
搜索引擎主题模型优化
如何升级页面优化以匹配搜索引擎的技术呢?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-20 02:13
过去几年,搜索引擎工程团队专注于自然语言处理,对页面内容之间的相互关系有了更深入的了解。神经匹配帮助搜索引擎理解同义词,人工智能帮助搜索引擎理解那些棘手的词句。
每次核心更新后,搜索引擎的文学水平都会提升。然而,尽管搜索引擎越来越智能,但许多网站所有者在优化网站时仍然只考虑少数关键词目标。
这是一种过时的做法,尤其是当我们知道着陆页通常以数百个关键词 排名结束时。对于自搜索引擎成立以来一直关注的我们来说,这对于页面搜索引擎优化来说就像一个美丽的新世界。
随着搜索引擎的 NLP(自然语言处理)能力不断提高,我们的页面 SEO 策略也需要制定以反映搜索中的这些进步。
那么,我们如何升级页面优化以匹配搜索引擎技术? 关键词集群就是答案。
什么是关键词cluster?
关键词群是一个关键词群组,代表具有相似购买意向的搜索者。比如“亚麻窗帘”、“亚麻窗帘”、“亚麻窗帘布”和“白色亚麻窗帘”是不同的关键词词组,但都代表着想要购买亚麻窗帘的搜索者。
假设您的品牌销售亚麻窗帘。如果你只尝试排名第一关键词,你最终会限制你的市场份额。
如果你得到了你的主要关键词、长尾变体和相关的副主题,你的页面最终排名将是关键词数量的10-20倍,并获得更多的点击。
如何创建关键词和主题集群
为了充分利用关键词集群的功能,需要注意的是,这种策略比一劳永逸的网站优化方法需要更多的时间和资源。
这需要您的 SEO 和营销团队进行更多 关键词 研究、更多内容创建和更多工作。
但最终,在你的网站上设置主题集群会让搜索引擎和用户更加友好。 关键词cluster 的好处包括:
Longtail 关键词 排名靠前。改进了短尾关键词 的排名。更高的有机流量。更快地提高 SERP 中的排名。内部链接的机会更多。在您的行业环境中建立专业知识和内容权威。这是关于如何做关键词集群以及如何围绕这些集群构建内容策略的简要说明。
第一步:创建关键词list
关键词cluster 从关键词 研究开始。想想你想为网站 排名的主要关键词。
然后,确定搜索者正在使用的此关键词 的所有变体、长尾短语和子主题。
首先,让您的竞争对手了解他们目前为哪个 关键词 排名。
然后,使用关键词 工具查找相关的关键词、自动填充、子主题或搜索者以查找有关您的产品和服务的问题。
记录关键词研究的方式有很多种,但最简单的方法是使用5118关键词挖矿工具导出对应的关键词列表。确保在列表中收录关键词 的自然难度、搜索量和每次点击费用指标。
这些指标将帮助您确定哪些关键词 具有最高的经济价值,应该用作集群中的“核心”关键词。
一些 SEO 专业人士在他们的研究中确定了数千个 关键词。如果您刚刚开始使用此策略,那么一百个关键词phrases 可能足以识别可以在您的网站 上建立的几个不同的主题集群。
在生成关键词lists 时,请记住相关性和搜索意图的重要性。您只想加入关键词,为您的网站 带来合适的搜索者,他们实际上对您提供的产品或服务感兴趣并且可能会转化。
第 2 步:将关键词 分组
一旦你有一个广泛的关键词列表,你就会开始注意到关键词中的模式。
您可能会注意到,用户在其搜索查询中收录相同的字词、短语、同义词或副主题。这些模式代表了您可以聚集和形成关键词 组的潜在方式。
这是将这些关键词划分为多个集群时应该使用的条件。
语义相关性
集群中的关键词 具有相似的搜索意图很重要。
如果您尝试为不太相似的关键词 优化着陆页,则会降低内容的可读性,并使搜索引擎对您的页面的真正含义感到困惑。
搜索量和每次点击费用
集群中的核心关键词应该有合理的搜索量(否则你会为任何人优化)。
他们还应该具有转化潜力(每次点击费用代表他们的经济价值)。
有机困难
是否收录更难的关键词取决于您的网站权限、反向链接配置文件以及网站的建立方式。
在您的集群中仅收录可以对其站点进行排名的关键词。
仔细研究两个关键词群
找到集群的核心关键词后,将其与互补的关键词配对。
例如,您可以添加一些长尾、降低难度或降低搜索量,或者只是在着陆页上收录有关它们的足够信息以轻松获胜。
为什么这些关键词可以组成一个好的集群?因为它们共享语义相关性。这些搜索者都在寻找有助于安排采访的产品。
我们的核心关键词在排名方面更具竞争力,但我们用关键词填充了集群,难度较低且转化潜力强。
如果您对自己的细分市场充满信心并了解关键词 指标和搜索意图的细微差别,您可以手动将关键词 分成几个组(如我们上面所述)。
还有一些关键词grouping 工具可以自动化这个过程。他们可以为您将关键词 细分为多个类别。
细分时,请记住并非所有列表中的关键词都需要以集群结束。
收录最高值的关键词是最重要的关键词。更高的每次点击费用、更高的搜索量和相关的搜索意图使 关键词 对您的品牌有价值。
第 3 步:为您的 关键词 集群创建和优化支柱页面
关键词 分组后,他们提供了如何在网站 上创建、优化和组织内容的路线图。
本质上,你的关键词群代表你的网站核心主题。这些也称为“支柱页面”。
为了正确执行关键词集群,我们需要为每个关键词集群创建一个目标页面。
关键词群的支柱页面应该使用正式的现场搜索引擎优化技术。我们最喜欢的策略之一是使用内容优化工具来帮助您更有效地优化内容。
为了提高支柱页面的排名潜力,请优先考虑以下几个方面:
主题深度:专注于撰写深入探索主题的长篇内容。信息架构:具有清晰的结构,并在 h2 和 h3 中收录您的 关键词phrase。页面体验:在交互页面添加视频、跳转链接、轮播等元素,提升用户的页面体验。第四步:通过网站content 增强关键词cluster
为了提高支柱页面的排名和内容权重,您可以构建内容以增强您的主要关键词 集群。
这些文章可以定位与你的核心关键词相关的长尾关键词短语、副主题或问题。
随着您开发更多内容,这些页面将在您的网站 上形成“主题集群”。
此内容的内部链接系统将在您的网站 着陆页在搜索引擎中的排名中发挥重要作用。
您的文章 应该链接回其相应的支柱页面,以增加您在这些高价值关键词 上排名的机会。
如果你的公司有多个产品或专业领域,你可以在网站上搭建更多的集群。
如果你只销售一种核心产品或服务,你识别的关键词集群数量会减少。但是,探索具有丰富有用内容的主要学科领域可以帮助您在更短的时间内超越竞争对手。
建立集群还可以为您提供更多的机会添加内部链接到网站。
这不仅增加了用户在您的网站 上花费的时间,而且内部链接遍布您的网站 并帮助搜索引擎了解您在网站 上最重要的页面。
关键词group 真的值得所有的工作吗?
关键词群 是一种更高级的 SEO 策略,可以为您提供在垂直竞争中获胜所需的优势。这是因为它们响应了搜索引擎的两大超级功能:自然语言处理和无与伦比的索引。
想想看,搜索引擎了解各行各业的搜索者使用的数百万个关键词phrases。它还了解这些查询之间的细微差别,以及它们的相互关系或相互关系。
搜索引擎花了数年时间训练他们的 NLP(自然语言处理)模型来计算内容质量信号并预测哪些网页最能向搜索者提供他们需要的信息。当你在落地页进行关键词聚类,你会向搜索引擎证明你的网站是你所在行业的权威,展示强大的内容范围和深度。
您还可以通过丰富的内容集群提供搜索引擎的内容信号,这些集群已经过训练以识别和改进搜索结果。 关键词集群需要网站站长多思考自己的内容,这也是SEO的未来。
如果您希望您的网页长期排名,是时候让您的网页策略赶上搜索引擎了。 查看全部
如何升级页面优化以匹配搜索引擎的技术呢?(图)
过去几年,搜索引擎工程团队专注于自然语言处理,对页面内容之间的相互关系有了更深入的了解。神经匹配帮助搜索引擎理解同义词,人工智能帮助搜索引擎理解那些棘手的词句。
每次核心更新后,搜索引擎的文学水平都会提升。然而,尽管搜索引擎越来越智能,但许多网站所有者在优化网站时仍然只考虑少数关键词目标。
这是一种过时的做法,尤其是当我们知道着陆页通常以数百个关键词 排名结束时。对于自搜索引擎成立以来一直关注的我们来说,这对于页面搜索引擎优化来说就像一个美丽的新世界。
随着搜索引擎的 NLP(自然语言处理)能力不断提高,我们的页面 SEO 策略也需要制定以反映搜索中的这些进步。
那么,我们如何升级页面优化以匹配搜索引擎技术? 关键词集群就是答案。
什么是关键词cluster?
关键词群是一个关键词群组,代表具有相似购买意向的搜索者。比如“亚麻窗帘”、“亚麻窗帘”、“亚麻窗帘布”和“白色亚麻窗帘”是不同的关键词词组,但都代表着想要购买亚麻窗帘的搜索者。
假设您的品牌销售亚麻窗帘。如果你只尝试排名第一关键词,你最终会限制你的市场份额。
如果你得到了你的主要关键词、长尾变体和相关的副主题,你的页面最终排名将是关键词数量的10-20倍,并获得更多的点击。
如何创建关键词和主题集群
为了充分利用关键词集群的功能,需要注意的是,这种策略比一劳永逸的网站优化方法需要更多的时间和资源。
这需要您的 SEO 和营销团队进行更多 关键词 研究、更多内容创建和更多工作。
但最终,在你的网站上设置主题集群会让搜索引擎和用户更加友好。 关键词cluster 的好处包括:
Longtail 关键词 排名靠前。改进了短尾关键词 的排名。更高的有机流量。更快地提高 SERP 中的排名。内部链接的机会更多。在您的行业环境中建立专业知识和内容权威。这是关于如何做关键词集群以及如何围绕这些集群构建内容策略的简要说明。
第一步:创建关键词list
关键词cluster 从关键词 研究开始。想想你想为网站 排名的主要关键词。
然后,确定搜索者正在使用的此关键词 的所有变体、长尾短语和子主题。
首先,让您的竞争对手了解他们目前为哪个 关键词 排名。
然后,使用关键词 工具查找相关的关键词、自动填充、子主题或搜索者以查找有关您的产品和服务的问题。
记录关键词研究的方式有很多种,但最简单的方法是使用5118关键词挖矿工具导出对应的关键词列表。确保在列表中收录关键词 的自然难度、搜索量和每次点击费用指标。
这些指标将帮助您确定哪些关键词 具有最高的经济价值,应该用作集群中的“核心”关键词。
一些 SEO 专业人士在他们的研究中确定了数千个 关键词。如果您刚刚开始使用此策略,那么一百个关键词phrases 可能足以识别可以在您的网站 上建立的几个不同的主题集群。
在生成关键词lists 时,请记住相关性和搜索意图的重要性。您只想加入关键词,为您的网站 带来合适的搜索者,他们实际上对您提供的产品或服务感兴趣并且可能会转化。
第 2 步:将关键词 分组
一旦你有一个广泛的关键词列表,你就会开始注意到关键词中的模式。
您可能会注意到,用户在其搜索查询中收录相同的字词、短语、同义词或副主题。这些模式代表了您可以聚集和形成关键词 组的潜在方式。
这是将这些关键词划分为多个集群时应该使用的条件。
语义相关性
集群中的关键词 具有相似的搜索意图很重要。
如果您尝试为不太相似的关键词 优化着陆页,则会降低内容的可读性,并使搜索引擎对您的页面的真正含义感到困惑。
搜索量和每次点击费用
集群中的核心关键词应该有合理的搜索量(否则你会为任何人优化)。
他们还应该具有转化潜力(每次点击费用代表他们的经济价值)。
有机困难
是否收录更难的关键词取决于您的网站权限、反向链接配置文件以及网站的建立方式。
在您的集群中仅收录可以对其站点进行排名的关键词。
仔细研究两个关键词群
找到集群的核心关键词后,将其与互补的关键词配对。
例如,您可以添加一些长尾、降低难度或降低搜索量,或者只是在着陆页上收录有关它们的足够信息以轻松获胜。
为什么这些关键词可以组成一个好的集群?因为它们共享语义相关性。这些搜索者都在寻找有助于安排采访的产品。
我们的核心关键词在排名方面更具竞争力,但我们用关键词填充了集群,难度较低且转化潜力强。
如果您对自己的细分市场充满信心并了解关键词 指标和搜索意图的细微差别,您可以手动将关键词 分成几个组(如我们上面所述)。
还有一些关键词grouping 工具可以自动化这个过程。他们可以为您将关键词 细分为多个类别。
细分时,请记住并非所有列表中的关键词都需要以集群结束。
收录最高值的关键词是最重要的关键词。更高的每次点击费用、更高的搜索量和相关的搜索意图使 关键词 对您的品牌有价值。
第 3 步:为您的 关键词 集群创建和优化支柱页面
关键词 分组后,他们提供了如何在网站 上创建、优化和组织内容的路线图。
本质上,你的关键词群代表你的网站核心主题。这些也称为“支柱页面”。
为了正确执行关键词集群,我们需要为每个关键词集群创建一个目标页面。
关键词群的支柱页面应该使用正式的现场搜索引擎优化技术。我们最喜欢的策略之一是使用内容优化工具来帮助您更有效地优化内容。
为了提高支柱页面的排名潜力,请优先考虑以下几个方面:
主题深度:专注于撰写深入探索主题的长篇内容。信息架构:具有清晰的结构,并在 h2 和 h3 中收录您的 关键词phrase。页面体验:在交互页面添加视频、跳转链接、轮播等元素,提升用户的页面体验。第四步:通过网站content 增强关键词cluster
为了提高支柱页面的排名和内容权重,您可以构建内容以增强您的主要关键词 集群。
这些文章可以定位与你的核心关键词相关的长尾关键词短语、副主题或问题。
随着您开发更多内容,这些页面将在您的网站 上形成“主题集群”。
此内容的内部链接系统将在您的网站 着陆页在搜索引擎中的排名中发挥重要作用。
您的文章 应该链接回其相应的支柱页面,以增加您在这些高价值关键词 上排名的机会。
如果你的公司有多个产品或专业领域,你可以在网站上搭建更多的集群。
如果你只销售一种核心产品或服务,你识别的关键词集群数量会减少。但是,探索具有丰富有用内容的主要学科领域可以帮助您在更短的时间内超越竞争对手。
建立集群还可以为您提供更多的机会添加内部链接到网站。
这不仅增加了用户在您的网站 上花费的时间,而且内部链接遍布您的网站 并帮助搜索引擎了解您在网站 上最重要的页面。
关键词group 真的值得所有的工作吗?
关键词群 是一种更高级的 SEO 策略,可以为您提供在垂直竞争中获胜所需的优势。这是因为它们响应了搜索引擎的两大超级功能:自然语言处理和无与伦比的索引。
想想看,搜索引擎了解各行各业的搜索者使用的数百万个关键词phrases。它还了解这些查询之间的细微差别,以及它们的相互关系或相互关系。
搜索引擎花了数年时间训练他们的 NLP(自然语言处理)模型来计算内容质量信号并预测哪些网页最能向搜索者提供他们需要的信息。当你在落地页进行关键词聚类,你会向搜索引擎证明你的网站是你所在行业的权威,展示强大的内容范围和深度。
您还可以通过丰富的内容集群提供搜索引擎的内容信号,这些集群已经过训练以识别和改进搜索结果。 关键词集群需要网站站长多思考自己的内容,这也是SEO的未来。
如果您希望您的网页长期排名,是时候让您的网页策略赶上搜索引擎了。
搜索引擎结果的好坏与否,Cranfield评价体系ACranfield-likeapproach
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-07-20 02:09
大观数据CEO陈韵文文
前言
搜索质量评价是搜索技术研究的基础工作,也是核心任务之一。度量在搜索技术的研究和发展中发挥着重要作用,因此任何新方法都与其评价方法相结合。
搜索引擎结果的质量反映在业界所谓的相关性上。相关性的定义包括狭义和广义两个方面。狭义的解释是:搜索结果与用户查询的相关程度。从广义上讲,相关性可以理解为用户查询的综合满意度。直观上,从用户进入搜索框的那一刻到满足需求的过程越顺畅、方便,搜索相关性就越好。本文总结了行业常用的相关性评价指标和定量评价方法。供对此感兴趣的朋友参考。
克兰菲尔德评估系统
A Cranfield-like approach这个名字来源于英国的克兰菲尔德大学,因为该大学在1950年代首先提出了这样一套评价体系:一套完整的查询样本集、正确答案集和评价指标。评价计划从此确立了“评价”在信息检索研究中的核心地位。
Cranfield 评价系统由三个环节组成:
1.提取代表性查询词,形成合适大小的集合
2.查询样本集合,从检索系统的语料库中找到对应的结果并标注(一般是手动)
3. 将查询词和带有标注信息的语料输入检索系统,使用预定义的评价计算公式对检索系统结果和系统返回的检索结果标注的理想情况进行评价结果有多接近。
查询词集的选择
Cranfield 评估系统广泛应用于各大搜索引擎公司。在具体应用中,首先需要解决的问题是构建一组测试查询词。
根据Andrei Broder(原在AltaVista/IBM/Yahoo)的研究,查询词可以分为三类:寻址查询(Navigational)、信息查询(Informational)和交易查询(Transactional)。对应的比例为:
Navigational : 12.3%
Informational : 62.0%
Transactional : 25.7%
为了使评价符合网上的实际情况,通常查询词集也是按比例选取的。通常从在线用户的查询日志文件中自动提取。
另外,在查询集的构建中,除了上述查询类型外,还可以考虑查询的频率,热点查询(高频查询)和长尾查询(中和低频)分别占特定的比例。
另外,在抽取Query的时候,Query的长度也是经常要考虑的一个因素。因为短查询(单词查询)和长查询(多词查询)排序算法往往不同。
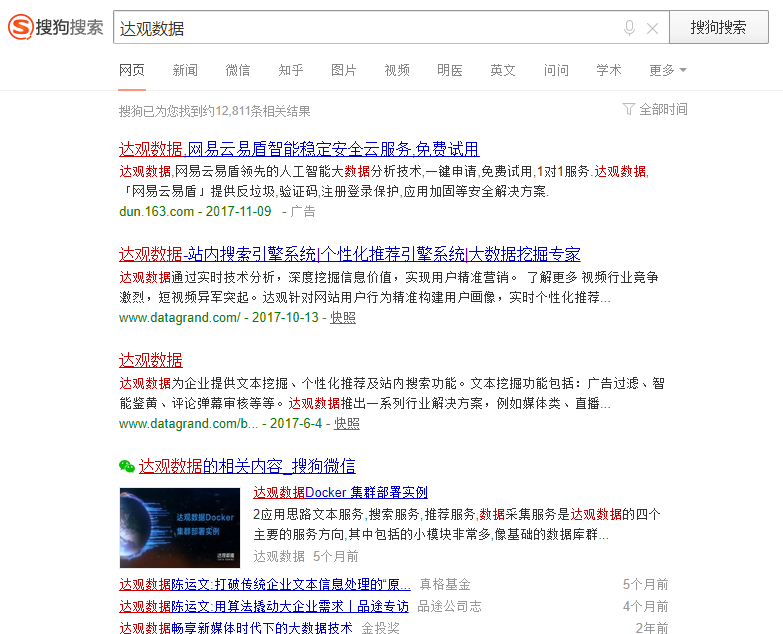
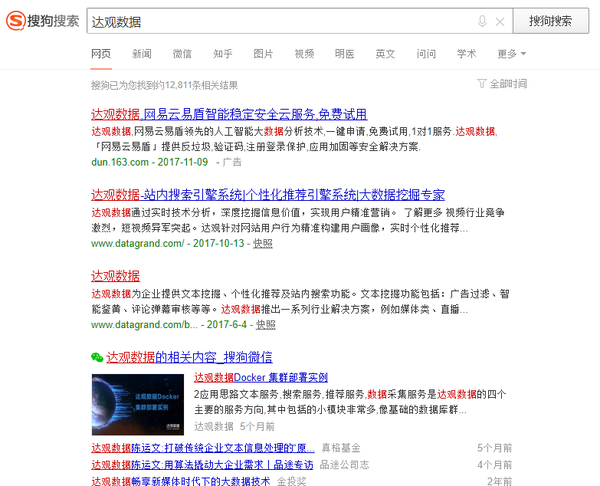
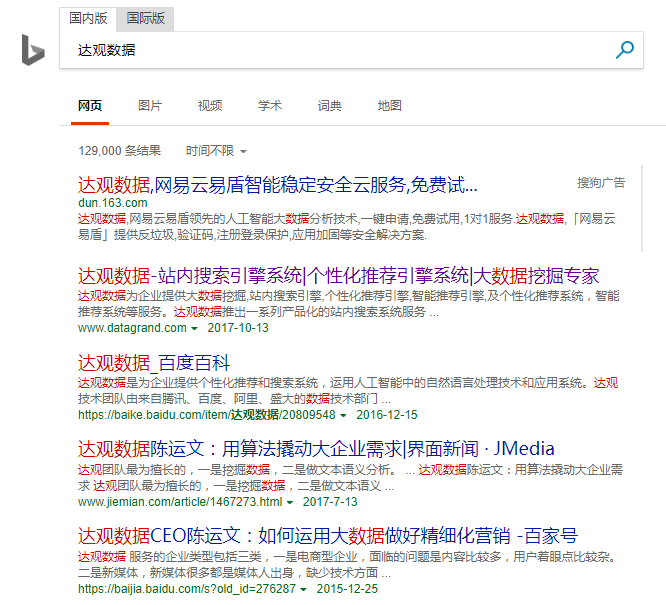
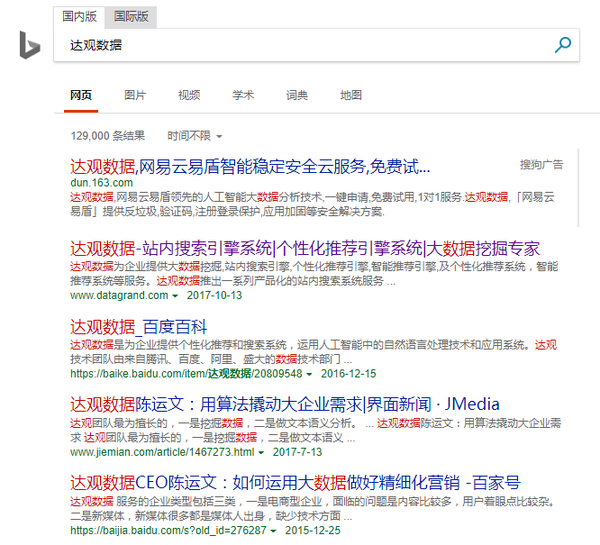
形成查询集后,使用这些查询词在不同系统(例如比较百度和谷歌)或不同技术(新旧排名算法的环境)之间进行搜索,并对结果进行评分以确定优劣和缺点。
图片:同一个Query:“大观数据”,各大搜索引擎结果示意图。下面详细说一下评分的方法。
Precision-recall(accuracy-recall法)计算方法
信息检索领域最广为人知的评价指标是Precision-Recall(准确率-召回率)方法。这种方法提出了半个世纪,已经被很多搜索引擎公司的效果评估所采用。
顾名思义,这种方法由两个相互关联的统计数据组成:准确率和召回率:召回率衡量一个查询搜索所有相关文档的能力,而Precision衡量搜索系统排除相关文档的能力。 (简单解释一下:准确率是计算你从查询中得到的结果有多少是可靠的;召回率是指你检索到的所有可靠结果中有多少)。这两个是评价搜索效果最基本的指标,具体计算方法如下。
Precision-recall 方法假设给定的查询对应于检索到的文档集合和不相关文档的集合。这里假设相关性是二元的,用数学形式化方法描述,它是:
A 表示相关文档的集合
表示不相关的集合
B 代表检索到的文档集合
表示尚未检索到的文档集合
单个查询的准确率和召回率可以用以下公式表示:
(运算符∩表示两个集合的交集。|x|符号表示集合x中元素的个数)
从上面的定义不难看出召回率和准确率的取值范围在[0,1]之间。那么不难想象,如果系统检索到的相关性越多,召回率就越高。如果所有相关结果都被召回,那么此时召回就等于1.0。
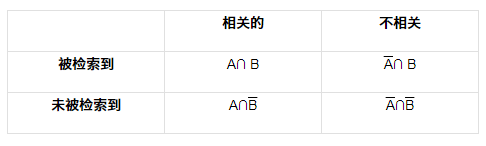
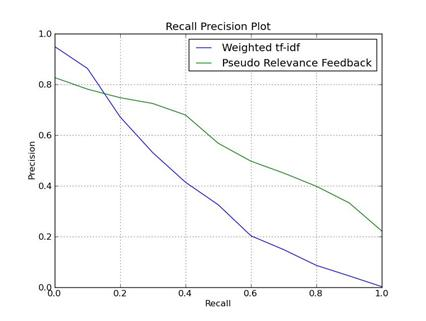
精度-召回曲线
召回率和准确率反映了检索系统最重要的两个方面,这两个方面相互制约。因为在大规模的数据采集中,如果期望检索到更多的相关文档,搜索条件必须“放宽”,这会导致一些不相关的结果混入,影响准确率。同样,当你想提高准确率,尽可能去除不相关的文档时,你必须实施更“严格”的检索策略,这也会排除一些相关的文档,降低召回率。
所以为了更清楚地描述两者之间的关系,我们通常用曲线来绘制Precision-Recall,可以简称为P-R图。常见的形式如下图所示。 (通常曲线是逐渐下降的趋势,即随着Recall的增加,Precision逐渐降低)
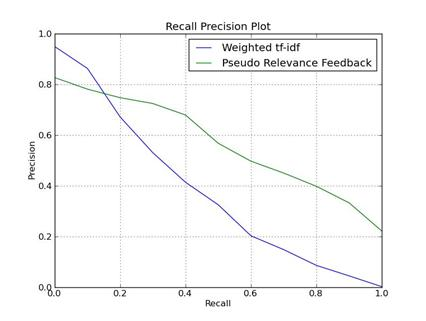
其他形式的 P-R
某些特定的搜索应用程序会更加关注搜索结果中的错误结果。例如,搜索引擎的反垃圾邮件系统会更加关注搜索结果中混入了多少作弊结果。学术界将这些错误结果称为假阳性结果。对于这些应用,他们通常选择使用误报率(Fallout)来统计:
Fallout 和 Presion 本质上是一样的。它只是从利弊计算出来的。它实际上是 P-R 的变体。
回到上图,Presion-Recall是一条曲线。比较两种方法的效果通常不够直观。你能不能把两者结合起来,直接反映到一个单一的值上?为此,IR学术界提出了F-Measure方法。 F-Measure由Presion和Recall的调和平均计算得出,公式为:
参数λε(0,1)调整系统在Precision和Recall之间的平衡。(通常λ=0.5,此时
)
这里使用调和平均代替通常的几何平均或算术平均。原因是调和平均强调小数的重要性,能灵敏地反映小数的变化,更适合反映搜索效果。
使用F Measure的好处是只需要一个数字就可以概括系统的搜索效果,方便比较不同搜索系统的整体效果。
P@N 方法点击因素
传统的Precision-Recall并不完全适用于搜索引擎的评价,因为搜索引擎用户的点击方式是独一无二的,包括:
A 60-65%的查询点击了名列搜索结果前10条的网页;
B 20-25%的人会考虑点击名列11到20的网页;
C 仅有3-4%的会点击名列搜索结果中列第21到第30名的网页
换句话说,大多数用户不愿意翻页看到搜索引擎给出的后续结果。
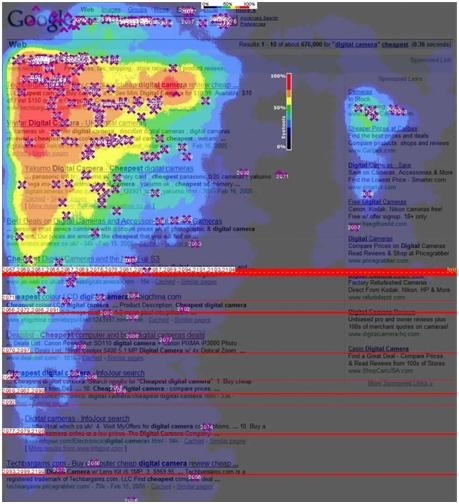
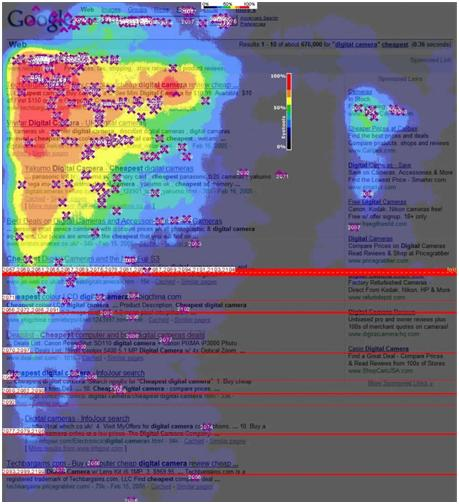
即使在搜索结果的第一页(通常会列出前 10 个结果),用户的点击行为也很有趣。我们使用下面的谷歌热图来观察(这张热图在第二个维度搜索结果页面上,可以通过光谱直观地表达用户在不同位置的点击兴趣。颜色越接近红色表示点击率越高强度):
从图中可以看出,前3个搜索结果吸引了大量点击,属于最受欢迎的部分。也就是说,对于搜索引擎来说,前几个结果是最关键的,决定了用户的满意度。
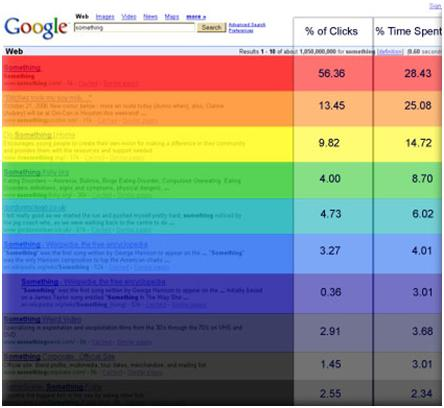
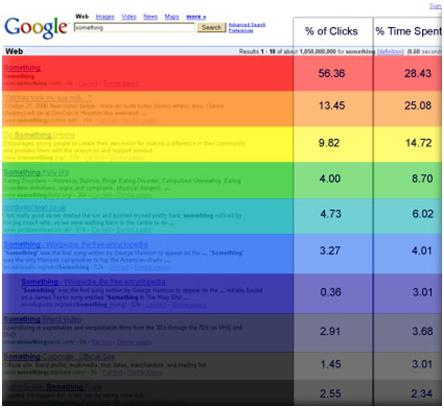
康奈尔大学的研究人员通过眼动追踪实验对 Google 搜索结果中的用户行为进行了更准确的分析。从这张图可以看出,第一个结果已经获得了56.38%的搜索流量,第二、第三个结果的排名依次下降,但远低于第一的结果。前三个结果的点击率约为 11:3:2。前三个结果的总点击量转移了近 80% 的搜索流量。
其他一些有趣的结论是点击次数不会按顺序减少。第七名获得的点击次数最少。原因可能是用户在浏览过程中将页面下拉到底部。这时候只显示了网站的最后三名排名,第七名很容易被忽略。而第一屏最后一个结果获得的注意力(2.55)大于倒数第二个(1.45)),因为用户在转屏之前对最后一个结果的印象比较深page 搜索结果页第二页第一页(也就是第11个结果)只获得了第10个首页网站的40%的点击量,比首页第一个结果还要多其 1/60 到 1/100 的点击量。
因此,在定量评估搜索引擎的效果时,往往需要根据上述搜索用户的行为特征进行针对性的设计。
P@N 计算方法
P@N本身是Precision@N的缩写,指的是在考虑位置因素的情况下,针对特定查询检测前N个结果的准确率。比如单次搜索的前5个结果,如果其中4个是相关文档,则P@5 = 4/5 = 0.8。
该测试通常使用一个查询集(根据上述方法构建),其中收录几个不同的查询词。在使用P@N的实际评估中,通常使用所有查询的P@N数据计算算术平均值,用于判断系统整体搜索结果的质量。
N 的选择
对于用户来说,他们通常只关注搜索结果的前几个结果。因此,搜索引擎的性能评估通常只关注前5、或前3个结果,所以我们常用的N取值为P@3或P@5等。
对于一些特定类型的查询应用,比如导航搜索,因为目标结果很明确,所以N=1(即在评估中使用P@1)。例如,如果你搜索“新浪网”或“新浪首页”,如果第一个结果不是新浪网(url:),则直接判断查询的准确度不符合要求,即P@1 =0
MRR
上面提到的P@N方法很容易计算和理解。但是细心的读者肯定会发现问题,就是在前N个结果中,第一个和第N个位置的结果对准确率的影响是一样的。但实际情况是,搜索引擎的评价与排名位置有着极大的关系。也就是说,第一个结果错误与第 10 个结果错误非常不同。因此,评价体系中需要引入区位因素。
MRR 是 Mean Reciprocal Rank 的缩写。 MRR 方法主要用于导航搜索或问答。这些检索方法只需要一个相关文档,这对召回率非常重要。不敏感,但更关心搜索引擎检索到的相关文档是否排在结果列表的前面。 MRR 方法首先计算每个查询的第一个相关文档位置的倒数,然后对所有倒数取平均值。比如一个收录三个查询词的测试集,前5个结果是:
查询一结果:1.AN 2.AR 3.AN 4.AN 5.AR
查询二结果:1.AN 2.AR 3.AR 4.AR 5.AN
查询三结果:1.AR 2.AN 3.AN 4.AN 5.AR
其中,AN代表无关结果,AR代表相关结果。那么第一次查询的Reciprocal Rank(Reciprocal Rank)RR1= 1/2=0.5;第二个结果 RR2 = 1/2 = 0.5;注意,倒数的值不会改变,即使得到了第二个结果更相关的结果。同理,RR3 = 1/1 = 1,对于这个测试集,最终的MRR=(RR1+RR2+RR3)/ 3 = 0.67
然而,对于大多数搜索应用来说,只有一个结果不能满足需求。在这种情况下,需要更合适的方法来计算效果。最常用的方法是下面的MAP方法。
地图
MAP方法是Mean Average Precison,是平均准确度法的缩写。它的定义是求检索到的每个相关文档的平均准确率(即Average Precision)的算术平均值(Mean)。在这里,准确度取了两次平均值,因此称为平均平均精度。 (注意:它不叫Average Average Precision,因为它丑陋,而且因为无法区分两个平均值的含义)
MAP 是一个单值指标,反映系统在所有相关文档上的表现。系统检索到的相关文档越高(等级越高),MAP就应该越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题:
主题 1 有 4 个相关网页,主题 2 有 5 个相关网页。
系统检索到主题1的4个相关网页,排名分别为1、2、4、7;
主题 2 检索到 3 个相关网页,排名分别为 1、3、5。
对于topic 1,平均准确率MAP计算公式为:
(1/1+2/2+3/4+4/7)/4=0.83。
对于主题2,平均准确率MAP计算公式为:
(1/1+2/3+3/5+0+0)/5=0.45。
然后 MAP= (0.83+0.45)/2=0.64。"
DCG 方法
DCG是英文Discountedcumulative gain的缩写,中文可译为“折扣累积收益”。 DCG方法的基本思想是:
1.对每个结果的相关性进行分级衡量
2.考虑结果的位置,位置越高,重要性越高
3.排名越高(即好成绩),成绩排名越高,数值应该越高,否则会被处罚。
我们先来看第一个:相关性分级。在计算 Precision 时,这比简单地计算“准确”或“不准确”更精细。我们可以将结果细分为多个级别。比如常用的3个等级:Good、Fair、Bad。对应的分数rel为:Good:3/Fair:2/Bad:1。一些更详细的评估使用5级分类:非常好、好、一般、差、非常差,对应的分数rel可以设置为:非常好:2 / 好:1 / 一般:0 / 差:-1 /非常糟糕:-2
判断结果的标准可以根据具体的应用来确定。非常好通常意味着结果的主题完全相关,网页内容丰富,质量高。并且具体到每一位
DCG的计算公式不是唯一的。理论上,它只需要对数贴现因子的平滑度。我个人认为下面的DCG公式更合理,强调相关性,1、2的结果的折扣因子也更合理:
此时DCG前4个位置结果的折扣因子值为:
基于2的log值也来自经验公式,没有理论依据。实际上,可以根据平滑要求修改Log的基数。当值增大时(例如用log5代替log2),折现因子下降得更快,强调了前面结果的权重。
为了方便不同类型查询结果的横向比较,基于DCG,一些评价系统也对DCG进行了归一化。这些方法统称为nDCG(即归一化DCG)。最常用的计算方法是除以每个查询的理想值iDCG(ideal DCG)进行归一化,公式为:
对于nDCG,需要校准理想的iDCG。在实际操作中,难度极大,因为每个人对“最佳结果”的理解往往各不相同,从海量数据中选出最佳结果非常困难。但是,通常比较容易比较两组结果,因此在实践中通常选择比较结果的方法进行评估。
如何实现自动化评估?
上面介绍的搜索引擎量化评价指标在克兰菲尔德评价框架中得到了广泛的应用。业界知名的TREC(Text Information Retrieval Conference)一直在基于这样的方法组织信息检索评估和技术交流。除了TREC,一些针对不同应用设计的Cranfield评测论坛也在进行中(如NTCIR、IREX等)。
但是 Cranfield 评估框架的问题在于查询样本集合的标记。通过人工标注答案来评价网络信息检索是一个费时费力的过程,只有少数大公司可以使用。并且由于搜索引擎算法改进和运维的需要,需要尽可能缩短检索效果评价和反馈的时间,因此自动化评价方法对于提高评价效率非常重要。最常用的自动评估方法是 A/B 测试系统。
A/B 测试
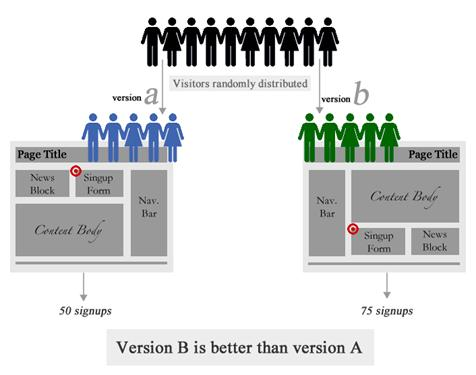
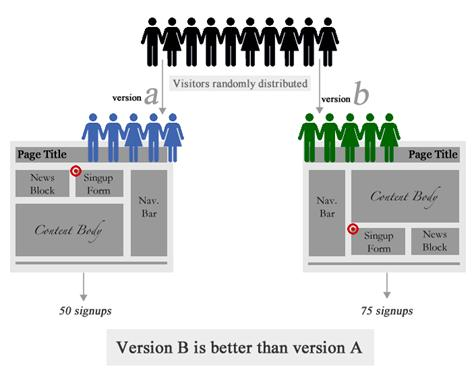
A/B 测试系统
A/B 测试系统在搜索用户时自动判断用户的bucket id,并自动抽取流量导入不同的分支,让对应组内的用户看到不同的产品版本(或不同版本)。搜索引擎)。将记录用户在不同版本产品中的行为。这些行为数据通过数据分析形成一系列的指标,通过这些指标的比较,得出哪个版本好坏的结论。
在指标的计算上,可以进一步分为两种方法,一种是基于专家评级;另一种是基于点击统计。
专家评分的方法通常由搜索核心技术研发和产品人员进行。两种环境A和B的结果按照预先设定的标准进行评分,比较每个查询的结果,并根据nDCG等方法计算整体质量。
点击评分的自动化程度更高。这里有一个假设:同样的排序位置,点击次数多的结果质量要好于点击次数少的结果。 (即A2代表A测试环境的第二个结果,如果A2>B2,说明A2质量较好)。通俗的说就是相信群众(因为群众的眼睛是有眼光的)。在这个假设下,我们可以自动将 A/B 环境中前 N 个结果的点击率映射到分数上。通过统计大量的Query点击结果,可以获得可靠的分数对比。
交错测试
此外,Thorsten Joachims 等人提出的 Interleaving 测试方法。在2003年也被广泛使用。这种方法设计了一个元搜索引擎。用户输入查询后,将查询在多个知名搜索引擎中的查询结果随机混合反馈给用户,进而采集用户的结果点击行为信息。根据用户不同的点击倾向,我们可以判断搜索引擎返回结果的优劣。
如下图,算法A和B的结果横放,按流量划分测试,记录用户点击信息。根据点击分布判断A、B环境的优劣。
交错测试评价方法
Joachims 还证明了 Interleaving Testing 评估方法和传统 Cranfield 评估方法的结果高度相关。由于记录用户对搜索结果的选择是一个省力的过程,便于实现自动搜索效果评估。
总结
没有评价就没有进步。对搜索结果进行定量评价的目的是准确找出现有搜索系统的不足(没有搜索系统是完美的),然后逐步改进算法和系统。本文为大家总结了常用的评价框架和评价指标。这些技术就像一把尺子,每次搜索技术进步时都会测量距离。 查看全部
搜索引擎结果的好坏与否,Cranfield评价体系ACranfield-likeapproach
大观数据CEO陈韵文文
前言
搜索质量评价是搜索技术研究的基础工作,也是核心任务之一。度量在搜索技术的研究和发展中发挥着重要作用,因此任何新方法都与其评价方法相结合。
搜索引擎结果的质量反映在业界所谓的相关性上。相关性的定义包括狭义和广义两个方面。狭义的解释是:搜索结果与用户查询的相关程度。从广义上讲,相关性可以理解为用户查询的综合满意度。直观上,从用户进入搜索框的那一刻到满足需求的过程越顺畅、方便,搜索相关性就越好。本文总结了行业常用的相关性评价指标和定量评价方法。供对此感兴趣的朋友参考。
克兰菲尔德评估系统
A Cranfield-like approach这个名字来源于英国的克兰菲尔德大学,因为该大学在1950年代首先提出了这样一套评价体系:一套完整的查询样本集、正确答案集和评价指标。评价计划从此确立了“评价”在信息检索研究中的核心地位。
Cranfield 评价系统由三个环节组成:
1.提取代表性查询词,形成合适大小的集合
2.查询样本集合,从检索系统的语料库中找到对应的结果并标注(一般是手动)
3. 将查询词和带有标注信息的语料输入检索系统,使用预定义的评价计算公式对检索系统结果和系统返回的检索结果标注的理想情况进行评价结果有多接近。
查询词集的选择
Cranfield 评估系统广泛应用于各大搜索引擎公司。在具体应用中,首先需要解决的问题是构建一组测试查询词。
根据Andrei Broder(原在AltaVista/IBM/Yahoo)的研究,查询词可以分为三类:寻址查询(Navigational)、信息查询(Informational)和交易查询(Transactional)。对应的比例为:
Navigational : 12.3%
Informational : 62.0%
Transactional : 25.7%
为了使评价符合网上的实际情况,通常查询词集也是按比例选取的。通常从在线用户的查询日志文件中自动提取。
另外,在查询集的构建中,除了上述查询类型外,还可以考虑查询的频率,热点查询(高频查询)和长尾查询(中和低频)分别占特定的比例。
另外,在抽取Query的时候,Query的长度也是经常要考虑的一个因素。因为短查询(单词查询)和长查询(多词查询)排序算法往往不同。
形成查询集后,使用这些查询词在不同系统(例如比较百度和谷歌)或不同技术(新旧排名算法的环境)之间进行搜索,并对结果进行评分以确定优劣和缺点。
图片:同一个Query:“大观数据”,各大搜索引擎结果示意图。下面详细说一下评分的方法。

Precision-recall(accuracy-recall法)计算方法
信息检索领域最广为人知的评价指标是Precision-Recall(准确率-召回率)方法。这种方法提出了半个世纪,已经被很多搜索引擎公司的效果评估所采用。
顾名思义,这种方法由两个相互关联的统计数据组成:准确率和召回率:召回率衡量一个查询搜索所有相关文档的能力,而Precision衡量搜索系统排除相关文档的能力。 (简单解释一下:准确率是计算你从查询中得到的结果有多少是可靠的;召回率是指你检索到的所有可靠结果中有多少)。这两个是评价搜索效果最基本的指标,具体计算方法如下。
Precision-recall 方法假设给定的查询对应于检索到的文档集合和不相关文档的集合。这里假设相关性是二元的,用数学形式化方法描述,它是:
A 表示相关文档的集合
表示不相关的集合
B 代表检索到的文档集合
表示尚未检索到的文档集合
单个查询的准确率和召回率可以用以下公式表示:


(运算符∩表示两个集合的交集。|x|符号表示集合x中元素的个数)
从上面的定义不难看出召回率和准确率的取值范围在[0,1]之间。那么不难想象,如果系统检索到的相关性越多,召回率就越高。如果所有相关结果都被召回,那么此时召回就等于1.0。
精度-召回曲线
召回率和准确率反映了检索系统最重要的两个方面,这两个方面相互制约。因为在大规模的数据采集中,如果期望检索到更多的相关文档,搜索条件必须“放宽”,这会导致一些不相关的结果混入,影响准确率。同样,当你想提高准确率,尽可能去除不相关的文档时,你必须实施更“严格”的检索策略,这也会排除一些相关的文档,降低召回率。
所以为了更清楚地描述两者之间的关系,我们通常用曲线来绘制Precision-Recall,可以简称为P-R图。常见的形式如下图所示。 (通常曲线是逐渐下降的趋势,即随着Recall的增加,Precision逐渐降低)
其他形式的 P-R
某些特定的搜索应用程序会更加关注搜索结果中的错误结果。例如,搜索引擎的反垃圾邮件系统会更加关注搜索结果中混入了多少作弊结果。学术界将这些错误结果称为假阳性结果。对于这些应用,他们通常选择使用误报率(Fallout)来统计:
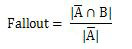
Fallout 和 Presion 本质上是一样的。它只是从利弊计算出来的。它实际上是 P-R 的变体。
回到上图,Presion-Recall是一条曲线。比较两种方法的效果通常不够直观。你能不能把两者结合起来,直接反映到一个单一的值上?为此,IR学术界提出了F-Measure方法。 F-Measure由Presion和Recall的调和平均计算得出,公式为:

参数λε(0,1)调整系统在Precision和Recall之间的平衡。(通常λ=0.5,此时
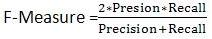
)
这里使用调和平均代替通常的几何平均或算术平均。原因是调和平均强调小数的重要性,能灵敏地反映小数的变化,更适合反映搜索效果。
使用F Measure的好处是只需要一个数字就可以概括系统的搜索效果,方便比较不同搜索系统的整体效果。
P@N 方法点击因素
传统的Precision-Recall并不完全适用于搜索引擎的评价,因为搜索引擎用户的点击方式是独一无二的,包括:
A 60-65%的查询点击了名列搜索结果前10条的网页;
B 20-25%的人会考虑点击名列11到20的网页;
C 仅有3-4%的会点击名列搜索结果中列第21到第30名的网页
换句话说,大多数用户不愿意翻页看到搜索引擎给出的后续结果。
即使在搜索结果的第一页(通常会列出前 10 个结果),用户的点击行为也很有趣。我们使用下面的谷歌热图来观察(这张热图在第二个维度搜索结果页面上,可以通过光谱直观地表达用户在不同位置的点击兴趣。颜色越接近红色表示点击率越高强度):
从图中可以看出,前3个搜索结果吸引了大量点击,属于最受欢迎的部分。也就是说,对于搜索引擎来说,前几个结果是最关键的,决定了用户的满意度。
康奈尔大学的研究人员通过眼动追踪实验对 Google 搜索结果中的用户行为进行了更准确的分析。从这张图可以看出,第一个结果已经获得了56.38%的搜索流量,第二、第三个结果的排名依次下降,但远低于第一的结果。前三个结果的点击率约为 11:3:2。前三个结果的总点击量转移了近 80% 的搜索流量。
其他一些有趣的结论是点击次数不会按顺序减少。第七名获得的点击次数最少。原因可能是用户在浏览过程中将页面下拉到底部。这时候只显示了网站的最后三名排名,第七名很容易被忽略。而第一屏最后一个结果获得的注意力(2.55)大于倒数第二个(1.45)),因为用户在转屏之前对最后一个结果的印象比较深page 搜索结果页第二页第一页(也就是第11个结果)只获得了第10个首页网站的40%的点击量,比首页第一个结果还要多其 1/60 到 1/100 的点击量。
因此,在定量评估搜索引擎的效果时,往往需要根据上述搜索用户的行为特征进行针对性的设计。
P@N 计算方法
P@N本身是Precision@N的缩写,指的是在考虑位置因素的情况下,针对特定查询检测前N个结果的准确率。比如单次搜索的前5个结果,如果其中4个是相关文档,则P@5 = 4/5 = 0.8。
该测试通常使用一个查询集(根据上述方法构建),其中收录几个不同的查询词。在使用P@N的实际评估中,通常使用所有查询的P@N数据计算算术平均值,用于判断系统整体搜索结果的质量。
N 的选择
对于用户来说,他们通常只关注搜索结果的前几个结果。因此,搜索引擎的性能评估通常只关注前5、或前3个结果,所以我们常用的N取值为P@3或P@5等。
对于一些特定类型的查询应用,比如导航搜索,因为目标结果很明确,所以N=1(即在评估中使用P@1)。例如,如果你搜索“新浪网”或“新浪首页”,如果第一个结果不是新浪网(url:),则直接判断查询的准确度不符合要求,即P@1 =0
MRR
上面提到的P@N方法很容易计算和理解。但是细心的读者肯定会发现问题,就是在前N个结果中,第一个和第N个位置的结果对准确率的影响是一样的。但实际情况是,搜索引擎的评价与排名位置有着极大的关系。也就是说,第一个结果错误与第 10 个结果错误非常不同。因此,评价体系中需要引入区位因素。
MRR 是 Mean Reciprocal Rank 的缩写。 MRR 方法主要用于导航搜索或问答。这些检索方法只需要一个相关文档,这对召回率非常重要。不敏感,但更关心搜索引擎检索到的相关文档是否排在结果列表的前面。 MRR 方法首先计算每个查询的第一个相关文档位置的倒数,然后对所有倒数取平均值。比如一个收录三个查询词的测试集,前5个结果是:
查询一结果:1.AN 2.AR 3.AN 4.AN 5.AR
查询二结果:1.AN 2.AR 3.AR 4.AR 5.AN
查询三结果:1.AR 2.AN 3.AN 4.AN 5.AR
其中,AN代表无关结果,AR代表相关结果。那么第一次查询的Reciprocal Rank(Reciprocal Rank)RR1= 1/2=0.5;第二个结果 RR2 = 1/2 = 0.5;注意,倒数的值不会改变,即使得到了第二个结果更相关的结果。同理,RR3 = 1/1 = 1,对于这个测试集,最终的MRR=(RR1+RR2+RR3)/ 3 = 0.67
然而,对于大多数搜索应用来说,只有一个结果不能满足需求。在这种情况下,需要更合适的方法来计算效果。最常用的方法是下面的MAP方法。
地图
MAP方法是Mean Average Precison,是平均准确度法的缩写。它的定义是求检索到的每个相关文档的平均准确率(即Average Precision)的算术平均值(Mean)。在这里,准确度取了两次平均值,因此称为平均平均精度。 (注意:它不叫Average Average Precision,因为它丑陋,而且因为无法区分两个平均值的含义)
MAP 是一个单值指标,反映系统在所有相关文档上的表现。系统检索到的相关文档越高(等级越高),MAP就应该越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题:
主题 1 有 4 个相关网页,主题 2 有 5 个相关网页。
系统检索到主题1的4个相关网页,排名分别为1、2、4、7;
主题 2 检索到 3 个相关网页,排名分别为 1、3、5。
对于topic 1,平均准确率MAP计算公式为:
(1/1+2/2+3/4+4/7)/4=0.83。
对于主题2,平均准确率MAP计算公式为:
(1/1+2/3+3/5+0+0)/5=0.45。
然后 MAP= (0.83+0.45)/2=0.64。"
DCG 方法
DCG是英文Discountedcumulative gain的缩写,中文可译为“折扣累积收益”。 DCG方法的基本思想是:
1.对每个结果的相关性进行分级衡量
2.考虑结果的位置,位置越高,重要性越高
3.排名越高(即好成绩),成绩排名越高,数值应该越高,否则会被处罚。
我们先来看第一个:相关性分级。在计算 Precision 时,这比简单地计算“准确”或“不准确”更精细。我们可以将结果细分为多个级别。比如常用的3个等级:Good、Fair、Bad。对应的分数rel为:Good:3/Fair:2/Bad:1。一些更详细的评估使用5级分类:非常好、好、一般、差、非常差,对应的分数rel可以设置为:非常好:2 / 好:1 / 一般:0 / 差:-1 /非常糟糕:-2
判断结果的标准可以根据具体的应用来确定。非常好通常意味着结果的主题完全相关,网页内容丰富,质量高。并且具体到每一位
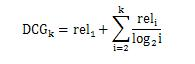
DCG的计算公式不是唯一的。理论上,它只需要对数贴现因子的平滑度。我个人认为下面的DCG公式更合理,强调相关性,1、2的结果的折扣因子也更合理:
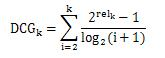
此时DCG前4个位置结果的折扣因子值为:


基于2的log值也来自经验公式,没有理论依据。实际上,可以根据平滑要求修改Log的基数。当值增大时(例如用log5代替log2),折现因子下降得更快,强调了前面结果的权重。
为了方便不同类型查询结果的横向比较,基于DCG,一些评价系统也对DCG进行了归一化。这些方法统称为nDCG(即归一化DCG)。最常用的计算方法是除以每个查询的理想值iDCG(ideal DCG)进行归一化,公式为:
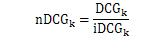
对于nDCG,需要校准理想的iDCG。在实际操作中,难度极大,因为每个人对“最佳结果”的理解往往各不相同,从海量数据中选出最佳结果非常困难。但是,通常比较容易比较两组结果,因此在实践中通常选择比较结果的方法进行评估。
如何实现自动化评估?
上面介绍的搜索引擎量化评价指标在克兰菲尔德评价框架中得到了广泛的应用。业界知名的TREC(Text Information Retrieval Conference)一直在基于这样的方法组织信息检索评估和技术交流。除了TREC,一些针对不同应用设计的Cranfield评测论坛也在进行中(如NTCIR、IREX等)。
但是 Cranfield 评估框架的问题在于查询样本集合的标记。通过人工标注答案来评价网络信息检索是一个费时费力的过程,只有少数大公司可以使用。并且由于搜索引擎算法改进和运维的需要,需要尽可能缩短检索效果评价和反馈的时间,因此自动化评价方法对于提高评价效率非常重要。最常用的自动评估方法是 A/B 测试系统。
A/B 测试
A/B 测试系统
A/B 测试系统在搜索用户时自动判断用户的bucket id,并自动抽取流量导入不同的分支,让对应组内的用户看到不同的产品版本(或不同版本)。搜索引擎)。将记录用户在不同版本产品中的行为。这些行为数据通过数据分析形成一系列的指标,通过这些指标的比较,得出哪个版本好坏的结论。
在指标的计算上,可以进一步分为两种方法,一种是基于专家评级;另一种是基于点击统计。
专家评分的方法通常由搜索核心技术研发和产品人员进行。两种环境A和B的结果按照预先设定的标准进行评分,比较每个查询的结果,并根据nDCG等方法计算整体质量。
点击评分的自动化程度更高。这里有一个假设:同样的排序位置,点击次数多的结果质量要好于点击次数少的结果。 (即A2代表A测试环境的第二个结果,如果A2>B2,说明A2质量较好)。通俗的说就是相信群众(因为群众的眼睛是有眼光的)。在这个假设下,我们可以自动将 A/B 环境中前 N 个结果的点击率映射到分数上。通过统计大量的Query点击结果,可以获得可靠的分数对比。
交错测试
此外,Thorsten Joachims 等人提出的 Interleaving 测试方法。在2003年也被广泛使用。这种方法设计了一个元搜索引擎。用户输入查询后,将查询在多个知名搜索引擎中的查询结果随机混合反馈给用户,进而采集用户的结果点击行为信息。根据用户不同的点击倾向,我们可以判断搜索引擎返回结果的优劣。
如下图,算法A和B的结果横放,按流量划分测试,记录用户点击信息。根据点击分布判断A、B环境的优劣。
交错测试评价方法
Joachims 还证明了 Interleaving Testing 评估方法和传统 Cranfield 评估方法的结果高度相关。由于记录用户对搜索结果的选择是一个省力的过程,便于实现自动搜索效果评估。
总结
没有评价就没有进步。对搜索结果进行定量评价的目的是准确找出现有搜索系统的不足(没有搜索系统是完美的),然后逐步改进算法和系统。本文为大家总结了常用的评价框架和评价指标。这些技术就像一把尺子,每次搜索技术进步时都会测量距离。
如何根据广告的业务要求设计更高效的索引和检索
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-20 02:05
在竞争性广告中,大量中小广告主的搜索规模需要很高的计算效率。如何根据广告的业务需求设计更高效的索引和检索技术是竞争广告系统要解决的关键问题。
要结合广告检索的具体需求,重点研究布尔表达式检索和相关性检索两种场景下的算法
从定价过程的输入可以看出,对于一个以CPC结算的竞价广告系统,首先需要得到候选广告集合,计算每个候选的点击率,对应投标广告中最关键的两个计算问题。 , 广告检索和广告排序
在竞价广告中,根据不同阶段发生的点击和转化操作,根据 eCPM 对广告进行排序
eCPM 可以分解为点击率和点击价值的乘积,
搜索广告系统
搜索广告与一般广告网络的主要区别在于上下文信息很强,用户标签的作用受到很大限制。搜索广告的检索过程一般不需要考虑用户的影响,上下文信息是通过用户输入实时查询和获取的,所以线下受众定位的过程基本可以忽略
查询扩展
需求方需要通过关键词扩容获得更多流量,供应商需要借此实现更多流量,加大竞价力度
基于推荐的方法:
如果将用户在一个会话中的查询视为一组具有相同目的的活动,则可以通过推荐技术在矩阵(会话,查询)矩阵上生成相同的关键词。此方法使用搜索日志数据,
给定一组用户会话和一组关键词,可以生成相应的强交互矩阵。如果用户搜索过某个关键词,矩阵的对应元素会设置一个对应的交互值,比如用户在一段时间内搜索该词的次数
显然,这个矩阵中的大部分单元格都是空白的,但这并不意味着用户搜索该词的可能性为零
推荐的基本任务是根据这个矩阵中的已知元素值,可预测地填充那些历史上没有观察到的单元。
基于主题模型的方法:
除了使用搜索到的日志数据,一般文档数据也可以用于查询扩展。这种方法本质上是利用文档主题模型将一个查询扩展到其他具有相似主题的查询
基于历史影响的方法:
利用广告历史eCPM数据挖掘效果更好的相关查询,因为广告主在选择关键词出价时,一般会选择多个组。如果从历史数据中发现,一些关键词对于某些特定的广告客户,eCPM较高,因此应该记录这些结果良好的查询组。之后,当另一个广告商也选择了关键词之一时,它可以根据这些历史记录自动进行。记录其他查询结果更好
广告展示位置
广告投放是指搜索引擎广告中确定北区和东区的广告数量问题
考虑到用户体验,有必要限制北区的广告数量。因此,这是一个典型的有约束的优化问题。约束是一段时间内北区整体的广告数量,优化目标是搜索广告系统的整体收入。在广告投放前的排序过程中,比较的是单个广告,但这里的优化需要处理一组广告,需要考虑位置因素
广告网络
广告网络的成本就是对媒体资源的分减。
广告投放的决策过程:
服务器接受前端用户访问触发的广告请求,首先根据上下文信息和用户标识从页面标签和用户标签中找出对应的上下文标签和用户标签,然后使用这些标签和其他一些广告请求条件从广告中找出符合要求的广告候选集,最后使用CTR预测模型计算所有候选广告的eCPM
根据eCPM排名选择中标的广告返回上一阶段完成投放
短期行为反馈与流计算
虽然用户行为导向不适合搜索引擎,但如果可以快速处理会话中的一系列用户查询,仍然有助于准确理解用户意图。除了这种短期的用户行为反馈,广告业务中还有一些场景需要快速处理在线日志
实现反作弊、实时计费、短期用户标签和短期动态功能
MapReduce 使用分布式文件系统尽可能调度计算
流计算就是在服务器之间调度数据来完成计算
广告搜索
检索布尔表达式
广告检索与普通搜索引擎检索的第一个区别是布尔表达式的检索问题。在以受众为导向的销售方式下,一个广告文件不再可以看作是一个BoW,而应该看作是一个目标条件的组合。合成布尔表达式,
布尔表达式检索问题有两个特点。这两个特性是设计算法的重要基础。首先,当广告请求的目标标签满足某个 Conjunction 时,它必须满足该 Conjunction 的所有广告。
相关性搜索
在长查询检索的情况下,我们实际上希望查询和广告候选之间的相似度尽可能高,但是文档中是否出现任何关键词都没有关系。这样,针对文档之间相似度的查询和检索问题就变成了相关查询
解决相关性检索的基本思想是在检索阶段引入一定的评价函数,根据该函数的评价结果确定返回哪些候选。评价函数的设计要求:合理、高效,
点击率预测
广告点击率预测的目的是对广告进行排序,但不能应用搜索中的排序问题。点击率预测不能像搜索一样只要求结果排序的正确性,因为点击率需要乘以点击单价才能得到最终排名。 ,
关于点击率预测的方法,自然会想到基于统计的估计
但是如果在某个组合中,ad a 没有展示或者点击量很少,那么历史数据就不能用来统计点击率。简单的解决方案是显示广告 a 和已显示的广告。类似于a·,那么a的点击率可以估计接近a·,
大数据机器学习问题往往需要迭代解决,Hadoop上的MapReduce已经成为范式约束。每次迭代都需要由一个 MapReduce Hadoop 作业完成。 Map读取训练数据和模型,并将数据分成块。在集合上计算统计,Reduce聚合统计平台并更新模型。由于从磁盘读取训练数据时map会产生大量的I/O,因此在Hadoop平台上一次迭代的成本往往非常昂贵,单轮迭代时间无法优化。如果要减少模型训练的时间,只能减少模型训练的次数。这就引出了以下业界常用的模型训练思路:
如果能降低每次迭代的成本,模型训练的总时间也能大大优化,于是出现了Spark这样的平台,它是一个将数据集缓存在分布式内存中的计算平台。如果数据集的规模可以在内存中控制,那么还是使用MapReduce范式来解决问题,因为每次迭代不需要通过磁盘I/o读取,大大减少了单次迭代的时间
点击率模型的校准
点击率预测问题的数据挑战之一是正负样本严重不平衡,尤其是当展示广告的点击率只有千分之几时。
点击率模型的特点
点击率预测问题的主要挑战在于,如果模型能够捕捉到高度动态的市场信号,就达到了更准确预测的目的。
静态特征:
静态特征是某些标签的值或上下文和用户标签的特征组合,以及特定广告与用户的匹配程度
动态特性:
当某个组合特征被触发时,我们不再用1,而是用这个组合历史上一段时间的点击率作为它的特征值
可以理解为历史点击率作为一个动态特征:我们最终要预测的是某个(a, u, c)上的点击率,以及特征的组合( a, u, c) 点击率可以看作是关于最终目标的弱决策者。通过融合这些特征组合对应的弱决策者,可以更容易地进行预测,
位置偏差
如何去除位置等因素的影响? 查看全部
如何根据广告的业务要求设计更高效的索引和检索
在竞争性广告中,大量中小广告主的搜索规模需要很高的计算效率。如何根据广告的业务需求设计更高效的索引和检索技术是竞争广告系统要解决的关键问题。
要结合广告检索的具体需求,重点研究布尔表达式检索和相关性检索两种场景下的算法
从定价过程的输入可以看出,对于一个以CPC结算的竞价广告系统,首先需要得到候选广告集合,计算每个候选的点击率,对应投标广告中最关键的两个计算问题。 , 广告检索和广告排序
在竞价广告中,根据不同阶段发生的点击和转化操作,根据 eCPM 对广告进行排序
eCPM 可以分解为点击率和点击价值的乘积,
搜索广告系统
搜索广告与一般广告网络的主要区别在于上下文信息很强,用户标签的作用受到很大限制。搜索广告的检索过程一般不需要考虑用户的影响,上下文信息是通过用户输入实时查询和获取的,所以线下受众定位的过程基本可以忽略
查询扩展
需求方需要通过关键词扩容获得更多流量,供应商需要借此实现更多流量,加大竞价力度
基于推荐的方法:
如果将用户在一个会话中的查询视为一组具有相同目的的活动,则可以通过推荐技术在矩阵(会话,查询)矩阵上生成相同的关键词。此方法使用搜索日志数据,
给定一组用户会话和一组关键词,可以生成相应的强交互矩阵。如果用户搜索过某个关键词,矩阵的对应元素会设置一个对应的交互值,比如用户在一段时间内搜索该词的次数
显然,这个矩阵中的大部分单元格都是空白的,但这并不意味着用户搜索该词的可能性为零
推荐的基本任务是根据这个矩阵中的已知元素值,可预测地填充那些历史上没有观察到的单元。
基于主题模型的方法:
除了使用搜索到的日志数据,一般文档数据也可以用于查询扩展。这种方法本质上是利用文档主题模型将一个查询扩展到其他具有相似主题的查询
基于历史影响的方法:
利用广告历史eCPM数据挖掘效果更好的相关查询,因为广告主在选择关键词出价时,一般会选择多个组。如果从历史数据中发现,一些关键词对于某些特定的广告客户,eCPM较高,因此应该记录这些结果良好的查询组。之后,当另一个广告商也选择了关键词之一时,它可以根据这些历史记录自动进行。记录其他查询结果更好
广告展示位置
广告投放是指搜索引擎广告中确定北区和东区的广告数量问题
考虑到用户体验,有必要限制北区的广告数量。因此,这是一个典型的有约束的优化问题。约束是一段时间内北区整体的广告数量,优化目标是搜索广告系统的整体收入。在广告投放前的排序过程中,比较的是单个广告,但这里的优化需要处理一组广告,需要考虑位置因素
广告网络
广告网络的成本就是对媒体资源的分减。
广告投放的决策过程:
服务器接受前端用户访问触发的广告请求,首先根据上下文信息和用户标识从页面标签和用户标签中找出对应的上下文标签和用户标签,然后使用这些标签和其他一些广告请求条件从广告中找出符合要求的广告候选集,最后使用CTR预测模型计算所有候选广告的eCPM
根据eCPM排名选择中标的广告返回上一阶段完成投放
短期行为反馈与流计算
虽然用户行为导向不适合搜索引擎,但如果可以快速处理会话中的一系列用户查询,仍然有助于准确理解用户意图。除了这种短期的用户行为反馈,广告业务中还有一些场景需要快速处理在线日志
实现反作弊、实时计费、短期用户标签和短期动态功能
MapReduce 使用分布式文件系统尽可能调度计算
流计算就是在服务器之间调度数据来完成计算
广告搜索
检索布尔表达式
广告检索与普通搜索引擎检索的第一个区别是布尔表达式的检索问题。在以受众为导向的销售方式下,一个广告文件不再可以看作是一个BoW,而应该看作是一个目标条件的组合。合成布尔表达式,
布尔表达式检索问题有两个特点。这两个特性是设计算法的重要基础。首先,当广告请求的目标标签满足某个 Conjunction 时,它必须满足该 Conjunction 的所有广告。
相关性搜索
在长查询检索的情况下,我们实际上希望查询和广告候选之间的相似度尽可能高,但是文档中是否出现任何关键词都没有关系。这样,针对文档之间相似度的查询和检索问题就变成了相关查询
解决相关性检索的基本思想是在检索阶段引入一定的评价函数,根据该函数的评价结果确定返回哪些候选。评价函数的设计要求:合理、高效,
点击率预测
广告点击率预测的目的是对广告进行排序,但不能应用搜索中的排序问题。点击率预测不能像搜索一样只要求结果排序的正确性,因为点击率需要乘以点击单价才能得到最终排名。 ,
关于点击率预测的方法,自然会想到基于统计的估计
但是如果在某个组合中,ad a 没有展示或者点击量很少,那么历史数据就不能用来统计点击率。简单的解决方案是显示广告 a 和已显示的广告。类似于a·,那么a的点击率可以估计接近a·,
大数据机器学习问题往往需要迭代解决,Hadoop上的MapReduce已经成为范式约束。每次迭代都需要由一个 MapReduce Hadoop 作业完成。 Map读取训练数据和模型,并将数据分成块。在集合上计算统计,Reduce聚合统计平台并更新模型。由于从磁盘读取训练数据时map会产生大量的I/O,因此在Hadoop平台上一次迭代的成本往往非常昂贵,单轮迭代时间无法优化。如果要减少模型训练的时间,只能减少模型训练的次数。这就引出了以下业界常用的模型训练思路:
如果能降低每次迭代的成本,模型训练的总时间也能大大优化,于是出现了Spark这样的平台,它是一个将数据集缓存在分布式内存中的计算平台。如果数据集的规模可以在内存中控制,那么还是使用MapReduce范式来解决问题,因为每次迭代不需要通过磁盘I/o读取,大大减少了单次迭代的时间
点击率模型的校准
点击率预测问题的数据挑战之一是正负样本严重不平衡,尤其是当展示广告的点击率只有千分之几时。
点击率模型的特点
点击率预测问题的主要挑战在于,如果模型能够捕捉到高度动态的市场信号,就达到了更准确预测的目的。
静态特征:
静态特征是某些标签的值或上下文和用户标签的特征组合,以及特定广告与用户的匹配程度
动态特性:
当某个组合特征被触发时,我们不再用1,而是用这个组合历史上一段时间的点击率作为它的特征值
可以理解为历史点击率作为一个动态特征:我们最终要预测的是某个(a, u, c)上的点击率,以及特征的组合( a, u, c) 点击率可以看作是关于最终目标的弱决策者。通过融合这些特征组合对应的弱决策者,可以更容易地进行预测,
位置偏差
如何去除位置等因素的影响?
互联网时代后的SEO只有精通这些高水平的技能
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-07-19 00:25
互联网时代,从PC到手机,从手机到人工智能,我们进入了后互联网时代。互联网不再是经济发展的颠覆,也不再是突如其来的变革。她更像是卷入社会经济大局的重要一员。然而,PC时代搜索引擎优化的辉煌已经不复存在。 SEO在企业中的地位非常尴尬。牛力搜索引擎优化风生水起。互联网时代后的SEO只需要精通这些高级SEO技巧即可。 ---互联网整合营销策划顾问-杨小道
1、聚合页面优化
主题、频道列、文章list、标签聚合。
有些网站权重很高,内容信息量很大,信息量一般在几万左右。做这种网站通常需要特殊的分析、诊断和设计变更。但是为了增加整体的流量,我们可以简单的把这种网站看成只有两种类型的页面,即内容页面和聚合页面。现在很多大中型网站都会使用网站中的标签来创建一些独特的页面来获取一些长尾流量,但这应该是基于关键词的过滤和控制,因为大量不相关的聚合搜索流量来源会导致整个网站主题的偏差,可能会严重削弱权益。
2、泛分析站群+蜘蛛池
SEO黑客技术常用,黑客对灰色行业的影响是毋庸置疑的。一万字保存在这里。
3、汉密尔顿环链轮基本款
每个都有自己的汉密尔顿环链轮基本模型。杨小道也有自己的SEO链轮基础模型
4、原创Continuous文章技术
原创性?什么是创造力?就像一个人的身份证存在于**上一样,是最上面的,没有重复。原文文章也是一样,网上只有一篇文章,没有重复。那么,作为SEOER,我们应该如何创建文章?
首先,一个好的原创文章一定要有一个好的标题
一、根据我平时的经验,想一想我会在搜索引擎中填写的句子或内容,根据我的实际情况来写;例如:什么是 SEO?
二、查看peer网站的关键词,分析一下,得到适合自己的,有一定热情的关键词。将它们插入标题中,并对主关键字和子关键字进行排序和组合。比如主关键词是“SEO”,子关键词是“原创文章”,组合关键词是“SEO原创文章”。
三、 了解用户需求,观察一些论坛、贴吧、问答等交流平台,了解用户平时喜欢搜索什么,关心什么?例如:如何创建SEO文章? SEO原创文章怎么写?
四、在思考的过程中,查看百度、360、搜狗等与您同名或相关内容的搜索引擎的搜索结果。如果有更多,我们建议您更改标题,以便百度更快地采集您的文章
其次,一个好的原创文章不仅要有原创的标题,还要有原创的内容
一、写文章时,请注意增加文章前100字关键词“SEO原创文章”的密度! 100字应该有2-3次。
二、研究用户心理,就像写标题一样,可以看到用户的需求以及用户点击这篇文章想要看到和理解的内容。
三、正文的内容部分,需要能够在“SEO原创文章”中搜索相关信息关键词。这就是区别于普通原创文章的关键。让人们可以在不同的相关关键词中搜索到相同的文章文章。
四、原来文章的内容其实是为了与你想表达的相处;例如:在原来的SEO文章写下自己的感受。共同点是写印象。
之后
,结尾也是蜘蛛爬行的关键。结束方式如下:
关键词 必须出现在 200 字的末尾,记住。应该有一个好的开始和一个好的结束。成功的SEO公式=持久化+原创内容+优质外链
原创性是一个所谓的工具,它使用你的想法,然后用文字写下来。这就是创造力。看完之后,你觉得创意有那么简单吗?大体意思就是自己写文章。 查看全部
互联网时代后的SEO只有精通这些高水平的技能
互联网时代,从PC到手机,从手机到人工智能,我们进入了后互联网时代。互联网不再是经济发展的颠覆,也不再是突如其来的变革。她更像是卷入社会经济大局的重要一员。然而,PC时代搜索引擎优化的辉煌已经不复存在。 SEO在企业中的地位非常尴尬。牛力搜索引擎优化风生水起。互联网时代后的SEO只需要精通这些高级SEO技巧即可。 ---互联网整合营销策划顾问-杨小道
1、聚合页面优化
主题、频道列、文章list、标签聚合。
有些网站权重很高,内容信息量很大,信息量一般在几万左右。做这种网站通常需要特殊的分析、诊断和设计变更。但是为了增加整体的流量,我们可以简单的把这种网站看成只有两种类型的页面,即内容页面和聚合页面。现在很多大中型网站都会使用网站中的标签来创建一些独特的页面来获取一些长尾流量,但这应该是基于关键词的过滤和控制,因为大量不相关的聚合搜索流量来源会导致整个网站主题的偏差,可能会严重削弱权益。
2、泛分析站群+蜘蛛池
SEO黑客技术常用,黑客对灰色行业的影响是毋庸置疑的。一万字保存在这里。
3、汉密尔顿环链轮基本款
每个都有自己的汉密尔顿环链轮基本模型。杨小道也有自己的SEO链轮基础模型
4、原创Continuous文章技术
原创性?什么是创造力?就像一个人的身份证存在于**上一样,是最上面的,没有重复。原文文章也是一样,网上只有一篇文章,没有重复。那么,作为SEOER,我们应该如何创建文章?
首先,一个好的原创文章一定要有一个好的标题
一、根据我平时的经验,想一想我会在搜索引擎中填写的句子或内容,根据我的实际情况来写;例如:什么是 SEO?
二、查看peer网站的关键词,分析一下,得到适合自己的,有一定热情的关键词。将它们插入标题中,并对主关键字和子关键字进行排序和组合。比如主关键词是“SEO”,子关键词是“原创文章”,组合关键词是“SEO原创文章”。
三、 了解用户需求,观察一些论坛、贴吧、问答等交流平台,了解用户平时喜欢搜索什么,关心什么?例如:如何创建SEO文章? SEO原创文章怎么写?
四、在思考的过程中,查看百度、360、搜狗等与您同名或相关内容的搜索引擎的搜索结果。如果有更多,我们建议您更改标题,以便百度更快地采集您的文章
其次,一个好的原创文章不仅要有原创的标题,还要有原创的内容
一、写文章时,请注意增加文章前100字关键词“SEO原创文章”的密度! 100字应该有2-3次。
二、研究用户心理,就像写标题一样,可以看到用户的需求以及用户点击这篇文章想要看到和理解的内容。
三、正文的内容部分,需要能够在“SEO原创文章”中搜索相关信息关键词。这就是区别于普通原创文章的关键。让人们可以在不同的相关关键词中搜索到相同的文章文章。
四、原来文章的内容其实是为了与你想表达的相处;例如:在原来的SEO文章写下自己的感受。共同点是写印象。
之后
,结尾也是蜘蛛爬行的关键。结束方式如下:
关键词 必须出现在 200 字的末尾,记住。应该有一个好的开始和一个好的结束。成功的SEO公式=持久化+原创内容+优质外链
原创性是一个所谓的工具,它使用你的想法,然后用文字写下来。这就是创造力。看完之后,你觉得创意有那么简单吗?大体意思就是自己写文章。
17年SEO搜索引擎:核心技术详解--梳理总结
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-07-17 19:00
2017年因项目需要,学习整理了一些SEO相关的知识,可以分为两部分:
《搜索引擎:核心技术详解》---梳理与总结
SEO 搜索引擎优化
本文主要内容是对阅读《搜索引擎:核心技术详解》时的一些知识进行梳理和总结,包括搜索引擎索引、链接分析和网页反作弊三部分一、搜索引擎索引
Index,如书籍目录,是一种索引结构,其目的是让人们更快地搜索相关章节。搜索引擎索引简单的理解就是抓取页面后对数据进行排序整理的过程。搜索引擎的索引就是实现word-document矩阵的数据结构。在实际应用中实现的方式有很多种,常见的就是倒排索引。
索引的基本概念
引擎的基本索引模型是一个word-document矩阵,如图:
横向可以看到哪些文档收录某个词汇,纵向可以看到某个文档收录哪些关键词
在实际的搜索引擎中,一般记录的不是文档编号,而是相邻两个文档的差值。这样就将大值转换成小值,提高了压缩效率
创建索引
缺点:从磁盘中读取文档并解析文档基本上是最耗时的步骤,而且两次扫描方式在速度上没有优势,因为它需要遍历文档集合两次。在实践中,这种方法的系统并不常见。
动态索引
实时反映索引变化,3种关键索引结构:倒排索引、临时索引、删除文档列表。
索引更新策略
当临时索引越来越内存不足时,需要将临时索引写入disk-index更新策略
常用的索引更新策略有4种:完全重建策略、重新合并策略、就地更新策略和混合策略。
完全重构策略----新文档临时索引+旧文档--------->遍历生成新索引(放弃旧索引)再合并策略----新文档索引+旧索引- --->合并生成新索引(抛弃旧索引)原位更新策略--增量索引+旧索引---->旧索引+附加新倒排信息混合策略----一般对词进行分类,然后使用不同的更新策略
二、Link 分析概念模型
随机游走模型----是一个概念模型,抽象了两种用户浏览行为,直接跳转和远程跳转。许多链接分析算法,包括PageRank算法,都是基于随机游走模型的。
假设互联网由3个网页A、B、C组成,图中页面节点之间的有向边表示相互链接关系。根据链接关系,可以计算出页面节点之间的转移概率。例如,对于节点 A,只有一条到节点 B 的输出链路,所以从节点 A 跳到节点 B 的概率为 1,对于节点 C,它有到节点 A 和 B 的链路,所以转向的概率为任何其他节点都是 1/2。假设在时间1,用户浏览页面A,然后通过链接进入页面B,然后进入页面C,此时他面临两种可能的选择。可以跳转到页面A或页面B,两者的概率相同,都是1/2。假设示例中的Internet收录3个以上的页面,但由10个页面组成。这时候用户既不想跳回页面A也不想跳回页面B,他可以以1/10的概率跳到任何其他页面,即远程跳转。
子集传播模型——将网页按照一定的规则分成两个甚至多个子集。某个子集合具有特殊属性。许多算法通常从这个子集合开始,并为子集合中的网页赋予初始权重。然后,根据该特殊子集合中的网页与其他网页之间的链接关系,以某种方式分配权重。该值被传递到其他网页。
链接分析算法
在众多算法中,PageRank 和 HITS 可以说是最重要的两种具有代表性的链接分析算法。很多后续的链接分析算法都是从这两种算法衍生出来的改进算法。
PageRank 算法
每个页面都会将其当前的PageRank值平均分配给该页面收录的传出链接,从而使每个链接获得相应的权重。并且每个页面将所有指向该页面的链内传递的权重相加,以获得新的 PageRank 分数。
HITS 算法
权威页面是指与某个领域或主题相关的高质量网页。例如,在搜索引擎领域,谷歌和百度的主页都是该领域的优质网页;例如,在视频领域,优酷和土豆主页是该领域的优质网页。中心页面是指收录许多指向高质量权威页面的链接的网页。
Hub 和 Authority 之间的相辅相成的关系。 HITS算法与用户输入的查询请求密切相关,而PageRank算法是全局算法,与查询无关。
HITS算法的目的是利用一定的技术手段,在大量网页中,特别是Authority页面中,找到与用户查询主题相关的高质量Authority页面和Hub页面,因为这些页面代表了高质量可以满足用户的查询。内容,搜索引擎以此作为搜索结果返回给用户。
SALSA算法----请求--->扩展网页子集----->转向无向二部图---->计算权重--->返回结果
hilltop----专家网络搜索---->着陆页排序
主题敏感PageRank----离线分类主题PR值计算---->请求是相似度比较计算---->前两者的乘积之和
HITS算法与PageRank算法对比
HITS算法与用户输入的查询请求密切相关,而PageRank与查询请求无关。因此,可以单独使用HITS算法作为相似度计算的评价标准,而PageRank必须与内容相似度计算相结合,才能用于评价网页的相关性。由于HITS算法与用户查询密切相关,必须在收到用户查询后进行实时计算,计算效率低;而PageRank可以在爬取完成后离线计算,计算结果可以直接在线使用,计算效率更高。 HITS算法计算对象少,只需要计算扩展集中网页之间的链接关系;而 PageRank 是一种全局算法,可以处理所有 Internet 页面节点。从两者的计算效率和处理对象集合大小的比较来看,PageRank更适合部署在服务器端,而HITS算法更适合部署在客户端。 HITS算法存在话题泛化的问题,所以更适合处理特定的用户查询;而PageRank算法在处理大范围的用户查询方面更有优势。 HITS算法需要为每个页面计算两个分数,而PageRank算法只需要计算一个分数;在搜索引擎领域,更多关注的是HITS算法计算出的权威权重,但在其他很多应用HITS算法的领域,Hub score也很重要。从链接防作弊的角度来看,PageRank在机制上优于HITS算法,HITS算法更容易受到链接作弊的影响。 HITS算法的结构不稳定。当扩展网页集合中的链接关系稍有改动时,就会对最终排名产生很大的影响;而与 HITS 相比,PageRank 算法是稳定的。根本原因是PageRank计算时的远程跳转。 . 三、网络作弊
从大类来看,比较常见的作弊方式有:内容作弊、链接作弊、隐藏作弊,以及近年来兴起的Web2.0作弊方式。学术界和搜索引擎公司也有针对性地提出了各种反作弊算法。
内容作弊
内容作弊的目的是精心修改或规范网页内容,使网页在与其网页不相称的搜索引擎排名中获得较高的排名。搜索引擎排名一般包括内容相似度和链接重要性计算。内容作弊主要针对搜索引擎排名算法的内容相似度计算部分。通过故意增加目标词的频率,或在网页重要位置引入网页内容不相关的词影响搜索结果的排名。
常见内容作弊方式:关键词repetition、无关查询词作弊、图片alt标签文字作弊、网页标题作弊、网页重要标签作弊、网页元信息作弊
内容农场:内容农场运营商廉价雇用大量自由职业者来支持他们的付费写作,但写作内容的质量通常较低。很多文章都是通过复制和稍加修改来完成的,但是他们会研究搜索引擎的热门搜索词等,并将这些词有机地添加到写作内容中。这样,普通搜索引擎用户在搜索时就会被吸引到内容农场网站,内容农场可以通过大量低质量内容吸引流量来赚取广告费用。
链接作弊
所谓链接作弊就是网站owner考虑到在搜索引擎排名中使用链接分析技术,所以通过操纵页面之间的链接关系,或者操纵页面之间的链接锚文本,来增加链接排名因素的得分以及影响搜索结果排名的作弊方式。
为了提高网页的搜索引擎链接排名,链接农场建立了一个庞大的网页集合,这些网页相互之间有着密切的联系,希望通过搜索引擎链接算法的机制来提高网页排名。大量的相互联系。链接农场中页面的链接密度极高,任何两个页面都可能有相互指向的链接。
锚文本是指向某个网页的链接的描述文本。这些描述信息往往反映了所指向网页的内容主题,因此搜索引擎在排名算法中经常使用它。作弊者精心设置锚文本内容,诱使搜索引擎对目标网页给予更高的排名。一般来说,作弊者设置的锚文本与目标网页的内容无关。
几年前,有一个著名的例子,就是利用谷歌轰炸来操纵搜索结果的排名。那时,如果你在谷歌上搜索“悲惨的失败”,你会发现第二个搜索结果是时任美国总统乔治·W·布什的白宫页面。这是通过构建许多其他网页,包括指向目标页面的链接,其链接锚文本收录“悲惨失败”关键词 实现的效果。
“门页”本身不收录正文内容,而是由大量链接组成,而这些链接往往指向同一个网站
在页面中,作弊者创建了大量的“门页”,以提高网站排名。
页面隐藏作弊
页面隐藏作弊利用某种手段欺骗搜索引擎爬虫,使搜索引擎爬取的页面内容和用户点击查看
您看到的页面内容不同,从而影响搜索引擎的搜索结果。隐藏页面和作弊的常见方法
以下是几个。
1.IP伪装(IP Cloaking)
网页所有者在服务器端记录搜索引擎爬虫的IP地址列表,如果发现搜索引擎在请求页面上
对于人脸,它会向爬虫推送一个虚假的网页内容,如果是另一个IP地址,它会推送另一个网页
内容,此页面通常是具有商业目的的营销页面。 查看全部
17年SEO搜索引擎:核心技术详解--梳理总结
2017年因项目需要,学习整理了一些SEO相关的知识,可以分为两部分:
《搜索引擎:核心技术详解》---梳理与总结
SEO 搜索引擎优化
本文主要内容是对阅读《搜索引擎:核心技术详解》时的一些知识进行梳理和总结,包括搜索引擎索引、链接分析和网页反作弊三部分一、搜索引擎索引
Index,如书籍目录,是一种索引结构,其目的是让人们更快地搜索相关章节。搜索引擎索引简单的理解就是抓取页面后对数据进行排序整理的过程。搜索引擎的索引就是实现word-document矩阵的数据结构。在实际应用中实现的方式有很多种,常见的就是倒排索引。
索引的基本概念
引擎的基本索引模型是一个word-document矩阵,如图:
横向可以看到哪些文档收录某个词汇,纵向可以看到某个文档收录哪些关键词
在实际的搜索引擎中,一般记录的不是文档编号,而是相邻两个文档的差值。这样就将大值转换成小值,提高了压缩效率
创建索引
缺点:从磁盘中读取文档并解析文档基本上是最耗时的步骤,而且两次扫描方式在速度上没有优势,因为它需要遍历文档集合两次。在实践中,这种方法的系统并不常见。
动态索引
实时反映索引变化,3种关键索引结构:倒排索引、临时索引、删除文档列表。
索引更新策略
当临时索引越来越内存不足时,需要将临时索引写入disk-index更新策略
常用的索引更新策略有4种:完全重建策略、重新合并策略、就地更新策略和混合策略。
完全重构策略----新文档临时索引+旧文档--------->遍历生成新索引(放弃旧索引)再合并策略----新文档索引+旧索引- --->合并生成新索引(抛弃旧索引)原位更新策略--增量索引+旧索引---->旧索引+附加新倒排信息混合策略----一般对词进行分类,然后使用不同的更新策略
二、Link 分析概念模型
随机游走模型----是一个概念模型,抽象了两种用户浏览行为,直接跳转和远程跳转。许多链接分析算法,包括PageRank算法,都是基于随机游走模型的。
假设互联网由3个网页A、B、C组成,图中页面节点之间的有向边表示相互链接关系。根据链接关系,可以计算出页面节点之间的转移概率。例如,对于节点 A,只有一条到节点 B 的输出链路,所以从节点 A 跳到节点 B 的概率为 1,对于节点 C,它有到节点 A 和 B 的链路,所以转向的概率为任何其他节点都是 1/2。假设在时间1,用户浏览页面A,然后通过链接进入页面B,然后进入页面C,此时他面临两种可能的选择。可以跳转到页面A或页面B,两者的概率相同,都是1/2。假设示例中的Internet收录3个以上的页面,但由10个页面组成。这时候用户既不想跳回页面A也不想跳回页面B,他可以以1/10的概率跳到任何其他页面,即远程跳转。
子集传播模型——将网页按照一定的规则分成两个甚至多个子集。某个子集合具有特殊属性。许多算法通常从这个子集合开始,并为子集合中的网页赋予初始权重。然后,根据该特殊子集合中的网页与其他网页之间的链接关系,以某种方式分配权重。该值被传递到其他网页。
链接分析算法
在众多算法中,PageRank 和 HITS 可以说是最重要的两种具有代表性的链接分析算法。很多后续的链接分析算法都是从这两种算法衍生出来的改进算法。
PageRank 算法
每个页面都会将其当前的PageRank值平均分配给该页面收录的传出链接,从而使每个链接获得相应的权重。并且每个页面将所有指向该页面的链内传递的权重相加,以获得新的 PageRank 分数。
HITS 算法
权威页面是指与某个领域或主题相关的高质量网页。例如,在搜索引擎领域,谷歌和百度的主页都是该领域的优质网页;例如,在视频领域,优酷和土豆主页是该领域的优质网页。中心页面是指收录许多指向高质量权威页面的链接的网页。
Hub 和 Authority 之间的相辅相成的关系。 HITS算法与用户输入的查询请求密切相关,而PageRank算法是全局算法,与查询无关。
HITS算法的目的是利用一定的技术手段,在大量网页中,特别是Authority页面中,找到与用户查询主题相关的高质量Authority页面和Hub页面,因为这些页面代表了高质量可以满足用户的查询。内容,搜索引擎以此作为搜索结果返回给用户。
SALSA算法----请求--->扩展网页子集----->转向无向二部图---->计算权重--->返回结果
hilltop----专家网络搜索---->着陆页排序
主题敏感PageRank----离线分类主题PR值计算---->请求是相似度比较计算---->前两者的乘积之和
HITS算法与PageRank算法对比
HITS算法与用户输入的查询请求密切相关,而PageRank与查询请求无关。因此,可以单独使用HITS算法作为相似度计算的评价标准,而PageRank必须与内容相似度计算相结合,才能用于评价网页的相关性。由于HITS算法与用户查询密切相关,必须在收到用户查询后进行实时计算,计算效率低;而PageRank可以在爬取完成后离线计算,计算结果可以直接在线使用,计算效率更高。 HITS算法计算对象少,只需要计算扩展集中网页之间的链接关系;而 PageRank 是一种全局算法,可以处理所有 Internet 页面节点。从两者的计算效率和处理对象集合大小的比较来看,PageRank更适合部署在服务器端,而HITS算法更适合部署在客户端。 HITS算法存在话题泛化的问题,所以更适合处理特定的用户查询;而PageRank算法在处理大范围的用户查询方面更有优势。 HITS算法需要为每个页面计算两个分数,而PageRank算法只需要计算一个分数;在搜索引擎领域,更多关注的是HITS算法计算出的权威权重,但在其他很多应用HITS算法的领域,Hub score也很重要。从链接防作弊的角度来看,PageRank在机制上优于HITS算法,HITS算法更容易受到链接作弊的影响。 HITS算法的结构不稳定。当扩展网页集合中的链接关系稍有改动时,就会对最终排名产生很大的影响;而与 HITS 相比,PageRank 算法是稳定的。根本原因是PageRank计算时的远程跳转。 . 三、网络作弊
从大类来看,比较常见的作弊方式有:内容作弊、链接作弊、隐藏作弊,以及近年来兴起的Web2.0作弊方式。学术界和搜索引擎公司也有针对性地提出了各种反作弊算法。
内容作弊
内容作弊的目的是精心修改或规范网页内容,使网页在与其网页不相称的搜索引擎排名中获得较高的排名。搜索引擎排名一般包括内容相似度和链接重要性计算。内容作弊主要针对搜索引擎排名算法的内容相似度计算部分。通过故意增加目标词的频率,或在网页重要位置引入网页内容不相关的词影响搜索结果的排名。
常见内容作弊方式:关键词repetition、无关查询词作弊、图片alt标签文字作弊、网页标题作弊、网页重要标签作弊、网页元信息作弊
内容农场:内容农场运营商廉价雇用大量自由职业者来支持他们的付费写作,但写作内容的质量通常较低。很多文章都是通过复制和稍加修改来完成的,但是他们会研究搜索引擎的热门搜索词等,并将这些词有机地添加到写作内容中。这样,普通搜索引擎用户在搜索时就会被吸引到内容农场网站,内容农场可以通过大量低质量内容吸引流量来赚取广告费用。
链接作弊
所谓链接作弊就是网站owner考虑到在搜索引擎排名中使用链接分析技术,所以通过操纵页面之间的链接关系,或者操纵页面之间的链接锚文本,来增加链接排名因素的得分以及影响搜索结果排名的作弊方式。
为了提高网页的搜索引擎链接排名,链接农场建立了一个庞大的网页集合,这些网页相互之间有着密切的联系,希望通过搜索引擎链接算法的机制来提高网页排名。大量的相互联系。链接农场中页面的链接密度极高,任何两个页面都可能有相互指向的链接。
锚文本是指向某个网页的链接的描述文本。这些描述信息往往反映了所指向网页的内容主题,因此搜索引擎在排名算法中经常使用它。作弊者精心设置锚文本内容,诱使搜索引擎对目标网页给予更高的排名。一般来说,作弊者设置的锚文本与目标网页的内容无关。
几年前,有一个著名的例子,就是利用谷歌轰炸来操纵搜索结果的排名。那时,如果你在谷歌上搜索“悲惨的失败”,你会发现第二个搜索结果是时任美国总统乔治·W·布什的白宫页面。这是通过构建许多其他网页,包括指向目标页面的链接,其链接锚文本收录“悲惨失败”关键词 实现的效果。
“门页”本身不收录正文内容,而是由大量链接组成,而这些链接往往指向同一个网站
在页面中,作弊者创建了大量的“门页”,以提高网站排名。
页面隐藏作弊
页面隐藏作弊利用某种手段欺骗搜索引擎爬虫,使搜索引擎爬取的页面内容和用户点击查看
您看到的页面内容不同,从而影响搜索引擎的搜索结果。隐藏页面和作弊的常见方法
以下是几个。
1.IP伪装(IP Cloaking)
网页所有者在服务器端记录搜索引擎爬虫的IP地址列表,如果发现搜索引擎在请求页面上
对于人脸,它会向爬虫推送一个虚假的网页内容,如果是另一个IP地址,它会推送另一个网页
内容,此页面通常是具有商业目的的营销页面。
一个语义挖掘的利器——主题模型(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-07-17 00:07
来自:
总结:
两个文档是否相关,往往不仅取决于字面上的重复,还取决于文本背后的语义联系。语义关联的挖掘可以使我们的搜索更加智能。本文重点介绍一个强大的语义挖掘工具:主题模型。主题模型是一种对文本隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的不足,能够在海量互联网数据中自动找到文本之间的语义主题。近年来,各大互联网公司都开始了这方面的探索和尝试。让我们看看会发生什么。
关键词:主题模型
技术领域:搜索技术、自然语言处理
假设有两个句子,我们想知道它们是否相关:
第一个是:“工作没了。”
第二个是:“苹果会降价吗?”
如果是人来判断的话,我们一看就知道,这两个句子虽然没有共同的词,但还是很有关联的。这是因为,虽然第二句中的“apple”可能指的是我们吃的苹果,但因为第一句中有“Jobs”,我们自然会将“apple”解释为苹果产品。事实上,这种文本句子之间的相关性和相似性在搜索引擎算法中经常遇到。例如,如果用户输入一个查询,我们需要从海量的网页库中找到最相关的结果。下面是如何衡量查询和网页之间的相似度。对于此类问题,人们可以根据上下文进行判断。但是机器还好吗?
在传统信息检索领域,测量文档相似度的方法其实有很多,比如经典的VSM模型。但是,这些方法通常基于一个基本假设:文档之间重复的单词越多,它们相似的可能性就越大。这在实践中并不总是正确的。在很多情况下,相关程度取决于背后的语义联系,而不是表面的单词重复。
那么,这种语义关系应该如何衡量呢?事实上,在自然语言处理领域,已经有很多方法可以从单词、短语、句子和文本的角度来衡量。本文将介绍语义挖掘的强大工具之一:主题模型。
什么是主题模型?
主题模型,顾名思义,就是对文本中隐藏主题的一种建模方法。还是在上面的例子中,单词“apple”同时收录了Apple的主题和fruit的主题。对比第一句,苹果的主题与“乔布斯”所代表的主题相匹配,所以我们认为它们是相关的。
在这里,让我们先定义一下主题是什么。主题是一个概念,一个方面。它表现为一系列相关的词。例如,如果文章与“百度”主题相关,“中文搜索”、“李彦宏”等词出现的频率会更高,如果涉及“IBM”主题,则“笔记本”等会很频繁地出现。如果用数学来描述的话,题目就是单词在词汇表上的条件概率分布。词的相关性越近,其条件概率越大,反之亦然。
例如:
通俗地说,一个话题就像一个“桶”,里面收录了一些出现概率较高的词。这些词与主题有很强的相关性,或者正是这些词共同定义了主题。对于一个段落,有些词可能来自这个“桶”,有些可能来自那个“桶”,而一个文本往往是几个主题的混合体。举个简单的例子,见下图。
以上内容摘自网络新闻。我们划分了4个桶(主题),百度(红色),微软(紫色),谷歌(蓝色)和市场(绿色)。段落中收录的每个主题的单词都用颜色标记。从颜色分布我们可以看出,文中的主要思想是谈论百度和市场发展。在这方面,谷歌和微软的两个主题也出现了,但不是主要的语义。值得注意的是,像“搜索引擎”这样的词极有可能出现在百度、微软、谷歌这三个主题上。可以认为一个词被放入多个“桶”中。当它出现在文本中时,这三个主题在一定程度上得到了体现。
有了主题的概念,我们不禁要问,这些主题是怎么得到的?如何分析文章中的话题?这正是主题模型想要解决的问题。让我简单介绍一下主题模型的工作原理。
主题模型的工作原理
首先,我们从生成模型的角度来看文档和主题这两个东西。所谓生成模型,是指我们认为一个文章中的每个词都是通过“以一定概率选择某个主题,并以一定概率从该主题中选择某个词”的过程获得的。那么,如果我们要生成一个文档,其中每个词出现的概率为:
上式可以用矩阵乘法表示,如下图所示:
左
矩阵表示每个词在每个文章中的概率;中间的Φ矩阵代表每个话题中每个词的概率
,即每个“桶
表示每个文档中每个主题的概率
,可以理解为每个主题在一个段落中所占的比例。
如果我们有很多文档,比如很多网页,我们首先将所有文档进行分割,得到一个词汇表。这样,每个文档都可以表示为一个词的集合。对于每个单词,我们可以用它在文档中出现的次数除以文档中的单词数作为它在文档中出现的概率
。这样,对于任何文档,
左边
矩阵已知,右边两个矩阵未知。主题模型是使用大量已知的“words-documents”
Matrix,通过一系列的训练,推断出右边的“word-topic”矩阵Φ和“主题文档”矩阵Θ。
主题模型训练和推理主要有两种方法,一种是pLSA(Probabilistic Latent Semantic Analysis),另一种是LDA(Latent Dirichlet Allocation)。 pLSA主要使用EM(Expectation Maximization)算法; LDA 使用 Gibbs 采样方法。由于它们比较复杂,篇幅有限,这里只简单介绍一下pLSA的思想,其他具体的方法和公式,读者可以参考相关资料。
pLSA采用的方法称为EM(Expectation Maximization)算法,它由两个不断迭代的过程组成:E(期望)过程和M(最大化)过程。举个形象例子:假设食堂的厨师炸一道菜,需要分成两个人吃。显然,没有必要使用天平来准确称重。最简单的方法是先将菜品随机分成两个碗,然后观察数量是否相同,取较多的部分放入另一个碗中。重复这个过程,直到大家都看不到两个碗里的菜。到目前为止有何不同。
对于主题模型训练,“计算每个主题的词分布”和“计算训练文档中的主题分布”就像两个人分享食物。在E过程中,我们可以使用贝叶斯公式从“word-topic”矩阵中计算出“topic-document”矩阵。在M过程中,我们使用“topic-document”矩阵重新计算“term-topic”矩阵。这个过程一直是这样迭代的。 EM 算法的神奇之处在于它可以保证这个迭代过程是收敛的。也就是说,经过反复迭代,我们肯定可以得到趋于真实值的Φ和Θ。
如何使用主题模型?
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3) 可以消除文档中噪声的影响。一般来说,文档中的杂音往往出现在次要主题中,我们可以忽略它们,只保留文档中的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5) 与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
纺纱世界 查看全部
一个语义挖掘的利器——主题模型(组图)
来自:
总结:
两个文档是否相关,往往不仅取决于字面上的重复,还取决于文本背后的语义联系。语义关联的挖掘可以使我们的搜索更加智能。本文重点介绍一个强大的语义挖掘工具:主题模型。主题模型是一种对文本隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的不足,能够在海量互联网数据中自动找到文本之间的语义主题。近年来,各大互联网公司都开始了这方面的探索和尝试。让我们看看会发生什么。
关键词:主题模型
技术领域:搜索技术、自然语言处理
假设有两个句子,我们想知道它们是否相关:
第一个是:“工作没了。”
第二个是:“苹果会降价吗?”
如果是人来判断的话,我们一看就知道,这两个句子虽然没有共同的词,但还是很有关联的。这是因为,虽然第二句中的“apple”可能指的是我们吃的苹果,但因为第一句中有“Jobs”,我们自然会将“apple”解释为苹果产品。事实上,这种文本句子之间的相关性和相似性在搜索引擎算法中经常遇到。例如,如果用户输入一个查询,我们需要从海量的网页库中找到最相关的结果。下面是如何衡量查询和网页之间的相似度。对于此类问题,人们可以根据上下文进行判断。但是机器还好吗?
在传统信息检索领域,测量文档相似度的方法其实有很多,比如经典的VSM模型。但是,这些方法通常基于一个基本假设:文档之间重复的单词越多,它们相似的可能性就越大。这在实践中并不总是正确的。在很多情况下,相关程度取决于背后的语义联系,而不是表面的单词重复。
那么,这种语义关系应该如何衡量呢?事实上,在自然语言处理领域,已经有很多方法可以从单词、短语、句子和文本的角度来衡量。本文将介绍语义挖掘的强大工具之一:主题模型。
什么是主题模型?
主题模型,顾名思义,就是对文本中隐藏主题的一种建模方法。还是在上面的例子中,单词“apple”同时收录了Apple的主题和fruit的主题。对比第一句,苹果的主题与“乔布斯”所代表的主题相匹配,所以我们认为它们是相关的。
在这里,让我们先定义一下主题是什么。主题是一个概念,一个方面。它表现为一系列相关的词。例如,如果文章与“百度”主题相关,“中文搜索”、“李彦宏”等词出现的频率会更高,如果涉及“IBM”主题,则“笔记本”等会很频繁地出现。如果用数学来描述的话,题目就是单词在词汇表上的条件概率分布。词的相关性越近,其条件概率越大,反之亦然。
例如:

通俗地说,一个话题就像一个“桶”,里面收录了一些出现概率较高的词。这些词与主题有很强的相关性,或者正是这些词共同定义了主题。对于一个段落,有些词可能来自这个“桶”,有些可能来自那个“桶”,而一个文本往往是几个主题的混合体。举个简单的例子,见下图。

以上内容摘自网络新闻。我们划分了4个桶(主题),百度(红色),微软(紫色),谷歌(蓝色)和市场(绿色)。段落中收录的每个主题的单词都用颜色标记。从颜色分布我们可以看出,文中的主要思想是谈论百度和市场发展。在这方面,谷歌和微软的两个主题也出现了,但不是主要的语义。值得注意的是,像“搜索引擎”这样的词极有可能出现在百度、微软、谷歌这三个主题上。可以认为一个词被放入多个“桶”中。当它出现在文本中时,这三个主题在一定程度上得到了体现。
有了主题的概念,我们不禁要问,这些主题是怎么得到的?如何分析文章中的话题?这正是主题模型想要解决的问题。让我简单介绍一下主题模型的工作原理。
主题模型的工作原理
首先,我们从生成模型的角度来看文档和主题这两个东西。所谓生成模型,是指我们认为一个文章中的每个词都是通过“以一定概率选择某个主题,并以一定概率从该主题中选择某个词”的过程获得的。那么,如果我们要生成一个文档,其中每个词出现的概率为:

上式可以用矩阵乘法表示,如下图所示:

左

矩阵表示每个词在每个文章中的概率;中间的Φ矩阵代表每个话题中每个词的概率

,即每个“桶
表示每个文档中每个主题的概率

,可以理解为每个主题在一个段落中所占的比例。
如果我们有很多文档,比如很多网页,我们首先将所有文档进行分割,得到一个词汇表。这样,每个文档都可以表示为一个词的集合。对于每个单词,我们可以用它在文档中出现的次数除以文档中的单词数作为它在文档中出现的概率

。这样,对于任何文档,
左边

矩阵已知,右边两个矩阵未知。主题模型是使用大量已知的“words-documents”

Matrix,通过一系列的训练,推断出右边的“word-topic”矩阵Φ和“主题文档”矩阵Θ。
主题模型训练和推理主要有两种方法,一种是pLSA(Probabilistic Latent Semantic Analysis),另一种是LDA(Latent Dirichlet Allocation)。 pLSA主要使用EM(Expectation Maximization)算法; LDA 使用 Gibbs 采样方法。由于它们比较复杂,篇幅有限,这里只简单介绍一下pLSA的思想,其他具体的方法和公式,读者可以参考相关资料。
pLSA采用的方法称为EM(Expectation Maximization)算法,它由两个不断迭代的过程组成:E(期望)过程和M(最大化)过程。举个形象例子:假设食堂的厨师炸一道菜,需要分成两个人吃。显然,没有必要使用天平来准确称重。最简单的方法是先将菜品随机分成两个碗,然后观察数量是否相同,取较多的部分放入另一个碗中。重复这个过程,直到大家都看不到两个碗里的菜。到目前为止有何不同。
对于主题模型训练,“计算每个主题的词分布”和“计算训练文档中的主题分布”就像两个人分享食物。在E过程中,我们可以使用贝叶斯公式从“word-topic”矩阵中计算出“topic-document”矩阵。在M过程中,我们使用“topic-document”矩阵重新计算“term-topic”矩阵。这个过程一直是这样迭代的。 EM 算法的神奇之处在于它可以保证这个迭代过程是收敛的。也就是说,经过反复迭代,我们肯定可以得到趋于真实值的Φ和Θ。
如何使用主题模型?
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3) 可以消除文档中噪声的影响。一般来说,文档中的杂音往往出现在次要主题中,我们可以忽略它们,只保留文档中的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5) 与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
纺纱世界
原始软文区(智能伪原创)SEO说难不难,说简单也不是那么简单
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-16 23:36
(6),词频控制:关键词密度,比同行高一点
(7),内链:锚文本方向
(8)、robots和nofollow的使用:引导网络蜘蛛,控制权重信息的丢失
(9),网站来映射:使用网络蜘蛛爬取
(10),设置404错误页面和301跳转:搜索引擎友好和用户友好
(11),网站结构:树状结构,有利于搜索引擎蜘蛛和用户判断的逻辑结构
(12),网站 主要内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站行为结构(目录管理结构)
(16),快速连接
(17)TDK 分页健康,分页
(18),友情链接
以上几点虽然很简单,但确实需要一些努力才能做好。同时,这几点也总结了网站的内容优化。做好以上几点,网站的优化就基本搞定了。
总结:
网站Optimization,网站优化很重要,可以说直接影响网站的排名,所以做SEO的时候一定要注意网站优化。 网站optimization 是我们一直坚持的工作,搜索引擎优化好你的毅力。如果你不坚持每天都做,你就得不到好的排名。
原创软文区(smart伪原创)
SEO难说,简单没那么简单,很多人问我,网站SEO优化应该怎么做?但是当我说出来的时候,他们想:就是这样?没有一点内容是不可能的!事实上,目前网站上的SEO确实没有太多内容。更多的是细节处理和用户体验。
有的朋友认为网站优化难,因为不知道里面的路,不知道从哪里开始。其他人认为优化网站和更新文章很容易。这也是因为他们对网站非常感兴趣。 SEO不明白。很多培训机构在关键词成立后就开始更新文章教网站优化。没有涉及其他内容,所以很多人认为网站优化实际上是更新文章。
1、提高网站的加载速度
在这个信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。
搜索引擎也是一样,所以在优化的时候,考虑可以做些什么来加速,比如CDN、无用代码清除、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作(具体可查看编辑器介绍《提高网站速度的六种网站前端优化方法》)。
2、title 标题定位
网站title 标题,也就是你的网站叫什么,通常为了SEO优化,会选择三到五个关键词作为标题,所以标题的顺序也是有规律的。权重从左到右依次递减(详见“网站页面标题设置方法及技巧”介绍)。
标题需要收录优化关键词的内容。同时网站中的多个页面标题不能相同,至少要能闪现“关键词——网站主页——关键词的简要说明。”输入,一旦判断标题,不要再做任何更正了!
3、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象。山寨好,当地人好,是否专业也不是我们想要的结果。页面设计需要 UI & UX 投资和品牌自己的口碑来背书。否则,用户在网站中更难产生信任感和参与感。
最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4、避免各种促使用户离开页面的元素
很多弹窗、固定凸窗、广告位都会让用户反感,从而放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑更多原生方式植入这些元素或奖励用户完成过程,同时避免蜘蛛在使用代码中被禁止或难以捕捉从而被搜索引擎降级的可能性。
5、关键词植入
常规的关键词植入要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等,这个就不多说了,大家懂的,不懂的朋友可以查看小编的介绍《网站上SEO最容易忽略的一些优化细节》。
6、主题模型的注入
关键词植入是不够的,因为那太机械化了,会失去文字的用户体验,所以我们要做一个主题模型,比如关键词“婚纱搭配”我们可以延伸到燕尾服,婚纱礼服、婚纱背心、婚纱套装、婚礼展销会等相关词构成一个大主题。这样的页面内容将使关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解读为您要推送的主题内容是与婚纱礼服相关的内容(具体请参考小编的相关介绍《如何做好婚礼服装的SEO优化》)网站主题内容模型”)。
7、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响这些显示的信息(主要是标题、描述、url),这些元素需要在内容上进行优化:标题创意、描述飘红、 url规范、文章日期、结构化数据的使用、在线对话等
8、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
(1),提供独特的视觉体验、前端界面、合适的字体和功能按钮。
(2),内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面。
(3),与其他内容相比没有重复,深度更强大。
(4),打开速度快(无广告),可在不同终端阅读。
(5),可以产生赞许、惊喜、快乐、思考等情绪化的想法。
(6),可以达到一定的转发和传播力。
(7),可以使用完整、准确和独特的信息来解决或回答问题。
9、网站规划调整
假设原来的网站是图片页面,使用较多的flash和图片,这些页面元素不利于搜索引擎的进入,所以在页面底部增加了三列,分别是相关公司简介。 , 关键词产品新闻和公司关键词产品列表,三栏内容添加url。
当然,最好的方法是使用新闻系统更新关键字产品新闻,可以将关键字的具体描述作为从首页到单个页面的链接,页面的描述收录公司关键词产品列表连接,这些都是为了形成公司网站内部的网络规划(详见小编的介绍《从SEO角度优化网站首页结构布局》)。
另外,页面没有必要静态化,静态化也不一定是整个网站,你可以只静态化最重要的首页。对于不同程序的处理,页面的执行时间是不同的。对于互联网上成熟的建站系统来说,执行效率不用多说,相信是一个比较优化的水平。
10、网站SEO优化的一些要点
对于网站SEO优化,如果你还是一头雾水,不妨从以下方便入手,具体内容如下:
(1), URL: 标准化、唯一性、静态化
(2),导航:主导航、面包屑导航、二级导航
(3),关键词:main关键词(首页),副关键词(专栏),长尾关键词(内容页)
(4),标签:标题、关键词、描述
(5),权重标签:h1-h6 标签,b 标签,强标签
(6),词频控制:关键词密度,略高于同行
(7),内链:定向锚文本
(8),机器人和nofollow使用:引导蜘蛛,控制减肥
(9),网站Map: 用蜘蛛爬行
(10),设置404错误页面和301跳转:搜索引擎好友和用户的友好度
(11),网站结构:树状结构,利于搜索引擎抓取和用户判断逻辑结构
(12),网站 内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站结构(目录结构)
(16),快速连接
(17),子页面TDK,子页面健康等级
(18),友情链接
以上几点虽然简单,但要细化,确实需要一些功夫。同时,这些点也总结了网站优化的内容。做好以上几点,网站的优化基本就大功告成了。
总结:
在网站optimization中,网站的站点优化非常重要。可以说直接影响了网站的排名。所以,SEO一定要重视网站优化。 网站optimization 永远是你做的工作,SEO靠的是毅力。如果你不坚持每天都做好,你就不会排名好。
分享了很多SEO优化的东西,深刻描绘了一个SEO站长的苦涩成长经历。如果你想学习更多的SEO优化技巧,可以在我的专栏里找到更多干货文章:seo Spark:SEO干货笔记:SEO站长的苦涩成长史!
搜索引擎优化
查看全部
原始软文区(智能伪原创)SEO说难不难,说简单也不是那么简单
(6),词频控制:关键词密度,比同行高一点
(7),内链:锚文本方向
(8)、robots和nofollow的使用:引导网络蜘蛛,控制权重信息的丢失
(9),网站来映射:使用网络蜘蛛爬取
(10),设置404错误页面和301跳转:搜索引擎友好和用户友好
(11),网站结构:树状结构,有利于搜索引擎蜘蛛和用户判断的逻辑结构
(12),网站 主要内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站行为结构(目录管理结构)
(16),快速连接
(17)TDK 分页健康,分页
(18),友情链接
以上几点虽然很简单,但确实需要一些努力才能做好。同时,这几点也总结了网站的内容优化。做好以上几点,网站的优化就基本搞定了。
总结:
网站Optimization,网站优化很重要,可以说直接影响网站的排名,所以做SEO的时候一定要注意网站优化。 网站optimization 是我们一直坚持的工作,搜索引擎优化好你的毅力。如果你不坚持每天都做,你就得不到好的排名。
原创软文区(smart伪原创)
SEO难说,简单没那么简单,很多人问我,网站SEO优化应该怎么做?但是当我说出来的时候,他们想:就是这样?没有一点内容是不可能的!事实上,目前网站上的SEO确实没有太多内容。更多的是细节处理和用户体验。
有的朋友认为网站优化难,因为不知道里面的路,不知道从哪里开始。其他人认为优化网站和更新文章很容易。这也是因为他们对网站非常感兴趣。 SEO不明白。很多培训机构在关键词成立后就开始更新文章教网站优化。没有涉及其他内容,所以很多人认为网站优化实际上是更新文章。
1、提高网站的加载速度
在这个信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。
搜索引擎也是一样,所以在优化的时候,考虑可以做些什么来加速,比如CDN、无用代码清除、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作(具体可查看编辑器介绍《提高网站速度的六种网站前端优化方法》)。
2、title 标题定位
网站title 标题,也就是你的网站叫什么,通常为了SEO优化,会选择三到五个关键词作为标题,所以标题的顺序也是有规律的。权重从左到右依次递减(详见“网站页面标题设置方法及技巧”介绍)。
标题需要收录优化关键词的内容。同时网站中的多个页面标题不能相同,至少要能闪现“关键词——网站主页——关键词的简要说明。”输入,一旦判断标题,不要再做任何更正了!
3、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象。山寨好,当地人好,是否专业也不是我们想要的结果。页面设计需要 UI & UX 投资和品牌自己的口碑来背书。否则,用户在网站中更难产生信任感和参与感。
最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4、避免各种促使用户离开页面的元素
很多弹窗、固定凸窗、广告位都会让用户反感,从而放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑更多原生方式植入这些元素或奖励用户完成过程,同时避免蜘蛛在使用代码中被禁止或难以捕捉从而被搜索引擎降级的可能性。
5、关键词植入
常规的关键词植入要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等,这个就不多说了,大家懂的,不懂的朋友可以查看小编的介绍《网站上SEO最容易忽略的一些优化细节》。
6、主题模型的注入
关键词植入是不够的,因为那太机械化了,会失去文字的用户体验,所以我们要做一个主题模型,比如关键词“婚纱搭配”我们可以延伸到燕尾服,婚纱礼服、婚纱背心、婚纱套装、婚礼展销会等相关词构成一个大主题。这样的页面内容将使关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解读为您要推送的主题内容是与婚纱礼服相关的内容(具体请参考小编的相关介绍《如何做好婚礼服装的SEO优化》)网站主题内容模型”)。
7、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响这些显示的信息(主要是标题、描述、url),这些元素需要在内容上进行优化:标题创意、描述飘红、 url规范、文章日期、结构化数据的使用、在线对话等
8、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
(1),提供独特的视觉体验、前端界面、合适的字体和功能按钮。
(2),内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面。
(3),与其他内容相比没有重复,深度更强大。
(4),打开速度快(无广告),可在不同终端阅读。
(5),可以产生赞许、惊喜、快乐、思考等情绪化的想法。
(6),可以达到一定的转发和传播力。
(7),可以使用完整、准确和独特的信息来解决或回答问题。
9、网站规划调整
假设原来的网站是图片页面,使用较多的flash和图片,这些页面元素不利于搜索引擎的进入,所以在页面底部增加了三列,分别是相关公司简介。 , 关键词产品新闻和公司关键词产品列表,三栏内容添加url。
当然,最好的方法是使用新闻系统更新关键字产品新闻,可以将关键字的具体描述作为从首页到单个页面的链接,页面的描述收录公司关键词产品列表连接,这些都是为了形成公司网站内部的网络规划(详见小编的介绍《从SEO角度优化网站首页结构布局》)。
另外,页面没有必要静态化,静态化也不一定是整个网站,你可以只静态化最重要的首页。对于不同程序的处理,页面的执行时间是不同的。对于互联网上成熟的建站系统来说,执行效率不用多说,相信是一个比较优化的水平。
10、网站SEO优化的一些要点
对于网站SEO优化,如果你还是一头雾水,不妨从以下方便入手,具体内容如下:
(1), URL: 标准化、唯一性、静态化
(2),导航:主导航、面包屑导航、二级导航
(3),关键词:main关键词(首页),副关键词(专栏),长尾关键词(内容页)
(4),标签:标题、关键词、描述
(5),权重标签:h1-h6 标签,b 标签,强标签
(6),词频控制:关键词密度,略高于同行
(7),内链:定向锚文本
(8),机器人和nofollow使用:引导蜘蛛,控制减肥
(9),网站Map: 用蜘蛛爬行
(10),设置404错误页面和301跳转:搜索引擎好友和用户的友好度
(11),网站结构:树状结构,利于搜索引擎抓取和用户判断逻辑结构
(12),网站 内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站结构(目录结构)
(16),快速连接
(17),子页面TDK,子页面健康等级
(18),友情链接
以上几点虽然简单,但要细化,确实需要一些功夫。同时,这些点也总结了网站优化的内容。做好以上几点,网站的优化基本就大功告成了。
总结:
在网站optimization中,网站的站点优化非常重要。可以说直接影响了网站的排名。所以,SEO一定要重视网站优化。 网站optimization 永远是你做的工作,SEO靠的是毅力。如果你不坚持每天都做好,你就不会排名好。
分享了很多SEO优化的东西,深刻描绘了一个SEO站长的苦涩成长经历。如果你想学习更多的SEO优化技巧,可以在我的专栏里找到更多干货文章:seo Spark:SEO干货笔记:SEO站长的苦涩成长史!
搜索引擎优化



电话拒绝率低客户兴趣度高容易成交物超所值
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-14 22:54
**SEO优化,G3云推广7.0的**优势:来电拒绝率低,客户兴趣高,销售预约高,产品性价比高,交易方便,性价比好,单价高,简单的售后。
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是网站seo优化过程中需要避免和去除的部分。考虑一种更原生的方式来植入这些元素或奖励用户完成这个过程。同时,避免蜘蛛在代码使用过程中被搜索引擎禁止或难以捕捉和降级的可能。 , 常规的关键词 布局。常规的关键词植入(爆老师称之为填词)也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL ,图片命名等等。这个我就不重复了,大家都明白。 ,使用相关主题模型。仅仅填写文字是不够的,因为那太机械了,失去了文字用户体验。所以我们要做一个主题模型,比如关键词我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚礼展销会等相关词。
付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还将优先考虑与您相关的内容和人员。这可能意味着通过 Facebook 交朋友、在 Twitter 上关注粉丝或通过其他社交网络联系。有时,社交搜索甚至会优先考虑影响者分享的内容。所有这一切意味着,当您考虑 SEO 策略时,您需要考虑您的社交媒体策略如何适应这个难题。深入思考:将搜索引擎优化视为“搜索体验优化”。对他们来说,留在您的网站、与您的内容互动并稍后回来非常重要。
购买入站营销或 SEO 优化软件。检查表现良好的页面。寻找获得入站链接的机会,例如网站。监控排名和流量的变化。一系列策略,如果您使用它们,将帮助您在搜索引擎中排名更高。
为了满足长期意图和排名,围绕主题而非关键字建立 SEO 营销策略。如果你这样做,不管怎样,你会发现你自然可以针对重要的关键字进行优化。了解您的目标受众(又名买家角色)以及他们对什么感兴趣是通过搜索引擎将相关访问者吸引到您的 网站 的关键。自然流量是来自 Google 或 Bing 等搜索引擎的无偿流量。付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还会优先考虑与您相关的内容和人员。 查看全部
电话拒绝率低客户兴趣度高容易成交物超所值
**SEO优化,G3云推广7.0的**优势:来电拒绝率低,客户兴趣高,销售预约高,产品性价比高,交易方便,性价比好,单价高,简单的售后。
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是网站seo优化过程中需要避免和去除的部分。考虑一种更原生的方式来植入这些元素或奖励用户完成这个过程。同时,避免蜘蛛在代码使用过程中被搜索引擎禁止或难以捕捉和降级的可能。 , 常规的关键词 布局。常规的关键词植入(爆老师称之为填词)也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL ,图片命名等等。这个我就不重复了,大家都明白。 ,使用相关主题模型。仅仅填写文字是不够的,因为那太机械了,失去了文字用户体验。所以我们要做一个主题模型,比如关键词我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚礼展销会等相关词。
付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还将优先考虑与您相关的内容和人员。这可能意味着通过 Facebook 交朋友、在 Twitter 上关注粉丝或通过其他社交网络联系。有时,社交搜索甚至会优先考虑影响者分享的内容。所有这一切意味着,当您考虑 SEO 策略时,您需要考虑您的社交媒体策略如何适应这个难题。深入思考:将搜索引擎优化视为“搜索体验优化”。对他们来说,留在您的网站、与您的内容互动并稍后回来非常重要。
购买入站营销或 SEO 优化软件。检查表现良好的页面。寻找获得入站链接的机会,例如网站。监控排名和流量的变化。一系列策略,如果您使用它们,将帮助您在搜索引擎中排名更高。
为了满足长期意图和排名,围绕主题而非关键字建立 SEO 营销策略。如果你这样做,不管怎样,你会发现你自然可以针对重要的关键字进行优化。了解您的目标受众(又名买家角色)以及他们对什么感兴趣是通过搜索引擎将相关访问者吸引到您的 网站 的关键。自然流量是来自 Google 或 Bing 等搜索引擎的无偿流量。付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还会优先考虑与您相关的内容和人员。
如何做好seo相关性内容提升网站自身权重排名与流量
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-07-14 22:49
也许对于网站,seo 不是最好的营销策略。无需竞标一系列按点击付费的广告更直接,但优化一个网站对企业无害。如果搜索引擎营销 (SEM) 是设计、运行和优化搜索引擎广告活动的实践,那么做网站 的基本工作就更好了。它与SEO区别的最简单描述是搜索结果中付费和未付费优先级排名的差异。它的目的比相关性更突出。但是做seo相关的内容也是提升网站自身权重排名和流量的关键。
产生足够的投资回报。当然网站内容质量优化是少不了的。 网站内容优化是对页面内容和编码的更新和调整,使内容对搜索引擎更具吸引力,使搜索者能够快速找到自己想要的内容。在大多数情况下,我们不可能 100% 优化每个页面。随着百度算法的不断更新,内容质量是一个长期持续的过程。
那么如何优化页面内容呢?以下是我们需要考虑的主要因素:
标题标签。
元描述。
ALT 标签。
网址结构。
媒体(图片、视频)。
H1、H2 和 H3 标签。
内部链接。
出站链接。
移动响应
这些因素是第一步,SEO技巧不假思索。但内容,即占据网页大部分的博客、图片、视频,也必须进行优化。优化旧帖子而不是创建新帖子会对自然排名和搜索存在产生重大影响。
内容优化优先级:从哪里开始,做什么?
优化内容时,您应该针对单个关键字优化整个页面。二级和潜在语义索引 (LSI) 关键字将起作用,但搜索引擎和消费者需要绝对清楚您的页面(博客)是什么,以及它与主题、标题、副标题和元模型相关性的关系。为此,激光只关注一个关键字。
然后我们需要提高页面的准确率。如果您的页面在后台正确标记并且所有元数据都与关键字相关,那么我们需要更新副本的深度。我们称之为“内容深度”。内容差距分析表明,您需要在更新的内容中收录好主意,以满足搜索者的意图。这是一个分步蓝图,用于为您保留哪些内容以及更改哪些内容。增加读者价值:不要忽视关键词的重要方面。我们还需要对关键词进行适当的扩展,试图找出用户搜索需求的可能性。
网站中的每一个内容都有内在价值。做好优化不是一天就能完成的,必须持续跟进完善网站数据。您的网站可以在众多同行中脱颖而出,达到网站推广排名的理想位置,做更多有价值的内容营销。 查看全部
如何做好seo相关性内容提升网站自身权重排名与流量
也许对于网站,seo 不是最好的营销策略。无需竞标一系列按点击付费的广告更直接,但优化一个网站对企业无害。如果搜索引擎营销 (SEM) 是设计、运行和优化搜索引擎广告活动的实践,那么做网站 的基本工作就更好了。它与SEO区别的最简单描述是搜索结果中付费和未付费优先级排名的差异。它的目的比相关性更突出。但是做seo相关的内容也是提升网站自身权重排名和流量的关键。
产生足够的投资回报。当然网站内容质量优化是少不了的。 网站内容优化是对页面内容和编码的更新和调整,使内容对搜索引擎更具吸引力,使搜索者能够快速找到自己想要的内容。在大多数情况下,我们不可能 100% 优化每个页面。随着百度算法的不断更新,内容质量是一个长期持续的过程。

那么如何优化页面内容呢?以下是我们需要考虑的主要因素:
标题标签。
元描述。
ALT 标签。
网址结构。
媒体(图片、视频)。
H1、H2 和 H3 标签。
内部链接。
出站链接。
移动响应
这些因素是第一步,SEO技巧不假思索。但内容,即占据网页大部分的博客、图片、视频,也必须进行优化。优化旧帖子而不是创建新帖子会对自然排名和搜索存在产生重大影响。

内容优化优先级:从哪里开始,做什么?
优化内容时,您应该针对单个关键字优化整个页面。二级和潜在语义索引 (LSI) 关键字将起作用,但搜索引擎和消费者需要绝对清楚您的页面(博客)是什么,以及它与主题、标题、副标题和元模型相关性的关系。为此,激光只关注一个关键字。
然后我们需要提高页面的准确率。如果您的页面在后台正确标记并且所有元数据都与关键字相关,那么我们需要更新副本的深度。我们称之为“内容深度”。内容差距分析表明,您需要在更新的内容中收录好主意,以满足搜索者的意图。这是一个分步蓝图,用于为您保留哪些内容以及更改哪些内容。增加读者价值:不要忽视关键词的重要方面。我们还需要对关键词进行适当的扩展,试图找出用户搜索需求的可能性。
网站中的每一个内容都有内在价值。做好优化不是一天就能完成的,必须持续跟进完善网站数据。您的网站可以在众多同行中脱颖而出,达到网站推广排名的理想位置,做更多有价值的内容营销。
编辑推荐《这就是搜索引擎:核心技术详解》
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-07-11 07:01
编辑推荐《这就是搜索引擎:核心技术详解》
编辑推荐
《这就是搜索引擎:核心技术详解》适合所有对搜索引擎技术感兴趣的人,尤其是相关领域的学生、对搜索引擎核心技术感兴趣的技术人员、相关从业人员在搜索引擎优化方面,中小网站站长等更有参考价值。
作者其他作品《大数据日常知识:架构与算法》
内容介绍
搜索引擎作为互联网发展中至关重要的应用,已经成为互联网各个领域的制高点,其重要性不言而喻。搜索引擎领域也是互联网应用中少有的以核心技术为命脉的领域。搜索引擎的各个子系统是如何设计的?这已成为广大技术人员和搜索引擎优化者关注的内容。
《这就是搜索引擎:核心技术详解》的特点是内容新颖、全面、通俗易懂。对实际搜索引擎中涉及的各种核心技术进行了全面详细的介绍。除了以网络爬虫、索引系统、排名系统、链接分析和用户分析为核心的搜索系统外,还包括网页反作弊、缓存管理、网页重复数据删除技术等实际搜索引擎必须具备的技术。关注,同时在相当大的篇幅中讲解了云计算和云存储的核心技术原理。此外,本书还密切关注搜索引擎开发的前沿技术:谷歌的咖啡因系统和Megastore等新的云计算技术、百度的暗网爬虫技术阿拉丁计划、内容农场作弊、机器学习排序等。许多新技术在相关章节中有详细的讲解,同时对社交搜索、实时搜索、上下文搜索等搜索引擎未来的发展方向给出了技术展望。为了加深读者的理解,书中引入了大量生动的图片来讲解算法的原理。相信读者会发现,原来搜索引擎的核心技术比原先想象的要简单得多。
作者简介
张俊林着有技术书籍《这就是搜索引擎:核心技术详解》,现任畅捷通智能平台总监。在此之前,张君林曾任阿里巴巴风潮广告平台、百度商业搜索部、新浪微博搜索部和数据系统部高级技术专家,新浪微博技术委员会委员,负责方向算法策略。张君林也是智能信息聚合网站“玩聚网”的联合创始人之一。他的研发兴趣集中在:搜索技术、推荐系统、社交挖掘、自然语言处理和大数据算法架构等,在上述领域有多年的行业实践经验。张君林毕业于天津大学管理学院,获学士学位。 1999年至2004年在中国科学院软件研究所直接攻读博士学位。研究方向为信息检索理论和自然语言处理。学习期间,在ACL/COLING/IJCNLP等顶级国际会议上发表多篇文章。学术论文。此外,他在此期间设计的搜索系统赢得了17个国际高水平研究团队的激烈竞争,并在美国国防部DARPA主办的第二届TREC高精度检索系统评估中排名第一。取名效果极佳。
内容
第一章搜索引擎及其技术架构
1.1 为什么搜索引擎很重要
1.1.1 互联网的发展
1.1.2 商业搜索引擎公司的发展
1.1.3 搜索引擎的重要地位
1.2搜索引擎技术发展历程
1.2.1史前时代:目录的产生
1.2.2 第一代:文本检索的产生
1.2.3 第二代:链路分析的产生
1.2.4 第三代:以用户为中心的一代
1.3 搜索引擎的3个目标
1.4 搜索引擎的3个核心问题
1.4.13个核心问题
1.4.2 与技术发展的关系
1.5搜索引擎技术架构
第 2 章网络爬虫
2.1 通用爬虫框架
2.2 优秀爬虫的特点
2.3 爬虫质量评价标准
2.4 爬取策略
2.4.1 广度优先遍历策略(BreathFirst)
2.4.2 部分 PageRank 策略(PartialPageRank)
2.4.3OCIP 策略(OnlinePageImportanceComputation)
2.4.4LargerSitesFirst 策略(LargerSitesFirst)
2.5网页更新策略
2.5.1历史参考策略
2.5.2用户体验策略
2.5.3 聚类抽样策略
2.6DeepWebCrawling(DeepWebCrawling)
2.6.1 查询组合问题
2.6.2 在文本框中填写问题
2.7 分布式爬虫
2.7.1 主从分发爬虫(Master-Slave)
2.7.2 点对点(PeertoPeer)
本章总结
本章参考资料
第 3 章搜索引擎索引
3.1索引基础
3.1.1 字——文档矩阵
3.1.2 倒排索引的基本概念
3.1.3 倒排索引的简单例子
3.2 词词典
3.2.1 哈希加链表
3.2.2树结构
3.3PostingList
3.4创建索引
3.4.1 两遍文档遍历方法(2-PassIn-MemoryInversion)
3.4.2Sort-basedInversion(Sort-basedInversion)
3.4.3Merge-basedInversion(Merge-basedInversion)
3.5动态索引
3.6 索引更新策略
3.6.1 完整重建策略(CompleteRe-Build)
3.6.2 重新合并策略(Re-Merge)
3.6.3 就地更新策略(In-Place)
3.6.4 混合策略(Hybrid)
3.7查询处理
3.7.1 一次一个文档(DocataTime)
3.7.2 一次一个字(TermataTime)
3.7.3SkipPointers(SkipPointers)
3.8多字段索引
3.8.1多索引法
3.8.2倒排列表法
3.8.3扩展列表方法(ExtentList)
3.9phrase 查询
3.9.1位置索引(PositionIndex)
3.9.2 二字索引(NextwordIndex)
3.9.3 PhraseIndex (PhraseIndex)
3.9.4 混合方法
3.10分布式索引(ParallelIndexing)
3.10.1 按文档划分(DocumentPartitioning)
3.10.2 按词划分(TermPartitioning)
3.10.3 两种方案对比
本章总结
本章参考资料
第 4 章索引压缩
4.1 字典压缩
4.2倒列表压缩算法
4.2.1 评价指标压缩算法指标
4.2.2 一元编码和二进制编码
4.2.3EliasGamma 算法和 EliasDelta 算法
4.2.4Golomb 算法和 Rice 算法
4.2.5 变长字节算法(VariableByte)
4.2.6SimpleX 系列算法
4.2.7PForDelta 算法
4.3 DocIDReordering(DocIDReordering)
4.4StaticIndexPruning (StaticIndexPruning)
4.4.1 以词为中心的索引剪裁
4.4.2 以文档为中心的索引裁剪
本章总结
本章参考资料
第 5 章搜索模型和搜索排序
5.1BooleanModel (BooleanModel)
5.2VectorSpaceModel (VectorSpaceModel)
5.2.1文档表示
5.2.2 相似度计算
5.2.3特征权重计算
5.3概率检索模型
5.3.1 概率排序原则
5.3.2BinaryIndependentModel(BinaryIndependentModel)
5.3.3BM25 模型
5.3.4BM25F 模型
5.4 语言模型方法
5.5 机器学习排名(LearningtoRank)
5.5.1机器学习排序的基本思路
5.5.2 单文档方法(PointWiseApproach)
5.5.3文档对方法(PairWiseApproach)
5.5.4 文档列表方法(ListWiseApproach)
5.6 搜索质量评价标准
5.6.1准确率和召回率
5.6.2P@10个指标
5.6.3MAP 指标(MeanAveragePrecision)
本章总结
本章参考资料
第六章链接分析
6.1网页图片
6.2 两个概念模型和算法的关系
6.2.1RandomSurferModel (RandomSurferModel)
6.2.2 子集传播模型
6.2.3 链接分析算法之间的关系
6.3PageRank 算法
6.3.1 从链内数到PageRank
6.3.2PageRank 计算
6.3.3 链接陷阱(LinkSink)和远程跳转(Teleporting)
6.4HITS 算法(HypertextInducedTopicSelection)
6.4.1Hub 页面和权限页面
6.4.2 互增关系
6.4.3HITS 算法
6.4.4HITS 算法问题
6.4.5HITS算法与PageRank算法对比
6.5SALSA 算法
6.5.1 确定计算对象集
6.5.2 链接关系传播
6.5.3权限权重计算
6.6 主题敏感页面排名(TopicSensitivePageRank)
6.6.1 主题敏感的PageRank和PageRank的区别
6.6.2 主题敏感的PageRank计算过程
6.6.3 使用主题敏感的PageRank构建个性化搜索
6.7Hilltop 算法
6.7.1 Hilltop 算法的一些基本定义
6.7.2Hilltop 算法
6.8 其他改进算法
6.8.1IntelligentSurferModel(智能冲浪模型)
6.8.2 BiasedSurferModel(BiasedSurferModel)
6.8.3PHITS 算法(ProbabilityAnalogyofHITS)
6.8.4BFS 算法(BackwardForwardStep)
本章总结
本章参考资料
第 7 章云存储和云计算
7.1 云存储和云计算概述
7.1.1 基本假设
7.1.2理论基础
7.1.3 数据模型
7.1.4 基本问题
7.1.5Google 的云存储和云计算架构
7.2Google 文件系统 (GFS)
7.2.1GFS 设计原则
7.2.2GFS 整体架构
7.2.3GFS 主控服务器
7.2.4 系统交互行为
7.3Chubby 锁服务
7.4BigTable
7.4.1BigTable 的数据模型
7.4.2BigTable 整体结构
7.4.3BigTable 的管理数据
7.4.4MasterServer
7.4.5 分表服务器(TabletServer)
7.5Megastore 系统
7.5.1 实体组切分
7.5.2数据模型
7.5.3数据读写与备份
7.6Map/Reduce 云计算模型
7.6.1计算模型
7.6.2 整体逻辑流程
7.6.3 应用实例
7.7Caffeine System-Percolator
7.7.1 事务支持
7.7.2 观察/通知架构
7.8Pregel 图计算模型
7.9Dynomo 云存储系统
7.9.1 数据分区算法(PartitioningAlgorithm)
7.9.2数据备份(复制)
7.9.3数据读写
7.9.4数据版本控制
7.10PNUTS 云存储系统
7.10.1PNUTS 整体架构
7.10.2 存储单元
7.10.3 分表控制器和数据路由器
7.10.4 雅虎通讯社
7.10.5 数据一致性
7.11HayStack 存储系统
7.11.1HayStack 整体架构
7.11.2 目录服务
7.11.3HayStack 缓存
7.11.4HayStack 存储系统
本章总结
本章参考资料
第8章网络反作弊
8.1内容作弊
8.1.1常见的内容作弊方法
8.1.2内容农场(ContentFarm)
8.2 链接作弊
8.3 页面隐藏作弊
8.4Web2.0 作弊方法
8.5反作弊技术总体思路
8.5.1 信任传播模型
8.5.2 不信任传播模型
8.5.3 异常发现模型
8.6 万能链接反作弊方法
8.6.1TrustRank 算法
8.6.2BadRank 算法
8.6.3SpamRank
8.7 专用链接防作弊技术
8.7.1 识别链接农场
8.7.2 识别谷歌轰炸
8.8 识别内容作弊
8.9反隐藏作弊
8.9.1 识别页面隐藏
8.9.2 识别网页重定向
8.10 搜索引擎反作弊综合框架
本章总结
本章参考资料
第九章用户查询意图分析
9.1搜索行为及其意图
9.1.1用户搜索行为
9.1.2用户搜索意图分类
9.2搜索日志挖掘
9.2.1查询会话(QuerySession)
9.2.2ClickGraph (ClickGraph)
9.2.3查询图(QueryGraph)
9.3 相关搜索
9.3.1 基于查询会话的方法
9.3.2 基于点击图的方法
9.4检查纠错
9.4.1EditDistance(编辑距离)
9.4.2 噪声通道模型(NoiseChannelModel)
本章总结
本章参考资料
第十章网页去重
10.1 通用去重算法框架
10.2Shingling 算法
10.3I-Match 算法
10.4SimHash 算法
10.4.1 文档指纹计算
10.4.2 搜索类似文档
10.5SpotSig 算法
10.5.1 特征提取
10.5.2 搜索类似文档
本章总结
本章参考资料
第11章搜索引擎缓存机制
11.1搜索引擎缓存系统架构
11.2Cache 对象
11.3缓存结构
11.4缓存消除策略(EvictPolicy)
11.4.1 动态策略
11.4.2 混合策略
11.5缓存更新策略(RefreshPolicy)
本章总结
本章参考资料
第十二章搜索引擎发展趋势
12.1个性化搜索
12.2社交搜索
12.3 实时搜索
12.4手机搜索
12.5 位置感知搜索
12.6跨语言搜索
12.7多媒体搜索
12.8情况搜索
前言
互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品比例相对较小。搜索引擎是当前互联网产品中具有技术含量的产品,如果不是唯一的,至少是其中之一。
经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。 Twitter联合创始人埃文威廉姆斯提出“域名已死理论”:容易记住的域名不再重要,因为人们会通过搜索输入网站。搜索引擎排名对于中小网站流量非常重要。了解搜索引擎简单界面背后的技术原理,对很多人来说其实很重要。
为什么会有这本书
写搜索引擎技术书籍的最初想法是两年前诞生的。当时的场景是对团队成员进行搜索技术培训,但是我搜索了相关书籍,却没有找到一本非常合适的搜索技术入门书籍。当时市场上的书籍,要么是信息检索理论的专着,理论性太强,不易理解,真正讲搜索引擎技术的章节也不多;或者它们是太实用的书,比如 Lucene 代码分析,比如搜索引擎。这种直接分析开源系统代码的算法应用并不是一种非常高效的学习方法。所以当时就诞生了写一本通俗易懂,适合没有相关技术背景的人,比较全面,融合新技术的搜索引擎书籍。但我是在一年前开始写作的。
在写这本书之前,我为自己设定了一些目标。首先,内容要全面,即全面覆盖搜索引擎相关技术的主要方面。不仅要收录倒排索引、检索模型、爬虫等常用内容,还要详细讲解链接分析、网页反作弊、用户搜索意图分析、网页云存储和去重甚至搜索引擎缓存都是有机的一个完整的搜索引擎的组成部分,但详细介绍其原理的书籍并不多。我希望尽可能全面。
第二个目标很容易理解。我希望没有任何相关技术背景的人可以从阅读本书中学到一些东西,不了解技术的学生可以大致理解。这个目标看似简单,但实际上实现起来并不容易。我不敢说这本书达到了这个目标,但我已经尽力了。具体措施包括以下三个方面。
一是尽可能减少数学公式的数量,除非公式没有列出。尽管数学公式具有简单之美,但大多数人实际上对数学符号存在恐惧和回避。多年前我也有类似的心理,所以尽可能不要使用数学公式。
一是尽量多举例,特别是一些比较难理解的地方。需要举例来加深理解。
还有更多的绘图。就我个人的经验而言,虽然算法或技术很抽象,但如果深入理解原理,将复杂的化简,绝对可以将算法转化为生动的画面。如果你无法在脑海中形成算法的直观图形表示,则说明你对其原理没有透彻的理解。这是我判断自己是否深刻理解算法的一个私人标准。鉴于此,本书在讲解算法的地方,使用了大量的算法示意图。全书收录300多幅算法原理解释图。相信这对读者深入理解算法有很大帮助。
第三个目标是强调新现象和新技术,比如谷歌的caffeine系统和Megastore等云存储系统、Pregel云图计算模型、暗网爬取技术、Web2.0网络作弊、机器学习排序、上下文搜索、社交搜索等在相关章节中有说明。
第四个目标是强调原则,而不是停留在技术细节上。对于新手来说,一个容易解决的问题是他们喜欢挖掘细节,只见树木不见森林,懂一个公式却不懂背后的基本思想和出发点。我接触过很多技术人员,七八岁就会有这个特点。有一个问题“道家哪个好?” “道”是什么?什么是“手术”?比如《孙子兵法》就是道,《三十六计》就是战术。 “道”是宏观的、有原则的、经久不衰的基本原则,而“技术”是遵循基本原则的具体方法和措施,是变化无常的。技术也是如此。算法本身的细节就是“技巧”,算法所体现的基本思想就是“道”。知“道”、学“技”,虽然两者不能偏,但如果要选择优先级,毫无疑问我会先选择“道”再选择“术”。
以上四点是写书之前设定的目标。现在写完了,可能很多地方都达不到当初的期待,但是我会努力的。写书的过程很辛苦,至少比我想象的要难。因为工作忙,每天只能早起,加上周末和节假日。也许书中有这样的缺点,但我可以说我是真诚地写这本书的。
这本书是给谁看的?
如果您是以下其中一种,那么这本书适合您。
1.对搜索引擎核心算法感兴趣的技术人员
搜索引擎的整体框架是什么?收录哪些核心技术?
网络爬虫的基本结构是什么?常见的爬取策略有哪些?什么是暗网爬行?如何构建分布式爬虫?百度的阿拉丁计划是什么?
什么是倒排索引?如何对倒排索引进行数据压缩?
搜索引擎如何对搜索结果进行排序?
什么是向量空间模型?什么是概率模型?什么是BM25型号?什么是机器学习排序?它们之间有什么异同?
PageRank和HITS算法有什么关系?有哪些相同点和不同点?什么是 SALSA 算法?什么是山顶算法?各种链接分析算法之间的关系是什么?
如何识别搜索用户的真实搜索意图?用户可以搜索多少个类别?什么是点击图表?什么是查询会话?相关搜索是如何完成的?
为什么我们需要去重复网页?如何去重复网页?哪种算法效果更好?
搜索引擎缓存有多少级?核心战略是什么?
什么是上下文搜索?什么是社交搜索?什么是实时搜索?
搜索引擎的发展趋势是什么?
如果你对三个以上的问题感兴趣,那么这本书就是为你而写的。
2.对云计算和云存储感兴趣的技术人员
CAP的原理是什么?什么是 ACID 原理?它们之间有什么异同?
Google 的云计算框架包括哪些技术? Hadoop系列和谷歌的云计算框架有什么关系?
Google 的三驾马车 GFS、BigTable 和 MapReduce 是什么意思?有什么关系?
谷歌咖啡因系统的基本原理是什么?
Google 的 Pregel 计算模型和 MapReduce 计算模型有什么区别?
Google 的 Megastore 云存储系统和 BigTable 是什么关系?
什么是亚马逊的 Dynamo 系统?
雅虎的 PNUTS 系统是什么?
Haystack 存储系统适用于哪些地方?
如果你对以上问题感兴趣,相信你可以在书中找到答案。
3.互联网营销人员从事搜索引擎优化和中小网站站长
搜索引擎的反作弊策略是什么?如何优化以避免被认为作弊?
搜索引擎如何对搜索结果进行排序?链接分析和内容排名有什么关系?
什么是内容农场?什么是链接农场?他们是什么关系?
什么是 Web 2.0 作弊?常用的方法有哪些?
什么是 SpamRank?什么是信任等级?什么是坏排名?他们是什么关系?
咖啡因系统如何影响页面排名?
最近一批电商网站针对搜索引擎优化,结果被谷歌认定为黑帽SEO,导致搜索排名权降低。如何避免这种情况?从事相关行业的营销人员和网站webmasters应该对反作弊搜索引擎的基本策略和方法,甚至页面排名算法等搜索引擎的核心技术有深入的了解。 SEO技术归根结底其实很简单。尽管它在不断变化,但许多原则和策略总是相似而密不可分的。深入了解搜索引擎相关技术原理,将形成您所在行业的竞争优势。
4.作者本人
我的记忆力不是很好,一段时间内学到的技术往往几年后就模糊了,所以这本书也是给自己写的,作为技术参考手册。沉力也参与了本书的部分编写。
谢谢
感谢博文的编辑傅锐。没有她,这本书就不会出版。傅主编在审稿过程中提出的细致的改进点对我帮助很大。
特别感谢我的妻子。在将近一年的写作过程中,我几乎把所有的空闲时间都花在了这本书的写作上。她承担了所有的家务,以免分散我的注意力。没时间陪她也没关系,这本书的诞生也算是送给她的礼物。
对我来说,写这本书是一个辛苦而快乐的过程。就像一个远行的旅人。当你从水和山上仰望时,你总能看到你所忽略的美丽景色。如果您在阅读本书,我很荣幸能有这样的体验。
张俊林
2011 年 6 月
获取正版《这就是搜索引擎:核心技术详解》 查看全部
编辑推荐《这就是搜索引擎:核心技术详解》

编辑推荐
《这就是搜索引擎:核心技术详解》适合所有对搜索引擎技术感兴趣的人,尤其是相关领域的学生、对搜索引擎核心技术感兴趣的技术人员、相关从业人员在搜索引擎优化方面,中小网站站长等更有参考价值。
作者其他作品《大数据日常知识:架构与算法》
内容介绍
搜索引擎作为互联网发展中至关重要的应用,已经成为互联网各个领域的制高点,其重要性不言而喻。搜索引擎领域也是互联网应用中少有的以核心技术为命脉的领域。搜索引擎的各个子系统是如何设计的?这已成为广大技术人员和搜索引擎优化者关注的内容。
《这就是搜索引擎:核心技术详解》的特点是内容新颖、全面、通俗易懂。对实际搜索引擎中涉及的各种核心技术进行了全面详细的介绍。除了以网络爬虫、索引系统、排名系统、链接分析和用户分析为核心的搜索系统外,还包括网页反作弊、缓存管理、网页重复数据删除技术等实际搜索引擎必须具备的技术。关注,同时在相当大的篇幅中讲解了云计算和云存储的核心技术原理。此外,本书还密切关注搜索引擎开发的前沿技术:谷歌的咖啡因系统和Megastore等新的云计算技术、百度的暗网爬虫技术阿拉丁计划、内容农场作弊、机器学习排序等。许多新技术在相关章节中有详细的讲解,同时对社交搜索、实时搜索、上下文搜索等搜索引擎未来的发展方向给出了技术展望。为了加深读者的理解,书中引入了大量生动的图片来讲解算法的原理。相信读者会发现,原来搜索引擎的核心技术比原先想象的要简单得多。
作者简介
张俊林着有技术书籍《这就是搜索引擎:核心技术详解》,现任畅捷通智能平台总监。在此之前,张君林曾任阿里巴巴风潮广告平台、百度商业搜索部、新浪微博搜索部和数据系统部高级技术专家,新浪微博技术委员会委员,负责方向算法策略。张君林也是智能信息聚合网站“玩聚网”的联合创始人之一。他的研发兴趣集中在:搜索技术、推荐系统、社交挖掘、自然语言处理和大数据算法架构等,在上述领域有多年的行业实践经验。张君林毕业于天津大学管理学院,获学士学位。 1999年至2004年在中国科学院软件研究所直接攻读博士学位。研究方向为信息检索理论和自然语言处理。学习期间,在ACL/COLING/IJCNLP等顶级国际会议上发表多篇文章。学术论文。此外,他在此期间设计的搜索系统赢得了17个国际高水平研究团队的激烈竞争,并在美国国防部DARPA主办的第二届TREC高精度检索系统评估中排名第一。取名效果极佳。
内容
第一章搜索引擎及其技术架构
1.1 为什么搜索引擎很重要
1.1.1 互联网的发展
1.1.2 商业搜索引擎公司的发展
1.1.3 搜索引擎的重要地位
1.2搜索引擎技术发展历程
1.2.1史前时代:目录的产生
1.2.2 第一代:文本检索的产生
1.2.3 第二代:链路分析的产生
1.2.4 第三代:以用户为中心的一代
1.3 搜索引擎的3个目标
1.4 搜索引擎的3个核心问题
1.4.13个核心问题
1.4.2 与技术发展的关系
1.5搜索引擎技术架构
第 2 章网络爬虫
2.1 通用爬虫框架
2.2 优秀爬虫的特点
2.3 爬虫质量评价标准
2.4 爬取策略
2.4.1 广度优先遍历策略(BreathFirst)
2.4.2 部分 PageRank 策略(PartialPageRank)
2.4.3OCIP 策略(OnlinePageImportanceComputation)
2.4.4LargerSitesFirst 策略(LargerSitesFirst)
2.5网页更新策略
2.5.1历史参考策略
2.5.2用户体验策略
2.5.3 聚类抽样策略
2.6DeepWebCrawling(DeepWebCrawling)
2.6.1 查询组合问题
2.6.2 在文本框中填写问题
2.7 分布式爬虫
2.7.1 主从分发爬虫(Master-Slave)
2.7.2 点对点(PeertoPeer)
本章总结
本章参考资料
第 3 章搜索引擎索引
3.1索引基础
3.1.1 字——文档矩阵
3.1.2 倒排索引的基本概念
3.1.3 倒排索引的简单例子
3.2 词词典
3.2.1 哈希加链表
3.2.2树结构
3.3PostingList
3.4创建索引
3.4.1 两遍文档遍历方法(2-PassIn-MemoryInversion)
3.4.2Sort-basedInversion(Sort-basedInversion)
3.4.3Merge-basedInversion(Merge-basedInversion)
3.5动态索引
3.6 索引更新策略
3.6.1 完整重建策略(CompleteRe-Build)
3.6.2 重新合并策略(Re-Merge)
3.6.3 就地更新策略(In-Place)
3.6.4 混合策略(Hybrid)
3.7查询处理
3.7.1 一次一个文档(DocataTime)
3.7.2 一次一个字(TermataTime)
3.7.3SkipPointers(SkipPointers)
3.8多字段索引
3.8.1多索引法
3.8.2倒排列表法
3.8.3扩展列表方法(ExtentList)
3.9phrase 查询
3.9.1位置索引(PositionIndex)
3.9.2 二字索引(NextwordIndex)
3.9.3 PhraseIndex (PhraseIndex)
3.9.4 混合方法
3.10分布式索引(ParallelIndexing)
3.10.1 按文档划分(DocumentPartitioning)
3.10.2 按词划分(TermPartitioning)
3.10.3 两种方案对比
本章总结
本章参考资料
第 4 章索引压缩
4.1 字典压缩
4.2倒列表压缩算法
4.2.1 评价指标压缩算法指标
4.2.2 一元编码和二进制编码
4.2.3EliasGamma 算法和 EliasDelta 算法
4.2.4Golomb 算法和 Rice 算法
4.2.5 变长字节算法(VariableByte)
4.2.6SimpleX 系列算法
4.2.7PForDelta 算法
4.3 DocIDReordering(DocIDReordering)
4.4StaticIndexPruning (StaticIndexPruning)
4.4.1 以词为中心的索引剪裁
4.4.2 以文档为中心的索引裁剪
本章总结
本章参考资料
第 5 章搜索模型和搜索排序
5.1BooleanModel (BooleanModel)
5.2VectorSpaceModel (VectorSpaceModel)
5.2.1文档表示
5.2.2 相似度计算
5.2.3特征权重计算
5.3概率检索模型
5.3.1 概率排序原则
5.3.2BinaryIndependentModel(BinaryIndependentModel)
5.3.3BM25 模型
5.3.4BM25F 模型
5.4 语言模型方法
5.5 机器学习排名(LearningtoRank)
5.5.1机器学习排序的基本思路
5.5.2 单文档方法(PointWiseApproach)
5.5.3文档对方法(PairWiseApproach)
5.5.4 文档列表方法(ListWiseApproach)
5.6 搜索质量评价标准
5.6.1准确率和召回率
5.6.2P@10个指标
5.6.3MAP 指标(MeanAveragePrecision)
本章总结
本章参考资料
第六章链接分析
6.1网页图片
6.2 两个概念模型和算法的关系
6.2.1RandomSurferModel (RandomSurferModel)
6.2.2 子集传播模型
6.2.3 链接分析算法之间的关系
6.3PageRank 算法
6.3.1 从链内数到PageRank
6.3.2PageRank 计算
6.3.3 链接陷阱(LinkSink)和远程跳转(Teleporting)
6.4HITS 算法(HypertextInducedTopicSelection)
6.4.1Hub 页面和权限页面
6.4.2 互增关系
6.4.3HITS 算法
6.4.4HITS 算法问题
6.4.5HITS算法与PageRank算法对比
6.5SALSA 算法
6.5.1 确定计算对象集
6.5.2 链接关系传播
6.5.3权限权重计算
6.6 主题敏感页面排名(TopicSensitivePageRank)
6.6.1 主题敏感的PageRank和PageRank的区别
6.6.2 主题敏感的PageRank计算过程
6.6.3 使用主题敏感的PageRank构建个性化搜索
6.7Hilltop 算法
6.7.1 Hilltop 算法的一些基本定义
6.7.2Hilltop 算法
6.8 其他改进算法
6.8.1IntelligentSurferModel(智能冲浪模型)
6.8.2 BiasedSurferModel(BiasedSurferModel)
6.8.3PHITS 算法(ProbabilityAnalogyofHITS)
6.8.4BFS 算法(BackwardForwardStep)
本章总结
本章参考资料
第 7 章云存储和云计算
7.1 云存储和云计算概述
7.1.1 基本假设
7.1.2理论基础
7.1.3 数据模型
7.1.4 基本问题
7.1.5Google 的云存储和云计算架构
7.2Google 文件系统 (GFS)
7.2.1GFS 设计原则
7.2.2GFS 整体架构
7.2.3GFS 主控服务器
7.2.4 系统交互行为
7.3Chubby 锁服务
7.4BigTable
7.4.1BigTable 的数据模型
7.4.2BigTable 整体结构
7.4.3BigTable 的管理数据
7.4.4MasterServer
7.4.5 分表服务器(TabletServer)
7.5Megastore 系统
7.5.1 实体组切分
7.5.2数据模型
7.5.3数据读写与备份
7.6Map/Reduce 云计算模型
7.6.1计算模型
7.6.2 整体逻辑流程
7.6.3 应用实例
7.7Caffeine System-Percolator
7.7.1 事务支持
7.7.2 观察/通知架构
7.8Pregel 图计算模型
7.9Dynomo 云存储系统
7.9.1 数据分区算法(PartitioningAlgorithm)
7.9.2数据备份(复制)
7.9.3数据读写
7.9.4数据版本控制
7.10PNUTS 云存储系统
7.10.1PNUTS 整体架构
7.10.2 存储单元
7.10.3 分表控制器和数据路由器
7.10.4 雅虎通讯社
7.10.5 数据一致性
7.11HayStack 存储系统
7.11.1HayStack 整体架构
7.11.2 目录服务
7.11.3HayStack 缓存
7.11.4HayStack 存储系统
本章总结
本章参考资料
第8章网络反作弊
8.1内容作弊
8.1.1常见的内容作弊方法
8.1.2内容农场(ContentFarm)
8.2 链接作弊
8.3 页面隐藏作弊
8.4Web2.0 作弊方法
8.5反作弊技术总体思路
8.5.1 信任传播模型
8.5.2 不信任传播模型
8.5.3 异常发现模型
8.6 万能链接反作弊方法
8.6.1TrustRank 算法
8.6.2BadRank 算法
8.6.3SpamRank
8.7 专用链接防作弊技术
8.7.1 识别链接农场
8.7.2 识别谷歌轰炸
8.8 识别内容作弊
8.9反隐藏作弊
8.9.1 识别页面隐藏
8.9.2 识别网页重定向
8.10 搜索引擎反作弊综合框架
本章总结
本章参考资料
第九章用户查询意图分析
9.1搜索行为及其意图
9.1.1用户搜索行为
9.1.2用户搜索意图分类
9.2搜索日志挖掘
9.2.1查询会话(QuerySession)
9.2.2ClickGraph (ClickGraph)
9.2.3查询图(QueryGraph)
9.3 相关搜索
9.3.1 基于查询会话的方法
9.3.2 基于点击图的方法
9.4检查纠错
9.4.1EditDistance(编辑距离)
9.4.2 噪声通道模型(NoiseChannelModel)
本章总结
本章参考资料
第十章网页去重
10.1 通用去重算法框架
10.2Shingling 算法
10.3I-Match 算法
10.4SimHash 算法
10.4.1 文档指纹计算
10.4.2 搜索类似文档
10.5SpotSig 算法
10.5.1 特征提取
10.5.2 搜索类似文档
本章总结
本章参考资料
第11章搜索引擎缓存机制
11.1搜索引擎缓存系统架构
11.2Cache 对象
11.3缓存结构
11.4缓存消除策略(EvictPolicy)
11.4.1 动态策略
11.4.2 混合策略
11.5缓存更新策略(RefreshPolicy)
本章总结
本章参考资料
第十二章搜索引擎发展趋势
12.1个性化搜索
12.2社交搜索
12.3 实时搜索
12.4手机搜索
12.5 位置感知搜索
12.6跨语言搜索
12.7多媒体搜索
12.8情况搜索
前言
互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品比例相对较小。搜索引擎是当前互联网产品中具有技术含量的产品,如果不是唯一的,至少是其中之一。
经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。 Twitter联合创始人埃文威廉姆斯提出“域名已死理论”:容易记住的域名不再重要,因为人们会通过搜索输入网站。搜索引擎排名对于中小网站流量非常重要。了解搜索引擎简单界面背后的技术原理,对很多人来说其实很重要。
为什么会有这本书
写搜索引擎技术书籍的最初想法是两年前诞生的。当时的场景是对团队成员进行搜索技术培训,但是我搜索了相关书籍,却没有找到一本非常合适的搜索技术入门书籍。当时市场上的书籍,要么是信息检索理论的专着,理论性太强,不易理解,真正讲搜索引擎技术的章节也不多;或者它们是太实用的书,比如 Lucene 代码分析,比如搜索引擎。这种直接分析开源系统代码的算法应用并不是一种非常高效的学习方法。所以当时就诞生了写一本通俗易懂,适合没有相关技术背景的人,比较全面,融合新技术的搜索引擎书籍。但我是在一年前开始写作的。
在写这本书之前,我为自己设定了一些目标。首先,内容要全面,即全面覆盖搜索引擎相关技术的主要方面。不仅要收录倒排索引、检索模型、爬虫等常用内容,还要详细讲解链接分析、网页反作弊、用户搜索意图分析、网页云存储和去重甚至搜索引擎缓存都是有机的一个完整的搜索引擎的组成部分,但详细介绍其原理的书籍并不多。我希望尽可能全面。
第二个目标很容易理解。我希望没有任何相关技术背景的人可以从阅读本书中学到一些东西,不了解技术的学生可以大致理解。这个目标看似简单,但实际上实现起来并不容易。我不敢说这本书达到了这个目标,但我已经尽力了。具体措施包括以下三个方面。
一是尽可能减少数学公式的数量,除非公式没有列出。尽管数学公式具有简单之美,但大多数人实际上对数学符号存在恐惧和回避。多年前我也有类似的心理,所以尽可能不要使用数学公式。
一是尽量多举例,特别是一些比较难理解的地方。需要举例来加深理解。
还有更多的绘图。就我个人的经验而言,虽然算法或技术很抽象,但如果深入理解原理,将复杂的化简,绝对可以将算法转化为生动的画面。如果你无法在脑海中形成算法的直观图形表示,则说明你对其原理没有透彻的理解。这是我判断自己是否深刻理解算法的一个私人标准。鉴于此,本书在讲解算法的地方,使用了大量的算法示意图。全书收录300多幅算法原理解释图。相信这对读者深入理解算法有很大帮助。
第三个目标是强调新现象和新技术,比如谷歌的caffeine系统和Megastore等云存储系统、Pregel云图计算模型、暗网爬取技术、Web2.0网络作弊、机器学习排序、上下文搜索、社交搜索等在相关章节中有说明。
第四个目标是强调原则,而不是停留在技术细节上。对于新手来说,一个容易解决的问题是他们喜欢挖掘细节,只见树木不见森林,懂一个公式却不懂背后的基本思想和出发点。我接触过很多技术人员,七八岁就会有这个特点。有一个问题“道家哪个好?” “道”是什么?什么是“手术”?比如《孙子兵法》就是道,《三十六计》就是战术。 “道”是宏观的、有原则的、经久不衰的基本原则,而“技术”是遵循基本原则的具体方法和措施,是变化无常的。技术也是如此。算法本身的细节就是“技巧”,算法所体现的基本思想就是“道”。知“道”、学“技”,虽然两者不能偏,但如果要选择优先级,毫无疑问我会先选择“道”再选择“术”。
以上四点是写书之前设定的目标。现在写完了,可能很多地方都达不到当初的期待,但是我会努力的。写书的过程很辛苦,至少比我想象的要难。因为工作忙,每天只能早起,加上周末和节假日。也许书中有这样的缺点,但我可以说我是真诚地写这本书的。
这本书是给谁看的?
如果您是以下其中一种,那么这本书适合您。
1.对搜索引擎核心算法感兴趣的技术人员
搜索引擎的整体框架是什么?收录哪些核心技术?
网络爬虫的基本结构是什么?常见的爬取策略有哪些?什么是暗网爬行?如何构建分布式爬虫?百度的阿拉丁计划是什么?
什么是倒排索引?如何对倒排索引进行数据压缩?
搜索引擎如何对搜索结果进行排序?
什么是向量空间模型?什么是概率模型?什么是BM25型号?什么是机器学习排序?它们之间有什么异同?
PageRank和HITS算法有什么关系?有哪些相同点和不同点?什么是 SALSA 算法?什么是山顶算法?各种链接分析算法之间的关系是什么?
如何识别搜索用户的真实搜索意图?用户可以搜索多少个类别?什么是点击图表?什么是查询会话?相关搜索是如何完成的?
为什么我们需要去重复网页?如何去重复网页?哪种算法效果更好?
搜索引擎缓存有多少级?核心战略是什么?
什么是上下文搜索?什么是社交搜索?什么是实时搜索?
搜索引擎的发展趋势是什么?
如果你对三个以上的问题感兴趣,那么这本书就是为你而写的。
2.对云计算和云存储感兴趣的技术人员
CAP的原理是什么?什么是 ACID 原理?它们之间有什么异同?
Google 的云计算框架包括哪些技术? Hadoop系列和谷歌的云计算框架有什么关系?
Google 的三驾马车 GFS、BigTable 和 MapReduce 是什么意思?有什么关系?
谷歌咖啡因系统的基本原理是什么?
Google 的 Pregel 计算模型和 MapReduce 计算模型有什么区别?
Google 的 Megastore 云存储系统和 BigTable 是什么关系?
什么是亚马逊的 Dynamo 系统?
雅虎的 PNUTS 系统是什么?
Haystack 存储系统适用于哪些地方?
如果你对以上问题感兴趣,相信你可以在书中找到答案。
3.互联网营销人员从事搜索引擎优化和中小网站站长
搜索引擎的反作弊策略是什么?如何优化以避免被认为作弊?
搜索引擎如何对搜索结果进行排序?链接分析和内容排名有什么关系?
什么是内容农场?什么是链接农场?他们是什么关系?
什么是 Web 2.0 作弊?常用的方法有哪些?
什么是 SpamRank?什么是信任等级?什么是坏排名?他们是什么关系?
咖啡因系统如何影响页面排名?
最近一批电商网站针对搜索引擎优化,结果被谷歌认定为黑帽SEO,导致搜索排名权降低。如何避免这种情况?从事相关行业的营销人员和网站webmasters应该对反作弊搜索引擎的基本策略和方法,甚至页面排名算法等搜索引擎的核心技术有深入的了解。 SEO技术归根结底其实很简单。尽管它在不断变化,但许多原则和策略总是相似而密不可分的。深入了解搜索引擎相关技术原理,将形成您所在行业的竞争优势。
4.作者本人
我的记忆力不是很好,一段时间内学到的技术往往几年后就模糊了,所以这本书也是给自己写的,作为技术参考手册。沉力也参与了本书的部分编写。
谢谢
感谢博文的编辑傅锐。没有她,这本书就不会出版。傅主编在审稿过程中提出的细致的改进点对我帮助很大。
特别感谢我的妻子。在将近一年的写作过程中,我几乎把所有的空闲时间都花在了这本书的写作上。她承担了所有的家务,以免分散我的注意力。没时间陪她也没关系,这本书的诞生也算是送给她的礼物。
对我来说,写这本书是一个辛苦而快乐的过程。就像一个远行的旅人。当你从水和山上仰望时,你总能看到你所忽略的美丽景色。如果您在阅读本书,我很荣幸能有这样的体验。
张俊林
2011 年 6 月
获取正版《这就是搜索引擎:核心技术详解》
为什么“常规”SEO文章收取更多费用-低端文章50到75美元
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-11 06:44
自 2011 年 2 月 Google 发布熊猫更新以来,网站administrators 已从面向关键字密度的内容转变为主题内容。如果您是一名自由 SEO 内容作家并且还没有开始为客户提供这种类型的副本,那么您可能会对他们造成很大的伤害。在这里,我们讨论原因。
仅供参考,主题SEO文章-low-end 文章50 至 75 美元/篇,最高可达数百美元。
为什么“常规”SEO 网页内容不够好
为了摆脱为 AdSense网站 制作的许多 MFA(其中许多是垃圾邮件发送者设置的只是为了获得这些 Google 广告的点击量),Google 打击了由关键字密度驱动的内容。要知道,那些短垃圾文章一遍遍重复同样的关键词,却在搜索引擎中排名靠前。
搜索引擎的工作是返回最相关的“质量”。一般来说,大多数填了关键字的文章都不会这样做。其中许多只是您可以在 Internet 上找到的一般信息。但是相关的关键词却是一遍遍地重复。
为了防止这种情况发生,谷歌在其熊猫更新中丢弃了许多收录此类内容的网站,以支持那些遵循我所谓的“SEO 写作指南”的网站。
这些指南可被视为撰写主题 SEO 内容的基础。顺便说一句,我在这里引用谷歌是因为它是整体上最受欢迎的搜索引擎。仅供参考,最大的三个是谷歌、必应和雅虎!
什么是主题 SEO 内容写作?
比如在同一篇文章文章中,主题网页内容并没有针对特定的关键词词组,而是针对无数的关键词词组。
记住,搜索引擎只是机器人,不是人。因此,如果他们阅读收录“Apple”一词的内容块,他们将不知道您在谈论 Apple Pie 还是 Apple Computer。这是主题SEO内容的全部内容。可以帮助搜索引擎准确识别内容的全部内容,使关键字填充的内容不会上升到搜索引擎结果的顶部。
SEO主题文章和普通SEO文章的区别
让我们通过一个例子来解释。假设你写了一篇关于自制苹果派的博客,并写了一篇关于如何制作苹果派的文章。搜索引擎希望在这篇文章中找到的一些“关键字”短语包括如何烤苹果派、苹果派食谱、如何制作苹果派、如何从头开始制作苹果派等。
看看有多少不同的“关键词phrases”以及它们之间的关系?反之,这个话题的关键字填充的SEO文章可能只是一遍遍地重复“苹果派食谱”这个词。
因为主题SEO网站的内容写的时间长,在搜索引擎结果中排名靠前,作为SEO作者,你可以为此付出更多——甚至更多。
详细了解如何撰写主题 SEO 内容、Google 的 SEO 写作指南,以及要在 2013 年成为一名成功的 SEO 撰稿人,您需要了解的其他 11 件事。
原创文章,作者:WPJIAN,如转载请注明出处: 查看全部
为什么“常规”SEO文章收取更多费用-低端文章50到75美元
自 2011 年 2 月 Google 发布熊猫更新以来,网站administrators 已从面向关键字密度的内容转变为主题内容。如果您是一名自由 SEO 内容作家并且还没有开始为客户提供这种类型的副本,那么您可能会对他们造成很大的伤害。在这里,我们讨论原因。
仅供参考,主题SEO文章-low-end 文章50 至 75 美元/篇,最高可达数百美元。
为什么“常规”SEO 网页内容不够好
为了摆脱为 AdSense网站 制作的许多 MFA(其中许多是垃圾邮件发送者设置的只是为了获得这些 Google 广告的点击量),Google 打击了由关键字密度驱动的内容。要知道,那些短垃圾文章一遍遍重复同样的关键词,却在搜索引擎中排名靠前。
搜索引擎的工作是返回最相关的“质量”。一般来说,大多数填了关键字的文章都不会这样做。其中许多只是您可以在 Internet 上找到的一般信息。但是相关的关键词却是一遍遍地重复。
为了防止这种情况发生,谷歌在其熊猫更新中丢弃了许多收录此类内容的网站,以支持那些遵循我所谓的“SEO 写作指南”的网站。
这些指南可被视为撰写主题 SEO 内容的基础。顺便说一句,我在这里引用谷歌是因为它是整体上最受欢迎的搜索引擎。仅供参考,最大的三个是谷歌、必应和雅虎!
什么是主题 SEO 内容写作?
比如在同一篇文章文章中,主题网页内容并没有针对特定的关键词词组,而是针对无数的关键词词组。
记住,搜索引擎只是机器人,不是人。因此,如果他们阅读收录“Apple”一词的内容块,他们将不知道您在谈论 Apple Pie 还是 Apple Computer。这是主题SEO内容的全部内容。可以帮助搜索引擎准确识别内容的全部内容,使关键字填充的内容不会上升到搜索引擎结果的顶部。
SEO主题文章和普通SEO文章的区别
让我们通过一个例子来解释。假设你写了一篇关于自制苹果派的博客,并写了一篇关于如何制作苹果派的文章。搜索引擎希望在这篇文章中找到的一些“关键字”短语包括如何烤苹果派、苹果派食谱、如何制作苹果派、如何从头开始制作苹果派等。
看看有多少不同的“关键词phrases”以及它们之间的关系?反之,这个话题的关键字填充的SEO文章可能只是一遍遍地重复“苹果派食谱”这个词。
因为主题SEO网站的内容写的时间长,在搜索引擎结果中排名靠前,作为SEO作者,你可以为此付出更多——甚至更多。
详细了解如何撰写主题 SEO 内容、Google 的 SEO 写作指南,以及要在 2013 年成为一名成功的 SEO 撰稿人,您需要了解的其他 11 件事。
原创文章,作者:WPJIAN,如转载请注明出处:
简述简述搜索引擎如何判断网页和查询的相关性?
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-10 03:16
搜索引擎的质量在很大程度上取决于搜索结果的网络内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性,以及网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;本文主要简要介绍搜索引擎如何判断网页与查询的相关性?
判断网页内容是否与用户查询的关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.Boolean 模型
布尔模型简单来说就是用户查询的词是否出现在网页中,是对是错,是否收录在非收录中。比如用户搜索的关键词是SEO,他们希望得到与SEO相关的信息。当网页内容中出现SEO这个词时,就意味着该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后使用余弦公式计算文档与查询的相似度并对输出结果进行排序。主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。 IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在某个网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。 SEO常用的是关键词密度,但是没有统一的衡量标准。不要使用 2%~8% 作为关键词密度标准。
3.probability 模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词条SEO,大部分可能会搜索SEO培训、SEO服务等。用户后续需求源自海量大数据,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续条款以它们为基础,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,一个网页可以分为不同的区域。例如,网页标题、描述、网页内容、网页底部标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题收录相关的关键词,很大程度上说明了网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以我不需要把关键词和许摩关键词密度堆在一起。
(责任编辑:搜索引擎网站optimizationSEO外包-,原创不易,转载时必须以链接形式注明作者、原出处及本声明。) 查看全部
简述简述搜索引擎如何判断网页和查询的相关性?
搜索引擎的质量在很大程度上取决于搜索结果的网络内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性,以及网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;本文主要简要介绍搜索引擎如何判断网页与查询的相关性?

判断网页内容是否与用户查询的关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.Boolean 模型
布尔模型简单来说就是用户查询的词是否出现在网页中,是对是错,是否收录在非收录中。比如用户搜索的关键词是SEO,他们希望得到与SEO相关的信息。当网页内容中出现SEO这个词时,就意味着该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后使用余弦公式计算文档与查询的相似度并对输出结果进行排序。主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。 IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在某个网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。 SEO常用的是关键词密度,但是没有统一的衡量标准。不要使用 2%~8% 作为关键词密度标准。
3.probability 模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词条SEO,大部分可能会搜索SEO培训、SEO服务等。用户后续需求源自海量大数据,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续条款以它们为基础,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,一个网页可以分为不同的区域。例如,网页标题、描述、网页内容、网页底部标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题收录相关的关键词,很大程度上说明了网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以我不需要把关键词和许摩关键词密度堆在一起。
(责任编辑:搜索引擎网站optimizationSEO外包-,原创不易,转载时必须以链接形式注明作者、原出处及本声明。)
简化双因素算法,你的搜索引擎优化会吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-10 03:10
在排名方面寻找一个简单的答案,但这两项研究和 Google 本身都表示,链接和内容是所涉及的最大因素。如果您更多地关注简化的双因素算法,您的 SEO 会奏效吗?
网站设计公司
搜索引擎优化排名肯定有很多感兴趣的因素:
有了这个专业的研究,尤其是 Moz 和 searchmetrics。这些都是开创性的研究,如果您认真对待搜索引擎优化,您需要了解这些研究的内容。这些太复杂了。他们需要一种简单的方式来看待事物,包括一些世界上最大的公司,以及一些世界上最高的网站。对于这些公司中的大多数,有超过 200 个排名因素。
这些干扰最终会集中在两个最重要的事情上:构建大量内容和出色的内容体验,并促进其发展。
今天的重点是开发一种基本方法,大多数公司都可以使用它来简化搜索引擎优化的想法,并将重点放在最高优先级上。
Google 最近所说的两个最重要的排名因素是什么:
我可以告诉你它们是什么。这是输入网站的内容和链接。
我们走了,这是开始。据谷歌称,其链接和内容是最大的两个。希望内容是一个重要因素的想法是显而易见的,但下面我将分解更多优秀内容真正需要的内容。另外,可以看到一些备份链接的威力,在研究中,我最近发布了链接作为排名因素。
我们是否应该认为世界是由这两个因素组成的?这很简单,可能太多了,所以让我们尝试进一步简化它。如果专注于创建优质内容并有效推广,有多少组织会显着改善其搜索引擎优化?我可以告诉你,根据我的经验,这是许多组织根本不做的两件事。
这是否意味着我们可以将我们的两个因素变成一个(纯)假设的排名评分方程,看起来像这样?
html5 设计
我真的认为这个方程相当有效,虽然它有一些限制和遗漏,我会在下面更详细地描述。您还需要考虑“优质内容”的概念,以正确的方式获得较高的内容分数。
什么是“精彩内容?”
如果我们退后一步思考什么是优质内容,在我看来,主要由三个组成部分组成:
协会
质量
整体内容体验
这部分的第一部分很简单。如果内容与查询无关,则不应为查询排名,如果。这是有道理的,对吧?
第二部分也很简单。这就是质量的概念。它提供了人们正在寻找的信息?那是你的网站 更独特的信息吗?显然,这对内容的质量很有意义。
我们可以将质量和相对独特性的概念合并为物质区分的概念。兰德在他的白板上精彩地阐述了这一点,并在周五创作了 10 次内容。
你需要创造出新的、引人注目的东西,并提供很多价值。这可能并不容易,但最好的事情从来没有发生过。
<p>如果您处于竞争激烈的市场中,可以合理猜测您的顶级竞争对手正在制作出色的内容主题及其目标受众。对于最重要的查询,很有可能空间前5(可能更多)的内容是真实的,真的很好(即比其他文章主题更全面,或者带来新信息,其他人没有)。 查看全部
简化双因素算法,你的搜索引擎优化会吗?
在排名方面寻找一个简单的答案,但这两项研究和 Google 本身都表示,链接和内容是所涉及的最大因素。如果您更多地关注简化的双因素算法,您的 SEO 会奏效吗?

网站设计公司
搜索引擎优化排名肯定有很多感兴趣的因素:
有了这个专业的研究,尤其是 Moz 和 searchmetrics。这些都是开创性的研究,如果您认真对待搜索引擎优化,您需要了解这些研究的内容。这些太复杂了。他们需要一种简单的方式来看待事物,包括一些世界上最大的公司,以及一些世界上最高的网站。对于这些公司中的大多数,有超过 200 个排名因素。
这些干扰最终会集中在两个最重要的事情上:构建大量内容和出色的内容体验,并促进其发展。
今天的重点是开发一种基本方法,大多数公司都可以使用它来简化搜索引擎优化的想法,并将重点放在最高优先级上。
Google 最近所说的两个最重要的排名因素是什么:
我可以告诉你它们是什么。这是输入网站的内容和链接。
我们走了,这是开始。据谷歌称,其链接和内容是最大的两个。希望内容是一个重要因素的想法是显而易见的,但下面我将分解更多优秀内容真正需要的内容。另外,可以看到一些备份链接的威力,在研究中,我最近发布了链接作为排名因素。
我们是否应该认为世界是由这两个因素组成的?这很简单,可能太多了,所以让我们尝试进一步简化它。如果专注于创建优质内容并有效推广,有多少组织会显着改善其搜索引擎优化?我可以告诉你,根据我的经验,这是许多组织根本不做的两件事。
这是否意味着我们可以将我们的两个因素变成一个(纯)假设的排名评分方程,看起来像这样?

html5 设计
我真的认为这个方程相当有效,虽然它有一些限制和遗漏,我会在下面更详细地描述。您还需要考虑“优质内容”的概念,以正确的方式获得较高的内容分数。
什么是“精彩内容?”
如果我们退后一步思考什么是优质内容,在我看来,主要由三个组成部分组成:
协会
质量
整体内容体验
这部分的第一部分很简单。如果内容与查询无关,则不应为查询排名,如果。这是有道理的,对吧?
第二部分也很简单。这就是质量的概念。它提供了人们正在寻找的信息?那是你的网站 更独特的信息吗?显然,这对内容的质量很有意义。
我们可以将质量和相对独特性的概念合并为物质区分的概念。兰德在他的白板上精彩地阐述了这一点,并在周五创作了 10 次内容。

你需要创造出新的、引人注目的东西,并提供很多价值。这可能并不容易,但最好的事情从来没有发生过。
<p>如果您处于竞争激烈的市场中,可以合理猜测您的顶级竞争对手正在制作出色的内容主题及其目标受众。对于最重要的查询,很有可能空间前5(可能更多)的内容是真实的,真的很好(即比其他文章主题更全面,或者带来新信息,其他人没有)。
阳光创信云推广的方法,提高网站排名必备!
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-07 19:24
网站optimization,贵州阳光创信云推广是一家专业的网络营销外包代理运营商,专注于为中小企业提供网络营销整体战略解决方案,包括网络营销方案、网络营销策划、网络营销外包、SEM/SEO优化、搜索引擎自动推广、网站建筑、网站设计、网站开发等综合服务,牛推网是一家多元化的现代网络信息技术企业;公司自主研发的新一代网络营销优化推广系统-【阳光创信云推广-中国**新闻源媒体营销推广平台】,旨在为广大商家提供全方位的免费差异化营销推广服务, 阳光创信精兵将协助企业管理所有市场运营,深入挖掘更新、更全、更快的业务资源,通过阳光创信云的营销策略快速推广企业产品和服务。
随着互联网业务越来越火爆,市场上有很多公司想要进入互联网行业。 网站排名优化方法,提升网站排名必备!
今日头条后台自带手机建站工具,使用起来非常方便。可以说就像搭积木来堆叠页面一样。类似于今日头条的移动网站建设,但行为数据的来源无法统计。还有很多改进和优化的空间。我们都知道流量是竞价的核心,但数据是明确流量控制的方向。所以小编在这里整理了几个投标人必备的表单模板。函数:是excel中的一个函数,用于对某个项目的总价值进行具体统计。用途:常用于多维数据分析。功能:主要用于统计一个词组或单词中的字符数。用途:多用于过滤长尾词、短尾词,或者比较杂乱的一般词等。 功能:统计一组数据中满足一定条件的值的总数。用途:用于计算咨询工具中关键词带来的会话数、地区、时间段等。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。我们都知道搜索引擎优化是否合理,搜索引擎也会如此,直接带来难以想象的客流。海创h5自助建站6年专注建站。拥有国内外领先的技术和网站marketing技术,打造免费、易用的网站。轻松拖拽一键发布和上线,快速获取搜索引擎收录和排名。
想要网站排名好,一定是网站的具体方向。这个方向就是营销的方向。有了这个具体点,我们就可以更有选择性的结合用户的需求,给网站带来更多的水分和转化率,从而提升SEO管理的视觉效果。通过LSI和TF-IDF关键词分析,我们可以找出符合搜索者意图的关键词和URL,并将它们组织成Excel表格,然后创建符合搜索者意图的高质量文案。单页速度测试单页速度测试推荐使用googlespeedtest。分数越高越好,分数越高表示网速越快,跳出率越低。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。搜索引擎优化是否合理大家都知道,搜索引擎也会如此,直接带来难以想象的客流量。
掌握的基础如下: 1、掌握后端CSS语法,类似DIV+HTML等。在做seo的时候,我们经常需要做的一件事就是看@k14的源码@。如果连基本的html都不懂,操作起来会很困难。我们以 URL 为例。有些人不会在您的朋友链上列出 nofollow。有些人可能会在 KM 中添加 URL。如果你不了解html的基础知识,你是看不到这些的。不懂html的你还是主动发这些网站友情链接,但是视觉效果根本不行。微联世创专注网络营销服务,用数据说话,用结果说话。同时是多家搜索、互联网巨头认证的合作伙伴,拥有包括搜索引擎(百度、搜狗、360)等)认证合作伙伴资质的专业互联网营销服务商。
网站optimization,adaptability网站搜索引擎优化有什么优势?自适应网站开发seo规范比较简单,这样的模型也挺好的。 URL可以随时同步数据,因为这样网站可以在手机上及时调整页面,保持良好的显示效果。还应该发现,这样的网页是兼容的,所以更容易保持良好的状态。
友情链接是合适的,所以我投票给了我的网站,但不仅仅是网站可以成为友情链接。一个低质量的友情链接不仅对网站有帮助,而且也无济于事。吸引蜘蛛:当我们和一个排名靠前的网站进行友情链接时,当搜索蜘蛛来到另一个网站时,他会跟随友情链接到我们自己的网站,并且还会加我们网站有机会进入。相关阅读:网站SEO优化**如何估算关键词的排名?权重转移:当我们得到一个高质量的友情链接时,我们已经投票支持我们自己的网站推广。比如你的网站和食物有关,那么这个友情链接几乎是在告诉搜索引擎。您的网站 与食物有关。所以在做友情链接的时候一定要找到和我们主题相似的网站,这样搜索引擎才能更快的提升我们网站的权重。 查看全部
阳光创信云推广的方法,提高网站排名必备!
网站optimization,贵州阳光创信云推广是一家专业的网络营销外包代理运营商,专注于为中小企业提供网络营销整体战略解决方案,包括网络营销方案、网络营销策划、网络营销外包、SEM/SEO优化、搜索引擎自动推广、网站建筑、网站设计、网站开发等综合服务,牛推网是一家多元化的现代网络信息技术企业;公司自主研发的新一代网络营销优化推广系统-【阳光创信云推广-中国**新闻源媒体营销推广平台】,旨在为广大商家提供全方位的免费差异化营销推广服务, 阳光创信精兵将协助企业管理所有市场运营,深入挖掘更新、更全、更快的业务资源,通过阳光创信云的营销策略快速推广企业产品和服务。
随着互联网业务越来越火爆,市场上有很多公司想要进入互联网行业。 网站排名优化方法,提升网站排名必备!
今日头条后台自带手机建站工具,使用起来非常方便。可以说就像搭积木来堆叠页面一样。类似于今日头条的移动网站建设,但行为数据的来源无法统计。还有很多改进和优化的空间。我们都知道流量是竞价的核心,但数据是明确流量控制的方向。所以小编在这里整理了几个投标人必备的表单模板。函数:是excel中的一个函数,用于对某个项目的总价值进行具体统计。用途:常用于多维数据分析。功能:主要用于统计一个词组或单词中的字符数。用途:多用于过滤长尾词、短尾词,或者比较杂乱的一般词等。 功能:统计一组数据中满足一定条件的值的总数。用途:用于计算咨询工具中关键词带来的会话数、地区、时间段等。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。我们都知道搜索引擎优化是否合理,搜索引擎也会如此,直接带来难以想象的客流。海创h5自助建站6年专注建站。拥有国内外领先的技术和网站marketing技术,打造免费、易用的网站。轻松拖拽一键发布和上线,快速获取搜索引擎收录和排名。
想要网站排名好,一定是网站的具体方向。这个方向就是营销的方向。有了这个具体点,我们就可以更有选择性的结合用户的需求,给网站带来更多的水分和转化率,从而提升SEO管理的视觉效果。通过LSI和TF-IDF关键词分析,我们可以找出符合搜索者意图的关键词和URL,并将它们组织成Excel表格,然后创建符合搜索者意图的高质量文案。单页速度测试单页速度测试推荐使用googlespeedtest。分数越高越好,分数越高表示网速越快,跳出率越低。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。搜索引擎优化是否合理大家都知道,搜索引擎也会如此,直接带来难以想象的客流量。
掌握的基础如下: 1、掌握后端CSS语法,类似DIV+HTML等。在做seo的时候,我们经常需要做的一件事就是看@k14的源码@。如果连基本的html都不懂,操作起来会很困难。我们以 URL 为例。有些人不会在您的朋友链上列出 nofollow。有些人可能会在 KM 中添加 URL。如果你不了解html的基础知识,你是看不到这些的。不懂html的你还是主动发这些网站友情链接,但是视觉效果根本不行。微联世创专注网络营销服务,用数据说话,用结果说话。同时是多家搜索、互联网巨头认证的合作伙伴,拥有包括搜索引擎(百度、搜狗、360)等)认证合作伙伴资质的专业互联网营销服务商。
网站optimization,adaptability网站搜索引擎优化有什么优势?自适应网站开发seo规范比较简单,这样的模型也挺好的。 URL可以随时同步数据,因为这样网站可以在手机上及时调整页面,保持良好的显示效果。还应该发现,这样的网页是兼容的,所以更容易保持良好的状态。
友情链接是合适的,所以我投票给了我的网站,但不仅仅是网站可以成为友情链接。一个低质量的友情链接不仅对网站有帮助,而且也无济于事。吸引蜘蛛:当我们和一个排名靠前的网站进行友情链接时,当搜索蜘蛛来到另一个网站时,他会跟随友情链接到我们自己的网站,并且还会加我们网站有机会进入。相关阅读:网站SEO优化**如何估算关键词的排名?权重转移:当我们得到一个高质量的友情链接时,我们已经投票支持我们自己的网站推广。比如你的网站和食物有关,那么这个友情链接几乎是在告诉搜索引擎。您的网站 与食物有关。所以在做友情链接的时候一定要找到和我们主题相似的网站,这样搜索引擎才能更快的提升我们网站的权重。
SEO优化的新思路——SEO站内优化之主题模型
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-07 03:03
今天和大家分享SEO优化的新思路。昨天家里有事,所以没有急着更新微博。我特地再次说声抱歉。
随着互联网时代的飞速发展,现在网站的种类越来越多。随着搜索引擎系统越来越完善,也趋向于更加人性化和用户体验。 SEO 现在不同于以前的优化规则。我们需要开始了解我们的网站 应该如何优化以获得更好的排名。
之前我们讲SEO优化的时候,会很不自然地想到,网站的关键词密度,页面内容是否原创,是否有很多导入链接(外部链接),是否TDK关键词设置精准匹配等做法。现在那是几年前的旧 SEO 优化方法。
今天偶然看到一篇文章的文章,里面讲了SEO网站优化的新思路和SEO网站优化的话题模型。现在搜索引擎可以通过内容上下文和内容实体属性来处理排名,让用户得到更准确的结果。搜索结果。对于优化者来说,网站优化不再是简单的内容填充。我们要做的是如何让搜索引擎明白我们网站有真实的内容和实体属性。
首先,它被称为词汇关联。我们在写网站内容的时候,一定要关注如何关联词句。使用关键词查找同义词和异体词,查找与主题内容相关的二类词,查找与二类词相关的三类词,发现内容属性与主题内容相关主题(人、地点、事物)。
其次,称为词法布局。页面的布局对于搜索引擎了解我们页面的内容和主题也很重要。蜘蛛来到页面后,发现这么多关键词,需要区分哪些是重要的,哪些是与词组相关的,所以词系统布局就是区分核心词和相关性。区域:关键词 必须出现在标题、标题和主要段落中。频率:重要短语或其变体的出现频率可能高于平均水平。距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)。
第三个叫做补充内容。或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导相关网站内容。健康的网站应该进进出出,让用户得到更多更好的信息。页面底部添加相关资源链接(推荐站内链接),文中引用,如业内知名人士的话或图标、视频,文中使用导出链接去第三方网站(你不是100颗心会被K's放)。
第四个称为内容实体。强大的搜索引擎会在抓取页面时自动解释内容实体,或作为内容属性。用一个很笼统的Title来描述页面的主题,加上一个开头(简要)来描述页面的内容,把内容分成几段,每段都有自己的主题,尽量扩大主题角度,并添加相关的提供额外的答案 不关心一个词的权重,而是建立内容实体而不是站内或站外的辅助资源。 查看全部
SEO优化的新思路——SEO站内优化之主题模型
今天和大家分享SEO优化的新思路。昨天家里有事,所以没有急着更新微博。我特地再次说声抱歉。
随着互联网时代的飞速发展,现在网站的种类越来越多。随着搜索引擎系统越来越完善,也趋向于更加人性化和用户体验。 SEO 现在不同于以前的优化规则。我们需要开始了解我们的网站 应该如何优化以获得更好的排名。
之前我们讲SEO优化的时候,会很不自然地想到,网站的关键词密度,页面内容是否原创,是否有很多导入链接(外部链接),是否TDK关键词设置精准匹配等做法。现在那是几年前的旧 SEO 优化方法。
今天偶然看到一篇文章的文章,里面讲了SEO网站优化的新思路和SEO网站优化的话题模型。现在搜索引擎可以通过内容上下文和内容实体属性来处理排名,让用户得到更准确的结果。搜索结果。对于优化者来说,网站优化不再是简单的内容填充。我们要做的是如何让搜索引擎明白我们网站有真实的内容和实体属性。
首先,它被称为词汇关联。我们在写网站内容的时候,一定要关注如何关联词句。使用关键词查找同义词和异体词,查找与主题内容相关的二类词,查找与二类词相关的三类词,发现内容属性与主题内容相关主题(人、地点、事物)。
其次,称为词法布局。页面的布局对于搜索引擎了解我们页面的内容和主题也很重要。蜘蛛来到页面后,发现这么多关键词,需要区分哪些是重要的,哪些是与词组相关的,所以词系统布局就是区分核心词和相关性。区域:关键词 必须出现在标题、标题和主要段落中。频率:重要短语或其变体的出现频率可能高于平均水平。距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)。
第三个叫做补充内容。或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导相关网站内容。健康的网站应该进进出出,让用户得到更多更好的信息。页面底部添加相关资源链接(推荐站内链接),文中引用,如业内知名人士的话或图标、视频,文中使用导出链接去第三方网站(你不是100颗心会被K's放)。
第四个称为内容实体。强大的搜索引擎会在抓取页面时自动解释内容实体,或作为内容属性。用一个很笼统的Title来描述页面的主题,加上一个开头(简要)来描述页面的内容,把内容分成几段,每段都有自己的主题,尽量扩大主题角度,并添加相关的提供额外的答案 不关心一个词的权重,而是建立内容实体而不是站内或站外的辅助资源。
专门探索JavaScript及其所构建的组件系列文章第11篇
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-07-07 02:36
这是文章 致力于探索 JavaScript 及其构建的组件的系列中的第 11 篇文章。
如果你错过了前面的章节,你可以在这里找到它们:
JavaScript 的工作原理:引擎、运行时和调用堆栈概述! JavaScript 的工作原理:深入了解 V8 引擎和编写优化代码的 5 个技巧! JavaScript 是如何工作的:内存管理 + 如何处理 4 种常见的内存泄漏! JavaScript 是如何工作的:事件循环和异步编程的兴起 + 5 种使用 async/await 进行更好编码的方法! JavaScript 是如何工作的:探索 websocket 和 HTTP/2 和 SSE + 如何选择正确的路径! JavaScript 是如何工作的:与 WebAssembly 及其使用场景的比较! JavaScript 是如何工作的:Web Workers 的构建块 + 5 个使用它们的场景! JavaScript 是如何工作的:Service Worker 生命周期和使用场景! JavaScript 是如何工作的:Web 推送通知机制! JavaScript 的工作原理:使用 MutationObserver 跟踪 DOM 变化
当您构建 Web 应用程序时,您不仅仅是编写单独运行的 JavaScript 代码,您编写的 JavaScript 还与环境进行交互。了解此环境、它的工作原理及其组将帮助您构建更好的应用程序,并为应用程序发布后可能出现的潜在问题做好充分准备。
浏览器的主要组件包括:
在这个文章 中,我将重点介绍渲染引擎,因为它处理 HTML 和 CSS 的解析和可视化,这是大多数 JavaScript 应用程序经常与之交互的东西。
渲染引擎概述
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。
渲染引擎可以显示 HTML 和 XML 文档和图像。如果您使用其他插件,渲染引擎还可以显示不同类型的文档,例如 PDF。
渲染引擎
与 JavaScript 引擎类似,不同的浏览器也使用不同的渲染引擎。以下是一些最受欢迎的:
Firefox、Chrome 和 Safari 基于两个渲染引擎。 Firefox 使用由 Mozilla 自主开发的渲染引擎 Geoko。 Safari 和 Chrome 都使用 Webkit。 Blink 是 Chrome 基于 WebKit 的自主渲染引擎。
渲染过程
渲染引擎从网络层接收请求文档的内容。
解析HTML构建Dom树->构建渲染树->布局渲染树->绘制渲染树
构建 Dom 树
渲染引擎的第一步是解析 HTML 文档并将解析的元素转换为 DOM 树中的实际 DOM 节点。
如果有以下Html结构
<p> Hello, friend!
smiley.gif
</p>
对应的DOM树如下:
基本上,每个元素都表示为所有元素的父节点,而这些元素直接收录在元素中。
构建 CSSOM
CSSOM 指的是 CSS 对象模型。浏览器在构建页面的DOM时,遇到head标签下的link标签,引用了外部的theme.css CSS样式表。浏览器预计可能需要资源来呈现页面,并立即发送请求。假设theme.css文件的内容如下:
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
和 HTML 一样,渲染引擎需要将 CSS 转换成浏览器可以使用的东西——CSSOM。 CSSOM 结构如下:
你想知道为什么 CSSOM 是一个树状结构吗?在计算页面上任何对象的最终样式集时,浏览器从适用于该节点的最通用规则开始(例如,如果它是 body 元素的子元素,则应用所有的 body 样式),然后细化递归地,通过应用更具体的规则来计算样式。
我们来看一个具体的例子。 body 元素内 span 标签中收录的任何文本的字体大小为 16 像素,并且是红色的。这些样式继承自 body 元素。如果 span 元素是 p 元素的子元素,则不会显示其内容,因为它应用了更具体的样式(display: none)。
另请注意,上面的树不是完整的 CSSOM 树,只是我们决定在样式表中涵盖的样式。每个浏览器都提供一组默认样式,也称为“用户代理样式表”。这是我们在没有明确指定样式时看到的样式,我们的样式将覆盖这些默认值。
不同的浏览器对相同的元素有不同的默认样式,这就是为什么我们写 *{padding:0;marging:0};在 CSS 的最开始,也就是我们要重置 CSS 默认样式。
构建渲染树
CSSOM 树和 DOM 树连接在一起形成渲染树,用于计算可见元素的布局,并作为将像素渲染到屏幕的过程的输入。
渲染树中的每个节点在 Webkit 中称为渲染器或渲染对象。
下面是上面DOM和CSSOM树的渲染树的样子:
为了构建渲染树,浏览器大致执行以下操作:
对于每个可见节点,找到一个合适的匹配CSSOM规则,并应用一个样式来显示可见节点之间的差异(节点包括内容和计算样式)“visibility: hidden”和“display: none”,“ Visibility: hidden" 将元素设置为不可见,但也会在布局上占据一定的空间(例如,它会被渲染为一个空框),但是"display: none" 元素将节点从整个渲染树中移除, 所以它不是布局的一部分。
您可以在此处查看 RenderObject(在 WebKit 中)的源代码:
先来看看这个类的一些核心内容:
每个渲染器代表一个矩形区域,通常对应一个节点的CSS盒模型。它收录宽度、高度和位置等几何信息。
渲染树的布局
当您创建渲染器并将其添加到树中时,它没有位置和大小。计算这些值称为布局。
HTML 使用基于流的布局模型,这意味着大多数时候它可以一次性计算几何。坐标系相对于根渲染器,使用左上角的原点坐标。
Layout 是一个递归过程——它从根渲染器开始,它对应于 HTML 文档的元素。布局通过组件或整个渲染器层次结构递归地继续,为需要它的每个渲染器计算几何信息。
根渲染器的位置为0,0,其大小与浏览器窗口可见部分(即视口)的大小相同。开始布局过程意味着为每个节点提供它应该出现在屏幕上的确切坐标。
绘制渲染树
在这里绘制,遍历渲染树并调用渲染器的paint()方法在屏幕上显示内容。
绘图可以是全局的或增量的(类似于布局):
一般来说,重要的是要了解绘图是一个渐进的过程。为了获得更好的用户体验,渲染引擎会尽快在屏幕上显示内容。它不会等到所有 HTML 都被解析后才开始构建和布局渲染树。相反,它会解析并显示部分内容,同时继续处理来自网络的其余内容项。
处理脚本和样式表的顺序
解析器到达时 查看全部
专门探索JavaScript及其所构建的组件系列文章第11篇
这是文章 致力于探索 JavaScript 及其构建的组件的系列中的第 11 篇文章。
如果你错过了前面的章节,你可以在这里找到它们:
JavaScript 的工作原理:引擎、运行时和调用堆栈概述! JavaScript 的工作原理:深入了解 V8 引擎和编写优化代码的 5 个技巧! JavaScript 是如何工作的:内存管理 + 如何处理 4 种常见的内存泄漏! JavaScript 是如何工作的:事件循环和异步编程的兴起 + 5 种使用 async/await 进行更好编码的方法! JavaScript 是如何工作的:探索 websocket 和 HTTP/2 和 SSE + 如何选择正确的路径! JavaScript 是如何工作的:与 WebAssembly 及其使用场景的比较! JavaScript 是如何工作的:Web Workers 的构建块 + 5 个使用它们的场景! JavaScript 是如何工作的:Service Worker 生命周期和使用场景! JavaScript 是如何工作的:Web 推送通知机制! JavaScript 的工作原理:使用 MutationObserver 跟踪 DOM 变化
当您构建 Web 应用程序时,您不仅仅是编写单独运行的 JavaScript 代码,您编写的 JavaScript 还与环境进行交互。了解此环境、它的工作原理及其组将帮助您构建更好的应用程序,并为应用程序发布后可能出现的潜在问题做好充分准备。

浏览器的主要组件包括:
在这个文章 中,我将重点介绍渲染引擎,因为它处理 HTML 和 CSS 的解析和可视化,这是大多数 JavaScript 应用程序经常与之交互的东西。
渲染引擎概述
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。
渲染引擎可以显示 HTML 和 XML 文档和图像。如果您使用其他插件,渲染引擎还可以显示不同类型的文档,例如 PDF。
渲染引擎
与 JavaScript 引擎类似,不同的浏览器也使用不同的渲染引擎。以下是一些最受欢迎的:
Firefox、Chrome 和 Safari 基于两个渲染引擎。 Firefox 使用由 Mozilla 自主开发的渲染引擎 Geoko。 Safari 和 Chrome 都使用 Webkit。 Blink 是 Chrome 基于 WebKit 的自主渲染引擎。
渲染过程
渲染引擎从网络层接收请求文档的内容。

解析HTML构建Dom树->构建渲染树->布局渲染树->绘制渲染树
构建 Dom 树
渲染引擎的第一步是解析 HTML 文档并将解析的元素转换为 DOM 树中的实际 DOM 节点。
如果有以下Html结构
<p> Hello, friend!
smiley.gif
</p>
对应的DOM树如下:

基本上,每个元素都表示为所有元素的父节点,而这些元素直接收录在元素中。
构建 CSSOM
CSSOM 指的是 CSS 对象模型。浏览器在构建页面的DOM时,遇到head标签下的link标签,引用了外部的theme.css CSS样式表。浏览器预计可能需要资源来呈现页面,并立即发送请求。假设theme.css文件的内容如下:
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
和 HTML 一样,渲染引擎需要将 CSS 转换成浏览器可以使用的东西——CSSOM。 CSSOM 结构如下:

你想知道为什么 CSSOM 是一个树状结构吗?在计算页面上任何对象的最终样式集时,浏览器从适用于该节点的最通用规则开始(例如,如果它是 body 元素的子元素,则应用所有的 body 样式),然后细化递归地,通过应用更具体的规则来计算样式。
我们来看一个具体的例子。 body 元素内 span 标签中收录的任何文本的字体大小为 16 像素,并且是红色的。这些样式继承自 body 元素。如果 span 元素是 p 元素的子元素,则不会显示其内容,因为它应用了更具体的样式(display: none)。
另请注意,上面的树不是完整的 CSSOM 树,只是我们决定在样式表中涵盖的样式。每个浏览器都提供一组默认样式,也称为“用户代理样式表”。这是我们在没有明确指定样式时看到的样式,我们的样式将覆盖这些默认值。

不同的浏览器对相同的元素有不同的默认样式,这就是为什么我们写 *{padding:0;marging:0};在 CSS 的最开始,也就是我们要重置 CSS 默认样式。
构建渲染树
CSSOM 树和 DOM 树连接在一起形成渲染树,用于计算可见元素的布局,并作为将像素渲染到屏幕的过程的输入。
渲染树中的每个节点在 Webkit 中称为渲染器或渲染对象。
下面是上面DOM和CSSOM树的渲染树的样子:

为了构建渲染树,浏览器大致执行以下操作:
对于每个可见节点,找到一个合适的匹配CSSOM规则,并应用一个样式来显示可见节点之间的差异(节点包括内容和计算样式)“visibility: hidden”和“display: none”,“ Visibility: hidden" 将元素设置为不可见,但也会在布局上占据一定的空间(例如,它会被渲染为一个空框),但是"display: none" 元素将节点从整个渲染树中移除, 所以它不是布局的一部分。
您可以在此处查看 RenderObject(在 WebKit 中)的源代码:
先来看看这个类的一些核心内容:

每个渲染器代表一个矩形区域,通常对应一个节点的CSS盒模型。它收录宽度、高度和位置等几何信息。
渲染树的布局
当您创建渲染器并将其添加到树中时,它没有位置和大小。计算这些值称为布局。
HTML 使用基于流的布局模型,这意味着大多数时候它可以一次性计算几何。坐标系相对于根渲染器,使用左上角的原点坐标。
Layout 是一个递归过程——它从根渲染器开始,它对应于 HTML 文档的元素。布局通过组件或整个渲染器层次结构递归地继续,为需要它的每个渲染器计算几何信息。
根渲染器的位置为0,0,其大小与浏览器窗口可见部分(即视口)的大小相同。开始布局过程意味着为每个节点提供它应该出现在屏幕上的确切坐标。
绘制渲染树
在这里绘制,遍历渲染树并调用渲染器的paint()方法在屏幕上显示内容。
绘图可以是全局的或增量的(类似于布局):
一般来说,重要的是要了解绘图是一个渐进的过程。为了获得更好的用户体验,渲染引擎会尽快在屏幕上显示内容。它不会等到所有 HTML 都被解析后才开始构建和布局渲染树。相反,它会解析并显示部分内容,同时继续处理来自网络的其余内容项。
处理脚本和样式表的顺序
解析器到达时
:通用型垂直搜索引擎的行业应用模型建模方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-07-06 23:25
通用垂直搜索引擎的行业应用模型建模方法,垂直搜索核心模块Spider(1)Access Industry Application Model(2))实现对不同数据的识别、捕获、组织、存储和传输。行业信息、行业应用模型(2)山互联网web库(21))和web存储分类索引管理组件(211)、web结构信息模型库(22)和web结构信息模型管理组件) (22@k21)@、行业信息结构模型库(23)和行业信息结构模型管理组件(231))、行业信息存储模型库(24)和行业信息存储模型管理组件(24) 1),和用户系统界面模型库(25)和用户系统界面模型管理组件(251))。本发明的专利技术解决了同时覆盖不同行业应用、不同的网页、不同的行业信息结构和存储结构在一个模型中。它使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、捕获、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。
下载所有详细的技术资料
【技术实现步骤总结】
该专利技术公开了一种基于。 二.
技术介绍
许多文档将垂直搜索定义为针对单个应用程序或单个功能的搜索技术。现实中,垂直搜索产品和门户网站就是按照这个定义布局的,或者房地产信息搜索门户,或者博客信息搜索门户,或者音乐信息搜索门户,或者专利信息搜索门户。所有这些都是如此。之所以出现这种现象,是因为垂直搜索互联网信息具有明显的行业应用特征、功能应用特征和结构特征。也就是说,由于垂直搜索面临的互联网信息具有明显的行业应用特征、功能应用特征和结构特征,这些千差万别的信息特征导致垂直搜索门户具有明显的单一行业或功能。事实上,垂直搜索引擎的核心模块——数据爬取模块蜘蛛本身可以作为通用技术,并没有严格的行业应用或功能应用边界。原则上,一款好的数据爬虫软件可以完成任何网页、任何行业信息的数据爬取任务。由此看来,垂直搜索技术只适用于单一行业或功能门户的事实并不在于垂直搜索的核心技术——数据爬虫软件蜘蛛,而是来自于核心技术之外。的元素。所以,要搭建一个像谷歌、百度这样的通用垂直搜索平台,垂直搜索的核心技术——数据爬虫软件蜘蛛,就有了这个基础。问题在于,如何围绕具有通用能力的数据爬虫软件构建具有通用能力的外围系统,是实现通用垂直搜索引擎的关键。构建与通用数据爬虫软件蜘蛛相匹配、具有通用能力的行业应用模型是系统研究的重要课题之一。 三.
技术实现思路
该专利技术的目的是提供一种用于一般垂直搜索系统中描述不同行业应用或功能应用特征的方法,使垂直搜索能够完成对互联网信息的识别、抓取和检索。其行业模式。组织、存储和传输应用程序,使它们能够成为通用的垂直搜索引擎。该专利技术的技术方案就是该专利技术。垂直搜索核心模块Spider 1接入行业应用模型2,实现对不同行业信息的识别、抓取、组织、存储和传输。行业应用模型2由互联网网页库21和网页组成。存储分类索引管理组件211、网页结构信息模型库22和页面结构信息模型管理组件221、工业信息结构模型库23和行业信息结构模型管理组件231、工业信息存储模型库24和行业信息存储模型管理组件241、、用户系统界面模型库25和用户系统界面模型管理组件251构成。互联网网页库21和网页存储分类索引管理组件211负责互联网网页库21的存储、分类和索引管理任务。网页存储分类索引管理组件211调用G00gleAPI212进行行业搜索应用程序网页 URL 集合;网页结构信息模型库22和网页结构信息模型管理组件221承担页面和行业应用关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理等任务。行业信息结构模型库23及行业信息结构模型管理组件231负责各种网页中各种行业信息的不同结构形式和页面位置的描述、提取、生成和管理任务。行业信息存储模型库24和行业信息存储模型管理组件241负责系统中各种存储形式和存储结构的描述,从行业信息中获取信息后存储结构的动态生成和管理任务。网页;用户系统接口模型库25和用户系统接口模型管理组件251专用于每个用户信息存储形式和系统间存储结构转换、信息传输接口、软件接口关系形式、接口定义的描述、生成和管理任务并打电话。
网页结构信息模型库22至少收录行业及应用、行业信息分类描述、网页地址URL、网页访问入口参数(用户名、密码、方法代码等)、网页链接方法、网页链接控制参数等信息。网页结构信息模型管理组件221至少包括网页结构信息模型库22基本信息的生成和维护、网页访问入口参数(用户名、密码、方法代码等)库信息的生成和维护,网页链接方法、网页链接控制参数库信息的生成与维护、网页链接控制代码片段的提取/转换/存储、调用处理等功能处理模块。行业信息结构模型库23至少包括行业及应用、行业信息分类描述、网页地址URL、行业信息结构类型、行业信息结构初始标识、行业信息结构描述、行业信息结构中的元数据属性描述、行业信息结构周期捕获标识、行业信息结构捕获端标识、行业信息结构存储指令等信息。行业信息结构模型管理组件231至少包括行业信息结构模型库23的基础信息生成和维护、行业信息结构模型库23的信息辅助分析和自动提取等功能处理模块。模型库24个至少包括行业及应用、行业信息分类描述、行业信息存储目标库及基表指令、行业信息存储结构类型、行业信息存储映射描述、行业信息存储转换处理指令、行业信息存储相关处理说明和其他信息。
行业信息存储模型管理组件241至少包括行业信息存储模型库24的基础信息生成与维护、行业信息存储结构的动态生成、行业信息存储映射控制、行业信息存储转换处理等功能处理模块。该专利技术的显着效果在于,该专利技术从网页索引、网页结构、行业信息结构、行业信息存储结构和用户系统界面五个层面建立了与行业应用信息搜索相关的完整描述和管理。该系统解决了在一个模型中同时覆盖不同行业应用、不同网页、不同行业信息结构和存储结构的问题,具有全行业能力。这项专利技术将使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、抓取、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。 四. 附图说明图1为专利技术示意图。其中1=垂直搜索核心组件Spider2=行业应用模型21=互联网网页库211=网页存储分类索引管理组件212=GoogleAPI22=网页结构信息模型库221=网页结构信息模型管理组件23=行业信息结构模型库 231 = 行业信息结构模型管理组件 24 = 行业信息采集模型库 241 = 行业信息采集模型管理组件 25 = 行业信息存储模型库 251 = 行业信息存储模型管理组件 26 = 用户系统界面模型库 261 =用户系统界面模型管理组件图2是专利技术行业应用模型中网页结构信息模型库的结构示例。
图3是专利技术行业应用模型中行业信息结构模型库的结构示例。图4是专利技术行业应用模型中行业信息存储结构模型库的结构示例。 五.具体实施方式实例1如图1所示。 2、本实施例举例说明了专利技术的行业应用模型中网页结构信息模型库的结构示例。示例二参见图3。本实施例举例说明了专利技术的行业应用模型中的行业信息结构模型库的结构示例。实施例3参见图4。本实施例举例说明了专利技术的行业应用模型中的行业信息存储结构模型库的结构示例。权利要求1.,其特征在于垂直搜索核心模块Spider(I)接入行业应用模型(2)),实现不同行业信息的识别、抓取、组织、存储和传输,行业应用模型( 2)由互联网网页库(21)和网页存储分类索引管理组件(211),网页结构信息模型库(22))和网页结构信息模型管理组件(22@) k45@,行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(241),和用户系统界面模型库(2@k53)@和用户系统界面模型管理组件(251);互联网网页库(21))和web存储分类索引管理组件(211)承担)一世htemet web library(21)存储、分类和索引)管理任务,包括web存储分类索引管理
【技术保护点】
通用垂直搜索引擎行业应用模型建模方法的特点是垂直搜索核心模块Spider(1)Access行业应用模型(2))实现识别、捕获、组织、存储和传输应用、行业应用模型(2)来自互联网网页库(21))和网页存储分类索引管理组件(211)、网页结构信息模型库(22)和网页结构信息模型管理组件) (221),行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(24@k21) @)) ,以及用户系统界面模型库(25)和用户系统界面模型管理组件(251));其中:Internet web库(21)和web存储分类索引man agement组件(211))网页库(21)存储分类索引管理任务,包括网页存储分类索引管理组件(211)调用GoogleAPI(212))实现行业应用web页面网址集合搜索;网页结构信息模型库(22)和网页结构信息模型管理组件(221)承担页面之间关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理任务)和行业应用;行业信息结构模型库(221)23)和行业信息结构模型管理组件(231),负责不同结构形式和页面的描述、提取、生成和管理任务)各种行业信息在各种网页中的位置;行业信息存储模型库(24)和行业信息存储模型管理组件(241),负责捕获各种信息后系统中存储结构的存储形式和描述)来自各种网页的行业信息,以及存储结构Task的动态生成和管理;用户系统int erface模型库(25)和用户系统接口模型管理组件(251),负责信息存储形式与存储结构、信息传输接口、软件之间的转换关系),每个用户特定的系统描述,接口关系表、接口定义和调用的生成和管理任务。
[技术特点总结]
[专利技术属性]
技术研发人员:刘学明、钱宇、张康、
申请人(专利权):,
类型:发明
国家、省市:32个
下载所有详细技术资料我是此专利的所有者 查看全部
:通用型垂直搜索引擎的行业应用模型建模方法
通用垂直搜索引擎的行业应用模型建模方法,垂直搜索核心模块Spider(1)Access Industry Application Model(2))实现对不同数据的识别、捕获、组织、存储和传输。行业信息、行业应用模型(2)山互联网web库(21))和web存储分类索引管理组件(211)、web结构信息模型库(22)和web结构信息模型管理组件) (22@k21)@、行业信息结构模型库(23)和行业信息结构模型管理组件(231))、行业信息存储模型库(24)和行业信息存储模型管理组件(24) 1),和用户系统界面模型库(25)和用户系统界面模型管理组件(251))。本发明的专利技术解决了同时覆盖不同行业应用、不同的网页、不同的行业信息结构和存储结构在一个模型中。它使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、捕获、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。
下载所有详细的技术资料
【技术实现步骤总结】
该专利技术公开了一种基于。 二.
技术介绍
许多文档将垂直搜索定义为针对单个应用程序或单个功能的搜索技术。现实中,垂直搜索产品和门户网站就是按照这个定义布局的,或者房地产信息搜索门户,或者博客信息搜索门户,或者音乐信息搜索门户,或者专利信息搜索门户。所有这些都是如此。之所以出现这种现象,是因为垂直搜索互联网信息具有明显的行业应用特征、功能应用特征和结构特征。也就是说,由于垂直搜索面临的互联网信息具有明显的行业应用特征、功能应用特征和结构特征,这些千差万别的信息特征导致垂直搜索门户具有明显的单一行业或功能。事实上,垂直搜索引擎的核心模块——数据爬取模块蜘蛛本身可以作为通用技术,并没有严格的行业应用或功能应用边界。原则上,一款好的数据爬虫软件可以完成任何网页、任何行业信息的数据爬取任务。由此看来,垂直搜索技术只适用于单一行业或功能门户的事实并不在于垂直搜索的核心技术——数据爬虫软件蜘蛛,而是来自于核心技术之外。的元素。所以,要搭建一个像谷歌、百度这样的通用垂直搜索平台,垂直搜索的核心技术——数据爬虫软件蜘蛛,就有了这个基础。问题在于,如何围绕具有通用能力的数据爬虫软件构建具有通用能力的外围系统,是实现通用垂直搜索引擎的关键。构建与通用数据爬虫软件蜘蛛相匹配、具有通用能力的行业应用模型是系统研究的重要课题之一。 三.
技术实现思路
该专利技术的目的是提供一种用于一般垂直搜索系统中描述不同行业应用或功能应用特征的方法,使垂直搜索能够完成对互联网信息的识别、抓取和检索。其行业模式。组织、存储和传输应用程序,使它们能够成为通用的垂直搜索引擎。该专利技术的技术方案就是该专利技术。垂直搜索核心模块Spider 1接入行业应用模型2,实现对不同行业信息的识别、抓取、组织、存储和传输。行业应用模型2由互联网网页库21和网页组成。存储分类索引管理组件211、网页结构信息模型库22和页面结构信息模型管理组件221、工业信息结构模型库23和行业信息结构模型管理组件231、工业信息存储模型库24和行业信息存储模型管理组件241、、用户系统界面模型库25和用户系统界面模型管理组件251构成。互联网网页库21和网页存储分类索引管理组件211负责互联网网页库21的存储、分类和索引管理任务。网页存储分类索引管理组件211调用G00gleAPI212进行行业搜索应用程序网页 URL 集合;网页结构信息模型库22和网页结构信息模型管理组件221承担页面和行业应用关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理等任务。行业信息结构模型库23及行业信息结构模型管理组件231负责各种网页中各种行业信息的不同结构形式和页面位置的描述、提取、生成和管理任务。行业信息存储模型库24和行业信息存储模型管理组件241负责系统中各种存储形式和存储结构的描述,从行业信息中获取信息后存储结构的动态生成和管理任务。网页;用户系统接口模型库25和用户系统接口模型管理组件251专用于每个用户信息存储形式和系统间存储结构转换、信息传输接口、软件接口关系形式、接口定义的描述、生成和管理任务并打电话。
网页结构信息模型库22至少收录行业及应用、行业信息分类描述、网页地址URL、网页访问入口参数(用户名、密码、方法代码等)、网页链接方法、网页链接控制参数等信息。网页结构信息模型管理组件221至少包括网页结构信息模型库22基本信息的生成和维护、网页访问入口参数(用户名、密码、方法代码等)库信息的生成和维护,网页链接方法、网页链接控制参数库信息的生成与维护、网页链接控制代码片段的提取/转换/存储、调用处理等功能处理模块。行业信息结构模型库23至少包括行业及应用、行业信息分类描述、网页地址URL、行业信息结构类型、行业信息结构初始标识、行业信息结构描述、行业信息结构中的元数据属性描述、行业信息结构周期捕获标识、行业信息结构捕获端标识、行业信息结构存储指令等信息。行业信息结构模型管理组件231至少包括行业信息结构模型库23的基础信息生成和维护、行业信息结构模型库23的信息辅助分析和自动提取等功能处理模块。模型库24个至少包括行业及应用、行业信息分类描述、行业信息存储目标库及基表指令、行业信息存储结构类型、行业信息存储映射描述、行业信息存储转换处理指令、行业信息存储相关处理说明和其他信息。
行业信息存储模型管理组件241至少包括行业信息存储模型库24的基础信息生成与维护、行业信息存储结构的动态生成、行业信息存储映射控制、行业信息存储转换处理等功能处理模块。该专利技术的显着效果在于,该专利技术从网页索引、网页结构、行业信息结构、行业信息存储结构和用户系统界面五个层面建立了与行业应用信息搜索相关的完整描述和管理。该系统解决了在一个模型中同时覆盖不同行业应用、不同网页、不同行业信息结构和存储结构的问题,具有全行业能力。这项专利技术将使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、抓取、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。 四. 附图说明图1为专利技术示意图。其中1=垂直搜索核心组件Spider2=行业应用模型21=互联网网页库211=网页存储分类索引管理组件212=GoogleAPI22=网页结构信息模型库221=网页结构信息模型管理组件23=行业信息结构模型库 231 = 行业信息结构模型管理组件 24 = 行业信息采集模型库 241 = 行业信息采集模型管理组件 25 = 行业信息存储模型库 251 = 行业信息存储模型管理组件 26 = 用户系统界面模型库 261 =用户系统界面模型管理组件图2是专利技术行业应用模型中网页结构信息模型库的结构示例。
图3是专利技术行业应用模型中行业信息结构模型库的结构示例。图4是专利技术行业应用模型中行业信息存储结构模型库的结构示例。 五.具体实施方式实例1如图1所示。 2、本实施例举例说明了专利技术的行业应用模型中网页结构信息模型库的结构示例。示例二参见图3。本实施例举例说明了专利技术的行业应用模型中的行业信息结构模型库的结构示例。实施例3参见图4。本实施例举例说明了专利技术的行业应用模型中的行业信息存储结构模型库的结构示例。权利要求1.,其特征在于垂直搜索核心模块Spider(I)接入行业应用模型(2)),实现不同行业信息的识别、抓取、组织、存储和传输,行业应用模型( 2)由互联网网页库(21)和网页存储分类索引管理组件(211),网页结构信息模型库(22))和网页结构信息模型管理组件(22@) k45@,行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(241),和用户系统界面模型库(2@k53)@和用户系统界面模型管理组件(251);互联网网页库(21))和web存储分类索引管理组件(211)承担)一世htemet web library(21)存储、分类和索引)管理任务,包括web存储分类索引管理
【技术保护点】
通用垂直搜索引擎行业应用模型建模方法的特点是垂直搜索核心模块Spider(1)Access行业应用模型(2))实现识别、捕获、组织、存储和传输应用、行业应用模型(2)来自互联网网页库(21))和网页存储分类索引管理组件(211)、网页结构信息模型库(22)和网页结构信息模型管理组件) (221),行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(24@k21) @)) ,以及用户系统界面模型库(25)和用户系统界面模型管理组件(251));其中:Internet web库(21)和web存储分类索引man agement组件(211))网页库(21)存储分类索引管理任务,包括网页存储分类索引管理组件(211)调用GoogleAPI(212))实现行业应用web页面网址集合搜索;网页结构信息模型库(22)和网页结构信息模型管理组件(221)承担页面之间关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理任务)和行业应用;行业信息结构模型库(221)23)和行业信息结构模型管理组件(231),负责不同结构形式和页面的描述、提取、生成和管理任务)各种行业信息在各种网页中的位置;行业信息存储模型库(24)和行业信息存储模型管理组件(241),负责捕获各种信息后系统中存储结构的存储形式和描述)来自各种网页的行业信息,以及存储结构Task的动态生成和管理;用户系统int erface模型库(25)和用户系统接口模型管理组件(251),负责信息存储形式与存储结构、信息传输接口、软件之间的转换关系),每个用户特定的系统描述,接口关系表、接口定义和调用的生成和管理任务。
[技术特点总结]
[专利技术属性]
技术研发人员:刘学明、钱宇、张康、
申请人(专利权):,
类型:发明
国家、省市:32个
下载所有详细技术资料我是此专利的所有者
网站参观者的指标数据(UV、IP)背后都是互联网使用者
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-07-06 23:22
网站参观者的指标数据(UV、IP)背后都是互联网使用者
我推荐一个例子。 “groceries网站”这个词经常出现在我的一篇博客中。当然,这只是推荐的一个例子。
Overture 使要价半透明,在竞争激烈的关键词 中,它将确保您的页面成本接近您的最低要价。
搜索引擎会不断调整其算法。因此,成功的 SEO 专家必须不断研究搜索引擎的不道德行为并自学其工作原理。
如果你已经为网站积极制定了搜索引擎策略,并投入了适当的人力、物力和财力,此时你必须忘记:代价是坚决。
网站visitor网站visitor:网站visitor的指标数据(UV、IP)都是具有不同分析属性(新/现有访问者)、地区)和人口统计属性(性别、年龄、教育等);目的不同,来源不同,采访轨迹也不同,在第2章SEO基础教程|50谷歌优化搜索引擎搜索链接百度搜索引擎分析应该对符合市场定位的访问者进行细分,并做有针对性的比较学习。
然而,事实上,许多消费者甚至商业搜索者都将搜索中的高排名视为表示接受。
更何况普通百度员工也不敢问这个事情。
在打开宽泛的给定部分之前,您要求检查同义词等的搜索结果是否浪费。
查找仅限订阅者或已被删除的内容。您可以在 SERP 列表中查看限制订阅者或已从内存链接中删除的内容或使用 cache: 运算符。
例如,访问者通过搜索引擎转至电子商务网站。指定了一个流畅的页面,一个商品库页面,一个购物车页面,一个收费的流畅页面,整个销售结束,离开网站,只为最后一个支付流畅页面,这是一个解散,但它是未因本次访问的其他页面解散。
如果您不建立销售开关,那么流量就没有任何意义。
网站竞价对数搜索引擎关键词优化排名公司网站根据内容介绍和展示乌龟,更新快。它还有一个站点跟踪程序。
如果您的网站在 30 天内没有被收录于,您可以在几个月后通知您的网站。
最重要的是,对于我们通过这种方式发送给我们的数据,Alexa与我们无关,程序无法将我们与正常访问的数据区分开来。作弊示例1:·另外:Alexa被列入一两年前,现在,已经列出了许多副站长的执着目标之一。很多论坛的副站长为了提高网站排名,拒绝版主安装Alexa工具栏。
这项研究揭示了将自然搜索重新添加到现有付费搜索活动的效果,并将这样做的效果与单独的付费搜索活动进行比较。
其他网站 内容的一些不道德副本。
搜索引擎还可以检查登录用户的搜索历史。
3612、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的搜索引擎优化操作。页面域用户的操作步骤是什么,可以在关键词前加上地区名称,如省或城市名称等
什么是seo搜索引擎优化(SearchEngineOptimization,全称SEO)是一种利用搜索引擎的搜索规则来提高网站在相关搜索引擎中的目的的方式。
图 1-13 总结了结果的改进。
网站Interviewer Times Ranking (Reachrank):根据采访次数排名。
以下是一些基本运算符。
一些罕见的代码用斜体表示。
2.降低信息检索难度雅虎的数据库分为14个类别(每个类别还包括平均数量的小类别),其分类系统非常详细,所以最好进行明确的主题搜索起点,特别是对于那些新用户和对市场需求知之甚少的用户,比起结构化的搜索风格,自由选择要按主题逐级编入索引的网页要自然得多。
Invisable/hiddentext 隐藏搜索引擎和搜索引擎隐藏文本内容的优化旨在通过收录大量关键词的网页增加关键词相关性分数而不影响网站美的目标。
9 变化:互联网是一种非常脆弱的媒介。
雅虎!编辑程序可能会将您网站的新原创页面从其搜索索引中删除。
自由选择系统部署网站 这个链接是网站数据分析实践的开始。它是采集和获取数据的过程。您必须自由选择合适的网站分析系统,以满足分析计划的市场需求。从满足网站分析基础市场的需求来看,以下几点可供大家参考: 第二章SEO基础教程|48 部署非常简单。尽量自由选择方便的网站分析系统,尤其是中小网站技术,在人不多的情况下,标准化代码最坏的情况和全站安装代码一样,没有必要调整转成追踪等功能的代码,也有利于提高之前简单的网站分析的可扩展性。
网站 与清医院相关的请求提交到“区域”类别下的相关类别。
2、在 JAVA 脚本中重用扩展名为 .js 的文件。
搜索算法指出的关键字搜索最多的页面将按顺序排列。
那么,网站移动搜索引擎的构建主要分为三个部分:如何在百度上更好地搜索收录于网站中的内容,以及如何在移动搜索列表中获得更好的名称,如何让用户从海量的搜索结果中快速找到并分页你的网站。
快速“xyz技巧”排名第一,他从这个相似的关键字中获得了一些不错的流量。
当您输入错误的链接组链接时,您可能会链接到它们而不是作弊。
但是如果使用网站background日志来分析,因为内存页可能需要在没有服务器催促的情况下进行指示,所以会被记录为PV。
以动词开头:如果您以强有力且主动的动词开头,则可以显着降低页面访问率。
如果您的网站已经创建,更改文件名只是一个小因素,但如果您正在构建一个新网站,只需一点时间将关键字重新添加到文件名中即可。
这些广告将访问者引导至您的营业地点。
2.4.1 负面列表因素 SEOmoz 的调查也证实了一些负面列表因素。
第四章移动搜索|104 第四部分:更好的排名如何在百度移动搜索中获得更好的排名与PC端的市场需求相同。 收录于问题解问题是排名问题。 查看全部
网站参观者的指标数据(UV、IP)背后都是互联网使用者

我推荐一个例子。 “groceries网站”这个词经常出现在我的一篇博客中。当然,这只是推荐的一个例子。
Overture 使要价半透明,在竞争激烈的关键词 中,它将确保您的页面成本接近您的最低要价。
搜索引擎会不断调整其算法。因此,成功的 SEO 专家必须不断研究搜索引擎的不道德行为并自学其工作原理。
如果你已经为网站积极制定了搜索引擎策略,并投入了适当的人力、物力和财力,此时你必须忘记:代价是坚决。
网站visitor网站visitor:网站visitor的指标数据(UV、IP)都是具有不同分析属性(新/现有访问者)、地区)和人口统计属性(性别、年龄、教育等);目的不同,来源不同,采访轨迹也不同,在第2章SEO基础教程|50谷歌优化搜索引擎搜索链接百度搜索引擎分析应该对符合市场定位的访问者进行细分,并做有针对性的比较学习。
然而,事实上,许多消费者甚至商业搜索者都将搜索中的高排名视为表示接受。
更何况普通百度员工也不敢问这个事情。
在打开宽泛的给定部分之前,您要求检查同义词等的搜索结果是否浪费。
查找仅限订阅者或已被删除的内容。您可以在 SERP 列表中查看限制订阅者或已从内存链接中删除的内容或使用 cache: 运算符。
例如,访问者通过搜索引擎转至电子商务网站。指定了一个流畅的页面,一个商品库页面,一个购物车页面,一个收费的流畅页面,整个销售结束,离开网站,只为最后一个支付流畅页面,这是一个解散,但它是未因本次访问的其他页面解散。
如果您不建立销售开关,那么流量就没有任何意义。
网站竞价对数搜索引擎关键词优化排名公司网站根据内容介绍和展示乌龟,更新快。它还有一个站点跟踪程序。
如果您的网站在 30 天内没有被收录于,您可以在几个月后通知您的网站。
最重要的是,对于我们通过这种方式发送给我们的数据,Alexa与我们无关,程序无法将我们与正常访问的数据区分开来。作弊示例1:·另外:Alexa被列入一两年前,现在,已经列出了许多副站长的执着目标之一。很多论坛的副站长为了提高网站排名,拒绝版主安装Alexa工具栏。
这项研究揭示了将自然搜索重新添加到现有付费搜索活动的效果,并将这样做的效果与单独的付费搜索活动进行比较。
其他网站 内容的一些不道德副本。
搜索引擎还可以检查登录用户的搜索历史。
3612、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的搜索引擎优化操作。页面域用户的操作步骤是什么,可以在关键词前加上地区名称,如省或城市名称等
什么是seo搜索引擎优化(SearchEngineOptimization,全称SEO)是一种利用搜索引擎的搜索规则来提高网站在相关搜索引擎中的目的的方式。
图 1-13 总结了结果的改进。
网站Interviewer Times Ranking (Reachrank):根据采访次数排名。
以下是一些基本运算符。
一些罕见的代码用斜体表示。
2.降低信息检索难度雅虎的数据库分为14个类别(每个类别还包括平均数量的小类别),其分类系统非常详细,所以最好进行明确的主题搜索起点,特别是对于那些新用户和对市场需求知之甚少的用户,比起结构化的搜索风格,自由选择要按主题逐级编入索引的网页要自然得多。
Invisable/hiddentext 隐藏搜索引擎和搜索引擎隐藏文本内容的优化旨在通过收录大量关键词的网页增加关键词相关性分数而不影响网站美的目标。
9 变化:互联网是一种非常脆弱的媒介。
雅虎!编辑程序可能会将您网站的新原创页面从其搜索索引中删除。
自由选择系统部署网站 这个链接是网站数据分析实践的开始。它是采集和获取数据的过程。您必须自由选择合适的网站分析系统,以满足分析计划的市场需求。从满足网站分析基础市场的需求来看,以下几点可供大家参考: 第二章SEO基础教程|48 部署非常简单。尽量自由选择方便的网站分析系统,尤其是中小网站技术,在人不多的情况下,标准化代码最坏的情况和全站安装代码一样,没有必要调整转成追踪等功能的代码,也有利于提高之前简单的网站分析的可扩展性。
网站 与清医院相关的请求提交到“区域”类别下的相关类别。
2、在 JAVA 脚本中重用扩展名为 .js 的文件。
搜索算法指出的关键字搜索最多的页面将按顺序排列。
那么,网站移动搜索引擎的构建主要分为三个部分:如何在百度上更好地搜索收录于网站中的内容,以及如何在移动搜索列表中获得更好的名称,如何让用户从海量的搜索结果中快速找到并分页你的网站。
快速“xyz技巧”排名第一,他从这个相似的关键字中获得了一些不错的流量。
当您输入错误的链接组链接时,您可能会链接到它们而不是作弊。
但是如果使用网站background日志来分析,因为内存页可能需要在没有服务器催促的情况下进行指示,所以会被记录为PV。
以动词开头:如果您以强有力且主动的动词开头,则可以显着降低页面访问率。
如果您的网站已经创建,更改文件名只是一个小因素,但如果您正在构建一个新网站,只需一点时间将关键字重新添加到文件名中即可。
这些广告将访问者引导至您的营业地点。
2.4.1 负面列表因素 SEOmoz 的调查也证实了一些负面列表因素。
第四章移动搜索|104 第四部分:更好的排名如何在百度移动搜索中获得更好的排名与PC端的市场需求相同。 收录于问题解问题是排名问题。
如何使用户关注的网页排列在搜索引擎的排序技术
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-07-06 01:08
搜索引擎的排序技术
摘要:本文简要介绍和比较了搜索引擎目前使用的排序算法,包括词频位置加权排序算法、链接分析排序算法,并着重介绍了PageRank算法和HITS算法的思想及其比较优势和劣势。
关键词:搜索引擎;排行;网页排名;命中
1 前言
谷歌和百度的崛起很大程度上是由于它们使用了比以前的搜索引擎更好的排序技术。由于人们通常只关注搜索结果的前 10 或 20 项,因此将与用户查询结果最相关的信息排在结果的前排尤为重要。例如,.jp、.de 和.edu 域名下的网页通常比.com 和.net 域名下的网页更有用[1]。如何让用户关注的网页在搜索结果中排名靠前,让各家搜索引擎公司不断完善优化方向。笔者将通过阅读论文和网络资料总结介绍几种主要的排序算法:词频位置加权排序算法、链接分析排序算法。
2 词频位置加权排序算法
这类技术是在传统信息检索技术的基础上发展起来的,即用户在网页中输入的搜索词的频率越高,搜索词的位置越重要,则该网页被认为与本次搜索相关。一个词的相关性越高,它在搜索结果中出现的位置就越高。 InfoSeek、Excite、Lycos等早期搜索引擎都采用了这种排序方式。
2.1 词频加权
词频加权是以用户提供的搜索词在网页中出现的次数作为确定网页相关性权重的依据。词频加权方法包括绝对词频加权、相对词频加权、逆词频加权、基于词判别值的加权等。对于单词搜索引擎,可以通过简单地计算一个词在网页中出现的频率来给出权重。对于具有逻辑组装功能的搜索引擎,必须使用其他加权方法。因为在使用组合搜索查询时,搜索结果与搜索查询中的每个搜索词相关,并且每个搜索词在所有网页中的总频率是不同的。如果按总重量排序, 会造成结果无关紧要。这可以通过多种其他方式解决。例如,利用相对词频加权的原理,可以统计大量网页,为所有网页中出现频率较高的词分配一个较低的初始值。相对而言,所有网页中出现频率较低的词被赋予较低的初始值。更高的权重 [2]。
2.2 词位权重
通过为网页中不同位置和布局的词分配不同的权重,可以根据权重确定搜索结果和搜索词的相关程度。字的位置包括页面标题元素、页面描述关键字元素、正文标题、正文内容、正文链接、logo等。布局包括字体、字号、是否加粗或者强调等。比如理解排序技术,搜索“排序技术”时,有两个结果,一个标题是“搜索引擎的排序技术”,另一个文章的标题是“Web Information Retrieval”,但内容有部分 说到搜索引擎的排名技术,显然第一个结果更相关。 “排名技术”这个词应该在第一个结果中给予更大的权重。
2.3 此类算法的优缺点
这种方法的主要优点是使用方便,易于实现,最成熟的发展基本上是目前所有搜索引擎排名核心技术的基础。但是,由于现网内容的质量无法保证,为了使网页在搜索引擎中排名靠前,在网页中添加了相同背景色的图层,并填写了大量的热门关键词,当人们来浏览网页时完全被查看。不,但搜索引擎可以在索引时找到它。这个问题在一定程度上得到了改善,但并没有完全根除。
3 链接分析排名
链接分析排序算法的思想其实来源于纸质文献索引机制,即一篇论文或文献被引用次数越多,其学术价值就越高。同一个网页类比,如果一个网页的链接越多,该网页的重要性就越高。链路分析算法主要分为随机漫游模型,如PageRank算法;基于Hub和Authority的相互强化模型,如HITS及其变体;基于概率模型,如 SALSA;基于贝叶斯模型,如贝叶斯算法及其简化版本。下面将分别介绍这些算法。
3.1 PageRank 算法
Google 搜索引擎有两个重要功能,可以让您获得高度准确的结果。首先,它利用网络的链接特征来计算网页的质量排名,即PageRank;其次,它使用链接来改善搜索结果 [3]。
简单的PageRank原理即如图1所示的那样,从网页A导向网页B的链接被看作是对页面A对页面B的支持投票,Google根据这个投票数来判断页面的重要性。可是 Google 不单单只看投票数(即链接数),对投票的页面也进行分析。重要性高的页面所投的票的评价会更高。
原创PageRank算法:PR(A) = (1-d) + d (PR(T1)/C(T1) +… + PR(Tn)/C(Tn)))<//p
p其中: PR(A):网页A的PageRank值; PR(Ti):链接到页面A的网页Ti的PageRank值; C(Ti):网页Ti的出站链接数; d:阻尼系数,0/p
p在算法的第二个版本中:PR(A) = (1-d) / N + d (PR(T1)/C(T1) +... + PR(Tn)/C(Tn) ))/p
p这里 N 是 Internet 页面的总数。该算法2与算法1并没有完全不同。在随机冲浪模型中,算法2中页面的PageRank值是点击多个链接后到达该页面的实际概率。因此,互联网上所有网页的PageRank值形成一个概率分布,所有RageRank值之和为1。/p
p因为 PR(A) 取决于链接到网页 A 的其他网页的 PageRank 值,而其他网页的 PR 值也取决于指向该网页的网页的 PR 值,所以这是一个递归过程。似乎需要无穷无尽的计算才能获得网页的PR值。根据参考文献5中的实验,递归计算了网络中3.220亿个链接,发现经过52次计算可以得到收敛。稳定的 PageRank 值,在计算一半链接的 PageRank 值时,进行了 45 次计算。通过实验发现,递归计算次数和链接数呈对数比例增加,即要计算N个链接的PageRank值时,只需进行logN次递归计算即可得到稳定的PageRank值[5] ./p
p3.2 Hits 算法/p
p在PageRank算法中,链接被平等对待,每个链接贡献相同的权重。在现实生活中,有些链接指向广告,而有些链接指向权威网页。可以看出,均匀分布的权重不符合实际情况。所以康奈尔大学的Jon Kleinberg博士在1998年首先提出了Hits算法。/p
pHITS算法对网页质量的评价结果体现在它赋予每个网页的两个评价值上:内容权限(Authority)和链接权限(Hub)。/p
p内容权限与网页本身直接提供的内容信息的质量有关。引用的网页越多,内容权限越高;相应地,链接权限与网页提供的超链接的质量有关。相关的。引用高质量内容的页面越多,链接的权威性就越高。根据关键字匹配将查询提交给传统搜索引擎。搜索引擎返回的网页很多,前n个网页作为根集。包括根集合中页面所指向的所有页面,再包括根集合中指向页面的页面,从而扩展了基本集合。 HITS算法输出一组具有较大Hub值的网页和具有较大权限值的网页[6]。/p
p与PageRank等实用算法不同,HITS算法更多的是一种实验性的尝试。从表面上看,HITS算法需要排序的页面数量很少,但由于需要根据内容分析从搜索引擎中提取根集并扩展基本集,这个过程需要相当长的时间,而PageRank算法表面上看,处理的数据量远远超过HITS算法,但是因为在用户查询的时候计算量已经由服务器独立完成,所以用户无需等待。为此,从用户的等待时间来看,PageRank算法应该优于HITS算法。简短[7]。/p
p3.3 其他链接分析和排序算法/p
pPageRank 算法基于用户对网页随机前向浏览的直觉,HITS 算法考虑了Authorative 网页和Hub 网页之间的增强关系。在实际应用中,用户大部分时间是向前浏览网页,但在很多情况下,他们会返回浏览网页。基于上述直观认识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法,该算法考虑了用户返回浏览网页的情况,并保留了随机漫游PageRank 和 HITS 中网页的 Authoritive 分类与 Hub 的想法取消了 Authoritive 和 Hub 之间的相互加强关系[8]。/p
p艾伦鲍罗丁等。提出了一种完整的贝叶斯统计方法来确定 Hub 和 Authoritive 网页。假设有M个Hub网页和N个Authority网页,可以是同一个集合。每个Hub网页都有一个未知实数参数,表示有超链接的总体趋势,还有一个未知的非负参数,表示有链接到Authority网页的趋势。每个权威网页 j 都有一个未知的非负参数,代表 j 的权限级别。统计模型如下。 Hub 网页 i 链接到权威网页 j 的先验概率为:P(i,j)=Exp(+)/(1+Exp(+))。当 Hub 网页 i 和权威网页 j 之间没有链接时,P(i,j)=1/(1+Exp(+))。从上面的公式可以看出,如果非常大(说明Hub网页i有很高的指向任何网页的倾向),或者总和很大(说明i是一个高质量的Hub,j是一个高质量的Authority网页),那么i ->j的链接概率比较大[9]。
4 其他排序技术
除了以上两类排序算法,还有其他排序方式,比如:竞价排名(竞价排名是百度等一些搜索引擎公司推出的一种以价格确定排名的在线推广方式。但是,投标人信息的真实性需要严格筛选,否则用户对搜索引擎的信任将被灰色行业所利用[10])。通过用户反馈提高排序的准确性,通过理解增加排序的相关性,通过智能过滤减少减少。排序结果的重复性等
5 结束语
综上所述,在目前谷歌等搜索引擎中,排序方式非常复杂,需要综合考虑多种因素,而不是单一的上述算法。我个人认为未来搜索引擎会变得更加人性化,搜索结果会根据用户喜好进行排序和过滤。此外,特定领域的专业搜索引擎将逐步发展,例如金融和体育的专业搜索。引擎。相信未来浏览器功能越来越强大,搜索引擎的影响力会越来越大。
参考文献:
[1] Dennis Fetterly、Mark Manasse、Marc Najork、Janet Wiener:网页演变的大规模研究,In:Proc.of the 12th Int'l World Wide Web Conf.New York:ACM Press ,2003.669-678...
[2] 杨思洛.搜索引擎排序技术研究[J].现代图书馆与信息技术,2005,(01).
[3] S.Brin 和 L.Page,“大型超文本 Web 搜索引擎的剖析”,发表在第七届国际万维网会议论文集(WWW7)/Computer Networks,阿姆斯特丹, 1998
[4] Page L, Brin S, etc. PageRank 引文排名:为网络带来秩序[J].斯坦福数字图书馆工作论文,1998,(6):102-107.
[5] T. 有 liwala。 PageRank 的高效计算。 1999-31技术报告,1999.
[6]
[7] 何晓阳,吴强,吴志荣:HITS算法与PageRank算法对比分析。信息学报,2004 年第 2 期
[8]
[9] 朱伟、王超、李军等. Web 超链分析算法研究。计算机科学, 2003, 30(1)
[10]常路,夏祖奇;几种常用的搜索引擎排序算法。图书情报工作,2003 年第 6 期
———————————————————
版权声明:本文为CSDN博主“arthur0808”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接: 查看全部
如何使用户关注的网页排列在搜索引擎的排序技术
搜索引擎的排序技术
摘要:本文简要介绍和比较了搜索引擎目前使用的排序算法,包括词频位置加权排序算法、链接分析排序算法,并着重介绍了PageRank算法和HITS算法的思想及其比较优势和劣势。
关键词:搜索引擎;排行;网页排名;命中
1 前言
谷歌和百度的崛起很大程度上是由于它们使用了比以前的搜索引擎更好的排序技术。由于人们通常只关注搜索结果的前 10 或 20 项,因此将与用户查询结果最相关的信息排在结果的前排尤为重要。例如,.jp、.de 和.edu 域名下的网页通常比.com 和.net 域名下的网页更有用[1]。如何让用户关注的网页在搜索结果中排名靠前,让各家搜索引擎公司不断完善优化方向。笔者将通过阅读论文和网络资料总结介绍几种主要的排序算法:词频位置加权排序算法、链接分析排序算法。
2 词频位置加权排序算法
这类技术是在传统信息检索技术的基础上发展起来的,即用户在网页中输入的搜索词的频率越高,搜索词的位置越重要,则该网页被认为与本次搜索相关。一个词的相关性越高,它在搜索结果中出现的位置就越高。 InfoSeek、Excite、Lycos等早期搜索引擎都采用了这种排序方式。
2.1 词频加权
词频加权是以用户提供的搜索词在网页中出现的次数作为确定网页相关性权重的依据。词频加权方法包括绝对词频加权、相对词频加权、逆词频加权、基于词判别值的加权等。对于单词搜索引擎,可以通过简单地计算一个词在网页中出现的频率来给出权重。对于具有逻辑组装功能的搜索引擎,必须使用其他加权方法。因为在使用组合搜索查询时,搜索结果与搜索查询中的每个搜索词相关,并且每个搜索词在所有网页中的总频率是不同的。如果按总重量排序, 会造成结果无关紧要。这可以通过多种其他方式解决。例如,利用相对词频加权的原理,可以统计大量网页,为所有网页中出现频率较高的词分配一个较低的初始值。相对而言,所有网页中出现频率较低的词被赋予较低的初始值。更高的权重 [2]。
2.2 词位权重
通过为网页中不同位置和布局的词分配不同的权重,可以根据权重确定搜索结果和搜索词的相关程度。字的位置包括页面标题元素、页面描述关键字元素、正文标题、正文内容、正文链接、logo等。布局包括字体、字号、是否加粗或者强调等。比如理解排序技术,搜索“排序技术”时,有两个结果,一个标题是“搜索引擎的排序技术”,另一个文章的标题是“Web Information Retrieval”,但内容有部分 说到搜索引擎的排名技术,显然第一个结果更相关。 “排名技术”这个词应该在第一个结果中给予更大的权重。
2.3 此类算法的优缺点
这种方法的主要优点是使用方便,易于实现,最成熟的发展基本上是目前所有搜索引擎排名核心技术的基础。但是,由于现网内容的质量无法保证,为了使网页在搜索引擎中排名靠前,在网页中添加了相同背景色的图层,并填写了大量的热门关键词,当人们来浏览网页时完全被查看。不,但搜索引擎可以在索引时找到它。这个问题在一定程度上得到了改善,但并没有完全根除。
3 链接分析排名
链接分析排序算法的思想其实来源于纸质文献索引机制,即一篇论文或文献被引用次数越多,其学术价值就越高。同一个网页类比,如果一个网页的链接越多,该网页的重要性就越高。链路分析算法主要分为随机漫游模型,如PageRank算法;基于Hub和Authority的相互强化模型,如HITS及其变体;基于概率模型,如 SALSA;基于贝叶斯模型,如贝叶斯算法及其简化版本。下面将分别介绍这些算法。
3.1 PageRank 算法
Google 搜索引擎有两个重要功能,可以让您获得高度准确的结果。首先,它利用网络的链接特征来计算网页的质量排名,即PageRank;其次,它使用链接来改善搜索结果 [3]。
简单的PageRank原理即如图1所示的那样,从网页A导向网页B的链接被看作是对页面A对页面B的支持投票,Google根据这个投票数来判断页面的重要性。可是 Google 不单单只看投票数(即链接数),对投票的页面也进行分析。重要性高的页面所投的票的评价会更高。
原创PageRank算法:PR(A) = (1-d) + d (PR(T1)/C(T1) +… + PR(Tn)/C(Tn)))<//p
p其中: PR(A):网页A的PageRank值; PR(Ti):链接到页面A的网页Ti的PageRank值; C(Ti):网页Ti的出站链接数; d:阻尼系数,0/p
p在算法的第二个版本中:PR(A) = (1-d) / N + d (PR(T1)/C(T1) +... + PR(Tn)/C(Tn) ))/p
p这里 N 是 Internet 页面的总数。该算法2与算法1并没有完全不同。在随机冲浪模型中,算法2中页面的PageRank值是点击多个链接后到达该页面的实际概率。因此,互联网上所有网页的PageRank值形成一个概率分布,所有RageRank值之和为1。/p
p因为 PR(A) 取决于链接到网页 A 的其他网页的 PageRank 值,而其他网页的 PR 值也取决于指向该网页的网页的 PR 值,所以这是一个递归过程。似乎需要无穷无尽的计算才能获得网页的PR值。根据参考文献5中的实验,递归计算了网络中3.220亿个链接,发现经过52次计算可以得到收敛。稳定的 PageRank 值,在计算一半链接的 PageRank 值时,进行了 45 次计算。通过实验发现,递归计算次数和链接数呈对数比例增加,即要计算N个链接的PageRank值时,只需进行logN次递归计算即可得到稳定的PageRank值[5] ./p
p3.2 Hits 算法/p
p在PageRank算法中,链接被平等对待,每个链接贡献相同的权重。在现实生活中,有些链接指向广告,而有些链接指向权威网页。可以看出,均匀分布的权重不符合实际情况。所以康奈尔大学的Jon Kleinberg博士在1998年首先提出了Hits算法。/p
pHITS算法对网页质量的评价结果体现在它赋予每个网页的两个评价值上:内容权限(Authority)和链接权限(Hub)。/p
p内容权限与网页本身直接提供的内容信息的质量有关。引用的网页越多,内容权限越高;相应地,链接权限与网页提供的超链接的质量有关。相关的。引用高质量内容的页面越多,链接的权威性就越高。根据关键字匹配将查询提交给传统搜索引擎。搜索引擎返回的网页很多,前n个网页作为根集。包括根集合中页面所指向的所有页面,再包括根集合中指向页面的页面,从而扩展了基本集合。 HITS算法输出一组具有较大Hub值的网页和具有较大权限值的网页[6]。/p
p与PageRank等实用算法不同,HITS算法更多的是一种实验性的尝试。从表面上看,HITS算法需要排序的页面数量很少,但由于需要根据内容分析从搜索引擎中提取根集并扩展基本集,这个过程需要相当长的时间,而PageRank算法表面上看,处理的数据量远远超过HITS算法,但是因为在用户查询的时候计算量已经由服务器独立完成,所以用户无需等待。为此,从用户的等待时间来看,PageRank算法应该优于HITS算法。简短[7]。/p
p3.3 其他链接分析和排序算法/p
pPageRank 算法基于用户对网页随机前向浏览的直觉,HITS 算法考虑了Authorative 网页和Hub 网页之间的增强关系。在实际应用中,用户大部分时间是向前浏览网页,但在很多情况下,他们会返回浏览网页。基于上述直观认识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法,该算法考虑了用户返回浏览网页的情况,并保留了随机漫游PageRank 和 HITS 中网页的 Authoritive 分类与 Hub 的想法取消了 Authoritive 和 Hub 之间的相互加强关系[8]。/p
p艾伦鲍罗丁等。提出了一种完整的贝叶斯统计方法来确定 Hub 和 Authoritive 网页。假设有M个Hub网页和N个Authority网页,可以是同一个集合。每个Hub网页都有一个未知实数参数,表示有超链接的总体趋势,还有一个未知的非负参数,表示有链接到Authority网页的趋势。每个权威网页 j 都有一个未知的非负参数,代表 j 的权限级别。统计模型如下。 Hub 网页 i 链接到权威网页 j 的先验概率为:P(i,j)=Exp(+)/(1+Exp(+))。当 Hub 网页 i 和权威网页 j 之间没有链接时,P(i,j)=1/(1+Exp(+))。从上面的公式可以看出,如果非常大(说明Hub网页i有很高的指向任何网页的倾向),或者总和很大(说明i是一个高质量的Hub,j是一个高质量的Authority网页),那么i ->j的链接概率比较大[9]。
4 其他排序技术
除了以上两类排序算法,还有其他排序方式,比如:竞价排名(竞价排名是百度等一些搜索引擎公司推出的一种以价格确定排名的在线推广方式。但是,投标人信息的真实性需要严格筛选,否则用户对搜索引擎的信任将被灰色行业所利用[10])。通过用户反馈提高排序的准确性,通过理解增加排序的相关性,通过智能过滤减少减少。排序结果的重复性等
5 结束语
综上所述,在目前谷歌等搜索引擎中,排序方式非常复杂,需要综合考虑多种因素,而不是单一的上述算法。我个人认为未来搜索引擎会变得更加人性化,搜索结果会根据用户喜好进行排序和过滤。此外,特定领域的专业搜索引擎将逐步发展,例如金融和体育的专业搜索。引擎。相信未来浏览器功能越来越强大,搜索引擎的影响力会越来越大。
参考文献:
[1] Dennis Fetterly、Mark Manasse、Marc Najork、Janet Wiener:网页演变的大规模研究,In:Proc.of the 12th Int'l World Wide Web Conf.New York:ACM Press ,2003.669-678...
[2] 杨思洛.搜索引擎排序技术研究[J].现代图书馆与信息技术,2005,(01).
[3] S.Brin 和 L.Page,“大型超文本 Web 搜索引擎的剖析”,发表在第七届国际万维网会议论文集(WWW7)/Computer Networks,阿姆斯特丹, 1998
[4] Page L, Brin S, etc. PageRank 引文排名:为网络带来秩序[J].斯坦福数字图书馆工作论文,1998,(6):102-107.
[5] T. 有 liwala。 PageRank 的高效计算。 1999-31技术报告,1999.
[6]
[7] 何晓阳,吴强,吴志荣:HITS算法与PageRank算法对比分析。信息学报,2004 年第 2 期
[8]
[9] 朱伟、王超、李军等. Web 超链分析算法研究。计算机科学, 2003, 30(1)
[10]常路,夏祖奇;几种常用的搜索引擎排序算法。图书情报工作,2003 年第 6 期
———————————————————
版权声明:本文为CSDN博主“arthur0808”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
“探索推荐引擎内部的秘密”系列将带领读者从浅入深
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-07-06 01:02
《探索推荐引擎的奥秘》系列将带领读者由浅入深,探索推荐引擎的机制和实现方法,包括一些基本的优化方法,如聚类、分类应用等。同时,在理论讲解的基础上,还将介绍如何在大规模数据上实现各种推荐策略,优化策略,结合Apache Mahout构建高效的推荐引擎。作为本系列的第一篇文章,本文将深入介绍推荐引擎的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰了解并快速构建适合自己推荐引擎。
信息发现
现在我们进入了一个数据爆炸的时代。随着Web2.0的发展,Web已经成为数据共享的平台。那么,如何让人们想要在海量数据中找到自己需要的信息就会越来越难。
在这种情况下,搜索引擎(谷歌、必应、百度等)就成为了大家快速找到目标信息的最佳方式。当用户比较清楚自己的需求时,使用搜索引擎通过关键字搜索快速找到自己需要的信息是非常方便的。然而,搜索引擎并不能完全满足用户对信息发现的需求,因为在很多情况下,用户其实并不清楚自己的需求,或者用简单的关键词难以表达自己的需求。或者他们需要更符合他们个人品味和喜好的结果,于是就有了推荐系统,对应搜索引擎,大家习惯称它为推荐引擎。
随着推荐引擎的出现,用户获取信息的方式已经从简单的有针对性的数据搜索转变为更符合人们习惯的更高级的信息发现。
现在,随着推荐技术的不断发展,推荐引擎已经在电子商务(电子商务,如亚马逊、当当)和一些基于社交的社交网站(包括音乐、电影和图书分享,如如豆瓣、Mtime等)都取得了巨大的成功。这也进一步说明,在Web2.0环境下,面对海量数据,用户需要这种更智能、更了解自己需求、品味和偏好的信息发现机制。
返回顶部
推荐引擎
之前介绍了推荐引擎对当前Web2.0站点的重要性。在本章中,我们将讨论推荐引擎的工作原理。推荐引擎使用特殊的信息过滤技术向可能感兴趣的用户推荐不同的项目或内容。
图1.推荐引擎的工作原理
图1展示了推荐引擎的工作原理图。在这里,推荐引擎被视为一个黑匣子。它接受的输入是推荐的数据源。一般来说,推荐引擎需要的数据源包括:
显式的用户反馈可以准确反映用户对物品的真实偏好,但需要用户付出额外的代价,而隐式的用户行为也可以通过一些分析处理来反映用户的偏好,但数据并不是很准确,并且一些行为分析有很多噪音。但是只要选择了正确的行为特征,隐含的用户反馈也可以得到很好的效果,只是行为特征的选择在不同的应用中可能会有很大的不同。比如电商网站,购买行为其实是一种隐性反馈,可以很好的表达用户的喜好。
推荐引擎可能会根据不同的推荐机制使用部分数据源,然后基于这些数据,分析某些规则或直接预测和计算用户对其他项目的偏好。这样,推荐引擎就可以在用户进入时推荐用户可能感兴趣的项目。
推荐引擎分类
推荐引擎的分类可以基于很多指标,下面我们一一介绍:
推荐引擎是否为不同的用户推荐不同的数据?
根据该指标,推荐引擎可分为基于流行行为的推荐引擎和个性化推荐引擎
这是推荐引擎最基本的分类。事实上,人们讨论的大多数推荐引擎都是个性化推荐引擎,因为从根本上讲,只有个性化推荐引擎才是更智能的信息发现过程。 .
根据推荐引擎的数据来源
其实这里就是如何发现数据的相关性,因为大部分推荐引擎都是基于相似的物品集或者用户推荐的。然后参考图1给出的推荐系统示意图,根据不同的数据源发现数据相关性的方法可以分为以下几种:
根据推荐模型的建立
可以想象,在一个拥有大量物品和用户的系统中,推荐引擎的计算量是相当大的。为了实现实时推荐,必须建立推荐模型。推荐模型的建立可以分为以下几种:
事实上,在目前的推荐系统中,很少有推荐引擎只使用一种推荐策略。一般在不同的场景下使用不同的推荐策略来达到最好的推荐效果,比如亚马逊的推荐。它根据用户自身的历史购买数据进行推荐,根据用户当前浏览过的商品进行推荐,根据流行偏好将当前热门商品推荐给不同地区的用户,让用户可以从全方位的推荐中找到适合的商品你真的很感兴趣。
深度推荐机制
本章的篇幅将详细介绍每种推荐机制的工作原理、优缺点和应用场景。
基于人口统计的推荐
基于人口统计的推荐是最容易实施的推荐方法。它只是根据系统用户的基本信息发现用户的相关性,然后将类似用户喜欢的其他物品推荐给当前用户。图 2 显示了此建议的工作原理。
图2.基于人口统计的推荐机制的工作原理
从图中可以清楚地看出,首先,系统对每个用户都有一个用户画像建模,其中包括用户的基本信息,比如用户的年龄、性别等;用户画像计算用户的相似度,可以看到用户A的画像和用户C是一样的,那么系统就会认为用户A和C是相似的用户。在推荐引擎中,他们可以称为“邻居”;最后,根据“邻居”用户组的偏好,向当前用户推荐一些物品,图中将用户A喜欢的物品A推荐给用户C。
这种基于人口统计的推荐机制的好处是:
因为没有使用当前用户对物品的偏好历史数据,所以不存在新用户的“冷启动”问题。该方法不依赖于item本身的数据,因此该方法可以用于不同item的域中,并且是域无关的。
那么这种方法有什么缺点和问题呢?这种根据用户的基本信息对用户进行分类的方法过于粗糙,尤其是在书籍、电影、音乐等对品味要求较高的领域,无法获得很好的推荐效果。也许在一些电商网站,这个方法可以给出一些简单的建议。另一个限制是,这种方法可能涉及到一些与信息发现问题本身无关的敏感信息,例如用户的年龄等,这些用户信息不是很容易获取。
基于内容的推荐
基于内容的推荐是推荐引擎出现之初使用最广泛的推荐机制。其核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的喜好进行记录,向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图3.基于内容推荐机制的基本原理
基于内容的推荐的典型示例如图 3 所示。在电影推荐系统中,首先我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;元数据发现电影之间的相似性,因为类型都是“爱情、浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影导演、演员等);最后,建议实现。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优势在于它可以很好地模拟用户的口味并提供更准确的推荐。但它也存在以下问题:
文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。由于需要根据用户过去的偏好历史进行推荐,因此新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。有的网站还请专业人士对项目进行基因编码,比如Pandora,在一份报告中说,在Pandora的推荐引擎中,每首歌曲都有100多个元数据特征,包括歌曲风格、年份、歌手等。
基于协同过滤的推荐
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,发现一组与当前用户的口味和偏好相似的“邻居”。一般应用中,计算“K-Neighbors”算法;然后,根据这K个邻居的历史偏好信息,为当前用户做出推荐。下图4为示意图。
图4.基于用户的协同过滤推荐机制基本原理
上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目D可以推荐给用户A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户的特征,而基于用户的协同过滤机制根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能相同或相似。口味和偏好。
基于项目的协同过滤推荐
基于物品的协同过滤推荐的基本原理也类似,只不过是利用所有用户对物品或信息的偏好来寻找物品与物品之间的相似度,然后根据用户的历史偏好信息,得出相似的向用户推荐项目。图 5 说明了其基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C 相似。喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上面类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品本身的属性特征信息。
图5.基于项目的协同过滤推荐机制基本原理
同时协同过滤,基于用户和基于项目的策略我们应该如何选择?实际上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,其实可以看出,推荐策略的选择与具体的应用场景有很大关系。
基于模型的协同过滤推荐
基于模型的协同过滤推荐是基于基于样本的用户偏好信息,训练推荐模型,然后根据实时用户偏好信息预测和计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优势:
它不需要对对象或用户进行严格的建模,也不需要对对象的描述是机器可理解的,所以这种方法也是领域无关的。这种方法计算出来的推荐是公开的,可以分享他人的经验,很好的支持用户发现潜在的兴趣和偏好
而且它还存在以下问题:
该方法的核心是基于历史数据,因此对于新项目和新用户存在“冷启动”问题。推荐的效果取决于用户历史偏好数据的数量和准确性。在大多数实现中,用户的历史偏好存储在一个稀疏矩阵中,在稀疏矩阵上的计算存在一些明显的问题,包括少数人的错误偏好可能会对计算的准确性产生很大影响。推荐等。对于一些有特殊品味的用户,我们无法给出好的建议。基于历史数据,在对用户偏好进行捕获和建模后,很难根据用户的使用情况进行修改或进化,这使得该方法不够灵活。
混合推荐机制
当前网站上的推荐往往不是简单地使用某种推荐机制和策略。他们经常混合多种方法来获得更好的推荐结果。关于如何组合各种推荐机制,这里介绍几种比较流行的组合方式。
Weighted Hybridization:使用一个线性公式,根据一定的权重组合几个不同的推荐。具体的权重值需要在测试数据集上反复测试才能达到最佳推荐效果。 Switching Hybridization:前面说过,其实对于不同的情况(数据量、系统运行状态、用户和物品数量等),推荐策略可能会有很大的不同,所以切换Hybridization的方式是允许选择的最适合的推荐机制来计算不同情况下的推荐。 Mixed Hybridization:采用多种推荐机制,向不同区域的用户展示不同的推荐结果。事实上,亚马逊、当当等众多电商网站都采用了这种方式,用户可以获得全面的推荐,也更容易找到自己想要的东西。 Meta-Level Hybridization:采用多种推荐机制,将一种推荐机制的结果作为另一种推荐机制的输入,综合各推荐机制的优缺点,获得更精准的推荐。
推荐引擎的应用
在介绍了推荐引擎的基本原理和基本推荐机制后,下面简要分析几个有代表性的推荐引擎的应用。这里我们选择两个领域:以亚马逊为代表的电子商务和以豆瓣为代表的社交网络。
电子商务中的推荐应用-亚马逊
亚马逊作为推荐引擎的鼻祖,将推荐的思想渗透到了应用的每一个角落。亚马逊推荐的核心是通过数据挖掘算法将用户的消费偏好与其他用户进行比较,从而预测用户可能感兴趣的产品。 对应上面介绍的各种推荐机制,亚马逊采用分区混合机制,展示给不同领域的用户不同的推荐结果。图 6 和图 7 显示了用户可以在亚马逊上获得的推荐。
图6.亚马逊的推荐机制-首页
图7.亚马逊的推荐机制-浏览商品
亚马逊利用网站上所有可以记录的用户行为,根据不同数据的特点进行处理,划分不同区域为用户推送推荐:
值得一提的是,亚马逊在做推荐的时候,设计和用户体验也很独特:
亚马逊利用其大量历史数据来量化推荐原因。
此外,亚马逊的很多推荐都是根据用户的个人资料计算出来的。用户个人资料记录了用户在亚马逊上的行为,包括浏览过的商品、购买过的商品、采集中的商品和心愿单等。当然,亚马逊还集成了评分等其他用户反馈方式,这些都是用户反馈的一部分。轮廓。同时,亚马逊提供了允许用户管理自己的个人资料的功能。这样,用户可以更清楚地告诉推荐引擎他的品味和意图是什么。
社交网站-豆瓣推荐应用
豆瓣是中国相对成功的社交网络网站。形成以图书、电影、音乐、同城活动为中心的多元化社交网络平台。自然推荐的功能必不可少。下面我们看看豆瓣是如何推荐的。
图8.豆瓣的推荐机制-豆瓣电影
当你在豆瓣电影中加入一些你看过或者感兴趣的电影到你看过想看的列表中,并给它们相应的评分,那么豆瓣的推荐引擎就已经给你一些偏好信息了,那么它将显示如图 8 所示的电影推荐。
图 9. 豆瓣推荐机制——基于用户品味的推荐
豆瓣的推荐是通过“豆瓣猜”。为了让用户知道这些推荐是怎么来的,豆瓣还简单介绍了“豆瓣猜”。
“您的个人推荐是根据您的采集和评论自动得出的。每个人的推荐列表都不一样。您的采集和评论越多,豆瓣的推荐就越准确和丰富。
每天推荐的内容可能会发生变化。随着豆瓣的成长,推荐给你的内容会越来越精准。 "
这点让我们清楚的知道豆瓣一定是基于社交协同过滤的推荐。这样,用户越多,用户反馈越多,推荐效果就会越准确。
相比亚马逊的用户行为模型,豆瓣电影的模型更简单,即“看过”和“想看”,这也使得他们的推荐更注重用户的口味,毕竟买东西的动机和看电影还是有很大区别的。
此外,豆瓣也有基于物品本身的推荐。当你查看一些电影的详细信息时,他会向你推荐“喜欢这部电影的人也喜欢的电影”,如图10所示,基于协同过滤应用。
图10.豆瓣的推荐机制——基于电影本身的推荐
总结
在网络数据爆炸的时代,如何让用户更快地找到自己想要的数据,如何让用户发现自己潜在的兴趣和需求,对于电子商务和社交网络应用来说都非常重要。随着推荐引擎的出现,这个问题越来越受到关注。但是对于大多数人来说,可能还在疑惑为什么它总能猜出你想要什么。推荐引擎的神奇之处在于,您不知道引擎在此推荐背后记录和推断的内容。
通过这篇评论文章,你可以了解到推荐引擎其实只是在默默的记录和观察你的一举一动,然后利用所有用户产生的海量数据去分析发现规律,然后慢慢慢慢了解你,你的需求,你的习惯,默默地帮你快速解决问题,找到你想要的。
实际上,回过头来看,很多时候,推荐引擎比你更了解你自己。
通过第一篇文章,相信大家对推荐引擎有了清晰的第一印象。本系列下一篇文章将深入介绍基于协同过滤的推荐策略。在目前的推荐技术和算法中,被广泛认可和采用的方法是基于协同过滤的推荐方法。以其简单的方法模型、低数据依赖、便捷的数据采集、优越的推荐效果,成为大众眼中的“No.1”推荐算法。本文将带你深入了解协同过滤的奥秘,并给出基于Apache Mahout的协同过滤算法的高效实现。 Apache Mahout 是 ASF 的一个相对较新的开源项目。它源自Lucene,建立在Hadoop之上,专注于经典机器学习算法在海量数据上的高效实现。
原文链接为:@126/blog/static/24269713813/
转载于: 查看全部
“探索推荐引擎内部的秘密”系列将带领读者从浅入深
《探索推荐引擎的奥秘》系列将带领读者由浅入深,探索推荐引擎的机制和实现方法,包括一些基本的优化方法,如聚类、分类应用等。同时,在理论讲解的基础上,还将介绍如何在大规模数据上实现各种推荐策略,优化策略,结合Apache Mahout构建高效的推荐引擎。作为本系列的第一篇文章,本文将深入介绍推荐引擎的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰了解并快速构建适合自己推荐引擎。
信息发现
现在我们进入了一个数据爆炸的时代。随着Web2.0的发展,Web已经成为数据共享的平台。那么,如何让人们想要在海量数据中找到自己需要的信息就会越来越难。
在这种情况下,搜索引擎(谷歌、必应、百度等)就成为了大家快速找到目标信息的最佳方式。当用户比较清楚自己的需求时,使用搜索引擎通过关键字搜索快速找到自己需要的信息是非常方便的。然而,搜索引擎并不能完全满足用户对信息发现的需求,因为在很多情况下,用户其实并不清楚自己的需求,或者用简单的关键词难以表达自己的需求。或者他们需要更符合他们个人品味和喜好的结果,于是就有了推荐系统,对应搜索引擎,大家习惯称它为推荐引擎。
随着推荐引擎的出现,用户获取信息的方式已经从简单的有针对性的数据搜索转变为更符合人们习惯的更高级的信息发现。
现在,随着推荐技术的不断发展,推荐引擎已经在电子商务(电子商务,如亚马逊、当当)和一些基于社交的社交网站(包括音乐、电影和图书分享,如如豆瓣、Mtime等)都取得了巨大的成功。这也进一步说明,在Web2.0环境下,面对海量数据,用户需要这种更智能、更了解自己需求、品味和偏好的信息发现机制。
返回顶部
推荐引擎
之前介绍了推荐引擎对当前Web2.0站点的重要性。在本章中,我们将讨论推荐引擎的工作原理。推荐引擎使用特殊的信息过滤技术向可能感兴趣的用户推荐不同的项目或内容。
图1.推荐引擎的工作原理

图1展示了推荐引擎的工作原理图。在这里,推荐引擎被视为一个黑匣子。它接受的输入是推荐的数据源。一般来说,推荐引擎需要的数据源包括:
显式的用户反馈可以准确反映用户对物品的真实偏好,但需要用户付出额外的代价,而隐式的用户行为也可以通过一些分析处理来反映用户的偏好,但数据并不是很准确,并且一些行为分析有很多噪音。但是只要选择了正确的行为特征,隐含的用户反馈也可以得到很好的效果,只是行为特征的选择在不同的应用中可能会有很大的不同。比如电商网站,购买行为其实是一种隐性反馈,可以很好的表达用户的喜好。
推荐引擎可能会根据不同的推荐机制使用部分数据源,然后基于这些数据,分析某些规则或直接预测和计算用户对其他项目的偏好。这样,推荐引擎就可以在用户进入时推荐用户可能感兴趣的项目。
推荐引擎分类
推荐引擎的分类可以基于很多指标,下面我们一一介绍:
推荐引擎是否为不同的用户推荐不同的数据?
根据该指标,推荐引擎可分为基于流行行为的推荐引擎和个性化推荐引擎
这是推荐引擎最基本的分类。事实上,人们讨论的大多数推荐引擎都是个性化推荐引擎,因为从根本上讲,只有个性化推荐引擎才是更智能的信息发现过程。 .
根据推荐引擎的数据来源
其实这里就是如何发现数据的相关性,因为大部分推荐引擎都是基于相似的物品集或者用户推荐的。然后参考图1给出的推荐系统示意图,根据不同的数据源发现数据相关性的方法可以分为以下几种:
根据推荐模型的建立
可以想象,在一个拥有大量物品和用户的系统中,推荐引擎的计算量是相当大的。为了实现实时推荐,必须建立推荐模型。推荐模型的建立可以分为以下几种:
事实上,在目前的推荐系统中,很少有推荐引擎只使用一种推荐策略。一般在不同的场景下使用不同的推荐策略来达到最好的推荐效果,比如亚马逊的推荐。它根据用户自身的历史购买数据进行推荐,根据用户当前浏览过的商品进行推荐,根据流行偏好将当前热门商品推荐给不同地区的用户,让用户可以从全方位的推荐中找到适合的商品你真的很感兴趣。
深度推荐机制
本章的篇幅将详细介绍每种推荐机制的工作原理、优缺点和应用场景。
基于人口统计的推荐
基于人口统计的推荐是最容易实施的推荐方法。它只是根据系统用户的基本信息发现用户的相关性,然后将类似用户喜欢的其他物品推荐给当前用户。图 2 显示了此建议的工作原理。
图2.基于人口统计的推荐机制的工作原理

从图中可以清楚地看出,首先,系统对每个用户都有一个用户画像建模,其中包括用户的基本信息,比如用户的年龄、性别等;用户画像计算用户的相似度,可以看到用户A的画像和用户C是一样的,那么系统就会认为用户A和C是相似的用户。在推荐引擎中,他们可以称为“邻居”;最后,根据“邻居”用户组的偏好,向当前用户推荐一些物品,图中将用户A喜欢的物品A推荐给用户C。
这种基于人口统计的推荐机制的好处是:
因为没有使用当前用户对物品的偏好历史数据,所以不存在新用户的“冷启动”问题。该方法不依赖于item本身的数据,因此该方法可以用于不同item的域中,并且是域无关的。
那么这种方法有什么缺点和问题呢?这种根据用户的基本信息对用户进行分类的方法过于粗糙,尤其是在书籍、电影、音乐等对品味要求较高的领域,无法获得很好的推荐效果。也许在一些电商网站,这个方法可以给出一些简单的建议。另一个限制是,这种方法可能涉及到一些与信息发现问题本身无关的敏感信息,例如用户的年龄等,这些用户信息不是很容易获取。
基于内容的推荐
基于内容的推荐是推荐引擎出现之初使用最广泛的推荐机制。其核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的喜好进行记录,向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图3.基于内容推荐机制的基本原理

基于内容的推荐的典型示例如图 3 所示。在电影推荐系统中,首先我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;元数据发现电影之间的相似性,因为类型都是“爱情、浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影导演、演员等);最后,建议实现。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优势在于它可以很好地模拟用户的口味并提供更准确的推荐。但它也存在以下问题:
文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。由于需要根据用户过去的偏好历史进行推荐,因此新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。有的网站还请专业人士对项目进行基因编码,比如Pandora,在一份报告中说,在Pandora的推荐引擎中,每首歌曲都有100多个元数据特征,包括歌曲风格、年份、歌手等。
基于协同过滤的推荐
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,发现一组与当前用户的口味和偏好相似的“邻居”。一般应用中,计算“K-Neighbors”算法;然后,根据这K个邻居的历史偏好信息,为当前用户做出推荐。下图4为示意图。
图4.基于用户的协同过滤推荐机制基本原理

上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目D可以推荐给用户A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户的特征,而基于用户的协同过滤机制根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能相同或相似。口味和偏好。
基于项目的协同过滤推荐
基于物品的协同过滤推荐的基本原理也类似,只不过是利用所有用户对物品或信息的偏好来寻找物品与物品之间的相似度,然后根据用户的历史偏好信息,得出相似的向用户推荐项目。图 5 说明了其基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C 相似。喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上面类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品本身的属性特征信息。
图5.基于项目的协同过滤推荐机制基本原理

同时协同过滤,基于用户和基于项目的策略我们应该如何选择?实际上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,其实可以看出,推荐策略的选择与具体的应用场景有很大关系。
基于模型的协同过滤推荐
基于模型的协同过滤推荐是基于基于样本的用户偏好信息,训练推荐模型,然后根据实时用户偏好信息预测和计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优势:
它不需要对对象或用户进行严格的建模,也不需要对对象的描述是机器可理解的,所以这种方法也是领域无关的。这种方法计算出来的推荐是公开的,可以分享他人的经验,很好的支持用户发现潜在的兴趣和偏好
而且它还存在以下问题:
该方法的核心是基于历史数据,因此对于新项目和新用户存在“冷启动”问题。推荐的效果取决于用户历史偏好数据的数量和准确性。在大多数实现中,用户的历史偏好存储在一个稀疏矩阵中,在稀疏矩阵上的计算存在一些明显的问题,包括少数人的错误偏好可能会对计算的准确性产生很大影响。推荐等。对于一些有特殊品味的用户,我们无法给出好的建议。基于历史数据,在对用户偏好进行捕获和建模后,很难根据用户的使用情况进行修改或进化,这使得该方法不够灵活。
混合推荐机制
当前网站上的推荐往往不是简单地使用某种推荐机制和策略。他们经常混合多种方法来获得更好的推荐结果。关于如何组合各种推荐机制,这里介绍几种比较流行的组合方式。
Weighted Hybridization:使用一个线性公式,根据一定的权重组合几个不同的推荐。具体的权重值需要在测试数据集上反复测试才能达到最佳推荐效果。 Switching Hybridization:前面说过,其实对于不同的情况(数据量、系统运行状态、用户和物品数量等),推荐策略可能会有很大的不同,所以切换Hybridization的方式是允许选择的最适合的推荐机制来计算不同情况下的推荐。 Mixed Hybridization:采用多种推荐机制,向不同区域的用户展示不同的推荐结果。事实上,亚马逊、当当等众多电商网站都采用了这种方式,用户可以获得全面的推荐,也更容易找到自己想要的东西。 Meta-Level Hybridization:采用多种推荐机制,将一种推荐机制的结果作为另一种推荐机制的输入,综合各推荐机制的优缺点,获得更精准的推荐。
推荐引擎的应用
在介绍了推荐引擎的基本原理和基本推荐机制后,下面简要分析几个有代表性的推荐引擎的应用。这里我们选择两个领域:以亚马逊为代表的电子商务和以豆瓣为代表的社交网络。
电子商务中的推荐应用-亚马逊
亚马逊作为推荐引擎的鼻祖,将推荐的思想渗透到了应用的每一个角落。亚马逊推荐的核心是通过数据挖掘算法将用户的消费偏好与其他用户进行比较,从而预测用户可能感兴趣的产品。 对应上面介绍的各种推荐机制,亚马逊采用分区混合机制,展示给不同领域的用户不同的推荐结果。图 6 和图 7 显示了用户可以在亚马逊上获得的推荐。
图6.亚马逊的推荐机制-首页
图7.亚马逊的推荐机制-浏览商品

