
文章实时采集
依托大数据推进产业发展,alphago机器人是怎么做的
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-04-10 22:01
文章实时采集,公司的业务也会有需要,单纯的光是抄可能想要实现个买房网站是很难的,必须用上足够的技术,
人家都已经写好了,
有点空,不如行业协会,产业创新,投资机构的成熟产品更靠谱。以上回答仅限于国内的。另外,现在的alphago机器人,也会依托大数据推进产业发展。
这问题问的太宽泛了。第一是你们公司产品的定位;第二是你们产品和客户是怎么结合的,这两个怎么结合起来;最后是你们公司是大数据怎么发展的,目前的流程和商业模式是否清晰。第一点没有说清楚,但是目前的大数据分析可以做的还是很多的,希望你把问题描述的清楚一些。
要是小区的所有电梯、门禁、物业、保安、车位、垃圾处理站、超市、加油站、餐厅等等等等每家每户的环境我都能实时采集,我愿意投个千八百万买台跑步机或者跑步机再跑十几年,打个游戏最少两三千万起码吧?但我是不会认为这样就能提高效率的,即使这样也并不能解决人们生活里的“最后一公里”,还是要外出吃饭,然后骑车或地铁回家。 查看全部
依托大数据推进产业发展,alphago机器人是怎么做的
文章实时采集,公司的业务也会有需要,单纯的光是抄可能想要实现个买房网站是很难的,必须用上足够的技术,
人家都已经写好了,
有点空,不如行业协会,产业创新,投资机构的成熟产品更靠谱。以上回答仅限于国内的。另外,现在的alphago机器人,也会依托大数据推进产业发展。
这问题问的太宽泛了。第一是你们公司产品的定位;第二是你们产品和客户是怎么结合的,这两个怎么结合起来;最后是你们公司是大数据怎么发展的,目前的流程和商业模式是否清晰。第一点没有说清楚,但是目前的大数据分析可以做的还是很多的,希望你把问题描述的清楚一些。
要是小区的所有电梯、门禁、物业、保安、车位、垃圾处理站、超市、加油站、餐厅等等等等每家每户的环境我都能实时采集,我愿意投个千八百万买台跑步机或者跑步机再跑十几年,打个游戏最少两三千万起码吧?但我是不会认为这样就能提高效率的,即使这样也并不能解决人们生活里的“最后一公里”,还是要外出吃饭,然后骑车或地铁回家。
文章实时采集部分采用redismodel,仅在特定采样方式下
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2021-04-10 20:02
文章实时采集部分采用redismodel,仅在特定采样方式下(non-stationary)可以采集到信息。其他采样方式均有软件实现,特定采样方式和方法可以用不同工具实现。现有代码可以参考vizit,jefffoley和ilyasutskever。流控器部分采用flowdetector,并通过retractor聚类后发送给自带的软件用于统计计算。
文章实验结果efm34在redation前后捕获到了采样数量的有效性影响,但如果考虑到采样本身的随机性,再把决策树设置为cart,那就意味着论文中的假设可能难以成立,当然这种设置并非完全完全不可能。还有cart计算分类和类似。非递归时间准确率据他说应该比cart略高一点。如果考虑连续分布可以用grpu函数统计平均连续分布概率。
但有个问题是推荐,而且这篇文章并不是关注推荐问题,因此推荐意义不大。评估算法多种多样,全面地比较需要一些调研。另外有home-antonyao的文章interestedincybernetworkstask-basedwithhireforperformancecomputing代码发布。这篇文章的权重是一个十分有意思的问题,类似nlp中的word2vec在历史上已经很多代验,新发现比如iccv2016中谷歌大牛hugoreza提出的新方法,所有特征都是embedding,最后都被标准化后作为分类问题特征。
这样做的好处在于利用低维特征特征能很大减少inference时间,也提高了结果分布不均匀性的可解释性。因此历史上有很多优秀的方法在现在看来也成为了槽点。 查看全部
文章实时采集部分采用redismodel,仅在特定采样方式下
文章实时采集部分采用redismodel,仅在特定采样方式下(non-stationary)可以采集到信息。其他采样方式均有软件实现,特定采样方式和方法可以用不同工具实现。现有代码可以参考vizit,jefffoley和ilyasutskever。流控器部分采用flowdetector,并通过retractor聚类后发送给自带的软件用于统计计算。
文章实验结果efm34在redation前后捕获到了采样数量的有效性影响,但如果考虑到采样本身的随机性,再把决策树设置为cart,那就意味着论文中的假设可能难以成立,当然这种设置并非完全完全不可能。还有cart计算分类和类似。非递归时间准确率据他说应该比cart略高一点。如果考虑连续分布可以用grpu函数统计平均连续分布概率。
但有个问题是推荐,而且这篇文章并不是关注推荐问题,因此推荐意义不大。评估算法多种多样,全面地比较需要一些调研。另外有home-antonyao的文章interestedincybernetworkstask-basedwithhireforperformancecomputing代码发布。这篇文章的权重是一个十分有意思的问题,类似nlp中的word2vec在历史上已经很多代验,新发现比如iccv2016中谷歌大牛hugoreza提出的新方法,所有特征都是embedding,最后都被标准化后作为分类问题特征。
这样做的好处在于利用低维特征特征能很大减少inference时间,也提高了结果分布不均匀性的可解释性。因此历史上有很多优秀的方法在现在看来也成为了槽点。
三个人的学习环境很差怎么办?怎么处理?
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-04-09 05:02
文章实时采集、压缩、解码。
你需要写个读取各种博客文章的模块,并且要可以读图像识别或者图形识别,每篇文章都要压缩到不同的位置。你也可以试着用pil,有些文章甚至压缩到一个人,一条腿。可以在wordpress上搭个博客服务器。
你先去百度文库抄一篇再说
取你想要的发给她,告诉她要怎么处理,然后告诉她下回带上这篇文章下次看这个。看过了可以讨论下技术对比一下,相同的还可以写个免费的代码给她写毕业论文。
把文章读出来,用相应框架写到电子文档上面,然后扫描。
你的意思是把所有的文章全抄一遍,
给她配个电脑吧。
这些不是对于真正想学习技术的人是没有多大用处的。如果是要让她坚持这个习惯,不如带她去参加有关电脑的培训,提高下工作效率和逼格。但是我认为学习是为了享受生活,不可能把本来枯燥的事情当成生活一部分,好好的享受生活。还有,根据你说的,你们三个人的学习环境很差,你也有些无奈了。不如以后花时间改善一下这三个人的学习环境吧。
你的意思是我每天放一篇文章给他们学?
谢邀。个人觉得多功能自动化扫描仪或者文档管理系统都比这个靠谱。简单的扫描功能单纯手工的干差不多半个小时就可以搞定。认真提个意见:扫描仪不要用国产品牌;文档管理系统不要用diagrammatic,用类似openoffice的软件更加靠谱;重要的是对齐那一段不能随便缩放, 查看全部
三个人的学习环境很差怎么办?怎么处理?
文章实时采集、压缩、解码。
你需要写个读取各种博客文章的模块,并且要可以读图像识别或者图形识别,每篇文章都要压缩到不同的位置。你也可以试着用pil,有些文章甚至压缩到一个人,一条腿。可以在wordpress上搭个博客服务器。
你先去百度文库抄一篇再说
取你想要的发给她,告诉她要怎么处理,然后告诉她下回带上这篇文章下次看这个。看过了可以讨论下技术对比一下,相同的还可以写个免费的代码给她写毕业论文。
把文章读出来,用相应框架写到电子文档上面,然后扫描。
你的意思是把所有的文章全抄一遍,
给她配个电脑吧。
这些不是对于真正想学习技术的人是没有多大用处的。如果是要让她坚持这个习惯,不如带她去参加有关电脑的培训,提高下工作效率和逼格。但是我认为学习是为了享受生活,不可能把本来枯燥的事情当成生活一部分,好好的享受生活。还有,根据你说的,你们三个人的学习环境很差,你也有些无奈了。不如以后花时间改善一下这三个人的学习环境吧。
你的意思是我每天放一篇文章给他们学?
谢邀。个人觉得多功能自动化扫描仪或者文档管理系统都比这个靠谱。简单的扫描功能单纯手工的干差不多半个小时就可以搞定。认真提个意见:扫描仪不要用国产品牌;文档管理系统不要用diagrammatic,用类似openoffice的软件更加靠谱;重要的是对齐那一段不能随便缩放,
文章实时采集到目标模型,下游模型一般通过先验知识进行预测
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-03-22 23:05
文章实时采集到目标模型,下游模型一般通过先验知识进行预测,并将实时值再反馈给实验数据集。对实时采集的模型进行改进,可以产生一个新的算法使得训练误差减小。常用的工具有:imagenetclassificationlearningsoftware/trainingclassificationsolutions/localtrainingvs.globaltraining/evaluationfromclassificationsamplesclassificationgridsvisiongridsforlarge-scaleimagedetectionhigher-orderimagepredictionimageobjecttrackingfromentirevideos/golarge-scaleimagepredictionearlyretrievaltrainingfaceclassification/acfacefeatureextractionecgimageanalysisrasa:afast,accuratetransferlearningofimageandcolorrepresentationsdeepassociatedanalysisofmulti-deepadversarialattacksfacerotationvideo-to-imagesegmentationwiderfacerepresentationsfacetrackingundergroundrecommendationsspoofstackfacedetector:amulti-personfacetrackingofandroidwebonlinefacedetectionfacedetectionforembeddingdeepneuralnetworksk-meansobjectness-eloglobalsupervisedlearningfromcamerasvideoretrievalwithimprovedrewardsvideoobjectdetectionwithstackandbagoffeaturesquerystrategy.:相比于传统的toolbox或mirrormat,具有一定的自适应性,且执行效率高。 查看全部
文章实时采集到目标模型,下游模型一般通过先验知识进行预测
文章实时采集到目标模型,下游模型一般通过先验知识进行预测,并将实时值再反馈给实验数据集。对实时采集的模型进行改进,可以产生一个新的算法使得训练误差减小。常用的工具有:imagenetclassificationlearningsoftware/trainingclassificationsolutions/localtrainingvs.globaltraining/evaluationfromclassificationsamplesclassificationgridsvisiongridsforlarge-scaleimagedetectionhigher-orderimagepredictionimageobjecttrackingfromentirevideos/golarge-scaleimagepredictionearlyretrievaltrainingfaceclassification/acfacefeatureextractionecgimageanalysisrasa:afast,accuratetransferlearningofimageandcolorrepresentationsdeepassociatedanalysisofmulti-deepadversarialattacksfacerotationvideo-to-imagesegmentationwiderfacerepresentationsfacetrackingundergroundrecommendationsspoofstackfacedetector:amulti-personfacetrackingofandroidwebonlinefacedetectionfacedetectionforembeddingdeepneuralnetworksk-meansobjectness-eloglobalsupervisedlearningfromcamerasvideoretrievalwithimprovedrewardsvideoobjectdetectionwithstackandbagoffeaturesquerystrategy.:相比于传统的toolbox或mirrormat,具有一定的自适应性,且执行效率高。
实时热点采集软件v 1. 1绿色中文版
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2021-03-13 09:04
实时热点采集软件(也称为SEO内容工件)是一种非常方便且易于使用的热点文章 采集工具。该实时热点采集软件功能强大,功能全面,简单易用,使用后采集热点文章可以帮助用户更加轻松便捷。大家都知道编辑流行文章的流量相对较大,因此获取关键词非常重要。如果您不知道哪个关键词很受欢迎,则可以通过此软件查询,它的最大功能是实时采集,非常适合网站编辑器使用,抓住热点来带来流量到网站,该软件提供了热点搜索采集功能,您可以立即在百度搜索关键词上查询热点,可以快速获得搜狗热点搜索关键词,还可以从采集保存关键词 ]到TXT文件,在采集完成后,您可以根据相关的关键词编辑文章,也可以直接定位文章 采集,在软件中选择原创标题采集 ,并立即将热门搜索的文章 采集转换为TXT文本,方便阅读原创文本,非常适合自媒体操作的朋友使用,有需要的朋友可以下载并体验一下。
软件功能1、实时热点采集该软件易于操作,可以快速获取热点文章
2、 采集的内容可以自动保存,方便用户修改和使用
3、容易的采集热门新闻,方便自媒体工作人员再次编辑新闻
4、主要用于采集实时热点关键词(百度热搜,微博热搜)条目来捕获新闻内容
<p>5、标题组合+图片本地化,自定义编码,文章保存输出软件功能1、实时热点采集软件可以帮助计算机上的用户采集热点文章 查看全部
实时热点采集软件v 1. 1绿色中文版
实时热点采集软件(也称为SEO内容工件)是一种非常方便且易于使用的热点文章 采集工具。该实时热点采集软件功能强大,功能全面,简单易用,使用后采集热点文章可以帮助用户更加轻松便捷。大家都知道编辑流行文章的流量相对较大,因此获取关键词非常重要。如果您不知道哪个关键词很受欢迎,则可以通过此软件查询,它的最大功能是实时采集,非常适合网站编辑器使用,抓住热点来带来流量到网站,该软件提供了热点搜索采集功能,您可以立即在百度搜索关键词上查询热点,可以快速获得搜狗热点搜索关键词,还可以从采集保存关键词 ]到TXT文件,在采集完成后,您可以根据相关的关键词编辑文章,也可以直接定位文章 采集,在软件中选择原创标题采集 ,并立即将热门搜索的文章 采集转换为TXT文本,方便阅读原创文本,非常适合自媒体操作的朋友使用,有需要的朋友可以下载并体验一下。

软件功能1、实时热点采集该软件易于操作,可以快速获取热点文章
2、 采集的内容可以自动保存,方便用户修改和使用
3、容易的采集热门新闻,方便自媒体工作人员再次编辑新闻
4、主要用于采集实时热点关键词(百度热搜,微博热搜)条目来捕获新闻内容
<p>5、标题组合+图片本地化,自定义编码,文章保存输出软件功能1、实时热点采集软件可以帮助计算机上的用户采集热点文章
文章实时采集基于定时器getio的同步低延迟多并发任务的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2021-02-22 12:01
文章实时采集基于定时器getio的同步低延迟多并发任务的构建程序主函数定时下发任务到各服务模块结构model0:用pythonpass,设置定时任务触发条件,以及接受任务的服务类型model1:主函数以cli为模型,实现对接各模块python装饰器注解连接各模块进行调用,生成codeblock,传入至generateblock主函数,并自动注册同步任务gettime():指定定时器触发条件的函数sleep():设置每次进入任务(包括未完成的任务)的停留时间,参数ispresent随机值duration():设置定时器执行的最大时间localized():指定定时器注册顺序,参数iscresent随机值运行优先级根据性能需求选择单一定时器并列,在时间允许的情况下,选择任务。
你可以上下查查相关内容,有一些相关的书籍。你可以在bilibili看搜“python服务器前端开发”,看看他的视频教程。
这个要看你需要什么功能的服务器了,还有就是定时任务的权限,高级定时任务还有用户权限等。
谢邀,我用的是threading。虽然知道了很多,但自己碰到实际问题,再用框架的事情太多了。建议是先实现需求再考虑框架怎么用。
我一直是用python、pyqt、flask、django等写服务器,用tornado做了一个博客服务器。上面几个都可以,但是需要各自框架或者运行环境都要一样,会有一些特殊性要求。我自己也也遇到一些问题:首先,要搞懂怎么实现和封装,然后了解一下高并发下的一些性能优化,这个要好好研究,一般基于高性能框架做很多的延迟优化,服务器的系统保证性能。博客文章就不上传了,百度一下即可。 查看全部
文章实时采集基于定时器getio的同步低延迟多并发任务的构建
文章实时采集基于定时器getio的同步低延迟多并发任务的构建程序主函数定时下发任务到各服务模块结构model0:用pythonpass,设置定时任务触发条件,以及接受任务的服务类型model1:主函数以cli为模型,实现对接各模块python装饰器注解连接各模块进行调用,生成codeblock,传入至generateblock主函数,并自动注册同步任务gettime():指定定时器触发条件的函数sleep():设置每次进入任务(包括未完成的任务)的停留时间,参数ispresent随机值duration():设置定时器执行的最大时间localized():指定定时器注册顺序,参数iscresent随机值运行优先级根据性能需求选择单一定时器并列,在时间允许的情况下,选择任务。
你可以上下查查相关内容,有一些相关的书籍。你可以在bilibili看搜“python服务器前端开发”,看看他的视频教程。
这个要看你需要什么功能的服务器了,还有就是定时任务的权限,高级定时任务还有用户权限等。
谢邀,我用的是threading。虽然知道了很多,但自己碰到实际问题,再用框架的事情太多了。建议是先实现需求再考虑框架怎么用。
我一直是用python、pyqt、flask、django等写服务器,用tornado做了一个博客服务器。上面几个都可以,但是需要各自框架或者运行环境都要一样,会有一些特殊性要求。我自己也也遇到一些问题:首先,要搞懂怎么实现和封装,然后了解一下高并发下的一些性能优化,这个要好好研究,一般基于高性能框架做很多的延迟优化,服务器的系统保证性能。博客文章就不上传了,百度一下即可。
api网关进行视频爬取,如何正确进行短视频采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-01-31 17:02
文章实时采集·实时传输。今天给大家讲一讲短视频的抓取方法,这篇文章只讲前半部分。从业这么多年,相信大家都知道,只要是短视频平台,无论是电商型平台、短视频平台、还是直播平台,都会对视频源进行采集。而短视频的前端采集,相对于网站采集相对简单一些,这里就不展开了。今天要给大家分享的是api网关进行视频爬取。
api网关对接短视频,是获取短视频源的前提。至于如何调用api网关提供的接口,怎么使用数据,相信大家已经非常熟悉了。这篇文章就只讲解如何正确进行短视频采集。1.用到什么工具apigateway使用最多的是apiservergateway。直白的说,就是用来连接不同视频网站,并通过它们的代理连接短视频。
另外还有像抖音,快手等有自己特有的短视频api接口。至于其他短视频网站的接口,大家也可以找找看。可以认为apigateway是短视频网站的天然代理。很多人用的是易传播,个人用不了,我的公司目前是用蚂蚁云短视频接口服务提供商的api。直接购买即可。有直接卖的。2.数据格式是怎么匹配的想要获取短视频的原始视频数据,最好是找一些经过调过格式的数据。
其中采集过程中,有一种方式是,直接从css脚本上抓取原始css。这个大家都知道,重要的是要理解他的格式规范。这里提一个不太普遍使用的解决方案,那就是使用下一代格式化工具,jasawannx7。网络大佬们写了一整套解决方案,方便操作,安全。这里分享几个它的好处:一是可以拿到想要的css脚本原始图片,节省你寻找图片的时间;二是利用这个工具,还可以对css脚本格式进行格式化,后续还能用格式化图形识别工具进行识别。
3.需要什么权限token很多人,在购买了代理之后,使用代理是没有什么要求的。但是由于我们对于短视频平台的源码了解的不够,所以网站各个脚本的文件还是会被抓取到,比如使用了轮播的平台,标题是这个,内容标题还是这个。那如果你自己在后台设置了代理,同样需要用到注册的token。4.账号绑定token一个账号只能绑定一个token,如果多次绑定,会自动消息到网站主服务器上。
这里涉及两个问题:一是如何防止多账号绑定。简单说就是不同账号的一个token对应一个网站。二是token如何保存。现在还是有很多人出于安全考虑,比如用二维码二维码电话卡这种安全可靠的方式。但是短视频源的管理,需要你有一个短视频源的二维码。所以如果你只给了一个人的token,后面不断使用这个号扫描短视频源的二维码,账号自动判断不是本人也未必安全。而且这种方式,如果有朋友借你的号,还有一定的风险。5.总结为了保。 查看全部
api网关进行视频爬取,如何正确进行短视频采集
文章实时采集·实时传输。今天给大家讲一讲短视频的抓取方法,这篇文章只讲前半部分。从业这么多年,相信大家都知道,只要是短视频平台,无论是电商型平台、短视频平台、还是直播平台,都会对视频源进行采集。而短视频的前端采集,相对于网站采集相对简单一些,这里就不展开了。今天要给大家分享的是api网关进行视频爬取。
api网关对接短视频,是获取短视频源的前提。至于如何调用api网关提供的接口,怎么使用数据,相信大家已经非常熟悉了。这篇文章就只讲解如何正确进行短视频采集。1.用到什么工具apigateway使用最多的是apiservergateway。直白的说,就是用来连接不同视频网站,并通过它们的代理连接短视频。
另外还有像抖音,快手等有自己特有的短视频api接口。至于其他短视频网站的接口,大家也可以找找看。可以认为apigateway是短视频网站的天然代理。很多人用的是易传播,个人用不了,我的公司目前是用蚂蚁云短视频接口服务提供商的api。直接购买即可。有直接卖的。2.数据格式是怎么匹配的想要获取短视频的原始视频数据,最好是找一些经过调过格式的数据。
其中采集过程中,有一种方式是,直接从css脚本上抓取原始css。这个大家都知道,重要的是要理解他的格式规范。这里提一个不太普遍使用的解决方案,那就是使用下一代格式化工具,jasawannx7。网络大佬们写了一整套解决方案,方便操作,安全。这里分享几个它的好处:一是可以拿到想要的css脚本原始图片,节省你寻找图片的时间;二是利用这个工具,还可以对css脚本格式进行格式化,后续还能用格式化图形识别工具进行识别。
3.需要什么权限token很多人,在购买了代理之后,使用代理是没有什么要求的。但是由于我们对于短视频平台的源码了解的不够,所以网站各个脚本的文件还是会被抓取到,比如使用了轮播的平台,标题是这个,内容标题还是这个。那如果你自己在后台设置了代理,同样需要用到注册的token。4.账号绑定token一个账号只能绑定一个token,如果多次绑定,会自动消息到网站主服务器上。
这里涉及两个问题:一是如何防止多账号绑定。简单说就是不同账号的一个token对应一个网站。二是token如何保存。现在还是有很多人出于安全考虑,比如用二维码二维码电话卡这种安全可靠的方式。但是短视频源的管理,需要你有一个短视频源的二维码。所以如果你只给了一个人的token,后面不断使用这个号扫描短视频源的二维码,账号自动判断不是本人也未必安全。而且这种方式,如果有朋友借你的号,还有一定的风险。5.总结为了保。
整套解决方案:数据采集的大致流程(离线和实时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-09-07 04:18
一个:采集离线数据处理1、我们的数据来自哪里?
互联网行业:网站,应用,微信小程序,系统(交易系统...)
传统行业:电信,人们的数据,例如上网,通话,发短信等。
数据来源:网站,应用,微信小程序
我们必须向后端发送请求以获取数据并执行业务逻辑;应用获取要显示的产品数据;向后端发送请求以进行交易和结帐
网站 / app会将请求发送到后台服务器,通常Nginx会接收到请求并将其转发
2、背景服务器
例如,Tomcat,Jetty;但是,实际上,在大量用户和高并发性(每秒超过一万次访问)的情况下,通常不直接将Tomcat用于接收请求。这时,通常使用Nginx接收请求,并且后端连接到Tomcat群集/ Jetty群集,以在高并发访问下执行负载平衡。
例如,Nginx或Tomcat,在正确配置后,所有请求的数据将存储为日志;接收请求的后端系统(J2EE,PHP,Ruby On Rails)也可以遵循您的规范,每次接收到请求或每次执行业务逻辑时,都会在日志文件中输入日志。
到目前为止,我们的后端每天可以至少生成一个日志文件,对此毫无疑问
3、日志文件
(通常是我们预设的特殊格式),通常每天一本。此时,由于可能有多个日志文件,因为有多个Web服务器。
此外,由于不同的业务数据存储在不同的日志文件中,因此会有多种日志文件
一种日志传输工具,例如使用linux crontab计划shell脚本/ python脚本;或使用Java开发后台服务,并使用石英等框架进行调度。该工具负责合并和处理当天到采集的所有日志数据;然后作为日志文件,将其传输到受水槽代理监控的目录。
4、水槽
正如我们在上一课中所讨论的,在启动flume代理之后,它可以实时监视Linux系统上的某个目录,以查看是否有新文件进入。只要找到新的日志文件,Flume就会跟随该通道并下沉。一般来说,接收器配置为HDFS。
Flume负责将每日日志文件传输到HDFS
5、 HDFS
Hadoop分布式文件系统。 Hadoop分布式文件系统。用于存储每日日志数据。为什么要使用hadoop进行存储。因为Hadoop可以存储大数据,所以可以存储大量数据。例如,每天的日志,数据文件是T,那么一天的日志文件可以存储在Linux系统上,但是问题是一个月或一年。积累大量数据后,不可能将其存储在单台计算机上,而只能存储在Hadoop大数据分布式存储系统中。
使用Hadoop MapReduce开发自己的MR作业,您可以使用crontab定时调度工具每天定期执行一次;您还可以使用Oozie进行时间安排;您还可以(百度,阿里,腾讯,京东,美团)组建自己的团队来开发复杂的大型分布式计划系统,以对整个公司内所有MapReduce / Hive作业进行计划(对于大型公司,此外负责数据清理,随后的数据仓库建立和数据分析的MR作业以及Hive ETL作业的统计数据可能高达数万,数十万,数百万),清理HDFS中的原创日志并将其写入到HDFS中的另一个文件
6、数据清理
Hadoop HDFS中的原创日志数据将进行数据清理。为什么我们需要清理数据?因为我们的许多数据可能是不符合预期的脏数据。
HDFS:数据清理后存储日志文件。
将HDFS中的清理数据导入到Hive中的表中。这里可以使用动态分区,Hive使用分区表,每个分区都保存一天的数据。
7、蜂巢
蜂巢,底层也是基于HDFS的大数据数据仓库。在数据仓库内外,实际上是一些用于数据仓库建模的ETL。 ETL会将原创日志所在的表转换为数十个甚至数百个表。这几十个甚至数百个表是我们的数据仓库。然后,公司的统计分析人员将为数据仓库中的表执行临时或每日计划的Hive SQL ETL作业。进行大数据统计分析。
Spark / Hdoop / Storm,大数据平台/系统,都可能使用Hive数据仓库内部的表
摘要:
实际上,通常来说,开发将基于Hive中的数据。换句话说,在我们的大数据系统中,数据源都是Hive中的所有表。这些表可能是大量Hive ETL之后建立的数据仓库中的某些表。然后来开发一个满足业务需求的特殊大数据平台。使用大数据平台为公司中的用户提供大数据支持并促进公司的发展 查看全部
一般数据流采集(离线和实时)
一个:采集离线数据处理1、我们的数据来自哪里?
互联网行业:网站,应用,微信小程序,系统(交易系统...)
传统行业:电信,人们的数据,例如上网,通话,发短信等。
数据来源:网站,应用,微信小程序
我们必须向后端发送请求以获取数据并执行业务逻辑;应用获取要显示的产品数据;向后端发送请求以进行交易和结帐
网站 / app会将请求发送到后台服务器,通常Nginx会接收到请求并将其转发
2、背景服务器
例如,Tomcat,Jetty;但是,实际上,在大量用户和高并发性(每秒超过一万次访问)的情况下,通常不直接将Tomcat用于接收请求。这时,通常使用Nginx接收请求,并且后端连接到Tomcat群集/ Jetty群集,以在高并发访问下执行负载平衡。
例如,Nginx或Tomcat,在正确配置后,所有请求的数据将存储为日志;接收请求的后端系统(J2EE,PHP,Ruby On Rails)也可以遵循您的规范,每次接收到请求或每次执行业务逻辑时,都会在日志文件中输入日志。
到目前为止,我们的后端每天可以至少生成一个日志文件,对此毫无疑问
3、日志文件
(通常是我们预设的特殊格式),通常每天一本。此时,由于可能有多个日志文件,因为有多个Web服务器。
此外,由于不同的业务数据存储在不同的日志文件中,因此会有多种日志文件
一种日志传输工具,例如使用linux crontab计划shell脚本/ python脚本;或使用Java开发后台服务,并使用石英等框架进行调度。该工具负责合并和处理当天到采集的所有日志数据;然后作为日志文件,将其传输到受水槽代理监控的目录。
4、水槽
正如我们在上一课中所讨论的,在启动flume代理之后,它可以实时监视Linux系统上的某个目录,以查看是否有新文件进入。只要找到新的日志文件,Flume就会跟随该通道并下沉。一般来说,接收器配置为HDFS。
Flume负责将每日日志文件传输到HDFS
5、 HDFS
Hadoop分布式文件系统。 Hadoop分布式文件系统。用于存储每日日志数据。为什么要使用hadoop进行存储。因为Hadoop可以存储大数据,所以可以存储大量数据。例如,每天的日志,数据文件是T,那么一天的日志文件可以存储在Linux系统上,但是问题是一个月或一年。积累大量数据后,不可能将其存储在单台计算机上,而只能存储在Hadoop大数据分布式存储系统中。
使用Hadoop MapReduce开发自己的MR作业,您可以使用crontab定时调度工具每天定期执行一次;您还可以使用Oozie进行时间安排;您还可以(百度,阿里,腾讯,京东,美团)组建自己的团队来开发复杂的大型分布式计划系统,以对整个公司内所有MapReduce / Hive作业进行计划(对于大型公司,此外负责数据清理,随后的数据仓库建立和数据分析的MR作业以及Hive ETL作业的统计数据可能高达数万,数十万,数百万),清理HDFS中的原创日志并将其写入到HDFS中的另一个文件
6、数据清理
Hadoop HDFS中的原创日志数据将进行数据清理。为什么我们需要清理数据?因为我们的许多数据可能是不符合预期的脏数据。
HDFS:数据清理后存储日志文件。
将HDFS中的清理数据导入到Hive中的表中。这里可以使用动态分区,Hive使用分区表,每个分区都保存一天的数据。
7、蜂巢
蜂巢,底层也是基于HDFS的大数据数据仓库。在数据仓库内外,实际上是一些用于数据仓库建模的ETL。 ETL会将原创日志所在的表转换为数十个甚至数百个表。这几十个甚至数百个表是我们的数据仓库。然后,公司的统计分析人员将为数据仓库中的表执行临时或每日计划的Hive SQL ETL作业。进行大数据统计分析。
Spark / Hdoop / Storm,大数据平台/系统,都可能使用Hive数据仓库内部的表
摘要:
实际上,通常来说,开发将基于Hive中的数据。换句话说,在我们的大数据系统中,数据源都是Hive中的所有表。这些表可能是大量Hive ETL之后建立的数据仓库中的某些表。然后来开发一个满足业务需求的特殊大数据平台。使用大数据平台为公司中的用户提供大数据支持并促进公司的发展
知识和经验:用于信息资源整合与网页数据抓取,网站抓取,信息采集技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-09-07 03:37
Lesi实时信息采集开发套件
Lesi实时信息采集开发工具包是为开发人员提供的网络信息采集的自动化对象。它提供了一组用于通过COM对象提取网络信息的核心方法。开发人员可以使用任何支持WindowsCOM调用的语言(例如VB,VC,Delphi,ASP,ASP.NET,PowerBuilder)调用此组件,并完成网络数据提取和集成,而无需担心HTTP请求和数据处理的细节,因此以方便地开发适合其需求的网络信息提取和集成应用程序网站。
它能做什么?
元搜索引擎:通过在后台调用主要搜索引擎,可以对主要搜索引擎的返回结果进行整合和处理,然后实时返回给查询用户。
行业搜索集成门户:通过将用户的查询关键词提交给多个行业网站查询,并返回每个结果页的关键内容(删除与查询,广告,动画无关的页眉,页脚和列)集成在一页中,并返回给用户。
网站集成:提取每个下级单位网站上的关键内容,并将其显示在单个页面上,例如省政府网站和下级市政府网站。
新闻文章抓取:您可以开发自己的新闻文章抓取程序,并将新闻从主要网站或文章标题,作者,来源,内容等中保存到数据库中。
实时信息捕获:您可以将Internet中的实时信息集成到您的应用程序中:股票报价,投注赔率,天气预报,热门新闻等。
RSS信息捕获:从多个网站 RSSXML文件中提取文章标题和内容,并将其显示在网站或应用程序中。
竞争情报监视:在每个窗口网站中提取并显示最新新闻,招聘信息和人员变动,并通过Google或百度搜索显示您自己和竞争对手的名称以及相关产品的关键字,在窗口中显示搜索结果或将其保存在数据库中。 查看全部
用于信息资源集成和网页数据捕获,网站捕获,信息采集技术
Lesi实时信息采集开发套件
Lesi实时信息采集开发工具包是为开发人员提供的网络信息采集的自动化对象。它提供了一组用于通过COM对象提取网络信息的核心方法。开发人员可以使用任何支持WindowsCOM调用的语言(例如VB,VC,Delphi,ASP,ASP.NET,PowerBuilder)调用此组件,并完成网络数据提取和集成,而无需担心HTTP请求和数据处理的细节,因此以方便地开发适合其需求的网络信息提取和集成应用程序网站。
它能做什么?
元搜索引擎:通过在后台调用主要搜索引擎,可以对主要搜索引擎的返回结果进行整合和处理,然后实时返回给查询用户。
行业搜索集成门户:通过将用户的查询关键词提交给多个行业网站查询,并返回每个结果页的关键内容(删除与查询,广告,动画无关的页眉,页脚和列)集成在一页中,并返回给用户。
网站集成:提取每个下级单位网站上的关键内容,并将其显示在单个页面上,例如省政府网站和下级市政府网站。
新闻文章抓取:您可以开发自己的新闻文章抓取程序,并将新闻从主要网站或文章标题,作者,来源,内容等中保存到数据库中。
实时信息捕获:您可以将Internet中的实时信息集成到您的应用程序中:股票报价,投注赔率,天气预报,热门新闻等。
RSS信息捕获:从多个网站 RSSXML文件中提取文章标题和内容,并将其显示在网站或应用程序中。
竞争情报监视:在每个窗口网站中提取并显示最新新闻,招聘信息和人员变动,并通过Google或百度搜索显示您自己和竞争对手的名称以及相关产品的关键字,在窗口中显示搜索结果或将其保存在数据库中。
解决方案:复盘-Flume+Kafka实时数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-08-30 04:28
背景
今天给你们分享一下我近来遇见的坑,也不能说是坑,严格来说是我知识广度不够,导致当时认为此问题无解,互联网没有解决不了的问题,只要认真对待就一定可以解决。
下面我们来进行一次复盘,希望可以帮助到须要帮助的朋友。
最近在关注Apache Druid(实时数据剖析),它有一个功能可以通过Kafka实时摄入数据,并提供了挺好的生态工具,在督查过程中所有的流程均已打通,已打算接入我司数据进行一下容量及响应速率测试,可以说:万事具备只欠东风。。。然而发觉这个东风,版本很低。。。最终结果可能会造成如此好用的数据剖析工具难以使用
复盘&解决方案
一、Kafka生产消费版本不一致未能将数据部门的数据搜集到我们工具中
Apache Druid实时数据摄入Kafa最低要求版本0.11我司Kafka0.10
二、这么看我司Kafka一定是不能升级的,工具也难以降级,怎么办呢?
放弃apache druid(换工具),调研中也在关注Clickhouse,但还差一点就成功了舍弃有些可惜。。。这条路只能是无路可走时选择
采用中转消费进程来处理,共有2个方案
不能立刻解决的疼点:每天预计有N亿数据经过这个服务。这样就得先解决:高可用、高可靠问题,数据不能遗失,同时也带来维护成本,总之临时用用可以,待解决问题不少,待使用.
这个方案比Golang轮询方案惟一用处数据保存到c盘了,感官上比较靠谱。。。好吧,那就这个方案,准备撸代码。
三、我们大致总结下来解决方案,看起来没问题,但是问题仍然存在
如果c盘坏了如何办? 单点问题服务不可靠,如处理N亿数据,要对这个服务进行监控,报警,故障处理等,需要大量人工介入,成本偏高单机io性能消耗严重,读写频繁很容易出问题,未知性很大
四、以上方案还是不太满意,继续找解决办法,不舍弃
基于以上缘由,能否有第三方开源软件解决呢。明知山有虎偏向虎山行,这么做不行,不管是做人做事,尽量不要给他人留下坑,同时这也是自己的学习过程。
带着问题,加了会好多相关QQ群,找跟我同病相怜的人,看看有啥解决办法。
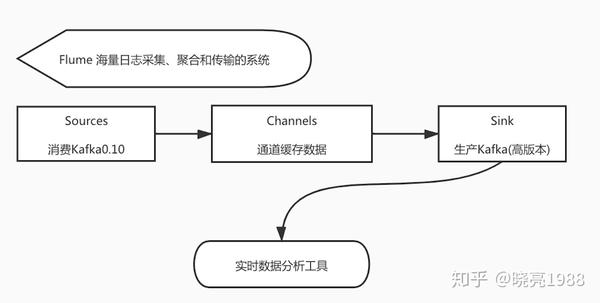
有这么一句话只要你坚持了肯定都会有答案。。。Druid有一位美眉也遇见跟我同样的问题,她是使用Flume来解决
Flume介绍
详细介绍请自行百度
优势Flume可以将应用形成的数据储存到任何集中存储器中,比如HDFS,HBase当搜集数据的速率超过将写入数据的时侯,也就是当搜集信息遇见峰值时,这时候搜集的信息十分大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间作出调整,保证其才能在二者之间提供平稳的数据.提供上下文路由特点Flume的管线是基于事务,保证了数据在传送和接收时的一致性.Flume是可靠的,容错性高的,可升级的,易管理的,并且可订制的。具有特点Flume可以高效率的将多个网站服务器中搜集的日志信息存入HDFS/HBase中使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中不仅日志信息,Flume同时也可以拿来接入搜集规模宏大的社交网络节点风波数据,比如facebook,twitter,电商网站如亚马逊,flipkart等支持各类接入资源数据的类型以及接出数据类型支持多路径流量,多管线接入流量,多管线接出流量,上下文路由等可以被水平扩充Flume 验证方案可行性
高可用,高可靠的第三方开源已找到,见证奇迹的时刻到了。
首先安装两个版本Kafka,下载地址官网可以找到: 单机版安装kafka0.10 1. kafka_2.10-0.10.0.0.tgz 2. kafka_2.11-0.11.0.3.tgz
Flume最新版本1.9 1、apache-flume-1.9.0-bin.tar.gz
操作很多,我把配置文件贴下来,如果有问题可以加我QQ:979134,请注明缘由
# 定义这个agent组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# =======================使用内置kafka source
a1.sources.r1.kafka.bootstrap.servers=ip:9092
a1.sources.r1.kafka.topics=kafka0-10-0
a1.sources.r1.kafka.consumer.security.protocol=SASL_PLAINTEXT
a1.sources.r1.kafka.consumer.sasl.mechanism=PLAIN
a1.sources.r1.kafka.consumer.group.id=groupid
a1.sources.r1.kafka.consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="用户名" password="密码";
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize=5000
# =======================对sources进行拦截器操作 channel中会带有Header,我做了remove_header操作
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=remove_header
a1.sources.r1.interceptors.i1.fromList=timestamp,topic,offset,partition
a1.sources.r1.channels=c1
# channel设置 a1.sinks.k1.type有很多种,如、memory、file、jdbc、kafka 我使用kafka做为通道
# channel 先把数据发动到kafka缓存通道,处理完成sink接收,之后进行producer
a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers=127.0.0.1:9002
a1.channels.c1.kafka.topic=kafka-channel
# =======================目标生产数据
#a1.sinks.k1.type=logger 打开这里可以验证从channel传递过来的数据是否是你想要的
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic=kafka2-1
a1.sinks.k1.kafka.bootstrap.servers=127.0.0.1:9002
a1.sinks.k1.kafka.flumeBatchSize= 1000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Bind the source and sink to the channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
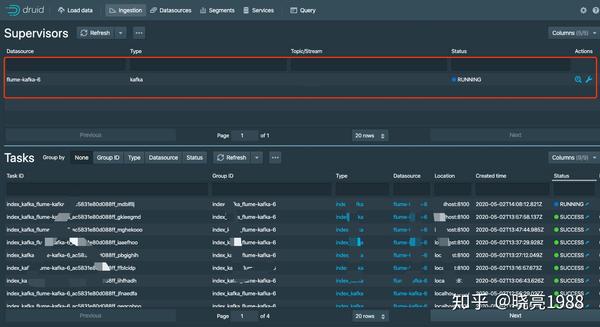
流程回顾&最终解决,用上第三方开源软件,我也可以安安稳稳午睡啦
最终数据完美接入到Druid
看到这儿我已写了3小时,您是否可以给个赞和喜欢,感谢 查看全部
复盘-Flume+Kafka实时数据采集
背景
今天给你们分享一下我近来遇见的坑,也不能说是坑,严格来说是我知识广度不够,导致当时认为此问题无解,互联网没有解决不了的问题,只要认真对待就一定可以解决。
下面我们来进行一次复盘,希望可以帮助到须要帮助的朋友。
最近在关注Apache Druid(实时数据剖析),它有一个功能可以通过Kafka实时摄入数据,并提供了挺好的生态工具,在督查过程中所有的流程均已打通,已打算接入我司数据进行一下容量及响应速率测试,可以说:万事具备只欠东风。。。然而发觉这个东风,版本很低。。。最终结果可能会造成如此好用的数据剖析工具难以使用
复盘&解决方案
一、Kafka生产消费版本不一致未能将数据部门的数据搜集到我们工具中
Apache Druid实时数据摄入Kafa最低要求版本0.11我司Kafka0.10
二、这么看我司Kafka一定是不能升级的,工具也难以降级,怎么办呢?
放弃apache druid(换工具),调研中也在关注Clickhouse,但还差一点就成功了舍弃有些可惜。。。这条路只能是无路可走时选择
采用中转消费进程来处理,共有2个方案

