
抓取动态网页
抓取动态网页(不要将动态网页和页面内容是否有动感混为一谈(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-13 01:16
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页都可以称为动态网页。
简而言之,动态网页是融合了基本的html语法规范、Java、VB、VC等高级编程语言、数据库编程等技术,以实现高效、动态、交互的内容和网站管理风格。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。
动态网页简述如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)Dynamic 网页实际上并不是一个独立存在于服务器上的网页文件,只有在用户请求时服务器才会返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站数据库中的所有网页,或者出于技术考虑,搜索中国确实可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求。
四种常用的动态网络技术
1、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最流行的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但它只需要很少的编程知识。您可以使用 PHP 来构建真正的交互式网站。
它与HTML语言有很好的兼容性。用户可以直接在脚本代码中添加 HTML 标签,也可以在 HTML 标签中添加脚本代码,以更好地实现页面控制。 PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象编程。
2、ASP 是 Active Server Pages(活动服务器页面),是微软开发的超文本标记语言(HTML)、脚本(Script)和 CGI(通用网关接口)的组合。它没有提供自己专门的编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。 ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP 最大的优点是可以收录 HTML 标签,也可以直接访问数据库,使用 ActiveX 控件的无限扩展,所以在编程上比 HTML 更方便、更灵活。通过使用ASP组件和对象技术,用户可以直接使用ActiveX控件,调用对象方法和属性,以简单的方式实现强大的交互功能。
但是ASP技术并不完善,因为它基本上仅限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能很容易地工作一个跨平台的网络服务器。
aspx 是微软在服务器端运行的动态网页文件。通过IIS分析执行后,就可以得到动态页面了。它是微软推出的一种新的网络编程方法,不是asp的简单升级,因为它的编程方法和asp有很大的不同。它在服务器端编译并执行程序代码。 ASP 使用脚本语言。每次发出请求,服务器都会调用脚本解析引擎来解析和执行程序代码,可以使用 more 它是用两种语言编写的,完全编译执行,比 ASP 要快。而且,这不仅仅是速度问题,还有很多优点。
3、JSP 是Java Server Pages(Java Server Pages),它是由于1999年6月推出的新技术,是基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只用在Windows NT/2000平台上,而JSP可以运行在85%以上的服务器上,并且基于JSP技术的应用比基于ASP的应用更易于维护和管理,因此被很多人认为是未来最有前途的动态网站技术。
4、CGI(通用网关接口)是一种较早的用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行一些 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
动态网页的优势
1、增强的性能。它是在服务器上运行的已编译的公共语言运行时代码。与之前解释的不同,可以使用早期绑定、实时编译、原生优化和开箱即用的缓存服务。这相当于在编写代码行之前显着提高了性能。
2、世界级的工具支持。该框架补充了 Visual Studio 集成开发环境中的大量工具箱和设计器。 WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的部分功能。
3、力量和灵活性。由于它基于公共语言运行时,因此 Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。 .NET 框架类库、消息处理和数据访问解决方案都可以从 Web 无缝访问。它也与语言无关,因此您可以选择最适合应用程序的语言,或者将应用程序拆分为多种语言。此外,公共语言运行时的交互性确保在迁移到基于 COM 的开发方面的现有投资得以保留。
动态网页的缺点
1、首先,动态网页在访问速度上没有优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,将动态页面编译成标准的HTML代码传递给用户浏览,这样用户就可以看到网页了。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的网站。
静态网页很简单。静态网页实际上是存在的,它是直接加载到客户端浏览器中显示的,无需服务器编译。
可见动态网页在访问速度上没有优势。
2、在搜索引擎收录中不占优势
以上是从服务器和用户体验的角度,以下是从搜索引擎收录的角度。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会抓取现成的,不会自己输入,所以网站在搜索引擎收录中没有优势。搜索引擎仍然喜欢静态页面。但是,搜索引擎也在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。 查看全部
抓取动态网页(不要将动态网页和页面内容是否有动感混为一谈(图))
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页都可以称为动态网页。
简而言之,动态网页是融合了基本的html语法规范、Java、VB、VC等高级编程语言、数据库编程等技术,以实现高效、动态、交互的内容和网站管理风格。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。
动态网页简述如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)Dynamic 网页实际上并不是一个独立存在于服务器上的网页文件,只有在用户请求时服务器才会返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站数据库中的所有网页,或者出于技术考虑,搜索中国确实可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求。
四种常用的动态网络技术
1、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最流行的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但它只需要很少的编程知识。您可以使用 PHP 来构建真正的交互式网站。
它与HTML语言有很好的兼容性。用户可以直接在脚本代码中添加 HTML 标签,也可以在 HTML 标签中添加脚本代码,以更好地实现页面控制。 PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象编程。
2、ASP 是 Active Server Pages(活动服务器页面),是微软开发的超文本标记语言(HTML)、脚本(Script)和 CGI(通用网关接口)的组合。它没有提供自己专门的编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。 ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP 最大的优点是可以收录 HTML 标签,也可以直接访问数据库,使用 ActiveX 控件的无限扩展,所以在编程上比 HTML 更方便、更灵活。通过使用ASP组件和对象技术,用户可以直接使用ActiveX控件,调用对象方法和属性,以简单的方式实现强大的交互功能。
但是ASP技术并不完善,因为它基本上仅限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能很容易地工作一个跨平台的网络服务器。
aspx 是微软在服务器端运行的动态网页文件。通过IIS分析执行后,就可以得到动态页面了。它是微软推出的一种新的网络编程方法,不是asp的简单升级,因为它的编程方法和asp有很大的不同。它在服务器端编译并执行程序代码。 ASP 使用脚本语言。每次发出请求,服务器都会调用脚本解析引擎来解析和执行程序代码,可以使用 more 它是用两种语言编写的,完全编译执行,比 ASP 要快。而且,这不仅仅是速度问题,还有很多优点。
3、JSP 是Java Server Pages(Java Server Pages),它是由于1999年6月推出的新技术,是基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只用在Windows NT/2000平台上,而JSP可以运行在85%以上的服务器上,并且基于JSP技术的应用比基于ASP的应用更易于维护和管理,因此被很多人认为是未来最有前途的动态网站技术。
4、CGI(通用网关接口)是一种较早的用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行一些 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
动态网页的优势
1、增强的性能。它是在服务器上运行的已编译的公共语言运行时代码。与之前解释的不同,可以使用早期绑定、实时编译、原生优化和开箱即用的缓存服务。这相当于在编写代码行之前显着提高了性能。
2、世界级的工具支持。该框架补充了 Visual Studio 集成开发环境中的大量工具箱和设计器。 WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的部分功能。
3、力量和灵活性。由于它基于公共语言运行时,因此 Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。 .NET 框架类库、消息处理和数据访问解决方案都可以从 Web 无缝访问。它也与语言无关,因此您可以选择最适合应用程序的语言,或者将应用程序拆分为多种语言。此外,公共语言运行时的交互性确保在迁移到基于 COM 的开发方面的现有投资得以保留。
动态网页的缺点
1、首先,动态网页在访问速度上没有优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,将动态页面编译成标准的HTML代码传递给用户浏览,这样用户就可以看到网页了。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的网站。
静态网页很简单。静态网页实际上是存在的,它是直接加载到客户端浏览器中显示的,无需服务器编译。
可见动态网页在访问速度上没有优势。
2、在搜索引擎收录中不占优势
以上是从服务器和用户体验的角度,以下是从搜索引擎收录的角度。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会抓取现成的,不会自己输入,所以网站在搜索引擎收录中没有优势。搜索引擎仍然喜欢静态页面。但是,搜索引擎也在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。
抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处和坏处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-13 01:15
目前的网页大多是动态网页。如果单纯爬取网页的HTML文件,就无法爬取到商品价格或者后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了,对于小型爬虫来说,换句话说就是分析那些复杂的脚本不值得损失,更何况网站会与时俱进,而且很难破解。一旦更新,他们必须从头开始。这大大增加了小爬虫的难度。
不过好在Node.js中有这样的神器,不怕网站的登录限制和反爬虫措施。它将保持不变,可以通过简单的模拟用户操作来破解。部分限制在于它是 Puppeteer,一个由 Google 生产的爬行动态网页神器。
1.Puppeteer 的利弊
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按钮向导。网页很难区分这是人类用户还是爬虫,因此无处可谈。
它的优点是简单,非常简单,可能是所有可以抓取动态网页的库中最简单的一个。
但是缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以效率远不如其他库,不适合抓取大数据。但是对于一个小型爬虫来说已经绰绰有余了。
接下来以我写的爬取jd产品页面的小爬虫为例,看看这个有多么简单。本文章仅供学习交流使用,请勿用于其他用途。
我写这个爬虫是为了买苹果的魔控板。找了之后发现jd金银岛的价格很诱人。这应该是金银岛唯一值得抢的物品,但数量稀少。 ,要等很久才会出现。
于是想到了监控产品页面,发现新的魔控板会弹出提示。甚至可以实现自动竞价,不过我没写。毕竟除了触控板我不想买。我无法测试它是否可以成功拍摄。
好的,开始吧!
2.Install Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
3.开始链接网页
链接网页也很简单,只需要几行代码:
const puppeteer = require('puppeteer')
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
这样,链接就成功了! Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为ture,如果为false,则显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦发现有符合条件的产品就将headless改成false。
4.crawl 产品信息
链接网页后,下一步就是抓取产品信息并进行分析。
网址:魔法控制板
4.1 获取对应的元素标签
从页面中可以看出,一旦旁边的同类宝藏中出现类似的商品,我们只需要抓取那里的信息即可。有两种方式:
一个是$eval,相当于js中的document.querySelector,只抓取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与 document.querySelector 相同。看代码:
//拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
4.2.分析产品信息
既然我已经拿到了同一种宝贝所有产品的标签信息,我就开始分析信息了。
获取里面所有产品的名称,然后检查关键字是否存在,如果存在,把headless改成false提醒弹窗,如果不存在,半小时后再链接。
Puppeteer 提供了一个等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据某个元素的加载进度进行等待。
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el => {
//错误和关键字不存在都会返回false
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
5.优化代码
对于这个小爬虫来说,效率的损失并不多,不需要优化,但作为强迫症,还是希望尽量去除。
5.1块图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了稍微提高一点操作效率,所有图片都被屏蔽了:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断加载的url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
5.2 调整窗口大小
当浏览器弹出时,你会发现打开的窗口显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是有必要的调整:
await page.setViewport({
width: 1920,
height: 1080,
})
到此,所有的代码都已经完成了,来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
也可以通过Github获取完整代码:watchJd.js
如果对你有帮助,欢迎关注我,我会继续输出更多好的文章! 查看全部
抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处和坏处)
目前的网页大多是动态网页。如果单纯爬取网页的HTML文件,就无法爬取到商品价格或者后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了,对于小型爬虫来说,换句话说就是分析那些复杂的脚本不值得损失,更何况网站会与时俱进,而且很难破解。一旦更新,他们必须从头开始。这大大增加了小爬虫的难度。
不过好在Node.js中有这样的神器,不怕网站的登录限制和反爬虫措施。它将保持不变,可以通过简单的模拟用户操作来破解。部分限制在于它是 Puppeteer,一个由 Google 生产的爬行动态网页神器。
1.Puppeteer 的利弊
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按钮向导。网页很难区分这是人类用户还是爬虫,因此无处可谈。
它的优点是简单,非常简单,可能是所有可以抓取动态网页的库中最简单的一个。
但是缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以效率远不如其他库,不适合抓取大数据。但是对于一个小型爬虫来说已经绰绰有余了。
接下来以我写的爬取jd产品页面的小爬虫为例,看看这个有多么简单。本文章仅供学习交流使用,请勿用于其他用途。
我写这个爬虫是为了买苹果的魔控板。找了之后发现jd金银岛的价格很诱人。这应该是金银岛唯一值得抢的物品,但数量稀少。 ,要等很久才会出现。
于是想到了监控产品页面,发现新的魔控板会弹出提示。甚至可以实现自动竞价,不过我没写。毕竟除了触控板我不想买。我无法测试它是否可以成功拍摄。
好的,开始吧!
2.Install Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
3.开始链接网页
链接网页也很简单,只需要几行代码:
const puppeteer = require('puppeteer')
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
这样,链接就成功了! Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为ture,如果为false,则显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦发现有符合条件的产品就将headless改成false。
4.crawl 产品信息
链接网页后,下一步就是抓取产品信息并进行分析。
网址:魔法控制板
4.1 获取对应的元素标签
从页面中可以看出,一旦旁边的同类宝藏中出现类似的商品,我们只需要抓取那里的信息即可。有两种方式:
一个是$eval,相当于js中的document.querySelector,只抓取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与 document.querySelector 相同。看代码:
//拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
4.2.分析产品信息
既然我已经拿到了同一种宝贝所有产品的标签信息,我就开始分析信息了。
获取里面所有产品的名称,然后检查关键字是否存在,如果存在,把headless改成false提醒弹窗,如果不存在,半小时后再链接。
Puppeteer 提供了一个等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据某个元素的加载进度进行等待。
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el => {
//错误和关键字不存在都会返回false
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
5.优化代码
对于这个小爬虫来说,效率的损失并不多,不需要优化,但作为强迫症,还是希望尽量去除。
5.1块图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了稍微提高一点操作效率,所有图片都被屏蔽了:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断加载的url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
5.2 调整窗口大小
当浏览器弹出时,你会发现打开的窗口显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是有必要的调整:
await page.setViewport({
width: 1920,
height: 1080,
})
到此,所有的代码都已经完成了,来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
也可以通过Github获取完整代码:watchJd.js
如果对你有帮助,欢迎关注我,我会继续输出更多好的文章!
抓取动态网页(Python中有之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-12 13:15
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用urllib抓取页面的HTML还不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。 Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。 Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
库,而不是创建者。 Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则安装可能会失败。
官网:
2、SIP, PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。 Mac和Linux需要自己编译。
下载地址为:
在终端中,切换到解压文件所在的目录。
在终端输入
python configure.py
制作
sudo make install
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在Python shell中输入import PyQt4,看看能不能找到PyQt4模块。
3、Spynner
spynner 是一个 QtWebKit 客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载地址:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在python shell中尝试import spynner,看看是否安装了模块。
Spynner 的简单使用
Spynner 的功能很强大,但由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python #-*-coding: utf-8 -*- import spynner browser = spynner.Browser() #创建一个浏览器对象 browser.hide() #打开浏览器,并隐藏。 browser.load("http://www.baidu.com") #browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。 #load(是你想要加载的网址的字符串形式) print browser.html.encode("utf-8") #browser 类中有一个成员是html,是页面进过处理后的源码的字符串. #将其转码为UTF-8编码 open("Test.html", 'w+').write(browser.html.encode("utf-8")) #你也可以将它写到文件中,用浏览器打开。 browser.close() #关闭该浏览器
通过这个程序,你可以很方便的显示webkit处理的页面的HTML源代码。
spynner 应用程序
先介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python import spynner import HTMLParser import os import urllib class MyParser(HTMLParser.HTMLParser): def handle_starttag(self, tag, attrs): if tag == 'img': url = dict(attrs)['src'] name = os.path.basename(dict(attrs)['src']) if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'): print "Download.....", name urllib.urlretrieve(url, name) if __name__ == "__main__": browser = spynner.Browser() browser.show() browser.load("http://www.artist.cn/snakewu19 ... 6quot;) Parser = MyParser() Parser.feed(browser.html) print "Done" browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,就让繁重的任务交给第三方吧。
来自: 查看全部
抓取动态网页(Python中有之前)
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用urllib抓取页面的HTML还不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。 Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。 Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
库,而不是创建者。 Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则安装可能会失败。
官网:
2、SIP, PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。 Mac和Linux需要自己编译。
下载地址为:
在终端中,切换到解压文件所在的目录。
在终端输入
python configure.py
制作
sudo make install
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在Python shell中输入import PyQt4,看看能不能找到PyQt4模块。
3、Spynner
spynner 是一个 QtWebKit 客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载地址:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在python shell中尝试import spynner,看看是否安装了模块。
Spynner 的简单使用
Spynner 的功能很强大,但由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python #-*-coding: utf-8 -*- import spynner browser = spynner.Browser() #创建一个浏览器对象 browser.hide() #打开浏览器,并隐藏。 browser.load("http://www.baidu.com";) #browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。 #load(是你想要加载的网址的字符串形式) print browser.html.encode("utf-8") #browser 类中有一个成员是html,是页面进过处理后的源码的字符串. #将其转码为UTF-8编码 open("Test.html", 'w+').write(browser.html.encode("utf-8")) #你也可以将它写到文件中,用浏览器打开。 browser.close() #关闭该浏览器
通过这个程序,你可以很方便的显示webkit处理的页面的HTML源代码。
spynner 应用程序
先介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python import spynner import HTMLParser import os import urllib class MyParser(HTMLParser.HTMLParser): def handle_starttag(self, tag, attrs): if tag == 'img': url = dict(attrs)['src'] name = os.path.basename(dict(attrs)['src']) if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'): print "Download.....", name urllib.urlretrieve(url, name) if __name__ == "__main__": browser = spynner.Browser() browser.show() browser.load("http://www.artist.cn/snakewu19 ... 6quot;) Parser = MyParser() Parser.feed(browser.html) print "Done" browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,就让繁重的任务交给第三方吧。
来自:
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-12 02:02
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说一下如何使用python抓取页面中JS动态加载的数据。
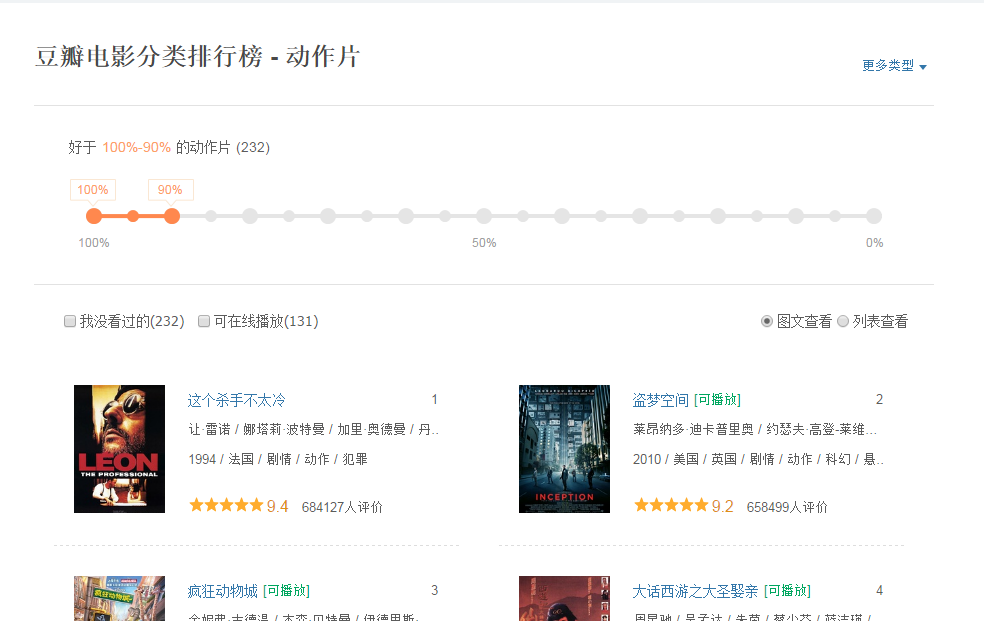
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
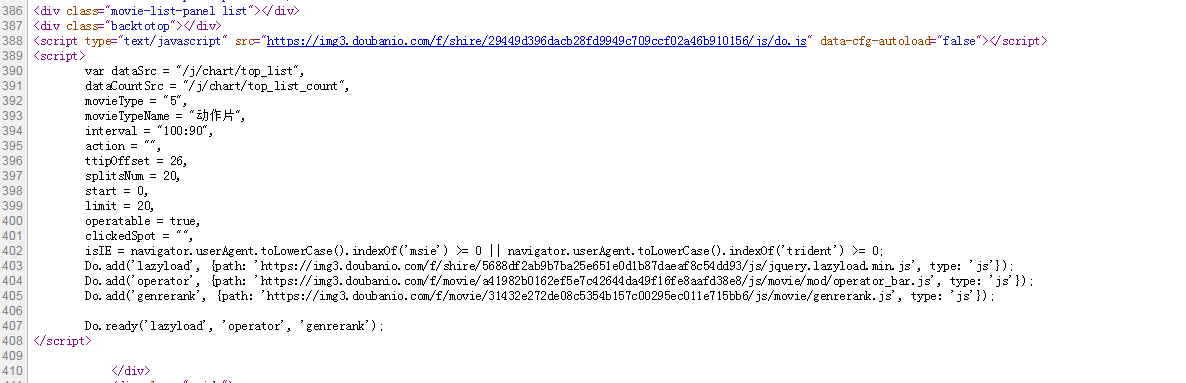
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:
在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这看起来很不自动化,很多其他的网站RequestURLs都不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说一下如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:
在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这看起来很不自动化,很多其他的网站RequestURLs都不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
抓取动态网页(如何有效的促进业务增长?亚马逊首席执行官贝佐斯告诉你 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-10 16:01
)
钥匙。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据有助于:
(1)让数据驱动的决策更快
采集Dynamic 数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。借助所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出以数据为依据的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展意义重大。
(2)建立更强大的数据库
随着数据量的不断增长,与每条数据相关的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要不断采集动态数据,构建全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度逐年增加一倍,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期数据采集可以帮助解决近期的问题并做出较小的决策,而长期数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以在多方面应用动态数据分析来促进业务发展,例如:
(1)产品管理
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从 eBay 上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
该公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度。”
例如,提取亚马逊上某产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)market 营销策略
动态数据分析可让公司了解过去哪些策略最有效、当前营销策略的效果如何以及可以改进的地方。动态数据的采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您研究不同网站结构的大量时间。
(3)Timing 爬取
这需要网络爬虫工具来支持云端采集data,而不仅仅是运行在本地计算机上。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云云采集的功能远不止这些。
(4)灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
5)采集 更快
同时使用 8-12 台云服务器采集,可以比在本地计算机上运行快 8-12 倍的速度捕获同一组数据。
(6)获取数据的成本更低
优采云云采集支持在云端采集数据,并将采集收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集中断。
此外,优采云采集器的数据采集成本与市场上同类竞争者相比降低了50%。 优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然cloud采集data可以自动导出到用户的数据库,但是API可以大大提高数据导出到自己系统的灵活性,轻松实现自己系统与优采云采集器Docking的无缝对接.
你需要知道的是优采云采集器有两种API:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
查看全部
抓取动态网页(如何有效的促进业务增长?亚马逊首席执行官贝佐斯告诉你
)
钥匙。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据有助于:
(1)让数据驱动的决策更快
采集Dynamic 数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。借助所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出以数据为依据的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展意义重大。
(2)建立更强大的数据库
随着数据量的不断增长,与每条数据相关的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要不断采集动态数据,构建全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度逐年增加一倍,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期数据采集可以帮助解决近期的问题并做出较小的决策,而长期数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以在多方面应用动态数据分析来促进业务发展,例如:
(1)产品管理
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从 eBay 上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
该公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度。”
例如,提取亚马逊上某产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)market 营销策略
动态数据分析可让公司了解过去哪些策略最有效、当前营销策略的效果如何以及可以改进的地方。动态数据的采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您研究不同网站结构的大量时间。
(3)Timing 爬取
这需要网络爬虫工具来支持云端采集data,而不仅仅是运行在本地计算机上。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云云采集的功能远不止这些。
(4)灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
5)采集 更快
同时使用 8-12 台云服务器采集,可以比在本地计算机上运行快 8-12 倍的速度捕获同一组数据。
(6)获取数据的成本更低
优采云云采集支持在云端采集数据,并将采集收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集中断。
此外,优采云采集器的数据采集成本与市场上同类竞争者相比降低了50%。 优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然cloud采集data可以自动导出到用户的数据库,但是API可以大大提高数据导出到自己系统的灵活性,轻松实现自己系统与优采云采集器Docking的无缝对接.
你需要知道的是优采云采集器有两种API:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。

抓取动态网页( 五一假期Python抓取动态网页信息的相关操作、网上教程编写出)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-10 15:18
五一假期Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(#cb)
考前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:
注意三点:
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
抓取动态网页(
五一假期Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(#cb)
考前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:
注意三点:
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。
抓取动态网页(云无穷团队:如何做好动态页面seo优化?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-10 06:06
随着互联网行业的飞速发展,SEO逐渐受到各家公司的重视和重视。企业要做SEO优化,首先要仔细了解搜索引擎的爬取规则,这样才能做好动态页面优化。相信大家都知道,搜索引擎抓取动态页面是非常困难的。让我们一路跟随云无限团队,看看如何做好动态页面SEO优化。
建立静态门户:在“动静结合,静制动”的原则指导下,Yun Infinity团队建议修改网站,增加动态网页在搜索引擎中的可见度尽可能。将动态网页编译成静态首页或网站map的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
付费登录搜索引擎:对于使用连接数据库的内容管理系统的动态网站,最直接的SEO优化方法是付费登录。 Yuninfinity 团队建议直接提交动态网页到搜索引擎目录,或者做关键词广告,确保网站被搜索到engine收录。
对搜索引擎的支持和改进:我了解到搜索引擎过去只会抓取从静态页面链接的动态页面,从动态页面链接的动态页面不再被抓取,这意味着它们不会对。动态页面中的链接,用于深入访问。但如今,搜索引擎一直在提高对动态页面的支持,以避免陷入搜索机器人的陷阱。
想必大家看完这篇文章,对百度动态页面SEO优化有了自己的理解。当然,我们总结的并不是那么全面。更多关于动态页面SEO优化的专业内容,喜欢的话可以关注我们网站。 查看全部
抓取动态网页(云无穷团队:如何做好动态页面seo优化?(图))
随着互联网行业的飞速发展,SEO逐渐受到各家公司的重视和重视。企业要做SEO优化,首先要仔细了解搜索引擎的爬取规则,这样才能做好动态页面优化。相信大家都知道,搜索引擎抓取动态页面是非常困难的。让我们一路跟随云无限团队,看看如何做好动态页面SEO优化。

建立静态门户:在“动静结合,静制动”的原则指导下,Yun Infinity团队建议修改网站,增加动态网页在搜索引擎中的可见度尽可能。将动态网页编译成静态首页或网站map的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
付费登录搜索引擎:对于使用连接数据库的内容管理系统的动态网站,最直接的SEO优化方法是付费登录。 Yuninfinity 团队建议直接提交动态网页到搜索引擎目录,或者做关键词广告,确保网站被搜索到engine收录。
对搜索引擎的支持和改进:我了解到搜索引擎过去只会抓取从静态页面链接的动态页面,从动态页面链接的动态页面不再被抓取,这意味着它们不会对。动态页面中的链接,用于深入访问。但如今,搜索引擎一直在提高对动态页面的支持,以避免陷入搜索机器人的陷阱。
想必大家看完这篇文章,对百度动态页面SEO优化有了自己的理解。当然,我们总结的并不是那么全面。更多关于动态页面SEO优化的专业内容,喜欢的话可以关注我们网站。
抓取动态网页(不要将动态网页和页面内容是否有动感混为一谈(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-13 01:16
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页都可以称为动态网页。
简而言之,动态网页是融合了基本的html语法规范、Java、VB、VC等高级编程语言、数据库编程等技术,以实现高效、动态、交互的内容和网站管理风格。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。
动态网页简述如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)Dynamic 网页实际上并不是一个独立存在于服务器上的网页文件,只有在用户请求时服务器才会返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站数据库中的所有网页,或者出于技术考虑,搜索中国确实可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求。
四种常用的动态网络技术
1、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最流行的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但它只需要很少的编程知识。您可以使用 PHP 来构建真正的交互式网站。
它与HTML语言有很好的兼容性。用户可以直接在脚本代码中添加 HTML 标签,也可以在 HTML 标签中添加脚本代码,以更好地实现页面控制。 PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象编程。
2、ASP 是 Active Server Pages(活动服务器页面),是微软开发的超文本标记语言(HTML)、脚本(Script)和 CGI(通用网关接口)的组合。它没有提供自己专门的编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。 ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP 最大的优点是可以收录 HTML 标签,也可以直接访问数据库,使用 ActiveX 控件的无限扩展,所以在编程上比 HTML 更方便、更灵活。通过使用ASP组件和对象技术,用户可以直接使用ActiveX控件,调用对象方法和属性,以简单的方式实现强大的交互功能。
但是ASP技术并不完善,因为它基本上仅限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能很容易地工作一个跨平台的网络服务器。
aspx 是微软在服务器端运行的动态网页文件。通过IIS分析执行后,就可以得到动态页面了。它是微软推出的一种新的网络编程方法,不是asp的简单升级,因为它的编程方法和asp有很大的不同。它在服务器端编译并执行程序代码。 ASP 使用脚本语言。每次发出请求,服务器都会调用脚本解析引擎来解析和执行程序代码,可以使用 more 它是用两种语言编写的,完全编译执行,比 ASP 要快。而且,这不仅仅是速度问题,还有很多优点。
3、JSP 是Java Server Pages(Java Server Pages),它是由于1999年6月推出的新技术,是基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只用在Windows NT/2000平台上,而JSP可以运行在85%以上的服务器上,并且基于JSP技术的应用比基于ASP的应用更易于维护和管理,因此被很多人认为是未来最有前途的动态网站技术。
4、CGI(通用网关接口)是一种较早的用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行一些 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
动态网页的优势
1、增强的性能。它是在服务器上运行的已编译的公共语言运行时代码。与之前解释的不同,可以使用早期绑定、实时编译、原生优化和开箱即用的缓存服务。这相当于在编写代码行之前显着提高了性能。
2、世界级的工具支持。该框架补充了 Visual Studio 集成开发环境中的大量工具箱和设计器。 WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的部分功能。
3、力量和灵活性。由于它基于公共语言运行时,因此 Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。 .NET 框架类库、消息处理和数据访问解决方案都可以从 Web 无缝访问。它也与语言无关,因此您可以选择最适合应用程序的语言,或者将应用程序拆分为多种语言。此外,公共语言运行时的交互性确保在迁移到基于 COM 的开发方面的现有投资得以保留。
动态网页的缺点
1、首先,动态网页在访问速度上没有优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,将动态页面编译成标准的HTML代码传递给用户浏览,这样用户就可以看到网页了。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的网站。
静态网页很简单。静态网页实际上是存在的,它是直接加载到客户端浏览器中显示的,无需服务器编译。
可见动态网页在访问速度上没有优势。
2、在搜索引擎收录中不占优势
以上是从服务器和用户体验的角度,以下是从搜索引擎收录的角度。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会抓取现成的,不会自己输入,所以网站在搜索引擎收录中没有优势。搜索引擎仍然喜欢静态页面。但是,搜索引擎也在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。 查看全部
抓取动态网页(不要将动态网页和页面内容是否有动感混为一谈(图))
所谓动态网页,是指相对于静态网页的网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,不要将动态网页与动态页面内容混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是网页的细节。内容的呈现形式,无论网页是否有动态效果,只要是使用动态网站技术生成的网页都可以称为动态网页。
简而言之,动态网页是融合了基本的html语法规范、Java、VB、VC等高级编程语言、数据库编程等技术,以实现高效、动态、交互的内容和网站管理风格。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。
动态网页简述如下:
(1)动态网页一般基于数据库技术,可以大大减少网站维护的工作量;
(2)网站使用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)Dynamic 网页实际上并不是一个独立存在于服务器上的网页文件,只有在用户请求时服务器才会返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站数据库中的所有网页,或者出于技术考虑,搜索中国确实可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求。
四种常用的动态网络技术
1、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最流行的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但它只需要很少的编程知识。您可以使用 PHP 来构建真正的交互式网站。
它与HTML语言有很好的兼容性。用户可以直接在脚本代码中添加 HTML 标签,也可以在 HTML 标签中添加脚本代码,以更好地实现页面控制。 PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象编程。
2、ASP 是 Active Server Pages(活动服务器页面),是微软开发的超文本标记语言(HTML)、脚本(Script)和 CGI(通用网关接口)的组合。它没有提供自己专门的编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。 ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP 最大的优点是可以收录 HTML 标签,也可以直接访问数据库,使用 ActiveX 控件的无限扩展,所以在编程上比 HTML 更方便、更灵活。通过使用ASP组件和对象技术,用户可以直接使用ActiveX控件,调用对象方法和属性,以简单的方式实现强大的交互功能。
但是ASP技术并不完善,因为它基本上仅限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能很容易地工作一个跨平台的网络服务器。
aspx 是微软在服务器端运行的动态网页文件。通过IIS分析执行后,就可以得到动态页面了。它是微软推出的一种新的网络编程方法,不是asp的简单升级,因为它的编程方法和asp有很大的不同。它在服务器端编译并执行程序代码。 ASP 使用脚本语言。每次发出请求,服务器都会调用脚本解析引擎来解析和执行程序代码,可以使用 more 它是用两种语言编写的,完全编译执行,比 ASP 要快。而且,这不仅仅是速度问题,还有很多优点。
3、JSP 是Java Server Pages(Java Server Pages),它是由于1999年6月推出的新技术,是基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只用在Windows NT/2000平台上,而JSP可以运行在85%以上的服务器上,并且基于JSP技术的应用比基于ASP的应用更易于维护和管理,因此被很多人认为是未来最有前途的动态网站技术。
4、CGI(通用网关接口)是一种较早的用于构建动态网页的技术。当客户端向 Web 服务器上指定的 CGI 程序发送请求时,Web 服务器会启动一个新的进程来执行一些 CGI 程序,程序执行完毕后,将结果以一个网页。
CGI 的优点是可以用多种语言编写,例如 C、C++、VB 和 Perl。语言的选择有很大的灵活性。最常用的 CGI 开发语言是 Perl。
动态网页的优势
1、增强的性能。它是在服务器上运行的已编译的公共语言运行时代码。与之前解释的不同,可以使用早期绑定、实时编译、原生优化和开箱即用的缓存服务。这相当于在编写代码行之前显着提高了性能。
2、世界级的工具支持。该框架补充了 Visual Studio 集成开发环境中的大量工具箱和设计器。 WYSIWYG 编辑、拖放服务器控件和自动部署只是这个强大工具提供的部分功能。
3、力量和灵活性。由于它基于公共语言运行时,因此 Web 应用程序开发人员可以利用整个平台的强大功能和灵活性。 .NET 框架类库、消息处理和数据访问解决方案都可以从 Web 无缝访问。它也与语言无关,因此您可以选择最适合应用程序的语言,或者将应用程序拆分为多种语言。此外,公共语言运行时的交互性确保在迁移到基于 COM 的开发方面的现有投资得以保留。
动态网页的缺点
1、首先,动态网页在访问速度上没有优势
动态网页首先获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,将动态页面编译成标准的HTML代码传递给用户浏览,这样用户就可以看到网页了。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。 从用户的角度来看,网页加载缓慢,没有响应。下次谁会访问你的网站。
静态网页很简单。静态网页实际上是存在的,它是直接加载到客户端浏览器中显示的,无需服务器编译。
可见动态网页在访问速度上没有优势。
2、在搜索引擎收录中不占优势
以上是从服务器和用户体验的角度,以下是从搜索引擎收录的角度。动态网页是用户输入指令后形成的页面。这个页面不存在,搜索引擎只会抓取现成的,不会自己输入,所以网站在搜索引擎收录中没有优势。搜索引擎仍然喜欢静态页面。但是,搜索引擎也在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。
抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处和坏处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-13 01:15
目前的网页大多是动态网页。如果单纯爬取网页的HTML文件,就无法爬取到商品价格或者后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了,对于小型爬虫来说,换句话说就是分析那些复杂的脚本不值得损失,更何况网站会与时俱进,而且很难破解。一旦更新,他们必须从头开始。这大大增加了小爬虫的难度。
不过好在Node.js中有这样的神器,不怕网站的登录限制和反爬虫措施。它将保持不变,可以通过简单的模拟用户操作来破解。部分限制在于它是 Puppeteer,一个由 Google 生产的爬行动态网页神器。
1.Puppeteer 的利弊
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按钮向导。网页很难区分这是人类用户还是爬虫,因此无处可谈。
它的优点是简单,非常简单,可能是所有可以抓取动态网页的库中最简单的一个。
但是缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以效率远不如其他库,不适合抓取大数据。但是对于一个小型爬虫来说已经绰绰有余了。
接下来以我写的爬取jd产品页面的小爬虫为例,看看这个有多么简单。本文章仅供学习交流使用,请勿用于其他用途。
我写这个爬虫是为了买苹果的魔控板。找了之后发现jd金银岛的价格很诱人。这应该是金银岛唯一值得抢的物品,但数量稀少。 ,要等很久才会出现。
于是想到了监控产品页面,发现新的魔控板会弹出提示。甚至可以实现自动竞价,不过我没写。毕竟除了触控板我不想买。我无法测试它是否可以成功拍摄。
好的,开始吧!
2.Install Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
3.开始链接网页
链接网页也很简单,只需要几行代码:
const puppeteer = require('puppeteer')
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
这样,链接就成功了! Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为ture,如果为false,则显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦发现有符合条件的产品就将headless改成false。
4.crawl 产品信息
链接网页后,下一步就是抓取产品信息并进行分析。
网址:魔法控制板
4.1 获取对应的元素标签
从页面中可以看出,一旦旁边的同类宝藏中出现类似的商品,我们只需要抓取那里的信息即可。有两种方式:
一个是$eval,相当于js中的document.querySelector,只抓取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与 document.querySelector 相同。看代码:
//拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
4.2.分析产品信息
既然我已经拿到了同一种宝贝所有产品的标签信息,我就开始分析信息了。
获取里面所有产品的名称,然后检查关键字是否存在,如果存在,把headless改成false提醒弹窗,如果不存在,半小时后再链接。
Puppeteer 提供了一个等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据某个元素的加载进度进行等待。
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el => {
//错误和关键字不存在都会返回false
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
5.优化代码
对于这个小爬虫来说,效率的损失并不多,不需要优化,但作为强迫症,还是希望尽量去除。
5.1块图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了稍微提高一点操作效率,所有图片都被屏蔽了:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断加载的url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
5.2 调整窗口大小
当浏览器弹出时,你会发现打开的窗口显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是有必要的调整:
await page.setViewport({
width: 1920,
height: 1080,
})
到此,所有的代码都已经完成了,来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
也可以通过Github获取完整代码:watchJd.js
如果对你有帮助,欢迎关注我,我会继续输出更多好的文章! 查看全部
抓取动态网页(Node.js里的爬取动态网页神器Puppeteer的好处和坏处)
目前的网页大多是动态网页。如果单纯爬取网页的HTML文件,就无法爬取到商品价格或者后期需要加载的图片等重要信息,更别提那些疯狂的登录限制了,对于小型爬虫来说,换句话说就是分析那些复杂的脚本不值得损失,更何况网站会与时俱进,而且很难破解。一旦更新,他们必须从头开始。这大大增加了小爬虫的难度。
不过好在Node.js中有这样的神器,不怕网站的登录限制和反爬虫措施。它将保持不变,可以通过简单的模拟用户操作来破解。部分限制在于它是 Puppeteer,一个由 Google 生产的爬行动态网页神器。
1.Puppeteer 的利弊
Puppeteer 本质上是一个 chrome 浏览器,但它可以通过代码进行操作。比如模拟鼠标点击、键盘输入等操作,有点像按钮向导。网页很难区分这是人类用户还是爬虫,因此无处可谈。
它的优点是简单,非常简单,可能是所有可以抓取动态网页的库中最简单的一个。
但是缺点也很明显,就是速度慢,效率有点低。相当于每次运行都启动一个Chrome浏览器,所以效率远不如其他库,不适合抓取大数据。但是对于一个小型爬虫来说已经绰绰有余了。
接下来以我写的爬取jd产品页面的小爬虫为例,看看这个有多么简单。本文章仅供学习交流使用,请勿用于其他用途。
我写这个爬虫是为了买苹果的魔控板。找了之后发现jd金银岛的价格很诱人。这应该是金银岛唯一值得抢的物品,但数量稀少。 ,要等很久才会出现。
于是想到了监控产品页面,发现新的魔控板会弹出提示。甚至可以实现自动竞价,不过我没写。毕竟除了触控板我不想买。我无法测试它是否可以成功拍摄。
好的,开始吧!
2.Install Puppeteer:
先安装Puppeteer库,只用到这个库:
npm install puppeteer
3.开始链接网页
链接网页也很简单,只需要几行代码:
const puppeteer = require('puppeteer')
//启动浏览器
const browers = await puppeteer.launch()
//启动新页面
const page = await browers.newPage()
//链接网址
await page.goto(url)
这样,链接就成功了! Puppeteer.launch() 也可以接收很多参数,但是这里我们只使用headless,默认为ture,如果为false,则显示浏览器界面。我们可以利用这个功能来实现弹窗提醒,一旦发现有符合条件的产品就将headless改成false。
4.crawl 产品信息
链接网页后,下一步就是抓取产品信息并进行分析。
网址:魔法控制板
4.1 获取对应的元素标签
从页面中可以看出,一旦旁边的同类宝藏中出现类似的商品,我们只需要抓取那里的信息即可。有两种方式:
一个是$eval,相当于js中的document.querySelector,只抓取第一个匹配的元素;
另一个是$$eval,相当于js中的document.querySelectorAll,爬取所有匹配的元素;
他们收到的第一个参数是元素地址,第二个参数是回调函数。操作与 document.querySelector 相同。看代码:
//拿到同类夺宝里的所有子元素
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', ele => ele)
4.2.分析产品信息
既然我已经拿到了同一种宝贝所有产品的标签信息,我就开始分析信息了。
获取里面所有产品的名称,然后检查关键字是否存在,如果存在,把headless改成false提醒弹窗,如果不存在,半小时后再链接。
Puppeteer 提供了一个等待命令 page.waitFor(),它不仅可以根据时间等待,还可以根据某个元素的加载进度进行等待。
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el => {
//错误和关键字不存在都会返回false
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
5.优化代码
对于这个小爬虫来说,效率的损失并不多,不需要优化,但作为强迫症,还是希望尽量去除。
5.1块图片
在这个爬虫中,我们根本不需要看任何图片信息,所以不需要加载所有图片。为了稍微提高一点操作效率,所有图片都被屏蔽了:
//开启拦截器
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
//判断加载的url是否以jpg或png结尾,符合条件将不再加载
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
5.2 调整窗口大小
当浏览器弹出时,你会发现打开的窗口显示范围很小,不仅浏览不方便,还可能导致点击或输入等操作出错,所以还是有必要的调整:
await page.setViewport({
width: 1920,
height: 1080,
})
到此,所有的代码都已经完成了,来试试效果吧!
6.完整代码
const puppeteer = require('puppeteer')
const url = 'https://paipai.jd.com/auction- ... 39%3B
const requestUrl = async function(bool){
const browers = await puppeteer.launch({headless:bool})
const page = await browers.newPage()
await page.setRequestInterception(true)
await page.on('request',interceptedRequest => {
if(interceptedRequest.url().endsWith('.jpg') || interceptedRequest.url().endsWith('.png')){
interceptedRequest.abort();
}else{
interceptedRequest.continue();
}
})
await page.setViewport({
width: 1920,
height: 1080,
})
await page.goto(url)
const goods = page.$$eval('#auctionRecommend > div.mc > ul > li', el=>{
try {
for (let i = 0; i {
if(b){
console.log('有货了!')
await page.waitFor(2000)
await browers.close()
return requestUrl(false)
} else {
console.log('还没货')
console.log('三十分钟后再尝试')
await page.waitFor(1800000)
await browers.close()
return requestUrl(true)
}
})
}
requestUrl(true)
也可以通过Github获取完整代码:watchJd.js
如果对你有帮助,欢迎关注我,我会继续输出更多好的文章!
抓取动态网页(Python中有之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-12 13:15
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用urllib抓取页面的HTML还不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。 Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。 Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
库,而不是创建者。 Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则安装可能会失败。
官网:
2、SIP, PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。 Mac和Linux需要自己编译。
下载地址为:
在终端中,切换到解压文件所在的目录。
在终端输入
python configure.py
制作
sudo make install
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在Python shell中输入import PyQt4,看看能不能找到PyQt4模块。
3、Spynner
spynner 是一个 QtWebKit 客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载地址:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在python shell中尝试import spynner,看看是否安装了模块。
Spynner 的简单使用
Spynner 的功能很强大,但由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python #-*-coding: utf-8 -*- import spynner browser = spynner.Browser() #创建一个浏览器对象 browser.hide() #打开浏览器,并隐藏。 browser.load("http://www.baidu.com") #browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。 #load(是你想要加载的网址的字符串形式) print browser.html.encode("utf-8") #browser 类中有一个成员是html,是页面进过处理后的源码的字符串. #将其转码为UTF-8编码 open("Test.html", 'w+').write(browser.html.encode("utf-8")) #你也可以将它写到文件中,用浏览器打开。 browser.close() #关闭该浏览器
通过这个程序,你可以很方便的显示webkit处理的页面的HTML源代码。
spynner 应用程序
先介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python import spynner import HTMLParser import os import urllib class MyParser(HTMLParser.HTMLParser): def handle_starttag(self, tag, attrs): if tag == 'img': url = dict(attrs)['src'] name = os.path.basename(dict(attrs)['src']) if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'): print "Download.....", name urllib.urlretrieve(url, name) if __name__ == "__main__": browser = spynner.Browser() browser.show() browser.load("http://www.artist.cn/snakewu19 ... 6quot;) Parser = MyParser() Parser.feed(browser.html) print "Done" browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,就让繁重的任务交给第三方吧。
来自: 查看全部
抓取动态网页(Python中有之前)
很久以前,在学习Python web编程的时候,涉及到一个Python urllib。您可以使用 urllib.urlopen("url").read() 轻松读取页面上的静态信息。但是,随着时代的发展,越来越多的网页使用javascript、jQuery、PHP等语言来动态生成页面信息。因此,使用urllib抓取页面的HTML还不足以达到预期的效果。
解决方案:
动态分析页面信息有一个最简单的想法。 Urllib 无法解析动态信息,但浏览器可以。浏览器上显示的处理信息实际上是经过处理的 HTML 文档。这为我们抓取动态页面信息提供了一个很好的思路。 Python-PyQt 中有一个著名的图形库。虽然 PyQt 是一个图形库,但它在 QtWebkit 内部。这是非常实用的。谷歌的Chrome和苹果的Safari都是基于WebKit核心开发的,所以我们可以通过PyQt中的QtWebKit将页面中的信息读取加载成HTML文档,然后解析HTML文档,从HTML文档中提取我们想要的内容。信息。
所需材料:
作者本人使用的是 Mac OS X,Windows 和 Linux 平台应该使用相同的方法。
1、Qt4 库
库,而不是创建者。 Mac默认安装路径下的库应该是/home/username/Developor/,Qt4默认安装路径不要更改。否则安装可能会失败。
官网:
2、SIP, PyQt4
这两个软件可以在PyQt官网找到。源代码已下载。 Mac和Linux需要自己编译。
下载地址为:
在终端中,切换到解压文件所在的目录。
在终端输入
python configure.py
制作
sudo make install
安装和编译。
SIP 和 PyQt4 的安装方法是一样的。但是 PyQt4 依赖于 SIP。所以先安装SIP再安装PyQt4
1、2 两步完成后,安装Python的PyQt4模块。在Python shell中输入import PyQt4,看看能不能找到PyQt4模块。
3、Spynner
spynner 是一个 QtWebKit 客户端,可以模拟浏览器完成加载页面、触发事件、填写表单等操作。
这个模块可以在 Python 的官方网站上找到。
下载地址:
解压后cd到安装目录,然后输入sudo python configure.py install安装模块。
这样Spynner模块的安装就完成了。在python shell中尝试import spynner,看看是否安装了模块。
Spynner 的简单使用
Spynner 的功能很强大,但由于本人能力有限,下面介绍一下如何显示网页的源代码。
#! /usr/bin/python #-*-coding: utf-8 -*- import spynner browser = spynner.Browser() #创建一个浏览器对象 browser.hide() #打开浏览器,并隐藏。 browser.load("http://www.baidu.com";) #browser 类中有一个类方法load,可以用webkit加载你想加载的页面信息。 #load(是你想要加载的网址的字符串形式) print browser.html.encode("utf-8") #browser 类中有一个成员是html,是页面进过处理后的源码的字符串. #将其转码为UTF-8编码 open("Test.html", 'w+').write(browser.html.encode("utf-8")) #你也可以将它写到文件中,用浏览器打开。 browser.close() #关闭该浏览器
通过这个程序,你可以很方便的显示webkit处理的页面的HTML源代码。
spynner 应用程序
先介绍一下spynner的简单应用。通过一个简单的程序,你就可以得到你在浏览器中看到的页面的所有图片。可以使用 HTMLParser、BeautifulSoup 等来解析 HTMLParser 文档。我选择 HTMParser。
#!/usr/bin/python import spynner import HTMLParser import os import urllib class MyParser(HTMLParser.HTMLParser): def handle_starttag(self, tag, attrs): if tag == 'img': url = dict(attrs)['src'] name = os.path.basename(dict(attrs)['src']) if name.endswith('.jpg') or name.endswith('.png') or name.endswith('gif'): print "Download.....", name urllib.urlretrieve(url, name) if __name__ == "__main__": browser = spynner.Browser() browser.show() browser.load("http://www.artist.cn/snakewu19 ... 6quot;) Parser = MyParser() Parser.feed(browser.html) print "Done" browser.close()
通过这个程序,您可以下载您在页面上看到的所有图片。几行简单的程序就完成了这项艰巨的任务。实现图片的批量处理。这确实是Python语言的优势,就让繁重的任务交给第三方吧。
来自:
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-12 02:02
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说一下如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:
在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这看起来很不自动化,很多其他的网站RequestURLs都不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说一下如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:
在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这看起来很不自动化,很多其他的网站RequestURLs都不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
抓取动态网页(如何有效的促进业务增长?亚马逊首席执行官贝佐斯告诉你 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-10 16:01
)
钥匙。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据有助于:
(1)让数据驱动的决策更快
采集Dynamic 数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。借助所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出以数据为依据的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展意义重大。
(2)建立更强大的数据库
随着数据量的不断增长,与每条数据相关的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要不断采集动态数据,构建全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度逐年增加一倍,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期数据采集可以帮助解决近期的问题并做出较小的决策,而长期数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以在多方面应用动态数据分析来促进业务发展,例如:
(1)产品管理
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从 eBay 上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
该公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度。”
例如,提取亚马逊上某产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)market 营销策略
动态数据分析可让公司了解过去哪些策略最有效、当前营销策略的效果如何以及可以改进的地方。动态数据的采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您研究不同网站结构的大量时间。
(3)Timing 爬取
这需要网络爬虫工具来支持云端采集data,而不仅仅是运行在本地计算机上。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云云采集的功能远不止这些。
(4)灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
5)采集 更快
同时使用 8-12 台云服务器采集,可以比在本地计算机上运行快 8-12 倍的速度捕获同一组数据。
(6)获取数据的成本更低
优采云云采集支持在云端采集数据,并将采集收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集中断。
此外,优采云采集器的数据采集成本与市场上同类竞争者相比降低了50%。 优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然cloud采集data可以自动导出到用户的数据库,但是API可以大大提高数据导出到自己系统的灵活性,轻松实现自己系统与优采云采集器Docking的无缝对接.
你需要知道的是优采云采集器有两种API:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
查看全部
抓取动态网页(如何有效的促进业务增长?亚马逊首席执行官贝佐斯告诉你
)
钥匙。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据有助于:
(1)让数据驱动的决策更快
采集Dynamic 数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。借助所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出以数据为依据的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展意义重大。
(2)建立更强大的数据库
随着数据量的不断增长,与每条数据相关的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要不断采集动态数据,构建全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度逐年增加一倍,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期数据采集可以帮助解决近期的问题并做出较小的决策,而长期数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以在多方面应用动态数据分析来促进业务发展,例如:
(1)产品管理
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从 eBay 上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
该公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度。”
例如,提取亚马逊上某产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)market 营销策略
动态数据分析可让公司了解过去哪些策略最有效、当前营销策略的效果如何以及可以改进的地方。动态数据的采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您研究不同网站结构的大量时间。
(3)Timing 爬取
这需要网络爬虫工具来支持云端采集data,而不仅仅是运行在本地计算机上。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云云采集的功能远不止这些。
(4)灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
5)采集 更快
同时使用 8-12 台云服务器采集,可以比在本地计算机上运行快 8-12 倍的速度捕获同一组数据。
(6)获取数据的成本更低
优采云云采集支持在云端采集数据,并将采集收到的数据存入云端数据库。企业无需担心高昂的硬件维护成本或采集中断。
此外,优采云采集器的数据采集成本与市场上同类竞争者相比降低了50%。 优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然cloud采集data可以自动导出到用户的数据库,但是API可以大大提高数据导出到自己系统的灵活性,轻松实现自己系统与优采云采集器Docking的无缝对接.
你需要知道的是优采云采集器有两种API:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
抓取动态网页( 五一假期Python抓取动态网页信息的相关操作、网上教程编写出)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-10 15:18
五一假期Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(#cb)
考前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:
注意三点:
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
抓取动态网页(
五一假期Python抓取动态网页信息的相关操作、网上教程编写出)
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为避免日后出现问题,暂时找不到相关资料来创建本文。
准备工具:
Python 3.8Google Chrome 浏览器 Googledriver
测试网站:
1.集思录(#cb)
考前准备:
1.配置python运行的环境变量,参考链接()
*本次测试主要使用两种方式抓取动态网页数据,一种是requests和json解析;另一种是硒。 requests 方法速度快,但有些元素的链接信息无法捕获; selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合。
抓取的主要内容如下:(网站部分可转债数据)
通过请求获取网站信息:
Python需要安装的相关脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。一次装不下,多装几次。
(前提是相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbn ... 39%3B
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站(#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 对请求的数据格式进行转换,方便数据查找。 json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
python需要安装的脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
Selenium 爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
运行结果如下:
注意三点:
1、 应该添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。
抓取动态网页(云无穷团队:如何做好动态页面seo优化?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-10 06:06
随着互联网行业的飞速发展,SEO逐渐受到各家公司的重视和重视。企业要做SEO优化,首先要仔细了解搜索引擎的爬取规则,这样才能做好动态页面优化。相信大家都知道,搜索引擎抓取动态页面是非常困难的。让我们一路跟随云无限团队,看看如何做好动态页面SEO优化。
建立静态门户:在“动静结合,静制动”的原则指导下,Yun Infinity团队建议修改网站,增加动态网页在搜索引擎中的可见度尽可能。将动态网页编译成静态首页或网站map的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
付费登录搜索引擎:对于使用连接数据库的内容管理系统的动态网站,最直接的SEO优化方法是付费登录。 Yuninfinity 团队建议直接提交动态网页到搜索引擎目录,或者做关键词广告,确保网站被搜索到engine收录。
对搜索引擎的支持和改进:我了解到搜索引擎过去只会抓取从静态页面链接的动态页面,从动态页面链接的动态页面不再被抓取,这意味着它们不会对。动态页面中的链接,用于深入访问。但如今,搜索引擎一直在提高对动态页面的支持,以避免陷入搜索机器人的陷阱。
想必大家看完这篇文章,对百度动态页面SEO优化有了自己的理解。当然,我们总结的并不是那么全面。更多关于动态页面SEO优化的专业内容,喜欢的话可以关注我们网站。 查看全部
抓取动态网页(云无穷团队:如何做好动态页面seo优化?(图))
随着互联网行业的飞速发展,SEO逐渐受到各家公司的重视和重视。企业要做SEO优化,首先要仔细了解搜索引擎的爬取规则,这样才能做好动态页面优化。相信大家都知道,搜索引擎抓取动态页面是非常困难的。让我们一路跟随云无限团队,看看如何做好动态页面SEO优化。
建立静态门户:在“动静结合,静制动”的原则指导下,Yun Infinity团队建议修改网站,增加动态网页在搜索引擎中的可见度尽可能。将动态网页编译成静态首页或网站map的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
付费登录搜索引擎:对于使用连接数据库的内容管理系统的动态网站,最直接的SEO优化方法是付费登录。 Yuninfinity 团队建议直接提交动态网页到搜索引擎目录,或者做关键词广告,确保网站被搜索到engine收录。
对搜索引擎的支持和改进:我了解到搜索引擎过去只会抓取从静态页面链接的动态页面,从动态页面链接的动态页面不再被抓取,这意味着它们不会对。动态页面中的链接,用于深入访问。但如今,搜索引擎一直在提高对动态页面的支持,以避免陷入搜索机器人的陷阱。
想必大家看完这篇文章,对百度动态页面SEO优化有了自己的理解。当然,我们总结的并不是那么全面。更多关于动态页面SEO优化的专业内容,喜欢的话可以关注我们网站。

