
搜索引擎主题模型优化
企业网站如何进行SEO优化,提升站点在SERP中排名
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-06-20 06:14
不管人们怎么谈,那些专注于品牌塑造的公司都应该拥有自己的独立公司网站,并对SEO采取积极的态度,即使打造知名品牌并不容易。没有其他理由可以这么说。搜索引擎上的用户都是有实际需求的用户。无论这种需求是购买产品的即时需求还是信息需求,其他网络策略的效率都低得多,企业信息能否及时传递给“潜在客户”。
在之前的文章文章中,我们不止一次提到搜索引擎是内容供应和搜索需求的对接平台。品牌的新客户和您的新受众都在这些用户中。公司有什么理由让客户远离?这个文章将讨论企业网站如何优化SEO,提高网站在SERP中的排名。
什么是搜索引擎优化
SEO 是英文术语 Search Engine Optimization 的首字母缩写词。简体中文会翻译成搜索引擎优化,正统字体会翻译成搜索引擎优化。我觉得就白帽SEO而言,显然后者翻译的名字更靠谱。 SEO相对于搜索引擎的付费广告业务,针对的是自然搜索流量。当用户使用搜索引擎寻找他们需要的东西时,搜索引擎会提供一系列最相关的页面。 SEO 是通过提高相关性和价值来获取自然搜索流量的过程。
有些人简单地将 SEO 程序分为三个部分:创建优秀的内容、页内优化和链接构建。这也被认为是一个基本的 SEO 过程
至于什么是SEO,你可以从不同的角度来解释。 SEO是一种营销策略,这是无可非议的,从营销的角度来看,这是最现实的解释。学过营销课程的朋友可能都知道,营销管理就是需求的管理,涉及发现需求、适应需求、创造需求。营销信息的传播是品牌的理念和主张。它寻求适应客户心中的固有信念。有默契和噪音。企业需要控制一致性,消除噪声的影响。
如何理解SEO
如前所述,SEO 的目标是从搜索引擎获取自然的搜索流量。用营销的语言来说,就是获取目标受众。要实现这个目标,实际上需要平衡企业站点、搜索引擎、用户需求和搜索习惯三个方面的关系。传统营销中的市场细分、潜在客户分析和目标客户识别程序仍然有效。搜索引擎设定了某些原则来规范 SEO 行为。如果他们违反了这些原则,他们可能在 SERP 中表现不佳。严重违规也可能受到处罚,将网站降级甚至从索引数据库中删除。百度和谷歌都提供了 SEO 指南。
关键词 和查询词
用户在搜索引擎中输入查询词,搜索引擎匹配索引库中最相关的结果并呈现给用户。所谓的“关键词optimization”其实就是响应目标客户的查询词。 SEO 行业已将关键字从最高转换率分为“虚假”和“噪音”查询。在实践中,人们经常使用“核心词汇”、“长尾关键词”和“brand关键词”。 ”、“非品牌关键词”等。
网站的吸引力
有吸引力的网站 是一个对目标客户很有价值的网站。这些网站往往用户体验好,内容丰富,针对性强,值得信赖。目标客户可能会长时间停留在网站上,了解各种信息有助于提高网站的搜索性能。成功的SEO离不开网站的吸引力。有人说SEO是平衡的艺术。这并非没有道理。
SEO 是一种营销策略
毫无疑问,SEO可以直接为企业带来收入。至于为什么SEO是一种独特而高效的策略,我在很多文章中都讲过。传统营销一直在使用各种方法寻找潜在客户,但搜索引擎中的用户本身是有需求的,你只需要及时响应目标客户即可。
Enterprise网站如何开发SEO
有人可能会问,SEO是一项非常复杂的技术工作吗?营销人员可以自己做 SEO 吗?
如果一定要掌握各种算法,从“底层”打败搜索引擎,那么SEO不仅是一项非常复杂的技术任务,营销人员也不再是营销人员。 SEO 有各种各样的想法,但它们基本上都在搜索引擎友好的框架内。他们响应用户需求,遵守搜索引擎规范,并提高网站 的吸引力。坚持这三个方面,你的公司网站一定会有出色的表现。
那么企业网站是怎么做SEO的呢?简而言之,您可以将其分为两部分,即ON THE PAGE SEO和OFF THE PAGE SEO),最终目标指向域的权威。涉及的话题非常多,比如空间域名、网站structure、网站themes、内容、HTML、内外部链接等,以下是完整的企业SEO策略、SEO指南:
1、SEO 影响成功的因素很多
2、网站结构和主题相关性
3、HTML 代码结构优化
4、Homepage,着陆页优化策略
5、Link 优化:内链和外链策略
6、移动网站优化策略
帖子浏览量:666 查看全部
企业网站如何进行SEO优化,提升站点在SERP中排名
不管人们怎么谈,那些专注于品牌塑造的公司都应该拥有自己的独立公司网站,并对SEO采取积极的态度,即使打造知名品牌并不容易。没有其他理由可以这么说。搜索引擎上的用户都是有实际需求的用户。无论这种需求是购买产品的即时需求还是信息需求,其他网络策略的效率都低得多,企业信息能否及时传递给“潜在客户”。
在之前的文章文章中,我们不止一次提到搜索引擎是内容供应和搜索需求的对接平台。品牌的新客户和您的新受众都在这些用户中。公司有什么理由让客户远离?这个文章将讨论企业网站如何优化SEO,提高网站在SERP中的排名。
什么是搜索引擎优化
SEO 是英文术语 Search Engine Optimization 的首字母缩写词。简体中文会翻译成搜索引擎优化,正统字体会翻译成搜索引擎优化。我觉得就白帽SEO而言,显然后者翻译的名字更靠谱。 SEO相对于搜索引擎的付费广告业务,针对的是自然搜索流量。当用户使用搜索引擎寻找他们需要的东西时,搜索引擎会提供一系列最相关的页面。 SEO 是通过提高相关性和价值来获取自然搜索流量的过程。
 https://www.seozone.net/wp-con ... 1.jpg 500w" />
https://www.seozone.net/wp-con ... 1.jpg 500w" />有些人简单地将 SEO 程序分为三个部分:创建优秀的内容、页内优化和链接构建。这也被认为是一个基本的 SEO 过程
至于什么是SEO,你可以从不同的角度来解释。 SEO是一种营销策略,这是无可非议的,从营销的角度来看,这是最现实的解释。学过营销课程的朋友可能都知道,营销管理就是需求的管理,涉及发现需求、适应需求、创造需求。营销信息的传播是品牌的理念和主张。它寻求适应客户心中的固有信念。有默契和噪音。企业需要控制一致性,消除噪声的影响。
如何理解SEO
如前所述,SEO 的目标是从搜索引擎获取自然的搜索流量。用营销的语言来说,就是获取目标受众。要实现这个目标,实际上需要平衡企业站点、搜索引擎、用户需求和搜索习惯三个方面的关系。传统营销中的市场细分、潜在客户分析和目标客户识别程序仍然有效。搜索引擎设定了某些原则来规范 SEO 行为。如果他们违反了这些原则,他们可能在 SERP 中表现不佳。严重违规也可能受到处罚,将网站降级甚至从索引数据库中删除。百度和谷歌都提供了 SEO 指南。
关键词 和查询词
用户在搜索引擎中输入查询词,搜索引擎匹配索引库中最相关的结果并呈现给用户。所谓的“关键词optimization”其实就是响应目标客户的查询词。 SEO 行业已将关键字从最高转换率分为“虚假”和“噪音”查询。在实践中,人们经常使用“核心词汇”、“长尾关键词”和“brand关键词”。 ”、“非品牌关键词”等。
网站的吸引力
有吸引力的网站 是一个对目标客户很有价值的网站。这些网站往往用户体验好,内容丰富,针对性强,值得信赖。目标客户可能会长时间停留在网站上,了解各种信息有助于提高网站的搜索性能。成功的SEO离不开网站的吸引力。有人说SEO是平衡的艺术。这并非没有道理。
 https://www.seozone.net/wp-con ... 6.jpg 500w" />
https://www.seozone.net/wp-con ... 6.jpg 500w" />SEO 是一种营销策略
毫无疑问,SEO可以直接为企业带来收入。至于为什么SEO是一种独特而高效的策略,我在很多文章中都讲过。传统营销一直在使用各种方法寻找潜在客户,但搜索引擎中的用户本身是有需求的,你只需要及时响应目标客户即可。
Enterprise网站如何开发SEO
有人可能会问,SEO是一项非常复杂的技术工作吗?营销人员可以自己做 SEO 吗?
如果一定要掌握各种算法,从“底层”打败搜索引擎,那么SEO不仅是一项非常复杂的技术任务,营销人员也不再是营销人员。 SEO 有各种各样的想法,但它们基本上都在搜索引擎友好的框架内。他们响应用户需求,遵守搜索引擎规范,并提高网站 的吸引力。坚持这三个方面,你的公司网站一定会有出色的表现。
那么企业网站是怎么做SEO的呢?简而言之,您可以将其分为两部分,即ON THE PAGE SEO和OFF THE PAGE SEO),最终目标指向域的权威。涉及的话题非常多,比如空间域名、网站structure、网站themes、内容、HTML、内外部链接等,以下是完整的企业SEO策略、SEO指南:
1、SEO 影响成功的因素很多
2、网站结构和主题相关性
3、HTML 代码结构优化
4、Homepage,着陆页优化策略
5、Link 优化:内链和外链策略
6、移动网站优化策略
帖子浏览量:666
4.3关键词设定要突出网站的选择必须遵循的原则
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-06-20 06:10
4.3 关键词设置突出
网站 的关键词 很重要。它决定了网站是否可以被用户搜索到,所以必须特别注意关键词的选择。 关键词的选择一定要突出并遵循一定的原则,比如:关键词要与网站话题相关,不要盲目追求流行词汇;避免使用含义广泛的通用词汇;根据产品的类型和特点,尽可能选择具体的词;选择人们在使用搜索引擎时经常使用的词,这些词与网站 需要推广的产品和服务相关。 5~10个关键词的数量比较适中,密度可以在2%-8%。注意两个网页最重要最显眼的位置Page Title和Heading,反映关键词,网页内容、图片alt属性、META标签等网页描述可以不同。设置程度突出关键词。
4.4 网站架构层次一定要清楚
网站 结构中尽量避免使用框架结构,导航栏中尽量不要使用FLASH按钮[3]。首先要注意网站首页的设计,因为网站首页比其他网页更容易被搜索引擎检测到。通常网站的主页文件应该放在网站的根目录下,因为根目录下的检索速度是最快的。其次需要注意的是网站层级不要太多(即子目录),一级目录不要超过两级,详细目录不要超过四级。最后,网站的导航尽量使用纯文本,因为文字比图片传达的信息更多。
4.5 页面容量应该合理化
网页分为静态网页和动态网页两种。动态网页是具有交互功能的网页,即通过数据库搜索返回数据,使得搜索引擎搜索时间长,一旦数据库内容更新,搜索引擎抓取的数据不再准确,所以收录动态网页搜索引擎很少,排名结果不好。而且静态网页不具备交互功能,即简单的信息介绍,搜索引擎搜索时间短且准确,所以我愿意收录,排名结果更好。所以网站应该尽量使用静态网页,减少使用动态网页。
页面越小,显示速度越快,对搜索引擎蜘蛛程序的友好度越高。因此,在创建网页时,尽量精简 HTML 代码。通常,页面大小不超过 15kB。网页中的 Java.script 和 CSS 应尽可能与网页分开。应该鼓励遵循 W3C 的规范并使用更标准化的 XHTML 和 XML 作为显示格式。
4.6 网站Navigation 应该是清晰的
搜索引擎使用专有蜘蛛程序找出每个网页上的 HTML 代码。当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛程序访问所有页面需要很长时间,所以网站的导航需要方便蜘蛛程序索引收录。你可以根据你的网站结构创建网站mapsimemap.html,列出网站在web地图中的所有链接,把网站中的所有文件放在网站的根目录下。 网站Map 可以增加搜索引擎的友好度,让蜘蛛程序可以快速访问整个网站的所有网页和栏目。
4.7 网站post 更新
为了更好的实现与搜索引擎的对话,主动向搜索引擎提交优化的企业网站,让他们免费收录,争取更好的自然排名[4]。如果网站可以定期更新,对搜索引擎收录来说更容易。所以网站的合理更新也是搜索引擎优化的重要手段。
5 结论(结论)
为了提高电子商务的竞争力,企业网站会采用多种线上推广的方式。针对不同的搜索引擎进行合理的搜索引擎优化是网站维护中的一项重要工作。 网站的排名规则在搜索引擎中经常更新,规则的变化也会影响网站的排名,导致网站的排名发生变化。所以在网站的维护中,应该根据搜索引擎排名算法的变化更新自己的网站搜索引擎优化,以适应变化。
参考资料
[1] 刘冰,同。于勇等,译。 WEB数据挖掘[M].北京:清华大学出版社,2009.
[2] 赖文文.电子商务网站搜索引擎优化研究[J].科技创新指南,2011,21:21.
[3] 刘芳。 E-commerce网站市场初探[J].中小企业管理与技术,2011,24:282.
[4] 张娜. SEO技术在电子商务中的应用网站[J].中小企业管理与技术,2011,1:246. 查看全部
4.3关键词设定要突出网站的选择必须遵循的原则
4.3 关键词设置突出
网站 的关键词 很重要。它决定了网站是否可以被用户搜索到,所以必须特别注意关键词的选择。 关键词的选择一定要突出并遵循一定的原则,比如:关键词要与网站话题相关,不要盲目追求流行词汇;避免使用含义广泛的通用词汇;根据产品的类型和特点,尽可能选择具体的词;选择人们在使用搜索引擎时经常使用的词,这些词与网站 需要推广的产品和服务相关。 5~10个关键词的数量比较适中,密度可以在2%-8%。注意两个网页最重要最显眼的位置Page Title和Heading,反映关键词,网页内容、图片alt属性、META标签等网页描述可以不同。设置程度突出关键词。
4.4 网站架构层次一定要清楚
网站 结构中尽量避免使用框架结构,导航栏中尽量不要使用FLASH按钮[3]。首先要注意网站首页的设计,因为网站首页比其他网页更容易被搜索引擎检测到。通常网站的主页文件应该放在网站的根目录下,因为根目录下的检索速度是最快的。其次需要注意的是网站层级不要太多(即子目录),一级目录不要超过两级,详细目录不要超过四级。最后,网站的导航尽量使用纯文本,因为文字比图片传达的信息更多。
4.5 页面容量应该合理化
网页分为静态网页和动态网页两种。动态网页是具有交互功能的网页,即通过数据库搜索返回数据,使得搜索引擎搜索时间长,一旦数据库内容更新,搜索引擎抓取的数据不再准确,所以收录动态网页搜索引擎很少,排名结果不好。而且静态网页不具备交互功能,即简单的信息介绍,搜索引擎搜索时间短且准确,所以我愿意收录,排名结果更好。所以网站应该尽量使用静态网页,减少使用动态网页。
页面越小,显示速度越快,对搜索引擎蜘蛛程序的友好度越高。因此,在创建网页时,尽量精简 HTML 代码。通常,页面大小不超过 15kB。网页中的 Java.script 和 CSS 应尽可能与网页分开。应该鼓励遵循 W3C 的规范并使用更标准化的 XHTML 和 XML 作为显示格式。
4.6 网站Navigation 应该是清晰的
搜索引擎使用专有蜘蛛程序找出每个网页上的 HTML 代码。当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛程序访问所有页面需要很长时间,所以网站的导航需要方便蜘蛛程序索引收录。你可以根据你的网站结构创建网站mapsimemap.html,列出网站在web地图中的所有链接,把网站中的所有文件放在网站的根目录下。 网站Map 可以增加搜索引擎的友好度,让蜘蛛程序可以快速访问整个网站的所有网页和栏目。
4.7 网站post 更新
为了更好的实现与搜索引擎的对话,主动向搜索引擎提交优化的企业网站,让他们免费收录,争取更好的自然排名[4]。如果网站可以定期更新,对搜索引擎收录来说更容易。所以网站的合理更新也是搜索引擎优化的重要手段。
5 结论(结论)
为了提高电子商务的竞争力,企业网站会采用多种线上推广的方式。针对不同的搜索引擎进行合理的搜索引擎优化是网站维护中的一项重要工作。 网站的排名规则在搜索引擎中经常更新,规则的变化也会影响网站的排名,导致网站的排名发生变化。所以在网站的维护中,应该根据搜索引擎排名算法的变化更新自己的网站搜索引擎优化,以适应变化。
参考资料
[1] 刘冰,同。于勇等,译。 WEB数据挖掘[M].北京:清华大学出版社,2009.
[2] 赖文文.电子商务网站搜索引擎优化研究[J].科技创新指南,2011,21:21.
[3] 刘芳。 E-commerce网站市场初探[J].中小企业管理与技术,2011,24:282.
[4] 张娜. SEO技术在电子商务中的应用网站[J].中小企业管理与技术,2011,1:246.
为什么要了解搜索引擎优化的真相,最好是去真正的来源
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-06-20 06:03
文章directory
学习 SEO 优化是一项挑战。一方面,没有单一的知识体系,必须从许多不同的地方一点一点地采集信息。另一方面,信息经常被误解,产生错误的排名因素和牵强的理论。这就是为什么要了解搜索引擎优化的真相,最好去真正的源头——谷歌本身。
过去,我在谷歌上讨论过一些搜索引擎优化信息的来源,即SEO Starter Guide和Quality Rater Guide。今天,我们将更深入地探索谷歌的搜索专利——这些文档解释了谷歌如何评估和排列搜索结果的各个方面。
了解这些专利是什么,为什么要研究它们,以及哪些专利可以帮助您制定更好的 SEO 优化策略。
什么是 Google 搜索专利
每当 Google 发明一种改进搜索的新方法时,它都会向美国专利商标局 (USPTO) 提交专利申请。专利是详细描述搜索算法每一位的技术文档。他们的作用是保护创新的搜索方法不被复制,从而使 Google 比竞争对手的搜索引擎更具优势。
为什么要研究 Google 搜索专利
值得一提的是,专利技术不一定是搜索算法的一部分。专利申请和技术的实际实施之间可能会有一些延迟。也有可能该技术从未实现,或者专利在达到最终状态之前经历了多次迭代。专利申请基本上是谷歌想要保护的想法的集合,但实际上它可能会被使用,也可能不会被使用。
此外,这些专利提供了对算法如何工作的独特见解——在许多方面,它是最真实的 SEO 知识形式。研究专利可以让您预测即将到来的算法更新并确定新的和现有的排名信号。您可以利用这些知识来验证您的网站 过时并验证您当前的 SEO 策略。
在哪里可以找到 Google 搜索专利
专利申请和授权专利可以在美国专利商标局官方网站进行检索——只需添加谷歌作为申请人名称,查看文件名即可。问题是谷歌申请了数千项专利,其中大部分与搜索引擎优化无关。另外,专利在某种程度上是技术文件,理解它们可能需要一些习惯。因此,以这种方式理解专利对于普通读者来说可能不是最有效的方式。
更好的方法是跟踪专利爱好者-SEO,他们监控专利更新并被社会公认为专利专家。他们每年组织数百项专利,只为挑选那些对搜索引擎优化真正重要的专利。虽然多年来一直有一些专利专家,但Bill Slawski 是撰写谷歌搜索专利历史最长的人,他在个人博客(SEO by the Sea)中重点介绍了最重要的更新。
10 项 SEO 优化 Google 搜索专利
在本节中,我将列出一些专利,这些专利描述了新颖和/或有争议的优化思路,并且对 SEO 优化者具有实际意义。我将跳过描述著名排名因素的专利和搜索引擎优化经理几乎无法控制的主题的专利。
1. 内容聚类
该专利描述了按主题对网站 和页面进行分组,并创建可描述为专家集群的内容。然后,在为相关查询提供搜索结果时,优先考虑来自这些集群的内容。
有趣的是,不属于集群的内容可能会被搜索引擎完全跳过而不做任何评估,而不管它是否有任何其他内容质量信号。
SEO的意义
明显的含义是,对于SEO来说,在不偏离你主要专业领域的情况下,在特定领域构建网站内容是有益的。在实践中,这意味着创建一个分层的内容计划并围绕较大的支柱页面排列较小的页面。
2. 基于文件开始日期的文件分级
该专利至少在一定程度上讨论了根据年龄对页面进行排名。确定页面年龄的方法有很多种,但最常用的方法是通过第一次抓取的日期来确定。
该专利还说,它还可以使用页面的年龄来计算平均链接率,即页面上的反向链接总数除以页面的年龄。然后,平均链路速率也被用作偏序因子。
SEO意义
虽然根据年龄对页面进行排名并不是什么新鲜事,但平均链接率是一个您很少听到的概念。这意味着页面越旧,每个反向链接的权重就越小。因此,如果您希望您的页面排名,您必须随着它变得越来越老而不断添加越来越多的反向链接。实现这一目标的一种方法是创建常青内容,经常更新,并通过营销渠道回收利用。
3. 基于用户上下文的搜索引擎
多年来,Google 发布了一系列与关键字相关的文档,将其排名标准从关键字更改为关键字词组再到上下文词。最新的这些文档描述了词库的构建,其中不仅收录关键字,还收录上下文词,这些词与主题松散相关。
SEO的意义
从目前的情况来看,谷歌可能更喜欢带有上下文词和传统关键字的页面。例如,如果您正在创建一个关于最佳羽绒服的页面,Google 可能会看到一些不太明显的字词,例如水、徒步旅行和鹅。
4. 观看时间排名
从视频观看时间专利到网站duration 性能专利,谷歌似乎将访问时长作为排名因素。这些专利描述了特定类型内容的基准访问持续时间,然后根据网页相对于基准的性能对网页进行排名。
SEO的意义
寻找保持访问者参与度的方法可能对您的排名有益。实现这一目标的一种显而易见的方法是创建高质量、全面的内容,其中包括各种媒体和互动元素(图片、视频、投票、评论提示等)。
5. 根据隐式用户反馈修改搜索结果排名
过去,该专利使用简单的点击率作为搜索结果排名的一部分,但最近升级为使用加权点击率。较新的版本试图找到点击次数和访问时间之间的中点,这听起来很像跳出率的变化。基本上,您的代码段获得的点击次数越多,用户停留的时间就越长,效果就越好。
SEO的意义
Google 是否使用行为指标对网页进行排名一直存在争议。不管实际情况如何,该技术已经获得专利,所以机会来了。这意味着您应该格外小心,让您的代码片段在搜索结果中不可抗拒,从标题到元描述,再到使用结构化数据增强代码片段。
6. 预测页面质量
Google 已经申请了许多使用 n-gram(字符串)来评估副本质量的专利。它的工作方式是该算法使用一组已知质量的页面来创建语言模型。然后它使用新页面上的模型来确定写作与质量基准的相似程度,并相应地对页面进行排名。
SEO的意义
N-gram 可用于识别乱码内容、关键字填充和低质量写作。这意味着您可能应该远离抓取的、自动生成的内容,并聘请经验丰富的作家,或者至少使用校对人员来完善您的副本。
7.意图查询的自然语言搜索结果
该专利描述了一种用于确定特征片段的资格的机制。基本上,只要有一个意图非常明确的自然语言查询,比如“七大罪”是什么,谷歌就会扫描排名靠前的页面,寻找一个听起来与查询非常相似的标题,然后一个简洁的答案,例如七大罪的清单。
SEO意义
请记住,副本中的每个标题 (H2-H6)) 都可能用于丰富的代码片段。基本上,每个标题都必须像查询(自然语言+关键字)一样写,标题后面的文字应该提供查询的答案。
以下是丰富素材片段的完美示例-其中一个标题与如何更换尿布的查询完全匹配,后面是编号步骤列表:
8.基于用户行为/特征数据的排名文档
这是一个更麻木的专利阅读,但它本质上归结为您的锚文本的信息量。该专利描述了用于查看用户点击链接可能性的各种指标。概率越高,链路传输的能量就越多。
SEO意义
为反向链接和内部链接创建锚文本时,请遵循最佳做法。确保锚点代表它指向的页面,收录关键字,并被上下文词包围。
9.确定资源的质量度量
另一项与链接相关的专利使我们能够深入了解每个反向链接的价值。该专利描述了一种通过查看链接带来的流量来衡量链接价值的方法。如果实际用户没有点击链接,链接将不会传递任何权重值。
SEO的意义
当您构建反向链接时,尤其是通过访客帖子,您可能倾向于在每个帖子中收录尽可能多的链接。好吧,根据专利,你会浪费时间,因为没有点击的链接几乎没有用。因此,您还可以收录更少的链接并增加每个链接被点击的机会。同样,没有人访问过的网站购买链接可能没有用。
10. 确定本地专家进行本地搜索
该专利描述了根据本地专家的加权评论对本地结果的评级。使用总阈值来确定专家的数量。这些阈值包括评论总数、本地评论数量以及特定类别公司的评论数量。 “Google 我的商家”确实将一些评论者标记为本地指南,因此似乎该专利至少已部分实施。
SEO的意义
虽然您无法通过本地指南专门征求 GMB 评论,但还是有一些方法可以鼓励更多客户评论您的业务。您可以在开始业务时亲自询问他们、向他们发送跟进电子邮件、为忠诚度计划提供奖励,或使用社交媒体让您的客户对 GMB 留下一些反馈。
此外,如果您发现任何当地导游给您差评,您必须加倍努力让他们满意。
最后的想法
我对 Google 的搜索专利知之甚少,但我真的很着迷。其中一些甚至有点令人不安,例如建议使用手机摄像头查看用户对搜索结果的响应,或者建议听取背景噪音(电视、谈话等)并采集查询上下文的建议.
尽管他们确实提供了有关 Google 面临的问题以及他们试图解决的解决方案的宝贵见解。因此,这些见解有助于我们提供更好的内容。
属于主题 查看全部
为什么要了解搜索引擎优化的真相,最好是去真正的来源
文章directory
学习 SEO 优化是一项挑战。一方面,没有单一的知识体系,必须从许多不同的地方一点一点地采集信息。另一方面,信息经常被误解,产生错误的排名因素和牵强的理论。这就是为什么要了解搜索引擎优化的真相,最好去真正的源头——谷歌本身。
过去,我在谷歌上讨论过一些搜索引擎优化信息的来源,即SEO Starter Guide和Quality Rater Guide。今天,我们将更深入地探索谷歌的搜索专利——这些文档解释了谷歌如何评估和排列搜索结果的各个方面。
了解这些专利是什么,为什么要研究它们,以及哪些专利可以帮助您制定更好的 SEO 优化策略。
什么是 Google 搜索专利
每当 Google 发明一种改进搜索的新方法时,它都会向美国专利商标局 (USPTO) 提交专利申请。专利是详细描述搜索算法每一位的技术文档。他们的作用是保护创新的搜索方法不被复制,从而使 Google 比竞争对手的搜索引擎更具优势。

为什么要研究 Google 搜索专利
值得一提的是,专利技术不一定是搜索算法的一部分。专利申请和技术的实际实施之间可能会有一些延迟。也有可能该技术从未实现,或者专利在达到最终状态之前经历了多次迭代。专利申请基本上是谷歌想要保护的想法的集合,但实际上它可能会被使用,也可能不会被使用。
此外,这些专利提供了对算法如何工作的独特见解——在许多方面,它是最真实的 SEO 知识形式。研究专利可以让您预测即将到来的算法更新并确定新的和现有的排名信号。您可以利用这些知识来验证您的网站 过时并验证您当前的 SEO 策略。
在哪里可以找到 Google 搜索专利
专利申请和授权专利可以在美国专利商标局官方网站进行检索——只需添加谷歌作为申请人名称,查看文件名即可。问题是谷歌申请了数千项专利,其中大部分与搜索引擎优化无关。另外,专利在某种程度上是技术文件,理解它们可能需要一些习惯。因此,以这种方式理解专利对于普通读者来说可能不是最有效的方式。
更好的方法是跟踪专利爱好者-SEO,他们监控专利更新并被社会公认为专利专家。他们每年组织数百项专利,只为挑选那些对搜索引擎优化真正重要的专利。虽然多年来一直有一些专利专家,但Bill Slawski 是撰写谷歌搜索专利历史最长的人,他在个人博客(SEO by the Sea)中重点介绍了最重要的更新。
10 项 SEO 优化 Google 搜索专利
在本节中,我将列出一些专利,这些专利描述了新颖和/或有争议的优化思路,并且对 SEO 优化者具有实际意义。我将跳过描述著名排名因素的专利和搜索引擎优化经理几乎无法控制的主题的专利。
1. 内容聚类
该专利描述了按主题对网站 和页面进行分组,并创建可描述为专家集群的内容。然后,在为相关查询提供搜索结果时,优先考虑来自这些集群的内容。

有趣的是,不属于集群的内容可能会被搜索引擎完全跳过而不做任何评估,而不管它是否有任何其他内容质量信号。
SEO的意义
明显的含义是,对于SEO来说,在不偏离你主要专业领域的情况下,在特定领域构建网站内容是有益的。在实践中,这意味着创建一个分层的内容计划并围绕较大的支柱页面排列较小的页面。
2. 基于文件开始日期的文件分级
该专利至少在一定程度上讨论了根据年龄对页面进行排名。确定页面年龄的方法有很多种,但最常用的方法是通过第一次抓取的日期来确定。

该专利还说,它还可以使用页面的年龄来计算平均链接率,即页面上的反向链接总数除以页面的年龄。然后,平均链路速率也被用作偏序因子。
SEO意义
虽然根据年龄对页面进行排名并不是什么新鲜事,但平均链接率是一个您很少听到的概念。这意味着页面越旧,每个反向链接的权重就越小。因此,如果您希望您的页面排名,您必须随着它变得越来越老而不断添加越来越多的反向链接。实现这一目标的一种方法是创建常青内容,经常更新,并通过营销渠道回收利用。
3. 基于用户上下文的搜索引擎
多年来,Google 发布了一系列与关键字相关的文档,将其排名标准从关键字更改为关键字词组再到上下文词。最新的这些文档描述了词库的构建,其中不仅收录关键字,还收录上下文词,这些词与主题松散相关。

SEO的意义
从目前的情况来看,谷歌可能更喜欢带有上下文词和传统关键字的页面。例如,如果您正在创建一个关于最佳羽绒服的页面,Google 可能会看到一些不太明显的字词,例如水、徒步旅行和鹅。
4. 观看时间排名
从视频观看时间专利到网站duration 性能专利,谷歌似乎将访问时长作为排名因素。这些专利描述了特定类型内容的基准访问持续时间,然后根据网页相对于基准的性能对网页进行排名。
SEO的意义
寻找保持访问者参与度的方法可能对您的排名有益。实现这一目标的一种显而易见的方法是创建高质量、全面的内容,其中包括各种媒体和互动元素(图片、视频、投票、评论提示等)。
5. 根据隐式用户反馈修改搜索结果排名
过去,该专利使用简单的点击率作为搜索结果排名的一部分,但最近升级为使用加权点击率。较新的版本试图找到点击次数和访问时间之间的中点,这听起来很像跳出率的变化。基本上,您的代码段获得的点击次数越多,用户停留的时间就越长,效果就越好。

SEO的意义
Google 是否使用行为指标对网页进行排名一直存在争议。不管实际情况如何,该技术已经获得专利,所以机会来了。这意味着您应该格外小心,让您的代码片段在搜索结果中不可抗拒,从标题到元描述,再到使用结构化数据增强代码片段。
6. 预测页面质量
Google 已经申请了许多使用 n-gram(字符串)来评估副本质量的专利。它的工作方式是该算法使用一组已知质量的页面来创建语言模型。然后它使用新页面上的模型来确定写作与质量基准的相似程度,并相应地对页面进行排名。

SEO的意义
N-gram 可用于识别乱码内容、关键字填充和低质量写作。这意味着您可能应该远离抓取的、自动生成的内容,并聘请经验丰富的作家,或者至少使用校对人员来完善您的副本。
7.意图查询的自然语言搜索结果
该专利描述了一种用于确定特征片段的资格的机制。基本上,只要有一个意图非常明确的自然语言查询,比如“七大罪”是什么,谷歌就会扫描排名靠前的页面,寻找一个听起来与查询非常相似的标题,然后一个简洁的答案,例如七大罪的清单。

SEO意义
请记住,副本中的每个标题 (H2-H6)) 都可能用于丰富的代码片段。基本上,每个标题都必须像查询(自然语言+关键字)一样写,标题后面的文字应该提供查询的答案。
以下是丰富素材片段的完美示例-其中一个标题与如何更换尿布的查询完全匹配,后面是编号步骤列表:

8.基于用户行为/特征数据的排名文档
这是一个更麻木的专利阅读,但它本质上归结为您的锚文本的信息量。该专利描述了用于查看用户点击链接可能性的各种指标。概率越高,链路传输的能量就越多。
SEO意义
为反向链接和内部链接创建锚文本时,请遵循最佳做法。确保锚点代表它指向的页面,收录关键字,并被上下文词包围。
9.确定资源的质量度量
另一项与链接相关的专利使我们能够深入了解每个反向链接的价值。该专利描述了一种通过查看链接带来的流量来衡量链接价值的方法。如果实际用户没有点击链接,链接将不会传递任何权重值。
SEO的意义
当您构建反向链接时,尤其是通过访客帖子,您可能倾向于在每个帖子中收录尽可能多的链接。好吧,根据专利,你会浪费时间,因为没有点击的链接几乎没有用。因此,您还可以收录更少的链接并增加每个链接被点击的机会。同样,没有人访问过的网站购买链接可能没有用。
10. 确定本地专家进行本地搜索
该专利描述了根据本地专家的加权评论对本地结果的评级。使用总阈值来确定专家的数量。这些阈值包括评论总数、本地评论数量以及特定类别公司的评论数量。 “Google 我的商家”确实将一些评论者标记为本地指南,因此似乎该专利至少已部分实施。
SEO的意义
虽然您无法通过本地指南专门征求 GMB 评论,但还是有一些方法可以鼓励更多客户评论您的业务。您可以在开始业务时亲自询问他们、向他们发送跟进电子邮件、为忠诚度计划提供奖励,或使用社交媒体让您的客户对 GMB 留下一些反馈。
此外,如果您发现任何当地导游给您差评,您必须加倍努力让他们满意。
最后的想法
我对 Google 的搜索专利知之甚少,但我真的很着迷。其中一些甚至有点令人不安,例如建议使用手机摄像头查看用户对搜索结果的响应,或者建议听取背景噪音(电视、谈话等)并采集查询上下文的建议.
尽管他们确实提供了有关 Google 面临的问题以及他们试图解决的解决方案的宝贵见解。因此,这些见解有助于我们提供更好的内容。
属于主题
,主题搜索引擎技术成为新的研究方向(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-06-20 02:07
[摘要]:随着互联网信息时代的不断发展,互联网上广泛分布的各类信息已经深刻影响着人类生活的方方面面。如今,人们可以通过浏览网页来查询所需的各种目标信息。同时,由于互联网上的信息数以千计,信息量处于快速膨胀的状态,这使得如何通过网页轻松查询目标信息的问题更加突出。在信息多样化的趋势下,通用的搜索引擎在很大程度上为人们在互联网上查找信息提供了便利,但也暴露出各种不足。例如:精度低、信息内容相对陈旧、信息分布不均等。因此,主题搜索引擎技术成为一个新的研究方向。它为特定领域、特定人群或特定需求提供有价值的信息资源和检索服务。主题爬虫作为主题搜索引擎的信息抓取部分,负责抓取用户感兴趣的某个主题相关的网页。本文主要通过六章来分析主题爬虫的设计和实现。第一章主要介绍了搜索引擎的发展历程、网络爬虫在搜索引擎中的作用,并简要介绍了国内外的研究现状和课题的研究意义。第二章是本文的理论基础:首先对搜索引擎的基本原理进行讲解,然后通过比较通用爬虫和主题爬虫找出两者的区别和各自的特点,这两种类型的爬虫架构和基本工作原理。第三章主要讨论主题爬虫领域关键技术的研究和改进,包括文本特征项提取方法、搜索策略和网页去重技术的研究,提出基于主题相关性的PageRank算法的改进。第四章主要讨论主题爬虫的系统设计与实现,主要包括网络爬虫模块、网络分析模块、中文分词和URL管理模块。第五章介绍了主题爬虫系统的界面和操作细节,以及使用该系统的实验过程。通过对实验数据的分析,证明了前几章各种理论的合理性和有效性。第6章对前几章的内容进行总结和总结,提出本文的创新点和局限性。实验结果证明,主题爬虫在稳定运行的同时有更好的收获率,大大减少了时间和存储空间。及时的优势保证了网页的及时更新。此外,用户在搜索时获得的冗余和无用信息也较少,准确率较高。 查看全部
,主题搜索引擎技术成为新的研究方向(组图)
[摘要]:随着互联网信息时代的不断发展,互联网上广泛分布的各类信息已经深刻影响着人类生活的方方面面。如今,人们可以通过浏览网页来查询所需的各种目标信息。同时,由于互联网上的信息数以千计,信息量处于快速膨胀的状态,这使得如何通过网页轻松查询目标信息的问题更加突出。在信息多样化的趋势下,通用的搜索引擎在很大程度上为人们在互联网上查找信息提供了便利,但也暴露出各种不足。例如:精度低、信息内容相对陈旧、信息分布不均等。因此,主题搜索引擎技术成为一个新的研究方向。它为特定领域、特定人群或特定需求提供有价值的信息资源和检索服务。主题爬虫作为主题搜索引擎的信息抓取部分,负责抓取用户感兴趣的某个主题相关的网页。本文主要通过六章来分析主题爬虫的设计和实现。第一章主要介绍了搜索引擎的发展历程、网络爬虫在搜索引擎中的作用,并简要介绍了国内外的研究现状和课题的研究意义。第二章是本文的理论基础:首先对搜索引擎的基本原理进行讲解,然后通过比较通用爬虫和主题爬虫找出两者的区别和各自的特点,这两种类型的爬虫架构和基本工作原理。第三章主要讨论主题爬虫领域关键技术的研究和改进,包括文本特征项提取方法、搜索策略和网页去重技术的研究,提出基于主题相关性的PageRank算法的改进。第四章主要讨论主题爬虫的系统设计与实现,主要包括网络爬虫模块、网络分析模块、中文分词和URL管理模块。第五章介绍了主题爬虫系统的界面和操作细节,以及使用该系统的实验过程。通过对实验数据的分析,证明了前几章各种理论的合理性和有效性。第6章对前几章的内容进行总结和总结,提出本文的创新点和局限性。实验结果证明,主题爬虫在稳定运行的同时有更好的收获率,大大减少了时间和存储空间。及时的优势保证了网页的及时更新。此外,用户在搜索时获得的冗余和无用信息也较少,准确率较高。
寻找正确的信息总是很困难的具之一
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-19 01:30
编译:荣淮扬
指南
一般来说,搜索是非个性化的,但如果与推荐系统结合,会有意想不到的效果。
找到正确的信息总是很困难。不久前,文件还存放在实际的物理仓库中,很难找到相关文件。
当可以通过在线存储库访问文档时,索引文档的数量开始超过物理存储的限制。电子商务网站提供的产品数量或通过在线流媒体服务提供的内容数量也是如此。
用户倾向于在一个地方找到所有内容,并且大多数人喜欢从更相关的选项中进行选择,因此服务提供商需要适应这种需求。一些全球服务(如谷歌、亚马逊、Netflix、Spotify)发展迅速,用户几乎可以在上面找到任何东西。推动他们称霸世界的最强大工具之一是由机器学习技术驱动的高度先进的个性化技术。这些技术是推荐系统和个性化搜索。
推荐系统使用用户与项目交互的历史来为用户生成最相关项目的排名列表。搜索引擎会根据与给定查询的相似度对内容进行排名,而不考虑用户的历史记录。
推荐系统使用户能够在线发现相关文档、产品或内容。通常,用户可能最喜欢的项目隐藏在数以百万计的其他项目中。用户无法通过搜索引擎直接找到这些产品,因为他们很少知道它们的标签,甚至可能不知道它们的存在。
另一方面,有时用户需要找到特定的项目,并愿意通过表达他们的需求来帮助在线系统减少可能推荐的项目数量。
有多种方法可以帮助用户表达他们的需求。用户体验在这里起着非常重要的作用。许多用户通过手机访问在线服务,但他们表现出兴趣的能力有限。在线服务应侧重于使用所有可用信息来过滤可能的搜索结果。
用户地理位置可以显着缩小可能的搜索和推荐结果的范围。例如,在 Recombee 中,您可以选择仅推荐距离用户位置一定范围内的项目。另一种方法是,当某个项目在地理位置上离用户较近时,您可以增加该项目被推荐的可能性。
用户希望使用特定标签或类别过滤掉可能的搜索结果。通常只需要一键过滤除特定类别外的所有项目(例如,所有文章 除科幻小说外)。用户应该能够尽可能轻松地表达他们的兴趣。
一定比例的用户希望使用查询文本(即使只有几个字符)来缩小搜索范围。他们的目的可能是查找特定类别的商品,或者直接通过他们要查找的产品的标签来搜索特定的产品。他们输入的文本称为用户查询。这个博客文章 讨论了如何使用查询来帮助用户找到她/他正在寻找的内容。这个博客文章从理论部分开始,然后是实践部分。
信息检索
为给定的文本查询寻找合适的项目的问题已经作为信息检索 (IR) 研究了几十年。当用户向系统输入查询时,信息检索过程开始。查询是信息需求的正式形式,例如网络搜索引擎中的搜索字符串。在信息检索中,查询不能唯一标识集合中的单个项目(文档)。相反,有几个项目可以与查询匹配,它们可能具有不同程度的相关性。
传统方法尝试将查询与文档进行匹配并根据相似度获得相关性。机器学习方法通过从训练数据构建排名模型来解决 IR 问题。这个训练数据(用于搜索引擎)是什么样的?通常,它是针对每个查询“适当”排序的文档集合。
以下是相关博客中描述的IR系统方案:
经典的 IR 系统不是个性化的,它只是为查询返回大部分相关文档。通常不需要机器学习,因为系统遵循预定义的过程(例如 TF-IDF 相似性查找)。
该系统通过匹配查询和文档并计算它们的相似性来工作。大多数相似的文档按照与查询的相似性顺序返回。计算相似度,如TF-IDF向量的余弦相似度。
可以通过重新排序(使用机器学习模型)来改善搜索结果。在这个例子中,还使用了搜索引擎来减少机器学习模型的候选数量,从而提高评分速度。
学习排名 (LTR) 是机器学习的一种应用,它根据人们的期望对项目进行排名。 LTR 模型通常使用人工标记的数据进行训练。
在recall阶段,LTR模型获取搜索引擎生成的查询和返回文档(项目)的一个子集作为每个项目的输入和输出相关性。最后,它可以输出一个排序的文档列表(k 个最相关的文档)。请注意,现代系统还可以将用户配置文件作为输入并执行个性化学习以对机器学习任务进行排序。
经典预测模型、学习排名模型和推荐系统有什么区别?
下一部分对 LTR 和推荐系统都很有用,因为模型的评估类似于机器学习中的经典预测模型。
评估 LTR 和推荐系统
累积收入衡量学习排名系统或推荐系统返回的前 k 个项目的相关性。
例如,我们可以将 6 个返回项的相关性相加(注意,第 4 项是不相关的)。
向用户展示的项目很少有统一的可见性方式。例如,在电子商务中,由于大多数用户不想向下滚动列表,因此推荐产品的可见度急剧下降。在媒体领域,一个内容经常被突出显示,而其他内容却很难找到。
CG 的问题在于它没有考虑物品的位置。例如,第一个推荐可能比其他五个推荐具有更大的图像显示。此外,用户倾向于浏览列表顶部的一些项目,他们不太可能看到列表更下方的项目。因此,折现累积收益 (DCG) 比简单的 CG 更受欢迎。
在 DCG 中,相关值随着结果的位置呈对数下降。
DCG 很容易计算,如上例所示。
有些变体甚至更加强调搜索列表顶部的相关项目。
假设一个数据集收录 N 个查询。通常的方法是对每个查询的 DCG 分数进行归一化,并获得所有查询的平均 DCG(“NDCG”)分数。有这样的评价指标固然好,但切记现实世界是残酷的。
传统的LTR算法
以下是 LTR 算法的一些示例:
PRank 算法使用感知器(线性函数)从文档的特征向量估计文档的得分。查询附加到嵌入在文档中的特征向量。我们还可以将文档分类为相关类别(例如,相关/不相关)。该函数几乎可以通过任何机器学习方法进行建模。大多数算法使用决策树和森林。现代方法利用深度学习网络。
通过对所有文档进行评分并根据预测的相关性对它们进行排序得到最终的排名列表。显然,在训练输入嵌入和相应输出相关性的模型时,我们并没有直接最小化 NDCG 或其他上述评估标准。与Pointwise方法一致,Pairwise方法也使用了代理可微损失函数。
为了更好地理解成对方法,我们应该记住二元分类中使用的交叉熵损失,它惩罚了模型的高置信度错误预测。
可以通过对 0,1 标签的损失求和来计算对数损失:-(y log(p) +(1−y) log(1−p))
如您所见,错误的、高可信度的答案会导致高损失。
关于 LTR 系统的梯度训练算法的更多信息可以在这里找到:///en-us/research/wp-content/uploads/2005/08/icml_ranking.pdf。
Rankboost 直接优化分类错误。它源自 Adaboost,并在文档对上进行训练。它训练弱分类器,并为上一步中没有正确分类的对分配更多的权重。
RankSVM 是最早使用成对方法解决问题的算法之一。它以序数回归的方式进行排序,训练类的阈值。 RankSVM 使用铰链损失函数来最小化。它还允许直接使用内核进行非线性处理。
listwise 方法的动机
pairwise 方法很好,但也有缺点。训练过程成本高昂,并且存在固有的训练偏差,在不同的查询中差异很大。只考虑成对关系。我们希望使用一个评估指标,使我们能够在考虑所有项目的相关性的同时优化完整列表。
指数排序的优势在于,即使模型 f 给所有文档分配相似的分数,它们的最高概率也会相差很大——最好的文档接近 1,而不太相关的文档接近 0。
这里,损失是针对文档列表计算的。我们不太关心无关文档Py(x)=0,最大的损失是相关文档造成的。
如何获取LTR系统的训练数据?
为 LTR 系统获取训练数据可能是一个漫长而昂贵的过程。您通常需要一群人手动输入查询并判断搜索结果。关联判断也比较困难。评估者评估以下分数之一:
Relevance-两个值:相关和不相关(适用于pointwise)
成对偏好文件 A 比文件 B 更相关。
一般订单文件按照 A、B、C、... 的相关性进行排序。 (非常适合列表,但很耗时)
很明显,人工贴标签非常昂贵,而且他们的标签也不是很可靠。因此,排名和训练系统应该从用户在网站上的行为中获得。
更好的方法是用推荐系统替换前面提到的 LTR 算法。
个性化搜索审核
当搜索结果按照用户的喜好进行排序时,用户对搜索功能的整体满意度会显着提升。
个性化搜索还应考虑用户偏好、历史互动和类似用户的互动。为什么不使用推荐系统?对于相同的搜索查询,两个用户可能会得到截然不同的建议。
解决方案是将搜索引擎与强大的推荐系统相结合,而不是如上所述将经典学习应用于机器学习 (LTR) 模型。这种方法有几个优点,我们会在后续博客文章中分析。
我们的个性化搜索方法结合了搜索引擎和推荐系统。首先,搜索引擎对推荐项目(与查询无关)重新排序以过滤掉不相关的推荐,并推送与查询及其描述匹配的项目。其次,无论用户个人资料或交互历史如何,搜索引擎都会返回最匹配的候选者。然后,这些产品由推荐系统重新排名,以更好地适应每个特定用户的口味。最终结果由上游排名投票决定。
—结束—
英文原文:
查看全部
寻找正确的信息总是很困难的具之一
编译:荣淮扬
指南
一般来说,搜索是非个性化的,但如果与推荐系统结合,会有意想不到的效果。
找到正确的信息总是很困难。不久前,文件还存放在实际的物理仓库中,很难找到相关文件。
当可以通过在线存储库访问文档时,索引文档的数量开始超过物理存储的限制。电子商务网站提供的产品数量或通过在线流媒体服务提供的内容数量也是如此。
用户倾向于在一个地方找到所有内容,并且大多数人喜欢从更相关的选项中进行选择,因此服务提供商需要适应这种需求。一些全球服务(如谷歌、亚马逊、Netflix、Spotify)发展迅速,用户几乎可以在上面找到任何东西。推动他们称霸世界的最强大工具之一是由机器学习技术驱动的高度先进的个性化技术。这些技术是推荐系统和个性化搜索。
推荐系统使用用户与项目交互的历史来为用户生成最相关项目的排名列表。搜索引擎会根据与给定查询的相似度对内容进行排名,而不考虑用户的历史记录。
推荐系统使用户能够在线发现相关文档、产品或内容。通常,用户可能最喜欢的项目隐藏在数以百万计的其他项目中。用户无法通过搜索引擎直接找到这些产品,因为他们很少知道它们的标签,甚至可能不知道它们的存在。
另一方面,有时用户需要找到特定的项目,并愿意通过表达他们的需求来帮助在线系统减少可能推荐的项目数量。
有多种方法可以帮助用户表达他们的需求。用户体验在这里起着非常重要的作用。许多用户通过手机访问在线服务,但他们表现出兴趣的能力有限。在线服务应侧重于使用所有可用信息来过滤可能的搜索结果。
用户地理位置可以显着缩小可能的搜索和推荐结果的范围。例如,在 Recombee 中,您可以选择仅推荐距离用户位置一定范围内的项目。另一种方法是,当某个项目在地理位置上离用户较近时,您可以增加该项目被推荐的可能性。
用户希望使用特定标签或类别过滤掉可能的搜索结果。通常只需要一键过滤除特定类别外的所有项目(例如,所有文章 除科幻小说外)。用户应该能够尽可能轻松地表达他们的兴趣。
一定比例的用户希望使用查询文本(即使只有几个字符)来缩小搜索范围。他们的目的可能是查找特定类别的商品,或者直接通过他们要查找的产品的标签来搜索特定的产品。他们输入的文本称为用户查询。这个博客文章 讨论了如何使用查询来帮助用户找到她/他正在寻找的内容。这个博客文章从理论部分开始,然后是实践部分。
信息检索
为给定的文本查询寻找合适的项目的问题已经作为信息检索 (IR) 研究了几十年。当用户向系统输入查询时,信息检索过程开始。查询是信息需求的正式形式,例如网络搜索引擎中的搜索字符串。在信息检索中,查询不能唯一标识集合中的单个项目(文档)。相反,有几个项目可以与查询匹配,它们可能具有不同程度的相关性。
传统方法尝试将查询与文档进行匹配并根据相似度获得相关性。机器学习方法通过从训练数据构建排名模型来解决 IR 问题。这个训练数据(用于搜索引擎)是什么样的?通常,它是针对每个查询“适当”排序的文档集合。
以下是相关博客中描述的IR系统方案:
经典的 IR 系统不是个性化的,它只是为查询返回大部分相关文档。通常不需要机器学习,因为系统遵循预定义的过程(例如 TF-IDF 相似性查找)。
该系统通过匹配查询和文档并计算它们的相似性来工作。大多数相似的文档按照与查询的相似性顺序返回。计算相似度,如TF-IDF向量的余弦相似度。
可以通过重新排序(使用机器学习模型)来改善搜索结果。在这个例子中,还使用了搜索引擎来减少机器学习模型的候选数量,从而提高评分速度。
学习排名 (LTR) 是机器学习的一种应用,它根据人们的期望对项目进行排名。 LTR 模型通常使用人工标记的数据进行训练。
在recall阶段,LTR模型获取搜索引擎生成的查询和返回文档(项目)的一个子集作为每个项目的输入和输出相关性。最后,它可以输出一个排序的文档列表(k 个最相关的文档)。请注意,现代系统还可以将用户配置文件作为输入并执行个性化学习以对机器学习任务进行排序。
经典预测模型、学习排名模型和推荐系统有什么区别?
下一部分对 LTR 和推荐系统都很有用,因为模型的评估类似于机器学习中的经典预测模型。
评估 LTR 和推荐系统
累积收入衡量学习排名系统或推荐系统返回的前 k 个项目的相关性。
例如,我们可以将 6 个返回项的相关性相加(注意,第 4 项是不相关的)。
向用户展示的项目很少有统一的可见性方式。例如,在电子商务中,由于大多数用户不想向下滚动列表,因此推荐产品的可见度急剧下降。在媒体领域,一个内容经常被突出显示,而其他内容却很难找到。
CG 的问题在于它没有考虑物品的位置。例如,第一个推荐可能比其他五个推荐具有更大的图像显示。此外,用户倾向于浏览列表顶部的一些项目,他们不太可能看到列表更下方的项目。因此,折现累积收益 (DCG) 比简单的 CG 更受欢迎。
在 DCG 中,相关值随着结果的位置呈对数下降。
DCG 很容易计算,如上例所示。
有些变体甚至更加强调搜索列表顶部的相关项目。
假设一个数据集收录 N 个查询。通常的方法是对每个查询的 DCG 分数进行归一化,并获得所有查询的平均 DCG(“NDCG”)分数。有这样的评价指标固然好,但切记现实世界是残酷的。
传统的LTR算法
以下是 LTR 算法的一些示例:
PRank 算法使用感知器(线性函数)从文档的特征向量估计文档的得分。查询附加到嵌入在文档中的特征向量。我们还可以将文档分类为相关类别(例如,相关/不相关)。该函数几乎可以通过任何机器学习方法进行建模。大多数算法使用决策树和森林。现代方法利用深度学习网络。
通过对所有文档进行评分并根据预测的相关性对它们进行排序得到最终的排名列表。显然,在训练输入嵌入和相应输出相关性的模型时,我们并没有直接最小化 NDCG 或其他上述评估标准。与Pointwise方法一致,Pairwise方法也使用了代理可微损失函数。
为了更好地理解成对方法,我们应该记住二元分类中使用的交叉熵损失,它惩罚了模型的高置信度错误预测。
可以通过对 0,1 标签的损失求和来计算对数损失:-(y log(p) +(1−y) log(1−p))
如您所见,错误的、高可信度的答案会导致高损失。
关于 LTR 系统的梯度训练算法的更多信息可以在这里找到:///en-us/research/wp-content/uploads/2005/08/icml_ranking.pdf。
Rankboost 直接优化分类错误。它源自 Adaboost,并在文档对上进行训练。它训练弱分类器,并为上一步中没有正确分类的对分配更多的权重。
RankSVM 是最早使用成对方法解决问题的算法之一。它以序数回归的方式进行排序,训练类的阈值。 RankSVM 使用铰链损失函数来最小化。它还允许直接使用内核进行非线性处理。
listwise 方法的动机
pairwise 方法很好,但也有缺点。训练过程成本高昂,并且存在固有的训练偏差,在不同的查询中差异很大。只考虑成对关系。我们希望使用一个评估指标,使我们能够在考虑所有项目的相关性的同时优化完整列表。
指数排序的优势在于,即使模型 f 给所有文档分配相似的分数,它们的最高概率也会相差很大——最好的文档接近 1,而不太相关的文档接近 0。
这里,损失是针对文档列表计算的。我们不太关心无关文档Py(x)=0,最大的损失是相关文档造成的。
如何获取LTR系统的训练数据?
为 LTR 系统获取训练数据可能是一个漫长而昂贵的过程。您通常需要一群人手动输入查询并判断搜索结果。关联判断也比较困难。评估者评估以下分数之一:
Relevance-两个值:相关和不相关(适用于pointwise)
成对偏好文件 A 比文件 B 更相关。
一般订单文件按照 A、B、C、... 的相关性进行排序。 (非常适合列表,但很耗时)
很明显,人工贴标签非常昂贵,而且他们的标签也不是很可靠。因此,排名和训练系统应该从用户在网站上的行为中获得。
更好的方法是用推荐系统替换前面提到的 LTR 算法。
个性化搜索审核
当搜索结果按照用户的喜好进行排序时,用户对搜索功能的整体满意度会显着提升。
个性化搜索还应考虑用户偏好、历史互动和类似用户的互动。为什么不使用推荐系统?对于相同的搜索查询,两个用户可能会得到截然不同的建议。
解决方案是将搜索引擎与强大的推荐系统相结合,而不是如上所述将经典学习应用于机器学习 (LTR) 模型。这种方法有几个优点,我们会在后续博客文章中分析。
我们的个性化搜索方法结合了搜索引擎和推荐系统。首先,搜索引擎对推荐项目(与查询无关)重新排序以过滤掉不相关的推荐,并推送与查询及其描述匹配的项目。其次,无论用户个人资料或交互历史如何,搜索引擎都会返回最匹配的候选者。然后,这些产品由推荐系统重新排名,以更好地适应每个特定用户的口味。最终结果由上游排名投票决定。
—结束—
英文原文:
甘明光:新手及要转变思维的SEO人有所帮助
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-19 01:27
相信小编现在谈SEO的时候,大家的想法应该还停留在早年。我觉得SEO无非就是写伪原创,发到外链,另外就是查网站的关键词的排名。每天重复这项工作,希望能靠这个方法取得好的效果。时代在进步,我们必须对SEO有新的认识。
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今,百度已经不是5年前的百度。大量的算法更新对搜索引擎优化者的思维和技术提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。甘明光总结了8个核心要素和思维趋势,希望对SEO新手和想要转变思维的SEO人有所帮助。
1、网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以首先强调网站的访问速度,是因为它不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在构建网站的时候,一定要选择一个比较快速稳定的主机。关于主机的选择,根据小编的经验,美国品牌主机-bluehost是不错的选择。
2、网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容必须与标题相对应,而且必须能够解决用户的问题。例如,有人搜索“个人博客应该选择什么样的主机?”这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了最终帮他解决这个问题。
3、网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
4、减少不良因素的出现
大量网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了大量广告信息,或者频繁弹出对话框,让用户反感。影响用户停留在页面上的时间。
5、关键词的添加和分配
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
6、主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
7、搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
8、Unique and high quality网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。不然别人再好,也会觉得“花花”了。
以上就是小编分享的SEO八要素。相信看完之后,你应该对SEO有了新的认识。我们不会停留在过去。我们必须跟上时代的发展。 ,为了不被时代淘汰。希望小编分享的内容对大家有所帮助。如果喜欢,请多多支持。 查看全部
甘明光:新手及要转变思维的SEO人有所帮助
相信小编现在谈SEO的时候,大家的想法应该还停留在早年。我觉得SEO无非就是写伪原创,发到外链,另外就是查网站的关键词的排名。每天重复这项工作,希望能靠这个方法取得好的效果。时代在进步,我们必须对SEO有新的认识。
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今,百度已经不是5年前的百度。大量的算法更新对搜索引擎优化者的思维和技术提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。甘明光总结了8个核心要素和思维趋势,希望对SEO新手和想要转变思维的SEO人有所帮助。

1、网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以首先强调网站的访问速度,是因为它不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在构建网站的时候,一定要选择一个比较快速稳定的主机。关于主机的选择,根据小编的经验,美国品牌主机-bluehost是不错的选择。
2、网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容必须与标题相对应,而且必须能够解决用户的问题。例如,有人搜索“个人博客应该选择什么样的主机?”这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了最终帮他解决这个问题。
3、网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
4、减少不良因素的出现
大量网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了大量广告信息,或者频繁弹出对话框,让用户反感。影响用户停留在页面上的时间。
5、关键词的添加和分配
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
6、主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
7、搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
8、Unique and high quality网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。不然别人再好,也会觉得“花花”了。
以上就是小编分享的SEO八要素。相信看完之后,你应该对SEO有了新的认识。我们不会停留在过去。我们必须跟上时代的发展。 ,为了不被时代淘汰。希望小编分享的内容对大家有所帮助。如果喜欢,请多多支持。
搜索引擎的基础技术的评估标准及策略分析(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-06-19 01:26
内容
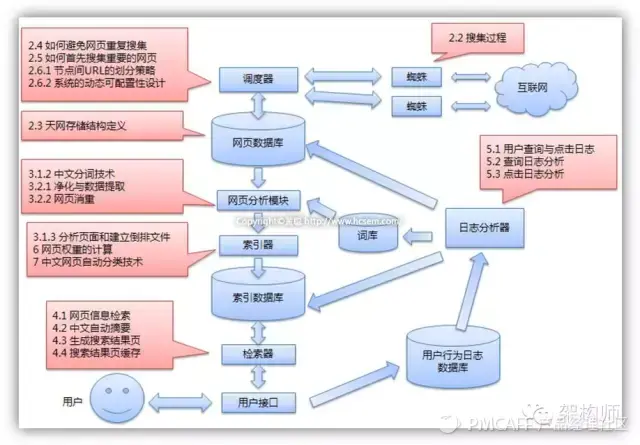
【1】搜索引擎概述
[2] 搜索引擎基础技术
[3] 搜索引擎的平台基础
[4] 搜索结果的改进和优化
__________________________________________________
【1】搜索引擎概述
过去15年,互联网信息快速扩张,已经无法通过人工方式过滤获取有用信息。于是,搜索引擎应运而生。按其发展可分为四个时代。
说到发展,不得不提搜索引擎的三个主要目标。无论发展到哪里,以下三个目标始终是一个很好的评价标准:
[2] 搜索引擎基础技术
这部分主要从以下四个部分介绍搜索引擎的基本技术,也是搜索引擎的重要环节。
2.1 网络爬虫
网络爬虫是搜索引擎的下载系统。它的功能是获取内容。其方法是通过万维网中的链接不断爬取和采集各种网页。然而,互联网上的页面如此之多,每天都在不断地产生新的内容。根据爬取目标和范围,爬虫可以简单分为以下几类:
抓取网页时,抓取工具应该如何确定下一个目标?主要策略如下:
接下来简单介绍一下搜索引擎中的一个重要问题:暗网爬虫。所谓暗网,是指通过常规方法难以抓取的网页,互联网上存在大量此类网页。有些网页没有外部链接,有些主要内容存储在数据库中(如携程网),这些记录没有链接。暗网挖掘是商业搜索引擎的一大研究重点,谷歌就是这样,百度的“阿拉丁”计划也来了。
2.2 创建索引
对于搜索引擎来说,搜索是最重要的核心技术之一。面对海量的网页内容,如何快速找到所有收录用户查询的网页?倒排索引在其中起到了关键作用。
对于一个网页,我们把它看成一个文档,它的内容是由单词组成的。为了快速为用户的搜索词提供文档结果,我们必须建立一个word-document存储结构。倒排索引是实现word-document矩阵的一种特定的存储形式。通过倒排索引,可以根据单词快速获取收录该单词的文档列表。倒排索引主要由词词典和倒排文件两部分组成。
单词字典主要有两种存储方式:hash加链接和树结构。
如何创建索引:
(1)Two-pass 文档遍历
在第一遍扫描文档集合时,此方法不会立即开始索引,而是采集一些全局统计信息。例如,文档集合中收录的文档数为N,文档集合中收录的不同词的个数为M,每个词出现在多少个文档中的信息DF。 得到以上三类信息后,可以知道最终索引的大小,然后在内存中分配足够的空间来存放倒排索引的内容。在第二次扫描中,实际上建立了每个词的倒排列表信息,即对于一个词,每个收录该词的文档的文档ID以及该词在文档TF中出现的次数
(2)排序方法
排序方法对此进行了改进。这种方法在索引过程中总是在内存中分配固定大小的空间来存储字典信息和索引的中间结果。当分配的空间用完时,此时将中间结果写入磁盘,将中间结果在内存中占用的空间清空,用作下一次存储索引中间结果的存储区圆形的。这种方法只需要固定大小的内存,所以它可以索引任意大小的文档集合。
(3)合合法
当分配的内存配额用完时,排序方法只是将中间结果写入磁盘,字典信息一直保存在内存中。随着处理的文档越来越多,字典中收录的字典项也越来越多。越来越多,所以占用的内存越来越多,导致后期中间结果可用的内存越来越少。合并方法对此进行了改进,即每次将内存中的数据写入磁盘时,将包括字典在内的所有中间结果信息写入磁盘,从而可以清空内存中的所有内容,并且后续索引可以使用所有配额内存。
索引更新策略:
2.3 内容检索
内容检索模型是搜索引擎排名的理论基础,用于计算网页和查询的相关性。
常用检索模型
检索系统评价指标
查询相关
查询无关
在搜索结果中
A
B
不在搜索结果中
C
D
2.4 链接分析
搜索引擎在寻找能够满足用户请求的网页时,主要考虑两个因素:一是用户发送的查询与网页内容的内容相似度得分,即网页与网页内容的相关性。查询;另一种是通过链接分析方法得到的分数就是网页的重要性。链接分析是通过网络的链接结构获取网页重要性的一种方法。
有很多链接分析算法。从模型上看,主要分为两类:
常用算法:
[3] 搜索引擎的平台基础
这部分主要讲搜索引擎的平台支持,主要是云存储和云计算模型。
对于商业搜索引擎来说,需要保存大量的数据,而这些海量的海量数据需要进行处理。云存储和云计算是解决这个问题的方法。
服务器上不能存在大量数据,必须是分布式存储。当数据更新时,这会导致多台服务器上的数据不一致,以及如何选择服务器的问题。
先介绍一些基本原理:
(1)CAP原理
CAP是Consistency, Availability, Partition Tolerance的缩写,即一致性、可用性、分区容错性。
对于一个数据系统来说,这三个原则不能兼得。云存储往往侧重于 CA,牺牲了一些一致性。
(2)ACID 原理
这是关系型数据库采用的原则。是Atomity、Consistency、Isolation、Durability的缩写,即原子性、一致性、事务独立性、持久性。
(3)BASE 原理
采用的大型多云存储系统,不同于ACID,牺牲了数据的强一致性来换取高可用。因为用户可能对数据的变化很敏感,无法提供服务。
它的三个方面是:
Google 的云存储和云计算架构
云存储:
云计算
其他云存储系统
[4] 搜索结果的改进和优化
如前所述,搜索引擎追求的三个目标是更快、更全面、更准确。但是要实现这些目标并不是一件很容易的事,需要很多环节来处理。这部分主要从以下几个方面谈,如何改善搜索引擎的搜索结果,提高搜索质量,提高搜索性能。
4.1作弊分析
作弊方法
反作弊的总体思路
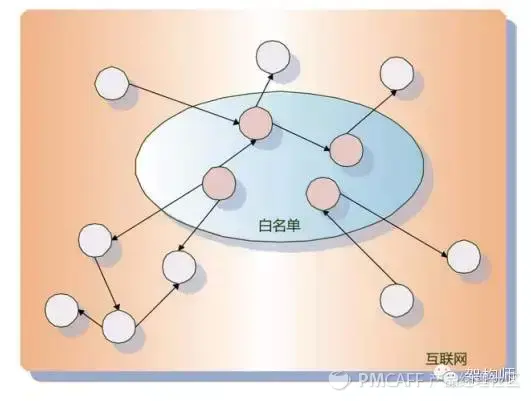
(1)所谓的信任传播模型,基本思想是:在海量的网页数据中,通过一定的技术手段或人工、半人工手段,筛选出一些完全可信的页面,从而表示他们绝对不会作弊页面(可以理解为白名单),算法以白名单中的这些页面为起点,为白名单中的页面节点分配更高的信任分数。其他页面是否作弊取决于在他们和白名单中的节点上。由链接关系决定。白名单中的节点通过链接关系向外传播信任分数。如果节点获得的信任分数高于某个阈值,则认为表示没有问题,低于这个阈值的页面将被视为作弊页面。
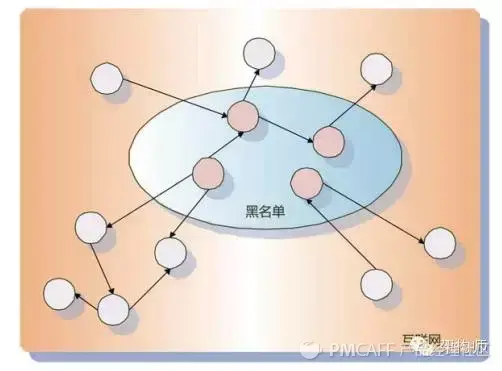
(2)不信任传播模型在框架上类似于信任传播模型。最大的不同是页面的初始子集不是可信页面节点,而是确认存在作弊的页面集合。 ,即不信任页面的集合(可以理解为黑名单)。为黑名单中的页面节点分配一个不信任分数,并通过链接关系传播这种不信任关系。如果最后一个页面节点的不信任分数为大于设置的阈值将被视为作弊网页。
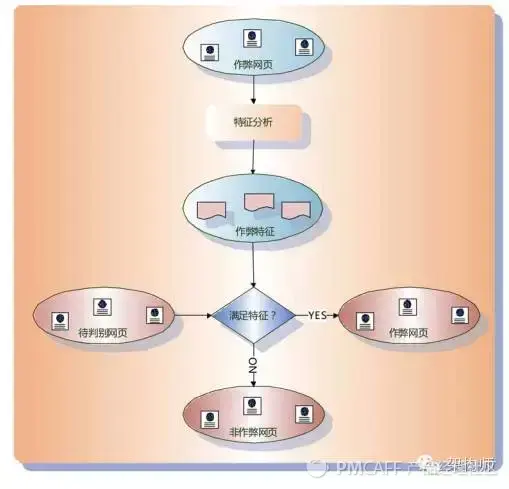
(3)异常发现模型也是一个高度抽象的算法框架模型。它的基本假设是:作弊的网页必须有不同于普通网页的特征。这个特征可能是内容,也可能是链接制定具体算法的过程往往是找到一组作弊网页,分析其异常特征,然后利用这些异常特征来识别作弊网页。
<p>只要操纵搜索引擎搜索结果可以带来利益,那么作弊的动机就会一直存在,尤其是在网络营销在宣传中发挥越来越重要作用的时代。作弊与反作弊是一个相互抑制、相互促进的互动过程。 “一尺高一尺”的故事不断重复。上述内容主要是基于技术手段进行反作弊。事实上,单纯的技术手段并不能完全解决作弊问题。需要人工和技术手段相结合,才能达到更好的防作弊效果。技术手段可以分为比较一般的手段和比较特殊的手段。相对通用的手段对可能出现的新作弊手段有一定的防范能力,但由于其普遍性,针对性不强,对特殊作弊手段有一定的作用。不一定好。专门的反作弊方法往往是事后,只有当作弊已经发生并且很严重时,才能总结作弊的特点,采取事后过滤的方法。人工手段与技术手段高度互补。一旦出现新的作弊方法,它们就可以被发现,并且可以作为作弊进行时的预防措施。因此,从时间维度考虑对作弊手段的抑制,一般反作弊手段侧重预防,人工手段侧重检测,专用反作弊手段侧重后处理,两者具有内在联系和互补关系。 查看全部
搜索引擎的基础技术的评估标准及策略分析(一)
内容
【1】搜索引擎概述
[2] 搜索引擎基础技术
[3] 搜索引擎的平台基础
[4] 搜索结果的改进和优化
__________________________________________________
【1】搜索引擎概述
过去15年,互联网信息快速扩张,已经无法通过人工方式过滤获取有用信息。于是,搜索引擎应运而生。按其发展可分为四个时代。
说到发展,不得不提搜索引擎的三个主要目标。无论发展到哪里,以下三个目标始终是一个很好的评价标准:
[2] 搜索引擎基础技术
这部分主要从以下四个部分介绍搜索引擎的基本技术,也是搜索引擎的重要环节。
2.1 网络爬虫
网络爬虫是搜索引擎的下载系统。它的功能是获取内容。其方法是通过万维网中的链接不断爬取和采集各种网页。然而,互联网上的页面如此之多,每天都在不断地产生新的内容。根据爬取目标和范围,爬虫可以简单分为以下几类:
抓取网页时,抓取工具应该如何确定下一个目标?主要策略如下:
接下来简单介绍一下搜索引擎中的一个重要问题:暗网爬虫。所谓暗网,是指通过常规方法难以抓取的网页,互联网上存在大量此类网页。有些网页没有外部链接,有些主要内容存储在数据库中(如携程网),这些记录没有链接。暗网挖掘是商业搜索引擎的一大研究重点,谷歌就是这样,百度的“阿拉丁”计划也来了。
2.2 创建索引
对于搜索引擎来说,搜索是最重要的核心技术之一。面对海量的网页内容,如何快速找到所有收录用户查询的网页?倒排索引在其中起到了关键作用。
对于一个网页,我们把它看成一个文档,它的内容是由单词组成的。为了快速为用户的搜索词提供文档结果,我们必须建立一个word-document存储结构。倒排索引是实现word-document矩阵的一种特定的存储形式。通过倒排索引,可以根据单词快速获取收录该单词的文档列表。倒排索引主要由词词典和倒排文件两部分组成。
单词字典主要有两种存储方式:hash加链接和树结构。
如何创建索引:
(1)Two-pass 文档遍历
在第一遍扫描文档集合时,此方法不会立即开始索引,而是采集一些全局统计信息。例如,文档集合中收录的文档数为N,文档集合中收录的不同词的个数为M,每个词出现在多少个文档中的信息DF。 得到以上三类信息后,可以知道最终索引的大小,然后在内存中分配足够的空间来存放倒排索引的内容。在第二次扫描中,实际上建立了每个词的倒排列表信息,即对于一个词,每个收录该词的文档的文档ID以及该词在文档TF中出现的次数
(2)排序方法
排序方法对此进行了改进。这种方法在索引过程中总是在内存中分配固定大小的空间来存储字典信息和索引的中间结果。当分配的空间用完时,此时将中间结果写入磁盘,将中间结果在内存中占用的空间清空,用作下一次存储索引中间结果的存储区圆形的。这种方法只需要固定大小的内存,所以它可以索引任意大小的文档集合。
(3)合合法
当分配的内存配额用完时,排序方法只是将中间结果写入磁盘,字典信息一直保存在内存中。随着处理的文档越来越多,字典中收录的字典项也越来越多。越来越多,所以占用的内存越来越多,导致后期中间结果可用的内存越来越少。合并方法对此进行了改进,即每次将内存中的数据写入磁盘时,将包括字典在内的所有中间结果信息写入磁盘,从而可以清空内存中的所有内容,并且后续索引可以使用所有配额内存。
索引更新策略:
2.3 内容检索
内容检索模型是搜索引擎排名的理论基础,用于计算网页和查询的相关性。
常用检索模型
检索系统评价指标
查询相关
查询无关
在搜索结果中
A
B
不在搜索结果中
C
D
2.4 链接分析
搜索引擎在寻找能够满足用户请求的网页时,主要考虑两个因素:一是用户发送的查询与网页内容的内容相似度得分,即网页与网页内容的相关性。查询;另一种是通过链接分析方法得到的分数就是网页的重要性。链接分析是通过网络的链接结构获取网页重要性的一种方法。
有很多链接分析算法。从模型上看,主要分为两类:
常用算法:
[3] 搜索引擎的平台基础
这部分主要讲搜索引擎的平台支持,主要是云存储和云计算模型。
对于商业搜索引擎来说,需要保存大量的数据,而这些海量的海量数据需要进行处理。云存储和云计算是解决这个问题的方法。
服务器上不能存在大量数据,必须是分布式存储。当数据更新时,这会导致多台服务器上的数据不一致,以及如何选择服务器的问题。
先介绍一些基本原理:
(1)CAP原理
CAP是Consistency, Availability, Partition Tolerance的缩写,即一致性、可用性、分区容错性。
对于一个数据系统来说,这三个原则不能兼得。云存储往往侧重于 CA,牺牲了一些一致性。
(2)ACID 原理
这是关系型数据库采用的原则。是Atomity、Consistency、Isolation、Durability的缩写,即原子性、一致性、事务独立性、持久性。
(3)BASE 原理
采用的大型多云存储系统,不同于ACID,牺牲了数据的强一致性来换取高可用。因为用户可能对数据的变化很敏感,无法提供服务。
它的三个方面是:
Google 的云存储和云计算架构
云存储:
云计算
其他云存储系统
[4] 搜索结果的改进和优化
如前所述,搜索引擎追求的三个目标是更快、更全面、更准确。但是要实现这些目标并不是一件很容易的事,需要很多环节来处理。这部分主要从以下几个方面谈,如何改善搜索引擎的搜索结果,提高搜索质量,提高搜索性能。
4.1作弊分析
作弊方法
反作弊的总体思路
(1)所谓的信任传播模型,基本思想是:在海量的网页数据中,通过一定的技术手段或人工、半人工手段,筛选出一些完全可信的页面,从而表示他们绝对不会作弊页面(可以理解为白名单),算法以白名单中的这些页面为起点,为白名单中的页面节点分配更高的信任分数。其他页面是否作弊取决于在他们和白名单中的节点上。由链接关系决定。白名单中的节点通过链接关系向外传播信任分数。如果节点获得的信任分数高于某个阈值,则认为表示没有问题,低于这个阈值的页面将被视为作弊页面。
(2)不信任传播模型在框架上类似于信任传播模型。最大的不同是页面的初始子集不是可信页面节点,而是确认存在作弊的页面集合。 ,即不信任页面的集合(可以理解为黑名单)。为黑名单中的页面节点分配一个不信任分数,并通过链接关系传播这种不信任关系。如果最后一个页面节点的不信任分数为大于设置的阈值将被视为作弊网页。
(3)异常发现模型也是一个高度抽象的算法框架模型。它的基本假设是:作弊的网页必须有不同于普通网页的特征。这个特征可能是内容,也可能是链接制定具体算法的过程往往是找到一组作弊网页,分析其异常特征,然后利用这些异常特征来识别作弊网页。
<p>只要操纵搜索引擎搜索结果可以带来利益,那么作弊的动机就会一直存在,尤其是在网络营销在宣传中发挥越来越重要作用的时代。作弊与反作弊是一个相互抑制、相互促进的互动过程。 “一尺高一尺”的故事不断重复。上述内容主要是基于技术手段进行反作弊。事实上,单纯的技术手段并不能完全解决作弊问题。需要人工和技术手段相结合,才能达到更好的防作弊效果。技术手段可以分为比较一般的手段和比较特殊的手段。相对通用的手段对可能出现的新作弊手段有一定的防范能力,但由于其普遍性,针对性不强,对特殊作弊手段有一定的作用。不一定好。专门的反作弊方法往往是事后,只有当作弊已经发生并且很严重时,才能总结作弊的特点,采取事后过滤的方法。人工手段与技术手段高度互补。一旦出现新的作弊方法,它们就可以被发现,并且可以作为作弊进行时的预防措施。因此,从时间维度考虑对作弊手段的抑制,一般反作弊手段侧重预防,人工手段侧重检测,专用反作弊手段侧重后处理,两者具有内在联系和互补关系。
8个核心要素和思维走向,希望对SEO新手及要转变思维
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-06-18 07:03
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今的百度已经不再是5年前的百度,大量的搜索引擎算法更新对SEO优化思路和技巧提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。文君数字营销总监,紫道学院创始人,帅气的Boom老师总结了8个核心要素和思维趋势,希望能帮助到SEO新手和想要转变思维的SEO人。点击了解:全面系统的网站SEO优化计划策略。
一、登陆页面的内容是解决问题而不是仅仅描述问题
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
二、重要的事情说三遍“加载速度,速度,速度”
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象,好山寨,好土鳖,这么专业不是我们想要的结果。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户更难在网站上产生信任感和参与感。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
四、避免各种促使用户离开页面的元素
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
五、关键词植入
常规的关键词植入(爆老师称之为填词)还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT 、网址、图片命名等,这个就不多说了,大家都懂的。
六、主题模型的注入
仅仅填写#5个词是不够的,因为太机械会失去文本用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以延伸到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素需要在内容上进行优化:title的创意、desc的热度、url的规范、文章日期、结构化数据的使用、在线对话等,下面的效果是什么?
让男嘉宾秒杀女嘉宾的20种婚礼搭配:
2016年5月31日-提供最新20款男士婚礼搭配建议,无论预算多低,都能搭配出瞬间秒杀周边女嘉宾的女嘉宾,全图+视频。
八、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
1)提供独特的视觉体验、前端界面、合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7) 可以使用完整、准确和独特的信息来解决或回答问题。 查看全部
8个核心要素和思维走向,希望对SEO新手及要转变思维
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今的百度已经不再是5年前的百度,大量的搜索引擎算法更新对SEO优化思路和技巧提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。文君数字营销总监,紫道学院创始人,帅气的Boom老师总结了8个核心要素和思维趋势,希望能帮助到SEO新手和想要转变思维的SEO人。点击了解:全面系统的网站SEO优化计划策略。

一、登陆页面的内容是解决问题而不是仅仅描述问题
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
二、重要的事情说三遍“加载速度,速度,速度”
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象,好山寨,好土鳖,这么专业不是我们想要的结果。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户更难在网站上产生信任感和参与感。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
四、避免各种促使用户离开页面的元素
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
五、关键词植入
常规的关键词植入(爆老师称之为填词)还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT 、网址、图片命名等,这个就不多说了,大家都懂的。
六、主题模型的注入
仅仅填写#5个词是不够的,因为太机械会失去文本用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以延伸到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素需要在内容上进行优化:title的创意、desc的热度、url的规范、文章日期、结构化数据的使用、在线对话等,下面的效果是什么?
让男嘉宾秒杀女嘉宾的20种婚礼搭配:
2016年5月31日-提供最新20款男士婚礼搭配建议,无论预算多低,都能搭配出瞬间秒杀周边女嘉宾的女嘉宾,全图+视频。
八、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
1)提供独特的视觉体验、前端界面、合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7) 可以使用完整、准确和独特的信息来解决或回答问题。
网站信息设计师试图确定用户如何归类,整理和标签上的站点信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-18 06:45
网站信息设计者试图确定用户如何对站点信息进行分类、组织和标记。信息架构师使用不同的方法来确定最佳网站架构,包括但不限于:
什么是心智模型?
思维模型,也称为概念模型,是对一个人的思维过程的解释,为什么现实世界中的一些作品忠实地代表了基本动机和匹配行为。每个人都有一个关于网站 或搜索引擎如何工作的心智模型,没有人对另一个有相同的心智模型。然而,心智模型的某些部分是一致的,并且因人而异。
例如,让我们使用电梯。我们大多数人在乘坐电梯时都有相同的期望和体验。如果我们按下标有“2 部电梯内”的按钮,我们希望电梯将我们带到二楼。如果我们按下标有“5”的按钮,我们想乘电梯到五楼。
我们怎么知道我们正在前往五楼?在大多数电梯中,我们通常会看到一个反映我们的数字,或者在到达地面之前通过的数字。当我们到达目的地五楼时会发生什么?
现场访谈直接,一对一观察正常用户/搜索表现,日常工作可用性测试数据网络分析软件,网站搜索引擎等。在网站上,目标信息架构师是确定一个正式的网站导航和网页相互连接,其他形式最符合网站用户的心智模型。一个有效的网站 结构应该能让用户/搜索者更容易、更有效地实现他们的目标。每次点击,用户的信息都应该加强气味,不会分心、混淆或打扰用户的验证。此外,网站的信息架构所要传达的网络内容“aboutness”概念被引入搜索引擎和网站访问者。
在一个特定的B2B医疗网站反复可用性测试三年后,我发现了一个有趣的事情:内部搜索引擎优化的专业不匹配导致的主要和次要目标受众的心态网页模式。诸如“绒毛”、“宣传”和我个人最喜欢的“什么[脏话]”等都是用来口头描述这些页面的。此外,这些相同的文本出现在参加考试的评论和类别/部分标签中。
深入挖掘,我还注意到他们的竞争对手创建的页面与用户/搜索者的心理模型不匹配。但是,这些页面排名很好。因此,即使是这家公司的竞争对手也没有建立网站来适应用户/搜索者的心理模型。
为什么网站 所有者会构建一个信息架构,其中相当多的 SEOed 属于标准类别中的网页,“什么是 [脏话]?”为什么SEO专家不断增长页面,整个网站,不符合搜索者的思维模式?
数字“5”点亮了电梯面板。电梯停了我们常听到的“叮”声,表示电梯门快要打开了。电梯门打开。通常,当我们离开电梯时,我们可以立即看到某些类型的视觉提示。 ,我们来到了五楼,比如展示房间号501-540的标志,和/或把数字“5”放在我们眼前的某个地方。电梯上的文字和视觉提示与网站 上的类似。当搜索用户单击搜索引擎结果页面上的链接时,他们希望被传送到收录其关键字的网页。然而,关键字并不是网络搜索想要看到的唯一项目。
查询人们的网站 和网页心智模型。他们希望了解网页上的元素是可点击的,而那些则不是。在电商网站,搜索你想看的产品照片。医疗保健网站Doctors 等医疗专业人士的标题、类别和目标将在不同的medical网站导航标签目标消费者上进行大标题、类别和导航标签。
SEO的专业心智模型
如何解决很多SEO专家搜索者的心智模型和网站的结构?以下是部分列表:
PageRank (PR) 雕塑(由 nofollow 和其他方法标记)使用有针对性的 micro网站link 农场和其他搜索引擎垃圾邮件形式传播到世界各地。不幸的是,许多 SEO 专家还没有验证检索思维模式,尽管他们诚实地相信它们。如果页面团队和网络搜索点击搜索列表,则假定它是匹配网络搜索者的心智模型。排名和其他页面?然后,搜索引擎优化假定检索目标明显满足。更多点击?甚至更多的证据。退货率低?互联网搜索者必须喜欢网站,即使网站 上显示的点击次数可能令人困惑,而不是用户满意度。
算了吧,算了吧,信息架构师和实用人才一直把“什么[脏话]”看作网站的结构标签。
就好像 SEO 专家和 网站 所有者正在构建 网站 和网络的个人心态作为基础,而不是目标受众的心态。没有专业,合格的信息架构师会推荐一个网站architecture 数据,纯粹来自关键词研究工具。
我会聘请专业 SEO 架构师 网站 吗?不可以,除非个人或公司拥有丰富的教育、培训和图书馆经验/信息科学。许多专业的信息架构师在这个领域是先进的。但是,我想聘请专业的SEO来促进对网站结构的讨论。 Query 是一种搜索行为,任何网站 所有者都应该忽略它。 查看全部
网站信息设计师试图确定用户如何归类,整理和标签上的站点信息
网站信息设计者试图确定用户如何对站点信息进行分类、组织和标记。信息架构师使用不同的方法来确定最佳网站架构,包括但不限于:
什么是心智模型?
思维模型,也称为概念模型,是对一个人的思维过程的解释,为什么现实世界中的一些作品忠实地代表了基本动机和匹配行为。每个人都有一个关于网站 或搜索引擎如何工作的心智模型,没有人对另一个有相同的心智模型。然而,心智模型的某些部分是一致的,并且因人而异。
例如,让我们使用电梯。我们大多数人在乘坐电梯时都有相同的期望和体验。如果我们按下标有“2 部电梯内”的按钮,我们希望电梯将我们带到二楼。如果我们按下标有“5”的按钮,我们想乘电梯到五楼。
我们怎么知道我们正在前往五楼?在大多数电梯中,我们通常会看到一个反映我们的数字,或者在到达地面之前通过的数字。当我们到达目的地五楼时会发生什么?
现场访谈直接,一对一观察正常用户/搜索表现,日常工作可用性测试数据网络分析软件,网站搜索引擎等。在网站上,目标信息架构师是确定一个正式的网站导航和网页相互连接,其他形式最符合网站用户的心智模型。一个有效的网站 结构应该能让用户/搜索者更容易、更有效地实现他们的目标。每次点击,用户的信息都应该加强气味,不会分心、混淆或打扰用户的验证。此外,网站的信息架构所要传达的网络内容“aboutness”概念被引入搜索引擎和网站访问者。
在一个特定的B2B医疗网站反复可用性测试三年后,我发现了一个有趣的事情:内部搜索引擎优化的专业不匹配导致的主要和次要目标受众的心态网页模式。诸如“绒毛”、“宣传”和我个人最喜欢的“什么[脏话]”等都是用来口头描述这些页面的。此外,这些相同的文本出现在参加考试的评论和类别/部分标签中。
深入挖掘,我还注意到他们的竞争对手创建的页面与用户/搜索者的心理模型不匹配。但是,这些页面排名很好。因此,即使是这家公司的竞争对手也没有建立网站来适应用户/搜索者的心理模型。
为什么网站 所有者会构建一个信息架构,其中相当多的 SEOed 属于标准类别中的网页,“什么是 [脏话]?”为什么SEO专家不断增长页面,整个网站,不符合搜索者的思维模式?
数字“5”点亮了电梯面板。电梯停了我们常听到的“叮”声,表示电梯门快要打开了。电梯门打开。通常,当我们离开电梯时,我们可以立即看到某些类型的视觉提示。 ,我们来到了五楼,比如展示房间号501-540的标志,和/或把数字“5”放在我们眼前的某个地方。电梯上的文字和视觉提示与网站 上的类似。当搜索用户单击搜索引擎结果页面上的链接时,他们希望被传送到收录其关键字的网页。然而,关键字并不是网络搜索想要看到的唯一项目。
查询人们的网站 和网页心智模型。他们希望了解网页上的元素是可点击的,而那些则不是。在电商网站,搜索你想看的产品照片。医疗保健网站Doctors 等医疗专业人士的标题、类别和目标将在不同的medical网站导航标签目标消费者上进行大标题、类别和导航标签。
SEO的专业心智模型
如何解决很多SEO专家搜索者的心智模型和网站的结构?以下是部分列表:
PageRank (PR) 雕塑(由 nofollow 和其他方法标记)使用有针对性的 micro网站link 农场和其他搜索引擎垃圾邮件形式传播到世界各地。不幸的是,许多 SEO 专家还没有验证检索思维模式,尽管他们诚实地相信它们。如果页面团队和网络搜索点击搜索列表,则假定它是匹配网络搜索者的心智模型。排名和其他页面?然后,搜索引擎优化假定检索目标明显满足。更多点击?甚至更多的证据。退货率低?互联网搜索者必须喜欢网站,即使网站 上显示的点击次数可能令人困惑,而不是用户满意度。
算了吧,算了吧,信息架构师和实用人才一直把“什么[脏话]”看作网站的结构标签。
就好像 SEO 专家和 网站 所有者正在构建 网站 和网络的个人心态作为基础,而不是目标受众的心态。没有专业,合格的信息架构师会推荐一个网站architecture 数据,纯粹来自关键词研究工具。
我会聘请专业 SEO 架构师 网站 吗?不可以,除非个人或公司拥有丰富的教育、培训和图书馆经验/信息科学。许多专业的信息架构师在这个领域是先进的。但是,我想聘请专业的SEO来促进对网站结构的讨论。 Query 是一种搜索行为,任何网站 所有者都应该忽略它。
青岛搜索引擎优化,网站排名上不去的原因是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-06-16 03:05
核心提示:青岛搜索引擎优化,在做网站优化之前没有对网站进行排名的原因,有时候你会发现改变网站内容很简单,关键词等可以提高网站 ,但是现在你做网站优化你会发现用以前的优化方法是多么的困难。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么? 1.使网站做好内部链接总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网页的粘性。 现在做网站链接,在用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这将使用户浏览网站更多
青岛搜索引擎优化,网站排名不靠前的原因
在你做网站优化之前,有时候你会发现改变网站内容很简单,关键词等可以提高网站的排名,但是现在你做网站优化,你会发现有多难,之前的优化方法都行不通。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么?
1.make网站内部链接做得很好
总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网站的粘性网页。现在做网站链接,用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这样用户浏览网站的时间会更长。
2.网站关键词和页面标题很吸引人
当用户搜索关键词时,用户展示的页面会显示页面图片、标题、描述等,这会吸引用户,用户自然会因为好奇而点击。比如用户搜索的关键词是,骨科哪个医院好?您的网站 描述XXX 医院是该地区最好的骨科医院。每天都会进行X手术,用户看完手术自然会进入。
3.关注企业品牌推广,提高网站转化率
一个公司的自有品牌够大,对网站优化很有帮助。如果你是百达翡丽、古驰或兰博基尼这样的品牌,那么搜索引擎自然会提升你的排名。搜索引擎也不喜欢贫穷和财富。品牌推广对企业来说更为重要。
4.网站的外链与网站theme优化相关。
在做外链之前,可以选择权重高的网站的链接。您不在乎其他网站 是否与您的网站 相关。现在网站链接是选项和资源权重网站,比如网站你可以与妇产医院网站或婴儿用品网站合作出售奶粉。
以上就是网站在青岛搜索引擎优化排名不上去的原因。如今,网站optimization 是不够的。使用以前的解决方案。搜索引擎算法太快,优化器需要自己找规则。比如搜索引擎抓取的时候,网站内容的更新也能起到很好的作用。
联系人:张经理
手机:
网址:
地址:青岛市城阳区正阳路630号 查看全部
青岛搜索引擎优化,网站排名上不去的原因是什么
核心提示:青岛搜索引擎优化,在做网站优化之前没有对网站进行排名的原因,有时候你会发现改变网站内容很简单,关键词等可以提高网站 ,但是现在你做网站优化你会发现用以前的优化方法是多么的困难。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么? 1.使网站做好内部链接总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网页的粘性。 现在做网站链接,在用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这将使用户浏览网站更多
青岛搜索引擎优化,网站排名不靠前的原因
在你做网站优化之前,有时候你会发现改变网站内容很简单,关键词等可以提高网站的排名,但是现在你做网站优化,你会发现有多难,之前的优化方法都行不通。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么?