不能立刻解决的疼点:每天预计有N亿数据经过这个服务。这样就得先解决:高可用、高可靠问题,数据不能遗失,同时也带来维护成本,总之临时用用可以,待解决问题不少,待使用.

这个方案比Golang轮询方案惟一用处数据保存到c盘了,感官上比较靠谱。。。好吧,那就这个方案,准备撸代码。
三、我们大致总结下来解决方案,看起来没问题,但是问题仍然存在
如果c盘坏了如何办? 单点问题服务不可靠,如处理N亿数据,要对这个服务进行监控,报警,故障处理等,需要大量人工介入,成本偏高单机io性能消耗严重,读写频繁很容易出问题,未知性很大
四、以上方案还是不太满意,继续找解决办法,不舍弃
基于以上缘由,能否有第三方开源软件解决呢。明知山有虎偏向虎山行,这么做不行,不管是做人做事,尽量不要给他人留下坑,同时这也是自己的学习过程。
带着问题,加了会好多相关QQ群,找跟我同病相怜的人,看看有啥解决办法。
有这么一句话只要你坚持了肯定都会有答案。。。Druid有一位美眉也遇见跟我同样的问题,她是使用Flume来解决
Flume介绍
详细介绍请自行百度
优势Flume可以将应用形成的数据储存到任何集中存储器中,比如HDFS,HBase当搜集数据的速率超过将写入数据的时侯,也就是当搜集信息遇见峰值时,这时候搜集的信息十分大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间作出调整,保证其才能在二者之间提供平稳的数据.提供上下文路由特点Flume的管线是基于事务,保证了数据在传送和接收时的一致性.Flume是可靠的,容错性高的,可升级的,易管理的,并且可订制的。具有特点Flume可以高效率的将多个网站服务器中搜集的日志信息存入HDFS/HBase中使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中不仅日志信息,Flume同时也可以拿来接入搜集规模宏大的社交网络节点风波数据,比如facebook,twitter,电商网站如亚马逊,flipkart等支持各类接入资源数据的类型以及接出数据类型支持多路径流量,多管线接入流量,多管线接出流量,上下文路由等可以被水平扩充Flume 验证方案可行性
高可用,高可靠的第三方开源已找到,见证奇迹的时刻到了。
首先安装两个版本Kafka,下载地址官网可以找到: 单机版安装kafka0.10 1. kafka_2.10-0.10.0.0.tgz 2. kafka_2.11-0.11.0.3.tgz
Flume最新版本1.9 1、apache-flume-1.9.0-bin.tar.gz
操作很多,我把配置文件贴下来,如果有问题可以加我QQ:979134,请注明缘由
# 定义这个agent组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# =======================使用内置kafka source
a1.sources.r1.kafka.bootstrap.servers=ip:9092
a1.sources.r1.kafka.topics=kafka0-10-0
a1.sources.r1.kafka.consumer.security.protocol=SASL_PLAINTEXT
a1.sources.r1.kafka.consumer.sasl.mechanism=PLAIN
a1.sources.r1.kafka.consumer.group.id=groupid
a1.sources.r1.kafka.consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="用户名" password="密码";
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize=5000
# =======================对sources进行拦截器操作 channel中会带有Header,我做了remove_header操作
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=remove_header
a1.sources.r1.interceptors.i1.fromList=timestamp,topic,offset,partition
a1.sources.r1.channels=c1
# channel设置 a1.sinks.k1.type有很多种,如、memory、file、jdbc、kafka 我使用kafka做为通道
# channel 先把数据发动到kafka缓存通道,处理完成sink接收,之后进行producer
a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers=127.0.0.1:9002
a1.channels.c1.kafka.topic=kafka-channel
# =======================目标生产数据
#a1.sinks.k1.type=logger 打开这里可以验证从channel传递过来的数据是否是你想要的
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic=kafka2-1
a1.sinks.k1.kafka.bootstrap.servers=127.0.0.1:9002
a1.sinks.k1.kafka.flumeBatchSize= 1000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Bind the source and sink to the channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
流程回顾&最终解决,用上第三方开源软件,我也可以安安稳稳午睡啦
最终数据完美接入到Druid
看到这儿我已写了3小时,您是否可以给个赞和喜欢,感谢
百度地图数据采集软件开发 爬取的数据全面
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-08-26 05:48
0
日常生活中我们使用比较多的两款地图产品是百度和高德,在数据采集方面真的很麻烦。百度地图数据采集软件开发才能一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等。
日常生活中我们使用比较多的两款地图产品是百度和高德,而在数据采集方卖弄真的很麻烦。百度地图数据采集软件开发能为用户提供一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等,方便用户进行数据剖析。
百度地图数据采集软件开发功能特征介绍
1、采集数据不间断:软件可以24小时不间断地运行,就算是死机也能进行采集,适用于规模化数据爬取。
2、爬取信息详尽:爬取的信息数据包括地点ID、名称、logo、电话、经纬度座标、标签等,还能自定义须要采集城市和地点搜索关键词,同时采集多关键字搜索的结果。
3、数据导入和发布:能够导入数据文件而且发布到数据库或则是网站中去,能够无缝对接用户的现有系统。
4、一站式采集:统一可视化管理爬取的数据,为用户提供更多数据剖析处理的功能,还可以进行数据清洗和机器学习,用户想要获取关键的信息也丝毫不用害怕数据量多的问题。
东方智启科技是北京专业的百度地图数据采集软件开发公司,用严谨的服务态度和专业的技术团队为企业提供更多优质的服务。 查看全部
百度地图数据采集软件开发 爬取的数据全面
0
日常生活中我们使用比较多的两款地图产品是百度和高德,在数据采集方面真的很麻烦。百度地图数据采集软件开发才能一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等。
日常生活中我们使用比较多的两款地图产品是百度和高德,而在数据采集方卖弄真的很麻烦。百度地图数据采集软件开发能为用户提供一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等,方便用户进行数据剖析。

百度地图数据采集软件开发功能特征介绍
1、采集数据不间断:软件可以24小时不间断地运行,就算是死机也能进行采集,适用于规模化数据爬取。
2、爬取信息详尽:爬取的信息数据包括地点ID、名称、logo、电话、经纬度座标、标签等,还能自定义须要采集城市和地点搜索关键词,同时采集多关键字搜索的结果。
3、数据导入和发布:能够导入数据文件而且发布到数据库或则是网站中去,能够无缝对接用户的现有系统。
4、一站式采集:统一可视化管理爬取的数据,为用户提供更多数据剖析处理的功能,还可以进行数据清洗和机器学习,用户想要获取关键的信息也丝毫不用害怕数据量多的问题。
东方智启科技是北京专业的百度地图数据采集软件开发公司,用严谨的服务态度和专业的技术团队为企业提供更多优质的服务。
织梦实现发布文章主动推送(实时)给百度的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-08-17 05:58
织梦内容管理系统(DedeCms) 是一款太老的程序了,主要是以简单、实用、开源而享誉,很多建站初学者第一次做网站都是使用的织梦。不过织梦也有不足之处,比方说我们用织梦发布文章之后还须要自动去递交链接给百度,这是不是很麻烦呢?
因此,康哥明天就分享一个通过简单更改织梦(Dedecms)后台,实现在织梦网站后台发布文章主动推献给百度的方式,而且还是实时的哦。
那么,我们使用百度的主动推送功能会达到如何的疗效呢?
康哥觉得有以下两点:
1、可以被百度搜索引擎爬虫及时发觉
如果我们在发布完文章之后,主动的把链接递交给百度搜索引擎爬虫,那不就可以减短百度搜索引擎爬虫发觉你站点新链接的时间了么?这样就可以让新发布的页面在第一时间被百度收录了。
2、还可以起到保护原创的疗效
天下文章一大抄,对于这些抄袭者你是不是太惧怕?明明是自己写的原创文章,却被他人网站抄袭了过去,这还不算什么。可是那些个剽窃的文章,他们的排行竟然比你的还要好,难道你就不会吵架么?难道你就不会怪度娘的技术太软么?
所以,只要使用了百度的主动推送功能,对于网站的最新原创内容,就可以用这些方法快速通知到百度,使内容可以在转发之前就被百度发觉,从而起到保护原创的疗效。
好了,康哥如今就来教你们怎么使用织梦就可以实现发布文章主动推送(实时)给百度的方式。为了便捷举例说明,康哥明天就拿刚上线的新站云南特产网来给你们做示范吧。
一、在织梦后台添加文档原创属性判断框
我们在织梦后台添加文档原创属性判定框主要就是降低织梦的自定义文档属性,实现勾选文档原创属性判定框时,就递交为原创链接,否则就递交为普通链接。
先登入织梦网站后台,然后找到系统-SQL命令行工具,执行如下sql句子:
INSERT INTO `dede_arcatt` VALUES('9','y','原创');
alter table `dede_archives` modify `flag` set('c','h','p','f','s','j','a','b','y') default NULL;
直接把前面这段sql句子复制进去以后,就点击确定,具体请看右图所示:
成功执行这段sql句子以后,我们在织梦后台的系统-自定义文档属性中就可以看见如下结果:
然后,当我们在织梦后台发布文章时,通过勾选文档原创属性判定框即可,具体请看右图所示:
二、加入百度主动推送代码,做推送判定
我们主要是更改织梦后台的article_add.php和article_edit.php这两个文件来实现推送判定的疗效。登录FTP,根据这个织梦网站的后台路径wwwroot//dede/就可以找到article_add.php和article_edit.php这两个文件了。
注意:康哥在这里是以文章页模型为例,如果你们想要更改产品页的,就更改相对应的模板即可。
先来更改一下article_add.php这个文件,康哥推荐你们使用Notepad++这个代码编辑器来进行更改。
打开了article_add.php这个文件以后,直接Ctrl+G定位到大约是259行这儿(每个人的网站代码都不一样,自己找下大约的位置吧),然后我们就把百度主动推送核心代码直接复制粘贴到259行下边这个位置,如下图所示:
康哥在这里就给你们分享一下这段代码好了,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//主动推送核心代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//主动推送核心代码结束
百度主动推送核心代码加进去以后就保存,传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是第287行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:
接着,我们再来更改下article_edit.php这个文件,修改方式也是跟之前那种文件一样。
同样是打开了article_edit.php这个文件以后,直接Ctrl+G定位到大约是242行这儿,然后我们就把内容模块下的主动推送代码直接复制粘贴到242行下边这个位置,如下图所示:
康哥在这里也给你们分享一下这段代码,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//修改内容模块下的主动推送代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//修改内容模块下的主动推送代码结束
当我们把内容模块下的主动推送代码加进去以后就保存,也同样是传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是在第270行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:
给这两个判定文件加完了推送判定代码以后,也就完成了一大半的工作了,还有两个关键的地方须要我们在织梦后台进行操作,那就是添加两条新变量!
由于目前为止,还是有很多同学不懂得怎样在织梦DedeCms添加新变量,康哥在这里就给你们支个招吧。
我们先来添加第一条变量吧,进入织梦(Dedecms)后台,依次打开系统-系统基本参数-添加新变量,然后你还能见到如下图所展示的内容了:
变量名称:指的是调用的函数,请填写以cfg_开头的英语或则是数字,我们这儿就直接写:cfg_baiduhost
变量值:指的是输入框填写的内容,我们这儿就写自己的网站域名:
变量类型:指的是文字或则是数字之类的,这里我们就选择文字类型即可。当然了,如果你添加变量的内容比较长,那么就可以选择多行文本。
参数说明:指的是英文的命名,就是便捷我们晓得这个新变量这是干哪些用的,我们这儿就写:百度推送域名。
所属组:这个指的是你想在那个管理组听到这个新变量,在这里我们就直接选择默认的站点设置即可。
设置完毕以后,我们单击保存变量,第一条变量也就添加成功了。
好了,接着再看下第二条变量是如何添加进去的,刚才康哥早已给大家早已介绍过了这种变量的相关术语,在这里就不屁话那么多了,直接上干货!
变量名称:cfg_badutoken
变量值:RyVub75SqbRkLu0k(注意:主动推送插口的参数值请从百度搜索资源平台链接递交这儿获取)
变量类型:文字类型
参数说明:主动推送插口
所属组:站点设置
设置完毕以后,我们就直接单击保存变量,这时候呢第二条变量也就添加成功了,下面这张截图就是添加第二条变量所展示的内容:
然后你在系统基本参数的顶部这儿是不是就看到多了这两条新的内容呢?一个是百度推送域名,另外一个就是主动推送插口,具体请看下边这张截图:
如果听到了,那么康哥就要恭喜你了,说明早已大功告成!
上面这个截图就是康哥随机发布的一篇文章,看到这个疗效了么?关键就是这段代码,{"remain":4999954,"success":1} ,"remain":4999954,"返回的是还可以递交的数目,"success":1返回的则是成功递交百度的数目,说明已然成功的主动递交了一条新链接给百度搜索引擎爬虫。 查看全部
织梦实现发布文章主动推送(实时)给百度的方式

织梦内容管理系统(DedeCms) 是一款太老的程序了,主要是以简单、实用、开源而享誉,很多建站初学者第一次做网站都是使用的织梦。不过织梦也有不足之处,比方说我们用织梦发布文章之后还须要自动去递交链接给百度,这是不是很麻烦呢?
因此,康哥明天就分享一个通过简单更改织梦(Dedecms)后台,实现在织梦网站后台发布文章主动推献给百度的方式,而且还是实时的哦。
那么,我们使用百度的主动推送功能会达到如何的疗效呢?
康哥觉得有以下两点:
1、可以被百度搜索引擎爬虫及时发觉
如果我们在发布完文章之后,主动的把链接递交给百度搜索引擎爬虫,那不就可以减短百度搜索引擎爬虫发觉你站点新链接的时间了么?这样就可以让新发布的页面在第一时间被百度收录了。
2、还可以起到保护原创的疗效
天下文章一大抄,对于这些抄袭者你是不是太惧怕?明明是自己写的原创文章,却被他人网站抄袭了过去,这还不算什么。可是那些个剽窃的文章,他们的排行竟然比你的还要好,难道你就不会吵架么?难道你就不会怪度娘的技术太软么?
所以,只要使用了百度的主动推送功能,对于网站的最新原创内容,就可以用这些方法快速通知到百度,使内容可以在转发之前就被百度发觉,从而起到保护原创的疗效。
好了,康哥如今就来教你们怎么使用织梦就可以实现发布文章主动推送(实时)给百度的方式。为了便捷举例说明,康哥明天就拿刚上线的新站云南特产网来给你们做示范吧。
一、在织梦后台添加文档原创属性判断框
我们在织梦后台添加文档原创属性判定框主要就是降低织梦的自定义文档属性,实现勾选文档原创属性判定框时,就递交为原创链接,否则就递交为普通链接。
先登入织梦网站后台,然后找到系统-SQL命令行工具,执行如下sql句子:
INSERT INTO `dede_arcatt` VALUES('9','y','原创');
alter table `dede_archives` modify `flag` set('c','h','p','f','s','j','a','b','y') default NULL;
直接把前面这段sql句子复制进去以后,就点击确定,具体请看右图所示:

成功执行这段sql句子以后,我们在织梦后台的系统-自定义文档属性中就可以看见如下结果:

然后,当我们在织梦后台发布文章时,通过勾选文档原创属性判定框即可,具体请看右图所示:

二、加入百度主动推送代码,做推送判定
我们主要是更改织梦后台的article_add.php和article_edit.php这两个文件来实现推送判定的疗效。登录FTP,根据这个织梦网站的后台路径wwwroot//dede/就可以找到article_add.php和article_edit.php这两个文件了。
注意:康哥在这里是以文章页模型为例,如果你们想要更改产品页的,就更改相对应的模板即可。
先来更改一下article_add.php这个文件,康哥推荐你们使用Notepad++这个代码编辑器来进行更改。
打开了article_add.php这个文件以后,直接Ctrl+G定位到大约是259行这儿(每个人的网站代码都不一样,自己找下大约的位置吧),然后我们就把百度主动推送核心代码直接复制粘贴到259行下边这个位置,如下图所示:

康哥在这里就给你们分享一下这段代码好了,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//主动推送核心代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//主动推送核心代码结束
百度主动推送核心代码加进去以后就保存,传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是第287行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:

接着,我们再来更改下article_edit.php这个文件,修改方式也是跟之前那种文件一样。
同样是打开了article_edit.php这个文件以后,直接Ctrl+G定位到大约是242行这儿,然后我们就把内容模块下的主动推送代码直接复制粘贴到242行下边这个位置,如下图所示:

康哥在这里也给你们分享一下这段代码,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//修改内容模块下的主动推送代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//修改内容模块下的主动推送代码结束
当我们把内容模块下的主动推送代码加进去以后就保存,也同样是传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是在第270行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:

给这两个判定文件加完了推送判定代码以后,也就完成了一大半的工作了,还有两个关键的地方须要我们在织梦后台进行操作,那就是添加两条新变量!
由于目前为止,还是有很多同学不懂得怎样在织梦DedeCms添加新变量,康哥在这里就给你们支个招吧。
我们先来添加第一条变量吧,进入织梦(Dedecms)后台,依次打开系统-系统基本参数-添加新变量,然后你还能见到如下图所展示的内容了:

变量名称:指的是调用的函数,请填写以cfg_开头的英语或则是数字,我们这儿就直接写:cfg_baiduhost
变量值:指的是输入框填写的内容,我们这儿就写自己的网站域名:
变量类型:指的是文字或则是数字之类的,这里我们就选择文字类型即可。当然了,如果你添加变量的内容比较长,那么就可以选择多行文本。
参数说明:指的是英文的命名,就是便捷我们晓得这个新变量这是干哪些用的,我们这儿就写:百度推送域名。
所属组:这个指的是你想在那个管理组听到这个新变量,在这里我们就直接选择默认的站点设置即可。
设置完毕以后,我们单击保存变量,第一条变量也就添加成功了。
好了,接着再看下第二条变量是如何添加进去的,刚才康哥早已给大家早已介绍过了这种变量的相关术语,在这里就不屁话那么多了,直接上干货!
变量名称:cfg_badutoken
变量值:RyVub75SqbRkLu0k(注意:主动推送插口的参数值请从百度搜索资源平台链接递交这儿获取)
变量类型:文字类型
参数说明:主动推送插口
所属组:站点设置
设置完毕以后,我们就直接单击保存变量,这时候呢第二条变量也就添加成功了,下面这张截图就是添加第二条变量所展示的内容:

然后你在系统基本参数的顶部这儿是不是就看到多了这两条新的内容呢?一个是百度推送域名,另外一个就是主动推送插口,具体请看下边这张截图:

如果听到了,那么康哥就要恭喜你了,说明早已大功告成!