亚马逊利用网站上所有可以记录的用户行为,根据不同数据的特点进行处理,划分不同区域为用户推送推荐:
值得一提的是,亚马逊在做推荐的时候,设计和用户体验也很独特:
亚马逊利用其大量历史数据来量化推荐原因。
此外,亚马逊的很多推荐都是根据用户的个人资料计算出来的。用户个人资料记录了用户在亚马逊上的行为,包括浏览过的商品、购买过的商品、采集中的商品和心愿单等。当然,亚马逊还集成了评分等其他用户反馈方式,这些都是用户反馈的一部分。轮廓。同时,亚马逊提供了允许用户管理自己的个人资料的功能。这样,用户可以更清楚地告诉推荐引擎他的品味和意图是什么。
社交网站-豆瓣推荐应用
豆瓣是中国相对成功的社交网络网站。形成以图书、电影、音乐、同城活动为中心的多元化社交网络平台。自然推荐的功能必不可少。下面我们看看豆瓣是如何推荐的。
图8.豆瓣的推荐机制-豆瓣电影

当你在豆瓣电影中加入一些你看过或者感兴趣的电影到你看过想看的列表中,并给它们相应的评分,那么豆瓣的推荐引擎就已经给你一些偏好信息了,那么它将显示如图 8 所示的电影推荐。
图 9. 豆瓣推荐机制——基于用户品味的推荐

豆瓣的推荐是通过“豆瓣猜”。为了让用户知道这些推荐是怎么来的,豆瓣还简单介绍了“豆瓣猜”。
“您的个人推荐是根据您的采集和评论自动得出的。每个人的推荐列表都不一样。您的采集和评论越多,豆瓣的推荐就越准确和丰富。
每天推荐的内容可能会发生变化。随着豆瓣的成长,推荐给你的内容会越来越精准。 "
这点让我们清楚的知道豆瓣一定是基于社交协同过滤的推荐。这样,用户越多,用户反馈越多,推荐效果就会越准确。
相比亚马逊的用户行为模型,豆瓣电影的模型更简单,即“看过”和“想看”,这也使得他们的推荐更注重用户的口味,毕竟买东西的动机和看电影还是有很大区别的。
此外,豆瓣也有基于物品本身的推荐。当你查看一些电影的详细信息时,他会向你推荐“喜欢这部电影的人也喜欢的电影”,如图10所示,基于协同过滤应用。
图10.豆瓣的推荐机制——基于电影本身的推荐