1.make网站内部链接做得很好
总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网站的粘性网页。现在做网站链接,用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这样用户浏览网站的时间会更长。
2.网站关键词和页面标题很吸引人
当用户搜索关键词时,用户展示的页面会显示页面图片、标题、描述等,这会吸引用户,用户自然会因为好奇而点击。比如用户搜索的关键词是,骨科哪个医院好?您的网站 描述XXX 医院是该地区最好的骨科医院。每天都会进行X手术,用户看完手术自然会进入。
3.关注企业品牌推广,提高网站转化率
一个公司的自有品牌够大,对网站优化很有帮助。如果你是百达翡丽、古驰或兰博基尼这样的品牌,那么搜索引擎自然会提升你的排名。搜索引擎也不喜欢贫穷和财富。品牌推广对企业来说更为重要。
4.网站的外链与网站theme优化相关。
在做外链之前,可以选择权重高的网站的链接。您不在乎其他网站 是否与您的网站 相关。现在网站链接是选项和资源权重网站,比如网站你可以与妇产医院网站或婴儿用品网站合作出售奶粉。
以上就是网站在青岛搜索引擎优化排名不上去的原因。如今,网站optimization 是不够的。使用以前的解决方案。搜索引擎算法太快,优化器需要自己找规则。比如搜索引擎抓取的时候,网站内容的更新也能起到很好的作用。
联系人:张经理
手机:
网址:
地址:青岛市城阳区正阳路630号
网站SEO标题在搜索引擎优化中的极其重要的存在
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-06-15 04:21
网站SEO 标题在搜索引擎优化中极为重要。
它甚至决定了网站排名的速度,网站排名的位置,以及我们抓取的用户类型。
网站title是指一个网页的标题,网站title分为首页标题、栏目页标题、内容页标题。标题可以直接显示在搜索结果中,所以其设计非常重要。
首先,标题会直接显示在搜索引擎中,所以标题不仅是搜索引擎计算出来的,也是用户看到的。吸引用户的标题可以获得更多用户点击。
其次,标题直接参与关键词排名,会参与搜索引擎排名的计算。所以标题上的文字设计直接关系到网站排名。
一、标题不要超过32个字。搜索引擎的建议是 26 个字。因为超过32个字后,标题无法完整显示。同时,过多的文字让搜索引擎难以识别网页的主题。
二、词和词之间要用英文字符分隔,如“_”“”“|” “-“ 等等。由于搜索引擎计算中使用中文和英文,因此可以使用英文来分隔单词。这里我们建议使用下划线。
三、 标题中必须有品牌词。品牌词是您在网站 中的品牌名称,相当于您网站 中的唯一名称。模型 1:核心关键词-品牌词。示例:网络推广服务-一一融合网络技术。模式二:核心关键词_需求词-品牌词。示例:网络推广服务_网络营销-一一融合网络技术。 查看全部
网站SEO标题在搜索引擎优化中的极其重要的存在
网站SEO 标题在搜索引擎优化中极为重要。
它甚至决定了网站排名的速度,网站排名的位置,以及我们抓取的用户类型。
网站title是指一个网页的标题,网站title分为首页标题、栏目页标题、内容页标题。标题可以直接显示在搜索结果中,所以其设计非常重要。
首先,标题会直接显示在搜索引擎中,所以标题不仅是搜索引擎计算出来的,也是用户看到的。吸引用户的标题可以获得更多用户点击。
其次,标题直接参与关键词排名,会参与搜索引擎排名的计算。所以标题上的文字设计直接关系到网站排名。
一、标题不要超过32个字。搜索引擎的建议是 26 个字。因为超过32个字后,标题无法完整显示。同时,过多的文字让搜索引擎难以识别网页的主题。
二、词和词之间要用英文字符分隔,如“_”“”“|” “-“ 等等。由于搜索引擎计算中使用中文和英文,因此可以使用英文来分隔单词。这里我们建议使用下划线。
三、 标题中必须有品牌词。品牌词是您在网站 中的品牌名称,相当于您网站 中的唯一名称。模型 1:核心关键词-品牌词。示例:网络推广服务-一一融合网络技术。模式二:核心关键词_需求词-品牌词。示例:网络推广服务_网络营销-一一融合网络技术。
向搜索引擎提交了网站,人家就收录你的网
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-06-15 04:20
提交网站到搜索引擎,我会收录you。这在目前是不现实的。现在搜索引擎收录你的网需要一些凭据,比如网站内容相关性、关键词密度、外链、google等pr值等等,所以即使你向搜索引擎k14@提交@,你可能不是收录。
其他网络上的链接越多,google的pr值就越高。其实我们首先要了解谷歌的pr排名算法是如何工作的。先看公式 PR(A) = (1-d)+ d(PR(t1)/C(t1)+ ... + PR(tn)/C(tn)), PR(A ) 是你能得到的pr值,d是阻尼系数,一般0.85,PR(t1)是你链接的网络的pr值,C(t1)表示有多个 URL 链接到您的 Linked 网络。例如,假设
它的pr值为1,有十个URL链接他(你的URL也在十个以内),那么你从中得到的pr值为PR(A)=(1-0.85)+0.85 (1/10)=0.15+0.085=0.235 当然,对方的网站上有10多个链接,所以你得到pr值更底,看这种情况,URL G:XXX.Net的pr值为9,上面有10个链接,那么你从中得到的pr值是PR(G)=(1-0.8 5)+0.85(9/10)=0.915,很高吧?所以不是你的网址在其他网站上的链接越多越好。 查看全部
向搜索引擎提交了网站,人家就收录你的网
提交网站到搜索引擎,我会收录you。这在目前是不现实的。现在搜索引擎收录你的网需要一些凭据,比如网站内容相关性、关键词密度、外链、google等pr值等等,所以即使你向搜索引擎k14@提交@,你可能不是收录。
其他网络上的链接越多,google的pr值就越高。其实我们首先要了解谷歌的pr排名算法是如何工作的。先看公式 PR(A) = (1-d)+ d(PR(t1)/C(t1)+ ... + PR(tn)/C(tn)), PR(A ) 是你能得到的pr值,d是阻尼系数,一般0.85,PR(t1)是你链接的网络的pr值,C(t1)表示有多个 URL 链接到您的 Linked 网络。例如,假设
它的pr值为1,有十个URL链接他(你的URL也在十个以内),那么你从中得到的pr值为PR(A)=(1-0.85)+0.85 (1/10)=0.15+0.085=0.235 当然,对方的网站上有10多个链接,所以你得到pr值更底,看这种情况,URL G:XXX.Net的pr值为9,上面有10个链接,那么你从中得到的pr值是PR(G)=(1-0.8 5)+0.85(9/10)=0.915,很高吧?所以不是你的网址在其他网站上的链接越多越好。
黑帽seo技术能够逃脱百度的法眼效应期延长
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-14 21:11
11、Baidu 实际上对于不同的地区、不同的城市、不同的网络有不同的排名位置。比如东莞和九江;长沙和深圳;电信和网通都略有不同。
12、百度在常见的采集software伪原创方法的基础上,增强了检查伪原创的算法,如乱段、关键词替换、拦截等,百度现在可以检测到了,百度会处理网站伪原创和垃圾内容的比例。对于小网站,百度会删除收录的伪原创页面。相信很多人都遇到过这种情况,页面被删除主要是因为质量不高。
13、新站审核时间更长,审核更严格。百度对新站的信任度降低。也可以说是沙盒效应期延长了。百度致力于减少数据库的垃圾邮件内容。而低质量的内容,2012年的几个k站点也是原因。主要是牺牲一些网站来换取用户使用搜索引擎的用户体验。毕竟,如果百度数据库中的垃圾邮件太多,就会为用户编入索引。 ,不利于百度未来的发展。
另外,2012年新站的关键词排名在半年内波动较大,老站相对稳定;
14、百度 降低了论坛和博客网站的导入链接权重,百度也降低了论坛签名的链接权重(相信未来论坛签名百度不会被收录外链的权重,但百度并没有在2012年实现这项技术。
未来百度将实现对论坛发帖和回复用户的识别,垃圾帖子和垃圾回复不分配权重。
15、百度进一步完善了对黑帽seo技术和seo作弊的识别。百度能以最短的速度检测你的作弊,从而减轻体重或k站,所以不要以为你的黑帽seo技术可以逃过百度的视野,良好的用户体验仍然是网站运营的基础。
根据以上百度算法的大更新和大变化,作为seoer应该进行网站诊断分析,并及时做出相应的调整和变化,避免造成功率降低和关键词排名下降由百度算法更新。甚至收录全无等的困境,百度2015年排名方法的具体做法请参考以下经验:
1.每页标题简洁,不超过30字。
2.每个网页核心关键词不超过3个。
如果可以,你必须学会放弃。
3.最重要的关键词放在标题的第一位,以此类推。
4.网站的描述简洁明了,关键词自然出现在开头和结尾。
5.网站 导航使用文本导航。
6.网站图片原创,加alt标签,不要乱加。
搜索引擎可以理解图片。
7. 制作内容与主题无关的js或图片。
8.网站 简洁而翔实。
关键词分布合理自然。
如果你自己看不懂,就放弃。
9.网站 联系方式为原创,如邮箱、电话、姓名等
10.网站 代码简洁。
11.JS 和主题相关的框架做了兼容性优化。
12.网站设计大方美观。
13.网站域名超过2年,最好3年。
14.域名最好出现在核心关键词,这对百度以外的搜索引擎有效。
15.如果是新域名,必须公布联系方式和新信息。
16.空间一定要稳定。经常被网站打不开的网站肯定不会上榜。
17.在其他地方找到网站的友情链接。
18.友情链接不看pr,看快照,看核心关键词排名,看网站首页的存在。
19.网站 外链要丰富,新闻,行业,生活,公关,越丰富越好。
20.网站 外链不在于数量,而在于质量。
增加一定要掌握节奏。
21.网站 外部链接必须出现在URL中,占70%,并且锚文本要合适。
想想自己的原因。
22.网站外联必须先增加首页的权重,首页快照在7天内,核心关键词在前3页,那么网站weight是可以接受的。
23.网站外联应该出现在人气高的地方。
24.网站 有链接的地方,避免垃圾链接和过多链接。
25.网站添加流量统计,大概数据应该公开。
26.适当刷网站ip和路,绝不网站流量来自某个搜索引擎。
27.网站 内容应围绕主题进行组织。
切勿发布不相关的内容。
28.网站添加xml和html格式图,帮助各大搜索引擎收录抓取。
29.网站 定期更新。不要一次更新一篇,也不要一次更新数百篇。
30.distribution good网站internal link.
Core关键词 指向 core关键词 页面。
31.关键词在网页内容中的加粗效果不好。避免所有粗体和粗体链接。
32. 最好每页有一次h标签。此内容与页面标题一致。
33.网站404 页面。
34. 与主题无关的页面,使用robots.txt禁止。
35.制造网站主题相关的pdf、doc、exe等文档和软件可供下载。
在这些资源上写下您自己的网站。
36.网站 一开始最好一次性全部完成,收录之后不要频繁更改
37.网站页面不要经常换主题,而关键词密度,95%的原因都是k。
38.网站外联请勿同账号同名发布。
例如,博客都是同一个人的博客。
论坛都是同一个帐户。
39.工作已完成,您需要等待!同时持续更新、维护、添加外链和内链,定期添加相关内容!
40.还在等网站排名出现。
41.将此代码添加到robots.txt:
42.user-agent: baiduspider
43.allow: /
图片需加44.文章,配图文效果最佳,图片需加alt标签。
最好总结5个字:静、全、真、好、好!
百度seo优化排名方法[2]
seo 流程操作和网站optimization Skills网站 的 seo 流程假设需要一年时间才能完成。
大致可以分为以下四个阶段:
第一阶段为准备期,主要完成以下三个任务: 站点分析---站点分析报告的形成 竞争对手分析---竞争对手分析报告的形成 战略政策的确定和部署---初步完成seo实施计划。在战略部署上,遵循这个原则:先治内伤,后优化外伤。
第二阶段为预备阶段。采集到足够的材料后,就可以开始前期工作了。
这个时间大概会持续 1-2 个月。
本阶段主要任务如下:关键词分析挖掘---形成关键词分析报告和部署计划搜索引擎友好---撰写网站修改建议内容增强---信息渠道建立,内部编辑团队培训优化---url优化、各级页面div重构、关键词布局、目录逻辑结构调整、js优化、专页搭建等
第三阶段是中期。
中期时间跨度会比较长,大概5-6个月。
此期间的主要工作是:外部优化---外部链支持和规则制定、资源站群规划、整体目录调整、博客群建设运营
第四阶段为后期。
后期大约2-3个月。
外部优化:a、链接策略b、站群站群,最大的难点不是建立,而是维护。
假设有二十个站,每个站每天更新十条信息,就会枯竭。
每个站之间必须有唯一的信息。
c、博客群建一个、链接策略。
建议使用单向链接。
获得单向链接的两种方法:
一是自己创建站群、博客、论坛签名等。
这种方式要注意单反向链接的建立。使用收录长尾关键字的关键字作为锚文本比使用单个锚文本链接要好得多。
第二个是链接交换中的策略交换。
后期工作主要包括以下内容:分析观察——用户搜索行为分析、关键词效果评估、搜索引擎性能观察、转化率分析评估、搜索引擎份额分析、网站行为分析、两个基本因素影响搜索结果页(serp)在ue分析和修改、竞争对手分析和监控、资源站群推广、对话seo网站排名的有:
1.网站这是客户最想找到的东西吗?
2.This网站 浏览者能不能找到sem:是search engine marketing的英文缩写,即搜索引擎营销。
seo:是英文search engine optimization的缩写,即搜索引擎优化。
serp:是搜索引擎结果页的缩写,即搜索引擎结果页。
是搜索引擎对搜索请求的反馈结果。
内部优化和外部优化。
a、meta、url和目录结构c、关键词布局d、js优化e、话题页f、tagsg、信息渠道(企业站点+zblog)h、页面代码层优化1、内优化a、meta:一般我们只关注三个:title、keywords、deion。就标题而言,网站最常见的问题就是关键词堆砌。
使用以下两种方法替换:一种是直接调用文章第一段的内容,100字左右;另一种是叫标题,但是加了一些自定义词。
例如,使用“这是yiyuandir站(呼叫标题)的内容,希望你喜欢””作为b、url、医院目录网络、域名的组合。
大多存在两个问题:一是url动态参数过多,不利于抓取;第二,静态页面目录太深。 C。关键词布局 关键词布局,有两种:一、是单页站点 这种站就是典型的垃圾站。
在位置有限的情况下,如何将关键字放置得更自然、更自然是关键。
二、是一个多页站点,尤其是一些有统一模板的站点,或者站点内容由第三方提供。
d、js优化后的网页代码头部充斥着大量java代码,这个问题存在很多网站。
e.话题页网站对话题页关注的不多,但其实。
一个好的话题完全可以替代一些门户网站的排名。
f、tags(tag(中文叫“tag”))g、信息通道h、页面代码层优化
新手道教[3]
一性包容一切性,一法包容一切法。
网站Optimization 也是一种启示。
了解全局,才能有一个明确的目标,展示你的技能。
Chachen将在本文中与大家分享seo优化的出现,seo优化全貌及一些相关干货概念,以及对seo的整体认识。希望对seo从业者有所帮助。如果你不是,请纠正我。
1.seo 的出现
说到seo的出现,不得不提一下搜索营销。
自1990年代以来,计算机作为第三次世界革命的标志之一出现在人们的生活中,然后网站的数量不断增加,搜索引擎出现,搜索营销成为一种新的营销方式。营销。渠道已成为营销人员不可忽视的营销方式。
简单来说,搜索营销就是在搜索引擎上进行营销,营销就是抓住消费者的大脑。
<p>按照海因茨·米戈德曼的艾达模型,一个产品要想成功地向消费者推销,首先需要引起他们的注意,然后引起兴趣,然后激发欲望,最后形成转化(行动)。 查看全部
黑帽seo技术能够逃脱百度的法眼效应期延长
11、Baidu 实际上对于不同的地区、不同的城市、不同的网络有不同的排名位置。比如东莞和九江;长沙和深圳;电信和网通都略有不同。
12、百度在常见的采集software伪原创方法的基础上,增强了检查伪原创的算法,如乱段、关键词替换、拦截等,百度现在可以检测到了,百度会处理网站伪原创和垃圾内容的比例。对于小网站,百度会删除收录的伪原创页面。相信很多人都遇到过这种情况,页面被删除主要是因为质量不高。
13、新站审核时间更长,审核更严格。百度对新站的信任度降低。也可以说是沙盒效应期延长了。百度致力于减少数据库的垃圾邮件内容。而低质量的内容,2012年的几个k站点也是原因。主要是牺牲一些网站来换取用户使用搜索引擎的用户体验。毕竟,如果百度数据库中的垃圾邮件太多,就会为用户编入索引。 ,不利于百度未来的发展。
另外,2012年新站的关键词排名在半年内波动较大,老站相对稳定;
14、百度 降低了论坛和博客网站的导入链接权重,百度也降低了论坛签名的链接权重(相信未来论坛签名百度不会被收录外链的权重,但百度并没有在2012年实现这项技术。
未来百度将实现对论坛发帖和回复用户的识别,垃圾帖子和垃圾回复不分配权重。
15、百度进一步完善了对黑帽seo技术和seo作弊的识别。百度能以最短的速度检测你的作弊,从而减轻体重或k站,所以不要以为你的黑帽seo技术可以逃过百度的视野,良好的用户体验仍然是网站运营的基础。
根据以上百度算法的大更新和大变化,作为seoer应该进行网站诊断分析,并及时做出相应的调整和变化,避免造成功率降低和关键词排名下降由百度算法更新。甚至收录全无等的困境,百度2015年排名方法的具体做法请参考以下经验:
1.每页标题简洁,不超过30字。
2.每个网页核心关键词不超过3个。
如果可以,你必须学会放弃。
3.最重要的关键词放在标题的第一位,以此类推。
4.网站的描述简洁明了,关键词自然出现在开头和结尾。
5.网站 导航使用文本导航。
6.网站图片原创,加alt标签,不要乱加。
搜索引擎可以理解图片。
7. 制作内容与主题无关的js或图片。
8.网站 简洁而翔实。
关键词分布合理自然。
如果你自己看不懂,就放弃。
9.网站 联系方式为原创,如邮箱、电话、姓名等
10.网站 代码简洁。
11.JS 和主题相关的框架做了兼容性优化。
12.网站设计大方美观。
13.网站域名超过2年,最好3年。
14.域名最好出现在核心关键词,这对百度以外的搜索引擎有效。
15.如果是新域名,必须公布联系方式和新信息。
16.空间一定要稳定。经常被网站打不开的网站肯定不会上榜。
17.在其他地方找到网站的友情链接。
18.友情链接不看pr,看快照,看核心关键词排名,看网站首页的存在。
19.网站 外链要丰富,新闻,行业,生活,公关,越丰富越好。
20.网站 外链不在于数量,而在于质量。
增加一定要掌握节奏。
21.网站 外部链接必须出现在URL中,占70%,并且锚文本要合适。
想想自己的原因。
22.网站外联必须先增加首页的权重,首页快照在7天内,核心关键词在前3页,那么网站weight是可以接受的。
23.网站外联应该出现在人气高的地方。
24.网站 有链接的地方,避免垃圾链接和过多链接。
25.网站添加流量统计,大概数据应该公开。
26.适当刷网站ip和路,绝不网站流量来自某个搜索引擎。
27.网站 内容应围绕主题进行组织。
切勿发布不相关的内容。
28.网站添加xml和html格式图,帮助各大搜索引擎收录抓取。
29.网站 定期更新。不要一次更新一篇,也不要一次更新数百篇。
30.distribution good网站internal link.
Core关键词 指向 core关键词 页面。
31.关键词在网页内容中的加粗效果不好。避免所有粗体和粗体链接。
32. 最好每页有一次h标签。此内容与页面标题一致。
33.网站404 页面。
34. 与主题无关的页面,使用robots.txt禁止。
35.制造网站主题相关的pdf、doc、exe等文档和软件可供下载。
在这些资源上写下您自己的网站。
36.网站 一开始最好一次性全部完成,收录之后不要频繁更改
37.网站页面不要经常换主题,而关键词密度,95%的原因都是k。
38.网站外联请勿同账号同名发布。
例如,博客都是同一个人的博客。
论坛都是同一个帐户。
39.工作已完成,您需要等待!同时持续更新、维护、添加外链和内链,定期添加相关内容!
40.还在等网站排名出现。
41.将此代码添加到robots.txt:
42.user-agent: baiduspider
43.allow: /
图片需加44.文章,配图文效果最佳,图片需加alt标签。
最好总结5个字:静、全、真、好、好!
百度seo优化排名方法[2]
seo 流程操作和网站optimization Skills网站 的 seo 流程假设需要一年时间才能完成。
大致可以分为以下四个阶段:
第一阶段为准备期,主要完成以下三个任务: 站点分析---站点分析报告的形成 竞争对手分析---竞争对手分析报告的形成 战略政策的确定和部署---初步完成seo实施计划。在战略部署上,遵循这个原则:先治内伤,后优化外伤。
第二阶段为预备阶段。采集到足够的材料后,就可以开始前期工作了。
这个时间大概会持续 1-2 个月。
本阶段主要任务如下:关键词分析挖掘---形成关键词分析报告和部署计划搜索引擎友好---撰写网站修改建议内容增强---信息渠道建立,内部编辑团队培训优化---url优化、各级页面div重构、关键词布局、目录逻辑结构调整、js优化、专页搭建等
第三阶段是中期。
中期时间跨度会比较长,大概5-6个月。
此期间的主要工作是:外部优化---外部链支持和规则制定、资源站群规划、整体目录调整、博客群建设运营
第四阶段为后期。
后期大约2-3个月。
外部优化:a、链接策略b、站群站群,最大的难点不是建立,而是维护。
假设有二十个站,每个站每天更新十条信息,就会枯竭。
每个站之间必须有唯一的信息。
c、博客群建一个、链接策略。
建议使用单向链接。
获得单向链接的两种方法:
一是自己创建站群、博客、论坛签名等。
这种方式要注意单反向链接的建立。使用收录长尾关键字的关键字作为锚文本比使用单个锚文本链接要好得多。
第二个是链接交换中的策略交换。
后期工作主要包括以下内容:分析观察——用户搜索行为分析、关键词效果评估、搜索引擎性能观察、转化率分析评估、搜索引擎份额分析、网站行为分析、两个基本因素影响搜索结果页(serp)在ue分析和修改、竞争对手分析和监控、资源站群推广、对话seo网站排名的有:
1.网站这是客户最想找到的东西吗?
2.This网站 浏览者能不能找到sem:是search engine marketing的英文缩写,即搜索引擎营销。
seo:是英文search engine optimization的缩写,即搜索引擎优化。
serp:是搜索引擎结果页的缩写,即搜索引擎结果页。
是搜索引擎对搜索请求的反馈结果。
内部优化和外部优化。
a、meta、url和目录结构c、关键词布局d、js优化e、话题页f、tagsg、信息渠道(企业站点+zblog)h、页面代码层优化1、内优化a、meta:一般我们只关注三个:title、keywords、deion。就标题而言,网站最常见的问题就是关键词堆砌。
使用以下两种方法替换:一种是直接调用文章第一段的内容,100字左右;另一种是叫标题,但是加了一些自定义词。
例如,使用“这是yiyuandir站(呼叫标题)的内容,希望你喜欢””作为b、url、医院目录网络、域名的组合。
大多存在两个问题:一是url动态参数过多,不利于抓取;第二,静态页面目录太深。 C。关键词布局 关键词布局,有两种:一、是单页站点 这种站就是典型的垃圾站。
在位置有限的情况下,如何将关键字放置得更自然、更自然是关键。
二、是一个多页站点,尤其是一些有统一模板的站点,或者站点内容由第三方提供。
d、js优化后的网页代码头部充斥着大量java代码,这个问题存在很多网站。
e.话题页网站对话题页关注的不多,但其实。
一个好的话题完全可以替代一些门户网站的排名。
f、tags(tag(中文叫“tag”))g、信息通道h、页面代码层优化
新手道教[3]
一性包容一切性,一法包容一切法。
网站Optimization 也是一种启示。
了解全局,才能有一个明确的目标,展示你的技能。
Chachen将在本文中与大家分享seo优化的出现,seo优化全貌及一些相关干货概念,以及对seo的整体认识。希望对seo从业者有所帮助。如果你不是,请纠正我。
1.seo 的出现
说到seo的出现,不得不提一下搜索营销。
自1990年代以来,计算机作为第三次世界革命的标志之一出现在人们的生活中,然后网站的数量不断增加,搜索引擎出现,搜索营销成为一种新的营销方式。营销。渠道已成为营销人员不可忽视的营销方式。
简单来说,搜索营销就是在搜索引擎上进行营销,营销就是抓住消费者的大脑。
<p>按照海因茨·米戈德曼的艾达模型,一个产品要想成功地向消费者推销,首先需要引起他们的注意,然后引起兴趣,然后激发欲望,最后形成转化(行动)。
目录摘要:基于用户兴趣挖掘的个性化搜索引擎模型
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-06-14 18:28
28 页,共 18268 字
总结
随着互联网技术的飞速发展,互联网提供给人们的信息量越来越大。搜索引擎作为人们在万维网上查找和获取信息的重要手段之一,已被广泛应用于各个领域。为了向用户提供个性化的查询服务,个性化搜索引擎应运而生。经过众多研究者的不懈努力,个性化搜索引擎技术取得了一定的进展。针对当前搜索引擎的不足和当前用户的个性化查询需求,在深入研究搜索引擎及相关技术的基础上,设计了一种基于用户兴趣挖掘的个性化搜索引擎模型。本文的主要工作是:
(1)个性化模型研究与实现本文深入分析了个性化搜索的特点,研究了搜索引擎及相关技术,设计了一个基于用户兴趣挖掘的个性化模型。该模型基于用户的历史从访问过的页面中提取用户的兴趣特征,对相同兴趣的页面进行分类,对用户兴趣进行分类管理;本文构建用户兴趣树动态存储用户兴趣,并结合短期和长期兴趣描述用户的兴趣特征;为了及时反映用户的兴趣变化,本文采用基于遗忘机制的兴趣更新算法。
(2)个性化搜索引擎(个性化模型除外)其他模块研究与实现本文还研究了与个性化搜索引擎相关的其他模块,包括:中文分词、查询扩展、网络蜘蛛、索引建立与更新、以及结果排序。本文在综合考虑技术实现难度和用户个性化查询需求的基础上,给出了上述模块的实现算法。
(3)通过实验证明本文设计的个性化搜索引擎的有效性。实验内容包括个性化模型的建立和个性化搜索两个方面。
内容
总结四
关键词IV
抽象电视
关键词SV
1 前言 1
1.1 研究背景 1
1.2 个性化搜索引擎1的含义
1.3 个性化搜索引擎主要研究问题1
2 搜索引擎概述 2
2.1 个性化搜索引擎 2
2.2 搜索引擎工作原理2
2.3 个性化搜索引擎系统模型3
2.4 未来搜索引擎的发展趋势4
3 个性化搜索引擎相关技术 5
3.1 信息抽取技术5
3.2 LUCENE 搜索工具包 5
3.3 中文分词技术6
3.4 自动聚类技术6
3.5 用户行为分析7
4 个性化搜索引擎总体设计7
4.1 系统需求分析与总体设计7
4.2 系统功能与架构设计8
4.3 系统流程设计8
4.4 系统数据库设计12
5 个性化搜索引擎的具体实现 13
5.1 模块设计 13
5.2 用户界面模块 14
5.3 搜索模块 16
5.4 搜索结果优化模块 19
5.5 系统运行结果及示例21
6 总结 22
参考文献:22
谢谢 23
关键词
个性化模型、用户兴趣挖掘、用户兴趣树
参考文献:
[2] 李爱明。武汉个性化搜索引擎用户模型研究:华中师范大学,2007.
[3] 张博。个性化网页搜索系统研究。秦皇岛:燕山大学,2006.
[4] 庞杰.搜索引擎技术的研究与实现。上海:上海交通大学,2006.
[5]李培欢.基于Lucene的搜索引擎设计与优化。吉林:吉林大学,2008.
[6]种梅。元搜索引擎关键技术研究。山东:山东师范大学,2008
[7]霍长青.个性化元搜索引擎的研究与设计。山东:山东科技大学,2006.
[8] 许文。从HTML网页中提取土壤问题的方法研究。北京:北京机械工业研究所,2007.
[9] 刘青。基于SVM的网络文本分类研究与应用。南昌:南昌大学,2007.
[10] 陆晓峰,郑全。基于用户行为分析的搜索引擎模型。华北理工大学学报,2004
[11] 张衡,曲景辉,张亮。网页文本信息提取与结果评价微机应用,2007.9.
[12] 费伟,黄如华。基于用户行为分析库和信息服务的搜索引擎优化策略,2005年10月(49):75一77
[13] 刘涛。用于文本分类和文本聚类的特征选择字段。武汉:南开大学,2004.
[14]冯刚。基于JZEE的多语言元搜索引擎研究与实现成都:电子科技大学,
[16] 王玲,穆志春,郭辉 一种基于聚类的支持向量机增量学习算法。北京科技人文学报,2007
[17]何士林.基于JAVA技术的搜索引擎研究与实现[J].成都:西南交通大学,2006.
[18] 张衡,曲景辉,张亮。网页文本信息提取与结果评估。微机应用,2007.9.
[19]PQi He, PKuiyuChang, Ee-peng Lim.分析事件的特征轨迹
检测 •第 30 届年度国际 ACM SIGIR 会议的论文
信息检索研究与开发,2007.6:35一37.
[20]WangDeqing, ZhangHui, ZhaoLiPing 一种无分词的聚类算法
中文搜索引擎结果[C].第三届语义知识国际会议,
and Grid, SKG2007, 2007:258一261.
[21]KumarHarshit,Kang Sanggil.seareh 引擎的另一面[C].Web seareh API's.Lecture
计算机科学笔记,v5027LNAI,应用人工智能新前沿-
第二届工业、工程和其他应用应用国际会议
智能系统,IEA/AIE2008,会刊,2008:311-320.
[22]Yuanyu-Yu, LuoXue-Chao.一种搜索引擎检索性能的测量方法
基于用户路径模式[J].Tien Tzu Hsueh Pao/Acta Eleetronica Siniea, 2008.5(36):969一973.
[23]刘春双,张志强,谢晓琴,等.元搜索引擎的评价
Merge algorithm[C].Proceedings ICICSE2008-2008 International Conference on Internet
科学与工程计算,2008:9一14. 查看全部
目录摘要:基于用户兴趣挖掘的个性化搜索引擎模型
28 页,共 18268 字
总结
随着互联网技术的飞速发展,互联网提供给人们的信息量越来越大。搜索引擎作为人们在万维网上查找和获取信息的重要手段之一,已被广泛应用于各个领域。为了向用户提供个性化的查询服务,个性化搜索引擎应运而生。经过众多研究者的不懈努力,个性化搜索引擎技术取得了一定的进展。针对当前搜索引擎的不足和当前用户的个性化查询需求,在深入研究搜索引擎及相关技术的基础上,设计了一种基于用户兴趣挖掘的个性化搜索引擎模型。本文的主要工作是:
(1)个性化模型研究与实现本文深入分析了个性化搜索的特点,研究了搜索引擎及相关技术,设计了一个基于用户兴趣挖掘的个性化模型。该模型基于用户的历史从访问过的页面中提取用户的兴趣特征,对相同兴趣的页面进行分类,对用户兴趣进行分类管理;本文构建用户兴趣树动态存储用户兴趣,并结合短期和长期兴趣描述用户的兴趣特征;为了及时反映用户的兴趣变化,本文采用基于遗忘机制的兴趣更新算法。
(2)个性化搜索引擎(个性化模型除外)其他模块研究与实现本文还研究了与个性化搜索引擎相关的其他模块,包括:中文分词、查询扩展、网络蜘蛛、索引建立与更新、以及结果排序。本文在综合考虑技术实现难度和用户个性化查询需求的基础上,给出了上述模块的实现算法。
(3)通过实验证明本文设计的个性化搜索引擎的有效性。实验内容包括个性化模型的建立和个性化搜索两个方面。
内容
总结四
关键词IV
抽象电视
关键词SV
1 前言 1
1.1 研究背景 1
1.2 个性化搜索引擎1的含义
1.3 个性化搜索引擎主要研究问题1
2 搜索引擎概述 2
2.1 个性化搜索引擎 2
2.2 搜索引擎工作原理2
2.3 个性化搜索引擎系统模型3
2.4 未来搜索引擎的发展趋势4
3 个性化搜索引擎相关技术 5
3.1 信息抽取技术5
3.2 LUCENE 搜索工具包 5
3.3 中文分词技术6
3.4 自动聚类技术6
3.5 用户行为分析7
4 个性化搜索引擎总体设计7
4.1 系统需求分析与总体设计7
4.2 系统功能与架构设计8
4.3 系统流程设计8
4.4 系统数据库设计12
5 个性化搜索引擎的具体实现 13
5.1 模块设计 13
5.2 用户界面模块 14
5.3 搜索模块 16
5.4 搜索结果优化模块 19
5.5 系统运行结果及示例21
6 总结 22
参考文献:22
谢谢 23
关键词
个性化模型、用户兴趣挖掘、用户兴趣树
参考文献:
[2] 李爱明。武汉个性化搜索引擎用户模型研究:华中师范大学,2007.
[3] 张博。个性化网页搜索系统研究。秦皇岛:燕山大学,2006.
[4] 庞杰.搜索引擎技术的研究与实现。上海:上海交通大学,2006.
[5]李培欢.基于Lucene的搜索引擎设计与优化。吉林:吉林大学,2008.
[6]种梅。元搜索引擎关键技术研究。山东:山东师范大学,2008
[7]霍长青.个性化元搜索引擎的研究与设计。山东:山东科技大学,2006.
[8] 许文。从HTML网页中提取土壤问题的方法研究。北京:北京机械工业研究所,2007.
[9] 刘青。基于SVM的网络文本分类研究与应用。南昌:南昌大学,2007.
[10] 陆晓峰,郑全。基于用户行为分析的搜索引擎模型。华北理工大学学报,2004
[11] 张衡,曲景辉,张亮。网页文本信息提取与结果评价微机应用,2007.9.
[12] 费伟,黄如华。基于用户行为分析库和信息服务的搜索引擎优化策略,2005年10月(49):75一77
[13] 刘涛。用于文本分类和文本聚类的特征选择字段。武汉:南开大学,2004.
[14]冯刚。基于JZEE的多语言元搜索引擎研究与实现成都:电子科技大学,
[16] 王玲,穆志春,郭辉 一种基于聚类的支持向量机增量学习算法。北京科技人文学报,2007
[17]何士林.基于JAVA技术的搜索引擎研究与实现[J].成都:西南交通大学,2006.
[18] 张衡,曲景辉,张亮。网页文本信息提取与结果评估。微机应用,2007.9.
[19]PQi He, PKuiyuChang, Ee-peng Lim.分析事件的特征轨迹
检测 •第 30 届年度国际 ACM SIGIR 会议的论文
信息检索研究与开发,2007.6:35一37.
[20]WangDeqing, ZhangHui, ZhaoLiPing 一种无分词的聚类算法
中文搜索引擎结果[C].第三届语义知识国际会议,
and Grid, SKG2007, 2007:258一261.
[21]KumarHarshit,Kang Sanggil.seareh 引擎的另一面[C].Web seareh API's.Lecture
计算机科学笔记,v5027LNAI,应用人工智能新前沿-
第二届工业、工程和其他应用应用国际会议
智能系统,IEA/AIE2008,会刊,2008:311-320.
[22]Yuanyu-Yu, LuoXue-Chao.一种搜索引擎检索性能的测量方法
基于用户路径模式[J].Tien Tzu Hsueh Pao/Acta Eleetronica Siniea, 2008.5(36):969一973.
[23]刘春双,张志强,谢晓琴,等.元搜索引擎的评价
Merge algorithm[C].Proceedings ICICSE2008-2008 International Conference on Internet
科学与工程计算,2008:9一14.
较多企业新网站搭建没有考虑到主机空间队网站优化关键性
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-14 18:18
很多公司新的网站building没有考虑宿主空间team网站优化的重要性。首先,易启航强调网站加载速度会影响网站在搜索引擎中的排名。
很多人还停留在两年前的SEO优化方法上,天天写洗稿,发链接等,然后天天查百度关键词的排名,希望能成很好的作用。我认为这种方法对于今天的引擎搜索来说不是那么有效。要想取得好成绩,就必须适应搜索引擎偏好的变化,完善我们的网站。现在,我们来谈谈网站SEO优化的网站SEO优化技巧。
(1)网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以在这里首先强调网站的访问速度,不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在搭建网站的时候一定要选择一个比较快稳定的主机。
(2)网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容一定要和标题相对应,而且一定要能够解决用户的问题。例如,有人搜索“个人博客应该使用什么样的主机”。这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了帮他最终解决这个问题。
(3)网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
(4)减少不良因素的出现
很多网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了很多广告信息,或者频繁弹出对话框,让用户反感影响用户停留在页面上的时间。
(5)关键词的添加和分发
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
(6)主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
(7)搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
(8)独特的优质网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。否则,即使做得好,也会有“开花”的感觉。 查看全部
较多企业新网站搭建没有考虑到主机空间队网站优化关键性
很多公司新的网站building没有考虑宿主空间team网站优化的重要性。首先,易启航强调网站加载速度会影响网站在搜索引擎中的排名。
很多人还停留在两年前的SEO优化方法上,天天写洗稿,发链接等,然后天天查百度关键词的排名,希望能成很好的作用。我认为这种方法对于今天的引擎搜索来说不是那么有效。要想取得好成绩,就必须适应搜索引擎偏好的变化,完善我们的网站。现在,我们来谈谈网站SEO优化的网站SEO优化技巧。
(1)网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以在这里首先强调网站的访问速度,不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在搭建网站的时候一定要选择一个比较快稳定的主机。
(2)网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容一定要和标题相对应,而且一定要能够解决用户的问题。例如,有人搜索“个人博客应该使用什么样的主机”。这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了帮他最终解决这个问题。
(3)网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
(4)减少不良因素的出现
很多网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了很多广告信息,或者频繁弹出对话框,让用户反感影响用户停留在页面上的时间。
(5)关键词的添加和分发
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
(6)主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
(7)搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
(8)独特的优质网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。否则,即使做得好,也会有“开花”的感觉。
【干货】一种基于主题的网页实时分类模型的研究
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-13 00:28
基于主题的网页实时分类模型研究
开始时间:2013-07-12
马建红 1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先研究了通用分类模型,分析了该模型对网页实时分类的不足。在此基础上,为了更适合网页的实时分类,本文提出了一种基于主题的网页分类模型。第一,垂直搜索引擎的主题爬虫由Nutch构建,可以随时抓取互联网上的网页,保证网页的实时性;然后对Nutch的爬取结果进行主题去噪处理,其中一部分与分类无关。页;最后,对抓取的网页进行分类。实验证明,通过该模型,可以大大提高网页分类的速度和准确率。针对网页实时分类的大数据需求,该模型可以有效优化输入样本,节省计算时间。
关键词:
如需英文信息,请点击此处
基于主题的实时网页分类研究
马建红1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先对通用分类模型进行了研究,分析了通用模型对网页实时分类的不足。在此基础上,为了更适合实时分类,本文提出一种基于主题的分类模型。首先,通过Nutch构建垂直搜索引擎爬虫的主题,网页可以一直被抓取,从而保证网页的实时性。其次,去除部分页面女巫通过主题去噪对Nutch的抓取结果进行处理,与分类无关。最终可以对抓取的网页进行分类。实验表明,该模型可以提高速度和准确性。针对大数据的需求实时网页分类,该模型可以有效优化输入样本,节省计算时间。
关键字:
点击折叠 查看全部
【干货】一种基于主题的网页实时分类模型的研究
基于主题的网页实时分类模型研究
开始时间:2013-07-12
马建红 1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先研究了通用分类模型,分析了该模型对网页实时分类的不足。在此基础上,为了更适合网页的实时分类,本文提出了一种基于主题的网页分类模型。第一,垂直搜索引擎的主题爬虫由Nutch构建,可以随时抓取互联网上的网页,保证网页的实时性;然后对Nutch的爬取结果进行主题去噪处理,其中一部分与分类无关。页;最后,对抓取的网页进行分类。实验证明,通过该模型,可以大大提高网页分类的速度和准确率。针对网页实时分类的大数据需求,该模型可以有效优化输入样本,节省计算时间。
关键词:
如需英文信息,请点击此处
基于主题的实时网页分类研究
马建红1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先对通用分类模型进行了研究,分析了通用模型对网页实时分类的不足。在此基础上,为了更适合实时分类,本文提出一种基于主题的分类模型。首先,通过Nutch构建垂直搜索引擎爬虫的主题,网页可以一直被抓取,从而保证网页的实时性。其次,去除部分页面女巫通过主题去噪对Nutch的抓取结果进行处理,与分类无关。最终可以对抓取的网页进行分类。实验表明,该模型可以提高速度和准确性。针对大数据的需求实时网页分类,该模型可以有效优化输入样本,节省计算时间。
关键字:
点击折叠
SEO优化的几个小技巧,你值得拥有!!
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-06-13 00:18
百度的算法悄然改变,新规则对你的SEO思维和方法提出了更高的要求。百度更喜欢系统的用户体验优化,网站的优化部分不仅仅是靠关键词和TITLE走天下。今天我们将一起讨论一些SEO优化技巧。
1 着陆页的内容是解决问题而不是仅仅描述问题:
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
2 重要的事情要说三遍“加载速度,速度,速度”:
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
3 是增强 UI、UX 和品牌的信任感和参与感:
很多用户打开网站后会有第一印象,他们是好山寨,好土鳖,所以不专业。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户很难在网站产生信任和参与。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4 避免各种促使用户离开页面的元素:
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
5关键词Implant:
常规的关键词植入也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等。
注入6个主题模型:
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
7 显示文字深度优化:
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
创造8个独特有价值的内容:
归根结底,营销离不开内容质量。好的内容包括:
1、提供独特的视觉体验、前端界面、合适的字体和功能按钮;
2、内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面;
3、与其他内容相比没有重复性,深度更强大;
4、打开速度快(无广告),可以在不同终端阅读;
5、可以产生认同、惊喜、快乐、思考等情感想法;
6、可以达到一定的转发和传播能力;
7、 可以使用完整、准确和独特的信息来解决或回答问题。 查看全部
SEO优化的几个小技巧,你值得拥有!!
百度的算法悄然改变,新规则对你的SEO思维和方法提出了更高的要求。百度更喜欢系统的用户体验优化,网站的优化部分不仅仅是靠关键词和TITLE走天下。今天我们将一起讨论一些SEO优化技巧。
1 着陆页的内容是解决问题而不是仅仅描述问题:
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
2 重要的事情要说三遍“加载速度,速度,速度”:
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
3 是增强 UI、UX 和品牌的信任感和参与感:
很多用户打开网站后会有第一印象,他们是好山寨,好土鳖,所以不专业。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户很难在网站产生信任和参与。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4 避免各种促使用户离开页面的元素:
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
5关键词Implant:
常规的关键词植入也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等。
注入6个主题模型:
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
7 显示文字深度优化:
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
创造8个独特有价值的内容:
归根结底,营销离不开内容质量。好的内容包括:
1、提供独特的视觉体验、前端界面、合适的字体和功能按钮;
2、内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面;
3、与其他内容相比没有重复性,深度更强大;
4、打开速度快(无广告),可以在不同终端阅读;
5、可以产生认同、惊喜、快乐、思考等情感想法;
6、可以达到一定的转发和传播能力;
7、 可以使用完整、准确和独特的信息来解决或回答问题。
【知识点】数据库索引的原理是怎样的?
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-06-08 20:22
问题一:数据库索引的原理是什么?
索引原则:为列值创建排序存储,数据结构={列值,行地址}。在有序的数据列表中,可以通过二分查找快速找到待查找行的地址,然后根据地址直接获取行数据。
问题2:索引是如何排序的?
值列
时间列
文本栏
问题 3:在新闻标题栏上建立索引。当我们查询title = ‘Diaoyu Islands’时,数据库将如何查找?而当我们查询标题LIKE ‘%Diaoyu Islands%’时,数据库应该怎么查?
像索引失效,全表扫描,数据量大的时候简直就是噩梦。
问题4:如何判断一列是否可以在数据库中建立索引?
基本原则:
该表访问频繁,数据量很大,每次查询的数据只占很小一部分
列的数据值分布广泛
该列收录大量空值
列常用于查询条件(不能收录在表达式中)
注意:文本列需要特别考虑:它们通常用于模糊查询,不适合索引。准确查询没问题。
问题5:如果要对查询结果的相关性进行排序,数据库能做到吗?
例如,如果您想查询有关苍夫人、托尼、火锅的新闻:
收录三个关键词(最相关)的新闻排名第一
收录两个关键词(相关性第二),第二个是排名
有关键字的排在第二位。
如果要为搜索到的新闻字段设置不同的权重,例如,新闻标题中收录这三个关键字的新闻的相关性远高于收录这三个词的新闻内容的相关性。数据库能做到吗?
答案:如果不能,此时您需要一个搜索引擎。
问题 6:常见的数据结构有哪些?
结构化数据:以表格和字段表示的数据
半结构化数据:xml、html
非结构化数据:文本、文档、图片、音频、视频等
在讨论了前面的问题之后,我得出了为什么需要搜索引擎的结论:
数据库适用于结构化数据的精确查询,但不适合半结构化和非结构化数据的模糊查询和灵活搜索(尤其是数据量较大时),不能提供理想的实时性能。
二、如何创建反向索引
问题一:如何快速找到与苍夫人相关的新闻?
分析:我们搜索的时候输入的是仓先生,我们想得到一个标题或内容中收录“仓先生”的新闻列表。
如果title和content列有这样的索引,可以快速找到仓先生的关键字对应的文章id,然后根据文章id快速找到文章。
标题列索引:
内容列索引:
词到文章id的索引,这是:倒排索引
问题 2:问题 1 的标题列索引和内容列索引可以合并在一起。有什么好处?
合并的好处是:可以减少访问数据库的次数
问题3:反向索引的记录数会不会很大?如果是英文,最大是多少?如果是中文,最大可能是多少?
英文单词的大概数量是 100,000。汉字总数已超过80,000个,而常用字仅3,500个。
《现代汉语标准词典》的字词比《现代汉语词典》收录多。前者13000多字72000多字,后者11000多字69000多字
结论:金额不会很大,30万以内;通过这个索引找到文章会非常快
问题 4:如何构建问题 2 中的倒排索引?
数据示例:
新闻 ID:1
新闻标题:托尼和仓太太一起吃火锅
新闻内容:2018年4月1日,Tony在四川成都参加一个活动的时候,恰巧主办方还邀请了苍老师来增加自己的人气。应主办方的邀请,他和苍夫人一起吃了火锅。酷!
如果是英文文章,分一下怎么样?
找到与查询匹配的 10 个最佳文档是一回事
英文好(有空格),但中文不好。但必须打分,否则无法建立反向指标。
你必须编写一个特殊的程序来做到这一点:分词器
中文分词器原理:有词词典,前后词结合,与词典匹配,歧义分析
问题5:java开源中文分词器很多,如何选择?
准确率、分词效率、中英文混合分词支持
常用的中文分词器:
IKAnalyzer、mmseg4j
问题 6:你、我、他、“、”、“a”、标点符号……这些需要索引吗?
这些词被称为:停用词。分词器支持指定/添加停用词,无需为其创建索引
问题7:出现新词怎么办?
嫂子,老司机,软妹儿,直男,玩腿,苍老师
分词器应支持在其字典中添加新词。
总结:
根据分词结果,我们建立倒排索引如下:
三、我有反向索引,怎么搜索?
搜索“tony OR苍老师”相关新闻的步骤是什么?
第 1 步:分割搜索输入
托尼,苍老师
第2步:在反向索引中找到收录Tony和Cang夫人的文章list
第三步:合并两个列表,对输出进行排序
{1,12,8,5}
四、如何建立相关性评价模型?