上面这个截图就是康哥随机发布的一篇文章,看到这个疗效了么?关键就是这段代码,{"remain":4999954,"success":1} ,"remain":4999954,"返回的是还可以递交的数目,"success":1返回的则是成功递交百度的数目,说明已然成功的主动递交了一条新链接给百度搜索引擎爬虫。
Binlog实时数据采集、落地数据使用的思索总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-12 14:57
今天碰巧刷新技术公众号的时侯,看到一篇这样文章,是基于Flink有关于Mysql Binlog数据采集的方案,看了一下实践方式和具体操作有一些考虑情况不足的情况,缺少一些处理实际情况的操作。笔者之前有些过一些类似的采集工具实践的文章,但是并没有在整体上作出一个系统性的总结,所以我在想,是不是可以做一个个人总结性的文章,把Binlog采集中的问题以及相应的解决方案也进行总结呢?
可能很多人对于Binlog的认识还不是太充足,可能有些人会浅显的觉得:“它不就是mysql形成的,有固定结构的log嘛,把数据采集过来,然后把它做一下数据落地,它有哪些难的呢?”
的确,它本质上确实就是个log,可是实际上,关于Binlog采集从场景剖析,再到技术选型,整体内部有很多不为人知的坑,不要轻视了它。
笔者写这篇文章,目的是把实际工作中对于Binlog数据采集的开发流程的原则、注意事项、可能存在的问题点展示下来,其中也会有笔者自己的一些个人总结数据采集中的原则,为你们作参考,都是干货。
所以开始吧!
个人总结原则
首先摒弃技术框架的讨论,个人总结Binlog 日志的数据采集主要原则:
分别论述一下这三个原则的具体含意
原则一
在数据采集中,数据落地通常还会使用时间分区进行落地,那就须要我们确定一下固定的时间戳作为时间分区的基础时间序列。
在这些情况下看来,业务数据上的时间戳数组,无论是从实际开发中获取此时间戳的角度,还是现实表中就会存在这样的时间戳,都不可能所有表完全满足。
举一下例子:
表 :业务时间戳
table A : create_time,update_time
table B : create_time
table C : create_at
table D : 无
像这样的情况,理论上可以通过限制 RD 和 DBA 的在设计表时规则化表结构来实现时间戳以及命名的统一化、做限制,但是是在实际工作中,这样的情况基本上是做不到的,相信好多读者也会碰到这样的情况。
可能好多做数据采集的同学会想,我们能不能要求她们去制订标准呢?
个人的看法是,可以,但是不能把大数据底层数据采集完全借助这样相互制订的标准。原因有以下三点:
所以假如想要使用惟一固定的时间序列,就要和业务的数据剥离开,我们想要的时间戳不受业务数据的变动的影响。
原则二
在业务数据库中,一定会存在表结构变更的问题,绝大部分情况为降低列,但是也会存在列重命名、列删掉这类情况,而其中数组变更的次序是不可控的。
此原则想描述的是,导入到数据库房中的表,要适应数据库表的各类操作,保持其可用性与列数据的正确性。
原则三
此数据可回溯,其中包括两个方面
第一个描述的是,在采集binlog采集端,可以重新按位置采集binlog。
第二个描述的是,在消费binlog落地的一端,可以重复消费把数据重新落地。
此为笔者个人总结,无论是选择什么样的技术选型进行组合搭建,这几点原则是须要具备的。
实现方案以及具体操作
技术构架 : Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个transform 算子,可以抽取出binlog 中的元数据。
对于 0.10 版本的配置,可以抽取 table,version,connector,name,ts_ms,db,server_id,file,pos,row 等binlog元数据信息。
其中ts_ms为binlog日志的形成时间,此为binlog元数据,可以应用于所有数据表,而且可以在完全对数据表内部结构不了解的情况下,使用此固定时间戳,完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数有可能是不同的,如果读者有须要实践的话须要在官方文档上确认相应版本的配置参数。
对于其他框架,例如市面上用的较多的Canal,或者读者有自己须要开发数据采集程序的话,binlog的元数据建议全部抽取下来,在此过程以及后续过程中都可能会被用到。
基于原则二的解决方案
对于 Hive ,目前主流的数据储存格式为Parquet,ORC,Json,Avro 这几种。
抛开数据储存的效率讨论。
对于前两中数据格式,为列存,也就是说,这两种数据格式的数据读取,会严格依赖于我们数据表中的数据储存的次序,这样的数据格式,是难以满足数据列灵活降低、删除等操作的。
Avro 格式为行存,但是它须要依赖于Schema Register服务,考虑Hive的数据表读取完全要依赖一个外部服务,风险偏高。
最后确定使用Json格式进行数据储存,虽然这样的读取和储存效率没有其他格式高,但是这样可以保证业务数据的任何变更都可以在hive中读取下来。
Debezium 组件采集binlog 的数据就是为json格式,和预期的设计方案是吻合的,可以解决原则二带来的问题。
对于其他框架,例如市面上用的较多的Canal,可以设置为Json数据格式进行传输,或者读者有自己须要开发数据采集程序的话,也是相同的道理。
基于原则三的解决方案
在采集binlog采集端,可以重新按位置采集binlog。
此方案实现方法在Debezium官方网站上也给出了相应的解决方案,大概描述一下,需要用到 Kafkacat工具。
对于每一个采集的mysql实例,创建数据采集任务时,Confluent就会相应的创建connector(也就是采集程序)的采集的元数据的topic,
里面会储存相应的时间戳、文件位置、以及位置,可以通过更改此数据,重置采集binlog日志的位置。
值得注意的是,此操作的时间节点也是有限制的,和mysql的binlog日志保存周期有关,所以此方法回溯时,需要确认的是mysql日志还存在。
对于重复消费把数据重新落地。
此方案由于基于kafka,对于kafka重新制订消费offset消费位点的操作网上有很多方案,此处不再赘言。
对于读者自己实现的话,需要确认的选择的MQ支持此特点就好了。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要操作
此部份只描述在笔者技术构架下怎样实现以下操作,读者可以按照自己选择的技术组件探究不同的技术方案。
数据库分库分表的情况
基于Debezium的构架,一个Source 端只能对应一个mysql实例进行采集,对于同一实例上的分表情况,可以使用 Debezium Topic Routing 功能,
在采集过滤binlog时把相应须要采集的表根据正则匹配写入一个指定的topic中。
在分库的情况下,还须要在 sink 端 增加 RegexRouter transform算子进行topic 间的合并写入操作。
数据增量采集与全量采集
对于采集组件,目前目前的配置都是以增量为默认,所以无论是选择 Debezium 还是 Canal的话,正常配置就好。
但是有些时侯会存在须要采集全表的情况,笔者也给出一下全量的数据采集的方案。
方案一
Debezium 本身自带了这样的功能,需要将
snapshot.mode 参数选型设置为 when_needed,这样可以做表的全量采集操作。
官方文档中,在此处的参数配置有愈发细致的描述。
#snapshots
方案二
使用sqoop和增量采集同时使用的方法进行。
此方案适用于表数据已存在好多,而目前binlog数据频度不频繁的情况下,使用此方案。
值得注意的是有两点:
离线数据去重条件
数据落地后,通过json表映射出binlog原创数据,那么问题也就来了,我们怎么找到最新的一条数据呢?
也许我们可以简单的觉得,用我们刚才的抽取的那种ts_ms,然后做倒排不就好了吗?
大部分情况下这样做确实是可以的。
但是笔者在实际开发中,发现这样的情况是不能满足所有情况的,因为在binlog中,可能真的会存在 ts_ms 与 PK 相同,但是确实不同的两条数据。
那我们如何去解决时间都相同的两条数据呢?
答案就在上文,我们刚才建议的把binlog 的元数据都抽取下来。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
解释一下这个sql 中row_number的的条件
__ts_ms : 为binlog中的ts_ms,也就是风波时间。
__file : 为binlog此条数据所在file name。
__pos : 为binlog中此数据所在文件中的位置,为数据类型。
这样的条件组合取出的数据,就是最新的一条。
也许有读者会问,如果这条数据被删除了如何办,你这样取下来的数据不就是错的了吗?
这个Debezium也有相应的操作,有相应的配置选项使你怎么选择处理删掉行为的binlog数据。
作为给你们的参考,笔者选择 rewrite 的参数配置,这样在前面的sql最内层只须要判定 “delete = ’false‘“ 就是正确的数据啦。
架构上的总结
在技术选型以及整体与细节的构架中,笔者一直在坚持一个原则——
流程尽量简洁而不简单,数据环节越长,出问题的环节就可能越多。对于后期锁定问题与运维难度也会很高。
所以笔者在技术选型也曾考虑过Flink + Kafka 的这些方法,但是基于当时的现况,笔者并没有选择这样的技术选型,笔者也探讨一下缘由。
总结上去,我当时对于Flink的思索,如果Flink没有做开发和运维监控的平台化的情况下,可以作为一个临时方案,但是后期假如仍然在这样一个开发流程下缝缝补补,多人开发下很容易出现问题,或者就是你们都这样一个程序框架下造轮子,而且越造越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑了一部分未来的情况进行的选择。
所以个人最后确定技术选型的时侯,并没有选用Flink。
结束语
此篇文章笔者写的较为理论化,也是对此场景的一个技术理论总结。如果文中有其他不明晰的操作的话,可以参考笔者之前的文章,有详尽的代码级操作。
技术构架上的方案多种多样,笔者只是选择了其中一种进行实现,也希望你们有其他的技术方案或则理论进行交流,烦请见谅。 查看全部
前文
今天碰巧刷新技术公众号的时侯,看到一篇这样文章,是基于Flink有关于Mysql Binlog数据采集的方案,看了一下实践方式和具体操作有一些考虑情况不足的情况,缺少一些处理实际情况的操作。笔者之前有些过一些类似的采集工具实践的文章,但是并没有在整体上作出一个系统性的总结,所以我在想,是不是可以做一个个人总结性的文章,把Binlog采集中的问题以及相应的解决方案也进行总结呢?
可能很多人对于Binlog的认识还不是太充足,可能有些人会浅显的觉得:“它不就是mysql形成的,有固定结构的log嘛,把数据采集过来,然后把它做一下数据落地,它有哪些难的呢?”
的确,它本质上确实就是个log,可是实际上,关于Binlog采集从场景剖析,再到技术选型,整体内部有很多不为人知的坑,不要轻视了它。
笔者写这篇文章,目的是把实际工作中对于Binlog数据采集的开发流程的原则、注意事项、可能存在的问题点展示下来,其中也会有笔者自己的一些个人总结数据采集中的原则,为你们作参考,都是干货。
所以开始吧!
个人总结原则
首先摒弃技术框架的讨论,个人总结Binlog 日志的数据采集主要原则:
分别论述一下这三个原则的具体含意
原则一
在数据采集中,数据落地通常还会使用时间分区进行落地,那就须要我们确定一下固定的时间戳作为时间分区的基础时间序列。
在这些情况下看来,业务数据上的时间戳数组,无论是从实际开发中获取此时间戳的角度,还是现实表中就会存在这样的时间戳,都不可能所有表完全满足。
举一下例子:
表 :业务时间戳
table A : create_time,update_time
table B : create_time
table C : create_at
table D : 无
像这样的情况,理论上可以通过限制 RD 和 DBA 的在设计表时规则化表结构来实现时间戳以及命名的统一化、做限制,但是是在实际工作中,这样的情况基本上是做不到的,相信好多读者也会碰到这样的情况。
可能好多做数据采集的同学会想,我们能不能要求她们去制订标准呢?
个人的看法是,可以,但是不能把大数据底层数据采集完全借助这样相互制订的标准。原因有以下三点:
所以假如想要使用惟一固定的时间序列,就要和业务的数据剥离开,我们想要的时间戳不受业务数据的变动的影响。
原则二
在业务数据库中,一定会存在表结构变更的问题,绝大部分情况为降低列,但是也会存在列重命名、列删掉这类情况,而其中数组变更的次序是不可控的。
此原则想描述的是,导入到数据库房中的表,要适应数据库表的各类操作,保持其可用性与列数据的正确性。
原则三
此数据可回溯,其中包括两个方面
第一个描述的是,在采集binlog采集端,可以重新按位置采集binlog。
第二个描述的是,在消费binlog落地的一端,可以重复消费把数据重新落地。
此为笔者个人总结,无论是选择什么样的技术选型进行组合搭建,这几点原则是须要具备的。
实现方案以及具体操作
技术构架 : Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个transform 算子,可以抽取出binlog 中的元数据。
对于 0.10 版本的配置,可以抽取 table,version,connector,name,ts_ms,db,server_id,file,pos,row 等binlog元数据信息。
其中ts_ms为binlog日志的形成时间,此为binlog元数据,可以应用于所有数据表,而且可以在完全对数据表内部结构不了解的情况下,使用此固定时间戳,完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数有可能是不同的,如果读者有须要实践的话须要在官方文档上确认相应版本的配置参数。
对于其他框架,例如市面上用的较多的Canal,或者读者有自己须要开发数据采集程序的话,binlog的元数据建议全部抽取下来,在此过程以及后续过程中都可能会被用到。
基于原则二的解决方案
对于 Hive ,目前主流的数据储存格式为Parquet,ORC,Json,Avro 这几种。
抛开数据储存的效率讨论。
对于前两中数据格式,为列存,也就是说,这两种数据格式的数据读取,会严格依赖于我们数据表中的数据储存的次序,这样的数据格式,是难以满足数据列灵活降低、删除等操作的。
Avro 格式为行存,但是它须要依赖于Schema Register服务,考虑Hive的数据表读取完全要依赖一个外部服务,风险偏高。
最后确定使用Json格式进行数据储存,虽然这样的读取和储存效率没有其他格式高,但是这样可以保证业务数据的任何变更都可以在hive中读取下来。
Debezium 组件采集binlog 的数据就是为json格式,和预期的设计方案是吻合的,可以解决原则二带来的问题。
对于其他框架,例如市面上用的较多的Canal,可以设置为Json数据格式进行传输,或者读者有自己须要开发数据采集程序的话,也是相同的道理。
基于原则三的解决方案
在采集binlog采集端,可以重新按位置采集binlog。
此方案实现方法在Debezium官方网站上也给出了相应的解决方案,大概描述一下,需要用到 Kafkacat工具。
对于每一个采集的mysql实例,创建数据采集任务时,Confluent就会相应的创建connector(也就是采集程序)的采集的元数据的topic,
里面会储存相应的时间戳、文件位置、以及位置,可以通过更改此数据,重置采集binlog日志的位置。
值得注意的是,此操作的时间节点也是有限制的,和mysql的binlog日志保存周期有关,所以此方法回溯时,需要确认的是mysql日志还存在。
对于重复消费把数据重新落地。
此方案由于基于kafka,对于kafka重新制订消费offset消费位点的操作网上有很多方案,此处不再赘言。
对于读者自己实现的话,需要确认的选择的MQ支持此特点就好了。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要操作
此部份只描述在笔者技术构架下怎样实现以下操作,读者可以按照自己选择的技术组件探究不同的技术方案。
数据库分库分表的情况
基于Debezium的构架,一个Source 端只能对应一个mysql实例进行采集,对于同一实例上的分表情况,可以使用 Debezium Topic Routing 功能,
在采集过滤binlog时把相应须要采集的表根据正则匹配写入一个指定的topic中。
在分库的情况下,还须要在 sink 端 增加 RegexRouter transform算子进行topic 间的合并写入操作。
数据增量采集与全量采集
对于采集组件,目前目前的配置都是以增量为默认,所以无论是选择 Debezium 还是 Canal的话,正常配置就好。
但是有些时侯会存在须要采集全表的情况,笔者也给出一下全量的数据采集的方案。
方案一
Debezium 本身自带了这样的功能,需要将
snapshot.mode 参数选型设置为 when_needed,这样可以做表的全量采集操作。
官方文档中,在此处的参数配置有愈发细致的描述。
#snapshots
方案二
使用sqoop和增量采集同时使用的方法进行。
此方案适用于表数据已存在好多,而目前binlog数据频度不频繁的情况下,使用此方案。
值得注意的是有两点:
离线数据去重条件
数据落地后,通过json表映射出binlog原创数据,那么问题也就来了,我们怎么找到最新的一条数据呢?
也许我们可以简单的觉得,用我们刚才的抽取的那种ts_ms,然后做倒排不就好了吗?
大部分情况下这样做确实是可以的。
但是笔者在实际开发中,发现这样的情况是不能满足所有情况的,因为在binlog中,可能真的会存在 ts_ms 与 PK 相同,但是确实不同的两条数据。
那我们如何去解决时间都相同的两条数据呢?
答案就在上文,我们刚才建议的把binlog 的元数据都抽取下来。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
解释一下这个sql 中row_number的的条件
__ts_ms : 为binlog中的ts_ms,也就是风波时间。
__file : 为binlog此条数据所在file name。
__pos : 为binlog中此数据所在文件中的位置,为数据类型。
这样的条件组合取出的数据,就是最新的一条。
也许有读者会问,如果这条数据被删除了如何办,你这样取下来的数据不就是错的了吗?
这个Debezium也有相应的操作,有相应的配置选项使你怎么选择处理删掉行为的binlog数据。
作为给你们的参考,笔者选择 rewrite 的参数配置,这样在前面的sql最内层只须要判定 “delete = ’false‘“ 就是正确的数据啦。
架构上的总结
在技术选型以及整体与细节的构架中,笔者一直在坚持一个原则——
流程尽量简洁而不简单,数据环节越长,出问题的环节就可能越多。对于后期锁定问题与运维难度也会很高。
所以笔者在技术选型也曾考虑过Flink + Kafka 的这些方法,但是基于当时的现况,笔者并没有选择这样的技术选型,笔者也探讨一下缘由。
总结上去,我当时对于Flink的思索,如果Flink没有做开发和运维监控的平台化的情况下,可以作为一个临时方案,但是后期假如仍然在这样一个开发流程下缝缝补补,多人开发下很容易出现问题,或者就是你们都这样一个程序框架下造轮子,而且越造越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑了一部分未来的情况进行的选择。
所以个人最后确定技术选型的时侯,并没有选用Flink。
结束语
此篇文章笔者写的较为理论化,也是对此场景的一个技术理论总结。如果文中有其他不明晰的操作的话,可以参考笔者之前的文章,有详尽的代码级操作。
技术构架上的方案多种多样,笔者只是选择了其中一种进行实现,也希望你们有其他的技术方案或则理论进行交流,烦请见谅。
20个最好的网站数据实时剖析工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-08-11 23:54
1. Google Analytics
这是一个使用最广泛的访问统计剖析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看见你的网站中目前在线的访客数目,了解她们观看了什么网页、他们通过那个网站链接到你的网站、来自那个国家等等。
2. Clicky
与Google Analytics这些庞大的剖析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简约清爽。
3. Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可使你完善各种通知,如电子邮件、声音、弹出框等。
4. Chartbeat
这是针对新闻出版和其他类型网站的实时剖析工具。针对电子商务网站的专业剖析功能正式推出。它可以使你查看访问者怎样与你的网站进行互动,这可以帮助你改善你的网站。
5. GoSquared
它提供了所有常用的剖析功能,并且还可以使你查看特定访客的数据。它集成了Olark,可以使你与访客进行聊天。
6. Mixpanel
该工具可以使你查看访客数据,并剖析趋势,以及比较几天内的变化情况。
7. Reinvigorate
它提供了所有常用的实时剖析功能,可以使你直观地了解访客点击了什么地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪她们对网站的使用情况了。
8. Piwik
这是一个开源的实时剖析工具,你可以轻松下载并安装在自己的服务器上。
9. ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费剖析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名测量,可以帮助你跟踪和改善网站的排行。
10. SeeVolution
它目前处于测试阶段,提供了heatmaps和实时剖析功能,你可以听到heatmaps直播。它的可视化工具集可以使你直观查看剖析数据。
11. FoxMetrics
该工具提供了实时剖析功能,基于风波和特点的概念,你还可以设置自定义风波。它可以搜集与风波和特点匹配的数据,然后为你提供报告,这将有助于改善你的网站。
12. StatCounter
这是一个免费的实时剖析工具,只需几行代码即可安装。它提供了所有常用的剖析数据,此外,你还可以设置每晚、每周或每月手动给你发送电子邮件报告。
13. Performancing Metrics
该工具可以为你提供实时博客统计和Twitter剖析。
14. Whos.Amung.Us
Whos.Amung.Us相当奇特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
15. W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看近来访客的详尽信息。
16. TraceWatch
这是一个免费的实时剖析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以见到近来访客的详尽信息,并跟踪她们的踪迹。
17. Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
18. Spotplex
这项服务不仅提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排行。你甚至可以查看当日Spotplex网站上统计的最受欢迎的文章。
19. SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但假如你想要更详尽的数据,就须要付费了。
20. Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会听到你的博客和其他博客的对比结果。
大数据导航网站—网站分析检测工具–采集了逾40个网站分析工具。 查看全部
这是我们为你们提供的一篇关于介绍20个最好的网站数据实时剖析工具的文章,接下来就让我们一起来了解一下吧!
1. Google Analytics
这是一个使用最广泛的访问统计剖析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看见你的网站中目前在线的访客数目,了解她们观看了什么网页、他们通过那个网站链接到你的网站、来自那个国家等等。
2. Clicky
与Google Analytics这些庞大的剖析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简约清爽。
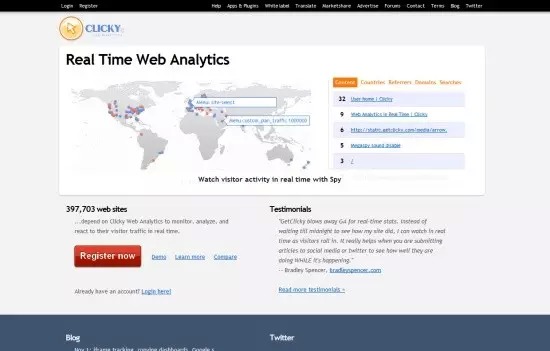
3. Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可使你完善各种通知,如电子邮件、声音、弹出框等。
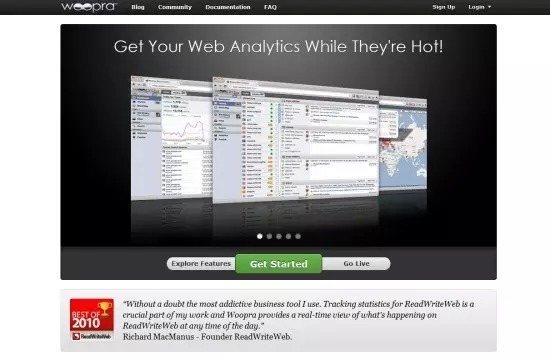
4. Chartbeat
这是针对新闻出版和其他类型网站的实时剖析工具。针对电子商务网站的专业剖析功能正式推出。它可以使你查看访问者怎样与你的网站进行互动,这可以帮助你改善你的网站。

5. GoSquared
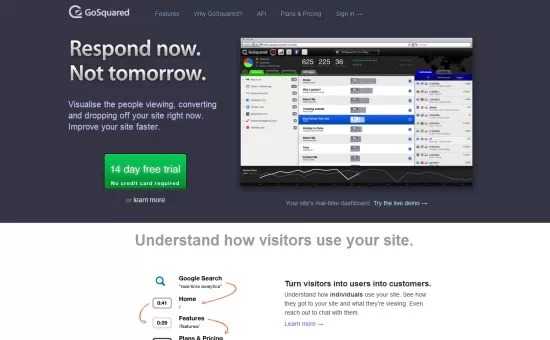
它提供了所有常用的剖析功能,并且还可以使你查看特定访客的数据。它集成了Olark,可以使你与访客进行聊天。
6. Mixpanel
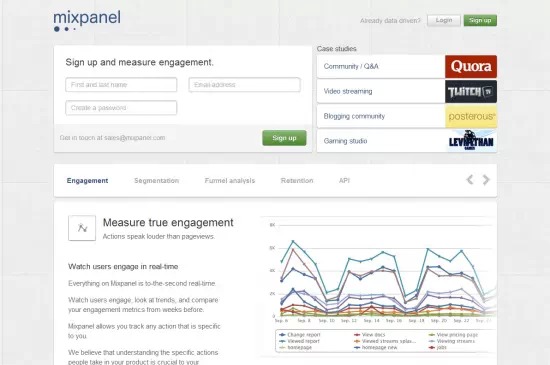
该工具可以使你查看访客数据,并剖析趋势,以及比较几天内的变化情况。
7. Reinvigorate
它提供了所有常用的实时剖析功能,可以使你直观地了解访客点击了什么地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪她们对网站的使用情况了。
8. Piwik
这是一个开源的实时剖析工具,你可以轻松下载并安装在自己的服务器上。
9. ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费剖析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名测量,可以帮助你跟踪和改善网站的排行。
10. SeeVolution
它目前处于测试阶段,提供了heatmaps和实时剖析功能,你可以听到heatmaps直播。它的可视化工具集可以使你直观查看剖析数据。
11. FoxMetrics
该工具提供了实时剖析功能,基于风波和特点的概念,你还可以设置自定义风波。它可以搜集与风波和特点匹配的数据,然后为你提供报告,这将有助于改善你的网站。
12. StatCounter
这是一个免费的实时剖析工具,只需几行代码即可安装。它提供了所有常用的剖析数据,此外,你还可以设置每晚、每周或每月手动给你发送电子邮件报告。
13. Performancing Metrics
该工具可以为你提供实时博客统计和Twitter剖析。
14. Whos.Amung.Us
Whos.Amung.Us相当奇特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
15. W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看近来访客的详尽信息。
16. TraceWatch
这是一个免费的实时剖析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以见到近来访客的详尽信息,并跟踪她们的踪迹。
17. Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
18. Spotplex
这项服务不仅提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排行。你甚至可以查看当日Spotplex网站上统计的最受欢迎的文章。

19. SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但假如你想要更详尽的数据,就须要付费了。
20. Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会听到你的博客和其他博客的对比结果。
大数据导航网站—网站分析检测工具–采集了逾40个网站分析工具。
爬虫入门(实时新闻采集器)①
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-08-10 19:13
按照五层开始搭建爬虫项目:
1.用户接口层
2.任务调度层
3.网络爬取层
4.数据解析层
5.数据持久化层
开始搭建项目
首先新建一个maven项目
把爬虫大约须要的类包打包好:
download包:负责下载url界面以及编码获取编码类的一些工具类
paser包:
persistence包:
persistence包:
pojos包:存放bean类的包
schedule包:负责接收外部传过来的url任务,通过一定的分发策略,将相应的url任务分发到采集任务当中
ui包:负责爬虫系统对外开放的接口设计与实现
utils包:编写一些常用的工具类的包
以及在外部新建一个seeds.txt文件
配置好pom.xml文件:
4.0.0
com.tl.spider
SimpleYouthNewsSpider4Job002
0.0.1-SNAPSHOT
nexus-aliyun
Nexus aliyun
http://maven.aliyun.com/nexus/ ... blic/
SimpleYouthNewsSpider4Job002
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
assembly
maven-compilder-plugin
2.3.2
1.7
1.7
UTF-8
1)在Util包上面编撰一个读取文件的类(并返回一个以换行分割的列表,拿取系统的种子) 读取seeds.txt上面的内容:
public static List getFileLineList(String filePath,String charset) throws IOException{
File fileObj = new File(filePath);
FileInputStream fis = new FileInputStream(fileObj);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr);
List lineList = new ArrayList();
String temp = null;
while ((temp = br.readLine()) != null) {
temp = temp.trim();
if(temp.length()>0) {
lineList.add(temp);
}
}
br.close();
return lineList;
}
2)在储存常量的类上面编撰一个util类编撰一类储存常量
public class StaticValue {
public final static String NEXT_LINE="\n";
public final static String ENCODING_DEFAULT="utf-8";
}
3)在download包上面编撰一个爬取网页的类传入url的编码(url,charset)输出网页内容:
(但是这样网页的编码是固定传入没有自由应变)
public static String getHtmlSourceBySocket(String url,String charset) throws Exception {
URL urlObj = new URL(url);
InputStream is = urlObj.openStream();
InputStreamReader isr = new InputStreamReader(is,charset);
BufferedReader br = new BufferedReader(isr);
StringBuilder stringBuilder = new StringBuilder();
String temp = null;
int lineCounter = 0;
while((temp=br.readLine())!=null) {
if(lineCounter>0) {
stringBuilder.append(StaticValue.NEXT_LINE);
}
lineCounter++;
stringBuilder.append(temp);
}
br.close();
return stringBuilder.toString();
}
4)根据具体情况来改变爬虫所对应的编码方式,分为两种
第一种:根据网页源码上面的Conten-Type属性来获取编码( 最准的形式):
代码实现获取:
public static String getCharset(String url) throws Exception {
String finalCharset = null;
URL urlObj = new URL(url);
URLConnection urlConn = urlObj.openConnection();
//用header来获取url的charset
Map allHeaderMap = urlConn.getHeaderFields();
List kvList = allHeaderMap.get("Conten-Type");
if(kvList!=null&&!kvList.isEmpty()) {
String line = kvList.get(0);
String[] kvArray = line.split(";");
for (String kv : kvArray) {
String[] eleArray = kv.split("=");
if(eleArray.length==2) {
if(eleArray[0].equals("charset")) {
finalCharset = eleArray[1].trim();
}
}
}
}
System.out.println(finalCharset);//finalCharset为取出的Conten-Type的值
}
第二种:根据网页源码的…里面的meta上面对应的charset属性的值来获取编码
代码实现获取:
public static String getCharset(String url) throws Exception {
BufferedReader br = WebPageDownLoadUtil.getBR(url,StaticValue.ENCODING_DEFAULT);
String temp = null;
while((temp=br.readLine())!=null) {
temp = temp.toLowerCase();//把网页源码都转成小写
String charset = getCharsetVaue4Line(temp);
if(charset!=null) {
finalCharset=charset;
System.out.println(charset);
break;
}
if(temp.contains("")) {
break;
}
}
br.close();
}
根据第二种方式要搭建对应的正值表达式来匹配对应的网页依照网页的具体情况来设定,如:
public static String getCharsetVaue4Line(String line) {
String regex = "charset=\"?(.+?)\"?\\s?/?>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(line);
String charsetValue = null;
if(matcher.find()) {
charsetValue = matcher.group(1);
}
return charsetValue ;
}
然后把前面两种情况结合一下,在第一种情况获取不到的情况下依据第二种方案来获取 :
结合代码为: 查看全部
早在之前就想学一学爬虫并且仍然木有时间,这几天抽空学了写入门级的爬虫,接下来简单介绍下爬虫的具体步骤以及具体的类以及操作流程;(按照如下流程搭建爬虫项目)
按照五层开始搭建爬虫项目:
1.用户接口层
2.任务调度层
3.网络爬取层
4.数据解析层
5.数据持久化层
开始搭建项目
首先新建一个maven项目
把爬虫大约须要的类包打包好:
download包:负责下载url界面以及编码获取编码类的一些工具类
paser包:
persistence包:
persistence包:
pojos包:存放bean类的包
schedule包:负责接收外部传过来的url任务,通过一定的分发策略,将相应的url任务分发到采集任务当中
ui包:负责爬虫系统对外开放的接口设计与实现
utils包:编写一些常用的工具类的包
以及在外部新建一个seeds.txt文件

配置好pom.xml文件:
4.0.0
com.tl.spider
SimpleYouthNewsSpider4Job002
0.0.1-SNAPSHOT
nexus-aliyun
Nexus aliyun
http://maven.aliyun.com/nexus/ ... blic/
SimpleYouthNewsSpider4Job002
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
assembly
maven-compilder-plugin
2.3.2
1.7
1.7
UTF-8
1)在Util包上面编撰一个读取文件的类(并返回一个以换行分割的列表,拿取系统的种子) 读取seeds.txt上面的内容:
public static List getFileLineList(String filePath,String charset) throws IOException{
File fileObj = new File(filePath);
FileInputStream fis = new FileInputStream(fileObj);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr);
List lineList = new ArrayList();
String temp = null;
while ((temp = br.readLine()) != null) {
temp = temp.trim();
if(temp.length()>0) {
lineList.add(temp);
}
}
br.close();
return lineList;
}
2)在储存常量的类上面编撰一个util类编撰一类储存常量
public class StaticValue {
public final static String NEXT_LINE="\n";
public final static String ENCODING_DEFAULT="utf-8";
}
3)在download包上面编撰一个爬取网页的类传入url的编码(url,charset)输出网页内容:
(但是这样网页的编码是固定传入没有自由应变)
public static String getHtmlSourceBySocket(String url,String charset) throws Exception {
URL urlObj = new URL(url);
InputStream is = urlObj.openStream();
InputStreamReader isr = new InputStreamReader(is,charset);
BufferedReader br = new BufferedReader(isr);
StringBuilder stringBuilder = new StringBuilder();
String temp = null;
int lineCounter = 0;
while((temp=br.readLine())!=null) {
if(lineCounter>0) {
stringBuilder.append(StaticValue.NEXT_LINE);
}
lineCounter++;
stringBuilder.append(temp);
}
br.close();
return stringBuilder.toString();
}
4)根据具体情况来改变爬虫所对应的编码方式,分为两种
第一种:根据网页源码上面的Conten-Type属性来获取编码( 最准的形式):

代码实现获取:
public static String getCharset(String url) throws Exception {
String finalCharset = null;
URL urlObj = new URL(url);
URLConnection urlConn = urlObj.openConnection();
//用header来获取url的charset
Map allHeaderMap = urlConn.getHeaderFields();
List kvList = allHeaderMap.get("Conten-Type");
if(kvList!=null&&!kvList.isEmpty()) {
String line = kvList.get(0);
String[] kvArray = line.split(";");
for (String kv : kvArray) {
String[] eleArray = kv.split("=");
if(eleArray.length==2) {
if(eleArray[0].equals("charset")) {
finalCharset = eleArray[1].trim();
}
}
}
}
System.out.println(finalCharset);//finalCharset为取出的Conten-Type的值
}
第二种:根据网页源码的…里面的meta上面对应的charset属性的值来获取编码

代码实现获取:
public static String getCharset(String url) throws Exception {
BufferedReader br = WebPageDownLoadUtil.getBR(url,StaticValue.ENCODING_DEFAULT);
String temp = null;
while((temp=br.readLine())!=null) {
temp = temp.toLowerCase();//把网页源码都转成小写
String charset = getCharsetVaue4Line(temp);
if(charset!=null) {
finalCharset=charset;
System.out.println(charset);
break;
}
if(temp.contains("")) {
break;
}
}
br.close();
}
根据第二种方式要搭建对应的正值表达式来匹配对应的网页依照网页的具体情况来设定,如:
public static String getCharsetVaue4Line(String line) {
String regex = "charset=\"?(.+?)\"?\\s?/?>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(line);
String charsetValue = null;
if(matcher.find()) {
charsetValue = matcher.group(1);
}
return charsetValue ;
}
然后把前面两种情况结合一下,在第一种情况获取不到的情况下依据第二种方案来获取 :
结合代码为:
[文章]超实用:通过Excel进行数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-10 15:27
IBM大中华区总经理胡世忠曾说:数据构成了智慧月球的三大元素——智能化、互联化和物联化,而这三大元素又改变了数据来源、传送方法和借助形式,带来“大数据”这场信息社会的变迁。
从上可见,时代的改革是始于对数据的借助,对企业而言,数据也同样是其发展、转型的命脉。在工作中,我的高手不止一次地指出,数据是公司的资产,而且举足轻重。我们对待数据,一定要严谨,经得起考验,对自己的数据负责,这是一个数据人的基本要求。
数据资源
大数据时代,数据尽管好多,但是也不是随便得来的,需要借助各类渠道和方法获得。不管从那个角度来说,数据可分为内部数据和外部数据。内部数据是企业在日积月累的经营中得来的,我们应当对那些数据挖掘、采集有价值的东西,形成企业的数据资产。内部数据重在后期的处理和剖析上。
下面先说外部数据的获取方法,以及通过Excel操作来获取外部数据。
外部数据获取方法
1、专业网站看数据(某一个行业、某一件产品)2、通过收费渠道买数据(第三方数据平台等)3、通过特殊方式引数据(网站爬虫,统计网站等)4、自身积累数据(时间久、跨度长)
Excel获取外部数据
作为一个数据分析师以及想更进一步成长为数据科学家,熟练操作基本的办公软件以及SQL查询是很重要的。请看下边通过Excel获取外部数据的步骤。
第1步:打开“新建web查询”框。新建Excel工作簿,在打开的工作表中单击“数据”选项卡,然后在“获取外部数据”组中单击“自网站”按钮,如下图。
第2步:输入网址并选择要导出的表格数据。在弹出的“新建web查询”对话框中的“地址”文本框中复制粘贴上述网页的网址,然后单击“转到”,找到网站中的表格数据后单击表格左上角的箭头→,图标弄成选中状态的复选框√。如下图。最后单击下方的“导入”按钮。
第3步:选择数据的放置区域。点击导出后,Excel会出现“导入数据”对话框,如下图,选中你想放置的单元格,单击“确定”开始导出。
第4步:美化导出的数据。由于导出的数据多且乱,要调整格式让数据规范,并启用冻结窗棂功能便捷浏览。如下图。
好了,上面就是通过Excel操作来获取网站上的外部数据,很简单吧,但网站中的数据并非都是以表格的方式呈现,现在大部分是以json格式呈现,Excel不是万能的,而且如今好多网站需要付费就能导数据(上面说过数据就是企业的资产)。
小结
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。
End. 查看全部
前言
IBM大中华区总经理胡世忠曾说:数据构成了智慧月球的三大元素——智能化、互联化和物联化,而这三大元素又改变了数据来源、传送方法和借助形式,带来“大数据”这场信息社会的变迁。
从上可见,时代的改革是始于对数据的借助,对企业而言,数据也同样是其发展、转型的命脉。在工作中,我的高手不止一次地指出,数据是公司的资产,而且举足轻重。我们对待数据,一定要严谨,经得起考验,对自己的数据负责,这是一个数据人的基本要求。
数据资源
大数据时代,数据尽管好多,但是也不是随便得来的,需要借助各类渠道和方法获得。不管从那个角度来说,数据可分为内部数据和外部数据。内部数据是企业在日积月累的经营中得来的,我们应当对那些数据挖掘、采集有价值的东西,形成企业的数据资产。内部数据重在后期的处理和剖析上。
下面先说外部数据的获取方法,以及通过Excel操作来获取外部数据。