总结
在网络数据爆炸的时代,如何让用户更快地找到自己想要的数据,如何让用户发现自己潜在的兴趣和需求,对于电子商务和社交网络应用来说都非常重要。随着推荐引擎的出现,这个问题越来越受到关注。但是对于大多数人来说,可能还在疑惑为什么它总能猜出你想要什么。推荐引擎的神奇之处在于,您不知道引擎在此推荐背后记录和推断的内容。
通过这篇评论文章,你可以了解到推荐引擎其实只是在默默的记录和观察你的一举一动,然后利用所有用户产生的海量数据去分析发现规律,然后慢慢慢慢了解你,你的需求,你的习惯,默默地帮你快速解决问题,找到你想要的。
实际上,回过头来看,很多时候,推荐引擎比你更了解你自己。
通过第一篇文章,相信大家对推荐引擎有了清晰的第一印象。本系列下一篇文章将深入介绍基于协同过滤的推荐策略。在目前的推荐技术和算法中,被广泛认可和采用的方法是基于协同过滤的推荐方法。以其简单的方法模型、低数据依赖、便捷的数据采集、优越的推荐效果,成为大众眼中的“No.1”推荐算法。本文将带你深入了解协同过滤的奥秘,并给出基于Apache Mahout的协同过滤算法的高效实现。 Apache Mahout 是 ASF 的一个相对较新的开源项目。它源自Lucene,建立在Hadoop之上,专注于经典机器学习算法在海量数据上的高效实现。
原文链接为:@126/blog/static/24269713813/
转载于:
如何升级页面优化以匹配搜索引擎的技术呢?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-07-20 02:13
过去几年,搜索引擎工程团队专注于自然语言处理,对页面内容之间的相互关系有了更深入的了解。神经匹配帮助搜索引擎理解同义词,人工智能帮助搜索引擎理解那些棘手的词句。
每次核心更新后,搜索引擎的文学水平都会提升。然而,尽管搜索引擎越来越智能,但许多网站所有者在优化网站时仍然只考虑少数关键词目标。
这是一种过时的做法,尤其是当我们知道着陆页通常以数百个关键词 排名结束时。对于自搜索引擎成立以来一直关注的我们来说,这对于页面搜索引擎优化来说就像一个美丽的新世界。
随着搜索引擎的 NLP(自然语言处理)能力不断提高,我们的页面 SEO 策略也需要制定以反映搜索中的这些进步。
那么,我们如何升级页面优化以匹配搜索引擎技术? 关键词集群就是答案。
什么是关键词cluster?
关键词群是一个关键词群组,代表具有相似购买意向的搜索者。比如“亚麻窗帘”、“亚麻窗帘”、“亚麻窗帘布”和“白色亚麻窗帘”是不同的关键词词组,但都代表着想要购买亚麻窗帘的搜索者。
假设您的品牌销售亚麻窗帘。如果你只尝试排名第一关键词,你最终会限制你的市场份额。
如果你得到了你的主要关键词、长尾变体和相关的副主题,你的页面最终排名将是关键词数量的10-20倍,并获得更多的点击。
如何创建关键词和主题集群
为了充分利用关键词集群的功能,需要注意的是,这种策略比一劳永逸的网站优化方法需要更多的时间和资源。
这需要您的 SEO 和营销团队进行更多 关键词 研究、更多内容创建和更多工作。
但最终,在你的网站上设置主题集群会让搜索引擎和用户更加友好。 关键词cluster 的好处包括:
Longtail 关键词 排名靠前。改进了短尾关键词 的排名。更高的有机流量。更快地提高 SERP 中的排名。内部链接的机会更多。在您的行业环境中建立专业知识和内容权威。这是关于如何做关键词集群以及如何围绕这些集群构建内容策略的简要说明。
第一步:创建关键词list
关键词cluster 从关键词 研究开始。想想你想为网站 排名的主要关键词。
然后,确定搜索者正在使用的此关键词 的所有变体、长尾短语和子主题。
首先,让您的竞争对手了解他们目前为哪个 关键词 排名。
然后,使用关键词 工具查找相关的关键词、自动填充、子主题或搜索者以查找有关您的产品和服务的问题。
记录关键词研究的方式有很多种,但最简单的方法是使用5118关键词挖矿工具导出对应的关键词列表。确保在列表中收录关键词 的自然难度、搜索量和每次点击费用指标。
这些指标将帮助您确定哪些关键词 具有最高的经济价值,应该用作集群中的“核心”关键词。
一些 SEO 专业人士在他们的研究中确定了数千个 关键词。如果您刚刚开始使用此策略,那么一百个关键词phrases 可能足以识别可以在您的网站 上建立的几个不同的主题集群。
在生成关键词lists 时,请记住相关性和搜索意图的重要性。您只想加入关键词,为您的网站 带来合适的搜索者,他们实际上对您提供的产品或服务感兴趣并且可能会转化。
第 2 步:将关键词 分组
一旦你有一个广泛的关键词列表,你就会开始注意到关键词中的模式。
您可能会注意到,用户在其搜索查询中收录相同的字词、短语、同义词或副主题。这些模式代表了您可以聚集和形成关键词 组的潜在方式。
这是将这些关键词划分为多个集群时应该使用的条件。
语义相关性
集群中的关键词 具有相似的搜索意图很重要。
如果您尝试为不太相似的关键词 优化着陆页,则会降低内容的可读性,并使搜索引擎对您的页面的真正含义感到困惑。
搜索量和每次点击费用
集群中的核心关键词应该有合理的搜索量(否则你会为任何人优化)。
他们还应该具有转化潜力(每次点击费用代表他们的经济价值)。
有机困难
是否收录更难的关键词取决于您的网站权限、反向链接配置文件以及网站的建立方式。
在您的集群中仅收录可以对其站点进行排名的关键词。
仔细研究两个关键词群
找到集群的核心关键词后,将其与互补的关键词配对。
例如,您可以添加一些长尾、降低难度或降低搜索量,或者只是在着陆页上收录有关它们的足够信息以轻松获胜。
为什么这些关键词可以组成一个好的集群?因为它们共享语义相关性。这些搜索者都在寻找有助于安排采访的产品。
我们的核心关键词在排名方面更具竞争力,但我们用关键词填充了集群,难度较低且转化潜力强。
如果您对自己的细分市场充满信心并了解关键词 指标和搜索意图的细微差别,您可以手动将关键词 分成几个组(如我们上面所述)。
还有一些关键词grouping 工具可以自动化这个过程。他们可以为您将关键词 细分为多个类别。
细分时,请记住并非所有列表中的关键词都需要以集群结束。
收录最高值的关键词是最重要的关键词。更高的每次点击费用、更高的搜索量和相关的搜索意图使 关键词 对您的品牌有价值。
第 3 步:为您的 关键词 集群创建和优化支柱页面
关键词 分组后,他们提供了如何在网站 上创建、优化和组织内容的路线图。
本质上,你的关键词群代表你的网站核心主题。这些也称为“支柱页面”。
为了正确执行关键词集群,我们需要为每个关键词集群创建一个目标页面。
关键词群的支柱页面应该使用正式的现场搜索引擎优化技术。我们最喜欢的策略之一是使用内容优化工具来帮助您更有效地优化内容。
为了提高支柱页面的排名潜力,请优先考虑以下几个方面:
主题深度:专注于撰写深入探索主题的长篇内容。信息架构:具有清晰的结构,并在 h2 和 h3 中收录您的 关键词phrase。页面体验:在交互页面添加视频、跳转链接、轮播等元素,提升用户的页面体验。第四步:通过网站content 增强关键词cluster
为了提高支柱页面的排名和内容权重,您可以构建内容以增强您的主要关键词 集群。
这些文章可以定位与你的核心关键词相关的长尾关键词短语、副主题或问题。
随着您开发更多内容,这些页面将在您的网站 上形成“主题集群”。
此内容的内部链接系统将在您的网站 着陆页在搜索引擎中的排名中发挥重要作用。
您的文章 应该链接回其相应的支柱页面,以增加您在这些高价值关键词 上排名的机会。
如果你的公司有多个产品或专业领域,你可以在网站上搭建更多的集群。
如果你只销售一种核心产品或服务,你识别的关键词集群数量会减少。但是,探索具有丰富有用内容的主要学科领域可以帮助您在更短的时间内超越竞争对手。
建立集群还可以为您提供更多的机会添加内部链接到网站。
这不仅增加了用户在您的网站 上花费的时间,而且内部链接遍布您的网站 并帮助搜索引擎了解您在网站 上最重要的页面。
关键词group 真的值得所有的工作吗?
关键词群 是一种更高级的 SEO 策略,可以为您提供在垂直竞争中获胜所需的优势。这是因为它们响应了搜索引擎的两大超级功能:自然语言处理和无与伦比的索引。
想想看,搜索引擎了解各行各业的搜索者使用的数百万个关键词phrases。它还了解这些查询之间的细微差别,以及它们的相互关系或相互关系。
搜索引擎花了数年时间训练他们的 NLP(自然语言处理)模型来计算内容质量信号并预测哪些网页最能向搜索者提供他们需要的信息。当你在落地页进行关键词聚类,你会向搜索引擎证明你的网站是你所在行业的权威,展示强大的内容范围和深度。
您还可以通过丰富的内容集群提供搜索引擎的内容信号,这些集群已经过训练以识别和改进搜索结果。 关键词集群需要网站站长多思考自己的内容,这也是SEO的未来。
如果您希望您的网页长期排名,是时候让您的网页策略赶上搜索引擎了。 查看全部
如何升级页面优化以匹配搜索引擎的技术呢?(图)
过去几年,搜索引擎工程团队专注于自然语言处理,对页面内容之间的相互关系有了更深入的了解。神经匹配帮助搜索引擎理解同义词,人工智能帮助搜索引擎理解那些棘手的词句。
每次核心更新后,搜索引擎的文学水平都会提升。然而,尽管搜索引擎越来越智能,但许多网站所有者在优化网站时仍然只考虑少数关键词目标。
这是一种过时的做法,尤其是当我们知道着陆页通常以数百个关键词 排名结束时。对于自搜索引擎成立以来一直关注的我们来说,这对于页面搜索引擎优化来说就像一个美丽的新世界。
随着搜索引擎的 NLP(自然语言处理)能力不断提高,我们的页面 SEO 策略也需要制定以反映搜索中的这些进步。
那么,我们如何升级页面优化以匹配搜索引擎技术? 关键词集群就是答案。
什么是关键词cluster?
关键词群是一个关键词群组,代表具有相似购买意向的搜索者。比如“亚麻窗帘”、“亚麻窗帘”、“亚麻窗帘布”和“白色亚麻窗帘”是不同的关键词词组,但都代表着想要购买亚麻窗帘的搜索者。
假设您的品牌销售亚麻窗帘。如果你只尝试排名第一关键词,你最终会限制你的市场份额。
如果你得到了你的主要关键词、长尾变体和相关的副主题,你的页面最终排名将是关键词数量的10-20倍,并获得更多的点击。
如何创建关键词和主题集群
为了充分利用关键词集群的功能,需要注意的是,这种策略比一劳永逸的网站优化方法需要更多的时间和资源。
这需要您的 SEO 和营销团队进行更多 关键词 研究、更多内容创建和更多工作。
但最终,在你的网站上设置主题集群会让搜索引擎和用户更加友好。 关键词cluster 的好处包括:
Longtail 关键词 排名靠前。改进了短尾关键词 的排名。更高的有机流量。更快地提高 SERP 中的排名。内部链接的机会更多。在您的行业环境中建立专业知识和内容权威。这是关于如何做关键词集群以及如何围绕这些集群构建内容策略的简要说明。
第一步:创建关键词list
关键词cluster 从关键词 研究开始。想想你想为网站 排名的主要关键词。
然后,确定搜索者正在使用的此关键词 的所有变体、长尾短语和子主题。
首先,让您的竞争对手了解他们目前为哪个 关键词 排名。
然后,使用关键词 工具查找相关的关键词、自动填充、子主题或搜索者以查找有关您的产品和服务的问题。
记录关键词研究的方式有很多种,但最简单的方法是使用5118关键词挖矿工具导出对应的关键词列表。确保在列表中收录关键词 的自然难度、搜索量和每次点击费用指标。
这些指标将帮助您确定哪些关键词 具有最高的经济价值,应该用作集群中的“核心”关键词。
一些 SEO 专业人士在他们的研究中确定了数千个 关键词。如果您刚刚开始使用此策略,那么一百个关键词phrases 可能足以识别可以在您的网站 上建立的几个不同的主题集群。
在生成关键词lists 时,请记住相关性和搜索意图的重要性。您只想加入关键词,为您的网站 带来合适的搜索者,他们实际上对您提供的产品或服务感兴趣并且可能会转化。
第 2 步:将关键词 分组
一旦你有一个广泛的关键词列表,你就会开始注意到关键词中的模式。
您可能会注意到,用户在其搜索查询中收录相同的字词、短语、同义词或副主题。这些模式代表了您可以聚集和形成关键词 组的潜在方式。
这是将这些关键词划分为多个集群时应该使用的条件。
语义相关性
集群中的关键词 具有相似的搜索意图很重要。
如果您尝试为不太相似的关键词 优化着陆页,则会降低内容的可读性,并使搜索引擎对您的页面的真正含义感到困惑。
搜索量和每次点击费用
集群中的核心关键词应该有合理的搜索量(否则你会为任何人优化)。
他们还应该具有转化潜力(每次点击费用代表他们的经济价值)。
有机困难
是否收录更难的关键词取决于您的网站权限、反向链接配置文件以及网站的建立方式。
在您的集群中仅收录可以对其站点进行排名的关键词。
仔细研究两个关键词群
找到集群的核心关键词后,将其与互补的关键词配对。
例如,您可以添加一些长尾、降低难度或降低搜索量,或者只是在着陆页上收录有关它们的足够信息以轻松获胜。
为什么这些关键词可以组成一个好的集群?因为它们共享语义相关性。这些搜索者都在寻找有助于安排采访的产品。
我们的核心关键词在排名方面更具竞争力,但我们用关键词填充了集群,难度较低且转化潜力强。
如果您对自己的细分市场充满信心并了解关键词 指标和搜索意图的细微差别,您可以手动将关键词 分成几个组(如我们上面所述)。
还有一些关键词grouping 工具可以自动化这个过程。他们可以为您将关键词 细分为多个类别。
细分时,请记住并非所有列表中的关键词都需要以集群结束。
收录最高值的关键词是最重要的关键词。更高的每次点击费用、更高的搜索量和相关的搜索意图使 关键词 对您的品牌有价值。
第 3 步:为您的 关键词 集群创建和优化支柱页面
关键词 分组后,他们提供了如何在网站 上创建、优化和组织内容的路线图。
本质上,你的关键词群代表你的网站核心主题。这些也称为“支柱页面”。
为了正确执行关键词集群,我们需要为每个关键词集群创建一个目标页面。
关键词群的支柱页面应该使用正式的现场搜索引擎优化技术。我们最喜欢的策略之一是使用内容优化工具来帮助您更有效地优化内容。
为了提高支柱页面的排名潜力,请优先考虑以下几个方面:
主题深度:专注于撰写深入探索主题的长篇内容。信息架构:具有清晰的结构,并在 h2 和 h3 中收录您的 关键词phrase。页面体验:在交互页面添加视频、跳转链接、轮播等元素,提升用户的页面体验。第四步:通过网站content 增强关键词cluster
为了提高支柱页面的排名和内容权重,您可以构建内容以增强您的主要关键词 集群。
这些文章可以定位与你的核心关键词相关的长尾关键词短语、副主题或问题。
随着您开发更多内容,这些页面将在您的网站 上形成“主题集群”。
此内容的内部链接系统将在您的网站 着陆页在搜索引擎中的排名中发挥重要作用。
您的文章 应该链接回其相应的支柱页面,以增加您在这些高价值关键词 上排名的机会。
如果你的公司有多个产品或专业领域,你可以在网站上搭建更多的集群。
如果你只销售一种核心产品或服务,你识别的关键词集群数量会减少。但是,探索具有丰富有用内容的主要学科领域可以帮助您在更短的时间内超越竞争对手。
建立集群还可以为您提供更多的机会添加内部链接到网站。
这不仅增加了用户在您的网站 上花费的时间,而且内部链接遍布您的网站 并帮助搜索引擎了解您在网站 上最重要的页面。
关键词group 真的值得所有的工作吗?
关键词群 是一种更高级的 SEO 策略,可以为您提供在垂直竞争中获胜所需的优势。这是因为它们响应了搜索引擎的两大超级功能:自然语言处理和无与伦比的索引。
想想看,搜索引擎了解各行各业的搜索者使用的数百万个关键词phrases。它还了解这些查询之间的细微差别,以及它们的相互关系或相互关系。
搜索引擎花了数年时间训练他们的 NLP(自然语言处理)模型来计算内容质量信号并预测哪些网页最能向搜索者提供他们需要的信息。当你在落地页进行关键词聚类,你会向搜索引擎证明你的网站是你所在行业的权威,展示强大的内容范围和深度。
您还可以通过丰富的内容集群提供搜索引擎的内容信号,这些集群已经过训练以识别和改进搜索结果。 关键词集群需要网站站长多思考自己的内容,这也是SEO的未来。
如果您希望您的网页长期排名,是时候让您的网页策略赶上搜索引擎了。
搜索引擎结果的好坏与否,Cranfield评价体系ACranfield-likeapproach
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-07-20 02:09
大观数据CEO陈韵文文
前言
搜索质量评价是搜索技术研究的基础工作,也是核心任务之一。度量在搜索技术的研究和发展中发挥着重要作用,因此任何新方法都与其评价方法相结合。
搜索引擎结果的质量反映在业界所谓的相关性上。相关性的定义包括狭义和广义两个方面。狭义的解释是:搜索结果与用户查询的相关程度。从广义上讲,相关性可以理解为用户查询的综合满意度。直观上,从用户进入搜索框的那一刻到满足需求的过程越顺畅、方便,搜索相关性就越好。本文总结了行业常用的相关性评价指标和定量评价方法。供对此感兴趣的朋友参考。
克兰菲尔德评估系统
A Cranfield-like approach这个名字来源于英国的克兰菲尔德大学,因为该大学在1950年代首先提出了这样一套评价体系:一套完整的查询样本集、正确答案集和评价指标。评价计划从此确立了“评价”在信息检索研究中的核心地位。
Cranfield 评价系统由三个环节组成:
1.提取代表性查询词,形成合适大小的集合
2.查询样本集合,从检索系统的语料库中找到对应的结果并标注(一般是手动)
3. 将查询词和带有标注信息的语料输入检索系统,使用预定义的评价计算公式对检索系统结果和系统返回的检索结果标注的理想情况进行评价结果有多接近。
查询词集的选择
Cranfield 评估系统广泛应用于各大搜索引擎公司。在具体应用中,首先需要解决的问题是构建一组测试查询词。
根据Andrei Broder(原在AltaVista/IBM/Yahoo)的研究,查询词可以分为三类:寻址查询(Navigational)、信息查询(Informational)和交易查询(Transactional)。对应的比例为:
Navigational : 12.3%
Informational : 62.0%
Transactional : 25.7%
为了使评价符合网上的实际情况,通常查询词集也是按比例选取的。通常从在线用户的查询日志文件中自动提取。
另外,在查询集的构建中,除了上述查询类型外,还可以考虑查询的频率,热点查询(高频查询)和长尾查询(中和低频)分别占特定的比例。
另外,在抽取Query的时候,Query的长度也是经常要考虑的一个因素。因为短查询(单词查询)和长查询(多词查询)排序算法往往不同。
形成查询集后,使用这些查询词在不同系统(例如比较百度和谷歌)或不同技术(新旧排名算法的环境)之间进行搜索,并对结果进行评分以确定优劣和缺点。
图片:同一个Query:“大观数据”,各大搜索引擎结果示意图。下面详细说一下评分的方法。
Precision-recall(accuracy-recall法)计算方法
信息检索领域最广为人知的评价指标是Precision-Recall(准确率-召回率)方法。这种方法提出了半个世纪,已经被很多搜索引擎公司的效果评估所采用。
顾名思义,这种方法由两个相互关联的统计数据组成:准确率和召回率:召回率衡量一个查询搜索所有相关文档的能力,而Precision衡量搜索系统排除相关文档的能力。 (简单解释一下:准确率是计算你从查询中得到的结果有多少是可靠的;召回率是指你检索到的所有可靠结果中有多少)。这两个是评价搜索效果最基本的指标,具体计算方法如下。
Precision-recall 方法假设给定的查询对应于检索到的文档集合和不相关文档的集合。这里假设相关性是二元的,用数学形式化方法描述,它是:
A 表示相关文档的集合
表示不相关的集合
B 代表检索到的文档集合
表示尚未检索到的文档集合
单个查询的准确率和召回率可以用以下公式表示:
(运算符∩表示两个集合的交集。|x|符号表示集合x中元素的个数)
从上面的定义不难看出召回率和准确率的取值范围在[0,1]之间。那么不难想象,如果系统检索到的相关性越多,召回率就越高。如果所有相关结果都被召回,那么此时召回就等于1.0。
精度-召回曲线
召回率和准确率反映了检索系统最重要的两个方面,这两个方面相互制约。因为在大规模的数据采集中,如果期望检索到更多的相关文档,搜索条件必须“放宽”,这会导致一些不相关的结果混入,影响准确率。同样,当你想提高准确率,尽可能去除不相关的文档时,你必须实施更“严格”的检索策略,这也会排除一些相关的文档,降低召回率。
所以为了更清楚地描述两者之间的关系,我们通常用曲线来绘制Precision-Recall,可以简称为P-R图。常见的形式如下图所示。 (通常曲线是逐渐下降的趋势,即随着Recall的增加,Precision逐渐降低)
其他形式的 P-R
某些特定的搜索应用程序会更加关注搜索结果中的错误结果。例如,搜索引擎的反垃圾邮件系统会更加关注搜索结果中混入了多少作弊结果。学术界将这些错误结果称为假阳性结果。对于这些应用,他们通常选择使用误报率(Fallout)来统计:
Fallout 和 Presion 本质上是一样的。它只是从利弊计算出来的。它实际上是 P-R 的变体。
回到上图,Presion-Recall是一条曲线。比较两种方法的效果通常不够直观。你能不能把两者结合起来,直接反映到一个单一的值上?为此,IR学术界提出了F-Measure方法。 F-Measure由Presion和Recall的调和平均计算得出,公式为:
参数λε(0,1)调整系统在Precision和Recall之间的平衡。(通常λ=0.5,此时
)
这里使用调和平均代替通常的几何平均或算术平均。原因是调和平均强调小数的重要性,能灵敏地反映小数的变化,更适合反映搜索效果。
使用F Measure的好处是只需要一个数字就可以概括系统的搜索效果,方便比较不同搜索系统的整体效果。
P@N 方法点击因素
传统的Precision-Recall并不完全适用于搜索引擎的评价,因为搜索引擎用户的点击方式是独一无二的,包括:
A 60-65%的查询点击了名列搜索结果前10条的网页;
B 20-25%的人会考虑点击名列11到20的网页;
C 仅有3-4%的会点击名列搜索结果中列第21到第30名的网页
换句话说,大多数用户不愿意翻页看到搜索引擎给出的后续结果。
即使在搜索结果的第一页(通常会列出前 10 个结果),用户的点击行为也很有趣。我们使用下面的谷歌热图来观察(这张热图在第二个维度搜索结果页面上,可以通过光谱直观地表达用户在不同位置的点击兴趣。颜色越接近红色表示点击率越高强度):
从图中可以看出,前3个搜索结果吸引了大量点击,属于最受欢迎的部分。也就是说,对于搜索引擎来说,前几个结果是最关键的,决定了用户的满意度。
康奈尔大学的研究人员通过眼动追踪实验对 Google 搜索结果中的用户行为进行了更准确的分析。从这张图可以看出,第一个结果已经获得了56.38%的搜索流量,第二、第三个结果的排名依次下降,但远低于第一的结果。前三个结果的点击率约为 11:3:2。前三个结果的总点击量转移了近 80% 的搜索流量。
其他一些有趣的结论是点击次数不会按顺序减少。第七名获得的点击次数最少。原因可能是用户在浏览过程中将页面下拉到底部。这时候只显示了网站的最后三名排名,第七名很容易被忽略。而第一屏最后一个结果获得的注意力(2.55)大于倒数第二个(1.45)),因为用户在转屏之前对最后一个结果的印象比较深page 搜索结果页第二页第一页(也就是第11个结果)只获得了第10个首页网站的40%的点击量,比首页第一个结果还要多其 1/60 到 1/100 的点击量。
因此,在定量评估搜索引擎的效果时,往往需要根据上述搜索用户的行为特征进行针对性的设计。
P@N 计算方法
P@N本身是Precision@N的缩写,指的是在考虑位置因素的情况下,针对特定查询检测前N个结果的准确率。比如单次搜索的前5个结果,如果其中4个是相关文档,则P@5 = 4/5 = 0.8。
该测试通常使用一个查询集(根据上述方法构建),其中收录几个不同的查询词。在使用P@N的实际评估中,通常使用所有查询的P@N数据计算算术平均值,用于判断系统整体搜索结果的质量。
N 的选择
对于用户来说,他们通常只关注搜索结果的前几个结果。因此,搜索引擎的性能评估通常只关注前5、或前3个结果,所以我们常用的N取值为P@3或P@5等。
对于一些特定类型的查询应用,比如导航搜索,因为目标结果很明确,所以N=1(即在评估中使用P@1)。例如,如果你搜索“新浪网”或“新浪首页”,如果第一个结果不是新浪网(url:),则直接判断查询的准确度不符合要求,即P@1 =0
MRR
上面提到的P@N方法很容易计算和理解。但是细心的读者肯定会发现问题,就是在前N个结果中,第一个和第N个位置的结果对准确率的影响是一样的。但实际情况是,搜索引擎的评价与排名位置有着极大的关系。也就是说,第一个结果错误与第 10 个结果错误非常不同。因此,评价体系中需要引入区位因素。
MRR 是 Mean Reciprocal Rank 的缩写。 MRR 方法主要用于导航搜索或问答。这些检索方法只需要一个相关文档,这对召回率非常重要。不敏感,但更关心搜索引擎检索到的相关文档是否排在结果列表的前面。 MRR 方法首先计算每个查询的第一个相关文档位置的倒数,然后对所有倒数取平均值。比如一个收录三个查询词的测试集,前5个结果是:
查询一结果:1.AN 2.AR 3.AN 4.AN 5.AR
查询二结果:1.AN 2.AR 3.AR 4.AR 5.AN
查询三结果:1.AR 2.AN 3.AN 4.AN 5.AR
其中,AN代表无关结果,AR代表相关结果。那么第一次查询的Reciprocal Rank(Reciprocal Rank)RR1= 1/2=0.5;第二个结果 RR2 = 1/2 = 0.5;注意,倒数的值不会改变,即使得到了第二个结果更相关的结果。同理,RR3 = 1/1 = 1,对于这个测试集,最终的MRR=(RR1+RR2+RR3)/ 3 = 0.67
然而,对于大多数搜索应用来说,只有一个结果不能满足需求。在这种情况下,需要更合适的方法来计算效果。最常用的方法是下面的MAP方法。
地图
MAP方法是Mean Average Precison,是平均准确度法的缩写。它的定义是求检索到的每个相关文档的平均准确率(即Average Precision)的算术平均值(Mean)。在这里,准确度取了两次平均值,因此称为平均平均精度。 (注意:它不叫Average Average Precision,因为它丑陋,而且因为无法区分两个平均值的含义)
MAP 是一个单值指标,反映系统在所有相关文档上的表现。系统检索到的相关文档越高(等级越高),MAP就应该越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题:
主题 1 有 4 个相关网页,主题 2 有 5 个相关网页。
系统检索到主题1的4个相关网页,排名分别为1、2、4、7;
主题 2 检索到 3 个相关网页,排名分别为 1、3、5。
对于topic 1,平均准确率MAP计算公式为:
(1/1+2/2+3/4+4/7)/4=0.83。
对于主题2,平均准确率MAP计算公式为:
(1/1+2/3+3/5+0+0)/5=0.45。
然后 MAP= (0.83+0.45)/2=0.64。"
DCG 方法
DCG是英文Discountedcumulative gain的缩写,中文可译为“折扣累积收益”。 DCG方法的基本思想是:
1.对每个结果的相关性进行分级衡量
2.考虑结果的位置,位置越高,重要性越高
3.排名越高(即好成绩),成绩排名越高,数值应该越高,否则会被处罚。
我们先来看第一个:相关性分级。在计算 Precision 时,这比简单地计算“准确”或“不准确”更精细。我们可以将结果细分为多个级别。比如常用的3个等级:Good、Fair、Bad。对应的分数rel为:Good:3/Fair:2/Bad:1。一些更详细的评估使用5级分类:非常好、好、一般、差、非常差,对应的分数rel可以设置为:非常好:2 / 好:1 / 一般:0 / 差:-1 /非常糟糕:-2
判断结果的标准可以根据具体的应用来确定。非常好通常意味着结果的主题完全相关,网页内容丰富,质量高。并且具体到每一位
DCG的计算公式不是唯一的。理论上,它只需要对数贴现因子的平滑度。我个人认为下面的DCG公式更合理,强调相关性,1、2的结果的折扣因子也更合理:
此时DCG前4个位置结果的折扣因子值为:
基于2的log值也来自经验公式,没有理论依据。实际上,可以根据平滑要求修改Log的基数。当值增大时(例如用log5代替log2),折现因子下降得更快,强调了前面结果的权重。
为了方便不同类型查询结果的横向比较,基于DCG,一些评价系统也对DCG进行了归一化。这些方法统称为nDCG(即归一化DCG)。最常用的计算方法是除以每个查询的理想值iDCG(ideal DCG)进行归一化,公式为:
对于nDCG,需要校准理想的iDCG。在实际操作中,难度极大,因为每个人对“最佳结果”的理解往往各不相同,从海量数据中选出最佳结果非常困难。但是,通常比较容易比较两组结果,因此在实践中通常选择比较结果的方法进行评估。
如何实现自动化评估?
上面介绍的搜索引擎量化评价指标在克兰菲尔德评价框架中得到了广泛的应用。业界知名的TREC(Text Information Retrieval Conference)一直在基于这样的方法组织信息检索评估和技术交流。除了TREC,一些针对不同应用设计的Cranfield评测论坛也在进行中(如NTCIR、IREX等)。
但是 Cranfield 评估框架的问题在于查询样本集合的标记。通过人工标注答案来评价网络信息检索是一个费时费力的过程,只有少数大公司可以使用。并且由于搜索引擎算法改进和运维的需要,需要尽可能缩短检索效果评价和反馈的时间,因此自动化评价方法对于提高评价效率非常重要。最常用的自动评估方法是 A/B 测试系统。
A/B 测试
A/B 测试系统
A/B 测试系统在搜索用户时自动判断用户的bucket id,并自动抽取流量导入不同的分支,让对应组内的用户看到不同的产品版本(或不同版本)。搜索引擎)。将记录用户在不同版本产品中的行为。这些行为数据通过数据分析形成一系列的指标,通过这些指标的比较,得出哪个版本好坏的结论。
在指标的计算上,可以进一步分为两种方法,一种是基于专家评级;另一种是基于点击统计。
专家评分的方法通常由搜索核心技术研发和产品人员进行。两种环境A和B的结果按照预先设定的标准进行评分,比较每个查询的结果,并根据nDCG等方法计算整体质量。
点击评分的自动化程度更高。这里有一个假设:同样的排序位置,点击次数多的结果质量要好于点击次数少的结果。 (即A2代表A测试环境的第二个结果,如果A2>B2,说明A2质量较好)。通俗的说就是相信群众(因为群众的眼睛是有眼光的)。在这个假设下,我们可以自动将 A/B 环境中前 N 个结果的点击率映射到分数上。通过统计大量的Query点击结果,可以获得可靠的分数对比。
交错测试
此外,Thorsten Joachims 等人提出的 Interleaving 测试方法。在2003年也被广泛使用。这种方法设计了一个元搜索引擎。用户输入查询后,将查询在多个知名搜索引擎中的查询结果随机混合反馈给用户,进而采集用户的结果点击行为信息。根据用户不同的点击倾向,我们可以判断搜索引擎返回结果的优劣。
如下图,算法A和B的结果横放,按流量划分测试,记录用户点击信息。根据点击分布判断A、B环境的优劣。
交错测试评价方法
Joachims 还证明了 Interleaving Testing 评估方法和传统 Cranfield 评估方法的结果高度相关。由于记录用户对搜索结果的选择是一个省力的过程,便于实现自动搜索效果评估。
总结
没有评价就没有进步。对搜索结果进行定量评价的目的是准确找出现有搜索系统的不足(没有搜索系统是完美的),然后逐步改进算法和系统。本文为大家总结了常用的评价框架和评价指标。这些技术就像一把尺子,每次搜索技术进步时都会测量距离。 查看全部
搜索引擎结果的好坏与否,Cranfield评价体系ACranfield-likeapproach
大观数据CEO陈韵文文
前言
搜索质量评价是搜索技术研究的基础工作,也是核心任务之一。度量在搜索技术的研究和发展中发挥着重要作用,因此任何新方法都与其评价方法相结合。
搜索引擎结果的质量反映在业界所谓的相关性上。相关性的定义包括狭义和广义两个方面。狭义的解释是:搜索结果与用户查询的相关程度。从广义上讲,相关性可以理解为用户查询的综合满意度。直观上,从用户进入搜索框的那一刻到满足需求的过程越顺畅、方便,搜索相关性就越好。本文总结了行业常用的相关性评价指标和定量评价方法。供对此感兴趣的朋友参考。
克兰菲尔德评估系统
A Cranfield-like approach这个名字来源于英国的克兰菲尔德大学,因为该大学在1950年代首先提出了这样一套评价体系:一套完整的查询样本集、正确答案集和评价指标。评价计划从此确立了“评价”在信息检索研究中的核心地位。
Cranfield 评价系统由三个环节组成:
1.提取代表性查询词,形成合适大小的集合
2.查询样本集合,从检索系统的语料库中找到对应的结果并标注(一般是手动)
3. 将查询词和带有标注信息的语料输入检索系统,使用预定义的评价计算公式对检索系统结果和系统返回的检索结果标注的理想情况进行评价结果有多接近。
查询词集的选择
Cranfield 评估系统广泛应用于各大搜索引擎公司。在具体应用中,首先需要解决的问题是构建一组测试查询词。
根据Andrei Broder(原在AltaVista/IBM/Yahoo)的研究,查询词可以分为三类:寻址查询(Navigational)、信息查询(Informational)和交易查询(Transactional)。对应的比例为:
Navigational : 12.3%
Informational : 62.0%
Transactional : 25.7%
为了使评价符合网上的实际情况,通常查询词集也是按比例选取的。通常从在线用户的查询日志文件中自动提取。
另外,在查询集的构建中,除了上述查询类型外,还可以考虑查询的频率,热点查询(高频查询)和长尾查询(中和低频)分别占特定的比例。
另外,在抽取Query的时候,Query的长度也是经常要考虑的一个因素。因为短查询(单词查询)和长查询(多词查询)排序算法往往不同。
形成查询集后,使用这些查询词在不同系统(例如比较百度和谷歌)或不同技术(新旧排名算法的环境)之间进行搜索,并对结果进行评分以确定优劣和缺点。
图片:同一个Query:“大观数据”,各大搜索引擎结果示意图。下面详细说一下评分的方法。
Precision-recall(accuracy-recall法)计算方法
信息检索领域最广为人知的评价指标是Precision-Recall(准确率-召回率)方法。这种方法提出了半个世纪,已经被很多搜索引擎公司的效果评估所采用。
顾名思义,这种方法由两个相互关联的统计数据组成:准确率和召回率:召回率衡量一个查询搜索所有相关文档的能力,而Precision衡量搜索系统排除相关文档的能力。 (简单解释一下:准确率是计算你从查询中得到的结果有多少是可靠的;召回率是指你检索到的所有可靠结果中有多少)。这两个是评价搜索效果最基本的指标,具体计算方法如下。
Precision-recall 方法假设给定的查询对应于检索到的文档集合和不相关文档的集合。这里假设相关性是二元的,用数学形式化方法描述,它是:
A 表示相关文档的集合
表示不相关的集合
B 代表检索到的文档集合
表示尚未检索到的文档集合
单个查询的准确率和召回率可以用以下公式表示:
(运算符∩表示两个集合的交集。|x|符号表示集合x中元素的个数)
从上面的定义不难看出召回率和准确率的取值范围在[0,1]之间。那么不难想象,如果系统检索到的相关性越多,召回率就越高。如果所有相关结果都被召回,那么此时召回就等于1.0。
精度-召回曲线
召回率和准确率反映了检索系统最重要的两个方面,这两个方面相互制约。因为在大规模的数据采集中,如果期望检索到更多的相关文档,搜索条件必须“放宽”,这会导致一些不相关的结果混入,影响准确率。同样,当你想提高准确率,尽可能去除不相关的文档时,你必须实施更“严格”的检索策略,这也会排除一些相关的文档,降低召回率。
所以为了更清楚地描述两者之间的关系,我们通常用曲线来绘制Precision-Recall,可以简称为P-R图。常见的形式如下图所示。 (通常曲线是逐渐下降的趋势,即随着Recall的增加,Precision逐渐降低)
其他形式的 P-R
某些特定的搜索应用程序会更加关注搜索结果中的错误结果。例如,搜索引擎的反垃圾邮件系统会更加关注搜索结果中混入了多少作弊结果。学术界将这些错误结果称为假阳性结果。对于这些应用,他们通常选择使用误报率(Fallout)来统计:
Fallout 和 Presion 本质上是一样的。它只是从利弊计算出来的。它实际上是 P-R 的变体。
回到上图,Presion-Recall是一条曲线。比较两种方法的效果通常不够直观。你能不能把两者结合起来,直接反映到一个单一的值上?为此,IR学术界提出了F-Measure方法。 F-Measure由Presion和Recall的调和平均计算得出,公式为:
参数λε(0,1)调整系统在Precision和Recall之间的平衡。(通常λ=0.5,此时
)
这里使用调和平均代替通常的几何平均或算术平均。原因是调和平均强调小数的重要性,能灵敏地反映小数的变化,更适合反映搜索效果。
使用F Measure的好处是只需要一个数字就可以概括系统的搜索效果,方便比较不同搜索系统的整体效果。
P@N 方法点击因素
传统的Precision-Recall并不完全适用于搜索引擎的评价,因为搜索引擎用户的点击方式是独一无二的,包括:
A 60-65%的查询点击了名列搜索结果前10条的网页;
B 20-25%的人会考虑点击名列11到20的网页;
C 仅有3-4%的会点击名列搜索结果中列第21到第30名的网页
换句话说,大多数用户不愿意翻页看到搜索引擎给出的后续结果。
即使在搜索结果的第一页(通常会列出前 10 个结果),用户的点击行为也很有趣。我们使用下面的谷歌热图来观察(这张热图在第二个维度搜索结果页面上,可以通过光谱直观地表达用户在不同位置的点击兴趣。颜色越接近红色表示点击率越高强度):
从图中可以看出,前3个搜索结果吸引了大量点击,属于最受欢迎的部分。也就是说,对于搜索引擎来说,前几个结果是最关键的,决定了用户的满意度。
康奈尔大学的研究人员通过眼动追踪实验对 Google 搜索结果中的用户行为进行了更准确的分析。从这张图可以看出,第一个结果已经获得了56.38%的搜索流量,第二、第三个结果的排名依次下降,但远低于第一的结果。前三个结果的点击率约为 11:3:2。前三个结果的总点击量转移了近 80% 的搜索流量。
其他一些有趣的结论是点击次数不会按顺序减少。第七名获得的点击次数最少。原因可能是用户在浏览过程中将页面下拉到底部。这时候只显示了网站的最后三名排名,第七名很容易被忽略。而第一屏最后一个结果获得的注意力(2.55)大于倒数第二个(1.45)),因为用户在转屏之前对最后一个结果的印象比较深page 搜索结果页第二页第一页(也就是第11个结果)只获得了第10个首页网站的40%的点击量,比首页第一个结果还要多其 1/60 到 1/100 的点击量。
因此,在定量评估搜索引擎的效果时,往往需要根据上述搜索用户的行为特征进行针对性的设计。
P@N 计算方法
P@N本身是Precision@N的缩写,指的是在考虑位置因素的情况下,针对特定查询检测前N个结果的准确率。比如单次搜索的前5个结果,如果其中4个是相关文档,则P@5 = 4/5 = 0.8。
该测试通常使用一个查询集(根据上述方法构建),其中收录几个不同的查询词。在使用P@N的实际评估中,通常使用所有查询的P@N数据计算算术平均值,用于判断系统整体搜索结果的质量。
N 的选择
对于用户来说,他们通常只关注搜索结果的前几个结果。因此,搜索引擎的性能评估通常只关注前5、或前3个结果,所以我们常用的N取值为P@3或P@5等。
对于一些特定类型的查询应用,比如导航搜索,因为目标结果很明确,所以N=1(即在评估中使用P@1)。例如,如果你搜索“新浪网”或“新浪首页”,如果第一个结果不是新浪网(url:),则直接判断查询的准确度不符合要求,即P@1 =0
MRR
上面提到的P@N方法很容易计算和理解。但是细心的读者肯定会发现问题,就是在前N个结果中,第一个和第N个位置的结果对准确率的影响是一样的。但实际情况是,搜索引擎的评价与排名位置有着极大的关系。也就是说,第一个结果错误与第 10 个结果错误非常不同。因此,评价体系中需要引入区位因素。
MRR 是 Mean Reciprocal Rank 的缩写。 MRR 方法主要用于导航搜索或问答。这些检索方法只需要一个相关文档,这对召回率非常重要。不敏感,但更关心搜索引擎检索到的相关文档是否排在结果列表的前面。 MRR 方法首先计算每个查询的第一个相关文档位置的倒数,然后对所有倒数取平均值。比如一个收录三个查询词的测试集,前5个结果是:
查询一结果:1.AN 2.AR 3.AN 4.AN 5.AR
查询二结果:1.AN 2.AR 3.AR 4.AR 5.AN
查询三结果:1.AR 2.AN 3.AN 4.AN 5.AR
其中,AN代表无关结果,AR代表相关结果。那么第一次查询的Reciprocal Rank(Reciprocal Rank)RR1= 1/2=0.5;第二个结果 RR2 = 1/2 = 0.5;注意,倒数的值不会改变,即使得到了第二个结果更相关的结果。同理,RR3 = 1/1 = 1,对于这个测试集,最终的MRR=(RR1+RR2+RR3)/ 3 = 0.67
然而,对于大多数搜索应用来说,只有一个结果不能满足需求。在这种情况下,需要更合适的方法来计算效果。最常用的方法是下面的MAP方法。
地图
MAP方法是Mean Average Precison,是平均准确度法的缩写。它的定义是求检索到的每个相关文档的平均准确率(即Average Precision)的算术平均值(Mean)。在这里,准确度取了两次平均值,因此称为平均平均精度。 (注意:它不叫Average Average Precision,因为它丑陋,而且因为无法区分两个平均值的含义)
MAP 是一个单值指标,反映系统在所有相关文档上的表现。系统检索到的相关文档越高(等级越高),MAP就应该越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题:
主题 1 有 4 个相关网页,主题 2 有 5 个相关网页。
系统检索到主题1的4个相关网页,排名分别为1、2、4、7;
主题 2 检索到 3 个相关网页,排名分别为 1、3、5。
对于topic 1,平均准确率MAP计算公式为:
(1/1+2/2+3/4+4/7)/4=0.83。
对于主题2,平均准确率MAP计算公式为:
(1/1+2/3+3/5+0+0)/5=0.45。
然后 MAP= (0.83+0.45)/2=0.64。"
DCG 方法
DCG是英文Discountedcumulative gain的缩写,中文可译为“折扣累积收益”。 DCG方法的基本思想是:
1.对每个结果的相关性进行分级衡量
2.考虑结果的位置,位置越高,重要性越高
3.排名越高(即好成绩),成绩排名越高,数值应该越高,否则会被处罚。
我们先来看第一个:相关性分级。在计算 Precision 时,这比简单地计算“准确”或“不准确”更精细。我们可以将结果细分为多个级别。比如常用的3个等级:Good、Fair、Bad。对应的分数rel为:Good:3/Fair:2/Bad:1。一些更详细的评估使用5级分类:非常好、好、一般、差、非常差,对应的分数rel可以设置为:非常好:2 / 好:1 / 一般:0 / 差:-1 /非常糟糕:-2
判断结果的标准可以根据具体的应用来确定。非常好通常意味着结果的主题完全相关,网页内容丰富,质量高。并且具体到每一位
DCG的计算公式不是唯一的。理论上,它只需要对数贴现因子的平滑度。我个人认为下面的DCG公式更合理,强调相关性,1、2的结果的折扣因子也更合理:
此时DCG前4个位置结果的折扣因子值为:
基于2的log值也来自经验公式,没有理论依据。实际上,可以根据平滑要求修改Log的基数。当值增大时(例如用log5代替log2),折现因子下降得更快,强调了前面结果的权重。
为了方便不同类型查询结果的横向比较,基于DCG,一些评价系统也对DCG进行了归一化。这些方法统称为nDCG(即归一化DCG)。最常用的计算方法是除以每个查询的理想值iDCG(ideal DCG)进行归一化,公式为:
对于nDCG,需要校准理想的iDCG。在实际操作中,难度极大,因为每个人对“最佳结果”的理解往往各不相同,从海量数据中选出最佳结果非常困难。但是,通常比较容易比较两组结果,因此在实践中通常选择比较结果的方法进行评估。
如何实现自动化评估?
上面介绍的搜索引擎量化评价指标在克兰菲尔德评价框架中得到了广泛的应用。业界知名的TREC(Text Information Retrieval Conference)一直在基于这样的方法组织信息检索评估和技术交流。除了TREC,一些针对不同应用设计的Cranfield评测论坛也在进行中(如NTCIR、IREX等)。
但是 Cranfield 评估框架的问题在于查询样本集合的标记。通过人工标注答案来评价网络信息检索是一个费时费力的过程,只有少数大公司可以使用。并且由于搜索引擎算法改进和运维的需要,需要尽可能缩短检索效果评价和反馈的时间,因此自动化评价方法对于提高评价效率非常重要。最常用的自动评估方法是 A/B 测试系统。
A/B 测试
A/B 测试系统
A/B 测试系统在搜索用户时自动判断用户的bucket id,并自动抽取流量导入不同的分支,让对应组内的用户看到不同的产品版本(或不同版本)。搜索引擎)。将记录用户在不同版本产品中的行为。这些行为数据通过数据分析形成一系列的指标,通过这些指标的比较,得出哪个版本好坏的结论。
在指标的计算上,可以进一步分为两种方法,一种是基于专家评级;另一种是基于点击统计。
专家评分的方法通常由搜索核心技术研发和产品人员进行。两种环境A和B的结果按照预先设定的标准进行评分,比较每个查询的结果,并根据nDCG等方法计算整体质量。
点击评分的自动化程度更高。这里有一个假设:同样的排序位置,点击次数多的结果质量要好于点击次数少的结果。 (即A2代表A测试环境的第二个结果,如果A2>B2,说明A2质量较好)。通俗的说就是相信群众(因为群众的眼睛是有眼光的)。在这个假设下,我们可以自动将 A/B 环境中前 N 个结果的点击率映射到分数上。通过统计大量的Query点击结果,可以获得可靠的分数对比。
交错测试
此外,Thorsten Joachims 等人提出的 Interleaving 测试方法。在2003年也被广泛使用。这种方法设计了一个元搜索引擎。用户输入查询后,将查询在多个知名搜索引擎中的查询结果随机混合反馈给用户,进而采集用户的结果点击行为信息。根据用户不同的点击倾向,我们可以判断搜索引擎返回结果的优劣。
如下图,算法A和B的结果横放,按流量划分测试,记录用户点击信息。根据点击分布判断A、B环境的优劣。
交错测试评价方法
Joachims 还证明了 Interleaving Testing 评估方法和传统 Cranfield 评估方法的结果高度相关。由于记录用户对搜索结果的选择是一个省力的过程,便于实现自动搜索效果评估。
总结
没有评价就没有进步。对搜索结果进行定量评价的目的是准确找出现有搜索系统的不足(没有搜索系统是完美的),然后逐步改进算法和系统。本文为大家总结了常用的评价框架和评价指标。这些技术就像一把尺子,每次搜索技术进步时都会测量距离。
如何根据广告的业务要求设计更高效的索引和检索
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-20 02:05
在竞争性广告中,大量中小广告主的搜索规模需要很高的计算效率。如何根据广告的业务需求设计更高效的索引和检索技术是竞争广告系统要解决的关键问题。
要结合广告检索的具体需求,重点研究布尔表达式检索和相关性检索两种场景下的算法
从定价过程的输入可以看出,对于一个以CPC结算的竞价广告系统,首先需要得到候选广告集合,计算每个候选的点击率,对应投标广告中最关键的两个计算问题。 , 广告检索和广告排序
在竞价广告中,根据不同阶段发生的点击和转化操作,根据 eCPM 对广告进行排序
eCPM 可以分解为点击率和点击价值的乘积,
搜索广告系统
搜索广告与一般广告网络的主要区别在于上下文信息很强,用户标签的作用受到很大限制。搜索广告的检索过程一般不需要考虑用户的影响,上下文信息是通过用户输入实时查询和获取的,所以线下受众定位的过程基本可以忽略
查询扩展
需求方需要通过关键词扩容获得更多流量,供应商需要借此实现更多流量,加大竞价力度
基于推荐的方法:
如果将用户在一个会话中的查询视为一组具有相同目的的活动,则可以通过推荐技术在矩阵(会话,查询)矩阵上生成相同的关键词。此方法使用搜索日志数据,
给定一组用户会话和一组关键词,可以生成相应的强交互矩阵。如果用户搜索过某个关键词,矩阵的对应元素会设置一个对应的交互值,比如用户在一段时间内搜索该词的次数
显然,这个矩阵中的大部分单元格都是空白的,但这并不意味着用户搜索该词的可能性为零
推荐的基本任务是根据这个矩阵中的已知元素值,可预测地填充那些历史上没有观察到的单元。
基于主题模型的方法:
除了使用搜索到的日志数据,一般文档数据也可以用于查询扩展。这种方法本质上是利用文档主题模型将一个查询扩展到其他具有相似主题的查询
基于历史影响的方法:
利用广告历史eCPM数据挖掘效果更好的相关查询,因为广告主在选择关键词出价时,一般会选择多个组。如果从历史数据中发现,一些关键词对于某些特定的广告客户,eCPM较高,因此应该记录这些结果良好的查询组。之后,当另一个广告商也选择了关键词之一时,它可以根据这些历史记录自动进行。记录其他查询结果更好
广告展示位置
广告投放是指搜索引擎广告中确定北区和东区的广告数量问题
考虑到用户体验,有必要限制北区的广告数量。因此,这是一个典型的有约束的优化问题。约束是一段时间内北区整体的广告数量,优化目标是搜索广告系统的整体收入。在广告投放前的排序过程中,比较的是单个广告,但这里的优化需要处理一组广告,需要考虑位置因素
广告网络
广告网络的成本就是对媒体资源的分减。
广告投放的决策过程:
服务器接受前端用户访问触发的广告请求,首先根据上下文信息和用户标识从页面标签和用户标签中找出对应的上下文标签和用户标签,然后使用这些标签和其他一些广告请求条件从广告中找出符合要求的广告候选集,最后使用CTR预测模型计算所有候选广告的eCPM
根据eCPM排名选择中标的广告返回上一阶段完成投放
短期行为反馈与流计算
虽然用户行为导向不适合搜索引擎,但如果可以快速处理会话中的一系列用户查询,仍然有助于准确理解用户意图。除了这种短期的用户行为反馈,广告业务中还有一些场景需要快速处理在线日志
实现反作弊、实时计费、短期用户标签和短期动态功能
MapReduce 使用分布式文件系统尽可能调度计算
流计算就是在服务器之间调度数据来完成计算
广告搜索
检索布尔表达式
广告检索与普通搜索引擎检索的第一个区别是布尔表达式的检索问题。在以受众为导向的销售方式下,一个广告文件不再可以看作是一个BoW,而应该看作是一个目标条件的组合。合成布尔表达式,
布尔表达式检索问题有两个特点。这两个特性是设计算法的重要基础。首先,当广告请求的目标标签满足某个 Conjunction 时,它必须满足该 Conjunction 的所有广告。
相关性搜索
在长查询检索的情况下,我们实际上希望查询和广告候选之间的相似度尽可能高,但是文档中是否出现任何关键词都没有关系。这样,针对文档之间相似度的查询和检索问题就变成了相关查询
解决相关性检索的基本思想是在检索阶段引入一定的评价函数,根据该函数的评价结果确定返回哪些候选。评价函数的设计要求:合理、高效,
点击率预测
广告点击率预测的目的是对广告进行排序,但不能应用搜索中的排序问题。点击率预测不能像搜索一样只要求结果排序的正确性,因为点击率需要乘以点击单价才能得到最终排名。 ,
关于点击率预测的方法,自然会想到基于统计的估计
但是如果在某个组合中,ad a 没有展示或者点击量很少,那么历史数据就不能用来统计点击率。简单的解决方案是显示广告 a 和已显示的广告。类似于a·,那么a的点击率可以估计接近a·,
大数据机器学习问题往往需要迭代解决,Hadoop上的MapReduce已经成为范式约束。每次迭代都需要由一个 MapReduce Hadoop 作业完成。 Map读取训练数据和模型,并将数据分成块。在集合上计算统计,Reduce聚合统计平台并更新模型。由于从磁盘读取训练数据时map会产生大量的I/O,因此在Hadoop平台上一次迭代的成本往往非常昂贵,单轮迭代时间无法优化。如果要减少模型训练的时间,只能减少模型训练的次数。这就引出了以下业界常用的模型训练思路:
如果能降低每次迭代的成本,模型训练的总时间也能大大优化,于是出现了Spark这样的平台,它是一个将数据集缓存在分布式内存中的计算平台。如果数据集的规模可以在内存中控制,那么还是使用MapReduce范式来解决问题,因为每次迭代不需要通过磁盘I/o读取,大大减少了单次迭代的时间
点击率模型的校准
点击率预测问题的数据挑战之一是正负样本严重不平衡,尤其是当展示广告的点击率只有千分之几时。
点击率模型的特点
点击率预测问题的主要挑战在于,如果模型能够捕捉到高度动态的市场信号,就达到了更准确预测的目的。
静态特征:
静态特征是某些标签的值或上下文和用户标签的特征组合,以及特定广告与用户的匹配程度
动态特性:
当某个组合特征被触发时,我们不再用1,而是用这个组合历史上一段时间的点击率作为它的特征值
可以理解为历史点击率作为一个动态特征:我们最终要预测的是某个(a, u, c)上的点击率,以及特征的组合( a, u, c) 点击率可以看作是关于最终目标的弱决策者。通过融合这些特征组合对应的弱决策者,可以更容易地进行预测,
位置偏差
如何去除位置等因素的影响? 查看全部
如何根据广告的业务要求设计更高效的索引和检索
在竞争性广告中,大量中小广告主的搜索规模需要很高的计算效率。如何根据广告的业务需求设计更高效的索引和检索技术是竞争广告系统要解决的关键问题。
要结合广告检索的具体需求,重点研究布尔表达式检索和相关性检索两种场景下的算法
从定价过程的输入可以看出,对于一个以CPC结算的竞价广告系统,首先需要得到候选广告集合,计算每个候选的点击率,对应投标广告中最关键的两个计算问题。 , 广告检索和广告排序
在竞价广告中,根据不同阶段发生的点击和转化操作,根据 eCPM 对广告进行排序
eCPM 可以分解为点击率和点击价值的乘积,
搜索广告系统
搜索广告与一般广告网络的主要区别在于上下文信息很强,用户标签的作用受到很大限制。搜索广告的检索过程一般不需要考虑用户的影响,上下文信息是通过用户输入实时查询和获取的,所以线下受众定位的过程基本可以忽略
查询扩展
需求方需要通过关键词扩容获得更多流量,供应商需要借此实现更多流量,加大竞价力度
基于推荐的方法:
如果将用户在一个会话中的查询视为一组具有相同目的的活动,则可以通过推荐技术在矩阵(会话,查询)矩阵上生成相同的关键词。此方法使用搜索日志数据,
给定一组用户会话和一组关键词,可以生成相应的强交互矩阵。如果用户搜索过某个关键词,矩阵的对应元素会设置一个对应的交互值,比如用户在一段时间内搜索该词的次数
显然,这个矩阵中的大部分单元格都是空白的,但这并不意味着用户搜索该词的可能性为零
推荐的基本任务是根据这个矩阵中的已知元素值,可预测地填充那些历史上没有观察到的单元。
基于主题模型的方法:
除了使用搜索到的日志数据,一般文档数据也可以用于查询扩展。这种方法本质上是利用文档主题模型将一个查询扩展到其他具有相似主题的查询
基于历史影响的方法:
利用广告历史eCPM数据挖掘效果更好的相关查询,因为广告主在选择关键词出价时,一般会选择多个组。如果从历史数据中发现,一些关键词对于某些特定的广告客户,eCPM较高,因此应该记录这些结果良好的查询组。之后,当另一个广告商也选择了关键词之一时,它可以根据这些历史记录自动进行。记录其他查询结果更好
广告展示位置
广告投放是指搜索引擎广告中确定北区和东区的广告数量问题
考虑到用户体验,有必要限制北区的广告数量。因此,这是一个典型的有约束的优化问题。约束是一段时间内北区整体的广告数量,优化目标是搜索广告系统的整体收入。在广告投放前的排序过程中,比较的是单个广告,但这里的优化需要处理一组广告,需要考虑位置因素
广告网络
广告网络的成本就是对媒体资源的分减。
广告投放的决策过程:
服务器接受前端用户访问触发的广告请求,首先根据上下文信息和用户标识从页面标签和用户标签中找出对应的上下文标签和用户标签,然后使用这些标签和其他一些广告请求条件从广告中找出符合要求的广告候选集,最后使用CTR预测模型计算所有候选广告的eCPM
根据eCPM排名选择中标的广告返回上一阶段完成投放
短期行为反馈与流计算
虽然用户行为导向不适合搜索引擎,但如果可以快速处理会话中的一系列用户查询,仍然有助于准确理解用户意图。除了这种短期的用户行为反馈,广告业务中还有一些场景需要快速处理在线日志
实现反作弊、实时计费、短期用户标签和短期动态功能
MapReduce 使用分布式文件系统尽可能调度计算
流计算就是在服务器之间调度数据来完成计算
广告搜索
检索布尔表达式
广告检索与普通搜索引擎检索的第一个区别是布尔表达式的检索问题。在以受众为导向的销售方式下,一个广告文件不再可以看作是一个BoW,而应该看作是一个目标条件的组合。合成布尔表达式,
布尔表达式检索问题有两个特点。这两个特性是设计算法的重要基础。首先,当广告请求的目标标签满足某个 Conjunction 时,它必须满足该 Conjunction 的所有广告。
相关性搜索
在长查询检索的情况下,我们实际上希望查询和广告候选之间的相似度尽可能高,但是文档中是否出现任何关键词都没有关系。这样,针对文档之间相似度的查询和检索问题就变成了相关查询
解决相关性检索的基本思想是在检索阶段引入一定的评价函数,根据该函数的评价结果确定返回哪些候选。评价函数的设计要求:合理、高效,
点击率预测
广告点击率预测的目的是对广告进行排序,但不能应用搜索中的排序问题。点击率预测不能像搜索一样只要求结果排序的正确性,因为点击率需要乘以点击单价才能得到最终排名。 ,
关于点击率预测的方法,自然会想到基于统计的估计
但是如果在某个组合中,ad a 没有展示或者点击量很少,那么历史数据就不能用来统计点击率。简单的解决方案是显示广告 a 和已显示的广告。类似于a·,那么a的点击率可以估计接近a·,
大数据机器学习问题往往需要迭代解决,Hadoop上的MapReduce已经成为范式约束。每次迭代都需要由一个 MapReduce Hadoop 作业完成。 Map读取训练数据和模型,并将数据分成块。在集合上计算统计,Reduce聚合统计平台并更新模型。由于从磁盘读取训练数据时map会产生大量的I/O,因此在Hadoop平台上一次迭代的成本往往非常昂贵,单轮迭代时间无法优化。如果要减少模型训练的时间,只能减少模型训练的次数。这就引出了以下业界常用的模型训练思路:
如果能降低每次迭代的成本,模型训练的总时间也能大大优化,于是出现了Spark这样的平台,它是一个将数据集缓存在分布式内存中的计算平台。如果数据集的规模可以在内存中控制,那么还是使用MapReduce范式来解决问题,因为每次迭代不需要通过磁盘I/o读取,大大减少了单次迭代的时间
点击率模型的校准
点击率预测问题的数据挑战之一是正负样本严重不平衡,尤其是当展示广告的点击率只有千分之几时。
点击率模型的特点
点击率预测问题的主要挑战在于,如果模型能够捕捉到高度动态的市场信号,就达到了更准确预测的目的。
静态特征:
静态特征是某些标签的值或上下文和用户标签的特征组合,以及特定广告与用户的匹配程度
动态特性:
当某个组合特征被触发时,我们不再用1,而是用这个组合历史上一段时间的点击率作为它的特征值
可以理解为历史点击率作为一个动态特征:我们最终要预测的是某个(a, u, c)上的点击率,以及特征的组合( a, u, c) 点击率可以看作是关于最终目标的弱决策者。通过融合这些特征组合对应的弱决策者,可以更容易地进行预测,
位置偏差
如何去除位置等因素的影响?
互联网时代后的SEO只有精通这些高水平的技能
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-07-19 00:25
互联网时代,从PC到手机,从手机到人工智能,我们进入了后互联网时代。互联网不再是经济发展的颠覆,也不再是突如其来的变革。她更像是卷入社会经济大局的重要一员。然而,PC时代搜索引擎优化的辉煌已经不复存在。 SEO在企业中的地位非常尴尬。牛力搜索引擎优化风生水起。互联网时代后的SEO只需要精通这些高级SEO技巧即可。 ---互联网整合营销策划顾问-杨小道
1、聚合页面优化
主题、频道列、文章list、标签聚合。
有些网站权重很高,内容信息量很大,信息量一般在几万左右。做这种网站通常需要特殊的分析、诊断和设计变更。但是为了增加整体的流量,我们可以简单的把这种网站看成只有两种类型的页面,即内容页面和聚合页面。现在很多大中型网站都会使用网站中的标签来创建一些独特的页面来获取一些长尾流量,但这应该是基于关键词的过滤和控制,因为大量不相关的聚合搜索流量来源会导致整个网站主题的偏差,可能会严重削弱权益。
2、泛分析站群+蜘蛛池
SEO黑客技术常用,黑客对灰色行业的影响是毋庸置疑的。一万字保存在这里。
3、汉密尔顿环链轮基本款
每个都有自己的汉密尔顿环链轮基本模型。杨小道也有自己的SEO链轮基础模型
4、原创Continuous文章技术
原创性?什么是创造力?就像一个人的身份证存在于**上一样,是最上面的,没有重复。原文文章也是一样,网上只有一篇文章,没有重复。那么,作为SEOER,我们应该如何创建文章?
首先,一个好的原创文章一定要有一个好的标题
一、根据我平时的经验,想一想我会在搜索引擎中填写的句子或内容,根据我的实际情况来写;例如:什么是 SEO?
二、查看peer网站的关键词,分析一下,得到适合自己的,有一定热情的关键词。将它们插入标题中,并对主关键字和子关键字进行排序和组合。比如主关键词是“SEO”,子关键词是“原创文章”,组合关键词是“SEO原创文章”。
三、 了解用户需求,观察一些论坛、贴吧、问答等交流平台,了解用户平时喜欢搜索什么,关心什么?例如:如何创建SEO文章? SEO原创文章怎么写?
四、在思考的过程中,查看百度、360、搜狗等与您同名或相关内容的搜索引擎的搜索结果。如果有更多,我们建议您更改标题,以便百度更快地采集您的文章
其次,一个好的原创文章不仅要有原创的标题,还要有原创的内容
一、写文章时,请注意增加文章前100字关键词“SEO原创文章”的密度! 100字应该有2-3次。
二、研究用户心理,就像写标题一样,可以看到用户的需求以及用户点击这篇文章想要看到和理解的内容。
三、正文的内容部分,需要能够在“SEO原创文章”中搜索相关信息关键词。这就是区别于普通原创文章的关键。让人们可以在不同的相关关键词中搜索到相同的文章文章。
四、原来文章的内容其实是为了与你想表达的相处;例如:在原来的SEO文章写下自己的感受。共同点是写印象。
之后
,结尾也是蜘蛛爬行的关键。结束方式如下:
关键词 必须出现在 200 字的末尾,记住。应该有一个好的开始和一个好的结束。成功的SEO公式=持久化+原创内容+优质外链
原创性是一个所谓的工具,它使用你的想法,然后用文字写下来。这就是创造力。看完之后,你觉得创意有那么简单吗?大体意思就是自己写文章。 查看全部
互联网时代后的SEO只有精通这些高水平的技能
互联网时代,从PC到手机,从手机到人工智能,我们进入了后互联网时代。互联网不再是经济发展的颠覆,也不再是突如其来的变革。她更像是卷入社会经济大局的重要一员。然而,PC时代搜索引擎优化的辉煌已经不复存在。 SEO在企业中的地位非常尴尬。牛力搜索引擎优化风生水起。互联网时代后的SEO只需要精通这些高级SEO技巧即可。 ---互联网整合营销策划顾问-杨小道
1、聚合页面优化
主题、频道列、文章list、标签聚合。
有些网站权重很高,内容信息量很大,信息量一般在几万左右。做这种网站通常需要特殊的分析、诊断和设计变更。但是为了增加整体的流量,我们可以简单的把这种网站看成只有两种类型的页面,即内容页面和聚合页面。现在很多大中型网站都会使用网站中的标签来创建一些独特的页面来获取一些长尾流量,但这应该是基于关键词的过滤和控制,因为大量不相关的聚合搜索流量来源会导致整个网站主题的偏差,可能会严重削弱权益。
2、泛分析站群+蜘蛛池
SEO黑客技术常用,黑客对灰色行业的影响是毋庸置疑的。一万字保存在这里。
3、汉密尔顿环链轮基本款
每个都有自己的汉密尔顿环链轮基本模型。杨小道也有自己的SEO链轮基础模型
4、原创Continuous文章技术
原创性?什么是创造力?就像一个人的身份证存在于**上一样,是最上面的,没有重复。原文文章也是一样,网上只有一篇文章,没有重复。那么,作为SEOER,我们应该如何创建文章?
首先,一个好的原创文章一定要有一个好的标题
一、根据我平时的经验,想一想我会在搜索引擎中填写的句子或内容,根据我的实际情况来写;例如:什么是 SEO?
二、查看peer网站的关键词,分析一下,得到适合自己的,有一定热情的关键词。将它们插入标题中,并对主关键字和子关键字进行排序和组合。比如主关键词是“SEO”,子关键词是“原创文章”,组合关键词是“SEO原创文章”。
三、 了解用户需求,观察一些论坛、贴吧、问答等交流平台,了解用户平时喜欢搜索什么,关心什么?例如:如何创建SEO文章? SEO原创文章怎么写?
四、在思考的过程中,查看百度、360、搜狗等与您同名或相关内容的搜索引擎的搜索结果。如果有更多,我们建议您更改标题,以便百度更快地采集您的文章
其次,一个好的原创文章不仅要有原创的标题,还要有原创的内容
一、写文章时,请注意增加文章前100字关键词“SEO原创文章”的密度! 100字应该有2-3次。
二、研究用户心理,就像写标题一样,可以看到用户的需求以及用户点击这篇文章想要看到和理解的内容。
三、正文的内容部分,需要能够在“SEO原创文章”中搜索相关信息关键词。这就是区别于普通原创文章的关键。让人们可以在不同的相关关键词中搜索到相同的文章文章。
四、原来文章的内容其实是为了与你想表达的相处;例如:在原来的SEO文章写下自己的感受。共同点是写印象。
之后
,结尾也是蜘蛛爬行的关键。结束方式如下:
关键词 必须出现在 200 字的末尾,记住。应该有一个好的开始和一个好的结束。成功的SEO公式=持久化+原创内容+优质外链
原创性是一个所谓的工具,它使用你的想法,然后用文字写下来。这就是创造力。看完之后,你觉得创意有那么简单吗?大体意思就是自己写文章。
17年SEO搜索引擎:核心技术详解--梳理总结
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-07-17 19:00
2017年因项目需要,学习整理了一些SEO相关的知识,可以分为两部分:
《搜索引擎:核心技术详解》---梳理与总结
SEO 搜索引擎优化
本文主要内容是对阅读《搜索引擎:核心技术详解》时的一些知识进行梳理和总结,包括搜索引擎索引、链接分析和网页反作弊三部分一、搜索引擎索引
Index,如书籍目录,是一种索引结构,其目的是让人们更快地搜索相关章节。搜索引擎索引简单的理解就是抓取页面后对数据进行排序整理的过程。搜索引擎的索引就是实现word-document矩阵的数据结构。在实际应用中实现的方式有很多种,常见的就是倒排索引。
索引的基本概念
引擎的基本索引模型是一个word-document矩阵,如图:
横向可以看到哪些文档收录某个词汇,纵向可以看到某个文档收录哪些关键词
在实际的搜索引擎中,一般记录的不是文档编号,而是相邻两个文档的差值。这样就将大值转换成小值,提高了压缩效率
创建索引
缺点:从磁盘中读取文档并解析文档基本上是最耗时的步骤,而且两次扫描方式在速度上没有优势,因为它需要遍历文档集合两次。在实践中,这种方法的系统并不常见。
动态索引
实时反映索引变化,3种关键索引结构:倒排索引、临时索引、删除文档列表。
索引更新策略
当临时索引越来越内存不足时,需要将临时索引写入disk-index更新策略
常用的索引更新策略有4种:完全重建策略、重新合并策略、就地更新策略和混合策略。
完全重构策略----新文档临时索引+旧文档--------->遍历生成新索引(放弃旧索引)再合并策略----新文档索引+旧索引- --->合并生成新索引(抛弃旧索引)原位更新策略--增量索引+旧索引---->旧索引+附加新倒排信息混合策略----一般对词进行分类,然后使用不同的更新策略
二、Link 分析概念模型
随机游走模型----是一个概念模型,抽象了两种用户浏览行为,直接跳转和远程跳转。许多链接分析算法,包括PageRank算法,都是基于随机游走模型的。
假设互联网由3个网页A、B、C组成,图中页面节点之间的有向边表示相互链接关系。根据链接关系,可以计算出页面节点之间的转移概率。例如,对于节点 A,只有一条到节点 B 的输出链路,所以从节点 A 跳到节点 B 的概率为 1,对于节点 C,它有到节点 A 和 B 的链路,所以转向的概率为任何其他节点都是 1/2。假设在时间1,用户浏览页面A,然后通过链接进入页面B,然后进入页面C,此时他面临两种可能的选择。可以跳转到页面A或页面B,两者的概率相同,都是1/2。假设示例中的Internet收录3个以上的页面,但由10个页面组成。这时候用户既不想跳回页面A也不想跳回页面B,他可以以1/10的概率跳到任何其他页面,即远程跳转。
子集传播模型——将网页按照一定的规则分成两个甚至多个子集。某个子集合具有特殊属性。许多算法通常从这个子集合开始,并为子集合中的网页赋予初始权重。然后,根据该特殊子集合中的网页与其他网页之间的链接关系,以某种方式分配权重。该值被传递到其他网页。
链接分析算法
在众多算法中,PageRank 和 HITS 可以说是最重要的两种具有代表性的链接分析算法。很多后续的链接分析算法都是从这两种算法衍生出来的改进算法。
PageRank 算法
每个页面都会将其当前的PageRank值平均分配给该页面收录的传出链接,从而使每个链接获得相应的权重。并且每个页面将所有指向该页面的链内传递的权重相加,以获得新的 PageRank 分数。
HITS 算法
权威页面是指与某个领域或主题相关的高质量网页。例如,在搜索引擎领域,谷歌和百度的主页都是该领域的优质网页;例如,在视频领域,优酷和土豆主页是该领域的优质网页。中心页面是指收录许多指向高质量权威页面的链接的网页。
Hub 和 Authority 之间的相辅相成的关系。 HITS算法与用户输入的查询请求密切相关,而PageRank算法是全局算法,与查询无关。
HITS算法的目的是利用一定的技术手段,在大量网页中,特别是Authority页面中,找到与用户查询主题相关的高质量Authority页面和Hub页面,因为这些页面代表了高质量可以满足用户的查询。内容,搜索引擎以此作为搜索结果返回给用户。
SALSA算法----请求--->扩展网页子集----->转向无向二部图---->计算权重--->返回结果
hilltop----专家网络搜索---->着陆页排序
主题敏感PageRank----离线分类主题PR值计算---->请求是相似度比较计算---->前两者的乘积之和
HITS算法与PageRank算法对比
HITS算法与用户输入的查询请求密切相关,而PageRank与查询请求无关。因此,可以单独使用HITS算法作为相似度计算的评价标准,而PageRank必须与内容相似度计算相结合,才能用于评价网页的相关性。由于HITS算法与用户查询密切相关,必须在收到用户查询后进行实时计算,计算效率低;而PageRank可以在爬取完成后离线计算,计算结果可以直接在线使用,计算效率更高。 HITS算法计算对象少,只需要计算扩展集中网页之间的链接关系;而 PageRank 是一种全局算法,可以处理所有 Internet 页面节点。从两者的计算效率和处理对象集合大小的比较来看,PageRank更适合部署在服务器端,而HITS算法更适合部署在客户端。 HITS算法存在话题泛化的问题,所以更适合处理特定的用户查询;而PageRank算法在处理大范围的用户查询方面更有优势。 HITS算法需要为每个页面计算两个分数,而PageRank算法只需要计算一个分数;在搜索引擎领域,更多关注的是HITS算法计算出的权威权重,但在其他很多应用HITS算法的领域,Hub score也很重要。从链接防作弊的角度来看,PageRank在机制上优于HITS算法,HITS算法更容易受到链接作弊的影响。 HITS算法的结构不稳定。当扩展网页集合中的链接关系稍有改动时,就会对最终排名产生很大的影响;而与 HITS 相比,PageRank 算法是稳定的。根本原因是PageRank计算时的远程跳转。 . 三、网络作弊
从大类来看,比较常见的作弊方式有:内容作弊、链接作弊、隐藏作弊,以及近年来兴起的Web2.0作弊方式。学术界和搜索引擎公司也有针对性地提出了各种反作弊算法。
内容作弊
内容作弊的目的是精心修改或规范网页内容,使网页在与其网页不相称的搜索引擎排名中获得较高的排名。搜索引擎排名一般包括内容相似度和链接重要性计算。内容作弊主要针对搜索引擎排名算法的内容相似度计算部分。通过故意增加目标词的频率,或在网页重要位置引入网页内容不相关的词影响搜索结果的排名。
常见内容作弊方式:关键词repetition、无关查询词作弊、图片alt标签文字作弊、网页标题作弊、网页重要标签作弊、网页元信息作弊
内容农场:内容农场运营商廉价雇用大量自由职业者来支持他们的付费写作,但写作内容的质量通常较低。很多文章都是通过复制和稍加修改来完成的,但是他们会研究搜索引擎的热门搜索词等,并将这些词有机地添加到写作内容中。这样,普通搜索引擎用户在搜索时就会被吸引到内容农场网站,内容农场可以通过大量低质量内容吸引流量来赚取广告费用。
链接作弊
所谓链接作弊就是网站owner考虑到在搜索引擎排名中使用链接分析技术,所以通过操纵页面之间的链接关系,或者操纵页面之间的链接锚文本,来增加链接排名因素的得分以及影响搜索结果排名的作弊方式。
为了提高网页的搜索引擎链接排名,链接农场建立了一个庞大的网页集合,这些网页相互之间有着密切的联系,希望通过搜索引擎链接算法的机制来提高网页排名。大量的相互联系。链接农场中页面的链接密度极高,任何两个页面都可能有相互指向的链接。
锚文本是指向某个网页的链接的描述文本。这些描述信息往往反映了所指向网页的内容主题,因此搜索引擎在排名算法中经常使用它。作弊者精心设置锚文本内容,诱使搜索引擎对目标网页给予更高的排名。一般来说,作弊者设置的锚文本与目标网页的内容无关。
几年前,有一个著名的例子,就是利用谷歌轰炸来操纵搜索结果的排名。那时,如果你在谷歌上搜索“悲惨的失败”,你会发现第二个搜索结果是时任美国总统乔治·W·布什的白宫页面。这是通过构建许多其他网页,包括指向目标页面的链接,其链接锚文本收录“悲惨失败”关键词 实现的效果。
“门页”本身不收录正文内容,而是由大量链接组成,而这些链接往往指向同一个网站
在页面中,作弊者创建了大量的“门页”,以提高网站排名。
页面隐藏作弊
页面隐藏作弊利用某种手段欺骗搜索引擎爬虫,使搜索引擎爬取的页面内容和用户点击查看
您看到的页面内容不同,从而影响搜索引擎的搜索结果。隐藏页面和作弊的常见方法
以下是几个。
1.IP伪装(IP Cloaking)
网页所有者在服务器端记录搜索引擎爬虫的IP地址列表,如果发现搜索引擎在请求页面上
对于人脸,它会向爬虫推送一个虚假的网页内容,如果是另一个IP地址,它会推送另一个网页
内容,此页面通常是具有商业目的的营销页面。 查看全部
17年SEO搜索引擎:核心技术详解--梳理总结
2017年因项目需要,学习整理了一些SEO相关的知识,可以分为两部分:
《搜索引擎:核心技术详解》---梳理与总结
SEO 搜索引擎优化
本文主要内容是对阅读《搜索引擎:核心技术详解》时的一些知识进行梳理和总结,包括搜索引擎索引、链接分析和网页反作弊三部分一、搜索引擎索引
Index,如书籍目录,是一种索引结构,其目的是让人们更快地搜索相关章节。搜索引擎索引简单的理解就是抓取页面后对数据进行排序整理的过程。搜索引擎的索引就是实现word-document矩阵的数据结构。在实际应用中实现的方式有很多种,常见的就是倒排索引。
索引的基本概念
引擎的基本索引模型是一个word-document矩阵,如图:
横向可以看到哪些文档收录某个词汇,纵向可以看到某个文档收录哪些关键词
在实际的搜索引擎中,一般记录的不是文档编号,而是相邻两个文档的差值。这样就将大值转换成小值,提高了压缩效率
创建索引
缺点:从磁盘中读取文档并解析文档基本上是最耗时的步骤,而且两次扫描方式在速度上没有优势,因为它需要遍历文档集合两次。在实践中,这种方法的系统并不常见。
动态索引
实时反映索引变化,3种关键索引结构:倒排索引、临时索引、删除文档列表。
索引更新策略
当临时索引越来越内存不足时,需要将临时索引写入disk-index更新策略
常用的索引更新策略有4种:完全重建策略、重新合并策略、就地更新策略和混合策略。
完全重构策略----新文档临时索引+旧文档--------->遍历生成新索引(放弃旧索引)再合并策略----新文档索引+旧索引- --->合并生成新索引(抛弃旧索引)原位更新策略--增量索引+旧索引---->旧索引+附加新倒排信息混合策略----一般对词进行分类,然后使用不同的更新策略
二、Link 分析概念模型
随机游走模型----是一个概念模型,抽象了两种用户浏览行为,直接跳转和远程跳转。许多链接分析算法,包括PageRank算法,都是基于随机游走模型的。
假设互联网由3个网页A、B、C组成,图中页面节点之间的有向边表示相互链接关系。根据链接关系,可以计算出页面节点之间的转移概率。例如,对于节点 A,只有一条到节点 B 的输出链路,所以从节点 A 跳到节点 B 的概率为 1,对于节点 C,它有到节点 A 和 B 的链路,所以转向的概率为任何其他节点都是 1/2。假设在时间1,用户浏览页面A,然后通过链接进入页面B,然后进入页面C,此时他面临两种可能的选择。可以跳转到页面A或页面B,两者的概率相同,都是1/2。假设示例中的Internet收录3个以上的页面,但由10个页面组成。这时候用户既不想跳回页面A也不想跳回页面B,他可以以1/10的概率跳到任何其他页面,即远程跳转。
子集传播模型——将网页按照一定的规则分成两个甚至多个子集。某个子集合具有特殊属性。许多算法通常从这个子集合开始,并为子集合中的网页赋予初始权重。然后,根据该特殊子集合中的网页与其他网页之间的链接关系,以某种方式分配权重。该值被传递到其他网页。
链接分析算法
在众多算法中,PageRank 和 HITS 可以说是最重要的两种具有代表性的链接分析算法。很多后续的链接分析算法都是从这两种算法衍生出来的改进算法。
PageRank 算法
每个页面都会将其当前的PageRank值平均分配给该页面收录的传出链接,从而使每个链接获得相应的权重。并且每个页面将所有指向该页面的链内传递的权重相加,以获得新的 PageRank 分数。
HITS 算法
权威页面是指与某个领域或主题相关的高质量网页。例如,在搜索引擎领域,谷歌和百度的主页都是该领域的优质网页;例如,在视频领域,优酷和土豆主页是该领域的优质网页。中心页面是指收录许多指向高质量权威页面的链接的网页。
Hub 和 Authority 之间的相辅相成的关系。 HITS算法与用户输入的查询请求密切相关,而PageRank算法是全局算法,与查询无关。
HITS算法的目的是利用一定的技术手段,在大量网页中,特别是Authority页面中,找到与用户查询主题相关的高质量Authority页面和Hub页面,因为这些页面代表了高质量可以满足用户的查询。内容,搜索引擎以此作为搜索结果返回给用户。
SALSA算法----请求--->扩展网页子集----->转向无向二部图---->计算权重--->返回结果
hilltop----专家网络搜索---->着陆页排序
主题敏感PageRank----离线分类主题PR值计算---->请求是相似度比较计算---->前两者的乘积之和
HITS算法与PageRank算法对比
HITS算法与用户输入的查询请求密切相关,而PageRank与查询请求无关。因此,可以单独使用HITS算法作为相似度计算的评价标准,而PageRank必须与内容相似度计算相结合,才能用于评价网页的相关性。由于HITS算法与用户查询密切相关,必须在收到用户查询后进行实时计算,计算效率低;而PageRank可以在爬取完成后离线计算,计算结果可以直接在线使用,计算效率更高。 HITS算法计算对象少,只需要计算扩展集中网页之间的链接关系;而 PageRank 是一种全局算法,可以处理所有 Internet 页面节点。从两者的计算效率和处理对象集合大小的比较来看,PageRank更适合部署在服务器端,而HITS算法更适合部署在客户端。 HITS算法存在话题泛化的问题,所以更适合处理特定的用户查询;而PageRank算法在处理大范围的用户查询方面更有优势。 HITS算法需要为每个页面计算两个分数,而PageRank算法只需要计算一个分数;在搜索引擎领域,更多关注的是HITS算法计算出的权威权重,但在其他很多应用HITS算法的领域,Hub score也很重要。从链接防作弊的角度来看,PageRank在机制上优于HITS算法,HITS算法更容易受到链接作弊的影响。 HITS算法的结构不稳定。当扩展网页集合中的链接关系稍有改动时,就会对最终排名产生很大的影响;而与 HITS 相比,PageRank 算法是稳定的。根本原因是PageRank计算时的远程跳转。 . 三、网络作弊
从大类来看,比较常见的作弊方式有:内容作弊、链接作弊、隐藏作弊,以及近年来兴起的Web2.0作弊方式。学术界和搜索引擎公司也有针对性地提出了各种反作弊算法。
内容作弊
内容作弊的目的是精心修改或规范网页内容,使网页在与其网页不相称的搜索引擎排名中获得较高的排名。搜索引擎排名一般包括内容相似度和链接重要性计算。内容作弊主要针对搜索引擎排名算法的内容相似度计算部分。通过故意增加目标词的频率,或在网页重要位置引入网页内容不相关的词影响搜索结果的排名。
常见内容作弊方式:关键词repetition、无关查询词作弊、图片alt标签文字作弊、网页标题作弊、网页重要标签作弊、网页元信息作弊
内容农场:内容农场运营商廉价雇用大量自由职业者来支持他们的付费写作,但写作内容的质量通常较低。很多文章都是通过复制和稍加修改来完成的,但是他们会研究搜索引擎的热门搜索词等,并将这些词有机地添加到写作内容中。这样,普通搜索引擎用户在搜索时就会被吸引到内容农场网站,内容农场可以通过大量低质量内容吸引流量来赚取广告费用。
链接作弊
所谓链接作弊就是网站owner考虑到在搜索引擎排名中使用链接分析技术,所以通过操纵页面之间的链接关系,或者操纵页面之间的链接锚文本,来增加链接排名因素的得分以及影响搜索结果排名的作弊方式。
为了提高网页的搜索引擎链接排名,链接农场建立了一个庞大的网页集合,这些网页相互之间有着密切的联系,希望通过搜索引擎链接算法的机制来提高网页排名。大量的相互联系。链接农场中页面的链接密度极高,任何两个页面都可能有相互指向的链接。
锚文本是指向某个网页的链接的描述文本。这些描述信息往往反映了所指向网页的内容主题,因此搜索引擎在排名算法中经常使用它。作弊者精心设置锚文本内容,诱使搜索引擎对目标网页给予更高的排名。一般来说,作弊者设置的锚文本与目标网页的内容无关。
几年前,有一个著名的例子,就是利用谷歌轰炸来操纵搜索结果的排名。那时,如果你在谷歌上搜索“悲惨的失败”,你会发现第二个搜索结果是时任美国总统乔治·W·布什的白宫页面。这是通过构建许多其他网页,包括指向目标页面的链接,其链接锚文本收录“悲惨失败”关键词 实现的效果。
“门页”本身不收录正文内容,而是由大量链接组成,而这些链接往往指向同一个网站
在页面中,作弊者创建了大量的“门页”,以提高网站排名。
页面隐藏作弊
页面隐藏作弊利用某种手段欺骗搜索引擎爬虫,使搜索引擎爬取的页面内容和用户点击查看
您看到的页面内容不同,从而影响搜索引擎的搜索结果。隐藏页面和作弊的常见方法
以下是几个。
1.IP伪装(IP Cloaking)
网页所有者在服务器端记录搜索引擎爬虫的IP地址列表,如果发现搜索引擎在请求页面上
对于人脸,它会向爬虫推送一个虚假的网页内容,如果是另一个IP地址,它会推送另一个网页
内容,此页面通常是具有商业目的的营销页面。
一个语义挖掘的利器——主题模型(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-07-17 00:07
来自:
总结:
两个文档是否相关,往往不仅取决于字面上的重复,还取决于文本背后的语义联系。语义关联的挖掘可以使我们的搜索更加智能。本文重点介绍一个强大的语义挖掘工具:主题模型。主题模型是一种对文本隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的不足,能够在海量互联网数据中自动找到文本之间的语义主题。近年来,各大互联网公司都开始了这方面的探索和尝试。让我们看看会发生什么。
关键词:主题模型
技术领域:搜索技术、自然语言处理
假设有两个句子,我们想知道它们是否相关:
第一个是:“工作没了。”
第二个是:“苹果会降价吗?”
如果是人来判断的话,我们一看就知道,这两个句子虽然没有共同的词,但还是很有关联的。这是因为,虽然第二句中的“apple”可能指的是我们吃的苹果,但因为第一句中有“Jobs”,我们自然会将“apple”解释为苹果产品。事实上,这种文本句子之间的相关性和相似性在搜索引擎算法中经常遇到。例如,如果用户输入一个查询,我们需要从海量的网页库中找到最相关的结果。下面是如何衡量查询和网页之间的相似度。对于此类问题,人们可以根据上下文进行判断。但是机器还好吗?
在传统信息检索领域,测量文档相似度的方法其实有很多,比如经典的VSM模型。但是,这些方法通常基于一个基本假设:文档之间重复的单词越多,它们相似的可能性就越大。这在实践中并不总是正确的。在很多情况下,相关程度取决于背后的语义联系,而不是表面的单词重复。
那么,这种语义关系应该如何衡量呢?事实上,在自然语言处理领域,已经有很多方法可以从单词、短语、句子和文本的角度来衡量。本文将介绍语义挖掘的强大工具之一:主题模型。
什么是主题模型?
主题模型,顾名思义,就是对文本中隐藏主题的一种建模方法。还是在上面的例子中,单词“apple”同时收录了Apple的主题和fruit的主题。对比第一句,苹果的主题与“乔布斯”所代表的主题相匹配,所以我们认为它们是相关的。
在这里,让我们先定义一下主题是什么。主题是一个概念,一个方面。它表现为一系列相关的词。例如,如果文章与“百度”主题相关,“中文搜索”、“李彦宏”等词出现的频率会更高,如果涉及“IBM”主题,则“笔记本”等会很频繁地出现。如果用数学来描述的话,题目就是单词在词汇表上的条件概率分布。词的相关性越近,其条件概率越大,反之亦然。
例如:
通俗地说,一个话题就像一个“桶”,里面收录了一些出现概率较高的词。这些词与主题有很强的相关性,或者正是这些词共同定义了主题。对于一个段落,有些词可能来自这个“桶”,有些可能来自那个“桶”,而一个文本往往是几个主题的混合体。举个简单的例子,见下图。
以上内容摘自网络新闻。我们划分了4个桶(主题),百度(红色),微软(紫色),谷歌(蓝色)和市场(绿色)。段落中收录的每个主题的单词都用颜色标记。从颜色分布我们可以看出,文中的主要思想是谈论百度和市场发展。在这方面,谷歌和微软的两个主题也出现了,但不是主要的语义。值得注意的是,像“搜索引擎”这样的词极有可能出现在百度、微软、谷歌这三个主题上。可以认为一个词被放入多个“桶”中。当它出现在文本中时,这三个主题在一定程度上得到了体现。
有了主题的概念,我们不禁要问,这些主题是怎么得到的?如何分析文章中的话题?这正是主题模型想要解决的问题。让我简单介绍一下主题模型的工作原理。
主题模型的工作原理
首先,我们从生成模型的角度来看文档和主题这两个东西。所谓生成模型,是指我们认为一个文章中的每个词都是通过“以一定概率选择某个主题,并以一定概率从该主题中选择某个词”的过程获得的。那么,如果我们要生成一个文档,其中每个词出现的概率为:
上式可以用矩阵乘法表示,如下图所示:
左
矩阵表示每个词在每个文章中的概率;中间的Φ矩阵代表每个话题中每个词的概率
,即每个“桶
表示每个文档中每个主题的概率
,可以理解为每个主题在一个段落中所占的比例。
如果我们有很多文档,比如很多网页,我们首先将所有文档进行分割,得到一个词汇表。这样,每个文档都可以表示为一个词的集合。对于每个单词,我们可以用它在文档中出现的次数除以文档中的单词数作为它在文档中出现的概率
。这样,对于任何文档,
左边
矩阵已知,右边两个矩阵未知。主题模型是使用大量已知的“words-documents”
Matrix,通过一系列的训练,推断出右边的“word-topic”矩阵Φ和“主题文档”矩阵Θ。
主题模型训练和推理主要有两种方法,一种是pLSA(Probabilistic Latent Semantic Analysis),另一种是LDA(Latent Dirichlet Allocation)。 pLSA主要使用EM(Expectation Maximization)算法; LDA 使用 Gibbs 采样方法。由于它们比较复杂,篇幅有限,这里只简单介绍一下pLSA的思想,其他具体的方法和公式,读者可以参考相关资料。
pLSA采用的方法称为EM(Expectation Maximization)算法,它由两个不断迭代的过程组成:E(期望)过程和M(最大化)过程。举个形象例子:假设食堂的厨师炸一道菜,需要分成两个人吃。显然,没有必要使用天平来准确称重。最简单的方法是先将菜品随机分成两个碗,然后观察数量是否相同,取较多的部分放入另一个碗中。重复这个过程,直到大家都看不到两个碗里的菜。到目前为止有何不同。
对于主题模型训练,“计算每个主题的词分布”和“计算训练文档中的主题分布”就像两个人分享食物。在E过程中,我们可以使用贝叶斯公式从“word-topic”矩阵中计算出“topic-document”矩阵。在M过程中,我们使用“topic-document”矩阵重新计算“term-topic”矩阵。这个过程一直是这样迭代的。 EM 算法的神奇之处在于它可以保证这个迭代过程是收敛的。也就是说,经过反复迭代,我们肯定可以得到趋于真实值的Φ和Θ。
如何使用主题模型?
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3) 可以消除文档中噪声的影响。一般来说,文档中的杂音往往出现在次要主题中,我们可以忽略它们,只保留文档中的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5) 与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
纺纱世界 查看全部
一个语义挖掘的利器——主题模型(组图)
来自:
总结:
两个文档是否相关,往往不仅取决于字面上的重复,还取决于文本背后的语义联系。语义关联的挖掘可以使我们的搜索更加智能。本文重点介绍一个强大的语义挖掘工具:主题模型。主题模型是一种对文本隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的不足,能够在海量互联网数据中自动找到文本之间的语义主题。近年来,各大互联网公司都开始了这方面的探索和尝试。让我们看看会发生什么。
关键词:主题模型
技术领域:搜索技术、自然语言处理
假设有两个句子,我们想知道它们是否相关:
第一个是:“工作没了。”
第二个是:“苹果会降价吗?”
如果是人来判断的话,我们一看就知道,这两个句子虽然没有共同的词,但还是很有关联的。这是因为,虽然第二句中的“apple”可能指的是我们吃的苹果,但因为第一句中有“Jobs”,我们自然会将“apple”解释为苹果产品。事实上,这种文本句子之间的相关性和相似性在搜索引擎算法中经常遇到。例如,如果用户输入一个查询,我们需要从海量的网页库中找到最相关的结果。下面是如何衡量查询和网页之间的相似度。对于此类问题,人们可以根据上下文进行判断。但是机器还好吗?
在传统信息检索领域,测量文档相似度的方法其实有很多,比如经典的VSM模型。但是,这些方法通常基于一个基本假设:文档之间重复的单词越多,它们相似的可能性就越大。这在实践中并不总是正确的。在很多情况下,相关程度取决于背后的语义联系,而不是表面的单词重复。
那么,这种语义关系应该如何衡量呢?事实上,在自然语言处理领域,已经有很多方法可以从单词、短语、句子和文本的角度来衡量。本文将介绍语义挖掘的强大工具之一:主题模型。
什么是主题模型?
主题模型,顾名思义,就是对文本中隐藏主题的一种建模方法。还是在上面的例子中,单词“apple”同时收录了Apple的主题和fruit的主题。对比第一句,苹果的主题与“乔布斯”所代表的主题相匹配,所以我们认为它们是相关的。
在这里,让我们先定义一下主题是什么。主题是一个概念,一个方面。它表现为一系列相关的词。例如,如果文章与“百度”主题相关,“中文搜索”、“李彦宏”等词出现的频率会更高,如果涉及“IBM”主题,则“笔记本”等会很频繁地出现。如果用数学来描述的话,题目就是单词在词汇表上的条件概率分布。词的相关性越近,其条件概率越大,反之亦然。
例如:
通俗地说,一个话题就像一个“桶”,里面收录了一些出现概率较高的词。这些词与主题有很强的相关性,或者正是这些词共同定义了主题。对于一个段落,有些词可能来自这个“桶”,有些可能来自那个“桶”,而一个文本往往是几个主题的混合体。举个简单的例子,见下图。
以上内容摘自网络新闻。我们划分了4个桶(主题),百度(红色),微软(紫色),谷歌(蓝色)和市场(绿色)。段落中收录的每个主题的单词都用颜色标记。从颜色分布我们可以看出,文中的主要思想是谈论百度和市场发展。在这方面,谷歌和微软的两个主题也出现了,但不是主要的语义。值得注意的是,像“搜索引擎”这样的词极有可能出现在百度、微软、谷歌这三个主题上。可以认为一个词被放入多个“桶”中。当它出现在文本中时,这三个主题在一定程度上得到了体现。
有了主题的概念,我们不禁要问,这些主题是怎么得到的?如何分析文章中的话题?这正是主题模型想要解决的问题。让我简单介绍一下主题模型的工作原理。
主题模型的工作原理
首先,我们从生成模型的角度来看文档和主题这两个东西。所谓生成模型,是指我们认为一个文章中的每个词都是通过“以一定概率选择某个主题,并以一定概率从该主题中选择某个词”的过程获得的。那么,如果我们要生成一个文档,其中每个词出现的概率为:
上式可以用矩阵乘法表示,如下图所示:
左
矩阵表示每个词在每个文章中的概率;中间的Φ矩阵代表每个话题中每个词的概率
,即每个“桶
表示每个文档中每个主题的概率
,可以理解为每个主题在一个段落中所占的比例。
如果我们有很多文档,比如很多网页,我们首先将所有文档进行分割,得到一个词汇表。这样,每个文档都可以表示为一个词的集合。对于每个单词,我们可以用它在文档中出现的次数除以文档中的单词数作为它在文档中出现的概率
。这样,对于任何文档,
左边
矩阵已知,右边两个矩阵未知。主题模型是使用大量已知的“words-documents”
Matrix,通过一系列的训练,推断出右边的“word-topic”矩阵Φ和“主题文档”矩阵Θ。
主题模型训练和推理主要有两种方法,一种是pLSA(Probabilistic Latent Semantic Analysis),另一种是LDA(Latent Dirichlet Allocation)。 pLSA主要使用EM(Expectation Maximization)算法; LDA 使用 Gibbs 采样方法。由于它们比较复杂,篇幅有限,这里只简单介绍一下pLSA的思想,其他具体的方法和公式,读者可以参考相关资料。
pLSA采用的方法称为EM(Expectation Maximization)算法,它由两个不断迭代的过程组成:E(期望)过程和M(最大化)过程。举个形象例子:假设食堂的厨师炸一道菜,需要分成两个人吃。显然,没有必要使用天平来准确称重。最简单的方法是先将菜品随机分成两个碗,然后观察数量是否相同,取较多的部分放入另一个碗中。重复这个过程,直到大家都看不到两个碗里的菜。到目前为止有何不同。
