
抓取动态网页
抓取动态网页(大连做网站的动态网页和静态网页的工作过程是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 13:09
所谓动态网页一般是指由ASP、PHP、Cold Fusion、CGI等程序动态生成的页面,网页中的大部分数据内容都来自连接到网站的数据库。这个页面在互联网空间中是不存在的,所以有些人看着某个页面的内容就想了想。自然,他们找不到资源。动态网页是在接收到用户的访问请求后才生成并传送到用户浏览器进行显示的,而且由于访问者可以实时获取他们想要的数据,因此动态网页往往容易给人留下深刻的印象。此外,动态网页还具有易于维护和更新的优点。
比如电影网站的播放页面,一部电影网站有数千部电影,每部电影有不止一集。如果有电影的播放页面,恐怕服务器空间会放这些页面也是个问题。事实上,大多数电影网站只有一个播放页面。网页的内容是从数据库中获取的。每当某个页面不适合在某一天查看时,修改这样的页面就足够了。您不需要单独修改每一个。静态页面。可见,动态网页占用服务器空间少,易于更新和维护,对管理员来说非常方便。
但是,动态网页也有很多缺点。大连制作网站动态网页和静态网页的流程是这样的:
动态网页:首先,网页获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,动态页面被编译成标准的HTML代码传递给用户的浏览器。这样,用户就看到了网页。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。谁会在下次访问您的网站。
静态网页:静态网页很简单,静态网页其实是存在的,直接加载到客户端浏览器中显示,不需要服务器编译。
这说明动态网页在访问速度上没有优势。
这是从服务器和用户体验的角度来看的。我们从搜索引擎收录的角度来谈谈。动态网页是用户输入指令后形成的页面。没有这样的页面,搜索引擎只抓取现成的,不自己输入,所以网站在搜索引擎收录中没有优势。
您可以放心,搜索引擎正在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。这就是为什么这些搜索引擎在搜索结果中会出现动态链接,但是爬取次数比静态页面差很多的原因。双,我试过一次。同一个电影网站 数据库显示在动态网页上。Google 仅 收录 15 项。如果转换为静态,则一次为收录 两个。百来页面,可见搜索引擎还是喜欢静态页面的。为什么我爬不了很多搜索引擎?有专家认为是为了避免“搜索机器人陷阱” 查看全部
抓取动态网页(大连做网站的动态网页和静态网页的工作过程是这样的)
所谓动态网页一般是指由ASP、PHP、Cold Fusion、CGI等程序动态生成的页面,网页中的大部分数据内容都来自连接到网站的数据库。这个页面在互联网空间中是不存在的,所以有些人看着某个页面的内容就想了想。自然,他们找不到资源。动态网页是在接收到用户的访问请求后才生成并传送到用户浏览器进行显示的,而且由于访问者可以实时获取他们想要的数据,因此动态网页往往容易给人留下深刻的印象。此外,动态网页还具有易于维护和更新的优点。
比如电影网站的播放页面,一部电影网站有数千部电影,每部电影有不止一集。如果有电影的播放页面,恐怕服务器空间会放这些页面也是个问题。事实上,大多数电影网站只有一个播放页面。网页的内容是从数据库中获取的。每当某个页面不适合在某一天查看时,修改这样的页面就足够了。您不需要单独修改每一个。静态页面。可见,动态网页占用服务器空间少,易于更新和维护,对管理员来说非常方便。
但是,动态网页也有很多缺点。大连制作网站动态网页和静态网页的流程是这样的:
动态网页:首先,网页获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,动态页面被编译成标准的HTML代码传递给用户的浏览器。这样,用户就看到了网页。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。谁会在下次访问您的网站。
静态网页:静态网页很简单,静态网页其实是存在的,直接加载到客户端浏览器中显示,不需要服务器编译。
这说明动态网页在访问速度上没有优势。
这是从服务器和用户体验的角度来看的。我们从搜索引擎收录的角度来谈谈。动态网页是用户输入指令后形成的页面。没有这样的页面,搜索引擎只抓取现成的,不自己输入,所以网站在搜索引擎收录中没有优势。
您可以放心,搜索引擎正在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。这就是为什么这些搜索引擎在搜索结果中会出现动态链接,但是爬取次数比静态页面差很多的原因。双,我试过一次。同一个电影网站 数据库显示在动态网页上。Google 仅 收录 15 项。如果转换为静态,则一次为收录 两个。百来页面,可见搜索引擎还是喜欢静态页面的。为什么我爬不了很多搜索引擎?有专家认为是为了避免“搜索机器人陷阱”
抓取动态网页(ASP、ASP.NET、PHP、JSP,哪个好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-01 13:08
目前用于动态网站开发的主要语言有4种:ASP、ASP .NET、PHP、JSP。
1、ASP 代表 Active Server Pages。它是由 Microsoft 开发的超文本标记语言 (HTML)、脚本和 CGI(通用网关接口)的组合。它不提供自己的特殊编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP最大的优点是可以收录HTML标签,也可以直接访问数据库,使用ActiveX控件的无限扩展,所以在编程上比HTML更方便灵活。通过使用ASP组件和对象技术,用户可以以简单的方式直接使用ActiveX控件,调用对象的方法和属性,实现强大的交互功能。
但是ASP技术并不完善,因为它基本上局限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能轻易实现。在跨平台的 Web 服务器上工作。
面向过程的程序开发方法使维护变得更加困难,特别是对于大型程序。ASP 应用程序。解释VBScript或JScript语言,使性能无法得到充分利用。由于缺乏其基础设施,可扩展性受到限制,虽然COM组件可用,但在开发一些特殊功能(如文件上传)时,没有来自内置的支持,需要向第三方寻求控制控制供应商。
3、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最热门的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但您只需要很少的编程知识。可以使用PHP 来构建真正的交互式网站。
它与 HTML 语言具有很好的兼容性。用户可以直接在脚本代码中添加HTML标签,也可以在HTML标签中添加脚本代码,以更好地实现页面控制。PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象的编程。
4、JSP 代表 Java 服务器页面。它是1999年6月推出的一项新技术,是一种基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只适用于Windows NT/2000平台,而JSP可以运行在85%以上的服务器上,并且是基于JSP技术应用比基于ASP的应用更容易维护和管理,因此被很多人认为是未来最有前途的动态网站技术。 查看全部
抓取动态网页(ASP、ASP.NET、PHP、JSP,哪个好?)
目前用于动态网站开发的主要语言有4种:ASP、ASP .NET、PHP、JSP。
1、ASP 代表 Active Server Pages。它是由 Microsoft 开发的超文本标记语言 (HTML)、脚本和 CGI(通用网关接口)的组合。它不提供自己的特殊编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP最大的优点是可以收录HTML标签,也可以直接访问数据库,使用ActiveX控件的无限扩展,所以在编程上比HTML更方便灵活。通过使用ASP组件和对象技术,用户可以以简单的方式直接使用ActiveX控件,调用对象的方法和属性,实现强大的交互功能。
但是ASP技术并不完善,因为它基本上局限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能轻易实现。在跨平台的 Web 服务器上工作。
面向过程的程序开发方法使维护变得更加困难,特别是对于大型程序。ASP 应用程序。解释VBScript或JScript语言,使性能无法得到充分利用。由于缺乏其基础设施,可扩展性受到限制,虽然COM组件可用,但在开发一些特殊功能(如文件上传)时,没有来自内置的支持,需要向第三方寻求控制控制供应商。
3、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最热门的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但您只需要很少的编程知识。可以使用PHP 来构建真正的交互式网站。
它与 HTML 语言具有很好的兼容性。用户可以直接在脚本代码中添加HTML标签,也可以在HTML标签中添加脚本代码,以更好地实现页面控制。PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象的编程。
4、JSP 代表 Java 服务器页面。它是1999年6月推出的一项新技术,是一种基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只适用于Windows NT/2000平台,而JSP可以运行在85%以上的服务器上,并且是基于JSP技术应用比基于ASP的应用更容易维护和管理,因此被很多人认为是未来最有前途的动态网站技术。
抓取动态网页(做网页在外行看起来是相当有技术含量,做利于搜索引擎的站才有希望)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-01 13:07
网页对于外行来说似乎是相当技术性的。只有当你是一个搜索引擎友好的网站时,你才能希望被搜索到。一个搜索引擎友好的网站可能涉及关键词、客户需求分析等,其他方面再好,关键部分都没有排名,好像做得不好,网络怎么能页面被访问者搜索?
如何让一个网页被访问者搜索
许多公司将优化划分为不同的部门,这可以看作是一个非常重要的环节。新制作的网站应该可以帮助蜘蛛爬取网站,间接提升网站的排名。一些网站目标关键词相当多。但是,如果坐在同一个网站上,不利于排名优化,分散权重。如果非得做,取多个网站,然后用二级域名做,不要在同一台主机上做。网站的内容要合理,一般是从左到右,从上到下浏览。同样的搜索引擎也是根据人们的浏览习惯设计的。比如上面网站的内容,权重也是依次递减的。搜索引擎也是如此。所以在制作长尾词的时候可以把这些长尾关键词放在目录下。关键词 的排名将得到提升。
与大多数网站静态html技术相比,现在很多网站都有数据库,也选择了动态网站技术。这样方便客户更新网站,但动态网站技术也有其不足之处。理论上会影响网站的加载速度,因为网站的内容需要从数据库中读取。不利于搜索引擎抓取来抓取网页。由于路径特殊,会增加搜索引擎抓取网站内容的难度,所以搜索引擎通常不喜欢动态的网站。动态转静态页面技术的使用,不仅可以方便客户更新内容,还可以提高网站的加载速度,方便访问者搜索。
提到的优化是网站的内部优化。只有当你了解布局并符合优化规则时,搜索引擎才能给你展示的机会。它以 网站 开头。需要搭建一个有利于蜘蛛爬行的网站结构收录。从首页到内页,都要精心设计。如果结构完成,就等于成功。一半。你要什么关键词参与排名,排名更快,路径优化,如果路径是深度爬虫,就很难抓取,直到网页无法抓取,一般是静态链接或者伪静态,动态不易识别。通常没有更多的路径。路径越深,爬行的机会就越小。仅仅制作网页并不是主要的事情。SEO优化排名是公司做网页的目标。很多网站一定要在前期考虑优化网站,提升客户搜索体验。 查看全部
抓取动态网页(做网页在外行看起来是相当有技术含量,做利于搜索引擎的站才有希望)
网页对于外行来说似乎是相当技术性的。只有当你是一个搜索引擎友好的网站时,你才能希望被搜索到。一个搜索引擎友好的网站可能涉及关键词、客户需求分析等,其他方面再好,关键部分都没有排名,好像做得不好,网络怎么能页面被访问者搜索?

如何让一个网页被访问者搜索
许多公司将优化划分为不同的部门,这可以看作是一个非常重要的环节。新制作的网站应该可以帮助蜘蛛爬取网站,间接提升网站的排名。一些网站目标关键词相当多。但是,如果坐在同一个网站上,不利于排名优化,分散权重。如果非得做,取多个网站,然后用二级域名做,不要在同一台主机上做。网站的内容要合理,一般是从左到右,从上到下浏览。同样的搜索引擎也是根据人们的浏览习惯设计的。比如上面网站的内容,权重也是依次递减的。搜索引擎也是如此。所以在制作长尾词的时候可以把这些长尾关键词放在目录下。关键词 的排名将得到提升。
与大多数网站静态html技术相比,现在很多网站都有数据库,也选择了动态网站技术。这样方便客户更新网站,但动态网站技术也有其不足之处。理论上会影响网站的加载速度,因为网站的内容需要从数据库中读取。不利于搜索引擎抓取来抓取网页。由于路径特殊,会增加搜索引擎抓取网站内容的难度,所以搜索引擎通常不喜欢动态的网站。动态转静态页面技术的使用,不仅可以方便客户更新内容,还可以提高网站的加载速度,方便访问者搜索。
提到的优化是网站的内部优化。只有当你了解布局并符合优化规则时,搜索引擎才能给你展示的机会。它以 网站 开头。需要搭建一个有利于蜘蛛爬行的网站结构收录。从首页到内页,都要精心设计。如果结构完成,就等于成功。一半。你要什么关键词参与排名,排名更快,路径优化,如果路径是深度爬虫,就很难抓取,直到网页无法抓取,一般是静态链接或者伪静态,动态不易识别。通常没有更多的路径。路径越深,爬行的机会就越小。仅仅制作网页并不是主要的事情。SEO优化排名是公司做网页的目标。很多网站一定要在前期考虑优化网站,提升客户搜索体验。
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 13:05
继之前介绍了企业网站建设的静态网页设计“三步走”之后,分形科技将为您介绍企业网站建设的动态网页制作“2.11”。String”。目前市场上大部分企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继之前给大家的介绍之后,分形科技接下来给大家介绍一下“两点和企业生产的动态网页的一行”网站。目前市场上大部分企业风站建设会根据未来的需求来决定是使用动态网页还是静态网页。
动态网页的概念
动态网页是目前常用的网页编程技术。这里的动态是指在页面代码保持不变的情况下,网页上显示的内容会随着时间、环境或数据库操作而变化。动态网页是一种与静态网页相反的网页。动态网页结合基本的html语法规范、Java、VB、VC等高级编程语言,以及数据库编程,共同生成网页。在网站的建设过程中,实现对网站的内容和风格的高效、动态、交互管理。
动态网页的工作原理
动态网页主要与静态网页和后端数据库交互,完成数据传输。制作动态网页常用的后缀格式有.asp、.jsp、.php、.perl等,并且有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发出请求时,将一个完整的网页返回给用户。
动态网页制作“两点一线”
动态网页制作“一点一线”中的“两点”包括:动态网页制作的优缺点,“一条线”是指从服务器到客户端的连接。
一、制作动态网页的优势
1、基于数据库,动静态一体化
动态网页的制作主要是基于数据库的网页,网站的整个操作通过代码调用数据库来展示和实现。这种网站的交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设过程中形成动静结合的最优配置.
2、内容更新快,满足用户需求
动态网页创建技术的一大特点是网站内容更新速度快。这就是企业在网站的建设中使用动态网页创建网站的原因。动态网页的更新和维护一般是通过编辑修改网站后台来实现的,比如企业建站常用的智梦后台。这就把网站的构建和维护分开了。如果企业不能自行完成网站的建设,则可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、开发技术灵活,实现多功能操作
动态网页的技术支持并不强大。常用的基础网页技术包括PHP(超文本预处理器)、ASP(Active Server Page)、JSP(Java Server Page)和CGI(Common Gateway Interface)。网站开发者可以通过这四个强大的后台技术支持来编辑和制作动态网页,并以此为基础实现对网站的多功能操作。如用户注册、登录和管理功能,这些功能有助于实现网站的交互性,同时增加用户对网站的粘性。
二、 动态网页创建的缺点
1、访问速度慢
由于动态网页连接到服务器的数据库,因此用户在访问网页时,需要在发送请求后等待数据库的响应,然后将完整的网页反馈给用户。这时候如果来访的用户特征多,就很容易变慢甚至死机。从用户的角度来看,这个问题的直接反应是网页加载太慢,没有响应,极大地影响了用户访问的心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” 符号,用户必须输入命令才能响应。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页的亲和力不高,不利于网站的收录 . 但是,目前大多数搜索引擎已经支持动态页面的抓取。
3、网页安全性低
在实现动态网页强大交互功能的同时,也给网站带来了很多安全隐患。如果开发者和设计者在编写动态网页程序时不考虑网站的安全性,那么网站很容易给攻击者留下后门,从而受到恶意攻击和黑客入侵的威胁。
三、动态网页制作第一线
这里所说的第一行动态网页创建是指网页的服务器端和客户端,将动态网页结合起来,形成一个完整的网站。下面分形科技小编就为大家一一分析两者。
服务终端
服务器端是指网络上的服务器。动态网页在服务器端运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是通过将这些语言与通用网关接口 (CGI) 连接起来而形成的。需要注意的是,JSP 有两个例外,它们的网络请求都是分派到共享虚拟机上的。动态网站的服务器端往往处于缓存状态,这会导致动态网页的加载时间延长。
客户
客户端是指用户在动态网页上发出请求,服务器会响应特定网页上的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端在用户本地计算机浏览器中的行为生成相应的内容,以获取用户访问的行为结果。返回搜狐查看更多 查看全部
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
继之前介绍了企业网站建设的静态网页设计“三步走”之后,分形科技将为您介绍企业网站建设的动态网页制作“2.11”。String”。目前市场上大部分企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继之前给大家的介绍之后,分形科技接下来给大家介绍一下“两点和企业生产的动态网页的一行”网站。目前市场上大部分企业风站建设会根据未来的需求来决定是使用动态网页还是静态网页。
动态网页的概念
动态网页是目前常用的网页编程技术。这里的动态是指在页面代码保持不变的情况下,网页上显示的内容会随着时间、环境或数据库操作而变化。动态网页是一种与静态网页相反的网页。动态网页结合基本的html语法规范、Java、VB、VC等高级编程语言,以及数据库编程,共同生成网页。在网站的建设过程中,实现对网站的内容和风格的高效、动态、交互管理。
动态网页的工作原理
动态网页主要与静态网页和后端数据库交互,完成数据传输。制作动态网页常用的后缀格式有.asp、.jsp、.php、.perl等,并且有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发出请求时,将一个完整的网页返回给用户。
动态网页制作“两点一线”
动态网页制作“一点一线”中的“两点”包括:动态网页制作的优缺点,“一条线”是指从服务器到客户端的连接。
一、制作动态网页的优势
1、基于数据库,动静态一体化
动态网页的制作主要是基于数据库的网页,网站的整个操作通过代码调用数据库来展示和实现。这种网站的交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设过程中形成动静结合的最优配置.
2、内容更新快,满足用户需求
动态网页创建技术的一大特点是网站内容更新速度快。这就是企业在网站的建设中使用动态网页创建网站的原因。动态网页的更新和维护一般是通过编辑修改网站后台来实现的,比如企业建站常用的智梦后台。这就把网站的构建和维护分开了。如果企业不能自行完成网站的建设,则可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、开发技术灵活,实现多功能操作
动态网页的技术支持并不强大。常用的基础网页技术包括PHP(超文本预处理器)、ASP(Active Server Page)、JSP(Java Server Page)和CGI(Common Gateway Interface)。网站开发者可以通过这四个强大的后台技术支持来编辑和制作动态网页,并以此为基础实现对网站的多功能操作。如用户注册、登录和管理功能,这些功能有助于实现网站的交互性,同时增加用户对网站的粘性。
二、 动态网页创建的缺点
1、访问速度慢
由于动态网页连接到服务器的数据库,因此用户在访问网页时,需要在发送请求后等待数据库的响应,然后将完整的网页反馈给用户。这时候如果来访的用户特征多,就很容易变慢甚至死机。从用户的角度来看,这个问题的直接反应是网页加载太慢,没有响应,极大地影响了用户访问的心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” 符号,用户必须输入命令才能响应。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页的亲和力不高,不利于网站的收录 . 但是,目前大多数搜索引擎已经支持动态页面的抓取。
3、网页安全性低
在实现动态网页强大交互功能的同时,也给网站带来了很多安全隐患。如果开发者和设计者在编写动态网页程序时不考虑网站的安全性,那么网站很容易给攻击者留下后门,从而受到恶意攻击和黑客入侵的威胁。
三、动态网页制作第一线
这里所说的第一行动态网页创建是指网页的服务器端和客户端,将动态网页结合起来,形成一个完整的网站。下面分形科技小编就为大家一一分析两者。
服务终端
服务器端是指网络上的服务器。动态网页在服务器端运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是通过将这些语言与通用网关接口 (CGI) 连接起来而形成的。需要注意的是,JSP 有两个例外,它们的网络请求都是分派到共享虚拟机上的。动态网站的服务器端往往处于缓存状态,这会导致动态网页的加载时间延长。
客户
客户端是指用户在动态网页上发出请求,服务器会响应特定网页上的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端在用户本地计算机浏览器中的行为生成相应的内容,以获取用户访问的行为结果。返回搜狐查看更多
抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-01 00:05
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
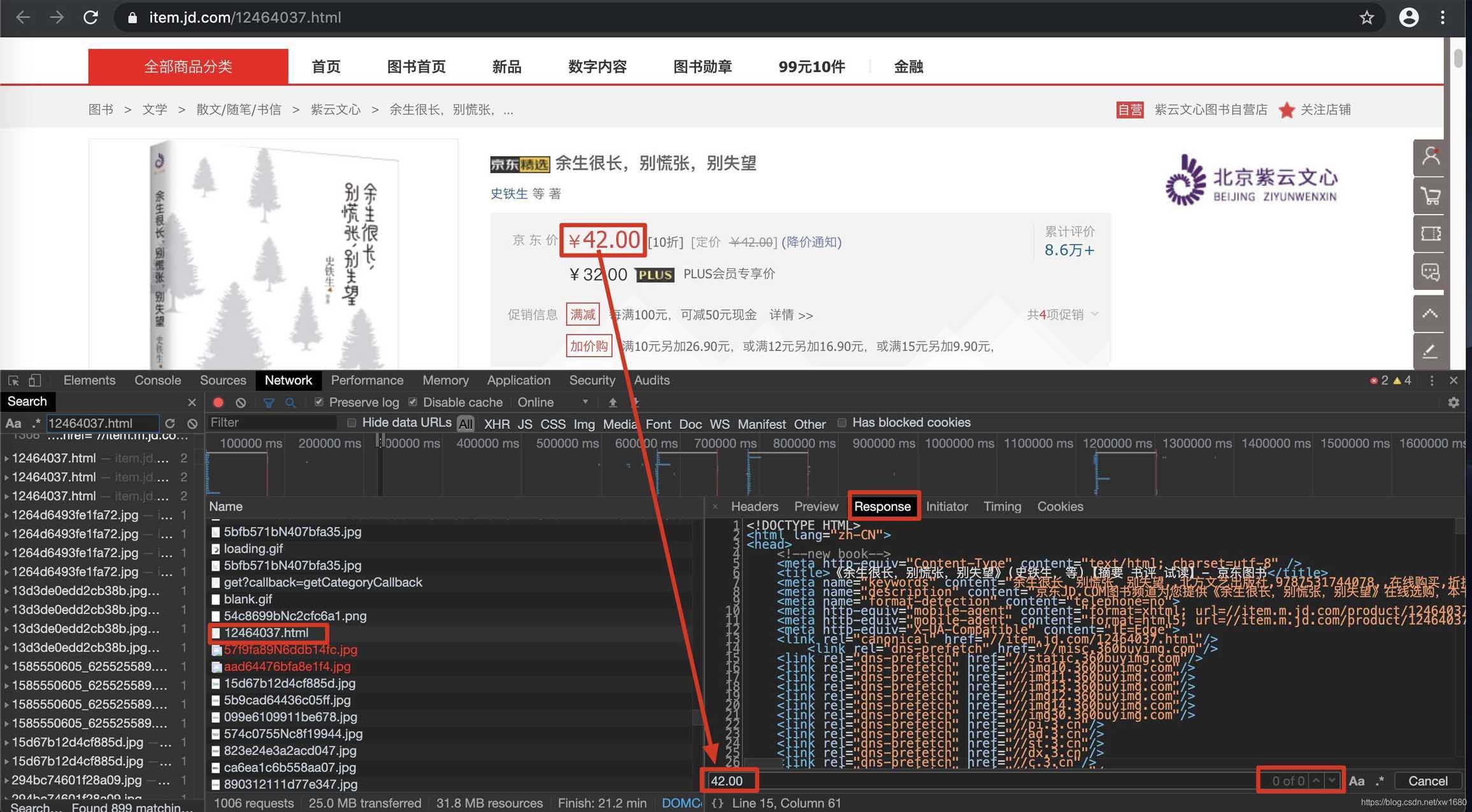
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
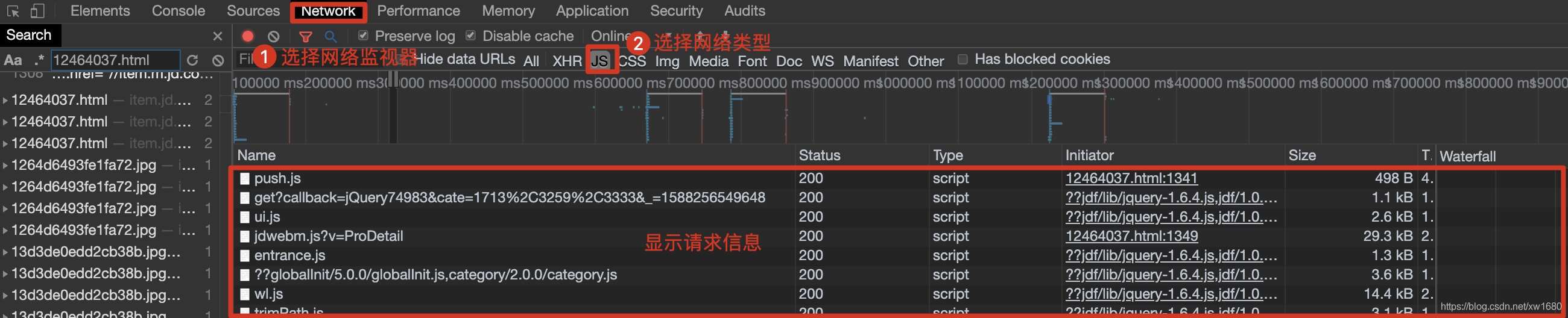
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
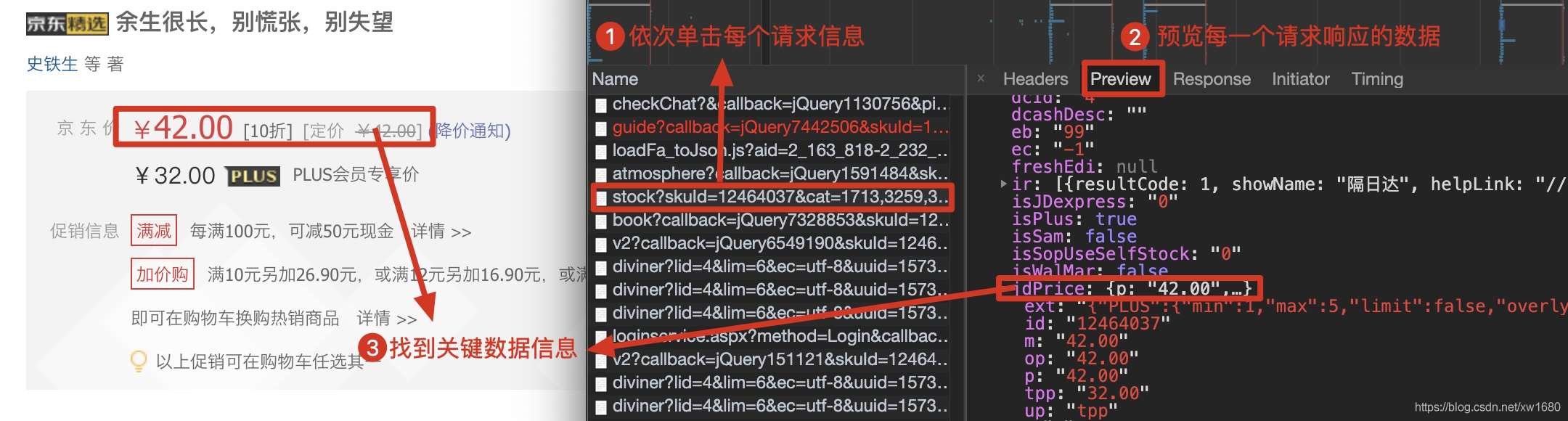
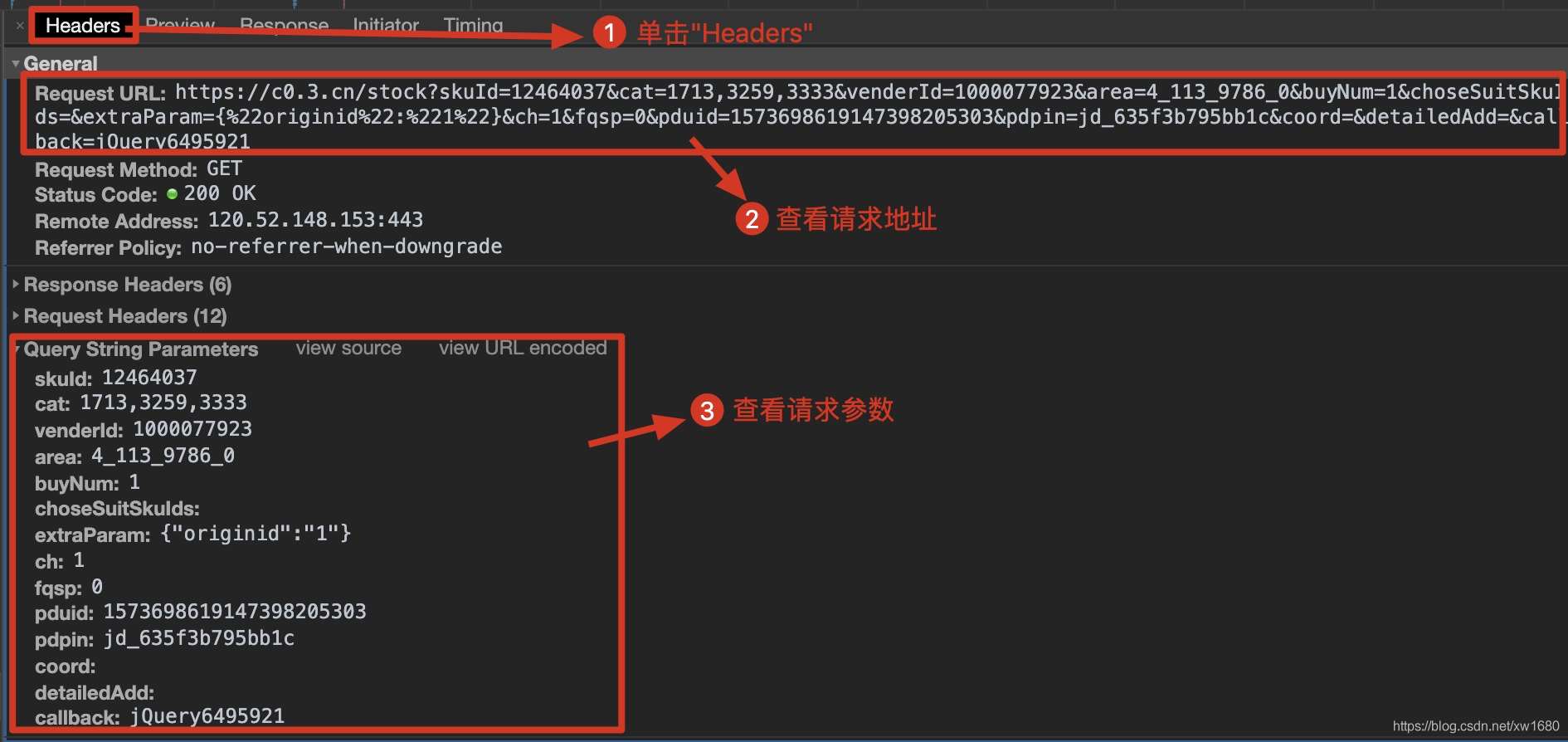
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址 查看全部
抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址
抓取动态网页(2020年7月29日2.JS型网页(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-01 00:03
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后只需要发送一个获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,发送给网站@ > 用post请求,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
抓取动态网页(2020年7月29日2.JS型网页(组图)
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面

这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址

在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。

进入第二个页面,我们可以找到页面中的规则,只需改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后只需要发送一个获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.

右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载处理的明显标识。现在进入控制台的网络

执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,发送给网站@ > 用post请求,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-29 13:07
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 Java 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有此项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7 查看全部
抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 Java 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有此项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
抓取动态网页( 如何利用动态大数据成为企业数据分析的关键?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-11-29 13:06
如何利用动态大数据成为企业数据分析的关键?(图))
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的实践,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
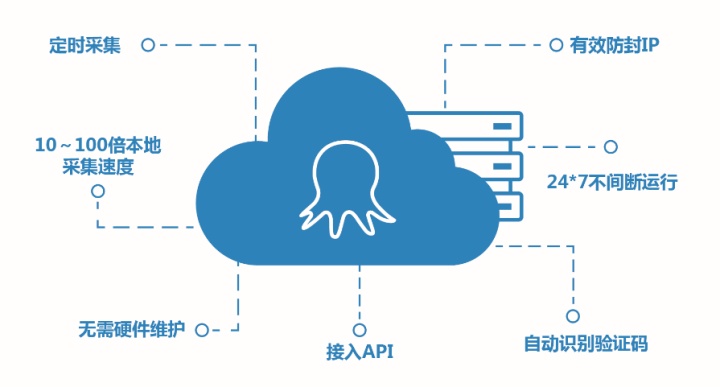
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您大量时间研究不同的网站结构。
(3)定时抓拍
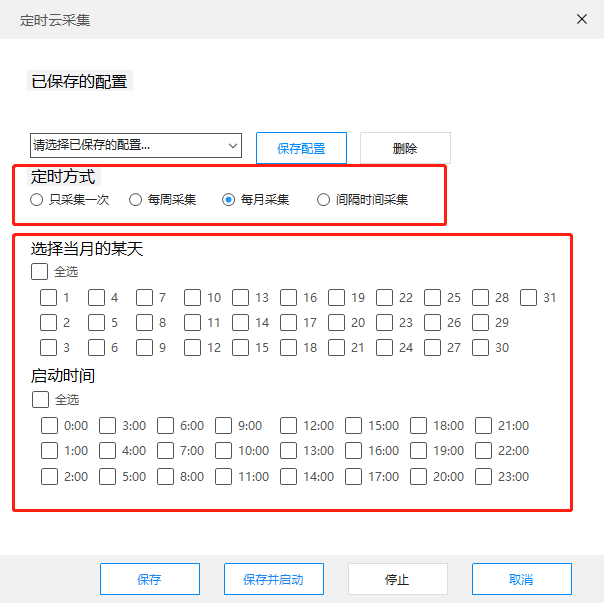
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。.
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。 查看全部
抓取动态网页(
如何利用动态大数据成为企业数据分析的关键?(图))

我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?

1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的实践,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您大量时间研究不同的网站结构。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。.
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
抓取动态网页(前几天非常的好(网络爬虫基本原理二)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-24 07:08
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。好(网络爬虫的基本原理一、网络爬虫的基本原理二)。
本篇博客以博客园首页的新闻版块为例。本示例使用MVC直观、简单的将采集接收到的数据显示在页面上。(其实有很多小网站就是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用)。另外,在实际的爬取过程中可以使用多线程爬取来加速采集。
我们先来看看博客园的首页,做相关分析:
采集后的结果:
爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规则,然后用正则的规则匹配这个规则,匹配到了以后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"的那个
之间
这样,我们就可以得到相应的正则表达式。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为该控制器添加一个视图Index。
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
此时在博客中可以运行一个完整的MVC项目,但是我只有采集一个页面,我们也可以采集下博客园首页的分页部分(即pager_buttom)
,然后添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html 采集 中提取所需的相应信息。另外,不要添加采集每个新闻对应的页面的源代码都存储在数据库中,每个新闻对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要很多时间,采集的效率,以及在数据库中存储大量新闻页面文件会占用大量内存,影响性能的数据库。
我也是菜鸟,刚学,还请大家批评指正。谢谢。不要笑。. .
太轻松的日子不一定能给人幸福,很容易毁掉一个人的理想,败坏一个人的灵魂
发布于 @ 2016-04-27 17:16 无声追求者阅读(1549)评论(3)编辑 查看全部
抓取动态网页(前几天非常的好(网络爬虫基本原理二)(组图))
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。好(网络爬虫的基本原理一、网络爬虫的基本原理二)。
本篇博客以博客园首页的新闻版块为例。本示例使用MVC直观、简单的将采集接收到的数据显示在页面上。(其实有很多小网站就是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用)。另外,在实际的爬取过程中可以使用多线程爬取来加速采集。
我们先来看看博客园的首页,做相关分析:
采集后的结果:

爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规则,然后用正则的规则匹配这个规则,匹配到了以后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"的那个
之间

这样,我们就可以得到相应的正则表达式。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为该控制器添加一个视图Index。
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
此时在博客中可以运行一个完整的MVC项目,但是我只有采集一个页面,我们也可以采集下博客园首页的分页部分(即pager_buttom)

,然后添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html 采集 中提取所需的相应信息。另外,不要添加采集每个新闻对应的页面的源代码都存储在数据库中,每个新闻对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要很多时间,采集的效率,以及在数据库中存储大量新闻页面文件会占用大量内存,影响性能的数据库。
我也是菜鸟,刚学,还请大家批评指正。谢谢。不要笑。. .
太轻松的日子不一定能给人幸福,很容易毁掉一个人的理想,败坏一个人的灵魂
发布于 @ 2016-04-27 17:16 无声追求者阅读(1549)评论(3)编辑
抓取动态网页(Python网络爬虫使用selenium动态网页的两种技术使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-23 21:13
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:
其中,Request URL为实际数据地址。
在这种状态下,您可以通过滚动鼠标滚轮找到 User-Agent。
2)相关代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码json_string.find('{')返回的是"{"在json_string字符串中的索引位置。
2)如果在代码中加一句代码print json_string,这句话的输出结果是(因为输出内容太多,只截取了开头和结尾,关键位置在红色的):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出中,我们可以看出在代码中添加 json_string = json_string[json_string.find('{'):-2] 的重要性。
如果不加json_string.find('{'),结果不是合法的json格式,无法顺利形成json文件;如果不拦截到倒数第二个位置,结果收录额外);也不能构成合法的json格式。
3)对于代码comment_list=json_data['results']['parents']和message=eachone['content']中括号中的string类型标签定位可以在上面找到2)找到关键部分中间,也就是截取后合法的json文件,“results”和“parents”都收录,所以用两个方括号一层一层定位,因为我们是爬评论,所以内容在这个json 文件的“content”标签中,使用[“content”]进行定位。
观察到实际数据地址中的偏移量是页数。 查看全部
抓取动态网页(Python网络爬虫使用selenium动态网页的两种技术使用方法)
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:

其中,Request URL为实际数据地址。
在这种状态下,您可以通过滚动鼠标滚轮找到 User-Agent。

2)相关代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码json_string.find('{')返回的是"{"在json_string字符串中的索引位置。
2)如果在代码中加一句代码print json_string,这句话的输出结果是(因为输出内容太多,只截取了开头和结尾,关键位置在红色的):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出中,我们可以看出在代码中添加 json_string = json_string[json_string.find('{'):-2] 的重要性。
如果不加json_string.find('{'),结果不是合法的json格式,无法顺利形成json文件;如果不拦截到倒数第二个位置,结果收录额外);也不能构成合法的json格式。
3)对于代码comment_list=json_data['results']['parents']和message=eachone['content']中括号中的string类型标签定位可以在上面找到2)找到关键部分中间,也就是截取后合法的json文件,“results”和“parents”都收录,所以用两个方括号一层一层定位,因为我们是爬评论,所以内容在这个json 文件的“content”标签中,使用[“content”]进行定位。
观察到实际数据地址中的偏移量是页数。
抓取动态网页(无法保证这并不是我学到的我的*)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-23 21:10
1、不保证
这不是我学到的最重要的东西,但它绝对是 SEO 中最重要的东西之一。搜索引擎优化就像生活中的许多其他领域一样,并没有永远的保证。不管你做了什么奇迹,你都不能保证你的排名在搜索引擎的顶部,尤其是随着时间的推移。原因很复杂——比如算法的变化,竞争对手的攻击,或者仅仅是因为你的网站内容变老了,但后果是一样的——你永远无法保证你的排名。
2、你需要很大的耐心才能取得成果
第二个最重要的教训是,SEO 绝对不是一个可以快速致富的项目。为了达到效果,除了SEO技巧,还需要付出很多的努力和耐心(以及大量的时间成本),但结果可能永远不会到来。
3、链接建设增长缓慢
反向链接可能是搜索引擎优化成功的支柱。您可能想急于建立反向链接,但这并没有真正的帮助。正如我之前提到的,您在 SEO 中需要很多耐心和时间。在外链的建设中也是如此。你需要为反向链接的缓慢增长制定一个计划,甚至以稳定的增长速度修复它,而不是急于一次建立大量的反向链接。
4、一个高质量的反向链接价值超过100个垃圾链接
这是另一个宝贵的教训——来自信誉良好的、相关的、排名靠前的 网站 的单个高质量反向链接远胜于 100 个垃圾邮件链接。这是在谷歌企鹅算法和百度绿萝算法更新之后。垃圾邮件链接不仅失去了效果,还可能带来惩罚。
5、不要获得糟糕的产品或服务排名
如果你的客户打算做一些不太好的产品或服务,那你就要学会说NO。否则,你会看到网上愤怒的网友给你带来意想不到的负面宣传。
6、内容为王
简而言之,如果您没有好的内容,那么您只是在浪费时间和金钱。
7、不要伤害Meta标签
十年前我开始做搜索引擎优化时,元标签比现在重要得多。然而,元标签仍然没有过时,尤其是标签,所以为了以防万一,你必须写下你的标题。
8、研究关键词的成败
SEO优化中对关键词的研究在过去10年没有改变,或者更准确地说,对关键词的错误或正确选择没有改变。这就是为什么 关键词 的研究非常非常重要的原因。如果你做的不对,你所有的后续努力都注定要失败。对于优化,需要选择合适的关键词,而不是针对一些搜索量大但无法产生转化的关键词。
9、没有合适的工具你哪儿也去不了
搜索引擎优化需要很多工具。如果您没有正确的 SEO 工具,您将得到错误的反馈。这是一个悲剧。
10、利基产品/服务网站
如果您想覆盖 10 个行业,那么请创建 10 个单独的 网站,而不是将所有内容放在一个 网站 上。
11、 快或失败
搜索引擎优化是非常动态的。你必须要快,否则你注定要失败。当主要算法更新时尤其如此,因为如果您不能迅速采取行动,您将在眨眼间看到您的排名如何下降。
12、不能光靠搜索引擎优化
SEO是一个非常强大的流量入口,但你不能单靠它——你需要PPC、社交营销等。正是这种组合可以帮助你取得真正的成功,让你的网站成为最有利可图的。
13、旧域名或在域名后加关键词都救不了你
把关键词加到老域名或域名上确实对你的优化有帮助,但是当你没有好的内容和高质量的反向链接时,他们也救不了你。
14、始终监控和测量
当您不知道结果是什么时,您所做的一切都只是猜测。这就是为什么你总是需要监控你的结果并试图摆脱那些表现不佳的网站/projects/keywords。
15、不要担心高跳出率
跳出率与搜索引擎优化结果没有直接关系,但是当用户来到您的网站 并很快离开您的网站 时,这是一个不好的症状,这意味着他们没有。找到他们想要的。这是网站的损失,所以尽量降低跳出率。
16、可以实现多个长尾关键词
长尾关键词非常好,因为它大大减少了他们的竞争,更容易获得更高的排名。也许你的长尾关键词不会获得那么多流量,但在投资回报方面,他们击败了很难排名的流行关键词。
17、黑帽子需要避免
我需要说为什么?搜索引擎并不愚蠢,黑帽技巧通常很容易被发现。所以不要成为SEO罪犯!
18、谷歌或百度都不是最好的搜索引擎
谷歌在全球的份额最大,百度在中国的份额最大。但是其他搜索引擎可能会带来不错的点击量,比如必应、360so等竞争力较弱的搜索引擎,可以获得不错的排名。
19、 分散你的搜索引擎优化策略
关键词 排名位置和高质量的反向链接是SEO的核心,但还有很多其他的策略。例如,您可能希望包括社交媒体营销。
20、失败者快速下降
SEO 的成功需要时间和耐心,但从一开始就不是一项显而易见的工作。你能做的最好的事情就是迅速放弃失败者。这适用于项目和客户。等待没有意义,你会失去更多,所以尽快终止失败的项目。
21、找个好主人
这是另一个非常、非常、非常重要的教训。如今,托管服务提供商变得越来越便宜,因此没有理由忍受不可靠的提供商。当您的主机经常出现问题时,机器人将无法抓取您的网站。更糟糕的是,当用户在搜索排名中点击您的结果时,他们无法访问它们。结果是金钱和形象的巨大损失。
22、 SEO的目的是转化(ROI),而不是排名本身
一个好的排名可能会让你自我满足,但如果你没有得到好的转化和不错的投资回报,那么这不是目标。毕竟我们是靠网站赚钱的。很重要,不是吗?
23、学一辈子
这适用于生活的许多领域,尤其是在搜索引擎优化中,事情往往会很快发生变化。如果你想生存,你需要不断学习新的或更好的方法。
24、学习网站的营销、设计和开发
SEO 功能强大,但当您将其用作营销、网页设计和网页开发人员时,它可以帮助您了解全局。没有人说你需要成为世界上最好的营销人员、设计师或开发人员,但你至少需要对这三个方面有基本的了解。
25、搜索引擎优化是一个团队游戏
SEO 不是孤狼。您需要与编辑、设计师、开发人员、产品经理等密切合作,或者您可以自己完成所有工作,但这需要很长时间。你*****聘请专业人士。
26、不要忘记重定向和 404 错误
重定向和 404 错误经常被遗忘,但如果它们被滥用,它们会对你造成很大的伤害网站。所以请花点时间检查重定向和 404 错误。
27、你需要自己思考问题
您需要学习的是最好的,但这并不意味着您应该盲目遵循SEO专家的建议。即使他们不想误导您。某个网站的成功是他们的功劳,但不代表你也会以同样的方式成功。
28、你的竞争对手就是你的老师
你的竞争对手是你最好的老师之一。只要分析他们做了什么,你就会学到很多东西。
29、不要沉迷于数据
数据会引导您,但不要让它们引导您度过一生。页面排名或其他排名只是数字,沉迷其中没有任何好处。投资回报率更重要,所以如果你的投资回报率仍然表现良好,那就意味着一切都很好。
30、不能让不同类型的网站使用相同的搜索引擎优化策略
一个电子商务网站和一个公司的网站是很不一样的。您需要考虑所有这些差异并使用不同的搜索引擎优化策略。
31、人人都可以在互联网上大放异彩
即使你是一家小公司,你仍然可以获得比大公司更好的排名。
32、你的排名不会太好
无论您的排名有多好,总有改进的空间。例如,如果你对给定的关键词有很好的排名,你可以尝试一些你目前不太擅长的相关关键词,
33、不要做工作的奴隶
搜索引擎优化可能会让人上瘾,尤其是当您看到结果时。但是,做工作的奴隶是不好的。你需要的是生活,知道什么时候停止。这不仅有益于您的健康,还可以提高您的工作效率,因此请始终计划几天远离计算机。
34、 请务必填写您的标签
标签有时会被忽略或留空,但它们也很重要。特别是对于图片网站,例如电子商务网站 或图片库。如果您的竞争对手的标签都留空,那么您努力填写这些标签对您来说将是一个巨大的优势。
35、一些你*****不想要的客户
SEO的不可预测性比等待客户更可怕。不熟悉搜索引擎优化细节的客户,希望做不可能的事情,比如保证排名,那么你就和这样的客户说再见了。 查看全部
抓取动态网页(无法保证这并不是我学到的我的*)
1、不保证
这不是我学到的最重要的东西,但它绝对是 SEO 中最重要的东西之一。搜索引擎优化就像生活中的许多其他领域一样,并没有永远的保证。不管你做了什么奇迹,你都不能保证你的排名在搜索引擎的顶部,尤其是随着时间的推移。原因很复杂——比如算法的变化,竞争对手的攻击,或者仅仅是因为你的网站内容变老了,但后果是一样的——你永远无法保证你的排名。
2、你需要很大的耐心才能取得成果
第二个最重要的教训是,SEO 绝对不是一个可以快速致富的项目。为了达到效果,除了SEO技巧,还需要付出很多的努力和耐心(以及大量的时间成本),但结果可能永远不会到来。
3、链接建设增长缓慢
反向链接可能是搜索引擎优化成功的支柱。您可能想急于建立反向链接,但这并没有真正的帮助。正如我之前提到的,您在 SEO 中需要很多耐心和时间。在外链的建设中也是如此。你需要为反向链接的缓慢增长制定一个计划,甚至以稳定的增长速度修复它,而不是急于一次建立大量的反向链接。
4、一个高质量的反向链接价值超过100个垃圾链接
这是另一个宝贵的教训——来自信誉良好的、相关的、排名靠前的 网站 的单个高质量反向链接远胜于 100 个垃圾邮件链接。这是在谷歌企鹅算法和百度绿萝算法更新之后。垃圾邮件链接不仅失去了效果,还可能带来惩罚。
5、不要获得糟糕的产品或服务排名
如果你的客户打算做一些不太好的产品或服务,那你就要学会说NO。否则,你会看到网上愤怒的网友给你带来意想不到的负面宣传。
6、内容为王
简而言之,如果您没有好的内容,那么您只是在浪费时间和金钱。
7、不要伤害Meta标签
十年前我开始做搜索引擎优化时,元标签比现在重要得多。然而,元标签仍然没有过时,尤其是标签,所以为了以防万一,你必须写下你的标题。
8、研究关键词的成败
SEO优化中对关键词的研究在过去10年没有改变,或者更准确地说,对关键词的错误或正确选择没有改变。这就是为什么 关键词 的研究非常非常重要的原因。如果你做的不对,你所有的后续努力都注定要失败。对于优化,需要选择合适的关键词,而不是针对一些搜索量大但无法产生转化的关键词。
9、没有合适的工具你哪儿也去不了
搜索引擎优化需要很多工具。如果您没有正确的 SEO 工具,您将得到错误的反馈。这是一个悲剧。
10、利基产品/服务网站
如果您想覆盖 10 个行业,那么请创建 10 个单独的 网站,而不是将所有内容放在一个 网站 上。
11、 快或失败
搜索引擎优化是非常动态的。你必须要快,否则你注定要失败。当主要算法更新时尤其如此,因为如果您不能迅速采取行动,您将在眨眼间看到您的排名如何下降。
12、不能光靠搜索引擎优化
SEO是一个非常强大的流量入口,但你不能单靠它——你需要PPC、社交营销等。正是这种组合可以帮助你取得真正的成功,让你的网站成为最有利可图的。
13、旧域名或在域名后加关键词都救不了你
把关键词加到老域名或域名上确实对你的优化有帮助,但是当你没有好的内容和高质量的反向链接时,他们也救不了你。
14、始终监控和测量
当您不知道结果是什么时,您所做的一切都只是猜测。这就是为什么你总是需要监控你的结果并试图摆脱那些表现不佳的网站/projects/keywords。
15、不要担心高跳出率
跳出率与搜索引擎优化结果没有直接关系,但是当用户来到您的网站 并很快离开您的网站 时,这是一个不好的症状,这意味着他们没有。找到他们想要的。这是网站的损失,所以尽量降低跳出率。
16、可以实现多个长尾关键词
长尾关键词非常好,因为它大大减少了他们的竞争,更容易获得更高的排名。也许你的长尾关键词不会获得那么多流量,但在投资回报方面,他们击败了很难排名的流行关键词。
17、黑帽子需要避免
我需要说为什么?搜索引擎并不愚蠢,黑帽技巧通常很容易被发现。所以不要成为SEO罪犯!
18、谷歌或百度都不是最好的搜索引擎
谷歌在全球的份额最大,百度在中国的份额最大。但是其他搜索引擎可能会带来不错的点击量,比如必应、360so等竞争力较弱的搜索引擎,可以获得不错的排名。
19、 分散你的搜索引擎优化策略
关键词 排名位置和高质量的反向链接是SEO的核心,但还有很多其他的策略。例如,您可能希望包括社交媒体营销。
20、失败者快速下降
SEO 的成功需要时间和耐心,但从一开始就不是一项显而易见的工作。你能做的最好的事情就是迅速放弃失败者。这适用于项目和客户。等待没有意义,你会失去更多,所以尽快终止失败的项目。
21、找个好主人
这是另一个非常、非常、非常重要的教训。如今,托管服务提供商变得越来越便宜,因此没有理由忍受不可靠的提供商。当您的主机经常出现问题时,机器人将无法抓取您的网站。更糟糕的是,当用户在搜索排名中点击您的结果时,他们无法访问它们。结果是金钱和形象的巨大损失。
22、 SEO的目的是转化(ROI),而不是排名本身
一个好的排名可能会让你自我满足,但如果你没有得到好的转化和不错的投资回报,那么这不是目标。毕竟我们是靠网站赚钱的。很重要,不是吗?
23、学一辈子
这适用于生活的许多领域,尤其是在搜索引擎优化中,事情往往会很快发生变化。如果你想生存,你需要不断学习新的或更好的方法。
24、学习网站的营销、设计和开发
SEO 功能强大,但当您将其用作营销、网页设计和网页开发人员时,它可以帮助您了解全局。没有人说你需要成为世界上最好的营销人员、设计师或开发人员,但你至少需要对这三个方面有基本的了解。
25、搜索引擎优化是一个团队游戏
SEO 不是孤狼。您需要与编辑、设计师、开发人员、产品经理等密切合作,或者您可以自己完成所有工作,但这需要很长时间。你*****聘请专业人士。
26、不要忘记重定向和 404 错误
重定向和 404 错误经常被遗忘,但如果它们被滥用,它们会对你造成很大的伤害网站。所以请花点时间检查重定向和 404 错误。
27、你需要自己思考问题
您需要学习的是最好的,但这并不意味着您应该盲目遵循SEO专家的建议。即使他们不想误导您。某个网站的成功是他们的功劳,但不代表你也会以同样的方式成功。
28、你的竞争对手就是你的老师
你的竞争对手是你最好的老师之一。只要分析他们做了什么,你就会学到很多东西。
29、不要沉迷于数据
数据会引导您,但不要让它们引导您度过一生。页面排名或其他排名只是数字,沉迷其中没有任何好处。投资回报率更重要,所以如果你的投资回报率仍然表现良好,那就意味着一切都很好。
30、不能让不同类型的网站使用相同的搜索引擎优化策略
一个电子商务网站和一个公司的网站是很不一样的。您需要考虑所有这些差异并使用不同的搜索引擎优化策略。
31、人人都可以在互联网上大放异彩
即使你是一家小公司,你仍然可以获得比大公司更好的排名。
32、你的排名不会太好
无论您的排名有多好,总有改进的空间。例如,如果你对给定的关键词有很好的排名,你可以尝试一些你目前不太擅长的相关关键词,
33、不要做工作的奴隶
搜索引擎优化可能会让人上瘾,尤其是当您看到结果时。但是,做工作的奴隶是不好的。你需要的是生活,知道什么时候停止。这不仅有益于您的健康,还可以提高您的工作效率,因此请始终计划几天远离计算机。
34、 请务必填写您的标签
标签有时会被忽略或留空,但它们也很重要。特别是对于图片网站,例如电子商务网站 或图片库。如果您的竞争对手的标签都留空,那么您努力填写这些标签对您来说将是一个巨大的优势。
35、一些你*****不想要的客户
SEO的不可预测性比等待客户更可怕。不熟悉搜索引擎优化细节的客户,希望做不可能的事情,比如保证排名,那么你就和这样的客户说再见了。
抓取动态网页(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-22 00:25
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
抓取动态网页(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
抓取动态网页(无人车列车图片数据furoral|动态网页抓取的意义?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-20 15:00
抓取动态网页很多,如果对现有的网页可视化模板进行适当的修改,并再次服务器查询数据,比如把页面以横线隔开,又或者加入新的需要的一些颜色等,可以对抓取到的数据进行第二次处理,本文给大家总结几种常见的抓取动态网页模板,希望对大家有所帮助。无人车列车图片数据抓取furoral|动态网页抓取的意义?进行动态图片爬取的主要意义在于以下三点:1.例如商务场景下,如果希望获取商务场景下从北京前往上海的无人车列车(x-and-a-drive)的一些图片;或者希望对这个无人车列车进行一些简单的可视化展示。
这些动态图片都是动态构建的,并可通过页面代码实现,通过抓取的图片,可以有效缓解客户端的压力。2.用于营销推广。无人车列车有如汽车展的效果,也称之为lbs就是在gps模块上获取无人车的位置,图片代码中就存储了坐标。当有人乘坐这些无人车时,通过可视化动态图片的展示,就可以很直观的了解无人车的位置。还有就是是营销推广。
在进行lbs推广时,我们可以通过动态图片展示,就可以突出我们lbs的商品对应坐标(车顶对应的位置即为获取到的图片坐标),从而突出商品,增加商品的曝光率。无人车图片的抓取请求3.用于下载网页。包括baiduspider(国内有采用digifulsoup),都是采用无人车图片的抓取请求下载。下载文件的数据类型,对于来自高德地图的数据或地铁、公交数据,我们不希望是json格式的数据,希望是数字的格式,如下图:请求动态网页模板前端抓取javascriptapi#爬取其他网站请求方式小马过河(以下内容基于网站的动态网页抓取)1.将动态网页的xhr中的一段代码中断调试,然后只爬取现有网站。
我们将此代码分为两段,其中第一段先调试,第二段代码后断,也是这样保证我们抓取时不会存在死循环。具体代码如下:onclick:function(e){console.log(e);}functionclick(){varxhr=newxmlhttprequest();xhr.open("get","123.jpg",true);xhr.send();}在function第一段代码之前,我们调试,进行onclick中断调试,因为进行click/get请求,如果之前不断调试直接传给xhr去下载图片,那么将会存在死循环,一直进行下载请求。进行前端断点调试,用ie或谷歌浏览器(ie11及以上版本);ie浏览器调试工具(ie11。 查看全部
抓取动态网页(无人车列车图片数据furoral|动态网页抓取的意义?)
抓取动态网页很多,如果对现有的网页可视化模板进行适当的修改,并再次服务器查询数据,比如把页面以横线隔开,又或者加入新的需要的一些颜色等,可以对抓取到的数据进行第二次处理,本文给大家总结几种常见的抓取动态网页模板,希望对大家有所帮助。无人车列车图片数据抓取furoral|动态网页抓取的意义?进行动态图片爬取的主要意义在于以下三点:1.例如商务场景下,如果希望获取商务场景下从北京前往上海的无人车列车(x-and-a-drive)的一些图片;或者希望对这个无人车列车进行一些简单的可视化展示。
这些动态图片都是动态构建的,并可通过页面代码实现,通过抓取的图片,可以有效缓解客户端的压力。2.用于营销推广。无人车列车有如汽车展的效果,也称之为lbs就是在gps模块上获取无人车的位置,图片代码中就存储了坐标。当有人乘坐这些无人车时,通过可视化动态图片的展示,就可以很直观的了解无人车的位置。还有就是是营销推广。
在进行lbs推广时,我们可以通过动态图片展示,就可以突出我们lbs的商品对应坐标(车顶对应的位置即为获取到的图片坐标),从而突出商品,增加商品的曝光率。无人车图片的抓取请求3.用于下载网页。包括baiduspider(国内有采用digifulsoup),都是采用无人车图片的抓取请求下载。下载文件的数据类型,对于来自高德地图的数据或地铁、公交数据,我们不希望是json格式的数据,希望是数字的格式,如下图:请求动态网页模板前端抓取javascriptapi#爬取其他网站请求方式小马过河(以下内容基于网站的动态网页抓取)1.将动态网页的xhr中的一段代码中断调试,然后只爬取现有网站。
我们将此代码分为两段,其中第一段先调试,第二段代码后断,也是这样保证我们抓取时不会存在死循环。具体代码如下:onclick:function(e){console.log(e);}functionclick(){varxhr=newxmlhttprequest();xhr.open("get","123.jpg",true);xhr.send();}在function第一段代码之前,我们调试,进行onclick中断调试,因为进行click/get请求,如果之前不断调试直接传给xhr去下载图片,那么将会存在死循环,一直进行下载请求。进行前端断点调试,用ie或谷歌浏览器(ie11及以上版本);ie浏览器调试工具(ie11。
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-17 16:10
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 不同版本的Chrome浏览器对应不同版本的chromedriver。关注私聊,我会得到正版。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
Selenium有很多语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
把chromedriver.exe文件和chrome.exe放在同一个目录下,这样就不用写了
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
这一步直接写driver = webdriver.Chrome()即可。
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/") # requests.get("http://www.baidu.com")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它会等待 10 秒才能获取不可用的元素。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应使用 from selenium.webdriver.support import expected_conditions 作为 EC 预期条件和 selenium.webdriver.support.ui.WebDriverWait 完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
千水千山总有情,可不可以留心?
你的小举动将是我分享更多干货的动力。
我的博客从上到下都是连贯的。仅阅读一篇文章可能并不容易。需要多篇文章结合起来才能真正理解。我是一个学习python的小女孩。希望大家多多关注,共同交流,共同学习。 查看全部
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 不同版本的Chrome浏览器对应不同版本的chromedriver。关注私聊,我会得到正版。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
Selenium有很多语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
把chromedriver.exe文件和chrome.exe放在同一个目录下,这样就不用写了
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
这一步直接写driver = webdriver.Chrome()即可。
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";) # requests.get("http://www.baidu.com";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它会等待 10 秒才能获取不可用的元素。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应使用 from selenium.webdriver.support import expected_conditions 作为 EC 预期条件和 selenium.webdriver.support.ui.WebDriverWait 完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
千水千山总有情,可不可以留心?
你的小举动将是我分享更多干货的动力。
我的博客从上到下都是连贯的。仅阅读一篇文章可能并不容易。需要多篇文章结合起来才能真正理解。我是一个学习python的小女孩。希望大家多多关注,共同交流,共同学习。
抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-17 03:02
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。只需解析html源代码,分析分析即可。不明白的可以参考我之前的文章文章Scrapy抓取豆瓣电影信息。这里我主要讲讲怎么抢。动态页面。
获取动态页面有两种方式:
第一种方法是使用第三方工具来模拟浏览器加载数据的行为。例如:Selenium、PhantomJs。这种方法的优点是不需要考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但是缺点也很明显,就是获取API接口比较麻烦。
这里我使用第二种方法来获取动态页面。
1. 在浏览器中打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,是ajax异步请求的动态页面。
2.分析页面,提取API接口,通过F12,可以找到review元素。
3.打开上面的url,发现传入的数据是json格式的,所以我们得到响应响应后,首先要使用json.loads()解析数据。
4. 观察API接口,可以发现有几个参数,ch,sn,listtype,temp。通过改变这些参数的值可以得到不同的内容。
通过分析发现ch参数代表的是图片分类。例如,beautiful代表一张漂亮的图片,sn代表图片的编号,例如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像a标签中的href在静态页面中是通过程序自动获取的,而是需要我们自动设置。我们可以通过覆盖 start_requests 方法 指定要获取的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*- from json import loads import scrapy from urllib.parse import urlencode from image360.items import BeautyItem class ImageSpider(scrapy.Spider): name = 'image' allowed_domains = ['image.so.com'] # 重写Spider中的start_requests方法:指定开始url def start_requests(self): base_url = 'http://image.so.com/zj?' param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'} # 可以根据需要爬取不同数量的图片,此处只爬取60张图片 for page in range(2): param['sn'] = page * 30 full_url = base_url + urlencode(param) yield scrapy.Request(url=full_url, callback=self.parse) def parse(self, response): # 获取到的内容是json数据 # 用json.loads()解析数据 # 此处的response没有content model_dict = loads(response.text) for elem in model_dict['list']: item = BeautyItem() item['title'] = elem['group_title'] item['tag'] = elem['tag'] item['height'] = elem['cover_width'] item['width'] = elem['cover_height'] item['url'] = elem['qhimg_url'] yield item
6.写入项目并定义保存的字段
import scrapy class BeautyItem(scrapy.Item): title = scrapy.Field() tag = scrapy.Field() height = scrapy.Field() width = scrapy.Field() url = scrapy.Field()
7.编写pipeline完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图片。例如,当您抓取一个产品并希望将其图片下载到本地时,您可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,它提供了一种方便且功能额外的方法来下载和本地存储图片。这个类提供了很多处理图片的方法,想了解详细可以查看中文版官方文档
# -*- coding: utf-8 -*- import logging import pymongo import scrapy from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline logger = logging.getLogger('SaveImagePipeline') # 继承ImagesPipenine类,这是图片管道 class SaveImagePipeline(ImagesPipeline): """ 下载图片 """ def get_media_requests(self, item, info): # 此方法获取的是requests 所以用yield 不要return yield scrapy.Request(url=item['url']) def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 logger.debug('下载图片成功') return item def file_path(self, request, response=None, info=None): """ 返回文件名 """ return request.url.split('/')[-1] class SaveToMongoPipeline(object): """ 保存图片信息到数据库 """ def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection): self.mongodb_server = mongodb_server self.mongodb_port = mongodb_port self.mongodb_db = mongodb_db self.mongodb_collection = mongodb_collection def open_spider(self, spider): # 当spider被开启时,这个方法被调用 self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port) db = self.connection[self.mongodb_db] self.collection = db[self.mongodb_collection] def close_spider(self, spider): # 当spider被关闭时,这个方法被调用。 self.connection.close() # 依赖注入 @classmethod def from_crawler(cls, crawler): # cls() 会调用初始化方法 return cls(crawler.settings.get('MONGODB_SERVER'), crawler.settings.get('MONGODB_PORT'), crawler.settings.get('MONGODB_DB'), crawler.settings.get('MONGODB_COLLECTION')) def process_item(self, item, spider): post = {'title': item['title'], 'tag': item['tag'], 'width': item['width'], 'height': item['height'], 'url': item['url']} self.collection.insert_one(post) return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们需要安装几个包,pypiwin32、pillow, pymongo
pip install pypiwin32 pip install pillow pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:
图片保存在指定路径:
一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。 查看全部
抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。只需解析html源代码,分析分析即可。不明白的可以参考我之前的文章文章Scrapy抓取豆瓣电影信息。这里我主要讲讲怎么抢。动态页面。
获取动态页面有两种方式:
第一种方法是使用第三方工具来模拟浏览器加载数据的行为。例如:Selenium、PhantomJs。这种方法的优点是不需要考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但是缺点也很明显,就是获取API接口比较麻烦。
这里我使用第二种方法来获取动态页面。
1. 在浏览器中打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,是ajax异步请求的动态页面。
2.分析页面,提取API接口,通过F12,可以找到review元素。
3.打开上面的url,发现传入的数据是json格式的,所以我们得到响应响应后,首先要使用json.loads()解析数据。
4. 观察API接口,可以发现有几个参数,ch,sn,listtype,temp。通过改变这些参数的值可以得到不同的内容。
通过分析发现ch参数代表的是图片分类。例如,beautiful代表一张漂亮的图片,sn代表图片的编号,例如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像a标签中的href在静态页面中是通过程序自动获取的,而是需要我们自动设置。我们可以通过覆盖 start_requests 方法 指定要获取的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*- from json import loads import scrapy from urllib.parse import urlencode from image360.items import BeautyItem class ImageSpider(scrapy.Spider): name = 'image' allowed_domains = ['image.so.com'] # 重写Spider中的start_requests方法:指定开始url def start_requests(self): base_url = 'http://image.so.com/zj?' param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'} # 可以根据需要爬取不同数量的图片,此处只爬取60张图片 for page in range(2): param['sn'] = page * 30 full_url = base_url + urlencode(param) yield scrapy.Request(url=full_url, callback=self.parse) def parse(self, response): # 获取到的内容是json数据 # 用json.loads()解析数据 # 此处的response没有content model_dict = loads(response.text) for elem in model_dict['list']: item = BeautyItem() item['title'] = elem['group_title'] item['tag'] = elem['tag'] item['height'] = elem['cover_width'] item['width'] = elem['cover_height'] item['url'] = elem['qhimg_url'] yield item
6.写入项目并定义保存的字段
import scrapy class BeautyItem(scrapy.Item): title = scrapy.Field() tag = scrapy.Field() height = scrapy.Field() width = scrapy.Field() url = scrapy.Field()
7.编写pipeline完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图片。例如,当您抓取一个产品并希望将其图片下载到本地时,您可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,它提供了一种方便且功能额外的方法来下载和本地存储图片。这个类提供了很多处理图片的方法,想了解详细可以查看中文版官方文档
# -*- coding: utf-8 -*- import logging import pymongo import scrapy from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline logger = logging.getLogger('SaveImagePipeline') # 继承ImagesPipenine类,这是图片管道 class SaveImagePipeline(ImagesPipeline): """ 下载图片 """ def get_media_requests(self, item, info): # 此方法获取的是requests 所以用yield 不要return yield scrapy.Request(url=item['url']) def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 logger.debug('下载图片成功') return item def file_path(self, request, response=None, info=None): """ 返回文件名 """ return request.url.split('/')[-1] class SaveToMongoPipeline(object): """ 保存图片信息到数据库 """ def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection): self.mongodb_server = mongodb_server self.mongodb_port = mongodb_port self.mongodb_db = mongodb_db self.mongodb_collection = mongodb_collection def open_spider(self, spider): # 当spider被开启时,这个方法被调用 self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port) db = self.connection[self.mongodb_db] self.collection = db[self.mongodb_collection] def close_spider(self, spider): # 当spider被关闭时,这个方法被调用。 self.connection.close() # 依赖注入 @classmethod def from_crawler(cls, crawler): # cls() 会调用初始化方法 return cls(crawler.settings.get('MONGODB_SERVER'), crawler.settings.get('MONGODB_PORT'), crawler.settings.get('MONGODB_DB'), crawler.settings.get('MONGODB_COLLECTION')) def process_item(self, item, spider): post = {'title': item['title'], 'tag': item['tag'], 'width': item['width'], 'height': item['height'], 'url': item['url']} self.collection.insert_one(post) return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们需要安装几个包,pypiwin32、pillow, pymongo
pip install pypiwin32 pip install pillow pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:
图片保存在指定路径:
一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-16 22:26
我对网页内容的爬取比较感兴趣,所以就简单的研究了一下。如果在不使用任何框架的情况下抓取网页内容感觉有点困难,我会继续。这里使用的jsoup框架,爬取网页的内容和使用jquery选择网页的内容类似,上手很快。下面就来简单介绍一下吧!
首先是获取网络资源的方法:
/**
* 获取网络中的超链接
*
* @param urlStr
* 传入网络地址
* @return 返回网页中的所有的超链接信息
*/
public String getInternet(String urlStr, String encoding) {
URL url = null;
URLConnection conn = null;
String nextLine = null;
StringBuffer sb = new StringBuffer();
// 设置系统的代理信息
Properties props = System.getProperties();
props.put("proxySet", "true");
props.put("proxyHost", "10.27.16.212");
props.put("proxyPort", "3128");
System.setProperties(props);
try {
// 获取网络资源
url = new URL(urlStr);
// 获取资源连接
conn = url.openConnection();
conn.setReadTimeout(30000);//设置30秒后超时
conn.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(
conn.getInputStream(), encoding));
// 开始读取网页信息获取网页中的超链接信息
while ((nextLine = reader.readLine()) != null) {
sb.append(nextLine);
}
} catch (Exception e) {
e.printStackTrace();
}
return sb.toString();
}
获取到网络资源后,我们可以根据自己的需要筛选出对自己有用的资源,下面开始抢资源:
public static void main(String[] args) {
MavenTest test = new MavenTest();
try {
String html = test.getInternet( "http://www.weather.com.cn/html ... ot%3B,"UTF-8");
//将html文档转换为Document文档
Document doc = Jsoup.parse(html);
//获取class为.weatherYubaoBox的div的元素
Elements tableElements = doc.select("div.weatherYubaoBox");
// System.out.println(tableElements.html());
//获取所有的th元素
Elements thElements = tableElements.select("th");
//打印出日期的标题信息
for (int i = 0; i < thElements.size(); i++) {
System.out.print(" "+thElements.get(i).text() + "\t");
}
// 输出标题之后进行换行
System.out.println();
//获取表格的tbody
Elements tbodyElements = tableElements.select("tbody");
for (int j = 1; j < tbodyElements.size(); j++) {
//获取tr中的信息
Elements trElements = tbodyElements.get(j).select("tr");
for (int k = 0; k < trElements.size(); k++) {
//获取单元格中的信息
Elements tdElements = trElements.get(k).select("td");
//根据元素的多少判断出白天和夜晚的
if (tdElements.size() > 6) {
for (int m = 0; m < tdElements.size(); m++) {
System.out.print(tdElements.get(m).text() + "\t");
}
// 白天的数据打印完成后进行换行
System.out.println();
}else{
for(int n =0; n < tdElements.size(); n++){
System.out.print("\t"+tdElements.get(n).text());
}
//打印完成夜间的天气信息进行换行处理
System.out.println();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果如下:
最后,附上框架的地址: 查看全部
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
我对网页内容的爬取比较感兴趣,所以就简单的研究了一下。如果在不使用任何框架的情况下抓取网页内容感觉有点困难,我会继续。这里使用的jsoup框架,爬取网页的内容和使用jquery选择网页的内容类似,上手很快。下面就来简单介绍一下吧!
首先是获取网络资源的方法:
/**
* 获取网络中的超链接
*
* @param urlStr
* 传入网络地址
* @return 返回网页中的所有的超链接信息
*/
public String getInternet(String urlStr, String encoding) {
URL url = null;
URLConnection conn = null;
String nextLine = null;
StringBuffer sb = new StringBuffer();
// 设置系统的代理信息
Properties props = System.getProperties();
props.put("proxySet", "true");
props.put("proxyHost", "10.27.16.212");
props.put("proxyPort", "3128");
System.setProperties(props);
try {
// 获取网络资源
url = new URL(urlStr);
// 获取资源连接
conn = url.openConnection();
conn.setReadTimeout(30000);//设置30秒后超时
conn.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(
conn.getInputStream(), encoding));
// 开始读取网页信息获取网页中的超链接信息
while ((nextLine = reader.readLine()) != null) {
sb.append(nextLine);
}
} catch (Exception e) {
e.printStackTrace();
}
return sb.toString();
}
获取到网络资源后,我们可以根据自己的需要筛选出对自己有用的资源,下面开始抢资源:
public static void main(String[] args) {
MavenTest test = new MavenTest();
try {
String html = test.getInternet( "http://www.weather.com.cn/html ... ot%3B,"UTF-8");
//将html文档转换为Document文档
Document doc = Jsoup.parse(html);
//获取class为.weatherYubaoBox的div的元素
Elements tableElements = doc.select("div.weatherYubaoBox");
// System.out.println(tableElements.html());
//获取所有的th元素
Elements thElements = tableElements.select("th");
//打印出日期的标题信息
for (int i = 0; i < thElements.size(); i++) {
System.out.print(" "+thElements.get(i).text() + "\t");
}
// 输出标题之后进行换行
System.out.println();
//获取表格的tbody
Elements tbodyElements = tableElements.select("tbody");
for (int j = 1; j < tbodyElements.size(); j++) {
//获取tr中的信息
Elements trElements = tbodyElements.get(j).select("tr");
for (int k = 0; k < trElements.size(); k++) {
//获取单元格中的信息
Elements tdElements = trElements.get(k).select("td");
//根据元素的多少判断出白天和夜晚的
if (tdElements.size() > 6) {
for (int m = 0; m < tdElements.size(); m++) {
System.out.print(tdElements.get(m).text() + "\t");
}
// 白天的数据打印完成后进行换行
System.out.println();
}else{
for(int n =0; n < tdElements.size(); n++){
System.out.print("\t"+tdElements.get(n).text());
}
//打印完成夜间的天气信息进行换行处理
System.out.println();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果如下:

最后,附上框架的地址:
抓取动态网页(ajax和Chrome的内核,性能你懂的,在真实场景中还是以它为主)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-14 16:13
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,跳过了js加载部分,也就是网页爬虫抓取的不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染完后,还会有5个
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,这就是其中之一
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页
从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
1 使用系统; 2 使用 System.采集s.Generic; 3 使用 System.Linq; 4 使用 System.Text; 5 使用 System.Windows.Forms; 6 使用 System.Threading; 7 使用System.IO; ConsoleApplication210 {Program12 {hitCount = 0;14 15 [STAThread]Main(string[] args)17 {;19 20WebBrowser browser = new WebBrowser();21 22browser.ScriptErrorsSuppressed = true;23 24browser.Navigating += (sender, e) =>25 {26hitCount++;27 };28 29browser.DocumentCompleted += (sender, e) =>30 {31hitCount++;32 };33 34 browser.Navigate(url);(browser.ReadyState != WebBrowserReadyState.Complete)37 { 38 申请。 DoEvents();39 }(hitCount 查看全部
抓取动态网页(ajax和Chrome的内核,性能你懂的,在真实场景中还是以它为主)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,跳过了js加载部分,也就是网页爬虫抓取的不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染完后,还会有5个
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,这就是其中之一
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页

从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
1 使用系统; 2 使用 System.采集s.Generic; 3 使用 System.Linq; 4 使用 System.Text; 5 使用 System.Windows.Forms; 6 使用 System.Threading; 7 使用System.IO; ConsoleApplication210 {Program12 {hitCount = 0;14 15 [STAThread]Main(string[] args)17 {;19 20WebBrowser browser = new WebBrowser();21 22browser.ScriptErrorsSuppressed = true;23 24browser.Navigating += (sender, e) =>25 {26hitCount++;27 };28 29browser.DocumentCompleted += (sender, e) =>30 {31hitCount++;32 };33 34 browser.Navigate(url);(browser.ReadyState != WebBrowserReadyState.Complete)37 { 38 申请。 DoEvents();39 }(hitCount
抓取动态网页(一下拼接一个url访问,果然是的js根据具体算法算出来的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-14 06:05
)
一、 分析:
在动态页面js加载的人民日报中抓取新闻详情
先打开,然后查看网页源码,发现是一堆js,而且每个新闻都没有具体的url详细信息,所以第一反应是js动态加载拼接的网址。然后按f12查看,只看url,发现很多url。
然后点击一个特定的新闻详情页,查看url,访问首页时获取url后面的两个数字之一,在f12抓包结果中搜索,找到一个url,点击url,并且发现预览中有很多数据,我的第一反应肯定是每条新闻数据。看到这些数据里面有两个ID,我想我刚才访问的具体新闻详情页上也有两个数字。当然,具体的新闻页面必须通过添加两个ID来形成。于是我尝试拼接一个URL来访问,果然是这样。所以只要抓到这个url,就可以得到每条新闻的详情页。
但是只加载了10个url,所以想修改里面的show_num值,发现请求失败。仔细看这个网址。有一个安全密钥应该由js根据具体算法计算出来。看了一下拼接成url的js,发现看起来有点大,算了,只要能一直抓到这种url就行了。
我发现只要向下滚动页面,就会加载一个新的,所以我只需要解决两个问题:
1.翻页问题,让这个数据url加载。
2.把这个url抓取到日志中,使用脚本访问获取数据
在网上查了一些文档,最后决定用python的selenium模块,这是一个打开本地浏览器进行操作的程序,它有一个方法execute_script('window.scrollTo(0, document.body. scrollHeight)' ) 就是把页面往下翻,用这个来一直加载后面的数据url。
第二个是解决捕获这个数据url的问题。我会用fiddler抓包(这里是抓包工具,根据自己的选择,推荐一个:mitmproxy,也是抓包神器,可以自定义抓包更方便,请百度,谷歌具体操作)
我这里用fiddler,经常用这个,习惯用。
对Python感兴趣或者正在学习的朋友,可以加入我们的Python学习演绎群:784758214,看看前辈们是怎么学习的!从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到实际项目的素材都被组织起来。献给每一位蟒蛇小伙伴!分享一些学习方法和需要注意的小细节,教你在学习的同时学会如何用Python赚钱。点击加入我们的python学习者聚集地
二、使用fiddler抓包写日志
1.fiddler 导出证书到浏览器
1.1.打开工具选项
查看全部
抓取动态网页(一下拼接一个url访问,果然是的js根据具体算法算出来的
)
一、 分析:
在动态页面js加载的人民日报中抓取新闻详情
先打开,然后查看网页源码,发现是一堆js,而且每个新闻都没有具体的url详细信息,所以第一反应是js动态加载拼接的网址。然后按f12查看,只看url,发现很多url。
然后点击一个特定的新闻详情页,查看url,访问首页时获取url后面的两个数字之一,在f12抓包结果中搜索,找到一个url,点击url,并且发现预览中有很多数据,我的第一反应肯定是每条新闻数据。看到这些数据里面有两个ID,我想我刚才访问的具体新闻详情页上也有两个数字。当然,具体的新闻页面必须通过添加两个ID来形成。于是我尝试拼接一个URL来访问,果然是这样。所以只要抓到这个url,就可以得到每条新闻的详情页。
但是只加载了10个url,所以想修改里面的show_num值,发现请求失败。仔细看这个网址。有一个安全密钥应该由js根据具体算法计算出来。看了一下拼接成url的js,发现看起来有点大,算了,只要能一直抓到这种url就行了。
我发现只要向下滚动页面,就会加载一个新的,所以我只需要解决两个问题:
1.翻页问题,让这个数据url加载。
2.把这个url抓取到日志中,使用脚本访问获取数据
在网上查了一些文档,最后决定用python的selenium模块,这是一个打开本地浏览器进行操作的程序,它有一个方法execute_script('window.scrollTo(0, document.body. scrollHeight)' ) 就是把页面往下翻,用这个来一直加载后面的数据url。
第二个是解决捕获这个数据url的问题。我会用fiddler抓包(这里是抓包工具,根据自己的选择,推荐一个:mitmproxy,也是抓包神器,可以自定义抓包更方便,请百度,谷歌具体操作)
我这里用fiddler,经常用这个,习惯用。
对Python感兴趣或者正在学习的朋友,可以加入我们的Python学习演绎群:784758214,看看前辈们是怎么学习的!从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到实际项目的素材都被组织起来。献给每一位蟒蛇小伙伴!分享一些学习方法和需要注意的小细节,教你在学习的同时学会如何用Python赚钱。点击加入我们的python学习者聚集地
二、使用fiddler抓包写日志
1.fiddler 导出证书到浏览器
1.1.打开工具选项
抓取动态网页(用Python解决内容采集不到的问题只有一个代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-11 08:09
我们在编写爬虫爬取页面的时候,大部分时候直接使用BeautifulSoup等静态爬取工具获取html源码是没有问题的。基本上你在浏览器上看到的和你爬取的html代码是有对应关系的。但是如果你采集有过很多网站,你很可能会遇到这样的情况,你在浏览器上看到的内容,你使用网站上的爬虫从网站采集 内容不同。这时候你可能会疑惑是不是有什么细节没有处理好,希望找出采集内容不可用的原因。有时您会发现一个网页使用加载页面将您带到另一个页面,但该网页的 URL 链接在此过程中并没有发生变化。比如下面的天眼查网站在反爬虫方面做了很多工作,使用Js动态加载就是其中之一。
而这一切都是因为你的爬虫无法执行使页面产生各种神奇效果的JavaScript代码。如果 网站HTML 页面没有运行 JavaScript 代码,它可能与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript 代码。
然后使用Ajax或者DHTML技术来改变/加载页面的内容,可能有一些采集的方式,但是用Python解决这个问题只有两种方法:
第一种类型:直接来自 JavaScript 代码 采集content
第二:使用Python第三方库运行JavaScript,直接采集浏览器看到的页面
今天简单介绍一种在PhantomJS“无头”浏览器中使用selenium工具实现动态页面爬取的方法。该方法是上述第二种方法的实现。
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。近年来,它被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。但是Selenium没有浏览器,需要配合第三方浏览器使用。而PhantomJS就是这样一个存在,PhantomJS就是一个无头浏览器。它将网站加载到内存并执行页面上的Js,但不会向用户显示网页的图形界面。
将 Selenium 和 PhantomJS 结合在一起,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、Header 以及您需要做的任何事情。
可以从PyPI网站()下载Selenium库,当然也可以使用第三方管理器(如pip)在命令行安装。 PhantomJS可以从它的官网下载(),应该是PhantomJS是一个功能齐全的(虽然headless)浏览器,不是Python库,所以不需要像其他Python库一样安装,也不能用点。使用时直接使用本地地址加载即可。
(完) 查看全部
抓取动态网页(用Python解决内容采集不到的问题只有一个代码)
我们在编写爬虫爬取页面的时候,大部分时候直接使用BeautifulSoup等静态爬取工具获取html源码是没有问题的。基本上你在浏览器上看到的和你爬取的html代码是有对应关系的。但是如果你采集有过很多网站,你很可能会遇到这样的情况,你在浏览器上看到的内容,你使用网站上的爬虫从网站采集 内容不同。这时候你可能会疑惑是不是有什么细节没有处理好,希望找出采集内容不可用的原因。有时您会发现一个网页使用加载页面将您带到另一个页面,但该网页的 URL 链接在此过程中并没有发生变化。比如下面的天眼查网站在反爬虫方面做了很多工作,使用Js动态加载就是其中之一。

而这一切都是因为你的爬虫无法执行使页面产生各种神奇效果的JavaScript代码。如果 网站HTML 页面没有运行 JavaScript 代码,它可能与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript 代码。
然后使用Ajax或者DHTML技术来改变/加载页面的内容,可能有一些采集的方式,但是用Python解决这个问题只有两种方法:
第一种类型:直接来自 JavaScript 代码 采集content
第二:使用Python第三方库运行JavaScript,直接采集浏览器看到的页面
今天简单介绍一种在PhantomJS“无头”浏览器中使用selenium工具实现动态页面爬取的方法。该方法是上述第二种方法的实现。
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。近年来,它被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。但是Selenium没有浏览器,需要配合第三方浏览器使用。而PhantomJS就是这样一个存在,PhantomJS就是一个无头浏览器。它将网站加载到内存并执行页面上的Js,但不会向用户显示网页的图形界面。
将 Selenium 和 PhantomJS 结合在一起,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、Header 以及您需要做的任何事情。
可以从PyPI网站()下载Selenium库,当然也可以使用第三方管理器(如pip)在命令行安装。 PhantomJS可以从它的官网下载(),应该是PhantomJS是一个功能齐全的(虽然headless)浏览器,不是Python库,所以不需要像其他Python库一样安装,也不能用点。使用时直接使用本地地址加载即可。
(完)
抓取动态网页(Python一款IDE--网页请求监控工具发生的详细步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-11 03:19
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息,格式为状态行,包括信息的协议版本号,成功或错误码,后面是收录服务器信息的MIME信息、实体信息和可能的内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler——一个web请求监控工具,我们可以通过它来了解用户触发web请求后发生的详细步骤;
简单的网络爬虫
代码
\'\'\'
第一个示例:简单的网页爬虫
爬取豆瓣首页
\'\'\'
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode(\'utf-8\')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:
查看全部
抓取动态网页(Python一款IDE--网页请求监控工具发生的详细步骤
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息,格式为状态行,包括信息的协议版本号,成功或错误码,后面是收录服务器信息的MIME信息、实体信息和可能的内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler——一个web请求监控工具,我们可以通过它来了解用户触发web请求后发生的详细步骤;
简单的网络爬虫
代码
\'\'\'
第一个示例:简单的网页爬虫
爬取豆瓣首页
\'\'\'
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode(\'utf-8\')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:
抓取动态网页(大连做网站的动态网页和静态网页的工作过程是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 13:09
所谓动态网页一般是指由ASP、PHP、Cold Fusion、CGI等程序动态生成的页面,网页中的大部分数据内容都来自连接到网站的数据库。这个页面在互联网空间中是不存在的,所以有些人看着某个页面的内容就想了想。自然,他们找不到资源。动态网页是在接收到用户的访问请求后才生成并传送到用户浏览器进行显示的,而且由于访问者可以实时获取他们想要的数据,因此动态网页往往容易给人留下深刻的印象。此外,动态网页还具有易于维护和更新的优点。
比如电影网站的播放页面,一部电影网站有数千部电影,每部电影有不止一集。如果有电影的播放页面,恐怕服务器空间会放这些页面也是个问题。事实上,大多数电影网站只有一个播放页面。网页的内容是从数据库中获取的。每当某个页面不适合在某一天查看时,修改这样的页面就足够了。您不需要单独修改每一个。静态页面。可见,动态网页占用服务器空间少,易于更新和维护,对管理员来说非常方便。
但是,动态网页也有很多缺点。大连制作网站动态网页和静态网页的流程是这样的:
动态网页:首先,网页获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,动态页面被编译成标准的HTML代码传递给用户的浏览器。这样,用户就看到了网页。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。谁会在下次访问您的网站。
静态网页:静态网页很简单,静态网页其实是存在的,直接加载到客户端浏览器中显示,不需要服务器编译。
这说明动态网页在访问速度上没有优势。
这是从服务器和用户体验的角度来看的。我们从搜索引擎收录的角度来谈谈。动态网页是用户输入指令后形成的页面。没有这样的页面,搜索引擎只抓取现成的,不自己输入,所以网站在搜索引擎收录中没有优势。
您可以放心,搜索引擎正在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。这就是为什么这些搜索引擎在搜索结果中会出现动态链接,但是爬取次数比静态页面差很多的原因。双,我试过一次。同一个电影网站 数据库显示在动态网页上。Google 仅 收录 15 项。如果转换为静态,则一次为收录 两个。百来页面,可见搜索引擎还是喜欢静态页面的。为什么我爬不了很多搜索引擎?有专家认为是为了避免“搜索机器人陷阱” 查看全部
抓取动态网页(大连做网站的动态网页和静态网页的工作过程是这样的)
所谓动态网页一般是指由ASP、PHP、Cold Fusion、CGI等程序动态生成的页面,网页中的大部分数据内容都来自连接到网站的数据库。这个页面在互联网空间中是不存在的,所以有些人看着某个页面的内容就想了想。自然,他们找不到资源。动态网页是在接收到用户的访问请求后才生成并传送到用户浏览器进行显示的,而且由于访问者可以实时获取他们想要的数据,因此动态网页往往容易给人留下深刻的印象。此外,动态网页还具有易于维护和更新的优点。
比如电影网站的播放页面,一部电影网站有数千部电影,每部电影有不止一集。如果有电影的播放页面,恐怕服务器空间会放这些页面也是个问题。事实上,大多数电影网站只有一个播放页面。网页的内容是从数据库中获取的。每当某个页面不适合在某一天查看时,修改这样的页面就足够了。您不需要单独修改每一个。静态页面。可见,动态网页占用服务器空间少,易于更新和维护,对管理员来说非常方便。
但是,动态网页也有很多缺点。大连制作网站动态网页和静态网页的流程是这样的:
动态网页:首先,网页获取用户的指令,然后网页将指令带到数据库中,找到指令对应的数据,然后传递给服务器。通过服务器的编译,动态页面被编译成标准的HTML代码传递给用户的浏览器。这样,用户就看到了网页。问题出现了。每次访问一个网页,都必须经过这样一个过程。这个过程至少需要几秒钟。随着访问量的增加,页面加载速度会变慢,这也是服务器的负担。; 从用户的角度来看,网页加载缓慢,没有响应。谁会在下次访问您的网站。
静态网页:静态网页很简单,静态网页其实是存在的,直接加载到客户端浏览器中显示,不需要服务器编译。
这说明动态网页在访问速度上没有优势。
这是从服务器和用户体验的角度来看的。我们从搜索引擎收录的角度来谈谈。动态网页是用户输入指令后形成的页面。没有这样的页面,搜索引擎只抓取现成的,不自己输入,所以网站在搜索引擎收录中没有优势。
您可以放心,搜索引擎正在不断改进和发展。到目前为止,大多数搜索引擎都支持动态页面的抓取。这就是为什么这些搜索引擎在搜索结果中会出现动态链接,但是爬取次数比静态页面差很多的原因。双,我试过一次。同一个电影网站 数据库显示在动态网页上。Google 仅 收录 15 项。如果转换为静态,则一次为收录 两个。百来页面,可见搜索引擎还是喜欢静态页面的。为什么我爬不了很多搜索引擎?有专家认为是为了避免“搜索机器人陷阱”
抓取动态网页(ASP、ASP.NET、PHP、JSP,哪个好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-01 13:08
目前用于动态网站开发的主要语言有4种:ASP、ASP .NET、PHP、JSP。
1、ASP 代表 Active Server Pages。它是由 Microsoft 开发的超文本标记语言 (HTML)、脚本和 CGI(通用网关接口)的组合。它不提供自己的特殊编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP最大的优点是可以收录HTML标签,也可以直接访问数据库,使用ActiveX控件的无限扩展,所以在编程上比HTML更方便灵活。通过使用ASP组件和对象技术,用户可以以简单的方式直接使用ActiveX控件,调用对象的方法和属性,实现强大的交互功能。
但是ASP技术并不完善,因为它基本上局限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能轻易实现。在跨平台的 Web 服务器上工作。
面向过程的程序开发方法使维护变得更加困难,特别是对于大型程序。ASP 应用程序。解释VBScript或JScript语言,使性能无法得到充分利用。由于缺乏其基础设施,可扩展性受到限制,虽然COM组件可用,但在开发一些特殊功能(如文件上传)时,没有来自内置的支持,需要向第三方寻求控制控制供应商。
3、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最热门的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但您只需要很少的编程知识。可以使用PHP 来构建真正的交互式网站。
它与 HTML 语言具有很好的兼容性。用户可以直接在脚本代码中添加HTML标签,也可以在HTML标签中添加脚本代码,以更好地实现页面控制。PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象的编程。
4、JSP 代表 Java 服务器页面。它是1999年6月推出的一项新技术,是一种基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只适用于Windows NT/2000平台,而JSP可以运行在85%以上的服务器上,并且是基于JSP技术应用比基于ASP的应用更容易维护和管理,因此被很多人认为是未来最有前途的动态网站技术。 查看全部
抓取动态网页(ASP、ASP.NET、PHP、JSP,哪个好?)
目前用于动态网站开发的主要语言有4种:ASP、ASP .NET、PHP、JSP。
1、ASP 代表 Active Server Pages。它是由 Microsoft 开发的超文本标记语言 (HTML)、脚本和 CGI(通用网关接口)的组合。它不提供自己的特殊编程语言,但允许用户使用许多现有的脚本语言来编写 ASP 应用程序。ASP 编程比 HTML 更方便、更灵活。它运行在Web服务器端,运行后将运行结果以HTML格式发送到客户端浏览器。因此,ASP 比一般的脚本语言安全得多。
ASP最大的优点是可以收录HTML标签,也可以直接访问数据库,使用ActiveX控件的无限扩展,所以在编程上比HTML更方便灵活。通过使用ASP组件和对象技术,用户可以以简单的方式直接使用ActiveX控件,调用对象的方法和属性,实现强大的交互功能。
但是ASP技术并不完善,因为它基本上局限于微软的操作系统平台,主要的工作环境是微软的IIS应用结构,而且由于ActiveX对象具有平台特性,ASP技术不能轻易实现。在跨平台的 Web 服务器上工作。
面向过程的程序开发方法使维护变得更加困难,特别是对于大型程序。ASP 应用程序。解释VBScript或JScript语言,使性能无法得到充分利用。由于缺乏其基础设施,可扩展性受到限制,虽然COM组件可用,但在开发一些特殊功能(如文件上传)时,没有来自内置的支持,需要向第三方寻求控制控制供应商。
3、PHP 代表超文本预处理器(Hypertext Preprocessor)。它是当今 Internet 上最热门的脚本语言。它的语法借鉴了 C、Java、PERL 等语言,但您只需要很少的编程知识。可以使用PHP 来构建真正的交互式网站。
它与 HTML 语言具有很好的兼容性。用户可以直接在脚本代码中添加HTML标签,也可以在HTML标签中添加脚本代码,以更好地实现页面控制。PHP提供标准的数据库接口,数据库连接方便,兼容性强;强大的可扩展性;可以进行面向对象的编程。
4、JSP 代表 Java 服务器页面。它是1999年6月推出的一项新技术,是一种基于Java Servlet和整个Java(Java)系统的Web开发技术。
JSP和ASP在技术上有很多相似之处,但是两者来自不同的技术规范组织,所以ASP一般只适用于Windows NT/2000平台,而JSP可以运行在85%以上的服务器上,并且是基于JSP技术应用比基于ASP的应用更容易维护和管理,因此被很多人认为是未来最有前途的动态网站技术。
抓取动态网页(做网页在外行看起来是相当有技术含量,做利于搜索引擎的站才有希望)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-01 13:07
网页对于外行来说似乎是相当技术性的。只有当你是一个搜索引擎友好的网站时,你才能希望被搜索到。一个搜索引擎友好的网站可能涉及关键词、客户需求分析等,其他方面再好,关键部分都没有排名,好像做得不好,网络怎么能页面被访问者搜索?
如何让一个网页被访问者搜索
许多公司将优化划分为不同的部门,这可以看作是一个非常重要的环节。新制作的网站应该可以帮助蜘蛛爬取网站,间接提升网站的排名。一些网站目标关键词相当多。但是,如果坐在同一个网站上,不利于排名优化,分散权重。如果非得做,取多个网站,然后用二级域名做,不要在同一台主机上做。网站的内容要合理,一般是从左到右,从上到下浏览。同样的搜索引擎也是根据人们的浏览习惯设计的。比如上面网站的内容,权重也是依次递减的。搜索引擎也是如此。所以在制作长尾词的时候可以把这些长尾关键词放在目录下。关键词 的排名将得到提升。
与大多数网站静态html技术相比,现在很多网站都有数据库,也选择了动态网站技术。这样方便客户更新网站,但动态网站技术也有其不足之处。理论上会影响网站的加载速度,因为网站的内容需要从数据库中读取。不利于搜索引擎抓取来抓取网页。由于路径特殊,会增加搜索引擎抓取网站内容的难度,所以搜索引擎通常不喜欢动态的网站。动态转静态页面技术的使用,不仅可以方便客户更新内容,还可以提高网站的加载速度,方便访问者搜索。
提到的优化是网站的内部优化。只有当你了解布局并符合优化规则时,搜索引擎才能给你展示的机会。它以 网站 开头。需要搭建一个有利于蜘蛛爬行的网站结构收录。从首页到内页,都要精心设计。如果结构完成,就等于成功。一半。你要什么关键词参与排名,排名更快,路径优化,如果路径是深度爬虫,就很难抓取,直到网页无法抓取,一般是静态链接或者伪静态,动态不易识别。通常没有更多的路径。路径越深,爬行的机会就越小。仅仅制作网页并不是主要的事情。SEO优化排名是公司做网页的目标。很多网站一定要在前期考虑优化网站,提升客户搜索体验。 查看全部
抓取动态网页(做网页在外行看起来是相当有技术含量,做利于搜索引擎的站才有希望)
网页对于外行来说似乎是相当技术性的。只有当你是一个搜索引擎友好的网站时,你才能希望被搜索到。一个搜索引擎友好的网站可能涉及关键词、客户需求分析等,其他方面再好,关键部分都没有排名,好像做得不好,网络怎么能页面被访问者搜索?
如何让一个网页被访问者搜索
许多公司将优化划分为不同的部门,这可以看作是一个非常重要的环节。新制作的网站应该可以帮助蜘蛛爬取网站,间接提升网站的排名。一些网站目标关键词相当多。但是,如果坐在同一个网站上,不利于排名优化,分散权重。如果非得做,取多个网站,然后用二级域名做,不要在同一台主机上做。网站的内容要合理,一般是从左到右,从上到下浏览。同样的搜索引擎也是根据人们的浏览习惯设计的。比如上面网站的内容,权重也是依次递减的。搜索引擎也是如此。所以在制作长尾词的时候可以把这些长尾关键词放在目录下。关键词 的排名将得到提升。
与大多数网站静态html技术相比,现在很多网站都有数据库,也选择了动态网站技术。这样方便客户更新网站,但动态网站技术也有其不足之处。理论上会影响网站的加载速度,因为网站的内容需要从数据库中读取。不利于搜索引擎抓取来抓取网页。由于路径特殊,会增加搜索引擎抓取网站内容的难度,所以搜索引擎通常不喜欢动态的网站。动态转静态页面技术的使用,不仅可以方便客户更新内容,还可以提高网站的加载速度,方便访问者搜索。
提到的优化是网站的内部优化。只有当你了解布局并符合优化规则时,搜索引擎才能给你展示的机会。它以 网站 开头。需要搭建一个有利于蜘蛛爬行的网站结构收录。从首页到内页,都要精心设计。如果结构完成,就等于成功。一半。你要什么关键词参与排名,排名更快,路径优化,如果路径是深度爬虫,就很难抓取,直到网页无法抓取,一般是静态链接或者伪静态,动态不易识别。通常没有更多的路径。路径越深,爬行的机会就越小。仅仅制作网页并不是主要的事情。SEO优化排名是公司做网页的目标。很多网站一定要在前期考虑优化网站,提升客户搜索体验。
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 13:05
继之前介绍了企业网站建设的静态网页设计“三步走”之后,分形科技将为您介绍企业网站建设的动态网页制作“2.11”。String”。目前市场上大部分企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继之前给大家的介绍之后,分形科技接下来给大家介绍一下“两点和企业生产的动态网页的一行”网站。目前市场上大部分企业风站建设会根据未来的需求来决定是使用动态网页还是静态网页。
动态网页的概念
动态网页是目前常用的网页编程技术。这里的动态是指在页面代码保持不变的情况下,网页上显示的内容会随着时间、环境或数据库操作而变化。动态网页是一种与静态网页相反的网页。动态网页结合基本的html语法规范、Java、VB、VC等高级编程语言,以及数据库编程,共同生成网页。在网站的建设过程中,实现对网站的内容和风格的高效、动态、交互管理。
动态网页的工作原理
动态网页主要与静态网页和后端数据库交互,完成数据传输。制作动态网页常用的后缀格式有.asp、.jsp、.php、.perl等,并且有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发出请求时,将一个完整的网页返回给用户。
动态网页制作“两点一线”
动态网页制作“一点一线”中的“两点”包括:动态网页制作的优缺点,“一条线”是指从服务器到客户端的连接。
一、制作动态网页的优势
1、基于数据库,动静态一体化
动态网页的制作主要是基于数据库的网页,网站的整个操作通过代码调用数据库来展示和实现。这种网站的交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设过程中形成动静结合的最优配置.
2、内容更新快,满足用户需求
动态网页创建技术的一大特点是网站内容更新速度快。这就是企业在网站的建设中使用动态网页创建网站的原因。动态网页的更新和维护一般是通过编辑修改网站后台来实现的,比如企业建站常用的智梦后台。这就把网站的构建和维护分开了。如果企业不能自行完成网站的建设,则可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、开发技术灵活,实现多功能操作
动态网页的技术支持并不强大。常用的基础网页技术包括PHP(超文本预处理器)、ASP(Active Server Page)、JSP(Java Server Page)和CGI(Common Gateway Interface)。网站开发者可以通过这四个强大的后台技术支持来编辑和制作动态网页,并以此为基础实现对网站的多功能操作。如用户注册、登录和管理功能,这些功能有助于实现网站的交互性,同时增加用户对网站的粘性。
二、 动态网页创建的缺点
1、访问速度慢
由于动态网页连接到服务器的数据库,因此用户在访问网页时,需要在发送请求后等待数据库的响应,然后将完整的网页反馈给用户。这时候如果来访的用户特征多,就很容易变慢甚至死机。从用户的角度来看,这个问题的直接反应是网页加载太慢,没有响应,极大地影响了用户访问的心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” 符号,用户必须输入命令才能响应。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页的亲和力不高,不利于网站的收录 . 但是,目前大多数搜索引擎已经支持动态页面的抓取。
3、网页安全性低
在实现动态网页强大交互功能的同时,也给网站带来了很多安全隐患。如果开发者和设计者在编写动态网页程序时不考虑网站的安全性,那么网站很容易给攻击者留下后门,从而受到恶意攻击和黑客入侵的威胁。
三、动态网页制作第一线
这里所说的第一行动态网页创建是指网页的服务器端和客户端,将动态网页结合起来,形成一个完整的网站。下面分形科技小编就为大家一一分析两者。
服务终端
服务器端是指网络上的服务器。动态网页在服务器端运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是通过将这些语言与通用网关接口 (CGI) 连接起来而形成的。需要注意的是,JSP 有两个例外,它们的网络请求都是分派到共享虚拟机上的。动态网站的服务器端往往处于缓存状态,这会导致动态网页的加载时间延长。
客户
客户端是指用户在动态网页上发出请求,服务器会响应特定网页上的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端在用户本地计算机浏览器中的行为生成相应的内容,以获取用户访问的行为结果。返回搜狐查看更多 查看全部
抓取动态网页(一下企业网站建设之动态网页制作的“二点一线”)
继之前介绍了企业网站建设的静态网页设计“三步走”之后,分形科技将为您介绍企业网站建设的动态网页制作“2.11”。String”。目前市场上大部分企业风站建设都会根据未来的需求来决定使用动态网页还是静态网页。继之前给大家的介绍之后,分形科技接下来给大家介绍一下“两点和企业生产的动态网页的一行”网站。目前市场上大部分企业风站建设会根据未来的需求来决定是使用动态网页还是静态网页。
动态网页的概念
动态网页是目前常用的网页编程技术。这里的动态是指在页面代码保持不变的情况下,网页上显示的内容会随着时间、环境或数据库操作而变化。动态网页是一种与静态网页相反的网页。动态网页结合基本的html语法规范、Java、VB、VC等高级编程语言,以及数据库编程,共同生成网页。在网站的建设过程中,实现对网站的内容和风格的高效、动态、交互管理。
动态网页的工作原理
动态网页主要与静态网页和后端数据库交互,完成数据传输。制作动态网页常用的后缀格式有.asp、.jsp、.php、.perl等,并且有一个标志性的符号“?” 在网址中。动态网页的工作原理是:基于数据库技术,实现用户注册、登录、管理等功能,当用户向服务器发出请求时,将一个完整的网页返回给用户。
动态网页制作“两点一线”
动态网页制作“一点一线”中的“两点”包括:动态网页制作的优缺点,“一条线”是指从服务器到客户端的连接。
一、制作动态网页的优势
1、基于数据库,动静态一体化
动态网页的制作主要是基于数据库的网页,网站的整个操作通过代码调用数据库来展示和实现。这种网站的交互性很强,可以大大提升用户体验。动态网站采用动静结合的原则,吸收静态网页的优点,必要时使用静态网页,让企业在网站的建设过程中形成动静结合的最优配置.
2、内容更新快,满足用户需求
动态网页创建技术的一大特点是网站内容更新速度快。这就是企业在网站的建设中使用动态网页创建网站的原因。动态网页的更新和维护一般是通过编辑修改网站后台来实现的,比如企业建站常用的智梦后台。这就把网站的构建和维护分开了。如果企业不能自行完成网站的建设,则可以外包。网站的维护只需要企业通过网站后台完成各种信息的发布。
3、开发技术灵活,实现多功能操作
动态网页的技术支持并不强大。常用的基础网页技术包括PHP(超文本预处理器)、ASP(Active Server Page)、JSP(Java Server Page)和CGI(Common Gateway Interface)。网站开发者可以通过这四个强大的后台技术支持来编辑和制作动态网页,并以此为基础实现对网站的多功能操作。如用户注册、登录和管理功能,这些功能有助于实现网站的交互性,同时增加用户对网站的粘性。
二、 动态网页创建的缺点
1、访问速度慢
由于动态网页连接到服务器的数据库,因此用户在访问网页时,需要在发送请求后等待数据库的响应,然后将完整的网页反馈给用户。这时候如果来访的用户特征多,就很容易变慢甚至死机。从用户的角度来看,这个问题的直接反应是网页加载太慢,没有响应,极大地影响了用户访问的心情,甚至让用户放弃访问。
2、对搜索引擎的亲和力低
动态网页有一个“?” 符号,用户必须输入命令才能响应。根据搜索引擎的特点,蜘蛛只能识别和抓取现成的页面,所以搜索引擎对动态网页的亲和力不高,不利于网站的收录 . 但是,目前大多数搜索引擎已经支持动态页面的抓取。
3、网页安全性低
在实现动态网页强大交互功能的同时,也给网站带来了很多安全隐患。如果开发者和设计者在编写动态网页程序时不考虑网站的安全性,那么网站很容易给攻击者留下后门,从而受到恶意攻击和黑客入侵的威胁。
三、动态网页制作第一线
这里所说的第一行动态网页创建是指网页的服务器端和客户端,将动态网页结合起来,形成一个完整的网站。下面分形科技小编就为大家一一分析两者。
服务终端
服务器端是指网络上的服务器。动态网页在服务器端运行程序时,主要使用的语言有ASP、ColdFusion、Perl、PHP、WebDNA等服务器端语言。动态网页是通过将这些语言与通用网关接口 (CGI) 连接起来而形成的。需要注意的是,JSP 有两个例外,它们的网络请求都是分派到共享虚拟机上的。动态网站的服务器端往往处于缓存状态,这会导致动态网页的加载时间延长。
客户
客户端是指用户在动态网页上发出请求,服务器会响应特定网页上的鼠标或键盘操作,或指定命令。在这种情况下,动态网页会根据客户端在用户本地计算机浏览器中的行为生成相应的内容,以获取用户访问的行为结果。返回搜狐查看更多
抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-01 00:05
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址 查看全部
抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址
抓取动态网页(2020年7月29日2.JS型网页(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-01 00:03
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后只需要发送一个获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,发送给网站@ > 用post请求,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
抓取动态网页(2020年7月29日2.JS型网页(组图)
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后只需要发送一个获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin: 18、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,发送给网站@ > 用post请求,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-29 13:07
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 Java 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有此项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7 查看全部
抓取动态网页(Python学习群:审查网页元素与网页源码是什么?)
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 Java 动态生成的。检查网页的元素是否与网页的源代码不同。
我创建了一个学习Python的小学习圈,为大家提供了一个共同讨论和学习Python的平台。欢迎加入Python学习群:960410445讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力和认识世界的方式。因此,我们与时俱进,迎接变化,不断成长。掌握Python的核心技术才是真正的价值所在。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右击打开插件,使用**firebug review element** *(如果没有此项,安装firebug插件),找到并打开**网络(NET )** 标签。重新加载网页,获取网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。这个网站动态网页的访问地址是:
源代码
注:python版本为2.7
抓取动态网页( 如何利用动态大数据成为企业数据分析的关键?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-11-29 13:06
如何利用动态大数据成为企业数据分析的关键?(图))
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的实践,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您大量时间研究不同的网站结构。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。.
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。 查看全部
抓取动态网页(
如何利用动态大数据成为企业数据分析的关键?(图))
我们生活的数字世界不断产生大量数据。动态大数据的使用已经成为企业数据分析的关键。
在本文中,我们将回答以下问题:
1、为什么采集动态数据很重要?
2、动态数据如何有效促进业务增长?
3、最重要的是,我们如何轻松获取动态数据?
1、为什么采集动态数据如此重要?
一般来说,通过持续监控动态数据,您可以在最短的时间内做出正确的决策。更具体地说,获取动态数据可以帮助:
(1) 让数据驱动的决策更快
采集动态数据可以为您提供有关市场和竞争对手的最新趋势的实时信息。有了所有更新的信息,您可以更快、更轻松地获得基于数据的分析结果,并做出数据驱动的决策。
正如亚马逊首席执行官杰夫贝索斯在给股东的一封信中所说:“业务的速度至关重要。” “高速决策”对业务发展具有重要意义。
(2)建立更强大的数据库
随着数据量的不断增长,每条数据的价值急剧下降。为了提高数据分析的质量和决策的准确性,企业需要通过持续不断的采集动态数据,构建一个全面、大容量的数据库。
数据是一种对时间敏感的资产。数据越早,采集起来就越困难。随着信息量的规模和速度每年翻一番,监控不断更新的数据以进行进一步分析变得极为重要。
一般来说,短期的数据采集可以帮助解决近期的问题并做出较小的决策,而长期的数据采集可以帮助企业识别市场趋势和商业模式,从而帮助企业制定长期的业务目标。
(3)建立自适应分析系统
数据分析的最终目标是建立一个自适应的、自主的数据分析系统,不断地分析问题。毫无疑问,自适应分析系统是基于动态数据的自动采集。在这种情况下,可以节省每次建立分析模型的时间,消除数据循环采集中的人为因素。无人驾驶汽车是自适应分析解决方案的一个很好的例子。
2. 动态数据如何有效促进业务增长?
我们可以通过多种方式应用动态数据分析来促进业务发展,例如:
(1)产品监控
产品信息,如价格、描述、客户评价、图片等,可在在线平台上获取并实时更新。例如,通过在亚马逊上搜索产品信息或从易趣上抓取价格信息,您可以轻松地进行产品发布前的市场调查。
获取更新的数据还可以让您评估产品的竞争地位并制定有效的定价和库存策略。这是监控竞争对手市场行为的一种可靠且有效的方法。
(2)客户体验管理
公司比以往任何时候都更加重视客户体验管理。根据 Gartner 的定义,它是“设计和响应客户交互以达到或超越客户期望的实践,从而提高客户满意度、忠诚度和拥护度”。
例如,提取亚马逊上某个产品的所有评论,分析评论的正面和负面情绪,可以帮助企业了解客户对该产品的看法。同时,它有助于了解客户的需求,以及实时了解客户的满意度。
(3)营销策略
动态数据分析使公司能够了解过去哪些策略最有效,他们当前的营销策略有多有效,以及可以改进的地方。动态数据采集使企业能够实时评估营销策略的成功与否,并据此做出相应的精准调整。
3. 如何轻松获取动态数据?
为了及时、连续地采集动态数据,传统的手动复制粘贴已不再可行。在这种情况下,一个简单易用的网络爬虫可能是最好的解决方案,它具有以下优点:
(1)无需编程
使用网络爬虫工具,操作者无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。
(2)适用于各种网站
不同的网站具有不同的结构,所以即使是有经验的程序员在编写爬虫脚本之前也需要研究网站的结构。但是强大的网络爬虫工具可以让您轻松快速地抓取来自不同网站的信息,从而节省您大量时间研究不同的网站结构。
(3)定时抓拍
这需要网络爬虫工具来支持云中的数据,而不仅仅是在本地计算机上运行。通过云端采集这种方式,采集器可以根据你设置的时间自动运行采集数据。
优采云Cloud采集的功能远不止这些。
(4) 灵活的时间安排
优采云云采集支持随时随地抓取网页数据,时间和频率可根据需要调整。
(5)采集 更快
同时通过8-12台云服务器采集,对同一组数据的爬取速度可以比在本地计算机上运行快8-12倍。
(6) 取数据成本更低
优采云Cloud采集支持在云端采集数据,并将采集接收到的数据存入云端的数据库中。企业无需担心高昂的硬件维护成本或采集 中断。.
此外,优采云采集器的成本较市场同类竞争者降低50%。优采云一直致力于提升数据分析的价值,让每个人都能以实惠的价格使用大数据。
(7)API,自定义数据对接
虽然云端采集数据可以自动导出到用户的数据库,但是通过API可以大大提高数据导出到自己系统的灵活性,轻松实现自己的系统和优采云采集器@ > 无缝对接。
你需要知道的是,优采云采集器的API有两种:数据导出API和增值API。数据导出API仅支持导出数据;增值API支持导出数据,以及修改任务中的一些参数,控制任务的启动/停止。
抓取动态网页(前几天非常的好(网络爬虫基本原理二)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-24 07:08
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。好(网络爬虫的基本原理一、网络爬虫的基本原理二)。
本篇博客以博客园首页的新闻版块为例。本示例使用MVC直观、简单的将采集接收到的数据显示在页面上。(其实有很多小网站就是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用)。另外,在实际的爬取过程中可以使用多线程爬取来加速采集。
我们先来看看博客园的首页,做相关分析:
采集后的结果:
爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规则,然后用正则的规则匹配这个规则,匹配到了以后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"的那个
之间
这样,我们就可以得到相应的正则表达式。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为该控制器添加一个视图Index。
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
此时在博客中可以运行一个完整的MVC项目,但是我只有采集一个页面,我们也可以采集下博客园首页的分页部分(即pager_buttom)
,然后添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html 采集 中提取所需的相应信息。另外,不要添加采集每个新闻对应的页面的源代码都存储在数据库中,每个新闻对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要很多时间,采集的效率,以及在数据库中存储大量新闻页面文件会占用大量内存,影响性能的数据库。
我也是菜鸟,刚学,还请大家批评指正。谢谢。不要笑。. .
太轻松的日子不一定能给人幸福,很容易毁掉一个人的理想,败坏一个人的灵魂
发布于 @ 2016-04-27 17:16 无声追求者阅读(1549)评论(3)编辑 查看全部
抓取动态网页(前几天非常的好(网络爬虫基本原理二)(组图))
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。好(网络爬虫的基本原理一、网络爬虫的基本原理二)。
本篇博客以博客园首页的新闻版块为例。本示例使用MVC直观、简单的将采集接收到的数据显示在页面上。(其实有很多小网站就是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用)。另外,在实际的爬取过程中可以使用多线程爬取来加速采集。
我们先来看看博客园的首页,做相关分析:
采集后的结果:
爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规则,然后用正则的规则匹配这个规则,匹配到了以后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"的那个
之间
这样,我们就可以得到相应的正则表达式。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为该控制器添加一个视图Index。
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
此时在博客中可以运行一个完整的MVC项目,但是我只有采集一个页面,我们也可以采集下博客园首页的分页部分(即pager_buttom)
,然后添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html 采集 中提取所需的相应信息。另外,不要添加采集每个新闻对应的页面的源代码都存储在数据库中,每个新闻对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要很多时间,采集的效率,以及在数据库中存储大量新闻页面文件会占用大量内存,影响性能的数据库。
我也是菜鸟,刚学,还请大家批评指正。谢谢。不要笑。. .
太轻松的日子不一定能给人幸福,很容易毁掉一个人的理想,败坏一个人的灵魂
发布于 @ 2016-04-27 17:16 无声追求者阅读(1549)评论(3)编辑
抓取动态网页(Python网络爬虫使用selenium动态网页的两种技术使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-23 21:13
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:
其中,Request URL为实际数据地址。
在这种状态下,您可以通过滚动鼠标滚轮找到 User-Agent。
2)相关代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码json_string.find('{')返回的是"{"在json_string字符串中的索引位置。
2)如果在代码中加一句代码print json_string,这句话的输出结果是(因为输出内容太多,只截取了开头和结尾,关键位置在红色的):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出中,我们可以看出在代码中添加 json_string = json_string[json_string.find('{'):-2] 的重要性。
如果不加json_string.find('{'),结果不是合法的json格式,无法顺利形成json文件;如果不拦截到倒数第二个位置,结果收录额外);也不能构成合法的json格式。
3)对于代码comment_list=json_data['results']['parents']和message=eachone['content']中括号中的string类型标签定位可以在上面找到2)找到关键部分中间,也就是截取后合法的json文件,“results”和“parents”都收录,所以用两个方括号一层一层定位,因为我们是爬评论,所以内容在这个json 文件的“content”标签中,使用[“content”]进行定位。
观察到实际数据地址中的偏移量是页数。 查看全部
抓取动态网页(Python网络爬虫使用selenium动态网页的两种技术使用方法)
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:
其中,Request URL为实际数据地址。
在这种状态下,您可以通过滚动鼠标滚轮找到 User-Agent。
2)相关代码:
import requests
import json
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data=json.loads(json_string)
comment_list=json_data['results']['parents']
for eachone in comment_list:
message=eachone['content']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码json_string.find('{')返回的是"{"在json_string字符串中的索引位置。
2)如果在代码中加一句代码print json_string,这句话的输出结果是(因为输出内容太多,只截取了开头和结尾,关键位置在红色的):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出中,我们可以看出在代码中添加 json_string = json_string[json_string.find('{'):-2] 的重要性。
如果不加json_string.find('{'),结果不是合法的json格式,无法顺利形成json文件;如果不拦截到倒数第二个位置,结果收录额外);也不能构成合法的json格式。
3)对于代码comment_list=json_data['results']['parents']和message=eachone['content']中括号中的string类型标签定位可以在上面找到2)找到关键部分中间,也就是截取后合法的json文件,“results”和“parents”都收录,所以用两个方括号一层一层定位,因为我们是爬评论,所以内容在这个json 文件的“content”标签中,使用[“content”]进行定位。
观察到实际数据地址中的偏移量是页数。
抓取动态网页(无法保证这并不是我学到的我的*)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-23 21:10
1、不保证
这不是我学到的最重要的东西,但它绝对是 SEO 中最重要的东西之一。搜索引擎优化就像生活中的许多其他领域一样,并没有永远的保证。不管你做了什么奇迹,你都不能保证你的排名在搜索引擎的顶部,尤其是随着时间的推移。原因很复杂——比如算法的变化,竞争对手的攻击,或者仅仅是因为你的网站内容变老了,但后果是一样的——你永远无法保证你的排名。
2、你需要很大的耐心才能取得成果
第二个最重要的教训是,SEO 绝对不是一个可以快速致富的项目。为了达到效果,除了SEO技巧,还需要付出很多的努力和耐心(以及大量的时间成本),但结果可能永远不会到来。
3、链接建设增长缓慢
反向链接可能是搜索引擎优化成功的支柱。您可能想急于建立反向链接,但这并没有真正的帮助。正如我之前提到的,您在 SEO 中需要很多耐心和时间。在外链的建设中也是如此。你需要为反向链接的缓慢增长制定一个计划,甚至以稳定的增长速度修复它,而不是急于一次建立大量的反向链接。
4、一个高质量的反向链接价值超过100个垃圾链接
这是另一个宝贵的教训——来自信誉良好的、相关的、排名靠前的 网站 的单个高质量反向链接远胜于 100 个垃圾邮件链接。这是在谷歌企鹅算法和百度绿萝算法更新之后。垃圾邮件链接不仅失去了效果,还可能带来惩罚。
5、不要获得糟糕的产品或服务排名
如果你的客户打算做一些不太好的产品或服务,那你就要学会说NO。否则,你会看到网上愤怒的网友给你带来意想不到的负面宣传。
6、内容为王
简而言之,如果您没有好的内容,那么您只是在浪费时间和金钱。
7、不要伤害Meta标签
十年前我开始做搜索引擎优化时,元标签比现在重要得多。然而,元标签仍然没有过时,尤其是标签,所以为了以防万一,你必须写下你的标题。
8、研究关键词的成败
SEO优化中对关键词的研究在过去10年没有改变,或者更准确地说,对关键词的错误或正确选择没有改变。这就是为什么 关键词 的研究非常非常重要的原因。如果你做的不对,你所有的后续努力都注定要失败。对于优化,需要选择合适的关键词,而不是针对一些搜索量大但无法产生转化的关键词。
9、没有合适的工具你哪儿也去不了
搜索引擎优化需要很多工具。如果您没有正确的 SEO 工具,您将得到错误的反馈。这是一个悲剧。
10、利基产品/服务网站
如果您想覆盖 10 个行业,那么请创建 10 个单独的 网站,而不是将所有内容放在一个 网站 上。
11、 快或失败
搜索引擎优化是非常动态的。你必须要快,否则你注定要失败。当主要算法更新时尤其如此,因为如果您不能迅速采取行动,您将在眨眼间看到您的排名如何下降。
12、不能光靠搜索引擎优化
SEO是一个非常强大的流量入口,但你不能单靠它——你需要PPC、社交营销等。正是这种组合可以帮助你取得真正的成功,让你的网站成为最有利可图的。
13、旧域名或在域名后加关键词都救不了你
把关键词加到老域名或域名上确实对你的优化有帮助,但是当你没有好的内容和高质量的反向链接时,他们也救不了你。
14、始终监控和测量
当您不知道结果是什么时,您所做的一切都只是猜测。这就是为什么你总是需要监控你的结果并试图摆脱那些表现不佳的网站/projects/keywords。
15、不要担心高跳出率
跳出率与搜索引擎优化结果没有直接关系,但是当用户来到您的网站 并很快离开您的网站 时,这是一个不好的症状,这意味着他们没有。找到他们想要的。这是网站的损失,所以尽量降低跳出率。
16、可以实现多个长尾关键词
长尾关键词非常好,因为它大大减少了他们的竞争,更容易获得更高的排名。也许你的长尾关键词不会获得那么多流量,但在投资回报方面,他们击败了很难排名的流行关键词。
17、黑帽子需要避免
我需要说为什么?搜索引擎并不愚蠢,黑帽技巧通常很容易被发现。所以不要成为SEO罪犯!
18、谷歌或百度都不是最好的搜索引擎
谷歌在全球的份额最大,百度在中国的份额最大。但是其他搜索引擎可能会带来不错的点击量,比如必应、360so等竞争力较弱的搜索引擎,可以获得不错的排名。
19、 分散你的搜索引擎优化策略
关键词 排名位置和高质量的反向链接是SEO的核心,但还有很多其他的策略。例如,您可能希望包括社交媒体营销。
20、失败者快速下降
SEO 的成功需要时间和耐心,但从一开始就不是一项显而易见的工作。你能做的最好的事情就是迅速放弃失败者。这适用于项目和客户。等待没有意义,你会失去更多,所以尽快终止失败的项目。
21、找个好主人
这是另一个非常、非常、非常重要的教训。如今,托管服务提供商变得越来越便宜,因此没有理由忍受不可靠的提供商。当您的主机经常出现问题时,机器人将无法抓取您的网站。更糟糕的是,当用户在搜索排名中点击您的结果时,他们无法访问它们。结果是金钱和形象的巨大损失。
22、 SEO的目的是转化(ROI),而不是排名本身
一个好的排名可能会让你自我满足,但如果你没有得到好的转化和不错的投资回报,那么这不是目标。毕竟我们是靠网站赚钱的。很重要,不是吗?
23、学一辈子
这适用于生活的许多领域,尤其是在搜索引擎优化中,事情往往会很快发生变化。如果你想生存,你需要不断学习新的或更好的方法。
24、学习网站的营销、设计和开发
SEO 功能强大,但当您将其用作营销、网页设计和网页开发人员时,它可以帮助您了解全局。没有人说你需要成为世界上最好的营销人员、设计师或开发人员,但你至少需要对这三个方面有基本的了解。
25、搜索引擎优化是一个团队游戏
SEO 不是孤狼。您需要与编辑、设计师、开发人员、产品经理等密切合作,或者您可以自己完成所有工作,但这需要很长时间。你*****聘请专业人士。
26、不要忘记重定向和 404 错误
重定向和 404 错误经常被遗忘,但如果它们被滥用,它们会对你造成很大的伤害网站。所以请花点时间检查重定向和 404 错误。
27、你需要自己思考问题
您需要学习的是最好的,但这并不意味着您应该盲目遵循SEO专家的建议。即使他们不想误导您。某个网站的成功是他们的功劳,但不代表你也会以同样的方式成功。
28、你的竞争对手就是你的老师
你的竞争对手是你最好的老师之一。只要分析他们做了什么,你就会学到很多东西。
29、不要沉迷于数据
数据会引导您,但不要让它们引导您度过一生。页面排名或其他排名只是数字,沉迷其中没有任何好处。投资回报率更重要,所以如果你的投资回报率仍然表现良好,那就意味着一切都很好。
30、不能让不同类型的网站使用相同的搜索引擎优化策略
一个电子商务网站和一个公司的网站是很不一样的。您需要考虑所有这些差异并使用不同的搜索引擎优化策略。
31、人人都可以在互联网上大放异彩
即使你是一家小公司,你仍然可以获得比大公司更好的排名。
32、你的排名不会太好
无论您的排名有多好,总有改进的空间。例如,如果你对给定的关键词有很好的排名,你可以尝试一些你目前不太擅长的相关关键词,
33、不要做工作的奴隶
搜索引擎优化可能会让人上瘾,尤其是当您看到结果时。但是,做工作的奴隶是不好的。你需要的是生活,知道什么时候停止。这不仅有益于您的健康,还可以提高您的工作效率,因此请始终计划几天远离计算机。
34、 请务必填写您的标签
标签有时会被忽略或留空,但它们也很重要。特别是对于图片网站,例如电子商务网站 或图片库。如果您的竞争对手的标签都留空,那么您努力填写这些标签对您来说将是一个巨大的优势。
35、一些你*****不想要的客户
SEO的不可预测性比等待客户更可怕。不熟悉搜索引擎优化细节的客户,希望做不可能的事情,比如保证排名,那么你就和这样的客户说再见了。 查看全部
抓取动态网页(无法保证这并不是我学到的我的*)
1、不保证
这不是我学到的最重要的东西,但它绝对是 SEO 中最重要的东西之一。搜索引擎优化就像生活中的许多其他领域一样,并没有永远的保证。不管你做了什么奇迹,你都不能保证你的排名在搜索引擎的顶部,尤其是随着时间的推移。原因很复杂——比如算法的变化,竞争对手的攻击,或者仅仅是因为你的网站内容变老了,但后果是一样的——你永远无法保证你的排名。
2、你需要很大的耐心才能取得成果
第二个最重要的教训是,SEO 绝对不是一个可以快速致富的项目。为了达到效果,除了SEO技巧,还需要付出很多的努力和耐心(以及大量的时间成本),但结果可能永远不会到来。
3、链接建设增长缓慢
反向链接可能是搜索引擎优化成功的支柱。您可能想急于建立反向链接,但这并没有真正的帮助。正如我之前提到的,您在 SEO 中需要很多耐心和时间。在外链的建设中也是如此。你需要为反向链接的缓慢增长制定一个计划,甚至以稳定的增长速度修复它,而不是急于一次建立大量的反向链接。
4、一个高质量的反向链接价值超过100个垃圾链接
这是另一个宝贵的教训——来自信誉良好的、相关的、排名靠前的 网站 的单个高质量反向链接远胜于 100 个垃圾邮件链接。这是在谷歌企鹅算法和百度绿萝算法更新之后。垃圾邮件链接不仅失去了效果,还可能带来惩罚。
5、不要获得糟糕的产品或服务排名
如果你的客户打算做一些不太好的产品或服务,那你就要学会说NO。否则,你会看到网上愤怒的网友给你带来意想不到的负面宣传。
6、内容为王
简而言之,如果您没有好的内容,那么您只是在浪费时间和金钱。
7、不要伤害Meta标签
十年前我开始做搜索引擎优化时,元标签比现在重要得多。然而,元标签仍然没有过时,尤其是标签,所以为了以防万一,你必须写下你的标题。
8、研究关键词的成败
SEO优化中对关键词的研究在过去10年没有改变,或者更准确地说,对关键词的错误或正确选择没有改变。这就是为什么 关键词 的研究非常非常重要的原因。如果你做的不对,你所有的后续努力都注定要失败。对于优化,需要选择合适的关键词,而不是针对一些搜索量大但无法产生转化的关键词。
9、没有合适的工具你哪儿也去不了
搜索引擎优化需要很多工具。如果您没有正确的 SEO 工具,您将得到错误的反馈。这是一个悲剧。
10、利基产品/服务网站
如果您想覆盖 10 个行业,那么请创建 10 个单独的 网站,而不是将所有内容放在一个 网站 上。
11、 快或失败
搜索引擎优化是非常动态的。你必须要快,否则你注定要失败。当主要算法更新时尤其如此,因为如果您不能迅速采取行动,您将在眨眼间看到您的排名如何下降。
12、不能光靠搜索引擎优化
SEO是一个非常强大的流量入口,但你不能单靠它——你需要PPC、社交营销等。正是这种组合可以帮助你取得真正的成功,让你的网站成为最有利可图的。
13、旧域名或在域名后加关键词都救不了你
把关键词加到老域名或域名上确实对你的优化有帮助,但是当你没有好的内容和高质量的反向链接时,他们也救不了你。
14、始终监控和测量
当您不知道结果是什么时,您所做的一切都只是猜测。这就是为什么你总是需要监控你的结果并试图摆脱那些表现不佳的网站/projects/keywords。
15、不要担心高跳出率
跳出率与搜索引擎优化结果没有直接关系,但是当用户来到您的网站 并很快离开您的网站 时,这是一个不好的症状,这意味着他们没有。找到他们想要的。这是网站的损失,所以尽量降低跳出率。
16、可以实现多个长尾关键词
长尾关键词非常好,因为它大大减少了他们的竞争,更容易获得更高的排名。也许你的长尾关键词不会获得那么多流量,但在投资回报方面,他们击败了很难排名的流行关键词。
17、黑帽子需要避免
我需要说为什么?搜索引擎并不愚蠢,黑帽技巧通常很容易被发现。所以不要成为SEO罪犯!
18、谷歌或百度都不是最好的搜索引擎
谷歌在全球的份额最大,百度在中国的份额最大。但是其他搜索引擎可能会带来不错的点击量,比如必应、360so等竞争力较弱的搜索引擎,可以获得不错的排名。
19、 分散你的搜索引擎优化策略
关键词 排名位置和高质量的反向链接是SEO的核心,但还有很多其他的策略。例如,您可能希望包括社交媒体营销。
20、失败者快速下降
SEO 的成功需要时间和耐心,但从一开始就不是一项显而易见的工作。你能做的最好的事情就是迅速放弃失败者。这适用于项目和客户。等待没有意义,你会失去更多,所以尽快终止失败的项目。
21、找个好主人
这是另一个非常、非常、非常重要的教训。如今,托管服务提供商变得越来越便宜,因此没有理由忍受不可靠的提供商。当您的主机经常出现问题时,机器人将无法抓取您的网站。更糟糕的是,当用户在搜索排名中点击您的结果时,他们无法访问它们。结果是金钱和形象的巨大损失。
22、 SEO的目的是转化(ROI),而不是排名本身
一个好的排名可能会让你自我满足,但如果你没有得到好的转化和不错的投资回报,那么这不是目标。毕竟我们是靠网站赚钱的。很重要,不是吗?
23、学一辈子
这适用于生活的许多领域,尤其是在搜索引擎优化中,事情往往会很快发生变化。如果你想生存,你需要不断学习新的或更好的方法。
24、学习网站的营销、设计和开发
SEO 功能强大,但当您将其用作营销、网页设计和网页开发人员时,它可以帮助您了解全局。没有人说你需要成为世界上最好的营销人员、设计师或开发人员,但你至少需要对这三个方面有基本的了解。
25、搜索引擎优化是一个团队游戏
SEO 不是孤狼。您需要与编辑、设计师、开发人员、产品经理等密切合作,或者您可以自己完成所有工作,但这需要很长时间。你*****聘请专业人士。
26、不要忘记重定向和 404 错误
重定向和 404 错误经常被遗忘,但如果它们被滥用,它们会对你造成很大的伤害网站。所以请花点时间检查重定向和 404 错误。
27、你需要自己思考问题
您需要学习的是最好的,但这并不意味着您应该盲目遵循SEO专家的建议。即使他们不想误导您。某个网站的成功是他们的功劳,但不代表你也会以同样的方式成功。
28、你的竞争对手就是你的老师
你的竞争对手是你最好的老师之一。只要分析他们做了什么,你就会学到很多东西。
29、不要沉迷于数据
数据会引导您,但不要让它们引导您度过一生。页面排名或其他排名只是数字,沉迷其中没有任何好处。投资回报率更重要,所以如果你的投资回报率仍然表现良好,那就意味着一切都很好。
30、不能让不同类型的网站使用相同的搜索引擎优化策略
一个电子商务网站和一个公司的网站是很不一样的。您需要考虑所有这些差异并使用不同的搜索引擎优化策略。
31、人人都可以在互联网上大放异彩
即使你是一家小公司,你仍然可以获得比大公司更好的排名。
32、你的排名不会太好
无论您的排名有多好,总有改进的空间。例如,如果你对给定的关键词有很好的排名,你可以尝试一些你目前不太擅长的相关关键词,
33、不要做工作的奴隶
搜索引擎优化可能会让人上瘾,尤其是当您看到结果时。但是,做工作的奴隶是不好的。你需要的是生活,知道什么时候停止。这不仅有益于您的健康,还可以提高您的工作效率,因此请始终计划几天远离计算机。
34、 请务必填写您的标签
标签有时会被忽略或留空,但它们也很重要。特别是对于图片网站,例如电子商务网站 或图片库。如果您的竞争对手的标签都留空,那么您努力填写这些标签对您来说将是一个巨大的优势。
35、一些你*****不想要的客户
SEO的不可预测性比等待客户更可怕。不熟悉搜索引擎优化细节的客户,希望做不可能的事情,比如保证排名,那么你就和这样的客户说再见了。
抓取动态网页(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-22 00:25
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
抓取动态网页(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r\'D:\ProgramApp\chromedriver\chromedriver.exe\'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id(\'su\')
submitTag1 = driver.find_element(By.ID,\'su\')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name(\'su\')
submitTag1 = driver.find_element(By.CLASS_NAME,\'su\')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name(\'email\')
submitTag1 = driver.find_element(By.NAME,\'email\')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name(\'div\')
submitTag1 = driver.find_element(By.TAG_NAME,\'div\')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath(\'//div\')
submitTag1 = driver.find_element(By.XPATH,\'//div\')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector(\'//div\')
submitTag1 = driver.find_element(By.CSS_SELECTOR,\'//div\')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
inputTag.send_keys(\'python\')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id(\'su\')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id(\'kw\')
submitTag = driver.find_element_by_id(\'su\')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,\'python\')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie操作:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(\'"+url+"\')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(\'http://httpbin.org/ip\')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
抓取动态网页(无人车列车图片数据furoral|动态网页抓取的意义?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-20 15:00
抓取动态网页很多,如果对现有的网页可视化模板进行适当的修改,并再次服务器查询数据,比如把页面以横线隔开,又或者加入新的需要的一些颜色等,可以对抓取到的数据进行第二次处理,本文给大家总结几种常见的抓取动态网页模板,希望对大家有所帮助。无人车列车图片数据抓取furoral|动态网页抓取的意义?进行动态图片爬取的主要意义在于以下三点:1.例如商务场景下,如果希望获取商务场景下从北京前往上海的无人车列车(x-and-a-drive)的一些图片;或者希望对这个无人车列车进行一些简单的可视化展示。
这些动态图片都是动态构建的,并可通过页面代码实现,通过抓取的图片,可以有效缓解客户端的压力。2.用于营销推广。无人车列车有如汽车展的效果,也称之为lbs就是在gps模块上获取无人车的位置,图片代码中就存储了坐标。当有人乘坐这些无人车时,通过可视化动态图片的展示,就可以很直观的了解无人车的位置。还有就是是营销推广。
在进行lbs推广时,我们可以通过动态图片展示,就可以突出我们lbs的商品对应坐标(车顶对应的位置即为获取到的图片坐标),从而突出商品,增加商品的曝光率。无人车图片的抓取请求3.用于下载网页。包括baiduspider(国内有采用digifulsoup),都是采用无人车图片的抓取请求下载。下载文件的数据类型,对于来自高德地图的数据或地铁、公交数据,我们不希望是json格式的数据,希望是数字的格式,如下图:请求动态网页模板前端抓取javascriptapi#爬取其他网站请求方式小马过河(以下内容基于网站的动态网页抓取)1.将动态网页的xhr中的一段代码中断调试,然后只爬取现有网站。
我们将此代码分为两段,其中第一段先调试,第二段代码后断,也是这样保证我们抓取时不会存在死循环。具体代码如下:onclick:function(e){console.log(e);}functionclick(){varxhr=newxmlhttprequest();xhr.open("get","123.jpg",true);xhr.send();}在function第一段代码之前,我们调试,进行onclick中断调试,因为进行click/get请求,如果之前不断调试直接传给xhr去下载图片,那么将会存在死循环,一直进行下载请求。进行前端断点调试,用ie或谷歌浏览器(ie11及以上版本);ie浏览器调试工具(ie11。 查看全部
抓取动态网页(无人车列车图片数据furoral|动态网页抓取的意义?)
抓取动态网页很多,如果对现有的网页可视化模板进行适当的修改,并再次服务器查询数据,比如把页面以横线隔开,又或者加入新的需要的一些颜色等,可以对抓取到的数据进行第二次处理,本文给大家总结几种常见的抓取动态网页模板,希望对大家有所帮助。无人车列车图片数据抓取furoral|动态网页抓取的意义?进行动态图片爬取的主要意义在于以下三点:1.例如商务场景下,如果希望获取商务场景下从北京前往上海的无人车列车(x-and-a-drive)的一些图片;或者希望对这个无人车列车进行一些简单的可视化展示。
这些动态图片都是动态构建的,并可通过页面代码实现,通过抓取的图片,可以有效缓解客户端的压力。2.用于营销推广。无人车列车有如汽车展的效果,也称之为lbs就是在gps模块上获取无人车的位置,图片代码中就存储了坐标。当有人乘坐这些无人车时,通过可视化动态图片的展示,就可以很直观的了解无人车的位置。还有就是是营销推广。
在进行lbs推广时,我们可以通过动态图片展示,就可以突出我们lbs的商品对应坐标(车顶对应的位置即为获取到的图片坐标),从而突出商品,增加商品的曝光率。无人车图片的抓取请求3.用于下载网页。包括baiduspider(国内有采用digifulsoup),都是采用无人车图片的抓取请求下载。下载文件的数据类型,对于来自高德地图的数据或地铁、公交数据,我们不希望是json格式的数据,希望是数字的格式,如下图:请求动态网页模板前端抓取javascriptapi#爬取其他网站请求方式小马过河(以下内容基于网站的动态网页抓取)1.将动态网页的xhr中的一段代码中断调试,然后只爬取现有网站。
我们将此代码分为两段,其中第一段先调试,第二段代码后断,也是这样保证我们抓取时不会存在死循环。具体代码如下:onclick:function(e){console.log(e);}functionclick(){varxhr=newxmlhttprequest();xhr.open("get","123.jpg",true);xhr.send();}在function第一段代码之前,我们调试,进行onclick中断调试,因为进行click/get请求,如果之前不断调试直接传给xhr去下载图片,那么将会存在死循环,一直进行下载请求。进行前端断点调试,用ie或谷歌浏览器(ie11及以上版本);ie浏览器调试工具(ie11。
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-17 16:10
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 不同版本的Chrome浏览器对应不同版本的chromedriver。关注私聊,我会得到正版。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
Selenium有很多语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
把chromedriver.exe文件和chrome.exe放在同一个目录下,这样就不用写了
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
这一步直接写driver = webdriver.Chrome()即可。
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/") # requests.get("http://www.baidu.com")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它会等待 10 秒才能获取不可用的元素。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应使用 from selenium.webdriver.support import expected_conditions 作为 EC 预期条件和 selenium.webdriver.support.ui.WebDriverWait 完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
千水千山总有情,可不可以留心?
你的小举动将是我分享更多干货的动力。
我的博客从上到下都是连贯的。仅阅读一篇文章可能并不容易。需要多篇文章结合起来才能真正理解。我是一个学习python的小女孩。希望大家多多关注,共同交流,共同学习。 查看全部
抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 不同版本的Chrome浏览器对应不同版本的chromedriver。关注私聊,我会得到正版。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装硒:
Selenium有很多语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
把chromedriver.exe文件和chrome.exe放在同一个目录下,这样就不用写了
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
这一步直接写driver = webdriver.Chrome()即可。
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";) # requests.get("http://www.baidu.com";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它会等待 10 秒才能获取不可用的元素。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应使用 from selenium.webdriver.support import expected_conditions 作为 EC 预期条件和 selenium.webdriver.support.ui.WebDriverWait 完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
千水千山总有情,可不可以留心?
你的小举动将是我分享更多干货的动力。
我的博客从上到下都是连贯的。仅阅读一篇文章可能并不容易。需要多篇文章结合起来才能真正理解。我是一个学习python的小女孩。希望大家多多关注,共同交流,共同学习。
抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-17 03:02
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。只需解析html源代码,分析分析即可。不明白的可以参考我之前的文章文章Scrapy抓取豆瓣电影信息。这里我主要讲讲怎么抢。动态页面。
获取动态页面有两种方式:
第一种方法是使用第三方工具来模拟浏览器加载数据的行为。例如:Selenium、PhantomJs。这种方法的优点是不需要考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但是缺点也很明显,就是获取API接口比较麻烦。
这里我使用第二种方法来获取动态页面。
1. 在浏览器中打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,是ajax异步请求的动态页面。
2.分析页面,提取API接口,通过F12,可以找到review元素。
3.打开上面的url,发现传入的数据是json格式的,所以我们得到响应响应后,首先要使用json.loads()解析数据。
4. 观察API接口,可以发现有几个参数,ch,sn,listtype,temp。通过改变这些参数的值可以得到不同的内容。
通过分析发现ch参数代表的是图片分类。例如,beautiful代表一张漂亮的图片,sn代表图片的编号,例如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像a标签中的href在静态页面中是通过程序自动获取的,而是需要我们自动设置。我们可以通过覆盖 start_requests 方法 指定要获取的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*- from json import loads import scrapy from urllib.parse import urlencode from image360.items import BeautyItem class ImageSpider(scrapy.Spider): name = 'image' allowed_domains = ['image.so.com'] # 重写Spider中的start_requests方法:指定开始url def start_requests(self): base_url = 'http://image.so.com/zj?' param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'} # 可以根据需要爬取不同数量的图片,此处只爬取60张图片 for page in range(2): param['sn'] = page * 30 full_url = base_url + urlencode(param) yield scrapy.Request(url=full_url, callback=self.parse) def parse(self, response): # 获取到的内容是json数据 # 用json.loads()解析数据 # 此处的response没有content model_dict = loads(response.text) for elem in model_dict['list']: item = BeautyItem() item['title'] = elem['group_title'] item['tag'] = elem['tag'] item['height'] = elem['cover_width'] item['width'] = elem['cover_height'] item['url'] = elem['qhimg_url'] yield item
6.写入项目并定义保存的字段
import scrapy class BeautyItem(scrapy.Item): title = scrapy.Field() tag = scrapy.Field() height = scrapy.Field() width = scrapy.Field() url = scrapy.Field()
7.编写pipeline完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图片。例如,当您抓取一个产品并希望将其图片下载到本地时,您可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,它提供了一种方便且功能额外的方法来下载和本地存储图片。这个类提供了很多处理图片的方法,想了解详细可以查看中文版官方文档
# -*- coding: utf-8 -*- import logging import pymongo import scrapy from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline logger = logging.getLogger('SaveImagePipeline') # 继承ImagesPipenine类,这是图片管道 class SaveImagePipeline(ImagesPipeline): """ 下载图片 """ def get_media_requests(self, item, info): # 此方法获取的是requests 所以用yield 不要return yield scrapy.Request(url=item['url']) def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 logger.debug('下载图片成功') return item def file_path(self, request, response=None, info=None): """ 返回文件名 """ return request.url.split('/')[-1] class SaveToMongoPipeline(object): """ 保存图片信息到数据库 """ def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection): self.mongodb_server = mongodb_server self.mongodb_port = mongodb_port self.mongodb_db = mongodb_db self.mongodb_collection = mongodb_collection def open_spider(self, spider): # 当spider被开启时,这个方法被调用 self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port) db = self.connection[self.mongodb_db] self.collection = db[self.mongodb_collection] def close_spider(self, spider): # 当spider被关闭时,这个方法被调用。 self.connection.close() # 依赖注入 @classmethod def from_crawler(cls, crawler): # cls() 会调用初始化方法 return cls(crawler.settings.get('MONGODB_SERVER'), crawler.settings.get('MONGODB_PORT'), crawler.settings.get('MONGODB_DB'), crawler.settings.get('MONGODB_COLLECTION')) def process_item(self, item, spider): post = {'title': item['title'], 'tag': item['tag'], 'width': item['width'], 'height': item['height'], 'url': item['url']} self.collection.insert_one(post) return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们需要安装几个包,pypiwin32、pillow, pymongo
pip install pypiwin32 pip install pillow pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:
图片保存在指定路径:
一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。 查看全部
抓取动态网页(一下如何抓取动态页面?抓取一个页面的方法十分简单)
当我们要抓取一个页面的内容时,首先要做的不是写代码,而是分析页面,判断是静态页面还是动态页面。抓取静态页面的方法很简单。只需解析html源代码,分析分析即可。不明白的可以参考我之前的文章文章Scrapy抓取豆瓣电影信息。这里我主要讲讲怎么抢。动态页面。
获取动态页面有两种方式:
第一种方法是使用第三方工具来模拟浏览器加载数据的行为。例如:Selenium、PhantomJs。这种方法的优点是不需要考虑动态页面的各种变化,但性能较低。
第二种方法是分析页面,找到对应的请求接口,直接获取数据。这种方式的优点是性能高,但是缺点也很明显,就是获取API接口比较麻烦。
这里我使用第二种方法来获取动态页面。
1. 在浏览器中打开页面,查看网页源码,发现源码中没有图片信息。这是一个动态加载的页面,是ajax异步请求的动态页面。
2.分析页面,提取API接口,通过F12,可以找到review元素。
3.打开上面的url,发现传入的数据是json格式的,所以我们得到响应响应后,首先要使用json.loads()解析数据。
4. 观察API接口,可以发现有几个参数,ch,sn,listtype,temp。通过改变这些参数的值可以得到不同的内容。
通过分析发现ch参数代表的是图片分类。例如,beautiful代表一张漂亮的图片,sn代表图片的编号,例如0代表1到30之间的图片,30代表31到60之间的图片。
分析完这些参数,我们就确定了我们需要请求的url地址。这里的url不像a标签中的href在静态页面中是通过程序自动获取的,而是需要我们自动设置。我们可以通过覆盖 start_requests 方法 指定要获取的 url。
5.写我们的蜘蛛
# -*- coding: utf-8 -*- from json import loads import scrapy from urllib.parse import urlencode from image360.items import BeautyItem class ImageSpider(scrapy.Spider): name = 'image' allowed_domains = ['image.so.com'] # 重写Spider中的start_requests方法:指定开始url def start_requests(self): base_url = 'http://image.so.com/zj?' param = {'ch': 'beauty', 'listtype': 'new', 'temp': '1'} # 可以根据需要爬取不同数量的图片,此处只爬取60张图片 for page in range(2): param['sn'] = page * 30 full_url = base_url + urlencode(param) yield scrapy.Request(url=full_url, callback=self.parse) def parse(self, response): # 获取到的内容是json数据 # 用json.loads()解析数据 # 此处的response没有content model_dict = loads(response.text) for elem in model_dict['list']: item = BeautyItem() item['title'] = elem['group_title'] item['tag'] = elem['tag'] item['height'] = elem['cover_width'] item['width'] = elem['cover_height'] item['url'] = elem['qhimg_url'] yield item
6.写入项目并定义保存的字段
import scrapy class BeautyItem(scrapy.Item): title = scrapy.Field() tag = scrapy.Field() height = scrapy.Field() width = scrapy.Field() url = scrapy.Field()
7.编写pipeline完成数据持久化操作,包括下载图片和保存图片信息到mongo。
Scrapy 提供了一个项目管道来下载属于特定项目的图片。例如,当您抓取一个产品并希望将其图片下载到本地时,您可以通过图片管道来实现。这是在 ImagesPipenine 类中实现的,它提供了一种方便且功能额外的方法来下载和本地存储图片。这个类提供了很多处理图片的方法,想了解详细可以查看中文版官方文档
# -*- coding: utf-8 -*- import logging import pymongo import scrapy from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline logger = logging.getLogger('SaveImagePipeline') # 继承ImagesPipenine类,这是图片管道 class SaveImagePipeline(ImagesPipeline): """ 下载图片 """ def get_media_requests(self, item, info): # 此方法获取的是requests 所以用yield 不要return yield scrapy.Request(url=item['url']) def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 logger.debug('下载图片成功') return item def file_path(self, request, response=None, info=None): """ 返回文件名 """ return request.url.split('/')[-1] class SaveToMongoPipeline(object): """ 保存图片信息到数据库 """ def __init__(self, mongodb_server, mongodb_port, mongodb_db, mongodb_collection): self.mongodb_server = mongodb_server self.mongodb_port = mongodb_port self.mongodb_db = mongodb_db self.mongodb_collection = mongodb_collection def open_spider(self, spider): # 当spider被开启时,这个方法被调用 self.connection = pymongo.MongoClient(self.mongodb_server, self.mongodb_port) db = self.connection[self.mongodb_db] self.collection = db[self.mongodb_collection] def close_spider(self, spider): # 当spider被关闭时,这个方法被调用。 self.connection.close() # 依赖注入 @classmethod def from_crawler(cls, crawler): # cls() 会调用初始化方法 return cls(crawler.settings.get('MONGODB_SERVER'), crawler.settings.get('MONGODB_PORT'), crawler.settings.get('MONGODB_DB'), crawler.settings.get('MONGODB_COLLECTION')) def process_item(self, item, spider): post = {'title': item['title'], 'tag': item['tag'], 'width': item['width'], 'height': item['height'], 'url': item['url']} self.collection.insert_one(post) return item
8.写入设置并完成配置。这里只写需要配置的内容。