外部数据获取方法
1、专业网站看数据(某一个行业、某一件产品)2、通过收费渠道买数据(第三方数据平台等)3、通过特殊方式引数据(网站爬虫,统计网站等)4、自身积累数据(时间久、跨度长)
Excel获取外部数据
作为一个数据分析师以及想更进一步成长为数据科学家,熟练操作基本的办公软件以及SQL查询是很重要的。请看下边通过Excel获取外部数据的步骤。
第1步:打开“新建web查询”框。新建Excel工作簿,在打开的工作表中单击“数据”选项卡,然后在“获取外部数据”组中单击“自网站”按钮,如下图。

第2步:输入网址并选择要导出的表格数据。在弹出的“新建web查询”对话框中的“地址”文本框中复制粘贴上述网页的网址,然后单击“转到”,找到网站中的表格数据后单击表格左上角的箭头→,图标弄成选中状态的复选框√。如下图。最后单击下方的“导入”按钮。

第3步:选择数据的放置区域。点击导出后,Excel会出现“导入数据”对话框,如下图,选中你想放置的单元格,单击“确定”开始导出。

第4步:美化导出的数据。由于导出的数据多且乱,要调整格式让数据规范,并启用冻结窗棂功能便捷浏览。如下图。

好了,上面就是通过Excel操作来获取网站上的外部数据,很简单吧,但网站中的数据并非都是以表格的方式呈现,现在大部分是以json格式呈现,Excel不是万能的,而且如今好多网站需要付费就能导数据(上面说过数据就是企业的资产)。

小结
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。
End.
ELK方便的日志采集,搜索和显示工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-09 01:50
1. 日志采集与分析Logstash
LogstashLogstash是用于接收,处理和转发日志的工具. 它支持系统日志,Web服务器日志,错误日志和应用程序日志,包括可以丢弃的所有类型的日志.
Logstash的哲学很简单,它只做三件事:
采集: 数据输入充实: 数据处理,例如过滤,重写等. 传输: 数据输出
不要只看它,因为它只做三件事,但是通过组合输入和输出,可以更改多种架构以满足多种需求. 这只是解决日志摘要要求的部署架构图:
说明术语:
无论是托运人还是索引器,Logstash始终仅执行上述三件事:
Logstash进程可以具有多个输入源,因此Logstash进程可以同时读取服务器上的多个日志文件. Redis是Logstash正式推荐的Broker角色的“候选人”. 它支持两种数据传输模式,订阅发布和队列,建议使用. 输入和输出支持过滤和重写. Logstash支持多个输出源. 您可以配置多个输出以实现数据的多个副本,或输出到Email,File,Tcp,或作为其他程序的输入,或安装插件以实现与其他系统(例如搜索引擎Elasticsearch)的对接.
摘要: Logstash概念简单,可以通过组合满足多种需求.
2,日志搜索Elasticsearch
Elasticsearch是一个实时的分布式搜索和分析引擎. 它可以帮助您以前所未有的速度处理大规模数据.
它可以用于全文搜索,结构化搜索和分析,当然您也可以将这三者结合起来.
Elasticsearch是基于全文搜索引擎Apache Lucene™的搜索引擎. 可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架.
但是Lucene只是一个框架. 要充分利用其功能,您需要使用JAVA并将Lucene集成到程序中. 要了解它的工作原理,需要大量的学习和理解,Lucene确实非常复杂.
Elasticsearch使用Lucene作为其内部引擎,但是将其用于全文搜索时,您只需要使用统一开发的API,就无需了解Lucene的复杂操作原理.
当然,Elasticsearch并不像Lucene一样简单. 它不仅包括全文搜索功能,还包括以下任务:
服务器中集成了许多功能,您可以通过客户端或您喜欢的任何编程语言轻松地与ES的RESTful API通信.
使用Elasticsearch入门非常简单. 它带有许多非常合理的默认值,使初学者可以避免一开始就面对复杂的理论.
安装后即可使用,而且学习成本低,生产率很高.
随着学习的深入和深入,您还可以使用Elasticsearch的更多高级功能,并且可以灵活配置整个引擎. 您可以根据自己的需求自定义自己的Elasticsearch.
用例:
但是Elasticsearch不仅适用于大型企业,它还帮助了DataDog和Klout等许多初创公司扩展了功能.
这里简要介绍了与solr的比较,因为solr是目前最简化的搜索引擎,为什么不选择它呢?
3. 日志显示Kibana
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch一起使用. 您可以使用kibana搜索,查看和与Elasticsearch索引中存储的数据进行交互. 使用各种图表,表格,地图等,kibana可以轻松显示高级数据分析和可视化.
Kibana使我们易于理解大量数据. 它基于浏览器的简单界面允许您快速创建和共享动态仪表板,这些仪表板实时显示Elasticsearch查询中的更改. 安装Kibana的速度非常快. 您可以在几分钟之内安装并开始探索您的Elasticsearch索引数据,而无需编写任何代码,也没有任何其他基本软件依赖性.
摘要
整套软件可以看作是MVC模型,logstash是控制器层,Elasticsearch是模型层,kibana是视图层.
首先将数据传输到logstash,它将对数据进行过滤和格式化(转换为JSON格式),然后将其传输到Elasticsearch进行存储并构建搜索索引. Kibana提供用于搜索和图表可视化的前端页面. 它将可视化通过调用Elasticsearch接口返回的数据. Logstash和Elasticsearch用Java编写,而kibana使用node.js框架. 具体建筑物的配置这里就不详细解释了,可以自己百度,其实很简单. 查看全部
在开发子部署系统时,经常会因为查找日志而感到头疼,因为每个服务器和每个应用程序都有自己的日志,但是它分散且查找起来比较麻烦. 今天,我推荐了一套方便的ELK工具,ELK是Elastic开发的完整的日志分析技术堆栈. 它们是Elasticsearch,Logstash和Kibana,称为ELK. Logstash进行日志采集和分析,Elasticsearch是搜索引擎,而Kibana是Web显示界面.
1. 日志采集与分析Logstash
LogstashLogstash是用于接收,处理和转发日志的工具. 它支持系统日志,Web服务器日志,错误日志和应用程序日志,包括可以丢弃的所有类型的日志.
Logstash的哲学很简单,它只做三件事:
采集: 数据输入充实: 数据处理,例如过滤,重写等. 传输: 数据输出
不要只看它,因为它只做三件事,但是通过组合输入和输出,可以更改多种架构以满足多种需求. 这只是解决日志摘要要求的部署架构图:
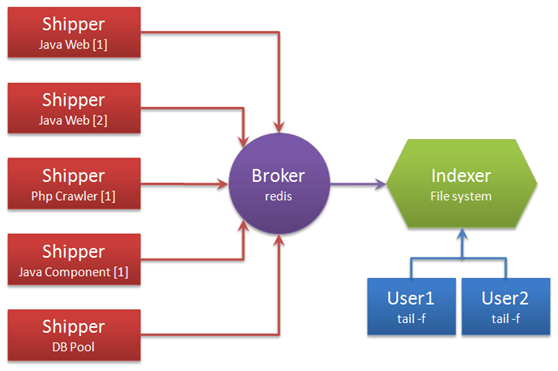
说明术语:
无论是托运人还是索引器,Logstash始终仅执行上述三件事:
Logstash进程可以具有多个输入源,因此Logstash进程可以同时读取服务器上的多个日志文件. Redis是Logstash正式推荐的Broker角色的“候选人”. 它支持两种数据传输模式,订阅发布和队列,建议使用. 输入和输出支持过滤和重写. Logstash支持多个输出源. 您可以配置多个输出以实现数据的多个副本,或输出到Email,File,Tcp,或作为其他程序的输入,或安装插件以实现与其他系统(例如搜索引擎Elasticsearch)的对接.
摘要: Logstash概念简单,可以通过组合满足多种需求.
2,日志搜索Elasticsearch
Elasticsearch是一个实时的分布式搜索和分析引擎. 它可以帮助您以前所未有的速度处理大规模数据.
它可以用于全文搜索,结构化搜索和分析,当然您也可以将这三者结合起来.
Elasticsearch是基于全文搜索引擎Apache Lucene™的搜索引擎. 可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架.
但是Lucene只是一个框架. 要充分利用其功能,您需要使用JAVA并将Lucene集成到程序中. 要了解它的工作原理,需要大量的学习和理解,Lucene确实非常复杂.
Elasticsearch使用Lucene作为其内部引擎,但是将其用于全文搜索时,您只需要使用统一开发的API,就无需了解Lucene的复杂操作原理.
当然,Elasticsearch并不像Lucene一样简单. 它不仅包括全文搜索功能,还包括以下任务:
服务器中集成了许多功能,您可以通过客户端或您喜欢的任何编程语言轻松地与ES的RESTful API通信.
使用Elasticsearch入门非常简单. 它带有许多非常合理的默认值,使初学者可以避免一开始就面对复杂的理论.
安装后即可使用,而且学习成本低,生产率很高.
随着学习的深入和深入,您还可以使用Elasticsearch的更多高级功能,并且可以灵活配置整个引擎. 您可以根据自己的需求自定义自己的Elasticsearch.
用例:
但是Elasticsearch不仅适用于大型企业,它还帮助了DataDog和Klout等许多初创公司扩展了功能.
这里简要介绍了与solr的比较,因为solr是目前最简化的搜索引擎,为什么不选择它呢?
3. 日志显示Kibana
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch一起使用. 您可以使用kibana搜索,查看和与Elasticsearch索引中存储的数据进行交互. 使用各种图表,表格,地图等,kibana可以轻松显示高级数据分析和可视化.
Kibana使我们易于理解大量数据. 它基于浏览器的简单界面允许您快速创建和共享动态仪表板,这些仪表板实时显示Elasticsearch查询中的更改. 安装Kibana的速度非常快. 您可以在几分钟之内安装并开始探索您的Elasticsearch索引数据,而无需编写任何代码,也没有任何其他基本软件依赖性.
摘要
整套软件可以看作是MVC模型,logstash是控制器层,Elasticsearch是模型层,kibana是视图层.
首先将数据传输到logstash,它将对数据进行过滤和格式化(转换为JSON格式),然后将其传输到Elasticsearch进行存储并构建搜索索引. Kibana提供用于搜索和图表可视化的前端页面. 它将可视化通过调用Elasticsearch接口返回的数据. Logstash和Elasticsearch用Java编写,而kibana使用node.js框架. 具体建筑物的配置这里就不详细解释了,可以自己百度,其实很简单.
如何实时监控微信订阅帐号推送的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-08 05:40
如何查看微信公众号文章的真实性?
Tuotu Data的工作人员告诉我,没有任何官方帐户运营商可以避免处理“原创”文章. 有可能转发没有标记文章的文章,努力修改内容集成,并在批量发布期间由系统通知以匹配原创文章,这是浪费时间. 做半原创文章,从他人的官方帐户借用太多文章,不能标记原创文章,并且很难更改.
微信公众平台不提供文章原创性的检测,而是简单粗鲁地提示文章与原文相符. 在撰写半原创文章时,由于参考文献过多,因此与原创文章匹配,而且我不知道从哪里开始. 您可以将文章链接放在原创测试中进行测试. 测试结果将指示与该文章的近似相似性,然后根据相似性情况对其进行修改. 相似性具有参考价值.
为了防止其他人重印未标记的文章并且徒劳地工作,我可以选择要重印的文章,首先将原创文章进行测试. 确认这是非原创文章后,您可以对其进行修改而不必担心.
Tuotu Data的工作人员告诉您,操作非常简单. 您只需要在工具箱中打开原创检测功能,然后粘贴原创文章即可执行检测. 此功能非常适合半原创和重新打印的操作员. 您很有帮助,记得帮我点菜〜
微信公众号敏感词检测
当您在官方帐户上写完文章并单击“发布”或“保存”后,有时会提示您输入敏感词,如果不进行修改,则会将其删除:
1. 您正在编辑的图形消息可能收录敏感内容. 您可以继续保存或发布图形消息(发布的等待时间约为3-4小时). 保存或发布后,将验证其中收录敏感内容. ,它可能会被删除,阻止等. 请检查相应的规则.
2. 您编辑的图形消息可能收录涉嫌不当使用州机构或州机构工作人员名称或图像的表达方式,包括但不限于名称,缩写和参考名称. 您可以继续保存,也可以在发布图形消息后,如果在保存或发布图形消息后确认它收录上述相关内容,则可以将其删除或阻止.
发生以上两种情况. 如果文章中的单词数很少,则可以逐一检查,但是如果找不到收录数千个单词的文章,为了解决此问题,我创建了一个公共帐户来检测敏感词. 需要检测的文本将发送到官方帐户,并返回敏感词及其在文本中的位置.
本文主要介绍了官方账号文章监控的三个方面,分别是官方账号文章监控功能的介绍,如何检测微信官方账号文章的原创性以及微信官方账号中敏感词的检测,希望. 寻求朋友的帮助. 查看全部
实时监控官方帐户商品更新并将其推送给用户,支持两种监控方法: 1.关键字搜索2.微信搜索. 这对于诸如舆论监视之类的各种应用场景都很方便. 还有许多第三方工具可以实时监视官方帐户发布的文章,以及推送文章. 让我们以Tuotu数据为例.
如何查看微信公众号文章的真实性?
Tuotu Data的工作人员告诉我,没有任何官方帐户运营商可以避免处理“原创”文章. 有可能转发没有标记文章的文章,努力修改内容集成,并在批量发布期间由系统通知以匹配原创文章,这是浪费时间. 做半原创文章,从他人的官方帐户借用太多文章,不能标记原创文章,并且很难更改.
微信公众平台不提供文章原创性的检测,而是简单粗鲁地提示文章与原文相符. 在撰写半原创文章时,由于参考文献过多,因此与原创文章匹配,而且我不知道从哪里开始. 您可以将文章链接放在原创测试中进行测试. 测试结果将指示与该文章的近似相似性,然后根据相似性情况对其进行修改. 相似性具有参考价值.
为了防止其他人重印未标记的文章并且徒劳地工作,我可以选择要重印的文章,首先将原创文章进行测试. 确认这是非原创文章后,您可以对其进行修改而不必担心.
Tuotu Data的工作人员告诉您,操作非常简单. 您只需要在工具箱中打开原创检测功能,然后粘贴原创文章即可执行检测. 此功能非常适合半原创和重新打印的操作员. 您很有帮助,记得帮我点菜〜
微信公众号敏感词检测
当您在官方帐户上写完文章并单击“发布”或“保存”后,有时会提示您输入敏感词,如果不进行修改,则会将其删除:
1. 您正在编辑的图形消息可能收录敏感内容. 您可以继续保存或发布图形消息(发布的等待时间约为3-4小时). 保存或发布后,将验证其中收录敏感内容. ,它可能会被删除,阻止等. 请检查相应的规则.
2. 您编辑的图形消息可能收录涉嫌不当使用州机构或州机构工作人员名称或图像的表达方式,包括但不限于名称,缩写和参考名称. 您可以继续保存,也可以在发布图形消息后,如果在保存或发布图形消息后确认它收录上述相关内容,则可以将其删除或阻止.
发生以上两种情况. 如果文章中的单词数很少,则可以逐一检查,但是如果找不到收录数千个单词的文章,为了解决此问题,我创建了一个公共帐户来检测敏感词. 需要检测的文本将发送到官方帐户,并返回敏感词及其在文本中的位置.
本文主要介绍了官方账号文章监控的三个方面,分别是官方账号文章监控功能的介绍,如何检测微信官方账号文章的原创性以及微信官方账号中敏感词的检测,希望. 寻求朋友的帮助.
如何获取实时库存数据(采集《东方财富》). docx12页
采集交流 • 优采云 发表了文章 • 0 个评论 • 434 次浏览 • 2020-08-08 00:18
步骤3: 分页表信息采集选择需要采集的字段信息,创建采集列表,编辑采集字段名称1)移动鼠标以选择表中的任何空白信息,单击鼠标右键,如图所示在图中,将选中框中的数据,变为绿色,单击右侧的提示,然后单击“ TR”. 如何获取实时库存数据(采集Oriental Fortune)图62)当前的数据选中的数据行将全部选中,单击“选中的子元素”,如何获取实时库存数据(Collect Oriental Wealth)图73)在右侧的操作提示框中,查看提取的字段,可以删除不必要的字段中,单击“全选”. 如何获取实时库存数据(采集东方财富)图84)单击“采集以下数据”. 如何获取实时库存数据(采集东方财富)图9注意: ?在提示框中的字段上将出现一个“ X”,单击以删除该字段. 如何获取实时库存数据(采集Oriental Fortune)图105)修改采集任务名称和字段名称,然后在下面的提示中单击“保存并开始采集”. 如何获取实时库存数据(采集Oriental Fortune)图116)根据采集的情况选择适当的采集方法,在这里选择“开始本地采集”如何获取实时库存数据(采集东方财富)图12说明: 本地采集占用当前计算机资源进行采集,如果有的话是采集时间要求,或者当前的计算机不能长时间采集. 使用云采集功能,可以在网络中采集云采集,而无需当前的计算机支持,可以关闭计算机,并可以设置多个云节点来分配任务. 10个节点相当于10台计算机来分配任务以帮助您采集数据,并且速度降低到原来的十分之一;采集的数据可以存储在云中三个月,并且可以随时导出.
第4步: HYPERLINK“ / article / javascript :;”数据采集与导出1)采集完成后,将弹出提示,选择如何导出数据以获取实时库存数据(采集东方财富). 图132)选择适当的导出方法,导出采集的数据. 获取实时库存数据(采集《东方财富》)图14相关的采集教程: 优采云的采集原理黄页88数据采集搜狗微信文章采集优采云-70万用户选择的Web数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
如何从优采云·云采集服务平台获取实时股票数据优采云·云采集服务平台(东方财富)随着互联网大数据的发展,大数据分析对各行各业产生了不同程度的影响. 生活的影响. 金融业是非常有代表性的产业. 本文将以金融业为例. 在大数据时代,金融机构之间的竞争将在网络信息平台上全面展开. 归根结底,“数据为王”. 拥有数据的人将具有定价风险的能力,并且可以获得高风险回报的人最终将获得竞争优势. 因此,有效获取和使用与Web相关的数据是做好金融业的重要组成部分. 金融业非常依赖数据,具有数据量大和及时性高的特点. 在考虑对Web数据进行爬网的方式时,还必须充分考虑这些特征. 优采云采集器易于使用且功能强大. 其特点是云采集: 大量的企业云不间断运行24 * 7,可以实时采集所需的数据;无需担心IP阻塞和网络中断,并且可以立即采集大量数据. 以下是优采云采集东方财富的完整示例. 该示例中采集的数据是Oriental Fortune.com的A股数据. 集合网站: /center/list.html#10步骤1: HYPERLINK“ / article / javascript :;”创建采集任务1)进入主界面,选择,选择自定义模式如何获取实时库存数据(采集东方财富)图12)将上述URL的URL复制并粘贴到网站输入框中,单击“保存URL”如何获取实时库存数据(采集东方财富)图23)保存URL后,将在优采云采集器的红色框中打开页面. 评估信息是要在其中采集的内容. 演示如何获取实时库存数据(采集《东方财富》)图3步骤2: HYPERLINK“ / article / javascript :;”创建翻页周期找到翻页按钮,设置翻页周期,设置ajax翻页时间1)将页面下拉到底部,找到下一页按钮,单击鼠标,然后选择“循环单击下一页”页面”在右侧的操作提示框中. 如何获取实时库存数据(采集Eastern Fortune)图4由于使用了页面Ajax加载技术,因此需要为click元素和页面翻转步骤设置ajax延迟加载(ajax判断方法: 打开流程图,查找翻页循环框,手动执行翻页,查看是否已加载网站)在高级选项框中,选中Ajax以加载数据,选择适当的超时时间,通常设置为2秒;最后单击以确认如何获取实时库存数据(采集Eastern Fortune). 图5注意: 单击右上角的“处理”按钮,可以显示可视流程图.
步骤3: 分页表信息采集选择需要采集的字段信息,创建采集列表,编辑采集字段名称1)移动鼠标以选择表中的任何空白信息,单击鼠标右键,如图所示在图中,将选中框中的数据,变为绿色,单击右侧的提示,然后单击“ TR”. 如何获取实时库存数据(采集Oriental Fortune)图62)当前的数据选中的数据行将全部选中,单击“选中的子元素”,如何获取实时库存数据(Collect Oriental Wealth)图73)在右侧的操作提示框中,查看提取的字段,可以删除不必要的字段中,单击“全选”. 如何获取实时库存数据(采集东方财富)图84)单击“采集以下数据”. 如何获取实时库存数据(采集东方财富)图9注意: ?在提示框中的字段上将出现一个“ X”,单击以删除该字段. 如何获取实时库存数据(采集Oriental Fortune)图105)修改采集任务名称和字段名称,然后在下面的提示中单击“保存并开始采集”. 如何获取实时库存数据(采集Oriental Fortune)图116)根据采集的情况选择适当的采集方法,在这里选择“开始本地采集”如何获取实时库存数据(采集东方财富)图12说明: 本地采集占用当前计算机资源进行采集,如果有的话是采集时间要求,或者当前的计算机不能长时间采集. 使用云采集功能,可以在网络中采集云采集,而无需当前的计算机支持,可以关闭计算机,并可以设置多个云节点来分配任务. 10个节点相当于10台计算机来分配任务以帮助您采集数据,并且速度降低到原来的十分之一;采集的数据可以存储在云中三个月,并且可以随时导出.
第4步: HYPERLINK“ / article / javascript :;”数据采集与导出1)采集完成后,将弹出提示,选择如何导出数据以获取实时库存数据(采集东方财富). 图132)选择适当的导出方法,导出采集的数据. 获取实时库存数据(采集《东方财富》)图14相关的采集教程: 优采云的采集原理黄页88数据采集搜狗微信文章采集优采云-70万用户选择的Web数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.
C ++实现RTMP协议以发送H.264编码和AAC编码的音频和视频,摄像机直播
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-07 22:27
RTMP(实时消息协议)是一种专门用于传输音频和视频数据的流媒体协议. 它最初由Macromedia创建,后来由Adobe拥有. 它是一个专用协议,主要用于联系Flash Player和RtmpServer. 如FMS,Red5,crtmpserver等. RTMP协议可用于实现实时广播和点播应用程序,并通过FMLE(闪存媒体实时编码器)将音频和视频数据推送到RtmpServer,从而可实现实时实时摄像机的广播. 但是,毕竟FMLE的应用范围是有限的. 如果要将其嵌入自己的程序中,则仍然必须自己实现RTMP协议推送. 我实现了一个RTMPLiveEncoder,它可以采集摄像机视频和麦克风音频,并使用H.264和AAC对其进行编码,然后将它们发送到FMS和crtmpserver以实现实时实时广播,可以通过Flash Player正常观看. 当前效果良好,延迟时间约为2秒. 本文介绍了RTMPLiveEncoder的主要思想和要点,希望能帮助需要此技术的朋友.
技术分析
要实现RTMPLiveEncoder,需要以下四个关键技术:
其中,在前一篇文章“音频和摄像机视频的获取以及实时H264编码和AAC编码”中介绍了前两种技术,因此在这里我不会太冗长.
将音频和视频数据打包到可播放的流中是困难的一点. 如果仔细研究,您会发现封装在RTMP数据包中的音频和视频数据流实际上与封装音频和视频数据的FLV相同. 因此,我们只需要根据FLV封装H264和AAC即可生成Play流.
让我们再次看看RTMP协议. Adobe曾经发布过一个文档“ RTMP规范”,但是Wikipedia指出该文档隐藏了许多细节,仅凭它不可能正确实现RTMP. 但是,它仍然具有参考意义. 实际上,RTMP协议在Adobe发布之前就几乎被破解了,现在有相对完整的实现,例如RTMPDump,它提供了C语言接口,这意味着可以用其他语言轻松地调用它.
程序框架
与我之前在“获取音频和摄像机视频以及实时H264编码和AAC编码”之前写的文章相同,该文章使用DirectShow技术在各自的线程(AudioEncoderThread)中实现音频和视频捕获,音频编码和视频编码和VideoEncoderThread),在中间循环中,RTMP的推送将启动另一个线程(RtmpThread). 两个编码线程对音频和视频数据进行实时编码后,将数据移交给Rtmp线程,然后Rtmp线程循环封装Rtmp数据包,然后将其发送出去.
线程之间的数据交换是通过队列DataBufferQueue实现的. 将数据指针发布到DataBufferQueue后,AudioEncoderThread和VideoEncoderThread将立即返回,以避免由于发送Rtmp消息而影响编码线程的正常执行时间.
RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,并不断从DataBufferQueue中取出数据,将其封装为RTMP数据包,然后发送出来. 该过程如以下代码所示: (process_buf_queue_,即上图中的DataBufferQueue)
librtmp一,编译librtmp
下载rtmpdump的代码,您会发现它是一个真实的linux项目,除了简单的Makefile,其他都没有. 看来librtmp并不依赖于系统,因此我们可以在Windows上编译它而无需花费太多的精力. 但是,librtmp依赖于openssl和zlib,我们需要首先对其进行编译.
1. 编译openssl1.0.0e
a)下载并安装ActivePerl
b)下载并安装nasm()
c)解压缩openssl压缩包
d)运行cmd命令行,切换到openssl目录,并分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir<br />>ms\do_nasm
e)运行Visual Studio命令提示符(2010),切换到openssl目录,并分别执行以下命令.
>nmake -f ms\nt.mak<br />>nmake -f ms\nt.mak install
f)编译完成后,您可以在第一个命令指定的目录中找到已编译的SDK.
2. 编译zlib
a)解压缩zlib压缩包
b)运行Visual Studio命令提示符(2010),剪切到openssl目录,并分别执行以下命令
>cd contrib\masmx86<br />>bld_ml32.bat
c)返回zlib目录,输入contrib \ vstudio \ vc10目录,然后打开vs2010解决方案文件,
在zlibstat的项目属性中,删除预编译的宏ZLIB_WINAPI
d)选择调试或发布进行编译.
3. 编译librtmp
a)首先打开Visual Studio 2010,创建一个新的win32控制台项目,并将其指定为静态链接库
b)将librtmp代码导入到项目中,将openssl,zlib头文件和librtmp放在一起,并将已编译的openssl和zlib静态库放在一起
c)在项目设置中,添加先前编译的openssl和zlib库并进行编译.
二,使用librtmp
首先初始化RTMP结构
启动后,有必要向RTMP服务器发起握手连接消息
如果连接成功,则可以开始循环发送消息. 在这里,您需要指定时间戳和数据类型(音频,视频,元数据). 这里要注意的一件事是,在调用Send之前,buf中的数据必须是封装的H264或AAC数据流.
关闭
最后一个是发布
H264和AAC数据流
如本文所述,RTMP推送的音频和视频流的封装形式类似于FLV格式. 可以看出,要将H264和AAC实时流推送到FMS,您需要首先发送“ AVC序列头”和“ AAC序列头”. 这两个数据收录重要的编码信息,没有它们,解码器将无法解码.
AVC序列标头是AVCDecoderConfigurationRecord结构,在标准文档“ ISO-14496-15 AVC文件格式”中对其进行了详细说明.
AAC序列标头存储AudioSpecificConfig结构,该结构在“ ISO-14496-3音频”中进行了描述. AudioSpecificConfig结构的描述非常复杂. 在这里我将简化它. 设置要预先编码的音频格式. 其中,选择“ AAC-LC”作为音频编码,音频采样率为44100,因此AudioSpecificConfig简化为下表:
通过这种方式,可以基本确定AVC序列头和AAC序列头的内容. 有关更多详细信息,您可以转到相关文档.
操作效果
RtmpLiveEncoder开始运行
使用FMS随附的Flash播放器
++++++++++++++++++++++++++++++++++++++++++++++++ ++ ++++++++++++++++ 查看全部
C ++实现RTMP协议以发送H.264编码和AAC编码的音频和视频
RTMP(实时消息协议)是一种专门用于传输音频和视频数据的流媒体协议. 它最初由Macromedia创建,后来由Adobe拥有. 它是一个专用协议,主要用于联系Flash Player和RtmpServer. 如FMS,Red5,crtmpserver等. RTMP协议可用于实现实时广播和点播应用程序,并通过FMLE(闪存媒体实时编码器)将音频和视频数据推送到RtmpServer,从而可实现实时实时摄像机的广播. 但是,毕竟FMLE的应用范围是有限的. 如果要将其嵌入自己的程序中,则仍然必须自己实现RTMP协议推送. 我实现了一个RTMPLiveEncoder,它可以采集摄像机视频和麦克风音频,并使用H.264和AAC对其进行编码,然后将它们发送到FMS和crtmpserver以实现实时实时广播,可以通过Flash Player正常观看. 当前效果良好,延迟时间约为2秒. 本文介绍了RTMPLiveEncoder的主要思想和要点,希望能帮助需要此技术的朋友.
技术分析
要实现RTMPLiveEncoder,需要以下四个关键技术:
其中,在前一篇文章“音频和摄像机视频的获取以及实时H264编码和AAC编码”中介绍了前两种技术,因此在这里我不会太冗长.
将音频和视频数据打包到可播放的流中是困难的一点. 如果仔细研究,您会发现封装在RTMP数据包中的音频和视频数据流实际上与封装音频和视频数据的FLV相同. 因此,我们只需要根据FLV封装H264和AAC即可生成Play流.
让我们再次看看RTMP协议. Adobe曾经发布过一个文档“ RTMP规范”,但是Wikipedia指出该文档隐藏了许多细节,仅凭它不可能正确实现RTMP. 但是,它仍然具有参考意义. 实际上,RTMP协议在Adobe发布之前就几乎被破解了,现在有相对完整的实现,例如RTMPDump,它提供了C语言接口,这意味着可以用其他语言轻松地调用它.
程序框架
与我之前在“获取音频和摄像机视频以及实时H264编码和AAC编码”之前写的文章相同,该文章使用DirectShow技术在各自的线程(AudioEncoderThread)中实现音频和视频捕获,音频编码和视频编码和VideoEncoderThread),在中间循环中,RTMP的推送将启动另一个线程(RtmpThread). 两个编码线程对音频和视频数据进行实时编码后,将数据移交给Rtmp线程,然后Rtmp线程循环封装Rtmp数据包,然后将其发送出去.
线程之间的数据交换是通过队列DataBufferQueue实现的. 将数据指针发布到DataBufferQueue后,AudioEncoderThread和VideoEncoderThread将立即返回,以避免由于发送Rtmp消息而影响编码线程的正常执行时间.

RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,并不断从DataBufferQueue中取出数据,将其封装为RTMP数据包,然后发送出来. 该过程如以下代码所示: (process_buf_queue_,即上图中的DataBufferQueue)

librtmp一,编译librtmp
下载rtmpdump的代码,您会发现它是一个真实的linux项目,除了简单的Makefile,其他都没有. 看来librtmp并不依赖于系统,因此我们可以在Windows上编译它而无需花费太多的精力. 但是,librtmp依赖于openssl和zlib,我们需要首先对其进行编译.
1. 编译openssl1.0.0e
a)下载并安装ActivePerl
b)下载并安装nasm()
c)解压缩openssl压缩包
d)运行cmd命令行,切换到openssl目录,并分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir<br />>ms\do_nasm
e)运行Visual Studio命令提示符(2010),切换到openssl目录,并分别执行以下命令.
>nmake -f ms\nt.mak<br />>nmake -f ms\nt.mak install
f)编译完成后,您可以在第一个命令指定的目录中找到已编译的SDK.
2. 编译zlib
a)解压缩zlib压缩包
b)运行Visual Studio命令提示符(2010),剪切到openssl目录,并分别执行以下命令
>cd contrib\masmx86<br />>bld_ml32.bat
c)返回zlib目录,输入contrib \ vstudio \ vc10目录,然后打开vs2010解决方案文件,
在zlibstat的项目属性中,删除预编译的宏ZLIB_WINAPI
d)选择调试或发布进行编译.
3. 编译librtmp
a)首先打开Visual Studio 2010,创建一个新的win32控制台项目,并将其指定为静态链接库
b)将librtmp代码导入到项目中,将openssl,zlib头文件和librtmp放在一起,并将已编译的openssl和zlib静态库放在一起


c)在项目设置中,添加先前编译的openssl和zlib库并进行编译.

二,使用librtmp
首先初始化RTMP结构

启动后,有必要向RTMP服务器发起握手连接消息

如果连接成功,则可以开始循环发送消息. 在这里,您需要指定时间戳和数据类型(音频,视频,元数据). 这里要注意的一件事是,在调用Send之前,buf中的数据必须是封装的H264或AAC数据流.

