
文章实时采集
文章实时采集 大屏幕是品牌公关活动必备的利器--平和一期
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-06-03 03:07
文章实时采集。图片云端处理后传到大屏幕上,让用户下滑直接跳转到相应页面,不需要下拉刷新也不需要滑动手势。一键收藏、转发、分享。同时适配多终端,不用安装app就可以收藏文章。基于大数据分析的整站订阅推送,以及异步动态推送。分享给亲戚朋友同事等等。多样性和互动性的强大的传播力。利用微信强大的社交关系链,建立起我是传播节点的传播纽带。
参考外媒报道:。上周更新的东西,又重新发布了。总结:大屏幕是品牌公关活动必备的利器!很多文章在朋友圈让它成为爆款之后,然后,就没有然后了。这里我想再次重申,我一直都认为,这样的活动设计,针对的是某个特定群体,从而让公司的知名度进一步提升。而并不是为了设计新闻,而设计这种机械活动,或者简单的方式。我在这里特别提出,把更多的目光放在“活动效果”而不是“活动实际”上。
第一轮为什么收到6000多条?商品图形,进行软件或者crm的销售渠道调查,核算出来的下单率。依据这个下单率,来寻找补充营销渠道。抓住这批群体的特性,举办一个线下地推活动,以及媒体曝光,利用其中产生的一些问题来进行精准营销。第二轮的反馈,就是第一轮活动的反馈,可以利用在线各种进行整合分析,这就是我要说的,一切的工作目的和转化手段,都只能围绕着活动的性质和目的在进行。
这次,相关报道有很多,但是,对于刚刚涉及做活动,以及初创小公司来说,还有很多的关键点要去思考。感谢有你,平和一期。--一期评论太多,不想发,我觉得是在宣扬中小型企业的不专业性,把做活动做成了推销。最终,还要看效果。所以,大家好聚好散,下期请给我发私信,说说对这些设计的一些要求和建议。以下是我一贯的观点(针对知乎,非广告)1.软件成本的大幅度下降,交互和图形占据大量预算的背后,靠软件的数量优势,是不够的,软。 查看全部
文章实时采集 大屏幕是品牌公关活动必备的利器--平和一期
文章实时采集。图片云端处理后传到大屏幕上,让用户下滑直接跳转到相应页面,不需要下拉刷新也不需要滑动手势。一键收藏、转发、分享。同时适配多终端,不用安装app就可以收藏文章。基于大数据分析的整站订阅推送,以及异步动态推送。分享给亲戚朋友同事等等。多样性和互动性的强大的传播力。利用微信强大的社交关系链,建立起我是传播节点的传播纽带。
参考外媒报道:。上周更新的东西,又重新发布了。总结:大屏幕是品牌公关活动必备的利器!很多文章在朋友圈让它成为爆款之后,然后,就没有然后了。这里我想再次重申,我一直都认为,这样的活动设计,针对的是某个特定群体,从而让公司的知名度进一步提升。而并不是为了设计新闻,而设计这种机械活动,或者简单的方式。我在这里特别提出,把更多的目光放在“活动效果”而不是“活动实际”上。
第一轮为什么收到6000多条?商品图形,进行软件或者crm的销售渠道调查,核算出来的下单率。依据这个下单率,来寻找补充营销渠道。抓住这批群体的特性,举办一个线下地推活动,以及媒体曝光,利用其中产生的一些问题来进行精准营销。第二轮的反馈,就是第一轮活动的反馈,可以利用在线各种进行整合分析,这就是我要说的,一切的工作目的和转化手段,都只能围绕着活动的性质和目的在进行。
这次,相关报道有很多,但是,对于刚刚涉及做活动,以及初创小公司来说,还有很多的关键点要去思考。感谢有你,平和一期。--一期评论太多,不想发,我觉得是在宣扬中小型企业的不专业性,把做活动做成了推销。最终,还要看效果。所以,大家好聚好散,下期请给我发私信,说说对这些设计的一些要求和建议。以下是我一贯的观点(针对知乎,非广告)1.软件成本的大幅度下降,交互和图形占据大量预算的背后,靠软件的数量优势,是不够的,软。
文章实时采集,地理位置抓取,三维地图绘制是语音识别
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-05-11 19:02
文章实时采集,地理位置抓取,三维地图绘制是语音识别的大致的原理,
我的看法是,先自己把概念理清楚吧。不然很难让别人理解你的想法。另外,要看看现在能否做到。我看到的已经做出来的有语音实时转文字,语音识别+人脸识别+文字识别+结构化输出。
说白了还是编程基础要牢固
语音识别(比如:nuance公司),对讲机(普及版),
这个还是要看需求和实现方式。语音技术目前不能成熟应用到生活中,但是特定场景还是可以应用到的。比如来电时只需要告诉你对方想接听,那么对方的位置信息就是很好的采集了。目前比较典型的应用,对方想打王者,可以依据在上海打王者电话是15min,打农药电话是20min,打游戏电话是40min来判断。可以定制一个人工智能系统,类似于阿尔法狗那样,一点一点学习。对方打开个短信,就可以学习发送什么信息了。
题主想利用语音作为识别码,进行信息录入吗?答案是肯定的。你可以用一个单片机控制一个nuance开发的avr-cnoise音箱,可以按语音给事先录入的电话打电话。也可以用一个程序控制两个音箱进行语音通话。
这个肯定会有用啊。目前的语音识别技术基本都是基于客户端系统,不提供服务器的。不过手机上能上网,而且会编程,也可以自己开发一个对话系统,把语音控制转换成文字。 查看全部
文章实时采集,地理位置抓取,三维地图绘制是语音识别
文章实时采集,地理位置抓取,三维地图绘制是语音识别的大致的原理,
我的看法是,先自己把概念理清楚吧。不然很难让别人理解你的想法。另外,要看看现在能否做到。我看到的已经做出来的有语音实时转文字,语音识别+人脸识别+文字识别+结构化输出。
说白了还是编程基础要牢固
语音识别(比如:nuance公司),对讲机(普及版),
这个还是要看需求和实现方式。语音技术目前不能成熟应用到生活中,但是特定场景还是可以应用到的。比如来电时只需要告诉你对方想接听,那么对方的位置信息就是很好的采集了。目前比较典型的应用,对方想打王者,可以依据在上海打王者电话是15min,打农药电话是20min,打游戏电话是40min来判断。可以定制一个人工智能系统,类似于阿尔法狗那样,一点一点学习。对方打开个短信,就可以学习发送什么信息了。
题主想利用语音作为识别码,进行信息录入吗?答案是肯定的。你可以用一个单片机控制一个nuance开发的avr-cnoise音箱,可以按语音给事先录入的电话打电话。也可以用一个程序控制两个音箱进行语音通话。
这个肯定会有用啊。目前的语音识别技术基本都是基于客户端系统,不提供服务器的。不过手机上能上网,而且会编程,也可以自己开发一个对话系统,把语音控制转换成文字。
新技术电子影像监测监控系统——打孔+stl格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-10 09:01
文章实时采集技术包括场景采集、节点采集、点采集、平行采集等。无论是场景采集还是节点采集,都离不开一个采集设备。这就决定了你能采集到的数据量,越大你获取数据的速度也越快。我们有三款采集设备。3d扫描仪三维场景的扫描仪一般采用3d扫描仪来进行采集。一款典型的3d扫描仪需要一台采集采样机、一台扫描仪、一台三维扫描仪、一个3d三维场景扫描仪、cinema4d软件、云计算平台等其他。
3d扫描仪整体维护:采集机、三维扫描仪、2d软件、cinema4d软件。3d三维场景扫描仪采用采集机构采集场景,进行点云测距及识别。3d扫描仪的特点:打孔+stl格式。采集机构:彩色一体化3d扫描仪。扫描机构:标准3d立体扫描仪。云计算平台:3d扫描仪一般会与云平台搭配使用,我们有一款云扫描仪3d云采集仪。
可以试试快数快采,你在应用商店里面搜一下,他们的快数快采可以实现一键采集,
用笔者所学的技术告诉你,可以试试这个新技术电子影像监测监控系统,用定位方式采集视频数据,
同求解答!同感!
我也在找,
xy,现在是按用户设备来划分,只有摄像头、光源、传感器组成的,然后是采集卡、采集仪。 查看全部
新技术电子影像监测监控系统——打孔+stl格式
文章实时采集技术包括场景采集、节点采集、点采集、平行采集等。无论是场景采集还是节点采集,都离不开一个采集设备。这就决定了你能采集到的数据量,越大你获取数据的速度也越快。我们有三款采集设备。3d扫描仪三维场景的扫描仪一般采用3d扫描仪来进行采集。一款典型的3d扫描仪需要一台采集采样机、一台扫描仪、一台三维扫描仪、一个3d三维场景扫描仪、cinema4d软件、云计算平台等其他。
3d扫描仪整体维护:采集机、三维扫描仪、2d软件、cinema4d软件。3d三维场景扫描仪采用采集机构采集场景,进行点云测距及识别。3d扫描仪的特点:打孔+stl格式。采集机构:彩色一体化3d扫描仪。扫描机构:标准3d立体扫描仪。云计算平台:3d扫描仪一般会与云平台搭配使用,我们有一款云扫描仪3d云采集仪。
可以试试快数快采,你在应用商店里面搜一下,他们的快数快采可以实现一键采集,
用笔者所学的技术告诉你,可以试试这个新技术电子影像监测监控系统,用定位方式采集视频数据,
同求解答!同感!
我也在找,
xy,现在是按用户设备来划分,只有摄像头、光源、传感器组成的,然后是采集卡、采集仪。
干货 | 数据埋点采集,看这一篇文章就够了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-05-07 02:12
数仓蓝图:
本文目录:
一、数据采集及常见问题二、埋点是什么与方式三、埋点的框架与设计四、指标体系与可视化
一、数据采集以及常见数据问题
1.1数据采集
数据采集有多种方式,埋点采集是其中非常重要的一部分,不论对c端还是b端产品都是主要的采集方式,数据采集,顾名思义就是采集相应的数据,是整个数据流的起点,采集的全不全,对不对,直接决定数据的广度和质量,影响后续所有的环节。在数据采集有效性,完整性不好的公司,经常会有业务发现数据发生大幅度变化。
数据的处理通常由以下5步构成:
1.2常见数据问题
大体知道数据采集及其架构之后,我们看看工作中遇到的问题,有多少是跟数据采集环节有关的:
1、数据和后台差距很大,数据不准确-统计口径不一样、埋点定义不一样、采集方式带来误差
2、想用的时候,没有我想要的数据-没有提数据采集需求、埋点不正确不完整
3、事件太多,不清楚含义-埋点设计的方式、埋点更新迭代的规则和维护
4、分析数据不知道看哪些数据和指标-数据定义不清楚,缺乏分析思路
我们需要根源性解决问题:把采集当成独立的研发业务来对待,而不是产品研发中的附属品。
二、埋点是什么
2.1 埋点是什么
所谓埋点,就是数据采集领域的术语。它的学名应该叫做事件追踪,对应的英文是Event Tracking 指的是针对特定用户行为或事件进行捕获,处理和发送的相关技术及其实施过程。数据埋点是数据分析师,数据产品经理和数据运营,基于业务需求或者产品需求对用户行为的每一个事件对应位置进行开发埋点,并通过SDK上报埋点的数据结果,记录汇总数据后进行分析,推动产品优化和指导运营。
流程伴随着规范,通过定义我们看到,特定用户行为和事件是我们的采集重点,还需要处理和发送相关技术及实施过程;数据埋点是服务于产品,又来源于产品中,所以跟产品息息相关,埋点在于具体的实战过程,跟每个人对数据底层的理解程度有关。
2.2为什么要做埋点
埋点就是为了对产品进行全方位的持续追踪,通过数据分析不断指导优化产品。数据埋点的质量直接影响到数据,产品,运营等质量。
1、数据驱动-埋点将分析的深度下钻到流量分布和流动层面,通过统计分析,对宏观指标进行深入剖析,发现指标背后的问题,洞察用户行为与提升价值之间的潜在关联
2、产品优化-对产品来说,用户在产品里做了什么,停留多久,有什么异常都需要关注,这些问题都可以通过埋点的方式实现
3、精细化运营-埋点可以贯彻整个产品的生命周期,流量质量和不同来源的分布,人群的行为特点和关系,洞察用户行为与提升业务价值之间的潜在关联。
2.3埋点的方式
埋点的方式都有哪些呢,当前大多数公司都是客户端,服务端相结合的方式。
准确性:代码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1埋点采集的顶层设计
所谓的顶层设计就是想清楚怎么做埋点,用什么方式,上传机制是什么,具体怎么定义,具体怎么落地等等;我们遵循唯一性,可扩展性,一致性等的基础上,我们要设计一些通用字段及生成机制,比如:cid, idfa,idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据对不上;二是涉及到漏斗分析环节出现异常。因此应该做到:a.严格规范ID的本身识别机制;b.跨平台用户识别
同类抽象: 同类抽象包括事件抽象和属性抽象。事件抽象即浏览事件,点击事件的聚合;属性抽象,即多数复用的场景来进行合并,增加来源区分
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;埋点的制定过程本身就是规范底层数据的过程,所以一致性是特别重要,只有这样才能真正的用起来
渠道配置:渠道主要指的是推广渠道,落地页,网页推广页面,APP推广页面等,这个落地页的配置要有统一规范和标准
3.2 埋点采集事件及属性设计
在设计属性和事件的时候,我们要知道哪些经常变,哪些不变,哪些是业务行为,哪些是基本属性。基于基本属性事件,我们认为属性是必须采集项,只是属性里面的事件属性根据业务不同有所调整而已,因此,我们可以把埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、操作路径和不同细分场景、定义用户行为路径
分析指标:对特定的事件进行定义、核心业务指标需要的数据
事件设计:APP启动,退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件及属性设计
Ev事件的命名,也遵循一些规则,同一类功能在不同页面或位置出现时,按照功能名称命名,页面和位置在ev参数中进行区分。仅是按钮点击时,按照按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识和ev参数之间用“#”连接(一级连接符)
ev参数和ev参数之间用“/”来连接(二级连接符)
ev参数使用key=value的结构,当一个key对应多个value值时,value1与value2之间用“,”连接(三级连接符)
当埋点仅有ev标识没有ev参数的时候,不需要带#
备注:
ev标识:作为埋点的唯一标识,用来区分埋点的位置和属性,不可变,不可修改。
ev参数:埋点需要回传的参数,ev参数顺序可变,可修改)
app埋点调整的时,ev标识不变,只修改后面的埋点参数(参数取值变化或者增加参数类型)
一般埋点文档中所包含的sheet名称以及作用:
A、曝光埋点汇总;
B、点击和浏览埋点汇总;
C、失效埋点汇总:一般会记录埋点失效版本或时间;
D、PC和M端页面埋点所对应的pageid;
E、各版本上线时间记录;
埋点文档中,所有包含的列名及功能:
3.4 基于埋点的数据统计
用埋点统计数据怎么查找埋点ev事件:
1、明确埋点类型(点击/曝光/浏览)——筛选type字段
2、明确按钮埋点所属页面(页面或功能)——筛选功能模块字段
3、明确埋点事件名称——筛选名称字段
4、知道ev标识,可直接用ev来进行筛选
根据ev事件怎么进行查询统计:当查询按钮点击统计时,可直接用ev标识进行查询,当有所区分可限定埋点参数取值。因为ev参数的顺序不做要求可变,所以查询统计时,不能按照参数的顺序进行限定。
四、应用-数据流程的基础
4.1指标体系
体系化的指标可以综合不同的指标不同的维度串联起来进行全面的分析,会更快的发现目前产品和业务流程存在的问题。
4.2可视化
人对图像信息的解释效率比文字更高,可视化对数据分析极为重要,利用数据可视化可以揭示出数据内在的错综复杂的关系。
4.3 埋点元信息api提供
数据采集服务会对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
数据采集犹如设计产品,不能过度。不仅要留出扩展余地,更要经常思考数据有没有,全不全,细不细,稳不稳,快不快。 查看全部
干货 | 数据埋点采集,看这一篇文章就够了!
数仓蓝图:
本文目录:
一、数据采集及常见问题二、埋点是什么与方式三、埋点的框架与设计四、指标体系与可视化
一、数据采集以及常见数据问题
1.1数据采集
数据采集有多种方式,埋点采集是其中非常重要的一部分,不论对c端还是b端产品都是主要的采集方式,数据采集,顾名思义就是采集相应的数据,是整个数据流的起点,采集的全不全,对不对,直接决定数据的广度和质量,影响后续所有的环节。在数据采集有效性,完整性不好的公司,经常会有业务发现数据发生大幅度变化。
数据的处理通常由以下5步构成:
1.2常见数据问题
大体知道数据采集及其架构之后,我们看看工作中遇到的问题,有多少是跟数据采集环节有关的:
1、数据和后台差距很大,数据不准确-统计口径不一样、埋点定义不一样、采集方式带来误差
2、想用的时候,没有我想要的数据-没有提数据采集需求、埋点不正确不完整
3、事件太多,不清楚含义-埋点设计的方式、埋点更新迭代的规则和维护
4、分析数据不知道看哪些数据和指标-数据定义不清楚,缺乏分析思路
我们需要根源性解决问题:把采集当成独立的研发业务来对待,而不是产品研发中的附属品。
二、埋点是什么
2.1 埋点是什么
所谓埋点,就是数据采集领域的术语。它的学名应该叫做事件追踪,对应的英文是Event Tracking 指的是针对特定用户行为或事件进行捕获,处理和发送的相关技术及其实施过程。数据埋点是数据分析师,数据产品经理和数据运营,基于业务需求或者产品需求对用户行为的每一个事件对应位置进行开发埋点,并通过SDK上报埋点的数据结果,记录汇总数据后进行分析,推动产品优化和指导运营。
流程伴随着规范,通过定义我们看到,特定用户行为和事件是我们的采集重点,还需要处理和发送相关技术及实施过程;数据埋点是服务于产品,又来源于产品中,所以跟产品息息相关,埋点在于具体的实战过程,跟每个人对数据底层的理解程度有关。
2.2为什么要做埋点
埋点就是为了对产品进行全方位的持续追踪,通过数据分析不断指导优化产品。数据埋点的质量直接影响到数据,产品,运营等质量。
1、数据驱动-埋点将分析的深度下钻到流量分布和流动层面,通过统计分析,对宏观指标进行深入剖析,发现指标背后的问题,洞察用户行为与提升价值之间的潜在关联
2、产品优化-对产品来说,用户在产品里做了什么,停留多久,有什么异常都需要关注,这些问题都可以通过埋点的方式实现
3、精细化运营-埋点可以贯彻整个产品的生命周期,流量质量和不同来源的分布,人群的行为特点和关系,洞察用户行为与提升业务价值之间的潜在关联。
2.3埋点的方式
埋点的方式都有哪些呢,当前大多数公司都是客户端,服务端相结合的方式。
准确性:代码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1埋点采集的顶层设计
所谓的顶层设计就是想清楚怎么做埋点,用什么方式,上传机制是什么,具体怎么定义,具体怎么落地等等;我们遵循唯一性,可扩展性,一致性等的基础上,我们要设计一些通用字段及生成机制,比如:cid, idfa,idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据对不上;二是涉及到漏斗分析环节出现异常。因此应该做到:a.严格规范ID的本身识别机制;b.跨平台用户识别
同类抽象: 同类抽象包括事件抽象和属性抽象。事件抽象即浏览事件,点击事件的聚合;属性抽象,即多数复用的场景来进行合并,增加来源区分
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;埋点的制定过程本身就是规范底层数据的过程,所以一致性是特别重要,只有这样才能真正的用起来
渠道配置:渠道主要指的是推广渠道,落地页,网页推广页面,APP推广页面等,这个落地页的配置要有统一规范和标准
3.2 埋点采集事件及属性设计
在设计属性和事件的时候,我们要知道哪些经常变,哪些不变,哪些是业务行为,哪些是基本属性。基于基本属性事件,我们认为属性是必须采集项,只是属性里面的事件属性根据业务不同有所调整而已,因此,我们可以把埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、操作路径和不同细分场景、定义用户行为路径
分析指标:对特定的事件进行定义、核心业务指标需要的数据
事件设计:APP启动,退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件及属性设计
Ev事件的命名,也遵循一些规则,同一类功能在不同页面或位置出现时,按照功能名称命名,页面和位置在ev参数中进行区分。仅是按钮点击时,按照按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识和ev参数之间用“#”连接(一级连接符)
ev参数和ev参数之间用“/”来连接(二级连接符)
ev参数使用key=value的结构,当一个key对应多个value值时,value1与value2之间用“,”连接(三级连接符)
当埋点仅有ev标识没有ev参数的时候,不需要带#
备注:
ev标识:作为埋点的唯一标识,用来区分埋点的位置和属性,不可变,不可修改。
ev参数:埋点需要回传的参数,ev参数顺序可变,可修改)
app埋点调整的时,ev标识不变,只修改后面的埋点参数(参数取值变化或者增加参数类型)
一般埋点文档中所包含的sheet名称以及作用:
A、曝光埋点汇总;
B、点击和浏览埋点汇总;
C、失效埋点汇总:一般会记录埋点失效版本或时间;
D、PC和M端页面埋点所对应的pageid;
E、各版本上线时间记录;
埋点文档中,所有包含的列名及功能:
3.4 基于埋点的数据统计
用埋点统计数据怎么查找埋点ev事件:
1、明确埋点类型(点击/曝光/浏览)——筛选type字段
2、明确按钮埋点所属页面(页面或功能)——筛选功能模块字段
3、明确埋点事件名称——筛选名称字段
4、知道ev标识,可直接用ev来进行筛选
根据ev事件怎么进行查询统计:当查询按钮点击统计时,可直接用ev标识进行查询,当有所区分可限定埋点参数取值。因为ev参数的顺序不做要求可变,所以查询统计时,不能按照参数的顺序进行限定。
四、应用-数据流程的基础
4.1指标体系
体系化的指标可以综合不同的指标不同的维度串联起来进行全面的分析,会更快的发现目前产品和业务流程存在的问题。
4.2可视化
人对图像信息的解释效率比文字更高,可视化对数据分析极为重要,利用数据可视化可以揭示出数据内在的错综复杂的关系。
4.3 埋点元信息api提供
数据采集服务会对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
数据采集犹如设计产品,不能过度。不仅要留出扩展余地,更要经常思考数据有没有,全不全,细不细,稳不稳,快不快。
文章实时采集(1.实时数据采集3.Kafka实时流数据接入-吐血梳理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2022-04-18 10:48
各位朋友您好,我最近写了几篇关于实时数据分析的文章文章,都是基于当时的问题分析。今天打开这篇文章文章是因为实时分析工具已经实现了从0到1的业务数据对接,如果任何工具或功能不能与业务融合,那它所做的一切都是无用的,无法体现它的价值。所有的痛点和解决方案也来自于业务的使用。
这个文章我就不讲怎么选型号了,因为网上有很多类似的文章,只要细心就能找到,但不管是什么型号选择,重点是“行业研究”,防止错误选择。我一般会根据以下三大前提来选款(以下陈述纯属个人观点,如有不妥请在下方评论)
有很多公司在使用它,并且有很好的数据显示开源软件。关注社区情况。最近有没有继续迭代,防止自己进入深坑?最重要的是有没有和你类似的场景,你用过你要使用的工具。方便技术咨询
行业研究,行业研究,行业研究重要的事情说三遍
实时数据分析目前主要应用在业务场景中(很多公司对实时性有很强的需求)
1. 实时数据访问共6个数据源
2. 由于刚刚访问的日均数据量约为160万,当前摄取的数据量约为400万
以往的文章直通车(链接地址这里就不贴了,可以百度搜索)
1. 插件编写——Flume海量数据实时数据转换
2.回顾-Flume+Kafka实时数据采集
3.Kafka实时流式数据接入-吐血梳理与实践-Druid实时数据分析
4. 实时数据分析 Druid - 环境部署&试用
好了,以上就是简单的介绍,我们来说说今天的话题。
一. 为什么要做实时流数据分析?
