
抓取动态网页
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-29 15:28
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 using System.IO; 8 9 namespace ConsoleApplication210 {11 public class Program12 {13 static int hitCount = 0;14 15 [STAThread]16 static void Main(string[] args)17 {18 string url = "http://www.cnblogs.com";19 20 WebBrowser browser = new WebBrowser();21 22 browser.ScriptErrorsSuppressed = true;23 24 browser.Navigating += (sender, e) =>25 {26 hitCount++;27 };28 29 browser.DocumentCompleted += (sender, e) =>30 {31 hitCount++;32 };33 34 browser.Navigate(url);35 36 while (browser.ReadyState != WebBrowserReadyState.Complete)37 {38 Application.DoEvents();39 }40 41 while (hitCount 35 {36 //加载完毕37 isComplete = true;38 39 timer.Stop();40 });41 42 timer.Interval = 1000 * 5;43 44 timer.Start();45 46 //继续等待 5s,等待js加载完47 while (!isComplete)48 Application.DoEvents();49 50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;51 52 string gethtml = htmldocument.documentElement.outerHTML;53 54 //写入文件55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))56 {57 sw.WriteLine(gethtml);58 }59 60 Console.WriteLine("html 文件 已经生成!");61 62 Console.Read();63 }64 }65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
<p> 1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 8 namespace ConsoleApplication2 9 {10 public class Program11 {12 static int hitCount = 0;13 14 //[STAThread]15 static void Main(string[] args)16 {17 Thread thread = new Thread(new ThreadStart(() =>18 {19 Init();20 System.Windows.Forms.Application.Run();21 }));22 23 //将该工作线程设定为STA模式24 thread.SetApartmentState(ApartmentState.STA);25 26 thread.Start();27 28 Console.Read();29 }30 31 static void Init()32 {33 string url = "http://www.cnblogs.com";34 35 WebBrowser browser = new WebBrowser();36 37 browser.ScriptErrorsSuppressed = true;38 39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);40 41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);42 43 browser.Navigate(url);44 45 while (browser.ReadyState != WebBrowserReadyState.Complete)46 {47 Application.DoEvents();48 }49 50 while (hitCount 查看全部
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在

1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 using System.IO; 8 9 namespace ConsoleApplication210 {11 public class Program12 {13 static int hitCount = 0;14 15 [STAThread]16 static void Main(string[] args)17 {18 string url = "http://www.cnblogs.com";19 20 WebBrowser browser = new WebBrowser();21 22 browser.ScriptErrorsSuppressed = true;23 24 browser.Navigating += (sender, e) =>25 {26 hitCount++;27 };28 29 browser.DocumentCompleted += (sender, e) =>30 {31 hitCount++;32 };33 34 browser.Navigate(url);35 36 while (browser.ReadyState != WebBrowserReadyState.Complete)37 {38 Application.DoEvents();39 }40 41 while (hitCount 35 {36 //加载完毕37 isComplete = true;38 39 timer.Stop();40 });41 42 timer.Interval = 1000 * 5;43 44 timer.Start();45 46 //继续等待 5s,等待js加载完47 while (!isComplete)48 Application.DoEvents();49 50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;51 52 string gethtml = htmldocument.documentElement.outerHTML;53 54 //写入文件55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))56 {57 sw.WriteLine(gethtml);58 }59 60 Console.WriteLine("html 文件 已经生成!");61 62 Console.Read();63 }64 }65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
<p> 1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 8 namespace ConsoleApplication2 9 {10 public class Program11 {12 static int hitCount = 0;13 14 //[STAThread]15 static void Main(string[] args)16 {17 Thread thread = new Thread(new ThreadStart(() =>18 {19 Init();20 System.Windows.Forms.Application.Run();21 }));22 23 //将该工作线程设定为STA模式24 thread.SetApartmentState(ApartmentState.STA);25 26 thread.Start();27 28 Console.Read();29 }30 31 static void Init()32 {33 string url = "http://www.cnblogs.com";34 35 WebBrowser browser = new WebBrowser();36 37 browser.ScriptErrorsSuppressed = true;38 39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);40 41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);42 43 browser.Navigate(url);44 45 while (browser.ReadyState != WebBrowserReadyState.Complete)46 {47 Application.DoEvents();48 }49 50 while (hitCount
抓取动态网页(知乎如何把一个网页爬下来?搞flask吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-28 16:33
抓取动态网页可以用imgurl()方法,这是python很早之前的方法,通过网页中的cookie,从cookie里提取title,description,transitiontime等参数,解析出图片链接,就可以定制它的url了。很久以前我用imgurl()方法做图片采集,不是很稳定,还会出现丢图片的情况,后来我采用appium这个安卓和ios双平台的api,这就是用selenium+sdk吧,很方便,可以弄出很多网页的截图,appium在跨平台方面做的比python要好很多,它只做获取,不做解析,解析更费时间,python搞一大堆代码才解析出来。
安卓的appium挺好用的,而且selenium也能做python的整合,我自己写了个第三方的测试框架,据说selenium有接口,不知道能不能用,可以免费测试,如果大家需要,私信我,我放链接给大家,测试框架的链接:密码:kafz。
python的安卓获取图片之前有个比较简单的案例用python抓取qq音乐一段音乐的图片(小米账号是否登录是一张图)可以在线看,
爬虫目前做过的有:1.-spider/spider/三种方式:官方提供的api,
来看看我的网站吧
-bootstrap/img
下面有个概念总结,相对比较全面的。
知乎如何把一个网页爬下来?
搞flask吧 查看全部
抓取动态网页(知乎如何把一个网页爬下来?搞flask吧!)
抓取动态网页可以用imgurl()方法,这是python很早之前的方法,通过网页中的cookie,从cookie里提取title,description,transitiontime等参数,解析出图片链接,就可以定制它的url了。很久以前我用imgurl()方法做图片采集,不是很稳定,还会出现丢图片的情况,后来我采用appium这个安卓和ios双平台的api,这就是用selenium+sdk吧,很方便,可以弄出很多网页的截图,appium在跨平台方面做的比python要好很多,它只做获取,不做解析,解析更费时间,python搞一大堆代码才解析出来。
安卓的appium挺好用的,而且selenium也能做python的整合,我自己写了个第三方的测试框架,据说selenium有接口,不知道能不能用,可以免费测试,如果大家需要,私信我,我放链接给大家,测试框架的链接:密码:kafz。
python的安卓获取图片之前有个比较简单的案例用python抓取qq音乐一段音乐的图片(小米账号是否登录是一张图)可以在线看,
爬虫目前做过的有:1.-spider/spider/三种方式:官方提供的api,
来看看我的网站吧
-bootstrap/img
下面有个概念总结,相对比较全面的。
知乎如何把一个网页爬下来?
搞flask吧
抓取动态网页(代码也可以从我的开源项目HtmlExtractor中获取。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-28 07:27
)
代码也可以从我的开源项目htmlextractor获得
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i 查看全部
抓取动态网页(代码也可以从我的开源项目HtmlExtractor中获取。。
)
代码也可以从我的开源项目htmlextractor获得
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i
抓取动态网页(动态网站解析的动态网页爬取方法(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-28 07:26
)
我刚才讲的是抓取静态网页。本篇博客介绍动态网站的爬取。动态网站的爬取比静态网页更难,涉及的主要技术是Ajax和动态Html。简单的网页访问无法获取完整的数据,需要分析数据加载过程。将通过具体的例子来介绍不同的动态网页爬取方法。本篇博客主要使用ajax直接获取数据。
页面分析
本博客以MTime电影网为例,主要爬取电影收视率、票房等信息。首先使用火狐浏览器的控制台查看页面信息。
页面中的票房信息无法以 HTML 格式获取。是通过js动态加载得到的,然后搜索对应的js响应。就是从一堆js请求中查看一些收录ajax字段的请求。%3A%2F%%2F242129%2F&t=27406&Ajax_CallBackArgument0=242129
点击查看返回数据:
找到对应的链接并返回数据后,需要分析这个链接的构造方法,分析返回的数据。
(1)链接一共7个参数,我们首先要分析哪些参数没有变化,哪些参数在不同的电影中差异更大。通过对比两个不同的电影链接,可以发现其中4个是not 有动态变化的三个参数,分别是Ajax_RequestRrl、t和Ajax_CallBackArgument0,通过分析可以发现这三个参数分别代表当前页面url、当前请求时间、电影所代表的数量。
(2) 提取响应数据。响应内容主要分为三类,分别是正在上映的电影信息,即将上映的电影信息,最后一种是即将上映的电影信息发布很久了,详情见代码。
具体实现代码
本文代码基于博客实现。本博客只修改需要改动的部分。
网页分析
在HtmlParser类中定义一个parser_url方法,代码如下:
def parser_url(self, page_url, response):
pattern = re.compile(r'(http://movie.mtime.com/(\d+)/)')
urls = pattern.findall(response)
if urls != None:
return list(set(urls))
else:
return None
提取响应数据中的有效数据:
def parser_json(self, page_url, respone):
"""
解析响应
:param page_url:
:param respone:
:return:
"""
#将“=”和“;”之间的内容提取出来
pattern = re.compile(r'=(.*?);')
result = pattern.findall(respone)[0]
if result != None:
value = json.loads(result)
try:
isRelease = value.get('value').get('isRelease')
except Exception,e:
print(e)
return None
if isRelease:
if value.get('value').get('hotValue') == None:
return self._parser_release(page_url, value)
else:
self._parser_no_release(page_url, value, isRelease = 2)
else:
return self._parser_no_release(page_url, value)
def _parser_release(self, page_url, value):
"""
解析已上映的影片
:param page_url:
:param value:
:return:
"""
try:
isRelease = 1
movieRating = value.get('value').get('movieRating')
boxOffice = value.get('value').get('boxOffice')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
TotalBoxOffice = boxOffice.get('TotalBoxOffice')
TotalBoxOfficeUnit = boxOffice.get('TotalBoxOfficeUnit')
TodayBoxOffice = boxOffice.get('TodayBoxOffice')
TodayBoxOfficeUnit = boxOffice.get('TodayBoxOfficeUnit')
showDays = boxOffice.get('ShowDays')
try:
Rank = boxOffice.get('Rank')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,
TotalBoxOffice+TotalBoxOfficeUnit,
TodayBoxOffice+TodayBoxOfficeUnit,
Rank,showDays,isRelease)
except Exception,e:
print(e,page_url,value)
return None
def _parser_no_release(self,page_url,value,isRelease = 0):
try:
movieRating = value.get('value').get('movieRating')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
try:
Rank = value.get('value').get('hotValue').get('Ranking')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,u'无',
u'无',Rank,0,isRelease)
except Exception,e:
print(e, page_url, value)
return None
爬虫调度器
def dynamic_crawl(self, root_url):
content = self.downloader.download(root_url)
urls = self.parser.parser_url(root_url,content)
for url in urls:
try:
t = time.strftime("%Y%m%d%H%M%S3282", time.localtime())
rank_url ='http://service.library.mtime.com/Movie.api'\
'?Ajax_CallBack=true'\
'&Ajax_CallBackType=Mtime.Library.Services'\
'&Ajax_CallBackMethod=GetMovieOverviewRating'\
'&Ajax_CrossDomain=1'\
'&Ajax_RequestRrl=%s'\
'&t=%s'\
'&Ajax_CallBackArgument0=%s'%(url[0],t,url[1])
rank_content = self.downloader.download(rank_url)
data = self.parser.parser_json(rank_url,rank_content)
print(data)
except Exception,e:
print('Crawl failed')
if __name__=="__main__":
spider_main = SpiderMain()
spider_main.dynamic_crawl("http://theater.mtime.com/China_Beijing/") 查看全部
抓取动态网页(动态网站解析的动态网页爬取方法(组图)
)
我刚才讲的是抓取静态网页。本篇博客介绍动态网站的爬取。动态网站的爬取比静态网页更难,涉及的主要技术是Ajax和动态Html。简单的网页访问无法获取完整的数据,需要分析数据加载过程。将通过具体的例子来介绍不同的动态网页爬取方法。本篇博客主要使用ajax直接获取数据。
页面分析
本博客以MTime电影网为例,主要爬取电影收视率、票房等信息。首先使用火狐浏览器的控制台查看页面信息。
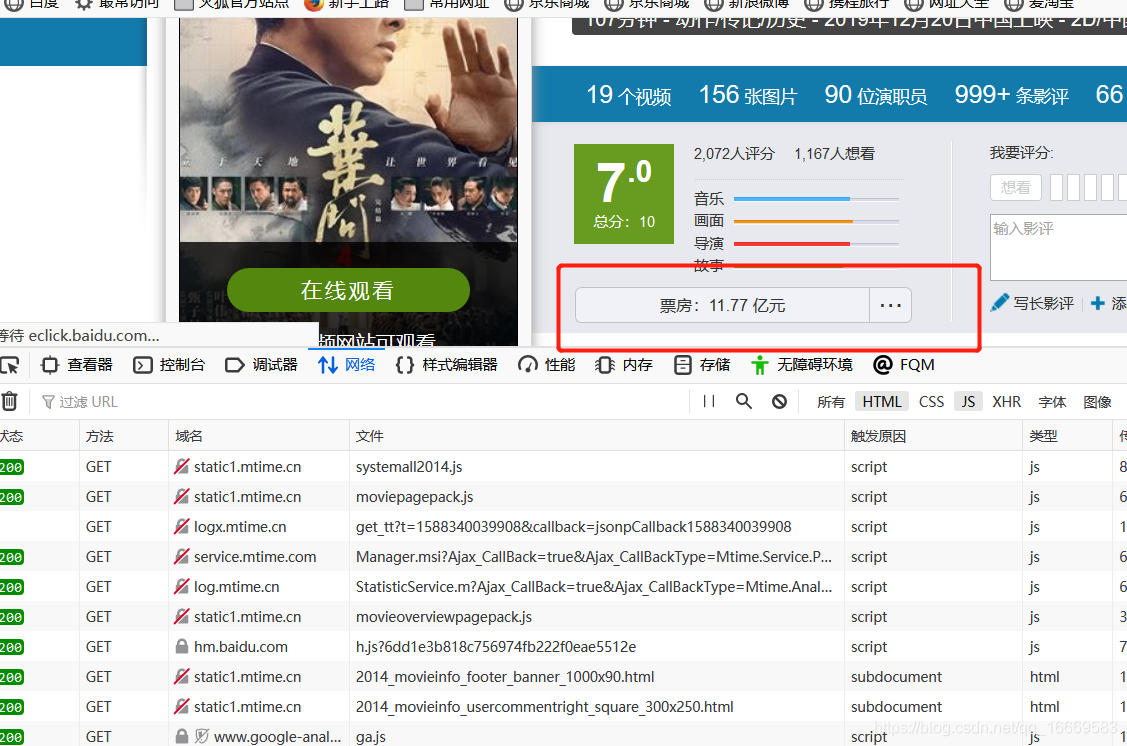
页面中的票房信息无法以 HTML 格式获取。是通过js动态加载得到的,然后搜索对应的js响应。就是从一堆js请求中查看一些收录ajax字段的请求。%3A%2F%%2F242129%2F&t=27406&Ajax_CallBackArgument0=242129
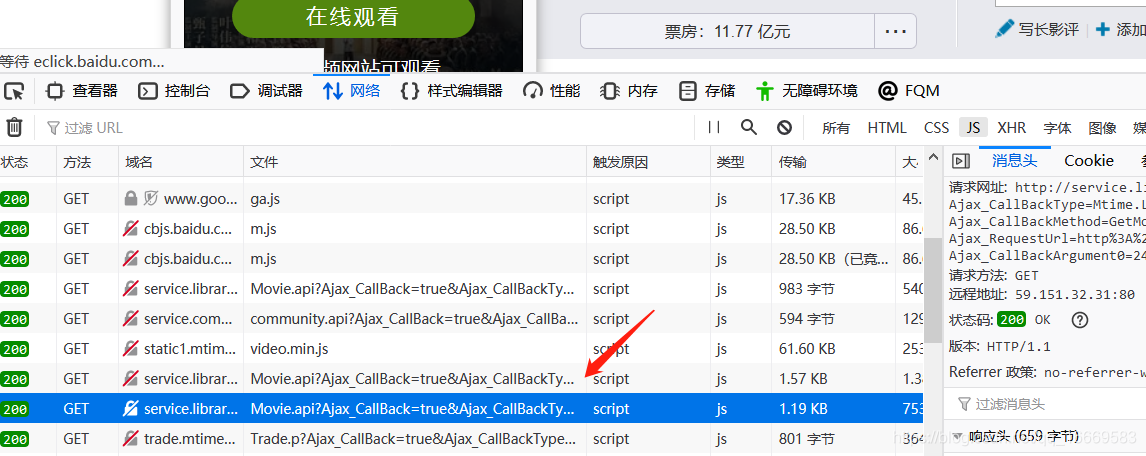
点击查看返回数据:

找到对应的链接并返回数据后,需要分析这个链接的构造方法,分析返回的数据。
(1)链接一共7个参数,我们首先要分析哪些参数没有变化,哪些参数在不同的电影中差异更大。通过对比两个不同的电影链接,可以发现其中4个是not 有动态变化的三个参数,分别是Ajax_RequestRrl、t和Ajax_CallBackArgument0,通过分析可以发现这三个参数分别代表当前页面url、当前请求时间、电影所代表的数量。
(2) 提取响应数据。响应内容主要分为三类,分别是正在上映的电影信息,即将上映的电影信息,最后一种是即将上映的电影信息发布很久了,详情见代码。
具体实现代码
本文代码基于博客实现。本博客只修改需要改动的部分。
网页分析
在HtmlParser类中定义一个parser_url方法,代码如下:
def parser_url(self, page_url, response):
pattern = re.compile(r'(http://movie.mtime.com/(\d+)/)')
urls = pattern.findall(response)
if urls != None:
return list(set(urls))
else:
return None
提取响应数据中的有效数据:
def parser_json(self, page_url, respone):
"""
解析响应
:param page_url:
:param respone:
:return:
"""
#将“=”和“;”之间的内容提取出来
pattern = re.compile(r'=(.*?);')
result = pattern.findall(respone)[0]
if result != None:
value = json.loads(result)
try:
isRelease = value.get('value').get('isRelease')
except Exception,e:
print(e)
return None
if isRelease:
if value.get('value').get('hotValue') == None:
return self._parser_release(page_url, value)
else:
self._parser_no_release(page_url, value, isRelease = 2)
else:
return self._parser_no_release(page_url, value)
def _parser_release(self, page_url, value):
"""
解析已上映的影片
:param page_url:
:param value:
:return:
"""
try:
isRelease = 1
movieRating = value.get('value').get('movieRating')
boxOffice = value.get('value').get('boxOffice')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
TotalBoxOffice = boxOffice.get('TotalBoxOffice')
TotalBoxOfficeUnit = boxOffice.get('TotalBoxOfficeUnit')
TodayBoxOffice = boxOffice.get('TodayBoxOffice')
TodayBoxOfficeUnit = boxOffice.get('TodayBoxOfficeUnit')
showDays = boxOffice.get('ShowDays')
try:
Rank = boxOffice.get('Rank')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,
TotalBoxOffice+TotalBoxOfficeUnit,
TodayBoxOffice+TodayBoxOfficeUnit,
Rank,showDays,isRelease)
except Exception,e:
print(e,page_url,value)
return None
def _parser_no_release(self,page_url,value,isRelease = 0):
try:
movieRating = value.get('value').get('movieRating')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
try:
Rank = value.get('value').get('hotValue').get('Ranking')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,u'无',
u'无',Rank,0,isRelease)
except Exception,e:
print(e, page_url, value)
return None
爬虫调度器
def dynamic_crawl(self, root_url):
content = self.downloader.download(root_url)
urls = self.parser.parser_url(root_url,content)
for url in urls:
try:
t = time.strftime("%Y%m%d%H%M%S3282", time.localtime())
rank_url ='http://service.library.mtime.com/Movie.api'\
'?Ajax_CallBack=true'\
'&Ajax_CallBackType=Mtime.Library.Services'\
'&Ajax_CallBackMethod=GetMovieOverviewRating'\
'&Ajax_CrossDomain=1'\
'&Ajax_RequestRrl=%s'\
'&t=%s'\
'&Ajax_CallBackArgument0=%s'%(url[0],t,url[1])
rank_content = self.downloader.download(rank_url)
data = self.parser.parser_json(rank_url,rank_content)
print(data)
except Exception,e:
print('Crawl failed')
if __name__=="__main__":
spider_main = SpiderMain()
spider_main.dynamic_crawl("http://theater.mtime.com/China_Beijing/";)
抓取动态网页(准备工作python基础入门jupyternotebook自动补全代码request_html )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-28 07:22
)
准备好工作了
开始使用 Python 基础知识
Jupyter notebook 自动补全代码
request_html 是python3中的一个包,python2不能用
在pycharm中导入第三方包
使用python爬取数据(pyhton2)
网络爬虫是一种自动从 Internet 获取数据的程序。基本上我们在浏览网站时看到的所有数据都可以通过爬虫程序保存下来。我们可以学习爬虫来获取相关数据。但是,数据是可归属的,而不是你想使用的,所以我们需要在合法的情况下使用爬虫。因此,我们必须遵守互联网世界的机器人协议。引自爬虫的介绍
1.请求抓取静态网页
import requests
from lxml import etree
aaa=requests.get("https://blog.csdn.net/IT_XF/ar ... 6quot;)
bbb=etree.HTML(aaa.text)
ccc=aaa.xpath('//*[@id="content_views"]/p/text()')
for each in bbb:
print (each)
按照上面的代码爬取网页中的文字内容
2. 模拟登录
参考资料:
(1)在浏览器中获取cookie字符串
服务器使用 cookie 来区分不同的客户端。当服务器一次收到多个请求时,它无法分辨哪些请求是由同一个客户端发起的。因此,cookie是向服务器端向客户端证明:“我是刚刚登录的客户端”。这意味着只要我们从另一个客户端获取 cookie,我们就可以伪造它与服务器通信。
通过抓包获取cookie,然后将cookie放入请求中发送请求:
完成
# -*- coding: utf-8 -*-
#python2
import urllib2
aaa={"cookie":'在浏览器中找到的目标网址的cookie'}
url='https://i.csdn.net/#/uc/profile'
bbb=urllib2.Request(url,headers=aaa)
ccc=urllib2.urlopen(bbb).read()
print ccc
#python2
import requests
aaa={"cookie":'在浏览器中找到的目标网址的cookie'
ccc=requests.get(bbb,headers=aaa)
print ccc.text
(2)
上面的方法是可行的,但是太麻烦了。我们首先需要在浏览器中登录账号,设置保存密码,通过抓包获取这个cookie。让我们尝试使用会话。
会话的意思是会话。与 cookie 的相似之处在于它也允许服务器“识别”客户端。简单的理解是,客户端和服务器之间的每一次交互都被视为一个“会话”。既然是在同一个“会话”中,服务器自然会知道客户端是否登录了。
(3).使用Selenium和PhantomJS模拟登录
以上两个是使用的请求。requests 模块是一个不完全模拟浏览器行为的模块。它只能抓取网页的 HTML 文档信息,不能解析和执行 CSS 和 JavaScript 代码。这是它的缺点。
下面我们用selenium来处理上面的问题
selenium模块的本质是驱动浏览器完全模拟浏览器的操作,如跳转、输入、点击、下拉等,得到网页渲染的结果,可以支持多种浏览器;(因为 selenium 解析并执行 CSS、JavaScript,所以它的性能相对于请求来说是低的;)
import time
import selenium
aaa=webdriver.Chrome() #生成chrome浏览器对象
#bbb=WebDriverWait(aaa,10) #浏览器加载完毕的最大等待时间,设置为10秒
try:
aaa.get('https://www.baidu.com/') #打开百度网页
ccc=aaa.find_element_by_id("kw")
ddd=ccc.send_keys('张根硕')
eee_button=aaa.find_element_by_id('su')
eee_button.click()
print(aaa.page_source)
#wait.until(EC.presence_of_element_located((By.ID,'4')))
finally:
time.sleep(100)#页面存在的时长100s
aaa.close()
3.使用selenum动态爬虫
参考:
4. 静态抓取网页并输入到csv
利用 urlib 库和 csv 库 + BeautifulSoup
<p># -*- coding: utf-8 -*-
import urllib
from bs4 import BeautifulSoup
import csv
import codecs
#i = 1
#while i 查看全部
抓取动态网页(准备工作python基础入门jupyternotebook自动补全代码request_html
)
准备好工作了
开始使用 Python 基础知识
Jupyter notebook 自动补全代码
request_html 是python3中的一个包,python2不能用
在pycharm中导入第三方包
使用python爬取数据(pyhton2)
网络爬虫是一种自动从 Internet 获取数据的程序。基本上我们在浏览网站时看到的所有数据都可以通过爬虫程序保存下来。我们可以学习爬虫来获取相关数据。但是,数据是可归属的,而不是你想使用的,所以我们需要在合法的情况下使用爬虫。因此,我们必须遵守互联网世界的机器人协议。引自爬虫的介绍
1.请求抓取静态网页
import requests
from lxml import etree
aaa=requests.get("https://blog.csdn.net/IT_XF/ar ... 6quot;)
bbb=etree.HTML(aaa.text)
ccc=aaa.xpath('//*[@id="content_views"]/p/text()')
for each in bbb:
print (each)
按照上面的代码爬取网页中的文字内容
2. 模拟登录
参考资料:
(1)在浏览器中获取cookie字符串
服务器使用 cookie 来区分不同的客户端。当服务器一次收到多个请求时,它无法分辨哪些请求是由同一个客户端发起的。因此,cookie是向服务器端向客户端证明:“我是刚刚登录的客户端”。这意味着只要我们从另一个客户端获取 cookie,我们就可以伪造它与服务器通信。
通过抓包获取cookie,然后将cookie放入请求中发送请求:
完成
# -*- coding: utf-8 -*-
#python2
import urllib2
aaa={"cookie":'在浏览器中找到的目标网址的cookie'}
url='https://i.csdn.net/#/uc/profile'
bbb=urllib2.Request(url,headers=aaa)
ccc=urllib2.urlopen(bbb).read()
print ccc
#python2
import requests
aaa={"cookie":'在浏览器中找到的目标网址的cookie'
ccc=requests.get(bbb,headers=aaa)
print ccc.text
(2)
上面的方法是可行的,但是太麻烦了。我们首先需要在浏览器中登录账号,设置保存密码,通过抓包获取这个cookie。让我们尝试使用会话。
会话的意思是会话。与 cookie 的相似之处在于它也允许服务器“识别”客户端。简单的理解是,客户端和服务器之间的每一次交互都被视为一个“会话”。既然是在同一个“会话”中,服务器自然会知道客户端是否登录了。
(3).使用Selenium和PhantomJS模拟登录
以上两个是使用的请求。requests 模块是一个不完全模拟浏览器行为的模块。它只能抓取网页的 HTML 文档信息,不能解析和执行 CSS 和 JavaScript 代码。这是它的缺点。
下面我们用selenium来处理上面的问题
selenium模块的本质是驱动浏览器完全模拟浏览器的操作,如跳转、输入、点击、下拉等,得到网页渲染的结果,可以支持多种浏览器;(因为 selenium 解析并执行 CSS、JavaScript,所以它的性能相对于请求来说是低的;)
import time
import selenium
aaa=webdriver.Chrome() #生成chrome浏览器对象
#bbb=WebDriverWait(aaa,10) #浏览器加载完毕的最大等待时间,设置为10秒
try:
aaa.get('https://www.baidu.com/') #打开百度网页
ccc=aaa.find_element_by_id("kw")
ddd=ccc.send_keys('张根硕')
eee_button=aaa.find_element_by_id('su')
eee_button.click()
print(aaa.page_source)
#wait.until(EC.presence_of_element_located((By.ID,'4')))
finally:
time.sleep(100)#页面存在的时长100s
aaa.close()
3.使用selenum动态爬虫
参考:
4. 静态抓取网页并输入到csv
利用 urlib 库和 csv 库 + BeautifulSoup
<p># -*- coding: utf-8 -*-
import urllib
from bs4 import BeautifulSoup
import csv
import codecs
#i = 1
#while i
抓取动态网页(抓取静态页面中的数据都包含在网页的HTML中 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-27 20:05
)
抓取静态页面。静态页面中的数据收录在网页的HTML中(通常是get请求)
所需的包解释
请求是常见的网络请求包
Lxml解析生成XML对象
XPath是一种用于在XML文档中查找信息的语言
静态网页捕获文章(网易新闻)
我们以网易新闻的一个新闻页面为例文章capture
下面的代码解析网易文章并存储它。它是通过XPath解析从网页的静态源代码中获得的
#coding=utf-8
import requests
from lxml import etree
import json
class WangyiCollect():
def __init__(self,url):
self.url = url
def responseHtml(self):
#获取网页源码
content = requests.get(url=self.url).text
#初始化生成一个XPath解析对象
html = etree.HTML(content)
#提取文章页内容,采用xpath解析方式
title = html.xpath('//h1/text()')[0]
pubTime = html.xpath('//div[@class="post_time_source"]/text()')[0].replace('来源:', '').strip()
pubSource = html.xpath('//a[@id="ne_article_source"]/text()')[0]
contentList = html.xpath('//div[@id="endText"]/p//text() | //div[@id="endText"]//img/@src')
newContentList = []
for paragraph in contentList:
newparagraph = paragraph
if paragraph.endswith('.jpg') or paragraph.endswith('.png') or paragraph.endswith('.gif') or paragraph.startswith('http'):newparagraph = '
' + paragraph + '<br /><br />'
newContentList.append(newparagraph)
content = ''.join(newContentList)
#存储文章内容,存储格式为json格式
articleJson = {}
articleJson['title'] = title
articleJson['pubTime'] = pubTime
articleJson['pubSource'] = pubSource
articleJson['content'] = content
print(json.dumps(articleJson,ensure_ascii=False))
#之前为字典,需要转成json的字符串
strArticleJson = json.dumps(articleJson,ensure_ascii=False)
self.writeFile(strArticleJson)
#写入文本文件
def writeFile(self,text):
file = open('./wangyiArticle.txt','a',encoding='utf-8')
file.write(text+'\n')
if __name__=="__main__":
wangyiCollect = WangyiCollect('http://bj.news.163.com/19/0731/10/ELDHE9I604388CSB.html')
wangyiCollect.responseHtml()
抓取动态加载的网页
结构化数据:JSON、XML等
动态页面和静态页面之间的主要区别在于在刷新数据时使用Ajax技术。刷新数据时,将从数据库中查询数据并重新呈现到前端页面。数据存储在网络包中,无法通过爬行HTML获取数据
获取此动态页面有两种常见方法:
1.抓取网络请求包,请求接口传递一些参数,并破解参数。这将写在未来的博客,破解JS和破解参数
image.png
您可以看到右侧网络包中的文章数据是通过chrome数据包捕获通过数据包传输的
取出网络包的地址请求数据,它是JSON格式的数据片段
{
"title":"智能垃圾回收机重启 居民区里遇冷",
"digest":"",
"docurl":"[http://bj.news.163.com/19/0729 ... .html](http://bj.news.163.com/19/0729 ... B.html)",
"commenturl":"[http://comment.tie.163.com/EL8DU15104388CSB.html](http://comment.tie.163.com/EL8DU15104388CSB.html)",
"tienum":"0",
"tlastid":"",
"tlink":"",
"label":"",
"keywords":[
{
"akey_link":"/keywords/5/0/5c0f9ec472d7/1.html",
"keyname":"小黄狗"
},
{
"akey_link":"/keywords/5/d/56de6536673a/1.html",
"keyname":"回收机"
}
],
"time":"07/29/2019 10:39:26",
"newstype":"article",
"imgurl":"[http://cms-bucket.ws.126.net/2 ... .jpeg](http://cms-bucket.ws.126.net/2 ... 8.jpeg)",
"add1":"",
"add2":"",
"add3":"",
"pics3":[
],
"channelname":"bendi"
}
获取JSON数据
#coding=utf-8
import requests,json
content = requests.get('https://house.163.com/special/00078GU7/beijign_xw_news_v1_02.js?callback=data_callback').text
#取出来的为json字符串
jsonArticle = content.split('data_callback(')[1].rstrip(')')
#将json字符串转为字典格式
dictArticleList = json.loads(jsonArticle)
for dictArticle in dictArticleList:
#取出title
title = dictArticle['title']
print(title)
2.无头浏览器渲染
硒+铬
#coding=utf-8
from selenium import webdriver
Chrome_options = webdriver.ChromeOptions()
Chrome_options.add_argument('--headless')
drive = webdriver.Chrome(chrome_options=Chrome_options)
drive.get('http://public.163.com/#/list/movie')
html = drive.page_source
print(html)
drive.quit() 查看全部
抓取动态网页(抓取静态页面中的数据都包含在网页的HTML中
)
抓取静态页面。静态页面中的数据收录在网页的HTML中(通常是get请求)
所需的包解释
请求是常见的网络请求包
Lxml解析生成XML对象
XPath是一种用于在XML文档中查找信息的语言
静态网页捕获文章(网易新闻)
我们以网易新闻的一个新闻页面为例文章capture
下面的代码解析网易文章并存储它。它是通过XPath解析从网页的静态源代码中获得的
#coding=utf-8
import requests
from lxml import etree
import json
class WangyiCollect():
def __init__(self,url):
self.url = url
def responseHtml(self):
#获取网页源码
content = requests.get(url=self.url).text
#初始化生成一个XPath解析对象
html = etree.HTML(content)
#提取文章页内容,采用xpath解析方式
title = html.xpath('//h1/text()')[0]
pubTime = html.xpath('//div[@class="post_time_source"]/text()')[0].replace('来源:', '').strip()
pubSource = html.xpath('//a[@id="ne_article_source"]/text()')[0]
contentList = html.xpath('//div[@id="endText"]/p//text() | //div[@id="endText"]//img/@src')
newContentList = []
for paragraph in contentList:
newparagraph = paragraph
if paragraph.endswith('.jpg') or paragraph.endswith('.png') or paragraph.endswith('.gif') or paragraph.startswith('http'):newparagraph = '
' + paragraph + '<br /><br />'
newContentList.append(newparagraph)
content = ''.join(newContentList)
#存储文章内容,存储格式为json格式
articleJson = {}
articleJson['title'] = title
articleJson['pubTime'] = pubTime
articleJson['pubSource'] = pubSource
articleJson['content'] = content
print(json.dumps(articleJson,ensure_ascii=False))
#之前为字典,需要转成json的字符串
strArticleJson = json.dumps(articleJson,ensure_ascii=False)
self.writeFile(strArticleJson)
#写入文本文件
def writeFile(self,text):
file = open('./wangyiArticle.txt','a',encoding='utf-8')
file.write(text+'\n')
if __name__=="__main__":
wangyiCollect = WangyiCollect('http://bj.news.163.com/19/0731/10/ELDHE9I604388CSB.html')
wangyiCollect.responseHtml()
抓取动态加载的网页
结构化数据:JSON、XML等
动态页面和静态页面之间的主要区别在于在刷新数据时使用Ajax技术。刷新数据时,将从数据库中查询数据并重新呈现到前端页面。数据存储在网络包中,无法通过爬行HTML获取数据
获取此动态页面有两种常见方法:
1.抓取网络请求包,请求接口传递一些参数,并破解参数。这将写在未来的博客,破解JS和破解参数

image.png
您可以看到右侧网络包中的文章数据是通过chrome数据包捕获通过数据包传输的
取出网络包的地址请求数据,它是JSON格式的数据片段
{
"title":"智能垃圾回收机重启 居民区里遇冷",
"digest":"",
"docurl":"[http://bj.news.163.com/19/0729 ... .html](http://bj.news.163.com/19/0729 ... B.html)",
"commenturl":"[http://comment.tie.163.com/EL8DU15104388CSB.html](http://comment.tie.163.com/EL8DU15104388CSB.html)",
"tienum":"0",
"tlastid":"",
"tlink":"",
"label":"",
"keywords":[
{
"akey_link":"/keywords/5/0/5c0f9ec472d7/1.html",
"keyname":"小黄狗"
},
{
"akey_link":"/keywords/5/d/56de6536673a/1.html",
"keyname":"回收机"
}
],
"time":"07/29/2019 10:39:26",
"newstype":"article",
"imgurl":"[http://cms-bucket.ws.126.net/2 ... .jpeg](http://cms-bucket.ws.126.net/2 ... 8.jpeg)",
"add1":"",
"add2":"",
"add3":"",
"pics3":[
],
"channelname":"bendi"
}
获取JSON数据
#coding=utf-8
import requests,json
content = requests.get('https://house.163.com/special/00078GU7/beijign_xw_news_v1_02.js?callback=data_callback').text
#取出来的为json字符串
jsonArticle = content.split('data_callback(')[1].rstrip(')')
#将json字符串转为字典格式
dictArticleList = json.loads(jsonArticle)
for dictArticle in dictArticleList:
#取出title
title = dictArticle['title']
print(title)
2.无头浏览器渲染
硒+铬
#coding=utf-8
from selenium import webdriver
Chrome_options = webdriver.ChromeOptions()
Chrome_options.add_argument('--headless')
drive = webdriver.Chrome(chrome_options=Chrome_options)
drive.get('http://public.163.com/#/list/movie')
html = drive.page_source
print(html)
drive.quit()
抓取动态网页(一下动态网站快讯 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-27 20:03
)
今天研究了一下动态网站的爬取,以及这里使用的世轩股票宝网站:
这个小案例简单抓取了轩宝的7x24时事通讯的信息内容,并将数据保存在Mysql数据库中。
网页分为静态网页和动态网页。静态网页一般是指不与嵌入在页面或js中的后端数据交互的网页,而动态网页通过Ajax与数据库交互,可以实时从数据库中获取数据并显示在页面上.
如何判断一个网站是动态的网站:
1. 浏览网页时,部分网站可以在翻页的同时不断向下滚动和加载数据。这通常是动态的网站。
2. 也可以在网络上查看XHR,在浏览器控制台查看和后台数据交互记录。
首先,我们必须找到数据源。经过观察,我们发现时事通讯是由上图中名为newsflash的请求加载的。通过这个请求,我们可以得到他的url,10,723,35,469,821&platform=pcweb。通过观察这个请求,我们可以找到newsflashlimit参数控制请求。返回的记录数,游标是毫秒时间戳,因为这里的咨询内容是动态更新的,每隔一段时间就会加载新的咨询,这里是按时间排序的,所以只要控制这两个参数就可以得到咨询你想要的内容。
这里我尝试抓取一个时间段内的咨询内容,时间间隔设置为10分钟。也就是说,每次咨询内容在10分钟内生成,当然可能会有重复,这里就不做处理了。
用于时间戳和时间转换的在线工具:
代码显示如下
#!/usr/bin/env python
# -*- 编码:utf-8 -*-
# @File: 蜘蛛侠.py
# @Author: 小橙
# @日期:2019-1-6
# @Desc :Dynamic 网站 抓取选择共享
进口请求
从 fake_useragent 导入 UserAgent
从 sqlalchemy 导入 create_engine
将熊猫导入为 pd
导入时间
#时间:1月7日12:00-17:00
#对应时间戳:00-00
#发送请求获取返回数据
定义获取数据(网址):
如果 url 为 None:
返回
ua = 用户代理()
headers = {'User-Agnet':ua.random}
r = requests.get(url,headers=headers)
如果 r.status_code == 200:
#如果请求返回的是json格式的数据,可以使用json()函数
#也可以使用json.load()函数将json格式的字符串转换成json对象
返回 r.json()
#提取返回数据中的字段信息
定义解析器数据(数据):
#提取数据中的id、title、汇总字段信息
retdata = data.get('数据')
msglist = retdata.get('消息')
保存列表 = []
对于 msglist 中的 msg:
id = int(msg.get('id'))
title = msg.get('title')
总结 =''
#summary中的字段为空时,将title的值赋给summary
如果 msg.get('summary') !='':
summary = msg.get('summary').replace('\n','')#去掉摘要中的换行符
别的:
摘要 = 标题
温度 = []
temp.append(id)
temp.append(标题)
temp.append(总结)
savelist.append(temp)
返回保存列表
#保存数据到数据库
def saveData(result_data,con):
#向数据库写入数据
如果 len(result_data)>0:
#这里创建DataFrame的时候忘记加header了,写数据的时候一直报错
df = pd.DataFrame(result_data,columns=['id','title','summary'])
# 打印('df:',df)
#如果要自动建表,用replace替换if_exists的值,建议自己建表,if_exists的值是append
#name是表名,con是数据库连接
df.to_sql(name="stock_news", con=con, if_exists='append', index=False)
# print('数据保存成功!')
#获取数据库连接
def getContact():
#连接数据库
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/demo01?charset=utf8')
con = engine.connect()
print('Mysql 连接创建成功...')
返回引擎
如果 __name__ =='__main__':
url =';cursor={}&subj_ids=9,10,723,35,469,821&platform=pcweb'
开始时间 = 00
con = getContact() #创建数据库连接
计数 = 0
为真:
#这里设置的时间间隔是10分钟,意思是每次取消息10分钟内更新
结束时间 = 开始时间 + 600000
如果 end_time>00:
休息
开始时间 = 结束时间
now_url = url.format(end_time)
数据 = 获取数据(now_url)
time.sleep(2) #每2秒请求一次
result_data = parserData(data)
# 打印(结果数据)
保存数据(result_data,con)
计数 += len(result_data)
print('{} 数据保存成功!'.format(count))
两小时的测试更新
查看全部
抓取动态网页(一下动态网站快讯
)
今天研究了一下动态网站的爬取,以及这里使用的世轩股票宝网站:
这个小案例简单抓取了轩宝的7x24时事通讯的信息内容,并将数据保存在Mysql数据库中。
网页分为静态网页和动态网页。静态网页一般是指不与嵌入在页面或js中的后端数据交互的网页,而动态网页通过Ajax与数据库交互,可以实时从数据库中获取数据并显示在页面上.
如何判断一个网站是动态的网站:
1. 浏览网页时,部分网站可以在翻页的同时不断向下滚动和加载数据。这通常是动态的网站。
2. 也可以在网络上查看XHR,在浏览器控制台查看和后台数据交互记录。
首先,我们必须找到数据源。经过观察,我们发现时事通讯是由上图中名为newsflash的请求加载的。通过这个请求,我们可以得到他的url,10,723,35,469,821&platform=pcweb。通过观察这个请求,我们可以找到newsflashlimit参数控制请求。返回的记录数,游标是毫秒时间戳,因为这里的咨询内容是动态更新的,每隔一段时间就会加载新的咨询,这里是按时间排序的,所以只要控制这两个参数就可以得到咨询你想要的内容。
这里我尝试抓取一个时间段内的咨询内容,时间间隔设置为10分钟。也就是说,每次咨询内容在10分钟内生成,当然可能会有重复,这里就不做处理了。
用于时间戳和时间转换的在线工具:
代码显示如下
#!/usr/bin/env python
# -*- 编码:utf-8 -*-
# @File: 蜘蛛侠.py
# @Author: 小橙
# @日期:2019-1-6
# @Desc :Dynamic 网站 抓取选择共享
进口请求
从 fake_useragent 导入 UserAgent
从 sqlalchemy 导入 create_engine
将熊猫导入为 pd
导入时间
#时间:1月7日12:00-17:00
#对应时间戳:00-00
#发送请求获取返回数据
定义获取数据(网址):
如果 url 为 None:
返回
ua = 用户代理()
headers = {'User-Agnet':ua.random}
r = requests.get(url,headers=headers)
如果 r.status_code == 200:
#如果请求返回的是json格式的数据,可以使用json()函数
#也可以使用json.load()函数将json格式的字符串转换成json对象
返回 r.json()
#提取返回数据中的字段信息
定义解析器数据(数据):
#提取数据中的id、title、汇总字段信息
retdata = data.get('数据')
msglist = retdata.get('消息')
保存列表 = []
对于 msglist 中的 msg:
id = int(msg.get('id'))
title = msg.get('title')
总结 =''
#summary中的字段为空时,将title的值赋给summary
如果 msg.get('summary') !='':
summary = msg.get('summary').replace('\n','')#去掉摘要中的换行符
别的:
摘要 = 标题
温度 = []
temp.append(id)
temp.append(标题)
temp.append(总结)
savelist.append(temp)
返回保存列表
#保存数据到数据库
def saveData(result_data,con):
#向数据库写入数据
如果 len(result_data)>0:
#这里创建DataFrame的时候忘记加header了,写数据的时候一直报错
df = pd.DataFrame(result_data,columns=['id','title','summary'])
# 打印('df:',df)
#如果要自动建表,用replace替换if_exists的值,建议自己建表,if_exists的值是append
#name是表名,con是数据库连接
df.to_sql(name="stock_news", con=con, if_exists='append', index=False)
# print('数据保存成功!')
#获取数据库连接
def getContact():
#连接数据库
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/demo01?charset=utf8')
con = engine.connect()
print('Mysql 连接创建成功...')
返回引擎
如果 __name__ =='__main__':
url =';cursor={}&subj_ids=9,10,723,35,469,821&platform=pcweb'
开始时间 = 00
con = getContact() #创建数据库连接
计数 = 0
为真:
#这里设置的时间间隔是10分钟,意思是每次取消息10分钟内更新
结束时间 = 开始时间 + 600000
如果 end_time>00:
休息
开始时间 = 结束时间
now_url = url.format(end_time)
数据 = 获取数据(now_url)
time.sleep(2) #每2秒请求一次
result_data = parserData(data)
# 打印(结果数据)
保存数据(result_data,con)
计数 += len(result_data)
print('{} 数据保存成功!'.format(count))
两小时的测试更新
抓取动态网页(什么是Ajax即“AsynchronousJavascript”(异步JavaScript和XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-27 15:23
)
什么是阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。使用ajax加载的数据,即使使用js将数据渲染到浏览器中,在右键查看网页源码中仍然看不到通过ajax加载的数据,只有使用这个url加载的html代码.
获取ajax数据的方法直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器获取数据的行为。的优点和缺点
分析界面
可以直接请求数据。无需做一些分析工作。代码少,性能高
解析接口比较复杂,尤其是通过一些js混淆的接口,必须有一定的js基础。容易被发现的粪便爬虫
硒
直接模拟浏览器行为。爬虫更稳定
代码量大,性能低
注:异步加载的数据不会显示在原创网页代码中,但您可以使用查看器进行选择查看,然后可以在 Elements 属性中查看代码的标签结构,方便后续数据分析。
另外也可以在Network中找到对应的异步加载的数据,然后根据响应获取json数据,然后在线分析得到规范化的json数据。
查看全部
抓取动态网页(什么是Ajax即“AsynchronousJavascript”(异步JavaScript和XML)
)
什么是阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。使用ajax加载的数据,即使使用js将数据渲染到浏览器中,在右键查看网页源码中仍然看不到通过ajax加载的数据,只有使用这个url加载的html代码.
获取ajax数据的方法直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器获取数据的行为。的优点和缺点
分析界面
可以直接请求数据。无需做一些分析工作。代码少,性能高
解析接口比较复杂,尤其是通过一些js混淆的接口,必须有一定的js基础。容易被发现的粪便爬虫
硒
直接模拟浏览器行为。爬虫更稳定
代码量大,性能低
注:异步加载的数据不会显示在原创网页代码中,但您可以使用查看器进行选择查看,然后可以在 Elements 属性中查看代码的标签结构,方便后续数据分析。

另外也可以在Network中找到对应的异步加载的数据,然后根据响应获取json数据,然后在线分析得到规范化的json数据。

抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-26 18:30
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
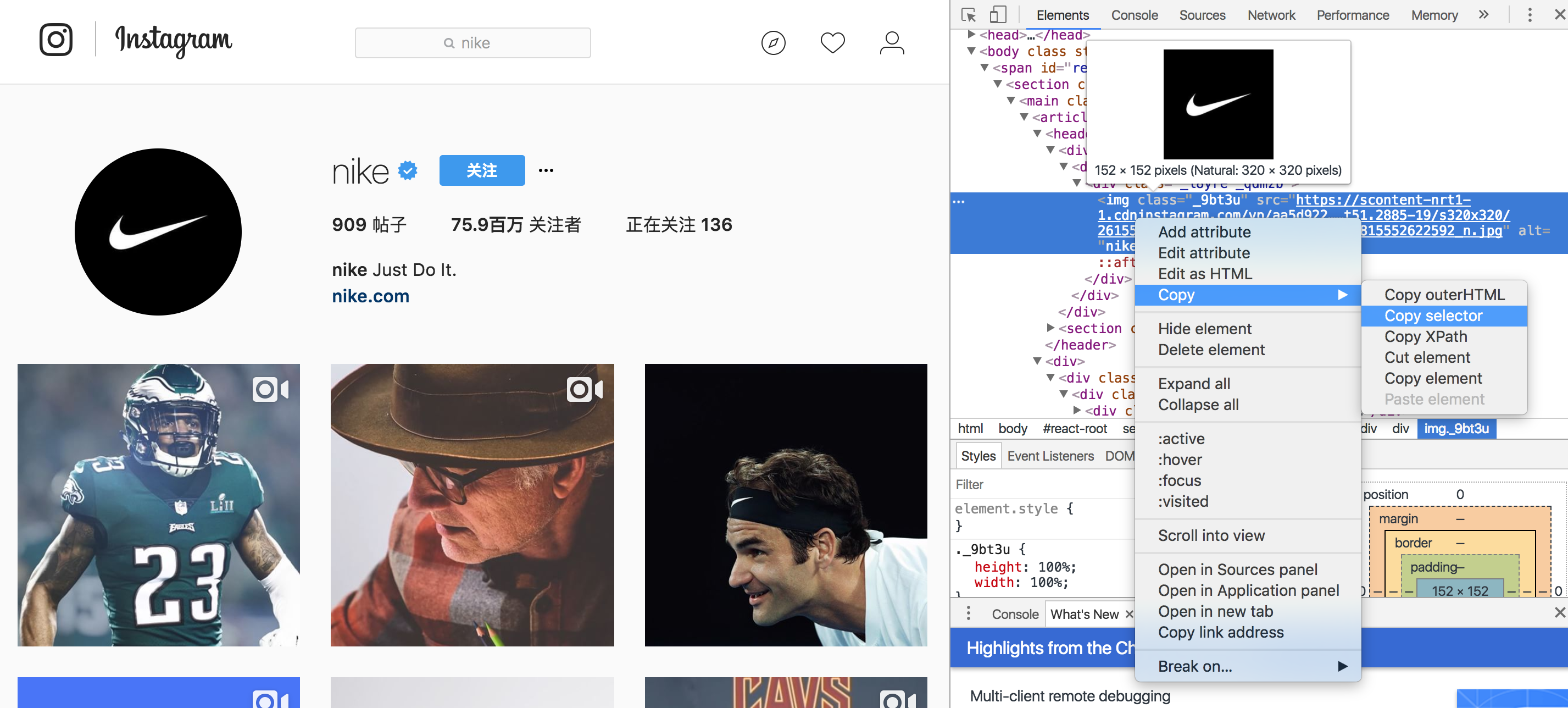
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多时候我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置 查看全部
抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多时候我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置
抓取动态网页(google实现爬虫,有多种定位方法?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-23 13:34
)
这个过程更麻烦,你需要采取几步完成,你会介绍:
1.安装selenium库,可以直接使用'pip安装selenium'命令安装。
2.下载ChromedRiver并将其添加到环境变量,或直接将.exe文件放入Python安装目录脚本文件夹中。下载时,您必须选择与浏览器对应的版本。查看浏览器版本是:右上角 - &gt;帮助 - &gt;关于Google Chrome可以查看,下载驱动程序的地址是ChromedRiver下载地址,与Chrome版本相应的关系相应,验证下载和安装是否成功,只需要执行以下代码。如果没有错误,它将被成功安装。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3.硒实现爬行动物,有多种定位方法,简要介绍:
官方网站地址是:
找到一个元素方法:
找到多个元素(返回列表)方法:
4.基本功能在你有一个快乐的爬行动物之后(因为你没有搅拌,首先把一些代码放在那里)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
更改:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run() 查看全部
抓取动态网页(google实现爬虫,有多种定位方法?(图)
)
这个过程更麻烦,你需要采取几步完成,你会介绍:
1.安装selenium库,可以直接使用'pip安装selenium'命令安装。
2.下载ChromedRiver并将其添加到环境变量,或直接将.exe文件放入Python安装目录脚本文件夹中。下载时,您必须选择与浏览器对应的版本。查看浏览器版本是:右上角 - &gt;帮助 - &gt;关于Google Chrome可以查看,下载驱动程序的地址是ChromedRiver下载地址,与Chrome版本相应的关系相应,验证下载和安装是否成功,只需要执行以下代码。如果没有错误,它将被成功安装。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3.硒实现爬行动物,有多种定位方法,简要介绍:
官方网站地址是:
找到一个元素方法:
找到多个元素(返回列表)方法:
4.基本功能在你有一个快乐的爬行动物之后(因为你没有搅拌,首先把一些代码放在那里)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
更改:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run()
抓取动态网页(soup搜索节点操作删除节点的一种好的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-18 22:23
之前:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文基于Python中的selenium(pyhton包)+Chrome(谷歌浏览器)+Chrome驱动器(谷歌浏览器驱动程序)
建议下载chrome和chromdrive的最新版本(参考地址:)
还支持无头模式(无需打开浏览器)
直接代码:站点\ URL:要爬网的地址,chrome \驱动程序\路径:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
返回一个soup,以便在此soup中搜索节点,并使用select、search、find和其他方法查找所需的节点或数据
同样,如果您想将其作为文本下载,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
让我们详细谈谈寻找美丽的汤
首先,如何导航到标签
1.use find(博主详细介绍)
2.使用选择
通过类似于jQuery的标记名、类名和ID选择器选择位置,例如soup。选择('p.Link#link1')
通过属性查找,如href、title、link和其他属性,如soup。选择('PA[href=”“]”)
这里的比赛是最小的,他的上级是
然后我们来讨论节点的操作
删除节点标记。分解
插入子节点标记。在指定位置插入(0,chlid_标记)
最后,使用靓汤是过滤滤芯的好方法。在下一章中,我们将引入正则表达式匹配来过滤爬虫内容 查看全部
抓取动态网页(soup搜索节点操作删除节点的一种好的方法(上))
之前:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文基于Python中的selenium(pyhton包)+Chrome(谷歌浏览器)+Chrome驱动器(谷歌浏览器驱动程序)
建议下载chrome和chromdrive的最新版本(参考地址:)
还支持无头模式(无需打开浏览器)
直接代码:站点\ URL:要爬网的地址,chrome \驱动程序\路径:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
返回一个soup,以便在此soup中搜索节点,并使用select、search、find和其他方法查找所需的节点或数据
同样,如果您想将其作为文本下载,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
让我们详细谈谈寻找美丽的汤
首先,如何导航到标签
1.use find(博主详细介绍)
2.使用选择
通过类似于jQuery的标记名、类名和ID选择器选择位置,例如soup。选择('p.Link#link1')
通过属性查找,如href、title、link和其他属性,如soup。选择('PA[href=”“]”)
这里的比赛是最小的,他的上级是
然后我们来讨论节点的操作
删除节点标记。分解
插入子节点标记。在指定位置插入(0,chlid_标记)
最后,使用靓汤是过滤滤芯的好方法。在下一章中,我们将引入正则表达式匹配来过滤爬虫内容
抓取动态网页(如何用python自带urllib2库打开网页的爬虫实现之旅?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-18 22:21
一、背景
记录一次周末赶回家的爬行动物实现之旅。受他人委托,我想从这一页的明星名单上爬下来。当你在chrome中打开它时,实际上有1000条记录。然后单击“右键菜单”->;“检查”查看网页的结构,这并不特别复杂。因此,我直观地看到,只要我用Python自己的urlib2库打开网页,获取HTML代码,然后将其交给beautiful soup库解析HTML代码,我就应该能够快速完成
但是当你仔细看的时候,点击下一页,网页的URL不会改变。您只需使用js加载新数据,然后动态更改表中的数据。这与本盘的上一页不同,因此这次我们应该找到一种模拟翻页的方法,然后重新阅读新的HTML代码并对其进行分析
实现翻页有两种方法。首先是分析JS的实现,以模拟翻页。翻页操作实际上是JS向后台发送请求。在这里,它必须请求具有跳转目标页码的背景,然后获取新数据并重新呈现HTML的表部分。这种方法效率更高,但难度更大。因为如果您可以模拟请求,这意味着您已经知道其他人的服务器接口。然后,您可以通过进一步分析响应得到结果。你甚至不需要分析HTML代码,是吗?第二个相对简单的方法,也是我在这里使用的方法,是模拟单击web页面中的“下一页”按钮,然后重新读取HTML代码进行解析
二、ideas
如前所述,此处处理该想法:
在这里,打开和阅读网页的HTML代码是通过selenium实现的
解析HTML代码是通过Beauty soup实现的
三、implementation1.相关库的准备和安装
我使用Mac,因此我可以使用easy Direct_uuInstall命令行安装
1
sudo easy_install beautifulsoup4
或简易安装命令
1
sudo easy_install selenium
在这里,selenium版本已经到达3.0.2,如果要使用此版本的selenium打开网页,则需要使用相应的驱动程序。所以我需要安装一个驱动程序
我在这里使用自制安装的chromediver。安装后,请记住查找chromediver的安装目录。我们将在编写下面的代码时使用它
1
brew install chromedirver
注意:Mac下有许多软件管理包。除了我的安装方法,你可以用pip安装它们,或者直接从官方网站下载安装程序。但您必须安装上述三个程序。在这里我突然有了一个想法。老实说,如果Python拥有与gradle相同的构建管理工具,我现在花在安装这些依赖库上的时间比写代码要多
2.分析页面
只需发布我想要爬升的网页的HTML代码的一部分,在其中我使用//写一些评论:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152
// 本周排行榜,这是我要抓的内容 排名 明星 鲜花数 TOP粉丝 1 // 这个td标签,star-name的css class是我要抓的内容 王俊凯 1790892 送花 1183*****630 2185*****759 3wx526298988 ...此处省略巨量代码... // 这里是本周排行榜分页的html代码,可以看到一页20个明星,共有50页 首页 尾页// 下面开始就是“上周排行榜”,html结构和上面完全类似...此处再次省略巨量代码...
3.完整代码
1234567891011121314151617181920212223242526272829303132333435
import sysimport urllib2import timefrom bs4 import BeautifulSoupfrom selenium import webdriverreload(sys)sys.setdefaultencoding('utf8') # 设置编码url = 'http://baike.baidu.com/starrank?fr=lemmaxianhua'driver = webdriver.Chrome('/usr/local/Cellar/chromedriver/2.20/bin/chromedriver') # 创建一个driver用于打开网页,记得找到brew安装的chromedriver的位置,在创建driver的时候指定这个位置driver.get(url) # 打开网页name_counter = 1page = 0;while page < 50: # 共50页,这里是手工指定的 soup = BeautifulSoup(driver.page_source, "html.parser") current_names = soup.select('div.ranking-table') # 选择器用ranking-table css class,可以取出包含本周、上周的两个table的div标签 for current_name_list in current_names: # print current_name_list['data-cat'] if current_name_list['data-cat'] == 'thisWeek': # 这次我只想抓取本周,如果想抓上周,改一下这里为lastWeek即可 names = current_name_list.select('td.star-name > a') # beautifulsoup选择器语法 counter = 0; for star_name in names: counter = counter + 1; print star_name.text # 明星的名字是a标签里面的文本,虽然a标签下面除了文本还有一个与文本同级别的img标签,但是.text输出的只是文本而已 name_counter = name_counter + 1; driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click() # selenium的xpath用法,找到包含“下一页”的a标签去点击 page = page + 1 time.sleep(2) # 睡2秒让网页加载完再去读它的html代码print name_counter # 共爬取得明星的名字数量driver.quit()
四、总结
这里只简单记录了一个稍微复杂一点的网页爬行的实现思想。硒和beatifulsoup有很多用法,我没有仔细阅读。这里有一些参考资料。将来有机会我会学到更多 查看全部
抓取动态网页(如何用python自带urllib2库打开网页的爬虫实现之旅?)
一、背景
记录一次周末赶回家的爬行动物实现之旅。受他人委托,我想从这一页的明星名单上爬下来。当你在chrome中打开它时,实际上有1000条记录。然后单击“右键菜单”->;“检查”查看网页的结构,这并不特别复杂。因此,我直观地看到,只要我用Python自己的urlib2库打开网页,获取HTML代码,然后将其交给beautiful soup库解析HTML代码,我就应该能够快速完成

但是当你仔细看的时候,点击下一页,网页的URL不会改变。您只需使用js加载新数据,然后动态更改表中的数据。这与本盘的上一页不同,因此这次我们应该找到一种模拟翻页的方法,然后重新阅读新的HTML代码并对其进行分析
实现翻页有两种方法。首先是分析JS的实现,以模拟翻页。翻页操作实际上是JS向后台发送请求。在这里,它必须请求具有跳转目标页码的背景,然后获取新数据并重新呈现HTML的表部分。这种方法效率更高,但难度更大。因为如果您可以模拟请求,这意味着您已经知道其他人的服务器接口。然后,您可以通过进一步分析响应得到结果。你甚至不需要分析HTML代码,是吗?第二个相对简单的方法,也是我在这里使用的方法,是模拟单击web页面中的“下一页”按钮,然后重新读取HTML代码进行解析
二、ideas
如前所述,此处处理该想法:
在这里,打开和阅读网页的HTML代码是通过selenium实现的
解析HTML代码是通过Beauty soup实现的
三、implementation1.相关库的准备和安装
我使用Mac,因此我可以使用easy Direct_uuInstall命令行安装
1
sudo easy_install beautifulsoup4
或简易安装命令
1
sudo easy_install selenium
在这里,selenium版本已经到达3.0.2,如果要使用此版本的selenium打开网页,则需要使用相应的驱动程序。所以我需要安装一个驱动程序
我在这里使用自制安装的chromediver。安装后,请记住查找chromediver的安装目录。我们将在编写下面的代码时使用它
1
brew install chromedirver
注意:Mac下有许多软件管理包。除了我的安装方法,你可以用pip安装它们,或者直接从官方网站下载安装程序。但您必须安装上述三个程序。在这里我突然有了一个想法。老实说,如果Python拥有与gradle相同的构建管理工具,我现在花在安装这些依赖库上的时间比写代码要多
2.分析页面
只需发布我想要爬升的网页的HTML代码的一部分,在其中我使用//写一些评论:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152
// 本周排行榜,这是我要抓的内容 排名 明星 鲜花数 TOP粉丝 1 // 这个td标签,star-name的css class是我要抓的内容 王俊凯 1790892 送花 1183*****630 2185*****759 3wx526298988 ...此处省略巨量代码... // 这里是本周排行榜分页的html代码,可以看到一页20个明星,共有50页 首页 尾页// 下面开始就是“上周排行榜”,html结构和上面完全类似...此处再次省略巨量代码...
3.完整代码
1234567891011121314151617181920212223242526272829303132333435
import sysimport urllib2import timefrom bs4 import BeautifulSoupfrom selenium import webdriverreload(sys)sys.setdefaultencoding('utf8') # 设置编码url = 'http://baike.baidu.com/starrank?fr=lemmaxianhua'driver = webdriver.Chrome('/usr/local/Cellar/chromedriver/2.20/bin/chromedriver') # 创建一个driver用于打开网页,记得找到brew安装的chromedriver的位置,在创建driver的时候指定这个位置driver.get(url) # 打开网页name_counter = 1page = 0;while page < 50: # 共50页,这里是手工指定的 soup = BeautifulSoup(driver.page_source, "html.parser") current_names = soup.select('div.ranking-table') # 选择器用ranking-table css class,可以取出包含本周、上周的两个table的div标签 for current_name_list in current_names: # print current_name_list['data-cat'] if current_name_list['data-cat'] == 'thisWeek': # 这次我只想抓取本周,如果想抓上周,改一下这里为lastWeek即可 names = current_name_list.select('td.star-name > a') # beautifulsoup选择器语法 counter = 0; for star_name in names: counter = counter + 1; print star_name.text # 明星的名字是a标签里面的文本,虽然a标签下面除了文本还有一个与文本同级别的img标签,但是.text输出的只是文本而已 name_counter = name_counter + 1; driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click() # selenium的xpath用法,找到包含“下一页”的a标签去点击 page = page + 1 time.sleep(2) # 睡2秒让网页加载完再去读它的html代码print name_counter # 共爬取得明星的名字数量driver.quit()
四、总结
这里只简单记录了一个稍微复杂一点的网页爬行的实现思想。硒和beatifulsoup有很多用法,我没有仔细阅读。这里有一些参考资料。将来有机会我会学到更多
抓取动态网页(如何从javascript页面爬取信息中进行数据爬取?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-17 21:00
一、simple动态页面爬行
我们以前的页面爬行工作是基于静态页面的。但是现在很多页面使用动态页面,其中70%的动态页面是由JavaScript编写的。因此,了解如何从JavaScript页面抓取信息对我们来说非常重要
在了解具体情况之前,我们需要了解AJAX是什么。它的英文全称是AsynchronousJavaScript和XML,它是一种异步JavaScript和XML。我们可以通过Ajax请求页面数据,返回的数据格式是JSON类型
然后我们可以根据页面的Ajax格式抓取数据。下面是一个简单的页面爬网
import json
from Chapter3 import download
import csv
def simpletest():
'''
it will write the date to the country.csv
the json data has the attribute records, and the records has area, country and capital value
:return:
'''
fileds = ('area', 'country', 'capital')
writer = csv.writer(open("country.csv", "w"))
writer.writerow(fileds)
d = download.Downloader()
html = d("http://example.webscraping.com ... 6quot;)
try:
ajax = json.loads(html)
except Exception as e:
print str(e)
else:
for record in ajax['records']:
row = [record[filed] for filed in fileds]
writer.writerow(row)
if __name__ == "__main__":
simpletest()
我不知道这是否是问题所在。现在我无法从上述网站下载数据。执行上述程序。以下是结果图:
二、呈现动态页面
在开始之前,首先下载pyside并直接使用PIP install pyside命令行
然后我们可以使用pyside来抓取数据
from PySide.QtWebKit import *
from PySide.QtGui import *
from PySide.QtCore import *
import lxml.html
def simpletest():
'''
get content of the div # result in http://example.webscraping.com ... namic
:return: content
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
htmled = webview.page().mainFrame().toHtml()
# get the special content
tree = lxml.html.fromstring(htmled)
return tree.cssselect('#result')[0].text_content()
content = simpletest()
print content
我们回顾了简单动态页面爬行的内容。以前的方法不成功。我认为主要原因是我的网站写得不正确,所以在学习pyside之后,我们可以使用这种新方法进行数据爬行。以下是具体代码:
def getallcountry():
'''
open the html and set search term = a and page_size = 10
and then click auto by javascript
:return:
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
# show the webview
webview.show()
frame = webview.page().mainFrame()
# set search text is b
frame.findFirstElement('#search_term').setAttribute('value', 'b')
# set page_size is 10
frame.findFirstElement('#page_size option:checked').setPlainText('10')
# click search button auto
frame.findFirstElement('#search').evaluateJavaScript('this.click()')
app.exec_()
以下是结果图:
在上面的过程中,我们只使用pyside在页面上获取结果,但还没有对数据进行爬网。因为Ajax在响应事件时有一定的延迟,所以有三种方法可以抓取数据:
1、等待一定时间(效率低下)
2、rewrite QT的网络管理器,以跟踪URL请求的完成时间(不适用于客户端问题的情况)
3、轮询页面并等待特定内容出现(检查时浪费CPU时间)
一般来说,第三种方法更可靠、更方便。下面是它的概念代码:它的主要思想是while循环。如果找不到元素,请继续尝试
为了使上述方法更通用,我们可以将它们编写在一个类中。此类收录以下功能:下载、获取HTML、查找对应元素、设置属性值、设置文本值、单击、轮询页面并等待下载
<p>from PySide.QtCore import *
from PySide.QtGui import *
from PySide.QtWebKit import *
import time
import sys
class BrowserRender(QWebView):
def __init__(self, show=True):
'''
if the show is true then we can see webview
:param show:
'''
self.app = QApplication(sys.argv)
QWebView.__init__(self)
if show:
self.show()
def download(self, url, timeout=60):
'''
download the url if timeout is false
:param url: the download url
:param timeout: the timeout time
:return: html if not timeout
'''
loop = QEventLoop()
timer = QTimer()
timer.setSingleShot(True)
timer.timeout.connect(loop.quit)
self.loadFinished.connect(loop.quit)
self.load(QUrl(url))
timer.start(timeout*1000)
loop.exec_()
if timer.isActive():
timer.stop()
return self.html()
else:
print "Request time out "+url
def html(self):
'''
shortcut to return the current html
:return:
'''
return self.page().mainFrame().toHtml()
def find(self, pattern):
'''
find all elements that match the pattern
:param pattern:
:return:
'''
return self.page().mainFrame().findAllElements(pattern)
def attr(self, pattern, name, value):
'''
set attribute for matching pattern
:param pattern:
:param name:
:param value:
:return:
'''
for e in self.find(pattern):
e.setAttribute(name, value)
def text(self, pattern, value):
'''
set plaintext for matching pattern
:param pattern:
:param value:
:return:
'''
for e in self.find(pattern):
e.setPlainText(value)
def click(self, pattern):
'''
click matching pattern
:param pattern:
:return:
'''
for e in self.find(pattern):
e.evaluateJavaScript("this.click()")
def wait_load(self, pattern, timeout=60):
'''
wait untill pattern is found and return matches
:param pattern:
:param timeout:
:return:
'''
deadtiem = time.time() + timeout
while time.time() 查看全部
抓取动态网页(如何从javascript页面爬取信息中进行数据爬取?(一))
一、simple动态页面爬行
我们以前的页面爬行工作是基于静态页面的。但是现在很多页面使用动态页面,其中70%的动态页面是由JavaScript编写的。因此,了解如何从JavaScript页面抓取信息对我们来说非常重要
在了解具体情况之前,我们需要了解AJAX是什么。它的英文全称是AsynchronousJavaScript和XML,它是一种异步JavaScript和XML。我们可以通过Ajax请求页面数据,返回的数据格式是JSON类型
然后我们可以根据页面的Ajax格式抓取数据。下面是一个简单的页面爬网
import json
from Chapter3 import download
import csv
def simpletest():
'''
it will write the date to the country.csv
the json data has the attribute records, and the records has area, country and capital value
:return:
'''
fileds = ('area', 'country', 'capital')
writer = csv.writer(open("country.csv", "w"))
writer.writerow(fileds)
d = download.Downloader()
html = d("http://example.webscraping.com ... 6quot;)
try:
ajax = json.loads(html)
except Exception as e:
print str(e)
else:
for record in ajax['records']:
row = [record[filed] for filed in fileds]
writer.writerow(row)
if __name__ == "__main__":
simpletest()
我不知道这是否是问题所在。现在我无法从上述网站下载数据。执行上述程序。以下是结果图:
二、呈现动态页面
在开始之前,首先下载pyside并直接使用PIP install pyside命令行
然后我们可以使用pyside来抓取数据
from PySide.QtWebKit import *
from PySide.QtGui import *
from PySide.QtCore import *
import lxml.html
def simpletest():
'''
get content of the div # result in http://example.webscraping.com ... namic
:return: content
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
htmled = webview.page().mainFrame().toHtml()
# get the special content
tree = lxml.html.fromstring(htmled)
return tree.cssselect('#result')[0].text_content()
content = simpletest()
print content
我们回顾了简单动态页面爬行的内容。以前的方法不成功。我认为主要原因是我的网站写得不正确,所以在学习pyside之后,我们可以使用这种新方法进行数据爬行。以下是具体代码:
def getallcountry():
'''
open the html and set search term = a and page_size = 10
and then click auto by javascript
:return:
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
# show the webview
webview.show()
frame = webview.page().mainFrame()
# set search text is b
frame.findFirstElement('#search_term').setAttribute('value', 'b')
# set page_size is 10
frame.findFirstElement('#page_size option:checked').setPlainText('10')
# click search button auto
frame.findFirstElement('#search').evaluateJavaScript('this.click()')
app.exec_()
以下是结果图:

在上面的过程中,我们只使用pyside在页面上获取结果,但还没有对数据进行爬网。因为Ajax在响应事件时有一定的延迟,所以有三种方法可以抓取数据:
1、等待一定时间(效率低下)
2、rewrite QT的网络管理器,以跟踪URL请求的完成时间(不适用于客户端问题的情况)
3、轮询页面并等待特定内容出现(检查时浪费CPU时间)
一般来说,第三种方法更可靠、更方便。下面是它的概念代码:它的主要思想是while循环。如果找不到元素,请继续尝试

为了使上述方法更通用,我们可以将它们编写在一个类中。此类收录以下功能:下载、获取HTML、查找对应元素、设置属性值、设置文本值、单击、轮询页面并等待下载
<p>from PySide.QtCore import *
from PySide.QtGui import *
from PySide.QtWebKit import *
import time
import sys
class BrowserRender(QWebView):
def __init__(self, show=True):
'''
if the show is true then we can see webview
:param show:
'''
self.app = QApplication(sys.argv)
QWebView.__init__(self)
if show:
self.show()
def download(self, url, timeout=60):
'''
download the url if timeout is false
:param url: the download url
:param timeout: the timeout time
:return: html if not timeout
'''
loop = QEventLoop()
timer = QTimer()
timer.setSingleShot(True)
timer.timeout.connect(loop.quit)
self.loadFinished.connect(loop.quit)
self.load(QUrl(url))
timer.start(timeout*1000)
loop.exec_()
if timer.isActive():
timer.stop()
return self.html()
else:
print "Request time out "+url
def html(self):
'''
shortcut to return the current html
:return:
'''
return self.page().mainFrame().toHtml()
def find(self, pattern):
'''
find all elements that match the pattern
:param pattern:
:return:
'''
return self.page().mainFrame().findAllElements(pattern)
def attr(self, pattern, name, value):
'''
set attribute for matching pattern
:param pattern:
:param name:
:param value:
:return:
'''
for e in self.find(pattern):
e.setAttribute(name, value)
def text(self, pattern, value):
'''
set plaintext for matching pattern
:param pattern:
:param value:
:return:
'''
for e in self.find(pattern):
e.setPlainText(value)
def click(self, pattern):
'''
click matching pattern
:param pattern:
:return:
'''
for e in self.find(pattern):
e.evaluateJavaScript("this.click()")
def wait_load(self, pattern, timeout=60):
'''
wait untill pattern is found and return matches
:param pattern:
:param timeout:
:return:
'''
deadtiem = time.time() + timeout
while time.time()
抓取动态网页(怎样让搜索引擎更好地为站点服务与提高站点的访问量有着)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-15 15:21
随着互联网上网站的增加,网站的宣传越来越依赖于搜索引擎的搜索结果。如何使搜索引擎更好地为网站服务与提高网站的流量密切相关。搜索引擎不是上帝赐予互联网的礼物。搜索引擎本身不仅是一个站点,而且是由各种程序构建的。各种搜索引擎通常使用一种称为搜索引擎机器人的技术。这个机器人将根据一定的规则访问互联网上的站点,并将有价值的页面采集到搜索引擎缓存数据库中。一旦用户搜索,搜索引擎将直接缓存搜索结果并向用户报告结果
搜索机器人的搜索规则比较复杂,但最重要的规则之一是搜索机器人对静态页面的处理能力强于对动态页面的处理能力。一般来说,搜索机器人只是简单地将静态页面理解为具有。HTML或。HTM扩展,而带有。ASP,。PHP和。CGI扩展被理解为动态页面。换句话说,如果一个站点是a。HTML页面,它在搜索引擎的全文中被发现的可能性比a高几个数量级。PHP页面。当然,访问的次数会多得多
如何让你的站点的所有内容都是静态页面,最简单的方法自然就是用页面设计软件将每个页面直接制作成静态页面,这对于小站点来说并不难,但是对于拥有数万页面的大中型站点来说,使用手工静态页面设计将带来高成本和保存和修改的困难。在这种情况下,资金充裕的大型网站公司将采用一种可以生成数据的内容管理(cms)系统。背景中的HTML文件。是否是手册。HTML文件或a。HTML文件在后台生成,可以实现真正的静态页面
然而,相当多的中型网站仍然使用cms动态发布系统。动态系统更新网页效率高,可在前台显示,在后台调度。缺点是它消耗了大量的服务器资源,并通过扩展获取了大量页面。同时使用Asp.php。要完全取代cms系统并不容易,成熟的cms系统具有静态页面后台生成功能,价格非常高
动态cms系统是否有一个简单的方法来获得扩展。HTML文件?当然,采用了URL重写转向功能
对URL重写和重定向的支持由Apache服务器上的非默认模块(mod_rewrite)完成。这个模块非常强大和笨重。IIS下有类似的模块,即ISAPI重写和IIS重写。无论是在Apache还是IIS中,重写的语法都基于正则表达式,只有一些区别。当然,对于一般应用,不需要移交所有手册和说明文件。下面以一个虚拟动态站点为例介绍一些简单的方法,读者可以根据网站的情况进行调整 查看全部
抓取动态网页(怎样让搜索引擎更好地为站点服务与提高站点的访问量有着)
随着互联网上网站的增加,网站的宣传越来越依赖于搜索引擎的搜索结果。如何使搜索引擎更好地为网站服务与提高网站的流量密切相关。搜索引擎不是上帝赐予互联网的礼物。搜索引擎本身不仅是一个站点,而且是由各种程序构建的。各种搜索引擎通常使用一种称为搜索引擎机器人的技术。这个机器人将根据一定的规则访问互联网上的站点,并将有价值的页面采集到搜索引擎缓存数据库中。一旦用户搜索,搜索引擎将直接缓存搜索结果并向用户报告结果
搜索机器人的搜索规则比较复杂,但最重要的规则之一是搜索机器人对静态页面的处理能力强于对动态页面的处理能力。一般来说,搜索机器人只是简单地将静态页面理解为具有。HTML或。HTM扩展,而带有。ASP,。PHP和。CGI扩展被理解为动态页面。换句话说,如果一个站点是a。HTML页面,它在搜索引擎的全文中被发现的可能性比a高几个数量级。PHP页面。当然,访问的次数会多得多
如何让你的站点的所有内容都是静态页面,最简单的方法自然就是用页面设计软件将每个页面直接制作成静态页面,这对于小站点来说并不难,但是对于拥有数万页面的大中型站点来说,使用手工静态页面设计将带来高成本和保存和修改的困难。在这种情况下,资金充裕的大型网站公司将采用一种可以生成数据的内容管理(cms)系统。背景中的HTML文件。是否是手册。HTML文件或a。HTML文件在后台生成,可以实现真正的静态页面
然而,相当多的中型网站仍然使用cms动态发布系统。动态系统更新网页效率高,可在前台显示,在后台调度。缺点是它消耗了大量的服务器资源,并通过扩展获取了大量页面。同时使用Asp.php。要完全取代cms系统并不容易,成熟的cms系统具有静态页面后台生成功能,价格非常高
动态cms系统是否有一个简单的方法来获得扩展。HTML文件?当然,采用了URL重写转向功能
对URL重写和重定向的支持由Apache服务器上的非默认模块(mod_rewrite)完成。这个模块非常强大和笨重。IIS下有类似的模块,即ISAPI重写和IIS重写。无论是在Apache还是IIS中,重写的语法都基于正则表达式,只有一些区别。当然,对于一般应用,不需要移交所有手册和说明文件。下面以一个虚拟动态站点为例介绍一些简单的方法,读者可以根据网站的情况进行调整
抓取动态网页(SEO(搜索引擎优化)推广中最重要的关键词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-15 15:20
对于SEO,只要搜索引擎抓取更多的网站页面,就可以提高收录和排名,但有时蜘蛛不会主动抓取网站. 此时,我们需要人工引导搜索引擎,然后提高排名和收录. 今天,小编将与大家分享八种有利于搜索引擎抓取网站页面的方法
提高网站最重要的关键词和在主要搜索平台的排名是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,因此SEO(搜索引擎优化)的推广策略应从优化网页开始
1、添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题应简洁,删除一些繁琐、多余和不重要的词语,并解释页面和网站最重要的内容。页面标题将出现在搜索结果页面的链接上,因此可以写得稍微挑逗一些,以吸引搜索者点击链接。同时,写下你的企业名称和你认为最重要的关键词,而不仅仅是你的企业名称
2、添加描述性元标记
元素可以提供关于页面的元信息,例如描述和关键词
除了页面标题,许多搜索引擎还会搜索元标记。这是一个说明性的句子,描述了网页主体的内容。句子还应包括本页使用的关键词、短语等
目前,带有关键词的meta标签对网站排名没有帮助,但有时meta标签将用于付费登录技术。谁知道搜索引擎什么时候会再次关注它呢
3、将您的关键词以粗体文本(通常为“文章title”)嵌入网页
搜索引擎非常重视粗体文本,并会认为它是本页面非常重要的内容。因此,请务必写下您的关键词
4、确保关键词出现在文本的第一段中@
搜索引擎希望在第一段中找到你的关键词,但它们不能填充太多关键词. 谷歌将出现在每100字的全文中。"1.5-2关键词“被视为最好的关键词密度,以获得更好的排名
可以考虑放置关键词的其他位置可以在代码的ALT标记或comment标记中
5、导航设计应便于搜索引擎搜索
有些人在网页制作中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,它也可能会错过关键导航列,因此无法进一步搜索其他页面
用Java和flash制作的导航按钮看起来很漂亮,但搜索引擎找不到。补救方法是在页面底部创建一个带有常规HTML链接的导航栏,以确保您可以通过该导航栏的链接进入每个页面网站。您还可以制作网站地图或链接每个网站页面。此外,一些内容管理系统和电子商务目录使用动态网页。通常,在这些网页的网址后面有一个带数字的问号。过度工作的搜索引擎通常会在问号前停止搜索。这种情况可以通过更改URL(统一资源定位器)和支付登录费用来解决
6、对于一些特别重要的关键词,专门制作了几页
SEO(搜索引擎优化)专家不建议为搜索引擎使用任何欺骗性的过渡页面,因为这些页面几乎都是复制的,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页集收录不同的关键词短语。例如,您不需要在一个页面上介绍所有服务,而是为每个服务创建一个页面。这样,每个页面都有相应的关键词,这些页面的内容将提高网站排名,因为它们收录目标关键词,而不是一般内容
7、向搜索引擎提交网页
在搜索引擎上找到“添加您的URL”(网站login)的链接。搜索机器人将自动为您提交的网页编制索引。美国最著名的搜索引擎是谷歌、inktomi、Alta Vista和tehoma
这些搜索引擎向其他主要搜索引擎平台和门户提供搜索内容网站. 在欧洲和其他地方,您可以发布到区域搜索引擎
至于付钱给某人为你提交“数百”个搜索引擎的做法,这是徒劳的。不要使用FFA(所有页面都免费)网站,这是一个所谓的网站,可以自动将你的网站免费提交给数百个搜索引擎。这种提交不仅会产生不良影响,还会给你带来大量的垃圾邮件,并可能导致搜索引擎平台以网站惩罚你@
8、调整重要内容页面以提高排名
对最重要的页面(可能是主页)进行一些调整,以提高其排名。一些软件允许你检查当前排名,比较关键词与你相同竞争对手的网页排名,并在你的网页上获得搜索引擎的首选统计数据,以便调整你自己的网页
最后,还有另一种提高网站搜索排名的方法,即部署和安装SSL证书。@以“HTTPS”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌已明确表示将优先考虑收录“HTTPS”网站
百度官方指出,它一直支持“HTTPS”。它将“HTTPS”作为网站的高质量功能之一,影响搜索排名,并为“HTTPS站点”网站提供多维支持要以“HTTPS”开头,必须安装和部署SSL证书。当网站安装部署SSL证书时,你会得到“百度蜘蛛”的权重倾斜,这可以使网站排名上升并保持稳定
这些都是搜索引擎主动捕获网站页面的方式。我希望南方联合小编的分享能对你有所帮助。南联致力于提供香港主机租赁、香港服务器租赁、服务器托管、云主机租赁等服务,欢迎咨询客户服务详解 查看全部
抓取动态网页(SEO(搜索引擎优化)推广中最重要的关键词)
对于SEO,只要搜索引擎抓取更多的网站页面,就可以提高收录和排名,但有时蜘蛛不会主动抓取网站. 此时,我们需要人工引导搜索引擎,然后提高排名和收录. 今天,小编将与大家分享八种有利于搜索引擎抓取网站页面的方法

提高网站最重要的关键词和在主要搜索平台的排名是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,因此SEO(搜索引擎优化)的推广策略应从优化网页开始
1、添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题应简洁,删除一些繁琐、多余和不重要的词语,并解释页面和网站最重要的内容。页面标题将出现在搜索结果页面的链接上,因此可以写得稍微挑逗一些,以吸引搜索者点击链接。同时,写下你的企业名称和你认为最重要的关键词,而不仅仅是你的企业名称
2、添加描述性元标记
元素可以提供关于页面的元信息,例如描述和关键词
除了页面标题,许多搜索引擎还会搜索元标记。这是一个说明性的句子,描述了网页主体的内容。句子还应包括本页使用的关键词、短语等
目前,带有关键词的meta标签对网站排名没有帮助,但有时meta标签将用于付费登录技术。谁知道搜索引擎什么时候会再次关注它呢
3、将您的关键词以粗体文本(通常为“文章title”)嵌入网页
搜索引擎非常重视粗体文本,并会认为它是本页面非常重要的内容。因此,请务必写下您的关键词
4、确保关键词出现在文本的第一段中@
搜索引擎希望在第一段中找到你的关键词,但它们不能填充太多关键词. 谷歌将出现在每100字的全文中。"1.5-2关键词“被视为最好的关键词密度,以获得更好的排名
可以考虑放置关键词的其他位置可以在代码的ALT标记或comment标记中
5、导航设计应便于搜索引擎搜索
有些人在网页制作中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,它也可能会错过关键导航列,因此无法进一步搜索其他页面
用Java和flash制作的导航按钮看起来很漂亮,但搜索引擎找不到。补救方法是在页面底部创建一个带有常规HTML链接的导航栏,以确保您可以通过该导航栏的链接进入每个页面网站。您还可以制作网站地图或链接每个网站页面。此外,一些内容管理系统和电子商务目录使用动态网页。通常,在这些网页的网址后面有一个带数字的问号。过度工作的搜索引擎通常会在问号前停止搜索。这种情况可以通过更改URL(统一资源定位器)和支付登录费用来解决
6、对于一些特别重要的关键词,专门制作了几页
SEO(搜索引擎优化)专家不建议为搜索引擎使用任何欺骗性的过渡页面,因为这些页面几乎都是复制的,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页集收录不同的关键词短语。例如,您不需要在一个页面上介绍所有服务,而是为每个服务创建一个页面。这样,每个页面都有相应的关键词,这些页面的内容将提高网站排名,因为它们收录目标关键词,而不是一般内容
7、向搜索引擎提交网页
在搜索引擎上找到“添加您的URL”(网站login)的链接。搜索机器人将自动为您提交的网页编制索引。美国最著名的搜索引擎是谷歌、inktomi、Alta Vista和tehoma
这些搜索引擎向其他主要搜索引擎平台和门户提供搜索内容网站. 在欧洲和其他地方,您可以发布到区域搜索引擎
至于付钱给某人为你提交“数百”个搜索引擎的做法,这是徒劳的。不要使用FFA(所有页面都免费)网站,这是一个所谓的网站,可以自动将你的网站免费提交给数百个搜索引擎。这种提交不仅会产生不良影响,还会给你带来大量的垃圾邮件,并可能导致搜索引擎平台以网站惩罚你@
8、调整重要内容页面以提高排名
对最重要的页面(可能是主页)进行一些调整,以提高其排名。一些软件允许你检查当前排名,比较关键词与你相同竞争对手的网页排名,并在你的网页上获得搜索引擎的首选统计数据,以便调整你自己的网页
最后,还有另一种提高网站搜索排名的方法,即部署和安装SSL证书。@以“HTTPS”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌已明确表示将优先考虑收录“HTTPS”网站
百度官方指出,它一直支持“HTTPS”。它将“HTTPS”作为网站的高质量功能之一,影响搜索排名,并为“HTTPS站点”网站提供多维支持要以“HTTPS”开头,必须安装和部署SSL证书。当网站安装部署SSL证书时,你会得到“百度蜘蛛”的权重倾斜,这可以使网站排名上升并保持稳定
这些都是搜索引擎主动捕获网站页面的方式。我希望南方联合小编的分享能对你有所帮助。南联致力于提供香港主机租赁、香港服务器租赁、服务器托管、云主机租赁等服务,欢迎咨询客户服务详解
抓取动态网页(企业想做好SEO推广营销就必须把握搜索引擎搜索引擎蜘蛛的抓取规范)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-15 15:18
企业要想做好SEO推广和营销工作,就必须掌握搜索引擎蜘蛛的捕获规范,做好web搜索动态页面SEO。非常有必要确保每个人都掌握了中国台湾SEO技术的范例课程:捕捉动态页面非常困难。接下来,WebEditor将告诉您如何通过SEO改进动态页面:
一、建立静态入口
在“动静结合,不改变台湾SEO技术范例课程:应该改变”的标准指导下,我们可以根据网站对网站进行一些修改,尽可能提高搜索引擎在动态网页上的可视性。SEO优化方法,如将动态网页列为静态主页或sitmap的多层SEO连接,并以静态文件名的形式呈现动态页面。或者为动态页面建立一个技术专业的静态输入页面,连接到台湾的SEO技术示例教程:动态页面,并将静态输入页面提交给搜索引擎
二、付费登录搜索引擎
对于连接到数据库的内容智能管理系统发布的动态网站,提高SEO的最直接方法是付费登录。建议立即将动态网页提交到搜索引擎文件名或进行关键字广告,以确保搜索引擎网站收录使用该网站@
三、搜索引擎可用性改进
搜索引擎一直在提高其动态页面的可用性,但当此类搜索引擎的爬行器爬行动态页面时,它们很容易避免寻找服务机器人的陷阱。搜索引擎只抓取从静态页面连接的动态页面,而从动态页面连接的动态页面长期以来一直被忽略,换言之,在很多方面都不容易访问动态页面中的链接
热门搜索词 查看全部
抓取动态网页(企业想做好SEO推广营销就必须把握搜索引擎搜索引擎蜘蛛的抓取规范)
企业要想做好SEO推广和营销工作,就必须掌握搜索引擎蜘蛛的捕获规范,做好web搜索动态页面SEO。非常有必要确保每个人都掌握了中国台湾SEO技术的范例课程:捕捉动态页面非常困难。接下来,WebEditor将告诉您如何通过SEO改进动态页面:

一、建立静态入口
在“动静结合,不改变台湾SEO技术范例课程:应该改变”的标准指导下,我们可以根据网站对网站进行一些修改,尽可能提高搜索引擎在动态网页上的可视性。SEO优化方法,如将动态网页列为静态主页或sitmap的多层SEO连接,并以静态文件名的形式呈现动态页面。或者为动态页面建立一个技术专业的静态输入页面,连接到台湾的SEO技术示例教程:动态页面,并将静态输入页面提交给搜索引擎
二、付费登录搜索引擎
对于连接到数据库的内容智能管理系统发布的动态网站,提高SEO的最直接方法是付费登录。建议立即将动态网页提交到搜索引擎文件名或进行关键字广告,以确保搜索引擎网站收录使用该网站@

三、搜索引擎可用性改进
搜索引擎一直在提高其动态页面的可用性,但当此类搜索引擎的爬行器爬行动态页面时,它们很容易避免寻找服务机器人的陷阱。搜索引擎只抓取从静态页面连接的动态页面,而从动态页面连接的动态页面长期以来一直被忽略,换言之,在很多方面都不容易访问动态页面中的链接
热门搜索词
抓取动态网页(动态网页元素与网页源码的实现思路及源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-13 23:06
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是回顾网页元素
所以这里不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
有两种使用正则表达式的方法。可以参考个人简述:简单爬虫的python实现及正则表达式简述
更多详情请参考网上资料,搜索关键词:正则表达式python
json:
参考网上对json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks) 查看全部
抓取动态网页(动态网页元素与网页源码的实现思路及源码
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是回顾网页元素
所以这里不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
有两种使用正则表达式的方法。可以参考个人简述:简单爬虫的python实现及正则表达式简述
更多详情请参考网上资料,搜索关键词:正则表达式python
json:
参考网上对json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-13 23:05
文章directory
本章将带大家使用selenium抓取一些动态加载的页面,让大家体验selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片为百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
获取动态数据我在找雪球网,爬取雪球网首页推荐数据,以及雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
我这里看到的是一样的数据,是当前的url,可以点击Headers复制url
如上图,数据已经存在,但是你往下看抓包会发现只有几条数据,所以需要用selenium打开当前页面配合用js实现页面下拉获取更多数据
分析获取的数据(xpath或bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲)
2.2 编写爬虫代码并进行页面爬取
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.Summary
相信如果你用上面的代码自己抓取数据,你就会知道selenium的方便了。如果你不使用selenium去抓取一些数据,你抓取可能会很不方便,但是selenium也有自己的缺点,那就是效率不高。就像上面爬的雪球网一样,我自己测试的时候用了220s。有时也可以选择抓取js包进行数据分析(后面会有案例),当然,如果用其他方法拿不到数据,使用selenium也是不错的选择。 查看全部
抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
文章directory
本章将带大家使用selenium抓取一些动态加载的页面,让大家体验selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片为百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
获取动态数据我在找雪球网,爬取雪球网首页推荐数据,以及雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
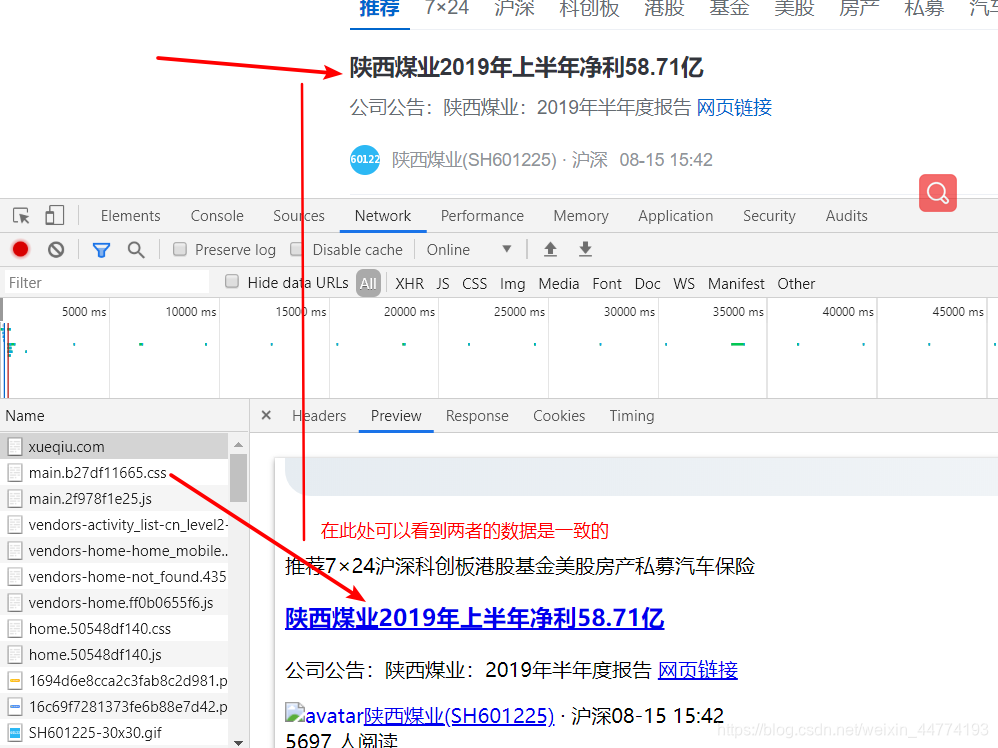
我这里看到的是一样的数据,是当前的url,可以点击Headers复制url
如上图,数据已经存在,但是你往下看抓包会发现只有几条数据,所以需要用selenium打开当前页面配合用js实现页面下拉获取更多数据
分析获取的数据(xpath或bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲)
2.2 编写爬虫代码并进行页面爬取
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.Summary
相信如果你用上面的代码自己抓取数据,你就会知道selenium的方便了。如果你不使用selenium去抓取一些数据,你抓取可能会很不方便,但是selenium也有自己的缺点,那就是效率不高。就像上面爬的雪球网一样,我自己测试的时候用了220s。有时也可以选择抓取js包进行数据分析(后面会有案例),当然,如果用其他方法拿不到数据,使用selenium也是不错的选择。
抓取动态网页(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-13 02:02
我们在做网络爬虫的时候,一般来说urllib和urllib2可以满足大部分需求。
但有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取页面中空白内容的一部分。就像下面百度图片的结果页:
在查看元素后,。发现在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无界面爬取。
所以使用 selenium+phantomjs 进行无接口爬取
什么是phantomjs?它是一个基于webkit核心的无头浏览器,即没有UI界面,即只是一个浏览器
selenium 和 phantomjs 的安装配置可以google一下,这里忽略
代码如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i%3Fie% ... ry%3B
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器。 查看全部
抓取动态网页(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
我们在做网络爬虫的时候,一般来说urllib和urllib2可以满足大部分需求。
但有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取页面中空白内容的一部分。就像下面百度图片的结果页:
在查看元素后,。发现在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无界面爬取。
所以使用 selenium+phantomjs 进行无接口爬取
什么是phantomjs?它是一个基于webkit核心的无头浏览器,即没有UI界面,即只是一个浏览器
selenium 和 phantomjs 的安装配置可以google一下,这里忽略
代码如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i%3Fie% ... ry%3B
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器。
抓取动态网页(实习僧招聘网爬虫打造灵活强大的网络爬虫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-13 01:17
关于基础网络数据抓取相关内容,本公众号已经多次分享,特别是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但所有这些都是基于静态页面的(抓包和API访问除外)。很多动态网页不提供API访问,只能希望selenium是基于浏览器驱动的技术。
好在R语言已经有selenium接口包-RSelenium包,让我们爬取动态网页成为可能。今年年初写了一个实习生网站的爬虫,使用另一个R语言的基于selenium驱动的接口包-Rwebdriver完成。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我使用导航器突然遍历了 500 页内容。虽然最后爬取了所有的数据,但是耗时很长(将近40分钟),效率也比较低。 . (有兴趣的朋友可以参考上面的文章,不过实习和尚官网最近改版很大,现在爬肯定比刚开始难!那个代码可能不能用)
最近抽空学习了一下RSelenium包的相关内容。感谢陈彦平先生在R语言上海会议上的“用RSelenium构建灵活强大的网络爬虫”的演讲。虽然不在现场,但我有幸观看了。视频版之后,一些细节解决了我最近的一些困惑,谢谢大家。
小姐陈彦平:《用RSelenium打造灵活强大的网络爬虫》/course/88 老外关于RSelenium的介绍视频(youtube,请自行翻墙):/watch?v=ic65SWRWrKA&feature=youtu.be
目前有几个包可以解析R语言的动态网页(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩(别问为什么,因为我之前没爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器并添加系统路径;
本地有plantomjs浏览器并添加系统路径;
RSelenium 包已安装。
因为自动点击操作,Chrome浏览器整个下午都在点击链接中直接崩溃了,找到原因了,因为dragnet页面很长,而且下一页按钮不在默认窗口范围内,并且js脚本中使用控件滑动条失败,原因未知。我见过有人用firefox浏览器测试成功。我还没有尝试过。这里切换到plantomjs无头浏览器(无需考虑元素是否被窗口遮挡)
R 语言版本:
#!!!这两句是在cmd或者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行获取函数
<p>url 查看全部
抓取动态网页(实习僧招聘网爬虫打造灵活强大的网络爬虫(组图))
关于基础网络数据抓取相关内容,本公众号已经多次分享,特别是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但所有这些都是基于静态页面的(抓包和API访问除外)。很多动态网页不提供API访问,只能希望selenium是基于浏览器驱动的技术。
好在R语言已经有selenium接口包-RSelenium包,让我们爬取动态网页成为可能。今年年初写了一个实习生网站的爬虫,使用另一个R语言的基于selenium驱动的接口包-Rwebdriver完成。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我使用导航器突然遍历了 500 页内容。虽然最后爬取了所有的数据,但是耗时很长(将近40分钟),效率也比较低。 . (有兴趣的朋友可以参考上面的文章,不过实习和尚官网最近改版很大,现在爬肯定比刚开始难!那个代码可能不能用)
最近抽空学习了一下RSelenium包的相关内容。感谢陈彦平先生在R语言上海会议上的“用RSelenium构建灵活强大的网络爬虫”的演讲。虽然不在现场,但我有幸观看了。视频版之后,一些细节解决了我最近的一些困惑,谢谢大家。
小姐陈彦平:《用RSelenium打造灵活强大的网络爬虫》/course/88 老外关于RSelenium的介绍视频(youtube,请自行翻墙):/watch?v=ic65SWRWrKA&feature=youtu.be
目前有几个包可以解析R语言的动态网页(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩(别问为什么,因为我之前没爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器并添加系统路径;
本地有plantomjs浏览器并添加系统路径;
RSelenium 包已安装。
因为自动点击操作,Chrome浏览器整个下午都在点击链接中直接崩溃了,找到原因了,因为dragnet页面很长,而且下一页按钮不在默认窗口范围内,并且js脚本中使用控件滑动条失败,原因未知。我见过有人用firefox浏览器测试成功。我还没有尝试过。这里切换到plantomjs无头浏览器(无需考虑元素是否被窗口遮挡)
R 语言版本:
#!!!这两句是在cmd或者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行获取函数

<p>url
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-29 15:28
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 using System.IO; 8 9 namespace ConsoleApplication210 {11 public class Program12 {13 static int hitCount = 0;14 15 [STAThread]16 static void Main(string[] args)17 {18 string url = "http://www.cnblogs.com";19 20 WebBrowser browser = new WebBrowser();21 22 browser.ScriptErrorsSuppressed = true;23 24 browser.Navigating += (sender, e) =>25 {26 hitCount++;27 };28 29 browser.DocumentCompleted += (sender, e) =>30 {31 hitCount++;32 };33 34 browser.Navigate(url);35 36 while (browser.ReadyState != WebBrowserReadyState.Complete)37 {38 Application.DoEvents();39 }40 41 while (hitCount 35 {36 //加载完毕37 isComplete = true;38 39 timer.Stop();40 });41 42 timer.Interval = 1000 * 5;43 44 timer.Start();45 46 //继续等待 5s,等待js加载完47 while (!isComplete)48 Application.DoEvents();49 50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;51 52 string gethtml = htmldocument.documentElement.outerHTML;53 54 //写入文件55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))56 {57 sw.WriteLine(gethtml);58 }59 60 Console.WriteLine("html 文件 已经生成!");61 62 Console.Read();63 }64 }65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
<p> 1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 8 namespace ConsoleApplication2 9 {10 public class Program11 {12 static int hitCount = 0;13 14 //[STAThread]15 static void Main(string[] args)16 {17 Thread thread = new Thread(new ThreadStart(() =>18 {19 Init();20 System.Windows.Forms.Application.Run();21 }));22 23 //将该工作线程设定为STA模式24 thread.SetApartmentState(ApartmentState.STA);25 26 thread.Start();27 28 Console.Read();29 }30 31 static void Init()32 {33 string url = "http://www.cnblogs.com";34 35 WebBrowser browser = new WebBrowser();36 37 browser.ScriptErrorsSuppressed = true;38 39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);40 41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);42 43 browser.Navigate(url);44 45 while (browser.ReadyState != WebBrowserReadyState.Complete)46 {47 Application.DoEvents();48 }49 50 while (hitCount 查看全部
抓取动态网页(ajax横行的年代,我们的网页是残缺的吗?
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 using System.IO; 8 9 namespace ConsoleApplication210 {11 public class Program12 {13 static int hitCount = 0;14 15 [STAThread]16 static void Main(string[] args)17 {18 string url = "http://www.cnblogs.com";19 20 WebBrowser browser = new WebBrowser();21 22 browser.ScriptErrorsSuppressed = true;23 24 browser.Navigating += (sender, e) =>25 {26 hitCount++;27 };28 29 browser.DocumentCompleted += (sender, e) =>30 {31 hitCount++;32 };33 34 browser.Navigate(url);35 36 while (browser.ReadyState != WebBrowserReadyState.Complete)37 {38 Application.DoEvents();39 }40 41 while (hitCount 35 {36 //加载完毕37 isComplete = true;38 39 timer.Stop();40 });41 42 timer.Interval = 1000 * 5;43 44 timer.Start();45 46 //继续等待 5s,等待js加载完47 while (!isComplete)48 Application.DoEvents();49 50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;51 52 string gethtml = htmldocument.documentElement.outerHTML;53 54 //写入文件55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))56 {57 sw.WriteLine(gethtml);58 }59 60 Console.WriteLine("html 文件 已经生成!");61 62 Console.Read();63 }64 }65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
<p> 1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Windows.Forms; 6 using System.Threading; 7 8 namespace ConsoleApplication2 9 {10 public class Program11 {12 static int hitCount = 0;13 14 //[STAThread]15 static void Main(string[] args)16 {17 Thread thread = new Thread(new ThreadStart(() =>18 {19 Init();20 System.Windows.Forms.Application.Run();21 }));22 23 //将该工作线程设定为STA模式24 thread.SetApartmentState(ApartmentState.STA);25 26 thread.Start();27 28 Console.Read();29 }30 31 static void Init()32 {33 string url = "http://www.cnblogs.com";34 35 WebBrowser browser = new WebBrowser();36 37 browser.ScriptErrorsSuppressed = true;38 39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);40 41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);42 43 browser.Navigate(url);44 45 while (browser.ReadyState != WebBrowserReadyState.Complete)46 {47 Application.DoEvents();48 }49 50 while (hitCount
抓取动态网页(知乎如何把一个网页爬下来?搞flask吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-28 16:33
抓取动态网页可以用imgurl()方法,这是python很早之前的方法,通过网页中的cookie,从cookie里提取title,description,transitiontime等参数,解析出图片链接,就可以定制它的url了。很久以前我用imgurl()方法做图片采集,不是很稳定,还会出现丢图片的情况,后来我采用appium这个安卓和ios双平台的api,这就是用selenium+sdk吧,很方便,可以弄出很多网页的截图,appium在跨平台方面做的比python要好很多,它只做获取,不做解析,解析更费时间,python搞一大堆代码才解析出来。
安卓的appium挺好用的,而且selenium也能做python的整合,我自己写了个第三方的测试框架,据说selenium有接口,不知道能不能用,可以免费测试,如果大家需要,私信我,我放链接给大家,测试框架的链接:密码:kafz。
python的安卓获取图片之前有个比较简单的案例用python抓取qq音乐一段音乐的图片(小米账号是否登录是一张图)可以在线看,
爬虫目前做过的有:1.-spider/spider/三种方式:官方提供的api,
来看看我的网站吧
-bootstrap/img
下面有个概念总结,相对比较全面的。
知乎如何把一个网页爬下来?
搞flask吧 查看全部
抓取动态网页(知乎如何把一个网页爬下来?搞flask吧!)
抓取动态网页可以用imgurl()方法,这是python很早之前的方法,通过网页中的cookie,从cookie里提取title,description,transitiontime等参数,解析出图片链接,就可以定制它的url了。很久以前我用imgurl()方法做图片采集,不是很稳定,还会出现丢图片的情况,后来我采用appium这个安卓和ios双平台的api,这就是用selenium+sdk吧,很方便,可以弄出很多网页的截图,appium在跨平台方面做的比python要好很多,它只做获取,不做解析,解析更费时间,python搞一大堆代码才解析出来。
安卓的appium挺好用的,而且selenium也能做python的整合,我自己写了个第三方的测试框架,据说selenium有接口,不知道能不能用,可以免费测试,如果大家需要,私信我,我放链接给大家,测试框架的链接:密码:kafz。
python的安卓获取图片之前有个比较简单的案例用python抓取qq音乐一段音乐的图片(小米账号是否登录是一张图)可以在线看,
爬虫目前做过的有:1.-spider/spider/三种方式:官方提供的api,
来看看我的网站吧
-bootstrap/img
下面有个概念总结,相对比较全面的。
知乎如何把一个网页爬下来?
搞flask吧
抓取动态网页(代码也可以从我的开源项目HtmlExtractor中获取。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-28 07:27
)
代码也可以从我的开源项目htmlextractor获得
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i 查看全部
抓取动态网页(代码也可以从我的开源项目HtmlExtractor中获取。。
)
代码也可以从我的开源项目htmlextractor获得
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
< dependency >
< groupId >org.seleniumhq.selenium
< artifactId >selenium-java
< version >2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000 ;
int waitLoadRandomTime = 3000 ;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get( "http://toutiao.com/" );
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages= 5 ;
for ( int i= 0 ; i
抓取动态网页(动态网站解析的动态网页爬取方法(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-28 07:26
)
我刚才讲的是抓取静态网页。本篇博客介绍动态网站的爬取。动态网站的爬取比静态网页更难,涉及的主要技术是Ajax和动态Html。简单的网页访问无法获取完整的数据,需要分析数据加载过程。将通过具体的例子来介绍不同的动态网页爬取方法。本篇博客主要使用ajax直接获取数据。
页面分析
本博客以MTime电影网为例,主要爬取电影收视率、票房等信息。首先使用火狐浏览器的控制台查看页面信息。
页面中的票房信息无法以 HTML 格式获取。是通过js动态加载得到的,然后搜索对应的js响应。就是从一堆js请求中查看一些收录ajax字段的请求。%3A%2F%%2F242129%2F&t=27406&Ajax_CallBackArgument0=242129
点击查看返回数据:
找到对应的链接并返回数据后,需要分析这个链接的构造方法,分析返回的数据。
(1)链接一共7个参数,我们首先要分析哪些参数没有变化,哪些参数在不同的电影中差异更大。通过对比两个不同的电影链接,可以发现其中4个是not 有动态变化的三个参数,分别是Ajax_RequestRrl、t和Ajax_CallBackArgument0,通过分析可以发现这三个参数分别代表当前页面url、当前请求时间、电影所代表的数量。
(2) 提取响应数据。响应内容主要分为三类,分别是正在上映的电影信息,即将上映的电影信息,最后一种是即将上映的电影信息发布很久了,详情见代码。
具体实现代码
本文代码基于博客实现。本博客只修改需要改动的部分。
网页分析
在HtmlParser类中定义一个parser_url方法,代码如下:
def parser_url(self, page_url, response):
pattern = re.compile(r'(http://movie.mtime.com/(\d+)/)')
urls = pattern.findall(response)
if urls != None:
return list(set(urls))
else:
return None
提取响应数据中的有效数据:
def parser_json(self, page_url, respone):
"""
解析响应
:param page_url:
:param respone:
:return:
"""
#将“=”和“;”之间的内容提取出来
pattern = re.compile(r'=(.*?);')
result = pattern.findall(respone)[0]
if result != None:
value = json.loads(result)
try:
isRelease = value.get('value').get('isRelease')
except Exception,e:
print(e)
return None
if isRelease:
if value.get('value').get('hotValue') == None:
return self._parser_release(page_url, value)
else:
self._parser_no_release(page_url, value, isRelease = 2)
else:
return self._parser_no_release(page_url, value)
def _parser_release(self, page_url, value):
"""
解析已上映的影片
:param page_url:
:param value:
:return:
"""
try:
isRelease = 1
movieRating = value.get('value').get('movieRating')
boxOffice = value.get('value').get('boxOffice')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
TotalBoxOffice = boxOffice.get('TotalBoxOffice')
TotalBoxOfficeUnit = boxOffice.get('TotalBoxOfficeUnit')
TodayBoxOffice = boxOffice.get('TodayBoxOffice')
TodayBoxOfficeUnit = boxOffice.get('TodayBoxOfficeUnit')
showDays = boxOffice.get('ShowDays')
try:
Rank = boxOffice.get('Rank')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,
TotalBoxOffice+TotalBoxOfficeUnit,
TodayBoxOffice+TodayBoxOfficeUnit,
Rank,showDays,isRelease)
except Exception,e:
print(e,page_url,value)
return None
def _parser_no_release(self,page_url,value,isRelease = 0):
try:
movieRating = value.get('value').get('movieRating')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
try:
Rank = value.get('value').get('hotValue').get('Ranking')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,u'无',
u'无',Rank,0,isRelease)
except Exception,e:
print(e, page_url, value)
return None
爬虫调度器
def dynamic_crawl(self, root_url):
content = self.downloader.download(root_url)
urls = self.parser.parser_url(root_url,content)
for url in urls:
try:
t = time.strftime("%Y%m%d%H%M%S3282", time.localtime())
rank_url ='http://service.library.mtime.com/Movie.api'\
'?Ajax_CallBack=true'\
'&Ajax_CallBackType=Mtime.Library.Services'\
'&Ajax_CallBackMethod=GetMovieOverviewRating'\
'&Ajax_CrossDomain=1'\
'&Ajax_RequestRrl=%s'\
'&t=%s'\
'&Ajax_CallBackArgument0=%s'%(url[0],t,url[1])
rank_content = self.downloader.download(rank_url)
data = self.parser.parser_json(rank_url,rank_content)
print(data)
except Exception,e:
print('Crawl failed')
if __name__=="__main__":
spider_main = SpiderMain()
spider_main.dynamic_crawl("http://theater.mtime.com/China_Beijing/") 查看全部
抓取动态网页(动态网站解析的动态网页爬取方法(组图)
)
我刚才讲的是抓取静态网页。本篇博客介绍动态网站的爬取。动态网站的爬取比静态网页更难,涉及的主要技术是Ajax和动态Html。简单的网页访问无法获取完整的数据,需要分析数据加载过程。将通过具体的例子来介绍不同的动态网页爬取方法。本篇博客主要使用ajax直接获取数据。
页面分析
本博客以MTime电影网为例,主要爬取电影收视率、票房等信息。首先使用火狐浏览器的控制台查看页面信息。
页面中的票房信息无法以 HTML 格式获取。是通过js动态加载得到的,然后搜索对应的js响应。就是从一堆js请求中查看一些收录ajax字段的请求。%3A%2F%%2F242129%2F&t=27406&Ajax_CallBackArgument0=242129
点击查看返回数据:
找到对应的链接并返回数据后,需要分析这个链接的构造方法,分析返回的数据。
(1)链接一共7个参数,我们首先要分析哪些参数没有变化,哪些参数在不同的电影中差异更大。通过对比两个不同的电影链接,可以发现其中4个是not 有动态变化的三个参数,分别是Ajax_RequestRrl、t和Ajax_CallBackArgument0,通过分析可以发现这三个参数分别代表当前页面url、当前请求时间、电影所代表的数量。
(2) 提取响应数据。响应内容主要分为三类,分别是正在上映的电影信息,即将上映的电影信息,最后一种是即将上映的电影信息发布很久了,详情见代码。
具体实现代码
本文代码基于博客实现。本博客只修改需要改动的部分。
网页分析
在HtmlParser类中定义一个parser_url方法,代码如下:
def parser_url(self, page_url, response):
pattern = re.compile(r'(http://movie.mtime.com/(\d+)/)')
urls = pattern.findall(response)
if urls != None:
return list(set(urls))
else:
return None
提取响应数据中的有效数据:
def parser_json(self, page_url, respone):
"""
解析响应
:param page_url:
:param respone:
:return:
"""
#将“=”和“;”之间的内容提取出来
pattern = re.compile(r'=(.*?);')
result = pattern.findall(respone)[0]
if result != None:
value = json.loads(result)
try:
isRelease = value.get('value').get('isRelease')
except Exception,e:
print(e)
return None
if isRelease:
if value.get('value').get('hotValue') == None:
return self._parser_release(page_url, value)
else:
self._parser_no_release(page_url, value, isRelease = 2)
else:
return self._parser_no_release(page_url, value)
def _parser_release(self, page_url, value):
"""
解析已上映的影片
:param page_url:
:param value:
:return:
"""
try:
isRelease = 1
movieRating = value.get('value').get('movieRating')
boxOffice = value.get('value').get('boxOffice')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
TotalBoxOffice = boxOffice.get('TotalBoxOffice')
TotalBoxOfficeUnit = boxOffice.get('TotalBoxOfficeUnit')
TodayBoxOffice = boxOffice.get('TodayBoxOffice')
TodayBoxOfficeUnit = boxOffice.get('TodayBoxOfficeUnit')
showDays = boxOffice.get('ShowDays')
try:
Rank = boxOffice.get('Rank')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,
TotalBoxOffice+TotalBoxOfficeUnit,
TodayBoxOffice+TodayBoxOfficeUnit,
Rank,showDays,isRelease)
except Exception,e:
print(e,page_url,value)
return None
def _parser_no_release(self,page_url,value,isRelease = 0):
try:
movieRating = value.get('value').get('movieRating')
movieTitle = value.get('value').get('movieTitle')
RPictureFinal = movieRating.get('RPictureFinal')
RStoryFinal = movieRating.get('RStoryFinal')
RDirectorFinal = movieRating.get('RDirectorFinal')
ROtherFinal = movieRating.get('ROtherFinal')
RatingFinal = movieRating.get('RatingFinal')
MovieId = movieRating.get('MovieId')
Usercount = movieRating.get('Usercount')
AttitudeCount = movieRating.get('AttitudeCount')
try:
Rank = value.get('value').get('hotValue').get('Ranking')
except Exception,e:
Rank = 0
return (MovieId,movieTitle,RatingFinal,
ROtherFinal,RPictureFinal,RDirectorFinal,
RStoryFinal,Usercount,AttitudeCount,u'无',
u'无',Rank,0,isRelease)
except Exception,e:
print(e, page_url, value)
return None
爬虫调度器
def dynamic_crawl(self, root_url):
content = self.downloader.download(root_url)
urls = self.parser.parser_url(root_url,content)
for url in urls:
try:
t = time.strftime("%Y%m%d%H%M%S3282", time.localtime())
rank_url ='http://service.library.mtime.com/Movie.api'\
'?Ajax_CallBack=true'\
'&Ajax_CallBackType=Mtime.Library.Services'\
'&Ajax_CallBackMethod=GetMovieOverviewRating'\
'&Ajax_CrossDomain=1'\
'&Ajax_RequestRrl=%s'\
'&t=%s'\
'&Ajax_CallBackArgument0=%s'%(url[0],t,url[1])
rank_content = self.downloader.download(rank_url)
data = self.parser.parser_json(rank_url,rank_content)
print(data)
except Exception,e:
print('Crawl failed')
if __name__=="__main__":
spider_main = SpiderMain()
spider_main.dynamic_crawl("http://theater.mtime.com/China_Beijing/";)
抓取动态网页(准备工作python基础入门jupyternotebook自动补全代码request_html )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-28 07:22
)
准备好工作了
开始使用 Python 基础知识
Jupyter notebook 自动补全代码
request_html 是python3中的一个包,python2不能用
在pycharm中导入第三方包
使用python爬取数据(pyhton2)
网络爬虫是一种自动从 Internet 获取数据的程序。基本上我们在浏览网站时看到的所有数据都可以通过爬虫程序保存下来。我们可以学习爬虫来获取相关数据。但是,数据是可归属的,而不是你想使用的,所以我们需要在合法的情况下使用爬虫。因此,我们必须遵守互联网世界的机器人协议。引自爬虫的介绍
1.请求抓取静态网页
import requests
from lxml import etree
aaa=requests.get("https://blog.csdn.net/IT_XF/ar ... 6quot;)
bbb=etree.HTML(aaa.text)
ccc=aaa.xpath('//*[@id="content_views"]/p/text()')
for each in bbb:
print (each)
按照上面的代码爬取网页中的文字内容
2. 模拟登录
参考资料:
(1)在浏览器中获取cookie字符串
服务器使用 cookie 来区分不同的客户端。当服务器一次收到多个请求时,它无法分辨哪些请求是由同一个客户端发起的。因此,cookie是向服务器端向客户端证明:“我是刚刚登录的客户端”。这意味着只要我们从另一个客户端获取 cookie,我们就可以伪造它与服务器通信。
通过抓包获取cookie,然后将cookie放入请求中发送请求:
完成
# -*- coding: utf-8 -*-
#python2
import urllib2
aaa={"cookie":'在浏览器中找到的目标网址的cookie'}
url='https://i.csdn.net/#/uc/profile'
bbb=urllib2.Request(url,headers=aaa)
ccc=urllib2.urlopen(bbb).read()
print ccc
#python2
import requests
aaa={"cookie":'在浏览器中找到的目标网址的cookie'
ccc=requests.get(bbb,headers=aaa)
print ccc.text
(2)
上面的方法是可行的,但是太麻烦了。我们首先需要在浏览器中登录账号,设置保存密码,通过抓包获取这个cookie。让我们尝试使用会话。
会话的意思是会话。与 cookie 的相似之处在于它也允许服务器“识别”客户端。简单的理解是,客户端和服务器之间的每一次交互都被视为一个“会话”。既然是在同一个“会话”中,服务器自然会知道客户端是否登录了。
(3).使用Selenium和PhantomJS模拟登录
以上两个是使用的请求。requests 模块是一个不完全模拟浏览器行为的模块。它只能抓取网页的 HTML 文档信息,不能解析和执行 CSS 和 JavaScript 代码。这是它的缺点。
下面我们用selenium来处理上面的问题
selenium模块的本质是驱动浏览器完全模拟浏览器的操作,如跳转、输入、点击、下拉等,得到网页渲染的结果,可以支持多种浏览器;(因为 selenium 解析并执行 CSS、JavaScript,所以它的性能相对于请求来说是低的;)
import time
import selenium
aaa=webdriver.Chrome() #生成chrome浏览器对象
#bbb=WebDriverWait(aaa,10) #浏览器加载完毕的最大等待时间,设置为10秒
try:
aaa.get('https://www.baidu.com/') #打开百度网页
ccc=aaa.find_element_by_id("kw")
ddd=ccc.send_keys('张根硕')
eee_button=aaa.find_element_by_id('su')
eee_button.click()
print(aaa.page_source)
#wait.until(EC.presence_of_element_located((By.ID,'4')))
finally:
time.sleep(100)#页面存在的时长100s
aaa.close()
3.使用selenum动态爬虫
参考:
4. 静态抓取网页并输入到csv
利用 urlib 库和 csv 库 + BeautifulSoup
<p># -*- coding: utf-8 -*-
import urllib
from bs4 import BeautifulSoup
import csv
import codecs
#i = 1
#while i 查看全部
抓取动态网页(准备工作python基础入门jupyternotebook自动补全代码request_html
)
准备好工作了
开始使用 Python 基础知识
Jupyter notebook 自动补全代码
request_html 是python3中的一个包,python2不能用
在pycharm中导入第三方包
使用python爬取数据(pyhton2)
网络爬虫是一种自动从 Internet 获取数据的程序。基本上我们在浏览网站时看到的所有数据都可以通过爬虫程序保存下来。我们可以学习爬虫来获取相关数据。但是,数据是可归属的,而不是你想使用的,所以我们需要在合法的情况下使用爬虫。因此,我们必须遵守互联网世界的机器人协议。引自爬虫的介绍
1.请求抓取静态网页
import requests
from lxml import etree
aaa=requests.get("https://blog.csdn.net/IT_XF/ar ... 6quot;)
bbb=etree.HTML(aaa.text)
ccc=aaa.xpath('//*[@id="content_views"]/p/text()')
for each in bbb:
print (each)
按照上面的代码爬取网页中的文字内容
2. 模拟登录
参考资料:
(1)在浏览器中获取cookie字符串
服务器使用 cookie 来区分不同的客户端。当服务器一次收到多个请求时,它无法分辨哪些请求是由同一个客户端发起的。因此,cookie是向服务器端向客户端证明:“我是刚刚登录的客户端”。这意味着只要我们从另一个客户端获取 cookie,我们就可以伪造它与服务器通信。
通过抓包获取cookie,然后将cookie放入请求中发送请求:
完成
# -*- coding: utf-8 -*-
#python2
import urllib2
aaa={"cookie":'在浏览器中找到的目标网址的cookie'}
url='https://i.csdn.net/#/uc/profile'
bbb=urllib2.Request(url,headers=aaa)
ccc=urllib2.urlopen(bbb).read()
print ccc
#python2
import requests
aaa={"cookie":'在浏览器中找到的目标网址的cookie'
ccc=requests.get(bbb,headers=aaa)
print ccc.text
(2)
上面的方法是可行的,但是太麻烦了。我们首先需要在浏览器中登录账号,设置保存密码,通过抓包获取这个cookie。让我们尝试使用会话。
会话的意思是会话。与 cookie 的相似之处在于它也允许服务器“识别”客户端。简单的理解是,客户端和服务器之间的每一次交互都被视为一个“会话”。既然是在同一个“会话”中,服务器自然会知道客户端是否登录了。
(3).使用Selenium和PhantomJS模拟登录
以上两个是使用的请求。requests 模块是一个不完全模拟浏览器行为的模块。它只能抓取网页的 HTML 文档信息,不能解析和执行 CSS 和 JavaScript 代码。这是它的缺点。
下面我们用selenium来处理上面的问题
selenium模块的本质是驱动浏览器完全模拟浏览器的操作,如跳转、输入、点击、下拉等,得到网页渲染的结果,可以支持多种浏览器;(因为 selenium 解析并执行 CSS、JavaScript,所以它的性能相对于请求来说是低的;)
import time
import selenium
aaa=webdriver.Chrome() #生成chrome浏览器对象
#bbb=WebDriverWait(aaa,10) #浏览器加载完毕的最大等待时间,设置为10秒
try:
aaa.get('https://www.baidu.com/') #打开百度网页
ccc=aaa.find_element_by_id("kw")
ddd=ccc.send_keys('张根硕')
eee_button=aaa.find_element_by_id('su')
eee_button.click()
print(aaa.page_source)
#wait.until(EC.presence_of_element_located((By.ID,'4')))
finally:
time.sleep(100)#页面存在的时长100s
aaa.close()
3.使用selenum动态爬虫
参考:
4. 静态抓取网页并输入到csv
利用 urlib 库和 csv 库 + BeautifulSoup
<p># -*- coding: utf-8 -*-
import urllib
from bs4 import BeautifulSoup
import csv
import codecs
#i = 1
#while i
抓取动态网页(抓取静态页面中的数据都包含在网页的HTML中 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-27 20:05
)
抓取静态页面。静态页面中的数据收录在网页的HTML中(通常是get请求)
所需的包解释
请求是常见的网络请求包
Lxml解析生成XML对象
XPath是一种用于在XML文档中查找信息的语言
静态网页捕获文章(网易新闻)
我们以网易新闻的一个新闻页面为例文章capture
下面的代码解析网易文章并存储它。它是通过XPath解析从网页的静态源代码中获得的
#coding=utf-8
import requests
from lxml import etree
import json
class WangyiCollect():
def __init__(self,url):
self.url = url
def responseHtml(self):
#获取网页源码
content = requests.get(url=self.url).text
#初始化生成一个XPath解析对象
html = etree.HTML(content)
#提取文章页内容,采用xpath解析方式
title = html.xpath('//h1/text()')[0]
pubTime = html.xpath('//div[@class="post_time_source"]/text()')[0].replace('来源:', '').strip()
pubSource = html.xpath('//a[@id="ne_article_source"]/text()')[0]
contentList = html.xpath('//div[@id="endText"]/p//text() | //div[@id="endText"]//img/@src')
newContentList = []
for paragraph in contentList:
newparagraph = paragraph
if paragraph.endswith('.jpg') or paragraph.endswith('.png') or paragraph.endswith('.gif') or paragraph.startswith('http'):newparagraph = '
' + paragraph + '<br /><br />'
newContentList.append(newparagraph)
content = ''.join(newContentList)
#存储文章内容,存储格式为json格式
articleJson = {}
articleJson['title'] = title
articleJson['pubTime'] = pubTime
articleJson['pubSource'] = pubSource
articleJson['content'] = content
print(json.dumps(articleJson,ensure_ascii=False))
#之前为字典,需要转成json的字符串
strArticleJson = json.dumps(articleJson,ensure_ascii=False)
self.writeFile(strArticleJson)
#写入文本文件
def writeFile(self,text):
file = open('./wangyiArticle.txt','a',encoding='utf-8')
file.write(text+'\n')
if __name__=="__main__":
wangyiCollect = WangyiCollect('http://bj.news.163.com/19/0731/10/ELDHE9I604388CSB.html')
wangyiCollect.responseHtml()
抓取动态加载的网页
结构化数据:JSON、XML等
动态页面和静态页面之间的主要区别在于在刷新数据时使用Ajax技术。刷新数据时,将从数据库中查询数据并重新呈现到前端页面。数据存储在网络包中,无法通过爬行HTML获取数据
获取此动态页面有两种常见方法:
1.抓取网络请求包,请求接口传递一些参数,并破解参数。这将写在未来的博客,破解JS和破解参数
image.png
您可以看到右侧网络包中的文章数据是通过chrome数据包捕获通过数据包传输的
取出网络包的地址请求数据,它是JSON格式的数据片段
{
"title":"智能垃圾回收机重启 居民区里遇冷",
"digest":"",
"docurl":"[http://bj.news.163.com/19/0729 ... .html](http://bj.news.163.com/19/0729 ... B.html)",
"commenturl":"[http://comment.tie.163.com/EL8DU15104388CSB.html](http://comment.tie.163.com/EL8DU15104388CSB.html)",
"tienum":"0",
"tlastid":"",
"tlink":"",
"label":"",
"keywords":[
{
"akey_link":"/keywords/5/0/5c0f9ec472d7/1.html",
"keyname":"小黄狗"
},
{
"akey_link":"/keywords/5/d/56de6536673a/1.html",
"keyname":"回收机"
}
],
"time":"07/29/2019 10:39:26",
"newstype":"article",
"imgurl":"[http://cms-bucket.ws.126.net/2 ... .jpeg](http://cms-bucket.ws.126.net/2 ... 8.jpeg)",
"add1":"",
"add2":"",
"add3":"",
"pics3":[
],
"channelname":"bendi"
}
获取JSON数据
#coding=utf-8
import requests,json
content = requests.get('https://house.163.com/special/00078GU7/beijign_xw_news_v1_02.js?callback=data_callback').text
#取出来的为json字符串
jsonArticle = content.split('data_callback(')[1].rstrip(')')
#将json字符串转为字典格式
dictArticleList = json.loads(jsonArticle)
for dictArticle in dictArticleList:
#取出title
title = dictArticle['title']
print(title)
2.无头浏览器渲染
硒+铬
#coding=utf-8
from selenium import webdriver
Chrome_options = webdriver.ChromeOptions()
Chrome_options.add_argument('--headless')
drive = webdriver.Chrome(chrome_options=Chrome_options)
drive.get('http://public.163.com/#/list/movie')
html = drive.page_source
print(html)
drive.quit() 查看全部
抓取动态网页(抓取静态页面中的数据都包含在网页的HTML中
)
抓取静态页面。静态页面中的数据收录在网页的HTML中(通常是get请求)
所需的包解释
请求是常见的网络请求包
Lxml解析生成XML对象
XPath是一种用于在XML文档中查找信息的语言
静态网页捕获文章(网易新闻)
我们以网易新闻的一个新闻页面为例文章capture
下面的代码解析网易文章并存储它。它是通过XPath解析从网页的静态源代码中获得的
#coding=utf-8
import requests
from lxml import etree
import json
class WangyiCollect():
def __init__(self,url):
self.url = url
def responseHtml(self):
#获取网页源码
content = requests.get(url=self.url).text
#初始化生成一个XPath解析对象
html = etree.HTML(content)
#提取文章页内容,采用xpath解析方式
title = html.xpath('//h1/text()')[0]
pubTime = html.xpath('//div[@class="post_time_source"]/text()')[0].replace('来源:', '').strip()
pubSource = html.xpath('//a[@id="ne_article_source"]/text()')[0]
contentList = html.xpath('//div[@id="endText"]/p//text() | //div[@id="endText"]//img/@src')
newContentList = []
for paragraph in contentList:
newparagraph = paragraph
if paragraph.endswith('.jpg') or paragraph.endswith('.png') or paragraph.endswith('.gif') or paragraph.startswith('http'):newparagraph = '
' + paragraph + '<br /><br />'
newContentList.append(newparagraph)
content = ''.join(newContentList)
#存储文章内容,存储格式为json格式
articleJson = {}
articleJson['title'] = title
articleJson['pubTime'] = pubTime
articleJson['pubSource'] = pubSource
articleJson['content'] = content
print(json.dumps(articleJson,ensure_ascii=False))
#之前为字典,需要转成json的字符串
strArticleJson = json.dumps(articleJson,ensure_ascii=False)
self.writeFile(strArticleJson)
#写入文本文件
def writeFile(self,text):
file = open('./wangyiArticle.txt','a',encoding='utf-8')
file.write(text+'\n')
if __name__=="__main__":
wangyiCollect = WangyiCollect('http://bj.news.163.com/19/0731/10/ELDHE9I604388CSB.html')
wangyiCollect.responseHtml()
抓取动态加载的网页
结构化数据:JSON、XML等
动态页面和静态页面之间的主要区别在于在刷新数据时使用Ajax技术。刷新数据时,将从数据库中查询数据并重新呈现到前端页面。数据存储在网络包中,无法通过爬行HTML获取数据
获取此动态页面有两种常见方法:
1.抓取网络请求包,请求接口传递一些参数,并破解参数。这将写在未来的博客,破解JS和破解参数
image.png
您可以看到右侧网络包中的文章数据是通过chrome数据包捕获通过数据包传输的
取出网络包的地址请求数据,它是JSON格式的数据片段
{
"title":"智能垃圾回收机重启 居民区里遇冷",
"digest":"",
"docurl":"[http://bj.news.163.com/19/0729 ... .html](http://bj.news.163.com/19/0729 ... B.html)",
"commenturl":"[http://comment.tie.163.com/EL8DU15104388CSB.html](http://comment.tie.163.com/EL8DU15104388CSB.html)",
"tienum":"0",
"tlastid":"",
"tlink":"",
"label":"",
"keywords":[
{
"akey_link":"/keywords/5/0/5c0f9ec472d7/1.html",
"keyname":"小黄狗"
},
{
"akey_link":"/keywords/5/d/56de6536673a/1.html",
"keyname":"回收机"
}
],
"time":"07/29/2019 10:39:26",
"newstype":"article",
"imgurl":"[http://cms-bucket.ws.126.net/2 ... .jpeg](http://cms-bucket.ws.126.net/2 ... 8.jpeg)",
"add1":"",
"add2":"",
"add3":"",
"pics3":[
],
"channelname":"bendi"
}
获取JSON数据
#coding=utf-8
import requests,json
content = requests.get('https://house.163.com/special/00078GU7/beijign_xw_news_v1_02.js?callback=data_callback').text
#取出来的为json字符串
jsonArticle = content.split('data_callback(')[1].rstrip(')')
#将json字符串转为字典格式
dictArticleList = json.loads(jsonArticle)
for dictArticle in dictArticleList:
#取出title
title = dictArticle['title']
print(title)
2.无头浏览器渲染
硒+铬
#coding=utf-8
from selenium import webdriver
Chrome_options = webdriver.ChromeOptions()
Chrome_options.add_argument('--headless')
drive = webdriver.Chrome(chrome_options=Chrome_options)
drive.get('http://public.163.com/#/list/movie')
html = drive.page_source
print(html)
drive.quit()
抓取动态网页(一下动态网站快讯 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-27 20:03
)
今天研究了一下动态网站的爬取,以及这里使用的世轩股票宝网站:
这个小案例简单抓取了轩宝的7x24时事通讯的信息内容,并将数据保存在Mysql数据库中。
网页分为静态网页和动态网页。静态网页一般是指不与嵌入在页面或js中的后端数据交互的网页,而动态网页通过Ajax与数据库交互,可以实时从数据库中获取数据并显示在页面上.
如何判断一个网站是动态的网站:
1. 浏览网页时,部分网站可以在翻页的同时不断向下滚动和加载数据。这通常是动态的网站。
2. 也可以在网络上查看XHR,在浏览器控制台查看和后台数据交互记录。
首先,我们必须找到数据源。经过观察,我们发现时事通讯是由上图中名为newsflash的请求加载的。通过这个请求,我们可以得到他的url,10,723,35,469,821&platform=pcweb。通过观察这个请求,我们可以找到newsflashlimit参数控制请求。返回的记录数,游标是毫秒时间戳,因为这里的咨询内容是动态更新的,每隔一段时间就会加载新的咨询,这里是按时间排序的,所以只要控制这两个参数就可以得到咨询你想要的内容。
这里我尝试抓取一个时间段内的咨询内容,时间间隔设置为10分钟。也就是说,每次咨询内容在10分钟内生成,当然可能会有重复,这里就不做处理了。
用于时间戳和时间转换的在线工具:
代码显示如下
#!/usr/bin/env python
# -*- 编码:utf-8 -*-
# @File: 蜘蛛侠.py
# @Author: 小橙
# @日期:2019-1-6
# @Desc :Dynamic 网站 抓取选择共享
进口请求
从 fake_useragent 导入 UserAgent
从 sqlalchemy 导入 create_engine
将熊猫导入为 pd
导入时间
#时间:1月7日12:00-17:00
#对应时间戳:00-00
#发送请求获取返回数据
定义获取数据(网址):
如果 url 为 None:
返回
ua = 用户代理()
headers = {'User-Agnet':ua.random}
r = requests.get(url,headers=headers)
如果 r.status_code == 200:
#如果请求返回的是json格式的数据,可以使用json()函数
#也可以使用json.load()函数将json格式的字符串转换成json对象
返回 r.json()
#提取返回数据中的字段信息
定义解析器数据(数据):
#提取数据中的id、title、汇总字段信息
retdata = data.get('数据')
msglist = retdata.get('消息')
保存列表 = []
对于 msglist 中的 msg:
id = int(msg.get('id'))
title = msg.get('title')
总结 =''
#summary中的字段为空时,将title的值赋给summary
如果 msg.get('summary') !='':
summary = msg.get('summary').replace('\n','')#去掉摘要中的换行符
别的:
摘要 = 标题
温度 = []
temp.append(id)
temp.append(标题)
temp.append(总结)
savelist.append(temp)
返回保存列表
#保存数据到数据库
def saveData(result_data,con):
#向数据库写入数据
如果 len(result_data)>0:
#这里创建DataFrame的时候忘记加header了,写数据的时候一直报错
df = pd.DataFrame(result_data,columns=['id','title','summary'])
# 打印('df:',df)
#如果要自动建表,用replace替换if_exists的值,建议自己建表,if_exists的值是append
#name是表名,con是数据库连接
df.to_sql(name="stock_news", con=con, if_exists='append', index=False)
# print('数据保存成功!')
#获取数据库连接
def getContact():
#连接数据库
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/demo01?charset=utf8')
con = engine.connect()
print('Mysql 连接创建成功...')
返回引擎
如果 __name__ =='__main__':
url =';cursor={}&subj_ids=9,10,723,35,469,821&platform=pcweb'
开始时间 = 00
con = getContact() #创建数据库连接
计数 = 0
为真:
#这里设置的时间间隔是10分钟,意思是每次取消息10分钟内更新
结束时间 = 开始时间 + 600000
如果 end_time>00:
休息
开始时间 = 结束时间
now_url = url.format(end_time)
数据 = 获取数据(now_url)
time.sleep(2) #每2秒请求一次
result_data = parserData(data)
# 打印(结果数据)
保存数据(result_data,con)
计数 += len(result_data)
print('{} 数据保存成功!'.format(count))
两小时的测试更新
查看全部
抓取动态网页(一下动态网站快讯
)
今天研究了一下动态网站的爬取,以及这里使用的世轩股票宝网站:
这个小案例简单抓取了轩宝的7x24时事通讯的信息内容,并将数据保存在Mysql数据库中。
网页分为静态网页和动态网页。静态网页一般是指不与嵌入在页面或js中的后端数据交互的网页,而动态网页通过Ajax与数据库交互,可以实时从数据库中获取数据并显示在页面上.
如何判断一个网站是动态的网站:
1. 浏览网页时,部分网站可以在翻页的同时不断向下滚动和加载数据。这通常是动态的网站。
2. 也可以在网络上查看XHR,在浏览器控制台查看和后台数据交互记录。
首先,我们必须找到数据源。经过观察,我们发现时事通讯是由上图中名为newsflash的请求加载的。通过这个请求,我们可以得到他的url,10,723,35,469,821&platform=pcweb。通过观察这个请求,我们可以找到newsflashlimit参数控制请求。返回的记录数,游标是毫秒时间戳,因为这里的咨询内容是动态更新的,每隔一段时间就会加载新的咨询,这里是按时间排序的,所以只要控制这两个参数就可以得到咨询你想要的内容。
这里我尝试抓取一个时间段内的咨询内容,时间间隔设置为10分钟。也就是说,每次咨询内容在10分钟内生成,当然可能会有重复,这里就不做处理了。
用于时间戳和时间转换的在线工具:
代码显示如下
#!/usr/bin/env python
# -*- 编码:utf-8 -*-
# @File: 蜘蛛侠.py
# @Author: 小橙
# @日期:2019-1-6
# @Desc :Dynamic 网站 抓取选择共享
进口请求
从 fake_useragent 导入 UserAgent
从 sqlalchemy 导入 create_engine
将熊猫导入为 pd
导入时间
#时间:1月7日12:00-17:00
#对应时间戳:00-00
#发送请求获取返回数据
定义获取数据(网址):
如果 url 为 None:
返回
ua = 用户代理()
headers = {'User-Agnet':ua.random}
r = requests.get(url,headers=headers)
如果 r.status_code == 200:
#如果请求返回的是json格式的数据,可以使用json()函数
#也可以使用json.load()函数将json格式的字符串转换成json对象
返回 r.json()
#提取返回数据中的字段信息
定义解析器数据(数据):
#提取数据中的id、title、汇总字段信息
retdata = data.get('数据')
msglist = retdata.get('消息')
保存列表 = []
对于 msglist 中的 msg:
id = int(msg.get('id'))
title = msg.get('title')
总结 =''
#summary中的字段为空时,将title的值赋给summary
如果 msg.get('summary') !='':
summary = msg.get('summary').replace('\n','')#去掉摘要中的换行符
别的:
摘要 = 标题
温度 = []
temp.append(id)
temp.append(标题)
temp.append(总结)
savelist.append(temp)
返回保存列表
#保存数据到数据库
def saveData(result_data,con):
#向数据库写入数据
如果 len(result_data)>0:
#这里创建DataFrame的时候忘记加header了,写数据的时候一直报错
df = pd.DataFrame(result_data,columns=['id','title','summary'])
# 打印('df:',df)
#如果要自动建表,用replace替换if_exists的值,建议自己建表,if_exists的值是append
#name是表名,con是数据库连接
df.to_sql(name="stock_news", con=con, if_exists='append', index=False)
# print('数据保存成功!')
#获取数据库连接
def getContact():
#连接数据库
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/demo01?charset=utf8')
con = engine.connect()
print('Mysql 连接创建成功...')
返回引擎
如果 __name__ =='__main__':
url =';cursor={}&subj_ids=9,10,723,35,469,821&platform=pcweb'
开始时间 = 00
con = getContact() #创建数据库连接
计数 = 0
为真:
#这里设置的时间间隔是10分钟,意思是每次取消息10分钟内更新
结束时间 = 开始时间 + 600000
如果 end_time>00:
休息
开始时间 = 结束时间
now_url = url.format(end_time)
数据 = 获取数据(now_url)
time.sleep(2) #每2秒请求一次
result_data = parserData(data)
# 打印(结果数据)
保存数据(result_data,con)
计数 += len(result_data)
print('{} 数据保存成功!'.format(count))
两小时的测试更新
抓取动态网页(什么是Ajax即“AsynchronousJavascript”(异步JavaScript和XML) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-27 15:23
)
什么是阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。使用ajax加载的数据,即使使用js将数据渲染到浏览器中,在右键查看网页源码中仍然看不到通过ajax加载的数据,只有使用这个url加载的html代码.
获取ajax数据的方法直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器获取数据的行为。的优点和缺点
分析界面
可以直接请求数据。无需做一些分析工作。代码少,性能高
解析接口比较复杂,尤其是通过一些js混淆的接口,必须有一定的js基础。容易被发现的粪便爬虫
硒
直接模拟浏览器行为。爬虫更稳定
代码量大,性能低
注:异步加载的数据不会显示在原创网页代码中,但您可以使用查看器进行选择查看,然后可以在 Elements 属性中查看代码的标签结构,方便后续数据分析。
另外也可以在Network中找到对应的异步加载的数据,然后根据响应获取json数据,然后在线分析得到规范化的json数据。
查看全部
抓取动态网页(什么是Ajax即“AsynchronousJavascript”(异步JavaScript和XML)
)
什么是阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。使用ajax加载的数据,即使使用js将数据渲染到浏览器中,在右键查看网页源码中仍然看不到通过ajax加载的数据,只有使用这个url加载的html代码.
获取ajax数据的方法直接分析ajax调用的接口,然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器获取数据的行为。的优点和缺点
分析界面
可以直接请求数据。无需做一些分析工作。代码少,性能高
解析接口比较复杂,尤其是通过一些js混淆的接口,必须有一定的js基础。容易被发现的粪便爬虫
硒
直接模拟浏览器行为。爬虫更稳定
代码量大,性能低
注:异步加载的数据不会显示在原创网页代码中,但您可以使用查看器进行选择查看,然后可以在 Elements 属性中查看代码的标签结构,方便后续数据分析。
另外也可以在Network中找到对应的异步加载的数据,然后根据响应获取json数据,然后在线分析得到规范化的json数据。
抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-26 18:30
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多时候我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置 查看全部
抓取动态网页(完整的使用方式如下最近更新Workflow命令行帮助工具(组图))
现在越来越多的网页使用前端渲染页面,这给抓取工作带来了很多麻烦。通过通常的方法,只会得到一堆js方法或者api接口。当然,我们不希望每个网站都那么努力地探索他们的 api。
那有什么好办法,叫全能的谷歌老爸,puppeteer可以模拟chrome打开网页,还可以截图转换成pdf文件。当然,抓取数据不是问题,因为截图的前提是模拟前端渲染。效果就像实际打开网站。
本文文章主要介绍如何通过puppeteer进行简单爬行
下载
1
$ yarn add puppeteer
用
先看一个简单的例子,我们还是不问为什么直接运行代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了文档的宽度、高度和标题的各个属性。现在让我们分析一下这段代码的作用。
分析选择器
抓取页面时,可以借助谷歌浏览器的开发者工具直接复制选择器
我们要获取这个页面的头像信息。从开发者工具复制的选择器如下
1
#react-root > section > main > article > header > div > div > div > img
这时候我们就可以直接使用了
1
2
3
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们就可以很方便的分析某个dom元素了。当然,这种粘贴复制也不是万能的。很多时候我们需要对页面样式进行分析,才能找到更好的分析方法。
完整的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
最近更新
Alfred Workflow 命令行帮助工具
最近阅读
Go 判断数组中是否收录某项
Vim 高级功能 vimgrep 全局搜索文件
申请北京工作居留许可的一些细节
Go 语法错误:函数体外的非声明语句
Mac电脑查看字体文件位置
抓取动态网页(google实现爬虫,有多种定位方法?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-23 13:34
)
这个过程更麻烦,你需要采取几步完成,你会介绍:
1.安装selenium库,可以直接使用'pip安装selenium'命令安装。
2.下载ChromedRiver并将其添加到环境变量,或直接将.exe文件放入Python安装目录脚本文件夹中。下载时,您必须选择与浏览器对应的版本。查看浏览器版本是:右上角 - &gt;帮助 - &gt;关于Google Chrome可以查看,下载驱动程序的地址是ChromedRiver下载地址,与Chrome版本相应的关系相应,验证下载和安装是否成功,只需要执行以下代码。如果没有错误,它将被成功安装。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3.硒实现爬行动物,有多种定位方法,简要介绍:
官方网站地址是:
找到一个元素方法:
找到多个元素(返回列表)方法:
4.基本功能在你有一个快乐的爬行动物之后(因为你没有搅拌,首先把一些代码放在那里)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
更改:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run() 查看全部
抓取动态网页(google实现爬虫,有多种定位方法?(图)
)
这个过程更麻烦,你需要采取几步完成,你会介绍:
1.安装selenium库,可以直接使用'pip安装selenium'命令安装。
2.下载ChromedRiver并将其添加到环境变量,或直接将.exe文件放入Python安装目录脚本文件夹中。下载时,您必须选择与浏览器对应的版本。查看浏览器版本是:右上角 - &gt;帮助 - &gt;关于Google Chrome可以查看,下载驱动程序的地址是ChromedRiver下载地址,与Chrome版本相应的关系相应,验证下载和安装是否成功,只需要执行以下代码。如果没有错误,它将被成功安装。
import selenium.webdriver as driver
index = driver.Chrome()
index.get('https://www.wdzj.com/dangan')
print(index)
3.硒实现爬行动物,有多种定位方法,简要介绍:
官方网站地址是:
找到一个元素方法:
找到多个元素(返回列表)方法:
4.基本功能在你有一个快乐的爬行动物之后(因为你没有搅拌,首先把一些代码放在那里)!
import selenium.webdriver as driver
import xlwt
import types
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
# index = driver.Chrome()
# index.get(URL)
# select_data = index.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
# print(index.current_url)
# keyword_index = index.find_element_by_link_text()
# keyword_index.click()
names = []
banks = []
tel_nums = []
urls = []
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('/html/body/div[10]/div/div[1]/div[1]/dl[1]/dd[2]/div[2]')
banks.append(yhcg.text)
# print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
index_sec.close()
# print(page_url)
# next_page = index.find_element_by_link_text('下一页')
# next_page.click()
return names, banks, tel_nums, urls
def xls():
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
names, banks, tel_nums, urls = key_word()
print(len(names))
for i in range (0, len(names)):
ws.write(i + 1, 0, i+1)
ws.write(i + 1, 1, names[i])
ws.write(i + 1, 2, banks[i])
ws.write(i + 1, 3, tel_nums[i])
ws.write(i + 1, 4, urls[i])
wb.save('D:\\number.xls')
def run():
xls()
run()
更改:
import selenium.webdriver as driver
import xlwt
from xlutils.copy import copy
import xlrd
URL = 'https://www.wdzj.com/dangan/'
# KEYWORD = '银行存管'
def key_word():
names = []
banks = []
tel_nums = []
urls = []
count= 0
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
ws.write(0, 0, '序号')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '银行存管')
ws.write(0, 3, '客服电话')
ws.write(0, 4, '公司域名')
wb.save('D:\\number.xls')
for i in range(0, 76):
page_url = URL + 'search?filter=e1¤tPage=' + str(i + 1)
index_page = driver.Chrome()
index_page.get(page_url)
select_data = index_page.find_elements_by_xpath('//*[@id="showTable"]/ul/li/div[1]/h2/a')
print(index_page.current_url)
for data in select_data:
names.append(data.text)
print(names) #名字
sec_url = data.get_attribute("href")
index_sec = driver.Chrome()
index_sec.get(sec_url)
# print(index_sec.current_url) #链接
yhcg = index_sec.find_element_by_xpath('//*[@class="bgbox-bt zzfwbox"]/dl/dd/div[@class="r" and contains(text(),"存管")]')
banks.append(yhcg.text)
print(banks) #银行存管
tel_num = index_sec.find_element_by_link_text('联系方式')
tel_num.click()
number = index_sec.find_element_by_xpath('//*[@class="da-lxfs zzfwbox"]/dl[1]/dd[1]/div[2]')
tel_nums.append(number.text)
# print(tel_nums) #客服电话
yuming = index_sec.find_element_by_link_text('工商/备案')
yuming.click()
yu_beian = index_sec.find_element_by_xpath('//*[@class="lcen"]/table/tbody/tr[7]/td[2]')
urls.append(yu_beian.text)
print(urls) #域名
oldWb =xlrd.open_workbook('D:\\number.xls', formatting_info=True)
newWb = copy(oldWb)
news = newWb.get_sheet(0)
news.write(count + 1, 0, count + 1)
news.write(count + 1, 1, names[count])
news.write(count + 1, 2, banks[count])
news.write(count + 1, 3, tel_nums[count])
news.write(count + 1, 4, urls[count])
newWb.save('D:\\number.xls')
print(count)
count+=1
index_sec.close()
index_page.close()
return names, banks, tel_nums, urls
def run():
key_word()
run()
抓取动态网页(soup搜索节点操作删除节点的一种好的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-18 22:23
之前:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文基于Python中的selenium(pyhton包)+Chrome(谷歌浏览器)+Chrome驱动器(谷歌浏览器驱动程序)
建议下载chrome和chromdrive的最新版本(参考地址:)
还支持无头模式(无需打开浏览器)
直接代码:站点\ URL:要爬网的地址,chrome \驱动程序\路径:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
返回一个soup,以便在此soup中搜索节点,并使用select、search、find和其他方法查找所需的节点或数据
同样,如果您想将其作为文本下载,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
让我们详细谈谈寻找美丽的汤
首先,如何导航到标签
1.use find(博主详细介绍)
2.使用选择
通过类似于jQuery的标记名、类名和ID选择器选择位置,例如soup。选择('p.Link#link1')
通过属性查找,如href、title、link和其他属性,如soup。选择('PA[href=”“]”)
这里的比赛是最小的,他的上级是
然后我们来讨论节点的操作
删除节点标记。分解
插入子节点标记。在指定位置插入(0,chlid_标记)
最后,使用靓汤是过滤滤芯的好方法。在下一章中,我们将引入正则表达式匹配来过滤爬虫内容 查看全部
抓取动态网页(soup搜索节点操作删除节点的一种好的方法(上))
之前:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文基于Python中的selenium(pyhton包)+Chrome(谷歌浏览器)+Chrome驱动器(谷歌浏览器驱动程序)
建议下载chrome和chromdrive的最新版本(参考地址:)
还支持无头模式(无需打开浏览器)
直接代码:站点\ URL:要爬网的地址,chrome \驱动程序\路径:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
返回一个soup,以便在此soup中搜索节点,并使用select、search、find和其他方法查找所需的节点或数据
同样,如果您想将其作为文本下载,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
让我们详细谈谈寻找美丽的汤
首先,如何导航到标签
1.use find(博主详细介绍)
2.使用选择
通过类似于jQuery的标记名、类名和ID选择器选择位置,例如soup。选择('p.Link#link1')
通过属性查找,如href、title、link和其他属性,如soup。选择('PA[href=”“]”)
这里的比赛是最小的,他的上级是
然后我们来讨论节点的操作
删除节点标记。分解
插入子节点标记。在指定位置插入(0,chlid_标记)
最后,使用靓汤是过滤滤芯的好方法。在下一章中,我们将引入正则表达式匹配来过滤爬虫内容
抓取动态网页(如何用python自带urllib2库打开网页的爬虫实现之旅?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-18 22:21
一、背景
记录一次周末赶回家的爬行动物实现之旅。受他人委托,我想从这一页的明星名单上爬下来。当你在chrome中打开它时,实际上有1000条记录。然后单击“右键菜单”->;“检查”查看网页的结构,这并不特别复杂。因此,我直观地看到,只要我用Python自己的urlib2库打开网页,获取HTML代码,然后将其交给beautiful soup库解析HTML代码,我就应该能够快速完成
但是当你仔细看的时候,点击下一页,网页的URL不会改变。您只需使用js加载新数据,然后动态更改表中的数据。这与本盘的上一页不同,因此这次我们应该找到一种模拟翻页的方法,然后重新阅读新的HTML代码并对其进行分析
实现翻页有两种方法。首先是分析JS的实现,以模拟翻页。翻页操作实际上是JS向后台发送请求。在这里,它必须请求具有跳转目标页码的背景,然后获取新数据并重新呈现HTML的表部分。这种方法效率更高,但难度更大。因为如果您可以模拟请求,这意味着您已经知道其他人的服务器接口。然后,您可以通过进一步分析响应得到结果。你甚至不需要分析HTML代码,是吗?第二个相对简单的方法,也是我在这里使用的方法,是模拟单击web页面中的“下一页”按钮,然后重新读取HTML代码进行解析
二、ideas
如前所述,此处处理该想法:
在这里,打开和阅读网页的HTML代码是通过selenium实现的
解析HTML代码是通过Beauty soup实现的
三、implementation1.相关库的准备和安装
我使用Mac,因此我可以使用easy Direct_uuInstall命令行安装
1
sudo easy_install beautifulsoup4
或简易安装命令
1
sudo easy_install selenium
在这里,selenium版本已经到达3.0.2,如果要使用此版本的selenium打开网页,则需要使用相应的驱动程序。所以我需要安装一个驱动程序
我在这里使用自制安装的chromediver。安装后,请记住查找chromediver的安装目录。我们将在编写下面的代码时使用它
1
brew install chromedirver
注意:Mac下有许多软件管理包。除了我的安装方法,你可以用pip安装它们,或者直接从官方网站下载安装程序。但您必须安装上述三个程序。在这里我突然有了一个想法。老实说,如果Python拥有与gradle相同的构建管理工具,我现在花在安装这些依赖库上的时间比写代码要多
2.分析页面
只需发布我想要爬升的网页的HTML代码的一部分,在其中我使用//写一些评论:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152
// 本周排行榜,这是我要抓的内容 排名 明星 鲜花数 TOP粉丝 1 // 这个td标签,star-name的css class是我要抓的内容 王俊凯 1790892 送花 1183*****630 2185*****759 3wx526298988 ...此处省略巨量代码... // 这里是本周排行榜分页的html代码,可以看到一页20个明星,共有50页 首页 尾页// 下面开始就是“上周排行榜”,html结构和上面完全类似...此处再次省略巨量代码...
3.完整代码
1234567891011121314151617181920212223242526272829303132333435
import sysimport urllib2import timefrom bs4 import BeautifulSoupfrom selenium import webdriverreload(sys)sys.setdefaultencoding('utf8') # 设置编码url = 'http://baike.baidu.com/starrank?fr=lemmaxianhua'driver = webdriver.Chrome('/usr/local/Cellar/chromedriver/2.20/bin/chromedriver') # 创建一个driver用于打开网页,记得找到brew安装的chromedriver的位置,在创建driver的时候指定这个位置driver.get(url) # 打开网页name_counter = 1page = 0;while page < 50: # 共50页,这里是手工指定的 soup = BeautifulSoup(driver.page_source, "html.parser") current_names = soup.select('div.ranking-table') # 选择器用ranking-table css class,可以取出包含本周、上周的两个table的div标签 for current_name_list in current_names: # print current_name_list['data-cat'] if current_name_list['data-cat'] == 'thisWeek': # 这次我只想抓取本周,如果想抓上周,改一下这里为lastWeek即可 names = current_name_list.select('td.star-name > a') # beautifulsoup选择器语法 counter = 0; for star_name in names: counter = counter + 1; print star_name.text # 明星的名字是a标签里面的文本,虽然a标签下面除了文本还有一个与文本同级别的img标签,但是.text输出的只是文本而已 name_counter = name_counter + 1; driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click() # selenium的xpath用法,找到包含“下一页”的a标签去点击 page = page + 1 time.sleep(2) # 睡2秒让网页加载完再去读它的html代码print name_counter # 共爬取得明星的名字数量driver.quit()
四、总结
这里只简单记录了一个稍微复杂一点的网页爬行的实现思想。硒和beatifulsoup有很多用法,我没有仔细阅读。这里有一些参考资料。将来有机会我会学到更多 查看全部
抓取动态网页(如何用python自带urllib2库打开网页的爬虫实现之旅?)
一、背景
记录一次周末赶回家的爬行动物实现之旅。受他人委托,我想从这一页的明星名单上爬下来。当你在chrome中打开它时,实际上有1000条记录。然后单击“右键菜单”->;“检查”查看网页的结构,这并不特别复杂。因此,我直观地看到,只要我用Python自己的urlib2库打开网页,获取HTML代码,然后将其交给beautiful soup库解析HTML代码,我就应该能够快速完成
但是当你仔细看的时候,点击下一页,网页的URL不会改变。您只需使用js加载新数据,然后动态更改表中的数据。这与本盘的上一页不同,因此这次我们应该找到一种模拟翻页的方法,然后重新阅读新的HTML代码并对其进行分析
实现翻页有两种方法。首先是分析JS的实现,以模拟翻页。翻页操作实际上是JS向后台发送请求。在这里,它必须请求具有跳转目标页码的背景,然后获取新数据并重新呈现HTML的表部分。这种方法效率更高,但难度更大。因为如果您可以模拟请求,这意味着您已经知道其他人的服务器接口。然后,您可以通过进一步分析响应得到结果。你甚至不需要分析HTML代码,是吗?第二个相对简单的方法,也是我在这里使用的方法,是模拟单击web页面中的“下一页”按钮,然后重新读取HTML代码进行解析
二、ideas
如前所述,此处处理该想法:
在这里,打开和阅读网页的HTML代码是通过selenium实现的
解析HTML代码是通过Beauty soup实现的
三、implementation1.相关库的准备和安装
我使用Mac,因此我可以使用easy Direct_uuInstall命令行安装
1
sudo easy_install beautifulsoup4
或简易安装命令
1
sudo easy_install selenium
在这里,selenium版本已经到达3.0.2,如果要使用此版本的selenium打开网页,则需要使用相应的驱动程序。所以我需要安装一个驱动程序
我在这里使用自制安装的chromediver。安装后,请记住查找chromediver的安装目录。我们将在编写下面的代码时使用它
1
brew install chromedirver
注意:Mac下有许多软件管理包。除了我的安装方法,你可以用pip安装它们,或者直接从官方网站下载安装程序。但您必须安装上述三个程序。在这里我突然有了一个想法。老实说,如果Python拥有与gradle相同的构建管理工具,我现在花在安装这些依赖库上的时间比写代码要多
2.分析页面
只需发布我想要爬升的网页的HTML代码的一部分,在其中我使用//写一些评论:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152
// 本周排行榜,这是我要抓的内容 排名 明星 鲜花数 TOP粉丝 1 // 这个td标签,star-name的css class是我要抓的内容 王俊凯 1790892 送花 1183*****630 2185*****759 3wx526298988 ...此处省略巨量代码... // 这里是本周排行榜分页的html代码,可以看到一页20个明星,共有50页 首页 尾页// 下面开始就是“上周排行榜”,html结构和上面完全类似...此处再次省略巨量代码...
3.完整代码
1234567891011121314151617181920212223242526272829303132333435
import sysimport urllib2import timefrom bs4 import BeautifulSoupfrom selenium import webdriverreload(sys)sys.setdefaultencoding('utf8') # 设置编码url = 'http://baike.baidu.com/starrank?fr=lemmaxianhua'driver = webdriver.Chrome('/usr/local/Cellar/chromedriver/2.20/bin/chromedriver') # 创建一个driver用于打开网页,记得找到brew安装的chromedriver的位置,在创建driver的时候指定这个位置driver.get(url) # 打开网页name_counter = 1page = 0;while page < 50: # 共50页,这里是手工指定的 soup = BeautifulSoup(driver.page_source, "html.parser") current_names = soup.select('div.ranking-table') # 选择器用ranking-table css class,可以取出包含本周、上周的两个table的div标签 for current_name_list in current_names: # print current_name_list['data-cat'] if current_name_list['data-cat'] == 'thisWeek': # 这次我只想抓取本周,如果想抓上周,改一下这里为lastWeek即可 names = current_name_list.select('td.star-name > a') # beautifulsoup选择器语法 counter = 0; for star_name in names: counter = counter + 1; print star_name.text # 明星的名字是a标签里面的文本,虽然a标签下面除了文本还有一个与文本同级别的img标签,但是.text输出的只是文本而已 name_counter = name_counter + 1; driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click() # selenium的xpath用法,找到包含“下一页”的a标签去点击 page = page + 1 time.sleep(2) # 睡2秒让网页加载完再去读它的html代码print name_counter # 共爬取得明星的名字数量driver.quit()
四、总结
这里只简单记录了一个稍微复杂一点的网页爬行的实现思想。硒和beatifulsoup有很多用法,我没有仔细阅读。这里有一些参考资料。将来有机会我会学到更多
抓取动态网页(如何从javascript页面爬取信息中进行数据爬取?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-17 21:00
一、simple动态页面爬行
我们以前的页面爬行工作是基于静态页面的。但是现在很多页面使用动态页面,其中70%的动态页面是由JavaScript编写的。因此,了解如何从JavaScript页面抓取信息对我们来说非常重要
在了解具体情况之前,我们需要了解AJAX是什么。它的英文全称是AsynchronousJavaScript和XML,它是一种异步JavaScript和XML。我们可以通过Ajax请求页面数据,返回的数据格式是JSON类型
然后我们可以根据页面的Ajax格式抓取数据。下面是一个简单的页面爬网
import json
from Chapter3 import download
import csv
def simpletest():
'''
it will write the date to the country.csv
the json data has the attribute records, and the records has area, country and capital value
:return:
'''
fileds = ('area', 'country', 'capital')
writer = csv.writer(open("country.csv", "w"))
writer.writerow(fileds)
d = download.Downloader()
html = d("http://example.webscraping.com ... 6quot;)
try:
ajax = json.loads(html)
except Exception as e:
print str(e)
else:
for record in ajax['records']:
row = [record[filed] for filed in fileds]
writer.writerow(row)
if __name__ == "__main__":
simpletest()
我不知道这是否是问题所在。现在我无法从上述网站下载数据。执行上述程序。以下是结果图:
二、呈现动态页面
在开始之前,首先下载pyside并直接使用PIP install pyside命令行
然后我们可以使用pyside来抓取数据
from PySide.QtWebKit import *
from PySide.QtGui import *
from PySide.QtCore import *
import lxml.html
def simpletest():
'''
get content of the div # result in http://example.webscraping.com ... namic
:return: content
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
htmled = webview.page().mainFrame().toHtml()
# get the special content
tree = lxml.html.fromstring(htmled)
return tree.cssselect('#result')[0].text_content()
content = simpletest()
print content
我们回顾了简单动态页面爬行的内容。以前的方法不成功。我认为主要原因是我的网站写得不正确,所以在学习pyside之后,我们可以使用这种新方法进行数据爬行。以下是具体代码:
def getallcountry():
'''
open the html and set search term = a and page_size = 10
and then click auto by javascript
:return:
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
# show the webview
webview.show()
frame = webview.page().mainFrame()
# set search text is b
frame.findFirstElement('#search_term').setAttribute('value', 'b')
# set page_size is 10
frame.findFirstElement('#page_size option:checked').setPlainText('10')
# click search button auto
frame.findFirstElement('#search').evaluateJavaScript('this.click()')
app.exec_()
以下是结果图:
在上面的过程中,我们只使用pyside在页面上获取结果,但还没有对数据进行爬网。因为Ajax在响应事件时有一定的延迟,所以有三种方法可以抓取数据:
1、等待一定时间(效率低下)
2、rewrite QT的网络管理器,以跟踪URL请求的完成时间(不适用于客户端问题的情况)
3、轮询页面并等待特定内容出现(检查时浪费CPU时间)
一般来说,第三种方法更可靠、更方便。下面是它的概念代码:它的主要思想是while循环。如果找不到元素,请继续尝试
为了使上述方法更通用,我们可以将它们编写在一个类中。此类收录以下功能:下载、获取HTML、查找对应元素、设置属性值、设置文本值、单击、轮询页面并等待下载
<p>from PySide.QtCore import *
from PySide.QtGui import *
from PySide.QtWebKit import *
import time
import sys
class BrowserRender(QWebView):
def __init__(self, show=True):
'''
if the show is true then we can see webview
:param show:
'''
self.app = QApplication(sys.argv)
QWebView.__init__(self)
if show:
self.show()
def download(self, url, timeout=60):
'''
download the url if timeout is false
:param url: the download url
:param timeout: the timeout time
:return: html if not timeout
'''
loop = QEventLoop()
timer = QTimer()
timer.setSingleShot(True)
timer.timeout.connect(loop.quit)
self.loadFinished.connect(loop.quit)
self.load(QUrl(url))
timer.start(timeout*1000)
loop.exec_()
if timer.isActive():
timer.stop()
return self.html()
else:
print "Request time out "+url
def html(self):
'''
shortcut to return the current html
:return:
'''
return self.page().mainFrame().toHtml()
def find(self, pattern):
'''
find all elements that match the pattern
:param pattern:
:return:
'''
return self.page().mainFrame().findAllElements(pattern)
def attr(self, pattern, name, value):
'''
set attribute for matching pattern
:param pattern:
:param name:
:param value:
:return:
'''
for e in self.find(pattern):
e.setAttribute(name, value)
def text(self, pattern, value):
'''
set plaintext for matching pattern
:param pattern:
:param value:
:return:
'''
for e in self.find(pattern):
e.setPlainText(value)
def click(self, pattern):
'''
click matching pattern
:param pattern:
:return:
'''
for e in self.find(pattern):
e.evaluateJavaScript("this.click()")
def wait_load(self, pattern, timeout=60):
'''
wait untill pattern is found and return matches
:param pattern:
:param timeout:
:return:
'''
deadtiem = time.time() + timeout
while time.time() 查看全部
抓取动态网页(如何从javascript页面爬取信息中进行数据爬取?(一))
一、simple动态页面爬行
我们以前的页面爬行工作是基于静态页面的。但是现在很多页面使用动态页面,其中70%的动态页面是由JavaScript编写的。因此,了解如何从JavaScript页面抓取信息对我们来说非常重要
在了解具体情况之前,我们需要了解AJAX是什么。它的英文全称是AsynchronousJavaScript和XML,它是一种异步JavaScript和XML。我们可以通过Ajax请求页面数据,返回的数据格式是JSON类型
然后我们可以根据页面的Ajax格式抓取数据。下面是一个简单的页面爬网
import json
from Chapter3 import download
import csv
def simpletest():
'''
it will write the date to the country.csv
the json data has the attribute records, and the records has area, country and capital value
:return:
'''
fileds = ('area', 'country', 'capital')
writer = csv.writer(open("country.csv", "w"))
writer.writerow(fileds)
d = download.Downloader()
html = d("http://example.webscraping.com ... 6quot;)
try:
ajax = json.loads(html)
except Exception as e:
print str(e)
else:
for record in ajax['records']:
row = [record[filed] for filed in fileds]
writer.writerow(row)
if __name__ == "__main__":
simpletest()
我不知道这是否是问题所在。现在我无法从上述网站下载数据。执行上述程序。以下是结果图:
二、呈现动态页面
在开始之前,首先下载pyside并直接使用PIP install pyside命令行
然后我们可以使用pyside来抓取数据
from PySide.QtWebKit import *
from PySide.QtGui import *
from PySide.QtCore import *
import lxml.html
def simpletest():
'''
get content of the div # result in http://example.webscraping.com ... namic
:return: content
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
htmled = webview.page().mainFrame().toHtml()
# get the special content
tree = lxml.html.fromstring(htmled)
return tree.cssselect('#result')[0].text_content()
content = simpletest()
print content
我们回顾了简单动态页面爬行的内容。以前的方法不成功。我认为主要原因是我的网站写得不正确,所以在学习pyside之后,我们可以使用这种新方法进行数据爬行。以下是具体代码:
def getallcountry():
'''
open the html and set search term = a and page_size = 10
and then click auto by javascript
:return:
'''
app = QApplication([])
webview = QWebView()
loop = QEventLoop()
# finish the loop if we have finished load the html
webview.loadFinished.connect(loop.quit)
webview.load(QUrl("http://example.webscraping.com ... 6quot;))
loop.exec_()
# show the webview
webview.show()
frame = webview.page().mainFrame()
# set search text is b
frame.findFirstElement('#search_term').setAttribute('value', 'b')
# set page_size is 10
frame.findFirstElement('#page_size option:checked').setPlainText('10')
# click search button auto
frame.findFirstElement('#search').evaluateJavaScript('this.click()')
app.exec_()
以下是结果图:
在上面的过程中,我们只使用pyside在页面上获取结果,但还没有对数据进行爬网。因为Ajax在响应事件时有一定的延迟,所以有三种方法可以抓取数据:
1、等待一定时间(效率低下)
2、rewrite QT的网络管理器,以跟踪URL请求的完成时间(不适用于客户端问题的情况)
3、轮询页面并等待特定内容出现(检查时浪费CPU时间)
一般来说,第三种方法更可靠、更方便。下面是它的概念代码:它的主要思想是while循环。如果找不到元素,请继续尝试
为了使上述方法更通用,我们可以将它们编写在一个类中。此类收录以下功能:下载、获取HTML、查找对应元素、设置属性值、设置文本值、单击、轮询页面并等待下载
<p>from PySide.QtCore import *
from PySide.QtGui import *
from PySide.QtWebKit import *
import time
import sys
class BrowserRender(QWebView):
def __init__(self, show=True):
'''
if the show is true then we can see webview
:param show:
'''
self.app = QApplication(sys.argv)
QWebView.__init__(self)
if show:
self.show()
def download(self, url, timeout=60):
'''
download the url if timeout is false
:param url: the download url
:param timeout: the timeout time
:return: html if not timeout
'''
loop = QEventLoop()
timer = QTimer()
timer.setSingleShot(True)
timer.timeout.connect(loop.quit)
self.loadFinished.connect(loop.quit)
self.load(QUrl(url))
timer.start(timeout*1000)
loop.exec_()
if timer.isActive():
timer.stop()
return self.html()
else:
print "Request time out "+url
def html(self):
'''
shortcut to return the current html
:return:
'''
return self.page().mainFrame().toHtml()
def find(self, pattern):
'''
find all elements that match the pattern
:param pattern:
:return:
'''
return self.page().mainFrame().findAllElements(pattern)
def attr(self, pattern, name, value):
'''
set attribute for matching pattern
:param pattern:
:param name:
:param value:
:return:
'''
for e in self.find(pattern):
e.setAttribute(name, value)
def text(self, pattern, value):
'''
set plaintext for matching pattern
:param pattern:
:param value:
:return:
'''
for e in self.find(pattern):
e.setPlainText(value)
def click(self, pattern):
'''
click matching pattern
:param pattern:
:return:
'''
for e in self.find(pattern):
e.evaluateJavaScript("this.click()")
def wait_load(self, pattern, timeout=60):
'''
wait untill pattern is found and return matches
:param pattern:
:param timeout:
:return:
'''
deadtiem = time.time() + timeout
while time.time()
抓取动态网页(怎样让搜索引擎更好地为站点服务与提高站点的访问量有着)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-15 15:21
随着互联网上网站的增加,网站的宣传越来越依赖于搜索引擎的搜索结果。如何使搜索引擎更好地为网站服务与提高网站的流量密切相关。搜索引擎不是上帝赐予互联网的礼物。搜索引擎本身不仅是一个站点,而且是由各种程序构建的。各种搜索引擎通常使用一种称为搜索引擎机器人的技术。这个机器人将根据一定的规则访问互联网上的站点,并将有价值的页面采集到搜索引擎缓存数据库中。一旦用户搜索,搜索引擎将直接缓存搜索结果并向用户报告结果
搜索机器人的搜索规则比较复杂,但最重要的规则之一是搜索机器人对静态页面的处理能力强于对动态页面的处理能力。一般来说,搜索机器人只是简单地将静态页面理解为具有。HTML或。HTM扩展,而带有。ASP,。PHP和。CGI扩展被理解为动态页面。换句话说,如果一个站点是a。HTML页面,它在搜索引擎的全文中被发现的可能性比a高几个数量级。PHP页面。当然,访问的次数会多得多
如何让你的站点的所有内容都是静态页面,最简单的方法自然就是用页面设计软件将每个页面直接制作成静态页面,这对于小站点来说并不难,但是对于拥有数万页面的大中型站点来说,使用手工静态页面设计将带来高成本和保存和修改的困难。在这种情况下,资金充裕的大型网站公司将采用一种可以生成数据的内容管理(cms)系统。背景中的HTML文件。是否是手册。HTML文件或a。HTML文件在后台生成,可以实现真正的静态页面
然而,相当多的中型网站仍然使用cms动态发布系统。动态系统更新网页效率高,可在前台显示,在后台调度。缺点是它消耗了大量的服务器资源,并通过扩展获取了大量页面。同时使用Asp.php。要完全取代cms系统并不容易,成熟的cms系统具有静态页面后台生成功能,价格非常高
动态cms系统是否有一个简单的方法来获得扩展。HTML文件?当然,采用了URL重写转向功能
对URL重写和重定向的支持由Apache服务器上的非默认模块(mod_rewrite)完成。这个模块非常强大和笨重。IIS下有类似的模块,即ISAPI重写和IIS重写。无论是在Apache还是IIS中,重写的语法都基于正则表达式,只有一些区别。当然,对于一般应用,不需要移交所有手册和说明文件。下面以一个虚拟动态站点为例介绍一些简单的方法,读者可以根据网站的情况进行调整 查看全部
抓取动态网页(怎样让搜索引擎更好地为站点服务与提高站点的访问量有着)
随着互联网上网站的增加,网站的宣传越来越依赖于搜索引擎的搜索结果。如何使搜索引擎更好地为网站服务与提高网站的流量密切相关。搜索引擎不是上帝赐予互联网的礼物。搜索引擎本身不仅是一个站点,而且是由各种程序构建的。各种搜索引擎通常使用一种称为搜索引擎机器人的技术。这个机器人将根据一定的规则访问互联网上的站点,并将有价值的页面采集到搜索引擎缓存数据库中。一旦用户搜索,搜索引擎将直接缓存搜索结果并向用户报告结果
搜索机器人的搜索规则比较复杂,但最重要的规则之一是搜索机器人对静态页面的处理能力强于对动态页面的处理能力。一般来说,搜索机器人只是简单地将静态页面理解为具有。HTML或。HTM扩展,而带有。ASP,。PHP和。CGI扩展被理解为动态页面。换句话说,如果一个站点是a。HTML页面,它在搜索引擎的全文中被发现的可能性比a高几个数量级。PHP页面。当然,访问的次数会多得多
如何让你的站点的所有内容都是静态页面,最简单的方法自然就是用页面设计软件将每个页面直接制作成静态页面,这对于小站点来说并不难,但是对于拥有数万页面的大中型站点来说,使用手工静态页面设计将带来高成本和保存和修改的困难。在这种情况下,资金充裕的大型网站公司将采用一种可以生成数据的内容管理(cms)系统。背景中的HTML文件。是否是手册。HTML文件或a。HTML文件在后台生成,可以实现真正的静态页面
然而,相当多的中型网站仍然使用cms动态发布系统。动态系统更新网页效率高,可在前台显示,在后台调度。缺点是它消耗了大量的服务器资源,并通过扩展获取了大量页面。同时使用Asp.php。要完全取代cms系统并不容易,成熟的cms系统具有静态页面后台生成功能,价格非常高
动态cms系统是否有一个简单的方法来获得扩展。HTML文件?当然,采用了URL重写转向功能
对URL重写和重定向的支持由Apache服务器上的非默认模块(mod_rewrite)完成。这个模块非常强大和笨重。IIS下有类似的模块,即ISAPI重写和IIS重写。无论是在Apache还是IIS中,重写的语法都基于正则表达式,只有一些区别。当然,对于一般应用,不需要移交所有手册和说明文件。下面以一个虚拟动态站点为例介绍一些简单的方法,读者可以根据网站的情况进行调整
抓取动态网页(SEO(搜索引擎优化)推广中最重要的关键词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-15 15:20
对于SEO,只要搜索引擎抓取更多的网站页面,就可以提高收录和排名,但有时蜘蛛不会主动抓取网站. 此时,我们需要人工引导搜索引擎,然后提高排名和收录. 今天,小编将与大家分享八种有利于搜索引擎抓取网站页面的方法
提高网站最重要的关键词和在主要搜索平台的排名是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,因此SEO(搜索引擎优化)的推广策略应从优化网页开始
1、添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题应简洁,删除一些繁琐、多余和不重要的词语,并解释页面和网站最重要的内容。页面标题将出现在搜索结果页面的链接上,因此可以写得稍微挑逗一些,以吸引搜索者点击链接。同时,写下你的企业名称和你认为最重要的关键词,而不仅仅是你的企业名称
2、添加描述性元标记
元素可以提供关于页面的元信息,例如描述和关键词
除了页面标题,许多搜索引擎还会搜索元标记。这是一个说明性的句子,描述了网页主体的内容。句子还应包括本页使用的关键词、短语等
目前,带有关键词的meta标签对网站排名没有帮助,但有时meta标签将用于付费登录技术。谁知道搜索引擎什么时候会再次关注它呢
3、将您的关键词以粗体文本(通常为“文章title”)嵌入网页
搜索引擎非常重视粗体文本,并会认为它是本页面非常重要的内容。因此,请务必写下您的关键词
4、确保关键词出现在文本的第一段中@
搜索引擎希望在第一段中找到你的关键词,但它们不能填充太多关键词. 谷歌将出现在每100字的全文中。"1.5-2关键词“被视为最好的关键词密度,以获得更好的排名
可以考虑放置关键词的其他位置可以在代码的ALT标记或comment标记中
5、导航设计应便于搜索引擎搜索
有些人在网页制作中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,它也可能会错过关键导航列,因此无法进一步搜索其他页面
用Java和flash制作的导航按钮看起来很漂亮,但搜索引擎找不到。补救方法是在页面底部创建一个带有常规HTML链接的导航栏,以确保您可以通过该导航栏的链接进入每个页面网站。您还可以制作网站地图或链接每个网站页面。此外,一些内容管理系统和电子商务目录使用动态网页。通常,在这些网页的网址后面有一个带数字的问号。过度工作的搜索引擎通常会在问号前停止搜索。这种情况可以通过更改URL(统一资源定位器)和支付登录费用来解决
6、对于一些特别重要的关键词,专门制作了几页
SEO(搜索引擎优化)专家不建议为搜索引擎使用任何欺骗性的过渡页面,因为这些页面几乎都是复制的,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页集收录不同的关键词短语。例如,您不需要在一个页面上介绍所有服务,而是为每个服务创建一个页面。这样,每个页面都有相应的关键词,这些页面的内容将提高网站排名,因为它们收录目标关键词,而不是一般内容
7、向搜索引擎提交网页
在搜索引擎上找到“添加您的URL”(网站login)的链接。搜索机器人将自动为您提交的网页编制索引。美国最著名的搜索引擎是谷歌、inktomi、Alta Vista和tehoma
这些搜索引擎向其他主要搜索引擎平台和门户提供搜索内容网站. 在欧洲和其他地方,您可以发布到区域搜索引擎
至于付钱给某人为你提交“数百”个搜索引擎的做法,这是徒劳的。不要使用FFA(所有页面都免费)网站,这是一个所谓的网站,可以自动将你的网站免费提交给数百个搜索引擎。这种提交不仅会产生不良影响,还会给你带来大量的垃圾邮件,并可能导致搜索引擎平台以网站惩罚你@
8、调整重要内容页面以提高排名
对最重要的页面(可能是主页)进行一些调整,以提高其排名。一些软件允许你检查当前排名,比较关键词与你相同竞争对手的网页排名,并在你的网页上获得搜索引擎的首选统计数据,以便调整你自己的网页
最后,还有另一种提高网站搜索排名的方法,即部署和安装SSL证书。@以“HTTPS”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌已明确表示将优先考虑收录“HTTPS”网站
百度官方指出,它一直支持“HTTPS”。它将“HTTPS”作为网站的高质量功能之一,影响搜索排名,并为“HTTPS站点”网站提供多维支持要以“HTTPS”开头,必须安装和部署SSL证书。当网站安装部署SSL证书时,你会得到“百度蜘蛛”的权重倾斜,这可以使网站排名上升并保持稳定
这些都是搜索引擎主动捕获网站页面的方式。我希望南方联合小编的分享能对你有所帮助。南联致力于提供香港主机租赁、香港服务器租赁、服务器托管、云主机租赁等服务,欢迎咨询客户服务详解 查看全部
抓取动态网页(SEO(搜索引擎优化)推广中最重要的关键词)
对于SEO,只要搜索引擎抓取更多的网站页面,就可以提高收录和排名,但有时蜘蛛不会主动抓取网站. 此时,我们需要人工引导搜索引擎,然后提高排名和收录. 今天,小编将与大家分享八种有利于搜索引擎抓取网站页面的方法
提高网站最重要的关键词和在主要搜索平台的排名是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,因此SEO(搜索引擎优化)的推广策略应从优化网页开始
1、添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题应简洁,删除一些繁琐、多余和不重要的词语,并解释页面和网站最重要的内容。页面标题将出现在搜索结果页面的链接上,因此可以写得稍微挑逗一些,以吸引搜索者点击链接。同时,写下你的企业名称和你认为最重要的关键词,而不仅仅是你的企业名称
2、添加描述性元标记
元素可以提供关于页面的元信息,例如描述和关键词
除了页面标题,许多搜索引擎还会搜索元标记。这是一个说明性的句子,描述了网页主体的内容。句子还应包括本页使用的关键词、短语等
目前,带有关键词的meta标签对网站排名没有帮助,但有时meta标签将用于付费登录技术。谁知道搜索引擎什么时候会再次关注它呢
3、将您的关键词以粗体文本(通常为“文章title”)嵌入网页
搜索引擎非常重视粗体文本,并会认为它是本页面非常重要的内容。因此,请务必写下您的关键词
4、确保关键词出现在文本的第一段中@
搜索引擎希望在第一段中找到你的关键词,但它们不能填充太多关键词. 谷歌将出现在每100字的全文中。"1.5-2关键词“被视为最好的关键词密度,以获得更好的排名
可以考虑放置关键词的其他位置可以在代码的ALT标记或comment标记中
5、导航设计应便于搜索引擎搜索
有些人在网页制作中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,它也可能会错过关键导航列,因此无法进一步搜索其他页面
用Java和flash制作的导航按钮看起来很漂亮,但搜索引擎找不到。补救方法是在页面底部创建一个带有常规HTML链接的导航栏,以确保您可以通过该导航栏的链接进入每个页面网站。您还可以制作网站地图或链接每个网站页面。此外,一些内容管理系统和电子商务目录使用动态网页。通常,在这些网页的网址后面有一个带数字的问号。过度工作的搜索引擎通常会在问号前停止搜索。这种情况可以通过更改URL(统一资源定位器)和支付登录费用来解决
6、对于一些特别重要的关键词,专门制作了几页
SEO(搜索引擎优化)专家不建议为搜索引擎使用任何欺骗性的过渡页面,因为这些页面几乎都是复制的,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页集收录不同的关键词短语。例如,您不需要在一个页面上介绍所有服务,而是为每个服务创建一个页面。这样,每个页面都有相应的关键词,这些页面的内容将提高网站排名,因为它们收录目标关键词,而不是一般内容
7、向搜索引擎提交网页
在搜索引擎上找到“添加您的URL”(网站login)的链接。搜索机器人将自动为您提交的网页编制索引。美国最著名的搜索引擎是谷歌、inktomi、Alta Vista和tehoma
这些搜索引擎向其他主要搜索引擎平台和门户提供搜索内容网站. 在欧洲和其他地方,您可以发布到区域搜索引擎
至于付钱给某人为你提交“数百”个搜索引擎的做法,这是徒劳的。不要使用FFA(所有页面都免费)网站,这是一个所谓的网站,可以自动将你的网站免费提交给数百个搜索引擎。这种提交不仅会产生不良影响,还会给你带来大量的垃圾邮件,并可能导致搜索引擎平台以网站惩罚你@
8、调整重要内容页面以提高排名
对最重要的页面(可能是主页)进行一些调整,以提高其排名。一些软件允许你检查当前排名,比较关键词与你相同竞争对手的网页排名,并在你的网页上获得搜索引擎的首选统计数据,以便调整你自己的网页
最后,还有另一种提高网站搜索排名的方法,即部署和安装SSL证书。@以“HTTPS”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌已明确表示将优先考虑收录“HTTPS”网站
百度官方指出,它一直支持“HTTPS”。它将“HTTPS”作为网站的高质量功能之一,影响搜索排名,并为“HTTPS站点”网站提供多维支持要以“HTTPS”开头,必须安装和部署SSL证书。当网站安装部署SSL证书时,你会得到“百度蜘蛛”的权重倾斜,这可以使网站排名上升并保持稳定
这些都是搜索引擎主动捕获网站页面的方式。我希望南方联合小编的分享能对你有所帮助。南联致力于提供香港主机租赁、香港服务器租赁、服务器托管、云主机租赁等服务,欢迎咨询客户服务详解
抓取动态网页(企业想做好SEO推广营销就必须把握搜索引擎搜索引擎蜘蛛的抓取规范)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-15 15:18
企业要想做好SEO推广和营销工作,就必须掌握搜索引擎蜘蛛的捕获规范,做好web搜索动态页面SEO。非常有必要确保每个人都掌握了中国台湾SEO技术的范例课程:捕捉动态页面非常困难。接下来,WebEditor将告诉您如何通过SEO改进动态页面:
一、建立静态入口
在“动静结合,不改变台湾SEO技术范例课程:应该改变”的标准指导下,我们可以根据网站对网站进行一些修改,尽可能提高搜索引擎在动态网页上的可视性。SEO优化方法,如将动态网页列为静态主页或sitmap的多层SEO连接,并以静态文件名的形式呈现动态页面。或者为动态页面建立一个技术专业的静态输入页面,连接到台湾的SEO技术示例教程:动态页面,并将静态输入页面提交给搜索引擎
二、付费登录搜索引擎
对于连接到数据库的内容智能管理系统发布的动态网站,提高SEO的最直接方法是付费登录。建议立即将动态网页提交到搜索引擎文件名或进行关键字广告,以确保搜索引擎网站收录使用该网站@
三、搜索引擎可用性改进
搜索引擎一直在提高其动态页面的可用性,但当此类搜索引擎的爬行器爬行动态页面时,它们很容易避免寻找服务机器人的陷阱。搜索引擎只抓取从静态页面连接的动态页面,而从动态页面连接的动态页面长期以来一直被忽略,换言之,在很多方面都不容易访问动态页面中的链接
热门搜索词 查看全部
抓取动态网页(企业想做好SEO推广营销就必须把握搜索引擎搜索引擎蜘蛛的抓取规范)
企业要想做好SEO推广和营销工作,就必须掌握搜索引擎蜘蛛的捕获规范,做好web搜索动态页面SEO。非常有必要确保每个人都掌握了中国台湾SEO技术的范例课程:捕捉动态页面非常困难。接下来,WebEditor将告诉您如何通过SEO改进动态页面:
一、建立静态入口
在“动静结合,不改变台湾SEO技术范例课程:应该改变”的标准指导下,我们可以根据网站对网站进行一些修改,尽可能提高搜索引擎在动态网页上的可视性。SEO优化方法,如将动态网页列为静态主页或sitmap的多层SEO连接,并以静态文件名的形式呈现动态页面。或者为动态页面建立一个技术专业的静态输入页面,连接到台湾的SEO技术示例教程:动态页面,并将静态输入页面提交给搜索引擎
二、付费登录搜索引擎
对于连接到数据库的内容智能管理系统发布的动态网站,提高SEO的最直接方法是付费登录。建议立即将动态网页提交到搜索引擎文件名或进行关键字广告,以确保搜索引擎网站收录使用该网站@
三、搜索引擎可用性改进
搜索引擎一直在提高其动态页面的可用性,但当此类搜索引擎的爬行器爬行动态页面时,它们很容易避免寻找服务机器人的陷阱。搜索引擎只抓取从静态页面连接的动态页面,而从动态页面连接的动态页面长期以来一直被忽略,换言之,在很多方面都不容易访问动态页面中的链接
热门搜索词
抓取动态网页(动态网页元素与网页源码的实现思路及源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-13 23:06
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是回顾网页元素
所以这里不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
有两种使用正则表达式的方法。可以参考个人简述:简单爬虫的python实现及正则表达式简述
更多详情请参考网上资料,搜索关键词:正则表达式python
json:
参考网上对json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks) 查看全部
抓取动态网页(动态网页元素与网页源码的实现思路及源码
)
简介
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是回顾网页元素
所以这里不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实施思路:
抓取实际访问的动态页面的url-使用正则表达式获取需要的内容-解析内容-存储内容
以上过程部分文字说明:
获取实际访问过的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
有两种使用正则表达式的方法。可以参考个人简述:简单爬虫的python实现及正则表达式简述
更多详情请参考网上资料,搜索关键词:正则表达式python
json:
参考网上对json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-13 23:05
文章directory
本章将带大家使用selenium抓取一些动态加载的页面,让大家体验selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片为百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
获取动态数据我在找雪球网,爬取雪球网首页推荐数据,以及雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
我这里看到的是一样的数据,是当前的url,可以点击Headers复制url
如上图,数据已经存在,但是你往下看抓包会发现只有几条数据,所以需要用selenium打开当前页面配合用js实现页面下拉获取更多数据
分析获取的数据(xpath或bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲)
2.2 编写爬虫代码并进行页面爬取
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.Summary
相信如果你用上面的代码自己抓取数据,你就会知道selenium的方便了。如果你不使用selenium去抓取一些数据,你抓取可能会很不方便,但是selenium也有自己的缺点,那就是效率不高。就像上面爬的雪球网一样,我自己测试的时候用了220s。有时也可以选择抓取js包进行数据分析(后面会有案例),当然,如果用其他方法拿不到数据,使用selenium也是不错的选择。 查看全部
抓取动态网页(selenium1.使用selenium抓取动态图片本次抓取的流程确认)
文章directory
本章将带大家使用selenium抓取一些动态加载的页面,让大家体验selenium的用处
1.使用selenium抓取动态图片
本次拍摄的图片为百度图片中安吉拉的相关图片
import time
import requests # 使用requests下载图片
from urllib import request # 下载图片
from bs4 import BeautifulSoup # 使用bs4解析
from selenium import webdriver # 自动化测试工具
# 配置下载的图片的地址, 文件夹需要先创建好
IMAGE_PATH = './images/'
# 实例化驱动程序的Chrome对象, driverpath: 驱动的路径
browser = webdriver.Chrome(r'driverpath')
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 打开百度图片页面
browser.get('https://image.baidu.com/')
# 获取输入框并向输入框内输入数据
input_box = browser.find_element_by_id('kw')
input_box.send_keys('安琪拉')
time.sleep(2)
# 点击搜索按钮获取响应输入
button = browser.find_element_by_class_name('s_search')
button.click()
time.sleep(1)
# 下拉滚动条, 循环多次下拉, 可以获取到更多的图片
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取网页的str源代码
response = browser.page_source
# 实现数据解析--使用测试工具获取到的源码就是str类型,不需要再使用text获取文本数据
soup = BeautifulSoup(response, 'lxml')
li_list = soup.select('.imgpage ul li')
for li in li_list:
# li内的data-objurl属性存储的是图片的地址
href = li['data-objurl']
# 首先使用urllib模块下的request.urlretrieve下载, 此处我注释了, 大家可以尝试一下
# request.urlretrieve(href, IMAGE_PATH+'%s.jpg' % li_list.index(li))
# print('正在下载地址为%s的图片...' % href)
# time.sleep(0.5)
# 使用requests模块下载 -- 需要自己写入文件,因为requests没有自带的下载方法
image_response = requests.get(url=href, headers=headers)
# 写入文件必须使用二进制写入
with open(IMAGE_PATH + "%s.jpg" % li_list.index(li), 'wb') as f:
# 访问的是图片页面,图片是二进制流,使用content获取
f.write(image_response.content)
# 循环下载完成后退出
browser.quit()
2.使用 selenium 捕获动态数据
获取动态数据我在找雪球网,爬取雪球网首页推荐数据,以及雪球网地址
2.1 分析爬虫页面,制定爬虫流程
确认网址
我这里看到的是一样的数据,是当前的url,可以点击Headers复制url
如上图,数据已经存在,但是你往下看抓包会发现只有几条数据,所以需要用selenium打开当前页面配合用js实现页面下拉获取更多数据
分析获取的数据(xpath或bs4),得到需要的数据
对数据进行封装和持久化,存储在文件或数据库中(后面会讲)
2.2 编写爬虫代码并进行页面爬取
import time
import json # 用于格式化存入文件
from selenium import webdriver # 自动化测试工具
from lxml import etree # 使用xpath解析
def spider_snowball():
"""
1.爬取雪球网,获取url
2.使用自动化测试工具打开雪球网
3.需要使用自动化测试工具循环下拉滚动条三次,获取到动态加载的数据
4.然后使用自动化测试工具点击加载更多的button按钮,来获取到更多的数据
5.对获取到的数据进行解析,拿取需要的数据
6.将数据循环以词典添加到列表中
7.将列表数据写入到文件中,并且需要将列表转换为json字符串
"""
# 开始时间, 用于测试爬虫的时长
start_time = time.time()
# 雪球网的url, 默认就为推荐数据
url = 'https://xueqiu.com'
# 定制请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
"Chrome/74.0.3729.108 Safari/537.36",
}
# 实例化浏览器对象,以谷歌浏览器运行, driverpath: 自己驱动的存放路径
browser = webdriver.Chrome(r'driverpath')
# 打开对应的url
browser.get(url)
# 下拉滚动条三次, 三次之后就需要点击加载更多的按钮, 可自己下拉查看
for i in range(3):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1.5)
# 获取加载更多的按钮
button = browser.find_element_by_class_name('AnonymousHome_home__timeline__more_6RI')
try:
# 循环点击这个按钮,并且下拉获取到更多的数据, 此处循环自行设置, 可以不必循环太多次
for i in range(100):
# 点击这个按钮
button.click()
# 点击按钮之后会展示更多的数据,然后继续下拉滚动条来获取加载更多按钮
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
except Exception as e:
print('出错了:', e)
else:
# 如果没有出错,那么则获取到了全部(大量)的数据,下面要对数据进行解析,取出所需数据
# 获取到的网页源码就是str类型,不需要再使用text获取html文本数据
tree = etree.HTML(browser.page_source)
# 获取到所有的a标签
a_list = tree.xpath('//div[@class="AnonymousHome_home__timeline__item_3vU"]/h3/a')
result_list = []
for a in a_list:
result_dict = dict()
# 标签中的文字可直接使用text获取文本或者再次使用xpath匹配
title = a.text
# 因为xpath匹配出来后的数据是放在列表中,所以要从列表中拿出来
href = url + a.xpath('./@href')[0]
# 将数据添加到字典中
result_dict["title"] = title
result_dict["url"] = href
# 将字典添加到列表中
result_list.append(result_dict)
# 此处循环完毕后,列表中有多个字典,可以将列表写入文件(数据库)中,以便查看数据
with open('xue_qiu.json', 'w', encoding='utf-8') as f:
# 写入文件要将python格式转换为json字符串写入
f.write(json.dumps(result_list, ensure_ascii=False, indent=2))
# 退出浏览器
browser.quit()
end_time = time.time()
# 打印爬取数据的总时长
print("总耗时:%d" % (end_time-start_time))
if __name__ == '__main__':
spider_snowball()
3.Summary
相信如果你用上面的代码自己抓取数据,你就会知道selenium的方便了。如果你不使用selenium去抓取一些数据,你抓取可能会很不方便,但是selenium也有自己的缺点,那就是效率不高。就像上面爬的雪球网一样,我自己测试的时候用了220s。有时也可以选择抓取js包进行数据分析(后面会有案例),当然,如果用其他方法拿不到数据,使用selenium也是不错的选择。
抓取动态网页(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-13 02:02
我们在做网络爬虫的时候,一般来说urllib和urllib2可以满足大部分需求。
但有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取页面中空白内容的一部分。就像下面百度图片的结果页:
在查看元素后,。发现在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无界面爬取。
所以使用 selenium+phantomjs 进行无接口爬取
什么是phantomjs?它是一个基于webkit核心的无头浏览器,即没有UI界面,即只是一个浏览器
selenium 和 phantomjs 的安装配置可以google一下,这里忽略
代码如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i%3Fie% ... ry%3B
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器。 查看全部
抓取动态网页(使用urllib+phantomjs是什么呢?使用js动态加载的网页)
我们在做网络爬虫的时候,一般来说urllib和urllib2可以满足大部分需求。
但有时我们会遇到使用js动态加载的网页。你会发现 urllib 只能抓取页面中空白内容的一部分。就像下面百度图片的结果页:
在查看元素后,。发现在百度图片中,显示图片的div为:pullimages
这个div里面的内容是动态加载的。但是使用urllib&urllib2无法捕获。
要抓取动态加载的元素,首先考虑使用 selenium 调用浏览器进行抓取。
我们运行的环境是Linux,理想的方式是无界面爬取。
所以使用 selenium+phantomjs 进行无接口爬取
什么是phantomjs?它是一个基于webkit核心的无头浏览器,即没有UI界面,即只是一个浏览器
selenium 和 phantomjs 的安装配置可以google一下,这里忽略
代码如下:
from selenium import webdriver
def fetchBdImage(query):
#如果不方便配置环境变量。填入phantomjs的绝对路径也可以
driver =webdriver.PhantomJS(executable_path='/bin/phantomjs/bin/phantomjs')
#抓取百度图片页面,query由参数决定
url = 'http://image.baidu.com/i%3Fie% ... ry%3B
driver.get(url)
#这就是获取页面内容了,与urllib2.urlopen().read()的效果是类似的。
html = driver.page_source
#抓取结束,记得释放资源
driver.quit()
#返回抓取到的页面内容
return html
这里。抓取成功。
【备注】:linux下使用phantomJS,windows下可以使用chrome、firefox等浏览器。
抓取动态网页(实习僧招聘网爬虫打造灵活强大的网络爬虫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-13 01:17
关于基础网络数据抓取相关内容,本公众号已经多次分享,特别是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但所有这些都是基于静态页面的(抓包和API访问除外)。很多动态网页不提供API访问,只能希望selenium是基于浏览器驱动的技术。
好在R语言已经有selenium接口包-RSelenium包,让我们爬取动态网页成为可能。今年年初写了一个实习生网站的爬虫,使用另一个R语言的基于selenium驱动的接口包-Rwebdriver完成。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我使用导航器突然遍历了 500 页内容。虽然最后爬取了所有的数据,但是耗时很长(将近40分钟),效率也比较低。 . (有兴趣的朋友可以参考上面的文章,不过实习和尚官网最近改版很大,现在爬肯定比刚开始难!那个代码可能不能用)
最近抽空学习了一下RSelenium包的相关内容。感谢陈彦平先生在R语言上海会议上的“用RSelenium构建灵活强大的网络爬虫”的演讲。虽然不在现场,但我有幸观看了。视频版之后,一些细节解决了我最近的一些困惑,谢谢大家。
小姐陈彦平:《用RSelenium打造灵活强大的网络爬虫》/course/88 老外关于RSelenium的介绍视频(youtube,请自行翻墙):/watch?v=ic65SWRWrKA&feature=youtu.be
目前有几个包可以解析R语言的动态网页(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩(别问为什么,因为我之前没爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器并添加系统路径;
本地有plantomjs浏览器并添加系统路径;
RSelenium 包已安装。
因为自动点击操作,Chrome浏览器整个下午都在点击链接中直接崩溃了,找到原因了,因为dragnet页面很长,而且下一页按钮不在默认窗口范围内,并且js脚本中使用控件滑动条失败,原因未知。我见过有人用firefox浏览器测试成功。我还没有尝试过。这里切换到plantomjs无头浏览器(无需考虑元素是否被窗口遮挡)
R 语言版本:
#!!!这两句是在cmd或者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行获取函数
<p>url 查看全部
抓取动态网页(实习僧招聘网爬虫打造灵活强大的网络爬虫(组图))
关于基础网络数据抓取相关内容,本公众号已经多次分享,特别是R语言的爬虫框架(RCurl+XML/httr+rvest[xml2+selectr])形成了比较丰富的教程体系。
但所有这些都是基于静态页面的(抓包和API访问除外)。很多动态网页不提供API访问,只能希望selenium是基于浏览器驱动的技术。
好在R语言已经有selenium接口包-RSelenium包,让我们爬取动态网页成为可能。今年年初写了一个实习生网站的爬虫,使用另一个R语言的基于selenium驱动的接口包-Rwebdriver完成。
实习僧招聘网络爬虫数据可视化
当时技术还不成熟,想法也比较幼稚。我使用导航器突然遍历了 500 页内容。虽然最后爬取了所有的数据,但是耗时很长(将近40分钟),效率也比较低。 . (有兴趣的朋友可以参考上面的文章,不过实习和尚官网最近改版很大,现在爬肯定比刚开始难!那个代码可能不能用)
最近抽空学习了一下RSelenium包的相关内容。感谢陈彦平先生在R语言上海会议上的“用RSelenium构建灵活强大的网络爬虫”的演讲。虽然不在现场,但我有幸观看了。视频版之后,一些细节解决了我最近的一些困惑,谢谢大家。
小姐陈彦平:《用RSelenium打造灵活强大的网络爬虫》/course/88 老外关于RSelenium的介绍视频(youtube,请自行翻墙):/watch?v=ic65SWRWrKA&feature=youtu.be
目前有几个包可以解析R语言的动态网页(欢迎补充):
本节以下内容正式分享今天的案例,目标是拉钩(别问为什么,因为我之前没爬过钩)!
在介绍案例之前,请确保系统具备以下条件:
本地有selenium服务器并添加系统路径;
本地有plantomjs浏览器并添加系统路径;
RSelenium 包已安装。
因为自动点击操作,Chrome浏览器整个下午都在点击链接中直接崩溃了,找到原因了,因为dragnet页面很长,而且下一页按钮不在默认窗口范围内,并且js脚本中使用控件滑动条失败,原因未知。我见过有人用firefox浏览器测试成功。我还没有尝试过。这里切换到plantomjs无头浏览器(无需考虑元素是否被窗口遮挡)
R 语言版本:
#!!!这两句是在cmd或者PowerShell中运行的!
#RSelenium服务未关闭之前,请务必保持该窗口状态!
###启动selenium服务:
cd D:\
java -jar selenium-server-standalone-3.3.1.jar
##selenium服务器也可以直接在R语言中启动(无弹出窗口)
system("java -jar \"D:/selenium-server-standalone-2.53.1.jar\"",wait = FALSE,invisible = FALSE)
#加载包
library("RSelenium")
library("magrittr")
library("xml2")
启动服务
#给plantomjs浏览器伪装UserAgent
eCap % xml_text(trim=TRUE)
#职位所述行业
position.industry % read_html() %>% xml_find_all('//div[@class="industry"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "",.)
#职位福利
position.bonus % read_html() %>% xml_find_all('//div[@class="list_item_bot"]/div[@class="li_b_l"]') %>% xml_text(trim=TRUE) %>% gsub("[[:space:]\\u00a0]+|\\n", "/",.)
#职位工作环境
position.environment% read_html() %>% xml_find_all('//div[@class="li_b_r"]') %>% xml_text(trim=TRUE)
#收集数据
mydata% xml_find_all('//div[@class="page-number"]/span[1]') %>% xml_text() !="30"){
#如果页面未到尾部,则点击下一页
remDr$findElement('xpath','//div[@class="pager_container"]/a[last()]')$clickElement()
#但因当前任务进度
cat(sprintf("第【%d】页抓取成功",i),sep = "\n")
} else {
#如果页面到尾部则跳出while循环
break
}
}
#跳出循环后关闭remDr服务窗口
remDr$close()
#但因全局任务状态(也即任务结束)
cat("all work is done!!!",sep = "\n")
#返回最终数据
return(myresult)
}
运行获取函数
<p>url