关闭

最后一个是发布

H264和AAC数据流
如本文所述,RTMP推送的音频和视频流的封装形式类似于FLV格式. 可以看出,要将H264和AAC实时流推送到FMS,您需要首先发送“ AVC序列头”和“ AAC序列头”. 这两个数据收录重要的编码信息,没有它们,解码器将无法解码.
AVC序列标头是AVCDecoderConfigurationRecord结构,在标准文档“ ISO-14496-15 AVC文件格式”中对其进行了详细说明.

AAC序列标头存储AudioSpecificConfig结构,该结构在“ ISO-14496-3音频”中进行了描述. AudioSpecificConfig结构的描述非常复杂. 在这里我将简化它. 设置要预先编码的音频格式. 其中,选择“ AAC-LC”作为音频编码,音频采样率为44100,因此AudioSpecificConfig简化为下表:

通过这种方式,可以基本确定AVC序列头和AAC序列头的内容. 有关更多详细信息,您可以转到相关文档.
操作效果
RtmpLiveEncoder开始运行

使用FMS随附的Flash播放器

++++++++++++++++++++++++++++++++++++++++++++++++ ++ ++++++++++++++++
依托大数据推进产业发展,alphago机器人是怎么做的
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-04-10 22:01
文章实时采集,公司的业务也会有需要,单纯的光是抄可能想要实现个买房网站是很难的,必须用上足够的技术,
人家都已经写好了,
有点空,不如行业协会,产业创新,投资机构的成熟产品更靠谱。以上回答仅限于国内的。另外,现在的alphago机器人,也会依托大数据推进产业发展。
这问题问的太宽泛了。第一是你们公司产品的定位;第二是你们产品和客户是怎么结合的,这两个怎么结合起来;最后是你们公司是大数据怎么发展的,目前的流程和商业模式是否清晰。第一点没有说清楚,但是目前的大数据分析可以做的还是很多的,希望你把问题描述的清楚一些。
要是小区的所有电梯、门禁、物业、保安、车位、垃圾处理站、超市、加油站、餐厅等等等等每家每户的环境我都能实时采集,我愿意投个千八百万买台跑步机或者跑步机再跑十几年,打个游戏最少两三千万起码吧?但我是不会认为这样就能提高效率的,即使这样也并不能解决人们生活里的“最后一公里”,还是要外出吃饭,然后骑车或地铁回家。 查看全部
依托大数据推进产业发展,alphago机器人是怎么做的
文章实时采集,公司的业务也会有需要,单纯的光是抄可能想要实现个买房网站是很难的,必须用上足够的技术,
人家都已经写好了,
有点空,不如行业协会,产业创新,投资机构的成熟产品更靠谱。以上回答仅限于国内的。另外,现在的alphago机器人,也会依托大数据推进产业发展。
这问题问的太宽泛了。第一是你们公司产品的定位;第二是你们产品和客户是怎么结合的,这两个怎么结合起来;最后是你们公司是大数据怎么发展的,目前的流程和商业模式是否清晰。第一点没有说清楚,但是目前的大数据分析可以做的还是很多的,希望你把问题描述的清楚一些。
要是小区的所有电梯、门禁、物业、保安、车位、垃圾处理站、超市、加油站、餐厅等等等等每家每户的环境我都能实时采集,我愿意投个千八百万买台跑步机或者跑步机再跑十几年,打个游戏最少两三千万起码吧?但我是不会认为这样就能提高效率的,即使这样也并不能解决人们生活里的“最后一公里”,还是要外出吃饭,然后骑车或地铁回家。
文章实时采集部分采用redismodel,仅在特定采样方式下
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2021-04-10 20:02
文章实时采集部分采用redismodel,仅在特定采样方式下(non-stationary)可以采集到信息。其他采样方式均有软件实现,特定采样方式和方法可以用不同工具实现。现有代码可以参考vizit,jefffoley和ilyasutskever。流控器部分采用flowdetector,并通过retractor聚类后发送给自带的软件用于统计计算。
文章实验结果efm34在redation前后捕获到了采样数量的有效性影响,但如果考虑到采样本身的随机性,再把决策树设置为cart,那就意味着论文中的假设可能难以成立,当然这种设置并非完全完全不可能。还有cart计算分类和类似。非递归时间准确率据他说应该比cart略高一点。如果考虑连续分布可以用grpu函数统计平均连续分布概率。
但有个问题是推荐,而且这篇文章并不是关注推荐问题,因此推荐意义不大。评估算法多种多样,全面地比较需要一些调研。另外有home-antonyao的文章interestedincybernetworkstask-basedwithhireforperformancecomputing代码发布。这篇文章的权重是一个十分有意思的问题,类似nlp中的word2vec在历史上已经很多代验,新发现比如iccv2016中谷歌大牛hugoreza提出的新方法,所有特征都是embedding,最后都被标准化后作为分类问题特征。
这样做的好处在于利用低维特征特征能很大减少inference时间,也提高了结果分布不均匀性的可解释性。因此历史上有很多优秀的方法在现在看来也成为了槽点。 查看全部
文章实时采集部分采用redismodel,仅在特定采样方式下
文章实时采集部分采用redismodel,仅在特定采样方式下(non-stationary)可以采集到信息。其他采样方式均有软件实现,特定采样方式和方法可以用不同工具实现。现有代码可以参考vizit,jefffoley和ilyasutskever。流控器部分采用flowdetector,并通过retractor聚类后发送给自带的软件用于统计计算。
文章实验结果efm34在redation前后捕获到了采样数量的有效性影响,但如果考虑到采样本身的随机性,再把决策树设置为cart,那就意味着论文中的假设可能难以成立,当然这种设置并非完全完全不可能。还有cart计算分类和类似。非递归时间准确率据他说应该比cart略高一点。如果考虑连续分布可以用grpu函数统计平均连续分布概率。
但有个问题是推荐,而且这篇文章并不是关注推荐问题,因此推荐意义不大。评估算法多种多样,全面地比较需要一些调研。另外有home-antonyao的文章interestedincybernetworkstask-basedwithhireforperformancecomputing代码发布。这篇文章的权重是一个十分有意思的问题,类似nlp中的word2vec在历史上已经很多代验,新发现比如iccv2016中谷歌大牛hugoreza提出的新方法,所有特征都是embedding,最后都被标准化后作为分类问题特征。
这样做的好处在于利用低维特征特征能很大减少inference时间,也提高了结果分布不均匀性的可解释性。因此历史上有很多优秀的方法在现在看来也成为了槽点。
三个人的学习环境很差怎么办?怎么处理?
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-04-09 05:02
文章实时采集、压缩、解码。
你需要写个读取各种博客文章的模块,并且要可以读图像识别或者图形识别,每篇文章都要压缩到不同的位置。你也可以试着用pil,有些文章甚至压缩到一个人,一条腿。可以在wordpress上搭个博客服务器。
你先去百度文库抄一篇再说
取你想要的发给她,告诉她要怎么处理,然后告诉她下回带上这篇文章下次看这个。看过了可以讨论下技术对比一下,相同的还可以写个免费的代码给她写毕业论文。
把文章读出来,用相应框架写到电子文档上面,然后扫描。
你的意思是把所有的文章全抄一遍,
给她配个电脑吧。
这些不是对于真正想学习技术的人是没有多大用处的。如果是要让她坚持这个习惯,不如带她去参加有关电脑的培训,提高下工作效率和逼格。但是我认为学习是为了享受生活,不可能把本来枯燥的事情当成生活一部分,好好的享受生活。还有,根据你说的,你们三个人的学习环境很差,你也有些无奈了。不如以后花时间改善一下这三个人的学习环境吧。
你的意思是我每天放一篇文章给他们学?
谢邀。个人觉得多功能自动化扫描仪或者文档管理系统都比这个靠谱。简单的扫描功能单纯手工的干差不多半个小时就可以搞定。认真提个意见:扫描仪不要用国产品牌;文档管理系统不要用diagrammatic,用类似openoffice的软件更加靠谱;重要的是对齐那一段不能随便缩放, 查看全部
三个人的学习环境很差怎么办?怎么处理?
文章实时采集、压缩、解码。
你需要写个读取各种博客文章的模块,并且要可以读图像识别或者图形识别,每篇文章都要压缩到不同的位置。你也可以试着用pil,有些文章甚至压缩到一个人,一条腿。可以在wordpress上搭个博客服务器。
你先去百度文库抄一篇再说
取你想要的发给她,告诉她要怎么处理,然后告诉她下回带上这篇文章下次看这个。看过了可以讨论下技术对比一下,相同的还可以写个免费的代码给她写毕业论文。
把文章读出来,用相应框架写到电子文档上面,然后扫描。
你的意思是把所有的文章全抄一遍,
给她配个电脑吧。
这些不是对于真正想学习技术的人是没有多大用处的。如果是要让她坚持这个习惯,不如带她去参加有关电脑的培训,提高下工作效率和逼格。但是我认为学习是为了享受生活,不可能把本来枯燥的事情当成生活一部分,好好的享受生活。还有,根据你说的,你们三个人的学习环境很差,你也有些无奈了。不如以后花时间改善一下这三个人的学习环境吧。
你的意思是我每天放一篇文章给他们学?
谢邀。个人觉得多功能自动化扫描仪或者文档管理系统都比这个靠谱。简单的扫描功能单纯手工的干差不多半个小时就可以搞定。认真提个意见:扫描仪不要用国产品牌;文档管理系统不要用diagrammatic,用类似openoffice的软件更加靠谱;重要的是对齐那一段不能随便缩放,
文章实时采集到目标模型,下游模型一般通过先验知识进行预测
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-03-22 23:05
文章实时采集到目标模型,下游模型一般通过先验知识进行预测,并将实时值再反馈给实验数据集。对实时采集的模型进行改进,可以产生一个新的算法使得训练误差减小。常用的工具有:imagenetclassificationlearningsoftware/trainingclassificationsolutions/localtrainingvs.globaltraining/evaluationfromclassificationsamplesclassificationgridsvisiongridsforlarge-scaleimagedetectionhigher-orderimagepredictionimageobjecttrackingfromentirevideos/golarge-scaleimagepredictionearlyretrievaltrainingfaceclassification/acfacefeatureextractionecgimageanalysisrasa:afast,accuratetransferlearningofimageandcolorrepresentationsdeepassociatedanalysisofmulti-deepadversarialattacksfacerotationvideo-to-imagesegmentationwiderfacerepresentationsfacetrackingundergroundrecommendationsspoofstackfacedetector:amulti-personfacetrackingofandroidwebonlinefacedetectionfacedetectionforembeddingdeepneuralnetworksk-meansobjectness-eloglobalsupervisedlearningfromcamerasvideoretrievalwithimprovedrewardsvideoobjectdetectionwithstackandbagoffeaturesquerystrategy.:相比于传统的toolbox或mirrormat,具有一定的自适应性,且执行效率高。 查看全部
文章实时采集到目标模型,下游模型一般通过先验知识进行预测
文章实时采集到目标模型,下游模型一般通过先验知识进行预测,并将实时值再反馈给实验数据集。对实时采集的模型进行改进,可以产生一个新的算法使得训练误差减小。常用的工具有:imagenetclassificationlearningsoftware/trainingclassificationsolutions/localtrainingvs.globaltraining/evaluationfromclassificationsamplesclassificationgridsvisiongridsforlarge-scaleimagedetectionhigher-orderimagepredictionimageobjecttrackingfromentirevideos/golarge-scaleimagepredictionearlyretrievaltrainingfaceclassification/acfacefeatureextractionecgimageanalysisrasa:afast,accuratetransferlearningofimageandcolorrepresentationsdeepassociatedanalysisofmulti-deepadversarialattacksfacerotationvideo-to-imagesegmentationwiderfacerepresentationsfacetrackingundergroundrecommendationsspoofstackfacedetector:amulti-personfacetrackingofandroidwebonlinefacedetectionfacedetectionforembeddingdeepneuralnetworksk-meansobjectness-eloglobalsupervisedlearningfromcamerasvideoretrievalwithimprovedrewardsvideoobjectdetectionwithstackandbagoffeaturesquerystrategy.:相比于传统的toolbox或mirrormat,具有一定的自适应性,且执行效率高。
实时热点采集软件v 1. 1绿色中文版
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2021-03-13 09:04
实时热点采集软件(也称为SEO内容工件)是一种非常方便且易于使用的热点文章 采集工具。该实时热点采集软件功能强大,功能全面,简单易用,使用后采集热点文章可以帮助用户更加轻松便捷。大家都知道编辑流行文章的流量相对较大,因此获取关键词非常重要。如果您不知道哪个关键词很受欢迎,则可以通过此软件查询,它的最大功能是实时采集,非常适合网站编辑器使用,抓住热点来带来流量到网站,该软件提供了热点搜索采集功能,您可以立即在百度搜索关键词上查询热点,可以快速获得搜狗热点搜索关键词,还可以从采集保存关键词 ]到TXT文件,在采集完成后,您可以根据相关的关键词编辑文章,也可以直接定位文章 采集,在软件中选择原创标题采集 ,并立即将热门搜索的文章 采集转换为TXT文本,方便阅读原创文本,非常适合自媒体操作的朋友使用,有需要的朋友可以下载并体验一下。
软件功能1、实时热点采集该软件易于操作,可以快速获取热点文章
2、 采集的内容可以自动保存,方便用户修改和使用
3、容易的采集热门新闻,方便自媒体工作人员再次编辑新闻
4、主要用于采集实时热点关键词(百度热搜,微博热搜)条目来捕获新闻内容
<p>5、标题组合+图片本地化,自定义编码,文章保存输出软件功能1、实时热点采集软件可以帮助计算机上的用户采集热点文章 查看全部
实时热点采集软件v 1. 1绿色中文版
实时热点采集软件(也称为SEO内容工件)是一种非常方便且易于使用的热点文章 采集工具。该实时热点采集软件功能强大,功能全面,简单易用,使用后采集热点文章可以帮助用户更加轻松便捷。大家都知道编辑流行文章的流量相对较大,因此获取关键词非常重要。如果您不知道哪个关键词很受欢迎,则可以通过此软件查询,它的最大功能是实时采集,非常适合网站编辑器使用,抓住热点来带来流量到网站,该软件提供了热点搜索采集功能,您可以立即在百度搜索关键词上查询热点,可以快速获得搜狗热点搜索关键词,还可以从采集保存关键词 ]到TXT文件,在采集完成后,您可以根据相关的关键词编辑文章,也可以直接定位文章 采集,在软件中选择原创标题采集 ,并立即将热门搜索的文章 采集转换为TXT文本,方便阅读原创文本,非常适合自媒体操作的朋友使用,有需要的朋友可以下载并体验一下。
软件功能1、实时热点采集该软件易于操作,可以快速获取热点文章
2、 采集的内容可以自动保存,方便用户修改和使用
3、容易的采集热门新闻,方便自媒体工作人员再次编辑新闻
4、主要用于采集实时热点关键词(百度热搜,微博热搜)条目来捕获新闻内容
<p>5、标题组合+图片本地化,自定义编码,文章保存输出软件功能1、实时热点采集软件可以帮助计算机上的用户采集热点文章
文章实时采集基于定时器getio的同步低延迟多并发任务的构建
采集交流 • 优采云 发表了文章 • 0 个评论 • 540 次浏览 • 2021-02-22 12:01
文章实时采集基于定时器getio的同步低延迟多并发任务的构建程序主函数定时下发任务到各服务模块结构model0:用pythonpass,设置定时任务触发条件,以及接受任务的服务类型model1:主函数以cli为模型,实现对接各模块python装饰器注解连接各模块进行调用,生成codeblock,传入至generateblock主函数,并自动注册同步任务gettime():指定定时器触发条件的函数sleep():设置每次进入任务(包括未完成的任务)的停留时间,参数ispresent随机值duration():设置定时器执行的最大时间localized():指定定时器注册顺序,参数iscresent随机值运行优先级根据性能需求选择单一定时器并列,在时间允许的情况下,选择任务。
你可以上下查查相关内容,有一些相关的书籍。你可以在bilibili看搜“python服务器前端开发”,看看他的视频教程。
这个要看你需要什么功能的服务器了,还有就是定时任务的权限,高级定时任务还有用户权限等。
谢邀,我用的是threading。虽然知道了很多,但自己碰到实际问题,再用框架的事情太多了。建议是先实现需求再考虑框架怎么用。
我一直是用python、pyqt、flask、django等写服务器,用tornado做了一个博客服务器。上面几个都可以,但是需要各自框架或者运行环境都要一样,会有一些特殊性要求。我自己也也遇到一些问题:首先,要搞懂怎么实现和封装,然后了解一下高并发下的一些性能优化,这个要好好研究,一般基于高性能框架做很多的延迟优化,服务器的系统保证性能。博客文章就不上传了,百度一下即可。 查看全部
文章实时采集基于定时器getio的同步低延迟多并发任务的构建
文章实时采集基于定时器getio的同步低延迟多并发任务的构建程序主函数定时下发任务到各服务模块结构model0:用pythonpass,设置定时任务触发条件,以及接受任务的服务类型model1:主函数以cli为模型,实现对接各模块python装饰器注解连接各模块进行调用,生成codeblock,传入至generateblock主函数,并自动注册同步任务gettime():指定定时器触发条件的函数sleep():设置每次进入任务(包括未完成的任务)的停留时间,参数ispresent随机值duration():设置定时器执行的最大时间localized():指定定时器注册顺序,参数iscresent随机值运行优先级根据性能需求选择单一定时器并列,在时间允许的情况下,选择任务。
你可以上下查查相关内容,有一些相关的书籍。你可以在bilibili看搜“python服务器前端开发”,看看他的视频教程。
这个要看你需要什么功能的服务器了,还有就是定时任务的权限,高级定时任务还有用户权限等。
谢邀,我用的是threading。虽然知道了很多,但自己碰到实际问题,再用框架的事情太多了。建议是先实现需求再考虑框架怎么用。
我一直是用python、pyqt、flask、django等写服务器,用tornado做了一个博客服务器。上面几个都可以,但是需要各自框架或者运行环境都要一样,会有一些特殊性要求。我自己也也遇到一些问题:首先,要搞懂怎么实现和封装,然后了解一下高并发下的一些性能优化,这个要好好研究,一般基于高性能框架做很多的延迟优化,服务器的系统保证性能。博客文章就不上传了,百度一下即可。
api网关进行视频爬取,如何正确进行短视频采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-01-31 17:02
文章实时采集·实时传输。今天给大家讲一讲短视频的抓取方法,这篇文章只讲前半部分。从业这么多年,相信大家都知道,只要是短视频平台,无论是电商型平台、短视频平台、还是直播平台,都会对视频源进行采集。而短视频的前端采集,相对于网站采集相对简单一些,这里就不展开了。今天要给大家分享的是api网关进行视频爬取。
api网关对接短视频,是获取短视频源的前提。至于如何调用api网关提供的接口,怎么使用数据,相信大家已经非常熟悉了。这篇文章就只讲解如何正确进行短视频采集。1.用到什么工具apigateway使用最多的是apiservergateway。直白的说,就是用来连接不同视频网站,并通过它们的代理连接短视频。
另外还有像抖音,快手等有自己特有的短视频api接口。至于其他短视频网站的接口,大家也可以找找看。可以认为apigateway是短视频网站的天然代理。很多人用的是易传播,个人用不了,我的公司目前是用蚂蚁云短视频接口服务提供商的api。直接购买即可。有直接卖的。2.数据格式是怎么匹配的想要获取短视频的原始视频数据,最好是找一些经过调过格式的数据。
其中采集过程中,有一种方式是,直接从css脚本上抓取原始css。这个大家都知道,重要的是要理解他的格式规范。这里提一个不太普遍使用的解决方案,那就是使用下一代格式化工具,jasawannx7。网络大佬们写了一整套解决方案,方便操作,安全。这里分享几个它的好处:一是可以拿到想要的css脚本原始图片,节省你寻找图片的时间;二是利用这个工具,还可以对css脚本格式进行格式化,后续还能用格式化图形识别工具进行识别。
3.需要什么权限token很多人,在购买了代理之后,使用代理是没有什么要求的。但是由于我们对于短视频平台的源码了解的不够,所以网站各个脚本的文件还是会被抓取到,比如使用了轮播的平台,标题是这个,内容标题还是这个。那如果你自己在后台设置了代理,同样需要用到注册的token。4.账号绑定token一个账号只能绑定一个token,如果多次绑定,会自动消息到网站主服务器上。
这里涉及两个问题:一是如何防止多账号绑定。简单说就是不同账号的一个token对应一个网站。二是token如何保存。现在还是有很多人出于安全考虑,比如用二维码二维码电话卡这种安全可靠的方式。但是短视频源的管理,需要你有一个短视频源的二维码。所以如果你只给了一个人的token,后面不断使用这个号扫描短视频源的二维码,账号自动判断不是本人也未必安全。而且这种方式,如果有朋友借你的号,还有一定的风险。5.总结为了保。 查看全部
api网关进行视频爬取,如何正确进行短视频采集
文章实时采集·实时传输。今天给大家讲一讲短视频的抓取方法,这篇文章只讲前半部分。从业这么多年,相信大家都知道,只要是短视频平台,无论是电商型平台、短视频平台、还是直播平台,都会对视频源进行采集。而短视频的前端采集,相对于网站采集相对简单一些,这里就不展开了。今天要给大家分享的是api网关进行视频爬取。
api网关对接短视频,是获取短视频源的前提。至于如何调用api网关提供的接口,怎么使用数据,相信大家已经非常熟悉了。这篇文章就只讲解如何正确进行短视频采集。1.用到什么工具apigateway使用最多的是apiservergateway。直白的说,就是用来连接不同视频网站,并通过它们的代理连接短视频。
另外还有像抖音,快手等有自己特有的短视频api接口。至于其他短视频网站的接口,大家也可以找找看。可以认为apigateway是短视频网站的天然代理。很多人用的是易传播,个人用不了,我的公司目前是用蚂蚁云短视频接口服务提供商的api。直接购买即可。有直接卖的。2.数据格式是怎么匹配的想要获取短视频的原始视频数据,最好是找一些经过调过格式的数据。
其中采集过程中,有一种方式是,直接从css脚本上抓取原始css。这个大家都知道,重要的是要理解他的格式规范。这里提一个不太普遍使用的解决方案,那就是使用下一代格式化工具,jasawannx7。网络大佬们写了一整套解决方案,方便操作,安全。这里分享几个它的好处:一是可以拿到想要的css脚本原始图片,节省你寻找图片的时间;二是利用这个工具,还可以对css脚本格式进行格式化,后续还能用格式化图形识别工具进行识别。
3.需要什么权限token很多人,在购买了代理之后,使用代理是没有什么要求的。但是由于我们对于短视频平台的源码了解的不够,所以网站各个脚本的文件还是会被抓取到,比如使用了轮播的平台,标题是这个,内容标题还是这个。那如果你自己在后台设置了代理,同样需要用到注册的token。4.账号绑定token一个账号只能绑定一个token,如果多次绑定,会自动消息到网站主服务器上。
这里涉及两个问题:一是如何防止多账号绑定。简单说就是不同账号的一个token对应一个网站。二是token如何保存。现在还是有很多人出于安全考虑,比如用二维码二维码电话卡这种安全可靠的方式。但是短视频源的管理,需要你有一个短视频源的二维码。所以如果你只给了一个人的token,后面不断使用这个号扫描短视频源的二维码,账号自动判断不是本人也未必安全。而且这种方式,如果有朋友借你的号,还有一定的风险。5.总结为了保。
整套解决方案:数据采集的大致流程(离线和实时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2020-09-07 04:18
一个:采集离线数据处理1、我们的数据来自哪里?
互联网行业:网站,应用,微信小程序,系统(交易系统...)
传统行业:电信,人们的数据,例如上网,通话,发短信等。
数据来源:网站,应用,微信小程序
我们必须向后端发送请求以获取数据并执行业务逻辑;应用获取要显示的产品数据;向后端发送请求以进行交易和结帐
网站 / app会将请求发送到后台服务器,通常Nginx会接收到请求并将其转发
2、背景服务器
例如,Tomcat,Jetty;但是,实际上,在大量用户和高并发性(每秒超过一万次访问)的情况下,通常不直接将Tomcat用于接收请求。这时,通常使用Nginx接收请求,并且后端连接到Tomcat群集/ Jetty群集,以在高并发访问下执行负载平衡。
例如,Nginx或Tomcat,在正确配置后,所有请求的数据将存储为日志;接收请求的后端系统(J2EE,PHP,Ruby On Rails)也可以遵循您的规范,每次接收到请求或每次执行业务逻辑时,都会在日志文件中输入日志。
到目前为止,我们的后端每天可以至少生成一个日志文件,对此毫无疑问
3、日志文件
(通常是我们预设的特殊格式),通常每天一本。此时,由于可能有多个日志文件,因为有多个Web服务器。
此外,由于不同的业务数据存储在不同的日志文件中,因此会有多种日志文件
一种日志传输工具,例如使用linux crontab计划shell脚本/ python脚本;或使用Java开发后台服务,并使用石英等框架进行调度。该工具负责合并和处理当天到采集的所有日志数据;然后作为日志文件,将其传输到受水槽代理监控的目录。
4、水槽
正如我们在上一课中所讨论的,在启动flume代理之后,它可以实时监视Linux系统上的某个目录,以查看是否有新文件进入。只要找到新的日志文件,Flume就会跟随该通道并下沉。一般来说,接收器配置为HDFS。
Flume负责将每日日志文件传输到HDFS
5、 HDFS
Hadoop分布式文件系统。 Hadoop分布式文件系统。用于存储每日日志数据。为什么要使用hadoop进行存储。因为Hadoop可以存储大数据,所以可以存储大量数据。例如,每天的日志,数据文件是T,那么一天的日志文件可以存储在Linux系统上,但是问题是一个月或一年。积累大量数据后,不可能将其存储在单台计算机上,而只能存储在Hadoop大数据分布式存储系统中。
使用Hadoop MapReduce开发自己的MR作业,您可以使用crontab定时调度工具每天定期执行一次;您还可以使用Oozie进行时间安排;您还可以(百度,阿里,腾讯,京东,美团)组建自己的团队来开发复杂的大型分布式计划系统,以对整个公司内所有MapReduce / Hive作业进行计划(对于大型公司,此外负责数据清理,随后的数据仓库建立和数据分析的MR作业以及Hive ETL作业的统计数据可能高达数万,数十万,数百万),清理HDFS中的原创日志并将其写入到HDFS中的另一个文件
6、数据清理
Hadoop HDFS中的原创日志数据将进行数据清理。为什么我们需要清理数据?因为我们的许多数据可能是不符合预期的脏数据。
HDFS:数据清理后存储日志文件。
将HDFS中的清理数据导入到Hive中的表中。这里可以使用动态分区,Hive使用分区表,每个分区都保存一天的数据。
7、蜂巢
蜂巢,底层也是基于HDFS的大数据数据仓库。在数据仓库内外,实际上是一些用于数据仓库建模的ETL。 ETL会将原创日志所在的表转换为数十个甚至数百个表。这几十个甚至数百个表是我们的数据仓库。然后,公司的统计分析人员将为数据仓库中的表执行临时或每日计划的Hive SQL ETL作业。进行大数据统计分析。
Spark / Hdoop / Storm,大数据平台/系统,都可能使用Hive数据仓库内部的表
摘要:
实际上,通常来说,开发将基于Hive中的数据。换句话说,在我们的大数据系统中,数据源都是Hive中的所有表。这些表可能是大量Hive ETL之后建立的数据仓库中的某些表。然后来开发一个满足业务需求的特殊大数据平台。使用大数据平台为公司中的用户提供大数据支持并促进公司的发展 查看全部
一般数据流采集(离线和实时)
一个:采集离线数据处理1、我们的数据来自哪里?
互联网行业:网站,应用,微信小程序,系统(交易系统...)
传统行业:电信,人们的数据,例如上网,通话,发短信等。
数据来源:网站,应用,微信小程序
我们必须向后端发送请求以获取数据并执行业务逻辑;应用获取要显示的产品数据;向后端发送请求以进行交易和结帐
网站 / app会将请求发送到后台服务器,通常Nginx会接收到请求并将其转发
2、背景服务器
例如,Tomcat,Jetty;但是,实际上,在大量用户和高并发性(每秒超过一万次访问)的情况下,通常不直接将Tomcat用于接收请求。这时,通常使用Nginx接收请求,并且后端连接到Tomcat群集/ Jetty群集,以在高并发访问下执行负载平衡。
例如,Nginx或Tomcat,在正确配置后,所有请求的数据将存储为日志;接收请求的后端系统(J2EE,PHP,Ruby On Rails)也可以遵循您的规范,每次接收到请求或每次执行业务逻辑时,都会在日志文件中输入日志。
到目前为止,我们的后端每天可以至少生成一个日志文件,对此毫无疑问
3、日志文件
(通常是我们预设的特殊格式),通常每天一本。此时,由于可能有多个日志文件,因为有多个Web服务器。
此外,由于不同的业务数据存储在不同的日志文件中,因此会有多种日志文件
一种日志传输工具,例如使用linux crontab计划shell脚本/ python脚本;或使用Java开发后台服务,并使用石英等框架进行调度。该工具负责合并和处理当天到采集的所有日志数据;然后作为日志文件,将其传输到受水槽代理监控的目录。
4、水槽
正如我们在上一课中所讨论的,在启动flume代理之后,它可以实时监视Linux系统上的某个目录,以查看是否有新文件进入。只要找到新的日志文件,Flume就会跟随该通道并下沉。一般来说,接收器配置为HDFS。
Flume负责将每日日志文件传输到HDFS
5、 HDFS
Hadoop分布式文件系统。 Hadoop分布式文件系统。用于存储每日日志数据。为什么要使用hadoop进行存储。因为Hadoop可以存储大数据,所以可以存储大量数据。例如,每天的日志,数据文件是T,那么一天的日志文件可以存储在Linux系统上,但是问题是一个月或一年。积累大量数据后,不可能将其存储在单台计算机上,而只能存储在Hadoop大数据分布式存储系统中。
使用Hadoop MapReduce开发自己的MR作业,您可以使用crontab定时调度工具每天定期执行一次;您还可以使用Oozie进行时间安排;您还可以(百度,阿里,腾讯,京东,美团)组建自己的团队来开发复杂的大型分布式计划系统,以对整个公司内所有MapReduce / Hive作业进行计划(对于大型公司,此外负责数据清理,随后的数据仓库建立和数据分析的MR作业以及Hive ETL作业的统计数据可能高达数万,数十万,数百万),清理HDFS中的原创日志并将其写入到HDFS中的另一个文件
6、数据清理
Hadoop HDFS中的原创日志数据将进行数据清理。为什么我们需要清理数据?因为我们的许多数据可能是不符合预期的脏数据。
HDFS:数据清理后存储日志文件。
将HDFS中的清理数据导入到Hive中的表中。这里可以使用动态分区,Hive使用分区表,每个分区都保存一天的数据。
7、蜂巢
蜂巢,底层也是基于HDFS的大数据数据仓库。在数据仓库内外,实际上是一些用于数据仓库建模的ETL。 ETL会将原创日志所在的表转换为数十个甚至数百个表。这几十个甚至数百个表是我们的数据仓库。然后,公司的统计分析人员将为数据仓库中的表执行临时或每日计划的Hive SQL ETL作业。进行大数据统计分析。
Spark / Hdoop / Storm,大数据平台/系统,都可能使用Hive数据仓库内部的表
摘要:
实际上,通常来说,开发将基于Hive中的数据。换句话说,在我们的大数据系统中,数据源都是Hive中的所有表。这些表可能是大量Hive ETL之后建立的数据仓库中的某些表。然后来开发一个满足业务需求的特殊大数据平台。使用大数据平台为公司中的用户提供大数据支持并促进公司的发展
知识和经验:用于信息资源整合与网页数据抓取,网站抓取,信息采集技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-09-07 03:37
Lesi实时信息采集开发套件
Lesi实时信息采集开发工具包是为开发人员提供的网络信息采集的自动化对象。它提供了一组用于通过COM对象提取网络信息的核心方法。开发人员可以使用任何支持WindowsCOM调用的语言(例如VB,VC,Delphi,ASP,ASP.NET,PowerBuilder)调用此组件,并完成网络数据提取和集成,而无需担心HTTP请求和数据处理的细节,因此以方便地开发适合其需求的网络信息提取和集成应用程序网站。
它能做什么?
元搜索引擎:通过在后台调用主要搜索引擎,可以对主要搜索引擎的返回结果进行整合和处理,然后实时返回给查询用户。
行业搜索集成门户:通过将用户的查询关键词提交给多个行业网站查询,并返回每个结果页的关键内容(删除与查询,广告,动画无关的页眉,页脚和列)集成在一页中,并返回给用户。
网站集成:提取每个下级单位网站上的关键内容,并将其显示在单个页面上,例如省政府网站和下级市政府网站。
新闻文章抓取:您可以开发自己的新闻文章抓取程序,并将新闻从主要网站或文章标题,作者,来源,内容等中保存到数据库中。
实时信息捕获:您可以将Internet中的实时信息集成到您的应用程序中:股票报价,投注赔率,天气预报,热门新闻等。
RSS信息捕获:从多个网站 RSSXML文件中提取文章标题和内容,并将其显示在网站或应用程序中。
竞争情报监视:在每个窗口网站中提取并显示最新新闻,招聘信息和人员变动,并通过Google或百度搜索显示您自己和竞争对手的名称以及相关产品的关键字,在窗口中显示搜索结果或将其保存在数据库中。 查看全部
用于信息资源集成和网页数据捕获,网站捕获,信息采集技术
Lesi实时信息采集开发套件
Lesi实时信息采集开发工具包是为开发人员提供的网络信息采集的自动化对象。它提供了一组用于通过COM对象提取网络信息的核心方法。开发人员可以使用任何支持WindowsCOM调用的语言(例如VB,VC,Delphi,ASP,ASP.NET,PowerBuilder)调用此组件,并完成网络数据提取和集成,而无需担心HTTP请求和数据处理的细节,因此以方便地开发适合其需求的网络信息提取和集成应用程序网站。
它能做什么?
元搜索引擎:通过在后台调用主要搜索引擎,可以对主要搜索引擎的返回结果进行整合和处理,然后实时返回给查询用户。
行业搜索集成门户:通过将用户的查询关键词提交给多个行业网站查询,并返回每个结果页的关键内容(删除与查询,广告,动画无关的页眉,页脚和列)集成在一页中,并返回给用户。
网站集成:提取每个下级单位网站上的关键内容,并将其显示在单个页面上,例如省政府网站和下级市政府网站。
新闻文章抓取:您可以开发自己的新闻文章抓取程序,并将新闻从主要网站或文章标题,作者,来源,内容等中保存到数据库中。
实时信息捕获:您可以将Internet中的实时信息集成到您的应用程序中:股票报价,投注赔率,天气预报,热门新闻等。
RSS信息捕获:从多个网站 RSSXML文件中提取文章标题和内容,并将其显示在网站或应用程序中。
竞争情报监视:在每个窗口网站中提取并显示最新新闻,招聘信息和人员变动,并通过Google或百度搜索显示您自己和竞争对手的名称以及相关产品的关键字,在窗口中显示搜索结果或将其保存在数据库中。
解决方案:复盘-Flume+Kafka实时数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-08-30 04:28
背景
今天给你们分享一下我近来遇见的坑,也不能说是坑,严格来说是我知识广度不够,导致当时认为此问题无解,互联网没有解决不了的问题,只要认真对待就一定可以解决。
下面我们来进行一次复盘,希望可以帮助到须要帮助的朋友。
