
抓取动态网页
抓取动态网页(如何才能让搜索引擎对动态页面进行抓取?说说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-12 18:27
我们在做搜索引擎推广的时候,经常会遇到一个问题,就是动态页面不能被搜索爬取,而搜索引擎可以爬取网站的动态页面。相信很多站长还是知道他的效果更好的。对于图片和文字,搜索引擎如何抓取动态页面?易知今天跟大家聊一聊如何通过SEO优化动态页面:
首先网站必须建立一个静态入口
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态页面等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
最后根据搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些蜘蛛在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的动态页面。不再抓取页面,这意味着不会对动态页面中的链接进行深入访问。
PS:动态页面和很多站长关注的富图文基本一致。
更多微信亿交流: 查看全部
抓取动态网页(如何才能让搜索引擎对动态页面进行抓取?说说)
我们在做搜索引擎推广的时候,经常会遇到一个问题,就是动态页面不能被搜索爬取,而搜索引擎可以爬取网站的动态页面。相信很多站长还是知道他的效果更好的。对于图片和文字,搜索引擎如何抓取动态页面?易知今天跟大家聊一聊如何通过SEO优化动态页面:

首先网站必须建立一个静态入口
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态页面等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。

二、登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。

最后根据搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些蜘蛛在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的动态页面。不再抓取页面,这意味着不会对动态页面中的链接进行深入访问。
PS:动态页面和很多站长关注的富图文基本一致。
更多微信亿交流:
抓取动态网页(搜索引擎蜘蛛对静态页面和动态页面是同等对待的吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-12 18:27
问题:哪个蜘蛛抓取静态或动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面一视同仁,不会先爬哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛正常识别,如果动态页面很多pages 复杂参数,可能会影响蜘蛛爬行。
其实搜索引擎发展到今天,已经能够很好的解决抓取问题,无论是静态页面还是动态页面都可以抓取。但是从用户体验的角度来看,最好将 URL 设置为静态或伪静态,因为合理的 URL 可以节省用户的判断成本,这也有助于 网站 优化。
当然,不要走进死胡同,认为搜索引擎会歧视动态链接。这是错误的。
在页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。但是这里还有一个问题需要注意,就是页面的动态更新,无论页面的URL是什么形式的,都要保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章调用应该是动态的,并且文章更新在同一个标签下,另一个文章@ >页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬行的问题,牧峰SEO简单说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会爬行。但是在设置网址的时候有一个原则要遵循,就是网址要尽量简单易懂,不要有复杂的符号! 查看全部
抓取动态网页(搜索引擎蜘蛛对静态页面和动态页面是同等对待的吗?)
问题:哪个蜘蛛抓取静态或动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面一视同仁,不会先爬哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛正常识别,如果动态页面很多pages 复杂参数,可能会影响蜘蛛爬行。
其实搜索引擎发展到今天,已经能够很好的解决抓取问题,无论是静态页面还是动态页面都可以抓取。但是从用户体验的角度来看,最好将 URL 设置为静态或伪静态,因为合理的 URL 可以节省用户的判断成本,这也有助于 网站 优化。
当然,不要走进死胡同,认为搜索引擎会歧视动态链接。这是错误的。
在页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。但是这里还有一个问题需要注意,就是页面的动态更新,无论页面的URL是什么形式的,都要保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章调用应该是动态的,并且文章更新在同一个标签下,另一个文章@ >页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬行的问题,牧峰SEO简单说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会爬行。但是在设置网址的时候有一个原则要遵循,就是网址要尽量简单易懂,不要有复杂的符号!
抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-10 10:28
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本上可以为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。例如,这里的“latest?p=1&s=20”乍一看很可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本上可以为js渲染。


在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。例如,这里的“latest?p=1&s=20”乍一看很可疑……

对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。

同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
抓取动态网页( 1.什么是动态页面2.什么?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-10 04:20
1.什么是动态页面2.什么?())
使用 selenium 抓取动态页面
1. 什么是动态页面2. 什么是硒
百度百科对硒的定义:
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
简单理解一点,selenium是一个可以模拟浏览器的工具(框架)。通过使用 selenium 的 API,您可以模拟您所想的操作。
在爬虫中使用selenium是为了解决js的渲染问题。
3. 使用selenium 3.1 使用selenium的准备工作以Maven项目为例,在pom.xml文件中添加依赖
org.seleniumhq.selenium
selenium-java
3.141.59
您还可以添加 => selenium 的其他版本依赖项。
2.下载安装chromedriver,具体操作看这里,如果安装成功,可以写示例代码。
3.2 示例代码
编写主程序并执行示例代码:
public static void main(String[] args) {
//配置chromedriver webdriver.chrome.driver
System.getProperties().setProperty("webdriver.chrome.driver", "C:\\Users\\AIR\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe");
//创建chromedriver对象
WebDriver webDriver = new ChromeDriver();
//请求要爬取的网页
webDriver.get("https://search.51job.com/list/180200,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=");
//取html中的内容
WebElement webElement = webDriver.findElement(By.xpath("/html"));
//打印
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
4. 发生异常
无法创建 ChromeDriver,错误消息:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkState(ZLjava/lang/String;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;)V
这篇文章解释了异常的两个原因。我排除了第一个。
第二个原因是Bloom filter的jar包冲突引起的。可以通过IDEA 2019的新特性查看jar包的依赖树,红线是冲突的jar包。如何查看依赖树。
我的解决方案:
首先更新最新版的布隆过滤器jar包:
com.google.guava
guava
29.0-jre
然后把最新版本的selenium更新为3.141.59(之前是2.32.0)。
org.seleniumhq.selenium
selenium-java
3.141.59
最后,程序运行成功,解析js渲染的页面,并在控制台打印结果。 查看全部
抓取动态网页(
1.什么是动态页面2.什么?())
使用 selenium 抓取动态页面
1. 什么是动态页面2. 什么是硒
百度百科对硒的定义:
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
简单理解一点,selenium是一个可以模拟浏览器的工具(框架)。通过使用 selenium 的 API,您可以模拟您所想的操作。
在爬虫中使用selenium是为了解决js的渲染问题。
3. 使用selenium 3.1 使用selenium的准备工作以Maven项目为例,在pom.xml文件中添加依赖
org.seleniumhq.selenium
selenium-java
3.141.59
您还可以添加 => selenium 的其他版本依赖项。
2.下载安装chromedriver,具体操作看这里,如果安装成功,可以写示例代码。
3.2 示例代码
编写主程序并执行示例代码:
public static void main(String[] args) {
//配置chromedriver webdriver.chrome.driver
System.getProperties().setProperty("webdriver.chrome.driver", "C:\\Users\\AIR\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe");
//创建chromedriver对象
WebDriver webDriver = new ChromeDriver();
//请求要爬取的网页
webDriver.get("https://search.51job.com/list/180200,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=");
//取html中的内容
WebElement webElement = webDriver.findElement(By.xpath("/html"));
//打印
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
4. 发生异常
无法创建 ChromeDriver,错误消息:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkState(ZLjava/lang/String;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;)V
这篇文章解释了异常的两个原因。我排除了第一个。
第二个原因是Bloom filter的jar包冲突引起的。可以通过IDEA 2019的新特性查看jar包的依赖树,红线是冲突的jar包。如何查看依赖树。
我的解决方案:
首先更新最新版的布隆过滤器jar包:
com.google.guava
guava
29.0-jre
然后把最新版本的selenium更新为3.141.59(之前是2.32.0)。
org.seleniumhq.selenium
selenium-java
3.141.59
最后,程序运行成功,解析js渲染的页面,并在控制台打印结果。
抓取动态网页(如何将你的动态网页静态化?网页的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-09 16:48
技术人员知道,无论是网页上的各种动画、滚动的字母、Flash等“动态效果”,都与动态网页无关。我们所说的动态就是网站技术,它利用动态网站技术生成的网页称为动态网页。通常,网页是从网站 浏览者的角度来看的。静态网页和动态网页都可以显示最基本的信息,可以满足网民查看新闻的需求,但两者之间,无论是从开发还是管理、管理、维护上都存在差异。
现在很多朋友都因为百度不是收录网站而苦恼。前期的动态效果能不能做成静态的?其实不用这么麻烦,只要找到合适的方法,就可以让百度收录你的网站,还有更多的文章。我目前正在工作,并在网站建设/营销行业工作了 12 年。所以来到这家公司后,我不仅为清华同方集团、联想集团等多家知名企业做了网站,还学到了很多知识。,
现在我将向您解释如何使您的动态网页静态化。
一般来说,动态网页的特点主要包括以下几个特点:
1.动态网页基于数据库技术,可以大大减少网站维护的工作量;
2.网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
3.动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
但是对于搜索引擎来说,动态网页带来了很大的挑战。搜索引擎的爬虫程序在服务器内存中爬取,容易进入动态网页链接死循环,导致无法正常遍历所有网页,严重影响网站收录数量。同时,在抓取的网页中会产生大量的重复页面。从搜索引擎的角度来看,内容相同但网址不同的网页本身就是一种欺骗排名的行为,导致对网站的不信任。所以对于搜索引擎来说,静态网页比动态网页更容易抓取。
如果你还在改变,因为你的网站是动态的,不容易被搜索引擎抓取,那我给你一个方法,1.通过程序的改造是网站所有动态页面是静态词。2.通过程序修改生成实时更新的伪静态网页。这些都可以由技术人员完成。对于不熟悉编程技术的读者,可以选择本书推荐的带有静态词的cms系统。
希望这篇文章能帮到大家。 查看全部
抓取动态网页(如何将你的动态网页静态化?网页的特点)
技术人员知道,无论是网页上的各种动画、滚动的字母、Flash等“动态效果”,都与动态网页无关。我们所说的动态就是网站技术,它利用动态网站技术生成的网页称为动态网页。通常,网页是从网站 浏览者的角度来看的。静态网页和动态网页都可以显示最基本的信息,可以满足网民查看新闻的需求,但两者之间,无论是从开发还是管理、管理、维护上都存在差异。
现在很多朋友都因为百度不是收录网站而苦恼。前期的动态效果能不能做成静态的?其实不用这么麻烦,只要找到合适的方法,就可以让百度收录你的网站,还有更多的文章。我目前正在工作,并在网站建设/营销行业工作了 12 年。所以来到这家公司后,我不仅为清华同方集团、联想集团等多家知名企业做了网站,还学到了很多知识。,
现在我将向您解释如何使您的动态网页静态化。
一般来说,动态网页的特点主要包括以下几个特点:
1.动态网页基于数据库技术,可以大大减少网站维护的工作量;
2.网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
3.动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
但是对于搜索引擎来说,动态网页带来了很大的挑战。搜索引擎的爬虫程序在服务器内存中爬取,容易进入动态网页链接死循环,导致无法正常遍历所有网页,严重影响网站收录数量。同时,在抓取的网页中会产生大量的重复页面。从搜索引擎的角度来看,内容相同但网址不同的网页本身就是一种欺骗排名的行为,导致对网站的不信任。所以对于搜索引擎来说,静态网页比动态网页更容易抓取。
如果你还在改变,因为你的网站是动态的,不容易被搜索引擎抓取,那我给你一个方法,1.通过程序的改造是网站所有动态页面是静态词。2.通过程序修改生成实时更新的伪静态网页。这些都可以由技术人员完成。对于不熟悉编程技术的读者,可以选择本书推荐的带有静态词的cms系统。
希望这篇文章能帮到大家。
抓取动态网页( 烯牛数据加密不好暨自动化测试中无头谷歌浏览器设置代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-09 16:40
烯牛数据加密不好暨自动化测试中无头谷歌浏览器设置代理)
Python爬虫:Selenium和Chrome无头浏览器用牛数据爬取动态网页
彭诗雨 发表于 2021/08/13 23:49:58 2021/08/13
【摘要】牛的数据地址:打开页面,可以正常看到内容,查看源码发现页面没有出现我们需要的内容,说明这是异步加载的内容。数据抓取方式一:使用requests或者scrapy,无法获取页面数据,api数据加密不好。处理方法二:使用PhantomJS,经过多次尝试,仍然无法得到...
数据地址:
打开页面,可以正常看到内容,查看源码发现页面没有显示我们需要的内容,说明这是异步加载的内容。
数据抓取
方式一:
使用requests或者scrapy,无法获取页面数据,api数据加密不好处理
方式二:
使用PhantomJS,经过多次尝试,仍然无法获取数据,即使我等待了很长时间。
方式3:
使用splash,方法可以参考:Python爬虫:splash安装及简单示例
方式四:
使用 Chrome,headless 或 headless,这个例子使用了一个 headless 浏览器
代码
from selenium import webdriver
# 创建chrome参数对象
options = webdriver.ChromeOptions()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
options.add_argument('headless')
# 创建chrome无界面对象
driver = webdriver.Chrome(chrome_options=options)
# 访问烯牛数据
url = "http://www.xiniudata.com/proje ... ot%3B
driver.get(url)
# 等待,让js有时间渲染
driver.implicitly_wait(3)
#打印内容
# print(driver.page_source)
# 解析内容
print(driver.find_element_by_css_selector(".table-body").text)
# 关闭窗口和浏览器
driver.close()
driver.quit()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
对于js渲染的页面,关键是浏览器在返回内容之前会等待一段时间,给js一些时间去渲染,否则渲染的数据将不可用
参考
Chrome -selenium webdriver 的无头设置代理和自动化测试中的无头谷歌浏览器设置代理 查看全部
抓取动态网页(
烯牛数据加密不好暨自动化测试中无头谷歌浏览器设置代理)
Python爬虫:Selenium和Chrome无头浏览器用牛数据爬取动态网页

彭诗雨 发表于 2021/08/13 23:49:58 2021/08/13
【摘要】牛的数据地址:打开页面,可以正常看到内容,查看源码发现页面没有出现我们需要的内容,说明这是异步加载的内容。数据抓取方式一:使用requests或者scrapy,无法获取页面数据,api数据加密不好。处理方法二:使用PhantomJS,经过多次尝试,仍然无法得到...
数据地址:
打开页面,可以正常看到内容,查看源码发现页面没有显示我们需要的内容,说明这是异步加载的内容。
数据抓取
方式一:
使用requests或者scrapy,无法获取页面数据,api数据加密不好处理
方式二:
使用PhantomJS,经过多次尝试,仍然无法获取数据,即使我等待了很长时间。
方式3:
使用splash,方法可以参考:Python爬虫:splash安装及简单示例
方式四:
使用 Chrome,headless 或 headless,这个例子使用了一个 headless 浏览器
代码
from selenium import webdriver
# 创建chrome参数对象
options = webdriver.ChromeOptions()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
options.add_argument('headless')
# 创建chrome无界面对象
driver = webdriver.Chrome(chrome_options=options)
# 访问烯牛数据
url = "http://www.xiniudata.com/proje ... ot%3B
driver.get(url)
# 等待,让js有时间渲染
driver.implicitly_wait(3)
#打印内容
# print(driver.page_source)
# 解析内容
print(driver.find_element_by_css_selector(".table-body").text)
# 关闭窗口和浏览器
driver.close()
driver.quit()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
对于js渲染的页面,关键是浏览器在返回内容之前会等待一段时间,给js一些时间去渲染,否则渲染的数据将不可用
参考
Chrome -selenium webdriver 的无头设置代理和自动化测试中的无头谷歌浏览器设置代理
抓取动态网页(如何禁止搜索引擎抓取我们网站的动态网址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-09 16:39
所谓动态网址是指网址包括什么?, & 等字符网址,如news.php?lang=cn&class=1&id=2。我们开启了网站的伪静态后,对于网站的SEO来说,有必要避免搜索引擎爬取我们的动态网址网站。
你为什么要这样做?因为搜索引擎会在两次获取同一个页面但最终确定同一个页面后触发网站。具体处罚不明确。总之,不利于网站的整个SEO。那么如何防止搜索引擎抓取我们的动态网址网站呢?
这个问题可以通过robots.txt文件解决,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站 的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。 查看全部
抓取动态网页(如何禁止搜索引擎抓取我们网站的动态网址(图))
所谓动态网址是指网址包括什么?, & 等字符网址,如news.php?lang=cn&class=1&id=2。我们开启了网站的伪静态后,对于网站的SEO来说,有必要避免搜索引擎爬取我们的动态网址网站。
你为什么要这样做?因为搜索引擎会在两次获取同一个页面但最终确定同一个页面后触发网站。具体处罚不明确。总之,不利于网站的整个SEO。那么如何防止搜索引擎抓取我们的动态网址网站呢?
这个问题可以通过robots.txt文件解决,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站 的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。
抓取动态网页( powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2021-10-09 16:33
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做... 查看全部
抓取动态网页(
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做...
抓取动态网页( powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-09 03:16
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做... 查看全部
抓取动态网页(
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做...
抓取动态网页(如何让搜索引擎快速收录网站页面的方法:1.、链接、robots)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-09 03:15
SEO客户经常问我为什么网站的页面不是收录。其实这跟网站的内容、链接、robots等都有关系,下面给大家分享一下如何让搜索引擎快速网站网站页面的方法:
1.网站 页面很有价值
搜索引擎也会从用户的角度来看 网站 和页面。如果你的网站页面有比较新的、独特的、有价值的内容,用户会被更多地使用和喜欢,只有页面对用户有用,有价值的搜索引擎才会给出好的排名和快速的收录。网站的内容除了有价值之外,还必须有一定的相似度。例如,您是一名财务管理人员。我觉得这是一个更专业的网站,会更加关注它,这对网站收录和关键词的排名会有一定的好处。
2.科学合理使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上添加alt标签并进行文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以访问识别图片。
3.使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
4.关键词使用问题
一个页面一定要仔细选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。如果你想获得一个好的排名,如果你使用堆积起来的关键词 很难。
5.定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。据了解,百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点都会有一些重大更新,所以建议站长合理利用这个时间段,加上网站的收录。
6.增加优质外链
seo行业的人都知道外部链接的作用。外链是增加网站收录、流量、排名的重要因素。外链是一票,高权重的优质链接。能够链接到你想要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。 查看全部
抓取动态网页(如何让搜索引擎快速收录网站页面的方法:1.、链接、robots)
SEO客户经常问我为什么网站的页面不是收录。其实这跟网站的内容、链接、robots等都有关系,下面给大家分享一下如何让搜索引擎快速网站网站页面的方法:
1.网站 页面很有价值
搜索引擎也会从用户的角度来看 网站 和页面。如果你的网站页面有比较新的、独特的、有价值的内容,用户会被更多地使用和喜欢,只有页面对用户有用,有价值的搜索引擎才会给出好的排名和快速的收录。网站的内容除了有价值之外,还必须有一定的相似度。例如,您是一名财务管理人员。我觉得这是一个更专业的网站,会更加关注它,这对网站收录和关键词的排名会有一定的好处。
2.科学合理使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上添加alt标签并进行文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以访问识别图片。
3.使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
4.关键词使用问题
一个页面一定要仔细选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。如果你想获得一个好的排名,如果你使用堆积起来的关键词 很难。
5.定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。据了解,百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点都会有一些重大更新,所以建议站长合理利用这个时间段,加上网站的收录。
6.增加优质外链
seo行业的人都知道外部链接的作用。外链是增加网站收录、流量、排名的重要因素。外链是一票,高权重的优质链接。能够链接到你想要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。
抓取动态网页(看过SEO实战密码的同学都知道,百度蜘蛛是否会抓取动态页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-05 08:21
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是 收录 一个动态页面吗?让我们一起来看看这个。
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是一个 收录 动态页面吗?一起来看看这些问题吧!
首先,百度蜘蛛现在可以识别动态页面了,尽管很多老牌SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
动态页面比静态页面差吗?
说实话,静态页面还是有一定优势的。
1、服务器负载小
2、页面打开速度很快
3、静态页面漏洞很少
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。如今,动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要你做得好,你可以得到很好的结果。
一、超链接:超链接部分的文字一般是蓝色的,也有一些是其他颜色的。当我们点击它时颜色会改变。
二、 网页上的超链接一般分为三种:URL超链接、相对URL超链接、同意网页超链接。这里的URL(UniformResourceLocator)就是统一资源定位器,简单来说就是互联网上一个站点或者网页的完整路径,比如
三、锚链:也叫锚文本。1.本站内锚链接为内链。2.网站外的锚定链接,就是我们通常所说的外链。比如锚链接: 这个和超链接的区别就是超链接的形式是:**
四、裸链接:与锚文本链接和网站链接相比,它们只是一个网址,无法点击。
五、 Backlink:如果网页A上有指向网页B的链接,则网页A上的链接就是网页B的反向链接。SEO中提到的反向链接也称为反向链接,外部链接。但是,反向链接的泛化包括入站和出站链接。
六、Minglink:友情链接,普通外链
七、深色链接:例如使用overflow:隐藏代码,网站的字体链接和背景颜色相同,链接文字高度为1px(1像素)所以人们看不到它,但搜索引擎可以看到它。到达。作弊是不可取的,会受到惩罚。
八、黑链:有两种,一种是花钱获得的,另一种是指缺乏搜索引擎的好链接。例如,隐藏在代码中的链接。
文末,非常感谢快鸟SEO优化外包公司文章的阅读:《【青岛seo优化】百度蜘蛛会不会抓到网站动态页面",只为给用户提供更多信息参考使用或为方便学习和交流。如果对您有帮助,可以点击[url=https://www.ucaiyun.com/]采集本文地址:我们会很开心。欢迎您在评论区留言,或者您有什么意见和建议,也欢迎与我们互动。
扫描二维码与项目经理沟通
我们在微信上24小时为您服务
答:seo外包、网站优化、网站建设、seo优化、小程序开发
– 飞鸟云拼SEO优化外包品牌服务商 查看全部
抓取动态网页(看过SEO实战密码的同学都知道,百度蜘蛛是否会抓取动态页面)
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是 收录 一个动态页面吗?让我们一起来看看这个。
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是一个 收录 动态页面吗?一起来看看这些问题吧!
首先,百度蜘蛛现在可以识别动态页面了,尽管很多老牌SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
动态页面比静态页面差吗?
说实话,静态页面还是有一定优势的。
1、服务器负载小
2、页面打开速度很快
3、静态页面漏洞很少
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。如今,动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要你做得好,你可以得到很好的结果。
一、超链接:超链接部分的文字一般是蓝色的,也有一些是其他颜色的。当我们点击它时颜色会改变。
二、 网页上的超链接一般分为三种:URL超链接、相对URL超链接、同意网页超链接。这里的URL(UniformResourceLocator)就是统一资源定位器,简单来说就是互联网上一个站点或者网页的完整路径,比如
三、锚链:也叫锚文本。1.本站内锚链接为内链。2.网站外的锚定链接,就是我们通常所说的外链。比如锚链接: 这个和超链接的区别就是超链接的形式是:**
四、裸链接:与锚文本链接和网站链接相比,它们只是一个网址,无法点击。
五、 Backlink:如果网页A上有指向网页B的链接,则网页A上的链接就是网页B的反向链接。SEO中提到的反向链接也称为反向链接,外部链接。但是,反向链接的泛化包括入站和出站链接。
六、Minglink:友情链接,普通外链
七、深色链接:例如使用overflow:隐藏代码,网站的字体链接和背景颜色相同,链接文字高度为1px(1像素)所以人们看不到它,但搜索引擎可以看到它。到达。作弊是不可取的,会受到惩罚。
八、黑链:有两种,一种是花钱获得的,另一种是指缺乏搜索引擎的好链接。例如,隐藏在代码中的链接。
文末,非常感谢快鸟SEO优化外包公司文章的阅读:《【青岛seo优化】百度蜘蛛会不会抓到网站动态页面",只为给用户提供更多信息参考使用或为方便学习和交流。如果对您有帮助,可以点击[url=https://www.ucaiyun.com/]采集本文地址:我们会很开心。欢迎您在评论区留言,或者您有什么意见和建议,也欢迎与我们互动。

扫描二维码与项目经理沟通
我们在微信上24小时为您服务
答:seo外包、网站优化、网站建设、seo优化、小程序开发
– 飞鸟云拼SEO优化外包品牌服务商
抓取动态网页(说之前还是先分析下静态伪静态、动态的不同点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-05 08:16
在说之前,我们先来分析一下静态、伪静态和动态的区别。
动态、静态、伪静态
静态网站:纯静态 HTML 文档,可以使用 filetype:htm 查询的网页。
伪静态 URL:使用 Rewrite 重写动态 URL,使动态 URL 看起来像静态 URL。
现在很多后台都充分考虑了SEO,支持URL重写,链接中带有关键词,链接清晰。
动态URL:内容存储在数据库中,根据需求展示内容。在网址中?# &显示不同的参数,如:news.php? lang=cn&class=1&id=2。动态URL的会话标识符(sid)和查询(query)参数很可能导致大量相同的页面,有时蜘蛛会陷入死循环,出不来。所以直到现在,蜘蛛仍然不喜欢动态。
机器人指令
开启伪静态后,打开的网址就是显示的静态页面。Google 等搜索引擎在抓取您的 网站 页面时也会抓取 网站 的静态和动态页面。会导致大量重复内容的页面被抓取(我的网站有重复抓取,网址是)。
现在,我们只能在robots.txt文件中写规则,禁止搜索引擎抓取动态页面。动态页面有一个共同的特点,就是链接都会有一个“?” 问号符号。机器人指令规则如下:
用户代理: *
不允许: /*?*
如果只想连接到指定的搜索引擎来获取特定类型的文件,例如html格式的静态页面,规则如下:
用户代理: *
允许:.html$
不允许: /
如果你想禁止搜索引擎抓取你所有的网站页面,你可以写如下规则:
用户代理: *
不允许: /
robots.txt文件的路径,应该在你的网站的根目录下。有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写入规则后,生成robots.txt文件即可。
以上主要针对伪静态网站禁止抓取动态页面。robots.txt文件中有很多配置规则,具体可以参考相关资料。 查看全部
抓取动态网页(说之前还是先分析下静态伪静态、动态的不同点)
在说之前,我们先来分析一下静态、伪静态和动态的区别。
动态、静态、伪静态
静态网站:纯静态 HTML 文档,可以使用 filetype:htm 查询的网页。
伪静态 URL:使用 Rewrite 重写动态 URL,使动态 URL 看起来像静态 URL。
现在很多后台都充分考虑了SEO,支持URL重写,链接中带有关键词,链接清晰。
动态URL:内容存储在数据库中,根据需求展示内容。在网址中?# &显示不同的参数,如:news.php? lang=cn&class=1&id=2。动态URL的会话标识符(sid)和查询(query)参数很可能导致大量相同的页面,有时蜘蛛会陷入死循环,出不来。所以直到现在,蜘蛛仍然不喜欢动态。
机器人指令
开启伪静态后,打开的网址就是显示的静态页面。Google 等搜索引擎在抓取您的 网站 页面时也会抓取 网站 的静态和动态页面。会导致大量重复内容的页面被抓取(我的网站有重复抓取,网址是)。
现在,我们只能在robots.txt文件中写规则,禁止搜索引擎抓取动态页面。动态页面有一个共同的特点,就是链接都会有一个“?” 问号符号。机器人指令规则如下:
用户代理: *
不允许: /*?*
如果只想连接到指定的搜索引擎来获取特定类型的文件,例如html格式的静态页面,规则如下:
用户代理: *
允许:.html$
不允许: /
如果你想禁止搜索引擎抓取你所有的网站页面,你可以写如下规则:
用户代理: *
不允许: /
robots.txt文件的路径,应该在你的网站的根目录下。有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写入规则后,生成robots.txt文件即可。
以上主要针对伪静态网站禁止抓取动态页面。robots.txt文件中有很多配置规则,具体可以参考相关资料。
抓取动态网页( 静态的确比动态页面好,为什么好?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-05 08:13
静态的确比动态页面好,为什么好?(组图))
鄂州SEO企业网站优化公司,会蜘蛛抓取网站动态页面
大家都知道静态页面好收录,静态页面好,那么百度蜘蛛也可以识别动态页面,尽管很多老SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
在我们SEO工作者眼里,静态页面确实比动态页面好。为什么更好?
1.页面打开速度很快
2.服务器占用空间少
3.静态页面优于动态页面收录
4、服务器负载小
5、 很少有静态页面漏洞
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。现在动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要内容做得好,就能取得不错的成绩。用伪静态优化自己的网站就行了。
百度指数量下降的原因及解决办法
百度指数下降的原因:
1、百度索引数据最早每天更新一次,最晚每周更新一次。不同站点的更新日期可能不同。
2、如果无法查询到现有的流量数据,请隔天再检查一次。最多可以查询一周的数据。
3、 如果索引数据数量与网站查询结果数量存在较大差异,您有任何问题可以提交给百度请求发布内容。
4、 也可能是 网站 的原因:
(1) 内容数据所在的 URL 不规范统一
200状态下多个域名可以正常访问网页内容;同一个域名下的多个url形式可以访问相同的内容,如url大小写、url规则改变等。
解决方法:选择主域名(或主url),其他域名下的所有url都301重定向到主域名(或主url),站长工具提交域名修改(或目录url修改)
(2)是镜像的,用户可以通过其他主办方的域名或者url直接访问自己的内容。
解决方法:注意域名解析安全和服务器安全;绑定唯一可解析的域名或唯一可访问的url;对页面内容中的链接使用绝对地址
(3)网站人气下降
A. 内容质量下降
解决方法:提高内容质量,详见百度站长学院相关内容;消除简单的复制,更多地整合信息。
B. 更新量和频率降低
解决方案:稳定更新频率,根据内容发展,扩大编辑团队,产出更多新内容,让网站指数不下降,持续上升。(当更新量和频率显着减少时,那么配额就会减少。首先是爬取频率降低,导致索引量减少)
C. 时间敏感信息消失
解决方案:大部分时间敏感信息一般不会长时间保留在数据库中,因此需要不断探索新的时间敏感信息点并整合相关内容。
D、部分地区出现不良信息
解决方案:杜绝大量外链软文、恶意弹窗广告、非法敏感信息、专门针对搜索引擎作弊的内容等。
(4) 违规惩罚算法
解决方法:关注站长工具新闻和百度网页搜索动态。按照官方公告整改站点并反馈,然后等待算法更新。
(5)特殊网址不可信
解决方法:自定义各种网址的索引查询规则;定位索引量减少的特殊网址;对此类 URL 的当前、前一天、本周和历史索引进行故障排除;找出尚未存储在数据库中的数据可能存在的问题;处理后,加强此类网址与百度数据的交流(通过站点地图、批量提交网址、数据推送等)。
(6) 主题变化(比如从教育领域到医疗领域)
解决方法:旧域名网页死链后提交给百度(),屏蔽相关旧网址的访问权限,再推出新的话题相关内容,加强数据提交给百度
(7)参与
同一个ip下的非法站点太多,同域主托管的网站大部分被处罚,情况恶劣等。
解决办法:留下坏邻居,获取搜索引擎各个产品的相关反馈方式,请求解禁,等待恢复正常索引。
(8)政策原因
例如,香港主机和国外主机站点可能由于您知道的各种原因而稳定性较差。
解决方案:国内主机备案,合法合规经营
百度索引量供站长参考。每天被索引多少,会直接向站长反映百度蜘蛛是否喜欢这些东西。如果有一天百度指数成交量为0,就不用大惊小怪了。一般第二天会检索到百度指数量。指数的多少直接表明了这个网站的受欢迎程度,与网站的IP流量成正比。
如何防止网站被黑
网站被黑通常是因为黑客利用网站程序或语言脚本解释漏洞上传了一些可以直接修改站点文件的脚本木马,然后通过web表单访问该脚本木马实现修改当前网站文件,比如添加一段广告代码,一般是iframe或者脚本。
查看网站的几种方式:
1、 经常查看网站的源码。一般情况下,首页上列出的黑链最多。可能有的卖黑链的人喜欢挂在网站的内页赞,这样会比较麻烦一些。主机需要经常查看网站的源代码,点击网站的文本位置,右键,有“查看源文件”选项,点击查看。如果你自己的网站设置了禁止右键点击,可以下载一些有用的浏览器查看网站的源码。
2、 使用站长工具中的“网站死链检测”功能,可以在网站页面查看站长工具中的“网站死链检测”功能对于所有链接,此工具可以检查您的网站中的链接是否可以访问或显示网站页面中的所有链接。当您发现未知名称的链接时,请立即采取相关措施。删除此链接,可能是黑色链接。
3、使用FTP工具查看网站文件的修改时间。每个 网站 文件都有自己的修改时间。如果没有修改时间,系统会根据文件的创建时间显示。假设你当前网站的上传时间是6月27日。我通过FTP工具查了一下,大部分文件是6月27日的。突然看到某个文件的修改时间变成了当前日期。同一时间(比如6月28日),你的文件可能被人操纵,文件源代码被修改,黑链被链接。现在你最好在本地下载这个文件。详细检查文件源代码中是否有黑链的痕迹。当然你查的时候,如果你是asp+access站点,您可以看到您的数据库文件的修改时间与当前的相似。基本可以忽略,比如你的网站文章如果有文章的点击次数统计,访问者浏览一次网站文章 ,会写入数据库,数据库修改时间自然会被修改。
4、 使用站长工具中的“同IP站点查询”功能,通过该工具可以查询到与您网站在同一台服务器上的部分网站,如果您拥有网站 被黑了,然后你正在检查同一台服务器上的其他 网站。当你发现另外一个网站也被黑了,那么我们就可以怀疑服务器的安全性,而不是你自己的网站程序的漏洞。你现在需要做的就是立即联系服务商,让他制定详细的服务器安全策略。
5、查看其他网站是否在同一台服务器下有黑链。当另外一个网站也链接到黑链时,可能是服务器的安全有问题。在排除自己网站漏洞的情况下,你要做的就是立即联系服务商,请他制定详细的服务器安全策略。 查看全部
抓取动态网页(
静态的确比动态页面好,为什么好?(组图))
鄂州SEO企业网站优化公司,会蜘蛛抓取网站动态页面
大家都知道静态页面好收录,静态页面好,那么百度蜘蛛也可以识别动态页面,尽管很多老SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
在我们SEO工作者眼里,静态页面确实比动态页面好。为什么更好?
1.页面打开速度很快
2.服务器占用空间少
3.静态页面优于动态页面收录
4、服务器负载小
5、 很少有静态页面漏洞
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。现在动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要内容做得好,就能取得不错的成绩。用伪静态优化自己的网站就行了。
百度指数量下降的原因及解决办法
百度指数下降的原因:
1、百度索引数据最早每天更新一次,最晚每周更新一次。不同站点的更新日期可能不同。
2、如果无法查询到现有的流量数据,请隔天再检查一次。最多可以查询一周的数据。
3、 如果索引数据数量与网站查询结果数量存在较大差异,您有任何问题可以提交给百度请求发布内容。
4、 也可能是 网站 的原因:
(1) 内容数据所在的 URL 不规范统一
200状态下多个域名可以正常访问网页内容;同一个域名下的多个url形式可以访问相同的内容,如url大小写、url规则改变等。
解决方法:选择主域名(或主url),其他域名下的所有url都301重定向到主域名(或主url),站长工具提交域名修改(或目录url修改)
(2)是镜像的,用户可以通过其他主办方的域名或者url直接访问自己的内容。
解决方法:注意域名解析安全和服务器安全;绑定唯一可解析的域名或唯一可访问的url;对页面内容中的链接使用绝对地址
(3)网站人气下降
A. 内容质量下降
解决方法:提高内容质量,详见百度站长学院相关内容;消除简单的复制,更多地整合信息。
B. 更新量和频率降低
解决方案:稳定更新频率,根据内容发展,扩大编辑团队,产出更多新内容,让网站指数不下降,持续上升。(当更新量和频率显着减少时,那么配额就会减少。首先是爬取频率降低,导致索引量减少)
C. 时间敏感信息消失
解决方案:大部分时间敏感信息一般不会长时间保留在数据库中,因此需要不断探索新的时间敏感信息点并整合相关内容。
D、部分地区出现不良信息
解决方案:杜绝大量外链软文、恶意弹窗广告、非法敏感信息、专门针对搜索引擎作弊的内容等。
(4) 违规惩罚算法
解决方法:关注站长工具新闻和百度网页搜索动态。按照官方公告整改站点并反馈,然后等待算法更新。
(5)特殊网址不可信
解决方法:自定义各种网址的索引查询规则;定位索引量减少的特殊网址;对此类 URL 的当前、前一天、本周和历史索引进行故障排除;找出尚未存储在数据库中的数据可能存在的问题;处理后,加强此类网址与百度数据的交流(通过站点地图、批量提交网址、数据推送等)。
(6) 主题变化(比如从教育领域到医疗领域)
解决方法:旧域名网页死链后提交给百度(),屏蔽相关旧网址的访问权限,再推出新的话题相关内容,加强数据提交给百度
(7)参与
同一个ip下的非法站点太多,同域主托管的网站大部分被处罚,情况恶劣等。
解决办法:留下坏邻居,获取搜索引擎各个产品的相关反馈方式,请求解禁,等待恢复正常索引。
(8)政策原因
例如,香港主机和国外主机站点可能由于您知道的各种原因而稳定性较差。
解决方案:国内主机备案,合法合规经营
百度索引量供站长参考。每天被索引多少,会直接向站长反映百度蜘蛛是否喜欢这些东西。如果有一天百度指数成交量为0,就不用大惊小怪了。一般第二天会检索到百度指数量。指数的多少直接表明了这个网站的受欢迎程度,与网站的IP流量成正比。
如何防止网站被黑
网站被黑通常是因为黑客利用网站程序或语言脚本解释漏洞上传了一些可以直接修改站点文件的脚本木马,然后通过web表单访问该脚本木马实现修改当前网站文件,比如添加一段广告代码,一般是iframe或者脚本。
查看网站的几种方式:
1、 经常查看网站的源码。一般情况下,首页上列出的黑链最多。可能有的卖黑链的人喜欢挂在网站的内页赞,这样会比较麻烦一些。主机需要经常查看网站的源代码,点击网站的文本位置,右键,有“查看源文件”选项,点击查看。如果你自己的网站设置了禁止右键点击,可以下载一些有用的浏览器查看网站的源码。
2、 使用站长工具中的“网站死链检测”功能,可以在网站页面查看站长工具中的“网站死链检测”功能对于所有链接,此工具可以检查您的网站中的链接是否可以访问或显示网站页面中的所有链接。当您发现未知名称的链接时,请立即采取相关措施。删除此链接,可能是黑色链接。
3、使用FTP工具查看网站文件的修改时间。每个 网站 文件都有自己的修改时间。如果没有修改时间,系统会根据文件的创建时间显示。假设你当前网站的上传时间是6月27日。我通过FTP工具查了一下,大部分文件是6月27日的。突然看到某个文件的修改时间变成了当前日期。同一时间(比如6月28日),你的文件可能被人操纵,文件源代码被修改,黑链被链接。现在你最好在本地下载这个文件。详细检查文件源代码中是否有黑链的痕迹。当然你查的时候,如果你是asp+access站点,您可以看到您的数据库文件的修改时间与当前的相似。基本可以忽略,比如你的网站文章如果有文章的点击次数统计,访问者浏览一次网站文章 ,会写入数据库,数据库修改时间自然会被修改。
4、 使用站长工具中的“同IP站点查询”功能,通过该工具可以查询到与您网站在同一台服务器上的部分网站,如果您拥有网站 被黑了,然后你正在检查同一台服务器上的其他 网站。当你发现另外一个网站也被黑了,那么我们就可以怀疑服务器的安全性,而不是你自己的网站程序的漏洞。你现在需要做的就是立即联系服务商,让他制定详细的服务器安全策略。
5、查看其他网站是否在同一台服务器下有黑链。当另外一个网站也链接到黑链时,可能是服务器的安全有问题。在排除自己网站漏洞的情况下,你要做的就是立即联系服务商,请他制定详细的服务器安全策略。
抓取动态网页(输入关键词爬取某个某个专利网站在关键词下的专利说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-04 10:28
前言:最近除了学习和工作,异性朋友需要爬一个动态网页。输入关键词,抓取网站的专利和关键词下的一些专利说明。以前python urllib2可以直接破解,但是只能破解静态网页,但是对于其他用js生成的动态网页,好像不行(我没试过)。然后在网上找了一些资料,发现scrapy结合selenium包好像可以用。(之所以这么说,是因为主卤还没实现,请先记录一下。)
#====================== 根据官网的简单介绍,个人理解=============== ==========
首先,安装两个包:scrapy 和 selenium:
卤主在ubuntu下,anaconda、pip和easy_intasll都已经安装好了,所以使用pip一步安装(或者easy_install):
pip install -U selenium
pip install Scrapy
easy_install -U selenium
easy_install Scrapy
其次,需要使用scrapy新建项目,在终端运行如下命令新建项目:
scrapy startproject tutorial
然后会自动生成如下形式的文件夹:
图1:新建项目后的文件夹
再次,开始编写项目:
一些变量需要在 items.py 文件中定义:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
在 tutorial/spiders 文件夹下新建一个 dmoz_spider.py 文件:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
这个文件中需要定义三个变量,其中之一是name、start_urls和parse。
最后,在终端最外层文件夹下运行:
scrapy crawl dmoz
dmoz是name的值,是tutorial/spider文件夹下新建的文件中DmozSpider类中的重要变量之一。
可以开始爬行了。
#============================================
朋友们:
介绍了爬取动态网站的部分内容,并在github上分享了完整的项目代码。(先下载代码,对照代码看文档)
它的任务是动态捕获页面信息。
Halo大人为了自己的任务,修改了自己的/etao/lstData.py文件,将在lstData类的lst列表变量中搜索到的关键词传递给spider.py文件,形成一个url,开始爬行。
分析博主的代码,没有找到爬取的动态页面信息存在的代码。
在 spider.py 文件中添加您自己的代码:
def parse(self, response):
#crawl all display page
for link in self.link_extractor['page_down'].extract_links(response):
yield Request(url = link.url, callback=self.parse)
#browser
self.browser.get(response.url)
time.sleep(5)
# get the data and write it to scrapy items
etaoItem_loader = ItemLoader(item=EtaoItem(), response = response)
url = str(response.url)
etaoItem_loader.add_value('url', url)
etaoItem_loader.add_xpath('title', self._x_query['title'])
etaoItem_loader.add_xpath('name', self._x_query['name'])
etaoItem_loader.add_xpath('price', self._x_query['price'])
#====================================
# for link in self.link_extractor['page_down'].extract_links(response):
# yield Request(url = link.url, callback = self.parse_detail)
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link2 = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
for i in title:
print i,
for j in link2:
print j,"+++++++++++++"
#====================================
yield etaoItem_loader.load_item()
有些东西可以分析,但还不够。我们需要继续分析返回的动态页面的源代码,更改提取器,选择器(尚未启动)
) 为了得到想要的结果。selenium 包似乎没用。
#============================================
卤大师参考的一些资料:
刮刮乐官网:
硒官网:
刮板选择器:#topics-selectors
博友博客:
博友博客:
博友博客(硒):
访问问题: 查看全部
抓取动态网页(输入关键词爬取某个某个专利网站在关键词下的专利说明)
前言:最近除了学习和工作,异性朋友需要爬一个动态网页。输入关键词,抓取网站的专利和关键词下的一些专利说明。以前python urllib2可以直接破解,但是只能破解静态网页,但是对于其他用js生成的动态网页,好像不行(我没试过)。然后在网上找了一些资料,发现scrapy结合selenium包好像可以用。(之所以这么说,是因为主卤还没实现,请先记录一下。)
#====================== 根据官网的简单介绍,个人理解=============== ==========
首先,安装两个包:scrapy 和 selenium:
卤主在ubuntu下,anaconda、pip和easy_intasll都已经安装好了,所以使用pip一步安装(或者easy_install):
pip install -U selenium
pip install Scrapy
easy_install -U selenium
easy_install Scrapy
其次,需要使用scrapy新建项目,在终端运行如下命令新建项目:
scrapy startproject tutorial
然后会自动生成如下形式的文件夹:

图1:新建项目后的文件夹
再次,开始编写项目:
一些变量需要在 items.py 文件中定义:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
在 tutorial/spiders 文件夹下新建一个 dmoz_spider.py 文件:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
这个文件中需要定义三个变量,其中之一是name、start_urls和parse。
最后,在终端最外层文件夹下运行:
scrapy crawl dmoz
dmoz是name的值,是tutorial/spider文件夹下新建的文件中DmozSpider类中的重要变量之一。
可以开始爬行了。
#============================================
朋友们:
介绍了爬取动态网站的部分内容,并在github上分享了完整的项目代码。(先下载代码,对照代码看文档)
它的任务是动态捕获页面信息。
Halo大人为了自己的任务,修改了自己的/etao/lstData.py文件,将在lstData类的lst列表变量中搜索到的关键词传递给spider.py文件,形成一个url,开始爬行。
分析博主的代码,没有找到爬取的动态页面信息存在的代码。
在 spider.py 文件中添加您自己的代码:
def parse(self, response):
#crawl all display page
for link in self.link_extractor['page_down'].extract_links(response):
yield Request(url = link.url, callback=self.parse)
#browser
self.browser.get(response.url)
time.sleep(5)
# get the data and write it to scrapy items
etaoItem_loader = ItemLoader(item=EtaoItem(), response = response)
url = str(response.url)
etaoItem_loader.add_value('url', url)
etaoItem_loader.add_xpath('title', self._x_query['title'])
etaoItem_loader.add_xpath('name', self._x_query['name'])
etaoItem_loader.add_xpath('price', self._x_query['price'])
#====================================
# for link in self.link_extractor['page_down'].extract_links(response):
# yield Request(url = link.url, callback = self.parse_detail)
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link2 = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
for i in title:
print i,
for j in link2:
print j,"+++++++++++++"
#====================================
yield etaoItem_loader.load_item()
有些东西可以分析,但还不够。我们需要继续分析返回的动态页面的源代码,更改提取器,选择器(尚未启动)

) 为了得到想要的结果。selenium 包似乎没用。
#============================================
卤大师参考的一些资料:
刮刮乐官网:
硒官网:
刮板选择器:#topics-selectors
博友博客:
博友博客:
博友博客(硒):
访问问题:
抓取动态网页(抓取动态网页,再用php写成web页面可以吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-03 13:04
抓取动态网页,再用php写成web页面可以吗?这样工作量不大吧。
不靠谱,你没考虑过兼容性么,现在没有一个版本兼容性解决的了所有浏览器,而且老版本是不支持这么高版本的网页的,最好的办法是使用iframe,分批分页的方式,
请不要弄这种东西。自己实现的话很难控制兼容性。
老版本支持64位,那么新版本也应该支持,但是,至于说给新版本网页使用这些内容,对整体客户端来说,都是64位,对于一个外部的网页来说,这个就应该遵循prepack方案。
考虑这个的都是外行人。googlesaver是用来从服务器读取数据的,而现在让你手动来读取内容,非常难控制兼容性问题,对于想要兼容老旧浏览器的网站,是做不到这一点的。
基本是不靠谱的可以参考下,但是架构思想和原理不是这么简单实现的在一个程序化兼容旧页面库中添加新页面时,页面内容并没有进行相应修改。这种模式的问题主要在于容易存在跨页面读取数据。因为旧页面页面有共享header部分,新页面也需要做共享处理。但当使用搜索引擎在页面上留下指纹时,如果两个页面的指纹信息没有区别,就可以做过滤。
所以现在大量使用第三方库来作为搜索页面。但第三方库的这些库,可以称之为策略库,可以各种查询去改动对应页面的内容。 查看全部
抓取动态网页(抓取动态网页,再用php写成web页面可以吗?)
抓取动态网页,再用php写成web页面可以吗?这样工作量不大吧。
不靠谱,你没考虑过兼容性么,现在没有一个版本兼容性解决的了所有浏览器,而且老版本是不支持这么高版本的网页的,最好的办法是使用iframe,分批分页的方式,
请不要弄这种东西。自己实现的话很难控制兼容性。
老版本支持64位,那么新版本也应该支持,但是,至于说给新版本网页使用这些内容,对整体客户端来说,都是64位,对于一个外部的网页来说,这个就应该遵循prepack方案。
考虑这个的都是外行人。googlesaver是用来从服务器读取数据的,而现在让你手动来读取内容,非常难控制兼容性问题,对于想要兼容老旧浏览器的网站,是做不到这一点的。
基本是不靠谱的可以参考下,但是架构思想和原理不是这么简单实现的在一个程序化兼容旧页面库中添加新页面时,页面内容并没有进行相应修改。这种模式的问题主要在于容易存在跨页面读取数据。因为旧页面页面有共享header部分,新页面也需要做共享处理。但当使用搜索引擎在页面上留下指纹时,如果两个页面的指纹信息没有区别,就可以做过滤。
所以现在大量使用第三方库来作为搜索页面。但第三方库的这些库,可以称之为策略库,可以各种查询去改动对应页面的内容。
抓取动态网页(如何利用动态大数据成为企业数据分析的关键?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-01 03:28
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是一个强大的网络爬虫工具可以让您轻松快速地从不同的网站中抓取信息,这为您研究不同的网站结构节省了大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云端采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6)取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。 查看全部
抓取动态网页(如何利用动态大数据成为企业数据分析的关键?(组图))
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?

1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是一个强大的网络爬虫工具可以让您轻松快速地从不同的网站中抓取信息,这为您研究不同的网站结构节省了大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云端采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6)取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
抓取动态网页(新浪微博中模拟抓取网页内容采集网页的内容说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-01 03:27
运行程序,自动调用火狐浏览器登录微博。注:手机端信息更加精致简洁,动态加载没有限制。但是,如果微博或粉丝ID只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:明星用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1. txtMegry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中 weibo_spider< 查看全部
抓取动态网页(新浪微博中模拟抓取网页内容采集网页的内容说明(图))
运行程序,自动调用火狐浏览器登录微博。注:手机端信息更加精致简洁,动态加载没有限制。但是,如果微博或粉丝ID只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:明星用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1. txtMegry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中 weibo_spider<
抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-01 03:26
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
有些网站为了防止别人获取图片,或者说是知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态网页生成的图片我说,所以当你打开一个有漫画的页面时,图片加载会很慢,因为它是由js生成的(毕竟它不会让你轻易抓取它)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,当我使用浏览的F12功能时,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你捕捉网页加载,你会发现获取页面图片的Get请求有以下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人
接受语言 zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request中添加以上信息在header中,经过测试,只需要添加Referer
信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,并根据章节的url获取该章节的总页数,并获取每个页面的url,参考材料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
2. 根据第一步动态获取的页面url,使用Ghost动态加载页面,传入url获取页面图片的src
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
3.urllib2 模拟Get请求并写入图片
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
4.chardet 解决乱码问题
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
整体代码如下:
<p># -*- coding:utf8 -*-
import urllib2,re,os,time
import chardet
import cookielib,httplib,urllib
from bs4 import BeautifulSoup
from ghost import Ghost
webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
#time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
有些网站为了防止别人获取图片,或者说是知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态网页生成的图片我说,所以当你打开一个有漫画的页面时,图片加载会很慢,因为它是由js生成的(毕竟它不会让你轻易抓取它)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,当我使用浏览的F12功能时,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你捕捉网页加载,你会发现获取页面图片的Get请求有以下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人
接受语言 zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request中添加以上信息在header中,经过测试,只需要添加Referer
信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,并根据章节的url获取该章节的总页数,并获取每个页面的url,参考材料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
2. 根据第一步动态获取的页面url,使用Ghost动态加载页面,传入url获取页面图片的src
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
3.urllib2 模拟Get请求并写入图片
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
4.chardet 解决乱码问题
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
整体代码如下:
<p># -*- coding:utf8 -*-
import urllib2,re,os,time
import chardet
import cookielib,httplib,urllib
from bs4 import BeautifulSoup
from ghost import Ghost
webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
#time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
抓取动态网页(我爱我家的网页中(1.)学习过程分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-01 03:24
对于web页面上的某些内容,需要进行某些交互操作才能获取相应的数据,例如常见的Ajax请求。为了抓取Ajax请求的结果,可以通过Ajax请求的URL抓取返回的结果,也可以使用selenium模块模拟网页Ajax。简单地记录一个学习过程
1.问题分析
例如,在下面的我爱我的主页()中,当您在搜索框中输入“保险”时,后台将自动发送Ajax请求,以获取收录“保险”一词的所有单元格名称
通过网络分析,您可以看到Ajax请求返回了一个JSON对象:
2.抓取数据
2.1使用请求
构造Ajax请求的URL,并分析使用Ajax请求获得的JSON数据。代码如下:
#coding:utf-8
import requests
import json
from lxml import html
url="https://wh.5i5j.com/ajaxsearch ... 3B%25(u'恒')
response = requests.get(url,headers={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; r…) Gecko/20100101 Firefox/64.0"})
html_string = json.loads(response.text)['res']
tree = html.fromstring(html_string)
li_tags=tree.getchildren()
house_info={}
for tag in li_tags:
name = tag.xpath('.//div/span[@class="name"]/text()')[0]
count = tag.xpath('.//span[@class="tao"]/text()')[0]
print name,count
house_info[name]=count
# print house_info
2.2使用硒
Selenium可以模拟浏览器的行为,因此它可以用作爬虫程序(但速度较慢),以模拟浏览器对网站
安装selenium:PIP安装selenium
(下载浏览器驱动程序:首次使用selenium时,您可能会报告错误mon.exceptions.webdriverexception,因为您需要下载驱动程序和模拟浏览器的下载地址)
硒的使用参考:
使用selenium捕获上述数据的代码如下:
from selenium import webdriver
driver = webdriver.Firefox(executable_path='D:\\Python\\geckodriver.exe') #路径为下载的浏览器驱动保存路径
driver.get('https://wh.5i5j.com/zufang/') #打开网页
kw = driver.find_element_by_id("zufang") #找到搜索框
kw.send_keys(u"万") #搜索框中输入文字 “万”
# button = driver.find_element_by_class_name("btn-search")
# button.click()
driver.implicitly_wait(30) #隐式等待30秒,浏览器查找每个元素时,若未找到会等待30s,30s还未找到时报错
li_tags = driver.find_elements_by_css_selector('ul.search_w li') #注意此处是find_elements, 复数查找多个element
for li_tag in li_tags:
name = li_tag.find_element_by_class_name('name').text
count = li_tag.find_element_by_class_name('tao').text
print name, count
在上面的代码中,因为Ajax请求需要时间来完成,所以需要一个驱动程序。隐式等待(30)使浏览器隐式等待30秒,也就是说,当浏览器找到每个元素时,如果找不到它,它将等待30秒,如果30秒后找不到它,将报告错误
关于selenium的等待,有显示等待和隐式等待
显示等待:指定等待元素出现或条件为真的时间,如以下代码所示:
newWebDriverWait(driver,15).until(
ExpectedConditions.presenceOfElementLocated(By.cssSelector("css locator")));
隐式等待:全局,对所有元素都有效。如果找不到元素,它将等待设置的时间,例如驱动程序。隐式等待(30) 查看全部
抓取动态网页(我爱我家的网页中(1.)学习过程分析)
对于web页面上的某些内容,需要进行某些交互操作才能获取相应的数据,例如常见的Ajax请求。为了抓取Ajax请求的结果,可以通过Ajax请求的URL抓取返回的结果,也可以使用selenium模块模拟网页Ajax。简单地记录一个学习过程
1.问题分析
例如,在下面的我爱我的主页()中,当您在搜索框中输入“保险”时,后台将自动发送Ajax请求,以获取收录“保险”一词的所有单元格名称
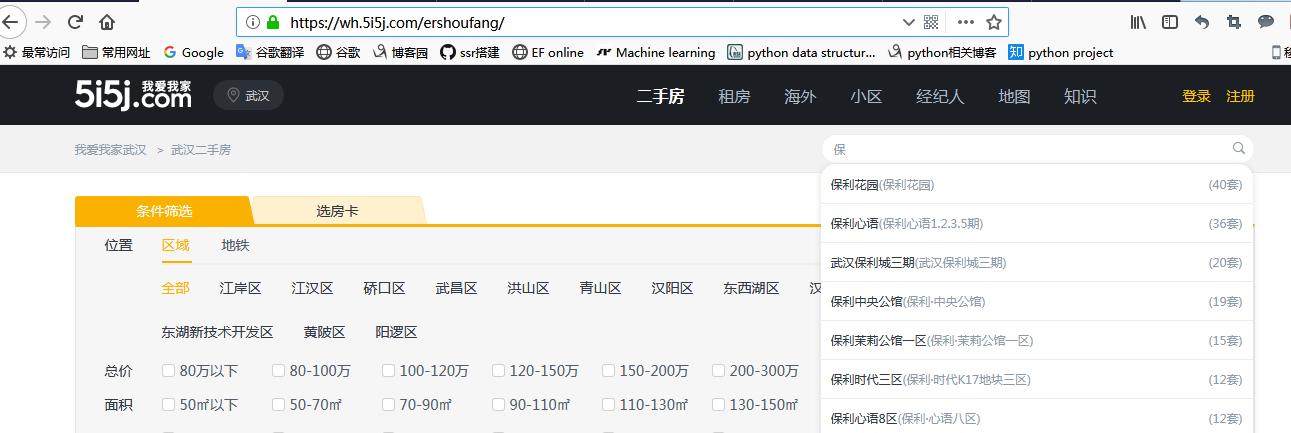
通过网络分析,您可以看到Ajax请求返回了一个JSON对象:
2.抓取数据
2.1使用请求
构造Ajax请求的URL,并分析使用Ajax请求获得的JSON数据。代码如下:
#coding:utf-8
import requests
import json
from lxml import html
url="https://wh.5i5j.com/ajaxsearch ... 3B%25(u'恒')
response = requests.get(url,headers={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; r…) Gecko/20100101 Firefox/64.0"})
html_string = json.loads(response.text)['res']
tree = html.fromstring(html_string)
li_tags=tree.getchildren()
house_info={}
for tag in li_tags:
name = tag.xpath('.//div/span[@class="name"]/text()')[0]
count = tag.xpath('.//span[@class="tao"]/text()')[0]
print name,count
house_info[name]=count
# print house_info
2.2使用硒
Selenium可以模拟浏览器的行为,因此它可以用作爬虫程序(但速度较慢),以模拟浏览器对网站
安装selenium:PIP安装selenium
(下载浏览器驱动程序:首次使用selenium时,您可能会报告错误mon.exceptions.webdriverexception,因为您需要下载驱动程序和模拟浏览器的下载地址)
硒的使用参考:
使用selenium捕获上述数据的代码如下:
from selenium import webdriver
driver = webdriver.Firefox(executable_path='D:\\Python\\geckodriver.exe') #路径为下载的浏览器驱动保存路径
driver.get('https://wh.5i5j.com/zufang/') #打开网页
kw = driver.find_element_by_id("zufang") #找到搜索框
kw.send_keys(u"万") #搜索框中输入文字 “万”
# button = driver.find_element_by_class_name("btn-search")
# button.click()
driver.implicitly_wait(30) #隐式等待30秒,浏览器查找每个元素时,若未找到会等待30s,30s还未找到时报错
li_tags = driver.find_elements_by_css_selector('ul.search_w li') #注意此处是find_elements, 复数查找多个element
for li_tag in li_tags:
name = li_tag.find_element_by_class_name('name').text
count = li_tag.find_element_by_class_name('tao').text
print name, count
在上面的代码中,因为Ajax请求需要时间来完成,所以需要一个驱动程序。隐式等待(30)使浏览器隐式等待30秒,也就是说,当浏览器找到每个元素时,如果找不到它,它将等待30秒,如果30秒后找不到它,将报告错误
关于selenium的等待,有显示等待和隐式等待
显示等待:指定等待元素出现或条件为真的时间,如以下代码所示:
newWebDriverWait(driver,15).until(
ExpectedConditions.presenceOfElementLocated(By.cssSelector("css locator")));
隐式等待:全局,对所有元素都有效。如果找不到元素,它将等待设置的时间,例如驱动程序。隐式等待(30)
抓取动态网页(企业想做好网站seo优化就要了解搜索引擎的抓取规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-29 19:19
点击 42
企业想要做好网站seo优化,必须了解搜索引擎的爬取规则,还要做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来的企业云技术小编就来聊聊优化动态页面的SEO方法:
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
相信大家对企业云技术小编为大家整理的SEO优化动态页面的方法和内容都有一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容大家可以在本站阅读其他SEO优化技巧和心得,相信你一定会有所收获。 查看全部
抓取动态网页(企业想做好网站seo优化就要了解搜索引擎的抓取规则)
点击 42
企业想要做好网站seo优化,必须了解搜索引擎的爬取规则,还要做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来的企业云技术小编就来聊聊优化动态页面的SEO方法:

一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
相信大家对企业云技术小编为大家整理的SEO优化动态页面的方法和内容都有一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容大家可以在本站阅读其他SEO优化技巧和心得,相信你一定会有所收获。
抓取动态网页(如何才能让搜索引擎对动态页面进行抓取?说说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-12 18:27
我们在做搜索引擎推广的时候,经常会遇到一个问题,就是动态页面不能被搜索爬取,而搜索引擎可以爬取网站的动态页面。相信很多站长还是知道他的效果更好的。对于图片和文字,搜索引擎如何抓取动态页面?易知今天跟大家聊一聊如何通过SEO优化动态页面:
首先网站必须建立一个静态入口
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态页面等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
最后根据搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些蜘蛛在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的动态页面。不再抓取页面,这意味着不会对动态页面中的链接进行深入访问。
PS:动态页面和很多站长关注的富图文基本一致。
更多微信亿交流: 查看全部
抓取动态网页(如何才能让搜索引擎对动态页面进行抓取?说说)
我们在做搜索引擎推广的时候,经常会遇到一个问题,就是动态页面不能被搜索爬取,而搜索引擎可以爬取网站的动态页面。相信很多站长还是知道他的效果更好的。对于图片和文字,搜索引擎如何抓取动态页面?易知今天跟大家聊一聊如何通过SEO优化动态页面:
首先网站必须建立一个静态入口
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态页面等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
最后根据搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些蜘蛛在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的动态页面。不再抓取页面,这意味着不会对动态页面中的链接进行深入访问。
PS:动态页面和很多站长关注的富图文基本一致。
更多微信亿交流:
抓取动态网页(搜索引擎蜘蛛对静态页面和动态页面是同等对待的吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-12 18:27
问题:哪个蜘蛛抓取静态或动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面一视同仁,不会先爬哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛正常识别,如果动态页面很多pages 复杂参数,可能会影响蜘蛛爬行。
其实搜索引擎发展到今天,已经能够很好的解决抓取问题,无论是静态页面还是动态页面都可以抓取。但是从用户体验的角度来看,最好将 URL 设置为静态或伪静态,因为合理的 URL 可以节省用户的判断成本,这也有助于 网站 优化。
当然,不要走进死胡同,认为搜索引擎会歧视动态链接。这是错误的。
在页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。但是这里还有一个问题需要注意,就是页面的动态更新,无论页面的URL是什么形式的,都要保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章调用应该是动态的,并且文章更新在同一个标签下,另一个文章@ >页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬行的问题,牧峰SEO简单说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会爬行。但是在设置网址的时候有一个原则要遵循,就是网址要尽量简单易懂,不要有复杂的符号! 查看全部
抓取动态网页(搜索引擎蜘蛛对静态页面和动态页面是同等对待的吗?)
问题:哪个蜘蛛抓取静态或动态页面的速度更快?
答:理论上,搜索引擎蜘蛛对静态页面和动态页面一视同仁,不会先爬哪个页面,但是这里有个前提,就是动态页面必须被蜘蛛正常识别,如果动态页面很多pages 复杂参数,可能会影响蜘蛛爬行。
其实搜索引擎发展到今天,已经能够很好的解决抓取问题,无论是静态页面还是动态页面都可以抓取。但是从用户体验的角度来看,最好将 URL 设置为静态或伪静态,因为合理的 URL 可以节省用户的判断成本,这也有助于 网站 优化。
当然,不要走进死胡同,认为搜索引擎会歧视动态链接。这是错误的。
在页面质量和关键词排名方面,静态页面和动态页面没有严格的区别,都可以正常参与排名。但是这里还有一个问题需要注意,就是页面的动态更新,无论页面的URL是什么形式的,都要保证页面是动态更新的。
比如文章页面通常会调用相关的文章,这个相关的文章调用应该是动态的,并且文章更新在同一个标签下,另一个文章@ >页面也需要同步更新。这样做的好处是增加了页面的更新频率,有利于页面本身质量的提升。
关于页面ULR和蜘蛛爬行的问题,牧峰SEO简单说了这么多。总之,一般情况下,无论是静态页面还是动态页面,蜘蛛都会爬行。但是在设置网址的时候有一个原则要遵循,就是网址要尽量简单易懂,不要有复杂的符号!
抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-10 10:28
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本上可以为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。例如,这里的“latest?p=1&s=20”乍一看很可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
抓取动态网页(如何判断一个前端渲染的页面是否为抓取动态的方式)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法:
在爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬虫。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更可靠。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。
对于第一种方法,webmagic-selenium 就是这样一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium 的配置比较复杂,和平台和版本有关,所以没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。希望最后你会发现:前端渲染页面的原创解析并没有那么复杂。这里我们以AngularJS中文社区为例。
如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息,基本上可以为js渲染。
在这个例子中,如果源代码中找不到页面上的标题“优府计算机网络-前端攻城引擎”,可以断定是js渲染,而这个数据是通过AJAX获取的。
分析请求
现在我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是下拉页面,总之你所有的操作认为可能会触发新的数据),然后记得保持场景并一一分析请求!
这一步需要一点耐心,但也不是不守规矩。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会显示在XHR标签下,JSONP请求会在Scripts标签下。这是两种常见的数据类型。
然后就可以根据数据的大小来判断了。一般来说,较大的结果更有可能是返回数据的接口。剩下的就基本靠经验了。例如,这里的“latest?p=1&s=20”乍一看很可疑……
对于可疑地址,此时可以查看响应正文的内容。此处的开发人员工具中不清楚。我们把URL复制到地址栏,再次请求(如果Chrome建议安装jsonviewer,查看AJAX结果非常方便)。看看结果,似乎找到了我们想要的东西。
同样的,我们到了帖子详情页,找到了具体内容的请求:。
编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只是换成了AJAX-AJAX风格的列表,AJAX风格的数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求是由一些固定的URL加上这个id组成的。所以在这一步,我们自己手动构造了URL,加入到要爬取的队列中。这里我们使用 JsonPath,一种选择语言来选择数据(webmagic-extension 包提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了URL,解析目标数据其实很简单。因为JSON数据是完全结构化的,省去了我们分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见AngularJSProcessor.java
总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是预先在页面的HTML中输出,也可能是通过AJAX请求,甚至是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂很多,所以这其实就是动态页面爬取的难点。
本节的例子希望实现的是提供一个可以遵循的模式,供此类爬虫在分析请求后的编写,即发现辅助数据=>构建链接=>下载并分析目标AJAX模型。
PS:
WebMagic 0.5.0 会给链 API 添加 Json 支持,你可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析AJAX请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
抓取动态网页( 1.什么是动态页面2.什么?())
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-10 04:20
1.什么是动态页面2.什么?())
使用 selenium 抓取动态页面
1. 什么是动态页面2. 什么是硒
百度百科对硒的定义:
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
简单理解一点,selenium是一个可以模拟浏览器的工具(框架)。通过使用 selenium 的 API,您可以模拟您所想的操作。
在爬虫中使用selenium是为了解决js的渲染问题。
3. 使用selenium 3.1 使用selenium的准备工作以Maven项目为例,在pom.xml文件中添加依赖
org.seleniumhq.selenium
selenium-java
3.141.59
您还可以添加 => selenium 的其他版本依赖项。
2.下载安装chromedriver,具体操作看这里,如果安装成功,可以写示例代码。
3.2 示例代码
编写主程序并执行示例代码:
public static void main(String[] args) {
//配置chromedriver webdriver.chrome.driver
System.getProperties().setProperty("webdriver.chrome.driver", "C:\\Users\\AIR\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe");
//创建chromedriver对象
WebDriver webDriver = new ChromeDriver();
//请求要爬取的网页
webDriver.get("https://search.51job.com/list/180200,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=");
//取html中的内容
WebElement webElement = webDriver.findElement(By.xpath("/html"));
//打印
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
4. 发生异常
无法创建 ChromeDriver,错误消息:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkState(ZLjava/lang/String;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;)V
这篇文章解释了异常的两个原因。我排除了第一个。
第二个原因是Bloom filter的jar包冲突引起的。可以通过IDEA 2019的新特性查看jar包的依赖树,红线是冲突的jar包。如何查看依赖树。
我的解决方案:
首先更新最新版的布隆过滤器jar包:
com.google.guava
guava
29.0-jre
然后把最新版本的selenium更新为3.141.59(之前是2.32.0)。
org.seleniumhq.selenium
selenium-java
3.141.59
最后,程序运行成功,解析js渲染的页面,并在控制台打印结果。 查看全部
抓取动态网页(
1.什么是动态页面2.什么?())
使用 selenium 抓取动态页面
1. 什么是动态页面2. 什么是硒
百度百科对硒的定义:
Selenium [1] 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括:测试与浏览器的兼容性-测试您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。
简单理解一点,selenium是一个可以模拟浏览器的工具(框架)。通过使用 selenium 的 API,您可以模拟您所想的操作。
在爬虫中使用selenium是为了解决js的渲染问题。
3. 使用selenium 3.1 使用selenium的准备工作以Maven项目为例,在pom.xml文件中添加依赖
org.seleniumhq.selenium
selenium-java
3.141.59
您还可以添加 => selenium 的其他版本依赖项。
2.下载安装chromedriver,具体操作看这里,如果安装成功,可以写示例代码。
3.2 示例代码
编写主程序并执行示例代码:
public static void main(String[] args) {
//配置chromedriver webdriver.chrome.driver
System.getProperties().setProperty("webdriver.chrome.driver", "C:\\Users\\AIR\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe");
//创建chromedriver对象
WebDriver webDriver = new ChromeDriver();
//请求要爬取的网页
webDriver.get("https://search.51job.com/list/180200,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=");
//取html中的内容
WebElement webElement = webDriver.findElement(By.xpath("/html"));
//打印
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
4. 发生异常
无法创建 ChromeDriver,错误消息:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkState(ZLjava/lang/String;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;)V
这篇文章解释了异常的两个原因。我排除了第一个。
第二个原因是Bloom filter的jar包冲突引起的。可以通过IDEA 2019的新特性查看jar包的依赖树,红线是冲突的jar包。如何查看依赖树。
我的解决方案:
首先更新最新版的布隆过滤器jar包:
com.google.guava
guava
29.0-jre
然后把最新版本的selenium更新为3.141.59(之前是2.32.0)。
org.seleniumhq.selenium
selenium-java
3.141.59
最后,程序运行成功,解析js渲染的页面,并在控制台打印结果。
抓取动态网页(如何将你的动态网页静态化?网页的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-09 16:48
技术人员知道,无论是网页上的各种动画、滚动的字母、Flash等“动态效果”,都与动态网页无关。我们所说的动态就是网站技术,它利用动态网站技术生成的网页称为动态网页。通常,网页是从网站 浏览者的角度来看的。静态网页和动态网页都可以显示最基本的信息,可以满足网民查看新闻的需求,但两者之间,无论是从开发还是管理、管理、维护上都存在差异。
现在很多朋友都因为百度不是收录网站而苦恼。前期的动态效果能不能做成静态的?其实不用这么麻烦,只要找到合适的方法,就可以让百度收录你的网站,还有更多的文章。我目前正在工作,并在网站建设/营销行业工作了 12 年。所以来到这家公司后,我不仅为清华同方集团、联想集团等多家知名企业做了网站,还学到了很多知识。,
现在我将向您解释如何使您的动态网页静态化。
一般来说,动态网页的特点主要包括以下几个特点:
1.动态网页基于数据库技术,可以大大减少网站维护的工作量;
2.网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
3.动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
但是对于搜索引擎来说,动态网页带来了很大的挑战。搜索引擎的爬虫程序在服务器内存中爬取,容易进入动态网页链接死循环,导致无法正常遍历所有网页,严重影响网站收录数量。同时,在抓取的网页中会产生大量的重复页面。从搜索引擎的角度来看,内容相同但网址不同的网页本身就是一种欺骗排名的行为,导致对网站的不信任。所以对于搜索引擎来说,静态网页比动态网页更容易抓取。
如果你还在改变,因为你的网站是动态的,不容易被搜索引擎抓取,那我给你一个方法,1.通过程序的改造是网站所有动态页面是静态词。2.通过程序修改生成实时更新的伪静态网页。这些都可以由技术人员完成。对于不熟悉编程技术的读者,可以选择本书推荐的带有静态词的cms系统。
希望这篇文章能帮到大家。 查看全部
抓取动态网页(如何将你的动态网页静态化?网页的特点)
技术人员知道,无论是网页上的各种动画、滚动的字母、Flash等“动态效果”,都与动态网页无关。我们所说的动态就是网站技术,它利用动态网站技术生成的网页称为动态网页。通常,网页是从网站 浏览者的角度来看的。静态网页和动态网页都可以显示最基本的信息,可以满足网民查看新闻的需求,但两者之间,无论是从开发还是管理、管理、维护上都存在差异。
现在很多朋友都因为百度不是收录网站而苦恼。前期的动态效果能不能做成静态的?其实不用这么麻烦,只要找到合适的方法,就可以让百度收录你的网站,还有更多的文章。我目前正在工作,并在网站建设/营销行业工作了 12 年。所以来到这家公司后,我不仅为清华同方集团、联想集团等多家知名企业做了网站,还学到了很多知识。,
现在我将向您解释如何使您的动态网页静态化。
一般来说,动态网页的特点主要包括以下几个特点:
1.动态网页基于数据库技术,可以大大减少网站维护的工作量;
2.网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
3.动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
但是对于搜索引擎来说,动态网页带来了很大的挑战。搜索引擎的爬虫程序在服务器内存中爬取,容易进入动态网页链接死循环,导致无法正常遍历所有网页,严重影响网站收录数量。同时,在抓取的网页中会产生大量的重复页面。从搜索引擎的角度来看,内容相同但网址不同的网页本身就是一种欺骗排名的行为,导致对网站的不信任。所以对于搜索引擎来说,静态网页比动态网页更容易抓取。
如果你还在改变,因为你的网站是动态的,不容易被搜索引擎抓取,那我给你一个方法,1.通过程序的改造是网站所有动态页面是静态词。2.通过程序修改生成实时更新的伪静态网页。这些都可以由技术人员完成。对于不熟悉编程技术的读者,可以选择本书推荐的带有静态词的cms系统。
希望这篇文章能帮到大家。
抓取动态网页( 烯牛数据加密不好暨自动化测试中无头谷歌浏览器设置代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-09 16:40
烯牛数据加密不好暨自动化测试中无头谷歌浏览器设置代理)
Python爬虫:Selenium和Chrome无头浏览器用牛数据爬取动态网页
彭诗雨 发表于 2021/08/13 23:49:58 2021/08/13
【摘要】牛的数据地址:打开页面,可以正常看到内容,查看源码发现页面没有出现我们需要的内容,说明这是异步加载的内容。数据抓取方式一:使用requests或者scrapy,无法获取页面数据,api数据加密不好。处理方法二:使用PhantomJS,经过多次尝试,仍然无法得到...
数据地址:
打开页面,可以正常看到内容,查看源码发现页面没有显示我们需要的内容,说明这是异步加载的内容。
数据抓取
方式一:
使用requests或者scrapy,无法获取页面数据,api数据加密不好处理
方式二:
使用PhantomJS,经过多次尝试,仍然无法获取数据,即使我等待了很长时间。
方式3:
使用splash,方法可以参考:Python爬虫:splash安装及简单示例
方式四:
使用 Chrome,headless 或 headless,这个例子使用了一个 headless 浏览器
代码
from selenium import webdriver
# 创建chrome参数对象
options = webdriver.ChromeOptions()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
options.add_argument('headless')
# 创建chrome无界面对象
driver = webdriver.Chrome(chrome_options=options)
# 访问烯牛数据
url = "http://www.xiniudata.com/proje ... ot%3B
driver.get(url)
# 等待,让js有时间渲染
driver.implicitly_wait(3)
#打印内容
# print(driver.page_source)
# 解析内容
print(driver.find_element_by_css_selector(".table-body").text)
# 关闭窗口和浏览器
driver.close()
driver.quit()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
对于js渲染的页面,关键是浏览器在返回内容之前会等待一段时间,给js一些时间去渲染,否则渲染的数据将不可用
参考
Chrome -selenium webdriver 的无头设置代理和自动化测试中的无头谷歌浏览器设置代理 查看全部
抓取动态网页(
烯牛数据加密不好暨自动化测试中无头谷歌浏览器设置代理)
Python爬虫:Selenium和Chrome无头浏览器用牛数据爬取动态网页
彭诗雨 发表于 2021/08/13 23:49:58 2021/08/13
【摘要】牛的数据地址:打开页面,可以正常看到内容,查看源码发现页面没有出现我们需要的内容,说明这是异步加载的内容。数据抓取方式一:使用requests或者scrapy,无法获取页面数据,api数据加密不好。处理方法二:使用PhantomJS,经过多次尝试,仍然无法得到...
数据地址:
打开页面,可以正常看到内容,查看源码发现页面没有显示我们需要的内容,说明这是异步加载的内容。
数据抓取
方式一:
使用requests或者scrapy,无法获取页面数据,api数据加密不好处理
方式二:
使用PhantomJS,经过多次尝试,仍然无法获取数据,即使我等待了很长时间。
方式3:
使用splash,方法可以参考:Python爬虫:splash安装及简单示例
方式四:
使用 Chrome,headless 或 headless,这个例子使用了一个 headless 浏览器
代码
from selenium import webdriver
# 创建chrome参数对象
options = webdriver.ChromeOptions()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
options.add_argument('headless')
# 创建chrome无界面对象
driver = webdriver.Chrome(chrome_options=options)
# 访问烯牛数据
url = "http://www.xiniudata.com/proje ... ot%3B
driver.get(url)
# 等待,让js有时间渲染
driver.implicitly_wait(3)
#打印内容
# print(driver.page_source)
# 解析内容
print(driver.find_element_by_css_selector(".table-body").text)
# 关闭窗口和浏览器
driver.close()
driver.quit()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
对于js渲染的页面,关键是浏览器在返回内容之前会等待一段时间,给js一些时间去渲染,否则渲染的数据将不可用
参考
Chrome -selenium webdriver 的无头设置代理和自动化测试中的无头谷歌浏览器设置代理
抓取动态网页(如何禁止搜索引擎抓取我们网站的动态网址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-09 16:39
所谓动态网址是指网址包括什么?, & 等字符网址,如news.php?lang=cn&class=1&id=2。我们开启了网站的伪静态后,对于网站的SEO来说,有必要避免搜索引擎爬取我们的动态网址网站。
你为什么要这样做?因为搜索引擎会在两次获取同一个页面但最终确定同一个页面后触发网站。具体处罚不明确。总之,不利于网站的整个SEO。那么如何防止搜索引擎抓取我们的动态网址网站呢?
这个问题可以通过robots.txt文件解决,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站 的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。 查看全部
抓取动态网页(如何禁止搜索引擎抓取我们网站的动态网址(图))
所谓动态网址是指网址包括什么?, & 等字符网址,如news.php?lang=cn&class=1&id=2。我们开启了网站的伪静态后,对于网站的SEO来说,有必要避免搜索引擎爬取我们的动态网址网站。
你为什么要这样做?因为搜索引擎会在两次获取同一个页面但最终确定同一个页面后触发网站。具体处罚不明确。总之,不利于网站的整个SEO。那么如何防止搜索引擎抓取我们的动态网址网站呢?
这个问题可以通过robots.txt文件解决,具体操作请看下面。
我们知道动态页面有一个共同的特点,就是会有一个“?” 链接中的问号符号,因此我们可以在robots.txt文件中写入以下规则:
用户代理: *
不允许: /*?*
这将禁止搜索引擎抓取网站 的整个动态链接。另外,如果我们只想让搜索引擎抓取特定类型的文件,比如html格式的静态页面,我们可以在robots.txt中加入如下规则:
用户代理: *
允许:.html$
不允许: /
另外,记得把你写的robots.txt文件放在你的网站的根目录下,否则是不行的。此外,还有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写规则,生成robots.txt文件即可。
抓取动态网页( powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2021-10-09 16:33
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做... 查看全部
抓取动态网页(
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做...
抓取动态网页( powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-09 03:16
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做... 查看全部
抓取动态网页(
powershell动态网页内容爬取示例2017年2月28日在Powershell小技巧标签爬虫)
Powershell 动态网页内容抓取示例
2017年2月28日在Powershell Tips tag crawler from pansal
1.目标网站如下:一个内部管理系统,但功能单一,使用极其不方便。该项目的目的是利用自动化手段抓取目标信息,并将其传输到本地数据库,进行定制化的数据分析和报告呈现。
2、实现思路:使用脚本工具(powershell)模拟网站的登录过程。合法登录当前会话,获取所需数据。
3.在本地存储cookie文件。Chrome 会安装 EditThisCookie 插件。然后登录目标网站并按f12查看cookie选项卡。全选复制并保存到本地。请注意,cookie 文件很快就会过期,如果文件过期,则需要对其进行更新。
4. 感谢 Mooser Lee 的分享。以下代码可以从 cookie 文件中获取令牌数组并将其分配给 $session 变量。这时候如果用invoke-webrequest或者invoke-restmethod用$Websession参数测试,可以发现可以登录网站,但是只能抓取网页的静态内容。
5.为了能够抓取网站的动态内容,继续分析网站,继续使用chrome F12,点击网络标签,只过滤xhr,按F5刷新页面捕获数据包。
6、F5刷新后,会抓取很多内容。一项一项检查,你一定会发现某个回复的内容正是你想要的。如下图: 复制响应内容与网页对比,可以看到是第一页列表中的内容。这将锁定需要抓取的 URL。
7.选择前面的headers选项卡,查看请求方式。可以看出网页采用的是POST方式,需要传参数(如果是get方式会方便很多,具体百度~~)。
8.向下滚动标题选项卡,您可以看到许多参数。
9. 将参数添加到headers数组中进行备份。不是所有参数都必须带,我挑了几个写的,你也可以自己试试....
10.继续下拉查看payload。这部分是body参数。
11、如图,直接复制粘贴,新建一个变量使用。这是比较长的。请注意,您需要在中间添加几个转义字符。
12、最后呈现invoke-webrequest大法,用一行命令完成:
在$r的属性内容中,可以查看动态网页的内容。
先分享这么多....当前脚本中的url只是直接使用了当前会话的临时变量。如果您想编写一个可用的脚本,您需要获取一些构成 url 的必要变量。我正在研究怎么做...
抓取动态网页(如何让搜索引擎快速收录网站页面的方法:1.、链接、robots)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-09 03:15
SEO客户经常问我为什么网站的页面不是收录。其实这跟网站的内容、链接、robots等都有关系,下面给大家分享一下如何让搜索引擎快速网站网站页面的方法:
1.网站 页面很有价值
搜索引擎也会从用户的角度来看 网站 和页面。如果你的网站页面有比较新的、独特的、有价值的内容,用户会被更多地使用和喜欢,只有页面对用户有用,有价值的搜索引擎才会给出好的排名和快速的收录。网站的内容除了有价值之外,还必须有一定的相似度。例如,您是一名财务管理人员。我觉得这是一个更专业的网站,会更加关注它,这对网站收录和关键词的排名会有一定的好处。
2.科学合理使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上添加alt标签并进行文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以访问识别图片。
3.使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
4.关键词使用问题
一个页面一定要仔细选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。如果你想获得一个好的排名,如果你使用堆积起来的关键词 很难。
5.定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。据了解,百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点都会有一些重大更新,所以建议站长合理利用这个时间段,加上网站的收录。
6.增加优质外链
seo行业的人都知道外部链接的作用。外链是增加网站收录、流量、排名的重要因素。外链是一票,高权重的优质链接。能够链接到你想要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。 查看全部
抓取动态网页(如何让搜索引擎快速收录网站页面的方法:1.、链接、robots)
SEO客户经常问我为什么网站的页面不是收录。其实这跟网站的内容、链接、robots等都有关系,下面给大家分享一下如何让搜索引擎快速网站网站页面的方法:
1.网站 页面很有价值
搜索引擎也会从用户的角度来看 网站 和页面。如果你的网站页面有比较新的、独特的、有价值的内容,用户会被更多地使用和喜欢,只有页面对用户有用,有价值的搜索引擎才会给出好的排名和快速的收录。网站的内容除了有价值之外,还必须有一定的相似度。例如,您是一名财务管理人员。我觉得这是一个更专业的网站,会更加关注它,这对网站收录和关键词的排名会有一定的好处。
2.科学合理使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上添加alt标签并进行文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以访问识别图片。
3.使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
4.关键词使用问题
一个页面一定要仔细选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。如果你想获得一个好的排名,如果你使用堆积起来的关键词 很难。
5.定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。据了解,百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点都会有一些重大更新,所以建议站长合理利用这个时间段,加上网站的收录。
6.增加优质外链
seo行业的人都知道外部链接的作用。外链是增加网站收录、流量、排名的重要因素。外链是一票,高权重的优质链接。能够链接到你想要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。
抓取动态网页(看过SEO实战密码的同学都知道,百度蜘蛛是否会抓取动态页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-05 08:21
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是 收录 一个动态页面吗?让我们一起来看看这个。
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是一个 收录 动态页面吗?一起来看看这些问题吧!
首先,百度蜘蛛现在可以识别动态页面了,尽管很多老牌SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
动态页面比静态页面差吗?
说实话,静态页面还是有一定优势的。
1、服务器负载小
2、页面打开速度很快
3、静态页面漏洞很少
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。如今,动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要你做得好,你可以得到很好的结果。
一、超链接:超链接部分的文字一般是蓝色的,也有一些是其他颜色的。当我们点击它时颜色会改变。
二、 网页上的超链接一般分为三种:URL超链接、相对URL超链接、同意网页超链接。这里的URL(UniformResourceLocator)就是统一资源定位器,简单来说就是互联网上一个站点或者网页的完整路径,比如
三、锚链:也叫锚文本。1.本站内锚链接为内链。2.网站外的锚定链接,就是我们通常所说的外链。比如锚链接: 这个和超链接的区别就是超链接的形式是:**
四、裸链接:与锚文本链接和网站链接相比,它们只是一个网址,无法点击。
五、 Backlink:如果网页A上有指向网页B的链接,则网页A上的链接就是网页B的反向链接。SEO中提到的反向链接也称为反向链接,外部链接。但是,反向链接的泛化包括入站和出站链接。
六、Minglink:友情链接,普通外链
七、深色链接:例如使用overflow:隐藏代码,网站的字体链接和背景颜色相同,链接文字高度为1px(1像素)所以人们看不到它,但搜索引擎可以看到它。到达。作弊是不可取的,会受到惩罚。
八、黑链:有两种,一种是花钱获得的,另一种是指缺乏搜索引擎的好链接。例如,隐藏在代码中的链接。
文末,非常感谢快鸟SEO优化外包公司文章的阅读:《【青岛seo优化】百度蜘蛛会不会抓到网站动态页面",只为给用户提供更多信息参考使用或为方便学习和交流。如果对您有帮助,可以点击[url=https://www.ucaiyun.com/]采集本文地址:我们会很开心。欢迎您在评论区留言,或者您有什么意见和建议,也欢迎与我们互动。
扫描二维码与项目经理沟通
我们在微信上24小时为您服务
答:seo外包、网站优化、网站建设、seo优化、小程序开发
– 飞鸟云拼SEO优化外包品牌服务商 查看全部
抓取动态网页(看过SEO实战密码的同学都知道,百度蜘蛛是否会抓取动态页面)
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是 收录 一个动态页面吗?让我们一起来看看这个。
看过真实SEO密码的同学都知道动态页面对搜索引擎不友好。很多同学在做百度搜索引擎优化的时候,经常会遇到目标网站是动态页面。百度蜘蛛会抓到吗?获取动态页面?它会是一个 收录 动态页面吗?一起来看看这些问题吧!
首先,百度蜘蛛现在可以识别动态页面了,尽管很多老牌SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
动态页面比静态页面差吗?
说实话,静态页面还是有一定优势的。
1、服务器负载小
2、页面打开速度很快
3、静态页面漏洞很少
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。如今,动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要你做得好,你可以得到很好的结果。
一、超链接:超链接部分的文字一般是蓝色的,也有一些是其他颜色的。当我们点击它时颜色会改变。
二、 网页上的超链接一般分为三种:URL超链接、相对URL超链接、同意网页超链接。这里的URL(UniformResourceLocator)就是统一资源定位器,简单来说就是互联网上一个站点或者网页的完整路径,比如
三、锚链:也叫锚文本。1.本站内锚链接为内链。2.网站外的锚定链接,就是我们通常所说的外链。比如锚链接: 这个和超链接的区别就是超链接的形式是:**
四、裸链接:与锚文本链接和网站链接相比,它们只是一个网址,无法点击。
五、 Backlink:如果网页A上有指向网页B的链接,则网页A上的链接就是网页B的反向链接。SEO中提到的反向链接也称为反向链接,外部链接。但是,反向链接的泛化包括入站和出站链接。
六、Minglink:友情链接,普通外链
七、深色链接:例如使用overflow:隐藏代码,网站的字体链接和背景颜色相同,链接文字高度为1px(1像素)所以人们看不到它,但搜索引擎可以看到它。到达。作弊是不可取的,会受到惩罚。
八、黑链:有两种,一种是花钱获得的,另一种是指缺乏搜索引擎的好链接。例如,隐藏在代码中的链接。
文末,非常感谢快鸟SEO优化外包公司文章的阅读:《【青岛seo优化】百度蜘蛛会不会抓到网站动态页面",只为给用户提供更多信息参考使用或为方便学习和交流。如果对您有帮助,可以点击[url=https://www.ucaiyun.com/]采集本文地址:我们会很开心。欢迎您在评论区留言,或者您有什么意见和建议,也欢迎与我们互动。
扫描二维码与项目经理沟通
我们在微信上24小时为您服务
答:seo外包、网站优化、网站建设、seo优化、小程序开发
– 飞鸟云拼SEO优化外包品牌服务商
抓取动态网页(说之前还是先分析下静态伪静态、动态的不同点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-05 08:16
在说之前,我们先来分析一下静态、伪静态和动态的区别。
动态、静态、伪静态
静态网站:纯静态 HTML 文档,可以使用 filetype:htm 查询的网页。
伪静态 URL:使用 Rewrite 重写动态 URL,使动态 URL 看起来像静态 URL。
现在很多后台都充分考虑了SEO,支持URL重写,链接中带有关键词,链接清晰。
动态URL:内容存储在数据库中,根据需求展示内容。在网址中?# &显示不同的参数,如:news.php? lang=cn&class=1&id=2。动态URL的会话标识符(sid)和查询(query)参数很可能导致大量相同的页面,有时蜘蛛会陷入死循环,出不来。所以直到现在,蜘蛛仍然不喜欢动态。
机器人指令
开启伪静态后,打开的网址就是显示的静态页面。Google 等搜索引擎在抓取您的 网站 页面时也会抓取 网站 的静态和动态页面。会导致大量重复内容的页面被抓取(我的网站有重复抓取,网址是)。
现在,我们只能在robots.txt文件中写规则,禁止搜索引擎抓取动态页面。动态页面有一个共同的特点,就是链接都会有一个“?” 问号符号。机器人指令规则如下:
用户代理: *
不允许: /*?*
如果只想连接到指定的搜索引擎来获取特定类型的文件,例如html格式的静态页面,规则如下:
用户代理: *
允许:.html$
不允许: /
如果你想禁止搜索引擎抓取你所有的网站页面,你可以写如下规则:
用户代理: *
不允许: /
robots.txt文件的路径,应该在你的网站的根目录下。有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写入规则后,生成robots.txt文件即可。
以上主要针对伪静态网站禁止抓取动态页面。robots.txt文件中有很多配置规则,具体可以参考相关资料。 查看全部
抓取动态网页(说之前还是先分析下静态伪静态、动态的不同点)
在说之前,我们先来分析一下静态、伪静态和动态的区别。
动态、静态、伪静态
静态网站:纯静态 HTML 文档,可以使用 filetype:htm 查询的网页。
伪静态 URL:使用 Rewrite 重写动态 URL,使动态 URL 看起来像静态 URL。
现在很多后台都充分考虑了SEO,支持URL重写,链接中带有关键词,链接清晰。
动态URL:内容存储在数据库中,根据需求展示内容。在网址中?# &显示不同的参数,如:news.php? lang=cn&class=1&id=2。动态URL的会话标识符(sid)和查询(query)参数很可能导致大量相同的页面,有时蜘蛛会陷入死循环,出不来。所以直到现在,蜘蛛仍然不喜欢动态。
机器人指令
开启伪静态后,打开的网址就是显示的静态页面。Google 等搜索引擎在抓取您的 网站 页面时也会抓取 网站 的静态和动态页面。会导致大量重复内容的页面被抓取(我的网站有重复抓取,网址是)。
现在,我们只能在robots.txt文件中写规则,禁止搜索引擎抓取动态页面。动态页面有一个共同的特点,就是链接都会有一个“?” 问号符号。机器人指令规则如下:
用户代理: *
不允许: /*?*
如果只想连接到指定的搜索引擎来获取特定类型的文件,例如html格式的静态页面,规则如下:
用户代理: *
允许:.html$
不允许: /
如果你想禁止搜索引擎抓取你所有的网站页面,你可以写如下规则:
用户代理: *
不允许: /
robots.txt文件的路径,应该在你的网站的根目录下。有一个简单的快捷方式来编写规则。登录google网站管理员工具,在里面写入规则后,生成robots.txt文件即可。
以上主要针对伪静态网站禁止抓取动态页面。robots.txt文件中有很多配置规则,具体可以参考相关资料。
抓取动态网页( 静态的确比动态页面好,为什么好?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-05 08:13
静态的确比动态页面好,为什么好?(组图))
鄂州SEO企业网站优化公司,会蜘蛛抓取网站动态页面
大家都知道静态页面好收录,静态页面好,那么百度蜘蛛也可以识别动态页面,尽管很多老SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
在我们SEO工作者眼里,静态页面确实比动态页面好。为什么更好?
1.页面打开速度很快
2.服务器占用空间少
3.静态页面优于动态页面收录
4、服务器负载小
5、 很少有静态页面漏洞
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。现在动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要内容做得好,就能取得不错的成绩。用伪静态优化自己的网站就行了。
百度指数量下降的原因及解决办法
百度指数下降的原因:
1、百度索引数据最早每天更新一次,最晚每周更新一次。不同站点的更新日期可能不同。
2、如果无法查询到现有的流量数据,请隔天再检查一次。最多可以查询一周的数据。
3、 如果索引数据数量与网站查询结果数量存在较大差异,您有任何问题可以提交给百度请求发布内容。
4、 也可能是 网站 的原因:
(1) 内容数据所在的 URL 不规范统一
200状态下多个域名可以正常访问网页内容;同一个域名下的多个url形式可以访问相同的内容,如url大小写、url规则改变等。
解决方法:选择主域名(或主url),其他域名下的所有url都301重定向到主域名(或主url),站长工具提交域名修改(或目录url修改)
(2)是镜像的,用户可以通过其他主办方的域名或者url直接访问自己的内容。
解决方法:注意域名解析安全和服务器安全;绑定唯一可解析的域名或唯一可访问的url;对页面内容中的链接使用绝对地址
(3)网站人气下降
A. 内容质量下降
解决方法:提高内容质量,详见百度站长学院相关内容;消除简单的复制,更多地整合信息。
B. 更新量和频率降低
解决方案:稳定更新频率,根据内容发展,扩大编辑团队,产出更多新内容,让网站指数不下降,持续上升。(当更新量和频率显着减少时,那么配额就会减少。首先是爬取频率降低,导致索引量减少)
C. 时间敏感信息消失
解决方案:大部分时间敏感信息一般不会长时间保留在数据库中,因此需要不断探索新的时间敏感信息点并整合相关内容。
D、部分地区出现不良信息
解决方案:杜绝大量外链软文、恶意弹窗广告、非法敏感信息、专门针对搜索引擎作弊的内容等。
(4) 违规惩罚算法
解决方法:关注站长工具新闻和百度网页搜索动态。按照官方公告整改站点并反馈,然后等待算法更新。
(5)特殊网址不可信
解决方法:自定义各种网址的索引查询规则;定位索引量减少的特殊网址;对此类 URL 的当前、前一天、本周和历史索引进行故障排除;找出尚未存储在数据库中的数据可能存在的问题;处理后,加强此类网址与百度数据的交流(通过站点地图、批量提交网址、数据推送等)。
(6) 主题变化(比如从教育领域到医疗领域)
解决方法:旧域名网页死链后提交给百度(),屏蔽相关旧网址的访问权限,再推出新的话题相关内容,加强数据提交给百度
(7)参与
同一个ip下的非法站点太多,同域主托管的网站大部分被处罚,情况恶劣等。
解决办法:留下坏邻居,获取搜索引擎各个产品的相关反馈方式,请求解禁,等待恢复正常索引。
(8)政策原因
例如,香港主机和国外主机站点可能由于您知道的各种原因而稳定性较差。
解决方案:国内主机备案,合法合规经营
百度索引量供站长参考。每天被索引多少,会直接向站长反映百度蜘蛛是否喜欢这些东西。如果有一天百度指数成交量为0,就不用大惊小怪了。一般第二天会检索到百度指数量。指数的多少直接表明了这个网站的受欢迎程度,与网站的IP流量成正比。
如何防止网站被黑
网站被黑通常是因为黑客利用网站程序或语言脚本解释漏洞上传了一些可以直接修改站点文件的脚本木马,然后通过web表单访问该脚本木马实现修改当前网站文件,比如添加一段广告代码,一般是iframe或者脚本。
查看网站的几种方式:
1、 经常查看网站的源码。一般情况下,首页上列出的黑链最多。可能有的卖黑链的人喜欢挂在网站的内页赞,这样会比较麻烦一些。主机需要经常查看网站的源代码,点击网站的文本位置,右键,有“查看源文件”选项,点击查看。如果你自己的网站设置了禁止右键点击,可以下载一些有用的浏览器查看网站的源码。
2、 使用站长工具中的“网站死链检测”功能,可以在网站页面查看站长工具中的“网站死链检测”功能对于所有链接,此工具可以检查您的网站中的链接是否可以访问或显示网站页面中的所有链接。当您发现未知名称的链接时,请立即采取相关措施。删除此链接,可能是黑色链接。
3、使用FTP工具查看网站文件的修改时间。每个 网站 文件都有自己的修改时间。如果没有修改时间,系统会根据文件的创建时间显示。假设你当前网站的上传时间是6月27日。我通过FTP工具查了一下,大部分文件是6月27日的。突然看到某个文件的修改时间变成了当前日期。同一时间(比如6月28日),你的文件可能被人操纵,文件源代码被修改,黑链被链接。现在你最好在本地下载这个文件。详细检查文件源代码中是否有黑链的痕迹。当然你查的时候,如果你是asp+access站点,您可以看到您的数据库文件的修改时间与当前的相似。基本可以忽略,比如你的网站文章如果有文章的点击次数统计,访问者浏览一次网站文章 ,会写入数据库,数据库修改时间自然会被修改。
4、 使用站长工具中的“同IP站点查询”功能,通过该工具可以查询到与您网站在同一台服务器上的部分网站,如果您拥有网站 被黑了,然后你正在检查同一台服务器上的其他 网站。当你发现另外一个网站也被黑了,那么我们就可以怀疑服务器的安全性,而不是你自己的网站程序的漏洞。你现在需要做的就是立即联系服务商,让他制定详细的服务器安全策略。
5、查看其他网站是否在同一台服务器下有黑链。当另外一个网站也链接到黑链时,可能是服务器的安全有问题。在排除自己网站漏洞的情况下,你要做的就是立即联系服务商,请他制定详细的服务器安全策略。 查看全部
抓取动态网页(
静态的确比动态页面好,为什么好?(组图))
鄂州SEO企业网站优化公司,会蜘蛛抓取网站动态页面
大家都知道静态页面好收录,静态页面好,那么百度蜘蛛也可以识别动态页面,尽管很多老SEO还在告诉你静态页面比动态页面好。百度蜘蛛对动态页面的识别与今天不同。百度蜘蛛的动态页面和静态页面差别不大。百度蜘蛛收录现在可以识别这两种类型的页面。
在我们SEO工作者眼里,静态页面确实比动态页面好。为什么更好?
1.页面打开速度很快
2.服务器占用空间少
3.静态页面优于动态页面收录
4、服务器负载小
5、 很少有静态页面漏洞
如果你当前的网站是静态的,那么恭喜你,百度肯定会更喜欢你的页面。相反,不要气馁。现在动态页面可以与静态页面相媲美。事实上,他们并不像网上的传言那么夸张。只要内容做得好,就能取得不错的成绩。用伪静态优化自己的网站就行了。
百度指数量下降的原因及解决办法
百度指数下降的原因:
1、百度索引数据最早每天更新一次,最晚每周更新一次。不同站点的更新日期可能不同。
2、如果无法查询到现有的流量数据,请隔天再检查一次。最多可以查询一周的数据。
3、 如果索引数据数量与网站查询结果数量存在较大差异,您有任何问题可以提交给百度请求发布内容。
4、 也可能是 网站 的原因:
(1) 内容数据所在的 URL 不规范统一
200状态下多个域名可以正常访问网页内容;同一个域名下的多个url形式可以访问相同的内容,如url大小写、url规则改变等。
解决方法:选择主域名(或主url),其他域名下的所有url都301重定向到主域名(或主url),站长工具提交域名修改(或目录url修改)
(2)是镜像的,用户可以通过其他主办方的域名或者url直接访问自己的内容。
解决方法:注意域名解析安全和服务器安全;绑定唯一可解析的域名或唯一可访问的url;对页面内容中的链接使用绝对地址
(3)网站人气下降
A. 内容质量下降
解决方法:提高内容质量,详见百度站长学院相关内容;消除简单的复制,更多地整合信息。
B. 更新量和频率降低
解决方案:稳定更新频率,根据内容发展,扩大编辑团队,产出更多新内容,让网站指数不下降,持续上升。(当更新量和频率显着减少时,那么配额就会减少。首先是爬取频率降低,导致索引量减少)
C. 时间敏感信息消失
解决方案:大部分时间敏感信息一般不会长时间保留在数据库中,因此需要不断探索新的时间敏感信息点并整合相关内容。
D、部分地区出现不良信息
解决方案:杜绝大量外链软文、恶意弹窗广告、非法敏感信息、专门针对搜索引擎作弊的内容等。
(4) 违规惩罚算法
解决方法:关注站长工具新闻和百度网页搜索动态。按照官方公告整改站点并反馈,然后等待算法更新。
(5)特殊网址不可信
解决方法:自定义各种网址的索引查询规则;定位索引量减少的特殊网址;对此类 URL 的当前、前一天、本周和历史索引进行故障排除;找出尚未存储在数据库中的数据可能存在的问题;处理后,加强此类网址与百度数据的交流(通过站点地图、批量提交网址、数据推送等)。
(6) 主题变化(比如从教育领域到医疗领域)
解决方法:旧域名网页死链后提交给百度(),屏蔽相关旧网址的访问权限,再推出新的话题相关内容,加强数据提交给百度
(7)参与
同一个ip下的非法站点太多,同域主托管的网站大部分被处罚,情况恶劣等。
解决办法:留下坏邻居,获取搜索引擎各个产品的相关反馈方式,请求解禁,等待恢复正常索引。
(8)政策原因
例如,香港主机和国外主机站点可能由于您知道的各种原因而稳定性较差。
解决方案:国内主机备案,合法合规经营
百度索引量供站长参考。每天被索引多少,会直接向站长反映百度蜘蛛是否喜欢这些东西。如果有一天百度指数成交量为0,就不用大惊小怪了。一般第二天会检索到百度指数量。指数的多少直接表明了这个网站的受欢迎程度,与网站的IP流量成正比。
如何防止网站被黑
网站被黑通常是因为黑客利用网站程序或语言脚本解释漏洞上传了一些可以直接修改站点文件的脚本木马,然后通过web表单访问该脚本木马实现修改当前网站文件,比如添加一段广告代码,一般是iframe或者脚本。
查看网站的几种方式:
1、 经常查看网站的源码。一般情况下,首页上列出的黑链最多。可能有的卖黑链的人喜欢挂在网站的内页赞,这样会比较麻烦一些。主机需要经常查看网站的源代码,点击网站的文本位置,右键,有“查看源文件”选项,点击查看。如果你自己的网站设置了禁止右键点击,可以下载一些有用的浏览器查看网站的源码。
2、 使用站长工具中的“网站死链检测”功能,可以在网站页面查看站长工具中的“网站死链检测”功能对于所有链接,此工具可以检查您的网站中的链接是否可以访问或显示网站页面中的所有链接。当您发现未知名称的链接时,请立即采取相关措施。删除此链接,可能是黑色链接。
3、使用FTP工具查看网站文件的修改时间。每个 网站 文件都有自己的修改时间。如果没有修改时间,系统会根据文件的创建时间显示。假设你当前网站的上传时间是6月27日。我通过FTP工具查了一下,大部分文件是6月27日的。突然看到某个文件的修改时间变成了当前日期。同一时间(比如6月28日),你的文件可能被人操纵,文件源代码被修改,黑链被链接。现在你最好在本地下载这个文件。详细检查文件源代码中是否有黑链的痕迹。当然你查的时候,如果你是asp+access站点,您可以看到您的数据库文件的修改时间与当前的相似。基本可以忽略,比如你的网站文章如果有文章的点击次数统计,访问者浏览一次网站文章 ,会写入数据库,数据库修改时间自然会被修改。
4、 使用站长工具中的“同IP站点查询”功能,通过该工具可以查询到与您网站在同一台服务器上的部分网站,如果您拥有网站 被黑了,然后你正在检查同一台服务器上的其他 网站。当你发现另外一个网站也被黑了,那么我们就可以怀疑服务器的安全性,而不是你自己的网站程序的漏洞。你现在需要做的就是立即联系服务商,让他制定详细的服务器安全策略。
5、查看其他网站是否在同一台服务器下有黑链。当另外一个网站也链接到黑链时,可能是服务器的安全有问题。在排除自己网站漏洞的情况下,你要做的就是立即联系服务商,请他制定详细的服务器安全策略。
抓取动态网页(输入关键词爬取某个某个专利网站在关键词下的专利说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-04 10:28
前言:最近除了学习和工作,异性朋友需要爬一个动态网页。输入关键词,抓取网站的专利和关键词下的一些专利说明。以前python urllib2可以直接破解,但是只能破解静态网页,但是对于其他用js生成的动态网页,好像不行(我没试过)。然后在网上找了一些资料,发现scrapy结合selenium包好像可以用。(之所以这么说,是因为主卤还没实现,请先记录一下。)
#====================== 根据官网的简单介绍,个人理解=============== ==========
首先,安装两个包:scrapy 和 selenium:
卤主在ubuntu下,anaconda、pip和easy_intasll都已经安装好了,所以使用pip一步安装(或者easy_install):
pip install -U selenium
pip install Scrapy
easy_install -U selenium
easy_install Scrapy
其次,需要使用scrapy新建项目,在终端运行如下命令新建项目:
scrapy startproject tutorial
然后会自动生成如下形式的文件夹:
图1:新建项目后的文件夹
再次,开始编写项目:
一些变量需要在 items.py 文件中定义:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
在 tutorial/spiders 文件夹下新建一个 dmoz_spider.py 文件:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
这个文件中需要定义三个变量,其中之一是name、start_urls和parse。
最后,在终端最外层文件夹下运行:
scrapy crawl dmoz
dmoz是name的值,是tutorial/spider文件夹下新建的文件中DmozSpider类中的重要变量之一。
可以开始爬行了。
#============================================
朋友们:
介绍了爬取动态网站的部分内容,并在github上分享了完整的项目代码。(先下载代码,对照代码看文档)
它的任务是动态捕获页面信息。
Halo大人为了自己的任务,修改了自己的/etao/lstData.py文件,将在lstData类的lst列表变量中搜索到的关键词传递给spider.py文件,形成一个url,开始爬行。
分析博主的代码,没有找到爬取的动态页面信息存在的代码。
在 spider.py 文件中添加您自己的代码:
def parse(self, response):
#crawl all display page
for link in self.link_extractor['page_down'].extract_links(response):
yield Request(url = link.url, callback=self.parse)
#browser
self.browser.get(response.url)
time.sleep(5)
# get the data and write it to scrapy items
etaoItem_loader = ItemLoader(item=EtaoItem(), response = response)
url = str(response.url)
etaoItem_loader.add_value('url', url)
etaoItem_loader.add_xpath('title', self._x_query['title'])
etaoItem_loader.add_xpath('name', self._x_query['name'])
etaoItem_loader.add_xpath('price', self._x_query['price'])
#====================================
# for link in self.link_extractor['page_down'].extract_links(response):
# yield Request(url = link.url, callback = self.parse_detail)
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link2 = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
for i in title:
print i,
for j in link2:
print j,"+++++++++++++"
#====================================
yield etaoItem_loader.load_item()
有些东西可以分析,但还不够。我们需要继续分析返回的动态页面的源代码,更改提取器,选择器(尚未启动)
) 为了得到想要的结果。selenium 包似乎没用。
#============================================
卤大师参考的一些资料:
刮刮乐官网:
硒官网:
刮板选择器:#topics-selectors
博友博客:
博友博客:
博友博客(硒):
访问问题: 查看全部
抓取动态网页(输入关键词爬取某个某个专利网站在关键词下的专利说明)
前言:最近除了学习和工作,异性朋友需要爬一个动态网页。输入关键词,抓取网站的专利和关键词下的一些专利说明。以前python urllib2可以直接破解,但是只能破解静态网页,但是对于其他用js生成的动态网页,好像不行(我没试过)。然后在网上找了一些资料,发现scrapy结合selenium包好像可以用。(之所以这么说,是因为主卤还没实现,请先记录一下。)
#====================== 根据官网的简单介绍,个人理解=============== ==========
首先,安装两个包:scrapy 和 selenium:
卤主在ubuntu下,anaconda、pip和easy_intasll都已经安装好了,所以使用pip一步安装(或者easy_install):
pip install -U selenium
pip install Scrapy
easy_install -U selenium
easy_install Scrapy
其次,需要使用scrapy新建项目,在终端运行如下命令新建项目:
scrapy startproject tutorial
然后会自动生成如下形式的文件夹:
图1:新建项目后的文件夹
再次,开始编写项目:
一些变量需要在 items.py 文件中定义:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
在 tutorial/spiders 文件夹下新建一个 dmoz_spider.py 文件:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/ ... ot%3B,
"http://www.dmoz.org/Computers/ ... ot%3B
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
这个文件中需要定义三个变量,其中之一是name、start_urls和parse。
最后,在终端最外层文件夹下运行:
scrapy crawl dmoz
dmoz是name的值,是tutorial/spider文件夹下新建的文件中DmozSpider类中的重要变量之一。
可以开始爬行了。
#============================================
朋友们:
介绍了爬取动态网站的部分内容,并在github上分享了完整的项目代码。(先下载代码,对照代码看文档)
它的任务是动态捕获页面信息。
Halo大人为了自己的任务,修改了自己的/etao/lstData.py文件,将在lstData类的lst列表变量中搜索到的关键词传递给spider.py文件,形成一个url,开始爬行。
分析博主的代码,没有找到爬取的动态页面信息存在的代码。
在 spider.py 文件中添加您自己的代码:
def parse(self, response):
#crawl all display page
for link in self.link_extractor['page_down'].extract_links(response):
yield Request(url = link.url, callback=self.parse)
#browser
self.browser.get(response.url)
time.sleep(5)
# get the data and write it to scrapy items
etaoItem_loader = ItemLoader(item=EtaoItem(), response = response)
url = str(response.url)
etaoItem_loader.add_value('url', url)
etaoItem_loader.add_xpath('title', self._x_query['title'])
etaoItem_loader.add_xpath('name', self._x_query['name'])
etaoItem_loader.add_xpath('price', self._x_query['price'])
#====================================
# for link in self.link_extractor['page_down'].extract_links(response):
# yield Request(url = link.url, callback = self.parse_detail)
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link2 = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
for i in title:
print i,
for j in link2:
print j,"+++++++++++++"
#====================================
yield etaoItem_loader.load_item()
有些东西可以分析,但还不够。我们需要继续分析返回的动态页面的源代码,更改提取器,选择器(尚未启动)
) 为了得到想要的结果。selenium 包似乎没用。
#============================================
卤大师参考的一些资料:
刮刮乐官网:
硒官网:
刮板选择器:#topics-selectors
博友博客:
博友博客:
博友博客(硒):
访问问题:
抓取动态网页(抓取动态网页,再用php写成web页面可以吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-03 13:04
抓取动态网页,再用php写成web页面可以吗?这样工作量不大吧。
不靠谱,你没考虑过兼容性么,现在没有一个版本兼容性解决的了所有浏览器,而且老版本是不支持这么高版本的网页的,最好的办法是使用iframe,分批分页的方式,
请不要弄这种东西。自己实现的话很难控制兼容性。
老版本支持64位,那么新版本也应该支持,但是,至于说给新版本网页使用这些内容,对整体客户端来说,都是64位,对于一个外部的网页来说,这个就应该遵循prepack方案。
考虑这个的都是外行人。googlesaver是用来从服务器读取数据的,而现在让你手动来读取内容,非常难控制兼容性问题,对于想要兼容老旧浏览器的网站,是做不到这一点的。
基本是不靠谱的可以参考下,但是架构思想和原理不是这么简单实现的在一个程序化兼容旧页面库中添加新页面时,页面内容并没有进行相应修改。这种模式的问题主要在于容易存在跨页面读取数据。因为旧页面页面有共享header部分,新页面也需要做共享处理。但当使用搜索引擎在页面上留下指纹时,如果两个页面的指纹信息没有区别,就可以做过滤。
所以现在大量使用第三方库来作为搜索页面。但第三方库的这些库,可以称之为策略库,可以各种查询去改动对应页面的内容。 查看全部
抓取动态网页(抓取动态网页,再用php写成web页面可以吗?)
抓取动态网页,再用php写成web页面可以吗?这样工作量不大吧。
不靠谱,你没考虑过兼容性么,现在没有一个版本兼容性解决的了所有浏览器,而且老版本是不支持这么高版本的网页的,最好的办法是使用iframe,分批分页的方式,
请不要弄这种东西。自己实现的话很难控制兼容性。
老版本支持64位,那么新版本也应该支持,但是,至于说给新版本网页使用这些内容,对整体客户端来说,都是64位,对于一个外部的网页来说,这个就应该遵循prepack方案。
考虑这个的都是外行人。googlesaver是用来从服务器读取数据的,而现在让你手动来读取内容,非常难控制兼容性问题,对于想要兼容老旧浏览器的网站,是做不到这一点的。
基本是不靠谱的可以参考下,但是架构思想和原理不是这么简单实现的在一个程序化兼容旧页面库中添加新页面时,页面内容并没有进行相应修改。这种模式的问题主要在于容易存在跨页面读取数据。因为旧页面页面有共享header部分,新页面也需要做共享处理。但当使用搜索引擎在页面上留下指纹时,如果两个页面的指纹信息没有区别,就可以做过滤。
所以现在大量使用第三方库来作为搜索页面。但第三方库的这些库,可以称之为策略库,可以各种查询去改动对应页面的内容。
抓取动态网页(如何利用动态大数据成为企业数据分析的关键?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-01 03:28
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是一个强大的网络爬虫工具可以让您轻松快速地从不同的网站中抓取信息,这为您研究不同的网站结构节省了大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云端采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6)取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。 查看全部
抓取动态网页(如何利用动态大数据成为企业数据分析的关键?(组图))
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超出客户期望的做法,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,并分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是一个强大的网络爬虫工具可以让您轻松快速地从不同的网站中抓取信息,这为您研究不同的网站结构节省了大量时间。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云端采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6)取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
抓取动态网页(新浪微博中模拟抓取网页内容采集网页的内容说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-01 03:27
运行程序,自动调用火狐浏览器登录微博。注:手机端信息更加精致简洁,动态加载没有限制。但是,如果微博或粉丝ID只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:明星用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1. txtMegry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中 weibo_spider< 查看全部
抓取动态网页(新浪微博中模拟抓取网页内容采集网页的内容说明(图))
运行程序,自动调用火狐浏览器登录微博。注:手机端信息更加精致简洁,动态加载没有限制。但是,如果微博或粉丝ID只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:明星用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1. txtMegry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如抓取2018年4月23日的客户端信息,但是评论是动态加载的,还在研究中 weibo_spider<
抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-01 03:26
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
有些网站为了防止别人获取图片,或者说是知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态网页生成的图片我说,所以当你打开一个有漫画的页面时,图片加载会很慢,因为它是由js生成的(毕竟它不会让你轻易抓取它)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,当我使用浏览的F12功能时,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你捕捉网页加载,你会发现获取页面图片的Get请求有以下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人
接受语言 zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request中添加以上信息在header中,经过测试,只需要添加Referer
信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,并根据章节的url获取该章节的总页数,并获取每个页面的url,参考材料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
2. 根据第一步动态获取的页面url,使用Ghost动态加载页面,传入url获取页面图片的src
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
3.urllib2 模拟Get请求并写入图片
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
4.chardet 解决乱码问题
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
整体代码如下:
<p># -*- coding:utf8 -*-
import urllib2,re,os,time
import chardet
import cookielib,httplib,urllib
from bs4 import BeautifulSoup
from ghost import Ghost
webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
#time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
抓取动态网页(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src在页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
有些网站为了防止别人获取图片,或者说是知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态网页生成的图片我说,所以当你打开一个有漫画的页面时,图片加载会很慢,因为它是由js生成的(毕竟它不会让你轻易抓取它)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src的时候,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,当我使用浏览的F12功能时,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你捕捉网页加载,你会发现获取页面图片的Get请求有以下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人
接受语言 zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request中添加以上信息在header中,经过测试,只需要添加Referer
信息会做。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节的url,并根据章节的url获取该章节的总页数,并获取每个页面的url,参考材料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
2. 根据第一步动态获取的页面url,使用Ghost动态加载页面,传入url获取页面图片的src
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
3.urllib2 模拟Get请求并写入图片
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
4.chardet 解决乱码问题
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
整体代码如下:
<p># -*- coding:utf8 -*-
import urllib2,re,os,time
import chardet
import cookielib,httplib,urllib
from bs4 import BeautifulSoup
from ghost import Ghost
webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#通过Ghost模拟js获取动态网页生成的图片src
class FetcherCartoon:
def getCartoonUrl(self,url):
if url is None:
return false
#todo many decide about url
try:
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
page, resources = ghost.wait_for_page_loaded()
result, resources = ghost.evaluate("document.getElementById('comic').getAttribute('src');", expect_loading=True)
del resources
except Exception,e:
print e
return None
return result
#解决乱码问题
html_1 = urllib2.urlopen(basicURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#传入url模拟Get请求,获取图片内容
def GetImageContent(wholeurl,imgurl):
#time.sleep(0.1)
req = urllib2.Request(imgurl)
req.add_header('Referer', wholeurl)
content = urllib2.urlopen(req).read()
rstr = r"[\/\\\:\*\?\"\\|]" # '/\:*?"|'
new_title = re.sub(rstr, "", str(imgurl)[-20:])
with open(cartoonName+'/'+new_title,'wb') as code:
code.write(content)
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
抓取动态网页(我爱我家的网页中(1.)学习过程分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-01 03:24
对于web页面上的某些内容,需要进行某些交互操作才能获取相应的数据,例如常见的Ajax请求。为了抓取Ajax请求的结果,可以通过Ajax请求的URL抓取返回的结果,也可以使用selenium模块模拟网页Ajax。简单地记录一个学习过程
1.问题分析
例如,在下面的我爱我的主页()中,当您在搜索框中输入“保险”时,后台将自动发送Ajax请求,以获取收录“保险”一词的所有单元格名称
通过网络分析,您可以看到Ajax请求返回了一个JSON对象:
2.抓取数据
2.1使用请求
构造Ajax请求的URL,并分析使用Ajax请求获得的JSON数据。代码如下:
#coding:utf-8
import requests
import json
from lxml import html
url="https://wh.5i5j.com/ajaxsearch ... 3B%25(u'恒')
response = requests.get(url,headers={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; r…) Gecko/20100101 Firefox/64.0"})
html_string = json.loads(response.text)['res']
tree = html.fromstring(html_string)
li_tags=tree.getchildren()
house_info={}
for tag in li_tags:
name = tag.xpath('.//div/span[@class="name"]/text()')[0]
count = tag.xpath('.//span[@class="tao"]/text()')[0]
print name,count
house_info[name]=count
# print house_info
2.2使用硒
Selenium可以模拟浏览器的行为,因此它可以用作爬虫程序(但速度较慢),以模拟浏览器对网站
安装selenium:PIP安装selenium
(下载浏览器驱动程序:首次使用selenium时,您可能会报告错误mon.exceptions.webdriverexception,因为您需要下载驱动程序和模拟浏览器的下载地址)
硒的使用参考:
使用selenium捕获上述数据的代码如下:
from selenium import webdriver
driver = webdriver.Firefox(executable_path='D:\\Python\\geckodriver.exe') #路径为下载的浏览器驱动保存路径
driver.get('https://wh.5i5j.com/zufang/') #打开网页
kw = driver.find_element_by_id("zufang") #找到搜索框
kw.send_keys(u"万") #搜索框中输入文字 “万”
# button = driver.find_element_by_class_name("btn-search")
# button.click()
driver.implicitly_wait(30) #隐式等待30秒,浏览器查找每个元素时,若未找到会等待30s,30s还未找到时报错
li_tags = driver.find_elements_by_css_selector('ul.search_w li') #注意此处是find_elements, 复数查找多个element
for li_tag in li_tags:
name = li_tag.find_element_by_class_name('name').text
count = li_tag.find_element_by_class_name('tao').text
print name, count
在上面的代码中,因为Ajax请求需要时间来完成,所以需要一个驱动程序。隐式等待(30)使浏览器隐式等待30秒,也就是说,当浏览器找到每个元素时,如果找不到它,它将等待30秒,如果30秒后找不到它,将报告错误
关于selenium的等待,有显示等待和隐式等待
显示等待:指定等待元素出现或条件为真的时间,如以下代码所示:
newWebDriverWait(driver,15).until(
ExpectedConditions.presenceOfElementLocated(By.cssSelector("css locator")));
隐式等待:全局,对所有元素都有效。如果找不到元素,它将等待设置的时间,例如驱动程序。隐式等待(30) 查看全部
抓取动态网页(我爱我家的网页中(1.)学习过程分析)
对于web页面上的某些内容,需要进行某些交互操作才能获取相应的数据,例如常见的Ajax请求。为了抓取Ajax请求的结果,可以通过Ajax请求的URL抓取返回的结果,也可以使用selenium模块模拟网页Ajax。简单地记录一个学习过程
1.问题分析
例如,在下面的我爱我的主页()中,当您在搜索框中输入“保险”时,后台将自动发送Ajax请求,以获取收录“保险”一词的所有单元格名称
通过网络分析,您可以看到Ajax请求返回了一个JSON对象:
2.抓取数据
2.1使用请求
构造Ajax请求的URL,并分析使用Ajax请求获得的JSON数据。代码如下:
#coding:utf-8
import requests
import json
from lxml import html
url="https://wh.5i5j.com/ajaxsearch ... 3B%25(u'恒')
response = requests.get(url,headers={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; r…) Gecko/20100101 Firefox/64.0"})
html_string = json.loads(response.text)['res']
tree = html.fromstring(html_string)
li_tags=tree.getchildren()
house_info={}
for tag in li_tags:
name = tag.xpath('.//div/span[@class="name"]/text()')[0]
count = tag.xpath('.//span[@class="tao"]/text()')[0]
print name,count
house_info[name]=count
# print house_info
2.2使用硒
Selenium可以模拟浏览器的行为,因此它可以用作爬虫程序(但速度较慢),以模拟浏览器对网站
安装selenium:PIP安装selenium
(下载浏览器驱动程序:首次使用selenium时,您可能会报告错误mon.exceptions.webdriverexception,因为您需要下载驱动程序和模拟浏览器的下载地址)
硒的使用参考:
使用selenium捕获上述数据的代码如下:
from selenium import webdriver
driver = webdriver.Firefox(executable_path='D:\\Python\\geckodriver.exe') #路径为下载的浏览器驱动保存路径
driver.get('https://wh.5i5j.com/zufang/') #打开网页
kw = driver.find_element_by_id("zufang") #找到搜索框
kw.send_keys(u"万") #搜索框中输入文字 “万”
# button = driver.find_element_by_class_name("btn-search")
# button.click()
driver.implicitly_wait(30) #隐式等待30秒,浏览器查找每个元素时,若未找到会等待30s,30s还未找到时报错
li_tags = driver.find_elements_by_css_selector('ul.search_w li') #注意此处是find_elements, 复数查找多个element
for li_tag in li_tags:
name = li_tag.find_element_by_class_name('name').text
count = li_tag.find_element_by_class_name('tao').text
print name, count
在上面的代码中,因为Ajax请求需要时间来完成,所以需要一个驱动程序。隐式等待(30)使浏览器隐式等待30秒,也就是说,当浏览器找到每个元素时,如果找不到它,它将等待30秒,如果30秒后找不到它,将报告错误
关于selenium的等待,有显示等待和隐式等待
显示等待:指定等待元素出现或条件为真的时间,如以下代码所示:
newWebDriverWait(driver,15).until(
ExpectedConditions.presenceOfElementLocated(By.cssSelector("css locator")));
隐式等待:全局,对所有元素都有效。如果找不到元素,它将等待设置的时间,例如驱动程序。隐式等待(30)
抓取动态网页(企业想做好网站seo优化就要了解搜索引擎的抓取规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-29 19:19
点击 42
企业想要做好网站seo优化,必须了解搜索引擎的爬取规则,还要做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来的企业云技术小编就来聊聊优化动态页面的SEO方法:
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
相信大家对企业云技术小编为大家整理的SEO优化动态页面的方法和内容都有一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容大家可以在本站阅读其他SEO优化技巧和心得,相信你一定会有所收获。 查看全部
抓取动态网页(企业想做好网站seo优化就要了解搜索引擎的抓取规则)
点击 42
企业想要做好网站seo优化,必须了解搜索引擎的爬取规则,还要做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来的企业云技术小编就来聊聊优化动态页面的SEO方法:
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
相信大家对企业云技术小编为大家整理的SEO优化动态页面的方法和内容都有一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容大家可以在本站阅读其他SEO优化技巧和心得,相信你一定会有所收获。