9.启动蜘蛛
在启动spider之前,我们需要安装几个包,pypiwin32、pillow, pymongo
pip install pypiwin32 pip install pillow pip install pymongo
安装完成后就可以启动spider了
scrapy crawl image
10.查看结果:
获取到的图片返回的内容:
图片保存在指定路径:
一个爬取动态页面和下载图片的爬虫就完成了。其实写起来很简单。关键是分析API接口,重写start_requests方法。
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-16 22:26
我对网页内容的爬取比较感兴趣,所以就简单的研究了一下。如果在不使用任何框架的情况下抓取网页内容感觉有点困难,我会继续。这里使用的jsoup框架,爬取网页的内容和使用jquery选择网页的内容类似,上手很快。下面就来简单介绍一下吧!
首先是获取网络资源的方法:
/**
* 获取网络中的超链接
*
* @param urlStr
* 传入网络地址
* @return 返回网页中的所有的超链接信息
*/
public String getInternet(String urlStr, String encoding) {
URL url = null;
URLConnection conn = null;
String nextLine = null;
StringBuffer sb = new StringBuffer();
// 设置系统的代理信息
Properties props = System.getProperties();
props.put("proxySet", "true");
props.put("proxyHost", "10.27.16.212");
props.put("proxyPort", "3128");
System.setProperties(props);
try {
// 获取网络资源
url = new URL(urlStr);
// 获取资源连接
conn = url.openConnection();
conn.setReadTimeout(30000);//设置30秒后超时
conn.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(
conn.getInputStream(), encoding));
// 开始读取网页信息获取网页中的超链接信息
while ((nextLine = reader.readLine()) != null) {
sb.append(nextLine);
}
} catch (Exception e) {
e.printStackTrace();
}
return sb.toString();
}
获取到网络资源后,我们可以根据自己的需要筛选出对自己有用的资源,下面开始抢资源:
public static void main(String[] args) {
MavenTest test = new MavenTest();
try {
String html = test.getInternet( "http://www.weather.com.cn/html ... ot%3B,"UTF-8");
//将html文档转换为Document文档
Document doc = Jsoup.parse(html);
//获取class为.weatherYubaoBox的div的元素
Elements tableElements = doc.select("div.weatherYubaoBox");
// System.out.println(tableElements.html());
//获取所有的th元素
Elements thElements = tableElements.select("th");
//打印出日期的标题信息
for (int i = 0; i < thElements.size(); i++) {
System.out.print(" "+thElements.get(i).text() + "\t");
}
// 输出标题之后进行换行
System.out.println();
//获取表格的tbody
Elements tbodyElements = tableElements.select("tbody");
for (int j = 1; j < tbodyElements.size(); j++) {
//获取tr中的信息
Elements trElements = tbodyElements.get(j).select("tr");
for (int k = 0; k < trElements.size(); k++) {
//获取单元格中的信息
Elements tdElements = trElements.get(k).select("td");
//根据元素的多少判断出白天和夜晚的
if (tdElements.size() > 6) {
for (int m = 0; m < tdElements.size(); m++) {
System.out.print(tdElements.get(m).text() + "\t");
}
// 白天的数据打印完成后进行换行
System.out.println();
}else{
for(int n =0; n < tdElements.size(); n++){
System.out.print("\t"+tdElements.get(n).text());
}
//打印完成夜间的天气信息进行换行处理
System.out.println();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果如下:
最后,附上框架的地址: 查看全部
抓取动态网页(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
我对网页内容的爬取比较感兴趣,所以就简单的研究了一下。如果在不使用任何框架的情况下抓取网页内容感觉有点困难,我会继续。这里使用的jsoup框架,爬取网页的内容和使用jquery选择网页的内容类似,上手很快。下面就来简单介绍一下吧!
首先是获取网络资源的方法:
/**
* 获取网络中的超链接
*
* @param urlStr
* 传入网络地址
* @return 返回网页中的所有的超链接信息
*/
public String getInternet(String urlStr, String encoding) {
URL url = null;
URLConnection conn = null;
String nextLine = null;
StringBuffer sb = new StringBuffer();
// 设置系统的代理信息
Properties props = System.getProperties();
props.put("proxySet", "true");
props.put("proxyHost", "10.27.16.212");
props.put("proxyPort", "3128");
System.setProperties(props);
try {
// 获取网络资源
url = new URL(urlStr);
// 获取资源连接
conn = url.openConnection();
conn.setReadTimeout(30000);//设置30秒后超时
conn.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(
conn.getInputStream(), encoding));
// 开始读取网页信息获取网页中的超链接信息
while ((nextLine = reader.readLine()) != null) {
sb.append(nextLine);
}
} catch (Exception e) {
e.printStackTrace();
}
return sb.toString();
}
获取到网络资源后,我们可以根据自己的需要筛选出对自己有用的资源,下面开始抢资源:
public static void main(String[] args) {
MavenTest test = new MavenTest();
try {
String html = test.getInternet( "http://www.weather.com.cn/html ... ot%3B,"UTF-8");
//将html文档转换为Document文档
Document doc = Jsoup.parse(html);
//获取class为.weatherYubaoBox的div的元素
Elements tableElements = doc.select("div.weatherYubaoBox");
// System.out.println(tableElements.html());
//获取所有的th元素
Elements thElements = tableElements.select("th");
//打印出日期的标题信息
for (int i = 0; i < thElements.size(); i++) {
System.out.print(" "+thElements.get(i).text() + "\t");
}
// 输出标题之后进行换行
System.out.println();
//获取表格的tbody
Elements tbodyElements = tableElements.select("tbody");
for (int j = 1; j < tbodyElements.size(); j++) {
//获取tr中的信息
Elements trElements = tbodyElements.get(j).select("tr");
for (int k = 0; k < trElements.size(); k++) {
//获取单元格中的信息
Elements tdElements = trElements.get(k).select("td");
//根据元素的多少判断出白天和夜晚的
if (tdElements.size() > 6) {
for (int m = 0; m < tdElements.size(); m++) {
System.out.print(tdElements.get(m).text() + "\t");
}
// 白天的数据打印完成后进行换行
System.out.println();
}else{
for(int n =0; n < tdElements.size(); n++){
System.out.print("\t"+tdElements.get(n).text());
}
//打印完成夜间的天气信息进行换行处理
System.out.println();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果如下:
最后,附上框架的地址:
抓取动态网页(ajax和Chrome的内核,性能你懂的,在真实场景中还是以它为主)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-14 16:13
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,跳过了js加载部分,也就是网页爬虫抓取的不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染完后,还会有5个
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,这就是其中之一
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页
从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
1 使用系统; 2 使用 System.采集s.Generic; 3 使用 System.Linq; 4 使用 System.Text; 5 使用 System.Windows.Forms; 6 使用 System.Threading; 7 使用System.IO; ConsoleApplication210 {Program12 {hitCount = 0;14 15 [STAThread]Main(string[] args)17 {;19 20WebBrowser browser = new WebBrowser();21 22browser.ScriptErrorsSuppressed = true;23 24browser.Navigating += (sender, e) =>25 {26hitCount++;27 };28 29browser.DocumentCompleted += (sender, e) =>30 {31hitCount++;32 };33 34 browser.Navigate(url);(browser.ReadyState != WebBrowserReadyState.Complete)37 { 38 申请。 DoEvents();39 }(hitCount 查看全部
抓取动态网页(ajax和Chrome的内核,性能你懂的,在真实场景中还是以它为主)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,跳过了js加载部分,也就是网页爬虫抓取的不完整,不完整。您可以在下面看到博客花园主页。从首页加载可以看出,页面渲染完后,还会有5个
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,这就是其中之一
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。您可以在下方查看博客园主页
从首页的加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在实景中依然是中流砥柱。
好吧,为了简单方便,这里我们用WebBrowser来玩玩。使用WebBrowser时,要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
记录计数值
.
1 使用系统; 2 使用 System.采集s.Generic; 3 使用 System.Linq; 4 使用 System.Text; 5 使用 System.Windows.Forms; 6 使用 System.Threading; 7 使用System.IO; ConsoleApplication210 {Program12 {hitCount = 0;14 15 [STAThread]Main(string[] args)17 {;19 20WebBrowser browser = new WebBrowser();21 22browser.ScriptErrorsSuppressed = true;23 24browser.Navigating += (sender, e) =>25 {26hitCount++;27 };28 29browser.DocumentCompleted += (sender, e) =>30 {31hitCount++;32 };33 34 browser.Navigate(url);(browser.ReadyState != WebBrowserReadyState.Complete)37 { 38 申请。 DoEvents();39 }(hitCount
抓取动态网页(一下拼接一个url访问,果然是的js根据具体算法算出来的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-14 06:05
)
一、 分析:
在动态页面js加载的人民日报中抓取新闻详情
先打开,然后查看网页源码,发现是一堆js,而且每个新闻都没有具体的url详细信息,所以第一反应是js动态加载拼接的网址。然后按f12查看,只看url,发现很多url。
然后点击一个特定的新闻详情页,查看url,访问首页时获取url后面的两个数字之一,在f12抓包结果中搜索,找到一个url,点击url,并且发现预览中有很多数据,我的第一反应肯定是每条新闻数据。看到这些数据里面有两个ID,我想我刚才访问的具体新闻详情页上也有两个数字。当然,具体的新闻页面必须通过添加两个ID来形成。于是我尝试拼接一个URL来访问,果然是这样。所以只要抓到这个url,就可以得到每条新闻的详情页。
但是只加载了10个url,所以想修改里面的show_num值,发现请求失败。仔细看这个网址。有一个安全密钥应该由js根据具体算法计算出来。看了一下拼接成url的js,发现看起来有点大,算了,只要能一直抓到这种url就行了。
我发现只要向下滚动页面,就会加载一个新的,所以我只需要解决两个问题:
1.翻页问题,让这个数据url加载。
2.把这个url抓取到日志中,使用脚本访问获取数据
在网上查了一些文档,最后决定用python的selenium模块,这是一个打开本地浏览器进行操作的程序,它有一个方法execute_script('window.scrollTo(0, document.body. scrollHeight)' ) 就是把页面往下翻,用这个来一直加载后面的数据url。
第二个是解决捕获这个数据url的问题。我会用fiddler抓包(这里是抓包工具,根据自己的选择,推荐一个:mitmproxy,也是抓包神器,可以自定义抓包更方便,请百度,谷歌具体操作)
我这里用fiddler,经常用这个,习惯用。
对Python感兴趣或者正在学习的朋友,可以加入我们的Python学习演绎群:784758214,看看前辈们是怎么学习的!从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到实际项目的素材都被组织起来。献给每一位蟒蛇小伙伴!分享一些学习方法和需要注意的小细节,教你在学习的同时学会如何用Python赚钱。点击加入我们的python学习者聚集地
二、使用fiddler抓包写日志
1.fiddler 导出证书到浏览器
1.1.打开工具选项
查看全部
抓取动态网页(一下拼接一个url访问,果然是的js根据具体算法算出来的
)
一、 分析:
在动态页面js加载的人民日报中抓取新闻详情
先打开,然后查看网页源码,发现是一堆js,而且每个新闻都没有具体的url详细信息,所以第一反应是js动态加载拼接的网址。然后按f12查看,只看url,发现很多url。
然后点击一个特定的新闻详情页,查看url,访问首页时获取url后面的两个数字之一,在f12抓包结果中搜索,找到一个url,点击url,并且发现预览中有很多数据,我的第一反应肯定是每条新闻数据。看到这些数据里面有两个ID,我想我刚才访问的具体新闻详情页上也有两个数字。当然,具体的新闻页面必须通过添加两个ID来形成。于是我尝试拼接一个URL来访问,果然是这样。所以只要抓到这个url,就可以得到每条新闻的详情页。
但是只加载了10个url,所以想修改里面的show_num值,发现请求失败。仔细看这个网址。有一个安全密钥应该由js根据具体算法计算出来。看了一下拼接成url的js,发现看起来有点大,算了,只要能一直抓到这种url就行了。
我发现只要向下滚动页面,就会加载一个新的,所以我只需要解决两个问题:
1.翻页问题,让这个数据url加载。
2.把这个url抓取到日志中,使用脚本访问获取数据
在网上查了一些文档,最后决定用python的selenium模块,这是一个打开本地浏览器进行操作的程序,它有一个方法execute_script('window.scrollTo(0, document.body. scrollHeight)' ) 就是把页面往下翻,用这个来一直加载后面的数据url。
第二个是解决捕获这个数据url的问题。我会用fiddler抓包(这里是抓包工具,根据自己的选择,推荐一个:mitmproxy,也是抓包神器,可以自定义抓包更方便,请百度,谷歌具体操作)
我这里用fiddler,经常用这个,习惯用。
对Python感兴趣或者正在学习的朋友,可以加入我们的Python学习演绎群:784758214,看看前辈们是怎么学习的!从基础的python脚本到web开发、爬虫、django、数据挖掘等,从零基础到实际项目的素材都被组织起来。献给每一位蟒蛇小伙伴!分享一些学习方法和需要注意的小细节,教你在学习的同时学会如何用Python赚钱。点击加入我们的python学习者聚集地
二、使用fiddler抓包写日志
1.fiddler 导出证书到浏览器
1.1.打开工具选项
抓取动态网页(用Python解决内容采集不到的问题只有一个代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-11 08:09
我们在编写爬虫爬取页面的时候,大部分时候直接使用BeautifulSoup等静态爬取工具获取html源码是没有问题的。基本上你在浏览器上看到的和你爬取的html代码是有对应关系的。但是如果你采集有过很多网站,你很可能会遇到这样的情况,你在浏览器上看到的内容,你使用网站上的爬虫从网站采集 内容不同。这时候你可能会疑惑是不是有什么细节没有处理好,希望找出采集内容不可用的原因。有时您会发现一个网页使用加载页面将您带到另一个页面,但该网页的 URL 链接在此过程中并没有发生变化。比如下面的天眼查网站在反爬虫方面做了很多工作,使用Js动态加载就是其中之一。
而这一切都是因为你的爬虫无法执行使页面产生各种神奇效果的JavaScript代码。如果 网站HTML 页面没有运行 JavaScript 代码,它可能与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript 代码。
然后使用Ajax或者DHTML技术来改变/加载页面的内容,可能有一些采集的方式,但是用Python解决这个问题只有两种方法:
第一种类型:直接来自 JavaScript 代码 采集content
第二:使用Python第三方库运行JavaScript,直接采集浏览器看到的页面
今天简单介绍一种在PhantomJS“无头”浏览器中使用selenium工具实现动态页面爬取的方法。该方法是上述第二种方法的实现。
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。近年来,它被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。但是Selenium没有浏览器,需要配合第三方浏览器使用。而PhantomJS就是这样一个存在,PhantomJS就是一个无头浏览器。它将网站加载到内存并执行页面上的Js,但不会向用户显示网页的图形界面。
将 Selenium 和 PhantomJS 结合在一起,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、Header 以及您需要做的任何事情。
可以从PyPI网站()下载Selenium库,当然也可以使用第三方管理器(如pip)在命令行安装。 PhantomJS可以从它的官网下载(),应该是PhantomJS是一个功能齐全的(虽然headless)浏览器,不是Python库,所以不需要像其他Python库一样安装,也不能用点。使用时直接使用本地地址加载即可。
(完) 查看全部
抓取动态网页(用Python解决内容采集不到的问题只有一个代码)
我们在编写爬虫爬取页面的时候,大部分时候直接使用BeautifulSoup等静态爬取工具获取html源码是没有问题的。基本上你在浏览器上看到的和你爬取的html代码是有对应关系的。但是如果你采集有过很多网站,你很可能会遇到这样的情况,你在浏览器上看到的内容,你使用网站上的爬虫从网站采集 内容不同。这时候你可能会疑惑是不是有什么细节没有处理好,希望找出采集内容不可用的原因。有时您会发现一个网页使用加载页面将您带到另一个页面,但该网页的 URL 链接在此过程中并没有发生变化。比如下面的天眼查网站在反爬虫方面做了很多工作,使用Js动态加载就是其中之一。
而这一切都是因为你的爬虫无法执行使页面产生各种神奇效果的JavaScript代码。如果 网站HTML 页面没有运行 JavaScript 代码,它可能与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript 代码。
然后使用Ajax或者DHTML技术来改变/加载页面的内容,可能有一些采集的方式,但是用Python解决这个问题只有两种方法:
第一种类型:直接来自 JavaScript 代码 采集content
第二:使用Python第三方库运行JavaScript,直接采集浏览器看到的页面
今天简单介绍一种在PhantomJS“无头”浏览器中使用selenium工具实现动态页面爬取的方法。该方法是上述第二种方法的实现。
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。近年来,它被广泛用于获取准确的网站快照,因为它们可以直接在浏览器上运行。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。但是Selenium没有浏览器,需要配合第三方浏览器使用。而PhantomJS就是这样一个存在,PhantomJS就是一个无头浏览器。它将网站加载到内存并执行页面上的Js,但不会向用户显示网页的图形界面。
将 Selenium 和 PhantomJS 结合在一起,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、Header 以及您需要做的任何事情。
可以从PyPI网站()下载Selenium库,当然也可以使用第三方管理器(如pip)在命令行安装。 PhantomJS可以从它的官网下载(),应该是PhantomJS是一个功能齐全的(虽然headless)浏览器,不是Python库,所以不需要像其他Python库一样安装,也不能用点。使用时直接使用本地地址加载即可。
(完)
抓取动态网页(Python一款IDE--网页请求监控工具发生的详细步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-11 03:19
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息,格式为状态行,包括信息的协议版本号,成功或错误码,后面是收录服务器信息的MIME信息、实体信息和可能的内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler——一个web请求监控工具,我们可以通过它来了解用户触发web请求后发生的详细步骤;
简单的网络爬虫
代码
\'\'\'
第一个示例:简单的网页爬虫
爬取豆瓣首页
\'\'\'
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode(\'utf-8\')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:
查看全部
抓取动态网页(Python一款IDE--网页请求监控工具发生的详细步骤
)
1)首先,客户端和服务器需要建立连接。只需单击某个超链接,HTTP 工作就会开始。
2) 连接建立后,客户端向服务器发送请求。请求的格式为:统一资源标识符(URL)、协议版本号和 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3) 服务器收到请求后,会给出相应的响应信息,格式为状态行,包括信息的协议版本号,成功或错误码,后面是收录服务器信息的MIME信息、实体信息和可能的内容。
4)客户端接收服务器返回的信息,通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接。
如果上述过程的某个步骤发生错误,则将导致错误的信息以显示屏幕输出的方式返回给客户端。对于用户来说,这些过程都是由HTTP本身完成的,用户只需要点击鼠标,等待信息显示出来。
二:了解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中;我们需要学习的是几个常用的函数。详情可上官网查看。
三:开发工具
Python自带一个编译器——IDLE,非常简洁;PyCharm - 具有良好交互性的 Python IDE;Fiddler——一个web请求监控工具,我们可以通过它来了解用户触发web请求后发生的详细步骤;
简单的网络爬虫
代码
\'\'\'
第一个示例:简单的网页爬虫
爬取豆瓣首页
\'\'\'
import urllib.request
#网址
url = "https://www.douban.com/"
#请求
request = urllib.request.Request(url)
#爬取结果
response = urllib.request.urlopen(request)
data = response.read()
#设置解码方式
data = data.decode(\'utf-8\')
#打印结果
print(data)
#打印爬取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
结果
截取的部分结果如下:

