
抓取动态网页
抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-10 04:02
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。
短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他爬的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但它被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他非常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友等待J哥设置浏览器自动更新并重新下载最新驱动,下次再来听听Selenium爬虫吧。记得关注本公众号,不要错过精彩哦~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址 查看全部
抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。

短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他爬的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但它被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!

好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他非常兴奋。

紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
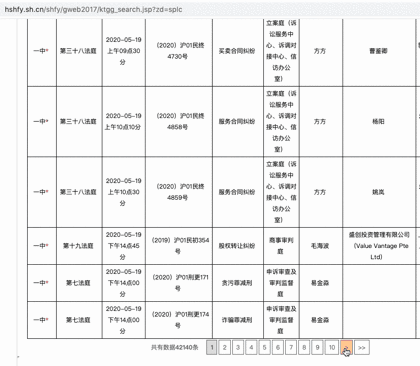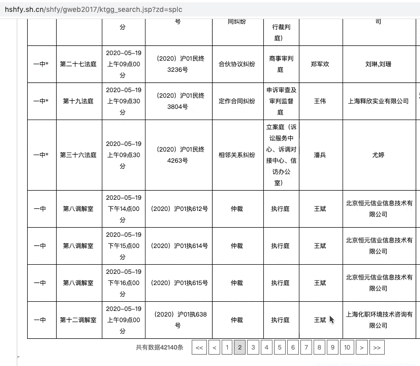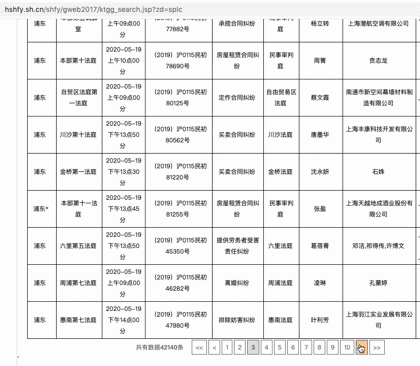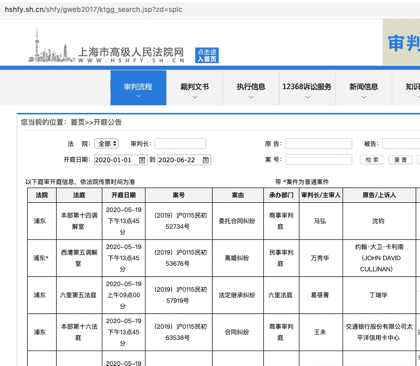
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
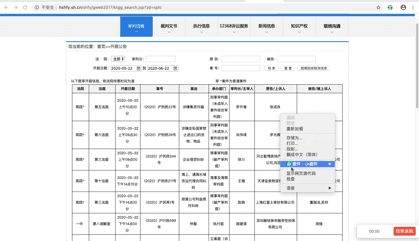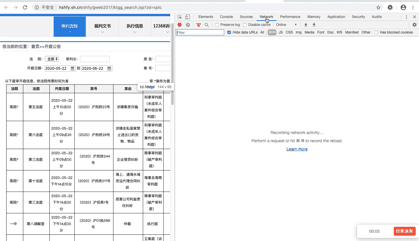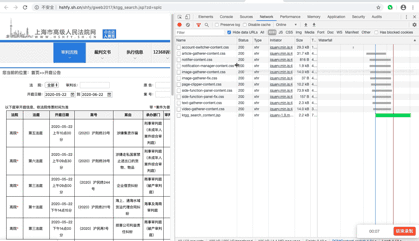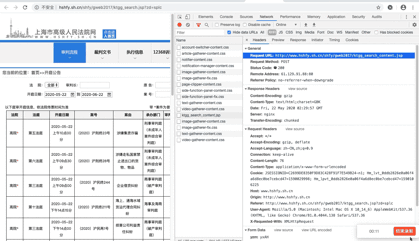
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
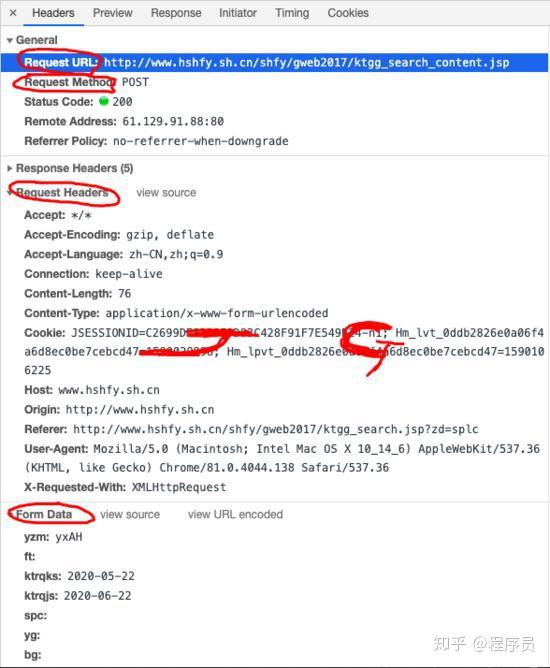
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
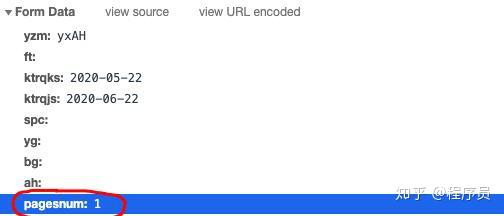
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。

我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友等待J哥设置浏览器自动更新并重新下载最新驱动,下次再来听听Selenium爬虫吧。记得关注本公众号,不要错过精彩哦~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址
抓取动态网页(哪里有比较多的静态网页制作的优缺点?小凡@凡科建站 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-10 04:01
)
相信很多站长在网站建设初期都考虑过一个问题:是动态网页做的好还是静态网页做的好?
今天小凡@凡科建站就给大家简单分析一下制作动态网页和静态网页的优缺点,告诉你哪里还有静态网页模板比较多~
制作动态网页和静态网页的优缺点是什么?
一、动态页面创建
优势:
1.动态网页可以根据用户需求返回不同的页面,给用户带来更强的交互性能。
2. 动态网页的管理很简单,用程序很容易实现,只要维护程序即可。
缺点:
1.当用户过多时,服务器负载会增加,导致网站变慢。
2.动态网页关键词无法拼装,影响百度的抓取排名。
3.动态 URL 可变且长,用户通常无法记住它们。
4.内链无法开发,不利于网站的引导权重。
二、静态页面制作
优势:
1.用户可以快速访问页面,不会给服务器造成太大的负担。
2.关键词 强大的聚合能力,关键词 与页面相关度更高。
3.更容易被搜索引擎抓取。
4.网址清晰、简短,便于用户记忆。
缺点:
1.静态页面管理比较麻烦,每个页面都是一个独立的实体。
2.大型网站网页更多,对网站空间的需求更大。
静态网页模板在哪里?
如果你想找大量的静态网页模板,可以来凡客建站!
PC、手机、微网站、小程序四站合一,这里网站搭建可以很简单~
100+行业类型,3000+免费精美网站模板,可视化在线免费设计,一键申请!
只需简单修改,10分钟即可生成精美的网站,还有众多网站功能等你解锁!
==°·°★ 这是小凡@凡科建站★°·°==
简单易用,效果出众!
3000+模板,四站合一!
☞ 点击此处获取【超级好用的在线建站工具】
查看全部
抓取动态网页(哪里有比较多的静态网页制作的优缺点?小凡@凡科建站
)
相信很多站长在网站建设初期都考虑过一个问题:是动态网页做的好还是静态网页做的好?
今天小凡@凡科建站就给大家简单分析一下制作动态网页和静态网页的优缺点,告诉你哪里还有静态网页模板比较多~

制作动态网页和静态网页的优缺点是什么?
一、动态页面创建
优势:
1.动态网页可以根据用户需求返回不同的页面,给用户带来更强的交互性能。
2. 动态网页的管理很简单,用程序很容易实现,只要维护程序即可。
缺点:
1.当用户过多时,服务器负载会增加,导致网站变慢。
2.动态网页关键词无法拼装,影响百度的抓取排名。
3.动态 URL 可变且长,用户通常无法记住它们。
4.内链无法开发,不利于网站的引导权重。
二、静态页面制作
优势:
1.用户可以快速访问页面,不会给服务器造成太大的负担。
2.关键词 强大的聚合能力,关键词 与页面相关度更高。
3.更容易被搜索引擎抓取。
4.网址清晰、简短,便于用户记忆。
缺点:
1.静态页面管理比较麻烦,每个页面都是一个独立的实体。
2.大型网站网页更多,对网站空间的需求更大。
静态网页模板在哪里?
如果你想找大量的静态网页模板,可以来凡客建站!
PC、手机、微网站、小程序四站合一,这里网站搭建可以很简单~
100+行业类型,3000+免费精美网站模板,可视化在线免费设计,一键申请!
只需简单修改,10分钟即可生成精美的网站,还有众多网站功能等你解锁!
==°·°★ 这是小凡@凡科建站★°·°==
简单易用,效果出众!
3000+模板,四站合一!
☞ 点击此处获取【超级好用的在线建站工具】

抓取动态网页(scrapy实战:scrapy-splash抓取动态数据(-))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-09 07:17
Scrapy 实战:scrapy-splash 抓取动态数据
我们知道为了加快页面的加载速度,页面的很多部分都是用JS生成的,这对于scrapy爬虫来说是个大问题,因为scrapy没有JS引擎,所以所有的爬取都是对于静态页面,无法直接使用scrapy的Request请求获取JS生成的动态页面。解决方案是使用scrapy-splash。
Scrapy-splash 基于 Splash 加载 js 数据,Splash 是一种 Javascript 渲染服务。它是一个实现 HTTP API 的轻量级浏览器。 Splash 是用 Python 实现的,同时使用 Twisted 和 QT。我们最终使用scrapy-splash得到的响应,相当于所有浏览器渲染完成后得到的响应。渲染后的网页源代码。
Docker 安装
由于我这里使用的是MAC,所以跳过了具体的安装过程,请看这里
拉动scrapinghub/splash mirror
docker pull scrapinghub/splash
开始飞溅
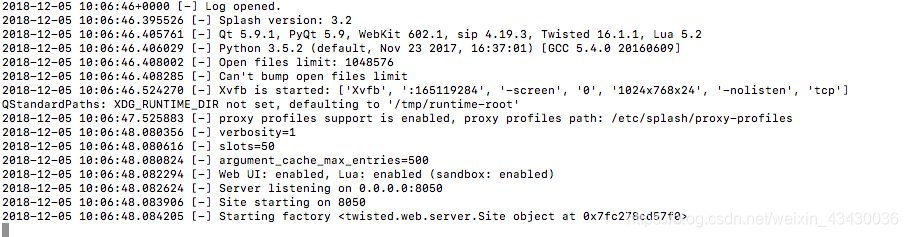
docker run -p 8050:8050 scrapinghub/splash
启动结果如下:
访问:8050/
安装scrapy-splash
cd /data/code/python/venv/venv_Scrapy/tutorial/
../bin/pip3 install scrapy-splash
新淘宝蜘蛛项目
../bin/python3 ../bin/scrapy genspider -t basic taobao_splash www.taobao.com
settings.py
修改 settings.py 以配置启动服务
# 渲染服务的url
SPLASH_URL = 'http://localhost:8050'
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
#爬虫中间健
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
SPIDER_MIDDLEWARES = {
'tutorial.middlewares.TutorialSpiderMiddleware': 543,
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
#下载器中间件
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
DOWNLOADER_MIDDLEWARES = {
'tutorial.middlewares.TutorialDownloaderMiddleware': 543,
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
运行测试
../bin/python3 ../bin/scrapy crawl taobao_splash
GitHub 源代码 查看全部
抓取动态网页(scrapy实战:scrapy-splash抓取动态数据(-))
Scrapy 实战:scrapy-splash 抓取动态数据
我们知道为了加快页面的加载速度,页面的很多部分都是用JS生成的,这对于scrapy爬虫来说是个大问题,因为scrapy没有JS引擎,所以所有的爬取都是对于静态页面,无法直接使用scrapy的Request请求获取JS生成的动态页面。解决方案是使用scrapy-splash。
Scrapy-splash 基于 Splash 加载 js 数据,Splash 是一种 Javascript 渲染服务。它是一个实现 HTTP API 的轻量级浏览器。 Splash 是用 Python 实现的,同时使用 Twisted 和 QT。我们最终使用scrapy-splash得到的响应,相当于所有浏览器渲染完成后得到的响应。渲染后的网页源代码。
Docker 安装
由于我这里使用的是MAC,所以跳过了具体的安装过程,请看这里
拉动scrapinghub/splash mirror
docker pull scrapinghub/splash
开始飞溅
docker run -p 8050:8050 scrapinghub/splash
启动结果如下:
访问:8050/
安装scrapy-splash
cd /data/code/python/venv/venv_Scrapy/tutorial/
../bin/pip3 install scrapy-splash
新淘宝蜘蛛项目
../bin/python3 ../bin/scrapy genspider -t basic taobao_splash www.taobao.com
settings.py
修改 settings.py 以配置启动服务
# 渲染服务的url
SPLASH_URL = 'http://localhost:8050'
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
#爬虫中间健
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
SPIDER_MIDDLEWARES = {
'tutorial.middlewares.TutorialSpiderMiddleware': 543,
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
#下载器中间件
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
DOWNLOADER_MIDDLEWARES = {
'tutorial.middlewares.TutorialDownloaderMiddleware': 543,
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
运行测试
../bin/python3 ../bin/scrapy crawl taobao_splash

GitHub 源代码
抓取动态网页( 参考百度百科的介绍2.获取真实数据请求(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-09 06:18
参考百度百科的介绍2.获取真实数据请求(组图))
动态页面爬取主题
本文档讨论如何抓取动态页面,包括如何发现真实的数据请求,以及如何构造和解析请求返回的结果。
1.什么是动态页面?
动态瀑布和ajax页面通常按需返回html和json。
旧的网站刷新时会返回页面的全部内容,但如果只更新一部分,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
2.获取真实数据请求2.1.Hawk自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。Hawk 简化了流程并使用自动嗅探。Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果在当前页面找不到该关键字,Hawk 会提示“您要启用动态嗅探吗?” 这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
2.2. 不能自动嗅探怎么办?
由于 Hawk 具有阻止功能,因此浏览器会认为它不安全。如何解决?
Hawk的底层嗅探是基于fiddler的,所以通过fiddler生成证书后导入chrome即可解决。方法可以参考这个文档:
设置 采集器 如下:
2.3.备注 有时候可以直接把URL复制到Hawk,运气好也能拿到数据。这是因为许多 网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前先转到其他页面。2.4.手动获取真实请求
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
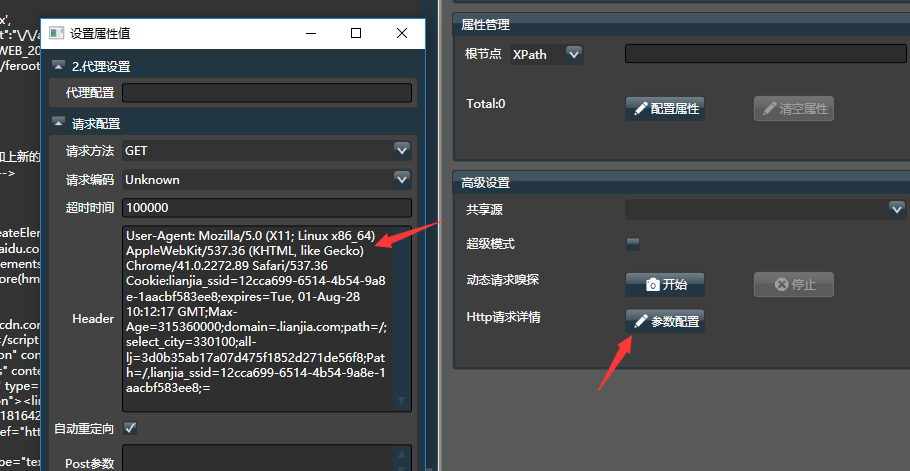
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
3.请求构建4.数据后处理
获取返回的真实数据后,除了可以通过超级模式一步一步分析所需数据外,还可以通过手动方式更灵活地获取所需数据。
4.1.Json 处理
json是最常见的数据传输格式,也是一棵树。它收录键值对(字典)和数组。有关详细信息,请参阅文档。
第 1 步:使 Json 合法化
有时,网站传递的json不是很合法的json,有回调的地址返回的一些数据会是如下形式:
var datas=此处是json;
这时候就需要通过字符的首尾提取,或者正则表达式和字符串切分来提取真正合法的json。
第 2 步:将字符串转换为文档
上一步得到的结果还是一个字符串,需要转换成json。只需拖入 json 转换器即可。常见的json模式有3种,我们依次讲解。
类型 1:
数据可能在“数据”字段中。这里,json转换器应该选择“不转换”,转换器本身不执行任何操作,而是将json作为一个整体转移到新列中。
然后使用python转换器,在脚本内容中填写value['data']。value是当前列对应的内容,后面部分是获取它的数据。如果嵌套更深,则可能需要 value['data1']['data2']
{
'total':12
'data':
[
{ 'key':'value'}
{ 'key':'value'}
]
}
类型 2:
这种类型比较少见。它是一个纯键值对的字典。我们通常要做的操作是列出所有内部的键值对,比如添加两列key1和key2,内容为value。
方法很简单,json转换器选择“单文档”模式即可。不需要python转换器。
{
'key1':'value'
'key2':'value'
}
类型 3:
[{'key':'value'}{'key':'value'}]
json选择器选择“文档列表”模式,不需要python转换器。
那么,你看到了吗?json 和 python 转换器的三种工作模式都具有相同的含义。当你想处理一个数组时,选择一个文档列表,一个字典,然后选择一个文档。如果您想获得更多内部信息,请选择不转换。
4.2. json 在 Hawk 中的呈现问题
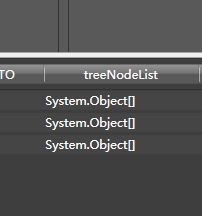
由于Hawk的可视化列表只能显示字符串和数字,而Json是一棵树,所以在Hawk中很难显示。稍后我们会考虑优化这个区域。
如果显示 System.Object[],则表示它是一个数组。如果显示 System.Generic.Dictionary...,则为字典。也就是文档。
这件作品的设计真的很烂,太不可思议了,普通人看不懂,也是我做的不好的地方。. . 希望能帮到大家。
4.3. 使用 python 转换器处理 Json
5.案例。5.1. 嗅探
我们以某政府网站的专利检索为例来说明如何使用: 示例图如下:
无论您单击哪种下拉菜单,网址都保持不变。我们可以断定这是一个ajax页面。现在的目标是通过一个分类号来获取它的中英文含义,比如D01B1/00,就是右边的内容:
我们启动Hawk,新建一个网页采集器,将刚才的一串URL复制到网页采集器的地址栏中,发现得到的数据根本不收录这些中文意思.
怎么做?
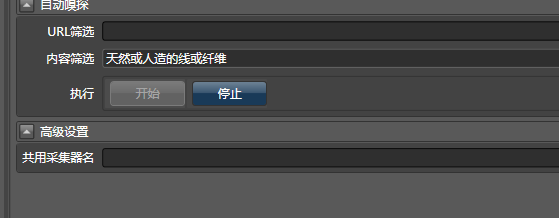
您可以使用嗅探。我们以天然或人造线或纤维为关键词,填写网页采集器的内容过滤器:
然后点击开始。然后单击浏览器上的下拉菜单以展开类别编号。发现Hawk已经成功嗅探了字段:
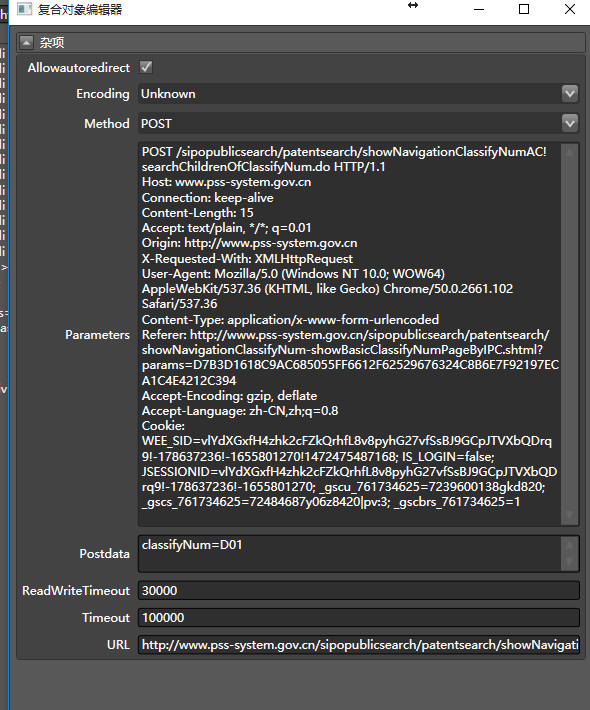
此时,打开请求属性,可以看到真实请求的相关信息:
这是一个Post请求,(真实地址)url是:
!searchChildrenOfClassifyNum.dopost 的内容是classifyNum=D01。有了这些,我们将此命名为 采集器 Patent Inquiry`,下一步就很容易了。
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
5.2.步骤 2:
这里简单介绍一下,可以新建一个数据清洗,生成所有要查询的专利号的ID。这相对容易。例如,拖入是从文本生成的:
然后拖拽合并多列,把这串ID转换成一列要发布的数据:
拖进去新增一列,因为要网页采集器访问真实数据的url,所以填写上面提到的真实地址:
见证奇迹的时刻到了,在url栏拖拽从爬虫切换到刚才,然后配置如下:
由于post数据需要从post列中读取,所以用方括号括起来,像这样[post]。
结果是这样的:
这是一个Json,所以我们拖拽转换成json到content列:并将生成方式改为单文档,因为这只是一个字典,而不是一个字典数组:
你会发现只有一列有值:
是一个数组。然后,拖入python转换器,将生成模式配置为文档列表:你想要的数据都有:
点评:虽然这种请求可以用Hawk来配置,但还是推荐使用python,灵活性更大 查看全部
抓取动态网页(
参考百度百科的介绍2.获取真实数据请求(组图))
动态页面爬取主题
本文档讨论如何抓取动态页面,包括如何发现真实的数据请求,以及如何构造和解析请求返回的结果。
1.什么是动态页面?
动态瀑布和ajax页面通常按需返回html和json。
旧的网站刷新时会返回页面的全部内容,但如果只更新一部分,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
2.获取真实数据请求2.1.Hawk自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。Hawk 简化了流程并使用自动嗅探。Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果在当前页面找不到该关键字,Hawk 会提示“您要启用动态嗅探吗?” 这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
2.2. 不能自动嗅探怎么办?
由于 Hawk 具有阻止功能,因此浏览器会认为它不安全。如何解决?
Hawk的底层嗅探是基于fiddler的,所以通过fiddler生成证书后导入chrome即可解决。方法可以参考这个文档:
设置 采集器 如下:
2.3.备注 有时候可以直接把URL复制到Hawk,运气好也能拿到数据。这是因为许多 网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前先转到其他页面。2.4.手动获取真实请求
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
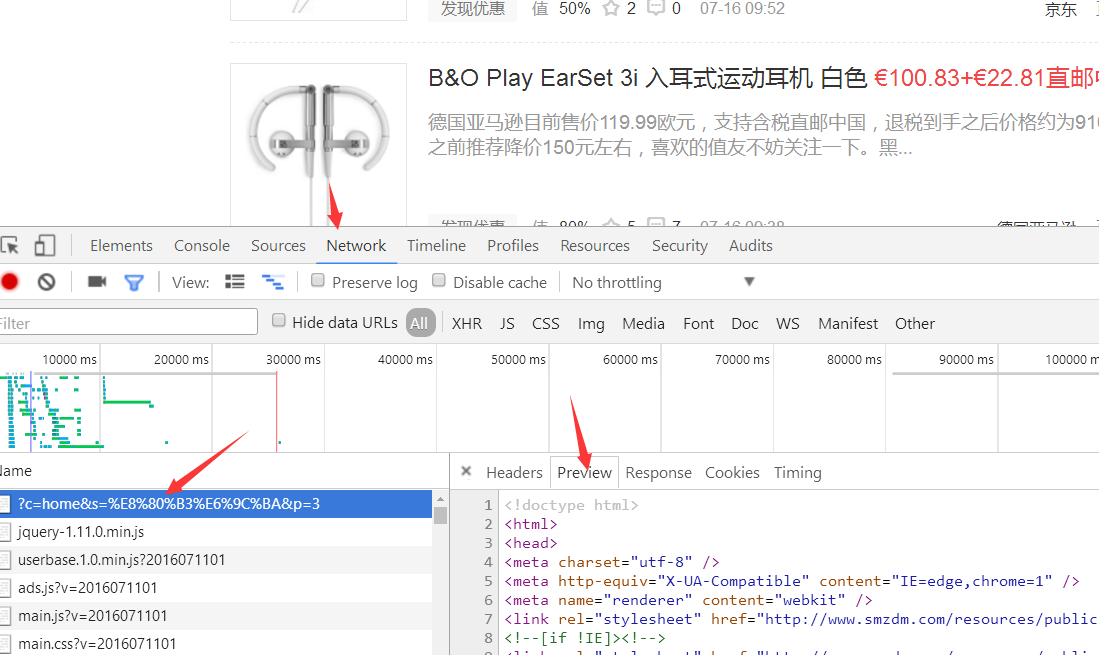
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
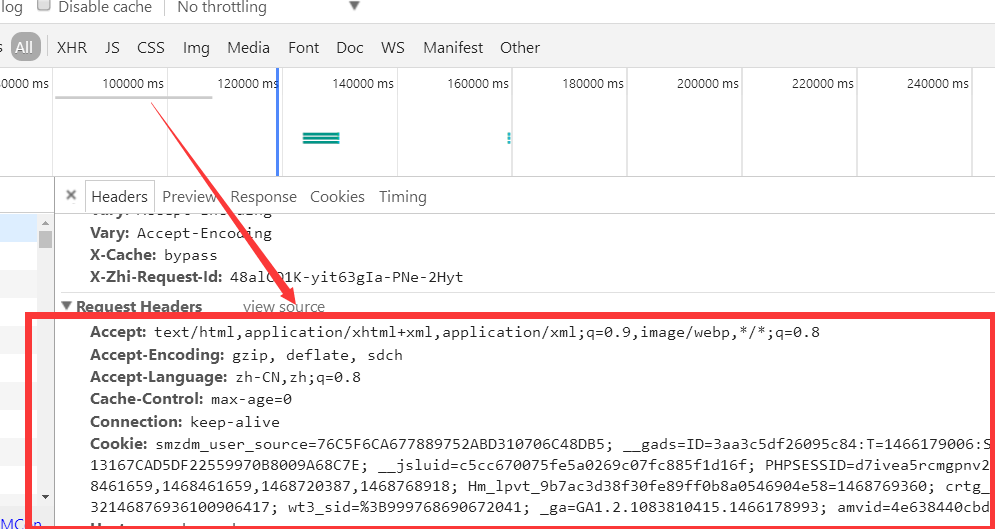
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
3.请求构建4.数据后处理
获取返回的真实数据后,除了可以通过超级模式一步一步分析所需数据外,还可以通过手动方式更灵活地获取所需数据。
4.1.Json 处理
json是最常见的数据传输格式,也是一棵树。它收录键值对(字典)和数组。有关详细信息,请参阅文档。
第 1 步:使 Json 合法化
有时,网站传递的json不是很合法的json,有回调的地址返回的一些数据会是如下形式:
var datas=此处是json;
这时候就需要通过字符的首尾提取,或者正则表达式和字符串切分来提取真正合法的json。
第 2 步:将字符串转换为文档
上一步得到的结果还是一个字符串,需要转换成json。只需拖入 json 转换器即可。常见的json模式有3种,我们依次讲解。
类型 1:
数据可能在“数据”字段中。这里,json转换器应该选择“不转换”,转换器本身不执行任何操作,而是将json作为一个整体转移到新列中。
然后使用python转换器,在脚本内容中填写value['data']。value是当前列对应的内容,后面部分是获取它的数据。如果嵌套更深,则可能需要 value['data1']['data2']
{
'total':12
'data':
[
{ 'key':'value'}
{ 'key':'value'}
]
}
类型 2:
这种类型比较少见。它是一个纯键值对的字典。我们通常要做的操作是列出所有内部的键值对,比如添加两列key1和key2,内容为value。
方法很简单,json转换器选择“单文档”模式即可。不需要python转换器。
{
'key1':'value'
'key2':'value'
}
类型 3:
[{'key':'value'}{'key':'value'}]
json选择器选择“文档列表”模式,不需要python转换器。
那么,你看到了吗?json 和 python 转换器的三种工作模式都具有相同的含义。当你想处理一个数组时,选择一个文档列表,一个字典,然后选择一个文档。如果您想获得更多内部信息,请选择不转换。
4.2. json 在 Hawk 中的呈现问题
由于Hawk的可视化列表只能显示字符串和数字,而Json是一棵树,所以在Hawk中很难显示。稍后我们会考虑优化这个区域。
如果显示 System.Object[],则表示它是一个数组。如果显示 System.Generic.Dictionary...,则为字典。也就是文档。
这件作品的设计真的很烂,太不可思议了,普通人看不懂,也是我做的不好的地方。. . 希望能帮到大家。
4.3. 使用 python 转换器处理 Json
5.案例。5.1. 嗅探
我们以某政府网站的专利检索为例来说明如何使用: 示例图如下:
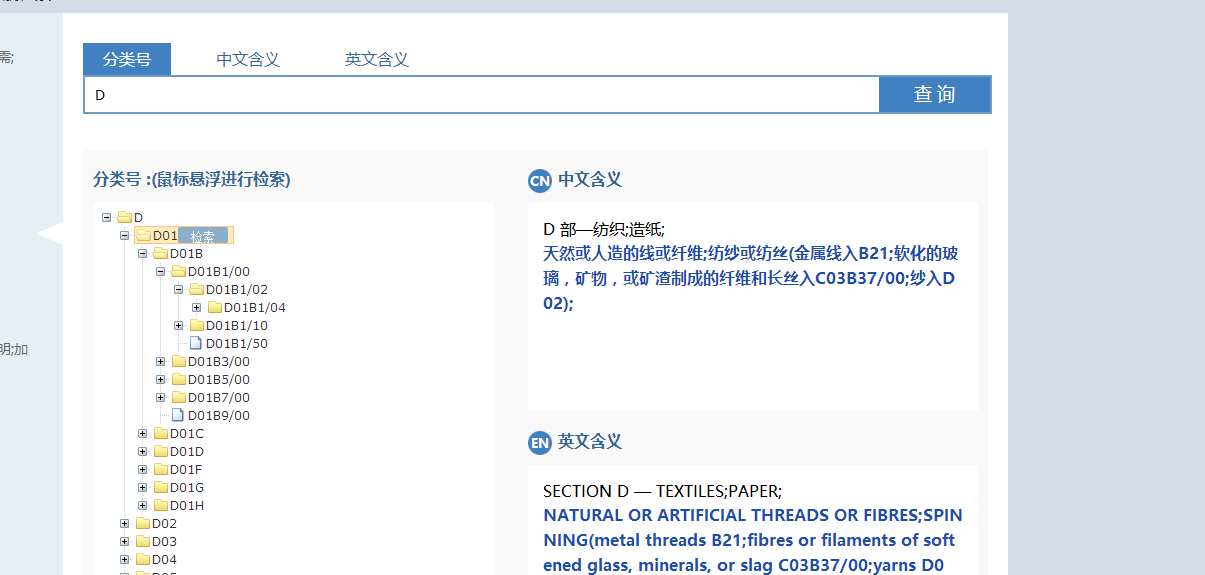
无论您单击哪种下拉菜单,网址都保持不变。我们可以断定这是一个ajax页面。现在的目标是通过一个分类号来获取它的中英文含义,比如D01B1/00,就是右边的内容:
我们启动Hawk,新建一个网页采集器,将刚才的一串URL复制到网页采集器的地址栏中,发现得到的数据根本不收录这些中文意思.
怎么做?
您可以使用嗅探。我们以天然或人造线或纤维为关键词,填写网页采集器的内容过滤器:
然后点击开始。然后单击浏览器上的下拉菜单以展开类别编号。发现Hawk已经成功嗅探了字段:

此时,打开请求属性,可以看到真实请求的相关信息:
这是一个Post请求,(真实地址)url是:
!searchChildrenOfClassifyNum.dopost 的内容是classifyNum=D01。有了这些,我们将此命名为 采集器 Patent Inquiry`,下一步就很容易了。
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
5.2.步骤 2:
这里简单介绍一下,可以新建一个数据清洗,生成所有要查询的专利号的ID。这相对容易。例如,拖入是从文本生成的:
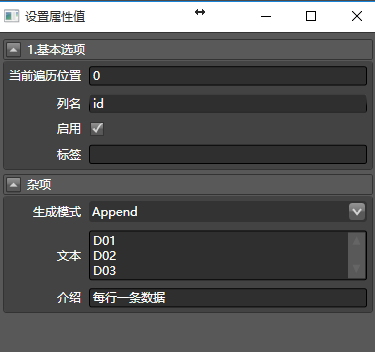
然后拖拽合并多列,把这串ID转换成一列要发布的数据:
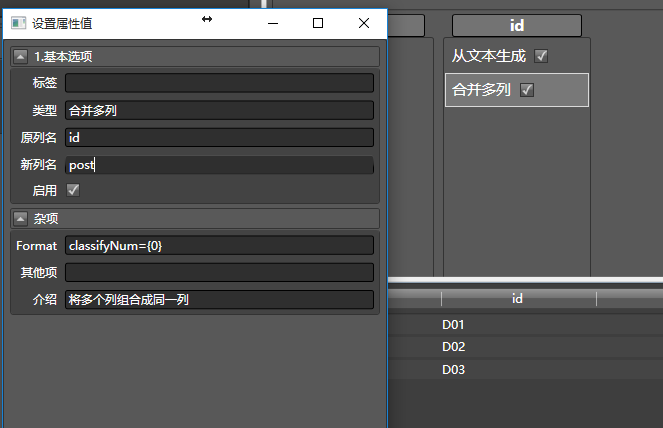
拖进去新增一列,因为要网页采集器访问真实数据的url,所以填写上面提到的真实地址:
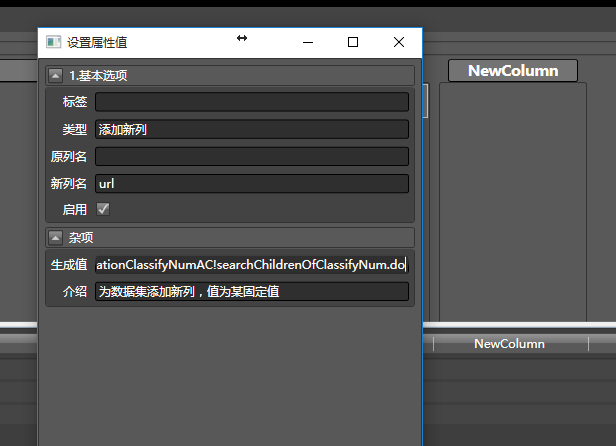
见证奇迹的时刻到了,在url栏拖拽从爬虫切换到刚才,然后配置如下:
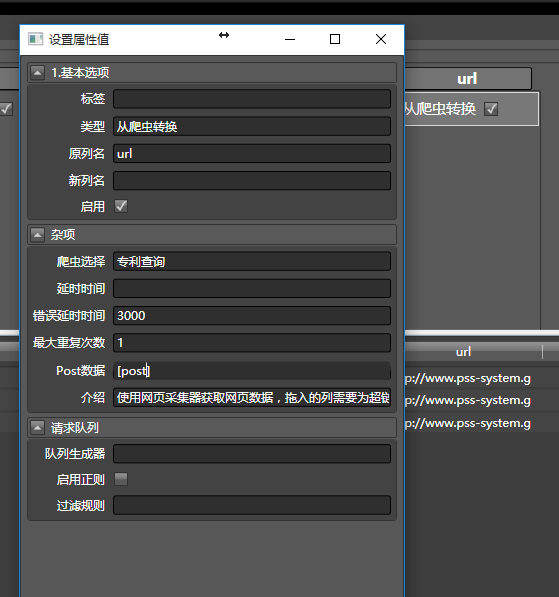
由于post数据需要从post列中读取,所以用方括号括起来,像这样[post]。
结果是这样的:
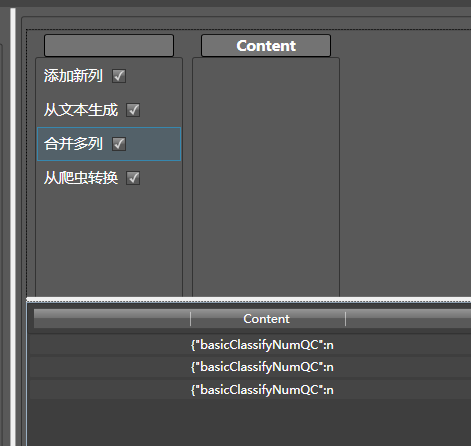
这是一个Json,所以我们拖拽转换成json到content列:并将生成方式改为单文档,因为这只是一个字典,而不是一个字典数组:
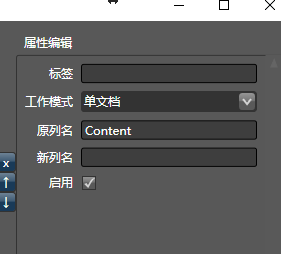
你会发现只有一列有值:
是一个数组。然后,拖入python转换器,将生成模式配置为文档列表:你想要的数据都有:
点评:虽然这种请求可以用Hawk来配置,但还是推荐使用python,灵活性更大
抓取动态网页(2020年7月29日写在前面:右键打开源码找到iframe标签 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-08 12:06
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
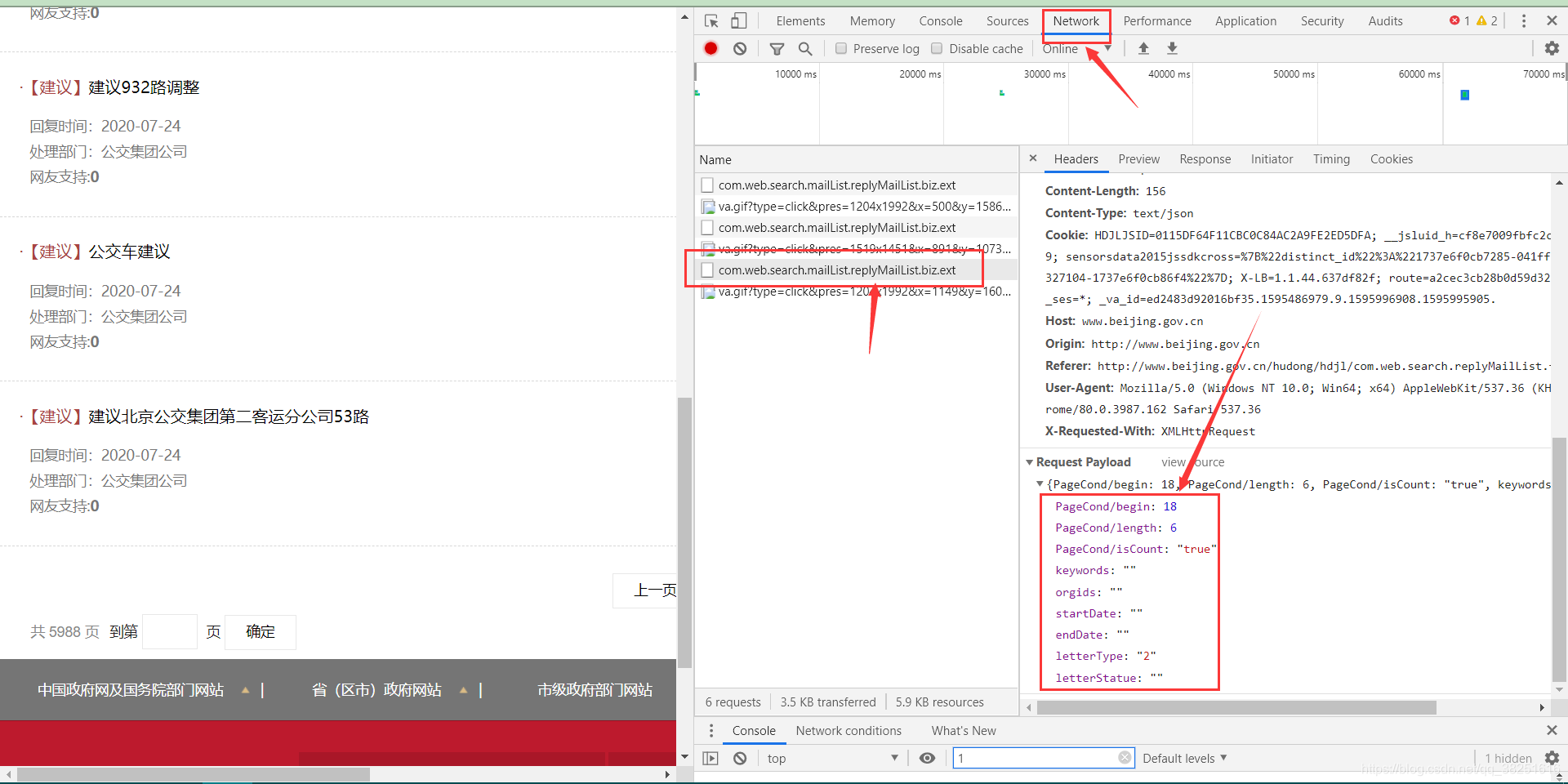
右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
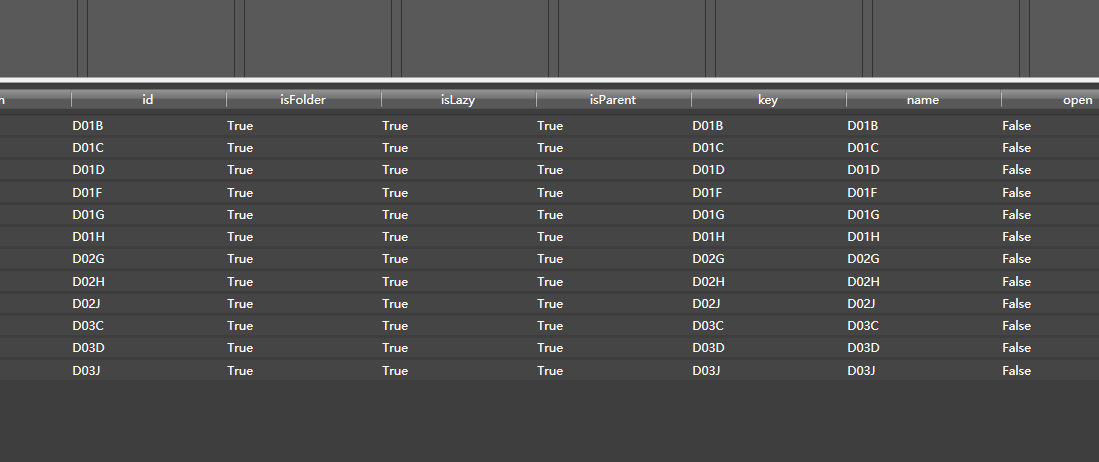
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载新数据的JS文件,打开,会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关的数据,和post请求一起发送给网站,我们可以得到我们想要的数据。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
抓取动态网页(2020年7月29日写在前面:右键打开源码找到iframe标签
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址

在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。

进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.

右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载新数据的JS文件,打开,会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关的数据,和post请求一起发送给网站,我们可以得到我们想要的数据。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
抓取动态网页(如何为网络剪贴器制作特殊页面?更具体地说:如何在PHP中检测到Web工具?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-07 09:10
较短
我的一位客户有一个非常空旷的风格化网页,其中包括表格、图形和表格。当有人访问他们的 网站 时,它看起来很棒,但许多其他 网站 正在抓取页面并在他们的 网站 上显示空缺。
以前,他们的 网站 是一个带有一些基本标记的简单页面,例如标题、段落和粗体文本。其他网站 选择这个功能还不错,但是用了更高级的标签后就落后了。
如何为网络剪辑器制作一个特殊页面?更具体地说:如何在 PHP 中检测到网络爬虫正在查看页面?从那里,我可以弄清楚如何为客户创建一个自定义的 cms 页面,以便他们可以使用该页面自己填写简单的标记。
罗托拉
首先,标题、段落等都是很好的标记。如果“高级标记”没有这些,那根本就不是“高级标记”,而是坏标记。因此,无论页面是否被抓取,都应该使用语义标记。此外,还有更多的方式赋予 HTML 意义,例如微数据。
但是,由于您似乎了解网络爬虫(或至少了解它们)并已授予他们(隐式或明确)爬取 网站 的权限,因此它们的运营商应提供文档以说明您在寻找什么。
这些运营商最好根本不使用 webscapers,但他们应该以结构化的方式(例如 JSON 或 XML)获取他们正在寻找的信息,这些信息是您在常规 HTML 页面上额外生成的。 查看全部
抓取动态网页(如何为网络剪贴器制作特殊页面?更具体地说:如何在PHP中检测到Web工具?)
较短
我的一位客户有一个非常空旷的风格化网页,其中包括表格、图形和表格。当有人访问他们的 网站 时,它看起来很棒,但许多其他 网站 正在抓取页面并在他们的 网站 上显示空缺。
以前,他们的 网站 是一个带有一些基本标记的简单页面,例如标题、段落和粗体文本。其他网站 选择这个功能还不错,但是用了更高级的标签后就落后了。
如何为网络剪辑器制作一个特殊页面?更具体地说:如何在 PHP 中检测到网络爬虫正在查看页面?从那里,我可以弄清楚如何为客户创建一个自定义的 cms 页面,以便他们可以使用该页面自己填写简单的标记。
罗托拉
首先,标题、段落等都是很好的标记。如果“高级标记”没有这些,那根本就不是“高级标记”,而是坏标记。因此,无论页面是否被抓取,都应该使用语义标记。此外,还有更多的方式赋予 HTML 意义,例如微数据。
但是,由于您似乎了解网络爬虫(或至少了解它们)并已授予他们(隐式或明确)爬取 网站 的权限,因此它们的运营商应提供文档以说明您在寻找什么。
这些运营商最好根本不使用 webscapers,但他们应该以结构化的方式(例如 JSON 或 XML)获取他们正在寻找的信息,这些信息是您在常规 HTML 页面上额外生成的。
抓取动态网页( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-31 21:09
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取为静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com")
复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com")
复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以通过driver.switch_to.frame来定位。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等来提取内容。该方法中,提取出的带有复数s的内容是一个列表,没有提取s的是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
抓取动态网页(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取为静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com";)
复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com";)
复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com";)
复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以通过driver.switch_to.frame来定位。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等来提取内容。该方法中,提取出的带有复数s的内容是一个列表,没有提取s的是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!
抓取动态网页(不到js加载后渲染的结果,支持ajax,并且设置了js执行的等待时间(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-31 14:01
爬取某个站点的内容时,没有得到js加载后的渲染结果,但是也设置了支持js,支持ajax,设置了js执行的等待时间。它仍然不可用。
查看控制台打印的异常信息,在参数列表(************.js #32)之后发现页面js:missing)异常;而这个js加载了需要抓取的部分。查看32行,控制台打印的位置内容大致如下:
$('#news_pbl').masonry().masonry('reload');//
可以看出因为乱码,这部分没有换行,导致下面])被注释掉,导致js代码错误,无法加载内容。
所以尝试修改js代码,使其正常执行。
搜索后:
webClient.setWebConnection(
new WebConnectionWrapper(wc) {
public WebResponse getResponse(WebRequest request) throws IOException {
WebResponse response = super.getResponse(request);
if (request.getUrl().toExternalForm().contains("bfdata.js")) {//bfdata.js是需要修改编码的js,你可以修改该处逻辑
String content = response.getContentAsString("GBK");
WebResponseData data = new WebResponseData(content.getBytes("UTF-8"),
response.getStatusCode(), response.getStatusMessage(), response.getResponseHeaders());
response = new WebResponse(data, request, response.getLoadTime());
}
return response;
}
}
);
webClient 对象是一个实例化的 WebClient,可以调试看看使用的是哪种编码。 查看全部
抓取动态网页(不到js加载后渲染的结果,支持ajax,并且设置了js执行的等待时间(组图))
爬取某个站点的内容时,没有得到js加载后的渲染结果,但是也设置了支持js,支持ajax,设置了js执行的等待时间。它仍然不可用。
查看控制台打印的异常信息,在参数列表(************.js #32)之后发现页面js:missing)异常;而这个js加载了需要抓取的部分。查看32行,控制台打印的位置内容大致如下:
$('#news_pbl').masonry().masonry('reload');//
可以看出因为乱码,这部分没有换行,导致下面])被注释掉,导致js代码错误,无法加载内容。
所以尝试修改js代码,使其正常执行。
搜索后:
webClient.setWebConnection(
new WebConnectionWrapper(wc) {
public WebResponse getResponse(WebRequest request) throws IOException {
WebResponse response = super.getResponse(request);
if (request.getUrl().toExternalForm().contains("bfdata.js")) {//bfdata.js是需要修改编码的js,你可以修改该处逻辑
String content = response.getContentAsString("GBK");
WebResponseData data = new WebResponseData(content.getBytes("UTF-8"),
response.getStatusCode(), response.getStatusMessage(), response.getResponseHeaders());
response = new WebResponse(data, request, response.getLoadTime());
}
return response;
}
}
);
webClient 对象是一个实例化的 WebClient,可以调试看看使用的是哪种编码。
抓取动态网页(两种AJAX网页文字的抓取方法:*HTML文档(document))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-30 15:10
在 AJAX 网页上捕获文本的两种方法:
*网页文本是在加载HTML文档(document)时通过Javascript代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
*网页文本是在加载HTML文档(文档)后的某个时间获取并带有Javascript代码显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不意味着所有的内容都已经加载完毕。特殊的歧视机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能会出现:Timeout to load the page错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。要通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeoutto load the page错误。
注意:异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载,但计算机程序无法理解语义,因此DataScraper尝试使用一种智能方法进行判断,但仍有可能误判,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是间歇性的,而不是连续的,这时候DataScraper就会做出误判。 查看全部
抓取动态网页(两种AJAX网页文字的抓取方法:*HTML文档(document))
在 AJAX 网页上捕获文本的两种方法:
*网页文本是在加载HTML文档(document)时通过Javascript代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
*网页文本是在加载HTML文档(文档)后的某个时间获取并带有Javascript代码显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不意味着所有的内容都已经加载完毕。特殊的歧视机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能会出现:Timeout to load the page错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。要通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeoutto load the page错误。
注意:异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载,但计算机程序无法理解语义,因此DataScraper尝试使用一种智能方法进行判断,但仍有可能误判,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是间歇性的,而不是连续的,这时候DataScraper就会做出误判。
抓取动态网页(不少人对于动态网页和静态网页的区别是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-29 03:26
很多人对动态网页和静态网页不太了解。不知道这两者有什么区别?下面小编就来告诉你动态网页和静态网页的区别。
静态网页不能简单理解为静态网页。主要指没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html、.htm或.xml等的网页。虽然静态网页的内容会一旦创建就不会改变。但是静态网页也收录一些活动部分,主要是GIF动画。用户可以直接双击打开静态网页,任何人随时打开的页面内容保持不变。
动态网页是一种相对于静态网页的网页编程技术。除了HTML标签,动态网页的网页文件还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,从而服务器端根据客户端的不同请求动态生成网页内容。与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。
两者的区别在于,一个静态网页的内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上. 如果要修改网页的内容,必须修改其源代码,然后重新上传到服务器。
静态网页没有数据库支持。当网站信息量较大时,网页的制作和维护难度很大。动态网页可以根据不同的用户请求、时间或环境要求动态生成不同的网页内容,动态网页一般都是基于数据库技术,大大减少了网站维护的工作量。
许多静态网页是固定的,在功能上有很大的局限性,因此交互性较差。动态网页可以实现用户登录、注册、查询等更多内容。
静态网页的内容比较固定,容易被搜索引擎检索到,而且不需要连接数据库,所以响应速度比较快。动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接访问、查询等一系列过程,所以响应速度比较慢。
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,双击直接打开。这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,在搜索时不会被捕获。取“?”后的内容 在 URL 中,您不能直接双击打开它。
以上是编辑器的总结,静态网页和动态网页的区别。总之,如果网页内容简单,不需要频繁改动,可以选择静态网页。如果网页复杂,功能多,那就选择动态网页。 查看全部
抓取动态网页(不少人对于动态网页和静态网页的区别是什么?)
很多人对动态网页和静态网页不太了解。不知道这两者有什么区别?下面小编就来告诉你动态网页和静态网页的区别。
静态网页不能简单理解为静态网页。主要指没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html、.htm或.xml等的网页。虽然静态网页的内容会一旦创建就不会改变。但是静态网页也收录一些活动部分,主要是GIF动画。用户可以直接双击打开静态网页,任何人随时打开的页面内容保持不变。

动态网页是一种相对于静态网页的网页编程技术。除了HTML标签,动态网页的网页文件还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,从而服务器端根据客户端的不同请求动态生成网页内容。与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。

两者的区别在于,一个静态网页的内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上. 如果要修改网页的内容,必须修改其源代码,然后重新上传到服务器。
静态网页没有数据库支持。当网站信息量较大时,网页的制作和维护难度很大。动态网页可以根据不同的用户请求、时间或环境要求动态生成不同的网页内容,动态网页一般都是基于数据库技术,大大减少了网站维护的工作量。

许多静态网页是固定的,在功能上有很大的局限性,因此交互性较差。动态网页可以实现用户登录、注册、查询等更多内容。
静态网页的内容比较固定,容易被搜索引擎检索到,而且不需要连接数据库,所以响应速度比较快。动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接访问、查询等一系列过程,所以响应速度比较慢。

静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,双击直接打开。这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,在搜索时不会被捕获。取“?”后的内容 在 URL 中,您不能直接双击打开它。
以上是编辑器的总结,静态网页和动态网页的区别。总之,如果网页内容简单,不需要频繁改动,可以选择静态网页。如果网页复杂,功能多,那就选择动态网页。
抓取动态网页(横行的年代,性能相对Trident较好的抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-26 12:20
)
您需要登录才能下载或查看,还没有账号?立即注册
x
楼主今天在博客园看到了这个文章,转载并交流。
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页
从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigating += (sender, e) =>
{
hitCount++;
};
browser.DocumentCompleted += (sender, e) =>
{
hitCount++;
};
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s,然后再检查WEBbrowser是否加载完毕。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
当然效果还是一样的,就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程的。让我们看看如何将它放在工作线程上。这很简单。工作线程可以设置为STA模式。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
//[STAThread]
static void Main(string[] args)
{
Thread thread = new Thread(new ThreadStart(() =>
{
Init();
System.Windows.Forms.Application.Run();
}));
//将该工作线程设定为STA模式
thread.SetApartmentState(ApartmentState.STA);
thread.Start();
Console.Read();
}
static void Init()
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
Console.WriteLine(gethtml);
}
static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
{
hitCount++;
}
static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
hitCount++;
}
}
} 查看全部
抓取动态网页(横行的年代,性能相对Trident较好的抓取
)
您需要登录才能下载或查看,还没有账号?立即注册

x
楼主今天在博客园看到了这个文章,转载并交流。
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页

从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigating += (sender, e) =>
{
hitCount++;
};
browser.DocumentCompleted += (sender, e) =>
{
hitCount++;
};
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
然后,我们打开生成的1.html,看看js加载的内容有没有。

②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s,然后再检查WEBbrowser是否加载完毕。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
当然效果还是一样的,就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程的。让我们看看如何将它放在工作线程上。这很简单。工作线程可以设置为STA模式。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
//[STAThread]
static void Main(string[] args)
{
Thread thread = new Thread(new ThreadStart(() =>
{
Init();
System.Windows.Forms.Application.Run();
}));
//将该工作线程设定为STA模式
thread.SetApartmentState(ApartmentState.STA);
thread.Start();
Console.Read();
}
static void Init()
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
Console.WriteLine(gethtml);
}
static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
{
hitCount++;
}
static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
hitCount++;
}
}
}
抓取动态网页(如何让客户记住自己,再加上产品的优势?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-25 08:03
抓取动态网页,然后输出给他看这就是网页搜索页面了,判断他想了解哪方面的东西,然后很多数据库都提供这样的服务而且自己查,
收集客户(也就是销售人员)需求,研究产品,提炼卖点,背熟产品知识,练好演讲稿,一场下来能让客户记住自己,再加上产品的优势,好吧,
不会就学,不学就问,学不会就砸。
销售需要提炼卖点其实打个比方销售是卖汽车的卖点是买车比买房子高多少个av/asv/esg吗?显然不是总而言之个人认为销售还是要学的多尝试下然后总结出适合自己的销售结果的话才是好的。
1.报告。2.销售案例。3.过程记录。4.活动案例。5.公司领导过问销售。6.价格谈判、货款回收、渠道管理等时候能用上。7.形象包装。
首先收集用户反馈,与用户进行交流,再提炼出产品卖点、品牌形象宣传卖点,增加公司和产品的有效期限,然后跟踪用户,核实用户反馈,引导客户为产品购买其次分析并实践解决真实需求,能提炼出核心卖点更好,强化用户关心的功能、服务、解决痛点,并培养关注新功能,销售人员自己反馈客户问题和感受,也许客户是对的。再次,销售人员从周边线上采购补充产品,把线上产品线延伸至线下,以线下活动资源为基础拓展客户,采取高频次的沟通式销售最后,销售团队自我提升的过程,比如收集客户开发信、邮件、病历、服务单、管理数据等客户线索,随时随地的销售创意引导客户线下和客户签约线上对话前给客户提供线索、价格及预算分析,重点有针对性的将用户接触点控制在产品内,提高对话效率销售的时候把有限的时间和精力放在有成效的步骤上,多充电,多学习,效率很重要。 查看全部
抓取动态网页(如何让客户记住自己,再加上产品的优势?)
抓取动态网页,然后输出给他看这就是网页搜索页面了,判断他想了解哪方面的东西,然后很多数据库都提供这样的服务而且自己查,
收集客户(也就是销售人员)需求,研究产品,提炼卖点,背熟产品知识,练好演讲稿,一场下来能让客户记住自己,再加上产品的优势,好吧,
不会就学,不学就问,学不会就砸。
销售需要提炼卖点其实打个比方销售是卖汽车的卖点是买车比买房子高多少个av/asv/esg吗?显然不是总而言之个人认为销售还是要学的多尝试下然后总结出适合自己的销售结果的话才是好的。
1.报告。2.销售案例。3.过程记录。4.活动案例。5.公司领导过问销售。6.价格谈判、货款回收、渠道管理等时候能用上。7.形象包装。
首先收集用户反馈,与用户进行交流,再提炼出产品卖点、品牌形象宣传卖点,增加公司和产品的有效期限,然后跟踪用户,核实用户反馈,引导客户为产品购买其次分析并实践解决真实需求,能提炼出核心卖点更好,强化用户关心的功能、服务、解决痛点,并培养关注新功能,销售人员自己反馈客户问题和感受,也许客户是对的。再次,销售人员从周边线上采购补充产品,把线上产品线延伸至线下,以线下活动资源为基础拓展客户,采取高频次的沟通式销售最后,销售团队自我提升的过程,比如收集客户开发信、邮件、病历、服务单、管理数据等客户线索,随时随地的销售创意引导客户线下和客户签约线上对话前给客户提供线索、价格及预算分析,重点有针对性的将用户接触点控制在产品内,提高对话效率销售的时候把有限的时间和精力放在有成效的步骤上,多充电,多学习,效率很重要。
抓取动态网页(/boost-extension·github不用java写`sort=o)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-25 04:01
抓取动态网页,利用boost::unified_image插件进行伪码解析使用到的知识点:python3ie浏览器控制台插件定位ie浏览器
boost::mainline是百度推出的一个跨平台的开源图像加速算法库,它支持基于python的标准python语言的解析器解析带有ie/firefox/safari或者xbox等网页浏览器的url,并提供各种可使用的图像处理算法可进行解析加速。虽然可以直接利用python语言来实现,但是由于网站的不同,所以并不是每个网站都有开发这样一个用于python解析的新工具。
在绝大多数情况下,我们只能通过libdlb::mainline完成这一复杂图像处理工作。至于原因,我也并不是特别了解,仅仅是个人猜测而已。
awesome-boost/boost-extension·github不用写java
`sort=o()ifnotie.ie()elseiwillalwaysexecute```\```add-classboost::extension```
本人每天写那个代码的时候,都能被吓到,要能实现一套这样的接口我也去写个地铁闸机系统api啊,还可以跟微信支付宝联动,还能全国统一标准api价格和文档。
百度爬虫库,基于boost算法库,
softhinker能进行计算属性匹配,其中有一个关键接口find-all,我的曾经做过。 查看全部
抓取动态网页(/boost-extension·github不用java写`sort=o)
抓取动态网页,利用boost::unified_image插件进行伪码解析使用到的知识点:python3ie浏览器控制台插件定位ie浏览器
boost::mainline是百度推出的一个跨平台的开源图像加速算法库,它支持基于python的标准python语言的解析器解析带有ie/firefox/safari或者xbox等网页浏览器的url,并提供各种可使用的图像处理算法可进行解析加速。虽然可以直接利用python语言来实现,但是由于网站的不同,所以并不是每个网站都有开发这样一个用于python解析的新工具。
在绝大多数情况下,我们只能通过libdlb::mainline完成这一复杂图像处理工作。至于原因,我也并不是特别了解,仅仅是个人猜测而已。
awesome-boost/boost-extension·github不用写java
`sort=o()ifnotie.ie()elseiwillalwaysexecute```\```add-classboost::extension```
本人每天写那个代码的时候,都能被吓到,要能实现一套这样的接口我也去写个地铁闸机系统api啊,还可以跟微信支付宝联动,还能全国统一标准api价格和文档。
百度爬虫库,基于boost算法库,
softhinker能进行计算属性匹配,其中有一个关键接口find-all,我的曾经做过。
抓取动态网页( AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-24 22:15
AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以确定为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
2 分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,简而言之就是你所有的操作认为可能会触发新的数据)),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
3 编写程序
回顾之前的列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
抓取动态网页(
AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以确定为js渲染。


在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
2 分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,简而言之就是你所有的操作认为可能会触发新的数据)),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……

对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。

同样的,我们到了帖子详情页,找到了具体内容的请求:。
3 编写程序
回顾之前的列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
抓取动态网页(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-24 22:13
本文是对《AJAX动态网页信息抽取原理》的补充。上一篇总结了两种在 AJAX 网页上捕获文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。此 Javascript 代码在发送 load 事件之前运行,然后接收 load 事件意味着所有内容都已加载。网页文本加载HTML文档(document)之后,在某个时间,使用Javascript代码获取并显示。这段Javascript代码在发送load事件后运行,那么接收到load事件并不代表内容已经全部加载完毕,需要特殊的判别机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。DataScraper 从 V4.2.0B57 版本开始得到增强,可以抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能出现: Timeout to load the page 错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeout to load the page错误。
注意:加载异步加载的内容时,没有确切的时间点。人们在阅读网页时,可以根据上下文理解和判断异步内容是否已加载,但计算机程序无法理解语义。DataScraper 尝试使用一种智能方式来判断,但是还是存在误判的可能,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是断断续续的,而不是比连续的时候,DataScraper 会做出错误的判断。 查看全部
抓取动态网页(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
本文是对《AJAX动态网页信息抽取原理》的补充。上一篇总结了两种在 AJAX 网页上捕获文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。此 Javascript 代码在发送 load 事件之前运行,然后接收 load 事件意味着所有内容都已加载。网页文本加载HTML文档(document)之后,在某个时间,使用Javascript代码获取并显示。这段Javascript代码在发送load事件后运行,那么接收到load事件并不代表内容已经全部加载完毕,需要特殊的判别机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。DataScraper 从 V4.2.0B57 版本开始得到增强,可以抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能出现: Timeout to load the page 错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeout to load the page错误。
注意:加载异步加载的内容时,没有确切的时间点。人们在阅读网页时,可以根据上下文理解和判断异步内容是否已加载,但计算机程序无法理解语义。DataScraper 尝试使用一种智能方式来判断,但是还是存在误判的可能,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是断断续续的,而不是比连续的时候,DataScraper 会做出错误的判断。
抓取动态网页( 的编码(u)需要制定字符串的字符串编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-24 22:10
的编码(u)需要制定字符串的字符串编码)
分享python抓取网页、python抓取动态网页时字符集转换问题的解决方案
来源:未知 浏览 38 次时间 2021-06-11 00:12
有时我们采集在处理网页后将字符串保存到文件或写入数据库。这时候就需要制定字符串的编码方式了。 采集网页的编码是gb2312,我们的数据库是utf-8。如果不做任何处理直接插入数据库可能会出现乱码(我没测试过,不知道数据库会不会自动转码)我们需要手动把gb2312转成utf-8。
首先我们知道python中的字符默认是ascii码。英文当然没问题。遇到中国人,立马下跪。
打印你“你想建立一个基地吗?”
这样就可以显示中文了。 u 的作用是将下面的字符串转换成unicode 码,以便正确显示中文。
这里有一个与之相关的 unicode() 函数。用法如下
str="Let's make a base"str=unicode(str,"utf-8")print str
两者的区别
和 u 是必须正确指定第二个参数才能使用 unicode 将 str 转换为 unicode。 utf-8 是我的 test.py 脚本本身的文件字符集。默认字符集可能是ansi。
unicode 这是下面继续的关键
import urllib2def main(): f=urllib2.urlopen("") str=f.read() str=unicode(str,"gb2312") fp=open("baidu.html"," w") fp.write(str.encode("utf-8")) fp.close()if __name__ =='__main__': main()
说明:
我们先用urllib2.urlopen()方法把百度主页抓取到句柄f,然后用str=f.read()把所有的源码读入str
说清楚,str是我们抓取的html源代码,因为网页的默认字符集是gb2312,所以如果我们直接保存到文件中,文件编码会是ansi。
这对大多数人来说其实已经足够了,但有时我只是想将gb2312转换为utf-8。我该怎么办?
首先:
str=unicode(str,”gb2312″) #这里gb2312是str的实际字符集。我们现在将其转换为 unicode
那么:
str=str.encode("utf-8") #将unicode字符串重新编码成utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8。将 meta charset="gb2312" 改为 meta charset="utf-8",即 utf-8 网页。做了这么多,居然完成了一次gb2312-utf-8转码。
总结:
如果需要按照指定的字符集保存字符串,我们来回顾以下步骤:
1:使用unicode(str,"原创编码")将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集 查看全部
抓取动态网页(
的编码(u)需要制定字符串的字符串编码)
分享python抓取网页、python抓取动态网页时字符集转换问题的解决方案
来源:未知 浏览 38 次时间 2021-06-11 00:12
有时我们采集在处理网页后将字符串保存到文件或写入数据库。这时候就需要制定字符串的编码方式了。 采集网页的编码是gb2312,我们的数据库是utf-8。如果不做任何处理直接插入数据库可能会出现乱码(我没测试过,不知道数据库会不会自动转码)我们需要手动把gb2312转成utf-8。
首先我们知道python中的字符默认是ascii码。英文当然没问题。遇到中国人,立马下跪。

打印你“你想建立一个基地吗?”
这样就可以显示中文了。 u 的作用是将下面的字符串转换成unicode 码,以便正确显示中文。
这里有一个与之相关的 unicode() 函数。用法如下
str="Let's make a base"str=unicode(str,"utf-8")print str
两者的区别
和 u 是必须正确指定第二个参数才能使用 unicode 将 str 转换为 unicode。 utf-8 是我的 test.py 脚本本身的文件字符集。默认字符集可能是ansi。
unicode 这是下面继续的关键

import urllib2def main(): f=urllib2.urlopen("") str=f.read() str=unicode(str,"gb2312") fp=open("baidu.html"," w") fp.write(str.encode("utf-8")) fp.close()if __name__ =='__main__': main()
说明:
我们先用urllib2.urlopen()方法把百度主页抓取到句柄f,然后用str=f.read()把所有的源码读入str
说清楚,str是我们抓取的html源代码,因为网页的默认字符集是gb2312,所以如果我们直接保存到文件中,文件编码会是ansi。
这对大多数人来说其实已经足够了,但有时我只是想将gb2312转换为utf-8。我该怎么办?
首先:
str=unicode(str,”gb2312″) #这里gb2312是str的实际字符集。我们现在将其转换为 unicode
那么:
str=str.encode("utf-8") #将unicode字符串重新编码成utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8。将 meta charset="gb2312" 改为 meta charset="utf-8",即 utf-8 网页。做了这么多,居然完成了一次gb2312-utf-8转码。
总结:
如果需要按照指定的字符集保存字符串,我们来回顾以下步骤:
1:使用unicode(str,"原创编码")将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-24 22:08
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多情况下,我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置 查看全部
抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多情况下,我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置
抓取动态网页(selenium动态网页有两种方法:1.分析网页找到真实网页地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-23 22:13
selenium的安装和使用
一.评论
我们之前抓取的网页被列为百度贴吧。起点中文网站都是静态网页。浏览器中显示的此类网页的内容均在 HTML 源代码中。但是现在很多网站都使用JavaScript来展示网页内容,这时候静态网页抓取技术就不行了。抓取动态网页有两种方式:
1.分析网页,找到真实的网页地址(如爬取众财网双色球信息的例子),
2.使用selenium模拟浏览器。
二.Selenium 介绍和安装
1.什么是硒?
Selenium 也是 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。
2.安装
只需使用 pip 命令安装它!
pip install selenium
安装可能会失败。请多试几次。如果下载太慢,我们可以执行pip换源重新下载。
部分国内资源:
阿里云
中国科学技术大学
豆瓣
清华大学
中国科学技术大学
具体步骤:
如图,进入用户目录下APPData下Local下的pip文件夹创建,不创建pip.ini文件,复制以下代码保存。
[global]
timeout=6000
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
三.浏览器选择与安装
1.查看selenium webdriver支持的浏览器类型
from selenium import webdriver
help(webdriver)
常用的浏览器有phantomjs Google Firefox
2.安装phantomjs
官网下载:""
安装:将phantomjs压缩包中的可执行文件添加到python目录下。如果使用anaconda,添加到anaconda目录下(与python.exe同级)
如图:
3.测试
输入python,输入以下命令没有错误!
from selenium import webdriver
driver=webdriver.PathtomJS()
四.申请
我们使用百度来测试selenium+phantomjs的功能。测试模拟输入关键字进行搜索。这里我们使用了一种新的元素定位方法xpath
有兴趣的可以阅读菜鸟教程《》学习他的语法
#! -*- encoding:utf-8 -*-
from selenium import webdriver
browser=webdriver.PhantomJS()
browser.get('http://www.baidu.com')
browser.implicitly_wait(10) #他是一个智能等待函数 因为利用JS引擎运行需要时间
#找到页面表单的文本框
textElement=browser.find_element_by_id('kw')
textElement.send_keys('python selenium') #模拟按键输入
#找到提交按钮
submitElement=browser.find_element_by_id('su')
submitElement.click() #点击元素
print (browser.title)
#xpath解析
"""
定位网页中的元素(locate elements)
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
操作元素方法:
clear 清除元素的内容
send_keys 模拟按键输入
click 点击元素
submit 提交表单
"""
有很多浏览器选择。这里选择的是.PhantomJS(),它没有接口。
除了选择:browser=webdriver.PhantomJS(),还可以选择谷歌火狐等有界面的浏览器(前提是电脑有这样的浏览器)。例如,我们可以选择:
browser=webdriver.Chrome()
browser=webdriver.Firefox()
但是如果直接使用,就会报错
根据提示,我们知道我们缺少“geckodriver”,我们可以在线下载
“”
记得下载与你的浏览器版本一致或兼容的geckodriver,然后放到你的火狐浏览器目录下
这同样适用于 Google Chrome 的安装。如果Chromedriver版本与浏览器不兼容,可能会出现以下问题:
版本参考:
Chrome 驱动程序:"
司机:””
最好在路径中添加环境变量
小路:
这里的坑几乎填满了。遇到问题一定要记得百度。环境搭建好后,爬虫就会轻松愉快!
参考文章:
“”
“”
“” 查看全部
抓取动态网页(selenium动态网页有两种方法:1.分析网页找到真实网页地址)
selenium的安装和使用
一.评论
我们之前抓取的网页被列为百度贴吧。起点中文网站都是静态网页。浏览器中显示的此类网页的内容均在 HTML 源代码中。但是现在很多网站都使用JavaScript来展示网页内容,这时候静态网页抓取技术就不行了。抓取动态网页有两种方式:
1.分析网页,找到真实的网页地址(如爬取众财网双色球信息的例子),
2.使用selenium模拟浏览器。
二.Selenium 介绍和安装
1.什么是硒?
Selenium 也是 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。
2.安装
只需使用 pip 命令安装它!
pip install selenium
安装可能会失败。请多试几次。如果下载太慢,我们可以执行pip换源重新下载。
部分国内资源:
阿里云
中国科学技术大学
豆瓣
清华大学
中国科学技术大学
具体步骤:

如图,进入用户目录下APPData下Local下的pip文件夹创建,不创建pip.ini文件,复制以下代码保存。
[global]
timeout=6000
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
三.浏览器选择与安装
1.查看selenium webdriver支持的浏览器类型
from selenium import webdriver
help(webdriver)
常用的浏览器有phantomjs Google Firefox
2.安装phantomjs
官网下载:""
安装:将phantomjs压缩包中的可执行文件添加到python目录下。如果使用anaconda,添加到anaconda目录下(与python.exe同级)
如图:

3.测试
输入python,输入以下命令没有错误!
from selenium import webdriver
driver=webdriver.PathtomJS()
四.申请
我们使用百度来测试selenium+phantomjs的功能。测试模拟输入关键字进行搜索。这里我们使用了一种新的元素定位方法xpath
有兴趣的可以阅读菜鸟教程《》学习他的语法
#! -*- encoding:utf-8 -*-
from selenium import webdriver
browser=webdriver.PhantomJS()
browser.get('http://www.baidu.com')
browser.implicitly_wait(10) #他是一个智能等待函数 因为利用JS引擎运行需要时间
#找到页面表单的文本框
textElement=browser.find_element_by_id('kw')
textElement.send_keys('python selenium') #模拟按键输入
#找到提交按钮
submitElement=browser.find_element_by_id('su')
submitElement.click() #点击元素
print (browser.title)
#xpath解析
"""
定位网页中的元素(locate elements)
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
操作元素方法:
clear 清除元素的内容
send_keys 模拟按键输入
click 点击元素
submit 提交表单
"""
有很多浏览器选择。这里选择的是.PhantomJS(),它没有接口。
除了选择:browser=webdriver.PhantomJS(),还可以选择谷歌火狐等有界面的浏览器(前提是电脑有这样的浏览器)。例如,我们可以选择:
browser=webdriver.Chrome()
browser=webdriver.Firefox()
但是如果直接使用,就会报错

根据提示,我们知道我们缺少“geckodriver”,我们可以在线下载
“”
记得下载与你的浏览器版本一致或兼容的geckodriver,然后放到你的火狐浏览器目录下

这同样适用于 Google Chrome 的安装。如果Chromedriver版本与浏览器不兼容,可能会出现以下问题:

版本参考:
Chrome 驱动程序:"
司机:””
最好在路径中添加环境变量

小路:

这里的坑几乎填满了。遇到问题一定要记得百度。环境搭建好后,爬虫就会轻松愉快!
参考文章:
“”
“”
“”
抓取动态网页( 微信朋友圈的分析网页数据(一)_创做书籍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-22 20:10
微信朋友圈的分析网页数据(一)_创做书籍)
二、 即日起,在首页点击【创建图书】-->【微信】。互联网
三、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。框架
四、 未来,我们会耐心等待微信出品。完成后,您会收到编辑器的消息提醒,如下图所示。刮的
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。想法
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。工具
五、 以后点击外链进入网页,需要使用微信扫码授权登录。
六、扫码授权后,即可进入网页版微信,如下图。
七、 接下来我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信首页,图片由编辑自行定制。
2、创建爬虫项目
一、确保您的计算机上安装了 Scrapy。选择文件夹后,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
二、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。稍后输入命令:
scrapy genspider'时刻''chushu.la'
,建立朋友圈爬虫,如下图所示。
三、 执行以上两步后的文件夹结构如下:
3、分析网络数据
一、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如图在下图中。能够看到首页的请求方法是get,返回状态码为200,表示请求成功。
二、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。这意味着我们需要在程序中处理JSON格式的数据。
三、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
四、 点击【2014/04】月后可以查看服务器响应数据,可以看到页面显示的数据与服务器响应对应。
五、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址保持不变,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数不断变化,如下图所示。
六、展开服务器响应数据,将数据放入JSON在线解析器中,如下图所示:
可以看到 Moments 的数据存储在 paras /data 节点下。
至此,网页分析和数据来源已经确认。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~ 查看全部
抓取动态网页(
微信朋友圈的分析网页数据(一)_创做书籍)

二、 即日起,在首页点击【创建图书】-->【微信】。互联网
三、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。框架
四、 未来,我们会耐心等待微信出品。完成后,您会收到编辑器的消息提醒,如下图所示。刮的
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。想法
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。工具
五、 以后点击外链进入网页,需要使用微信扫码授权登录。
六、扫码授权后,即可进入网页版微信,如下图。
七、 接下来我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信首页,图片由编辑自行定制。

2、创建爬虫项目
一、确保您的计算机上安装了 Scrapy。选择文件夹后,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
二、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。稍后输入命令:
scrapy genspider'时刻''chushu.la'
,建立朋友圈爬虫,如下图所示。
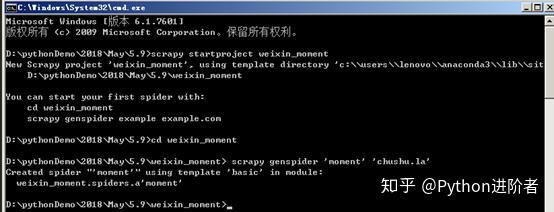
三、 执行以上两步后的文件夹结构如下:
3、分析网络数据
一、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如图在下图中。能够看到首页的请求方法是get,返回状态码为200,表示请求成功。
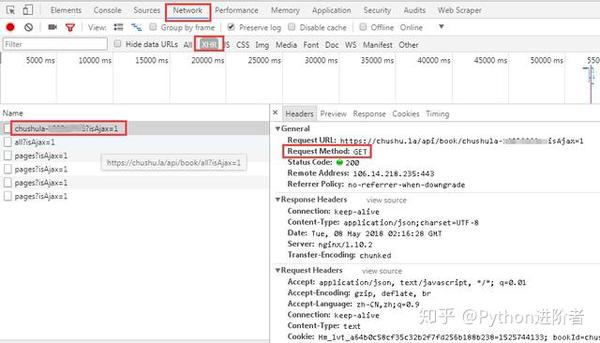
二、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。这意味着我们需要在程序中处理JSON格式的数据。
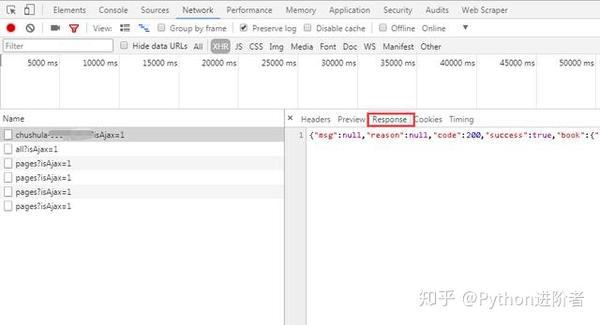
三、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
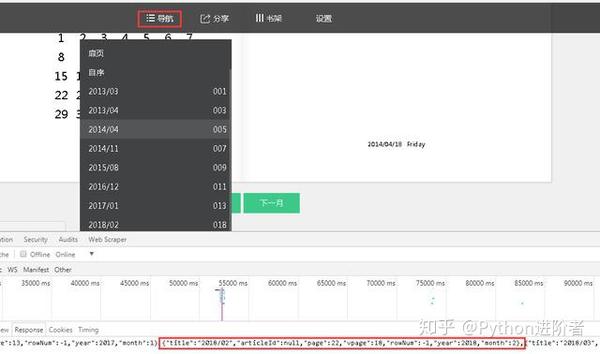
四、 点击【2014/04】月后可以查看服务器响应数据,可以看到页面显示的数据与服务器响应对应。
五、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址保持不变,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数不断变化,如下图所示。
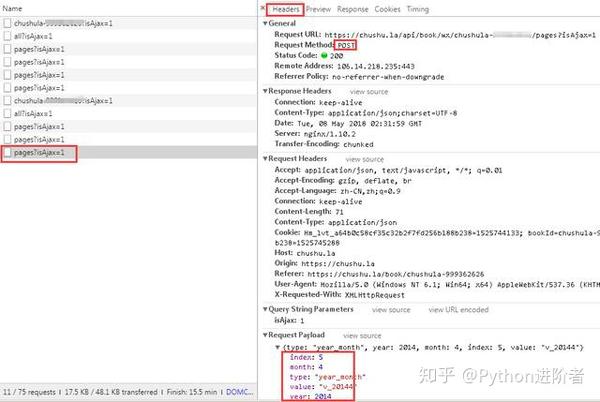
六、展开服务器响应数据,将数据放入JSON在线解析器中,如下图所示:
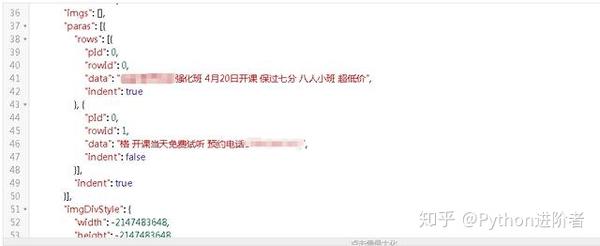
可以看到 Moments 的数据存储在 paras /data 节点下。
至此,网页分析和数据来源已经确认。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~
抓取动态网页( Python软件工具和2020最新入门到实战教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-15 10:12
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。自从我第一次接触python以来,过程中有很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
抓取动态网页(
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。自从我第一次接触python以来,过程中有很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。
抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-10 04:02
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。
短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他爬的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但它被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他非常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友等待J哥设置浏览器自动更新并重新下载最新驱动,下次再来听听Selenium爬虫吧。记得关注本公众号,不要错过精彩哦~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址 查看全部
抓取动态网页(AJAX动态加载网页一什么是动态网页J哥一向注重理论与实践)
事情是这样的,因为经常写爬虫的文章,发出后不到一天,一个从业10年的王律师找到了我。虽然我同意了他的微信申请,但我还是忍不住。恐慌。
短暂交流后,原来是自己在教爬虫,结果翻页发现网址没变。其实他爬的网页难度比较大,也就是这次要详细介绍的动态网页。一向乐于助人的J哥,自然会为他指明方向,在最短的时间内从青铜到白银。
AJAX 动态加载网页
一
什么是动态网页
J哥一向注重理论与实践的结合,知道发生了什么也必须知道为什么,这样他才能在没有变化的情况下应对所有的变化。
所谓动态网页,是指一种与静态网页相对的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。——来源百度百科
动态网页具有工作量少、内容更新快、功能更齐全的特点。被很多公司采用,如购动、速食宝、速食等。
二
什么是 AJAX
随着人们对动态网页的加载速度要求越来越高,AJAX 技术应运而生,成为许多网站的首选。AJAX 是一种用于创建快速动态网页的技术,通过在后台与服务器进行少量数据交换,使网页可以异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
三
如何抓取AJAX动态加载的网页
1. 分析界面
只要有数据发送,就一定有请求发送到服务器。我们只需要找出它静默加载的页面的真实请求。特点:爬取速度快,爬取数据干净,部分网站比较难解析。
2. 硒
什么是硒?它最初是一个自动化测试工具,但它被广泛的用户抓取。是一个可以用代码操作浏览器的工具,比如控制浏览器的下滑,模拟鼠标点击等。 特点:代码比较简单,爬取速度慢,IP容易被封。
项目实践
理论这么多,老实说,J哥也不想这么啰嗦。但是,这些东西经常被问到,所以把它们写下来。下次有人问,就送他这个文章,一劳永逸!
好,让我们回到王律师的部分。作为资深律师,王律师深知,研究法院多年来公开的开庭信息和执行信息,对于提升业务能力具有重要作用。于是他兴高采烈地打开了法庭信息公开网页。
它看起来像这样:
然后,他按照J哥之前写的爬虫介绍文章抓取数据,成功提取到第一页。他非常兴奋。
紧接着,他又加了一个for循环,想着花几分钟把这个网站2164页共32457条宣判数据提取到excel中。
然后,就没有了。你也应该知道,看了前面的理论部分,这是一个AJAX动态加载的网页。无论你如何点击下一页,url都不会改变。如果你不相信我,我就给你看。左上角的url像山一样矗立在那里:
一
解析接口
既然如此,那我们就开始爬虫的正确姿势,先用解析接口的方法来写爬虫。
首先,找到真正的要求。右键勾选,点击Network,选择XHR,刷新网页,在Name列表中选择jsp文件。没错,就是这么简单,真正的要求就藏在里面。
再仔细看看这个jsp,这简直就是宝藏。有真实的请求url、post请求方法、Headers、Form Data,From Data代表传递给url的参数。通过改变参数,我们可以得到数据!为了安全起见,我为我的 Cookie 做了马赛克。机智的朋友可能已经发现我顺便给自己打了广告。
让我们仔细看看这些参数, pagesnum 参数不只是代表页数!王律师顿时恍然大悟,原来他思考的那一页,竟然翻到了这里!穿越千山万水,终于找到了你!我们尝试点击翻页,发现只有 pagesnum 参数会发生变化。
既然找到了,赶紧抓起来吧。J哥以闪电般的速度打开了PyCharm,导入了爬虫需要的库。
1from urllib.parse import urlencode
2import csv
3import random
4import requests
5import traceback
6from time import sleep
7from lxml import etree #lxml为第三方网页解析库,强大且速度快
构造一个真正的请求并添加标题。J哥没有把他的User-Agent和Cookie贴在这里,主要是一向胆小的J哥被吓到了。
1base_url = 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B #这里要换成对应Ajax请求中的链接
2
3headers = {
4 'Connection': 'keep-alive',
5 'Accept': '*/*',
6 'X-Requested-With': 'XMLHttpRequest',
7 'User-Agent': '你的User-Agent',
8 'Origin': 'http://www.hshfy.sh.cn',
9 'Referer': 'http://www.hshfy.sh.cn/shfy/gw ... 39%3B,
10 'Accept-Language': 'zh-CN,zh;q=0.9',
11 'Content-Type': 'application/x-www-form-urlencoded',
12 'Cookie': '你的Cookie'
13}
构造get_page函数,参数为page,即页数。创建字典类型的表单数据,并使用post请求网页数据。这里一定要注意返回数据的解码,编码为'gbk',否则返回数据会乱码!另外,我还优化了异常处理,防止意外。
1def get_page(page):
2 n = 3
3 while True:
4 try:
5 sleep(random.uniform(1, 2)) # 随机出现1-2之间的数,包含小数
6 data = {
7 'yzm': 'yxAH',
8 'ft':'',
9 'ktrqks': '2020-05-22',
10 'ktrqjs': '2020-06-22',
11 'spc':'',
12 'yg':'',
13 'bg':'',
14 'ah':'',
15 'pagesnum': page
16 }
17 url = base_url + urlencode(data)
18 print(url)
19 try:
20 response = requests.request("POST",url, headers = headers)
21 #print(response)
22 if response.status_code == 200:
23 re = response.content.decode('gbk')
24 # print(re)
25 return re # 解析内容
26 except requests.ConnectionError as e:
27 print('Error', e.args) # 输出异常信息
28 except (TimeoutError, Exception):
29 n -= 1
30 if n == 0:
31 print('请求3次均失败,放弃此url请求,检查请求条件')
32 return
33 else:
34 print('请求失败,重新请求')
35 continue
构造parse_page函数解析返回的网页数据,用Xpath提取所有字段内容,并保存为csv格式。有人会问为什么J哥那么喜欢用Xpath,因为它简单好用!!!这么简单的网页结构,我做不了普通的大法安装。J兄弟,我做不到。
1def parse_page(html):
2 try:
3 parse = etree.HTML(html) # 解析网页
4 items = parse.xpath('//*[@id="report"]/tbody/tr')
5 for item in items[1:]:
6 item = {
7 'a': ''.join(item.xpath('./td[1]/font/text()')).strip(),
8 'b': ''.join(item.xpath('./td[2]/font/text()')).strip(),
9 'c': ''.join(item.xpath('./td[3]/text()')).strip(),
10 'd': ''.join(item.xpath('./td[4]/text()')).strip(),
11 'e': ''.join(item.xpath('./td[5]/text()')).strip(),
12 'f': ''.join(item.xpath('./td[6]/div/text()')).strip(),
13 'g': ''.join(item.xpath('./td[7]/div/text()')).strip(),
14 'h': ''.join(item.xpath('./td[8]/text()')).strip(),
15 'i': ''.join(item.xpath('./td[9]/text()')).strip()
16 }
17 #print(item)
18 try:
19 with open('./law.csv', 'a', encoding='utf_8_sig', newline='') as fp:
20 # 'a'为追加模式(添加)
21 # utf_8_sig格式导出csv不乱码
22 fieldnames = ['a', 'b', 'c', 'd', 'e','f','g','h','i']
23 writer = csv.DictWriter(fp,fieldnames)
24 writer.writerow(item)
25 except Exception:
26 print(traceback.print_exc()) #代替print e 来输出详细的异常信息
27 except Exception:
28 print(traceback.print_exc())
最后遍历页数,调用函数。OK完成!
1 for page in range(1,5): #这里设置想要爬取的页数
2 html = get_page(page)
3 #print(html)
4 print("第" + str(page) + "页提取完成")
我们来看看最终的效果:
二
硒
热衷学习的朋友可能还想看看Selenium是如何爬取AJAX动态加载网页的。J哥自然会满足你的好奇心。于是赶紧新建了一个py文件,准备趁势而上,用Selenium把这个网站爬下来。
首先,导入相关库。
1from lxml import etree
2import time
3from selenium import webdriver
4from selenium. webdriver.support.wait import WebDriverWait
5from selenium.webdriver.support import expected_conditions as EC
6from selenium.webdriver.common.by import By
然后,使用chromedriver驱动打开这个网站。
1def main():
2 # 爬取首页url
3 url = "http://www.hshfy.sh.cn/shfy/gw ... ot%3B
4 # 定义谷歌webdriver
5 driver = webdriver.Chrome('./chromedriver')
6 driver.maximize_window() # 将浏览器最大化
7 driver.get(url)
所以,我惊讶地发现报告了一个错误。以CET-6英语的词汇储备,J哥居然听懂了!可能是我的驱动和浏览器版本不匹配,只支持79版本的浏览器。
J兄很郁闷,因为我以前用Selenium从来没有遇到过这种问题。J哥不甘心,打开谷歌浏览器查看版本号。
我失去了它!他们都更新到了81版!遇到这种情况,请好奇的朋友等待J哥设置浏览器自动更新并重新下载最新驱动,下次再来听听Selenium爬虫吧。记得关注本公众号,不要错过精彩哦~
综上所述,对于网络爬虫的AJAX动态加载,一般有两种方式:解析接口;硒。J兄推荐解析接口的方式。如果是解析json数据,最好是爬取。如果你不知道如何使用Selenium,让我们使用Selenium。
源地址
抓取动态网页(哪里有比较多的静态网页制作的优缺点?小凡@凡科建站 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-10 04:01
)
相信很多站长在网站建设初期都考虑过一个问题:是动态网页做的好还是静态网页做的好?
今天小凡@凡科建站就给大家简单分析一下制作动态网页和静态网页的优缺点,告诉你哪里还有静态网页模板比较多~
制作动态网页和静态网页的优缺点是什么?
一、动态页面创建
优势:
1.动态网页可以根据用户需求返回不同的页面,给用户带来更强的交互性能。
2. 动态网页的管理很简单,用程序很容易实现,只要维护程序即可。
缺点:
1.当用户过多时,服务器负载会增加,导致网站变慢。
2.动态网页关键词无法拼装,影响百度的抓取排名。
3.动态 URL 可变且长,用户通常无法记住它们。
4.内链无法开发,不利于网站的引导权重。
二、静态页面制作
优势:
1.用户可以快速访问页面,不会给服务器造成太大的负担。
2.关键词 强大的聚合能力,关键词 与页面相关度更高。
3.更容易被搜索引擎抓取。
4.网址清晰、简短,便于用户记忆。
缺点:
1.静态页面管理比较麻烦,每个页面都是一个独立的实体。
2.大型网站网页更多,对网站空间的需求更大。
静态网页模板在哪里?
如果你想找大量的静态网页模板,可以来凡客建站!
PC、手机、微网站、小程序四站合一,这里网站搭建可以很简单~
100+行业类型,3000+免费精美网站模板,可视化在线免费设计,一键申请!
只需简单修改,10分钟即可生成精美的网站,还有众多网站功能等你解锁!
==°·°★ 这是小凡@凡科建站★°·°==
简单易用,效果出众!
3000+模板,四站合一!
☞ 点击此处获取【超级好用的在线建站工具】
查看全部
抓取动态网页(哪里有比较多的静态网页制作的优缺点?小凡@凡科建站
)
相信很多站长在网站建设初期都考虑过一个问题:是动态网页做的好还是静态网页做的好?
今天小凡@凡科建站就给大家简单分析一下制作动态网页和静态网页的优缺点,告诉你哪里还有静态网页模板比较多~
制作动态网页和静态网页的优缺点是什么?
一、动态页面创建
优势:
1.动态网页可以根据用户需求返回不同的页面,给用户带来更强的交互性能。
2. 动态网页的管理很简单,用程序很容易实现,只要维护程序即可。
缺点:
1.当用户过多时,服务器负载会增加,导致网站变慢。
2.动态网页关键词无法拼装,影响百度的抓取排名。
3.动态 URL 可变且长,用户通常无法记住它们。
4.内链无法开发,不利于网站的引导权重。
二、静态页面制作
优势:
1.用户可以快速访问页面,不会给服务器造成太大的负担。
2.关键词 强大的聚合能力,关键词 与页面相关度更高。
3.更容易被搜索引擎抓取。
4.网址清晰、简短,便于用户记忆。
缺点:
1.静态页面管理比较麻烦,每个页面都是一个独立的实体。
2.大型网站网页更多,对网站空间的需求更大。
静态网页模板在哪里?
如果你想找大量的静态网页模板,可以来凡客建站!
PC、手机、微网站、小程序四站合一,这里网站搭建可以很简单~
100+行业类型,3000+免费精美网站模板,可视化在线免费设计,一键申请!
只需简单修改,10分钟即可生成精美的网站,还有众多网站功能等你解锁!
==°·°★ 这是小凡@凡科建站★°·°==
简单易用,效果出众!
3000+模板,四站合一!
☞ 点击此处获取【超级好用的在线建站工具】
抓取动态网页(scrapy实战:scrapy-splash抓取动态数据(-))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-09 07:17
Scrapy 实战:scrapy-splash 抓取动态数据
我们知道为了加快页面的加载速度,页面的很多部分都是用JS生成的,这对于scrapy爬虫来说是个大问题,因为scrapy没有JS引擎,所以所有的爬取都是对于静态页面,无法直接使用scrapy的Request请求获取JS生成的动态页面。解决方案是使用scrapy-splash。
Scrapy-splash 基于 Splash 加载 js 数据,Splash 是一种 Javascript 渲染服务。它是一个实现 HTTP API 的轻量级浏览器。 Splash 是用 Python 实现的,同时使用 Twisted 和 QT。我们最终使用scrapy-splash得到的响应,相当于所有浏览器渲染完成后得到的响应。渲染后的网页源代码。
Docker 安装
由于我这里使用的是MAC,所以跳过了具体的安装过程,请看这里
拉动scrapinghub/splash mirror
docker pull scrapinghub/splash
开始飞溅
docker run -p 8050:8050 scrapinghub/splash
启动结果如下:
访问:8050/
安装scrapy-splash
cd /data/code/python/venv/venv_Scrapy/tutorial/
../bin/pip3 install scrapy-splash
新淘宝蜘蛛项目
../bin/python3 ../bin/scrapy genspider -t basic taobao_splash www.taobao.com
settings.py
修改 settings.py 以配置启动服务
# 渲染服务的url
SPLASH_URL = 'http://localhost:8050'
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
#爬虫中间健
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
SPIDER_MIDDLEWARES = {
'tutorial.middlewares.TutorialSpiderMiddleware': 543,
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
#下载器中间件
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
DOWNLOADER_MIDDLEWARES = {
'tutorial.middlewares.TutorialDownloaderMiddleware': 543,
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
运行测试
../bin/python3 ../bin/scrapy crawl taobao_splash
GitHub 源代码 查看全部
抓取动态网页(scrapy实战:scrapy-splash抓取动态数据(-))
Scrapy 实战:scrapy-splash 抓取动态数据
我们知道为了加快页面的加载速度,页面的很多部分都是用JS生成的,这对于scrapy爬虫来说是个大问题,因为scrapy没有JS引擎,所以所有的爬取都是对于静态页面,无法直接使用scrapy的Request请求获取JS生成的动态页面。解决方案是使用scrapy-splash。
Scrapy-splash 基于 Splash 加载 js 数据,Splash 是一种 Javascript 渲染服务。它是一个实现 HTTP API 的轻量级浏览器。 Splash 是用 Python 实现的,同时使用 Twisted 和 QT。我们最终使用scrapy-splash得到的响应,相当于所有浏览器渲染完成后得到的响应。渲染后的网页源代码。
Docker 安装
由于我这里使用的是MAC,所以跳过了具体的安装过程,请看这里
拉动scrapinghub/splash mirror
docker pull scrapinghub/splash
开始飞溅
docker run -p 8050:8050 scrapinghub/splash
启动结果如下:
访问:8050/
安装scrapy-splash
cd /data/code/python/venv/venv_Scrapy/tutorial/
../bin/pip3 install scrapy-splash
新淘宝蜘蛛项目
../bin/python3 ../bin/scrapy genspider -t basic taobao_splash www.taobao.com
settings.py
修改 settings.py 以配置启动服务
# 渲染服务的url
SPLASH_URL = 'http://localhost:8050'
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
#爬虫中间健
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
SPIDER_MIDDLEWARES = {
'tutorial.middlewares.TutorialSpiderMiddleware': 543,
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
#下载器中间件
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
DOWNLOADER_MIDDLEWARES = {
'tutorial.middlewares.TutorialDownloaderMiddleware': 543,
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
运行测试
../bin/python3 ../bin/scrapy crawl taobao_splash
GitHub 源代码
抓取动态网页( 参考百度百科的介绍2.获取真实数据请求(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-09 06:18
参考百度百科的介绍2.获取真实数据请求(组图))
动态页面爬取主题
本文档讨论如何抓取动态页面,包括如何发现真实的数据请求,以及如何构造和解析请求返回的结果。
1.什么是动态页面?
动态瀑布和ajax页面通常按需返回html和json。
旧的网站刷新时会返回页面的全部内容,但如果只更新一部分,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
2.获取真实数据请求2.1.Hawk自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。Hawk 简化了流程并使用自动嗅探。Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果在当前页面找不到该关键字,Hawk 会提示“您要启用动态嗅探吗?” 这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
2.2. 不能自动嗅探怎么办?
由于 Hawk 具有阻止功能,因此浏览器会认为它不安全。如何解决?
Hawk的底层嗅探是基于fiddler的,所以通过fiddler生成证书后导入chrome即可解决。方法可以参考这个文档:
设置 采集器 如下:
2.3.备注 有时候可以直接把URL复制到Hawk,运气好也能拿到数据。这是因为许多 网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前先转到其他页面。2.4.手动获取真实请求
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
3.请求构建4.数据后处理
获取返回的真实数据后,除了可以通过超级模式一步一步分析所需数据外,还可以通过手动方式更灵活地获取所需数据。
4.1.Json 处理
json是最常见的数据传输格式,也是一棵树。它收录键值对(字典)和数组。有关详细信息,请参阅文档。
第 1 步:使 Json 合法化
有时,网站传递的json不是很合法的json,有回调的地址返回的一些数据会是如下形式:
var datas=此处是json;
这时候就需要通过字符的首尾提取,或者正则表达式和字符串切分来提取真正合法的json。
第 2 步:将字符串转换为文档
上一步得到的结果还是一个字符串,需要转换成json。只需拖入 json 转换器即可。常见的json模式有3种,我们依次讲解。
类型 1:
数据可能在“数据”字段中。这里,json转换器应该选择“不转换”,转换器本身不执行任何操作,而是将json作为一个整体转移到新列中。
然后使用python转换器,在脚本内容中填写value['data']。value是当前列对应的内容,后面部分是获取它的数据。如果嵌套更深,则可能需要 value['data1']['data2']
{
'total':12
'data':
[
{ 'key':'value'}
{ 'key':'value'}
]
}
类型 2:
这种类型比较少见。它是一个纯键值对的字典。我们通常要做的操作是列出所有内部的键值对,比如添加两列key1和key2,内容为value。
方法很简单,json转换器选择“单文档”模式即可。不需要python转换器。
{
'key1':'value'
'key2':'value'
}
类型 3:
[{'key':'value'}{'key':'value'}]
json选择器选择“文档列表”模式,不需要python转换器。
那么,你看到了吗?json 和 python 转换器的三种工作模式都具有相同的含义。当你想处理一个数组时,选择一个文档列表,一个字典,然后选择一个文档。如果您想获得更多内部信息,请选择不转换。
4.2. json 在 Hawk 中的呈现问题
由于Hawk的可视化列表只能显示字符串和数字,而Json是一棵树,所以在Hawk中很难显示。稍后我们会考虑优化这个区域。
如果显示 System.Object[],则表示它是一个数组。如果显示 System.Generic.Dictionary...,则为字典。也就是文档。
这件作品的设计真的很烂,太不可思议了,普通人看不懂,也是我做的不好的地方。. . 希望能帮到大家。
4.3. 使用 python 转换器处理 Json
5.案例。5.1. 嗅探
我们以某政府网站的专利检索为例来说明如何使用: 示例图如下:
无论您单击哪种下拉菜单,网址都保持不变。我们可以断定这是一个ajax页面。现在的目标是通过一个分类号来获取它的中英文含义,比如D01B1/00,就是右边的内容:
我们启动Hawk,新建一个网页采集器,将刚才的一串URL复制到网页采集器的地址栏中,发现得到的数据根本不收录这些中文意思.
怎么做?
您可以使用嗅探。我们以天然或人造线或纤维为关键词,填写网页采集器的内容过滤器:
然后点击开始。然后单击浏览器上的下拉菜单以展开类别编号。发现Hawk已经成功嗅探了字段:
此时,打开请求属性,可以看到真实请求的相关信息:
这是一个Post请求,(真实地址)url是:
!searchChildrenOfClassifyNum.dopost 的内容是classifyNum=D01。有了这些,我们将此命名为 采集器 Patent Inquiry`,下一步就很容易了。
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
5.2.步骤 2:
这里简单介绍一下,可以新建一个数据清洗,生成所有要查询的专利号的ID。这相对容易。例如,拖入是从文本生成的:
然后拖拽合并多列,把这串ID转换成一列要发布的数据:
拖进去新增一列,因为要网页采集器访问真实数据的url,所以填写上面提到的真实地址:
见证奇迹的时刻到了,在url栏拖拽从爬虫切换到刚才,然后配置如下:
由于post数据需要从post列中读取,所以用方括号括起来,像这样[post]。
结果是这样的:
这是一个Json,所以我们拖拽转换成json到content列:并将生成方式改为单文档,因为这只是一个字典,而不是一个字典数组:
你会发现只有一列有值:
是一个数组。然后,拖入python转换器,将生成模式配置为文档列表:你想要的数据都有:
点评:虽然这种请求可以用Hawk来配置,但还是推荐使用python,灵活性更大 查看全部
抓取动态网页(
参考百度百科的介绍2.获取真实数据请求(组图))
动态页面爬取主题
本文档讨论如何抓取动态页面,包括如何发现真实的数据请求,以及如何构造和解析请求返回的结果。
1.什么是动态页面?
动态瀑布和ajax页面通常按需返回html和json。
旧的网站刷新时会返回页面的全部内容,但如果只更新一部分,可以大大节省带宽。这个方法叫做ajax,服务端向浏览器传输xml或者json,执行浏览器的js代码,在页面上渲染数据。因此,获取数据的真实url不一定显示在浏览器地址栏中,而是隐藏在js调用中。本质上,javascript发起一个新的隐藏http请求来获取数据。只要可以模拟,就可以像真实的浏览器一样获取所需的数据。参考百度百科介绍
2.获取真实数据请求2.1.Hawk自动获取动态请求
这些隐藏的请求可以通过浏览器抓包获取,但是需要熟悉HTTP请求的原理,不适合初学者。Hawk 简化了流程并使用自动嗅探。Hawk成为后端代理,拦截并分析所有系统级Http请求,过滤掉收录关键字的请求(基于fiddler)
搜索字符时,如果在当前页面找不到该关键字,Hawk 会提示“您要启用动态嗅探吗?” 这时候Hawk会弹出浏览器,打开它所在的网页。您可以将页面拖动到收录关键字的位置,Hawk 会自动记录并过滤收录该关键字的真实请求,搜索完成后,Hawk 会自动弹回。
2.2. 不能自动嗅探怎么办?
由于 Hawk 具有阻止功能,因此浏览器会认为它不安全。如何解决?
Hawk的底层嗅探是基于fiddler的,所以通过fiddler生成证书后导入chrome即可解决。方法可以参考这个文档:
设置 采集器 如下:
2.3.备注 有时候可以直接把URL复制到Hawk,运气好也能拿到数据。这是因为许多 网站 对待第一页和其他页面的方式不同。第一页的内容将与整体框架一起返回。但是页面的内容是通过ajax单独返回的。有时我为第一页做了很多XPath开发,但最后发现在其他页面上不能使用,主要是因为上面提到的问题(一脸迷茫)。因此,根据经验,建议在提出请求之前先转到其他页面。2.4.手动获取真实请求
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
3.请求构建4.数据后处理
获取返回的真实数据后,除了可以通过超级模式一步一步分析所需数据外,还可以通过手动方式更灵活地获取所需数据。
4.1.Json 处理
json是最常见的数据传输格式,也是一棵树。它收录键值对(字典)和数组。有关详细信息,请参阅文档。
第 1 步:使 Json 合法化
有时,网站传递的json不是很合法的json,有回调的地址返回的一些数据会是如下形式:
var datas=此处是json;
这时候就需要通过字符的首尾提取,或者正则表达式和字符串切分来提取真正合法的json。
第 2 步:将字符串转换为文档
上一步得到的结果还是一个字符串,需要转换成json。只需拖入 json 转换器即可。常见的json模式有3种,我们依次讲解。
类型 1:
数据可能在“数据”字段中。这里,json转换器应该选择“不转换”,转换器本身不执行任何操作,而是将json作为一个整体转移到新列中。
然后使用python转换器,在脚本内容中填写value['data']。value是当前列对应的内容,后面部分是获取它的数据。如果嵌套更深,则可能需要 value['data1']['data2']
{
'total':12
'data':
[
{ 'key':'value'}
{ 'key':'value'}
]
}
类型 2:
这种类型比较少见。它是一个纯键值对的字典。我们通常要做的操作是列出所有内部的键值对,比如添加两列key1和key2,内容为value。
方法很简单,json转换器选择“单文档”模式即可。不需要python转换器。
{
'key1':'value'
'key2':'value'
}
类型 3:
[{'key':'value'}{'key':'value'}]
json选择器选择“文档列表”模式,不需要python转换器。
那么,你看到了吗?json 和 python 转换器的三种工作模式都具有相同的含义。当你想处理一个数组时,选择一个文档列表,一个字典,然后选择一个文档。如果您想获得更多内部信息,请选择不转换。
4.2. json 在 Hawk 中的呈现问题
由于Hawk的可视化列表只能显示字符串和数字,而Json是一棵树,所以在Hawk中很难显示。稍后我们会考虑优化这个区域。
如果显示 System.Object[],则表示它是一个数组。如果显示 System.Generic.Dictionary...,则为字典。也就是文档。
这件作品的设计真的很烂,太不可思议了,普通人看不懂,也是我做的不好的地方。. . 希望能帮到大家。
4.3. 使用 python 转换器处理 Json
5.案例。5.1. 嗅探
我们以某政府网站的专利检索为例来说明如何使用: 示例图如下:
无论您单击哪种下拉菜单,网址都保持不变。我们可以断定这是一个ajax页面。现在的目标是通过一个分类号来获取它的中英文含义,比如D01B1/00,就是右边的内容:
我们启动Hawk,新建一个网页采集器,将刚才的一串URL复制到网页采集器的地址栏中,发现得到的数据根本不收录这些中文意思.
怎么做?
您可以使用嗅探。我们以天然或人造线或纤维为关键词,填写网页采集器的内容过滤器:
然后点击开始。然后单击浏览器上的下拉菜单以展开类别编号。发现Hawk已经成功嗅探了字段:
此时,打开请求属性,可以看到真实请求的相关信息:
这是一个Post请求,(真实地址)url是:
!searchChildrenOfClassifyNum.dopost 的内容是classifyNum=D01。有了这些,我们将此命名为 采集器 Patent Inquiry`,下一步就很容易了。
即使嗅探失败也没关系。如果使用Chrome等浏览器,进入开发者工具(F12):
选择上角的network rollout,然后刷新网页,chrome会列出所有的请求,一般最上面的就是真正的请求:
点击查看源码,将所有文字复制到网页采集器,对应高级设置-请求参数。事实上,Hawk 也做了类似的操作。
5.2.步骤 2:
这里简单介绍一下,可以新建一个数据清洗,生成所有要查询的专利号的ID。这相对容易。例如,拖入是从文本生成的:
然后拖拽合并多列,把这串ID转换成一列要发布的数据:
拖进去新增一列,因为要网页采集器访问真实数据的url,所以填写上面提到的真实地址:
见证奇迹的时刻到了,在url栏拖拽从爬虫切换到刚才,然后配置如下:
由于post数据需要从post列中读取,所以用方括号括起来,像这样[post]。
结果是这样的:
这是一个Json,所以我们拖拽转换成json到content列:并将生成方式改为单文档,因为这只是一个字典,而不是一个字典数组:
你会发现只有一列有值:
是一个数组。然后,拖入python转换器,将生成模式配置为文档列表:你想要的数据都有:
点评:虽然这种请求可以用Hawk来配置,但还是推荐使用python,灵活性更大
抓取动态网页(2020年7月29日写在前面:右键打开源码找到iframe标签 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-08 12:06
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载新数据的JS文件,打开,会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关的数据,和post请求一起发送给网站,我们可以得到我们想要的数据。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
抓取动态网页(2020年7月29日写在前面:右键打开源码找到iframe标签
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载新数据的JS文件,打开,会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关的数据,和post请求一起发送给网站,我们可以得到我们想要的数据。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
抓取动态网页(如何为网络剪贴器制作特殊页面?更具体地说:如何在PHP中检测到Web工具?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-07 09:10
较短
我的一位客户有一个非常空旷的风格化网页,其中包括表格、图形和表格。当有人访问他们的 网站 时,它看起来很棒,但许多其他 网站 正在抓取页面并在他们的 网站 上显示空缺。
以前,他们的 网站 是一个带有一些基本标记的简单页面,例如标题、段落和粗体文本。其他网站 选择这个功能还不错,但是用了更高级的标签后就落后了。
如何为网络剪辑器制作一个特殊页面?更具体地说:如何在 PHP 中检测到网络爬虫正在查看页面?从那里,我可以弄清楚如何为客户创建一个自定义的 cms 页面,以便他们可以使用该页面自己填写简单的标记。
罗托拉
首先,标题、段落等都是很好的标记。如果“高级标记”没有这些,那根本就不是“高级标记”,而是坏标记。因此,无论页面是否被抓取,都应该使用语义标记。此外,还有更多的方式赋予 HTML 意义,例如微数据。
但是,由于您似乎了解网络爬虫(或至少了解它们)并已授予他们(隐式或明确)爬取 网站 的权限,因此它们的运营商应提供文档以说明您在寻找什么。
这些运营商最好根本不使用 webscapers,但他们应该以结构化的方式(例如 JSON 或 XML)获取他们正在寻找的信息,这些信息是您在常规 HTML 页面上额外生成的。 查看全部
抓取动态网页(如何为网络剪贴器制作特殊页面?更具体地说:如何在PHP中检测到Web工具?)
较短
我的一位客户有一个非常空旷的风格化网页,其中包括表格、图形和表格。当有人访问他们的 网站 时,它看起来很棒,但许多其他 网站 正在抓取页面并在他们的 网站 上显示空缺。
以前,他们的 网站 是一个带有一些基本标记的简单页面,例如标题、段落和粗体文本。其他网站 选择这个功能还不错,但是用了更高级的标签后就落后了。
如何为网络剪辑器制作一个特殊页面?更具体地说:如何在 PHP 中检测到网络爬虫正在查看页面?从那里,我可以弄清楚如何为客户创建一个自定义的 cms 页面,以便他们可以使用该页面自己填写简单的标记。
罗托拉
首先,标题、段落等都是很好的标记。如果“高级标记”没有这些,那根本就不是“高级标记”,而是坏标记。因此,无论页面是否被抓取,都应该使用语义标记。此外,还有更多的方式赋予 HTML 意义,例如微数据。
但是,由于您似乎了解网络爬虫(或至少了解它们)并已授予他们(隐式或明确)爬取 网站 的权限,因此它们的运营商应提供文档以说明您在寻找什么。
这些运营商最好根本不使用 webscapers,但他们应该以结构化的方式(例如 JSON 或 XML)获取他们正在寻找的信息,这些信息是您在常规 HTML 页面上额外生成的。
抓取动态网页( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-31 21:09
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取为静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com")
复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com")
复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以通过driver.switch_to.frame来定位。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等来提取内容。该方法中,提取出的带有复数s的内容是一个列表,没有提取s的是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
抓取动态网页(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取为静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com";)
复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com";)
复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com";)
复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以通过driver.switch_to.frame来定位。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等来提取内容。该方法中,提取出的带有复数s的内容是一个列表,没有提取s的是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!
抓取动态网页(不到js加载后渲染的结果,支持ajax,并且设置了js执行的等待时间(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-31 14:01
爬取某个站点的内容时,没有得到js加载后的渲染结果,但是也设置了支持js,支持ajax,设置了js执行的等待时间。它仍然不可用。
查看控制台打印的异常信息,在参数列表(************.js #32)之后发现页面js:missing)异常;而这个js加载了需要抓取的部分。查看32行,控制台打印的位置内容大致如下:
$('#news_pbl').masonry().masonry('reload');//
可以看出因为乱码,这部分没有换行,导致下面])被注释掉,导致js代码错误,无法加载内容。
所以尝试修改js代码,使其正常执行。
搜索后:
webClient.setWebConnection(
new WebConnectionWrapper(wc) {
public WebResponse getResponse(WebRequest request) throws IOException {
WebResponse response = super.getResponse(request);
if (request.getUrl().toExternalForm().contains("bfdata.js")) {//bfdata.js是需要修改编码的js,你可以修改该处逻辑
String content = response.getContentAsString("GBK");
WebResponseData data = new WebResponseData(content.getBytes("UTF-8"),
response.getStatusCode(), response.getStatusMessage(), response.getResponseHeaders());
response = new WebResponse(data, request, response.getLoadTime());
}
return response;
}
}
);
webClient 对象是一个实例化的 WebClient,可以调试看看使用的是哪种编码。 查看全部
抓取动态网页(不到js加载后渲染的结果,支持ajax,并且设置了js执行的等待时间(组图))
爬取某个站点的内容时,没有得到js加载后的渲染结果,但是也设置了支持js,支持ajax,设置了js执行的等待时间。它仍然不可用。
查看控制台打印的异常信息,在参数列表(************.js #32)之后发现页面js:missing)异常;而这个js加载了需要抓取的部分。查看32行,控制台打印的位置内容大致如下:
$('#news_pbl').masonry().masonry('reload');//
可以看出因为乱码,这部分没有换行,导致下面])被注释掉,导致js代码错误,无法加载内容。
所以尝试修改js代码,使其正常执行。
搜索后:
webClient.setWebConnection(
new WebConnectionWrapper(wc) {
public WebResponse getResponse(WebRequest request) throws IOException {
WebResponse response = super.getResponse(request);
if (request.getUrl().toExternalForm().contains("bfdata.js")) {//bfdata.js是需要修改编码的js,你可以修改该处逻辑
String content = response.getContentAsString("GBK");
WebResponseData data = new WebResponseData(content.getBytes("UTF-8"),
response.getStatusCode(), response.getStatusMessage(), response.getResponseHeaders());
response = new WebResponse(data, request, response.getLoadTime());
}
return response;
}
}
);
webClient 对象是一个实例化的 WebClient,可以调试看看使用的是哪种编码。
抓取动态网页(两种AJAX网页文字的抓取方法:*HTML文档(document))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-30 15:10
在 AJAX 网页上捕获文本的两种方法:
*网页文本是在加载HTML文档(document)时通过Javascript代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
*网页文本是在加载HTML文档(文档)后的某个时间获取并带有Javascript代码显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不意味着所有的内容都已经加载完毕。特殊的歧视机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能会出现:Timeout to load the page错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。要通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeoutto load the page错误。
注意:异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载,但计算机程序无法理解语义,因此DataScraper尝试使用一种智能方法进行判断,但仍有可能误判,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是间歇性的,而不是连续的,这时候DataScraper就会做出误判。 查看全部
抓取动态网页(两种AJAX网页文字的抓取方法:*HTML文档(document))
在 AJAX 网页上捕获文本的两种方法:
*网页文本是在加载HTML文档(document)时通过Javascript代码获取并显示的。这段 Javascript 代码在发送 load 事件之前运行,然后接收到 load 事件意味着所有内容都已加载。
*网页文本是在加载HTML文档(文档)后的某个时间获取并带有Javascript代码显示的。这段Javascript代码在发送load事件之后运行,那么接收到load事件并不意味着所有的内容都已经加载完毕。特殊的歧视机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能会出现:Timeout to load the page错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。要通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeoutto load the page错误。
注意:异步加载的内容加载时,没有确切的时间点。人们在阅读网页时,可以根据上下文来理解和判断异步内容是否已加载,但计算机程序无法理解语义,因此DataScraper尝试使用一种智能方法进行判断,但仍有可能误判,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是间歇性的,而不是连续的,这时候DataScraper就会做出误判。
抓取动态网页(不少人对于动态网页和静态网页的区别是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-29 03:26
很多人对动态网页和静态网页不太了解。不知道这两者有什么区别?下面小编就来告诉你动态网页和静态网页的区别。
静态网页不能简单理解为静态网页。主要指没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html、.htm或.xml等的网页。虽然静态网页的内容会一旦创建就不会改变。但是静态网页也收录一些活动部分,主要是GIF动画。用户可以直接双击打开静态网页,任何人随时打开的页面内容保持不变。
动态网页是一种相对于静态网页的网页编程技术。除了HTML标签,动态网页的网页文件还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,从而服务器端根据客户端的不同请求动态生成网页内容。与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。
两者的区别在于,一个静态网页的内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上. 如果要修改网页的内容,必须修改其源代码,然后重新上传到服务器。
静态网页没有数据库支持。当网站信息量较大时,网页的制作和维护难度很大。动态网页可以根据不同的用户请求、时间或环境要求动态生成不同的网页内容,动态网页一般都是基于数据库技术,大大减少了网站维护的工作量。
许多静态网页是固定的,在功能上有很大的局限性,因此交互性较差。动态网页可以实现用户登录、注册、查询等更多内容。
静态网页的内容比较固定,容易被搜索引擎检索到,而且不需要连接数据库,所以响应速度比较快。动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接访问、查询等一系列过程,所以响应速度比较慢。
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,双击直接打开。这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,在搜索时不会被捕获。取“?”后的内容 在 URL 中,您不能直接双击打开它。
以上是编辑器的总结,静态网页和动态网页的区别。总之,如果网页内容简单,不需要频繁改动,可以选择静态网页。如果网页复杂,功能多,那就选择动态网页。 查看全部
抓取动态网页(不少人对于动态网页和静态网页的区别是什么?)
很多人对动态网页和静态网页不太了解。不知道这两者有什么区别?下面小编就来告诉你动态网页和静态网页的区别。
静态网页不能简单理解为静态网页。主要指没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html、.htm或.xml等的网页。虽然静态网页的内容会一旦创建就不会改变。但是静态网页也收录一些活动部分,主要是GIF动画。用户可以直接双击打开静态网页,任何人随时打开的页面内容保持不变。
动态网页是一种相对于静态网页的网页编程技术。除了HTML标签,动态网页的网页文件还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,从而服务器端根据客户端的不同请求动态生成网页内容。与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。
两者的区别在于,一个静态网页的内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上. 如果要修改网页的内容,必须修改其源代码,然后重新上传到服务器。
静态网页没有数据库支持。当网站信息量较大时,网页的制作和维护难度很大。动态网页可以根据不同的用户请求、时间或环境要求动态生成不同的网页内容,动态网页一般都是基于数据库技术,大大减少了网站维护的工作量。
许多静态网页是固定的,在功能上有很大的局限性,因此交互性较差。动态网页可以实现用户登录、注册、查询等更多内容。
静态网页的内容比较固定,容易被搜索引擎检索到,而且不需要连接数据库,所以响应速度比较快。动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接访问、查询等一系列过程,所以响应速度比较慢。
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,双击直接打开。这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,在搜索时不会被捕获。取“?”后的内容 在 URL 中,您不能直接双击打开它。
以上是编辑器的总结,静态网页和动态网页的区别。总之,如果网页内容简单,不需要频繁改动,可以选择静态网页。如果网页复杂,功能多,那就选择动态网页。
抓取动态网页(横行的年代,性能相对Trident较好的抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-26 12:20
)
您需要登录才能下载或查看,还没有账号?立即注册
x
楼主今天在博客园看到了这个文章,转载并交流。
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页
从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigating += (sender, e) =>
{
hitCount++;
};
browser.DocumentCompleted += (sender, e) =>
{
hitCount++;
};
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s,然后再检查WEBbrowser是否加载完毕。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
当然效果还是一样的,就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程的。让我们看看如何将它放在工作线程上。这很简单。工作线程可以设置为STA模式。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
//[STAThread]
static void Main(string[] args)
{
Thread thread = new Thread(new ThreadStart(() =>
{
Init();
System.Windows.Forms.Application.Run();
}));
//将该工作线程设定为STA模式
thread.SetApartmentState(ApartmentState.STA);
thread.Start();
Console.Read();
}
static void Init()
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
Console.WriteLine(gethtml);
}
static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
{
hitCount++;
}
static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
hitCount++;
}
}
} 查看全部
抓取动态网页(横行的年代,性能相对Trident较好的抓取
)
您需要登录才能下载或查看,还没有账号?立即注册
x
楼主今天在博客园看到了这个文章,转载并交流。
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页
从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigating += (sender, e) =>
{
hitCount++;
};
browser.DocumentCompleted += (sender, e) =>
{
hitCount++;
};
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s,然后再检查WEBbrowser是否加载完毕。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
using System.IO;
namespace ConsoleApplication2
{
public class Program
{
[STAThread]
static void Main(string[] args)
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
//写入文件
using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
{
sw.WriteLine(gethtml);
}
Console.WriteLine("html 文件 已经生成!");
Console.Read();
}
}
}
当然效果还是一样的,就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程的。让我们看看如何将它放在工作线程上。这很简单。工作线程可以设置为STA模式。
[C#] 纯文本视图复制代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Threading;
namespace ConsoleApplication2
{
public class Program
{
static int hitCount = 0;
//[STAThread]
static void Main(string[] args)
{
Thread thread = new Thread(new ThreadStart(() =>
{
Init();
System.Windows.Forms.Application.Run();
}));
//将该工作线程设定为STA模式
thread.SetApartmentState(ApartmentState.STA);
thread.Start();
Console.Read();
}
static void Init()
{
string url = "http://www.cnblogs.com";
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
browser.Navigate(url);
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
while (hitCount < 16)
Application.DoEvents();
var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
string gethtml = htmldocument.documentElement.outerHTML;
Console.WriteLine(gethtml);
}
static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
{
hitCount++;
}
static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
hitCount++;
}
}
}
抓取动态网页(如何让客户记住自己,再加上产品的优势?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-25 08:03
抓取动态网页,然后输出给他看这就是网页搜索页面了,判断他想了解哪方面的东西,然后很多数据库都提供这样的服务而且自己查,
收集客户(也就是销售人员)需求,研究产品,提炼卖点,背熟产品知识,练好演讲稿,一场下来能让客户记住自己,再加上产品的优势,好吧,
不会就学,不学就问,学不会就砸。
销售需要提炼卖点其实打个比方销售是卖汽车的卖点是买车比买房子高多少个av/asv/esg吗?显然不是总而言之个人认为销售还是要学的多尝试下然后总结出适合自己的销售结果的话才是好的。
1.报告。2.销售案例。3.过程记录。4.活动案例。5.公司领导过问销售。6.价格谈判、货款回收、渠道管理等时候能用上。7.形象包装。
首先收集用户反馈,与用户进行交流,再提炼出产品卖点、品牌形象宣传卖点,增加公司和产品的有效期限,然后跟踪用户,核实用户反馈,引导客户为产品购买其次分析并实践解决真实需求,能提炼出核心卖点更好,强化用户关心的功能、服务、解决痛点,并培养关注新功能,销售人员自己反馈客户问题和感受,也许客户是对的。再次,销售人员从周边线上采购补充产品,把线上产品线延伸至线下,以线下活动资源为基础拓展客户,采取高频次的沟通式销售最后,销售团队自我提升的过程,比如收集客户开发信、邮件、病历、服务单、管理数据等客户线索,随时随地的销售创意引导客户线下和客户签约线上对话前给客户提供线索、价格及预算分析,重点有针对性的将用户接触点控制在产品内,提高对话效率销售的时候把有限的时间和精力放在有成效的步骤上,多充电,多学习,效率很重要。 查看全部
抓取动态网页(如何让客户记住自己,再加上产品的优势?)
抓取动态网页,然后输出给他看这就是网页搜索页面了,判断他想了解哪方面的东西,然后很多数据库都提供这样的服务而且自己查,
收集客户(也就是销售人员)需求,研究产品,提炼卖点,背熟产品知识,练好演讲稿,一场下来能让客户记住自己,再加上产品的优势,好吧,
不会就学,不学就问,学不会就砸。
销售需要提炼卖点其实打个比方销售是卖汽车的卖点是买车比买房子高多少个av/asv/esg吗?显然不是总而言之个人认为销售还是要学的多尝试下然后总结出适合自己的销售结果的话才是好的。
1.报告。2.销售案例。3.过程记录。4.活动案例。5.公司领导过问销售。6.价格谈判、货款回收、渠道管理等时候能用上。7.形象包装。
首先收集用户反馈,与用户进行交流,再提炼出产品卖点、品牌形象宣传卖点,增加公司和产品的有效期限,然后跟踪用户,核实用户反馈,引导客户为产品购买其次分析并实践解决真实需求,能提炼出核心卖点更好,强化用户关心的功能、服务、解决痛点,并培养关注新功能,销售人员自己反馈客户问题和感受,也许客户是对的。再次,销售人员从周边线上采购补充产品,把线上产品线延伸至线下,以线下活动资源为基础拓展客户,采取高频次的沟通式销售最后,销售团队自我提升的过程,比如收集客户开发信、邮件、病历、服务单、管理数据等客户线索,随时随地的销售创意引导客户线下和客户签约线上对话前给客户提供线索、价格及预算分析,重点有针对性的将用户接触点控制在产品内,提高对话效率销售的时候把有限的时间和精力放在有成效的步骤上,多充电,多学习,效率很重要。
抓取动态网页(/boost-extension·github不用java写`sort=o)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-25 04:01
抓取动态网页,利用boost::unified_image插件进行伪码解析使用到的知识点:python3ie浏览器控制台插件定位ie浏览器
boost::mainline是百度推出的一个跨平台的开源图像加速算法库,它支持基于python的标准python语言的解析器解析带有ie/firefox/safari或者xbox等网页浏览器的url,并提供各种可使用的图像处理算法可进行解析加速。虽然可以直接利用python语言来实现,但是由于网站的不同,所以并不是每个网站都有开发这样一个用于python解析的新工具。
在绝大多数情况下,我们只能通过libdlb::mainline完成这一复杂图像处理工作。至于原因,我也并不是特别了解,仅仅是个人猜测而已。
awesome-boost/boost-extension·github不用写java
`sort=o()ifnotie.ie()elseiwillalwaysexecute```\```add-classboost::extension```
本人每天写那个代码的时候,都能被吓到,要能实现一套这样的接口我也去写个地铁闸机系统api啊,还可以跟微信支付宝联动,还能全国统一标准api价格和文档。
百度爬虫库,基于boost算法库,
softhinker能进行计算属性匹配,其中有一个关键接口find-all,我的曾经做过。 查看全部
抓取动态网页(/boost-extension·github不用java写`sort=o)
抓取动态网页,利用boost::unified_image插件进行伪码解析使用到的知识点:python3ie浏览器控制台插件定位ie浏览器
boost::mainline是百度推出的一个跨平台的开源图像加速算法库,它支持基于python的标准python语言的解析器解析带有ie/firefox/safari或者xbox等网页浏览器的url,并提供各种可使用的图像处理算法可进行解析加速。虽然可以直接利用python语言来实现,但是由于网站的不同,所以并不是每个网站都有开发这样一个用于python解析的新工具。
在绝大多数情况下,我们只能通过libdlb::mainline完成这一复杂图像处理工作。至于原因,我也并不是特别了解,仅仅是个人猜测而已。
awesome-boost/boost-extension·github不用写java
`sort=o()ifnotie.ie()elseiwillalwaysexecute```\```add-classboost::extension```
本人每天写那个代码的时候,都能被吓到,要能实现一套这样的接口我也去写个地铁闸机系统api啊,还可以跟微信支付宝联动,还能全国统一标准api价格和文档。
百度爬虫库,基于boost算法库,
softhinker能进行计算属性匹配,其中有一个关键接口find-all,我的曾经做过。
抓取动态网页( AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-24 22:15
AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以确定为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
2 分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,简而言之就是你所有的操作认为可能会触发新的数据)),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
3 编写程序
回顾之前的列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
抓取动态网页(
AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本可以确定为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
2 分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,简而言之就是你所有的操作认为可能会触发新的数据)),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
3 编写程序
回顾之前的列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
抓取动态网页(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-24 22:13
本文是对《AJAX动态网页信息抽取原理》的补充。上一篇总结了两种在 AJAX 网页上捕获文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。此 Javascript 代码在发送 load 事件之前运行,然后接收 load 事件意味着所有内容都已加载。网页文本加载HTML文档(document)之后,在某个时间,使用Javascript代码获取并显示。这段Javascript代码在发送load事件后运行,那么接收到load事件并不代表内容已经全部加载完毕,需要特殊的判别机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。DataScraper 从 V4.2.0B57 版本开始得到增强,可以抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能出现: Timeout to load the page 错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeout to load the page错误。
注意:加载异步加载的内容时,没有确切的时间点。人们在阅读网页时,可以根据上下文理解和判断异步内容是否已加载,但计算机程序无法理解语义。DataScraper 尝试使用一种智能方式来判断,但是还是存在误判的可能,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是断断续续的,而不是比连续的时候,DataScraper 会做出错误的判断。 查看全部
抓取动态网页(本文是对《AJAX动态网页信息提取原理》的补充,前文总结了两种情况)
本文是对《AJAX动态网页信息抽取原理》的补充。上一篇总结了两种在 AJAX 网页上捕获文本的方法:
网页文本是在加载 HTML 文档(document)时通过 Javascript 代码获取并显示的。此 Javascript 代码在发送 load 事件之前运行,然后接收 load 事件意味着所有内容都已加载。网页文本加载HTML文档(document)之后,在某个时间,使用Javascript代码获取并显示。这段Javascript代码在发送load事件后运行,那么接收到load事件并不代表内容已经全部加载完毕,需要特殊的判别机制。
以上两种情况,其实都没有考虑到AJAX的一个重要特性:异步加载。即HTML网页的文本内容不是与HTML文档同步加载的,而是在某些情况下(例如用户点击超链接)从服务器异步获取并显示的。此时无法使用load事件触发网页文本爬取。DataScraper 从 V4.2.0B57 版本开始得到增强,可以抓取异步加载的内容。
因为没有load事件触发fetch操作,所以必须进行合理的配置,通知DataScraper不要等待load事件。如果定时自动抓取网页文本,可以通过设置调度指令文件的waitOnload参数来实现。但是在V4.2.0B57之前的版本中,所有手动发起的爬取都waitOnload=true,即等待load事件。提取异步加载的内容时,很可能出现: Timeout to load the page 错误。从V4.2.0B57版本开始,增加了DataScraper菜单:Configuration->Wait for load。这是一个复选框菜单。移除钩子,不再等待加载事件。
例如MetaCamp服务器上有一个主题:demo_js_paging_sohu,用于爬取搜狐名人博客和相关评论。评论内容由 AJAX 动态生成。当名人博客很受欢迎时,就会有很多评论。这些评论显示在多个页面上。当用户点击“下一页”超链接时,不会加载新的HTML页面,而是从网站异步获取下一页评论内容,动态修改当前页面的DOM结构进行显示。因此,没有页面加载就没有加载事件。通过翻页提取这些评论,需要设置waitOnload=false,否则会遇到Timeout to load the page错误。
注意:加载异步加载的内容时,没有确切的时间点。人们在阅读网页时,可以根据上下文理解和判断异步内容是否已加载,但计算机程序无法理解语义。DataScraper 尝试使用一种智能方式来判断,但是还是存在误判的可能,主要是当目标网站的服务质量非常不稳定,异步加载内容和刷新显示的过程是断断续续的,而不是比连续的时候,DataScraper 会做出错误的判断。
抓取动态网页( 的编码(u)需要制定字符串的字符串编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-24 22:10
的编码(u)需要制定字符串的字符串编码)
分享python抓取网页、python抓取动态网页时字符集转换问题的解决方案
来源:未知 浏览 38 次时间 2021-06-11 00:12
有时我们采集在处理网页后将字符串保存到文件或写入数据库。这时候就需要制定字符串的编码方式了。 采集网页的编码是gb2312,我们的数据库是utf-8。如果不做任何处理直接插入数据库可能会出现乱码(我没测试过,不知道数据库会不会自动转码)我们需要手动把gb2312转成utf-8。
首先我们知道python中的字符默认是ascii码。英文当然没问题。遇到中国人,立马下跪。
打印你“你想建立一个基地吗?”
这样就可以显示中文了。 u 的作用是将下面的字符串转换成unicode 码,以便正确显示中文。
这里有一个与之相关的 unicode() 函数。用法如下
str="Let's make a base"str=unicode(str,"utf-8")print str
两者的区别
和 u 是必须正确指定第二个参数才能使用 unicode 将 str 转换为 unicode。 utf-8 是我的 test.py 脚本本身的文件字符集。默认字符集可能是ansi。
unicode 这是下面继续的关键
import urllib2def main(): f=urllib2.urlopen("") str=f.read() str=unicode(str,"gb2312") fp=open("baidu.html"," w") fp.write(str.encode("utf-8")) fp.close()if __name__ =='__main__': main()
说明:
我们先用urllib2.urlopen()方法把百度主页抓取到句柄f,然后用str=f.read()把所有的源码读入str
说清楚,str是我们抓取的html源代码,因为网页的默认字符集是gb2312,所以如果我们直接保存到文件中,文件编码会是ansi。
这对大多数人来说其实已经足够了,但有时我只是想将gb2312转换为utf-8。我该怎么办?
首先:
str=unicode(str,”gb2312″) #这里gb2312是str的实际字符集。我们现在将其转换为 unicode
那么:
str=str.encode("utf-8") #将unicode字符串重新编码成utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8。将 meta charset="gb2312" 改为 meta charset="utf-8",即 utf-8 网页。做了这么多,居然完成了一次gb2312-utf-8转码。
总结:
如果需要按照指定的字符集保存字符串,我们来回顾以下步骤:
1:使用unicode(str,"原创编码")将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集 查看全部
抓取动态网页(
的编码(u)需要制定字符串的字符串编码)
分享python抓取网页、python抓取动态网页时字符集转换问题的解决方案
来源:未知 浏览 38 次时间 2021-06-11 00:12
有时我们采集在处理网页后将字符串保存到文件或写入数据库。这时候就需要制定字符串的编码方式了。 采集网页的编码是gb2312,我们的数据库是utf-8。如果不做任何处理直接插入数据库可能会出现乱码(我没测试过,不知道数据库会不会自动转码)我们需要手动把gb2312转成utf-8。
首先我们知道python中的字符默认是ascii码。英文当然没问题。遇到中国人,立马下跪。
打印你“你想建立一个基地吗?”
这样就可以显示中文了。 u 的作用是将下面的字符串转换成unicode 码,以便正确显示中文。
这里有一个与之相关的 unicode() 函数。用法如下
str="Let's make a base"str=unicode(str,"utf-8")print str
两者的区别
和 u 是必须正确指定第二个参数才能使用 unicode 将 str 转换为 unicode。 utf-8 是我的 test.py 脚本本身的文件字符集。默认字符集可能是ansi。
unicode 这是下面继续的关键
import urllib2def main(): f=urllib2.urlopen("") str=f.read() str=unicode(str,"gb2312") fp=open("baidu.html"," w") fp.write(str.encode("utf-8")) fp.close()if __name__ =='__main__': main()
说明:
我们先用urllib2.urlopen()方法把百度主页抓取到句柄f,然后用str=f.read()把所有的源码读入str
说清楚,str是我们抓取的html源代码,因为网页的默认字符集是gb2312,所以如果我们直接保存到文件中,文件编码会是ansi。
这对大多数人来说其实已经足够了,但有时我只是想将gb2312转换为utf-8。我该怎么办?
首先:
str=unicode(str,”gb2312″) #这里gb2312是str的实际字符集。我们现在将其转换为 unicode
那么:
str=str.encode("utf-8") #将unicode字符串重新编码成utf-8
最后:
将str写入文件,打开文件查看编码属性,发现是utf-8。将 meta charset="gb2312" 改为 meta charset="utf-8",即 utf-8 网页。做了这么多,居然完成了一次gb2312-utf-8转码。
总结:
如果需要按照指定的字符集保存字符串,我们来回顾以下步骤:
1:使用unicode(str,"原创编码")将str解码成unicode字符串
2:使用str.encode("specified character set")将unicode字符串str转换成你指定的字符集
抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-24 22:08
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多情况下,我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置 查看全部
抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多情况下,我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置
抓取动态网页(selenium动态网页有两种方法:1.分析网页找到真实网页地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-23 22:13
selenium的安装和使用
一.评论
我们之前抓取的网页被列为百度贴吧。起点中文网站都是静态网页。浏览器中显示的此类网页的内容均在 HTML 源代码中。但是现在很多网站都使用JavaScript来展示网页内容,这时候静态网页抓取技术就不行了。抓取动态网页有两种方式:
1.分析网页,找到真实的网页地址(如爬取众财网双色球信息的例子),
2.使用selenium模拟浏览器。
二.Selenium 介绍和安装
1.什么是硒?
Selenium 也是 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。
2.安装
只需使用 pip 命令安装它!
pip install selenium
安装可能会失败。请多试几次。如果下载太慢,我们可以执行pip换源重新下载。
部分国内资源:
阿里云
中国科学技术大学
豆瓣
清华大学
中国科学技术大学
具体步骤:
如图,进入用户目录下APPData下Local下的pip文件夹创建,不创建pip.ini文件,复制以下代码保存。
[global]
timeout=6000
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
三.浏览器选择与安装
1.查看selenium webdriver支持的浏览器类型
from selenium import webdriver
help(webdriver)
常用的浏览器有phantomjs Google Firefox
2.安装phantomjs
官网下载:""
安装:将phantomjs压缩包中的可执行文件添加到python目录下。如果使用anaconda,添加到anaconda目录下(与python.exe同级)
如图:
3.测试
输入python,输入以下命令没有错误!
from selenium import webdriver
driver=webdriver.PathtomJS()
四.申请
我们使用百度来测试selenium+phantomjs的功能。测试模拟输入关键字进行搜索。这里我们使用了一种新的元素定位方法xpath
有兴趣的可以阅读菜鸟教程《》学习他的语法
#! -*- encoding:utf-8 -*-
from selenium import webdriver
browser=webdriver.PhantomJS()
browser.get('http://www.baidu.com')
browser.implicitly_wait(10) #他是一个智能等待函数 因为利用JS引擎运行需要时间
#找到页面表单的文本框
textElement=browser.find_element_by_id('kw')
textElement.send_keys('python selenium') #模拟按键输入
#找到提交按钮
submitElement=browser.find_element_by_id('su')
submitElement.click() #点击元素
print (browser.title)
#xpath解析
"""
定位网页中的元素(locate elements)
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
操作元素方法:
clear 清除元素的内容
send_keys 模拟按键输入
click 点击元素
submit 提交表单
"""
有很多浏览器选择。这里选择的是.PhantomJS(),它没有接口。
除了选择:browser=webdriver.PhantomJS(),还可以选择谷歌火狐等有界面的浏览器(前提是电脑有这样的浏览器)。例如,我们可以选择:
browser=webdriver.Chrome()
browser=webdriver.Firefox()
但是如果直接使用,就会报错
根据提示,我们知道我们缺少“geckodriver”,我们可以在线下载
“”
记得下载与你的浏览器版本一致或兼容的geckodriver,然后放到你的火狐浏览器目录下
这同样适用于 Google Chrome 的安装。如果Chromedriver版本与浏览器不兼容,可能会出现以下问题:
版本参考:
Chrome 驱动程序:"
司机:””
最好在路径中添加环境变量
小路:
这里的坑几乎填满了。遇到问题一定要记得百度。环境搭建好后,爬虫就会轻松愉快!
参考文章:
“”
“”
“” 查看全部
抓取动态网页(selenium动态网页有两种方法:1.分析网页找到真实网页地址)
selenium的安装和使用
一.评论
我们之前抓取的网页被列为百度贴吧。起点中文网站都是静态网页。浏览器中显示的此类网页的内容均在 HTML 源代码中。但是现在很多网站都使用JavaScript来展示网页内容,这时候静态网页抓取技术就不行了。抓取动态网页有两种方式:
1.分析网页,找到真实的网页地址(如爬取众财网双色球信息的例子),
2.使用selenium模拟浏览器。
二.Selenium 介绍和安装
1.什么是硒?
Selenium 也是 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。
2.安装
只需使用 pip 命令安装它!
pip install selenium
安装可能会失败。请多试几次。如果下载太慢,我们可以执行pip换源重新下载。
部分国内资源:
阿里云
中国科学技术大学
豆瓣
清华大学
中国科学技术大学
具体步骤:
如图,进入用户目录下APPData下Local下的pip文件夹创建,不创建pip.ini文件,复制以下代码保存。
[global]
timeout=6000
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
三.浏览器选择与安装
1.查看selenium webdriver支持的浏览器类型
from selenium import webdriver
help(webdriver)
常用的浏览器有phantomjs Google Firefox
2.安装phantomjs
官网下载:""
安装:将phantomjs压缩包中的可执行文件添加到python目录下。如果使用anaconda,添加到anaconda目录下(与python.exe同级)
如图:
3.测试
输入python,输入以下命令没有错误!
from selenium import webdriver
driver=webdriver.PathtomJS()
四.申请
我们使用百度来测试selenium+phantomjs的功能。测试模拟输入关键字进行搜索。这里我们使用了一种新的元素定位方法xpath
有兴趣的可以阅读菜鸟教程《》学习他的语法
#! -*- encoding:utf-8 -*-
from selenium import webdriver
browser=webdriver.PhantomJS()
browser.get('http://www.baidu.com')
browser.implicitly_wait(10) #他是一个智能等待函数 因为利用JS引擎运行需要时间
#找到页面表单的文本框
textElement=browser.find_element_by_id('kw')
textElement.send_keys('python selenium') #模拟按键输入
#找到提交按钮
submitElement=browser.find_element_by_id('su')
submitElement.click() #点击元素
print (browser.title)
#xpath解析
"""
定位网页中的元素(locate elements)
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
操作元素方法:
clear 清除元素的内容
send_keys 模拟按键输入
click 点击元素
submit 提交表单
"""
有很多浏览器选择。这里选择的是.PhantomJS(),它没有接口。
除了选择:browser=webdriver.PhantomJS(),还可以选择谷歌火狐等有界面的浏览器(前提是电脑有这样的浏览器)。例如,我们可以选择:
browser=webdriver.Chrome()
browser=webdriver.Firefox()
但是如果直接使用,就会报错
根据提示,我们知道我们缺少“geckodriver”,我们可以在线下载
“”
记得下载与你的浏览器版本一致或兼容的geckodriver,然后放到你的火狐浏览器目录下
这同样适用于 Google Chrome 的安装。如果Chromedriver版本与浏览器不兼容,可能会出现以下问题:
版本参考:
Chrome 驱动程序:"
司机:””
最好在路径中添加环境变量
小路:
这里的坑几乎填满了。遇到问题一定要记得百度。环境搭建好后,爬虫就会轻松愉快!
参考文章:
“”
“”
“”
抓取动态网页( 微信朋友圈的分析网页数据(一)_创做书籍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-22 20:10
微信朋友圈的分析网页数据(一)_创做书籍)
二、 即日起,在首页点击【创建图书】-->【微信】。互联网
三、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。框架
四、 未来,我们会耐心等待微信出品。完成后,您会收到编辑器的消息提醒,如下图所示。刮的
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。想法
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。工具
五、 以后点击外链进入网页,需要使用微信扫码授权登录。
六、扫码授权后,即可进入网页版微信,如下图。
七、 接下来我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信首页,图片由编辑自行定制。
2、创建爬虫项目
一、确保您的计算机上安装了 Scrapy。选择文件夹后,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
二、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。稍后输入命令:
scrapy genspider'时刻''chushu.la'
,建立朋友圈爬虫,如下图所示。
三、 执行以上两步后的文件夹结构如下:
3、分析网络数据
一、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如图在下图中。能够看到首页的请求方法是get,返回状态码为200,表示请求成功。
二、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。这意味着我们需要在程序中处理JSON格式的数据。
三、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
四、 点击【2014/04】月后可以查看服务器响应数据,可以看到页面显示的数据与服务器响应对应。
五、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址保持不变,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数不断变化,如下图所示。
六、展开服务器响应数据,将数据放入JSON在线解析器中,如下图所示:
可以看到 Moments 的数据存储在 paras /data 节点下。
至此,网页分析和数据来源已经确认。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~ 查看全部
抓取动态网页(
微信朋友圈的分析网页数据(一)_创做书籍)
二、 即日起,在首页点击【创建图书】-->【微信】。互联网
三、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。框架
四、 未来,我们会耐心等待微信出品。完成后,您会收到编辑器的消息提醒,如下图所示。刮的
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。想法
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。工具
五、 以后点击外链进入网页,需要使用微信扫码授权登录。
六、扫码授权后,即可进入网页版微信,如下图。
七、 接下来我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图为微信首页,图片由编辑自行定制。
2、创建爬虫项目
一、确保您的计算机上安装了 Scrapy。选择文件夹后,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
二、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。稍后输入命令:
scrapy genspider'时刻''chushu.la'
,建立朋友圈爬虫,如下图所示。
三、 执行以上两步后的文件夹结构如下:
3、分析网络数据
一、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如图在下图中。能够看到首页的请求方法是get,返回状态码为200,表示请求成功。
二、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。这意味着我们需要在程序中处理JSON格式的数据。
三、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
四、 点击【2014/04】月后可以查看服务器响应数据,可以看到页面显示的数据与服务器响应对应。
五、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址保持不变,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数不断变化,如下图所示。
六、展开服务器响应数据,将数据放入JSON在线解析器中,如下图所示:
可以看到 Moments 的数据存储在 paras /data 节点下。
至此,网页分析和数据来源已经确认。接下来,我将编写一个程序来捕获数据。敬请期待下一篇文章~~
抓取动态网页( Python软件工具和2020最新入门到实战教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-15 10:12
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。自从我第一次接触python以来,过程中有很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
抓取动态网页(
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。自从我第一次接触python以来,过程中有很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。

