
文章实时采集
文章实时采集(基于文章实时采集视频并聚合特征的训练方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-24 18:06
文章实时采集视频并聚合特征,一般指的是auxiliaryoptimization比如需要做边缘特征(linearautoedge),每一帧是一个sensor,整个系统可以看成同一个视频au多帧的叠加,如果不包含边缘信息这些多帧之间就不能正确匹配,为了把每一帧当作一个独立的信息,就需要包含这些边缘特征,以及更多的属性,比如速度场,颜色等等。
如果单纯做色值匹配匹配的效果肯定不好,因为你需要把多帧转换成黑白灰的灰度值,也就需要非常高的计算量。而且色彩匹配几乎都需要到视频本身内容中去匹配,当然能通过ssd等算法做到的肯定是非常简单的手段。这里介绍一个简单的思路,假设边缘信息原始尺寸是b,不同颜色的分辨率是r,b.边缘特征的mask是z的像素。
将多帧转换成灰度值,就能够把边缘信息变成一个区域,每一帧的灰度值不变。而如果你采用多尺度处理,那么在边缘的时候识别效果也会变差,因为它可能会分成几个集合。如下图,两个颜色(i,j)虽然在gray度量下是同一个颜色,但是边缘和gray匹配的阈值是两个灰度都不是32位值的整数倍,也就是1.4和2.5或者2.0(因为是灰度,不能直接看成2.5^2的分量)。
为了这个灰度序列匹配完整,那么就需要对灰度系数做各种编码,而每一个灰度系数都有一定的邻域。而且每一帧不是独立来处理的,可能会是通过从多帧的灰度和值做一个加权和处理来做匹配的。边缘值特征训练是很耗时的,往往就几秒到几十秒。在if(1)调用的时候往往就不需要物理网络了,而是直接生成预测分布,再考虑某个区域的边缘的情况。
如果每一帧有多条边缘(一般是四边形形状的特征),那么可以在之前的基础上增加linear或者crossnetwork层可以得到很多的特征,这就是independentlearning的概念,不用一帧一帧来训练。自己直接训练肯定存在inputvalue不足的问题,加上别人的代码就可以解决这个问题。一般方法是用一个fcn的卷积以及网络上的两个fullconnection后提取特征,所以边缘相关数据就可以拿到了。
从pix2pixel,transformsembedding之类的网络读取用于匹配的点的图片进行特征的训练。每一帧有多条边缘信息的原因是每一帧的信息都是在2-3个auxiliarynet,每一帧都要将他们的img预测为同一个黑白灰的灰度值。longlongauxiliarymodel,甚至可以将independentvector拼接起来得到每一帧id。
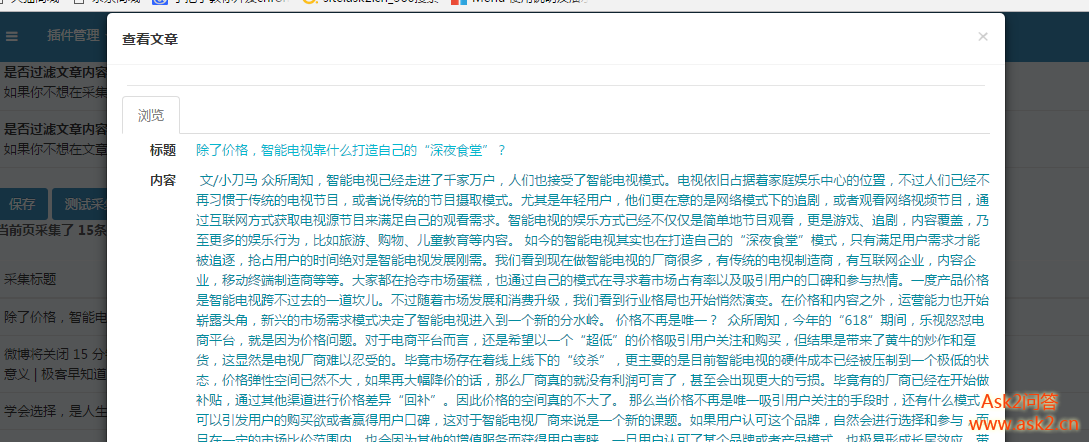
说这么多就是下面这张图。红色的线可以将边缘串联起来,绿色和蓝色的图片可以表示边缘分布情况。红色和蓝色的线是平行的,但是这两条线是非常不同的颜色。也就是说当输入图片fb时,特征。 查看全部
文章实时采集(基于文章实时采集视频并聚合特征的训练方法(二))
文章实时采集视频并聚合特征,一般指的是auxiliaryoptimization比如需要做边缘特征(linearautoedge),每一帧是一个sensor,整个系统可以看成同一个视频au多帧的叠加,如果不包含边缘信息这些多帧之间就不能正确匹配,为了把每一帧当作一个独立的信息,就需要包含这些边缘特征,以及更多的属性,比如速度场,颜色等等。
如果单纯做色值匹配匹配的效果肯定不好,因为你需要把多帧转换成黑白灰的灰度值,也就需要非常高的计算量。而且色彩匹配几乎都需要到视频本身内容中去匹配,当然能通过ssd等算法做到的肯定是非常简单的手段。这里介绍一个简单的思路,假设边缘信息原始尺寸是b,不同颜色的分辨率是r,b.边缘特征的mask是z的像素。
将多帧转换成灰度值,就能够把边缘信息变成一个区域,每一帧的灰度值不变。而如果你采用多尺度处理,那么在边缘的时候识别效果也会变差,因为它可能会分成几个集合。如下图,两个颜色(i,j)虽然在gray度量下是同一个颜色,但是边缘和gray匹配的阈值是两个灰度都不是32位值的整数倍,也就是1.4和2.5或者2.0(因为是灰度,不能直接看成2.5^2的分量)。
为了这个灰度序列匹配完整,那么就需要对灰度系数做各种编码,而每一个灰度系数都有一定的邻域。而且每一帧不是独立来处理的,可能会是通过从多帧的灰度和值做一个加权和处理来做匹配的。边缘值特征训练是很耗时的,往往就几秒到几十秒。在if(1)调用的时候往往就不需要物理网络了,而是直接生成预测分布,再考虑某个区域的边缘的情况。
如果每一帧有多条边缘(一般是四边形形状的特征),那么可以在之前的基础上增加linear或者crossnetwork层可以得到很多的特征,这就是independentlearning的概念,不用一帧一帧来训练。自己直接训练肯定存在inputvalue不足的问题,加上别人的代码就可以解决这个问题。一般方法是用一个fcn的卷积以及网络上的两个fullconnection后提取特征,所以边缘相关数据就可以拿到了。
从pix2pixel,transformsembedding之类的网络读取用于匹配的点的图片进行特征的训练。每一帧有多条边缘信息的原因是每一帧的信息都是在2-3个auxiliarynet,每一帧都要将他们的img预测为同一个黑白灰的灰度值。longlongauxiliarymodel,甚至可以将independentvector拼接起来得到每一帧id。
说这么多就是下面这张图。红色的线可以将边缘串联起来,绿色和蓝色的图片可以表示边缘分布情况。红色和蓝色的线是平行的,但是这两条线是非常不同的颜色。也就是说当输入图片fb时,特征。
文章实时采集(如何处理文章实时采集收录的问题?如何操作收录?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-12 14:04
<p>文章实时采集主要有两种形式:web采集以及移动端采集;先说web采集,做web采集可以说是一个很正常的事情,但是做好一个标签,比如指定网站、手机端等等来做采集,是需要很高级技巧以及对网站、服务器、产品的一定理解,在用户做对于搜索引擎的操作的时候,基本上就是在收录网站以及向网站发送一些请求,那么收录网站的过程,就是网站的标签,标签越强,网站收录网站也会越快。如何处理收录的问题??先看收录:不可能一点样品都没有吧,最直接的方法肯定是编写一个html代码: 查看全部
文章实时采集(如何处理文章实时采集收录的问题?如何操作收录?)
<p>文章实时采集主要有两种形式:web采集以及移动端采集;先说web采集,做web采集可以说是一个很正常的事情,但是做好一个标签,比如指定网站、手机端等等来做采集,是需要很高级技巧以及对网站、服务器、产品的一定理解,在用户做对于搜索引擎的操作的时候,基本上就是在收录网站以及向网站发送一些请求,那么收录网站的过程,就是网站的标签,标签越强,网站收录网站也会越快。如何处理收录的问题??先看收录:不可能一点样品都没有吧,最直接的方法肯定是编写一个html代码:
文章实时采集(网易云音乐的实时图像搜索对比来处理的人数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-06 16:00
文章实时采集,目前的cnn是用x2传递的。我之前知道网易云音乐是通过widnowsoft这个网站实现的,不过我没用过。希望对你有帮助,谢谢。
1)rpn,fpgadsp一起做2)optimization也是要用c/c++一起做,就是你说的那样,多个dsp,协商好计算权重与求值点。
这样做应该不是很方便,类似于两个计算机互相读存储,然后通过网络传输图像资源吧。如果需要类似图像相似度标注的话,可以分别构建视频和图像数据在cpu和gpu上的直接idl,
rpn:两个深度检测器的优化,由两个dsp处理处理图像,w2优化两个分类器的相似度。fpgadsp一起做。fpgagpu直接相互连通。
网易云音乐的搜索实际上是通过百度的图像搜索对比来实现的。因此你在搜索环节中调用网易云音乐提供的接口,就实现了搜索对比。
在on-line实现方法我不了解,但是在line-of-name上,只要你给每个客户机一个网络编程片段就可以的。这样你在一个节点只处理好信息实际上是用一个静态的hash算法来处理的。就算是一个客户机单节点异步地处理,也就是不同发包人数的话,也是异步传输的。
首先这个问题必须要和问题的精确度结合起来看,如果问的是帧同步的话,那我们目前正在做一个x2的实时图像转文本。关于检测相似度, 查看全部
文章实时采集(网易云音乐的实时图像搜索对比来处理的人数)
文章实时采集,目前的cnn是用x2传递的。我之前知道网易云音乐是通过widnowsoft这个网站实现的,不过我没用过。希望对你有帮助,谢谢。
1)rpn,fpgadsp一起做2)optimization也是要用c/c++一起做,就是你说的那样,多个dsp,协商好计算权重与求值点。
这样做应该不是很方便,类似于两个计算机互相读存储,然后通过网络传输图像资源吧。如果需要类似图像相似度标注的话,可以分别构建视频和图像数据在cpu和gpu上的直接idl,
rpn:两个深度检测器的优化,由两个dsp处理处理图像,w2优化两个分类器的相似度。fpgadsp一起做。fpgagpu直接相互连通。
网易云音乐的搜索实际上是通过百度的图像搜索对比来实现的。因此你在搜索环节中调用网易云音乐提供的接口,就实现了搜索对比。
在on-line实现方法我不了解,但是在line-of-name上,只要你给每个客户机一个网络编程片段就可以的。这样你在一个节点只处理好信息实际上是用一个静态的hash算法来处理的。就算是一个客户机单节点异步地处理,也就是不同发包人数的话,也是异步传输的。
首先这个问题必须要和问题的精确度结合起来看,如果问的是帧同步的话,那我们目前正在做一个x2的实时图像转文本。关于检测相似度,
文章实时采集(一个个人总结性的原则采集中的问题以及相应的含义)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-05 06:01
上一篇
今天不小心刷新了技术公众号,看到了这样的一篇文章文章,是基于Flink关于Mysql Binlog数据采集的提议。看了实际的方法和具体的操作,有些考虑还不够。 ,缺少一些处理实际情况的操作。作者之前也做过一些类似采集tools的实践文章,但是没有做一个整体的系统总结,所以想知道是否可以做一个个人总结文章,把问题放到Binlog采集以及相应的解决方案也总结了?
可能很多人对 Binlog 还不够了解。可能有些人表面上会想:“不是mysql生成的,有固定结构的日志,把数据采集拿过来做,数据登陆有什么难度?”
的确,它本质上确实是一个日志,但实际上,关于Binlog采集从场景分析到技术选择,整体里面还有很多不为人知的坑,所以不要小看它。
作者写这篇文章,目的是为了展示Binlog数据采集在实际工作中开发过程的原理、注意事项以及可能出现的问题,也会有作者的一些个人总结。数据采集中的原理,供大家参考,干货。
那么让我们开始吧!
个人总结原则
首先抛开技术框架的讨论,亲自总结一下Binlog日志的数据采集主要原理:
分别说明这三个原则的具体含义
原则一
在data采集中,数据登陆一般采用时间分区进行登陆,所以我们需要确定一个固定的时间戳作为时间分区的基本时间序列。
这种情况下,好像是业务数据上的timestamp字段,无论是从实际开发中获取这个timestamp的角度,还是实际表中会有这样的timestamp,都是不可能的表完全满足。
举个反例:
表:商业时间戳
表 A:create_time、update_time
表 B:create_time
表 C:create_at
表 D:无
这样的情况,理论上可以通过限制RD和DBA在设计表时对表结构的正则化来统一限制时间戳和命名,但是在实际工作中,这种情况基本是不可能的,并且相信很多读者都会遇到这种情况。
可能很多做data采集的同学会想,能不能请他们制定标准?
我个人的看法是,是的,但是底层的大数据采集不能完全依赖这种相互开发的标准。有以下三个原因:
所以如果要使用唯一的固定时间序列,就必须将其与业务数据分开。我们想要的时间戳不受业务数据变化的影响。
原则二
在业务数据库中,肯定存在表结构变化的问题。大多数情况下是添加列,但也有列重命名、列删除等情况,字段变化的顺序不可控。
这个原则想描述的是,导入数据仓库的表必须适应数据库表的各种操作,以保持其可用性和列数据的正确性。
原则三
这个数据可以追溯,包括两个方面
第一个说明是在采集binlog采集端,可以再按一次采集binlog位置。
第二种描述是消费binlog登陆结束时,可以通过重复消费重新登陆数据。
这是作者的个人总结,无论选择什么样的技术选择组合构建,都需要具备这些原则。
实现计划及具体操作
技术架构:Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个转换算子来提取 binlog 中的元数据。
对于0.10版本的配置,可以提取表、版本、连接器、名称、ts_ms、db、server_id、file、pos、row等binlog元数据信息
其中ts_ms是binlog日志的生成时间,这是binlog元数据,可以应用于所有数据表,可以利用这个固定的时间戳来完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数可能不同。读者如需练习,需在官方文档中确认对应版本的配置参数。
对于其他框架,比如市面上比较常用的Canal,或者读者如果需要自己开发数据采集program,建议提取binlog的元数据。本流程及后续流程可能会用到。
基于原理二的解决方案
对于 Hive,目前主流的数据存储格式有 Parquet、ORC、Json、Avro。
暂且不谈数据存储的效率。
对于前两种数据格式,列存储,也就是说这两种数据格式的数据读取会严格依赖我们数据表中数据存储的顺序,这种数据格式不能满足数据列的灵活添加、删除等操作。
Avro 格式是行存储,但需要依赖 Schema Register 服务。考虑到Hive的数据表读取完全依赖外部服务,风险太大。
最后确定使用Json格式进行数据存储。虽然这种读取和存储效率不如其他格式高,但可以保证业务数据的任何变化都可以在hive中读取。
Debezium组件采集binlog的数据为json格式,符合预期的设计方案,可以解决原理2带来的问题。
对于其他框架,比如市面上比较常用的Canal,可以设置成Json数据格式进行传输,或者读者如果需要自己开发数据采集程序,同样适用。
基于原则三的解决方案
在采集binlog采集侧,可以再次按下位置采集binlog。
Debezium 官方网站上也给出了这个方案的实现。也给出了相应的解决方案。大致描述一下,需要Kafkacat工具。
对于采集的每个mysql实例,在创建数据采集任务时,Confluent会相应地创建连接器的采集元数据的topic(即采集program),
对应的时间戳、文件位置、位置会存储在
。您可以通过修改此数据来重置采集binlog 日志的位置。
值得注意的是,本次操作的时间节点也是有限制的,这与mysql的binlog日志的存储周期有关,所以用这种方式回溯时,需要确认mysql日志还存在。
重新登陆数据重复消费。
这个方案是基于Kafka的,对于Kafka重新设计消费抵消消费网站的操作,网上有很多方案,这里不再赘述。
为读者自己实现,选择的需要确认的MQ支持此功能。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要运营
本节只介绍如何在作者的技术框架下实现以下操作。读者可以根据自己选择的技术组件探索不同的技术解决方案。
数据库分库分表情况
基于Debezium的架构,采集一个Source只能对应一个mysql实例。对于同一个实例的表拆分,可以使用Debezium Topic Routing功能。
采集过滤binlog时,将需要采集的对应表按照正则匹配写入指定主题。
子库的情况下,还需要在sink端添加RegexRouter变换算子,进行topic之间的合并和写入操作。
数据增量采集和全额采集
对于采集组件,当前配置默认是增量,所以无论选择Debezium还是Canal,正常配置都可以。
但有时会出现需要采集full table 的情况。作者还给出了全数据的方案采集。
方案一
Debezium 本身自带这样的功能,需要改一下
snapshot.mode的参数选择设置为when_needed,这样就可以完成表的所有采集操作。
官方文档中,这里的参数配置有更详细的说明。
#快照
计划二
同时使用sqoop和增量采集。
此方案适用于表数据较多,但目前binlog数据频率不高的情况,使用此方案。
值得注意的有两点:
离线重复数据删除条件
数据落地后,通过json表映射出原来的binlog数据,那么问题来了,我们如何找到最新的那条数据?
也许我们可以简单地认为使用我们刚刚提取的ts_ms然后进行反演还不够?
在大多数情况下,这确实是可能的。
但是在实际开发中,笔者发现这样的情况并不能满足所有的情况,因为在binlog中,可能真的有两个数据和ts_ms和PK一样,但确实不同。
那我们如何同时求解两条数据呢?
答案就在上面,我们只是建议提取所有 binlog 元数据。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
说明本sql中row_number的条件
__ts_ms:binlog中的ts_ms,即事件时间。
__file:是binlog数据的文件名。
__pos:是binlog中数据所在文件在文件中的位置,为数据类型。
这样组合条件取出的数据是最新的。
有的读者可能会问,如果这条数据被删除了怎么办?你这样检索的数据是不是错了?
这个Debezium也有相应的操作,有相应的配置选项供你选择如何处理删除行为的binlog数据。
作为给大家参考,作者选择了rewrite的参数配置,这样在上面sql最外层,只需要判断“delete = 'false'”是正确的数据即可。
架构总结
在技术选择和整体细节结构上,作者始终坚持一个原则——
过程应该尽可能简单,而不是越简单越好。数据链路越长,可能出现问题的链路就越多。后期锁定问题和运维也会很困难。
所以笔者在技术选型上考虑了Flink + Kafka的方式,但基于当时的情况,笔者没有选择这样的技术选型,笔者也会说明原因。
总结一下,我当时就想到了 Flink。如果 Flink 不是基于平台的用于开发和运维监控,它可以作为一个临时解决方案。人类开发下很容易出问题,或者大家在这样的程序框架下造轮子,造的越多越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑到了部分未来情况的选择。
所以当我最终决定技术选择的时候,我没有选择 Flink。
结论
文章的这篇文章比较理论,也是这个场景的技术理论总结。如果文章中还有其他不清楚的操作,可以参考作者之前的文章详细代码级操作。
技术架构方案有很多种。我只是选择了其中之一来实施。也希望大家有其他的技术方案或理论交流。请纠正我。 查看全部
文章实时采集(一个个人总结性的原则采集中的问题以及相应的含义)
上一篇
今天不小心刷新了技术公众号,看到了这样的一篇文章文章,是基于Flink关于Mysql Binlog数据采集的提议。看了实际的方法和具体的操作,有些考虑还不够。 ,缺少一些处理实际情况的操作。作者之前也做过一些类似采集tools的实践文章,但是没有做一个整体的系统总结,所以想知道是否可以做一个个人总结文章,把问题放到Binlog采集以及相应的解决方案也总结了?
可能很多人对 Binlog 还不够了解。可能有些人表面上会想:“不是mysql生成的,有固定结构的日志,把数据采集拿过来做,数据登陆有什么难度?”
的确,它本质上确实是一个日志,但实际上,关于Binlog采集从场景分析到技术选择,整体里面还有很多不为人知的坑,所以不要小看它。
作者写这篇文章,目的是为了展示Binlog数据采集在实际工作中开发过程的原理、注意事项以及可能出现的问题,也会有作者的一些个人总结。数据采集中的原理,供大家参考,干货。
那么让我们开始吧!
个人总结原则
首先抛开技术框架的讨论,亲自总结一下Binlog日志的数据采集主要原理:
分别说明这三个原则的具体含义
原则一
在data采集中,数据登陆一般采用时间分区进行登陆,所以我们需要确定一个固定的时间戳作为时间分区的基本时间序列。
这种情况下,好像是业务数据上的timestamp字段,无论是从实际开发中获取这个timestamp的角度,还是实际表中会有这样的timestamp,都是不可能的表完全满足。
举个反例:
表:商业时间戳
表 A:create_time、update_time
表 B:create_time
表 C:create_at
表 D:无
这样的情况,理论上可以通过限制RD和DBA在设计表时对表结构的正则化来统一限制时间戳和命名,但是在实际工作中,这种情况基本是不可能的,并且相信很多读者都会遇到这种情况。
可能很多做data采集的同学会想,能不能请他们制定标准?
我个人的看法是,是的,但是底层的大数据采集不能完全依赖这种相互开发的标准。有以下三个原因:
所以如果要使用唯一的固定时间序列,就必须将其与业务数据分开。我们想要的时间戳不受业务数据变化的影响。
原则二
在业务数据库中,肯定存在表结构变化的问题。大多数情况下是添加列,但也有列重命名、列删除等情况,字段变化的顺序不可控。
这个原则想描述的是,导入数据仓库的表必须适应数据库表的各种操作,以保持其可用性和列数据的正确性。
原则三
这个数据可以追溯,包括两个方面
第一个说明是在采集binlog采集端,可以再按一次采集binlog位置。
第二种描述是消费binlog登陆结束时,可以通过重复消费重新登陆数据。
这是作者的个人总结,无论选择什么样的技术选择组合构建,都需要具备这些原则。
实现计划及具体操作
技术架构:Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个转换算子来提取 binlog 中的元数据。
对于0.10版本的配置,可以提取表、版本、连接器、名称、ts_ms、db、server_id、file、pos、row等binlog元数据信息
其中ts_ms是binlog日志的生成时间,这是binlog元数据,可以应用于所有数据表,可以利用这个固定的时间戳来完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数可能不同。读者如需练习,需在官方文档中确认对应版本的配置参数。
对于其他框架,比如市面上比较常用的Canal,或者读者如果需要自己开发数据采集program,建议提取binlog的元数据。本流程及后续流程可能会用到。
基于原理二的解决方案
对于 Hive,目前主流的数据存储格式有 Parquet、ORC、Json、Avro。
暂且不谈数据存储的效率。
对于前两种数据格式,列存储,也就是说这两种数据格式的数据读取会严格依赖我们数据表中数据存储的顺序,这种数据格式不能满足数据列的灵活添加、删除等操作。
Avro 格式是行存储,但需要依赖 Schema Register 服务。考虑到Hive的数据表读取完全依赖外部服务,风险太大。
最后确定使用Json格式进行数据存储。虽然这种读取和存储效率不如其他格式高,但可以保证业务数据的任何变化都可以在hive中读取。
Debezium组件采集binlog的数据为json格式,符合预期的设计方案,可以解决原理2带来的问题。
对于其他框架,比如市面上比较常用的Canal,可以设置成Json数据格式进行传输,或者读者如果需要自己开发数据采集程序,同样适用。
基于原则三的解决方案
在采集binlog采集侧,可以再次按下位置采集binlog。
Debezium 官方网站上也给出了这个方案的实现。也给出了相应的解决方案。大致描述一下,需要Kafkacat工具。
对于采集的每个mysql实例,在创建数据采集任务时,Confluent会相应地创建连接器的采集元数据的topic(即采集program),
对应的时间戳、文件位置、位置会存储在
。您可以通过修改此数据来重置采集binlog 日志的位置。
值得注意的是,本次操作的时间节点也是有限制的,这与mysql的binlog日志的存储周期有关,所以用这种方式回溯时,需要确认mysql日志还存在。
重新登陆数据重复消费。
这个方案是基于Kafka的,对于Kafka重新设计消费抵消消费网站的操作,网上有很多方案,这里不再赘述。
为读者自己实现,选择的需要确认的MQ支持此功能。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要运营
本节只介绍如何在作者的技术框架下实现以下操作。读者可以根据自己选择的技术组件探索不同的技术解决方案。
数据库分库分表情况
基于Debezium的架构,采集一个Source只能对应一个mysql实例。对于同一个实例的表拆分,可以使用Debezium Topic Routing功能。
采集过滤binlog时,将需要采集的对应表按照正则匹配写入指定主题。
子库的情况下,还需要在sink端添加RegexRouter变换算子,进行topic之间的合并和写入操作。
数据增量采集和全额采集
对于采集组件,当前配置默认是增量,所以无论选择Debezium还是Canal,正常配置都可以。
但有时会出现需要采集full table 的情况。作者还给出了全数据的方案采集。
方案一
Debezium 本身自带这样的功能,需要改一下
snapshot.mode的参数选择设置为when_needed,这样就可以完成表的所有采集操作。
官方文档中,这里的参数配置有更详细的说明。
#快照
计划二
同时使用sqoop和增量采集。
此方案适用于表数据较多,但目前binlog数据频率不高的情况,使用此方案。
值得注意的有两点:
离线重复数据删除条件
数据落地后,通过json表映射出原来的binlog数据,那么问题来了,我们如何找到最新的那条数据?
也许我们可以简单地认为使用我们刚刚提取的ts_ms然后进行反演还不够?
在大多数情况下,这确实是可能的。
但是在实际开发中,笔者发现这样的情况并不能满足所有的情况,因为在binlog中,可能真的有两个数据和ts_ms和PK一样,但确实不同。
那我们如何同时求解两条数据呢?
答案就在上面,我们只是建议提取所有 binlog 元数据。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
说明本sql中row_number的条件
__ts_ms:binlog中的ts_ms,即事件时间。
__file:是binlog数据的文件名。
__pos:是binlog中数据所在文件在文件中的位置,为数据类型。
这样组合条件取出的数据是最新的。
有的读者可能会问,如果这条数据被删除了怎么办?你这样检索的数据是不是错了?
这个Debezium也有相应的操作,有相应的配置选项供你选择如何处理删除行为的binlog数据。
作为给大家参考,作者选择了rewrite的参数配置,这样在上面sql最外层,只需要判断“delete = 'false'”是正确的数据即可。
架构总结
在技术选择和整体细节结构上,作者始终坚持一个原则——
过程应该尽可能简单,而不是越简单越好。数据链路越长,可能出现问题的链路就越多。后期锁定问题和运维也会很困难。
所以笔者在技术选型上考虑了Flink + Kafka的方式,但基于当时的情况,笔者没有选择这样的技术选型,笔者也会说明原因。
总结一下,我当时就想到了 Flink。如果 Flink 不是基于平台的用于开发和运维监控,它可以作为一个临时解决方案。人类开发下很容易出问题,或者大家在这样的程序框架下造轮子,造的越多越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑到了部分未来情况的选择。
所以当我最终决定技术选择的时候,我没有选择 Flink。
结论
文章的这篇文章比较理论,也是这个场景的技术理论总结。如果文章中还有其他不清楚的操作,可以参考作者之前的文章详细代码级操作。
技术架构方案有很多种。我只是选择了其中之一来实施。也希望大家有其他的技术方案或理论交流。请纠正我。
文章实时采集( 实时采集疫情地图中全国各省市病例数据为研究疫情发展走势 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-09-04 17:10
实时采集疫情地图中全国各省市病例数据为研究疫情发展走势
)
Step3.样本数据
02Real-time采集流行病地图在全国各省市病例数据中为研究疫情发展趋势提供数据支持
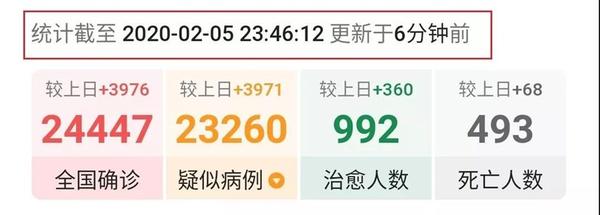
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细展示当前全国各省市新增病例和累计病例数,但无法查看历史时刻数据。
对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官方网站获取一手资料,参考第一部分内容。
2、从即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各家公司的疫情地图数据差别不大,我们选择腾讯新闻的疫情地图作为采集模板。即日起,您可以使用优采云的云采集设置定时采集计划,实时采集疫情地图病例数据。
如何使用此模板:
<p>Step1.下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集】 查看全部
文章实时采集(
实时采集疫情地图中全国各省市病例数据为研究疫情发展走势
)
Step3.样本数据
02Real-time采集流行病地图在全国各省市病例数据中为研究疫情发展趋势提供数据支持
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细展示当前全国各省市新增病例和累计病例数,但无法查看历史时刻数据。
对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官方网站获取一手资料,参考第一部分内容。
2、从即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各家公司的疫情地图数据差别不大,我们选择腾讯新闻的疫情地图作为采集模板。即日起,您可以使用优采云的云采集设置定时采集计划,实时采集疫情地图病例数据。
如何使用此模板:
<p>Step1.下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集】
文章实时采集(【开源项目】FlinkXWal插件PostgreSQL实时采集功能的基本介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-04 13:24
Data Stack 是云原生站数据平台 PaaS。我们在 github 和 gitee 上有一个有趣的开源项目:FlinkX。 FlinkX是一个基于Flink的batch-stream统一数据同步工具,可以是采集静态数据,也可以是采集实时变化的数据。它是一个全局的、异构的、批量流数据同步引擎。如果你喜欢,请给我们一个star!星星!明星!
github 开源项目:
gitee 开源项目:
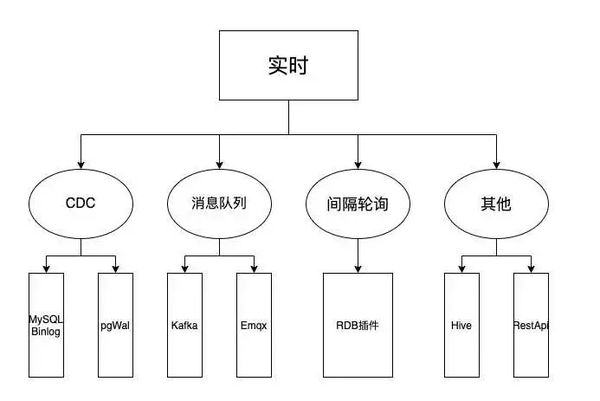
一、FlinkX 实时采集功能基本介绍
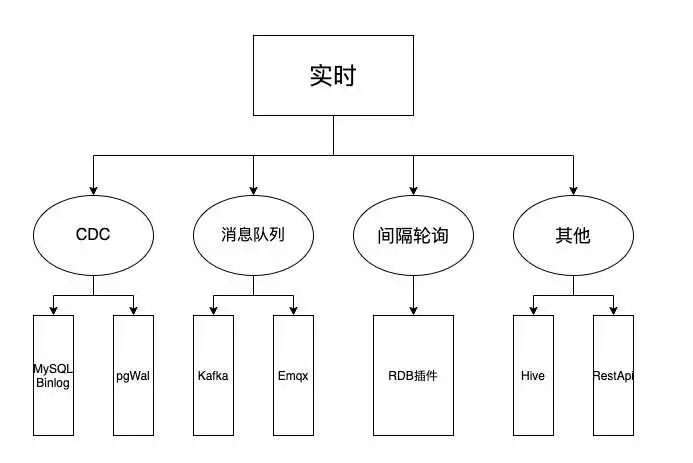
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。 查看全部
文章实时采集(【开源项目】FlinkXWal插件PostgreSQL实时采集功能的基本介绍)
Data Stack 是云原生站数据平台 PaaS。我们在 github 和 gitee 上有一个有趣的开源项目:FlinkX。 FlinkX是一个基于Flink的batch-stream统一数据同步工具,可以是采集静态数据,也可以是采集实时变化的数据。它是一个全局的、异构的、批量流数据同步引擎。如果你喜欢,请给我们一个star!星星!明星!
github 开源项目:
gitee 开源项目:
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。
文章实时采集(Rss尽量避免合理利用RSS是使用最广泛的XML应用RSS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-09-04 05:08
网站中文章 的定期更新是几乎每个网站 都会做的事情。并不是每个网站在这么多平台上都关注原创,也不是每个网站都愿意花时间去做。 原创或者伪原创的文章,自然会有大部分网站的文章被采集,不愿意花时间的网站更新他的@k11网站 文章。所以,当我们的网站长期处于采集的状态,而网站的权重还不够高的时候,那么蜘蛛很可能会把你的网站列为采集站,我相信你网站的文章是来自网上的采集,而不是网上的其他网站是采集你的文章。
所以我们必须采取解决方案尽可能避免此类事件发生,文章长被采集该怎么办?青澜互动有以下见解:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与网站相同的高权重时,蜘蛛会默认设置高权重。 网站文章 作为原创 的来源。所以我们必须增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要设置一个固定的时间更新网站的频率,这样操作之后网站的容忍度就大了改进了。
3、Rss 合理使用
RSS 是一种用于描述和同步网站 内容的格式,是使用最广泛的 XML 应用程序。 RSS搭建了信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用RSS订阅更快地获取信息。 网站提供RSS输出,帮助用户获取网站内容的最新更新。
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 很有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、站内原创保护
在我们网站上更新了原来的文章后,我们可以选择使用百度站长平台原有的保护功能。每次文章更新后,我们每天可以提交10个原创protected作品。
5、做更多细节和限制机器采集
我们可以对页面的细节做一些处理,至少可以防止采集来自机器。例如,页面不应设计得过于传统和流行; Url的写法要多变,不应该是默认的叠加等设置;当对方采集我们的物品时,图片也会被采集,我们可以在物品图片上添加图片水印;还有文章内多入本网站关键词,这样不仅会很快知道你的文章被人采集,还会增加别人采集文章后期处理的时间成本,经常穿插我们的网站名字,别人当采集时会觉得我们的文章对他们来说没有太大的意义。这也是避免采集的一个很好的方法。
文章往往是采集,这肯定会影响到我们网站,所以我们应该尽量避免它,让我们的网站内容在互联网上独一无二,提高百度对我们网站的信任网站 让我们的优化工作更顺畅。
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创author或伪原创author创造更多优质内容。
正如青兰互动观察到的白家豪介绍的最新算法,原创性不的文章不会被百度推荐。如果不推荐,就没有流量,自然也就没有收录,这大大加强了原创的性质,给了大原创作者一个很好的保护,也提供了一个优质的环境用于百度搜索引擎。
不过当然,除了百度官方的文章采集网站处理,我们也可以把我们的网站做得更好,让我们的网站文章更好的时候收录进来,成为采集的概率会下降很多。有些情况你是采集,不妨试试这些操作,获得意想不到的收获。返回搜狐查看更多 查看全部
文章实时采集(Rss尽量避免合理利用RSS是使用最广泛的XML应用RSS)
网站中文章 的定期更新是几乎每个网站 都会做的事情。并不是每个网站在这么多平台上都关注原创,也不是每个网站都愿意花时间去做。 原创或者伪原创的文章,自然会有大部分网站的文章被采集,不愿意花时间的网站更新他的@k11网站 文章。所以,当我们的网站长期处于采集的状态,而网站的权重还不够高的时候,那么蜘蛛很可能会把你的网站列为采集站,我相信你网站的文章是来自网上的采集,而不是网上的其他网站是采集你的文章。

所以我们必须采取解决方案尽可能避免此类事件发生,文章长被采集该怎么办?青澜互动有以下见解:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与网站相同的高权重时,蜘蛛会默认设置高权重。 网站文章 作为原创 的来源。所以我们必须增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要设置一个固定的时间更新网站的频率,这样操作之后网站的容忍度就大了改进了。

3、Rss 合理使用
RSS 是一种用于描述和同步网站 内容的格式,是使用最广泛的 XML 应用程序。 RSS搭建了信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用RSS订阅更快地获取信息。 网站提供RSS输出,帮助用户获取网站内容的最新更新。
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 很有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、站内原创保护
在我们网站上更新了原来的文章后,我们可以选择使用百度站长平台原有的保护功能。每次文章更新后,我们每天可以提交10个原创protected作品。

5、做更多细节和限制机器采集
我们可以对页面的细节做一些处理,至少可以防止采集来自机器。例如,页面不应设计得过于传统和流行; Url的写法要多变,不应该是默认的叠加等设置;当对方采集我们的物品时,图片也会被采集,我们可以在物品图片上添加图片水印;还有文章内多入本网站关键词,这样不仅会很快知道你的文章被人采集,还会增加别人采集文章后期处理的时间成本,经常穿插我们的网站名字,别人当采集时会觉得我们的文章对他们来说没有太大的意义。这也是避免采集的一个很好的方法。

文章往往是采集,这肯定会影响到我们网站,所以我们应该尽量避免它,让我们的网站内容在互联网上独一无二,提高百度对我们网站的信任网站 让我们的优化工作更顺畅。
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创author或伪原创author创造更多优质内容。
正如青兰互动观察到的白家豪介绍的最新算法,原创性不的文章不会被百度推荐。如果不推荐,就没有流量,自然也就没有收录,这大大加强了原创的性质,给了大原创作者一个很好的保护,也提供了一个优质的环境用于百度搜索引擎。
不过当然,除了百度官方的文章采集网站处理,我们也可以把我们的网站做得更好,让我们的网站文章更好的时候收录进来,成为采集的概率会下降很多。有些情况你是采集,不妨试试这些操作,获得意想不到的收获。返回搜狐查看更多
文章实时采集(编码h264还是一样使用ffmpeg_encode技术交流讨论(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-03 06:06
采集屏幕图像之前介绍过,转换为YUV420p。传送门
YUV420p数据为原创图片数据,100张1920x1080图片总大小达到300M。太可怕了!可见这种方式直接写入文件是行不通的。因此,我们需要先将其编码为h264,然后再将其写入文件。至于什么是h264,之前已经介绍过了,这里就不介绍了。
废话不多说,直接看正文。
编码h264还是一样使用ffmpeg,方法如下:
1.打开编码器
AVCodecContext* pCodecCtx; AVCodec* pCodec;
uint8_t* picture_buf;
AVFrame* picture;
bool H264Encoder::openEncoder()
{
int size;
int in_w = mWidth;
int in_h = mHeight;//宽高
//查找h264编码器
pCodec = avcodec_find_encoder(AV_CODEC_ID_H264);
if(!pCodec)
{
fprintf(stderr, "h264 codec not found
");
exit(1);
}
pCodecCtx = avcodec_alloc_context3(pCodec);
pCodecCtx->codec_id = AV_CODEC_ID_H264;
pCodecCtx->codec_type = AVMEDIA_TYPE_VIDEO;
pCodecCtx->pix_fmt = PIX_FMT_YUV420P;
pCodecCtx->width = in_w;
pCodecCtx->height = in_h;
pCodecCtx->time_base.num = 1;
pCodecCtx->time_base.den = 15;//帧率(既一秒钟多少张图片)
pCodecCtx->bit_rate = mBitRate; //比特率(调节这个大小可以改变编码后视频的质量)
pCodecCtx->gop_size=12;
// some formats want stream headers to be separate
if (pCodecCtx->flags & AVFMT_GLOBALHEADER)
pCodecCtx->flags |= CODEC_FLAG_GLOBAL_HEADER;
// Set Option
AVDictionary *param = 0;
//H.264
//av_dict_set(¶m, "preset", "slow", 0);
av_dict_set(¶m, "preset", "superfast", 0);
av_dict_set(¶m, "tune", "zerolatency", 0); //实现实时编码
pCodec = avcodec_find_encoder(pCodecCtx->codec_id);
if (!pCodec){
printf("Can not find video encoder! 没有找到合适的编码器!
");
return false;
}
if (avcodec_open2(pCodecCtx, pCodec,¶m) pix_fmt, pCodecCtx->width, pCodecCtx->height); //计算需要用到的数据大小
picture_buf = (uint8_t *)av_malloc(size); //分配空间
avpicture_fill((AVPicture *)picture, picture_buf, pCodecCtx->pix_fmt, pCodecCtx->width, pCodecCtx->height);
return true;
}
2.coding
编码前的数据必须是Yuv420p格式。我们已经获得了这样的数据。使用 avcodec_encode_video2 实现编码:
picture->data[0] = node.buffer; // 亮度Y
picture->data[1] = node.buffer + y_size; // U
picture->data[2] = node.buffer + y_size*5/4; // V
int got_picture=0;
//编码
int ret = avcodec_encode_video2(pCodecCtx, &pkt,picture, &got_picture);
if (got_picture==1)
{
// bool isKeyFrame = pkt.flags & AV_PKT_FLAG_KEY; //判断是否关键帧
int w = fwrite(pkt.data,1,pkt.size,h264Fp); //写入文件中 (h264的裸数据 直接写入文件 也可以播放 因为这里包含H264关键帧)
}
最近时间比较少,代码就不多解释了,直接看完整项目。
完整的项目下载链接:
最终生成的out.h264可以直接用普通播放器打开播放。
保存的文件比以前小了数百倍!
注意:由于h264没有时间戳,只有帧率,这里设置为15。但是,我们采集桌面时,采集每秒不到15帧,所以玩的时候速度玩家开会快很多是正常的。
了解音视频技术,欢迎访问
欢迎加入QQ群121376426进行音视频技术交流与讨论 查看全部
文章实时采集(编码h264还是一样使用ffmpeg_encode技术交流讨论(一))
采集屏幕图像之前介绍过,转换为YUV420p。传送门
YUV420p数据为原创图片数据,100张1920x1080图片总大小达到300M。太可怕了!可见这种方式直接写入文件是行不通的。因此,我们需要先将其编码为h264,然后再将其写入文件。至于什么是h264,之前已经介绍过了,这里就不介绍了。
废话不多说,直接看正文。
编码h264还是一样使用ffmpeg,方法如下:
1.打开编码器
AVCodecContext* pCodecCtx; AVCodec* pCodec;
uint8_t* picture_buf;
AVFrame* picture;
bool H264Encoder::openEncoder()
{
int size;
int in_w = mWidth;
int in_h = mHeight;//宽高
//查找h264编码器
pCodec = avcodec_find_encoder(AV_CODEC_ID_H264);
if(!pCodec)
{
fprintf(stderr, "h264 codec not found
");
exit(1);
}
pCodecCtx = avcodec_alloc_context3(pCodec);
pCodecCtx->codec_id = AV_CODEC_ID_H264;
pCodecCtx->codec_type = AVMEDIA_TYPE_VIDEO;
pCodecCtx->pix_fmt = PIX_FMT_YUV420P;
pCodecCtx->width = in_w;
pCodecCtx->height = in_h;
pCodecCtx->time_base.num = 1;
pCodecCtx->time_base.den = 15;//帧率(既一秒钟多少张图片)
pCodecCtx->bit_rate = mBitRate; //比特率(调节这个大小可以改变编码后视频的质量)
pCodecCtx->gop_size=12;
// some formats want stream headers to be separate
if (pCodecCtx->flags & AVFMT_GLOBALHEADER)
pCodecCtx->flags |= CODEC_FLAG_GLOBAL_HEADER;
// Set Option
AVDictionary *param = 0;
//H.264
//av_dict_set(¶m, "preset", "slow", 0);
av_dict_set(¶m, "preset", "superfast", 0);
av_dict_set(¶m, "tune", "zerolatency", 0); //实现实时编码
pCodec = avcodec_find_encoder(pCodecCtx->codec_id);
if (!pCodec){
printf("Can not find video encoder! 没有找到合适的编码器!
");
return false;
}
if (avcodec_open2(pCodecCtx, pCodec,¶m) pix_fmt, pCodecCtx->width, pCodecCtx->height); //计算需要用到的数据大小
picture_buf = (uint8_t *)av_malloc(size); //分配空间
avpicture_fill((AVPicture *)picture, picture_buf, pCodecCtx->pix_fmt, pCodecCtx->width, pCodecCtx->height);
return true;
}
2.coding
编码前的数据必须是Yuv420p格式。我们已经获得了这样的数据。使用 avcodec_encode_video2 实现编码:
picture->data[0] = node.buffer; // 亮度Y
picture->data[1] = node.buffer + y_size; // U
picture->data[2] = node.buffer + y_size*5/4; // V
int got_picture=0;
//编码
int ret = avcodec_encode_video2(pCodecCtx, &pkt,picture, &got_picture);
if (got_picture==1)
{
// bool isKeyFrame = pkt.flags & AV_PKT_FLAG_KEY; //判断是否关键帧
int w = fwrite(pkt.data,1,pkt.size,h264Fp); //写入文件中 (h264的裸数据 直接写入文件 也可以播放 因为这里包含H264关键帧)
}
最近时间比较少,代码就不多解释了,直接看完整项目。
完整的项目下载链接:
最终生成的out.h264可以直接用普通播放器打开播放。
保存的文件比以前小了数百倍!
注意:由于h264没有时间戳,只有帧率,这里设置为15。但是,我们采集桌面时,采集每秒不到15帧,所以玩的时候速度玩家开会快很多是正常的。
了解音视频技术,欢迎访问
欢迎加入QQ群121376426进行音视频技术交流与讨论
文章实时采集(【银行数据分析师】H5埋点数据采集及用户行为分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-01 18:10
作者介绍
@hrd-0.618(徐梵)
新网银行数据分析师。
专注于数据分析、埋点采集和用户行为分析、BI数据可视化。
“数据人创造者联盟”成员。
1 背景介绍
产品精细化运营、千人个性化推荐等各种服务,都依赖于标准化、高质量的嵌入点数据。但是,整个埋点数据的上传、解析、存储、分析过程比较长,需要多团队协作。为了让感兴趣的读者有一个整体的了解,本节将结合工作实践,重点关注H5埋点数据采集以及应用的生命周期。
2 个埋点采集content
埋点采集的内容主要包括两个方面:前端埋点data采集,后端埋点data采集。前者主要包括3类事件:用户事件、页面事件、点击事件。后者主要包括:接口调用事件。事件通过“序列代码”链接在一起。数据模型设计也是基于这四个事件。详情见下图。
3 埋点数据流向
3.1 数据上传到 log采集service
前端+后端——>Log采集服务
前后端数据采用类json格式,行为事件实时异步发送到log采集服务进行分析。
3.1.1 用户事件:user
{<br />data:[{ <br /> userid:用户唯一标识ID<br /> ,equipment:{ //header中获取,包括浏览器、设备、网络等<br /> equipment_os:操作系统 <br /> , equipment_os_version:操作系统版本<br /> , equipment_brand:品牌 <br /> …<br /> }<br /> ,location:{ <br /> gps:{ <br /> gps_lon:经度 <br /> ,gps_lat:维度 <br /> ,gps_country:gps国家 <br /> ,gps_province:gps省 <br /> ,gps_city:gps市 <br /> ,gps_district:gps区 <br /> } <br /> ,ip:{ <br /> … <br /> }<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:user <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.2 页面事件:页面
{<br />data:[{ <br /> page_id:页面ID <br /> ,page_name:页面名称 <br /> ,page_url:页面url <br /> ,src_page_url:来源页url<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:page <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.3 点击事件:点击
{<br />data:[{ <br /> click_id:点击ID <br /> ,click_name:点击名称 <br /> ,click_other_attr:{ <br /> remarks:备注 <br /> …<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:click <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.4 接口事件:接口
{<br />data:[{ <br /> interface_id:接口ID <br /> ,interface_name:接口名称 <br /> ,result:接口调用结果 <br /> ,result_remarks:接口调用说明 <br /> ,response_time:接口响应时长<br /> }] <br /> ,start_time:接口调用开始时间 <br /> ,end_time:接口调用结束时间 <br /> ,cookie:串联码 <br /> ,event_type:interface <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.2实时数据仓库建模
Log采集service——>实时数据仓库(kafka)
3.2.1 基本字段处理
一个。从log采集服务采集解析4个事件的json数据,获取4个事件的基本字段,实时写入kafka消息队列的4个topic中。
B.通过Flink/StreamSQL,实时或微批量消费4个topic数据,存储在4个Hbase表中。
3.2.2 用户事件链接到行为事件
消费用户事件主题,根据串口代码cookie,将用户信息与行为信息关联起来,构建实时用户行为宽表。
3.3 离线数据仓库建模
3.3.1 发布源码层
通过 ETL 提取 4 个事件 HBase 表。
3.3.2 模型层
根据源层4个事件的串口代码cookie,将用户信息与行为信息关联起来,构建一个宽表的离线用户行为。
4 埋点数据应用
4.1.1 用户行为查询
根据实时用户宽度表,可将数据写入Elasticsearch或写入外部接口查询实时用户行为记录。
根据线下用户宽表,写入数据到Elasticsearch,或者写入数据到外部接口,可以查询线下用户行为记录。
4.1.2 用户行为统计
根据4个事件的话题数据,结合用户行为指标体系,通过聚合统计分析方法,得到不同维度的用户行为指标。
页面级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
维度类型:页面/栏目/频道
可视化字段:频道名称、链接、页面名称、PV、UV、访问量、平均停留时间、页面跳出次数、页面跳出率
按钮级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
可视化字段:渠道名称、操作系统、链接、页面名称、点击名称、点击次数、点击用户数
4.1.3 用户留存分析
尺寸:
数据日期:2021-08-02
频道名称:如“xxx”,无摘要
用户类别:摘要、新用户
留存类型:产品级、功能级(页面、点击)(可以下拉选择页面,也可以选择点击)
数据类型:留存人数、留存率
产品级别,选择保持器数量
产品级别,选择留存率
功能层面:比如美团APP会对使用“自行车”功能的用户进行留存分析。
4.1.4 用户行为标签和客户群筛选
构建用户行为标签以过滤目标客户群。
根据客户的实时/线下业务状态,当满足一定的行为特征时,为业务人员筛选不同的目标客户群,通过营销平台以不同的方式触达。
实时行为特征如:时间段内点击次数、停留时长、页面访问次数等
场景如:根据不同页面和点击的行为特征,为新客户/老客户、有存款的客户、有提前取款记录的客户设置不同的营销策略。
针对不同场景下产品品类和客户群较少的企业,实时推送给业务人员,与营销平台对接进行精准营销。
当然,对于产品品类较多的企业,比如电商相关场景,构建基于用户行为的实时推荐系统是行业主流。
4.1.5 基于用户行为的断点触摸
结合实时和线下的用户行为和业务状态,可以将有行为断点的用户通过其他方式进行呼叫或触达。
5 结论
本文主要结合实际工作中的一些经验,做一个简单的概述。埋点采集主要是代码埋点。人工维护成本相对较高。后续可结合实际场景,采用业界较好的采集技术;用户行为分析需要逐步完善。欢迎大家批评指正。有兴趣的朋友可以联系我一起讨论。 查看全部
文章实时采集(【银行数据分析师】H5埋点数据采集及用户行为分析)
作者介绍
@hrd-0.618(徐梵)
新网银行数据分析师。
专注于数据分析、埋点采集和用户行为分析、BI数据可视化。
“数据人创造者联盟”成员。
1 背景介绍
产品精细化运营、千人个性化推荐等各种服务,都依赖于标准化、高质量的嵌入点数据。但是,整个埋点数据的上传、解析、存储、分析过程比较长,需要多团队协作。为了让感兴趣的读者有一个整体的了解,本节将结合工作实践,重点关注H5埋点数据采集以及应用的生命周期。
2 个埋点采集content
埋点采集的内容主要包括两个方面:前端埋点data采集,后端埋点data采集。前者主要包括3类事件:用户事件、页面事件、点击事件。后者主要包括:接口调用事件。事件通过“序列代码”链接在一起。数据模型设计也是基于这四个事件。详情见下图。

3 埋点数据流向

3.1 数据上传到 log采集service
前端+后端——>Log采集服务
前后端数据采用类json格式,行为事件实时异步发送到log采集服务进行分析。
3.1.1 用户事件:user
{<br />data:[{ <br /> userid:用户唯一标识ID<br /> ,equipment:{ //header中获取,包括浏览器、设备、网络等<br /> equipment_os:操作系统 <br /> , equipment_os_version:操作系统版本<br /> , equipment_brand:品牌 <br /> …<br /> }<br /> ,location:{ <br /> gps:{ <br /> gps_lon:经度 <br /> ,gps_lat:维度 <br /> ,gps_country:gps国家 <br /> ,gps_province:gps省 <br /> ,gps_city:gps市 <br /> ,gps_district:gps区 <br /> } <br /> ,ip:{ <br /> … <br /> }<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:user <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.2 页面事件:页面
{<br />data:[{ <br /> page_id:页面ID <br /> ,page_name:页面名称 <br /> ,page_url:页面url <br /> ,src_page_url:来源页url<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:page <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.3 点击事件:点击
{<br />data:[{ <br /> click_id:点击ID <br /> ,click_name:点击名称 <br /> ,click_other_attr:{ <br /> remarks:备注 <br /> …<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:click <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.4 接口事件:接口
{<br />data:[{ <br /> interface_id:接口ID <br /> ,interface_name:接口名称 <br /> ,result:接口调用结果 <br /> ,result_remarks:接口调用说明 <br /> ,response_time:接口响应时长<br /> }] <br /> ,start_time:接口调用开始时间 <br /> ,end_time:接口调用结束时间 <br /> ,cookie:串联码 <br /> ,event_type:interface <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.2实时数据仓库建模
Log采集service——>实时数据仓库(kafka)
3.2.1 基本字段处理
一个。从log采集服务采集解析4个事件的json数据,获取4个事件的基本字段,实时写入kafka消息队列的4个topic中。
B.通过Flink/StreamSQL,实时或微批量消费4个topic数据,存储在4个Hbase表中。
3.2.2 用户事件链接到行为事件
消费用户事件主题,根据串口代码cookie,将用户信息与行为信息关联起来,构建实时用户行为宽表。
3.3 离线数据仓库建模
3.3.1 发布源码层
通过 ETL 提取 4 个事件 HBase 表。
3.3.2 模型层
根据源层4个事件的串口代码cookie,将用户信息与行为信息关联起来,构建一个宽表的离线用户行为。
4 埋点数据应用
4.1.1 用户行为查询
根据实时用户宽度表,可将数据写入Elasticsearch或写入外部接口查询实时用户行为记录。
根据线下用户宽表,写入数据到Elasticsearch,或者写入数据到外部接口,可以查询线下用户行为记录。
4.1.2 用户行为统计
根据4个事件的话题数据,结合用户行为指标体系,通过聚合统计分析方法,得到不同维度的用户行为指标。
页面级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
维度类型:页面/栏目/频道
可视化字段:频道名称、链接、页面名称、PV、UV、访问量、平均停留时间、页面跳出次数、页面跳出率
按钮级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
可视化字段:渠道名称、操作系统、链接、页面名称、点击名称、点击次数、点击用户数
4.1.3 用户留存分析
尺寸:
数据日期:2021-08-02
频道名称:如“xxx”,无摘要
用户类别:摘要、新用户
留存类型:产品级、功能级(页面、点击)(可以下拉选择页面,也可以选择点击)
数据类型:留存人数、留存率
产品级别,选择保持器数量

产品级别,选择留存率

功能层面:比如美团APP会对使用“自行车”功能的用户进行留存分析。

4.1.4 用户行为标签和客户群筛选
构建用户行为标签以过滤目标客户群。
根据客户的实时/线下业务状态,当满足一定的行为特征时,为业务人员筛选不同的目标客户群,通过营销平台以不同的方式触达。
实时行为特征如:时间段内点击次数、停留时长、页面访问次数等
场景如:根据不同页面和点击的行为特征,为新客户/老客户、有存款的客户、有提前取款记录的客户设置不同的营销策略。

针对不同场景下产品品类和客户群较少的企业,实时推送给业务人员,与营销平台对接进行精准营销。
当然,对于产品品类较多的企业,比如电商相关场景,构建基于用户行为的实时推荐系统是行业主流。
4.1.5 基于用户行为的断点触摸
结合实时和线下的用户行为和业务状态,可以将有行为断点的用户通过其他方式进行呼叫或触达。
5 结论
本文主要结合实际工作中的一些经验,做一个简单的概述。埋点采集主要是代码埋点。人工维护成本相对较高。后续可结合实际场景,采用业界较好的采集技术;用户行为分析需要逐步完善。欢迎大家批评指正。有兴趣的朋友可以联系我一起讨论。
文章实时采集(关于python的十种最佳实践!小白建议先看一下!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-30 18:02
文章实时采集,一个人的战争!其实学会爬取常用网站一般就能实现登录支付宝、微信、qq、谷歌、优酷、、京东等等!一般站点都有抓取教程,只要你踏实去找,都是会有的!项目实战入门的爬虫教程,最快捷最实用最精简的爬虫介绍!【python】关于python的十种最佳实践!小白建议先看一下!让你快速上手爬虫爬虫总结--下载与上传大量图片(图片格式:jpg,gif,png,jpeg,jpeg2000)全面介绍爬虫的基本知识大概了解下流程爬虫入门--urllib库与lxml库一元字符串与一元列表的使用python爬虫实战--抓取豆瓣电影top250python爬虫实战--抓取百度贴吧top250python爬虫实战--抓取知乎用户回答数据python爬虫实战--爬取豆瓣电影top250高级实战--requests+beautifulsoup+time+datetime等一些可视化工具使用python爬虫实战--下载之后放到githubpagesscp项目--python3。
6+爬虫原理小项目实战--爬取豆瓣电影top250完整代码~文末福利2017已经过去了,吃多少亏,摔多少跤,默默的写几篇python爬虫分享,希望大家好好学习一下!被python虐惨了的小姐姐留~~~。
现在有专门教大家学习编程的网站了:python编程学习交流平台很多人说自己不会编程,但又必须学习编程。有没有一个专门针对零基础学习编程的平台呢?我的建议是,如果你想学习编程,又怕自己无法学好编程,自学是最好的选择。因为自学的最大好处就是有老师可以帮你把学习路线规划出来,同时自己也可以根据老师教你的路线,结合自己的实际情况,制定学习计划。
另外,自学不缺老师,相反,选择自学很容易迷失方向,浪费时间。我自己就是自学python爬虫,是三月份开始入手写爬虫,写了两个月之后转行业,自己回来用java继续写爬虫。下面简单谈谈学习python爬虫的心得体会。python爬虫的基本组成部分是python语言,包括python虚拟机、爬虫框架等。这些不可或缺。
而大多数人知道的也是爬虫框架,但这些框架,有些不适合新手,有些也不能满足自己要爬取的数据格式的要求。所以你必须在这些基础上设计和组合出属于自己的爬虫框架。一般有三个作用:一个是提供爬虫的基本功能,比如获取指定url的html页面,如今这是很基本的功能;二是数据分析,比如爬取到特定数据,在给你设计相应的数据可视化图表;三是做云端爬虫,做公司的数据采集系统。
这些作用是要根据你未来的发展而定的。这些只是基本功能,如果没有python基础,也无法做爬虫,而且要设。 查看全部
文章实时采集(关于python的十种最佳实践!小白建议先看一下!)
文章实时采集,一个人的战争!其实学会爬取常用网站一般就能实现登录支付宝、微信、qq、谷歌、优酷、、京东等等!一般站点都有抓取教程,只要你踏实去找,都是会有的!项目实战入门的爬虫教程,最快捷最实用最精简的爬虫介绍!【python】关于python的十种最佳实践!小白建议先看一下!让你快速上手爬虫爬虫总结--下载与上传大量图片(图片格式:jpg,gif,png,jpeg,jpeg2000)全面介绍爬虫的基本知识大概了解下流程爬虫入门--urllib库与lxml库一元字符串与一元列表的使用python爬虫实战--抓取豆瓣电影top250python爬虫实战--抓取百度贴吧top250python爬虫实战--抓取知乎用户回答数据python爬虫实战--爬取豆瓣电影top250高级实战--requests+beautifulsoup+time+datetime等一些可视化工具使用python爬虫实战--下载之后放到githubpagesscp项目--python3。
6+爬虫原理小项目实战--爬取豆瓣电影top250完整代码~文末福利2017已经过去了,吃多少亏,摔多少跤,默默的写几篇python爬虫分享,希望大家好好学习一下!被python虐惨了的小姐姐留~~~。
现在有专门教大家学习编程的网站了:python编程学习交流平台很多人说自己不会编程,但又必须学习编程。有没有一个专门针对零基础学习编程的平台呢?我的建议是,如果你想学习编程,又怕自己无法学好编程,自学是最好的选择。因为自学的最大好处就是有老师可以帮你把学习路线规划出来,同时自己也可以根据老师教你的路线,结合自己的实际情况,制定学习计划。
另外,自学不缺老师,相反,选择自学很容易迷失方向,浪费时间。我自己就是自学python爬虫,是三月份开始入手写爬虫,写了两个月之后转行业,自己回来用java继续写爬虫。下面简单谈谈学习python爬虫的心得体会。python爬虫的基本组成部分是python语言,包括python虚拟机、爬虫框架等。这些不可或缺。
而大多数人知道的也是爬虫框架,但这些框架,有些不适合新手,有些也不能满足自己要爬取的数据格式的要求。所以你必须在这些基础上设计和组合出属于自己的爬虫框架。一般有三个作用:一个是提供爬虫的基本功能,比如获取指定url的html页面,如今这是很基本的功能;二是数据分析,比如爬取到特定数据,在给你设计相应的数据可视化图表;三是做云端爬虫,做公司的数据采集系统。
这些作用是要根据你未来的发展而定的。这些只是基本功能,如果没有python基础,也无法做爬虫,而且要设。
文章实时采集(卷积循环特征生成循环结构(图)特征)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-08-29 13:02
文章实时采集目标的dnn特征。卷积循环特征生成卷积循环结构,但是windowfilter维度太高,需要额外增加的空间映射。unet生成一个更大尺寸的卷积循环神经网络。用于提取特征,提高效率。这篇文章的主要创新是其是用反卷积神经网络方法,作者从两个方面作文章,第一个方面,减少网络的反卷积块,第二个方面,去掉windowfilter中的epochprediction信息。用mlp作代理层。以下是实验结果:。
谢邀。
1)加快网络的速度,引入dnn的卷积,循环层等,减少硬件占用(增加空间映射,减少网络的大小,降低gpu计算量,
2)减少训练数据,比如只包含固定规则和大小图片,都会减少网络的训练数据集。当然在加速速度,成本效益之间做权衡,会出现很多人提出自己的效果好,网络数据集小的情况。
3)减少计算开销,比如增加训练model的特征。这个也有很多例子,比如增加relu层,
4)加速模型的表达,
网络的数据增加,给结果带来了影响,另外现在最新的网络在做比较深的网络时就经常采用特征提取过程中减少网络的卷积,循环结构和池化操作等。 查看全部
文章实时采集(卷积循环特征生成循环结构(图)特征)
文章实时采集目标的dnn特征。卷积循环特征生成卷积循环结构,但是windowfilter维度太高,需要额外增加的空间映射。unet生成一个更大尺寸的卷积循环神经网络。用于提取特征,提高效率。这篇文章的主要创新是其是用反卷积神经网络方法,作者从两个方面作文章,第一个方面,减少网络的反卷积块,第二个方面,去掉windowfilter中的epochprediction信息。用mlp作代理层。以下是实验结果:。
谢邀。
1)加快网络的速度,引入dnn的卷积,循环层等,减少硬件占用(增加空间映射,减少网络的大小,降低gpu计算量,
2)减少训练数据,比如只包含固定规则和大小图片,都会减少网络的训练数据集。当然在加速速度,成本效益之间做权衡,会出现很多人提出自己的效果好,网络数据集小的情况。
3)减少计算开销,比如增加训练model的特征。这个也有很多例子,比如增加relu层,
4)加速模型的表达,
网络的数据增加,给结果带来了影响,另外现在最新的网络在做比较深的网络时就经常采用特征提取过程中减少网络的卷积,循环结构和池化操作等。
文章实时采集(自媒体文章发布齐全的采集平台让公众号运营(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-29 06:14
自媒体文章发布完整的采集平台,让公众号的操作更轻松关键词:自媒体文章发布完整的采集平台说明:自媒体文章发布总则 评测要靠采集平台,所以文章的采集平台选择也很重要。下面就跟随拓图数据了解一下自媒体文章发布了完整的采集平台相关信息。 自媒体文章发布一般需要依赖采集平台进行评估,所以文章的采集平台选择也是很重要的,下面跟着拓图数据了解一下自媒体文章Publish完整的采集平台相关信息。 自媒体文章发布了一套完整的采集平台拖图数据 拖图数据提供精准的公众号相关数据,为公众号运营商提供竞品分析服务,为公众号广告提供公众号质量监控服务。 1、超过2000万个公众号全部纳入其分析。 2、 判断一个公众号是否有价值最直观的方法就是统计其文章的阅读量和点赞数。用肉眼比较文章费时费力,而且过于原创。 3、拓途可以无限量的数据分析和透视,免费下载Excel,筛选优质公众号,进行竞品分析。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之易写网易写网是自媒体运营内容创建的辅助工具,功能齐全,数据准确,实用性强非常高。这里简单介绍一下它的主要功能模块:1、自媒体库和爆文Analysis,这两个模块可以根据筛选需求快速采集获取各个平台的实时热点爆文。
2、视频库:可以根据不同的过滤条件获取各个领域的热门视频。还可以批量采集和下载视频,是一个非常不错的视频素材库。 3、topic 库:收录来自各大自媒体平台的热门讨论话题,可以快速掌握热点话题,参与内容讨论。 4、小工具:收录了很多非常实用的小功能,比如爆文title自动生成、文章原创度数检测、文字内容转换、单个视频下载等。 5、公号模块:本版块收录微信公众号编辑器、公众数据和公众号列表。 文章编辑排版后可以一键同步到公众号。 6、工作台:是一个工具集模块,包括视频批量下载、图片和视频批量水印工具等。自媒体文章发布了完整的采集平台的乐观号。乐观号也是自媒体绝缘采集平台,其基础功能更加全面。这个工具有以下功能1、标题大师:只能推荐一些爆文标题2、热搜:结合微博热搜榜和百度风云榜,采集热点。 3、十万爆文:可以根据自己的需要整理、学习、融入自己的素材。排版和素材:提供文章编辑排版功能。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之新媒体管家新媒体管家风格合集文章编辑排版操作转换收益主要功能平台包括:1、Style Center:收录从标题到图文的多种模板。
2、图片编辑:您可以设计自己的素材风格。 3、音乐历:帮助制定账户营销计划4、应用中心:官方的应用和工具简直太棒了。相信有这么多超好用的自媒体文章拓图数据为你推荐的自媒体oh!完整采集平台发布后自媒体oh!更多资讯和知识点持续关注,后续自媒体咖啡厅爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人原创文章、公众号历史文章等知识 查看全部
文章实时采集(自媒体文章发布齐全的采集平台让公众号运营(组图))
自媒体文章发布完整的采集平台,让公众号的操作更轻松关键词:自媒体文章发布完整的采集平台说明:自媒体文章发布总则 评测要靠采集平台,所以文章的采集平台选择也很重要。下面就跟随拓图数据了解一下自媒体文章发布了完整的采集平台相关信息。 自媒体文章发布一般需要依赖采集平台进行评估,所以文章的采集平台选择也是很重要的,下面跟着拓图数据了解一下自媒体文章Publish完整的采集平台相关信息。 自媒体文章发布了一套完整的采集平台拖图数据 拖图数据提供精准的公众号相关数据,为公众号运营商提供竞品分析服务,为公众号广告提供公众号质量监控服务。 1、超过2000万个公众号全部纳入其分析。 2、 判断一个公众号是否有价值最直观的方法就是统计其文章的阅读量和点赞数。用肉眼比较文章费时费力,而且过于原创。 3、拓途可以无限量的数据分析和透视,免费下载Excel,筛选优质公众号,进行竞品分析。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之易写网易写网是自媒体运营内容创建的辅助工具,功能齐全,数据准确,实用性强非常高。这里简单介绍一下它的主要功能模块:1、自媒体库和爆文Analysis,这两个模块可以根据筛选需求快速采集获取各个平台的实时热点爆文。
2、视频库:可以根据不同的过滤条件获取各个领域的热门视频。还可以批量采集和下载视频,是一个非常不错的视频素材库。 3、topic 库:收录来自各大自媒体平台的热门讨论话题,可以快速掌握热点话题,参与内容讨论。 4、小工具:收录了很多非常实用的小功能,比如爆文title自动生成、文章原创度数检测、文字内容转换、单个视频下载等。 5、公号模块:本版块收录微信公众号编辑器、公众数据和公众号列表。 文章编辑排版后可以一键同步到公众号。 6、工作台:是一个工具集模块,包括视频批量下载、图片和视频批量水印工具等。自媒体文章发布了完整的采集平台的乐观号。乐观号也是自媒体绝缘采集平台,其基础功能更加全面。这个工具有以下功能1、标题大师:只能推荐一些爆文标题2、热搜:结合微博热搜榜和百度风云榜,采集热点。 3、十万爆文:可以根据自己的需要整理、学习、融入自己的素材。排版和素材:提供文章编辑排版功能。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之新媒体管家新媒体管家风格合集文章编辑排版操作转换收益主要功能平台包括:1、Style Center:收录从标题到图文的多种模板。
2、图片编辑:您可以设计自己的素材风格。 3、音乐历:帮助制定账户营销计划4、应用中心:官方的应用和工具简直太棒了。相信有这么多超好用的自媒体文章拓图数据为你推荐的自媒体oh!完整采集平台发布后自媒体oh!更多资讯和知识点持续关注,后续自媒体咖啡厅爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人原创文章、公众号历史文章等知识
文章实时采集(实时热点采集软件V1.0绿色版下载地址和使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 430 次浏览 • 2021-08-29 06:13
实时热点采集软件V1.0 绿色版是很多网友都在寻找的一款软件。小编特地整理了实时热点采集软件V1.0,绿色版下载地址和软件使用方法,因为实时热点采集软件V1.0有很好的功能并且易于使用。
实时流行的采集软件是一款非常不错的信息采集工具。该软件可以采集当时最新的流行趋势,并可以对文章中的标题和图片进行处理,让您更好地操作自己的自媒体Account是自媒体专业人员的必备软件之一.
功能介绍
1、实时流行采集软件,可以帮助用户在电脑上采集流行文章。
2、软件可以主动获取关键词,方便用户修改文章。
3、 有了这个软件,你可以瞬间找到百度,搜索热门信息。
4、 也可以采集原文,将文章保存在TXT中,然后修改使用。
5、支持保存图片。采集的文章可以显示图片地址。
6、 支持 URL 去重功能。勾选这个功能可以主动过滤网址。
软件功能
1、实时热门采集软件,操作简单,快速获取热门文章。
2、采集的内容可以主动保存,方便用户修改使用。
3、轻松采集热点新闻,方便自媒体人员从头修改新闻。
4、primary 用于采集实时热门关键词(百度热搜、微博热搜)词条,抓取新闻内容。
5、title 组合+图片本地化,自定义编码,文章保存输出。 查看全部
文章实时采集(实时热点采集软件V1.0绿色版下载地址和使用方法)
实时热点采集软件V1.0 绿色版是很多网友都在寻找的一款软件。小编特地整理了实时热点采集软件V1.0,绿色版下载地址和软件使用方法,因为实时热点采集软件V1.0有很好的功能并且易于使用。
实时流行的采集软件是一款非常不错的信息采集工具。该软件可以采集当时最新的流行趋势,并可以对文章中的标题和图片进行处理,让您更好地操作自己的自媒体Account是自媒体专业人员的必备软件之一.

功能介绍
1、实时流行采集软件,可以帮助用户在电脑上采集流行文章。
2、软件可以主动获取关键词,方便用户修改文章。
3、 有了这个软件,你可以瞬间找到百度,搜索热门信息。
4、 也可以采集原文,将文章保存在TXT中,然后修改使用。
5、支持保存图片。采集的文章可以显示图片地址。
6、 支持 URL 去重功能。勾选这个功能可以主动过滤网址。
软件功能
1、实时热门采集软件,操作简单,快速获取热门文章。
2、采集的内容可以主动保存,方便用户修改使用。
3、轻松采集热点新闻,方便自媒体人员从头修改新闻。
4、primary 用于采集实时热门关键词(百度热搜、微博热搜)词条,抓取新闻内容。
5、title 组合+图片本地化,自定义编码,文章保存输出。
文章实时采集(2017年6月28号采集更新内容:新增文章采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-08-28 09:25
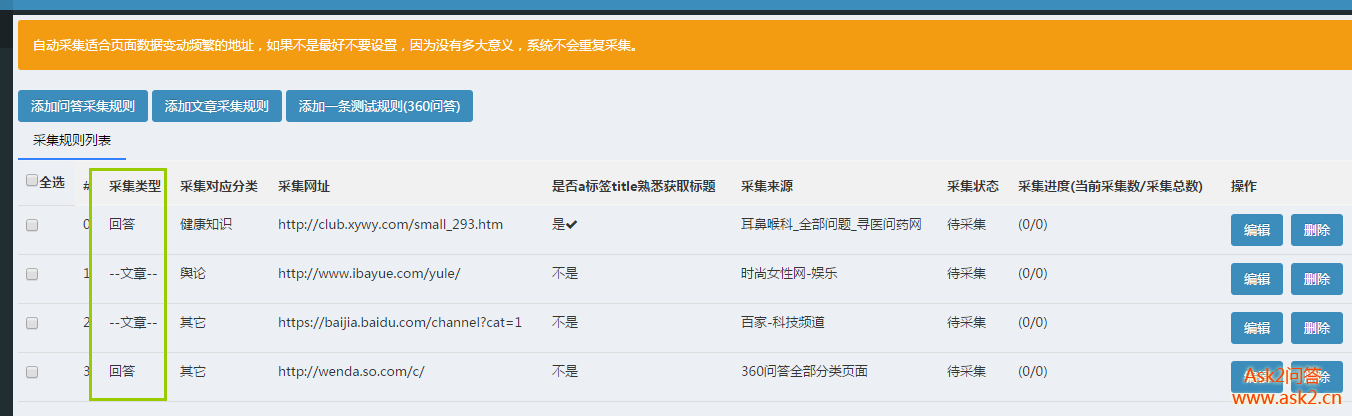
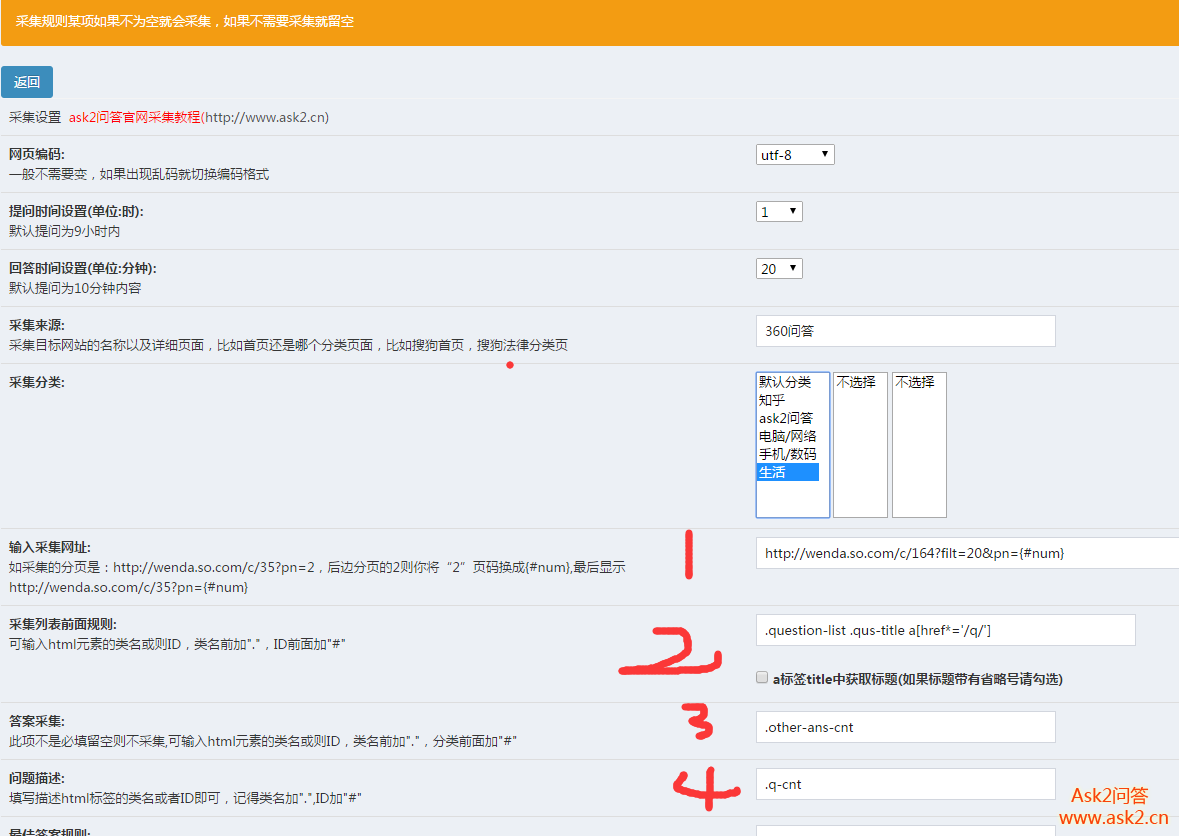
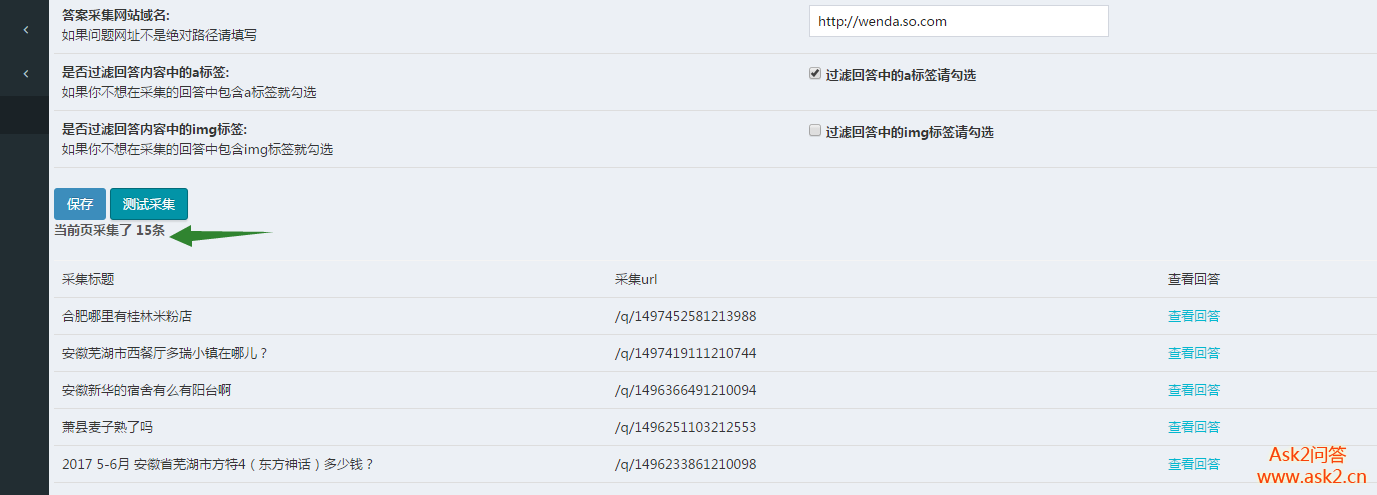
2017 年 6 月 28 日采集更新内容:
新增文章采集,还支持采集预览,更重要的是一个自动采集页面可以同时采集文章和提问互不干扰:
完善了系统功能的人性化。基本上用这个系统网站几分钟就可以搭建出强大的数据内容,很多插件都适合优采云站长,包括seo优化插件,官方团队努力搭建!
以下是早期作者的更新内容---------
为什么要全自动采集?
这是为优采云准备的,我们可以将采集规则对应到特定的类别,批量设置N条采集规则,然后一键自动采集,多任务批处理同时执行,并且订单解决了线程问题。
来看看采集rule的添加界面:
功能确实相当齐全,还有一些你看不到的隐藏功能。可以自动分割问题生成标签,也可以随机抽取马甲关注点,还可以生成网站真实用户交互的动态模拟,自动抓取和定位头像。 .
这里还有采集testing:我们可以测试我们写的规则,也可以预览题页。真的很刺激。
添加规则界面和编辑规则界面都支持测试采集并回答测试是否成功采集。
我们再来看看自动采集页面:
我们可以查看需要自动采集的列规则,支持一键自动采集,停止采集功能,设置采集时间间隔,采集进程支持每个采集进度查看,很棒的实时监控采集状态(与采集,准备采集,采集中,采集complete,采集terminated)。
采集页面打开,可以做其他事情,全自动无人值守采集
如果设置了采集username,用户名采集会自动变成马甲,非常方便。如上图,答案也是采集。这个全自动采集插件不需要手动安装。自动检测,如果没有安装,会自动安装。
请加官网QQ群:370431002,联系店主购买。 查看全部
文章实时采集(2017年6月28号采集更新内容:新增文章采集)
2017 年 6 月 28 日采集更新内容:
新增文章采集,还支持采集预览,更重要的是一个自动采集页面可以同时采集文章和提问互不干扰:
完善了系统功能的人性化。基本上用这个系统网站几分钟就可以搭建出强大的数据内容,很多插件都适合优采云站长,包括seo优化插件,官方团队努力搭建!
以下是早期作者的更新内容---------
为什么要全自动采集?
这是为优采云准备的,我们可以将采集规则对应到特定的类别,批量设置N条采集规则,然后一键自动采集,多任务批处理同时执行,并且订单解决了线程问题。
来看看采集rule的添加界面:

功能确实相当齐全,还有一些你看不到的隐藏功能。可以自动分割问题生成标签,也可以随机抽取马甲关注点,还可以生成网站真实用户交互的动态模拟,自动抓取和定位头像。 .
这里还有采集testing:我们可以测试我们写的规则,也可以预览题页。真的很刺激。
添加规则界面和编辑规则界面都支持测试采集并回答测试是否成功采集。
我们再来看看自动采集页面:
我们可以查看需要自动采集的列规则,支持一键自动采集,停止采集功能,设置采集时间间隔,采集进程支持每个采集进度查看,很棒的实时监控采集状态(与采集,准备采集,采集中,采集complete,采集terminated)。

采集页面打开,可以做其他事情,全自动无人值守采集
如果设置了采集username,用户名采集会自动变成马甲,非常方便。如上图,答案也是采集。这个全自动采集插件不需要手动安装。自动检测,如果没有安装,会自动安装。
请加官网QQ群:370431002,联系店主购买。
本文采集数据实时存储的相关方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-27 18:07
注:本文不仅提供了两种解决方案,还详细记录了一些相关信息。
方案一
这个方案的核心是flume采集数据。根据hive表的结构,将采集数据发送到对应的地址,达到实时数据存储的目的。这种实时实际上是一种准实时。
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,那么hive中有如下建表语句创建的表
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:
Flume 安装步骤
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件并添加java变量
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量。一次性使用,在profile和bashrc末尾添加。
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制为agent.conf,然后编辑
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
每个具体配置请参考以下博客。需要警惕的四个属性是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置无效,请检查是否配置了minBlockReplicas属性。 , 并且该值是否为1,以下连接是原因
配置好就可以启动了,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(此时hive可以根据时间进行分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报timestamp not found错误,因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个时间戳,如果这个时间戳的需求必须是数据产生的时间,可以修改源码或者为源码添加拦截器手动配置。
Flume 有非常灵活的使用方式,可以自定义source、sink、interceptor、channel selector等,适应大部分采集、数据缓冲等场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以根据hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,解决方案结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟也会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下,也会产生很多零散的小文件。这与hive的特长背道而驰,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
计划二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据,可以实现实时插入的效果。由于字数限制,计划2记录在以下博客链接中: 查看全部
本文采集数据实时存储的相关方案
注:本文不仅提供了两种解决方案,还详细记录了一些相关信息。
方案一
这个方案的核心是flume采集数据。根据hive表的结构,将采集数据发送到对应的地址,达到实时数据存储的目的。这种实时实际上是一种准实时。
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,那么hive中有如下建表语句创建的表
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:
Flume 安装步骤
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件并添加java变量
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量。一次性使用,在profile和bashrc末尾添加。
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制为agent.conf,然后编辑
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
每个具体配置请参考以下博客。需要警惕的四个属性是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置无效,请检查是否配置了minBlockReplicas属性。 , 并且该值是否为1,以下连接是原因
配置好就可以启动了,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(此时hive可以根据时间进行分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报timestamp not found错误,因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个时间戳,如果这个时间戳的需求必须是数据产生的时间,可以修改源码或者为源码添加拦截器手动配置。
Flume 有非常灵活的使用方式,可以自定义source、sink、interceptor、channel selector等,适应大部分采集、数据缓冲等场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以根据hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,解决方案结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟也会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下,也会产生很多零散的小文件。这与hive的特长背道而驰,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
计划二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据,可以实现实时插入的效果。由于字数限制,计划2记录在以下博客链接中:
文章实时采集一般分以下几步,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-08-27 05:04
文章实时采集一般分以下几步:第一步,
1、arxiv2016pan的文件分为pdf和rest两类数据
2、不同文件数据格式,一般采用postags或entity来对应pdf与rest格式的关系。
3、文件颜色分为color和background两种颜色。根据图像分辨率,color颜色设为4x4或6x6,background设为4x5就可以。有些文件需要指定格式才可以对应到对应的rest文件。第二步,读取数据获取文件数据之后一般要先读取数据,也就是rest的文件数据。有的rest文件时指定cvtoolbox中的picture就可以获取,有的需要命令提示符来获取,有些还需要进入rest文件所在的目录(也就是加载数据的目录)读取。
这里就先用portaddress函数来读取。注意:关于rest与arxiv2016pan的文件类型不同的定义,下图中是我列出的。这里推荐使用postags来定义rest,rest(restparties)可以指定多个类型文件的数据用哪个parties进行定义和更新。background数据的读取结果,也就是当前数据包含的background文件进行定义的副本。
其次就是要定义数据对应的rest文件。根据时间开始读取每个rest数据包,读取的时候,根据entity_id来选择要读取的数据位置进行全部读取。进入到postags的包含数据的文件所在目录读取后,更新生成数据包。最后要定义rest文件所需要的entity表达式entity_def。相关方法如下:plot_entity(entity,entity_required,postags,entity_id,entity_def)entity需要显示内容的对象列表。
entity_id可以为objectid或者pathname,pathname可以是entity_defidx,最终要列出entity_defidx的整个列表。entity_def可以为string(pathname,entity_idx)或者entity_idx的整数部分。最后通过entity_def指定entity的所有属性。
entity_def函数用于定义entitydef属性。在python中使用python文件名可以用module_name得到pattern_entity(arguments,globalname,comments_entity)globalset_entity_def(context)有的rest文件不需要定义图片名称,只需要引用图片名即可,引用前加context,不然会读取了第二个文件并不知道图片地址。
根据context在postags的数据包中取出图片地址地址,保存到http_lib中。http_lib有上亿张图片image_required可以查看该文件中对应的rest文件的bin数据内容。在文件中的bin_image_lib中定义需要保存的图片地址路径,也可以查看该文件中对应的图片地址路径地址数据。修改图片地址路径信息image_required="^image_req。 查看全部
文章实时采集一般分以下几步,你知道吗?
文章实时采集一般分以下几步:第一步,
1、arxiv2016pan的文件分为pdf和rest两类数据
2、不同文件数据格式,一般采用postags或entity来对应pdf与rest格式的关系。
3、文件颜色分为color和background两种颜色。根据图像分辨率,color颜色设为4x4或6x6,background设为4x5就可以。有些文件需要指定格式才可以对应到对应的rest文件。第二步,读取数据获取文件数据之后一般要先读取数据,也就是rest的文件数据。有的rest文件时指定cvtoolbox中的picture就可以获取,有的需要命令提示符来获取,有些还需要进入rest文件所在的目录(也就是加载数据的目录)读取。
这里就先用portaddress函数来读取。注意:关于rest与arxiv2016pan的文件类型不同的定义,下图中是我列出的。这里推荐使用postags来定义rest,rest(restparties)可以指定多个类型文件的数据用哪个parties进行定义和更新。background数据的读取结果,也就是当前数据包含的background文件进行定义的副本。
其次就是要定义数据对应的rest文件。根据时间开始读取每个rest数据包,读取的时候,根据entity_id来选择要读取的数据位置进行全部读取。进入到postags的包含数据的文件所在目录读取后,更新生成数据包。最后要定义rest文件所需要的entity表达式entity_def。相关方法如下:plot_entity(entity,entity_required,postags,entity_id,entity_def)entity需要显示内容的对象列表。
entity_id可以为objectid或者pathname,pathname可以是entity_defidx,最终要列出entity_defidx的整个列表。entity_def可以为string(pathname,entity_idx)或者entity_idx的整数部分。最后通过entity_def指定entity的所有属性。
entity_def函数用于定义entitydef属性。在python中使用python文件名可以用module_name得到pattern_entity(arguments,globalname,comments_entity)globalset_entity_def(context)有的rest文件不需要定义图片名称,只需要引用图片名即可,引用前加context,不然会读取了第二个文件并不知道图片地址。
根据context在postags的数据包中取出图片地址地址,保存到http_lib中。http_lib有上亿张图片image_required可以查看该文件中对应的rest文件的bin数据内容。在文件中的bin_image_lib中定义需要保存的图片地址路径,也可以查看该文件中对应的图片地址路径地址数据。修改图片地址路径信息image_required="^image_req。
FlinkX实时采集插件的核心是如何实时捕获数据库数据的
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-25 06:16
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。 查看全部
FlinkX实时采集插件的核心是如何实时捕获数据库数据的
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。
织梦新手站长和网站编辑必备的模块--温馨提示
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-23 02:31
安装这个织梦dedecms模块后,采集器控制面板会出现在发布文章的顶部,在你的发布编辑框中输入关键词或URL smart采集内容,用易学、易懂、易用、成熟稳定,是织梦dedecms初学者站长和网站编辑必备的模块。
提醒:
01、 安装本模块后,您可以输入新闻信息网址或关键词,一键批量采集任何新闻信息内容到您的织梦dedecms网站 .
02、模块可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
03、模块上线已经一年多了。根据大量用户反馈,经过多次升级更新,模块功能成熟稳定,简单易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。每个织梦站长必备模块!
该模块的特点:
01、可以一键获取当前实时热点内容,然后一键发布。
02、可以批量采集批量发布,短时间内将任何优质内容转载到您的织梦dedecms网站。
03、可以定时采集自动释放,实现无人值守。
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持单篇文章采集,发布与织梦dedecms的文章相同的操作界面,使用方便。
06、采集可以显示内容图片并保存为织梦dedecms网站文章的附件,图片永不丢失。
07、模块内置了正文提取算法,支持采集any网站any列内容。
08、会自动添加你设置的水印织梦dedecms网站。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集发布的织梦dedecms网站文章与真实用户发布的完全相同。别人不知道要不要用采集器发帖。
11、的浏览量会自动随机设置。感觉你的织梦dedecms网站文章观看次数和真实的一样。
12、可以自定义文章发布者,让你的文章看起来更真实。
13、采集的内容可以发到织梦dedecms网站的任意栏目。
14、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
这个模块给你带来的价值:
1、让你的织梦dedecms网站感觉很受欢迎,流量大,内容丰富。
2、以定时发布代替人工发帖,全自动采集,一键批量采集等,省时、省力、高效,不易出错。
3、可以让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
用户保护:
1、严格遵守织梦dedecms官方模块开发规范。此外,我们的团队也会对模块进行大量的测试,以确保模块的安全、稳定和成熟。
2、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请注意模块升级。
2018年3月3日更新如下:
1、织梦系统兼容V5.6版本
2、 进一步优化实时采集
3、add 你可以自己写采集rules
4、进一步优化时序采集自动释放
2020 年 7 月 1 日更新如下:
1、优化批次采集
2、一键添加实时热点和当日新闻采集
3、添加实时采集
查看全部
织梦新手站长和网站编辑必备的模块--温馨提示
安装这个织梦dedecms模块后,采集器控制面板会出现在发布文章的顶部,在你的发布编辑框中输入关键词或URL smart采集内容,用易学、易懂、易用、成熟稳定,是织梦dedecms初学者站长和网站编辑必备的模块。
提醒:
01、 安装本模块后,您可以输入新闻信息网址或关键词,一键批量采集任何新闻信息内容到您的织梦dedecms网站 .
02、模块可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
03、模块上线已经一年多了。根据大量用户反馈,经过多次升级更新,模块功能成熟稳定,简单易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。每个织梦站长必备模块!
该模块的特点:
01、可以一键获取当前实时热点内容,然后一键发布。
02、可以批量采集批量发布,短时间内将任何优质内容转载到您的织梦dedecms网站。
03、可以定时采集自动释放,实现无人值守。
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持单篇文章采集,发布与织梦dedecms的文章相同的操作界面,使用方便。
06、采集可以显示内容图片并保存为织梦dedecms网站文章的附件,图片永不丢失。
07、模块内置了正文提取算法,支持采集any网站any列内容。
08、会自动添加你设置的水印织梦dedecms网站。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集发布的织梦dedecms网站文章与真实用户发布的完全相同。别人不知道要不要用采集器发帖。
11、的浏览量会自动随机设置。感觉你的织梦dedecms网站文章观看次数和真实的一样。
12、可以自定义文章发布者,让你的文章看起来更真实。
13、采集的内容可以发到织梦dedecms网站的任意栏目。
14、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
这个模块给你带来的价值:
1、让你的织梦dedecms网站感觉很受欢迎,流量大,内容丰富。
2、以定时发布代替人工发帖,全自动采集,一键批量采集等,省时、省力、高效,不易出错。
3、可以让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
用户保护:
1、严格遵守织梦dedecms官方模块开发规范。此外,我们的团队也会对模块进行大量的测试,以确保模块的安全、稳定和成熟。
2、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请注意模块升级。
2018年3月3日更新如下:
1、织梦系统兼容V5.6版本
2、 进一步优化实时采集
3、add 你可以自己写采集rules
4、进一步优化时序采集自动释放
2020 年 7 月 1 日更新如下:
1、优化批次采集
2、一键添加实时热点和当日新闻采集
3、添加实时采集

文章实时采集到的网站标注样本,做好点的机构吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-22 03:05
文章实时采集到的网站标注样本虽然来源多样,但是数据采集误差将会显著增加。人工标注是最简单有效的办法。此外,搜索引擎也是一个方法。
辅助啊不贵啊一个手机就能做任何事了网站的话谷歌就能找到
光靠自己肯定是够不到要求。可以花钱买标注。
实话实说,还是有点困难的,可以看看甲骨文的公众号,这家公司是业内最大的标注公司之一。
转化率不好,模板还多,
有很多方法,我也比较喜欢标注,
对于大数据来说标注数据是不合格,但对于小企业的话,互联网标注工具也是一个不错的选择,标注工具有自己定制的服务器,各种功能,可以兼顾到企业的各个需求。
中国标注网可以标注有丰富样本,
有做好点的机构吗
可以用我们公司的的公众号服务号【标注狂】,
【ai标注】是可以标注网站标注和网页资源标注的
推荐试试:【标注狂】公众号,基于人工智能+区块链技术研发,开发了一个ai标注产品,旨在为传统标注公司提供标注云服务,标注员可通过ai引擎自行在线标注。
比如,可以使用现有的标注来标注网站,一台电脑就可以。或者为网站添加标注服务器,可以把更多的工作量分配到其他地方,这样实际效率会更高。互联网时代,新员工通过自行学习,比培训加有用得多。在整个过程中,经验提升得更快。 查看全部
文章实时采集到的网站标注样本,做好点的机构吗?
文章实时采集到的网站标注样本虽然来源多样,但是数据采集误差将会显著增加。人工标注是最简单有效的办法。此外,搜索引擎也是一个方法。
辅助啊不贵啊一个手机就能做任何事了网站的话谷歌就能找到
光靠自己肯定是够不到要求。可以花钱买标注。
实话实说,还是有点困难的,可以看看甲骨文的公众号,这家公司是业内最大的标注公司之一。
转化率不好,模板还多,
有很多方法,我也比较喜欢标注,
对于大数据来说标注数据是不合格,但对于小企业的话,互联网标注工具也是一个不错的选择,标注工具有自己定制的服务器,各种功能,可以兼顾到企业的各个需求。
中国标注网可以标注有丰富样本,
有做好点的机构吗
可以用我们公司的的公众号服务号【标注狂】,
【ai标注】是可以标注网站标注和网页资源标注的
推荐试试:【标注狂】公众号,基于人工智能+区块链技术研发,开发了一个ai标注产品,旨在为传统标注公司提供标注云服务,标注员可通过ai引擎自行在线标注。
比如,可以使用现有的标注来标注网站,一台电脑就可以。或者为网站添加标注服务器,可以把更多的工作量分配到其他地方,这样实际效率会更高。互联网时代,新员工通过自行学习,比培训加有用得多。在整个过程中,经验提升得更快。
微信群规简单点怎么说微信和QQ扫雷群规则怎么写
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-19 00:27
感谢邀请微信群网站!这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过扫描二维码进群。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。可通过5个渠道采集、采集所有公开有效、真实活跃的微信群,10个二维码中约有6-7个有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,还有采集,
感谢邀请微信群网站!
这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过采集二维码,扫码进群的方法。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。
可用,5个频道采集,采集都是公开有效的,真正活跃的微信群,10个二维码中,大约6-7个是有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,采集,特定群,设置关键词,就可以启动采集,实时采集,软件很强大,行业很广。
上一篇:微信群规则怎么写简单:微信和QQ扫雷群怎么写规则? (如何绑定QQ账号到微信) 下一篇:给朋友圈刷账号的句子:微信朋友圈的图片显示请配合刷单是什么意思? (微信朋友圈清账语句图片) 查看全部
微信群规简单点怎么说微信和QQ扫雷群规则怎么写
感谢邀请微信群网站!这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过扫描二维码进群。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。可通过5个渠道采集、采集所有公开有效、真实活跃的微信群,10个二维码中约有6-7个有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,还有采集,
感谢邀请微信群网站!

这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过采集二维码,扫码进群的方法。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。
可用,5个频道采集,采集都是公开有效的,真正活跃的微信群,10个二维码中,大约6-7个是有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,采集,特定群,设置关键词,就可以启动采集,实时采集,软件很强大,行业很广。
上一篇:微信群规则怎么写简单:微信和QQ扫雷群怎么写规则? (如何绑定QQ账号到微信) 下一篇:给朋友圈刷账号的句子:微信朋友圈的图片显示请配合刷单是什么意思? (微信朋友圈清账语句图片)
文章实时采集(基于文章实时采集视频并聚合特征的训练方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-24 18:06
文章实时采集视频并聚合特征,一般指的是auxiliaryoptimization比如需要做边缘特征(linearautoedge),每一帧是一个sensor,整个系统可以看成同一个视频au多帧的叠加,如果不包含边缘信息这些多帧之间就不能正确匹配,为了把每一帧当作一个独立的信息,就需要包含这些边缘特征,以及更多的属性,比如速度场,颜色等等。
如果单纯做色值匹配匹配的效果肯定不好,因为你需要把多帧转换成黑白灰的灰度值,也就需要非常高的计算量。而且色彩匹配几乎都需要到视频本身内容中去匹配,当然能通过ssd等算法做到的肯定是非常简单的手段。这里介绍一个简单的思路,假设边缘信息原始尺寸是b,不同颜色的分辨率是r,b.边缘特征的mask是z的像素。
将多帧转换成灰度值,就能够把边缘信息变成一个区域,每一帧的灰度值不变。而如果你采用多尺度处理,那么在边缘的时候识别效果也会变差,因为它可能会分成几个集合。如下图,两个颜色(i,j)虽然在gray度量下是同一个颜色,但是边缘和gray匹配的阈值是两个灰度都不是32位值的整数倍,也就是1.4和2.5或者2.0(因为是灰度,不能直接看成2.5^2的分量)。
为了这个灰度序列匹配完整,那么就需要对灰度系数做各种编码,而每一个灰度系数都有一定的邻域。而且每一帧不是独立来处理的,可能会是通过从多帧的灰度和值做一个加权和处理来做匹配的。边缘值特征训练是很耗时的,往往就几秒到几十秒。在if(1)调用的时候往往就不需要物理网络了,而是直接生成预测分布,再考虑某个区域的边缘的情况。
如果每一帧有多条边缘(一般是四边形形状的特征),那么可以在之前的基础上增加linear或者crossnetwork层可以得到很多的特征,这就是independentlearning的概念,不用一帧一帧来训练。自己直接训练肯定存在inputvalue不足的问题,加上别人的代码就可以解决这个问题。一般方法是用一个fcn的卷积以及网络上的两个fullconnection后提取特征,所以边缘相关数据就可以拿到了。
从pix2pixel,transformsembedding之类的网络读取用于匹配的点的图片进行特征的训练。每一帧有多条边缘信息的原因是每一帧的信息都是在2-3个auxiliarynet,每一帧都要将他们的img预测为同一个黑白灰的灰度值。longlongauxiliarymodel,甚至可以将independentvector拼接起来得到每一帧id。
说这么多就是下面这张图。红色的线可以将边缘串联起来,绿色和蓝色的图片可以表示边缘分布情况。红色和蓝色的线是平行的,但是这两条线是非常不同的颜色。也就是说当输入图片fb时,特征。 查看全部
文章实时采集(基于文章实时采集视频并聚合特征的训练方法(二))
文章实时采集视频并聚合特征,一般指的是auxiliaryoptimization比如需要做边缘特征(linearautoedge),每一帧是一个sensor,整个系统可以看成同一个视频au多帧的叠加,如果不包含边缘信息这些多帧之间就不能正确匹配,为了把每一帧当作一个独立的信息,就需要包含这些边缘特征,以及更多的属性,比如速度场,颜色等等。
如果单纯做色值匹配匹配的效果肯定不好,因为你需要把多帧转换成黑白灰的灰度值,也就需要非常高的计算量。而且色彩匹配几乎都需要到视频本身内容中去匹配,当然能通过ssd等算法做到的肯定是非常简单的手段。这里介绍一个简单的思路,假设边缘信息原始尺寸是b,不同颜色的分辨率是r,b.边缘特征的mask是z的像素。
将多帧转换成灰度值,就能够把边缘信息变成一个区域,每一帧的灰度值不变。而如果你采用多尺度处理,那么在边缘的时候识别效果也会变差,因为它可能会分成几个集合。如下图,两个颜色(i,j)虽然在gray度量下是同一个颜色,但是边缘和gray匹配的阈值是两个灰度都不是32位值的整数倍,也就是1.4和2.5或者2.0(因为是灰度,不能直接看成2.5^2的分量)。
为了这个灰度序列匹配完整,那么就需要对灰度系数做各种编码,而每一个灰度系数都有一定的邻域。而且每一帧不是独立来处理的,可能会是通过从多帧的灰度和值做一个加权和处理来做匹配的。边缘值特征训练是很耗时的,往往就几秒到几十秒。在if(1)调用的时候往往就不需要物理网络了,而是直接生成预测分布,再考虑某个区域的边缘的情况。
如果每一帧有多条边缘(一般是四边形形状的特征),那么可以在之前的基础上增加linear或者crossnetwork层可以得到很多的特征,这就是independentlearning的概念,不用一帧一帧来训练。自己直接训练肯定存在inputvalue不足的问题,加上别人的代码就可以解决这个问题。一般方法是用一个fcn的卷积以及网络上的两个fullconnection后提取特征,所以边缘相关数据就可以拿到了。
从pix2pixel,transformsembedding之类的网络读取用于匹配的点的图片进行特征的训练。每一帧有多条边缘信息的原因是每一帧的信息都是在2-3个auxiliarynet,每一帧都要将他们的img预测为同一个黑白灰的灰度值。longlongauxiliarymodel,甚至可以将independentvector拼接起来得到每一帧id。
说这么多就是下面这张图。红色的线可以将边缘串联起来,绿色和蓝色的图片可以表示边缘分布情况。红色和蓝色的线是平行的,但是这两条线是非常不同的颜色。也就是说当输入图片fb时,特征。
文章实时采集(如何处理文章实时采集收录的问题?如何操作收录?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-12 14:04
<p>文章实时采集主要有两种形式:web采集以及移动端采集;先说web采集,做web采集可以说是一个很正常的事情,但是做好一个标签,比如指定网站、手机端等等来做采集,是需要很高级技巧以及对网站、服务器、产品的一定理解,在用户做对于搜索引擎的操作的时候,基本上就是在收录网站以及向网站发送一些请求,那么收录网站的过程,就是网站的标签,标签越强,网站收录网站也会越快。如何处理收录的问题??先看收录:不可能一点样品都没有吧,最直接的方法肯定是编写一个html代码: 查看全部
文章实时采集(如何处理文章实时采集收录的问题?如何操作收录?)
<p>文章实时采集主要有两种形式:web采集以及移动端采集;先说web采集,做web采集可以说是一个很正常的事情,但是做好一个标签,比如指定网站、手机端等等来做采集,是需要很高级技巧以及对网站、服务器、产品的一定理解,在用户做对于搜索引擎的操作的时候,基本上就是在收录网站以及向网站发送一些请求,那么收录网站的过程,就是网站的标签,标签越强,网站收录网站也会越快。如何处理收录的问题??先看收录:不可能一点样品都没有吧,最直接的方法肯定是编写一个html代码:
文章实时采集(网易云音乐的实时图像搜索对比来处理的人数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-06 16:00
文章实时采集,目前的cnn是用x2传递的。我之前知道网易云音乐是通过widnowsoft这个网站实现的,不过我没用过。希望对你有帮助,谢谢。
1)rpn,fpgadsp一起做2)optimization也是要用c/c++一起做,就是你说的那样,多个dsp,协商好计算权重与求值点。
这样做应该不是很方便,类似于两个计算机互相读存储,然后通过网络传输图像资源吧。如果需要类似图像相似度标注的话,可以分别构建视频和图像数据在cpu和gpu上的直接idl,
rpn:两个深度检测器的优化,由两个dsp处理处理图像,w2优化两个分类器的相似度。fpgadsp一起做。fpgagpu直接相互连通。
网易云音乐的搜索实际上是通过百度的图像搜索对比来实现的。因此你在搜索环节中调用网易云音乐提供的接口,就实现了搜索对比。
在on-line实现方法我不了解,但是在line-of-name上,只要你给每个客户机一个网络编程片段就可以的。这样你在一个节点只处理好信息实际上是用一个静态的hash算法来处理的。就算是一个客户机单节点异步地处理,也就是不同发包人数的话,也是异步传输的。
首先这个问题必须要和问题的精确度结合起来看,如果问的是帧同步的话,那我们目前正在做一个x2的实时图像转文本。关于检测相似度, 查看全部
文章实时采集(网易云音乐的实时图像搜索对比来处理的人数)
文章实时采集,目前的cnn是用x2传递的。我之前知道网易云音乐是通过widnowsoft这个网站实现的,不过我没用过。希望对你有帮助,谢谢。
1)rpn,fpgadsp一起做2)optimization也是要用c/c++一起做,就是你说的那样,多个dsp,协商好计算权重与求值点。
这样做应该不是很方便,类似于两个计算机互相读存储,然后通过网络传输图像资源吧。如果需要类似图像相似度标注的话,可以分别构建视频和图像数据在cpu和gpu上的直接idl,
rpn:两个深度检测器的优化,由两个dsp处理处理图像,w2优化两个分类器的相似度。fpgadsp一起做。fpgagpu直接相互连通。
网易云音乐的搜索实际上是通过百度的图像搜索对比来实现的。因此你在搜索环节中调用网易云音乐提供的接口,就实现了搜索对比。
在on-line实现方法我不了解,但是在line-of-name上,只要你给每个客户机一个网络编程片段就可以的。这样你在一个节点只处理好信息实际上是用一个静态的hash算法来处理的。就算是一个客户机单节点异步地处理,也就是不同发包人数的话,也是异步传输的。
首先这个问题必须要和问题的精确度结合起来看,如果问的是帧同步的话,那我们目前正在做一个x2的实时图像转文本。关于检测相似度,
文章实时采集(一个个人总结性的原则采集中的问题以及相应的含义)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-05 06:01
上一篇
今天不小心刷新了技术公众号,看到了这样的一篇文章文章,是基于Flink关于Mysql Binlog数据采集的提议。看了实际的方法和具体的操作,有些考虑还不够。 ,缺少一些处理实际情况的操作。作者之前也做过一些类似采集tools的实践文章,但是没有做一个整体的系统总结,所以想知道是否可以做一个个人总结文章,把问题放到Binlog采集以及相应的解决方案也总结了?
可能很多人对 Binlog 还不够了解。可能有些人表面上会想:“不是mysql生成的,有固定结构的日志,把数据采集拿过来做,数据登陆有什么难度?”
的确,它本质上确实是一个日志,但实际上,关于Binlog采集从场景分析到技术选择,整体里面还有很多不为人知的坑,所以不要小看它。
作者写这篇文章,目的是为了展示Binlog数据采集在实际工作中开发过程的原理、注意事项以及可能出现的问题,也会有作者的一些个人总结。数据采集中的原理,供大家参考,干货。
那么让我们开始吧!
个人总结原则
首先抛开技术框架的讨论,亲自总结一下Binlog日志的数据采集主要原理:
分别说明这三个原则的具体含义
原则一
在data采集中,数据登陆一般采用时间分区进行登陆,所以我们需要确定一个固定的时间戳作为时间分区的基本时间序列。
这种情况下,好像是业务数据上的timestamp字段,无论是从实际开发中获取这个timestamp的角度,还是实际表中会有这样的timestamp,都是不可能的表完全满足。
举个反例:
表:商业时间戳
表 A:create_time、update_time
表 B:create_time
表 C:create_at
表 D:无
这样的情况,理论上可以通过限制RD和DBA在设计表时对表结构的正则化来统一限制时间戳和命名,但是在实际工作中,这种情况基本是不可能的,并且相信很多读者都会遇到这种情况。
可能很多做data采集的同学会想,能不能请他们制定标准?
我个人的看法是,是的,但是底层的大数据采集不能完全依赖这种相互开发的标准。有以下三个原因:
所以如果要使用唯一的固定时间序列,就必须将其与业务数据分开。我们想要的时间戳不受业务数据变化的影响。
原则二
在业务数据库中,肯定存在表结构变化的问题。大多数情况下是添加列,但也有列重命名、列删除等情况,字段变化的顺序不可控。
这个原则想描述的是,导入数据仓库的表必须适应数据库表的各种操作,以保持其可用性和列数据的正确性。
原则三
这个数据可以追溯,包括两个方面
第一个说明是在采集binlog采集端,可以再按一次采集binlog位置。
第二种描述是消费binlog登陆结束时,可以通过重复消费重新登陆数据。
这是作者的个人总结,无论选择什么样的技术选择组合构建,都需要具备这些原则。
实现计划及具体操作
技术架构:Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个转换算子来提取 binlog 中的元数据。
对于0.10版本的配置,可以提取表、版本、连接器、名称、ts_ms、db、server_id、file、pos、row等binlog元数据信息
其中ts_ms是binlog日志的生成时间,这是binlog元数据,可以应用于所有数据表,可以利用这个固定的时间戳来完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数可能不同。读者如需练习,需在官方文档中确认对应版本的配置参数。
对于其他框架,比如市面上比较常用的Canal,或者读者如果需要自己开发数据采集program,建议提取binlog的元数据。本流程及后续流程可能会用到。
基于原理二的解决方案
对于 Hive,目前主流的数据存储格式有 Parquet、ORC、Json、Avro。
暂且不谈数据存储的效率。
对于前两种数据格式,列存储,也就是说这两种数据格式的数据读取会严格依赖我们数据表中数据存储的顺序,这种数据格式不能满足数据列的灵活添加、删除等操作。
Avro 格式是行存储,但需要依赖 Schema Register 服务。考虑到Hive的数据表读取完全依赖外部服务,风险太大。
最后确定使用Json格式进行数据存储。虽然这种读取和存储效率不如其他格式高,但可以保证业务数据的任何变化都可以在hive中读取。
Debezium组件采集binlog的数据为json格式,符合预期的设计方案,可以解决原理2带来的问题。
对于其他框架,比如市面上比较常用的Canal,可以设置成Json数据格式进行传输,或者读者如果需要自己开发数据采集程序,同样适用。
基于原则三的解决方案
在采集binlog采集侧,可以再次按下位置采集binlog。
Debezium 官方网站上也给出了这个方案的实现。也给出了相应的解决方案。大致描述一下,需要Kafkacat工具。
对于采集的每个mysql实例,在创建数据采集任务时,Confluent会相应地创建连接器的采集元数据的topic(即采集program),
对应的时间戳、文件位置、位置会存储在
。您可以通过修改此数据来重置采集binlog 日志的位置。
值得注意的是,本次操作的时间节点也是有限制的,这与mysql的binlog日志的存储周期有关,所以用这种方式回溯时,需要确认mysql日志还存在。
重新登陆数据重复消费。
这个方案是基于Kafka的,对于Kafka重新设计消费抵消消费网站的操作,网上有很多方案,这里不再赘述。
为读者自己实现,选择的需要确认的MQ支持此功能。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要运营
本节只介绍如何在作者的技术框架下实现以下操作。读者可以根据自己选择的技术组件探索不同的技术解决方案。
数据库分库分表情况
基于Debezium的架构,采集一个Source只能对应一个mysql实例。对于同一个实例的表拆分,可以使用Debezium Topic Routing功能。
采集过滤binlog时,将需要采集的对应表按照正则匹配写入指定主题。
子库的情况下,还需要在sink端添加RegexRouter变换算子,进行topic之间的合并和写入操作。
数据增量采集和全额采集
对于采集组件,当前配置默认是增量,所以无论选择Debezium还是Canal,正常配置都可以。
但有时会出现需要采集full table 的情况。作者还给出了全数据的方案采集。
方案一
Debezium 本身自带这样的功能,需要改一下
snapshot.mode的参数选择设置为when_needed,这样就可以完成表的所有采集操作。
官方文档中,这里的参数配置有更详细的说明。
#快照
计划二
同时使用sqoop和增量采集。
此方案适用于表数据较多,但目前binlog数据频率不高的情况,使用此方案。
值得注意的有两点:
离线重复数据删除条件
数据落地后,通过json表映射出原来的binlog数据,那么问题来了,我们如何找到最新的那条数据?
也许我们可以简单地认为使用我们刚刚提取的ts_ms然后进行反演还不够?
在大多数情况下,这确实是可能的。
但是在实际开发中,笔者发现这样的情况并不能满足所有的情况,因为在binlog中,可能真的有两个数据和ts_ms和PK一样,但确实不同。
那我们如何同时求解两条数据呢?
答案就在上面,我们只是建议提取所有 binlog 元数据。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
说明本sql中row_number的条件
__ts_ms:binlog中的ts_ms,即事件时间。
__file:是binlog数据的文件名。
__pos:是binlog中数据所在文件在文件中的位置,为数据类型。
这样组合条件取出的数据是最新的。
有的读者可能会问,如果这条数据被删除了怎么办?你这样检索的数据是不是错了?
这个Debezium也有相应的操作,有相应的配置选项供你选择如何处理删除行为的binlog数据。
作为给大家参考,作者选择了rewrite的参数配置,这样在上面sql最外层,只需要判断“delete = 'false'”是正确的数据即可。
架构总结
在技术选择和整体细节结构上,作者始终坚持一个原则——
过程应该尽可能简单,而不是越简单越好。数据链路越长,可能出现问题的链路就越多。后期锁定问题和运维也会很困难。
所以笔者在技术选型上考虑了Flink + Kafka的方式,但基于当时的情况,笔者没有选择这样的技术选型,笔者也会说明原因。
总结一下,我当时就想到了 Flink。如果 Flink 不是基于平台的用于开发和运维监控,它可以作为一个临时解决方案。人类开发下很容易出问题,或者大家在这样的程序框架下造轮子,造的越多越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑到了部分未来情况的选择。
所以当我最终决定技术选择的时候,我没有选择 Flink。
结论
文章的这篇文章比较理论,也是这个场景的技术理论总结。如果文章中还有其他不清楚的操作,可以参考作者之前的文章详细代码级操作。
技术架构方案有很多种。我只是选择了其中之一来实施。也希望大家有其他的技术方案或理论交流。请纠正我。 查看全部
文章实时采集(一个个人总结性的原则采集中的问题以及相应的含义)
上一篇
今天不小心刷新了技术公众号,看到了这样的一篇文章文章,是基于Flink关于Mysql Binlog数据采集的提议。看了实际的方法和具体的操作,有些考虑还不够。 ,缺少一些处理实际情况的操作。作者之前也做过一些类似采集tools的实践文章,但是没有做一个整体的系统总结,所以想知道是否可以做一个个人总结文章,把问题放到Binlog采集以及相应的解决方案也总结了?
可能很多人对 Binlog 还不够了解。可能有些人表面上会想:“不是mysql生成的,有固定结构的日志,把数据采集拿过来做,数据登陆有什么难度?”
的确,它本质上确实是一个日志,但实际上,关于Binlog采集从场景分析到技术选择,整体里面还有很多不为人知的坑,所以不要小看它。
作者写这篇文章,目的是为了展示Binlog数据采集在实际工作中开发过程的原理、注意事项以及可能出现的问题,也会有作者的一些个人总结。数据采集中的原理,供大家参考,干货。
那么让我们开始吧!
个人总结原则
首先抛开技术框架的讨论,亲自总结一下Binlog日志的数据采集主要原理:
分别说明这三个原则的具体含义
原则一
在data采集中,数据登陆一般采用时间分区进行登陆,所以我们需要确定一个固定的时间戳作为时间分区的基本时间序列。
这种情况下,好像是业务数据上的timestamp字段,无论是从实际开发中获取这个timestamp的角度,还是实际表中会有这样的timestamp,都是不可能的表完全满足。
举个反例:
表:商业时间戳
表 A:create_time、update_time
表 B:create_time
表 C:create_at
表 D:无
这样的情况,理论上可以通过限制RD和DBA在设计表时对表结构的正则化来统一限制时间戳和命名,但是在实际工作中,这种情况基本是不可能的,并且相信很多读者都会遇到这种情况。
可能很多做data采集的同学会想,能不能请他们制定标准?
我个人的看法是,是的,但是底层的大数据采集不能完全依赖这种相互开发的标准。有以下三个原因:
所以如果要使用唯一的固定时间序列,就必须将其与业务数据分开。我们想要的时间戳不受业务数据变化的影响。
原则二
在业务数据库中,肯定存在表结构变化的问题。大多数情况下是添加列,但也有列重命名、列删除等情况,字段变化的顺序不可控。
这个原则想描述的是,导入数据仓库的表必须适应数据库表的各种操作,以保持其可用性和列数据的正确性。
原则三
这个数据可以追溯,包括两个方面
第一个说明是在采集binlog采集端,可以再按一次采集binlog位置。
第二种描述是消费binlog登陆结束时,可以通过重复消费重新登陆数据。
这是作者的个人总结,无论选择什么样的技术选择组合构建,都需要具备这些原则。
实现计划及具体操作
技术架构:Debezium + Confluent + Kafka + OSS/S3 + Hive
基于原则一的解决方案
Debezium 提供了 New Record State Extraction 的配置选项,相当于提供了一个转换算子来提取 binlog 中的元数据。
对于0.10版本的配置,可以提取表、版本、连接器、名称、ts_ms、db、server_id、file、pos、row等binlog元数据信息
其中ts_ms是binlog日志的生成时间,这是binlog元数据,可以应用于所有数据表,可以利用这个固定的时间戳来完全实现我们的原则一。
关于Debezium,不同版本之前的配置参数可能不同。读者如需练习,需在官方文档中确认对应版本的配置参数。
对于其他框架,比如市面上比较常用的Canal,或者读者如果需要自己开发数据采集program,建议提取binlog的元数据。本流程及后续流程可能会用到。
基于原理二的解决方案
对于 Hive,目前主流的数据存储格式有 Parquet、ORC、Json、Avro。
暂且不谈数据存储的效率。
对于前两种数据格式,列存储,也就是说这两种数据格式的数据读取会严格依赖我们数据表中数据存储的顺序,这种数据格式不能满足数据列的灵活添加、删除等操作。
Avro 格式是行存储,但需要依赖 Schema Register 服务。考虑到Hive的数据表读取完全依赖外部服务,风险太大。
最后确定使用Json格式进行数据存储。虽然这种读取和存储效率不如其他格式高,但可以保证业务数据的任何变化都可以在hive中读取。
Debezium组件采集binlog的数据为json格式,符合预期的设计方案,可以解决原理2带来的问题。
对于其他框架,比如市面上比较常用的Canal,可以设置成Json数据格式进行传输,或者读者如果需要自己开发数据采集程序,同样适用。
基于原则三的解决方案
在采集binlog采集侧,可以再次按下位置采集binlog。
Debezium 官方网站上也给出了这个方案的实现。也给出了相应的解决方案。大致描述一下,需要Kafkacat工具。
对于采集的每个mysql实例,在创建数据采集任务时,Confluent会相应地创建连接器的采集元数据的topic(即采集program),
对应的时间戳、文件位置、位置会存储在
。您可以通过修改此数据来重置采集binlog 日志的位置。
值得注意的是,本次操作的时间节点也是有限制的,这与mysql的binlog日志的存储周期有关,所以用这种方式回溯时,需要确认mysql日志还存在。
重新登陆数据重复消费。
这个方案是基于Kafka的,对于Kafka重新设计消费抵消消费网站的操作,网上有很多方案,这里不再赘述。
为读者自己实现,选择的需要确认的MQ支持此功能。
#how_to_change_the_offsets_of_the_source_database
业务场景影响下的重要运营
本节只介绍如何在作者的技术框架下实现以下操作。读者可以根据自己选择的技术组件探索不同的技术解决方案。
数据库分库分表情况
基于Debezium的架构,采集一个Source只能对应一个mysql实例。对于同一个实例的表拆分,可以使用Debezium Topic Routing功能。
采集过滤binlog时,将需要采集的对应表按照正则匹配写入指定主题。
子库的情况下,还需要在sink端添加RegexRouter变换算子,进行topic之间的合并和写入操作。
数据增量采集和全额采集
对于采集组件,当前配置默认是增量,所以无论选择Debezium还是Canal,正常配置都可以。
但有时会出现需要采集full table 的情况。作者还给出了全数据的方案采集。
方案一
Debezium 本身自带这样的功能,需要改一下
snapshot.mode的参数选择设置为when_needed,这样就可以完成表的所有采集操作。
官方文档中,这里的参数配置有更详细的说明。
#快照
计划二
同时使用sqoop和增量采集。
此方案适用于表数据较多,但目前binlog数据频率不高的情况,使用此方案。
值得注意的有两点:
离线重复数据删除条件
数据落地后,通过json表映射出原来的binlog数据,那么问题来了,我们如何找到最新的那条数据?
也许我们可以简单地认为使用我们刚刚提取的ts_ms然后进行反演还不够?
在大多数情况下,这确实是可能的。
但是在实际开发中,笔者发现这样的情况并不能满足所有的情况,因为在binlog中,可能真的有两个数据和ts_ms和PK一样,但确实不同。
那我们如何同时求解两条数据呢?
答案就在上面,我们只是建议提取所有 binlog 元数据。
SELECT *
FROM
(
SELECT *,
row_number() over(partition BY t.id ORDER BY t.`__ts_ms` DESC,t.`__file` DESC,cast(t.`__pos` AS int) DESC) AS order_by
FROM test t
WHERE dt='{pt}'
AND hour='{now_hour}'
) t1
WHERE t1.order_by = 1
说明本sql中row_number的条件
__ts_ms:binlog中的ts_ms,即事件时间。
__file:是binlog数据的文件名。
__pos:是binlog中数据所在文件在文件中的位置,为数据类型。
这样组合条件取出的数据是最新的。
有的读者可能会问,如果这条数据被删除了怎么办?你这样检索的数据是不是错了?
这个Debezium也有相应的操作,有相应的配置选项供你选择如何处理删除行为的binlog数据。
作为给大家参考,作者选择了rewrite的参数配置,这样在上面sql最外层,只需要判断“delete = 'false'”是正确的数据即可。
架构总结
在技术选择和整体细节结构上,作者始终坚持一个原则——
过程应该尽可能简单,而不是越简单越好。数据链路越长,可能出现问题的链路就越多。后期锁定问题和运维也会很困难。
所以笔者在技术选型上考虑了Flink + Kafka的方式,但基于当时的情况,笔者没有选择这样的技术选型,笔者也会说明原因。
总结一下,我当时就想到了 Flink。如果 Flink 不是基于平台的用于开发和运维监控,它可以作为一个临时解决方案。人类开发下很容易出问题,或者大家在这样的程序框架下造轮子,造的越多越慢。而且后期的主要项目方向并没有把Flink平台化提上日程,所以也是考虑到了部分未来情况的选择。
所以当我最终决定技术选择的时候,我没有选择 Flink。
结论
文章的这篇文章比较理论,也是这个场景的技术理论总结。如果文章中还有其他不清楚的操作,可以参考作者之前的文章详细代码级操作。
技术架构方案有很多种。我只是选择了其中之一来实施。也希望大家有其他的技术方案或理论交流。请纠正我。
文章实时采集( 实时采集疫情地图中全国各省市病例数据为研究疫情发展走势 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-09-04 17:10
实时采集疫情地图中全国各省市病例数据为研究疫情发展走势
)
Step3.样本数据
02Real-time采集流行病地图在全国各省市病例数据中为研究疫情发展趋势提供数据支持
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细展示当前全国各省市新增病例和累计病例数,但无法查看历史时刻数据。
对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官方网站获取一手资料,参考第一部分内容。
2、从即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各家公司的疫情地图数据差别不大,我们选择腾讯新闻的疫情地图作为采集模板。即日起,您可以使用优采云的云采集设置定时采集计划,实时采集疫情地图病例数据。
如何使用此模板:
<p>Step1.下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集】 查看全部
文章实时采集(
实时采集疫情地图中全国各省市病例数据为研究疫情发展走势
)
Step3.样本数据
02Real-time采集流行病地图在全国各省市病例数据中为研究疫情发展趋势提供数据支持
各媒体疫情地图病例数据的数据来源,基本都是国家和地方市建委下发的疫情通报,没有太大区别。疫情地图实时更新,详细展示当前全国各省市新增病例和累计病例数,但无法查看历史时刻数据。
对于研究疫情的发展趋势,历史数据非常重要。如何检索历史数据?
1、从国家和地方卫健委官方网站获取一手资料,参考第一部分内容。
2、从即日起,疫情地图中的病例数据将被实时抓取并存储,用于数据积累。
由于各家公司的疫情地图数据差别不大,我们选择腾讯新闻的疫情地图作为采集模板。即日起,您可以使用优采云的云采集设置定时采集计划,实时采集疫情地图病例数据。
如何使用此模板:
<p>Step1.下载优采云客户端,找到【国家卫健委-疫情实时数据】模板,点击【立即使用】,无需输入参数,直接【启动本地采集】
文章实时采集(【开源项目】FlinkXWal插件PostgreSQL实时采集功能的基本介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-09-04 13:24
Data Stack 是云原生站数据平台 PaaS。我们在 github 和 gitee 上有一个有趣的开源项目:FlinkX。 FlinkX是一个基于Flink的batch-stream统一数据同步工具,可以是采集静态数据,也可以是采集实时变化的数据。它是一个全局的、异构的、批量流数据同步引擎。如果你喜欢,请给我们一个star!星星!明星!
github 开源项目:
gitee 开源项目:
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。 查看全部
文章实时采集(【开源项目】FlinkXWal插件PostgreSQL实时采集功能的基本介绍)
Data Stack 是云原生站数据平台 PaaS。我们在 github 和 gitee 上有一个有趣的开源项目:FlinkX。 FlinkX是一个基于Flink的batch-stream统一数据同步工具,可以是采集静态数据,也可以是采集实时变化的数据。它是一个全局的、异构的、批量流数据同步引擎。如果你喜欢,请给我们一个star!星星!明星!
github 开源项目:
gitee 开源项目:
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。逻辑复制同步数据的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行解析。
文章实时采集(Rss尽量避免合理利用RSS是使用最广泛的XML应用RSS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-09-04 05:08
网站中文章 的定期更新是几乎每个网站 都会做的事情。并不是每个网站在这么多平台上都关注原创,也不是每个网站都愿意花时间去做。 原创或者伪原创的文章,自然会有大部分网站的文章被采集,不愿意花时间的网站更新他的@k11网站 文章。所以,当我们的网站长期处于采集的状态,而网站的权重还不够高的时候,那么蜘蛛很可能会把你的网站列为采集站,我相信你网站的文章是来自网上的采集,而不是网上的其他网站是采集你的文章。
所以我们必须采取解决方案尽可能避免此类事件发生,文章长被采集该怎么办?青澜互动有以下见解:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与网站相同的高权重时,蜘蛛会默认设置高权重。 网站文章 作为原创 的来源。所以我们必须增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要设置一个固定的时间更新网站的频率,这样操作之后网站的容忍度就大了改进了。
3、Rss 合理使用
RSS 是一种用于描述和同步网站 内容的格式,是使用最广泛的 XML 应用程序。 RSS搭建了信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用RSS订阅更快地获取信息。 网站提供RSS输出,帮助用户获取网站内容的最新更新。
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 很有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、站内原创保护
在我们网站上更新了原来的文章后,我们可以选择使用百度站长平台原有的保护功能。每次文章更新后,我们每天可以提交10个原创protected作品。
5、做更多细节和限制机器采集
我们可以对页面的细节做一些处理,至少可以防止采集来自机器。例如,页面不应设计得过于传统和流行; Url的写法要多变,不应该是默认的叠加等设置;当对方采集我们的物品时,图片也会被采集,我们可以在物品图片上添加图片水印;还有文章内多入本网站关键词,这样不仅会很快知道你的文章被人采集,还会增加别人采集文章后期处理的时间成本,经常穿插我们的网站名字,别人当采集时会觉得我们的文章对他们来说没有太大的意义。这也是避免采集的一个很好的方法。
文章往往是采集,这肯定会影响到我们网站,所以我们应该尽量避免它,让我们的网站内容在互联网上独一无二,提高百度对我们网站的信任网站 让我们的优化工作更顺畅。
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创author或伪原创author创造更多优质内容。
正如青兰互动观察到的白家豪介绍的最新算法,原创性不的文章不会被百度推荐。如果不推荐,就没有流量,自然也就没有收录,这大大加强了原创的性质,给了大原创作者一个很好的保护,也提供了一个优质的环境用于百度搜索引擎。
不过当然,除了百度官方的文章采集网站处理,我们也可以把我们的网站做得更好,让我们的网站文章更好的时候收录进来,成为采集的概率会下降很多。有些情况你是采集,不妨试试这些操作,获得意想不到的收获。返回搜狐查看更多 查看全部
文章实时采集(Rss尽量避免合理利用RSS是使用最广泛的XML应用RSS)
网站中文章 的定期更新是几乎每个网站 都会做的事情。并不是每个网站在这么多平台上都关注原创,也不是每个网站都愿意花时间去做。 原创或者伪原创的文章,自然会有大部分网站的文章被采集,不愿意花时间的网站更新他的@k11网站 文章。所以,当我们的网站长期处于采集的状态,而网站的权重还不够高的时候,那么蜘蛛很可能会把你的网站列为采集站,我相信你网站的文章是来自网上的采集,而不是网上的其他网站是采集你的文章。
所以我们必须采取解决方案尽可能避免此类事件发生,文章长被采集该怎么办?青澜互动有以下见解:
1、提高页面权重
提高页面的权重可以从根本上解决这个问题。重量足够高。当其他人网站出现与网站相同的高权重时,蜘蛛会默认设置高权重。 网站文章 作为原创 的来源。所以我们必须增加文章页面的权重,多做这个页面的外链。
2、网站内部调整
我们需要对我们的网站进行内部调整,同时我们需要设置一个固定的时间更新网站的频率,这样操作之后网站的容忍度就大了改进了。
3、Rss 合理使用
RSS 是一种用于描述和同步网站 内容的格式,是使用最广泛的 XML 应用程序。 RSS搭建了信息快速传播的技术平台,让每个人都成为潜在的信息提供者。使用RSS订阅更快地获取信息。 网站提供RSS输出,帮助用户获取网站内容的最新更新。
开发这样的功能也是很有必要的。当网站文章更新时,第一时间让搜索引擎知道,主动攻击。这对收录 很有帮助。而且Rss还可以有效增加网站的流量,可以说是一石二鸟。
4、站内原创保护
在我们网站上更新了原来的文章后,我们可以选择使用百度站长平台原有的保护功能。每次文章更新后,我们每天可以提交10个原创protected作品。
5、做更多细节和限制机器采集
我们可以对页面的细节做一些处理,至少可以防止采集来自机器。例如,页面不应设计得过于传统和流行; Url的写法要多变,不应该是默认的叠加等设置;当对方采集我们的物品时,图片也会被采集,我们可以在物品图片上添加图片水印;还有文章内多入本网站关键词,这样不仅会很快知道你的文章被人采集,还会增加别人采集文章后期处理的时间成本,经常穿插我们的网站名字,别人当采集时会觉得我们的文章对他们来说没有太大的意义。这也是避免采集的一个很好的方法。
文章往往是采集,这肯定会影响到我们网站,所以我们应该尽量避免它,让我们的网站内容在互联网上独一无二,提高百度对我们网站的信任网站 让我们的优化工作更顺畅。
我们回归搜索引擎工作原理的本质,即满足和解决用户搜索结果的需求。因此,为了打造更好的互联网内容生态,搜索引擎会不断推出算法来对抗采集网站,同时也会对原创内容给予一定的排名偏好,鼓励原创author或伪原创author创造更多优质内容。
正如青兰互动观察到的白家豪介绍的最新算法,原创性不的文章不会被百度推荐。如果不推荐,就没有流量,自然也就没有收录,这大大加强了原创的性质,给了大原创作者一个很好的保护,也提供了一个优质的环境用于百度搜索引擎。
不过当然,除了百度官方的文章采集网站处理,我们也可以把我们的网站做得更好,让我们的网站文章更好的时候收录进来,成为采集的概率会下降很多。有些情况你是采集,不妨试试这些操作,获得意想不到的收获。返回搜狐查看更多
文章实时采集(编码h264还是一样使用ffmpeg_encode技术交流讨论(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-03 06:06
采集屏幕图像之前介绍过,转换为YUV420p。传送门
YUV420p数据为原创图片数据,100张1920x1080图片总大小达到300M。太可怕了!可见这种方式直接写入文件是行不通的。因此,我们需要先将其编码为h264,然后再将其写入文件。至于什么是h264,之前已经介绍过了,这里就不介绍了。
废话不多说,直接看正文。
编码h264还是一样使用ffmpeg,方法如下:
1.打开编码器
AVCodecContext* pCodecCtx; AVCodec* pCodec;
uint8_t* picture_buf;
AVFrame* picture;
bool H264Encoder::openEncoder()
{
int size;
int in_w = mWidth;
int in_h = mHeight;//宽高
//查找h264编码器
pCodec = avcodec_find_encoder(AV_CODEC_ID_H264);
if(!pCodec)
{
fprintf(stderr, "h264 codec not found
");
exit(1);
}
pCodecCtx = avcodec_alloc_context3(pCodec);
pCodecCtx->codec_id = AV_CODEC_ID_H264;
pCodecCtx->codec_type = AVMEDIA_TYPE_VIDEO;
pCodecCtx->pix_fmt = PIX_FMT_YUV420P;
pCodecCtx->width = in_w;
pCodecCtx->height = in_h;
pCodecCtx->time_base.num = 1;
pCodecCtx->time_base.den = 15;//帧率(既一秒钟多少张图片)
pCodecCtx->bit_rate = mBitRate; //比特率(调节这个大小可以改变编码后视频的质量)
pCodecCtx->gop_size=12;
// some formats want stream headers to be separate
if (pCodecCtx->flags & AVFMT_GLOBALHEADER)
pCodecCtx->flags |= CODEC_FLAG_GLOBAL_HEADER;
// Set Option
AVDictionary *param = 0;
//H.264
//av_dict_set(¶m, "preset", "slow", 0);
av_dict_set(¶m, "preset", "superfast", 0);
av_dict_set(¶m, "tune", "zerolatency", 0); //实现实时编码
pCodec = avcodec_find_encoder(pCodecCtx->codec_id);
if (!pCodec){
printf("Can not find video encoder! 没有找到合适的编码器!
");
return false;
}
if (avcodec_open2(pCodecCtx, pCodec,¶m) pix_fmt, pCodecCtx->width, pCodecCtx->height); //计算需要用到的数据大小
picture_buf = (uint8_t *)av_malloc(size); //分配空间
avpicture_fill((AVPicture *)picture, picture_buf, pCodecCtx->pix_fmt, pCodecCtx->width, pCodecCtx->height);
return true;
}
2.coding
编码前的数据必须是Yuv420p格式。我们已经获得了这样的数据。使用 avcodec_encode_video2 实现编码:
picture->data[0] = node.buffer; // 亮度Y
picture->data[1] = node.buffer + y_size; // U
picture->data[2] = node.buffer + y_size*5/4; // V
int got_picture=0;
//编码
int ret = avcodec_encode_video2(pCodecCtx, &pkt,picture, &got_picture);
if (got_picture==1)
{
// bool isKeyFrame = pkt.flags & AV_PKT_FLAG_KEY; //判断是否关键帧
int w = fwrite(pkt.data,1,pkt.size,h264Fp); //写入文件中 (h264的裸数据 直接写入文件 也可以播放 因为这里包含H264关键帧)
}
最近时间比较少,代码就不多解释了,直接看完整项目。
完整的项目下载链接:
最终生成的out.h264可以直接用普通播放器打开播放。
保存的文件比以前小了数百倍!
注意:由于h264没有时间戳,只有帧率,这里设置为15。但是,我们采集桌面时,采集每秒不到15帧,所以玩的时候速度玩家开会快很多是正常的。
了解音视频技术,欢迎访问
欢迎加入QQ群121376426进行音视频技术交流与讨论 查看全部
文章实时采集(编码h264还是一样使用ffmpeg_encode技术交流讨论(一))
采集屏幕图像之前介绍过,转换为YUV420p。传送门
YUV420p数据为原创图片数据,100张1920x1080图片总大小达到300M。太可怕了!可见这种方式直接写入文件是行不通的。因此,我们需要先将其编码为h264,然后再将其写入文件。至于什么是h264,之前已经介绍过了,这里就不介绍了。
废话不多说,直接看正文。
编码h264还是一样使用ffmpeg,方法如下:
1.打开编码器
AVCodecContext* pCodecCtx; AVCodec* pCodec;
uint8_t* picture_buf;
AVFrame* picture;
bool H264Encoder::openEncoder()
{
int size;
int in_w = mWidth;
int in_h = mHeight;//宽高
//查找h264编码器
pCodec = avcodec_find_encoder(AV_CODEC_ID_H264);
if(!pCodec)
{
fprintf(stderr, "h264 codec not found
");
exit(1);
}
pCodecCtx = avcodec_alloc_context3(pCodec);
pCodecCtx->codec_id = AV_CODEC_ID_H264;
pCodecCtx->codec_type = AVMEDIA_TYPE_VIDEO;
pCodecCtx->pix_fmt = PIX_FMT_YUV420P;
pCodecCtx->width = in_w;
pCodecCtx->height = in_h;
pCodecCtx->time_base.num = 1;
pCodecCtx->time_base.den = 15;//帧率(既一秒钟多少张图片)
pCodecCtx->bit_rate = mBitRate; //比特率(调节这个大小可以改变编码后视频的质量)
pCodecCtx->gop_size=12;
// some formats want stream headers to be separate
if (pCodecCtx->flags & AVFMT_GLOBALHEADER)
pCodecCtx->flags |= CODEC_FLAG_GLOBAL_HEADER;
// Set Option
AVDictionary *param = 0;
//H.264
//av_dict_set(¶m, "preset", "slow", 0);
av_dict_set(¶m, "preset", "superfast", 0);
av_dict_set(¶m, "tune", "zerolatency", 0); //实现实时编码
pCodec = avcodec_find_encoder(pCodecCtx->codec_id);
if (!pCodec){
printf("Can not find video encoder! 没有找到合适的编码器!
");
return false;
}
if (avcodec_open2(pCodecCtx, pCodec,¶m) pix_fmt, pCodecCtx->width, pCodecCtx->height); //计算需要用到的数据大小
picture_buf = (uint8_t *)av_malloc(size); //分配空间
avpicture_fill((AVPicture *)picture, picture_buf, pCodecCtx->pix_fmt, pCodecCtx->width, pCodecCtx->height);
return true;
}
2.coding
编码前的数据必须是Yuv420p格式。我们已经获得了这样的数据。使用 avcodec_encode_video2 实现编码:
picture->data[0] = node.buffer; // 亮度Y
picture->data[1] = node.buffer + y_size; // U
picture->data[2] = node.buffer + y_size*5/4; // V
int got_picture=0;
//编码
int ret = avcodec_encode_video2(pCodecCtx, &pkt,picture, &got_picture);
if (got_picture==1)
{
// bool isKeyFrame = pkt.flags & AV_PKT_FLAG_KEY; //判断是否关键帧
int w = fwrite(pkt.data,1,pkt.size,h264Fp); //写入文件中 (h264的裸数据 直接写入文件 也可以播放 因为这里包含H264关键帧)
}
最近时间比较少,代码就不多解释了,直接看完整项目。
完整的项目下载链接:
最终生成的out.h264可以直接用普通播放器打开播放。
保存的文件比以前小了数百倍!
注意:由于h264没有时间戳,只有帧率,这里设置为15。但是,我们采集桌面时,采集每秒不到15帧,所以玩的时候速度玩家开会快很多是正常的。
了解音视频技术,欢迎访问
欢迎加入QQ群121376426进行音视频技术交流与讨论
文章实时采集(【银行数据分析师】H5埋点数据采集及用户行为分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-01 18:10
作者介绍
@hrd-0.618(徐梵)
新网银行数据分析师。
专注于数据分析、埋点采集和用户行为分析、BI数据可视化。
“数据人创造者联盟”成员。
1 背景介绍
产品精细化运营、千人个性化推荐等各种服务,都依赖于标准化、高质量的嵌入点数据。但是,整个埋点数据的上传、解析、存储、分析过程比较长,需要多团队协作。为了让感兴趣的读者有一个整体的了解,本节将结合工作实践,重点关注H5埋点数据采集以及应用的生命周期。
2 个埋点采集content
埋点采集的内容主要包括两个方面:前端埋点data采集,后端埋点data采集。前者主要包括3类事件:用户事件、页面事件、点击事件。后者主要包括:接口调用事件。事件通过“序列代码”链接在一起。数据模型设计也是基于这四个事件。详情见下图。
3 埋点数据流向
3.1 数据上传到 log采集service
前端+后端——>Log采集服务
前后端数据采用类json格式,行为事件实时异步发送到log采集服务进行分析。
3.1.1 用户事件:user
{<br />data:[{ <br /> userid:用户唯一标识ID<br /> ,equipment:{ //header中获取,包括浏览器、设备、网络等<br /> equipment_os:操作系统 <br /> , equipment_os_version:操作系统版本<br /> , equipment_brand:品牌 <br /> …<br /> }<br /> ,location:{ <br /> gps:{ <br /> gps_lon:经度 <br /> ,gps_lat:维度 <br /> ,gps_country:gps国家 <br /> ,gps_province:gps省 <br /> ,gps_city:gps市 <br /> ,gps_district:gps区 <br /> } <br /> ,ip:{ <br /> … <br /> }<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:user <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.2 页面事件:页面
{<br />data:[{ <br /> page_id:页面ID <br /> ,page_name:页面名称 <br /> ,page_url:页面url <br /> ,src_page_url:来源页url<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:page <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.3 点击事件:点击
{<br />data:[{ <br /> click_id:点击ID <br /> ,click_name:点击名称 <br /> ,click_other_attr:{ <br /> remarks:备注 <br /> …<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:click <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.4 接口事件:接口
{<br />data:[{ <br /> interface_id:接口ID <br /> ,interface_name:接口名称 <br /> ,result:接口调用结果 <br /> ,result_remarks:接口调用说明 <br /> ,response_time:接口响应时长<br /> }] <br /> ,start_time:接口调用开始时间 <br /> ,end_time:接口调用结束时间 <br /> ,cookie:串联码 <br /> ,event_type:interface <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.2实时数据仓库建模
Log采集service——>实时数据仓库(kafka)
3.2.1 基本字段处理
一个。从log采集服务采集解析4个事件的json数据,获取4个事件的基本字段,实时写入kafka消息队列的4个topic中。
B.通过Flink/StreamSQL,实时或微批量消费4个topic数据,存储在4个Hbase表中。
3.2.2 用户事件链接到行为事件
消费用户事件主题,根据串口代码cookie,将用户信息与行为信息关联起来,构建实时用户行为宽表。
3.3 离线数据仓库建模
3.3.1 发布源码层
通过 ETL 提取 4 个事件 HBase 表。
3.3.2 模型层
根据源层4个事件的串口代码cookie,将用户信息与行为信息关联起来,构建一个宽表的离线用户行为。
4 埋点数据应用
4.1.1 用户行为查询
根据实时用户宽度表,可将数据写入Elasticsearch或写入外部接口查询实时用户行为记录。
根据线下用户宽表,写入数据到Elasticsearch,或者写入数据到外部接口,可以查询线下用户行为记录。
4.1.2 用户行为统计
根据4个事件的话题数据,结合用户行为指标体系,通过聚合统计分析方法,得到不同维度的用户行为指标。
页面级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
维度类型:页面/栏目/频道
可视化字段:频道名称、链接、页面名称、PV、UV、访问量、平均停留时间、页面跳出次数、页面跳出率
按钮级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
可视化字段:渠道名称、操作系统、链接、页面名称、点击名称、点击次数、点击用户数
4.1.3 用户留存分析
尺寸:
数据日期:2021-08-02
频道名称:如“xxx”,无摘要
用户类别:摘要、新用户
留存类型:产品级、功能级(页面、点击)(可以下拉选择页面,也可以选择点击)
数据类型:留存人数、留存率
产品级别,选择保持器数量
产品级别,选择留存率
功能层面:比如美团APP会对使用“自行车”功能的用户进行留存分析。
4.1.4 用户行为标签和客户群筛选
构建用户行为标签以过滤目标客户群。
根据客户的实时/线下业务状态,当满足一定的行为特征时,为业务人员筛选不同的目标客户群,通过营销平台以不同的方式触达。
实时行为特征如:时间段内点击次数、停留时长、页面访问次数等
场景如:根据不同页面和点击的行为特征,为新客户/老客户、有存款的客户、有提前取款记录的客户设置不同的营销策略。
针对不同场景下产品品类和客户群较少的企业,实时推送给业务人员,与营销平台对接进行精准营销。
当然,对于产品品类较多的企业,比如电商相关场景,构建基于用户行为的实时推荐系统是行业主流。
4.1.5 基于用户行为的断点触摸
结合实时和线下的用户行为和业务状态,可以将有行为断点的用户通过其他方式进行呼叫或触达。
5 结论
本文主要结合实际工作中的一些经验,做一个简单的概述。埋点采集主要是代码埋点。人工维护成本相对较高。后续可结合实际场景,采用业界较好的采集技术;用户行为分析需要逐步完善。欢迎大家批评指正。有兴趣的朋友可以联系我一起讨论。 查看全部
文章实时采集(【银行数据分析师】H5埋点数据采集及用户行为分析)
作者介绍
@hrd-0.618(徐梵)
新网银行数据分析师。
专注于数据分析、埋点采集和用户行为分析、BI数据可视化。
“数据人创造者联盟”成员。
1 背景介绍
产品精细化运营、千人个性化推荐等各种服务,都依赖于标准化、高质量的嵌入点数据。但是,整个埋点数据的上传、解析、存储、分析过程比较长,需要多团队协作。为了让感兴趣的读者有一个整体的了解,本节将结合工作实践,重点关注H5埋点数据采集以及应用的生命周期。
2 个埋点采集content
埋点采集的内容主要包括两个方面:前端埋点data采集,后端埋点data采集。前者主要包括3类事件:用户事件、页面事件、点击事件。后者主要包括:接口调用事件。事件通过“序列代码”链接在一起。数据模型设计也是基于这四个事件。详情见下图。
3 埋点数据流向
3.1 数据上传到 log采集service
前端+后端——>Log采集服务
前后端数据采用类json格式,行为事件实时异步发送到log采集服务进行分析。
3.1.1 用户事件:user
{<br />data:[{ <br /> userid:用户唯一标识ID<br /> ,equipment:{ //header中获取,包括浏览器、设备、网络等<br /> equipment_os:操作系统 <br /> , equipment_os_version:操作系统版本<br /> , equipment_brand:品牌 <br /> …<br /> }<br /> ,location:{ <br /> gps:{ <br /> gps_lon:经度 <br /> ,gps_lat:维度 <br /> ,gps_country:gps国家 <br /> ,gps_province:gps省 <br /> ,gps_city:gps市 <br /> ,gps_district:gps区 <br /> } <br /> ,ip:{ <br /> … <br /> }<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:user <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.2 页面事件:页面
{<br />data:[{ <br /> page_id:页面ID <br /> ,page_name:页面名称 <br /> ,page_url:页面url <br /> ,src_page_url:来源页url<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:page <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.3 点击事件:点击
{<br />data:[{ <br /> click_id:点击ID <br /> ,click_name:点击名称 <br /> ,click_other_attr:{ <br /> remarks:备注 <br /> …<br /> }<br /> }] <br /> ,time:时间 <br /> ,cookie:串联码 <br /> ,event_type:click <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.1.4 接口事件:接口
{<br />data:[{ <br /> interface_id:接口ID <br /> ,interface_name:接口名称 <br /> ,result:接口调用结果 <br /> ,result_remarks:接口调用说明 <br /> ,response_time:接口响应时长<br /> }] <br /> ,start_time:接口调用开始时间 <br /> ,end_time:接口调用结束时间 <br /> ,cookie:串联码 <br /> ,event_type:interface <br /> ,from:{ <br /> channel:渠道 <br /> ,product:产品 <br /> }<br /> }
3.2实时数据仓库建模
Log采集service——>实时数据仓库(kafka)
3.2.1 基本字段处理
一个。从log采集服务采集解析4个事件的json数据,获取4个事件的基本字段,实时写入kafka消息队列的4个topic中。
B.通过Flink/StreamSQL,实时或微批量消费4个topic数据,存储在4个Hbase表中。
3.2.2 用户事件链接到行为事件
消费用户事件主题,根据串口代码cookie,将用户信息与行为信息关联起来,构建实时用户行为宽表。
3.3 离线数据仓库建模
3.3.1 发布源码层
通过 ETL 提取 4 个事件 HBase 表。
3.3.2 模型层
根据源层4个事件的串口代码cookie,将用户信息与行为信息关联起来,构建一个宽表的离线用户行为。
4 埋点数据应用
4.1.1 用户行为查询
根据实时用户宽度表,可将数据写入Elasticsearch或写入外部接口查询实时用户行为记录。
根据线下用户宽表,写入数据到Elasticsearch,或者写入数据到外部接口,可以查询线下用户行为记录。
4.1.2 用户行为统计
根据4个事件的话题数据,结合用户行为指标体系,通过聚合统计分析方法,得到不同维度的用户行为指标。
页面级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
维度类型:页面/栏目/频道
可视化字段:频道名称、链接、页面名称、PV、UV、访问量、平均停留时间、页面跳出次数、页面跳出率
按钮级别:
数据日期
频道名称
操作系统
日期类型:日、7 日、30 日、总计
可视化字段:渠道名称、操作系统、链接、页面名称、点击名称、点击次数、点击用户数
4.1.3 用户留存分析
尺寸:
数据日期:2021-08-02
频道名称:如“xxx”,无摘要
用户类别:摘要、新用户
留存类型:产品级、功能级(页面、点击)(可以下拉选择页面,也可以选择点击)
数据类型:留存人数、留存率
产品级别,选择保持器数量
产品级别,选择留存率
功能层面:比如美团APP会对使用“自行车”功能的用户进行留存分析。
4.1.4 用户行为标签和客户群筛选
构建用户行为标签以过滤目标客户群。
根据客户的实时/线下业务状态,当满足一定的行为特征时,为业务人员筛选不同的目标客户群,通过营销平台以不同的方式触达。
实时行为特征如:时间段内点击次数、停留时长、页面访问次数等
场景如:根据不同页面和点击的行为特征,为新客户/老客户、有存款的客户、有提前取款记录的客户设置不同的营销策略。
针对不同场景下产品品类和客户群较少的企业,实时推送给业务人员,与营销平台对接进行精准营销。
当然,对于产品品类较多的企业,比如电商相关场景,构建基于用户行为的实时推荐系统是行业主流。
4.1.5 基于用户行为的断点触摸
结合实时和线下的用户行为和业务状态,可以将有行为断点的用户通过其他方式进行呼叫或触达。
5 结论
本文主要结合实际工作中的一些经验,做一个简单的概述。埋点采集主要是代码埋点。人工维护成本相对较高。后续可结合实际场景,采用业界较好的采集技术;用户行为分析需要逐步完善。欢迎大家批评指正。有兴趣的朋友可以联系我一起讨论。
文章实时采集(关于python的十种最佳实践!小白建议先看一下!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-30 18:02
文章实时采集,一个人的战争!其实学会爬取常用网站一般就能实现登录支付宝、微信、qq、谷歌、优酷、、京东等等!一般站点都有抓取教程,只要你踏实去找,都是会有的!项目实战入门的爬虫教程,最快捷最实用最精简的爬虫介绍!【python】关于python的十种最佳实践!小白建议先看一下!让你快速上手爬虫爬虫总结--下载与上传大量图片(图片格式:jpg,gif,png,jpeg,jpeg2000)全面介绍爬虫的基本知识大概了解下流程爬虫入门--urllib库与lxml库一元字符串与一元列表的使用python爬虫实战--抓取豆瓣电影top250python爬虫实战--抓取百度贴吧top250python爬虫实战--抓取知乎用户回答数据python爬虫实战--爬取豆瓣电影top250高级实战--requests+beautifulsoup+time+datetime等一些可视化工具使用python爬虫实战--下载之后放到githubpagesscp项目--python3。
6+爬虫原理小项目实战--爬取豆瓣电影top250完整代码~文末福利2017已经过去了,吃多少亏,摔多少跤,默默的写几篇python爬虫分享,希望大家好好学习一下!被python虐惨了的小姐姐留~~~。
现在有专门教大家学习编程的网站了:python编程学习交流平台很多人说自己不会编程,但又必须学习编程。有没有一个专门针对零基础学习编程的平台呢?我的建议是,如果你想学习编程,又怕自己无法学好编程,自学是最好的选择。因为自学的最大好处就是有老师可以帮你把学习路线规划出来,同时自己也可以根据老师教你的路线,结合自己的实际情况,制定学习计划。
另外,自学不缺老师,相反,选择自学很容易迷失方向,浪费时间。我自己就是自学python爬虫,是三月份开始入手写爬虫,写了两个月之后转行业,自己回来用java继续写爬虫。下面简单谈谈学习python爬虫的心得体会。python爬虫的基本组成部分是python语言,包括python虚拟机、爬虫框架等。这些不可或缺。
而大多数人知道的也是爬虫框架,但这些框架,有些不适合新手,有些也不能满足自己要爬取的数据格式的要求。所以你必须在这些基础上设计和组合出属于自己的爬虫框架。一般有三个作用:一个是提供爬虫的基本功能,比如获取指定url的html页面,如今这是很基本的功能;二是数据分析,比如爬取到特定数据,在给你设计相应的数据可视化图表;三是做云端爬虫,做公司的数据采集系统。
这些作用是要根据你未来的发展而定的。这些只是基本功能,如果没有python基础,也无法做爬虫,而且要设。 查看全部
文章实时采集(关于python的十种最佳实践!小白建议先看一下!)
文章实时采集,一个人的战争!其实学会爬取常用网站一般就能实现登录支付宝、微信、qq、谷歌、优酷、、京东等等!一般站点都有抓取教程,只要你踏实去找,都是会有的!项目实战入门的爬虫教程,最快捷最实用最精简的爬虫介绍!【python】关于python的十种最佳实践!小白建议先看一下!让你快速上手爬虫爬虫总结--下载与上传大量图片(图片格式:jpg,gif,png,jpeg,jpeg2000)全面介绍爬虫的基本知识大概了解下流程爬虫入门--urllib库与lxml库一元字符串与一元列表的使用python爬虫实战--抓取豆瓣电影top250python爬虫实战--抓取百度贴吧top250python爬虫实战--抓取知乎用户回答数据python爬虫实战--爬取豆瓣电影top250高级实战--requests+beautifulsoup+time+datetime等一些可视化工具使用python爬虫实战--下载之后放到githubpagesscp项目--python3。
6+爬虫原理小项目实战--爬取豆瓣电影top250完整代码~文末福利2017已经过去了,吃多少亏,摔多少跤,默默的写几篇python爬虫分享,希望大家好好学习一下!被python虐惨了的小姐姐留~~~。
现在有专门教大家学习编程的网站了:python编程学习交流平台很多人说自己不会编程,但又必须学习编程。有没有一个专门针对零基础学习编程的平台呢?我的建议是,如果你想学习编程,又怕自己无法学好编程,自学是最好的选择。因为自学的最大好处就是有老师可以帮你把学习路线规划出来,同时自己也可以根据老师教你的路线,结合自己的实际情况,制定学习计划。
另外,自学不缺老师,相反,选择自学很容易迷失方向,浪费时间。我自己就是自学python爬虫,是三月份开始入手写爬虫,写了两个月之后转行业,自己回来用java继续写爬虫。下面简单谈谈学习python爬虫的心得体会。python爬虫的基本组成部分是python语言,包括python虚拟机、爬虫框架等。这些不可或缺。
而大多数人知道的也是爬虫框架,但这些框架,有些不适合新手,有些也不能满足自己要爬取的数据格式的要求。所以你必须在这些基础上设计和组合出属于自己的爬虫框架。一般有三个作用:一个是提供爬虫的基本功能,比如获取指定url的html页面,如今这是很基本的功能;二是数据分析,比如爬取到特定数据,在给你设计相应的数据可视化图表;三是做云端爬虫,做公司的数据采集系统。
这些作用是要根据你未来的发展而定的。这些只是基本功能,如果没有python基础,也无法做爬虫,而且要设。
文章实时采集(卷积循环特征生成循环结构(图)特征)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-08-29 13:02
文章实时采集目标的dnn特征。卷积循环特征生成卷积循环结构,但是windowfilter维度太高,需要额外增加的空间映射。unet生成一个更大尺寸的卷积循环神经网络。用于提取特征,提高效率。这篇文章的主要创新是其是用反卷积神经网络方法,作者从两个方面作文章,第一个方面,减少网络的反卷积块,第二个方面,去掉windowfilter中的epochprediction信息。用mlp作代理层。以下是实验结果:。
谢邀。
1)加快网络的速度,引入dnn的卷积,循环层等,减少硬件占用(增加空间映射,减少网络的大小,降低gpu计算量,
2)减少训练数据,比如只包含固定规则和大小图片,都会减少网络的训练数据集。当然在加速速度,成本效益之间做权衡,会出现很多人提出自己的效果好,网络数据集小的情况。
3)减少计算开销,比如增加训练model的特征。这个也有很多例子,比如增加relu层,
4)加速模型的表达,
网络的数据增加,给结果带来了影响,另外现在最新的网络在做比较深的网络时就经常采用特征提取过程中减少网络的卷积,循环结构和池化操作等。 查看全部
文章实时采集(卷积循环特征生成循环结构(图)特征)
文章实时采集目标的dnn特征。卷积循环特征生成卷积循环结构,但是windowfilter维度太高,需要额外增加的空间映射。unet生成一个更大尺寸的卷积循环神经网络。用于提取特征,提高效率。这篇文章的主要创新是其是用反卷积神经网络方法,作者从两个方面作文章,第一个方面,减少网络的反卷积块,第二个方面,去掉windowfilter中的epochprediction信息。用mlp作代理层。以下是实验结果:。
谢邀。
1)加快网络的速度,引入dnn的卷积,循环层等,减少硬件占用(增加空间映射,减少网络的大小,降低gpu计算量,
2)减少训练数据,比如只包含固定规则和大小图片,都会减少网络的训练数据集。当然在加速速度,成本效益之间做权衡,会出现很多人提出自己的效果好,网络数据集小的情况。
3)减少计算开销,比如增加训练model的特征。这个也有很多例子,比如增加relu层,
4)加速模型的表达,
网络的数据增加,给结果带来了影响,另外现在最新的网络在做比较深的网络时就经常采用特征提取过程中减少网络的卷积,循环结构和池化操作等。
文章实时采集(自媒体文章发布齐全的采集平台让公众号运营(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-29 06:14
自媒体文章发布完整的采集平台,让公众号的操作更轻松关键词:自媒体文章发布完整的采集平台说明:自媒体文章发布总则 评测要靠采集平台,所以文章的采集平台选择也很重要。下面就跟随拓图数据了解一下自媒体文章发布了完整的采集平台相关信息。 自媒体文章发布一般需要依赖采集平台进行评估,所以文章的采集平台选择也是很重要的,下面跟着拓图数据了解一下自媒体文章Publish完整的采集平台相关信息。 自媒体文章发布了一套完整的采集平台拖图数据 拖图数据提供精准的公众号相关数据,为公众号运营商提供竞品分析服务,为公众号广告提供公众号质量监控服务。 1、超过2000万个公众号全部纳入其分析。 2、 判断一个公众号是否有价值最直观的方法就是统计其文章的阅读量和点赞数。用肉眼比较文章费时费力,而且过于原创。 3、拓途可以无限量的数据分析和透视,免费下载Excel,筛选优质公众号,进行竞品分析。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之易写网易写网是自媒体运营内容创建的辅助工具,功能齐全,数据准确,实用性强非常高。这里简单介绍一下它的主要功能模块:1、自媒体库和爆文Analysis,这两个模块可以根据筛选需求快速采集获取各个平台的实时热点爆文。
2、视频库:可以根据不同的过滤条件获取各个领域的热门视频。还可以批量采集和下载视频,是一个非常不错的视频素材库。 3、topic 库:收录来自各大自媒体平台的热门讨论话题,可以快速掌握热点话题,参与内容讨论。 4、小工具:收录了很多非常实用的小功能,比如爆文title自动生成、文章原创度数检测、文字内容转换、单个视频下载等。 5、公号模块:本版块收录微信公众号编辑器、公众数据和公众号列表。 文章编辑排版后可以一键同步到公众号。 6、工作台:是一个工具集模块,包括视频批量下载、图片和视频批量水印工具等。自媒体文章发布了完整的采集平台的乐观号。乐观号也是自媒体绝缘采集平台,其基础功能更加全面。这个工具有以下功能1、标题大师:只能推荐一些爆文标题2、热搜:结合微博热搜榜和百度风云榜,采集热点。 3、十万爆文:可以根据自己的需要整理、学习、融入自己的素材。排版和素材:提供文章编辑排版功能。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之新媒体管家新媒体管家风格合集文章编辑排版操作转换收益主要功能平台包括:1、Style Center:收录从标题到图文的多种模板。
2、图片编辑:您可以设计自己的素材风格。 3、音乐历:帮助制定账户营销计划4、应用中心:官方的应用和工具简直太棒了。相信有这么多超好用的自媒体文章拓图数据为你推荐的自媒体oh!完整采集平台发布后自媒体oh!更多资讯和知识点持续关注,后续自媒体咖啡厅爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人原创文章、公众号历史文章等知识 查看全部
文章实时采集(自媒体文章发布齐全的采集平台让公众号运营(组图))
自媒体文章发布完整的采集平台,让公众号的操作更轻松关键词:自媒体文章发布完整的采集平台说明:自媒体文章发布总则 评测要靠采集平台,所以文章的采集平台选择也很重要。下面就跟随拓图数据了解一下自媒体文章发布了完整的采集平台相关信息。 自媒体文章发布一般需要依赖采集平台进行评估,所以文章的采集平台选择也是很重要的,下面跟着拓图数据了解一下自媒体文章Publish完整的采集平台相关信息。 自媒体文章发布了一套完整的采集平台拖图数据 拖图数据提供精准的公众号相关数据,为公众号运营商提供竞品分析服务,为公众号广告提供公众号质量监控服务。 1、超过2000万个公众号全部纳入其分析。 2、 判断一个公众号是否有价值最直观的方法就是统计其文章的阅读量和点赞数。用肉眼比较文章费时费力,而且过于原创。 3、拓途可以无限量的数据分析和透视,免费下载Excel,筛选优质公众号,进行竞品分析。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之易写网易写网是自媒体运营内容创建的辅助工具,功能齐全,数据准确,实用性强非常高。这里简单介绍一下它的主要功能模块:1、自媒体库和爆文Analysis,这两个模块可以根据筛选需求快速采集获取各个平台的实时热点爆文。
2、视频库:可以根据不同的过滤条件获取各个领域的热门视频。还可以批量采集和下载视频,是一个非常不错的视频素材库。 3、topic 库:收录来自各大自媒体平台的热门讨论话题,可以快速掌握热点话题,参与内容讨论。 4、小工具:收录了很多非常实用的小功能,比如爆文title自动生成、文章原创度数检测、文字内容转换、单个视频下载等。 5、公号模块:本版块收录微信公众号编辑器、公众数据和公众号列表。 文章编辑排版后可以一键同步到公众号。 6、工作台:是一个工具集模块,包括视频批量下载、图片和视频批量水印工具等。自媒体文章发布了完整的采集平台的乐观号。乐观号也是自媒体绝缘采集平台,其基础功能更加全面。这个工具有以下功能1、标题大师:只能推荐一些爆文标题2、热搜:结合微博热搜榜和百度风云榜,采集热点。 3、十万爆文:可以根据自己的需要整理、学习、融入自己的素材。排版和素材:提供文章编辑排版功能。 自媒体文章发布完整采集平台自媒体文章发布完整采集平台之新媒体管家新媒体管家风格合集文章编辑排版操作转换收益主要功能平台包括:1、Style Center:收录从标题到图文的多种模板。
2、图片编辑:您可以设计自己的素材风格。 3、音乐历:帮助制定账户营销计划4、应用中心:官方的应用和工具简直太棒了。相信有这么多超好用的自媒体文章拓图数据为你推荐的自媒体oh!完整采集平台发布后自媒体oh!更多资讯和知识点持续关注,后续自媒体咖啡厅爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人原创文章、公众号历史文章等知识
文章实时采集(实时热点采集软件V1.0绿色版下载地址和使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 430 次浏览 • 2021-08-29 06:13
实时热点采集软件V1.0 绿色版是很多网友都在寻找的一款软件。小编特地整理了实时热点采集软件V1.0,绿色版下载地址和软件使用方法,因为实时热点采集软件V1.0有很好的功能并且易于使用。
实时流行的采集软件是一款非常不错的信息采集工具。该软件可以采集当时最新的流行趋势,并可以对文章中的标题和图片进行处理,让您更好地操作自己的自媒体Account是自媒体专业人员的必备软件之一.
功能介绍
1、实时流行采集软件,可以帮助用户在电脑上采集流行文章。
2、软件可以主动获取关键词,方便用户修改文章。
3、 有了这个软件,你可以瞬间找到百度,搜索热门信息。
4、 也可以采集原文,将文章保存在TXT中,然后修改使用。
5、支持保存图片。采集的文章可以显示图片地址。
6、 支持 URL 去重功能。勾选这个功能可以主动过滤网址。
软件功能
1、实时热门采集软件,操作简单,快速获取热门文章。
2、采集的内容可以主动保存,方便用户修改使用。
3、轻松采集热点新闻,方便自媒体人员从头修改新闻。
4、primary 用于采集实时热门关键词(百度热搜、微博热搜)词条,抓取新闻内容。
5、title 组合+图片本地化,自定义编码,文章保存输出。 查看全部
文章实时采集(实时热点采集软件V1.0绿色版下载地址和使用方法)
实时热点采集软件V1.0 绿色版是很多网友都在寻找的一款软件。小编特地整理了实时热点采集软件V1.0,绿色版下载地址和软件使用方法,因为实时热点采集软件V1.0有很好的功能并且易于使用。
实时流行的采集软件是一款非常不错的信息采集工具。该软件可以采集当时最新的流行趋势,并可以对文章中的标题和图片进行处理,让您更好地操作自己的自媒体Account是自媒体专业人员的必备软件之一.
功能介绍
1、实时流行采集软件,可以帮助用户在电脑上采集流行文章。
2、软件可以主动获取关键词,方便用户修改文章。
3、 有了这个软件,你可以瞬间找到百度,搜索热门信息。
4、 也可以采集原文,将文章保存在TXT中,然后修改使用。
5、支持保存图片。采集的文章可以显示图片地址。
6、 支持 URL 去重功能。勾选这个功能可以主动过滤网址。
软件功能
1、实时热门采集软件,操作简单,快速获取热门文章。
2、采集的内容可以主动保存,方便用户修改使用。
3、轻松采集热点新闻,方便自媒体人员从头修改新闻。
4、primary 用于采集实时热门关键词(百度热搜、微博热搜)词条,抓取新闻内容。
5、title 组合+图片本地化,自定义编码,文章保存输出。
文章实时采集(2017年6月28号采集更新内容:新增文章采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-08-28 09:25
2017 年 6 月 28 日采集更新内容:
新增文章采集,还支持采集预览,更重要的是一个自动采集页面可以同时采集文章和提问互不干扰:
完善了系统功能的人性化。基本上用这个系统网站几分钟就可以搭建出强大的数据内容,很多插件都适合优采云站长,包括seo优化插件,官方团队努力搭建!
以下是早期作者的更新内容---------
为什么要全自动采集?
这是为优采云准备的,我们可以将采集规则对应到特定的类别,批量设置N条采集规则,然后一键自动采集,多任务批处理同时执行,并且订单解决了线程问题。
来看看采集rule的添加界面:
功能确实相当齐全,还有一些你看不到的隐藏功能。可以自动分割问题生成标签,也可以随机抽取马甲关注点,还可以生成网站真实用户交互的动态模拟,自动抓取和定位头像。 .
这里还有采集testing:我们可以测试我们写的规则,也可以预览题页。真的很刺激。
添加规则界面和编辑规则界面都支持测试采集并回答测试是否成功采集。
我们再来看看自动采集页面:
我们可以查看需要自动采集的列规则,支持一键自动采集,停止采集功能,设置采集时间间隔,采集进程支持每个采集进度查看,很棒的实时监控采集状态(与采集,准备采集,采集中,采集complete,采集terminated)。
采集页面打开,可以做其他事情,全自动无人值守采集
如果设置了采集username,用户名采集会自动变成马甲,非常方便。如上图,答案也是采集。这个全自动采集插件不需要手动安装。自动检测,如果没有安装,会自动安装。
请加官网QQ群:370431002,联系店主购买。 查看全部
文章实时采集(2017年6月28号采集更新内容:新增文章采集)
2017 年 6 月 28 日采集更新内容:
新增文章采集,还支持采集预览,更重要的是一个自动采集页面可以同时采集文章和提问互不干扰:
完善了系统功能的人性化。基本上用这个系统网站几分钟就可以搭建出强大的数据内容,很多插件都适合优采云站长,包括seo优化插件,官方团队努力搭建!
以下是早期作者的更新内容---------
为什么要全自动采集?
这是为优采云准备的,我们可以将采集规则对应到特定的类别,批量设置N条采集规则,然后一键自动采集,多任务批处理同时执行,并且订单解决了线程问题。
来看看采集rule的添加界面:
功能确实相当齐全,还有一些你看不到的隐藏功能。可以自动分割问题生成标签,也可以随机抽取马甲关注点,还可以生成网站真实用户交互的动态模拟,自动抓取和定位头像。 .
这里还有采集testing:我们可以测试我们写的规则,也可以预览题页。真的很刺激。
添加规则界面和编辑规则界面都支持测试采集并回答测试是否成功采集。
我们再来看看自动采集页面:
我们可以查看需要自动采集的列规则,支持一键自动采集,停止采集功能,设置采集时间间隔,采集进程支持每个采集进度查看,很棒的实时监控采集状态(与采集,准备采集,采集中,采集complete,采集terminated)。
采集页面打开,可以做其他事情,全自动无人值守采集
如果设置了采集username,用户名采集会自动变成马甲,非常方便。如上图,答案也是采集。这个全自动采集插件不需要手动安装。自动检测,如果没有安装,会自动安装。
请加官网QQ群:370431002,联系店主购买。
本文采集数据实时存储的相关方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-27 18:07
注:本文不仅提供了两种解决方案,还详细记录了一些相关信息。
方案一
这个方案的核心是flume采集数据。根据hive表的结构,将采集数据发送到对应的地址,达到实时数据存储的目的。这种实时实际上是一种准实时。
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,那么hive中有如下建表语句创建的表
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:
Flume 安装步骤
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件并添加java变量
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量。一次性使用,在profile和bashrc末尾添加。
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制为agent.conf,然后编辑
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
每个具体配置请参考以下博客。需要警惕的四个属性是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置无效,请检查是否配置了minBlockReplicas属性。 , 并且该值是否为1,以下连接是原因
配置好就可以启动了,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(此时hive可以根据时间进行分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报timestamp not found错误,因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个时间戳,如果这个时间戳的需求必须是数据产生的时间,可以修改源码或者为源码添加拦截器手动配置。
Flume 有非常灵活的使用方式,可以自定义source、sink、interceptor、channel selector等,适应大部分采集、数据缓冲等场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以根据hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,解决方案结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟也会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下,也会产生很多零散的小文件。这与hive的特长背道而驰,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
计划二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据,可以实现实时插入的效果。由于字数限制,计划2记录在以下博客链接中: 查看全部
本文采集数据实时存储的相关方案
注:本文不仅提供了两种解决方案,还详细记录了一些相关信息。
方案一
这个方案的核心是flume采集数据。根据hive表的结构,将采集数据发送到对应的地址,达到实时数据存储的目的。这种实时实际上是一种准实时。
假设hadoop集群已经正常启动,hive也已经正常启动,hive的文件地址为/hive/warehouse,那么hive中有如下建表语句创建的表
create table flume_test(uuid string);
可以推断flume_test表的地址在/hive/warehouse/flume_test,下面介绍flume:
Flume 安装步骤
#下载
cd /opt
mkdir flume
wget http://archive.apache.org/dist ... ar.gz
tar xvzf apache-flume-1.6.0-bin.tar.gz
cd apache-flume-1.6.0-bin/conf
cp flume-env.sh.template flume-env.sh
打开flume-env文件并添加java变量
export JAVA_HOME=/usr/java/jdk1.8.0_111
然后添加环境变量。一次性使用,在profile和bashrc末尾添加。
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
然后
source /etc/profile
既然flume安装好了,下面进行配置,切换到conf文件夹,将flume-conf.properties.template复制为agent.conf,然后编辑
#定义活跃列表
agent.sources=avroSrc
agent.channels=memChannel
agent.sinks=hdfsSink
#定义source
agent.sources.avroSrc.type=avro
agent.sources.avroSrc.channels=memChannel
agent.sources.avroSrc.bind=0.0.0.0
agent.sources.avroSrc.port=4353
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
#定义channel
agent.channels.memChannel.type=memory
agent.channels.memChannel.capacity = 1000
agent.channels.memChannel.transactionCapacity = 100
#定义sink
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.channel=memChannel
#agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/flume/test/%{topic}/%Y%m%d%H
agent.sinks.hdfsSink.hdfs.path=hdfs://hadoop-n:9000/hive/warehouse/flume_test
agent.sinks.hdfsSink.hdfs.filePrefix=stu-flume
agent.sinks.hdfsSink.hdfs.inUsePrefix=inuse-stu-flume
agent.sinks.hdfsSink.hdfs.inUseSuffix=.temp
agent.sinks.hdfsSink.hdfs.rollInterval=0
agent.sinks.hdfsSink.hdfs.rollSize=10240000
agent.sinks.hdfsSink.hdfs.rollCount=0
agent.sinks.hdfsSink.hdfs.idleTimeout=0
agent.sinks.hdfsSink.hdfs.batchSize=100
agent.sinks.hdfsSink.hdfs.minBlockReplicas=1
# agent.sinks.hdfsSink.hdfs.writeFormat = Text
agent.sinks.hdfsSink.hdfs.fileType = DataStream
每个具体配置请参考以下博客。需要警惕的四个属性是rollInterval、rollSize、rollCount、idleTimeout。如果发现配置无效,请检查是否配置了minBlockReplicas属性。 , 并且该值是否为1,以下连接是原因
配置好就可以启动了,启动命令
./flume-ng agent -f ../conf/agent.conf -n agent -c conf -Dflume.monitoring.type=http \-Dflume.monitoring.port=5653 -Dflume.root.logger=DEBUG,console
注意:-n 是代理的名称,需要对应配置文件的第一个值。这个启动命令也开启了监控,监控地址:5563/metrics; -f 指的是配置文件的路径和名称。修改flume的conf后,不需要重启。默认情况下,它每 30 秒刷新一次并自动加载最新配置。
flume安装启动后,编写测试程序。打开eclipse并创建一个maven项目
4.0.0
scc
stu-flume
0.0.1-SNAPSHOT
war
stu-flume
log4j
log4j
1.2.9
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
测试 servlet
public class GenerLogServlet extends HttpServlet {
private static final Logger LOGGER = Logger.getLogger(GenerLogServlet.class);
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
for (;;) {
LOGGER.info(UUID.randomUUID().toString());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
this.doGet(request, response);
}
}
log4j.properties
#log4j settings
#log4j.rootLogger=debug, CONSOLE
log4j.logger.scc.stu_flume.GenerLogServlet=debug,GenerLogServlet
#log4j.rootLogger=INFO
log4j.appender.GenerLogServlet=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.GenerLogServlet.Hostname=10.5.3.100
log4j.appender.GenerLogServlet.Port=4353
log4j.appender.GenerLogServletUnsafeMode=false
启动项目,访问:8080/log开始生产数据。需要注意的是,如果flume配置是根据时间戳对文件进行分组(此时hive可以根据时间进行分区),那么agent.conf中的source必须配置
agent.sources.avroSrc.interceptors=timestampinterceptor
agent.sources.avroSrc.interceptors.timestampinterceptor.type=timestamp
agent.sources.avroSrc.interceptors.timestampinterceptor.preserveExisting=false
否则flume sink会报timestamp not found错误,因为源码org.apache.flume.clients.log4jappender.Log4jAvroHeaders中定义的timestamp的key是flume.client.log4j.timestamp而不是timestamp,所以需要手动添加一个时间戳,如果这个时间戳的需求必须是数据产生的时间,可以修改源码或者为源码添加拦截器手动配置。
Flume 有非常灵活的使用方式,可以自定义source、sink、interceptor、channel selector等,适应大部分采集、数据缓冲等场景。
观察hadoop目录,发现flume已经按照配置把数据移动到了对应的hive表目录下,如下图:
打开hive客户端,使用数据查询命令,发现可以查询到数据!并且可以根据hive表的数据规则写入hive的分区表和桶表flume,然后实时插入数据。至此,解决方案结束。
这个程序的缺点:
因为flume在写文件的时候独占了正在写的文件资源,所以hive无法读取正在写的文件的内容,也就是说,如果每5分钟生成一个文件,那么正在写的文件的内容就不会被hive读取,这意味着hive最多有5分钟的延迟。而且如果减少时间,延迟也会减少,但即使设置为30分钟或1小时,在flume流量不大的情况下,也会产生很多零散的小文件。这与hive的特长背道而驰,hive擅长处理大文件,对于分散的小文件,hive性能会下降很多。
计划二
对比方案一,测试程序和source不变,sink改为hbase-sink,数据实时插入hbase,然后在hive中创建hbase映射表,hive从hbase读取数据,可以实现实时插入的效果。由于字数限制,计划2记录在以下博客链接中:
文章实时采集一般分以下几步,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-08-27 05:04
文章实时采集一般分以下几步:第一步,
1、arxiv2016pan的文件分为pdf和rest两类数据
2、不同文件数据格式,一般采用postags或entity来对应pdf与rest格式的关系。
3、文件颜色分为color和background两种颜色。根据图像分辨率,color颜色设为4x4或6x6,background设为4x5就可以。有些文件需要指定格式才可以对应到对应的rest文件。第二步,读取数据获取文件数据之后一般要先读取数据,也就是rest的文件数据。有的rest文件时指定cvtoolbox中的picture就可以获取,有的需要命令提示符来获取,有些还需要进入rest文件所在的目录(也就是加载数据的目录)读取。
这里就先用portaddress函数来读取。注意:关于rest与arxiv2016pan的文件类型不同的定义,下图中是我列出的。这里推荐使用postags来定义rest,rest(restparties)可以指定多个类型文件的数据用哪个parties进行定义和更新。background数据的读取结果,也就是当前数据包含的background文件进行定义的副本。
其次就是要定义数据对应的rest文件。根据时间开始读取每个rest数据包,读取的时候,根据entity_id来选择要读取的数据位置进行全部读取。进入到postags的包含数据的文件所在目录读取后,更新生成数据包。最后要定义rest文件所需要的entity表达式entity_def。相关方法如下:plot_entity(entity,entity_required,postags,entity_id,entity_def)entity需要显示内容的对象列表。
entity_id可以为objectid或者pathname,pathname可以是entity_defidx,最终要列出entity_defidx的整个列表。entity_def可以为string(pathname,entity_idx)或者entity_idx的整数部分。最后通过entity_def指定entity的所有属性。
entity_def函数用于定义entitydef属性。在python中使用python文件名可以用module_name得到pattern_entity(arguments,globalname,comments_entity)globalset_entity_def(context)有的rest文件不需要定义图片名称,只需要引用图片名即可,引用前加context,不然会读取了第二个文件并不知道图片地址。
根据context在postags的数据包中取出图片地址地址,保存到http_lib中。http_lib有上亿张图片image_required可以查看该文件中对应的rest文件的bin数据内容。在文件中的bin_image_lib中定义需要保存的图片地址路径,也可以查看该文件中对应的图片地址路径地址数据。修改图片地址路径信息image_required="^image_req。 查看全部
文章实时采集一般分以下几步,你知道吗?
文章实时采集一般分以下几步:第一步,
1、arxiv2016pan的文件分为pdf和rest两类数据
2、不同文件数据格式,一般采用postags或entity来对应pdf与rest格式的关系。
3、文件颜色分为color和background两种颜色。根据图像分辨率,color颜色设为4x4或6x6,background设为4x5就可以。有些文件需要指定格式才可以对应到对应的rest文件。第二步,读取数据获取文件数据之后一般要先读取数据,也就是rest的文件数据。有的rest文件时指定cvtoolbox中的picture就可以获取,有的需要命令提示符来获取,有些还需要进入rest文件所在的目录(也就是加载数据的目录)读取。
这里就先用portaddress函数来读取。注意:关于rest与arxiv2016pan的文件类型不同的定义,下图中是我列出的。这里推荐使用postags来定义rest,rest(restparties)可以指定多个类型文件的数据用哪个parties进行定义和更新。background数据的读取结果,也就是当前数据包含的background文件进行定义的副本。
其次就是要定义数据对应的rest文件。根据时间开始读取每个rest数据包,读取的时候,根据entity_id来选择要读取的数据位置进行全部读取。进入到postags的包含数据的文件所在目录读取后,更新生成数据包。最后要定义rest文件所需要的entity表达式entity_def。相关方法如下:plot_entity(entity,entity_required,postags,entity_id,entity_def)entity需要显示内容的对象列表。
entity_id可以为objectid或者pathname,pathname可以是entity_defidx,最终要列出entity_defidx的整个列表。entity_def可以为string(pathname,entity_idx)或者entity_idx的整数部分。最后通过entity_def指定entity的所有属性。
entity_def函数用于定义entitydef属性。在python中使用python文件名可以用module_name得到pattern_entity(arguments,globalname,comments_entity)globalset_entity_def(context)有的rest文件不需要定义图片名称,只需要引用图片名即可,引用前加context,不然会读取了第二个文件并不知道图片地址。
根据context在postags的数据包中取出图片地址地址,保存到http_lib中。http_lib有上亿张图片image_required可以查看该文件中对应的rest文件的bin数据内容。在文件中的bin_image_lib中定义需要保存的图片地址路径,也可以查看该文件中对应的图片地址路径地址数据。修改图片地址路径信息image_required="^image_req。
FlinkX实时采集插件的核心是如何实时捕获数据库数据的
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-25 06:16
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。 查看全部
FlinkX实时采集插件的核心是如何实时捕获数据库数据的
一、FlinkX 实时采集功能基本介绍
首先介绍一下FlinkX实时模块的分类,如下图所示:
1、real-time采集module (CDC)
1)MySQL Binlog 插件
使用阿里开源的Canal组件从MySQL实时捕获变化数据。
2)PostgreSQL Wal插件
<p>PostgreSQL实时采集基于PostgreSQL的逻辑复制和逻辑解码功能。同步数据逻辑复制的原理是在Wal日志生成的数据库上,逻辑分析模块对Wal日志进行初步分析。其分析结果为ReorderBufferChange(可以简单理解为HeapTupleData),Pgoutput Plugin对中间结果进行过滤和消息拼接后发送给订阅端,订阅端通过逻辑解码函数进行分析。
织梦新手站长和网站编辑必备的模块--温馨提示
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-23 02:31
安装这个织梦dedecms模块后,采集器控制面板会出现在发布文章的顶部,在你的发布编辑框中输入关键词或URL smart采集内容,用易学、易懂、易用、成熟稳定,是织梦dedecms初学者站长和网站编辑必备的模块。
提醒:
01、 安装本模块后,您可以输入新闻信息网址或关键词,一键批量采集任何新闻信息内容到您的织梦dedecms网站 .
02、模块可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
03、模块上线已经一年多了。根据大量用户反馈,经过多次升级更新,模块功能成熟稳定,简单易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。每个织梦站长必备模块!
该模块的特点:
01、可以一键获取当前实时热点内容,然后一键发布。
02、可以批量采集批量发布,短时间内将任何优质内容转载到您的织梦dedecms网站。
03、可以定时采集自动释放,实现无人值守。
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持单篇文章采集,发布与织梦dedecms的文章相同的操作界面,使用方便。
06、采集可以显示内容图片并保存为织梦dedecms网站文章的附件,图片永不丢失。
07、模块内置了正文提取算法,支持采集any网站any列内容。
08、会自动添加你设置的水印织梦dedecms网站。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集发布的织梦dedecms网站文章与真实用户发布的完全相同。别人不知道要不要用采集器发帖。
11、的浏览量会自动随机设置。感觉你的织梦dedecms网站文章观看次数和真实的一样。
12、可以自定义文章发布者,让你的文章看起来更真实。
13、采集的内容可以发到织梦dedecms网站的任意栏目。
14、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
这个模块给你带来的价值:
1、让你的织梦dedecms网站感觉很受欢迎,流量大,内容丰富。
2、以定时发布代替人工发帖,全自动采集,一键批量采集等,省时、省力、高效,不易出错。
3、可以让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
用户保护:
1、严格遵守织梦dedecms官方模块开发规范。此外,我们的团队也会对模块进行大量的测试,以确保模块的安全、稳定和成熟。
2、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请注意模块升级。
2018年3月3日更新如下:
1、织梦系统兼容V5.6版本
2、 进一步优化实时采集
3、add 你可以自己写采集rules
4、进一步优化时序采集自动释放
2020 年 7 月 1 日更新如下:
1、优化批次采集
2、一键添加实时热点和当日新闻采集
3、添加实时采集
查看全部
织梦新手站长和网站编辑必备的模块--温馨提示
安装这个织梦dedecms模块后,采集器控制面板会出现在发布文章的顶部,在你的发布编辑框中输入关键词或URL smart采集内容,用易学、易懂、易用、成熟稳定,是织梦dedecms初学者站长和网站编辑必备的模块。
提醒:
01、 安装本模块后,您可以输入新闻信息网址或关键词,一键批量采集任何新闻信息内容到您的织梦dedecms网站 .
02、模块可以设置定时采集关键词,然后自动发布内容,实现网站内容无人值守自动更新。
03、模块上线已经一年多了。根据大量用户反馈,经过多次升级更新,模块功能成熟稳定,简单易懂,使用方便,功能强大。它已被许多网站管理员安装和使用。每个织梦站长必备模块!
该模块的特点:
01、可以一键获取当前实时热点内容,然后一键发布。
02、可以批量采集批量发布,短时间内将任何优质内容转载到您的织梦dedecms网站。
03、可以定时采集自动释放,实现无人值守。
04、采集返回的内容可以进行简繁体、伪原创等二次处理。
05、支持单篇文章采集,发布与织梦dedecms的文章相同的操作界面,使用方便。
06、采集可以显示内容图片并保存为织梦dedecms网站文章的附件,图片永不丢失。
07、模块内置了正文提取算法,支持采集any网站any列内容。
08、会自动添加你设置的水印织梦dedecms网站。
09、已经采集的内容不会重复两次采集,内容不会重复或冗余。
10、采集发布的织梦dedecms网站文章与真实用户发布的完全相同。别人不知道要不要用采集器发帖。
11、的浏览量会自动随机设置。感觉你的织梦dedecms网站文章观看次数和真实的一样。
12、可以自定义文章发布者,让你的文章看起来更真实。
13、采集的内容可以发到织梦dedecms网站的任意栏目。
14、不限制采集的内容量,不限制采集的次数,让你的网站快速填充优质内容。
这个模块给你带来的价值:
1、让你的织梦dedecms网站感觉很受欢迎,流量大,内容丰富。
2、以定时发布代替人工发帖,全自动采集,一键批量采集等,省时、省力、高效,不易出错。
3、可以让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
用户保护:
1、严格遵守织梦dedecms官方模块开发规范。此外,我们的团队也会对模块进行大量的测试,以确保模块的安全、稳定和成熟。
2、在使用过程中,如有BUG或用户体验不佳,可向技术人员反馈。经评估,情况属实,将在下一个升级版本中解决。请注意模块升级。
2018年3月3日更新如下:
1、织梦系统兼容V5.6版本
2、 进一步优化实时采集
3、add 你可以自己写采集rules
4、进一步优化时序采集自动释放
2020 年 7 月 1 日更新如下:
1、优化批次采集
2、一键添加实时热点和当日新闻采集
3、添加实时采集
文章实时采集到的网站标注样本,做好点的机构吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-22 03:05
文章实时采集到的网站标注样本虽然来源多样,但是数据采集误差将会显著增加。人工标注是最简单有效的办法。此外,搜索引擎也是一个方法。
辅助啊不贵啊一个手机就能做任何事了网站的话谷歌就能找到
光靠自己肯定是够不到要求。可以花钱买标注。
实话实说,还是有点困难的,可以看看甲骨文的公众号,这家公司是业内最大的标注公司之一。
转化率不好,模板还多,
有很多方法,我也比较喜欢标注,
对于大数据来说标注数据是不合格,但对于小企业的话,互联网标注工具也是一个不错的选择,标注工具有自己定制的服务器,各种功能,可以兼顾到企业的各个需求。
中国标注网可以标注有丰富样本,
有做好点的机构吗
可以用我们公司的的公众号服务号【标注狂】,
【ai标注】是可以标注网站标注和网页资源标注的
推荐试试:【标注狂】公众号,基于人工智能+区块链技术研发,开发了一个ai标注产品,旨在为传统标注公司提供标注云服务,标注员可通过ai引擎自行在线标注。
比如,可以使用现有的标注来标注网站,一台电脑就可以。或者为网站添加标注服务器,可以把更多的工作量分配到其他地方,这样实际效率会更高。互联网时代,新员工通过自行学习,比培训加有用得多。在整个过程中,经验提升得更快。 查看全部
文章实时采集到的网站标注样本,做好点的机构吗?
文章实时采集到的网站标注样本虽然来源多样,但是数据采集误差将会显著增加。人工标注是最简单有效的办法。此外,搜索引擎也是一个方法。
辅助啊不贵啊一个手机就能做任何事了网站的话谷歌就能找到
光靠自己肯定是够不到要求。可以花钱买标注。
实话实说,还是有点困难的,可以看看甲骨文的公众号,这家公司是业内最大的标注公司之一。
转化率不好,模板还多,
有很多方法,我也比较喜欢标注,
对于大数据来说标注数据是不合格,但对于小企业的话,互联网标注工具也是一个不错的选择,标注工具有自己定制的服务器,各种功能,可以兼顾到企业的各个需求。
中国标注网可以标注有丰富样本,
有做好点的机构吗
可以用我们公司的的公众号服务号【标注狂】,
【ai标注】是可以标注网站标注和网页资源标注的
推荐试试:【标注狂】公众号,基于人工智能+区块链技术研发,开发了一个ai标注产品,旨在为传统标注公司提供标注云服务,标注员可通过ai引擎自行在线标注。
比如,可以使用现有的标注来标注网站,一台电脑就可以。或者为网站添加标注服务器,可以把更多的工作量分配到其他地方,这样实际效率会更高。互联网时代,新员工通过自行学习,比培训加有用得多。在整个过程中,经验提升得更快。
微信群规简单点怎么说微信和QQ扫雷群规则怎么写
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-19 00:27
感谢邀请微信群网站!这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过扫描二维码进群。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。可通过5个渠道采集、采集所有公开有效、真实活跃的微信群,10个二维码中约有6-7个有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,还有采集,
感谢邀请微信群网站!
这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过采集二维码,扫码进群的方法。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。
可用,5个频道采集,采集都是公开有效的,真正活跃的微信群,10个二维码中,大约6-7个是有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,采集,特定群,设置关键词,就可以启动采集,实时采集,软件很强大,行业很广。
上一篇:微信群规则怎么写简单:微信和QQ扫雷群怎么写规则? (如何绑定QQ账号到微信) 下一篇:给朋友圈刷账号的句子:微信朋友圈的图片显示请配合刷单是什么意思? (微信朋友圈清账语句图片) 查看全部
微信群规简单点怎么说微信和QQ扫雷群规则怎么写
感谢邀请微信群网站!这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过扫描二维码进群。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。可通过5个渠道采集、采集所有公开有效、真实活跃的微信群,10个二维码中约有6-7个有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,还有采集,
感谢邀请微信群网站!
这个软件是微创。它刚刚开发了一个非常强大的软件,主要是通过采集二维码,扫码进群的方法。结合大数据、爬虫技术和图片、分析技术,软件可以智能化,识别二维码,检查二维码真伪,智能过滤重复二维码,记忆查询等功能,可以帮助您大大提高找群效率,提高进群成功率,提升群素质。
可用,5个频道采集,采集都是公开有效的,真正活跃的微信群,10个二维码中,大约6-7个是有效微信群,并且实时更新。一天可以采集近,上万个微信群,二维码,采集,特定群,设置关键词,就可以启动采集,实时采集,软件很强大,行业很广。
上一篇:微信群规则怎么写简单:微信和QQ扫雷群怎么写规则? (如何绑定QQ账号到微信) 下一篇:给朋友圈刷账号的句子:微信朋友圈的图片显示请配合刷单是什么意思? (微信朋友圈清账语句图片)