对于主题模型训练,“计算每个主题的词分布”和“计算训练文档中的主题分布”就像两个人分享食物。在E过程中,我们可以使用贝叶斯公式从“word-topic”矩阵中计算出“topic-document”矩阵。在M过程中,我们使用“topic-document”矩阵重新计算“term-topic”矩阵。这个过程一直是这样迭代的。 EM 算法的神奇之处在于它可以保证这个迭代过程是收敛的。也就是说,经过反复迭代,我们肯定可以得到趋于真实值的Φ和Θ。
如何使用主题模型?
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3) 可以消除文档中噪声的影响。一般来说,文档中的杂音往往出现在次要主题中,我们可以忽略它们,只保留文档中的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5) 与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
纺纱世界
原始软文区(智能伪原创)SEO说难不难,说简单也不是那么简单
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-07-16 23:36
(6),词频控制:关键词密度,比同行高一点
(7),内链:锚文本方向
(8)、robots和nofollow的使用:引导网络蜘蛛,控制权重信息的丢失
(9),网站来映射:使用网络蜘蛛爬取
(10),设置404错误页面和301跳转:搜索引擎友好和用户友好
(11),网站结构:树状结构,有利于搜索引擎蜘蛛和用户判断的逻辑结构
(12),网站 主要内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站行为结构(目录管理结构)
(16),快速连接
(17)TDK 分页健康,分页
(18),友情链接
以上几点虽然很简单,但确实需要一些努力才能做好。同时,这几点也总结了网站的内容优化。做好以上几点,网站的优化就基本搞定了。
总结:
网站Optimization,网站优化很重要,可以说直接影响网站的排名,所以做SEO的时候一定要注意网站优化。 网站optimization 是我们一直坚持的工作,搜索引擎优化好你的毅力。如果你不坚持每天都做,你就得不到好的排名。
原创软文区(smart伪原创)
SEO难说,简单没那么简单,很多人问我,网站SEO优化应该怎么做?但是当我说出来的时候,他们想:就是这样?没有一点内容是不可能的!事实上,目前网站上的SEO确实没有太多内容。更多的是细节处理和用户体验。
有的朋友认为网站优化难,因为不知道里面的路,不知道从哪里开始。其他人认为优化网站和更新文章很容易。这也是因为他们对网站非常感兴趣。 SEO不明白。很多培训机构在关键词成立后就开始更新文章教网站优化。没有涉及其他内容,所以很多人认为网站优化实际上是更新文章。
1、提高网站的加载速度
在这个信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。
搜索引擎也是一样,所以在优化的时候,考虑可以做些什么来加速,比如CDN、无用代码清除、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作(具体可查看编辑器介绍《提高网站速度的六种网站前端优化方法》)。
2、title 标题定位
网站title 标题,也就是你的网站叫什么,通常为了SEO优化,会选择三到五个关键词作为标题,所以标题的顺序也是有规律的。权重从左到右依次递减(详见“网站页面标题设置方法及技巧”介绍)。
标题需要收录优化关键词的内容。同时网站中的多个页面标题不能相同,至少要能闪现“关键词——网站主页——关键词的简要说明。”输入,一旦判断标题,不要再做任何更正了!
3、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象。山寨好,当地人好,是否专业也不是我们想要的结果。页面设计需要 UI & UX 投资和品牌自己的口碑来背书。否则,用户在网站中更难产生信任感和参与感。
最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4、避免各种促使用户离开页面的元素
很多弹窗、固定凸窗、广告位都会让用户反感,从而放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑更多原生方式植入这些元素或奖励用户完成过程,同时避免蜘蛛在使用代码中被禁止或难以捕捉从而被搜索引擎降级的可能性。
5、关键词植入
常规的关键词植入要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等,这个就不多说了,大家懂的,不懂的朋友可以查看小编的介绍《网站上SEO最容易忽略的一些优化细节》。
6、主题模型的注入
关键词植入是不够的,因为那太机械化了,会失去文字的用户体验,所以我们要做一个主题模型,比如关键词“婚纱搭配”我们可以延伸到燕尾服,婚纱礼服、婚纱背心、婚纱套装、婚礼展销会等相关词构成一个大主题。这样的页面内容将使关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解读为您要推送的主题内容是与婚纱礼服相关的内容(具体请参考小编的相关介绍《如何做好婚礼服装的SEO优化》)网站主题内容模型”)。
7、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响这些显示的信息(主要是标题、描述、url),这些元素需要在内容上进行优化:标题创意、描述飘红、 url规范、文章日期、结构化数据的使用、在线对话等
8、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
(1),提供独特的视觉体验、前端界面、合适的字体和功能按钮。
(2),内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面。
(3),与其他内容相比没有重复,深度更强大。
(4),打开速度快(无广告),可在不同终端阅读。
(5),可以产生赞许、惊喜、快乐、思考等情绪化的想法。
(6),可以达到一定的转发和传播力。
(7),可以使用完整、准确和独特的信息来解决或回答问题。
9、网站规划调整
假设原来的网站是图片页面,使用较多的flash和图片,这些页面元素不利于搜索引擎的进入,所以在页面底部增加了三列,分别是相关公司简介。 , 关键词产品新闻和公司关键词产品列表,三栏内容添加url。
当然,最好的方法是使用新闻系统更新关键字产品新闻,可以将关键字的具体描述作为从首页到单个页面的链接,页面的描述收录公司关键词产品列表连接,这些都是为了形成公司网站内部的网络规划(详见小编的介绍《从SEO角度优化网站首页结构布局》)。
另外,页面没有必要静态化,静态化也不一定是整个网站,你可以只静态化最重要的首页。对于不同程序的处理,页面的执行时间是不同的。对于互联网上成熟的建站系统来说,执行效率不用多说,相信是一个比较优化的水平。
10、网站SEO优化的一些要点
对于网站SEO优化,如果你还是一头雾水,不妨从以下方便入手,具体内容如下:
(1), URL: 标准化、唯一性、静态化
(2),导航:主导航、面包屑导航、二级导航
(3),关键词:main关键词(首页),副关键词(专栏),长尾关键词(内容页)
(4),标签:标题、关键词、描述
(5),权重标签:h1-h6 标签,b 标签,强标签
(6),词频控制:关键词密度,略高于同行
(7),内链:定向锚文本
(8),机器人和nofollow使用:引导蜘蛛,控制减肥
(9),网站Map: 用蜘蛛爬行
(10),设置404错误页面和301跳转:搜索引擎好友和用户的友好度
(11),网站结构:树状结构,利于搜索引擎抓取和用户判断逻辑结构
(12),网站 内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站结构(目录结构)
(16),快速连接
(17),子页面TDK,子页面健康等级
(18),友情链接
以上几点虽然简单,但要细化,确实需要一些功夫。同时,这些点也总结了网站优化的内容。做好以上几点,网站的优化基本就大功告成了。
总结:
在网站optimization中,网站的站点优化非常重要。可以说直接影响了网站的排名。所以,SEO一定要重视网站优化。 网站optimization 永远是你做的工作,SEO靠的是毅力。如果你不坚持每天都做好,你就不会排名好。
分享了很多SEO优化的东西,深刻描绘了一个SEO站长的苦涩成长经历。如果你想学习更多的SEO优化技巧,可以在我的专栏里找到更多干货文章:seo Spark:SEO干货笔记:SEO站长的苦涩成长史!
搜索引擎优化
查看全部
原始软文区(智能伪原创)SEO说难不难,说简单也不是那么简单
(6),词频控制:关键词密度,比同行高一点
(7),内链:锚文本方向
(8)、robots和nofollow的使用:引导网络蜘蛛,控制权重信息的丢失
(9),网站来映射:使用网络蜘蛛爬取
(10),设置404错误页面和301跳转:搜索引擎友好和用户友好
(11),网站结构:树状结构,有利于搜索引擎蜘蛛和用户判断的逻辑结构
(12),网站 主要内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站行为结构(目录管理结构)
(16),快速连接
(17)TDK 分页健康,分页
(18),友情链接
以上几点虽然很简单,但确实需要一些努力才能做好。同时,这几点也总结了网站的内容优化。做好以上几点,网站的优化就基本搞定了。
总结:
网站Optimization,网站优化很重要,可以说直接影响网站的排名,所以做SEO的时候一定要注意网站优化。 网站optimization 是我们一直坚持的工作,搜索引擎优化好你的毅力。如果你不坚持每天都做,你就得不到好的排名。
原创软文区(smart伪原创)
SEO难说,简单没那么简单,很多人问我,网站SEO优化应该怎么做?但是当我说出来的时候,他们想:就是这样?没有一点内容是不可能的!事实上,目前网站上的SEO确实没有太多内容。更多的是细节处理和用户体验。
有的朋友认为网站优化难,因为不知道里面的路,不知道从哪里开始。其他人认为优化网站和更新文章很容易。这也是因为他们对网站非常感兴趣。 SEO不明白。很多培训机构在关键词成立后就开始更新文章教网站优化。没有涉及其他内容,所以很多人认为网站优化实际上是更新文章。
1、提高网站的加载速度
在这个信息碎片化的时代,没有人愿意给你等待的机会,所以网站open加载速度比任何优化点都重要。开放时间越短,用户满意度越高。
搜索引擎也是一样,所以在优化的时候,考虑可以做些什么来加速,比如CDN、无用代码清除、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作(具体可查看编辑器介绍《提高网站速度的六种网站前端优化方法》)。
2、title 标题定位
网站title 标题,也就是你的网站叫什么,通常为了SEO优化,会选择三到五个关键词作为标题,所以标题的顺序也是有规律的。权重从左到右依次递减(详见“网站页面标题设置方法及技巧”介绍)。
标题需要收录优化关键词的内容。同时网站中的多个页面标题不能相同,至少要能闪现“关键词——网站主页——关键词的简要说明。”输入,一旦判断标题,不要再做任何更正了!
3、 是增强 UI、UX 和品牌的信任感和参与感
很多用户打开网站后会有第一印象。山寨好,当地人好,是否专业也不是我们想要的结果。页面设计需要 UI & UX 投资和品牌自己的口碑来背书。否则,用户在网站中更难产生信任感和参与感。
最实用的做法是参考业内比较好的网站进行模仿,购买付费版网站模板,或者让用户参与每一个设计过程。
4、避免各种促使用户离开页面的元素
很多弹窗、固定凸窗、广告位都会让用户反感,从而放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑更多原生方式植入这些元素或奖励用户完成过程,同时避免蜘蛛在使用代码中被禁止或难以捕捉从而被搜索引擎降级的可能性。
5、关键词植入
常规的关键词植入要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等,这个就不多说了,大家懂的,不懂的朋友可以查看小编的介绍《网站上SEO最容易忽略的一些优化细节》。
6、主题模型的注入
关键词植入是不够的,因为那太机械化了,会失去文字的用户体验,所以我们要做一个主题模型,比如关键词“婚纱搭配”我们可以延伸到燕尾服,婚纱礼服、婚纱背心、婚纱套装、婚礼展销会等相关词构成一个大主题。这样的页面内容将使关键词排名更全面,对更多用户有帮助。同时,搜索引擎可以解读为您要推送的主题内容是与婚纱礼服相关的内容(具体请参考小编的相关介绍《如何做好婚礼服装的SEO优化》)网站主题内容模型”)。
7、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响这些显示的信息(主要是标题、描述、url),这些元素需要在内容上进行优化:标题创意、描述飘红、 url规范、文章日期、结构化数据的使用、在线对话等
8、创造独特有价值的内容
归根结底,营销离不开内容质量。好的内容包括:
(1),提供独特的视觉体验、前端界面、合适的字体和功能按钮。
(2),内容一定要实用,高价值,高可靠,很有趣,值得采集的点都在里面。
(3),与其他内容相比没有重复,深度更强大。
(4),打开速度快(无广告),可在不同终端阅读。
(5),可以产生赞许、惊喜、快乐、思考等情绪化的想法。
(6),可以达到一定的转发和传播力。
(7),可以使用完整、准确和独特的信息来解决或回答问题。
9、网站规划调整
假设原来的网站是图片页面,使用较多的flash和图片,这些页面元素不利于搜索引擎的进入,所以在页面底部增加了三列,分别是相关公司简介。 , 关键词产品新闻和公司关键词产品列表,三栏内容添加url。
当然,最好的方法是使用新闻系统更新关键字产品新闻,可以将关键字的具体描述作为从首页到单个页面的链接,页面的描述收录公司关键词产品列表连接,这些都是为了形成公司网站内部的网络规划(详见小编的介绍《从SEO角度优化网站首页结构布局》)。
另外,页面没有必要静态化,静态化也不一定是整个网站,你可以只静态化最重要的首页。对于不同程序的处理,页面的执行时间是不同的。对于互联网上成熟的建站系统来说,执行效率不用多说,相信是一个比较优化的水平。
10、网站SEO优化的一些要点
对于网站SEO优化,如果你还是一头雾水,不妨从以下方便入手,具体内容如下:
(1), URL: 标准化、唯一性、静态化
(2),导航:主导航、面包屑导航、二级导航
(3),关键词:main关键词(首页),副关键词(专栏),长尾关键词(内容页)
(4),标签:标题、关键词、描述
(5),权重标签:h1-h6 标签,b 标签,强标签
(6),词频控制:关键词密度,略高于同行
(7),内链:定向锚文本
(8),机器人和nofollow使用:引导蜘蛛,控制减肥
(9),网站Map: 用蜘蛛爬行
(10),设置404错误页面和301跳转:搜索引擎好友和用户的友好度
(11),网站结构:树状结构,利于搜索引擎抓取和用户判断逻辑结构
(12),网站 内容:原创,独特,有价值
(13), 网站description, 图片标签
(14),静态页面)
(15),网站结构(目录结构)
(16),快速连接
(17),子页面TDK,子页面健康等级
(18),友情链接
以上几点虽然简单,但要细化,确实需要一些功夫。同时,这些点也总结了网站优化的内容。做好以上几点,网站的优化基本就大功告成了。
总结:
在网站optimization中,网站的站点优化非常重要。可以说直接影响了网站的排名。所以,SEO一定要重视网站优化。 网站optimization 永远是你做的工作,SEO靠的是毅力。如果你不坚持每天都做好,你就不会排名好。
分享了很多SEO优化的东西,深刻描绘了一个SEO站长的苦涩成长经历。如果你想学习更多的SEO优化技巧,可以在我的专栏里找到更多干货文章:seo Spark:SEO干货笔记:SEO站长的苦涩成长史!
搜索引擎优化
电话拒绝率低客户兴趣度高容易成交物超所值
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-14 22:54
**SEO优化,G3云推广7.0的**优势:来电拒绝率低,客户兴趣高,销售预约高,产品性价比高,交易方便,性价比好,单价高,简单的售后。
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是网站seo优化过程中需要避免和去除的部分。考虑一种更原生的方式来植入这些元素或奖励用户完成这个过程。同时,避免蜘蛛在代码使用过程中被搜索引擎禁止或难以捕捉和降级的可能。 , 常规的关键词 布局。常规的关键词植入(爆老师称之为填词)也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL ,图片命名等等。这个我就不重复了,大家都明白。 ,使用相关主题模型。仅仅填写文字是不够的,因为那太机械了,失去了文字用户体验。所以我们要做一个主题模型,比如关键词我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚礼展销会等相关词。
付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还将优先考虑与您相关的内容和人员。这可能意味着通过 Facebook 交朋友、在 Twitter 上关注粉丝或通过其他社交网络联系。有时,社交搜索甚至会优先考虑影响者分享的内容。所有这一切意味着,当您考虑 SEO 策略时,您需要考虑您的社交媒体策略如何适应这个难题。深入思考:将搜索引擎优化视为“搜索体验优化”。对他们来说,留在您的网站、与您的内容互动并稍后回来非常重要。
购买入站营销或 SEO 优化软件。检查表现良好的页面。寻找获得入站链接的机会,例如网站。监控排名和流量的变化。一系列策略,如果您使用它们,将帮助您在搜索引擎中排名更高。
为了满足长期意图和排名,围绕主题而非关键字建立 SEO 营销策略。如果你这样做,不管怎样,你会发现你自然可以针对重要的关键字进行优化。了解您的目标受众(又名买家角色)以及他们对什么感兴趣是通过搜索引擎将相关访问者吸引到您的 网站 的关键。自然流量是来自 Google 或 Bing 等搜索引擎的无偿流量。付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还会优先考虑与您相关的内容和人员。 查看全部
电话拒绝率低客户兴趣度高容易成交物超所值
**SEO优化,G3云推广7.0的**优势:来电拒绝率低,客户兴趣高,销售预约高,产品性价比高,交易方便,性价比好,单价高,简单的售后。
大量的弹窗、固定凸窗、广告位会让用户反感,放弃整个浏览过程。这是网站seo优化过程中需要避免和去除的部分。考虑一种更原生的方式来植入这些元素或奖励用户完成这个过程。同时,避免蜘蛛在代码使用过程中被搜索引擎禁止或难以捕捉和降级的可能。 , 常规的关键词 布局。常规的关键词植入(爆老师称之为填词)也要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL ,图片命名等等。这个我就不重复了,大家都明白。 ,使用相关主题模型。仅仅填写文字是不够的,因为那太机械了,失去了文字用户体验。所以我们要做一个主题模型,比如关键词我们可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚礼展销会等相关词。
付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还将优先考虑与您相关的内容和人员。这可能意味着通过 Facebook 交朋友、在 Twitter 上关注粉丝或通过其他社交网络联系。有时,社交搜索甚至会优先考虑影响者分享的内容。所有这一切意味着,当您考虑 SEO 策略时,您需要考虑您的社交媒体策略如何适应这个难题。深入思考:将搜索引擎优化视为“搜索体验优化”。对他们来说,留在您的网站、与您的内容互动并稍后回来非常重要。
购买入站营销或 SEO 优化软件。检查表现良好的页面。寻找获得入站链接的机会,例如网站。监控排名和流量的变化。一系列策略,如果您使用它们,将帮助您在搜索引擎中排名更高。
为了满足长期意图和排名,围绕主题而非关键字建立 SEO 营销策略。如果你这样做,不管怎样,你会发现你自然可以针对重要的关键字进行优化。了解您的目标受众(又名买家角色)以及他们对什么感兴趣是通过搜索引擎将相关访问者吸引到您的 网站 的关键。自然流量是来自 Google 或 Bing 等搜索引擎的无偿流量。付费搜索营销不会增加您的自然流量,但您可以使用入站营销软件来优化您的网站 以获得更多访问者。今天,社交媒体可以对您的自然流量趋势线产生重大影响。即使在几年前,通过社交搜索找到您的内容也不例外。但现在 SEO 将考虑推文、转推、Google+ 作者身份和其他社交信号。社交搜索还会优先考虑与您相关的内容和人员。
如何做好seo相关性内容提升网站自身权重排名与流量
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-07-14 22:49
也许对于网站,seo 不是最好的营销策略。无需竞标一系列按点击付费的广告更直接,但优化一个网站对企业无害。如果搜索引擎营销 (SEM) 是设计、运行和优化搜索引擎广告活动的实践,那么做网站 的基本工作就更好了。它与SEO区别的最简单描述是搜索结果中付费和未付费优先级排名的差异。它的目的比相关性更突出。但是做seo相关的内容也是提升网站自身权重排名和流量的关键。
产生足够的投资回报。当然网站内容质量优化是少不了的。 网站内容优化是对页面内容和编码的更新和调整,使内容对搜索引擎更具吸引力,使搜索者能够快速找到自己想要的内容。在大多数情况下,我们不可能 100% 优化每个页面。随着百度算法的不断更新,内容质量是一个长期持续的过程。
那么如何优化页面内容呢?以下是我们需要考虑的主要因素:
标题标签。
元描述。
ALT 标签。
网址结构。
媒体(图片、视频)。
H1、H2 和 H3 标签。
内部链接。
出站链接。
移动响应
这些因素是第一步,SEO技巧不假思索。但内容,即占据网页大部分的博客、图片、视频,也必须进行优化。优化旧帖子而不是创建新帖子会对自然排名和搜索存在产生重大影响。
内容优化优先级:从哪里开始,做什么?
优化内容时,您应该针对单个关键字优化整个页面。二级和潜在语义索引 (LSI) 关键字将起作用,但搜索引擎和消费者需要绝对清楚您的页面(博客)是什么,以及它与主题、标题、副标题和元模型相关性的关系。为此,激光只关注一个关键字。
然后我们需要提高页面的准确率。如果您的页面在后台正确标记并且所有元数据都与关键字相关,那么我们需要更新副本的深度。我们称之为“内容深度”。内容差距分析表明,您需要在更新的内容中收录好主意,以满足搜索者的意图。这是一个分步蓝图,用于为您保留哪些内容以及更改哪些内容。增加读者价值:不要忽视关键词的重要方面。我们还需要对关键词进行适当的扩展,试图找出用户搜索需求的可能性。
网站中的每一个内容都有内在价值。做好优化不是一天就能完成的,必须持续跟进完善网站数据。您的网站可以在众多同行中脱颖而出,达到网站推广排名的理想位置,做更多有价值的内容营销。 查看全部
如何做好seo相关性内容提升网站自身权重排名与流量
也许对于网站,seo 不是最好的营销策略。无需竞标一系列按点击付费的广告更直接,但优化一个网站对企业无害。如果搜索引擎营销 (SEM) 是设计、运行和优化搜索引擎广告活动的实践,那么做网站 的基本工作就更好了。它与SEO区别的最简单描述是搜索结果中付费和未付费优先级排名的差异。它的目的比相关性更突出。但是做seo相关的内容也是提升网站自身权重排名和流量的关键。
产生足够的投资回报。当然网站内容质量优化是少不了的。 网站内容优化是对页面内容和编码的更新和调整,使内容对搜索引擎更具吸引力,使搜索者能够快速找到自己想要的内容。在大多数情况下,我们不可能 100% 优化每个页面。随着百度算法的不断更新,内容质量是一个长期持续的过程。
那么如何优化页面内容呢?以下是我们需要考虑的主要因素:
标题标签。
元描述。
ALT 标签。
网址结构。
媒体(图片、视频)。
H1、H2 和 H3 标签。
内部链接。
出站链接。
移动响应
这些因素是第一步,SEO技巧不假思索。但内容,即占据网页大部分的博客、图片、视频,也必须进行优化。优化旧帖子而不是创建新帖子会对自然排名和搜索存在产生重大影响。
内容优化优先级:从哪里开始,做什么?
优化内容时,您应该针对单个关键字优化整个页面。二级和潜在语义索引 (LSI) 关键字将起作用,但搜索引擎和消费者需要绝对清楚您的页面(博客)是什么,以及它与主题、标题、副标题和元模型相关性的关系。为此,激光只关注一个关键字。
然后我们需要提高页面的准确率。如果您的页面在后台正确标记并且所有元数据都与关键字相关,那么我们需要更新副本的深度。我们称之为“内容深度”。内容差距分析表明,您需要在更新的内容中收录好主意,以满足搜索者的意图。这是一个分步蓝图,用于为您保留哪些内容以及更改哪些内容。增加读者价值:不要忽视关键词的重要方面。我们还需要对关键词进行适当的扩展,试图找出用户搜索需求的可能性。
网站中的每一个内容都有内在价值。做好优化不是一天就能完成的,必须持续跟进完善网站数据。您的网站可以在众多同行中脱颖而出,达到网站推广排名的理想位置,做更多有价值的内容营销。
编辑推荐《这就是搜索引擎:核心技术详解》
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-07-11 07:01
编辑推荐《这就是搜索引擎:核心技术详解》
编辑推荐
《这就是搜索引擎:核心技术详解》适合所有对搜索引擎技术感兴趣的人,尤其是相关领域的学生、对搜索引擎核心技术感兴趣的技术人员、相关从业人员在搜索引擎优化方面,中小网站站长等更有参考价值。
作者其他作品《大数据日常知识:架构与算法》
内容介绍
搜索引擎作为互联网发展中至关重要的应用,已经成为互联网各个领域的制高点,其重要性不言而喻。搜索引擎领域也是互联网应用中少有的以核心技术为命脉的领域。搜索引擎的各个子系统是如何设计的?这已成为广大技术人员和搜索引擎优化者关注的内容。
《这就是搜索引擎:核心技术详解》的特点是内容新颖、全面、通俗易懂。对实际搜索引擎中涉及的各种核心技术进行了全面详细的介绍。除了以网络爬虫、索引系统、排名系统、链接分析和用户分析为核心的搜索系统外,还包括网页反作弊、缓存管理、网页重复数据删除技术等实际搜索引擎必须具备的技术。关注,同时在相当大的篇幅中讲解了云计算和云存储的核心技术原理。此外,本书还密切关注搜索引擎开发的前沿技术:谷歌的咖啡因系统和Megastore等新的云计算技术、百度的暗网爬虫技术阿拉丁计划、内容农场作弊、机器学习排序等。许多新技术在相关章节中有详细的讲解,同时对社交搜索、实时搜索、上下文搜索等搜索引擎未来的发展方向给出了技术展望。为了加深读者的理解,书中引入了大量生动的图片来讲解算法的原理。相信读者会发现,原来搜索引擎的核心技术比原先想象的要简单得多。
作者简介
张俊林着有技术书籍《这就是搜索引擎:核心技术详解》,现任畅捷通智能平台总监。在此之前,张君林曾任阿里巴巴风潮广告平台、百度商业搜索部、新浪微博搜索部和数据系统部高级技术专家,新浪微博技术委员会委员,负责方向算法策略。张君林也是智能信息聚合网站“玩聚网”的联合创始人之一。他的研发兴趣集中在:搜索技术、推荐系统、社交挖掘、自然语言处理和大数据算法架构等,在上述领域有多年的行业实践经验。张君林毕业于天津大学管理学院,获学士学位。 1999年至2004年在中国科学院软件研究所直接攻读博士学位。研究方向为信息检索理论和自然语言处理。学习期间,在ACL/COLING/IJCNLP等顶级国际会议上发表多篇文章。学术论文。此外,他在此期间设计的搜索系统赢得了17个国际高水平研究团队的激烈竞争,并在美国国防部DARPA主办的第二届TREC高精度检索系统评估中排名第一。取名效果极佳。
内容
第一章搜索引擎及其技术架构
1.1 为什么搜索引擎很重要
1.1.1 互联网的发展
1.1.2 商业搜索引擎公司的发展
1.1.3 搜索引擎的重要地位
1.2搜索引擎技术发展历程
1.2.1史前时代:目录的产生
1.2.2 第一代:文本检索的产生
1.2.3 第二代:链路分析的产生
1.2.4 第三代:以用户为中心的一代
1.3 搜索引擎的3个目标
1.4 搜索引擎的3个核心问题
1.4.13个核心问题
1.4.2 与技术发展的关系
1.5搜索引擎技术架构
第 2 章网络爬虫
2.1 通用爬虫框架
2.2 优秀爬虫的特点
2.3 爬虫质量评价标准
2.4 爬取策略
2.4.1 广度优先遍历策略(BreathFirst)
2.4.2 部分 PageRank 策略(PartialPageRank)
2.4.3OCIP 策略(OnlinePageImportanceComputation)
2.4.4LargerSitesFirst 策略(LargerSitesFirst)
2.5网页更新策略
2.5.1历史参考策略
2.5.2用户体验策略
2.5.3 聚类抽样策略
2.6DeepWebCrawling(DeepWebCrawling)
2.6.1 查询组合问题
2.6.2 在文本框中填写问题
2.7 分布式爬虫
2.7.1 主从分发爬虫(Master-Slave)
2.7.2 点对点(PeertoPeer)
本章总结
本章参考资料
第 3 章搜索引擎索引
3.1索引基础
3.1.1 字——文档矩阵
3.1.2 倒排索引的基本概念
3.1.3 倒排索引的简单例子
3.2 词词典
3.2.1 哈希加链表
3.2.2树结构
3.3PostingList
3.4创建索引
3.4.1 两遍文档遍历方法(2-PassIn-MemoryInversion)
3.4.2Sort-basedInversion(Sort-basedInversion)
3.4.3Merge-basedInversion(Merge-basedInversion)
3.5动态索引
3.6 索引更新策略
3.6.1 完整重建策略(CompleteRe-Build)
3.6.2 重新合并策略(Re-Merge)
3.6.3 就地更新策略(In-Place)
3.6.4 混合策略(Hybrid)
3.7查询处理
3.7.1 一次一个文档(DocataTime)
3.7.2 一次一个字(TermataTime)
3.7.3SkipPointers(SkipPointers)
3.8多字段索引
3.8.1多索引法
3.8.2倒排列表法
3.8.3扩展列表方法(ExtentList)
3.9phrase 查询
3.9.1位置索引(PositionIndex)
3.9.2 二字索引(NextwordIndex)
3.9.3 PhraseIndex (PhraseIndex)
3.9.4 混合方法
3.10分布式索引(ParallelIndexing)
3.10.1 按文档划分(DocumentPartitioning)
3.10.2 按词划分(TermPartitioning)
3.10.3 两种方案对比
本章总结
本章参考资料
第 4 章索引压缩
4.1 字典压缩
4.2倒列表压缩算法
4.2.1 评价指标压缩算法指标
4.2.2 一元编码和二进制编码
4.2.3EliasGamma 算法和 EliasDelta 算法
4.2.4Golomb 算法和 Rice 算法
4.2.5 变长字节算法(VariableByte)
4.2.6SimpleX 系列算法
4.2.7PForDelta 算法
4.3 DocIDReordering(DocIDReordering)
4.4StaticIndexPruning (StaticIndexPruning)
4.4.1 以词为中心的索引剪裁
4.4.2 以文档为中心的索引裁剪
本章总结
本章参考资料
第 5 章搜索模型和搜索排序
5.1BooleanModel (BooleanModel)
5.2VectorSpaceModel (VectorSpaceModel)
5.2.1文档表示
5.2.2 相似度计算
5.2.3特征权重计算
5.3概率检索模型
5.3.1 概率排序原则
5.3.2BinaryIndependentModel(BinaryIndependentModel)
5.3.3BM25 模型
5.3.4BM25F 模型
5.4 语言模型方法
5.5 机器学习排名(LearningtoRank)
5.5.1机器学习排序的基本思路
5.5.2 单文档方法(PointWiseApproach)
5.5.3文档对方法(PairWiseApproach)
5.5.4 文档列表方法(ListWiseApproach)
5.6 搜索质量评价标准
5.6.1准确率和召回率
5.6.2P@10个指标
5.6.3MAP 指标(MeanAveragePrecision)
本章总结
本章参考资料
第六章链接分析
6.1网页图片
6.2 两个概念模型和算法的关系
6.2.1RandomSurferModel (RandomSurferModel)
6.2.2 子集传播模型
6.2.3 链接分析算法之间的关系
6.3PageRank 算法
6.3.1 从链内数到PageRank
6.3.2PageRank 计算
6.3.3 链接陷阱(LinkSink)和远程跳转(Teleporting)
6.4HITS 算法(HypertextInducedTopicSelection)
6.4.1Hub 页面和权限页面
6.4.2 互增关系
6.4.3HITS 算法
6.4.4HITS 算法问题
6.4.5HITS算法与PageRank算法对比
6.5SALSA 算法
6.5.1 确定计算对象集
6.5.2 链接关系传播
6.5.3权限权重计算
6.6 主题敏感页面排名(TopicSensitivePageRank)
6.6.1 主题敏感的PageRank和PageRank的区别
6.6.2 主题敏感的PageRank计算过程
6.6.3 使用主题敏感的PageRank构建个性化搜索
6.7Hilltop 算法
6.7.1 Hilltop 算法的一些基本定义
6.7.2Hilltop 算法
6.8 其他改进算法
6.8.1IntelligentSurferModel(智能冲浪模型)
6.8.2 BiasedSurferModel(BiasedSurferModel)
6.8.3PHITS 算法(ProbabilityAnalogyofHITS)
6.8.4BFS 算法(BackwardForwardStep)
本章总结
本章参考资料
第 7 章云存储和云计算
7.1 云存储和云计算概述
7.1.1 基本假设
7.1.2理论基础
7.1.3 数据模型
7.1.4 基本问题
7.1.5Google 的云存储和云计算架构
7.2Google 文件系统 (GFS)
7.2.1GFS 设计原则
7.2.2GFS 整体架构
7.2.3GFS 主控服务器
7.2.4 系统交互行为
7.3Chubby 锁服务
7.4BigTable
7.4.1BigTable 的数据模型
7.4.2BigTable 整体结构
7.4.3BigTable 的管理数据
7.4.4MasterServer
7.4.5 分表服务器(TabletServer)
7.5Megastore 系统
7.5.1 实体组切分
7.5.2数据模型
7.5.3数据读写与备份
7.6Map/Reduce 云计算模型
7.6.1计算模型
7.6.2 整体逻辑流程
7.6.3 应用实例
7.7Caffeine System-Percolator
7.7.1 事务支持
7.7.2 观察/通知架构
7.8Pregel 图计算模型
7.9Dynomo 云存储系统
7.9.1 数据分区算法(PartitioningAlgorithm)
7.9.2数据备份(复制)
7.9.3数据读写
7.9.4数据版本控制
7.10PNUTS 云存储系统
7.10.1PNUTS 整体架构
7.10.2 存储单元
7.10.3 分表控制器和数据路由器
7.10.4 雅虎通讯社
7.10.5 数据一致性
7.11HayStack 存储系统
7.11.1HayStack 整体架构
7.11.2 目录服务
7.11.3HayStack 缓存
7.11.4HayStack 存储系统
本章总结
本章参考资料
第8章网络反作弊
8.1内容作弊
8.1.1常见的内容作弊方法
8.1.2内容农场(ContentFarm)
8.2 链接作弊
8.3 页面隐藏作弊
8.4Web2.0 作弊方法
8.5反作弊技术总体思路
8.5.1 信任传播模型
8.5.2 不信任传播模型
8.5.3 异常发现模型
8.6 万能链接反作弊方法
8.6.1TrustRank 算法
8.6.2BadRank 算法
8.6.3SpamRank
8.7 专用链接防作弊技术
8.7.1 识别链接农场
8.7.2 识别谷歌轰炸
8.8 识别内容作弊
8.9反隐藏作弊
8.9.1 识别页面隐藏
8.9.2 识别网页重定向
8.10 搜索引擎反作弊综合框架
本章总结
本章参考资料
第九章用户查询意图分析
9.1搜索行为及其意图
9.1.1用户搜索行为
9.1.2用户搜索意图分类
9.2搜索日志挖掘
9.2.1查询会话(QuerySession)
9.2.2ClickGraph (ClickGraph)
9.2.3查询图(QueryGraph)
9.3 相关搜索
9.3.1 基于查询会话的方法
9.3.2 基于点击图的方法
9.4检查纠错
9.4.1EditDistance(编辑距离)
9.4.2 噪声通道模型(NoiseChannelModel)
本章总结
本章参考资料
第十章网页去重
10.1 通用去重算法框架
10.2Shingling 算法
10.3I-Match 算法
10.4SimHash 算法
10.4.1 文档指纹计算
10.4.2 搜索类似文档
10.5SpotSig 算法
10.5.1 特征提取
10.5.2 搜索类似文档
本章总结
本章参考资料
第11章搜索引擎缓存机制
11.1搜索引擎缓存系统架构
11.2Cache 对象
11.3缓存结构
11.4缓存消除策略(EvictPolicy)
11.4.1 动态策略
11.4.2 混合策略
11.5缓存更新策略(RefreshPolicy)
本章总结
本章参考资料
第十二章搜索引擎发展趋势
12.1个性化搜索
12.2社交搜索
12.3 实时搜索
12.4手机搜索
12.5 位置感知搜索
12.6跨语言搜索
12.7多媒体搜索
12.8情况搜索
前言
互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品比例相对较小。搜索引擎是当前互联网产品中具有技术含量的产品,如果不是唯一的,至少是其中之一。
经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。 Twitter联合创始人埃文威廉姆斯提出“域名已死理论”:容易记住的域名不再重要,因为人们会通过搜索输入网站。搜索引擎排名对于中小网站流量非常重要。了解搜索引擎简单界面背后的技术原理,对很多人来说其实很重要。
为什么会有这本书
写搜索引擎技术书籍的最初想法是两年前诞生的。当时的场景是对团队成员进行搜索技术培训,但是我搜索了相关书籍,却没有找到一本非常合适的搜索技术入门书籍。当时市场上的书籍,要么是信息检索理论的专着,理论性太强,不易理解,真正讲搜索引擎技术的章节也不多;或者它们是太实用的书,比如 Lucene 代码分析,比如搜索引擎。这种直接分析开源系统代码的算法应用并不是一种非常高效的学习方法。所以当时就诞生了写一本通俗易懂,适合没有相关技术背景的人,比较全面,融合新技术的搜索引擎书籍。但我是在一年前开始写作的。
在写这本书之前,我为自己设定了一些目标。首先,内容要全面,即全面覆盖搜索引擎相关技术的主要方面。不仅要收录倒排索引、检索模型、爬虫等常用内容,还要详细讲解链接分析、网页反作弊、用户搜索意图分析、网页云存储和去重甚至搜索引擎缓存都是有机的一个完整的搜索引擎的组成部分,但详细介绍其原理的书籍并不多。我希望尽可能全面。
第二个目标很容易理解。我希望没有任何相关技术背景的人可以从阅读本书中学到一些东西,不了解技术的学生可以大致理解。这个目标看似简单,但实际上实现起来并不容易。我不敢说这本书达到了这个目标,但我已经尽力了。具体措施包括以下三个方面。
一是尽可能减少数学公式的数量,除非公式没有列出。尽管数学公式具有简单之美,但大多数人实际上对数学符号存在恐惧和回避。多年前我也有类似的心理,所以尽可能不要使用数学公式。
一是尽量多举例,特别是一些比较难理解的地方。需要举例来加深理解。
还有更多的绘图。就我个人的经验而言,虽然算法或技术很抽象,但如果深入理解原理,将复杂的化简,绝对可以将算法转化为生动的画面。如果你无法在脑海中形成算法的直观图形表示,则说明你对其原理没有透彻的理解。这是我判断自己是否深刻理解算法的一个私人标准。鉴于此,本书在讲解算法的地方,使用了大量的算法示意图。全书收录300多幅算法原理解释图。相信这对读者深入理解算法有很大帮助。
第三个目标是强调新现象和新技术,比如谷歌的caffeine系统和Megastore等云存储系统、Pregel云图计算模型、暗网爬取技术、Web2.0网络作弊、机器学习排序、上下文搜索、社交搜索等在相关章节中有说明。
第四个目标是强调原则,而不是停留在技术细节上。对于新手来说,一个容易解决的问题是他们喜欢挖掘细节,只见树木不见森林,懂一个公式却不懂背后的基本思想和出发点。我接触过很多技术人员,七八岁就会有这个特点。有一个问题“道家哪个好?” “道”是什么?什么是“手术”?比如《孙子兵法》就是道,《三十六计》就是战术。 “道”是宏观的、有原则的、经久不衰的基本原则,而“技术”是遵循基本原则的具体方法和措施,是变化无常的。技术也是如此。算法本身的细节就是“技巧”,算法所体现的基本思想就是“道”。知“道”、学“技”,虽然两者不能偏,但如果要选择优先级,毫无疑问我会先选择“道”再选择“术”。
以上四点是写书之前设定的目标。现在写完了,可能很多地方都达不到当初的期待,但是我会努力的。写书的过程很辛苦,至少比我想象的要难。因为工作忙,每天只能早起,加上周末和节假日。也许书中有这样的缺点,但我可以说我是真诚地写这本书的。
这本书是给谁看的?
如果您是以下其中一种,那么这本书适合您。
1.对搜索引擎核心算法感兴趣的技术人员
搜索引擎的整体框架是什么?收录哪些核心技术?
网络爬虫的基本结构是什么?常见的爬取策略有哪些?什么是暗网爬行?如何构建分布式爬虫?百度的阿拉丁计划是什么?
什么是倒排索引?如何对倒排索引进行数据压缩?
搜索引擎如何对搜索结果进行排序?
什么是向量空间模型?什么是概率模型?什么是BM25型号?什么是机器学习排序?它们之间有什么异同?
PageRank和HITS算法有什么关系?有哪些相同点和不同点?什么是 SALSA 算法?什么是山顶算法?各种链接分析算法之间的关系是什么?
如何识别搜索用户的真实搜索意图?用户可以搜索多少个类别?什么是点击图表?什么是查询会话?相关搜索是如何完成的?
为什么我们需要去重复网页?如何去重复网页?哪种算法效果更好?
搜索引擎缓存有多少级?核心战略是什么?
什么是上下文搜索?什么是社交搜索?什么是实时搜索?
搜索引擎的发展趋势是什么?
如果你对三个以上的问题感兴趣,那么这本书就是为你而写的。
2.对云计算和云存储感兴趣的技术人员
CAP的原理是什么?什么是 ACID 原理?它们之间有什么异同?
Google 的云计算框架包括哪些技术? Hadoop系列和谷歌的云计算框架有什么关系?
Google 的三驾马车 GFS、BigTable 和 MapReduce 是什么意思?有什么关系?
谷歌咖啡因系统的基本原理是什么?
Google 的 Pregel 计算模型和 MapReduce 计算模型有什么区别?
Google 的 Megastore 云存储系统和 BigTable 是什么关系?
什么是亚马逊的 Dynamo 系统?
雅虎的 PNUTS 系统是什么?
Haystack 存储系统适用于哪些地方?
如果你对以上问题感兴趣,相信你可以在书中找到答案。
3.互联网营销人员从事搜索引擎优化和中小网站站长
搜索引擎的反作弊策略是什么?如何优化以避免被认为作弊?
搜索引擎如何对搜索结果进行排序?链接分析和内容排名有什么关系?
什么是内容农场?什么是链接农场?他们是什么关系?
什么是 Web 2.0 作弊?常用的方法有哪些?
什么是 SpamRank?什么是信任等级?什么是坏排名?他们是什么关系?
咖啡因系统如何影响页面排名?
最近一批电商网站针对搜索引擎优化,结果被谷歌认定为黑帽SEO,导致搜索排名权降低。如何避免这种情况?从事相关行业的营销人员和网站webmasters应该对反作弊搜索引擎的基本策略和方法,甚至页面排名算法等搜索引擎的核心技术有深入的了解。 SEO技术归根结底其实很简单。尽管它在不断变化,但许多原则和策略总是相似而密不可分的。深入了解搜索引擎相关技术原理,将形成您所在行业的竞争优势。
4.作者本人
我的记忆力不是很好,一段时间内学到的技术往往几年后就模糊了,所以这本书也是给自己写的,作为技术参考手册。沉力也参与了本书的部分编写。
谢谢
感谢博文的编辑傅锐。没有她,这本书就不会出版。傅主编在审稿过程中提出的细致的改进点对我帮助很大。
特别感谢我的妻子。在将近一年的写作过程中,我几乎把所有的空闲时间都花在了这本书的写作上。她承担了所有的家务,以免分散我的注意力。没时间陪她也没关系,这本书的诞生也算是送给她的礼物。
对我来说,写这本书是一个辛苦而快乐的过程。就像一个远行的旅人。当你从水和山上仰望时,你总能看到你所忽略的美丽景色。如果您在阅读本书,我很荣幸能有这样的体验。
张俊林
2011 年 6 月
获取正版《这就是搜索引擎:核心技术详解》 查看全部
编辑推荐《这就是搜索引擎:核心技术详解》
编辑推荐
《这就是搜索引擎:核心技术详解》适合所有对搜索引擎技术感兴趣的人,尤其是相关领域的学生、对搜索引擎核心技术感兴趣的技术人员、相关从业人员在搜索引擎优化方面,中小网站站长等更有参考价值。
作者其他作品《大数据日常知识:架构与算法》
内容介绍
搜索引擎作为互联网发展中至关重要的应用,已经成为互联网各个领域的制高点,其重要性不言而喻。搜索引擎领域也是互联网应用中少有的以核心技术为命脉的领域。搜索引擎的各个子系统是如何设计的?这已成为广大技术人员和搜索引擎优化者关注的内容。
《这就是搜索引擎:核心技术详解》的特点是内容新颖、全面、通俗易懂。对实际搜索引擎中涉及的各种核心技术进行了全面详细的介绍。除了以网络爬虫、索引系统、排名系统、链接分析和用户分析为核心的搜索系统外,还包括网页反作弊、缓存管理、网页重复数据删除技术等实际搜索引擎必须具备的技术。关注,同时在相当大的篇幅中讲解了云计算和云存储的核心技术原理。此外,本书还密切关注搜索引擎开发的前沿技术:谷歌的咖啡因系统和Megastore等新的云计算技术、百度的暗网爬虫技术阿拉丁计划、内容农场作弊、机器学习排序等。许多新技术在相关章节中有详细的讲解,同时对社交搜索、实时搜索、上下文搜索等搜索引擎未来的发展方向给出了技术展望。为了加深读者的理解,书中引入了大量生动的图片来讲解算法的原理。相信读者会发现,原来搜索引擎的核心技术比原先想象的要简单得多。
作者简介
张俊林着有技术书籍《这就是搜索引擎:核心技术详解》,现任畅捷通智能平台总监。在此之前,张君林曾任阿里巴巴风潮广告平台、百度商业搜索部、新浪微博搜索部和数据系统部高级技术专家,新浪微博技术委员会委员,负责方向算法策略。张君林也是智能信息聚合网站“玩聚网”的联合创始人之一。他的研发兴趣集中在:搜索技术、推荐系统、社交挖掘、自然语言处理和大数据算法架构等,在上述领域有多年的行业实践经验。张君林毕业于天津大学管理学院,获学士学位。 1999年至2004年在中国科学院软件研究所直接攻读博士学位。研究方向为信息检索理论和自然语言处理。学习期间,在ACL/COLING/IJCNLP等顶级国际会议上发表多篇文章。学术论文。此外,他在此期间设计的搜索系统赢得了17个国际高水平研究团队的激烈竞争,并在美国国防部DARPA主办的第二届TREC高精度检索系统评估中排名第一。取名效果极佳。
内容
第一章搜索引擎及其技术架构
1.1 为什么搜索引擎很重要
1.1.1 互联网的发展
1.1.2 商业搜索引擎公司的发展
1.1.3 搜索引擎的重要地位
1.2搜索引擎技术发展历程
1.2.1史前时代:目录的产生
1.2.2 第一代:文本检索的产生
1.2.3 第二代:链路分析的产生
1.2.4 第三代:以用户为中心的一代
1.3 搜索引擎的3个目标
1.4 搜索引擎的3个核心问题
1.4.13个核心问题
1.4.2 与技术发展的关系
1.5搜索引擎技术架构
第 2 章网络爬虫
2.1 通用爬虫框架
2.2 优秀爬虫的特点
2.3 爬虫质量评价标准
2.4 爬取策略
2.4.1 广度优先遍历策略(BreathFirst)
2.4.2 部分 PageRank 策略(PartialPageRank)
2.4.3OCIP 策略(OnlinePageImportanceComputation)
2.4.4LargerSitesFirst 策略(LargerSitesFirst)
2.5网页更新策略
2.5.1历史参考策略
2.5.2用户体验策略
2.5.3 聚类抽样策略
2.6DeepWebCrawling(DeepWebCrawling)
2.6.1 查询组合问题
2.6.2 在文本框中填写问题
2.7 分布式爬虫
2.7.1 主从分发爬虫(Master-Slave)
2.7.2 点对点(PeertoPeer)
本章总结
本章参考资料
第 3 章搜索引擎索引
3.1索引基础
3.1.1 字——文档矩阵
3.1.2 倒排索引的基本概念
3.1.3 倒排索引的简单例子
3.2 词词典
3.2.1 哈希加链表
3.2.2树结构
3.3PostingList
3.4创建索引
3.4.1 两遍文档遍历方法(2-PassIn-MemoryInversion)
3.4.2Sort-basedInversion(Sort-basedInversion)
3.4.3Merge-basedInversion(Merge-basedInversion)
3.5动态索引
3.6 索引更新策略
3.6.1 完整重建策略(CompleteRe-Build)
3.6.2 重新合并策略(Re-Merge)
3.6.3 就地更新策略(In-Place)
3.6.4 混合策略(Hybrid)
3.7查询处理
3.7.1 一次一个文档(DocataTime)
3.7.2 一次一个字(TermataTime)
3.7.3SkipPointers(SkipPointers)
3.8多字段索引
3.8.1多索引法
3.8.2倒排列表法
3.8.3扩展列表方法(ExtentList)
3.9phrase 查询
3.9.1位置索引(PositionIndex)
3.9.2 二字索引(NextwordIndex)
3.9.3 PhraseIndex (PhraseIndex)
3.9.4 混合方法
3.10分布式索引(ParallelIndexing)
3.10.1 按文档划分(DocumentPartitioning)
3.10.2 按词划分(TermPartitioning)
3.10.3 两种方案对比
本章总结
本章参考资料
第 4 章索引压缩
4.1 字典压缩
4.2倒列表压缩算法
4.2.1 评价指标压缩算法指标
4.2.2 一元编码和二进制编码
4.2.3EliasGamma 算法和 EliasDelta 算法
4.2.4Golomb 算法和 Rice 算法
4.2.5 变长字节算法(VariableByte)
4.2.6SimpleX 系列算法
4.2.7PForDelta 算法
4.3 DocIDReordering(DocIDReordering)
4.4StaticIndexPruning (StaticIndexPruning)
4.4.1 以词为中心的索引剪裁
4.4.2 以文档为中心的索引裁剪
本章总结
本章参考资料
第 5 章搜索模型和搜索排序
5.1BooleanModel (BooleanModel)
5.2VectorSpaceModel (VectorSpaceModel)
5.2.1文档表示
5.2.2 相似度计算
5.2.3特征权重计算
5.3概率检索模型
5.3.1 概率排序原则
5.3.2BinaryIndependentModel(BinaryIndependentModel)
5.3.3BM25 模型
5.3.4BM25F 模型
5.4 语言模型方法
5.5 机器学习排名(LearningtoRank)
5.5.1机器学习排序的基本思路
5.5.2 单文档方法(PointWiseApproach)
5.5.3文档对方法(PairWiseApproach)
5.5.4 文档列表方法(ListWiseApproach)
5.6 搜索质量评价标准
5.6.1准确率和召回率
5.6.2P@10个指标
5.6.3MAP 指标(MeanAveragePrecision)
本章总结
本章参考资料
第六章链接分析
6.1网页图片
6.2 两个概念模型和算法的关系
6.2.1RandomSurferModel (RandomSurferModel)
6.2.2 子集传播模型
6.2.3 链接分析算法之间的关系
6.3PageRank 算法
6.3.1 从链内数到PageRank
6.3.2PageRank 计算
6.3.3 链接陷阱(LinkSink)和远程跳转(Teleporting)
6.4HITS 算法(HypertextInducedTopicSelection)
6.4.1Hub 页面和权限页面
6.4.2 互增关系
6.4.3HITS 算法
6.4.4HITS 算法问题
6.4.5HITS算法与PageRank算法对比
6.5SALSA 算法
6.5.1 确定计算对象集
6.5.2 链接关系传播
6.5.3权限权重计算
6.6 主题敏感页面排名(TopicSensitivePageRank)
6.6.1 主题敏感的PageRank和PageRank的区别
6.6.2 主题敏感的PageRank计算过程
6.6.3 使用主题敏感的PageRank构建个性化搜索
6.7Hilltop 算法
6.7.1 Hilltop 算法的一些基本定义
6.7.2Hilltop 算法
6.8 其他改进算法
6.8.1IntelligentSurferModel(智能冲浪模型)
6.8.2 BiasedSurferModel(BiasedSurferModel)
6.8.3PHITS 算法(ProbabilityAnalogyofHITS)
6.8.4BFS 算法(BackwardForwardStep)
本章总结
本章参考资料
第 7 章云存储和云计算
7.1 云存储和云计算概述
7.1.1 基本假设
7.1.2理论基础
7.1.3 数据模型
7.1.4 基本问题
7.1.5Google 的云存储和云计算架构
7.2Google 文件系统 (GFS)
7.2.1GFS 设计原则
7.2.2GFS 整体架构
7.2.3GFS 主控服务器
7.2.4 系统交互行为
7.3Chubby 锁服务
7.4BigTable
7.4.1BigTable 的数据模型
7.4.2BigTable 整体结构
7.4.3BigTable 的管理数据
7.4.4MasterServer
7.4.5 分表服务器(TabletServer)
7.5Megastore 系统
7.5.1 实体组切分
7.5.2数据模型
7.5.3数据读写与备份
7.6Map/Reduce 云计算模型
7.6.1计算模型
7.6.2 整体逻辑流程
7.6.3 应用实例
7.7Caffeine System-Percolator
7.7.1 事务支持
7.7.2 观察/通知架构
7.8Pregel 图计算模型
7.9Dynomo 云存储系统
7.9.1 数据分区算法(PartitioningAlgorithm)
7.9.2数据备份(复制)
7.9.3数据读写
7.9.4数据版本控制
7.10PNUTS 云存储系统
7.10.1PNUTS 整体架构
7.10.2 存储单元
7.10.3 分表控制器和数据路由器
7.10.4 雅虎通讯社
7.10.5 数据一致性
7.11HayStack 存储系统
7.11.1HayStack 整体架构
7.11.2 目录服务
7.11.3HayStack 缓存
7.11.4HayStack 存储系统
本章总结
本章参考资料
第8章网络反作弊
8.1内容作弊
8.1.1常见的内容作弊方法
8.1.2内容农场(ContentFarm)
8.2 链接作弊
8.3 页面隐藏作弊
8.4Web2.0 作弊方法
8.5反作弊技术总体思路
8.5.1 信任传播模型
8.5.2 不信任传播模型
8.5.3 异常发现模型
8.6 万能链接反作弊方法
8.6.1TrustRank 算法
8.6.2BadRank 算法
8.6.3SpamRank
8.7 专用链接防作弊技术
8.7.1 识别链接农场
8.7.2 识别谷歌轰炸
8.8 识别内容作弊
8.9反隐藏作弊
8.9.1 识别页面隐藏
8.9.2 识别网页重定向
8.10 搜索引擎反作弊综合框架
本章总结
本章参考资料
第九章用户查询意图分析
9.1搜索行为及其意图
9.1.1用户搜索行为
9.1.2用户搜索意图分类
9.2搜索日志挖掘
9.2.1查询会话(QuerySession)
9.2.2ClickGraph (ClickGraph)
9.2.3查询图(QueryGraph)
9.3 相关搜索
9.3.1 基于查询会话的方法
9.3.2 基于点击图的方法
9.4检查纠错
9.4.1EditDistance(编辑距离)
9.4.2 噪声通道模型(NoiseChannelModel)
本章总结
本章参考资料
第十章网页去重
10.1 通用去重算法框架
10.2Shingling 算法
10.3I-Match 算法
10.4SimHash 算法
10.4.1 文档指纹计算
10.4.2 搜索类似文档
10.5SpotSig 算法
10.5.1 特征提取
10.5.2 搜索类似文档
本章总结
本章参考资料
第11章搜索引擎缓存机制
11.1搜索引擎缓存系统架构
11.2Cache 对象
11.3缓存结构
11.4缓存消除策略(EvictPolicy)
11.4.1 动态策略
11.4.2 混合策略
11.5缓存更新策略(RefreshPolicy)
本章总结
本章参考资料
第十二章搜索引擎发展趋势
12.1个性化搜索
12.2社交搜索
12.3 实时搜索
12.4手机搜索
12.5 位置感知搜索
12.6跨语言搜索
12.7多媒体搜索
12.8情况搜索
前言
互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品比例相对较小。搜索引擎是当前互联网产品中具有技术含量的产品,如果不是唯一的,至少是其中之一。
经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。 Twitter联合创始人埃文威廉姆斯提出“域名已死理论”:容易记住的域名不再重要,因为人们会通过搜索输入网站。搜索引擎排名对于中小网站流量非常重要。了解搜索引擎简单界面背后的技术原理,对很多人来说其实很重要。
为什么会有这本书
写搜索引擎技术书籍的最初想法是两年前诞生的。当时的场景是对团队成员进行搜索技术培训,但是我搜索了相关书籍,却没有找到一本非常合适的搜索技术入门书籍。当时市场上的书籍,要么是信息检索理论的专着,理论性太强,不易理解,真正讲搜索引擎技术的章节也不多;或者它们是太实用的书,比如 Lucene 代码分析,比如搜索引擎。这种直接分析开源系统代码的算法应用并不是一种非常高效的学习方法。所以当时就诞生了写一本通俗易懂,适合没有相关技术背景的人,比较全面,融合新技术的搜索引擎书籍。但我是在一年前开始写作的。
在写这本书之前,我为自己设定了一些目标。首先,内容要全面,即全面覆盖搜索引擎相关技术的主要方面。不仅要收录倒排索引、检索模型、爬虫等常用内容,还要详细讲解链接分析、网页反作弊、用户搜索意图分析、网页云存储和去重甚至搜索引擎缓存都是有机的一个完整的搜索引擎的组成部分,但详细介绍其原理的书籍并不多。我希望尽可能全面。
第二个目标很容易理解。我希望没有任何相关技术背景的人可以从阅读本书中学到一些东西,不了解技术的学生可以大致理解。这个目标看似简单,但实际上实现起来并不容易。我不敢说这本书达到了这个目标,但我已经尽力了。具体措施包括以下三个方面。
一是尽可能减少数学公式的数量,除非公式没有列出。尽管数学公式具有简单之美,但大多数人实际上对数学符号存在恐惧和回避。多年前我也有类似的心理,所以尽可能不要使用数学公式。
一是尽量多举例,特别是一些比较难理解的地方。需要举例来加深理解。
还有更多的绘图。就我个人的经验而言,虽然算法或技术很抽象,但如果深入理解原理,将复杂的化简,绝对可以将算法转化为生动的画面。如果你无法在脑海中形成算法的直观图形表示,则说明你对其原理没有透彻的理解。这是我判断自己是否深刻理解算法的一个私人标准。鉴于此,本书在讲解算法的地方,使用了大量的算法示意图。全书收录300多幅算法原理解释图。相信这对读者深入理解算法有很大帮助。
第三个目标是强调新现象和新技术,比如谷歌的caffeine系统和Megastore等云存储系统、Pregel云图计算模型、暗网爬取技术、Web2.0网络作弊、机器学习排序、上下文搜索、社交搜索等在相关章节中有说明。
第四个目标是强调原则,而不是停留在技术细节上。对于新手来说,一个容易解决的问题是他们喜欢挖掘细节,只见树木不见森林,懂一个公式却不懂背后的基本思想和出发点。我接触过很多技术人员,七八岁就会有这个特点。有一个问题“道家哪个好?” “道”是什么?什么是“手术”?比如《孙子兵法》就是道,《三十六计》就是战术。 “道”是宏观的、有原则的、经久不衰的基本原则,而“技术”是遵循基本原则的具体方法和措施,是变化无常的。技术也是如此。算法本身的细节就是“技巧”,算法所体现的基本思想就是“道”。知“道”、学“技”,虽然两者不能偏,但如果要选择优先级,毫无疑问我会先选择“道”再选择“术”。
以上四点是写书之前设定的目标。现在写完了,可能很多地方都达不到当初的期待,但是我会努力的。写书的过程很辛苦,至少比我想象的要难。因为工作忙,每天只能早起,加上周末和节假日。也许书中有这样的缺点,但我可以说我是真诚地写这本书的。
这本书是给谁看的?
如果您是以下其中一种,那么这本书适合您。
1.对搜索引擎核心算法感兴趣的技术人员
搜索引擎的整体框架是什么?收录哪些核心技术?
网络爬虫的基本结构是什么?常见的爬取策略有哪些?什么是暗网爬行?如何构建分布式爬虫?百度的阿拉丁计划是什么?
什么是倒排索引?如何对倒排索引进行数据压缩?
搜索引擎如何对搜索结果进行排序?
什么是向量空间模型?什么是概率模型?什么是BM25型号?什么是机器学习排序?它们之间有什么异同?
PageRank和HITS算法有什么关系?有哪些相同点和不同点?什么是 SALSA 算法?什么是山顶算法?各种链接分析算法之间的关系是什么?
如何识别搜索用户的真实搜索意图?用户可以搜索多少个类别?什么是点击图表?什么是查询会话?相关搜索是如何完成的?
为什么我们需要去重复网页?如何去重复网页?哪种算法效果更好?
搜索引擎缓存有多少级?核心战略是什么?
什么是上下文搜索?什么是社交搜索?什么是实时搜索?
搜索引擎的发展趋势是什么?
如果你对三个以上的问题感兴趣,那么这本书就是为你而写的。
2.对云计算和云存储感兴趣的技术人员
CAP的原理是什么?什么是 ACID 原理?它们之间有什么异同?
Google 的云计算框架包括哪些技术? Hadoop系列和谷歌的云计算框架有什么关系?
Google 的三驾马车 GFS、BigTable 和 MapReduce 是什么意思?有什么关系?
谷歌咖啡因系统的基本原理是什么?
Google 的 Pregel 计算模型和 MapReduce 计算模型有什么区别?
Google 的 Megastore 云存储系统和 BigTable 是什么关系?
什么是亚马逊的 Dynamo 系统?
雅虎的 PNUTS 系统是什么?
Haystack 存储系统适用于哪些地方?
如果你对以上问题感兴趣,相信你可以在书中找到答案。
3.互联网营销人员从事搜索引擎优化和中小网站站长
搜索引擎的反作弊策略是什么?如何优化以避免被认为作弊?
搜索引擎如何对搜索结果进行排序?链接分析和内容排名有什么关系?
什么是内容农场?什么是链接农场?他们是什么关系?
什么是 Web 2.0 作弊?常用的方法有哪些?
什么是 SpamRank?什么是信任等级?什么是坏排名?他们是什么关系?
咖啡因系统如何影响页面排名?
最近一批电商网站针对搜索引擎优化,结果被谷歌认定为黑帽SEO,导致搜索排名权降低。如何避免这种情况?从事相关行业的营销人员和网站webmasters应该对反作弊搜索引擎的基本策略和方法,甚至页面排名算法等搜索引擎的核心技术有深入的了解。 SEO技术归根结底其实很简单。尽管它在不断变化,但许多原则和策略总是相似而密不可分的。深入了解搜索引擎相关技术原理,将形成您所在行业的竞争优势。
4.作者本人
我的记忆力不是很好,一段时间内学到的技术往往几年后就模糊了,所以这本书也是给自己写的,作为技术参考手册。沉力也参与了本书的部分编写。
谢谢
感谢博文的编辑傅锐。没有她,这本书就不会出版。傅主编在审稿过程中提出的细致的改进点对我帮助很大。
特别感谢我的妻子。在将近一年的写作过程中,我几乎把所有的空闲时间都花在了这本书的写作上。她承担了所有的家务,以免分散我的注意力。没时间陪她也没关系,这本书的诞生也算是送给她的礼物。
对我来说,写这本书是一个辛苦而快乐的过程。就像一个远行的旅人。当你从水和山上仰望时,你总能看到你所忽略的美丽景色。如果您在阅读本书,我很荣幸能有这样的体验。
张俊林
2011 年 6 月
获取正版《这就是搜索引擎:核心技术详解》
为什么“常规”SEO文章收取更多费用-低端文章50到75美元
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-11 06:44
自 2011 年 2 月 Google 发布熊猫更新以来,网站administrators 已从面向关键字密度的内容转变为主题内容。如果您是一名自由 SEO 内容作家并且还没有开始为客户提供这种类型的副本,那么您可能会对他们造成很大的伤害。在这里,我们讨论原因。
仅供参考,主题SEO文章-low-end 文章50 至 75 美元/篇,最高可达数百美元。
为什么“常规”SEO 网页内容不够好
为了摆脱为 AdSense网站 制作的许多 MFA(其中许多是垃圾邮件发送者设置的只是为了获得这些 Google 广告的点击量),Google 打击了由关键字密度驱动的内容。要知道,那些短垃圾文章一遍遍重复同样的关键词,却在搜索引擎中排名靠前。
搜索引擎的工作是返回最相关的“质量”。一般来说,大多数填了关键字的文章都不会这样做。其中许多只是您可以在 Internet 上找到的一般信息。但是相关的关键词却是一遍遍地重复。
为了防止这种情况发生,谷歌在其熊猫更新中丢弃了许多收录此类内容的网站,以支持那些遵循我所谓的“SEO 写作指南”的网站。
这些指南可被视为撰写主题 SEO 内容的基础。顺便说一句,我在这里引用谷歌是因为它是整体上最受欢迎的搜索引擎。仅供参考,最大的三个是谷歌、必应和雅虎!
什么是主题 SEO 内容写作?
比如在同一篇文章文章中,主题网页内容并没有针对特定的关键词词组,而是针对无数的关键词词组。
记住,搜索引擎只是机器人,不是人。因此,如果他们阅读收录“Apple”一词的内容块,他们将不知道您在谈论 Apple Pie 还是 Apple Computer。这是主题SEO内容的全部内容。可以帮助搜索引擎准确识别内容的全部内容,使关键字填充的内容不会上升到搜索引擎结果的顶部。
SEO主题文章和普通SEO文章的区别
让我们通过一个例子来解释。假设你写了一篇关于自制苹果派的博客,并写了一篇关于如何制作苹果派的文章。搜索引擎希望在这篇文章中找到的一些“关键字”短语包括如何烤苹果派、苹果派食谱、如何制作苹果派、如何从头开始制作苹果派等。
看看有多少不同的“关键词phrases”以及它们之间的关系?反之,这个话题的关键字填充的SEO文章可能只是一遍遍地重复“苹果派食谱”这个词。
因为主题SEO网站的内容写的时间长,在搜索引擎结果中排名靠前,作为SEO作者,你可以为此付出更多——甚至更多。
详细了解如何撰写主题 SEO 内容、Google 的 SEO 写作指南,以及要在 2013 年成为一名成功的 SEO 撰稿人,您需要了解的其他 11 件事。
原创文章,作者:WPJIAN,如转载请注明出处: 查看全部
为什么“常规”SEO文章收取更多费用-低端文章50到75美元
自 2011 年 2 月 Google 发布熊猫更新以来,网站administrators 已从面向关键字密度的内容转变为主题内容。如果您是一名自由 SEO 内容作家并且还没有开始为客户提供这种类型的副本,那么您可能会对他们造成很大的伤害。在这里,我们讨论原因。
仅供参考,主题SEO文章-low-end 文章50 至 75 美元/篇,最高可达数百美元。
为什么“常规”SEO 网页内容不够好
为了摆脱为 AdSense网站 制作的许多 MFA(其中许多是垃圾邮件发送者设置的只是为了获得这些 Google 广告的点击量),Google 打击了由关键字密度驱动的内容。要知道,那些短垃圾文章一遍遍重复同样的关键词,却在搜索引擎中排名靠前。
搜索引擎的工作是返回最相关的“质量”。一般来说,大多数填了关键字的文章都不会这样做。其中许多只是您可以在 Internet 上找到的一般信息。但是相关的关键词却是一遍遍地重复。
为了防止这种情况发生,谷歌在其熊猫更新中丢弃了许多收录此类内容的网站,以支持那些遵循我所谓的“SEO 写作指南”的网站。
这些指南可被视为撰写主题 SEO 内容的基础。顺便说一句,我在这里引用谷歌是因为它是整体上最受欢迎的搜索引擎。仅供参考,最大的三个是谷歌、必应和雅虎!
什么是主题 SEO 内容写作?
比如在同一篇文章文章中,主题网页内容并没有针对特定的关键词词组,而是针对无数的关键词词组。
记住,搜索引擎只是机器人,不是人。因此,如果他们阅读收录“Apple”一词的内容块,他们将不知道您在谈论 Apple Pie 还是 Apple Computer。这是主题SEO内容的全部内容。可以帮助搜索引擎准确识别内容的全部内容,使关键字填充的内容不会上升到搜索引擎结果的顶部。
SEO主题文章和普通SEO文章的区别
让我们通过一个例子来解释。假设你写了一篇关于自制苹果派的博客,并写了一篇关于如何制作苹果派的文章。搜索引擎希望在这篇文章中找到的一些“关键字”短语包括如何烤苹果派、苹果派食谱、如何制作苹果派、如何从头开始制作苹果派等。
看看有多少不同的“关键词phrases”以及它们之间的关系?反之,这个话题的关键字填充的SEO文章可能只是一遍遍地重复“苹果派食谱”这个词。
因为主题SEO网站的内容写的时间长,在搜索引擎结果中排名靠前,作为SEO作者,你可以为此付出更多——甚至更多。
详细了解如何撰写主题 SEO 内容、Google 的 SEO 写作指南,以及要在 2013 年成为一名成功的 SEO 撰稿人,您需要了解的其他 11 件事。
原创文章,作者:WPJIAN,如转载请注明出处:
简述简述搜索引擎如何判断网页和查询的相关性?
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-10 03:16
搜索引擎的质量在很大程度上取决于搜索结果的网络内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性,以及网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;本文主要简要介绍搜索引擎如何判断网页与查询的相关性?
判断网页内容是否与用户查询的关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.Boolean 模型
布尔模型简单来说就是用户查询的词是否出现在网页中,是对是错,是否收录在非收录中。比如用户搜索的关键词是SEO,他们希望得到与SEO相关的信息。当网页内容中出现SEO这个词时,就意味着该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后使用余弦公式计算文档与查询的相似度并对输出结果进行排序。主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。 IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在某个网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。 SEO常用的是关键词密度,但是没有统一的衡量标准。不要使用 2%~8% 作为关键词密度标准。
3.probability 模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词条SEO,大部分可能会搜索SEO培训、SEO服务等。用户后续需求源自海量大数据,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续条款以它们为基础,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,一个网页可以分为不同的区域。例如,网页标题、描述、网页内容、网页底部标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题收录相关的关键词,很大程度上说明了网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以我不需要把关键词和许摩关键词密度堆在一起。
(责任编辑:搜索引擎网站optimizationSEO外包-,原创不易,转载时必须以链接形式注明作者、原出处及本声明。) 查看全部
简述简述搜索引擎如何判断网页和查询的相关性?
搜索引擎的质量在很大程度上取决于搜索结果的网络内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性,以及网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;本文主要简要介绍搜索引擎如何判断网页与查询的相关性?
判断网页内容是否与用户查询的关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.Boolean 模型
布尔模型简单来说就是用户查询的词是否出现在网页中,是对是错,是否收录在非收录中。比如用户搜索的关键词是SEO,他们希望得到与SEO相关的信息。当网页内容中出现SEO这个词时,就意味着该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后使用余弦公式计算文档与查询的相似度并对输出结果进行排序。主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。 IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在某个网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。 SEO常用的是关键词密度,但是没有统一的衡量标准。不要使用 2%~8% 作为关键词密度标准。
3.probability 模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词条SEO,大部分可能会搜索SEO培训、SEO服务等。用户后续需求源自海量大数据,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续条款以它们为基础,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,一个网页可以分为不同的区域。例如,网页标题、描述、网页内容、网页底部标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题收录相关的关键词,很大程度上说明了网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以我不需要把关键词和许摩关键词密度堆在一起。
(责任编辑:搜索引擎网站optimizationSEO外包-,原创不易,转载时必须以链接形式注明作者、原出处及本声明。)
简化双因素算法,你的搜索引擎优化会吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-07-10 03:10
在排名方面寻找一个简单的答案,但这两项研究和 Google 本身都表示,链接和内容是所涉及的最大因素。如果您更多地关注简化的双因素算法,您的 SEO 会奏效吗?
网站设计公司
搜索引擎优化排名肯定有很多感兴趣的因素:
有了这个专业的研究,尤其是 Moz 和 searchmetrics。这些都是开创性的研究,如果您认真对待搜索引擎优化,您需要了解这些研究的内容。这些太复杂了。他们需要一种简单的方式来看待事物,包括一些世界上最大的公司,以及一些世界上最高的网站。对于这些公司中的大多数,有超过 200 个排名因素。
这些干扰最终会集中在两个最重要的事情上:构建大量内容和出色的内容体验,并促进其发展。
今天的重点是开发一种基本方法,大多数公司都可以使用它来简化搜索引擎优化的想法,并将重点放在最高优先级上。
Google 最近所说的两个最重要的排名因素是什么:
我可以告诉你它们是什么。这是输入网站的内容和链接。
我们走了,这是开始。据谷歌称,其链接和内容是最大的两个。希望内容是一个重要因素的想法是显而易见的,但下面我将分解更多优秀内容真正需要的内容。另外,可以看到一些备份链接的威力,在研究中,我最近发布了链接作为排名因素。
我们是否应该认为世界是由这两个因素组成的?这很简单,可能太多了,所以让我们尝试进一步简化它。如果专注于创建优质内容并有效推广,有多少组织会显着改善其搜索引擎优化?我可以告诉你,根据我的经验,这是许多组织根本不做的两件事。
这是否意味着我们可以将我们的两个因素变成一个(纯)假设的排名评分方程,看起来像这样?
html5 设计
我真的认为这个方程相当有效,虽然它有一些限制和遗漏,我会在下面更详细地描述。您还需要考虑“优质内容”的概念,以正确的方式获得较高的内容分数。
什么是“精彩内容?”
如果我们退后一步思考什么是优质内容,在我看来,主要由三个组成部分组成:
协会
质量
整体内容体验
这部分的第一部分很简单。如果内容与查询无关,则不应为查询排名,如果。这是有道理的,对吧?
第二部分也很简单。这就是质量的概念。它提供了人们正在寻找的信息?那是你的网站 更独特的信息吗?显然,这对内容的质量很有意义。
我们可以将质量和相对独特性的概念合并为物质区分的概念。兰德在他的白板上精彩地阐述了这一点,并在周五创作了 10 次内容。
你需要创造出新的、引人注目的东西,并提供很多价值。这可能并不容易,但最好的事情从来没有发生过。
<p>如果您处于竞争激烈的市场中,可以合理猜测您的顶级竞争对手正在制作出色的内容主题及其目标受众。对于最重要的查询,很有可能空间前5(可能更多)的内容是真实的,真的很好(即比其他文章主题更全面,或者带来新信息,其他人没有)。 查看全部
简化双因素算法,你的搜索引擎优化会吗?
在排名方面寻找一个简单的答案,但这两项研究和 Google 本身都表示,链接和内容是所涉及的最大因素。如果您更多地关注简化的双因素算法,您的 SEO 会奏效吗?
网站设计公司
搜索引擎优化排名肯定有很多感兴趣的因素:
有了这个专业的研究,尤其是 Moz 和 searchmetrics。这些都是开创性的研究,如果您认真对待搜索引擎优化,您需要了解这些研究的内容。这些太复杂了。他们需要一种简单的方式来看待事物,包括一些世界上最大的公司,以及一些世界上最高的网站。对于这些公司中的大多数,有超过 200 个排名因素。
这些干扰最终会集中在两个最重要的事情上:构建大量内容和出色的内容体验,并促进其发展。
今天的重点是开发一种基本方法,大多数公司都可以使用它来简化搜索引擎优化的想法,并将重点放在最高优先级上。
Google 最近所说的两个最重要的排名因素是什么:
我可以告诉你它们是什么。这是输入网站的内容和链接。
我们走了,这是开始。据谷歌称,其链接和内容是最大的两个。希望内容是一个重要因素的想法是显而易见的,但下面我将分解更多优秀内容真正需要的内容。另外,可以看到一些备份链接的威力,在研究中,我最近发布了链接作为排名因素。
我们是否应该认为世界是由这两个因素组成的?这很简单,可能太多了,所以让我们尝试进一步简化它。如果专注于创建优质内容并有效推广,有多少组织会显着改善其搜索引擎优化?我可以告诉你,根据我的经验,这是许多组织根本不做的两件事。
这是否意味着我们可以将我们的两个因素变成一个(纯)假设的排名评分方程,看起来像这样?
html5 设计
我真的认为这个方程相当有效,虽然它有一些限制和遗漏,我会在下面更详细地描述。您还需要考虑“优质内容”的概念,以正确的方式获得较高的内容分数。
什么是“精彩内容?”
如果我们退后一步思考什么是优质内容,在我看来,主要由三个组成部分组成:
协会
质量
整体内容体验
这部分的第一部分很简单。如果内容与查询无关,则不应为查询排名,如果。这是有道理的,对吧?
第二部分也很简单。这就是质量的概念。它提供了人们正在寻找的信息?那是你的网站 更独特的信息吗?显然,这对内容的质量很有意义。
我们可以将质量和相对独特性的概念合并为物质区分的概念。兰德在他的白板上精彩地阐述了这一点,并在周五创作了 10 次内容。
你需要创造出新的、引人注目的东西,并提供很多价值。这可能并不容易,但最好的事情从来没有发生过。
<p>如果您处于竞争激烈的市场中,可以合理猜测您的顶级竞争对手正在制作出色的内容主题及其目标受众。对于最重要的查询,很有可能空间前5(可能更多)的内容是真实的,真的很好(即比其他文章主题更全面,或者带来新信息,其他人没有)。
阳光创信云推广的方法,提高网站排名必备!
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-07-07 19:24
网站optimization,贵州阳光创信云推广是一家专业的网络营销外包代理运营商,专注于为中小企业提供网络营销整体战略解决方案,包括网络营销方案、网络营销策划、网络营销外包、SEM/SEO优化、搜索引擎自动推广、网站建筑、网站设计、网站开发等综合服务,牛推网是一家多元化的现代网络信息技术企业;公司自主研发的新一代网络营销优化推广系统-【阳光创信云推广-中国**新闻源媒体营销推广平台】,旨在为广大商家提供全方位的免费差异化营销推广服务, 阳光创信精兵将协助企业管理所有市场运营,深入挖掘更新、更全、更快的业务资源,通过阳光创信云的营销策略快速推广企业产品和服务。
随着互联网业务越来越火爆,市场上有很多公司想要进入互联网行业。 网站排名优化方法,提升网站排名必备!
今日头条后台自带手机建站工具,使用起来非常方便。可以说就像搭积木来堆叠页面一样。类似于今日头条的移动网站建设,但行为数据的来源无法统计。还有很多改进和优化的空间。我们都知道流量是竞价的核心,但数据是明确流量控制的方向。所以小编在这里整理了几个投标人必备的表单模板。函数:是excel中的一个函数,用于对某个项目的总价值进行具体统计。用途:常用于多维数据分析。功能:主要用于统计一个词组或单词中的字符数。用途:多用于过滤长尾词、短尾词,或者比较杂乱的一般词等。 功能:统计一组数据中满足一定条件的值的总数。用途:用于计算咨询工具中关键词带来的会话数、地区、时间段等。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。我们都知道搜索引擎优化是否合理,搜索引擎也会如此,直接带来难以想象的客流。海创h5自助建站6年专注建站。拥有国内外领先的技术和网站marketing技术,打造免费、易用的网站。轻松拖拽一键发布和上线,快速获取搜索引擎收录和排名。
想要网站排名好,一定是网站的具体方向。这个方向就是营销的方向。有了这个具体点,我们就可以更有选择性的结合用户的需求,给网站带来更多的水分和转化率,从而提升SEO管理的视觉效果。通过LSI和TF-IDF关键词分析,我们可以找出符合搜索者意图的关键词和URL,并将它们组织成Excel表格,然后创建符合搜索者意图的高质量文案。单页速度测试单页速度测试推荐使用googlespeedtest。分数越高越好,分数越高表示网速越快,跳出率越低。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。搜索引擎优化是否合理大家都知道,搜索引擎也会如此,直接带来难以想象的客流量。
掌握的基础如下: 1、掌握后端CSS语法,类似DIV+HTML等。在做seo的时候,我们经常需要做的一件事就是看@k14的源码@。如果连基本的html都不懂,操作起来会很困难。我们以 URL 为例。有些人不会在您的朋友链上列出 nofollow。有些人可能会在 KM 中添加 URL。如果你不了解html的基础知识,你是看不到这些的。不懂html的你还是主动发这些网站友情链接,但是视觉效果根本不行。微联世创专注网络营销服务,用数据说话,用结果说话。同时是多家搜索、互联网巨头认证的合作伙伴,拥有包括搜索引擎(百度、搜狗、360)等)认证合作伙伴资质的专业互联网营销服务商。
网站optimization,adaptability网站搜索引擎优化有什么优势?自适应网站开发seo规范比较简单,这样的模型也挺好的。 URL可以随时同步数据,因为这样网站可以在手机上及时调整页面,保持良好的显示效果。还应该发现,这样的网页是兼容的,所以更容易保持良好的状态。
友情链接是合适的,所以我投票给了我的网站,但不仅仅是网站可以成为友情链接。一个低质量的友情链接不仅对网站有帮助,而且也无济于事。吸引蜘蛛:当我们和一个排名靠前的网站进行友情链接时,当搜索蜘蛛来到另一个网站时,他会跟随友情链接到我们自己的网站,并且还会加我们网站有机会进入。相关阅读:网站SEO优化**如何估算关键词的排名?权重转移:当我们得到一个高质量的友情链接时,我们已经投票支持我们自己的网站推广。比如你的网站和食物有关,那么这个友情链接几乎是在告诉搜索引擎。您的网站 与食物有关。所以在做友情链接的时候一定要找到和我们主题相似的网站,这样搜索引擎才能更快的提升我们网站的权重。 查看全部
阳光创信云推广的方法,提高网站排名必备!
网站optimization,贵州阳光创信云推广是一家专业的网络营销外包代理运营商,专注于为中小企业提供网络营销整体战略解决方案,包括网络营销方案、网络营销策划、网络营销外包、SEM/SEO优化、搜索引擎自动推广、网站建筑、网站设计、网站开发等综合服务,牛推网是一家多元化的现代网络信息技术企业;公司自主研发的新一代网络营销优化推广系统-【阳光创信云推广-中国**新闻源媒体营销推广平台】,旨在为广大商家提供全方位的免费差异化营销推广服务, 阳光创信精兵将协助企业管理所有市场运营,深入挖掘更新、更全、更快的业务资源,通过阳光创信云的营销策略快速推广企业产品和服务。
随着互联网业务越来越火爆,市场上有很多公司想要进入互联网行业。 网站排名优化方法,提升网站排名必备!
今日头条后台自带手机建站工具,使用起来非常方便。可以说就像搭积木来堆叠页面一样。类似于今日头条的移动网站建设,但行为数据的来源无法统计。还有很多改进和优化的空间。我们都知道流量是竞价的核心,但数据是明确流量控制的方向。所以小编在这里整理了几个投标人必备的表单模板。函数:是excel中的一个函数,用于对某个项目的总价值进行具体统计。用途:常用于多维数据分析。功能:主要用于统计一个词组或单词中的字符数。用途:多用于过滤长尾词、短尾词,或者比较杂乱的一般词等。 功能:统计一组数据中满足一定条件的值的总数。用途:用于计算咨询工具中关键词带来的会话数、地区、时间段等。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。我们都知道搜索引擎优化是否合理,搜索引擎也会如此,直接带来难以想象的客流。海创h5自助建站6年专注建站。拥有国内外领先的技术和网站marketing技术,打造免费、易用的网站。轻松拖拽一键发布和上线,快速获取搜索引擎收录和排名。
想要网站排名好,一定是网站的具体方向。这个方向就是营销的方向。有了这个具体点,我们就可以更有选择性的结合用户的需求,给网站带来更多的水分和转化率,从而提升SEO管理的视觉效果。通过LSI和TF-IDF关键词分析,我们可以找出符合搜索者意图的关键词和URL,并将它们组织成Excel表格,然后创建符合搜索者意图的高质量文案。单页速度测试单页速度测试推荐使用googlespeedtest。分数越高越好,分数越高表示网速越快,跳出率越低。
网站Optimization,在互联网+时代,网站是每个大中型企业的必备工具。有了这把武器,我们如何才能带来实际利益?搜索引擎网站收录 和排名很重要。这将大大增加公司的曝光率,带来更多的流量。关于网站搜索引擎优化和搜索引擎,一直是商谈的话题。搜索引擎优化是否合理大家都知道,搜索引擎也会如此,直接带来难以想象的客流量。
掌握的基础如下: 1、掌握后端CSS语法,类似DIV+HTML等。在做seo的时候,我们经常需要做的一件事就是看@k14的源码@。如果连基本的html都不懂,操作起来会很困难。我们以 URL 为例。有些人不会在您的朋友链上列出 nofollow。有些人可能会在 KM 中添加 URL。如果你不了解html的基础知识,你是看不到这些的。不懂html的你还是主动发这些网站友情链接,但是视觉效果根本不行。微联世创专注网络营销服务,用数据说话,用结果说话。同时是多家搜索、互联网巨头认证的合作伙伴,拥有包括搜索引擎(百度、搜狗、360)等)认证合作伙伴资质的专业互联网营销服务商。
网站optimization,adaptability网站搜索引擎优化有什么优势?自适应网站开发seo规范比较简单,这样的模型也挺好的。 URL可以随时同步数据,因为这样网站可以在手机上及时调整页面,保持良好的显示效果。还应该发现,这样的网页是兼容的,所以更容易保持良好的状态。
友情链接是合适的,所以我投票给了我的网站,但不仅仅是网站可以成为友情链接。一个低质量的友情链接不仅对网站有帮助,而且也无济于事。吸引蜘蛛:当我们和一个排名靠前的网站进行友情链接时,当搜索蜘蛛来到另一个网站时,他会跟随友情链接到我们自己的网站,并且还会加我们网站有机会进入。相关阅读:网站SEO优化**如何估算关键词的排名?权重转移:当我们得到一个高质量的友情链接时,我们已经投票支持我们自己的网站推广。比如你的网站和食物有关,那么这个友情链接几乎是在告诉搜索引擎。您的网站 与食物有关。所以在做友情链接的时候一定要找到和我们主题相似的网站,这样搜索引擎才能更快的提升我们网站的权重。
SEO优化的新思路——SEO站内优化之主题模型
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-07-07 03:03
今天和大家分享SEO优化的新思路。昨天家里有事,所以没有急着更新微博。我特地再次说声抱歉。
随着互联网时代的飞速发展,现在网站的种类越来越多。随着搜索引擎系统越来越完善,也趋向于更加人性化和用户体验。 SEO 现在不同于以前的优化规则。我们需要开始了解我们的网站 应该如何优化以获得更好的排名。
之前我们讲SEO优化的时候,会很不自然地想到,网站的关键词密度,页面内容是否原创,是否有很多导入链接(外部链接),是否TDK关键词设置精准匹配等做法。现在那是几年前的旧 SEO 优化方法。
今天偶然看到一篇文章的文章,里面讲了SEO网站优化的新思路和SEO网站优化的话题模型。现在搜索引擎可以通过内容上下文和内容实体属性来处理排名,让用户得到更准确的结果。搜索结果。对于优化者来说,网站优化不再是简单的内容填充。我们要做的是如何让搜索引擎明白我们网站有真实的内容和实体属性。
首先,它被称为词汇关联。我们在写网站内容的时候,一定要关注如何关联词句。使用关键词查找同义词和异体词,查找与主题内容相关的二类词,查找与二类词相关的三类词,发现内容属性与主题内容相关主题(人、地点、事物)。
其次,称为词法布局。页面的布局对于搜索引擎了解我们页面的内容和主题也很重要。蜘蛛来到页面后,发现这么多关键词,需要区分哪些是重要的,哪些是与词组相关的,所以词系统布局就是区分核心词和相关性。区域:关键词 必须出现在标题、标题和主要段落中。频率:重要短语或其变体的出现频率可能高于平均水平。距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)。
第三个叫做补充内容。或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导相关网站内容。健康的网站应该进进出出,让用户得到更多更好的信息。页面底部添加相关资源链接(推荐站内链接),文中引用,如业内知名人士的话或图标、视频,文中使用导出链接去第三方网站(你不是100颗心会被K's放)。
第四个称为内容实体。强大的搜索引擎会在抓取页面时自动解释内容实体,或作为内容属性。用一个很笼统的Title来描述页面的主题,加上一个开头(简要)来描述页面的内容,把内容分成几段,每段都有自己的主题,尽量扩大主题角度,并添加相关的提供额外的答案 不关心一个词的权重,而是建立内容实体而不是站内或站外的辅助资源。 查看全部
SEO优化的新思路——SEO站内优化之主题模型
今天和大家分享SEO优化的新思路。昨天家里有事,所以没有急着更新微博。我特地再次说声抱歉。
随着互联网时代的飞速发展,现在网站的种类越来越多。随着搜索引擎系统越来越完善,也趋向于更加人性化和用户体验。 SEO 现在不同于以前的优化规则。我们需要开始了解我们的网站 应该如何优化以获得更好的排名。
之前我们讲SEO优化的时候,会很不自然地想到,网站的关键词密度,页面内容是否原创,是否有很多导入链接(外部链接),是否TDK关键词设置精准匹配等做法。现在那是几年前的旧 SEO 优化方法。
今天偶然看到一篇文章的文章,里面讲了SEO网站优化的新思路和SEO网站优化的话题模型。现在搜索引擎可以通过内容上下文和内容实体属性来处理排名,让用户得到更准确的结果。搜索结果。对于优化者来说,网站优化不再是简单的内容填充。我们要做的是如何让搜索引擎明白我们网站有真实的内容和实体属性。
首先,它被称为词汇关联。我们在写网站内容的时候,一定要关注如何关联词句。使用关键词查找同义词和异体词,查找与主题内容相关的二类词,查找与二类词相关的三类词,发现内容属性与主题内容相关主题(人、地点、事物)。
其次,称为词法布局。页面的布局对于搜索引擎了解我们页面的内容和主题也很重要。蜘蛛来到页面后,发现这么多关键词,需要区分哪些是重要的,哪些是与词组相关的,所以词系统布局就是区分核心词和相关性。区域:关键词 必须出现在标题、标题和主要段落中。频率:重要短语或其变体的出现频率可能高于平均水平。距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)。
第三个叫做补充内容。或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导相关网站内容。健康的网站应该进进出出,让用户得到更多更好的信息。页面底部添加相关资源链接(推荐站内链接),文中引用,如业内知名人士的话或图标、视频,文中使用导出链接去第三方网站(你不是100颗心会被K's放)。
第四个称为内容实体。强大的搜索引擎会在抓取页面时自动解释内容实体,或作为内容属性。用一个很笼统的Title来描述页面的主题,加上一个开头(简要)来描述页面的内容,把内容分成几段,每段都有自己的主题,尽量扩大主题角度,并添加相关的提供额外的答案 不关心一个词的权重,而是建立内容实体而不是站内或站外的辅助资源。
专门探索JavaScript及其所构建的组件系列文章第11篇
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-07-07 02:36
这是文章 致力于探索 JavaScript 及其构建的组件的系列中的第 11 篇文章。
如果你错过了前面的章节,你可以在这里找到它们:
JavaScript 的工作原理:引擎、运行时和调用堆栈概述! JavaScript 的工作原理:深入了解 V8 引擎和编写优化代码的 5 个技巧! JavaScript 是如何工作的:内存管理 + 如何处理 4 种常见的内存泄漏! JavaScript 是如何工作的:事件循环和异步编程的兴起 + 5 种使用 async/await 进行更好编码的方法! JavaScript 是如何工作的:探索 websocket 和 HTTP/2 和 SSE + 如何选择正确的路径! JavaScript 是如何工作的:与 WebAssembly 及其使用场景的比较! JavaScript 是如何工作的:Web Workers 的构建块 + 5 个使用它们的场景! JavaScript 是如何工作的:Service Worker 生命周期和使用场景! JavaScript 是如何工作的:Web 推送通知机制! JavaScript 的工作原理:使用 MutationObserver 跟踪 DOM 变化
当您构建 Web 应用程序时,您不仅仅是编写单独运行的 JavaScript 代码,您编写的 JavaScript 还与环境进行交互。了解此环境、它的工作原理及其组将帮助您构建更好的应用程序,并为应用程序发布后可能出现的潜在问题做好充分准备。
浏览器的主要组件包括:
在这个文章 中,我将重点介绍渲染引擎,因为它处理 HTML 和 CSS 的解析和可视化,这是大多数 JavaScript 应用程序经常与之交互的东西。
渲染引擎概述
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。
渲染引擎可以显示 HTML 和 XML 文档和图像。如果您使用其他插件,渲染引擎还可以显示不同类型的文档,例如 PDF。
渲染引擎
与 JavaScript 引擎类似,不同的浏览器也使用不同的渲染引擎。以下是一些最受欢迎的:
Firefox、Chrome 和 Safari 基于两个渲染引擎。 Firefox 使用由 Mozilla 自主开发的渲染引擎 Geoko。 Safari 和 Chrome 都使用 Webkit。 Blink 是 Chrome 基于 WebKit 的自主渲染引擎。
渲染过程
渲染引擎从网络层接收请求文档的内容。
解析HTML构建Dom树->构建渲染树->布局渲染树->绘制渲染树
构建 Dom 树
渲染引擎的第一步是解析 HTML 文档并将解析的元素转换为 DOM 树中的实际 DOM 节点。
如果有以下Html结构
<p> Hello, friend!
smiley.gif
</p>
对应的DOM树如下:
基本上,每个元素都表示为所有元素的父节点,而这些元素直接收录在元素中。
构建 CSSOM
CSSOM 指的是 CSS 对象模型。浏览器在构建页面的DOM时,遇到head标签下的link标签,引用了外部的theme.css CSS样式表。浏览器预计可能需要资源来呈现页面,并立即发送请求。假设theme.css文件的内容如下:
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
和 HTML 一样,渲染引擎需要将 CSS 转换成浏览器可以使用的东西——CSSOM。 CSSOM 结构如下:
你想知道为什么 CSSOM 是一个树状结构吗?在计算页面上任何对象的最终样式集时,浏览器从适用于该节点的最通用规则开始(例如,如果它是 body 元素的子元素,则应用所有的 body 样式),然后细化递归地,通过应用更具体的规则来计算样式。
我们来看一个具体的例子。 body 元素内 span 标签中收录的任何文本的字体大小为 16 像素,并且是红色的。这些样式继承自 body 元素。如果 span 元素是 p 元素的子元素,则不会显示其内容,因为它应用了更具体的样式(display: none)。
另请注意,上面的树不是完整的 CSSOM 树,只是我们决定在样式表中涵盖的样式。每个浏览器都提供一组默认样式,也称为“用户代理样式表”。这是我们在没有明确指定样式时看到的样式,我们的样式将覆盖这些默认值。
不同的浏览器对相同的元素有不同的默认样式,这就是为什么我们写 *{padding:0;marging:0};在 CSS 的最开始,也就是我们要重置 CSS 默认样式。
构建渲染树
CSSOM 树和 DOM 树连接在一起形成渲染树,用于计算可见元素的布局,并作为将像素渲染到屏幕的过程的输入。
渲染树中的每个节点在 Webkit 中称为渲染器或渲染对象。
下面是上面DOM和CSSOM树的渲染树的样子:
为了构建渲染树,浏览器大致执行以下操作:
对于每个可见节点,找到一个合适的匹配CSSOM规则,并应用一个样式来显示可见节点之间的差异(节点包括内容和计算样式)“visibility: hidden”和“display: none”,“ Visibility: hidden" 将元素设置为不可见,但也会在布局上占据一定的空间(例如,它会被渲染为一个空框),但是"display: none" 元素将节点从整个渲染树中移除, 所以它不是布局的一部分。
您可以在此处查看 RenderObject(在 WebKit 中)的源代码:
先来看看这个类的一些核心内容:
每个渲染器代表一个矩形区域,通常对应一个节点的CSS盒模型。它收录宽度、高度和位置等几何信息。
渲染树的布局
当您创建渲染器并将其添加到树中时,它没有位置和大小。计算这些值称为布局。
HTML 使用基于流的布局模型,这意味着大多数时候它可以一次性计算几何。坐标系相对于根渲染器,使用左上角的原点坐标。
Layout 是一个递归过程——它从根渲染器开始,它对应于 HTML 文档的元素。布局通过组件或整个渲染器层次结构递归地继续,为需要它的每个渲染器计算几何信息。
根渲染器的位置为0,0,其大小与浏览器窗口可见部分(即视口)的大小相同。开始布局过程意味着为每个节点提供它应该出现在屏幕上的确切坐标。
绘制渲染树
在这里绘制,遍历渲染树并调用渲染器的paint()方法在屏幕上显示内容。
绘图可以是全局的或增量的(类似于布局):
一般来说,重要的是要了解绘图是一个渐进的过程。为了获得更好的用户体验,渲染引擎会尽快在屏幕上显示内容。它不会等到所有 HTML 都被解析后才开始构建和布局渲染树。相反,它会解析并显示部分内容,同时继续处理来自网络的其余内容项。
处理脚本和样式表的顺序
解析器到达时 查看全部
专门探索JavaScript及其所构建的组件系列文章第11篇
这是文章 致力于探索 JavaScript 及其构建的组件的系列中的第 11 篇文章。
如果你错过了前面的章节,你可以在这里找到它们:
JavaScript 的工作原理:引擎、运行时和调用堆栈概述! JavaScript 的工作原理:深入了解 V8 引擎和编写优化代码的 5 个技巧! JavaScript 是如何工作的:内存管理 + 如何处理 4 种常见的内存泄漏! JavaScript 是如何工作的:事件循环和异步编程的兴起 + 5 种使用 async/await 进行更好编码的方法! JavaScript 是如何工作的:探索 websocket 和 HTTP/2 和 SSE + 如何选择正确的路径! JavaScript 是如何工作的:与 WebAssembly 及其使用场景的比较! JavaScript 是如何工作的:Web Workers 的构建块 + 5 个使用它们的场景! JavaScript 是如何工作的:Service Worker 生命周期和使用场景! JavaScript 是如何工作的:Web 推送通知机制! JavaScript 的工作原理:使用 MutationObserver 跟踪 DOM 变化
当您构建 Web 应用程序时,您不仅仅是编写单独运行的 JavaScript 代码,您编写的 JavaScript 还与环境进行交互。了解此环境、它的工作原理及其组将帮助您构建更好的应用程序,并为应用程序发布后可能出现的潜在问题做好充分准备。
浏览器的主要组件包括:
在这个文章 中,我将重点介绍渲染引擎,因为它处理 HTML 和 CSS 的解析和可视化,这是大多数 JavaScript 应用程序经常与之交互的东西。
渲染引擎概述
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。
渲染引擎可以显示 HTML 和 XML 文档和图像。如果您使用其他插件,渲染引擎还可以显示不同类型的文档,例如 PDF。
渲染引擎
与 JavaScript 引擎类似,不同的浏览器也使用不同的渲染引擎。以下是一些最受欢迎的:
Firefox、Chrome 和 Safari 基于两个渲染引擎。 Firefox 使用由 Mozilla 自主开发的渲染引擎 Geoko。 Safari 和 Chrome 都使用 Webkit。 Blink 是 Chrome 基于 WebKit 的自主渲染引擎。
渲染过程
渲染引擎从网络层接收请求文档的内容。
解析HTML构建Dom树->构建渲染树->布局渲染树->绘制渲染树
构建 Dom 树
渲染引擎的第一步是解析 HTML 文档并将解析的元素转换为 DOM 树中的实际 DOM 节点。
如果有以下Html结构
<p> Hello, friend!
smiley.gif
</p>
对应的DOM树如下:
基本上,每个元素都表示为所有元素的父节点,而这些元素直接收录在元素中。
构建 CSSOM
CSSOM 指的是 CSS 对象模型。浏览器在构建页面的DOM时,遇到head标签下的link标签,引用了外部的theme.css CSS样式表。浏览器预计可能需要资源来呈现页面,并立即发送请求。假设theme.css文件的内容如下:
body {
font-size: 16px;
}
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
和 HTML 一样,渲染引擎需要将 CSS 转换成浏览器可以使用的东西——CSSOM。 CSSOM 结构如下:
你想知道为什么 CSSOM 是一个树状结构吗?在计算页面上任何对象的最终样式集时,浏览器从适用于该节点的最通用规则开始(例如,如果它是 body 元素的子元素,则应用所有的 body 样式),然后细化递归地,通过应用更具体的规则来计算样式。
我们来看一个具体的例子。 body 元素内 span 标签中收录的任何文本的字体大小为 16 像素,并且是红色的。这些样式继承自 body 元素。如果 span 元素是 p 元素的子元素,则不会显示其内容,因为它应用了更具体的样式(display: none)。
另请注意,上面的树不是完整的 CSSOM 树,只是我们决定在样式表中涵盖的样式。每个浏览器都提供一组默认样式,也称为“用户代理样式表”。这是我们在没有明确指定样式时看到的样式,我们的样式将覆盖这些默认值。
不同的浏览器对相同的元素有不同的默认样式,这就是为什么我们写 *{padding:0;marging:0};在 CSS 的最开始,也就是我们要重置 CSS 默认样式。
构建渲染树
CSSOM 树和 DOM 树连接在一起形成渲染树,用于计算可见元素的布局,并作为将像素渲染到屏幕的过程的输入。
渲染树中的每个节点在 Webkit 中称为渲染器或渲染对象。
下面是上面DOM和CSSOM树的渲染树的样子:
为了构建渲染树,浏览器大致执行以下操作:
对于每个可见节点,找到一个合适的匹配CSSOM规则,并应用一个样式来显示可见节点之间的差异(节点包括内容和计算样式)“visibility: hidden”和“display: none”,“ Visibility: hidden" 将元素设置为不可见,但也会在布局上占据一定的空间(例如,它会被渲染为一个空框),但是"display: none" 元素将节点从整个渲染树中移除, 所以它不是布局的一部分。
您可以在此处查看 RenderObject(在 WebKit 中)的源代码:
先来看看这个类的一些核心内容:
每个渲染器代表一个矩形区域,通常对应一个节点的CSS盒模型。它收录宽度、高度和位置等几何信息。
渲染树的布局
当您创建渲染器并将其添加到树中时,它没有位置和大小。计算这些值称为布局。
HTML 使用基于流的布局模型,这意味着大多数时候它可以一次性计算几何。坐标系相对于根渲染器,使用左上角的原点坐标。
Layout 是一个递归过程——它从根渲染器开始,它对应于 HTML 文档的元素。布局通过组件或整个渲染器层次结构递归地继续,为需要它的每个渲染器计算几何信息。
根渲染器的位置为0,0,其大小与浏览器窗口可见部分(即视口)的大小相同。开始布局过程意味着为每个节点提供它应该出现在屏幕上的确切坐标。
绘制渲染树
在这里绘制,遍历渲染树并调用渲染器的paint()方法在屏幕上显示内容。
绘图可以是全局的或增量的(类似于布局):
一般来说,重要的是要了解绘图是一个渐进的过程。为了获得更好的用户体验,渲染引擎会尽快在屏幕上显示内容。它不会等到所有 HTML 都被解析后才开始构建和布局渲染树。相反,它会解析并显示部分内容,同时继续处理来自网络的其余内容项。
处理脚本和样式表的顺序
解析器到达时
:通用型垂直搜索引擎的行业应用模型建模方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-07-06 23:25
通用垂直搜索引擎的行业应用模型建模方法,垂直搜索核心模块Spider(1)Access Industry Application Model(2))实现对不同数据的识别、捕获、组织、存储和传输。行业信息、行业应用模型(2)山互联网web库(21))和web存储分类索引管理组件(211)、web结构信息模型库(22)和web结构信息模型管理组件) (22@k21)@、行业信息结构模型库(23)和行业信息结构模型管理组件(231))、行业信息存储模型库(24)和行业信息存储模型管理组件(24) 1),和用户系统界面模型库(25)和用户系统界面模型管理组件(251))。本发明的专利技术解决了同时覆盖不同行业应用、不同的网页、不同的行业信息结构和存储结构在一个模型中。它使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、捕获、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。
下载所有详细的技术资料
【技术实现步骤总结】
该专利技术公开了一种基于。 二.
技术介绍
许多文档将垂直搜索定义为针对单个应用程序或单个功能的搜索技术。现实中,垂直搜索产品和门户网站就是按照这个定义布局的,或者房地产信息搜索门户,或者博客信息搜索门户,或者音乐信息搜索门户,或者专利信息搜索门户。所有这些都是如此。之所以出现这种现象,是因为垂直搜索互联网信息具有明显的行业应用特征、功能应用特征和结构特征。也就是说,由于垂直搜索面临的互联网信息具有明显的行业应用特征、功能应用特征和结构特征,这些千差万别的信息特征导致垂直搜索门户具有明显的单一行业或功能。事实上,垂直搜索引擎的核心模块——数据爬取模块蜘蛛本身可以作为通用技术,并没有严格的行业应用或功能应用边界。原则上,一款好的数据爬虫软件可以完成任何网页、任何行业信息的数据爬取任务。由此看来,垂直搜索技术只适用于单一行业或功能门户的事实并不在于垂直搜索的核心技术——数据爬虫软件蜘蛛,而是来自于核心技术之外。的元素。所以,要搭建一个像谷歌、百度这样的通用垂直搜索平台,垂直搜索的核心技术——数据爬虫软件蜘蛛,就有了这个基础。问题在于,如何围绕具有通用能力的数据爬虫软件构建具有通用能力的外围系统,是实现通用垂直搜索引擎的关键。构建与通用数据爬虫软件蜘蛛相匹配、具有通用能力的行业应用模型是系统研究的重要课题之一。 三.
技术实现思路
该专利技术的目的是提供一种用于一般垂直搜索系统中描述不同行业应用或功能应用特征的方法,使垂直搜索能够完成对互联网信息的识别、抓取和检索。其行业模式。组织、存储和传输应用程序,使它们能够成为通用的垂直搜索引擎。该专利技术的技术方案就是该专利技术。垂直搜索核心模块Spider 1接入行业应用模型2,实现对不同行业信息的识别、抓取、组织、存储和传输。行业应用模型2由互联网网页库21和网页组成。存储分类索引管理组件211、网页结构信息模型库22和页面结构信息模型管理组件221、工业信息结构模型库23和行业信息结构模型管理组件231、工业信息存储模型库24和行业信息存储模型管理组件241、、用户系统界面模型库25和用户系统界面模型管理组件251构成。互联网网页库21和网页存储分类索引管理组件211负责互联网网页库21的存储、分类和索引管理任务。网页存储分类索引管理组件211调用G00gleAPI212进行行业搜索应用程序网页 URL 集合;网页结构信息模型库22和网页结构信息模型管理组件221承担页面和行业应用关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理等任务。行业信息结构模型库23及行业信息结构模型管理组件231负责各种网页中各种行业信息的不同结构形式和页面位置的描述、提取、生成和管理任务。行业信息存储模型库24和行业信息存储模型管理组件241负责系统中各种存储形式和存储结构的描述,从行业信息中获取信息后存储结构的动态生成和管理任务。网页;用户系统接口模型库25和用户系统接口模型管理组件251专用于每个用户信息存储形式和系统间存储结构转换、信息传输接口、软件接口关系形式、接口定义的描述、生成和管理任务并打电话。
网页结构信息模型库22至少收录行业及应用、行业信息分类描述、网页地址URL、网页访问入口参数(用户名、密码、方法代码等)、网页链接方法、网页链接控制参数等信息。网页结构信息模型管理组件221至少包括网页结构信息模型库22基本信息的生成和维护、网页访问入口参数(用户名、密码、方法代码等)库信息的生成和维护,网页链接方法、网页链接控制参数库信息的生成与维护、网页链接控制代码片段的提取/转换/存储、调用处理等功能处理模块。行业信息结构模型库23至少包括行业及应用、行业信息分类描述、网页地址URL、行业信息结构类型、行业信息结构初始标识、行业信息结构描述、行业信息结构中的元数据属性描述、行业信息结构周期捕获标识、行业信息结构捕获端标识、行业信息结构存储指令等信息。行业信息结构模型管理组件231至少包括行业信息结构模型库23的基础信息生成和维护、行业信息结构模型库23的信息辅助分析和自动提取等功能处理模块。模型库24个至少包括行业及应用、行业信息分类描述、行业信息存储目标库及基表指令、行业信息存储结构类型、行业信息存储映射描述、行业信息存储转换处理指令、行业信息存储相关处理说明和其他信息。
行业信息存储模型管理组件241至少包括行业信息存储模型库24的基础信息生成与维护、行业信息存储结构的动态生成、行业信息存储映射控制、行业信息存储转换处理等功能处理模块。该专利技术的显着效果在于,该专利技术从网页索引、网页结构、行业信息结构、行业信息存储结构和用户系统界面五个层面建立了与行业应用信息搜索相关的完整描述和管理。该系统解决了在一个模型中同时覆盖不同行业应用、不同网页、不同行业信息结构和存储结构的问题,具有全行业能力。这项专利技术将使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、抓取、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。 四. 附图说明图1为专利技术示意图。其中1=垂直搜索核心组件Spider2=行业应用模型21=互联网网页库211=网页存储分类索引管理组件212=GoogleAPI22=网页结构信息模型库221=网页结构信息模型管理组件23=行业信息结构模型库 231 = 行业信息结构模型管理组件 24 = 行业信息采集模型库 241 = 行业信息采集模型管理组件 25 = 行业信息存储模型库 251 = 行业信息存储模型管理组件 26 = 用户系统界面模型库 261 =用户系统界面模型管理组件图2是专利技术行业应用模型中网页结构信息模型库的结构示例。
图3是专利技术行业应用模型中行业信息结构模型库的结构示例。图4是专利技术行业应用模型中行业信息存储结构模型库的结构示例。 五.具体实施方式实例1如图1所示。 2、本实施例举例说明了专利技术的行业应用模型中网页结构信息模型库的结构示例。示例二参见图3。本实施例举例说明了专利技术的行业应用模型中的行业信息结构模型库的结构示例。实施例3参见图4。本实施例举例说明了专利技术的行业应用模型中的行业信息存储结构模型库的结构示例。权利要求1.,其特征在于垂直搜索核心模块Spider(I)接入行业应用模型(2)),实现不同行业信息的识别、抓取、组织、存储和传输,行业应用模型( 2)由互联网网页库(21)和网页存储分类索引管理组件(211),网页结构信息模型库(22))和网页结构信息模型管理组件(22@) k45@,行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(241),和用户系统界面模型库(2@k53)@和用户系统界面模型管理组件(251);互联网网页库(21))和web存储分类索引管理组件(211)承担)一世htemet web library(21)存储、分类和索引)管理任务,包括web存储分类索引管理
【技术保护点】
通用垂直搜索引擎行业应用模型建模方法的特点是垂直搜索核心模块Spider(1)Access行业应用模型(2))实现识别、捕获、组织、存储和传输应用、行业应用模型(2)来自互联网网页库(21))和网页存储分类索引管理组件(211)、网页结构信息模型库(22)和网页结构信息模型管理组件) (221),行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(24@k21) @)) ,以及用户系统界面模型库(25)和用户系统界面模型管理组件(251));其中:Internet web库(21)和web存储分类索引man agement组件(211))网页库(21)存储分类索引管理任务,包括网页存储分类索引管理组件(211)调用GoogleAPI(212))实现行业应用web页面网址集合搜索;网页结构信息模型库(22)和网页结构信息模型管理组件(221)承担页面之间关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理任务)和行业应用;行业信息结构模型库(221)23)和行业信息结构模型管理组件(231),负责不同结构形式和页面的描述、提取、生成和管理任务)各种行业信息在各种网页中的位置;行业信息存储模型库(24)和行业信息存储模型管理组件(241),负责捕获各种信息后系统中存储结构的存储形式和描述)来自各种网页的行业信息,以及存储结构Task的动态生成和管理;用户系统int erface模型库(25)和用户系统接口模型管理组件(251),负责信息存储形式与存储结构、信息传输接口、软件之间的转换关系),每个用户特定的系统描述,接口关系表、接口定义和调用的生成和管理任务。
[技术特点总结]
[专利技术属性]
技术研发人员:刘学明、钱宇、张康、
申请人(专利权):,
类型:发明
国家、省市:32个
下载所有详细技术资料我是此专利的所有者 查看全部
:通用型垂直搜索引擎的行业应用模型建模方法
通用垂直搜索引擎的行业应用模型建模方法,垂直搜索核心模块Spider(1)Access Industry Application Model(2))实现对不同数据的识别、捕获、组织、存储和传输。行业信息、行业应用模型(2)山互联网web库(21))和web存储分类索引管理组件(211)、web结构信息模型库(22)和web结构信息模型管理组件) (22@k21)@、行业信息结构模型库(23)和行业信息结构模型管理组件(231))、行业信息存储模型库(24)和行业信息存储模型管理组件(24) 1),和用户系统界面模型库(25)和用户系统界面模型管理组件(251))。本发明的专利技术解决了同时覆盖不同行业应用、不同的网页、不同的行业信息结构和存储结构在一个模型中。它使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、捕获、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。
下载所有详细的技术资料
【技术实现步骤总结】
该专利技术公开了一种基于。 二.
技术介绍
许多文档将垂直搜索定义为针对单个应用程序或单个功能的搜索技术。现实中,垂直搜索产品和门户网站就是按照这个定义布局的,或者房地产信息搜索门户,或者博客信息搜索门户,或者音乐信息搜索门户,或者专利信息搜索门户。所有这些都是如此。之所以出现这种现象,是因为垂直搜索互联网信息具有明显的行业应用特征、功能应用特征和结构特征。也就是说,由于垂直搜索面临的互联网信息具有明显的行业应用特征、功能应用特征和结构特征,这些千差万别的信息特征导致垂直搜索门户具有明显的单一行业或功能。事实上,垂直搜索引擎的核心模块——数据爬取模块蜘蛛本身可以作为通用技术,并没有严格的行业应用或功能应用边界。原则上,一款好的数据爬虫软件可以完成任何网页、任何行业信息的数据爬取任务。由此看来,垂直搜索技术只适用于单一行业或功能门户的事实并不在于垂直搜索的核心技术——数据爬虫软件蜘蛛,而是来自于核心技术之外。的元素。所以,要搭建一个像谷歌、百度这样的通用垂直搜索平台,垂直搜索的核心技术——数据爬虫软件蜘蛛,就有了这个基础。问题在于,如何围绕具有通用能力的数据爬虫软件构建具有通用能力的外围系统,是实现通用垂直搜索引擎的关键。构建与通用数据爬虫软件蜘蛛相匹配、具有通用能力的行业应用模型是系统研究的重要课题之一。 三.
技术实现思路
该专利技术的目的是提供一种用于一般垂直搜索系统中描述不同行业应用或功能应用特征的方法,使垂直搜索能够完成对互联网信息的识别、抓取和检索。其行业模式。组织、存储和传输应用程序,使它们能够成为通用的垂直搜索引擎。该专利技术的技术方案就是该专利技术。垂直搜索核心模块Spider 1接入行业应用模型2,实现对不同行业信息的识别、抓取、组织、存储和传输。行业应用模型2由互联网网页库21和网页组成。存储分类索引管理组件211、网页结构信息模型库22和页面结构信息模型管理组件221、工业信息结构模型库23和行业信息结构模型管理组件231、工业信息存储模型库24和行业信息存储模型管理组件241、、用户系统界面模型库25和用户系统界面模型管理组件251构成。互联网网页库21和网页存储分类索引管理组件211负责互联网网页库21的存储、分类和索引管理任务。网页存储分类索引管理组件211调用G00gleAPI212进行行业搜索应用程序网页 URL 集合;网页结构信息模型库22和网页结构信息模型管理组件221承担页面和行业应用关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理等任务。行业信息结构模型库23及行业信息结构模型管理组件231负责各种网页中各种行业信息的不同结构形式和页面位置的描述、提取、生成和管理任务。行业信息存储模型库24和行业信息存储模型管理组件241负责系统中各种存储形式和存储结构的描述,从行业信息中获取信息后存储结构的动态生成和管理任务。网页;用户系统接口模型库25和用户系统接口模型管理组件251专用于每个用户信息存储形式和系统间存储结构转换、信息传输接口、软件接口关系形式、接口定义的描述、生成和管理任务并打电话。
网页结构信息模型库22至少收录行业及应用、行业信息分类描述、网页地址URL、网页访问入口参数(用户名、密码、方法代码等)、网页链接方法、网页链接控制参数等信息。网页结构信息模型管理组件221至少包括网页结构信息模型库22基本信息的生成和维护、网页访问入口参数(用户名、密码、方法代码等)库信息的生成和维护,网页链接方法、网页链接控制参数库信息的生成与维护、网页链接控制代码片段的提取/转换/存储、调用处理等功能处理模块。行业信息结构模型库23至少包括行业及应用、行业信息分类描述、网页地址URL、行业信息结构类型、行业信息结构初始标识、行业信息结构描述、行业信息结构中的元数据属性描述、行业信息结构周期捕获标识、行业信息结构捕获端标识、行业信息结构存储指令等信息。行业信息结构模型管理组件231至少包括行业信息结构模型库23的基础信息生成和维护、行业信息结构模型库23的信息辅助分析和自动提取等功能处理模块。模型库24个至少包括行业及应用、行业信息分类描述、行业信息存储目标库及基表指令、行业信息存储结构类型、行业信息存储映射描述、行业信息存储转换处理指令、行业信息存储相关处理说明和其他信息。
行业信息存储模型管理组件241至少包括行业信息存储模型库24的基础信息生成与维护、行业信息存储结构的动态生成、行业信息存储映射控制、行业信息存储转换处理等功能处理模块。该专利技术的显着效果在于,该专利技术从网页索引、网页结构、行业信息结构、行业信息存储结构和用户系统界面五个层面建立了与行业应用信息搜索相关的完整描述和管理。该系统解决了在一个模型中同时覆盖不同行业应用、不同网页、不同行业信息结构和存储结构的问题,具有全行业能力。这项专利技术将使垂直搜索能够完成对不同行业、不同结构的互联网信息的识别、抓取、组织、存储和传输,从而具备通用垂直搜索引擎的多行业应用能力。 四. 附图说明图1为专利技术示意图。其中1=垂直搜索核心组件Spider2=行业应用模型21=互联网网页库211=网页存储分类索引管理组件212=GoogleAPI22=网页结构信息模型库221=网页结构信息模型管理组件23=行业信息结构模型库 231 = 行业信息结构模型管理组件 24 = 行业信息采集模型库 241 = 行业信息采集模型管理组件 25 = 行业信息存储模型库 251 = 行业信息存储模型管理组件 26 = 用户系统界面模型库 261 =用户系统界面模型管理组件图2是专利技术行业应用模型中网页结构信息模型库的结构示例。
图3是专利技术行业应用模型中行业信息结构模型库的结构示例。图4是专利技术行业应用模型中行业信息存储结构模型库的结构示例。 五.具体实施方式实例1如图1所示。 2、本实施例举例说明了专利技术的行业应用模型中网页结构信息模型库的结构示例。示例二参见图3。本实施例举例说明了专利技术的行业应用模型中的行业信息结构模型库的结构示例。实施例3参见图4。本实施例举例说明了专利技术的行业应用模型中的行业信息存储结构模型库的结构示例。权利要求1.,其特征在于垂直搜索核心模块Spider(I)接入行业应用模型(2)),实现不同行业信息的识别、抓取、组织、存储和传输,行业应用模型( 2)由互联网网页库(21)和网页存储分类索引管理组件(211),网页结构信息模型库(22))和网页结构信息模型管理组件(22@) k45@,行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(241),和用户系统界面模型库(2@k53)@和用户系统界面模型管理组件(251);互联网网页库(21))和web存储分类索引管理组件(211)承担)一世htemet web library(21)存储、分类和索引)管理任务,包括web存储分类索引管理
【技术保护点】
通用垂直搜索引擎行业应用模型建模方法的特点是垂直搜索核心模块Spider(1)Access行业应用模型(2))实现识别、捕获、组织、存储和传输应用、行业应用模型(2)来自互联网网页库(21))和网页存储分类索引管理组件(211)、网页结构信息模型库(22)和网页结构信息模型管理组件) (221),行业信息结构模型库(23)和行业信息结构模型管理组件(231),行业信息存储模型库(24)和行业信息存储模型管理组(24@k21) @)) ,以及用户系统界面模型库(25)和用户系统界面模型管理组件(251));其中:Internet web库(21)和web存储分类索引man agement组件(211))网页库(21)存储分类索引管理任务,包括网页存储分类索引管理组件(211)调用GoogleAPI(212))实现行业应用web页面网址集合搜索;网页结构信息模型库(22)和网页结构信息模型管理组件(221)承担页面之间关系的分析、描述、页面访问控制、页面转换链接控制、描述和管理任务)和行业应用;行业信息结构模型库(221)23)和行业信息结构模型管理组件(231),负责不同结构形式和页面的描述、提取、生成和管理任务)各种行业信息在各种网页中的位置;行业信息存储模型库(24)和行业信息存储模型管理组件(241),负责捕获各种信息后系统中存储结构的存储形式和描述)来自各种网页的行业信息,以及存储结构Task的动态生成和管理;用户系统int erface模型库(25)和用户系统接口模型管理组件(251),负责信息存储形式与存储结构、信息传输接口、软件之间的转换关系),每个用户特定的系统描述,接口关系表、接口定义和调用的生成和管理任务。
[技术特点总结]
[专利技术属性]
技术研发人员:刘学明、钱宇、张康、
申请人(专利权):,
类型:发明
国家、省市:32个
下载所有详细技术资料我是此专利的所有者
网站参观者的指标数据(UV、IP)背后都是互联网使用者
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-07-06 23:22
网站参观者的指标数据(UV、IP)背后都是互联网使用者
我推荐一个例子。 “groceries网站”这个词经常出现在我的一篇博客中。当然,这只是推荐的一个例子。
Overture 使要价半透明,在竞争激烈的关键词 中,它将确保您的页面成本接近您的最低要价。
搜索引擎会不断调整其算法。因此,成功的 SEO 专家必须不断研究搜索引擎的不道德行为并自学其工作原理。
如果你已经为网站积极制定了搜索引擎策略,并投入了适当的人力、物力和财力,此时你必须忘记:代价是坚决。
网站visitor网站visitor:网站visitor的指标数据(UV、IP)都是具有不同分析属性(新/现有访问者)、地区)和人口统计属性(性别、年龄、教育等);目的不同,来源不同,采访轨迹也不同,在第2章SEO基础教程|50谷歌优化搜索引擎搜索链接百度搜索引擎分析应该对符合市场定位的访问者进行细分,并做有针对性的比较学习。
然而,事实上,许多消费者甚至商业搜索者都将搜索中的高排名视为表示接受。
更何况普通百度员工也不敢问这个事情。
在打开宽泛的给定部分之前,您要求检查同义词等的搜索结果是否浪费。
查找仅限订阅者或已被删除的内容。您可以在 SERP 列表中查看限制订阅者或已从内存链接中删除的内容或使用 cache: 运算符。
例如,访问者通过搜索引擎转至电子商务网站。指定了一个流畅的页面,一个商品库页面,一个购物车页面,一个收费的流畅页面,整个销售结束,离开网站,只为最后一个支付流畅页面,这是一个解散,但它是未因本次访问的其他页面解散。
如果您不建立销售开关,那么流量就没有任何意义。
网站竞价对数搜索引擎关键词优化排名公司网站根据内容介绍和展示乌龟,更新快。它还有一个站点跟踪程序。
如果您的网站在 30 天内没有被收录于,您可以在几个月后通知您的网站。
最重要的是,对于我们通过这种方式发送给我们的数据,Alexa与我们无关,程序无法将我们与正常访问的数据区分开来。作弊示例1:·另外:Alexa被列入一两年前,现在,已经列出了许多副站长的执着目标之一。很多论坛的副站长为了提高网站排名,拒绝版主安装Alexa工具栏。
这项研究揭示了将自然搜索重新添加到现有付费搜索活动的效果,并将这样做的效果与单独的付费搜索活动进行比较。
其他网站 内容的一些不道德副本。
搜索引擎还可以检查登录用户的搜索历史。
3612、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的搜索引擎优化操作。页面域用户的操作步骤是什么,可以在关键词前加上地区名称,如省或城市名称等
什么是seo搜索引擎优化(SearchEngineOptimization,全称SEO)是一种利用搜索引擎的搜索规则来提高网站在相关搜索引擎中的目的的方式。
图 1-13 总结了结果的改进。
网站Interviewer Times Ranking (Reachrank):根据采访次数排名。
以下是一些基本运算符。
一些罕见的代码用斜体表示。
2.降低信息检索难度雅虎的数据库分为14个类别(每个类别还包括平均数量的小类别),其分类系统非常详细,所以最好进行明确的主题搜索起点,特别是对于那些新用户和对市场需求知之甚少的用户,比起结构化的搜索风格,自由选择要按主题逐级编入索引的网页要自然得多。
Invisable/hiddentext 隐藏搜索引擎和搜索引擎隐藏文本内容的优化旨在通过收录大量关键词的网页增加关键词相关性分数而不影响网站美的目标。
9 变化:互联网是一种非常脆弱的媒介。
雅虎!编辑程序可能会将您网站的新原创页面从其搜索索引中删除。
自由选择系统部署网站 这个链接是网站数据分析实践的开始。它是采集和获取数据的过程。您必须自由选择合适的网站分析系统,以满足分析计划的市场需求。从满足网站分析基础市场的需求来看,以下几点可供大家参考: 第二章SEO基础教程|48 部署非常简单。尽量自由选择方便的网站分析系统,尤其是中小网站技术,在人不多的情况下,标准化代码最坏的情况和全站安装代码一样,没有必要调整转成追踪等功能的代码,也有利于提高之前简单的网站分析的可扩展性。
网站 与清医院相关的请求提交到“区域”类别下的相关类别。
2、在 JAVA 脚本中重用扩展名为 .js 的文件。
搜索算法指出的关键字搜索最多的页面将按顺序排列。
那么,网站移动搜索引擎的构建主要分为三个部分:如何在百度上更好地搜索收录于网站中的内容,以及如何在移动搜索列表中获得更好的名称,如何让用户从海量的搜索结果中快速找到并分页你的网站。
快速“xyz技巧”排名第一,他从这个相似的关键字中获得了一些不错的流量。
当您输入错误的链接组链接时,您可能会链接到它们而不是作弊。
但是如果使用网站background日志来分析,因为内存页可能需要在没有服务器催促的情况下进行指示,所以会被记录为PV。
以动词开头:如果您以强有力且主动的动词开头,则可以显着降低页面访问率。
如果您的网站已经创建,更改文件名只是一个小因素,但如果您正在构建一个新网站,只需一点时间将关键字重新添加到文件名中即可。
这些广告将访问者引导至您的营业地点。
2.4.1 负面列表因素 SEOmoz 的调查也证实了一些负面列表因素。
第四章移动搜索|104 第四部分:更好的排名如何在百度移动搜索中获得更好的排名与PC端的市场需求相同。 收录于问题解问题是排名问题。 查看全部
网站参观者的指标数据(UV、IP)背后都是互联网使用者
我推荐一个例子。 “groceries网站”这个词经常出现在我的一篇博客中。当然,这只是推荐的一个例子。
Overture 使要价半透明,在竞争激烈的关键词 中,它将确保您的页面成本接近您的最低要价。
搜索引擎会不断调整其算法。因此,成功的 SEO 专家必须不断研究搜索引擎的不道德行为并自学其工作原理。
如果你已经为网站积极制定了搜索引擎策略,并投入了适当的人力、物力和财力,此时你必须忘记:代价是坚决。
网站visitor网站visitor:网站visitor的指标数据(UV、IP)都是具有不同分析属性(新/现有访问者)、地区)和人口统计属性(性别、年龄、教育等);目的不同,来源不同,采访轨迹也不同,在第2章SEO基础教程|50谷歌优化搜索引擎搜索链接百度搜索引擎分析应该对符合市场定位的访问者进行细分,并做有针对性的比较学习。
然而,事实上,许多消费者甚至商业搜索者都将搜索中的高排名视为表示接受。
更何况普通百度员工也不敢问这个事情。
在打开宽泛的给定部分之前,您要求检查同义词等的搜索结果是否浪费。
查找仅限订阅者或已被删除的内容。您可以在 SERP 列表中查看限制订阅者或已从内存链接中删除的内容或使用 cache: 运算符。
例如,访问者通过搜索引擎转至电子商务网站。指定了一个流畅的页面,一个商品库页面,一个购物车页面,一个收费的流畅页面,整个销售结束,离开网站,只为最后一个支付流畅页面,这是一个解散,但它是未因本次访问的其他页面解散。
如果您不建立销售开关,那么流量就没有任何意义。
网站竞价对数搜索引擎关键词优化排名公司网站根据内容介绍和展示乌龟,更新快。它还有一个站点跟踪程序。
如果您的网站在 30 天内没有被收录于,您可以在几个月后通知您的网站。
最重要的是,对于我们通过这种方式发送给我们的数据,Alexa与我们无关,程序无法将我们与正常访问的数据区分开来。作弊示例1:·另外:Alexa被列入一两年前,现在,已经列出了许多副站长的执着目标之一。很多论坛的副站长为了提高网站排名,拒绝版主安装Alexa工具栏。
这项研究揭示了将自然搜索重新添加到现有付费搜索活动的效果,并将这样做的效果与单独的付费搜索活动进行比较。
其他网站 内容的一些不道德副本。
搜索引擎还可以检查登录用户的搜索历史。
3612、 与地理位置相关的词汇 如果您的产品或服务针对特定区域的搜索引擎优化操作。页面域用户的操作步骤是什么,可以在关键词前加上地区名称,如省或城市名称等
什么是seo搜索引擎优化(SearchEngineOptimization,全称SEO)是一种利用搜索引擎的搜索规则来提高网站在相关搜索引擎中的目的的方式。
图 1-13 总结了结果的改进。
网站Interviewer Times Ranking (Reachrank):根据采访次数排名。
以下是一些基本运算符。
一些罕见的代码用斜体表示。
2.降低信息检索难度雅虎的数据库分为14个类别(每个类别还包括平均数量的小类别),其分类系统非常详细,所以最好进行明确的主题搜索起点,特别是对于那些新用户和对市场需求知之甚少的用户,比起结构化的搜索风格,自由选择要按主题逐级编入索引的网页要自然得多。
Invisable/hiddentext 隐藏搜索引擎和搜索引擎隐藏文本内容的优化旨在通过收录大量关键词的网页增加关键词相关性分数而不影响网站美的目标。
9 变化:互联网是一种非常脆弱的媒介。
雅虎!编辑程序可能会将您网站的新原创页面从其搜索索引中删除。
自由选择系统部署网站 这个链接是网站数据分析实践的开始。它是采集和获取数据的过程。您必须自由选择合适的网站分析系统,以满足分析计划的市场需求。从满足网站分析基础市场的需求来看,以下几点可供大家参考: 第二章SEO基础教程|48 部署非常简单。尽量自由选择方便的网站分析系统,尤其是中小网站技术,在人不多的情况下,标准化代码最坏的情况和全站安装代码一样,没有必要调整转成追踪等功能的代码,也有利于提高之前简单的网站分析的可扩展性。
网站 与清医院相关的请求提交到“区域”类别下的相关类别。
2、在 JAVA 脚本中重用扩展名为 .js 的文件。
搜索算法指出的关键字搜索最多的页面将按顺序排列。
那么,网站移动搜索引擎的构建主要分为三个部分:如何在百度上更好地搜索收录于网站中的内容,以及如何在移动搜索列表中获得更好的名称,如何让用户从海量的搜索结果中快速找到并分页你的网站。
快速“xyz技巧”排名第一,他从这个相似的关键字中获得了一些不错的流量。
当您输入错误的链接组链接时,您可能会链接到它们而不是作弊。
但是如果使用网站background日志来分析,因为内存页可能需要在没有服务器催促的情况下进行指示,所以会被记录为PV。
以动词开头:如果您以强有力且主动的动词开头,则可以显着降低页面访问率。
如果您的网站已经创建,更改文件名只是一个小因素,但如果您正在构建一个新网站,只需一点时间将关键字重新添加到文件名中即可。
这些广告将访问者引导至您的营业地点。
2.4.1 负面列表因素 SEOmoz 的调查也证实了一些负面列表因素。
第四章移动搜索|104 第四部分:更好的排名如何在百度移动搜索中获得更好的排名与PC端的市场需求相同。 收录于问题解问题是排名问题。
如何使用户关注的网页排列在搜索引擎的排序技术
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-07-06 01:08
搜索引擎的排序技术
摘要:本文简要介绍和比较了搜索引擎目前使用的排序算法,包括词频位置加权排序算法、链接分析排序算法,并着重介绍了PageRank算法和HITS算法的思想及其比较优势和劣势。
关键词:搜索引擎;排行;网页排名;命中
1 前言
谷歌和百度的崛起很大程度上是由于它们使用了比以前的搜索引擎更好的排序技术。由于人们通常只关注搜索结果的前 10 或 20 项,因此将与用户查询结果最相关的信息排在结果的前排尤为重要。例如,.jp、.de 和.edu 域名下的网页通常比.com 和.net 域名下的网页更有用[1]。如何让用户关注的网页在搜索结果中排名靠前,让各家搜索引擎公司不断完善优化方向。笔者将通过阅读论文和网络资料总结介绍几种主要的排序算法:词频位置加权排序算法、链接分析排序算法。
2 词频位置加权排序算法
这类技术是在传统信息检索技术的基础上发展起来的,即用户在网页中输入的搜索词的频率越高,搜索词的位置越重要,则该网页被认为与本次搜索相关。一个词的相关性越高,它在搜索结果中出现的位置就越高。 InfoSeek、Excite、Lycos等早期搜索引擎都采用了这种排序方式。
2.1 词频加权
词频加权是以用户提供的搜索词在网页中出现的次数作为确定网页相关性权重的依据。词频加权方法包括绝对词频加权、相对词频加权、逆词频加权、基于词判别值的加权等。对于单词搜索引擎,可以通过简单地计算一个词在网页中出现的频率来给出权重。对于具有逻辑组装功能的搜索引擎,必须使用其他加权方法。因为在使用组合搜索查询时,搜索结果与搜索查询中的每个搜索词相关,并且每个搜索词在所有网页中的总频率是不同的。如果按总重量排序, 会造成结果无关紧要。这可以通过多种其他方式解决。例如,利用相对词频加权的原理,可以统计大量网页,为所有网页中出现频率较高的词分配一个较低的初始值。相对而言,所有网页中出现频率较低的词被赋予较低的初始值。更高的权重 [2]。
2.2 词位权重
通过为网页中不同位置和布局的词分配不同的权重,可以根据权重确定搜索结果和搜索词的相关程度。字的位置包括页面标题元素、页面描述关键字元素、正文标题、正文内容、正文链接、logo等。布局包括字体、字号、是否加粗或者强调等。比如理解排序技术,搜索“排序技术”时,有两个结果,一个标题是“搜索引擎的排序技术”,另一个文章的标题是“Web Information Retrieval”,但内容有部分 说到搜索引擎的排名技术,显然第一个结果更相关。 “排名技术”这个词应该在第一个结果中给予更大的权重。
2.3 此类算法的优缺点
这种方法的主要优点是使用方便,易于实现,最成熟的发展基本上是目前所有搜索引擎排名核心技术的基础。但是,由于现网内容的质量无法保证,为了使网页在搜索引擎中排名靠前,在网页中添加了相同背景色的图层,并填写了大量的热门关键词,当人们来浏览网页时完全被查看。不,但搜索引擎可以在索引时找到它。这个问题在一定程度上得到了改善,但并没有完全根除。
3 链接分析排名
链接分析排序算法的思想其实来源于纸质文献索引机制,即一篇论文或文献被引用次数越多,其学术价值就越高。同一个网页类比,如果一个网页的链接越多,该网页的重要性就越高。链路分析算法主要分为随机漫游模型,如PageRank算法;基于Hub和Authority的相互强化模型,如HITS及其变体;基于概率模型,如 SALSA;基于贝叶斯模型,如贝叶斯算法及其简化版本。下面将分别介绍这些算法。
3.1 PageRank 算法
Google 搜索引擎有两个重要功能,可以让您获得高度准确的结果。首先,它利用网络的链接特征来计算网页的质量排名,即PageRank;其次,它使用链接来改善搜索结果 [3]。
简单的PageRank原理即如图1所示的那样,从网页A导向网页B的链接被看作是对页面A对页面B的支持投票,Google根据这个投票数来判断页面的重要性。可是 Google 不单单只看投票数(即链接数),对投票的页面也进行分析。重要性高的页面所投的票的评价会更高。
原创PageRank算法:PR(A) = (1-d) + d (PR(T1)/C(T1) +… + PR(Tn)/C(Tn)))<//p
p其中: PR(A):网页A的PageRank值; PR(Ti):链接到页面A的网页Ti的PageRank值; C(Ti):网页Ti的出站链接数; d:阻尼系数,0/p
p在算法的第二个版本中:PR(A) = (1-d) / N + d (PR(T1)/C(T1) +... + PR(Tn)/C(Tn) ))/p
p这里 N 是 Internet 页面的总数。该算法2与算法1并没有完全不同。在随机冲浪模型中,算法2中页面的PageRank值是点击多个链接后到达该页面的实际概率。因此,互联网上所有网页的PageRank值形成一个概率分布,所有RageRank值之和为1。/p
p因为 PR(A) 取决于链接到网页 A 的其他网页的 PageRank 值,而其他网页的 PR 值也取决于指向该网页的网页的 PR 值,所以这是一个递归过程。似乎需要无穷无尽的计算才能获得网页的PR值。根据参考文献5中的实验,递归计算了网络中3.220亿个链接,发现经过52次计算可以得到收敛。稳定的 PageRank 值,在计算一半链接的 PageRank 值时,进行了 45 次计算。通过实验发现,递归计算次数和链接数呈对数比例增加,即要计算N个链接的PageRank值时,只需进行logN次递归计算即可得到稳定的PageRank值[5] ./p
p3.2 Hits 算法/p
p在PageRank算法中,链接被平等对待,每个链接贡献相同的权重。在现实生活中,有些链接指向广告,而有些链接指向权威网页。可以看出,均匀分布的权重不符合实际情况。所以康奈尔大学的Jon Kleinberg博士在1998年首先提出了Hits算法。/p
pHITS算法对网页质量的评价结果体现在它赋予每个网页的两个评价值上:内容权限(Authority)和链接权限(Hub)。/p
p内容权限与网页本身直接提供的内容信息的质量有关。引用的网页越多,内容权限越高;相应地,链接权限与网页提供的超链接的质量有关。相关的。引用高质量内容的页面越多,链接的权威性就越高。根据关键字匹配将查询提交给传统搜索引擎。搜索引擎返回的网页很多,前n个网页作为根集。包括根集合中页面所指向的所有页面,再包括根集合中指向页面的页面,从而扩展了基本集合。 HITS算法输出一组具有较大Hub值的网页和具有较大权限值的网页[6]。/p
p与PageRank等实用算法不同,HITS算法更多的是一种实验性的尝试。从表面上看,HITS算法需要排序的页面数量很少,但由于需要根据内容分析从搜索引擎中提取根集并扩展基本集,这个过程需要相当长的时间,而PageRank算法表面上看,处理的数据量远远超过HITS算法,但是因为在用户查询的时候计算量已经由服务器独立完成,所以用户无需等待。为此,从用户的等待时间来看,PageRank算法应该优于HITS算法。简短[7]。/p
p3.3 其他链接分析和排序算法/p
pPageRank 算法基于用户对网页随机前向浏览的直觉,HITS 算法考虑了Authorative 网页和Hub 网页之间的增强关系。在实际应用中,用户大部分时间是向前浏览网页,但在很多情况下,他们会返回浏览网页。基于上述直观认识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法,该算法考虑了用户返回浏览网页的情况,并保留了随机漫游PageRank 和 HITS 中网页的 Authoritive 分类与 Hub 的想法取消了 Authoritive 和 Hub 之间的相互加强关系[8]。/p
p艾伦鲍罗丁等。提出了一种完整的贝叶斯统计方法来确定 Hub 和 Authoritive 网页。假设有M个Hub网页和N个Authority网页,可以是同一个集合。每个Hub网页都有一个未知实数参数,表示有超链接的总体趋势,还有一个未知的非负参数,表示有链接到Authority网页的趋势。每个权威网页 j 都有一个未知的非负参数,代表 j 的权限级别。统计模型如下。 Hub 网页 i 链接到权威网页 j 的先验概率为:P(i,j)=Exp(+)/(1+Exp(+))。当 Hub 网页 i 和权威网页 j 之间没有链接时,P(i,j)=1/(1+Exp(+))。从上面的公式可以看出,如果非常大(说明Hub网页i有很高的指向任何网页的倾向),或者总和很大(说明i是一个高质量的Hub,j是一个高质量的Authority网页),那么i ->j的链接概率比较大[9]。
4 其他排序技术
除了以上两类排序算法,还有其他排序方式,比如:竞价排名(竞价排名是百度等一些搜索引擎公司推出的一种以价格确定排名的在线推广方式。但是,投标人信息的真实性需要严格筛选,否则用户对搜索引擎的信任将被灰色行业所利用[10])。通过用户反馈提高排序的准确性,通过理解增加排序的相关性,通过智能过滤减少减少。排序结果的重复性等
5 结束语
综上所述,在目前谷歌等搜索引擎中,排序方式非常复杂,需要综合考虑多种因素,而不是单一的上述算法。我个人认为未来搜索引擎会变得更加人性化,搜索结果会根据用户喜好进行排序和过滤。此外,特定领域的专业搜索引擎将逐步发展,例如金融和体育的专业搜索。引擎。相信未来浏览器功能越来越强大,搜索引擎的影响力会越来越大。
参考文献:
[1] Dennis Fetterly、Mark Manasse、Marc Najork、Janet Wiener:网页演变的大规模研究,In:Proc.of the 12th Int'l World Wide Web Conf.New York:ACM Press ,2003.669-678...
[2] 杨思洛.搜索引擎排序技术研究[J].现代图书馆与信息技术,2005,(01).
[3] S.Brin 和 L.Page,“大型超文本 Web 搜索引擎的剖析”,发表在第七届国际万维网会议论文集(WWW7)/Computer Networks,阿姆斯特丹, 1998
[4] Page L, Brin S, etc. PageRank 引文排名:为网络带来秩序[J].斯坦福数字图书馆工作论文,1998,(6):102-107.
[5] T. 有 liwala。 PageRank 的高效计算。 1999-31技术报告,1999.
[6]
[7] 何晓阳,吴强,吴志荣:HITS算法与PageRank算法对比分析。信息学报,2004 年第 2 期
[8]
[9] 朱伟、王超、李军等. Web 超链分析算法研究。计算机科学, 2003, 30(1)
[10]常路,夏祖奇;几种常用的搜索引擎排序算法。图书情报工作,2003 年第 6 期
———————————————————
版权声明:本文为CSDN博主“arthur0808”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接: 查看全部
如何使用户关注的网页排列在搜索引擎的排序技术
搜索引擎的排序技术
摘要:本文简要介绍和比较了搜索引擎目前使用的排序算法,包括词频位置加权排序算法、链接分析排序算法,并着重介绍了PageRank算法和HITS算法的思想及其比较优势和劣势。
关键词:搜索引擎;排行;网页排名;命中
1 前言
谷歌和百度的崛起很大程度上是由于它们使用了比以前的搜索引擎更好的排序技术。由于人们通常只关注搜索结果的前 10 或 20 项,因此将与用户查询结果最相关的信息排在结果的前排尤为重要。例如,.jp、.de 和.edu 域名下的网页通常比.com 和.net 域名下的网页更有用[1]。如何让用户关注的网页在搜索结果中排名靠前,让各家搜索引擎公司不断完善优化方向。笔者将通过阅读论文和网络资料总结介绍几种主要的排序算法:词频位置加权排序算法、链接分析排序算法。
2 词频位置加权排序算法
这类技术是在传统信息检索技术的基础上发展起来的,即用户在网页中输入的搜索词的频率越高,搜索词的位置越重要,则该网页被认为与本次搜索相关。一个词的相关性越高,它在搜索结果中出现的位置就越高。 InfoSeek、Excite、Lycos等早期搜索引擎都采用了这种排序方式。
2.1 词频加权
词频加权是以用户提供的搜索词在网页中出现的次数作为确定网页相关性权重的依据。词频加权方法包括绝对词频加权、相对词频加权、逆词频加权、基于词判别值的加权等。对于单词搜索引擎,可以通过简单地计算一个词在网页中出现的频率来给出权重。对于具有逻辑组装功能的搜索引擎,必须使用其他加权方法。因为在使用组合搜索查询时,搜索结果与搜索查询中的每个搜索词相关,并且每个搜索词在所有网页中的总频率是不同的。如果按总重量排序, 会造成结果无关紧要。这可以通过多种其他方式解决。例如,利用相对词频加权的原理,可以统计大量网页,为所有网页中出现频率较高的词分配一个较低的初始值。相对而言,所有网页中出现频率较低的词被赋予较低的初始值。更高的权重 [2]。
2.2 词位权重
通过为网页中不同位置和布局的词分配不同的权重,可以根据权重确定搜索结果和搜索词的相关程度。字的位置包括页面标题元素、页面描述关键字元素、正文标题、正文内容、正文链接、logo等。布局包括字体、字号、是否加粗或者强调等。比如理解排序技术,搜索“排序技术”时,有两个结果,一个标题是“搜索引擎的排序技术”,另一个文章的标题是“Web Information Retrieval”,但内容有部分 说到搜索引擎的排名技术,显然第一个结果更相关。 “排名技术”这个词应该在第一个结果中给予更大的权重。
2.3 此类算法的优缺点
这种方法的主要优点是使用方便,易于实现,最成熟的发展基本上是目前所有搜索引擎排名核心技术的基础。但是,由于现网内容的质量无法保证,为了使网页在搜索引擎中排名靠前,在网页中添加了相同背景色的图层,并填写了大量的热门关键词,当人们来浏览网页时完全被查看。不,但搜索引擎可以在索引时找到它。这个问题在一定程度上得到了改善,但并没有完全根除。
3 链接分析排名
链接分析排序算法的思想其实来源于纸质文献索引机制,即一篇论文或文献被引用次数越多,其学术价值就越高。同一个网页类比,如果一个网页的链接越多,该网页的重要性就越高。链路分析算法主要分为随机漫游模型,如PageRank算法;基于Hub和Authority的相互强化模型,如HITS及其变体;基于概率模型,如 SALSA;基于贝叶斯模型,如贝叶斯算法及其简化版本。下面将分别介绍这些算法。
3.1 PageRank 算法
Google 搜索引擎有两个重要功能,可以让您获得高度准确的结果。首先,它利用网络的链接特征来计算网页的质量排名,即PageRank;其次,它使用链接来改善搜索结果 [3]。
简单的PageRank原理即如图1所示的那样,从网页A导向网页B的链接被看作是对页面A对页面B的支持投票,Google根据这个投票数来判断页面的重要性。可是 Google 不单单只看投票数(即链接数),对投票的页面也进行分析。重要性高的页面所投的票的评价会更高。
原创PageRank算法:PR(A) = (1-d) + d (PR(T1)/C(T1) +… + PR(Tn)/C(Tn)))<//p
p其中: PR(A):网页A的PageRank值; PR(Ti):链接到页面A的网页Ti的PageRank值; C(Ti):网页Ti的出站链接数; d:阻尼系数,0/p
p在算法的第二个版本中:PR(A) = (1-d) / N + d (PR(T1)/C(T1) +... + PR(Tn)/C(Tn) ))/p
p这里 N 是 Internet 页面的总数。该算法2与算法1并没有完全不同。在随机冲浪模型中,算法2中页面的PageRank值是点击多个链接后到达该页面的实际概率。因此,互联网上所有网页的PageRank值形成一个概率分布,所有RageRank值之和为1。/p
p因为 PR(A) 取决于链接到网页 A 的其他网页的 PageRank 值,而其他网页的 PR 值也取决于指向该网页的网页的 PR 值,所以这是一个递归过程。似乎需要无穷无尽的计算才能获得网页的PR值。根据参考文献5中的实验,递归计算了网络中3.220亿个链接,发现经过52次计算可以得到收敛。稳定的 PageRank 值,在计算一半链接的 PageRank 值时,进行了 45 次计算。通过实验发现,递归计算次数和链接数呈对数比例增加,即要计算N个链接的PageRank值时,只需进行logN次递归计算即可得到稳定的PageRank值[5] ./p
p3.2 Hits 算法/p
p在PageRank算法中,链接被平等对待,每个链接贡献相同的权重。在现实生活中,有些链接指向广告,而有些链接指向权威网页。可以看出,均匀分布的权重不符合实际情况。所以康奈尔大学的Jon Kleinberg博士在1998年首先提出了Hits算法。/p
pHITS算法对网页质量的评价结果体现在它赋予每个网页的两个评价值上:内容权限(Authority)和链接权限(Hub)。/p
p内容权限与网页本身直接提供的内容信息的质量有关。引用的网页越多,内容权限越高;相应地,链接权限与网页提供的超链接的质量有关。相关的。引用高质量内容的页面越多,链接的权威性就越高。根据关键字匹配将查询提交给传统搜索引擎。搜索引擎返回的网页很多,前n个网页作为根集。包括根集合中页面所指向的所有页面,再包括根集合中指向页面的页面,从而扩展了基本集合。 HITS算法输出一组具有较大Hub值的网页和具有较大权限值的网页[6]。/p
p与PageRank等实用算法不同,HITS算法更多的是一种实验性的尝试。从表面上看,HITS算法需要排序的页面数量很少,但由于需要根据内容分析从搜索引擎中提取根集并扩展基本集,这个过程需要相当长的时间,而PageRank算法表面上看,处理的数据量远远超过HITS算法,但是因为在用户查询的时候计算量已经由服务器独立完成,所以用户无需等待。为此,从用户的等待时间来看,PageRank算法应该优于HITS算法。简短[7]。/p
p3.3 其他链接分析和排序算法/p
pPageRank 算法基于用户对网页随机前向浏览的直觉,HITS 算法考虑了Authorative 网页和Hub 网页之间的增强关系。在实际应用中,用户大部分时间是向前浏览网页,但在很多情况下,他们会返回浏览网页。基于上述直观认识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法,该算法考虑了用户返回浏览网页的情况,并保留了随机漫游PageRank 和 HITS 中网页的 Authoritive 分类与 Hub 的想法取消了 Authoritive 和 Hub 之间的相互加强关系[8]。/p
p艾伦鲍罗丁等。提出了一种完整的贝叶斯统计方法来确定 Hub 和 Authoritive 网页。假设有M个Hub网页和N个Authority网页,可以是同一个集合。每个Hub网页都有一个未知实数参数,表示有超链接的总体趋势,还有一个未知的非负参数,表示有链接到Authority网页的趋势。每个权威网页 j 都有一个未知的非负参数,代表 j 的权限级别。统计模型如下。 Hub 网页 i 链接到权威网页 j 的先验概率为:P(i,j)=Exp(+)/(1+Exp(+))。当 Hub 网页 i 和权威网页 j 之间没有链接时,P(i,j)=1/(1+Exp(+))。从上面的公式可以看出,如果非常大(说明Hub网页i有很高的指向任何网页的倾向),或者总和很大(说明i是一个高质量的Hub,j是一个高质量的Authority网页),那么i ->j的链接概率比较大[9]。
4 其他排序技术
除了以上两类排序算法,还有其他排序方式,比如:竞价排名(竞价排名是百度等一些搜索引擎公司推出的一种以价格确定排名的在线推广方式。但是,投标人信息的真实性需要严格筛选,否则用户对搜索引擎的信任将被灰色行业所利用[10])。通过用户反馈提高排序的准确性,通过理解增加排序的相关性,通过智能过滤减少减少。排序结果的重复性等
5 结束语
综上所述,在目前谷歌等搜索引擎中,排序方式非常复杂,需要综合考虑多种因素,而不是单一的上述算法。我个人认为未来搜索引擎会变得更加人性化,搜索结果会根据用户喜好进行排序和过滤。此外,特定领域的专业搜索引擎将逐步发展,例如金融和体育的专业搜索。引擎。相信未来浏览器功能越来越强大,搜索引擎的影响力会越来越大。
参考文献:
[1] Dennis Fetterly、Mark Manasse、Marc Najork、Janet Wiener:网页演变的大规模研究,In:Proc.of the 12th Int'l World Wide Web Conf.New York:ACM Press ,2003.669-678...
[2] 杨思洛.搜索引擎排序技术研究[J].现代图书馆与信息技术,2005,(01).
[3] S.Brin 和 L.Page,“大型超文本 Web 搜索引擎的剖析”,发表在第七届国际万维网会议论文集(WWW7)/Computer Networks,阿姆斯特丹, 1998
[4] Page L, Brin S, etc. PageRank 引文排名:为网络带来秩序[J].斯坦福数字图书馆工作论文,1998,(6):102-107.
[5] T. 有 liwala。 PageRank 的高效计算。 1999-31技术报告,1999.
[6]
[7] 何晓阳,吴强,吴志荣:HITS算法与PageRank算法对比分析。信息学报,2004 年第 2 期
[8]
[9] 朱伟、王超、李军等. Web 超链分析算法研究。计算机科学, 2003, 30(1)
[10]常路,夏祖奇;几种常用的搜索引擎排序算法。图书情报工作,2003 年第 6 期
———————————————————
版权声明:本文为CSDN博主“arthur0808”原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
“探索推荐引擎内部的秘密”系列将带领读者从浅入深
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-07-06 01:02
《探索推荐引擎的奥秘》系列将带领读者由浅入深,探索推荐引擎的机制和实现方法,包括一些基本的优化方法,如聚类、分类应用等。同时,在理论讲解的基础上,还将介绍如何在大规模数据上实现各种推荐策略,优化策略,结合Apache Mahout构建高效的推荐引擎。作为本系列的第一篇文章,本文将深入介绍推荐引擎的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰了解并快速构建适合自己推荐引擎。
信息发现
现在我们进入了一个数据爆炸的时代。随着Web2.0的发展,Web已经成为数据共享的平台。那么,如何让人们想要在海量数据中找到自己需要的信息就会越来越难。
在这种情况下,搜索引擎(谷歌、必应、百度等)就成为了大家快速找到目标信息的最佳方式。当用户比较清楚自己的需求时,使用搜索引擎通过关键字搜索快速找到自己需要的信息是非常方便的。然而,搜索引擎并不能完全满足用户对信息发现的需求,因为在很多情况下,用户其实并不清楚自己的需求,或者用简单的关键词难以表达自己的需求。或者他们需要更符合他们个人品味和喜好的结果,于是就有了推荐系统,对应搜索引擎,大家习惯称它为推荐引擎。
随着推荐引擎的出现,用户获取信息的方式已经从简单的有针对性的数据搜索转变为更符合人们习惯的更高级的信息发现。
现在,随着推荐技术的不断发展,推荐引擎已经在电子商务(电子商务,如亚马逊、当当)和一些基于社交的社交网站(包括音乐、电影和图书分享,如如豆瓣、Mtime等)都取得了巨大的成功。这也进一步说明,在Web2.0环境下,面对海量数据,用户需要这种更智能、更了解自己需求、品味和偏好的信息发现机制。
返回顶部
推荐引擎
之前介绍了推荐引擎对当前Web2.0站点的重要性。在本章中,我们将讨论推荐引擎的工作原理。推荐引擎使用特殊的信息过滤技术向可能感兴趣的用户推荐不同的项目或内容。
图1.推荐引擎的工作原理
图1展示了推荐引擎的工作原理图。在这里,推荐引擎被视为一个黑匣子。它接受的输入是推荐的数据源。一般来说,推荐引擎需要的数据源包括:
显式的用户反馈可以准确反映用户对物品的真实偏好,但需要用户付出额外的代价,而隐式的用户行为也可以通过一些分析处理来反映用户的偏好,但数据并不是很准确,并且一些行为分析有很多噪音。但是只要选择了正确的行为特征,隐含的用户反馈也可以得到很好的效果,只是行为特征的选择在不同的应用中可能会有很大的不同。比如电商网站,购买行为其实是一种隐性反馈,可以很好的表达用户的喜好。
推荐引擎可能会根据不同的推荐机制使用部分数据源,然后基于这些数据,分析某些规则或直接预测和计算用户对其他项目的偏好。这样,推荐引擎就可以在用户进入时推荐用户可能感兴趣的项目。
推荐引擎分类
推荐引擎的分类可以基于很多指标,下面我们一一介绍:
推荐引擎是否为不同的用户推荐不同的数据?
根据该指标,推荐引擎可分为基于流行行为的推荐引擎和个性化推荐引擎
这是推荐引擎最基本的分类。事实上,人们讨论的大多数推荐引擎都是个性化推荐引擎,因为从根本上讲,只有个性化推荐引擎才是更智能的信息发现过程。 .
根据推荐引擎的数据来源
其实这里就是如何发现数据的相关性,因为大部分推荐引擎都是基于相似的物品集或者用户推荐的。然后参考图1给出的推荐系统示意图,根据不同的数据源发现数据相关性的方法可以分为以下几种:
根据推荐模型的建立
可以想象,在一个拥有大量物品和用户的系统中,推荐引擎的计算量是相当大的。为了实现实时推荐,必须建立推荐模型。推荐模型的建立可以分为以下几种:
事实上,在目前的推荐系统中,很少有推荐引擎只使用一种推荐策略。一般在不同的场景下使用不同的推荐策略来达到最好的推荐效果,比如亚马逊的推荐。它根据用户自身的历史购买数据进行推荐,根据用户当前浏览过的商品进行推荐,根据流行偏好将当前热门商品推荐给不同地区的用户,让用户可以从全方位的推荐中找到适合的商品你真的很感兴趣。
深度推荐机制
本章的篇幅将详细介绍每种推荐机制的工作原理、优缺点和应用场景。
基于人口统计的推荐
基于人口统计的推荐是最容易实施的推荐方法。它只是根据系统用户的基本信息发现用户的相关性,然后将类似用户喜欢的其他物品推荐给当前用户。图 2 显示了此建议的工作原理。
图2.基于人口统计的推荐机制的工作原理
从图中可以清楚地看出,首先,系统对每个用户都有一个用户画像建模,其中包括用户的基本信息,比如用户的年龄、性别等;用户画像计算用户的相似度,可以看到用户A的画像和用户C是一样的,那么系统就会认为用户A和C是相似的用户。在推荐引擎中,他们可以称为“邻居”;最后,根据“邻居”用户组的偏好,向当前用户推荐一些物品,图中将用户A喜欢的物品A推荐给用户C。
这种基于人口统计的推荐机制的好处是:
因为没有使用当前用户对物品的偏好历史数据,所以不存在新用户的“冷启动”问题。该方法不依赖于item本身的数据,因此该方法可以用于不同item的域中,并且是域无关的。
那么这种方法有什么缺点和问题呢?这种根据用户的基本信息对用户进行分类的方法过于粗糙,尤其是在书籍、电影、音乐等对品味要求较高的领域,无法获得很好的推荐效果。也许在一些电商网站,这个方法可以给出一些简单的建议。另一个限制是,这种方法可能涉及到一些与信息发现问题本身无关的敏感信息,例如用户的年龄等,这些用户信息不是很容易获取。
基于内容的推荐
基于内容的推荐是推荐引擎出现之初使用最广泛的推荐机制。其核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的喜好进行记录,向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图3.基于内容推荐机制的基本原理
基于内容的推荐的典型示例如图 3 所示。在电影推荐系统中,首先我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;元数据发现电影之间的相似性,因为类型都是“爱情、浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影导演、演员等);最后,建议实现。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优势在于它可以很好地模拟用户的口味并提供更准确的推荐。但它也存在以下问题:
文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。由于需要根据用户过去的偏好历史进行推荐,因此新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。有的网站还请专业人士对项目进行基因编码,比如Pandora,在一份报告中说,在Pandora的推荐引擎中,每首歌曲都有100多个元数据特征,包括歌曲风格、年份、歌手等。
基于协同过滤的推荐
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,发现一组与当前用户的口味和偏好相似的“邻居”。一般应用中,计算“K-Neighbors”算法;然后,根据这K个邻居的历史偏好信息,为当前用户做出推荐。下图4为示意图。
图4.基于用户的协同过滤推荐机制基本原理
上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目D可以推荐给用户A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户的特征,而基于用户的协同过滤机制根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能相同或相似。口味和偏好。
基于项目的协同过滤推荐
基于物品的协同过滤推荐的基本原理也类似,只不过是利用所有用户对物品或信息的偏好来寻找物品与物品之间的相似度,然后根据用户的历史偏好信息,得出相似的向用户推荐项目。图 5 说明了其基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C 相似。喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上面类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品本身的属性特征信息。
图5.基于项目的协同过滤推荐机制基本原理
同时协同过滤,基于用户和基于项目的策略我们应该如何选择?实际上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,其实可以看出,推荐策略的选择与具体的应用场景有很大关系。
基于模型的协同过滤推荐
基于模型的协同过滤推荐是基于基于样本的用户偏好信息,训练推荐模型,然后根据实时用户偏好信息预测和计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优势:
它不需要对对象或用户进行严格的建模,也不需要对对象的描述是机器可理解的,所以这种方法也是领域无关的。这种方法计算出来的推荐是公开的,可以分享他人的经验,很好的支持用户发现潜在的兴趣和偏好
而且它还存在以下问题:
该方法的核心是基于历史数据,因此对于新项目和新用户存在“冷启动”问题。推荐的效果取决于用户历史偏好数据的数量和准确性。在大多数实现中,用户的历史偏好存储在一个稀疏矩阵中,在稀疏矩阵上的计算存在一些明显的问题,包括少数人的错误偏好可能会对计算的准确性产生很大影响。推荐等。对于一些有特殊品味的用户,我们无法给出好的建议。基于历史数据,在对用户偏好进行捕获和建模后,很难根据用户的使用情况进行修改或进化,这使得该方法不够灵活。
混合推荐机制
当前网站上的推荐往往不是简单地使用某种推荐机制和策略。他们经常混合多种方法来获得更好的推荐结果。关于如何组合各种推荐机制,这里介绍几种比较流行的组合方式。
Weighted Hybridization:使用一个线性公式,根据一定的权重组合几个不同的推荐。具体的权重值需要在测试数据集上反复测试才能达到最佳推荐效果。 Switching Hybridization:前面说过,其实对于不同的情况(数据量、系统运行状态、用户和物品数量等),推荐策略可能会有很大的不同,所以切换Hybridization的方式是允许选择的最适合的推荐机制来计算不同情况下的推荐。 Mixed Hybridization:采用多种推荐机制,向不同区域的用户展示不同的推荐结果。事实上,亚马逊、当当等众多电商网站都采用了这种方式,用户可以获得全面的推荐,也更容易找到自己想要的东西。 Meta-Level Hybridization:采用多种推荐机制,将一种推荐机制的结果作为另一种推荐机制的输入,综合各推荐机制的优缺点,获得更精准的推荐。
推荐引擎的应用
在介绍了推荐引擎的基本原理和基本推荐机制后,下面简要分析几个有代表性的推荐引擎的应用。这里我们选择两个领域:以亚马逊为代表的电子商务和以豆瓣为代表的社交网络。
电子商务中的推荐应用-亚马逊
亚马逊作为推荐引擎的鼻祖,将推荐的思想渗透到了应用的每一个角落。亚马逊推荐的核心是通过数据挖掘算法将用户的消费偏好与其他用户进行比较,从而预测用户可能感兴趣的产品。 对应上面介绍的各种推荐机制,亚马逊采用分区混合机制,展示给不同领域的用户不同的推荐结果。图 6 和图 7 显示了用户可以在亚马逊上获得的推荐。
图6.亚马逊的推荐机制-首页
图7.亚马逊的推荐机制-浏览商品
亚马逊利用网站上所有可以记录的用户行为,根据不同数据的特点进行处理,划分不同区域为用户推送推荐:
值得一提的是,亚马逊在做推荐的时候,设计和用户体验也很独特:
亚马逊利用其大量历史数据来量化推荐原因。
此外,亚马逊的很多推荐都是根据用户的个人资料计算出来的。用户个人资料记录了用户在亚马逊上的行为,包括浏览过的商品、购买过的商品、采集中的商品和心愿单等。当然,亚马逊还集成了评分等其他用户反馈方式,这些都是用户反馈的一部分。轮廓。同时,亚马逊提供了允许用户管理自己的个人资料的功能。这样,用户可以更清楚地告诉推荐引擎他的品味和意图是什么。
社交网站-豆瓣推荐应用
豆瓣是中国相对成功的社交网络网站。形成以图书、电影、音乐、同城活动为中心的多元化社交网络平台。自然推荐的功能必不可少。下面我们看看豆瓣是如何推荐的。
图8.豆瓣的推荐机制-豆瓣电影
当你在豆瓣电影中加入一些你看过或者感兴趣的电影到你看过想看的列表中,并给它们相应的评分,那么豆瓣的推荐引擎就已经给你一些偏好信息了,那么它将显示如图 8 所示的电影推荐。
图 9. 豆瓣推荐机制——基于用户品味的推荐
豆瓣的推荐是通过“豆瓣猜”。为了让用户知道这些推荐是怎么来的,豆瓣还简单介绍了“豆瓣猜”。
“您的个人推荐是根据您的采集和评论自动得出的。每个人的推荐列表都不一样。您的采集和评论越多,豆瓣的推荐就越准确和丰富。
每天推荐的内容可能会发生变化。随着豆瓣的成长,推荐给你的内容会越来越精准。 "
这点让我们清楚的知道豆瓣一定是基于社交协同过滤的推荐。这样,用户越多,用户反馈越多,推荐效果就会越准确。
相比亚马逊的用户行为模型,豆瓣电影的模型更简单,即“看过”和“想看”,这也使得他们的推荐更注重用户的口味,毕竟买东西的动机和看电影还是有很大区别的。
此外,豆瓣也有基于物品本身的推荐。当你查看一些电影的详细信息时,他会向你推荐“喜欢这部电影的人也喜欢的电影”,如图10所示,基于协同过滤应用。
图10.豆瓣的推荐机制——基于电影本身的推荐
总结
在网络数据爆炸的时代,如何让用户更快地找到自己想要的数据,如何让用户发现自己潜在的兴趣和需求,对于电子商务和社交网络应用来说都非常重要。随着推荐引擎的出现,这个问题越来越受到关注。但是对于大多数人来说,可能还在疑惑为什么它总能猜出你想要什么。推荐引擎的神奇之处在于,您不知道引擎在此推荐背后记录和推断的内容。
通过这篇评论文章,你可以了解到推荐引擎其实只是在默默的记录和观察你的一举一动,然后利用所有用户产生的海量数据去分析发现规律,然后慢慢慢慢了解你,你的需求,你的习惯,默默地帮你快速解决问题,找到你想要的。
实际上,回过头来看,很多时候,推荐引擎比你更了解你自己。
通过第一篇文章,相信大家对推荐引擎有了清晰的第一印象。本系列下一篇文章将深入介绍基于协同过滤的推荐策略。在目前的推荐技术和算法中,被广泛认可和采用的方法是基于协同过滤的推荐方法。以其简单的方法模型、低数据依赖、便捷的数据采集、优越的推荐效果,成为大众眼中的“No.1”推荐算法。本文将带你深入了解协同过滤的奥秘,并给出基于Apache Mahout的协同过滤算法的高效实现。 Apache Mahout 是 ASF 的一个相对较新的开源项目。它源自Lucene,建立在Hadoop之上,专注于经典机器学习算法在海量数据上的高效实现。
原文链接为:@126/blog/static/24269713813/
转载于: 查看全部
“探索推荐引擎内部的秘密”系列将带领读者从浅入深
《探索推荐引擎的奥秘》系列将带领读者由浅入深,探索推荐引擎的机制和实现方法,包括一些基本的优化方法,如聚类、分类应用等。同时,在理论讲解的基础上,还将介绍如何在大规模数据上实现各种推荐策略,优化策略,结合Apache Mahout构建高效的推荐引擎。作为本系列的第一篇文章,本文将深入介绍推荐引擎的工作原理,涉及的各种推荐机制,以及各自的优缺点和适用场景,帮助用户清晰了解并快速构建适合自己推荐引擎。
信息发现
现在我们进入了一个数据爆炸的时代。随着Web2.0的发展,Web已经成为数据共享的平台。那么,如何让人们想要在海量数据中找到自己需要的信息就会越来越难。
在这种情况下,搜索引擎(谷歌、必应、百度等)就成为了大家快速找到目标信息的最佳方式。当用户比较清楚自己的需求时,使用搜索引擎通过关键字搜索快速找到自己需要的信息是非常方便的。然而,搜索引擎并不能完全满足用户对信息发现的需求,因为在很多情况下,用户其实并不清楚自己的需求,或者用简单的关键词难以表达自己的需求。或者他们需要更符合他们个人品味和喜好的结果,于是就有了推荐系统,对应搜索引擎,大家习惯称它为推荐引擎。
随着推荐引擎的出现,用户获取信息的方式已经从简单的有针对性的数据搜索转变为更符合人们习惯的更高级的信息发现。
现在,随着推荐技术的不断发展,推荐引擎已经在电子商务(电子商务,如亚马逊、当当)和一些基于社交的社交网站(包括音乐、电影和图书分享,如如豆瓣、Mtime等)都取得了巨大的成功。这也进一步说明,在Web2.0环境下,面对海量数据,用户需要这种更智能、更了解自己需求、品味和偏好的信息发现机制。
返回顶部
推荐引擎
之前介绍了推荐引擎对当前Web2.0站点的重要性。在本章中,我们将讨论推荐引擎的工作原理。推荐引擎使用特殊的信息过滤技术向可能感兴趣的用户推荐不同的项目或内容。
图1.推荐引擎的工作原理
图1展示了推荐引擎的工作原理图。在这里,推荐引擎被视为一个黑匣子。它接受的输入是推荐的数据源。一般来说,推荐引擎需要的数据源包括:
显式的用户反馈可以准确反映用户对物品的真实偏好,但需要用户付出额外的代价,而隐式的用户行为也可以通过一些分析处理来反映用户的偏好,但数据并不是很准确,并且一些行为分析有很多噪音。但是只要选择了正确的行为特征,隐含的用户反馈也可以得到很好的效果,只是行为特征的选择在不同的应用中可能会有很大的不同。比如电商网站,购买行为其实是一种隐性反馈,可以很好的表达用户的喜好。
推荐引擎可能会根据不同的推荐机制使用部分数据源,然后基于这些数据,分析某些规则或直接预测和计算用户对其他项目的偏好。这样,推荐引擎就可以在用户进入时推荐用户可能感兴趣的项目。
推荐引擎分类
推荐引擎的分类可以基于很多指标,下面我们一一介绍:
推荐引擎是否为不同的用户推荐不同的数据?
根据该指标,推荐引擎可分为基于流行行为的推荐引擎和个性化推荐引擎
这是推荐引擎最基本的分类。事实上,人们讨论的大多数推荐引擎都是个性化推荐引擎,因为从根本上讲,只有个性化推荐引擎才是更智能的信息发现过程。 .
根据推荐引擎的数据来源
其实这里就是如何发现数据的相关性,因为大部分推荐引擎都是基于相似的物品集或者用户推荐的。然后参考图1给出的推荐系统示意图,根据不同的数据源发现数据相关性的方法可以分为以下几种:
根据推荐模型的建立
可以想象,在一个拥有大量物品和用户的系统中,推荐引擎的计算量是相当大的。为了实现实时推荐,必须建立推荐模型。推荐模型的建立可以分为以下几种:
事实上,在目前的推荐系统中,很少有推荐引擎只使用一种推荐策略。一般在不同的场景下使用不同的推荐策略来达到最好的推荐效果,比如亚马逊的推荐。它根据用户自身的历史购买数据进行推荐,根据用户当前浏览过的商品进行推荐,根据流行偏好将当前热门商品推荐给不同地区的用户,让用户可以从全方位的推荐中找到适合的商品你真的很感兴趣。
深度推荐机制
本章的篇幅将详细介绍每种推荐机制的工作原理、优缺点和应用场景。
基于人口统计的推荐
基于人口统计的推荐是最容易实施的推荐方法。它只是根据系统用户的基本信息发现用户的相关性,然后将类似用户喜欢的其他物品推荐给当前用户。图 2 显示了此建议的工作原理。
图2.基于人口统计的推荐机制的工作原理
从图中可以清楚地看出,首先,系统对每个用户都有一个用户画像建模,其中包括用户的基本信息,比如用户的年龄、性别等;用户画像计算用户的相似度,可以看到用户A的画像和用户C是一样的,那么系统就会认为用户A和C是相似的用户。在推荐引擎中,他们可以称为“邻居”;最后,根据“邻居”用户组的偏好,向当前用户推荐一些物品,图中将用户A喜欢的物品A推荐给用户C。
这种基于人口统计的推荐机制的好处是:
因为没有使用当前用户对物品的偏好历史数据,所以不存在新用户的“冷启动”问题。该方法不依赖于item本身的数据,因此该方法可以用于不同item的域中,并且是域无关的。
那么这种方法有什么缺点和问题呢?这种根据用户的基本信息对用户进行分类的方法过于粗糙,尤其是在书籍、电影、音乐等对品味要求较高的领域,无法获得很好的推荐效果。也许在一些电商网站,这个方法可以给出一些简单的建议。另一个限制是,这种方法可能涉及到一些与信息发现问题本身无关的敏感信息,例如用户的年龄等,这些用户信息不是很容易获取。
基于内容的推荐
基于内容的推荐是推荐引擎出现之初使用最广泛的推荐机制。其核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的喜好进行记录,向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图3.基于内容推荐机制的基本原理
基于内容的推荐的典型示例如图 3 所示。在电影推荐系统中,首先我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;元数据发现电影之间的相似性,因为类型都是“爱情、浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影导演、演员等);最后,建议实现。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优势在于它可以很好地模拟用户的口味并提供更准确的推荐。但它也存在以下问题:
文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。由于需要根据用户过去的偏好历史进行推荐,因此新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。有的网站还请专业人士对项目进行基因编码,比如Pandora,在一份报告中说,在Pandora的推荐引擎中,每首歌曲都有100多个元数据特征,包括歌曲风格、年份、歌手等。
基于协同过滤的推荐
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,发现一组与当前用户的口味和偏好相似的“邻居”。一般应用中,计算“K-Neighbors”算法;然后,根据这K个邻居的历史偏好信息,为当前用户做出推荐。下图4为示意图。
图4.基于用户的协同过滤推荐机制基本原理
上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目D可以推荐给用户A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户的特征,而基于用户的协同过滤机制根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能相同或相似。口味和偏好。
基于项目的协同过滤推荐
基于物品的协同过滤推荐的基本原理也类似,只不过是利用所有用户对物品或信息的偏好来寻找物品与物品之间的相似度,然后根据用户的历史偏好信息,得出相似的向用户推荐项目。图 5 说明了其基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C 相似。喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上面类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品本身的属性特征信息。
图5.基于项目的协同过滤推荐机制基本原理
同时协同过滤,基于用户和基于项目的策略我们应该如何选择?实际上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,其实可以看出,推荐策略的选择与具体的应用场景有很大关系。
基于模型的协同过滤推荐
基于模型的协同过滤推荐是基于基于样本的用户偏好信息,训练推荐模型,然后根据实时用户偏好信息预测和计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优势:
它不需要对对象或用户进行严格的建模,也不需要对对象的描述是机器可理解的,所以这种方法也是领域无关的。这种方法计算出来的推荐是公开的,可以分享他人的经验,很好的支持用户发现潜在的兴趣和偏好
而且它还存在以下问题:
该方法的核心是基于历史数据,因此对于新项目和新用户存在“冷启动”问题。推荐的效果取决于用户历史偏好数据的数量和准确性。在大多数实现中,用户的历史偏好存储在一个稀疏矩阵中,在稀疏矩阵上的计算存在一些明显的问题,包括少数人的错误偏好可能会对计算的准确性产生很大影响。推荐等。对于一些有特殊品味的用户,我们无法给出好的建议。基于历史数据,在对用户偏好进行捕获和建模后,很难根据用户的使用情况进行修改或进化,这使得该方法不够灵活。
混合推荐机制
当前网站上的推荐往往不是简单地使用某种推荐机制和策略。他们经常混合多种方法来获得更好的推荐结果。关于如何组合各种推荐机制,这里介绍几种比较流行的组合方式。
Weighted Hybridization:使用一个线性公式,根据一定的权重组合几个不同的推荐。具体的权重值需要在测试数据集上反复测试才能达到最佳推荐效果。 Switching Hybridization:前面说过,其实对于不同的情况(数据量、系统运行状态、用户和物品数量等),推荐策略可能会有很大的不同,所以切换Hybridization的方式是允许选择的最适合的推荐机制来计算不同情况下的推荐。 Mixed Hybridization:采用多种推荐机制,向不同区域的用户展示不同的推荐结果。事实上,亚马逊、当当等众多电商网站都采用了这种方式,用户可以获得全面的推荐,也更容易找到自己想要的东西。 Meta-Level Hybridization:采用多种推荐机制,将一种推荐机制的结果作为另一种推荐机制的输入,综合各推荐机制的优缺点,获得更精准的推荐。
推荐引擎的应用
在介绍了推荐引擎的基本原理和基本推荐机制后,下面简要分析几个有代表性的推荐引擎的应用。这里我们选择两个领域:以亚马逊为代表的电子商务和以豆瓣为代表的社交网络。
电子商务中的推荐应用-亚马逊
亚马逊作为推荐引擎的鼻祖,将推荐的思想渗透到了应用的每一个角落。亚马逊推荐的核心是通过数据挖掘算法将用户的消费偏好与其他用户进行比较,从而预测用户可能感兴趣的产品。 对应上面介绍的各种推荐机制,亚马逊采用分区混合机制,展示给不同领域的用户不同的推荐结果。图 6 和图 7 显示了用户可以在亚马逊上获得的推荐。
图6.亚马逊的推荐机制-首页
图7.亚马逊的推荐机制-浏览商品
亚马逊利用网站上所有可以记录的用户行为,根据不同数据的特点进行处理,划分不同区域为用户推送推荐:
值得一提的是,亚马逊在做推荐的时候,设计和用户体验也很独特:
亚马逊利用其大量历史数据来量化推荐原因。
此外,亚马逊的很多推荐都是根据用户的个人资料计算出来的。用户个人资料记录了用户在亚马逊上的行为,包括浏览过的商品、购买过的商品、采集中的商品和心愿单等。当然,亚马逊还集成了评分等其他用户反馈方式,这些都是用户反馈的一部分。轮廓。同时,亚马逊提供了允许用户管理自己的个人资料的功能。这样,用户可以更清楚地告诉推荐引擎他的品味和意图是什么。
社交网站-豆瓣推荐应用
豆瓣是中国相对成功的社交网络网站。形成以图书、电影、音乐、同城活动为中心的多元化社交网络平台。自然推荐的功能必不可少。下面我们看看豆瓣是如何推荐的。
图8.豆瓣的推荐机制-豆瓣电影
当你在豆瓣电影中加入一些你看过或者感兴趣的电影到你看过想看的列表中,并给它们相应的评分,那么豆瓣的推荐引擎就已经给你一些偏好信息了,那么它将显示如图 8 所示的电影推荐。
图 9. 豆瓣推荐机制——基于用户品味的推荐
豆瓣的推荐是通过“豆瓣猜”。为了让用户知道这些推荐是怎么来的,豆瓣还简单介绍了“豆瓣猜”。
“您的个人推荐是根据您的采集和评论自动得出的。每个人的推荐列表都不一样。您的采集和评论越多,豆瓣的推荐就越准确和丰富。
每天推荐的内容可能会发生变化。随着豆瓣的成长,推荐给你的内容会越来越精准。 "
这点让我们清楚的知道豆瓣一定是基于社交协同过滤的推荐。这样,用户越多,用户反馈越多,推荐效果就会越准确。
相比亚马逊的用户行为模型,豆瓣电影的模型更简单,即“看过”和“想看”,这也使得他们的推荐更注重用户的口味,毕竟买东西的动机和看电影还是有很大区别的。
此外,豆瓣也有基于物品本身的推荐。当你查看一些电影的详细信息时,他会向你推荐“喜欢这部电影的人也喜欢的电影”,如图10所示,基于协同过滤应用。
图10.豆瓣的推荐机制——基于电影本身的推荐
总结
在网络数据爆炸的时代,如何让用户更快地找到自己想要的数据,如何让用户发现自己潜在的兴趣和需求,对于电子商务和社交网络应用来说都非常重要。随着推荐引擎的出现,这个问题越来越受到关注。但是对于大多数人来说,可能还在疑惑为什么它总能猜出你想要什么。推荐引擎的神奇之处在于,您不知道引擎在此推荐背后记录和推断的内容。
通过这篇评论文章,你可以了解到推荐引擎其实只是在默默的记录和观察你的一举一动,然后利用所有用户产生的海量数据去分析发现规律,然后慢慢慢慢了解你,你的需求,你的习惯,默默地帮你快速解决问题,找到你想要的。
实际上,回过头来看,很多时候,推荐引擎比你更了解你自己。
通过第一篇文章,相信大家对推荐引擎有了清晰的第一印象。本系列下一篇文章将深入介绍基于协同过滤的推荐策略。在目前的推荐技术和算法中,被广泛认可和采用的方法是基于协同过滤的推荐方法。以其简单的方法模型、低数据依赖、便捷的数据采集、优越的推荐效果,成为大众眼中的“No.1”推荐算法。本文将带你深入了解协同过滤的奥秘,并给出基于Apache Mahout的协同过滤算法的高效实现。 Apache Mahout 是 ASF 的一个相对较新的开源项目。它源自Lucene,建立在Hadoop之上,专注于经典机器学习算法在海量数据上的高效实现。
原文链接为:@126/blog/static/24269713813/
转载于:

