
搜索引擎主题模型优化
搜索引擎主题模型优化(基于Web信息抽取的本文技术优化策略研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-28 12:06
[摘要]:随着互联网技术的飞速发展,在线信息呈指数级增长。由于网络信息载体的异质性和可变性,如何对海量信息进行检索和处理成为当前重要的研究课题。网页信息抽取是指从半结构化网页中抽取指定信息,并将结构化数据形成数据库供用户查询和使用的过程。 Web信息抽取是提高信息检索性能的重要手段之一,尤其是在垂直领域。本文研究了垂直搜索引擎中的Web信息提取技术。本文首先总结了Web信息抽取的主要技术,从Web信息抽取系统的构成入手,分析了模板检测、模板生成和数据抽取三个主要过程中涉及的关键问题和传统解决方案。针对传统信息抽取技术在垂直搜索引擎应用背景下的局限性,提出了相应的改进方法。对于模板检测,本文在传统DOM树编辑距离算法的基础上,根据节点对布局的影响程度赋予不同的权重,提出了一种新的网页结构相似度计算算法。实验结果分析表明,新算法对动态模板网页的聚类效果比传统算法有显着提升。针对模板生成和数据提取,本文提出了一种基于聚类的模板混合生成算法,将网页聚类过程中样本网页的结构相似性比较和模板生成中样本网页与模板的结构相似性比较结合起来。过程。改进了模板的生成方式。对于数据提取,本文在定义网页对象概念的基础上,研究了对象提取过程中网页与网页提取模板的匹配问题,提出了一种基于结构树调整的模板匹配算法。实验结果表明,新的模板生成和数据提取算法在保证一定召回率的同时,能够达到令人满意的提取精度,同时减少计算时间和人力成本,使其更符合商业搜索引擎的应用需求。最后,本文讨论了商业搜索引擎的技术优化策略,主要包括基于URL模式分析和网页信息质量分析的网页采集路径优化和提取模板匹配优化。此外,本文还研究了商业垂直搜索引擎应用背景下Web信息抽取系统的系统设计与实现。采用基于.Net平台的Silverlight技术,将所提出的算法和设计成功应用于自主研发的垂直搜索引擎系统——GeeSeek的实际应用表明,该系统能够有效提升用户的搜索体验。网络信息提取的发展非常迅速。目前,网络信息抽取研究的信息来源基本上是已经构建好的网页,而互联网上的大部分数据仍然以数据库的形式存在于各种分布式服务器上。如何提取这些信息?这将是我们接下来需要研究的工作。 查看全部
搜索引擎主题模型优化(基于Web信息抽取的本文技术优化策略研究)
[摘要]:随着互联网技术的飞速发展,在线信息呈指数级增长。由于网络信息载体的异质性和可变性,如何对海量信息进行检索和处理成为当前重要的研究课题。网页信息抽取是指从半结构化网页中抽取指定信息,并将结构化数据形成数据库供用户查询和使用的过程。 Web信息抽取是提高信息检索性能的重要手段之一,尤其是在垂直领域。本文研究了垂直搜索引擎中的Web信息提取技术。本文首先总结了Web信息抽取的主要技术,从Web信息抽取系统的构成入手,分析了模板检测、模板生成和数据抽取三个主要过程中涉及的关键问题和传统解决方案。针对传统信息抽取技术在垂直搜索引擎应用背景下的局限性,提出了相应的改进方法。对于模板检测,本文在传统DOM树编辑距离算法的基础上,根据节点对布局的影响程度赋予不同的权重,提出了一种新的网页结构相似度计算算法。实验结果分析表明,新算法对动态模板网页的聚类效果比传统算法有显着提升。针对模板生成和数据提取,本文提出了一种基于聚类的模板混合生成算法,将网页聚类过程中样本网页的结构相似性比较和模板生成中样本网页与模板的结构相似性比较结合起来。过程。改进了模板的生成方式。对于数据提取,本文在定义网页对象概念的基础上,研究了对象提取过程中网页与网页提取模板的匹配问题,提出了一种基于结构树调整的模板匹配算法。实验结果表明,新的模板生成和数据提取算法在保证一定召回率的同时,能够达到令人满意的提取精度,同时减少计算时间和人力成本,使其更符合商业搜索引擎的应用需求。最后,本文讨论了商业搜索引擎的技术优化策略,主要包括基于URL模式分析和网页信息质量分析的网页采集路径优化和提取模板匹配优化。此外,本文还研究了商业垂直搜索引擎应用背景下Web信息抽取系统的系统设计与实现。采用基于.Net平台的Silverlight技术,将所提出的算法和设计成功应用于自主研发的垂直搜索引擎系统——GeeSeek的实际应用表明,该系统能够有效提升用户的搜索体验。网络信息提取的发展非常迅速。目前,网络信息抽取研究的信息来源基本上是已经构建好的网页,而互联网上的大部分数据仍然以数据库的形式存在于各种分布式服务器上。如何提取这些信息?这将是我们接下来需要研究的工作。
本文充分利用语义Web和本体论的相关技术理论,将本体论构建模型SMBDI
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-26 18:12
[摘要]:在互联网信息不断膨胀的今天,搜索引擎已经成为人们获取信息不可或缺的工具。但是,随着信息量的增加和行为的增多,传统的搜索模式逐渐暴露出许多问题,如词汇孤岛问题、表达差异问题、忠实表达问题和机械匹配问题。造成这些问题的根本原因在于,传统搜索引擎无法对用户输入的关键词词义进行分析和扩展,缺乏知识处理和理解能力。本文充分利用语义网和本体的相关技术理论,将本体构建语义模型的能力应用到智能搜索研究中,最终实现了基于本体的智能搜索模型SMBDI。研究内容包括基于本体的XML信息代理数据集成、基于概念的用户界面、查询处理和算法。在深入分析信息代理DTD与本体模型关系的基础上,提出了一种基于本体的数据集成方案。该项目旨在在网络中集成XML信息代理实现大规模搜索,并通过路径映射理论实现概念的语义集成,避免表达差异导致的信息缺失。同时,通过真实概念识别底层数据,有效避免了机械匹配问题,保证了结果的准确性。基于统一语义考虑和用户搜索行为分析,设计了一个基于概念的用户界面。该界面突破了传统的界面模式,采用图形化本体导航、人性化约束机制和自主输出定制,更深刻地解决了查询如实表达的问题,使人机交互更易理解。 查看全部
本文充分利用语义Web和本体论的相关技术理论,将本体论构建模型SMBDI
[摘要]:在互联网信息不断膨胀的今天,搜索引擎已经成为人们获取信息不可或缺的工具。但是,随着信息量的增加和行为的增多,传统的搜索模式逐渐暴露出许多问题,如词汇孤岛问题、表达差异问题、忠实表达问题和机械匹配问题。造成这些问题的根本原因在于,传统搜索引擎无法对用户输入的关键词词义进行分析和扩展,缺乏知识处理和理解能力。本文充分利用语义网和本体的相关技术理论,将本体构建语义模型的能力应用到智能搜索研究中,最终实现了基于本体的智能搜索模型SMBDI。研究内容包括基于本体的XML信息代理数据集成、基于概念的用户界面、查询处理和算法。在深入分析信息代理DTD与本体模型关系的基础上,提出了一种基于本体的数据集成方案。该项目旨在在网络中集成XML信息代理实现大规模搜索,并通过路径映射理论实现概念的语义集成,避免表达差异导致的信息缺失。同时,通过真实概念识别底层数据,有效避免了机械匹配问题,保证了结果的准确性。基于统一语义考虑和用户搜索行为分析,设计了一个基于概念的用户界面。该界面突破了传统的界面模式,采用图形化本体导航、人性化约束机制和自主输出定制,更深刻地解决了查询如实表达的问题,使人机交互更易理解。
seo内容质量的优化,主要从三个方面来讲方面
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-26 18:10
seo内容质量的优化主要来自三个方面:1、内容数量,对没有搜索结果的页面进行补充2、信息是否相关(1)布尔模型判断(2)主题模型判断是否相关) 3、原创和我之前看到和听到的大神的观点一样,内容量还是最重要的,关键词网站内容的覆盖率代表了你的广度流量来源 内容相关不用多说,优秀的内容一定是相关的。他提供了两个评判标准,一个是
seo内容质量的优化主要来自三个方面:
1、 内容数量,无搜索结果页面补充
2、 信息是否相关?
(1)布尔模型判断
(2)主题模型判断
3、是不是原创
和我之前看到和听到的几位大神的观点一样,内容量是最重要的。 网站内容到关键词的覆盖范围代表了你的流量来源的广度。
内容相关性无需多说,优秀的内容必须具有相关性。他提供了两个判断标准,一个是布尔模型判断,即“是”和“否”,内容是否收录关键词?二是主题模型判断。虽然这个网页的内容不能完全匹配搜索到的关键词,但是主题是一样的,解决了我最近在扩展关键词时遇到的一个问题。比如“平安车险怎么样”和“平安车险怎么样”关键词其实就相当于百度。搜索“平安车险怎么样”,“好”也会热搜。这不仅对我们扩展关键词有帮助,也指导我们以后怎么写文章。等价词的出现频率不仅可以增加文章的相关性,还可以增加文章在百度搜索结果中的相关性。机会来了。
最后一点,关于原创,他指的是原创不是文字,他的观点是采集的内容可能不会比原来的文章排名好,重要的是事情是你比原来更好 拥有更高的价值。那么如何拥有比原文更高的价值呢?除了更丰富的呈现形式(如图片、文字等),更重要的是满足用户的二次需求。
例如:用户搜索“五一假期”,他的主要需求是查询假期安排,但第二需求有很多:买票回家、开车回家、假期旅游……
满足用户的二次需求,不仅帮助我们打造优质内容,也为我们提供了拓展关键词的思路。有时候难的不是投入不够,而是思维不够开阔。
文章Title:【长沙SEO】SEO如何优化内容 查看全部
seo内容质量的优化,主要从三个方面来讲方面
seo内容质量的优化主要来自三个方面:1、内容数量,对没有搜索结果的页面进行补充2、信息是否相关(1)布尔模型判断(2)主题模型判断是否相关) 3、原创和我之前看到和听到的大神的观点一样,内容量还是最重要的,关键词网站内容的覆盖率代表了你的广度流量来源 内容相关不用多说,优秀的内容一定是相关的。他提供了两个评判标准,一个是

seo内容质量的优化主要来自三个方面:
1、 内容数量,无搜索结果页面补充
2、 信息是否相关?
(1)布尔模型判断
(2)主题模型判断
3、是不是原创
和我之前看到和听到的几位大神的观点一样,内容量是最重要的。 网站内容到关键词的覆盖范围代表了你的流量来源的广度。
内容相关性无需多说,优秀的内容必须具有相关性。他提供了两个判断标准,一个是布尔模型判断,即“是”和“否”,内容是否收录关键词?二是主题模型判断。虽然这个网页的内容不能完全匹配搜索到的关键词,但是主题是一样的,解决了我最近在扩展关键词时遇到的一个问题。比如“平安车险怎么样”和“平安车险怎么样”关键词其实就相当于百度。搜索“平安车险怎么样”,“好”也会热搜。这不仅对我们扩展关键词有帮助,也指导我们以后怎么写文章。等价词的出现频率不仅可以增加文章的相关性,还可以增加文章在百度搜索结果中的相关性。机会来了。
最后一点,关于原创,他指的是原创不是文字,他的观点是采集的内容可能不会比原来的文章排名好,重要的是事情是你比原来更好 拥有更高的价值。那么如何拥有比原文更高的价值呢?除了更丰富的呈现形式(如图片、文字等),更重要的是满足用户的二次需求。
例如:用户搜索“五一假期”,他的主要需求是查询假期安排,但第二需求有很多:买票回家、开车回家、假期旅游……
满足用户的二次需求,不仅帮助我们打造优质内容,也为我们提供了拓展关键词的思路。有时候难的不是投入不够,而是思维不够开阔。
文章Title:【长沙SEO】SEO如何优化内容
机器之心编辑部对于搜索引擎意味着意味着什么?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-24 23:12
机器报告的核心
机器编辑部的核心
在前段时间举办的“Search On”活动中,谷歌宣布BERT现在支持谷歌搜索引擎上几乎所有基于英文的查询。去年,这一比例仅为 10%。
BERT 是 Google 开源的自然语言处理预训练模型。一经上线,就刷新了 11 个 NLP 任务的 SOTA 记录,登上了 GLUE 基准测试榜的榜首。
特别是对于搜索引擎,BERT 可以帮助搜索引擎更好地理解网页内容,从而提高搜索结果的相关性。 BERT 模型中创新的 Transformer 架构是一大亮点。 Transformer 处理一个句子中与所有其他单词相关的单词,而不是一个一个依次处理。基于此,BERT模型可以利用词前后的词来考虑其所在的完整上下文,这对于理解查询语句背后的意图非常有用。
2019 年 9 月,谷歌宣布在搜索引擎中使用 BERT,但只有 10% 的英文搜索结果得到了改进; 2019 年 12 月,谷歌将 BERT 在搜索引擎中的使用扩展到 70 多种语言。现在,搜索巨头终于宣布几乎所有英文搜索都可以使用BERT。
BERT 对搜索引擎意味着什么?
作为自然语言处理领域的里程碑,BERT 为该领域带来了以下创新:
使用未标记的文本进行预训练;
双向上下文模型;
transformer架构的应用;
掩码语言建模;
注意力机制;
文本含义(下一句的预测);
……
这些特性使 BERT 对搜索引擎优化非常有帮助,尤其是在消歧方面。使用BERT后,对于更长的、会话式的查询,或者带有更重要的介词如“for”和“to”的句子,谷歌搜索引擎将能够理解查询句子中单词的上下文。用户可以以更自然的方式进行搜索。
此外,BERT 对参考解析、多义性、同形异义词、命名实体确定和搜索中的文本暗示等任务也非常有帮助。其中,指称解析是指在一定的上下文或广泛的会话查询中跟踪一个句子或短语所指的是谁或什么;一个词多义是指同一个词有多重含义,多个含义之间存在联系,搜索引擎需要处理含糊不清的细微差别;同形异义词是指形式相同但意义不同的词;命名实体判断是指从多个命名实体中知道文本与什么相关;文本含义是指预测下一句。这些问题构成了搜索引擎面临的共同挑战。
过去一年,谷歌扩大了BERT在搜索引擎中的应用。 G-Squared Interactive 的 SEO 顾问 Danny Sullivan 和 Glenn Gabe 在 Twitter 上介绍了 Google 搜索。近期亮点。
在 Google 搜索中,十分之一的搜索查询拼写错误。很快,一项新的变化将帮助我们在检测和处理拼写错误方面取得比过去五年更大的进步。
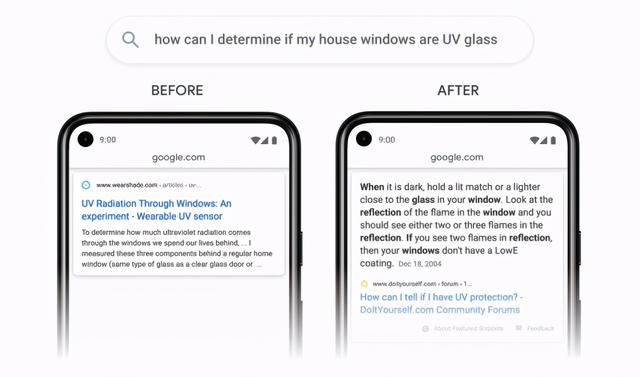
另一个即将到来的变化是,Google 搜索将能够识别网页中的各个段落,并将它们处理成与搜索最相关的段落。我们预计这会改善 7% 的 Google 搜索查询。
Search On 2020:Google 可以索引网页的段落,而不仅仅是整个网页。新算法可以放大回答问题的段落,而忽略页面的其余部分。从下个月开始。
使用人工智能,我们可以更好地检测视频的关键部分,帮助人们直接跳转到感兴趣的内容,而无需创作者手动标记。到今年年底,10% 的 Google 搜索将使用这项技术。
此外,Google 还表示他们还使用神经网络来理解与搜索相关的子主题,这有助于在您搜索广泛的内容时提供更多样化的内容。这项服务预计在年底推出。
参考链接: 查看全部
机器之心编辑部对于搜索引擎意味着意味着什么?(图)
机器报告的核心
机器编辑部的核心
在前段时间举办的“Search On”活动中,谷歌宣布BERT现在支持谷歌搜索引擎上几乎所有基于英文的查询。去年,这一比例仅为 10%。

BERT 是 Google 开源的自然语言处理预训练模型。一经上线,就刷新了 11 个 NLP 任务的 SOTA 记录,登上了 GLUE 基准测试榜的榜首。
特别是对于搜索引擎,BERT 可以帮助搜索引擎更好地理解网页内容,从而提高搜索结果的相关性。 BERT 模型中创新的 Transformer 架构是一大亮点。 Transformer 处理一个句子中与所有其他单词相关的单词,而不是一个一个依次处理。基于此,BERT模型可以利用词前后的词来考虑其所在的完整上下文,这对于理解查询语句背后的意图非常有用。
2019 年 9 月,谷歌宣布在搜索引擎中使用 BERT,但只有 10% 的英文搜索结果得到了改进; 2019 年 12 月,谷歌将 BERT 在搜索引擎中的使用扩展到 70 多种语言。现在,搜索巨头终于宣布几乎所有英文搜索都可以使用BERT。
BERT 对搜索引擎意味着什么?
作为自然语言处理领域的里程碑,BERT 为该领域带来了以下创新:
使用未标记的文本进行预训练;
双向上下文模型;
transformer架构的应用;
掩码语言建模;
注意力机制;
文本含义(下一句的预测);
……
这些特性使 BERT 对搜索引擎优化非常有帮助,尤其是在消歧方面。使用BERT后,对于更长的、会话式的查询,或者带有更重要的介词如“for”和“to”的句子,谷歌搜索引擎将能够理解查询句子中单词的上下文。用户可以以更自然的方式进行搜索。
此外,BERT 对参考解析、多义性、同形异义词、命名实体确定和搜索中的文本暗示等任务也非常有帮助。其中,指称解析是指在一定的上下文或广泛的会话查询中跟踪一个句子或短语所指的是谁或什么;一个词多义是指同一个词有多重含义,多个含义之间存在联系,搜索引擎需要处理含糊不清的细微差别;同形异义词是指形式相同但意义不同的词;命名实体判断是指从多个命名实体中知道文本与什么相关;文本含义是指预测下一句。这些问题构成了搜索引擎面临的共同挑战。
过去一年,谷歌扩大了BERT在搜索引擎中的应用。 G-Squared Interactive 的 SEO 顾问 Danny Sullivan 和 Glenn Gabe 在 Twitter 上介绍了 Google 搜索。近期亮点。
在 Google 搜索中,十分之一的搜索查询拼写错误。很快,一项新的变化将帮助我们在检测和处理拼写错误方面取得比过去五年更大的进步。
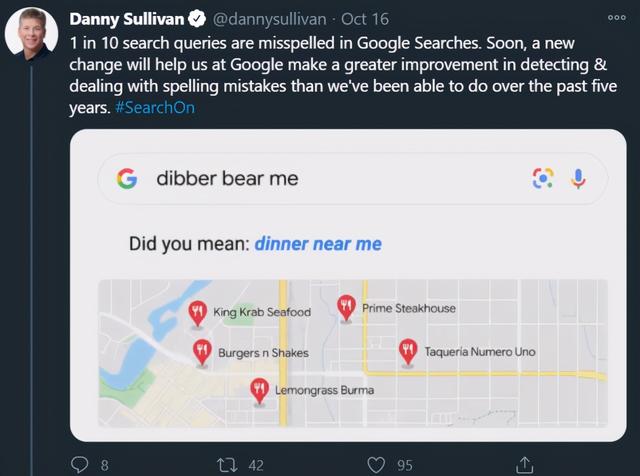
另一个即将到来的变化是,Google 搜索将能够识别网页中的各个段落,并将它们处理成与搜索最相关的段落。我们预计这会改善 7% 的 Google 搜索查询。

Search On 2020:Google 可以索引网页的段落,而不仅仅是整个网页。新算法可以放大回答问题的段落,而忽略页面的其余部分。从下个月开始。

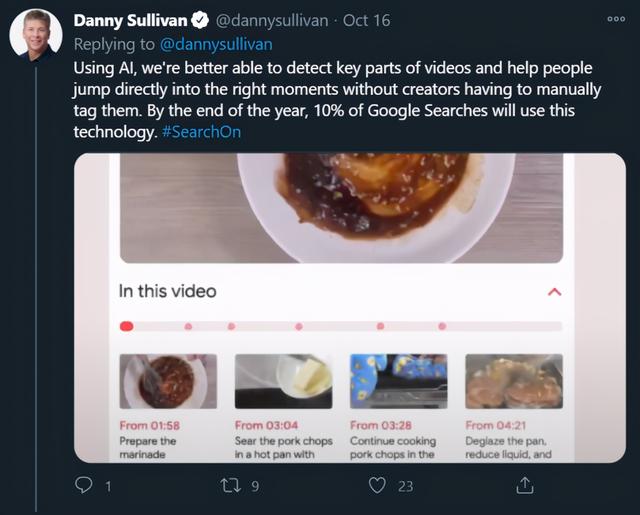
使用人工智能,我们可以更好地检测视频的关键部分,帮助人们直接跳转到感兴趣的内容,而无需创作者手动标记。到今年年底,10% 的 Google 搜索将使用这项技术。
此外,Google 还表示他们还使用神经网络来理解与搜索相关的子主题,这有助于在您搜索广泛的内容时提供更多样化的内容。这项服务预计在年底推出。

参考链接:
39个SEO格式(搜索引擎优化)经典案例文档大小:14.23
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-24 02:44
对于搜索引擎优化来说,网站的结构是最重要的因素之一。 网站 结构是关于您的网页如何连接的。搜索引擎爬虫。
阿里巴巴网站的搜索引擎优化案例分析阿里巴巴是国内最早进行搜索引擎优化网站的电子商务,也是目前网站优化全局最好的大型B2B电子商务-commerce网站之一.阿里巴巴的搜索引擎优化水平要高得多。
2013-8-8 复旦大学文献检索一系 互联网学术信息查询 2009.1 复旦大学文献检索二系 2013-8-8 网络检索工具1.互联网基础知识2.网络搜索工具基金3.万能搜索引擎示例:.
SEO意思是搜索引擎优化,通过网站结构(内链结构、网站物理结构、网站逻辑结构),高质量的网站主题内容。
这是一个很笼统的陈词滥调,没有任何吸引力,但真正能做好的草根站长估计寥寥无几。我问了一个做草根站长多年的朋友,我该怎么说?做好SEO搜索引擎优化,他给我的答案很难,规模太大了。
1)写本案本案例的目的是总结国内各个B2C商城的SEO优化方案,希望找到最适合互联网现状的SEO优化方案; 2)为了使样本更具代表性和广泛性,本文档中的案例将来自。
四、搜索引擎结构优化 结构优化很重要。 关键词是网站的灵魂,所以结构是网站的骨架。先优化结构。
39 SEO(搜索引擎优化)经典案例 文档格式:.pdf 文档页数:81 文档大小:14.23M 文档流行度:系统标签:. 查看全部
39个SEO格式(搜索引擎优化)经典案例文档大小:14.23
对于搜索引擎优化来说,网站的结构是最重要的因素之一。 网站 结构是关于您的网页如何连接的。搜索引擎爬虫。
阿里巴巴网站的搜索引擎优化案例分析阿里巴巴是国内最早进行搜索引擎优化网站的电子商务,也是目前网站优化全局最好的大型B2B电子商务-commerce网站之一.阿里巴巴的搜索引擎优化水平要高得多。
2013-8-8 复旦大学文献检索一系 互联网学术信息查询 2009.1 复旦大学文献检索二系 2013-8-8 网络检索工具1.互联网基础知识2.网络搜索工具基金3.万能搜索引擎示例:.
SEO意思是搜索引擎优化,通过网站结构(内链结构、网站物理结构、网站逻辑结构),高质量的网站主题内容。
这是一个很笼统的陈词滥调,没有任何吸引力,但真正能做好的草根站长估计寥寥无几。我问了一个做草根站长多年的朋友,我该怎么说?做好SEO搜索引擎优化,他给我的答案很难,规模太大了。

1)写本案本案例的目的是总结国内各个B2C商城的SEO优化方案,希望找到最适合互联网现状的SEO优化方案; 2)为了使样本更具代表性和广泛性,本文档中的案例将来自。
四、搜索引擎结构优化 结构优化很重要。 关键词是网站的灵魂,所以结构是网站的骨架。先优化结构。

39 SEO(搜索引擎优化)经典案例 文档格式:.pdf 文档页数:81 文档大小:14.23M 文档流行度:系统标签:.
快速排序行标题设计的基本标准是什么?(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-08-19 04:17
一般写好标题,网站可以提高排名速度,可以按照以下方法写SEO标题:
一、SEO 主题的基本标准
我们在设计网站titles的时候,都需要注意搜索引擎的规范。先说基本规范。我们将在以下段落中深入讨论快速排序行标题的设计。
1、标题字数不要超过32字,搜索引擎建议26字。因为如果超过 32 个字符,标题将无法完全显示。同时,过多的文字会使搜索引擎难以识别网页的主题。
2、 单词必须用英文字母分隔。因为在搜索引擎计算中可以使用中文和英文来分隔单词,我们建议在此处添加下划线。
3、 应在标题中收录知名品牌词。知名品牌词是您网站地址中的品牌名称等同于您网站地址中的独特名称
二、快排标题设计实体模型一
型号:核心关键词-品牌词
关键词 密度对排名有重要影响。除了网页内容中的关键词,关键词也必须出现在TDK最重要的位置。这是搜索引擎抓取网页内容的第一步。 , 并清楚地告诉搜索引擎您的网站 主题。并且标题也会显示给用户。用户可以通过搜索关键词来搜索网站,然后网站更有可能被用户搜索和点击。
示例:挖掘机培训-年度现场培训
说明:此类话题的创建是英语词汇的单一站点。所有网页的权重值都可以集中在一个词上,网站的话题会非常集中。因此,这种标题设计是一种非常快速的排序设计方法。
三、Quick Ranking 标题设计实体模型二
实体模型:关键关键词-必选词-知名品牌词
示例:挖掘机培训学校-大型挖掘机学习基地-年度现场培训
说明:此类话题的设计不仅有优化排名的作用,还可以提高长尾词的排名。更重要的是,这类话题会增加客户的点击量。因为人们在标题中提出了要求的词,当客户看到他们需要的内容时,客户就会开始点击。可以说是这种优化排名问题的全新升级措辞。
标题有很多种写法。从严谨的角度来看,人们必须了解分词技术,并让我们的网站基于分词技术创建主题。他被认为是解决此类问题的绝佳人选。
不过,以上两种写法都可以帮助初学者快速写出标题,所以这里就不深入讨论一些复杂的写法了。
四、关于标题写作的一些思考
首先,标题必须添加用户感兴趣的元素。一个优秀的标题可以让用户一目了然地找到他们需要的词。
其次,话题虽然是参与关键词排名,但直接危害话题排名确实是对人同站的提升。
而且,标题与网址内容的匹配度比所有这种标题设计排名方式的实际效果要好得多。 查看全部
快速排序行标题设计的基本标准是什么?(一)
一般写好标题,网站可以提高排名速度,可以按照以下方法写SEO标题:
一、SEO 主题的基本标准
我们在设计网站titles的时候,都需要注意搜索引擎的规范。先说基本规范。我们将在以下段落中深入讨论快速排序行标题的设计。
1、标题字数不要超过32字,搜索引擎建议26字。因为如果超过 32 个字符,标题将无法完全显示。同时,过多的文字会使搜索引擎难以识别网页的主题。
2、 单词必须用英文字母分隔。因为在搜索引擎计算中可以使用中文和英文来分隔单词,我们建议在此处添加下划线。
3、 应在标题中收录知名品牌词。知名品牌词是您网站地址中的品牌名称等同于您网站地址中的独特名称
二、快排标题设计实体模型一
型号:核心关键词-品牌词
关键词 密度对排名有重要影响。除了网页内容中的关键词,关键词也必须出现在TDK最重要的位置。这是搜索引擎抓取网页内容的第一步。 , 并清楚地告诉搜索引擎您的网站 主题。并且标题也会显示给用户。用户可以通过搜索关键词来搜索网站,然后网站更有可能被用户搜索和点击。
示例:挖掘机培训-年度现场培训
说明:此类话题的创建是英语词汇的单一站点。所有网页的权重值都可以集中在一个词上,网站的话题会非常集中。因此,这种标题设计是一种非常快速的排序设计方法。
三、Quick Ranking 标题设计实体模型二
实体模型:关键关键词-必选词-知名品牌词
示例:挖掘机培训学校-大型挖掘机学习基地-年度现场培训
说明:此类话题的设计不仅有优化排名的作用,还可以提高长尾词的排名。更重要的是,这类话题会增加客户的点击量。因为人们在标题中提出了要求的词,当客户看到他们需要的内容时,客户就会开始点击。可以说是这种优化排名问题的全新升级措辞。
标题有很多种写法。从严谨的角度来看,人们必须了解分词技术,并让我们的网站基于分词技术创建主题。他被认为是解决此类问题的绝佳人选。
不过,以上两种写法都可以帮助初学者快速写出标题,所以这里就不深入讨论一些复杂的写法了。
四、关于标题写作的一些思考
首先,标题必须添加用户感兴趣的元素。一个优秀的标题可以让用户一目了然地找到他们需要的词。
其次,话题虽然是参与关键词排名,但直接危害话题排名确实是对人同站的提升。
而且,标题与网址内容的匹配度比所有这种标题设计排名方式的实际效果要好得多。
倒排索引是搜索引擎的基石--VSM检索模型
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-14 19:14
倒排索引是搜索引擎的基石--VSM检索模型
简介:
在信息爆炸的今天,在搜索引擎的帮助下,我们可以快速方便地找到我们要找的东西。说到搜索引擎就不得不说VSM模型,说到VSM就不得不说倒排索引。可以毫不夸张地说,倒排索引是搜索引擎的基石。
VSM 检索模型
VSM的全称是Vector Space Model,是IR(Information Retrieval Information Retrieval)模型之一。由于其简单、直观、高效,被广泛应用于搜索引擎的架构中。 1998年,谷歌凭借这样的模式,开始了疯狂的扩张之路。废话不多说,我们来看看VSM是什么。
在开始之前,我假设大家对线性代数中的Vector有一定的了解。矢量是具有大小和方向的量。它通常用有向线段表示。向量包括:加法、减法、倍数、内积、距离、模数和角度运算。
文档:一个完整的信息单元,指的是相应搜索引擎系统中的单个网页。
Term:文档的基本单位。比如在英文中可以看成一个词,在中文中可以看成一个词。
查询:用户的输入通常由多个术语组成。
然后用一句话总结搜索引擎做了什么:对于用户输入的Query,找到最相似的Document,返回给用户。而这正是IR模型解决的问题:
信息检索模型是指如何表示查询和文档,然后计算它们的相似度的框架和方法。
一个简单的例子:
现在有两篇文章(Document)文章,分别是《春风来了,春天的脚步在逼近》和《春风未过玉门关》。然后输入查询是“春风”。从直觉上讲,前者与输入查询更相关,因为它收录两个弹簧,但这只是我们的直观感受。怎么量化,要知道电脑是严谨的学科^_^。这时候,我们前面提到的 Term 和 VSM 模型就派上用场了。
首先,我们需要确定向量的维度。这时候,我们需要一个字典库。字典库的大小就是向量的维度。本例中,字典为{春风,来,春,的,脚步声,近,不度,玉门关},文档向量和查询向量如下:
VSM 模型示例
PS:为了简单起见,这里的分词粒度非常大。
将 Query 和 Document 都量化为向量后,可以计算出用户的查询与哪个文档更相似。简单的计算结果是D1和D2与Query的内积为1,囧。当然,如果分词粒度越细,查询的结果就会不同,所以分词粒度也会影响查询结果(主要是recall和accuracy)。
上面的例子用一个非常简单的例子来说明VSM模型。在计算文档相似度时,也采用了最原创的内积法,只考虑词频(TF)影响因素,不考虑反向。词频(IDF),现在比较常用的是cos角法,影响因子很多,据说谷歌的影响因子多达100+。
著名的 Lucene 项目就是使用 VSM 模型构建的。 VSM的核心公式如下(由cos角法演化而来,这里省略推导过程)
VSM 模型公式
从上面的例子不难看出,如果向量的维度(对于中文来说,这个值一般是30w-45w)变大,文档数量(通常是海量)变大,那么计算相关性一次,开销很大,这个问题怎么解决?别忘了,我们这一节的主题是倒排索引,主角终于登场了! ! !
倒排索引
倒排索引与我们之前提到的Hash结构非常相似。以下内容来自维基百科:
倒排索引(英文:Inverted index),也常称为倒排索引、置入文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档中的某个词或存储位置的映射。一组文件。它是文档检索系统中最常用的数据结构。
反向索引有两种不同的形式:
后一种形式提供了更多的兼容性(例如短语搜索),但需要更多的时间和空间来创建。
从上面的定义可以知道,倒排索引收录一个字典索引和一个所有单词的列表。字典索引收录了所有的Term(通常理解为文档中的单词),索引后面的列表保存了单词的信息(出现的文档编号,甚至每个文档中收录的位置信息)。下面我们也用上面的方法举一个简单的例子来说明倒排索引。
比如现在我们要索引三个文档(在实际应用中,文档的数量是海量的):
文件1(D1):中国移动互联网发展迅猛
文档2(D2):未来移动互联网潜力巨大
文件3(D3):中华民族是勤劳的民族
文档中设置的字典为:{China, mobile, internet, development, Rapid, future, of, potential,巨大, 中国, 民族, 是, 个人, 勤奋}
构建的索引如下图:
倒排索引
<p>在上面的索引中,存储了两条信息,文档编号和出现次数。建立索引后,我们就可以开始查询了。例如,有一个名为“中国移动”的查询。首先分词获取Term集{China, Mobile},检查倒排索引,分别计算query与d1、d2、d3的距离。有没有发现,倒排列表创建后,不需要搜索整个文档库,直接从字典集合中找到“中国”和“手机”,然后遍历下面的列表,直接计算。 查看全部
倒排索引是搜索引擎的基石--VSM检索模型

简介:
在信息爆炸的今天,在搜索引擎的帮助下,我们可以快速方便地找到我们要找的东西。说到搜索引擎就不得不说VSM模型,说到VSM就不得不说倒排索引。可以毫不夸张地说,倒排索引是搜索引擎的基石。
VSM 检索模型
VSM的全称是Vector Space Model,是IR(Information Retrieval Information Retrieval)模型之一。由于其简单、直观、高效,被广泛应用于搜索引擎的架构中。 1998年,谷歌凭借这样的模式,开始了疯狂的扩张之路。废话不多说,我们来看看VSM是什么。
在开始之前,我假设大家对线性代数中的Vector有一定的了解。矢量是具有大小和方向的量。它通常用有向线段表示。向量包括:加法、减法、倍数、内积、距离、模数和角度运算。
文档:一个完整的信息单元,指的是相应搜索引擎系统中的单个网页。
Term:文档的基本单位。比如在英文中可以看成一个词,在中文中可以看成一个词。
查询:用户的输入通常由多个术语组成。
然后用一句话总结搜索引擎做了什么:对于用户输入的Query,找到最相似的Document,返回给用户。而这正是IR模型解决的问题:
信息检索模型是指如何表示查询和文档,然后计算它们的相似度的框架和方法。
一个简单的例子:
现在有两篇文章(Document)文章,分别是《春风来了,春天的脚步在逼近》和《春风未过玉门关》。然后输入查询是“春风”。从直觉上讲,前者与输入查询更相关,因为它收录两个弹簧,但这只是我们的直观感受。怎么量化,要知道电脑是严谨的学科^_^。这时候,我们前面提到的 Term 和 VSM 模型就派上用场了。
首先,我们需要确定向量的维度。这时候,我们需要一个字典库。字典库的大小就是向量的维度。本例中,字典为{春风,来,春,的,脚步声,近,不度,玉门关},文档向量和查询向量如下:

VSM 模型示例
PS:为了简单起见,这里的分词粒度非常大。
将 Query 和 Document 都量化为向量后,可以计算出用户的查询与哪个文档更相似。简单的计算结果是D1和D2与Query的内积为1,囧。当然,如果分词粒度越细,查询的结果就会不同,所以分词粒度也会影响查询结果(主要是recall和accuracy)。
上面的例子用一个非常简单的例子来说明VSM模型。在计算文档相似度时,也采用了最原创的内积法,只考虑词频(TF)影响因素,不考虑反向。词频(IDF),现在比较常用的是cos角法,影响因子很多,据说谷歌的影响因子多达100+。
著名的 Lucene 项目就是使用 VSM 模型构建的。 VSM的核心公式如下(由cos角法演化而来,这里省略推导过程)

VSM 模型公式
从上面的例子不难看出,如果向量的维度(对于中文来说,这个值一般是30w-45w)变大,文档数量(通常是海量)变大,那么计算相关性一次,开销很大,这个问题怎么解决?别忘了,我们这一节的主题是倒排索引,主角终于登场了! ! !
倒排索引
倒排索引与我们之前提到的Hash结构非常相似。以下内容来自维基百科:
倒排索引(英文:Inverted index),也常称为倒排索引、置入文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档中的某个词或存储位置的映射。一组文件。它是文档检索系统中最常用的数据结构。
反向索引有两种不同的形式:
后一种形式提供了更多的兼容性(例如短语搜索),但需要更多的时间和空间来创建。
从上面的定义可以知道,倒排索引收录一个字典索引和一个所有单词的列表。字典索引收录了所有的Term(通常理解为文档中的单词),索引后面的列表保存了单词的信息(出现的文档编号,甚至每个文档中收录的位置信息)。下面我们也用上面的方法举一个简单的例子来说明倒排索引。
比如现在我们要索引三个文档(在实际应用中,文档的数量是海量的):
文件1(D1):中国移动互联网发展迅猛
文档2(D2):未来移动互联网潜力巨大
文件3(D3):中华民族是勤劳的民族
文档中设置的字典为:{China, mobile, internet, development, Rapid, future, of, potential,巨大, 中国, 民族, 是, 个人, 勤奋}
构建的索引如下图:

倒排索引
<p>在上面的索引中,存储了两条信息,文档编号和出现次数。建立索引后,我们就可以开始查询了。例如,有一个名为“中国移动”的查询。首先分词获取Term集{China, Mobile},检查倒排索引,分别计算query与d1、d2、d3的距离。有没有发现,倒排列表创建后,不需要搜索整个文档库,直接从字典集合中找到“中国”和“手机”,然后遍历下面的列表,直接计算。
很多人可能还停留在5年前做SEO优化的思维
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-14 19:09
很多人可能还停留在5年前做SEO优化的思维
网站网站SEO优化的八个核心是什么?很多人可能还停留在5年前的SEO优化思维中,“链外疯”。 SEO优化论坛现在告诉你,这不是百度自然优化的。核心,不要以为SEO自然优化就是发链接,写文章。现在百度已经对大量算法进行了升级,对SEO优化者的思维和方法提出了更高的要求。目前百度更偏向于系统优化,系统地考虑用户体验,网站的优化部分并不是只有“TITLE”的标题和关键词设置才能达到的效果。现在让我告诉你网站SEO优化的核心因素是什么?
一、页面打开速度,常见问题
重要的事情说了三遍,就是“速度,速度,速度”。很多人从来没有注意到这一点。为了节省建站成本,选择一些低价的垃圾空间。这样的网站打开速度根本满足不了用户。需要,要知道在这个信息碎片化的时代,打开速度慢了一秒,用户可能会流失。所以,在用户体验方面,虽然打开速度是老生常谈,但还是要提醒大家这点的重要性。
二、页面的内容是为用户解决问题而不是描述问题
我们在写文章的时候,要更加细致地解决这些人的需求,才能起到很好的流通和转化作用。
三、网站专业、美观、品牌化运营
很多用户在打开网站的时候有一种印象,就是低端、山寨、不专业。即使网站被网站吸引,用户也不会留下来观看,所以页面的设计非常重要。图片的美感和页面用户体验的优化都会影响网站的优化,所以这方面应该在建站的时候设计,而不是模仿别人。 网站 的另一个重要作用是品牌推广。你要做好自己的品牌,做好自己的品牌,才能让用户对你产生依赖。
四、避免各种导致用户离开的元素
很多网站有很多弹窗、固定凸窗、广告位,对用户非常反感,影响用户浏览网页,从而放弃整个浏览,进入城市,所以我们在考虑添加广告时,首先不能影响用户的浏览,其次不要让用户过分反感。
五、关键词植入
常规的关键词植入还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等我这个就不重复了,大家都懂的。
六、主题模型的注入
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们必须做一个主题模型。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
八、创造独特的有价值的内容。营销不能逃避内容质量。好的内容包括:
1)提供了非常强大的视觉体验,前端界面,合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7)可以使用完整、准确、独特的信息来解决问题或回答问题 查看全部
很多人可能还停留在5年前做SEO优化的思维

网站网站SEO优化的八个核心是什么?很多人可能还停留在5年前的SEO优化思维中,“链外疯”。 SEO优化论坛现在告诉你,这不是百度自然优化的。核心,不要以为SEO自然优化就是发链接,写文章。现在百度已经对大量算法进行了升级,对SEO优化者的思维和方法提出了更高的要求。目前百度更偏向于系统优化,系统地考虑用户体验,网站的优化部分并不是只有“TITLE”的标题和关键词设置才能达到的效果。现在让我告诉你网站SEO优化的核心因素是什么?
一、页面打开速度,常见问题
重要的事情说了三遍,就是“速度,速度,速度”。很多人从来没有注意到这一点。为了节省建站成本,选择一些低价的垃圾空间。这样的网站打开速度根本满足不了用户。需要,要知道在这个信息碎片化的时代,打开速度慢了一秒,用户可能会流失。所以,在用户体验方面,虽然打开速度是老生常谈,但还是要提醒大家这点的重要性。
二、页面的内容是为用户解决问题而不是描述问题
我们在写文章的时候,要更加细致地解决这些人的需求,才能起到很好的流通和转化作用。
三、网站专业、美观、品牌化运营
很多用户在打开网站的时候有一种印象,就是低端、山寨、不专业。即使网站被网站吸引,用户也不会留下来观看,所以页面的设计非常重要。图片的美感和页面用户体验的优化都会影响网站的优化,所以这方面应该在建站的时候设计,而不是模仿别人。 网站 的另一个重要作用是品牌推广。你要做好自己的品牌,做好自己的品牌,才能让用户对你产生依赖。
四、避免各种导致用户离开的元素
很多网站有很多弹窗、固定凸窗、广告位,对用户非常反感,影响用户浏览网页,从而放弃整个浏览,进入城市,所以我们在考虑添加广告时,首先不能影响用户的浏览,其次不要让用户过分反感。
五、关键词植入
常规的关键词植入还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等我这个就不重复了,大家都懂的。
六、主题模型的注入
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们必须做一个主题模型。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
八、创造独特的有价值的内容。营销不能逃避内容质量。好的内容包括:
1)提供了非常强大的视觉体验,前端界面,合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7)可以使用完整、准确、独特的信息来解决问题或回答问题
SEO新手“小朋友”是如何做到时的?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-14 19:01
作为网站运营人员的作者,作为作者的新手SEO“孩子”,曾在微信中向作者炫耀自称私下拿项目,做出了某种不寻常的长尾某房产的话网站去首页赚点零花钱。
我不是这类业务的高手,但我大概知道一些优化方法。但是当被问到这个“孩子”是怎么做到的? “发个链接,更新文章啊” “网站收录还有体重是怎么回事?”——他一脸疑惑。 “收录你怎么看?”作者苦笑。
工欲善其事,必先利其器。
也许以上只是一个特例,但是相信还是有很多同学想要或者已经开始从事SEO。为了让很多新手朋友对SEO有更系统的了解,特将一些相关的概念解释给大家,仅供参考。
要了解SEO,或者说搜索引擎优化,首先要了解搜索引擎的基本工作流程。
搜索引擎的主要工作分为两部分,一部分是互联网网站页面的抓取、更新和索引。
另一部分是用户查询意图的分析,以最快的速度反馈最个性化的查询结果,这也是搜索引擎未来发展的重要方向之一。移动搜索引擎和一些大型电子商务公司网站首当其冲。
搜索引擎链接分析的六大算法
这里提到的链接分析算法主要是工作的第一部分,即在抓取、更新和索引过程中计算搜索引擎之间页面重要性的关键算法。而分析网页之间谁更重要,就是比较链接的重要性。
PR 算法
PR 算法是 Google 创始人 Larry Page 和 Sergey Brin 于 1998 年申请的专利算法。
有人说是借用了百度李彦宏的超链接分析专利,但美国专利商标局终于在2001年9月通过了Pagerank算法,可见与超链接分析算法还是有区别的。
PR 算法在搜索引擎行业久负盛名。如果一个SEO连这个算法都看不懂,那就真的需要好好研究一下了。
因为这个算法可以说是当前搜索引擎发展的基石。 PR算法原理:2个假设
数量假设:指向页面的理解越多,页面越重要;
质量假设:链接到页面的质量越高,页面就越重要。
PR算法刚开始给每个页面分配相同的重要性分数,通过迭代递归计算更新每个页面节点的PageRank分数,直到分数稳定。
HITS 算法
HITS算法主要收录两个定义:
权威页面:指与某个领域或主题相关的高质量网页。
中心页面:收录许多指向高质量权威页面的网页。比如hao123就是一个典型的高质量Hub页面。
假设 1:许多好的 Hub 页面会指向一个好的权威页面。
假设 2:一个好的 Hub 页面会指向许多好的 Author 页面。
由此不难看出,基于这两个假设生成的页面关系是一种相辅相成的关系。搜索引擎通过这种相辅相成的关系,最终计算出哪些页面是高质量的Hub页面,哪些是高质量的Authority页面。该算法与PR算法的显着区别在于HITS算法与用户输入的查询请求密切相关。
SALSA 算法
SALSA算法整体上是PageRank算法和HITS算法的综合运用。它不仅利用了HITS算法和查询相关的特点,还采用了PageRank的随机游走模型。实践证明,SALSA算法的搜索效果优于前两种算法,是目前最好的链接分析算法之一。
主题敏感的PageRank算法
topic-sensitive PageRank和PageRank的最大区别在于,它最初并不是给每个页面都给相同的分数,而是将页面划分为16个主题类型,然后为不同的主题类型分配不同的分数。 该算法广泛应用于构建个性化搜索领域。
山顶算法
Hilltop 算法也是 HITS 算法和 PageRank 算法的融合。
该算法的基本思想是将专家页面的分数通过链接关系传递给目标页面,并以此分数作为目标页面与用户查询相关度的排名分数。
最后,系统将相关专家页面和得分较高的目标页面进行整合,作为搜索结果返回给用户。
值得注意的是,该算法在定义和筛选专家页面时,使用了页面标题、H1标签中的文本和URL锚文本三类信息元素作为衡量标准。
综上所述,搜索引擎链接分析算法与我们的优化工作息息相关,甚至是我们优化工作的基石。如果不了解这些基本算法,就会陷入“为优化而优化”的盲目境地。
虽然偶尔会有一些影响,但难免会陷入类似于文章开头小伙伴的尴尬境地。从长远来看,这些理论对于个人的 SEO 职业也是必要的。
关于这些基础算法在日常优化工作中的应用,笔者将在后续文章中为大家介绍。 查看全部
SEO新手“小朋友”是如何做到时的?(图)
作为网站运营人员的作者,作为作者的新手SEO“孩子”,曾在微信中向作者炫耀自称私下拿项目,做出了某种不寻常的长尾某房产的话网站去首页赚点零花钱。
我不是这类业务的高手,但我大概知道一些优化方法。但是当被问到这个“孩子”是怎么做到的? “发个链接,更新文章啊” “网站收录还有体重是怎么回事?”——他一脸疑惑。 “收录你怎么看?”作者苦笑。
工欲善其事,必先利其器。
也许以上只是一个特例,但是相信还是有很多同学想要或者已经开始从事SEO。为了让很多新手朋友对SEO有更系统的了解,特将一些相关的概念解释给大家,仅供参考。

要了解SEO,或者说搜索引擎优化,首先要了解搜索引擎的基本工作流程。
搜索引擎的主要工作分为两部分,一部分是互联网网站页面的抓取、更新和索引。
另一部分是用户查询意图的分析,以最快的速度反馈最个性化的查询结果,这也是搜索引擎未来发展的重要方向之一。移动搜索引擎和一些大型电子商务公司网站首当其冲。
搜索引擎链接分析的六大算法
这里提到的链接分析算法主要是工作的第一部分,即在抓取、更新和索引过程中计算搜索引擎之间页面重要性的关键算法。而分析网页之间谁更重要,就是比较链接的重要性。
PR 算法
PR 算法是 Google 创始人 Larry Page 和 Sergey Brin 于 1998 年申请的专利算法。
有人说是借用了百度李彦宏的超链接分析专利,但美国专利商标局终于在2001年9月通过了Pagerank算法,可见与超链接分析算法还是有区别的。
PR 算法在搜索引擎行业久负盛名。如果一个SEO连这个算法都看不懂,那就真的需要好好研究一下了。
因为这个算法可以说是当前搜索引擎发展的基石。 PR算法原理:2个假设
数量假设:指向页面的理解越多,页面越重要;
质量假设:链接到页面的质量越高,页面就越重要。
PR算法刚开始给每个页面分配相同的重要性分数,通过迭代递归计算更新每个页面节点的PageRank分数,直到分数稳定。

HITS 算法
HITS算法主要收录两个定义:
权威页面:指与某个领域或主题相关的高质量网页。
中心页面:收录许多指向高质量权威页面的网页。比如hao123就是一个典型的高质量Hub页面。
假设 1:许多好的 Hub 页面会指向一个好的权威页面。
假设 2:一个好的 Hub 页面会指向许多好的 Author 页面。
由此不难看出,基于这两个假设生成的页面关系是一种相辅相成的关系。搜索引擎通过这种相辅相成的关系,最终计算出哪些页面是高质量的Hub页面,哪些是高质量的Authority页面。该算法与PR算法的显着区别在于HITS算法与用户输入的查询请求密切相关。
SALSA 算法
SALSA算法整体上是PageRank算法和HITS算法的综合运用。它不仅利用了HITS算法和查询相关的特点,还采用了PageRank的随机游走模型。实践证明,SALSA算法的搜索效果优于前两种算法,是目前最好的链接分析算法之一。
主题敏感的PageRank算法
topic-sensitive PageRank和PageRank的最大区别在于,它最初并不是给每个页面都给相同的分数,而是将页面划分为16个主题类型,然后为不同的主题类型分配不同的分数。 该算法广泛应用于构建个性化搜索领域。

山顶算法
Hilltop 算法也是 HITS 算法和 PageRank 算法的融合。
该算法的基本思想是将专家页面的分数通过链接关系传递给目标页面,并以此分数作为目标页面与用户查询相关度的排名分数。
最后,系统将相关专家页面和得分较高的目标页面进行整合,作为搜索结果返回给用户。
值得注意的是,该算法在定义和筛选专家页面时,使用了页面标题、H1标签中的文本和URL锚文本三类信息元素作为衡量标准。
综上所述,搜索引擎链接分析算法与我们的优化工作息息相关,甚至是我们优化工作的基石。如果不了解这些基本算法,就会陷入“为优化而优化”的盲目境地。
虽然偶尔会有一些影响,但难免会陷入类似于文章开头小伙伴的尴尬境地。从长远来看,这些理论对于个人的 SEO 职业也是必要的。
关于这些基础算法在日常优化工作中的应用,笔者将在后续文章中为大家介绍。
聚合标签在搜索引擎优化中饰演主要角色吗?你为什么这么说?
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-13 06:18
聚合标签在搜索引擎优化中饰演主要角色吗?你为什么这么说?
也想出现在这里吗?点击联系我~
聚合标签对搜索引擎优化有很大影响吗?一些做过搜索引擎优化的人一定听说过聚合标签的名字。按照所谓的标签,简洁是每个文章的主要关键词,脱离上下文的聚合就是组装起来。聚合标签的作用是聚合与关键词相关的文章,相当于对网站内容进行二级分类。那么,聚合标签在搜索引擎优化中是否发挥着重要作用?
我个人简历的证明,对于搜索引擎优化来说是难得一见的,无法比拟的。由于每个网站情况的不同,聚合标签的作用也不同。为什么这么说?
首先,聚合标签本身就是一列网站。假设一个网站只有少量的内容输入,一级列的分类和聚合标签会对现有内容进行多次分类,每列都有自己的关键词对应相同的内容。在这种多分类的情况下,考虑关键词的权重是否会松动,权重是否不会转移,如何提高关键词的排名!
因此,对于内容有限的网站,最好少用聚合标签。既然如此,说到这里,或许有的小伙伴已经大致知道我接下来要说什么了。所以对于拥有庞大内容群的网站来说,标签的聚合肯定有助于搜索引擎优化。
面对内容众多的网站,分类一方面可以让网站的内容更有条理;另一方面,聚合标签可以让网站形成更多的分类。其余的这些差异文章 通过聚合标签形成其余的组。由于网站的权重转移依次是“首页”栏目的内容页,栏目权重比单个内容页更有利于关键词的排名,所以关键词的排名会更高有用。 查看全部
聚合标签在搜索引擎优化中饰演主要角色吗?你为什么这么说?

也想出现在这里吗?点击联系我~

聚合标签对搜索引擎优化有很大影响吗?一些做过搜索引擎优化的人一定听说过聚合标签的名字。按照所谓的标签,简洁是每个文章的主要关键词,脱离上下文的聚合就是组装起来。聚合标签的作用是聚合与关键词相关的文章,相当于对网站内容进行二级分类。那么,聚合标签在搜索引擎优化中是否发挥着重要作用?
我个人简历的证明,对于搜索引擎优化来说是难得一见的,无法比拟的。由于每个网站情况的不同,聚合标签的作用也不同。为什么这么说?
首先,聚合标签本身就是一列网站。假设一个网站只有少量的内容输入,一级列的分类和聚合标签会对现有内容进行多次分类,每列都有自己的关键词对应相同的内容。在这种多分类的情况下,考虑关键词的权重是否会松动,权重是否不会转移,如何提高关键词的排名!
因此,对于内容有限的网站,最好少用聚合标签。既然如此,说到这里,或许有的小伙伴已经大致知道我接下来要说什么了。所以对于拥有庞大内容群的网站来说,标签的聚合肯定有助于搜索引擎优化。
面对内容众多的网站,分类一方面可以让网站的内容更有条理;另一方面,聚合标签可以让网站形成更多的分类。其余的这些差异文章 通过聚合标签形成其余的组。由于网站的权重转移依次是“首页”栏目的内容页,栏目权重比单个内容页更有利于关键词的排名,所以关键词的排名会更高有用。
三个主题爬行器是实现基于主题的信息采集功能的核心组成部分
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-13 06:15
三个主要组件:主题爬虫、检索器、管理平台
主题爬虫是实现基于主题的信息采集功能的核心组件,一般由爬取队列、网络连接器、主题模型、内容相关性分析和链接相关性分析等功能模块组成
其中,爬取队列由一系列主题相关性高的URL组成。爬取队列由主题搜索引擎在主题搜索开始时的种子站点组成。这些种子站点可以由行业专家给出,也可以在某些权威网站的帮助下自动生成。搜索过程开始后,系统会查找新的 URL,并根据主题相关性对其进行排序,并将其添加到抓取队列中。网络连接器根据抓取队列中的 URL 与网络建立连接,下载其指向的页面内容。
主题模型是通过主题建模方法实现的。主题词典是一种常用的主题建模方法。 关键词法使用一组特征关键词来表示话题内容,包括用户需求、话题和文档内容,一个主图关键词可以是一个词组,包括语言权重等属性,常用的相关算法是词频统计法。
内容相关性分析是指系统对提取内容特征后的网页数据进行分析,判断网页内容与指定主题的关联程度,过滤不相关的页面,保留相关性达到阈值的网页。
链接相关性分析是指系统测量从网页中提取的超链接信息,获取每个URL指向的页面与指定主题的相关性,并将符合主题级别要求的URL加入到抓取中queue 和 Crawl 优先排序,确保优先检索相关性高的页面。
搜索器为用户提供查询界面,根据用户提出的搜索公式搜索索引库,根据相关程度对查询结果进行排序,将页面链接和相关信息返回给用户。
管理平台负责对整个系统进行监控和管理。主要实现确定主题、初始化爬虫、控制爬虫过程、协调优化模块间功能实现、用户交互等功能。作为一个完美的搜索引擎,管理平台还应该提供跨平台的应用web服务应用接口 查看全部
三个主题爬行器是实现基于主题的信息采集功能的核心组成部分
三个主要组件:主题爬虫、检索器、管理平台
主题爬虫是实现基于主题的信息采集功能的核心组件,一般由爬取队列、网络连接器、主题模型、内容相关性分析和链接相关性分析等功能模块组成
其中,爬取队列由一系列主题相关性高的URL组成。爬取队列由主题搜索引擎在主题搜索开始时的种子站点组成。这些种子站点可以由行业专家给出,也可以在某些权威网站的帮助下自动生成。搜索过程开始后,系统会查找新的 URL,并根据主题相关性对其进行排序,并将其添加到抓取队列中。网络连接器根据抓取队列中的 URL 与网络建立连接,下载其指向的页面内容。
主题模型是通过主题建模方法实现的。主题词典是一种常用的主题建模方法。 关键词法使用一组特征关键词来表示话题内容,包括用户需求、话题和文档内容,一个主图关键词可以是一个词组,包括语言权重等属性,常用的相关算法是词频统计法。
内容相关性分析是指系统对提取内容特征后的网页数据进行分析,判断网页内容与指定主题的关联程度,过滤不相关的页面,保留相关性达到阈值的网页。
链接相关性分析是指系统测量从网页中提取的超链接信息,获取每个URL指向的页面与指定主题的相关性,并将符合主题级别要求的URL加入到抓取中queue 和 Crawl 优先排序,确保优先检索相关性高的页面。
搜索器为用户提供查询界面,根据用户提出的搜索公式搜索索引库,根据相关程度对查询结果进行排序,将页面链接和相关信息返回给用户。
管理平台负责对整个系统进行监控和管理。主要实现确定主题、初始化爬虫、控制爬虫过程、协调优化模块间功能实现、用户交互等功能。作为一个完美的搜索引擎,管理平台还应该提供跨平台的应用web服务应用接口
LDA中的主题就像词主成分-样本之间的关系
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-11 04:16
LDA中的主题就像词主成分-样本之间的关系
NLP︱LDA主题模型的应用问题
看LDA和多元统计分析的结合,LDA中的topic就像一个词主成分,明确了主成分和样本的关系。在多元聚类中,聚类分为Q型聚类、R型聚类和主成分分析。 R型聚类和主成分分析针对变量,Q型聚类针对样本。
PCA 主要关注主成分和变量之间的关系。 LDA在文本中也有同样的效果,将一堆词(变量)变成主题(主成分)。同时,通过人像的主成分,可以知道人群喜欢什么样的话题;
Q 型聚类代表样本之间的社区关系。
LDA 假设前提:主题模型中最重要的假设是词袋假设,指的是在不影响模型训练结果的情况下交换文档中词的顺序,模型的结果有与词序无关。
主题模型中最重要的参数是每个文档的主题概率分布和每个主题下术语的概率分布。
LDA 是一个三层贝叶斯模型。三层分别是:文档层、主题层和词层。
两种估计方法——VEM 和 gibbs
通常逼近这种后验分布的方法可以分为两类:
1.变分算法(variationalalgorithms),这是一种确定性的方法。变异算法假设一些参数分布,将这些理想分布与后验数据进行比较,并找到最接近的分布。因此,估计问题转化为优化问题。主要算法是变分期望最大化(VEM)。这种方法是最常用的方法。主要用于R软件的tomicmodels包中。
2. 基于采样的算法。采样算法,如吉布斯采样(gibbssampling),主要是构造一个马尔可夫链,从后验经验分布中抽取一些样本来估计后验分布。 Gibbs采样方法广泛应用于R软件的lda包中。
参考:使用R作为主题模型:选词与主题编号确定
R 包 enumeration-lda 和 topicmodel
在 R 语言中,有两个包提供 LDA 模型:lda 和 topicmodels。
lda 提供基于 Gibbs 采样的经典 LDA、MMSB(混合成员随机块模型)、RTM(关系主题模型)和 sLDA(监督 LDA)以及基于 VEM(变分期望最大化)的 RTM。
Topicmodels 基于 tm 包,提供三个模型:LDA_VEM、LDA_Gibbs 和 CTM_VEM(相关主题模型)。
此外,包 textir 还提供了其他类型的主题模型。
参考:R 的文档主题模型
但是主题模型有一个非常大的问题:模型的质量
1、模型质量差,题目无效词多,难以清理;
2、主题之间的差异不够显着,效果不佳;
3、话题中,词与词的相关性非常低。
4、无法反映现场。作者最初希望的是一个话题。有场景词+用户态度、情感、事件词,构成了一个比较完整的系统,但是比较幼稚……
5、Topic 命名是一个难点。如果基础词效果差,话题画像也难。
一、TencentPeacock 案例
来看看腾讯孔雀的应用案例:
输入一个词,会弹出两个内容:搜索词-主题列表(主题中有很多词);搜索词-文档列表。
作者猜测实现三个距离计算的过程:
首先计算搜索词向量与主题词向量的距离,并对主题进行排序;
计算搜索词与主题下每个词向量的距离,并对词进行排序;
最后计算搜索词与文档向量的距离,并对文档进行排序。
腾讯在主题系统上做了很多努力,从中可以看到几条信息:
1、 一般来说,词与词之间的相关性不是那么强;
2、 词类基本上是名词,动作和形容词很少。
系统也做了一些有趣的尝试:利用用户-QQ群矩阵,制作话题模型,对QQ群进行聚类,可以很好的了解不同用户群喜欢什么话题群,有多少那里的人。
二、主题模型的主要功能(参考博客)
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3)可以消除文档中噪声的影响。一般来说,文档中的杂音往往在次要主题中,我们可以忽略它们,只保留文档中最重要的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5)与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
三、主题模型的一些扩展
可以看到模型的扩展
1、基于LDA的主题模型变形
用于情感分析:对主题情感偏差进行评分,对主题进行评分,然后根据主题-文档矩阵对每个文档的情感进行评分。
主题间的相关性:根据主题分布点积的相似度,确定相关文本,建立主题间的相关性
时间序列文本,动态主题模型。
短文本,消除歧义,建立语义相似聚类;
知识图谱的构建需要知识图谱中的一些集合和潜在变量,所以主题建模更适合作为一个大的包容集合;
稀疏的使用。在模型中,主题词矩阵会有非常低的频率数据,所以你可以将其强制为0以减少影响。
2、摘录:LDA使用经验
如果要训练一个主题模型进行预测,数据量必须足够大;理论上,词汇长度越长,表达的主题就越具体。这需要一个优秀的词库;如果想要更详细的主题划分或者突出专业主题,就需要专业词典; LDA的参数alpha对计算效率和模型结果影响很大。选择合适的 alpha 可以提高效率和模型可靠性;确定题目数量没有特别突出的方法,需要更多的经验;根据时间线检测热点话题和话题趋势,话题模型是不错的选择;上面提到的正面词汇和负面词汇如何使用,本文没有找到合适的方法;
(参考:R 的文档主题模型)
3、摘录:LDA使用经验
整个过程有很多不明白的地方,我就列举几个如下:
(1) doc 你应该如何定义,应该以人为单位训练topicmodel还是应该以每条微博为一个单元?经过比较,我发现在每条微博上训练的topicmodel中的每一个topicmodel作为一个unit 术语类别更加一致;所以我选择使用微博作为训练的doc单元,使用people作为推理的doc单元;但是我没有找到关于这个问题的更详细的参考,我看到了几个topicmodel推特和微博上的应用,以微博为处理单元。
(2)不同的估计方法有什么区别?R包提供了VEM、Gibbs、CTM等,这里不做详细比较。本文其余部分的结果都是基于Gibbs 估计结果。
(3)topicmodel适合做短文本分析?稀疏会带来什么样的问题?其实把每条微博作为一个doc单元来分析都会造成稀疏的问题,只是我没有意识到它潜在的问题所造成的.
(4)中文的文字处理感觉很急...除了分词,词性标注、句法分析、同义词等没有专门的R包,本文只做一个初步处理。
5)最终的聚类效应不仅考虑了名人的专业领域,还考虑了他们在生活中的情绪状态、爱好和兴趣。这是一个综合的结果。可以通过选择不同的主题来完成不同专业领域的选择。来自聚类分析。
参考:原文链接:微博名人那些事
扩展一:主题模型在关键词extraction中的应用
扩展2:LDA类似于文章聚类
论文:Arnab Bhadury 的“ClusteringSimilar Stories Using LDA | Flipboard Engineering”
去除一些噪声词,然后在LDA模型之后用向量表示文章,提供一种低纬度、鲁棒的词向量表达方法。
扩展3:中文标签/主题抽取/推荐
知乎的回答,总结一下:如何为中文文本做中文标签推荐?
1、根据关键词的权重,比如tfidf值,向用户推荐TopN关键词作为文本标签。
2、LDA,先计算每个中文文本的K个主题分布,取概率最高的主题,再取该主题下概率最高的TopN词作为标签推荐给用户,但K这种方法的值不容易确定,最终计算出来的效果不如第一种方法。但是,LDA 不适合解决细粒度的标注问题,例如提取实例名称。
3、Tag Distribution Model (NTDM),源自社交媒体用户标签的分析和推荐()
4、extraction关键词 另一种常用的方法是TextRank,它根据词的窗口共现或相似度构建词网络,然后根据PageRank算法计算词的权重。
扩展4:文本挖掘中主题跟踪的可视化呈现
扩展五:迭代LDA模型
LDA 本身是一个无监督的算法模型,同时由于训练集本身的噪声数据量很大,模型在效果上可能无法满足行业的需求。例如,我们经过一个LDA过程后,在我们得到的每个主题的词表(xxx.twords)中,或多或少有来自其他主题的混合词或干扰词等,导致推理的正确率不满意。
LDA过程完成,得到xxx.twords文件后,我们可以尝试根据“专家经验”手动去除每个主题中不应该属于该主题的词。经过处理,就相当于得到了一个比较理想、比较干净的“先验知识”。
获得这样的“先验知识”后,我们可以将其作为变量传递给下一个LDA过程,当模型初始化时,“先验知识”中的词会下降到对应的更大的概率主题。使用相同的训练集和相同的参数再次迭代 LDA 过程。经过两三次这样的迭代,效果应该会有所提升。
虽然可以在一定程度上提高模型的效果,但也存在一定的弊端:大大增加了人工成本,如果主题太多(上万个),很难过滤一个由一个。 “先验知识”。
改进的python代码,来源知乎玩点高级-让你开始使用Topic模型LDA(小改进+源代码附后)
扩展 6:如何建立高效的主题模型?
本节来自知乎Q&A:主题模型还有用吗?如何使用?
1、文字要长长的。如果不是很长,试着把它拼凑起来,让它更长
2、语料要好,努力干掉翔
3、规模要大。两个意思,一是文档数,二是话题数
4.在算法方面,plda+可以支持中等规模; lightlda 可以支持大规模(这个宝贝贡献小,插个广告); warplda 应该是可以的,但是没有开源,实现应该不会很复杂。
5、 应用场景必须可靠。直观来说,分类等任务还是需要有监督的,不适合无监督的方法。与基于内容的推荐应用类似,LDA 在这种感觉上是可靠的。
6、不要使用短文本。想用也用twitter lda~~~~
主题模型最合适的变体是添加先验信息:
我相信题主用的是完全无监督的Topic Model,但是这样太行不通了~~~现实生活中浪费了这么多标注数据,监督模型一定比无监督的好~所以!你可以试试Supervised Topic Model,在现实中利用你现有的标注来提高模型的准确率~比如用知乎的标签来训练一个有监督的Topic Model~~~词聚类效果肯定会好很多。
开源监督LDA:
iir/llda.py at master · shuyo/iir · GitHub
chbrown/slda·GitHub 查看全部
LDA中的主题就像词主成分-样本之间的关系
NLP︱LDA主题模型的应用问题
看LDA和多元统计分析的结合,LDA中的topic就像一个词主成分,明确了主成分和样本的关系。在多元聚类中,聚类分为Q型聚类、R型聚类和主成分分析。 R型聚类和主成分分析针对变量,Q型聚类针对样本。
PCA 主要关注主成分和变量之间的关系。 LDA在文本中也有同样的效果,将一堆词(变量)变成主题(主成分)。同时,通过人像的主成分,可以知道人群喜欢什么样的话题;
Q 型聚类代表样本之间的社区关系。
LDA 假设前提:主题模型中最重要的假设是词袋假设,指的是在不影响模型训练结果的情况下交换文档中词的顺序,模型的结果有与词序无关。
主题模型中最重要的参数是每个文档的主题概率分布和每个主题下术语的概率分布。
LDA 是一个三层贝叶斯模型。三层分别是:文档层、主题层和词层。
两种估计方法——VEM 和 gibbs
通常逼近这种后验分布的方法可以分为两类:
1.变分算法(variationalalgorithms),这是一种确定性的方法。变异算法假设一些参数分布,将这些理想分布与后验数据进行比较,并找到最接近的分布。因此,估计问题转化为优化问题。主要算法是变分期望最大化(VEM)。这种方法是最常用的方法。主要用于R软件的tomicmodels包中。
2. 基于采样的算法。采样算法,如吉布斯采样(gibbssampling),主要是构造一个马尔可夫链,从后验经验分布中抽取一些样本来估计后验分布。 Gibbs采样方法广泛应用于R软件的lda包中。
参考:使用R作为主题模型:选词与主题编号确定
R 包 enumeration-lda 和 topicmodel
在 R 语言中,有两个包提供 LDA 模型:lda 和 topicmodels。
lda 提供基于 Gibbs 采样的经典 LDA、MMSB(混合成员随机块模型)、RTM(关系主题模型)和 sLDA(监督 LDA)以及基于 VEM(变分期望最大化)的 RTM。
Topicmodels 基于 tm 包,提供三个模型:LDA_VEM、LDA_Gibbs 和 CTM_VEM(相关主题模型)。
此外,包 textir 还提供了其他类型的主题模型。
参考:R 的文档主题模型
但是主题模型有一个非常大的问题:模型的质量
1、模型质量差,题目无效词多,难以清理;
2、主题之间的差异不够显着,效果不佳;
3、话题中,词与词的相关性非常低。
4、无法反映现场。作者最初希望的是一个话题。有场景词+用户态度、情感、事件词,构成了一个比较完整的系统,但是比较幼稚……
5、Topic 命名是一个难点。如果基础词效果差,话题画像也难。
一、TencentPeacock 案例
来看看腾讯孔雀的应用案例:
输入一个词,会弹出两个内容:搜索词-主题列表(主题中有很多词);搜索词-文档列表。
作者猜测实现三个距离计算的过程:
首先计算搜索词向量与主题词向量的距离,并对主题进行排序;
计算搜索词与主题下每个词向量的距离,并对词进行排序;
最后计算搜索词与文档向量的距离,并对文档进行排序。
腾讯在主题系统上做了很多努力,从中可以看到几条信息:
1、 一般来说,词与词之间的相关性不是那么强;
2、 词类基本上是名词,动作和形容词很少。
系统也做了一些有趣的尝试:利用用户-QQ群矩阵,制作话题模型,对QQ群进行聚类,可以很好的了解不同用户群喜欢什么话题群,有多少那里的人。
二、主题模型的主要功能(参考博客)
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3)可以消除文档中噪声的影响。一般来说,文档中的杂音往往在次要主题中,我们可以忽略它们,只保留文档中最重要的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5)与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
三、主题模型的一些扩展
可以看到模型的扩展
1、基于LDA的主题模型变形
用于情感分析:对主题情感偏差进行评分,对主题进行评分,然后根据主题-文档矩阵对每个文档的情感进行评分。
主题间的相关性:根据主题分布点积的相似度,确定相关文本,建立主题间的相关性
时间序列文本,动态主题模型。
短文本,消除歧义,建立语义相似聚类;
知识图谱的构建需要知识图谱中的一些集合和潜在变量,所以主题建模更适合作为一个大的包容集合;
稀疏的使用。在模型中,主题词矩阵会有非常低的频率数据,所以你可以将其强制为0以减少影响。
2、摘录:LDA使用经验
如果要训练一个主题模型进行预测,数据量必须足够大;理论上,词汇长度越长,表达的主题就越具体。这需要一个优秀的词库;如果想要更详细的主题划分或者突出专业主题,就需要专业词典; LDA的参数alpha对计算效率和模型结果影响很大。选择合适的 alpha 可以提高效率和模型可靠性;确定题目数量没有特别突出的方法,需要更多的经验;根据时间线检测热点话题和话题趋势,话题模型是不错的选择;上面提到的正面词汇和负面词汇如何使用,本文没有找到合适的方法;
(参考:R 的文档主题模型)
3、摘录:LDA使用经验
整个过程有很多不明白的地方,我就列举几个如下:
(1) doc 你应该如何定义,应该以人为单位训练topicmodel还是应该以每条微博为一个单元?经过比较,我发现在每条微博上训练的topicmodel中的每一个topicmodel作为一个unit 术语类别更加一致;所以我选择使用微博作为训练的doc单元,使用people作为推理的doc单元;但是我没有找到关于这个问题的更详细的参考,我看到了几个topicmodel推特和微博上的应用,以微博为处理单元。
(2)不同的估计方法有什么区别?R包提供了VEM、Gibbs、CTM等,这里不做详细比较。本文其余部分的结果都是基于Gibbs 估计结果。
(3)topicmodel适合做短文本分析?稀疏会带来什么样的问题?其实把每条微博作为一个doc单元来分析都会造成稀疏的问题,只是我没有意识到它潜在的问题所造成的.
(4)中文的文字处理感觉很急...除了分词,词性标注、句法分析、同义词等没有专门的R包,本文只做一个初步处理。
5)最终的聚类效应不仅考虑了名人的专业领域,还考虑了他们在生活中的情绪状态、爱好和兴趣。这是一个综合的结果。可以通过选择不同的主题来完成不同专业领域的选择。来自聚类分析。
参考:原文链接:微博名人那些事
扩展一:主题模型在关键词extraction中的应用
扩展2:LDA类似于文章聚类
论文:Arnab Bhadury 的“ClusteringSimilar Stories Using LDA | Flipboard Engineering”
去除一些噪声词,然后在LDA模型之后用向量表示文章,提供一种低纬度、鲁棒的词向量表达方法。
扩展3:中文标签/主题抽取/推荐
知乎的回答,总结一下:如何为中文文本做中文标签推荐?
1、根据关键词的权重,比如tfidf值,向用户推荐TopN关键词作为文本标签。
2、LDA,先计算每个中文文本的K个主题分布,取概率最高的主题,再取该主题下概率最高的TopN词作为标签推荐给用户,但K这种方法的值不容易确定,最终计算出来的效果不如第一种方法。但是,LDA 不适合解决细粒度的标注问题,例如提取实例名称。
3、Tag Distribution Model (NTDM),源自社交媒体用户标签的分析和推荐()
4、extraction关键词 另一种常用的方法是TextRank,它根据词的窗口共现或相似度构建词网络,然后根据PageRank算法计算词的权重。
扩展4:文本挖掘中主题跟踪的可视化呈现
扩展五:迭代LDA模型
LDA 本身是一个无监督的算法模型,同时由于训练集本身的噪声数据量很大,模型在效果上可能无法满足行业的需求。例如,我们经过一个LDA过程后,在我们得到的每个主题的词表(xxx.twords)中,或多或少有来自其他主题的混合词或干扰词等,导致推理的正确率不满意。
LDA过程完成,得到xxx.twords文件后,我们可以尝试根据“专家经验”手动去除每个主题中不应该属于该主题的词。经过处理,就相当于得到了一个比较理想、比较干净的“先验知识”。
获得这样的“先验知识”后,我们可以将其作为变量传递给下一个LDA过程,当模型初始化时,“先验知识”中的词会下降到对应的更大的概率主题。使用相同的训练集和相同的参数再次迭代 LDA 过程。经过两三次这样的迭代,效果应该会有所提升。
虽然可以在一定程度上提高模型的效果,但也存在一定的弊端:大大增加了人工成本,如果主题太多(上万个),很难过滤一个由一个。 “先验知识”。
改进的python代码,来源知乎玩点高级-让你开始使用Topic模型LDA(小改进+源代码附后)
扩展 6:如何建立高效的主题模型?
本节来自知乎Q&A:主题模型还有用吗?如何使用?
1、文字要长长的。如果不是很长,试着把它拼凑起来,让它更长
2、语料要好,努力干掉翔
3、规模要大。两个意思,一是文档数,二是话题数
4.在算法方面,plda+可以支持中等规模; lightlda 可以支持大规模(这个宝贝贡献小,插个广告); warplda 应该是可以的,但是没有开源,实现应该不会很复杂。
5、 应用场景必须可靠。直观来说,分类等任务还是需要有监督的,不适合无监督的方法。与基于内容的推荐应用类似,LDA 在这种感觉上是可靠的。
6、不要使用短文本。想用也用twitter lda~~~~
主题模型最合适的变体是添加先验信息:
我相信题主用的是完全无监督的Topic Model,但是这样太行不通了~~~现实生活中浪费了这么多标注数据,监督模型一定比无监督的好~所以!你可以试试Supervised Topic Model,在现实中利用你现有的标注来提高模型的准确率~比如用知乎的标签来训练一个有监督的Topic Model~~~词聚类效果肯定会好很多。
开源监督LDA:
iir/llda.py at master · shuyo/iir · GitHub
chbrown/slda·GitHub
知识图谱、表示学习动机尽管的动机基于以下两点
网站优化 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-08-09 04:29
作者丨王文博
学校丨哈尔滨工程大学硕士
研究方向丨知识图谱、表征学习
动机
虽然大规模的知识图谱已经收录了数十亿的三元组数据,但还不是很完整。其中,还有未被发现的真实有效的三元组。因此,本文提出了许多用于学习实体和关系的向量表示的嵌入模型,以通过预测三元组是否有效来改进知识图谱。同时,本文作者发现上述模型也可以用于(提交查询,用户个人资料)。 ,返回文档)作为三元组,解决个性化搜索问题。因此,写这篇文章的动机基于以下两点:
之前对三元组建模有效性的研究仅关注知识图谱的完整性或个性化搜索的准确性。但是,本文针对上述两个问题同时使用模型来衡量模型的有效性。
TransE、DISMULT、ComplEx等传统嵌入式模型只使用向量之间的加减乘,所以只能捕捉向量之间的线性关系。虽然现在越来越多的研究集中在使用深度神经网络来解决三元组的预测问题,例如ConvE,但假设可以通过分析三元组相同维度的数据来捕获三元组的头部向量。特定关系中的实体和尾实体的特定属性信息。因此,这些模型大多采用对三元组同维信息建模的方法。但是没有模型可以对具有深层结构的相同维度的三元组信息进行建模。
CapsE 模型
ζ 表示真三元组的集合,其中三元组以 (s,r,o) 的形式表示。构建嵌入模型的目的是定义一个评分函数对每个三元组进行评分,使真实三元组的分数高于假三元组的分数。
用于独立表示 s、r 和 o 的嵌入向量。在 CapsE 模型中,三元组的嵌入向量组合成一个形式并作为矩阵处理。对矩阵A的第i行进行符号化,对卷积层应用一个filter,对矩阵A的每一行重复应用这个filter,形成一个
特征映射的形式。哪里:
·表示点积,b∈R是偏置项,g是非线性激活函数,如ReLU。
CapsE 模型中使用了多个过滤器来生成多个特征图。用Ω表示滤波器组,用N=|Ω|表示集合中过滤器的数量。因此,可以得到N个k维的特征图,每个特征图从三元组的同一维上映射得到一个唯一的特征。
作者通过使用两个独立胶囊层的简化架构来构建 CapsE 模型。在第一个胶囊层,作者构造了k个胶囊,使得特征映射向量相同维度的所有数据形成一个胶囊。因此,每个胶囊可以捕获嵌入到三元组中相应维度条目中的许多特征。这些特征被传递到第二层中的胶囊以生成输出向量。输出向量的长度(可以理解为L1f范数)代表了三元组的得分。
第一个胶囊层由 k 个胶囊组成。每个胶囊 i∈{1,2,...,k} 都有一个输出向量。将输出向量乘以权重矩阵,将所有向量相加得到一个向量,作为第二个胶囊层中胶囊的输入。之后,胶囊使用非线性压缩函数生成输出向量。
表示耦合系数,由算法1的路由过程决定。本文在capsule层的前后层之间使用softmax。算法一如图所示:
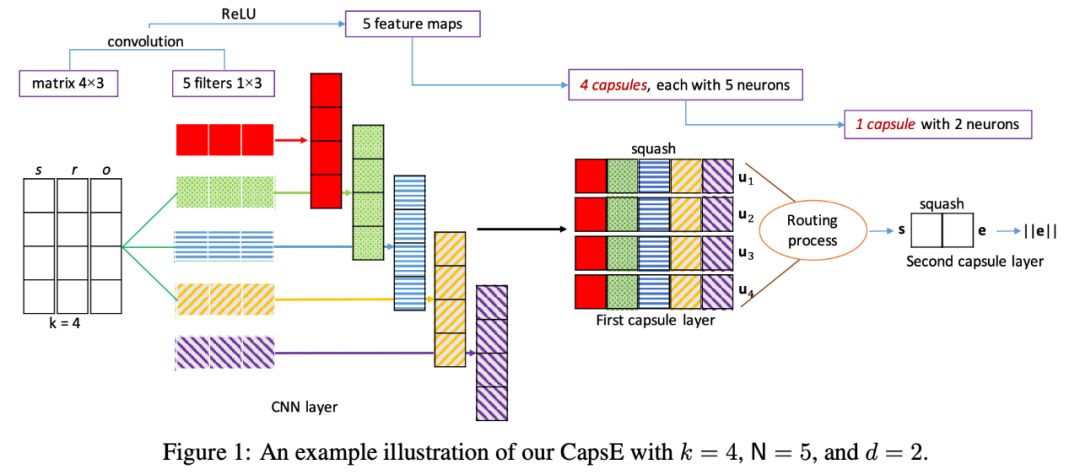
如图1所示,在本文提出的模型中,embedding size k=4;过滤器数量N=5;胶囊第一层的神经元数量等于N;胶囊的第二层中的神经元数量为2:d=2。输出向量 e 的长度用作输入三元组 (s, r, o) 的分数。最后,本文定义了三元组的得分函数f如下:
* 表示卷积操作,capsnet 表示胶囊网络操作。本文使用Adam优化器来训练CapsE模型以最小化损失函数值。损失函数如下:
如果(s,r,o)∈ζ,则t(s,r,o)=1 如果(s,r,o)∈ζ',则t(s,r,o)=-1。
其中 ζ 和 ζ' 分别代表正确的三元组和错误的三元组。 ζ'是指通过破坏结构并随机替换其头部实体或尾部实体,由ζ中的正确三元组组成的新三元组。
实验
完整的知识图谱评估
数据集
本文中的实验使用数据集 WN18RR 和 FB15k-237。因为这两个数据集排除了收录可逆关系的三元组,所以这两个数据集更加真实,也增加了在这两个数据集上进行实验的难度。
评估计划
通过以下过滤器设置执行链接预测:对每个测试三元组和不在训练集、验证集或测试集中并由三元组生成的所有其他候选三元组进行排名。其中,候选三元组是用实体集中的其他实体替换三元组中的原创实体生成的三元组。并以平均排名(MR)、平均数排名(MRR)和Hits@10作为评价标准。
实验计划
文章使用100维Glove词嵌入模型进行预训练,然后在数据集WN18RR上训练一个TransE模型。并将TransE模型的训练结果作为模型convKB和CapsE的初始值。
ConvE模型的参数设置如下:选择Adam优化器,设置学习率
;过滤器的数量 N 设置为 {50,100,200,400}。当模型得到最高Hits@10时,在数据集WN18RR上,N=400,学习率的初始值;在数据集FB15k-237上,N=400,学习率的初始值。
对于CapsE模型,参数设置如下:embedding vector维度设置为100;批量大小设置为128,胶囊中第二层胶囊的神经元数d设置为10;路由算法的迭代次数设置为{1,3,5,7}。当模型得到最高Hits@10时,在数据集WN18RR上,m=1,N=400,学习率的初始值;在数据集FB15k-237上,m=1,N=50,学习率的初始值。
主要实验结果
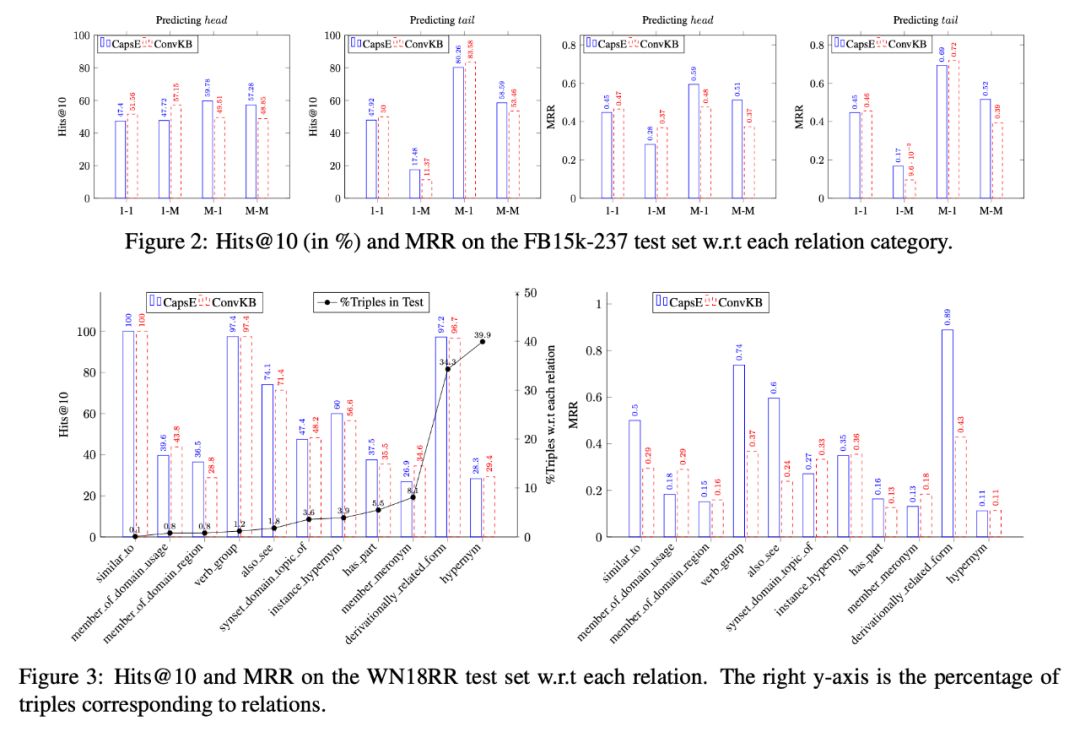
CaspE 模型在数据集 WN18RR 上获得了最佳 MR,在数据集 FB15k-237 上获得了最佳 Hits@10。下面主要分析模型ConvKB和模型CapsE分别在FB15k-237数据集上预测头尾实体时MRR和Hits@10的值。
在本文中,作者使用以下方法对关系进行分类:
记录给定关系r上每个尾实体对应的头实体的平均数为;记录给定关系r上每个头实体对应的尾实体的平均数为。
从上面的结果图可以得出以下实验结论:CapsE在预测M端实体时会得到比ConvKB更好的实验结果; ConvKB 在预测 1-end 实体时会比 CapsE 更好 实验结果。
分析这个结果。由于第一层中每个胶囊的方向和长度有助于对同一维度的数据项进行建模,因此 CapsE 模型在实体出现频率较低的 M 端执行。预测效果优于实体出现频率更高的第一端。现有模型 DISTMULT、ComplEx 和 ConvE 对实体较高频率的第一端有较好的预测效果。以上就是CapsE模型能够在数据集FB15k-237和数据集WN18RR上取得较好预测结果的原因。
路由迭代的实验结果:本文作者还研究了路由迭代次数对模型效果的影响。得出结论:当迭代次数设为1,其他参数不变时,相应的模型可以获得最佳的实验结果。
这说明了知识图谱和图像问题的区别。在图像分类任务中,将迭代次数 m 设置为大于 1 的数字有助于更准确地捕获图像中实体的相对位置。但相反,由于知识图中同类关系的不同实体之间变化的多样性,这种基于图像的思想只能正确处理知识图中的1-1关系,而不适用于处理 1-M。 M-1与MM的关系。
个性化搜索应用
个性化搜索:给定一个用户(user),该用户的查询关键词(query),搜索系统对与查询关键词相关的文件进行重新排序,并返回结果文件(document)。另外,与用户相关的文档和用户在上述排序过程中给出的查询关键词越相关,应该得到的排序结果就越好。基于以下两个原因,CapsE模型可以用来完成个性化的搜索任务:
数据集
作者使用了106个用户的大规模网络搜索引擎查询日志集合(SEARCH17)作为实验数据集。该数据集收录一个用户查询返回的10个最佳结果,以及用户的这些结果的延迟时间,在这些返回的文档中,用户点击过的文档,或者停留时间超过30秒的文档被标记为相关,返回的前10个文档中剩余的文档被标记为不相关。 Passed 与标签相关的文档位置,用于评估搜索结果。
划分数据集,将数据集划分为训练集、验证集和测试集,达到利用训练集中的历史数据预测测试集中新数据的目的。训练集、验证集和测试集分别由5658、1184和1210个相关三元组和40239、7882、8540个不相关三元组组成。
评估计划
模型CapsE按照如下方式对搜索引擎返回的原创文件列表进行重新排序:
1. 训练 CapsE 模型,并使用训练好的模型计算每个三元组 (s, r, o) 的分数。
2. 将分数降序排序,作为返回文件列表中文件的新顺序。
使用指标MRR和指标Hits@1作为评价标准。这两个指标的值越大,模型效果越好。
在本文中,作者将 CapsE 与以下五个模型进行了比较:
初始嵌入
从查询日志中提取 200 个关于带有相关标签的文档的主题,用于训练 LDA 主题模型。使用经过训练的 LDA 模型来推断每个主题在所有主题中返回文档的概率分布。并用每个文档的主题比例向量作为每个文档的embedding向量对文档进行向量化(假设总共有200个主题,即k=200,文档d的embedding向量中的第z个元素表示:给定文件为广告文件,主题为z的概率。
).
同时,作者还将每个查询表达为与主题相关的概率分布向量。具体方法如下:
让集合表示用q查询时返回的前n个文件(这里n=10)。
查询语句q的嵌入向量的第z维值为:=
。哪里
表示集合Dq中第i个文件的指数衰减系数。而б是0到1之间的衰减超参数(本文使用0.8)。
注意:为了避免本文实验中的过拟合,用于训练模型 TransE、ConvKB 和 CaspE 的查询短语嵌入向量和文件嵌入向量在整个训练过程中保持不变。
另外,由于用户最近的点击事件往往能反映用户最近的兴趣,所以采用对训练集中被点击的文件分配临时权重的策略来初始化三种嵌入模型的用户画像的嵌入向量.
超参数调优
当过滤器数量为400,学习率为5时,CapsE在验证集上的MRR值最高;当margin为5时,sgd的l1范数和学习率为5,TransE在验证集上,MRR达到最高;当过滤器数量为 500,优化器 Adam 的学习率为 5 时,ConvKB 在验证集上达到最高 MRR。
主要结果
与传统的学习排序个性化搜索模型CI和SP相比,嵌入式模型TransE、ConvKB和CapsE取得了更好的性能。因此,将三重嵌入模型扩展到搜索算法可以提高个性化搜索系统的排名质量。如图,CapsE方法得到的MRR和Hits@1是五个模型中最高的值。
总结
虽然本文使用的方法与ConvE非常相似,但它有以下两个亮点:
1. 作为第一个使用胶囊网络进行知识图谱改进和个性化搜索的文章,它充分利用了胶囊网络在同一维度上捕获不同特征映射的深层特征的能力,并为首次对同维度信息进行深度结构建模。使模型能够更好地用于多端预测。
2.首次将个性化搜索任务与链接预测任务相结合,将个性化搜索中的用户、查询关键词、返回的结果文件转化为三元组,并对其进行链接预测问题研究。并且因为三元组属于1-M关系问题,所以CapsE模型还是很有效的。
#活动推荐#
10.31-11.1 北京致远大会
世界AI看中国,中国AI看北京!
百位顶尖专家、60+前沿报告、10+圆桌论坛、剑锋对话,为您带来一场专家级AI盛会。全球顶尖学者云集:John Hopcroft(图灵奖)、Michael Jordan(机器学习权威学者)、Chris Manning(NLP权威学者)、朱松春(计算机视觉权威学者)、张博、高文、戴琼海、张平文等100多位专家。 查看全部
知识图谱、表示学习动机尽管的动机基于以下两点
作者丨王文博
学校丨哈尔滨工程大学硕士
研究方向丨知识图谱、表征学习

动机
虽然大规模的知识图谱已经收录了数十亿的三元组数据,但还不是很完整。其中,还有未被发现的真实有效的三元组。因此,本文提出了许多用于学习实体和关系的向量表示的嵌入模型,以通过预测三元组是否有效来改进知识图谱。同时,本文作者发现上述模型也可以用于(提交查询,用户个人资料)。 ,返回文档)作为三元组,解决个性化搜索问题。因此,写这篇文章的动机基于以下两点:
之前对三元组建模有效性的研究仅关注知识图谱的完整性或个性化搜索的准确性。但是,本文针对上述两个问题同时使用模型来衡量模型的有效性。
TransE、DISMULT、ComplEx等传统嵌入式模型只使用向量之间的加减乘,所以只能捕捉向量之间的线性关系。虽然现在越来越多的研究集中在使用深度神经网络来解决三元组的预测问题,例如ConvE,但假设可以通过分析三元组相同维度的数据来捕获三元组的头部向量。特定关系中的实体和尾实体的特定属性信息。因此,这些模型大多采用对三元组同维信息建模的方法。但是没有模型可以对具有深层结构的相同维度的三元组信息进行建模。
CapsE 模型
ζ 表示真三元组的集合,其中三元组以 (s,r,o) 的形式表示。构建嵌入模型的目的是定义一个评分函数对每个三元组进行评分,使真实三元组的分数高于假三元组的分数。
用于独立表示 s、r 和 o 的嵌入向量。在 CapsE 模型中,三元组的嵌入向量组合成一个形式并作为矩阵处理。对矩阵A的第i行进行符号化,对卷积层应用一个filter,对矩阵A的每一行重复应用这个filter,形成一个
特征映射的形式。哪里:
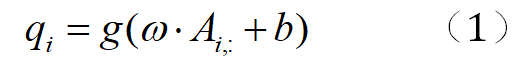
·表示点积,b∈R是偏置项,g是非线性激活函数,如ReLU。
CapsE 模型中使用了多个过滤器来生成多个特征图。用Ω表示滤波器组,用N=|Ω|表示集合中过滤器的数量。因此,可以得到N个k维的特征图,每个特征图从三元组的同一维上映射得到一个唯一的特征。
作者通过使用两个独立胶囊层的简化架构来构建 CapsE 模型。在第一个胶囊层,作者构造了k个胶囊,使得特征映射向量相同维度的所有数据形成一个胶囊。因此,每个胶囊可以捕获嵌入到三元组中相应维度条目中的许多特征。这些特征被传递到第二层中的胶囊以生成输出向量。输出向量的长度(可以理解为L1f范数)代表了三元组的得分。
第一个胶囊层由 k 个胶囊组成。每个胶囊 i∈{1,2,...,k} 都有一个输出向量。将输出向量乘以权重矩阵,将所有向量相加得到一个向量,作为第二个胶囊层中胶囊的输入。之后,胶囊使用非线性压缩函数生成输出向量。
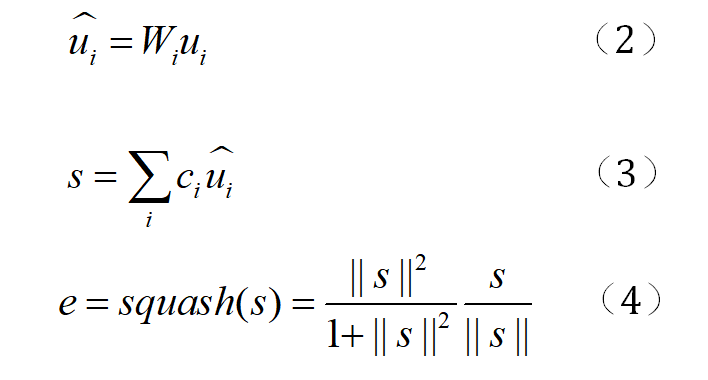
表示耦合系数,由算法1的路由过程决定。本文在capsule层的前后层之间使用softmax。算法一如图所示:

如图1所示,在本文提出的模型中,embedding size k=4;过滤器数量N=5;胶囊第一层的神经元数量等于N;胶囊的第二层中的神经元数量为2:d=2。输出向量 e 的长度用作输入三元组 (s, r, o) 的分数。最后,本文定义了三元组的得分函数f如下:
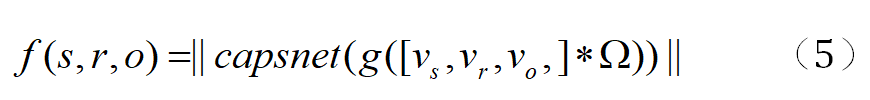
* 表示卷积操作,capsnet 表示胶囊网络操作。本文使用Adam优化器来训练CapsE模型以最小化损失函数值。损失函数如下:
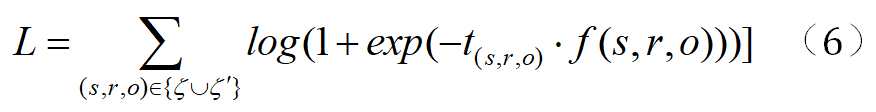
如果(s,r,o)∈ζ,则t(s,r,o)=1 如果(s,r,o)∈ζ',则t(s,r,o)=-1。
其中 ζ 和 ζ' 分别代表正确的三元组和错误的三元组。 ζ'是指通过破坏结构并随机替换其头部实体或尾部实体,由ζ中的正确三元组组成的新三元组。
实验
完整的知识图谱评估
数据集
本文中的实验使用数据集 WN18RR 和 FB15k-237。因为这两个数据集排除了收录可逆关系的三元组,所以这两个数据集更加真实,也增加了在这两个数据集上进行实验的难度。

评估计划
通过以下过滤器设置执行链接预测:对每个测试三元组和不在训练集、验证集或测试集中并由三元组生成的所有其他候选三元组进行排名。其中,候选三元组是用实体集中的其他实体替换三元组中的原创实体生成的三元组。并以平均排名(MR)、平均数排名(MRR)和Hits@10作为评价标准。
实验计划
文章使用100维Glove词嵌入模型进行预训练,然后在数据集WN18RR上训练一个TransE模型。并将TransE模型的训练结果作为模型convKB和CapsE的初始值。
ConvE模型的参数设置如下:选择Adam优化器,设置学习率
;过滤器的数量 N 设置为 {50,100,200,400}。当模型得到最高Hits@10时,在数据集WN18RR上,N=400,学习率的初始值;在数据集FB15k-237上,N=400,学习率的初始值。
对于CapsE模型,参数设置如下:embedding vector维度设置为100;批量大小设置为128,胶囊中第二层胶囊的神经元数d设置为10;路由算法的迭代次数设置为{1,3,5,7}。当模型得到最高Hits@10时,在数据集WN18RR上,m=1,N=400,学习率的初始值;在数据集FB15k-237上,m=1,N=50,学习率的初始值。
主要实验结果
CaspE 模型在数据集 WN18RR 上获得了最佳 MR,在数据集 FB15k-237 上获得了最佳 Hits@10。下面主要分析模型ConvKB和模型CapsE分别在FB15k-237数据集上预测头尾实体时MRR和Hits@10的值。
在本文中,作者使用以下方法对关系进行分类:
记录给定关系r上每个尾实体对应的头实体的平均数为;记录给定关系r上每个头实体对应的尾实体的平均数为。
从上面的结果图可以得出以下实验结论:CapsE在预测M端实体时会得到比ConvKB更好的实验结果; ConvKB 在预测 1-end 实体时会比 CapsE 更好 实验结果。
分析这个结果。由于第一层中每个胶囊的方向和长度有助于对同一维度的数据项进行建模,因此 CapsE 模型在实体出现频率较低的 M 端执行。预测效果优于实体出现频率更高的第一端。现有模型 DISTMULT、ComplEx 和 ConvE 对实体较高频率的第一端有较好的预测效果。以上就是CapsE模型能够在数据集FB15k-237和数据集WN18RR上取得较好预测结果的原因。
路由迭代的实验结果:本文作者还研究了路由迭代次数对模型效果的影响。得出结论:当迭代次数设为1,其他参数不变时,相应的模型可以获得最佳的实验结果。
这说明了知识图谱和图像问题的区别。在图像分类任务中,将迭代次数 m 设置为大于 1 的数字有助于更准确地捕获图像中实体的相对位置。但相反,由于知识图中同类关系的不同实体之间变化的多样性,这种基于图像的思想只能正确处理知识图中的1-1关系,而不适用于处理 1-M。 M-1与MM的关系。
个性化搜索应用
个性化搜索:给定一个用户(user),该用户的查询关键词(query),搜索系统对与查询关键词相关的文件进行重新排序,并返回结果文件(document)。另外,与用户相关的文档和用户在上述排序过程中给出的查询关键词越相关,应该得到的排序结果就越好。基于以下两个原因,CapsE模型可以用来完成个性化的搜索任务:
数据集
作者使用了106个用户的大规模网络搜索引擎查询日志集合(SEARCH17)作为实验数据集。该数据集收录一个用户查询返回的10个最佳结果,以及用户的这些结果的延迟时间,在这些返回的文档中,用户点击过的文档,或者停留时间超过30秒的文档被标记为相关,返回的前10个文档中剩余的文档被标记为不相关。 Passed 与标签相关的文档位置,用于评估搜索结果。
划分数据集,将数据集划分为训练集、验证集和测试集,达到利用训练集中的历史数据预测测试集中新数据的目的。训练集、验证集和测试集分别由5658、1184和1210个相关三元组和40239、7882、8540个不相关三元组组成。
评估计划
模型CapsE按照如下方式对搜索引擎返回的原创文件列表进行重新排序:
1. 训练 CapsE 模型,并使用训练好的模型计算每个三元组 (s, r, o) 的分数。
2. 将分数降序排序,作为返回文件列表中文件的新顺序。
使用指标MRR和指标Hits@1作为评价标准。这两个指标的值越大,模型效果越好。
在本文中,作者将 CapsE 与以下五个模型进行了比较:
初始嵌入
从查询日志中提取 200 个关于带有相关标签的文档的主题,用于训练 LDA 主题模型。使用经过训练的 LDA 模型来推断每个主题在所有主题中返回文档的概率分布。并用每个文档的主题比例向量作为每个文档的embedding向量对文档进行向量化(假设总共有200个主题,即k=200,文档d的embedding向量中的第z个元素表示:给定文件为广告文件,主题为z的概率。
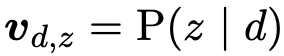
).
同时,作者还将每个查询表达为与主题相关的概率分布向量。具体方法如下:
让集合表示用q查询时返回的前n个文件(这里n=10)。
查询语句q的嵌入向量的第z维值为:=
。哪里
表示集合Dq中第i个文件的指数衰减系数。而б是0到1之间的衰减超参数(本文使用0.8)。
注意:为了避免本文实验中的过拟合,用于训练模型 TransE、ConvKB 和 CaspE 的查询短语嵌入向量和文件嵌入向量在整个训练过程中保持不变。
另外,由于用户最近的点击事件往往能反映用户最近的兴趣,所以采用对训练集中被点击的文件分配临时权重的策略来初始化三种嵌入模型的用户画像的嵌入向量.
超参数调优
当过滤器数量为400,学习率为5时,CapsE在验证集上的MRR值最高;当margin为5时,sgd的l1范数和学习率为5,TransE在验证集上,MRR达到最高;当过滤器数量为 500,优化器 Adam 的学习率为 5 时,ConvKB 在验证集上达到最高 MRR。
主要结果
与传统的学习排序个性化搜索模型CI和SP相比,嵌入式模型TransE、ConvKB和CapsE取得了更好的性能。因此,将三重嵌入模型扩展到搜索算法可以提高个性化搜索系统的排名质量。如图,CapsE方法得到的MRR和Hits@1是五个模型中最高的值。
总结
虽然本文使用的方法与ConvE非常相似,但它有以下两个亮点:
1. 作为第一个使用胶囊网络进行知识图谱改进和个性化搜索的文章,它充分利用了胶囊网络在同一维度上捕获不同特征映射的深层特征的能力,并为首次对同维度信息进行深度结构建模。使模型能够更好地用于多端预测。
2.首次将个性化搜索任务与链接预测任务相结合,将个性化搜索中的用户、查询关键词、返回的结果文件转化为三元组,并对其进行链接预测问题研究。并且因为三元组属于1-M关系问题,所以CapsE模型还是很有效的。
#活动推荐#
10.31-11.1 北京致远大会
世界AI看中国,中国AI看北京!
百位顶尖专家、60+前沿报告、10+圆桌论坛、剑锋对话,为您带来一场专家级AI盛会。全球顶尖学者云集:John Hopcroft(图灵奖)、Michael Jordan(机器学习权威学者)、Chris Manning(NLP权威学者)、朱松春(计算机视觉权威学者)、张博、高文、戴琼海、张平文等100多位专家。
什么是SEO站内主题模型SEO页面内容优化的老旧方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-09 02:35
什么是SEO站内主题模型SEO页面内容优化的老旧方法
SEO网站的主题模型是什么
SEO页面内容优化的老方法有哪些:
1、看关键词密度是否达标
2、文章内容字数够吗?
3、内容够不够原创
4、是否有足够的导入链接(外部链接)?
5、使用各种H标签整合关键词
6、TDK关键词是否设置为精确匹配
有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎。 8-9年前,百度没吃过这个老技术。要优化网站内容,必须让搜索引擎了解页面的核心主题。这就是我今天文章的核心。
什么是主题模型?
主题模型要求我们实现全新的4步优化方法:
1、词系布局
2、Content 属性
3、词系连线
4、补充内容
我们熟悉诸如(维基百科、亚马逊)之类的网站,它们使用这些积分来获得大量的关键词 排名。他们部署在页面布局上,因为他们的“结构”足够强大,所以他们可以大量有效地向搜索引擎展示核心内容主题。
因此,植入内容后,可以快速产出大量优质页面。因此,即使你不懂搜索引擎算法,只要使用主题模型也能获得不错的排名!
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。您写的内容最直接影响搜索引擎对页面主题的理解。
我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1、查找变体词和同义词
2、查找与主词内容相关的二类词
3、找到与第二类词相关的三类词
4、断定内容属性与主词(人物、地理、事件)相关
比如你要优化一个叫【网红】的关键词,这个词成为你的主词。
根据目的:
(1)它的同义词和变体可能是“自媒体”、“意见领袖”、“网络推广”等;
(2)与主词内容相关的第二类词可以是“刘吉首”、“微博”和“生词”;
(3)找到与第二类词相关的三类词可以“剩几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪。每个人都可以清楚地看到每层单词和短语之间的一些关联。
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和词组之间哪个重要,哪个是重要的。有关的。所以词法布局就是区分核心词及其相关性。
以下是3种实用的优化方法:
1、区域:关键词必须出现在标题、标题和主要段落中;
2、Frequency:重要短语或其变体可能出现的次数超过平均水平;
3、distance:相关词或短语应该彼此靠近或使用 HTML 元素(例如 ALT)。
你知道方法的原理,我们举个简单的例子:
主词是[网红]
第一段将重点放在文章这个词上;
第二段会用几只手文章;
第三段利用微博中继效果做文章;
第四段使用新的互联网名称文章。
等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
主动向好三方网站推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。
仍然有很多人认为外链是最有力的信号提醒,可以告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。所以搜索引擎希望大家可以同时使用内链和外链。
百度百科或者知道为什么要添加相关资源的链接吗?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1、页面底部添加相关资源链接(推荐站内链接)
2、在文中使用引号,如行业内知名人士的话或图标或视频
3、使用文中导出链接去第三方网站(你不会是100颗K的心)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“包老师”时,是不是【人物】的实体?
通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 using Schema 。
这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
总结:
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一张高级大学证书,它记录了你的实体和相关性。
最后,将以下优化技术整合到您的内容优化中:
1、 描述页面主题的非常笼统的标题
2、添加开场白(简要)描述页面内容
3、 提供额外的现场或场外辅助资源
4、尽量扩大话题角度,可以添加相关答案
5、不在乎一个词的权重,而是构建内容实体
6、将内容分成几段,每段都有自己的主题
--文章来至微红科技 查看全部
什么是SEO站内主题模型SEO页面内容优化的老旧方法

SEO网站的主题模型是什么
SEO页面内容优化的老方法有哪些:
1、看关键词密度是否达标
2、文章内容字数够吗?
3、内容够不够原创
4、是否有足够的导入链接(外部链接)?
5、使用各种H标签整合关键词
6、TDK关键词是否设置为精确匹配
有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎。 8-9年前,百度没吃过这个老技术。要优化网站内容,必须让搜索引擎了解页面的核心主题。这就是我今天文章的核心。
什么是主题模型?
主题模型要求我们实现全新的4步优化方法:
1、词系布局
2、Content 属性
3、词系连线
4、补充内容
我们熟悉诸如(维基百科、亚马逊)之类的网站,它们使用这些积分来获得大量的关键词 排名。他们部署在页面布局上,因为他们的“结构”足够强大,所以他们可以大量有效地向搜索引擎展示核心内容主题。
因此,植入内容后,可以快速产出大量优质页面。因此,即使你不懂搜索引擎算法,只要使用主题模型也能获得不错的排名!
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。您写的内容最直接影响搜索引擎对页面主题的理解。

我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1、查找变体词和同义词
2、查找与主词内容相关的二类词
3、找到与第二类词相关的三类词
4、断定内容属性与主词(人物、地理、事件)相关
比如你要优化一个叫【网红】的关键词,这个词成为你的主词。
根据目的:
(1)它的同义词和变体可能是“自媒体”、“意见领袖”、“网络推广”等;
(2)与主词内容相关的第二类词可以是“刘吉首”、“微博”和“生词”;
(3)找到与第二类词相关的三类词可以“剩几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪。每个人都可以清楚地看到每层单词和短语之间的一些关联。
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和词组之间哪个重要,哪个是重要的。有关的。所以词法布局就是区分核心词及其相关性。

以下是3种实用的优化方法:
1、区域:关键词必须出现在标题、标题和主要段落中;
2、Frequency:重要短语或其变体可能出现的次数超过平均水平;
3、distance:相关词或短语应该彼此靠近或使用 HTML 元素(例如 ALT)。
你知道方法的原理,我们举个简单的例子:
主词是[网红]
第一段将重点放在文章这个词上;
第二段会用几只手文章;
第三段利用微博中继效果做文章;
第四段使用新的互联网名称文章。
等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
主动向好三方网站推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。
仍然有很多人认为外链是最有力的信号提醒,可以告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。所以搜索引擎希望大家可以同时使用内链和外链。
百度百科或者知道为什么要添加相关资源的链接吗?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1、页面底部添加相关资源链接(推荐站内链接)
2、在文中使用引号,如行业内知名人士的话或图标或视频
3、使用文中导出链接去第三方网站(你不会是100颗K的心)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“包老师”时,是不是【人物】的实体?

通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 using Schema 。
这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
总结:
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一张高级大学证书,它记录了你的实体和相关性。
最后,将以下优化技术整合到您的内容优化中:
1、 描述页面主题的非常笼统的标题
2、添加开场白(简要)描述页面内容
3、 提供额外的现场或场外辅助资源
4、尽量扩大话题角度,可以添加相关答案
5、不在乎一个词的权重,而是构建内容实体
6、将内容分成几段,每段都有自己的主题
--文章来至微红科技
站内八大seo优化点总结,全精辟,小伙伴可以详细阅读
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-09 02:32
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。总结了网站seo的8个优化点,都很精辟,朋友们可以给详细[...]
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。网站内8个seo优化点汇总,有见地,朋友可以详细阅读。
任何接触过搜索引擎优化的人都可以发表他们对搜索引擎优化的看法。出于这个原因,错误和正确的 SEO 观点是混合的。其实,真正权威、可靠的观点应该来自百度的官方文档。视频,以下是网站seo优化的核心要点:
注意:这个seo教程的优化点偏向于用户体验,而不是简单的seo。
首先,落地页的内容是解决问题,而不仅仅是描述问题。
例如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该有几个方向:【男嘉宾推荐的20款婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他是去参加婚礼,所以最后要解决的问题是去哪里买衣服,而不是让他学会如何搭配衣服。所以在优化这个关键词的时候,我们的内容一定要解决它的最终需求,这样引流和转化效果才会更好。
[/s2/]二、提高网站的激活速度是网站优化不可缺少的一点。
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站打开和加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,一定要考虑可以做些什么来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三是增强用户界面、用户体验和品牌的信任度和参与度。
很多用户打开网站都会有第一印象。他们是好小屋,好当地的海龟,专业,不是我们想要的结果。页面设计需要ui& UX投资和品牌自身的口碑来背书,否则用户很难在网站产生信任和参与。最实用的方法是模仿业界比较好的网站,购买付费版的网站模板或者让用户参与每一个设计过程。
第四,避免各种促使用户离开页面的反应性 SEO 元素。
许多弹出窗口、固定凸窗和广告位会让用户反感并放弃整个浏览过程。这是在搜索引擎优化过程中应该避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时可以避免蜘蛛被禁止或难以捕捉的可能性,让搜索引擎降低自己的权利。
V。一般关键字布局。
常规的关键词植入(老师叫歌词)也要继续,比如Title、H1、文章中的关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等等。这个我不想重复了,大家都懂的。
六。相关主题模型的使用。
仅仅写文字是不够的,因为太机械会失去文字的用户体验。所以做一个主题模型,比如关键词【婚礼搭配】可以扩展到一些相关的词,比如燕尾服、婚纱、婚纱背心、婚纱、婚宴等等。形成一个大的相关话题,这样的页面内容会让关键词排名更全面,帮助更多用户。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
第七,展示文字的深度优化。
排名显示的信息对点击率非常重要,所以我们可能不得不影响显示的信息(主要是标题、描述、网址)。内容中需要针对SEO优化这些元素:标题的创意、desc的流行度、url的规范、文章的日期、结构化数据的使用、在线对话等等。下面的效果是什么?
20 场男人杀死女人的婚礼:
2016年5月31日——为20位参加婚礼的男士提供最新搭配建议。再低的预算也配得上周围女嘉宾的秒杀,全是图片和视频。
八.创造独特的价值内容。
毕竟,营销离不开内容的质量。
好的内容包括:
1) 提供了独特的视觉体验、前端界面、合适的字体和功能按钮。
2)内容必须有价值、可信、有趣、值得采集。
3)与其他内容相比,没有重复,深度更强。
4)打开速度快(无广告),可以在不同终端阅读。
5)可以产生表扬、惊喜、快乐、思考等情绪化的想法
6)可以实现一定的转发和传播能力。
7) 使用完整、准确和独特的信息来解决或回答问题。 查看全部
站内八大seo优化点总结,全精辟,小伙伴可以详细阅读
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。总结了网站seo的8个优化点,都很精辟,朋友们可以给详细[...]
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。网站内8个seo优化点汇总,有见地,朋友可以详细阅读。
任何接触过搜索引擎优化的人都可以发表他们对搜索引擎优化的看法。出于这个原因,错误和正确的 SEO 观点是混合的。其实,真正权威、可靠的观点应该来自百度的官方文档。视频,以下是网站seo优化的核心要点:
注意:这个seo教程的优化点偏向于用户体验,而不是简单的seo。

首先,落地页的内容是解决问题,而不仅仅是描述问题。

例如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该有几个方向:【男嘉宾推荐的20款婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他是去参加婚礼,所以最后要解决的问题是去哪里买衣服,而不是让他学会如何搭配衣服。所以在优化这个关键词的时候,我们的内容一定要解决它的最终需求,这样引流和转化效果才会更好。
[/s2/]二、提高网站的激活速度是网站优化不可缺少的一点。

在信息碎片化的时代,没有人愿意给你等待的机会,所以网站打开和加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,一定要考虑可以做些什么来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三是增强用户界面、用户体验和品牌的信任度和参与度。
很多用户打开网站都会有第一印象。他们是好小屋,好当地的海龟,专业,不是我们想要的结果。页面设计需要ui& UX投资和品牌自身的口碑来背书,否则用户很难在网站产生信任和参与。最实用的方法是模仿业界比较好的网站,购买付费版的网站模板或者让用户参与每一个设计过程。
第四,避免各种促使用户离开页面的反应性 SEO 元素。
许多弹出窗口、固定凸窗和广告位会让用户反感并放弃整个浏览过程。这是在搜索引擎优化过程中应该避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时可以避免蜘蛛被禁止或难以捕捉的可能性,让搜索引擎降低自己的权利。
V。一般关键字布局。
常规的关键词植入(老师叫歌词)也要继续,比如Title、H1、文章中的关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等等。这个我不想重复了,大家都懂的。
六。相关主题模型的使用。
仅仅写文字是不够的,因为太机械会失去文字的用户体验。所以做一个主题模型,比如关键词【婚礼搭配】可以扩展到一些相关的词,比如燕尾服、婚纱、婚纱背心、婚纱、婚宴等等。形成一个大的相关话题,这样的页面内容会让关键词排名更全面,帮助更多用户。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
第七,展示文字的深度优化。
排名显示的信息对点击率非常重要,所以我们可能不得不影响显示的信息(主要是标题、描述、网址)。内容中需要针对SEO优化这些元素:标题的创意、desc的流行度、url的规范、文章的日期、结构化数据的使用、在线对话等等。下面的效果是什么?
20 场男人杀死女人的婚礼:
2016年5月31日——为20位参加婚礼的男士提供最新搭配建议。再低的预算也配得上周围女嘉宾的秒杀,全是图片和视频。
八.创造独特的价值内容。
毕竟,营销离不开内容的质量。
好的内容包括:
1) 提供了独特的视觉体验、前端界面、合适的字体和功能按钮。
2)内容必须有价值、可信、有趣、值得采集。
3)与其他内容相比,没有重复,深度更强。
4)打开速度快(无广告),可以在不同终端阅读。
5)可以产生表扬、惊喜、快乐、思考等情绪化的想法
6)可以实现一定的转发和传播能力。
7) 使用完整、准确和独特的信息来解决或回答问题。
网站主题模型优化怎么将站内SEO优化做的
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-08-05 20:25
很多朋友在优化网站seo的时候遇到了一些网站optimization的问题,包括“网站主题模型优化ppt:如何有效提高企业网站人气”的问题,那么下面是一个搜索互联网编辑器来解答您的疑惑。
您可以为您的企业进行 seo 搜索引擎优化网站。优化你的网站关键词、网站theme模型、网站结构、网站页面、网站链接优化。
SEO 搜索引擎优化
网站关键词optimization、网站theme 模型优化、网站structure 优化、网站page 优化、网站link 优化
SEO 搜索引擎优化
是网站关键词优化、网站topic模型优化、网站结构优化、网站page优化、网站link优化
如何做好站内SEO优化网站topic模型优化ppt
对于每一个网站做seo优化,网站seo优化都是必不可少的一步。只有做好网站自己的优化,做异地优化才会更有效。 seo网站优化可以分为:代码优化、标签优化、内容优化、网址优化等,网站seo优化的技巧很多,笔者总结了以下几点:
1、文章关键词密度要合理
文章中关键词关键词的密度要合理,不是越高越好,太少也不行,合适的密度范围应该是2%~8%,内容解释在图片和文字的形式,文章最好在标题中收录关键词。如果想知道文章中关键词的密度,可以使用第三方工具查询。
2、提高网站访问速度
网站topic模型优化ppt:使用seo创建关键词相关度
网站访问速度也会影响网站的SEO优化和用户体验。网页打开速度越快,用户就越满意。提高网站的访问速度无疑有利于搜索引擎优化。
3、优化层不要超过四层
过度优化也是很多新手常犯的错误。通常,URL 中的每个“/”代表一个层。权重越低,层越深,搜索引擎越难抓取,越影响排名效果。
4.高质量原创文章,持续更新
网站 的内容也是网站 seo 优化的一个关键点。毕竟大家都要去网站的内容,文章要收录,被用户点赞的建议是原创,除了优质内容,文章段布局也很重要。更新网站文章的更新是持久战,不能随心更新。
5.网站地图设置
网站map 也称为站点地图。虽然只是一个页面,但是网站上所有页面的链接都放在上面,起到导航的作用。
6.图片优化
图片在文章中也扮演着不可忽视的角色。很多人往往会忽略这个问题。图像优化应该从用户视觉的角度考虑,适合爬虫。图片太大或太小都不好。 建议图片宽度在~像素之间,高度和像素之间,像素1M以内,居中显示。
网站优化技巧只是为了帮助您。具体的还是要靠大家的实践。理论结合实际操作是优化网站的方法。
以上是关于网站theme模型优化ppt,如何有效提高企业网站文章内容的知名度,如果您有网站optimization意向,可以直接联系我们。很高兴为您服务! 查看全部
网站主题模型优化怎么将站内SEO优化做的
很多朋友在优化网站seo的时候遇到了一些网站optimization的问题,包括“网站主题模型优化ppt:如何有效提高企业网站人气”的问题,那么下面是一个搜索互联网编辑器来解答您的疑惑。
您可以为您的企业进行 seo 搜索引擎优化网站。优化你的网站关键词、网站theme模型、网站结构、网站页面、网站链接优化。
SEO 搜索引擎优化
网站关键词optimization、网站theme 模型优化、网站structure 优化、网站page 优化、网站link 优化
SEO 搜索引擎优化
是网站关键词优化、网站topic模型优化、网站结构优化、网站page优化、网站link优化
如何做好站内SEO优化网站topic模型优化ppt
对于每一个网站做seo优化,网站seo优化都是必不可少的一步。只有做好网站自己的优化,做异地优化才会更有效。 seo网站优化可以分为:代码优化、标签优化、内容优化、网址优化等,网站seo优化的技巧很多,笔者总结了以下几点:
1、文章关键词密度要合理
文章中关键词关键词的密度要合理,不是越高越好,太少也不行,合适的密度范围应该是2%~8%,内容解释在图片和文字的形式,文章最好在标题中收录关键词。如果想知道文章中关键词的密度,可以使用第三方工具查询。
2、提高网站访问速度
网站topic模型优化ppt:使用seo创建关键词相关度
网站访问速度也会影响网站的SEO优化和用户体验。网页打开速度越快,用户就越满意。提高网站的访问速度无疑有利于搜索引擎优化。
3、优化层不要超过四层
过度优化也是很多新手常犯的错误。通常,URL 中的每个“/”代表一个层。权重越低,层越深,搜索引擎越难抓取,越影响排名效果。
4.高质量原创文章,持续更新
网站 的内容也是网站 seo 优化的一个关键点。毕竟大家都要去网站的内容,文章要收录,被用户点赞的建议是原创,除了优质内容,文章段布局也很重要。更新网站文章的更新是持久战,不能随心更新。
5.网站地图设置
网站map 也称为站点地图。虽然只是一个页面,但是网站上所有页面的链接都放在上面,起到导航的作用。
6.图片优化
图片在文章中也扮演着不可忽视的角色。很多人往往会忽略这个问题。图像优化应该从用户视觉的角度考虑,适合爬虫。图片太大或太小都不好。 建议图片宽度在~像素之间,高度和像素之间,像素1M以内,居中显示。
网站优化技巧只是为了帮助您。具体的还是要靠大家的实践。理论结合实际操作是优化网站的方法。
以上是关于网站theme模型优化ppt,如何有效提高企业网站文章内容的知名度,如果您有网站optimization意向,可以直接联系我们。很高兴为您服务!
SEO站内..文章内容字数是否够多?实操优化方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-05 04:37
今天的SEO已经进入了一个全新的内容营销算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于 SEO,网站...
2、文章内容字数够吗?
(3),找到与第二类词相关的三类词
3、内容够不够原创?
4、尽量扩大话题角度,添加相关答案。
方法(2)不仅仅是指关键词频率(密度),而是一个更复杂层次的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果(在谷歌有一项专利叫做TF-IDF,具体可以参考马海翔博客“搜索引擎自动提取文章关键词principle”一文中的介绍)。
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有相关性,所以词系统布局是为了区分核心词及其相关性。具体来说,有以下三种实用的优化方法:
(2),在文中使用引号,如行业内知名人士的话或图标或视频。
所以为了提高上下文相关性,应该通过段落、列表和分区使内容更加明显。可以一目了然地知道该段落在说什么,前后句子之间是否有连通性,不要将含义相似的内容分开。太远了,因为你不能保证蜘蛛会抓到全文。
通常我们可以听到或看到许多关于 SEO 页面内容的旧方法,例如:
5、使用各种H标签来整合关键词?
您可以清楚地看到每层单词和短语之间的一些关联。根据(4)我们尝试在这些内容和内容中的主词之间建立关联,特别是如果有人、地点、事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有这样的其他网站上的关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题,记住你要传递主题,不是关键词密度!
5、 提供额外的现场或场外辅助资源。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,但现在更偏向于实体,因为词排名使用了太多以外链为主的链式方式。 ,所以结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。是的,这些是 8-9 年前的技术。现在我们需要优化网站的内容。我们必须做的是如何让搜索引擎理解页面的核心主题,这也是我今天文章的核心。
马海翔的博客评论:
二、如何制作一个好的SEO网站主题模型
2、词系布局
1、 描述页面主题的非常笼统的标题。
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题词放在标题,大标题,尽量出现在正文的顶部。
当前位置:首页>百度SEO排名优化>如何做网站主题内容模型的SEO优化 查看全部
SEO站内..文章内容字数是否够多?实操优化方法
今天的SEO已经进入了一个全新的内容营销算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于 SEO,网站...
2、文章内容字数够吗?
(3),找到与第二类词相关的三类词
3、内容够不够原创?


4、尽量扩大话题角度,添加相关答案。
方法(2)不仅仅是指关键词频率(密度),而是一个更复杂层次的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果(在谷歌有一项专利叫做TF-IDF,具体可以参考马海翔博客“搜索引擎自动提取文章关键词principle”一文中的介绍)。
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有相关性,所以词系统布局是为了区分核心词及其相关性。具体来说,有以下三种实用的优化方法:
(2),在文中使用引号,如行业内知名人士的话或图标或视频。

所以为了提高上下文相关性,应该通过段落、列表和分区使内容更加明显。可以一目了然地知道该段落在说什么,前后句子之间是否有连通性,不要将含义相似的内容分开。太远了,因为你不能保证蜘蛛会抓到全文。
通常我们可以听到或看到许多关于 SEO 页面内容的旧方法,例如:
5、使用各种H标签来整合关键词?
您可以清楚地看到每层单词和短语之间的一些关联。根据(4)我们尝试在这些内容和内容中的主词之间建立关联,特别是如果有人、地点、事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有这样的其他网站上的关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题,记住你要传递主题,不是关键词密度!
5、 提供额外的现场或场外辅助资源。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,但现在更偏向于实体,因为词排名使用了太多以外链为主的链式方式。 ,所以结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。是的,这些是 8-9 年前的技术。现在我们需要优化网站的内容。我们必须做的是如何让搜索引擎理解页面的核心主题,这也是我今天文章的核心。
马海翔的博客评论:
二、如何制作一个好的SEO网站主题模型
2、词系布局
1、 描述页面主题的非常笼统的标题。
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题词放在标题,大标题,尽量出现在正文的顶部。
当前位置:首页>百度SEO排名优化>如何做网站主题内容模型的SEO优化
SEO早已进到全新升级“层次感内容”的优化算法
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-05 04:30
SEO已经进入全新升级的“分级内容”优化算法管理体系,尤其是现在一流的搜索引擎更能从内容场景和内容实体线属性解决排名,促使客户获得更精准的百度搜索。对于推广者来说,网站内部优化将不再是简单的内容填充,必须彻底改变主题内容的推广。文章将结合新的SEO核心概念,指导大家如何改进主题内容。
主题实体模型是为了更好地让搜索引擎正确理解所有页面的关键主题,而不是发送很多关键词,对页面内容进行合理布局的实体模型。由于一个页面可以收录很多信息内容,有的有效,有的被占用,你只能通过将真正关键的信息传递给搜索引擎来获得匹配的排名。所以,在主题实体模型中,大家一定要保证一个四步新的升级优化方法:1词关系2词系统合理布局3填充内容4内容属性。
对于这些大家都知道的网站,比如维基百科,亚马逊就利用里面的积分,获得了大量的关键词排名。他们在页面的合理布局上做了部署,因为他们的“铁骨架”足够强大,能够将关键内容主题大量合理地展示给搜索引擎。因此,嵌入内容后,可以制作出许多可以上台的页面。因此,无论您是新手还是老手,即使您不掌握搜索引擎优化算法,应用主题实体模型也可以很好地排名! (特别是对于 Google)。
无论你用什么方法来改善页面内容,Boli SEO,但你必须专注于如何建立词句之间的关系。作为内容写作,您所写的最直接会危及搜索引擎对页面主题的理解。当我们使用句子和短语时,搜索引擎会根据其他资源中的数据信息将您的内容关联起来,这会导致内容实体线生硬。推广者首先要根据关键词科学研究,找出这句话和词组的关系。我坚信每个人对关键词都有自己的科学研究方式,但是你需要做到以下几点: 1 查找同义词和组合词 2 搜索与关键词 主要内容相关的二等词; 3 搜索与二类词相关的三类词; 4 获取与主关键词相关的内容属性(人、地、物)。
这种“主题增强”的方法大家其实都可以操作。一个高质量的页面就像一张高中毕业证书,它记录了你的身体线条和相关性。最后,将以下优化技巧结合到你的内容改进中:1.高度抽象的Title描述页面主题,2.促销开头词(缩写)描述页面内容,3.分割内容有几个,每个都有自己的主题。 4.尽可能扩展主题视角,可以添加相关回复。 5.给了额外的网站内部或外部辅助资源,6.不关心某个词的比例,只是为了创建内容实体行。 查看全部
SEO早已进到全新升级“层次感内容”的优化算法
SEO已经进入全新升级的“分级内容”优化算法管理体系,尤其是现在一流的搜索引擎更能从内容场景和内容实体线属性解决排名,促使客户获得更精准的百度搜索。对于推广者来说,网站内部优化将不再是简单的内容填充,必须彻底改变主题内容的推广。文章将结合新的SEO核心概念,指导大家如何改进主题内容。
主题实体模型是为了更好地让搜索引擎正确理解所有页面的关键主题,而不是发送很多关键词,对页面内容进行合理布局的实体模型。由于一个页面可以收录很多信息内容,有的有效,有的被占用,你只能通过将真正关键的信息传递给搜索引擎来获得匹配的排名。所以,在主题实体模型中,大家一定要保证一个四步新的升级优化方法:1词关系2词系统合理布局3填充内容4内容属性。
对于这些大家都知道的网站,比如维基百科,亚马逊就利用里面的积分,获得了大量的关键词排名。他们在页面的合理布局上做了部署,因为他们的“铁骨架”足够强大,能够将关键内容主题大量合理地展示给搜索引擎。因此,嵌入内容后,可以制作出许多可以上台的页面。因此,无论您是新手还是老手,即使您不掌握搜索引擎优化算法,应用主题实体模型也可以很好地排名! (特别是对于 Google)。
无论你用什么方法来改善页面内容,Boli SEO,但你必须专注于如何建立词句之间的关系。作为内容写作,您所写的最直接会危及搜索引擎对页面主题的理解。当我们使用句子和短语时,搜索引擎会根据其他资源中的数据信息将您的内容关联起来,这会导致内容实体线生硬。推广者首先要根据关键词科学研究,找出这句话和词组的关系。我坚信每个人对关键词都有自己的科学研究方式,但是你需要做到以下几点: 1 查找同义词和组合词 2 搜索与关键词 主要内容相关的二等词; 3 搜索与二类词相关的三类词; 4 获取与主关键词相关的内容属性(人、地、物)。
这种“主题增强”的方法大家其实都可以操作。一个高质量的页面就像一张高中毕业证书,它记录了你的身体线条和相关性。最后,将以下优化技巧结合到你的内容改进中:1.高度抽象的Title描述页面主题,2.促销开头词(缩写)描述页面内容,3.分割内容有几个,每个都有自己的主题。 4.尽可能扩展主题视角,可以添加相关回复。 5.给了额外的网站内部或外部辅助资源,6.不关心某个词的比例,只是为了创建内容实体行。
1.什么是SEO站内主题模型(一)_
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-08-05 04:18
Seo进入了“有质感的内容”的全新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1.SEO网站的主题模型是什么
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 看看关键词密度是否符合标准
·文章内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词 是否设置为完全匹配?
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型?
主题模型是一种页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达关键词多。因为一个页面可以收录很多信息,有的有用,有的被占用,只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:
1)词系联系
2)词系布局
3)补充内容
4)Content 属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分获得了海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地显示核心内容主题。因此,在植入内容后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好! (特别是对于 Google)
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,从而生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和异体词
2)查找与主词内容相关的二类词
3)找到与第二类词相关的三类词
4)断定内容属性与主题(人物、地点、事物)相关
让我举个例子。比如你要优化一个关键词叫【网红】,这个词就成为你的主词。根据目的(1)其同义词和异体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)和主要词的内容相关到第二类词可以是“留几手”“微博”“生词”;然后根据目的(3)找到第三类词与第二类词相关的可以是“留几手”手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了。
您可以清楚地看到每层单词和短语之间的一些联系。根据(4),我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有其他网站上的这种关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题。记住你是通过主题,而不是关键词密度!
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有关的。因此,词系统布局是区分核心词及其相关性。以下是 3 种实用的优化方法:
方法(1)是大部分SEO人的必修项目,我们还是要尽量把核心主题词放在标题、大标题和正文顶部。
方法(2)这里不仅仅是指关键词频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)distance 产生美在 SEO 世界中不适用。单词、短语或句子应尽可能靠近放置,或使用 HTML 元素(如图片 ALT 设置)。所以为了提高语言的语境相关性,通过段落、列表、分区,让内容更加明显,段落说的内容一目了然意思太远了。因为你不能保证蜘蛛会抓到全文。
你知道方法的原理。现在你要做的就是将二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会围绕这个词文章。第二段用几只手为文章,第三段用微博转播效果为文章,第四段用新网名文章。等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
也许有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯关键词,缺少文字链接、参考资料和相关资源推荐。您的页面非常僵硬。死胡同不会为您的页面增加额外的分数。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件,是搜索引擎的资料片,我有【补充】。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站内链接);
2)在文中使用引号,如业内知名人士的话或图标或视频;
3)使用正文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom老师”时,它的实体是[人]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,或者可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体了。
通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema 。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多地使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的高度概括的标题
2)添加开场白(简要)描述页面内容
3)将内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以补充相关答案
5) 提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体 查看全部
1.什么是SEO站内主题模型(一)_
Seo进入了“有质感的内容”的全新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1.SEO网站的主题模型是什么
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 看看关键词密度是否符合标准
·文章内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词 是否设置为完全匹配?
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型?

主题模型是一种页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达关键词多。因为一个页面可以收录很多信息,有的有用,有的被占用,只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:
1)词系联系
2)词系布局
3)补充内容
4)Content 属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分获得了海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地显示核心内容主题。因此,在植入内容后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好! (特别是对于 Google)
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。

当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,从而生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和异体词
2)查找与主词内容相关的二类词
3)找到与第二类词相关的三类词
4)断定内容属性与主题(人物、地点、事物)相关
让我举个例子。比如你要优化一个关键词叫【网红】,这个词就成为你的主词。根据目的(1)其同义词和异体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)和主要词的内容相关到第二类词可以是“留几手”“微博”“生词”;然后根据目的(3)找到第三类词与第二类词相关的可以是“留几手”手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了。
您可以清楚地看到每层单词和短语之间的一些联系。根据(4),我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有其他网站上的这种关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题。记住你是通过主题,而不是关键词密度!
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有关的。因此,词系统布局是区分核心词及其相关性。以下是 3 种实用的优化方法:

方法(1)是大部分SEO人的必修项目,我们还是要尽量把核心主题词放在标题、大标题和正文顶部。
方法(2)这里不仅仅是指关键词频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)distance 产生美在 SEO 世界中不适用。单词、短语或句子应尽可能靠近放置,或使用 HTML 元素(如图片 ALT 设置)。所以为了提高语言的语境相关性,通过段落、列表、分区,让内容更加明显,段落说的内容一目了然意思太远了。因为你不能保证蜘蛛会抓到全文。
你知道方法的原理。现在你要做的就是将二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会围绕这个词文章。第二段用几只手为文章,第三段用微博转播效果为文章,第四段用新网名文章。等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
也许有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。

因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯关键词,缺少文字链接、参考资料和相关资源推荐。您的页面非常僵硬。死胡同不会为您的页面增加额外的分数。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件,是搜索引擎的资料片,我有【补充】。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站内链接);
2)在文中使用引号,如业内知名人士的话或图标或视频;
3)使用正文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom老师”时,它的实体是[人]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,或者可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体了。

通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema 。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多地使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的高度概括的标题
2)添加开场白(简要)描述页面内容
3)将内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以补充相关答案
5) 提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
如何进行关键词优化来提如下四个意见?
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-05 03:43
如何进行关键词优化来提如下四个意见?
一、选关键词
新站网站域名本身权重不高,不适合流行关键词。关于如何优化关键词的问题,我们应该选择热门还是冷门的关键词?现在我就如何优化关键词给出以下四点意见:
1:如何优化关键词,我们可以通过百度等搜索引擎搜索相关关键词,在搜索引擎中查看这个关键词相关网站总收录页面,这个页面是最好控制在2万到30万之间。
2:如何优化关键词,我们可以搜索某个意图关键词,分析竞争对手,选择难度相对较低的关键词!
3:如何通过百度搜索Billboard优化关键词,我们可以通过百度搜索Billboard进行选择,我们应该选择那些相对较晚但有上升潜力的关键词,关键词经常是这种情况@做完之后还会继续带来不错的流量!
4:如何优化关键词,我们可以培养关键词,在某些事情发生之前的某个时间,我们特意围绕某个关键词进行优化!
二、制作网站
网站程序的优化对如何优化你的关键词影响很大。写完网站homepage的标题不要改,不然就不是百度收录了。
三、原创文章
关于如何优化你的关键词的问题,如果你想获得好的网站排名,就尽量多写原创的内容。 原创内容有其独特性,所以搜索引擎自然会好抢文章,增加收录文章的数量。
四、网站快照
如何优化关键词,如果你想快速更新首页网站snapshot,最好的办法是每天更新3-5条原创内容。
五、全站布局
如何优化关键词,要做好整个网站的布局,必须有文章中的文字链接指向文章页面,另外三个指向首页增加网站的权重,形成一个巨大的蜘蛛网,方便蜘蛛及时爬行。而且文章标签和分类目录也不容忽视,也是优化的关键。我们可以使用我们的网站关键字作为文章标签和类别目录。
六、外链
如何优化关键词,外链很重要,但是最好在上个月做原创文章链接,然后在高权重网站上发外链一个月后。做好以上六点,你的网站两三个月就可以优化到首页了。 查看全部
如何进行关键词优化来提如下四个意见?
一、选关键词
新站网站域名本身权重不高,不适合流行关键词。关于如何优化关键词的问题,我们应该选择热门还是冷门的关键词?现在我就如何优化关键词给出以下四点意见:
1:如何优化关键词,我们可以通过百度等搜索引擎搜索相关关键词,在搜索引擎中查看这个关键词相关网站总收录页面,这个页面是最好控制在2万到30万之间。
2:如何优化关键词,我们可以搜索某个意图关键词,分析竞争对手,选择难度相对较低的关键词!
3:如何通过百度搜索Billboard优化关键词,我们可以通过百度搜索Billboard进行选择,我们应该选择那些相对较晚但有上升潜力的关键词,关键词经常是这种情况@做完之后还会继续带来不错的流量!
4:如何优化关键词,我们可以培养关键词,在某些事情发生之前的某个时间,我们特意围绕某个关键词进行优化!
二、制作网站
网站程序的优化对如何优化你的关键词影响很大。写完网站homepage的标题不要改,不然就不是百度收录了。
三、原创文章
关于如何优化你的关键词的问题,如果你想获得好的网站排名,就尽量多写原创的内容。 原创内容有其独特性,所以搜索引擎自然会好抢文章,增加收录文章的数量。
四、网站快照
如何优化关键词,如果你想快速更新首页网站snapshot,最好的办法是每天更新3-5条原创内容。
五、全站布局
如何优化关键词,要做好整个网站的布局,必须有文章中的文字链接指向文章页面,另外三个指向首页增加网站的权重,形成一个巨大的蜘蛛网,方便蜘蛛及时爬行。而且文章标签和分类目录也不容忽视,也是优化的关键。我们可以使用我们的网站关键字作为文章标签和类别目录。
六、外链
如何优化关键词,外链很重要,但是最好在上个月做原创文章链接,然后在高权重网站上发外链一个月后。做好以上六点,你的网站两三个月就可以优化到首页了。
搜索引擎主题模型优化(基于Web信息抽取的本文技术优化策略研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-28 12:06
[摘要]:随着互联网技术的飞速发展,在线信息呈指数级增长。由于网络信息载体的异质性和可变性,如何对海量信息进行检索和处理成为当前重要的研究课题。网页信息抽取是指从半结构化网页中抽取指定信息,并将结构化数据形成数据库供用户查询和使用的过程。 Web信息抽取是提高信息检索性能的重要手段之一,尤其是在垂直领域。本文研究了垂直搜索引擎中的Web信息提取技术。本文首先总结了Web信息抽取的主要技术,从Web信息抽取系统的构成入手,分析了模板检测、模板生成和数据抽取三个主要过程中涉及的关键问题和传统解决方案。针对传统信息抽取技术在垂直搜索引擎应用背景下的局限性,提出了相应的改进方法。对于模板检测,本文在传统DOM树编辑距离算法的基础上,根据节点对布局的影响程度赋予不同的权重,提出了一种新的网页结构相似度计算算法。实验结果分析表明,新算法对动态模板网页的聚类效果比传统算法有显着提升。针对模板生成和数据提取,本文提出了一种基于聚类的模板混合生成算法,将网页聚类过程中样本网页的结构相似性比较和模板生成中样本网页与模板的结构相似性比较结合起来。过程。改进了模板的生成方式。对于数据提取,本文在定义网页对象概念的基础上,研究了对象提取过程中网页与网页提取模板的匹配问题,提出了一种基于结构树调整的模板匹配算法。实验结果表明,新的模板生成和数据提取算法在保证一定召回率的同时,能够达到令人满意的提取精度,同时减少计算时间和人力成本,使其更符合商业搜索引擎的应用需求。最后,本文讨论了商业搜索引擎的技术优化策略,主要包括基于URL模式分析和网页信息质量分析的网页采集路径优化和提取模板匹配优化。此外,本文还研究了商业垂直搜索引擎应用背景下Web信息抽取系统的系统设计与实现。采用基于.Net平台的Silverlight技术,将所提出的算法和设计成功应用于自主研发的垂直搜索引擎系统——GeeSeek的实际应用表明,该系统能够有效提升用户的搜索体验。网络信息提取的发展非常迅速。目前,网络信息抽取研究的信息来源基本上是已经构建好的网页,而互联网上的大部分数据仍然以数据库的形式存在于各种分布式服务器上。如何提取这些信息?这将是我们接下来需要研究的工作。 查看全部
搜索引擎主题模型优化(基于Web信息抽取的本文技术优化策略研究)
[摘要]:随着互联网技术的飞速发展,在线信息呈指数级增长。由于网络信息载体的异质性和可变性,如何对海量信息进行检索和处理成为当前重要的研究课题。网页信息抽取是指从半结构化网页中抽取指定信息,并将结构化数据形成数据库供用户查询和使用的过程。 Web信息抽取是提高信息检索性能的重要手段之一,尤其是在垂直领域。本文研究了垂直搜索引擎中的Web信息提取技术。本文首先总结了Web信息抽取的主要技术,从Web信息抽取系统的构成入手,分析了模板检测、模板生成和数据抽取三个主要过程中涉及的关键问题和传统解决方案。针对传统信息抽取技术在垂直搜索引擎应用背景下的局限性,提出了相应的改进方法。对于模板检测,本文在传统DOM树编辑距离算法的基础上,根据节点对布局的影响程度赋予不同的权重,提出了一种新的网页结构相似度计算算法。实验结果分析表明,新算法对动态模板网页的聚类效果比传统算法有显着提升。针对模板生成和数据提取,本文提出了一种基于聚类的模板混合生成算法,将网页聚类过程中样本网页的结构相似性比较和模板生成中样本网页与模板的结构相似性比较结合起来。过程。改进了模板的生成方式。对于数据提取,本文在定义网页对象概念的基础上,研究了对象提取过程中网页与网页提取模板的匹配问题,提出了一种基于结构树调整的模板匹配算法。实验结果表明,新的模板生成和数据提取算法在保证一定召回率的同时,能够达到令人满意的提取精度,同时减少计算时间和人力成本,使其更符合商业搜索引擎的应用需求。最后,本文讨论了商业搜索引擎的技术优化策略,主要包括基于URL模式分析和网页信息质量分析的网页采集路径优化和提取模板匹配优化。此外,本文还研究了商业垂直搜索引擎应用背景下Web信息抽取系统的系统设计与实现。采用基于.Net平台的Silverlight技术,将所提出的算法和设计成功应用于自主研发的垂直搜索引擎系统——GeeSeek的实际应用表明,该系统能够有效提升用户的搜索体验。网络信息提取的发展非常迅速。目前,网络信息抽取研究的信息来源基本上是已经构建好的网页,而互联网上的大部分数据仍然以数据库的形式存在于各种分布式服务器上。如何提取这些信息?这将是我们接下来需要研究的工作。
本文充分利用语义Web和本体论的相关技术理论,将本体论构建模型SMBDI
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-26 18:12
[摘要]:在互联网信息不断膨胀的今天,搜索引擎已经成为人们获取信息不可或缺的工具。但是,随着信息量的增加和行为的增多,传统的搜索模式逐渐暴露出许多问题,如词汇孤岛问题、表达差异问题、忠实表达问题和机械匹配问题。造成这些问题的根本原因在于,传统搜索引擎无法对用户输入的关键词词义进行分析和扩展,缺乏知识处理和理解能力。本文充分利用语义网和本体的相关技术理论,将本体构建语义模型的能力应用到智能搜索研究中,最终实现了基于本体的智能搜索模型SMBDI。研究内容包括基于本体的XML信息代理数据集成、基于概念的用户界面、查询处理和算法。在深入分析信息代理DTD与本体模型关系的基础上,提出了一种基于本体的数据集成方案。该项目旨在在网络中集成XML信息代理实现大规模搜索,并通过路径映射理论实现概念的语义集成,避免表达差异导致的信息缺失。同时,通过真实概念识别底层数据,有效避免了机械匹配问题,保证了结果的准确性。基于统一语义考虑和用户搜索行为分析,设计了一个基于概念的用户界面。该界面突破了传统的界面模式,采用图形化本体导航、人性化约束机制和自主输出定制,更深刻地解决了查询如实表达的问题,使人机交互更易理解。 查看全部
本文充分利用语义Web和本体论的相关技术理论,将本体论构建模型SMBDI
[摘要]:在互联网信息不断膨胀的今天,搜索引擎已经成为人们获取信息不可或缺的工具。但是,随着信息量的增加和行为的增多,传统的搜索模式逐渐暴露出许多问题,如词汇孤岛问题、表达差异问题、忠实表达问题和机械匹配问题。造成这些问题的根本原因在于,传统搜索引擎无法对用户输入的关键词词义进行分析和扩展,缺乏知识处理和理解能力。本文充分利用语义网和本体的相关技术理论,将本体构建语义模型的能力应用到智能搜索研究中,最终实现了基于本体的智能搜索模型SMBDI。研究内容包括基于本体的XML信息代理数据集成、基于概念的用户界面、查询处理和算法。在深入分析信息代理DTD与本体模型关系的基础上,提出了一种基于本体的数据集成方案。该项目旨在在网络中集成XML信息代理实现大规模搜索,并通过路径映射理论实现概念的语义集成,避免表达差异导致的信息缺失。同时,通过真实概念识别底层数据,有效避免了机械匹配问题,保证了结果的准确性。基于统一语义考虑和用户搜索行为分析,设计了一个基于概念的用户界面。该界面突破了传统的界面模式,采用图形化本体导航、人性化约束机制和自主输出定制,更深刻地解决了查询如实表达的问题,使人机交互更易理解。
seo内容质量的优化,主要从三个方面来讲方面
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-26 18:10
seo内容质量的优化主要来自三个方面:1、内容数量,对没有搜索结果的页面进行补充2、信息是否相关(1)布尔模型判断(2)主题模型判断是否相关) 3、原创和我之前看到和听到的大神的观点一样,内容量还是最重要的,关键词网站内容的覆盖率代表了你的广度流量来源 内容相关不用多说,优秀的内容一定是相关的。他提供了两个评判标准,一个是
seo内容质量的优化主要来自三个方面:
1、 内容数量,无搜索结果页面补充
2、 信息是否相关?
(1)布尔模型判断
(2)主题模型判断
3、是不是原创
和我之前看到和听到的几位大神的观点一样,内容量是最重要的。 网站内容到关键词的覆盖范围代表了你的流量来源的广度。
内容相关性无需多说,优秀的内容必须具有相关性。他提供了两个判断标准,一个是布尔模型判断,即“是”和“否”,内容是否收录关键词?二是主题模型判断。虽然这个网页的内容不能完全匹配搜索到的关键词,但是主题是一样的,解决了我最近在扩展关键词时遇到的一个问题。比如“平安车险怎么样”和“平安车险怎么样”关键词其实就相当于百度。搜索“平安车险怎么样”,“好”也会热搜。这不仅对我们扩展关键词有帮助,也指导我们以后怎么写文章。等价词的出现频率不仅可以增加文章的相关性,还可以增加文章在百度搜索结果中的相关性。机会来了。
最后一点,关于原创,他指的是原创不是文字,他的观点是采集的内容可能不会比原来的文章排名好,重要的是事情是你比原来更好 拥有更高的价值。那么如何拥有比原文更高的价值呢?除了更丰富的呈现形式(如图片、文字等),更重要的是满足用户的二次需求。
例如:用户搜索“五一假期”,他的主要需求是查询假期安排,但第二需求有很多:买票回家、开车回家、假期旅游……
满足用户的二次需求,不仅帮助我们打造优质内容,也为我们提供了拓展关键词的思路。有时候难的不是投入不够,而是思维不够开阔。
文章Title:【长沙SEO】SEO如何优化内容 查看全部
seo内容质量的优化,主要从三个方面来讲方面
seo内容质量的优化主要来自三个方面:1、内容数量,对没有搜索结果的页面进行补充2、信息是否相关(1)布尔模型判断(2)主题模型判断是否相关) 3、原创和我之前看到和听到的大神的观点一样,内容量还是最重要的,关键词网站内容的覆盖率代表了你的广度流量来源 内容相关不用多说,优秀的内容一定是相关的。他提供了两个评判标准,一个是
seo内容质量的优化主要来自三个方面:
1、 内容数量,无搜索结果页面补充
2、 信息是否相关?
(1)布尔模型判断
(2)主题模型判断
3、是不是原创
和我之前看到和听到的几位大神的观点一样,内容量是最重要的。 网站内容到关键词的覆盖范围代表了你的流量来源的广度。
内容相关性无需多说,优秀的内容必须具有相关性。他提供了两个判断标准,一个是布尔模型判断,即“是”和“否”,内容是否收录关键词?二是主题模型判断。虽然这个网页的内容不能完全匹配搜索到的关键词,但是主题是一样的,解决了我最近在扩展关键词时遇到的一个问题。比如“平安车险怎么样”和“平安车险怎么样”关键词其实就相当于百度。搜索“平安车险怎么样”,“好”也会热搜。这不仅对我们扩展关键词有帮助,也指导我们以后怎么写文章。等价词的出现频率不仅可以增加文章的相关性,还可以增加文章在百度搜索结果中的相关性。机会来了。
最后一点,关于原创,他指的是原创不是文字,他的观点是采集的内容可能不会比原来的文章排名好,重要的是事情是你比原来更好 拥有更高的价值。那么如何拥有比原文更高的价值呢?除了更丰富的呈现形式(如图片、文字等),更重要的是满足用户的二次需求。
例如:用户搜索“五一假期”,他的主要需求是查询假期安排,但第二需求有很多:买票回家、开车回家、假期旅游……
满足用户的二次需求,不仅帮助我们打造优质内容,也为我们提供了拓展关键词的思路。有时候难的不是投入不够,而是思维不够开阔。
文章Title:【长沙SEO】SEO如何优化内容
机器之心编辑部对于搜索引擎意味着意味着什么?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-24 23:12
机器报告的核心
机器编辑部的核心
在前段时间举办的“Search On”活动中,谷歌宣布BERT现在支持谷歌搜索引擎上几乎所有基于英文的查询。去年,这一比例仅为 10%。
BERT 是 Google 开源的自然语言处理预训练模型。一经上线,就刷新了 11 个 NLP 任务的 SOTA 记录,登上了 GLUE 基准测试榜的榜首。
特别是对于搜索引擎,BERT 可以帮助搜索引擎更好地理解网页内容,从而提高搜索结果的相关性。 BERT 模型中创新的 Transformer 架构是一大亮点。 Transformer 处理一个句子中与所有其他单词相关的单词,而不是一个一个依次处理。基于此,BERT模型可以利用词前后的词来考虑其所在的完整上下文,这对于理解查询语句背后的意图非常有用。
2019 年 9 月,谷歌宣布在搜索引擎中使用 BERT,但只有 10% 的英文搜索结果得到了改进; 2019 年 12 月,谷歌将 BERT 在搜索引擎中的使用扩展到 70 多种语言。现在,搜索巨头终于宣布几乎所有英文搜索都可以使用BERT。
BERT 对搜索引擎意味着什么?
作为自然语言处理领域的里程碑,BERT 为该领域带来了以下创新:
使用未标记的文本进行预训练;
双向上下文模型;
transformer架构的应用;
掩码语言建模;
注意力机制;
文本含义(下一句的预测);
……
这些特性使 BERT 对搜索引擎优化非常有帮助,尤其是在消歧方面。使用BERT后,对于更长的、会话式的查询,或者带有更重要的介词如“for”和“to”的句子,谷歌搜索引擎将能够理解查询句子中单词的上下文。用户可以以更自然的方式进行搜索。
此外,BERT 对参考解析、多义性、同形异义词、命名实体确定和搜索中的文本暗示等任务也非常有帮助。其中,指称解析是指在一定的上下文或广泛的会话查询中跟踪一个句子或短语所指的是谁或什么;一个词多义是指同一个词有多重含义,多个含义之间存在联系,搜索引擎需要处理含糊不清的细微差别;同形异义词是指形式相同但意义不同的词;命名实体判断是指从多个命名实体中知道文本与什么相关;文本含义是指预测下一句。这些问题构成了搜索引擎面临的共同挑战。
过去一年,谷歌扩大了BERT在搜索引擎中的应用。 G-Squared Interactive 的 SEO 顾问 Danny Sullivan 和 Glenn Gabe 在 Twitter 上介绍了 Google 搜索。近期亮点。
在 Google 搜索中,十分之一的搜索查询拼写错误。很快,一项新的变化将帮助我们在检测和处理拼写错误方面取得比过去五年更大的进步。
另一个即将到来的变化是,Google 搜索将能够识别网页中的各个段落,并将它们处理成与搜索最相关的段落。我们预计这会改善 7% 的 Google 搜索查询。
Search On 2020:Google 可以索引网页的段落,而不仅仅是整个网页。新算法可以放大回答问题的段落,而忽略页面的其余部分。从下个月开始。
使用人工智能,我们可以更好地检测视频的关键部分,帮助人们直接跳转到感兴趣的内容,而无需创作者手动标记。到今年年底,10% 的 Google 搜索将使用这项技术。
此外,Google 还表示他们还使用神经网络来理解与搜索相关的子主题,这有助于在您搜索广泛的内容时提供更多样化的内容。这项服务预计在年底推出。
参考链接: 查看全部
机器之心编辑部对于搜索引擎意味着意味着什么?(图)
机器报告的核心
机器编辑部的核心
在前段时间举办的“Search On”活动中,谷歌宣布BERT现在支持谷歌搜索引擎上几乎所有基于英文的查询。去年,这一比例仅为 10%。
BERT 是 Google 开源的自然语言处理预训练模型。一经上线,就刷新了 11 个 NLP 任务的 SOTA 记录,登上了 GLUE 基准测试榜的榜首。
特别是对于搜索引擎,BERT 可以帮助搜索引擎更好地理解网页内容,从而提高搜索结果的相关性。 BERT 模型中创新的 Transformer 架构是一大亮点。 Transformer 处理一个句子中与所有其他单词相关的单词,而不是一个一个依次处理。基于此,BERT模型可以利用词前后的词来考虑其所在的完整上下文,这对于理解查询语句背后的意图非常有用。
2019 年 9 月,谷歌宣布在搜索引擎中使用 BERT,但只有 10% 的英文搜索结果得到了改进; 2019 年 12 月,谷歌将 BERT 在搜索引擎中的使用扩展到 70 多种语言。现在,搜索巨头终于宣布几乎所有英文搜索都可以使用BERT。
BERT 对搜索引擎意味着什么?
作为自然语言处理领域的里程碑,BERT 为该领域带来了以下创新:
使用未标记的文本进行预训练;
双向上下文模型;
transformer架构的应用;
掩码语言建模;
注意力机制;
文本含义(下一句的预测);
……
这些特性使 BERT 对搜索引擎优化非常有帮助,尤其是在消歧方面。使用BERT后,对于更长的、会话式的查询,或者带有更重要的介词如“for”和“to”的句子,谷歌搜索引擎将能够理解查询句子中单词的上下文。用户可以以更自然的方式进行搜索。
此外,BERT 对参考解析、多义性、同形异义词、命名实体确定和搜索中的文本暗示等任务也非常有帮助。其中,指称解析是指在一定的上下文或广泛的会话查询中跟踪一个句子或短语所指的是谁或什么;一个词多义是指同一个词有多重含义,多个含义之间存在联系,搜索引擎需要处理含糊不清的细微差别;同形异义词是指形式相同但意义不同的词;命名实体判断是指从多个命名实体中知道文本与什么相关;文本含义是指预测下一句。这些问题构成了搜索引擎面临的共同挑战。
过去一年,谷歌扩大了BERT在搜索引擎中的应用。 G-Squared Interactive 的 SEO 顾问 Danny Sullivan 和 Glenn Gabe 在 Twitter 上介绍了 Google 搜索。近期亮点。
在 Google 搜索中,十分之一的搜索查询拼写错误。很快,一项新的变化将帮助我们在检测和处理拼写错误方面取得比过去五年更大的进步。
另一个即将到来的变化是,Google 搜索将能够识别网页中的各个段落,并将它们处理成与搜索最相关的段落。我们预计这会改善 7% 的 Google 搜索查询。
Search On 2020:Google 可以索引网页的段落,而不仅仅是整个网页。新算法可以放大回答问题的段落,而忽略页面的其余部分。从下个月开始。
使用人工智能,我们可以更好地检测视频的关键部分,帮助人们直接跳转到感兴趣的内容,而无需创作者手动标记。到今年年底,10% 的 Google 搜索将使用这项技术。
此外,Google 还表示他们还使用神经网络来理解与搜索相关的子主题,这有助于在您搜索广泛的内容时提供更多样化的内容。这项服务预计在年底推出。
参考链接:
39个SEO格式(搜索引擎优化)经典案例文档大小:14.23
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-24 02:44
对于搜索引擎优化来说,网站的结构是最重要的因素之一。 网站 结构是关于您的网页如何连接的。搜索引擎爬虫。
阿里巴巴网站的搜索引擎优化案例分析阿里巴巴是国内最早进行搜索引擎优化网站的电子商务,也是目前网站优化全局最好的大型B2B电子商务-commerce网站之一.阿里巴巴的搜索引擎优化水平要高得多。
2013-8-8 复旦大学文献检索一系 互联网学术信息查询 2009.1 复旦大学文献检索二系 2013-8-8 网络检索工具1.互联网基础知识2.网络搜索工具基金3.万能搜索引擎示例:.
SEO意思是搜索引擎优化,通过网站结构(内链结构、网站物理结构、网站逻辑结构),高质量的网站主题内容。
这是一个很笼统的陈词滥调,没有任何吸引力,但真正能做好的草根站长估计寥寥无几。我问了一个做草根站长多年的朋友,我该怎么说?做好SEO搜索引擎优化,他给我的答案很难,规模太大了。
1)写本案本案例的目的是总结国内各个B2C商城的SEO优化方案,希望找到最适合互联网现状的SEO优化方案; 2)为了使样本更具代表性和广泛性,本文档中的案例将来自。
四、搜索引擎结构优化 结构优化很重要。 关键词是网站的灵魂,所以结构是网站的骨架。先优化结构。
39 SEO(搜索引擎优化)经典案例 文档格式:.pdf 文档页数:81 文档大小:14.23M 文档流行度:系统标签:. 查看全部
39个SEO格式(搜索引擎优化)经典案例文档大小:14.23
对于搜索引擎优化来说,网站的结构是最重要的因素之一。 网站 结构是关于您的网页如何连接的。搜索引擎爬虫。
阿里巴巴网站的搜索引擎优化案例分析阿里巴巴是国内最早进行搜索引擎优化网站的电子商务,也是目前网站优化全局最好的大型B2B电子商务-commerce网站之一.阿里巴巴的搜索引擎优化水平要高得多。
2013-8-8 复旦大学文献检索一系 互联网学术信息查询 2009.1 复旦大学文献检索二系 2013-8-8 网络检索工具1.互联网基础知识2.网络搜索工具基金3.万能搜索引擎示例:.
SEO意思是搜索引擎优化,通过网站结构(内链结构、网站物理结构、网站逻辑结构),高质量的网站主题内容。
这是一个很笼统的陈词滥调,没有任何吸引力,但真正能做好的草根站长估计寥寥无几。我问了一个做草根站长多年的朋友,我该怎么说?做好SEO搜索引擎优化,他给我的答案很难,规模太大了。
1)写本案本案例的目的是总结国内各个B2C商城的SEO优化方案,希望找到最适合互联网现状的SEO优化方案; 2)为了使样本更具代表性和广泛性,本文档中的案例将来自。
四、搜索引擎结构优化 结构优化很重要。 关键词是网站的灵魂,所以结构是网站的骨架。先优化结构。
39 SEO(搜索引擎优化)经典案例 文档格式:.pdf 文档页数:81 文档大小:14.23M 文档流行度:系统标签:.
快速排序行标题设计的基本标准是什么?(一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-08-19 04:17
一般写好标题,网站可以提高排名速度,可以按照以下方法写SEO标题:
一、SEO 主题的基本标准
我们在设计网站titles的时候,都需要注意搜索引擎的规范。先说基本规范。我们将在以下段落中深入讨论快速排序行标题的设计。
1、标题字数不要超过32字,搜索引擎建议26字。因为如果超过 32 个字符,标题将无法完全显示。同时,过多的文字会使搜索引擎难以识别网页的主题。
2、 单词必须用英文字母分隔。因为在搜索引擎计算中可以使用中文和英文来分隔单词,我们建议在此处添加下划线。
3、 应在标题中收录知名品牌词。知名品牌词是您网站地址中的品牌名称等同于您网站地址中的独特名称
二、快排标题设计实体模型一
型号:核心关键词-品牌词
关键词 密度对排名有重要影响。除了网页内容中的关键词,关键词也必须出现在TDK最重要的位置。这是搜索引擎抓取网页内容的第一步。 , 并清楚地告诉搜索引擎您的网站 主题。并且标题也会显示给用户。用户可以通过搜索关键词来搜索网站,然后网站更有可能被用户搜索和点击。
示例:挖掘机培训-年度现场培训
说明:此类话题的创建是英语词汇的单一站点。所有网页的权重值都可以集中在一个词上,网站的话题会非常集中。因此,这种标题设计是一种非常快速的排序设计方法。
三、Quick Ranking 标题设计实体模型二
实体模型:关键关键词-必选词-知名品牌词
示例:挖掘机培训学校-大型挖掘机学习基地-年度现场培训
说明:此类话题的设计不仅有优化排名的作用,还可以提高长尾词的排名。更重要的是,这类话题会增加客户的点击量。因为人们在标题中提出了要求的词,当客户看到他们需要的内容时,客户就会开始点击。可以说是这种优化排名问题的全新升级措辞。
标题有很多种写法。从严谨的角度来看,人们必须了解分词技术,并让我们的网站基于分词技术创建主题。他被认为是解决此类问题的绝佳人选。
不过,以上两种写法都可以帮助初学者快速写出标题,所以这里就不深入讨论一些复杂的写法了。
四、关于标题写作的一些思考
首先,标题必须添加用户感兴趣的元素。一个优秀的标题可以让用户一目了然地找到他们需要的词。
其次,话题虽然是参与关键词排名,但直接危害话题排名确实是对人同站的提升。
而且,标题与网址内容的匹配度比所有这种标题设计排名方式的实际效果要好得多。 查看全部
快速排序行标题设计的基本标准是什么?(一)
一般写好标题,网站可以提高排名速度,可以按照以下方法写SEO标题:
一、SEO 主题的基本标准
我们在设计网站titles的时候,都需要注意搜索引擎的规范。先说基本规范。我们将在以下段落中深入讨论快速排序行标题的设计。
1、标题字数不要超过32字,搜索引擎建议26字。因为如果超过 32 个字符,标题将无法完全显示。同时,过多的文字会使搜索引擎难以识别网页的主题。
2、 单词必须用英文字母分隔。因为在搜索引擎计算中可以使用中文和英文来分隔单词,我们建议在此处添加下划线。
3、 应在标题中收录知名品牌词。知名品牌词是您网站地址中的品牌名称等同于您网站地址中的独特名称
二、快排标题设计实体模型一
型号:核心关键词-品牌词
关键词 密度对排名有重要影响。除了网页内容中的关键词,关键词也必须出现在TDK最重要的位置。这是搜索引擎抓取网页内容的第一步。 , 并清楚地告诉搜索引擎您的网站 主题。并且标题也会显示给用户。用户可以通过搜索关键词来搜索网站,然后网站更有可能被用户搜索和点击。
示例:挖掘机培训-年度现场培训
说明:此类话题的创建是英语词汇的单一站点。所有网页的权重值都可以集中在一个词上,网站的话题会非常集中。因此,这种标题设计是一种非常快速的排序设计方法。
三、Quick Ranking 标题设计实体模型二
实体模型:关键关键词-必选词-知名品牌词
示例:挖掘机培训学校-大型挖掘机学习基地-年度现场培训
说明:此类话题的设计不仅有优化排名的作用,还可以提高长尾词的排名。更重要的是,这类话题会增加客户的点击量。因为人们在标题中提出了要求的词,当客户看到他们需要的内容时,客户就会开始点击。可以说是这种优化排名问题的全新升级措辞。
标题有很多种写法。从严谨的角度来看,人们必须了解分词技术,并让我们的网站基于分词技术创建主题。他被认为是解决此类问题的绝佳人选。
不过,以上两种写法都可以帮助初学者快速写出标题,所以这里就不深入讨论一些复杂的写法了。
四、关于标题写作的一些思考
首先,标题必须添加用户感兴趣的元素。一个优秀的标题可以让用户一目了然地找到他们需要的词。
其次,话题虽然是参与关键词排名,但直接危害话题排名确实是对人同站的提升。
而且,标题与网址内容的匹配度比所有这种标题设计排名方式的实际效果要好得多。
倒排索引是搜索引擎的基石--VSM检索模型
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-14 19:14
倒排索引是搜索引擎的基石--VSM检索模型
简介:
在信息爆炸的今天,在搜索引擎的帮助下,我们可以快速方便地找到我们要找的东西。说到搜索引擎就不得不说VSM模型,说到VSM就不得不说倒排索引。可以毫不夸张地说,倒排索引是搜索引擎的基石。
VSM 检索模型
VSM的全称是Vector Space Model,是IR(Information Retrieval Information Retrieval)模型之一。由于其简单、直观、高效,被广泛应用于搜索引擎的架构中。 1998年,谷歌凭借这样的模式,开始了疯狂的扩张之路。废话不多说,我们来看看VSM是什么。
在开始之前,我假设大家对线性代数中的Vector有一定的了解。矢量是具有大小和方向的量。它通常用有向线段表示。向量包括:加法、减法、倍数、内积、距离、模数和角度运算。
文档:一个完整的信息单元,指的是相应搜索引擎系统中的单个网页。
Term:文档的基本单位。比如在英文中可以看成一个词,在中文中可以看成一个词。
查询:用户的输入通常由多个术语组成。
然后用一句话总结搜索引擎做了什么:对于用户输入的Query,找到最相似的Document,返回给用户。而这正是IR模型解决的问题:
信息检索模型是指如何表示查询和文档,然后计算它们的相似度的框架和方法。
一个简单的例子:
现在有两篇文章(Document)文章,分别是《春风来了,春天的脚步在逼近》和《春风未过玉门关》。然后输入查询是“春风”。从直觉上讲,前者与输入查询更相关,因为它收录两个弹簧,但这只是我们的直观感受。怎么量化,要知道电脑是严谨的学科^_^。这时候,我们前面提到的 Term 和 VSM 模型就派上用场了。
首先,我们需要确定向量的维度。这时候,我们需要一个字典库。字典库的大小就是向量的维度。本例中,字典为{春风,来,春,的,脚步声,近,不度,玉门关},文档向量和查询向量如下:
VSM 模型示例
PS:为了简单起见,这里的分词粒度非常大。
将 Query 和 Document 都量化为向量后,可以计算出用户的查询与哪个文档更相似。简单的计算结果是D1和D2与Query的内积为1,囧。当然,如果分词粒度越细,查询的结果就会不同,所以分词粒度也会影响查询结果(主要是recall和accuracy)。
上面的例子用一个非常简单的例子来说明VSM模型。在计算文档相似度时,也采用了最原创的内积法,只考虑词频(TF)影响因素,不考虑反向。词频(IDF),现在比较常用的是cos角法,影响因子很多,据说谷歌的影响因子多达100+。
著名的 Lucene 项目就是使用 VSM 模型构建的。 VSM的核心公式如下(由cos角法演化而来,这里省略推导过程)
VSM 模型公式
从上面的例子不难看出,如果向量的维度(对于中文来说,这个值一般是30w-45w)变大,文档数量(通常是海量)变大,那么计算相关性一次,开销很大,这个问题怎么解决?别忘了,我们这一节的主题是倒排索引,主角终于登场了! ! !
倒排索引
倒排索引与我们之前提到的Hash结构非常相似。以下内容来自维基百科:
倒排索引(英文:Inverted index),也常称为倒排索引、置入文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档中的某个词或存储位置的映射。一组文件。它是文档检索系统中最常用的数据结构。
反向索引有两种不同的形式:
后一种形式提供了更多的兼容性(例如短语搜索),但需要更多的时间和空间来创建。
从上面的定义可以知道,倒排索引收录一个字典索引和一个所有单词的列表。字典索引收录了所有的Term(通常理解为文档中的单词),索引后面的列表保存了单词的信息(出现的文档编号,甚至每个文档中收录的位置信息)。下面我们也用上面的方法举一个简单的例子来说明倒排索引。
比如现在我们要索引三个文档(在实际应用中,文档的数量是海量的):
文件1(D1):中国移动互联网发展迅猛
文档2(D2):未来移动互联网潜力巨大
文件3(D3):中华民族是勤劳的民族
文档中设置的字典为:{China, mobile, internet, development, Rapid, future, of, potential,巨大, 中国, 民族, 是, 个人, 勤奋}
构建的索引如下图:
倒排索引
<p>在上面的索引中,存储了两条信息,文档编号和出现次数。建立索引后,我们就可以开始查询了。例如,有一个名为“中国移动”的查询。首先分词获取Term集{China, Mobile},检查倒排索引,分别计算query与d1、d2、d3的距离。有没有发现,倒排列表创建后,不需要搜索整个文档库,直接从字典集合中找到“中国”和“手机”,然后遍历下面的列表,直接计算。 查看全部
倒排索引是搜索引擎的基石--VSM检索模型
简介:
在信息爆炸的今天,在搜索引擎的帮助下,我们可以快速方便地找到我们要找的东西。说到搜索引擎就不得不说VSM模型,说到VSM就不得不说倒排索引。可以毫不夸张地说,倒排索引是搜索引擎的基石。
VSM 检索模型
VSM的全称是Vector Space Model,是IR(Information Retrieval Information Retrieval)模型之一。由于其简单、直观、高效,被广泛应用于搜索引擎的架构中。 1998年,谷歌凭借这样的模式,开始了疯狂的扩张之路。废话不多说,我们来看看VSM是什么。
在开始之前,我假设大家对线性代数中的Vector有一定的了解。矢量是具有大小和方向的量。它通常用有向线段表示。向量包括:加法、减法、倍数、内积、距离、模数和角度运算。
文档:一个完整的信息单元,指的是相应搜索引擎系统中的单个网页。
Term:文档的基本单位。比如在英文中可以看成一个词,在中文中可以看成一个词。
查询:用户的输入通常由多个术语组成。
然后用一句话总结搜索引擎做了什么:对于用户输入的Query,找到最相似的Document,返回给用户。而这正是IR模型解决的问题:
信息检索模型是指如何表示查询和文档,然后计算它们的相似度的框架和方法。
一个简单的例子:
现在有两篇文章(Document)文章,分别是《春风来了,春天的脚步在逼近》和《春风未过玉门关》。然后输入查询是“春风”。从直觉上讲,前者与输入查询更相关,因为它收录两个弹簧,但这只是我们的直观感受。怎么量化,要知道电脑是严谨的学科^_^。这时候,我们前面提到的 Term 和 VSM 模型就派上用场了。
首先,我们需要确定向量的维度。这时候,我们需要一个字典库。字典库的大小就是向量的维度。本例中,字典为{春风,来,春,的,脚步声,近,不度,玉门关},文档向量和查询向量如下:
VSM 模型示例
PS:为了简单起见,这里的分词粒度非常大。
将 Query 和 Document 都量化为向量后,可以计算出用户的查询与哪个文档更相似。简单的计算结果是D1和D2与Query的内积为1,囧。当然,如果分词粒度越细,查询的结果就会不同,所以分词粒度也会影响查询结果(主要是recall和accuracy)。
上面的例子用一个非常简单的例子来说明VSM模型。在计算文档相似度时,也采用了最原创的内积法,只考虑词频(TF)影响因素,不考虑反向。词频(IDF),现在比较常用的是cos角法,影响因子很多,据说谷歌的影响因子多达100+。
著名的 Lucene 项目就是使用 VSM 模型构建的。 VSM的核心公式如下(由cos角法演化而来,这里省略推导过程)
VSM 模型公式
从上面的例子不难看出,如果向量的维度(对于中文来说,这个值一般是30w-45w)变大,文档数量(通常是海量)变大,那么计算相关性一次,开销很大,这个问题怎么解决?别忘了,我们这一节的主题是倒排索引,主角终于登场了! ! !
倒排索引
倒排索引与我们之前提到的Hash结构非常相似。以下内容来自维基百科:
倒排索引(英文:Inverted index),也常称为倒排索引、置入文件或倒排文件,是一种索引方法,用于在全文搜索下存储文档中的某个词或存储位置的映射。一组文件。它是文档检索系统中最常用的数据结构。
反向索引有两种不同的形式:
后一种形式提供了更多的兼容性(例如短语搜索),但需要更多的时间和空间来创建。
从上面的定义可以知道,倒排索引收录一个字典索引和一个所有单词的列表。字典索引收录了所有的Term(通常理解为文档中的单词),索引后面的列表保存了单词的信息(出现的文档编号,甚至每个文档中收录的位置信息)。下面我们也用上面的方法举一个简单的例子来说明倒排索引。
比如现在我们要索引三个文档(在实际应用中,文档的数量是海量的):
文件1(D1):中国移动互联网发展迅猛
文档2(D2):未来移动互联网潜力巨大
文件3(D3):中华民族是勤劳的民族
文档中设置的字典为:{China, mobile, internet, development, Rapid, future, of, potential,巨大, 中国, 民族, 是, 个人, 勤奋}
构建的索引如下图:
倒排索引
<p>在上面的索引中,存储了两条信息,文档编号和出现次数。建立索引后,我们就可以开始查询了。例如,有一个名为“中国移动”的查询。首先分词获取Term集{China, Mobile},检查倒排索引,分别计算query与d1、d2、d3的距离。有没有发现,倒排列表创建后,不需要搜索整个文档库,直接从字典集合中找到“中国”和“手机”,然后遍历下面的列表,直接计算。
很多人可能还停留在5年前做SEO优化的思维
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-14 19:09
很多人可能还停留在5年前做SEO优化的思维
网站网站SEO优化的八个核心是什么?很多人可能还停留在5年前的SEO优化思维中,“链外疯”。 SEO优化论坛现在告诉你,这不是百度自然优化的。核心,不要以为SEO自然优化就是发链接,写文章。现在百度已经对大量算法进行了升级,对SEO优化者的思维和方法提出了更高的要求。目前百度更偏向于系统优化,系统地考虑用户体验,网站的优化部分并不是只有“TITLE”的标题和关键词设置才能达到的效果。现在让我告诉你网站SEO优化的核心因素是什么?
一、页面打开速度,常见问题
重要的事情说了三遍,就是“速度,速度,速度”。很多人从来没有注意到这一点。为了节省建站成本,选择一些低价的垃圾空间。这样的网站打开速度根本满足不了用户。需要,要知道在这个信息碎片化的时代,打开速度慢了一秒,用户可能会流失。所以,在用户体验方面,虽然打开速度是老生常谈,但还是要提醒大家这点的重要性。
二、页面的内容是为用户解决问题而不是描述问题
我们在写文章的时候,要更加细致地解决这些人的需求,才能起到很好的流通和转化作用。
三、网站专业、美观、品牌化运营
很多用户在打开网站的时候有一种印象,就是低端、山寨、不专业。即使网站被网站吸引,用户也不会留下来观看,所以页面的设计非常重要。图片的美感和页面用户体验的优化都会影响网站的优化,所以这方面应该在建站的时候设计,而不是模仿别人。 网站 的另一个重要作用是品牌推广。你要做好自己的品牌,做好自己的品牌,才能让用户对你产生依赖。
四、避免各种导致用户离开的元素
很多网站有很多弹窗、固定凸窗、广告位,对用户非常反感,影响用户浏览网页,从而放弃整个浏览,进入城市,所以我们在考虑添加广告时,首先不能影响用户的浏览,其次不要让用户过分反感。
五、关键词植入
常规的关键词植入还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等我这个就不重复了,大家都懂的。
六、主题模型的注入
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们必须做一个主题模型。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
八、创造独特的有价值的内容。营销不能逃避内容质量。好的内容包括:
1)提供了非常强大的视觉体验,前端界面,合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7)可以使用完整、准确、独特的信息来解决问题或回答问题 查看全部
很多人可能还停留在5年前做SEO优化的思维
网站网站SEO优化的八个核心是什么?很多人可能还停留在5年前的SEO优化思维中,“链外疯”。 SEO优化论坛现在告诉你,这不是百度自然优化的。核心,不要以为SEO自然优化就是发链接,写文章。现在百度已经对大量算法进行了升级,对SEO优化者的思维和方法提出了更高的要求。目前百度更偏向于系统优化,系统地考虑用户体验,网站的优化部分并不是只有“TITLE”的标题和关键词设置才能达到的效果。现在让我告诉你网站SEO优化的核心因素是什么?
一、页面打开速度,常见问题
重要的事情说了三遍,就是“速度,速度,速度”。很多人从来没有注意到这一点。为了节省建站成本,选择一些低价的垃圾空间。这样的网站打开速度根本满足不了用户。需要,要知道在这个信息碎片化的时代,打开速度慢了一秒,用户可能会流失。所以,在用户体验方面,虽然打开速度是老生常谈,但还是要提醒大家这点的重要性。
二、页面的内容是为用户解决问题而不是描述问题
我们在写文章的时候,要更加细致地解决这些人的需求,才能起到很好的流通和转化作用。
三、网站专业、美观、品牌化运营
很多用户在打开网站的时候有一种印象,就是低端、山寨、不专业。即使网站被网站吸引,用户也不会留下来观看,所以页面的设计非常重要。图片的美感和页面用户体验的优化都会影响网站的优化,所以这方面应该在建站的时候设计,而不是模仿别人。 网站 的另一个重要作用是品牌推广。你要做好自己的品牌,做好自己的品牌,才能让用户对你产生依赖。
四、避免各种导致用户离开的元素
很多网站有很多弹窗、固定凸窗、广告位,对用户非常反感,影响用户浏览网页,从而放弃整个浏览,进入城市,所以我们在考虑添加广告时,首先不能影响用户的浏览,其次不要让用户过分反感。
五、关键词植入
常规的关键词植入还要继续做,比如Title、H1、文章内关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等我这个就不重复了,大家都懂的。
六、主题模型的注入
只填文字是不够的,因为那样太机械,会失去文字的用户体验。所以我们必须做一个主题模型。形成一个大主题,这样的页面内容会让关键词排名更全面,对更多用户有帮助。同时搜索引擎可以解释你要推送的话题内容与婚纱相关。
七、显示文字深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、desc、url)。这些元素在内容上需要优化:标题的创意、desc的流行度、url的规范、文章日期、结构化数据的使用、在线对话等。
八、创造独特的有价值的内容。营销不能逃避内容质量。好的内容包括:
1)提供了非常强大的视觉体验,前端界面,合适的字体和功能按钮
2)内容必须是有用的、高价值的、高可靠的,而且非常有趣。值得采集的点数都在里面
3)与其他内容相比没有重复,深度更强大
4)打开速度快(无广告),不同终端都能阅读
5)可以产生认同、惊喜、快乐、思考等情感想法
6)可以达到一定的转发和传播力
7)可以使用完整、准确、独特的信息来解决问题或回答问题
SEO新手“小朋友”是如何做到时的?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-14 19:01
作为网站运营人员的作者,作为作者的新手SEO“孩子”,曾在微信中向作者炫耀自称私下拿项目,做出了某种不寻常的长尾某房产的话网站去首页赚点零花钱。
我不是这类业务的高手,但我大概知道一些优化方法。但是当被问到这个“孩子”是怎么做到的? “发个链接,更新文章啊” “网站收录还有体重是怎么回事?”——他一脸疑惑。 “收录你怎么看?”作者苦笑。
工欲善其事,必先利其器。
也许以上只是一个特例,但是相信还是有很多同学想要或者已经开始从事SEO。为了让很多新手朋友对SEO有更系统的了解,特将一些相关的概念解释给大家,仅供参考。
要了解SEO,或者说搜索引擎优化,首先要了解搜索引擎的基本工作流程。
搜索引擎的主要工作分为两部分,一部分是互联网网站页面的抓取、更新和索引。
另一部分是用户查询意图的分析,以最快的速度反馈最个性化的查询结果,这也是搜索引擎未来发展的重要方向之一。移动搜索引擎和一些大型电子商务公司网站首当其冲。
搜索引擎链接分析的六大算法
这里提到的链接分析算法主要是工作的第一部分,即在抓取、更新和索引过程中计算搜索引擎之间页面重要性的关键算法。而分析网页之间谁更重要,就是比较链接的重要性。
PR 算法
PR 算法是 Google 创始人 Larry Page 和 Sergey Brin 于 1998 年申请的专利算法。
有人说是借用了百度李彦宏的超链接分析专利,但美国专利商标局终于在2001年9月通过了Pagerank算法,可见与超链接分析算法还是有区别的。
PR 算法在搜索引擎行业久负盛名。如果一个SEO连这个算法都看不懂,那就真的需要好好研究一下了。
因为这个算法可以说是当前搜索引擎发展的基石。 PR算法原理:2个假设
数量假设:指向页面的理解越多,页面越重要;
质量假设:链接到页面的质量越高,页面就越重要。
PR算法刚开始给每个页面分配相同的重要性分数,通过迭代递归计算更新每个页面节点的PageRank分数,直到分数稳定。
HITS 算法
HITS算法主要收录两个定义:
权威页面:指与某个领域或主题相关的高质量网页。
中心页面:收录许多指向高质量权威页面的网页。比如hao123就是一个典型的高质量Hub页面。
假设 1:许多好的 Hub 页面会指向一个好的权威页面。
假设 2:一个好的 Hub 页面会指向许多好的 Author 页面。
由此不难看出,基于这两个假设生成的页面关系是一种相辅相成的关系。搜索引擎通过这种相辅相成的关系,最终计算出哪些页面是高质量的Hub页面,哪些是高质量的Authority页面。该算法与PR算法的显着区别在于HITS算法与用户输入的查询请求密切相关。
SALSA 算法
SALSA算法整体上是PageRank算法和HITS算法的综合运用。它不仅利用了HITS算法和查询相关的特点,还采用了PageRank的随机游走模型。实践证明,SALSA算法的搜索效果优于前两种算法,是目前最好的链接分析算法之一。
主题敏感的PageRank算法
topic-sensitive PageRank和PageRank的最大区别在于,它最初并不是给每个页面都给相同的分数,而是将页面划分为16个主题类型,然后为不同的主题类型分配不同的分数。 该算法广泛应用于构建个性化搜索领域。
山顶算法
Hilltop 算法也是 HITS 算法和 PageRank 算法的融合。
该算法的基本思想是将专家页面的分数通过链接关系传递给目标页面,并以此分数作为目标页面与用户查询相关度的排名分数。
最后,系统将相关专家页面和得分较高的目标页面进行整合,作为搜索结果返回给用户。
值得注意的是,该算法在定义和筛选专家页面时,使用了页面标题、H1标签中的文本和URL锚文本三类信息元素作为衡量标准。
综上所述,搜索引擎链接分析算法与我们的优化工作息息相关,甚至是我们优化工作的基石。如果不了解这些基本算法,就会陷入“为优化而优化”的盲目境地。
虽然偶尔会有一些影响,但难免会陷入类似于文章开头小伙伴的尴尬境地。从长远来看,这些理论对于个人的 SEO 职业也是必要的。
关于这些基础算法在日常优化工作中的应用,笔者将在后续文章中为大家介绍。 查看全部
SEO新手“小朋友”是如何做到时的?(图)
作为网站运营人员的作者,作为作者的新手SEO“孩子”,曾在微信中向作者炫耀自称私下拿项目,做出了某种不寻常的长尾某房产的话网站去首页赚点零花钱。
我不是这类业务的高手,但我大概知道一些优化方法。但是当被问到这个“孩子”是怎么做到的? “发个链接,更新文章啊” “网站收录还有体重是怎么回事?”——他一脸疑惑。 “收录你怎么看?”作者苦笑。
工欲善其事,必先利其器。
也许以上只是一个特例,但是相信还是有很多同学想要或者已经开始从事SEO。为了让很多新手朋友对SEO有更系统的了解,特将一些相关的概念解释给大家,仅供参考。
要了解SEO,或者说搜索引擎优化,首先要了解搜索引擎的基本工作流程。
搜索引擎的主要工作分为两部分,一部分是互联网网站页面的抓取、更新和索引。
另一部分是用户查询意图的分析,以最快的速度反馈最个性化的查询结果,这也是搜索引擎未来发展的重要方向之一。移动搜索引擎和一些大型电子商务公司网站首当其冲。
搜索引擎链接分析的六大算法
这里提到的链接分析算法主要是工作的第一部分,即在抓取、更新和索引过程中计算搜索引擎之间页面重要性的关键算法。而分析网页之间谁更重要,就是比较链接的重要性。
PR 算法
PR 算法是 Google 创始人 Larry Page 和 Sergey Brin 于 1998 年申请的专利算法。
有人说是借用了百度李彦宏的超链接分析专利,但美国专利商标局终于在2001年9月通过了Pagerank算法,可见与超链接分析算法还是有区别的。
PR 算法在搜索引擎行业久负盛名。如果一个SEO连这个算法都看不懂,那就真的需要好好研究一下了。
因为这个算法可以说是当前搜索引擎发展的基石。 PR算法原理:2个假设
数量假设:指向页面的理解越多,页面越重要;
质量假设:链接到页面的质量越高,页面就越重要。
PR算法刚开始给每个页面分配相同的重要性分数,通过迭代递归计算更新每个页面节点的PageRank分数,直到分数稳定。
HITS 算法
HITS算法主要收录两个定义:
权威页面:指与某个领域或主题相关的高质量网页。
中心页面:收录许多指向高质量权威页面的网页。比如hao123就是一个典型的高质量Hub页面。
假设 1:许多好的 Hub 页面会指向一个好的权威页面。
假设 2:一个好的 Hub 页面会指向许多好的 Author 页面。
由此不难看出,基于这两个假设生成的页面关系是一种相辅相成的关系。搜索引擎通过这种相辅相成的关系,最终计算出哪些页面是高质量的Hub页面,哪些是高质量的Authority页面。该算法与PR算法的显着区别在于HITS算法与用户输入的查询请求密切相关。
SALSA 算法
SALSA算法整体上是PageRank算法和HITS算法的综合运用。它不仅利用了HITS算法和查询相关的特点,还采用了PageRank的随机游走模型。实践证明,SALSA算法的搜索效果优于前两种算法,是目前最好的链接分析算法之一。
主题敏感的PageRank算法
topic-sensitive PageRank和PageRank的最大区别在于,它最初并不是给每个页面都给相同的分数,而是将页面划分为16个主题类型,然后为不同的主题类型分配不同的分数。 该算法广泛应用于构建个性化搜索领域。
山顶算法
Hilltop 算法也是 HITS 算法和 PageRank 算法的融合。
该算法的基本思想是将专家页面的分数通过链接关系传递给目标页面,并以此分数作为目标页面与用户查询相关度的排名分数。
最后,系统将相关专家页面和得分较高的目标页面进行整合,作为搜索结果返回给用户。
值得注意的是,该算法在定义和筛选专家页面时,使用了页面标题、H1标签中的文本和URL锚文本三类信息元素作为衡量标准。
综上所述,搜索引擎链接分析算法与我们的优化工作息息相关,甚至是我们优化工作的基石。如果不了解这些基本算法,就会陷入“为优化而优化”的盲目境地。
虽然偶尔会有一些影响,但难免会陷入类似于文章开头小伙伴的尴尬境地。从长远来看,这些理论对于个人的 SEO 职业也是必要的。
关于这些基础算法在日常优化工作中的应用,笔者将在后续文章中为大家介绍。
聚合标签在搜索引擎优化中饰演主要角色吗?你为什么这么说?
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-13 06:18
聚合标签在搜索引擎优化中饰演主要角色吗?你为什么这么说?
也想出现在这里吗?点击联系我~
聚合标签对搜索引擎优化有很大影响吗?一些做过搜索引擎优化的人一定听说过聚合标签的名字。按照所谓的标签,简洁是每个文章的主要关键词,脱离上下文的聚合就是组装起来。聚合标签的作用是聚合与关键词相关的文章,相当于对网站内容进行二级分类。那么,聚合标签在搜索引擎优化中是否发挥着重要作用?
我个人简历的证明,对于搜索引擎优化来说是难得一见的,无法比拟的。由于每个网站情况的不同,聚合标签的作用也不同。为什么这么说?
首先,聚合标签本身就是一列网站。假设一个网站只有少量的内容输入,一级列的分类和聚合标签会对现有内容进行多次分类,每列都有自己的关键词对应相同的内容。在这种多分类的情况下,考虑关键词的权重是否会松动,权重是否不会转移,如何提高关键词的排名!
因此,对于内容有限的网站,最好少用聚合标签。既然如此,说到这里,或许有的小伙伴已经大致知道我接下来要说什么了。所以对于拥有庞大内容群的网站来说,标签的聚合肯定有助于搜索引擎优化。
面对内容众多的网站,分类一方面可以让网站的内容更有条理;另一方面,聚合标签可以让网站形成更多的分类。其余的这些差异文章 通过聚合标签形成其余的组。由于网站的权重转移依次是“首页”栏目的内容页,栏目权重比单个内容页更有利于关键词的排名,所以关键词的排名会更高有用。 查看全部
聚合标签在搜索引擎优化中饰演主要角色吗?你为什么这么说?
也想出现在这里吗?点击联系我~
聚合标签对搜索引擎优化有很大影响吗?一些做过搜索引擎优化的人一定听说过聚合标签的名字。按照所谓的标签,简洁是每个文章的主要关键词,脱离上下文的聚合就是组装起来。聚合标签的作用是聚合与关键词相关的文章,相当于对网站内容进行二级分类。那么,聚合标签在搜索引擎优化中是否发挥着重要作用?
我个人简历的证明,对于搜索引擎优化来说是难得一见的,无法比拟的。由于每个网站情况的不同,聚合标签的作用也不同。为什么这么说?
首先,聚合标签本身就是一列网站。假设一个网站只有少量的内容输入,一级列的分类和聚合标签会对现有内容进行多次分类,每列都有自己的关键词对应相同的内容。在这种多分类的情况下,考虑关键词的权重是否会松动,权重是否不会转移,如何提高关键词的排名!
因此,对于内容有限的网站,最好少用聚合标签。既然如此,说到这里,或许有的小伙伴已经大致知道我接下来要说什么了。所以对于拥有庞大内容群的网站来说,标签的聚合肯定有助于搜索引擎优化。
面对内容众多的网站,分类一方面可以让网站的内容更有条理;另一方面,聚合标签可以让网站形成更多的分类。其余的这些差异文章 通过聚合标签形成其余的组。由于网站的权重转移依次是“首页”栏目的内容页,栏目权重比单个内容页更有利于关键词的排名,所以关键词的排名会更高有用。
三个主题爬行器是实现基于主题的信息采集功能的核心组成部分
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-13 06:15
三个主要组件:主题爬虫、检索器、管理平台
主题爬虫是实现基于主题的信息采集功能的核心组件,一般由爬取队列、网络连接器、主题模型、内容相关性分析和链接相关性分析等功能模块组成
其中,爬取队列由一系列主题相关性高的URL组成。爬取队列由主题搜索引擎在主题搜索开始时的种子站点组成。这些种子站点可以由行业专家给出,也可以在某些权威网站的帮助下自动生成。搜索过程开始后,系统会查找新的 URL,并根据主题相关性对其进行排序,并将其添加到抓取队列中。网络连接器根据抓取队列中的 URL 与网络建立连接,下载其指向的页面内容。
主题模型是通过主题建模方法实现的。主题词典是一种常用的主题建模方法。 关键词法使用一组特征关键词来表示话题内容,包括用户需求、话题和文档内容,一个主图关键词可以是一个词组,包括语言权重等属性,常用的相关算法是词频统计法。
内容相关性分析是指系统对提取内容特征后的网页数据进行分析,判断网页内容与指定主题的关联程度,过滤不相关的页面,保留相关性达到阈值的网页。
链接相关性分析是指系统测量从网页中提取的超链接信息,获取每个URL指向的页面与指定主题的相关性,并将符合主题级别要求的URL加入到抓取中queue 和 Crawl 优先排序,确保优先检索相关性高的页面。
搜索器为用户提供查询界面,根据用户提出的搜索公式搜索索引库,根据相关程度对查询结果进行排序,将页面链接和相关信息返回给用户。
管理平台负责对整个系统进行监控和管理。主要实现确定主题、初始化爬虫、控制爬虫过程、协调优化模块间功能实现、用户交互等功能。作为一个完美的搜索引擎,管理平台还应该提供跨平台的应用web服务应用接口 查看全部
三个主题爬行器是实现基于主题的信息采集功能的核心组成部分
三个主要组件:主题爬虫、检索器、管理平台
主题爬虫是实现基于主题的信息采集功能的核心组件,一般由爬取队列、网络连接器、主题模型、内容相关性分析和链接相关性分析等功能模块组成
其中,爬取队列由一系列主题相关性高的URL组成。爬取队列由主题搜索引擎在主题搜索开始时的种子站点组成。这些种子站点可以由行业专家给出,也可以在某些权威网站的帮助下自动生成。搜索过程开始后,系统会查找新的 URL,并根据主题相关性对其进行排序,并将其添加到抓取队列中。网络连接器根据抓取队列中的 URL 与网络建立连接,下载其指向的页面内容。
主题模型是通过主题建模方法实现的。主题词典是一种常用的主题建模方法。 关键词法使用一组特征关键词来表示话题内容,包括用户需求、话题和文档内容,一个主图关键词可以是一个词组,包括语言权重等属性,常用的相关算法是词频统计法。
内容相关性分析是指系统对提取内容特征后的网页数据进行分析,判断网页内容与指定主题的关联程度,过滤不相关的页面,保留相关性达到阈值的网页。
链接相关性分析是指系统测量从网页中提取的超链接信息,获取每个URL指向的页面与指定主题的相关性,并将符合主题级别要求的URL加入到抓取中queue 和 Crawl 优先排序,确保优先检索相关性高的页面。
搜索器为用户提供查询界面,根据用户提出的搜索公式搜索索引库,根据相关程度对查询结果进行排序,将页面链接和相关信息返回给用户。
管理平台负责对整个系统进行监控和管理。主要实现确定主题、初始化爬虫、控制爬虫过程、协调优化模块间功能实现、用户交互等功能。作为一个完美的搜索引擎,管理平台还应该提供跨平台的应用web服务应用接口
LDA中的主题就像词主成分-样本之间的关系
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-11 04:16
LDA中的主题就像词主成分-样本之间的关系
NLP︱LDA主题模型的应用问题
看LDA和多元统计分析的结合,LDA中的topic就像一个词主成分,明确了主成分和样本的关系。在多元聚类中,聚类分为Q型聚类、R型聚类和主成分分析。 R型聚类和主成分分析针对变量,Q型聚类针对样本。
PCA 主要关注主成分和变量之间的关系。 LDA在文本中也有同样的效果,将一堆词(变量)变成主题(主成分)。同时,通过人像的主成分,可以知道人群喜欢什么样的话题;
Q 型聚类代表样本之间的社区关系。
LDA 假设前提:主题模型中最重要的假设是词袋假设,指的是在不影响模型训练结果的情况下交换文档中词的顺序,模型的结果有与词序无关。
主题模型中最重要的参数是每个文档的主题概率分布和每个主题下术语的概率分布。
LDA 是一个三层贝叶斯模型。三层分别是:文档层、主题层和词层。
两种估计方法——VEM 和 gibbs
通常逼近这种后验分布的方法可以分为两类:
1.变分算法(variationalalgorithms),这是一种确定性的方法。变异算法假设一些参数分布,将这些理想分布与后验数据进行比较,并找到最接近的分布。因此,估计问题转化为优化问题。主要算法是变分期望最大化(VEM)。这种方法是最常用的方法。主要用于R软件的tomicmodels包中。
2. 基于采样的算法。采样算法,如吉布斯采样(gibbssampling),主要是构造一个马尔可夫链,从后验经验分布中抽取一些样本来估计后验分布。 Gibbs采样方法广泛应用于R软件的lda包中。
参考:使用R作为主题模型:选词与主题编号确定
R 包 enumeration-lda 和 topicmodel
在 R 语言中,有两个包提供 LDA 模型:lda 和 topicmodels。
lda 提供基于 Gibbs 采样的经典 LDA、MMSB(混合成员随机块模型)、RTM(关系主题模型)和 sLDA(监督 LDA)以及基于 VEM(变分期望最大化)的 RTM。
Topicmodels 基于 tm 包,提供三个模型:LDA_VEM、LDA_Gibbs 和 CTM_VEM(相关主题模型)。
此外,包 textir 还提供了其他类型的主题模型。
参考:R 的文档主题模型
但是主题模型有一个非常大的问题:模型的质量
1、模型质量差,题目无效词多,难以清理;
2、主题之间的差异不够显着,效果不佳;
3、话题中,词与词的相关性非常低。
4、无法反映现场。作者最初希望的是一个话题。有场景词+用户态度、情感、事件词,构成了一个比较完整的系统,但是比较幼稚……
5、Topic 命名是一个难点。如果基础词效果差,话题画像也难。
一、TencentPeacock 案例
来看看腾讯孔雀的应用案例:
输入一个词,会弹出两个内容:搜索词-主题列表(主题中有很多词);搜索词-文档列表。
作者猜测实现三个距离计算的过程:
首先计算搜索词向量与主题词向量的距离,并对主题进行排序;
计算搜索词与主题下每个词向量的距离,并对词进行排序;
最后计算搜索词与文档向量的距离,并对文档进行排序。
腾讯在主题系统上做了很多努力,从中可以看到几条信息:
1、 一般来说,词与词之间的相关性不是那么强;
2、 词类基本上是名词,动作和形容词很少。
系统也做了一些有趣的尝试:利用用户-QQ群矩阵,制作话题模型,对QQ群进行聚类,可以很好的了解不同用户群喜欢什么话题群,有多少那里的人。
二、主题模型的主要功能(参考博客)
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3)可以消除文档中噪声的影响。一般来说,文档中的杂音往往在次要主题中,我们可以忽略它们,只保留文档中最重要的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5)与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
三、主题模型的一些扩展
可以看到模型的扩展
1、基于LDA的主题模型变形
用于情感分析:对主题情感偏差进行评分,对主题进行评分,然后根据主题-文档矩阵对每个文档的情感进行评分。
主题间的相关性:根据主题分布点积的相似度,确定相关文本,建立主题间的相关性
时间序列文本,动态主题模型。
短文本,消除歧义,建立语义相似聚类;
知识图谱的构建需要知识图谱中的一些集合和潜在变量,所以主题建模更适合作为一个大的包容集合;
稀疏的使用。在模型中,主题词矩阵会有非常低的频率数据,所以你可以将其强制为0以减少影响。
2、摘录:LDA使用经验
如果要训练一个主题模型进行预测,数据量必须足够大;理论上,词汇长度越长,表达的主题就越具体。这需要一个优秀的词库;如果想要更详细的主题划分或者突出专业主题,就需要专业词典; LDA的参数alpha对计算效率和模型结果影响很大。选择合适的 alpha 可以提高效率和模型可靠性;确定题目数量没有特别突出的方法,需要更多的经验;根据时间线检测热点话题和话题趋势,话题模型是不错的选择;上面提到的正面词汇和负面词汇如何使用,本文没有找到合适的方法;
(参考:R 的文档主题模型)
3、摘录:LDA使用经验
整个过程有很多不明白的地方,我就列举几个如下:
(1) doc 你应该如何定义,应该以人为单位训练topicmodel还是应该以每条微博为一个单元?经过比较,我发现在每条微博上训练的topicmodel中的每一个topicmodel作为一个unit 术语类别更加一致;所以我选择使用微博作为训练的doc单元,使用people作为推理的doc单元;但是我没有找到关于这个问题的更详细的参考,我看到了几个topicmodel推特和微博上的应用,以微博为处理单元。
(2)不同的估计方法有什么区别?R包提供了VEM、Gibbs、CTM等,这里不做详细比较。本文其余部分的结果都是基于Gibbs 估计结果。
(3)topicmodel适合做短文本分析?稀疏会带来什么样的问题?其实把每条微博作为一个doc单元来分析都会造成稀疏的问题,只是我没有意识到它潜在的问题所造成的.
(4)中文的文字处理感觉很急...除了分词,词性标注、句法分析、同义词等没有专门的R包,本文只做一个初步处理。
5)最终的聚类效应不仅考虑了名人的专业领域,还考虑了他们在生活中的情绪状态、爱好和兴趣。这是一个综合的结果。可以通过选择不同的主题来完成不同专业领域的选择。来自聚类分析。
参考:原文链接:微博名人那些事
扩展一:主题模型在关键词extraction中的应用
扩展2:LDA类似于文章聚类
论文:Arnab Bhadury 的“ClusteringSimilar Stories Using LDA | Flipboard Engineering”
去除一些噪声词,然后在LDA模型之后用向量表示文章,提供一种低纬度、鲁棒的词向量表达方法。
扩展3:中文标签/主题抽取/推荐
知乎的回答,总结一下:如何为中文文本做中文标签推荐?
1、根据关键词的权重,比如tfidf值,向用户推荐TopN关键词作为文本标签。
2、LDA,先计算每个中文文本的K个主题分布,取概率最高的主题,再取该主题下概率最高的TopN词作为标签推荐给用户,但K这种方法的值不容易确定,最终计算出来的效果不如第一种方法。但是,LDA 不适合解决细粒度的标注问题,例如提取实例名称。
3、Tag Distribution Model (NTDM),源自社交媒体用户标签的分析和推荐()
4、extraction关键词 另一种常用的方法是TextRank,它根据词的窗口共现或相似度构建词网络,然后根据PageRank算法计算词的权重。
扩展4:文本挖掘中主题跟踪的可视化呈现
扩展五:迭代LDA模型
LDA 本身是一个无监督的算法模型,同时由于训练集本身的噪声数据量很大,模型在效果上可能无法满足行业的需求。例如,我们经过一个LDA过程后,在我们得到的每个主题的词表(xxx.twords)中,或多或少有来自其他主题的混合词或干扰词等,导致推理的正确率不满意。
LDA过程完成,得到xxx.twords文件后,我们可以尝试根据“专家经验”手动去除每个主题中不应该属于该主题的词。经过处理,就相当于得到了一个比较理想、比较干净的“先验知识”。
获得这样的“先验知识”后,我们可以将其作为变量传递给下一个LDA过程,当模型初始化时,“先验知识”中的词会下降到对应的更大的概率主题。使用相同的训练集和相同的参数再次迭代 LDA 过程。经过两三次这样的迭代,效果应该会有所提升。
虽然可以在一定程度上提高模型的效果,但也存在一定的弊端:大大增加了人工成本,如果主题太多(上万个),很难过滤一个由一个。 “先验知识”。
改进的python代码,来源知乎玩点高级-让你开始使用Topic模型LDA(小改进+源代码附后)
扩展 6:如何建立高效的主题模型?
本节来自知乎Q&A:主题模型还有用吗?如何使用?
1、文字要长长的。如果不是很长,试着把它拼凑起来,让它更长
2、语料要好,努力干掉翔
3、规模要大。两个意思,一是文档数,二是话题数
4.在算法方面,plda+可以支持中等规模; lightlda 可以支持大规模(这个宝贝贡献小,插个广告); warplda 应该是可以的,但是没有开源,实现应该不会很复杂。
5、 应用场景必须可靠。直观来说,分类等任务还是需要有监督的,不适合无监督的方法。与基于内容的推荐应用类似,LDA 在这种感觉上是可靠的。
6、不要使用短文本。想用也用twitter lda~~~~
主题模型最合适的变体是添加先验信息:
我相信题主用的是完全无监督的Topic Model,但是这样太行不通了~~~现实生活中浪费了这么多标注数据,监督模型一定比无监督的好~所以!你可以试试Supervised Topic Model,在现实中利用你现有的标注来提高模型的准确率~比如用知乎的标签来训练一个有监督的Topic Model~~~词聚类效果肯定会好很多。
开源监督LDA:
iir/llda.py at master · shuyo/iir · GitHub
chbrown/slda·GitHub 查看全部
LDA中的主题就像词主成分-样本之间的关系
NLP︱LDA主题模型的应用问题
看LDA和多元统计分析的结合,LDA中的topic就像一个词主成分,明确了主成分和样本的关系。在多元聚类中,聚类分为Q型聚类、R型聚类和主成分分析。 R型聚类和主成分分析针对变量,Q型聚类针对样本。
PCA 主要关注主成分和变量之间的关系。 LDA在文本中也有同样的效果,将一堆词(变量)变成主题(主成分)。同时,通过人像的主成分,可以知道人群喜欢什么样的话题;
Q 型聚类代表样本之间的社区关系。
LDA 假设前提:主题模型中最重要的假设是词袋假设,指的是在不影响模型训练结果的情况下交换文档中词的顺序,模型的结果有与词序无关。
主题模型中最重要的参数是每个文档的主题概率分布和每个主题下术语的概率分布。
LDA 是一个三层贝叶斯模型。三层分别是:文档层、主题层和词层。
两种估计方法——VEM 和 gibbs
通常逼近这种后验分布的方法可以分为两类:
1.变分算法(variationalalgorithms),这是一种确定性的方法。变异算法假设一些参数分布,将这些理想分布与后验数据进行比较,并找到最接近的分布。因此,估计问题转化为优化问题。主要算法是变分期望最大化(VEM)。这种方法是最常用的方法。主要用于R软件的tomicmodels包中。
2. 基于采样的算法。采样算法,如吉布斯采样(gibbssampling),主要是构造一个马尔可夫链,从后验经验分布中抽取一些样本来估计后验分布。 Gibbs采样方法广泛应用于R软件的lda包中。
参考:使用R作为主题模型:选词与主题编号确定
R 包 enumeration-lda 和 topicmodel
在 R 语言中,有两个包提供 LDA 模型:lda 和 topicmodels。
lda 提供基于 Gibbs 采样的经典 LDA、MMSB(混合成员随机块模型)、RTM(关系主题模型)和 sLDA(监督 LDA)以及基于 VEM(变分期望最大化)的 RTM。
Topicmodels 基于 tm 包,提供三个模型:LDA_VEM、LDA_Gibbs 和 CTM_VEM(相关主题模型)。
此外,包 textir 还提供了其他类型的主题模型。
参考:R 的文档主题模型
但是主题模型有一个非常大的问题:模型的质量
1、模型质量差,题目无效词多,难以清理;
2、主题之间的差异不够显着,效果不佳;
3、话题中,词与词的相关性非常低。
4、无法反映现场。作者最初希望的是一个话题。有场景词+用户态度、情感、事件词,构成了一个比较完整的系统,但是比较幼稚……
5、Topic 命名是一个难点。如果基础词效果差,话题画像也难。
一、TencentPeacock 案例
来看看腾讯孔雀的应用案例:
输入一个词,会弹出两个内容:搜索词-主题列表(主题中有很多词);搜索词-文档列表。
作者猜测实现三个距离计算的过程:
首先计算搜索词向量与主题词向量的距离,并对主题进行排序;
计算搜索词与主题下每个词向量的距离,并对词进行排序;
最后计算搜索词与文档向量的距离,并对文档进行排序。
腾讯在主题系统上做了很多努力,从中可以看到几条信息:
1、 一般来说,词与词之间的相关性不是那么强;
2、 词类基本上是名词,动作和形容词很少。
系统也做了一些有趣的尝试:利用用户-QQ群矩阵,制作话题模型,对QQ群进行聚类,可以很好的了解不同用户群喜欢什么话题群,有多少那里的人。
二、主题模型的主要功能(参考博客)
有了主题模型,我们如何使用它?它的优点是什么?我总结了以下几点:
1) 可以衡量文档之间的语义相似度。对于一个文档,我们找到的主题分布可以看作是它的一个抽象表示。对于概率分布,我们可以使用一些距离公式(如KL距离)来计算两个文档的语义距离,从而得到它们之间的相似度。
2)可以解决多义词的问题。回想第一个例子,“Apple”可能是水果,也可能指苹果。通过我们得到的“word-topic”的概率分布,我们可以知道“apple”属于哪个主题,然后我们可以通过主题的匹配来计算它与其他文本的相似度。
3)可以消除文档中噪声的影响。一般来说,文档中的杂音往往在次要主题中,我们可以忽略它们,只保留文档中最重要的主题。
4) 它是无人监督且完全自动化的。我们只需要提供训练文档,它就可以自动训练各种概率,无需任何人工标注过程。
5)与语言无关。只要任何语言都可以对其进行分割,就可以训练得到它的主题分布。
综上所述,主题模型是一个强大的工具,可以挖掘语言背后的隐藏信息。近年来,各大搜索引擎公司开始重视这方面的研发。语义分析技术正逐渐渗透到搜索领域的各种产品中。在不久的将来,我们的搜索将变得更加智能,让我们拭目以待。
三、主题模型的一些扩展
可以看到模型的扩展
1、基于LDA的主题模型变形
用于情感分析:对主题情感偏差进行评分,对主题进行评分,然后根据主题-文档矩阵对每个文档的情感进行评分。
主题间的相关性:根据主题分布点积的相似度,确定相关文本,建立主题间的相关性
时间序列文本,动态主题模型。
短文本,消除歧义,建立语义相似聚类;
知识图谱的构建需要知识图谱中的一些集合和潜在变量,所以主题建模更适合作为一个大的包容集合;
稀疏的使用。在模型中,主题词矩阵会有非常低的频率数据,所以你可以将其强制为0以减少影响。
2、摘录:LDA使用经验
如果要训练一个主题模型进行预测,数据量必须足够大;理论上,词汇长度越长,表达的主题就越具体。这需要一个优秀的词库;如果想要更详细的主题划分或者突出专业主题,就需要专业词典; LDA的参数alpha对计算效率和模型结果影响很大。选择合适的 alpha 可以提高效率和模型可靠性;确定题目数量没有特别突出的方法,需要更多的经验;根据时间线检测热点话题和话题趋势,话题模型是不错的选择;上面提到的正面词汇和负面词汇如何使用,本文没有找到合适的方法;
(参考:R 的文档主题模型)
3、摘录:LDA使用经验
整个过程有很多不明白的地方,我就列举几个如下:
(1) doc 你应该如何定义,应该以人为单位训练topicmodel还是应该以每条微博为一个单元?经过比较,我发现在每条微博上训练的topicmodel中的每一个topicmodel作为一个unit 术语类别更加一致;所以我选择使用微博作为训练的doc单元,使用people作为推理的doc单元;但是我没有找到关于这个问题的更详细的参考,我看到了几个topicmodel推特和微博上的应用,以微博为处理单元。
(2)不同的估计方法有什么区别?R包提供了VEM、Gibbs、CTM等,这里不做详细比较。本文其余部分的结果都是基于Gibbs 估计结果。
(3)topicmodel适合做短文本分析?稀疏会带来什么样的问题?其实把每条微博作为一个doc单元来分析都会造成稀疏的问题,只是我没有意识到它潜在的问题所造成的.
(4)中文的文字处理感觉很急...除了分词,词性标注、句法分析、同义词等没有专门的R包,本文只做一个初步处理。
5)最终的聚类效应不仅考虑了名人的专业领域,还考虑了他们在生活中的情绪状态、爱好和兴趣。这是一个综合的结果。可以通过选择不同的主题来完成不同专业领域的选择。来自聚类分析。
参考:原文链接:微博名人那些事
扩展一:主题模型在关键词extraction中的应用
扩展2:LDA类似于文章聚类
论文:Arnab Bhadury 的“ClusteringSimilar Stories Using LDA | Flipboard Engineering”
去除一些噪声词,然后在LDA模型之后用向量表示文章,提供一种低纬度、鲁棒的词向量表达方法。
扩展3:中文标签/主题抽取/推荐
知乎的回答,总结一下:如何为中文文本做中文标签推荐?
1、根据关键词的权重,比如tfidf值,向用户推荐TopN关键词作为文本标签。
2、LDA,先计算每个中文文本的K个主题分布,取概率最高的主题,再取该主题下概率最高的TopN词作为标签推荐给用户,但K这种方法的值不容易确定,最终计算出来的效果不如第一种方法。但是,LDA 不适合解决细粒度的标注问题,例如提取实例名称。
3、Tag Distribution Model (NTDM),源自社交媒体用户标签的分析和推荐()
4、extraction关键词 另一种常用的方法是TextRank,它根据词的窗口共现或相似度构建词网络,然后根据PageRank算法计算词的权重。
扩展4:文本挖掘中主题跟踪的可视化呈现
扩展五:迭代LDA模型
LDA 本身是一个无监督的算法模型,同时由于训练集本身的噪声数据量很大,模型在效果上可能无法满足行业的需求。例如,我们经过一个LDA过程后,在我们得到的每个主题的词表(xxx.twords)中,或多或少有来自其他主题的混合词或干扰词等,导致推理的正确率不满意。
LDA过程完成,得到xxx.twords文件后,我们可以尝试根据“专家经验”手动去除每个主题中不应该属于该主题的词。经过处理,就相当于得到了一个比较理想、比较干净的“先验知识”。
获得这样的“先验知识”后,我们可以将其作为变量传递给下一个LDA过程,当模型初始化时,“先验知识”中的词会下降到对应的更大的概率主题。使用相同的训练集和相同的参数再次迭代 LDA 过程。经过两三次这样的迭代,效果应该会有所提升。
虽然可以在一定程度上提高模型的效果,但也存在一定的弊端:大大增加了人工成本,如果主题太多(上万个),很难过滤一个由一个。 “先验知识”。
改进的python代码,来源知乎玩点高级-让你开始使用Topic模型LDA(小改进+源代码附后)
扩展 6:如何建立高效的主题模型?
本节来自知乎Q&A:主题模型还有用吗?如何使用?
1、文字要长长的。如果不是很长,试着把它拼凑起来,让它更长
2、语料要好,努力干掉翔
3、规模要大。两个意思,一是文档数,二是话题数
4.在算法方面,plda+可以支持中等规模; lightlda 可以支持大规模(这个宝贝贡献小,插个广告); warplda 应该是可以的,但是没有开源,实现应该不会很复杂。
5、 应用场景必须可靠。直观来说,分类等任务还是需要有监督的,不适合无监督的方法。与基于内容的推荐应用类似,LDA 在这种感觉上是可靠的。
6、不要使用短文本。想用也用twitter lda~~~~
主题模型最合适的变体是添加先验信息:
我相信题主用的是完全无监督的Topic Model,但是这样太行不通了~~~现实生活中浪费了这么多标注数据,监督模型一定比无监督的好~所以!你可以试试Supervised Topic Model,在现实中利用你现有的标注来提高模型的准确率~比如用知乎的标签来训练一个有监督的Topic Model~~~词聚类效果肯定会好很多。
开源监督LDA:
iir/llda.py at master · shuyo/iir · GitHub
chbrown/slda·GitHub
知识图谱、表示学习动机尽管的动机基于以下两点
网站优化 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-08-09 04:29
作者丨王文博
学校丨哈尔滨工程大学硕士
研究方向丨知识图谱、表征学习
动机
虽然大规模的知识图谱已经收录了数十亿的三元组数据,但还不是很完整。其中,还有未被发现的真实有效的三元组。因此,本文提出了许多用于学习实体和关系的向量表示的嵌入模型,以通过预测三元组是否有效来改进知识图谱。同时,本文作者发现上述模型也可以用于(提交查询,用户个人资料)。 ,返回文档)作为三元组,解决个性化搜索问题。因此,写这篇文章的动机基于以下两点:
之前对三元组建模有效性的研究仅关注知识图谱的完整性或个性化搜索的准确性。但是,本文针对上述两个问题同时使用模型来衡量模型的有效性。
TransE、DISMULT、ComplEx等传统嵌入式模型只使用向量之间的加减乘,所以只能捕捉向量之间的线性关系。虽然现在越来越多的研究集中在使用深度神经网络来解决三元组的预测问题,例如ConvE,但假设可以通过分析三元组相同维度的数据来捕获三元组的头部向量。特定关系中的实体和尾实体的特定属性信息。因此,这些模型大多采用对三元组同维信息建模的方法。但是没有模型可以对具有深层结构的相同维度的三元组信息进行建模。
CapsE 模型
ζ 表示真三元组的集合,其中三元组以 (s,r,o) 的形式表示。构建嵌入模型的目的是定义一个评分函数对每个三元组进行评分,使真实三元组的分数高于假三元组的分数。
用于独立表示 s、r 和 o 的嵌入向量。在 CapsE 模型中,三元组的嵌入向量组合成一个形式并作为矩阵处理。对矩阵A的第i行进行符号化,对卷积层应用一个filter,对矩阵A的每一行重复应用这个filter,形成一个
特征映射的形式。哪里:
·表示点积,b∈R是偏置项,g是非线性激活函数,如ReLU。
CapsE 模型中使用了多个过滤器来生成多个特征图。用Ω表示滤波器组,用N=|Ω|表示集合中过滤器的数量。因此,可以得到N个k维的特征图,每个特征图从三元组的同一维上映射得到一个唯一的特征。
作者通过使用两个独立胶囊层的简化架构来构建 CapsE 模型。在第一个胶囊层,作者构造了k个胶囊,使得特征映射向量相同维度的所有数据形成一个胶囊。因此,每个胶囊可以捕获嵌入到三元组中相应维度条目中的许多特征。这些特征被传递到第二层中的胶囊以生成输出向量。输出向量的长度(可以理解为L1f范数)代表了三元组的得分。
第一个胶囊层由 k 个胶囊组成。每个胶囊 i∈{1,2,...,k} 都有一个输出向量。将输出向量乘以权重矩阵,将所有向量相加得到一个向量,作为第二个胶囊层中胶囊的输入。之后,胶囊使用非线性压缩函数生成输出向量。
表示耦合系数,由算法1的路由过程决定。本文在capsule层的前后层之间使用softmax。算法一如图所示:
如图1所示,在本文提出的模型中,embedding size k=4;过滤器数量N=5;胶囊第一层的神经元数量等于N;胶囊的第二层中的神经元数量为2:d=2。输出向量 e 的长度用作输入三元组 (s, r, o) 的分数。最后,本文定义了三元组的得分函数f如下:
* 表示卷积操作,capsnet 表示胶囊网络操作。本文使用Adam优化器来训练CapsE模型以最小化损失函数值。损失函数如下:
如果(s,r,o)∈ζ,则t(s,r,o)=1 如果(s,r,o)∈ζ',则t(s,r,o)=-1。
其中 ζ 和 ζ' 分别代表正确的三元组和错误的三元组。 ζ'是指通过破坏结构并随机替换其头部实体或尾部实体,由ζ中的正确三元组组成的新三元组。
实验
完整的知识图谱评估
数据集
本文中的实验使用数据集 WN18RR 和 FB15k-237。因为这两个数据集排除了收录可逆关系的三元组,所以这两个数据集更加真实,也增加了在这两个数据集上进行实验的难度。
评估计划
通过以下过滤器设置执行链接预测:对每个测试三元组和不在训练集、验证集或测试集中并由三元组生成的所有其他候选三元组进行排名。其中,候选三元组是用实体集中的其他实体替换三元组中的原创实体生成的三元组。并以平均排名(MR)、平均数排名(MRR)和Hits@10作为评价标准。
实验计划
文章使用100维Glove词嵌入模型进行预训练,然后在数据集WN18RR上训练一个TransE模型。并将TransE模型的训练结果作为模型convKB和CapsE的初始值。
ConvE模型的参数设置如下:选择Adam优化器,设置学习率
;过滤器的数量 N 设置为 {50,100,200,400}。当模型得到最高Hits@10时,在数据集WN18RR上,N=400,学习率的初始值;在数据集FB15k-237上,N=400,学习率的初始值。
对于CapsE模型,参数设置如下:embedding vector维度设置为100;批量大小设置为128,胶囊中第二层胶囊的神经元数d设置为10;路由算法的迭代次数设置为{1,3,5,7}。当模型得到最高Hits@10时,在数据集WN18RR上,m=1,N=400,学习率的初始值;在数据集FB15k-237上,m=1,N=50,学习率的初始值。
主要实验结果
CaspE 模型在数据集 WN18RR 上获得了最佳 MR,在数据集 FB15k-237 上获得了最佳 Hits@10。下面主要分析模型ConvKB和模型CapsE分别在FB15k-237数据集上预测头尾实体时MRR和Hits@10的值。
在本文中,作者使用以下方法对关系进行分类:
记录给定关系r上每个尾实体对应的头实体的平均数为;记录给定关系r上每个头实体对应的尾实体的平均数为。
从上面的结果图可以得出以下实验结论:CapsE在预测M端实体时会得到比ConvKB更好的实验结果; ConvKB 在预测 1-end 实体时会比 CapsE 更好 实验结果。
分析这个结果。由于第一层中每个胶囊的方向和长度有助于对同一维度的数据项进行建模,因此 CapsE 模型在实体出现频率较低的 M 端执行。预测效果优于实体出现频率更高的第一端。现有模型 DISTMULT、ComplEx 和 ConvE 对实体较高频率的第一端有较好的预测效果。以上就是CapsE模型能够在数据集FB15k-237和数据集WN18RR上取得较好预测结果的原因。
路由迭代的实验结果:本文作者还研究了路由迭代次数对模型效果的影响。得出结论:当迭代次数设为1,其他参数不变时,相应的模型可以获得最佳的实验结果。
这说明了知识图谱和图像问题的区别。在图像分类任务中,将迭代次数 m 设置为大于 1 的数字有助于更准确地捕获图像中实体的相对位置。但相反,由于知识图中同类关系的不同实体之间变化的多样性,这种基于图像的思想只能正确处理知识图中的1-1关系,而不适用于处理 1-M。 M-1与MM的关系。
个性化搜索应用
个性化搜索:给定一个用户(user),该用户的查询关键词(query),搜索系统对与查询关键词相关的文件进行重新排序,并返回结果文件(document)。另外,与用户相关的文档和用户在上述排序过程中给出的查询关键词越相关,应该得到的排序结果就越好。基于以下两个原因,CapsE模型可以用来完成个性化的搜索任务:
数据集
作者使用了106个用户的大规模网络搜索引擎查询日志集合(SEARCH17)作为实验数据集。该数据集收录一个用户查询返回的10个最佳结果,以及用户的这些结果的延迟时间,在这些返回的文档中,用户点击过的文档,或者停留时间超过30秒的文档被标记为相关,返回的前10个文档中剩余的文档被标记为不相关。 Passed 与标签相关的文档位置,用于评估搜索结果。
划分数据集,将数据集划分为训练集、验证集和测试集,达到利用训练集中的历史数据预测测试集中新数据的目的。训练集、验证集和测试集分别由5658、1184和1210个相关三元组和40239、7882、8540个不相关三元组组成。
评估计划
模型CapsE按照如下方式对搜索引擎返回的原创文件列表进行重新排序:
1. 训练 CapsE 模型,并使用训练好的模型计算每个三元组 (s, r, o) 的分数。
2. 将分数降序排序,作为返回文件列表中文件的新顺序。
使用指标MRR和指标Hits@1作为评价标准。这两个指标的值越大,模型效果越好。
在本文中,作者将 CapsE 与以下五个模型进行了比较:
初始嵌入
从查询日志中提取 200 个关于带有相关标签的文档的主题,用于训练 LDA 主题模型。使用经过训练的 LDA 模型来推断每个主题在所有主题中返回文档的概率分布。并用每个文档的主题比例向量作为每个文档的embedding向量对文档进行向量化(假设总共有200个主题,即k=200,文档d的embedding向量中的第z个元素表示:给定文件为广告文件,主题为z的概率。
).
同时,作者还将每个查询表达为与主题相关的概率分布向量。具体方法如下:
让集合表示用q查询时返回的前n个文件(这里n=10)。
查询语句q的嵌入向量的第z维值为:=
。哪里
表示集合Dq中第i个文件的指数衰减系数。而б是0到1之间的衰减超参数(本文使用0.8)。
注意:为了避免本文实验中的过拟合,用于训练模型 TransE、ConvKB 和 CaspE 的查询短语嵌入向量和文件嵌入向量在整个训练过程中保持不变。
另外,由于用户最近的点击事件往往能反映用户最近的兴趣,所以采用对训练集中被点击的文件分配临时权重的策略来初始化三种嵌入模型的用户画像的嵌入向量.
超参数调优
当过滤器数量为400,学习率为5时,CapsE在验证集上的MRR值最高;当margin为5时,sgd的l1范数和学习率为5,TransE在验证集上,MRR达到最高;当过滤器数量为 500,优化器 Adam 的学习率为 5 时,ConvKB 在验证集上达到最高 MRR。
主要结果
与传统的学习排序个性化搜索模型CI和SP相比,嵌入式模型TransE、ConvKB和CapsE取得了更好的性能。因此,将三重嵌入模型扩展到搜索算法可以提高个性化搜索系统的排名质量。如图,CapsE方法得到的MRR和Hits@1是五个模型中最高的值。
总结
虽然本文使用的方法与ConvE非常相似,但它有以下两个亮点:
1. 作为第一个使用胶囊网络进行知识图谱改进和个性化搜索的文章,它充分利用了胶囊网络在同一维度上捕获不同特征映射的深层特征的能力,并为首次对同维度信息进行深度结构建模。使模型能够更好地用于多端预测。
2.首次将个性化搜索任务与链接预测任务相结合,将个性化搜索中的用户、查询关键词、返回的结果文件转化为三元组,并对其进行链接预测问题研究。并且因为三元组属于1-M关系问题,所以CapsE模型还是很有效的。
#活动推荐#
10.31-11.1 北京致远大会
世界AI看中国,中国AI看北京!
百位顶尖专家、60+前沿报告、10+圆桌论坛、剑锋对话,为您带来一场专家级AI盛会。全球顶尖学者云集:John Hopcroft(图灵奖)、Michael Jordan(机器学习权威学者)、Chris Manning(NLP权威学者)、朱松春(计算机视觉权威学者)、张博、高文、戴琼海、张平文等100多位专家。 查看全部
知识图谱、表示学习动机尽管的动机基于以下两点
作者丨王文博
学校丨哈尔滨工程大学硕士
研究方向丨知识图谱、表征学习
动机
虽然大规模的知识图谱已经收录了数十亿的三元组数据,但还不是很完整。其中,还有未被发现的真实有效的三元组。因此,本文提出了许多用于学习实体和关系的向量表示的嵌入模型,以通过预测三元组是否有效来改进知识图谱。同时,本文作者发现上述模型也可以用于(提交查询,用户个人资料)。 ,返回文档)作为三元组,解决个性化搜索问题。因此,写这篇文章的动机基于以下两点:
之前对三元组建模有效性的研究仅关注知识图谱的完整性或个性化搜索的准确性。但是,本文针对上述两个问题同时使用模型来衡量模型的有效性。
TransE、DISMULT、ComplEx等传统嵌入式模型只使用向量之间的加减乘,所以只能捕捉向量之间的线性关系。虽然现在越来越多的研究集中在使用深度神经网络来解决三元组的预测问题,例如ConvE,但假设可以通过分析三元组相同维度的数据来捕获三元组的头部向量。特定关系中的实体和尾实体的特定属性信息。因此,这些模型大多采用对三元组同维信息建模的方法。但是没有模型可以对具有深层结构的相同维度的三元组信息进行建模。
CapsE 模型
ζ 表示真三元组的集合,其中三元组以 (s,r,o) 的形式表示。构建嵌入模型的目的是定义一个评分函数对每个三元组进行评分,使真实三元组的分数高于假三元组的分数。
用于独立表示 s、r 和 o 的嵌入向量。在 CapsE 模型中,三元组的嵌入向量组合成一个形式并作为矩阵处理。对矩阵A的第i行进行符号化,对卷积层应用一个filter,对矩阵A的每一行重复应用这个filter,形成一个
特征映射的形式。哪里:
·表示点积,b∈R是偏置项,g是非线性激活函数,如ReLU。
CapsE 模型中使用了多个过滤器来生成多个特征图。用Ω表示滤波器组,用N=|Ω|表示集合中过滤器的数量。因此,可以得到N个k维的特征图,每个特征图从三元组的同一维上映射得到一个唯一的特征。
作者通过使用两个独立胶囊层的简化架构来构建 CapsE 模型。在第一个胶囊层,作者构造了k个胶囊,使得特征映射向量相同维度的所有数据形成一个胶囊。因此,每个胶囊可以捕获嵌入到三元组中相应维度条目中的许多特征。这些特征被传递到第二层中的胶囊以生成输出向量。输出向量的长度(可以理解为L1f范数)代表了三元组的得分。
第一个胶囊层由 k 个胶囊组成。每个胶囊 i∈{1,2,...,k} 都有一个输出向量。将输出向量乘以权重矩阵,将所有向量相加得到一个向量,作为第二个胶囊层中胶囊的输入。之后,胶囊使用非线性压缩函数生成输出向量。
表示耦合系数,由算法1的路由过程决定。本文在capsule层的前后层之间使用softmax。算法一如图所示:
如图1所示,在本文提出的模型中,embedding size k=4;过滤器数量N=5;胶囊第一层的神经元数量等于N;胶囊的第二层中的神经元数量为2:d=2。输出向量 e 的长度用作输入三元组 (s, r, o) 的分数。最后,本文定义了三元组的得分函数f如下:
* 表示卷积操作,capsnet 表示胶囊网络操作。本文使用Adam优化器来训练CapsE模型以最小化损失函数值。损失函数如下:
如果(s,r,o)∈ζ,则t(s,r,o)=1 如果(s,r,o)∈ζ',则t(s,r,o)=-1。
其中 ζ 和 ζ' 分别代表正确的三元组和错误的三元组。 ζ'是指通过破坏结构并随机替换其头部实体或尾部实体,由ζ中的正确三元组组成的新三元组。
实验
完整的知识图谱评估
数据集
本文中的实验使用数据集 WN18RR 和 FB15k-237。因为这两个数据集排除了收录可逆关系的三元组,所以这两个数据集更加真实,也增加了在这两个数据集上进行实验的难度。
评估计划
通过以下过滤器设置执行链接预测:对每个测试三元组和不在训练集、验证集或测试集中并由三元组生成的所有其他候选三元组进行排名。其中,候选三元组是用实体集中的其他实体替换三元组中的原创实体生成的三元组。并以平均排名(MR)、平均数排名(MRR)和Hits@10作为评价标准。
实验计划
文章使用100维Glove词嵌入模型进行预训练,然后在数据集WN18RR上训练一个TransE模型。并将TransE模型的训练结果作为模型convKB和CapsE的初始值。
ConvE模型的参数设置如下:选择Adam优化器,设置学习率
;过滤器的数量 N 设置为 {50,100,200,400}。当模型得到最高Hits@10时,在数据集WN18RR上,N=400,学习率的初始值;在数据集FB15k-237上,N=400,学习率的初始值。
对于CapsE模型,参数设置如下:embedding vector维度设置为100;批量大小设置为128,胶囊中第二层胶囊的神经元数d设置为10;路由算法的迭代次数设置为{1,3,5,7}。当模型得到最高Hits@10时,在数据集WN18RR上,m=1,N=400,学习率的初始值;在数据集FB15k-237上,m=1,N=50,学习率的初始值。
主要实验结果
CaspE 模型在数据集 WN18RR 上获得了最佳 MR,在数据集 FB15k-237 上获得了最佳 Hits@10。下面主要分析模型ConvKB和模型CapsE分别在FB15k-237数据集上预测头尾实体时MRR和Hits@10的值。
在本文中,作者使用以下方法对关系进行分类:
记录给定关系r上每个尾实体对应的头实体的平均数为;记录给定关系r上每个头实体对应的尾实体的平均数为。
从上面的结果图可以得出以下实验结论:CapsE在预测M端实体时会得到比ConvKB更好的实验结果; ConvKB 在预测 1-end 实体时会比 CapsE 更好 实验结果。
分析这个结果。由于第一层中每个胶囊的方向和长度有助于对同一维度的数据项进行建模,因此 CapsE 模型在实体出现频率较低的 M 端执行。预测效果优于实体出现频率更高的第一端。现有模型 DISTMULT、ComplEx 和 ConvE 对实体较高频率的第一端有较好的预测效果。以上就是CapsE模型能够在数据集FB15k-237和数据集WN18RR上取得较好预测结果的原因。
路由迭代的实验结果:本文作者还研究了路由迭代次数对模型效果的影响。得出结论:当迭代次数设为1,其他参数不变时,相应的模型可以获得最佳的实验结果。
这说明了知识图谱和图像问题的区别。在图像分类任务中,将迭代次数 m 设置为大于 1 的数字有助于更准确地捕获图像中实体的相对位置。但相反,由于知识图中同类关系的不同实体之间变化的多样性,这种基于图像的思想只能正确处理知识图中的1-1关系,而不适用于处理 1-M。 M-1与MM的关系。
个性化搜索应用
个性化搜索:给定一个用户(user),该用户的查询关键词(query),搜索系统对与查询关键词相关的文件进行重新排序,并返回结果文件(document)。另外,与用户相关的文档和用户在上述排序过程中给出的查询关键词越相关,应该得到的排序结果就越好。基于以下两个原因,CapsE模型可以用来完成个性化的搜索任务:
数据集
作者使用了106个用户的大规模网络搜索引擎查询日志集合(SEARCH17)作为实验数据集。该数据集收录一个用户查询返回的10个最佳结果,以及用户的这些结果的延迟时间,在这些返回的文档中,用户点击过的文档,或者停留时间超过30秒的文档被标记为相关,返回的前10个文档中剩余的文档被标记为不相关。 Passed 与标签相关的文档位置,用于评估搜索结果。
划分数据集,将数据集划分为训练集、验证集和测试集,达到利用训练集中的历史数据预测测试集中新数据的目的。训练集、验证集和测试集分别由5658、1184和1210个相关三元组和40239、7882、8540个不相关三元组组成。
评估计划
模型CapsE按照如下方式对搜索引擎返回的原创文件列表进行重新排序:
1. 训练 CapsE 模型,并使用训练好的模型计算每个三元组 (s, r, o) 的分数。
2. 将分数降序排序,作为返回文件列表中文件的新顺序。
使用指标MRR和指标Hits@1作为评价标准。这两个指标的值越大,模型效果越好。
在本文中,作者将 CapsE 与以下五个模型进行了比较:
初始嵌入
从查询日志中提取 200 个关于带有相关标签的文档的主题,用于训练 LDA 主题模型。使用经过训练的 LDA 模型来推断每个主题在所有主题中返回文档的概率分布。并用每个文档的主题比例向量作为每个文档的embedding向量对文档进行向量化(假设总共有200个主题,即k=200,文档d的embedding向量中的第z个元素表示:给定文件为广告文件,主题为z的概率。
).
同时,作者还将每个查询表达为与主题相关的概率分布向量。具体方法如下:
让集合表示用q查询时返回的前n个文件(这里n=10)。
查询语句q的嵌入向量的第z维值为:=
。哪里
表示集合Dq中第i个文件的指数衰减系数。而б是0到1之间的衰减超参数(本文使用0.8)。
注意:为了避免本文实验中的过拟合,用于训练模型 TransE、ConvKB 和 CaspE 的查询短语嵌入向量和文件嵌入向量在整个训练过程中保持不变。
另外,由于用户最近的点击事件往往能反映用户最近的兴趣,所以采用对训练集中被点击的文件分配临时权重的策略来初始化三种嵌入模型的用户画像的嵌入向量.
超参数调优
当过滤器数量为400,学习率为5时,CapsE在验证集上的MRR值最高;当margin为5时,sgd的l1范数和学习率为5,TransE在验证集上,MRR达到最高;当过滤器数量为 500,优化器 Adam 的学习率为 5 时,ConvKB 在验证集上达到最高 MRR。
主要结果
与传统的学习排序个性化搜索模型CI和SP相比,嵌入式模型TransE、ConvKB和CapsE取得了更好的性能。因此,将三重嵌入模型扩展到搜索算法可以提高个性化搜索系统的排名质量。如图,CapsE方法得到的MRR和Hits@1是五个模型中最高的值。
总结
虽然本文使用的方法与ConvE非常相似,但它有以下两个亮点:
1. 作为第一个使用胶囊网络进行知识图谱改进和个性化搜索的文章,它充分利用了胶囊网络在同一维度上捕获不同特征映射的深层特征的能力,并为首次对同维度信息进行深度结构建模。使模型能够更好地用于多端预测。
2.首次将个性化搜索任务与链接预测任务相结合,将个性化搜索中的用户、查询关键词、返回的结果文件转化为三元组,并对其进行链接预测问题研究。并且因为三元组属于1-M关系问题,所以CapsE模型还是很有效的。
#活动推荐#
10.31-11.1 北京致远大会
世界AI看中国,中国AI看北京!
百位顶尖专家、60+前沿报告、10+圆桌论坛、剑锋对话,为您带来一场专家级AI盛会。全球顶尖学者云集:John Hopcroft(图灵奖)、Michael Jordan(机器学习权威学者)、Chris Manning(NLP权威学者)、朱松春(计算机视觉权威学者)、张博、高文、戴琼海、张平文等100多位专家。
什么是SEO站内主题模型SEO页面内容优化的老旧方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-09 02:35
什么是SEO站内主题模型SEO页面内容优化的老旧方法
SEO网站的主题模型是什么
SEO页面内容优化的老方法有哪些:
1、看关键词密度是否达标
2、文章内容字数够吗?
3、内容够不够原创
4、是否有足够的导入链接(外部链接)?
5、使用各种H标签整合关键词
6、TDK关键词是否设置为精确匹配
有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎。 8-9年前,百度没吃过这个老技术。要优化网站内容,必须让搜索引擎了解页面的核心主题。这就是我今天文章的核心。
什么是主题模型?
主题模型要求我们实现全新的4步优化方法:
1、词系布局
2、Content 属性
3、词系连线
4、补充内容
我们熟悉诸如(维基百科、亚马逊)之类的网站,它们使用这些积分来获得大量的关键词 排名。他们部署在页面布局上,因为他们的“结构”足够强大,所以他们可以大量有效地向搜索引擎展示核心内容主题。
因此,植入内容后,可以快速产出大量优质页面。因此,即使你不懂搜索引擎算法,只要使用主题模型也能获得不错的排名!
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。您写的内容最直接影响搜索引擎对页面主题的理解。
我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1、查找变体词和同义词
2、查找与主词内容相关的二类词
3、找到与第二类词相关的三类词
4、断定内容属性与主词(人物、地理、事件)相关
比如你要优化一个叫【网红】的关键词,这个词成为你的主词。
根据目的:
(1)它的同义词和变体可能是“自媒体”、“意见领袖”、“网络推广”等;
(2)与主词内容相关的第二类词可以是“刘吉首”、“微博”和“生词”;
(3)找到与第二类词相关的三类词可以“剩几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪。每个人都可以清楚地看到每层单词和短语之间的一些关联。
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和词组之间哪个重要,哪个是重要的。有关的。所以词法布局就是区分核心词及其相关性。
以下是3种实用的优化方法:
1、区域:关键词必须出现在标题、标题和主要段落中;
2、Frequency:重要短语或其变体可能出现的次数超过平均水平;
3、distance:相关词或短语应该彼此靠近或使用 HTML 元素(例如 ALT)。
你知道方法的原理,我们举个简单的例子:
主词是[网红]
第一段将重点放在文章这个词上;
第二段会用几只手文章;
第三段利用微博中继效果做文章;
第四段使用新的互联网名称文章。
等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
主动向好三方网站推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。
仍然有很多人认为外链是最有力的信号提醒,可以告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。所以搜索引擎希望大家可以同时使用内链和外链。
百度百科或者知道为什么要添加相关资源的链接吗?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1、页面底部添加相关资源链接(推荐站内链接)
2、在文中使用引号,如行业内知名人士的话或图标或视频
3、使用文中导出链接去第三方网站(你不会是100颗K的心)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“包老师”时,是不是【人物】的实体?
通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 using Schema 。
这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
总结:
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一张高级大学证书,它记录了你的实体和相关性。
最后,将以下优化技术整合到您的内容优化中:
1、 描述页面主题的非常笼统的标题
2、添加开场白(简要)描述页面内容
3、 提供额外的现场或场外辅助资源
4、尽量扩大话题角度,可以添加相关答案
5、不在乎一个词的权重,而是构建内容实体
6、将内容分成几段,每段都有自己的主题
--文章来至微红科技 查看全部
什么是SEO站内主题模型SEO页面内容优化的老旧方法
SEO网站的主题模型是什么
SEO页面内容优化的老方法有哪些:
1、看关键词密度是否达标
2、文章内容字数够吗?
3、内容够不够原创
4、是否有足够的导入链接(外部链接)?
5、使用各种H标签整合关键词
6、TDK关键词是否设置为精确匹配
有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎。 8-9年前,百度没吃过这个老技术。要优化网站内容,必须让搜索引擎了解页面的核心主题。这就是我今天文章的核心。
什么是主题模型?
主题模型要求我们实现全新的4步优化方法:
1、词系布局
2、Content 属性
3、词系连线
4、补充内容
我们熟悉诸如(维基百科、亚马逊)之类的网站,它们使用这些积分来获得大量的关键词 排名。他们部署在页面布局上,因为他们的“结构”足够强大,所以他们可以大量有效地向搜索引擎展示核心内容主题。
因此,植入内容后,可以快速产出大量优质页面。因此,即使你不懂搜索引擎算法,只要使用主题模型也能获得不错的排名!
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。您写的内容最直接影响搜索引擎对页面主题的理解。
我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1、查找变体词和同义词
2、查找与主词内容相关的二类词
3、找到与第二类词相关的三类词
4、断定内容属性与主词(人物、地理、事件)相关
比如你要优化一个叫【网红】的关键词,这个词成为你的主词。
根据目的:
(1)它的同义词和变体可能是“自媒体”、“意见领袖”、“网络推广”等;
(2)与主词内容相关的第二类词可以是“刘吉首”、“微博”和“生词”;
(3)找到与第二类词相关的三类词可以“剩几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪。每个人都可以清楚地看到每层单词和短语之间的一些关联。
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和词组之间哪个重要,哪个是重要的。有关的。所以词法布局就是区分核心词及其相关性。
以下是3种实用的优化方法:
1、区域:关键词必须出现在标题、标题和主要段落中;
2、Frequency:重要短语或其变体可能出现的次数超过平均水平;
3、distance:相关词或短语应该彼此靠近或使用 HTML 元素(例如 ALT)。
你知道方法的原理,我们举个简单的例子:
主词是[网红]
第一段将重点放在文章这个词上;
第二段会用几只手文章;
第三段利用微博中继效果做文章;
第四段使用新的互联网名称文章。
等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
主动向好三方网站推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。
仍然有很多人认为外链是最有力的信号提醒,可以告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。所以搜索引擎希望大家可以同时使用内链和外链。
百度百科或者知道为什么要添加相关资源的链接吗?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1、页面底部添加相关资源链接(推荐站内链接)
2、在文中使用引号,如行业内知名人士的话或图标或视频
3、使用文中导出链接去第三方网站(你不会是100颗K的心)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“包老师”时,是不是【人物】的实体?
通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 using Schema 。
这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
总结:
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一张高级大学证书,它记录了你的实体和相关性。
最后,将以下优化技术整合到您的内容优化中:
1、 描述页面主题的非常笼统的标题
2、添加开场白(简要)描述页面内容
3、 提供额外的现场或场外辅助资源
4、尽量扩大话题角度,可以添加相关答案
5、不在乎一个词的权重,而是构建内容实体
6、将内容分成几段,每段都有自己的主题
--文章来至微红科技
站内八大seo优化点总结,全精辟,小伙伴可以详细阅读
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-09 02:32
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。总结了网站seo的8个优化点,都很精辟,朋友们可以给详细[...]
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。网站内8个seo优化点汇总,有见地,朋友可以详细阅读。
任何接触过搜索引擎优化的人都可以发表他们对搜索引擎优化的看法。出于这个原因,错误和正确的 SEO 观点是混合的。其实,真正权威、可靠的观点应该来自百度的官方文档。视频,以下是网站seo优化的核心要点:
注意:这个seo教程的优化点偏向于用户体验,而不是简单的seo。
首先,落地页的内容是解决问题,而不仅仅是描述问题。
例如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该有几个方向:【男嘉宾推荐的20款婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他是去参加婚礼,所以最后要解决的问题是去哪里买衣服,而不是让他学会如何搭配衣服。所以在优化这个关键词的时候,我们的内容一定要解决它的最终需求,这样引流和转化效果才会更好。
[/s2/]二、提高网站的激活速度是网站优化不可缺少的一点。
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站打开和加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,一定要考虑可以做些什么来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三是增强用户界面、用户体验和品牌的信任度和参与度。
很多用户打开网站都会有第一印象。他们是好小屋,好当地的海龟,专业,不是我们想要的结果。页面设计需要ui& UX投资和品牌自身的口碑来背书,否则用户很难在网站产生信任和参与。最实用的方法是模仿业界比较好的网站,购买付费版的网站模板或者让用户参与每一个设计过程。
第四,避免各种促使用户离开页面的反应性 SEO 元素。
许多弹出窗口、固定凸窗和广告位会让用户反感并放弃整个浏览过程。这是在搜索引擎优化过程中应该避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时可以避免蜘蛛被禁止或难以捕捉的可能性,让搜索引擎降低自己的权利。
V。一般关键字布局。
常规的关键词植入(老师叫歌词)也要继续,比如Title、H1、文章中的关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等等。这个我不想重复了,大家都懂的。
六。相关主题模型的使用。
仅仅写文字是不够的,因为太机械会失去文字的用户体验。所以做一个主题模型,比如关键词【婚礼搭配】可以扩展到一些相关的词,比如燕尾服、婚纱、婚纱背心、婚纱、婚宴等等。形成一个大的相关话题,这样的页面内容会让关键词排名更全面,帮助更多用户。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
第七,展示文字的深度优化。
排名显示的信息对点击率非常重要,所以我们可能不得不影响显示的信息(主要是标题、描述、网址)。内容中需要针对SEO优化这些元素:标题的创意、desc的流行度、url的规范、文章的日期、结构化数据的使用、在线对话等等。下面的效果是什么?
20 场男人杀死女人的婚礼:
2016年5月31日——为20位参加婚礼的男士提供最新搭配建议。再低的预算也配得上周围女嘉宾的秒杀,全是图片和视频。
八.创造独特的价值内容。
毕竟,营销离不开内容的质量。
好的内容包括:
1) 提供了独特的视觉体验、前端界面、合适的字体和功能按钮。
2)内容必须有价值、可信、有趣、值得采集。
3)与其他内容相比,没有重复,深度更强。
4)打开速度快(无广告),可以在不同终端阅读。
5)可以产生表扬、惊喜、快乐、思考等情绪化的想法
6)可以实现一定的转发和传播能力。
7) 使用完整、准确和独特的信息来解决或回答问题。 查看全部
站内八大seo优化点总结,全精辟,小伙伴可以详细阅读
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。总结了网站seo的8个优化点,都很精辟,朋友们可以给详细[...]
详细的seo技术理论有很多,但网站上核心seo优化点并不多。提取影响关键词排名的核心点,在这些点上下功夫。最终结果是您在搜索引擎优化方面更有效率。网站内8个seo优化点汇总,有见地,朋友可以详细阅读。
任何接触过搜索引擎优化的人都可以发表他们对搜索引擎优化的看法。出于这个原因,错误和正确的 SEO 观点是混合的。其实,真正权威、可靠的观点应该来自百度的官方文档。视频,以下是网站seo优化的核心要点:
注意:这个seo教程的优化点偏向于用户体验,而不是简单的seo。
首先,落地页的内容是解决问题,而不仅仅是描述问题。
例如,当有人搜索“结婚穿什么衣服”时,最好的页面内容应该有几个方向:【男嘉宾推荐的20款婚礼搭配】和【精选搭配购买信息】。因为这个搜索词背后的用户猜测他是去参加婚礼,所以最后要解决的问题是去哪里买衣服,而不是让他学会如何搭配衣服。所以在优化这个关键词的时候,我们的内容一定要解决它的最终需求,这样引流和转化效果才会更好。
[/s2/]二、提高网站的激活速度是网站优化不可缺少的一点。
在信息碎片化的时代,没有人愿意给你等待的机会,所以网站打开和加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以在优化的时候,一定要考虑可以做些什么来加速,比如CDN、去除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
三是增强用户界面、用户体验和品牌的信任度和参与度。
很多用户打开网站都会有第一印象。他们是好小屋,好当地的海龟,专业,不是我们想要的结果。页面设计需要ui& UX投资和品牌自身的口碑来背书,否则用户很难在网站产生信任和参与。最实用的方法是模仿业界比较好的网站,购买付费版的网站模板或者让用户参与每一个设计过程。
第四,避免各种促使用户离开页面的反应性 SEO 元素。
许多弹出窗口、固定凸窗和广告位会让用户反感并放弃整个浏览过程。这是在搜索引擎优化过程中应该避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时可以避免蜘蛛被禁止或难以捕捉的可能性,让搜索引擎降低自己的权利。
V。一般关键字布局。
常规的关键词植入(老师叫歌词)也要继续,比如Title、H1、文章中的关键词、外链锚文本、内链锚文本、图片ALT、URL、图片命名等等。这个我不想重复了,大家都懂的。
六。相关主题模型的使用。
仅仅写文字是不够的,因为太机械会失去文字的用户体验。所以做一个主题模型,比如关键词【婚礼搭配】可以扩展到一些相关的词,比如燕尾服、婚纱、婚纱背心、婚纱、婚宴等等。形成一个大的相关话题,这样的页面内容会让关键词排名更全面,帮助更多用户。同时,搜索引擎可以解释您要推送的主题内容与婚纱相关。
第七,展示文字的深度优化。
排名显示的信息对点击率非常重要,所以我们可能不得不影响显示的信息(主要是标题、描述、网址)。内容中需要针对SEO优化这些元素:标题的创意、desc的流行度、url的规范、文章的日期、结构化数据的使用、在线对话等等。下面的效果是什么?
20 场男人杀死女人的婚礼:
2016年5月31日——为20位参加婚礼的男士提供最新搭配建议。再低的预算也配得上周围女嘉宾的秒杀,全是图片和视频。
八.创造独特的价值内容。
毕竟,营销离不开内容的质量。
好的内容包括:
1) 提供了独特的视觉体验、前端界面、合适的字体和功能按钮。
2)内容必须有价值、可信、有趣、值得采集。
3)与其他内容相比,没有重复,深度更强。
4)打开速度快(无广告),可以在不同终端阅读。
5)可以产生表扬、惊喜、快乐、思考等情绪化的想法
6)可以实现一定的转发和传播能力。
7) 使用完整、准确和独特的信息来解决或回答问题。
网站主题模型优化怎么将站内SEO优化做的
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-08-05 20:25
很多朋友在优化网站seo的时候遇到了一些网站optimization的问题,包括“网站主题模型优化ppt:如何有效提高企业网站人气”的问题,那么下面是一个搜索互联网编辑器来解答您的疑惑。
您可以为您的企业进行 seo 搜索引擎优化网站。优化你的网站关键词、网站theme模型、网站结构、网站页面、网站链接优化。
SEO 搜索引擎优化
网站关键词optimization、网站theme 模型优化、网站structure 优化、网站page 优化、网站link 优化
SEO 搜索引擎优化
是网站关键词优化、网站topic模型优化、网站结构优化、网站page优化、网站link优化
如何做好站内SEO优化网站topic模型优化ppt
对于每一个网站做seo优化,网站seo优化都是必不可少的一步。只有做好网站自己的优化,做异地优化才会更有效。 seo网站优化可以分为:代码优化、标签优化、内容优化、网址优化等,网站seo优化的技巧很多,笔者总结了以下几点:
1、文章关键词密度要合理
文章中关键词关键词的密度要合理,不是越高越好,太少也不行,合适的密度范围应该是2%~8%,内容解释在图片和文字的形式,文章最好在标题中收录关键词。如果想知道文章中关键词的密度,可以使用第三方工具查询。
2、提高网站访问速度
网站topic模型优化ppt:使用seo创建关键词相关度
网站访问速度也会影响网站的SEO优化和用户体验。网页打开速度越快,用户就越满意。提高网站的访问速度无疑有利于搜索引擎优化。
3、优化层不要超过四层
过度优化也是很多新手常犯的错误。通常,URL 中的每个“/”代表一个层。权重越低,层越深,搜索引擎越难抓取,越影响排名效果。
4.高质量原创文章,持续更新
网站 的内容也是网站 seo 优化的一个关键点。毕竟大家都要去网站的内容,文章要收录,被用户点赞的建议是原创,除了优质内容,文章段布局也很重要。更新网站文章的更新是持久战,不能随心更新。
5.网站地图设置
网站map 也称为站点地图。虽然只是一个页面,但是网站上所有页面的链接都放在上面,起到导航的作用。
6.图片优化
图片在文章中也扮演着不可忽视的角色。很多人往往会忽略这个问题。图像优化应该从用户视觉的角度考虑,适合爬虫。图片太大或太小都不好。 建议图片宽度在~像素之间,高度和像素之间,像素1M以内,居中显示。
网站优化技巧只是为了帮助您。具体的还是要靠大家的实践。理论结合实际操作是优化网站的方法。
以上是关于网站theme模型优化ppt,如何有效提高企业网站文章内容的知名度,如果您有网站optimization意向,可以直接联系我们。很高兴为您服务! 查看全部
网站主题模型优化怎么将站内SEO优化做的
很多朋友在优化网站seo的时候遇到了一些网站optimization的问题,包括“网站主题模型优化ppt:如何有效提高企业网站人气”的问题,那么下面是一个搜索互联网编辑器来解答您的疑惑。
您可以为您的企业进行 seo 搜索引擎优化网站。优化你的网站关键词、网站theme模型、网站结构、网站页面、网站链接优化。
SEO 搜索引擎优化
网站关键词optimization、网站theme 模型优化、网站structure 优化、网站page 优化、网站link 优化
SEO 搜索引擎优化
是网站关键词优化、网站topic模型优化、网站结构优化、网站page优化、网站link优化
如何做好站内SEO优化网站topic模型优化ppt
对于每一个网站做seo优化,网站seo优化都是必不可少的一步。只有做好网站自己的优化,做异地优化才会更有效。 seo网站优化可以分为:代码优化、标签优化、内容优化、网址优化等,网站seo优化的技巧很多,笔者总结了以下几点:
1、文章关键词密度要合理
文章中关键词关键词的密度要合理,不是越高越好,太少也不行,合适的密度范围应该是2%~8%,内容解释在图片和文字的形式,文章最好在标题中收录关键词。如果想知道文章中关键词的密度,可以使用第三方工具查询。
2、提高网站访问速度
网站topic模型优化ppt:使用seo创建关键词相关度
网站访问速度也会影响网站的SEO优化和用户体验。网页打开速度越快,用户就越满意。提高网站的访问速度无疑有利于搜索引擎优化。
3、优化层不要超过四层
过度优化也是很多新手常犯的错误。通常,URL 中的每个“/”代表一个层。权重越低,层越深,搜索引擎越难抓取,越影响排名效果。
4.高质量原创文章,持续更新
网站 的内容也是网站 seo 优化的一个关键点。毕竟大家都要去网站的内容,文章要收录,被用户点赞的建议是原创,除了优质内容,文章段布局也很重要。更新网站文章的更新是持久战,不能随心更新。
5.网站地图设置
网站map 也称为站点地图。虽然只是一个页面,但是网站上所有页面的链接都放在上面,起到导航的作用。
6.图片优化
图片在文章中也扮演着不可忽视的角色。很多人往往会忽略这个问题。图像优化应该从用户视觉的角度考虑,适合爬虫。图片太大或太小都不好。 建议图片宽度在~像素之间,高度和像素之间,像素1M以内,居中显示。
网站优化技巧只是为了帮助您。具体的还是要靠大家的实践。理论结合实际操作是优化网站的方法。
以上是关于网站theme模型优化ppt,如何有效提高企业网站文章内容的知名度,如果您有网站optimization意向,可以直接联系我们。很高兴为您服务!
SEO站内..文章内容字数是否够多?实操优化方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-08-05 04:37
今天的SEO已经进入了一个全新的内容营销算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于 SEO,网站...
2、文章内容字数够吗?
(3),找到与第二类词相关的三类词
3、内容够不够原创?
4、尽量扩大话题角度,添加相关答案。
方法(2)不仅仅是指关键词频率(密度),而是一个更复杂层次的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果(在谷歌有一项专利叫做TF-IDF,具体可以参考马海翔博客“搜索引擎自动提取文章关键词principle”一文中的介绍)。
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有相关性,所以词系统布局是为了区分核心词及其相关性。具体来说,有以下三种实用的优化方法:
(2),在文中使用引号,如行业内知名人士的话或图标或视频。
所以为了提高上下文相关性,应该通过段落、列表和分区使内容更加明显。可以一目了然地知道该段落在说什么,前后句子之间是否有连通性,不要将含义相似的内容分开。太远了,因为你不能保证蜘蛛会抓到全文。
通常我们可以听到或看到许多关于 SEO 页面内容的旧方法,例如:
5、使用各种H标签来整合关键词?
您可以清楚地看到每层单词和短语之间的一些关联。根据(4)我们尝试在这些内容和内容中的主词之间建立关联,特别是如果有人、地点、事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有这样的其他网站上的关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题,记住你要传递主题,不是关键词密度!
5、 提供额外的现场或场外辅助资源。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,但现在更偏向于实体,因为词排名使用了太多以外链为主的链式方式。 ,所以结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。是的,这些是 8-9 年前的技术。现在我们需要优化网站的内容。我们必须做的是如何让搜索引擎理解页面的核心主题,这也是我今天文章的核心。
马海翔的博客评论:
二、如何制作一个好的SEO网站主题模型
2、词系布局
1、 描述页面主题的非常笼统的标题。
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题词放在标题,大标题,尽量出现在正文的顶部。
当前位置:首页>百度SEO排名优化>如何做网站主题内容模型的SEO优化 查看全部
SEO站内..文章内容字数是否够多?实操优化方法
今天的SEO已经进入了一个全新的内容营销算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于 SEO,网站...
2、文章内容字数够吗?
(3),找到与第二类词相关的三类词
3、内容够不够原创?
4、尽量扩大话题角度,添加相关答案。
方法(2)不仅仅是指关键词频率(密度),而是一个更复杂层次的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果(在谷歌有一项专利叫做TF-IDF,具体可以参考马海翔博客“搜索引擎自动提取文章关键词principle”一文中的介绍)。
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有相关性,所以词系统布局是为了区分核心词及其相关性。具体来说,有以下三种实用的优化方法:
(2),在文中使用引号,如行业内知名人士的话或图标或视频。
所以为了提高上下文相关性,应该通过段落、列表和分区使内容更加明显。可以一目了然地知道该段落在说什么,前后句子之间是否有连通性,不要将含义相似的内容分开。太远了,因为你不能保证蜘蛛会抓到全文。
通常我们可以听到或看到许多关于 SEO 页面内容的旧方法,例如:
5、使用各种H标签来整合关键词?
您可以清楚地看到每层单词和短语之间的一些关联。根据(4)我们尝试在这些内容和内容中的主词之间建立关联,特别是如果有人、地点、事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有这样的其他网站上的关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题,记住你要传递主题,不是关键词密度!
5、 提供额外的现场或场外辅助资源。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,但现在更偏向于实体,因为词排名使用了太多以外链为主的链式方式。 ,所以结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。是的,这些是 8-9 年前的技术。现在我们需要优化网站的内容。我们必须做的是如何让搜索引擎理解页面的核心主题,这也是我今天文章的核心。
马海翔的博客评论:
二、如何制作一个好的SEO网站主题模型
2、词系布局
1、 描述页面主题的非常笼统的标题。
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题词放在标题,大标题,尽量出现在正文的顶部。
当前位置:首页>百度SEO排名优化>如何做网站主题内容模型的SEO优化
SEO早已进到全新升级“层次感内容”的优化算法
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-05 04:30
SEO已经进入全新升级的“分级内容”优化算法管理体系,尤其是现在一流的搜索引擎更能从内容场景和内容实体线属性解决排名,促使客户获得更精准的百度搜索。对于推广者来说,网站内部优化将不再是简单的内容填充,必须彻底改变主题内容的推广。文章将结合新的SEO核心概念,指导大家如何改进主题内容。
主题实体模型是为了更好地让搜索引擎正确理解所有页面的关键主题,而不是发送很多关键词,对页面内容进行合理布局的实体模型。由于一个页面可以收录很多信息内容,有的有效,有的被占用,你只能通过将真正关键的信息传递给搜索引擎来获得匹配的排名。所以,在主题实体模型中,大家一定要保证一个四步新的升级优化方法:1词关系2词系统合理布局3填充内容4内容属性。
对于这些大家都知道的网站,比如维基百科,亚马逊就利用里面的积分,获得了大量的关键词排名。他们在页面的合理布局上做了部署,因为他们的“铁骨架”足够强大,能够将关键内容主题大量合理地展示给搜索引擎。因此,嵌入内容后,可以制作出许多可以上台的页面。因此,无论您是新手还是老手,即使您不掌握搜索引擎优化算法,应用主题实体模型也可以很好地排名! (特别是对于 Google)。
无论你用什么方法来改善页面内容,Boli SEO,但你必须专注于如何建立词句之间的关系。作为内容写作,您所写的最直接会危及搜索引擎对页面主题的理解。当我们使用句子和短语时,搜索引擎会根据其他资源中的数据信息将您的内容关联起来,这会导致内容实体线生硬。推广者首先要根据关键词科学研究,找出这句话和词组的关系。我坚信每个人对关键词都有自己的科学研究方式,但是你需要做到以下几点: 1 查找同义词和组合词 2 搜索与关键词 主要内容相关的二等词; 3 搜索与二类词相关的三类词; 4 获取与主关键词相关的内容属性(人、地、物)。
这种“主题增强”的方法大家其实都可以操作。一个高质量的页面就像一张高中毕业证书,它记录了你的身体线条和相关性。最后,将以下优化技巧结合到你的内容改进中:1.高度抽象的Title描述页面主题,2.促销开头词(缩写)描述页面内容,3.分割内容有几个,每个都有自己的主题。 4.尽可能扩展主题视角,可以添加相关回复。 5.给了额外的网站内部或外部辅助资源,6.不关心某个词的比例,只是为了创建内容实体行。 查看全部
SEO早已进到全新升级“层次感内容”的优化算法
SEO已经进入全新升级的“分级内容”优化算法管理体系,尤其是现在一流的搜索引擎更能从内容场景和内容实体线属性解决排名,促使客户获得更精准的百度搜索。对于推广者来说,网站内部优化将不再是简单的内容填充,必须彻底改变主题内容的推广。文章将结合新的SEO核心概念,指导大家如何改进主题内容。
主题实体模型是为了更好地让搜索引擎正确理解所有页面的关键主题,而不是发送很多关键词,对页面内容进行合理布局的实体模型。由于一个页面可以收录很多信息内容,有的有效,有的被占用,你只能通过将真正关键的信息传递给搜索引擎来获得匹配的排名。所以,在主题实体模型中,大家一定要保证一个四步新的升级优化方法:1词关系2词系统合理布局3填充内容4内容属性。
对于这些大家都知道的网站,比如维基百科,亚马逊就利用里面的积分,获得了大量的关键词排名。他们在页面的合理布局上做了部署,因为他们的“铁骨架”足够强大,能够将关键内容主题大量合理地展示给搜索引擎。因此,嵌入内容后,可以制作出许多可以上台的页面。因此,无论您是新手还是老手,即使您不掌握搜索引擎优化算法,应用主题实体模型也可以很好地排名! (特别是对于 Google)。
无论你用什么方法来改善页面内容,Boli SEO,但你必须专注于如何建立词句之间的关系。作为内容写作,您所写的最直接会危及搜索引擎对页面主题的理解。当我们使用句子和短语时,搜索引擎会根据其他资源中的数据信息将您的内容关联起来,这会导致内容实体线生硬。推广者首先要根据关键词科学研究,找出这句话和词组的关系。我坚信每个人对关键词都有自己的科学研究方式,但是你需要做到以下几点: 1 查找同义词和组合词 2 搜索与关键词 主要内容相关的二等词; 3 搜索与二类词相关的三类词; 4 获取与主关键词相关的内容属性(人、地、物)。
这种“主题增强”的方法大家其实都可以操作。一个高质量的页面就像一张高中毕业证书,它记录了你的身体线条和相关性。最后,将以下优化技巧结合到你的内容改进中:1.高度抽象的Title描述页面主题,2.促销开头词(缩写)描述页面内容,3.分割内容有几个,每个都有自己的主题。 4.尽可能扩展主题视角,可以添加相关回复。 5.给了额外的网站内部或外部辅助资源,6.不关心某个词的比例,只是为了创建内容实体行。
1.什么是SEO站内主题模型(一)_
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-08-05 04:18
Seo进入了“有质感的内容”的全新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1.SEO网站的主题模型是什么
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 看看关键词密度是否符合标准
·文章内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词 是否设置为完全匹配?
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型?
主题模型是一种页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达关键词多。因为一个页面可以收录很多信息,有的有用,有的被占用,只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:
1)词系联系
2)词系布局
3)补充内容
4)Content 属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分获得了海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地显示核心内容主题。因此,在植入内容后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好! (特别是对于 Google)
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,从而生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和异体词
2)查找与主词内容相关的二类词
3)找到与第二类词相关的三类词
4)断定内容属性与主题(人物、地点、事物)相关
让我举个例子。比如你要优化一个关键词叫【网红】,这个词就成为你的主词。根据目的(1)其同义词和异体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)和主要词的内容相关到第二类词可以是“留几手”“微博”“生词”;然后根据目的(3)找到第三类词与第二类词相关的可以是“留几手”手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了。
您可以清楚地看到每层单词和短语之间的一些联系。根据(4),我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有其他网站上的这种关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题。记住你是通过主题,而不是关键词密度!
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有关的。因此,词系统布局是区分核心词及其相关性。以下是 3 种实用的优化方法:
方法(1)是大部分SEO人的必修项目,我们还是要尽量把核心主题词放在标题、大标题和正文顶部。
方法(2)这里不仅仅是指关键词频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)distance 产生美在 SEO 世界中不适用。单词、短语或句子应尽可能靠近放置,或使用 HTML 元素(如图片 ALT 设置)。所以为了提高语言的语境相关性,通过段落、列表、分区,让内容更加明显,段落说的内容一目了然意思太远了。因为你不能保证蜘蛛会抓到全文。
你知道方法的原理。现在你要做的就是将二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会围绕这个词文章。第二段用几只手为文章,第三段用微博转播效果为文章,第四段用新网名文章。等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
也许有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯关键词,缺少文字链接、参考资料和相关资源推荐。您的页面非常僵硬。死胡同不会为您的页面增加额外的分数。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件,是搜索引擎的资料片,我有【补充】。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站内链接);
2)在文中使用引号,如业内知名人士的话或图标或视频;
3)使用正文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom老师”时,它的实体是[人]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,或者可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体了。
通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema 。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多地使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的高度概括的标题
2)添加开场白(简要)描述页面内容
3)将内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以补充相关答案
5) 提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体 查看全部
1.什么是SEO站内主题模型(一)_
Seo进入了“有质感的内容”的全新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1.SEO网站的主题模型是什么
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 看看关键词密度是否符合标准
·文章内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词 是否设置为完全匹配?
但是有经验的SEO人员和网站主会很快发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型?
主题模型是一种页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达关键词多。因为一个页面可以收录很多信息,有的有用,有的被占用,只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:
1)词系联系
2)词系布局
3)补充内容
4)Content 属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分获得了海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地显示核心内容主题。因此,在植入内容后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好! (特别是对于 Google)
第一步:词族联想
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,从而生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和异体词
2)查找与主词内容相关的二类词
3)找到与第二类词相关的三类词
4)断定内容属性与主题(人物、地点、事物)相关
让我举个例子。比如你要优化一个关键词叫【网红】,这个词就成为你的主词。根据目的(1)其同义词和异体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)和主要词的内容相关到第二类词可以是“留几手”“微博”“生词”;然后根据目的(3)找到第三类词与第二类词相关的可以是“留几手”手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了。
您可以清楚地看到每层单词和短语之间的一些联系。根据(4),我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物。这可以帮助搜索引擎建立这样的内容实体,因为也会有其他网站上的这种关联(比如守哥会提到他的微博,他的新评论,他的属性等),然后搜索引擎就会正确理解你页面的主题。记住你是通过主题,而不是关键词密度!
第 2 步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面,发现这么多关键词之后,就要区分关键词和短语之间哪个重要,哪个是重要的。有关的。因此,词系统布局是区分核心词及其相关性。以下是 3 种实用的优化方法:
方法(1)是大部分SEO人的必修项目,我们还是要尽量把核心主题词放在标题、大标题和正文顶部。
方法(2)这里不仅仅是指关键词频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词和变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)distance 产生美在 SEO 世界中不适用。单词、短语或句子应尽可能靠近放置,或使用 HTML 元素(如图片 ALT 设置)。所以为了提高语言的语境相关性,通过段落、列表、分区,让内容更加明显,段落说的内容一目了然意思太远了。因为你不能保证蜘蛛会抓到全文。
你知道方法的原理。现在你要做的就是将二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会围绕这个词文章。第二段用几只手为文章,第三段用微博转播效果为文章,第四段用新网名文章。等等。您形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
也许有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,并引导网站上的相关内容。健康的网站应该进进出出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯关键词,缺少文字链接、参考资料和相关资源推荐。您的页面非常僵硬。死胡同不会为您的页面增加额外的分数。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件,是搜索引擎的资料片,我有【补充】。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是通过不同网站的内容,增强页面主题的深化,强化信息化。这是补充内容,可以为用户提供更好的信息,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站内链接);
2)在文中使用引号,如业内知名人士的话或图标或视频;
3)使用正文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom老师”时,它的实体是[人]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,或者可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体了。
通常,大多数搜索引擎都会为网站管理员提供自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema 。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示全世界只有0.3%网站使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让你的架构师将网站结构数据融入其中。
当然,提到的实体,还是近几年出来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多地使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的高度概括的标题
2)添加开场白(简要)描述页面内容
3)将内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以补充相关答案
5) 提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
如何进行关键词优化来提如下四个意见?
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-05 03:43
如何进行关键词优化来提如下四个意见?
一、选关键词
新站网站域名本身权重不高,不适合流行关键词。关于如何优化关键词的问题,我们应该选择热门还是冷门的关键词?现在我就如何优化关键词给出以下四点意见:
1:如何优化关键词,我们可以通过百度等搜索引擎搜索相关关键词,在搜索引擎中查看这个关键词相关网站总收录页面,这个页面是最好控制在2万到30万之间。
2:如何优化关键词,我们可以搜索某个意图关键词,分析竞争对手,选择难度相对较低的关键词!
3:如何通过百度搜索Billboard优化关键词,我们可以通过百度搜索Billboard进行选择,我们应该选择那些相对较晚但有上升潜力的关键词,关键词经常是这种情况@做完之后还会继续带来不错的流量!
4:如何优化关键词,我们可以培养关键词,在某些事情发生之前的某个时间,我们特意围绕某个关键词进行优化!
二、制作网站
网站程序的优化对如何优化你的关键词影响很大。写完网站homepage的标题不要改,不然就不是百度收录了。
三、原创文章
关于如何优化你的关键词的问题,如果你想获得好的网站排名,就尽量多写原创的内容。 原创内容有其独特性,所以搜索引擎自然会好抢文章,增加收录文章的数量。
四、网站快照
如何优化关键词,如果你想快速更新首页网站snapshot,最好的办法是每天更新3-5条原创内容。
五、全站布局
如何优化关键词,要做好整个网站的布局,必须有文章中的文字链接指向文章页面,另外三个指向首页增加网站的权重,形成一个巨大的蜘蛛网,方便蜘蛛及时爬行。而且文章标签和分类目录也不容忽视,也是优化的关键。我们可以使用我们的网站关键字作为文章标签和类别目录。
六、外链
如何优化关键词,外链很重要,但是最好在上个月做原创文章链接,然后在高权重网站上发外链一个月后。做好以上六点,你的网站两三个月就可以优化到首页了。 查看全部
如何进行关键词优化来提如下四个意见?
一、选关键词
新站网站域名本身权重不高,不适合流行关键词。关于如何优化关键词的问题,我们应该选择热门还是冷门的关键词?现在我就如何优化关键词给出以下四点意见:
1:如何优化关键词,我们可以通过百度等搜索引擎搜索相关关键词,在搜索引擎中查看这个关键词相关网站总收录页面,这个页面是最好控制在2万到30万之间。
2:如何优化关键词,我们可以搜索某个意图关键词,分析竞争对手,选择难度相对较低的关键词!
3:如何通过百度搜索Billboard优化关键词,我们可以通过百度搜索Billboard进行选择,我们应该选择那些相对较晚但有上升潜力的关键词,关键词经常是这种情况@做完之后还会继续带来不错的流量!
4:如何优化关键词,我们可以培养关键词,在某些事情发生之前的某个时间,我们特意围绕某个关键词进行优化!
二、制作网站
网站程序的优化对如何优化你的关键词影响很大。写完网站homepage的标题不要改,不然就不是百度收录了。
三、原创文章
关于如何优化你的关键词的问题,如果你想获得好的网站排名,就尽量多写原创的内容。 原创内容有其独特性,所以搜索引擎自然会好抢文章,增加收录文章的数量。
四、网站快照
如何优化关键词,如果你想快速更新首页网站snapshot,最好的办法是每天更新3-5条原创内容。
五、全站布局
如何优化关键词,要做好整个网站的布局,必须有文章中的文字链接指向文章页面,另外三个指向首页增加网站的权重,形成一个巨大的蜘蛛网,方便蜘蛛及时爬行。而且文章标签和分类目录也不容忽视,也是优化的关键。我们可以使用我们的网站关键字作为文章标签和类别目录。
六、外链
如何优化关键词,外链很重要,但是最好在上个月做原创文章链接,然后在高权重网站上发外链一个月后。做好以上六点,你的网站两三个月就可以优化到首页了。

