。

操作要求
在操作过程中,发现了以下问题:
获取用户难。向渠道(网页、微信推送)投放大量广告费,接收部分用户,但无法判断各渠道效果
用户经常抱怨发货慢,但是下单、发货、处理的慢在什么阶段?如何优化?
用户操作,经常搞一些优惠活动(送优惠券),却得不到效果
排期问题,如何在高峰时段帮助商家提前备货?如何派送更多的快递到指定区域?
客服,用户反馈下单失败,用户背后是什么操作?系统是否有错误?
数据采集难点
在数据操作的过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集分散的外部和内部日志并统一管理。以前这个区域需要做很多工作,现在可以通过LogHub采集函数访问。
统一的日志管理和配置
创建一个管理日志项目Project,例如叫myorder
创建日志存储Logstore,用于从不同数据源生成日志,例如:
如果需要清理原创数据和ETL,可以创建一些中间结果logstore
(更多操作请参考快速入门/管理控制台)
用户推广日志采集实践
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册和扫描。当用户扫描页面进行注册时,他知道用户是通过特定来源进入并记录日志的。
;ref=kd4b
当服务器接受请求时,服务器输出如下日志:
2016-06-2019:00:00e41234ab342ef034,102345,5k4d,467890
采集方式:
1. 应用通过Logtail将日志输出到硬盘采集
2. 应用是通过SDK编写的,见SDK
服务器数据采集
支付宝/微信公众号编程是典型的web端模式,日志一般分为三种:
实践
日志写入本地文件,通过Logtail配置正则表达式写入指定Logstore
Docker 中生成的日志可以使用容器服务来集成日志服务
Java程序可以使用Log4J Appender日志,无需日志记录,LogHub Producer Library(客户端高并发写入);Log4J 附加程序
可以使用SDK编写C#、Python、Java、PHP、C等
Windows服务器可以使用Logstash采集
最终用户日志访问
Web/M 站点页面用户行为
页面用户行为采集可以分为两类:
1. 页面与后台服务器交互:如下单、登录、退出等。
2. 页面无后台服务器交互:前端直接处理请求,如滚动、关闭页面等。
实践
第一种方法可以参考服务器采集方法
第二个可以使用Tracking Pixel/JS Library来采集页面行为,参考Tracking Web interface
服务器日志运维
例如:

实践
不同网络环境下的数据采集
LogHub在每个区域提供接入点,每个区域提供三个接入点:
更多信息请参考网络接入,总有一款适合您。
其他
查看LogHub的完整采集方法。
查看日志实时消耗,涉及流计算、数据清洗、数据仓库、索引查询等功能。
作者:简志,阿里云计算高级专家,擅长日志分析处理领域
文章实时采集( 启蒙续集之Halcon联合C#以及手眼以及标定实时采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-10-30 22:22
启蒙续集之Halcon联合C#以及手眼以及标定实时采集方法)
Halcon结合C#实时采集图像 Halcon结合C#实时采集图像
内容中引用的学习课程为超人视频:Halcon结合C#和手眼校准
实时采集方法有四种:循环采集、定时器、多线程、回调函数
这篇文章在之前的代码上做了改进,所以我把之前的代码复制了一份,再次打开发现这个界面:
如何打开 C# 设计窗口:
改进过程:
1.halcon 部分
在halcon中打开采集助手,自动检测接口,连接,实时,插入代码
Halcon 代码的一部分是:
* Image Acquisition 01: Code generated by Image Acquisition 01
open_framegrabber ('GigEVision2', 0, 0, 0, 0, 0, 0, 'progressive', 8, 'rgb', -1, 'false', 'default', '0030532361ef_Basler_acA160020gc', 0, -1, AcqHandle)
grab_image_start (AcqHandle, -1)
while (true)
grab_image_async (Image, AcqHandle, -1)
get_image_size (Image, Width, Height)
dev_set_part (0, 0, Height, Width)
endwhile
close_framegrabber (AcqHandle)
2.C#部分
配置如上一篇文章,我直接用上次代码改了,所以没有重新配置。
添加控件定时器,属性栏如下。定时器方法不准确,间隔越长越不准确。单击闪电符号,Interval 更改为 40ms,事件将在 40ms 后执行。定时器开启后,不要采集关闭,否则会出现错误:HALCON error #2454: HALCON handle has already clear in operatorgrab_image_async
下一步就是双击不同的控件,然后将halcon导出的代码复制粘贴到相应位置即可。
在Halcon导出的C#代码中,只需要关注action函数中的代码即可:
// Local iconic variables
HObject ho_Image=null;
// Local control variables
HTuple hv_AcqHandle = new HTuple(), hv_Width = new HTuple();
HTuple hv_Height = new HTuple();
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Image);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
while ((int)(1) != 0)
{
ho_Image.Dispose();
HOperatorSet.GrabImageAsync(out ho_Image, hv_AcqHandle, -1);
hv_Width.Dispose();hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Image, out hv_Width, out hv_Height);
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
}
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Image.Dispose();
hv_AcqHandle.Dispose();
hv_Width.Dispose();
hv_Height.Dispose();
打开相机部分的代码:
#region 打开相机
private void button3_Click(object sender, EventArgs e)
{
//清空、打开、初始化相机
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Timg);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
textBox1.Text = "相机已打开!";
}
#endregion
采集显示部分代码:
注意:如果显示的图像只是halcon中可以看到的一部分,则说明halcon中没有使用dev_set_part()函数
#region 采集显示
///
/// 此部分包含定时器的触发
///
///
///
private void button4_Click(object sender, EventArgs e)
{
timer1.Enabled = true;
//打开窗口显示图片
HOperatorSet.OpenWindow(0, 0, hWindowControl1.Width, hWindowControl1.Height, hWindowControl1.HalconWindow, "visible", "", out hv_WindowHandle);
HDevWindowStack.Push(hv_WindowHandle);
}
private void timer1_Tick(object sender, EventArgs e)
{
ho_Timg.Dispose();
//获取图片
HOperatorSet.GrabImageAsync(out ho_Timg, hv_AcqHandle, -1);
//获取图片长宽
hv_Width.Dispose(); hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Timg, out hv_Width, out hv_Height);
//设置获取的图片在窗口中显示大小(此部分如果没有,则只能显示采集到的一部分图像)
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
//如果窗口打开,显示图片
if (HDevWindowStack.IsOpen())
{
HOperatorSet.DispObj(ho_Timg, HDevWindowStack.GetActive());
textBox1.Text = "实时录像成功!";
}
}
#endregion
关闭相机部分代码:
#region 关闭相机
private void button5_Click(object sender, EventArgs e)
{
//关闭定时器这步十分重要,不能少了
timer1.Enabled = false;
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Timg.Dispose();
textBox1.Text = "关闭相机成功!";
}
#endregion
Halcon与C#实时采集图像相关教程Unity与nodejs实时连接,实时音视频图像识别halcon基础应用及方法经验分享构建直播时实时音视频平台(一)实时预测用户对物品的偏好阿里云推荐引擎帮助您更好的提升业务。海量数据实时查询域名数据库设计小记(一)Spark实时e -商务数据分析与可视化HTML前端实时可视化开发工具Android平台美颜相机/相机实时滤镜/视频编解码/图片贴/人脸 查看全部
文章实时采集(
启蒙续集之Halcon联合C#以及手眼以及标定实时采集方法)
Halcon结合C#实时采集图像 Halcon结合C#实时采集图像
内容中引用的学习课程为超人视频:Halcon结合C#和手眼校准
实时采集方法有四种:循环采集、定时器、多线程、回调函数
这篇文章在之前的代码上做了改进,所以我把之前的代码复制了一份,再次打开发现这个界面:

如何打开 C# 设计窗口:

改进过程:
1.halcon 部分
在halcon中打开采集助手,自动检测接口,连接,实时,插入代码




Halcon 代码的一部分是:
* Image Acquisition 01: Code generated by Image Acquisition 01
open_framegrabber ('GigEVision2', 0, 0, 0, 0, 0, 0, 'progressive', 8, 'rgb', -1, 'false', 'default', '0030532361ef_Basler_acA160020gc', 0, -1, AcqHandle)
grab_image_start (AcqHandle, -1)
while (true)
grab_image_async (Image, AcqHandle, -1)
get_image_size (Image, Width, Height)
dev_set_part (0, 0, Height, Width)
endwhile
close_framegrabber (AcqHandle)
2.C#部分
配置如上一篇文章,我直接用上次代码改了,所以没有重新配置。
添加控件定时器,属性栏如下。定时器方法不准确,间隔越长越不准确。单击闪电符号,Interval 更改为 40ms,事件将在 40ms 后执行。定时器开启后,不要采集关闭,否则会出现错误:HALCON error #2454: HALCON handle has already clear in operatorgrab_image_async


下一步就是双击不同的控件,然后将halcon导出的代码复制粘贴到相应位置即可。
在Halcon导出的C#代码中,只需要关注action函数中的代码即可:
// Local iconic variables
HObject ho_Image=null;
// Local control variables
HTuple hv_AcqHandle = new HTuple(), hv_Width = new HTuple();
HTuple hv_Height = new HTuple();
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Image);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
while ((int)(1) != 0)
{
ho_Image.Dispose();
HOperatorSet.GrabImageAsync(out ho_Image, hv_AcqHandle, -1);
hv_Width.Dispose();hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Image, out hv_Width, out hv_Height);
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
}
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Image.Dispose();
hv_AcqHandle.Dispose();
hv_Width.Dispose();
hv_Height.Dispose();
打开相机部分的代码:
#region 打开相机
private void button3_Click(object sender, EventArgs e)
{
//清空、打开、初始化相机
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Timg);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
textBox1.Text = "相机已打开!";
}
#endregion
采集显示部分代码:
注意:如果显示的图像只是halcon中可以看到的一部分,则说明halcon中没有使用dev_set_part()函数
#region 采集显示
///
/// 此部分包含定时器的触发
///
///
///
private void button4_Click(object sender, EventArgs e)
{
timer1.Enabled = true;
//打开窗口显示图片
HOperatorSet.OpenWindow(0, 0, hWindowControl1.Width, hWindowControl1.Height, hWindowControl1.HalconWindow, "visible", "", out hv_WindowHandle);
HDevWindowStack.Push(hv_WindowHandle);
}
private void timer1_Tick(object sender, EventArgs e)
{
ho_Timg.Dispose();
//获取图片
HOperatorSet.GrabImageAsync(out ho_Timg, hv_AcqHandle, -1);
//获取图片长宽
hv_Width.Dispose(); hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Timg, out hv_Width, out hv_Height);
//设置获取的图片在窗口中显示大小(此部分如果没有,则只能显示采集到的一部分图像)
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
//如果窗口打开,显示图片
if (HDevWindowStack.IsOpen())
{
HOperatorSet.DispObj(ho_Timg, HDevWindowStack.GetActive());
textBox1.Text = "实时录像成功!";
}
}
#endregion
关闭相机部分代码:
#region 关闭相机
private void button5_Click(object sender, EventArgs e)
{
//关闭定时器这步十分重要,不能少了
timer1.Enabled = false;
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Timg.Dispose();
textBox1.Text = "关闭相机成功!";
}
#endregion
Halcon与C#实时采集图像相关教程Unity与nodejs实时连接,实时音视频图像识别halcon基础应用及方法经验分享构建直播时实时音视频平台(一)实时预测用户对物品的偏好阿里云推荐引擎帮助您更好的提升业务。海量数据实时查询域名数据库设计小记(一)Spark实时e -商务数据分析与可视化HTML前端实时可视化开发工具Android平台美颜相机/相机实时滤镜/视频编解码/图片贴/人脸
文章实时采集(优采云·云采集网络爬虫软件如何高效抓取网站文章(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-29 08:10
优采云·Cloud采集网络爬虫软件优采云·Cloud采集网络爬虫软件如何高效爬取网站文章现在大部分内容已经完成需要参考很多网页文章,那么今天的互联网报告开发中如何高效抓取网站文章。本文以UO标题为例。UC头条是UC浏览器团队打造的新闻资讯推荐平台,拥有海量新闻资讯内容,通过阿里大数据推荐和机器学习算法,为用户提供优质贴心的文章 . 很多用户可能有采集UC头条文章采集的需求,这里有采集文章的文字和图片。正文可以直接采集,对于图片,必须先下载图片网址采集,然后将图片网址批量转换成图片。本文中采集UC标题文章和采集的字段为:标题、出版商、发布时间、文章内容、页面网址、图片网址、图片存储地址. 采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门
网页打开后,默认显示“推荐”文章。观察到该网页没有翻页按钮,而是通过下拉加载,不断加载新内容。因此,我们选择“打开网页”这一步,在高级选项中勾选“页面加载后向下滚动”,滚动根据自己的需要设置次数,根据网页设置间隔时间装载情况。滚动方式为“向下滚动一屏”,然后点击“确定”(注意:间隔时间需要针对网站情况设置,不是绝对。一般情况下间隔时间>网站 加载时间够了,有时候网速慢,网页加载慢,并且需要根据具体情况进行调整。详情请看:优采云7.0Tutorial-AJAX滚动教程HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t =1) 超链接 "/article /javascript:;" 第二步:创建翻页循环并提取数据 1) 移动鼠标,选择页面上的第一个文章链接。系统会自动识别相似链接。在操作提示框中选择“全选”2)选择“循环点击每个链接”3)系统会自动进入文章详情页面。点击需要采集的字段(先点击这里文章title),在操作提示框中选择“采集元素的文本”<
以下采集是文章 HYPERLINK "/article/javascript:;" 的正文 第三步:提取UC标题文章图片地址1)接下来开始采集图片地址。点击文章中的第一张图片,然后点击页面上的第二张图片。在弹出的操作提示框中选择“采集下图地址”2)修改字段名,然后点击“确定”3)现在我们有了采集@ > 到达图片网址,我们准备批量导出图片。批量导出图片时,我们希望将同一文章文章中的图片放到同一个文件中,文件夹名称为文章。首先我们选择标题,在操作提示框中选择“采集
我们通过这个Xpath发现://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,都需要在页面文章都位于。3) 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定” 第五步:文章Data采集并导出1)点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集” 注意:本地采集占用当前电脑资源继续采集,如果有采集时间要求或当前电脑长时间无法执行采集可以使用云采集功能,云采集在网络 采集 ,没有当前电脑的支持,电脑可以关机,可以设置多个云节点共享任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集 @>数据可以在云端存储三个月,随时可以导出。采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好的数据。这里我们选择excel作为导出格式,导出数据如下图 Step 6: HYPERLINK "/article/javascript:;" 批量将图片网址转换为图片。经过以上操作,我们得到了图片的URL为采集。接下来使用优采云专用图片批量下载工具
图片批量下载工具:HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)download优采云 图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件< @2) 打开文件菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式的文件)3) 进行相关设置。设置完成后,单击“确定”导入文件。选择EXCEL文件:导入需要下载图片地址的EXCEL文件。名称:对应数据表的名称 File URL 列名称:表中对应URL的列名称,这里是“图片网址”保存文件夹名称:EXCEL中需要单独的一栏列出图片所在的路径想要保存到文件夹中,
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。2、功能强大,任意一个网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。3、云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。4、特色免费+增值服务,您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 查看全部
文章实时采集(优采云·云采集网络爬虫软件如何高效抓取网站文章(组图))
优采云·Cloud采集网络爬虫软件优采云·Cloud采集网络爬虫软件如何高效爬取网站文章现在大部分内容已经完成需要参考很多网页文章,那么今天的互联网报告开发中如何高效抓取网站文章。本文以UO标题为例。UC头条是UC浏览器团队打造的新闻资讯推荐平台,拥有海量新闻资讯内容,通过阿里大数据推荐和机器学习算法,为用户提供优质贴心的文章 . 很多用户可能有采集UC头条文章采集的需求,这里有采集文章的文字和图片。正文可以直接采集,对于图片,必须先下载图片网址采集,然后将图片网址批量转换成图片。本文中采集UC标题文章和采集的字段为:标题、出版商、发布时间、文章内容、页面网址、图片网址、图片存储地址. 采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门
网页打开后,默认显示“推荐”文章。观察到该网页没有翻页按钮,而是通过下拉加载,不断加载新内容。因此,我们选择“打开网页”这一步,在高级选项中勾选“页面加载后向下滚动”,滚动根据自己的需要设置次数,根据网页设置间隔时间装载情况。滚动方式为“向下滚动一屏”,然后点击“确定”(注意:间隔时间需要针对网站情况设置,不是绝对。一般情况下间隔时间>网站 加载时间够了,有时候网速慢,网页加载慢,并且需要根据具体情况进行调整。详情请看:优采云7.0Tutorial-AJAX滚动教程HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t =1) 超链接 "/article /javascript:;" 第二步:创建翻页循环并提取数据 1) 移动鼠标,选择页面上的第一个文章链接。系统会自动识别相似链接。在操作提示框中选择“全选”2)选择“循环点击每个链接”3)系统会自动进入文章详情页面。点击需要采集的字段(先点击这里文章title),在操作提示框中选择“采集元素的文本”<
以下采集是文章 HYPERLINK "/article/javascript:;" 的正文 第三步:提取UC标题文章图片地址1)接下来开始采集图片地址。点击文章中的第一张图片,然后点击页面上的第二张图片。在弹出的操作提示框中选择“采集下图地址”2)修改字段名,然后点击“确定”3)现在我们有了采集@ > 到达图片网址,我们准备批量导出图片。批量导出图片时,我们希望将同一文章文章中的图片放到同一个文件中,文件夹名称为文章。首先我们选择标题,在操作提示框中选择“采集
我们通过这个Xpath发现://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,都需要在页面文章都位于。3) 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定” 第五步:文章Data采集并导出1)点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集” 注意:本地采集占用当前电脑资源继续采集,如果有采集时间要求或当前电脑长时间无法执行采集可以使用云采集功能,云采集在网络 采集 ,没有当前电脑的支持,电脑可以关机,可以设置多个云节点共享任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集 @>数据可以在云端存储三个月,随时可以导出。采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好的数据。这里我们选择excel作为导出格式,导出数据如下图 Step 6: HYPERLINK "/article/javascript:;" 批量将图片网址转换为图片。经过以上操作,我们得到了图片的URL为采集。接下来使用优采云专用图片批量下载工具
图片批量下载工具:HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)download优采云 图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件< @2) 打开文件菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式的文件)3) 进行相关设置。设置完成后,单击“确定”导入文件。选择EXCEL文件:导入需要下载图片地址的EXCEL文件。名称:对应数据表的名称 File URL 列名称:表中对应URL的列名称,这里是“图片网址”保存文件夹名称:EXCEL中需要单独的一栏列出图片所在的路径想要保存到文件夹中,
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。2、功能强大,任意一个网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。3、云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。4、特色免费+增值服务,您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。
文章实时采集(p2p贷款如何让你看到的不仅仅是你想看到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-27 04:05
文章实时采集人们的无形财富并保存。请认真阅读此文,及时阅读最新的渠道策略和工具策略,对于你未来的理财非常有帮助。人们在网上获取有价值的信息。所以让你看到的不仅仅是你想看到的。就算不那么好,也是必要的。让我们先来看一下以下这张图:来自一个很有个性的网站,它内容全是你自己的财务状况,收入和支出情况。它也是一个非常有名气的服务供应商,它的名字叫p2p贷款。
在这个网站上的所有公司名称全是独特的,但它们的所有内容全是相同的。我相信这样做会有助于你解决风险和预期成本。风险:风险在于,我不确定我看到的是不是我想看到的。但我在网上找到了我想看到的东西。支出:收入支出全是相同的。(实际上要比收入支出总量更少)。所以不要在这样的一个服务上投入太多精力。并且分散到很多低风险的贷款上,这会提高我们的收益。
当然最好选择那些产品太丰富而有一些小问题的网站。重要的是,人们不会将这个服务当成一个额外的放贷者来看待。而是将它看成一个有生意的好客户。同时他们也会为了符合我们的规则和尽可能多的贷款资质来创建。如果你要征信违约的,很遗憾,你的钱是不会到另一个人手里。换句话说,我建议你提供个人信息,还是要看那些需要的细节情况。
如果你已经做到了,就应该尽量多提供这些数据和信息,这就像如果你已经成为一个常人,你就应该能基本做到一样。当然比你想象的那样,你提供信息的人们会要求更多。这个时候你就不得不提供给他们我们需要的数据,这就是后话了。回到基础设施角度,你要问自己,那么多公司,不同的风险偏好,如何保存这些信息?你将他们分割到尽可能多的贷款上吗?有两种做法。
1.将这些贷款不要提供给不想对他们负责的人,就比如要设置自己的账户,它的利率,还款方式。2.将他们打包在一起。3.或者你再其他地方存储这些数据的时候,只分发前2种。4.不对他们负责5.不对他们负责6.不对他们负责一个更快捷的方法是购买短期贷款,然后把每月的款项打到那里7.将短期贷款作为其他可支配贷款的替代品而不是存在自己的账户8.重要的是要记住,到头来他们都只是一次性贷款。
如果你不把他们放到新贷款,那你之前所有的贷款都会消失。他们也不再能帮助你。这意味着你把所有的短期贷款一次性购买一次性偿还,而不是分别购买。9.银行的支持,找一个靠谱的信用卡公司或者支付公司,让他们们看看你的资金状况,然后帮你审批贷款。10.没有谁需要你花钱买他们,重要的是你的钱。11.不要将短期贷款放在不确定的贷款机构。你正在设置你的账户,通常。 查看全部
文章实时采集(p2p贷款如何让你看到的不仅仅是你想看到)
文章实时采集人们的无形财富并保存。请认真阅读此文,及时阅读最新的渠道策略和工具策略,对于你未来的理财非常有帮助。人们在网上获取有价值的信息。所以让你看到的不仅仅是你想看到的。就算不那么好,也是必要的。让我们先来看一下以下这张图:来自一个很有个性的网站,它内容全是你自己的财务状况,收入和支出情况。它也是一个非常有名气的服务供应商,它的名字叫p2p贷款。
在这个网站上的所有公司名称全是独特的,但它们的所有内容全是相同的。我相信这样做会有助于你解决风险和预期成本。风险:风险在于,我不确定我看到的是不是我想看到的。但我在网上找到了我想看到的东西。支出:收入支出全是相同的。(实际上要比收入支出总量更少)。所以不要在这样的一个服务上投入太多精力。并且分散到很多低风险的贷款上,这会提高我们的收益。
当然最好选择那些产品太丰富而有一些小问题的网站。重要的是,人们不会将这个服务当成一个额外的放贷者来看待。而是将它看成一个有生意的好客户。同时他们也会为了符合我们的规则和尽可能多的贷款资质来创建。如果你要征信违约的,很遗憾,你的钱是不会到另一个人手里。换句话说,我建议你提供个人信息,还是要看那些需要的细节情况。
如果你已经做到了,就应该尽量多提供这些数据和信息,这就像如果你已经成为一个常人,你就应该能基本做到一样。当然比你想象的那样,你提供信息的人们会要求更多。这个时候你就不得不提供给他们我们需要的数据,这就是后话了。回到基础设施角度,你要问自己,那么多公司,不同的风险偏好,如何保存这些信息?你将他们分割到尽可能多的贷款上吗?有两种做法。
1.将这些贷款不要提供给不想对他们负责的人,就比如要设置自己的账户,它的利率,还款方式。2.将他们打包在一起。3.或者你再其他地方存储这些数据的时候,只分发前2种。4.不对他们负责5.不对他们负责6.不对他们负责一个更快捷的方法是购买短期贷款,然后把每月的款项打到那里7.将短期贷款作为其他可支配贷款的替代品而不是存在自己的账户8.重要的是要记住,到头来他们都只是一次性贷款。
如果你不把他们放到新贷款,那你之前所有的贷款都会消失。他们也不再能帮助你。这意味着你把所有的短期贷款一次性购买一次性偿还,而不是分别购买。9.银行的支持,找一个靠谱的信用卡公司或者支付公司,让他们们看看你的资金状况,然后帮你审批贷款。10.没有谁需要你花钱买他们,重要的是你的钱。11.不要将短期贷款放在不确定的贷款机构。你正在设置你的账户,通常。
文章实时采集( 80集Python基础入门视频教学点免费观看事百科段子)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-24 11:17
80集Python基础入门视频教学点免费观看事百科段子)
Python爬虫实战练习:采集尴尬百科段数据
更新时间:2021年10月21日10:45:35 作者:松鼠爱吃饼干
读一万本书不如行万里。仅仅学习书中的理论是远远不够的。只有在实战中才能获得能力的提升。段落的数据,可以检查过程中的差距,提高水平
内容
知识点
1.爬行的基本步骤
2.请求模块
3.解析模块
4.xpath数据分析方法
5.分页功能
爬虫的基本步骤:
1.获取网页地址(维基百科段落地址)
2.发送请求
3.数据分析
4.本地保存
爬虫代码导入需要的模块
import re
import requests
import parsel
获取网址
url = 'https://www.qiushibaike.com/text/'
# 请求头 伪装客户端向服务器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
发送请求
requ = requests.get(url=url, headers=headers).text
数据分析
sel = parsel.Selector(requ) # 解析对象
href = sel.xpath('//body/div/div/div[2]/div/a[1]/@href').getall()
for html in href:
txt_href = 'https://www.qiushibaike.com' + html
requ2 = requests.get(url=txt_href, headers=headers).text
sel2 = parsel.Selector(requ2)
title = sel2.xpath('//body/div[2]/div/div[2]/h1/text()').get().strip()
title = re.sub(r'[|/\:?*]','_',title)
# content = sel2.xpath('//div[@class="content"]/text()').getall()
content = sel2.xpath('//body/div[2]/div/div[2]/div[2]/div[1]/div/text()').getall()
contents = '\n'.join(content)
保存数据
with open('糗事百科text\\'+title + '.txt', mode='w', encoding='utf-8') as fp:
fp.write(contents)
print(title, '下载成功')
运行代码获取数据
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
至此,这篇关于Python爬虫实战演练采集尴尬百科段落数据文章的介绍就到这里,更多Python相关采集尴尬百科段落内容,请搜索脚本首页上一页< @文章 或继续浏览下方的相关文章,希望大家以后多多支持Scripthome! 查看全部
文章实时采集(
80集Python基础入门视频教学点免费观看事百科段子)
Python爬虫实战练习:采集尴尬百科段数据
更新时间:2021年10月21日10:45:35 作者:松鼠爱吃饼干
读一万本书不如行万里。仅仅学习书中的理论是远远不够的。只有在实战中才能获得能力的提升。段落的数据,可以检查过程中的差距,提高水平
内容
知识点
1.爬行的基本步骤
2.请求模块
3.解析模块
4.xpath数据分析方法
5.分页功能
爬虫的基本步骤:
1.获取网页地址(维基百科段落地址)
2.发送请求
3.数据分析
4.本地保存
爬虫代码导入需要的模块
import re
import requests
import parsel
获取网址
url = 'https://www.qiushibaike.com/text/'
# 请求头 伪装客户端向服务器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
发送请求
requ = requests.get(url=url, headers=headers).text
数据分析
sel = parsel.Selector(requ) # 解析对象
href = sel.xpath('//body/div/div/div[2]/div/a[1]/@href').getall()
for html in href:
txt_href = 'https://www.qiushibaike.com' + html
requ2 = requests.get(url=txt_href, headers=headers).text
sel2 = parsel.Selector(requ2)
title = sel2.xpath('//body/div[2]/div/div[2]/h1/text()').get().strip()
title = re.sub(r'[|/\:?*]','_',title)
# content = sel2.xpath('//div[@class="content"]/text()').getall()
content = sel2.xpath('//body/div[2]/div/div[2]/div[2]/div[1]/div/text()').getall()
contents = '\n'.join(content)
保存数据
with open('糗事百科text\\'+title + '.txt', mode='w', encoding='utf-8') as fp:
fp.write(contents)
print(title, '下载成功')
运行代码获取数据