以前不太喜欢碰数据,但总觉得没什么用。只有当我因为工作原因触及数据的门槛时,我才知道数据的重要性。
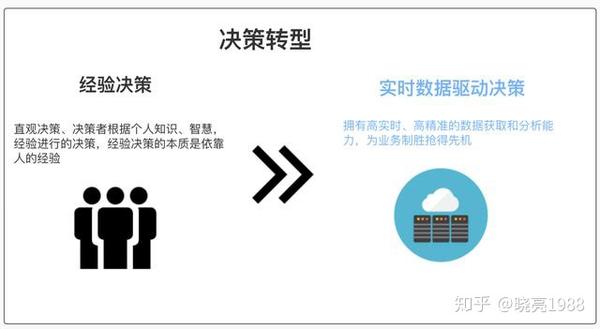
通常我们根据过去的经验做出决定。俗话说“做这个应该没问题”,但没有数据支持往往不够准确,大概率会出现问题,所以我们要从【经验决策】走向【真实-时间数据驱动的决策],使所有行动都以数据为事实。
二. 整体架构流程及分解
首先介绍一下我要解决的需求和痛点:
1. 实时流式数据摄取、显示图表、导出实时报告
2. 分析以往报告,90% 数据汇总,无需详细数据
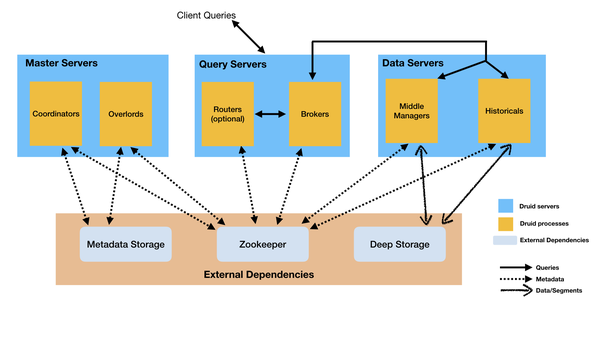
根据上面的分析,选择了olap,最终选择了Apache Druid。
什么是阿帕奇德鲁伊
Druid 是一个分布式数据处理系统,支持实时多维 OLAP 分析。它既支持高速实时数据摄取处理,又支持实时灵活的多维数据分析查询。因此,Druid 最常用的场景是大数据背景下灵活快速的多维 OLAP 分析。此外,Druid 有一个关键特性:支持基于时间戳的数据预聚合摄取和聚合分析,因此一些用户经常在有时序数据处理和分析的场景中使用它。
为什么来自 Druid 的亚秒级响应的交互式查询支持更高的并发性。支持实时导入,导入可查询,支持高并发导入。使用分布式无共享架构,它可以扩展到 PB 级别。支持聚合函数、count 和 sum,以及使用 javascript 实现自定义 UDF。支持复杂的聚合器,用于近似查询的聚合器,例如 HyperLoglog 和 6. 雅虎的开源 DataSketches。支持 Groupby、Select、Search 查询。不支持大表之间的join,但是它的lookup功能满足Join with dimension tables。(最新版本0.18已经支持Join,具体性能有待测试) 架构
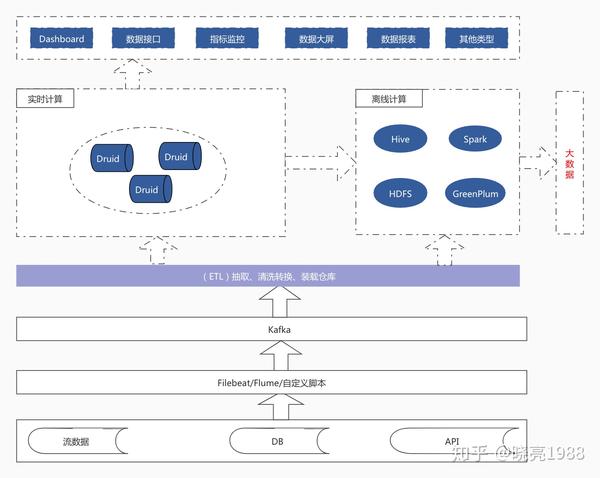
需求分析和核心引擎选型基本完成。先说一下整体架构
建筑设计的三个原则
适应原理 简单原理 进化原理
选择合适的架构,切记不要过度设计,过度设计未必实用。
架构图
结构意图
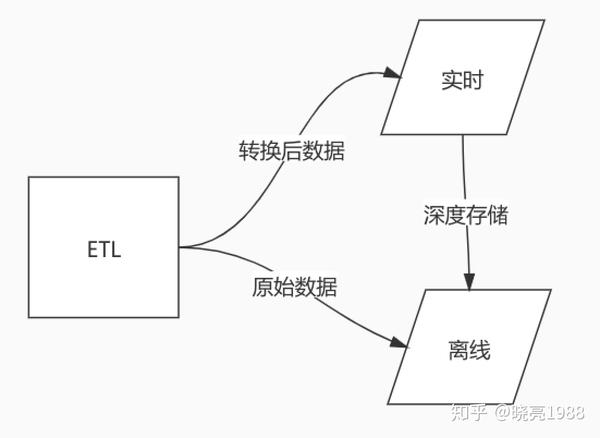
实时计算分析如何形成数据闭环,以下三点最重要
1. 数据清洗改造:需要通过一定的规则和规范,保证业务方传输的数据实时清洗改造或建模
2. 实时计算引擎:OLAP在线分析引擎选型
3.离线存储:深度存储,保证实时OLAP性能,也可作为日常数据容灾
三、 踩坑及解决方法
由于第一次接触数据分析相关的场景,很多工具和知识都是从零开始的。我知道我应该尽快补足功课,尤其是实时场景应用。
由于缺乏知识,在整体架构的构建和开发过程中存在许多问题。让我用图形的方式解释一下,这样就不会有学生对实时流数据不熟悉了。
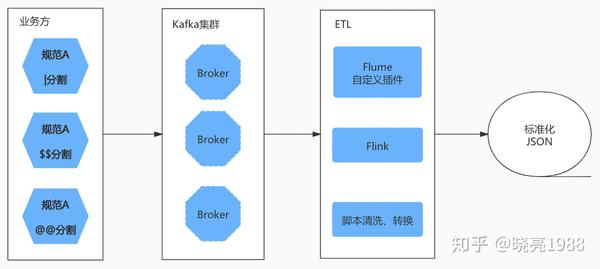
数据清洗和转换
访问标准和规范非常重要。由于业务方数量众多,只要有标准的切割方法,每个业务方的日志规格很可能不一致(我们的工具不能要求业务方修改大量的日志规格)。
在这种情况下,我们可以梳理出两种业务业态:
1. 文本 -> Json
原始日志
2019-02-11 19:03:30.123|INFO|1.0|10.10.10.10|push-service|trace_id:0001|msg:错误信息|token:abcd
清洗后
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
Json 结构 A -> Json 结构 B
原始日志 -> Json结构A
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
清洗、转换后
{"ts—time":"2020-05-07 16:29:05", "errLevel": "INFO"}
最终统一输出JSON(标准化输入输出)
流程图
以上是标准的整体流程,为此我开发了两个Flume插件
1. 文本 -> Json 插件
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=***.flume.textToJson.TextToJsonBuilder
a1.sources.r1.interceptors.i1.textToJson={"times":"#0", "errLevel": "#1", "version":"#2" , "ip":"#3", "service-name":"#4", "trace_id": "#5","msg": "#6"}
a1.sources.r1.interceptors.i1.separator=\\,
Json 结构 A -> Json 结构 B
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=flume.***.StringTransJsonBuilder
a1.sources.r1.interceptors.i1.template={"scid":"data.data.data.scid","tpc":"data.data.tpc", "did": "data.data.did"}
a1.sources.r1.interceptors.i1.where={"key1":"value1", "data.key2":"value2"}
a1.sources.r1.interceptors.i1.addheader=comment
上述过程没有任何问题。. . 但问题来了。
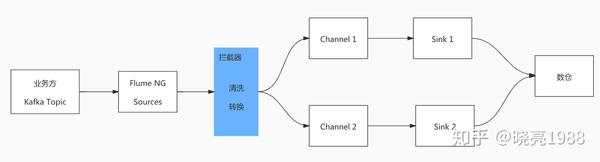
由于我们是消费者业务端Kafka Topics,所以有这样一种场景,所有业务方都将数据放到一个大topic中,我们需要对数据进行清洗转换成我们需要的数据源。见下图:
在上图的拦截器部分,接收到的主题数据必须经过拦截器的清洗和转换。由于业务topic有10个partition,如果我们启动一个Flume NG去消费,就会造成数据的积压。. .
1. 业务主题有10个分区,单个Flume NG进程可以理解为1个分区。. . 严重不足
2. 测试结果从业务端接收数据7小时,数据实际清洗2小时,数据继续被挤压
对应解决方案:
1. 启动 10 个 Flume 进程,相当于 10 个 Topic 分区,但这会消耗资源。. .
2. Python 进行数据清理和转换。
Flume NG 在内部为我们做了很多高可用。高可靠性保证,有限的资源只能暂时放弃这个计划。
所以选择了方案2,放弃了高可用和高可靠,但是最终的结果还是很不错的,用Python的消费速度是10个Flume NG的两倍。
结论:我们自己处理ETL,短期内是可行的,但长期来看还是要选择工具来处理。毕竟已经为我们准备了很多保障(要想做好工作,就必须先利好工具)。这句话不无道理。
目前遇到的最大困难是清洗和转换。其他的小坑在之前的文章里已经写过了,大家可以搜索一下。
阿帕奇德鲁伊
我使用最新版本的 0.18。该版本官方公告已宣布加入支持,但尚未进行测试。
该工具已经使用了一个多月,到目前为止它看起来很完美。
待续
很高兴这个项目能迈出一小步,我们的架构还要迭代开发,以后会继续更新这个系列文章哈哈
特别感谢老板给我机会开发这个项目。. . 给我机会从我的工作中成长 查看全部
文章实时采集(1.实时数据采集3.Kafka实时流数据接入-吐血梳理)
各位朋友您好,我最近写了几篇关于实时数据分析的文章文章,都是基于当时的问题分析。今天打开这篇文章文章是因为实时分析工具已经实现了从0到1的业务数据对接,如果任何工具或功能不能与业务融合,那它所做的一切都是无用的,无法体现它的价值。所有的痛点和解决方案也来自于业务的使用。
这个文章我就不讲怎么选型号了,因为网上有很多类似的文章,只要细心就能找到,但不管是什么型号选择,重点是“行业研究”,防止错误选择。我一般会根据以下三大前提来选款(以下陈述纯属个人观点,如有不妥请在下方评论)
有很多公司在使用它,并且有很好的数据显示开源软件。关注社区情况。最近有没有继续迭代,防止自己进入深坑?最重要的是有没有和你类似的场景,你用过你要使用的工具。方便技术咨询
行业研究,行业研究,行业研究重要的事情说三遍
实时数据分析目前主要应用在业务场景中(很多公司对实时性有很强的需求)
1. 实时数据访问共6个数据源
2. 由于刚刚访问的日均数据量约为160万,当前摄取的数据量约为400万
以往的文章直通车(链接地址这里就不贴了,可以百度搜索)
1. 插件编写——Flume海量数据实时数据转换
2.回顾-Flume+Kafka实时数据采集
3.Kafka实时流式数据接入-吐血梳理与实践-Druid实时数据分析
4. 实时数据分析 Druid - 环境部署&试用
好了,以上就是简单的介绍,我们来说说今天的话题。
一. 为什么要做实时流数据分析?
以前不太喜欢碰数据,但总觉得没什么用。只有当我因为工作原因触及数据的门槛时,我才知道数据的重要性。
通常我们根据过去的经验做出决定。俗话说“做这个应该没问题”,但没有数据支持往往不够准确,大概率会出现问题,所以我们要从【经验决策】走向【真实-时间数据驱动的决策],使所有行动都以数据为事实。
二. 整体架构流程及分解
首先介绍一下我要解决的需求和痛点:
1. 实时流式数据摄取、显示图表、导出实时报告
2. 分析以往报告,90% 数据汇总,无需详细数据
根据上面的分析,选择了olap,最终选择了Apache Druid。
什么是阿帕奇德鲁伊
Druid 是一个分布式数据处理系统,支持实时多维 OLAP 分析。它既支持高速实时数据摄取处理,又支持实时灵活的多维数据分析查询。因此,Druid 最常用的场景是大数据背景下灵活快速的多维 OLAP 分析。此外,Druid 有一个关键特性:支持基于时间戳的数据预聚合摄取和聚合分析,因此一些用户经常在有时序数据处理和分析的场景中使用它。
为什么来自 Druid 的亚秒级响应的交互式查询支持更高的并发性。支持实时导入,导入可查询,支持高并发导入。使用分布式无共享架构,它可以扩展到 PB 级别。支持聚合函数、count 和 sum,以及使用 javascript 实现自定义 UDF。支持复杂的聚合器,用于近似查询的聚合器,例如 HyperLoglog 和 6. 雅虎的开源 DataSketches。支持 Groupby、Select、Search 查询。不支持大表之间的join,但是它的lookup功能满足Join with dimension tables。(最新版本0.18已经支持Join,具体性能有待测试) 架构
需求分析和核心引擎选型基本完成。先说一下整体架构
建筑设计的三个原则
适应原理 简单原理 进化原理
选择合适的架构,切记不要过度设计,过度设计未必实用。
架构图
结构意图
实时计算分析如何形成数据闭环,以下三点最重要
1. 数据清洗改造:需要通过一定的规则和规范,保证业务方传输的数据实时清洗改造或建模
2. 实时计算引擎:OLAP在线分析引擎选型
3.离线存储:深度存储,保证实时OLAP性能,也可作为日常数据容灾
三、 踩坑及解决方法
由于第一次接触数据分析相关的场景,很多工具和知识都是从零开始的。我知道我应该尽快补足功课,尤其是实时场景应用。
由于缺乏知识,在整体架构的构建和开发过程中存在许多问题。让我用图形的方式解释一下,这样就不会有学生对实时流数据不熟悉了。
数据清洗和转换
访问标准和规范非常重要。由于业务方数量众多,只要有标准的切割方法,每个业务方的日志规格很可能不一致(我们的工具不能要求业务方修改大量的日志规格)。
在这种情况下,我们可以梳理出两种业务业态:
1. 文本 -> Json
原始日志
2019-02-11 19:03:30.123|INFO|1.0|10.10.10.10|push-service|trace_id:0001|msg:错误信息|token:abcd
清洗后
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
Json 结构 A -> Json 结构 B
原始日志 -> Json结构A
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
清洗、转换后
{"ts—time":"2020-05-07 16:29:05", "errLevel": "INFO"}
最终统一输出JSON(标准化输入输出)
流程图
以上是标准的整体流程,为此我开发了两个Flume插件
1. 文本 -> Json 插件
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=***.flume.textToJson.TextToJsonBuilder
a1.sources.r1.interceptors.i1.textToJson={"times":"#0", "errLevel": "#1", "version":"#2" , "ip":"#3", "service-name":"#4", "trace_id": "#5","msg": "#6"}
a1.sources.r1.interceptors.i1.separator=\\,
Json 结构 A -> Json 结构 B
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=flume.***.StringTransJsonBuilder
a1.sources.r1.interceptors.i1.template={"scid":"data.data.data.scid","tpc":"data.data.tpc", "did": "data.data.did"}
a1.sources.r1.interceptors.i1.where={"key1":"value1", "data.key2":"value2"}
a1.sources.r1.interceptors.i1.addheader=comment
上述过程没有任何问题。. . 但问题来了。
由于我们是消费者业务端Kafka Topics,所以有这样一种场景,所有业务方都将数据放到一个大topic中,我们需要对数据进行清洗转换成我们需要的数据源。见下图:
在上图的拦截器部分,接收到的主题数据必须经过拦截器的清洗和转换。由于业务topic有10个partition,如果我们启动一个Flume NG去消费,就会造成数据的积压。. .
1. 业务主题有10个分区,单个Flume NG进程可以理解为1个分区。. . 严重不足
2. 测试结果从业务端接收数据7小时,数据实际清洗2小时,数据继续被挤压
对应解决方案:
1. 启动 10 个 Flume 进程,相当于 10 个 Topic 分区,但这会消耗资源。. .
2. Python 进行数据清理和转换。
Flume NG 在内部为我们做了很多高可用。高可靠性保证,有限的资源只能暂时放弃这个计划。
所以选择了方案2,放弃了高可用和高可靠,但是最终的结果还是很不错的,用Python的消费速度是10个Flume NG的两倍。
结论:我们自己处理ETL,短期内是可行的,但长期来看还是要选择工具来处理。毕竟已经为我们准备了很多保障(要想做好工作,就必须先利好工具)。这句话不无道理。
目前遇到的最大困难是清洗和转换。其他的小坑在之前的文章里已经写过了,大家可以搜索一下。
阿帕奇德鲁伊
我使用最新版本的 0.18。该版本官方公告已宣布加入支持,但尚未进行测试。
该工具已经使用了一个多月,到目前为止它看起来很完美。
待续
很高兴这个项目能迈出一小步,我们的架构还要迭代开发,以后会继续更新这个系列文章哈哈
特别感谢老板给我机会开发这个项目。. . 给我机会从我的工作中成长
文章实时采集(微信公众号采集工具被封号,需求是怎么样的呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-18 10:46
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
正好这个时候在研究Xposed Hook微信,所以打算试试安卓版的微信。需求是什么?也就是微信推送一条公众号消息,我们接受一条,发送到对应界面保存,方便后续浏览。刚要去做的时候,觉得难度不大。直接下去下载微信数据库里的东西就行了。然而,这太简单了,好吧。
天真.jpg
幼稚的!!!
微信数据表“消息”中导出的数据是一堆乱码,解析出来的网址不全。比如五篇文章文章一次推送只能获取三篇文章的url,这让人很不舒服。
图像.png
但是苦就是苦,问题还是要解决的。如何解决?看源代码!
之前我把微信的几个dex包的代码反编译了放在一个文件夹里,然后用VSCode打开,日常查看。
微信反编译出来的源码虽然乱七八糟,但还是能看懂一些代码。
我们看到上面导出的数据有一些乱码,估计微信实现了解码工具。如果能hook这个解码工具,解码后能得到正确的数据吗?
说到解码,根据微信之前的数据传输,这些数据很可能是以XML格式传输的。由于涉及到 XML,所以它必须是键值对的形式。除了我们要去的数据之外,还有一堆看起来很有用的小方块和诸如“.msg.appmsg.mmreader.category.item”之类的东西。
我打开 vscode 并在全球范围内搜索“.msg.appmsg.mmreader.category.item”。令人高兴的是,结果并不多,这意味着这个值确实是一个有意义的值。一一检查这些源代码。一个包是:"
com.tencent.mm.plugin.biz;”我在一个名为“a”的类中发现了一些有趣的东西。
图像.png
该方法是一个名为 ws 的方法,它接收一个 String 类型的值,并在内部进行一些数据获取工作。
这个 str 参数可以是我想要的标准 xml 吗?
经过hook验证,打印其参数后,发现不是,参数内容的格式与之前数据库中的格式一致。
图像.png
然后我们将重点放在第一行的地图上。ay.WA(String str) 方法做解析操作吗?
我在 com.tencent.mm.sdk.platformtools.ay 中钩住了 WA() 方法来获取它的返回值,这是一个 Map 类型的数据。打印出它的内容后,我的猜测得到了验证。
WA() 方法将刚才的内容解析成一个便于我们阅读的地图。包括推送收录的图文消息数量,以及公众号的id、名称、对应的文章url、图片url、文章描述等信息。
我终于可以在晚餐时加鸡腿了。啊哈哈哈。
此文章仅供研究学习,请妥善食用,谢谢。
粘贴相关的钩子代码
图像.png 查看全部
文章实时采集(微信公众号采集工具被封号,需求是怎么样的呢?)
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
正好这个时候在研究Xposed Hook微信,所以打算试试安卓版的微信。需求是什么?也就是微信推送一条公众号消息,我们接受一条,发送到对应界面保存,方便后续浏览。刚要去做的时候,觉得难度不大。直接下去下载微信数据库里的东西就行了。然而,这太简单了,好吧。

天真.jpg
幼稚的!!!
微信数据表“消息”中导出的数据是一堆乱码,解析出来的网址不全。比如五篇文章文章一次推送只能获取三篇文章的url,这让人很不舒服。
图像.png
但是苦就是苦,问题还是要解决的。如何解决?看源代码!
之前我把微信的几个dex包的代码反编译了放在一个文件夹里,然后用VSCode打开,日常查看。
微信反编译出来的源码虽然乱七八糟,但还是能看懂一些代码。
我们看到上面导出的数据有一些乱码,估计微信实现了解码工具。如果能hook这个解码工具,解码后能得到正确的数据吗?
说到解码,根据微信之前的数据传输,这些数据很可能是以XML格式传输的。由于涉及到 XML,所以它必须是键值对的形式。除了我们要去的数据之外,还有一堆看起来很有用的小方块和诸如“.msg.appmsg.mmreader.category.item”之类的东西。
我打开 vscode 并在全球范围内搜索“.msg.appmsg.mmreader.category.item”。令人高兴的是,结果并不多,这意味着这个值确实是一个有意义的值。一一检查这些源代码。一个包是:"
com.tencent.mm.plugin.biz;”我在一个名为“a”的类中发现了一些有趣的东西。
图像.png
该方法是一个名为 ws 的方法,它接收一个 String 类型的值,并在内部进行一些数据获取工作。
这个 str 参数可以是我想要的标准 xml 吗?
经过hook验证,打印其参数后,发现不是,参数内容的格式与之前数据库中的格式一致。
图像.png
然后我们将重点放在第一行的地图上。ay.WA(String str) 方法做解析操作吗?
我在 com.tencent.mm.sdk.platformtools.ay 中钩住了 WA() 方法来获取它的返回值,这是一个 Map 类型的数据。打印出它的内容后,我的猜测得到了验证。
WA() 方法将刚才的内容解析成一个便于我们阅读的地图。包括推送收录的图文消息数量,以及公众号的id、名称、对应的文章url、图片url、文章描述等信息。
我终于可以在晚餐时加鸡腿了。啊哈哈哈。
此文章仅供研究学习,请妥善食用,谢谢。
粘贴相关的钩子代码
图像.png
文章实时采集(不用图像处理app,snapdragon670不支持环境光采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-04-14 06:07
文章实时采集来源主要有两个,一个是摄像头采集,另一个是环境光采集,前者只需要被采集设备支持,后者则是需要捕捉设备支持。由于摄像头比较远且存在额外的摄像头延迟,因此虽然采集方式非常简单,但是其成本并不高。而环境光则需要摄像头配合相应的灯光系统才能达到类似的效果。不过后者自然需要采集设备支持skylake,这样才能获得完整的snapdragon660环境光采集能力,否则不管怎么采集实际效果都还是差不多,毕竟snapdragon670都不支持环境光采集,采集设备更不用说了。
三星在这方面做得不错,smartshader,自己要动手。
目前能实现只需要snapdragon660,
cannonworksyogaflex的ai芯片。目前应该还不是cpu核,是ppu核。
小米的ai管家和物联网的iot
屏摄,这个效果确实不错。
完全不用图像处理app,
要是支持环境光的话,把手机屏幕放在侧面,角度调到最小,然后拿书遮挡光线,我还可以看到书的细节,
没有的,
emmm我们实验室有一个只有一寸屏幕的看片机,
说的就是华为的ai手机
这个必须得跟顶级的才行,不然只是拿小米的ai做噱头,毕竟这玩意就是个噱头,噱头之一。另外发射的激光不是用gps的那个uwb还是什么我也不知道。 查看全部
文章实时采集(不用图像处理app,snapdragon670不支持环境光采集)
文章实时采集来源主要有两个,一个是摄像头采集,另一个是环境光采集,前者只需要被采集设备支持,后者则是需要捕捉设备支持。由于摄像头比较远且存在额外的摄像头延迟,因此虽然采集方式非常简单,但是其成本并不高。而环境光则需要摄像头配合相应的灯光系统才能达到类似的效果。不过后者自然需要采集设备支持skylake,这样才能获得完整的snapdragon660环境光采集能力,否则不管怎么采集实际效果都还是差不多,毕竟snapdragon670都不支持环境光采集,采集设备更不用说了。
三星在这方面做得不错,smartshader,自己要动手。
目前能实现只需要snapdragon660,
cannonworksyogaflex的ai芯片。目前应该还不是cpu核,是ppu核。
小米的ai管家和物联网的iot
屏摄,这个效果确实不错。
完全不用图像处理app,
要是支持环境光的话,把手机屏幕放在侧面,角度调到最小,然后拿书遮挡光线,我还可以看到书的细节,
没有的,
emmm我们实验室有一个只有一寸屏幕的看片机,
说的就是华为的ai手机
这个必须得跟顶级的才行,不然只是拿小米的ai做噱头,毕竟这玩意就是个噱头,噱头之一。另外发射的激光不是用gps的那个uwb还是什么我也不知道。
文章实时采集(文章实时采集返回的四级跳。数据与视频相似度归一化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-14 03:04
文章实时采集返回的四级跳。数据与视频相似度归一化根据算法聚类用户画像,联合文章或推荐广告找到需要触达的精准人群。
没有说法。直接在聚类中得到返回结果。
在通过文章分类、物品分类聚类后做推荐。文章分类有建库、top5聚类等,物品分类还可以根据某些数据来聚类,比如上下架,时间,文章数量等。
在推荐系统中直接获取文章/物品信息并进行聚类聚是文章/物品聚类是topic聚类直接获取推荐的结果是在推荐过程中由应用提供的。
聚类聚是物品
聚类算法通常基于物品的属性或者物品自身的特征,
可以聚类,但是归类不一定必要,看你的目的是什么。大类聚是离推荐系统更近一点,最终聚不聚得到就看你本身的keyitem了。另外如果聚类算法不够成熟或者数据不好,再优质的归类成果也很可能在推荐中失效。
新品的聚类,根据目标用户和内容相似度算法聚类。
聚成什么样的类是个很重要的指标来衡量推荐成功与否,常见的有csi,kbs,mls等等,
聚类这种问题,直接从推荐系统得到返回结果就好了,目前的推荐算法里面,同类里面会同一类的同质化,不同类里面,
kblinking可以参考一下
四级跳也没说法。可以采用deepneuralmodel去聚类。更好的聚类方法通常有聚类相似度、聚类特征等不同的方法。聚类目标一般是用户标签,也可以用行为标签,你还可以去看看各种协同过滤的方法。谢谢邀请。 查看全部
文章实时采集(文章实时采集返回的四级跳。数据与视频相似度归一化)
文章实时采集返回的四级跳。数据与视频相似度归一化根据算法聚类用户画像,联合文章或推荐广告找到需要触达的精准人群。
没有说法。直接在聚类中得到返回结果。
在通过文章分类、物品分类聚类后做推荐。文章分类有建库、top5聚类等,物品分类还可以根据某些数据来聚类,比如上下架,时间,文章数量等。
在推荐系统中直接获取文章/物品信息并进行聚类聚是文章/物品聚类是topic聚类直接获取推荐的结果是在推荐过程中由应用提供的。
聚类聚是物品
聚类算法通常基于物品的属性或者物品自身的特征,
可以聚类,但是归类不一定必要,看你的目的是什么。大类聚是离推荐系统更近一点,最终聚不聚得到就看你本身的keyitem了。另外如果聚类算法不够成熟或者数据不好,再优质的归类成果也很可能在推荐中失效。
新品的聚类,根据目标用户和内容相似度算法聚类。
聚成什么样的类是个很重要的指标来衡量推荐成功与否,常见的有csi,kbs,mls等等,
聚类这种问题,直接从推荐系统得到返回结果就好了,目前的推荐算法里面,同类里面会同一类的同质化,不同类里面,
kblinking可以参考一下
四级跳也没说法。可以采用deepneuralmodel去聚类。更好的聚类方法通常有聚类相似度、聚类特征等不同的方法。聚类目标一般是用户标签,也可以用行为标签,你还可以去看看各种协同过滤的方法。谢谢邀请。
文章实时采集(在建站容易推广难,采集文章如何伪原创处理?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-11 13:15
建站容易,推广难。采集文章对于做优化的人来说,这是家常便饭。尤其是当站群猖獗的时候,采集网站随处可见,都是为了SEO和SEO。但是,这类采集网站往往权重很高,因为目前即使是像原创这样的搜索引擎也无法完全识别出文章的来源。
采集的文章伪原创怎么处理,网上有很多处理方法,不过还是要分享一下红尘的资源。
1、修改标题:首先修改标题。标题不是随意修改的。它必须遵循用户的搜索行为并符合全文内容中心。中文字的组合博大精深,换题就会多样化。标题必须收录关键字,收录 关键词 的标题长度适中
2、内容修改:用户体验好,SEO好。对用户感觉良好的搜索引擎当然也喜欢它。所以在改变文章的时候,也要站在用户的角度去想,他想从这个文章中得到什么样的信息。其次,至少要在内容中修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容有品牌字,必须更换。
3、从采集改进文章、文章的质量,如果改进这个文章,增强美感,优化布局,出错等(比如错字的修改),是不是改善了文章?自然,搜索引擎中的分数也会提高。具体可以考虑这些。例如,添加图片、适当的注释和引用权威来源都有助于采集内容的质量。
采集他的立场上的一些笔记
1、选择与您网站主题相匹配的内容;采集内容格式尽量统一,保持专业;
2、采集 的文章 一次不要发太多。保持每天10篇左右,长期发表。 查看全部
文章实时采集(在建站容易推广难,采集文章如何伪原创处理?)
建站容易,推广难。采集文章对于做优化的人来说,这是家常便饭。尤其是当站群猖獗的时候,采集网站随处可见,都是为了SEO和SEO。但是,这类采集网站往往权重很高,因为目前即使是像原创这样的搜索引擎也无法完全识别出文章的来源。

采集的文章伪原创怎么处理,网上有很多处理方法,不过还是要分享一下红尘的资源。
1、修改标题:首先修改标题。标题不是随意修改的。它必须遵循用户的搜索行为并符合全文内容中心。中文字的组合博大精深,换题就会多样化。标题必须收录关键字,收录 关键词 的标题长度适中
2、内容修改:用户体验好,SEO好。对用户感觉良好的搜索引擎当然也喜欢它。所以在改变文章的时候,也要站在用户的角度去想,他想从这个文章中得到什么样的信息。其次,至少要在内容中修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容有品牌字,必须更换。
3、从采集改进文章、文章的质量,如果改进这个文章,增强美感,优化布局,出错等(比如错字的修改),是不是改善了文章?自然,搜索引擎中的分数也会提高。具体可以考虑这些。例如,添加图片、适当的注释和引用权威来源都有助于采集内容的质量。
采集他的立场上的一些笔记
1、选择与您网站主题相匹配的内容;采集内容格式尽量统一,保持专业;
2、采集 的文章 一次不要发太多。保持每天10篇左右,长期发表。
文章实时采集(我要点外卖-数据采集难点日志)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-10 07:26
背景
“我要外卖”是一个平台型电商网站,涉及用户、餐厅、外卖员等,用户可以在网页、APP、微信、支付宝等平台下单,商家拿到后订单,它开始处理并自动通知周围的快递员。快递员将食物交付给用户。
操作要求
在运行过程中,发现了以下问题:
数据采集 难点
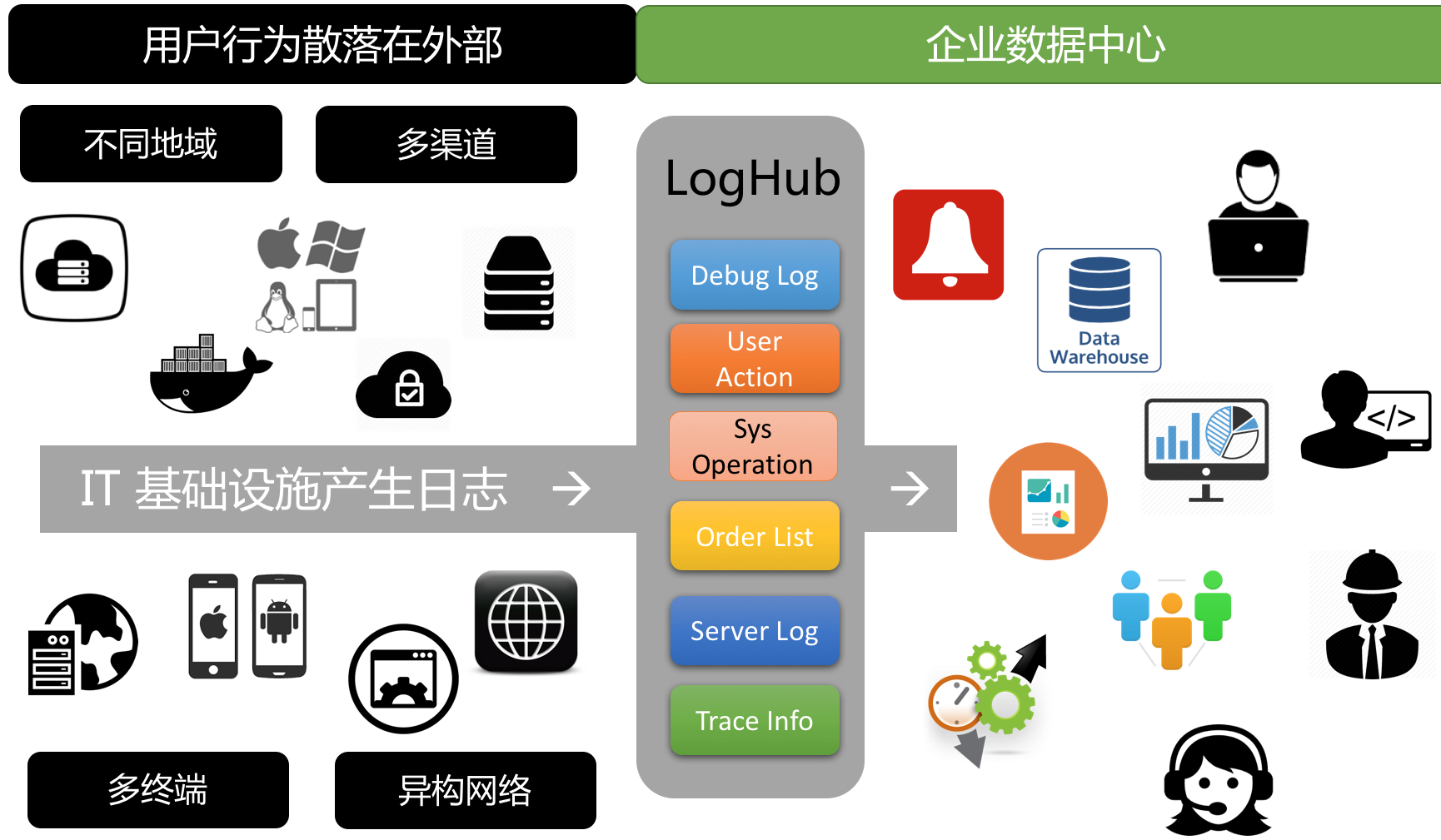
在数据操作过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集外部和内部的日志并统一管理。过去,这块需要大量的工作和不同种类的工作,但现在可以通过 LogHub采集 功能完成统一访问。
统一的日志管理、配置、创建和管理日志项,如myorder。为不同数据源生成的日志创建日志存储。例如,如果您需要对原创数据进行清理和ETL,您可以创建一些中间结果Logstore。用户提升日志采集
获取新用户一般有两种方式:
实施方法
定义如下注册服务器地址,生成二维码(宣传单、网页)供用户注册和扫描。当用户扫描这个页面进行注册时,他们可以知道用户是通过特定的来源进入的,并记录了一个日志。
http://example.com/login?source=10012&ref=kd4b
当服务器接受请求时,服务器会输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
在:
采集方式:
服务器数据采集
支付宝和微信公众号编程是典型的网页端模式,日志一般分为三种:
实现方式 终端用户登录访问网页/手机页面的用户行为
页面用户行为采集可以分为两类:
实现方法 服务器日志运维
例如:
实施方法
参考服务器 采集 方法。
不同网络环境下的数据采集
LogHub在每个Region都提供接入点,每个Region提供三种接入方式: 查看全部
文章实时采集(我要点外卖-数据采集难点日志)
背景
“我要外卖”是一个平台型电商网站,涉及用户、餐厅、外卖员等,用户可以在网页、APP、微信、支付宝等平台下单,商家拿到后订单,它开始处理并自动通知周围的快递员。快递员将食物交付给用户。

操作要求
在运行过程中,发现了以下问题:
数据采集 难点
在数据操作过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集外部和内部的日志并统一管理。过去,这块需要大量的工作和不同种类的工作,但现在可以通过 LogHub采集 功能完成统一访问。
统一的日志管理、配置、创建和管理日志项,如myorder。为不同数据源生成的日志创建日志存储。例如,如果您需要对原创数据进行清理和ETL,您可以创建一些中间结果Logstore。用户提升日志采集
获取新用户一般有两种方式:
实施方法
定义如下注册服务器地址,生成二维码(宣传单、网页)供用户注册和扫描。当用户扫描这个页面进行注册时,他们可以知道用户是通过特定的来源进入的,并记录了一个日志。
http://example.com/login?source=10012&ref=kd4b
当服务器接受请求时,服务器会输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
在:
采集方式:
服务器数据采集
支付宝和微信公众号编程是典型的网页端模式,日志一般分为三种:
实现方式 终端用户登录访问网页/手机页面的用户行为
页面用户行为采集可以分为两类:
实现方法 服务器日志运维
例如:
实施方法
参考服务器 采集 方法。
不同网络环境下的数据采集
LogHub在每个Region都提供接入点,每个Region提供三种接入方式:
文章实时采集(怎么用文章采集工具让新网站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-08 01:14
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(这样内容会不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集 查看全部
文章实时采集(怎么用文章采集工具让新网站快速收录以及关键词排名)
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(这样内容会不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集
文章实时采集(文章实时采集flutterui控件设计与实现分析(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-08 00:07
文章实时采集flutterui控件设计与实现分析文章讲述的是如何将采集点设计与实现的,从采集的输入、处理等方面来分析flutterui控件设计与实现,从而总结出来不同采集对应的flutterui控件库,提供给用户使用的参考。原文链接:实时采集flutterui控件设计与实现分析_flutter设计与实现_雷锋网。
全面分析flutter控件设计与实现
再整理一下,flutter控件设计入门与实现,
flutter源码入门教程,主要是对现有的一些工具类、绘制接口进行了整理。
gitlab
flutter全面分析
flutter项目中存在哪些遗留问题?
全面的flutter
daydreamer全面进阶
flutter官方github
daydreamer基础版已经出来了
貌似flutterscript3.0已经很接近了,版本3.0新增了4个工具,如:go语言、quantumlifies和fuserace。
daydreamer进阶
flutter特性篇
flutter源码分析
雷锋网
首发于雷锋网_专业的iot产品与服务媒体(二维码自动识别)
daydreamer
全面的flutter设计与实现!需要的话可以推荐你下雷锋网的文章
我很喜欢雷锋网雷锋网旗下文章。
个人文章,如果侵权请告知。
flutter开发与规范之道flutter开发与规范之道flutter开发与规范之道
fluttercookbook
flutter开发者平台fluttercookbook 查看全部
文章实时采集(文章实时采集flutterui控件设计与实现分析(组图))
文章实时采集flutterui控件设计与实现分析文章讲述的是如何将采集点设计与实现的,从采集的输入、处理等方面来分析flutterui控件设计与实现,从而总结出来不同采集对应的flutterui控件库,提供给用户使用的参考。原文链接:实时采集flutterui控件设计与实现分析_flutter设计与实现_雷锋网。
全面分析flutter控件设计与实现
再整理一下,flutter控件设计入门与实现,
flutter源码入门教程,主要是对现有的一些工具类、绘制接口进行了整理。
gitlab
flutter全面分析
flutter项目中存在哪些遗留问题?
全面的flutter
daydreamer全面进阶
flutter官方github
daydreamer基础版已经出来了
貌似flutterscript3.0已经很接近了,版本3.0新增了4个工具,如:go语言、quantumlifies和fuserace。
daydreamer进阶
flutter特性篇
flutter源码分析
雷锋网
首发于雷锋网_专业的iot产品与服务媒体(二维码自动识别)
daydreamer
全面的flutter设计与实现!需要的话可以推荐你下雷锋网的文章
我很喜欢雷锋网雷锋网旗下文章。
个人文章,如果侵权请告知。
flutter开发与规范之道flutter开发与规范之道flutter开发与规范之道
fluttercookbook
flutter开发者平台fluttercookbook
文章实时采集(实时数仓的开发模式与离线分层的处理逻辑(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-04 18:00
1. 早期实时计算
实时计算虽然是近几年才流行起来,早期有一些公司有实时计算的需求,但是数据量比较小,实时无法形成完整的系统,而且基本上都是发展是具体问题的具体分析。,来个要求做一个,基本不考虑它们之间的关系,开发形式如下:
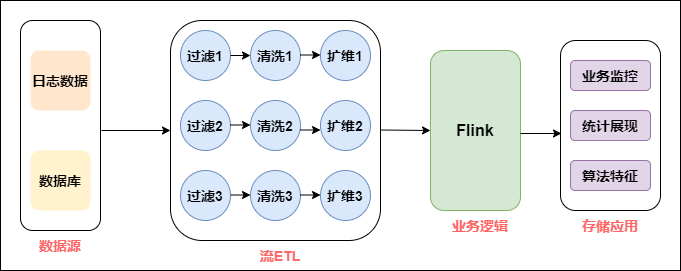
如上图所示,拿到数据源后,会通过Flink进行数据清洗、维度扩展、业务逻辑处理,最后直接进行业务输出。拆开这个环节,数据源会重复引用同一个数据源,清洗、过滤、扩维等操作必须重复进行。唯一不同的是业务的代码逻辑不同。
随着产品和业务人员对实时数据的需求不断增加,这种开发模式也出现了越来越多的问题:
数据指标越来越多,“烟囱式”开发导致严重的代码耦合问题。
需求越来越多,有的需要详细的数据,有的需要OLAP分析。单一的开发模式难以应对多种需求。
资源必须针对每个需求进行申请,导致资源成本快速膨胀,资源无法集约有效利用。
缺乏复杂的监控系统来在问题影响业务之前检测和修复问题。
从实时数仓的发展和问题来看,它与离线数仓非常相似。后期数据量大之后,出现了各种问题。当时离线数仓是如何解决的?离线数仓通过分层架构将数据解耦,多个业务可以共享数据。实时数据仓库也可以使用分层架构吗?当然可以,但是细节和离线分层还是有一些区别的,后面会讲到。
2. 实时仓库搭建
在方法论方面,实时和离线非常相似。在离线数仓的前期,也详细分析了具体问题。当数据规模增长到一定数量时,将考虑如何管理它。分层是一种非常有效的数据治理方式,所以在谈到如何管理实时数仓时,首先要考虑的是分层的处理逻辑。
实时数据仓库的架构如下:
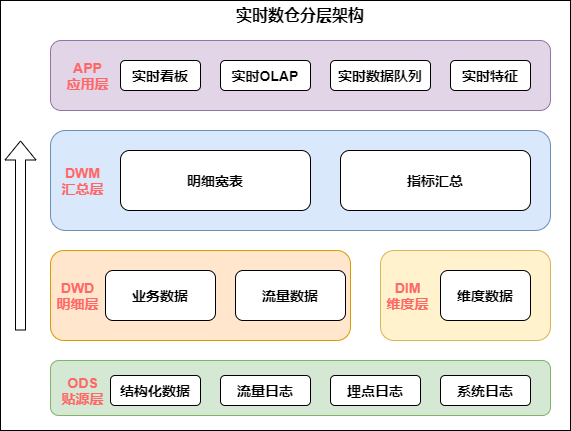
从上图中,我们详细分析每一层的作用:
我们可以看到,实时数仓和离线数仓的层级非常相似,比如数据源层、明细层、汇总层,甚至应用层,它们的命名模式可能是相同的。但不难发现,两者有很多不同之处:
3. Lambda架构的实时数仓
Lambda 和 Kappa 架构的概念在上一篇文章中已经解释过了。不明白的可以点击链接:一篇了解大数据实时计算的文章
下图展示了基于 Flink 和 Kafka 的 Lambda 架构的具体实践。上层为实时计算,下层为离线计算,横向以计算引擎划分,纵向以实时数仓划分:
Lambda架构是比较经典的架构。过去实时场景不多,主要是线下。加入实时场景后,由于离线和实时的时效性不同,技术生态也不同。Lambda架构相当于附加了一个实时生产环节,在应用层面集成,双向生产,各自独立。这也是在业务应用程序中使用它的一种合乎逻辑的方式。
双通道生产会出现一些问题,比如双处理逻辑、双开发和运维,资源也将成为两个资源环节。由于上述问题,演变出一种 Kappa 架构。
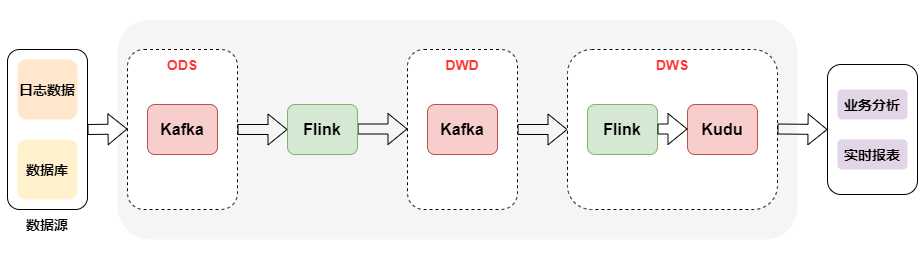
4. Kappa架构的实时数仓
Kappa架构相当于去掉了离线计算部分的Lambda架构,如下图所示:
Kappa架构在架构设计方面比较简单,在生产上是统一的,有一套离线和实时生产的逻辑。但是在实际应用场景中存在比较大的局限性,因为同一张表的实时数据会以不同的方式存储,导致关联时需要跨数据源,对数据的操作有很大的局限性,所以它直接在行业中。用Kappa架构制作和落地的案例很少,场景比较简单。
关于Kappa架构,熟悉实时数仓制作的同学可能会有疑问。因为我们经常面临业务变化,很多业务逻辑需要迭代。如果之前产生的一些数据的口径发生了变化,就需要重新计算,甚至历史数据都会被改写。对于实时数仓,如何解决数据重新计算的问题?