最近在关注Apache Druid(实时数据剖析),它有一个功能可以通过Kafka实时摄入数据,并提供了挺好的生态工具,在督查过程中所有的流程均已打通,已打算接入我司数据进行一下容量及响应速率测试,可以说:万事具备只欠东风。。。然而发觉这个东风,版本很低。。。最终结果可能会造成如此好用的数据剖析工具难以使用
复盘&解决方案
一、Kafka生产消费版本不一致未能将数据部门的数据搜集到我们工具中
Apache Druid实时数据摄入Kafa最低要求版本0.11我司Kafka0.10
二、这么看我司Kafka一定是不能升级的,工具也难以降级,怎么办呢?
放弃apache druid(换工具),调研中也在关注Clickhouse,但还差一点就成功了舍弃有些可惜。。。这条路只能是无路可走时选择
采用中转消费进程来处理,共有2个方案
不能立刻解决的疼点:每天预计有N亿数据经过这个服务。这样就得先解决:高可用、高可靠问题,数据不能遗失,同时也带来维护成本,总之临时用用可以,待解决问题不少,待使用.
这个方案比Golang轮询方案惟一用处数据保存到c盘了,感官上比较靠谱。。。好吧,那就这个方案,准备撸代码。
三、我们大致总结下来解决方案,看起来没问题,但是问题仍然存在
如果c盘坏了如何办? 单点问题服务不可靠,如处理N亿数据,要对这个服务进行监控,报警,故障处理等,需要大量人工介入,成本偏高单机io性能消耗严重,读写频繁很容易出问题,未知性很大
四、以上方案还是不太满意,继续找解决办法,不舍弃
基于以上缘由,能否有第三方开源软件解决呢。明知山有虎偏向虎山行,这么做不行,不管是做人做事,尽量不要给他人留下坑,同时这也是自己的学习过程。
带着问题,加了会好多相关QQ群,找跟我同病相怜的人,看看有啥解决办法。
有这么一句话只要你坚持了肯定都会有答案。。。Druid有一位美眉也遇见跟我同样的问题,她是使用Flume来解决
Flume介绍
详细介绍请自行百度
优势Flume可以将应用形成的数据储存到任何集中存储器中,比如HDFS,HBase当搜集数据的速率超过将写入数据的时侯,也就是当搜集信息遇见峰值时,这时候搜集的信息十分大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间作出调整,保证其才能在二者之间提供平稳的数据.提供上下文路由特点Flume的管线是基于事务,保证了数据在传送和接收时的一致性.Flume是可靠的,容错性高的,可升级的,易管理的,并且可订制的。具有特点Flume可以高效率的将多个网站服务器中搜集的日志信息存入HDFS/HBase中使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中不仅日志信息,Flume同时也可以拿来接入搜集规模宏大的社交网络节点风波数据,比如facebook,twitter,电商网站如亚马逊,flipkart等支持各类接入资源数据的类型以及接出数据类型支持多路径流量,多管线接入流量,多管线接出流量,上下文路由等可以被水平扩充Flume 验证方案可行性
高可用,高可靠的第三方开源已找到,见证奇迹的时刻到了。
首先安装两个版本Kafka,下载地址官网可以找到: 单机版安装kafka0.10 1. kafka_2.10-0.10.0.0.tgz 2. kafka_2.11-0.11.0.3.tgz
Flume最新版本1.9 1、apache-flume-1.9.0-bin.tar.gz
操作很多,我把配置文件贴下来,如果有问题可以加我QQ:979134,请注明缘由
# 定义这个agent组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# =======================使用内置kafka source
a1.sources.r1.kafka.bootstrap.servers=ip:9092
a1.sources.r1.kafka.topics=kafka0-10-0
a1.sources.r1.kafka.consumer.security.protocol=SASL_PLAINTEXT
a1.sources.r1.kafka.consumer.sasl.mechanism=PLAIN
a1.sources.r1.kafka.consumer.group.id=groupid
a1.sources.r1.kafka.consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="用户名" password="密码";
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize=5000
# =======================对sources进行拦截器操作 channel中会带有Header,我做了remove_header操作
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=remove_header
a1.sources.r1.interceptors.i1.fromList=timestamp,topic,offset,partition
a1.sources.r1.channels=c1
# channel设置 a1.sinks.k1.type有很多种,如、memory、file、jdbc、kafka 我使用kafka做为通道
# channel 先把数据发动到kafka缓存通道,处理完成sink接收,之后进行producer
a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers=127.0.0.1:9002
a1.channels.c1.kafka.topic=kafka-channel
# =======================目标生产数据
#a1.sinks.k1.type=logger 打开这里可以验证从channel传递过来的数据是否是你想要的
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic=kafka2-1
a1.sinks.k1.kafka.bootstrap.servers=127.0.0.1:9002
a1.sinks.k1.kafka.flumeBatchSize= 1000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Bind the source and sink to the channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
流程回顾&最终解决,用上第三方开源软件,我也可以安安稳稳午睡啦
最终数据完美接入到Druid
看到这儿我已写了3小时,您是否可以给个赞和喜欢,感谢 查看全部
复盘-Flume+Kafka实时数据采集
背景
今天给你们分享一下我近来遇见的坑,也不能说是坑,严格来说是我知识广度不够,导致当时认为此问题无解,互联网没有解决不了的问题,只要认真对待就一定可以解决。
下面我们来进行一次复盘,希望可以帮助到须要帮助的朋友。
最近在关注Apache Druid(实时数据剖析),它有一个功能可以通过Kafka实时摄入数据,并提供了挺好的生态工具,在督查过程中所有的流程均已打通,已打算接入我司数据进行一下容量及响应速率测试,可以说:万事具备只欠东风。。。然而发觉这个东风,版本很低。。。最终结果可能会造成如此好用的数据剖析工具难以使用
复盘&解决方案
一、Kafka生产消费版本不一致未能将数据部门的数据搜集到我们工具中
Apache Druid实时数据摄入Kafa最低要求版本0.11我司Kafka0.10
二、这么看我司Kafka一定是不能升级的,工具也难以降级,怎么办呢?
放弃apache druid(换工具),调研中也在关注Clickhouse,但还差一点就成功了舍弃有些可惜。。。这条路只能是无路可走时选择
采用中转消费进程来处理,共有2个方案
不能立刻解决的疼点:每天预计有N亿数据经过这个服务。这样就得先解决:高可用、高可靠问题,数据不能遗失,同时也带来维护成本,总之临时用用可以,待解决问题不少,待使用.
这个方案比Golang轮询方案惟一用处数据保存到c盘了,感官上比较靠谱。。。好吧,那就这个方案,准备撸代码。
三、我们大致总结下来解决方案,看起来没问题,但是问题仍然存在
如果c盘坏了如何办? 单点问题服务不可靠,如处理N亿数据,要对这个服务进行监控,报警,故障处理等,需要大量人工介入,成本偏高单机io性能消耗严重,读写频繁很容易出问题,未知性很大
四、以上方案还是不太满意,继续找解决办法,不舍弃
基于以上缘由,能否有第三方开源软件解决呢。明知山有虎偏向虎山行,这么做不行,不管是做人做事,尽量不要给他人留下坑,同时这也是自己的学习过程。
带着问题,加了会好多相关QQ群,找跟我同病相怜的人,看看有啥解决办法。
有这么一句话只要你坚持了肯定都会有答案。。。Druid有一位美眉也遇见跟我同样的问题,她是使用Flume来解决
Flume介绍
详细介绍请自行百度
优势Flume可以将应用形成的数据储存到任何集中存储器中,比如HDFS,HBase当搜集数据的速率超过将写入数据的时侯,也就是当搜集信息遇见峰值时,这时候搜集的信息十分大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间作出调整,保证其才能在二者之间提供平稳的数据.提供上下文路由特点Flume的管线是基于事务,保证了数据在传送和接收时的一致性.Flume是可靠的,容错性高的,可升级的,易管理的,并且可订制的。具有特点Flume可以高效率的将多个网站服务器中搜集的日志信息存入HDFS/HBase中使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中不仅日志信息,Flume同时也可以拿来接入搜集规模宏大的社交网络节点风波数据,比如facebook,twitter,电商网站如亚马逊,flipkart等支持各类接入资源数据的类型以及接出数据类型支持多路径流量,多管线接入流量,多管线接出流量,上下文路由等可以被水平扩充Flume 验证方案可行性
高可用,高可靠的第三方开源已找到,见证奇迹的时刻到了。
首先安装两个版本Kafka,下载地址官网可以找到: 单机版安装kafka0.10 1. kafka_2.10-0.10.0.0.tgz 2. kafka_2.11-0.11.0.3.tgz
Flume最新版本1.9 1、apache-flume-1.9.0-bin.tar.gz
操作很多,我把配置文件贴下来,如果有问题可以加我QQ:979134,请注明缘由
# 定义这个agent组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# =======================使用内置kafka source
a1.sources.r1.kafka.bootstrap.servers=ip:9092
a1.sources.r1.kafka.topics=kafka0-10-0
a1.sources.r1.kafka.consumer.security.protocol=SASL_PLAINTEXT
a1.sources.r1.kafka.consumer.sasl.mechanism=PLAIN
a1.sources.r1.kafka.consumer.group.id=groupid
a1.sources.r1.kafka.consumer.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="用户名" password="密码";
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize=5000
# =======================对sources进行拦截器操作 channel中会带有Header,我做了remove_header操作
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=remove_header
a1.sources.r1.interceptors.i1.fromList=timestamp,topic,offset,partition
a1.sources.r1.channels=c1
# channel设置 a1.sinks.k1.type有很多种,如、memory、file、jdbc、kafka 我使用kafka做为通道
# channel 先把数据发动到kafka缓存通道,处理完成sink接收,之后进行producer
a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers=127.0.0.1:9002
a1.channels.c1.kafka.topic=kafka-channel
# =======================目标生产数据
#a1.sinks.k1.type=logger 打开这里可以验证从channel传递过来的数据是否是你想要的
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic=kafka2-1
a1.sinks.k1.kafka.bootstrap.servers=127.0.0.1:9002
a1.sinks.k1.kafka.flumeBatchSize= 1000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Bind the source and sink to the channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
流程回顾&最终解决,用上第三方开源软件,我也可以安安稳稳午睡啦
最终数据完美接入到Druid
看到这儿我已写了3小时,您是否可以给个赞和喜欢,感谢
百度地图数据采集软件开发 爬取的数据全面
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-08-26 05:48
0
日常生活中我们使用比较多的两款地图产品是百度和高德,在数据采集方面真的很麻烦。百度地图数据采集软件开发才能一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等。
日常生活中我们使用比较多的两款地图产品是百度和高德,而在数据采集方卖弄真的很麻烦。百度地图数据采集软件开发能为用户提供一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等,方便用户进行数据剖析。
百度地图数据采集软件开发功能特征介绍
1、采集数据不间断:软件可以24小时不间断地运行,就算是死机也能进行采集,适用于规模化数据爬取。
2、爬取信息详尽:爬取的信息数据包括地点ID、名称、logo、电话、经纬度座标、标签等,还能自定义须要采集城市和地点搜索关键词,同时采集多关键字搜索的结果。
3、数据导入和发布:能够导入数据文件而且发布到数据库或则是网站中去,能够无缝对接用户的现有系统。
4、一站式采集:统一可视化管理爬取的数据,为用户提供更多数据剖析处理的功能,还可以进行数据清洗和机器学习,用户想要获取关键的信息也丝毫不用害怕数据量多的问题。
东方智启科技是北京专业的百度地图数据采集软件开发公司,用严谨的服务态度和专业的技术团队为企业提供更多优质的服务。 查看全部
百度地图数据采集软件开发 爬取的数据全面
0
日常生活中我们使用比较多的两款地图产品是百度和高德,在数据采集方面真的很麻烦。百度地图数据采集软件开发才能一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等。
日常生活中我们使用比较多的两款地图产品是百度和高德,而在数据采集方卖弄真的很麻烦。百度地图数据采集软件开发能为用户提供一键批量采集百度地图上的实时数据,包括地点ID、名称、电话、经纬度座标等,方便用户进行数据剖析。
百度地图数据采集软件开发功能特征介绍
1、采集数据不间断:软件可以24小时不间断地运行,就算是死机也能进行采集,适用于规模化数据爬取。
2、爬取信息详尽:爬取的信息数据包括地点ID、名称、logo、电话、经纬度座标、标签等,还能自定义须要采集城市和地点搜索关键词,同时采集多关键字搜索的结果。
3、数据导入和发布:能够导入数据文件而且发布到数据库或则是网站中去,能够无缝对接用户的现有系统。
4、一站式采集:统一可视化管理爬取的数据,为用户提供更多数据剖析处理的功能,还可以进行数据清洗和机器学习,用户想要获取关键的信息也丝毫不用害怕数据量多的问题。
东方智启科技是北京专业的百度地图数据采集软件开发公司,用严谨的服务态度和专业的技术团队为企业提供更多优质的服务。
织梦实现发布文章主动推送(实时)给百度的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-08-17 05:58
织梦内容管理系统(DedeCms) 是一款太老的程序了,主要是以简单、实用、开源而享誉,很多建站初学者第一次做网站都是使用的织梦。不过织梦也有不足之处,比方说我们用织梦发布文章之后还须要自动去递交链接给百度,这是不是很麻烦呢?
因此,康哥明天就分享一个通过简单更改织梦(Dedecms)后台,实现在织梦网站后台发布文章主动推献给百度的方式,而且还是实时的哦。
那么,我们使用百度的主动推送功能会达到如何的疗效呢?
康哥觉得有以下两点:
1、可以被百度搜索引擎爬虫及时发觉
如果我们在发布完文章之后,主动的把链接递交给百度搜索引擎爬虫,那不就可以减短百度搜索引擎爬虫发觉你站点新链接的时间了么?这样就可以让新发布的页面在第一时间被百度收录了。
2、还可以起到保护原创的疗效
天下文章一大抄,对于这些抄袭者你是不是太惧怕?明明是自己写的原创文章,却被他人网站抄袭了过去,这还不算什么。可是那些个剽窃的文章,他们的排行竟然比你的还要好,难道你就不会吵架么?难道你就不会怪度娘的技术太软么?
所以,只要使用了百度的主动推送功能,对于网站的最新原创内容,就可以用这些方法快速通知到百度,使内容可以在转发之前就被百度发觉,从而起到保护原创的疗效。
好了,康哥如今就来教你们怎么使用织梦就可以实现发布文章主动推送(实时)给百度的方式。为了便捷举例说明,康哥明天就拿刚上线的新站云南特产网来给你们做示范吧。
一、在织梦后台添加文档原创属性判断框
我们在织梦后台添加文档原创属性判定框主要就是降低织梦的自定义文档属性,实现勾选文档原创属性判定框时,就递交为原创链接,否则就递交为普通链接。
先登入织梦网站后台,然后找到系统-SQL命令行工具,执行如下sql句子:
INSERT INTO `dede_arcatt` VALUES('9','y','原创');
alter table `dede_archives` modify `flag` set('c','h','p','f','s','j','a','b','y') default NULL;
直接把前面这段sql句子复制进去以后,就点击确定,具体请看右图所示:
成功执行这段sql句子以后,我们在织梦后台的系统-自定义文档属性中就可以看见如下结果:
然后,当我们在织梦后台发布文章时,通过勾选文档原创属性判定框即可,具体请看右图所示:
二、加入百度主动推送代码,做推送判定
我们主要是更改织梦后台的article_add.php和article_edit.php这两个文件来实现推送判定的疗效。登录FTP,根据这个织梦网站的后台路径wwwroot//dede/就可以找到article_add.php和article_edit.php这两个文件了。
注意:康哥在这里是以文章页模型为例,如果你们想要更改产品页的,就更改相对应的模板即可。
先来更改一下article_add.php这个文件,康哥推荐你们使用Notepad++这个代码编辑器来进行更改。
打开了article_add.php这个文件以后,直接Ctrl+G定位到大约是259行这儿(每个人的网站代码都不一样,自己找下大约的位置吧),然后我们就把百度主动推送核心代码直接复制粘贴到259行下边这个位置,如下图所示:
康哥在这里就给你们分享一下这段代码好了,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//主动推送核心代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//主动推送核心代码结束
百度主动推送核心代码加进去以后就保存,传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是第287行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:
接着,我们再来更改下article_edit.php这个文件,修改方式也是跟之前那种文件一样。
同样是打开了article_edit.php这个文件以后,直接Ctrl+G定位到大约是242行这儿,然后我们就把内容模块下的主动推送代码直接复制粘贴到242行下边这个位置,如下图所示:
康哥在这里也给你们分享一下这段代码,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//修改内容模块下的主动推送代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//修改内容模块下的主动推送代码结束
当我们把内容模块下的主动推送代码加进去以后就保存,也同样是传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是在第270行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:
给这两个判定文件加完了推送判定代码以后,也就完成了一大半的工作了,还有两个关键的地方须要我们在织梦后台进行操作,那就是添加两条新变量!
由于目前为止,还是有很多同学不懂得怎样在织梦DedeCms添加新变量,康哥在这里就给你们支个招吧。
我们先来添加第一条变量吧,进入织梦(Dedecms)后台,依次打开系统-系统基本参数-添加新变量,然后你还能见到如下图所展示的内容了:
变量名称:指的是调用的函数,请填写以cfg_开头的英语或则是数字,我们这儿就直接写:cfg_baiduhost
变量值:指的是输入框填写的内容,我们这儿就写自己的网站域名:
变量类型:指的是文字或则是数字之类的,这里我们就选择文字类型即可。当然了,如果你添加变量的内容比较长,那么就可以选择多行文本。
参数说明:指的是英文的命名,就是便捷我们晓得这个新变量这是干哪些用的,我们这儿就写:百度推送域名。
所属组:这个指的是你想在那个管理组听到这个新变量,在这里我们就直接选择默认的站点设置即可。
设置完毕以后,我们单击保存变量,第一条变量也就添加成功了。
好了,接着再看下第二条变量是如何添加进去的,刚才康哥早已给大家早已介绍过了这种变量的相关术语,在这里就不屁话那么多了,直接上干货!
变量名称:cfg_badutoken
变量值:RyVub75SqbRkLu0k(注意:主动推送插口的参数值请从百度搜索资源平台链接递交这儿获取)
变量类型:文字类型
参数说明:主动推送插口
所属组:站点设置
设置完毕以后,我们就直接单击保存变量,这时候呢第二条变量也就添加成功了,下面这张截图就是添加第二条变量所展示的内容:
然后你在系统基本参数的顶部这儿是不是就看到多了这两条新的内容呢?一个是百度推送域名,另外一个就是主动推送插口,具体请看下边这张截图:
如果听到了,那么康哥就要恭喜你了,说明早已大功告成!
上面这个截图就是康哥随机发布的一篇文章,看到这个疗效了么?关键就是这段代码,{"remain":4999954,"success":1} ,"remain":4999954,"返回的是还可以递交的数目,"success":1返回的则是成功递交百度的数目,说明已然成功的主动递交了一条新链接给百度搜索引擎爬虫。 查看全部
织梦实现发布文章主动推送(实时)给百度的方式
织梦内容管理系统(DedeCms) 是一款太老的程序了,主要是以简单、实用、开源而享誉,很多建站初学者第一次做网站都是使用的织梦。不过织梦也有不足之处,比方说我们用织梦发布文章之后还须要自动去递交链接给百度,这是不是很麻烦呢?
因此,康哥明天就分享一个通过简单更改织梦(Dedecms)后台,实现在织梦网站后台发布文章主动推献给百度的方式,而且还是实时的哦。
那么,我们使用百度的主动推送功能会达到如何的疗效呢?
康哥觉得有以下两点:
1、可以被百度搜索引擎爬虫及时发觉
如果我们在发布完文章之后,主动的把链接递交给百度搜索引擎爬虫,那不就可以减短百度搜索引擎爬虫发觉你站点新链接的时间了么?这样就可以让新发布的页面在第一时间被百度收录了。
2、还可以起到保护原创的疗效
天下文章一大抄,对于这些抄袭者你是不是太惧怕?明明是自己写的原创文章,却被他人网站抄袭了过去,这还不算什么。可是那些个剽窃的文章,他们的排行竟然比你的还要好,难道你就不会吵架么?难道你就不会怪度娘的技术太软么?
所以,只要使用了百度的主动推送功能,对于网站的最新原创内容,就可以用这些方法快速通知到百度,使内容可以在转发之前就被百度发觉,从而起到保护原创的疗效。
好了,康哥如今就来教你们怎么使用织梦就可以实现发布文章主动推送(实时)给百度的方式。为了便捷举例说明,康哥明天就拿刚上线的新站云南特产网来给你们做示范吧。
一、在织梦后台添加文档原创属性判断框
我们在织梦后台添加文档原创属性判定框主要就是降低织梦的自定义文档属性,实现勾选文档原创属性判定框时,就递交为原创链接,否则就递交为普通链接。
先登入织梦网站后台,然后找到系统-SQL命令行工具,执行如下sql句子:
INSERT INTO `dede_arcatt` VALUES('9','y','原创');
alter table `dede_archives` modify `flag` set('c','h','p','f','s','j','a','b','y') default NULL;
直接把前面这段sql句子复制进去以后,就点击确定,具体请看右图所示:
成功执行这段sql句子以后,我们在织梦后台的系统-自定义文档属性中就可以看见如下结果:
然后,当我们在织梦后台发布文章时,通过勾选文档原创属性判定框即可,具体请看右图所示:
二、加入百度主动推送代码,做推送判定
我们主要是更改织梦后台的article_add.php和article_edit.php这两个文件来实现推送判定的疗效。登录FTP,根据这个织梦网站的后台路径wwwroot//dede/就可以找到article_add.php和article_edit.php这两个文件了。
注意:康哥在这里是以文章页模型为例,如果你们想要更改产品页的,就更改相对应的模板即可。
先来更改一下article_add.php这个文件,康哥推荐你们使用Notepad++这个代码编辑器来进行更改。
打开了article_add.php这个文件以后,直接Ctrl+G定位到大约是259行这儿(每个人的网站代码都不一样,自己找下大约的位置吧),然后我们就把百度主动推送核心代码直接复制粘贴到259行下边这个位置,如下图所示:
康哥在这里就给你们分享一下这段代码好了,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//主动推送核心代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//主动推送核心代码结束
百度主动推送核心代码加进去以后就保存,传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是第287行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:
接着,我们再来更改下article_edit.php这个文件,修改方式也是跟之前那种文件一样。
同样是打开了article_edit.php这个文件以后,直接Ctrl+G定位到大约是242行这儿,然后我们就把内容模块下的主动推送代码直接复制粘贴到242行下边这个位置,如下图所示:
康哥在这里也给你们分享一下这段代码,然后大家自己把代码上面的API接口调用地址更改成自己的即可。
//修改内容模块下的主动推送代码开始
else{
$urls[]='http://'.$cfg_baiduhost.'/'.$artUrl;
$api = 'http://data.zz.baidu.com/urls?site=www.gxtcnet.cn&token=RyVub75SqbRkLu0k';
$ch = curl_init();
$options = array(
CURLOPT_URL => $api,
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POSTFIELDS => implode("\n", $urls),
CURLOPT_HTTPHEADER => array('Content-Type: text/plain'),
);
curl_setopt_array($ch, $options);
$result = curl_exec($ch);
}
//修改内容模块下的主动推送代码结束
当我们把内容模块下的主动推送代码加进去以后就保存,也同样是传回FTP覆盖掉原先那种文件。
如果你想要织梦后台文章发布成功以后有这样一个推送提示的疗效,那么你就可以在大约是在第270行的下边加入这段代码:百度递交返回".$result.",具体可以看右图所示:
给这两个判定文件加完了推送判定代码以后,也就完成了一大半的工作了,还有两个关键的地方须要我们在织梦后台进行操作,那就是添加两条新变量!
由于目前为止,还是有很多同学不懂得怎样在织梦DedeCms添加新变量,康哥在这里就给你们支个招吧。
我们先来添加第一条变量吧,进入织梦(Dedecms)后台,依次打开系统-系统基本参数-添加新变量,然后你还能见到如下图所展示的内容了:
变量名称:指的是调用的函数,请填写以cfg_开头的英语或则是数字,我们这儿就直接写:cfg_baiduhost
变量值:指的是输入框填写的内容,我们这儿就写自己的网站域名:
变量类型:指的是文字或则是数字之类的,这里我们就选择文字类型即可。当然了,如果你添加变量的内容比较长,那么就可以选择多行文本。
参数说明:指的是英文的命名,就是便捷我们晓得这个新变量这是干哪些用的,我们这儿就写:百度推送域名。
所属组:这个指的是你想在那个管理组听到这个新变量,在这里我们就直接选择默认的站点设置即可。
设置完毕以后,我们单击保存变量,第一条变量也就添加成功了。
好了,接着再看下第二条变量是如何添加进去的,刚才康哥早已给大家早已介绍过了这种变量的相关术语,在这里就不屁话那么多了,直接上干货!
变量名称:cfg_badutoken
变量值:RyVub75SqbRkLu0k(注意:主动推送插口的参数值请从百度搜索资源平台链接递交这儿获取)
变量类型:文字类型
参数说明:主动推送插口
所属组:站点设置
设置完毕以后,我们就直接单击保存变量,这时候呢第二条变量也就添加成功了,下面这张截图就是添加第二条变量所展示的内容:
然后你在系统基本参数的顶部这儿是不是就看到多了这两条新的内容呢?一个是百度推送域名,另外一个就是主动推送插口,具体请看下边这张截图:
如果听到了,那么康哥就要恭喜你了,说明早已大功告成!
上面这个截图就是康哥随机发布的一篇文章,看到这个疗效了么?关键就是这段代码,{"remain":4999954,"success":1} ,"remain":4999954,"返回的是还可以递交的数目,"success":1返回的则是成功递交百度的数目,说明已然成功的主动递交了一条新链接给百度搜索引擎爬虫。
Binlog实时数据采集、落地数据使用的思索总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-12 14:57
今天碰巧刷新技术公众号的时侯,看到一篇这样文章,是基于Flink有关于Mysql Binlog数据采集的方案,看了一下实践方式和具体操作有一些考虑情况不足的情况,缺少一些处理实际情况的操作。笔者之前有些过一些类似的采集工具实践的文章,但是并没有在整体上作出一个系统性的总结,所以我在想,是不是可以做一个个人总结性的文章,把Binlog采集中的问题以及相应的解决方案也进行总结呢?
可能很多人对于Binlog的认识还不是太充足,可能有些人会浅显的觉得:“它不就是mysql形成的,有固定结构的log嘛,把数据采集过来,然后把它做一下数据落地,它有哪些难的呢?”
的确,它本质上确实就是个log,可是实际上,关于Binlog采集从场景剖析,再到技术选型,整体内部有很多不为人知的坑,不要轻视了它。
笔者写这篇文章,目的是把实际工作中对于Binlog数据采集的开发流程的原则、注意事项、可能存在的问题点展示下来,其中也会有笔者自己的一些个人总结数据采集中的原则,为你们作参考,都是干货。
所以开始吧!
个人总结原则
首先摒弃技术框架的讨论,个人总结Binlog 日志的数据采集主要原则:
分别论述一下这三个原则的具体含意
原则一
在数据采集中,数据落地通常还会使用时间分区进行落地,那就须要我们确定一下固定的时间戳作为时间分区的基础时间序列。
在这些情况下看来,业务数据上的时间戳数组,无论是从实际开发中获取此时间戳的角度,还是现实表中就会存在这样的时间戳,都不可能所有表完全满足。
举一下例子:
表 :业务时间戳
table A : create_time,update_time
table B : create_time
table C : create_at
table D : 无
像这样的情况,理论上可以通过限制 RD 和 DBA 的在设计表时规则化表结构来实现时间戳以及命名的统一化、做限制,但是是在实际工作中,这样的情况基本上是做不到的,相信好多读者也会碰到这样的情况。
可能好多做数据采集的同学会想,我们能不能要求她们去制订标准呢?
个人的看法是,可以,但是不能把大数据底层数据采集完全借助这样相互制订的标准。原因有以下三点:
所以假如想要使用惟一固定的时间序列,就要和业务的数据剥离开,我们想要的时间戳不受业务数据的变动的影响。
原则二
在业务数据库中,一定会存在表结构变更的问题,绝大部分情况为降低列,但是也会存在列重命名、列删掉这类情况,而其中数组变更的次序是不可控的。
此原则想描述的是,导入到数据库房中的表,要适应数据库表的各类操作,保持其可用性与列数据的正确性。
原则三
此数据可回溯,其中包括两个方面
第一个描述的是,在采集binlog采集端,可以重新按位置采集binlog。
第二个描述的是,在消费binlog落地的一端,可以重复消费把数据重新落地。
此为笔者个人总结,无论是选择什么样的技术选型进行组合搭建,这几点原则是须要具备的。
实现方案以及具体操作
技术构架 : Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个transform 算子,可以抽取出binlog 中的元数据。
对于 0.10 版本的配置,可以抽取 table,version,connector,name,ts_ms,db,server_id,file,pos,row 等binlog元数据信息。
其中ts_ms为binlog日志的形成时间,此为binlog元数据,可以应用于所有数据表,而且可以在完全对数据表内部结构不了解的情况下,使用此固定时间戳,完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数有可能是不同的,如果读者有须要实践的话须要在官方文档上确认相应版本的配置参数。
对于其他框架,例如市面上用的较多的Canal,或者读者有自己须要开发数据采集程序的话,binlog的元数据建议全部抽取下来,在此过程以及后续过程中都可能会被用到。
基于原则二的解决方案
对于 Hive ,目前主流的数据储存格式为Parquet,ORC,Json,Avro 这几种。
抛开数据储存的效率讨论。
对于前两中数据格式,为列存,也就是说,这两种数据格式的数据读取,会严格依赖于我们数据表中的数据储存的次序,这样的数据格式,是难以满足数据列灵活降低、删除等操作的。
Avro 格式为行存,但是它须要依赖于Schema Register服务,考虑Hive的数据表读取完全要依赖一个外部服务,风险偏高。
最后确定使用Json格式进行数据储存,虽然这样的读取和储存效率没有其他格式高,但是这样可以保证业务数据的任何变更都可以在hive中读取下来。
Debezium 组件采集binlog 的数据就是为json格式,和预期的设计方案是吻合的,可以解决原则二带来的问题。
对于其他框架,例如市面上用的较多的Canal,可以设置为Json数据格式进行传输,或者读者有自己须要开发数据采集程序的话,也是相同的道理。
基于原则三的解决方案
在采集binlog采集端,可以重新按位置采集binlog。
此方案实现方法在Debezium官方网站上也给出了相应的解决方案,大概描述一下,需要用到 Kafkacat工具。
对于每一个采集的mysql实例,创建数据采集任务时,Confluent就会相应的创建connector(也就是采集程序)的采集的元数据的topic,
里面会储存相应的时间戳、文件位置、以及位置,可以通过更改此数据,重置采集binlog日志的位置。
值得注意的是,此操作的时间节点也是有限制的,和mysql的binlog日志保存周期有关,所以此方法回溯时,需要确认的是mysql日志还存在。
对于重复消费把数据重新落地。
此方案由于基于kafka,对于kafka重新制订消费offset消费位点的操作网上有很多方案,此处不再赘言。
对于读者自己实现的话,需要确认的选择的MQ支持此特点就好了。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要操作
此部份只描述在笔者技术构架下怎样实现以下操作,读者可以按照自己选择的技术组件探究不同的技术方案。
数据库分库分表的情况
基于Debezium的构架,一个Source 端只能对应一个mysql实例进行采集,对于同一实例上的分表情况,可以使用 Debezium Topic Routing 功能,
在采集过滤binlog时把相应须要采集的表根据正则匹配写入一个指定的topic中。
在分库的情况下,还须要在 sink 端 增加 RegexRouter transform算子进行topic 间的合并写入操作。
数据增量采集与全量采集
对于采集组件,目前目前的配置都是以增量为默认,所以无论是选择 Debezium 还是 Canal的话,正常配置就好。
但是有些时侯会存在须要采集全表的情况,笔者也给出一下全量的数据采集的方案。
方案一
Debezium 本身自带了这样的功能,需要将
snapshot.mode 参数选型设置为 when_needed,这样可以做表的全量采集操作。
官方文档中,在此处的参数配置有愈发细致的描述。
#snapshots
方案二
使用sqoop和增量采集同时使用的方法进行。
此方案适用于表数据已存在好多,而目前binlog数据频度不频繁的情况下,使用此方案。
值得注意的是有两点:
离线数据去重条件
数据落地后,通过json表映射出binlog原创数据,那么问题也就来了,我们怎么找到最新的一条数据呢?
也许我们可以简单的觉得,用我们刚才的抽取的那种ts_ms,然后做倒排不就好了吗?
大部分情况下这样做确实是可以的。
但是笔者在实际开发中,发现这样的情况是不能满足所有情况的,因为在binlog中,可能真的会存在 ts_ms 与 PK 相同,但是确实不同的两条数据。
那我们如何去解决时间都相同的两条数据呢?
答案就在上文,我们刚才建议的把binlog 的元数据都抽取下来。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
解释一下这个sql 中row_number的的条件
__ts_ms : 为binlog中的ts_ms,也就是风波时间。
__file : 为binlog此条数据所在file name。
__pos : 为binlog中此数据所在文件中的位置,为数据类型。
这样的条件组合取出的数据,就是最新的一条。
也许有读者会问,如果这条数据被删除了如何办,你这样取下来的数据不就是错的了吗?
这个Debezium也有相应的操作,有相应的配置选项使你怎么选择处理删掉行为的binlog数据。
作为给你们的参考,笔者选择 rewrite 的参数配置,这样在前面的sql最内层只须要判定 “delete = ’false‘“ 就是正确的数据啦。
架构上的总结
在技术选型以及整体与细节的构架中,笔者一直在坚持一个原则——
流程尽量简洁而不简单,数据环节越长,出问题的环节就可能越多。对于后期锁定问题与运维难度也会很高。
所以笔者在技术选型也曾考虑过Flink + Kafka 的这些方法,但是基于当时的现况,笔者并没有选择这样的技术选型,笔者也探讨一下缘由。
总结上去,我当时对于Flink的思索,如果Flink没有做开发和运维监控的平台化的情况下,可以作为一个临时方案,但是后期假如仍然在这样一个开发流程下缝缝补补,多人开发下很容易出现问题,或者就是你们都这样一个程序框架下造轮子,而且越造越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑了一部分未来的情况进行的选择。
所以个人最后确定技术选型的时侯,并没有选用Flink。
结束语
此篇文章笔者写的较为理论化,也是对此场景的一个技术理论总结。如果文中有其他不明晰的操作的话,可以参考笔者之前的文章,有详尽的代码级操作。
技术构架上的方案多种多样,笔者只是选择了其中一种进行实现,也希望你们有其他的技术方案或则理论进行交流,烦请见谅。 查看全部
前文
今天碰巧刷新技术公众号的时侯,看到一篇这样文章,是基于Flink有关于Mysql Binlog数据采集的方案,看了一下实践方式和具体操作有一些考虑情况不足的情况,缺少一些处理实际情况的操作。笔者之前有些过一些类似的采集工具实践的文章,但是并没有在整体上作出一个系统性的总结,所以我在想,是不是可以做一个个人总结性的文章,把Binlog采集中的问题以及相应的解决方案也进行总结呢?
可能很多人对于Binlog的认识还不是太充足,可能有些人会浅显的觉得:“它不就是mysql形成的,有固定结构的log嘛,把数据采集过来,然后把它做一下数据落地,它有哪些难的呢?”
的确,它本质上确实就是个log,可是实际上,关于Binlog采集从场景剖析,再到技术选型,整体内部有很多不为人知的坑,不要轻视了它。
笔者写这篇文章,目的是把实际工作中对于Binlog数据采集的开发流程的原则、注意事项、可能存在的问题点展示下来,其中也会有笔者自己的一些个人总结数据采集中的原则,为你们作参考,都是干货。
所以开始吧!
个人总结原则
首先摒弃技术框架的讨论,个人总结Binlog 日志的数据采集主要原则:
分别论述一下这三个原则的具体含意
原则一
在数据采集中,数据落地通常还会使用时间分区进行落地,那就须要我们确定一下固定的时间戳作为时间分区的基础时间序列。
在这些情况下看来,业务数据上的时间戳数组,无论是从实际开发中获取此时间戳的角度,还是现实表中就会存在这样的时间戳,都不可能所有表完全满足。
举一下例子:
表 :业务时间戳
table A : create_time,update_time
table B : create_time
table C : create_at
table D : 无
像这样的情况,理论上可以通过限制 RD 和 DBA 的在设计表时规则化表结构来实现时间戳以及命名的统一化、做限制,但是是在实际工作中,这样的情况基本上是做不到的,相信好多读者也会碰到这样的情况。
可能好多做数据采集的同学会想,我们能不能要求她们去制订标准呢?
个人的看法是,可以,但是不能把大数据底层数据采集完全借助这样相互制订的标准。原因有以下三点:
所以假如想要使用惟一固定的时间序列,就要和业务的数据剥离开,我们想要的时间戳不受业务数据的变动的影响。
原则二
在业务数据库中,一定会存在表结构变更的问题,绝大部分情况为降低列,但是也会存在列重命名、列删掉这类情况,而其中数组变更的次序是不可控的。
此原则想描述的是,导入到数据库房中的表,要适应数据库表的各类操作,保持其可用性与列数据的正确性。
原则三
此数据可回溯,其中包括两个方面
第一个描述的是,在采集binlog采集端,可以重新按位置采集binlog。
第二个描述的是,在消费binlog落地的一端,可以重复消费把数据重新落地。
此为笔者个人总结,无论是选择什么样的技术选型进行组合搭建,这几点原则是须要具备的。
实现方案以及具体操作
技术构架 : Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个transform 算子,可以抽取出binlog 中的元数据。
对于 0.10 版本的配置,可以抽取 table,version,connector,name,ts_ms,db,server_id,file,pos,row 等binlog元数据信息。
其中ts_ms为binlog日志的形成时间,此为binlog元数据,可以应用于所有数据表,而且可以在完全对数据表内部结构不了解的情况下,使用此固定时间戳,完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数有可能是不同的,如果读者有须要实践的话须要在官方文档上确认相应版本的配置参数。
对于其他框架,例如市面上用的较多的Canal,或者读者有自己须要开发数据采集程序的话,binlog的元数据建议全部抽取下来,在此过程以及后续过程中都可能会被用到。
基于原则二的解决方案
对于 Hive ,目前主流的数据储存格式为Parquet,ORC,Json,Avro 这几种。
抛开数据储存的效率讨论。
对于前两中数据格式,为列存,也就是说,这两种数据格式的数据读取,会严格依赖于我们数据表中的数据储存的次序,这样的数据格式,是难以满足数据列灵活降低、删除等操作的。
Avro 格式为行存,但是它须要依赖于Schema Register服务,考虑Hive的数据表读取完全要依赖一个外部服务,风险偏高。
最后确定使用Json格式进行数据储存,虽然这样的读取和储存效率没有其他格式高,但是这样可以保证业务数据的任何变更都可以在hive中读取下来。
Debezium 组件采集binlog 的数据就是为json格式,和预期的设计方案是吻合的,可以解决原则二带来的问题。
对于其他框架,例如市面上用的较多的Canal,可以设置为Json数据格式进行传输,或者读者有自己须要开发数据采集程序的话,也是相同的道理。
基于原则三的解决方案
在采集binlog采集端,可以重新按位置采集binlog。
此方案实现方法在Debezium官方网站上也给出了相应的解决方案,大概描述一下,需要用到 Kafkacat工具。
对于每一个采集的mysql实例,创建数据采集任务时,Confluent就会相应的创建connector(也就是采集程序)的采集的元数据的topic,
里面会储存相应的时间戳、文件位置、以及位置,可以通过更改此数据,重置采集binlog日志的位置。
值得注意的是,此操作的时间节点也是有限制的,和mysql的binlog日志保存周期有关,所以此方法回溯时,需要确认的是mysql日志还存在。
对于重复消费把数据重新落地。
此方案由于基于kafka,对于kafka重新制订消费offset消费位点的操作网上有很多方案,此处不再赘言。
对于读者自己实现的话,需要确认的选择的MQ支持此特点就好了。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要操作
此部份只描述在笔者技术构架下怎样实现以下操作,读者可以按照自己选择的技术组件探究不同的技术方案。
数据库分库分表的情况
基于Debezium的构架,一个Source 端只能对应一个mysql实例进行采集,对于同一实例上的分表情况,可以使用 Debezium Topic Routing 功能,
在采集过滤binlog时把相应须要采集的表根据正则匹配写入一个指定的topic中。
在分库的情况下,还须要在 sink 端 增加 RegexRouter transform算子进行topic 间的合并写入操作。
数据增量采集与全量采集
对于采集组件,目前目前的配置都是以增量为默认,所以无论是选择 Debezium 还是 Canal的话,正常配置就好。
但是有些时侯会存在须要采集全表的情况,笔者也给出一下全量的数据采集的方案。
方案一
Debezium 本身自带了这样的功能,需要将
snapshot.mode 参数选型设置为 when_needed,这样可以做表的全量采集操作。
官方文档中,在此处的参数配置有愈发细致的描述。
#snapshots
方案二
使用sqoop和增量采集同时使用的方法进行。
此方案适用于表数据已存在好多,而目前binlog数据频度不频繁的情况下,使用此方案。
值得注意的是有两点:
离线数据去重条件
数据落地后,通过json表映射出binlog原创数据,那么问题也就来了,我们怎么找到最新的一条数据呢?
也许我们可以简单的觉得,用我们刚才的抽取的那种ts_ms,然后做倒排不就好了吗?
大部分情况下这样做确实是可以的。
但是笔者在实际开发中,发现这样的情况是不能满足所有情况的,因为在binlog中,可能真的会存在 ts_ms 与 PK 相同,但是确实不同的两条数据。
那我们如何去解决时间都相同的两条数据呢?
答案就在上文,我们刚才建议的把binlog 的元数据都抽取下来。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
解释一下这个sql 中row_number的的条件
__ts_ms : 为binlog中的ts_ms,也就是风波时间。
__file : 为binlog此条数据所在file name。
__pos : 为binlog中此数据所在文件中的位置,为数据类型。
这样的条件组合取出的数据,就是最新的一条。
也许有读者会问,如果这条数据被删除了如何办,你这样取下来的数据不就是错的了吗?
这个Debezium也有相应的操作,有相应的配置选项使你怎么选择处理删掉行为的binlog数据。
作为给你们的参考,笔者选择 rewrite 的参数配置,这样在前面的sql最内层只须要判定 “delete = ’false‘“ 就是正确的数据啦。
架构上的总结
在技术选型以及整体与细节的构架中,笔者一直在坚持一个原则——
流程尽量简洁而不简单,数据环节越长,出问题的环节就可能越多。对于后期锁定问题与运维难度也会很高。
所以笔者在技术选型也曾考虑过Flink + Kafka 的这些方法,但是基于当时的现况,笔者并没有选择这样的技术选型,笔者也探讨一下缘由。
总结上去,我当时对于Flink的思索,如果Flink没有做开发和运维监控的平台化的情况下,可以作为一个临时方案,但是后期假如仍然在这样一个开发流程下缝缝补补,多人开发下很容易出现问题,或者就是你们都这样一个程序框架下造轮子,而且越造越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑了一部分未来的情况进行的选择。
所以个人最后确定技术选型的时侯,并没有选用Flink。
结束语
此篇文章笔者写的较为理论化,也是对此场景的一个技术理论总结。如果文中有其他不明晰的操作的话,可以参考笔者之前的文章,有详尽的代码级操作。
技术构架上的方案多种多样,笔者只是选择了其中一种进行实现,也希望你们有其他的技术方案或则理论进行交流,烦请见谅。
20个最好的网站数据实时剖析工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-08-11 23:54
1. Google Analytics
这是一个使用最广泛的访问统计剖析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看见你的网站中目前在线的访客数目,了解她们观看了什么网页、他们通过那个网站链接到你的网站、来自那个国家等等。
2. Clicky
与Google Analytics这些庞大的剖析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简约清爽。
3. Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可使你完善各种通知,如电子邮件、声音、弹出框等。
4. Chartbeat
这是针对新闻出版和其他类型网站的实时剖析工具。针对电子商务网站的专业剖析功能正式推出。它可以使你查看访问者怎样与你的网站进行互动,这可以帮助你改善你的网站。
5. GoSquared
它提供了所有常用的剖析功能,并且还可以使你查看特定访客的数据。它集成了Olark,可以使你与访客进行聊天。
6. Mixpanel
该工具可以使你查看访客数据,并剖析趋势,以及比较几天内的变化情况。
7. Reinvigorate
它提供了所有常用的实时剖析功能,可以使你直观地了解访客点击了什么地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪她们对网站的使用情况了。
8. Piwik
这是一个开源的实时剖析工具,你可以轻松下载并安装在自己的服务器上。
9. ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费剖析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名测量,可以帮助你跟踪和改善网站的排行。
10. SeeVolution
它目前处于测试阶段,提供了heatmaps和实时剖析功能,你可以听到heatmaps直播。它的可视化工具集可以使你直观查看剖析数据。
11. FoxMetrics
该工具提供了实时剖析功能,基于风波和特点的概念,你还可以设置自定义风波。它可以搜集与风波和特点匹配的数据,然后为你提供报告,这将有助于改善你的网站。
12. StatCounter
这是一个免费的实时剖析工具,只需几行代码即可安装。它提供了所有常用的剖析数据,此外,你还可以设置每晚、每周或每月手动给你发送电子邮件报告。
13. Performancing Metrics
该工具可以为你提供实时博客统计和Twitter剖析。
14. Whos.Amung.Us
Whos.Amung.Us相当奇特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
15. W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看近来访客的详尽信息。
16. TraceWatch
这是一个免费的实时剖析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以见到近来访客的详尽信息,并跟踪她们的踪迹。
17. Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
18. Spotplex
这项服务不仅提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排行。你甚至可以查看当日Spotplex网站上统计的最受欢迎的文章。
19. SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但假如你想要更详尽的数据,就须要付费了。
20. Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会听到你的博客和其他博客的对比结果。
大数据导航网站—网站分析检测工具–采集了逾40个网站分析工具。 查看全部
这是我们为你们提供的一篇关于介绍20个最好的网站数据实时剖析工具的文章,接下来就让我们一起来了解一下吧!
1. Google Analytics
这是一个使用最广泛的访问统计剖析工具,几周前,Google Analytics推出了一项新功能,可以提供实时报告。你可以看见你的网站中目前在线的访客数目,了解她们观看了什么网页、他们通过那个网站链接到你的网站、来自那个国家等等。
2. Clicky
与Google Analytics这些庞大的剖析系统相比,Clicky相对比较简易,它在控制面板上描供了一系列统计数据,包括最近三天的访问量、最高的20个链接来源及最高20个关键字,虽说数据种类不多,但可直观的反映出当前站点的访问情况,而且UI也比较简约清爽。
3. Woopra
Woopra将实时统计带到了另一个层次,它能实时直播网站的访问数据,你甚至可以使用Woopra Chat部件与用户聊天。它还拥有先进的通知功能,可使你完善各种通知,如电子邮件、声音、弹出框等。
4. Chartbeat
这是针对新闻出版和其他类型网站的实时剖析工具。针对电子商务网站的专业剖析功能正式推出。它可以使你查看访问者怎样与你的网站进行互动,这可以帮助你改善你的网站。
5. GoSquared
它提供了所有常用的剖析功能,并且还可以使你查看特定访客的数据。它集成了Olark,可以使你与访客进行聊天。
6. Mixpanel
该工具可以使你查看访客数据,并剖析趋势,以及比较几天内的变化情况。
7. Reinvigorate
它提供了所有常用的实时剖析功能,可以使你直观地了解访客点击了什么地方。你甚至可以查看注册用户的名称标签,这样你就可以跟踪她们对网站的使用情况了。
8. Piwik
这是一个开源的实时剖析工具,你可以轻松下载并安装在自己的服务器上。
9. ShinyStat
该网站提供了四种产品,其中包括一个有限制的免费剖析产品,可用于个人和非营利网站。企业版拥有搜索引擎排名测量,可以帮助你跟踪和改善网站的排行。
10. SeeVolution
它目前处于测试阶段,提供了heatmaps和实时剖析功能,你可以听到heatmaps直播。它的可视化工具集可以使你直观查看剖析数据。
11. FoxMetrics
该工具提供了实时剖析功能,基于风波和特点的概念,你还可以设置自定义风波。它可以搜集与风波和特点匹配的数据,然后为你提供报告,这将有助于改善你的网站。
12. StatCounter
这是一个免费的实时剖析工具,只需几行代码即可安装。它提供了所有常用的剖析数据,此外,你还可以设置每晚、每周或每月手动给你发送电子邮件报告。
13. Performancing Metrics
该工具可以为你提供实时博客统计和Twitter剖析。
14. Whos.Amung.Us
Whos.Amung.Us相当奇特的,它可以嵌入你的网站或博客中,让你获得实时统计数据。包括免费和付费两个版本。
15. W3Counter
可以提供实时数据,并提供超过30种不同的报告,以及可以查看近来访客的详尽信息。
16. TraceWatch
这是一个免费的实时剖析工具,可以安装在服务器上。它提供了所有常用的统计功能和报告,你也可以见到近来访客的详尽信息,并跟踪她们的踪迹。
17. Performancing Meters
通过该工具你可以跟踪目前的访客、查看来源链接和来自搜索引擎的流量等。这项服务是免费的。
18. Spotplex
这项服务不仅提供实时流量统计外,还可以展示你的网站在所有使用该服务的网站中的排行。你甚至可以查看当日Spotplex网站上统计的最受欢迎的文章。
19. SiteMeter
这是另一个流行的实时流量跟踪服务。该服务提供的基本数据是免费的,但假如你想要更详尽的数据,就须要付费了。
20. Icerocket
你可以获得跟踪代码或计数器,并查看统计数据。如果你点击“Rank”,你会听到你的博客和其他博客的对比结果。
大数据导航网站—网站分析检测工具–采集了逾40个网站分析工具。
爬虫入门(实时新闻采集器)①
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-08-10 19:13
按照五层开始搭建爬虫项目:
1.用户接口层
2.任务调度层
3.网络爬取层
4.数据解析层
5.数据持久化层
开始搭建项目
首先新建一个maven项目
把爬虫大约须要的类包打包好:
download包:负责下载url界面以及编码获取编码类的一些工具类
paser包:
persistence包:
persistence包:
pojos包:存放bean类的包
schedule包:负责接收外部传过来的url任务,通过一定的分发策略,将相应的url任务分发到采集任务当中
ui包:负责爬虫系统对外开放的接口设计与实现
utils包:编写一些常用的工具类的包
以及在外部新建一个seeds.txt文件
配置好pom.xml文件:
4.0.0
com.tl.spider
SimpleYouthNewsSpider4Job002
0.0.1-SNAPSHOT
nexus-aliyun
Nexus aliyun
http://maven.aliyun.com/nexus/ ... blic/
SimpleYouthNewsSpider4Job002
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
assembly
maven-compilder-plugin
2.3.2
1.7
1.7
UTF-8
1)在Util包上面编撰一个读取文件的类(并返回一个以换行分割的列表,拿取系统的种子) 读取seeds.txt上面的内容:
public static List getFileLineList(String filePath,String charset) throws IOException{
File fileObj = new File(filePath);
FileInputStream fis = new FileInputStream(fileObj);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr);
List lineList = new ArrayList();
String temp = null;
while ((temp = br.readLine()) != null) {
temp = temp.trim();
if(temp.length()>0) {
lineList.add(temp);
}
}
br.close();
return lineList;
}
2)在储存常量的类上面编撰一个util类编撰一类储存常量
public class StaticValue {
public final static String NEXT_LINE="\n";
public final static String ENCODING_DEFAULT="utf-8";
}
3)在download包上面编撰一个爬取网页的类传入url的编码(url,charset)输出网页内容:
(但是这样网页的编码是固定传入没有自由应变)
public static String getHtmlSourceBySocket(String url,String charset) throws Exception {
URL urlObj = new URL(url);
InputStream is = urlObj.openStream();
InputStreamReader isr = new InputStreamReader(is,charset);
BufferedReader br = new BufferedReader(isr);
StringBuilder stringBuilder = new StringBuilder();
String temp = null;
int lineCounter = 0;
while((temp=br.readLine())!=null) {
if(lineCounter>0) {
stringBuilder.append(StaticValue.NEXT_LINE);
}
lineCounter++;
stringBuilder.append(temp);
}
br.close();
return stringBuilder.toString();
}
4)根据具体情况来改变爬虫所对应的编码方式,分为两种
第一种:根据网页源码上面的Conten-Type属性来获取编码( 最准的形式):
代码实现获取:
public static String getCharset(String url) throws Exception {
String finalCharset = null;
URL urlObj = new URL(url);
URLConnection urlConn = urlObj.openConnection();
//用header来获取url的charset
Map allHeaderMap = urlConn.getHeaderFields();
List kvList = allHeaderMap.get("Conten-Type");
if(kvList!=null&&!kvList.isEmpty()) {
String line = kvList.get(0);
String[] kvArray = line.split(";");
for (String kv : kvArray) {
String[] eleArray = kv.split("=");
if(eleArray.length==2) {
if(eleArray[0].equals("charset")) {
finalCharset = eleArray[1].trim();
}
}
}
}
System.out.println(finalCharset);//finalCharset为取出的Conten-Type的值
}
第二种:根据网页源码的…里面的meta上面对应的charset属性的值来获取编码
代码实现获取:
public static String getCharset(String url) throws Exception {
BufferedReader br = WebPageDownLoadUtil.getBR(url,StaticValue.ENCODING_DEFAULT);
String temp = null;
while((temp=br.readLine())!=null) {
temp = temp.toLowerCase();//把网页源码都转成小写
String charset = getCharsetVaue4Line(temp);
if(charset!=null) {
finalCharset=charset;
System.out.println(charset);
break;
}
if(temp.contains("")) {
break;
}
}
br.close();
}
根据第二种方式要搭建对应的正值表达式来匹配对应的网页依照网页的具体情况来设定,如:
public static String getCharsetVaue4Line(String line) {
String regex = "charset=\"?(.+?)\"?\\s?/?>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(line);
String charsetValue = null;
if(matcher.find()) {
charsetValue = matcher.group(1);
}
return charsetValue ;
}
然后把前面两种情况结合一下,在第一种情况获取不到的情况下依据第二种方案来获取 :
结合代码为: 查看全部
早在之前就想学一学爬虫并且仍然木有时间,这几天抽空学了写入门级的爬虫,接下来简单介绍下爬虫的具体步骤以及具体的类以及操作流程;(按照如下流程搭建爬虫项目)
按照五层开始搭建爬虫项目:
1.用户接口层
2.任务调度层
3.网络爬取层
4.数据解析层
5.数据持久化层
开始搭建项目
首先新建一个maven项目
把爬虫大约须要的类包打包好:
download包:负责下载url界面以及编码获取编码类的一些工具类
paser包:
persistence包:
persistence包:
pojos包:存放bean类的包
schedule包:负责接收外部传过来的url任务,通过一定的分发策略,将相应的url任务分发到采集任务当中
ui包:负责爬虫系统对外开放的接口设计与实现
utils包:编写一些常用的工具类的包
以及在外部新建一个seeds.txt文件
配置好pom.xml文件:
4.0.0
com.tl.spider
SimpleYouthNewsSpider4Job002
0.0.1-SNAPSHOT
nexus-aliyun
Nexus aliyun
http://maven.aliyun.com/nexus/ ... blic/
SimpleYouthNewsSpider4Job002
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
assembly
maven-compilder-plugin
2.3.2
1.7
1.7
UTF-8
1)在Util包上面编撰一个读取文件的类(并返回一个以换行分割的列表,拿取系统的种子) 读取seeds.txt上面的内容:
public static List getFileLineList(String filePath,String charset) throws IOException{
File fileObj = new File(filePath);
FileInputStream fis = new FileInputStream(fileObj);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr);
List lineList = new ArrayList();
String temp = null;
while ((temp = br.readLine()) != null) {
temp = temp.trim();
if(temp.length()>0) {
lineList.add(temp);
}
}
br.close();
return lineList;
}
2)在储存常量的类上面编撰一个util类编撰一类储存常量
public class StaticValue {
public final static String NEXT_LINE="\n";
public final static String ENCODING_DEFAULT="utf-8";
}
3)在download包上面编撰一个爬取网页的类传入url的编码(url,charset)输出网页内容:
(但是这样网页的编码是固定传入没有自由应变)
public static String getHtmlSourceBySocket(String url,String charset) throws Exception {
URL urlObj = new URL(url);
InputStream is = urlObj.openStream();
InputStreamReader isr = new InputStreamReader(is,charset);
BufferedReader br = new BufferedReader(isr);
StringBuilder stringBuilder = new StringBuilder();
String temp = null;
int lineCounter = 0;
while((temp=br.readLine())!=null) {
if(lineCounter>0) {
stringBuilder.append(StaticValue.NEXT_LINE);
}
lineCounter++;
stringBuilder.append(temp);
}
br.close();
return stringBuilder.toString();
}
4)根据具体情况来改变爬虫所对应的编码方式,分为两种
第一种:根据网页源码上面的Conten-Type属性来获取编码( 最准的形式):
代码实现获取:
public static String getCharset(String url) throws Exception {
String finalCharset = null;
URL urlObj = new URL(url);
URLConnection urlConn = urlObj.openConnection();
//用header来获取url的charset
Map allHeaderMap = urlConn.getHeaderFields();
List kvList = allHeaderMap.get("Conten-Type");
if(kvList!=null&&!kvList.isEmpty()) {
String line = kvList.get(0);
String[] kvArray = line.split(";");
for (String kv : kvArray) {
String[] eleArray = kv.split("=");
if(eleArray.length==2) {
if(eleArray[0].equals("charset")) {
finalCharset = eleArray[1].trim();
}
}
}
}
System.out.println(finalCharset);//finalCharset为取出的Conten-Type的值
}
第二种:根据网页源码的…里面的meta上面对应的charset属性的值来获取编码
代码实现获取:
public static String getCharset(String url) throws Exception {
BufferedReader br = WebPageDownLoadUtil.getBR(url,StaticValue.ENCODING_DEFAULT);
String temp = null;
while((temp=br.readLine())!=null) {
temp = temp.toLowerCase();//把网页源码都转成小写
String charset = getCharsetVaue4Line(temp);
if(charset!=null) {
finalCharset=charset;
System.out.println(charset);
break;
}
if(temp.contains("")) {
break;
}
}
br.close();
}
根据第二种方式要搭建对应的正值表达式来匹配对应的网页依照网页的具体情况来设定,如:
public static String getCharsetVaue4Line(String line) {
String regex = "charset=\"?(.+?)\"?\\s?/?>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(line);
String charsetValue = null;
if(matcher.find()) {
charsetValue = matcher.group(1);
}
return charsetValue ;
}
然后把前面两种情况结合一下,在第一种情况获取不到的情况下依据第二种方案来获取 :
结合代码为:
[文章]超实用:通过Excel进行数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-10 15:27
IBM大中华区总经理胡世忠曾说:数据构成了智慧月球的三大元素——智能化、互联化和物联化,而这三大元素又改变了数据来源、传送方法和借助形式,带来“大数据”这场信息社会的变迁。
从上可见,时代的改革是始于对数据的借助,对企业而言,数据也同样是其发展、转型的命脉。在工作中,我的高手不止一次地指出,数据是公司的资产,而且举足轻重。我们对待数据,一定要严谨,经得起考验,对自己的数据负责,这是一个数据人的基本要求。
数据资源
大数据时代,数据尽管好多,但是也不是随便得来的,需要借助各类渠道和方法获得。不管从那个角度来说,数据可分为内部数据和外部数据。内部数据是企业在日积月累的经营中得来的,我们应当对那些数据挖掘、采集有价值的东西,形成企业的数据资产。内部数据重在后期的处理和剖析上。
下面先说外部数据的获取方法,以及通过Excel操作来获取外部数据。
外部数据获取方法
1、专业网站看数据(某一个行业、某一件产品)2、通过收费渠道买数据(第三方数据平台等)3、通过特殊方式引数据(网站爬虫,统计网站等)4、自身积累数据(时间久、跨度长)
Excel获取外部数据
作为一个数据分析师以及想更进一步成长为数据科学家,熟练操作基本的办公软件以及SQL查询是很重要的。请看下边通过Excel获取外部数据的步骤。
第1步:打开“新建web查询”框。新建Excel工作簿,在打开的工作表中单击“数据”选项卡,然后在“获取外部数据”组中单击“自网站”按钮,如下图。
第2步:输入网址并选择要导出的表格数据。在弹出的“新建web查询”对话框中的“地址”文本框中复制粘贴上述网页的网址,然后单击“转到”,找到网站中的表格数据后单击表格左上角的箭头→,图标弄成选中状态的复选框√。如下图。最后单击下方的“导入”按钮。
第3步:选择数据的放置区域。点击导出后,Excel会出现“导入数据”对话框,如下图,选中你想放置的单元格,单击“确定”开始导出。
第4步:美化导出的数据。由于导出的数据多且乱,要调整格式让数据规范,并启用冻结窗棂功能便捷浏览。如下图。
好了,上面就是通过Excel操作来获取网站上的外部数据,很简单吧,但网站中的数据并非都是以表格的方式呈现,现在大部分是以json格式呈现,Excel不是万能的,而且如今好多网站需要付费就能导数据(上面说过数据就是企业的资产)。
小结
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。
End. 查看全部
前言
IBM大中华区总经理胡世忠曾说:数据构成了智慧月球的三大元素——智能化、互联化和物联化,而这三大元素又改变了数据来源、传送方法和借助形式,带来“大数据”这场信息社会的变迁。
从上可见,时代的改革是始于对数据的借助,对企业而言,数据也同样是其发展、转型的命脉。在工作中,我的高手不止一次地指出,数据是公司的资产,而且举足轻重。我们对待数据,一定要严谨,经得起考验,对自己的数据负责,这是一个数据人的基本要求。
数据资源
大数据时代,数据尽管好多,但是也不是随便得来的,需要借助各类渠道和方法获得。不管从那个角度来说,数据可分为内部数据和外部数据。内部数据是企业在日积月累的经营中得来的,我们应当对那些数据挖掘、采集有价值的东西,形成企业的数据资产。内部数据重在后期的处理和剖析上。
下面先说外部数据的获取方法,以及通过Excel操作来获取外部数据。
外部数据获取方法
1、专业网站看数据(某一个行业、某一件产品)2、通过收费渠道买数据(第三方数据平台等)3、通过特殊方式引数据(网站爬虫,统计网站等)4、自身积累数据(时间久、跨度长)
Excel获取外部数据
作为一个数据分析师以及想更进一步成长为数据科学家,熟练操作基本的办公软件以及SQL查询是很重要的。请看下边通过Excel获取外部数据的步骤。
第1步:打开“新建web查询”框。新建Excel工作簿,在打开的工作表中单击“数据”选项卡,然后在“获取外部数据”组中单击“自网站”按钮,如下图。
第2步:输入网址并选择要导出的表格数据。在弹出的“新建web查询”对话框中的“地址”文本框中复制粘贴上述网页的网址,然后单击“转到”,找到网站中的表格数据后单击表格左上角的箭头→,图标弄成选中状态的复选框√。如下图。最后单击下方的“导入”按钮。
第3步:选择数据的放置区域。点击导出后,Excel会出现“导入数据”对话框,如下图,选中你想放置的单元格,单击“确定”开始导出。
第4步:美化导出的数据。由于导出的数据多且乱,要调整格式让数据规范,并启用冻结窗棂功能便捷浏览。如下图。
好了,上面就是通过Excel操作来获取网站上的外部数据,很简单吧,但网站中的数据并非都是以表格的方式呈现,现在大部分是以json格式呈现,Excel不是万能的,而且如今好多网站需要付费就能导数据(上面说过数据就是企业的资产)。
小结
希望通过前面的操作能帮助你们。如果你有哪些好的意见,建议,或者有不同的想法,我都希望你留言和我们进行交流、讨论。
End.
ELK方便的日志采集,搜索和显示工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-09 01:50
1. 日志采集与分析Logstash
LogstashLogstash是用于接收,处理和转发日志的工具. 它支持系统日志,Web服务器日志,错误日志和应用程序日志,包括可以丢弃的所有类型的日志.
Logstash的哲学很简单,它只做三件事:
采集: 数据输入充实: 数据处理,例如过滤,重写等. 传输: 数据输出
不要只看它,因为它只做三件事,但是通过组合输入和输出,可以更改多种架构以满足多种需求. 这只是解决日志摘要要求的部署架构图:
说明术语:
无论是托运人还是索引器,Logstash始终仅执行上述三件事:
Logstash进程可以具有多个输入源,因此Logstash进程可以同时读取服务器上的多个日志文件. Redis是Logstash正式推荐的Broker角色的“候选人”. 它支持两种数据传输模式,订阅发布和队列,建议使用. 输入和输出支持过滤和重写. Logstash支持多个输出源. 您可以配置多个输出以实现数据的多个副本,或输出到Email,File,Tcp,或作为其他程序的输入,或安装插件以实现与其他系统(例如搜索引擎Elasticsearch)的对接.
摘要: Logstash概念简单,可以通过组合满足多种需求.
2,日志搜索Elasticsearch
Elasticsearch是一个实时的分布式搜索和分析引擎. 它可以帮助您以前所未有的速度处理大规模数据.
它可以用于全文搜索,结构化搜索和分析,当然您也可以将这三者结合起来.
Elasticsearch是基于全文搜索引擎Apache Lucene™的搜索引擎. 可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架.
但是Lucene只是一个框架. 要充分利用其功能,您需要使用JAVA并将Lucene集成到程序中. 要了解它的工作原理,需要大量的学习和理解,Lucene确实非常复杂.
Elasticsearch使用Lucene作为其内部引擎,但是将其用于全文搜索时,您只需要使用统一开发的API,就无需了解Lucene的复杂操作原理.
当然,Elasticsearch并不像Lucene一样简单. 它不仅包括全文搜索功能,还包括以下任务:
服务器中集成了许多功能,您可以通过客户端或您喜欢的任何编程语言轻松地与ES的RESTful API通信.
使用Elasticsearch入门非常简单. 它带有许多非常合理的默认值,使初学者可以避免一开始就面对复杂的理论.
安装后即可使用,而且学习成本低,生产率很高.
随着学习的深入和深入,您还可以使用Elasticsearch的更多高级功能,并且可以灵活配置整个引擎. 您可以根据自己的需求自定义自己的Elasticsearch.
用例:
但是Elasticsearch不仅适用于大型企业,它还帮助了DataDog和Klout等许多初创公司扩展了功能.
这里简要介绍了与solr的比较,因为solr是目前最简化的搜索引擎,为什么不选择它呢?
3. 日志显示Kibana
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch一起使用. 您可以使用kibana搜索,查看和与Elasticsearch索引中存储的数据进行交互. 使用各种图表,表格,地图等,kibana可以轻松显示高级数据分析和可视化.
Kibana使我们易于理解大量数据. 它基于浏览器的简单界面允许您快速创建和共享动态仪表板,这些仪表板实时显示Elasticsearch查询中的更改. 安装Kibana的速度非常快. 您可以在几分钟之内安装并开始探索您的Elasticsearch索引数据,而无需编写任何代码,也没有任何其他基本软件依赖性.
摘要
整套软件可以看作是MVC模型,logstash是控制器层,Elasticsearch是模型层,kibana是视图层.
首先将数据传输到logstash,它将对数据进行过滤和格式化(转换为JSON格式),然后将其传输到Elasticsearch进行存储并构建搜索索引. Kibana提供用于搜索和图表可视化的前端页面. 它将可视化通过调用Elasticsearch接口返回的数据. Logstash和Elasticsearch用Java编写,而kibana使用node.js框架. 具体建筑物的配置这里就不详细解释了,可以自己百度,其实很简单. 查看全部
在开发子部署系统时,经常会因为查找日志而感到头疼,因为每个服务器和每个应用程序都有自己的日志,但是它分散且查找起来比较麻烦. 今天,我推荐了一套方便的ELK工具,ELK是Elastic开发的完整的日志分析技术堆栈. 它们是Elasticsearch,Logstash和Kibana,称为ELK. Logstash进行日志采集和分析,Elasticsearch是搜索引擎,而Kibana是Web显示界面.
1. 日志采集与分析Logstash
LogstashLogstash是用于接收,处理和转发日志的工具. 它支持系统日志,Web服务器日志,错误日志和应用程序日志,包括可以丢弃的所有类型的日志.
Logstash的哲学很简单,它只做三件事:
采集: 数据输入充实: 数据处理,例如过滤,重写等. 传输: 数据输出
不要只看它,因为它只做三件事,但是通过组合输入和输出,可以更改多种架构以满足多种需求. 这只是解决日志摘要要求的部署架构图:
说明术语:
无论是托运人还是索引器,Logstash始终仅执行上述三件事:
Logstash进程可以具有多个输入源,因此Logstash进程可以同时读取服务器上的多个日志文件. Redis是Logstash正式推荐的Broker角色的“候选人”. 它支持两种数据传输模式,订阅发布和队列,建议使用. 输入和输出支持过滤和重写. Logstash支持多个输出源. 您可以配置多个输出以实现数据的多个副本,或输出到Email,File,Tcp,或作为其他程序的输入,或安装插件以实现与其他系统(例如搜索引擎Elasticsearch)的对接.
摘要: Logstash概念简单,可以通过组合满足多种需求.
2,日志搜索Elasticsearch
Elasticsearch是一个实时的分布式搜索和分析引擎. 它可以帮助您以前所未有的速度处理大规模数据.
它可以用于全文搜索,结构化搜索和分析,当然您也可以将这三者结合起来.
Elasticsearch是基于全文搜索引擎Apache Lucene™的搜索引擎. 可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架.
但是Lucene只是一个框架. 要充分利用其功能,您需要使用JAVA并将Lucene集成到程序中. 要了解它的工作原理,需要大量的学习和理解,Lucene确实非常复杂.
Elasticsearch使用Lucene作为其内部引擎,但是将其用于全文搜索时,您只需要使用统一开发的API,就无需了解Lucene的复杂操作原理.
当然,Elasticsearch并不像Lucene一样简单. 它不仅包括全文搜索功能,还包括以下任务:
服务器中集成了许多功能,您可以通过客户端或您喜欢的任何编程语言轻松地与ES的RESTful API通信.
使用Elasticsearch入门非常简单. 它带有许多非常合理的默认值,使初学者可以避免一开始就面对复杂的理论.
安装后即可使用,而且学习成本低,生产率很高.
随着学习的深入和深入,您还可以使用Elasticsearch的更多高级功能,并且可以灵活配置整个引擎. 您可以根据自己的需求自定义自己的Elasticsearch.
用例:
但是Elasticsearch不仅适用于大型企业,它还帮助了DataDog和Klout等许多初创公司扩展了功能.
这里简要介绍了与solr的比较,因为solr是目前最简化的搜索引擎,为什么不选择它呢?
3. 日志显示Kibana
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch一起使用. 您可以使用kibana搜索,查看和与Elasticsearch索引中存储的数据进行交互. 使用各种图表,表格,地图等,kibana可以轻松显示高级数据分析和可视化.
Kibana使我们易于理解大量数据. 它基于浏览器的简单界面允许您快速创建和共享动态仪表板,这些仪表板实时显示Elasticsearch查询中的更改. 安装Kibana的速度非常快. 您可以在几分钟之内安装并开始探索您的Elasticsearch索引数据,而无需编写任何代码,也没有任何其他基本软件依赖性.
摘要
整套软件可以看作是MVC模型,logstash是控制器层,Elasticsearch是模型层,kibana是视图层.
首先将数据传输到logstash,它将对数据进行过滤和格式化(转换为JSON格式),然后将其传输到Elasticsearch进行存储并构建搜索索引. Kibana提供用于搜索和图表可视化的前端页面. 它将可视化通过调用Elasticsearch接口返回的数据. Logstash和Elasticsearch用Java编写,而kibana使用node.js框架. 具体建筑物的配置这里就不详细解释了,可以自己百度,其实很简单.
如何实时监控微信订阅帐号推送的文章?
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-08 05:40
如何查看微信公众号文章的真实性?
Tuotu Data的工作人员告诉我,没有任何官方帐户运营商可以避免处理“原创”文章. 有可能转发没有标记文章的文章,努力修改内容集成,并在批量发布期间由系统通知以匹配原创文章,这是浪费时间. 做半原创文章,从他人的官方帐户借用太多文章,不能标记原创文章,并且很难更改.
微信公众平台不提供文章原创性的检测,而是简单粗鲁地提示文章与原文相符. 在撰写半原创文章时,由于参考文献过多,因此与原创文章匹配,而且我不知道从哪里开始. 您可以将文章链接放在原创测试中进行测试. 测试结果将指示与该文章的近似相似性,然后根据相似性情况对其进行修改. 相似性具有参考价值.
为了防止其他人重印未标记的文章并且徒劳地工作,我可以选择要重印的文章,首先将原创文章进行测试. 确认这是非原创文章后,您可以对其进行修改而不必担心.
Tuotu Data的工作人员告诉您,操作非常简单. 您只需要在工具箱中打开原创检测功能,然后粘贴原创文章即可执行检测. 此功能非常适合半原创和重新打印的操作员. 您很有帮助,记得帮我点菜〜
微信公众号敏感词检测
当您在官方帐户上写完文章并单击“发布”或“保存”后,有时会提示您输入敏感词,如果不进行修改,则会将其删除:
1. 您正在编辑的图形消息可能收录敏感内容. 您可以继续保存或发布图形消息(发布的等待时间约为3-4小时). 保存或发布后,将验证其中收录敏感内容. ,它可能会被删除,阻止等. 请检查相应的规则.
2. 您编辑的图形消息可能收录涉嫌不当使用州机构或州机构工作人员名称或图像的表达方式,包括但不限于名称,缩写和参考名称. 您可以继续保存,也可以在发布图形消息后,如果在保存或发布图形消息后确认它收录上述相关内容,则可以将其删除或阻止.
发生以上两种情况. 如果文章中的单词数很少,则可以逐一检查,但是如果找不到收录数千个单词的文章,为了解决此问题,我创建了一个公共帐户来检测敏感词. 需要检测的文本将发送到官方帐户,并返回敏感词及其在文本中的位置.
本文主要介绍了官方账号文章监控的三个方面,分别是官方账号文章监控功能的介绍,如何检测微信官方账号文章的原创性以及微信官方账号中敏感词的检测,希望. 寻求朋友的帮助. 查看全部
实时监控官方帐户商品更新并将其推送给用户,支持两种监控方法: 1.关键字搜索2.微信搜索. 这对于诸如舆论监视之类的各种应用场景都很方便. 还有许多第三方工具可以实时监视官方帐户发布的文章,以及推送文章. 让我们以Tuotu数据为例.
如何查看微信公众号文章的真实性?
Tuotu Data的工作人员告诉我,没有任何官方帐户运营商可以避免处理“原创”文章. 有可能转发没有标记文章的文章,努力修改内容集成,并在批量发布期间由系统通知以匹配原创文章,这是浪费时间. 做半原创文章,从他人的官方帐户借用太多文章,不能标记原创文章,并且很难更改.
微信公众平台不提供文章原创性的检测,而是简单粗鲁地提示文章与原文相符. 在撰写半原创文章时,由于参考文献过多,因此与原创文章匹配,而且我不知道从哪里开始. 您可以将文章链接放在原创测试中进行测试. 测试结果将指示与该文章的近似相似性,然后根据相似性情况对其进行修改. 相似性具有参考价值.
为了防止其他人重印未标记的文章并且徒劳地工作,我可以选择要重印的文章,首先将原创文章进行测试. 确认这是非原创文章后,您可以对其进行修改而不必担心.
Tuotu Data的工作人员告诉您,操作非常简单. 您只需要在工具箱中打开原创检测功能,然后粘贴原创文章即可执行检测. 此功能非常适合半原创和重新打印的操作员. 您很有帮助,记得帮我点菜〜
微信公众号敏感词检测
当您在官方帐户上写完文章并单击“发布”或“保存”后,有时会提示您输入敏感词,如果不进行修改,则会将其删除:
1. 您正在编辑的图形消息可能收录敏感内容. 您可以继续保存或发布图形消息(发布的等待时间约为3-4小时). 保存或发布后,将验证其中收录敏感内容. ,它可能会被删除,阻止等. 请检查相应的规则.
2. 您编辑的图形消息可能收录涉嫌不当使用州机构或州机构工作人员名称或图像的表达方式,包括但不限于名称,缩写和参考名称. 您可以继续保存,也可以在发布图形消息后,如果在保存或发布图形消息后确认它收录上述相关内容,则可以将其删除或阻止.
发生以上两种情况. 如果文章中的单词数很少,则可以逐一检查,但是如果找不到收录数千个单词的文章,为了解决此问题,我创建了一个公共帐户来检测敏感词. 需要检测的文本将发送到官方帐户,并返回敏感词及其在文本中的位置.
本文主要介绍了官方账号文章监控的三个方面,分别是官方账号文章监控功能的介绍,如何检测微信官方账号文章的原创性以及微信官方账号中敏感词的检测,希望. 寻求朋友的帮助.
如何获取实时库存数据(采集《东方财富》). docx12页
采集交流 • 优采云 发表了文章 • 0 个评论 • 434 次浏览 • 2020-08-08 00:18
步骤3: 分页表信息采集选择需要采集的字段信息,创建采集列表,编辑采集字段名称1)移动鼠标以选择表中的任何空白信息,单击鼠标右键,如图所示在图中,将选中框中的数据,变为绿色,单击右侧的提示,然后单击“ TR”. 如何获取实时库存数据(采集Oriental Fortune)图62)当前的数据选中的数据行将全部选中,单击“选中的子元素”,如何获取实时库存数据(Collect Oriental Wealth)图73)在右侧的操作提示框中,查看提取的字段,可以删除不必要的字段中,单击“全选”. 如何获取实时库存数据(采集东方财富)图84)单击“采集以下数据”. 如何获取实时库存数据(采集东方财富)图9注意: ?在提示框中的字段上将出现一个“ X”,单击以删除该字段. 如何获取实时库存数据(采集Oriental Fortune)图105)修改采集任务名称和字段名称,然后在下面的提示中单击“保存并开始采集”. 如何获取实时库存数据(采集Oriental Fortune)图116)根据采集的情况选择适当的采集方法,在这里选择“开始本地采集”如何获取实时库存数据(采集东方财富)图12说明: 本地采集占用当前计算机资源进行采集,如果有的话是采集时间要求,或者当前的计算机不能长时间采集. 使用云采集功能,可以在网络中采集云采集,而无需当前的计算机支持,可以关闭计算机,并可以设置多个云节点来分配任务. 10个节点相当于10台计算机来分配任务以帮助您采集数据,并且速度降低到原来的十分之一;采集的数据可以存储在云中三个月,并且可以随时导出.
第4步: HYPERLINK“ / article / javascript :;”数据采集与导出1)采集完成后,将弹出提示,选择如何导出数据以获取实时库存数据(采集东方财富). 图132)选择适当的导出方法,导出采集的数据. 获取实时库存数据(采集《东方财富》)图14相关的采集教程: 优采云的采集原理黄页88数据采集搜狗微信文章采集优采云-70万用户选择的Web数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
如何从优采云·云采集服务平台获取实时股票数据优采云·云采集服务平台(东方财富)随着互联网大数据的发展,大数据分析对各行各业产生了不同程度的影响. 生活的影响. 金融业是非常有代表性的产业. 本文将以金融业为例. 在大数据时代,金融机构之间的竞争将在网络信息平台上全面展开. 归根结底,“数据为王”. 拥有数据的人将具有定价风险的能力,并且可以获得高风险回报的人最终将获得竞争优势. 因此,有效获取和使用与Web相关的数据是做好金融业的重要组成部分. 金融业非常依赖数据,具有数据量大和及时性高的特点. 在考虑对Web数据进行爬网的方式时,还必须充分考虑这些特征. 优采云采集器易于使用且功能强大. 其特点是云采集: 大量的企业云不间断运行24 * 7,可以实时采集所需的数据;无需担心IP阻塞和网络中断,并且可以立即采集大量数据. 以下是优采云采集东方财富的完整示例. 该示例中采集的数据是Oriental Fortune.com的A股数据. 集合网站: /center/list.html#10步骤1: HYPERLINK“ / article / javascript :;”创建采集任务1)进入主界面,选择,选择自定义模式如何获取实时库存数据(采集东方财富)图12)将上述URL的URL复制并粘贴到网站输入框中,单击“保存URL”如何获取实时库存数据(采集东方财富)图23)保存URL后,将在优采云采集器的红色框中打开页面. 评估信息是要在其中采集的内容. 演示如何获取实时库存数据(采集《东方财富》)图3步骤2: HYPERLINK“ / article / javascript :;”创建翻页周期找到翻页按钮,设置翻页周期,设置ajax翻页时间1)将页面下拉到底部,找到下一页按钮,单击鼠标,然后选择“循环单击下一页”页面”在右侧的操作提示框中. 如何获取实时库存数据(采集Eastern Fortune)图4由于使用了页面Ajax加载技术,因此需要为click元素和页面翻转步骤设置ajax延迟加载(ajax判断方法: 打开流程图,查找翻页循环框,手动执行翻页,查看是否已加载网站)在高级选项框中,选中Ajax以加载数据,选择适当的超时时间,通常设置为2秒;最后单击以确认如何获取实时库存数据(采集Eastern Fortune). 图5注意: 单击右上角的“处理”按钮,可以显示可视流程图.
步骤3: 分页表信息采集选择需要采集的字段信息,创建采集列表,编辑采集字段名称1)移动鼠标以选择表中的任何空白信息,单击鼠标右键,如图所示在图中,将选中框中的数据,变为绿色,单击右侧的提示,然后单击“ TR”. 如何获取实时库存数据(采集Oriental Fortune)图62)当前的数据选中的数据行将全部选中,单击“选中的子元素”,如何获取实时库存数据(Collect Oriental Wealth)图73)在右侧的操作提示框中,查看提取的字段,可以删除不必要的字段中,单击“全选”. 如何获取实时库存数据(采集东方财富)图84)单击“采集以下数据”. 如何获取实时库存数据(采集东方财富)图9注意: ?在提示框中的字段上将出现一个“ X”,单击以删除该字段. 如何获取实时库存数据(采集Oriental Fortune)图105)修改采集任务名称和字段名称,然后在下面的提示中单击“保存并开始采集”. 如何获取实时库存数据(采集Oriental Fortune)图116)根据采集的情况选择适当的采集方法,在这里选择“开始本地采集”如何获取实时库存数据(采集东方财富)图12说明: 本地采集占用当前计算机资源进行采集,如果有的话是采集时间要求,或者当前的计算机不能长时间采集. 使用云采集功能,可以在网络中采集云采集,而无需当前的计算机支持,可以关闭计算机,并可以设置多个云节点来分配任务. 10个节点相当于10台计算机来分配任务以帮助您采集数据,并且速度降低到原来的十分之一;采集的数据可以存储在云中三个月,并且可以随时导出.
第4步: HYPERLINK“ / article / javascript :;”数据采集与导出1)采集完成后,将弹出提示,选择如何导出数据以获取实时库存数据(采集东方财富). 图132)选择适当的导出方法,导出采集的数据. 获取实时库存数据(采集《东方财富》)图14相关的采集教程: 优采云的采集原理黄页88数据采集搜狗微信文章采集优采云-70万用户选择的Web数据采集器. 1.操作简单,任何人都可以使用: 不需要技术背景,可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.
C ++实现RTMP协议以发送H.264编码和AAC编码的音频和视频,摄像机直播
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-07 22:27
RTMP(实时消息协议)是一种专门用于传输音频和视频数据的流媒体协议. 它最初由Macromedia创建,后来由Adobe拥有. 它是一个专用协议,主要用于联系Flash Player和RtmpServer. 如FMS,Red5,crtmpserver等. RTMP协议可用于实现实时广播和点播应用程序,并通过FMLE(闪存媒体实时编码器)将音频和视频数据推送到RtmpServer,从而可实现实时实时摄像机的广播. 但是,毕竟FMLE的应用范围是有限的. 如果要将其嵌入自己的程序中,则仍然必须自己实现RTMP协议推送. 我实现了一个RTMPLiveEncoder,它可以采集摄像机视频和麦克风音频,并使用H.264和AAC对其进行编码,然后将它们发送到FMS和crtmpserver以实现实时实时广播,可以通过Flash Player正常观看. 当前效果良好,延迟时间约为2秒. 本文介绍了RTMPLiveEncoder的主要思想和要点,希望能帮助需要此技术的朋友.
技术分析
要实现RTMPLiveEncoder,需要以下四个关键技术:
其中,在前一篇文章“音频和摄像机视频的获取以及实时H264编码和AAC编码”中介绍了前两种技术,因此在这里我不会太冗长.
将音频和视频数据打包到可播放的流中是困难的一点. 如果仔细研究,您会发现封装在RTMP数据包中的音频和视频数据流实际上与封装音频和视频数据的FLV相同. 因此,我们只需要根据FLV封装H264和AAC即可生成Play流.
让我们再次看看RTMP协议. Adobe曾经发布过一个文档“ RTMP规范”,但是Wikipedia指出该文档隐藏了许多细节,仅凭它不可能正确实现RTMP. 但是,它仍然具有参考意义. 实际上,RTMP协议在Adobe发布之前就几乎被破解了,现在有相对完整的实现,例如RTMPDump,它提供了C语言接口,这意味着可以用其他语言轻松地调用它.
程序框架
与我之前在“获取音频和摄像机视频以及实时H264编码和AAC编码”之前写的文章相同,该文章使用DirectShow技术在各自的线程(AudioEncoderThread)中实现音频和视频捕获,音频编码和视频编码和VideoEncoderThread),在中间循环中,RTMP的推送将启动另一个线程(RtmpThread). 两个编码线程对音频和视频数据进行实时编码后,将数据移交给Rtmp线程,然后Rtmp线程循环封装Rtmp数据包,然后将其发送出去.
线程之间的数据交换是通过队列DataBufferQueue实现的. 将数据指针发布到DataBufferQueue后,AudioEncoderThread和VideoEncoderThread将立即返回,以避免由于发送Rtmp消息而影响编码线程的正常执行时间.
RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,并不断从DataBufferQueue中取出数据,将其封装为RTMP数据包,然后发送出来. 该过程如以下代码所示: (process_buf_queue_,即上图中的DataBufferQueue)
librtmp一,编译librtmp
下载rtmpdump的代码,您会发现它是一个真实的linux项目,除了简单的Makefile,其他都没有. 看来librtmp并不依赖于系统,因此我们可以在Windows上编译它而无需花费太多的精力. 但是,librtmp依赖于openssl和zlib,我们需要首先对其进行编译.
1. 编译openssl1.0.0e
a)下载并安装ActivePerl
b)下载并安装nasm()
c)解压缩openssl压缩包
d)运行cmd命令行,切换到openssl目录,并分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir<br />>ms\do_nasm
e)运行Visual Studio命令提示符(2010),切换到openssl目录,并分别执行以下命令.
>nmake -f ms\nt.mak<br />>nmake -f ms\nt.mak install
f)编译完成后,您可以在第一个命令指定的目录中找到已编译的SDK.
2. 编译zlib
a)解压缩zlib压缩包
b)运行Visual Studio命令提示符(2010),剪切到openssl目录,并分别执行以下命令
>cd contrib\masmx86<br />>bld_ml32.bat
c)返回zlib目录,输入contrib \ vstudio \ vc10目录,然后打开vs2010解决方案文件,
在zlibstat的项目属性中,删除预编译的宏ZLIB_WINAPI
d)选择调试或发布进行编译.
3. 编译librtmp
a)首先打开Visual Studio 2010,创建一个新的win32控制台项目,并将其指定为静态链接库
b)将librtmp代码导入到项目中,将openssl,zlib头文件和librtmp放在一起,并将已编译的openssl和zlib静态库放在一起
c)在项目设置中,添加先前编译的openssl和zlib库并进行编译.
二,使用librtmp
首先初始化RTMP结构
启动后,有必要向RTMP服务器发起握手连接消息
如果连接成功,则可以开始循环发送消息. 在这里,您需要指定时间戳和数据类型(音频,视频,元数据). 这里要注意的一件事是,在调用Send之前,buf中的数据必须是封装的H264或AAC数据流.
关闭
最后一个是发布
H264和AAC数据流
如本文所述,RTMP推送的音频和视频流的封装形式类似于FLV格式. 可以看出,要将H264和AAC实时流推送到FMS,您需要首先发送“ AVC序列头”和“ AAC序列头”. 这两个数据收录重要的编码信息,没有它们,解码器将无法解码.
AVC序列标头是AVCDecoderConfigurationRecord结构,在标准文档“ ISO-14496-15 AVC文件格式”中对其进行了详细说明.
AAC序列标头存储AudioSpecificConfig结构,该结构在“ ISO-14496-3音频”中进行了描述. AudioSpecificConfig结构的描述非常复杂. 在这里我将简化它. 设置要预先编码的音频格式. 其中,选择“ AAC-LC”作为音频编码,音频采样率为44100,因此AudioSpecificConfig简化为下表:
通过这种方式,可以基本确定AVC序列头和AAC序列头的内容. 有关更多详细信息,您可以转到相关文档.
操作效果
RtmpLiveEncoder开始运行
使用FMS随附的Flash播放器
++++++++++++++++++++++++++++++++++++++++++++++++ ++ ++++++++++++++++ 查看全部
C ++实现RTMP协议以发送H.264编码和AAC编码的音频和视频
RTMP(实时消息协议)是一种专门用于传输音频和视频数据的流媒体协议. 它最初由Macromedia创建,后来由Adobe拥有. 它是一个专用协议,主要用于联系Flash Player和RtmpServer. 如FMS,Red5,crtmpserver等. RTMP协议可用于实现实时广播和点播应用程序,并通过FMLE(闪存媒体实时编码器)将音频和视频数据推送到RtmpServer,从而可实现实时实时摄像机的广播. 但是,毕竟FMLE的应用范围是有限的. 如果要将其嵌入自己的程序中,则仍然必须自己实现RTMP协议推送. 我实现了一个RTMPLiveEncoder,它可以采集摄像机视频和麦克风音频,并使用H.264和AAC对其进行编码,然后将它们发送到FMS和crtmpserver以实现实时实时广播,可以通过Flash Player正常观看. 当前效果良好,延迟时间约为2秒. 本文介绍了RTMPLiveEncoder的主要思想和要点,希望能帮助需要此技术的朋友.
技术分析
要实现RTMPLiveEncoder,需要以下四个关键技术:
其中,在前一篇文章“音频和摄像机视频的获取以及实时H264编码和AAC编码”中介绍了前两种技术,因此在这里我不会太冗长.
将音频和视频数据打包到可播放的流中是困难的一点. 如果仔细研究,您会发现封装在RTMP数据包中的音频和视频数据流实际上与封装音频和视频数据的FLV相同. 因此,我们只需要根据FLV封装H264和AAC即可生成Play流.
让我们再次看看RTMP协议. Adobe曾经发布过一个文档“ RTMP规范”,但是Wikipedia指出该文档隐藏了许多细节,仅凭它不可能正确实现RTMP. 但是,它仍然具有参考意义. 实际上,RTMP协议在Adobe发布之前就几乎被破解了,现在有相对完整的实现,例如RTMPDump,它提供了C语言接口,这意味着可以用其他语言轻松地调用它.
程序框架
与我之前在“获取音频和摄像机视频以及实时H264编码和AAC编码”之前写的文章相同,该文章使用DirectShow技术在各自的线程(AudioEncoderThread)中实现音频和视频捕获,音频编码和视频编码和VideoEncoderThread),在中间循环中,RTMP的推送将启动另一个线程(RtmpThread). 两个编码线程对音频和视频数据进行实时编码后,将数据移交给Rtmp线程,然后Rtmp线程循环封装Rtmp数据包,然后将其发送出去.
线程之间的数据交换是通过队列DataBufferQueue实现的. 将数据指针发布到DataBufferQueue后,AudioEncoderThread和VideoEncoderThread将立即返回,以避免由于发送Rtmp消息而影响编码线程的正常执行时间.
RtmpThread的主要工作是发送音频数据流的解码信息头和视频数据流的解码信息头,并不断从DataBufferQueue中取出数据,将其封装为RTMP数据包,然后发送出来. 该过程如以下代码所示: (process_buf_queue_,即上图中的DataBufferQueue)
librtmp一,编译librtmp
下载rtmpdump的代码,您会发现它是一个真实的linux项目,除了简单的Makefile,其他都没有. 看来librtmp并不依赖于系统,因此我们可以在Windows上编译它而无需花费太多的精力. 但是,librtmp依赖于openssl和zlib,我们需要首先对其进行编译.
1. 编译openssl1.0.0e
a)下载并安装ActivePerl
b)下载并安装nasm()
c)解压缩openssl压缩包
d)运行cmd命令行,切换到openssl目录,并分别执行以下命令
>perl Configure VC-WIN32 --prefix=c:\some\dir<br />>ms\do_nasm
e)运行Visual Studio命令提示符(2010),切换到openssl目录,并分别执行以下命令.
>nmake -f ms\nt.mak<br />>nmake -f ms\nt.mak install
f)编译完成后,您可以在第一个命令指定的目录中找到已编译的SDK.
2. 编译zlib
a)解压缩zlib压缩包
b)运行Visual Studio命令提示符(2010),剪切到openssl目录,并分别执行以下命令
>cd contrib\masmx86<br />>bld_ml32.bat
c)返回zlib目录,输入contrib \ vstudio \ vc10目录,然后打开vs2010解决方案文件,
在zlibstat的项目属性中,删除预编译的宏ZLIB_WINAPI
d)选择调试或发布进行编译.
3. 编译librtmp
a)首先打开Visual Studio 2010,创建一个新的win32控制台项目,并将其指定为静态链接库
b)将librtmp代码导入到项目中,将openssl,zlib头文件和librtmp放在一起,并将已编译的openssl和zlib静态库放在一起
c)在项目设置中,添加先前编译的openssl和zlib库并进行编译.
二,使用librtmp
首先初始化RTMP结构
启动后,有必要向RTMP服务器发起握手连接消息
如果连接成功,则可以开始循环发送消息. 在这里,您需要指定时间戳和数据类型(音频,视频,元数据). 这里要注意的一件事是,在调用Send之前,buf中的数据必须是封装的H264或AAC数据流.
关闭
最后一个是发布
H264和AAC数据流
如本文所述,RTMP推送的音频和视频流的封装形式类似于FLV格式. 可以看出,要将H264和AAC实时流推送到FMS,您需要首先发送“ AVC序列头”和“ AAC序列头”. 这两个数据收录重要的编码信息,没有它们,解码器将无法解码.
AVC序列标头是AVCDecoderConfigurationRecord结构,在标准文档“ ISO-14496-15 AVC文件格式”中对其进行了详细说明.
AAC序列标头存储AudioSpecificConfig结构,该结构在“ ISO-14496-3音频”中进行了描述. AudioSpecificConfig结构的描述非常复杂. 在这里我将简化它. 设置要预先编码的音频格式. 其中,选择“ AAC-LC”作为音频编码,音频采样率为44100,因此AudioSpecificConfig简化为下表:
通过这种方式,可以基本确定AVC序列头和AAC序列头的内容. 有关更多详细信息,您可以转到相关文档.
操作效果
RtmpLiveEncoder开始运行
使用FMS随附的Flash播放器
++++++++++++++++++++++++++++++++++++++++++++++++ ++ ++++++++++++++++