【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
至此,这篇关于Python爬虫实战演练采集尴尬百科段落数据文章的介绍就到这里,更多Python相关采集尴尬百科段落内容,请搜索脚本首页上一页< @文章 或继续浏览下方的相关文章,希望大家以后多多支持Scripthome!
文章实时采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-23 11:11
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,使用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、 方案说明(一) 概述 本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输到CKafka,将CKafka数据连接到Oceanus(Flink)进行流计算,通过简单的业务逻辑处理输出到Elasticsearch,最后通过Kibana页面查询结果。计划中使用Promethus监控系统指标,如作为流计算 Oceanus 作业运行状态,Cloud Grafana 监控 CVM 或业务应用指标。
(二)方案架构
二、前期准备 在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私网VPC 私网VPC是您在腾讯云上自定义的逻辑隔离的网络空间,建议在搭建CKafka、流计算Oceanus、Elasticsearch集群等时选择同一个VPC服务.详情创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka建议选择最新的2.4.1版本,与Filebeat兼容性更好< @采集工具购买完成后,创建一个Kafka主题:topic-app-info(三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。基于Apache Flink,一站式开发,无缝连接、亚秒级延迟、低成本、安全稳定的企业级实时大数据分析平台。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。在流计算中在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源独立Grafana在灰色发布中,需要在Grafana管理页面()单独购买,实现业务监控指标的展示。
(七)安装配置Filebeat Filebeat是一个轻量级的日志数据工具采集,通过监控指定位置的文件来采集信息,在这个VPC下提供给需要监控主机的云服务器信息及应用信息 安装Filebeat 安装方法一:下载Filebeat 下载地址(); 方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例采用方法一。下载到CVM然后配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集jar应用日志、JVM使用情况、监听端口等,详情请参考Filebeat官网
()。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、 进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。1、 定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据,在Kibana上查询数据ES控制台页面,或进入同一子网的CVM下,使用以下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。(三)系统指标监控本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据的存储、计算和告警。流计算Oceanus建议用户使用腾讯云监控提供的Prometheus服务,避免部署和运维成本,同时还支持腾讯云的通知模板,可以通过短信、电话、邮件等方式轻松到达不同的报警信息、企业微信机器人等 Receiver. 监控配置 流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任何流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(灰度级Grafana这里不能输入),并导入json文件。详情请参考访问 Prometheus 自定义监视器
()。
3、3、显示的Flink任务监控效果如下,用户也可以点击【编辑】设置不同的Panel,优化显示效果。
告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】 ] 配置相关信息。具体操作请参考访问Prometheus自定义监控()。
2、设置报警通知。选择[选择模板]或[新建]设置通知模板。
3、短信通知信息
(四)业务指标监控通过Filebeat采集给应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰色发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】 ,搜索elasticsearch,填写相关ES实例信息,添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:
注:本办公室仅为示例,无实际业务
四、总结 本方案尝试了系统监控指标和业务监控指标两个监控方案。如果只需要监控业务指标,可以省略Prometus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”,了解更多腾讯云流媒体Oceanus~腾讯云大数据
长按二维码 查看全部
文章实时采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,使用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、 方案说明(一) 概述 本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输到CKafka,将CKafka数据连接到Oceanus(Flink)进行流计算,通过简单的业务逻辑处理输出到Elasticsearch,最后通过Kibana页面查询结果。计划中使用Promethus监控系统指标,如作为流计算 Oceanus 作业运行状态,Cloud Grafana 监控 CVM 或业务应用指标。

(二)方案架构

二、前期准备 在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私网VPC 私网VPC是您在腾讯云上自定义的逻辑隔离的网络空间,建议在搭建CKafka、流计算Oceanus、Elasticsearch集群等时选择同一个VPC服务.详情创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka建议选择最新的2.4.1版本,与Filebeat兼容性更好< @采集工具购买完成后,创建一个Kafka主题:topic-app-info(三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。基于Apache Flink,一站式开发,无缝连接、亚秒级延迟、低成本、安全稳定的企业级实时大数据分析平台。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。在流计算中在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源独立Grafana在灰色发布中,需要在Grafana管理页面()单独购买,实现业务监控指标的展示。
(七)安装配置Filebeat Filebeat是一个轻量级的日志数据工具采集,通过监控指定位置的文件来采集信息,在这个VPC下提供给需要监控主机的云服务器信息及应用信息 安装Filebeat 安装方法一:下载Filebeat 下载地址(); 方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例采用方法一。下载到CVM然后配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集jar应用日志、JVM使用情况、监听端口等,详情请参考Filebeat官网
()。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、 进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。1、 定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据,在Kibana上查询数据ES控制台页面,或进入同一子网的CVM下,使用以下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。(三)系统指标监控本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据的存储、计算和告警。流计算Oceanus建议用户使用腾讯云监控提供的Prometheus服务,避免部署和运维成本,同时还支持腾讯云的通知模板,可以通过短信、电话、邮件等方式轻松到达不同的报警信息、企业微信机器人等 Receiver. 监控配置 流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任何流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(灰度级Grafana这里不能输入),并导入json文件。详情请参考访问 Prometheus 自定义监视器
()。

3、3、显示的Flink任务监控效果如下,用户也可以点击【编辑】设置不同的Panel,优化显示效果。

告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】 ] 配置相关信息。具体操作请参考访问Prometheus自定义监控()。

2、设置报警通知。选择[选择模板]或[新建]设置通知模板。

3、短信通知信息
(四)业务指标监控通过Filebeat采集给应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰色发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】 ,搜索elasticsearch,填写相关ES实例信息,添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:

注:本办公室仅为示例,无实际业务
四、总结 本方案尝试了系统监控指标和业务监控指标两个监控方案。如果只需要监控业务指标,可以省略Prometus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”,了解更多腾讯云流媒体Oceanus~腾讯云大数据
长按二维码
文章实时采集(查找自媒体爆文素材比较方便的渠道,合理的使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2021-10-22 00:03
从事自媒体运营行业,每天都需要不断学习新知识,比如标题的写作技巧是什么,如何切入热点跟踪角度,这些都需要积极阅读材料和然后学习,但学习的目的归根结底还是你自己的实际操作。如果我们每天都需要大量的文章素材,而且都是优质的爆文素材,我们不可能天天到处搜索,那么有没有什么工具可以实现呢?
今天小编为大家推荐三个采集站点自媒体爆文。当你需要大量爆文资料参考时,只要根据自己的行业数据想知道关键词都可以看到。
1、简单的文章
易传采集拥有市面上所有主流自媒体平台的所有爆文数据,并提供基础阅读分析数据和互动数据。参考采集的爆文的分析,为我自己的创作提供灵感和方向。
您也可以根据您的特定领域搜索您想要的爆文材料。除了采集爆文,您还可以提供文章编辑、短视频素材采集和下载、文章原创度检测和真实-时间热点追踪功能,是一款非常好用的自媒体辅助工具。
2、西瓜助手
西瓜助手的西瓜数据也是采集很多领域的爆文素材。不同的是它有提取标签的功能,而且在一些有用的工具中还有热门标题的更新,聊胜于无。毕竟,不是每个人都可以使用它。
3、乐观
Optimism的优势之一是网站的部分功能无需注册即可应用,详细功能需要登录。Optimism 没有很多内容筛选,但是可以绑定一些边缘自媒体平台,然后一键将内容同步到这些平台。
以上三个网站是小编觉得找自媒体爆文素材比较方便的渠道。对于刚刚进入行业的新人来说,合理使用这三个。一个网站可以大大提高自己的运营效率。 查看全部
文章实时采集(查找自媒体爆文素材比较方便的渠道,合理的使用)
从事自媒体运营行业,每天都需要不断学习新知识,比如标题的写作技巧是什么,如何切入热点跟踪角度,这些都需要积极阅读材料和然后学习,但学习的目的归根结底还是你自己的实际操作。如果我们每天都需要大量的文章素材,而且都是优质的爆文素材,我们不可能天天到处搜索,那么有没有什么工具可以实现呢?

今天小编为大家推荐三个采集站点自媒体爆文。当你需要大量爆文资料参考时,只要根据自己的行业数据想知道关键词都可以看到。
1、简单的文章
易传采集拥有市面上所有主流自媒体平台的所有爆文数据,并提供基础阅读分析数据和互动数据。参考采集的爆文的分析,为我自己的创作提供灵感和方向。
您也可以根据您的特定领域搜索您想要的爆文材料。除了采集爆文,您还可以提供文章编辑、短视频素材采集和下载、文章原创度检测和真实-时间热点追踪功能,是一款非常好用的自媒体辅助工具。
2、西瓜助手
西瓜助手的西瓜数据也是采集很多领域的爆文素材。不同的是它有提取标签的功能,而且在一些有用的工具中还有热门标题的更新,聊胜于无。毕竟,不是每个人都可以使用它。
3、乐观
Optimism的优势之一是网站的部分功能无需注册即可应用,详细功能需要登录。Optimism 没有很多内容筛选,但是可以绑定一些边缘自媒体平台,然后一键将内容同步到这些平台。
以上三个网站是小编觉得找自媒体爆文素材比较方便的渠道。对于刚刚进入行业的新人来说,合理使用这三个。一个网站可以大大提高自己的运营效率。
文章实时采集(基于MIT开源协议发布NSQ的数据流模型结构如下图解析 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-12 21:19
)
NSQ 是一个基于 Go 语言的分布式实时消息平台。它是基于 MIT 开源协议发布的。代码托管在 GitHub 上。最新版本为0.3.1。NSQ 可用于大型系统中的实时消息服务,每天可处理数亿条消息。它的设计目标是为在分布式环境中运行的去中心化服务提供强大的基础设施。NSQ具有分布式、去中心化的拓扑结构,具有无单点故障、容错、高可用、消息传递可靠等特点。NSQ 非常易于配置和部署,并且具有最大的灵活性,支持多种消息传递协议。此外,官方还提供了开箱即用的 Go 和 Python 库。
NSQ 由四个重要组件组成:
NSQ的主要特点如下:
为了实现高效的分布式消息服务,NSQ 实现了合理的智能权衡,使其能够在生产环境中得到充分的应用。具体内容如下:
官方和第三方也为NSQ开发了很多客户端函数库,比如官方的基于HTTP、Go客户端go-nsq、Python客户端pynsq、基于Node.js的JavaScript客户端nsqjs,以及异步C客户端libnsq、Java客户端nsq -java 和许多基于各种语言的第三方客户端函数库。更多客户端函数库请点击查看。
从NSQ设计文档可知,单个nsqd被设计为一次处理多个流数据,NSQ中的数据流模型由stream和consumer组成。Topic 是一个独特的流,Channel 是订阅给定 Topic 的消费者的逻辑分组。NSQ的数据流模型结构如下图所示:
从上图可以看出,单个nsqd可以有多个topic,每个topic可以有多个channel。Channel可以接收所有Topic消息的副本,从而实现消息组播分发;并且Channel上的每条消息都分发给它的订阅者,从而实现负载均衡,所有这些形成一个单片,可以代表各种简单和复杂的拓扑结构。
NSQ 最初是为 Bitly 开发的,Bitly 是一个提供短链接服务的应用程序。另外还有很多使用NSQ的知名应用,比如社交新闻网站Digg、私有社交应用Path、知名开源应用容器引擎Docker、支付公司Stripe、新闻聚合网站@ >Buzzfeed,移动应用Life360、 网络工具公司SimpleReach 等,用于检查家庭成员的位置。
有兴趣的读者也可以向NSQ贡献代码,反馈问题,或者通过官方的快速入门教程体验NSQ给高吞吐量网络服务带来的性能提升。NSQ安装部署、客户端开发等相关信息请登录其官网。
感谢郭磊对本文的审阅。
如有问题请联系站长微信(非本文作者)
查看全部
文章实时采集(基于MIT开源协议发布NSQ的数据流模型结构如下图解析
)
NSQ 是一个基于 Go 语言的分布式实时消息平台。它是基于 MIT 开源协议发布的。代码托管在 GitHub 上。最新版本为0.3.1。NSQ 可用于大型系统中的实时消息服务,每天可处理数亿条消息。它的设计目标是为在分布式环境中运行的去中心化服务提供强大的基础设施。NSQ具有分布式、去中心化的拓扑结构,具有无单点故障、容错、高可用、消息传递可靠等特点。NSQ 非常易于配置和部署,并且具有最大的灵活性,支持多种消息传递协议。此外,官方还提供了开箱即用的 Go 和 Python 库。
NSQ 由四个重要组件组成:
NSQ的主要特点如下:
为了实现高效的分布式消息服务,NSQ 实现了合理的智能权衡,使其能够在生产环境中得到充分的应用。具体内容如下:
官方和第三方也为NSQ开发了很多客户端函数库,比如官方的基于HTTP、Go客户端go-nsq、Python客户端pynsq、基于Node.js的JavaScript客户端nsqjs,以及异步C客户端libnsq、Java客户端nsq -java 和许多基于各种语言的第三方客户端函数库。更多客户端函数库请点击查看。
从NSQ设计文档可知,单个nsqd被设计为一次处理多个流数据,NSQ中的数据流模型由stream和consumer组成。Topic 是一个独特的流,Channel 是订阅给定 Topic 的消费者的逻辑分组。NSQ的数据流模型结构如下图所示:

从上图可以看出,单个nsqd可以有多个topic,每个topic可以有多个channel。Channel可以接收所有Topic消息的副本,从而实现消息组播分发;并且Channel上的每条消息都分发给它的订阅者,从而实现负载均衡,所有这些形成一个单片,可以代表各种简单和复杂的拓扑结构。
NSQ 最初是为 Bitly 开发的,Bitly 是一个提供短链接服务的应用程序。另外还有很多使用NSQ的知名应用,比如社交新闻网站Digg、私有社交应用Path、知名开源应用容器引擎Docker、支付公司Stripe、新闻聚合网站@ >Buzzfeed,移动应用Life360、 网络工具公司SimpleReach 等,用于检查家庭成员的位置。
有兴趣的读者也可以向NSQ贡献代码,反馈问题,或者通过官方的快速入门教程体验NSQ给高吞吐量网络服务带来的性能提升。NSQ安装部署、客户端开发等相关信息请登录其官网。
感谢郭磊对本文的审阅。
如有问题请联系站长微信(非本文作者)

文章实时采集(日志解析失败错误json._root.yml)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-09 10:17
说明 Filebeat 版本为 5.3.0
之所以用beats家族的Filebeat来代替Logstash,是因为Logstash消耗资源太多(如果服务器资源充足请忽略)
官网下载Logstash有89M,而Filebeat只有8.4M,可见
Logstash 可以配置 jvm 参数。经过我自己调试,内存分配小,启动很慢,有时根本起不来。如果分配很大,其他服务将没有资源。
都说对于低配置的服务器,选择Filebeat是最好的选择,现在Filebeat已经开始替代Logstash了。还是需要修改nginx的日志格式,nginx.config。
更改日志记录的格式
log_format json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
文件节拍.yml
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/*access*.log
json.keys_under_root: true
json.overwrite_keys: true
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["ip:port","ip:port"]
index: "filebeat_server_nginx_%{+YYYY-MM}"
这里要注意的是
json.keys_under_root:默认值为FALSE,表示我们的json日志解析后会放在json key上。设置为 TRUE,所有键都将放置在根节点中
json.overwrite_keys:是否覆盖原来的key,这个是key的配置。设置keys_under_root为TRUE后,再设置overwrite_keys为TRUE,覆盖filebeat的默认key值
还有其他配置
json.add_error_key: 添加json_error key key 记录json解析失败错误
json.message_key:指定解析后的json日志放哪个key,默认为json,也可以指定log等。
说白了,区别就是elasticsearch的配置前的数据是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9sVOkCcRcg0IPg399",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T03:00:17.544Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"input_type": "log",
"json": {},
"message": "{ "@timestamp": "2018-05-08T11:00:11+08:00", "time": "2018-05-08T11:00:11+08:00", "remote_addr": "113.16.251.67", "remote_user": "-", "body_bytes_sent": "403", "request_time": "0.000", "status": "200", "host": "blog.joylau.cn", "request": "GET /img/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90.png HTTP/1.1", "request_method": "GET", "uri": "/img/\xE7\xBD\x91\xE6\x98\x93\xE4\xBA\x91\xE9\x9F\xB3\xE4\xB9\x90.png", "http_referrer": "http://blog.joylau.cn/css/style.css", "body_bytes_sent":"403", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" }",
"offset": 7633,
"source": "/var/log/nginx/access.log",
"type": "log"
}
}
配置好之后是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9rjLd8mVZNgvhdnN9",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T02:56:50.000Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"body_bytes_sent": "12576",
"host": "blog.joylau.cn",
"http_referrer": "http://blog.joylau.cn/",
"http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"http_x_forwarded_for": "-",
"input_type": "log",
"offset": 3916,
"remote_addr": "60.166.12.138",
"remote_user": "-",
"request": "GET /2018/03/01/JDK8-Stream-Distinct/ HTTP/1.1",
"request_method": "GET",
"request_time": "0.000",
"source": "/var/log/nginx/access.log",
"status": "200",
"time": "2018-05-08T10:56:50+08:00",
"type": "log",
"uri": "/2018/03/01/JDK8-Stream-Distinct/index.html"
}
}
所以看起来很舒服
启动 FileBeat
进入Filebeat目录
nohup sudo ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
更新
如果 nginx 日志收录中文,则会将中文转换为 Unicode 编码。如果没有,只需添加 escape=json 参数。
log_format json escape=json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
信息 查看全部
文章实时采集(日志解析失败错误json._root.yml)
说明 Filebeat 版本为 5.3.0
之所以用beats家族的Filebeat来代替Logstash,是因为Logstash消耗资源太多(如果服务器资源充足请忽略)
官网下载Logstash有89M,而Filebeat只有8.4M,可见
Logstash 可以配置 jvm 参数。经过我自己调试,内存分配小,启动很慢,有时根本起不来。如果分配很大,其他服务将没有资源。
都说对于低配置的服务器,选择Filebeat是最好的选择,现在Filebeat已经开始替代Logstash了。还是需要修改nginx的日志格式,nginx.config。
更改日志记录的格式
log_format json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
文件节拍.yml
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/*access*.log
json.keys_under_root: true
json.overwrite_keys: true
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["ip:port","ip:port"]
index: "filebeat_server_nginx_%{+YYYY-MM}"
这里要注意的是
json.keys_under_root:默认值为FALSE,表示我们的json日志解析后会放在json key上。设置为 TRUE,所有键都将放置在根节点中
json.overwrite_keys:是否覆盖原来的key,这个是key的配置。设置keys_under_root为TRUE后,再设置overwrite_keys为TRUE,覆盖filebeat的默认key值
还有其他配置
json.add_error_key: 添加json_error key key 记录json解析失败错误
json.message_key:指定解析后的json日志放哪个key,默认为json,也可以指定log等。
说白了,区别就是elasticsearch的配置前的数据是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9sVOkCcRcg0IPg399",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T03:00:17.544Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"input_type": "log",
"json": {},
"message": "{ "@timestamp": "2018-05-08T11:00:11+08:00", "time": "2018-05-08T11:00:11+08:00", "remote_addr": "113.16.251.67", "remote_user": "-", "body_bytes_sent": "403", "request_time": "0.000", "status": "200", "host": "blog.joylau.cn", "request": "GET /img/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90.png HTTP/1.1", "request_method": "GET", "uri": "/img/\xE7\xBD\x91\xE6\x98\x93\xE4\xBA\x91\xE9\x9F\xB3\xE4\xB9\x90.png", "http_referrer": "http://blog.joylau.cn/css/style.css", "body_bytes_sent":"403", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" }",
"offset": 7633,
"source": "/var/log/nginx/access.log",
"type": "log"
}
}
配置好之后是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9rjLd8mVZNgvhdnN9",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T02:56:50.000Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"body_bytes_sent": "12576",
"host": "blog.joylau.cn",
"http_referrer": "http://blog.joylau.cn/",
"http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"http_x_forwarded_for": "-",
"input_type": "log",
"offset": 3916,
"remote_addr": "60.166.12.138",
"remote_user": "-",
"request": "GET /2018/03/01/JDK8-Stream-Distinct/ HTTP/1.1",
"request_method": "GET",
"request_time": "0.000",
"source": "/var/log/nginx/access.log",
"status": "200",
"time": "2018-05-08T10:56:50+08:00",
"type": "log",
"uri": "/2018/03/01/JDK8-Stream-Distinct/index.html"
}
}
所以看起来很舒服
启动 FileBeat
进入Filebeat目录
nohup sudo ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
更新
如果 nginx 日志收录中文,则会将中文转换为 Unicode 编码。如果没有,只需添加 escape=json 参数。
log_format json escape=json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
信息
文章实时采集(如何实时采集微信公众号图文信息?(附教程))
采集交流 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2021-10-05 01:01
文章实时采集微信公众号图文信息
一、目标制定选择可采集优质图文的平台进行操作,或根据图文标题/封面等进行分析判断。
二、准备工作根据工作量,以及所能采集的资源,大致可分为以下3个步骤:1.采集图文背景图的过程,请在采集页面中进行操作,请不要把素材放入某些需要填写素材目录的文件夹中。素材采集时会产生大量data_file,需要保存一份到网盘上。(如出现素材丢失或丢失的现象,请抓取原始图片并进行相应的处理。)data_file定位要求:至少要预留上传素材的路径。
操作步骤:选择图文上传目录---图文上传---上传刚刚保存的data_file.png,部分目录定位需要多次操作。2.采集图文标题的过程,请在微信平台商务后台里将标题进行命名。操作步骤:选择自己想要采集的标题,点击插入---图文标题---发送。注意标题后,请使用编号进行标注。发送时请填写上传文件的路径。
3.采集图文封面的过程,请在商务后台里设置发送标题、采集位置、收货地址等内容,并命名图文封面。操作步骤:选择采集文件目录---收货地址---设置标题---开始采集文章。图文封面采集大致如此。
三、软件选择采集微信公众号内容主要靠软件,目前市面上提供采集、编辑、群发功能的软件较多,具体可参考:今日头条采集器【软件】今日头条订阅号内容采集。新浪扶翼采集器【软件】新浪网新闻源采集。pp红采集器【软件】pp红网站内容采集。(建议在使用pp红,性价比高,主要是采集标题、封面。)今日头条【采集器】(注意需版权问题,需要购买版权才能采集封面和封面图文章。)。
四、采集过程采集过程中请注意避免出现死链、延迟采集封面图文。建议把文章的标题/封面采集到服务器(专门的服务器文件夹中)。文章采集数量不要太多,也不要太少,两三篇差不多就行。如采集到500篇,在qq群/论坛等发布扩展地址出现繁杂信息,用户点击难,即为可能出现死链。因此,文章采集需要分页,建议每页都采集,采集较长文章也能通过多个页面进行多次采集。
只有文章真正的覆盖到了微信公众号所发布的文章,才算是完成初步采集和封面采集。更多采集、编辑、微信公众号编辑排版相关文章,请关注公众号:20155633473。 查看全部
文章实时采集(如何实时采集微信公众号图文信息?(附教程))
文章实时采集微信公众号图文信息
一、目标制定选择可采集优质图文的平台进行操作,或根据图文标题/封面等进行分析判断。
二、准备工作根据工作量,以及所能采集的资源,大致可分为以下3个步骤:1.采集图文背景图的过程,请在采集页面中进行操作,请不要把素材放入某些需要填写素材目录的文件夹中。素材采集时会产生大量data_file,需要保存一份到网盘上。(如出现素材丢失或丢失的现象,请抓取原始图片并进行相应的处理。)data_file定位要求:至少要预留上传素材的路径。
操作步骤:选择图文上传目录---图文上传---上传刚刚保存的data_file.png,部分目录定位需要多次操作。2.采集图文标题的过程,请在微信平台商务后台里将标题进行命名。操作步骤:选择自己想要采集的标题,点击插入---图文标题---发送。注意标题后,请使用编号进行标注。发送时请填写上传文件的路径。
3.采集图文封面的过程,请在商务后台里设置发送标题、采集位置、收货地址等内容,并命名图文封面。操作步骤:选择采集文件目录---收货地址---设置标题---开始采集文章。图文封面采集大致如此。
三、软件选择采集微信公众号内容主要靠软件,目前市面上提供采集、编辑、群发功能的软件较多,具体可参考:今日头条采集器【软件】今日头条订阅号内容采集。新浪扶翼采集器【软件】新浪网新闻源采集。pp红采集器【软件】pp红网站内容采集。(建议在使用pp红,性价比高,主要是采集标题、封面。)今日头条【采集器】(注意需版权问题,需要购买版权才能采集封面和封面图文章。)。
四、采集过程采集过程中请注意避免出现死链、延迟采集封面图文。建议把文章的标题/封面采集到服务器(专门的服务器文件夹中)。文章采集数量不要太多,也不要太少,两三篇差不多就行。如采集到500篇,在qq群/论坛等发布扩展地址出现繁杂信息,用户点击难,即为可能出现死链。因此,文章采集需要分页,建议每页都采集,采集较长文章也能通过多个页面进行多次采集。
只有文章真正的覆盖到了微信公众号所发布的文章,才算是完成初步采集和封面采集。更多采集、编辑、微信公众号编辑排版相关文章,请关注公众号:20155633473。
文章实时采集(文章实时采集并推送给服务器,前端路由好点的话)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-04 13:03
文章实时采集并推送给服务器,服务器再推送给客户端。前端路由好点的话,抓包,分析url的utm特征,爬虫最好也接入,能抓一抓也不错,
就题主的问题,
1、抓包容易丢包或中断;
2、人工分析每一次请求中每一个字段,
3、模拟返回很累,
4、别人抓包分析你也不放心;综上,建议题主用第一个方案:一步步弄清每个字段具体含义,分析并获取链接及验证其他参数,最后聚合显示结果。
1、登录:你的每一次访问都会在你自己的服务器上生成一个记录,当你从别人那里登录后,这个登录时间段的记录就会同步到你自己的服务器上。
2、抓包:爬取的是整个站点的数据,一般的服务器都会有默认的模拟ip,打开的网页是无法发起请求的,但是你可以通过修改其他字段发送请求。
3、模拟返回:在访问一些静态文件时,你可以把它模拟成你自己的网站,这样你就能返回给你合适的网站地址,这样你每次浏览这些文件都是获取你的网站地址,顺着网址就可以到对应的服务器上了。
4、聚合:看你的爬虫是不是有收集其他网站数据的,比如ip、cookie这些,如果有的话,你就可以把这些数据爬取过来,用聚合接口就可以聚合到一起。
5、最后,所有的信息统计是比较少的,估计做不下来,更何况你分析这些数据是不是有些数据是重复的,人工统计是比较费力的,如果是数据预处理,还要编写一些特征工程代码,实现这些功能,你不可能每一次都请求数据库把重复的数据过滤出来吧,而且到时候服务器出现问题还要花时间去处理,最后数据的可用性才能得到保证,如果每一次请求都需要使用nginx,你每次请求的数据都需要到nginx的数据库中去查询,然后就把数据保存到数据库中,有一点风险。
最后,根据我的理解,你没必要大费周章,一步步从第一个到后面一个,爬虫总会成熟的,不用有点困难就困难一步,会过的很吃力的。 查看全部
文章实时采集(文章实时采集并推送给服务器,前端路由好点的话)
文章实时采集并推送给服务器,服务器再推送给客户端。前端路由好点的话,抓包,分析url的utm特征,爬虫最好也接入,能抓一抓也不错,
就题主的问题,
1、抓包容易丢包或中断;
2、人工分析每一次请求中每一个字段,
3、模拟返回很累,
4、别人抓包分析你也不放心;综上,建议题主用第一个方案:一步步弄清每个字段具体含义,分析并获取链接及验证其他参数,最后聚合显示结果。
1、登录:你的每一次访问都会在你自己的服务器上生成一个记录,当你从别人那里登录后,这个登录时间段的记录就会同步到你自己的服务器上。
2、抓包:爬取的是整个站点的数据,一般的服务器都会有默认的模拟ip,打开的网页是无法发起请求的,但是你可以通过修改其他字段发送请求。
3、模拟返回:在访问一些静态文件时,你可以把它模拟成你自己的网站,这样你就能返回给你合适的网站地址,这样你每次浏览这些文件都是获取你的网站地址,顺着网址就可以到对应的服务器上了。
4、聚合:看你的爬虫是不是有收集其他网站数据的,比如ip、cookie这些,如果有的话,你就可以把这些数据爬取过来,用聚合接口就可以聚合到一起。
5、最后,所有的信息统计是比较少的,估计做不下来,更何况你分析这些数据是不是有些数据是重复的,人工统计是比较费力的,如果是数据预处理,还要编写一些特征工程代码,实现这些功能,你不可能每一次都请求数据库把重复的数据过滤出来吧,而且到时候服务器出现问题还要花时间去处理,最后数据的可用性才能得到保证,如果每一次请求都需要使用nginx,你每次请求的数据都需要到nginx的数据库中去查询,然后就把数据保存到数据库中,有一点风险。
最后,根据我的理解,你没必要大费周章,一步步从第一个到后面一个,爬虫总会成熟的,不用有点困难就困难一步,会过的很吃力的。
文章实时采集(mysql实时数据采集框架maxwell基本介绍-苏州安嘉 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-02 11:18
)
介绍本文文章主要介绍MaxWell(Mysql实时数据采集)及相关经验和技巧。文章约13381字,浏览量317,点赞2,值得参考!
mysql实时数据采集框架maxwell基础介绍
maxwell 是一个可以实时读取 MySQL 二进制日志 binlog 并生成 JSON 格式消息的应用程序,这些消息作为生产者发送到 Kafka、Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其他平台。其常见的应用场景包括ETL、维护缓存、采集表级dml指标、递增到搜索引擎、数据分区迁移、切割数据库binlog回滚方案等。
Maxwell主要提供以下功能:
支持 SELECT * FROM 表进行 44 行全数据初始化。支持主库故障转移后binlog位置(GTID)的自动恢复。可以对数据进行分区以解决数据倾斜问题。发送到 Kafka 的数据支持数据库、表和列。等级数据分区的工作方式是伪装成slave,接收binlog事件,然后根据scheme信息进行组装,可以接受ddl、xid、row等各种事件binlog的引入。
Binlog是mysql中的二进制日志。主要用于记录mysql数据库中发生或潜在改变数据的SQL语句,以二进制形式存储在磁盘中。如果我们后面需要配置主从数据库,如果我们需要从数据库同步主数据库的内容,我们可以通过binlog进行同步。说白了,可以用binlog来解决mysql数据库中数据的实时同步问题。还有三种 binlog 格式:STATEMENT、ROW 和 MIXED。
基于行的复制(RBR):它不记录每个 SQL 语句的上下文信息。它只需要记录修改了哪些数据,修改成了什么。混合复制(MBR):以上两种模式的结合。一般复制使用 STATEMENT 方式保存 binlog。对于 STATEMENT 模式下无法复制的操作,使用 ROW 模式保存 binlog。MySQL会根据执行的SQL语句进行选择。日志保存方法。
因为语句只有sql,没有数据,无法获取到原来的变更日志,一般建议使用ROW模式)mysql数据实时同步,我们可以通过解析mysql bin-log来实现,有很多bin-log的解析方式,可以通过canal或者max-well实现。下面是各种提取方法的对比介绍
启用binlog功能第一步:添加一个普通用户maxwell
在mysql中添加一个普通用户maxwell,因为maxwell软件默认用户是maxwell用户,进入mysql客户端,然后执行如下命令授权
mysql -uroot -p
set global validate_password_policy=LOW;
set global validate_password_length=6;
CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';
flush privileges;
第二步:开启binlog机制
对于我们的mysql数据库,我们可以打开mysql的binlog功能,通过修改mysql配置文件来启用。修改配置文件后,我们需要重启mysql服务
sudo vim /etc/my.cnf
# 添加或修改以下三行配置
log-bin= /var/lib/mysql/mysql-bin # 日志存放位置
binlog-format=ROW # binlog格式
server_id=1 # server id
# 重启mysql
sudo service mysqld restart
第三步:验证mysql服务
# 进入mysql客户端,并执行以下命令进行验证
mysql -uroot -p
mysql> show variables like '%log_bin%';
+---------------------------------+-----------------------------+
| Variable_name | Value |
+---------------------------------+-----------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/binlog |
| log_bin_index | /var/lib/mysql/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+-----------------------------+
root@0f3525c74115:/# cd /var/lib/mysql/
root@0f3525c74115:/var/lib/mysql# ls -la
-rw-r----- 1 mysql mysql 324 Jul 2 14:54 binlog.000007
-rw-r----- 1 mysql mysql 156 Jul 2 14:54 binlog.000008
-rw-r----- 1 mysql mysql 32 Jul 2 14:54 binlog.index
# 以上是binlog文件说明已经开启
安装maxwell实现实时采集mysql数据第一步:下载maxwell
下载:
第二步:修改配置
启动服务。启动我们的动物园管理员服务。启动kafka服务并创建kafka主题。启动maxwell服务,测试插入数据到数据库,查看kafka是否可以同步到mysql数据
# 创建kafka topic 分区 3 副本 2
bin/kafka-topics.sh --create --topic maxwell_kafka --partitions 3 --replication-factor 2 --zookeeper node01:2181
# 创建kafka 消费者
bin/kafka-console-consumer.sh --topic maxwell_kafka --from-beginning --bootstrap-server node01:9092,node02:9092,node03:9092
# 启动maxwell
bin/maxwell
插入数据测试
-- 创建目标库
CREATE DATABASE /*!32312 IF NOT EXISTS*/`test` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `test`;
-- 创建表
CREATE TABLE `myuser` (
`id` int(12) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 插入数据
insert into `myuser`(`id`,`name`,`age`) values (1,'zhangsan',NULL),(2,'xxx',NULL),(3,'ggg',NULL),(5,'xxxx',NULL),(8,'skldjlskdf',NULL),(10,'ggggg',NULL),(99,'ttttt',NULL),(114,NULL,NULL),(121,'xxx',NULL);
-- 岂容kafka消费者,会看到消费的数据
bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic maxwell_kafka 查看全部
文章实时采集(mysql实时数据采集框架maxwell基本介绍-苏州安嘉
)
介绍本文文章主要介绍MaxWell(Mysql实时数据采集)及相关经验和技巧。文章约13381字,浏览量317,点赞2,值得参考!
mysql实时数据采集框架maxwell基础介绍
maxwell 是一个可以实时读取 MySQL 二进制日志 binlog 并生成 JSON 格式消息的应用程序,这些消息作为生产者发送到 Kafka、Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其他平台。其常见的应用场景包括ETL、维护缓存、采集表级dml指标、递增到搜索引擎、数据分区迁移、切割数据库binlog回滚方案等。
Maxwell主要提供以下功能:
支持 SELECT * FROM 表进行 44 行全数据初始化。支持主库故障转移后binlog位置(GTID)的自动恢复。可以对数据进行分区以解决数据倾斜问题。发送到 Kafka 的数据支持数据库、表和列。等级数据分区的工作方式是伪装成slave,接收binlog事件,然后根据scheme信息进行组装,可以接受ddl、xid、row等各种事件binlog的引入。
Binlog是mysql中的二进制日志。主要用于记录mysql数据库中发生或潜在改变数据的SQL语句,以二进制形式存储在磁盘中。如果我们后面需要配置主从数据库,如果我们需要从数据库同步主数据库的内容,我们可以通过binlog进行同步。说白了,可以用binlog来解决mysql数据库中数据的实时同步问题。还有三种 binlog 格式:STATEMENT、ROW 和 MIXED。
基于行的复制(RBR):它不记录每个 SQL 语句的上下文信息。它只需要记录修改了哪些数据,修改成了什么。混合复制(MBR):以上两种模式的结合。一般复制使用 STATEMENT 方式保存 binlog。对于 STATEMENT 模式下无法复制的操作,使用 ROW 模式保存 binlog。MySQL会根据执行的SQL语句进行选择。日志保存方法。
因为语句只有sql,没有数据,无法获取到原来的变更日志,一般建议使用ROW模式)mysql数据实时同步,我们可以通过解析mysql bin-log来实现,有很多bin-log的解析方式,可以通过canal或者max-well实现。下面是各种提取方法的对比介绍
启用binlog功能第一步:添加一个普通用户maxwell
在mysql中添加一个普通用户maxwell,因为maxwell软件默认用户是maxwell用户,进入mysql客户端,然后执行如下命令授权
mysql -uroot -p
set global validate_password_policy=LOW;
set global validate_password_length=6;
CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';
flush privileges;
第二步:开启binlog机制
对于我们的mysql数据库,我们可以打开mysql的binlog功能,通过修改mysql配置文件来启用。修改配置文件后,我们需要重启mysql服务
sudo vim /etc/my.cnf
# 添加或修改以下三行配置
log-bin= /var/lib/mysql/mysql-bin # 日志存放位置
binlog-format=ROW # binlog格式
server_id=1 # server id
# 重启mysql
sudo service mysqld restart
第三步:验证mysql服务
# 进入mysql客户端,并执行以下命令进行验证
mysql -uroot -p
mysql> show variables like '%log_bin%';
+---------------------------------+-----------------------------+
| Variable_name | Value |
+---------------------------------+-----------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/binlog |
| log_bin_index | /var/lib/mysql/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+-----------------------------+
root@0f3525c74115:/# cd /var/lib/mysql/
root@0f3525c74115:/var/lib/mysql# ls -la
-rw-r----- 1 mysql mysql 324 Jul 2 14:54 binlog.000007
-rw-r----- 1 mysql mysql 156 Jul 2 14:54 binlog.000008
-rw-r----- 1 mysql mysql 32 Jul 2 14:54 binlog.index
# 以上是binlog文件说明已经开启
安装maxwell实现实时采集mysql数据第一步:下载maxwell
下载:
第二步:修改配置
启动服务。启动我们的动物园管理员服务。启动kafka服务并创建kafka主题。启动maxwell服务,测试插入数据到数据库,查看kafka是否可以同步到mysql数据
# 创建kafka topic 分区 3 副本 2
bin/kafka-topics.sh --create --topic maxwell_kafka --partitions 3 --replication-factor 2 --zookeeper node01:2181
# 创建kafka 消费者
bin/kafka-console-consumer.sh --topic maxwell_kafka --from-beginning --bootstrap-server node01:9092,node02:9092,node03:9092
# 启动maxwell
bin/maxwell
插入数据测试
-- 创建目标库
CREATE DATABASE /*!32312 IF NOT EXISTS*/`test` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `test`;
-- 创建表
CREATE TABLE `myuser` (
`id` int(12) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 插入数据
insert into `myuser`(`id`,`name`,`age`) values (1,'zhangsan',NULL),(2,'xxx',NULL),(3,'ggg',NULL),(5,'xxxx',NULL),(8,'skldjlskdf',NULL),(10,'ggggg',NULL),(99,'ttttt',NULL),(114,NULL,NULL),(121,'xxx',NULL);
-- 岂容kafka消费者,会看到消费的数据
bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic maxwell_kafka
文章实时采集(自动提交又可以分为主动推送和sitemap三种链接提交通道)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-01 10:07
很多人为了节省时间,选择了自动提交的方式。但是,如您所知,自动提交可以分为三个链接提交渠道:主动推送(实时)、自动推送和站点地图。
下面我就给大家分析一下这三种链接提交渠道的优劣,看看哪个更适合我们。
1、主动推送(实时)
这是最快的提交方式。技术改造后,您的网站每次更新文章时,都可以通过这种方式主动推送给百度,保证新链接能及时被百度收录接收。但有一个缺点,就是技术发展起来后才能使用。
2、自动推送
自动推送是百度搜索资源平台推出的一款提高网站新网页发现速度的工具。安装了自动推送JS代码的网页,无论访问哪个页面,页面URL都会立即自动推送到百度。
要使用它,需要将JS代码安装在一个全站共享的模板页面中,例如在一个类似于header.htm的header模板页面中,以达到一次安装,整个站点的效果。
这个方法很好,很适合优采云,安装完成后可以实现自动链接推送功能。但是这样的js代码会拖慢网站,一点也不友好。
3、站点地图提交
Sitemap是站点地图的意思,指的是你网站上的网页列表。创建并提交站点地图将帮助百度找到并理解您网站 上的所有网页。
除了这个便捷的功能,您还可以使用Sitemap提供关于您的其他信息网站,如最后更新日期、Sitemap文件的更新频率等,仅供百度蜘蛛参考。
百度不保证所提交的站点地图数据的所有网址都会被抓取并编入索引。不过,百度搜索引擎会利用Sitemap中的数据来了解网站的结构等信息,可以帮助百度搜索引擎蜘蛛改进爬取策略,在以后更好的捕获网站的Pick。
顺便说一下,Sitemap网站 地图可以使用爱站SEO toolkit 和SitemapX 等工具制作。还有一点需要说明的是,百度搜索引擎蜘蛛不会定期来更新Sitemap网站。
此站点地图与搜索排名无关。不是说更新站点地图越频繁,网站的排名就越高,不是这样的。
所以,综上所述,最适合我们的链接提交方式是主动推送(实时)。
接下来教大家修改API提交,实现只要在WordPress后台点击发布文章,就可以主动推送文章(实时)到百度.
其实方法很简单。我们只需要在funtions.php模板中写入如下代码,发布文章就会自动推送到百度。
date_default_timezone_set('Asia/Shanghai'); add_action('publish_post', 'publish_bd_submit', 999);
function publish_bd_submit($post_ID){ global $post;
$bd_submit_enabled = true;
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B
if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
}
上面的代码有两个API,改成自己的就好了。注:第一个api是天机收录的接口调用地址。只有受原创保护的站长才有资格使用它。第二个api地址是主动推送(实时)接口调用地址,别搞错了。
另一个是关于 funtions.php 模板的路径。现在我给你一些提示。目前Kang使用的wordpress主题是Robin,这个funtions.php模板的路径在/wp-content/themes/begin/根目录下,大家可以自己找。
版权所有:科鼎博客 © WNAG.COM.CN
文章标题:《wordpress如何实现向百度发布文章主动推送(实时)》
这篇文章的链接:
特别声明:除非另有说明,本站所有文章均为原创,本站文章原则上禁止转载。如果真的要转载请联系我们:尊重他人劳动成果,谢谢Over~ 查看全部
文章实时采集(自动提交又可以分为主动推送和sitemap三种链接提交通道)
很多人为了节省时间,选择了自动提交的方式。但是,如您所知,自动提交可以分为三个链接提交渠道:主动推送(实时)、自动推送和站点地图。
下面我就给大家分析一下这三种链接提交渠道的优劣,看看哪个更适合我们。
1、主动推送(实时)
这是最快的提交方式。技术改造后,您的网站每次更新文章时,都可以通过这种方式主动推送给百度,保证新链接能及时被百度收录接收。但有一个缺点,就是技术发展起来后才能使用。
2、自动推送
自动推送是百度搜索资源平台推出的一款提高网站新网页发现速度的工具。安装了自动推送JS代码的网页,无论访问哪个页面,页面URL都会立即自动推送到百度。
要使用它,需要将JS代码安装在一个全站共享的模板页面中,例如在一个类似于header.htm的header模板页面中,以达到一次安装,整个站点的效果。
这个方法很好,很适合优采云,安装完成后可以实现自动链接推送功能。但是这样的js代码会拖慢网站,一点也不友好。
3、站点地图提交
Sitemap是站点地图的意思,指的是你网站上的网页列表。创建并提交站点地图将帮助百度找到并理解您网站 上的所有网页。
除了这个便捷的功能,您还可以使用Sitemap提供关于您的其他信息网站,如最后更新日期、Sitemap文件的更新频率等,仅供百度蜘蛛参考。
百度不保证所提交的站点地图数据的所有网址都会被抓取并编入索引。不过,百度搜索引擎会利用Sitemap中的数据来了解网站的结构等信息,可以帮助百度搜索引擎蜘蛛改进爬取策略,在以后更好的捕获网站的Pick。
顺便说一下,Sitemap网站 地图可以使用爱站SEO toolkit 和SitemapX 等工具制作。还有一点需要说明的是,百度搜索引擎蜘蛛不会定期来更新Sitemap网站。
此站点地图与搜索排名无关。不是说更新站点地图越频繁,网站的排名就越高,不是这样的。
所以,综上所述,最适合我们的链接提交方式是主动推送(实时)。
接下来教大家修改API提交,实现只要在WordPress后台点击发布文章,就可以主动推送文章(实时)到百度.
其实方法很简单。我们只需要在funtions.php模板中写入如下代码,发布文章就会自动推送到百度。
date_default_timezone_set('Asia/Shanghai'); add_action('publish_post', 'publish_bd_submit', 999);
function publish_bd_submit($post_ID){ global $post;
$bd_submit_enabled = true;
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B
if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
}
上面的代码有两个API,改成自己的就好了。注:第一个api是天机收录的接口调用地址。只有受原创保护的站长才有资格使用它。第二个api地址是主动推送(实时)接口调用地址,别搞错了。
另一个是关于 funtions.php 模板的路径。现在我给你一些提示。目前Kang使用的wordpress主题是Robin,这个funtions.php模板的路径在/wp-content/themes/begin/根目录下,大家可以自己找。
版权所有:科鼎博客 © WNAG.COM.CN
文章标题:《wordpress如何实现向百度发布文章主动推送(实时)》
这篇文章的链接:
特别声明:除非另有说明,本站所有文章均为原创,本站文章原则上禁止转载。如果真的要转载请联系我们:尊重他人劳动成果,谢谢Over~
文章实时采集(gpu2:基于卷积神经网络的文本分类任务(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-29 13:08
文章实时采集简介gpu2:基于卷积神经网络的文本分类任务
1、原理简介1.1预备知识计算机视觉方面的基础知识,一般来说所谓cnn模型,即使是神经网络模型,其图像或者视频或者信号或者文本数据都是二维数据,而且有噪声(灰度、噪声、扭曲等)。一般来说在视频等情况下,由于存在信号的持续传播和速度的限制,一帧的信号单单通过激活函数是无法达到精确的分类结果。同样的道理,一个信号如果如果没有经过人工修正参数,或者完全只通过识别系统来识别,误识率也会不断提高,这样一个模型的分类精度也难以提高。
1.2卷积神经网络(cnn)1.2.1卷积层在计算机视觉计算上,卷积层有许多的应用。通过作用上的分类比如:图像、识别、文本分类、网页识别等等。由于cnn采用一个一个的卷积核使得该方法在图像分类和文本分类等其他的一些任务上都取得了非常好的效果。假设我们想要的是分类最准确的模型。简单设置是对角线和角接连的神经元节点统统连接输入。
但是,目前大多数计算机视觉任务中的大多数方法的维度是32x32以及更小的尺寸,但是对于要求大幅度提高分类精度的识别(如自然语言处理)任务来说,一般情况下是2x2尺寸的。设置一个32x32的输入节点,图像识别的分类效果达到80%,识别的分类效果达到90%。所以我们需要有一个足够大的输入,达到目标尺寸。
那么对于32x32的图像,将32x32输入到32x32的分类网络中将会得到32x32的输出(可以看出,对于cnn单个输入的输出个数,是可以很多的,并且同样的分类效果有很多的输出),结合图像分类一般用[0,1]输出一个概率值,1表示正类,0表示负类。因此,这种情况下设置输入,输出的神经元数量,是有些不合理。
而且目前有时候需要求一个最大公约数(极大的方法),以使得用极大算法进行计算,可以通过设置:计算函数,取非极大时的值作为输出的分类,来达到更大效果的分类结果。将这些值直接设置为[0,1]也可以达到预期的分类结果。然而,在复杂情况下会出现这种结果:例如:识别:如果输入尺寸是32x32,进行识别的话,一般会得到小于1的数据,即使用32x32进行识别结果依然是错误的结果。
2、神经网络简介2.1创建原理cnn结构简单的说,cnn是一种深度神经网络,每一层都是一种卷积层。
1、图像层进行层与层的连接,
1)分别输入卷积核;
2)通过运算
2、识别层进行参数化处理,
1)分别的输入是普通的音频信号;
3、文本识 查看全部
文章实时采集(gpu2:基于卷积神经网络的文本分类任务(一))
文章实时采集简介gpu2:基于卷积神经网络的文本分类任务
1、原理简介1.1预备知识计算机视觉方面的基础知识,一般来说所谓cnn模型,即使是神经网络模型,其图像或者视频或者信号或者文本数据都是二维数据,而且有噪声(灰度、噪声、扭曲等)。一般来说在视频等情况下,由于存在信号的持续传播和速度的限制,一帧的信号单单通过激活函数是无法达到精确的分类结果。同样的道理,一个信号如果如果没有经过人工修正参数,或者完全只通过识别系统来识别,误识率也会不断提高,这样一个模型的分类精度也难以提高。
1.2卷积神经网络(cnn)1.2.1卷积层在计算机视觉计算上,卷积层有许多的应用。通过作用上的分类比如:图像、识别、文本分类、网页识别等等。由于cnn采用一个一个的卷积核使得该方法在图像分类和文本分类等其他的一些任务上都取得了非常好的效果。假设我们想要的是分类最准确的模型。简单设置是对角线和角接连的神经元节点统统连接输入。
但是,目前大多数计算机视觉任务中的大多数方法的维度是32x32以及更小的尺寸,但是对于要求大幅度提高分类精度的识别(如自然语言处理)任务来说,一般情况下是2x2尺寸的。设置一个32x32的输入节点,图像识别的分类效果达到80%,识别的分类效果达到90%。所以我们需要有一个足够大的输入,达到目标尺寸。
那么对于32x32的图像,将32x32输入到32x32的分类网络中将会得到32x32的输出(可以看出,对于cnn单个输入的输出个数,是可以很多的,并且同样的分类效果有很多的输出),结合图像分类一般用[0,1]输出一个概率值,1表示正类,0表示负类。因此,这种情况下设置输入,输出的神经元数量,是有些不合理。
而且目前有时候需要求一个最大公约数(极大的方法),以使得用极大算法进行计算,可以通过设置:计算函数,取非极大时的值作为输出的分类,来达到更大效果的分类结果。将这些值直接设置为[0,1]也可以达到预期的分类结果。然而,在复杂情况下会出现这种结果:例如:识别:如果输入尺寸是32x32,进行识别的话,一般会得到小于1的数据,即使用32x32进行识别结果依然是错误的结果。
2、神经网络简介2.1创建原理cnn结构简单的说,cnn是一种深度神经网络,每一层都是一种卷积层。
1、图像层进行层与层的连接,
1)分别输入卷积核;
2)通过运算
2、识别层进行参数化处理,
1)分别的输入是普通的音频信号;
3、文本识
文章实时采集(小程序插件-gt实时日志使用规则(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-09-28 13:11
)
实时日志背景
为帮助小程序开发者快速排查小程序漏洞和定位问题,我们推出了实时日志功能。开发者可以通过提供的接口打印日志,采集日志并实时上报给小程序后端。开发者可以从小程序管理后台“开发->开发管理->运维中心->实时日志”进入小程序日志查询页面,或从“小程序插件->实时日志”进入插件日志查询页面Log”,然后查看开发者打印的日志信息。
小程序/小游戏使用方法
从基础库2.7.1开始,小终端可以使用实时日志,从基础库2.14.4开始支持小游戏终端.
1、调用相关接口。日志的接口是wx.getRealtimeLogManager。为了兼容旧版本,建议使用如下代码进行封装,例如封装在log.js文件中:
var log = wx.getRealtimeLogManager ? wx.getRealtimeLogManager() : null
module.exports = {
debug() {
if (!log) return
log.debug.apply(log, arguments)
},
info() {
if (!log) return
log.info.apply(log, arguments)
},
warn() {
if (!log) return
log.warn.apply(log, arguments)
},
error() {
if (!log) return
log.error.apply(log, arguments)
},
setFilterMsg(msg) { // 从基础库2.7.3开始支持
if (!log || !log.setFilterMsg) return
if (typeof msg !== 'string') return
log.setFilterMsg(msg)
},
addFilterMsg(msg) { // 从基础库2.8.1开始支持
if (!log || !log.addFilterMsg) return
if (typeof msg !== 'string') return
log.addFilterMsg(msg)
}
}
2、在页面特定位置打印日志:
var log = require('./log.js') // 引用上面的log.js文件
log.info('hello test hahaha') // 日志会和当前打开的页面关联,建议在页面的onHide、onShow等生命周期里面打
log.warn('warn')
log.error('error')
log.setFilterMsg('filterkeyword')
log.addFilterMsg('addfilterkeyword')
完整的例子可以参考代码片段:
插件端
从基础库2.16.0开始,插件也支持实时日志。为了让日志更加结构化以进行更复杂的分析,插件端采用了全新设计的格式。
1、 调用相关接口 wx.getRealtimeLogManager 获取实时日志管理器的实例:
const logManager = wx.getRealtimeLogManager()
2、在需要日志的逻辑中,获取日志实例:
// 标签名可以是任意字符串,一个标签名对应一组日志;同样的标签名允许被重复使用,具有相同标签名的日志在后台会被汇总到一个标签下
// 标签可为日志进行分类,因此建议开发者按逻辑来进行标签划分
const logger = logManager.tag('plugin-onUserTapSth')
3、在合适的位置打印日志:
logger.info('key1', 'value1') // 每条日志为一个 key-value 对,key 必须是字符串,value 可以是字符串/数值/对象/数组等可序列化类型
logger.error('key2', {str: 'value2'})
logger.warn('key3', 'value3')
logger.setFilterMsg('filterkeyword') // 和小程序/小游戏端接口一致
logger.setFilterMsg('addfilterkeyword') // 和小程序/小游戏端接口一致
如何查看日志
登录小程序管理后台,从“开发->开发管理->运维中心->实时日志”进入日志查询页面。开发者可以通过设置时间、微信ID/OpenID、页面链接、FilterMsg内容(基础库2.7.3及以上支持setFilterMsg)等过滤条件查询指定用户的日志信息。如果是插件上报的实时日志,可以通过“小程序插件->实时日志”进入日志查询页面进行查询。
预防措施
由于后台资源限制,“实时日志”的使用规则如下:
为了方便定位问题,将日志按页面划分,某个页面,在一定时间内(最短为5秒,最长为页面显示和隐藏的时间间隔),会聚合成一个小程序管理后台可以根据页面路径查找该日志。每个小程序账号每天限制1000万条日志,日志保存7天。建议及时定位问题。一个日志的上限为5KB,最多收录200个打印日志函数调用(info、warn、error调用都算在内),所以要注意log,避免循环调用log接口,避免直接覆盖console .log 点击日志。反馈中的日志可以根据OpenID查找。setFilterMsg 和 addFilterMsg 可以设置类似于日志标签的过滤字段。如果需要添加多个关键字,建议使用addFilterMsg。比如addFilterMsg('scene1'), addFilterMsg('scene2'), addFilterMsg('scene3'),设置后可以随机组合三个关键字在小程序管理后台搜索,如:“scene1 scene2 scene3”, "scene1 scene2" ", "scene1 scene3" or "scene2" 等(用空格隔开,所以addFilterMsg不能收录空格)日志可以通过以上几种检索方式进行检索,检索条件越多越准确会的,目前为了方便日志分析,插件实时日志只支持key-value格式。实时日志目前仅支持手机端测试。工具端的接口可以调用,但是不会上报后台。
查看全部
文章实时采集(小程序插件-gt实时日志使用规则(组图)
)
实时日志背景
为帮助小程序开发者快速排查小程序漏洞和定位问题,我们推出了实时日志功能。开发者可以通过提供的接口打印日志,采集日志并实时上报给小程序后端。开发者可以从小程序管理后台“开发->开发管理->运维中心->实时日志”进入小程序日志查询页面,或从“小程序插件->实时日志”进入插件日志查询页面Log”,然后查看开发者打印的日志信息。
小程序/小游戏使用方法
从基础库2.7.1开始,小终端可以使用实时日志,从基础库2.14.4开始支持小游戏终端.
1、调用相关接口。日志的接口是wx.getRealtimeLogManager。为了兼容旧版本,建议使用如下代码进行封装,例如封装在log.js文件中:
var log = wx.getRealtimeLogManager ? wx.getRealtimeLogManager() : null
module.exports = {
debug() {
if (!log) return
log.debug.apply(log, arguments)
},
info() {
if (!log) return
log.info.apply(log, arguments)
},
warn() {
if (!log) return
log.warn.apply(log, arguments)
},
error() {
if (!log) return
log.error.apply(log, arguments)
},
setFilterMsg(msg) { // 从基础库2.7.3开始支持
if (!log || !log.setFilterMsg) return
if (typeof msg !== 'string') return
log.setFilterMsg(msg)
},
addFilterMsg(msg) { // 从基础库2.8.1开始支持
if (!log || !log.addFilterMsg) return
if (typeof msg !== 'string') return
log.addFilterMsg(msg)
}
}
2、在页面特定位置打印日志:
var log = require('./log.js') // 引用上面的log.js文件
log.info('hello test hahaha') // 日志会和当前打开的页面关联,建议在页面的onHide、onShow等生命周期里面打
log.warn('warn')
log.error('error')
log.setFilterMsg('filterkeyword')
log.addFilterMsg('addfilterkeyword')
完整的例子可以参考代码片段:
插件端
从基础库2.16.0开始,插件也支持实时日志。为了让日志更加结构化以进行更复杂的分析,插件端采用了全新设计的格式。
1、 调用相关接口 wx.getRealtimeLogManager 获取实时日志管理器的实例:
const logManager = wx.getRealtimeLogManager()
2、在需要日志的逻辑中,获取日志实例:
// 标签名可以是任意字符串,一个标签名对应一组日志;同样的标签名允许被重复使用,具有相同标签名的日志在后台会被汇总到一个标签下
// 标签可为日志进行分类,因此建议开发者按逻辑来进行标签划分
const logger = logManager.tag('plugin-onUserTapSth')
3、在合适的位置打印日志:
logger.info('key1', 'value1') // 每条日志为一个 key-value 对,key 必须是字符串,value 可以是字符串/数值/对象/数组等可序列化类型
logger.error('key2', {str: 'value2'})
logger.warn('key3', 'value3')
logger.setFilterMsg('filterkeyword') // 和小程序/小游戏端接口一致
logger.setFilterMsg('addfilterkeyword') // 和小程序/小游戏端接口一致
如何查看日志
登录小程序管理后台,从“开发->开发管理->运维中心->实时日志”进入日志查询页面。开发者可以通过设置时间、微信ID/OpenID、页面链接、FilterMsg内容(基础库2.7.3及以上支持setFilterMsg)等过滤条件查询指定用户的日志信息。如果是插件上报的实时日志,可以通过“小程序插件->实时日志”进入日志查询页面进行查询。

预防措施
由于后台资源限制,“实时日志”的使用规则如下:
为了方便定位问题,将日志按页面划分,某个页面,在一定时间内(最短为5秒,最长为页面显示和隐藏的时间间隔),会聚合成一个小程序管理后台可以根据页面路径查找该日志。每个小程序账号每天限制1000万条日志,日志保存7天。建议及时定位问题。一个日志的上限为5KB,最多收录200个打印日志函数调用(info、warn、error调用都算在内),所以要注意log,避免循环调用log接口,避免直接覆盖console .log 点击日志。反馈中的日志可以根据OpenID查找。setFilterMsg 和 addFilterMsg 可以设置类似于日志标签的过滤字段。如果需要添加多个关键字,建议使用addFilterMsg。比如addFilterMsg('scene1'), addFilterMsg('scene2'), addFilterMsg('scene3'),设置后可以随机组合三个关键字在小程序管理后台搜索,如:“scene1 scene2 scene3”, "scene1 scene2" ", "scene1 scene3" or "scene2" 等(用空格隔开,所以addFilterMsg不能收录空格)日志可以通过以上几种检索方式进行检索,检索条件越多越准确会的,目前为了方便日志分析,插件实时日志只支持key-value格式。实时日志目前仅支持手机端测试。工具端的接口可以调用,但是不会上报后台。
文章实时采集(文章实时采集数据,批量下载图片并进行清洗预处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-27 08:02
文章实时采集数据,批量下载图片并进行清洗预处理。这是一篇具有实用性的python爬虫博客贴,包含了微信公众号的数据采集和清洗方法:笔者研究了一下这个问题,发现数据集取之不尽,也十分丰富。想获取更多的话,自己组织一下代码和数据集,甚至爬虫加上人肉采集也都可以爬上去。准备工作清洗及预处理resize,replace,andloadresizeresizetocenterwithpython'smagnitude-linewhitefillcolorgraycolorizetheusefullayer.loadbetweenthedirsizedfilesandinner_blocks.例如srt_get_url_info_path/http/resources/mx4_dist.gif由于博客无法登陆,所以也没有做cookiesharingwindows系统用shlife做ip或地址到文件夹的localsharedbasesecurity性能优化对于同一个data里的不同directory分别下载数据(全部一样就好)请避免对每个directory重复下载我这里用了3个directory:srt_dist/total,srt_dist/total.mx4和srt_dist/total.mx4.gif下载任务依次处理excel图片的数据如下:文本转json我一开始用的是pandassortimage.txt,最好的是用pandassortpdf.txt。
用inlineterminal下的infile函数速度最快jsonreader里的用expand_dims()函数减小dim边界比如要减去字符串中的content,改成decodeuricomponent(),保留四舍五入;要减去字符串中的text或者文本文件中的url如果以字典格式下载,df.to_csv()在windows编辑环境下,df.to_json()在linux下则直接下载就行,我这里直接用文本的方式content={'content':df.to_json()}text=json.loads(df.text)url=""'但是这样做可能在排序时遇到问题;有时候下载到txt后在importjson之前确实下载不出来json,那就用foriinrange(int(java.util.ioloop.task)):json.sort()或者new_url={"response_url":"","response_time":"","source":"","url":""}第三个问题json的包装字符串:url=""对于引入的模块urllib3defurllib3_cookies():ifyouwanttoincludetheresourceswithoutexistingjson.loadsinmodule:open("url.txt",encoding="utf-8").write(result)else:open("cookies.json",encoding="utf-8").write(result)print("followingoperationsarethosewhousethisimplementation:")。 查看全部
文章实时采集(文章实时采集数据,批量下载图片并进行清洗预处理)
文章实时采集数据,批量下载图片并进行清洗预处理。这是一篇具有实用性的python爬虫博客贴,包含了微信公众号的数据采集和清洗方法:笔者研究了一下这个问题,发现数据集取之不尽,也十分丰富。想获取更多的话,自己组织一下代码和数据集,甚至爬虫加上人肉采集也都可以爬上去。准备工作清洗及预处理resize,replace,andloadresizeresizetocenterwithpython'smagnitude-linewhitefillcolorgraycolorizetheusefullayer.loadbetweenthedirsizedfilesandinner_blocks.例如srt_get_url_info_path/http/resources/mx4_dist.gif由于博客无法登陆,所以也没有做cookiesharingwindows系统用shlife做ip或地址到文件夹的localsharedbasesecurity性能优化对于同一个data里的不同directory分别下载数据(全部一样就好)请避免对每个directory重复下载我这里用了3个directory:srt_dist/total,srt_dist/total.mx4和srt_dist/total.mx4.gif下载任务依次处理excel图片的数据如下:文本转json我一开始用的是pandassortimage.txt,最好的是用pandassortpdf.txt。
用inlineterminal下的infile函数速度最快jsonreader里的用expand_dims()函数减小dim边界比如要减去字符串中的content,改成decodeuricomponent(),保留四舍五入;要减去字符串中的text或者文本文件中的url如果以字典格式下载,df.to_csv()在windows编辑环境下,df.to_json()在linux下则直接下载就行,我这里直接用文本的方式content={'content':df.to_json()}text=json.loads(df.text)url=""'但是这样做可能在排序时遇到问题;有时候下载到txt后在importjson之前确实下载不出来json,那就用foriinrange(int(java.util.ioloop.task)):json.sort()或者new_url={"response_url":"","response_time":"","source":"","url":""}第三个问题json的包装字符串:url=""对于引入的模块urllib3defurllib3_cookies():ifyouwanttoincludetheresourceswithoutexistingjson.loadsinmodule:open("url.txt",encoding="utf-8").write(result)else:open("cookies.json",encoding="utf-8").write(result)print("followingoperationsarethosewhousethisimplementation:")。
文章实时采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-06 16:08
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、实时采集模块(CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal 插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。 查看全部
文章实时采集(FlinkX实时采集插件的核心是如何实时捕获数据库数据的)
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、实时采集模块(CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal 插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。
文章实时采集(如何用uid推送广告?爬虫爬虫爬虫爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-03 16:01
文章实时采集,开发者可以获取网页全部网址或者根据网页标题等特征设置ip地址获取指定url。用户通过特定策略,访问网页就能获取到相应内容,还是挺方便的。
谢邀推荐使用useragentmap
你看看这个:howtosurveythecontentofachineseuser?大部分问题你都能用这种手段解决。
allchineserequestswentintobecomeamoregeneralhackingads,alsonotinthebrandloginmethod.viacnncorruptchina
你需要自己搞一个简洁的用户界面。目前没什么好办法。不过新浪提供了服务接口。基本上你想用uid进行推送广告的方法你都能用上。如果你有这方面需求,可以联系找找看。如果涉及你在“南方日报”和“央视新闻”,也可以联系上面的市场部。
如果你像@layly说的那样,你得懂爬虫爬虫爬虫!你的技术可以想办法,但是爬虫爬虫,爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬库爬虫爬虫爬虫爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库。 查看全部
文章实时采集(如何用uid推送广告?爬虫爬虫爬虫爬虫)
文章实时采集,开发者可以获取网页全部网址或者根据网页标题等特征设置ip地址获取指定url。用户通过特定策略,访问网页就能获取到相应内容,还是挺方便的。
谢邀推荐使用useragentmap
你看看这个:howtosurveythecontentofachineseuser?大部分问题你都能用这种手段解决。
allchineserequestswentintobecomeamoregeneralhackingads,alsonotinthebrandloginmethod.viacnncorruptchina
你需要自己搞一个简洁的用户界面。目前没什么好办法。不过新浪提供了服务接口。基本上你想用uid进行推送广告的方法你都能用上。如果你有这方面需求,可以联系找找看。如果涉及你在“南方日报”和“央视新闻”,也可以联系上面的市场部。
如果你像@layly说的那样,你得懂爬虫爬虫爬虫!你的技术可以想办法,但是爬虫爬虫,爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬库爬虫爬虫爬虫爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库爬库。
文章实时采集(文章实时采集写字楼大堂(广告牌)的实现方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-02 22:01
文章实时采集写字楼大堂(广告牌)信息:数据要求是文字或者图片,前端只需要预览一次大堂的尺寸就可以保存到hbase。后端会实时写入数据库中。文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。需要的技术栈:开发环境tomcat7.0springboot5.0.6eclipse14.0.2python2.7.14sql2015版本前端:jquery+flask+requests数据库:mysql+mongodb主要实现方法:文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号码-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:1,设置请求url2,设置请求头,header:accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8;*/*;user-agent:mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/50.0.2724.116safari/537.3647.94save/first3,设置请求header,如下:header'content-type':'application/xhtml+xml;q=0.9,*/*;q=0.8'4,如果服务器不开放wifi接口,设置请求url用请求报文地址,即mysql和requests_file-db报文地址。
inet_native_private_port=8000jlink虚拟机大楼顶部的尺寸为15m*20m左右,所以尺寸有45*15*20=4800m。大堂的尺寸为15m*20m左右,所以尺寸有10m*40*20=3200m。每一个大堂的id号码都会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:将数据写入mysql中:1,创建一个mysql对象2,将每一个大堂的id号码写入mysql表中3,将表中每一个大堂的id号码写入数据库中4,重启mysql实例5,将该表中的每一个大堂编号写入db表中6,读取并写入数据库。 查看全部
文章实时采集(文章实时采集写字楼大堂(广告牌)的实现方法)
文章实时采集写字楼大堂(广告牌)信息:数据要求是文字或者图片,前端只需要预览一次大堂的尺寸就可以保存到hbase。后端会实时写入数据库中。文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。需要的技术栈:开发环境tomcat7.0springboot5.0.6eclipse14.0.2python2.7.14sql2015版本前端:jquery+flask+requests数据库:mysql+mongodb主要实现方法:文章内容是:每一个大堂的id号码会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号码-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:1,设置请求url2,设置请求头,header:accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8;*/*;user-agent:mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/50.0.2724.116safari/537.3647.94save/first3,设置请求header,如下:header'content-type':'application/xhtml+xml;q=0.9,*/*;q=0.8'4,如果服务器不开放wifi接口,设置请求url用请求报文地址,即mysql和requests_file-db报文地址。
inet_native_private_port=8000jlink虚拟机大楼顶部的尺寸为15m*20m左右,所以尺寸有45*15*20=4800m。大堂的尺寸为15m*20m左右,所以尺寸有10m*40*20=3200m。每一个大堂的id号码都会实时记录在数据库中,所以可以保存成文档,可以做外部的文章数据接入。
但这里会采集的信息有:1,房间号码2,号码房间号码-->1号大堂号码房间号-->2号大堂号码除此之外还会采集的信息:3,大堂主办方是否开放wifi等信息4,大堂主办方是否购买t恤,内衣等等内容实现过程如下:将数据写入mysql中:1,创建一个mysql对象2,将每一个大堂的id号码写入mysql表中3,将表中每一个大堂的id号码写入数据库中4,重启mysql实例5,将该表中的每一个大堂编号写入db表中6,读取并写入数据库。
文章实时采集(C++实现RTMP协议发送H.264编码及AAC编码的音视频RTMP )
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-11-02 09:02
)
C++实现RTMP协议发送H.264编码和AAC编码的音视频
RTMP(Real Time Messaging Protocol)是一种专门用于传输音视频数据的流媒体协议。它最初由Macromedia 创建,后来归它所有。它是一个私有协议,主要用于联系Flash Player和RtmpServer,如FMS、Red5、crtmpserver等。RTMP协议可以实现直播和点播应用,通过FMLE(Flash Media Live Encoder)将音视频数据推送到RtmpServer,可以实现摄像机的实时直播。但是,毕竟FMLE的应用范围是有限的。如果想嵌入到自己的程序中,还是要自己实现RTMP协议推送。我已经实现了一个 RTMPLiveEncoder,通过 采集 摄像头视频和麦克风音频,以及 H.264 和 AAC 编码,然后发送到FMS和crtmpserver实现实时直播,通过flash播放器可以正常观看,目前效果不错。延迟时间约为 2 秒。本文介绍了RTMPLiveEncoder的主要思想和关键点,希望对需要该技术的朋友有所帮助。
技术分析
实现RTMPLiveEncoder,需要以下四项关键技术:
其中,前两项技术在我之前的文章《采集音频和摄像头视频和实时H264编码和AAC编码》中已经介绍过,这里就不啰嗦了.
将音频和视频数据封装到可播放的流中是一个难点。仔细研究,你会发现RTMP Packet中封装的音视频数据流其实和FLV封装音视频数据的方式是一样的。所以我们只需要根据FLV封装H264和AAC就可以生成Play流了。
我们再来看看RTMP协议。Adobe 曾经发布过一个文档《RTMP 规范》,但维基百科指出该文档隐藏了很多细节,仅凭它是无法正确实现 RTMP 的。不过还是有参考意义的。事实上,在Adobe发布之前RTMP协议几乎就已经被破解了,现在已经有了比较完善的实现,比如RTMPDump,它提供了一个C语言的接口,这意味着它可以很容易地被其他语言调用。
计划框架
和我之前的文章《采集音视频与实时H264编码与AAC编码》文章一样,使用DirectShow技术实现音视频采集,音视频编码, 循环在各自的线程(AudioEncoderThread 和 VideoEncoderThread)中,RTMP的push开始一个新的线程(RtmpThread)。两个编码线程实时对音视频数据进行编码后,将数据交给Rtmp线程,Rtmp线程循环封装Rtmp Packet,然后发送出去。
线程之间的数据交换是通过一个队列DataBufferQueue来实现的。AudioEncoderThread 和 VideoEncoderThread 将数据指针发布到 DataBufferQueue 后立即返回,以免因发送 Rtmp 消息而影响编码线程的正常执行时间。
RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,不断地从DataBufferQueue中取出数据,封装成RTMP Packet,发送出去。流程如下代码所示:(process_buf_queue_,也就是上图中的DataBufferQueue)
librtmp一、 编译 librtmp
下载rtmpdump的代码,你会发现它是一个正宗的linux项目,除了一个简单的Makefile,没有别的。看来librtmp并不依赖系统,所以我们可以在windows上编译,不用花太多精力。但是,librtmp 依赖于 openssl 和 zlib,我们需要先编译它们。
1. 编译 openssl1.0.0e
a) 下载并安装 ActivePerl
b) 下载并安装 nasm()
c) 解压openssl压缩包
d) 运行cmd命令行,切换到openssl目录,分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir
>ms\do_nasm
e) 运行Visual Studio Command Prompt(2010),切入openssl目录,分别执行以下命令。
>nmake -f ms\nt.mak
>nmake -f ms\nt.mak install
f) 编译完成后,可以在第一条命令指定的目录中找到编译好的SDK。
2. 编译 zlib
a) 解压zlib压缩包
b) 运行Visual Studio Command Prompt(2010),切到openssl目录,分别执行以下命令
>cd contrib\masmx86
>bld_ml32.bat
c) 回到zlib目录,进入contrib\vstudio\vc10目录,打开vs2010解决方案文件,
在zlibstat项目属性中,去掉预编译宏ZLIB_WINAPI
d) 选择 debug 或 release 编译
3. 编译 librtmp
a) 首先打开visual studio 2010,新建一个win32控制台项目,指定为静态链接库
b) 将librtmp代码导入工程中,将openssl、zlib和librtmp的头文件放在一起,将编译好的openssl和zlib的静态库放在一起
c) 在项目设置中,添加之前编译好的openssl和zlib库,然后编译。
二、librtmp 的使用
首先初始化RTMP结构
启动后需要向RTMP Server发起握手连接消息
如果连接成功,就可以开始循环发送消息了。在这里您需要指定时间戳和数据类型(音频、视频、元数据)。这里需要注意的一点是,在调用Send之前,buf中的数据必须是封装好的H264或者AAC数据流。
关闭
终于发布了
H264 和 AAC 数据流
如本文所述,RTMP推送的音视频流的封装类似于FLV格式。可以看出,要将H264和AAC直播流推送到FMS,需要先发送“AVC序列头”和“AAC序列头”。数据收录重要的编码信息,没有它们,解码器将无法解码。
AVC 序列头是 AVCDecoderConfigurationRecord 结构,在标准文档“ISO-14496-15 AVC 文件格式”中有详细描述。
AAC 序列头存储 AudioSpecificConfig 结构,在“ISO-14496-3 Audio”中有描述。AudioSpecificConfig 结构体的描述非常复杂。在这里,我将简化它。预先设置要编码的音频格式。其中,音频编码选择“AAC-LC”,音频采样率为44100,因此AudioSpecificConfig简化为下表:
这样就可以基本确定AVC序列头和AAC序列头的内容了。更详细的信息,您可以查看相关文档。
运行结果
RtmpLiveEncoder 开始运行
用 FMS 自带的 flash 播放器玩
++++++++++++++++++++++++++++++++++++++++++++++++++ ++ +++++++++++++
查看全部
文章实时采集(C++实现RTMP协议发送H.264编码及AAC编码的音视频RTMP
)
C++实现RTMP协议发送H.264编码和AAC编码的音视频
RTMP(Real Time Messaging Protocol)是一种专门用于传输音视频数据的流媒体协议。它最初由Macromedia 创建,后来归它所有。它是一个私有协议,主要用于联系Flash Player和RtmpServer,如FMS、Red5、crtmpserver等。RTMP协议可以实现直播和点播应用,通过FMLE(Flash Media Live Encoder)将音视频数据推送到RtmpServer,可以实现摄像机的实时直播。但是,毕竟FMLE的应用范围是有限的。如果想嵌入到自己的程序中,还是要自己实现RTMP协议推送。我已经实现了一个 RTMPLiveEncoder,通过 采集 摄像头视频和麦克风音频,以及 H.264 和 AAC 编码,然后发送到FMS和crtmpserver实现实时直播,通过flash播放器可以正常观看,目前效果不错。延迟时间约为 2 秒。本文介绍了RTMPLiveEncoder的主要思想和关键点,希望对需要该技术的朋友有所帮助。
技术分析
实现RTMPLiveEncoder,需要以下四项关键技术:
其中,前两项技术在我之前的文章《采集音频和摄像头视频和实时H264编码和AAC编码》中已经介绍过,这里就不啰嗦了.
将音频和视频数据封装到可播放的流中是一个难点。仔细研究,你会发现RTMP Packet中封装的音视频数据流其实和FLV封装音视频数据的方式是一样的。所以我们只需要根据FLV封装H264和AAC就可以生成Play流了。
我们再来看看RTMP协议。Adobe 曾经发布过一个文档《RTMP 规范》,但维基百科指出该文档隐藏了很多细节,仅凭它是无法正确实现 RTMP 的。不过还是有参考意义的。事实上,在Adobe发布之前RTMP协议几乎就已经被破解了,现在已经有了比较完善的实现,比如RTMPDump,它提供了一个C语言的接口,这意味着它可以很容易地被其他语言调用。
计划框架
和我之前的文章《采集音视频与实时H264编码与AAC编码》文章一样,使用DirectShow技术实现音视频采集,音视频编码, 循环在各自的线程(AudioEncoderThread 和 VideoEncoderThread)中,RTMP的push开始一个新的线程(RtmpThread)。两个编码线程实时对音视频数据进行编码后,将数据交给Rtmp线程,Rtmp线程循环封装Rtmp Packet,然后发送出去。
线程之间的数据交换是通过一个队列DataBufferQueue来实现的。AudioEncoderThread 和 VideoEncoderThread 将数据指针发布到 DataBufferQueue 后立即返回,以免因发送 Rtmp 消息而影响编码线程的正常执行时间。
RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,不断地从DataBufferQueue中取出数据,封装成RTMP Packet,发送出去。流程如下代码所示:(process_buf_queue_,也就是上图中的DataBufferQueue)
librtmp一、 编译 librtmp
下载rtmpdump的代码,你会发现它是一个正宗的linux项目,除了一个简单的Makefile,没有别的。看来librtmp并不依赖系统,所以我们可以在windows上编译,不用花太多精力。但是,librtmp 依赖于 openssl 和 zlib,我们需要先编译它们。
1. 编译 openssl1.0.0e
a) 下载并安装 ActivePerl
b) 下载并安装 nasm()
c) 解压openssl压缩包
d) 运行cmd命令行,切换到openssl目录,分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir
>ms\do_nasm
e) 运行Visual Studio Command Prompt(2010),切入openssl目录,分别执行以下命令。
>nmake -f ms\nt.mak
>nmake -f ms\nt.mak install
f) 编译完成后,可以在第一条命令指定的目录中找到编译好的SDK。
2. 编译 zlib
a) 解压zlib压缩包
b) 运行Visual Studio Command Prompt(2010),切到openssl目录,分别执行以下命令
>cd contrib\masmx86
>bld_ml32.bat
c) 回到zlib目录,进入contrib\vstudio\vc10目录,打开vs2010解决方案文件,
在zlibstat项目属性中,去掉预编译宏ZLIB_WINAPI
d) 选择 debug 或 release 编译
3. 编译 librtmp
a) 首先打开visual studio 2010,新建一个win32控制台项目,指定为静态链接库
b) 将librtmp代码导入工程中,将openssl、zlib和librtmp的头文件放在一起,将编译好的openssl和zlib的静态库放在一起
c) 在项目设置中,添加之前编译好的openssl和zlib库,然后编译。
二、librtmp 的使用
首先初始化RTMP结构
启动后需要向RTMP Server发起握手连接消息
如果连接成功,就可以开始循环发送消息了。在这里您需要指定时间戳和数据类型(音频、视频、元数据)。这里需要注意的一点是,在调用Send之前,buf中的数据必须是封装好的H264或者AAC数据流。
关闭
终于发布了
H264 和 AAC 数据流
如本文所述,RTMP推送的音视频流的封装类似于FLV格式。可以看出,要将H264和AAC直播流推送到FMS,需要先发送“AVC序列头”和“AAC序列头”。数据收录重要的编码信息,没有它们,解码器将无法解码。
AVC 序列头是 AVCDecoderConfigurationRecord 结构,在标准文档“ISO-14496-15 AVC 文件格式”中有详细描述。
AAC 序列头存储 AudioSpecificConfig 结构,在“ISO-14496-3 Audio”中有描述。AudioSpecificConfig 结构体的描述非常复杂。在这里,我将简化它。预先设置要编码的音频格式。其中,音频编码选择“AAC-LC”,音频采样率为44100,因此AudioSpecificConfig简化为下表:
这样就可以基本确定AVC序列头和AAC序列头的内容了。更详细的信息,您可以查看相关文档。
运行结果
RtmpLiveEncoder 开始运行
用 FMS 自带的 flash 播放器玩
++++++++++++++++++++++++++++++++++++++++++++++++++ ++ +++++++++++++
文章实时采集( 日志服务LogHub提供日志数据实时采集功能支持30+种手段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-10-31 01:11
日志服务LogHub提供日志数据实时采集功能支持30+种手段)
21CTO 社区指南:日志服务 LogHub 提供日志数据的实时采集和消费。其中,实时采集功能支持30+种方法。下面简单介绍一下各个场景的采集方法。
日志服务LogHub功能提供日志数据的实时采集和消费。实时采集功能支持30+种方法。下面简单介绍一下各个场景的接入方式。
data采集一般有两种方式,区别如下。这里主要讨论通过LogHub采集进行流式导入(实时)。
背景
“我要点外卖”是一个基于平台的电商网站,用户、餐厅、送餐员等,用户可以通过网页、App、微信、支付宝等方式下单;商家收到订单后开始处理,并自动通知周边快递员;快递员将食物送到用户手中。
操作要求
在操作过程中,发现了以下问题:
获取用户难。向渠道(网页、微信推送)投放大量广告费,接收部分用户,但无法判断各渠道效果
用户经常抱怨发货慢,但是下单、发货、处理的慢在什么阶段?如何优化?
用户操作,经常搞一些优惠活动(送优惠券),却得不到效果
排期问题,如何在高峰时段帮助商家提前备货?如何派送更多的快递到指定区域?
客服,用户反馈下单失败,用户背后是什么操作?系统是否有错误?
数据采集难点
在数据操作的过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集分散的外部和内部日志并统一管理。以前这个区域需要做很多工作,现在可以通过LogHub采集函数访问。
统一的日志管理和配置
创建一个管理日志项目Project,例如叫myorder
创建日志存储Logstore,用于从不同数据源生成日志,例如:
如果需要清理原创数据和ETL,可以创建一些中间结果logstore
(更多操作请参考快速入门/管理控制台)
用户推广日志采集实践
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册和扫描。当用户扫描页面进行注册时,他知道用户是通过特定来源进入并记录日志的。
;ref=kd4b
当服务器接受请求时,服务器输出如下日志:
2016-06-2019:00:00e41234ab342ef034,102345,5k4d,467890
采集方式:
1. 应用通过Logtail将日志输出到硬盘采集
2. 应用是通过SDK编写的,见SDK
服务器数据采集
支付宝/微信公众号编程是典型的web端模式,日志一般分为三种:
实践
日志写入本地文件,通过Logtail配置正则表达式写入指定Logstore
Docker 中生成的日志可以使用容器服务来集成日志服务
Java程序可以使用Log4J Appender日志,无需日志记录,LogHub Producer Library(客户端高并发写入);Log4J 附加程序
可以使用SDK编写C#、Python、Java、PHP、C等
Windows服务器可以使用Logstash采集
最终用户日志访问
Web/M 站点页面用户行为
页面用户行为采集可以分为两类:
1. 页面与后台服务器交互:如下单、登录、退出等。
2. 页面无后台服务器交互:前端直接处理请求,如滚动、关闭页面等。
实践
第一种方法可以参考服务器采集方法
第二个可以使用Tracking Pixel/JS Library来采集页面行为,参考Tracking Web interface
服务器日志运维
例如:
实践
不同网络环境下的数据采集
LogHub在每个区域提供接入点,每个区域提供三个接入点:
更多信息请参考网络接入,总有一款适合您。
其他
查看LogHub的完整采集方法。
查看日志实时消耗,涉及流计算、数据清洗、数据仓库、索引查询等功能。
作者:简志,阿里云计算高级专家,擅长日志分析处理领域 查看全部
文章实时采集(
日志服务LogHub提供日志数据实时采集功能支持30+种手段)
21CTO 社区指南:日志服务 LogHub 提供日志数据的实时采集和消费。其中,实时采集功能支持30+种方法。下面简单介绍一下各个场景的采集方法。
日志服务LogHub功能提供日志数据的实时采集和消费。实时采集功能支持30+种方法。下面简单介绍一下各个场景的接入方式。
data采集一般有两种方式,区别如下。这里主要讨论通过LogHub采集进行流式导入(实时)。
背景
“我要点外卖”是一个基于平台的电商网站,用户、餐厅、送餐员等,用户可以通过网页、App、微信、支付宝等方式下单;商家收到订单后开始处理,并自动通知周边快递员;快递员将食物送到用户手中。
操作要求
在操作过程中,发现了以下问题:
获取用户难。向渠道(网页、微信推送)投放大量广告费,接收部分用户,但无法判断各渠道效果
用户经常抱怨发货慢,但是下单、发货、处理的慢在什么阶段?如何优化?
用户操作,经常搞一些优惠活动(送优惠券),却得不到效果
排期问题,如何在高峰时段帮助商家提前备货?如何派送更多的快递到指定区域?
客服,用户反馈下单失败,用户背后是什么操作?系统是否有错误?
数据采集难点
在数据操作的过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集分散的外部和内部日志并统一管理。以前这个区域需要做很多工作,现在可以通过LogHub采集函数访问。
统一的日志管理和配置
创建一个管理日志项目Project,例如叫myorder
创建日志存储Logstore,用于从不同数据源生成日志,例如:
如果需要清理原创数据和ETL,可以创建一些中间结果logstore
(更多操作请参考快速入门/管理控制台)
用户推广日志采集实践
定义如下注册服务器地址,生成二维码(传单、网页)供用户注册和扫描。当用户扫描页面进行注册时,他知道用户是通过特定来源进入并记录日志的。
;ref=kd4b
当服务器接受请求时,服务器输出如下日志:
2016-06-2019:00:00e41234ab342ef034,102345,5k4d,467890
采集方式:
1. 应用通过Logtail将日志输出到硬盘采集
2. 应用是通过SDK编写的,见SDK
服务器数据采集
支付宝/微信公众号编程是典型的web端模式,日志一般分为三种:
实践
日志写入本地文件,通过Logtail配置正则表达式写入指定Logstore
Docker 中生成的日志可以使用容器服务来集成日志服务
Java程序可以使用Log4J Appender日志,无需日志记录,LogHub Producer Library(客户端高并发写入);Log4J 附加程序
可以使用SDK编写C#、Python、Java、PHP、C等
Windows服务器可以使用Logstash采集
最终用户日志访问
Web/M 站点页面用户行为
页面用户行为采集可以分为两类:
1. 页面与后台服务器交互:如下单、登录、退出等。
2. 页面无后台服务器交互:前端直接处理请求,如滚动、关闭页面等。
实践
第一种方法可以参考服务器采集方法
第二个可以使用Tracking Pixel/JS Library来采集页面行为,参考Tracking Web interface
服务器日志运维
例如:
实践
不同网络环境下的数据采集
LogHub在每个区域提供接入点,每个区域提供三个接入点:
更多信息请参考网络接入,总有一款适合您。
其他
查看LogHub的完整采集方法。
查看日志实时消耗,涉及流计算、数据清洗、数据仓库、索引查询等功能。
作者:简志,阿里云计算高级专家,擅长日志分析处理领域
文章实时采集( 启蒙续集之Halcon联合C#以及手眼以及标定实时采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-10-30 22:22
启蒙续集之Halcon联合C#以及手眼以及标定实时采集方法)
Halcon结合C#实时采集图像 Halcon结合C#实时采集图像
内容中引用的学习课程为超人视频:Halcon结合C#和手眼校准
实时采集方法有四种:循环采集、定时器、多线程、回调函数
这篇文章在之前的代码上做了改进,所以我把之前的代码复制了一份,再次打开发现这个界面:
如何打开 C# 设计窗口:
改进过程:
1.halcon 部分
在halcon中打开采集助手,自动检测接口,连接,实时,插入代码
Halcon 代码的一部分是:
* Image Acquisition 01: Code generated by Image Acquisition 01
open_framegrabber ('GigEVision2', 0, 0, 0, 0, 0, 0, 'progressive', 8, 'rgb', -1, 'false', 'default', '0030532361ef_Basler_acA160020gc', 0, -1, AcqHandle)
grab_image_start (AcqHandle, -1)
while (true)
grab_image_async (Image, AcqHandle, -1)
get_image_size (Image, Width, Height)
dev_set_part (0, 0, Height, Width)
endwhile
close_framegrabber (AcqHandle)
2.C#部分
配置如上一篇文章,我直接用上次代码改了,所以没有重新配置。
添加控件定时器,属性栏如下。定时器方法不准确,间隔越长越不准确。单击闪电符号,Interval 更改为 40ms,事件将在 40ms 后执行。定时器开启后,不要采集关闭,否则会出现错误:HALCON error #2454: HALCON handle has already clear in operatorgrab_image_async
下一步就是双击不同的控件,然后将halcon导出的代码复制粘贴到相应位置即可。
在Halcon导出的C#代码中,只需要关注action函数中的代码即可:
// Local iconic variables
HObject ho_Image=null;
// Local control variables
HTuple hv_AcqHandle = new HTuple(), hv_Width = new HTuple();
HTuple hv_Height = new HTuple();
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Image);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
while ((int)(1) != 0)
{
ho_Image.Dispose();
HOperatorSet.GrabImageAsync(out ho_Image, hv_AcqHandle, -1);
hv_Width.Dispose();hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Image, out hv_Width, out hv_Height);
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
}
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Image.Dispose();
hv_AcqHandle.Dispose();
hv_Width.Dispose();
hv_Height.Dispose();
打开相机部分的代码:
#region 打开相机
private void button3_Click(object sender, EventArgs e)
{
//清空、打开、初始化相机
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Timg);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
textBox1.Text = "相机已打开!";
}
#endregion
采集显示部分代码:
注意:如果显示的图像只是halcon中可以看到的一部分,则说明halcon中没有使用dev_set_part()函数
#region 采集显示
///
/// 此部分包含定时器的触发
///
///
///
private void button4_Click(object sender, EventArgs e)
{
timer1.Enabled = true;
//打开窗口显示图片
HOperatorSet.OpenWindow(0, 0, hWindowControl1.Width, hWindowControl1.Height, hWindowControl1.HalconWindow, "visible", "", out hv_WindowHandle);
HDevWindowStack.Push(hv_WindowHandle);
}
private void timer1_Tick(object sender, EventArgs e)
{
ho_Timg.Dispose();
//获取图片
HOperatorSet.GrabImageAsync(out ho_Timg, hv_AcqHandle, -1);
//获取图片长宽
hv_Width.Dispose(); hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Timg, out hv_Width, out hv_Height);
//设置获取的图片在窗口中显示大小(此部分如果没有,则只能显示采集到的一部分图像)
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
//如果窗口打开,显示图片
if (HDevWindowStack.IsOpen())
{
HOperatorSet.DispObj(ho_Timg, HDevWindowStack.GetActive());
textBox1.Text = "实时录像成功!";
}
}
#endregion
关闭相机部分代码:
#region 关闭相机
private void button5_Click(object sender, EventArgs e)
{
//关闭定时器这步十分重要,不能少了
timer1.Enabled = false;
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Timg.Dispose();
textBox1.Text = "关闭相机成功!";
}
#endregion
Halcon与C#实时采集图像相关教程Unity与nodejs实时连接,实时音视频图像识别halcon基础应用及方法经验分享构建直播时实时音视频平台(一)实时预测用户对物品的偏好阿里云推荐引擎帮助您更好的提升业务。海量数据实时查询域名数据库设计小记(一)Spark实时e -商务数据分析与可视化HTML前端实时可视化开发工具Android平台美颜相机/相机实时滤镜/视频编解码/图片贴/人脸 查看全部
文章实时采集(
启蒙续集之Halcon联合C#以及手眼以及标定实时采集方法)
Halcon结合C#实时采集图像 Halcon结合C#实时采集图像
内容中引用的学习课程为超人视频:Halcon结合C#和手眼校准
实时采集方法有四种:循环采集、定时器、多线程、回调函数
这篇文章在之前的代码上做了改进,所以我把之前的代码复制了一份,再次打开发现这个界面:
如何打开 C# 设计窗口:
改进过程:
1.halcon 部分
在halcon中打开采集助手,自动检测接口,连接,实时,插入代码
Halcon 代码的一部分是:
* Image Acquisition 01: Code generated by Image Acquisition 01
open_framegrabber ('GigEVision2', 0, 0, 0, 0, 0, 0, 'progressive', 8, 'rgb', -1, 'false', 'default', '0030532361ef_Basler_acA160020gc', 0, -1, AcqHandle)
grab_image_start (AcqHandle, -1)
while (true)
grab_image_async (Image, AcqHandle, -1)
get_image_size (Image, Width, Height)
dev_set_part (0, 0, Height, Width)
endwhile
close_framegrabber (AcqHandle)
2.C#部分
配置如上一篇文章,我直接用上次代码改了,所以没有重新配置。
添加控件定时器,属性栏如下。定时器方法不准确,间隔越长越不准确。单击闪电符号,Interval 更改为 40ms,事件将在 40ms 后执行。定时器开启后,不要采集关闭,否则会出现错误:HALCON error #2454: HALCON handle has already clear in operatorgrab_image_async
下一步就是双击不同的控件,然后将halcon导出的代码复制粘贴到相应位置即可。
在Halcon导出的C#代码中,只需要关注action函数中的代码即可:
// Local iconic variables
HObject ho_Image=null;
// Local control variables
HTuple hv_AcqHandle = new HTuple(), hv_Width = new HTuple();
HTuple hv_Height = new HTuple();
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Image);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
while ((int)(1) != 0)
{
ho_Image.Dispose();
HOperatorSet.GrabImageAsync(out ho_Image, hv_AcqHandle, -1);
hv_Width.Dispose();hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Image, out hv_Width, out hv_Height);
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
}
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Image.Dispose();
hv_AcqHandle.Dispose();
hv_Width.Dispose();
hv_Height.Dispose();
打开相机部分的代码:
#region 打开相机
private void button3_Click(object sender, EventArgs e)
{
//清空、打开、初始化相机
// Initialize local and output iconic variables
HOperatorSet.GenEmptyObj(out ho_Timg);
//Image Acquisition 01: Code generated by Image Acquisition 01
hv_AcqHandle.Dispose();
HOperatorSet.OpenFramegrabber("GigEVision2", 0, 0, 0, 0, 0, 0, "progressive",
8, "rgb", -1, "false", "default", "0030532361ef_Basler_acA160020gc", 0, -1,
out hv_AcqHandle);
HOperatorSet.GrabImageStart(hv_AcqHandle, -1);
textBox1.Text = "相机已打开!";
}
#endregion
采集显示部分代码:
注意:如果显示的图像只是halcon中可以看到的一部分,则说明halcon中没有使用dev_set_part()函数
#region 采集显示
///
/// 此部分包含定时器的触发
///
///
///
private void button4_Click(object sender, EventArgs e)
{
timer1.Enabled = true;
//打开窗口显示图片
HOperatorSet.OpenWindow(0, 0, hWindowControl1.Width, hWindowControl1.Height, hWindowControl1.HalconWindow, "visible", "", out hv_WindowHandle);
HDevWindowStack.Push(hv_WindowHandle);
}
private void timer1_Tick(object sender, EventArgs e)
{
ho_Timg.Dispose();
//获取图片
HOperatorSet.GrabImageAsync(out ho_Timg, hv_AcqHandle, -1);
//获取图片长宽
hv_Width.Dispose(); hv_Height.Dispose();
HOperatorSet.GetImageSize(ho_Timg, out hv_Width, out hv_Height);
//设置获取的图片在窗口中显示大小(此部分如果没有,则只能显示采集到的一部分图像)
if (HDevWindowStack.IsOpen())
{
HOperatorSet.SetPart(HDevWindowStack.GetActive(), 0, 0, hv_Height, hv_Width);
}
//如果窗口打开,显示图片
if (HDevWindowStack.IsOpen())
{
HOperatorSet.DispObj(ho_Timg, HDevWindowStack.GetActive());
textBox1.Text = "实时录像成功!";
}
}
#endregion
关闭相机部分代码:
#region 关闭相机
private void button5_Click(object sender, EventArgs e)
{
//关闭定时器这步十分重要,不能少了
timer1.Enabled = false;
HOperatorSet.CloseFramegrabber(hv_AcqHandle);
ho_Timg.Dispose();
textBox1.Text = "关闭相机成功!";
}
#endregion
Halcon与C#实时采集图像相关教程Unity与nodejs实时连接,实时音视频图像识别halcon基础应用及方法经验分享构建直播时实时音视频平台(一)实时预测用户对物品的偏好阿里云推荐引擎帮助您更好的提升业务。海量数据实时查询域名数据库设计小记(一)Spark实时e -商务数据分析与可视化HTML前端实时可视化开发工具Android平台美颜相机/相机实时滤镜/视频编解码/图片贴/人脸
文章实时采集(优采云·云采集网络爬虫软件如何高效抓取网站文章(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-29 08:10
优采云·Cloud采集网络爬虫软件优采云·Cloud采集网络爬虫软件如何高效爬取网站文章现在大部分内容已经完成需要参考很多网页文章,那么今天的互联网报告开发中如何高效抓取网站文章。本文以UO标题为例。UC头条是UC浏览器团队打造的新闻资讯推荐平台,拥有海量新闻资讯内容,通过阿里大数据推荐和机器学习算法,为用户提供优质贴心的文章 . 很多用户可能有采集UC头条文章采集的需求,这里有采集文章的文字和图片。正文可以直接采集,对于图片,必须先下载图片网址采集,然后将图片网址批量转换成图片。本文中采集UC标题文章和采集的字段为:标题、出版商、发布时间、文章内容、页面网址、图片网址、图片存储地址. 采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门
网页打开后,默认显示“推荐”文章。观察到该网页没有翻页按钮,而是通过下拉加载,不断加载新内容。因此,我们选择“打开网页”这一步,在高级选项中勾选“页面加载后向下滚动”,滚动根据自己的需要设置次数,根据网页设置间隔时间装载情况。滚动方式为“向下滚动一屏”,然后点击“确定”(注意:间隔时间需要针对网站情况设置,不是绝对。一般情况下间隔时间>网站 加载时间够了,有时候网速慢,网页加载慢,并且需要根据具体情况进行调整。详情请看:优采云7.0Tutorial-AJAX滚动教程HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t =1) 超链接 "/article /javascript:;" 第二步:创建翻页循环并提取数据 1) 移动鼠标,选择页面上的第一个文章链接。系统会自动识别相似链接。在操作提示框中选择“全选”2)选择“循环点击每个链接”3)系统会自动进入文章详情页面。点击需要采集的字段(先点击这里文章title),在操作提示框中选择“采集元素的文本”<
以下采集是文章 HYPERLINK "/article/javascript:;" 的正文 第三步:提取UC标题文章图片地址1)接下来开始采集图片地址。点击文章中的第一张图片,然后点击页面上的第二张图片。在弹出的操作提示框中选择“采集下图地址”2)修改字段名,然后点击“确定”3)现在我们有了采集@ > 到达图片网址,我们准备批量导出图片。批量导出图片时,我们希望将同一文章文章中的图片放到同一个文件中,文件夹名称为文章。首先我们选择标题,在操作提示框中选择“采集
我们通过这个Xpath发现://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,都需要在页面文章都位于。3) 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定” 第五步:文章Data采集并导出1)点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集” 注意:本地采集占用当前电脑资源继续采集,如果有采集时间要求或当前电脑长时间无法执行采集可以使用云采集功能,云采集在网络 采集 ,没有当前电脑的支持,电脑可以关机,可以设置多个云节点共享任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集 @>数据可以在云端存储三个月,随时可以导出。采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好的数据。这里我们选择excel作为导出格式,导出数据如下图 Step 6: HYPERLINK "/article/javascript:;" 批量将图片网址转换为图片。经过以上操作,我们得到了图片的URL为采集。接下来使用优采云专用图片批量下载工具
图片批量下载工具:HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)download优采云 图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件< @2) 打开文件菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式的文件)3) 进行相关设置。设置完成后,单击“确定”导入文件。选择EXCEL文件:导入需要下载图片地址的EXCEL文件。名称:对应数据表的名称 File URL 列名称:表中对应URL的列名称,这里是“图片网址”保存文件夹名称:EXCEL中需要单独的一栏列出图片所在的路径想要保存到文件夹中,
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。2、功能强大,任意一个网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。3、云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。4、特色免费+增值服务,您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 查看全部
文章实时采集(优采云·云采集网络爬虫软件如何高效抓取网站文章(组图))
优采云·Cloud采集网络爬虫软件优采云·Cloud采集网络爬虫软件如何高效爬取网站文章现在大部分内容已经完成需要参考很多网页文章,那么今天的互联网报告开发中如何高效抓取网站文章。本文以UO标题为例。UC头条是UC浏览器团队打造的新闻资讯推荐平台,拥有海量新闻资讯内容,通过阿里大数据推荐和机器学习算法,为用户提供优质贴心的文章 . 很多用户可能有采集UC头条文章采集的需求,这里有采集文章的文字和图片。正文可以直接采集,对于图片,必须先下载图片网址采集,然后将图片网址批量转换成图片。本文中采集UC标题文章和采集的字段为:标题、出版商、发布时间、文章内容、页面网址、图片网址、图片存储地址. 采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门 采集UC标题文章和采集的字段为:标题、发布者、发布时间、文章内容、页面地址、图片地址、图片存储地址。采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK " /tutorialdetail-1/xpathrm1.html" xpath2/tutorialdetail-1/xpathrm1.html 超链接 "/tutorialdetail-1/xdxpath-7.html" 入门
网页打开后,默认显示“推荐”文章。观察到该网页没有翻页按钮,而是通过下拉加载,不断加载新内容。因此,我们选择“打开网页”这一步,在高级选项中勾选“页面加载后向下滚动”,滚动根据自己的需要设置次数,根据网页设置间隔时间装载情况。滚动方式为“向下滚动一屏”,然后点击“确定”(注意:间隔时间需要针对网站情况设置,不是绝对。一般情况下间隔时间>网站 加载时间够了,有时候网速慢,网页加载慢,并且需要根据具体情况进行调整。详情请看:优采云7.0Tutorial-AJAX滚动教程HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t =1) 超链接 "/article /javascript:;" 第二步:创建翻页循环并提取数据 1) 移动鼠标,选择页面上的第一个文章链接。系统会自动识别相似链接。在操作提示框中选择“全选”2)选择“循环点击每个链接”3)系统会自动进入文章详情页面。点击需要采集的字段(先点击这里文章title),在操作提示框中选择“采集元素的文本”<
以下采集是文章 HYPERLINK "/article/javascript:;" 的正文 第三步:提取UC标题文章图片地址1)接下来开始采集图片地址。点击文章中的第一张图片,然后点击页面上的第二张图片。在弹出的操作提示框中选择“采集下图地址”2)修改字段名,然后点击“确定”3)现在我们有了采集@ > 到达图片网址,我们准备批量导出图片。批量导出图片时,我们希望将同一文章文章中的图片放到同一个文件中,文件夹名称为文章。首先我们选择标题,在操作提示框中选择“采集
我们通过这个Xpath发现://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,都需要在页面文章都位于。3) 将修改后的Xpath复制粘贴到优采云所示位置,然后点击“确定” 第五步:文章Data采集并导出1)点击左上角“保存”,然后点击“开始采集”,选择“开始本地采集” 注意:本地采集占用当前电脑资源继续采集,如果有采集时间要求或当前电脑长时间无法执行采集可以使用云采集功能,云采集在网络 采集 ,没有当前电脑的支持,电脑可以关机,可以设置多个云节点共享任务,10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集 @>数据可以在云端存储三个月,随时可以导出。采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”,导出采集好的数据。这里我们选择excel作为导出格式,导出数据如下图 Step 6: HYPERLINK "/article/javascript:;" 批量将图片网址转换为图片。经过以上操作,我们得到了图片的URL为采集。接下来使用优采云专用图片批量下载工具
图片批量下载工具:HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)download优采云 图片批量下载工具,双击文件中的MyDownloader.app.exe文件打开软件< @2) 打开文件菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式的文件)3) 进行相关设置。设置完成后,单击“确定”导入文件。选择EXCEL文件:导入需要下载图片地址的EXCEL文件。名称:对应数据表的名称 File URL 列名称:表中对应URL的列名称,这里是“图片网址”保存文件夹名称:EXCEL中需要单独的一栏列出图片所在的路径想要保存到文件夹中,
1、操作简单,任何人都可以使用:无需技术背景,即可上网采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。2、功能强大,任意一个网站都可以:点击、登录、翻页、识别验证码、瀑布流、Ajax脚本,通过简单的设置异步加载数据页面。采集。3、云采集,可以关掉。配置完采集任务后,可以关闭,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封、网络中断。4、特色免费+增值服务,您可以根据自己的需要进行选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。
文章实时采集(p2p贷款如何让你看到的不仅仅是你想看到)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-27 04:05
文章实时采集人们的无形财富并保存。请认真阅读此文,及时阅读最新的渠道策略和工具策略,对于你未来的理财非常有帮助。人们在网上获取有价值的信息。所以让你看到的不仅仅是你想看到的。就算不那么好,也是必要的。让我们先来看一下以下这张图:来自一个很有个性的网站,它内容全是你自己的财务状况,收入和支出情况。它也是一个非常有名气的服务供应商,它的名字叫p2p贷款。
在这个网站上的所有公司名称全是独特的,但它们的所有内容全是相同的。我相信这样做会有助于你解决风险和预期成本。风险:风险在于,我不确定我看到的是不是我想看到的。但我在网上找到了我想看到的东西。支出:收入支出全是相同的。(实际上要比收入支出总量更少)。所以不要在这样的一个服务上投入太多精力。并且分散到很多低风险的贷款上,这会提高我们的收益。
当然最好选择那些产品太丰富而有一些小问题的网站。重要的是,人们不会将这个服务当成一个额外的放贷者来看待。而是将它看成一个有生意的好客户。同时他们也会为了符合我们的规则和尽可能多的贷款资质来创建。如果你要征信违约的,很遗憾,你的钱是不会到另一个人手里。换句话说,我建议你提供个人信息,还是要看那些需要的细节情况。
如果你已经做到了,就应该尽量多提供这些数据和信息,这就像如果你已经成为一个常人,你就应该能基本做到一样。当然比你想象的那样,你提供信息的人们会要求更多。这个时候你就不得不提供给他们我们需要的数据,这就是后话了。回到基础设施角度,你要问自己,那么多公司,不同的风险偏好,如何保存这些信息?你将他们分割到尽可能多的贷款上吗?有两种做法。
1.将这些贷款不要提供给不想对他们负责的人,就比如要设置自己的账户,它的利率,还款方式。2.将他们打包在一起。3.或者你再其他地方存储这些数据的时候,只分发前2种。4.不对他们负责5.不对他们负责6.不对他们负责一个更快捷的方法是购买短期贷款,然后把每月的款项打到那里7.将短期贷款作为其他可支配贷款的替代品而不是存在自己的账户8.重要的是要记住,到头来他们都只是一次性贷款。
如果你不把他们放到新贷款,那你之前所有的贷款都会消失。他们也不再能帮助你。这意味着你把所有的短期贷款一次性购买一次性偿还,而不是分别购买。9.银行的支持,找一个靠谱的信用卡公司或者支付公司,让他们们看看你的资金状况,然后帮你审批贷款。10.没有谁需要你花钱买他们,重要的是你的钱。11.不要将短期贷款放在不确定的贷款机构。你正在设置你的账户,通常。 查看全部
文章实时采集(p2p贷款如何让你看到的不仅仅是你想看到)
文章实时采集人们的无形财富并保存。请认真阅读此文,及时阅读最新的渠道策略和工具策略,对于你未来的理财非常有帮助。人们在网上获取有价值的信息。所以让你看到的不仅仅是你想看到的。就算不那么好,也是必要的。让我们先来看一下以下这张图:来自一个很有个性的网站,它内容全是你自己的财务状况,收入和支出情况。它也是一个非常有名气的服务供应商,它的名字叫p2p贷款。
在这个网站上的所有公司名称全是独特的,但它们的所有内容全是相同的。我相信这样做会有助于你解决风险和预期成本。风险:风险在于,我不确定我看到的是不是我想看到的。但我在网上找到了我想看到的东西。支出:收入支出全是相同的。(实际上要比收入支出总量更少)。所以不要在这样的一个服务上投入太多精力。并且分散到很多低风险的贷款上,这会提高我们的收益。
当然最好选择那些产品太丰富而有一些小问题的网站。重要的是,人们不会将这个服务当成一个额外的放贷者来看待。而是将它看成一个有生意的好客户。同时他们也会为了符合我们的规则和尽可能多的贷款资质来创建。如果你要征信违约的,很遗憾,你的钱是不会到另一个人手里。换句话说,我建议你提供个人信息,还是要看那些需要的细节情况。
如果你已经做到了,就应该尽量多提供这些数据和信息,这就像如果你已经成为一个常人,你就应该能基本做到一样。当然比你想象的那样,你提供信息的人们会要求更多。这个时候你就不得不提供给他们我们需要的数据,这就是后话了。回到基础设施角度,你要问自己,那么多公司,不同的风险偏好,如何保存这些信息?你将他们分割到尽可能多的贷款上吗?有两种做法。
1.将这些贷款不要提供给不想对他们负责的人,就比如要设置自己的账户,它的利率,还款方式。2.将他们打包在一起。3.或者你再其他地方存储这些数据的时候,只分发前2种。4.不对他们负责5.不对他们负责6.不对他们负责一个更快捷的方法是购买短期贷款,然后把每月的款项打到那里7.将短期贷款作为其他可支配贷款的替代品而不是存在自己的账户8.重要的是要记住,到头来他们都只是一次性贷款。
如果你不把他们放到新贷款,那你之前所有的贷款都会消失。他们也不再能帮助你。这意味着你把所有的短期贷款一次性购买一次性偿还,而不是分别购买。9.银行的支持,找一个靠谱的信用卡公司或者支付公司,让他们们看看你的资金状况,然后帮你审批贷款。10.没有谁需要你花钱买他们,重要的是你的钱。11.不要将短期贷款放在不确定的贷款机构。你正在设置你的账户,通常。
文章实时采集( 80集Python基础入门视频教学点免费观看事百科段子)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-24 11:17
80集Python基础入门视频教学点免费观看事百科段子)
Python爬虫实战练习:采集尴尬百科段数据
更新时间:2021年10月21日10:45:35 作者:松鼠爱吃饼干
读一万本书不如行万里。仅仅学习书中的理论是远远不够的。只有在实战中才能获得能力的提升。段落的数据,可以检查过程中的差距,提高水平
内容
知识点
1.爬行的基本步骤
2.请求模块
3.解析模块
4.xpath数据分析方法
5.分页功能
爬虫的基本步骤:
1.获取网页地址(维基百科段落地址)
2.发送请求
3.数据分析
4.本地保存
爬虫代码导入需要的模块
import re
import requests
import parsel
获取网址
url = 'https://www.qiushibaike.com/text/'
# 请求头 伪装客户端向服务器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
发送请求
requ = requests.get(url=url, headers=headers).text
数据分析
sel = parsel.Selector(requ) # 解析对象
href = sel.xpath('//body/div/div/div[2]/div/a[1]/@href').getall()
for html in href:
txt_href = 'https://www.qiushibaike.com' + html
requ2 = requests.get(url=txt_href, headers=headers).text
sel2 = parsel.Selector(requ2)
title = sel2.xpath('//body/div[2]/div/div[2]/h1/text()').get().strip()
title = re.sub(r'[|/\:?*]','_',title)
# content = sel2.xpath('//div[@class="content"]/text()').getall()
content = sel2.xpath('//body/div[2]/div/div[2]/div[2]/div[1]/div/text()').getall()
contents = '\n'.join(content)
保存数据
with open('糗事百科text\\'+title + '.txt', mode='w', encoding='utf-8') as fp:
fp.write(contents)
print(title, '下载成功')
运行代码获取数据
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
至此,这篇关于Python爬虫实战演练采集尴尬百科段落数据文章的介绍就到这里,更多Python相关采集尴尬百科段落内容,请搜索脚本首页上一页< @文章 或继续浏览下方的相关文章,希望大家以后多多支持Scripthome! 查看全部
文章实时采集(
80集Python基础入门视频教学点免费观看事百科段子)
Python爬虫实战练习:采集尴尬百科段数据
更新时间:2021年10月21日10:45:35 作者:松鼠爱吃饼干
读一万本书不如行万里。仅仅学习书中的理论是远远不够的。只有在实战中才能获得能力的提升。段落的数据,可以检查过程中的差距,提高水平
内容
知识点
1.爬行的基本步骤
2.请求模块
3.解析模块
4.xpath数据分析方法
5.分页功能
爬虫的基本步骤:
1.获取网页地址(维基百科段落地址)
2.发送请求
3.数据分析
4.本地保存
爬虫代码导入需要的模块
import re
import requests
import parsel
获取网址
url = 'https://www.qiushibaike.com/text/'
# 请求头 伪装客户端向服务器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
发送请求
requ = requests.get(url=url, headers=headers).text
数据分析
sel = parsel.Selector(requ) # 解析对象
href = sel.xpath('//body/div/div/div[2]/div/a[1]/@href').getall()
for html in href:
txt_href = 'https://www.qiushibaike.com' + html
requ2 = requests.get(url=txt_href, headers=headers).text
sel2 = parsel.Selector(requ2)
title = sel2.xpath('//body/div[2]/div/div[2]/h1/text()').get().strip()
title = re.sub(r'[|/\:?*]','_',title)
# content = sel2.xpath('//div[@class="content"]/text()').getall()
content = sel2.xpath('//body/div[2]/div/div[2]/div[2]/div[1]/div/text()').getall()
contents = '\n'.join(content)
保存数据
with open('糗事百科text\\'+title + '.txt', mode='w', encoding='utf-8') as fp:
fp.write(contents)
print(title, '下载成功')
运行代码获取数据
【付费VIP完整版】只要看完就能学会的教程,80集Python基础入门视频教学
点击这里免费在线观看
至此,这篇关于Python爬虫实战演练采集尴尬百科段落数据文章的介绍就到这里,更多Python相关采集尴尬百科段落内容,请搜索脚本首页上一页< @文章 或继续浏览下方的相关文章,希望大家以后多多支持Scripthome!
文章实时采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-23 11:11
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,使用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、 方案说明(一) 概述 本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输到CKafka,将CKafka数据连接到Oceanus(Flink)进行流计算,通过简单的业务逻辑处理输出到Elasticsearch,最后通过Kibana页面查询结果。计划中使用Promethus监控系统指标,如作为流计算 Oceanus 作业运行状态,Cloud Grafana 监控 CVM 或业务应用指标。
(二)方案架构
二、前期准备 在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私网VPC 私网VPC是您在腾讯云上自定义的逻辑隔离的网络空间,建议在搭建CKafka、流计算Oceanus、Elasticsearch集群等时选择同一个VPC服务.详情创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka建议选择最新的2.4.1版本,与Filebeat兼容性更好< @采集工具购买完成后,创建一个Kafka主题:topic-app-info(三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。基于Apache Flink,一站式开发,无缝连接、亚秒级延迟、低成本、安全稳定的企业级实时大数据分析平台。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。在流计算中在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源独立Grafana在灰色发布中,需要在Grafana管理页面()单独购买,实现业务监控指标的展示。
(七)安装配置Filebeat Filebeat是一个轻量级的日志数据工具采集,通过监控指定位置的文件来采集信息,在这个VPC下提供给需要监控主机的云服务器信息及应用信息 安装Filebeat 安装方法一:下载Filebeat 下载地址(); 方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例采用方法一。下载到CVM然后配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集jar应用日志、JVM使用情况、监听端口等,详情请参考Filebeat官网
()。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、 进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。1、 定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据,在Kibana上查询数据ES控制台页面,或进入同一子网的CVM下,使用以下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。(三)系统指标监控本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据的存储、计算和告警。流计算Oceanus建议用户使用腾讯云监控提供的Prometheus服务,避免部署和运维成本,同时还支持腾讯云的通知模板,可以通过短信、电话、邮件等方式轻松到达不同的报警信息、企业微信机器人等 Receiver. 监控配置 流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任何流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(灰度级Grafana这里不能输入),并导入json文件。详情请参考访问 Prometheus 自定义监视器
()。
3、3、显示的Flink任务监控效果如下,用户也可以点击【编辑】设置不同的Panel,优化显示效果。
告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】 ] 配置相关信息。具体操作请参考访问Prometheus自定义监控()。
2、设置报警通知。选择[选择模板]或[新建]设置通知模板。
3、短信通知信息
(四)业务指标监控通过Filebeat采集给应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰色发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】 ,搜索elasticsearch,填写相关ES实例信息,添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:
注:本办公室仅为示例,无实际业务
四、总结 本方案尝试了系统监控指标和业务监控指标两个监控方案。如果只需要监控业务指标,可以省略Prometus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”,了解更多腾讯云流媒体Oceanus~腾讯云大数据
长按二维码 查看全部
文章实时采集(如何使用腾讯云大数据组件来完成实时监控系统的设计和实现)
本文介绍如何使用腾讯云大数据组件完成实时监控系统的设计与实现。通过实时采集和分析云服务器(CVM)及其App应用的CPU和内存消耗数据,使用短信、电话、微信等方式实时反馈监控报警信息,有效保证系统的稳定运行。使用基于云的Kafka、Flink、ES等组件,大大减少了开发运维人员的投入。
一、 方案说明(一) 概述 本方案结合腾讯云CKafka、流计算Oceanus(Flink)、Elasticsearch、Prometheus等,通过Filebeat实时采集系统和应用监控数据,并传输到CKafka,将CKafka数据连接到Oceanus(Flink)进行流计算,通过简单的业务逻辑处理输出到Elasticsearch,最后通过Kibana页面查询结果。计划中使用Promethus监控系统指标,如作为流计算 Oceanus 作业运行状态,Cloud Grafana 监控 CVM 或业务应用指标。
(二)方案架构
二、前期准备 在实施本方案之前,请确保已经创建并配置了相应的大数据组件。(一)创建私网VPC 私网VPC是您在腾讯云上自定义的逻辑隔离的网络空间,建议在搭建CKafka、流计算Oceanus、Elasticsearch集群等时选择同一个VPC服务.详情创建步骤请参考帮助文档()。(二)创建CKafka实例Kafka建议选择最新的2.4.1版本,与Filebeat兼容性更好< @采集工具购买完成后,创建一个Kafka主题:topic-app-info(三) 创建流计算Oceanus集群 流计算Oceanus是大数据产品生态系统的实时分析工具。基于Apache Flink,一站式开发,无缝连接、亚秒级延迟、低成本、安全稳定的企业级实时大数据分析平台。流计算Oceanus旨在实现企业数据价值最大化,加速企业实时数字化建设。在流计算中在Oceanus控制台的【集群管理】->【新建集群】页面创建集群。具体步骤请参考帮助文档()。(四)在Elasticsearch控制台创建Elasticsearch实例,点击左上角【新建】创建集群,具体步骤请参考帮助文档()。(五)
为了显示自定义的系统指标,需要购买 Promethus 服务。只需要自定义业务指标的同学可以省略这一步。
进入云监控控制台,点击左侧的【Prometheus监控】,新建一个Prometheus实例。具体步骤请参考帮助文档()。
(六)创建独立的Grafana资源独立Grafana在灰色发布中,需要在Grafana管理页面()单独购买,实现业务监控指标的展示。
(七)安装配置Filebeat Filebeat是一个轻量级的日志数据工具采集,通过监控指定位置的文件来采集信息,在这个VPC下提供给需要监控主机的云服务器信息及应用信息 安装Filebeat 安装方法一:下载Filebeat 下载地址(); 方法二:使用【Elasticsearch管理页面】->【beats管理】中提供的Filebeat,本例采用方法一。下载到CVM然后配置Filebeat,在filebeat.yml文件中添加如下配置项:
# 监控日志文件配置- type: logenabled: truepaths: - /tmp/test.log #- c:programdataelasticsearchlogs*
# 监控数据输出项配置output.kafka:version: 2.0.0 # kafka 版本号hosts: ["xx.xx.xx.xx:xxxx"] # 请填写实际的 IP 地址+端口topic: 'topic-app-info' # 请填写实际的 topic
请根据实际业务需求配置相应的Filebeat.yml文件,参考Filebeat官方文档()。
注:示例中使用的是2.4.1的CKafka版本,此处配置版本:2.0.0。不兼容的版本可能会出现“ERROR [kafka] kafka/client.go:341 Kafka (topic=topic-app-info): drop invalid message”错误
三、项目实现
接下来通过一个案例来介绍如何通过流计算Oceanus实现个性化监控。
(一)Filebeat 采集 数据
1、进入Filebeat根目录,启动Filebeat获取数据采集。在示例中,采集 显示了 top 命令中显示的 CPU、内存等信息。还可以采集jar应用日志、JVM使用情况、监听端口等,详情请参考Filebeat官网
()。
# filebeat 启动<br />./filebeat -e -c filebeat.yml<br /><br /># 监控系统信息写入 test.log 文件<br />top -d 10 >>/tmp/test.log
2、 进入CKafka页面,点击左侧【消息查询】,查询对应的主题消息,验证数据是否为采集。
Filebeat采集中Kafka的数据格式:
{ "@timestamp": "2021-08-30T10:22:52.888Z", "@metadata": { "beat": "filebeat", "type": "_doc", "version": "7.14.0" }, "input": { "type": "log" }, "host": { "ip": ["xx.xx.xx.xx", "xx::xx:xx:xx:xx"], "mac": ["xx:xx:xx:xx:xx:xx"], "hostname": "xx.xx.xx.xx", "architecture": "x86_64", "os": { "type": "linux", "platform": "centos", "version": "7(Core)", "family": "redhat", "name": "CentOSLinux", "kernel": "3.10.0-1062.9.1.el7.x86_64", "codename": "Core" }, "id": "0ea734564f9a4e2881b866b82d679dfc", "name": "xx.xx.xx.xx", "containerized": false }, "agent": { "name": "xx.xx.xx.xx", "type": "filebeat", "version": "7.14.0", "hostname": "xx.xx.xx.xx", "ephemeral_id": "6c0922a6-17af-4474-9e88-1fc3b1c3b1a9", "id": "6b23463c-0654-4f8b-83a9-84ec75721311" }, "ecs": { "version": "1.10.0" }, "log": { "offset": 2449931, "file": { "path": "/tmp/test.log" } }, "message": "(B[m16root0-20000S0.00.00:00.00kworker/1:0H(B[m[39;49m[K"}
(二)创建 Flink SQL 作业
使用流计算 Oceanus 处理 CKafka 访问的数据并存储在 Elasticsearch 中。1、 定义Source,根据Filebeat中json消息的格式构造Flink Table Source。
CREATE TABLE DataInput ( `@timestamp` VARCHAR, `host` ROW, `log` ROW, `message` VARCHAR) WITH ( 'connector' = 'kafka', -- 可选 'kafka','kafka-0.11'. 注意选择对应的内置 Connector 'topic' = 'topic-app-info', -- 替换为您要消费的 Topic 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '10.0.0.29:9092', 'properties.group.id' = 'oceanus_group2', -- 必选参数, 一定要指定 Group ID 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 忽略 JSON 结构解析异常 'json.fail-on-missing-field' = 'false' -- 如果设置为 true, 则遇到缺失字段会报错 设置为 false 则缺失字段设置为 null);
2、定义接收器
CREATE TABLE es_output ( `id` VARCHAR, `ip` ARRAY, `path` VARCHAR, `num` INTEGER, `message` VARCHAR, `createTime` VARCHAR) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '6', 'connector.hosts' = 'http://10.0.0.175:9200', 'connector.index' = 'oceanus_test2', 'connector.document-type' = '_doc', 'connector.username' = 'elastic', 'connector.password' = 'yourpassword', 'update-mode' = 'upsert', -- 可选无主键的 'append' 模式,或有主键的 'upsert' 模式 'connector.key-null-literal' = 'n/a', -- 主键为 null 时的替代字符串,默认是 'null' 'format.type' = 'json' -- 输出数据格式, 目前只支持 'json');
3、处理业务数据
INSERT INTO es_outputSELECT host.id as `id`, host.ip as `ip`, log.file.path as `path`, log.`offset` as `num`, message, `@timestamp` as `createTime`from DataInput;
4、配置作业参数【内置连接器】选择flink-connector-elasticsearch6和flink-connector-kafka 注意:根据实际版本选择5、查询ES数据,在Kibana上查询数据ES控制台页面,或进入同一子网的CVM下,使用以下命令查询:
# 查询索引 username:password 请替换为实际账号密码curl -XGET -u username:password http://xx.xx.xx.xx:xxxx/oceanus_test2/_search -H 'Content-Type: application/json' -d'{ "query": { "match_all": {}}, "size": 10}'
更多访问方式请参考访问ES集群()。(三)系统指标监控本章主要实现系统信息监控,对Flink作业的运行状态进行监控和告警。Prometheus是一个非常灵活的时序数据库,通常用于监控数据的存储、计算和告警。流计算Oceanus建议用户使用腾讯云监控提供的Prometheus服务,避免部署和运维成本,同时还支持腾讯云的通知模板,可以通过短信、电话、邮件等方式轻松到达不同的报警信息、企业微信机器人等 Receiver. 监控配置 流计算 Oceanus 作业监控
除了流计算Oceanus控制台自带的监控信息外,还可以配置目前支持任务级细粒度监控、作业级监控、集群Flink作业列表监控。1、 流计算Oceanus作业详情页面,点击【作业参数】,在【高级参数】中添加如下配置:
pipeline.max-parallelism: 2048metrics.reporters: promgatewaymetrics.reporter.promgateway.host: xx.xx.xx.xx # Prometheus实例地址metrics.reporter.promgateway.port: 9090 # Prometheus实例端口metrics.reporter.promgateway.needBasicAuth: truemetrics.reporter.promgateway.password: xxxxxxxxxxx # Prometheus实例密码metrics.reporter.promgateway.interval: 10 SECONDS
2、 在任何流计算Oceanus作业中,点击【云监控】进入云Prometheus实例,点击链接进入Grafana(灰度级Grafana这里不能输入),并导入json文件。详情请参考访问 Prometheus 自定义监视器
()。
3、3、显示的Flink任务监控效果如下,用户也可以点击【编辑】设置不同的Panel,优化显示效果。
告警配置1、进入腾讯云监控界面,点击左侧【Prometheus监控】,点击购买的实例进入服务管理页面,点击左侧【告警策略】,点击【新建】 ] 配置相关信息。具体操作请参考访问Prometheus自定义监控()。
2、设置报警通知。选择[选择模板]或[新建]设置通知模板。
3、短信通知信息
(四)业务指标监控通过Filebeat采集给应用业务数据,通过流计算的Oceanus服务处理数据存储在ES中,使用ES+Grafana监控业务数据。
1、Grafana 配置 ES 数据源。进入灰色发布中的Grafana控制台(),进入刚刚创建的Grafana服务,找到外网地址打开登录,Grafana账号为admin,登录后点击【配置】,点击【添加源】 ,搜索elasticsearch,填写相关ES实例信息,添加数据源。
2、 点击左侧【Dashboards】,点击【Manage】,点击右上角的【New Dashboard】,新建面板,编辑面板。
3、 显示效果如下:
注:本办公室仅为示例,无实际业务
四、总结 本方案尝试了系统监控指标和业务监控指标两个监控方案。如果只需要监控业务指标,可以省略Prometus相关操作。此外,需要注意的是:
火热进行中↓↓
点击文末“阅读原文”,了解更多腾讯云流媒体Oceanus~腾讯云大数据
长按二维码
文章实时采集(查找自媒体爆文素材比较方便的渠道,合理的使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2021-10-22 00:03
从事自媒体运营行业,每天都需要不断学习新知识,比如标题的写作技巧是什么,如何切入热点跟踪角度,这些都需要积极阅读材料和然后学习,但学习的目的归根结底还是你自己的实际操作。如果我们每天都需要大量的文章素材,而且都是优质的爆文素材,我们不可能天天到处搜索,那么有没有什么工具可以实现呢?
今天小编为大家推荐三个采集站点自媒体爆文。当你需要大量爆文资料参考时,只要根据自己的行业数据想知道关键词都可以看到。
1、简单的文章
易传采集拥有市面上所有主流自媒体平台的所有爆文数据,并提供基础阅读分析数据和互动数据。参考采集的爆文的分析,为我自己的创作提供灵感和方向。
您也可以根据您的特定领域搜索您想要的爆文材料。除了采集爆文,您还可以提供文章编辑、短视频素材采集和下载、文章原创度检测和真实-时间热点追踪功能,是一款非常好用的自媒体辅助工具。
2、西瓜助手
西瓜助手的西瓜数据也是采集很多领域的爆文素材。不同的是它有提取标签的功能,而且在一些有用的工具中还有热门标题的更新,聊胜于无。毕竟,不是每个人都可以使用它。
3、乐观
Optimism的优势之一是网站的部分功能无需注册即可应用,详细功能需要登录。Optimism 没有很多内容筛选,但是可以绑定一些边缘自媒体平台,然后一键将内容同步到这些平台。
以上三个网站是小编觉得找自媒体爆文素材比较方便的渠道。对于刚刚进入行业的新人来说,合理使用这三个。一个网站可以大大提高自己的运营效率。 查看全部
文章实时采集(查找自媒体爆文素材比较方便的渠道,合理的使用)
从事自媒体运营行业,每天都需要不断学习新知识,比如标题的写作技巧是什么,如何切入热点跟踪角度,这些都需要积极阅读材料和然后学习,但学习的目的归根结底还是你自己的实际操作。如果我们每天都需要大量的文章素材,而且都是优质的爆文素材,我们不可能天天到处搜索,那么有没有什么工具可以实现呢?
今天小编为大家推荐三个采集站点自媒体爆文。当你需要大量爆文资料参考时,只要根据自己的行业数据想知道关键词都可以看到。
1、简单的文章
易传采集拥有市面上所有主流自媒体平台的所有爆文数据,并提供基础阅读分析数据和互动数据。参考采集的爆文的分析,为我自己的创作提供灵感和方向。
您也可以根据您的特定领域搜索您想要的爆文材料。除了采集爆文,您还可以提供文章编辑、短视频素材采集和下载、文章原创度检测和真实-时间热点追踪功能,是一款非常好用的自媒体辅助工具。
2、西瓜助手
西瓜助手的西瓜数据也是采集很多领域的爆文素材。不同的是它有提取标签的功能,而且在一些有用的工具中还有热门标题的更新,聊胜于无。毕竟,不是每个人都可以使用它。
3、乐观
Optimism的优势之一是网站的部分功能无需注册即可应用,详细功能需要登录。Optimism 没有很多内容筛选,但是可以绑定一些边缘自媒体平台,然后一键将内容同步到这些平台。
以上三个网站是小编觉得找自媒体爆文素材比较方便的渠道。对于刚刚进入行业的新人来说,合理使用这三个。一个网站可以大大提高自己的运营效率。
文章实时采集(基于MIT开源协议发布NSQ的数据流模型结构如下图解析 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-12 21:19
)
NSQ 是一个基于 Go 语言的分布式实时消息平台。它是基于 MIT 开源协议发布的。代码托管在 GitHub 上。最新版本为0.3.1。NSQ 可用于大型系统中的实时消息服务,每天可处理数亿条消息。它的设计目标是为在分布式环境中运行的去中心化服务提供强大的基础设施。NSQ具有分布式、去中心化的拓扑结构,具有无单点故障、容错、高可用、消息传递可靠等特点。NSQ 非常易于配置和部署,并且具有最大的灵活性,支持多种消息传递协议。此外,官方还提供了开箱即用的 Go 和 Python 库。
NSQ 由四个重要组件组成:
NSQ的主要特点如下:
为了实现高效的分布式消息服务,NSQ 实现了合理的智能权衡,使其能够在生产环境中得到充分的应用。具体内容如下:
官方和第三方也为NSQ开发了很多客户端函数库,比如官方的基于HTTP、Go客户端go-nsq、Python客户端pynsq、基于Node.js的JavaScript客户端nsqjs,以及异步C客户端libnsq、Java客户端nsq -java 和许多基于各种语言的第三方客户端函数库。更多客户端函数库请点击查看。
从NSQ设计文档可知,单个nsqd被设计为一次处理多个流数据,NSQ中的数据流模型由stream和consumer组成。Topic 是一个独特的流,Channel 是订阅给定 Topic 的消费者的逻辑分组。NSQ的数据流模型结构如下图所示:
从上图可以看出,单个nsqd可以有多个topic,每个topic可以有多个channel。Channel可以接收所有Topic消息的副本,从而实现消息组播分发;并且Channel上的每条消息都分发给它的订阅者,从而实现负载均衡,所有这些形成一个单片,可以代表各种简单和复杂的拓扑结构。
NSQ 最初是为 Bitly 开发的,Bitly 是一个提供短链接服务的应用程序。另外还有很多使用NSQ的知名应用,比如社交新闻网站Digg、私有社交应用Path、知名开源应用容器引擎Docker、支付公司Stripe、新闻聚合网站@ >Buzzfeed,移动应用Life360、 网络工具公司SimpleReach 等,用于检查家庭成员的位置。
有兴趣的读者也可以向NSQ贡献代码,反馈问题,或者通过官方的快速入门教程体验NSQ给高吞吐量网络服务带来的性能提升。NSQ安装部署、客户端开发等相关信息请登录其官网。
感谢郭磊对本文的审阅。
如有问题请联系站长微信(非本文作者)
查看全部
文章实时采集(基于MIT开源协议发布NSQ的数据流模型结构如下图解析
)
NSQ 是一个基于 Go 语言的分布式实时消息平台。它是基于 MIT 开源协议发布的。代码托管在 GitHub 上。最新版本为0.3.1。NSQ 可用于大型系统中的实时消息服务,每天可处理数亿条消息。它的设计目标是为在分布式环境中运行的去中心化服务提供强大的基础设施。NSQ具有分布式、去中心化的拓扑结构,具有无单点故障、容错、高可用、消息传递可靠等特点。NSQ 非常易于配置和部署,并且具有最大的灵活性,支持多种消息传递协议。此外,官方还提供了开箱即用的 Go 和 Python 库。
NSQ 由四个重要组件组成:
NSQ的主要特点如下:
为了实现高效的分布式消息服务,NSQ 实现了合理的智能权衡,使其能够在生产环境中得到充分的应用。具体内容如下:
官方和第三方也为NSQ开发了很多客户端函数库,比如官方的基于HTTP、Go客户端go-nsq、Python客户端pynsq、基于Node.js的JavaScript客户端nsqjs,以及异步C客户端libnsq、Java客户端nsq -java 和许多基于各种语言的第三方客户端函数库。更多客户端函数库请点击查看。
从NSQ设计文档可知,单个nsqd被设计为一次处理多个流数据,NSQ中的数据流模型由stream和consumer组成。Topic 是一个独特的流,Channel 是订阅给定 Topic 的消费者的逻辑分组。NSQ的数据流模型结构如下图所示:
从上图可以看出,单个nsqd可以有多个topic,每个topic可以有多个channel。Channel可以接收所有Topic消息的副本,从而实现消息组播分发;并且Channel上的每条消息都分发给它的订阅者,从而实现负载均衡,所有这些形成一个单片,可以代表各种简单和复杂的拓扑结构。
NSQ 最初是为 Bitly 开发的,Bitly 是一个提供短链接服务的应用程序。另外还有很多使用NSQ的知名应用,比如社交新闻网站Digg、私有社交应用Path、知名开源应用容器引擎Docker、支付公司Stripe、新闻聚合网站@ >Buzzfeed,移动应用Life360、 网络工具公司SimpleReach 等,用于检查家庭成员的位置。
有兴趣的读者也可以向NSQ贡献代码,反馈问题,或者通过官方的快速入门教程体验NSQ给高吞吐量网络服务带来的性能提升。NSQ安装部署、客户端开发等相关信息请登录其官网。
感谢郭磊对本文的审阅。
如有问题请联系站长微信(非本文作者)
文章实时采集(日志解析失败错误json._root.yml)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-09 10:17
说明 Filebeat 版本为 5.3.0
之所以用beats家族的Filebeat来代替Logstash,是因为Logstash消耗资源太多(如果服务器资源充足请忽略)
官网下载Logstash有89M,而Filebeat只有8.4M,可见
Logstash 可以配置 jvm 参数。经过我自己调试,内存分配小,启动很慢,有时根本起不来。如果分配很大,其他服务将没有资源。
都说对于低配置的服务器,选择Filebeat是最好的选择,现在Filebeat已经开始替代Logstash了。还是需要修改nginx的日志格式,nginx.config。
更改日志记录的格式
log_format json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
文件节拍.yml
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/*access*.log
json.keys_under_root: true
json.overwrite_keys: true
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["ip:port","ip:port"]
index: "filebeat_server_nginx_%{+YYYY-MM}"
这里要注意的是
json.keys_under_root:默认值为FALSE,表示我们的json日志解析后会放在json key上。设置为 TRUE,所有键都将放置在根节点中
json.overwrite_keys:是否覆盖原来的key,这个是key的配置。设置keys_under_root为TRUE后,再设置overwrite_keys为TRUE,覆盖filebeat的默认key值
还有其他配置
json.add_error_key: 添加json_error key key 记录json解析失败错误
json.message_key:指定解析后的json日志放哪个key,默认为json,也可以指定log等。
说白了,区别就是elasticsearch的配置前的数据是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9sVOkCcRcg0IPg399",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T03:00:17.544Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"input_type": "log",
"json": {},
"message": "{ "@timestamp": "2018-05-08T11:00:11+08:00", "time": "2018-05-08T11:00:11+08:00", "remote_addr": "113.16.251.67", "remote_user": "-", "body_bytes_sent": "403", "request_time": "0.000", "status": "200", "host": "blog.joylau.cn", "request": "GET /img/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90.png HTTP/1.1", "request_method": "GET", "uri": "/img/\xE7\xBD\x91\xE6\x98\x93\xE4\xBA\x91\xE9\x9F\xB3\xE4\xB9\x90.png", "http_referrer": "http://blog.joylau.cn/css/style.css", "body_bytes_sent":"403", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" }",
"offset": 7633,
"source": "/var/log/nginx/access.log",
"type": "log"
}
}
配置好之后是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9rjLd8mVZNgvhdnN9",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T02:56:50.000Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"body_bytes_sent": "12576",
"host": "blog.joylau.cn",
"http_referrer": "http://blog.joylau.cn/",
"http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"http_x_forwarded_for": "-",
"input_type": "log",
"offset": 3916,
"remote_addr": "60.166.12.138",
"remote_user": "-",
"request": "GET /2018/03/01/JDK8-Stream-Distinct/ HTTP/1.1",
"request_method": "GET",
"request_time": "0.000",
"source": "/var/log/nginx/access.log",
"status": "200",
"time": "2018-05-08T10:56:50+08:00",
"type": "log",
"uri": "/2018/03/01/JDK8-Stream-Distinct/index.html"
}
}
所以看起来很舒服
启动 FileBeat
进入Filebeat目录
nohup sudo ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
更新
如果 nginx 日志收录中文,则会将中文转换为 Unicode 编码。如果没有,只需添加 escape=json 参数。
log_format json escape=json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
信息 查看全部
文章实时采集(日志解析失败错误json._root.yml)
说明 Filebeat 版本为 5.3.0
之所以用beats家族的Filebeat来代替Logstash,是因为Logstash消耗资源太多(如果服务器资源充足请忽略)
官网下载Logstash有89M,而Filebeat只有8.4M,可见
Logstash 可以配置 jvm 参数。经过我自己调试,内存分配小,启动很慢,有时根本起不来。如果分配很大,其他服务将没有资源。
都说对于低配置的服务器,选择Filebeat是最好的选择,现在Filebeat已经开始替代Logstash了。还是需要修改nginx的日志格式,nginx.config。
更改日志记录的格式
log_format json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
文件节拍.yml
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/*access*.log
json.keys_under_root: true
json.overwrite_keys: true
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["ip:port","ip:port"]
index: "filebeat_server_nginx_%{+YYYY-MM}"
这里要注意的是
json.keys_under_root:默认值为FALSE,表示我们的json日志解析后会放在json key上。设置为 TRUE,所有键都将放置在根节点中
json.overwrite_keys:是否覆盖原来的key,这个是key的配置。设置keys_under_root为TRUE后,再设置overwrite_keys为TRUE,覆盖filebeat的默认key值
还有其他配置
json.add_error_key: 添加json_error key key 记录json解析失败错误
json.message_key:指定解析后的json日志放哪个key,默认为json,也可以指定log等。
说白了,区别就是elasticsearch的配置前的数据是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9sVOkCcRcg0IPg399",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T03:00:17.544Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"input_type": "log",
"json": {},
"message": "{ "@timestamp": "2018-05-08T11:00:11+08:00", "time": "2018-05-08T11:00:11+08:00", "remote_addr": "113.16.251.67", "remote_user": "-", "body_bytes_sent": "403", "request_time": "0.000", "status": "200", "host": "blog.joylau.cn", "request": "GET /img/%E7%BD%91%E6%98%93%E4%BA%91%E9%9F%B3%E4%B9%90.png HTTP/1.1", "request_method": "GET", "uri": "/img/\xE7\xBD\x91\xE6\x98\x93\xE4\xBA\x91\xE9\x9F\xB3\xE4\xB9\x90.png", "http_referrer": "http://blog.joylau.cn/css/style.css", "body_bytes_sent":"403", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" }",
"offset": 7633,
"source": "/var/log/nginx/access.log",
"type": "log"
}
}
配置好之后是这样的:
{
"_index": "filebeat_server_nginx_2018-05",
"_type": "log",
"_id": "AWM9rjLd8mVZNgvhdnN9",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2018-05-08T02:56:50.000Z",
"beat": {
"hostname": "VM_252_18_centos",
"name": "VM_252_18_centos",
"version": "5.3.0"
},
"body_bytes_sent": "12576",
"host": "blog.joylau.cn",
"http_referrer": "http://blog.joylau.cn/",
"http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"http_x_forwarded_for": "-",
"input_type": "log",
"offset": 3916,
"remote_addr": "60.166.12.138",
"remote_user": "-",
"request": "GET /2018/03/01/JDK8-Stream-Distinct/ HTTP/1.1",
"request_method": "GET",
"request_time": "0.000",
"source": "/var/log/nginx/access.log",
"status": "200",
"time": "2018-05-08T10:56:50+08:00",
"type": "log",
"uri": "/2018/03/01/JDK8-Stream-Distinct/index.html"
}
}
所以看起来很舒服
启动 FileBeat
进入Filebeat目录
nohup sudo ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
更新
如果 nginx 日志收录中文,则会将中文转换为 Unicode 编码。如果没有,只需添加 escape=json 参数。
log_format json escape=json '{ "@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"body_bytes_sent":"$body_bytes_sent", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
信息
文章实时采集(如何实时采集微信公众号图文信息?(附教程))
采集交流 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2021-10-05 01:01
文章实时采集微信公众号图文信息
一、目标制定选择可采集优质图文的平台进行操作,或根据图文标题/封面等进行分析判断。
二、准备工作根据工作量,以及所能采集的资源,大致可分为以下3个步骤:1.采集图文背景图的过程,请在采集页面中进行操作,请不要把素材放入某些需要填写素材目录的文件夹中。素材采集时会产生大量data_file,需要保存一份到网盘上。(如出现素材丢失或丢失的现象,请抓取原始图片并进行相应的处理。)data_file定位要求:至少要预留上传素材的路径。
操作步骤:选择图文上传目录---图文上传---上传刚刚保存的data_file.png,部分目录定位需要多次操作。2.采集图文标题的过程,请在微信平台商务后台里将标题进行命名。操作步骤:选择自己想要采集的标题,点击插入---图文标题---发送。注意标题后,请使用编号进行标注。发送时请填写上传文件的路径。
3.采集图文封面的过程,请在商务后台里设置发送标题、采集位置、收货地址等内容,并命名图文封面。操作步骤:选择采集文件目录---收货地址---设置标题---开始采集文章。图文封面采集大致如此。
三、软件选择采集微信公众号内容主要靠软件,目前市面上提供采集、编辑、群发功能的软件较多,具体可参考:今日头条采集器【软件】今日头条订阅号内容采集。新浪扶翼采集器【软件】新浪网新闻源采集。pp红采集器【软件】pp红网站内容采集。(建议在使用pp红,性价比高,主要是采集标题、封面。)今日头条【采集器】(注意需版权问题,需要购买版权才能采集封面和封面图文章。)。
四、采集过程采集过程中请注意避免出现死链、延迟采集封面图文。建议把文章的标题/封面采集到服务器(专门的服务器文件夹中)。文章采集数量不要太多,也不要太少,两三篇差不多就行。如采集到500篇,在qq群/论坛等发布扩展地址出现繁杂信息,用户点击难,即为可能出现死链。因此,文章采集需要分页,建议每页都采集,采集较长文章也能通过多个页面进行多次采集。
只有文章真正的覆盖到了微信公众号所发布的文章,才算是完成初步采集和封面采集。更多采集、编辑、微信公众号编辑排版相关文章,请关注公众号:20155633473。 查看全部
文章实时采集(如何实时采集微信公众号图文信息?(附教程))
文章实时采集微信公众号图文信息
一、目标制定选择可采集优质图文的平台进行操作,或根据图文标题/封面等进行分析判断。
二、准备工作根据工作量,以及所能采集的资源,大致可分为以下3个步骤:1.采集图文背景图的过程,请在采集页面中进行操作,请不要把素材放入某些需要填写素材目录的文件夹中。素材采集时会产生大量data_file,需要保存一份到网盘上。(如出现素材丢失或丢失的现象,请抓取原始图片并进行相应的处理。)data_file定位要求:至少要预留上传素材的路径。
操作步骤:选择图文上传目录---图文上传---上传刚刚保存的data_file.png,部分目录定位需要多次操作。2.采集图文标题的过程,请在微信平台商务后台里将标题进行命名。操作步骤:选择自己想要采集的标题,点击插入---图文标题---发送。注意标题后,请使用编号进行标注。发送时请填写上传文件的路径。
3.采集图文封面的过程,请在商务后台里设置发送标题、采集位置、收货地址等内容,并命名图文封面。操作步骤:选择采集文件目录---收货地址---设置标题---开始采集文章。图文封面采集大致如此。
三、软件选择采集微信公众号内容主要靠软件,目前市面上提供采集、编辑、群发功能的软件较多,具体可参考:今日头条采集器【软件】今日头条订阅号内容采集。新浪扶翼采集器【软件】新浪网新闻源采集。pp红采集器【软件】pp红网站内容采集。(建议在使用pp红,性价比高,主要是采集标题、封面。)今日头条【采集器】(注意需版权问题,需要购买版权才能采集封面和封面图文章。)。
四、采集过程采集过程中请注意避免出现死链、延迟采集封面图文。建议把文章的标题/封面采集到服务器(专门的服务器文件夹中)。文章采集数量不要太多,也不要太少,两三篇差不多就行。如采集到500篇,在qq群/论坛等发布扩展地址出现繁杂信息,用户点击难,即为可能出现死链。因此,文章采集需要分页,建议每页都采集,采集较长文章也能通过多个页面进行多次采集。
只有文章真正的覆盖到了微信公众号所发布的文章,才算是完成初步采集和封面采集。更多采集、编辑、微信公众号编辑排版相关文章,请关注公众号:20155633473。
文章实时采集(文章实时采集并推送给服务器,前端路由好点的话)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-04 13:03
文章实时采集并推送给服务器,服务器再推送给客户端。前端路由好点的话,抓包,分析url的utm特征,爬虫最好也接入,能抓一抓也不错,
就题主的问题,
1、抓包容易丢包或中断;
2、人工分析每一次请求中每一个字段,
3、模拟返回很累,
4、别人抓包分析你也不放心;综上,建议题主用第一个方案:一步步弄清每个字段具体含义,分析并获取链接及验证其他参数,最后聚合显示结果。
1、登录:你的每一次访问都会在你自己的服务器上生成一个记录,当你从别人那里登录后,这个登录时间段的记录就会同步到你自己的服务器上。
2、抓包:爬取的是整个站点的数据,一般的服务器都会有默认的模拟ip,打开的网页是无法发起请求的,但是你可以通过修改其他字段发送请求。
3、模拟返回:在访问一些静态文件时,你可以把它模拟成你自己的网站,这样你就能返回给你合适的网站地址,这样你每次浏览这些文件都是获取你的网站地址,顺着网址就可以到对应的服务器上了。
4、聚合:看你的爬虫是不是有收集其他网站数据的,比如ip、cookie这些,如果有的话,你就可以把这些数据爬取过来,用聚合接口就可以聚合到一起。
5、最后,所有的信息统计是比较少的,估计做不下来,更何况你分析这些数据是不是有些数据是重复的,人工统计是比较费力的,如果是数据预处理,还要编写一些特征工程代码,实现这些功能,你不可能每一次都请求数据库把重复的数据过滤出来吧,而且到时候服务器出现问题还要花时间去处理,最后数据的可用性才能得到保证,如果每一次请求都需要使用nginx,你每次请求的数据都需要到nginx的数据库中去查询,然后就把数据保存到数据库中,有一点风险。
最后,根据我的理解,你没必要大费周章,一步步从第一个到后面一个,爬虫总会成熟的,不用有点困难就困难一步,会过的很吃力的。 查看全部
文章实时采集(文章实时采集并推送给服务器,前端路由好点的话)
文章实时采集并推送给服务器,服务器再推送给客户端。前端路由好点的话,抓包,分析url的utm特征,爬虫最好也接入,能抓一抓也不错,
就题主的问题,
1、抓包容易丢包或中断;
2、人工分析每一次请求中每一个字段,
3、模拟返回很累,
4、别人抓包分析你也不放心;综上,建议题主用第一个方案:一步步弄清每个字段具体含义,分析并获取链接及验证其他参数,最后聚合显示结果。
1、登录:你的每一次访问都会在你自己的服务器上生成一个记录,当你从别人那里登录后,这个登录时间段的记录就会同步到你自己的服务器上。
2、抓包:爬取的是整个站点的数据,一般的服务器都会有默认的模拟ip,打开的网页是无法发起请求的,但是你可以通过修改其他字段发送请求。
3、模拟返回:在访问一些静态文件时,你可以把它模拟成你自己的网站,这样你就能返回给你合适的网站地址,这样你每次浏览这些文件都是获取你的网站地址,顺着网址就可以到对应的服务器上了。
4、聚合:看你的爬虫是不是有收集其他网站数据的,比如ip、cookie这些,如果有的话,你就可以把这些数据爬取过来,用聚合接口就可以聚合到一起。
5、最后,所有的信息统计是比较少的,估计做不下来,更何况你分析这些数据是不是有些数据是重复的,人工统计是比较费力的,如果是数据预处理,还要编写一些特征工程代码,实现这些功能,你不可能每一次都请求数据库把重复的数据过滤出来吧,而且到时候服务器出现问题还要花时间去处理,最后数据的可用性才能得到保证,如果每一次请求都需要使用nginx,你每次请求的数据都需要到nginx的数据库中去查询,然后就把数据保存到数据库中,有一点风险。
最后,根据我的理解,你没必要大费周章,一步步从第一个到后面一个,爬虫总会成熟的,不用有点困难就困难一步,会过的很吃力的。
文章实时采集(mysql实时数据采集框架maxwell基本介绍-苏州安嘉 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-02 11:18
)
介绍本文文章主要介绍MaxWell(Mysql实时数据采集)及相关经验和技巧。文章约13381字,浏览量317,点赞2,值得参考!
mysql实时数据采集框架maxwell基础介绍
maxwell 是一个可以实时读取 MySQL 二进制日志 binlog 并生成 JSON 格式消息的应用程序,这些消息作为生产者发送到 Kafka、Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其他平台。其常见的应用场景包括ETL、维护缓存、采集表级dml指标、递增到搜索引擎、数据分区迁移、切割数据库binlog回滚方案等。
Maxwell主要提供以下功能:
支持 SELECT * FROM 表进行 44 行全数据初始化。支持主库故障转移后binlog位置(GTID)的自动恢复。可以对数据进行分区以解决数据倾斜问题。发送到 Kafka 的数据支持数据库、表和列。等级数据分区的工作方式是伪装成slave,接收binlog事件,然后根据scheme信息进行组装,可以接受ddl、xid、row等各种事件binlog的引入。
Binlog是mysql中的二进制日志。主要用于记录mysql数据库中发生或潜在改变数据的SQL语句,以二进制形式存储在磁盘中。如果我们后面需要配置主从数据库,如果我们需要从数据库同步主数据库的内容,我们可以通过binlog进行同步。说白了,可以用binlog来解决mysql数据库中数据的实时同步问题。还有三种 binlog 格式:STATEMENT、ROW 和 MIXED。
基于行的复制(RBR):它不记录每个 SQL 语句的上下文信息。它只需要记录修改了哪些数据,修改成了什么。混合复制(MBR):以上两种模式的结合。一般复制使用 STATEMENT 方式保存 binlog。对于 STATEMENT 模式下无法复制的操作,使用 ROW 模式保存 binlog。MySQL会根据执行的SQL语句进行选择。日志保存方法。
因为语句只有sql,没有数据,无法获取到原来的变更日志,一般建议使用ROW模式)mysql数据实时同步,我们可以通过解析mysql bin-log来实现,有很多bin-log的解析方式,可以通过canal或者max-well实现。下面是各种提取方法的对比介绍
启用binlog功能第一步:添加一个普通用户maxwell
在mysql中添加一个普通用户maxwell,因为maxwell软件默认用户是maxwell用户,进入mysql客户端,然后执行如下命令授权
mysql -uroot -p
set global validate_password_policy=LOW;
set global validate_password_length=6;
CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';
flush privileges;
第二步:开启binlog机制
对于我们的mysql数据库,我们可以打开mysql的binlog功能,通过修改mysql配置文件来启用。修改配置文件后,我们需要重启mysql服务
sudo vim /etc/my.cnf
# 添加或修改以下三行配置
log-bin= /var/lib/mysql/mysql-bin # 日志存放位置
binlog-format=ROW # binlog格式
server_id=1 # server id
# 重启mysql
sudo service mysqld restart
第三步:验证mysql服务
# 进入mysql客户端,并执行以下命令进行验证
mysql -uroot -p
mysql> show variables like '%log_bin%';
+---------------------------------+-----------------------------+
| Variable_name | Value |
+---------------------------------+-----------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/binlog |
| log_bin_index | /var/lib/mysql/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+-----------------------------+
root@0f3525c74115:/# cd /var/lib/mysql/
root@0f3525c74115:/var/lib/mysql# ls -la
-rw-r----- 1 mysql mysql 324 Jul 2 14:54 binlog.000007
-rw-r----- 1 mysql mysql 156 Jul 2 14:54 binlog.000008
-rw-r----- 1 mysql mysql 32 Jul 2 14:54 binlog.index
# 以上是binlog文件说明已经开启
安装maxwell实现实时采集mysql数据第一步:下载maxwell
下载:
第二步:修改配置
启动服务。启动我们的动物园管理员服务。启动kafka服务并创建kafka主题。启动maxwell服务,测试插入数据到数据库,查看kafka是否可以同步到mysql数据
# 创建kafka topic 分区 3 副本 2
bin/kafka-topics.sh --create --topic maxwell_kafka --partitions 3 --replication-factor 2 --zookeeper node01:2181
# 创建kafka 消费者
bin/kafka-console-consumer.sh --topic maxwell_kafka --from-beginning --bootstrap-server node01:9092,node02:9092,node03:9092
# 启动maxwell
bin/maxwell
插入数据测试
-- 创建目标库
CREATE DATABASE /*!32312 IF NOT EXISTS*/`test` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `test`;
-- 创建表
CREATE TABLE `myuser` (
`id` int(12) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 插入数据
insert into `myuser`(`id`,`name`,`age`) values (1,'zhangsan',NULL),(2,'xxx',NULL),(3,'ggg',NULL),(5,'xxxx',NULL),(8,'skldjlskdf',NULL),(10,'ggggg',NULL),(99,'ttttt',NULL),(114,NULL,NULL),(121,'xxx',NULL);
-- 岂容kafka消费者,会看到消费的数据
bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic maxwell_kafka 查看全部
文章实时采集(mysql实时数据采集框架maxwell基本介绍-苏州安嘉
)
介绍本文文章主要介绍MaxWell(Mysql实时数据采集)及相关经验和技巧。文章约13381字,浏览量317,点赞2,值得参考!
mysql实时数据采集框架maxwell基础介绍
maxwell 是一个可以实时读取 MySQL 二进制日志 binlog 并生成 JSON 格式消息的应用程序,这些消息作为生产者发送到 Kafka、Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其他平台。其常见的应用场景包括ETL、维护缓存、采集表级dml指标、递增到搜索引擎、数据分区迁移、切割数据库binlog回滚方案等。
Maxwell主要提供以下功能:
支持 SELECT * FROM 表进行 44 行全数据初始化。支持主库故障转移后binlog位置(GTID)的自动恢复。可以对数据进行分区以解决数据倾斜问题。发送到 Kafka 的数据支持数据库、表和列。等级数据分区的工作方式是伪装成slave,接收binlog事件,然后根据scheme信息进行组装,可以接受ddl、xid、row等各种事件binlog的引入。
Binlog是mysql中的二进制日志。主要用于记录mysql数据库中发生或潜在改变数据的SQL语句,以二进制形式存储在磁盘中。如果我们后面需要配置主从数据库,如果我们需要从数据库同步主数据库的内容,我们可以通过binlog进行同步。说白了,可以用binlog来解决mysql数据库中数据的实时同步问题。还有三种 binlog 格式:STATEMENT、ROW 和 MIXED。
基于行的复制(RBR):它不记录每个 SQL 语句的上下文信息。它只需要记录修改了哪些数据,修改成了什么。混合复制(MBR):以上两种模式的结合。一般复制使用 STATEMENT 方式保存 binlog。对于 STATEMENT 模式下无法复制的操作,使用 ROW 模式保存 binlog。MySQL会根据执行的SQL语句进行选择。日志保存方法。
因为语句只有sql,没有数据,无法获取到原来的变更日志,一般建议使用ROW模式)mysql数据实时同步,我们可以通过解析mysql bin-log来实现,有很多bin-log的解析方式,可以通过canal或者max-well实现。下面是各种提取方法的对比介绍
启用binlog功能第一步:添加一个普通用户maxwell
在mysql中添加一个普通用户maxwell,因为maxwell软件默认用户是maxwell用户,进入mysql客户端,然后执行如下命令授权
mysql -uroot -p
set global validate_password_policy=LOW;
set global validate_password_length=6;
CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';
flush privileges;
第二步:开启binlog机制
对于我们的mysql数据库,我们可以打开mysql的binlog功能,通过修改mysql配置文件来启用。修改配置文件后,我们需要重启mysql服务
sudo vim /etc/my.cnf
# 添加或修改以下三行配置
log-bin= /var/lib/mysql/mysql-bin # 日志存放位置
binlog-format=ROW # binlog格式
server_id=1 # server id
# 重启mysql
sudo service mysqld restart
第三步:验证mysql服务
# 进入mysql客户端,并执行以下命令进行验证
mysql -uroot -p
mysql> show variables like '%log_bin%';
+---------------------------------+-----------------------------+
| Variable_name | Value |
+---------------------------------+-----------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/binlog |
| log_bin_index | /var/lib/mysql/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+-----------------------------+
root@0f3525c74115:/# cd /var/lib/mysql/
root@0f3525c74115:/var/lib/mysql# ls -la
-rw-r----- 1 mysql mysql 324 Jul 2 14:54 binlog.000007
-rw-r----- 1 mysql mysql 156 Jul 2 14:54 binlog.000008
-rw-r----- 1 mysql mysql 32 Jul 2 14:54 binlog.index
# 以上是binlog文件说明已经开启
安装maxwell实现实时采集mysql数据第一步:下载maxwell
下载:
第二步:修改配置
启动服务。启动我们的动物园管理员服务。启动kafka服务并创建kafka主题。启动maxwell服务,测试插入数据到数据库,查看kafka是否可以同步到mysql数据
# 创建kafka topic 分区 3 副本 2
bin/kafka-topics.sh --create --topic maxwell_kafka --partitions 3 --replication-factor 2 --zookeeper node01:2181
# 创建kafka 消费者
bin/kafka-console-consumer.sh --topic maxwell_kafka --from-beginning --bootstrap-server node01:9092,node02:9092,node03:9092
# 启动maxwell
bin/maxwell
插入数据测试
-- 创建目标库
CREATE DATABASE /*!32312 IF NOT EXISTS*/`test` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `test`;
-- 创建表
CREATE TABLE `myuser` (
`id` int(12) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 插入数据
insert into `myuser`(`id`,`name`,`age`) values (1,'zhangsan',NULL),(2,'xxx',NULL),(3,'ggg',NULL),(5,'xxxx',NULL),(8,'skldjlskdf',NULL),(10,'ggggg',NULL),(99,'ttttt',NULL),(114,NULL,NULL),(121,'xxx',NULL);
-- 岂容kafka消费者,会看到消费的数据
bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic maxwell_kafka
文章实时采集(自动提交又可以分为主动推送和sitemap三种链接提交通道)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-01 10:07
很多人为了节省时间,选择了自动提交的方式。但是,如您所知,自动提交可以分为三个链接提交渠道:主动推送(实时)、自动推送和站点地图。
下面我就给大家分析一下这三种链接提交渠道的优劣,看看哪个更适合我们。
1、主动推送(实时)
这是最快的提交方式。技术改造后,您的网站每次更新文章时,都可以通过这种方式主动推送给百度,保证新链接能及时被百度收录接收。但有一个缺点,就是技术发展起来后才能使用。
2、自动推送
自动推送是百度搜索资源平台推出的一款提高网站新网页发现速度的工具。安装了自动推送JS代码的网页,无论访问哪个页面,页面URL都会立即自动推送到百度。
要使用它,需要将JS代码安装在一个全站共享的模板页面中,例如在一个类似于header.htm的header模板页面中,以达到一次安装,整个站点的效果。
这个方法很好,很适合优采云,安装完成后可以实现自动链接推送功能。但是这样的js代码会拖慢网站,一点也不友好。
3、站点地图提交
Sitemap是站点地图的意思,指的是你网站上的网页列表。创建并提交站点地图将帮助百度找到并理解您网站 上的所有网页。
除了这个便捷的功能,您还可以使用Sitemap提供关于您的其他信息网站,如最后更新日期、Sitemap文件的更新频率等,仅供百度蜘蛛参考。
百度不保证所提交的站点地图数据的所有网址都会被抓取并编入索引。不过,百度搜索引擎会利用Sitemap中的数据来了解网站的结构等信息,可以帮助百度搜索引擎蜘蛛改进爬取策略,在以后更好的捕获网站的Pick。
顺便说一下,Sitemap网站 地图可以使用爱站SEO toolkit 和SitemapX 等工具制作。还有一点需要说明的是,百度搜索引擎蜘蛛不会定期来更新Sitemap网站。
此站点地图与搜索排名无关。不是说更新站点地图越频繁,网站的排名就越高,不是这样的。
所以,综上所述,最适合我们的链接提交方式是主动推送(实时)。
接下来教大家修改API提交,实现只要在WordPress后台点击发布文章,就可以主动推送文章(实时)到百度.
其实方法很简单。我们只需要在funtions.php模板中写入如下代码,发布文章就会自动推送到百度。
date_default_timezone_set('Asia/Shanghai'); add_action('publish_post', 'publish_bd_submit', 999);
function publish_bd_submit($post_ID){ global $post;
$bd_submit_enabled = true;
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B
if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
}
上面的代码有两个API,改成自己的就好了。注:第一个api是天机收录的接口调用地址。只有受原创保护的站长才有资格使用它。第二个api地址是主动推送(实时)接口调用地址,别搞错了。
另一个是关于 funtions.php 模板的路径。现在我给你一些提示。目前Kang使用的wordpress主题是Robin,这个funtions.php模板的路径在/wp-content/themes/begin/根目录下,大家可以自己找。
版权所有:科鼎博客 © WNAG.COM.CN
文章标题:《wordpress如何实现向百度发布文章主动推送(实时)》
这篇文章的链接:
特别声明:除非另有说明,本站所有文章均为原创,本站文章原则上禁止转载。如果真的要转载请联系我们:尊重他人劳动成果,谢谢Over~ 查看全部
文章实时采集(自动提交又可以分为主动推送和sitemap三种链接提交通道)
很多人为了节省时间,选择了自动提交的方式。但是,如您所知,自动提交可以分为三个链接提交渠道:主动推送(实时)、自动推送和站点地图。
下面我就给大家分析一下这三种链接提交渠道的优劣,看看哪个更适合我们。
1、主动推送(实时)
这是最快的提交方式。技术改造后,您的网站每次更新文章时,都可以通过这种方式主动推送给百度,保证新链接能及时被百度收录接收。但有一个缺点,就是技术发展起来后才能使用。
2、自动推送
自动推送是百度搜索资源平台推出的一款提高网站新网页发现速度的工具。安装了自动推送JS代码的网页,无论访问哪个页面,页面URL都会立即自动推送到百度。
要使用它,需要将JS代码安装在一个全站共享的模板页面中,例如在一个类似于header.htm的header模板页面中,以达到一次安装,整个站点的效果。
这个方法很好,很适合优采云,安装完成后可以实现自动链接推送功能。但是这样的js代码会拖慢网站,一点也不友好。
3、站点地图提交
Sitemap是站点地图的意思,指的是你网站上的网页列表。创建并提交站点地图将帮助百度找到并理解您网站 上的所有网页。
除了这个便捷的功能,您还可以使用Sitemap提供关于您的其他信息网站,如最后更新日期、Sitemap文件的更新频率等,仅供百度蜘蛛参考。
百度不保证所提交的站点地图数据的所有网址都会被抓取并编入索引。不过,百度搜索引擎会利用Sitemap中的数据来了解网站的结构等信息,可以帮助百度搜索引擎蜘蛛改进爬取策略,在以后更好的捕获网站的Pick。
顺便说一下,Sitemap网站 地图可以使用爱站SEO toolkit 和SitemapX 等工具制作。还有一点需要说明的是,百度搜索引擎蜘蛛不会定期来更新Sitemap网站。
此站点地图与搜索排名无关。不是说更新站点地图越频繁,网站的排名就越高,不是这样的。
所以,综上所述,最适合我们的链接提交方式是主动推送(实时)。
接下来教大家修改API提交,实现只要在WordPress后台点击发布文章,就可以主动推送文章(实时)到百度.
其实方法很简单。我们只需要在funtions.php模板中写入如下代码,发布文章就会自动推送到百度。
date_default_timezone_set('Asia/Shanghai'); add_action('publish_post', 'publish_bd_submit', 999);
function publish_bd_submit($post_ID){ global $post;
$bd_submit_enabled = true;
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
if($bd_submit_enabled){
$api ='http://data.zz.baidu.com/urls% ... 3B%3B
if($post->post_status != "publish"){
$url = get_permalink($post_ID);
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => $url,
CURLOPT_HTTPHEADER => array('Content-Type: text/plain')
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
// $result = json_decode($result, true);
$time = time();
$file = dirname(__FILE__).'/by_baiduSubmit.txt';//生成日志文件,与代码所处文件同目录
if(date('Y-m-d',filemtime($file)) != date('Y-m-d')){
$handle = fopen($file,"w");
}else{
$handle = fopen($file,"a");
}
$resultMessage="";
if($result['message']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交失败".$result['message'].":\n网址:".$url."\n\n".$result;
}
if($result['success']){
$resultMessage= date('Y-m-d G:i:s',$time)."\n提交成功".":".$url."\n\n";
}
fwrite($handle,$resultMessage);
fclose($handle);
}
}
}
上面的代码有两个API,改成自己的就好了。注:第一个api是天机收录的接口调用地址。只有受原创保护的站长才有资格使用它。第二个api地址是主动推送(实时)接口调用地址,别搞错了。
另一个是关于 funtions.php 模板的路径。现在我给你一些提示。目前Kang使用的wordpress主题是Robin,这个funtions.php模板的路径在/wp-content/themes/begin/根目录下,大家可以自己找。
版权所有:科鼎博客 © WNAG.COM.CN
文章标题:《wordpress如何实现向百度发布文章主动推送(实时)》
这篇文章的链接:
特别声明:除非另有说明,本站所有文章均为原创,本站文章原则上禁止转载。如果真的要转载请联系我们:尊重他人劳动成果,谢谢Over~
文章实时采集(gpu2:基于卷积神经网络的文本分类任务(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-29 13:08
文章实时采集简介gpu2:基于卷积神经网络的文本分类任务
1、原理简介1.1预备知识计算机视觉方面的基础知识,一般来说所谓cnn模型,即使是神经网络模型,其图像或者视频或者信号或者文本数据都是二维数据,而且有噪声(灰度、噪声、扭曲等)。一般来说在视频等情况下,由于存在信号的持续传播和速度的限制,一帧的信号单单通过激活函数是无法达到精确的分类结果。同样的道理,一个信号如果如果没有经过人工修正参数,或者完全只通过识别系统来识别,误识率也会不断提高,这样一个模型的分类精度也难以提高。
1.2卷积神经网络(cnn)1.2.1卷积层在计算机视觉计算上,卷积层有许多的应用。通过作用上的分类比如:图像、识别、文本分类、网页识别等等。由于cnn采用一个一个的卷积核使得该方法在图像分类和文本分类等其他的一些任务上都取得了非常好的效果。假设我们想要的是分类最准确的模型。简单设置是对角线和角接连的神经元节点统统连接输入。
但是,目前大多数计算机视觉任务中的大多数方法的维度是32x32以及更小的尺寸,但是对于要求大幅度提高分类精度的识别(如自然语言处理)任务来说,一般情况下是2x2尺寸的。设置一个32x32的输入节点,图像识别的分类效果达到80%,识别的分类效果达到90%。所以我们需要有一个足够大的输入,达到目标尺寸。
那么对于32x32的图像,将32x32输入到32x32的分类网络中将会得到32x32的输出(可以看出,对于cnn单个输入的输出个数,是可以很多的,并且同样的分类效果有很多的输出),结合图像分类一般用[0,1]输出一个概率值,1表示正类,0表示负类。因此,这种情况下设置输入,输出的神经元数量,是有些不合理。
而且目前有时候需要求一个最大公约数(极大的方法),以使得用极大算法进行计算,可以通过设置:计算函数,取非极大时的值作为输出的分类,来达到更大效果的分类结果。将这些值直接设置为[0,1]也可以达到预期的分类结果。然而,在复杂情况下会出现这种结果:例如:识别:如果输入尺寸是32x32,进行识别的话,一般会得到小于1的数据,即使用32x32进行识别结果依然是错误的结果。
2、神经网络简介2.1创建原理cnn结构简单的说,cnn是一种深度神经网络,每一层都是一种卷积层。
1、图像层进行层与层的连接,
1)分别输入卷积核;
2)通过运算
2、识别层进行参数化处理,
1)分别的输入是普通的音频信号;
3、文本识 查看全部
文章实时采集(gpu2:基于卷积神经网络的文本分类任务(一))
文章实时采集简介gpu2:基于卷积神经网络的文本分类任务
1、原理简介1.1预备知识计算机视觉方面的基础知识,一般来说所谓cnn模型,即使是神经网络模型,其图像或者视频或者信号或者文本数据都是二维数据,而且有噪声(灰度、噪声、扭曲等)。一般来说在视频等情况下,由于存在信号的持续传播和速度的限制,一帧的信号单单通过激活函数是无法达到精确的分类结果。同样的道理,一个信号如果如果没有经过人工修正参数,或者完全只通过识别系统来识别,误识率也会不断提高,这样一个模型的分类精度也难以提高。
1.2卷积神经网络(cnn)1.2.1卷积层在计算机视觉计算上,卷积层有许多的应用。通过作用上的分类比如:图像、识别、文本分类、网页识别等等。由于cnn采用一个一个的卷积核使得该方法在图像分类和文本分类等其他的一些任务上都取得了非常好的效果。假设我们想要的是分类最准确的模型。简单设置是对角线和角接连的神经元节点统统连接输入。
但是,目前大多数计算机视觉任务中的大多数方法的维度是32x32以及更小的尺寸,但是对于要求大幅度提高分类精度的识别(如自然语言处理)任务来说,一般情况下是2x2尺寸的。设置一个32x32的输入节点,图像识别的分类效果达到80%,识别的分类效果达到90%。所以我们需要有一个足够大的输入,达到目标尺寸。
那么对于32x32的图像,将32x32输入到32x32的分类网络中将会得到32x32的输出(可以看出,对于cnn单个输入的输出个数,是可以很多的,并且同样的分类效果有很多的输出),结合图像分类一般用[0,1]输出一个概率值,1表示正类,0表示负类。因此,这种情况下设置输入,输出的神经元数量,是有些不合理。
而且目前有时候需要求一个最大公约数(极大的方法),以使得用极大算法进行计算,可以通过设置:计算函数,取非极大时的值作为输出的分类,来达到更大效果的分类结果。将这些值直接设置为[0,1]也可以达到预期的分类结果。然而,在复杂情况下会出现这种结果:例如:识别:如果输入尺寸是32x32,进行识别的话,一般会得到小于1的数据,即使用32x32进行识别结果依然是错误的结果。
2、神经网络简介2.1创建原理cnn结构简单的说,cnn是一种深度神经网络,每一层都是一种卷积层。
1、图像层进行层与层的连接,
1)分别输入卷积核;
2)通过运算
2、识别层进行参数化处理,
1)分别的输入是普通的音频信号;
3、文本识
文章实时采集(小程序插件-gt实时日志使用规则(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-09-28 13:11
)
实时日志背景
为帮助小程序开发者快速排查小程序漏洞和定位问题,我们推出了实时日志功能。开发者可以通过提供的接口打印日志,采集日志并实时上报给小程序后端。开发者可以从小程序管理后台“开发->开发管理->运维中心->实时日志”进入小程序日志查询页面,或从“小程序插件->实时日志”进入插件日志查询页面Log”,然后查看开发者打印的日志信息。
小程序/小游戏使用方法
从基础库2.7.1开始,小终端可以使用实时日志,从基础库2.14.4开始支持小游戏终端.
1、调用相关接口。日志的接口是wx.getRealtimeLogManager。为了兼容旧版本,建议使用如下代码进行封装,例如封装在log.js文件中:
var log = wx.getRealtimeLogManager ? wx.getRealtimeLogManager() : null
module.exports = {
debug() {
if (!log) return
log.debug.apply(log, arguments)
},
info() {
if (!log) return
log.info.apply(log, arguments)
},
warn() {
if (!log) return
log.warn.apply(log, arguments)
},
error() {
if (!log) return
log.error.apply(log, arguments)
},
setFilterMsg(msg) { // 从基础库2.7.3开始支持
if (!log || !log.setFilterMsg) return
if (typeof msg !== 'string') return
log.setFilterMsg(msg)
},
addFilterMsg(msg) { // 从基础库2.8.1开始支持
if (!log || !log.addFilterMsg) return
if (typeof msg !== 'string') return
log.addFilterMsg(msg)
}
}
2、在页面特定位置打印日志:
var log = require('./log.js') // 引用上面的log.js文件
log.info('hello test hahaha') // 日志会和当前打开的页面关联,建议在页面的onHide、onShow等生命周期里面打
log.warn('warn')
log.error('error')
log.setFilterMsg('filterkeyword')
log.addFilterMsg('addfilterkeyword')
完整的例子可以参考代码片段:
插件端
从基础库2.16.0开始,插件也支持实时日志。为了让日志更加结构化以进行更复杂的分析,插件端采用了全新设计的格式。
1、 调用相关接口 wx.getRealtimeLogManager 获取实时日志管理器的实例:
const logManager = wx.getRealtimeLogManager()
2、在需要日志的逻辑中,获取日志实例:
// 标签名可以是任意字符串,一个标签名对应一组日志;同样的标签名允许被重复使用,具有相同标签名的日志在后台会被汇总到一个标签下
// 标签可为日志进行分类,因此建议开发者按逻辑来进行标签划分
const logger = logManager.tag('plugin-onUserTapSth')
3、在合适的位置打印日志:
logger.info('key1', 'value1') // 每条日志为一个 key-value 对,key 必须是字符串,value 可以是字符串/数值/对象/数组等可序列化类型
logger.error('key2', {str: 'value2'})
logger.warn('key3', 'value3')
logger.setFilterMsg('filterkeyword') // 和小程序/小游戏端接口一致
logger.setFilterMsg('addfilterkeyword') // 和小程序/小游戏端接口一致
如何查看日志
登录小程序管理后台,从“开发->开发管理->运维中心->实时日志”进入日志查询页面。开发者可以通过设置时间、微信ID/OpenID、页面链接、FilterMsg内容(基础库2.7.3及以上支持setFilterMsg)等过滤条件查询指定用户的日志信息。如果是插件上报的实时日志,可以通过“小程序插件->实时日志”进入日志查询页面进行查询。
预防措施
由于后台资源限制,“实时日志”的使用规则如下:
为了方便定位问题,将日志按页面划分,某个页面,在一定时间内(最短为5秒,最长为页面显示和隐藏的时间间隔),会聚合成一个小程序管理后台可以根据页面路径查找该日志。每个小程序账号每天限制1000万条日志,日志保存7天。建议及时定位问题。一个日志的上限为5KB,最多收录200个打印日志函数调用(info、warn、error调用都算在内),所以要注意log,避免循环调用log接口,避免直接覆盖console .log 点击日志。反馈中的日志可以根据OpenID查找。setFilterMsg 和 addFilterMsg 可以设置类似于日志标签的过滤字段。如果需要添加多个关键字,建议使用addFilterMsg。比如addFilterMsg('scene1'), addFilterMsg('scene2'), addFilterMsg('scene3'),设置后可以随机组合三个关键字在小程序管理后台搜索,如:“scene1 scene2 scene3”, "scene1 scene2" ", "scene1 scene3" or "scene2" 等(用空格隔开,所以addFilterMsg不能收录空格)日志可以通过以上几种检索方式进行检索,检索条件越多越准确会的,目前为了方便日志分析,插件实时日志只支持key-value格式。实时日志目前仅支持手机端测试。工具端的接口可以调用,但是不会上报后台。
查看全部
文章实时采集(小程序插件-gt实时日志使用规则(组图)
)
实时日志背景
为帮助小程序开发者快速排查小程序漏洞和定位问题,我们推出了实时日志功能。开发者可以通过提供的接口打印日志,采集日志并实时上报给小程序后端。开发者可以从小程序管理后台“开发->开发管理->运维中心->实时日志”进入小程序日志查询页面,或从“小程序插件->实时日志”进入插件日志查询页面Log”,然后查看开发者打印的日志信息。
小程序/小游戏使用方法
从基础库2.7.1开始,小终端可以使用实时日志,从基础库2.14.4开始支持小游戏终端.
1、调用相关接口。日志的接口是wx.getRealtimeLogManager。为了兼容旧版本,建议使用如下代码进行封装,例如封装在log.js文件中:
var log = wx.getRealtimeLogManager ? wx.getRealtimeLogManager() : null
module.exports = {
debug() {
if (!log) return
log.debug.apply(log, arguments)
},
info() {
if (!log) return
log.info.apply(log, arguments)
},
warn() {
if (!log) return
log.warn.apply(log, arguments)
},
error() {
if (!log) return
log.error.apply(log, arguments)
},
setFilterMsg(msg) { // 从基础库2.7.3开始支持
if (!log || !log.setFilterMsg) return
if (typeof msg !== 'string') return
log.setFilterMsg(msg)
},
addFilterMsg(msg) { // 从基础库2.8.1开始支持
if (!log || !log.addFilterMsg) return
if (typeof msg !== 'string') return
log.addFilterMsg(msg)
}
}
2、在页面特定位置打印日志:
var log = require('./log.js') // 引用上面的log.js文件
log.info('hello test hahaha') // 日志会和当前打开的页面关联,建议在页面的onHide、onShow等生命周期里面打
log.warn('warn')
log.error('error')
log.setFilterMsg('filterkeyword')
log.addFilterMsg('addfilterkeyword')
完整的例子可以参考代码片段:
插件端
从基础库2.16.0开始,插件也支持实时日志。为了让日志更加结构化以进行更复杂的分析,插件端采用了全新设计的格式。
1、 调用相关接口 wx.getRealtimeLogManager 获取实时日志管理器的实例:
const logManager = wx.getRealtimeLogManager()
2、在需要日志的逻辑中,获取日志实例:
// 标签名可以是任意字符串,一个标签名对应一组日志;同样的标签名允许被重复使用,具有相同标签名的日志在后台会被汇总到一个标签下
// 标签可为日志进行分类,因此建议开发者按逻辑来进行标签划分
const logger = logManager.tag('plugin-onUserTapSth')
3、在合适的位置打印日志:
logger.info('key1', 'value1') // 每条日志为一个 key-value 对,key 必须是字符串,value 可以是字符串/数值/对象/数组等可序列化类型
logger.error('key2', {str: 'value2'})
logger.warn('key3', 'value3')
logger.setFilterMsg('filterkeyword') // 和小程序/小游戏端接口一致
logger.setFilterMsg('addfilterkeyword') // 和小程序/小游戏端接口一致
如何查看日志
登录小程序管理后台,从“开发->开发管理->运维中心->实时日志”进入日志查询页面。开发者可以通过设置时间、微信ID/OpenID、页面链接、FilterMsg内容(基础库2.7.3及以上支持setFilterMsg)等过滤条件查询指定用户的日志信息。如果是插件上报的实时日志,可以通过“小程序插件->实时日志”进入日志查询页面进行查询。
预防措施
由于后台资源限制,“实时日志”的使用规则如下:
为了方便定位问题,将日志按页面划分,某个页面,在一定时间内(最短为5秒,最长为页面显示和隐藏的时间间隔),会聚合成一个小程序管理后台可以根据页面路径查找该日志。每个小程序账号每天限制1000万条日志,日志保存7天。建议及时定位问题。一个日志的上限为5KB,最多收录200个打印日志函数调用(info、warn、error调用都算在内),所以要注意log,避免循环调用log接口,避免直接覆盖console .log 点击日志。反馈中的日志可以根据OpenID查找。setFilterMsg 和 addFilterMsg 可以设置类似于日志标签的过滤字段。如果需要添加多个关键字,建议使用addFilterMsg。比如addFilterMsg('scene1'), addFilterMsg('scene2'), addFilterMsg('scene3'),设置后可以随机组合三个关键字在小程序管理后台搜索,如:“scene1 scene2 scene3”, "scene1 scene2" ", "scene1 scene3" or "scene2" 等(用空格隔开,所以addFilterMsg不能收录空格)日志可以通过以上几种检索方式进行检索,检索条件越多越准确会的,目前为了方便日志分析,插件实时日志只支持key-value格式。实时日志目前仅支持手机端测试。工具端的接口可以调用,但是不会上报后台。
文章实时采集(文章实时采集数据,批量下载图片并进行清洗预处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-27 08:02
文章实时采集数据,批量下载图片并进行清洗预处理。这是一篇具有实用性的python爬虫博客贴,包含了微信公众号的数据采集和清洗方法:笔者研究了一下这个问题,发现数据集取之不尽,也十分丰富。想获取更多的话,自己组织一下代码和数据集,甚至爬虫加上人肉采集也都可以爬上去。准备工作清洗及预处理resize,replace,andloadresizeresizetocenterwithpython'smagnitude-linewhitefillcolorgraycolorizetheusefullayer.loadbetweenthedirsizedfilesandinner_blocks.例如srt_get_url_info_path/http/resources/mx4_dist.gif由于博客无法登陆,所以也没有做cookiesharingwindows系统用shlife做ip或地址到文件夹的localsharedbasesecurity性能优化对于同一个data里的不同directory分别下载数据(全部一样就好)请避免对每个directory重复下载我这里用了3个directory:srt_dist/total,srt_dist/total.mx4和srt_dist/total.mx4.gif下载任务依次处理excel图片的数据如下:文本转json我一开始用的是pandassortimage.txt,最好的是用pandassortpdf.txt。
用inlineterminal下的infile函数速度最快jsonreader里的用expand_dims()函数减小dim边界比如要减去字符串中的content,改成decodeuricomponent(),保留四舍五入;要减去字符串中的text或者文本文件中的url如果以字典格式下载,df.to_csv()在windows编辑环境下,df.to_json()在linux下则直接下载就行,我这里直接用文本的方式content={'content':df.to_json()}text=json.loads(df.text)url=""'但是这样做可能在排序时遇到问题;有时候下载到txt后在importjson之前确实下载不出来json,那就用foriinrange(int(java.util.ioloop.task)):json.sort()或者new_url={"response_url":"","response_time":"","source":"","url":""}第三个问题json的包装字符串:url=""对于引入的模块urllib3defurllib3_cookies():ifyouwanttoincludetheresourceswithoutexistingjson.loadsinmodule:open("url.txt",encoding="utf-8").write(result)else:open("cookies.json",encoding="utf-8").write(result)print("followingoperationsarethosewhousethisimplementation:")。 查看全部
文章实时采集(文章实时采集数据,批量下载图片并进行清洗预处理)
文章实时采集数据,批量下载图片并进行清洗预处理。这是一篇具有实用性的python爬虫博客贴,包含了微信公众号的数据采集和清洗方法:笔者研究了一下这个问题,发现数据集取之不尽,也十分丰富。想获取更多的话,自己组织一下代码和数据集,甚至爬虫加上人肉采集也都可以爬上去。准备工作清洗及预处理resize,replace,andloadresizeresizetocenterwithpython'smagnitude-linewhitefillcolorgraycolorizetheusefullayer.loadbetweenthedirsizedfilesandinner_blocks.例如srt_get_url_info_path/http/resources/mx4_dist.gif由于博客无法登陆,所以也没有做cookiesharingwindows系统用shlife做ip或地址到文件夹的localsharedbasesecurity性能优化对于同一个data里的不同directory分别下载数据(全部一样就好)请避免对每个directory重复下载我这里用了3个directory:srt_dist/total,srt_dist/total.mx4和srt_dist/total.mx4.gif下载任务依次处理excel图片的数据如下:文本转json我一开始用的是pandassortimage.txt,最好的是用pandassortpdf.txt。
用inlineterminal下的infile函数速度最快jsonreader里的用expand_dims()函数减小dim边界比如要减去字符串中的content,改成decodeuricomponent(),保留四舍五入;要减去字符串中的text或者文本文件中的url如果以字典格式下载,df.to_csv()在windows编辑环境下,df.to_json()在linux下则直接下载就行,我这里直接用文本的方式content={'content':df.to_json()}text=json.loads(df.text)url=""'但是这样做可能在排序时遇到问题;有时候下载到txt后在importjson之前确实下载不出来json,那就用foriinrange(int(java.util.ioloop.task)):json.sort()或者new_url={"response_url":"","response_time":"","source":"","url":""}第三个问题json的包装字符串:url=""对于引入的模块urllib3defurllib3_cookies():ifyouwanttoincludetheresourceswithoutexistingjson.loadsinmodule:open("url.txt",encoding="utf-8").write(result)else:open("cookies.json",encoding="utf-8").write(result)print("followingoperationsarethosewhousethisimplementation:")。