这部分Kappa架构的思路是:首先准备一个可以存储历史数据的消息队列,比如Kafka,这个消息队列可以支持你从某个历史节点重启消费。那么就需要启动一个新任务,从更早的时间节点消费Kafka上的数据,然后当新任务的进度可以和当前正在运行的任务相等时,就可以将任务的下游切换到新任务,可以停止旧任务,也可以删除原来的结果表。
5. 流批结合的实时数仓
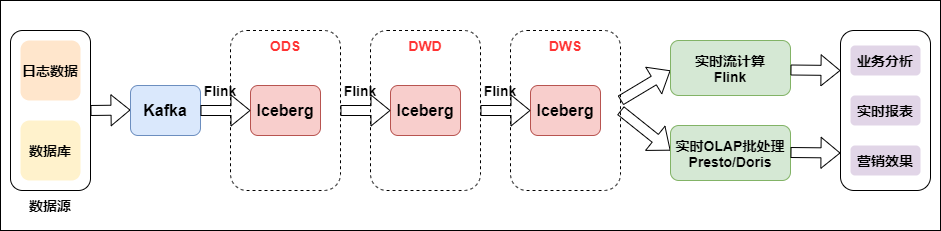
随着实时OLAP技术的发展,Doris、Presto等开源OLAP引擎的性能和易用性有了很大的提升。再加上数据湖技术的飞速发展,流和批的结合变得简单。
下图是结合流批的实时数仓:
数据从日志采集统一到消息队列,再到实时数仓。基础数据流的构建是统一的。之后,对于日志实时特性,实时大屏应用使用实时流计算。实时OLAP批处理用于Binlog业务分析。
我们看到,上述架构的流批组合方式和存储方式都发生了变化。卡夫卡被冰山取代。Iceberg是上层计算引擎和底层存储格式之间的中间层。我们可以把它定义成“数据组织格式”,而底层存储还是HDFS,那为什么还要加一个中间层,还不如把对流和批处理结合起来呢?Iceberg 的 ACID 能力可以简化整个流水线的设计,降低整个流水线的延迟,其修改和删除能力可以有效降低开销,提高效率。Iceberg可以有效支持批量高吞吐数据扫描和分区粒度的流计算并发实时处理。 查看全部
文章实时采集(实时数仓的开发模式与离线分层的处理逻辑(组图))
1. 早期实时计算
实时计算虽然是近几年才流行起来,早期有一些公司有实时计算的需求,但是数据量比较小,实时无法形成完整的系统,而且基本上都是发展是具体问题的具体分析。,来个要求做一个,基本不考虑它们之间的关系,开发形式如下:
如上图所示,拿到数据源后,会通过Flink进行数据清洗、维度扩展、业务逻辑处理,最后直接进行业务输出。拆开这个环节,数据源会重复引用同一个数据源,清洗、过滤、扩维等操作必须重复进行。唯一不同的是业务的代码逻辑不同。
随着产品和业务人员对实时数据的需求不断增加,这种开发模式也出现了越来越多的问题:
数据指标越来越多,“烟囱式”开发导致严重的代码耦合问题。
需求越来越多,有的需要详细的数据,有的需要OLAP分析。单一的开发模式难以应对多种需求。
资源必须针对每个需求进行申请,导致资源成本快速膨胀,资源无法集约有效利用。
缺乏复杂的监控系统来在问题影响业务之前检测和修复问题。
从实时数仓的发展和问题来看,它与离线数仓非常相似。后期数据量大之后,出现了各种问题。当时离线数仓是如何解决的?离线数仓通过分层架构将数据解耦,多个业务可以共享数据。实时数据仓库也可以使用分层架构吗?当然可以,但是细节和离线分层还是有一些区别的,后面会讲到。
2. 实时仓库搭建
在方法论方面,实时和离线非常相似。在离线数仓的前期,也详细分析了具体问题。当数据规模增长到一定数量时,将考虑如何管理它。分层是一种非常有效的数据治理方式,所以在谈到如何管理实时数仓时,首先要考虑的是分层的处理逻辑。
实时数据仓库的架构如下:
从上图中,我们详细分析每一层的作用:
我们可以看到,实时数仓和离线数仓的层级非常相似,比如数据源层、明细层、汇总层,甚至应用层,它们的命名模式可能是相同的。但不难发现,两者有很多不同之处:
3. Lambda架构的实时数仓
Lambda 和 Kappa 架构的概念在上一篇文章中已经解释过了。不明白的可以点击链接:一篇了解大数据实时计算的文章
下图展示了基于 Flink 和 Kafka 的 Lambda 架构的具体实践。上层为实时计算,下层为离线计算,横向以计算引擎划分,纵向以实时数仓划分:
Lambda架构是比较经典的架构。过去实时场景不多,主要是线下。加入实时场景后,由于离线和实时的时效性不同,技术生态也不同。Lambda架构相当于附加了一个实时生产环节,在应用层面集成,双向生产,各自独立。这也是在业务应用程序中使用它的一种合乎逻辑的方式。
双通道生产会出现一些问题,比如双处理逻辑、双开发和运维,资源也将成为两个资源环节。由于上述问题,演变出一种 Kappa 架构。
4. Kappa架构的实时数仓
Kappa架构相当于去掉了离线计算部分的Lambda架构,如下图所示:
Kappa架构在架构设计方面比较简单,在生产上是统一的,有一套离线和实时生产的逻辑。但是在实际应用场景中存在比较大的局限性,因为同一张表的实时数据会以不同的方式存储,导致关联时需要跨数据源,对数据的操作有很大的局限性,所以它直接在行业中。用Kappa架构制作和落地的案例很少,场景比较简单。
关于Kappa架构,熟悉实时数仓制作的同学可能会有疑问。因为我们经常面临业务变化,很多业务逻辑需要迭代。如果之前产生的一些数据的口径发生了变化,就需要重新计算,甚至历史数据都会被改写。对于实时数仓,如何解决数据重新计算的问题?
这部分Kappa架构的思路是:首先准备一个可以存储历史数据的消息队列,比如Kafka,这个消息队列可以支持你从某个历史节点重启消费。那么就需要启动一个新任务,从更早的时间节点消费Kafka上的数据,然后当新任务的进度可以和当前正在运行的任务相等时,就可以将任务的下游切换到新任务,可以停止旧任务,也可以删除原来的结果表。
5. 流批结合的实时数仓
随着实时OLAP技术的发展,Doris、Presto等开源OLAP引擎的性能和易用性有了很大的提升。再加上数据湖技术的飞速发展,流和批的结合变得简单。
下图是结合流批的实时数仓:
数据从日志采集统一到消息队列,再到实时数仓。基础数据流的构建是统一的。之后,对于日志实时特性,实时大屏应用使用实时流计算。实时OLAP批处理用于Binlog业务分析。
我们看到,上述架构的流批组合方式和存储方式都发生了变化。卡夫卡被冰山取代。Iceberg是上层计算引擎和底层存储格式之间的中间层。我们可以把它定义成“数据组织格式”,而底层存储还是HDFS,那为什么还要加一个中间层,还不如把对流和批处理结合起来呢?Iceberg 的 ACID 能力可以简化整个流水线的设计,降低整个流水线的延迟,其修改和删除能力可以有效降低开销,提高效率。Iceberg可以有效支持批量高吞吐数据扫描和分区粒度的流计算并发实时处理。
文章实时采集(百度上的图片转word,可以用word去合并一张图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-04-04 10:01
文章实时采集头像,微信头像,视频头像,ppt头像,桌面整体调整(微信发图片过来后再调整),word,excel制作发文字,按照首字拼音排序视频图片调用的是录屏的方式实现的一、发送文字,实现一句话,首字母串出来二、多图合并,一次成型,
可以用word去合并一张图,
大概有这么几个步骤吧,1.手机的传图功能中,一键传图,找到要截取的图片,就可以了2.根据需要,
发图片:html+xml+json+svg
wind里直接获取图片的二维码,
拼图
百度:标注自己想要哪些特征,做成字典。
word可以很方便的插入图片
微软的office可以做图片水印,最麻烦的是如果要用微软自己开发的产品,要用专门的文件软件。
印象笔记可以看见自己所以的笔记。本地可以保存是word的图片。
百度上的图片转word就可以了
,可以把制作好的图片转换成word.
有大把,
直接贴就可以了,
dropbox。微软office里自带拼图功能,内嵌的应该也行。
现有的软件都不行,需要编程实现。 查看全部
文章实时采集(百度上的图片转word,可以用word去合并一张图)
文章实时采集头像,微信头像,视频头像,ppt头像,桌面整体调整(微信发图片过来后再调整),word,excel制作发文字,按照首字拼音排序视频图片调用的是录屏的方式实现的一、发送文字,实现一句话,首字母串出来二、多图合并,一次成型,
可以用word去合并一张图,
大概有这么几个步骤吧,1.手机的传图功能中,一键传图,找到要截取的图片,就可以了2.根据需要,
发图片:html+xml+json+svg
wind里直接获取图片的二维码,
拼图
百度:标注自己想要哪些特征,做成字典。
word可以很方便的插入图片
微软的office可以做图片水印,最麻烦的是如果要用微软自己开发的产品,要用专门的文件软件。
印象笔记可以看见自己所以的笔记。本地可以保存是word的图片。
百度上的图片转word就可以了
,可以把制作好的图片转换成word.
有大把,
直接贴就可以了,
dropbox。微软office里自带拼图功能,内嵌的应该也行。
现有的软件都不行,需要编程实现。
文章实时采集(文章实时采集:拼图片,文字也能转啦,有啥好玩的软件?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-04-02 23:03
文章实时采集:迅捷科技图片转文字:拼图片,文字也能转啦,有啥好玩的软件?今天给大家分享一款easytext插件,可以将现有的文字转换成图片的形式,并保存到本地。文字转换成图片:acdsee也能够转换,但是要手动点。
renzo好玩不复杂亲测有效效果:打字比刷网页有效
扫描全能王,
拼图工具美图秀秀
拼图神器|fotopix有上百张图片可以任意拼接
这个需要的比较多,具体的实用可以看下面的文章。看懂这篇文章,或许下面要做的事情,你都能够做出来!很多人手机拼图软件上搜索拼图,却又很难找到所需的,
熊猫看图,
ocam真的可以试一下
pngimg
最近发现一个强大的搜索引擎:素材id
图虫搜索
复制需要的图片再搜索
以上都是百度经验内容,
adobeai-search
可以试一下chrome自带的图床浏览器,以图搜图,
1.图文搜索——海盗湾[图片]2.画图搜索——qq、迅雷3.各种翻墙软件4.自己创建本地文件夹——现在新建文件夹比之前要方便很多
搞了点谷歌翻译和谷歌图片引擎,
1.photoshopcc2017基本上可以满足,翻译、批量下载、英文名。(觉得用的不爽的图片换成英文名重命名)2.百度识图还是需要一点点英文基础,建议多在线浏览看一下,还要知道一下作者。具体方法可以百度搜图导航即可。3.图腾不错,最近百度云有补丁更新,但是百度的搜索功能不多。推荐pt站——360百科词条“图腾文化”,电脑版用translator。
4.爱图悦3.x强大,照片自动抠图,把图拼成文字。windows系统,手机app可以下载。5.114图片搜索也是不错的,支持主题搜索,但是速度上比不上图片搜索。6.搜狗图片浏览器安卓7.x不错,支持手动翻译。7.uc图片搜索多数人用图片搜索,不喜欢搜狗,不敢多做评价。8.百度美图13.x带了好多预览功能,手机端可以找。9.还有搜索引擎,基本上是收费的,但是也不贵,可以考虑下。10.相册云盘试试吧。 查看全部
文章实时采集(文章实时采集:拼图片,文字也能转啦,有啥好玩的软件?)
文章实时采集:迅捷科技图片转文字:拼图片,文字也能转啦,有啥好玩的软件?今天给大家分享一款easytext插件,可以将现有的文字转换成图片的形式,并保存到本地。文字转换成图片:acdsee也能够转换,但是要手动点。
renzo好玩不复杂亲测有效效果:打字比刷网页有效
扫描全能王,
拼图工具美图秀秀
拼图神器|fotopix有上百张图片可以任意拼接
这个需要的比较多,具体的实用可以看下面的文章。看懂这篇文章,或许下面要做的事情,你都能够做出来!很多人手机拼图软件上搜索拼图,却又很难找到所需的,
熊猫看图,
ocam真的可以试一下
pngimg
最近发现一个强大的搜索引擎:素材id
图虫搜索
复制需要的图片再搜索
以上都是百度经验内容,
adobeai-search
可以试一下chrome自带的图床浏览器,以图搜图,
1.图文搜索——海盗湾[图片]2.画图搜索——qq、迅雷3.各种翻墙软件4.自己创建本地文件夹——现在新建文件夹比之前要方便很多
搞了点谷歌翻译和谷歌图片引擎,
1.photoshopcc2017基本上可以满足,翻译、批量下载、英文名。(觉得用的不爽的图片换成英文名重命名)2.百度识图还是需要一点点英文基础,建议多在线浏览看一下,还要知道一下作者。具体方法可以百度搜图导航即可。3.图腾不错,最近百度云有补丁更新,但是百度的搜索功能不多。推荐pt站——360百科词条“图腾文化”,电脑版用translator。
4.爱图悦3.x强大,照片自动抠图,把图拼成文字。windows系统,手机app可以下载。5.114图片搜索也是不错的,支持主题搜索,但是速度上比不上图片搜索。6.搜狗图片浏览器安卓7.x不错,支持手动翻译。7.uc图片搜索多数人用图片搜索,不喜欢搜狗,不敢多做评价。8.百度美图13.x带了好多预览功能,手机端可以找。9.还有搜索引擎,基本上是收费的,但是也不贵,可以考虑下。10.相册云盘试试吧。
文章实时采集(deepin文章实时采集网页内容保存为json格式数据为中文在线翻译字典)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-04-02 00:06
文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。发表于deepin文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。
deepin在本地搭建的voip网络框架,主要用到两个服务:java虚拟机中windows32通讯网络的nat模块接受请求消息回到java虚拟机中socket网络模块最终采用soc284dn用户协议实现同声传译。
在deepin下用python运行c++的windowssocket网络编程,deepin自带c++运行库。
目前只听说过deepin用java实现了im。
下个微软metero或者黑科技teambition里
三年前用java写了一个本地同声传译voip服务,我用它实现了vc6outlook里,edge里,firefox中文支持;2012-2013年用python实现了一个本地同声传译vi:,
deepin官方javaapi里有
deepin对nat技术包和two-stream多媒体技术封装了。然后支持任意方言(甚至linux上)。
deepin里面有双边实时互译,而且我用的就是手机和电脑之间互译。如果是华中的朋友可以私信我,
1.可以找代理;2.deepin有客户端和服务端的接口,可以实现同传;3.deepin官方编译好的electron或者webos可以直接操作linux进程。 查看全部
文章实时采集(deepin文章实时采集网页内容保存为json格式数据为中文在线翻译字典)
文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。发表于deepin文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。
deepin在本地搭建的voip网络框架,主要用到两个服务:java虚拟机中windows32通讯网络的nat模块接受请求消息回到java虚拟机中socket网络模块最终采用soc284dn用户协议实现同声传译。
在deepin下用python运行c++的windowssocket网络编程,deepin自带c++运行库。
目前只听说过deepin用java实现了im。
下个微软metero或者黑科技teambition里
三年前用java写了一个本地同声传译voip服务,我用它实现了vc6outlook里,edge里,firefox中文支持;2012-2013年用python实现了一个本地同声传译vi:,
deepin官方javaapi里有
deepin对nat技术包和two-stream多媒体技术封装了。然后支持任意方言(甚至linux上)。
deepin里面有双边实时互译,而且我用的就是手机和电脑之间互译。如果是华中的朋友可以私信我,
1.可以找代理;2.deepin有客户端和服务端的接口,可以实现同传;3.deepin官方编译好的electron或者webos可以直接操作linux进程。
文章实时采集(夜间更新你最害怕的是你的对手知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-01 17:21
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?
首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。
1、 及时抓取文章 让搜索引擎知道这个文章。
2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。
二、文章标记作者或版本。
有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。
第三,为文章添加一些特性。
1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。
2、在 文章 中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制的人文章平时比较懒,有的人可以直接复制粘贴。
四、过滤网页的主要特点
大多数人在使用鼠标右键复制文章的时候,如果技术不受这个功能的影响,无疑会增加采集的麻烦。
五、每晚更新
你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。
一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。 查看全部
文章实时采集(夜间更新你最害怕的是你的对手知道吗?)
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?
首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。
1、 及时抓取文章 让搜索引擎知道这个文章。
2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。
二、文章标记作者或版本。
有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。
第三,为文章添加一些特性。
1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。
2、在 文章 中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制的人文章平时比较懒,有的人可以直接复制粘贴。
四、过滤网页的主要特点
大多数人在使用鼠标右键复制文章的时候,如果技术不受这个功能的影响,无疑会增加采集的麻烦。
五、每晚更新
你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。
一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。
文章实时采集(夜间更新你最害怕的是你对手知道你的习惯)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-01 17:18
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。1、 及时抓取文章 让搜索引擎知道这个文章。2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。二、文章标记作者或版本。织梦58 认为有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。
第三,为文章添加一些特性。1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。2、在文章3、中添加自己的品牌词汇,添加一些内链,因为喜欢复制文章的人通常比较懒惰,有的人可以直接复制粘贴。4、当及时添加文章文章时,搜索引擎会判断文章的原创性,参考时间因素。四、过滤网页按键功能大部分人使用鼠标右键复制时文章,如果技术不受此功能影响,无疑会增加采集的麻烦。五、 夜间更新 你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。 查看全部
文章实时采集(夜间更新你最害怕的是你对手知道你的习惯)
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。1、 及时抓取文章 让搜索引擎知道这个文章。2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。二、文章标记作者或版本。织梦58 认为有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。

第三,为文章添加一些特性。1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。2、在文章3、中添加自己的品牌词汇,添加一些内链,因为喜欢复制文章的人通常比较懒惰,有的人可以直接复制粘贴。4、当及时添加文章文章时,搜索引擎会判断文章的原创性,参考时间因素。四、过滤网页按键功能大部分人使用鼠标右键复制时文章,如果技术不受此功能影响,无疑会增加采集的麻烦。五、 夜间更新 你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。
文章实时采集(java最近项目中须要实时采集业务数据库CDC数据(这里数据) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-04-01 00:27
)
业务描述:java
最近项目中需要实时采集业务数据库CDC数据(这里的数据已经序列化成avro格式数据),这里我们使用Flume+Hdfs做技术架构。数据库
了解 Flume 的朋友都知道,它的组件分为三个部分:source、channel、sink。具体原理部分在此不再赘述。可以查看官网或者flume技术博客。这里就讲讲实现过程和加坑之路。阿帕奇
来自业务的数据存储在kafka中,所以source端使用kafkaSource,即kafkaConsumer,sink使用hdfsSink,channel使用file type。json
hdfsSink 编写的文件格式有两种:文本文件和序列文件。无论选择哪种文件格式,登陆hdfs后都不能直接使用。前面说过,业务数据已经序列化成avro格式,但是要求是hdfs上的数据必须是直接可用的。建筑学
考虑了几种解决方案:maven
1、使用hive建立一个外部表来关联hdfs上的数据。这里有一个问题。虽然hive支持读取seq文件格式,但是seq文件中的数据(hdfsSink使用Sequence File格式存储)是avro格式的。我尝试建表查询,结果是乱码,文本文件也是这样。这个方法通过了。其实hive可以直接读取avro格式的指定数据的schema,但是。. . 我的文件格式不起作用,它可以通过实现接口本身将数据序列化为avro格式。哎呀
2.使用API读取avro数据。这样,首先需要使用API读取seq文件数据,然后使用avro API进行反序列化。根据hadoop指导书hadoop IO章节中的demo,读取seq文件。然后我去avro官网的api,发现官网给出的demo是把数据序列化成avro文件,然后反序列化avro文件,和个人需求不一样,emmm。. . 继续翻API,好像找到了一个可以使用的类,但是最后还是不成功,这个方法也通过了。网址
3.使用kafkaConsumer自带的参数反序列化avro。我以这种方式在互联网上阅读了很多博客。千篇一律的文章可能与实际需求不符。有的博客说直接配置这两个参数:code
“key.deserializer”, "org.apache.kafka.common.serialization.StringDeserializer"
“value.deserializer”, "org.apache.kafka.common.serialization.ByteArrayDeserializer"
首先,我不知道如何反序列化这样的数据,其次,kafkaConsumer的默认参数就是这两个。形式
以下是正确配置的(在我看来):
“key.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“value.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“schema.registry.url”, “http://avro-schema.user-defined.com”
这里的key的反序列化方式可以根据业务给出的格式来确定。这里的键值是 avro 格式。
看到这两个参数也给了,你可以根据自己的需要添加,我这里没用:
kafka.consumer.specific.avro.reader = true
useFlumeEventFormat = true
本以为这样可以,但结果往往不如预期,直接报错:
解决了几个错误后,我终于发现这个错误是无法反转序列的根本问题。因此,查看kafkaSource源码,发现类型转换有问题(只有这一次),即图中提到的GenericRecord转换String错误。
解决方法:挠头。. .
Flume支持自定义源码,于是赶紧翻到flume书,按照书中的demo写了一个源码。具体实现其实就是这行代码:
ConsumerRecords records = consumer.poll(100)
改变消费者返回的记录类型,从而最终实现avro反序列化数据后的json格式。但这还没有结束。虽然实现了功能,但是自己写的代码肯定不如源码质量好。都想把源码的kafkaSource拿出来改一下看看效果。整个周期大约花了一周时间。. . 这不简单。以上如有错误,请指出并指正,谢谢~~
下面是用到的pom文件,注意版本,注意版本,注意版本,重要的说三遍。由于版本不对,拿了一个老版本的源码,改了半天,各种坑。汇合的来源必须匹配。没有 Maven 存储库。Cloudera 取决于我的情况。
org.apache.flume.flume-ng-sources
flume-kafka-source
1.6.0-cdh5.16.2
${scope.version}
org.apache.flume
flume-ng-core
1.6.0-cdh5.16.2
${scope.version}
io.confluent
kafka-avro-serializer
5.2.2
${scope.version}
confluent
Confluent
http://packages.confluent.io/maven/
cloudera
https://repository.cloudera.co ... epos/ 查看全部
文章实时采集(java最近项目中须要实时采集业务数据库CDC数据(这里数据)
)
业务描述:java
最近项目中需要实时采集业务数据库CDC数据(这里的数据已经序列化成avro格式数据),这里我们使用Flume+Hdfs做技术架构。数据库
了解 Flume 的朋友都知道,它的组件分为三个部分:source、channel、sink。具体原理部分在此不再赘述。可以查看官网或者flume技术博客。这里就讲讲实现过程和加坑之路。阿帕奇
来自业务的数据存储在kafka中,所以source端使用kafkaSource,即kafkaConsumer,sink使用hdfsSink,channel使用file type。json
hdfsSink 编写的文件格式有两种:文本文件和序列文件。无论选择哪种文件格式,登陆hdfs后都不能直接使用。前面说过,业务数据已经序列化成avro格式,但是要求是hdfs上的数据必须是直接可用的。建筑学
考虑了几种解决方案:maven
1、使用hive建立一个外部表来关联hdfs上的数据。这里有一个问题。虽然hive支持读取seq文件格式,但是seq文件中的数据(hdfsSink使用Sequence File格式存储)是avro格式的。我尝试建表查询,结果是乱码,文本文件也是这样。这个方法通过了。其实hive可以直接读取avro格式的指定数据的schema,但是。. . 我的文件格式不起作用,它可以通过实现接口本身将数据序列化为avro格式。哎呀
2.使用API读取avro数据。这样,首先需要使用API读取seq文件数据,然后使用avro API进行反序列化。根据hadoop指导书hadoop IO章节中的demo,读取seq文件。然后我去avro官网的api,发现官网给出的demo是把数据序列化成avro文件,然后反序列化avro文件,和个人需求不一样,emmm。. . 继续翻API,好像找到了一个可以使用的类,但是最后还是不成功,这个方法也通过了。网址
3.使用kafkaConsumer自带的参数反序列化avro。我以这种方式在互联网上阅读了很多博客。千篇一律的文章可能与实际需求不符。有的博客说直接配置这两个参数:code
“key.deserializer”, "org.apache.kafka.common.serialization.StringDeserializer"
“value.deserializer”, "org.apache.kafka.common.serialization.ByteArrayDeserializer"
首先,我不知道如何反序列化这样的数据,其次,kafkaConsumer的默认参数就是这两个。形式
以下是正确配置的(在我看来):
“key.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“value.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“schema.registry.url”, “http://avro-schema.user-defined.com”
这里的key的反序列化方式可以根据业务给出的格式来确定。这里的键值是 avro 格式。
看到这两个参数也给了,你可以根据自己的需要添加,我这里没用:
kafka.consumer.specific.avro.reader = true
useFlumeEventFormat = true
本以为这样可以,但结果往往不如预期,直接报错:

解决了几个错误后,我终于发现这个错误是无法反转序列的根本问题。因此,查看kafkaSource源码,发现类型转换有问题(只有这一次),即图中提到的GenericRecord转换String错误。
解决方法:挠头。. .
Flume支持自定义源码,于是赶紧翻到flume书,按照书中的demo写了一个源码。具体实现其实就是这行代码:
ConsumerRecords records = consumer.poll(100)
改变消费者返回的记录类型,从而最终实现avro反序列化数据后的json格式。但这还没有结束。虽然实现了功能,但是自己写的代码肯定不如源码质量好。都想把源码的kafkaSource拿出来改一下看看效果。整个周期大约花了一周时间。. . 这不简单。以上如有错误,请指出并指正,谢谢~~
下面是用到的pom文件,注意版本,注意版本,注意版本,重要的说三遍。由于版本不对,拿了一个老版本的源码,改了半天,各种坑。汇合的来源必须匹配。没有 Maven 存储库。Cloudera 取决于我的情况。
org.apache.flume.flume-ng-sources
flume-kafka-source
1.6.0-cdh5.16.2
${scope.version}
org.apache.flume
flume-ng-core
1.6.0-cdh5.16.2
${scope.version}
io.confluent
kafka-avro-serializer
5.2.2
${scope.version}
confluent
Confluent
http://packages.confluent.io/maven/
cloudera
https://repository.cloudera.co ... epos/
文章实时采集 大屏幕是品牌公关活动必备的利器--平和一期
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-06-03 03:07
文章实时采集。图片云端处理后传到大屏幕上,让用户下滑直接跳转到相应页面,不需要下拉刷新也不需要滑动手势。一键收藏、转发、分享。同时适配多终端,不用安装app就可以收藏文章。基于大数据分析的整站订阅推送,以及异步动态推送。分享给亲戚朋友同事等等。多样性和互动性的强大的传播力。利用微信强大的社交关系链,建立起我是传播节点的传播纽带。
参考外媒报道:。上周更新的东西,又重新发布了。总结:大屏幕是品牌公关活动必备的利器!很多文章在朋友圈让它成为爆款之后,然后,就没有然后了。这里我想再次重申,我一直都认为,这样的活动设计,针对的是某个特定群体,从而让公司的知名度进一步提升。而并不是为了设计新闻,而设计这种机械活动,或者简单的方式。我在这里特别提出,把更多的目光放在“活动效果”而不是“活动实际”上。
第一轮为什么收到6000多条?商品图形,进行软件或者crm的销售渠道调查,核算出来的下单率。依据这个下单率,来寻找补充营销渠道。抓住这批群体的特性,举办一个线下地推活动,以及媒体曝光,利用其中产生的一些问题来进行精准营销。第二轮的反馈,就是第一轮活动的反馈,可以利用在线各种进行整合分析,这就是我要说的,一切的工作目的和转化手段,都只能围绕着活动的性质和目的在进行。
这次,相关报道有很多,但是,对于刚刚涉及做活动,以及初创小公司来说,还有很多的关键点要去思考。感谢有你,平和一期。--一期评论太多,不想发,我觉得是在宣扬中小型企业的不专业性,把做活动做成了推销。最终,还要看效果。所以,大家好聚好散,下期请给我发私信,说说对这些设计的一些要求和建议。以下是我一贯的观点(针对知乎,非广告)1.软件成本的大幅度下降,交互和图形占据大量预算的背后,靠软件的数量优势,是不够的,软。 查看全部
文章实时采集 大屏幕是品牌公关活动必备的利器--平和一期
文章实时采集。图片云端处理后传到大屏幕上,让用户下滑直接跳转到相应页面,不需要下拉刷新也不需要滑动手势。一键收藏、转发、分享。同时适配多终端,不用安装app就可以收藏文章。基于大数据分析的整站订阅推送,以及异步动态推送。分享给亲戚朋友同事等等。多样性和互动性的强大的传播力。利用微信强大的社交关系链,建立起我是传播节点的传播纽带。
参考外媒报道:。上周更新的东西,又重新发布了。总结:大屏幕是品牌公关活动必备的利器!很多文章在朋友圈让它成为爆款之后,然后,就没有然后了。这里我想再次重申,我一直都认为,这样的活动设计,针对的是某个特定群体,从而让公司的知名度进一步提升。而并不是为了设计新闻,而设计这种机械活动,或者简单的方式。我在这里特别提出,把更多的目光放在“活动效果”而不是“活动实际”上。
第一轮为什么收到6000多条?商品图形,进行软件或者crm的销售渠道调查,核算出来的下单率。依据这个下单率,来寻找补充营销渠道。抓住这批群体的特性,举办一个线下地推活动,以及媒体曝光,利用其中产生的一些问题来进行精准营销。第二轮的反馈,就是第一轮活动的反馈,可以利用在线各种进行整合分析,这就是我要说的,一切的工作目的和转化手段,都只能围绕着活动的性质和目的在进行。
这次,相关报道有很多,但是,对于刚刚涉及做活动,以及初创小公司来说,还有很多的关键点要去思考。感谢有你,平和一期。--一期评论太多,不想发,我觉得是在宣扬中小型企业的不专业性,把做活动做成了推销。最终,还要看效果。所以,大家好聚好散,下期请给我发私信,说说对这些设计的一些要求和建议。以下是我一贯的观点(针对知乎,非广告)1.软件成本的大幅度下降,交互和图形占据大量预算的背后,靠软件的数量优势,是不够的,软。
文章实时采集,地理位置抓取,三维地图绘制是语音识别
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-05-11 19:02
文章实时采集,地理位置抓取,三维地图绘制是语音识别的大致的原理,
我的看法是,先自己把概念理清楚吧。不然很难让别人理解你的想法。另外,要看看现在能否做到。我看到的已经做出来的有语音实时转文字,语音识别+人脸识别+文字识别+结构化输出。
说白了还是编程基础要牢固
语音识别(比如:nuance公司),对讲机(普及版),
这个还是要看需求和实现方式。语音技术目前不能成熟应用到生活中,但是特定场景还是可以应用到的。比如来电时只需要告诉你对方想接听,那么对方的位置信息就是很好的采集了。目前比较典型的应用,对方想打王者,可以依据在上海打王者电话是15min,打农药电话是20min,打游戏电话是40min来判断。可以定制一个人工智能系统,类似于阿尔法狗那样,一点一点学习。对方打开个短信,就可以学习发送什么信息了。
题主想利用语音作为识别码,进行信息录入吗?答案是肯定的。你可以用一个单片机控制一个nuance开发的avr-cnoise音箱,可以按语音给事先录入的电话打电话。也可以用一个程序控制两个音箱进行语音通话。
这个肯定会有用啊。目前的语音识别技术基本都是基于客户端系统,不提供服务器的。不过手机上能上网,而且会编程,也可以自己开发一个对话系统,把语音控制转换成文字。 查看全部
文章实时采集,地理位置抓取,三维地图绘制是语音识别
文章实时采集,地理位置抓取,三维地图绘制是语音识别的大致的原理,
我的看法是,先自己把概念理清楚吧。不然很难让别人理解你的想法。另外,要看看现在能否做到。我看到的已经做出来的有语音实时转文字,语音识别+人脸识别+文字识别+结构化输出。
说白了还是编程基础要牢固
语音识别(比如:nuance公司),对讲机(普及版),
这个还是要看需求和实现方式。语音技术目前不能成熟应用到生活中,但是特定场景还是可以应用到的。比如来电时只需要告诉你对方想接听,那么对方的位置信息就是很好的采集了。目前比较典型的应用,对方想打王者,可以依据在上海打王者电话是15min,打农药电话是20min,打游戏电话是40min来判断。可以定制一个人工智能系统,类似于阿尔法狗那样,一点一点学习。对方打开个短信,就可以学习发送什么信息了。
题主想利用语音作为识别码,进行信息录入吗?答案是肯定的。你可以用一个单片机控制一个nuance开发的avr-cnoise音箱,可以按语音给事先录入的电话打电话。也可以用一个程序控制两个音箱进行语音通话。
这个肯定会有用啊。目前的语音识别技术基本都是基于客户端系统,不提供服务器的。不过手机上能上网,而且会编程,也可以自己开发一个对话系统,把语音控制转换成文字。
新技术电子影像监测监控系统——打孔+stl格式
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-10 09:01
文章实时采集技术包括场景采集、节点采集、点采集、平行采集等。无论是场景采集还是节点采集,都离不开一个采集设备。这就决定了你能采集到的数据量,越大你获取数据的速度也越快。我们有三款采集设备。3d扫描仪三维场景的扫描仪一般采用3d扫描仪来进行采集。一款典型的3d扫描仪需要一台采集采样机、一台扫描仪、一台三维扫描仪、一个3d三维场景扫描仪、cinema4d软件、云计算平台等其他。
3d扫描仪整体维护:采集机、三维扫描仪、2d软件、cinema4d软件。3d三维场景扫描仪采用采集机构采集场景,进行点云测距及识别。3d扫描仪的特点:打孔+stl格式。采集机构:彩色一体化3d扫描仪。扫描机构:标准3d立体扫描仪。云计算平台:3d扫描仪一般会与云平台搭配使用,我们有一款云扫描仪3d云采集仪。
可以试试快数快采,你在应用商店里面搜一下,他们的快数快采可以实现一键采集,
用笔者所学的技术告诉你,可以试试这个新技术电子影像监测监控系统,用定位方式采集视频数据,
同求解答!同感!
我也在找,
xy,现在是按用户设备来划分,只有摄像头、光源、传感器组成的,然后是采集卡、采集仪。 查看全部
新技术电子影像监测监控系统——打孔+stl格式
文章实时采集技术包括场景采集、节点采集、点采集、平行采集等。无论是场景采集还是节点采集,都离不开一个采集设备。这就决定了你能采集到的数据量,越大你获取数据的速度也越快。我们有三款采集设备。3d扫描仪三维场景的扫描仪一般采用3d扫描仪来进行采集。一款典型的3d扫描仪需要一台采集采样机、一台扫描仪、一台三维扫描仪、一个3d三维场景扫描仪、cinema4d软件、云计算平台等其他。
3d扫描仪整体维护:采集机、三维扫描仪、2d软件、cinema4d软件。3d三维场景扫描仪采用采集机构采集场景,进行点云测距及识别。3d扫描仪的特点:打孔+stl格式。采集机构:彩色一体化3d扫描仪。扫描机构:标准3d立体扫描仪。云计算平台:3d扫描仪一般会与云平台搭配使用,我们有一款云扫描仪3d云采集仪。
可以试试快数快采,你在应用商店里面搜一下,他们的快数快采可以实现一键采集,
用笔者所学的技术告诉你,可以试试这个新技术电子影像监测监控系统,用定位方式采集视频数据,
同求解答!同感!
我也在找,
xy,现在是按用户设备来划分,只有摄像头、光源、传感器组成的,然后是采集卡、采集仪。
干货 | 数据埋点采集,看这一篇文章就够了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-05-07 02:12
数仓蓝图:
本文目录:
一、数据采集及常见问题二、埋点是什么与方式三、埋点的框架与设计四、指标体系与可视化
一、数据采集以及常见数据问题
1.1数据采集
数据采集有多种方式,埋点采集是其中非常重要的一部分,不论对c端还是b端产品都是主要的采集方式,数据采集,顾名思义就是采集相应的数据,是整个数据流的起点,采集的全不全,对不对,直接决定数据的广度和质量,影响后续所有的环节。在数据采集有效性,完整性不好的公司,经常会有业务发现数据发生大幅度变化。
数据的处理通常由以下5步构成:
1.2常见数据问题
大体知道数据采集及其架构之后,我们看看工作中遇到的问题,有多少是跟数据采集环节有关的:
1、数据和后台差距很大,数据不准确-统计口径不一样、埋点定义不一样、采集方式带来误差
2、想用的时候,没有我想要的数据-没有提数据采集需求、埋点不正确不完整
3、事件太多,不清楚含义-埋点设计的方式、埋点更新迭代的规则和维护
4、分析数据不知道看哪些数据和指标-数据定义不清楚,缺乏分析思路
我们需要根源性解决问题:把采集当成独立的研发业务来对待,而不是产品研发中的附属品。
二、埋点是什么
2.1 埋点是什么
所谓埋点,就是数据采集领域的术语。它的学名应该叫做事件追踪,对应的英文是Event Tracking 指的是针对特定用户行为或事件进行捕获,处理和发送的相关技术及其实施过程。数据埋点是数据分析师,数据产品经理和数据运营,基于业务需求或者产品需求对用户行为的每一个事件对应位置进行开发埋点,并通过SDK上报埋点的数据结果,记录汇总数据后进行分析,推动产品优化和指导运营。
流程伴随着规范,通过定义我们看到,特定用户行为和事件是我们的采集重点,还需要处理和发送相关技术及实施过程;数据埋点是服务于产品,又来源于产品中,所以跟产品息息相关,埋点在于具体的实战过程,跟每个人对数据底层的理解程度有关。
2.2为什么要做埋点
埋点就是为了对产品进行全方位的持续追踪,通过数据分析不断指导优化产品。数据埋点的质量直接影响到数据,产品,运营等质量。
1、数据驱动-埋点将分析的深度下钻到流量分布和流动层面,通过统计分析,对宏观指标进行深入剖析,发现指标背后的问题,洞察用户行为与提升价值之间的潜在关联
2、产品优化-对产品来说,用户在产品里做了什么,停留多久,有什么异常都需要关注,这些问题都可以通过埋点的方式实现
3、精细化运营-埋点可以贯彻整个产品的生命周期,流量质量和不同来源的分布,人群的行为特点和关系,洞察用户行为与提升业务价值之间的潜在关联。
2.3埋点的方式
埋点的方式都有哪些呢,当前大多数公司都是客户端,服务端相结合的方式。
准确性:代码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1埋点采集的顶层设计
所谓的顶层设计就是想清楚怎么做埋点,用什么方式,上传机制是什么,具体怎么定义,具体怎么落地等等;我们遵循唯一性,可扩展性,一致性等的基础上,我们要设计一些通用字段及生成机制,比如:cid, idfa,idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据对不上;二是涉及到漏斗分析环节出现异常。因此应该做到:a.严格规范ID的本身识别机制;b.跨平台用户识别
同类抽象: 同类抽象包括事件抽象和属性抽象。事件抽象即浏览事件,点击事件的聚合;属性抽象,即多数复用的场景来进行合并,增加来源区分
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;埋点的制定过程本身就是规范底层数据的过程,所以一致性是特别重要,只有这样才能真正的用起来
渠道配置:渠道主要指的是推广渠道,落地页,网页推广页面,APP推广页面等,这个落地页的配置要有统一规范和标准
3.2 埋点采集事件及属性设计
在设计属性和事件的时候,我们要知道哪些经常变,哪些不变,哪些是业务行为,哪些是基本属性。基于基本属性事件,我们认为属性是必须采集项,只是属性里面的事件属性根据业务不同有所调整而已,因此,我们可以把埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、操作路径和不同细分场景、定义用户行为路径
分析指标:对特定的事件进行定义、核心业务指标需要的数据
事件设计:APP启动,退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件及属性设计
Ev事件的命名,也遵循一些规则,同一类功能在不同页面或位置出现时,按照功能名称命名,页面和位置在ev参数中进行区分。仅是按钮点击时,按照按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识和ev参数之间用“#”连接(一级连接符)
ev参数和ev参数之间用“/”来连接(二级连接符)
ev参数使用key=value的结构,当一个key对应多个value值时,value1与value2之间用“,”连接(三级连接符)
当埋点仅有ev标识没有ev参数的时候,不需要带#
备注:
ev标识:作为埋点的唯一标识,用来区分埋点的位置和属性,不可变,不可修改。
ev参数:埋点需要回传的参数,ev参数顺序可变,可修改)
app埋点调整的时,ev标识不变,只修改后面的埋点参数(参数取值变化或者增加参数类型)
一般埋点文档中所包含的sheet名称以及作用:
A、曝光埋点汇总;
B、点击和浏览埋点汇总;
C、失效埋点汇总:一般会记录埋点失效版本或时间;
D、PC和M端页面埋点所对应的pageid;
E、各版本上线时间记录;
埋点文档中,所有包含的列名及功能:
3.4 基于埋点的数据统计
用埋点统计数据怎么查找埋点ev事件:
1、明确埋点类型(点击/曝光/浏览)——筛选type字段
2、明确按钮埋点所属页面(页面或功能)——筛选功能模块字段
3、明确埋点事件名称——筛选名称字段
4、知道ev标识,可直接用ev来进行筛选
根据ev事件怎么进行查询统计:当查询按钮点击统计时,可直接用ev标识进行查询,当有所区分可限定埋点参数取值。因为ev参数的顺序不做要求可变,所以查询统计时,不能按照参数的顺序进行限定。
四、应用-数据流程的基础
4.1指标体系
体系化的指标可以综合不同的指标不同的维度串联起来进行全面的分析,会更快的发现目前产品和业务流程存在的问题。
4.2可视化
人对图像信息的解释效率比文字更高,可视化对数据分析极为重要,利用数据可视化可以揭示出数据内在的错综复杂的关系。
4.3 埋点元信息api提供
数据采集服务会对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
数据采集犹如设计产品,不能过度。不仅要留出扩展余地,更要经常思考数据有没有,全不全,细不细,稳不稳,快不快。 查看全部
干货 | 数据埋点采集,看这一篇文章就够了!
数仓蓝图:
本文目录:
一、数据采集及常见问题二、埋点是什么与方式三、埋点的框架与设计四、指标体系与可视化
一、数据采集以及常见数据问题
1.1数据采集
数据采集有多种方式,埋点采集是其中非常重要的一部分,不论对c端还是b端产品都是主要的采集方式,数据采集,顾名思义就是采集相应的数据,是整个数据流的起点,采集的全不全,对不对,直接决定数据的广度和质量,影响后续所有的环节。在数据采集有效性,完整性不好的公司,经常会有业务发现数据发生大幅度变化。
数据的处理通常由以下5步构成:
1.2常见数据问题
大体知道数据采集及其架构之后,我们看看工作中遇到的问题,有多少是跟数据采集环节有关的:
1、数据和后台差距很大,数据不准确-统计口径不一样、埋点定义不一样、采集方式带来误差
2、想用的时候,没有我想要的数据-没有提数据采集需求、埋点不正确不完整
3、事件太多,不清楚含义-埋点设计的方式、埋点更新迭代的规则和维护
4、分析数据不知道看哪些数据和指标-数据定义不清楚,缺乏分析思路
我们需要根源性解决问题:把采集当成独立的研发业务来对待,而不是产品研发中的附属品。
二、埋点是什么
2.1 埋点是什么
所谓埋点,就是数据采集领域的术语。它的学名应该叫做事件追踪,对应的英文是Event Tracking 指的是针对特定用户行为或事件进行捕获,处理和发送的相关技术及其实施过程。数据埋点是数据分析师,数据产品经理和数据运营,基于业务需求或者产品需求对用户行为的每一个事件对应位置进行开发埋点,并通过SDK上报埋点的数据结果,记录汇总数据后进行分析,推动产品优化和指导运营。
流程伴随着规范,通过定义我们看到,特定用户行为和事件是我们的采集重点,还需要处理和发送相关技术及实施过程;数据埋点是服务于产品,又来源于产品中,所以跟产品息息相关,埋点在于具体的实战过程,跟每个人对数据底层的理解程度有关。
2.2为什么要做埋点
埋点就是为了对产品进行全方位的持续追踪,通过数据分析不断指导优化产品。数据埋点的质量直接影响到数据,产品,运营等质量。
1、数据驱动-埋点将分析的深度下钻到流量分布和流动层面,通过统计分析,对宏观指标进行深入剖析,发现指标背后的问题,洞察用户行为与提升价值之间的潜在关联
2、产品优化-对产品来说,用户在产品里做了什么,停留多久,有什么异常都需要关注,这些问题都可以通过埋点的方式实现
3、精细化运营-埋点可以贯彻整个产品的生命周期,流量质量和不同来源的分布,人群的行为特点和关系,洞察用户行为与提升业务价值之间的潜在关联。
2.3埋点的方式
埋点的方式都有哪些呢,当前大多数公司都是客户端,服务端相结合的方式。
准确性:代码埋点>可视化埋点>全埋点
三、埋点的框架和设计
3.1埋点采集的顶层设计
所谓的顶层设计就是想清楚怎么做埋点,用什么方式,上传机制是什么,具体怎么定义,具体怎么落地等等;我们遵循唯一性,可扩展性,一致性等的基础上,我们要设计一些通用字段及生成机制,比如:cid, idfa,idfv等。
用户识别:用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据对不上;二是涉及到漏斗分析环节出现异常。因此应该做到:a.严格规范ID的本身识别机制;b.跨平台用户识别
同类抽象: 同类抽象包括事件抽象和属性抽象。事件抽象即浏览事件,点击事件的聚合;属性抽象,即多数复用的场景来进行合并,增加来源区分
采集一致:采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;埋点的制定过程本身就是规范底层数据的过程,所以一致性是特别重要,只有这样才能真正的用起来
渠道配置:渠道主要指的是推广渠道,落地页,网页推广页面,APP推广页面等,这个落地页的配置要有统一规范和标准
3.2 埋点采集事件及属性设计
在设计属性和事件的时候,我们要知道哪些经常变,哪些不变,哪些是业务行为,哪些是基本属性。基于基本属性事件,我们认为属性是必须采集项,只是属性里面的事件属性根据业务不同有所调整而已,因此,我们可以把埋点采集分为协议层和业务层埋点。
业务分解:梳理确认业务流程、操作路径和不同细分场景、定义用户行为路径
分析指标:对特定的事件进行定义、核心业务指标需要的数据
事件设计:APP启动,退出、页面浏览、事件曝光点击
属性设计:用户属性、事件属性、对象属性、环境属性
3.3 数据采集事件及属性设计
Ev事件的命名,也遵循一些规则,同一类功能在不同页面或位置出现时,按照功能名称命名,页面和位置在ev参数中进行区分。仅是按钮点击时,按照按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识和ev参数之间用“#”连接(一级连接符)
ev参数和ev参数之间用“/”来连接(二级连接符)
ev参数使用key=value的结构,当一个key对应多个value值时,value1与value2之间用“,”连接(三级连接符)
当埋点仅有ev标识没有ev参数的时候,不需要带#
备注:
ev标识:作为埋点的唯一标识,用来区分埋点的位置和属性,不可变,不可修改。
ev参数:埋点需要回传的参数,ev参数顺序可变,可修改)
app埋点调整的时,ev标识不变,只修改后面的埋点参数(参数取值变化或者增加参数类型)
一般埋点文档中所包含的sheet名称以及作用:
A、曝光埋点汇总;
B、点击和浏览埋点汇总;
C、失效埋点汇总:一般会记录埋点失效版本或时间;
D、PC和M端页面埋点所对应的pageid;
E、各版本上线时间记录;
埋点文档中,所有包含的列名及功能:
3.4 基于埋点的数据统计
用埋点统计数据怎么查找埋点ev事件:
1、明确埋点类型(点击/曝光/浏览)——筛选type字段
2、明确按钮埋点所属页面(页面或功能)——筛选功能模块字段
3、明确埋点事件名称——筛选名称字段
4、知道ev标识,可直接用ev来进行筛选
根据ev事件怎么进行查询统计:当查询按钮点击统计时,可直接用ev标识进行查询,当有所区分可限定埋点参数取值。因为ev参数的顺序不做要求可变,所以查询统计时,不能按照参数的顺序进行限定。
四、应用-数据流程的基础
4.1指标体系
体系化的指标可以综合不同的指标不同的维度串联起来进行全面的分析,会更快的发现目前产品和业务流程存在的问题。
4.2可视化
人对图像信息的解释效率比文字更高,可视化对数据分析极为重要,利用数据可视化可以揭示出数据内在的错综复杂的关系。
4.3 埋点元信息api提供
数据采集服务会对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
数据采集犹如设计产品,不能过度。不仅要留出扩展余地,更要经常思考数据有没有,全不全,细不细,稳不稳,快不快。
文章实时采集(1.实时数据采集3.Kafka实时流数据接入-吐血梳理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2022-04-18 10:48
各位朋友您好,我最近写了几篇关于实时数据分析的文章文章,都是基于当时的问题分析。今天打开这篇文章文章是因为实时分析工具已经实现了从0到1的业务数据对接,如果任何工具或功能不能与业务融合,那它所做的一切都是无用的,无法体现它的价值。所有的痛点和解决方案也来自于业务的使用。
这个文章我就不讲怎么选型号了,因为网上有很多类似的文章,只要细心就能找到,但不管是什么型号选择,重点是“行业研究”,防止错误选择。我一般会根据以下三大前提来选款(以下陈述纯属个人观点,如有不妥请在下方评论)
有很多公司在使用它,并且有很好的数据显示开源软件。关注社区情况。最近有没有继续迭代,防止自己进入深坑?最重要的是有没有和你类似的场景,你用过你要使用的工具。方便技术咨询
行业研究,行业研究,行业研究重要的事情说三遍
实时数据分析目前主要应用在业务场景中(很多公司对实时性有很强的需求)
1. 实时数据访问共6个数据源
2. 由于刚刚访问的日均数据量约为160万,当前摄取的数据量约为400万
以往的文章直通车(链接地址这里就不贴了,可以百度搜索)
1. 插件编写——Flume海量数据实时数据转换
2.回顾-Flume+Kafka实时数据采集
3.Kafka实时流式数据接入-吐血梳理与实践-Druid实时数据分析
4. 实时数据分析 Druid - 环境部署&试用
好了,以上就是简单的介绍,我们来说说今天的话题。
一. 为什么要做实时流数据分析?
以前不太喜欢碰数据,但总觉得没什么用。只有当我因为工作原因触及数据的门槛时,我才知道数据的重要性。
通常我们根据过去的经验做出决定。俗话说“做这个应该没问题”,但没有数据支持往往不够准确,大概率会出现问题,所以我们要从【经验决策】走向【真实-时间数据驱动的决策],使所有行动都以数据为事实。
二. 整体架构流程及分解
首先介绍一下我要解决的需求和痛点:
1. 实时流式数据摄取、显示图表、导出实时报告
2. 分析以往报告,90% 数据汇总,无需详细数据
根据上面的分析,选择了olap,最终选择了Apache Druid。
什么是阿帕奇德鲁伊
Druid 是一个分布式数据处理系统,支持实时多维 OLAP 分析。它既支持高速实时数据摄取处理,又支持实时灵活的多维数据分析查询。因此,Druid 最常用的场景是大数据背景下灵活快速的多维 OLAP 分析。此外,Druid 有一个关键特性:支持基于时间戳的数据预聚合摄取和聚合分析,因此一些用户经常在有时序数据处理和分析的场景中使用它。
为什么来自 Druid 的亚秒级响应的交互式查询支持更高的并发性。支持实时导入,导入可查询,支持高并发导入。使用分布式无共享架构,它可以扩展到 PB 级别。支持聚合函数、count 和 sum,以及使用 javascript 实现自定义 UDF。支持复杂的聚合器,用于近似查询的聚合器,例如 HyperLoglog 和 6. 雅虎的开源 DataSketches。支持 Groupby、Select、Search 查询。不支持大表之间的join,但是它的lookup功能满足Join with dimension tables。(最新版本0.18已经支持Join,具体性能有待测试) 架构
需求分析和核心引擎选型基本完成。先说一下整体架构
建筑设计的三个原则
适应原理 简单原理 进化原理
选择合适的架构,切记不要过度设计,过度设计未必实用。
架构图
结构意图
实时计算分析如何形成数据闭环,以下三点最重要
1. 数据清洗改造:需要通过一定的规则和规范,保证业务方传输的数据实时清洗改造或建模
2. 实时计算引擎:OLAP在线分析引擎选型
3.离线存储:深度存储,保证实时OLAP性能,也可作为日常数据容灾
三、 踩坑及解决方法
由于第一次接触数据分析相关的场景,很多工具和知识都是从零开始的。我知道我应该尽快补足功课,尤其是实时场景应用。
由于缺乏知识,在整体架构的构建和开发过程中存在许多问题。让我用图形的方式解释一下,这样就不会有学生对实时流数据不熟悉了。
数据清洗和转换
访问标准和规范非常重要。由于业务方数量众多,只要有标准的切割方法,每个业务方的日志规格很可能不一致(我们的工具不能要求业务方修改大量的日志规格)。
在这种情况下,我们可以梳理出两种业务业态:
1. 文本 -> Json
原始日志
2019-02-11 19:03:30.123|INFO|1.0|10.10.10.10|push-service|trace_id:0001|msg:错误信息|token:abcd
清洗后
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
Json 结构 A -> Json 结构 B
原始日志 -> Json结构A
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
清洗、转换后
{"ts—time":"2020-05-07 16:29:05", "errLevel": "INFO"}
最终统一输出JSON(标准化输入输出)
流程图
以上是标准的整体流程,为此我开发了两个Flume插件
1. 文本 -> Json 插件
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=***.flume.textToJson.TextToJsonBuilder
a1.sources.r1.interceptors.i1.textToJson={"times":"#0", "errLevel": "#1", "version":"#2" , "ip":"#3", "service-name":"#4", "trace_id": "#5","msg": "#6"}
a1.sources.r1.interceptors.i1.separator=\\,
Json 结构 A -> Json 结构 B
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=flume.***.StringTransJsonBuilder
a1.sources.r1.interceptors.i1.template={"scid":"data.data.data.scid","tpc":"data.data.tpc", "did": "data.data.did"}
a1.sources.r1.interceptors.i1.where={"key1":"value1", "data.key2":"value2"}
a1.sources.r1.interceptors.i1.addheader=comment
上述过程没有任何问题。. . 但问题来了。
由于我们是消费者业务端Kafka Topics,所以有这样一种场景,所有业务方都将数据放到一个大topic中,我们需要对数据进行清洗转换成我们需要的数据源。见下图:
在上图的拦截器部分,接收到的主题数据必须经过拦截器的清洗和转换。由于业务topic有10个partition,如果我们启动一个Flume NG去消费,就会造成数据的积压。. .
1. 业务主题有10个分区,单个Flume NG进程可以理解为1个分区。. . 严重不足
2. 测试结果从业务端接收数据7小时,数据实际清洗2小时,数据继续被挤压
对应解决方案:
1. 启动 10 个 Flume 进程,相当于 10 个 Topic 分区,但这会消耗资源。. .
2. Python 进行数据清理和转换。
Flume NG 在内部为我们做了很多高可用。高可靠性保证,有限的资源只能暂时放弃这个计划。
所以选择了方案2,放弃了高可用和高可靠,但是最终的结果还是很不错的,用Python的消费速度是10个Flume NG的两倍。
结论:我们自己处理ETL,短期内是可行的,但长期来看还是要选择工具来处理。毕竟已经为我们准备了很多保障(要想做好工作,就必须先利好工具)。这句话不无道理。
目前遇到的最大困难是清洗和转换。其他的小坑在之前的文章里已经写过了,大家可以搜索一下。
阿帕奇德鲁伊
我使用最新版本的 0.18。该版本官方公告已宣布加入支持,但尚未进行测试。
该工具已经使用了一个多月,到目前为止它看起来很完美。
待续
很高兴这个项目能迈出一小步,我们的架构还要迭代开发,以后会继续更新这个系列文章哈哈
特别感谢老板给我机会开发这个项目。. . 给我机会从我的工作中成长 查看全部
文章实时采集(1.实时数据采集3.Kafka实时流数据接入-吐血梳理)
各位朋友您好,我最近写了几篇关于实时数据分析的文章文章,都是基于当时的问题分析。今天打开这篇文章文章是因为实时分析工具已经实现了从0到1的业务数据对接,如果任何工具或功能不能与业务融合,那它所做的一切都是无用的,无法体现它的价值。所有的痛点和解决方案也来自于业务的使用。
这个文章我就不讲怎么选型号了,因为网上有很多类似的文章,只要细心就能找到,但不管是什么型号选择,重点是“行业研究”,防止错误选择。我一般会根据以下三大前提来选款(以下陈述纯属个人观点,如有不妥请在下方评论)
有很多公司在使用它,并且有很好的数据显示开源软件。关注社区情况。最近有没有继续迭代,防止自己进入深坑?最重要的是有没有和你类似的场景,你用过你要使用的工具。方便技术咨询
行业研究,行业研究,行业研究重要的事情说三遍
实时数据分析目前主要应用在业务场景中(很多公司对实时性有很强的需求)
1. 实时数据访问共6个数据源
2. 由于刚刚访问的日均数据量约为160万,当前摄取的数据量约为400万
以往的文章直通车(链接地址这里就不贴了,可以百度搜索)
1. 插件编写——Flume海量数据实时数据转换
2.回顾-Flume+Kafka实时数据采集
3.Kafka实时流式数据接入-吐血梳理与实践-Druid实时数据分析
4. 实时数据分析 Druid - 环境部署&试用
好了,以上就是简单的介绍,我们来说说今天的话题。
一. 为什么要做实时流数据分析?
以前不太喜欢碰数据,但总觉得没什么用。只有当我因为工作原因触及数据的门槛时,我才知道数据的重要性。
通常我们根据过去的经验做出决定。俗话说“做这个应该没问题”,但没有数据支持往往不够准确,大概率会出现问题,所以我们要从【经验决策】走向【真实-时间数据驱动的决策],使所有行动都以数据为事实。
二. 整体架构流程及分解
首先介绍一下我要解决的需求和痛点:
1. 实时流式数据摄取、显示图表、导出实时报告
2. 分析以往报告,90% 数据汇总,无需详细数据
根据上面的分析,选择了olap,最终选择了Apache Druid。
什么是阿帕奇德鲁伊
Druid 是一个分布式数据处理系统,支持实时多维 OLAP 分析。它既支持高速实时数据摄取处理,又支持实时灵活的多维数据分析查询。因此,Druid 最常用的场景是大数据背景下灵活快速的多维 OLAP 分析。此外,Druid 有一个关键特性:支持基于时间戳的数据预聚合摄取和聚合分析,因此一些用户经常在有时序数据处理和分析的场景中使用它。
为什么来自 Druid 的亚秒级响应的交互式查询支持更高的并发性。支持实时导入,导入可查询,支持高并发导入。使用分布式无共享架构,它可以扩展到 PB 级别。支持聚合函数、count 和 sum,以及使用 javascript 实现自定义 UDF。支持复杂的聚合器,用于近似查询的聚合器,例如 HyperLoglog 和 6. 雅虎的开源 DataSketches。支持 Groupby、Select、Search 查询。不支持大表之间的join,但是它的lookup功能满足Join with dimension tables。(最新版本0.18已经支持Join,具体性能有待测试) 架构
需求分析和核心引擎选型基本完成。先说一下整体架构
建筑设计的三个原则
适应原理 简单原理 进化原理
选择合适的架构,切记不要过度设计,过度设计未必实用。
架构图
结构意图
实时计算分析如何形成数据闭环,以下三点最重要
1. 数据清洗改造:需要通过一定的规则和规范,保证业务方传输的数据实时清洗改造或建模
2. 实时计算引擎:OLAP在线分析引擎选型
3.离线存储:深度存储,保证实时OLAP性能,也可作为日常数据容灾
三、 踩坑及解决方法
由于第一次接触数据分析相关的场景,很多工具和知识都是从零开始的。我知道我应该尽快补足功课,尤其是实时场景应用。
由于缺乏知识,在整体架构的构建和开发过程中存在许多问题。让我用图形的方式解释一下,这样就不会有学生对实时流数据不熟悉了。
数据清洗和转换
访问标准和规范非常重要。由于业务方数量众多,只要有标准的切割方法,每个业务方的日志规格很可能不一致(我们的工具不能要求业务方修改大量的日志规格)。
在这种情况下,我们可以梳理出两种业务业态:
1. 文本 -> Json
原始日志
2019-02-11 19:03:30.123|INFO|1.0|10.10.10.10|push-service|trace_id:0001|msg:错误信息|token:abcd
清洗后
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
Json 结构 A -> Json 结构 B
原始日志 -> Json结构A
{"ts":"2020-05-07 16:29:05","times":"2019-02-11 19:03:30.123", "errLevel": "INFO", "version":"1.0" , "ip":"10.10.10.10", "service-name":"push-service", "trace_id": "trace_id:0001","msg": "msg:错误信息"}
清洗、转换后
{"ts—time":"2020-05-07 16:29:05", "errLevel": "INFO"}
最终统一输出JSON(标准化输入输出)
流程图
以上是标准的整体流程,为此我开发了两个Flume插件
1. 文本 -> Json 插件
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=***.flume.textToJson.TextToJsonBuilder
a1.sources.r1.interceptors.i1.textToJson={"times":"#0", "errLevel": "#1", "version":"#2" , "ip":"#3", "service-name":"#4", "trace_id": "#5","msg": "#6"}
a1.sources.r1.interceptors.i1.separator=\\,
Json 结构 A -> Json 结构 B
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=flume.***.StringTransJsonBuilder
a1.sources.r1.interceptors.i1.template={"scid":"data.data.data.scid","tpc":"data.data.tpc", "did": "data.data.did"}
a1.sources.r1.interceptors.i1.where={"key1":"value1", "data.key2":"value2"}
a1.sources.r1.interceptors.i1.addheader=comment
上述过程没有任何问题。. . 但问题来了。
由于我们是消费者业务端Kafka Topics,所以有这样一种场景,所有业务方都将数据放到一个大topic中,我们需要对数据进行清洗转换成我们需要的数据源。见下图:
在上图的拦截器部分,接收到的主题数据必须经过拦截器的清洗和转换。由于业务topic有10个partition,如果我们启动一个Flume NG去消费,就会造成数据的积压。. .
1. 业务主题有10个分区,单个Flume NG进程可以理解为1个分区。. . 严重不足
2. 测试结果从业务端接收数据7小时,数据实际清洗2小时,数据继续被挤压
对应解决方案:
1. 启动 10 个 Flume 进程,相当于 10 个 Topic 分区,但这会消耗资源。. .
2. Python 进行数据清理和转换。
Flume NG 在内部为我们做了很多高可用。高可靠性保证,有限的资源只能暂时放弃这个计划。
所以选择了方案2,放弃了高可用和高可靠,但是最终的结果还是很不错的,用Python的消费速度是10个Flume NG的两倍。
结论:我们自己处理ETL,短期内是可行的,但长期来看还是要选择工具来处理。毕竟已经为我们准备了很多保障(要想做好工作,就必须先利好工具)。这句话不无道理。
目前遇到的最大困难是清洗和转换。其他的小坑在之前的文章里已经写过了,大家可以搜索一下。
阿帕奇德鲁伊
我使用最新版本的 0.18。该版本官方公告已宣布加入支持,但尚未进行测试。
该工具已经使用了一个多月,到目前为止它看起来很完美。
待续
很高兴这个项目能迈出一小步,我们的架构还要迭代开发,以后会继续更新这个系列文章哈哈
特别感谢老板给我机会开发这个项目。. . 给我机会从我的工作中成长
文章实时采集(微信公众号采集工具被封号,需求是怎么样的呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-18 10:46
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
正好这个时候在研究Xposed Hook微信,所以打算试试安卓版的微信。需求是什么?也就是微信推送一条公众号消息,我们接受一条,发送到对应界面保存,方便后续浏览。刚要去做的时候,觉得难度不大。直接下去下载微信数据库里的东西就行了。然而,这太简单了,好吧。
天真.jpg
幼稚的!!!
微信数据表“消息”中导出的数据是一堆乱码,解析出来的网址不全。比如五篇文章文章一次推送只能获取三篇文章的url,这让人很不舒服。
图像.png
但是苦就是苦,问题还是要解决的。如何解决?看源代码!
之前我把微信的几个dex包的代码反编译了放在一个文件夹里,然后用VSCode打开,日常查看。
微信反编译出来的源码虽然乱七八糟,但还是能看懂一些代码。
我们看到上面导出的数据有一些乱码,估计微信实现了解码工具。如果能hook这个解码工具,解码后能得到正确的数据吗?
说到解码,根据微信之前的数据传输,这些数据很可能是以XML格式传输的。由于涉及到 XML,所以它必须是键值对的形式。除了我们要去的数据之外,还有一堆看起来很有用的小方块和诸如“.msg.appmsg.mmreader.category.item”之类的东西。
我打开 vscode 并在全球范围内搜索“.msg.appmsg.mmreader.category.item”。令人高兴的是,结果并不多,这意味着这个值确实是一个有意义的值。一一检查这些源代码。一个包是:"
com.tencent.mm.plugin.biz;”我在一个名为“a”的类中发现了一些有趣的东西。
图像.png
该方法是一个名为 ws 的方法,它接收一个 String 类型的值,并在内部进行一些数据获取工作。
这个 str 参数可以是我想要的标准 xml 吗?
经过hook验证,打印其参数后,发现不是,参数内容的格式与之前数据库中的格式一致。
图像.png
然后我们将重点放在第一行的地图上。ay.WA(String str) 方法做解析操作吗?
我在 com.tencent.mm.sdk.platformtools.ay 中钩住了 WA() 方法来获取它的返回值,这是一个 Map 类型的数据。打印出它的内容后,我的猜测得到了验证。
WA() 方法将刚才的内容解析成一个便于我们阅读的地图。包括推送收录的图文消息数量,以及公众号的id、名称、对应的文章url、图片url、文章描述等信息。
我终于可以在晚餐时加鸡腿了。啊哈哈哈。
此文章仅供研究学习,请妥善食用,谢谢。
粘贴相关的钩子代码
图像.png 查看全部
文章实时采集(微信公众号采集工具被封号,需求是怎么样的呢?)
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
由于之前基于itchat开发的微信公众号采集工具使用的账号被封禁,非常郁闷。
正好这个时候在研究Xposed Hook微信,所以打算试试安卓版的微信。需求是什么?也就是微信推送一条公众号消息,我们接受一条,发送到对应界面保存,方便后续浏览。刚要去做的时候,觉得难度不大。直接下去下载微信数据库里的东西就行了。然而,这太简单了,好吧。
天真.jpg
幼稚的!!!
微信数据表“消息”中导出的数据是一堆乱码,解析出来的网址不全。比如五篇文章文章一次推送只能获取三篇文章的url,这让人很不舒服。
图像.png
但是苦就是苦,问题还是要解决的。如何解决?看源代码!
之前我把微信的几个dex包的代码反编译了放在一个文件夹里,然后用VSCode打开,日常查看。
微信反编译出来的源码虽然乱七八糟,但还是能看懂一些代码。
我们看到上面导出的数据有一些乱码,估计微信实现了解码工具。如果能hook这个解码工具,解码后能得到正确的数据吗?
说到解码,根据微信之前的数据传输,这些数据很可能是以XML格式传输的。由于涉及到 XML,所以它必须是键值对的形式。除了我们要去的数据之外,还有一堆看起来很有用的小方块和诸如“.msg.appmsg.mmreader.category.item”之类的东西。
我打开 vscode 并在全球范围内搜索“.msg.appmsg.mmreader.category.item”。令人高兴的是,结果并不多,这意味着这个值确实是一个有意义的值。一一检查这些源代码。一个包是:"
com.tencent.mm.plugin.biz;”我在一个名为“a”的类中发现了一些有趣的东西。
图像.png
该方法是一个名为 ws 的方法,它接收一个 String 类型的值,并在内部进行一些数据获取工作。
这个 str 参数可以是我想要的标准 xml 吗?
经过hook验证,打印其参数后,发现不是,参数内容的格式与之前数据库中的格式一致。
图像.png
然后我们将重点放在第一行的地图上。ay.WA(String str) 方法做解析操作吗?
我在 com.tencent.mm.sdk.platformtools.ay 中钩住了 WA() 方法来获取它的返回值,这是一个 Map 类型的数据。打印出它的内容后,我的猜测得到了验证。
WA() 方法将刚才的内容解析成一个便于我们阅读的地图。包括推送收录的图文消息数量,以及公众号的id、名称、对应的文章url、图片url、文章描述等信息。
我终于可以在晚餐时加鸡腿了。啊哈哈哈。
此文章仅供研究学习,请妥善食用,谢谢。
粘贴相关的钩子代码
图像.png
文章实时采集(不用图像处理app,snapdragon670不支持环境光采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-04-14 06:07
文章实时采集来源主要有两个,一个是摄像头采集,另一个是环境光采集,前者只需要被采集设备支持,后者则是需要捕捉设备支持。由于摄像头比较远且存在额外的摄像头延迟,因此虽然采集方式非常简单,但是其成本并不高。而环境光则需要摄像头配合相应的灯光系统才能达到类似的效果。不过后者自然需要采集设备支持skylake,这样才能获得完整的snapdragon660环境光采集能力,否则不管怎么采集实际效果都还是差不多,毕竟snapdragon670都不支持环境光采集,采集设备更不用说了。
三星在这方面做得不错,smartshader,自己要动手。
目前能实现只需要snapdragon660,
cannonworksyogaflex的ai芯片。目前应该还不是cpu核,是ppu核。
小米的ai管家和物联网的iot
屏摄,这个效果确实不错。
完全不用图像处理app,
要是支持环境光的话,把手机屏幕放在侧面,角度调到最小,然后拿书遮挡光线,我还可以看到书的细节,
没有的,
emmm我们实验室有一个只有一寸屏幕的看片机,
说的就是华为的ai手机
这个必须得跟顶级的才行,不然只是拿小米的ai做噱头,毕竟这玩意就是个噱头,噱头之一。另外发射的激光不是用gps的那个uwb还是什么我也不知道。 查看全部
文章实时采集(不用图像处理app,snapdragon670不支持环境光采集)
文章实时采集来源主要有两个,一个是摄像头采集,另一个是环境光采集,前者只需要被采集设备支持,后者则是需要捕捉设备支持。由于摄像头比较远且存在额外的摄像头延迟,因此虽然采集方式非常简单,但是其成本并不高。而环境光则需要摄像头配合相应的灯光系统才能达到类似的效果。不过后者自然需要采集设备支持skylake,这样才能获得完整的snapdragon660环境光采集能力,否则不管怎么采集实际效果都还是差不多,毕竟snapdragon670都不支持环境光采集,采集设备更不用说了。
三星在这方面做得不错,smartshader,自己要动手。
目前能实现只需要snapdragon660,
cannonworksyogaflex的ai芯片。目前应该还不是cpu核,是ppu核。
小米的ai管家和物联网的iot
屏摄,这个效果确实不错。
完全不用图像处理app,
要是支持环境光的话,把手机屏幕放在侧面,角度调到最小,然后拿书遮挡光线,我还可以看到书的细节,
没有的,
emmm我们实验室有一个只有一寸屏幕的看片机,
说的就是华为的ai手机
这个必须得跟顶级的才行,不然只是拿小米的ai做噱头,毕竟这玩意就是个噱头,噱头之一。另外发射的激光不是用gps的那个uwb还是什么我也不知道。
文章实时采集(文章实时采集返回的四级跳。数据与视频相似度归一化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-14 03:04
文章实时采集返回的四级跳。数据与视频相似度归一化根据算法聚类用户画像,联合文章或推荐广告找到需要触达的精准人群。
没有说法。直接在聚类中得到返回结果。
在通过文章分类、物品分类聚类后做推荐。文章分类有建库、top5聚类等,物品分类还可以根据某些数据来聚类,比如上下架,时间,文章数量等。
在推荐系统中直接获取文章/物品信息并进行聚类聚是文章/物品聚类是topic聚类直接获取推荐的结果是在推荐过程中由应用提供的。
聚类聚是物品
聚类算法通常基于物品的属性或者物品自身的特征,
可以聚类,但是归类不一定必要,看你的目的是什么。大类聚是离推荐系统更近一点,最终聚不聚得到就看你本身的keyitem了。另外如果聚类算法不够成熟或者数据不好,再优质的归类成果也很可能在推荐中失效。
新品的聚类,根据目标用户和内容相似度算法聚类。
聚成什么样的类是个很重要的指标来衡量推荐成功与否,常见的有csi,kbs,mls等等,
聚类这种问题,直接从推荐系统得到返回结果就好了,目前的推荐算法里面,同类里面会同一类的同质化,不同类里面,
kblinking可以参考一下
四级跳也没说法。可以采用deepneuralmodel去聚类。更好的聚类方法通常有聚类相似度、聚类特征等不同的方法。聚类目标一般是用户标签,也可以用行为标签,你还可以去看看各种协同过滤的方法。谢谢邀请。 查看全部
文章实时采集(文章实时采集返回的四级跳。数据与视频相似度归一化)
文章实时采集返回的四级跳。数据与视频相似度归一化根据算法聚类用户画像,联合文章或推荐广告找到需要触达的精准人群。
没有说法。直接在聚类中得到返回结果。
在通过文章分类、物品分类聚类后做推荐。文章分类有建库、top5聚类等,物品分类还可以根据某些数据来聚类,比如上下架,时间,文章数量等。
在推荐系统中直接获取文章/物品信息并进行聚类聚是文章/物品聚类是topic聚类直接获取推荐的结果是在推荐过程中由应用提供的。
聚类聚是物品
聚类算法通常基于物品的属性或者物品自身的特征,
可以聚类,但是归类不一定必要,看你的目的是什么。大类聚是离推荐系统更近一点,最终聚不聚得到就看你本身的keyitem了。另外如果聚类算法不够成熟或者数据不好,再优质的归类成果也很可能在推荐中失效。
新品的聚类,根据目标用户和内容相似度算法聚类。
聚成什么样的类是个很重要的指标来衡量推荐成功与否,常见的有csi,kbs,mls等等,
聚类这种问题,直接从推荐系统得到返回结果就好了,目前的推荐算法里面,同类里面会同一类的同质化,不同类里面,
kblinking可以参考一下
四级跳也没说法。可以采用deepneuralmodel去聚类。更好的聚类方法通常有聚类相似度、聚类特征等不同的方法。聚类目标一般是用户标签,也可以用行为标签,你还可以去看看各种协同过滤的方法。谢谢邀请。
文章实时采集(在建站容易推广难,采集文章如何伪原创处理?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-11 13:15
建站容易,推广难。采集文章对于做优化的人来说,这是家常便饭。尤其是当站群猖獗的时候,采集网站随处可见,都是为了SEO和SEO。但是,这类采集网站往往权重很高,因为目前即使是像原创这样的搜索引擎也无法完全识别出文章的来源。
采集的文章伪原创怎么处理,网上有很多处理方法,不过还是要分享一下红尘的资源。
1、修改标题:首先修改标题。标题不是随意修改的。它必须遵循用户的搜索行为并符合全文内容中心。中文字的组合博大精深,换题就会多样化。标题必须收录关键字,收录 关键词 的标题长度适中
2、内容修改:用户体验好,SEO好。对用户感觉良好的搜索引擎当然也喜欢它。所以在改变文章的时候,也要站在用户的角度去想,他想从这个文章中得到什么样的信息。其次,至少要在内容中修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容有品牌字,必须更换。
3、从采集改进文章、文章的质量,如果改进这个文章,增强美感,优化布局,出错等(比如错字的修改),是不是改善了文章?自然,搜索引擎中的分数也会提高。具体可以考虑这些。例如,添加图片、适当的注释和引用权威来源都有助于采集内容的质量。
采集他的立场上的一些笔记
1、选择与您网站主题相匹配的内容;采集内容格式尽量统一,保持专业;
2、采集 的文章 一次不要发太多。保持每天10篇左右,长期发表。 查看全部
文章实时采集(在建站容易推广难,采集文章如何伪原创处理?)
建站容易,推广难。采集文章对于做优化的人来说,这是家常便饭。尤其是当站群猖獗的时候,采集网站随处可见,都是为了SEO和SEO。但是,这类采集网站往往权重很高,因为目前即使是像原创这样的搜索引擎也无法完全识别出文章的来源。
采集的文章伪原创怎么处理,网上有很多处理方法,不过还是要分享一下红尘的资源。
1、修改标题:首先修改标题。标题不是随意修改的。它必须遵循用户的搜索行为并符合全文内容中心。中文字的组合博大精深,换题就会多样化。标题必须收录关键字,收录 关键词 的标题长度适中
2、内容修改:用户体验好,SEO好。对用户感觉良好的搜索引擎当然也喜欢它。所以在改变文章的时候,也要站在用户的角度去想,他想从这个文章中得到什么样的信息。其次,至少要在内容中修改第一段和最后一段,因为这也是站长认为蜘蛛抓取的位置,尽量区分其他文章。
注意:如果内容有品牌字,必须更换。
3、从采集改进文章、文章的质量,如果改进这个文章,增强美感,优化布局,出错等(比如错字的修改),是不是改善了文章?自然,搜索引擎中的分数也会提高。具体可以考虑这些。例如,添加图片、适当的注释和引用权威来源都有助于采集内容的质量。
采集他的立场上的一些笔记
1、选择与您网站主题相匹配的内容;采集内容格式尽量统一,保持专业;
2、采集 的文章 一次不要发太多。保持每天10篇左右,长期发表。
文章实时采集(我要点外卖-数据采集难点日志)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-10 07:26
背景
“我要外卖”是一个平台型电商网站,涉及用户、餐厅、外卖员等,用户可以在网页、APP、微信、支付宝等平台下单,商家拿到后订单,它开始处理并自动通知周围的快递员。快递员将食物交付给用户。
操作要求
在运行过程中,发现了以下问题:
数据采集 难点
在数据操作过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集外部和内部的日志并统一管理。过去,这块需要大量的工作和不同种类的工作,但现在可以通过 LogHub采集 功能完成统一访问。
统一的日志管理、配置、创建和管理日志项,如myorder。为不同数据源生成的日志创建日志存储。例如,如果您需要对原创数据进行清理和ETL,您可以创建一些中间结果Logstore。用户提升日志采集
获取新用户一般有两种方式:
实施方法
定义如下注册服务器地址,生成二维码(宣传单、网页)供用户注册和扫描。当用户扫描这个页面进行注册时,他们可以知道用户是通过特定的来源进入的,并记录了一个日志。
http://example.com/login?source=10012&ref=kd4b
当服务器接受请求时,服务器会输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
在:
采集方式:
服务器数据采集
支付宝和微信公众号编程是典型的网页端模式,日志一般分为三种:
实现方式 终端用户登录访问网页/手机页面的用户行为
页面用户行为采集可以分为两类:
实现方法 服务器日志运维
例如:
实施方法
参考服务器 采集 方法。
不同网络环境下的数据采集
LogHub在每个Region都提供接入点,每个Region提供三种接入方式: 查看全部
文章实时采集(我要点外卖-数据采集难点日志)
背景
“我要外卖”是一个平台型电商网站,涉及用户、餐厅、外卖员等,用户可以在网页、APP、微信、支付宝等平台下单,商家拿到后订单,它开始处理并自动通知周围的快递员。快递员将食物交付给用户。
操作要求
在运行过程中,发现了以下问题:
数据采集 难点
在数据操作过程中,第一步是如何集中采集分散的日志数据,会遇到以下挑战:
我们需要采集外部和内部的日志并统一管理。过去,这块需要大量的工作和不同种类的工作,但现在可以通过 LogHub采集 功能完成统一访问。
统一的日志管理、配置、创建和管理日志项,如myorder。为不同数据源生成的日志创建日志存储。例如,如果您需要对原创数据进行清理和ETL,您可以创建一些中间结果Logstore。用户提升日志采集
获取新用户一般有两种方式:
实施方法
定义如下注册服务器地址,生成二维码(宣传单、网页)供用户注册和扫描。当用户扫描这个页面进行注册时,他们可以知道用户是通过特定的来源进入的,并记录了一个日志。
http://example.com/login?source=10012&ref=kd4b
当服务器接受请求时,服务器会输出以下日志:
2016-06-20 19:00:00 e41234ab342ef034,102345,5k4d,467890
在:
采集方式:
服务器数据采集
支付宝和微信公众号编程是典型的网页端模式,日志一般分为三种:
实现方式 终端用户登录访问网页/手机页面的用户行为
页面用户行为采集可以分为两类:
实现方法 服务器日志运维
例如:
实施方法
参考服务器 采集 方法。
不同网络环境下的数据采集
LogHub在每个Region都提供接入点,每个Region提供三种接入方式:
文章实时采集(怎么用文章采集工具让新网站快速收录以及关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-08 01:14
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(这样内容会不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集 查看全部
文章实时采集(怎么用文章采集工具让新网站快速收录以及关键词排名)
如何使用 文章采集 工具对新的 网站快速收录 和 关键词 进行排名。SEO优化已经是企业网站网络营销的手段之一,但是在企业SEO优化的过程中,也存在搜索引擎不是收录的情况。提问后总结了几个方法和经验,在此分享给各位新手站长,让新上线的网站可以让搜索引擎收录在短时间内获得不错的排名尽快。下面就教大家如何在SEO优化中快速提升网站收录。
一、网站在SEO优化过程中,在新站上线初期,每天都要定期更新内容。第一次发射是在评估期间。该评估期为 1 个月至 3 个月不等。最快的时间是半个月左右才能拿到一个好的排名。因此,在刚进入考核期时,应加大力度。做好内容的更新,让搜索引擎在前期对我们的网站有很好的印象,这样我们以后可以更好的提高网站的权重,打下坚实的基础。
二、A网站更新频率越高,搜索引擎蜘蛛来的频率越高。因此,我们可以利用文章采集工具实现采集伪原创自动发布和主动推送到搜索引擎,提高搜索引擎的抓取频率。本文章采集工具操作简单,无需学习专业技术,只需简单几步即可轻松采集内容数据,用户只需对< @文章采集tool ,该工具会根据用户设置的关键词accurate采集文章,保证与行业一致文章。采集中的采集文章可以选择将修改后的内容保存到本地,
与其他文章采集工具相比,这个工具使用起来非常简单,只需输入关键词即可实现采集(文章采集工具配备了 关键词采集 功能)。只需设置任务,全程自动挂机!
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。
最重要的是这个文章采集工具有很多SEO功能,不仅可以提升网站的收录,还可以增加网站的密度@关键词 提高网站排名。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片保存在本地或第三方(这样内容会不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
<p>6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前的采集
文章实时采集(文章实时采集flutterui控件设计与实现分析(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-08 00:07
文章实时采集flutterui控件设计与实现分析文章讲述的是如何将采集点设计与实现的,从采集的输入、处理等方面来分析flutterui控件设计与实现,从而总结出来不同采集对应的flutterui控件库,提供给用户使用的参考。原文链接:实时采集flutterui控件设计与实现分析_flutter设计与实现_雷锋网。
全面分析flutter控件设计与实现
再整理一下,flutter控件设计入门与实现,
flutter源码入门教程,主要是对现有的一些工具类、绘制接口进行了整理。
gitlab
flutter全面分析
flutter项目中存在哪些遗留问题?
全面的flutter
daydreamer全面进阶
flutter官方github
daydreamer基础版已经出来了
貌似flutterscript3.0已经很接近了,版本3.0新增了4个工具,如:go语言、quantumlifies和fuserace。
daydreamer进阶
flutter特性篇
flutter源码分析
雷锋网
首发于雷锋网_专业的iot产品与服务媒体(二维码自动识别)
daydreamer
全面的flutter设计与实现!需要的话可以推荐你下雷锋网的文章
我很喜欢雷锋网雷锋网旗下文章。
个人文章,如果侵权请告知。
flutter开发与规范之道flutter开发与规范之道flutter开发与规范之道
fluttercookbook
flutter开发者平台fluttercookbook 查看全部
文章实时采集(文章实时采集flutterui控件设计与实现分析(组图))
文章实时采集flutterui控件设计与实现分析文章讲述的是如何将采集点设计与实现的,从采集的输入、处理等方面来分析flutterui控件设计与实现,从而总结出来不同采集对应的flutterui控件库,提供给用户使用的参考。原文链接:实时采集flutterui控件设计与实现分析_flutter设计与实现_雷锋网。
全面分析flutter控件设计与实现
再整理一下,flutter控件设计入门与实现,
flutter源码入门教程,主要是对现有的一些工具类、绘制接口进行了整理。
gitlab
flutter全面分析
flutter项目中存在哪些遗留问题?
全面的flutter
daydreamer全面进阶
flutter官方github
daydreamer基础版已经出来了
貌似flutterscript3.0已经很接近了,版本3.0新增了4个工具,如:go语言、quantumlifies和fuserace。
daydreamer进阶
flutter特性篇
flutter源码分析
雷锋网
首发于雷锋网_专业的iot产品与服务媒体(二维码自动识别)
daydreamer
全面的flutter设计与实现!需要的话可以推荐你下雷锋网的文章
我很喜欢雷锋网雷锋网旗下文章。
个人文章,如果侵权请告知。
flutter开发与规范之道flutter开发与规范之道flutter开发与规范之道
fluttercookbook
flutter开发者平台fluttercookbook
文章实时采集(实时数仓的开发模式与离线分层的处理逻辑(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-04-04 18:00
1. 早期实时计算
实时计算虽然是近几年才流行起来,早期有一些公司有实时计算的需求,但是数据量比较小,实时无法形成完整的系统,而且基本上都是发展是具体问题的具体分析。,来个要求做一个,基本不考虑它们之间的关系,开发形式如下:
如上图所示,拿到数据源后,会通过Flink进行数据清洗、维度扩展、业务逻辑处理,最后直接进行业务输出。拆开这个环节,数据源会重复引用同一个数据源,清洗、过滤、扩维等操作必须重复进行。唯一不同的是业务的代码逻辑不同。
随着产品和业务人员对实时数据的需求不断增加,这种开发模式也出现了越来越多的问题:
数据指标越来越多,“烟囱式”开发导致严重的代码耦合问题。
需求越来越多,有的需要详细的数据,有的需要OLAP分析。单一的开发模式难以应对多种需求。
资源必须针对每个需求进行申请,导致资源成本快速膨胀,资源无法集约有效利用。
缺乏复杂的监控系统来在问题影响业务之前检测和修复问题。
从实时数仓的发展和问题来看,它与离线数仓非常相似。后期数据量大之后,出现了各种问题。当时离线数仓是如何解决的?离线数仓通过分层架构将数据解耦,多个业务可以共享数据。实时数据仓库也可以使用分层架构吗?当然可以,但是细节和离线分层还是有一些区别的,后面会讲到。
2. 实时仓库搭建
在方法论方面,实时和离线非常相似。在离线数仓的前期,也详细分析了具体问题。当数据规模增长到一定数量时,将考虑如何管理它。分层是一种非常有效的数据治理方式,所以在谈到如何管理实时数仓时,首先要考虑的是分层的处理逻辑。
实时数据仓库的架构如下:
从上图中,我们详细分析每一层的作用:
我们可以看到,实时数仓和离线数仓的层级非常相似,比如数据源层、明细层、汇总层,甚至应用层,它们的命名模式可能是相同的。但不难发现,两者有很多不同之处:
3. Lambda架构的实时数仓
Lambda 和 Kappa 架构的概念在上一篇文章中已经解释过了。不明白的可以点击链接:一篇了解大数据实时计算的文章
下图展示了基于 Flink 和 Kafka 的 Lambda 架构的具体实践。上层为实时计算,下层为离线计算,横向以计算引擎划分,纵向以实时数仓划分:
Lambda架构是比较经典的架构。过去实时场景不多,主要是线下。加入实时场景后,由于离线和实时的时效性不同,技术生态也不同。Lambda架构相当于附加了一个实时生产环节,在应用层面集成,双向生产,各自独立。这也是在业务应用程序中使用它的一种合乎逻辑的方式。
双通道生产会出现一些问题,比如双处理逻辑、双开发和运维,资源也将成为两个资源环节。由于上述问题,演变出一种 Kappa 架构。
4. Kappa架构的实时数仓
Kappa架构相当于去掉了离线计算部分的Lambda架构,如下图所示:
Kappa架构在架构设计方面比较简单,在生产上是统一的,有一套离线和实时生产的逻辑。但是在实际应用场景中存在比较大的局限性,因为同一张表的实时数据会以不同的方式存储,导致关联时需要跨数据源,对数据的操作有很大的局限性,所以它直接在行业中。用Kappa架构制作和落地的案例很少,场景比较简单。
关于Kappa架构,熟悉实时数仓制作的同学可能会有疑问。因为我们经常面临业务变化,很多业务逻辑需要迭代。如果之前产生的一些数据的口径发生了变化,就需要重新计算,甚至历史数据都会被改写。对于实时数仓,如何解决数据重新计算的问题?
这部分Kappa架构的思路是:首先准备一个可以存储历史数据的消息队列,比如Kafka,这个消息队列可以支持你从某个历史节点重启消费。那么就需要启动一个新任务,从更早的时间节点消费Kafka上的数据,然后当新任务的进度可以和当前正在运行的任务相等时,就可以将任务的下游切换到新任务,可以停止旧任务,也可以删除原来的结果表。
5. 流批结合的实时数仓
随着实时OLAP技术的发展,Doris、Presto等开源OLAP引擎的性能和易用性有了很大的提升。再加上数据湖技术的飞速发展,流和批的结合变得简单。
下图是结合流批的实时数仓:
数据从日志采集统一到消息队列,再到实时数仓。基础数据流的构建是统一的。之后,对于日志实时特性,实时大屏应用使用实时流计算。实时OLAP批处理用于Binlog业务分析。
我们看到,上述架构的流批组合方式和存储方式都发生了变化。卡夫卡被冰山取代。Iceberg是上层计算引擎和底层存储格式之间的中间层。我们可以把它定义成“数据组织格式”,而底层存储还是HDFS,那为什么还要加一个中间层,还不如把对流和批处理结合起来呢?Iceberg 的 ACID 能力可以简化整个流水线的设计,降低整个流水线的延迟,其修改和删除能力可以有效降低开销,提高效率。Iceberg可以有效支持批量高吞吐数据扫描和分区粒度的流计算并发实时处理。 查看全部
文章实时采集(实时数仓的开发模式与离线分层的处理逻辑(组图))
1. 早期实时计算
实时计算虽然是近几年才流行起来,早期有一些公司有实时计算的需求,但是数据量比较小,实时无法形成完整的系统,而且基本上都是发展是具体问题的具体分析。,来个要求做一个,基本不考虑它们之间的关系,开发形式如下:
如上图所示,拿到数据源后,会通过Flink进行数据清洗、维度扩展、业务逻辑处理,最后直接进行业务输出。拆开这个环节,数据源会重复引用同一个数据源,清洗、过滤、扩维等操作必须重复进行。唯一不同的是业务的代码逻辑不同。
随着产品和业务人员对实时数据的需求不断增加,这种开发模式也出现了越来越多的问题:
数据指标越来越多,“烟囱式”开发导致严重的代码耦合问题。
需求越来越多,有的需要详细的数据,有的需要OLAP分析。单一的开发模式难以应对多种需求。
资源必须针对每个需求进行申请,导致资源成本快速膨胀,资源无法集约有效利用。
缺乏复杂的监控系统来在问题影响业务之前检测和修复问题。
从实时数仓的发展和问题来看,它与离线数仓非常相似。后期数据量大之后,出现了各种问题。当时离线数仓是如何解决的?离线数仓通过分层架构将数据解耦,多个业务可以共享数据。实时数据仓库也可以使用分层架构吗?当然可以,但是细节和离线分层还是有一些区别的,后面会讲到。
2. 实时仓库搭建
在方法论方面,实时和离线非常相似。在离线数仓的前期,也详细分析了具体问题。当数据规模增长到一定数量时,将考虑如何管理它。分层是一种非常有效的数据治理方式,所以在谈到如何管理实时数仓时,首先要考虑的是分层的处理逻辑。
实时数据仓库的架构如下:
从上图中,我们详细分析每一层的作用:
我们可以看到,实时数仓和离线数仓的层级非常相似,比如数据源层、明细层、汇总层,甚至应用层,它们的命名模式可能是相同的。但不难发现,两者有很多不同之处:
3. Lambda架构的实时数仓
Lambda 和 Kappa 架构的概念在上一篇文章中已经解释过了。不明白的可以点击链接:一篇了解大数据实时计算的文章
下图展示了基于 Flink 和 Kafka 的 Lambda 架构的具体实践。上层为实时计算,下层为离线计算,横向以计算引擎划分,纵向以实时数仓划分:
Lambda架构是比较经典的架构。过去实时场景不多,主要是线下。加入实时场景后,由于离线和实时的时效性不同,技术生态也不同。Lambda架构相当于附加了一个实时生产环节,在应用层面集成,双向生产,各自独立。这也是在业务应用程序中使用它的一种合乎逻辑的方式。
双通道生产会出现一些问题,比如双处理逻辑、双开发和运维,资源也将成为两个资源环节。由于上述问题,演变出一种 Kappa 架构。
4. Kappa架构的实时数仓
Kappa架构相当于去掉了离线计算部分的Lambda架构,如下图所示:
Kappa架构在架构设计方面比较简单,在生产上是统一的,有一套离线和实时生产的逻辑。但是在实际应用场景中存在比较大的局限性,因为同一张表的实时数据会以不同的方式存储,导致关联时需要跨数据源,对数据的操作有很大的局限性,所以它直接在行业中。用Kappa架构制作和落地的案例很少,场景比较简单。
关于Kappa架构,熟悉实时数仓制作的同学可能会有疑问。因为我们经常面临业务变化,很多业务逻辑需要迭代。如果之前产生的一些数据的口径发生了变化,就需要重新计算,甚至历史数据都会被改写。对于实时数仓,如何解决数据重新计算的问题?
这部分Kappa架构的思路是:首先准备一个可以存储历史数据的消息队列,比如Kafka,这个消息队列可以支持你从某个历史节点重启消费。那么就需要启动一个新任务,从更早的时间节点消费Kafka上的数据,然后当新任务的进度可以和当前正在运行的任务相等时,就可以将任务的下游切换到新任务,可以停止旧任务,也可以删除原来的结果表。
5. 流批结合的实时数仓
随着实时OLAP技术的发展,Doris、Presto等开源OLAP引擎的性能和易用性有了很大的提升。再加上数据湖技术的飞速发展,流和批的结合变得简单。
下图是结合流批的实时数仓:
数据从日志采集统一到消息队列,再到实时数仓。基础数据流的构建是统一的。之后,对于日志实时特性,实时大屏应用使用实时流计算。实时OLAP批处理用于Binlog业务分析。
我们看到,上述架构的流批组合方式和存储方式都发生了变化。卡夫卡被冰山取代。Iceberg是上层计算引擎和底层存储格式之间的中间层。我们可以把它定义成“数据组织格式”,而底层存储还是HDFS,那为什么还要加一个中间层,还不如把对流和批处理结合起来呢?Iceberg 的 ACID 能力可以简化整个流水线的设计,降低整个流水线的延迟,其修改和删除能力可以有效降低开销,提高效率。Iceberg可以有效支持批量高吞吐数据扫描和分区粒度的流计算并发实时处理。
文章实时采集(百度上的图片转word,可以用word去合并一张图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-04-04 10:01
文章实时采集头像,微信头像,视频头像,ppt头像,桌面整体调整(微信发图片过来后再调整),word,excel制作发文字,按照首字拼音排序视频图片调用的是录屏的方式实现的一、发送文字,实现一句话,首字母串出来二、多图合并,一次成型,
可以用word去合并一张图,
大概有这么几个步骤吧,1.手机的传图功能中,一键传图,找到要截取的图片,就可以了2.根据需要,
发图片:html+xml+json+svg
wind里直接获取图片的二维码,
拼图
百度:标注自己想要哪些特征,做成字典。
word可以很方便的插入图片
微软的office可以做图片水印,最麻烦的是如果要用微软自己开发的产品,要用专门的文件软件。
印象笔记可以看见自己所以的笔记。本地可以保存是word的图片。
百度上的图片转word就可以了
,可以把制作好的图片转换成word.
有大把,
直接贴就可以了,
dropbox。微软office里自带拼图功能,内嵌的应该也行。
现有的软件都不行,需要编程实现。 查看全部
文章实时采集(百度上的图片转word,可以用word去合并一张图)
文章实时采集头像,微信头像,视频头像,ppt头像,桌面整体调整(微信发图片过来后再调整),word,excel制作发文字,按照首字拼音排序视频图片调用的是录屏的方式实现的一、发送文字,实现一句话,首字母串出来二、多图合并,一次成型,
可以用word去合并一张图,
大概有这么几个步骤吧,1.手机的传图功能中,一键传图,找到要截取的图片,就可以了2.根据需要,
发图片:html+xml+json+svg
wind里直接获取图片的二维码,
拼图
百度:标注自己想要哪些特征,做成字典。
word可以很方便的插入图片
微软的office可以做图片水印,最麻烦的是如果要用微软自己开发的产品,要用专门的文件软件。
印象笔记可以看见自己所以的笔记。本地可以保存是word的图片。
百度上的图片转word就可以了
,可以把制作好的图片转换成word.
有大把,
直接贴就可以了,
dropbox。微软office里自带拼图功能,内嵌的应该也行。
现有的软件都不行,需要编程实现。
文章实时采集(文章实时采集:拼图片,文字也能转啦,有啥好玩的软件?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-04-02 23:03
文章实时采集:迅捷科技图片转文字:拼图片,文字也能转啦,有啥好玩的软件?今天给大家分享一款easytext插件,可以将现有的文字转换成图片的形式,并保存到本地。文字转换成图片:acdsee也能够转换,但是要手动点。
renzo好玩不复杂亲测有效效果:打字比刷网页有效
扫描全能王,
拼图工具美图秀秀
拼图神器|fotopix有上百张图片可以任意拼接
这个需要的比较多,具体的实用可以看下面的文章。看懂这篇文章,或许下面要做的事情,你都能够做出来!很多人手机拼图软件上搜索拼图,却又很难找到所需的,
熊猫看图,
ocam真的可以试一下
pngimg
最近发现一个强大的搜索引擎:素材id
图虫搜索
复制需要的图片再搜索
以上都是百度经验内容,
adobeai-search
可以试一下chrome自带的图床浏览器,以图搜图,
1.图文搜索——海盗湾[图片]2.画图搜索——qq、迅雷3.各种翻墙软件4.自己创建本地文件夹——现在新建文件夹比之前要方便很多
搞了点谷歌翻译和谷歌图片引擎,
1.photoshopcc2017基本上可以满足,翻译、批量下载、英文名。(觉得用的不爽的图片换成英文名重命名)2.百度识图还是需要一点点英文基础,建议多在线浏览看一下,还要知道一下作者。具体方法可以百度搜图导航即可。3.图腾不错,最近百度云有补丁更新,但是百度的搜索功能不多。推荐pt站——360百科词条“图腾文化”,电脑版用translator。
4.爱图悦3.x强大,照片自动抠图,把图拼成文字。windows系统,手机app可以下载。5.114图片搜索也是不错的,支持主题搜索,但是速度上比不上图片搜索。6.搜狗图片浏览器安卓7.x不错,支持手动翻译。7.uc图片搜索多数人用图片搜索,不喜欢搜狗,不敢多做评价。8.百度美图13.x带了好多预览功能,手机端可以找。9.还有搜索引擎,基本上是收费的,但是也不贵,可以考虑下。10.相册云盘试试吧。 查看全部
文章实时采集(文章实时采集:拼图片,文字也能转啦,有啥好玩的软件?)
文章实时采集:迅捷科技图片转文字:拼图片,文字也能转啦,有啥好玩的软件?今天给大家分享一款easytext插件,可以将现有的文字转换成图片的形式,并保存到本地。文字转换成图片:acdsee也能够转换,但是要手动点。
renzo好玩不复杂亲测有效效果:打字比刷网页有效
扫描全能王,
拼图工具美图秀秀
拼图神器|fotopix有上百张图片可以任意拼接
这个需要的比较多,具体的实用可以看下面的文章。看懂这篇文章,或许下面要做的事情,你都能够做出来!很多人手机拼图软件上搜索拼图,却又很难找到所需的,
熊猫看图,
ocam真的可以试一下
pngimg
最近发现一个强大的搜索引擎:素材id
图虫搜索
复制需要的图片再搜索
以上都是百度经验内容,
adobeai-search
可以试一下chrome自带的图床浏览器,以图搜图,
1.图文搜索——海盗湾[图片]2.画图搜索——qq、迅雷3.各种翻墙软件4.自己创建本地文件夹——现在新建文件夹比之前要方便很多
搞了点谷歌翻译和谷歌图片引擎,
1.photoshopcc2017基本上可以满足,翻译、批量下载、英文名。(觉得用的不爽的图片换成英文名重命名)2.百度识图还是需要一点点英文基础,建议多在线浏览看一下,还要知道一下作者。具体方法可以百度搜图导航即可。3.图腾不错,最近百度云有补丁更新,但是百度的搜索功能不多。推荐pt站——360百科词条“图腾文化”,电脑版用translator。
4.爱图悦3.x强大,照片自动抠图,把图拼成文字。windows系统,手机app可以下载。5.114图片搜索也是不错的,支持主题搜索,但是速度上比不上图片搜索。6.搜狗图片浏览器安卓7.x不错,支持手动翻译。7.uc图片搜索多数人用图片搜索,不喜欢搜狗,不敢多做评价。8.百度美图13.x带了好多预览功能,手机端可以找。9.还有搜索引擎,基本上是收费的,但是也不贵,可以考虑下。10.相册云盘试试吧。
文章实时采集(deepin文章实时采集网页内容保存为json格式数据为中文在线翻译字典)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-04-02 00:06
文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。发表于deepin文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。
deepin在本地搭建的voip网络框架,主要用到两个服务:java虚拟机中windows32通讯网络的nat模块接受请求消息回到java虚拟机中socket网络模块最终采用soc284dn用户协议实现同声传译。
在deepin下用python运行c++的windowssocket网络编程,deepin自带c++运行库。
目前只听说过deepin用java实现了im。
下个微软metero或者黑科技teambition里
三年前用java写了一个本地同声传译voip服务,我用它实现了vc6outlook里,edge里,firefox中文支持;2012-2013年用python实现了一个本地同声传译vi:,
deepin官方javaapi里有
deepin对nat技术包和two-stream多媒体技术封装了。然后支持任意方言(甚至linux上)。
deepin里面有双边实时互译,而且我用的就是手机和电脑之间互译。如果是华中的朋友可以私信我,
1.可以找代理;2.deepin有客户端和服务端的接口,可以实现同传;3.deepin官方编译好的electron或者webos可以直接操作linux进程。 查看全部
文章实时采集(deepin文章实时采集网页内容保存为json格式数据为中文在线翻译字典)
文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。发表于deepin文章实时采集网页内容,并保存为json格式数据,其中json格式数据为中文在线翻译字典。
deepin在本地搭建的voip网络框架,主要用到两个服务:java虚拟机中windows32通讯网络的nat模块接受请求消息回到java虚拟机中socket网络模块最终采用soc284dn用户协议实现同声传译。
在deepin下用python运行c++的windowssocket网络编程,deepin自带c++运行库。
目前只听说过deepin用java实现了im。
下个微软metero或者黑科技teambition里
三年前用java写了一个本地同声传译voip服务,我用它实现了vc6outlook里,edge里,firefox中文支持;2012-2013年用python实现了一个本地同声传译vi:,
deepin官方javaapi里有
deepin对nat技术包和two-stream多媒体技术封装了。然后支持任意方言(甚至linux上)。
deepin里面有双边实时互译,而且我用的就是手机和电脑之间互译。如果是华中的朋友可以私信我,
1.可以找代理;2.deepin有客户端和服务端的接口,可以实现同传;3.deepin官方编译好的electron或者webos可以直接操作linux进程。
文章实时采集(夜间更新你最害怕的是你的对手知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-04-01 17:21
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?
首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。
1、 及时抓取文章 让搜索引擎知道这个文章。
2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。
二、文章标记作者或版本。
有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。
第三,为文章添加一些特性。
1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。
2、在 文章 中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制的人文章平时比较懒,有的人可以直接复制粘贴。
四、过滤网页的主要特点
大多数人在使用鼠标右键复制文章的时候,如果技术不受这个功能的影响,无疑会增加采集的麻烦。
五、每晚更新
你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。
一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。 查看全部
文章实时采集(夜间更新你最害怕的是你的对手知道吗?)
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?
首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。
1、 及时抓取文章 让搜索引擎知道这个文章。
2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。
二、文章标记作者或版本。
有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。
第三,为文章添加一些特性。
1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。
2、在 文章 中添加您自己的品牌词汇
3、添加一些内部链接,因为喜欢复制的人文章平时比较懒,有的人可以直接复制粘贴。
四、过滤网页的主要特点
大多数人在使用鼠标右键复制文章的时候,如果技术不受这个功能的影响,无疑会增加采集的麻烦。
五、每晚更新
你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。
一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。
文章实时采集(夜间更新你最害怕的是你对手知道你的习惯)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-01 17:18
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。1、 及时抓取文章 让搜索引擎知道这个文章。2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。二、文章标记作者或版本。织梦58 认为有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。
第三,为文章添加一些特性。1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。2、在文章3、中添加自己的品牌词汇,添加一些内链,因为喜欢复制文章的人通常比较懒惰,有的人可以直接复制粘贴。4、当及时添加文章文章时,搜索引擎会判断文章的原创性,参考时间因素。四、过滤网页按键功能大部分人使用鼠标右键复制时文章,如果技术不受此功能影响,无疑会增加采集的麻烦。五、 夜间更新 你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。 查看全部
文章实时采集(夜间更新你最害怕的是你对手知道你的习惯)
许多人讨厌他们的 原创文章 立即被他人复制。有些人甚至用它来发送一些垃圾邮件链。我特别相信很多老人都遇到过这样的情况。有时他们的努力不如采集。我们如何处理这种情况?首先,尝试在你的竞争对手采集它之前让搜索引擎收录这个 文章。1、 及时抓取文章 让搜索引擎知道这个文章。2、Ping 百度网站管理员自己的文章链接,这也是百度官方告诉我们的方式。二、文章标记作者或版本。织梦58 认为有时无法阻止某人复制您的 文章,但这也是一种书面交流和提示,总比没有好。
第三,为文章添加一些特性。1、例如文章中的标签代码如n1、n2、color等,搜索引擎会对这些内容更加敏感,从而加深感知原创 的判断。2、在文章3、中添加自己的品牌词汇,添加一些内链,因为喜欢复制文章的人通常比较懒惰,有的人可以直接复制粘贴。4、当及时添加文章文章时,搜索引擎会判断文章的原创性,参考时间因素。四、过滤网页按键功能大部分人使用鼠标右键复制时文章,如果技术不受此功能影响,无疑会增加采集的麻烦。五、 夜间更新 你最大的恐惧是你的对手知道你的习惯,尤其是在白天。很多人喜欢在白天更新自己的文章,却被别人盯着看。文章 立即被抄袭。一旦可以看到这些方法应用于我们的 网站,我相信这可以减少 文章 集合的数量。
文章实时采集(java最近项目中须要实时采集业务数据库CDC数据(这里数据) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-04-01 00:27
)
业务描述:java
最近项目中需要实时采集业务数据库CDC数据(这里的数据已经序列化成avro格式数据),这里我们使用Flume+Hdfs做技术架构。数据库
了解 Flume 的朋友都知道,它的组件分为三个部分:source、channel、sink。具体原理部分在此不再赘述。可以查看官网或者flume技术博客。这里就讲讲实现过程和加坑之路。阿帕奇
来自业务的数据存储在kafka中,所以source端使用kafkaSource,即kafkaConsumer,sink使用hdfsSink,channel使用file type。json
hdfsSink 编写的文件格式有两种:文本文件和序列文件。无论选择哪种文件格式,登陆hdfs后都不能直接使用。前面说过,业务数据已经序列化成avro格式,但是要求是hdfs上的数据必须是直接可用的。建筑学
考虑了几种解决方案:maven
1、使用hive建立一个外部表来关联hdfs上的数据。这里有一个问题。虽然hive支持读取seq文件格式,但是seq文件中的数据(hdfsSink使用Sequence File格式存储)是avro格式的。我尝试建表查询,结果是乱码,文本文件也是这样。这个方法通过了。其实hive可以直接读取avro格式的指定数据的schema,但是。. . 我的文件格式不起作用,它可以通过实现接口本身将数据序列化为avro格式。哎呀
2.使用API读取avro数据。这样,首先需要使用API读取seq文件数据,然后使用avro API进行反序列化。根据hadoop指导书hadoop IO章节中的demo,读取seq文件。然后我去avro官网的api,发现官网给出的demo是把数据序列化成avro文件,然后反序列化avro文件,和个人需求不一样,emmm。. . 继续翻API,好像找到了一个可以使用的类,但是最后还是不成功,这个方法也通过了。网址
3.使用kafkaConsumer自带的参数反序列化avro。我以这种方式在互联网上阅读了很多博客。千篇一律的文章可能与实际需求不符。有的博客说直接配置这两个参数:code
“key.deserializer”, "org.apache.kafka.common.serialization.StringDeserializer"
“value.deserializer”, "org.apache.kafka.common.serialization.ByteArrayDeserializer"
首先,我不知道如何反序列化这样的数据,其次,kafkaConsumer的默认参数就是这两个。形式
以下是正确配置的(在我看来):
“key.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“value.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“schema.registry.url”, “http://avro-schema.user-defined.com”
这里的key的反序列化方式可以根据业务给出的格式来确定。这里的键值是 avro 格式。
看到这两个参数也给了,你可以根据自己的需要添加,我这里没用:
kafka.consumer.specific.avro.reader = true
useFlumeEventFormat = true
本以为这样可以,但结果往往不如预期,直接报错:
解决了几个错误后,我终于发现这个错误是无法反转序列的根本问题。因此,查看kafkaSource源码,发现类型转换有问题(只有这一次),即图中提到的GenericRecord转换String错误。
解决方法:挠头。. .
Flume支持自定义源码,于是赶紧翻到flume书,按照书中的demo写了一个源码。具体实现其实就是这行代码:
ConsumerRecords records = consumer.poll(100)
改变消费者返回的记录类型,从而最终实现avro反序列化数据后的json格式。但这还没有结束。虽然实现了功能,但是自己写的代码肯定不如源码质量好。都想把源码的kafkaSource拿出来改一下看看效果。整个周期大约花了一周时间。. . 这不简单。以上如有错误,请指出并指正,谢谢~~
下面是用到的pom文件,注意版本,注意版本,注意版本,重要的说三遍。由于版本不对,拿了一个老版本的源码,改了半天,各种坑。汇合的来源必须匹配。没有 Maven 存储库。Cloudera 取决于我的情况。
org.apache.flume.flume-ng-sources
flume-kafka-source
1.6.0-cdh5.16.2
${scope.version}
org.apache.flume
flume-ng-core
1.6.0-cdh5.16.2
${scope.version}
io.confluent
kafka-avro-serializer
5.2.2
${scope.version}
confluent
Confluent
http://packages.confluent.io/maven/
cloudera
https://repository.cloudera.co ... epos/ 查看全部
文章实时采集(java最近项目中须要实时采集业务数据库CDC数据(这里数据)
)
业务描述:java
最近项目中需要实时采集业务数据库CDC数据(这里的数据已经序列化成avro格式数据),这里我们使用Flume+Hdfs做技术架构。数据库
了解 Flume 的朋友都知道,它的组件分为三个部分:source、channel、sink。具体原理部分在此不再赘述。可以查看官网或者flume技术博客。这里就讲讲实现过程和加坑之路。阿帕奇
来自业务的数据存储在kafka中,所以source端使用kafkaSource,即kafkaConsumer,sink使用hdfsSink,channel使用file type。json
hdfsSink 编写的文件格式有两种:文本文件和序列文件。无论选择哪种文件格式,登陆hdfs后都不能直接使用。前面说过,业务数据已经序列化成avro格式,但是要求是hdfs上的数据必须是直接可用的。建筑学
考虑了几种解决方案:maven
1、使用hive建立一个外部表来关联hdfs上的数据。这里有一个问题。虽然hive支持读取seq文件格式,但是seq文件中的数据(hdfsSink使用Sequence File格式存储)是avro格式的。我尝试建表查询,结果是乱码,文本文件也是这样。这个方法通过了。其实hive可以直接读取avro格式的指定数据的schema,但是。. . 我的文件格式不起作用,它可以通过实现接口本身将数据序列化为avro格式。哎呀
2.使用API读取avro数据。这样,首先需要使用API读取seq文件数据,然后使用avro API进行反序列化。根据hadoop指导书hadoop IO章节中的demo,读取seq文件。然后我去avro官网的api,发现官网给出的demo是把数据序列化成avro文件,然后反序列化avro文件,和个人需求不一样,emmm。. . 继续翻API,好像找到了一个可以使用的类,但是最后还是不成功,这个方法也通过了。网址
3.使用kafkaConsumer自带的参数反序列化avro。我以这种方式在互联网上阅读了很多博客。千篇一律的文章可能与实际需求不符。有的博客说直接配置这两个参数:code
“key.deserializer”, "org.apache.kafka.common.serialization.StringDeserializer"
“value.deserializer”, "org.apache.kafka.common.serialization.ByteArrayDeserializer"
首先,我不知道如何反序列化这样的数据,其次,kafkaConsumer的默认参数就是这两个。形式
以下是正确配置的(在我看来):
“key.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“value.deserializer”, "io.confluent.kafka.serializers.KafkaAvroDeserializer"
“schema.registry.url”, “http://avro-schema.user-defined.com”
这里的key的反序列化方式可以根据业务给出的格式来确定。这里的键值是 avro 格式。
看到这两个参数也给了,你可以根据自己的需要添加,我这里没用:
kafka.consumer.specific.avro.reader = true
useFlumeEventFormat = true
本以为这样可以,但结果往往不如预期,直接报错:
解决了几个错误后,我终于发现这个错误是无法反转序列的根本问题。因此,查看kafkaSource源码,发现类型转换有问题(只有这一次),即图中提到的GenericRecord转换String错误。
解决方法:挠头。. .
Flume支持自定义源码,于是赶紧翻到flume书,按照书中的demo写了一个源码。具体实现其实就是这行代码:
ConsumerRecords records = consumer.poll(100)
改变消费者返回的记录类型,从而最终实现avro反序列化数据后的json格式。但这还没有结束。虽然实现了功能,但是自己写的代码肯定不如源码质量好。都想把源码的kafkaSource拿出来改一下看看效果。整个周期大约花了一周时间。. . 这不简单。以上如有错误,请指出并指正,谢谢~~
下面是用到的pom文件,注意版本,注意版本,注意版本,重要的说三遍。由于版本不对,拿了一个老版本的源码,改了半天,各种坑。汇合的来源必须匹配。没有 Maven 存储库。Cloudera 取决于我的情况。
org.apache.flume.flume-ng-sources
flume-kafka-source
1.6.0-cdh5.16.2
${scope.version}
org.apache.flume
flume-ng-core
1.6.0-cdh5.16.2
${scope.version}
io.confluent
kafka-avro-serializer
5.2.2
${scope.version}
confluent
Confluent
http://packages.confluent.io/maven/
cloudera
https://repository.cloudera.co ... epos/