使用出现次数建立模型
规则一:统计出现次数,按次数从高到低排序
{{1,5},{5,3},{12,1},{8,1}}:文章1出现5次,文章5出现3次,文章12出现1 次,文章8 出现 1 次
问题1:标题出现仓先生,新闻内容出现仓太太。哪个和仓先生更相关?怎么做
规则二:加权重,标题权重10,内容权重1,计算权重得分,按高低排序
{{1,23},{12,10},{5,3},{8,1}}
总结:关联模型非常简单,使用出现次数来构建模型。有时排序不是很准确。
复杂的相关性计算模型包括:
tf-idf 词频-逆文档率模型
矢量空间模型
贝叶斯概率模型,如:BM25
搜索引擎将提供一种或多种实现方式以供选择以及扩展。
电子商务网站搜索相关性的计算会越来越复杂。
五、反向索引更新:数据更新的时候索引一定要更新吗?更新好了吗?
更新情况分析:
Q1:添加新商品时,我需要如何更新?
Q2:删除时,我需要如何更新?
Q3:进行更改时,我需要如何更新?
六、反向索引应该存储在内存中还是磁盘上?
大的放磁盘,小的放内存,需要持久化
七、搜索引擎需要支持精准搜索吗?需要像数据库一样支持多条件AND OR组合搜索?
如类别IN()值>=
必须的,否则没人会用搜索引擎
八、Summary
1、什么是搜索引擎?
一套可以实时搜索大量结构化、半结构化数据和非结构化文本数据的专用软件
最早用于信息检索领域,通过谷歌、百度等公司推出网络搜索而为大众所熟知。后来被各大电商网站采用做网站产品搜索。现在广泛应用于各个行业和互联网应用。是大型系统和网站架构师必备的技能。
2、搜索引擎解决什么样的问题?
专门解决大量结构化、半结构化数据、非结构化文本数据的实时检索问题。这种实时搜索数据库是做不到的。
3、搜索引擎适合什么样的场景?
核心:实时搜索大量结构化、半结构化、非结构化文本数据
信息检索(例如电子图书馆、电子档案)
网页搜索
通过提供网站(如新闻、论坛、博客网站)进行内容搜索
E-commerce网站的产品搜索
如果你负责的系统数据量大,通过数据库检索速度慢,可以考虑使用搜索引擎专门检索。
4、搜索引擎的核心组件是什么?
数据源、tokenizer、倒排索引(inverted index)、相关计算模型
5、搜索引擎是如何工作的?
1、从数据源加载数据,切词,建立反向索引
2、搜索时,对搜索输入进行分段,找到反向索引
3、计算相关、排序、输出
6、实现一个搜索引擎,需要实现什么?
1、分词器
2、反向索引,索引存储
3、相关计算模型
7、使用搜索引擎,需要明确哪些方面?
1、分词器
2、反向索引创建、存储、更新
3、相关计算模型
8、java 是广泛使用的开源搜索引擎组件和系统
Lucene:Apache的顶级开源项目,Lucene-core是一个开源的全文搜索引擎工具包,但它并不是一个完整的全文搜索引擎,而是一个全文搜索引擎框架,提供了一个完整的查询引擎和索引引擎,文本切分引擎的一部分(英语和德语两种西方语言)。 Lucene 的目的是为软件开发者提供一个简单易用的工具包,以便在目标系统中轻松实现全文搜索功能,或者以此为基础构建一个完整的全文搜索引擎。
Nutch:Apache 的顶级开源项目,包括网络爬虫和搜索引擎(基于 lucene)系统(与百度和谷歌相同)。 Hadoop 因它而诞生。
Solr:Lucene 下的一个子项目,一个基于 Lucene 的独立企业级开源搜索平台,一个服务。提供基于xml/JSON/http的api对外访问,以及web管理接口。
Elasticsearch:基于 Lucene 的企业级分布式搜索平台。它提供了一个宁静的网络界面,让程序员无需了解 Lucene 即可轻松方便地使用搜索平台。
问题:如何选择搜索引擎组件或系统?
关注成熟度并使用企业量。
更多精彩内容,请扫描下方二维码进入网站。 . . . .
查看全部
【知识点】数据库索引的原理是怎样的?
问题一:数据库索引的原理是什么?
索引原则:为列值创建排序存储,数据结构={列值,行地址}。在有序的数据列表中,可以通过二分查找快速找到待查找行的地址,然后根据地址直接获取行数据。
问题2:索引是如何排序的?
值列
时间列
文本栏
问题 3:在新闻标题栏上建立索引。当我们查询title = ‘Diaoyu Islands’时,数据库将如何查找?而当我们查询标题LIKE ‘%Diaoyu Islands%’时,数据库应该怎么查?
像索引失效,全表扫描,数据量大的时候简直就是噩梦。
问题4:如何判断一列是否可以在数据库中建立索引?
基本原则:
该表访问频繁,数据量很大,每次查询的数据只占很小一部分
列的数据值分布广泛
该列收录大量空值
列常用于查询条件(不能收录在表达式中)
注意:文本列需要特别考虑:它们通常用于模糊查询,不适合索引。准确查询没问题。
问题5:如果要对查询结果的相关性进行排序,数据库能做到吗?
例如,如果您想查询有关苍夫人、托尼、火锅的新闻:
收录三个关键词(最相关)的新闻排名第一
收录两个关键词(相关性第二),第二个是排名
有关键字的排在第二位。
如果要为搜索到的新闻字段设置不同的权重,例如,新闻标题中收录这三个关键字的新闻的相关性远高于收录这三个词的新闻内容的相关性。数据库能做到吗?
答案:如果不能,此时您需要一个搜索引擎。
问题 6:常见的数据结构有哪些?
结构化数据:以表格和字段表示的数据
半结构化数据:xml、html
非结构化数据:文本、文档、图片、音频、视频等
在讨论了前面的问题之后,我得出了为什么需要搜索引擎的结论:
数据库适用于结构化数据的精确查询,但不适合半结构化和非结构化数据的模糊查询和灵活搜索(尤其是数据量较大时),不能提供理想的实时性能。
二、如何创建反向索引
问题一:如何快速找到与苍夫人相关的新闻?
分析:我们搜索的时候输入的是仓先生,我们想得到一个标题或内容中收录“仓先生”的新闻列表。
如果title和content列有这样的索引,可以快速找到仓先生的关键字对应的文章id,然后根据文章id快速找到文章。
标题列索引:
内容列索引:
词到文章id的索引,这是:倒排索引
问题 2:问题 1 的标题列索引和内容列索引可以合并在一起。有什么好处?
合并的好处是:可以减少访问数据库的次数
问题3:反向索引的记录数会不会很大?如果是英文,最大是多少?如果是中文,最大可能是多少?
英文单词的大概数量是 100,000。汉字总数已超过80,000个,而常用字仅3,500个。
《现代汉语标准词典》的字词比《现代汉语词典》收录多。前者13000多字72000多字,后者11000多字69000多字
结论:金额不会很大,30万以内;通过这个索引找到文章会非常快
问题 4:如何构建问题 2 中的倒排索引?
数据示例:
新闻 ID:1
新闻标题:托尼和仓太太一起吃火锅
新闻内容:2018年4月1日,Tony在四川成都参加一个活动的时候,恰巧主办方还邀请了苍老师来增加自己的人气。应主办方的邀请,他和苍夫人一起吃了火锅。酷!
如果是英文文章,分一下怎么样?
找到与查询匹配的 10 个最佳文档是一回事
英文好(有空格),但中文不好。但必须打分,否则无法建立反向指标。
你必须编写一个特殊的程序来做到这一点:分词器
中文分词器原理:有词词典,前后词结合,与词典匹配,歧义分析
问题5:java开源中文分词器很多,如何选择?
准确率、分词效率、中英文混合分词支持
常用的中文分词器:
IKAnalyzer、mmseg4j
问题 6:你、我、他、“、”、“a”、标点符号……这些需要索引吗?
这些词被称为:停用词。分词器支持指定/添加停用词,无需为其创建索引
问题7:出现新词怎么办?
嫂子,老司机,软妹儿,直男,玩腿,苍老师
分词器应支持在其字典中添加新词。
总结:
根据分词结果,我们建立倒排索引如下:
三、我有反向索引,怎么搜索?
搜索“tony OR苍老师”相关新闻的步骤是什么?
第 1 步:分割搜索输入
托尼,苍老师
第2步:在反向索引中找到收录Tony和Cang夫人的文章list
第三步:合并两个列表,对输出进行排序
{1,12,8,5}
四、如何建立相关性评价模型?
使用出现次数建立模型
规则一:统计出现次数,按次数从高到低排序
{{1,5},{5,3},{12,1},{8,1}}:文章1出现5次,文章5出现3次,文章12出现1 次,文章8 出现 1 次
问题1:标题出现仓先生,新闻内容出现仓太太。哪个和仓先生更相关?怎么做
规则二:加权重,标题权重10,内容权重1,计算权重得分,按高低排序
{{1,23},{12,10},{5,3},{8,1}}
总结:关联模型非常简单,使用出现次数来构建模型。有时排序不是很准确。
复杂的相关性计算模型包括:
tf-idf 词频-逆文档率模型
矢量空间模型
贝叶斯概率模型,如:BM25
搜索引擎将提供一种或多种实现方式以供选择以及扩展。
电子商务网站搜索相关性的计算会越来越复杂。
五、反向索引更新:数据更新的时候索引一定要更新吗?更新好了吗?
更新情况分析:
Q1:添加新商品时,我需要如何更新?
Q2:删除时,我需要如何更新?
Q3:进行更改时,我需要如何更新?
六、反向索引应该存储在内存中还是磁盘上?
大的放磁盘,小的放内存,需要持久化
七、搜索引擎需要支持精准搜索吗?需要像数据库一样支持多条件AND OR组合搜索?
如类别IN()值>=
必须的,否则没人会用搜索引擎
八、Summary
1、什么是搜索引擎?
一套可以实时搜索大量结构化、半结构化数据和非结构化文本数据的专用软件
最早用于信息检索领域,通过谷歌、百度等公司推出网络搜索而为大众所熟知。后来被各大电商网站采用做网站产品搜索。现在广泛应用于各个行业和互联网应用。是大型系统和网站架构师必备的技能。
2、搜索引擎解决什么样的问题?
专门解决大量结构化、半结构化数据、非结构化文本数据的实时检索问题。这种实时搜索数据库是做不到的。
3、搜索引擎适合什么样的场景?
核心:实时搜索大量结构化、半结构化、非结构化文本数据
信息检索(例如电子图书馆、电子档案)
网页搜索
通过提供网站(如新闻、论坛、博客网站)进行内容搜索
E-commerce网站的产品搜索
如果你负责的系统数据量大,通过数据库检索速度慢,可以考虑使用搜索引擎专门检索。
4、搜索引擎的核心组件是什么?
数据源、tokenizer、倒排索引(inverted index)、相关计算模型
5、搜索引擎是如何工作的?
1、从数据源加载数据,切词,建立反向索引
2、搜索时,对搜索输入进行分段,找到反向索引
3、计算相关、排序、输出
6、实现一个搜索引擎,需要实现什么?
1、分词器
2、反向索引,索引存储
3、相关计算模型
7、使用搜索引擎,需要明确哪些方面?
1、分词器
2、反向索引创建、存储、更新
3、相关计算模型
8、java 是广泛使用的开源搜索引擎组件和系统
Lucene:Apache的顶级开源项目,Lucene-core是一个开源的全文搜索引擎工具包,但它并不是一个完整的全文搜索引擎,而是一个全文搜索引擎框架,提供了一个完整的查询引擎和索引引擎,文本切分引擎的一部分(英语和德语两种西方语言)。 Lucene 的目的是为软件开发者提供一个简单易用的工具包,以便在目标系统中轻松实现全文搜索功能,或者以此为基础构建一个完整的全文搜索引擎。
Nutch:Apache 的顶级开源项目,包括网络爬虫和搜索引擎(基于 lucene)系统(与百度和谷歌相同)。 Hadoop 因它而诞生。
Solr:Lucene 下的一个子项目,一个基于 Lucene 的独立企业级开源搜索平台,一个服务。提供基于xml/JSON/http的api对外访问,以及web管理接口。
Elasticsearch:基于 Lucene 的企业级分布式搜索平台。它提供了一个宁静的网络界面,让程序员无需了解 Lucene 即可轻松方便地使用搜索平台。
问题:如何选择搜索引擎组件或系统?
关注成熟度并使用企业量。
更多精彩内容,请扫描下方二维码进入网站。 . . . .

智能搜索如何构建一个好的电商搜索引擎?
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-08 20:17
编辑整理:刘元景
制作平台:DataFunTalk
指南:机器学习算法的不断进步,搜索引擎巧妙的人机交互设计,分布式系统的创新,在不知不觉中,让搜索引擎成为了人们生活中不可或缺的一部分。与此同时,随着人们新需求的不断涌现,搜索引擎也没有停止其变革的步伐。本文主要分享智能搜索在电子商务中的应用探索,介绍如何构建一个好的电子商务搜索引擎。主要内容包括:
01
电商搜索需求背景
首先,让我与您分享为什么您需要搜索。
1.被忽视和低估的搜索行为
在电子商务应用中,流量来自许多不同的渠道,例如搜索、推荐、事件、直播等。搜索是电商APP非常重要的流量入口,很多电商APP可能占据搜索流量的一半以上。需求明确的用户主要通过搜索获得,需求不明确的用户主要通过推荐获得。然后,对于搜索来说,因为需求更明确,所以转化起来会更容易。
2.Search 用户体验痛点
一些电商巨头其实已经把搜索体验做得很好,但是一些小客户还是做不好搜索体验,所以这给我们提供了市场机会。
3.搜索痛点下的用户流失
如果搜索做得不好,用户搜索了很多次,浏览搜索结果超过一定时间,或者翻了几页,却找不到结果,就会失去搜索体验是因为他们无法忍受。
4.智能搜索挖掘用户行为数据价值
因此应优化搜索体验以留住用户。智能搜索呢?您可以通过用户行为日志挖掘出大量有价值的数据,从这些数据中发现丰富的特征,并利用这些特征来最大化搜索流量的价值。
5.电子商务搜索示例
一般来说,对于搜索来说,除了我们经常看到的搜索框输入一些关键词进行搜索之外,搜索中还有其他场景,比如搜索发现、搜索建议、热门搜索、猜你喜欢和搜索阴影,其实这些不再是单纯的搜索,而是结合推荐的场景。
6. 产品搜索 VS。网络搜索
日常生活中,大家最熟悉的网络搜索和商品搜索有什么区别?可以从这几个方面来分析:
02
技术方案探索
接下来介绍整体技术方案。
技术架构图主要分为三部分,一是数据,二是模型,二是搜索引擎本身。数据和模型用于搜索引擎。会有一些数据接入模块,将客户的数据接入系统,放入数据平台计算素材画像、用户画像等;接下来,你需要用这些数据建立一些模型,这些模型会用到搜索引擎的各个环节,比如intent和recall,每一个环节都会用到,粗排序,细排序;再往下,有一些基本的数据存储中间件。我们主要关注搜索引擎本身的过程。最右边是搜索引擎的进程。接下来,我们将介绍整个搜索是如何从上到下进行的。
1.查询预处理
当用户在电子商务应用中输入搜索词时,搜索词将被预处理。这种预处理包括常用停用词、归一化、拼音转文本、同义词替换和分词。完成、改写、纠错等一系列处理,然后将用户搜索到的不规则或不正确的查询处理成规范的、正确的形式,并做一些分词和转换处理。
2.实体识别
预处理完成后,得到用户搜索词切分的结果。当得到分词结果时,分词结果中的每个词都必须被识别为一个实体。什么是实体?电子商务中的实体实际上有很多种。这里列出了三个。有商品实体类型。矿泉水是一个实体,属于商品实体类型;农夫山泉是品牌的实体类型;饮用水是一个类别。或称为类。这些都是实体类型。实体类型下有特定的实体。实体是矿泉水,农夫山泉,所以需要知道输入的词是什么,比如输入“Oreo cookies”,做预处理后,得到“Oreo”和“biscuits”这两个词。这时候就需要实体识别。经过识别,可以知道“奥利奥”是一个品牌,“饼干”是一个商品。可以做后续处理。
实体识别是一种序列标注。可用于实体识别的方法有很多,如CRF、BERT等。在工程处理的时候,这些算法不一定在线使用,因为这些算法在线计算成本比较高,一般都是离线计算,计算结果存放在缓存中,这样在线只需要做一些简单的匹配即可,处理会快很多,有时需要一些人工修正才能得到更准确的实体词。实体识别有一些先决条件。你怎么知道矿泉水是商品?农夫山泉是品牌吗?这个知识其实需要外部输入才能知道,这就是领域知识,所以首先要积累一些领域知识。
① 领域知识积累
领域知识其实并不容易分析。比如猪舌和烟嘴其实是一回事,西葫芦和西葫芦是一回事。当然,这个知识是可以分析的,那么如何分析呢?事实上,有很多现成的知识可以抓取和使用,积累为领域知识。这个领域有许多形式的知识。最简单的就是词典。知识图谱也可以构建。知识图谱构建是最常用的领域知识构建方式。
②词库挖掘
如何构建同义词库需要挖掘出各种类型的词,例如最常用的同义词和上位词。使用前面的例子可以理解同义词。西瓜和西葫芦是同一个东西。有很多方法可以获得同义词。预训练的词向量求共现关系的方法可以找到大量的同义词(也就是类似word2vec的方法),但是找到后可能不准确,需要后期处理才能使用它。很多同义词可以从百度百科中抓取,同义词可以在企业经营数据库和企业现有词库中找到。有多种方法可以构建同义词库。
然后如何挖掘上位词,举个例子理解上位词,比如商品类别是具体商品的上位词,矿泉水的上位词是饮用水。词库的构建是为搜索做必要的工作,但是在词库的构建过程中,不一定是人工的过程。完全可以使用其他自动化的方法甚至模型来过滤词库,最后再做一些人工修正。
③商品知识图谱构建
如何构建产品知识图谱,我们可以构建很多不同类型的知识图谱。本文基于不同的实体构建知识图谱,比如基于三类实体构建知识图谱,如上图中最右边的示意图。苹果有很多型号。如果用户搜索Apple,用户可能想购买iPhone 11、iPhone X 或仍然无法买到的iPhone 12。可以通过先验知识构建知识图谱,并将这些知识用于最终排名。整合,比如用户更倾向于购买iPhone X,iPhone X在后期排序的时候会更高级。对于品类,搜索苹果可能是手机或水果。不管是买手机还是吃水果,都是有概率的。不同的用户有不同的倾向,但是我们目前构建的地图还不能个性化。这只是一个宏观统计。在搜索苹果时,80%的用户实际上是想买苹果手机,20%的用户想买水果。这给了我们一种参考。知识图谱实际上是一种非个性化的全局知识构建。通过商品库分析静态概率。最后会根据用户的点击行为进行一些动态调整。调整后的知识图谱用于后续排名。
3.意图识别
用户搜索词预处理后,根据分词结果识别搜索词对应的实体类型。当用户搜索产品时,可以知道用户搜索的是什么实体,是品牌还是产品名称。您还可以通过图表猜测用户的搜索意图。如果他只输了一个苹果,他可以猜测他很有可能会购买一部手机,他也可以猜测其他实体类型。经过猜测,还有一些部分是猜不出来的。猜不出来的部分怎么办?使用意图识别。
那么如何做意图识别,利用用户导入的素材库来自动训练意图模型。意图识别就是进行类别预测,甚至是对其他没有字面表达的实体类型进行预测。在最初的材料库中,产品的各种属性都是一些自然的标注数据。使用这些注释数据来训练初始意图模型来预测隐式实体类型。初始模型训练完成后,使用搜索日志动态调整这个意图模型。
经过预处理、分词、实体识别、基于知识图谱的预测和意图识别,能达到什么效果?可以搜索“手机”,根据用户的信息,可以知道手机是一个产品名称,可以猜出具体的产品,但猜的可能不是那么准确。这个用户可能有80%的概率购买苹果手机,而他购买的苹果手机可能是iPhone 11,他可能猜到他要买的颜色是红色。这样,当用户输入一个词时,他就可以预测他可能想要搜索的所有信息。当然,这种预测有时准确有时不准确,但稍后会进行调整。这样,你就可以带着这些信息做一些回忆了。
意图识别的方法有哪些?意图识别的方法有很多,因为意图识别本身使用分类器。分类器的种类其实很多,但是经过各种比较,我们选择了FastText,可以在线使用,在同样的效果下,FastText是最快、最简单、最高效、最实用的。
4.粗排
完成前面的工作后,我们将开始召回。从用户搜索一个词经过一系列的过程,通过知识图谱(其实知识图谱放了一些相对头部的实体,但是长尾实体词还是需要用意图识别方法来预测)各种信息被预测,并用这些信息构建召回条件,召回条件用于召回完整的结果集。至此,召回工作完成。
召回工作完成后,下一步就是粗选。一个简单的模型可用于粗略排序。这个模型中的特征可以是相关的(搜索和推荐不同,一开始搜索会相关,但是推荐不会有相关性,推荐不会先输入一些搜索词)、时间、人气、销量、数量点赞数和采集数等,训练一个简单的模型,做一些粗略的排序,截断,进入下一个链接,如果想要更简单,可以找出核心特征,做一个加权平均粗略的排序无法达到个性化的效果。当然,粗排序可以做得更加个性化,可以根据不同的搜索用户制作个性化的粗排序模型。
5.精排
得到粗排序结果后,下一步就是细排序。对于搜索,目前主要的优化目标是CTR,主要采用CTR估算方法。 CTR估计的方法很多,比如传统的特征工程方法、深度学习方法等,也可以使用自研的第四范式HyperCycle。
特征工程方法主要是利用不同类型的特征来构建机器学习排名模型。上面列出了几组特征,包括搜索词特征、相关性特征、用户特征、产品特征和行为特征。
深度学习方法也是常用的CTR估算方法。可用于对搜索场景进行排序的深度学习模型有很多,例如DeepFM、Wide&Deep等。
我们的系统主要使用自主研发的HyperCycle。简单来说,它会自动储水积累数据,自动探索模型,自动挖掘特征,自动训练上线,自动定时更新。更多信息请参考石广川分享的HyperCycle。
6. 其他
推荐相关的应用场景会出现在搜索中,比如搜索阴影、搜索发现、搜索提示、猜你喜欢和相关搜索等,都与推荐相关。
搜索模式是搜索框中唯一的词。它实际上是对搜索框top1的推荐。根据用户的历史行为,推荐用户最可能的搜索词,将top1放入搜索模式。然后推荐给用户。用户看到这个底纹后,可以搜索这个底纹上的搜索词。目的是引导用户,猜测用户想要搜索什么,提高转化率;搜索发现和搜索底纹原理类似,但是推荐的搜索词比较多;搜索提示是在搜索中做一些推荐,相关搜索是在没有搜索结果时做一些相关推荐;有些地方会出现猜你喜欢,猜你喜欢其实是一个纯推荐场景中,当用户打开搜索页面的时候,他猜测用户最想搜索什么,然后推荐给用户。这些其实就是搜索中的推荐,搜索中的流量和推荐中的流量是可以完全相连的。
上面,我已经一一讲了整个搜索过程。现在让我们一步一步地看一下搜索单词的过程。第一步,输入搜索词“康师傅方便面”。第二步是预处理。预处理会做一些事情。第一步是分词,然后计算搜索词可能的实体类型。比如康师傅是一个品牌,它认可楚康大师是一个品牌。方便面可以是修饰符,也可以是类型。还有一些同义词:袋装面、桶装面和方便面。经过第二步的处理,你会得到类似这样的处理结果;第三步意图识别,可以看到该类别有96%的概率属于粮油调味品;
第四步是构造一个搜索查询来召回来自ES的结果;第五步,得到ES召回的结果,做粗排序和截断;第六步,精细排序;最后根据业务规则进行操作干预,将最终的搜索结果返回给用户,以上就是完整的技术流程。
03
应用案例及效果
最后,我们来看看搜索技术解决方案的应用案例并分析结果。
应用部分零售企业场景后,搜索结果准确率提升50%,全产品覆盖率提升3倍,解决客户搜索体验痛点。
这是上线前后的搜索结果对比。在发布前搜索“Apple”时,排名第一的并不是Apple。启动Smart Search后,搜索结果都与“Apple”相关。
按类别搜索,优化前搜索“水”,前5名返回“风水梨”“柔肤露”等完全不相关的产品,优化后搜索“水”,前5名返回密切相关的产品浇水。
按品牌搜索,优化前搜索“安木喜”。前 5 名返回与“希翼”完全无关的产品。优化后搜索“安木喜”,Top 5返回与品牌密切相关的产品。
同义词搜索,优化前搜索“机会”,Top5返回“果汁饮料”和“芒果味果冻”无关产品,优化后搜索“机会”,Top5返回与圣人水果密切相关的商品.
优化后,可以进行智能纠错和拼音搜索。比如搜索“pingguo”、“pingguo”、“pinguo”,就可以准确搜索到苹果相关产品。
客人介绍:
邢少民,17年加入第四范式,一直在做商业产品研发。最初,他做智能客服系列产品。去年,他孵化了智能搜索产品。今年也在做智能推荐产品的研发。 查看全部
智能搜索如何构建一个好的电商搜索引擎?
编辑整理:刘元景
制作平台:DataFunTalk
指南:机器学习算法的不断进步,搜索引擎巧妙的人机交互设计,分布式系统的创新,在不知不觉中,让搜索引擎成为了人们生活中不可或缺的一部分。与此同时,随着人们新需求的不断涌现,搜索引擎也没有停止其变革的步伐。本文主要分享智能搜索在电子商务中的应用探索,介绍如何构建一个好的电子商务搜索引擎。主要内容包括:
01
电商搜索需求背景
首先,让我与您分享为什么您需要搜索。
1.被忽视和低估的搜索行为
在电子商务应用中,流量来自许多不同的渠道,例如搜索、推荐、事件、直播等。搜索是电商APP非常重要的流量入口,很多电商APP可能占据搜索流量的一半以上。需求明确的用户主要通过搜索获得,需求不明确的用户主要通过推荐获得。然后,对于搜索来说,因为需求更明确,所以转化起来会更容易。
2.Search 用户体验痛点
一些电商巨头其实已经把搜索体验做得很好,但是一些小客户还是做不好搜索体验,所以这给我们提供了市场机会。
3.搜索痛点下的用户流失
如果搜索做得不好,用户搜索了很多次,浏览搜索结果超过一定时间,或者翻了几页,却找不到结果,就会失去搜索体验是因为他们无法忍受。
4.智能搜索挖掘用户行为数据价值
因此应优化搜索体验以留住用户。智能搜索呢?您可以通过用户行为日志挖掘出大量有价值的数据,从这些数据中发现丰富的特征,并利用这些特征来最大化搜索流量的价值。
5.电子商务搜索示例
一般来说,对于搜索来说,除了我们经常看到的搜索框输入一些关键词进行搜索之外,搜索中还有其他场景,比如搜索发现、搜索建议、热门搜索、猜你喜欢和搜索阴影,其实这些不再是单纯的搜索,而是结合推荐的场景。
6. 产品搜索 VS。网络搜索
日常生活中,大家最熟悉的网络搜索和商品搜索有什么区别?可以从这几个方面来分析:
02
技术方案探索
接下来介绍整体技术方案。
技术架构图主要分为三部分,一是数据,二是模型,二是搜索引擎本身。数据和模型用于搜索引擎。会有一些数据接入模块,将客户的数据接入系统,放入数据平台计算素材画像、用户画像等;接下来,你需要用这些数据建立一些模型,这些模型会用到搜索引擎的各个环节,比如intent和recall,每一个环节都会用到,粗排序,细排序;再往下,有一些基本的数据存储中间件。我们主要关注搜索引擎本身的过程。最右边是搜索引擎的进程。接下来,我们将介绍整个搜索是如何从上到下进行的。
1.查询预处理
当用户在电子商务应用中输入搜索词时,搜索词将被预处理。这种预处理包括常用停用词、归一化、拼音转文本、同义词替换和分词。完成、改写、纠错等一系列处理,然后将用户搜索到的不规则或不正确的查询处理成规范的、正确的形式,并做一些分词和转换处理。
2.实体识别
预处理完成后,得到用户搜索词切分的结果。当得到分词结果时,分词结果中的每个词都必须被识别为一个实体。什么是实体?电子商务中的实体实际上有很多种。这里列出了三个。有商品实体类型。矿泉水是一个实体,属于商品实体类型;农夫山泉是品牌的实体类型;饮用水是一个类别。或称为类。这些都是实体类型。实体类型下有特定的实体。实体是矿泉水,农夫山泉,所以需要知道输入的词是什么,比如输入“Oreo cookies”,做预处理后,得到“Oreo”和“biscuits”这两个词。这时候就需要实体识别。经过识别,可以知道“奥利奥”是一个品牌,“饼干”是一个商品。可以做后续处理。
实体识别是一种序列标注。可用于实体识别的方法有很多,如CRF、BERT等。在工程处理的时候,这些算法不一定在线使用,因为这些算法在线计算成本比较高,一般都是离线计算,计算结果存放在缓存中,这样在线只需要做一些简单的匹配即可,处理会快很多,有时需要一些人工修正才能得到更准确的实体词。实体识别有一些先决条件。你怎么知道矿泉水是商品?农夫山泉是品牌吗?这个知识其实需要外部输入才能知道,这就是领域知识,所以首先要积累一些领域知识。
① 领域知识积累
领域知识其实并不容易分析。比如猪舌和烟嘴其实是一回事,西葫芦和西葫芦是一回事。当然,这个知识是可以分析的,那么如何分析呢?事实上,有很多现成的知识可以抓取和使用,积累为领域知识。这个领域有许多形式的知识。最简单的就是词典。知识图谱也可以构建。知识图谱构建是最常用的领域知识构建方式。
②词库挖掘
如何构建同义词库需要挖掘出各种类型的词,例如最常用的同义词和上位词。使用前面的例子可以理解同义词。西瓜和西葫芦是同一个东西。有很多方法可以获得同义词。预训练的词向量求共现关系的方法可以找到大量的同义词(也就是类似word2vec的方法),但是找到后可能不准确,需要后期处理才能使用它。很多同义词可以从百度百科中抓取,同义词可以在企业经营数据库和企业现有词库中找到。有多种方法可以构建同义词库。
然后如何挖掘上位词,举个例子理解上位词,比如商品类别是具体商品的上位词,矿泉水的上位词是饮用水。词库的构建是为搜索做必要的工作,但是在词库的构建过程中,不一定是人工的过程。完全可以使用其他自动化的方法甚至模型来过滤词库,最后再做一些人工修正。
③商品知识图谱构建
如何构建产品知识图谱,我们可以构建很多不同类型的知识图谱。本文基于不同的实体构建知识图谱,比如基于三类实体构建知识图谱,如上图中最右边的示意图。苹果有很多型号。如果用户搜索Apple,用户可能想购买iPhone 11、iPhone X 或仍然无法买到的iPhone 12。可以通过先验知识构建知识图谱,并将这些知识用于最终排名。整合,比如用户更倾向于购买iPhone X,iPhone X在后期排序的时候会更高级。对于品类,搜索苹果可能是手机或水果。不管是买手机还是吃水果,都是有概率的。不同的用户有不同的倾向,但是我们目前构建的地图还不能个性化。这只是一个宏观统计。在搜索苹果时,80%的用户实际上是想买苹果手机,20%的用户想买水果。这给了我们一种参考。知识图谱实际上是一种非个性化的全局知识构建。通过商品库分析静态概率。最后会根据用户的点击行为进行一些动态调整。调整后的知识图谱用于后续排名。
3.意图识别
用户搜索词预处理后,根据分词结果识别搜索词对应的实体类型。当用户搜索产品时,可以知道用户搜索的是什么实体,是品牌还是产品名称。您还可以通过图表猜测用户的搜索意图。如果他只输了一个苹果,他可以猜测他很有可能会购买一部手机,他也可以猜测其他实体类型。经过猜测,还有一些部分是猜不出来的。猜不出来的部分怎么办?使用意图识别。
那么如何做意图识别,利用用户导入的素材库来自动训练意图模型。意图识别就是进行类别预测,甚至是对其他没有字面表达的实体类型进行预测。在最初的材料库中,产品的各种属性都是一些自然的标注数据。使用这些注释数据来训练初始意图模型来预测隐式实体类型。初始模型训练完成后,使用搜索日志动态调整这个意图模型。
经过预处理、分词、实体识别、基于知识图谱的预测和意图识别,能达到什么效果?可以搜索“手机”,根据用户的信息,可以知道手机是一个产品名称,可以猜出具体的产品,但猜的可能不是那么准确。这个用户可能有80%的概率购买苹果手机,而他购买的苹果手机可能是iPhone 11,他可能猜到他要买的颜色是红色。这样,当用户输入一个词时,他就可以预测他可能想要搜索的所有信息。当然,这种预测有时准确有时不准确,但稍后会进行调整。这样,你就可以带着这些信息做一些回忆了。
意图识别的方法有哪些?意图识别的方法有很多,因为意图识别本身使用分类器。分类器的种类其实很多,但是经过各种比较,我们选择了FastText,可以在线使用,在同样的效果下,FastText是最快、最简单、最高效、最实用的。
4.粗排
完成前面的工作后,我们将开始召回。从用户搜索一个词经过一系列的过程,通过知识图谱(其实知识图谱放了一些相对头部的实体,但是长尾实体词还是需要用意图识别方法来预测)各种信息被预测,并用这些信息构建召回条件,召回条件用于召回完整的结果集。至此,召回工作完成。
召回工作完成后,下一步就是粗选。一个简单的模型可用于粗略排序。这个模型中的特征可以是相关的(搜索和推荐不同,一开始搜索会相关,但是推荐不会有相关性,推荐不会先输入一些搜索词)、时间、人气、销量、数量点赞数和采集数等,训练一个简单的模型,做一些粗略的排序,截断,进入下一个链接,如果想要更简单,可以找出核心特征,做一个加权平均粗略的排序无法达到个性化的效果。当然,粗排序可以做得更加个性化,可以根据不同的搜索用户制作个性化的粗排序模型。
5.精排
得到粗排序结果后,下一步就是细排序。对于搜索,目前主要的优化目标是CTR,主要采用CTR估算方法。 CTR估计的方法很多,比如传统的特征工程方法、深度学习方法等,也可以使用自研的第四范式HyperCycle。
特征工程方法主要是利用不同类型的特征来构建机器学习排名模型。上面列出了几组特征,包括搜索词特征、相关性特征、用户特征、产品特征和行为特征。
深度学习方法也是常用的CTR估算方法。可用于对搜索场景进行排序的深度学习模型有很多,例如DeepFM、Wide&Deep等。
我们的系统主要使用自主研发的HyperCycle。简单来说,它会自动储水积累数据,自动探索模型,自动挖掘特征,自动训练上线,自动定时更新。更多信息请参考石广川分享的HyperCycle。
6. 其他
推荐相关的应用场景会出现在搜索中,比如搜索阴影、搜索发现、搜索提示、猜你喜欢和相关搜索等,都与推荐相关。
搜索模式是搜索框中唯一的词。它实际上是对搜索框top1的推荐。根据用户的历史行为,推荐用户最可能的搜索词,将top1放入搜索模式。然后推荐给用户。用户看到这个底纹后,可以搜索这个底纹上的搜索词。目的是引导用户,猜测用户想要搜索什么,提高转化率;搜索发现和搜索底纹原理类似,但是推荐的搜索词比较多;搜索提示是在搜索中做一些推荐,相关搜索是在没有搜索结果时做一些相关推荐;有些地方会出现猜你喜欢,猜你喜欢其实是一个纯推荐场景中,当用户打开搜索页面的时候,他猜测用户最想搜索什么,然后推荐给用户。这些其实就是搜索中的推荐,搜索中的流量和推荐中的流量是可以完全相连的。
上面,我已经一一讲了整个搜索过程。现在让我们一步一步地看一下搜索单词的过程。第一步,输入搜索词“康师傅方便面”。第二步是预处理。预处理会做一些事情。第一步是分词,然后计算搜索词可能的实体类型。比如康师傅是一个品牌,它认可楚康大师是一个品牌。方便面可以是修饰符,也可以是类型。还有一些同义词:袋装面、桶装面和方便面。经过第二步的处理,你会得到类似这样的处理结果;第三步意图识别,可以看到该类别有96%的概率属于粮油调味品;
第四步是构造一个搜索查询来召回来自ES的结果;第五步,得到ES召回的结果,做粗排序和截断;第六步,精细排序;最后根据业务规则进行操作干预,将最终的搜索结果返回给用户,以上就是完整的技术流程。
03
应用案例及效果
最后,我们来看看搜索技术解决方案的应用案例并分析结果。
应用部分零售企业场景后,搜索结果准确率提升50%,全产品覆盖率提升3倍,解决客户搜索体验痛点。
这是上线前后的搜索结果对比。在发布前搜索“Apple”时,排名第一的并不是Apple。启动Smart Search后,搜索结果都与“Apple”相关。
按类别搜索,优化前搜索“水”,前5名返回“风水梨”“柔肤露”等完全不相关的产品,优化后搜索“水”,前5名返回密切相关的产品浇水。
按品牌搜索,优化前搜索“安木喜”。前 5 名返回与“希翼”完全无关的产品。优化后搜索“安木喜”,Top 5返回与品牌密切相关的产品。
同义词搜索,优化前搜索“机会”,Top5返回“果汁饮料”和“芒果味果冻”无关产品,优化后搜索“机会”,Top5返回与圣人水果密切相关的商品.
优化后,可以进行智能纠错和拼音搜索。比如搜索“pingguo”、“pingguo”、“pinguo”,就可以准确搜索到苹果相关产品。
客人介绍:
邢少民,17年加入第四范式,一直在做商业产品研发。最初,他做智能客服系列产品。去年,他孵化了智能搜索产品。今年也在做智能推荐产品的研发。
蝙蝠侠IT的“无点击”时代,相关解决方案的途径
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-06-08 03:47
其中,关于SEO技术排名的相关性就不多说了,比如:
①点击搜索页面。
②页面内容增加的频率和垂直度。
③ 页面的外部链接。
通常,在这三个影响因素中,我们都非常清楚页面上的搜索点击具有非常高的权重。
当然,即使推出了迅雷算法3.0,Batman IT也认为它的占比还是比较高的,不过这次搜索点击并不是其他点击,而是来自用户搜索结果的自然点击.
2、相关解决方法
今天我们讨论的是“无点击”时代。从蝙蝠侠 IT 的角度来看,我们基于以下两个因素:
① 以前刷IP点击高度依赖SEO排名系统,现在被算法识别,点击无效。
②过去,在某个时间点,整体网站优化关键词在没有点击的情况下排名明显落后。
如果您目前正面临这样的困境,我认为以下内容值得讨论:
①内容页面质量
搜索引擎总是喜欢高质量的内容。内容为王。这是毋庸置疑的事情。根据特定搜索需求编写相关内容关键词可以获得更高的搜索排名。
就像热词“射雷算法3.0”刚出现时,我们在CSDN上发布了相关内容。从目前来看,我们在SERP中的排名还是很高的。根据地区 显示不同地区的差异化结果。目前这个词的排名还在TOP5,部分地区展示第一。
因此,有一个小问题:高质量的内容在搜索结果中也很重要。目前,如果您考虑百度的搜索结果,我们认为:
1)百家号(企业百家号)、百度小程序、百度iSourcing、百度创新者等相关产品都是首选媒体。
2)工业立类网站,如:CSDN、OSCHINA、站长之家、A5等(IT技术类)
3)企业站,品牌站,优质解决方案服务商网站,接下来是域名KOL站。
如果你在运营网站,可以参考上述相关媒体,扩大你的内容展示和流量获取。如果你是独立个体网站,我们的建议是:保持持续稳定和高价值的内容输出,思考如何打造个人品牌。
②页面结构设计
如果你长期在SEO行业工作,我们总能看到一些通过“技术排名”的高权重网站。对于这种类型的网站,页面结构可能没有任何值。
但是我们都知道SEO是基于企业网站运营的策略。我们需要一个长期的推进和短期的页面“繁荣”,一段时间后可能是短暂的。
但是我们也发现了这么一个有趣的现象,那就是差异化的网站结构设计,尤其是前端页面的展示,在一定程度上确实对收录搜索引擎非常有利。
特别是新网站的成立,我经常遇到关于SEO操作的投诉。百度不是收录。反过来,你可能需要思考一个问题,为什么搜索引擎要收录you。
但我们不希望网站 推广者在设计页面时具有创新性,使用非常个性化的网站 框架。
根据Batman IT不同的网站框架设置,我们认为在构建新的网站时,仍然需要保持一个流行的基础结构,这有利于百度蜘蛛爬取和视觉前端页面效果可以适当区分,因为搜索引擎在不断加强对CSS和JS的解释能力。
③ 增量页面内容
老实说,基于页面增量,我认为这对于网站管理员来说是一个相对容易的策略。在一定程度上,只要保持高质量内容输出的高频率,搜索引擎总会给予更高的待遇,包括:抓取频率、索引量、权重增加等。
但我们不要忽视这里的一个实际问题:
页面的增量内容是什么?
基于 SEO 数据分析,高频率输出的页面内容不会有任何增加。
前提是您的页面正在解决问题并满足搜索要求。坦白说,这个页面的核心关键词可能需要一定的搜索量。
④ 外链扩展
对于外链的拓展,相信很多做过SEO快速排名的从业者已经很久没有做外链了。这也是为什么在近几年的SEO市场上,总有人说:外链的价值越来越低,相关性的作用几乎没有。
事实上,从某种角度来看,我们并不这么认为:尤其是当我们面临“无点击”排名时,快速获得更高信任度的一种相对有效的方式仍然是基于外链驱动。
因此,您可能需要善于学习:发现稀缺的 SEO 资源,尤其是高质量的外部链接。
⑤ 网站内的用户行为
这是一个我们后期可能会花大量时间去研究和测试的方向。不限于百度搜索。有时我们总是有一定的惯性思维,从外部寻找解决方案。对以上,需要适当增加逆向思维的判断,例如:
用户在1)网站的访问和点击行为是否会在一定程度上影响搜索排名。
2)网站内部相关链接可以与外部资源分离,影响网站排名。
3)网站结构的布局,百度怎么能正常表达收录。
4)页面停留时间和用户跳出率等数据指标会影响网站的排名。
5)网站页面分享的频率,特别是基于新媒体平台的传播能力。
从搜索引擎的长远发展来看,我们认为对方会关注这个位置。
总结:SEO排名,“无点击”时代,你怎么排名,以上内容只是蝙蝠侠IT家族的话,SEO每日一贴,仅供参考!
查看全部
蝙蝠侠IT的“无点击”时代,相关解决方案的途径
其中,关于SEO技术排名的相关性就不多说了,比如:
①点击搜索页面。
②页面内容增加的频率和垂直度。
③ 页面的外部链接。
通常,在这三个影响因素中,我们都非常清楚页面上的搜索点击具有非常高的权重。
当然,即使推出了迅雷算法3.0,Batman IT也认为它的占比还是比较高的,不过这次搜索点击并不是其他点击,而是来自用户搜索结果的自然点击.
2、相关解决方法
今天我们讨论的是“无点击”时代。从蝙蝠侠 IT 的角度来看,我们基于以下两个因素:
① 以前刷IP点击高度依赖SEO排名系统,现在被算法识别,点击无效。
②过去,在某个时间点,整体网站优化关键词在没有点击的情况下排名明显落后。
如果您目前正面临这样的困境,我认为以下内容值得讨论:
①内容页面质量
搜索引擎总是喜欢高质量的内容。内容为王。这是毋庸置疑的事情。根据特定搜索需求编写相关内容关键词可以获得更高的搜索排名。
就像热词“射雷算法3.0”刚出现时,我们在CSDN上发布了相关内容。从目前来看,我们在SERP中的排名还是很高的。根据地区 显示不同地区的差异化结果。目前这个词的排名还在TOP5,部分地区展示第一。
因此,有一个小问题:高质量的内容在搜索结果中也很重要。目前,如果您考虑百度的搜索结果,我们认为:
1)百家号(企业百家号)、百度小程序、百度iSourcing、百度创新者等相关产品都是首选媒体。
2)工业立类网站,如:CSDN、OSCHINA、站长之家、A5等(IT技术类)
3)企业站,品牌站,优质解决方案服务商网站,接下来是域名KOL站。
如果你在运营网站,可以参考上述相关媒体,扩大你的内容展示和流量获取。如果你是独立个体网站,我们的建议是:保持持续稳定和高价值的内容输出,思考如何打造个人品牌。
②页面结构设计
如果你长期在SEO行业工作,我们总能看到一些通过“技术排名”的高权重网站。对于这种类型的网站,页面结构可能没有任何值。
但是我们都知道SEO是基于企业网站运营的策略。我们需要一个长期的推进和短期的页面“繁荣”,一段时间后可能是短暂的。
但是我们也发现了这么一个有趣的现象,那就是差异化的网站结构设计,尤其是前端页面的展示,在一定程度上确实对收录搜索引擎非常有利。
特别是新网站的成立,我经常遇到关于SEO操作的投诉。百度不是收录。反过来,你可能需要思考一个问题,为什么搜索引擎要收录you。
但我们不希望网站 推广者在设计页面时具有创新性,使用非常个性化的网站 框架。
根据Batman IT不同的网站框架设置,我们认为在构建新的网站时,仍然需要保持一个流行的基础结构,这有利于百度蜘蛛爬取和视觉前端页面效果可以适当区分,因为搜索引擎在不断加强对CSS和JS的解释能力。
③ 增量页面内容
老实说,基于页面增量,我认为这对于网站管理员来说是一个相对容易的策略。在一定程度上,只要保持高质量内容输出的高频率,搜索引擎总会给予更高的待遇,包括:抓取频率、索引量、权重增加等。
但我们不要忽视这里的一个实际问题:
页面的增量内容是什么?
基于 SEO 数据分析,高频率输出的页面内容不会有任何增加。
前提是您的页面正在解决问题并满足搜索要求。坦白说,这个页面的核心关键词可能需要一定的搜索量。
④ 外链扩展
对于外链的拓展,相信很多做过SEO快速排名的从业者已经很久没有做外链了。这也是为什么在近几年的SEO市场上,总有人说:外链的价值越来越低,相关性的作用几乎没有。
事实上,从某种角度来看,我们并不这么认为:尤其是当我们面临“无点击”排名时,快速获得更高信任度的一种相对有效的方式仍然是基于外链驱动。
因此,您可能需要善于学习:发现稀缺的 SEO 资源,尤其是高质量的外部链接。
⑤ 网站内的用户行为
这是一个我们后期可能会花大量时间去研究和测试的方向。不限于百度搜索。有时我们总是有一定的惯性思维,从外部寻找解决方案。对以上,需要适当增加逆向思维的判断,例如:
用户在1)网站的访问和点击行为是否会在一定程度上影响搜索排名。
2)网站内部相关链接可以与外部资源分离,影响网站排名。
3)网站结构的布局,百度怎么能正常表达收录。
4)页面停留时间和用户跳出率等数据指标会影响网站的排名。
5)网站页面分享的频率,特别是基于新媒体平台的传播能力。
从搜索引擎的长远发展来看,我们认为对方会关注这个位置。
总结:SEO排名,“无点击”时代,你怎么排名,以上内容只是蝙蝠侠IT家族的话,SEO每日一贴,仅供参考!

企业网站如何进行SEO优化,提升站点在SERP中排名
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-06-20 06:14
不管人们怎么谈,那些专注于品牌塑造的公司都应该拥有自己的独立公司网站,并对SEO采取积极的态度,即使打造知名品牌并不容易。没有其他理由可以这么说。搜索引擎上的用户都是有实际需求的用户。无论这种需求是购买产品的即时需求还是信息需求,其他网络策略的效率都低得多,企业信息能否及时传递给“潜在客户”。
在之前的文章文章中,我们不止一次提到搜索引擎是内容供应和搜索需求的对接平台。品牌的新客户和您的新受众都在这些用户中。公司有什么理由让客户远离?这个文章将讨论企业网站如何优化SEO,提高网站在SERP中的排名。
什么是搜索引擎优化
SEO 是英文术语 Search Engine Optimization 的首字母缩写词。简体中文会翻译成搜索引擎优化,正统字体会翻译成搜索引擎优化。我觉得就白帽SEO而言,显然后者翻译的名字更靠谱。 SEO相对于搜索引擎的付费广告业务,针对的是自然搜索流量。当用户使用搜索引擎寻找他们需要的东西时,搜索引擎会提供一系列最相关的页面。 SEO 是通过提高相关性和价值来获取自然搜索流量的过程。
有些人简单地将 SEO 程序分为三个部分:创建优秀的内容、页内优化和链接构建。这也被认为是一个基本的 SEO 过程
至于什么是SEO,你可以从不同的角度来解释。 SEO是一种营销策略,这是无可非议的,从营销的角度来看,这是最现实的解释。学过营销课程的朋友可能都知道,营销管理就是需求的管理,涉及发现需求、适应需求、创造需求。营销信息的传播是品牌的理念和主张。它寻求适应客户心中的固有信念。有默契和噪音。企业需要控制一致性,消除噪声的影响。
如何理解SEO
如前所述,SEO 的目标是从搜索引擎获取自然的搜索流量。用营销的语言来说,就是获取目标受众。要实现这个目标,实际上需要平衡企业站点、搜索引擎、用户需求和搜索习惯三个方面的关系。传统营销中的市场细分、潜在客户分析和目标客户识别程序仍然有效。搜索引擎设定了某些原则来规范 SEO 行为。如果他们违反了这些原则,他们可能在 SERP 中表现不佳。严重违规也可能受到处罚,将网站降级甚至从索引数据库中删除。百度和谷歌都提供了 SEO 指南。
关键词 和查询词
用户在搜索引擎中输入查询词,搜索引擎匹配索引库中最相关的结果并呈现给用户。所谓的“关键词optimization”其实就是响应目标客户的查询词。 SEO 行业已将关键字从最高转换率分为“虚假”和“噪音”查询。在实践中,人们经常使用“核心词汇”、“长尾关键词”和“brand关键词”。 ”、“非品牌关键词”等。
网站的吸引力
有吸引力的网站 是一个对目标客户很有价值的网站。这些网站往往用户体验好,内容丰富,针对性强,值得信赖。目标客户可能会长时间停留在网站上,了解各种信息有助于提高网站的搜索性能。成功的SEO离不开网站的吸引力。有人说SEO是平衡的艺术。这并非没有道理。
SEO 是一种营销策略
毫无疑问,SEO可以直接为企业带来收入。至于为什么SEO是一种独特而高效的策略,我在很多文章中都讲过。传统营销一直在使用各种方法寻找潜在客户,但搜索引擎中的用户本身是有需求的,你只需要及时响应目标客户即可。
Enterprise网站如何开发SEO
有人可能会问,SEO是一项非常复杂的技术工作吗?营销人员可以自己做 SEO 吗?
如果一定要掌握各种算法,从“底层”打败搜索引擎,那么SEO不仅是一项非常复杂的技术任务,营销人员也不再是营销人员。 SEO 有各种各样的想法,但它们基本上都在搜索引擎友好的框架内。他们响应用户需求,遵守搜索引擎规范,并提高网站 的吸引力。坚持这三个方面,你的公司网站一定会有出色的表现。
那么企业网站是怎么做SEO的呢?简而言之,您可以将其分为两部分,即ON THE PAGE SEO和OFF THE PAGE SEO),最终目标指向域的权威。涉及的话题非常多,比如空间域名、网站structure、网站themes、内容、HTML、内外部链接等,以下是完整的企业SEO策略、SEO指南:
1、SEO 影响成功的因素很多
2、网站结构和主题相关性
3、HTML 代码结构优化
4、Homepage,着陆页优化策略
5、Link 优化:内链和外链策略
6、移动网站优化策略
帖子浏览量:666 查看全部
企业网站如何进行SEO优化,提升站点在SERP中排名
不管人们怎么谈,那些专注于品牌塑造的公司都应该拥有自己的独立公司网站,并对SEO采取积极的态度,即使打造知名品牌并不容易。没有其他理由可以这么说。搜索引擎上的用户都是有实际需求的用户。无论这种需求是购买产品的即时需求还是信息需求,其他网络策略的效率都低得多,企业信息能否及时传递给“潜在客户”。
在之前的文章文章中,我们不止一次提到搜索引擎是内容供应和搜索需求的对接平台。品牌的新客户和您的新受众都在这些用户中。公司有什么理由让客户远离?这个文章将讨论企业网站如何优化SEO,提高网站在SERP中的排名。
什么是搜索引擎优化
SEO 是英文术语 Search Engine Optimization 的首字母缩写词。简体中文会翻译成搜索引擎优化,正统字体会翻译成搜索引擎优化。我觉得就白帽SEO而言,显然后者翻译的名字更靠谱。 SEO相对于搜索引擎的付费广告业务,针对的是自然搜索流量。当用户使用搜索引擎寻找他们需要的东西时,搜索引擎会提供一系列最相关的页面。 SEO 是通过提高相关性和价值来获取自然搜索流量的过程。
https://www.seozone.net/wp-con ... 1.jpg 500w" />有些人简单地将 SEO 程序分为三个部分:创建优秀的内容、页内优化和链接构建。这也被认为是一个基本的 SEO 过程
至于什么是SEO,你可以从不同的角度来解释。 SEO是一种营销策略,这是无可非议的,从营销的角度来看,这是最现实的解释。学过营销课程的朋友可能都知道,营销管理就是需求的管理,涉及发现需求、适应需求、创造需求。营销信息的传播是品牌的理念和主张。它寻求适应客户心中的固有信念。有默契和噪音。企业需要控制一致性,消除噪声的影响。
如何理解SEO
如前所述,SEO 的目标是从搜索引擎获取自然的搜索流量。用营销的语言来说,就是获取目标受众。要实现这个目标,实际上需要平衡企业站点、搜索引擎、用户需求和搜索习惯三个方面的关系。传统营销中的市场细分、潜在客户分析和目标客户识别程序仍然有效。搜索引擎设定了某些原则来规范 SEO 行为。如果他们违反了这些原则,他们可能在 SERP 中表现不佳。严重违规也可能受到处罚,将网站降级甚至从索引数据库中删除。百度和谷歌都提供了 SEO 指南。
关键词 和查询词
用户在搜索引擎中输入查询词,搜索引擎匹配索引库中最相关的结果并呈现给用户。所谓的“关键词optimization”其实就是响应目标客户的查询词。 SEO 行业已将关键字从最高转换率分为“虚假”和“噪音”查询。在实践中,人们经常使用“核心词汇”、“长尾关键词”和“brand关键词”。 ”、“非品牌关键词”等。
网站的吸引力
有吸引力的网站 是一个对目标客户很有价值的网站。这些网站往往用户体验好,内容丰富,针对性强,值得信赖。目标客户可能会长时间停留在网站上,了解各种信息有助于提高网站的搜索性能。成功的SEO离不开网站的吸引力。有人说SEO是平衡的艺术。这并非没有道理。
https://www.seozone.net/wp-con ... 6.jpg 500w" />SEO 是一种营销策略
毫无疑问,SEO可以直接为企业带来收入。至于为什么SEO是一种独特而高效的策略,我在很多文章中都讲过。传统营销一直在使用各种方法寻找潜在客户,但搜索引擎中的用户本身是有需求的,你只需要及时响应目标客户即可。
Enterprise网站如何开发SEO
有人可能会问,SEO是一项非常复杂的技术工作吗?营销人员可以自己做 SEO 吗?
如果一定要掌握各种算法,从“底层”打败搜索引擎,那么SEO不仅是一项非常复杂的技术任务,营销人员也不再是营销人员。 SEO 有各种各样的想法,但它们基本上都在搜索引擎友好的框架内。他们响应用户需求,遵守搜索引擎规范,并提高网站 的吸引力。坚持这三个方面,你的公司网站一定会有出色的表现。
那么企业网站是怎么做SEO的呢?简而言之,您可以将其分为两部分,即ON THE PAGE SEO和OFF THE PAGE SEO),最终目标指向域的权威。涉及的话题非常多,比如空间域名、网站structure、网站themes、内容、HTML、内外部链接等,以下是完整的企业SEO策略、SEO指南:
1、SEO 影响成功的因素很多
2、网站结构和主题相关性
3、HTML 代码结构优化
4、Homepage,着陆页优化策略
5、Link 优化:内链和外链策略
6、移动网站优化策略
帖子浏览量:666
4.3关键词设定要突出网站的选择必须遵循的原则
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-06-20 06:10
4.3 关键词设置突出
网站 的关键词 很重要。它决定了网站是否可以被用户搜索到,所以必须特别注意关键词的选择。 关键词的选择一定要突出并遵循一定的原则,比如:关键词要与网站话题相关,不要盲目追求流行词汇;避免使用含义广泛的通用词汇;根据产品的类型和特点,尽可能选择具体的词;选择人们在使用搜索引擎时经常使用的词,这些词与网站 需要推广的产品和服务相关。 5~10个关键词的数量比较适中,密度可以在2%-8%。注意两个网页最重要最显眼的位置Page Title和Heading,反映关键词,网页内容、图片alt属性、META标签等网页描述可以不同。设置程度突出关键词。
4.4 网站架构层次一定要清楚
网站 结构中尽量避免使用框架结构,导航栏中尽量不要使用FLASH按钮[3]。首先要注意网站首页的设计,因为网站首页比其他网页更容易被搜索引擎检测到。通常网站的主页文件应该放在网站的根目录下,因为根目录下的检索速度是最快的。其次需要注意的是网站层级不要太多(即子目录),一级目录不要超过两级,详细目录不要超过四级。最后,网站的导航尽量使用纯文本,因为文字比图片传达的信息更多。
4.5 页面容量应该合理化
网页分为静态网页和动态网页两种。动态网页是具有交互功能的网页,即通过数据库搜索返回数据,使得搜索引擎搜索时间长,一旦数据库内容更新,搜索引擎抓取的数据不再准确,所以收录动态网页搜索引擎很少,排名结果不好。而且静态网页不具备交互功能,即简单的信息介绍,搜索引擎搜索时间短且准确,所以我愿意收录,排名结果更好。所以网站应该尽量使用静态网页,减少使用动态网页。
页面越小,显示速度越快,对搜索引擎蜘蛛程序的友好度越高。因此,在创建网页时,尽量精简 HTML 代码。通常,页面大小不超过 15kB。网页中的 Java.script 和 CSS 应尽可能与网页分开。应该鼓励遵循 W3C 的规范并使用更标准化的 XHTML 和 XML 作为显示格式。
4.6 网站Navigation 应该是清晰的
搜索引擎使用专有蜘蛛程序找出每个网页上的 HTML 代码。当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛程序访问所有页面需要很长时间,所以网站的导航需要方便蜘蛛程序索引收录。你可以根据你的网站结构创建网站mapsimemap.html,列出网站在web地图中的所有链接,把网站中的所有文件放在网站的根目录下。 网站Map 可以增加搜索引擎的友好度,让蜘蛛程序可以快速访问整个网站的所有网页和栏目。
4.7 网站post 更新
为了更好的实现与搜索引擎的对话,主动向搜索引擎提交优化的企业网站,让他们免费收录,争取更好的自然排名[4]。如果网站可以定期更新,对搜索引擎收录来说更容易。所以网站的合理更新也是搜索引擎优化的重要手段。
5 结论(结论)
为了提高电子商务的竞争力,企业网站会采用多种线上推广的方式。针对不同的搜索引擎进行合理的搜索引擎优化是网站维护中的一项重要工作。 网站的排名规则在搜索引擎中经常更新,规则的变化也会影响网站的排名,导致网站的排名发生变化。所以在网站的维护中,应该根据搜索引擎排名算法的变化更新自己的网站搜索引擎优化,以适应变化。
参考资料
[1] 刘冰,同。于勇等,译。 WEB数据挖掘[M].北京:清华大学出版社,2009.
[2] 赖文文.电子商务网站搜索引擎优化研究[J].科技创新指南,2011,21:21.
[3] 刘芳。 E-commerce网站市场初探[J].中小企业管理与技术,2011,24:282.
[4] 张娜. SEO技术在电子商务中的应用网站[J].中小企业管理与技术,2011,1:246. 查看全部
4.3关键词设定要突出网站的选择必须遵循的原则
4.3 关键词设置突出
网站 的关键词 很重要。它决定了网站是否可以被用户搜索到,所以必须特别注意关键词的选择。 关键词的选择一定要突出并遵循一定的原则,比如:关键词要与网站话题相关,不要盲目追求流行词汇;避免使用含义广泛的通用词汇;根据产品的类型和特点,尽可能选择具体的词;选择人们在使用搜索引擎时经常使用的词,这些词与网站 需要推广的产品和服务相关。 5~10个关键词的数量比较适中,密度可以在2%-8%。注意两个网页最重要最显眼的位置Page Title和Heading,反映关键词,网页内容、图片alt属性、META标签等网页描述可以不同。设置程度突出关键词。
4.4 网站架构层次一定要清楚
网站 结构中尽量避免使用框架结构,导航栏中尽量不要使用FLASH按钮[3]。首先要注意网站首页的设计,因为网站首页比其他网页更容易被搜索引擎检测到。通常网站的主页文件应该放在网站的根目录下,因为根目录下的检索速度是最快的。其次需要注意的是网站层级不要太多(即子目录),一级目录不要超过两级,详细目录不要超过四级。最后,网站的导航尽量使用纯文本,因为文字比图片传达的信息更多。
4.5 页面容量应该合理化
网页分为静态网页和动态网页两种。动态网页是具有交互功能的网页,即通过数据库搜索返回数据,使得搜索引擎搜索时间长,一旦数据库内容更新,搜索引擎抓取的数据不再准确,所以收录动态网页搜索引擎很少,排名结果不好。而且静态网页不具备交互功能,即简单的信息介绍,搜索引擎搜索时间短且准确,所以我愿意收录,排名结果更好。所以网站应该尽量使用静态网页,减少使用动态网页。
页面越小,显示速度越快,对搜索引擎蜘蛛程序的友好度越高。因此,在创建网页时,尽量精简 HTML 代码。通常,页面大小不超过 15kB。网页中的 Java.script 和 CSS 应尽可能与网页分开。应该鼓励遵循 W3C 的规范并使用更标准化的 XHTML 和 XML 作为显示格式。
4.6 网站Navigation 应该是清晰的
搜索引擎使用专有蜘蛛程序找出每个网页上的 HTML 代码。当网页上有链接时,它会一一搜索,直到没有任何页面的链接。蜘蛛程序访问所有页面需要很长时间,所以网站的导航需要方便蜘蛛程序索引收录。你可以根据你的网站结构创建网站mapsimemap.html,列出网站在web地图中的所有链接,把网站中的所有文件放在网站的根目录下。 网站Map 可以增加搜索引擎的友好度,让蜘蛛程序可以快速访问整个网站的所有网页和栏目。
4.7 网站post 更新
为了更好的实现与搜索引擎的对话,主动向搜索引擎提交优化的企业网站,让他们免费收录,争取更好的自然排名[4]。如果网站可以定期更新,对搜索引擎收录来说更容易。所以网站的合理更新也是搜索引擎优化的重要手段。
5 结论(结论)
为了提高电子商务的竞争力,企业网站会采用多种线上推广的方式。针对不同的搜索引擎进行合理的搜索引擎优化是网站维护中的一项重要工作。 网站的排名规则在搜索引擎中经常更新,规则的变化也会影响网站的排名,导致网站的排名发生变化。所以在网站的维护中,应该根据搜索引擎排名算法的变化更新自己的网站搜索引擎优化,以适应变化。
参考资料
[1] 刘冰,同。于勇等,译。 WEB数据挖掘[M].北京:清华大学出版社,2009.
[2] 赖文文.电子商务网站搜索引擎优化研究[J].科技创新指南,2011,21:21.
[3] 刘芳。 E-commerce网站市场初探[J].中小企业管理与技术,2011,24:282.
[4] 张娜. SEO技术在电子商务中的应用网站[J].中小企业管理与技术,2011,1:246.
为什么要了解搜索引擎优化的真相,最好是去真正的来源
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-06-20 06:03
文章directory
学习 SEO 优化是一项挑战。一方面,没有单一的知识体系,必须从许多不同的地方一点一点地采集信息。另一方面,信息经常被误解,产生错误的排名因素和牵强的理论。这就是为什么要了解搜索引擎优化的真相,最好去真正的源头——谷歌本身。
过去,我在谷歌上讨论过一些搜索引擎优化信息的来源,即SEO Starter Guide和Quality Rater Guide。今天,我们将更深入地探索谷歌的搜索专利——这些文档解释了谷歌如何评估和排列搜索结果的各个方面。
了解这些专利是什么,为什么要研究它们,以及哪些专利可以帮助您制定更好的 SEO 优化策略。
什么是 Google 搜索专利
每当 Google 发明一种改进搜索的新方法时,它都会向美国专利商标局 (USPTO) 提交专利申请。专利是详细描述搜索算法每一位的技术文档。他们的作用是保护创新的搜索方法不被复制,从而使 Google 比竞争对手的搜索引擎更具优势。
为什么要研究 Google 搜索专利
值得一提的是,专利技术不一定是搜索算法的一部分。专利申请和技术的实际实施之间可能会有一些延迟。也有可能该技术从未实现,或者专利在达到最终状态之前经历了多次迭代。专利申请基本上是谷歌想要保护的想法的集合,但实际上它可能会被使用,也可能不会被使用。
此外,这些专利提供了对算法如何工作的独特见解——在许多方面,它是最真实的 SEO 知识形式。研究专利可以让您预测即将到来的算法更新并确定新的和现有的排名信号。您可以利用这些知识来验证您的网站 过时并验证您当前的 SEO 策略。
在哪里可以找到 Google 搜索专利
专利申请和授权专利可以在美国专利商标局官方网站进行检索——只需添加谷歌作为申请人名称,查看文件名即可。问题是谷歌申请了数千项专利,其中大部分与搜索引擎优化无关。另外,专利在某种程度上是技术文件,理解它们可能需要一些习惯。因此,以这种方式理解专利对于普通读者来说可能不是最有效的方式。
更好的方法是跟踪专利爱好者-SEO,他们监控专利更新并被社会公认为专利专家。他们每年组织数百项专利,只为挑选那些对搜索引擎优化真正重要的专利。虽然多年来一直有一些专利专家,但Bill Slawski 是撰写谷歌搜索专利历史最长的人,他在个人博客(SEO by the Sea)中重点介绍了最重要的更新。
10 项 SEO 优化 Google 搜索专利
在本节中,我将列出一些专利,这些专利描述了新颖和/或有争议的优化思路,并且对 SEO 优化者具有实际意义。我将跳过描述著名排名因素的专利和搜索引擎优化经理几乎无法控制的主题的专利。
1. 内容聚类
该专利描述了按主题对网站 和页面进行分组,并创建可描述为专家集群的内容。然后,在为相关查询提供搜索结果时,优先考虑来自这些集群的内容。
有趣的是,不属于集群的内容可能会被搜索引擎完全跳过而不做任何评估,而不管它是否有任何其他内容质量信号。
SEO的意义
明显的含义是,对于SEO来说,在不偏离你主要专业领域的情况下,在特定领域构建网站内容是有益的。在实践中,这意味着创建一个分层的内容计划并围绕较大的支柱页面排列较小的页面。
2. 基于文件开始日期的文件分级
该专利至少在一定程度上讨论了根据年龄对页面进行排名。确定页面年龄的方法有很多种,但最常用的方法是通过第一次抓取的日期来确定。
该专利还说,它还可以使用页面的年龄来计算平均链接率,即页面上的反向链接总数除以页面的年龄。然后,平均链路速率也被用作偏序因子。
SEO意义
虽然根据年龄对页面进行排名并不是什么新鲜事,但平均链接率是一个您很少听到的概念。这意味着页面越旧,每个反向链接的权重就越小。因此,如果您希望您的页面排名,您必须随着它变得越来越老而不断添加越来越多的反向链接。实现这一目标的一种方法是创建常青内容,经常更新,并通过营销渠道回收利用。
3. 基于用户上下文的搜索引擎
多年来,Google 发布了一系列与关键字相关的文档,将其排名标准从关键字更改为关键字词组再到上下文词。最新的这些文档描述了词库的构建,其中不仅收录关键字,还收录上下文词,这些词与主题松散相关。
SEO的意义
从目前的情况来看,谷歌可能更喜欢带有上下文词和传统关键字的页面。例如,如果您正在创建一个关于最佳羽绒服的页面,Google 可能会看到一些不太明显的字词,例如水、徒步旅行和鹅。
4. 观看时间排名
从视频观看时间专利到网站duration 性能专利,谷歌似乎将访问时长作为排名因素。这些专利描述了特定类型内容的基准访问持续时间,然后根据网页相对于基准的性能对网页进行排名。
SEO的意义
寻找保持访问者参与度的方法可能对您的排名有益。实现这一目标的一种显而易见的方法是创建高质量、全面的内容,其中包括各种媒体和互动元素(图片、视频、投票、评论提示等)。
5. 根据隐式用户反馈修改搜索结果排名
过去,该专利使用简单的点击率作为搜索结果排名的一部分,但最近升级为使用加权点击率。较新的版本试图找到点击次数和访问时间之间的中点,这听起来很像跳出率的变化。基本上,您的代码段获得的点击次数越多,用户停留的时间就越长,效果就越好。
SEO的意义
Google 是否使用行为指标对网页进行排名一直存在争议。不管实际情况如何,该技术已经获得专利,所以机会来了。这意味着您应该格外小心,让您的代码片段在搜索结果中不可抗拒,从标题到元描述,再到使用结构化数据增强代码片段。
6. 预测页面质量
Google 已经申请了许多使用 n-gram(字符串)来评估副本质量的专利。它的工作方式是该算法使用一组已知质量的页面来创建语言模型。然后它使用新页面上的模型来确定写作与质量基准的相似程度,并相应地对页面进行排名。
SEO的意义
N-gram 可用于识别乱码内容、关键字填充和低质量写作。这意味着您可能应该远离抓取的、自动生成的内容,并聘请经验丰富的作家,或者至少使用校对人员来完善您的副本。
7.意图查询的自然语言搜索结果
该专利描述了一种用于确定特征片段的资格的机制。基本上,只要有一个意图非常明确的自然语言查询,比如“七大罪”是什么,谷歌就会扫描排名靠前的页面,寻找一个听起来与查询非常相似的标题,然后一个简洁的答案,例如七大罪的清单。
SEO意义
请记住,副本中的每个标题 (H2-H6)) 都可能用于丰富的代码片段。基本上,每个标题都必须像查询(自然语言+关键字)一样写,标题后面的文字应该提供查询的答案。
以下是丰富素材片段的完美示例-其中一个标题与如何更换尿布的查询完全匹配,后面是编号步骤列表:
8.基于用户行为/特征数据的排名文档
这是一个更麻木的专利阅读,但它本质上归结为您的锚文本的信息量。该专利描述了用于查看用户点击链接可能性的各种指标。概率越高,链路传输的能量就越多。
SEO意义
为反向链接和内部链接创建锚文本时,请遵循最佳做法。确保锚点代表它指向的页面,收录关键字,并被上下文词包围。
9.确定资源的质量度量
另一项与链接相关的专利使我们能够深入了解每个反向链接的价值。该专利描述了一种通过查看链接带来的流量来衡量链接价值的方法。如果实际用户没有点击链接,链接将不会传递任何权重值。
SEO的意义
当您构建反向链接时,尤其是通过访客帖子,您可能倾向于在每个帖子中收录尽可能多的链接。好吧,根据专利,你会浪费时间,因为没有点击的链接几乎没有用。因此,您还可以收录更少的链接并增加每个链接被点击的机会。同样,没有人访问过的网站购买链接可能没有用。
10. 确定本地专家进行本地搜索
该专利描述了根据本地专家的加权评论对本地结果的评级。使用总阈值来确定专家的数量。这些阈值包括评论总数、本地评论数量以及特定类别公司的评论数量。 “Google 我的商家”确实将一些评论者标记为本地指南,因此似乎该专利至少已部分实施。
SEO的意义
虽然您无法通过本地指南专门征求 GMB 评论,但还是有一些方法可以鼓励更多客户评论您的业务。您可以在开始业务时亲自询问他们、向他们发送跟进电子邮件、为忠诚度计划提供奖励,或使用社交媒体让您的客户对 GMB 留下一些反馈。
此外,如果您发现任何当地导游给您差评,您必须加倍努力让他们满意。
最后的想法
我对 Google 的搜索专利知之甚少,但我真的很着迷。其中一些甚至有点令人不安,例如建议使用手机摄像头查看用户对搜索结果的响应,或者建议听取背景噪音(电视、谈话等)并采集查询上下文的建议.
尽管他们确实提供了有关 Google 面临的问题以及他们试图解决的解决方案的宝贵见解。因此,这些见解有助于我们提供更好的内容。
属于主题 查看全部
为什么要了解搜索引擎优化的真相,最好是去真正的来源
文章directory
学习 SEO 优化是一项挑战。一方面,没有单一的知识体系,必须从许多不同的地方一点一点地采集信息。另一方面,信息经常被误解,产生错误的排名因素和牵强的理论。这就是为什么要了解搜索引擎优化的真相,最好去真正的源头——谷歌本身。
过去,我在谷歌上讨论过一些搜索引擎优化信息的来源,即SEO Starter Guide和Quality Rater Guide。今天,我们将更深入地探索谷歌的搜索专利——这些文档解释了谷歌如何评估和排列搜索结果的各个方面。
了解这些专利是什么,为什么要研究它们,以及哪些专利可以帮助您制定更好的 SEO 优化策略。
什么是 Google 搜索专利
每当 Google 发明一种改进搜索的新方法时,它都会向美国专利商标局 (USPTO) 提交专利申请。专利是详细描述搜索算法每一位的技术文档。他们的作用是保护创新的搜索方法不被复制,从而使 Google 比竞争对手的搜索引擎更具优势。
为什么要研究 Google 搜索专利
值得一提的是,专利技术不一定是搜索算法的一部分。专利申请和技术的实际实施之间可能会有一些延迟。也有可能该技术从未实现,或者专利在达到最终状态之前经历了多次迭代。专利申请基本上是谷歌想要保护的想法的集合,但实际上它可能会被使用,也可能不会被使用。
此外,这些专利提供了对算法如何工作的独特见解——在许多方面,它是最真实的 SEO 知识形式。研究专利可以让您预测即将到来的算法更新并确定新的和现有的排名信号。您可以利用这些知识来验证您的网站 过时并验证您当前的 SEO 策略。
在哪里可以找到 Google 搜索专利
专利申请和授权专利可以在美国专利商标局官方网站进行检索——只需添加谷歌作为申请人名称,查看文件名即可。问题是谷歌申请了数千项专利,其中大部分与搜索引擎优化无关。另外,专利在某种程度上是技术文件,理解它们可能需要一些习惯。因此,以这种方式理解专利对于普通读者来说可能不是最有效的方式。
更好的方法是跟踪专利爱好者-SEO,他们监控专利更新并被社会公认为专利专家。他们每年组织数百项专利,只为挑选那些对搜索引擎优化真正重要的专利。虽然多年来一直有一些专利专家,但Bill Slawski 是撰写谷歌搜索专利历史最长的人,他在个人博客(SEO by the Sea)中重点介绍了最重要的更新。
10 项 SEO 优化 Google 搜索专利
在本节中,我将列出一些专利,这些专利描述了新颖和/或有争议的优化思路,并且对 SEO 优化者具有实际意义。我将跳过描述著名排名因素的专利和搜索引擎优化经理几乎无法控制的主题的专利。
1. 内容聚类
该专利描述了按主题对网站 和页面进行分组,并创建可描述为专家集群的内容。然后,在为相关查询提供搜索结果时,优先考虑来自这些集群的内容。
有趣的是,不属于集群的内容可能会被搜索引擎完全跳过而不做任何评估,而不管它是否有任何其他内容质量信号。
SEO的意义
明显的含义是,对于SEO来说,在不偏离你主要专业领域的情况下,在特定领域构建网站内容是有益的。在实践中,这意味着创建一个分层的内容计划并围绕较大的支柱页面排列较小的页面。
2. 基于文件开始日期的文件分级
该专利至少在一定程度上讨论了根据年龄对页面进行排名。确定页面年龄的方法有很多种,但最常用的方法是通过第一次抓取的日期来确定。
该专利还说,它还可以使用页面的年龄来计算平均链接率,即页面上的反向链接总数除以页面的年龄。然后,平均链路速率也被用作偏序因子。
SEO意义
虽然根据年龄对页面进行排名并不是什么新鲜事,但平均链接率是一个您很少听到的概念。这意味着页面越旧,每个反向链接的权重就越小。因此,如果您希望您的页面排名,您必须随着它变得越来越老而不断添加越来越多的反向链接。实现这一目标的一种方法是创建常青内容,经常更新,并通过营销渠道回收利用。
3. 基于用户上下文的搜索引擎
多年来,Google 发布了一系列与关键字相关的文档,将其排名标准从关键字更改为关键字词组再到上下文词。最新的这些文档描述了词库的构建,其中不仅收录关键字,还收录上下文词,这些词与主题松散相关。
SEO的意义
从目前的情况来看,谷歌可能更喜欢带有上下文词和传统关键字的页面。例如,如果您正在创建一个关于最佳羽绒服的页面,Google 可能会看到一些不太明显的字词,例如水、徒步旅行和鹅。
4. 观看时间排名
从视频观看时间专利到网站duration 性能专利,谷歌似乎将访问时长作为排名因素。这些专利描述了特定类型内容的基准访问持续时间,然后根据网页相对于基准的性能对网页进行排名。
SEO的意义
寻找保持访问者参与度的方法可能对您的排名有益。实现这一目标的一种显而易见的方法是创建高质量、全面的内容,其中包括各种媒体和互动元素(图片、视频、投票、评论提示等)。
5. 根据隐式用户反馈修改搜索结果排名
过去,该专利使用简单的点击率作为搜索结果排名的一部分,但最近升级为使用加权点击率。较新的版本试图找到点击次数和访问时间之间的中点,这听起来很像跳出率的变化。基本上,您的代码段获得的点击次数越多,用户停留的时间就越长,效果就越好。
SEO的意义
Google 是否使用行为指标对网页进行排名一直存在争议。不管实际情况如何,该技术已经获得专利,所以机会来了。这意味着您应该格外小心,让您的代码片段在搜索结果中不可抗拒,从标题到元描述,再到使用结构化数据增强代码片段。
6. 预测页面质量
Google 已经申请了许多使用 n-gram(字符串)来评估副本质量的专利。它的工作方式是该算法使用一组已知质量的页面来创建语言模型。然后它使用新页面上的模型来确定写作与质量基准的相似程度,并相应地对页面进行排名。
SEO的意义
N-gram 可用于识别乱码内容、关键字填充和低质量写作。这意味着您可能应该远离抓取的、自动生成的内容,并聘请经验丰富的作家,或者至少使用校对人员来完善您的副本。
7.意图查询的自然语言搜索结果
该专利描述了一种用于确定特征片段的资格的机制。基本上,只要有一个意图非常明确的自然语言查询,比如“七大罪”是什么,谷歌就会扫描排名靠前的页面,寻找一个听起来与查询非常相似的标题,然后一个简洁的答案,例如七大罪的清单。
SEO意义
请记住,副本中的每个标题 (H2-H6)) 都可能用于丰富的代码片段。基本上,每个标题都必须像查询(自然语言+关键字)一样写,标题后面的文字应该提供查询的答案。
以下是丰富素材片段的完美示例-其中一个标题与如何更换尿布的查询完全匹配,后面是编号步骤列表:
8.基于用户行为/特征数据的排名文档
这是一个更麻木的专利阅读,但它本质上归结为您的锚文本的信息量。该专利描述了用于查看用户点击链接可能性的各种指标。概率越高,链路传输的能量就越多。
SEO意义
为反向链接和内部链接创建锚文本时,请遵循最佳做法。确保锚点代表它指向的页面,收录关键字,并被上下文词包围。
9.确定资源的质量度量
另一项与链接相关的专利使我们能够深入了解每个反向链接的价值。该专利描述了一种通过查看链接带来的流量来衡量链接价值的方法。如果实际用户没有点击链接,链接将不会传递任何权重值。
SEO的意义
当您构建反向链接时,尤其是通过访客帖子,您可能倾向于在每个帖子中收录尽可能多的链接。好吧,根据专利,你会浪费时间,因为没有点击的链接几乎没有用。因此,您还可以收录更少的链接并增加每个链接被点击的机会。同样,没有人访问过的网站购买链接可能没有用。
10. 确定本地专家进行本地搜索
该专利描述了根据本地专家的加权评论对本地结果的评级。使用总阈值来确定专家的数量。这些阈值包括评论总数、本地评论数量以及特定类别公司的评论数量。 “Google 我的商家”确实将一些评论者标记为本地指南,因此似乎该专利至少已部分实施。
SEO的意义
虽然您无法通过本地指南专门征求 GMB 评论,但还是有一些方法可以鼓励更多客户评论您的业务。您可以在开始业务时亲自询问他们、向他们发送跟进电子邮件、为忠诚度计划提供奖励,或使用社交媒体让您的客户对 GMB 留下一些反馈。
此外,如果您发现任何当地导游给您差评,您必须加倍努力让他们满意。
最后的想法
我对 Google 的搜索专利知之甚少,但我真的很着迷。其中一些甚至有点令人不安,例如建议使用手机摄像头查看用户对搜索结果的响应,或者建议听取背景噪音(电视、谈话等)并采集查询上下文的建议.
尽管他们确实提供了有关 Google 面临的问题以及他们试图解决的解决方案的宝贵见解。因此,这些见解有助于我们提供更好的内容。
属于主题
,主题搜索引擎技术成为新的研究方向(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-06-20 02:07
[摘要]:随着互联网信息时代的不断发展,互联网上广泛分布的各类信息已经深刻影响着人类生活的方方面面。如今,人们可以通过浏览网页来查询所需的各种目标信息。同时,由于互联网上的信息数以千计,信息量处于快速膨胀的状态,这使得如何通过网页轻松查询目标信息的问题更加突出。在信息多样化的趋势下,通用的搜索引擎在很大程度上为人们在互联网上查找信息提供了便利,但也暴露出各种不足。例如:精度低、信息内容相对陈旧、信息分布不均等。因此,主题搜索引擎技术成为一个新的研究方向。它为特定领域、特定人群或特定需求提供有价值的信息资源和检索服务。主题爬虫作为主题搜索引擎的信息抓取部分,负责抓取用户感兴趣的某个主题相关的网页。本文主要通过六章来分析主题爬虫的设计和实现。第一章主要介绍了搜索引擎的发展历程、网络爬虫在搜索引擎中的作用,并简要介绍了国内外的研究现状和课题的研究意义。第二章是本文的理论基础:首先对搜索引擎的基本原理进行讲解,然后通过比较通用爬虫和主题爬虫找出两者的区别和各自的特点,这两种类型的爬虫架构和基本工作原理。第三章主要讨论主题爬虫领域关键技术的研究和改进,包括文本特征项提取方法、搜索策略和网页去重技术的研究,提出基于主题相关性的PageRank算法的改进。第四章主要讨论主题爬虫的系统设计与实现,主要包括网络爬虫模块、网络分析模块、中文分词和URL管理模块。第五章介绍了主题爬虫系统的界面和操作细节,以及使用该系统的实验过程。通过对实验数据的分析,证明了前几章各种理论的合理性和有效性。第6章对前几章的内容进行总结和总结,提出本文的创新点和局限性。实验结果证明,主题爬虫在稳定运行的同时有更好的收获率,大大减少了时间和存储空间。及时的优势保证了网页的及时更新。此外,用户在搜索时获得的冗余和无用信息也较少,准确率较高。 查看全部
,主题搜索引擎技术成为新的研究方向(组图)
[摘要]:随着互联网信息时代的不断发展,互联网上广泛分布的各类信息已经深刻影响着人类生活的方方面面。如今,人们可以通过浏览网页来查询所需的各种目标信息。同时,由于互联网上的信息数以千计,信息量处于快速膨胀的状态,这使得如何通过网页轻松查询目标信息的问题更加突出。在信息多样化的趋势下,通用的搜索引擎在很大程度上为人们在互联网上查找信息提供了便利,但也暴露出各种不足。例如:精度低、信息内容相对陈旧、信息分布不均等。因此,主题搜索引擎技术成为一个新的研究方向。它为特定领域、特定人群或特定需求提供有价值的信息资源和检索服务。主题爬虫作为主题搜索引擎的信息抓取部分,负责抓取用户感兴趣的某个主题相关的网页。本文主要通过六章来分析主题爬虫的设计和实现。第一章主要介绍了搜索引擎的发展历程、网络爬虫在搜索引擎中的作用,并简要介绍了国内外的研究现状和课题的研究意义。第二章是本文的理论基础:首先对搜索引擎的基本原理进行讲解,然后通过比较通用爬虫和主题爬虫找出两者的区别和各自的特点,这两种类型的爬虫架构和基本工作原理。第三章主要讨论主题爬虫领域关键技术的研究和改进,包括文本特征项提取方法、搜索策略和网页去重技术的研究,提出基于主题相关性的PageRank算法的改进。第四章主要讨论主题爬虫的系统设计与实现,主要包括网络爬虫模块、网络分析模块、中文分词和URL管理模块。第五章介绍了主题爬虫系统的界面和操作细节,以及使用该系统的实验过程。通过对实验数据的分析,证明了前几章各种理论的合理性和有效性。第6章对前几章的内容进行总结和总结,提出本文的创新点和局限性。实验结果证明,主题爬虫在稳定运行的同时有更好的收获率,大大减少了时间和存储空间。及时的优势保证了网页的及时更新。此外,用户在搜索时获得的冗余和无用信息也较少,准确率较高。
寻找正确的信息总是很困难的具之一
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-19 01:30
编译:荣淮扬
指南
一般来说,搜索是非个性化的,但如果与推荐系统结合,会有意想不到的效果。
找到正确的信息总是很困难。不久前,文件还存放在实际的物理仓库中,很难找到相关文件。
当可以通过在线存储库访问文档时,索引文档的数量开始超过物理存储的限制。电子商务网站提供的产品数量或通过在线流媒体服务提供的内容数量也是如此。
用户倾向于在一个地方找到所有内容,并且大多数人喜欢从更相关的选项中进行选择,因此服务提供商需要适应这种需求。一些全球服务(如谷歌、亚马逊、Netflix、Spotify)发展迅速,用户几乎可以在上面找到任何东西。推动他们称霸世界的最强大工具之一是由机器学习技术驱动的高度先进的个性化技术。这些技术是推荐系统和个性化搜索。
推荐系统使用用户与项目交互的历史来为用户生成最相关项目的排名列表。搜索引擎会根据与给定查询的相似度对内容进行排名,而不考虑用户的历史记录。
推荐系统使用户能够在线发现相关文档、产品或内容。通常,用户可能最喜欢的项目隐藏在数以百万计的其他项目中。用户无法通过搜索引擎直接找到这些产品,因为他们很少知道它们的标签,甚至可能不知道它们的存在。
另一方面,有时用户需要找到特定的项目,并愿意通过表达他们的需求来帮助在线系统减少可能推荐的项目数量。
有多种方法可以帮助用户表达他们的需求。用户体验在这里起着非常重要的作用。许多用户通过手机访问在线服务,但他们表现出兴趣的能力有限。在线服务应侧重于使用所有可用信息来过滤可能的搜索结果。
用户地理位置可以显着缩小可能的搜索和推荐结果的范围。例如,在 Recombee 中,您可以选择仅推荐距离用户位置一定范围内的项目。另一种方法是,当某个项目在地理位置上离用户较近时,您可以增加该项目被推荐的可能性。
用户希望使用特定标签或类别过滤掉可能的搜索结果。通常只需要一键过滤除特定类别外的所有项目(例如,所有文章 除科幻小说外)。用户应该能够尽可能轻松地表达他们的兴趣。
一定比例的用户希望使用查询文本(即使只有几个字符)来缩小搜索范围。他们的目的可能是查找特定类别的商品,或者直接通过他们要查找的产品的标签来搜索特定的产品。他们输入的文本称为用户查询。这个博客文章 讨论了如何使用查询来帮助用户找到她/他正在寻找的内容。这个博客文章从理论部分开始,然后是实践部分。
信息检索
为给定的文本查询寻找合适的项目的问题已经作为信息检索 (IR) 研究了几十年。当用户向系统输入查询时,信息检索过程开始。查询是信息需求的正式形式,例如网络搜索引擎中的搜索字符串。在信息检索中,查询不能唯一标识集合中的单个项目(文档)。相反,有几个项目可以与查询匹配,它们可能具有不同程度的相关性。
传统方法尝试将查询与文档进行匹配并根据相似度获得相关性。机器学习方法通过从训练数据构建排名模型来解决 IR 问题。这个训练数据(用于搜索引擎)是什么样的?通常,它是针对每个查询“适当”排序的文档集合。
以下是相关博客中描述的IR系统方案:
经典的 IR 系统不是个性化的,它只是为查询返回大部分相关文档。通常不需要机器学习,因为系统遵循预定义的过程(例如 TF-IDF 相似性查找)。
该系统通过匹配查询和文档并计算它们的相似性来工作。大多数相似的文档按照与查询的相似性顺序返回。计算相似度,如TF-IDF向量的余弦相似度。
可以通过重新排序(使用机器学习模型)来改善搜索结果。在这个例子中,还使用了搜索引擎来减少机器学习模型的候选数量,从而提高评分速度。
学习排名 (LTR) 是机器学习的一种应用,它根据人们的期望对项目进行排名。 LTR 模型通常使用人工标记的数据进行训练。
在recall阶段,LTR模型获取搜索引擎生成的查询和返回文档(项目)的一个子集作为每个项目的输入和输出相关性。最后,它可以输出一个排序的文档列表(k 个最相关的文档)。请注意,现代系统还可以将用户配置文件作为输入并执行个性化学习以对机器学习任务进行排序。
经典预测模型、学习排名模型和推荐系统有什么区别?
下一部分对 LTR 和推荐系统都很有用,因为模型的评估类似于机器学习中的经典预测模型。
评估 LTR 和推荐系统
累积收入衡量学习排名系统或推荐系统返回的前 k 个项目的相关性。
例如,我们可以将 6 个返回项的相关性相加(注意,第 4 项是不相关的)。
向用户展示的项目很少有统一的可见性方式。例如,在电子商务中,由于大多数用户不想向下滚动列表,因此推荐产品的可见度急剧下降。在媒体领域,一个内容经常被突出显示,而其他内容却很难找到。
CG 的问题在于它没有考虑物品的位置。例如,第一个推荐可能比其他五个推荐具有更大的图像显示。此外,用户倾向于浏览列表顶部的一些项目,他们不太可能看到列表更下方的项目。因此,折现累积收益 (DCG) 比简单的 CG 更受欢迎。
在 DCG 中,相关值随着结果的位置呈对数下降。
DCG 很容易计算,如上例所示。
有些变体甚至更加强调搜索列表顶部的相关项目。
假设一个数据集收录 N 个查询。通常的方法是对每个查询的 DCG 分数进行归一化,并获得所有查询的平均 DCG(“NDCG”)分数。有这样的评价指标固然好,但切记现实世界是残酷的。
传统的LTR算法
以下是 LTR 算法的一些示例:
PRank 算法使用感知器(线性函数)从文档的特征向量估计文档的得分。查询附加到嵌入在文档中的特征向量。我们还可以将文档分类为相关类别(例如,相关/不相关)。该函数几乎可以通过任何机器学习方法进行建模。大多数算法使用决策树和森林。现代方法利用深度学习网络。
通过对所有文档进行评分并根据预测的相关性对它们进行排序得到最终的排名列表。显然,在训练输入嵌入和相应输出相关性的模型时,我们并没有直接最小化 NDCG 或其他上述评估标准。与Pointwise方法一致,Pairwise方法也使用了代理可微损失函数。
为了更好地理解成对方法,我们应该记住二元分类中使用的交叉熵损失,它惩罚了模型的高置信度错误预测。
可以通过对 0,1 标签的损失求和来计算对数损失:-(y log(p) +(1−y) log(1−p))
如您所见,错误的、高可信度的答案会导致高损失。
关于 LTR 系统的梯度训练算法的更多信息可以在这里找到:///en-us/research/wp-content/uploads/2005/08/icml_ranking.pdf。
Rankboost 直接优化分类错误。它源自 Adaboost,并在文档对上进行训练。它训练弱分类器,并为上一步中没有正确分类的对分配更多的权重。
RankSVM 是最早使用成对方法解决问题的算法之一。它以序数回归的方式进行排序,训练类的阈值。 RankSVM 使用铰链损失函数来最小化。它还允许直接使用内核进行非线性处理。
listwise 方法的动机
pairwise 方法很好,但也有缺点。训练过程成本高昂,并且存在固有的训练偏差,在不同的查询中差异很大。只考虑成对关系。我们希望使用一个评估指标,使我们能够在考虑所有项目的相关性的同时优化完整列表。
指数排序的优势在于,即使模型 f 给所有文档分配相似的分数,它们的最高概率也会相差很大——最好的文档接近 1,而不太相关的文档接近 0。
这里,损失是针对文档列表计算的。我们不太关心无关文档Py(x)=0,最大的损失是相关文档造成的。
如何获取LTR系统的训练数据?
为 LTR 系统获取训练数据可能是一个漫长而昂贵的过程。您通常需要一群人手动输入查询并判断搜索结果。关联判断也比较困难。评估者评估以下分数之一:
Relevance-两个值:相关和不相关(适用于pointwise)
成对偏好文件 A 比文件 B 更相关。
一般订单文件按照 A、B、C、... 的相关性进行排序。 (非常适合列表,但很耗时)
很明显,人工贴标签非常昂贵,而且他们的标签也不是很可靠。因此,排名和训练系统应该从用户在网站上的行为中获得。
更好的方法是用推荐系统替换前面提到的 LTR 算法。
个性化搜索审核
当搜索结果按照用户的喜好进行排序时,用户对搜索功能的整体满意度会显着提升。
个性化搜索还应考虑用户偏好、历史互动和类似用户的互动。为什么不使用推荐系统?对于相同的搜索查询,两个用户可能会得到截然不同的建议。
解决方案是将搜索引擎与强大的推荐系统相结合,而不是如上所述将经典学习应用于机器学习 (LTR) 模型。这种方法有几个优点,我们会在后续博客文章中分析。
我们的个性化搜索方法结合了搜索引擎和推荐系统。首先,搜索引擎对推荐项目(与查询无关)重新排序以过滤掉不相关的推荐,并推送与查询及其描述匹配的项目。其次,无论用户个人资料或交互历史如何,搜索引擎都会返回最匹配的候选者。然后,这些产品由推荐系统重新排名,以更好地适应每个特定用户的口味。最终结果由上游排名投票决定。
—结束—
英文原文:
查看全部
寻找正确的信息总是很困难的具之一
编译:荣淮扬
指南
一般来说,搜索是非个性化的,但如果与推荐系统结合,会有意想不到的效果。
找到正确的信息总是很困难。不久前,文件还存放在实际的物理仓库中,很难找到相关文件。
当可以通过在线存储库访问文档时,索引文档的数量开始超过物理存储的限制。电子商务网站提供的产品数量或通过在线流媒体服务提供的内容数量也是如此。
用户倾向于在一个地方找到所有内容,并且大多数人喜欢从更相关的选项中进行选择,因此服务提供商需要适应这种需求。一些全球服务(如谷歌、亚马逊、Netflix、Spotify)发展迅速,用户几乎可以在上面找到任何东西。推动他们称霸世界的最强大工具之一是由机器学习技术驱动的高度先进的个性化技术。这些技术是推荐系统和个性化搜索。
推荐系统使用用户与项目交互的历史来为用户生成最相关项目的排名列表。搜索引擎会根据与给定查询的相似度对内容进行排名,而不考虑用户的历史记录。
推荐系统使用户能够在线发现相关文档、产品或内容。通常,用户可能最喜欢的项目隐藏在数以百万计的其他项目中。用户无法通过搜索引擎直接找到这些产品,因为他们很少知道它们的标签,甚至可能不知道它们的存在。
另一方面,有时用户需要找到特定的项目,并愿意通过表达他们的需求来帮助在线系统减少可能推荐的项目数量。
有多种方法可以帮助用户表达他们的需求。用户体验在这里起着非常重要的作用。许多用户通过手机访问在线服务,但他们表现出兴趣的能力有限。在线服务应侧重于使用所有可用信息来过滤可能的搜索结果。
用户地理位置可以显着缩小可能的搜索和推荐结果的范围。例如,在 Recombee 中,您可以选择仅推荐距离用户位置一定范围内的项目。另一种方法是,当某个项目在地理位置上离用户较近时,您可以增加该项目被推荐的可能性。
用户希望使用特定标签或类别过滤掉可能的搜索结果。通常只需要一键过滤除特定类别外的所有项目(例如,所有文章 除科幻小说外)。用户应该能够尽可能轻松地表达他们的兴趣。
一定比例的用户希望使用查询文本(即使只有几个字符)来缩小搜索范围。他们的目的可能是查找特定类别的商品,或者直接通过他们要查找的产品的标签来搜索特定的产品。他们输入的文本称为用户查询。这个博客文章 讨论了如何使用查询来帮助用户找到她/他正在寻找的内容。这个博客文章从理论部分开始,然后是实践部分。
信息检索
为给定的文本查询寻找合适的项目的问题已经作为信息检索 (IR) 研究了几十年。当用户向系统输入查询时,信息检索过程开始。查询是信息需求的正式形式,例如网络搜索引擎中的搜索字符串。在信息检索中,查询不能唯一标识集合中的单个项目(文档)。相反,有几个项目可以与查询匹配,它们可能具有不同程度的相关性。
传统方法尝试将查询与文档进行匹配并根据相似度获得相关性。机器学习方法通过从训练数据构建排名模型来解决 IR 问题。这个训练数据(用于搜索引擎)是什么样的?通常,它是针对每个查询“适当”排序的文档集合。
以下是相关博客中描述的IR系统方案:
经典的 IR 系统不是个性化的,它只是为查询返回大部分相关文档。通常不需要机器学习,因为系统遵循预定义的过程(例如 TF-IDF 相似性查找)。
该系统通过匹配查询和文档并计算它们的相似性来工作。大多数相似的文档按照与查询的相似性顺序返回。计算相似度,如TF-IDF向量的余弦相似度。
可以通过重新排序(使用机器学习模型)来改善搜索结果。在这个例子中,还使用了搜索引擎来减少机器学习模型的候选数量,从而提高评分速度。
学习排名 (LTR) 是机器学习的一种应用,它根据人们的期望对项目进行排名。 LTR 模型通常使用人工标记的数据进行训练。
在recall阶段,LTR模型获取搜索引擎生成的查询和返回文档(项目)的一个子集作为每个项目的输入和输出相关性。最后,它可以输出一个排序的文档列表(k 个最相关的文档)。请注意,现代系统还可以将用户配置文件作为输入并执行个性化学习以对机器学习任务进行排序。
经典预测模型、学习排名模型和推荐系统有什么区别?
下一部分对 LTR 和推荐系统都很有用,因为模型的评估类似于机器学习中的经典预测模型。
评估 LTR 和推荐系统
累积收入衡量学习排名系统或推荐系统返回的前 k 个项目的相关性。
例如,我们可以将 6 个返回项的相关性相加(注意,第 4 项是不相关的)。
向用户展示的项目很少有统一的可见性方式。例如,在电子商务中,由于大多数用户不想向下滚动列表,因此推荐产品的可见度急剧下降。在媒体领域,一个内容经常被突出显示,而其他内容却很难找到。
CG 的问题在于它没有考虑物品的位置。例如,第一个推荐可能比其他五个推荐具有更大的图像显示。此外,用户倾向于浏览列表顶部的一些项目,他们不太可能看到列表更下方的项目。因此,折现累积收益 (DCG) 比简单的 CG 更受欢迎。
在 DCG 中,相关值随着结果的位置呈对数下降。
DCG 很容易计算,如上例所示。
有些变体甚至更加强调搜索列表顶部的相关项目。
假设一个数据集收录 N 个查询。通常的方法是对每个查询的 DCG 分数进行归一化,并获得所有查询的平均 DCG(“NDCG”)分数。有这样的评价指标固然好,但切记现实世界是残酷的。
传统的LTR算法
以下是 LTR 算法的一些示例:
PRank 算法使用感知器(线性函数)从文档的特征向量估计文档的得分。查询附加到嵌入在文档中的特征向量。我们还可以将文档分类为相关类别(例如,相关/不相关)。该函数几乎可以通过任何机器学习方法进行建模。大多数算法使用决策树和森林。现代方法利用深度学习网络。
通过对所有文档进行评分并根据预测的相关性对它们进行排序得到最终的排名列表。显然,在训练输入嵌入和相应输出相关性的模型时,我们并没有直接最小化 NDCG 或其他上述评估标准。与Pointwise方法一致,Pairwise方法也使用了代理可微损失函数。
为了更好地理解成对方法,我们应该记住二元分类中使用的交叉熵损失,它惩罚了模型的高置信度错误预测。
可以通过对 0,1 标签的损失求和来计算对数损失:-(y log(p) +(1−y) log(1−p))
如您所见,错误的、高可信度的答案会导致高损失。
关于 LTR 系统的梯度训练算法的更多信息可以在这里找到:///en-us/research/wp-content/uploads/2005/08/icml_ranking.pdf。
Rankboost 直接优化分类错误。它源自 Adaboost,并在文档对上进行训练。它训练弱分类器,并为上一步中没有正确分类的对分配更多的权重。
RankSVM 是最早使用成对方法解决问题的算法之一。它以序数回归的方式进行排序,训练类的阈值。 RankSVM 使用铰链损失函数来最小化。它还允许直接使用内核进行非线性处理。
listwise 方法的动机
pairwise 方法很好,但也有缺点。训练过程成本高昂,并且存在固有的训练偏差,在不同的查询中差异很大。只考虑成对关系。我们希望使用一个评估指标,使我们能够在考虑所有项目的相关性的同时优化完整列表。
指数排序的优势在于,即使模型 f 给所有文档分配相似的分数,它们的最高概率也会相差很大——最好的文档接近 1,而不太相关的文档接近 0。
这里,损失是针对文档列表计算的。我们不太关心无关文档Py(x)=0,最大的损失是相关文档造成的。
如何获取LTR系统的训练数据?
为 LTR 系统获取训练数据可能是一个漫长而昂贵的过程。您通常需要一群人手动输入查询并判断搜索结果。关联判断也比较困难。评估者评估以下分数之一:
Relevance-两个值:相关和不相关(适用于pointwise)
成对偏好文件 A 比文件 B 更相关。
一般订单文件按照 A、B、C、... 的相关性进行排序。 (非常适合列表,但很耗时)
很明显,人工贴标签非常昂贵,而且他们的标签也不是很可靠。因此,排名和训练系统应该从用户在网站上的行为中获得。
更好的方法是用推荐系统替换前面提到的 LTR 算法。
个性化搜索审核
当搜索结果按照用户的喜好进行排序时,用户对搜索功能的整体满意度会显着提升。
个性化搜索还应考虑用户偏好、历史互动和类似用户的互动。为什么不使用推荐系统?对于相同的搜索查询,两个用户可能会得到截然不同的建议。
解决方案是将搜索引擎与强大的推荐系统相结合,而不是如上所述将经典学习应用于机器学习 (LTR) 模型。这种方法有几个优点,我们会在后续博客文章中分析。
我们的个性化搜索方法结合了搜索引擎和推荐系统。首先,搜索引擎对推荐项目(与查询无关)重新排序以过滤掉不相关的推荐,并推送与查询及其描述匹配的项目。其次,无论用户个人资料或交互历史如何,搜索引擎都会返回最匹配的候选者。然后,这些产品由推荐系统重新排名,以更好地适应每个特定用户的口味。最终结果由上游排名投票决定。
—结束—
英文原文:
甘明光:新手及要转变思维的SEO人有所帮助
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-06-19 01:27
相信小编现在谈SEO的时候,大家的想法应该还停留在早年。我觉得SEO无非就是写伪原创,发到外链,另外就是查网站的关键词的排名。每天重复这项工作,希望能靠这个方法取得好的效果。时代在进步,我们必须对SEO有新的认识。
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今,百度已经不是5年前的百度。大量的算法更新对搜索引擎优化者的思维和技术提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。甘明光总结了8个核心要素和思维趋势,希望对SEO新手和想要转变思维的SEO人有所帮助。
1、网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以首先强调网站的访问速度,是因为它不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在构建网站的时候,一定要选择一个比较快速稳定的主机。关于主机的选择,根据小编的经验,美国品牌主机-bluehost是不错的选择。
2、网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容必须与标题相对应,而且必须能够解决用户的问题。例如,有人搜索“个人博客应该选择什么样的主机?”这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了最终帮他解决这个问题。
3、网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
4、减少不良因素的出现
大量网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了大量广告信息,或者频繁弹出对话框,让用户反感。影响用户停留在页面上的时间。
5、关键词的添加和分配
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
6、主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
7、搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
8、Unique and high quality网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。不然别人再好,也会觉得“花花”了。
以上就是小编分享的SEO八要素。相信看完之后,你应该对SEO有了新的认识。我们不会停留在过去。我们必须跟上时代的发展。 ,为了不被时代淘汰。希望小编分享的内容对大家有所帮助。如果喜欢,请多多支持。 查看全部
甘明光:新手及要转变思维的SEO人有所帮助
相信小编现在谈SEO的时候,大家的想法应该还停留在早年。我觉得SEO无非就是写伪原创,发到外链,另外就是查网站的关键词的排名。每天重复这项工作,希望能靠这个方法取得好的效果。时代在进步,我们必须对SEO有新的认识。
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今,百度已经不是5年前的百度。大量的算法更新对搜索引擎优化者的思维和技术提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。甘明光总结了8个核心要素和思维趋势,希望对SEO新手和想要转变思维的SEO人有所帮助。
1、网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以首先强调网站的访问速度,是因为它不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在构建网站的时候,一定要选择一个比较快速稳定的主机。关于主机的选择,根据小编的经验,美国品牌主机-bluehost是不错的选择。
2、网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容必须与标题相对应,而且必须能够解决用户的问题。例如,有人搜索“个人博客应该选择什么样的主机?”这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了最终帮他解决这个问题。
3、网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
4、减少不良因素的出现
大量网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了大量广告信息,或者频繁弹出对话框,让用户反感。影响用户停留在页面上的时间。
5、关键词的添加和分配
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
6、主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
7、搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
8、Unique and high quality网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。不然别人再好,也会觉得“花花”了。
以上就是小编分享的SEO八要素。相信看完之后,你应该对SEO有了新的认识。我们不会停留在过去。我们必须跟上时代的发展。 ,为了不被时代淘汰。希望小编分享的内容对大家有所帮助。如果喜欢,请多多支持。
搜索引擎的基础技术的评估标准及策略分析(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-06-19 01:26
内容
【1】搜索引擎概述
[2] 搜索引擎基础技术
[3] 搜索引擎的平台基础
[4] 搜索结果的改进和优化
__________________________________________________
【1】搜索引擎概述
过去15年,互联网信息快速扩张,已经无法通过人工方式过滤获取有用信息。于是,搜索引擎应运而生。按其发展可分为四个时代。
说到发展,不得不提搜索引擎的三个主要目标。无论发展到哪里,以下三个目标始终是一个很好的评价标准:
[2] 搜索引擎基础技术
这部分主要从以下四个部分介绍搜索引擎的基本技术,也是搜索引擎的重要环节。
2.1 网络爬虫
网络爬虫是搜索引擎的下载系统。它的功能是获取内容。其方法是通过万维网中的链接不断爬取和采集各种网页。然而,互联网上的页面如此之多,每天都在不断地产生新的内容。根据爬取目标和范围,爬虫可以简单分为以下几类:
抓取网页时,抓取工具应该如何确定下一个目标?主要策略如下:
接下来简单介绍一下搜索引擎中的一个重要问题:暗网爬虫。所谓暗网,是指通过常规方法难以抓取的网页,互联网上存在大量此类网页。有些网页没有外部链接,有些主要内容存储在数据库中(如携程网),这些记录没有链接。暗网挖掘是商业搜索引擎的一大研究重点,谷歌就是这样,百度的“阿拉丁”计划也来了。
2.2 创建索引
对于搜索引擎来说,搜索是最重要的核心技术之一。面对海量的网页内容,如何快速找到所有收录用户查询的网页?倒排索引在其中起到了关键作用。
对于一个网页,我们把它看成一个文档,它的内容是由单词组成的。为了快速为用户的搜索词提供文档结果,我们必须建立一个word-document存储结构。倒排索引是实现word-document矩阵的一种特定的存储形式。通过倒排索引,可以根据单词快速获取收录该单词的文档列表。倒排索引主要由词词典和倒排文件两部分组成。
单词字典主要有两种存储方式:hash加链接和树结构。
如何创建索引:
(1)Two-pass 文档遍历
在第一遍扫描文档集合时,此方法不会立即开始索引,而是采集一些全局统计信息。例如,文档集合中收录的文档数为N,文档集合中收录的不同词的个数为M,每个词出现在多少个文档中的信息DF。 得到以上三类信息后,可以知道最终索引的大小,然后在内存中分配足够的空间来存放倒排索引的内容。在第二次扫描中,实际上建立了每个词的倒排列表信息,即对于一个词,每个收录该词的文档的文档ID以及该词在文档TF中出现的次数
(2)排序方法
排序方法对此进行了改进。这种方法在索引过程中总是在内存中分配固定大小的空间来存储字典信息和索引的中间结果。当分配的空间用完时,此时将中间结果写入磁盘,将中间结果在内存中占用的空间清空,用作下一次存储索引中间结果的存储区圆形的。这种方法只需要固定大小的内存,所以它可以索引任意大小的文档集合。
(3)合合法
当分配的内存配额用完时,排序方法只是将中间结果写入磁盘,字典信息一直保存在内存中。随着处理的文档越来越多,字典中收录的字典项也越来越多。越来越多,所以占用的内存越来越多,导致后期中间结果可用的内存越来越少。合并方法对此进行了改进,即每次将内存中的数据写入磁盘时,将包括字典在内的所有中间结果信息写入磁盘,从而可以清空内存中的所有内容,并且后续索引可以使用所有配额内存。
索引更新策略:
2.3 内容检索
内容检索模型是搜索引擎排名的理论基础,用于计算网页和查询的相关性。
常用检索模型
检索系统评价指标
查询相关
查询无关
在搜索结果中
A
B
不在搜索结果中
C
D
2.4 链接分析
搜索引擎在寻找能够满足用户请求的网页时,主要考虑两个因素:一是用户发送的查询与网页内容的内容相似度得分,即网页与网页内容的相关性。查询;另一种是通过链接分析方法得到的分数就是网页的重要性。链接分析是通过网络的链接结构获取网页重要性的一种方法。
有很多链接分析算法。从模型上看,主要分为两类:
常用算法:
[3] 搜索引擎的平台基础
这部分主要讲搜索引擎的平台支持,主要是云存储和云计算模型。
对于商业搜索引擎来说,需要保存大量的数据,而这些海量的海量数据需要进行处理。云存储和云计算是解决这个问题的方法。
服务器上不能存在大量数据,必须是分布式存储。当数据更新时,这会导致多台服务器上的数据不一致,以及如何选择服务器的问题。
先介绍一些基本原理:
(1)CAP原理
CAP是Consistency, Availability, Partition Tolerance的缩写,即一致性、可用性、分区容错性。
对于一个数据系统来说,这三个原则不能兼得。云存储往往侧重于 CA,牺牲了一些一致性。
(2)ACID 原理
这是关系型数据库采用的原则。是Atomity、Consistency、Isolation、Durability的缩写,即原子性、一致性、事务独立性、持久性。
(3)BASE 原理
采用的大型多云存储系统,不同于ACID,牺牲了数据的强一致性来换取高可用。因为用户可能对数据的变化很敏感,无法提供服务。
它的三个方面是:
Google 的云存储和云计算架构
云存储:
云计算
其他云存储系统
[4] 搜索结果的改进和优化
如前所述,搜索引擎追求的三个目标是更快、更全面、更准确。但是要实现这些目标并不是一件很容易的事,需要很多环节来处理。这部分主要从以下几个方面谈,如何改善搜索引擎的搜索结果,提高搜索质量,提高搜索性能。
4.1作弊分析
作弊方法
反作弊的总体思路
(1)所谓的信任传播模型,基本思想是:在海量的网页数据中,通过一定的技术手段或人工、半人工手段,筛选出一些完全可信的页面,从而表示他们绝对不会作弊页面(可以理解为白名单),算法以白名单中的这些页面为起点,为白名单中的页面节点分配更高的信任分数。其他页面是否作弊取决于在他们和白名单中的节点上。由链接关系决定。白名单中的节点通过链接关系向外传播信任分数。如果节点获得的信任分数高于某个阈值,则认为表示没有问题,低于这个阈值的页面将被视为作弊页面。
(2)不信任传播模型在框架上类似于信任传播模型。最大的不同是页面的初始子集不是可信页面节点,而是确认存在作弊的页面集合。 ,即不信任页面的集合(可以理解为黑名单)。为黑名单中的页面节点分配一个不信任分数,并通过链接关系传播这种不信任关系。如果最后一个页面节点的不信任分数为大于设置的阈值将被视为作弊网页。
(3)异常发现模型也是一个高度抽象的算法框架模型。它的基本假设是:作弊的网页必须有不同于普通网页的特征。这个特征可能是内容,也可能是链接制定具体算法的过程往往是找到一组作弊网页,分析其异常特征,然后利用这些异常特征来识别作弊网页。
<p>只要操纵搜索引擎搜索结果可以带来利益,那么作弊的动机就会一直存在,尤其是在网络营销在宣传中发挥越来越重要作用的时代。作弊与反作弊是一个相互抑制、相互促进的互动过程。 “一尺高一尺”的故事不断重复。上述内容主要是基于技术手段进行反作弊。事实上,单纯的技术手段并不能完全解决作弊问题。需要人工和技术手段相结合,才能达到更好的防作弊效果。技术手段可以分为比较一般的手段和比较特殊的手段。相对通用的手段对可能出现的新作弊手段有一定的防范能力,但由于其普遍性,针对性不强,对特殊作弊手段有一定的作用。不一定好。专门的反作弊方法往往是事后,只有当作弊已经发生并且很严重时,才能总结作弊的特点,采取事后过滤的方法。人工手段与技术手段高度互补。一旦出现新的作弊方法,它们就可以被发现,并且可以作为作弊进行时的预防措施。因此,从时间维度考虑对作弊手段的抑制,一般反作弊手段侧重预防,人工手段侧重检测,专用反作弊手段侧重后处理,两者具有内在联系和互补关系。 查看全部
搜索引擎的基础技术的评估标准及策略分析(一)
内容
【1】搜索引擎概述
[2] 搜索引擎基础技术
[3] 搜索引擎的平台基础
[4] 搜索结果的改进和优化
__________________________________________________
【1】搜索引擎概述
过去15年,互联网信息快速扩张,已经无法通过人工方式过滤获取有用信息。于是,搜索引擎应运而生。按其发展可分为四个时代。
说到发展,不得不提搜索引擎的三个主要目标。无论发展到哪里,以下三个目标始终是一个很好的评价标准:
[2] 搜索引擎基础技术
这部分主要从以下四个部分介绍搜索引擎的基本技术,也是搜索引擎的重要环节。
2.1 网络爬虫
网络爬虫是搜索引擎的下载系统。它的功能是获取内容。其方法是通过万维网中的链接不断爬取和采集各种网页。然而,互联网上的页面如此之多,每天都在不断地产生新的内容。根据爬取目标和范围,爬虫可以简单分为以下几类:
抓取网页时,抓取工具应该如何确定下一个目标?主要策略如下:
接下来简单介绍一下搜索引擎中的一个重要问题:暗网爬虫。所谓暗网,是指通过常规方法难以抓取的网页,互联网上存在大量此类网页。有些网页没有外部链接,有些主要内容存储在数据库中(如携程网),这些记录没有链接。暗网挖掘是商业搜索引擎的一大研究重点,谷歌就是这样,百度的“阿拉丁”计划也来了。
2.2 创建索引
对于搜索引擎来说,搜索是最重要的核心技术之一。面对海量的网页内容,如何快速找到所有收录用户查询的网页?倒排索引在其中起到了关键作用。
对于一个网页,我们把它看成一个文档,它的内容是由单词组成的。为了快速为用户的搜索词提供文档结果,我们必须建立一个word-document存储结构。倒排索引是实现word-document矩阵的一种特定的存储形式。通过倒排索引,可以根据单词快速获取收录该单词的文档列表。倒排索引主要由词词典和倒排文件两部分组成。
单词字典主要有两种存储方式:hash加链接和树结构。
如何创建索引:
(1)Two-pass 文档遍历
在第一遍扫描文档集合时,此方法不会立即开始索引,而是采集一些全局统计信息。例如,文档集合中收录的文档数为N,文档集合中收录的不同词的个数为M,每个词出现在多少个文档中的信息DF。 得到以上三类信息后,可以知道最终索引的大小,然后在内存中分配足够的空间来存放倒排索引的内容。在第二次扫描中,实际上建立了每个词的倒排列表信息,即对于一个词,每个收录该词的文档的文档ID以及该词在文档TF中出现的次数
(2)排序方法
排序方法对此进行了改进。这种方法在索引过程中总是在内存中分配固定大小的空间来存储字典信息和索引的中间结果。当分配的空间用完时,此时将中间结果写入磁盘,将中间结果在内存中占用的空间清空,用作下一次存储索引中间结果的存储区圆形的。这种方法只需要固定大小的内存,所以它可以索引任意大小的文档集合。
(3)合合法
当分配的内存配额用完时,排序方法只是将中间结果写入磁盘,字典信息一直保存在内存中。随着处理的文档越来越多,字典中收录的字典项也越来越多。越来越多,所以占用的内存越来越多,导致后期中间结果可用的内存越来越少。合并方法对此进行了改进,即每次将内存中的数据写入磁盘时,将包括字典在内的所有中间结果信息写入磁盘,从而可以清空内存中的所有内容,并且后续索引可以使用所有配额内存。
索引更新策略:
2.3 内容检索
内容检索模型是搜索引擎排名的理论基础,用于计算网页和查询的相关性。
常用检索模型
检索系统评价指标
查询相关
查询无关
在搜索结果中
A
B
不在搜索结果中
C
D
2.4 链接分析
搜索引擎在寻找能够满足用户请求的网页时,主要考虑两个因素:一是用户发送的查询与网页内容的内容相似度得分,即网页与网页内容的相关性。查询;另一种是通过链接分析方法得到的分数就是网页的重要性。链接分析是通过网络的链接结构获取网页重要性的一种方法。
有很多链接分析算法。从模型上看,主要分为两类:
常用算法:
[3] 搜索引擎的平台基础
这部分主要讲搜索引擎的平台支持,主要是云存储和云计算模型。
对于商业搜索引擎来说,需要保存大量的数据,而这些海量的海量数据需要进行处理。云存储和云计算是解决这个问题的方法。
服务器上不能存在大量数据,必须是分布式存储。当数据更新时,这会导致多台服务器上的数据不一致,以及如何选择服务器的问题。
先介绍一些基本原理:
(1)CAP原理
CAP是Consistency, Availability, Partition Tolerance的缩写,即一致性、可用性、分区容错性。
对于一个数据系统来说,这三个原则不能兼得。云存储往往侧重于 CA,牺牲了一些一致性。
(2)ACID 原理
这是关系型数据库采用的原则。是Atomity、Consistency、Isolation、Durability的缩写,即原子性、一致性、事务独立性、持久性。
(3)BASE 原理
采用的大型多云存储系统,不同于ACID,牺牲了数据的强一致性来换取高可用。因为用户可能对数据的变化很敏感,无法提供服务。
它的三个方面是:
Google 的云存储和云计算架构
云存储:
云计算
其他云存储系统
[4] 搜索结果的改进和优化
如前所述,搜索引擎追求的三个目标是更快、更全面、更准确。但是要实现这些目标并不是一件很容易的事,需要很多环节来处理。这部分主要从以下几个方面谈,如何改善搜索引擎的搜索结果,提高搜索质量,提高搜索性能。
4.1作弊分析
作弊方法
反作弊的总体思路
(1)所谓的信任传播模型,基本思想是:在海量的网页数据中,通过一定的技术手段或人工、半人工手段,筛选出一些完全可信的页面,从而表示他们绝对不会作弊页面(可以理解为白名单),算法以白名单中的这些页面为起点,为白名单中的页面节点分配更高的信任分数。其他页面是否作弊取决于在他们和白名单中的节点上。由链接关系决定。白名单中的节点通过链接关系向外传播信任分数。如果节点获得的信任分数高于某个阈值,则认为表示没有问题,低于这个阈值的页面将被视为作弊页面。
(2)不信任传播模型在框架上类似于信任传播模型。最大的不同是页面的初始子集不是可信页面节点,而是确认存在作弊的页面集合。 ,即不信任页面的集合(可以理解为黑名单)。为黑名单中的页面节点分配一个不信任分数,并通过链接关系传播这种不信任关系。如果最后一个页面节点的不信任分数为大于设置的阈值将被视为作弊网页。
(3)异常发现模型也是一个高度抽象的算法框架模型。它的基本假设是:作弊的网页必须有不同于普通网页的特征。这个特征可能是内容,也可能是链接制定具体算法的过程往往是找到一组作弊网页,分析其异常特征,然后利用这些异常特征来识别作弊网页。
<p>只要操纵搜索引擎搜索结果可以带来利益,那么作弊的动机就会一直存在,尤其是在网络营销在宣传中发挥越来越重要作用的时代。作弊与反作弊是一个相互抑制、相互促进的互动过程。 “一尺高一尺”的故事不断重复。上述内容主要是基于技术手段进行反作弊。事实上,单纯的技术手段并不能完全解决作弊问题。需要人工和技术手段相结合,才能达到更好的防作弊效果。技术手段可以分为比较一般的手段和比较特殊的手段。相对通用的手段对可能出现的新作弊手段有一定的防范能力,但由于其普遍性,针对性不强,对特殊作弊手段有一定的作用。不一定好。专门的反作弊方法往往是事后,只有当作弊已经发生并且很严重时,才能总结作弊的特点,采取事后过滤的方法。人工手段与技术手段高度互补。一旦出现新的作弊方法,它们就可以被发现,并且可以作为作弊进行时的预防措施。因此,从时间维度考虑对作弊手段的抑制,一般反作弊手段侧重预防,人工手段侧重检测,专用反作弊手段侧重后处理,两者具有内在联系和互补关系。
8个核心要素和思维走向,希望对SEO新手及要转变思维
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-06-18 07:03
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今的百度已经不再是5年前的百度,大量的搜索引擎算法更新对SEO优化思路和技巧提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。文君数字营销总监,紫道学院创始人,帅气的Boom老师总结了8个核心要素和思维趋势,希望能帮助到SEO新手和想要转变思维的SEO人。点击了解:全面系统的网站SEO优化计划策略。
一、登陆页面的内容是解决问题而不是仅仅描述问题
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
二、重要的事情说三遍“加载速度,速度,速度”
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象,好山寨,好土鳖,这么专业不是我们想要的结果。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户更难在网站上产生信任感和参与感。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
四、避免各种促使用户离开页面的元素
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
五、关键词植入
常规的关键词植入(爆老师称之为填词)还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT 、网址、图片命名等,这个就不多说了,大家都懂的。
六、主题模型的注入
仅仅填写#5个词是不够的,因为太机械会失去文本用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以延伸到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素需要在内容上进行优化:title的创意、desc的热度、url的规范、文章日期、结构化数据的使用、在线对话等,下面的效果是什么?
让男嘉宾秒杀女嘉宾的20种婚礼搭配:
2016年5月31日-提供最新20款男士婚礼搭配建议,无论预算多低,都能搭配出瞬间秒杀周边女嘉宾的女嘉宾,全图+视频。
八、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
1)提供独特的视觉体验、前端界面、合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7) 可以使用完整、准确和独特的信息来解决或回答问题。 查看全部
8个核心要素和思维走向,希望对SEO新手及要转变思维
如果有人问你百度自然优化的本质是什么?我希望答案不再是“疯狂的外部链接”。如今的百度已经不再是5年前的百度,大量的搜索引擎算法更新对SEO优化思路和技巧提出了更高的要求。不过百度更喜欢系统性的用户体验优化,网站优化部分不仅仅是靠关键词和TITLE走天下。文君数字营销总监,紫道学院创始人,帅气的Boom老师总结了8个核心要素和思维趋势,希望能帮助到SEO新手和想要转变思维的SEO人。点击了解:全面系统的网站SEO优化计划策略。
一、登陆页面的内容是解决问题而不是仅仅描述问题
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
二、重要的事情说三遍“加载速度,速度,速度”
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象,好山寨,好土鳖,这么专业不是我们想要的结果。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户更难在网站上产生信任感和参与感。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
四、避免各种促使用户离开页面的元素
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
五、关键词植入
常规的关键词植入(爆老师称之为填词)还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT 、网址、图片命名等,这个就不多说了,大家都懂的。
六、主题模型的注入
仅仅填写#5个词是不够的,因为太机械会失去文本用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以延伸到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素需要在内容上进行优化:title的创意、desc的热度、url的规范、文章日期、结构化数据的使用、在线对话等,下面的效果是什么?
让男嘉宾秒杀女嘉宾的20种婚礼搭配:
2016年5月31日-提供最新20款男士婚礼搭配建议,无论预算多低,都能搭配出瞬间秒杀周边女嘉宾的女嘉宾,全图+视频。
八、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
1)提供独特的视觉体验、前端界面、合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7) 可以使用完整、准确和独特的信息来解决或回答问题。
网站信息设计师试图确定用户如何归类,整理和标签上的站点信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-18 06:45
网站信息设计者试图确定用户如何对站点信息进行分类、组织和标记。信息架构师使用不同的方法来确定最佳网站架构,包括但不限于:
什么是心智模型?
思维模型,也称为概念模型,是对一个人的思维过程的解释,为什么现实世界中的一些作品忠实地代表了基本动机和匹配行为。每个人都有一个关于网站 或搜索引擎如何工作的心智模型,没有人对另一个有相同的心智模型。然而,心智模型的某些部分是一致的,并且因人而异。
例如,让我们使用电梯。我们大多数人在乘坐电梯时都有相同的期望和体验。如果我们按下标有“2 部电梯内”的按钮,我们希望电梯将我们带到二楼。如果我们按下标有“5”的按钮,我们想乘电梯到五楼。
我们怎么知道我们正在前往五楼?在大多数电梯中,我们通常会看到一个反映我们的数字,或者在到达地面之前通过的数字。当我们到达目的地五楼时会发生什么?
现场访谈直接,一对一观察正常用户/搜索表现,日常工作可用性测试数据网络分析软件,网站搜索引擎等。在网站上,目标信息架构师是确定一个正式的网站导航和网页相互连接,其他形式最符合网站用户的心智模型。一个有效的网站 结构应该能让用户/搜索者更容易、更有效地实现他们的目标。每次点击,用户的信息都应该加强气味,不会分心、混淆或打扰用户的验证。此外,网站的信息架构所要传达的网络内容“aboutness”概念被引入搜索引擎和网站访问者。
在一个特定的B2B医疗网站反复可用性测试三年后,我发现了一个有趣的事情:内部搜索引擎优化的专业不匹配导致的主要和次要目标受众的心态网页模式。诸如“绒毛”、“宣传”和我个人最喜欢的“什么[脏话]”等都是用来口头描述这些页面的。此外,这些相同的文本出现在参加考试的评论和类别/部分标签中。
深入挖掘,我还注意到他们的竞争对手创建的页面与用户/搜索者的心理模型不匹配。但是,这些页面排名很好。因此,即使是这家公司的竞争对手也没有建立网站来适应用户/搜索者的心理模型。
为什么网站 所有者会构建一个信息架构,其中相当多的 SEOed 属于标准类别中的网页,“什么是 [脏话]?”为什么SEO专家不断增长页面,整个网站,不符合搜索者的思维模式?
数字“5”点亮了电梯面板。电梯停了我们常听到的“叮”声,表示电梯门快要打开了。电梯门打开。通常,当我们离开电梯时,我们可以立即看到某些类型的视觉提示。 ,我们来到了五楼,比如展示房间号501-540的标志,和/或把数字“5”放在我们眼前的某个地方。电梯上的文字和视觉提示与网站 上的类似。当搜索用户单击搜索引擎结果页面上的链接时,他们希望被传送到收录其关键字的网页。然而,关键字并不是网络搜索想要看到的唯一项目。
查询人们的网站 和网页心智模型。他们希望了解网页上的元素是可点击的,而那些则不是。在电商网站,搜索你想看的产品照片。医疗保健网站Doctors 等医疗专业人士的标题、类别和目标将在不同的medical网站导航标签目标消费者上进行大标题、类别和导航标签。
SEO的专业心智模型
如何解决很多SEO专家搜索者的心智模型和网站的结构?以下是部分列表:
PageRank (PR) 雕塑(由 nofollow 和其他方法标记)使用有针对性的 micro网站link 农场和其他搜索引擎垃圾邮件形式传播到世界各地。不幸的是,许多 SEO 专家还没有验证检索思维模式,尽管他们诚实地相信它们。如果页面团队和网络搜索点击搜索列表,则假定它是匹配网络搜索者的心智模型。排名和其他页面?然后,搜索引擎优化假定检索目标明显满足。更多点击?甚至更多的证据。退货率低?互联网搜索者必须喜欢网站,即使网站 上显示的点击次数可能令人困惑,而不是用户满意度。
算了吧,算了吧,信息架构师和实用人才一直把“什么[脏话]”看作网站的结构标签。
就好像 SEO 专家和 网站 所有者正在构建 网站 和网络的个人心态作为基础,而不是目标受众的心态。没有专业,合格的信息架构师会推荐一个网站architecture 数据,纯粹来自关键词研究工具。
我会聘请专业 SEO 架构师 网站 吗?不可以,除非个人或公司拥有丰富的教育、培训和图书馆经验/信息科学。许多专业的信息架构师在这个领域是先进的。但是,我想聘请专业的SEO来促进对网站结构的讨论。 Query 是一种搜索行为,任何网站 所有者都应该忽略它。 查看全部
网站信息设计师试图确定用户如何归类,整理和标签上的站点信息
网站信息设计者试图确定用户如何对站点信息进行分类、组织和标记。信息架构师使用不同的方法来确定最佳网站架构,包括但不限于:
什么是心智模型?
思维模型,也称为概念模型,是对一个人的思维过程的解释,为什么现实世界中的一些作品忠实地代表了基本动机和匹配行为。每个人都有一个关于网站 或搜索引擎如何工作的心智模型,没有人对另一个有相同的心智模型。然而,心智模型的某些部分是一致的,并且因人而异。
例如,让我们使用电梯。我们大多数人在乘坐电梯时都有相同的期望和体验。如果我们按下标有“2 部电梯内”的按钮,我们希望电梯将我们带到二楼。如果我们按下标有“5”的按钮,我们想乘电梯到五楼。
我们怎么知道我们正在前往五楼?在大多数电梯中,我们通常会看到一个反映我们的数字,或者在到达地面之前通过的数字。当我们到达目的地五楼时会发生什么?
现场访谈直接,一对一观察正常用户/搜索表现,日常工作可用性测试数据网络分析软件,网站搜索引擎等。在网站上,目标信息架构师是确定一个正式的网站导航和网页相互连接,其他形式最符合网站用户的心智模型。一个有效的网站 结构应该能让用户/搜索者更容易、更有效地实现他们的目标。每次点击,用户的信息都应该加强气味,不会分心、混淆或打扰用户的验证。此外,网站的信息架构所要传达的网络内容“aboutness”概念被引入搜索引擎和网站访问者。
在一个特定的B2B医疗网站反复可用性测试三年后,我发现了一个有趣的事情:内部搜索引擎优化的专业不匹配导致的主要和次要目标受众的心态网页模式。诸如“绒毛”、“宣传”和我个人最喜欢的“什么[脏话]”等都是用来口头描述这些页面的。此外,这些相同的文本出现在参加考试的评论和类别/部分标签中。
深入挖掘,我还注意到他们的竞争对手创建的页面与用户/搜索者的心理模型不匹配。但是,这些页面排名很好。因此,即使是这家公司的竞争对手也没有建立网站来适应用户/搜索者的心理模型。
为什么网站 所有者会构建一个信息架构,其中相当多的 SEOed 属于标准类别中的网页,“什么是 [脏话]?”为什么SEO专家不断增长页面,整个网站,不符合搜索者的思维模式?
数字“5”点亮了电梯面板。电梯停了我们常听到的“叮”声,表示电梯门快要打开了。电梯门打开。通常,当我们离开电梯时,我们可以立即看到某些类型的视觉提示。 ,我们来到了五楼,比如展示房间号501-540的标志,和/或把数字“5”放在我们眼前的某个地方。电梯上的文字和视觉提示与网站 上的类似。当搜索用户单击搜索引擎结果页面上的链接时,他们希望被传送到收录其关键字的网页。然而,关键字并不是网络搜索想要看到的唯一项目。
查询人们的网站 和网页心智模型。他们希望了解网页上的元素是可点击的,而那些则不是。在电商网站,搜索你想看的产品照片。医疗保健网站Doctors 等医疗专业人士的标题、类别和目标将在不同的medical网站导航标签目标消费者上进行大标题、类别和导航标签。
SEO的专业心智模型
如何解决很多SEO专家搜索者的心智模型和网站的结构?以下是部分列表:
PageRank (PR) 雕塑(由 nofollow 和其他方法标记)使用有针对性的 micro网站link 农场和其他搜索引擎垃圾邮件形式传播到世界各地。不幸的是,许多 SEO 专家还没有验证检索思维模式,尽管他们诚实地相信它们。如果页面团队和网络搜索点击搜索列表,则假定它是匹配网络搜索者的心智模型。排名和其他页面?然后,搜索引擎优化假定检索目标明显满足。更多点击?甚至更多的证据。退货率低?互联网搜索者必须喜欢网站,即使网站 上显示的点击次数可能令人困惑,而不是用户满意度。
算了吧,算了吧,信息架构师和实用人才一直把“什么[脏话]”看作网站的结构标签。
就好像 SEO 专家和 网站 所有者正在构建 网站 和网络的个人心态作为基础,而不是目标受众的心态。没有专业,合格的信息架构师会推荐一个网站architecture 数据,纯粹来自关键词研究工具。
我会聘请专业 SEO 架构师 网站 吗?不可以,除非个人或公司拥有丰富的教育、培训和图书馆经验/信息科学。许多专业的信息架构师在这个领域是先进的。但是,我想聘请专业的SEO来促进对网站结构的讨论。 Query 是一种搜索行为,任何网站 所有者都应该忽略它。
青岛搜索引擎优化,网站排名上不去的原因是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-06-16 03:05
核心提示:青岛搜索引擎优化,在做网站优化之前没有对网站进行排名的原因,有时候你会发现改变网站内容很简单,关键词等可以提高网站 ,但是现在你做网站优化你会发现用以前的优化方法是多么的困难。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么? 1.使网站做好内部链接总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网页的粘性。 现在做网站链接,在用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这将使用户浏览网站更多
青岛搜索引擎优化,网站排名不靠前的原因
在你做网站优化之前,有时候你会发现改变网站内容很简单,关键词等可以提高网站的排名,但是现在你做网站优化,你会发现有多难,之前的优化方法都行不通。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么?
1.make网站内部链接做得很好
总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网站的粘性网页。现在做网站链接,用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这样用户浏览网站的时间会更长。
2.网站关键词和页面标题很吸引人
当用户搜索关键词时,用户展示的页面会显示页面图片、标题、描述等,这会吸引用户,用户自然会因为好奇而点击。比如用户搜索的关键词是,骨科哪个医院好?您的网站 描述XXX 医院是该地区最好的骨科医院。每天都会进行X手术,用户看完手术自然会进入。
3.关注企业品牌推广,提高网站转化率
一个公司的自有品牌够大,对网站优化很有帮助。如果你是百达翡丽、古驰或兰博基尼这样的品牌,那么搜索引擎自然会提升你的排名。搜索引擎也不喜欢贫穷和财富。品牌推广对企业来说更为重要。
4.网站的外链与网站theme优化相关。
在做外链之前,可以选择权重高的网站的链接。您不在乎其他网站 是否与您的网站 相关。现在网站链接是选项和资源权重网站,比如网站你可以与妇产医院网站或婴儿用品网站合作出售奶粉。
以上就是网站在青岛搜索引擎优化排名不上去的原因。如今,网站optimization 是不够的。使用以前的解决方案。搜索引擎算法太快,优化器需要自己找规则。比如搜索引擎抓取的时候,网站内容的更新也能起到很好的作用。
联系人:张经理
手机:
网址:
地址:青岛市城阳区正阳路630号 查看全部
青岛搜索引擎优化,网站排名上不去的原因是什么
核心提示:青岛搜索引擎优化,在做网站优化之前没有对网站进行排名的原因,有时候你会发现改变网站内容很简单,关键词等可以提高网站 ,但是现在你做网站优化你会发现用以前的优化方法是多么的困难。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么? 1.使网站做好内部链接总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网页的粘性。 现在做网站链接,在用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这将使用户浏览网站更多
青岛搜索引擎优化,网站排名不靠前的原因
在你做网站优化之前,有时候你会发现改变网站内容很简单,关键词等可以提高网站的排名,但是现在你做网站优化,你会发现有多难,之前的优化方法都行不通。 网站没有提升排名,那么青岛搜索引擎优化,网站排名不上去的原因是什么?
1.make网站内部链接做得很好
总是讲网站的链接布局,所以网站链接布局不是网站文章之前的锚文本类型,因为没有人会点击这个锚文本,不会增加网站的粘性网页。现在做网站链接,用户搜索关键词,搜索什么关键字后,用户认为应该添加关键字文章链接,这样用户浏览网站的时间会更长。
2.网站关键词和页面标题很吸引人
当用户搜索关键词时,用户展示的页面会显示页面图片、标题、描述等,这会吸引用户,用户自然会因为好奇而点击。比如用户搜索的关键词是,骨科哪个医院好?您的网站 描述XXX 医院是该地区最好的骨科医院。每天都会进行X手术,用户看完手术自然会进入。
3.关注企业品牌推广,提高网站转化率
一个公司的自有品牌够大,对网站优化很有帮助。如果你是百达翡丽、古驰或兰博基尼这样的品牌,那么搜索引擎自然会提升你的排名。搜索引擎也不喜欢贫穷和财富。品牌推广对企业来说更为重要。
4.网站的外链与网站theme优化相关。
在做外链之前,可以选择权重高的网站的链接。您不在乎其他网站 是否与您的网站 相关。现在网站链接是选项和资源权重网站,比如网站你可以与妇产医院网站或婴儿用品网站合作出售奶粉。
以上就是网站在青岛搜索引擎优化排名不上去的原因。如今,网站optimization 是不够的。使用以前的解决方案。搜索引擎算法太快,优化器需要自己找规则。比如搜索引擎抓取的时候,网站内容的更新也能起到很好的作用。
联系人:张经理
手机:
网址:
地址:青岛市城阳区正阳路630号
网站SEO标题在搜索引擎优化中的极其重要的存在
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-06-15 04:21
网站SEO 标题在搜索引擎优化中极为重要。
它甚至决定了网站排名的速度,网站排名的位置,以及我们抓取的用户类型。
网站title是指一个网页的标题,网站title分为首页标题、栏目页标题、内容页标题。标题可以直接显示在搜索结果中,所以其设计非常重要。
首先,标题会直接显示在搜索引擎中,所以标题不仅是搜索引擎计算出来的,也是用户看到的。吸引用户的标题可以获得更多用户点击。
其次,标题直接参与关键词排名,会参与搜索引擎排名的计算。所以标题上的文字设计直接关系到网站排名。
一、标题不要超过32个字。搜索引擎的建议是 26 个字。因为超过32个字后,标题无法完整显示。同时,过多的文字让搜索引擎难以识别网页的主题。
二、词和词之间要用英文字符分隔,如“_”“”“|” “-“ 等等。由于搜索引擎计算中使用中文和英文,因此可以使用英文来分隔单词。这里我们建议使用下划线。
三、 标题中必须有品牌词。品牌词是您在网站 中的品牌名称,相当于您网站 中的唯一名称。模型 1:核心关键词-品牌词。示例:网络推广服务-一一融合网络技术。模式二:核心关键词_需求词-品牌词。示例:网络推广服务_网络营销-一一融合网络技术。 查看全部
网站SEO标题在搜索引擎优化中的极其重要的存在
网站SEO 标题在搜索引擎优化中极为重要。
它甚至决定了网站排名的速度,网站排名的位置,以及我们抓取的用户类型。
网站title是指一个网页的标题,网站title分为首页标题、栏目页标题、内容页标题。标题可以直接显示在搜索结果中,所以其设计非常重要。
首先,标题会直接显示在搜索引擎中,所以标题不仅是搜索引擎计算出来的,也是用户看到的。吸引用户的标题可以获得更多用户点击。
其次,标题直接参与关键词排名,会参与搜索引擎排名的计算。所以标题上的文字设计直接关系到网站排名。
一、标题不要超过32个字。搜索引擎的建议是 26 个字。因为超过32个字后,标题无法完整显示。同时,过多的文字让搜索引擎难以识别网页的主题。
二、词和词之间要用英文字符分隔,如“_”“”“|” “-“ 等等。由于搜索引擎计算中使用中文和英文,因此可以使用英文来分隔单词。这里我们建议使用下划线。
三、 标题中必须有品牌词。品牌词是您在网站 中的品牌名称,相当于您网站 中的唯一名称。模型 1:核心关键词-品牌词。示例:网络推广服务-一一融合网络技术。模式二:核心关键词_需求词-品牌词。示例:网络推广服务_网络营销-一一融合网络技术。
向搜索引擎提交了网站,人家就收录你的网
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-06-15 04:20
提交网站到搜索引擎,我会收录you。这在目前是不现实的。现在搜索引擎收录你的网需要一些凭据,比如网站内容相关性、关键词密度、外链、google等pr值等等,所以即使你向搜索引擎k14@提交@,你可能不是收录。
其他网络上的链接越多,google的pr值就越高。其实我们首先要了解谷歌的pr排名算法是如何工作的。先看公式 PR(A) = (1-d)+ d(PR(t1)/C(t1)+ ... + PR(tn)/C(tn)), PR(A ) 是你能得到的pr值,d是阻尼系数,一般0.85,PR(t1)是你链接的网络的pr值,C(t1)表示有多个 URL 链接到您的 Linked 网络。例如,假设
它的pr值为1,有十个URL链接他(你的URL也在十个以内),那么你从中得到的pr值为PR(A)=(1-0.85)+0.85 (1/10)=0.15+0.085=0.235 当然,对方的网站上有10多个链接,所以你得到pr值更底,看这种情况,URL G:XXX.Net的pr值为9,上面有10个链接,那么你从中得到的pr值是PR(G)=(1-0.8 5)+0.85(9/10)=0.915,很高吧?所以不是你的网址在其他网站上的链接越多越好。 查看全部
向搜索引擎提交了网站,人家就收录你的网
提交网站到搜索引擎,我会收录you。这在目前是不现实的。现在搜索引擎收录你的网需要一些凭据,比如网站内容相关性、关键词密度、外链、google等pr值等等,所以即使你向搜索引擎k14@提交@,你可能不是收录。
其他网络上的链接越多,google的pr值就越高。其实我们首先要了解谷歌的pr排名算法是如何工作的。先看公式 PR(A) = (1-d)+ d(PR(t1)/C(t1)+ ... + PR(tn)/C(tn)), PR(A ) 是你能得到的pr值,d是阻尼系数,一般0.85,PR(t1)是你链接的网络的pr值,C(t1)表示有多个 URL 链接到您的 Linked 网络。例如,假设
它的pr值为1,有十个URL链接他(你的URL也在十个以内),那么你从中得到的pr值为PR(A)=(1-0.85)+0.85 (1/10)=0.15+0.085=0.235 当然,对方的网站上有10多个链接,所以你得到pr值更底,看这种情况,URL G:XXX.Net的pr值为9,上面有10个链接,那么你从中得到的pr值是PR(G)=(1-0.8 5)+0.85(9/10)=0.915,很高吧?所以不是你的网址在其他网站上的链接越多越好。
黑帽seo技术能够逃脱百度的法眼效应期延长
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-06-14 21:11
11、Baidu 实际上对于不同的地区、不同的城市、不同的网络有不同的排名位置。比如东莞和九江;长沙和深圳;电信和网通都略有不同。
12、百度在常见的采集software伪原创方法的基础上,增强了检查伪原创的算法,如乱段、关键词替换、拦截等,百度现在可以检测到了,百度会处理网站伪原创和垃圾内容的比例。对于小网站,百度会删除收录的伪原创页面。相信很多人都遇到过这种情况,页面被删除主要是因为质量不高。
13、新站审核时间更长,审核更严格。百度对新站的信任度降低。也可以说是沙盒效应期延长了。百度致力于减少数据库的垃圾邮件内容。而低质量的内容,2012年的几个k站点也是原因。主要是牺牲一些网站来换取用户使用搜索引擎的用户体验。毕竟,如果百度数据库中的垃圾邮件太多,就会为用户编入索引。 ,不利于百度未来的发展。
另外,2012年新站的关键词排名在半年内波动较大,老站相对稳定;
14、百度 降低了论坛和博客网站的导入链接权重,百度也降低了论坛签名的链接权重(相信未来论坛签名百度不会被收录外链的权重,但百度并没有在2012年实现这项技术。
未来百度将实现对论坛发帖和回复用户的识别,垃圾帖子和垃圾回复不分配权重。
15、百度进一步完善了对黑帽seo技术和seo作弊的识别。百度能以最短的速度检测你的作弊,从而减轻体重或k站,所以不要以为你的黑帽seo技术可以逃过百度的视野,良好的用户体验仍然是网站运营的基础。
根据以上百度算法的大更新和大变化,作为seoer应该进行网站诊断分析,并及时做出相应的调整和变化,避免造成功率降低和关键词排名下降由百度算法更新。甚至收录全无等的困境,百度2015年排名方法的具体做法请参考以下经验:
1.每页标题简洁,不超过30字。
2.每个网页核心关键词不超过3个。
如果可以,你必须学会放弃。
3.最重要的关键词放在标题的第一位,以此类推。
4.网站的描述简洁明了,关键词自然出现在开头和结尾。
5.网站 导航使用文本导航。
6.网站图片原创,加alt标签,不要乱加。
搜索引擎可以理解图片。
7. 制作内容与主题无关的js或图片。
8.网站 简洁而翔实。
关键词分布合理自然。
如果你自己看不懂,就放弃。
9.网站 联系方式为原创,如邮箱、电话、姓名等
10.网站 代码简洁。
11.JS 和主题相关的框架做了兼容性优化。
12.网站设计大方美观。
13.网站域名超过2年,最好3年。
14.域名最好出现在核心关键词,这对百度以外的搜索引擎有效。
15.如果是新域名,必须公布联系方式和新信息。
16.空间一定要稳定。经常被网站打不开的网站肯定不会上榜。
17.在其他地方找到网站的友情链接。
18.友情链接不看pr,看快照,看核心关键词排名,看网站首页的存在。
19.网站 外链要丰富,新闻,行业,生活,公关,越丰富越好。
20.网站 外链不在于数量,而在于质量。
增加一定要掌握节奏。
21.网站 外部链接必须出现在URL中,占70%,并且锚文本要合适。
想想自己的原因。
22.网站外联必须先增加首页的权重,首页快照在7天内,核心关键词在前3页,那么网站weight是可以接受的。
23.网站外联应该出现在人气高的地方。
24.网站 有链接的地方,避免垃圾链接和过多链接。
25.网站添加流量统计,大概数据应该公开。
26.适当刷网站ip和路,绝不网站流量来自某个搜索引擎。
27.网站 内容应围绕主题进行组织。
切勿发布不相关的内容。
28.网站添加xml和html格式图,帮助各大搜索引擎收录抓取。
29.网站 定期更新。不要一次更新一篇,也不要一次更新数百篇。
30.distribution good网站internal link.
Core关键词 指向 core关键词 页面。
31.关键词在网页内容中的加粗效果不好。避免所有粗体和粗体链接。
32. 最好每页有一次h标签。此内容与页面标题一致。
33.网站404 页面。
34. 与主题无关的页面,使用robots.txt禁止。
35.制造网站主题相关的pdf、doc、exe等文档和软件可供下载。
在这些资源上写下您自己的网站。
36.网站 一开始最好一次性全部完成,收录之后不要频繁更改
37.网站页面不要经常换主题,而关键词密度,95%的原因都是k。
38.网站外联请勿同账号同名发布。
例如,博客都是同一个人的博客。
论坛都是同一个帐户。
39.工作已完成,您需要等待!同时持续更新、维护、添加外链和内链,定期添加相关内容!
40.还在等网站排名出现。
41.将此代码添加到robots.txt:
42.user-agent: baiduspider
43.allow: /
图片需加44.文章,配图文效果最佳,图片需加alt标签。
最好总结5个字:静、全、真、好、好!
百度seo优化排名方法[2]
seo 流程操作和网站optimization Skills网站 的 seo 流程假设需要一年时间才能完成。
大致可以分为以下四个阶段:
第一阶段为准备期,主要完成以下三个任务: 站点分析---站点分析报告的形成 竞争对手分析---竞争对手分析报告的形成 战略政策的确定和部署---初步完成seo实施计划。在战略部署上,遵循这个原则:先治内伤,后优化外伤。
第二阶段为预备阶段。采集到足够的材料后,就可以开始前期工作了。
这个时间大概会持续 1-2 个月。
本阶段主要任务如下:关键词分析挖掘---形成关键词分析报告和部署计划搜索引擎友好---撰写网站修改建议内容增强---信息渠道建立,内部编辑团队培训优化---url优化、各级页面div重构、关键词布局、目录逻辑结构调整、js优化、专页搭建等
第三阶段是中期。
中期时间跨度会比较长,大概5-6个月。
此期间的主要工作是:外部优化---外部链支持和规则制定、资源站群规划、整体目录调整、博客群建设运营
第四阶段为后期。
后期大约2-3个月。
外部优化:a、链接策略b、站群站群,最大的难点不是建立,而是维护。
假设有二十个站,每个站每天更新十条信息,就会枯竭。
每个站之间必须有唯一的信息。
c、博客群建一个、链接策略。
建议使用单向链接。
获得单向链接的两种方法:
一是自己创建站群、博客、论坛签名等。
这种方式要注意单反向链接的建立。使用收录长尾关键字的关键字作为锚文本比使用单个锚文本链接要好得多。
第二个是链接交换中的策略交换。
后期工作主要包括以下内容:分析观察——用户搜索行为分析、关键词效果评估、搜索引擎性能观察、转化率分析评估、搜索引擎份额分析、网站行为分析、两个基本因素影响搜索结果页(serp)在ue分析和修改、竞争对手分析和监控、资源站群推广、对话seo网站排名的有:
1.网站这是客户最想找到的东西吗?
2.This网站 浏览者能不能找到sem:是search engine marketing的英文缩写,即搜索引擎营销。
seo:是英文search engine optimization的缩写,即搜索引擎优化。
serp:是搜索引擎结果页的缩写,即搜索引擎结果页。
是搜索引擎对搜索请求的反馈结果。
内部优化和外部优化。
a、meta、url和目录结构c、关键词布局d、js优化e、话题页f、tagsg、信息渠道(企业站点+zblog)h、页面代码层优化1、内优化a、meta:一般我们只关注三个:title、keywords、deion。就标题而言,网站最常见的问题就是关键词堆砌。
使用以下两种方法替换:一种是直接调用文章第一段的内容,100字左右;另一种是叫标题,但是加了一些自定义词。
例如,使用“这是yiyuandir站(呼叫标题)的内容,希望你喜欢””作为b、url、医院目录网络、域名的组合。
大多存在两个问题:一是url动态参数过多,不利于抓取;第二,静态页面目录太深。 C。关键词布局 关键词布局,有两种:一、是单页站点 这种站就是典型的垃圾站。
在位置有限的情况下,如何将关键字放置得更自然、更自然是关键。
二、是一个多页站点,尤其是一些有统一模板的站点,或者站点内容由第三方提供。
d、js优化后的网页代码头部充斥着大量java代码,这个问题存在很多网站。
e.话题页网站对话题页关注的不多,但其实。
一个好的话题完全可以替代一些门户网站的排名。
f、tags(tag(中文叫“tag”))g、信息通道h、页面代码层优化
新手道教[3]
一性包容一切性,一法包容一切法。
网站Optimization 也是一种启示。
了解全局,才能有一个明确的目标,展示你的技能。
Chachen将在本文中与大家分享seo优化的出现,seo优化全貌及一些相关干货概念,以及对seo的整体认识。希望对seo从业者有所帮助。如果你不是,请纠正我。
1.seo 的出现
说到seo的出现,不得不提一下搜索营销。
自1990年代以来,计算机作为第三次世界革命的标志之一出现在人们的生活中,然后网站的数量不断增加,搜索引擎出现,搜索营销成为一种新的营销方式。营销。渠道已成为营销人员不可忽视的营销方式。
简单来说,搜索营销就是在搜索引擎上进行营销,营销就是抓住消费者的大脑。
<p>按照海因茨·米戈德曼的艾达模型,一个产品要想成功地向消费者推销,首先需要引起他们的注意,然后引起兴趣,然后激发欲望,最后形成转化(行动)。 查看全部
黑帽seo技术能够逃脱百度的法眼效应期延长
11、Baidu 实际上对于不同的地区、不同的城市、不同的网络有不同的排名位置。比如东莞和九江;长沙和深圳;电信和网通都略有不同。
12、百度在常见的采集software伪原创方法的基础上,增强了检查伪原创的算法,如乱段、关键词替换、拦截等,百度现在可以检测到了,百度会处理网站伪原创和垃圾内容的比例。对于小网站,百度会删除收录的伪原创页面。相信很多人都遇到过这种情况,页面被删除主要是因为质量不高。
13、新站审核时间更长,审核更严格。百度对新站的信任度降低。也可以说是沙盒效应期延长了。百度致力于减少数据库的垃圾邮件内容。而低质量的内容,2012年的几个k站点也是原因。主要是牺牲一些网站来换取用户使用搜索引擎的用户体验。毕竟,如果百度数据库中的垃圾邮件太多,就会为用户编入索引。 ,不利于百度未来的发展。
另外,2012年新站的关键词排名在半年内波动较大,老站相对稳定;
14、百度 降低了论坛和博客网站的导入链接权重,百度也降低了论坛签名的链接权重(相信未来论坛签名百度不会被收录外链的权重,但百度并没有在2012年实现这项技术。
未来百度将实现对论坛发帖和回复用户的识别,垃圾帖子和垃圾回复不分配权重。
15、百度进一步完善了对黑帽seo技术和seo作弊的识别。百度能以最短的速度检测你的作弊,从而减轻体重或k站,所以不要以为你的黑帽seo技术可以逃过百度的视野,良好的用户体验仍然是网站运营的基础。
根据以上百度算法的大更新和大变化,作为seoer应该进行网站诊断分析,并及时做出相应的调整和变化,避免造成功率降低和关键词排名下降由百度算法更新。甚至收录全无等的困境,百度2015年排名方法的具体做法请参考以下经验:
1.每页标题简洁,不超过30字。
2.每个网页核心关键词不超过3个。
如果可以,你必须学会放弃。
3.最重要的关键词放在标题的第一位,以此类推。
4.网站的描述简洁明了,关键词自然出现在开头和结尾。
5.网站 导航使用文本导航。
6.网站图片原创,加alt标签,不要乱加。
搜索引擎可以理解图片。
7. 制作内容与主题无关的js或图片。
8.网站 简洁而翔实。
关键词分布合理自然。
如果你自己看不懂,就放弃。
9.网站 联系方式为原创,如邮箱、电话、姓名等
10.网站 代码简洁。
11.JS 和主题相关的框架做了兼容性优化。
12.网站设计大方美观。
13.网站域名超过2年,最好3年。
14.域名最好出现在核心关键词,这对百度以外的搜索引擎有效。
15.如果是新域名,必须公布联系方式和新信息。
16.空间一定要稳定。经常被网站打不开的网站肯定不会上榜。
17.在其他地方找到网站的友情链接。
18.友情链接不看pr,看快照,看核心关键词排名,看网站首页的存在。
19.网站 外链要丰富,新闻,行业,生活,公关,越丰富越好。
20.网站 外链不在于数量,而在于质量。
增加一定要掌握节奏。
21.网站 外部链接必须出现在URL中,占70%,并且锚文本要合适。
想想自己的原因。
22.网站外联必须先增加首页的权重,首页快照在7天内,核心关键词在前3页,那么网站weight是可以接受的。
23.网站外联应该出现在人气高的地方。
24.网站 有链接的地方,避免垃圾链接和过多链接。
25.网站添加流量统计,大概数据应该公开。
26.适当刷网站ip和路,绝不网站流量来自某个搜索引擎。
27.网站 内容应围绕主题进行组织。
切勿发布不相关的内容。
28.网站添加xml和html格式图,帮助各大搜索引擎收录抓取。
29.网站 定期更新。不要一次更新一篇,也不要一次更新数百篇。
30.distribution good网站internal link.
Core关键词 指向 core关键词 页面。
31.关键词在网页内容中的加粗效果不好。避免所有粗体和粗体链接。
32. 最好每页有一次h标签。此内容与页面标题一致。
33.网站404 页面。
34. 与主题无关的页面,使用robots.txt禁止。
35.制造网站主题相关的pdf、doc、exe等文档和软件可供下载。
在这些资源上写下您自己的网站。
36.网站 一开始最好一次性全部完成,收录之后不要频繁更改
37.网站页面不要经常换主题,而关键词密度,95%的原因都是k。
38.网站外联请勿同账号同名发布。
例如,博客都是同一个人的博客。
论坛都是同一个帐户。
39.工作已完成,您需要等待!同时持续更新、维护、添加外链和内链,定期添加相关内容!
40.还在等网站排名出现。
41.将此代码添加到robots.txt:
42.user-agent: baiduspider
43.allow: /
图片需加44.文章,配图文效果最佳,图片需加alt标签。
最好总结5个字:静、全、真、好、好!
百度seo优化排名方法[2]
seo 流程操作和网站optimization Skills网站 的 seo 流程假设需要一年时间才能完成。
大致可以分为以下四个阶段:
第一阶段为准备期,主要完成以下三个任务: 站点分析---站点分析报告的形成 竞争对手分析---竞争对手分析报告的形成 战略政策的确定和部署---初步完成seo实施计划。在战略部署上,遵循这个原则:先治内伤,后优化外伤。
第二阶段为预备阶段。采集到足够的材料后,就可以开始前期工作了。
这个时间大概会持续 1-2 个月。
本阶段主要任务如下:关键词分析挖掘---形成关键词分析报告和部署计划搜索引擎友好---撰写网站修改建议内容增强---信息渠道建立,内部编辑团队培训优化---url优化、各级页面div重构、关键词布局、目录逻辑结构调整、js优化、专页搭建等
第三阶段是中期。
中期时间跨度会比较长,大概5-6个月。
此期间的主要工作是:外部优化---外部链支持和规则制定、资源站群规划、整体目录调整、博客群建设运营
第四阶段为后期。
后期大约2-3个月。
外部优化:a、链接策略b、站群站群,最大的难点不是建立,而是维护。
假设有二十个站,每个站每天更新十条信息,就会枯竭。
每个站之间必须有唯一的信息。
c、博客群建一个、链接策略。
建议使用单向链接。
获得单向链接的两种方法:
一是自己创建站群、博客、论坛签名等。
这种方式要注意单反向链接的建立。使用收录长尾关键字的关键字作为锚文本比使用单个锚文本链接要好得多。
第二个是链接交换中的策略交换。
后期工作主要包括以下内容:分析观察——用户搜索行为分析、关键词效果评估、搜索引擎性能观察、转化率分析评估、搜索引擎份额分析、网站行为分析、两个基本因素影响搜索结果页(serp)在ue分析和修改、竞争对手分析和监控、资源站群推广、对话seo网站排名的有:
1.网站这是客户最想找到的东西吗?
2.This网站 浏览者能不能找到sem:是search engine marketing的英文缩写,即搜索引擎营销。
seo:是英文search engine optimization的缩写,即搜索引擎优化。
serp:是搜索引擎结果页的缩写,即搜索引擎结果页。
是搜索引擎对搜索请求的反馈结果。
内部优化和外部优化。
a、meta、url和目录结构c、关键词布局d、js优化e、话题页f、tagsg、信息渠道(企业站点+zblog)h、页面代码层优化1、内优化a、meta:一般我们只关注三个:title、keywords、deion。就标题而言,网站最常见的问题就是关键词堆砌。
使用以下两种方法替换:一种是直接调用文章第一段的内容,100字左右;另一种是叫标题,但是加了一些自定义词。
例如,使用“这是yiyuandir站(呼叫标题)的内容,希望你喜欢””作为b、url、医院目录网络、域名的组合。
大多存在两个问题:一是url动态参数过多,不利于抓取;第二,静态页面目录太深。 C。关键词布局 关键词布局,有两种:一、是单页站点 这种站就是典型的垃圾站。
在位置有限的情况下,如何将关键字放置得更自然、更自然是关键。
二、是一个多页站点,尤其是一些有统一模板的站点,或者站点内容由第三方提供。
d、js优化后的网页代码头部充斥着大量java代码,这个问题存在很多网站。
e.话题页网站对话题页关注的不多,但其实。
一个好的话题完全可以替代一些门户网站的排名。
f、tags(tag(中文叫“tag”))g、信息通道h、页面代码层优化
新手道教[3]
一性包容一切性,一法包容一切法。
网站Optimization 也是一种启示。
了解全局,才能有一个明确的目标,展示你的技能。
Chachen将在本文中与大家分享seo优化的出现,seo优化全貌及一些相关干货概念,以及对seo的整体认识。希望对seo从业者有所帮助。如果你不是,请纠正我。
1.seo 的出现
说到seo的出现,不得不提一下搜索营销。
自1990年代以来,计算机作为第三次世界革命的标志之一出现在人们的生活中,然后网站的数量不断增加,搜索引擎出现,搜索营销成为一种新的营销方式。营销。渠道已成为营销人员不可忽视的营销方式。
简单来说,搜索营销就是在搜索引擎上进行营销,营销就是抓住消费者的大脑。
<p>按照海因茨·米戈德曼的艾达模型,一个产品要想成功地向消费者推销,首先需要引起他们的注意,然后引起兴趣,然后激发欲望,最后形成转化(行动)。
目录摘要:基于用户兴趣挖掘的个性化搜索引擎模型
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-06-14 18:28
28 页,共 18268 字
总结
随着互联网技术的飞速发展,互联网提供给人们的信息量越来越大。搜索引擎作为人们在万维网上查找和获取信息的重要手段之一,已被广泛应用于各个领域。为了向用户提供个性化的查询服务,个性化搜索引擎应运而生。经过众多研究者的不懈努力,个性化搜索引擎技术取得了一定的进展。针对当前搜索引擎的不足和当前用户的个性化查询需求,在深入研究搜索引擎及相关技术的基础上,设计了一种基于用户兴趣挖掘的个性化搜索引擎模型。本文的主要工作是:
(1)个性化模型研究与实现本文深入分析了个性化搜索的特点,研究了搜索引擎及相关技术,设计了一个基于用户兴趣挖掘的个性化模型。该模型基于用户的历史从访问过的页面中提取用户的兴趣特征,对相同兴趣的页面进行分类,对用户兴趣进行分类管理;本文构建用户兴趣树动态存储用户兴趣,并结合短期和长期兴趣描述用户的兴趣特征;为了及时反映用户的兴趣变化,本文采用基于遗忘机制的兴趣更新算法。
(2)个性化搜索引擎(个性化模型除外)其他模块研究与实现本文还研究了与个性化搜索引擎相关的其他模块,包括:中文分词、查询扩展、网络蜘蛛、索引建立与更新、以及结果排序。本文在综合考虑技术实现难度和用户个性化查询需求的基础上,给出了上述模块的实现算法。
(3)通过实验证明本文设计的个性化搜索引擎的有效性。实验内容包括个性化模型的建立和个性化搜索两个方面。
内容
总结四
关键词IV
抽象电视
关键词SV
1 前言 1
1.1 研究背景 1
1.2 个性化搜索引擎1的含义
1.3 个性化搜索引擎主要研究问题1
2 搜索引擎概述 2
2.1 个性化搜索引擎 2
2.2 搜索引擎工作原理2
2.3 个性化搜索引擎系统模型3
2.4 未来搜索引擎的发展趋势4
3 个性化搜索引擎相关技术 5
3.1 信息抽取技术5
3.2 LUCENE 搜索工具包 5
3.3 中文分词技术6
3.4 自动聚类技术6
3.5 用户行为分析7
4 个性化搜索引擎总体设计7
4.1 系统需求分析与总体设计7
4.2 系统功能与架构设计8
4.3 系统流程设计8
4.4 系统数据库设计12
5 个性化搜索引擎的具体实现 13
5.1 模块设计 13
5.2 用户界面模块 14
5.3 搜索模块 16
5.4 搜索结果优化模块 19
5.5 系统运行结果及示例21
6 总结 22
参考文献:22
谢谢 23
关键词
个性化模型、用户兴趣挖掘、用户兴趣树
参考文献:
[2] 李爱明。武汉个性化搜索引擎用户模型研究:华中师范大学,2007.
[3] 张博。个性化网页搜索系统研究。秦皇岛:燕山大学,2006.
[4] 庞杰.搜索引擎技术的研究与实现。上海:上海交通大学,2006.
[5]李培欢.基于Lucene的搜索引擎设计与优化。吉林:吉林大学,2008.
[6]种梅。元搜索引擎关键技术研究。山东:山东师范大学,2008
[7]霍长青.个性化元搜索引擎的研究与设计。山东:山东科技大学,2006.
[8] 许文。从HTML网页中提取土壤问题的方法研究。北京:北京机械工业研究所,2007.
[9] 刘青。基于SVM的网络文本分类研究与应用。南昌:南昌大学,2007.
[10] 陆晓峰,郑全。基于用户行为分析的搜索引擎模型。华北理工大学学报,2004
[11] 张衡,曲景辉,张亮。网页文本信息提取与结果评价微机应用,2007.9.
[12] 费伟,黄如华。基于用户行为分析库和信息服务的搜索引擎优化策略,2005年10月(49):75一77
[13] 刘涛。用于文本分类和文本聚类的特征选择字段。武汉:南开大学,2004.
[14]冯刚。基于JZEE的多语言元搜索引擎研究与实现成都:电子科技大学,
[16] 王玲,穆志春,郭辉 一种基于聚类的支持向量机增量学习算法。北京科技人文学报,2007
[17]何士林.基于JAVA技术的搜索引擎研究与实现[J].成都:西南交通大学,2006.
[18] 张衡,曲景辉,张亮。网页文本信息提取与结果评估。微机应用,2007.9.
[19]PQi He, PKuiyuChang, Ee-peng Lim.分析事件的特征轨迹
检测 •第 30 届年度国际 ACM SIGIR 会议的论文
信息检索研究与开发,2007.6:35一37.
[20]WangDeqing, ZhangHui, ZhaoLiPing 一种无分词的聚类算法
中文搜索引擎结果[C].第三届语义知识国际会议,
and Grid, SKG2007, 2007:258一261.
[21]KumarHarshit,Kang Sanggil.seareh 引擎的另一面[C].Web seareh API's.Lecture
计算机科学笔记,v5027LNAI,应用人工智能新前沿-
第二届工业、工程和其他应用应用国际会议
智能系统,IEA/AIE2008,会刊,2008:311-320.
[22]Yuanyu-Yu, LuoXue-Chao.一种搜索引擎检索性能的测量方法
基于用户路径模式[J].Tien Tzu Hsueh Pao/Acta Eleetronica Siniea, 2008.5(36):969一973.
[23]刘春双,张志强,谢晓琴,等.元搜索引擎的评价
Merge algorithm[C].Proceedings ICICSE2008-2008 International Conference on Internet
科学与工程计算,2008:9一14. 查看全部
目录摘要:基于用户兴趣挖掘的个性化搜索引擎模型
28 页,共 18268 字
总结
随着互联网技术的飞速发展,互联网提供给人们的信息量越来越大。搜索引擎作为人们在万维网上查找和获取信息的重要手段之一,已被广泛应用于各个领域。为了向用户提供个性化的查询服务,个性化搜索引擎应运而生。经过众多研究者的不懈努力,个性化搜索引擎技术取得了一定的进展。针对当前搜索引擎的不足和当前用户的个性化查询需求,在深入研究搜索引擎及相关技术的基础上,设计了一种基于用户兴趣挖掘的个性化搜索引擎模型。本文的主要工作是:
(1)个性化模型研究与实现本文深入分析了个性化搜索的特点,研究了搜索引擎及相关技术,设计了一个基于用户兴趣挖掘的个性化模型。该模型基于用户的历史从访问过的页面中提取用户的兴趣特征,对相同兴趣的页面进行分类,对用户兴趣进行分类管理;本文构建用户兴趣树动态存储用户兴趣,并结合短期和长期兴趣描述用户的兴趣特征;为了及时反映用户的兴趣变化,本文采用基于遗忘机制的兴趣更新算法。
(2)个性化搜索引擎(个性化模型除外)其他模块研究与实现本文还研究了与个性化搜索引擎相关的其他模块,包括:中文分词、查询扩展、网络蜘蛛、索引建立与更新、以及结果排序。本文在综合考虑技术实现难度和用户个性化查询需求的基础上,给出了上述模块的实现算法。
(3)通过实验证明本文设计的个性化搜索引擎的有效性。实验内容包括个性化模型的建立和个性化搜索两个方面。
内容
总结四
关键词IV
抽象电视
关键词SV
1 前言 1
1.1 研究背景 1
1.2 个性化搜索引擎1的含义
1.3 个性化搜索引擎主要研究问题1
2 搜索引擎概述 2
2.1 个性化搜索引擎 2
2.2 搜索引擎工作原理2
2.3 个性化搜索引擎系统模型3
2.4 未来搜索引擎的发展趋势4
3 个性化搜索引擎相关技术 5
3.1 信息抽取技术5
3.2 LUCENE 搜索工具包 5
3.3 中文分词技术6
3.4 自动聚类技术6
3.5 用户行为分析7
4 个性化搜索引擎总体设计7
4.1 系统需求分析与总体设计7
4.2 系统功能与架构设计8
4.3 系统流程设计8
4.4 系统数据库设计12
5 个性化搜索引擎的具体实现 13
5.1 模块设计 13
5.2 用户界面模块 14
5.3 搜索模块 16
5.4 搜索结果优化模块 19
5.5 系统运行结果及示例21
6 总结 22
参考文献:22
谢谢 23
关键词
个性化模型、用户兴趣挖掘、用户兴趣树
参考文献:
[2] 李爱明。武汉个性化搜索引擎用户模型研究:华中师范大学,2007.
[3] 张博。个性化网页搜索系统研究。秦皇岛:燕山大学,2006.
[4] 庞杰.搜索引擎技术的研究与实现。上海:上海交通大学,2006.
[5]李培欢.基于Lucene的搜索引擎设计与优化。吉林:吉林大学,2008.
[6]种梅。元搜索引擎关键技术研究。山东:山东师范大学,2008
[7]霍长青.个性化元搜索引擎的研究与设计。山东:山东科技大学,2006.
[8] 许文。从HTML网页中提取土壤问题的方法研究。北京:北京机械工业研究所,2007.
[9] 刘青。基于SVM的网络文本分类研究与应用。南昌:南昌大学,2007.
[10] 陆晓峰,郑全。基于用户行为分析的搜索引擎模型。华北理工大学学报,2004
[11] 张衡,曲景辉,张亮。网页文本信息提取与结果评价微机应用,2007.9.
[12] 费伟,黄如华。基于用户行为分析库和信息服务的搜索引擎优化策略,2005年10月(49):75一77
[13] 刘涛。用于文本分类和文本聚类的特征选择字段。武汉:南开大学,2004.
[14]冯刚。基于JZEE的多语言元搜索引擎研究与实现成都:电子科技大学,
[16] 王玲,穆志春,郭辉 一种基于聚类的支持向量机增量学习算法。北京科技人文学报,2007
[17]何士林.基于JAVA技术的搜索引擎研究与实现[J].成都:西南交通大学,2006.
[18] 张衡,曲景辉,张亮。网页文本信息提取与结果评估。微机应用,2007.9.
[19]PQi He, PKuiyuChang, Ee-peng Lim.分析事件的特征轨迹
检测 •第 30 届年度国际 ACM SIGIR 会议的论文
信息检索研究与开发,2007.6:35一37.
[20]WangDeqing, ZhangHui, ZhaoLiPing 一种无分词的聚类算法
中文搜索引擎结果[C].第三届语义知识国际会议,
and Grid, SKG2007, 2007:258一261.
[21]KumarHarshit,Kang Sanggil.seareh 引擎的另一面[C].Web seareh API's.Lecture
计算机科学笔记,v5027LNAI,应用人工智能新前沿-
第二届工业、工程和其他应用应用国际会议
智能系统,IEA/AIE2008,会刊,2008:311-320.
[22]Yuanyu-Yu, LuoXue-Chao.一种搜索引擎检索性能的测量方法
基于用户路径模式[J].Tien Tzu Hsueh Pao/Acta Eleetronica Siniea, 2008.5(36):969一973.
[23]刘春双,张志强,谢晓琴,等.元搜索引擎的评价
Merge algorithm[C].Proceedings ICICSE2008-2008 International Conference on Internet
科学与工程计算,2008:9一14.
较多企业新网站搭建没有考虑到主机空间队网站优化关键性
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-06-14 18:18
很多公司新的网站building没有考虑宿主空间team网站优化的重要性。首先,易启航强调网站加载速度会影响网站在搜索引擎中的排名。
很多人还停留在两年前的SEO优化方法上,天天写洗稿,发链接等,然后天天查百度关键词的排名,希望能成很好的作用。我认为这种方法对于今天的引擎搜索来说不是那么有效。要想取得好成绩,就必须适应搜索引擎偏好的变化,完善我们的网站。现在,我们来谈谈网站SEO优化的网站SEO优化技巧。
(1)网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以在这里首先强调网站的访问速度,不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在搭建网站的时候一定要选择一个比较快稳定的主机。
(2)网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容一定要和标题相对应,而且一定要能够解决用户的问题。例如,有人搜索“个人博客应该使用什么样的主机”。这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了帮他最终解决这个问题。
(3)网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
(4)减少不良因素的出现
很多网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了很多广告信息,或者频繁弹出对话框,让用户反感影响用户停留在页面上的时间。
(5)关键词的添加和分发
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
(6)主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
(7)搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
(8)独特的优质网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。否则,即使做得好,也会有“开花”的感觉。 查看全部
较多企业新网站搭建没有考虑到主机空间队网站优化关键性
很多公司新的网站building没有考虑宿主空间team网站优化的重要性。首先,易启航强调网站加载速度会影响网站在搜索引擎中的排名。
很多人还停留在两年前的SEO优化方法上,天天写洗稿,发链接等,然后天天查百度关键词的排名,希望能成很好的作用。我认为这种方法对于今天的引擎搜索来说不是那么有效。要想取得好成绩,就必须适应搜索引擎偏好的变化,完善我们的网站。现在,我们来谈谈网站SEO优化的网站SEO优化技巧。
(1)网站的访问速度
在搭建网站的时候,很多新手站长都没有考虑到主机空间对网站优化的重要性。小编之所以在这里首先强调网站的访问速度,不仅影响网站关键词排名的优化,还会影响网站的用户体验和跳出率。因为在这个快节奏的时代,没有人愿意花时间等待。即使你努力优化一些效果,但这些效果不能很好地转化,你将做无用功。所以我们在搭建网站的时候一定要选择一个比较快稳定的主机。
(2)网站着陆页内容优化
落地页是用户输入网站看到的第一个页面,所以落地页的优化非常重要。除了页面优化的美感,最重要的是内容。用户搜索信息,肯定是想找到自己想要的信息,所以内容一定要和标题相对应,而且一定要能够解决用户的问题。例如,有人搜索“个人博客应该使用什么样的主机”。这个时候,我们的内容不能只是分析选择虚拟主机的角度,还要为用户推荐合适的主机类型和购买虚拟主机。为了帮他最终解决这个问题。
(3)网站页面设计
无论是网站还是一个人,第一印象都很重要。虽然每个人都在欣赏灵魂的美丽,但遇到陌生人时,容貌真的是看不见的。你能更多地了解灵魂之美吗?所以网站的“外貌”也很重要。 网站的设计应该给人一种专业、简洁、值得信赖的感觉。这个时候就需要找专业的UI和UX进行设计,购买一些高质量的网站模板。
(4)减少不良因素的出现
很多网站,为了赚取广告费或者想拉取更多用户信息,在网站页面挂了很多广告信息,或者频繁弹出对话框,让用户反感影响用户停留在页面上的时间。
(5)关键词的添加和分发
之前的SEO优化方法,并不是所有人都可以完全放弃。部分地区仍有保留价值。关于关键词的设置,我们还要继续做,H1,文章内关键词,外链锚文本,内链锚文本,图片ALT,URL,图片命名等等这些都说了很多人无数次,这里就不重复了。
(6)主题模型的注入
仅仅添加关键词 是不够的。为了方便用户更好的查看和增加页面的权重,我们可以对内容进行分类。比如虚拟主机,我们可以扩展到Linux虚拟主机和windows虚拟主机,然后在它们各自的主题下,我们可以扩展很多相关的内容。不仅有利于用户观看,也有利于关键词排名。
(7)搜索引擎显示文字优化
在搜索引擎结果中,部分描述会显示在标题下方,这对于网站的点击率也很重要。主要优化元素有:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用等。
(8)独特的优质网站content
搜索引擎从头到尾强调的一点就是内容。不管网站如何优化,最终还是要创造出对用户有用的独特内容。否则,即使做得好,也会有“开花”的感觉。
【干货】一种基于主题的网页实时分类模型的研究
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-06-13 00:28
基于主题的网页实时分类模型研究
开始时间:2013-07-12
马建红 1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先研究了通用分类模型,分析了该模型对网页实时分类的不足。在此基础上,为了更适合网页的实时分类,本文提出了一种基于主题的网页分类模型。第一,垂直搜索引擎的主题爬虫由Nutch构建,可以随时抓取互联网上的网页,保证网页的实时性;然后对Nutch的爬取结果进行主题去噪处理,其中一部分与分类无关。页;最后,对抓取的网页进行分类。实验证明,通过该模型,可以大大提高网页分类的速度和准确率。针对网页实时分类的大数据需求,该模型可以有效优化输入样本,节省计算时间。
关键词:
如需英文信息,请点击此处
基于主题的实时网页分类研究
马建红1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先对通用分类模型进行了研究,分析了通用模型对网页实时分类的不足。在此基础上,为了更适合实时分类,本文提出一种基于主题的分类模型。首先,通过Nutch构建垂直搜索引擎爬虫的主题,网页可以一直被抓取,从而保证网页的实时性。其次,去除部分页面女巫通过主题去噪对Nutch的抓取结果进行处理,与分类无关。最终可以对抓取的网页进行分类。实验表明,该模型可以提高速度和准确性。针对大数据的需求实时网页分类,该模型可以有效优化输入样本,节省计算时间。
关键字:
点击折叠 查看全部
【干货】一种基于主题的网页实时分类模型的研究
基于主题的网页实时分类模型研究
开始时间:2013-07-12
马建红 1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先研究了通用分类模型,分析了该模型对网页实时分类的不足。在此基础上,为了更适合网页的实时分类,本文提出了一种基于主题的网页分类模型。第一,垂直搜索引擎的主题爬虫由Nutch构建,可以随时抓取互联网上的网页,保证网页的实时性;然后对Nutch的爬取结果进行主题去噪处理,其中一部分与分类无关。页;最后,对抓取的网页进行分类。实验证明,通过该模型,可以大大提高网页分类的速度和准确率。针对网页实时分类的大数据需求,该模型可以有效优化输入样本,节省计算时间。
关键词:
如需英文信息,请点击此处
基于主题的实时网页分类研究
马建红1
马建红,(1965-),女,教授,主要研究方向:人工智能、软件工程。
张晨光2
张晨光(1987-),男,硕士研究生,数据挖掘,机器学习。
摘要:本文首先对通用分类模型进行了研究,分析了通用模型对网页实时分类的不足。在此基础上,为了更适合实时分类,本文提出一种基于主题的分类模型。首先,通过Nutch构建垂直搜索引擎爬虫的主题,网页可以一直被抓取,从而保证网页的实时性。其次,去除部分页面女巫通过主题去噪对Nutch的抓取结果进行处理,与分类无关。最终可以对抓取的网页进行分类。实验表明,该模型可以提高速度和准确性。针对大数据的需求实时网页分类,该模型可以有效优化输入样本,节省计算时间。
关键字:
点击折叠
SEO优化的几个小技巧,你值得拥有!!
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-06-13 00:18
百度的算法悄然改变,新规则对你的SEO思维和方法提出了更高的要求。百度更喜欢系统的用户体验优化,网站的优化部分不仅仅是靠关键词和TITLE走天下。今天我们将一起讨论一些SEO优化技巧。
1 着陆页的内容是解决问题而不是仅仅描述问题:
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
2 重要的事情要说三遍“加载速度,速度,速度”:
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
3 是增强 UI、UX 和品牌的信任感和参与感:
很多用户打开网站后会有第一印象,他们是好山寨,好土鳖,所以不专业。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户很难在网站产生信任和参与。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4 避免各种促使用户离开页面的元素:
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
5关键词Implant:
常规的关键词植入也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等。
注入6个主题模型:
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
7 显示文字深度优化:
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
创造8个独特有价值的内容:
归根结底,营销离不开内容质量。好的内容包括:
1、提供独特的视觉体验、前端界面、合适的字体和功能按钮;
2、内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面;
3、与其他内容相比没有重复性,深度更强大;
4、打开速度快(无广告),可以在不同终端阅读;
5、可以产生认同、惊喜、快乐、思考等情感想法;
6、可以达到一定的转发和传播能力;
7、 可以使用完整、准确和独特的信息来解决或回答问题。 查看全部
SEO优化的几个小技巧,你值得拥有!!
百度的算法悄然改变,新规则对你的SEO思维和方法提出了更高的要求。百度更喜欢系统的用户体验优化,网站的优化部分不仅仅是靠关键词和TITLE走天下。今天我们将一起讨论一些SEO优化技巧。
1 着陆页的内容是解决问题而不是仅仅描述问题:
比如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该引向几个方面:【20款男嘉宾推荐婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他要去参加一个婚礼,他的问题最终的解决方案是在哪里买衣服,而不是让他学习如何搭配衣服。所以在优化这个关键词的时候,我们的内容要针对他的最终需求,这样引流和转化的效果会更好。
2 重要的事情要说三遍“加载速度,速度,速度”:
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,考虑可以做哪些点来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
3 是增强 UI、UX 和品牌的信任感和参与感:
很多用户打开网站后会有第一印象,他们是好山寨,好土鳖,所以不专业。页面设计需要UI&UX的投入和品牌自身的口碑背书,否则用户很难在网站产生信任和参与。最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4 避免各种促使用户离开页面的元素:
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更原生的方式植入这些元素或奖励用户完成该过程。同时避免蜘蛛在代码使用中被搜索引擎封禁或难以捕捉降级的可能。
5关键词Implant:
常规的关键词植入也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等。
注入6个主题模型:
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们要做一个主题模型,比如关键词【婚礼服装搭配】我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚宴等相关词。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
7 显示文字深度优化:
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
创造8个独特有价值的内容:
归根结底,营销离不开内容质量。好的内容包括:
1、提供独特的视觉体验、前端界面、合适的字体和功能按钮;
2、内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面;
3、与其他内容相比没有重复性,深度更强大;
4、打开速度快(无广告),可以在不同终端阅读;
5、可以产生认同、惊喜、快乐、思考等情感想法;
6、可以达到一定的转发和传播能力;
7、 可以使用完整、准确和独特的信息来解决或回答问题。
【知识点】数据库索引的原理是怎样的?
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-06-08 20:22
问题一:数据库索引的原理是什么?
索引原则:为列值创建排序存储,数据结构={列值,行地址}。在有序的数据列表中,可以通过二分查找快速找到待查找行的地址,然后根据地址直接获取行数据。
问题2:索引是如何排序的?
值列
时间列
文本栏
问题 3:在新闻标题栏上建立索引。当我们查询title = ‘Diaoyu Islands’时,数据库将如何查找?而当我们查询标题LIKE ‘%Diaoyu Islands%’时,数据库应该怎么查?
像索引失效,全表扫描,数据量大的时候简直就是噩梦。
问题4:如何判断一列是否可以在数据库中建立索引?
基本原则:
该表访问频繁,数据量很大,每次查询的数据只占很小一部分
列的数据值分布广泛
该列收录大量空值
列常用于查询条件(不能收录在表达式中)
注意:文本列需要特别考虑:它们通常用于模糊查询,不适合索引。准确查询没问题。
问题5:如果要对查询结果的相关性进行排序,数据库能做到吗?
例如,如果您想查询有关苍夫人、托尼、火锅的新闻:
收录三个关键词(最相关)的新闻排名第一
收录两个关键词(相关性第二),第二个是排名
有关键字的排在第二位。
如果要为搜索到的新闻字段设置不同的权重,例如,新闻标题中收录这三个关键字的新闻的相关性远高于收录这三个词的新闻内容的相关性。数据库能做到吗?
答案:如果不能,此时您需要一个搜索引擎。
问题 6:常见的数据结构有哪些?
结构化数据:以表格和字段表示的数据
半结构化数据:xml、html
非结构化数据:文本、文档、图片、音频、视频等
在讨论了前面的问题之后,我得出了为什么需要搜索引擎的结论:
数据库适用于结构化数据的精确查询,但不适合半结构化和非结构化数据的模糊查询和灵活搜索(尤其是数据量较大时),不能提供理想的实时性能。
二、如何创建反向索引
问题一:如何快速找到与苍夫人相关的新闻?
分析:我们搜索的时候输入的是仓先生,我们想得到一个标题或内容中收录“仓先生”的新闻列表。
如果title和content列有这样的索引,可以快速找到仓先生的关键字对应的文章id,然后根据文章id快速找到文章。
标题列索引:
内容列索引:
词到文章id的索引,这是:倒排索引
问题 2:问题 1 的标题列索引和内容列索引可以合并在一起。有什么好处?
合并的好处是:可以减少访问数据库的次数
问题3:反向索引的记录数会不会很大?如果是英文,最大是多少?如果是中文,最大可能是多少?
英文单词的大概数量是 100,000。汉字总数已超过80,000个,而常用字仅3,500个。
《现代汉语标准词典》的字词比《现代汉语词典》收录多。前者13000多字72000多字,后者11000多字69000多字
结论:金额不会很大,30万以内;通过这个索引找到文章会非常快
问题 4:如何构建问题 2 中的倒排索引?
数据示例:
新闻 ID:1
新闻标题:托尼和仓太太一起吃火锅
新闻内容:2018年4月1日,Tony在四川成都参加一个活动的时候,恰巧主办方还邀请了苍老师来增加自己的人气。应主办方的邀请,他和苍夫人一起吃了火锅。酷!
如果是英文文章,分一下怎么样?
找到与查询匹配的 10 个最佳文档是一回事
英文好(有空格),但中文不好。但必须打分,否则无法建立反向指标。
你必须编写一个特殊的程序来做到这一点:分词器
中文分词器原理:有词词典,前后词结合,与词典匹配,歧义分析
问题5:java开源中文分词器很多,如何选择?
准确率、分词效率、中英文混合分词支持
常用的中文分词器:
IKAnalyzer、mmseg4j
问题 6:你、我、他、“、”、“a”、标点符号……这些需要索引吗?
这些词被称为:停用词。分词器支持指定/添加停用词,无需为其创建索引
问题7:出现新词怎么办?
嫂子,老司机,软妹儿,直男,玩腿,苍老师
分词器应支持在其字典中添加新词。
总结:
根据分词结果,我们建立倒排索引如下:
三、我有反向索引,怎么搜索?
搜索“tony OR苍老师”相关新闻的步骤是什么?
第 1 步:分割搜索输入
托尼,苍老师
第2步:在反向索引中找到收录Tony和Cang夫人的文章list
第三步:合并两个列表,对输出进行排序
{1,12,8,5}
四、如何建立相关性评价模型?
使用出现次数建立模型
规则一:统计出现次数,按次数从高到低排序
{{1,5},{5,3},{12,1},{8,1}}:文章1出现5次,文章5出现3次,文章12出现1 次,文章8 出现 1 次
问题1:标题出现仓先生,新闻内容出现仓太太。哪个和仓先生更相关?怎么做
规则二:加权重,标题权重10,内容权重1,计算权重得分,按高低排序
{{1,23},{12,10},{5,3},{8,1}}
总结:关联模型非常简单,使用出现次数来构建模型。有时排序不是很准确。
复杂的相关性计算模型包括:
tf-idf 词频-逆文档率模型
矢量空间模型
贝叶斯概率模型,如:BM25
搜索引擎将提供一种或多种实现方式以供选择以及扩展。
电子商务网站搜索相关性的计算会越来越复杂。
五、反向索引更新:数据更新的时候索引一定要更新吗?更新好了吗?
更新情况分析:
Q1:添加新商品时,我需要如何更新?
Q2:删除时,我需要如何更新?
Q3:进行更改时,我需要如何更新?
六、反向索引应该存储在内存中还是磁盘上?
大的放磁盘,小的放内存,需要持久化
七、搜索引擎需要支持精准搜索吗?需要像数据库一样支持多条件AND OR组合搜索?
如类别IN()值>=
必须的,否则没人会用搜索引擎
八、Summary
1、什么是搜索引擎?
一套可以实时搜索大量结构化、半结构化数据和非结构化文本数据的专用软件
最早用于信息检索领域,通过谷歌、百度等公司推出网络搜索而为大众所熟知。后来被各大电商网站采用做网站产品搜索。现在广泛应用于各个行业和互联网应用。是大型系统和网站架构师必备的技能。
2、搜索引擎解决什么样的问题?
专门解决大量结构化、半结构化数据、非结构化文本数据的实时检索问题。这种实时搜索数据库是做不到的。
3、搜索引擎适合什么样的场景?
核心:实时搜索大量结构化、半结构化、非结构化文本数据
信息检索(例如电子图书馆、电子档案)
网页搜索
通过提供网站(如新闻、论坛、博客网站)进行内容搜索
E-commerce网站的产品搜索
如果你负责的系统数据量大,通过数据库检索速度慢,可以考虑使用搜索引擎专门检索。
4、搜索引擎的核心组件是什么?
数据源、tokenizer、倒排索引(inverted index)、相关计算模型
5、搜索引擎是如何工作的?
1、从数据源加载数据,切词,建立反向索引
2、搜索时,对搜索输入进行分段,找到反向索引
3、计算相关、排序、输出
6、实现一个搜索引擎,需要实现什么?
1、分词器
2、反向索引,索引存储
3、相关计算模型
7、使用搜索引擎,需要明确哪些方面?
1、分词器
2、反向索引创建、存储、更新
3、相关计算模型
8、java 是广泛使用的开源搜索引擎组件和系统
Lucene:Apache的顶级开源项目,Lucene-core是一个开源的全文搜索引擎工具包,但它并不是一个完整的全文搜索引擎,而是一个全文搜索引擎框架,提供了一个完整的查询引擎和索引引擎,文本切分引擎的一部分(英语和德语两种西方语言)。 Lucene 的目的是为软件开发者提供一个简单易用的工具包,以便在目标系统中轻松实现全文搜索功能,或者以此为基础构建一个完整的全文搜索引擎。
Nutch:Apache 的顶级开源项目,包括网络爬虫和搜索引擎(基于 lucene)系统(与百度和谷歌相同)。 Hadoop 因它而诞生。
Solr:Lucene 下的一个子项目,一个基于 Lucene 的独立企业级开源搜索平台,一个服务。提供基于xml/JSON/http的api对外访问,以及web管理接口。
Elasticsearch:基于 Lucene 的企业级分布式搜索平台。它提供了一个宁静的网络界面,让程序员无需了解 Lucene 即可轻松方便地使用搜索平台。
问题:如何选择搜索引擎组件或系统?
关注成熟度并使用企业量。
更多精彩内容,请扫描下方二维码进入网站。 . . . .
查看全部
【知识点】数据库索引的原理是怎样的?
问题一:数据库索引的原理是什么?
索引原则:为列值创建排序存储,数据结构={列值,行地址}。在有序的数据列表中,可以通过二分查找快速找到待查找行的地址,然后根据地址直接获取行数据。
问题2:索引是如何排序的?
值列
时间列
文本栏
问题 3:在新闻标题栏上建立索引。当我们查询title = ‘Diaoyu Islands’时,数据库将如何查找?而当我们查询标题LIKE ‘%Diaoyu Islands%’时,数据库应该怎么查?
像索引失效,全表扫描,数据量大的时候简直就是噩梦。
问题4:如何判断一列是否可以在数据库中建立索引?
基本原则:
该表访问频繁,数据量很大,每次查询的数据只占很小一部分
列的数据值分布广泛
该列收录大量空值
列常用于查询条件(不能收录在表达式中)
注意:文本列需要特别考虑:它们通常用于模糊查询,不适合索引。准确查询没问题。
问题5:如果要对查询结果的相关性进行排序,数据库能做到吗?
例如,如果您想查询有关苍夫人、托尼、火锅的新闻:
收录三个关键词(最相关)的新闻排名第一
收录两个关键词(相关性第二),第二个是排名
有关键字的排在第二位。
如果要为搜索到的新闻字段设置不同的权重,例如,新闻标题中收录这三个关键字的新闻的相关性远高于收录这三个词的新闻内容的相关性。数据库能做到吗?
答案:如果不能,此时您需要一个搜索引擎。
问题 6:常见的数据结构有哪些?
结构化数据:以表格和字段表示的数据
半结构化数据:xml、html
非结构化数据:文本、文档、图片、音频、视频等
在讨论了前面的问题之后,我得出了为什么需要搜索引擎的结论:
数据库适用于结构化数据的精确查询,但不适合半结构化和非结构化数据的模糊查询和灵活搜索(尤其是数据量较大时),不能提供理想的实时性能。
二、如何创建反向索引
问题一:如何快速找到与苍夫人相关的新闻?
分析:我们搜索的时候输入的是仓先生,我们想得到一个标题或内容中收录“仓先生”的新闻列表。
如果title和content列有这样的索引,可以快速找到仓先生的关键字对应的文章id,然后根据文章id快速找到文章。
标题列索引:
内容列索引:
词到文章id的索引,这是:倒排索引
问题 2:问题 1 的标题列索引和内容列索引可以合并在一起。有什么好处?
合并的好处是:可以减少访问数据库的次数
问题3:反向索引的记录数会不会很大?如果是英文,最大是多少?如果是中文,最大可能是多少?
英文单词的大概数量是 100,000。汉字总数已超过80,000个,而常用字仅3,500个。
《现代汉语标准词典》的字词比《现代汉语词典》收录多。前者13000多字72000多字,后者11000多字69000多字
结论:金额不会很大,30万以内;通过这个索引找到文章会非常快
问题 4:如何构建问题 2 中的倒排索引?
数据示例:
新闻 ID:1
新闻标题:托尼和仓太太一起吃火锅
新闻内容:2018年4月1日,Tony在四川成都参加一个活动的时候,恰巧主办方还邀请了苍老师来增加自己的人气。应主办方的邀请,他和苍夫人一起吃了火锅。酷!
如果是英文文章,分一下怎么样?
找到与查询匹配的 10 个最佳文档是一回事
英文好(有空格),但中文不好。但必须打分,否则无法建立反向指标。
你必须编写一个特殊的程序来做到这一点:分词器
中文分词器原理:有词词典,前后词结合,与词典匹配,歧义分析
问题5:java开源中文分词器很多,如何选择?
准确率、分词效率、中英文混合分词支持
常用的中文分词器:
IKAnalyzer、mmseg4j
问题 6:你、我、他、“、”、“a”、标点符号……这些需要索引吗?
这些词被称为:停用词。分词器支持指定/添加停用词,无需为其创建索引
问题7:出现新词怎么办?
嫂子,老司机,软妹儿,直男,玩腿,苍老师
分词器应支持在其字典中添加新词。
总结:
根据分词结果,我们建立倒排索引如下:
三、我有反向索引,怎么搜索?
搜索“tony OR苍老师”相关新闻的步骤是什么?
第 1 步:分割搜索输入
托尼,苍老师
第2步:在反向索引中找到收录Tony和Cang夫人的文章list
第三步:合并两个列表,对输出进行排序
{1,12,8,5}
四、如何建立相关性评价模型?
使用出现次数建立模型
规则一:统计出现次数,按次数从高到低排序
{{1,5},{5,3},{12,1},{8,1}}:文章1出现5次,文章5出现3次,文章12出现1 次,文章8 出现 1 次
问题1:标题出现仓先生,新闻内容出现仓太太。哪个和仓先生更相关?怎么做
规则二:加权重,标题权重10,内容权重1,计算权重得分,按高低排序
{{1,23},{12,10},{5,3},{8,1}}
总结:关联模型非常简单,使用出现次数来构建模型。有时排序不是很准确。
复杂的相关性计算模型包括:
tf-idf 词频-逆文档率模型
矢量空间模型
贝叶斯概率模型,如:BM25
搜索引擎将提供一种或多种实现方式以供选择以及扩展。
电子商务网站搜索相关性的计算会越来越复杂。
五、反向索引更新:数据更新的时候索引一定要更新吗?更新好了吗?
更新情况分析:
Q1:添加新商品时,我需要如何更新?
Q2:删除时,我需要如何更新?
Q3:进行更改时,我需要如何更新?
六、反向索引应该存储在内存中还是磁盘上?
大的放磁盘,小的放内存,需要持久化
七、搜索引擎需要支持精准搜索吗?需要像数据库一样支持多条件AND OR组合搜索?
如类别IN()值>=
必须的,否则没人会用搜索引擎
八、Summary
1、什么是搜索引擎?
一套可以实时搜索大量结构化、半结构化数据和非结构化文本数据的专用软件
最早用于信息检索领域,通过谷歌、百度等公司推出网络搜索而为大众所熟知。后来被各大电商网站采用做网站产品搜索。现在广泛应用于各个行业和互联网应用。是大型系统和网站架构师必备的技能。
2、搜索引擎解决什么样的问题?
专门解决大量结构化、半结构化数据、非结构化文本数据的实时检索问题。这种实时搜索数据库是做不到的。
3、搜索引擎适合什么样的场景?
核心:实时搜索大量结构化、半结构化、非结构化文本数据
信息检索(例如电子图书馆、电子档案)
网页搜索
通过提供网站(如新闻、论坛、博客网站)进行内容搜索
E-commerce网站的产品搜索
如果你负责的系统数据量大,通过数据库检索速度慢,可以考虑使用搜索引擎专门检索。
4、搜索引擎的核心组件是什么?
数据源、tokenizer、倒排索引(inverted index)、相关计算模型
5、搜索引擎是如何工作的?
1、从数据源加载数据,切词,建立反向索引
2、搜索时,对搜索输入进行分段,找到反向索引
3、计算相关、排序、输出
6、实现一个搜索引擎,需要实现什么?
1、分词器
2、反向索引,索引存储
3、相关计算模型
7、使用搜索引擎,需要明确哪些方面?
1、分词器
2、反向索引创建、存储、更新
3、相关计算模型
8、java 是广泛使用的开源搜索引擎组件和系统
Lucene:Apache的顶级开源项目,Lucene-core是一个开源的全文搜索引擎工具包,但它并不是一个完整的全文搜索引擎,而是一个全文搜索引擎框架,提供了一个完整的查询引擎和索引引擎,文本切分引擎的一部分(英语和德语两种西方语言)。 Lucene 的目的是为软件开发者提供一个简单易用的工具包,以便在目标系统中轻松实现全文搜索功能,或者以此为基础构建一个完整的全文搜索引擎。
Nutch:Apache 的顶级开源项目,包括网络爬虫和搜索引擎(基于 lucene)系统(与百度和谷歌相同)。 Hadoop 因它而诞生。
Solr:Lucene 下的一个子项目,一个基于 Lucene 的独立企业级开源搜索平台,一个服务。提供基于xml/JSON/http的api对外访问,以及web管理接口。
Elasticsearch:基于 Lucene 的企业级分布式搜索平台。它提供了一个宁静的网络界面,让程序员无需了解 Lucene 即可轻松方便地使用搜索平台。
问题:如何选择搜索引擎组件或系统?
关注成熟度并使用企业量。
更多精彩内容,请扫描下方二维码进入网站。 . . . .
智能搜索如何构建一个好的电商搜索引擎?
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-08 20:17
编辑整理:刘元景
制作平台:DataFunTalk
指南:机器学习算法的不断进步,搜索引擎巧妙的人机交互设计,分布式系统的创新,在不知不觉中,让搜索引擎成为了人们生活中不可或缺的一部分。与此同时,随着人们新需求的不断涌现,搜索引擎也没有停止其变革的步伐。本文主要分享智能搜索在电子商务中的应用探索,介绍如何构建一个好的电子商务搜索引擎。主要内容包括:
01
电商搜索需求背景
首先,让我与您分享为什么您需要搜索。
1.被忽视和低估的搜索行为
在电子商务应用中,流量来自许多不同的渠道,例如搜索、推荐、事件、直播等。搜索是电商APP非常重要的流量入口,很多电商APP可能占据搜索流量的一半以上。需求明确的用户主要通过搜索获得,需求不明确的用户主要通过推荐获得。然后,对于搜索来说,因为需求更明确,所以转化起来会更容易。
2.Search 用户体验痛点
一些电商巨头其实已经把搜索体验做得很好,但是一些小客户还是做不好搜索体验,所以这给我们提供了市场机会。
3.搜索痛点下的用户流失
如果搜索做得不好,用户搜索了很多次,浏览搜索结果超过一定时间,或者翻了几页,却找不到结果,就会失去搜索体验是因为他们无法忍受。
4.智能搜索挖掘用户行为数据价值
因此应优化搜索体验以留住用户。智能搜索呢?您可以通过用户行为日志挖掘出大量有价值的数据,从这些数据中发现丰富的特征,并利用这些特征来最大化搜索流量的价值。
5.电子商务搜索示例
一般来说,对于搜索来说,除了我们经常看到的搜索框输入一些关键词进行搜索之外,搜索中还有其他场景,比如搜索发现、搜索建议、热门搜索、猜你喜欢和搜索阴影,其实这些不再是单纯的搜索,而是结合推荐的场景。
6. 产品搜索 VS。网络搜索
日常生活中,大家最熟悉的网络搜索和商品搜索有什么区别?可以从这几个方面来分析:
02
技术方案探索
接下来介绍整体技术方案。
技术架构图主要分为三部分,一是数据,二是模型,二是搜索引擎本身。数据和模型用于搜索引擎。会有一些数据接入模块,将客户的数据接入系统,放入数据平台计算素材画像、用户画像等;接下来,你需要用这些数据建立一些模型,这些模型会用到搜索引擎的各个环节,比如intent和recall,每一个环节都会用到,粗排序,细排序;再往下,有一些基本的数据存储中间件。我们主要关注搜索引擎本身的过程。最右边是搜索引擎的进程。接下来,我们将介绍整个搜索是如何从上到下进行的。
1.查询预处理
当用户在电子商务应用中输入搜索词时,搜索词将被预处理。这种预处理包括常用停用词、归一化、拼音转文本、同义词替换和分词。完成、改写、纠错等一系列处理,然后将用户搜索到的不规则或不正确的查询处理成规范的、正确的形式,并做一些分词和转换处理。
2.实体识别
预处理完成后,得到用户搜索词切分的结果。当得到分词结果时,分词结果中的每个词都必须被识别为一个实体。什么是实体?电子商务中的实体实际上有很多种。这里列出了三个。有商品实体类型。矿泉水是一个实体,属于商品实体类型;农夫山泉是品牌的实体类型;饮用水是一个类别。或称为类。这些都是实体类型。实体类型下有特定的实体。实体是矿泉水,农夫山泉,所以需要知道输入的词是什么,比如输入“Oreo cookies”,做预处理后,得到“Oreo”和“biscuits”这两个词。这时候就需要实体识别。经过识别,可以知道“奥利奥”是一个品牌,“饼干”是一个商品。可以做后续处理。
实体识别是一种序列标注。可用于实体识别的方法有很多,如CRF、BERT等。在工程处理的时候,这些算法不一定在线使用,因为这些算法在线计算成本比较高,一般都是离线计算,计算结果存放在缓存中,这样在线只需要做一些简单的匹配即可,处理会快很多,有时需要一些人工修正才能得到更准确的实体词。实体识别有一些先决条件。你怎么知道矿泉水是商品?农夫山泉是品牌吗?这个知识其实需要外部输入才能知道,这就是领域知识,所以首先要积累一些领域知识。
① 领域知识积累
领域知识其实并不容易分析。比如猪舌和烟嘴其实是一回事,西葫芦和西葫芦是一回事。当然,这个知识是可以分析的,那么如何分析呢?事实上,有很多现成的知识可以抓取和使用,积累为领域知识。这个领域有许多形式的知识。最简单的就是词典。知识图谱也可以构建。知识图谱构建是最常用的领域知识构建方式。
②词库挖掘
如何构建同义词库需要挖掘出各种类型的词,例如最常用的同义词和上位词。使用前面的例子可以理解同义词。西瓜和西葫芦是同一个东西。有很多方法可以获得同义词。预训练的词向量求共现关系的方法可以找到大量的同义词(也就是类似word2vec的方法),但是找到后可能不准确,需要后期处理才能使用它。很多同义词可以从百度百科中抓取,同义词可以在企业经营数据库和企业现有词库中找到。有多种方法可以构建同义词库。
然后如何挖掘上位词,举个例子理解上位词,比如商品类别是具体商品的上位词,矿泉水的上位词是饮用水。词库的构建是为搜索做必要的工作,但是在词库的构建过程中,不一定是人工的过程。完全可以使用其他自动化的方法甚至模型来过滤词库,最后再做一些人工修正。
③商品知识图谱构建
如何构建产品知识图谱,我们可以构建很多不同类型的知识图谱。本文基于不同的实体构建知识图谱,比如基于三类实体构建知识图谱,如上图中最右边的示意图。苹果有很多型号。如果用户搜索Apple,用户可能想购买iPhone 11、iPhone X 或仍然无法买到的iPhone 12。可以通过先验知识构建知识图谱,并将这些知识用于最终排名。整合,比如用户更倾向于购买iPhone X,iPhone X在后期排序的时候会更高级。对于品类,搜索苹果可能是手机或水果。不管是买手机还是吃水果,都是有概率的。不同的用户有不同的倾向,但是我们目前构建的地图还不能个性化。这只是一个宏观统计。在搜索苹果时,80%的用户实际上是想买苹果手机,20%的用户想买水果。这给了我们一种参考。知识图谱实际上是一种非个性化的全局知识构建。通过商品库分析静态概率。最后会根据用户的点击行为进行一些动态调整。调整后的知识图谱用于后续排名。
3.意图识别
用户搜索词预处理后,根据分词结果识别搜索词对应的实体类型。当用户搜索产品时,可以知道用户搜索的是什么实体,是品牌还是产品名称。您还可以通过图表猜测用户的搜索意图。如果他只输了一个苹果,他可以猜测他很有可能会购买一部手机,他也可以猜测其他实体类型。经过猜测,还有一些部分是猜不出来的。猜不出来的部分怎么办?使用意图识别。
那么如何做意图识别,利用用户导入的素材库来自动训练意图模型。意图识别就是进行类别预测,甚至是对其他没有字面表达的实体类型进行预测。在最初的材料库中,产品的各种属性都是一些自然的标注数据。使用这些注释数据来训练初始意图模型来预测隐式实体类型。初始模型训练完成后,使用搜索日志动态调整这个意图模型。
经过预处理、分词、实体识别、基于知识图谱的预测和意图识别,能达到什么效果?可以搜索“手机”,根据用户的信息,可以知道手机是一个产品名称,可以猜出具体的产品,但猜的可能不是那么准确。这个用户可能有80%的概率购买苹果手机,而他购买的苹果手机可能是iPhone 11,他可能猜到他要买的颜色是红色。这样,当用户输入一个词时,他就可以预测他可能想要搜索的所有信息。当然,这种预测有时准确有时不准确,但稍后会进行调整。这样,你就可以带着这些信息做一些回忆了。
意图识别的方法有哪些?意图识别的方法有很多,因为意图识别本身使用分类器。分类器的种类其实很多,但是经过各种比较,我们选择了FastText,可以在线使用,在同样的效果下,FastText是最快、最简单、最高效、最实用的。
4.粗排
完成前面的工作后,我们将开始召回。从用户搜索一个词经过一系列的过程,通过知识图谱(其实知识图谱放了一些相对头部的实体,但是长尾实体词还是需要用意图识别方法来预测)各种信息被预测,并用这些信息构建召回条件,召回条件用于召回完整的结果集。至此,召回工作完成。
召回工作完成后,下一步就是粗选。一个简单的模型可用于粗略排序。这个模型中的特征可以是相关的(搜索和推荐不同,一开始搜索会相关,但是推荐不会有相关性,推荐不会先输入一些搜索词)、时间、人气、销量、数量点赞数和采集数等,训练一个简单的模型,做一些粗略的排序,截断,进入下一个链接,如果想要更简单,可以找出核心特征,做一个加权平均粗略的排序无法达到个性化的效果。当然,粗排序可以做得更加个性化,可以根据不同的搜索用户制作个性化的粗排序模型。
5.精排
得到粗排序结果后,下一步就是细排序。对于搜索,目前主要的优化目标是CTR,主要采用CTR估算方法。 CTR估计的方法很多,比如传统的特征工程方法、深度学习方法等,也可以使用自研的第四范式HyperCycle。
特征工程方法主要是利用不同类型的特征来构建机器学习排名模型。上面列出了几组特征,包括搜索词特征、相关性特征、用户特征、产品特征和行为特征。
深度学习方法也是常用的CTR估算方法。可用于对搜索场景进行排序的深度学习模型有很多,例如DeepFM、Wide&Deep等。
我们的系统主要使用自主研发的HyperCycle。简单来说,它会自动储水积累数据,自动探索模型,自动挖掘特征,自动训练上线,自动定时更新。更多信息请参考石广川分享的HyperCycle。
6. 其他
推荐相关的应用场景会出现在搜索中,比如搜索阴影、搜索发现、搜索提示、猜你喜欢和相关搜索等,都与推荐相关。
搜索模式是搜索框中唯一的词。它实际上是对搜索框top1的推荐。根据用户的历史行为,推荐用户最可能的搜索词,将top1放入搜索模式。然后推荐给用户。用户看到这个底纹后,可以搜索这个底纹上的搜索词。目的是引导用户,猜测用户想要搜索什么,提高转化率;搜索发现和搜索底纹原理类似,但是推荐的搜索词比较多;搜索提示是在搜索中做一些推荐,相关搜索是在没有搜索结果时做一些相关推荐;有些地方会出现猜你喜欢,猜你喜欢其实是一个纯推荐场景中,当用户打开搜索页面的时候,他猜测用户最想搜索什么,然后推荐给用户。这些其实就是搜索中的推荐,搜索中的流量和推荐中的流量是可以完全相连的。
上面,我已经一一讲了整个搜索过程。现在让我们一步一步地看一下搜索单词的过程。第一步,输入搜索词“康师傅方便面”。第二步是预处理。预处理会做一些事情。第一步是分词,然后计算搜索词可能的实体类型。比如康师傅是一个品牌,它认可楚康大师是一个品牌。方便面可以是修饰符,也可以是类型。还有一些同义词:袋装面、桶装面和方便面。经过第二步的处理,你会得到类似这样的处理结果;第三步意图识别,可以看到该类别有96%的概率属于粮油调味品;
第四步是构造一个搜索查询来召回来自ES的结果;第五步,得到ES召回的结果,做粗排序和截断;第六步,精细排序;最后根据业务规则进行操作干预,将最终的搜索结果返回给用户,以上就是完整的技术流程。
03
应用案例及效果
最后,我们来看看搜索技术解决方案的应用案例并分析结果。
应用部分零售企业场景后,搜索结果准确率提升50%,全产品覆盖率提升3倍,解决客户搜索体验痛点。
这是上线前后的搜索结果对比。在发布前搜索“Apple”时,排名第一的并不是Apple。启动Smart Search后,搜索结果都与“Apple”相关。
按类别搜索,优化前搜索“水”,前5名返回“风水梨”“柔肤露”等完全不相关的产品,优化后搜索“水”,前5名返回密切相关的产品浇水。
按品牌搜索,优化前搜索“安木喜”。前 5 名返回与“希翼”完全无关的产品。优化后搜索“安木喜”,Top 5返回与品牌密切相关的产品。
同义词搜索,优化前搜索“机会”,Top5返回“果汁饮料”和“芒果味果冻”无关产品,优化后搜索“机会”,Top5返回与圣人水果密切相关的商品.
优化后,可以进行智能纠错和拼音搜索。比如搜索“pingguo”、“pingguo”、“pinguo”,就可以准确搜索到苹果相关产品。
客人介绍:
邢少民,17年加入第四范式,一直在做商业产品研发。最初,他做智能客服系列产品。去年,他孵化了智能搜索产品。今年也在做智能推荐产品的研发。 查看全部
智能搜索如何构建一个好的电商搜索引擎?
编辑整理:刘元景
制作平台:DataFunTalk
指南:机器学习算法的不断进步,搜索引擎巧妙的人机交互设计,分布式系统的创新,在不知不觉中,让搜索引擎成为了人们生活中不可或缺的一部分。与此同时,随着人们新需求的不断涌现,搜索引擎也没有停止其变革的步伐。本文主要分享智能搜索在电子商务中的应用探索,介绍如何构建一个好的电子商务搜索引擎。主要内容包括:
01
电商搜索需求背景
首先,让我与您分享为什么您需要搜索。
1.被忽视和低估的搜索行为
在电子商务应用中,流量来自许多不同的渠道,例如搜索、推荐、事件、直播等。搜索是电商APP非常重要的流量入口,很多电商APP可能占据搜索流量的一半以上。需求明确的用户主要通过搜索获得,需求不明确的用户主要通过推荐获得。然后,对于搜索来说,因为需求更明确,所以转化起来会更容易。
2.Search 用户体验痛点
一些电商巨头其实已经把搜索体验做得很好,但是一些小客户还是做不好搜索体验,所以这给我们提供了市场机会。
3.搜索痛点下的用户流失
如果搜索做得不好,用户搜索了很多次,浏览搜索结果超过一定时间,或者翻了几页,却找不到结果,就会失去搜索体验是因为他们无法忍受。
4.智能搜索挖掘用户行为数据价值
因此应优化搜索体验以留住用户。智能搜索呢?您可以通过用户行为日志挖掘出大量有价值的数据,从这些数据中发现丰富的特征,并利用这些特征来最大化搜索流量的价值。
5.电子商务搜索示例
一般来说,对于搜索来说,除了我们经常看到的搜索框输入一些关键词进行搜索之外,搜索中还有其他场景,比如搜索发现、搜索建议、热门搜索、猜你喜欢和搜索阴影,其实这些不再是单纯的搜索,而是结合推荐的场景。
6. 产品搜索 VS。网络搜索
日常生活中,大家最熟悉的网络搜索和商品搜索有什么区别?可以从这几个方面来分析:
02
技术方案探索
接下来介绍整体技术方案。
技术架构图主要分为三部分,一是数据,二是模型,二是搜索引擎本身。数据和模型用于搜索引擎。会有一些数据接入模块,将客户的数据接入系统,放入数据平台计算素材画像、用户画像等;接下来,你需要用这些数据建立一些模型,这些模型会用到搜索引擎的各个环节,比如intent和recall,每一个环节都会用到,粗排序,细排序;再往下,有一些基本的数据存储中间件。我们主要关注搜索引擎本身的过程。最右边是搜索引擎的进程。接下来,我们将介绍整个搜索是如何从上到下进行的。
1.查询预处理
当用户在电子商务应用中输入搜索词时,搜索词将被预处理。这种预处理包括常用停用词、归一化、拼音转文本、同义词替换和分词。完成、改写、纠错等一系列处理,然后将用户搜索到的不规则或不正确的查询处理成规范的、正确的形式,并做一些分词和转换处理。
2.实体识别
预处理完成后,得到用户搜索词切分的结果。当得到分词结果时,分词结果中的每个词都必须被识别为一个实体。什么是实体?电子商务中的实体实际上有很多种。这里列出了三个。有商品实体类型。矿泉水是一个实体,属于商品实体类型;农夫山泉是品牌的实体类型;饮用水是一个类别。或称为类。这些都是实体类型。实体类型下有特定的实体。实体是矿泉水,农夫山泉,所以需要知道输入的词是什么,比如输入“Oreo cookies”,做预处理后,得到“Oreo”和“biscuits”这两个词。这时候就需要实体识别。经过识别,可以知道“奥利奥”是一个品牌,“饼干”是一个商品。可以做后续处理。
实体识别是一种序列标注。可用于实体识别的方法有很多,如CRF、BERT等。在工程处理的时候,这些算法不一定在线使用,因为这些算法在线计算成本比较高,一般都是离线计算,计算结果存放在缓存中,这样在线只需要做一些简单的匹配即可,处理会快很多,有时需要一些人工修正才能得到更准确的实体词。实体识别有一些先决条件。你怎么知道矿泉水是商品?农夫山泉是品牌吗?这个知识其实需要外部输入才能知道,这就是领域知识,所以首先要积累一些领域知识。
① 领域知识积累
领域知识其实并不容易分析。比如猪舌和烟嘴其实是一回事,西葫芦和西葫芦是一回事。当然,这个知识是可以分析的,那么如何分析呢?事实上,有很多现成的知识可以抓取和使用,积累为领域知识。这个领域有许多形式的知识。最简单的就是词典。知识图谱也可以构建。知识图谱构建是最常用的领域知识构建方式。
②词库挖掘
如何构建同义词库需要挖掘出各种类型的词,例如最常用的同义词和上位词。使用前面的例子可以理解同义词。西瓜和西葫芦是同一个东西。有很多方法可以获得同义词。预训练的词向量求共现关系的方法可以找到大量的同义词(也就是类似word2vec的方法),但是找到后可能不准确,需要后期处理才能使用它。很多同义词可以从百度百科中抓取,同义词可以在企业经营数据库和企业现有词库中找到。有多种方法可以构建同义词库。
然后如何挖掘上位词,举个例子理解上位词,比如商品类别是具体商品的上位词,矿泉水的上位词是饮用水。词库的构建是为搜索做必要的工作,但是在词库的构建过程中,不一定是人工的过程。完全可以使用其他自动化的方法甚至模型来过滤词库,最后再做一些人工修正。
③商品知识图谱构建
如何构建产品知识图谱,我们可以构建很多不同类型的知识图谱。本文基于不同的实体构建知识图谱,比如基于三类实体构建知识图谱,如上图中最右边的示意图。苹果有很多型号。如果用户搜索Apple,用户可能想购买iPhone 11、iPhone X 或仍然无法买到的iPhone 12。可以通过先验知识构建知识图谱,并将这些知识用于最终排名。整合,比如用户更倾向于购买iPhone X,iPhone X在后期排序的时候会更高级。对于品类,搜索苹果可能是手机或水果。不管是买手机还是吃水果,都是有概率的。不同的用户有不同的倾向,但是我们目前构建的地图还不能个性化。这只是一个宏观统计。在搜索苹果时,80%的用户实际上是想买苹果手机,20%的用户想买水果。这给了我们一种参考。知识图谱实际上是一种非个性化的全局知识构建。通过商品库分析静态概率。最后会根据用户的点击行为进行一些动态调整。调整后的知识图谱用于后续排名。
3.意图识别
用户搜索词预处理后,根据分词结果识别搜索词对应的实体类型。当用户搜索产品时,可以知道用户搜索的是什么实体,是品牌还是产品名称。您还可以通过图表猜测用户的搜索意图。如果他只输了一个苹果,他可以猜测他很有可能会购买一部手机,他也可以猜测其他实体类型。经过猜测,还有一些部分是猜不出来的。猜不出来的部分怎么办?使用意图识别。
那么如何做意图识别,利用用户导入的素材库来自动训练意图模型。意图识别就是进行类别预测,甚至是对其他没有字面表达的实体类型进行预测。在最初的材料库中,产品的各种属性都是一些自然的标注数据。使用这些注释数据来训练初始意图模型来预测隐式实体类型。初始模型训练完成后,使用搜索日志动态调整这个意图模型。
经过预处理、分词、实体识别、基于知识图谱的预测和意图识别,能达到什么效果?可以搜索“手机”,根据用户的信息,可以知道手机是一个产品名称,可以猜出具体的产品,但猜的可能不是那么准确。这个用户可能有80%的概率购买苹果手机,而他购买的苹果手机可能是iPhone 11,他可能猜到他要买的颜色是红色。这样,当用户输入一个词时,他就可以预测他可能想要搜索的所有信息。当然,这种预测有时准确有时不准确,但稍后会进行调整。这样,你就可以带着这些信息做一些回忆了。
意图识别的方法有哪些?意图识别的方法有很多,因为意图识别本身使用分类器。分类器的种类其实很多,但是经过各种比较,我们选择了FastText,可以在线使用,在同样的效果下,FastText是最快、最简单、最高效、最实用的。
4.粗排
完成前面的工作后,我们将开始召回。从用户搜索一个词经过一系列的过程,通过知识图谱(其实知识图谱放了一些相对头部的实体,但是长尾实体词还是需要用意图识别方法来预测)各种信息被预测,并用这些信息构建召回条件,召回条件用于召回完整的结果集。至此,召回工作完成。
召回工作完成后,下一步就是粗选。一个简单的模型可用于粗略排序。这个模型中的特征可以是相关的(搜索和推荐不同,一开始搜索会相关,但是推荐不会有相关性,推荐不会先输入一些搜索词)、时间、人气、销量、数量点赞数和采集数等,训练一个简单的模型,做一些粗略的排序,截断,进入下一个链接,如果想要更简单,可以找出核心特征,做一个加权平均粗略的排序无法达到个性化的效果。当然,粗排序可以做得更加个性化,可以根据不同的搜索用户制作个性化的粗排序模型。
5.精排
得到粗排序结果后,下一步就是细排序。对于搜索,目前主要的优化目标是CTR,主要采用CTR估算方法。 CTR估计的方法很多,比如传统的特征工程方法、深度学习方法等,也可以使用自研的第四范式HyperCycle。
特征工程方法主要是利用不同类型的特征来构建机器学习排名模型。上面列出了几组特征,包括搜索词特征、相关性特征、用户特征、产品特征和行为特征。
深度学习方法也是常用的CTR估算方法。可用于对搜索场景进行排序的深度学习模型有很多,例如DeepFM、Wide&Deep等。
我们的系统主要使用自主研发的HyperCycle。简单来说,它会自动储水积累数据,自动探索模型,自动挖掘特征,自动训练上线,自动定时更新。更多信息请参考石广川分享的HyperCycle。
6. 其他
推荐相关的应用场景会出现在搜索中,比如搜索阴影、搜索发现、搜索提示、猜你喜欢和相关搜索等,都与推荐相关。
搜索模式是搜索框中唯一的词。它实际上是对搜索框top1的推荐。根据用户的历史行为,推荐用户最可能的搜索词,将top1放入搜索模式。然后推荐给用户。用户看到这个底纹后,可以搜索这个底纹上的搜索词。目的是引导用户,猜测用户想要搜索什么,提高转化率;搜索发现和搜索底纹原理类似,但是推荐的搜索词比较多;搜索提示是在搜索中做一些推荐,相关搜索是在没有搜索结果时做一些相关推荐;有些地方会出现猜你喜欢,猜你喜欢其实是一个纯推荐场景中,当用户打开搜索页面的时候,他猜测用户最想搜索什么,然后推荐给用户。这些其实就是搜索中的推荐,搜索中的流量和推荐中的流量是可以完全相连的。
上面,我已经一一讲了整个搜索过程。现在让我们一步一步地看一下搜索单词的过程。第一步,输入搜索词“康师傅方便面”。第二步是预处理。预处理会做一些事情。第一步是分词,然后计算搜索词可能的实体类型。比如康师傅是一个品牌,它认可楚康大师是一个品牌。方便面可以是修饰符,也可以是类型。还有一些同义词:袋装面、桶装面和方便面。经过第二步的处理,你会得到类似这样的处理结果;第三步意图识别,可以看到该类别有96%的概率属于粮油调味品;
第四步是构造一个搜索查询来召回来自ES的结果;第五步,得到ES召回的结果,做粗排序和截断;第六步,精细排序;最后根据业务规则进行操作干预,将最终的搜索结果返回给用户,以上就是完整的技术流程。
03
应用案例及效果
最后,我们来看看搜索技术解决方案的应用案例并分析结果。
应用部分零售企业场景后,搜索结果准确率提升50%,全产品覆盖率提升3倍,解决客户搜索体验痛点。
这是上线前后的搜索结果对比。在发布前搜索“Apple”时,排名第一的并不是Apple。启动Smart Search后,搜索结果都与“Apple”相关。
按类别搜索,优化前搜索“水”,前5名返回“风水梨”“柔肤露”等完全不相关的产品,优化后搜索“水”,前5名返回密切相关的产品浇水。
按品牌搜索,优化前搜索“安木喜”。前 5 名返回与“希翼”完全无关的产品。优化后搜索“安木喜”,Top 5返回与品牌密切相关的产品。
同义词搜索,优化前搜索“机会”,Top5返回“果汁饮料”和“芒果味果冻”无关产品,优化后搜索“机会”,Top5返回与圣人水果密切相关的商品.
优化后,可以进行智能纠错和拼音搜索。比如搜索“pingguo”、“pingguo”、“pinguo”,就可以准确搜索到苹果相关产品。
客人介绍:
邢少民,17年加入第四范式,一直在做商业产品研发。最初,他做智能客服系列产品。去年,他孵化了智能搜索产品。今年也在做智能推荐产品的研发。
蝙蝠侠IT的“无点击”时代,相关解决方案的途径
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-06-08 03:47
其中,关于SEO技术排名的相关性就不多说了,比如:
①点击搜索页面。
②页面内容增加的频率和垂直度。
③ 页面的外部链接。
通常,在这三个影响因素中,我们都非常清楚页面上的搜索点击具有非常高的权重。
当然,即使推出了迅雷算法3.0,Batman IT也认为它的占比还是比较高的,不过这次搜索点击并不是其他点击,而是来自用户搜索结果的自然点击.
2、相关解决方法
今天我们讨论的是“无点击”时代。从蝙蝠侠 IT 的角度来看,我们基于以下两个因素:
① 以前刷IP点击高度依赖SEO排名系统,现在被算法识别,点击无效。
②过去,在某个时间点,整体网站优化关键词在没有点击的情况下排名明显落后。
如果您目前正面临这样的困境,我认为以下内容值得讨论:
①内容页面质量
搜索引擎总是喜欢高质量的内容。内容为王。这是毋庸置疑的事情。根据特定搜索需求编写相关内容关键词可以获得更高的搜索排名。
就像热词“射雷算法3.0”刚出现时,我们在CSDN上发布了相关内容。从目前来看,我们在SERP中的排名还是很高的。根据地区 显示不同地区的差异化结果。目前这个词的排名还在TOP5,部分地区展示第一。
因此,有一个小问题:高质量的内容在搜索结果中也很重要。目前,如果您考虑百度的搜索结果,我们认为:
1)百家号(企业百家号)、百度小程序、百度iSourcing、百度创新者等相关产品都是首选媒体。
2)工业立类网站,如:CSDN、OSCHINA、站长之家、A5等(IT技术类)
3)企业站,品牌站,优质解决方案服务商网站,接下来是域名KOL站。
如果你在运营网站,可以参考上述相关媒体,扩大你的内容展示和流量获取。如果你是独立个体网站,我们的建议是:保持持续稳定和高价值的内容输出,思考如何打造个人品牌。
②页面结构设计
如果你长期在SEO行业工作,我们总能看到一些通过“技术排名”的高权重网站。对于这种类型的网站,页面结构可能没有任何值。
但是我们都知道SEO是基于企业网站运营的策略。我们需要一个长期的推进和短期的页面“繁荣”,一段时间后可能是短暂的。
但是我们也发现了这么一个有趣的现象,那就是差异化的网站结构设计,尤其是前端页面的展示,在一定程度上确实对收录搜索引擎非常有利。
特别是新网站的成立,我经常遇到关于SEO操作的投诉。百度不是收录。反过来,你可能需要思考一个问题,为什么搜索引擎要收录you。
但我们不希望网站 推广者在设计页面时具有创新性,使用非常个性化的网站 框架。
根据Batman IT不同的网站框架设置,我们认为在构建新的网站时,仍然需要保持一个流行的基础结构,这有利于百度蜘蛛爬取和视觉前端页面效果可以适当区分,因为搜索引擎在不断加强对CSS和JS的解释能力。
③ 增量页面内容
老实说,基于页面增量,我认为这对于网站管理员来说是一个相对容易的策略。在一定程度上,只要保持高质量内容输出的高频率,搜索引擎总会给予更高的待遇,包括:抓取频率、索引量、权重增加等。
但我们不要忽视这里的一个实际问题:
页面的增量内容是什么?
基于 SEO 数据分析,高频率输出的页面内容不会有任何增加。
前提是您的页面正在解决问题并满足搜索要求。坦白说,这个页面的核心关键词可能需要一定的搜索量。
④ 外链扩展
对于外链的拓展,相信很多做过SEO快速排名的从业者已经很久没有做外链了。这也是为什么在近几年的SEO市场上,总有人说:外链的价值越来越低,相关性的作用几乎没有。
事实上,从某种角度来看,我们并不这么认为:尤其是当我们面临“无点击”排名时,快速获得更高信任度的一种相对有效的方式仍然是基于外链驱动。
因此,您可能需要善于学习:发现稀缺的 SEO 资源,尤其是高质量的外部链接。
⑤ 网站内的用户行为
这是一个我们后期可能会花大量时间去研究和测试的方向。不限于百度搜索。有时我们总是有一定的惯性思维,从外部寻找解决方案。对以上,需要适当增加逆向思维的判断,例如:
用户在1)网站的访问和点击行为是否会在一定程度上影响搜索排名。
2)网站内部相关链接可以与外部资源分离,影响网站排名。
3)网站结构的布局,百度怎么能正常表达收录。
4)页面停留时间和用户跳出率等数据指标会影响网站的排名。
5)网站页面分享的频率,特别是基于新媒体平台的传播能力。
从搜索引擎的长远发展来看,我们认为对方会关注这个位置。
总结:SEO排名,“无点击”时代,你怎么排名,以上内容只是蝙蝠侠IT家族的话,SEO每日一贴,仅供参考!
查看全部
蝙蝠侠IT的“无点击”时代,相关解决方案的途径
其中,关于SEO技术排名的相关性就不多说了,比如:
①点击搜索页面。
②页面内容增加的频率和垂直度。
③ 页面的外部链接。
通常,在这三个影响因素中,我们都非常清楚页面上的搜索点击具有非常高的权重。
当然,即使推出了迅雷算法3.0,Batman IT也认为它的占比还是比较高的,不过这次搜索点击并不是其他点击,而是来自用户搜索结果的自然点击.
2、相关解决方法
今天我们讨论的是“无点击”时代。从蝙蝠侠 IT 的角度来看,我们基于以下两个因素:
① 以前刷IP点击高度依赖SEO排名系统,现在被算法识别,点击无效。
②过去,在某个时间点,整体网站优化关键词在没有点击的情况下排名明显落后。
如果您目前正面临这样的困境,我认为以下内容值得讨论:
①内容页面质量
搜索引擎总是喜欢高质量的内容。内容为王。这是毋庸置疑的事情。根据特定搜索需求编写相关内容关键词可以获得更高的搜索排名。
就像热词“射雷算法3.0”刚出现时,我们在CSDN上发布了相关内容。从目前来看,我们在SERP中的排名还是很高的。根据地区 显示不同地区的差异化结果。目前这个词的排名还在TOP5,部分地区展示第一。
因此,有一个小问题:高质量的内容在搜索结果中也很重要。目前,如果您考虑百度的搜索结果,我们认为:
1)百家号(企业百家号)、百度小程序、百度iSourcing、百度创新者等相关产品都是首选媒体。
2)工业立类网站,如:CSDN、OSCHINA、站长之家、A5等(IT技术类)
3)企业站,品牌站,优质解决方案服务商网站,接下来是域名KOL站。
如果你在运营网站,可以参考上述相关媒体,扩大你的内容展示和流量获取。如果你是独立个体网站,我们的建议是:保持持续稳定和高价值的内容输出,思考如何打造个人品牌。
②页面结构设计
如果你长期在SEO行业工作,我们总能看到一些通过“技术排名”的高权重网站。对于这种类型的网站,页面结构可能没有任何值。
但是我们都知道SEO是基于企业网站运营的策略。我们需要一个长期的推进和短期的页面“繁荣”,一段时间后可能是短暂的。
但是我们也发现了这么一个有趣的现象,那就是差异化的网站结构设计,尤其是前端页面的展示,在一定程度上确实对收录搜索引擎非常有利。
特别是新网站的成立,我经常遇到关于SEO操作的投诉。百度不是收录。反过来,你可能需要思考一个问题,为什么搜索引擎要收录you。
但我们不希望网站 推广者在设计页面时具有创新性,使用非常个性化的网站 框架。
根据Batman IT不同的网站框架设置,我们认为在构建新的网站时,仍然需要保持一个流行的基础结构,这有利于百度蜘蛛爬取和视觉前端页面效果可以适当区分,因为搜索引擎在不断加强对CSS和JS的解释能力。
③ 增量页面内容
老实说,基于页面增量,我认为这对于网站管理员来说是一个相对容易的策略。在一定程度上,只要保持高质量内容输出的高频率,搜索引擎总会给予更高的待遇,包括:抓取频率、索引量、权重增加等。
但我们不要忽视这里的一个实际问题:
页面的增量内容是什么?
基于 SEO 数据分析,高频率输出的页面内容不会有任何增加。
前提是您的页面正在解决问题并满足搜索要求。坦白说,这个页面的核心关键词可能需要一定的搜索量。
④ 外链扩展
对于外链的拓展,相信很多做过SEO快速排名的从业者已经很久没有做外链了。这也是为什么在近几年的SEO市场上,总有人说:外链的价值越来越低,相关性的作用几乎没有。
事实上,从某种角度来看,我们并不这么认为:尤其是当我们面临“无点击”排名时,快速获得更高信任度的一种相对有效的方式仍然是基于外链驱动。
因此,您可能需要善于学习:发现稀缺的 SEO 资源,尤其是高质量的外部链接。
⑤ 网站内的用户行为
这是一个我们后期可能会花大量时间去研究和测试的方向。不限于百度搜索。有时我们总是有一定的惯性思维,从外部寻找解决方案。对以上,需要适当增加逆向思维的判断,例如:
用户在1)网站的访问和点击行为是否会在一定程度上影响搜索排名。
2)网站内部相关链接可以与外部资源分离,影响网站排名。
3)网站结构的布局,百度怎么能正常表达收录。
4)页面停留时间和用户跳出率等数据指标会影响网站的排名。
5)网站页面分享的频率,特别是基于新媒体平台的传播能力。
从搜索引擎的长远发展来看,我们认为对方会关注这个位置。
总结:SEO排名,“无点击”时代,你怎么排名,以上内容只是蝙蝠侠IT家族的话,SEO每日一贴,仅供参考!

